Thread: [HACKERS] Custom compression methods
Hello hackers! I've attached a patch that implements custom compression methods. This patch is based on Nikita Glukhov's code (which he hasn't publish in mailing lists) for jsonb compression. This is early but working version of the patch, and there are still few fixes and features that should be implemented (like pg_dump support and support of compression options for types), and it requires more testing. But I'd like to get some feedback at the current stage first. There's been a proposal [1] of Alexander Korotkov and some discussion about custom compression methods before. This is an implementation of per-datum compression. Syntax is similar to the one in proposal but not the same. Syntax: CREATE COMPRESSION METHOD <cmname> HANDLER <compression_handler>; DROP COMPRESSION METHOD <cmname>; Compression handler is a function that returns a structure containing compression routines: - configure - function called when the compression method applied to an attribute - drop - called when the compression method is removed from an attribute - compress - compress function - decompress - decompress function User can create compressed columns with the commands below: CREATE TABLE t(a tsvector COMPRESSED <cmname> WITH <options>); ALTER TABLE t ALTER COLUMN a SET COMPRESSED <cmname> WITH <options>; ALTER TABLE t ALTER COLUMN a SET NOT COMPRESSED; Also there is syntax of binding compression methods to types: ALTER TYPE <type> SET COMPRESSED <cmname>; ALTER TYPE <type> SET NOT COMPRESSED; There are two new tables in the catalog, pg_compression and pg_compression_opt. pg_compression is used as storage of compression methods, and pg_compression_opt is used to store specific compression options for particular column. When user binds a compression method to some column a new record in pg_compression_opt is created and all further attribute values will contain compression options Oid while old values will remain unchanged. And when we alter a compression method for the attribute it won't change previous record in pg_compression_opt. Instead it'll create a new one and new values will be stored with new Oid. That way there is no need of recompression of the old tuples. And also tuples containing compressed datums can be copied to other tables so records in pg_compression_opt shouldn't be removed. In the current patch they can be removed with DROP COMPRESSION METHOD CASCADE, but after that decompression won't be possible on compressed tuples. Maybe CASCADE should keep compression options. I haven't changed the base logic of working with compressed datums. It means that custom compressed datums behave exactly the same as current LZ compressed datums, and the logic differs only in toast_compress_datum and toast_decompress_datum. This patch doesn't break backward compability and should work seamlessly with older version of database. I used one of two free bits in `va_rawsize` from `varattrib_4b->va_compressed` as flag of custom compressed datums. Also I renamed it to `va_info` since it contains not only rawsize now. The patch also includes custom compression method for tsvector which is used in tests. [1] https://www.postgresql.org/message-id/CAPpHfdsdTA5uZeq6MNXL5ZRuNx%2BSig4ykWzWEAfkC6ZKMDy6%3DQ%40mail.gmail.com -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Thu, 7 Sep 2017 19:42:36 +0300 Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > Hello hackers! > > I've attached a patch that implements custom compression > methods. This patch is based on Nikita Glukhov's code (which he hasn't > publish in mailing lists) for jsonb compression. This is early but > working version of the patch, and there are still few fixes and > features that should be implemented (like pg_dump support and support > of compression options for types), and it requires more testing. But > I'd like to get some feedback at the current stage first. > > There's been a proposal [1] of Alexander Korotkov and some discussion > about custom compression methods before. This is an implementation of > per-datum compression. Syntax is similar to the one in proposal but > not the same. > > Syntax: > > CREATE COMPRESSION METHOD <cmname> HANDLER <compression_handler>; > DROP COMPRESSION METHOD <cmname>; > > Compression handler is a function that returns a structure containing > compression routines: > > - configure - function called when the compression method applied to > an attribute > - drop - called when the compression method is removed from an > attribute > - compress - compress function > - decompress - decompress function > > User can create compressed columns with the commands below: > > CREATE TABLE t(a tsvector COMPRESSED <cmname> WITH <options>); > ALTER TABLE t ALTER COLUMN a SET COMPRESSED <cmname> WITH <options>; > ALTER TABLE t ALTER COLUMN a SET NOT COMPRESSED; > > Also there is syntax of binding compression methods to types: > > ALTER TYPE <type> SET COMPRESSED <cmname>; > ALTER TYPE <type> SET NOT COMPRESSED; > > There are two new tables in the catalog, pg_compression and > pg_compression_opt. pg_compression is used as storage of compression > methods, and pg_compression_opt is used to store specific compression > options for particular column. > > When user binds a compression method to some column a new record in > pg_compression_opt is created and all further attribute values will > contain compression options Oid while old values will remain > unchanged. And when we alter a compression method for > the attribute it won't change previous record in pg_compression_opt. > Instead it'll create a new one and new values will be stored > with new Oid. That way there is no need of recompression of the old > tuples. And also tuples containing compressed datums can be copied to > other tables so records in pg_compression_opt shouldn't be removed. In > the current patch they can be removed with DROP COMPRESSION METHOD > CASCADE, but after that decompression won't be possible on compressed > tuples. Maybe CASCADE should keep compression options. > > I haven't changed the base logic of working with compressed datums. It > means that custom compressed datums behave exactly the same as current > LZ compressed datums, and the logic differs only in > toast_compress_datum and toast_decompress_datum. > > This patch doesn't break backward compability and should work > seamlessly with older version of database. I used one of two free > bits in `va_rawsize` from `varattrib_4b->va_compressed` as flag of > custom compressed datums. Also I renamed it to `va_info` since it > contains not only rawsize now. > > The patch also includes custom compression method for tsvector which > is used in tests. > > [1] > https://www.postgresql.org/message-id/CAPpHfdsdTA5uZeq6MNXL5ZRuNx%2BSig4ykWzWEAfkC6ZKMDy6%3DQ%40mail.gmail.com Attached rebased version of the patch. Added support of pg_dump, the code was simplified, and a separate cache for compression options was added. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On 9/12/17 10:55, Ildus Kurbangaliev wrote: >> The patch also includes custom compression method for tsvector which >> is used in tests. >> >> [1] >> https://www.postgresql.org/message-id/CAPpHfdsdTA5uZeq6MNXL5ZRuNx%2BSig4ykWzWEAfkC6ZKMDy6%3DQ%40mail.gmail.com > Attached rebased version of the patch. Added support of pg_dump, the > code was simplified, and a separate cache for compression options was > added. I would like to see some more examples of how this would be used, so we can see how it should all fit together. So far, it's not clear to me that we need a compression method as a standalone top-level object. It would make sense, perhaps, to have a compression function attached to a type, so a type can provide a compression function that is suitable for its specific storage. The proposal here is very general: You can use any of the eligible compression methods for any attribute. That seems very complicated to manage. Any attribute could be compressed using either a choice of general compression methods or a type-specific compression method, or perhaps another type-specific compression method. That's a lot. Is this about packing certain types better, or trying out different compression algorithms, or about changing the TOAST thresholds, and so on? Ideally, we would like something that just works, with minimal configuration and nudging. Let's see a list of problems to be solved and then we can discuss what the right set of primitives might be to address them. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Wed, 1 Nov 2017 17:05:58 -0400 Peter Eisentraut <peter.eisentraut@2ndquadrant.com> wrote: > On 9/12/17 10:55, Ildus Kurbangaliev wrote: > >> The patch also includes custom compression method for tsvector > >> which is used in tests. > >> > >> [1] > >> https://www.postgresql.org/message-id/CAPpHfdsdTA5uZeq6MNXL5ZRuNx%2BSig4ykWzWEAfkC6ZKMDy6%3DQ%40mail.gmail.com > > Attached rebased version of the patch. Added support of pg_dump, the > > code was simplified, and a separate cache for compression options > > was added. > > I would like to see some more examples of how this would be used, so > we can see how it should all fit together. > > So far, it's not clear to me that we need a compression method as a > standalone top-level object. It would make sense, perhaps, to have a > compression function attached to a type, so a type can provide a > compression function that is suitable for its specific storage. In this patch compression methods is suitable for MAIN and EXTENDED storages like in current implementation in postgres. Just instead only of LZ4 you can specify any other compression method. Idea is not to change compression for some types, but give the user and extension developers opportunity to change how data in some attribute will be compressed because they know about it more than database itself. > > The proposal here is very general: You can use any of the eligible > compression methods for any attribute. That seems very complicated to > manage. Any attribute could be compressed using either a choice of > general compression methods or a type-specific compression method, or > perhaps another type-specific compression method. That's a lot. Is > this about packing certain types better, or trying out different > compression algorithms, or about changing the TOAST thresholds, and > so on? It is about extensibility of postgres, for example if you need to store a lot of time series data you can create an extension that stores array of timestamps in more optimized way, using delta encoding or something else. I'm not sure that such specialized things should be in core. In case of array of timestamps in could look like this: CREATE EXTENSION timeseries; -- some extension that provides compression method Extension installs a compression method: CREATE OR REPLACE FUNCTION timestamps_compression_handler(INTERNAL) RETURNS COMPRESSION_HANDLER AS 'MODULE_PATHNAME', 'timestamps_compression_handler' LANGUAGE C STRICT; CREATE COMPRESSION METHOD cm1 HANDLER timestamps_compression_handler; And user can specify it in his table: CREATE TABLE t1 (time_series_data timestamp[] COMPRESSED cm1; ) I think generalization of some method to a type is not a good idea. For some attribute you could be happy with builtin LZ4, for other you can need more compressibility and so on. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Tue, 12 Sep 2017 17:55:05 +0300 Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > > Attached rebased version of the patch. Added support of pg_dump, the > code was simplified, and a separate cache for compression options was > added. > Attached version 3 of the patch. Rebased to the current master, removed ALTER TYPE .. SET COMPRESSED syntax, fixed bug in compression options cache. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On 2 November 2017 at 17:41, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > In this patch compression methods is suitable for MAIN and EXTENDED > storages like in current implementation in postgres. Just instead only > of LZ4 you can specify any other compression method. We've had this discussion before. Please read the "pluggable compression support" thread. See you in a few days ;) sorry, it's kinda long. https://www.postgresql.org/message-id/flat/20130621000900.GA12425%40alap2.anarazel.de#20130621000900.GA12425@alap2.anarazel.de IIRC there were some concerns about what happened with pg_upgrade, with consuming precious toast bits, and a few other things. -- Craig Ringer http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Thu, Nov 2, 2017 at 6:02 PM, Craig Ringer <craig@2ndquadrant.com> wrote: > On 2 November 2017 at 17:41, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: > >> In this patch compression methods is suitable for MAIN and EXTENDED >> storages like in current implementation in postgres. Just instead only >> of LZ4 you can specify any other compression method. > > We've had this discussion before. > > Please read the "pluggable compression support" thread. See you in a > few days ;) sorry, it's kinda long. > > https://www.postgresql.org/message-id/flat/20130621000900.GA12425%40alap2.anarazel.de#20130621000900.GA12425@alap2.anarazel.de > the proposed patch provides "pluggable" compression and let's user decide by their own which algorithm to use. The postgres core doesn't responsible for any patent problem. > IIRC there were some concerns about what happened with pg_upgrade, > with consuming precious toast bits, and a few other things. yes, pg_upgrade may be a problem. > > -- > Craig Ringer http://www.2ndQuadrant.com/ > PostgreSQL Development, 24x7 Support, Training & Services > > > -- > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-hackers -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Sun, Nov 5, 2017 at 2:22 PM, Oleg Bartunov <obartunov@gmail.com> wrote: >> IIRC there were some concerns about what happened with pg_upgrade, >> with consuming precious toast bits, and a few other things. > > yes, pg_upgrade may be a problem. A basic problem here is that, as proposed, DROP COMPRESSION METHOD may break your database irretrievably. If there's no data compressed using the compression method you dropped, everything is cool - otherwise everything is broken and there's no way to recover. The only obvious alternative is to disallow DROP altogether (or make it not really DROP). Both of those alternatives sound fairly unpleasant to me, but I'm not exactly sure what to recommend in terms of how to make it better. Ideally anything we expose as an SQL command should have a DROP command that undoes whatever CREATE did and leaves the database in an intact state, but that seems hard to achieve in this case. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
> If there's no data compressed > using the compression method you dropped, everything is cool - > otherwise everything is broken and there's no way to recover. > The only obvious alternative is to disallow DROP altogether (or make it > not really DROP). Wouldn't whatever was using the compression method have something marking which method was used? If so, couldn't we just scan if there is any data using it, and if so disallow the drop, or possibly an option to allow the drop and rewrite the table either uncompressed, or with the default compression method? -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Robert Haas <robertmhaas@gmail.com> writes:
> A basic problem here is that, as proposed, DROP COMPRESSION METHOD may
> break your database irretrievably. If there's no data compressed
> using the compression method you dropped, everything is cool -
> otherwise everything is broken and there's no way to recover. The
> only obvious alternative is to disallow DROP altogether (or make it
> not really DROP).
> Both of those alternatives sound fairly unpleasant to me, but I'm not
> exactly sure what to recommend in terms of how to make it better.
> Ideally anything we expose as an SQL command should have a DROP
> command that undoes whatever CREATE did and leaves the database in an
> intact state, but that seems hard to achieve in this case.
If the use of a compression method is tied to specific data types and/or
columns, then each of those could have a dependency on the compression
method, forcing a type or column drop if you did DROP COMPRESSION METHOD.
That would leave no reachable data using the removed compression method.
So that part doesn't seem unworkable on its face.
IIRC, the bigger concerns in the last discussion had to do with
replication, ie, can downstream servers make sense of the data.
Maybe that's not any worse than the issues you get with non-core
index AMs, but I'm not sure.
regards, tom lane
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
On Thu, 2 Nov 2017 23:02:34 +0800 Craig Ringer <craig@2ndquadrant.com> wrote: > On 2 November 2017 at 17:41, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: > > > In this patch compression methods is suitable for MAIN and EXTENDED > > storages like in current implementation in postgres. Just instead > > only of LZ4 you can specify any other compression method. > > We've had this discussion before. > > Please read the "pluggable compression support" thread. See you in a > few days ;) sorry, it's kinda long. > > https://www.postgresql.org/message-id/flat/20130621000900.GA12425%40alap2.anarazel.de#20130621000900.GA12425@alap2.anarazel.de > > IIRC there were some concerns about what happened with pg_upgrade, > with consuming precious toast bits, and a few other things. > Thank you for the link, I didn't see that thread when I looked over mailing lists. I read it briefly, and I can address few things relating to my patch. Most concerns have been related with legal issues. Actually that was the reason I did not include any new compression algorithms to my patch. Unlike that patch mine only provides syntax and is just a way to give the users use their own compression algorithms and deal with any legal issues themselves. I use only one unused bit in header (there's still one free ;), that's enough to determine that data is compressed or not. I did found out that pg_upgrade doesn't work properly with my patch, soon I will send fix for it. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Thu, 2 Nov 2017 15:28:36 +0300 Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > On Tue, 12 Sep 2017 17:55:05 +0300 > Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > > > > > Attached rebased version of the patch. Added support of pg_dump, the > > code was simplified, and a separate cache for compression options > > was added. > > > > Attached version 3 of the patch. Rebased to the current master, > removed ALTER TYPE .. SET COMPRESSED syntax, fixed bug in compression > options cache. > Attached version 4 of the patch. Fixed pg_upgrade and few other bugs. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On Sun, 5 Nov 2017 17:34:23 -0500 Robert Haas <robertmhaas@gmail.com> wrote: > On Sun, Nov 5, 2017 at 2:22 PM, Oleg Bartunov <obartunov@gmail.com> > wrote: > >> IIRC there were some concerns about what happened with pg_upgrade, > >> with consuming precious toast bits, and a few other things. > > > > yes, pg_upgrade may be a problem. > > A basic problem here is that, as proposed, DROP COMPRESSION METHOD may > break your database irretrievably. If there's no data compressed > using the compression method you dropped, everything is cool - > otherwise everything is broken and there's no way to recover. The > only obvious alternative is to disallow DROP altogether (or make it > not really DROP). In the patch I use separate table for compresssion options (because each attribute can have additional options for compression). So basicly compressed attribute linked to compression options, not the compression method and this method can be safely dropped. So in the next version of the patch I can just unlink the options from compression methods and dropping compression method will not affect already compressed tuples. They still could be decompressed. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Wed, Nov 15, 2017 at 4:09 AM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > So in the next version of the patch I can just unlink the options from > compression methods and dropping compression method will not affect > already compressed tuples. They still could be decompressed. I guess I don't understand how that can work. I mean, if somebody removes a compression method - i.e. uninstalls the library - and you don't have a way to make sure there are no tuples that can only be uncompressed by that library - then you've broken the database. Ideally, there should be a way to add a new compression method via an extension ... and then get rid of it and all dependencies thereupon. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi Ildus, On 14.11.2017 16:23, Ildus Kurbangaliev wrote: > On Thu, 2 Nov 2017 15:28:36 +0300 Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: > >> On Tue, 12 Sep 2017 17:55:05 +0300 Ildus Kurbangaliev >> <i.kurbangaliev@postgrespro.ru> wrote: >> >>> >>> Attached rebased version of the patch. Added support of pg_dump, >>> the code was simplified, and a separate cache for compression >>> options was added. >>> >> >> Attached version 3 of the patch. Rebased to the current master, >> removed ALTER TYPE .. SET COMPRESSED syntax, fixed bug in >> compression options cache. >> > > Attached version 4 of the patch. Fixed pg_upgrade and few other > bugs. > I've started to review your code. And even though it's fine overall I have few questions and comments (aside from DROP COMPRESSION METHOD discussion). 1. I'm not sure about proposed syntax for ALTER TABLE command: >> ALTER TABLE t ALTER COLUMN a SET COMPRESSED <cmname> WITH >> (<options>); ALTER TABLE t ALTER COLUMN a SET NOT COMPRESSED; ISTM it is more common for Postgres to use syntax like SET/DROP for column options (SET/DROP NOT NULL, DEFAULT etc). My suggestion would be: ALTER TABLE t ALTER COLUMN a SET COMPRESSED USING <compression_method> WITH (<options>); ALTER TABLE t ALTER COLUMN a DROP COMPRESSED; (keyword USING here is similar to "CREATE INDEX ... USING <method>" syntax) 2. The way you changed DefineRelation() implies that caller is responsible for creation of compression options. Probably it would be better to create them within DefineRelation(). 3. Few minor issues which seem like obsolete code: Function freeRelOptions() is defined but never used. Function getBaseTypeTuple() has been extracted from getBaseTypeAndTypmod() but never used separately. In toast_flatten_tuple_to_datum() there is untoasted_value variable which is only used for meaningless assignment. (Should I send a patch for that kind of issues?) -- Ildar Musin i.musin@postgrespro.ru
Hi, On 11/14/2017 02:23 PM, Ildus Kurbangaliev wrote: > > ... > > Attached version 4 of the patch. Fixed pg_upgrade and few other bugs. > I did a review of this today, and I think there are some things that need improvement / fixing. Firstly, some basic comments from just eye-balling the diff, then some bugs I discovered after writing an extension adding lz4. 1) formatRelOptions/freeRelOptions are no longer needed (I see Ildar already pointer that out) 2) There's unnecessary whitespace (extra newlines) on a couple of places, which is needlessly increasing the size of the patch. Small difference, but annoying. 3) tuptoaster.c Why do you change 'info' from int32 to uint32? Seems unnecessary. Adding new 'att' variable in toast_insert_or_update is confusing, as there already is 'att' in the very next loop. Technically it's correct, but I'd bet it'll lead to some WTF?! moments later. I propose to just use TupleDescAttr(tupleDesc,i) on the two places where it matters, around line 808. There are no comments for init_compression_options_htab and get_compression_options_info, so that needs to be fixed. Moreover, the names are confusing because what we really get is not just 'options' but the compression routines too. 4) gen_db_file_maps probably shouldn't do the fprints, right? 5) not sure why you modify src/tools/pgindent/exclude_file_patterns 6) I'm rather confused by AttributeCompression vs. ColumnCompression. I mean, attribute==column, right? Of course, one is for data from parser, the other one is for internal info. But can we make the naming clearer? 7) The docs in general are somewhat unsatisfactory, TBH. For example the ColumnCompression has no comments, unlike everything else in parsenodes. Similarly for the SGML docs - I suggest to expand them to resemble FDW docs (https://www.postgresql.org/docs/10/static/fdwhandler.html) which also follows the handler/routines pattern. 8) One of the unclear things if why we even need 'drop' routing. It seems that if it's defined DropAttributeCompression does something. But what should it do? I suppose dropping the options should be done using dependencies (just like we drop columns in this case). BTW why does DropAttributeCompression mess with att->attisdropped in this way? That seems a bit odd. 9) configure routines that only check if (options != NIL) and then error out (like tsvector_configure) seem a bit unnecessary. Just allow it to be NULL in CompressionMethodRoutine, and throw an error if options is not NIL for such compression method. 10) toast_compress_datum still does this: if (!ac && (valsize < PGLZ_strategy_default->min_input_size || valsize > PGLZ_strategy_default->max_input_size)) which seems rather pglz-specific (the naming is a hint). Why shouldn't this be specific to compression, exposed either as min/max constants, or wrapped in another routine - size_is_valid() or something like that? 11) The comments in toast_compress_datum probably need updating, as it still references to pglz specifically. I guess the new compression methods do matter too. 12) get_compression_options_info organizes the compression info into a hash table by OID. The hash table implementation assumes the hash key is at the beginning of the entry, but AttributeCompression is defined like this: typedef struct { CompressionMethodRoutine *routine; List *options; Oid cmoptoid; } AttributeCompression; Which means get_compression_options_info is busted, will never lookup anything, and the hash table will grow by adding more and more entries into the same bucket. Of course, this has extremely negative impact on performance (pretty much arbitrarily bad, depending on how many entries you've already added to the hash table). Moving the OID to the beginning of the struct fixes the issue. 13) When writing the experimental extension, I was extremely confused about the regular varlena headers, custom compression headers, etc. In the end I stole the code from tsvector.c and whacked it a bit until it worked, but I wouldn't dare to claim I understand how it works. This needs to be documented somewhere. For example postgres.h has a bunch of paragraphs about varlena headers, so perhaps it should be there? I see the patch tweaks some of the constants, but does not update the comment at all. Perhaps it would be useful to provide some additional macros making access to custom-compressed varlena values easier. Or perhaps the VARSIZE_ANY / VARSIZE_ANY_EXHDR / VARDATA_ANY already support that? This part is not very clear to me. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On 11/15/2017 02:13 PM, Robert Haas wrote: > On Wed, Nov 15, 2017 at 4:09 AM, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: >> So in the next version of the patch I can just unlink the options from >> compression methods and dropping compression method will not affect >> already compressed tuples. They still could be decompressed. > > I guess I don't understand how that can work. I mean, if somebody > removes a compression method - i.e. uninstalls the library - and you > don't have a way to make sure there are no tuples that can only be > uncompressed by that library - then you've broken the database. > Ideally, there should be a way to add a new compression method via an > extension ... and then get rid of it and all dependencies thereupon. > I share your confusion. Once you do DROP COMPRESSION METHOD, there must be no remaining data compressed with it. But that's what the patch is doing already - it enforces this using dependencies, as usual. Ildus, can you explain what you meant? How could the data still be decompressed after DROP COMPRESSION METHOD, and possibly after removing the .so library? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, 20 Nov 2017 00:23:23 +0100 Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 11/15/2017 02:13 PM, Robert Haas wrote: > > On Wed, Nov 15, 2017 at 4:09 AM, Ildus Kurbangaliev > > <i.kurbangaliev@postgrespro.ru> wrote: > >> So in the next version of the patch I can just unlink the options > >> from compression methods and dropping compression method will not > >> affect already compressed tuples. They still could be > >> decompressed. > > > > I guess I don't understand how that can work. I mean, if somebody > > removes a compression method - i.e. uninstalls the library - and you > > don't have a way to make sure there are no tuples that can only be > > uncompressed by that library - then you've broken the database. > > Ideally, there should be a way to add a new compression method via > > an extension ... and then get rid of it and all dependencies > > thereupon. > > I share your confusion. Once you do DROP COMPRESSION METHOD, there > must be no remaining data compressed with it. But that's what the > patch is doing already - it enforces this using dependencies, as > usual. > > Ildus, can you explain what you meant? How could the data still be > decompressed after DROP COMPRESSION METHOD, and possibly after > removing the .so library? The removal of the .so library will broke all compressed tuples. I don't see a way to avoid it. I meant that DROP COMPRESSION METHOD could remove the record from 'pg_compression' table, but actually the compressed tuple needs only a record from 'pg_compression_opt' where its options are located. And there is dependency between an extension and the options so you can't just remove the extension without CASCADE, postgres will complain. Still it's a problem if the user used for example `SELECT <compressed_column> INTO * FROM *` because postgres will copy compressed tuples, and there will not be any dependencies between destination and the options. Also thank you for review. I will look into it today. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On 11/20/2017 10:44 AM, Ildus Kurbangaliev wrote: > On Mon, 20 Nov 2017 00:23:23 +0100 > Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > >> On 11/15/2017 02:13 PM, Robert Haas wrote: >>> On Wed, Nov 15, 2017 at 4:09 AM, Ildus Kurbangaliev >>> <i.kurbangaliev@postgrespro.ru> wrote: >>>> So in the next version of the patch I can just unlink the options >>>> from compression methods and dropping compression method will not >>>> affect already compressed tuples. They still could be >>>> decompressed. >>> >>> I guess I don't understand how that can work. I mean, if somebody >>> removes a compression method - i.e. uninstalls the library - and you >>> don't have a way to make sure there are no tuples that can only be >>> uncompressed by that library - then you've broken the database. >>> Ideally, there should be a way to add a new compression method via >>> an extension ... and then get rid of it and all dependencies >>> thereupon. >> >> I share your confusion. Once you do DROP COMPRESSION METHOD, there >> must be no remaining data compressed with it. But that's what the >> patch is doing already - it enforces this using dependencies, as >> usual. >> >> Ildus, can you explain what you meant? How could the data still be >> decompressed after DROP COMPRESSION METHOD, and possibly after >> removing the .so library? > > The removal of the .so library will broke all compressed tuples. I > don't see a way to avoid it. I meant that DROP COMPRESSION METHOD could > remove the record from 'pg_compression' table, but actually the > compressed tuple needs only a record from 'pg_compression_opt' where > its options are located. And there is dependency between an extension > and the options so you can't just remove the extension without CASCADE, > postgres will complain. > I don't think we need to do anything smart here - it should behave just like dropping a data type, for example. That is, error out if there are columns using the compression method (without CASCADE), and drop all the columns (with CASCADE). Leaving around the pg_compression_opt is not a solution. Not only it's confusing and I'm not aware about any extension because the user is likely to remove the .so file (perhaps not directly, but e.g. by removing the rpm package providing it). > Still it's a problem if the user used for example `SELECT > <compressed_column> INTO * FROM *` because postgres will copy compressed > tuples, and there will not be any dependencies between destination and > the options. > This seems like a rather fatal design flaw, though. I'd say we need to force recompression of the data, in such cases. Otherwise all the dependency tracking is rather pointless. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Nov 20, 2017, at 18:18, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
I don't think we need to do anything smart here - it should behave just
like dropping a data type, for example. That is, error out if there are
columns using the compression method (without CASCADE), and drop all the
columns (with CASCADE).
What about instead of dropping column we leave data uncompressed?
On 11/20/2017 04:21 PM, Евгений Шишкин wrote: > > >> On Nov 20, 2017, at 18:18, Tomas Vondra <tomas.vondra@2ndquadrant.com >> <mailto:tomas.vondra@2ndquadrant.com>> wrote: >> >> >> I don't think we need to do anything smart here - it should behave just >> like dropping a data type, for example. That is, error out if there are >> columns using the compression method (without CASCADE), and drop all the >> columns (with CASCADE). > > What about instead of dropping column we leave data uncompressed? > That requires you to go through the data and rewrite the whole table. And I'm not aware of a DROP command doing that, instead they just drop the dependent objects (e.g. DROP TYPE, ...). So per PLOS the DROP COMPRESSION METHOD command should do that too. But I'm wondering if ALTER COLUMN ... SET NOT COMPRESSED should do that (currently it only disables compression for new data). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
> On Nov 20, 2017, at 18:29, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > >> >> What about instead of dropping column we leave data uncompressed? >> > > That requires you to go through the data and rewrite the whole table. > And I'm not aware of a DROP command doing that, instead they just drop > the dependent objects (e.g. DROP TYPE, ...). So per PLOS the DROP > COMPRESSION METHOD command should do that too. Well, there is no much you can do with DROP TYPE. But i'd argue that compression is different. We do not drop data in case of DROP STATISTICS or DROP INDEX. At least there should be a way to easily alter compression method then.
On Mon, 20 Nov 2017 16:29:11 +0100 Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 11/20/2017 04:21 PM, Евгений Шишкин wrote: > > > > > >> On Nov 20, 2017, at 18:18, Tomas Vondra > >> <tomas.vondra@2ndquadrant.com > >> <mailto:tomas.vondra@2ndquadrant.com>> wrote: > >> > >> > >> I don't think we need to do anything smart here - it should behave > >> just like dropping a data type, for example. That is, error out if > >> there are columns using the compression method (without CASCADE), > >> and drop all the columns (with CASCADE). > > > > What about instead of dropping column we leave data uncompressed? > > > > That requires you to go through the data and rewrite the whole table. > And I'm not aware of a DROP command doing that, instead they just drop > the dependent objects (e.g. DROP TYPE, ...). So per PLOS the DROP > COMPRESSION METHOD command should do that too. > > But I'm wondering if ALTER COLUMN ... SET NOT COMPRESSED should do > that (currently it only disables compression for new data). If the table is big, decompression could take an eternity. That's why i decided to only to disable it and the data could be decompressed using compression options. My idea was to keep compression options forever, since there will not be much of them in one database. Still that requires that extension is not removed. I will try to find a way how to recompress data first in case it moves to another table. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On 11/20/2017 04:43 PM, Евгений Шишкин wrote: > > >> On Nov 20, 2017, at 18:29, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >> >>> >>> What about instead of dropping column we leave data uncompressed? >>> >> >> That requires you to go through the data and rewrite the whole table. >> And I'm not aware of a DROP command doing that, instead they just drop >> the dependent objects (e.g. DROP TYPE, ...). So per PLOS the DROP >> COMPRESSION METHOD command should do that too. > > Well, there is no much you can do with DROP TYPE. But i'd argue that compression > is different. We do not drop data in case of DROP STATISTICS or DROP INDEX. > But those DROP commands do not 'invalidate' data in the heap, so there's no reason to drop the columns. > At least there should be a way to easily alter compression method then. > +1 regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, 20 Nov 2017 00:04:53 +0100 Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > I did a review of this today, and I think there are some things that > need improvement / fixing. > > Firstly, some basic comments from just eye-balling the diff, then some > bugs I discovered after writing an extension adding lz4. > > 1) formatRelOptions/freeRelOptions are no longer needed (I see Ildar > already pointer that out) I removed freeRelOptions, but formatRelOptions is used in other place. > > 2) There's unnecessary whitespace (extra newlines) on a couple of > places, which is needlessly increasing the size of the patch. Small > difference, but annoying. Cleaned up. > > 3) tuptoaster.c > > Why do you change 'info' from int32 to uint32? Seems unnecessary. That's because I use highest bit, and it makes number negative for int32. I use right shifting to get that bit and right shift on negative gives negative value too. > > Adding new 'att' variable in toast_insert_or_update is confusing, as > there already is 'att' in the very next loop. Technically it's > correct, but I'd bet it'll lead to some WTF?! moments later. I > propose to just use TupleDescAttr(tupleDesc,i) on the two places > where it matters, around line 808. > > There are no comments for init_compression_options_htab and > get_compression_options_info, so that needs to be fixed. Moreover, the > names are confusing because what we really get is not just 'options' > but the compression routines too. Removed extra 'att', and added comments. > > 4) gen_db_file_maps probably shouldn't do the fprints, right? > > 5) not sure why you modify src/tools/pgindent/exclude_file_patterns My bad, removed these lines. > > 6) I'm rather confused by AttributeCompression vs. ColumnCompression. > I mean, attribute==column, right? Of course, one is for data from > parser, the other one is for internal info. But can we make the > naming clearer? For now I have renamed AttributeCompression to CompressionOptions, not sure that's a good name but at least it gives less confusion. > > 7) The docs in general are somewhat unsatisfactory, TBH. For example > the ColumnCompression has no comments, unlike everything else in > parsenodes. Similarly for the SGML docs - I suggest to expand them to > resemble FDW docs > (https://www.postgresql.org/docs/10/static/fdwhandler.html) which > also follows the handler/routines pattern. I've added more comments. I think I'll add more documentation if the committers will approve current syntax. > > 8) One of the unclear things if why we even need 'drop' routing. It > seems that if it's defined DropAttributeCompression does something. > But what should it do? I suppose dropping the options should be done > using dependencies (just like we drop columns in this case). > > BTW why does DropAttributeCompression mess with att->attisdropped in > this way? That seems a bit odd. 'drop' routine could be useful. An extension could do something related with the attribute, like remove extra tables or something else. The compression options will not be removed after unlinking compression method from a column because there is still be stored compressed data in that column. That 'attisdropped' part has been removed. > > 9) configure routines that only check if (options != NIL) and then > error out (like tsvector_configure) seem a bit unnecessary. Just > allow it to be NULL in CompressionMethodRoutine, and throw an error > if options is not NIL for such compression method. Good idea, done. > > 10) toast_compress_datum still does this: > > if (!ac && (valsize < PGLZ_strategy_default->min_input_size || > valsize > PGLZ_strategy_default->max_input_size)) > > which seems rather pglz-specific (the naming is a hint). Why shouldn't > this be specific to compression, exposed either as min/max constants, > or wrapped in another routine - size_is_valid() or something like > that? I agree, moved to the next block related with pglz. > > 11) The comments in toast_compress_datum probably need updating, as it > still references to pglz specifically. I guess the new compression > methods do matter too. Done. > > 12) get_compression_options_info organizes the compression info into a > hash table by OID. The hash table implementation assumes the hash key > is at the beginning of the entry, but AttributeCompression is defined > like this: > > typedef struct > { > CompressionMethodRoutine *routine; > List *options; > Oid cmoptoid; > } AttributeCompression; > > Which means get_compression_options_info is busted, will never lookup > anything, and the hash table will grow by adding more and more entries > into the same bucket. Of course, this has extremely negative impact on > performance (pretty much arbitrarily bad, depending on how many > entries you've already added to the hash table). > > Moving the OID to the beginning of the struct fixes the issue. Yeah, I fixed it before, but somehow managed to do not include it to the patch. > > 13) When writing the experimental extension, I was extremely confused > about the regular varlena headers, custom compression headers, etc. In > the end I stole the code from tsvector.c and whacked it a bit until it > worked, but I wouldn't dare to claim I understand how it works. > > This needs to be documented somewhere. For example postgres.h has a > bunch of paragraphs about varlena headers, so perhaps it should be > there? I see the patch tweaks some of the constants, but does not > update the comment at all. This point is good, I'm not sure how this documentation should look like. I've just assumed that people should have deep undestanding of varlenas if they're going to compress them. But now it's easy to make mistake there. Maybe I should add some functions that help to construct varlena, with different headers. I like the way is how jsonb is constructed. It uses StringInfo and there are few helper functions (reserveFromBuffer, appendToBuffer and others). Maybe they should be not static. > > Perhaps it would be useful to provide some additional macros making > access to custom-compressed varlena values easier. Or perhaps the > VARSIZE_ANY / VARSIZE_ANY_EXHDR / VARDATA_ANY already support that? > This part is not very clear to me. These macros will work, custom compressed varlenas behave like old compressed varlenas. > > Still it's a problem if the user used for example `SELECT > > <compressed_column> INTO * FROM *` because postgres will copy > > compressed tuples, and there will not be any dependencies between > > destination and the options. > > > > This seems like a rather fatal design flaw, though. I'd say we need to > force recompression of the data, in such cases. Otherwise all the > dependency tracking is rather pointless. Fixed this problem too. I've added recompression for datum that use custom compression. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
Hi, On 11/21/2017 03:47 PM, Ildus Kurbangaliev wrote: > On Mon, 20 Nov 2017 00:04:53 +0100 > Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > ... > >> 6) I'm rather confused by AttributeCompression vs. >> ColumnCompression. I mean, attribute==column, right? Of course, one >> is for data from parser, the other one is for internal info. But >> can we make the naming clearer? > > For now I have renamed AttributeCompression to CompressionOptions, > not sure that's a good name but at least it gives less confusion. > I propose to use either CompressionMethodOptions (and CompressionMethodRoutine) or CompressionOptions (and CompressionRoutine) >> >> 7) The docs in general are somewhat unsatisfactory, TBH. For example >> the ColumnCompression has no comments, unlike everything else in >> parsenodes. Similarly for the SGML docs - I suggest to expand them to >> resemble FDW docs >> (https://www.postgresql.org/docs/10/static/fdwhandler.html) which >> also follows the handler/routines pattern. > > I've added more comments. I think I'll add more documentation if the > committers will approve current syntax. > OK. Haven't reviewed this yet. >> >> 8) One of the unclear things if why we even need 'drop' routing. It >> seems that if it's defined DropAttributeCompression does something. >> But what should it do? I suppose dropping the options should be done >> using dependencies (just like we drop columns in this case). >> >> BTW why does DropAttributeCompression mess with att->attisdropped in >> this way? That seems a bit odd. > > 'drop' routine could be useful. An extension could do something > related with the attribute, like remove extra tables or something > else. The compression options will not be removed after unlinking > compression method from a column because there is still be stored > compressed data in that column. > OK. So something like a "global" dictionary used for the column, or something like that? Sure, seems useful and I've been thinking about that, but I think we badly need some extension using that, even if in a very simple way. Firstly, we need a "how to" example, secondly we need some way to test it. >> >> 13) When writing the experimental extension, I was extremely >> confused about the regular varlena headers, custom compression >> headers, etc. In the end I stole the code from tsvector.c and >> whacked it a bit until it worked, but I wouldn't dare to claim I >> understand how it works. >> >> This needs to be documented somewhere. For example postgres.h has >> a bunch of paragraphs about varlena headers, so perhaps it should >> be there? I see the patch tweaks some of the constants, but does >> not update the comment at all. > > This point is good, I'm not sure how this documentation should look > like. I've just assumed that people should have deep undestanding of > varlenas if they're going to compress them. But now it's easy to > make mistake there. Maybe I should add some functions that help to > construct varlena, with different headers. I like the way is how > jsonb is constructed. It uses StringInfo and there are few helper > functions (reserveFromBuffer, appendToBuffer and others). Maybe they > should be not static. > Not sure. My main problem was not understanding how this affects the varlena header, etc. And I had no idea where to look. >> >> Perhaps it would be useful to provide some additional macros >> making access to custom-compressed varlena values easier. Or >> perhaps the VARSIZE_ANY / VARSIZE_ANY_EXHDR / VARDATA_ANY already >> support that? This part is not very clear to me. > > These macros will work, custom compressed varlenas behave like old > compressed varlenas. > OK. But then I don't understand why tsvector.c does things like VARSIZE(data) - VARHDRSZ_CUSTOM_COMPRESSED - arrsize VARRAWSIZE_4B_C(data) - arrsize instead of VARSIZE_ANY_EXHDR(data) - arrsize VARSIZE_ANY(data) - arrsize Seems somewhat confusing. >>> Still it's a problem if the user used for example `SELECT >>> <compressed_column> INTO * FROM *` because postgres will copy >>> compressed tuples, and there will not be any dependencies >>> between destination and the options. >>> >> >> This seems like a rather fatal design flaw, though. I'd say we need >> to force recompression of the data, in such cases. Otherwise all >> the dependency tracking is rather pointless. > > Fixed this problem too. I've added recompression for datum that use > custom compression. > Hmmm, it still doesn't work for me. See this: test=# create extension pg_lz4 ; CREATE EXTENSION test=# create table t_lz4 (v text compressed lz4); CREATE TABLE test=# create table t_pglz (v text); CREATE TABLE test=# insert into t_lz4 select repeat(md5(1::text),300); INSERT 0 1 test=# insert into t_pglz select * from t_lz4; INSERT 0 1 test=# drop extension pg_lz4 cascade; NOTICE: drop cascades to 2 other objects DETAIL: drop cascades to compression options for lz4 drop cascades to table t_lz4 column v DROP EXTENSION test=# \c test You are now connected to database "test" as user "user". test=# insert into t_lz4 select repeat(md5(1::text),300);^C test=# select * from t_pglz ; ERROR: cache lookup failed for compression options 16419 That suggests no recompression happened. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, 21 Nov 2017 18:47:49 +0100 Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > I propose to use either > > CompressionMethodOptions (and CompressionMethodRoutine) > > or > > CompressionOptions (and CompressionRoutine) Sounds good, thanks. > > OK. But then I don't understand why tsvector.c does things like > > VARSIZE(data) - VARHDRSZ_CUSTOM_COMPRESSED - arrsize > VARRAWSIZE_4B_C(data) - arrsize > > instead of > > VARSIZE_ANY_EXHDR(data) - arrsize > VARSIZE_ANY(data) - arrsize > > Seems somewhat confusing. > VARRAWSIZE_4B_C returns original size of data, before compression (from va_rawsize in current postgres, and from va_info in my patch), not size of the already compressed data, so you can't use VARSIZE_ANY here. VARSIZE_ANY_EXHDR in current postgres returns VARSIZE-VARHDRSZ, despite the varlena is compressed or not, so I just kept this behavior for custom compressed varlenas too. If you look into tuptoaster.c you will also see lines like 'VARSIZE(attr) - TOAST_COMPRESS_HDRSZ'. So I think if VARSIZE_ANY_EXHDR will subtract different header sizes then it should subtract them for usual compressed varlenas too. > > > > Hmmm, it still doesn't work for me. See this: > > test=# create extension pg_lz4 ; > CREATE EXTENSION > test=# create table t_lz4 (v text compressed lz4); > CREATE TABLE > test=# create table t_pglz (v text); > CREATE TABLE > test=# insert into t_lz4 select repeat(md5(1::text),300); > INSERT 0 1 > test=# insert into t_pglz select * from t_lz4; > INSERT 0 1 > test=# drop extension pg_lz4 cascade; > NOTICE: drop cascades to 2 other objects > DETAIL: drop cascades to compression options for lz4 > drop cascades to table t_lz4 column v > DROP EXTENSION > test=# \c test > You are now connected to database "test" as user "user". > test=# insert into t_lz4 select repeat(md5(1::text),300);^C > test=# select * from t_pglz ; > ERROR: cache lookup failed for compression options 16419 > > That suggests no recompression happened. I will check that. Is your extension published somewhere?
On 11/21/2017 09:28 PM, Ildus K wrote: >> Hmmm, it still doesn't work for me. See this: >> >> test=# create extension pg_lz4 ; >> CREATE EXTENSION >> test=# create table t_lz4 (v text compressed lz4); >> CREATE TABLE >> test=# create table t_pglz (v text); >> CREATE TABLE >> test=# insert into t_lz4 select repeat(md5(1::text),300); >> INSERT 0 1 >> test=# insert into t_pglz select * from t_lz4; >> INSERT 0 1 >> test=# drop extension pg_lz4 cascade; >> NOTICE: drop cascades to 2 other objects >> DETAIL: drop cascades to compression options for lz4 >> drop cascades to table t_lz4 column v >> DROP EXTENSION >> test=# \c test >> You are now connected to database "test" as user "user". >> test=# insert into t_lz4 select repeat(md5(1::text),300);^C >> test=# select * from t_pglz ; >> ERROR: cache lookup failed for compression options 16419 >> >> That suggests no recompression happened. > > I will check that. Is your extension published somewhere? > No, it was just an experiment, so I've only attached it to the initial review. Attached is an updated version, with a fix or two. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On Tue, 21 Nov 2017 18:47:49 +0100 Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > > > Hmmm, it still doesn't work for me. See this: > > test=# create extension pg_lz4 ; > CREATE EXTENSION > test=# create table t_lz4 (v text compressed lz4); > CREATE TABLE > test=# create table t_pglz (v text); > CREATE TABLE > test=# insert into t_lz4 select repeat(md5(1::text),300); > INSERT 0 1 > test=# insert into t_pglz select * from t_lz4; > INSERT 0 1 > test=# drop extension pg_lz4 cascade; > NOTICE: drop cascades to 2 other objects > DETAIL: drop cascades to compression options for lz4 > drop cascades to table t_lz4 column v > DROP EXTENSION > test=# \c test > You are now connected to database "test" as user "user". > test=# insert into t_lz4 select repeat(md5(1::text),300);^C > test=# select * from t_pglz ; > ERROR: cache lookup failed for compression options 16419 > > That suggests no recompression happened. Should be fixed in the attached patch. I've changed your extension a little bit according changes in the new patch (also in attachments). Also I renamed few functions, added more comments and simplified the code related with DefineRelation (thanks to Ildar Musin suggestion). -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
Hi,
On 11/23/2017 10:38 AM, Ildus Kurbangaliev wrote:
> On Tue, 21 Nov 2017 18:47:49 +0100
> Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
>
>>>
>>
>> Hmmm, it still doesn't work for me. See this:
>>
>> test=# create extension pg_lz4 ;
>> CREATE EXTENSION
>> test=# create table t_lz4 (v text compressed lz4);
>> CREATE TABLE
>> test=# create table t_pglz (v text);
>> CREATE TABLE
>> test=# insert into t_lz4 select repeat(md5(1::text),300);
>> INSERT 0 1
>> test=# insert into t_pglz select * from t_lz4;
>> INSERT 0 1
>> test=# drop extension pg_lz4 cascade;
>> NOTICE: drop cascades to 2 other objects
>> DETAIL: drop cascades to compression options for lz4
>> drop cascades to table t_lz4 column v
>> DROP EXTENSION
>> test=# \c test
>> You are now connected to database "test" as user "user".
>> test=# insert into t_lz4 select repeat(md5(1::text),300);^C
>> test=# select * from t_pglz ;
>> ERROR: cache lookup failed for compression options 16419
>>
>> That suggests no recompression happened.
>
> Should be fixed in the attached patch. I've changed your extension a
> little bit according changes in the new patch (also in attachments).
>
Hmm, this seems to have fixed it, but only in one direction. Consider this:
create table t_pglz (v text); create table t_lz4 (v text compressed lz4);
insert into t_pglz select repeat(md5(i::text),300) from generate_series(1,100000) s(i);
insert into t_lz4 select repeat(md5(i::text),300) from generate_series(1,100000) s(i);
\d+
Schema | Name | Type | Owner | Size | Description --------+--------+-------+-------+-------+-------------
public| t_lz4 | table | user | 12 MB | public | t_pglz | table | user | 18 MB | (2 rows)
truncate t_pglz; insert into t_pglz select * from t_lz4;
\d+
Schema | Name | Type | Owner | Size | Description --------+--------+-------+-------+-------+-------------
public| t_lz4 | table | user | 12 MB | public | t_pglz | table | user | 18 MB | (2 rows)
which is fine. But in the other direction, this happens
truncate t_lz4; insert into t_lz4 select * from t_pglz;
\d+ List of relations Schema | Name | Type | Owner | Size | Description
--------+--------+-------+-------+-------+------------- public | t_lz4 | table | user | 18 MB | public | t_pglz
|table | user | 18 MB | (2 rows)
which means the data is still pglz-compressed. That's rather strange, I
guess, and it should compress the data using the compression method set
for the target table instead.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, 23 Nov 2017 21:54:32 +0100
Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
>
> Hmm, this seems to have fixed it, but only in one direction. Consider
> this:
>
> create table t_pglz (v text);
> create table t_lz4 (v text compressed lz4);
>
> insert into t_pglz select repeat(md5(i::text),300)
> from generate_series(1,100000) s(i);
>
> insert into t_lz4 select repeat(md5(i::text),300)
> from generate_series(1,100000) s(i);
>
> \d+
>
> Schema | Name | Type | Owner | Size | Description
> --------+--------+-------+-------+-------+-------------
> public | t_lz4 | table | user | 12 MB |
> public | t_pglz | table | user | 18 MB |
> (2 rows)
>
> truncate t_pglz;
> insert into t_pglz select * from t_lz4;
>
> \d+
>
> Schema | Name | Type | Owner | Size | Description
> --------+--------+-------+-------+-------+-------------
> public | t_lz4 | table | user | 12 MB |
> public | t_pglz | table | user | 18 MB |
> (2 rows)
>
> which is fine. But in the other direction, this happens
>
> truncate t_lz4;
> insert into t_lz4 select * from t_pglz;
>
> \d+
> List of relations
> Schema | Name | Type | Owner | Size | Description
> --------+--------+-------+-------+-------+-------------
> public | t_lz4 | table | user | 18 MB |
> public | t_pglz | table | user | 18 MB |
> (2 rows)
>
> which means the data is still pglz-compressed. That's rather strange,
> I guess, and it should compress the data using the compression method
> set for the target table instead.
That's actually an interesting issue. It happens because if tuple fits
to page then postgres just moves it as is. I've just added
recompression if it has custom compressed datums to keep dependencies
right. But look:
create table t1(a text); create table t2(a text); alter table t2 alter column a set storage external; insert into t1
selectrepeat(md5(i::text),300) from generate_series(1,100000) s(i); \d+
List of relations Schema | Name | Type | Owner | Size | Description
--------+------+-------+-------+------------+------------- public | t1 | table | ildus | 18 MB | public | t2
|table | ildus | 8192 bytes | (2 rows)
insert into t2 select * from t1;
\d+
List of relations Schema | Name | Type | Owner | Size | Description
--------+------+-------+-------+-------+------------- public | t1 | table | ildus | 18 MB | public | t2 | table |
ildus| 18 MB | (2 rows)
That means compressed datums now in the column with storage specified as
external. I'm not sure that's a bug or a feature. Lets insert them
usual way:
delete from t2; insert into t2 select repeat(md5(i::text),300) from generate_series(1,100000) s(i); \d+
List of relations Schema | Name | Type | Owner | Size | Description
--------+------+-------+-------+---------+------------- public | t1 | table | ildus | 18 MB | public | t2 |
table| ildus | 1011 MB |
Maybe there should be more common solution like comparison of attribute
properties?
--
---
Ildus Kurbangaliev
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Hi, On 11/24/2017 10:38 AM, Ildus Kurbangaliev wrote: > ... > That means compressed datums now in the column with storage > specified as external. I'm not sure that's a bug or a feature. > Interesting. Never realized it behaves like this. Not sure if it's intentional or not (i.e. bug vs. feature). > Lets insert them usual way: > > delete from t2; > insert into t2 select repeat(md5(i::text),300) from > generate_series(1,100000) s(i); > \d+ > > List of relations > Schema | Name | Type | Owner | Size | Description > --------+------+-------+-------+---------+------------- > public | t1 | table | ildus | 18 MB | > public | t2 | table | ildus | 1011 MB | > > Maybe there should be more common solution like comparison of > attribute properties? > Maybe, not sure what the right solution is. I just know that if we allow inserting data into arbitrary tables without recompression, we may end up with data that can't be decompressed. I agree that the behavior with extended storage is somewhat similar, but the important distinction is that while that is surprising the data is still accessible. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi,
I ran into another issue - after inserting some data into a table with a
tsvector column (without any compression defined), I can no longer read
the data.
This is what I get in the console:
db=# select max(md5(body_tsvector::text)) from messages;
ERROR: cache lookup failed for compression options 6432
and the stack trace looks like this:
Breakpoint 1, get_cached_compression_options (cmoptoid=6432) at
tuptoaster.c:2563
2563 elog(ERROR, "cache lookup failed for compression options %u",
cmoptoid);
(gdb) bt
#0 get_cached_compression_options (cmoptoid=6432) at tuptoaster.c:2563
#1 0x00000000004bf3da in toast_decompress_datum (attr=0x2b44148) at
tuptoaster.c:2390
#2 0x00000000004c0c1e in heap_tuple_untoast_attr (attr=0x2b44148) at
tuptoaster.c:225
#3 0x000000000083f976 in pg_detoast_datum (datum=<optimized out>) at
fmgr.c:1829
#4 0x00000000008072de in tsvectorout (fcinfo=0x2b41e00) at tsvector.c:315
#5 0x00000000005fae00 in ExecInterpExpr (state=0x2b414b8,
econtext=0x2b25ab0, isnull=<optimized out>) at execExprInterp.c:1131
#6 0x000000000060bdf4 in ExecEvalExprSwitchContext
(isNull=0x7fffffe9bd37 "", econtext=0x2b25ab0, state=0x2b414b8) at
../../../src/include/executor/executor.h:299
It seems the VARATT_IS_CUSTOM_COMPRESSED incorrectly identifies the
value as custom-compressed for some reason.
Not sure why, but the tsvector column is populated by a trigger that
simply does
NEW.body_tsvector := to_tsvector('english', strip_replies(NEW.body_plain));
If needed, the complete tool is here:
https://bitbucket.org/tvondra/archie
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, 25 Nov 2017 06:40:00 +0100
Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
> Hi,
>
> I ran into another issue - after inserting some data into a table
> with a tsvector column (without any compression defined), I can no
> longer read the data.
>
> This is what I get in the console:
>
> db=# select max(md5(body_tsvector::text)) from messages;
> ERROR: cache lookup failed for compression options 6432
>
> and the stack trace looks like this:
>
> Breakpoint 1, get_cached_compression_options (cmoptoid=6432) at
> tuptoaster.c:2563
> 2563 elog(ERROR, "cache lookup failed for
> compression options %u", cmoptoid);
> (gdb) bt
> #0 get_cached_compression_options (cmoptoid=6432) at
> tuptoaster.c:2563 #1 0x00000000004bf3da in toast_decompress_datum
> (attr=0x2b44148) at tuptoaster.c:2390
> #2 0x00000000004c0c1e in heap_tuple_untoast_attr (attr=0x2b44148) at
> tuptoaster.c:225
> #3 0x000000000083f976 in pg_detoast_datum (datum=<optimized out>) at
> fmgr.c:1829
> #4 0x00000000008072de in tsvectorout (fcinfo=0x2b41e00) at
> tsvector.c:315 #5 0x00000000005fae00 in ExecInterpExpr
> (state=0x2b414b8, econtext=0x2b25ab0, isnull=<optimized out>) at
> execExprInterp.c:1131 #6 0x000000000060bdf4 in
> ExecEvalExprSwitchContext (isNull=0x7fffffe9bd37 "",
> econtext=0x2b25ab0, state=0x2b414b8)
> at ../../../src/include/executor/executor.h:299
>
> It seems the VARATT_IS_CUSTOM_COMPRESSED incorrectly identifies the
> value as custom-compressed for some reason.
>
> Not sure why, but the tsvector column is populated by a trigger that
> simply does
>
> NEW.body_tsvector
> := to_tsvector('english', strip_replies(NEW.body_plain));
>
> If needed, the complete tool is here:
>
> https://bitbucket.org/tvondra/archie
>
Hi. This looks like a serious bug, but I couldn't reproduce
it yet. Did you upgrade some old database or this bug happened after
insertion of all data to new database? I tried using your 'archie'
tool to download mailing lists and insert them to database, but couldn't
catch any errors.
--
---
Ildus Kurbangaliev
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Hi, On 11/27/2017 04:52 PM, Ildus Kurbangaliev wrote: > ... > > Hi. This looks like a serious bug, but I couldn't reproduce it yet. > Did you upgrade some old database or this bug happened after > insertion of all data to new database? I tried using your 'archie' > tool to download mailing lists and insert them to database, but > couldn't catch any errors. > I can trigger it pretty reliably with these steps: git checkout f65d21b258085bdc8ef2cc282ab1ff12da9c595c patch -p1 < ~/custom_compression_methods_v6.patch ./configure--enable-debug --enable-cassert \ CFLAGS="-fno-omit-frame-pointer -O0 -DRANDOMIZE_ALLOCATED_MEMORY" \ --prefix=/home/postgres/pg-compress make -s clean && make -s -j4 install cd contrib/ make -s clean && make -s -j4 install export PATH=/home/postgres/pg-compress/bin:$PATH pg_ctl -D /mnt/raid/pg-compress init pg_ctl -D /mnt/raid/pg-compress-l compress.log start createdb archie cd ~/archie/sql/ psql archie < create.sql ~/archie/bin/load.py --workers 4 --db archie */* > load.log 2>&1 I guess the trick might be -DRANDOMIZE_ALLOCATED_MEMORY (I first tried without it, and it seemed working fine). If that's the case, I bet there is a palloc that should have been palloc0, or something like that. If you still can't reproduce that, I may give you access to this machine so that you can debug it there. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, 27 Nov 2017 18:20:12 +0100 Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > I guess the trick might be -DRANDOMIZE_ALLOCATED_MEMORY (I first tried > without it, and it seemed working fine). If that's the case, I bet > there is a palloc that should have been palloc0, or something like > that. Thanks, that was it. I've been able to reproduce this bug. The attached patch should fix this bug and I've also added recompression when tuples moved to the relation with the compressed attribute. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On 11/28/2017 02:29 PM, Ildus Kurbangaliev wrote:
> On Mon, 27 Nov 2017 18:20:12 +0100
> Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
>
>> I guess the trick might be -DRANDOMIZE_ALLOCATED_MEMORY (I first
>> tried without it, and it seemed working fine). If that's the case,
>> I bet there is a palloc that should have been palloc0, or something
>> like that.
>
> Thanks, that was it. I've been able to reproduce this bug. The
> attached patch should fix this bug and I've also added recompression
> when tuples moved to the relation with the compressed attribute.
>
I've done many tests with fulltext search on the mail archive, using
different compression algorithm, and this time it worked fine. So I can
confirm v7 fixes the issue.
Let me elaborate a bit about the benchmarking I did. I realize the patch
is meant to provide only an "API" for custom compression methods, and so
benchmarking of existing general-purpose algorithms (replacing the
built-in pglz) may seem a bit irrelevant. But I'll draw some conclusions
from that, so please bear with me. Or just skip the next section.
------------------ benchmark / start ------------------
I was curious how much better we could do than the built-in compression,
so I've whipped together a bunch of extensions for a few common
general-purpose compression algorithms (lz4, gz, bz2, zstd, brotli and
snappy), loaded the community mailing list archives using "archie" [1]
and ran a bunch of real-world full-text queries on it. I've used
"default" (or "medium") compression levels for all algorithms.
For the loads, the results look like this:
seconds size
-------------------------
pglz 1631 9786
zstd 1844 7102
lz4 1582 9537
bz2 2382 7670
gz 1703 7067
snappy 1587 12288
brotli 10973 6180
According to those results the algorithms seem quite comparable, with
the exception of snappy and brotli. Snappy supposedly aims for fast
compression and not compression ratio, but it's about as fast as the
other algorithms and compression ratio is almost 2x worse. Brotli is
much slower, although it gets better compression ratio.
For the queries, I ran about 33k of real-world queries (executed on the
community mailing lists in the past). Firstly, a simple
-- unsorted
SELECT COUNT(id) FROM messages WHERE body_tsvector @@ $1::tsquery
and then
-- sorted
SELECT id FROM messages WHERE body_tsvector @@ $1::tsquery
ORDER BY ts_rank(body_tsvector, $1::tsquery) DESC LIMIT 100;
Attached are 4 different charts, plotting pglz on x-axis and the other
algorithms on y-axis (so below diagonal => new algorithm is faster,
above diagonal => pglz is faster). I did this on two different machines,
one with only 8GB of RAM (so the dataset does not fit) and one much
larger (so everything fits into RAM).
I'm actually surprised how well the built-in pglz compression fares,
both on compression ratio and (de)compression speed. There is a bit of
noise for the fastest queries, when the alternative algorithms perform
better in non-trivial number of cases.
I suspect those cases may be due to not implementing anything like
PGLZ_strategy_default->min_comp_rate (requiring 25% size reduction), but
I'm not sure about it.
For more expensive queries, pglz pretty much wins. Of course, increasing
compression level might change the results a bit, but it will also make
the data loads slower.
------------------ benchmark / end ------------------
While the results may look differently for other datasets, my conclusion
is that it's unlikely we'll find another general-purpose algorithm
beating pglz (enough for people to switch to it, as they'll need to
worry about testing, deployment of extensions etc).
That doesn't necessarily mean supporting custom compression algorithms
is pointless, of course, but I think people will be much more interested
in exploiting known features of the data (instead of treating the values
as opaque arrays of bytes).
For example, I see the patch implements a special compression method for
tsvector values (used in the tests), exploiting from knowledge of
internal structure. I haven't tested if that is an improvement (either
in compression/decompression speed or compression ratio), though.
I can imagine other interesting use cases - for example values in JSONB
columns often use the same "schema" (keys, nesting, ...), so can I
imagine building a "dictionary" of JSON keys for the whole column ...
Ildus, is this a use case you've been aiming for, or were you aiming to
use the new API in a different way?
I wonder if the patch can be improved to handle this use case better.
For example, it requires knowledge the actual data type, instead of
treating it as opaque varlena / byte array. I see tsvector compression
does that by checking typeid in the handler.
But that fails for example with this example
db=# create domain x as tsvector;
CREATE DOMAIN
db=# create table t (a x compressed ts1);
ERROR: unexpected type 28198672 for tsvector compression handler
which means it's a few brick shy to properly support domains. But I
wonder if this should be instead specified in CREATE COMPRESSION METHOD
instead. I mean, something like
CREATE COMPRESSION METHOD ts1 HANDLER tsvector_compression_handler
TYPE tsvector;
When type is no specified, it applies to all varlena values. Otherwise
only to that type. Also, why not to allow setting the compression as the
default method for a data type, e.g.
CREATE COMPRESSION METHOD ts1 HANDLER tsvector_compression_handler
TYPE tsvector DEFAULT;
would automatically add 'COMPRESSED ts1' to all tsvector columns in new
CREATE TABLE commands.
BTW do you expect the tsvector compression to be generally useful, or is
it meant to be used only by the tests? If generally useful, perhaps it
should be created in pg_compression by default. If only for tests, maybe
it should be implemented in an extension in contrib (thus also serving
as example how to implement new methods).
I haven't thought about the JSONB use case very much, but I suppose that
could be done using the configure/drop methods. I mean, allocating the
dictionary somewhere (e.g. in a table created by an extension?). The
configure method gets the Form_pg_attribute record, so that should be
enough I guess.
But the patch is not testing those two methods at all, which seems like
something that needs to be addresses before commit. I don't expect a
full-fledged JSONB compression extension, but something simple that
actually exercises those methods in a meaningful way.
Similarly for the compression options - we need to test that the WITH
part is handled correctly (tsvector does not provide configure method).
Which reminds me I'm confused by pg_compression_opt. Consider this:
CREATE COMPRESSION METHOD ts1 HANDLER tsvector_compression_handler;
CREATE TABLE t (a tsvector COMPRESSED ts1);
db=# select * from pg_compression_opt ;
cmoptoid | cmname | cmhandler | cmoptions
----------+--------+------------------------------+-----------
28198689 | ts1 | tsvector_compression_handler |
(1 row)
DROP TABLE t;
db=# select * from pg_compression_opt ;
cmoptoid | cmname | cmhandler | cmoptions
----------+--------+------------------------------+-----------
28198689 | ts1 | tsvector_compression_handler |
(1 row)
db=# DROP COMPRESSION METHOD ts1;
ERROR: cannot drop compression method ts1 because other objects
depend on it
DETAIL: compression options for ts1 depends on compression method
ts1
HINT: Use DROP ... CASCADE to drop the dependent objects too.
I believe the pg_compression_opt is actually linked to pg_attribute, in
which case it should include (attrelid,attnum), and should be dropped
when the table is dropped.
I suppose it was done this way to work around the lack of recompression
(i.e. the compressed value might have ended in other table), but that is
no longer true.
A few more comments:
1) The patch makes optionListToArray (in foreigncmds.c) non-static, but
it's not used anywhere. So this seems like change that is no longer
necessary.
2) I see we add two un-reserved keywords in gram.y - COMPRESSION and
COMPRESSED. Perhaps COMPRESSION would be enough? I mean, we could do
CREATE TABLE t (c TEXT COMPRESSION cm1);
ALTER ... SET COMPRESSION name ...
ALTER ... SET COMPRESSION none;
Although I agree the "SET COMPRESSION none" is a bit strange.
3) heap_prepare_insert uses this chunk of code
+ else if (HeapTupleHasExternal(tup)
+ || RelationGetDescr(relation)->tdflags & TD_ATTR_CUSTOM_COMPRESSED
+ || HeapTupleHasCustomCompressed(tup)
+ || tup->t_len > TOAST_TUPLE_THRESHOLD)
Shouldn't that be rather
+ else if (HeapTupleHasExternal(tup)
+ || (RelationGetDescr(relation)->tdflags & TD_ATTR_CUSTOM_COMPRESSED
+ && HeapTupleHasCustomCompressed(tup))
+ || tup->t_len > TOAST_TUPLE_THRESHOLD)
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
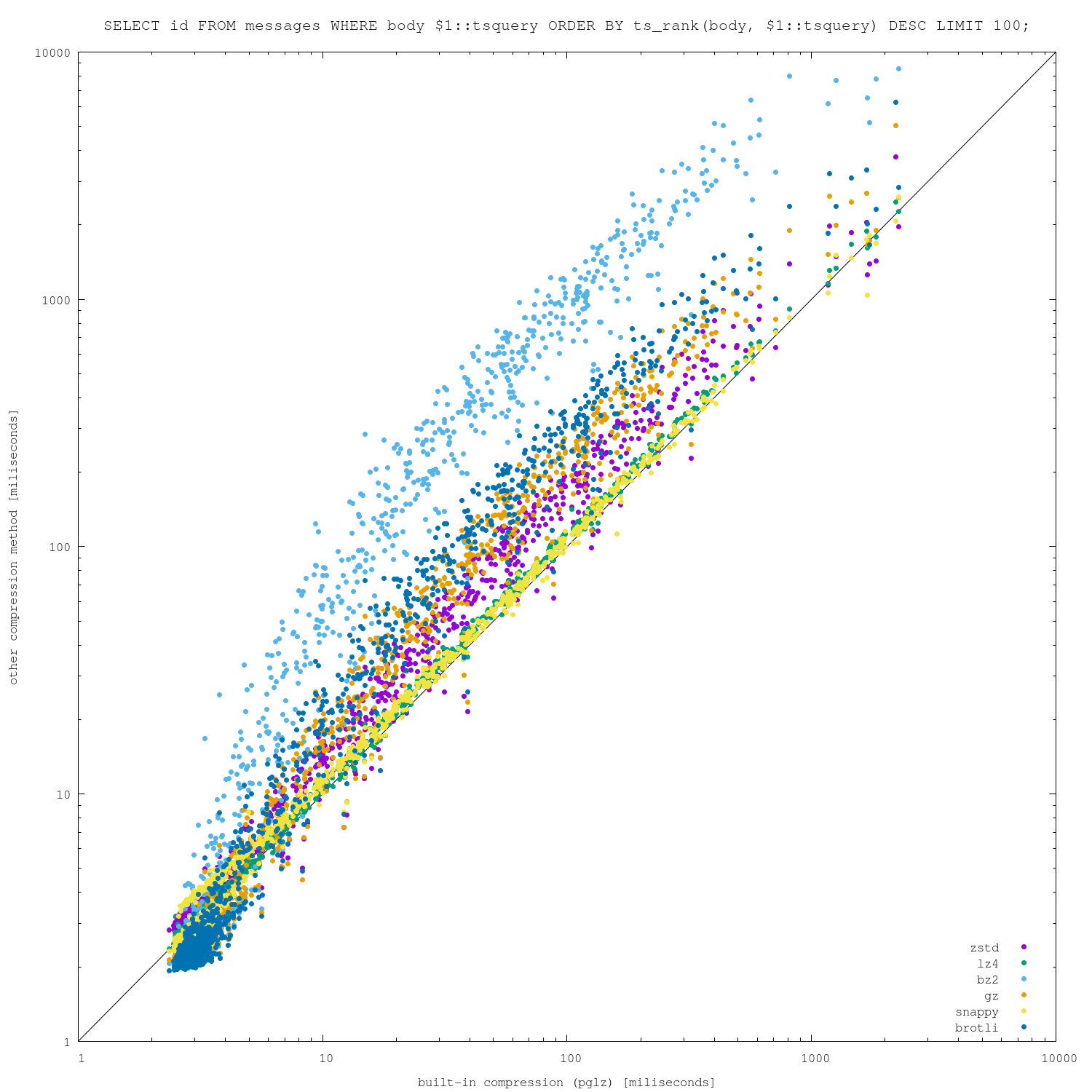{kind=link}
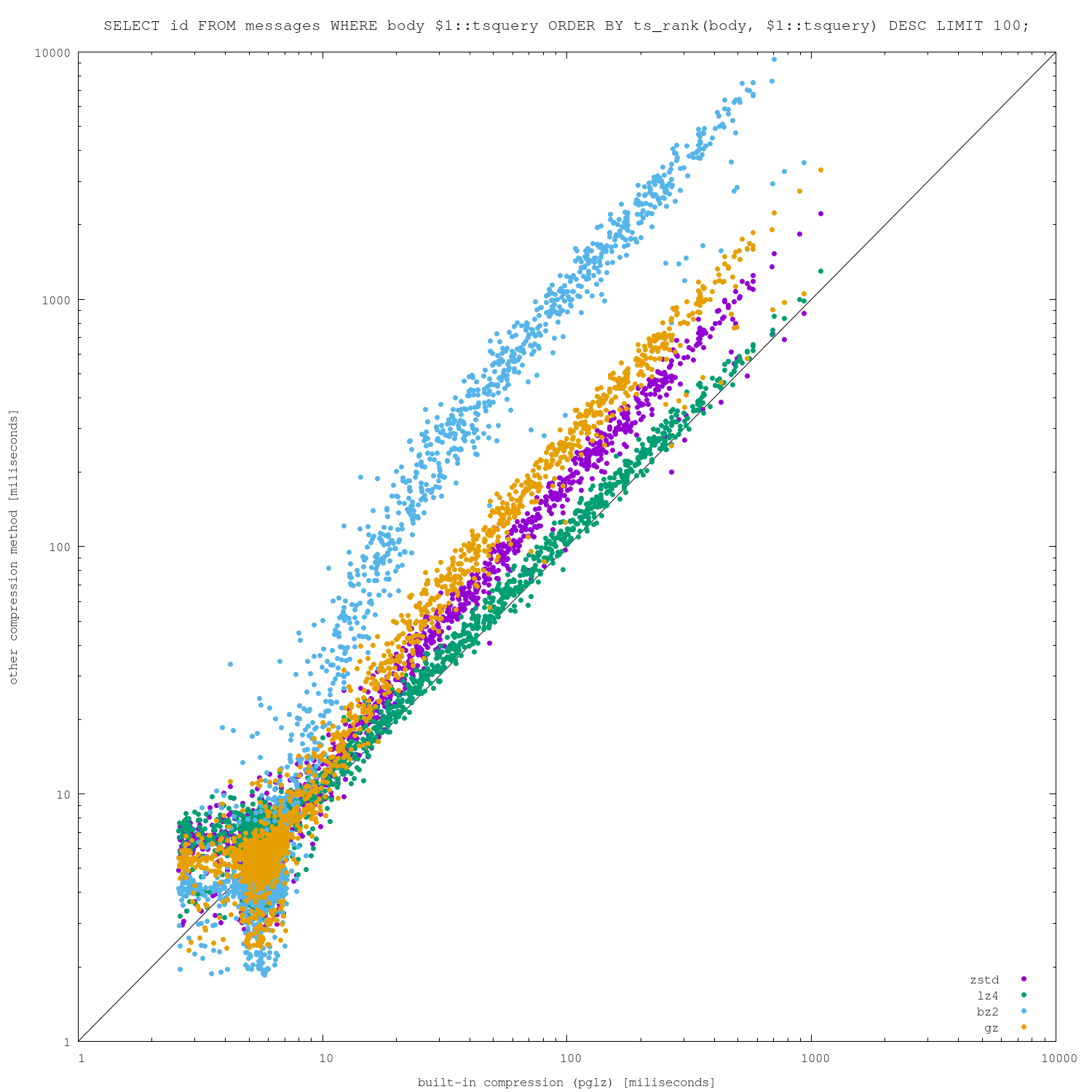{kind=link}
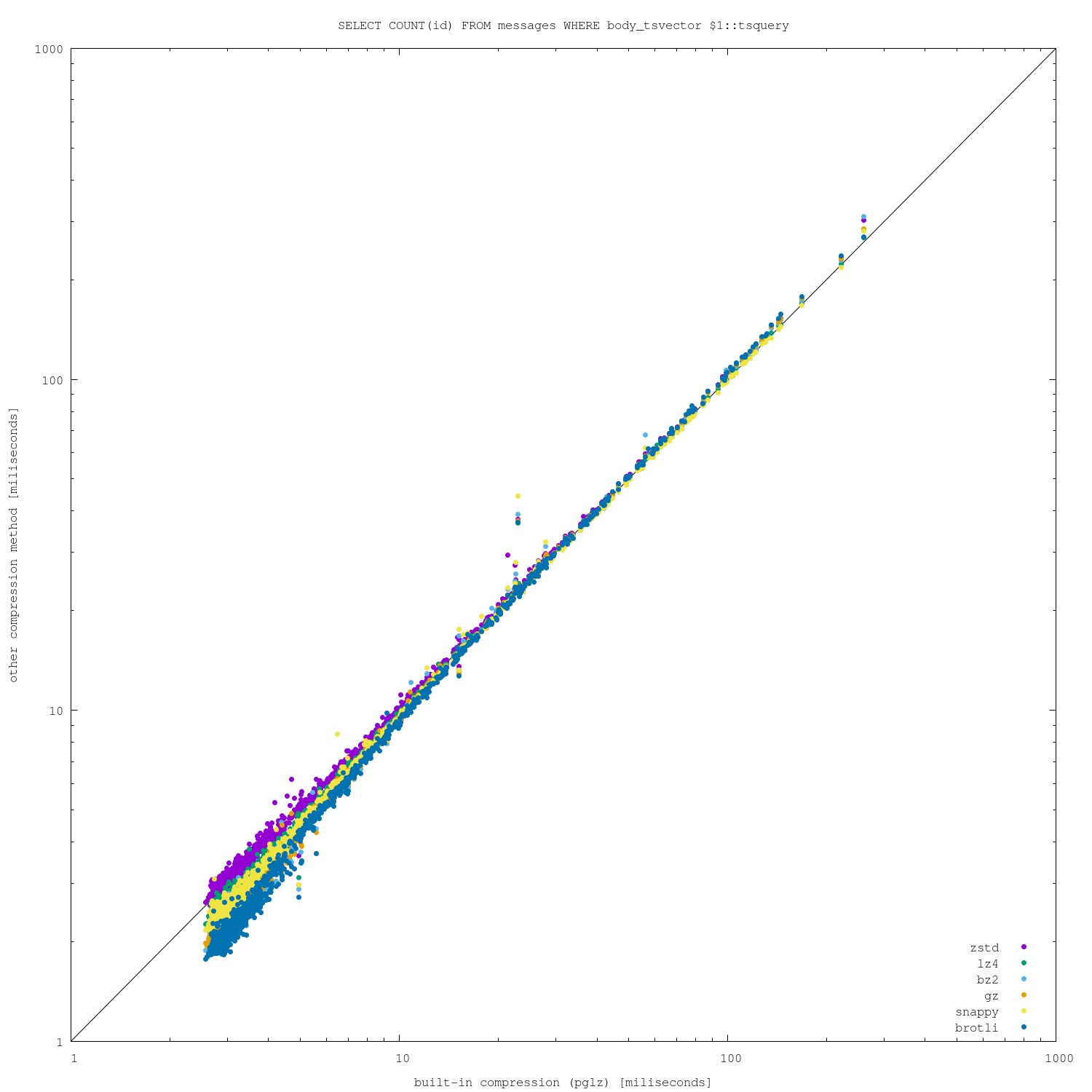{kind=link}
{kind=link}
On Thu, Nov 30, 2017 at 8:30 AM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 11/28/2017 02:29 PM, Ildus Kurbangaliev wrote: >> On Mon, 27 Nov 2017 18:20:12 +0100 >> Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >> >>> I guess the trick might be -DRANDOMIZE_ALLOCATED_MEMORY (I first >>> tried without it, and it seemed working fine). If that's the case, >>> I bet there is a palloc that should have been palloc0, or something >>> like that. >> >> Thanks, that was it. I've been able to reproduce this bug. The >> attached patch should fix this bug and I've also added recompression >> when tuples moved to the relation with the compressed attribute. >> > > I've done many tests with fulltext search on the mail archive, using > different compression algorithm, and this time it worked fine. So I can > confirm v7 fixes the issue. Moved to next CF. -- Michael
On Thu, 30 Nov 2017 00:30:37 +0100 Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > While the results may look differently for other datasets, my > conclusion is that it's unlikely we'll find another general-purpose > algorithm beating pglz (enough for people to switch to it, as they'll > need to worry about testing, deployment of extensions etc). > > That doesn't necessarily mean supporting custom compression algorithms > is pointless, of course, but I think people will be much more > interested in exploiting known features of the data (instead of > treating the values as opaque arrays of bytes). > > For example, I see the patch implements a special compression method > for tsvector values (used in the tests), exploiting from knowledge of > internal structure. I haven't tested if that is an improvement (either > in compression/decompression speed or compression ratio), though. > > I can imagine other interesting use cases - for example values in > JSONB columns often use the same "schema" (keys, nesting, ...), so > can I imagine building a "dictionary" of JSON keys for the whole > column ... > > Ildus, is this a use case you've been aiming for, or were you aiming > to use the new API in a different way? Thank you for such good overview. I agree that pglz is pretty good as general compression method, and there's no point to change it, at least now. I see few useful use cases for compression methods, it's special compression methods for int[], timestamp[] for time series and yes, dictionaries for jsonb, for which I have even already created an extension (https://github.com/postgrespro/jsonbd). It's working and giving promising results. > > I wonder if the patch can be improved to handle this use case better. > For example, it requires knowledge the actual data type, instead of > treating it as opaque varlena / byte array. I see tsvector compression > does that by checking typeid in the handler. > > But that fails for example with this example > > db=# create domain x as tsvector; > CREATE DOMAIN > db=# create table t (a x compressed ts1); > ERROR: unexpected type 28198672 for tsvector compression handler > > which means it's a few brick shy to properly support domains. But I > wonder if this should be instead specified in CREATE COMPRESSION > METHOD instead. I mean, something like > > CREATE COMPRESSION METHOD ts1 HANDLER tsvector_compression_handler > TYPE tsvector; > > When type is no specified, it applies to all varlena values. Otherwise > only to that type. Also, why not to allow setting the compression as > the default method for a data type, e.g. > > CREATE COMPRESSION METHOD ts1 HANDLER tsvector_compression_handler > TYPE tsvector DEFAULT; > > would automatically add 'COMPRESSED ts1' to all tsvector columns in > new CREATE TABLE commands. Initial version of the patch contains ALTER syntax that change compression method for whole types, but I have decided to remove that functionality for now because the patch is already quite complex and it could be added later as separate patch. Syntax was: ALTER TYPE <type> SET COMPRESSION <cm>; Specifying the supported type for the compression method is a good idea. Maybe the following syntax would be better? CREATE COMPRESSION METHOD ts1 FOR tsvector HANDLER tsvector_compression_handler; > > BTW do you expect the tsvector compression to be generally useful, or > is it meant to be used only by the tests? If generally useful, > perhaps it should be created in pg_compression by default. If only > for tests, maybe it should be implemented in an extension in contrib > (thus also serving as example how to implement new methods). > > I haven't thought about the JSONB use case very much, but I suppose > that could be done using the configure/drop methods. I mean, > allocating the dictionary somewhere (e.g. in a table created by an > extension?). The configure method gets the Form_pg_attribute record, > so that should be enough I guess. > > But the patch is not testing those two methods at all, which seems > like something that needs to be addresses before commit. I don't > expect a full-fledged JSONB compression extension, but something > simple that actually exercises those methods in a meaningful way. I will move to tsvector_compression_handler to separate extension in the next version. I added it more like as example, but also it could be used to achieve a better compression for tsvectors. Tests on maillists database ('archie' tables): usual compression: maillists=# select body_tsvector, subject_tsvector into t1 from messages; SELECT 1114213 maillists=# select pg_size_pretty(pg_total_relation_size('t1'));pg_size_pretty ----------------1637 MB (1 row) tsvector_compression_handler: maillists=# select pg_size_pretty(pg_total_relation_size('t2'));pg_size_pretty ----------------1521 MB (1 row) lz4: maillists=# select pg_size_pretty(pg_total_relation_size('t3'));pg_size_pretty ----------------1487 MB (1 row) I don't stick to tsvector_compression_handler, I think if there will some example that can use all the features then tsvector_compression_handler could be replaced with it. My extension for jsonb dictionaries is big enough and I'm not ready to try to include it to the patch. I just see the use of 'drop' method, since there should be way for extension to clean its resources, but I don't see some simple enough usage for it in tests. Maybe just dummy methods for 'drop' and 'configure' will be enough for testing purposes. > > Similarly for the compression options - we need to test that the WITH > part is handled correctly (tsvector does not provide configure > method). I could add some options to tsvector_compression_handler, like options that change pglz_compress parameters. > > Which reminds me I'm confused by pg_compression_opt. Consider this: > > CREATE COMPRESSION METHOD ts1 HANDLER > tsvector_compression_handler; CREATE TABLE t (a tsvector COMPRESSED > ts1); > > db=# select * from pg_compression_opt ; > cmoptoid | cmname | cmhandler | cmoptions > ----------+--------+------------------------------+----------- > 28198689 | ts1 | tsvector_compression_handler | > (1 row) > > DROP TABLE t; > > db=# select * from pg_compression_opt ; > cmoptoid | cmname | cmhandler | cmoptions > ----------+--------+------------------------------+----------- > 28198689 | ts1 | tsvector_compression_handler | > (1 row) > > db=# DROP COMPRESSION METHOD ts1; > ERROR: cannot drop compression method ts1 because other objects > depend on it > DETAIL: compression options for ts1 depends on compression method > ts1 > HINT: Use DROP ... CASCADE to drop the dependent objects too. > > I believe the pg_compression_opt is actually linked to pg_attribute, > in which case it should include (attrelid,attnum), and should be > dropped when the table is dropped. > > I suppose it was done this way to work around the lack of > recompression (i.e. the compressed value might have ended in other > table), but that is no longer true. Good point, since there is recompression now, the options could be safely removed in case of dropping table. It will complicate pg_upgrade but I think this is solvable. > > A few more comments: > > 1) The patch makes optionListToArray (in foreigncmds.c) non-static, > but it's not used anywhere. So this seems like change that is no > longer necessary. I use this function in CreateCompressionOptions. > > 2) I see we add two un-reserved keywords in gram.y - COMPRESSION and > COMPRESSED. Perhaps COMPRESSION would be enough? I mean, we could do > > CREATE TABLE t (c TEXT COMPRESSION cm1); > ALTER ... SET COMPRESSION name ... > ALTER ... SET COMPRESSION none; > > Although I agree the "SET COMPRESSION none" is a bit strange. I agree, I've already changed syntax for the next version of the patch. It's COMPRESSION instead of COMPRESSED and DROP COMPRESSION instead of SET NOT COMPRESSED. Minus one word from grammar and it looks nicer. > > 3) heap_prepare_insert uses this chunk of code > > + else if (HeapTupleHasExternal(tup) > + || RelationGetDescr(relation)->tdflags & > TD_ATTR_CUSTOM_COMPRESSED > + || HeapTupleHasCustomCompressed(tup) > + || tup->t_len > TOAST_TUPLE_THRESHOLD) > > Shouldn't that be rather > > + else if (HeapTupleHasExternal(tup) > + || (RelationGetDescr(relation)->tdflags & > TD_ATTR_CUSTOM_COMPRESSED > + && HeapTupleHasCustomCompressed(tup)) > + || tup->t_len > TOAST_TUPLE_THRESHOLD) These conditions used for opposite directions. HeapTupleHasCustomCompressed(tup) is true if tuple has compressed datums inside and we need to decompress them first, and TD_ATTR_CUSTOM_COMPRESSED flag means that relation we're putting the data have columns with custom compression and maybe we need to compress datums in current tuple. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On 11/30/2017 04:20 PM, Ildus Kurbangaliev wrote: > On Thu, 30 Nov 2017 00:30:37 +0100 > Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > ... > >> I can imagine other interesting use cases - for example values in >> JSONB columns often use the same "schema" (keys, nesting, ...), so >> can I imagine building a "dictionary" of JSON keys for the whole >> column ... >> >> Ildus, is this a use case you've been aiming for, or were you aiming >> to use the new API in a different way? > > Thank you for such good overview. I agree that pglz is pretty good as > general compression method, and there's no point to change it, at > least now. > > I see few useful use cases for compression methods, it's special > compression methods for int[], timestamp[] for time series and yes, > dictionaries for jsonb, for which I have even already created an > extension (https://github.com/postgrespro/jsonbd). It's working and > giving promising results. > I understand the reluctance to put everything into core, particularly for complex patches that evolve quickly. Also, not having to put everything into core is kinda why we have extensions. But perhaps some of the simpler cases would be good candidates for core, making it possible to test the feature? >> >> I wonder if the patch can be improved to handle this use case better. >> For example, it requires knowledge the actual data type, instead of >> treating it as opaque varlena / byte array. I see tsvector compression >> does that by checking typeid in the handler. >> >> But that fails for example with this example >> >> db=# create domain x as tsvector; >> CREATE DOMAIN >> db=# create table t (a x compressed ts1); >> ERROR: unexpected type 28198672 for tsvector compression handler >> >> which means it's a few brick shy to properly support domains. But I >> wonder if this should be instead specified in CREATE COMPRESSION >> METHOD instead. I mean, something like >> >> CREATE COMPRESSION METHOD ts1 HANDLER tsvector_compression_handler >> TYPE tsvector; >> >> When type is no specified, it applies to all varlena values. Otherwise >> only to that type. Also, why not to allow setting the compression as >> the default method for a data type, e.g. >> >> CREATE COMPRESSION METHOD ts1 HANDLER tsvector_compression_handler >> TYPE tsvector DEFAULT; >> >> would automatically add 'COMPRESSED ts1' to all tsvector columns in >> new CREATE TABLE commands. > > Initial version of the patch contains ALTER syntax that change > compression method for whole types, but I have decided to remove > that functionality for now because the patch is already quite complex > and it could be added later as separate patch. > > Syntax was: > ALTER TYPE <type> SET COMPRESSION <cm>; > > Specifying the supported type for the compression method is a good idea. > Maybe the following syntax would be better? > > CREATE COMPRESSION METHOD ts1 FOR tsvector HANDLER > tsvector_compression_handler; > Understood. Good to know you've considered it, and I agree it doesn't need to be there from the start (which makes the patch simpler). >> >> BTW do you expect the tsvector compression to be generally useful, or >> is it meant to be used only by the tests? If generally useful, >> perhaps it should be created in pg_compression by default. If only >> for tests, maybe it should be implemented in an extension in contrib >> (thus also serving as example how to implement new methods). >> >> I haven't thought about the JSONB use case very much, but I suppose >> that could be done using the configure/drop methods. I mean, >> allocating the dictionary somewhere (e.g. in a table created by an >> extension?). The configure method gets the Form_pg_attribute record, >> so that should be enough I guess. >> >> But the patch is not testing those two methods at all, which seems >> like something that needs to be addresses before commit. I don't >> expect a full-fledged JSONB compression extension, but something >> simple that actually exercises those methods in a meaningful way. > > I will move to tsvector_compression_handler to separate extension in > the next version. I added it more like as example, but also it could be > used to achieve a better compression for tsvectors. Tests on maillists > database ('archie' tables): > > usual compression: > > maillists=# select body_tsvector, subject_tsvector into t1 from > messages; SELECT 1114213 > maillists=# select pg_size_pretty(pg_total_relation_size('t1')); > pg_size_pretty > ---------------- > 1637 MB > (1 row) > > tsvector_compression_handler: > maillists=# select pg_size_pretty(pg_total_relation_size('t2')); > pg_size_pretty > ---------------- > 1521 MB > (1 row) > > lz4: > maillists=# select pg_size_pretty(pg_total_relation_size('t3')); > pg_size_pretty > ---------------- > 1487 MB > (1 row) > > I don't stick to tsvector_compression_handler, I think if there > will some example that can use all the features then > tsvector_compression_handler could be replaced with it. > OK. I think it's a nice use case (and nice gains on the compression ratio), demonstrating the datatype-aware compression. The question is why shouldn't this be built into the datatypes directly? That would certainly be possible for tsvector, although it wouldn't be as transparent (the datatype code would have to support it explicitly). I'm a bit torn on this. The custom compression method patch makes the compression mostly transparent for the datatype code (by adding an extra "compression" header). But it's coupled to the datatype quite strongly as it requires knowledge of the data type internals. It's a bit less coupled for "generic" datatypes (e.g. arrays of other types), where it may add important information (e.g. that the array represents a chunk of timeseries data, which the array code can't possibly know). > > My extension for jsonb dictionaries is big enough and I'm not ready > to try to include it to the patch. I just see the use of 'drop' > method, since there should be way for extension to clean its > resources, but I don't see some simple enough usage for it in tests. > Maybe just dummy methods for 'drop' and 'configure' will be enough > for testing purposes. > OK. >> >> Similarly for the compression options - we need to test that the WITH >> part is handled correctly (tsvector does not provide configure >> method). > > I could add some options to tsvector_compression_handler, like options > that change pglz_compress parameters. > +1 for doing that >> >> Which reminds me I'm confused by pg_compression_opt. Consider this: >> >> CREATE COMPRESSION METHOD ts1 HANDLER >> tsvector_compression_handler; CREATE TABLE t (a tsvector COMPRESSED >> ts1); >> >> db=# select * from pg_compression_opt ; >> cmoptoid | cmname | cmhandler | cmoptions >> ----------+--------+------------------------------+----------- >> 28198689 | ts1 | tsvector_compression_handler | >> (1 row) >> >> DROP TABLE t; >> >> db=# select * from pg_compression_opt ; >> cmoptoid | cmname | cmhandler | cmoptions >> ----------+--------+------------------------------+----------- >> 28198689 | ts1 | tsvector_compression_handler | >> (1 row) >> >> db=# DROP COMPRESSION METHOD ts1; >> ERROR: cannot drop compression method ts1 because other objects >> depend on it >> DETAIL: compression options for ts1 depends on compression method >> ts1 >> HINT: Use DROP ... CASCADE to drop the dependent objects too. >> >> I believe the pg_compression_opt is actually linked to pg_attribute, >> in which case it should include (attrelid,attnum), and should be >> dropped when the table is dropped. >> >> I suppose it was done this way to work around the lack of >> recompression (i.e. the compressed value might have ended in other >> table), but that is no longer true. > > Good point, since there is recompression now, the options could be > safely removed in case of dropping table. It will complicate pg_upgrade > but I think this is solvable. > +1 to do that. I've never dealt with pg_upgrade, but I suppose this shouldn't be more complicated than for custom data types, right? >> >> A few more comments: >> >> 1) The patch makes optionListToArray (in foreigncmds.c) non-static, >> but it's not used anywhere. So this seems like change that is no >> longer necessary. > > I use this function in CreateCompressionOptions. > Ah, my mistake. I only did 'git grep' which however does not search in new files (not added to git). But it seems a bit strange to have the function in foreigncmds.c, though, now that we use it outside of FDWs. >> >> 2) I see we add two un-reserved keywords in gram.y - COMPRESSION and >> COMPRESSED. Perhaps COMPRESSION would be enough? I mean, we could do >> >> CREATE TABLE t (c TEXT COMPRESSION cm1); >> ALTER ... SET COMPRESSION name ... >> ALTER ... SET COMPRESSION none; >> >> Although I agree the "SET COMPRESSION none" is a bit strange. > > I agree, I've already changed syntax for the next version of the patch. > It's COMPRESSION instead of COMPRESSED and DROP COMPRESSION instead of > SET NOT COMPRESSED. Minus one word from grammar and it looks nicer. > I'm not sure DROP COMPRESSION is a good idea. It implies that the data will be uncompressed, but I assume it merely switches to the built-in compression (pglz), right? Although "SET COMPRESSION none" has the same issue ... BTW, when you do DROP COMPRESSION (or whatever syntax we end up using), will that remove the dependencies on the compression method? I haven't tried, so maybe it does. >> >> 3) heap_prepare_insert uses this chunk of code >> >> + else if (HeapTupleHasExternal(tup) >> + || RelationGetDescr(relation)->tdflags & >> TD_ATTR_CUSTOM_COMPRESSED >> + || HeapTupleHasCustomCompressed(tup) >> + || tup->t_len > TOAST_TUPLE_THRESHOLD) >> >> Shouldn't that be rather >> >> + else if (HeapTupleHasExternal(tup) >> + || (RelationGetDescr(relation)->tdflags & >> TD_ATTR_CUSTOM_COMPRESSED >> + && HeapTupleHasCustomCompressed(tup)) >> + || tup->t_len > TOAST_TUPLE_THRESHOLD) > > These conditions used for opposite directions. > HeapTupleHasCustomCompressed(tup) is true if tuple has compressed > datums inside and we need to decompress them first, and > TD_ATTR_CUSTOM_COMPRESSED flag means that relation we're putting the > data have columns with custom compression and maybe we need to compress > datums in current tuple. > Ah, right, now it makes sense. Thanks for explaining. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 11/30/2017 09:51 PM, Alvaro Herrera wrote: > Tomas Vondra wrote: > >> On 11/30/2017 04:20 PM, Ildus Kurbangaliev wrote: > >>> CREATE COMPRESSION METHOD ts1 FOR tsvector HANDLER >>> tsvector_compression_handler; >> >> Understood. Good to know you've considered it, and I agree it doesn't >> need to be there from the start (which makes the patch simpler). > > Just passing by, but wouldn't this fit in the ACCESS METHOD group of > commands? So this could be simplified down to > CREATE ACCESS METHOD ts1 TYPE COMPRESSION > we have that for indexes and there are patches flying for heap storage, > sequences, etc. I think that's simpler than trying to invent all new > commands here. Then (in a future patch) you can use ALTER TYPE to > define compression for that type, or even add a column-level option to > reference a specific compression method. > I think that would conflate two very different concepts. In my mind, access methods define how rows are stored. Compression methods are an orthogonal concept, e.g. you can compress a value (using a custom compression algorithm) and store it in an index (using whatever access method it's using). So not only access methods operate on rows (while compression operates on varlena values), but you can combine those two things together. I don't see how you could do that if both are defined as "access methods" ... Furthermore, the "TYPE" in CREATE COMPRESSION method was meant to restrict the compression algorithm to a particular data type (so, if it relies on tsvector, you can't apply it to text columns). Which is very different from "TYPE COMPRESSION" in CREATE ACCESS METHOD. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Nov 30, 2017 at 2:47 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > OK. I think it's a nice use case (and nice gains on the compression > ratio), demonstrating the datatype-aware compression. The question is > why shouldn't this be built into the datatypes directly? Tomas, thanks for running benchmarks of this. I was surprised to see how little improvement there was from other modern compression methods, although lz4 did appear to be a modest win on both size and speed. But I share your intuition that a lot of the interesting work is in datatype-specific compression algorithms. I have noticed in a number of papers that I've read that teaching other parts of the system to operate directly on the compressed data, especially for column stores, is a critical performance optimization; of course, that only makes sense if the compression is datatype-specific. I don't know exactly what that means for the design of this patch, though. As a general point, no matter which way you go, you have to somehow deal with on-disk compatibility. If you want to build in compression to the datatype itself, you need to find at least one bit someplace to mark the fact that you applied built-in compression. If you want to build it in as a separate facility, you need to denote the compression used someplace else. I haven't looked at how this patch does it, but the proposal in the past has been to add a value to vartag_external. One nice thing about the latter method is that it can be used for any data type generically, regardless of how much bit-space is available in the data type representation itself. It's realistically hard to think of a data-type that has no bit space available anywhere but is still subject to data-type specific compression; bytea definitionally has no bit space but is also can't benefit from special-purpose compression, whereas even something like text could be handled by starting the varlena with a NUL byte to indicate compressed data following. However, you'd have to come up with a different trick for each data type. Piggybacking on the TOAST machinery avoids that. It also implies that we only try to compress values that are "big", which is probably be desirable if we're talking about a kind of compression that makes comprehending the value slower. Not all types of compression do, cf. commit 145343534c153d1e6c3cff1fa1855787684d9a38, and for those that don't it probably makes more sense to just build it into the data type. All of that is a somewhat separate question from whether we should have CREATE / DROP COMPRESSION, though (or Alvaro's proposal of using the ACCESS METHOD stuff instead). Even if we agree that piggybacking on TOAST is a good way to implement pluggable compression methods, it doesn't follow that the compression method is something that should be attached to the datatype from the outside; it could be built into it in a deep way. For example, "packed" varlenas (1-byte header) are a form of compression, and the default functions for detoasting always produced unpacked values, but the operators for the text data type know how to operate on the packed representation. That's sort of a trivial example, but it might well be that there are other cases where we can do something similar. Maybe jsonb, for example, can compress data in such a way that some of the jsonb functions can operate directly on the compressed representation -- perhaps the number of keys is easily visible, for example, or maybe more. In this view of the world, each data type should get to define its own compression method (or methods) but they are hard-wired into the datatype and you can't add more later, or if you do, you lose the advantages of the hard-wired stuff. BTW, another related concept that comes up a lot in discussions of this area is that we could do a lot better compression of columns if we had some place to store a per-column dictionary. I don't really know how to make that work. We could have a catalog someplace that stores an opaque blob for each column configured to use a compression method, and let the compression method store whatever it likes in there. That's probably fine if you are compressing the whole table at once and the blob is static thereafter. But if you want to update that blob as you see new column values there seem to be almost insurmountable problems. To be clear, I'm not trying to load this patch down with a requirement to solve every problem in the universe. On the other hand, I think it would be easy to beat a patch like this into shape in a fairly mechanical way and then commit-and-forget. That might be leaving a lot of money on the table; I'm glad you are thinking about the bigger picture and hope that my thoughts here somehow contribute. Thanks, -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 12/01/2017 03:23 PM, Robert Haas wrote:
> On Thu, Nov 30, 2017 at 2:47 PM, Tomas Vondra
> <tomas.vondra@2ndquadrant.com> wrote:
>> OK. I think it's a nice use case (and nice gains on the compression
>> ratio), demonstrating the datatype-aware compression. The question is
>> why shouldn't this be built into the datatypes directly?
>
> Tomas, thanks for running benchmarks of this. I was surprised to see
> how little improvement there was from other modern compression
> methods, although lz4 did appear to be a modest win on both size and
> speed. But I share your intuition that a lot of the interesting work
> is in datatype-specific compression algorithms. I have noticed in a
> number of papers that I've read that teaching other parts of the
> system to operate directly on the compressed data, especially for
> column stores, is a critical performance optimization; of course, that
> only makes sense if the compression is datatype-specific. I don't
> know exactly what that means for the design of this patch, though.
>
It has very little impact on this patch, as it has nothing to do with
columnar storage. That is, each value is compressed independently.
Column stores exploit the fact that they get a vector of values,
compressed in some data-aware way. E.g. some form of RLE or dictionary
compression, which allows them to evaluate expressions on the compressed
vector. But that's irrelevant here, we only get row-by-row execution.
Note: The idea to build dictionary for the whole jsonb column (which
this patch should allow) does not make it "columnar compression" in the
"column store" way. The executor will still get the decompressed value.
> As a general point, no matter which way you go, you have to somehow
> deal with on-disk compatibility. If you want to build in compression
> to the datatype itself, you need to find at least one bit someplace to
> mark the fact that you applied built-in compression. If you want to
> build it in as a separate facility, you need to denote the compression
> used someplace else. I haven't looked at how this patch does it, but
> the proposal in the past has been to add a value to vartag_external.
AFAICS the patch does that by setting a bit in the varlena header, and
then adding OID of the compression method after the varlena header. So
you get (verlena header + OID + data).
This has good and bad consequences.
Good: It's transparent for the datatype, so it does not have to worry
about the custom compression at all (and it may change arbitrarily).
Bad: It's transparent for the datatype, so it can't operate directly on
the compressed representation.
I don't think this is an argument against the patch, though. If the
datatype can support intelligent compression (and execution without
decompression), it has to be done in the datatype anyway.
> One nice thing about the latter method is that it can be used for any
> data type generically, regardless of how much bit-space is available
> in the data type representation itself. It's realistically hard to
> think of a data-type that has no bit space available anywhere but is
> still subject to data-type specific compression; bytea definitionally
> has no bit space but is also can't benefit from special-purpose
> compression, whereas even something like text could be handled by
> starting the varlena with a NUL byte to indicate compressed data
> following. However, you'd have to come up with a different trick for
> each data type. Piggybacking on the TOAST machinery avoids that. It
> also implies that we only try to compress values that are "big", which
> is probably be desirable if we're talking about a kind of compression
> that makes comprehending the value slower. Not all types of
> compression do, cf. commit 145343534c153d1e6c3cff1fa1855787684d9a38,
> and for those that don't it probably makes more sense to just build it
> into the data type.
>
> All of that is a somewhat separate question from whether we should
> have CREATE / DROP COMPRESSION, though (or Alvaro's proposal of using
> the ACCESS METHOD stuff instead). Even if we agree that piggybacking
> on TOAST is a good way to implement pluggable compression methods, it
> doesn't follow that the compression method is something that should be
> attached to the datatype from the outside; it could be built into it
> in a deep way. For example, "packed" varlenas (1-byte header) are a
> form of compression, and the default functions for detoasting always
> produced unpacked values, but the operators for the text data type
> know how to operate on the packed representation. That's sort of a
> trivial example, but it might well be that there are other cases where
> we can do something similar. Maybe jsonb, for example, can compress
> data in such a way that some of the jsonb functions can operate
> directly on the compressed representation -- perhaps the number of
> keys is easily visible, for example, or maybe more. In this view of
> the world, each data type should get to define its own compression
> method (or methods) but they are hard-wired into the datatype and you
> can't add more later, or if you do, you lose the advantages of the
> hard-wired stuff.
>
I agree with these thoughts in general, but I'm not quite sure what is
your conclusion regarding the patch.
The patch allows us to define custom compression methods that are
entirely transparent for the datatype machinery, i.e. allow compression
even for data types that did not consider compression at all. That seems
valuable to me.
Of course, if the same compression logic can be built into the datatype
itself, it may allow additional benefits (like execution on compressed
data directly).
I don't see these two approaches as conflicting.
>
> BTW, another related concept that comes up a lot in discussions of
> this area is that we could do a lot better compression of columns if
> we had some place to store a per-column dictionary. I don't really
> know how to make that work. We could have a catalog someplace that
> stores an opaque blob for each column configured to use a compression
> method, and let the compression method store whatever it likes in
> there. That's probably fine if you are compressing the whole table at
> once and the blob is static thereafter. But if you want to update
> that blob as you see new column values there seem to be almost
> insurmountable problems.
>
Well, that's kinda the idea behind the configure/drop methods in the
compression handler, and Ildus already did implement such dictionary
compression for the jsonb data type, see:
https://github.com/postgrespro/jsonbd
Essentially that stores the dictionary in a table, managed by a bunch of
background workers.
>
> To be clear, I'm not trying to load this patch down with a requirement
> to solve every problem in the universe. On the other hand, I think it
> would be easy to beat a patch like this into shape in a fairly
> mechanical way and then commit-and-forget. That might be leaving a
> lot of money on the table; I'm glad you are thinking about the bigger
> picture and hope that my thoughts here somehow contribute.
>
Thanks ;-)
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Dec 1, 2017 at 10:18 AM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > It has very little impact on this patch, as it has nothing to do with > columnar storage. That is, each value is compressed independently. I understand that this patch is not about columnar storage, but I think the idea that we may want to operate on the compressed data directly is not only applicable to that case. > I agree with these thoughts in general, but I'm not quite sure what is > your conclusion regarding the patch. I have not reached one. Sometimes I like to discuss problems before deciding what I think. :-) It does seem to me that the patch may be aiming at a relatively narrow target in a fairly large problem space, but I don't know whether to label that as short-sightedness or prudent incrementalism. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra wrote: > On 11/30/2017 09:51 PM, Alvaro Herrera wrote: > > Just passing by, but wouldn't this fit in the ACCESS METHOD group of > > commands? So this could be simplified down to > > CREATE ACCESS METHOD ts1 TYPE COMPRESSION > > we have that for indexes and there are patches flying for heap storage, > > sequences, etc. > > I think that would conflate two very different concepts. In my mind, > access methods define how rows are stored. In mine, they define how things are accessed (i.e. more general than what you're thinking). We *currently* use them to store rows [in indexes], but there is no reason why we couldn't expand that. So we group access methods in "types"; the current type we have is for indexes, and methods in that type define how are indexes accessed. This new type would indicate how would values be compressed. I disagree that there is no parallel there. I'm trying to avoid pointless proliferation of narrowly defined DDL commands. > Furthermore, the "TYPE" in CREATE COMPRESSION method was meant to > restrict the compression algorithm to a particular data type (so, if it > relies on tsvector, you can't apply it to text columns). Yes, of course. I'm saying that the "datatype" property of a compression access method would be declared somewhere else, not in the TYPE clause of the CREATE ACCESS METHOD command. Perhaps it makes sense to declare that a certain compression access method is good only for a certain data type, and then you can put that in the options clause, "CREATE ACCESS METHOD hyperz TYPE COMPRESSION WITH (type = tsvector)". But many compression access methods would be general in nature and so could be used for many datatypes (say, snappy). To me it makes sense to say "let's create this method which is for data compression" (CREATE ACCESS METHOD hyperz TYPE COMPRESSION) followed by either "let's use this new compression method for the type tsvector" (ALTER TYPE tsvector SET COMPRESSION hyperz) or "let's use this new compression method for the column tc" (ALTER TABLE ALTER COLUMN tc SET COMPRESSION hyperz). -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Ildus Kurbangaliev wrote: > If the table is big, decompression could take an eternity. That's why i > decided to only to disable it and the data could be decompressed using > compression options. > > My idea was to keep compression options forever, since there will not > be much of them in one database. Still that requires that extension is > not removed. > > I will try to find a way how to recompress data first in case it moves > to another table. I think what you should do is add a dependency between a column that compresses using a method, and that method. So the method cannot be dropped and leave compressed data behind. Since the method is part of the extension, the extension cannot be dropped either. If you ALTER the column so that it uses another compression method, then the table is rewritten and the dependency is removed; once you do that for all the columns that use the compression method, the compression method can be dropped. Maybe our dependency code needs to be extended in order to support this. I think the current logic would drop the column if you were to do "DROP COMPRESSION .. CASCADE", but I'm not sure we'd see that as a feature. I'd rather have DROP COMPRESSION always fail instead until no columns use it. Let's hear other's opinions on this bit though. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 12/01/2017 08:48 PM, Alvaro Herrera wrote: > Ildus Kurbangaliev wrote: > >> If the table is big, decompression could take an eternity. That's why i >> decided to only to disable it and the data could be decompressed using >> compression options. >> >> My idea was to keep compression options forever, since there will not >> be much of them in one database. Still that requires that extension is >> not removed. >> >> I will try to find a way how to recompress data first in case it moves >> to another table. > > I think what you should do is add a dependency between a column that > compresses using a method, and that method. So the method cannot be > dropped and leave compressed data behind. Since the method is part of > the extension, the extension cannot be dropped either. If you ALTER > the column so that it uses another compression method, then the table is > rewritten and the dependency is removed; once you do that for all the > columns that use the compression method, the compression method can be > dropped. > +1 to do the rewrite, just like for other similar ALTER TABLE commands > > Maybe our dependency code needs to be extended in order to support this. > I think the current logic would drop the column if you were to do "DROP > COMPRESSION .. CASCADE", but I'm not sure we'd see that as a feature. > I'd rather have DROP COMPRESSION always fail instead until no columns > use it. Let's hear other's opinions on this bit though. > Why should this behave differently compared to data types? Seems quite against POLA, if you ask me ... If you want to remove the compression, you can do the SET NOT COMPRESSED (or whatever syntax we end up using), and then DROP COMPRESSION METHOD. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 12/01/2017 08:20 PM, Robert Haas wrote: > On Fri, Dec 1, 2017 at 10:18 AM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> It has very little impact on this patch, as it has nothing to do with >> columnar storage. That is, each value is compressed independently. > > I understand that this patch is not about columnar storage, but I > think the idea that we may want to operate on the compressed data > directly is not only applicable to that case. > Yeah. To clarify, my point was that column stores benefit from compressing many values at once, and then operating on this compressed vector. That is not what this patch is doing (or can do), of course. But I certainly do agree that if the compression can be integrated into the data type, allowing processing on compressed representation, then that will beat whatever this patch is doing, of course ... >> >> I agree with these thoughts in general, but I'm not quite sure >> what is your conclusion regarding the patch. > > I have not reached one. Sometimes I like to discuss problems before > deciding what I think. :-) > That's lame! Let's make decisions without discussion ;-) > > It does seem to me that the patch may be aiming at a relatively narrow > target in a fairly large problem space, but I don't know whether to > label that as short-sightedness or prudent incrementalism. > I don't know either. I don't think people will start switching their text columns to lz4 just because they can, or because they get 4% space reduction compared to pglz. But the ability to build per-column dictionaries seems quite powerful, I guess. And I don't think that can be easily built directly into JSONB, because we don't have a way to provide information about the column (i.e. how would you fetch the correct dictionary?). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Dec 1, 2017 at 2:38 PM, Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > In mine, they define how things are accessed (i.e. more general than > what you're thinking). We *currently* use them to store rows [in > indexes], but there is no reason why we couldn't expand that. > > So we group access methods in "types"; the current type we have is for > indexes, and methods in that type define how are indexes accessed. This > new type would indicate how would values be compressed. I disagree that > there is no parallel there. +1. > I'm trying to avoid pointless proliferation of narrowly defined DDL > commands. I also think that's an important goal. > Yes, of course. I'm saying that the "datatype" property of a > compression access method would be declared somewhere else, not in the > TYPE clause of the CREATE ACCESS METHOD command. Perhaps it makes sense > to declare that a certain compression access method is good only for a > certain data type, and then you can put that in the options clause, > "CREATE ACCESS METHOD hyperz TYPE COMPRESSION WITH (type = tsvector)". > But many compression access methods would be general in nature and so > could be used for many datatypes (say, snappy). > > To me it makes sense to say "let's create this method which is for data > compression" (CREATE ACCESS METHOD hyperz TYPE COMPRESSION) followed by > either "let's use this new compression method for the type tsvector" > (ALTER TYPE tsvector SET COMPRESSION hyperz) or "let's use this new > compression method for the column tc" (ALTER TABLE ALTER COLUMN tc SET > COMPRESSION hyperz). +1 to this, too. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Dec 1, 2017 at 4:06 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >>> I agree with these thoughts in general, but I'm not quite sure >>> what is your conclusion regarding the patch. >> >> I have not reached one. Sometimes I like to discuss problems before >> deciding what I think. :-) > > That's lame! Let's make decisions without discussion ;-) Oh, right. What was I thinking? >> It does seem to me that the patch may be aiming at a relatively narrow >> target in a fairly large problem space, but I don't know whether to >> label that as short-sightedness or prudent incrementalism. > > I don't know either. I don't think people will start switching their > text columns to lz4 just because they can, or because they get 4% space > reduction compared to pglz. Honestly, if we can give everybody a 4% space reduction by switching to lz4, I think that's totally worth doing -- but let's not make people choose it, let's make it the default going forward, and keep pglz support around so we don't break pg_upgrade compatibility (and so people can continue to choose it if for some reason it works better in their use case). That kind of improvement is nothing special in a specific workload, but TOAST is a pretty general-purpose mechanism. I have become, through a few bitter experiences, a strong believer in the value of trying to reduce our on-disk footprint, and knocking 4% off the size of every TOAST table in the world does not sound worthless to me -- even though context-aware compression can doubtless do a lot better. > But the ability to build per-column dictionaries seems quite powerful, I > guess. And I don't think that can be easily built directly into JSONB, > because we don't have a way to provide information about the column > (i.e. how would you fetch the correct dictionary?). That's definitely a problem, but I think we should mull it over a bit more before giving up. I have a few thoughts, but the part of my life that doesn't happen on the PostgreSQL mailing list precludes expounding on them right this minute. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 12/01/2017 08:38 PM, Alvaro Herrera wrote: > Tomas Vondra wrote: > >> On 11/30/2017 09:51 PM, Alvaro Herrera wrote: > >>> Just passing by, but wouldn't this fit in the ACCESS METHOD group of >>> commands? So this could be simplified down to >>> CREATE ACCESS METHOD ts1 TYPE COMPRESSION >>> we have that for indexes and there are patches flying for heap storage, >>> sequences, etc. >> >> I think that would conflate two very different concepts. In my mind, >> access methods define how rows are stored. > > In mine, they define how things are accessed (i.e. more general than > what you're thinking). We *currently* use them to store rows [in > indexes], but there is no reason why we couldn't expand that. > Not sure I follow. My argument was not as much about whether the rows are stored as rows or in some other (columnar) format, but that access methods deal with "tuples" (i.e. row in the "logical" way). I assume that even if we end up implementing other access method types, they will still be tuple-based. OTOH compression methods (at least as introduced by this patch) operate on individual values, and have very little to do with access to the value (in a sense it's a transparent thing). > > So we group access methods in "types"; the current type we have is for > indexes, and methods in that type define how are indexes accessed. This > new type would indicate how would values be compressed. I disagree that > there is no parallel there. > > I'm trying to avoid pointless proliferation of narrowly defined DDL > commands. > Of course, the opposite case is using the same DDL for very different concepts (although I understand you don't see it that way). But in fairness, I don't really care if we call this COMPRESSION METHOD or ACCESS METHOD or DARTH VADER ... >> Furthermore, the "TYPE" in CREATE COMPRESSION method was meant to >> restrict the compression algorithm to a particular data type (so, if it >> relies on tsvector, you can't apply it to text columns). > > Yes, of course. I'm saying that the "datatype" property of a > compression access method would be declared somewhere else, not in the > TYPE clause of the CREATE ACCESS METHOD command. Perhaps it makes sense > to declare that a certain compression access method is good only for a > certain data type, and then you can put that in the options clause, > "CREATE ACCESS METHOD hyperz TYPE COMPRESSION WITH (type = tsvector)". > But many compression access methods would be general in nature and so > could be used for many datatypes (say, snappy). > > To me it makes sense to say "let's create this method which is for data > compression" (CREATE ACCESS METHOD hyperz TYPE COMPRESSION) followed by > either "let's use this new compression method for the type tsvector" > (ALTER TYPE tsvector SET COMPRESSION hyperz) or "let's use this new > compression method for the column tc" (ALTER TABLE ALTER COLUMN tc SET > COMPRESSION hyperz). > The WITH syntax does not seem particularly pretty to me, TBH. I'd be much happier with "TYPE tsvector" and leaving WITH for the options specific to each compression method. FWIW I think syntax is the least critical part of this patch. It's ~1% of the patch, and the gram.y additions are rather trivial. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2017-12-01 16:14:58 -0500, Robert Haas wrote: > Honestly, if we can give everybody a 4% space reduction by switching > to lz4, I think that's totally worth doing -- but let's not make > people choose it, let's make it the default going forward, and keep > pglz support around so we don't break pg_upgrade compatibility (and so > people can continue to choose it if for some reason it works better in > their use case). That kind of improvement is nothing special in a > specific workload, but TOAST is a pretty general-purpose mechanism. I > have become, through a few bitter experiences, a strong believer in > the value of trying to reduce our on-disk footprint, and knocking 4% > off the size of every TOAST table in the world does not sound > worthless to me -- even though context-aware compression can doubtless > do a lot better. +1. It's also a lot faster, and I've seen way way to many workloads with 50%+ time spent in pglz. Greetings, Andres Freund
Tomas Vondra wrote: > On 12/01/2017 08:48 PM, Alvaro Herrera wrote: > > Maybe our dependency code needs to be extended in order to support this. > > I think the current logic would drop the column if you were to do "DROP > > COMPRESSION .. CASCADE", but I'm not sure we'd see that as a feature. > > I'd rather have DROP COMPRESSION always fail instead until no columns > > use it. Let's hear other's opinions on this bit though. > > Why should this behave differently compared to data types? Seems quite > against POLA, if you ask me ... OK, DROP TYPE sounds good enough precedent, so +1 on that. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, 1 Dec 2017 16:38:42 -0300 Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > To me it makes sense to say "let's create this method which is for > data compression" (CREATE ACCESS METHOD hyperz TYPE COMPRESSION) > followed by either "let's use this new compression method for the > type tsvector" (ALTER TYPE tsvector SET COMPRESSION hyperz) or "let's > use this new compression method for the column tc" (ALTER TABLE ALTER > COLUMN tc SET COMPRESSION hyperz). > Hi, I think if CREATE ACCESS METHOD can be used for compression, then it could be nicer than CREATE COMPRESSION METHOD. I just don't know that compression could go as access method or not. Anyway it's easy to change syntax and I don't mind to do it, if it will be neccessary for the patch to be commited. -- ---- Regards, Ildus Kurbangaliev
On 12/01/2017 10:52 PM, Andres Freund wrote: > On 2017-12-01 16:14:58 -0500, Robert Haas wrote: >> Honestly, if we can give everybody a 4% space reduction by >> switching to lz4, I think that's totally worth doing -- but let's >> not make people choose it, let's make it the default going forward, >> and keep pglz support around so we don't break pg_upgrade >> compatibility (and so people can continue to choose it if for some >> reason it works better in their use case). That kind of improvement >> is nothing special in a specific workload, but TOAST is a pretty >> general-purpose mechanism. I have become, through a few bitter >> experiences, a strong believer in the value of trying to reduce our >> on-disk footprint, and knocking 4% off the size of every TOAST >> table in the world does not sound worthless to me -- even though >> context-aware compression can doubtless do a lot better. > > +1. It's also a lot faster, and I've seen way way to many workloads > with 50%+ time spent in pglz. > TBH the 4% figure is something I mostly made up (I'm fake news!). On the mailing list archive (which I believe is pretty compressible) I observed something like 2.5% size reduction with lz4 compared to pglz, at least with the compression levels I've used ... Other algorithms (e.g. zstd) got significantly better compression (25%) compared to pglz, but in exchange for longer compression. I'm sure we could lower compression level to make it faster, but that will of course hurt the compression ratio. I don't think switching to a different compression algorithm is a way forward - it was proposed and explored repeatedly in the past, and every time it failed for a number of reasons, most of which are still valid. Firstly, it's going to be quite hard (or perhaps impossible) to find an algorithm that is "universally better" than pglz. Some algorithms do work better for text documents, some for binary blobs, etc. I don't think there's a win-win option. Sure, there are workloads where pglz performs poorly (I've seen such cases too), but IMHO that's more an argument for the custom compression method approach. pglz gives you good default compression in most cases, and you can change it for columns where it matters, and where a different space/time trade-off makes sense. Secondly, all the previous attempts ran into some legal issues, i.e. licensing and/or patents. Maybe the situation changed since then (no idea, haven't looked into that), but in the past the "pluggable" approach was proposed as a way to address this. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Dec 2, 2017, at 6:04 PM, Tomas Vondra wrote:
> On 12/01/2017 10:52 PM, Andres Freund wrote:
>> On 2017-12-01 16:14:58 -0500, Robert Haas wrote:
>>> Honestly, if we can give everybody a 4% space reduction by
>>> switching to lz4, I think that's totally worth doing -- but let's
>>> not make people choose it, let's make it the default going forward,
>>> and keep pglz support around so we don't break pg_upgrade
>>> compatibility (and so people can continue to choose it if for some
>>> reason it works better in their use case). That kind of improvement
>>> is nothing special in a specific workload, but TOAST is a pretty
>>> general-purpose mechanism. I have become, through a few bitter
>>> experiences, a strong believer in the value of trying to reduce our
>>> on-disk footprint, and knocking 4% off the size of every TOAST
>>> table in the world does not sound worthless to me -- even though
>>> context-aware compression can doubtless do a lot better.
>>
>> +1. It's also a lot faster, and I've seen way way to many workloads
>> with 50%+ time spent in pglz.
>>
>
> TBH the 4% figure is something I mostly made up (I'm fake news!). On the
> mailing list archive (which I believe is pretty compressible) I observed
> something like 2.5% size reduction with lz4 compared to pglz, at least
> with the compression levels I've used ...
>
> Other algorithms (e.g. zstd) got significantly better compression (25%)
> compared to pglz, but in exchange for longer compression. I'm sure we
> could lower compression level to make it faster, but that will of course
> hurt the compression ratio.
>
> I don't think switching to a different compression algorithm is a way
> forward - it was proposed and explored repeatedly in the past, and every
> time it failed for a number of reasons, most of which are still valid.
>
>
> Firstly, it's going to be quite hard (or perhaps impossible) to find an
> algorithm that is "universally better" than pglz. Some algorithms do
> work better for text documents, some for binary blobs, etc. I don't
> think there's a win-win option.
>
> Sure, there are workloads where pglz performs poorly (I've seen such
> cases too), but IMHO that's more an argument for the custom compression
> method approach. pglz gives you good default compression in most cases,
> and you can change it for columns where it matters, and where a
> different space/time trade-off makes sense.
>
>
> Secondly, all the previous attempts ran into some legal issues, i.e.
> licensing and/or patents. Maybe the situation changed since then (no
> idea, haven't looked into that), but in the past the "pluggable"
> approach was proposed as a way to address this.
>
>
May be it will be interesting for you to see the following results of applying page-level compression (CFS in PgPro-EE) to pgbench data:
Configuration
Size (Gb)
Time (sec)
vanilla postgres
15.31
92
zlib (default level)
2.37
284
zlib (best speed)
2.43
191
postgres internal lz
3.89
214
lz4
4.12
95
snappy (google)
5.18
99
lzfse (apple)
2.80
1099
zstd (facebook)
1.69
125
All algorithms (except zlib) were used with best-speed option: using better compression level usually has not so large impact on compression ratio (<30%), but can significantly increase time (several times).
Certainly pgbench isnot the best candidate for testing compression algorithms: it generates a lot of artificial and redundant data.
But we measured it also on real customers data and still zstd seems to be the best compression methods: provides good compression with smallest CPU overhead.
Hi, On 2017-12-02 16:04:52 +0100, Tomas Vondra wrote: > Firstly, it's going to be quite hard (or perhaps impossible) to find an > algorithm that is "universally better" than pglz. Some algorithms do > work better for text documents, some for binary blobs, etc. I don't > think there's a win-win option. lz4 is pretty much there. > Secondly, all the previous attempts ran into some legal issues, i.e. > licensing and/or patents. Maybe the situation changed since then (no > idea, haven't looked into that), but in the past the "pluggable" > approach was proposed as a way to address this. Those were pretty bogus. I think we're not doing our users a favor if they've to download some external projects, then fiddle with things, just to not choose a compression algorithm that's been known bad for at least 5+ years. If we've a decent algorithm in-core *and* then allow extensibility, that's one thing, but keeping the bad and tell forks "please take our users with this code we give you" is ... Greetings, Andres Freund
On 12/02/2017 09:24 PM, konstantin knizhnik wrote: > > On Dec 2, 2017, at 6:04 PM, Tomas Vondra wrote: > >> On 12/01/2017 10:52 PM, Andres Freund wrote: >> ... >> >> Other algorithms (e.g. zstd) got significantly better compression (25%) >> compared to pglz, but in exchange for longer compression. I'm sure we >> could lower compression level to make it faster, but that will of course >> hurt the compression ratio. >> >> I don't think switching to a different compression algorithm is a way >> forward - it was proposed and explored repeatedly in the past, and every >> time it failed for a number of reasons, most of which are still valid. >> >> >> Firstly, it's going to be quite hard (or perhaps impossible) to >> find an algorithm that is "universally better" than pglz. Some >> algorithms do work better for text documents, some for binary >> blobs, etc. I don't think there's a win-win option. >> >> Sure, there are workloads where pglz performs poorly (I've seen >> such cases too), but IMHO that's more an argument for the custom >> compression method approach. pglz gives you good default >> compression in most cases, and you can change it for columns where >> it matters, and where a different space/time trade-off makes >> sense. >> >> >> Secondly, all the previous attempts ran into some legal issues, i.e. >> licensing and/or patents. Maybe the situation changed since then (no >> idea, haven't looked into that), but in the past the "pluggable" >> approach was proposed as a way to address this. >> >> > > May be it will be interesting for you to see the following results > of applying page-level compression (CFS in PgPro-EE) to pgbench > data: > I don't follow. If I understand what CFS does correctly (and I'm mostly guessing here, because I haven't seen the code published anywhere, and I assume it's proprietary), it essentially compresses whole 8kB blocks. I don't know it reorganizes the data into columnar format first, in some way (to make it more "columnar" which is more compressible), which would make somewhat similar to page-level compression in Oracle. But it's clearly a very different approach from what the patch aims to improve (compressing individual varlena values). > > All algorithms (except zlib) were used with best-speed option: using > better compression level usually has not so large impact on > compression ratio (<30%), but can significantly increase time > (several times). Certainly pgbench isnot the best candidate for > testing compression algorithms: it generates a lot of artificial and > redundant data. But we measured it also on real customers data and > still zstd seems to be the best compression methods: provides good > compression with smallest CPU overhead. > I think this really depends on the dataset, and drawing conclusions based on a single test is somewhat crazy. Especially when it's synthetic pgbench data with lots of inherent redundancy - sequential IDs, ... My takeaway from the results is rather that page-level compression may be very beneficial in some cases, although I wonder how much of that can be gained by simply using compressed filesystem (thus making it transparent to PostgreSQL). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 12/02/2017 09:38 PM, Andres Freund wrote: > Hi, > > On 2017-12-02 16:04:52 +0100, Tomas Vondra wrote: >> Firstly, it's going to be quite hard (or perhaps impossible) to find an >> algorithm that is "universally better" than pglz. Some algorithms do >> work better for text documents, some for binary blobs, etc. I don't >> think there's a win-win option. > > lz4 is pretty much there. > That's a matter of opinion, I guess. It's a solid compression algorithm, that's for sure ... >> Secondly, all the previous attempts ran into some legal issues, i.e. >> licensing and/or patents. Maybe the situation changed since then (no >> idea, haven't looked into that), but in the past the "pluggable" >> approach was proposed as a way to address this. > > Those were pretty bogus. IANAL so I don't dare to judge on bogusness of such claims. I assume if we made it optional (e.g. configure/initdb option, it'd be much less of an issue). Of course, that has disadvantages too (because when you compile/init with one algorithm, and then find something else would work better for your data, you have to start from scratch). > > I think we're not doing our users a favor if they've to download > some external projects, then fiddle with things, just to not choose > a compression algorithm that's been known bad for at least 5+ years. > If we've a decent algorithm in-core *and* then allow extensibility, > that's one thing, but keeping the bad and tell forks "please take > our users with this code we give you" is ... > I don't understand what exactly is your issue with external projects, TBH. I think extensibility is one of the great strengths of Postgres. It's not all rainbows and unicorns, of course, and it has costs too. FWIW I don't think pglz is a "known bad" algorithm. Perhaps there are cases where other algorithms (e.g. lz4) are running circles around it, particularly when it comes to decompression speed, but I wouldn't say it's "known bad". Not sure which forks you're talking about ... regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Dec 2, 2017 at 6:04 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 12/01/2017 10:52 PM, Andres Freund wrote: >> On 2017-12-01 16:14:58 -0500, Robert Haas wrote: >>> Honestly, if we can give everybody a 4% space reduction by >>> switching to lz4, I think that's totally worth doing -- but let's >>> not make people choose it, let's make it the default going forward, >>> and keep pglz support around so we don't break pg_upgrade >>> compatibility (and so people can continue to choose it if for some >>> reason it works better in their use case). That kind of improvement >>> is nothing special in a specific workload, but TOAST is a pretty >>> general-purpose mechanism. I have become, through a few bitter >>> experiences, a strong believer in the value of trying to reduce our >>> on-disk footprint, and knocking 4% off the size of every TOAST >>> table in the world does not sound worthless to me -- even though >>> context-aware compression can doubtless do a lot better. >> >> +1. It's also a lot faster, and I've seen way way to many workloads >> with 50%+ time spent in pglz. >> > > TBH the 4% figure is something I mostly made up (I'm fake news!). On the > mailing list archive (which I believe is pretty compressible) I observed > something like 2.5% size reduction with lz4 compared to pglz, at least > with the compression levels I've used ... Nikita Glukhove tested compression on real json data: Delicious bookmarks (js): json 1322MB jsonb 1369MB jsonbc 931MB 1.5x jsonb+lz4d 404MB 3.4x Citus customer reviews (jr): json 1391MB jsonb 1574MB jsonbc 622MB 2.5x jsonb+lz4d 601MB 2.5x I also attached a plot with wired tiger size (zstd compression) in Mongodb. Nikita has more numbers about compression. > > Other algorithms (e.g. zstd) got significantly better compression (25%) > compared to pglz, but in exchange for longer compression. I'm sure we > could lower compression level to make it faster, but that will of course > hurt the compression ratio. > > I don't think switching to a different compression algorithm is a way > forward - it was proposed and explored repeatedly in the past, and every > time it failed for a number of reasons, most of which are still valid. > > > Firstly, it's going to be quite hard (or perhaps impossible) to find an > algorithm that is "universally better" than pglz. Some algorithms do > work better for text documents, some for binary blobs, etc. I don't > think there's a win-win option. > > Sure, there are workloads where pglz performs poorly (I've seen such > cases too), but IMHO that's more an argument for the custom compression > method approach. pglz gives you good default compression in most cases, > and you can change it for columns where it matters, and where a > different space/time trade-off makes sense. > > > Secondly, all the previous attempts ran into some legal issues, i.e. > licensing and/or patents. Maybe the situation changed since then (no > idea, haven't looked into that), but in the past the "pluggable" > approach was proposed as a way to address this. I don't think so. Pluggable means that now we have more data types, which don't fit to the old compression scheme of TOAST and we need better flexibility. I see in future we could avoid decompression of the whole toast just to get on key from document, so we first slice data and compress each slice separately. > > > regards > > -- > Tomas Vondra http://www.2ndQuadrant.com > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services >
Attachment
{kind=link}
On Fri, 1 Dec 2017 21:47:43 +0100 Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > +1 to do the rewrite, just like for other similar ALTER TABLE commands Ok. What about the following syntax: ALTER COLUMN DROP COMPRESSION - removes compression from the column with the rewrite and removes related compression options, so the user can drop compression method. ALTER COLUMN SET COMPRESSION NONE for the cases when the users want to just disable compression for future tuples. After that they can keep compressed tuples, or in the case when they have a large table they can decompress tuples partially using e.g. UPDATE, and then use ALTER COLUMN DROP COMPRESSION which will be much faster then. ALTER COLUMN SET COMPRESSION <cm> WITH <cmoptions> will change compression for new tuples but will not touch old ones. If the users want the recompression they can use DROP/SET COMPRESSION combination. I don't think that SET COMPRESSION with the rewrite of the whole table will be useful enough on any somewhat big tables and same time big tables is where the user needs compression the most. I understand that ALTER with the rewrite sounds logical and much easier to implement (and it doesn't require Oids in tuples), but it could be unusable. -- ---- Regards, Ildus Kurbangaliev
On Wed, Dec 6, 2017 at 10:07 AM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > On Fri, 1 Dec 2017 21:47:43 +0100 > Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >> +1 to do the rewrite, just like for other similar ALTER TABLE commands > > Ok. What about the following syntax: > > ALTER COLUMN DROP COMPRESSION - removes compression from the column > with the rewrite and removes related compression options, so the user > can drop compression method. > > ALTER COLUMN SET COMPRESSION NONE for the cases when > the users want to just disable compression for future tuples. After > that they can keep compressed tuples, or in the case when they have a > large table they can decompress tuples partially using e.g. UPDATE, > and then use ALTER COLUMN DROP COMPRESSION which will be much faster > then. > > ALTER COLUMN SET COMPRESSION <cm> WITH <cmoptions> will change > compression for new tuples but will not touch old ones. If the users > want the recompression they can use DROP/SET COMPRESSION combination. > > I don't think that SET COMPRESSION with the rewrite of the whole table > will be useful enough on any somewhat big tables and same time big > tables is where the user needs compression the most. > > I understand that ALTER with the rewrite sounds logical and much easier > to implement (and it doesn't require Oids in tuples), but it could be > unusable. The problem with this is that old compression methods can still be floating around in the table even after you have done SET COMPRESSION to something else. The table still needs to have a dependency on the old compression method, because otherwise you might think it's safe to drop the old one when it really is not. Furthermore, if you do a pg_upgrade, you've got to preserve that dependency, which means it would have to show up in a pg_dump --binary-upgrade someplace. It's not obvious how any of that would work with this syntax. Maybe a better idea is ALTER COLUMN SET COMPRESSION x1, x2, x3 ... meaning that x1 is the default for new tuples but x2, x3, etc. are still allowed if present. If you issue a command that only adds things to the list, no table rewrite happens, but if you remove anything, then it does. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, 8 Dec 2017 15:12:42 -0500 Robert Haas <robertmhaas@gmail.com> wrote: > > Maybe a better idea is ALTER COLUMN SET COMPRESSION x1, x2, x3 ... > meaning that x1 is the default for new tuples but x2, x3, etc. are > still allowed if present. If you issue a command that only adds > things to the list, no table rewrite happens, but if you remove > anything, then it does. > I like this idea, but maybe it should be something like ALTER COLUMN SET COMPRESSION x1 [ PRESERVE x2, x3 ]? 'PRESERVE' is already used in syntax and this syntax will show better which one is current and which ones should be kept. -- ---- Regards, Ildus Kurbangaliev
On Mon, Dec 11, 2017 at 7:55 AM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > On Fri, 8 Dec 2017 15:12:42 -0500 > Robert Haas <robertmhaas@gmail.com> wrote: >> Maybe a better idea is ALTER COLUMN SET COMPRESSION x1, x2, x3 ... >> meaning that x1 is the default for new tuples but x2, x3, etc. are >> still allowed if present. If you issue a command that only adds >> things to the list, no table rewrite happens, but if you remove >> anything, then it does. > > I like this idea, but maybe it should be something like ALTER COLUMN > SET COMPRESSION x1 [ PRESERVE x2, x3 ]? 'PRESERVE' is already used in > syntax and this syntax will show better which one is current and which > ones should be kept. Sure, that works. And I think pglz should exist in the catalog as a predefined, undroppable compression algorithm. So the default for each column initially is: SET COMPRESSION pglz And if you want to rewrite the table with your awesome custom thing, you can do SET COMPRESSION awesome But if you want to just use the awesome custom thing for new rows, you can do SET COMPRESSION awesome PRESERVE pglz Then we can get all the dependencies right, pg_upgrade works, users have total control of rewrite behavior, and everything is great. :-) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Dec 11, 2017 at 8:25 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Mon, Dec 11, 2017 at 7:55 AM, Ildus Kurbangaliev
<i.kurbangaliev@postgrespro.ru> wrote:
> On Fri, 8 Dec 2017 15:12:42 -0500
> Robert Haas <robertmhaas@gmail.com> wrote:
>> Maybe a better idea is ALTER COLUMN SET COMPRESSION x1, x2, x3 ...
>> meaning that x1 is the default for new tuples but x2, x3, etc. are
>> still allowed if present. If you issue a command that only adds
>> things to the list, no table rewrite happens, but if you remove
>> anything, then it does.
>
> I like this idea, but maybe it should be something like ALTER COLUMN
> SET COMPRESSION x1 [ PRESERVE x2, x3 ]? 'PRESERVE' is already used in
> syntax and this syntax will show better which one is current and which
> ones should be kept.
Sure, that works. And I think pglz should exist in the catalog as a
predefined, undroppable compression algorithm. So the default for
each column initially is:
SET COMPRESSION pglz
And if you want to rewrite the table with your awesome custom thing, you can do
SET COMPRESSION awesome
But if you want to just use the awesome custom thing for new rows, you can do
SET COMPRESSION awesome PRESERVE pglz
Then we can get all the dependencies right, pg_upgrade works, users
have total control of rewrite behavior, and everything is great. :-)
Looks good.
Thus, in your example if user would like to further change awesome compression for evenbetter compression, she should write.
SET COMPRESSION evenbetter PRESERVE pglz, awesome; -- full list of previous compression methods
I wonder what should we do if user specifies only part of previous compression methods? For instance, pglz is specified but awesome is missing.
SET COMPRESSION evenbetter PRESERVE pglz; -- awesome is missing
I think we should trigger an error in this case. Because query is specified in form that is assuming to work without table rewrite, but we're unable to do this without table rewrite.
I also think that we need some way to change compression method for multiple columns in a single table rewrite. Because it would be way more efficient than rewriting table for each of columns. So as an alternative of
ALTER TABLE tbl ALTER COLUMN c1 SET COMPRESSION awesome; -- first table rewrite
ALTER TABLE tbl ALTER COLUMN c2 SET COMPRESSION awesome; -- second table rewrite
we could also provide
ALTER TABLE tbl ALTER COLUMN c1 SET COMPRESSION awesome PRESERVE pglz; -- no rewrite
ALTER TABLE tbl ALTER COLUMN c2 SET COMPRESSION awesome PRESERVE pglz; -- no rewrite
VACUUM FULL tbl RESET COMPRESSION PRESERVE c1, c2; -- rewrite with recompression of c1 and c2 and removing depedencies
?
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Mon, Dec 11, 2017 at 12:41 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Thus, in your example if user would like to further change awesome > compression for evenbetter compression, she should write. > > SET COMPRESSION evenbetter PRESERVE pglz, awesome; -- full list of previous > compression methods Right. > I wonder what should we do if user specifies only part of previous > compression methods? For instance, pglz is specified but awesome is > missing. > > SET COMPRESSION evenbetter PRESERVE pglz; -- awesome is missing > > I think we should trigger an error in this case. Because query is specified > in form that is assuming to work without table rewrite, but we're unable to > do this without table rewrite. I think that should just rewrite the table in that case. PRESERVE should specify the things that are allowed to be preserved -- its mere presence should not be read to preclude a rewrite. And it's completely reasonable for someone to want to do this, if they are thinking about de-installing awesome. > I also think that we need some way to change compression method for multiple > columns in a single table rewrite. Because it would be way more efficient > than rewriting table for each of columns. So as an alternative of > > ALTER TABLE tbl ALTER COLUMN c1 SET COMPRESSION awesome; -- first table > rewrite > ALTER TABLE tbl ALTER COLUMN c2 SET COMPRESSION awesome; -- second table > rewrite > > we could also provide > > ALTER TABLE tbl ALTER COLUMN c1 SET COMPRESSION awesome PRESERVE pglz; -- no > rewrite > ALTER TABLE tbl ALTER COLUMN c2 SET COMPRESSION awesome PRESERVE pglz; -- no > rewrite > VACUUM FULL tbl RESET COMPRESSION PRESERVE c1, c2; -- rewrite with > recompression of c1 and c2 and removing depedencies > > ? Hmm. ALTER TABLE allows multi comma-separated subcommands, so I don't think we need to drag VACUUM into this. The user can just say: ALTER TABLE tbl ALTER COLUMN c1 SET COMPRESSION awesome, ALTER COLUMN c2 SET COMPRESSION awesome; If this is properly integrated into tablecmds.c, that should cause a single rewrite affecting both columns. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Dec 11, 2017 at 8:46 PM, Robert Haas <robertmhaas@gmail.com> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On Mon, Dec 11, 2017 at 12:41 PM, Alexander Korotkov
<a.korotkov@postgrespro.ru> wrote:
> Thus, in your example if user would like to further change awesome
> compression for evenbetter compression, she should write.
>
> SET COMPRESSION evenbetter PRESERVE pglz, awesome; -- full list of previous
> compression methods
Right.
> I wonder what should we do if user specifies only part of previous
> compression methods? For instance, pglz is specified but awesome is
> missing.
>
> SET COMPRESSION evenbetter PRESERVE pglz; -- awesome is missing
>
> I think we should trigger an error in this case. Because query is specified
> in form that is assuming to work without table rewrite, but we're unable to
> do this without table rewrite.
I think that should just rewrite the table in that case. PRESERVE
should specify the things that are allowed to be preserved -- its mere
presence should not be read to preclude a rewrite. And it's
completely reasonable for someone to want to do this, if they are
thinking about de-installing awesome.
OK, but NOTICE that presumably unexpected table rewrite takes place could be still useful.
Also we probably should add some view that will expose compression methods whose are currently preserved for columns. So that user can correctly construct SET COMPRESSION query that doesn't rewrites table without digging into internals (like directly querying pg_depend).
> I also think that we need some way to change compression method for multiple
> columns in a single table rewrite. Because it would be way more efficient
> than rewriting table for each of columns. So as an alternative of
>
> ALTER TABLE tbl ALTER COLUMN c1 SET COMPRESSION awesome; -- first table
> rewrite
> ALTER TABLE tbl ALTER COLUMN c2 SET COMPRESSION awesome; -- second table
> rewrite
>
> we could also provide
>
> ALTER TABLE tbl ALTER COLUMN c1 SET COMPRESSION awesome PRESERVE pglz; -- no
> rewrite
> ALTER TABLE tbl ALTER COLUMN c2 SET COMPRESSION awesome PRESERVE pglz; -- no
> rewrite
> VACUUM FULL tbl RESET COMPRESSION PRESERVE c1, c2; -- rewrite with
> recompression of c1 and c2 and removing depedencies
>
> ?
Hmm. ALTER TABLE allows multi comma-separated subcommands, so I don't
think we need to drag VACUUM into this. The user can just say:
ALTER TABLE tbl ALTER COLUMN c1 SET COMPRESSION awesome, ALTER COLUMN
c2 SET COMPRESSION awesome;
If this is properly integrated into tablecmds.c, that should cause a
single rewrite affecting both columns.
OK. Sorry, I didn't notice we can use multiple subcommands for ALTER TABLE in this case...
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Hi, I see there's an ongoing discussion about the syntax and ALTER TABLE behavior when changing a compression method for a column. So the patch seems to be on the way to be ready in the January CF, I guess. But let me play the devil's advocate for a while and question the usefulness of this approach to compression. Some of the questions were mentioned in the thread before, but I don't think they got the attention they deserve. FWIW I don't know the answers, but I think it's important to ask them. Also, apologies if this post looks to be against the patch - that's part of the "devil's advocate" thing. The main question I'm asking myself is what use cases the patch addresses, and whether there is a better way to do that. I see about three main use-cases: 1) Replacing the algorithm used to compress all varlena types (in a way that makes it transparent for the data type code). 2) Custom datatype-aware compression (e.g. the tsvector). 3) Custom datatype-aware compression with additional column-specific metadata (e.g. the jsonb with external dictionary). Now, let's discuss those use cases one by one, and see if there are simpler (or better in some way) solutions ... Replacing the algorithm used to compress all varlena values (in a way that makes it transparent for the data type code). ---------------------------------------------------------------------- While pglz served us well over time, it was repeatedly mentioned that in some cases it becomes the bottleneck. So supporting other state of the art compression algorithms seems like a good idea, and this patch is one way to do that. But perhaps we should simply make it an initdb option (in which case the whole cluster would simply use e.g. lz4 instead of pglz)? That seems like a much simpler approach - it would only require some ./configure options to add --with-lz4 (and other compression libraries), an initdb option to pick compression algorithm, and probably noting the choice in cluster controldata. No dependencies tracking, no ALTER TABLE issues, etc. Of course, it would not allow using different compression algorithms for different columns (although it might perhaps allow different compression level, to some extent). Conclusion: If we want to offer a simple cluster-wide pglz alternative, perhaps this patch is not the right way to do that. Custom datatype-aware compression (e.g. the tsvector) ---------------------------------------------------------------------- Exploiting knowledge of the internal data type structure is a promising way to improve compression ratio and/or performance. The obvious question of course is why shouldn't this be done by the data type code directly, which would also allow additional benefits like operating directly on the compressed values. Another thing is that if the datatype representation changes in some way, the compression method has to change too. So it's tightly coupled to the datatype anyway. This does not really require any new infrastructure, all the pieces are already there. In some cases that may not be quite possible - the datatype may not be flexible enough to support alternative (compressed) representation, e.g. because there are no bits available for "compressed" flag, etc. Conclusion: IMHO if we want to exploit the knowledge of the data type internal structure, perhaps doing that in the datatype code directly would be a better choice. Custom datatype-aware compression with additional column-specific metadata (e.g. the jsonb with external dictionary). ---------------------------------------------------------------------- Exploiting redundancy in multiple values in the same column (instead of compressing them independently) is another attractive way to help the compression. It is inherently datatype-aware, but currently can't be implemented directly in datatype code as there's no concept of column-specific storage (e.g. to store dictionary shared by all values in a particular column). I believe any patch addressing this use case would have to introduce such column-specific storage, and any solution doing that would probably need to introduce the same catalogs, etc. The obvious disadvantage of course is that we need to decompress the varlena value before doing pretty much anything with it, because the datatype is not aware of the compression. So I wonder if the patch should instead provide infrastructure for doing that in the datatype code directly. The other question is if the patch should introduce some infrastructure for handling the column context (e.g. column dictionary). Right now, whoever implements the compression has to implement this bit too. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, 11 Dec 2017 20:53:29 +0100 Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > But let me play the devil's advocate for a while and question the > usefulness of this approach to compression. Some of the questions were > mentioned in the thread before, but I don't think they got the > attention they deserve. Hi. I will try to explain why this approach could be better than others. > > > Replacing the algorithm used to compress all varlena values (in a way > that makes it transparent for the data type code). > ---------------------------------------------------------------------- > > While pglz served us well over time, it was repeatedly mentioned that > in some cases it becomes the bottleneck. So supporting other state of > the art compression algorithms seems like a good idea, and this patch > is one way to do that. > > But perhaps we should simply make it an initdb option (in which case > the whole cluster would simply use e.g. lz4 instead of pglz)? > > That seems like a much simpler approach - it would only require some > ./configure options to add --with-lz4 (and other compression > libraries), an initdb option to pick compression algorithm, and > probably noting the choice in cluster controldata. Replacing pglz for all varlena values wasn't the goal of the patch, but it's possible to do with it and I think that's good. And as Robert mentioned pglz could appear as builtin undroppable compresssion method so the others could be added too. And in the future it can open the ways to specify compression for specific database or cluster. > > Custom datatype-aware compression (e.g. the tsvector) > ---------------------------------------------------------------------- > > Exploiting knowledge of the internal data type structure is a > promising way to improve compression ratio and/or performance. > > The obvious question of course is why shouldn't this be done by the > data type code directly, which would also allow additional benefits > like operating directly on the compressed values. > > Another thing is that if the datatype representation changes in some > way, the compression method has to change too. So it's tightly coupled > to the datatype anyway. > > This does not really require any new infrastructure, all the pieces > are already there. > > In some cases that may not be quite possible - the datatype may not be > flexible enough to support alternative (compressed) representation, > e.g. because there are no bits available for "compressed" flag, etc. > > Conclusion: IMHO if we want to exploit the knowledge of the data type > internal structure, perhaps doing that in the datatype code directly > would be a better choice. It could be, but let's imagine there will be internal compression for tsvector. It means that tsvector has two formats now and minus one bit somewhere in the header. After a while we found a better compression but we can't add it because there is already one and it's not good to have three different formats for one type. Or, the compression methods were implemented and we decided to use dictionaries for tsvector (if the user going to store limited number of words). But it will mean that tsvector will go two compression stages (for its internal and for dictionaries). > > > Custom datatype-aware compression with additional column-specific > metadata (e.g. the jsonb with external dictionary). > ---------------------------------------------------------------------- > > Exploiting redundancy in multiple values in the same column (instead > of compressing them independently) is another attractive way to help > the compression. It is inherently datatype-aware, but currently can't > be implemented directly in datatype code as there's no concept of > column-specific storage (e.g. to store dictionary shared by all values > in a particular column). > > I believe any patch addressing this use case would have to introduce > such column-specific storage, and any solution doing that would > probably need to introduce the same catalogs, etc. > > The obvious disadvantage of course is that we need to decompress the > varlena value before doing pretty much anything with it, because the > datatype is not aware of the compression. > > So I wonder if the patch should instead provide infrastructure for > doing that in the datatype code directly. > > The other question is if the patch should introduce some > infrastructure for handling the column context (e.g. column > dictionary). Right now, whoever implements the compression has to > implement this bit too. Column specific storage sounds optional to me. For example compressing timestamp[] using some delta compression will not require it. -- ---- Regards, Ildus Kurbangaliev
Hi!
Let me add my two cents too.
On Tue, Dec 12, 2017 at 2:41 PM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru
On Mon, 11 Dec 2017 20:53:29 +0100 Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
> Replacing the algorithm used to compress all varlena values (in a way
> that makes it transparent for the data type code).
> ------------------------------------------------------------ ----------
>
> While pglz served us well over time, it was repeatedly mentioned that
> in some cases it becomes the bottleneck. So supporting other state of
> the art compression algorithms seems like a good idea, and this patch
> is one way to do that.
>
> But perhaps we should simply make it an initdb option (in which case
> the whole cluster would simply use e.g. lz4 instead of pglz)?
>
> That seems like a much simpler approach - it would only require some
> ./configure options to add --with-lz4 (and other compression
> libraries), an initdb option to pick compression algorithm, and
> probably noting the choice in cluster controldata.
Replacing pglz for all varlena values wasn't the goal of the patch, but
it's possible to do with it and I think that's good. And as Robert
mentioned pglz could appear as builtin undroppable compresssion method
so the others could be added too. And in the future it can open the
ways to specify compression for specific database or cluster.
Yes, usage of custom compression methods to replace generic non type-specific compression method is really not the primary goal of this patch. However, I would consider that as useful side effect. However, even in this case I see some advantages of custom compression methods over initdb option.
1) In order to support alternative compression methods in initdb, we have to provide builtin support for them. Then we immediately run into dependencies/incompatible-licenses problem. Also, we tie appearance of new compression methods to our release cycle. In real life, flexibility means a lot. Giving users freedom to experiment with various compression libraries without having to recompile PostgreSQL core is great.
2) It's not necessary that users would be satisfied with applying single compression method to the whole database cluster. Various columns may have different data distributions with different workloads. Optimal compression type for one column is not necessary optimal for another column.
3) Possibility to change compression method on the fly without re-initdb is very good too.
> Custom datatype-aware compression (e.g. the tsvector)
> ------------------------------------------------------------ ----------
>
> Exploiting knowledge of the internal data type structure is a
> promising way to improve compression ratio and/or performance.
>
> The obvious question of course is why shouldn't this be done by the
> data type code directly, which would also allow additional benefits
> like operating directly on the compressed values.
>
> Another thing is that if the datatype representation changes in some
> way, the compression method has to change too. So it's tightly coupled
> to the datatype anyway.
>
> This does not really require any new infrastructure, all the pieces
> are already there.
>
> In some cases that may not be quite possible - the datatype may not be
> flexible enough to support alternative (compressed) representation,
> e.g. because there are no bits available for "compressed" flag, etc.
>
> Conclusion: IMHO if we want to exploit the knowledge of the data type
> internal structure, perhaps doing that in the datatype code directly
> would be a better choice.
It could be, but let's imagine there will be internal compression for
tsvector. It means that tsvector has two formats now and minus one bit
somewhere in the header. After a while we found a better compression
but we can't add it because there is already one and it's not good to
have three different formats for one type. Or, the compression methods
were implemented and we decided to use dictionaries for tsvector (if
the user going to store limited number of words). But it will mean that
tsvector will go two compression stages (for its internal and for
dictionaries).
I would like to add that even for single datatype various compression methods may have different tradeoffs. For instance, one compression method can have better compression ratio, but another one have faster decompression. And it's OK for user to choose different compression methods for different columns.
Depending extensions on datatype internal representation doesn't seem evil for me. We already have bunch of extension depending on much more deeper guts of PostgreSQL. On major release of PostgreSQL, extensions must adopt the changes, that is the rule. And note, the datatype internal representation alters relatively rare in comparison with other internals, because it's related to on-disk format and ability to pg_upgrade.
> Custom datatype-aware compression with additional column-specific
> metadata (e.g. the jsonb with external dictionary).
> ------------------------------------------------------------ ----------
>
> Exploiting redundancy in multiple values in the same column (instead
> of compressing them independently) is another attractive way to help
> the compression. It is inherently datatype-aware, but currently can't
> be implemented directly in datatype code as there's no concept of
> column-specific storage (e.g. to store dictionary shared by all values
> in a particular column).
>
> I believe any patch addressing this use case would have to introduce
> such column-specific storage, and any solution doing that would
> probably need to introduce the same catalogs, etc.
>
> The obvious disadvantage of course is that we need to decompress the
> varlena value before doing pretty much anything with it, because the
> datatype is not aware of the compression.
>
> So I wonder if the patch should instead provide infrastructure for
> doing that in the datatype code directly.
>
> The other question is if the patch should introduce some
> infrastructure for handling the column context (e.g. column
> dictionary). Right now, whoever implements the compression has to
> implement this bit too.
Column specific storage sounds optional to me. For example compressing
timestamp[] using some delta compression will not require it.
It's also could be useful to have custom compression method with fixed (not dynamically complemented) dictionary. See [1] for example what other databases do. We may specify fixed dictionary directly in the compression method options, I see no problems. We may also compress that way not only jsonb or other special data types, but also natural language texts. Using fixed dictionaries for natural language we can effectively compress short texts, when lz and other generic compression methods don't have enough of information to effectively train per-value dictionary.
For sure, further work to improve infrastructure is required including per-column storage for dictionary and tighter integration between compression method and datatype. However, we are typically deal with such complex tasks in step-by-step approach. And I'm not convinced that custom compression methods are bad for the first step in this direction. For me they look clear and already very useful in this shape.
The Russian Postgres Company
On Tue, Dec 12, 2017 at 6:07 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Hi! > > Let me add my two cents too. > > On Tue, Dec 12, 2017 at 2:41 PM, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: >> >> On Mon, 11 Dec 2017 20:53:29 +0100 Tomas Vondra >> <tomas.vondra@2ndquadrant.com> wrote: >> > Replacing the algorithm used to compress all varlena values (in a way >> > that makes it transparent for the data type code). >> > ---------------------------------------------------------------------- >> > >> > While pglz served us well over time, it was repeatedly mentioned that >> > in some cases it becomes the bottleneck. So supporting other state of >> > the art compression algorithms seems like a good idea, and this patch >> > is one way to do that. >> > >> > But perhaps we should simply make it an initdb option (in which case >> > the whole cluster would simply use e.g. lz4 instead of pglz)? >> > >> > That seems like a much simpler approach - it would only require some >> > ./configure options to add --with-lz4 (and other compression >> > libraries), an initdb option to pick compression algorithm, and >> > probably noting the choice in cluster controldata. >> >> Replacing pglz for all varlena values wasn't the goal of the patch, but >> it's possible to do with it and I think that's good. And as Robert >> mentioned pglz could appear as builtin undroppable compresssion method >> so the others could be added too. And in the future it can open the >> ways to specify compression for specific database or cluster. > > > Yes, usage of custom compression methods to replace generic non > type-specific compression method is really not the primary goal of this > patch. However, I would consider that as useful side effect. However, even > in this case I see some advantages of custom compression methods over initdb > option. > > 1) In order to support alternative compression methods in initdb, we have to > provide builtin support for them. Then we immediately run into > dependencies/incompatible-licenses problem. Also, we tie appearance of new > compression methods to our release cycle. In real life, flexibility means a > lot. Giving users freedom to experiment with various compression libraries > without having to recompile PostgreSQL core is great. > 2) It's not necessary that users would be satisfied with applying single > compression method to the whole database cluster. Various columns may have > different data distributions with different workloads. Optimal compression > type for one column is not necessary optimal for another column. > 3) Possibility to change compression method on the fly without re-initdb is > very good too. I consider custom compression as the way to custom TOAST. For example, to optimal access parts of very long document we need to compress slices of document. Currently, long jsonb document get compressed and then sliced and that killed all benefits of binary jsonb. Also, we are thinking about "lazy" access to the parts of jsonb from pl's, which is currently awfully unefficient. > >> > Custom datatype-aware compression (e.g. the tsvector) >> > ---------------------------------------------------------------------- >> > >> > Exploiting knowledge of the internal data type structure is a >> > promising way to improve compression ratio and/or performance. >> > >> > The obvious question of course is why shouldn't this be done by the >> > data type code directly, which would also allow additional benefits >> > like operating directly on the compressed values. >> > >> > Another thing is that if the datatype representation changes in some >> > way, the compression method has to change too. So it's tightly coupled >> > to the datatype anyway. >> > >> > This does not really require any new infrastructure, all the pieces >> > are already there. >> > >> > In some cases that may not be quite possible - the datatype may not be >> > flexible enough to support alternative (compressed) representation, >> > e.g. because there are no bits available for "compressed" flag, etc. >> > >> > Conclusion: IMHO if we want to exploit the knowledge of the data type >> > internal structure, perhaps doing that in the datatype code directly >> > would be a better choice. >> >> It could be, but let's imagine there will be internal compression for >> tsvector. It means that tsvector has two formats now and minus one bit >> somewhere in the header. After a while we found a better compression >> but we can't add it because there is already one and it's not good to >> have three different formats for one type. Or, the compression methods >> were implemented and we decided to use dictionaries for tsvector (if >> the user going to store limited number of words). But it will mean that >> tsvector will go two compression stages (for its internal and for >> dictionaries). > > > I would like to add that even for single datatype various compression > methods may have different tradeoffs. For instance, one compression method > can have better compression ratio, but another one have faster > decompression. And it's OK for user to choose different compression methods > for different columns. > > Depending extensions on datatype internal representation doesn't seem evil > for me. We already have bunch of extension depending on much more deeper > guts of PostgreSQL. On major release of PostgreSQL, extensions must adopt > the changes, that is the rule. And note, the datatype internal > representation alters relatively rare in comparison with other internals, > because it's related to on-disk format and ability to pg_upgrade. > >> > Custom datatype-aware compression with additional column-specific >> > metadata (e.g. the jsonb with external dictionary). >> > ---------------------------------------------------------------------- >> > >> > Exploiting redundancy in multiple values in the same column (instead >> > of compressing them independently) is another attractive way to help >> > the compression. It is inherently datatype-aware, but currently can't >> > be implemented directly in datatype code as there's no concept of >> > column-specific storage (e.g. to store dictionary shared by all values >> > in a particular column). >> > >> > I believe any patch addressing this use case would have to introduce >> > such column-specific storage, and any solution doing that would >> > probably need to introduce the same catalogs, etc. >> > >> > The obvious disadvantage of course is that we need to decompress the >> > varlena value before doing pretty much anything with it, because the >> > datatype is not aware of the compression. >> > >> > So I wonder if the patch should instead provide infrastructure for >> > doing that in the datatype code directly. >> > >> > The other question is if the patch should introduce some >> > infrastructure for handling the column context (e.g. column >> > dictionary). Right now, whoever implements the compression has to >> > implement this bit too. >> >> Column specific storage sounds optional to me. For example compressing >> timestamp[] using some delta compression will not require it. > > > It's also could be useful to have custom compression method with fixed (not > dynamically complemented) dictionary. See [1] for example what other > databases do. We may specify fixed dictionary directly in the compression > method options, I see no problems. We may also compress that way not only > jsonb or other special data types, but also natural language texts. Using > fixed dictionaries for natural language we can effectively compress short > texts, when lz and other generic compression methods don't have enough of > information to effectively train per-value dictionary. > > For sure, further work to improve infrastructure is required including > per-column storage for dictionary and tighter integration between > compression method and datatype. However, we are typically deal with such > complex tasks in step-by-step approach. And I'm not convinced that custom > compression methods are bad for the first step in this direction. For me > they look clear and already very useful in this shape. +1 > > 1. > https://www.percona.com/doc/percona-server/LATEST/flexibility/compressed_columns.html > > ------ > Alexander Korotkov > Postgres Professional: http://www.postgrespro.com > The Russian Postgres Company >
On Mon, Dec 11, 2017 at 1:06 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > OK, but NOTICE that presumably unexpected table rewrite takes place could be > still useful. I'm not going to complain too much about that, but I think that's mostly a failure of expectation rather than a real problem. If the documentation says what the user should expect, and they expect something else, tough luck for them. > Also we probably should add some view that will expose compression methods > whose are currently preserved for columns. So that user can correctly > construct SET COMPRESSION query that doesn't rewrites table without digging > into internals (like directly querying pg_depend). Yes. I wonder if \d or \d+ can show it somehow. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Dec 11, 2017 at 2:53 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > But let me play the devil's advocate for a while and question the > usefulness of this approach to compression. Some of the questions were > mentioned in the thread before, but I don't think they got the attention > they deserve. Sure, thanks for chiming in. I think it is good to make sure we are discussing this stuff. > But perhaps we should simply make it an initdb option (in which case the > whole cluster would simply use e.g. lz4 instead of pglz)? > > That seems like a much simpler approach - it would only require some > ./configure options to add --with-lz4 (and other compression libraries), > an initdb option to pick compression algorithm, and probably noting the > choice in cluster controldata. > > No dependencies tracking, no ALTER TABLE issues, etc. > > Of course, it would not allow using different compression algorithms for > different columns (although it might perhaps allow different compression > level, to some extent). > > Conclusion: If we want to offer a simple cluster-wide pglz alternative, > perhaps this patch is not the right way to do that. I actually disagree with your conclusion here. I mean, if you do it that way, then it has the same problem as checksums: changing compression algorithms requires a full dump-and-reload of the database, which makes it more or less a non-starter for large databases. On the other hand, with the infrastructure provided by this patch, we can have a default_compression_method GUC that will be set to 'pglz' initially. If the user changes it to 'lz4', or we ship a new release where the new default is 'lz4', then new tables created will use that new setting, but the existing stuff keeps working. If you want to upgrade your existing tables to use lz4 rather than pglz, you can change the compression option for those columns to COMPRESS lz4 PRESERVE pglz if you want to do it incrementally or just COMPRESS lz4 to force a rewrite of an individual table. That's really powerful, and I think users will like it a lot. In short, your approach, while perhaps a little simpler to code, seems like it is fraught with operational problems which this design avoids. > Custom datatype-aware compression (e.g. the tsvector) > ---------------------------------------------------------------------- > > Exploiting knowledge of the internal data type structure is a promising > way to improve compression ratio and/or performance. > > The obvious question of course is why shouldn't this be done by the data > type code directly, which would also allow additional benefits like > operating directly on the compressed values. > > Another thing is that if the datatype representation changes in some > way, the compression method has to change too. So it's tightly coupled > to the datatype anyway. > > This does not really require any new infrastructure, all the pieces are > already there. > > In some cases that may not be quite possible - the datatype may not be > flexible enough to support alternative (compressed) representation, e.g. > because there are no bits available for "compressed" flag, etc. > > Conclusion: IMHO if we want to exploit the knowledge of the data type > internal structure, perhaps doing that in the datatype code directly > would be a better choice. I definitely think there's a place for compression built right into the data type. I'm still happy about commit 145343534c153d1e6c3cff1fa1855787684d9a38 -- although really, more needs to be done there. But that type of improvement and what is proposed here are basically orthogonal. Having either one is good; having both is better. I think there may also be a place for declaring that a particular data type has a "privileged" type of TOAST compression; if you use that kind of compression for that data type, the data type will do smart things, and if not, it will have to decompress in more cases. But I think this infrastructure makes that kind of thing easier, not harder. > Custom datatype-aware compression with additional column-specific > metadata (e.g. the jsonb with external dictionary). > ---------------------------------------------------------------------- > > Exploiting redundancy in multiple values in the same column (instead of > compressing them independently) is another attractive way to help the > compression. It is inherently datatype-aware, but currently can't be > implemented directly in datatype code as there's no concept of > column-specific storage (e.g. to store dictionary shared by all values > in a particular column). > > I believe any patch addressing this use case would have to introduce > such column-specific storage, and any solution doing that would probably > need to introduce the same catalogs, etc. > > The obvious disadvantage of course is that we need to decompress the > varlena value before doing pretty much anything with it, because the > datatype is not aware of the compression. > > So I wonder if the patch should instead provide infrastructure for doing > that in the datatype code directly. > > The other question is if the patch should introduce some infrastructure > for handling the column context (e.g. column dictionary). Right now, > whoever implements the compression has to implement this bit too. I agree that having a place to store a per-column compression dictionary would be awesome, but I think that could be added later on top of this infrastructure. For example, suppose we stored each per-column compression dictionary in a separate file and provided some infrastructure for WAL-logging changes to the file on a logical basis and checkpointing those updates. Then we wouldn't be tied to the MVCC/transactional issues which storing the blobs in a table would have, which seems like a big win. Of course, it also creates a lot of little tiny files inside a directory that already tends to have too many files, but maybe with some more work we can figure out a way around that problem. Here again, it seems to me that the proposed design is going more in the right direction than the wrong direction: if some day we have per-column dictionaries, they will need to be tied to specific compression methods on specific columns. If we already have that concept, extending it to do something new is easier than if we have to create it from scratch. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 12/12/2017 10:33 PM, Robert Haas wrote: > On Mon, Dec 11, 2017 at 2:53 PM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> But let me play the devil's advocate for a while and question the >> usefulness of this approach to compression. Some of the questions were >> mentioned in the thread before, but I don't think they got the attention >> they deserve. > > Sure, thanks for chiming in. I think it is good to make sure we are > discussing this stuff. > >> But perhaps we should simply make it an initdb option (in which case the >> whole cluster would simply use e.g. lz4 instead of pglz)? >> >> That seems like a much simpler approach - it would only require some >> ./configure options to add --with-lz4 (and other compression libraries), >> an initdb option to pick compression algorithm, and probably noting the >> choice in cluster controldata. >> >> No dependencies tracking, no ALTER TABLE issues, etc. >> >> Of course, it would not allow using different compression algorithms for >> different columns (although it might perhaps allow different compression >> level, to some extent). >> >> Conclusion: If we want to offer a simple cluster-wide pglz alternative, >> perhaps this patch is not the right way to do that. > > I actually disagree with your conclusion here. I mean, if you do it > that way, then it has the same problem as checksums: changing > compression algorithms requires a full dump-and-reload of the > database, which makes it more or less a non-starter for large > databases. On the other hand, with the infrastructure provided by > this patch, we can have a default_compression_method GUC that will be > set to 'pglz' initially. If the user changes it to 'lz4', or we ship > a new release where the new default is 'lz4', then new tables created > will use that new setting, but the existing stuff keeps working. If > you want to upgrade your existing tables to use lz4 rather than pglz, > you can change the compression option for those columns to COMPRESS > lz4 PRESERVE pglz if you want to do it incrementally or just COMPRESS > lz4 to force a rewrite of an individual table. That's really > powerful, and I think users will like it a lot. > > In short, your approach, while perhaps a little simpler to code, seems > like it is fraught with operational problems which this design avoids. > I agree the checksum-like limitations are annoying and make it impossible to change the compression algorithm after the cluster is initialized (although I recall a discussion about addressing that). So yeah, if such flexibility is considered valuable/important, then the patch is a better solution. >> Custom datatype-aware compression (e.g. the tsvector) >> ---------------------------------------------------------------------- >> >> Exploiting knowledge of the internal data type structure is a promising >> way to improve compression ratio and/or performance. >> >> The obvious question of course is why shouldn't this be done by the data >> type code directly, which would also allow additional benefits like >> operating directly on the compressed values. >> >> Another thing is that if the datatype representation changes in some >> way, the compression method has to change too. So it's tightly coupled >> to the datatype anyway. >> >> This does not really require any new infrastructure, all the pieces are >> already there. >> >> In some cases that may not be quite possible - the datatype may not be >> flexible enough to support alternative (compressed) representation, e.g. >> because there are no bits available for "compressed" flag, etc. >> >> Conclusion: IMHO if we want to exploit the knowledge of the data type >> internal structure, perhaps doing that in the datatype code directly >> would be a better choice. > > I definitely think there's a place for compression built right into > the data type. I'm still happy about commit > 145343534c153d1e6c3cff1fa1855787684d9a38 -- although really, more > needs to be done there. But that type of improvement and what is > proposed here are basically orthogonal. Having either one is good; > having both is better. > Why orthogonal? For example, why couldn't (or shouldn't) the tsvector compression be done by tsvector code itself? Why should we be doing that at the varlena level (so that the tsvector code does not even know about it)? For example we could make the datatype EXTERNAL and do the compression on our own, using a custom algorithm. Of course, that would require datatype-specific implementation, but tsvector_compress does that too. It seems to me the main reason is that tsvector actually does not allow us to do that, as there's no good way to distinguish the different internal format (e.g. by storing a flag or format version in some sort of header, etc.). > I think there may also be a place for declaring that a particular data > type has a "privileged" type of TOAST compression; if you use that > kind of compression for that data type, the data type will do smart > things, and if not, it will have to decompress in more cases. But I > think this infrastructure makes that kind of thing easier, not harder. > I don't quite understand how that would be done. Isn't TOAST meant to be entirely transparent for the datatypes? I can imagine custom TOAST compression (which is pretty much what the patch does, after all), but I don't see how the datatype could do anything smart about it, because it has no idea which particular compression was used. And considering the OIDs of the compression methods do change, I'm not sure that's fixable. >> Custom datatype-aware compression with additional column-specific >> metadata (e.g. the jsonb with external dictionary). >> ---------------------------------------------------------------------- >> >> Exploiting redundancy in multiple values in the same column (instead of >> compressing them independently) is another attractive way to help the >> compression. It is inherently datatype-aware, but currently can't be >> implemented directly in datatype code as there's no concept of >> column-specific storage (e.g. to store dictionary shared by all values >> in a particular column). >> >> I believe any patch addressing this use case would have to introduce >> such column-specific storage, and any solution doing that would probably >> need to introduce the same catalogs, etc. >> >> The obvious disadvantage of course is that we need to decompress the >> varlena value before doing pretty much anything with it, because the >> datatype is not aware of the compression. >> >> So I wonder if the patch should instead provide infrastructure for doing >> that in the datatype code directly. >> >> The other question is if the patch should introduce some infrastructure >> for handling the column context (e.g. column dictionary). Right now, >> whoever implements the compression has to implement this bit too. > > I agree that having a place to store a per-column compression > dictionary would be awesome, but I think that could be added later on > top of this infrastructure. For example, suppose we stored each > per-column compression dictionary in a separate file and provided some > infrastructure for WAL-logging changes to the file on a logical basis > and checkpointing those updates. Then we wouldn't be tied to the > MVCC/transactional issues which storing the blobs in a table would > have, which seems like a big win. Of course, it also creates a lot of > little tiny files inside a directory that already tends to have too > many files, but maybe with some more work we can figure out a way > around that problem. Here again, it seems to me that the proposed > design is going more in the right direction than the wrong direction: > if some day we have per-column dictionaries, they will need to be tied > to specific compression methods on specific columns. If we already > have that concept, extending it to do something new is easier than if > we have to create it from scratch. > Well, it wasn't my goal to suddenly widen the scope of the patch and require it adds all these pieces. My intent was more to point to pieces that need to be filled in the future. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 12/12/2017 04:33 PM, Robert Haas wrote: > you want to upgrade your existing tables to use lz4 rather than pglz, > you can change the compression option for those columns to COMPRESS > lz4 PRESERVE pglz if you want to do it incrementally or just COMPRESS This is a thread I've only been following peripherally, so forgive a question that's probably covered somewhere upthread: how will this be done? Surely not with compression-type bits in each tuple? By remembering a txid where the compression was changed, and the former algorithm for older txids? -Chap
On Tue, Dec 12, 2017 at 5:07 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >> I definitely think there's a place for compression built right into >> the data type. I'm still happy about commit >> 145343534c153d1e6c3cff1fa1855787684d9a38 -- although really, more >> needs to be done there. But that type of improvement and what is >> proposed here are basically orthogonal. Having either one is good; >> having both is better. >> > Why orthogonal? I mean, they are different things. Data types are already free to invent more compact representations, and that does not preclude applying pglz to the result. > For example, why couldn't (or shouldn't) the tsvector compression be > done by tsvector code itself? Why should we be doing that at the varlena > level (so that the tsvector code does not even know about it)? We could do that, but then: 1. The compression algorithm would be hard-coded into the system rather than changeable. Pluggability has some value. 2. If several data types can benefit from a similar approach, it has to be separately implemented for each one. 3. Compression is only applied to large-ish values. If you are just making the data type representation more compact, you probably want to apply the new representation to all values. If you are compressing in the sense that the original data gets smaller but harder to interpret, then you probably only want to apply the technique where the value is already pretty wide, and maybe respect the user's configured storage attributes. TOAST knows about some of that kind of stuff. > It seems to me the main reason is that tsvector actually does not allow > us to do that, as there's no good way to distinguish the different > internal format (e.g. by storing a flag or format version in some sort > of header, etc.). That is also a potential problem, although I suspect it is possible to work around it somehow for most data types. It might be annoying, though. >> I think there may also be a place for declaring that a particular data >> type has a "privileged" type of TOAST compression; if you use that >> kind of compression for that data type, the data type will do smart >> things, and if not, it will have to decompress in more cases. But I >> think this infrastructure makes that kind of thing easier, not harder. > > I don't quite understand how that would be done. Isn't TOAST meant to be > entirely transparent for the datatypes? I can imagine custom TOAST > compression (which is pretty much what the patch does, after all), but I > don't see how the datatype could do anything smart about it, because it > has no idea which particular compression was used. And considering the > OIDs of the compression methods do change, I'm not sure that's fixable. I don't think TOAST needs to be entirely transparent for the datatypes. We've already dipped our toe in the water by allowing some operations on "short" varlenas, and there's really nothing to prevent a given datatype from going further. The OID problem you mentioned would presumably be solved by hard-coding the OIDs for any built-in, privileged compression methods. > Well, it wasn't my goal to suddenly widen the scope of the patch and > require it adds all these pieces. My intent was more to point to pieces > that need to be filled in the future. Sure, that's fine. I'm not worked up about this, just explaining why it seems reasonably well-designed to me. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 12/13/2017 01:54 AM, Robert Haas wrote: > On Tue, Dec 12, 2017 at 5:07 PM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >>> I definitely think there's a place for compression built right into >>> the data type. I'm still happy about commit >>> 145343534c153d1e6c3cff1fa1855787684d9a38 -- although really, more >>> needs to be done there. But that type of improvement and what is >>> proposed here are basically orthogonal. Having either one is good; >>> having both is better. >>> >> Why orthogonal? > > I mean, they are different things. Data types are already free to > invent more compact representations, and that does not preclude > applying pglz to the result. > >> For example, why couldn't (or shouldn't) the tsvector compression be >> done by tsvector code itself? Why should we be doing that at the varlena >> level (so that the tsvector code does not even know about it)? > > We could do that, but then: > > 1. The compression algorithm would be hard-coded into the system > rather than changeable. Pluggability has some value. > Sure. I agree extensibility of pretty much all parts is a significant asset of the project. > 2. If several data types can benefit from a similar approach, it has > to be separately implemented for each one. > I don't think the current solution improves that, though. If you want to exploit internal features of individual data types, it pretty much requires code customized to every such data type. For example you can't take the tsvector compression and just slap it on tsquery, because it relies on knowledge of internal tsvector structure. So you need separate implementations anyway. > 3. Compression is only applied to large-ish values. If you are just > making the data type representation more compact, you probably want to > apply the new representation to all values. If you are compressing in > the sense that the original data gets smaller but harder to interpret, > then you probably only want to apply the technique where the value is > already pretty wide, and maybe respect the user's configured storage > attributes. TOAST knows about some of that kind of stuff. > Good point. One such parameter that I really miss is compression level. I can imagine tuning it through CREATE COMPRESSION METHOD, but it does not seem quite possible with compression happening in a datatype. >> It seems to me the main reason is that tsvector actually does not allow >> us to do that, as there's no good way to distinguish the different >> internal format (e.g. by storing a flag or format version in some sort >> of header, etc.). > > That is also a potential problem, although I suspect it is possible to > work around it somehow for most data types. It might be annoying, > though. > >>> I think there may also be a place for declaring that a particular data >>> type has a "privileged" type of TOAST compression; if you use that >>> kind of compression for that data type, the data type will do smart >>> things, and if not, it will have to decompress in more cases. But I >>> think this infrastructure makes that kind of thing easier, not harder. >> >> I don't quite understand how that would be done. Isn't TOAST meant to be >> entirely transparent for the datatypes? I can imagine custom TOAST >> compression (which is pretty much what the patch does, after all), but I >> don't see how the datatype could do anything smart about it, because it >> has no idea which particular compression was used. And considering the >> OIDs of the compression methods do change, I'm not sure that's fixable. > > I don't think TOAST needs to be entirely transparent for the > datatypes. We've already dipped our toe in the water by allowing some > operations on "short" varlenas, and there's really nothing to prevent > a given datatype from going further. The OID problem you mentioned > would presumably be solved by hard-coding the OIDs for any built-in, > privileged compression methods. > Stupid question, but what do you mean by "short" varlenas? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, 12 Dec 2017 15:52:01 -0500 Robert Haas <robertmhaas@gmail.com> wrote: > > Yes. I wonder if \d or \d+ can show it somehow. > Yes, in current version of the patch, \d+ shows current compression. It can be extended to show a list of current compression methods. Since we agreed on ALTER syntax, i want to clear things about CREATE. Should it be CREATE ACCESS METHOD .. TYPE СOMPRESSION or CREATE COMPRESSION METHOD? I like the access method approach, and it simplifies the code, but I'm just not sure a compression is an access method or not. Current implementation ---------------------- To avoid extra patches I also want to clear things about current implementation. Right now there are two tables, "pg_compression" and "pg_compression_opt". When compression method is linked to a column it creates a record in pg_compression_opt. This record's Oid is stored in the varlena. These Oids kept in first column so I can move them in pg_upgrade but in all other aspects they behave like usual Oids. Also it's easy to restore them. Compression options linked to a specific column. When tuple is moved between relations it will be decompressed. Also in current implementation SET COMPRESSION contains WITH syntax which is used to provide extra options to compression method. What could be changed --------------------- As Alvaro mentioned COMPRESSION METHOD is practically an access method, so it could be created as CREATE ACCESS METHOD .. TYPE COMPRESSION. This approach simplifies the patch and "pg_compression" table could be removed. So compression method is created with something like: CREATE ACCESS METHOD .. TYPE COMPRESSION HANDLER awesome_compression_handler; Syntax of SET COMPRESSION changes to SET COMPRESSION .. PRESERVE which is useful to control rewrites and for pg_upgrade to make dependencies between moved compression options and compression methods from pg_am table. Default compression is always pglz and if users want to change they run: ALTER COLUMN <col> SET COMPRESSION awesome PRESERVE pglz; Without PRESERVE it will rewrite the whole relation using new compression. Also the rewrite removes all unlisted compression options so their compresssion methods could be safely dropped. "pg_compression_opt" table could be renamed to "pg_compression", and compression options will be stored there. I'd like to keep extra compression options, for example pglz can be configured with them. Syntax would be slightly changed: SET COMPRESSION pglz WITH (min_comp_rate=25) PRESERVE awesome; Setting the same compression method with different options will create new compression options record for future tuples but will not rewrite table. -- ---- Regards, Ildus Kurbangaliev
Tomas Vondra wrote: > On 12/13/2017 01:54 AM, Robert Haas wrote: > > 3. Compression is only applied to large-ish values. If you are just > > making the data type representation more compact, you probably want to > > apply the new representation to all values. If you are compressing in > > the sense that the original data gets smaller but harder to interpret, > > then you probably only want to apply the technique where the value is > > already pretty wide, and maybe respect the user's configured storage > > attributes. TOAST knows about some of that kind of stuff. > > Good point. One such parameter that I really miss is compression level. > I can imagine tuning it through CREATE COMPRESSION METHOD, but it does > not seem quite possible with compression happening in a datatype. Hmm, actually isn't that the sort of thing that you would tweak using a column-level option instead of a compression method? ALTER TABLE ALTER COLUMN SET (compression_level=123) The only thing we need for this is to make tuptoaster.c aware of the need to check for a parameter. > > I don't think TOAST needs to be entirely transparent for the > > datatypes. We've already dipped our toe in the water by allowing some > > operations on "short" varlenas, and there's really nothing to prevent > > a given datatype from going further. The OID problem you mentioned > > would presumably be solved by hard-coding the OIDs for any built-in, > > privileged compression methods. > > Stupid question, but what do you mean by "short" varlenas? Those are varlenas with 1-byte header rather than the standard 4-byte header. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 12/13/2017 05:55 PM, Alvaro Herrera wrote:
> Tomas Vondra wrote:
>
>> On 12/13/2017 01:54 AM, Robert Haas wrote:
>
>>> 3. Compression is only applied to large-ish values. If you are just
>>> making the data type representation more compact, you probably want to
>>> apply the new representation to all values. If you are compressing in
>>> the sense that the original data gets smaller but harder to interpret,
>>> then you probably only want to apply the technique where the value is
>>> already pretty wide, and maybe respect the user's configured storage
>>> attributes. TOAST knows about some of that kind of stuff.
>>
>> Good point. One such parameter that I really miss is compression level.
>> I can imagine tuning it through CREATE COMPRESSION METHOD, but it does
>> not seem quite possible with compression happening in a datatype.
>
> Hmm, actually isn't that the sort of thing that you would tweak using a
> column-level option instead of a compression method?
> ALTER TABLE ALTER COLUMN SET (compression_level=123)
> The only thing we need for this is to make tuptoaster.c aware of the
> need to check for a parameter.
>
Wouldn't that require some universal compression level, shared by all
supported compression algorithms? I don't think there is such thing.
Defining it should not be extremely difficult, although I'm sure there
will be some cumbersome cases. For example what if an algorithm "a"
supports compression levels 0-10, and algorithm "b" only supports 0-3?
You may define 11 "universal" compression levels, and map the four
levels for "b" to that (how). But then everyone has to understand how
that "universal" mapping is defined.
Another issue is that there are algorithms without a compression level
(e.g. pglz does not have one, AFAICS), or with somewhat definition (lz4
does not have levels, and instead has "acceleration" which may be an
arbitrary positive integer, so not really compatible with "universal"
compression level).
So to me the
ALTER TABLE ALTER COLUMN SET (compression_level=123)
seems more like an unnecessary hurdle ...
>>> I don't think TOAST needs to be entirely transparent for the
>>> datatypes. We've already dipped our toe in the water by allowing some
>>> operations on "short" varlenas, and there's really nothing to prevent
>>> a given datatype from going further. The OID problem you mentioned
>>> would presumably be solved by hard-coding the OIDs for any built-in,
>>> privileged compression methods.
>>
>> Stupid question, but what do you mean by "short" varlenas?
>
> Those are varlenas with 1-byte header rather than the standard 4-byte
> header.
>
OK, that's what I thought. But that is still pretty transparent to the
data types, no?
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Dec 13, 2017 at 5:10 AM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >> 2. If several data types can benefit from a similar approach, it has >> to be separately implemented for each one. > > I don't think the current solution improves that, though. If you want to > exploit internal features of individual data types, it pretty much > requires code customized to every such data type. > > For example you can't take the tsvector compression and just slap it on > tsquery, because it relies on knowledge of internal tsvector structure. > So you need separate implementations anyway. I don't think that's necessarily true. Certainly, it's true that *if* tsvector compression depends on knowledge of internal tsvector structure, *then* that you can't use the implementation for anything else (this, by the way, means that there needs to be some way for a compression method to reject being applied to a column of a data type it doesn't like). However, it seems possible to imagine compression algorithms that can work for a variety of data types, too. There might be a compression algorithm that is theoretically a general-purpose algorithm but has features which are particularly well-suited to, say, JSON or XML data, because it looks for word boundaries to decide on what strings to insert into the compression dictionary. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Dec 13, 2017 at 1:34 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Wouldn't that require some universal compression level, shared by all > supported compression algorithms? I don't think there is such thing. > > Defining it should not be extremely difficult, although I'm sure there > will be some cumbersome cases. For example what if an algorithm "a" > supports compression levels 0-10, and algorithm "b" only supports 0-3? > > You may define 11 "universal" compression levels, and map the four > levels for "b" to that (how). But then everyone has to understand how > that "universal" mapping is defined. What we could do is use the "namespace" feature of reloptions to distinguish options for the column itself from options for the compression algorithm. Currently namespaces are used only to allow you to configure toast.whatever = somevalue, but we could let you say pglz.something = somevalue or lz4.whatever = somevalue. Or maybe, to avoid confusion -- what happens if somebody invents a compression method called toast? -- we should do it as compress.lz4.whatever = somevalue. I think this takes us a bit far afield from the core purpose of this patch and should be a separate patch at a later time, but I think it would be cool. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Dec 13, 2017 at 7:18 AM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > Since we agreed on ALTER syntax, i want to clear things about CREATE. > Should it be CREATE ACCESS METHOD .. TYPE СOMPRESSION or CREATE > COMPRESSION METHOD? I like the access method approach, and it > simplifies the code, but I'm just not sure a compression is an access > method or not. +1 for ACCESS METHOD. > Current implementation > ---------------------- > > To avoid extra patches I also want to clear things about current > implementation. Right now there are two tables, "pg_compression" and > "pg_compression_opt". When compression method is linked to a column it > creates a record in pg_compression_opt. This record's Oid is stored in > the varlena. These Oids kept in first column so I can move them in > pg_upgrade but in all other aspects they behave like usual Oids. Also > it's easy to restore them. pg_compression_opt -> pg_attr_compression, maybe. > Compression options linked to a specific column. When tuple is > moved between relations it will be decompressed. Can we do this only if the compression method isn't OK for the new column? For example, if the old column is COMPRESS foo PRESERVE bar and the new column is COMPRESS bar PRESERVE foo, we don't need to force decompression in any case. > Also in current implementation SET COMPRESSION contains WITH syntax > which is used to provide extra options to compression method. Hmm, that's an alternative to use reloptions. Maybe that's fine. > What could be changed > --------------------- > > As Alvaro mentioned COMPRESSION METHOD is practically an access method, > so it could be created as CREATE ACCESS METHOD .. TYPE COMPRESSION. > This approach simplifies the patch and "pg_compression" table could be > removed. So compression method is created with something like: > > CREATE ACCESS METHOD .. TYPE COMPRESSION HANDLER > awesome_compression_handler; > > Syntax of SET COMPRESSION changes to SET COMPRESSION .. PRESERVE which > is useful to control rewrites and for pg_upgrade to make dependencies > between moved compression options and compression methods from pg_am > table. > > Default compression is always pglz and if users want to change they run: > > ALTER COLUMN <col> SET COMPRESSION awesome PRESERVE pglz; > > Without PRESERVE it will rewrite the whole relation using new > compression. Also the rewrite removes all unlisted compression options > so their compresssion methods could be safely dropped. That all sounds good. > "pg_compression_opt" table could be renamed to "pg_compression", and > compression options will be stored there. See notes above. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 12/14/2017 04:21 PM, Robert Haas wrote: > On Wed, Dec 13, 2017 at 5:10 AM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >>> 2. If several data types can benefit from a similar approach, it has >>> to be separately implemented for each one. >> >> I don't think the current solution improves that, though. If you >> want to exploit internal features of individual data types, it >> pretty much requires code customized to every such data type. >> >> For example you can't take the tsvector compression and just slap >> it on tsquery, because it relies on knowledge of internal tsvector >> structure. So you need separate implementations anyway. > > I don't think that's necessarily true. Certainly, it's true that > *if* tsvector compression depends on knowledge of internal tsvector > structure, *then* that you can't use the implementation for anything > else (this, by the way, means that there needs to be some way for a > compression method to reject being applied to a column of a data > type it doesn't like). I believe such dependency (on implementation details) is pretty much the main benefit of datatype-aware compression methods. If you don't rely on such assumption, then I'd say it's a general-purpose compression method. > However, it seems possible to imagine compression algorithms that can > work for a variety of data types, too. There might be a compression > algorithm that is theoretically a general-purpose algorithm but has > features which are particularly well-suited to, say, JSON or XML > data, because it looks for word boundaries to decide on what strings > to insert into the compression dictionary. > Can you give an example of such algorithm? Because I haven't seen such example, and I find arguments based on hypothetical compression methods somewhat suspicious. FWIW I'm not against considering such compression methods, but OTOH it may not be such a great primary use case to drive the overall design. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Dec 14, 2017 at 12:23 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Can you give an example of such algorithm? Because I haven't seen such > example, and I find arguments based on hypothetical compression methods > somewhat suspicious. > > FWIW I'm not against considering such compression methods, but OTOH it > may not be such a great primary use case to drive the overall design. Well it isn't, really. I am honestly not sure what we're arguing about at this point. I think you've agreed that (1) opening avenues for extensibility is useful, (2) substitution a general-purpose compression algorithm could be useful, and (3) having datatype compression that is enabled through TOAST rather than built into the datatype might sometimes be desirable. That's more than adequate justification for this proposal, whether half-general compression methods exist or not. I am prepared to concede that there may be no useful examples of such a thing. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, 14 Dec 2017 10:29:10 -0500 Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Dec 13, 2017 at 7:18 AM, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: > > Since we agreed on ALTER syntax, i want to clear things about > > CREATE. Should it be CREATE ACCESS METHOD .. TYPE СOMPRESSION or > > CREATE COMPRESSION METHOD? I like the access method approach, and it > > simplifies the code, but I'm just not sure a compression is an > > access method or not. > > +1 for ACCESS METHOD. An access method then. > > > Current implementation > > ---------------------- > > > > To avoid extra patches I also want to clear things about current > > implementation. Right now there are two tables, "pg_compression" and > > "pg_compression_opt". When compression method is linked to a column > > it creates a record in pg_compression_opt. This record's Oid is > > stored in the varlena. These Oids kept in first column so I can > > move them in pg_upgrade but in all other aspects they behave like > > usual Oids. Also it's easy to restore them. > > pg_compression_opt -> pg_attr_compression, maybe. > > > Compression options linked to a specific column. When tuple is > > moved between relations it will be decompressed. > > Can we do this only if the compression method isn't OK for the new > column? For example, if the old column is COMPRESS foo PRESERVE bar > and the new column is COMPRESS bar PRESERVE foo, we don't need to > force decompression in any case. Thanks, sounds right, i will add it to the patch. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On 12/17/2017 04:32 AM, Robert Haas wrote: > On Thu, Dec 14, 2017 at 12:23 PM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> Can you give an example of such algorithm? Because I haven't seen such >> example, and I find arguments based on hypothetical compression methods >> somewhat suspicious. >> >> FWIW I'm not against considering such compression methods, but OTOH it >> may not be such a great primary use case to drive the overall design. > > Well it isn't, really. I am honestly not sure what we're arguing > about at this point. I think you've agreed that (1) opening avenues > for extensibility is useful, (2) substitution a general-purpose > compression algorithm could be useful, and (3) having datatype > compression that is enabled through TOAST rather than built into the > datatype might sometimes be desirable. That's more than adequate > justification for this proposal, whether half-general compression > methods exist or not. I am prepared to concede that there may be no > useful examples of such a thing. > I don't think we're arguing - we're discussing if a proposed patch is the right design solving relevant use cases. I personally am not quite convinced about that, for the reason I tried to explain in my previous messages. I see it as a poor alternative to compression built into the data type. I do like the idea of compression with external dictionary, however. But don't forget that it's not me in this thread - it's my evil twin, moonlighting as Mr. Devil's lawyer ;-) -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Dec 18, 2017 at 10:43 AM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > I personally am not quite convinced about that, for the reason I tried > to explain in my previous messages. I see it as a poor alternative to > compression built into the data type. I do like the idea of compression > with external dictionary, however. I think that compression built into the datatype and what is proposed here are both useful and everybody's free to work on either one as the prefer, so I don't see that as a reason not to accept this patch. And I think this patch can be a stepping stone toward compression with an external dictionary, so that seems like an affirmative reason to accept this patch. > But don't forget that it's not me in this thread - it's my evil twin, > moonlighting as Mr. Devil's lawyer ;-) Well, I don't mind you objecting to the patch under any persona, but so far I'm not finding your reasons convincing... -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attached a new version of the patch. Main changes: * compression as an access method * pglz as default compression access method. * PRESERVE syntax for tables rewrite control. * pg_upgrade fixes * support partitioned tables. * more tests. Regards, Ildus Kurbangaliev
Attachment
Hello Ildus, 15/01/2018 00:49, Ildus Kurbangaliev пишет: > Attached a new version of the patch. Main changes: > > * compression as an access method > * pglz as default compression access method. > * PRESERVE syntax for tables rewrite control. > * pg_upgrade fixes > * support partitioned tables. > * more tests. > You need to rebase to the latest master, there are some conflicts. I've applied it to the three days old master to try it. As I can see the documentation is not yet complete. For example, there is no section for ALTER COLUMN ... SET COMPRESSION in ddl.sgml; and section "Compression Access Method Functions" in compression-am.sgml hasn't been finished. I've implemented an extension [1] to understand the way developer would go to work with new infrastructure. And for me it seems clear. (Except that it took me some effort to wrap my mind around varlena macros but it is probably a different topic). I noticed that you haven't cover 'cmdrop' in the regression tests and I saw the previous discussion about it. Have you considered using event triggers to handle the drop of column compression instead of 'cmdrop' function? This way you would kill two birds with one stone: it still provides sufficient infrastructure to catch those events (and it something postgres already has for different kinds of ddl commands) and it would be easier to test. Thanks! [1] https://github.com/zilder/pg_lz4 -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Mon, 22 Jan 2018 23:26:31 +0300 Ildar Musin <i.musin@postgrespro.ru> wrote: Thanks for review! Attached new version of the patch. Fixed few bugs, added more documentation and rebased to current master. > You need to rebase to the latest master, there are some conflicts. > I've applied it to the three days old master to try it. Done. > > As I can see the documentation is not yet complete. For example, there > is no section for ALTER COLUMN ... SET COMPRESSION in ddl.sgml; and > section "Compression Access Method Functions" in compression-am.sgml > hasn't been finished. Not sure about ddl.sgml, it contains more common things, but since postgres contains only pglz by default there is not much to show. > > I've implemented an extension [1] to understand the way developer > would go to work with new infrastructure. And for me it seems clear. > (Except that it took me some effort to wrap my mind around varlena > macros but it is probably a different topic). > > I noticed that you haven't cover 'cmdrop' in the regression tests and > I saw the previous discussion about it. Have you considered using > event triggers to handle the drop of column compression instead of > 'cmdrop' function? This way you would kill two birds with one stone: > it still provides sufficient infrastructure to catch those events > (and it something postgres already has for different kinds of ddl > commands) and it would be easier to test. I have added support for event triggers for ALTER SET COMPRESSION in current version. Event trigger on ALTER can be used to replace cmdrop function but it will be far from trivial. There is not easy way to understand that's attribute compression is really dropping in the command. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
Hello Ildus,
On 23.01.2018 16:04, Ildus Kurbangaliev wrote:
> On Mon, 22 Jan 2018 23:26:31 +0300
> Ildar Musin <i.musin@postgrespro.ru> wrote:
>
> Thanks for review! Attached new version of the patch. Fixed few bugs,
> added more documentation and rebased to current master.
>
>> You need to rebase to the latest master, there are some conflicts.
>> I've applied it to the three days old master to try it.
>
> Done.
>
>>
>> As I can see the documentation is not yet complete. For example, there
>> is no section for ALTER COLUMN ... SET COMPRESSION in ddl.sgml; and
>> section "Compression Access Method Functions" in compression-am.sgml
>> hasn't been finished.
>
> Not sure about ddl.sgml, it contains more common things, but since
> postgres contains only pglz by default there is not much to show.
>
>>
>> I've implemented an extension [1] to understand the way developer
>> would go to work with new infrastructure. And for me it seems clear.
>> (Except that it took me some effort to wrap my mind around varlena
>> macros but it is probably a different topic).
>>
>> I noticed that you haven't cover 'cmdrop' in the regression tests and
>> I saw the previous discussion about it. Have you considered using
>> event triggers to handle the drop of column compression instead of
>> 'cmdrop' function? This way you would kill two birds with one stone:
>> it still provides sufficient infrastructure to catch those events
>> (and it something postgres already has for different kinds of ddl
>> commands) and it would be easier to test.
>
> I have added support for event triggers for ALTER SET COMPRESSION in
> current version. Event trigger on ALTER can be used to replace cmdrop
> function but it will be far from trivial. There is not easy way to
> understand that's attribute compression is really dropping in the
> command.
>
I've encountered unexpected behavior in command 'CREATE TABLE ... (LIKE
...)'. It seems that it copies compression settings of the table
attributes no matter which INCLUDING options are specified. E.g.
create table xxx(id serial, msg text compression pg_lz4);
alter table xxx alter column msg set storage external;
\d+ xxx
Table "public.xxx"
Column | Type | ... | Storage | Compression |
--------+---------+ ... +----------+-------------+
id | integer | ... | plain | |
msg | text | ... | external | pg_lz4 |
Now copy the table structure with "INCLUDING ALL":
create table yyy (like xxx including all);
\d+ yyy
Table "public.yyy"
Column | Type | ... | Storage | Compression |
--------+---------+ ... +----------+-------------+
id | integer | ... | plain | |
msg | text | ... | external | pg_lz4 |
And now copy without "INCLUDING ALL":
create table zzz (like xxx);
\d+ zzz
Table "public.zzz"
Column | Type | ... | Storage | Compression |
--------+---------+ ... +----------+-------------+
id | integer | ... | plain | |
msg | text | ... | extended | pg_lz4 |
As you see, compression option is copied anyway. I suggest adding new
INCLUDING COMPRESSION option to enable user to explicitly specify
whether they want or not to copy compression settings.
I found a few phrases in documentation that can be improved. But the
documentation should be checked by a native speaker.
In compression-am.sgml:
"an compression access method" -> "a compression access method"
"compression method method" -> "compression method"
"compability" -> "compatibility"
Probably "local-backend cached state" would be better to replace with
"per backend cached state"?
"Useful to store the parsed view of the compression options" -> "It
could be useful for example to cache compression options"
"and stores result of" -> "and stores the result of"
"Called when CompressionAmOptions is creating." -> "Called when
<structname>CompressionAmOptions</structname> is being initialized"
"Note that in any system cache invalidation related with
pg_attr_compression relation the options will be cleaned" -> "Note that
any <literal>pg_attr_compression</literal> relation invalidation will
cause all the cached <literal>acstate</literal> options cleared."
"Function used to ..." -> "Function is used to ..."
I think it would be nice to mention custom compression methods in
storage.sgml. At this moment it only mentions built-in pglz compression.
--
Ildar Musin
i.musin@postgrespro.ru
On Thu, 25 Jan 2018 16:03:20 +0300 Ildar Musin <i.musin@postgrespro.ru> wrote: Thanks for review! > > As you see, compression option is copied anyway. I suggest adding new > INCLUDING COMPRESSION option to enable user to explicitly specify > whether they want or not to copy compression settings. Good catch, i missed INCLUDE options for LIKE command. Added INCLUDING COMPRESSION as you suggested. > > > I found a few phrases in documentation that can be improved. But the > documentation should be checked by a native speaker. > > In compression-am.sgml: > "an compression access method" -> "a compression access method" > "compression method method" -> "compression method" > "compability" -> "compatibility" > Probably "local-backend cached state" would be better to replace with > "per backend cached state"? > "Useful to store the parsed view of the compression options" -> "It > could be useful for example to cache compression options" > "and stores result of" -> "and stores the result of" > "Called when CompressionAmOptions is creating." -> "Called when > <structname>CompressionAmOptions</structname> is being initialized" > > "Note that in any system cache invalidation related with > pg_attr_compression relation the options will be cleaned" -> "Note > that any <literal>pg_attr_compression</literal> relation invalidation > will cause all the cached <literal>acstate</literal> options cleared." > "Function used to ..." -> "Function is used to ..." > > I think it would be nice to mention custom compression methods in > storage.sgml. At this moment it only mentions built-in pglz > compression. > I agree, the documentation would require a native speaker. Fixed the lines you mentioned. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
Hello Ildus,
I continue reviewing your patch. Here are some thoughts.
1. When I set column storage to EXTERNAL then I cannot set compression.
Seems reasonable:
create table test(id serial, msg text);
alter table test alter column msg set storage external;
alter table test alter column msg set compression pg_lz4;
ERROR: storage for "msg" should be MAIN or EXTENDED
But if I reorder commands then it's ok:
create table test(id serial, msg text);
alter table test alter column msg set compression pg_lz4;
alter table test alter column msg set storage external;
\d+ test
Table "public.test"
Column | Type | ... | Storage | Compression
--------+---------+ ... +----------+-------------
id | integer | ... | plain |
msg | text | ... | external | pg_lz4
So we could either allow user to set compression settings even when
storage is EXTERNAL but with warning or prohibit user to set compression
and external storage at the same time. The same thing is with setting
storage PLAIN.
2. I think TOAST_COMPRESS_SET_RAWSIZE macro could be rewritten like
following to prevent overwriting of higher bits of 'info':
((toast_compress_header *) (ptr))->info = \
((toast_compress_header *) (ptr))->info & ~RAWSIZEMASK | (len);
It maybe does not matter at the moment since it is only used once, but
it could save some efforts for other developers in future.
In TOAST_COMPRESS_SET_CUSTOM() instead of changing individual bits you
may do something like this:
#define TOAST_COMPRESS_SET_CUSTOM(ptr) \
do { \
((toast_compress_header *) (ptr))->info = \
((toast_compress_header *) (ptr))->info & RAWSIZEMASK | ((uint32) 0x02
<< 30) \
} while (0)
Also it would be nice if bit flags were explained and maybe replaced by
a macro.
3. In AlteredTableInfo, BulkInsertStateData and some functions (eg
toast_insert_or_update) there is a hash table used to keep preserved
compression methods list per attribute. I think a simple array of List*
would be sufficient in this case.
4. In optionListToArray() you can use list_qsort() to sort options list
instead of converting it manually into array and then back to a list.
5. Redundunt #includes:
In heap.c:
#include "access/reloptions.h"
In tsvector.c:
#include "catalog/pg_type.h"
#include "common/pg_lzcompress.h"
In relcache.c:
#include "utils/datum.h"
6. Just a minor thing: no reason to change formatting in copy.c
- heap_insert(resultRelInfo->ri_RelationDesc, tuple, mycid,
- hi_options, bistate);
+ heap_insert(resultRelInfo->ri_RelationDesc, tuple,
+ mycid, hi_options, bistate);
7. Also in utility.c the extra new line was added which isn't relevant
for this patch.
8. In parse_utilcmd.h the 'extern' keyword was removed from
transformRuleStmt declaration which doesn't make sense in this patch.
9. Comments. Again, they should be read by a native speaker. So just a
few suggestions:
toast_prepare_varlena() - comment needed
invalidate_amoptions_cache() - comment format doesn't match other
functions in the file
In htup_details.h:
/* tuple contain custom compressed
* varlenas */
should be "contains"
--
Ildar Musin
i.musin@postgrespro.ru
On Fri, 26 Jan 2018 19:07:28 +0300
Ildar Musin <i.musin@postgrespro.ru> wrote:
> Hello Ildus,
>
> I continue reviewing your patch. Here are some thoughts.
Thanks! Attached new version of the patch.
>
> 1. When I set column storage to EXTERNAL then I cannot set
> compression. Seems reasonable:
> create table test(id serial, msg text);
> alter table test alter column msg set storage external;
> alter table test alter column msg set compression pg_lz4;
> ERROR: storage for "msg" should be MAIN or EXTENDED
Changed the behaviour, now it's ok to change storages in any
directions for toastable types. Also added protection from untoastable
types.
>
>
> 2. I think TOAST_COMPRESS_SET_RAWSIZE macro could be rewritten like
> following to prevent overwriting of higher bits of 'info':
>
> ((toast_compress_header *) (ptr))->info = \
> ((toast_compress_header *) (ptr))->info & ~RAWSIZEMASK |
> (len);
>
> It maybe does not matter at the moment since it is only used once, but
> it could save some efforts for other developers in future.
> In TOAST_COMPRESS_SET_CUSTOM() instead of changing individual bits you
> may do something like this:
>
> #define TOAST_COMPRESS_SET_CUSTOM(ptr) \
> do { \
> ((toast_compress_header *) (ptr))->info = \
> ((toast_compress_header *) (ptr))->info & RAWSIZEMASK
> | ((uint32) 0x02 << 30) \
> } while (0)
>
> Also it would be nice if bit flags were explained and maybe replaced
> by a macro.
I noticed that there is no need of TOAST_COMPRESS_SET_CUSTOM at all,
so I just removed it, TOAST_COMPRESS_SET_RAWSIZE will set needed flags.
>
>
> 3. In AlteredTableInfo, BulkInsertStateData and some functions (eg
> toast_insert_or_update) there is a hash table used to keep preserved
> compression methods list per attribute. I think a simple array of
> List* would be sufficient in this case.
Not sure about that, it will just complicate things without sufficient
improvements. Also it would require the passing the length of the array
and require more memory for tables with large number of attributes. But,
I've made default size of the hash table smaller, since unlikely the
user will change compression of many attributes at once.
>
>
> 4. In optionListToArray() you can use list_qsort() to sort options
> list instead of converting it manually into array and then back to a
> list.
Good, didn't know about this function.
>
>
> 5. Redundunt #includes:
>
> In heap.c:
> #include "access/reloptions.h"
> In tsvector.c:
> #include "catalog/pg_type.h"
> #include "common/pg_lzcompress.h"
> In relcache.c:
> #include "utils/datum.h"
>
> 6. Just a minor thing: no reason to change formatting in copy.c
> - heap_insert(resultRelInfo->ri_RelationDesc, tuple, mycid,
> - hi_options, bistate);
> + heap_insert(resultRelInfo->ri_RelationDesc, tuple,
> + mycid, hi_options, bistate);
>
> 7. Also in utility.c the extra new line was added which isn't
> relevant for this patch.
>
> 8. In parse_utilcmd.h the 'extern' keyword was removed from
> transformRuleStmt declaration which doesn't make sense in this patch.
>
> 9. Comments. Again, they should be read by a native speaker. So just
> a few suggestions:
> toast_prepare_varlena() - comment needed
> invalidate_amoptions_cache() - comment format doesn't match other
> functions in the file
>
> In htup_details.h:
> /* tuple contain custom compressed
> * varlenas */
> should be "contains"
>
5-9, all done. Thank you for noticing.
--
---
Ildus Kurbangaliev
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Attachment
Hello Ildus, On 29.01.2018 14:44, Ildus Kurbangaliev wrote: > > Thanks! Attached new version of the patch. > Patch applies cleanly, builds without any warnings, documentation builds ok, all tests pass. A remark for the committers. The patch is quite big, so I really wish more reviewers looked into it for more comprehensive review. Also a native english speaker should check the documentation and comments. Another thing is that tests don't cover cmdrop method because the built-in pglz compression doesn't use it (I know there is an jsonbd extension [1] based on this patch and which should benefit from cmdrop method, but it doesn't test it either yet). I think I did what I could and so passing this patch to committers for the review. Changed status to "Ready for committer". [1] https://github.com/postgrespro/jsonbd -- Ildar Musin i.musin@postgrespro.ru
On Mon, 29 Jan 2018 17:29:29 +0300 Ildar Musin <i.musin@postgrespro.ru> wrote: > > Patch applies cleanly, builds without any warnings, documentation > builds ok, all tests pass. > > A remark for the committers. The patch is quite big, so I really wish > more reviewers looked into it for more comprehensive review. Also a > native english speaker should check the documentation and comments. > Another thing is that tests don't cover cmdrop method because the > built-in pglz compression doesn't use it (I know there is an jsonbd > extension [1] based on this patch and which should benefit from > cmdrop method, but it doesn't test it either yet). > > I think I did what I could and so passing this patch to committers > for the review. Changed status to "Ready for committer". > > > [1] https://github.com/postgrespro/jsonbd > Thank you! About cmdrop, I checked that's is called manually, but going to check it thoroughly in my extension. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Mon, 29 Jan 2018 17:29:29 +0300 Ildar Musin <i.musin@postgrespro.ru> wrote: > Hello Ildus, > > On 29.01.2018 14:44, Ildus Kurbangaliev wrote: > > > > Thanks! Attached new version of the patch. > > > > Patch applies cleanly, builds without any warnings, documentation > builds ok, all tests pass. > > A remark for the committers. The patch is quite big, so I really wish > more reviewers looked into it for more comprehensive review. Also a > native english speaker should check the documentation and comments. > Another thing is that tests don't cover cmdrop method because the > built-in pglz compression doesn't use it (I know there is an jsonbd > extension [1] based on this patch and which should benefit from > cmdrop method, but it doesn't test it either yet). > > I think I did what I could and so passing this patch to committers > for the review. Changed status to "Ready for committer". > > > [1] https://github.com/postgrespro/jsonbd > Attached rebased version of the patch so it can be applied to current master. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
Hi, Attached new version of the patch, rebased to current master, and fixed conflicting catalog Oids. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On Mon, 26 Feb 2018 15:25:56 +0300 Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > Hi, > Attached new version of the patch, rebased to current master, and > fixed conflicting catalog Oids. > Attached rebased version of the patch, fixed conficts in pg_proc, and tap tests. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
Attached rebased version of the patch. Fixed conflicts in pg_class.h. -- ---- Regards, Ildus Kurbangaliev
Attachment
On Mon, 26 Mar 2018 20:38:25 +0300 Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > Attached rebased version of the patch. Fixed conflicts in pg_class.h. > New rebased version due to conflicts in master. Also fixed few errors and removed cmdrop method since it couldnt be tested. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On 30.03.2018 19:50, Ildus Kurbangaliev wrote: > On Mon, 26 Mar 2018 20:38:25 +0300 > Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > >> Attached rebased version of the patch. Fixed conflicts in pg_class.h. >> > New rebased version due to conflicts in master. Also fixed few errors > and removed cmdrop method since it couldnt be tested. > I seems to be useful (and not so difficult) to use custom compression methods also for WAL compression: replace direct calls of pglz_compress in xloginsert.c -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Fri, Apr 20, 2018 at 7:45 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:
On 30.03.2018 19:50, Ildus Kurbangaliev wrote:On Mon, 26 Mar 2018 20:38:25 +0300I seems to be useful (and not so difficult) to use custom compression methods also for WAL compression: replace direct calls of pglz_compress in xloginsert.c
Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: Attached rebased version of the patch. Fixed conflicts in pg_class.h.New rebased version due to conflicts in master. Also fixed few errors
and removed cmdrop method since it couldnt be tested.
I'm going to object this at point, and I've following arguments for that:
1) WAL compression is much more critical for durability than datatype
compression. Imagine, compression algorithm contains a bug which
cause decompress method to issue a segfault. In the case of datatype
compression, that would cause crash on access to some value which
causes segfault; but in the rest database will be working giving you
a chance to localize the issue and investigate that. In the case of
WAL compression, recovery would cause a server crash. That seems
to be much more serious disaster. You wouldn't be able to make
your database up and running and the same happens on the standby.
2) Idea of custom compression method is that some columns may
have specific data distribution, which could be handled better with
particular compression method and particular parameters. In the
WAL compression you're dealing with the whole WAL stream containing
all the values from database cluster. Moreover, if custom compression
method are defined for columns, then in WAL stream you've values
already compressed in the most efficient way. However, it might
appear that some compression method is better for WAL in general
case (there are benchmarks showing our pglz is not very good in
comparison to the alternatives). But in this case I would prefer to just
switch our WAL to different compression method one day. Thankfully
we don't preserve WAL compatibility between major releases.
3) This patch provides custom compression methods recorded in
the catalog. During recovery you don't have access to the system
catalog, because it's not recovered yet, and can't fetch compression
method metadata from there. The possible thing is to have GUC,
which stores shared module and function names for WAL compression.
But that seems like quite different mechanism from the one present
in this patch.
Taking into account all of above, I think we would give up with custom
WAL compression method. Or, at least, consider it unrelated to this
patch.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Sun, 22 Apr 2018 16:21:31 +0300 Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > On Fri, Apr 20, 2018 at 7:45 PM, Konstantin Knizhnik < > k.knizhnik@postgrespro.ru> wrote: > > > On 30.03.2018 19:50, Ildus Kurbangaliev wrote: > > > >> On Mon, 26 Mar 2018 20:38:25 +0300 > >> Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > >> > >> Attached rebased version of the patch. Fixed conflicts in > >> pg_class.h. > >>> > >>> New rebased version due to conflicts in master. Also fixed few > >>> errors > >> and removed cmdrop method since it couldnt be tested. > >> > >> I seems to be useful (and not so difficult) to use custom > >> compression > > methods also for WAL compression: replace direct calls of > > pglz_compress in xloginsert.c > > > I'm going to object this at point, and I've following arguments for > that: > > 1) WAL compression is much more critical for durability than datatype > compression. Imagine, compression algorithm contains a bug which > cause decompress method to issue a segfault. In the case of datatype > compression, that would cause crash on access to some value which > causes segfault; but in the rest database will be working giving you > a chance to localize the issue and investigate that. In the case of > WAL compression, recovery would cause a server crash. That seems > to be much more serious disaster. You wouldn't be able to make > your database up and running and the same happens on the standby. > > 2) Idea of custom compression method is that some columns may > have specific data distribution, which could be handled better with > particular compression method and particular parameters. In the > WAL compression you're dealing with the whole WAL stream containing > all the values from database cluster. Moreover, if custom compression > method are defined for columns, then in WAL stream you've values > already compressed in the most efficient way. However, it might > appear that some compression method is better for WAL in general > case (there are benchmarks showing our pglz is not very good in > comparison to the alternatives). But in this case I would prefer to > just switch our WAL to different compression method one day. > Thankfully we don't preserve WAL compatibility between major releases. > > 3) This patch provides custom compression methods recorded in > the catalog. During recovery you don't have access to the system > catalog, because it's not recovered yet, and can't fetch compression > method metadata from there. The possible thing is to have GUC, > which stores shared module and function names for WAL compression. > But that seems like quite different mechanism from the one present > in this patch. > > Taking into account all of above, I think we would give up with custom > WAL compression method. Or, at least, consider it unrelated to this > patch. I agree with these points. I also think this should be done in another patch. It's not so hard to implement but would make sense if there will be few more builtin compression methods suitable for wal compression. Some static array could contain function pointers for direct calls. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On 22.04.2018 16:21, Alexander Korotkov wrote:
Well, I do not think that somebody will try to implement its own compression algorithm...On Fri, Apr 20, 2018 at 7:45 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:On 30.03.2018 19:50, Ildus Kurbangaliev wrote:On Mon, 26 Mar 2018 20:38:25 +0300I seems to be useful (and not so difficult) to use custom compression methods also for WAL compression: replace direct calls of pglz_compress in xloginsert.c
Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: Attached rebased version of the patch. Fixed conflicts in pg_class.h.New rebased version due to conflicts in master. Also fixed few errors
and removed cmdrop method since it couldnt be tested.I'm going to object this at point, and I've following arguments for that:1) WAL compression is much more critical for durability than datatypecompression. Imagine, compression algorithm contains a bug whichcause decompress method to issue a segfault. In the case of datatypecompression, that would cause crash on access to some value whichcauses segfault; but in the rest database will be working giving youa chance to localize the issue and investigate that. In the case ofWAL compression, recovery would cause a server crash. That seemsto be much more serious disaster. You wouldn't be able to makeyour database up and running and the same happens on the standby.
From my point of view the main value of this patch is that it allows to replace pglz algorithm with more efficient one, for example zstd.
At some data sets zstd provides more than 10 times better compression ratio and at the same time is faster then pglz.
I do not think that risk of data corruption caused by WAL compression with some alternative compression algorithm (zlib, zstd,...) is higher than in case of using builtin Postgres compression.
2) Idea of custom compression method is that some columns mayhave specific data distribution, which could be handled better withparticular compression method and particular parameters. In theWAL compression you're dealing with the whole WAL stream containingall the values from database cluster. Moreover, if custom compressionmethod are defined for columns, then in WAL stream you've valuesalready compressed in the most efficient way. However, it mightappear that some compression method is better for WAL in generalcase (there are benchmarks showing our pglz is not very good incomparison to the alternatives). But in this case I would prefer to justswitch our WAL to different compression method one day. Thankfullywe don't preserve WAL compatibility between major releases.
Frankly speaking I do not believe that somebody will use custom compression in this way: implement its own compression methods for the specific data type.
May be just for json/jsonb, but also only in the case when custom compression API allows to separately store compression dictionary (which as far as I understand is not currently supported).
When I worked for SciDB (database for scientists which has to deal mostly with multidimensional arrays of data) our first intention was to implement custom compression methods for the particular data types and data distributions. For example, there are very fast, simple and efficient algorithms for encoding sequence of monotonically increased integers, ....
But after several experiments we rejected this idea and switch to using generic compression methods. Mostly because we do not want compressor to know much about page layout, data type representation,... In Postgres, from my point of view, we have similar situation. Assume that we have column of serial type. So it is good candidate of compression, isn't it?
But this approach deals only with particular attribute values. It can not take any advantages from the fact that this particular column is monotonically increased. It can be done only with page level compression, but it is a different story.
So current approach works only for blob-like types: text, json,... But them usually have quite complex internal structure and for them universal compression algorithms used to be more efficient than any hand-written specific implementation. Also algorithms like zstd, are able to efficiently recognize and compress many common data distributions, line monotonic sequences, duplicates, repeated series,...
I do not think that assignment default compression method through GUC is so bad idea.3) This patch provides custom compression methods recorded inthe catalog. During recovery you don't have access to the systemcatalog, because it's not recovered yet, and can't fetch compressionmethod metadata from there. The possible thing is to have GUC,which stores shared module and function names for WAL compression.But that seems like quite different mechanism from the one presentin this patch.
Taking into account all of above, I think we would give up with customWAL compression method. Or, at least, consider it unrelated to thispatch.
Sorry for repeating the same thing, but from my point of view the main advantage of this patch is that it allows to replace pglz with more efficient compression algorithms.
I do not see much sense in specifying custom compression method for some particular columns.
It will be more useful from my point of view to include in this patch implementation of compression API not only or pglz, but also for zlib, zstd and may be for some other popular compressing libraries which proved their efficiency.
Postgres already has zlib dependency (unless explicitly excluded with --without-zlib), so zlib implementation can be included in Postgres build.
Other implementations can be left as module which customer can build himself. It is certainly less convenient, than using preexistred stuff, but much more convenient then making users to write this code themselves.
There is yet another aspect which is not covered by this patch: streaming compression.
Streaming compression is needed if we want to compress libpq traffic. It can be very efficient for COPY command and for replication. Also libpq compression can improve speed of queries returning large results (for example containing JSON columns) throw slow network.
I have proposed such patch for libpq, which is using either zlib, either zstd streaming API. Postgres built-in compression implementation doesn't have streaming API at all, so it can not be used here. Certainly support of streaming may significantly complicates compression API, so I am not sure that it actually needed to be included in this patch.
But I will be pleased if Ildus can consider this idea.
-- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Mon, Apr 23, 2018 at 12:40 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:
On 22.04.2018 16:21, Alexander Korotkov wrote:Well, I do not think that somebody will try to implement its own compression algorithm...On Fri, Apr 20, 2018 at 7:45 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:On 30.03.2018 19:50, Ildus Kurbangaliev wrote:On Mon, 26 Mar 2018 20:38:25 +0300I seems to be useful (and not so difficult) to use custom compression methods also for WAL compression: replace direct calls of pglz_compress in xloginsert.c
Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: Attached rebased version of the patch. Fixed conflicts in pg_class.h.New rebased version due to conflicts in master. Also fixed few errors
and removed cmdrop method since it couldnt be tested.I'm going to object this at point, and I've following arguments for that:1) WAL compression is much more critical for durability than datatypecompression. Imagine, compression algorithm contains a bug whichcause decompress method to issue a segfault. In the case of datatypecompression, that would cause crash on access to some value whichcauses segfault; but in the rest database will be working giving youa chance to localize the issue and investigate that. In the case ofWAL compression, recovery would cause a server crash. That seemsto be much more serious disaster. You wouldn't be able to makeyour database up and running and the same happens on the standby.
But that the main goal of this patch: let somebody implement own compression
algorithm which best fit for particular dataset.
From my point of view the main value of this patch is that it allows to replace pglz algorithm with more efficient one, for example zstd.
At some data sets zstd provides more than 10 times better compression ratio and at the same time is faster then pglz.
Not exactly. If we want to replace pglz with more efficient one, then we should
just replace pglz with better algorithm. Pluggable compression methods are
definitely don't worth it for just replacing pglz with zstd.
I do not think that risk of data corruption caused by WAL compression with some alternative compression algorithm (zlib, zstd,...) is higher than in case of using builtin Postgres compression.
It speaking about zlib or zstd, then yes risk of corruption is very low. But again,
switching to zlib or zstd don't justify this patch.
2) Idea of custom compression method is that some columns mayhave specific data distribution, which could be handled better withparticular compression method and particular parameters. In theWAL compression you're dealing with the whole WAL stream containingall the values from database cluster. Moreover, if custom compressionmethod are defined for columns, then in WAL stream you've valuesalready compressed in the most efficient way. However, it mightappear that some compression method is better for WAL in generalcase (there are benchmarks showing our pglz is not very good incomparison to the alternatives). But in this case I would prefer to justswitch our WAL to different compression method one day. Thankfullywe don't preserve WAL compatibility between major releases.
Frankly speaking I do not believe that somebody will use custom compression in this way: implement its own compression methods for the specific data type.
May be just for json/jsonb, but also only in the case when custom compression API allows to separately store compression dictionary (which as far as I understand is not currently supported).
When I worked for SciDB (database for scientists which has to deal mostly with multidimensional arrays of data) our first intention was to implement custom compression methods for the particular data types and data distributions. For example, there are very fast, simple and efficient algorithms for encoding sequence of monotonically increased integers, ....
But after several experiments we rejected this idea and switch to using generic compression methods. Mostly because we do not want compressor to know much about page layout, data type representation,... In Postgres, from my point of view, we have similar situation. Assume that we have column of serial type. So it is good candidate of compression, isn't it?
No, it's not. Exactly because compressor shouldn't deal with page layout etc.
But it's absolutely OK for datatype compressor to deal with particular type
representation.
But this approach deals only with particular attribute values. It can not take any advantages from the fact that this particular column is monotonically increased. It can be done only with page level compression, but it is a different story.
Yes, compression of data series spear across multiple rows is different story.
So current approach works only for blob-like types: text, json,... But them usually have quite complex internal structure and for them universal compression algorithms used to be more efficient than any hand-written specific implementation. Also algorithms like zstd, are able to efficiently recognize and compress many common data distributions, line monotonic sequences, duplicates, repeated series,...
Some types blob-like datatypes might be not long enough to let generic
compression algorithms like zlib or zstd train a dictionary. For example,
MySQL successfully utilize column-level dictionaries for JSON [1]. Also
JSON(B) might utilize some compression which let user extract
particular attributes without decompression of the whole document.
I do not think that assignment default compression method through GUC is so bad idea.3) This patch provides custom compression methods recorded inthe catalog. During recovery you don't have access to the systemcatalog, because it's not recovered yet, and can't fetch compressionmethod metadata from there. The possible thing is to have GUC,which stores shared module and function names for WAL compression.But that seems like quite different mechanism from the one presentin this patch.
It's probably not so bad, but it's a different story. Unrelated to this patch, I think.
Sorry for repeating the same thing, but from my point of view the main advantage of this patch is that it allows to replace pglz with more efficient compression algorithms.Taking into account all of above, I think we would give up with customWAL compression method. Or, at least, consider it unrelated to thispatch.
I do not see much sense in specifying custom compression method for some particular columns.
This patch is about giving user an ability to select particular compression
method and its parameters for particular column.
It will be more useful from my point of view to include in this patch implementation of compression API not only or pglz, but also for zlib, zstd and may be for some other popular compressing libraries which proved their efficiency.
Postgres already has zlib dependency (unless explicitly excluded with --without-zlib), so zlib implementation can be included in Postgres build.
Other implementations can be left as module which customer can build himself. It is certainly less convenient, than using preexistred stuff, but much more convenient then making users to write this code themselves.
There is yet another aspect which is not covered by this patch: streaming compression.
Streaming compression is needed if we want to compress libpq traffic. It can be very efficient for COPY command and for replication. Also libpq compression can improve speed of queries returning large results (for example containing JSON columns) throw slow network.
I have proposed such patch for libpq, which is using either zlib, either zstd streaming API. Postgres built-in compression implementation doesn't have streaming API at all, so it can not be used here. Certainly support of streaming may significantly complicates compression API, so I am not sure that it actually needed to be included in this patch.
But I will be pleased if Ildus can consider this idea.
I think streaming compression seems like a completely different story.
client-server traffic compression is not just server feature. It must
be also supported at client side. And I really doubt it should be
pluggable.
In my opinion, you propose good things like compression of WAL
with better algorithm and compression of client-server traffic.
But I think those features are unrelated to this patch and should
be considered separately. It's not features, which should be
added to this patch. Regarding this patch the points you provided
more seems like criticism of the general idea.
I think the problem of this patch is that it lacks of good example.
It would be nice if Ildus implement simple compression with
column-defined dictionary (like [1] does), and show its efficiency
of real-life examples, which can't be achieved with generic
compression methods (like zlib or zstd). That would be a good
answer to the criticism you provide.
Links
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 23.04.2018 18:32, Alexander Korotkov wrote:
But that the main goal of this patch: let somebody implement own compressionalgorithm which best fit for particular dataset.
Hmmm...Frankly speaking I don't believe in this "somebody".
From my point of view the main value of this patch is that it allows to replace pglz algorithm with more efficient one, for example zstd.
At some data sets zstd provides more than 10 times better compression ratio and at the same time is faster then pglz.Not exactly. If we want to replace pglz with more efficient one, then we shouldjust replace pglz with better algorithm. Pluggable compression methods aredefinitely don't worth it for just replacing pglz with zstd.
As far as I understand it is not possible for many reasons (portability, patents,...) to replace pglz with zstd.
I think that even replacing pglz with zlib (which is much worser than zstd) will not be accepted by community.
So from my point of view the main advantage of custom compression method is to replace builting pglz compression with more advanced one.
Some types blob-like datatypes might be not long enough to let genericcompression algorithms like zlib or zstd train a dictionary. For example,MySQL successfully utilize column-level dictionaries for JSON [1]. AlsoJSON(B) might utilize some compression which let user extractparticular attributes without decompression of the whole document.
Well, I am not an expert in compression.
But I will be very surprised if somebody will show me some real example with large enough compressed data buffer (>2kb) where some specialized algorithm will provide significantly
better compression ratio than advanced universal compression algorithm.
Also may be I missed something, but current compression API doesn't support partial extraction (extra some particular attribute or range).
If we really need it, then it should be expressed in custom compressor API. But I am not sure how frequently it will needed.
Large values are splitted into 2kb TOAST chunks. With compression it can be about 4-8k of raw data. IMHO storing larger JSON objects is database design flaw.
And taken in account that in JSONB we need also extract header (so at least two chunks), it makes more obscure advantages of partial JSONB decompression.
I do not think that assignment default compression method through GUC is so bad idea.It's probably not so bad, but it's a different story. Unrelated to this patch, I think.
May be. But in any cases, there are several direction where compression can be used:
- custom compression algorithms
- libpq compression
- page level compression
...
and them should be somehow finally "married" with each other.
Sorry, I really looking at this patch under the different angle.I think streaming compression seems like a completely different story.client-server traffic compression is not just server feature. It mustbe also supported at client side. And I really doubt it should bepluggable.In my opinion, you propose good things like compression of WALwith better algorithm and compression of client-server traffic.But I think those features are unrelated to this patch and shouldbe considered separately. It's not features, which should beadded to this patch. Regarding this patch the points you providedmore seems like criticism of the general idea.I think the problem of this patch is that it lacks of good example.It would be nice if Ildus implement simple compression withcolumn-defined dictionary (like [1] does), and show its efficiencyof real-life examples, which can't be achieved with genericcompression methods (like zlib or zstd). That would be a goodanswer to the criticism you provide.Links------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
And this is why I have some doubts about general idea.
Postgres allows to defined custom types, access methods,...
But do you know any production system using some special data types or custom indexes which are not included in standard Postgres distribution
or popular extensions (like postgis)?
IMHO end-user do not have skills and time to create their own compression algorithms. And without knowledge of specific of particular data set,
it is very hard to implement something more efficient than universal compression library.
But if you think that it is not a right place and time to discuss it, I do not insist.
But in any case, I think that it will be useful to provide some more examples of custom compression API usage.
From my point of view the most useful will be integration with zstd.
But if it is possible to find some example of data-specific compression algorithms which show better results than universal compression,
it will be even more impressive.
-- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Mon, 23 Apr 2018 19:34:38 +0300 Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > > Sorry, I really looking at this patch under the different angle. > And this is why I have some doubts about general idea. > Postgres allows to defined custom types, access methods,... > But do you know any production system using some special data types > or custom indexes which are not included in standard Postgres > distribution or popular extensions (like postgis)? > > IMHO end-user do not have skills and time to create their own > compression algorithms. And without knowledge of specific of > particular data set, > it is very hard to implement something more efficient than universal > compression library. > But if you think that it is not a right place and time to discuss it, > I do not insist. > > But in any case, I think that it will be useful to provide some more > examples of custom compression API usage. > From my point of view the most useful will be integration with zstd. > But if it is possible to find some example of data-specific > compression algorithms which show better results than universal > compression, it will be even more impressive. > > Ok, let me clear up the purpose of this patch. I understand that you want to compress everything by it but now the idea is just to bring basic functionality to compress toasting values with external compression algorithms. It's unlikely that compression algorithms like zstd, snappy and others will be in postgres core but with this patch it's really easy to make an extension and start to compress values using it right away. And the end-user should not be expert in compression algorithms to make such extension. One of these algorithms could end up in core if its license will allow it. I'm not trying to cover all the places in postgres which will benefit from compression, and this patch only is the first step. It's quite big already and with every new feature that will increase its size, chances of its reviewing and commiting will decrease. The API is very simple now and contains what an every compression method can do - get some block of data and return a compressed form of the data. And it can be extended with streaming and other features in the future. Maybe the reason of your confusion is that there is no GUC that changes pglz to some custom compression so all new attributes will use it. I will think about adding it. Also there was a discussion about specifying the compression for the type and it was decided that's better to do it later by a separate patch. As an example of specialized compression could be time series compression described in [1]. [2] contains an example of an extension that adds lz4 compression using this patch. [1] http://www.vldb.org/pvldb/vol8/p1816-teller.pdf [2] https://github.com/zilder/pg_lz4 -- ---- Regards, Ildus Kurbangaliev
On Mon, Apr 23, 2018 at 7:34 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:
IMHO end-user do not have skills and time to create their own compression algorithms. And without knowledge of specific of particular data set,
it is very hard to implement something more efficient than universal compression library.
But if you think that it is not a right place and time to discuss it, I do not insist.
For sure, end-users wouldn't implement own compression algorithms.
In the same way as end-users wouldn't implement custom datatypes,
operator classes, procedural language handlers etc. But those are
useful extension mechanisms which pass test of time. And extension
developers use them.
But in any case, I think that it will be useful to provide some more examples of custom compression API usage.
From my point of view the most useful will be integration with zstd.
But if it is possible to find some example of data-specific compression algorithms which show better results than universal compression,
it will be even more impressive.
Yes, this patch definitely lacks of good usage example. That may
lead to some misunderstanding of its purpose. Good use-cases
should be shown before we can consider committing this. I think
Ildus should try to implement at least custom dictionary compression
method where dictionary is specified by user in parameters.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Tue, 24 Apr 2018 14:05:20 +0300 Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > Yes, this patch definitely lacks of good usage example. That may > lead to some misunderstanding of its purpose. Good use-cases > should be shown before we can consider committing this. I think > Ildus should try to implement at least custom dictionary compression > method where dictionary is specified by user in parameters. > Hi, attached v16 of the patch. I have splitted the patch to 8 parts so now it should be easier to make a review. The main improvement is zlib compression method with dictionary support like you mentioned. My synthetic tests showed that zlib gives more compression but usually slower than pglz. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
- 0001-Make-syntax-changes-for-custom-compression-metho-v16.patch
- 0002-Add-compression-catalog-tables-and-the-basic-inf-v16.patch
- 0003-Add-rewrite-rules-and-tupdesc-flags-v16.patch
- 0004-Add-pglz-compression-method-v16.patch
- 0005-Add-zlib-compression-method-v16.patch
- 0006-Add-psql-pg_dump-and-pg_upgrade-support-v16.patch
- 0007-Add-tests-for-compression-methods-v16.patch
- 0008-Add-documentation-for-custom-compression-methods-v16.patch
On Mon, Apr 23, 2018 at 12:34 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > May be. But in any cases, there are several direction where compression can > be used: > - custom compression algorithms > - libpq compression > - page level compression > ... > > and them should be somehow finally "married" with each other. I agree that we should try to avoid multiplying the number of compression-related APIs. Ideally there should be one API for registering a compression algorithms, and then there can be different methods of selecting that compression algorithm depending on the purpose for which it will be used. For instance, you could select a column compression format using some variant of ALTER TABLE ... ALTER COLUMN, but you would obviously use some other method to select the WAL compression format. However, it's a little unclear to me how we would actually make the idea of a single API work. For column compression, we need everything to be accessible through the catalogs. For something like WAL compression, we need it to be completely independent of the catalogs. Those things are opposites, so a single API can't have both properties. Maybe there can be some pieces shared, but as much as I'd like it to be otherwise, it doesn't seem possible to share it completely. I also agree with Ildus and Alexander that we cannot and should not try to solve every problem in one patch. Rather, we should just think ahead, so that we make as much of what goes into this patch reusable in the future as we can. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, 18 Jun 2018 17:30:45 +0300 Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > On Tue, 24 Apr 2018 14:05:20 +0300 > Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > > > > Yes, this patch definitely lacks of good usage example. That may > > lead to some misunderstanding of its purpose. Good use-cases > > should be shown before we can consider committing this. I think > > Ildus should try to implement at least custom dictionary compression > > method where dictionary is specified by user in parameters. > > > > Hi, > > attached v16 of the patch. I have splitted the patch to 8 parts so now > it should be easier to make a review. The main improvement is zlib > compression method with dictionary support like you mentioned. My > synthetic tests showed that zlib gives more compression but usually > slower than pglz. > Hi, I have noticed that my patch is failing to apply on cputube. Attached a rebased version of the patch. Nothing have really changed, just added and fixed some tests for zlib and improved documentation. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
- 0001-Make-syntax-changes-for-custom-compression-metho-v17.patch
- 0002-Add-compression-catalog-tables-and-the-basic-inf-v17.patch
- 0003-Add-rewrite-rules-and-tupdesc-flags-v17.patch
- 0004-Add-pglz-compression-method-v17.patch
- 0005-Add-zlib-compression-method-v17.patch
- 0006-Add-psql-pg_dump-and-pg_upgrade-support-v17.patch
- 0007-Add-tests-for-compression-methods-v17.patch
- 0008-Add-documentation-for-custom-compression-methods-v17.patch
Hi! On Mon, Jul 2, 2018 at 3:56 PM Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > On Mon, 18 Jun 2018 17:30:45 +0300 > Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > > > On Tue, 24 Apr 2018 14:05:20 +0300 > > Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > > > > > > > Yes, this patch definitely lacks of good usage example. That may > > > lead to some misunderstanding of its purpose. Good use-cases > > > should be shown before we can consider committing this. I think > > > Ildus should try to implement at least custom dictionary compression > > > method where dictionary is specified by user in parameters. > > > > > > > Hi, > > > > attached v16 of the patch. I have splitted the patch to 8 parts so now > > it should be easier to make a review. The main improvement is zlib > > compression method with dictionary support like you mentioned. My > > synthetic tests showed that zlib gives more compression but usually > > slower than pglz. > > > > I have noticed that my patch is failing to apply on cputube. Attached a > rebased version of the patch. Nothing have really changed, just added > and fixed some tests for zlib and improved documentation. I'm going to review this patch. Could you please rebase it? It doesn't apply for me due to changes made in src/bin/psql/describe.c. patching file src/bin/psql/describe.c Hunk #1 FAILED at 1755. Hunk #2 FAILED at 1887. Hunk #3 FAILED at 1989. Hunk #4 FAILED at 2019. Hunk #5 FAILED at 2030. 5 out of 5 hunks FAILED -- saving rejects to file src/bin/psql/describe.c.rej Also, please not that PostgreSQL 11 already passed feature freeze some time ago. So, please adjust your patch to expect PostgreSQL 12 in the lines like this: + if (pset.sversion >= 110000) ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Mon, 23 Jul 2018 16:16:19 +0300 Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > I'm going to review this patch. Could you please rebase it? It > doesn't apply for me due to changes made in src/bin/psql/describe.c. > > patching file src/bin/psql/describe.c > Hunk #1 FAILED at 1755. > Hunk #2 FAILED at 1887. > Hunk #3 FAILED at 1989. > Hunk #4 FAILED at 2019. > Hunk #5 FAILED at 2030. > 5 out of 5 hunks FAILED -- saving rejects to file > src/bin/psql/describe.c.rej > > Also, please not that PostgreSQL 11 already passed feature freeze some > time ago. So, please adjust your patch to expect PostgreSQL 12 in the > lines like this: > > + if (pset.sversion >= 110000) > > ------ > Alexander Korotkov > Postgres Professional: http://www.postgrespro.com > The Russian Postgres Company > Hi, attached latest set of patches. Rebased and fixed pg_upgrade errors related with zlib support. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
- 0001-Make-syntax-changes-for-custom-compression-metho-v19.patch
- 0002-Add-compression-catalog-tables-and-the-basic-inf-v19.patch
- 0003-Add-rewrite-rules-and-tupdesc-flags-v19.patch
- 0004-Add-pglz-compression-method-v19.patch
- 0005-Add-zlib-compression-method-v19.patch
- 0006-Add-psql-pg_dump-and-pg_upgrade-support-v19.patch
- 0007-Add-tests-for-compression-methods-v19.patch
- 0008-Add-documentation-for-custom-compression-methods-v19.patch
On Thu, 6 Sep 2018 18:27:13 +0300 Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > > Hi, attached latest set of patches. Rebased and fixed pg_upgrade > errors related with zlib support. > Hi, just updated patches to current master. Nothing new. -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
- 0001-Make-syntax-changes-for-custom-compression-metho-v20.patch
- 0002-Add-compression-catalog-tables-and-the-basic-inf-v20.patch
- 0003-Add-rewrite-rules-and-tupdesc-flags-v20.patch
- 0004-Add-pglz-compression-method-v20.patch
- 0005-Add-zlib-compression-method-v20.patch
- 0006-Add-psql-pg_dump-and-pg_upgrade-support-v20.patch
- 0007-Add-tests-for-compression-methods-v20.patch
- 0008-Add-documentation-for-custom-compression-methods-v20.patch
> On Thu, Sep 6, 2018 at 5:27 PM Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > > Hi, attached latest set of patches. Rebased and fixed pg_upgrade errors > related with zlib support. Thank you for working on this patch, I believe the ideas mentioned in this thread are quite important for Postgres improvement. Unfortunately, patch has some conflicts now, could you post a rebased version one more time? > On Mon, 23 Jul 2018 16:16:19 +0300 > Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > > I'm going to review this patch. Could you please rebase it? It > > doesn't apply for me due to changes made in src/bin/psql/describe.c. Is there any review underway, could you share the results?
On Fri, 30 Nov 2018 15:08:39 +0100 Dmitry Dolgov <9erthalion6@gmail.com> wrote: > > On Thu, Sep 6, 2018 at 5:27 PM Ildus Kurbangaliev > > <i.kurbangaliev@postgrespro.ru> wrote: > > > > Hi, attached latest set of patches. Rebased and fixed pg_upgrade > > errors related with zlib support. > > Thank you for working on this patch, I believe the ideas mentioned in > this thread are quite important for Postgres improvement. > Unfortunately, patch has some conflicts now, could you post a rebased > version one more time? Hi, here is a rebased version. I hope it will get some review :) -- --- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
- 0001-Make-syntax-changes-for-custom-compression-metho-v20.patch
- 0002-Add-compression-catalog-tables-and-the-basic-inf-v20.patch
- 0003-Add-rewrite-rules-and-tupdesc-flags-v20.patch
- 0004-Add-pglz-compression-method-v20.patch
- 0005-Add-zlib-compression-method-v20.patch
- 0006-Add-psql-pg_dump-and-pg_upgrade-support-v20.patch
- 0007-Add-tests-for-compression-methods-v20.patch
- 0008-Add-documentation-for-custom-compression-methods-v20.patch
On Mon, Dec 03, 2018 at 03:43:32PM +0300, Ildus Kurbangaliev wrote: > Hi, here is a rebased version. I hope it will get some review :) This patch set is failing to apply, so moved to next CF, waiting for author. -- Michael
Attachment
Hi, there are another set of patches. Only rebased to current master. Also I will change status on commitfest to 'Needs review'. -- Regards, Ildus Kurbangaliev
Attachment
- 0001-Make-syntax-changes-for-custom-compression-metho-v21.patch
- 0002-Add-compression-catalog-tables-and-the-basic-inf-v21.patch
- 0003-Add-rewrite-rules-and-tupdesc-flags-v21.patch
- 0004-Add-pglz-compression-method-v21.patch
- 0005-Add-zlib-compression-method-v21.patch
- 0006-Add-psql-pg_dump-and-pg_upgrade-support-v21.patch
- 0007-Add-tests-for-compression-methods-v21.patch
- 0008-Add-documentation-for-custom-compression-methods-v21.patch
On 2/28/19 5:44 PM, Ildus Kurbangaliev wrote: > there are another set of patches. > Only rebased to current master. > > Also I will change status on commitfest to 'Needs review'. This patch has seen periodic rebases but no code review that I can see since last January 2018. As Andres noted in [1], I think that we need to decide if this is a feature that we want rather than just continuing to push it from CF to CF. -- -David david@pgmasters.net [1] https://www.postgresql.org/message-id/20190216054526.zss2cufdxfeudr4i%40alap3.anarazel.de
On Thu, Mar 7, 2019 at 10:43 AM David Steele <david@pgmasters.net> wrote:
On 2/28/19 5:44 PM, Ildus Kurbangaliev wrote:
> there are another set of patches.
> Only rebased to current master.
>
> Also I will change status on commitfest to 'Needs review'.
This patch has seen periodic rebases but no code review that I can see
since last January 2018.
As Andres noted in [1], I think that we need to decide if this is a
feature that we want rather than just continuing to push it from CF to CF.
Yes. I took a look at code of this patch. I think it's in pretty good shape. But high level review/discussion is required.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 3/7/19 11:50 AM, Alexander Korotkov wrote: > On Thu, Mar 7, 2019 at 10:43 AM David Steele <david@pgmasters.net > <mailto:david@pgmasters.net>> wrote: > > On 2/28/19 5:44 PM, Ildus Kurbangaliev wrote: > > > there are another set of patches. > > Only rebased to current master. > > > > Also I will change status on commitfest to 'Needs review'. > > This patch has seen periodic rebases but no code review that I can see > since last January 2018. > > As Andres noted in [1], I think that we need to decide if this is a > feature that we want rather than just continuing to push it from CF > to CF. > > > Yes. I took a look at code of this patch. I think it's in pretty good > shape. But high level review/discussion is required. OK, but I think this patch can only be pushed one more time, maximum, before it should be rejected. Regards, -- -David david@pgmasters.net
On Fri, 15 Mar 2019 14:07:14 +0400 David Steele <david@pgmasters.net> wrote: > On 3/7/19 11:50 AM, Alexander Korotkov wrote: > > On Thu, Mar 7, 2019 at 10:43 AM David Steele <david@pgmasters.net > > <mailto:david@pgmasters.net>> wrote: > > > > On 2/28/19 5:44 PM, Ildus Kurbangaliev wrote: > > > > > there are another set of patches. > > > Only rebased to current master. > > > > > > Also I will change status on commitfest to 'Needs review'. > > > > This patch has seen periodic rebases but no code review that I > > can see since last January 2018. > > > > As Andres noted in [1], I think that we need to decide if this > > is a feature that we want rather than just continuing to push it > > from CF to CF. > > > > > > Yes. I took a look at code of this patch. I think it's in pretty > > good shape. But high level review/discussion is required. > > OK, but I think this patch can only be pushed one more time, maximum, > before it should be rejected. > > Regards, Hi, in my opinion this patch is usually skipped not because it is not needed, but because of its size. It is not hard to maintain it until commiters will have time for it or I will get actual response that nobody is going to commit it. Attached latest set of patches. -- Best regards, Ildus Kurbangaliev
Attachment
- 0001-Make-syntax-changes-for-custom-compression-metho-v22.patch
- 0002-Add-compression-catalog-tables-and-the-basic-inf-v22.patch
- 0003-Add-rewrite-rules-and-tupdesc-flags-v22.patch
- 0004-Add-pglz-compression-method-v22.patch
- 0005-Add-zlib-compression-method-v22.patch
- 0006-Add-psql-pg_dump-and-pg_upgrade-support-v22.patch
- 0007-Add-tests-for-compression-methods-v22.patch
- 0008-Add-documentation-for-custom-compression-methods-v22.patch
On Fri, Mar 15, 2019 at 6:07 PM David Steele <david@pgmasters.net> wrote:
On 3/7/19 11:50 AM, Alexander Korotkov wrote:
> On Thu, Mar 7, 2019 at 10:43 AM David Steele <david@pgmasters.net
> <mailto:david@pgmasters.net>> wrote:
>
> On 2/28/19 5:44 PM, Ildus Kurbangaliev wrote:
>
> > there are another set of patches.
> > Only rebased to current master.
> >
> > Also I will change status on commitfest to 'Needs review'.
>
> This patch has seen periodic rebases but no code review that I can see
> since last January 2018.
>
> As Andres noted in [1], I think that we need to decide if this is a
> feature that we want rather than just continuing to push it from CF
> to CF.
>
>
> Yes. I took a look at code of this patch. I think it's in pretty good
> shape. But high level review/discussion is required.
OK, but I think this patch can only be pushed one more time, maximum,
before it should be rejected.
As a note, we believe at Adjust that this would be very helpful for some of our use cases and some other general use cases. I think as a feature, custom compression methods are a good thing but we are not the only ones with interests here and would be interested in pushing this forward if possible or finding ways to contribute to better approaches in this particular field.
Regards,
--
-David
david@pgmasters.net
Best Regards,
Chris Travers
Head of Database
Saarbrücker Straße 37a, 10405 Berlin
Hi Ildus,
On Fri, Mar 15, 2019 at 12:52 PM Ildus Kurbangaliev <i.kurbangaliev@gmail.com> wrote:
Hi,
in my opinion this patch is usually skipped not because it is not
needed, but because of its size. It is not hard to maintain it until
commiters will have time for it or I will get actual response that
nobody is going to commit it.
Attached latest set of patches.
As I understand, the only thing changed since my last review is an additional
compression method for zlib.
The code looks good. I have one suggestion though. Currently you only predefine
two compression levels: `best_speed` and `best_compression`. But zlib itself
allows a fine gradation between those two. It is possible to set level to the
values from 0 to 9 (where zero means no compression at all which I guess isn't
useful in our case). So I think we should allow user choose between either
textual representation (as you already did) or numeral. Another thing is that one
can specify, for instance, `best_speed` level, but not `BEST_SPEED`, which can
be a bit frustrating for user.
Regards,
Ildar Musin
On 3/15/19 12:52 PM, Ildus Kurbangaliev wrote: > On Fri, 15 Mar 2019 14:07:14 +0400 > David Steele <david@pgmasters.net> wrote: > >> On 3/7/19 11:50 AM, Alexander Korotkov wrote: >>> On Thu, Mar 7, 2019 at 10:43 AM David Steele <david@pgmasters.net >>> <mailto:david@pgmasters.net>> wrote: >>> >>> On 2/28/19 5:44 PM, Ildus Kurbangaliev wrote: >>> >>> > there are another set of patches. >>> > Only rebased to current master. >>> > >>> > Also I will change status on commitfest to 'Needs review'. >>> >>> This patch has seen periodic rebases but no code review that I >>> can see since last January 2018. >>> >>> As Andres noted in [1], I think that we need to decide if this >>> is a feature that we want rather than just continuing to push it >>> from CF to CF. >>> >>> >>> Yes. I took a look at code of this patch. I think it's in pretty >>> good shape. But high level review/discussion is required. >> >> OK, but I think this patch can only be pushed one more time, maximum, >> before it should be rejected. >> >> Regards, > > Hi, > in my opinion this patch is usually skipped not because it is not > needed, but because of its size. It is not hard to maintain it until > commiters will have time for it or I will get actual response that > nobody is going to commit it. > That may be one of the reasons, yes. But there are other reasons, which I think may be playing a bigger role. There's one practical issue with how the patch is structured - the docs and tests are in separate patches towards the end of the patch series, which makes it impossible to commit the preceding parts. This needs to change. Otherwise the patch size kills the patch as a whole. But there's a more important cost/benefit issue, I think. When I look at patches as a committer, I naturally have to weight how much time I spend on getting it in (and then dealing with fallout from bugs etc) vs. what I get in return (measured in benefits for community, users). This patch is pretty large and complex, so the "costs" are quite high, while the benefits from the patch itself is the ability to pick between pg_lz and zlib. Which is not great, and so people tend to pick other patches. Now, I understand there's a lot of potential benefits further down the line, like column-level compression (which I think is the main goal here). But that's not included in the patch, so the gains are somewhat far in the future. But hey, I think there are committers working for postgrespro, who might have the motivation to get this over the line. Of course, assuming that there are no serious objections to having this functionality or how it's implemented ... But I don't think that was the case. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Mar 18, 2019 at 11:09 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
On 3/15/19 12:52 PM, Ildus Kurbangaliev wrote:
> On Fri, 15 Mar 2019 14:07:14 +0400
> David Steele <david@pgmasters.net> wrote:
>
>> On 3/7/19 11:50 AM, Alexander Korotkov wrote:
>>> On Thu, Mar 7, 2019 at 10:43 AM David Steele <david@pgmasters.net
>>> <mailto:david@pgmasters.net>> wrote:
>>>
>>> On 2/28/19 5:44 PM, Ildus Kurbangaliev wrote:
>>>
>>> > there are another set of patches.
>>> > Only rebased to current master.
>>> >
>>> > Also I will change status on commitfest to 'Needs review'.
>>>
>>> This patch has seen periodic rebases but no code review that I
>>> can see since last January 2018.
>>>
>>> As Andres noted in [1], I think that we need to decide if this
>>> is a feature that we want rather than just continuing to push it
>>> from CF to CF.
>>>
>>>
>>> Yes. I took a look at code of this patch. I think it's in pretty
>>> good shape. But high level review/discussion is required.
>>
>> OK, but I think this patch can only be pushed one more time, maximum,
>> before it should be rejected.
>>
>> Regards,
>
> Hi,
> in my opinion this patch is usually skipped not because it is not
> needed, but because of its size. It is not hard to maintain it until
> commiters will have time for it or I will get actual response that
> nobody is going to commit it.
>
That may be one of the reasons, yes. But there are other reasons, which
I think may be playing a bigger role.
There's one practical issue with how the patch is structured - the docs
and tests are in separate patches towards the end of the patch series,
which makes it impossible to commit the preceding parts. This needs to
change. Otherwise the patch size kills the patch as a whole.
But there's a more important cost/benefit issue, I think. When I look at
patches as a committer, I naturally have to weight how much time I spend
on getting it in (and then dealing with fallout from bugs etc) vs. what
I get in return (measured in benefits for community, users). This patch
is pretty large and complex, so the "costs" are quite high, while the
benefits from the patch itself is the ability to pick between pg_lz and
zlib. Which is not great, and so people tend to pick other patches.
Now, I understand there's a lot of potential benefits further down the
line, like column-level compression (which I think is the main goal
here). But that's not included in the patch, so the gains are somewhat
far in the future.
Not discussing whether any particular committer should pick this up but I want to discuss an important use case we have at Adjust for this sort of patch.
The PostgreSQL compression strategy is something we find inadequate for at least one of our large deployments (a large debug log spanning 10PB+). Our current solution is to set storage so that it does not compress and then run on ZFS to get compression speedups on spinning disks.
But running PostgreSQL on ZFS has some annoying costs because we have copy-on-write on copy-on-write, and when you add file fragmentation... I would really like to be able to get away from having to do ZFS as an underlying filesystem. While we have good write throughput, read throughput is not as good as I would like.
An approach that would give us better row-level compression would allow us to ditch the COW filesystem under PostgreSQL approach.
So I think the benefits are actually quite high particularly for those dealing with volume/variety problems where things like JSONB might be a go-to solution. Similarly I could totally see having systems which handle large amounts of specialized text having extensions for dealing with these.
But hey, I think there are committers working for postgrespro, who might
have the motivation to get this over the line. Of course, assuming that
there are no serious objections to having this functionality or how it's
implemented ... But I don't think that was the case.
While I am not currently able to speak for questions of how it is implemented, I can say with very little doubt that we would almost certainly use this functionality if it were there and I could see plenty of other cases where this would be a very appropriate direction for some other projects as well.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Best Regards,
Chris Travers
Head of Database
Saarbrücker Straße 37a, 10405 Berlin
On 3/19/19 10:59 AM, Chris Travers wrote: > > > On Mon, Mar 18, 2019 at 11:09 PM Tomas Vondra > <tomas.vondra@2ndquadrant.com <mailto:tomas.vondra@2ndquadrant.com>> wrote: > > > > On 3/15/19 12:52 PM, Ildus Kurbangaliev wrote: > > On Fri, 15 Mar 2019 14:07:14 +0400 > > David Steele <david@pgmasters.net <mailto:david@pgmasters.net>> wrote: > > > >> On 3/7/19 11:50 AM, Alexander Korotkov wrote: > >>> On Thu, Mar 7, 2019 at 10:43 AM David Steele > <david@pgmasters.net <mailto:david@pgmasters.net> > >>> <mailto:david@pgmasters.net <mailto:david@pgmasters.net>>> wrote: > >>> > >>> On 2/28/19 5:44 PM, Ildus Kurbangaliev wrote: > >>> > >>> > there are another set of patches. > >>> > Only rebased to current master. > >>> > > >>> > Also I will change status on commitfest to 'Needs review'. > >>> > >>> This patch has seen periodic rebases but no code review that I > >>> can see since last January 2018. > >>> > >>> As Andres noted in [1], I think that we need to decide if this > >>> is a feature that we want rather than just continuing to push it > >>> from CF to CF. > >>> > >>> > >>> Yes. I took a look at code of this patch. I think it's in pretty > >>> good shape. But high level review/discussion is required. > >> > >> OK, but I think this patch can only be pushed one more time, > maximum, > >> before it should be rejected. > >> > >> Regards, > > > > Hi, > > in my opinion this patch is usually skipped not because it is not > > needed, but because of its size. It is not hard to maintain it until > > commiters will have time for it or I will get actual response that > > nobody is going to commit it. > > > > That may be one of the reasons, yes. But there are other reasons, which > I think may be playing a bigger role. > > There's one practical issue with how the patch is structured - the docs > and tests are in separate patches towards the end of the patch series, > which makes it impossible to commit the preceding parts. This needs to > change. Otherwise the patch size kills the patch as a whole. > > But there's a more important cost/benefit issue, I think. When I look at > patches as a committer, I naturally have to weight how much time I spend > on getting it in (and then dealing with fallout from bugs etc) vs. what > I get in return (measured in benefits for community, users). This patch > is pretty large and complex, so the "costs" are quite high, while the > benefits from the patch itself is the ability to pick between pg_lz and > zlib. Which is not great, and so people tend to pick other patches. > > Now, I understand there's a lot of potential benefits further down the > line, like column-level compression (which I think is the main goal > here). But that's not included in the patch, so the gains are somewhat > far in the future. > > > Not discussing whether any particular committer should pick this up but > I want to discuss an important use case we have at Adjust for this sort > of patch. > > The PostgreSQL compression strategy is something we find inadequate for > at least one of our large deployments (a large debug log spanning > 10PB+). Our current solution is to set storage so that it does not > compress and then run on ZFS to get compression speedups on spinning disks. > > But running PostgreSQL on ZFS has some annoying costs because we have > copy-on-write on copy-on-write, and when you add file fragmentation... I > would really like to be able to get away from having to do ZFS as an > underlying filesystem. While we have good write throughput, read > throughput is not as good as I would like. > > An approach that would give us better row-level compression would allow > us to ditch the COW filesystem under PostgreSQL approach. > > So I think the benefits are actually quite high particularly for those > dealing with volume/variety problems where things like JSONB might be a > go-to solution. Similarly I could totally see having systems which > handle large amounts of specialized text having extensions for dealing > with these. > Sure, I don't disagree - the proposed compression approach may be a big win for some deployments further down the road, no doubt about it. But as I said, it's unclear when we get there (or if the interesting stuff will be in some sort of extension, which I don't oppose in principle). > > But hey, I think there are committers working for postgrespro, who might > have the motivation to get this over the line. Of course, assuming that > there are no serious objections to having this functionality or how it's > implemented ... But I don't think that was the case. > > > While I am not currently able to speak for questions of how it is > implemented, I can say with very little doubt that we would almost > certainly use this functionality if it were there and I could see plenty > of other cases where this would be a very appropriate direction for some > other projects as well. > Well, I guess the best thing you can do to move this patch forward is to actually try that on your real-world use case, and report your results and possibly do a review of the patch. IIRC there was an extension [1] leveraging this custom compression interface for better jsonb compression, so perhaps that would work for you (not sure if it's up to date with the current patch, though). [1] https://www.postgresql.org/message-id/20171130182009.1b492eb2%40wp.localdomain regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Mar 19, 2019 at 12:19 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
On 3/19/19 10:59 AM, Chris Travers wrote:
>
>
> Not discussing whether any particular committer should pick this up but
> I want to discuss an important use case we have at Adjust for this sort
> of patch.
>
> The PostgreSQL compression strategy is something we find inadequate for
> at least one of our large deployments (a large debug log spanning
> 10PB+). Our current solution is to set storage so that it does not
> compress and then run on ZFS to get compression speedups on spinning disks.
>
> But running PostgreSQL on ZFS has some annoying costs because we have
> copy-on-write on copy-on-write, and when you add file fragmentation... I
> would really like to be able to get away from having to do ZFS as an
> underlying filesystem. While we have good write throughput, read
> throughput is not as good as I would like.
>
> An approach that would give us better row-level compression would allow
> us to ditch the COW filesystem under PostgreSQL approach.
>
> So I think the benefits are actually quite high particularly for those
> dealing with volume/variety problems where things like JSONB might be a
> go-to solution. Similarly I could totally see having systems which
> handle large amounts of specialized text having extensions for dealing
> with these.
>
Sure, I don't disagree - the proposed compression approach may be a big
win for some deployments further down the road, no doubt about it. But
as I said, it's unclear when we get there (or if the interesting stuff
will be in some sort of extension, which I don't oppose in principle).
I would assume that if extensions are particularly stable and useful they could be moved into core.
But I would also assume that at first, this area would be sufficiently experimental that folks (like us) would write our own extensions for it.
>
> But hey, I think there are committers working for postgrespro, who might
> have the motivation to get this over the line. Of course, assuming that
> there are no serious objections to having this functionality or how it's
> implemented ... But I don't think that was the case.
>
>
> While I am not currently able to speak for questions of how it is
> implemented, I can say with very little doubt that we would almost
> certainly use this functionality if it were there and I could see plenty
> of other cases where this would be a very appropriate direction for some
> other projects as well.
>
Well, I guess the best thing you can do to move this patch forward is to
actually try that on your real-world use case, and report your results
and possibly do a review of the patch.
Yeah, I expect to do this within the next month or two.
IIRC there was an extension [1] leveraging this custom compression
interface for better jsonb compression, so perhaps that would work for
you (not sure if it's up to date with the current patch, though).
[1]
https://www.postgresql.org/message-id/20171130182009.1b492eb2%40wp.localdomain
Yeah I will be looking at a couple different approaches here and reporting back. I don't expect it will be a full production workload but I do expect to be able to report on benchmarks in both storage and performance.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Best Regards,
Chris Travers
Head of Database
Saarbrücker Straße 37a, 10405 Berlin
On 3/19/19 4:44 PM, Chris Travers wrote: > > > On Tue, Mar 19, 2019 at 12:19 PM Tomas Vondra > <tomas.vondra@2ndquadrant.com <mailto:tomas.vondra@2ndquadrant.com>> wrote: > > > On 3/19/19 10:59 AM, Chris Travers wrote: > > > > > > Not discussing whether any particular committer should pick this > up but > > I want to discuss an important use case we have at Adjust for this > sort > > of patch. > > > > The PostgreSQL compression strategy is something we find > inadequate for > > at least one of our large deployments (a large debug log spanning > > 10PB+). Our current solution is to set storage so that it does not > > compress and then run on ZFS to get compression speedups on > spinning disks. > > > > But running PostgreSQL on ZFS has some annoying costs because we have > > copy-on-write on copy-on-write, and when you add file > fragmentation... I > > would really like to be able to get away from having to do ZFS as an > > underlying filesystem. While we have good write throughput, read > > throughput is not as good as I would like. > > > > An approach that would give us better row-level compression would > allow > > us to ditch the COW filesystem under PostgreSQL approach. > > > > So I think the benefits are actually quite high particularly for those > > dealing with volume/variety problems where things like JSONB might > be a > > go-to solution. Similarly I could totally see having systems which > > handle large amounts of specialized text having extensions for dealing > > with these. > > > > Sure, I don't disagree - the proposed compression approach may be a big > win for some deployments further down the road, no doubt about it. But > as I said, it's unclear when we get there (or if the interesting stuff > will be in some sort of extension, which I don't oppose in principle). > > > I would assume that if extensions are particularly stable and useful > they could be moved into core. > > But I would also assume that at first, this area would be sufficiently > experimental that folks (like us) would write our own extensions for it. > > > > > > > But hey, I think there are committers working for postgrespro, > who might > > have the motivation to get this over the line. Of course, > assuming that > > there are no serious objections to having this functionality > or how it's > > implemented ... But I don't think that was the case. > > > > > > While I am not currently able to speak for questions of how it is > > implemented, I can say with very little doubt that we would almost > > certainly use this functionality if it were there and I could see > plenty > > of other cases where this would be a very appropriate direction > for some > > other projects as well. > > > Well, I guess the best thing you can do to move this patch forward is to > actually try that on your real-world use case, and report your results > and possibly do a review of the patch. > > > Yeah, I expect to do this within the next month or two. > > > > IIRC there was an extension [1] leveraging this custom compression > interface for better jsonb compression, so perhaps that would work for > you (not sure if it's up to date with the current patch, though). > > [1] > https://www.postgresql.org/message-id/20171130182009.1b492eb2%40wp.localdomain > > Yeah I will be looking at a couple different approaches here and > reporting back. I don't expect it will be a full production workload but > I do expect to be able to report on benchmarks in both storage and > performance. > FWIW I was a bit curious how would that jsonb compression affect the data set I'm using for testing jsonpath patches, so I spent a bit of time getting it to work with master. It attached patch gets it to compile, but unfortunately then it fails like this: ERROR: jsonbd: worker has detached It seems there's some bug in how sh_mq is used, but I don't have time investigate that further. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On Sat, Mar 16, 2019 at 12:52 AM Ildus Kurbangaliev <i.kurbangaliev@gmail.com> wrote: > in my opinion this patch is usually skipped not because it is not > needed, but because of its size. It is not hard to maintain it until > commiters will have time for it or I will get actual response that > nobody is going to commit it. Hi Ildus, To maximise the chances of more review in the new Commitfest that is about to begin, could you please send a fresh rebase? This doesn't apply anymore. Thanks, -- Thomas Munro https://enterprisedb.com
Hi, Thomas! On Mon, Jul 1, 2019 at 1:22 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Sat, Mar 16, 2019 at 12:52 AM Ildus Kurbangaliev > <i.kurbangaliev@gmail.com> wrote: > > in my opinion this patch is usually skipped not because it is not > > needed, but because of its size. It is not hard to maintain it until > > commiters will have time for it or I will get actual response that > > nobody is going to commit it. > > To maximise the chances of more review in the new Commitfest that is > about to begin, could you please send a fresh rebase? This doesn't > apply anymore. As I get we're currently need to make high-level decision of whether we need this [1]. I was going to bring this topic up at last PGCon, but I didn't manage to attend. Does it worth bothering Ildus with continuous rebasing assuming we don't have this high-level decision yet? Links 1. https://www.postgresql.org/message-id/20190216054526.zss2cufdxfeudr4i%40alap3.anarazel.de ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 2019-Jul-01, Alexander Korotkov wrote: > As I get we're currently need to make high-level decision of whether > we need this [1]. I was going to bring this topic up at last PGCon, > but I didn't manage to attend. Does it worth bothering Ildus with > continuous rebasing assuming we don't have this high-level decision > yet? I agree that having to constantly rebase a patch that doesn't get acted upon is a bit pointless. I see a bit of a process problem here: if the patch doesn't apply, it gets punted out of commitfest and reviewers don't look at it. This means the discussion goes unseen and no decisions are made. My immediate suggestion is to rebase even if other changes are needed. Longer-term I think it'd be useful to have patches marked as needing "high-level decisions" that may lag behind current master; maybe we have them provide a git commit-ID on top of which the patch applies cleanly. I recently found git-imerge which can make rebasing of large patch series easier, by letting you deal with smaller conflicts one step at a time rather than one giant conflict; it may prove useful. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jul 1, 2019 at 5:51 PM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > On 2019-Jul-01, Alexander Korotkov wrote: > > > As I get we're currently need to make high-level decision of whether > > we need this [1]. I was going to bring this topic up at last PGCon, > > but I didn't manage to attend. Does it worth bothering Ildus with > > continuous rebasing assuming we don't have this high-level decision > > yet? > > I agree that having to constantly rebase a patch that doesn't get acted > upon is a bit pointless. I see a bit of a process problem here: if the > patch doesn't apply, it gets punted out of commitfest and reviewers > don't look at it. This means the discussion goes unseen and no > decisions are made. My immediate suggestion is to rebase even if other > changes are needed. OK, let's do this assuming Ildus didn't give up yet :) > Longer-term I think it'd be useful to have patches > marked as needing "high-level decisions" that may lag behind current > master; maybe we have them provide a git commit-ID on top of which the > patch applies cleanly. +1, Sounds like good approach for me. > I recently found git-imerge which can make rebasing of large patch > series easier, by letting you deal with smaller conflicts one step at a > time rather than one giant conflict; it may prove useful. Thank you for pointing, will try. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Mon, 1 Jul 2019 at 17:28, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Mon, Jul 1, 2019 at 5:51 PM Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
> On 2019-Jul-01, Alexander Korotkov wrote:
>
> > As I get we're currently need to make high-level decision of whether
> > we need this [1]. I was going to bring this topic up at last PGCon,
> > but I didn't manage to attend. Does it worth bothering Ildus with
> > continuous rebasing assuming we don't have this high-level decision
> > yet?
>
> I agree that having to constantly rebase a patch that doesn't get acted
> upon is a bit pointless. I see a bit of a process problem here: if the
> patch doesn't apply, it gets punted out of commitfest and reviewers
> don't look at it. This means the discussion goes unseen and no
> decisions are made. My immediate suggestion is to rebase even if other
> changes are needed.
OK, let's do this assuming Ildus didn't give up yet :)
No, I still didn't give up :)
I'm going to post rebased version in few days. I found that are new conflicts with
a slice decompression, not sure how to figure out them for now.
Also I was thinking maybe there is a point to add possibility to compress any data
that goes to some column despite toast threshold size. In our company we have
types that could benefit from compression even on smallest blocks.
Since pluggable storages were committed I think I should notice that compression
methods also can be used by them and are not supposed to work only with toast tables.
Basically it's just an interface to call compression functions which are related with some column.
Best regards,
Ildus Kurbangaliev
Attached latest version of the patch. Added slice decompression function to the compression handler. Based on: 6b8548964bccd0f2e65c687d591b7345d5146bfa Best regards, Ildus Kurbangaliev Best regards, Ildus Kurbangaliev On Tue, 2 Jul 2019 at 15:05, Ildus K <i.kurbangaliev@gmail.com> wrote: > > On Mon, 1 Jul 2019 at 17:28, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: >> >> On Mon, Jul 1, 2019 at 5:51 PM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: >> > On 2019-Jul-01, Alexander Korotkov wrote: >> > >> > > As I get we're currently need to make high-level decision of whether >> > > we need this [1]. I was going to bring this topic up at last PGCon, >> > > but I didn't manage to attend. Does it worth bothering Ildus with >> > > continuous rebasing assuming we don't have this high-level decision >> > > yet? >> > >> > I agree that having to constantly rebase a patch that doesn't get acted >> > upon is a bit pointless. I see a bit of a process problem here: if the >> > patch doesn't apply, it gets punted out of commitfest and reviewers >> > don't look at it. This means the discussion goes unseen and no >> > decisions are made. My immediate suggestion is to rebase even if other >> > changes are needed. >> >> OK, let's do this assuming Ildus didn't give up yet :) > > > No, I still didn't give up :) > I'm going to post rebased version in few days. I found that are new conflicts with > a slice decompression, not sure how to figure out them for now. > > Also I was thinking maybe there is a point to add possibility to compress any data > that goes to some column despite toast threshold size. In our company we have > types that could benefit from compression even on smallest blocks. > > Since pluggable storages were committed I think I should notice that compression > methods also can be used by them and are not supposed to work only with toast tables. > Basically it's just an interface to call compression functions which are related with some column. > > Best regards, > Ildus Kurbangaliev
Attachment
The compile of this one has been broken for a long time. Is there a rebase happening? -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Mar 7, 2019 at 2:51 AM Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Yes. I took a look at code of this patch. I think it's in pretty good shape. But high level review/discussion is required. I agree that the code of this patch is in pretty good shape, although there is a lot of rebasing needed at this point. Here is an attempt at some high level review and discussion: - As far as I can see, there is broad agreement that we shouldn't consider ourselves to be locked into 'pglz' forever. I believe numerous people have reported that there are other methods of doing compression that either compress better, or compress faster, or decompress faster, or all of the above. This isn't surprising and nor is it a knock on 'pglz'; Jan committed it in 1999, and it's not surprising that in 20 years some people have come up with better ideas. Not only that, but the quantity and quality of open source software that is available for this kind of thing and for many other kinds of things have improved dramatically in that time. - I can see three possible ways of breaking our dependence on 'pglz' for TOAST compression. Option #1 is to pick one new algorithm which we think is better than 'pglz' in all relevant ways and use it as the default for all new compressed datums. This would be dramatically simpler than what this patch does, because there would be no user interface. It would just be out with the old and in with the new. Option #2 is to create a short list of new algorithms that have different trade-offs; e.g. one that is very fast (like lz4) and one that has an extremely high compression ratio, and provide an interface for users to choose between them. This would be moderately simpler than what this patch does, because we would expose to the user anything about how a new compression method could be added, but it would still require a UI for the user to choose between the available (and hard-coded) options. It has the further advantage that every PostgreSQL cluster will offer the same options (or a subset of them, perhaps, depending on configure flags) and so you don't have to worry that, say, a pg_am row gets lost and suddenly all of your toasted data is inaccessible and uninterpretable. Option #3 is to do what this patch actually does, which is to allow for the addition of any number of compressors, including by extensions. It has the advantage that new compressors can be added with core's permission, so, for example, if it is unclear whether some excellent compressor is free of patent problems, we can elect not to ship support for it in core, while at the same time people who are willing to accept the associated legal risk can add that functionality to their own copy as an extension without having to patch core. The legal climate may even vary by jurisdiction, so what might be questionable in country A might be clearly just fine in country B. Aside from those issues, this approach allows people to experiment and innovate outside of core relatively quickly, instead of being bound by the somewhat cumbrous development process which has left this patch in limbo for the last few years. My view is that option #1 is likely to be impractical, because getting people to agree is hard, and better things are likely to come along later, and people like options. So I prefer either #2 or #3. - The next question is how a datum compressed with some non-default method should be represented on disk. The patch handles this first of all by making the observation that the compressed size can't be >=1GB, because the uncompressed size can't be >=1GB, and we wouldn't have stored it compressed if it expanded. Therefore, the upper two bits of the compressed size should always be zero on disk, and the patch steals one of them to indicate whether "custom" compression is in use. If it is, the 4-byte varlena header is followed not only by a 4-byte size (now with the new flag bit also included) but also by a 4-byte OID, indicating the compression AM in use. I don't think this is a terrible approach, but I don't think it's amazing, either. 4 bytes is quite a bit to use for this; if I guess correctly what will be a typical cluster configuration, you probably would really only need about 2 bits. For a datum that is both stored externally and compressed, the overhead is likely negligible, because the length is probably measured in kB or MB. But for a datum that is compressed but not stored externally, it seems pretty expensive; the datum is probably short, and having an extra 4 bytes of uncompressible data kinda sucks. One possibility would be to allow only one byte here: require each compression AM that is installed to advertise a one-byte value that will denote its compressed datums. If more than one AM tries to claim the same byte value, complain. Another possibility is to abandon this approach and go with #2 from the previous paragraph. Or maybe we add 1 or 2 "privileged" built-in compressors that get dedicated bit-patterns in the upper 2 bits of the size field, with the last bit pattern being reserved for future algorithms. (e.g. 0x00 = pglz, 0x01 = lz4, 0x10 = zstd, 0x11 = something else - see within for details). - I don't really like the use of the phrase "custom compression". I think the terminology needs to be rethought so that we just talk about compression methods. Perhaps in certain contexts we need to specify that we mean extensible compression methods or user-provided compression methods or something like that, but I don't think the word "custom" is very well-suited here. The main point of this shouldn't be for every cluster in the universe to use a different approach to compression, or to compress columns within a database in 47 different ways, but rather to help us get out from under 'pglz'. Eventually we probably want to change the default, but as the patch phrases things now, that default would be a custom method, which is almost a contradiction in terms. - Yet another possible approach to the on-disk format is to leave varatt_external.va_extsize and varattrib_4b.rawsize untouched and instead add new compression methods by adding new vartag_external values. There's quite a lot of bit-space available there: we have a whole byte, and we're currently only using 4 values. We could easily add a half-dozen new possibilities there for new compression methods without sweating the bit-space consumption. The main thing I don't like about this is that it only seems like a useful way to provide for out-of-line compression. Perhaps it could be generalized to allow for inline compression as well, but it seems like it would take some hacking. - One thing I really don't like about the patch is that it consumes a bit from infomask2 for a new flag HEAP_HASCUSTOMCOMPRESSED. infomask bits are at a premium, and there's been no real progress in the decade plus that I've been hanging around here in clawing back any bit-space. I think we really need to avoid burning our remaining bits for anything other than a really critical need, and I don't think I understand what the need is in this case. I might be missing something, but I'd really strongly suggest looking for a way to get rid of this. It also invents the concept of a TupleDesc flag, and the flag invented is TD_ATTR_CUSTOM_COMPRESSED; I'm not sure I see why we need that, either. - It seems like this kind of approach has a sort of built-in circularity problem. It means that every place that might need to detoast a datum needs to be able to access the pg_am catalog. I wonder if that's actually true. For instance, consider logical decoding. I guess that can do catalog lookups in general, but can it do them from the places where detoasting is happening? Moreover, can it do them with the right snapshot? Suppose we rewrite a table to change the compression method, then drop the old compression method, then try to decode a transaction that modified that table before those operations were performed. As an even more extreme example, suppose we need to open pg_am, and to do that we have to build a relcache entry for it, and suppose the relevant pg_class entry had a relacl or reloptions field that happened to be custom-compressed. Or equally suppose that any of the various other tables we use when building a relcache entry had the same kind of problem, especially those that have TOAST tables. We could just disallow the use of non-default compressors in the system catalogs, but the benefits mentioned in http://postgr.es/m/5541614A.5030208@2ndquadrant.com seem too large to ignore. - I think it would be awfully appealing if we could find some way of dividing this great big patch into some somewhat smaller patches. For example: Patch #1. Add syntax allowing a compression method to be specified, but the only possible choice is pglz, and the PRESERVE stuff isn't supported, and changing the value associated with an existing column isn't supported, but we can add tab-completion support and stuff. Patch #2. Add a second built-in method, like gzip or lz4. Patch #3. Add support for changing the compression method associated with a column, forcing a table rewrite. Patch #4. Add support for PRESERVE, so that you can change the compression method associated with a column without forcing a table rewrite, by including the old method in the PRESERVE list, or with a rewrite, by not including it in the PRESERVE list. Patch #5. Add support for compression methods via the AM interface. Perhaps methods added in this manner are prohibited in system catalogs. (This could also go before #4 or even before #3, but with a noticeable hit to usability.) Patch #6 (new development). Add a contrib module using the facility added in #5, perhaps with a slightly off-beat compressor like bzip2 that is more of a niche use case. I think that if the patch set were broken up this way, it would be a lot easier to review and get committed. I think you could commit each bit separately. I don't think you'd want to commit #1 unless you had a sense that #2 was pretty close to done, and similarly for #5 and #6, but that would still make things a lot easier than having one giant monolithic patch, at least IMHO. There might be more to say here, but that's what I have got for now. I hope it helps. Thanks, -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2020-06-19 13:03:02 -0400, Robert Haas wrote: > - I can see three possible ways of breaking our dependence on 'pglz' > for TOAST compression. Option #1 is to pick one new algorithm which we > think is better than 'pglz' in all relevant ways and use it as the > default for all new compressed datums. This would be dramatically > simpler than what this patch does, because there would be no user > interface. It would just be out with the old and in with the new. > Option #2 is to create a short list of new algorithms that have > different trade-offs; e.g. one that is very fast (like lz4) and one > that has an extremely high compression ratio, and provide an interface > for users to choose between them. This would be moderately simpler > than what this patch does, because we would expose to the user > anything about how a new compression method could be added, but it > would still require a UI for the user to choose between the available > (and hard-coded) options. It has the further advantage that every > PostgreSQL cluster will offer the same options (or a subset of them, > perhaps, depending on configure flags) and so you don't have to worry > that, say, a pg_am row gets lost and suddenly all of your toasted data > is inaccessible and uninterpretable. Option #3 is to do what this > patch actually does, which is to allow for the addition of any number > of compressors, including by extensions. It has the advantage that new > compressors can be added with core's permission, so, for example, if > it is unclear whether some excellent compressor is free of patent > problems, we can elect not to ship support for it in core, while at > the same time people who are willing to accept the associated legal > risk can add that functionality to their own copy as an extension > without having to patch core. The legal climate may even vary by > jurisdiction, so what might be questionable in country A might be > clearly just fine in country B. Aside from those issues, this approach > allows people to experiment and innovate outside of core relatively > quickly, instead of being bound by the somewhat cumbrous development > process which has left this patch in limbo for the last few years. My > view is that option #1 is likely to be impractical, because getting > people to agree is hard, and better things are likely to come along > later, and people like options. So I prefer either #2 or #3. I personally favor going for #2, at least initially. Then we can discuss the runtime-extensibility of #3 separately. > - The next question is how a datum compressed with some non-default > method should be represented on disk. The patch handles this first of > all by making the observation that the compressed size can't be >=1GB, > because the uncompressed size can't be >=1GB, and we wouldn't have > stored it compressed if it expanded. Therefore, the upper two bits of > the compressed size should always be zero on disk, and the patch > steals one of them to indicate whether "custom" compression is in use. > If it is, the 4-byte varlena header is followed not only by a 4-byte > size (now with the new flag bit also included) but also by a 4-byte > OID, indicating the compression AM in use. I don't think this is a > terrible approach, but I don't think it's amazing, either. 4 bytes is > quite a bit to use for this; if I guess correctly what will be a > typical cluster configuration, you probably would really only need > about 2 bits. For a datum that is both stored externally and > compressed, the overhead is likely negligible, because the length is > probably measured in kB or MB. But for a datum that is compressed but > not stored externally, it seems pretty expensive; the datum is > probably short, and having an extra 4 bytes of uncompressible data > kinda sucks. One possibility would be to allow only one byte here: > require each compression AM that is installed to advertise a one-byte > value that will denote its compressed datums. If more than one AM > tries to claim the same byte value, complain. Another possibility is > to abandon this approach and go with #2 from the previous paragraph. > Or maybe we add 1 or 2 "privileged" built-in compressors that get > dedicated bit-patterns in the upper 2 bits of the size field, with the > last bit pattern being reserved for future algorithms. (e.g. 0x00 = > pglz, 0x01 = lz4, 0x10 = zstd, 0x11 = something else - see within for > details). Agreed. I favor an approach roughly like I'd implemented below https://postgr.es/m/20130605150144.GD28067%40alap2.anarazel.de I.e. leave the vartag etc as-is, but utilize the fact that pglz compressed datums starts with a 4 byte length header, and that due to the 1GB limit, the first two bits currently have to be 0. That allows to indicate 2 compression methods without any space overhead, and additional compression methods are supported by using an additional byte (or some variable length encoded larger amount) if both bits are 1. > - Yet another possible approach to the on-disk format is to leave > varatt_external.va_extsize and varattrib_4b.rawsize untouched and > instead add new compression methods by adding new vartag_external > values. There's quite a lot of bit-space available there: we have a > whole byte, and we're currently only using 4 values. We could easily > add a half-dozen new possibilities there for new compression methods > without sweating the bit-space consumption. The main thing I don't > like about this is that it only seems like a useful way to provide for > out-of-line compression. Perhaps it could be generalized to allow for > inline compression as well, but it seems like it would take some > hacking. One additional note: Adding additional vartag_external values does incur some noticable cost, distributed across lots of places. > - One thing I really don't like about the patch is that it consumes a > bit from infomask2 for a new flag HEAP_HASCUSTOMCOMPRESSED. infomask > bits are at a premium, and there's been no real progress in the decade > plus that I've been hanging around here in clawing back any bit-space. > I think we really need to avoid burning our remaining bits for > anything other than a really critical need, and I don't think I > understand what the need is in this case. I might be missing > something, but I'd really strongly suggest looking for a way to get > rid of this. It also invents the concept of a TupleDesc flag, and the > flag invented is TD_ATTR_CUSTOM_COMPRESSED; I'm not sure I see why we > need that, either. +many Small note: The current patch adds #include "postgres.h" to a few headers - it shouldn't do so. Greetings, Andres Freund
On Mon, Jun 22, 2020 at 4:53 PM Andres Freund <andres@anarazel.de> wrote: > > Or maybe we add 1 or 2 "privileged" built-in compressors that get > > dedicated bit-patterns in the upper 2 bits of the size field, with the > > last bit pattern being reserved for future algorithms. (e.g. 0x00 = > > pglz, 0x01 = lz4, 0x10 = zstd, 0x11 = something else - see within for > > details). > > Agreed. I favor an approach roughly like I'd implemented below > https://postgr.es/m/20130605150144.GD28067%40alap2.anarazel.de > I.e. leave the vartag etc as-is, but utilize the fact that pglz > compressed datums starts with a 4 byte length header, and that due to > the 1GB limit, the first two bits currently have to be 0. That allows to > indicate 2 compression methods without any space overhead, and > additional compression methods are supported by using an additional byte > (or some variable length encoded larger amount) if both bits are 1. I think there's essentially no difference between these two ideas, unless the two bits we're talking about stealing are not the same in the two cases. Am I missing something? > One additional note: Adding additional vartag_external values does incur > some noticable cost, distributed across lots of places. OK. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2020-06-23 14:27:47 -0400, Robert Haas wrote: > On Mon, Jun 22, 2020 at 4:53 PM Andres Freund <andres@anarazel.de> wrote: > > > Or maybe we add 1 or 2 "privileged" built-in compressors that get > > > dedicated bit-patterns in the upper 2 bits of the size field, with the > > > last bit pattern being reserved for future algorithms. (e.g. 0x00 = > > > pglz, 0x01 = lz4, 0x10 = zstd, 0x11 = something else - see within for > > > details). > > > > Agreed. I favor an approach roughly like I'd implemented below > > https://postgr.es/m/20130605150144.GD28067%40alap2.anarazel.de > > I.e. leave the vartag etc as-is, but utilize the fact that pglz > > compressed datums starts with a 4 byte length header, and that due to > > the 1GB limit, the first two bits currently have to be 0. That allows to > > indicate 2 compression methods without any space overhead, and > > additional compression methods are supported by using an additional byte > > (or some variable length encoded larger amount) if both bits are 1. https://postgr.es/m/20130621000900.GA12425%40alap2.anarazel.de is a thread with more information / patches further along. > I think there's essentially no difference between these two ideas, > unless the two bits we're talking about stealing are not the same in > the two cases. Am I missing something? I confused this patch with the approach in https://www.postgresql.org/message-id/d8576096-76ba-487d-515b-44fdedba8bb5%402ndquadrant.com sorry for that. It obviously still differs by not having lower space overhead (by virtue of not having a 4 byte 'va_cmid', but no additional space for two methods, and then 1 byte overhead for 256 more), but that's not that fundamental a difference. I do think it's nicer to hide the details of the compression inside toast specific code as the version in the "further along" thread above did. The varlena stuff feels so archaic, it's hard to keep it all in my head... I think I've pondered that elsewhere before (but perhaps just on IM with you?), but I do think we'll need a better toast pointer format at some point. It's pretty fundamentally based on having the 1GB limit, which I don't think we can justify for that much longer. Using something like https://postgr.es/m/20191210015054.5otdfuftxrqb5gum%40alap3.anarazel.de I'd probably make it something roughly like: 1) signed varint indicating "in-place" length 1a) if positive, it's "plain" "in-place" data 1b) if negative, data type indicator follows. abs(length) includes size of metadata. 2) optional: unsigned varint metadata type indicator 3) data Because 1) is the size of the data, toast datums can be skipped with a relatively low amount of instructions during tuple deforming. Instead of needing a fair number of branches, as the case right now. So a small in-place uncompressed varlena2 would have an overhead of 1 byte up to 63 bytes, and 2 bytes otherwise (with 8 kb pages at least). An in-place compressed datum could have an overhead as low as 3 bytes (1 byte length, 1 byte indicator for type of compression, 1 byte raw size), although I suspect it's rarely going to be useful at that small sizes. Anyway. I think it's probably reasonable to utilize those two bits before going to a new toast format. But if somebody were more interested in working on toastv2 I'd not push back either. Regards, Andres
On Tue, Jun 23, 2020 at 4:00 PM Andres Freund <andres@anarazel.de> wrote: > https://postgr.es/m/20130621000900.GA12425%40alap2.anarazel.de is a > thread with more information / patches further along. > > I confused this patch with the approach in > https://www.postgresql.org/message-id/d8576096-76ba-487d-515b-44fdedba8bb5%402ndquadrant.com > sorry for that. It obviously still differs by not having lower space > overhead (by virtue of not having a 4 byte 'va_cmid', but no additional > space for two methods, and then 1 byte overhead for 256 more), but > that's not that fundamental a difference. Wait a minute. Are we saying there are three (3) dueling patches for adding an alternate TOAST algorithm? It seems like there is: This "custom compression methods" thread - vintage 2017 - Original code by Nikita Glukhov, later work by Ildus Kurbangaliev The "pluggable compression support" thread - vintage 2013 - Andres Freund The "plgz performance" thread - vintage 2019 - Petr Jelinek Anyone want to point to a FOURTH implementation of this feature? I guess the next thing to do is figure out which one is the best basis for further work. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Jun 24, 2020 at 5:30 PM Robert Haas <robertmhaas@gmail.com> wrote: > > On Tue, Jun 23, 2020 at 4:00 PM Andres Freund <andres@anarazel.de> wrote: > > https://postgr.es/m/20130621000900.GA12425%40alap2.anarazel.de is a > > thread with more information / patches further along. > > > > I confused this patch with the approach in > > https://www.postgresql.org/message-id/d8576096-76ba-487d-515b-44fdedba8bb5%402ndquadrant.com > > sorry for that. It obviously still differs by not having lower space > > overhead (by virtue of not having a 4 byte 'va_cmid', but no additional > > space for two methods, and then 1 byte overhead for 256 more), but > > that's not that fundamental a difference. > > Wait a minute. Are we saying there are three (3) dueling patches for > adding an alternate TOAST algorithm? It seems like there is: > > This "custom compression methods" thread - vintage 2017 - Original > code by Nikita Glukhov, later work by Ildus Kurbangaliev > The "pluggable compression support" thread - vintage 2013 - Andres Freund > The "plgz performance" thread - vintage 2019 - Petr Jelinek > > Anyone want to point to a FOURTH implementation of this feature? > > I guess the next thing to do is figure out which one is the best basis > for further work. I have gone through these 3 threads and here is a summary of what I understand from them. Feel free to correct me if I have missed something. #1. Custom compression methods: Provide a mechanism to create/drop compression methods by using external libraries, and it also provides a way to set the compression method for the columns/types. There are a few complexities with this approach those are listed below: a. We need to maintain the dependencies between the column and the compression method. And the bigger issue is, even if the compression method is changed, we need to maintain the dependencies with the older compression methods as we might have some older tuples that were compressed with older methods. b. Inside the compressed attribute, we need to maintain the compression method so that we know how to decompress it. For this, we use 2 bits from the raw_size of the compressed varlena header. #2. pglz performance: Along with pglz this patch provides an additional compression method using lz4. The new compression method can be enabled/disabled during configure time or using SIGHUP. We use 1 bit from the raw_size of the compressed varlena header to identify the compression method (pglz or lz4). #3. pluggable compression: This proposal is to replace the existing pglz algorithm, with the snappy or lz4 whichever is better. As per the performance data[1], it appeared that the lz4 is the winner in most of the cases. - This also provides an additional patch to plugin any compression method. - This will also use 2 bits from the raw_size of the compressed attribute for identifying the compression method. - Provide an option to select the compression method using GUC, but the comments in the patch suggest to remove the GUC. So it seems that GUC was used only for the POC. - Honestly, I did not clearly understand from this patch set that whether it proposes to replace the existing compression method with the best method (and the plugin is just provided for performance testing) or it actually proposes an option to have pluggable compression methods. IMHO, We can provide a solution based on #1 and #2, i.e. we can provide a few best compression methods in the core, and on top of that, we can also provide a mechanism to create/drop the external compression methods. [1] https://www.postgresql.org/message-id/20130621000900.GA12425%40alap2.anarazel.de -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Jun 29, 2020 at 12:31 PM Andres Freund <andres@anarazel.de> wrote: > > This "custom compression methods" thread - vintage 2017 - Original > > code by Nikita Glukhov, later work by Ildus Kurbangaliev > > The "pluggable compression support" thread - vintage 2013 - Andres Freund > > The "plgz performance" thread - vintage 2019 - Petr Jelinek > > > > Anyone want to point to a FOURTH implementation of this feature? > > To be clear, I don't think the 2003 patch should be considered as being > "in the running". I guess you mean 2013, not 2003? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Jun 19, 2020 at 10:33 PM Robert Haas <robertmhaas@gmail.com> wrote: > > On Thu, Mar 7, 2019 at 2:51 AM Alexander Korotkov > <a.korotkov@postgrespro.ru> wrote: > > Yes. I took a look at code of this patch. I think it's in pretty good shape. But high level review/discussion is required. > > I agree that the code of this patch is in pretty good shape, although > there is a lot of rebasing needed at this point. Here is an attempt at > some high level review and discussion: > > - As far as I can see, there is broad agreement that we shouldn't > consider ourselves to be locked into 'pglz' forever. I believe > numerous people have reported that there are other methods of doing > compression that either compress better, or compress faster, or > decompress faster, or all of the above. This isn't surprising and nor > is it a knock on 'pglz'; Jan committed it in 1999, and it's not > surprising that in 20 years some people have come up with better > ideas. Not only that, but the quantity and quality of open source > software that is available for this kind of thing and for many other > kinds of things have improved dramatically in that time. > > - I can see three possible ways of breaking our dependence on 'pglz' > for TOAST compression. Option #1 is to pick one new algorithm which we > think is better than 'pglz' in all relevant ways and use it as the > default for all new compressed datums. This would be dramatically > simpler than what this patch does, because there would be no user > interface. It would just be out with the old and in with the new. > Option #2 is to create a short list of new algorithms that have > different trade-offs; e.g. one that is very fast (like lz4) and one > that has an extremely high compression ratio, and provide an interface > for users to choose between them. This would be moderately simpler > than what this patch does, because we would expose to the user > anything about how a new compression method could be added, but it > would still require a UI for the user to choose between the available > (and hard-coded) options. It has the further advantage that every > PostgreSQL cluster will offer the same options (or a subset of them, > perhaps, depending on configure flags) and so you don't have to worry > that, say, a pg_am row gets lost and suddenly all of your toasted data > is inaccessible and uninterpretable. Option #3 is to do what this > patch actually does, which is to allow for the addition of any number > of compressors, including by extensions. It has the advantage that new > compressors can be added with core's permission, so, for example, if > it is unclear whether some excellent compressor is free of patent > problems, we can elect not to ship support for it in core, while at > the same time people who are willing to accept the associated legal > risk can add that functionality to their own copy as an extension > without having to patch core. The legal climate may even vary by > jurisdiction, so what might be questionable in country A might be > clearly just fine in country B. Aside from those issues, this approach > allows people to experiment and innovate outside of core relatively > quickly, instead of being bound by the somewhat cumbrous development > process which has left this patch in limbo for the last few years. My > view is that option #1 is likely to be impractical, because getting > people to agree is hard, and better things are likely to come along > later, and people like options. So I prefer either #2 or #3. > > - The next question is how a datum compressed with some non-default > method should be represented on disk. The patch handles this first of > all by making the observation that the compressed size can't be >=1GB, > because the uncompressed size can't be >=1GB, and we wouldn't have > stored it compressed if it expanded. Therefore, the upper two bits of > the compressed size should always be zero on disk, and the patch > steals one of them to indicate whether "custom" compression is in use. > If it is, the 4-byte varlena header is followed not only by a 4-byte > size (now with the new flag bit also included) but also by a 4-byte > OID, indicating the compression AM in use. I don't think this is a > terrible approach, but I don't think it's amazing, either. 4 bytes is > quite a bit to use for this; if I guess correctly what will be a > typical cluster configuration, you probably would really only need > about 2 bits. For a datum that is both stored externally and > compressed, the overhead is likely negligible, because the length is > probably measured in kB or MB. But for a datum that is compressed but > not stored externally, it seems pretty expensive; the datum is > probably short, and having an extra 4 bytes of uncompressible data > kinda sucks. One possibility would be to allow only one byte here: > require each compression AM that is installed to advertise a one-byte > value that will denote its compressed datums. If more than one AM > tries to claim the same byte value, complain. Another possibility is > to abandon this approach and go with #2 from the previous paragraph. > Or maybe we add 1 or 2 "privileged" built-in compressors that get > dedicated bit-patterns in the upper 2 bits of the size field, with the > last bit pattern being reserved for future algorithms. (e.g. 0x00 = > pglz, 0x01 = lz4, 0x10 = zstd, 0x11 = something else - see within for > details). > > - I don't really like the use of the phrase "custom compression". I > think the terminology needs to be rethought so that we just talk about > compression methods. Perhaps in certain contexts we need to specify > that we mean extensible compression methods or user-provided > compression methods or something like that, but I don't think the word > "custom" is very well-suited here. The main point of this shouldn't be > for every cluster in the universe to use a different approach to > compression, or to compress columns within a database in 47 different > ways, but rather to help us get out from under 'pglz'. Eventually we > probably want to change the default, but as the patch phrases things > now, that default would be a custom method, which is almost a > contradiction in terms. > > - Yet another possible approach to the on-disk format is to leave > varatt_external.va_extsize and varattrib_4b.rawsize untouched and > instead add new compression methods by adding new vartag_external > values. There's quite a lot of bit-space available there: we have a > whole byte, and we're currently only using 4 values. We could easily > add a half-dozen new possibilities there for new compression methods > without sweating the bit-space consumption. The main thing I don't > like about this is that it only seems like a useful way to provide for > out-of-line compression. Perhaps it could be generalized to allow for > inline compression as well, but it seems like it would take some > hacking. > > - One thing I really don't like about the patch is that it consumes a > bit from infomask2 for a new flag HEAP_HASCUSTOMCOMPRESSED. infomask > bits are at a premium, and there's been no real progress in the decade > plus that I've been hanging around here in clawing back any bit-space. > I think we really need to avoid burning our remaining bits for > anything other than a really critical need, and I don't think I > understand what the need is in this case. I might be missing > something, but I'd really strongly suggest looking for a way to get > rid of this. It also invents the concept of a TupleDesc flag, and the > flag invented is TD_ATTR_CUSTOM_COMPRESSED; I'm not sure I see why we > need that, either. > > - It seems like this kind of approach has a sort of built-in > circularity problem. It means that every place that might need to > detoast a datum needs to be able to access the pg_am catalog. I wonder > if that's actually true. For instance, consider logical decoding. I > guess that can do catalog lookups in general, but can it do them from > the places where detoasting is happening? Moreover, can it do them > with the right snapshot? Suppose we rewrite a table to change the > compression method, then drop the old compression method, then try to > decode a transaction that modified that table before those operations > were performed. As an even more extreme example, suppose we need to > open pg_am, and to do that we have to build a relcache entry for it, > and suppose the relevant pg_class entry had a relacl or reloptions > field that happened to be custom-compressed. Or equally suppose that > any of the various other tables we use when building a relcache entry > had the same kind of problem, especially those that have TOAST tables. > We could just disallow the use of non-default compressors in the > system catalogs, but the benefits mentioned in > http://postgr.es/m/5541614A.5030208@2ndquadrant.com seem too large to > ignore. > > - I think it would be awfully appealing if we could find some way of > dividing this great big patch into some somewhat smaller patches. For > example: > > Patch #1. Add syntax allowing a compression method to be specified, > but the only possible choice is pglz, and the PRESERVE stuff isn't > supported, and changing the value associated with an existing column > isn't supported, but we can add tab-completion support and stuff. > > Patch #2. Add a second built-in method, like gzip or lz4. > > Patch #3. Add support for changing the compression method associated > with a column, forcing a table rewrite. > > Patch #4. Add support for PRESERVE, so that you can change the > compression method associated with a column without forcing a table > rewrite, by including the old method in the PRESERVE list, or with a > rewrite, by not including it in the PRESERVE list. > > Patch #5. Add support for compression methods via the AM interface. > Perhaps methods added in this manner are prohibited in system > catalogs. (This could also go before #4 or even before #3, but with a > noticeable hit to usability.) > > Patch #6 (new development). Add a contrib module using the facility > added in #5, perhaps with a slightly off-beat compressor like bzip2 > that is more of a niche use case. > > I think that if the patch set were broken up this way, it would be a > lot easier to review and get committed. I think you could commit each > bit separately. I don't think you'd want to commit #1 unless you had a > sense that #2 was pretty close to done, and similarly for #5 and #6, > but that would still make things a lot easier than having one giant > monolithic patch, at least IMHO. > > There might be more to say here, but that's what I have got for now. I > hope it helps. I have rebased the patch on the latest head and currently, broken into 3 parts. v1-0001: As suggested by Robert, it provides the syntax support for setting the compression method for a column while creating a table and adding columns. However, we don't support changing the compression method for the existing column. As part of this patch, there is only one built-in compression method that can be set (pglz). In this, we have one in-build am (pglz) and the compressed attributes will directly store the oid of the AM. In this patch, I have removed the pg_attr_compresion as we don't support changing the compression for the existing column so we don't need to preserve the old compressions. v1-0002: Add another built-in compression method (zlib) v1:0003: Remaining patch set (nothing is changed except rebase on the current head, stabilizing check-world and 0001 and 0002 are pulled out of this) Next, I will be working on separating out the remaining patches as per the suggestion by Robert. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Thu, Aug 13, 2020 at 5:18 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > There was some question which Robert has asked in this mail, please find my answer inline. Also, I have a few questions regarding further splitting up this patch. > On Fri, Jun 19, 2020 at 10:33 PM Robert Haas <robertmhaas@gmail.com> wrote: > > > > > > - One thing I really don't like about the patch is that it consumes a > > bit from infomask2 for a new flag HEAP_HASCUSTOMCOMPRESSED. infomask > > bits are at a premium, and there's been no real progress in the decade > > plus that I've been hanging around here in clawing back any bit-space. > > I think we really need to avoid burning our remaining bits for > > anything other than a really critical need, and I don't think I > > understand what the need is in this case. IIUC, the main reason for using this flag is for taking the decision whether we need any detoasting for this tuple. For example, if we are rewriting the table because the compression method is changed then if HEAP_HASCUSTOMCOMPRESSED bit is not set in the tuple header and tuple length, not tup->t_len > TOAST_TUPLE_THRESHOLD then we don't need to call heap_toast_insert_or_update function for this tuple. Whereas if this flag is set then we need to because we might need to uncompress and compress back using a different compression method. The same is the case with INSERT into SELECT * FROM. I might be missing > > something, but I'd really strongly suggest looking for a way to get > > rid of this. It also invents the concept of a TupleDesc flag, and the > > flag invented is TD_ATTR_CUSTOM_COMPRESSED; I'm not sure I see why we > > need that, either. This is also used in a similar way as the above but for the target table, i.e. if the target table has the custom compressed attribute then maybe we can not directly insert the tuple because it might have compressed data which are compressed using the default compression methods. > > - It seems like this kind of approach has a sort of built-in > > circularity problem. It means that every place that might need to > > detoast a datum needs to be able to access the pg_am catalog. I wonder > > if that's actually true. For instance, consider logical decoding. I > > guess that can do catalog lookups in general, but can it do them from > > the places where detoasting is happening? Moreover, can it do them > > with the right snapshot? Suppose we rewrite a table to change the > > compression method, then drop the old compression method, then try to > > decode a transaction that modified that table before those operations > > were performed. As an even more extreme example, suppose we need to > > open pg_am, and to do that we have to build a relcache entry for it, > > and suppose the relevant pg_class entry had a relacl or reloptions > > field that happened to be custom-compressed. Or equally suppose that > > any of the various other tables we use when building a relcache entry > > had the same kind of problem, especially those that have TOAST tables. > > We could just disallow the use of non-default compressors in the > > system catalogs, but the benefits mentioned in > > http://postgr.es/m/5541614A.5030208@2ndquadrant.com seem too large to > > ignore. > > > > - I think it would be awfully appealing if we could find some way of > > dividing this great big patch into some somewhat smaller patches. For > > example: > > > > Patch #1. Add syntax allowing a compression method to be specified, > > but the only possible choice is pglz, and the PRESERVE stuff isn't > > supported, and changing the value associated with an existing column > > isn't supported, but we can add tab-completion support and stuff. > > > > Patch #2. Add a second built-in method, like gzip or lz4. I have already extracted these 2 patches from the main patch set. But, in these patches, I am still storing the am_oid in the toast header. I am not sure can we get rid of that at least for these 2 patches? But, then wherever we try to uncompress the tuple we need to know the tuple descriptor to get the am_oid but I think that is not possible in all the cases. Am I missing something here? > > Patch #3. Add support for changing the compression method associated > > with a column, forcing a table rewrite. > > > > Patch #4. Add support for PRESERVE, so that you can change the > > compression method associated with a column without forcing a table > > rewrite, by including the old method in the PRESERVE list, or with a > > rewrite, by not including it in the PRESERVE list. Does this make sense to have Patch #3 and Patch #4, without having Patch #5? I mean why do we need to support rewrite or preserve unless we have the customer compression methods right? because the build-in compression method can not be dropped so why do we need to preserve? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Aug 24, 2020 at 2:12 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > IIUC, the main reason for using this flag is for taking the decision > whether we need any detoasting for this tuple. For example, if we are > rewriting the table because the compression method is changed then if > HEAP_HASCUSTOMCOMPRESSED bit is not set in the tuple header and tuple > length, not tup->t_len > TOAST_TUPLE_THRESHOLD then we don't need to > call heap_toast_insert_or_update function for this tuple. Whereas if > this flag is set then we need to because we might need to uncompress > and compress back using a different compression method. The same is > the case with INSERT into SELECT * FROM. This doesn't really seem worth it to me. I don't see how we can justify burning an on-disk bit just to save a little bit of overhead during a rare maintenance operation. If there's a performance problem here we need to look for another way of mitigating it. Slowing CLUSTER and/or VACUUM FULL down by a large amount for this feature would be unacceptable, but is that really a problem? And if so, can we solve it without requiring this bit? > > > something, but I'd really strongly suggest looking for a way to get > > > rid of this. It also invents the concept of a TupleDesc flag, and the > > > flag invented is TD_ATTR_CUSTOM_COMPRESSED; I'm not sure I see why we > > > need that, either. > > This is also used in a similar way as the above but for the target > table, i.e. if the target table has the custom compressed attribute > then maybe we can not directly insert the tuple because it might have > compressed data which are compressed using the default compression > methods. I think this is just an in-memory flag, which is much less precious than an on-disk bit. However, I still wonder whether it's really the right design. I think that if we offer lz4 we may well want to make it the default eventually, or perhaps even right away. If that ends up causing this flag to get set on every tuple all the time, then it won't really optimize anything. > I have already extracted these 2 patches from the main patch set. > But, in these patches, I am still storing the am_oid in the toast > header. I am not sure can we get rid of that at least for these 2 > patches? But, then wherever we try to uncompress the tuple we need to > know the tuple descriptor to get the am_oid but I think that is not > possible in all the cases. Am I missing something here? I think we should instead use the high bits of the toast size word for patches #1-#4, as discussed upthread. > > > Patch #3. Add support for changing the compression method associated > > > with a column, forcing a table rewrite. > > > > > > Patch #4. Add support for PRESERVE, so that you can change the > > > compression method associated with a column without forcing a table > > > rewrite, by including the old method in the PRESERVE list, or with a > > > rewrite, by not including it in the PRESERVE list. > > Does this make sense to have Patch #3 and Patch #4, without having > Patch #5? I mean why do we need to support rewrite or preserve unless > we have the customer compression methods right? because the build-in > compression method can not be dropped so why do we need to preserve? I think that patch #3 makes sense because somebody might have a table that is currently compressed with pglz and they want to switch to lz4, and I think patch #4 also makes sense because they might want to start using lz4 for future data but not force a rewrite to get rid of all the pglz data they've already got. Those options are valuable as soon as there is more than one possible compression algorithm, even if they're all built in. Now, as I said upthread, it's also true that you could do #5 before #3 and #4. I don't think that's insane. But I prefer it in the other order, because I think having #5 without #3 and #4 wouldn't be too much fun for users. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, 13 Aug 2020 at 17:18, Dilip Kumar <dilipbalaut@gmail.com> wrote:
> I have rebased the patch on the latest head and currently, broken into 3 parts.
>
> v1-0001: As suggested by Robert, it provides the syntax support for
> setting the compression method for a column while creating a table and
> adding columns. However, we don't support changing the compression
> method for the existing column. As part of this patch, there is only
> one built-in compression method that can be set (pglz). In this, we
> have one in-build am (pglz) and the compressed attributes will directly
> store the oid of the AM. In this patch, I have removed the
> pg_attr_compresion as we don't support changing the compression
> for the existing column so we don't need to preserve the old
> compressions.
> v1-0002: Add another built-in compression method (zlib)
> v1:0003: Remaining patch set (nothing is changed except rebase on the
> current head, stabilizing check-world and 0001 and 0002 are pulled
> out of this)
>
> Next, I will be working on separating out the remaining patches as per
> the suggestion by Robert.
Thanks for this new feature. Looks promising and very useful, with so
many good compression libraries already available.
I see that with the patch-set, I would be able to create an extension
that defines a PostgreSQL C handler function which assigns all the
required hook function implementations for compressing, decompressing
and validating, etc. In short, I would be able to use a completely
different compression algorithm to compress toast data if I write such
an extension. Correct me if I am wrong with my interpretation.
Just a quick superficial set of review comments ....
A minor re-base is required due to a conflict in a regression test
-------------
In heap_toast_insert_or_update() and in other places, the comments for
new parameter preserved_am_info are missing.
-------------
+toast_compress_datum(Datum value, Oid acoid)
{
struct varlena *tmp = NULL;
int32 valsize;
- CompressionAmOptions cmoptions;
+ CompressionAmOptions *cmoptions = NULL;
I think tmp and cmoptions need not be initialized to NULL
-------------
- TOAST_COMPRESS_SET_RAWSIZE(tmp, valsize);
- SET_VARSIZE_COMPRESSED(tmp, len + TOAST_COMPRESS_HDRSZ);
/* successful compression */
+ toast_set_compressed_datum_info(tmp, amoid, valsize);
return PointerGetDatum(tmp);
Any particular reason why is this code put in a new extern function ?
Is there a plan to re-use it ? Otherwise, it's not necessary to do
this.
------------
Also, not sure why "HTAB *amoptions_cache" and "MemoryContext
amoptions_cache_mcxt" aren't static declarations. They are being used
only in toast_internals.c
-----------
The tab-completion doesn't show COMPRESSION :
postgres=# create access method my_method TYPE
INDEX TABLE
postgres=# create access method my_method TYPE
Also, the below syntax also would better be tab-completed so as to
display all the installed compression methods, in line with how we
show all the storage methods like plain,extended,etc:
postgres=# ALTER TABLE lztab ALTER COLUMN t SET COMPRESSION
------------
I could see the differences in compression ratio, and the compression
and decompression speed when I use lz versus zib :
CREATE TABLE zlibtab(t TEXT COMPRESSION zlib WITH (level '4'));
create table lztab(t text);
ALTER TABLE lztab ALTER COLUMN t SET COMPRESSION pglz;
pgg:s2:pg$ time psql -c "\copy zlibtab from text.data"
COPY 13050
real 0m1.344s
user 0m0.031s
sys 0m0.026s
pgg:s2:pg$ time psql -c "\copy lztab from text.data"
COPY 13050
real 0m2.088s
user 0m0.008s
sys 0m0.050s
pgg:s2:pg$ time psql -c "select pg_table_size('zlibtab'::regclass),
pg_table_size('lztab'::regclass)"
pg_table_size | pg_table_size
---------------+---------------
1261568 | 1687552
pgg:s2:pg$ time psql -c "select NULL from zlibtab where t like '0000'"
> /dev/null
real 0m0.127s
user 0m0.000s
sys 0m0.002s
pgg:s2:pg$ time psql -c "select NULL from lztab where t like '0000'"
> /dev/null
real 0m0.050s
user 0m0.002s
sys 0m0.000s
--
Thanks,
-Amit Khandekar
Huawei Technologies
> On Aug 13, 2020, at 4:48 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote: > > v1-0001: As suggested by Robert, it provides the syntax support for > setting the compression method for a column while creating a table and > adding columns. However, we don't support changing the compression > method for the existing column. As part of this patch, there is only > one built-in compression method that can be set (pglz). In this, we > have one in-build am (pglz) and the compressed attributes will directly > store the oid of the AM. In this patch, I have removed the > pg_attr_compresion as we don't support changing the compression > for the existing column so we don't need to preserve the old > compressions. I do not like the way pglz compression is handled in this patch. After upgrading PostgreSQL to the first version with thispatch included, pre-existing on-disk compressed data will not include any custom compression Oid in the header, and toast_decompress_datumwill notice that and decompress the data directly using pglz_decompress. If the same data were thenwritten back out, perhaps to another table, into a column with no custom compression method defined, it will get compressedby toast_compress_datum using DefaultCompressionOid, which is defined as PGLZ_COMPRESSION_AM_OID. That isn't aproper round-trip for the data, as when it gets re-compressed, the PGLZ_COMPRESSION_AM_OID gets written into the header,which makes the data a bit longer, but also means that it is not byte-for-byte the same as it was, which is counter-intuitive. Given that any given pglz compressed datum now has two totally different formats that might occur on disk,code may have to consider both of them, which increases code complexity, and regression tests will need to be writtenwith coverage for both of them, which increases test complexity. It's also not easy to write the extra tests, asthere isn't any way (that I see) to intentionally write out the traditional shorter form from a newer database server;you'd have to do something like a pg_upgrade test where you install an older server to write the older format, upgrade,and then check that the new server can handle it. The cleanest solution to this would seem to be removal of the compression am's Oid from the header for all compression ams,so that pre-patch written data and post-patch written data look exactly the same. The other solution is to give pglzpride-of-place as the original compression mechanism, and just say that when pglz is the compression method, no Oid getswritten to the header, and only when other compression methods are used does the Oid get written. This second optionseems closer to the implementation that you already have, because you already handle the decompression of data wherethe Oid is lacking, so all you have to do is intentionally not write the Oid when compressing using pglz. Or did I misunderstand your implementation? — Mark Dilger EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Sep 2, 2020 at 4:57 AM Mark Dilger <mark.dilger@enterprisedb.com> wrote: > > > > > On Aug 13, 2020, at 4:48 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > v1-0001: As suggested by Robert, it provides the syntax support for > > setting the compression method for a column while creating a table and > > adding columns. However, we don't support changing the compression > > method for the existing column. As part of this patch, there is only > > one built-in compression method that can be set (pglz). In this, we > > have one in-build am (pglz) and the compressed attributes will directly > > store the oid of the AM. In this patch, I have removed the > > pg_attr_compresion as we don't support changing the compression > > for the existing column so we don't need to preserve the old > > compressions. > > I do not like the way pglz compression is handled in this patch. After upgrading PostgreSQL to the first version withthis patch included, pre-existing on-disk compressed data will not include any custom compression Oid in the header,and toast_decompress_datum will notice that and decompress the data directly using pglz_decompress. If the samedata were then written back out, perhaps to another table, into a column with no custom compression method defined, itwill get compressed by toast_compress_datum using DefaultCompressionOid, which is defined as PGLZ_COMPRESSION_AM_OID. That isn't a proper round-trip for the data, as when it gets re-compressed, the PGLZ_COMPRESSION_AM_OID gets written intothe header, which makes the data a bit longer, but also means that it is not byte-for-byte the same as it was, whichis counter-intuitive. Given that any given pglz compressed datum now has two totally different formats that might occuron disk, code may have to consider both of them, which increases code complexity, and regression tests will need tobe written with coverage for both of them, which increases test complexity. It's also not easy to write the extra tests,as there isn't any way (that I see) to intentionally write out the traditional shorter form from a newer database server;you'd have to do something like a pg_upgrade test where you install an older server to write the older format, upgrade,and then check that the new server can handle it. > > The cleanest solution to this would seem to be removal of the compression am's Oid from the header for all compressionams, so that pre-patch written data and post-patch written data look exactly the same. The other solution isto give pglz pride-of-place as the original compression mechanism, and just say that when pglz is the compression method,no Oid gets written to the header, and only when other compression methods are used does the Oid get written. Thissecond option seems closer to the implementation that you already have, because you already handle the decompressionof data where the Oid is lacking, so all you have to do is intentionally not write the Oid when compressingusing pglz. > > Or did I misunderstand your implementation? Thanks for looking into it. Actually, I am planning to change this patch such that we will use the upper 2 bits of the size field instead of storing the amoid for the builtin compression methods. e. g. 0x00 = pglz, 0x01 = zlib, 0x10 = other built-in, 0x11 -> custom compression method. And when 0x11 is set then only we will store the amoid in the toast header. I think after a week or two I will make these changes and post my updated patch. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Aug 31, 2020 at 10:45 AM Amit Khandekar <amitdkhan.pg@gmail.com> wrote:
>
> On Thu, 13 Aug 2020 at 17:18, Dilip Kumar <dilipbalaut@gmail.com> wrote:
> > I have rebased the patch on the latest head and currently, broken into 3 parts.
> >
> > v1-0001: As suggested by Robert, it provides the syntax support for
> > setting the compression method for a column while creating a table and
> > adding columns. However, we don't support changing the compression
> > method for the existing column. As part of this patch, there is only
> > one built-in compression method that can be set (pglz). In this, we
> > have one in-build am (pglz) and the compressed attributes will directly
> > store the oid of the AM. In this patch, I have removed the
> > pg_attr_compresion as we don't support changing the compression
> > for the existing column so we don't need to preserve the old
> > compressions.
> > v1-0002: Add another built-in compression method (zlib)
> > v1:0003: Remaining patch set (nothing is changed except rebase on the
> > current head, stabilizing check-world and 0001 and 0002 are pulled
> > out of this)
> >
> > Next, I will be working on separating out the remaining patches as per
> > the suggestion by Robert.
>
> Thanks for this new feature. Looks promising and very useful, with so
> many good compression libraries already available.
Thanks for looking into it.
> I see that with the patch-set, I would be able to create an extension
> that defines a PostgreSQL C handler function which assigns all the
> required hook function implementations for compressing, decompressing
> and validating, etc. In short, I would be able to use a completely
> different compression algorithm to compress toast data if I write such
> an extension. Correct me if I am wrong with my interpretation.
>
> Just a quick superficial set of review comments ....
>
> A minor re-base is required due to a conflict in a regression test
Okay, I will do this.
> -------------
>
> In heap_toast_insert_or_update() and in other places, the comments for
> new parameter preserved_am_info are missing.
>
> -------------
ok
> +toast_compress_datum(Datum value, Oid acoid)
> {
> struct varlena *tmp = NULL;
> int32 valsize;
> - CompressionAmOptions cmoptions;
> + CompressionAmOptions *cmoptions = NULL;
>
> I think tmp and cmoptions need not be initialized to NULL
Right
> -------------
>
> - TOAST_COMPRESS_SET_RAWSIZE(tmp, valsize);
> - SET_VARSIZE_COMPRESSED(tmp, len + TOAST_COMPRESS_HDRSZ);
> /* successful compression */
> + toast_set_compressed_datum_info(tmp, amoid, valsize);
> return PointerGetDatum(tmp);
>
> Any particular reason why is this code put in a new extern function ?
> Is there a plan to re-use it ? Otherwise, it's not necessary to do
> this.
>
> ------------
>
> Also, not sure why "HTAB *amoptions_cache" and "MemoryContext
> amoptions_cache_mcxt" aren't static declarations. They are being used
> only in toast_internals.c
> -----------
>
> The tab-completion doesn't show COMPRESSION :
> postgres=# create access method my_method TYPE
> INDEX TABLE
> postgres=# create access method my_method TYPE
>
> Also, the below syntax also would better be tab-completed so as to
> display all the installed compression methods, in line with how we
> show all the storage methods like plain,extended,etc:
> postgres=# ALTER TABLE lztab ALTER COLUMN t SET COMPRESSION
>
> ------------
I will fix these comments in the next version of the patch.
> I could see the differences in compression ratio, and the compression
> and decompression speed when I use lz versus zib :
>
> CREATE TABLE zlibtab(t TEXT COMPRESSION zlib WITH (level '4'));
> create table lztab(t text);
> ALTER TABLE lztab ALTER COLUMN t SET COMPRESSION pglz;
>
> pgg:s2:pg$ time psql -c "\copy zlibtab from text.data"
> COPY 13050
>
> real 0m1.344s
> user 0m0.031s
> sys 0m0.026s
>
> pgg:s2:pg$ time psql -c "\copy lztab from text.data"
> COPY 13050
>
> real 0m2.088s
> user 0m0.008s
> sys 0m0.050s
>
>
> pgg:s2:pg$ time psql -c "select pg_table_size('zlibtab'::regclass),
> pg_table_size('lztab'::regclass)"
> pg_table_size | pg_table_size
> ---------------+---------------
> 1261568 | 1687552
>
> pgg:s2:pg$ time psql -c "select NULL from zlibtab where t like '0000'"
> > /dev/null
>
> real 0m0.127s
> user 0m0.000s
> sys 0m0.002s
>
> pgg:s2:pg$ time psql -c "select NULL from lztab where t like '0000'"
> > /dev/null
>
> real 0m0.050s
> user 0m0.002s
> sys 0m0.000s
>
Thanks for testing this.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Tue, Aug 25, 2020 at 11:20 PM Robert Haas <robertmhaas@gmail.com> wrote: > > On Mon, Aug 24, 2020 at 2:12 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > IIUC, the main reason for using this flag is for taking the decision > > whether we need any detoasting for this tuple. For example, if we are > > rewriting the table because the compression method is changed then if > > HEAP_HASCUSTOMCOMPRESSED bit is not set in the tuple header and tuple > > length, not tup->t_len > TOAST_TUPLE_THRESHOLD then we don't need to > > call heap_toast_insert_or_update function for this tuple. Whereas if > > this flag is set then we need to because we might need to uncompress > > and compress back using a different compression method. The same is > > the case with INSERT into SELECT * FROM. > > This doesn't really seem worth it to me. I don't see how we can > justify burning an on-disk bit just to save a little bit of overhead > during a rare maintenance operation. If there's a performance problem > here we need to look for another way of mitigating it. Slowing CLUSTER > and/or VACUUM FULL down by a large amount for this feature would be > unacceptable, but is that really a problem? And if so, can we solve it > without requiring this bit? Okay, if we want to avoid keeping the bit then there are multiple ways to handle this, but the only thing is none of that will be specific to those scenarios. approach1. In ExecModifyTable, we can process the source tuple and see if any of the varlena attributes is compressed and its stored compression method is not the same as the target table attribute then we can decompress it. approach2. In heap_prepare_insert, always call the heap_toast_insert_or_update, therein we can check if any of the source tuple attributes are compressed with different compression methods then the target table then we can decompress it. With either of the approach, we have to do this in a generic path because the source of the tuple is not known, I mean it can be a output from a function, or the join tuple or a subquery. So in the attached patch, I have implemented with approach1. For testing, I have implemented using approach1 as well as using approach2 and I have checked the performance of the pg_bench to see whether it impacts the performance of the generic paths or not, but I did not see any impact. > > > I have already extracted these 2 patches from the main patch set. > > But, in these patches, I am still storing the am_oid in the toast > > header. I am not sure can we get rid of that at least for these 2 > > patches? But, then wherever we try to uncompress the tuple we need to > > know the tuple descriptor to get the am_oid but I think that is not > > possible in all the cases. Am I missing something here? > > I think we should instead use the high bits of the toast size word for > patches #1-#4, as discussed upthread. > > > > > Patch #3. Add support for changing the compression method associated > > > > with a column, forcing a table rewrite. > > > > > > > > Patch #4. Add support for PRESERVE, so that you can change the > > > > compression method associated with a column without forcing a table > > > > rewrite, by including the old method in the PRESERVE list, or with a > > > > rewrite, by not including it in the PRESERVE list. > > > > Does this make sense to have Patch #3 and Patch #4, without having > > Patch #5? I mean why do we need to support rewrite or preserve unless > > we have the customer compression methods right? because the build-in > > compression method can not be dropped so why do we need to preserve? > > I think that patch #3 makes sense because somebody might have a table > that is currently compressed with pglz and they want to switch to lz4, > and I think patch #4 also makes sense because they might want to start > using lz4 for future data but not force a rewrite to get rid of all > the pglz data they've already got. Those options are valuable as soon > as there is more than one possible compression algorithm, even if > they're all built in. Now, as I said upthread, it's also true that you > could do #5 before #3 and #4. I don't think that's insane. But I > prefer it in the other order, because I think having #5 without #3 and > #4 wouldn't be too much fun for users. Details of the attached patch set 0001: This provides syntax to set the compression method from the built-in compression method (pglz or zlib). pg_attribute stores the compression method (char) and there are conversion functions to convert that compression method to the built-in compression array index. As discussed up thread the first 2 bits will be storing the compression method index using that we can directly get the handler routing using the built-in compression method array. 0002: This patch provides an option to changes the compression method for an existing column and it will rewrite the table. Next, I will be working on providing an option to alter the compression method without rewriting the whole table, basically, we can provide a preserve list to preserve old compression methods. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Sat, Sep 19, 2020 at 1:19 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Aug 25, 2020 at 11:20 PM Robert Haas <robertmhaas@gmail.com> wrote: > > > > On Mon, Aug 24, 2020 at 2:12 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > IIUC, the main reason for using this flag is for taking the decision > > > whether we need any detoasting for this tuple. For example, if we are > > > rewriting the table because the compression method is changed then if > > > HEAP_HASCUSTOMCOMPRESSED bit is not set in the tuple header and tuple > > > length, not tup->t_len > TOAST_TUPLE_THRESHOLD then we don't need to > > > call heap_toast_insert_or_update function for this tuple. Whereas if > > > this flag is set then we need to because we might need to uncompress > > > and compress back using a different compression method. The same is > > > the case with INSERT into SELECT * FROM. > > > > This doesn't really seem worth it to me. I don't see how we can > > justify burning an on-disk bit just to save a little bit of overhead > > during a rare maintenance operation. If there's a performance problem > > here we need to look for another way of mitigating it. Slowing CLUSTER > > and/or VACUUM FULL down by a large amount for this feature would be > > unacceptable, but is that really a problem? And if so, can we solve it > > without requiring this bit? > > Okay, if we want to avoid keeping the bit then there are multiple ways > to handle this, but the only thing is none of that will be specific to > those scenarios. > approach1. In ExecModifyTable, we can process the source tuple and see > if any of the varlena attributes is compressed and its stored > compression method is not the same as the target table attribute then > we can decompress it. > approach2. In heap_prepare_insert, always call the > heap_toast_insert_or_update, therein we can check if any of the source > tuple attributes are compressed with different compression methods > then the target table then we can decompress it. > > With either of the approach, we have to do this in a generic path > because the source of the tuple is not known, I mean it can be a > output from a function, or the join tuple or a subquery. So in the > attached patch, I have implemented with approach1. > > For testing, I have implemented using approach1 as well as using > approach2 and I have checked the performance of the pg_bench to see > whether it impacts the performance of the generic paths or not, but I > did not see any impact. > > > > > > I have already extracted these 2 patches from the main patch set. > > > But, in these patches, I am still storing the am_oid in the toast > > > header. I am not sure can we get rid of that at least for these 2 > > > patches? But, then wherever we try to uncompress the tuple we need to > > > know the tuple descriptor to get the am_oid but I think that is not > > > possible in all the cases. Am I missing something here? > > > > I think we should instead use the high bits of the toast size word for > > patches #1-#4, as discussed upthread. > > > > > > > Patch #3. Add support for changing the compression method associated > > > > > with a column, forcing a table rewrite. > > > > > > > > > > Patch #4. Add support for PRESERVE, so that you can change the > > > > > compression method associated with a column without forcing a table > > > > > rewrite, by including the old method in the PRESERVE list, or with a > > > > > rewrite, by not including it in the PRESERVE list. > > > > > > Does this make sense to have Patch #3 and Patch #4, without having > > > Patch #5? I mean why do we need to support rewrite or preserve unless > > > we have the customer compression methods right? because the build-in > > > compression method can not be dropped so why do we need to preserve? > > > > I think that patch #3 makes sense because somebody might have a table > > that is currently compressed with pglz and they want to switch to lz4, > > and I think patch #4 also makes sense because they might want to start > > using lz4 for future data but not force a rewrite to get rid of all > > the pglz data they've already got. Those options are valuable as soon > > as there is more than one possible compression algorithm, even if > > they're all built in. Now, as I said upthread, it's also true that you > > could do #5 before #3 and #4. I don't think that's insane. But I > > prefer it in the other order, because I think having #5 without #3 and > > #4 wouldn't be too much fun for users. > > Details of the attached patch set > > 0001: This provides syntax to set the compression method from the > built-in compression method (pglz or zlib). pg_attribute stores the > compression method (char) and there are conversion functions to > convert that compression method to the built-in compression array > index. As discussed up thread the first 2 bits will be storing the > compression method index using that we can directly get the handler > routing using the built-in compression method array. > > 0002: This patch provides an option to changes the compression method > for an existing column and it will rewrite the table. > > Next, I will be working on providing an option to alter the > compression method without rewriting the whole table, basically, we > can provide a preserve list to preserve old compression methods. I have rebased the patch and I have also done a couple of defect fixes and some cleanup. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Mon, Sep 28, 2020 at 4:18 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Sat, Sep 19, 2020 at 1:19 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Tue, Aug 25, 2020 at 11:20 PM Robert Haas <robertmhaas@gmail.com> wrote: > > > > > > On Mon, Aug 24, 2020 at 2:12 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > IIUC, the main reason for using this flag is for taking the decision > > > > whether we need any detoasting for this tuple. For example, if we are > > > > rewriting the table because the compression method is changed then if > > > > HEAP_HASCUSTOMCOMPRESSED bit is not set in the tuple header and tuple > > > > length, not tup->t_len > TOAST_TUPLE_THRESHOLD then we don't need to > > > > call heap_toast_insert_or_update function for this tuple. Whereas if > > > > this flag is set then we need to because we might need to uncompress > > > > and compress back using a different compression method. The same is > > > > the case with INSERT into SELECT * FROM. > > > > > > This doesn't really seem worth it to me. I don't see how we can > > > justify burning an on-disk bit just to save a little bit of overhead > > > during a rare maintenance operation. If there's a performance problem > > > here we need to look for another way of mitigating it. Slowing CLUSTER > > > and/or VACUUM FULL down by a large amount for this feature would be > > > unacceptable, but is that really a problem? And if so, can we solve it > > > without requiring this bit? > > > > Okay, if we want to avoid keeping the bit then there are multiple ways > > to handle this, but the only thing is none of that will be specific to > > those scenarios. > > approach1. In ExecModifyTable, we can process the source tuple and see > > if any of the varlena attributes is compressed and its stored > > compression method is not the same as the target table attribute then > > we can decompress it. > > approach2. In heap_prepare_insert, always call the > > heap_toast_insert_or_update, therein we can check if any of the source > > tuple attributes are compressed with different compression methods > > then the target table then we can decompress it. > > > > With either of the approach, we have to do this in a generic path > > because the source of the tuple is not known, I mean it can be a > > output from a function, or the join tuple or a subquery. So in the > > attached patch, I have implemented with approach1. > > > > For testing, I have implemented using approach1 as well as using > > approach2 and I have checked the performance of the pg_bench to see > > whether it impacts the performance of the generic paths or not, but I > > did not see any impact. > > > > > > > > > I have already extracted these 2 patches from the main patch set. > > > > But, in these patches, I am still storing the am_oid in the toast > > > > header. I am not sure can we get rid of that at least for these 2 > > > > patches? But, then wherever we try to uncompress the tuple we need to > > > > know the tuple descriptor to get the am_oid but I think that is not > > > > possible in all the cases. Am I missing something here? > > > > > > I think we should instead use the high bits of the toast size word for > > > patches #1-#4, as discussed upthread. > > > > > > > > > Patch #3. Add support for changing the compression method associated > > > > > > with a column, forcing a table rewrite. > > > > > > > > > > > > Patch #4. Add support for PRESERVE, so that you can change the > > > > > > compression method associated with a column without forcing a table > > > > > > rewrite, by including the old method in the PRESERVE list, or with a > > > > > > rewrite, by not including it in the PRESERVE list. > > > > > > > > Does this make sense to have Patch #3 and Patch #4, without having > > > > Patch #5? I mean why do we need to support rewrite or preserve unless > > > > we have the customer compression methods right? because the build-in > > > > compression method can not be dropped so why do we need to preserve? > > > > > > I think that patch #3 makes sense because somebody might have a table > > > that is currently compressed with pglz and they want to switch to lz4, > > > and I think patch #4 also makes sense because they might want to start > > > using lz4 for future data but not force a rewrite to get rid of all > > > the pglz data they've already got. Those options are valuable as soon > > > as there is more than one possible compression algorithm, even if > > > they're all built in. Now, as I said upthread, it's also true that you > > > could do #5 before #3 and #4. I don't think that's insane. But I > > > prefer it in the other order, because I think having #5 without #3 and > > > #4 wouldn't be too much fun for users. > > > > Details of the attached patch set > > > > 0001: This provides syntax to set the compression method from the > > built-in compression method (pglz or zlib). pg_attribute stores the > > compression method (char) and there are conversion functions to > > convert that compression method to the built-in compression array > > index. As discussed up thread the first 2 bits will be storing the > > compression method index using that we can directly get the handler > > routing using the built-in compression method array. > > > > 0002: This patch provides an option to changes the compression method > > for an existing column and it will rewrite the table. > > > > Next, I will be working on providing an option to alter the > > compression method without rewriting the whole table, basically, we > > can provide a preserve list to preserve old compression methods. > > I have rebased the patch and I have also done a couple of defect fixes > and some cleanup. Here is the next patch which allows providing a PRESERVE list using this we can avoid table rewrite while altering the compression method. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
Hi,
I took a look at this patch after a long time, and done a bit of a
review+testing. I haven't re-read the whole thread since 2017 so some of
the following comments might be mistaken - sorry about that :-(
1) The "cmapi.h" naming seems unnecessarily short. I'd suggest using
simply compression or something like that. I see little reason to
shorten "compression" to "cm", or to prefix files with "cm_". For
example compression/cm_zlib.c might just be compression/zlib.c.
2) I see index_form_tuple does this:
Datum cvalue = toast_compress_datum(untoasted_values[i],
DefaultCompressionMethod);
which seems wrong - why shouldn't the indexes use the same compression
method as the underlying table?
3) dumpTableSchema in pg_dump.c does this:
switch (tbinfo->attcompression[j])
{
case 'p':
cmname = "pglz";
case 'z':
cmname = "zlib";
}
which is broken as it's missing break, so 'p' will produce 'zlib'.
4) The name ExecCompareCompressionMethod is somewhat misleading, as the
functions is not merely comparing compression methods - it also
recompresses the data.
5) CheckCompressionMethodsPreserved should document what the return
value is (true when new list contains all old values, thus not requiring
a rewrite). Maybe "Compare" would be a better name?
6) The new field in ColumnDef is missing a comment.
7) It's not clear to me what "partial list" in the PRESERVE docs means.
+ which of them should be kept on the column. Without PRESERVE or partial
+ list of compression methods the table will be rewritten.
8) The initial synopsis in alter_table.sgml includes the PRESERVE
syntax, but then later in the page it's omitted (yet the section talks
about the keyword).
9) attcompression ...
The main issue I see is what the patch does with attcompression. Instead
of just using it to store a the compression method, it's also used to
store the preserved compression methods. And using NameData to store
this seems wrong too - if we really want to store this info, the correct
way is either using text[] or inventing charvector or similar.
But to me this seems very much like a misuse of attcompression to track
dependencies on compression methods, necessary because we don't have a
separate catalog listing compression methods. If we had that, I think we
could simply add dependencies between attributes and that catalog.
Moreover, having the catalog would allow adding compression methods
(from extensions etc) instead of just having a list of hard-coded
compression methods. Which seems like a strange limitation, considering
this thread is called "custom compression methods".
10) compression parameters?
I wonder if we could/should allow parameters, like compression level
(and maybe other stuff, depending on the compression method). PG13
allowed that for opclasses, so perhaps we should allow it here too.
11) pg_column_compression
When specifying compression method not present in attcompression, we get
this error message and hint:
test=# alter table t alter COLUMN a set compression "pglz" preserve (zlib);
ERROR: "zlib" compression access method cannot be preserved
HINT: use "pg_column_compression" function for list of compression methods
but there is no pg_column_compression function, so the hint is wrong.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: Thanks, Tomas for your feedback. > 9) attcompression ... > > The main issue I see is what the patch does with attcompression. Instead > of just using it to store a the compression method, it's also used to > store the preserved compression methods. And using NameData to store > this seems wrong too - if we really want to store this info, the correct > way is either using text[] or inventing charvector or similar. The reason for using the NameData is the get it in the fixed part of the data structure. > But to me this seems very much like a misuse of attcompression to track > dependencies on compression methods, necessary because we don't have a > separate catalog listing compression methods. If we had that, I think we > could simply add dependencies between attributes and that catalog. Basically, up to this patch, we are having only built-in compression methods and those can not be dropped so we don't need any dependency at all. We just want to know what is the current compression method and what is the preserve compression methods supported for this attribute. Maybe we can do it better instead of using the NameData but I don't think it makes sense to add a separate catalog? > Moreover, having the catalog would allow adding compression methods > (from extensions etc) instead of just having a list of hard-coded > compression methods. Which seems like a strange limitation, considering > this thread is called "custom compression methods". I think I forgot to mention while submitting the previous patch that the next patch I am planning to submit is, Support creating the custom compression methods wherein we can use pg_am catalog to insert the new compression method. And for dependency handling, we can create an attribute dependency on the pg_am row. Basically, we will create the attribute dependency on the current compression method AM as well as on the preserved compression methods AM. As part of this, we will add two build-in AMs for zlib and pglz, and the attcompression field will be converted to the oid_vector (first OID will be of the current compression method, followed by the preserved compression method's oids). > 10) compression parameters? > > I wonder if we could/should allow parameters, like compression level > (and maybe other stuff, depending on the compression method). PG13 > allowed that for opclasses, so perhaps we should allow it here too. Yes, that is also in the plan. For doing this we are planning to add an extra column in the pg_attribute which will store the compression options for the current compression method. The original patch was creating an extra catalog pg_column_compression, therein it maintains the oid of the compression method as well as the compression options. The advantage of creating an extra catalog is that we can keep the compression options for the preserved compression methods also so that we can support the options which can be used for decompressing the data as well. Whereas if we want to avoid this extra catalog then we can not use that compression option for decompressing. But most of the options e.g. compression level are just for the compressing so it is enough to store for the current compression method only. What's your thoughts? Other comments look fine to me so I will work on them and post the updated patch set. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Oct 5, 2020 at 11:17 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: > > Thanks, Tomas for your feedback. > > > 9) attcompression ... > > > > The main issue I see is what the patch does with attcompression. Instead > > of just using it to store a the compression method, it's also used to > > store the preserved compression methods. And using NameData to store > > this seems wrong too - if we really want to store this info, the correct > > way is either using text[] or inventing charvector or similar. > > The reason for using the NameData is the get it in the fixed part of > the data structure. > > > But to me this seems very much like a misuse of attcompression to track > > dependencies on compression methods, necessary because we don't have a > > separate catalog listing compression methods. If we had that, I think we > > could simply add dependencies between attributes and that catalog. > > Basically, up to this patch, we are having only built-in compression > methods and those can not be dropped so we don't need any dependency > at all. We just want to know what is the current compression method > and what is the preserve compression methods supported for this > attribute. Maybe we can do it better instead of using the NameData > but I don't think it makes sense to add a separate catalog? > > > Moreover, having the catalog would allow adding compression methods > > (from extensions etc) instead of just having a list of hard-coded > > compression methods. Which seems like a strange limitation, considering > > this thread is called "custom compression methods". > > I think I forgot to mention while submitting the previous patch that > the next patch I am planning to submit is, Support creating the custom > compression methods wherein we can use pg_am catalog to insert the new > compression method. And for dependency handling, we can create an > attribute dependency on the pg_am row. Basically, we will create the > attribute dependency on the current compression method AM as well as > on the preserved compression methods AM. As part of this, we will > add two build-in AMs for zlib and pglz, and the attcompression field > will be converted to the oid_vector (first OID will be of the current > compression method, followed by the preserved compression method's > oids). > > > 10) compression parameters? > > > > I wonder if we could/should allow parameters, like compression level > > (and maybe other stuff, depending on the compression method). PG13 > > allowed that for opclasses, so perhaps we should allow it here too. > > Yes, that is also in the plan. For doing this we are planning to add > an extra column in the pg_attribute which will store the compression > options for the current compression method. The original patch was > creating an extra catalog pg_column_compression, therein it maintains > the oid of the compression method as well as the compression options. > The advantage of creating an extra catalog is that we can keep the > compression options for the preserved compression methods also so that > we can support the options which can be used for decompressing the > data as well. Whereas if we want to avoid this extra catalog then we > can not use that compression option for decompressing. But most of > the options e.g. compression level are just for the compressing so it > is enough to store for the current compression method only. What's > your thoughts? > > Other comments look fine to me so I will work on them and post the > updated patch set. I have fixed the other comments except this, > 2) I see index_form_tuple does this: > > Datum cvalue = toast_compress_datum(untoasted_values[i], > DefaultCompressionMethod); > which seems wrong - why shouldn't the indexes use the same compression > method as the underlying table? I will fix this in the next version of the patch. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Mon, Oct 05, 2020 at 11:17:28AM +0530, Dilip Kumar wrote: >On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: > >Thanks, Tomas for your feedback. > >> 9) attcompression ... >> >> The main issue I see is what the patch does with attcompression. Instead >> of just using it to store a the compression method, it's also used to >> store the preserved compression methods. And using NameData to store >> this seems wrong too - if we really want to store this info, the correct >> way is either using text[] or inventing charvector or similar. > >The reason for using the NameData is the get it in the fixed part of >the data structure. > Why do we need that? It's possible to have varlena fields with direct access (see pg_index.indkey for example). Adding NameData just to make it fixed-length means we're always adding 64B even if we just need a single byte, which means ~30% overhead for the FormData_pg_attribute. That seems a bit unnecessary, and might be an issue with many attributes (e.g. with many temp tables, etc.). >> But to me this seems very much like a misuse of attcompression to track >> dependencies on compression methods, necessary because we don't have a >> separate catalog listing compression methods. If we had that, I think we >> could simply add dependencies between attributes and that catalog. > >Basically, up to this patch, we are having only built-in compression >methods and those can not be dropped so we don't need any dependency >at all. We just want to know what is the current compression method >and what is the preserve compression methods supported for this >attribute. Maybe we can do it better instead of using the NameData >but I don't think it makes sense to add a separate catalog? > Sure, I understand what the goal was - all I'm saying is that it looks very much like a workaround needed because we don't have the catalog. I don't quite understand how could we support custom compression methods without listing them in some sort of catalog? >> Moreover, having the catalog would allow adding compression methods >> (from extensions etc) instead of just having a list of hard-coded >> compression methods. Which seems like a strange limitation, considering >> this thread is called "custom compression methods". > >I think I forgot to mention while submitting the previous patch that >the next patch I am planning to submit is, Support creating the custom >compression methods wherein we can use pg_am catalog to insert the new >compression method. And for dependency handling, we can create an >attribute dependency on the pg_am row. Basically, we will create the >attribute dependency on the current compression method AM as well as >on the preserved compression methods AM. As part of this, we will >add two build-in AMs for zlib and pglz, and the attcompression field >will be converted to the oid_vector (first OID will be of the current >compression method, followed by the preserved compression method's >oids). > Hmmm, ok. Not sure pg_am is the right place - compression methods don't quite match what I though AMs are about, but maybe it's just my fault. FWIW it seems a bit strange to first do the attcompression magic and then add the catalog later - I think we should start with the catalog right away. The advantage is that if we end up committing only some of the patches in this cycle, we already have all the infrastructure etc. We can reorder that later, though. >> 10) compression parameters? >> >> I wonder if we could/should allow parameters, like compression level >> (and maybe other stuff, depending on the compression method). PG13 >> allowed that for opclasses, so perhaps we should allow it here too. > >Yes, that is also in the plan. For doing this we are planning to add >an extra column in the pg_attribute which will store the compression >options for the current compression method. The original patch was >creating an extra catalog pg_column_compression, therein it maintains >the oid of the compression method as well as the compression options. >The advantage of creating an extra catalog is that we can keep the >compression options for the preserved compression methods also so that >we can support the options which can be used for decompressing the >data as well. Whereas if we want to avoid this extra catalog then we >can not use that compression option for decompressing. But most of >the options e.g. compression level are just for the compressing so it >is enough to store for the current compression method only. What's >your thoughts? > Not sure. My assumption was we'd end up with a new catalog, but maybe stashing it into pg_attribute is fine. I was really thinking about two kinds of options - compression level, and some sort of column-level dictionary. Compression level is not necessary for decompression, but the dictionary ID would be needed. (I think the global dictionary was one of the use cases, aimed at JSON compression.) But I don't think stashing it in pg_attribute means we couldn't use it for decompression - we'd just need to keep an array of options, one for each compression method. Keeping it in a separate new catalog might be cleaner, and I'm not sure how large the configuration might be. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Oct 5, 2020 at 5:53 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > On Mon, Oct 05, 2020 at 11:17:28AM +0530, Dilip Kumar wrote: > >On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra > ><tomas.vondra@2ndquadrant.com> wrote: > > > >Thanks, Tomas for your feedback. > > > >> 9) attcompression ... > >> > >> The main issue I see is what the patch does with attcompression. Instead > >> of just using it to store a the compression method, it's also used to > >> store the preserved compression methods. And using NameData to store > >> this seems wrong too - if we really want to store this info, the correct > >> way is either using text[] or inventing charvector or similar. > > > >The reason for using the NameData is the get it in the fixed part of > >the data structure. > > > > Why do we need that? It's possible to have varlena fields with direct > access (see pg_index.indkey for example). I see. While making it NameData I was thinking whether we have an option to direct access the varlena. Thanks for pointing me there. I will change this. Adding NameData just to make > it fixed-length means we're always adding 64B even if we just need a > single byte, which means ~30% overhead for the FormData_pg_attribute. > That seems a bit unnecessary, and might be an issue with many attributes > (e.g. with many temp tables, etc.). You are right. Even I did not like to keep 64B for this, so I will change it. > > >> But to me this seems very much like a misuse of attcompression to track > >> dependencies on compression methods, necessary because we don't have a > >> separate catalog listing compression methods. If we had that, I think we > >> could simply add dependencies between attributes and that catalog. > > > >Basically, up to this patch, we are having only built-in compression > >methods and those can not be dropped so we don't need any dependency > >at all. We just want to know what is the current compression method > >and what is the preserve compression methods supported for this > >attribute. Maybe we can do it better instead of using the NameData > >but I don't think it makes sense to add a separate catalog? > > > > Sure, I understand what the goal was - all I'm saying is that it looks > very much like a workaround needed because we don't have the catalog. > > I don't quite understand how could we support custom compression methods > without listing them in some sort of catalog? Yeah for supporting custom compression we need some catalog. > >> Moreover, having the catalog would allow adding compression methods > >> (from extensions etc) instead of just having a list of hard-coded > >> compression methods. Which seems like a strange limitation, considering > >> this thread is called "custom compression methods". > > > >I think I forgot to mention while submitting the previous patch that > >the next patch I am planning to submit is, Support creating the custom > >compression methods wherein we can use pg_am catalog to insert the new > >compression method. And for dependency handling, we can create an > >attribute dependency on the pg_am row. Basically, we will create the > >attribute dependency on the current compression method AM as well as > >on the preserved compression methods AM. As part of this, we will > >add two build-in AMs for zlib and pglz, and the attcompression field > >will be converted to the oid_vector (first OID will be of the current > >compression method, followed by the preserved compression method's > >oids). > > > > Hmmm, ok. Not sure pg_am is the right place - compression methods don't > quite match what I though AMs are about, but maybe it's just my fault. > > FWIW it seems a bit strange to first do the attcompression magic and > then add the catalog later - I think we should start with the catalog > right away. The advantage is that if we end up committing only some of > the patches in this cycle, we already have all the infrastructure etc. > We can reorder that later, though. Hmm, yeah we can do this way as well that first create a new catalog table and add entries for these two built-in methods and the attcompression can store the oid vector. But if we only commit the build-in compression methods part then does it make sense to create an extra catalog or adding these build-in methods to the existing catalog (if we plan to use pg_am). Then in attcompression instead of using one byte for each preserve compression method, we need to use oid. So from Robert's mail[1], it appeared to me that he wants that the build-in compression methods part should be independently committable and if we think from that perspective then adding a catalog doesn't make much sense. But if we are planning to commit the custom method also then it makes more sense to directly start with the catalog because that way it will be easy to expand without much refactoring. [1] https://www.postgresql.org/message-id/CA%2BTgmobSDVgUage9qQ5P_%3DF_9jaMkCgyKxUQGtFQU7oN4kX-AA%40mail.gmail.com > >> 10) compression parameters? > >> > >> I wonder if we could/should allow parameters, like compression level > >> (and maybe other stuff, depending on the compression method). PG13 > >> allowed that for opclasses, so perhaps we should allow it here too. > > > >Yes, that is also in the plan. For doing this we are planning to add > >an extra column in the pg_attribute which will store the compression > >options for the current compression method. The original patch was > >creating an extra catalog pg_column_compression, therein it maintains > >the oid of the compression method as well as the compression options. > >The advantage of creating an extra catalog is that we can keep the > >compression options for the preserved compression methods also so that > >we can support the options which can be used for decompressing the > >data as well. Whereas if we want to avoid this extra catalog then we > >can not use that compression option for decompressing. But most of > >the options e.g. compression level are just for the compressing so it > >is enough to store for the current compression method only. What's > >your thoughts? > > > > Not sure. My assumption was we'd end up with a new catalog, but maybe > stashing it into pg_attribute is fine. I was really thinking about two > kinds of options - compression level, and some sort of column-level > dictionary. Compression level is not necessary for decompression, but > the dictionary ID would be needed. (I think the global dictionary was > one of the use cases, aimed at JSON compression.) Ok > But I don't think stashing it in pg_attribute means we couldn't use it > for decompression - we'd just need to keep an array of options, one for > each compression method. Yeah, we can do that. Keeping it in a separate new catalog might be > cleaner, and I'm not sure how large the configuration might be. Yeah in that case it will be better to store in a separate catalog, because sometimes if multiple attributes are using the same compression method with the same options then we can store the same oid in attcompression instead of duplicating the option field. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Oct 05, 2020 at 07:57:41PM +0530, Dilip Kumar wrote: >On Mon, Oct 5, 2020 at 5:53 PM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> >> On Mon, Oct 05, 2020 at 11:17:28AM +0530, Dilip Kumar wrote: >> >On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra >> ><tomas.vondra@2ndquadrant.com> wrote: >> > >> >Thanks, Tomas for your feedback. >> > >> >> 9) attcompression ... >> >> >> >> The main issue I see is what the patch does with attcompression. Instead >> >> of just using it to store a the compression method, it's also used to >> >> store the preserved compression methods. And using NameData to store >> >> this seems wrong too - if we really want to store this info, the correct >> >> way is either using text[] or inventing charvector or similar. >> > >> >The reason for using the NameData is the get it in the fixed part of >> >the data structure. >> > >> >> Why do we need that? It's possible to have varlena fields with direct >> access (see pg_index.indkey for example). > >I see. While making it NameData I was thinking whether we have an >option to direct access the varlena. Thanks for pointing me there. I >will change this. > > Adding NameData just to make >> it fixed-length means we're always adding 64B even if we just need a >> single byte, which means ~30% overhead for the FormData_pg_attribute. >> That seems a bit unnecessary, and might be an issue with many attributes >> (e.g. with many temp tables, etc.). > >You are right. Even I did not like to keep 64B for this, so I will change it. > >> >> >> But to me this seems very much like a misuse of attcompression to track >> >> dependencies on compression methods, necessary because we don't have a >> >> separate catalog listing compression methods. If we had that, I think we >> >> could simply add dependencies between attributes and that catalog. >> > >> >Basically, up to this patch, we are having only built-in compression >> >methods and those can not be dropped so we don't need any dependency >> >at all. We just want to know what is the current compression method >> >and what is the preserve compression methods supported for this >> >attribute. Maybe we can do it better instead of using the NameData >> >but I don't think it makes sense to add a separate catalog? >> > >> >> Sure, I understand what the goal was - all I'm saying is that it looks >> very much like a workaround needed because we don't have the catalog. >> >> I don't quite understand how could we support custom compression methods >> without listing them in some sort of catalog? > >Yeah for supporting custom compression we need some catalog. > >> >> Moreover, having the catalog would allow adding compression methods >> >> (from extensions etc) instead of just having a list of hard-coded >> >> compression methods. Which seems like a strange limitation, considering >> >> this thread is called "custom compression methods". >> > >> >I think I forgot to mention while submitting the previous patch that >> >the next patch I am planning to submit is, Support creating the custom >> >compression methods wherein we can use pg_am catalog to insert the new >> >compression method. And for dependency handling, we can create an >> >attribute dependency on the pg_am row. Basically, we will create the >> >attribute dependency on the current compression method AM as well as >> >on the preserved compression methods AM. As part of this, we will >> >add two build-in AMs for zlib and pglz, and the attcompression field >> >will be converted to the oid_vector (first OID will be of the current >> >compression method, followed by the preserved compression method's >> >oids). >> > >> >> Hmmm, ok. Not sure pg_am is the right place - compression methods don't >> quite match what I though AMs are about, but maybe it's just my fault. >> >> FWIW it seems a bit strange to first do the attcompression magic and >> then add the catalog later - I think we should start with the catalog >> right away. The advantage is that if we end up committing only some of >> the patches in this cycle, we already have all the infrastructure etc. >> We can reorder that later, though. > >Hmm, yeah we can do this way as well that first create a new catalog >table and add entries for these two built-in methods and the >attcompression can store the oid vector. But if we only commit the >build-in compression methods part then does it make sense to create an >extra catalog or adding these build-in methods to the existing catalog >(if we plan to use pg_am). Then in attcompression instead of using >one byte for each preserve compression method, we need to use oid. So >from Robert's mail[1], it appeared to me that he wants that the >build-in compression methods part should be independently committable >and if we think from that perspective then adding a catalog doesn't >make much sense. But if we are planning to commit the custom method >also then it makes more sense to directly start with the catalog >because that way it will be easy to expand without much refactoring. > >[1] https://www.postgresql.org/message-id/CA%2BTgmobSDVgUage9qQ5P_%3DF_9jaMkCgyKxUQGtFQU7oN4kX-AA%40mail.gmail.com > Hmmm. Maybe I'm missing something subtle, but I think that plan can be interpreted in various ways - it does not really say whether the initial list of built-in methods should be in some C array, or already in a proper catalog. All I'm saying is it seems a bit weird to first implement dependencies based on strange (mis)use of attcompression attribute, and then replace it with a proper catalog. My understanding is those patches are expected to be committable one by one, but the attcompression approach seems a bit too hacky to me - not sure I'd want to commit that ... >> >> 10) compression parameters? >> >> >> >> I wonder if we could/should allow parameters, like compression level >> >> (and maybe other stuff, depending on the compression method). PG13 >> >> allowed that for opclasses, so perhaps we should allow it here too. >> > >> >Yes, that is also in the plan. For doing this we are planning to add >> >an extra column in the pg_attribute which will store the compression >> >options for the current compression method. The original patch was >> >creating an extra catalog pg_column_compression, therein it maintains >> >the oid of the compression method as well as the compression options. >> >The advantage of creating an extra catalog is that we can keep the >> >compression options for the preserved compression methods also so that >> >we can support the options which can be used for decompressing the >> >data as well. Whereas if we want to avoid this extra catalog then we >> >can not use that compression option for decompressing. But most of >> >the options e.g. compression level are just for the compressing so it >> >is enough to store for the current compression method only. What's >> >your thoughts? >> > >> >> Not sure. My assumption was we'd end up with a new catalog, but maybe >> stashing it into pg_attribute is fine. I was really thinking about two >> kinds of options - compression level, and some sort of column-level >> dictionary. Compression level is not necessary for decompression, but >> the dictionary ID would be needed. (I think the global dictionary was >> one of the use cases, aimed at JSON compression.) > >Ok > >> But I don't think stashing it in pg_attribute means we couldn't use it >> for decompression - we'd just need to keep an array of options, one for >> each compression method. > >Yeah, we can do that. > >Keeping it in a separate new catalog might be >> cleaner, and I'm not sure how large the configuration might be. > >Yeah in that case it will be better to store in a separate catalog, >because sometimes if multiple attributes are using the same >compression method with the same options then we can store the same >oid in attcompression instead of duplicating the option field. > I doubt deduplicating the options like this is (sharing options between columns) is really worth it, as it means extra complexity e.g. during ALTER TABLE ... SET COMPRESSION. I don't think we do that for other catalogs, so why should we do it here? Ultimately I think it's a question of how large we expect the options to be, and how flexible it needs to be. For example, what happens if the user does this: ALTER ... SET COMPRESSION my_compression WITH (options1) PRESERVE; ALTER ... SET COMPRESSION pglz PRESERVE; ALTER ... SET COMPRESSION my_compression WITH (options2) PRESERVE; I believe it's enough to keep just the last value, but maybe I'm wrong and we need to keep the whole history? The use case I'm thinking about is the column-level JSON compression, where one of the options identifies the dictionary. OTOH I'm not sure this is the right way to track this info - we need to know which options were compressed with which options, i.e. it needs to be encoded in each value directly. It'd also require changes to the PRESERVE handling because it'd be necessary to identify which options to preserve ... So maybe this is either nonsense or something we don't want to support, and we should only allow one option for each compression method. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Oct 5, 2020 at 9:34 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > On Mon, Oct 05, 2020 at 07:57:41PM +0530, Dilip Kumar wrote: > >On Mon, Oct 5, 2020 at 5:53 PM Tomas Vondra > ><tomas.vondra@2ndquadrant.com> wrote: > >> > >> On Mon, Oct 05, 2020 at 11:17:28AM +0530, Dilip Kumar wrote: > >> >On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra > >> ><tomas.vondra@2ndquadrant.com> wrote: > >> > > >> >Thanks, Tomas for your feedback. > >> > > >> >> 9) attcompression ... > >> >> > >> >> The main issue I see is what the patch does with attcompression. Instead > >> >> of just using it to store a the compression method, it's also used to > >> >> store the preserved compression methods. And using NameData to store > >> >> this seems wrong too - if we really want to store this info, the correct > >> >> way is either using text[] or inventing charvector or similar. > >> > > >> >The reason for using the NameData is the get it in the fixed part of > >> >the data structure. > >> > > >> > >> Why do we need that? It's possible to have varlena fields with direct > >> access (see pg_index.indkey for example). > > > >I see. While making it NameData I was thinking whether we have an > >option to direct access the varlena. Thanks for pointing me there. I > >will change this. > > > > Adding NameData just to make > >> it fixed-length means we're always adding 64B even if we just need a > >> single byte, which means ~30% overhead for the FormData_pg_attribute. > >> That seems a bit unnecessary, and might be an issue with many attributes > >> (e.g. with many temp tables, etc.). > > > >You are right. Even I did not like to keep 64B for this, so I will change it. > > > >> > >> >> But to me this seems very much like a misuse of attcompression to track > >> >> dependencies on compression methods, necessary because we don't have a > >> >> separate catalog listing compression methods. If we had that, I think we > >> >> could simply add dependencies between attributes and that catalog. > >> > > >> >Basically, up to this patch, we are having only built-in compression > >> >methods and those can not be dropped so we don't need any dependency > >> >at all. We just want to know what is the current compression method > >> >and what is the preserve compression methods supported for this > >> >attribute. Maybe we can do it better instead of using the NameData > >> >but I don't think it makes sense to add a separate catalog? > >> > > >> > >> Sure, I understand what the goal was - all I'm saying is that it looks > >> very much like a workaround needed because we don't have the catalog. > >> > >> I don't quite understand how could we support custom compression methods > >> without listing them in some sort of catalog? > > > >Yeah for supporting custom compression we need some catalog. > > > >> >> Moreover, having the catalog would allow adding compression methods > >> >> (from extensions etc) instead of just having a list of hard-coded > >> >> compression methods. Which seems like a strange limitation, considering > >> >> this thread is called "custom compression methods". > >> > > >> >I think I forgot to mention while submitting the previous patch that > >> >the next patch I am planning to submit is, Support creating the custom > >> >compression methods wherein we can use pg_am catalog to insert the new > >> >compression method. And for dependency handling, we can create an > >> >attribute dependency on the pg_am row. Basically, we will create the > >> >attribute dependency on the current compression method AM as well as > >> >on the preserved compression methods AM. As part of this, we will > >> >add two build-in AMs for zlib and pglz, and the attcompression field > >> >will be converted to the oid_vector (first OID will be of the current > >> >compression method, followed by the preserved compression method's > >> >oids). > >> > > >> > >> Hmmm, ok. Not sure pg_am is the right place - compression methods don't > >> quite match what I though AMs are about, but maybe it's just my fault. > >> > >> FWIW it seems a bit strange to first do the attcompression magic and > >> then add the catalog later - I think we should start with the catalog > >> right away. The advantage is that if we end up committing only some of > >> the patches in this cycle, we already have all the infrastructure etc. > >> We can reorder that later, though. > > > >Hmm, yeah we can do this way as well that first create a new catalog > >table and add entries for these two built-in methods and the > >attcompression can store the oid vector. But if we only commit the > >build-in compression methods part then does it make sense to create an > >extra catalog or adding these build-in methods to the existing catalog > >(if we plan to use pg_am). Then in attcompression instead of using > >one byte for each preserve compression method, we need to use oid. So > >from Robert's mail[1], it appeared to me that he wants that the > >build-in compression methods part should be independently committable > >and if we think from that perspective then adding a catalog doesn't > >make much sense. But if we are planning to commit the custom method > >also then it makes more sense to directly start with the catalog > >because that way it will be easy to expand without much refactoring. > > > >[1] https://www.postgresql.org/message-id/CA%2BTgmobSDVgUage9qQ5P_%3DF_9jaMkCgyKxUQGtFQU7oN4kX-AA%40mail.gmail.com > > > > Hmmm. Maybe I'm missing something subtle, but I think that plan can be > interpreted in various ways - it does not really say whether the initial > list of built-in methods should be in some C array, or already in a proper > catalog. > > All I'm saying is it seems a bit weird to first implement dependencies > based on strange (mis)use of attcompression attribute, and then replace > it with a proper catalog. My understanding is those patches are expected > to be committable one by one, but the attcompression approach seems a > bit too hacky to me - not sure I'd want to commit that ... Okay, I will change this. So I will make create a new catalog pg_compression and add the entry for two built-in compression methods from the very first patch. > >> >> 10) compression parameters? > >> >> > >> >> I wonder if we could/should allow parameters, like compression level > >> >> (and maybe other stuff, depending on the compression method). PG13 > >> >> allowed that for opclasses, so perhaps we should allow it here too. > >> > > >> >Yes, that is also in the plan. For doing this we are planning to add > >> >an extra column in the pg_attribute which will store the compression > >> >options for the current compression method. The original patch was > >> >creating an extra catalog pg_column_compression, therein it maintains > >> >the oid of the compression method as well as the compression options. > >> >The advantage of creating an extra catalog is that we can keep the > >> >compression options for the preserved compression methods also so that > >> >we can support the options which can be used for decompressing the > >> >data as well. Whereas if we want to avoid this extra catalog then we > >> >can not use that compression option for decompressing. But most of > >> >the options e.g. compression level are just for the compressing so it > >> >is enough to store for the current compression method only. What's > >> >your thoughts? > >> > > >> > >> Not sure. My assumption was we'd end up with a new catalog, but maybe > >> stashing it into pg_attribute is fine. I was really thinking about two > >> kinds of options - compression level, and some sort of column-level > >> dictionary. Compression level is not necessary for decompression, but > >> the dictionary ID would be needed. (I think the global dictionary was > >> one of the use cases, aimed at JSON compression.) > > > >Ok > > > >> But I don't think stashing it in pg_attribute means we couldn't use it > >> for decompression - we'd just need to keep an array of options, one for > >> each compression method. > > > >Yeah, we can do that. > > > >Keeping it in a separate new catalog might be > >> cleaner, and I'm not sure how large the configuration might be. > > > >Yeah in that case it will be better to store in a separate catalog, > >because sometimes if multiple attributes are using the same > >compression method with the same options then we can store the same > >oid in attcompression instead of duplicating the option field. > > > > I doubt deduplicating the options like this is (sharing options between > columns) is really worth it, as it means extra complexity e.g. during > ALTER TABLE ... SET COMPRESSION. I don't think we do that for other > catalogs, so why should we do it here? Yeah, valid point. > > Ultimately I think it's a question of how large we expect the options to > be, and how flexible it needs to be. > > For example, what happens if the user does this: > > ALTER ... SET COMPRESSION my_compression WITH (options1) PRESERVE; > ALTER ... SET COMPRESSION pglz PRESERVE; > ALTER ... SET COMPRESSION my_compression WITH (options2) PRESERVE; > > I believe it's enough to keep just the last value, but maybe I'm wrong > and we need to keep the whole history? Currently, the syntax is like ALTER ... SET COMPRESSION my_compression WITH (options1) PRESERVE (old_compression1, old_compression2..). But I think if the user just gives PRESERVE without a list then we should just preserve the latest one. > The use case I'm thinking about is the column-level JSON compression, > where one of the options identifies the dictionary. OTOH I'm not sure > this is the right way to track this info - we need to know which options > were compressed with which options, i.e. it needs to be encoded in each > value directly. It'd also require changes to the PRESERVE handling > because it'd be necessary to identify which options to preserve ... > > So maybe this is either nonsense or something we don't want to support, > and we should only allow one option for each compression method. Yeah, it is a bit confusing to add the same compression method with different compression options, then in the preserve list, we will have to allow the option as well along with the compression method to know which compression method with what options we want to preserve. And also as you mentioned that in rows we need to know the option as well. I think for solving this anyways for the custom compression methods we will have to store the OID of the compression method in the toast header so we can provide an intermediate catalog which will create a new row for each combination of compression method + option and the toast header can store the OID of that row so that we know with which compression method + option it was compressed with. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Oct 06, 2020 at 11:00:55AM +0530, Dilip Kumar wrote: >On Mon, Oct 5, 2020 at 9:34 PM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> >> On Mon, Oct 05, 2020 at 07:57:41PM +0530, Dilip Kumar wrote: >> >On Mon, Oct 5, 2020 at 5:53 PM Tomas Vondra >> ><tomas.vondra@2ndquadrant.com> wrote: >> >> >> >> On Mon, Oct 05, 2020 at 11:17:28AM +0530, Dilip Kumar wrote: >> >> >On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra >> >> ><tomas.vondra@2ndquadrant.com> wrote: >> >> > >> >> >Thanks, Tomas for your feedback. >> >> > >> >> >> 9) attcompression ... >> >> >> >> >> >> The main issue I see is what the patch does with attcompression. Instead >> >> >> of just using it to store a the compression method, it's also used to >> >> >> store the preserved compression methods. And using NameData to store >> >> >> this seems wrong too - if we really want to store this info, the correct >> >> >> way is either using text[] or inventing charvector or similar. >> >> > >> >> >The reason for using the NameData is the get it in the fixed part of >> >> >the data structure. >> >> > >> >> >> >> Why do we need that? It's possible to have varlena fields with direct >> >> access (see pg_index.indkey for example). >> > >> >I see. While making it NameData I was thinking whether we have an >> >option to direct access the varlena. Thanks for pointing me there. I >> >will change this. >> > >> > Adding NameData just to make >> >> it fixed-length means we're always adding 64B even if we just need a >> >> single byte, which means ~30% overhead for the FormData_pg_attribute. >> >> That seems a bit unnecessary, and might be an issue with many attributes >> >> (e.g. with many temp tables, etc.). >> > >> >You are right. Even I did not like to keep 64B for this, so I will change it. >> > >> >> >> >> >> But to me this seems very much like a misuse of attcompression to track >> >> >> dependencies on compression methods, necessary because we don't have a >> >> >> separate catalog listing compression methods. If we had that, I think we >> >> >> could simply add dependencies between attributes and that catalog. >> >> > >> >> >Basically, up to this patch, we are having only built-in compression >> >> >methods and those can not be dropped so we don't need any dependency >> >> >at all. We just want to know what is the current compression method >> >> >and what is the preserve compression methods supported for this >> >> >attribute. Maybe we can do it better instead of using the NameData >> >> >but I don't think it makes sense to add a separate catalog? >> >> > >> >> >> >> Sure, I understand what the goal was - all I'm saying is that it looks >> >> very much like a workaround needed because we don't have the catalog. >> >> >> >> I don't quite understand how could we support custom compression methods >> >> without listing them in some sort of catalog? >> > >> >Yeah for supporting custom compression we need some catalog. >> > >> >> >> Moreover, having the catalog would allow adding compression methods >> >> >> (from extensions etc) instead of just having a list of hard-coded >> >> >> compression methods. Which seems like a strange limitation, considering >> >> >> this thread is called "custom compression methods". >> >> > >> >> >I think I forgot to mention while submitting the previous patch that >> >> >the next patch I am planning to submit is, Support creating the custom >> >> >compression methods wherein we can use pg_am catalog to insert the new >> >> >compression method. And for dependency handling, we can create an >> >> >attribute dependency on the pg_am row. Basically, we will create the >> >> >attribute dependency on the current compression method AM as well as >> >> >on the preserved compression methods AM. As part of this, we will >> >> >add two build-in AMs for zlib and pglz, and the attcompression field >> >> >will be converted to the oid_vector (first OID will be of the current >> >> >compression method, followed by the preserved compression method's >> >> >oids). >> >> > >> >> >> >> Hmmm, ok. Not sure pg_am is the right place - compression methods don't >> >> quite match what I though AMs are about, but maybe it's just my fault. >> >> >> >> FWIW it seems a bit strange to first do the attcompression magic and >> >> then add the catalog later - I think we should start with the catalog >> >> right away. The advantage is that if we end up committing only some of >> >> the patches in this cycle, we already have all the infrastructure etc. >> >> We can reorder that later, though. >> > >> >Hmm, yeah we can do this way as well that first create a new catalog >> >table and add entries for these two built-in methods and the >> >attcompression can store the oid vector. But if we only commit the >> >build-in compression methods part then does it make sense to create an >> >extra catalog or adding these build-in methods to the existing catalog >> >(if we plan to use pg_am). Then in attcompression instead of using >> >one byte for each preserve compression method, we need to use oid. So >> >from Robert's mail[1], it appeared to me that he wants that the >> >build-in compression methods part should be independently committable >> >and if we think from that perspective then adding a catalog doesn't >> >make much sense. But if we are planning to commit the custom method >> >also then it makes more sense to directly start with the catalog >> >because that way it will be easy to expand without much refactoring. >> > >> >[1] https://www.postgresql.org/message-id/CA%2BTgmobSDVgUage9qQ5P_%3DF_9jaMkCgyKxUQGtFQU7oN4kX-AA%40mail.gmail.com >> > >> >> Hmmm. Maybe I'm missing something subtle, but I think that plan can be >> interpreted in various ways - it does not really say whether the initial >> list of built-in methods should be in some C array, or already in a proper >> catalog. >> >> All I'm saying is it seems a bit weird to first implement dependencies >> based on strange (mis)use of attcompression attribute, and then replace >> it with a proper catalog. My understanding is those patches are expected >> to be committable one by one, but the attcompression approach seems a >> bit too hacky to me - not sure I'd want to commit that ... > >Okay, I will change this. So I will make create a new catalog >pg_compression and add the entry for two built-in compression methods >from the very first patch. > OK. >> >> >> 10) compression parameters? >> >> >> >> >> >> I wonder if we could/should allow parameters, like compression level >> >> >> (and maybe other stuff, depending on the compression method). PG13 >> >> >> allowed that for opclasses, so perhaps we should allow it here too. >> >> > >> >> >Yes, that is also in the plan. For doing this we are planning to add >> >> >an extra column in the pg_attribute which will store the compression >> >> >options for the current compression method. The original patch was >> >> >creating an extra catalog pg_column_compression, therein it maintains >> >> >the oid of the compression method as well as the compression options. >> >> >The advantage of creating an extra catalog is that we can keep the >> >> >compression options for the preserved compression methods also so that >> >> >we can support the options which can be used for decompressing the >> >> >data as well. Whereas if we want to avoid this extra catalog then we >> >> >can not use that compression option for decompressing. But most of >> >> >the options e.g. compression level are just for the compressing so it >> >> >is enough to store for the current compression method only. What's >> >> >your thoughts? >> >> > >> >> >> >> Not sure. My assumption was we'd end up with a new catalog, but maybe >> >> stashing it into pg_attribute is fine. I was really thinking about two >> >> kinds of options - compression level, and some sort of column-level >> >> dictionary. Compression level is not necessary for decompression, but >> >> the dictionary ID would be needed. (I think the global dictionary was >> >> one of the use cases, aimed at JSON compression.) >> > >> >Ok >> > >> >> But I don't think stashing it in pg_attribute means we couldn't use it >> >> for decompression - we'd just need to keep an array of options, one for >> >> each compression method. >> > >> >Yeah, we can do that. >> > >> >Keeping it in a separate new catalog might be >> >> cleaner, and I'm not sure how large the configuration might be. >> > >> >Yeah in that case it will be better to store in a separate catalog, >> >because sometimes if multiple attributes are using the same >> >compression method with the same options then we can store the same >> >oid in attcompression instead of duplicating the option field. >> > >> >> I doubt deduplicating the options like this is (sharing options between >> columns) is really worth it, as it means extra complexity e.g. during >> ALTER TABLE ... SET COMPRESSION. I don't think we do that for other >> catalogs, so why should we do it here? > >Yeah, valid point. > >> >> Ultimately I think it's a question of how large we expect the options to >> be, and how flexible it needs to be. >> >> For example, what happens if the user does this: >> >> ALTER ... SET COMPRESSION my_compression WITH (options1) PRESERVE; >> ALTER ... SET COMPRESSION pglz PRESERVE; >> ALTER ... SET COMPRESSION my_compression WITH (options2) PRESERVE; >> >> I believe it's enough to keep just the last value, but maybe I'm wrong >> and we need to keep the whole history? > >Currently, the syntax is like ALTER ... SET COMPRESSION my_compression >WITH (options1) PRESERVE (old_compression1, old_compression2..). But I >think if the user just gives PRESERVE without a list then we should >just preserve the latest one. > Hmmm. Not sure that's very convenient. I'd expect the most common use case for PRESERVE being "I want to change compression for new data, without rewrite". If PRESERVE by default preserves the latest one, that pretty much forces users to always list all methods. I suggest iterpreting it as "preserve everything" instead. Another option would be to require either a list of methods, or some keyword defining what to preserve. Like for example ... PRESERVE (m1, m2, ...) ... PRESERVE ALL ... PRESERVE LAST Does that make sense? >> The use case I'm thinking about is the column-level JSON compression, >> where one of the options identifies the dictionary. OTOH I'm not sure >> this is the right way to track this info - we need to know which options >> were compressed with which options, i.e. it needs to be encoded in each >> value directly. It'd also require changes to the PRESERVE handling >> because it'd be necessary to identify which options to preserve ... >> >> So maybe this is either nonsense or something we don't want to support, >> and we should only allow one option for each compression method. > >Yeah, it is a bit confusing to add the same compression method with >different compression options, then in the preserve list, we will >have to allow the option as well along with the compression method to >know which compression method with what options we want to preserve. > >And also as you mentioned that in rows we need to know the option as >well. I think for solving this anyways for the custom compression >methods we will have to store the OID of the compression method in the >toast header so we can provide an intermediate catalog which will >create a new row for each combination of compression method + option >and the toast header can store the OID of that row so that we know >with which compression method + option it was compressed with. > I agree. After thinking about this a bit more, I think we should just keep the last options for each compression method. If we need to allow multiple options for some future compression method, we can improve this, but until then it'd be an over-engineering. Let's do the simplest possible thing here. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Oct 6, 2020 at 10:21 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > On Tue, Oct 06, 2020 at 11:00:55AM +0530, Dilip Kumar wrote: > >On Mon, Oct 5, 2020 at 9:34 PM Tomas Vondra > ><tomas.vondra@2ndquadrant.com> wrote: > >> > >> On Mon, Oct 05, 2020 at 07:57:41PM +0530, Dilip Kumar wrote: > >> >On Mon, Oct 5, 2020 at 5:53 PM Tomas Vondra > >> ><tomas.vondra@2ndquadrant.com> wrote: > >> >> > >> >> On Mon, Oct 05, 2020 at 11:17:28AM +0530, Dilip Kumar wrote: > >> >> >On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra > >> >> ><tomas.vondra@2ndquadrant.com> wrote: > >> >> > > >> >> >Thanks, Tomas for your feedback. > >> >> > > >> >> >> 9) attcompression ... > >> >> >> > >> >> >> The main issue I see is what the patch does with attcompression. Instead > >> >> >> of just using it to store a the compression method, it's also used to > >> >> >> store the preserved compression methods. And using NameData to store > >> >> >> this seems wrong too - if we really want to store this info, the correct > >> >> >> way is either using text[] or inventing charvector or similar. > >> >> > > >> >> >The reason for using the NameData is the get it in the fixed part of > >> >> >the data structure. > >> >> > > >> >> > >> >> Why do we need that? It's possible to have varlena fields with direct > >> >> access (see pg_index.indkey for example). > >> > > >> >I see. While making it NameData I was thinking whether we have an > >> >option to direct access the varlena. Thanks for pointing me there. I > >> >will change this. > >> > > >> > Adding NameData just to make > >> >> it fixed-length means we're always adding 64B even if we just need a > >> >> single byte, which means ~30% overhead for the FormData_pg_attribute. > >> >> That seems a bit unnecessary, and might be an issue with many attributes > >> >> (e.g. with many temp tables, etc.). > >> > > >> >You are right. Even I did not like to keep 64B for this, so I will change it. > >> > > >> >> > >> >> >> But to me this seems very much like a misuse of attcompression to track > >> >> >> dependencies on compression methods, necessary because we don't have a > >> >> >> separate catalog listing compression methods. If we had that, I think we > >> >> >> could simply add dependencies between attributes and that catalog. > >> >> > > >> >> >Basically, up to this patch, we are having only built-in compression > >> >> >methods and those can not be dropped so we don't need any dependency > >> >> >at all. We just want to know what is the current compression method > >> >> >and what is the preserve compression methods supported for this > >> >> >attribute. Maybe we can do it better instead of using the NameData > >> >> >but I don't think it makes sense to add a separate catalog? > >> >> > > >> >> > >> >> Sure, I understand what the goal was - all I'm saying is that it looks > >> >> very much like a workaround needed because we don't have the catalog. > >> >> > >> >> I don't quite understand how could we support custom compression methods > >> >> without listing them in some sort of catalog? > >> > > >> >Yeah for supporting custom compression we need some catalog. > >> > > >> >> >> Moreover, having the catalog would allow adding compression methods > >> >> >> (from extensions etc) instead of just having a list of hard-coded > >> >> >> compression methods. Which seems like a strange limitation, considering > >> >> >> this thread is called "custom compression methods". > >> >> > > >> >> >I think I forgot to mention while submitting the previous patch that > >> >> >the next patch I am planning to submit is, Support creating the custom > >> >> >compression methods wherein we can use pg_am catalog to insert the new > >> >> >compression method. And for dependency handling, we can create an > >> >> >attribute dependency on the pg_am row. Basically, we will create the > >> >> >attribute dependency on the current compression method AM as well as > >> >> >on the preserved compression methods AM. As part of this, we will > >> >> >add two build-in AMs for zlib and pglz, and the attcompression field > >> >> >will be converted to the oid_vector (first OID will be of the current > >> >> >compression method, followed by the preserved compression method's > >> >> >oids). > >> >> > > >> >> > >> >> Hmmm, ok. Not sure pg_am is the right place - compression methods don't > >> >> quite match what I though AMs are about, but maybe it's just my fault. > >> >> > >> >> FWIW it seems a bit strange to first do the attcompression magic and > >> >> then add the catalog later - I think we should start with the catalog > >> >> right away. The advantage is that if we end up committing only some of > >> >> the patches in this cycle, we already have all the infrastructure etc. > >> >> We can reorder that later, though. > >> > > >> >Hmm, yeah we can do this way as well that first create a new catalog > >> >table and add entries for these two built-in methods and the > >> >attcompression can store the oid vector. But if we only commit the > >> >build-in compression methods part then does it make sense to create an > >> >extra catalog or adding these build-in methods to the existing catalog > >> >(if we plan to use pg_am). Then in attcompression instead of using > >> >one byte for each preserve compression method, we need to use oid. So > >> >from Robert's mail[1], it appeared to me that he wants that the > >> >build-in compression methods part should be independently committable > >> >and if we think from that perspective then adding a catalog doesn't > >> >make much sense. But if we are planning to commit the custom method > >> >also then it makes more sense to directly start with the catalog > >> >because that way it will be easy to expand without much refactoring. > >> > > >> >[1] https://www.postgresql.org/message-id/CA%2BTgmobSDVgUage9qQ5P_%3DF_9jaMkCgyKxUQGtFQU7oN4kX-AA%40mail.gmail.com > >> > > >> > >> Hmmm. Maybe I'm missing something subtle, but I think that plan can be > >> interpreted in various ways - it does not really say whether the initial > >> list of built-in methods should be in some C array, or already in a proper > >> catalog. > >> > >> All I'm saying is it seems a bit weird to first implement dependencies > >> based on strange (mis)use of attcompression attribute, and then replace > >> it with a proper catalog. My understanding is those patches are expected > >> to be committable one by one, but the attcompression approach seems a > >> bit too hacky to me - not sure I'd want to commit that ... > > > >Okay, I will change this. So I will make create a new catalog > >pg_compression and add the entry for two built-in compression methods > >from the very first patch. > > > > OK. > > >> >> >> 10) compression parameters? > >> >> >> > >> >> >> I wonder if we could/should allow parameters, like compression level > >> >> >> (and maybe other stuff, depending on the compression method). PG13 > >> >> >> allowed that for opclasses, so perhaps we should allow it here too. > >> >> > > >> >> >Yes, that is also in the plan. For doing this we are planning to add > >> >> >an extra column in the pg_attribute which will store the compression > >> >> >options for the current compression method. The original patch was > >> >> >creating an extra catalog pg_column_compression, therein it maintains > >> >> >the oid of the compression method as well as the compression options. > >> >> >The advantage of creating an extra catalog is that we can keep the > >> >> >compression options for the preserved compression methods also so that > >> >> >we can support the options which can be used for decompressing the > >> >> >data as well. Whereas if we want to avoid this extra catalog then we > >> >> >can not use that compression option for decompressing. But most of > >> >> >the options e.g. compression level are just for the compressing so it > >> >> >is enough to store for the current compression method only. What's > >> >> >your thoughts? > >> >> > > >> >> > >> >> Not sure. My assumption was we'd end up with a new catalog, but maybe > >> >> stashing it into pg_attribute is fine. I was really thinking about two > >> >> kinds of options - compression level, and some sort of column-level > >> >> dictionary. Compression level is not necessary for decompression, but > >> >> the dictionary ID would be needed. (I think the global dictionary was > >> >> one of the use cases, aimed at JSON compression.) > >> > > >> >Ok > >> > > >> >> But I don't think stashing it in pg_attribute means we couldn't use it > >> >> for decompression - we'd just need to keep an array of options, one for > >> >> each compression method. > >> > > >> >Yeah, we can do that. > >> > > >> >Keeping it in a separate new catalog might be > >> >> cleaner, and I'm not sure how large the configuration might be. > >> > > >> >Yeah in that case it will be better to store in a separate catalog, > >> >because sometimes if multiple attributes are using the same > >> >compression method with the same options then we can store the same > >> >oid in attcompression instead of duplicating the option field. > >> > > >> > >> I doubt deduplicating the options like this is (sharing options between > >> columns) is really worth it, as it means extra complexity e.g. during > >> ALTER TABLE ... SET COMPRESSION. I don't think we do that for other > >> catalogs, so why should we do it here? > > > >Yeah, valid point. > > > >> > >> Ultimately I think it's a question of how large we expect the options to > >> be, and how flexible it needs to be. > >> > >> For example, what happens if the user does this: > >> > >> ALTER ... SET COMPRESSION my_compression WITH (options1) PRESERVE; > >> ALTER ... SET COMPRESSION pglz PRESERVE; > >> ALTER ... SET COMPRESSION my_compression WITH (options2) PRESERVE; > >> > >> I believe it's enough to keep just the last value, but maybe I'm wrong > >> and we need to keep the whole history? > > > >Currently, the syntax is like ALTER ... SET COMPRESSION my_compression > >WITH (options1) PRESERVE (old_compression1, old_compression2..). But I > >think if the user just gives PRESERVE without a list then we should > >just preserve the latest one. > > > > Hmmm. Not sure that's very convenient. I'd expect the most common use > case for PRESERVE being "I want to change compression for new data, > without rewrite". If PRESERVE by default preserves the latest one, that > pretty much forces users to always list all methods. I suggest > iterpreting it as "preserve everything" instead. > > Another option would be to require either a list of methods, or some > keyword defining what to preserve. Like for example > > ... PRESERVE (m1, m2, ...) > ... PRESERVE ALL > ... PRESERVE LAST > > Does that make sense? Yeah, this makes sense to me. > > >> The use case I'm thinking about is the column-level JSON compression, > >> where one of the options identifies the dictionary. OTOH I'm not sure > >> this is the right way to track this info - we need to know which options > >> were compressed with which options, i.e. it needs to be encoded in each > >> value directly. It'd also require changes to the PRESERVE handling > >> because it'd be necessary to identify which options to preserve ... > >> > >> So maybe this is either nonsense or something we don't want to support, > >> and we should only allow one option for each compression method. > > > >Yeah, it is a bit confusing to add the same compression method with > >different compression options, then in the preserve list, we will > >have to allow the option as well along with the compression method to > >know which compression method with what options we want to preserve. > > > >And also as you mentioned that in rows we need to know the option as > >well. I think for solving this anyways for the custom compression > >methods we will have to store the OID of the compression method in the > >toast header so we can provide an intermediate catalog which will > >create a new row for each combination of compression method + option > >and the toast header can store the OID of that row so that we know > >with which compression method + option it was compressed with. > > > > I agree. After thinking about this a bit more, I think we should just > keep the last options for each compression method. If we need to allow > multiple options for some future compression method, we can improve > this, but until then it'd be an over-engineering. Let's do the simplest > possible thing here. Okay. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Oct 7, 2020 at 10:26 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Oct 6, 2020 at 10:21 PM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: > > > > On Tue, Oct 06, 2020 at 11:00:55AM +0530, Dilip Kumar wrote: > > >On Mon, Oct 5, 2020 at 9:34 PM Tomas Vondra > > ><tomas.vondra@2ndquadrant.com> wrote: > > >> > > >> On Mon, Oct 05, 2020 at 07:57:41PM +0530, Dilip Kumar wrote: > > >> >On Mon, Oct 5, 2020 at 5:53 PM Tomas Vondra > > >> ><tomas.vondra@2ndquadrant.com> wrote: > > >> >> > > >> >> On Mon, Oct 05, 2020 at 11:17:28AM +0530, Dilip Kumar wrote: > > >> >> >On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra > > >> >> ><tomas.vondra@2ndquadrant.com> wrote: > > >> >> > > > >> >> >Thanks, Tomas for your feedback. > > >> >> > > > >> >> >> 9) attcompression ... > > >> >> >> > > >> >> >> The main issue I see is what the patch does with attcompression. Instead > > >> >> >> of just using it to store a the compression method, it's also used to > > >> >> >> store the preserved compression methods. And using NameData to store > > >> >> >> this seems wrong too - if we really want to store this info, the correct > > >> >> >> way is either using text[] or inventing charvector or similar. > > >> >> > > > >> >> >The reason for using the NameData is the get it in the fixed part of > > >> >> >the data structure. > > >> >> > > > >> >> > > >> >> Why do we need that? It's possible to have varlena fields with direct > > >> >> access (see pg_index.indkey for example). > > >> > > > >> >I see. While making it NameData I was thinking whether we have an > > >> >option to direct access the varlena. Thanks for pointing me there. I > > >> >will change this. > > >> > > > >> > Adding NameData just to make > > >> >> it fixed-length means we're always adding 64B even if we just need a > > >> >> single byte, which means ~30% overhead for the FormData_pg_attribute. > > >> >> That seems a bit unnecessary, and might be an issue with many attributes > > >> >> (e.g. with many temp tables, etc.). > > >> > > > >> >You are right. Even I did not like to keep 64B for this, so I will change it. > > >> > > > >> >> > > >> >> >> But to me this seems very much like a misuse of attcompression to track > > >> >> >> dependencies on compression methods, necessary because we don't have a > > >> >> >> separate catalog listing compression methods. If we had that, I think we > > >> >> >> could simply add dependencies between attributes and that catalog. > > >> >> > > > >> >> >Basically, up to this patch, we are having only built-in compression > > >> >> >methods and those can not be dropped so we don't need any dependency > > >> >> >at all. We just want to know what is the current compression method > > >> >> >and what is the preserve compression methods supported for this > > >> >> >attribute. Maybe we can do it better instead of using the NameData > > >> >> >but I don't think it makes sense to add a separate catalog? > > >> >> > > > >> >> > > >> >> Sure, I understand what the goal was - all I'm saying is that it looks > > >> >> very much like a workaround needed because we don't have the catalog. > > >> >> > > >> >> I don't quite understand how could we support custom compression methods > > >> >> without listing them in some sort of catalog? > > >> > > > >> >Yeah for supporting custom compression we need some catalog. > > >> > > > >> >> >> Moreover, having the catalog would allow adding compression methods > > >> >> >> (from extensions etc) instead of just having a list of hard-coded > > >> >> >> compression methods. Which seems like a strange limitation, considering > > >> >> >> this thread is called "custom compression methods". > > >> >> > > > >> >> >I think I forgot to mention while submitting the previous patch that > > >> >> >the next patch I am planning to submit is, Support creating the custom > > >> >> >compression methods wherein we can use pg_am catalog to insert the new > > >> >> >compression method. And for dependency handling, we can create an > > >> >> >attribute dependency on the pg_am row. Basically, we will create the > > >> >> >attribute dependency on the current compression method AM as well as > > >> >> >on the preserved compression methods AM. As part of this, we will > > >> >> >add two build-in AMs for zlib and pglz, and the attcompression field > > >> >> >will be converted to the oid_vector (first OID will be of the current > > >> >> >compression method, followed by the preserved compression method's > > >> >> >oids). > > >> >> > > > >> >> > > >> >> Hmmm, ok. Not sure pg_am is the right place - compression methods don't > > >> >> quite match what I though AMs are about, but maybe it's just my fault. > > >> >> > > >> >> FWIW it seems a bit strange to first do the attcompression magic and > > >> >> then add the catalog later - I think we should start with the catalog > > >> >> right away. The advantage is that if we end up committing only some of > > >> >> the patches in this cycle, we already have all the infrastructure etc. > > >> >> We can reorder that later, though. > > >> > > > >> >Hmm, yeah we can do this way as well that first create a new catalog > > >> >table and add entries for these two built-in methods and the > > >> >attcompression can store the oid vector. But if we only commit the > > >> >build-in compression methods part then does it make sense to create an > > >> >extra catalog or adding these build-in methods to the existing catalog > > >> >(if we plan to use pg_am). Then in attcompression instead of using > > >> >one byte for each preserve compression method, we need to use oid. So > > >> >from Robert's mail[1], it appeared to me that he wants that the > > >> >build-in compression methods part should be independently committable > > >> >and if we think from that perspective then adding a catalog doesn't > > >> >make much sense. But if we are planning to commit the custom method > > >> >also then it makes more sense to directly start with the catalog > > >> >because that way it will be easy to expand without much refactoring. > > >> > > > >> >[1] https://www.postgresql.org/message-id/CA%2BTgmobSDVgUage9qQ5P_%3DF_9jaMkCgyKxUQGtFQU7oN4kX-AA%40mail.gmail.com > > >> > > > >> > > >> Hmmm. Maybe I'm missing something subtle, but I think that plan can be > > >> interpreted in various ways - it does not really say whether the initial > > >> list of built-in methods should be in some C array, or already in a proper > > >> catalog. > > >> > > >> All I'm saying is it seems a bit weird to first implement dependencies > > >> based on strange (mis)use of attcompression attribute, and then replace > > >> it with a proper catalog. My understanding is those patches are expected > > >> to be committable one by one, but the attcompression approach seems a > > >> bit too hacky to me - not sure I'd want to commit that ... > > > > > >Okay, I will change this. So I will make create a new catalog > > >pg_compression and add the entry for two built-in compression methods > > >from the very first patch. > > > > > > > OK. I have changed the first 2 patches, basically, now we are providing a new catalog pg_compression and the pg_attribute is storing the oid of the compression method. The patches still need some cleanup and there is also one open comment that for index we should use its table compression. I am still working on the preserve patch. For preserving the compression method I am planning to convert the attcompression field to the oidvector so that we can store the oid of the preserve method also. I am not sure whether we can access this oidvector as a fixed part of the FormData_pg_attribute or not. The reason is that for building the tuple descriptor, we need to give the size of the fixed part (#define ATTRIBUTE_FIXED_PART_SIZE \ (offsetof(FormData_pg_attribute,attcompression) + sizeof(Oid))). But if we convert this to the oidvector then we don't know the size of the fixed part. Am I missing something? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Oct 7, 2020 at 5:00 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Wed, Oct 7, 2020 at 10:26 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Tue, Oct 6, 2020 at 10:21 PM Tomas Vondra > > <tomas.vondra@2ndquadrant.com> wrote: > > > > > > On Tue, Oct 06, 2020 at 11:00:55AM +0530, Dilip Kumar wrote: > > > >On Mon, Oct 5, 2020 at 9:34 PM Tomas Vondra > > > ><tomas.vondra@2ndquadrant.com> wrote: > > > >> > > > >> On Mon, Oct 05, 2020 at 07:57:41PM +0530, Dilip Kumar wrote: > > > >> >On Mon, Oct 5, 2020 at 5:53 PM Tomas Vondra > > > >> ><tomas.vondra@2ndquadrant.com> wrote: > > > >> >> > > > >> >> On Mon, Oct 05, 2020 at 11:17:28AM +0530, Dilip Kumar wrote: > > > >> >> >On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra > > > >> >> ><tomas.vondra@2ndquadrant.com> wrote: > > > >> >> > > > > >> >> >Thanks, Tomas for your feedback. > > > >> >> > > > > >> >> >> 9) attcompression ... > > > >> >> >> > > > >> >> >> The main issue I see is what the patch does with attcompression. Instead > > > >> >> >> of just using it to store a the compression method, it's also used to > > > >> >> >> store the preserved compression methods. And using NameData to store > > > >> >> >> this seems wrong too - if we really want to store this info, the correct > > > >> >> >> way is either using text[] or inventing charvector or similar. > > > >> >> > > > > >> >> >The reason for using the NameData is the get it in the fixed part of > > > >> >> >the data structure. > > > >> >> > > > > >> >> > > > >> >> Why do we need that? It's possible to have varlena fields with direct > > > >> >> access (see pg_index.indkey for example). > > > >> > > > > >> >I see. While making it NameData I was thinking whether we have an > > > >> >option to direct access the varlena. Thanks for pointing me there. I > > > >> >will change this. > > > >> > > > > >> > Adding NameData just to make > > > >> >> it fixed-length means we're always adding 64B even if we just need a > > > >> >> single byte, which means ~30% overhead for the FormData_pg_attribute. > > > >> >> That seems a bit unnecessary, and might be an issue with many attributes > > > >> >> (e.g. with many temp tables, etc.). > > > >> > > > > >> >You are right. Even I did not like to keep 64B for this, so I will change it. > > > >> > > > > >> >> > > > >> >> >> But to me this seems very much like a misuse of attcompression to track > > > >> >> >> dependencies on compression methods, necessary because we don't have a > > > >> >> >> separate catalog listing compression methods. If we had that, I think we > > > >> >> >> could simply add dependencies between attributes and that catalog. > > > >> >> > > > > >> >> >Basically, up to this patch, we are having only built-in compression > > > >> >> >methods and those can not be dropped so we don't need any dependency > > > >> >> >at all. We just want to know what is the current compression method > > > >> >> >and what is the preserve compression methods supported for this > > > >> >> >attribute. Maybe we can do it better instead of using the NameData > > > >> >> >but I don't think it makes sense to add a separate catalog? > > > >> >> > > > > >> >> > > > >> >> Sure, I understand what the goal was - all I'm saying is that it looks > > > >> >> very much like a workaround needed because we don't have the catalog. > > > >> >> > > > >> >> I don't quite understand how could we support custom compression methods > > > >> >> without listing them in some sort of catalog? > > > >> > > > > >> >Yeah for supporting custom compression we need some catalog. > > > >> > > > > >> >> >> Moreover, having the catalog would allow adding compression methods > > > >> >> >> (from extensions etc) instead of just having a list of hard-coded > > > >> >> >> compression methods. Which seems like a strange limitation, considering > > > >> >> >> this thread is called "custom compression methods". > > > >> >> > > > > >> >> >I think I forgot to mention while submitting the previous patch that > > > >> >> >the next patch I am planning to submit is, Support creating the custom > > > >> >> >compression methods wherein we can use pg_am catalog to insert the new > > > >> >> >compression method. And for dependency handling, we can create an > > > >> >> >attribute dependency on the pg_am row. Basically, we will create the > > > >> >> >attribute dependency on the current compression method AM as well as > > > >> >> >on the preserved compression methods AM. As part of this, we will > > > >> >> >add two build-in AMs for zlib and pglz, and the attcompression field > > > >> >> >will be converted to the oid_vector (first OID will be of the current > > > >> >> >compression method, followed by the preserved compression method's > > > >> >> >oids). > > > >> >> > > > > >> >> > > > >> >> Hmmm, ok. Not sure pg_am is the right place - compression methods don't > > > >> >> quite match what I though AMs are about, but maybe it's just my fault. > > > >> >> > > > >> >> FWIW it seems a bit strange to first do the attcompression magic and > > > >> >> then add the catalog later - I think we should start with the catalog > > > >> >> right away. The advantage is that if we end up committing only some of > > > >> >> the patches in this cycle, we already have all the infrastructure etc. > > > >> >> We can reorder that later, though. > > > >> > > > > >> >Hmm, yeah we can do this way as well that first create a new catalog > > > >> >table and add entries for these two built-in methods and the > > > >> >attcompression can store the oid vector. But if we only commit the > > > >> >build-in compression methods part then does it make sense to create an > > > >> >extra catalog or adding these build-in methods to the existing catalog > > > >> >(if we plan to use pg_am). Then in attcompression instead of using > > > >> >one byte for each preserve compression method, we need to use oid. So > > > >> >from Robert's mail[1], it appeared to me that he wants that the > > > >> >build-in compression methods part should be independently committable > > > >> >and if we think from that perspective then adding a catalog doesn't > > > >> >make much sense. But if we are planning to commit the custom method > > > >> >also then it makes more sense to directly start with the catalog > > > >> >because that way it will be easy to expand without much refactoring. > > > >> > > > > >> >[1] https://www.postgresql.org/message-id/CA%2BTgmobSDVgUage9qQ5P_%3DF_9jaMkCgyKxUQGtFQU7oN4kX-AA%40mail.gmail.com > > > >> > > > > >> > > > >> Hmmm. Maybe I'm missing something subtle, but I think that plan can be > > > >> interpreted in various ways - it does not really say whether the initial > > > >> list of built-in methods should be in some C array, or already in a proper > > > >> catalog. > > > >> > > > >> All I'm saying is it seems a bit weird to first implement dependencies > > > >> based on strange (mis)use of attcompression attribute, and then replace > > > >> it with a proper catalog. My understanding is those patches are expected > > > >> to be committable one by one, but the attcompression approach seems a > > > >> bit too hacky to me - not sure I'd want to commit that ... > > > > > > > >Okay, I will change this. So I will make create a new catalog > > > >pg_compression and add the entry for two built-in compression methods > > > >from the very first patch. > > > > > > > > > > OK. > > I have changed the first 2 patches, basically, now we are providing a > new catalog pg_compression and the pg_attribute is storing the oid of > the compression method. The patches still need some cleanup and there > is also one open comment that for index we should use its table > compression. > > I am still working on the preserve patch. For preserving the > compression method I am planning to convert the attcompression field > to the oidvector so that we can store the oid of the preserve method > also. I am not sure whether we can access this oidvector as a fixed > part of the FormData_pg_attribute or not. The reason is that for > building the tuple descriptor, we need to give the size of the fixed > part (#define ATTRIBUTE_FIXED_PART_SIZE \ > (offsetof(FormData_pg_attribute,attcompression) + sizeof(Oid))). But > if we convert this to the oidvector then we don't know the size of the > fixed part. Am I missing something? I could think of two solutions here Sol1. Make the first oid of the oidvector as part of the fixed size, like below #define ATTRIBUTE_FIXED_PART_SIZE \ (offsetof(FormData_pg_attribute, attcompression) + OidVectorSize(1)) Sol2: Keep attcompression as oid only and for the preserve list, adds another field in the variable part which will be of type oidvector. I think most of the time we need to access the current compression method and with this solution, we will be able to access that as part of the tuple desc. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Oct 7, 2020 at 5:00 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Wed, Oct 7, 2020 at 10:26 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Tue, Oct 6, 2020 at 10:21 PM Tomas Vondra > > <tomas.vondra@2ndquadrant.com> wrote: > > > > > > On Tue, Oct 06, 2020 at 11:00:55AM +0530, Dilip Kumar wrote: > > > >On Mon, Oct 5, 2020 at 9:34 PM Tomas Vondra > > > ><tomas.vondra@2ndquadrant.com> wrote: > > > >> > > > >> On Mon, Oct 05, 2020 at 07:57:41PM +0530, Dilip Kumar wrote: > > > >> >On Mon, Oct 5, 2020 at 5:53 PM Tomas Vondra > > > >> ><tomas.vondra@2ndquadrant.com> wrote: > > > >> >> > > > >> >> On Mon, Oct 05, 2020 at 11:17:28AM +0530, Dilip Kumar wrote: > > > >> >> >On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra > > > >> >> ><tomas.vondra@2ndquadrant.com> wrote: > > > >> >> > > > > >> >> >Thanks, Tomas for your feedback. > > > >> >> > > > > >> >> >> 9) attcompression ... > > > >> >> >> > > > >> >> >> The main issue I see is what the patch does with attcompression. Instead > > > >> >> >> of just using it to store a the compression method, it's also used to > > > >> >> >> store the preserved compression methods. And using NameData to store > > > >> >> >> this seems wrong too - if we really want to store this info, the correct > > > >> >> >> way is either using text[] or inventing charvector or similar. > > > >> >> > > > > >> >> >The reason for using the NameData is the get it in the fixed part of > > > >> >> >the data structure. > > > >> >> > > > > >> >> > > > >> >> Why do we need that? It's possible to have varlena fields with direct > > > >> >> access (see pg_index.indkey for example). > > > >> > > > > >> >I see. While making it NameData I was thinking whether we have an > > > >> >option to direct access the varlena. Thanks for pointing me there. I > > > >> >will change this. > > > >> > > > > >> > Adding NameData just to make > > > >> >> it fixed-length means we're always adding 64B even if we just need a > > > >> >> single byte, which means ~30% overhead for the FormData_pg_attribute. > > > >> >> That seems a bit unnecessary, and might be an issue with many attributes > > > >> >> (e.g. with many temp tables, etc.). > > > >> > > > > >> >You are right. Even I did not like to keep 64B for this, so I will change it. > > > >> > > > > >> >> > > > >> >> >> But to me this seems very much like a misuse of attcompression to track > > > >> >> >> dependencies on compression methods, necessary because we don't have a > > > >> >> >> separate catalog listing compression methods. If we had that, I think we > > > >> >> >> could simply add dependencies between attributes and that catalog. > > > >> >> > > > > >> >> >Basically, up to this patch, we are having only built-in compression > > > >> >> >methods and those can not be dropped so we don't need any dependency > > > >> >> >at all. We just want to know what is the current compression method > > > >> >> >and what is the preserve compression methods supported for this > > > >> >> >attribute. Maybe we can do it better instead of using the NameData > > > >> >> >but I don't think it makes sense to add a separate catalog? > > > >> >> > > > > >> >> > > > >> >> Sure, I understand what the goal was - all I'm saying is that it looks > > > >> >> very much like a workaround needed because we don't have the catalog. > > > >> >> > > > >> >> I don't quite understand how could we support custom compression methods > > > >> >> without listing them in some sort of catalog? > > > >> > > > > >> >Yeah for supporting custom compression we need some catalog. > > > >> > > > > >> >> >> Moreover, having the catalog would allow adding compression methods > > > >> >> >> (from extensions etc) instead of just having a list of hard-coded > > > >> >> >> compression methods. Which seems like a strange limitation, considering > > > >> >> >> this thread is called "custom compression methods". > > > >> >> > > > > >> >> >I think I forgot to mention while submitting the previous patch that > > > >> >> >the next patch I am planning to submit is, Support creating the custom > > > >> >> >compression methods wherein we can use pg_am catalog to insert the new > > > >> >> >compression method. And for dependency handling, we can create an > > > >> >> >attribute dependency on the pg_am row. Basically, we will create the > > > >> >> >attribute dependency on the current compression method AM as well as > > > >> >> >on the preserved compression methods AM. As part of this, we will > > > >> >> >add two build-in AMs for zlib and pglz, and the attcompression field > > > >> >> >will be converted to the oid_vector (first OID will be of the current > > > >> >> >compression method, followed by the preserved compression method's > > > >> >> >oids). > > > >> >> > > > > >> >> > > > >> >> Hmmm, ok. Not sure pg_am is the right place - compression methods don't > > > >> >> quite match what I though AMs are about, but maybe it's just my fault. > > > >> >> > > > >> >> FWIW it seems a bit strange to first do the attcompression magic and > > > >> >> then add the catalog later - I think we should start with the catalog > > > >> >> right away. The advantage is that if we end up committing only some of > > > >> >> the patches in this cycle, we already have all the infrastructure etc. > > > >> >> We can reorder that later, though. > > > >> > > > > >> >Hmm, yeah we can do this way as well that first create a new catalog > > > >> >table and add entries for these two built-in methods and the > > > >> >attcompression can store the oid vector. But if we only commit the > > > >> >build-in compression methods part then does it make sense to create an > > > >> >extra catalog or adding these build-in methods to the existing catalog > > > >> >(if we plan to use pg_am). Then in attcompression instead of using > > > >> >one byte for each preserve compression method, we need to use oid. So > > > >> >from Robert's mail[1], it appeared to me that he wants that the > > > >> >build-in compression methods part should be independently committable > > > >> >and if we think from that perspective then adding a catalog doesn't > > > >> >make much sense. But if we are planning to commit the custom method > > > >> >also then it makes more sense to directly start with the catalog > > > >> >because that way it will be easy to expand without much refactoring. > > > >> > > > > >> >[1] https://www.postgresql.org/message-id/CA%2BTgmobSDVgUage9qQ5P_%3DF_9jaMkCgyKxUQGtFQU7oN4kX-AA%40mail.gmail.com > > > >> > > > > >> > > > >> Hmmm. Maybe I'm missing something subtle, but I think that plan can be > > > >> interpreted in various ways - it does not really say whether the initial > > > >> list of built-in methods should be in some C array, or already in a proper > > > >> catalog. > > > >> > > > >> All I'm saying is it seems a bit weird to first implement dependencies > > > >> based on strange (mis)use of attcompression attribute, and then replace > > > >> it with a proper catalog. My understanding is those patches are expected > > > >> to be committable one by one, but the attcompression approach seems a > > > >> bit too hacky to me - not sure I'd want to commit that ... > > > > > > > >Okay, I will change this. So I will make create a new catalog > > > >pg_compression and add the entry for two built-in compression methods > > > >from the very first patch. > > > > > > > > > > OK. > > I have changed the first 2 patches, basically, now we are providing a > new catalog pg_compression and the pg_attribute is storing the oid of > the compression method. The patches still need some cleanup and there > is also one open comment that for index we should use its table > compression. There was some unwanted code in the previous patch so attaching the updated patches. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Thu, Oct 08, 2020 at 02:38:27PM +0530, Dilip Kumar wrote: >On Wed, Oct 7, 2020 at 5:00 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: >> >> On Wed, Oct 7, 2020 at 10:26 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: >> > >> > On Tue, Oct 6, 2020 at 10:21 PM Tomas Vondra >> > <tomas.vondra@2ndquadrant.com> wrote: >> > > >> > > On Tue, Oct 06, 2020 at 11:00:55AM +0530, Dilip Kumar wrote: >> > > >On Mon, Oct 5, 2020 at 9:34 PM Tomas Vondra >> > > ><tomas.vondra@2ndquadrant.com> wrote: >> > > >> >> > > >> On Mon, Oct 05, 2020 at 07:57:41PM +0530, Dilip Kumar wrote: >> > > >> >On Mon, Oct 5, 2020 at 5:53 PM Tomas Vondra >> > > >> ><tomas.vondra@2ndquadrant.com> wrote: >> > > >> >> >> > > >> >> On Mon, Oct 05, 2020 at 11:17:28AM +0530, Dilip Kumar wrote: >> > > >> >> >On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra >> > > >> >> ><tomas.vondra@2ndquadrant.com> wrote: >> > > >> >> > >> > > >> >> >Thanks, Tomas for your feedback. >> > > >> >> > >> > > >> >> >> 9) attcompression ... >> > > >> >> >> >> > > >> >> >> The main issue I see is what the patch does with attcompression. Instead >> > > >> >> >> of just using it to store a the compression method, it's also used to >> > > >> >> >> store the preserved compression methods. And using NameData to store >> > > >> >> >> this seems wrong too - if we really want to store this info, the correct >> > > >> >> >> way is either using text[] or inventing charvector or similar. >> > > >> >> > >> > > >> >> >The reason for using the NameData is the get it in the fixed part of >> > > >> >> >the data structure. >> > > >> >> > >> > > >> >> >> > > >> >> Why do we need that? It's possible to have varlena fields with direct >> > > >> >> access (see pg_index.indkey for example). >> > > >> > >> > > >> >I see. While making it NameData I was thinking whether we have an >> > > >> >option to direct access the varlena. Thanks for pointing me there. I >> > > >> >will change this. >> > > >> > >> > > >> > Adding NameData just to make >> > > >> >> it fixed-length means we're always adding 64B even if we just need a >> > > >> >> single byte, which means ~30% overhead for the FormData_pg_attribute. >> > > >> >> That seems a bit unnecessary, and might be an issue with many attributes >> > > >> >> (e.g. with many temp tables, etc.). >> > > >> > >> > > >> >You are right. Even I did not like to keep 64B for this, so I will change it. >> > > >> > >> > > >> >> >> > > >> >> >> But to me this seems very much like a misuse of attcompression to track >> > > >> >> >> dependencies on compression methods, necessary because we don't have a >> > > >> >> >> separate catalog listing compression methods. If we had that, I think we >> > > >> >> >> could simply add dependencies between attributes and that catalog. >> > > >> >> > >> > > >> >> >Basically, up to this patch, we are having only built-in compression >> > > >> >> >methods and those can not be dropped so we don't need any dependency >> > > >> >> >at all. We just want to know what is the current compression method >> > > >> >> >and what is the preserve compression methods supported for this >> > > >> >> >attribute. Maybe we can do it better instead of using the NameData >> > > >> >> >but I don't think it makes sense to add a separate catalog? >> > > >> >> > >> > > >> >> >> > > >> >> Sure, I understand what the goal was - all I'm saying is that it looks >> > > >> >> very much like a workaround needed because we don't have the catalog. >> > > >> >> >> > > >> >> I don't quite understand how could we support custom compression methods >> > > >> >> without listing them in some sort of catalog? >> > > >> > >> > > >> >Yeah for supporting custom compression we need some catalog. >> > > >> > >> > > >> >> >> Moreover, having the catalog would allow adding compression methods >> > > >> >> >> (from extensions etc) instead of just having a list of hard-coded >> > > >> >> >> compression methods. Which seems like a strange limitation, considering >> > > >> >> >> this thread is called "custom compression methods". >> > > >> >> > >> > > >> >> >I think I forgot to mention while submitting the previous patch that >> > > >> >> >the next patch I am planning to submit is, Support creating the custom >> > > >> >> >compression methods wherein we can use pg_am catalog to insert the new >> > > >> >> >compression method. And for dependency handling, we can create an >> > > >> >> >attribute dependency on the pg_am row. Basically, we will create the >> > > >> >> >attribute dependency on the current compression method AM as well as >> > > >> >> >on the preserved compression methods AM. As part of this, we will >> > > >> >> >add two build-in AMs for zlib and pglz, and the attcompression field >> > > >> >> >will be converted to the oid_vector (first OID will be of the current >> > > >> >> >compression method, followed by the preserved compression method's >> > > >> >> >oids). >> > > >> >> > >> > > >> >> >> > > >> >> Hmmm, ok. Not sure pg_am is the right place - compression methods don't >> > > >> >> quite match what I though AMs are about, but maybe it's just my fault. >> > > >> >> >> > > >> >> FWIW it seems a bit strange to first do the attcompression magic and >> > > >> >> then add the catalog later - I think we should start with the catalog >> > > >> >> right away. The advantage is that if we end up committing only some of >> > > >> >> the patches in this cycle, we already have all the infrastructure etc. >> > > >> >> We can reorder that later, though. >> > > >> > >> > > >> >Hmm, yeah we can do this way as well that first create a new catalog >> > > >> >table and add entries for these two built-in methods and the >> > > >> >attcompression can store the oid vector. But if we only commit the >> > > >> >build-in compression methods part then does it make sense to create an >> > > >> >extra catalog or adding these build-in methods to the existing catalog >> > > >> >(if we plan to use pg_am). Then in attcompression instead of using >> > > >> >one byte for each preserve compression method, we need to use oid. So >> > > >> >from Robert's mail[1], it appeared to me that he wants that the >> > > >> >build-in compression methods part should be independently committable >> > > >> >and if we think from that perspective then adding a catalog doesn't >> > > >> >make much sense. But if we are planning to commit the custom method >> > > >> >also then it makes more sense to directly start with the catalog >> > > >> >because that way it will be easy to expand without much refactoring. >> > > >> > >> > > >> >[1] https://www.postgresql.org/message-id/CA%2BTgmobSDVgUage9qQ5P_%3DF_9jaMkCgyKxUQGtFQU7oN4kX-AA%40mail.gmail.com >> > > >> > >> > > >> >> > > >> Hmmm. Maybe I'm missing something subtle, but I think that plan can be >> > > >> interpreted in various ways - it does not really say whether the initial >> > > >> list of built-in methods should be in some C array, or already in a proper >> > > >> catalog. >> > > >> >> > > >> All I'm saying is it seems a bit weird to first implement dependencies >> > > >> based on strange (mis)use of attcompression attribute, and then replace >> > > >> it with a proper catalog. My understanding is those patches are expected >> > > >> to be committable one by one, but the attcompression approach seems a >> > > >> bit too hacky to me - not sure I'd want to commit that ... >> > > > >> > > >Okay, I will change this. So I will make create a new catalog >> > > >pg_compression and add the entry for two built-in compression methods >> > > >from the very first patch. >> > > > >> > > >> > > OK. >> >> I have changed the first 2 patches, basically, now we are providing a >> new catalog pg_compression and the pg_attribute is storing the oid of >> the compression method. The patches still need some cleanup and there >> is also one open comment that for index we should use its table >> compression. >> >> I am still working on the preserve patch. For preserving the >> compression method I am planning to convert the attcompression field >> to the oidvector so that we can store the oid of the preserve method >> also. I am not sure whether we can access this oidvector as a fixed >> part of the FormData_pg_attribute or not. The reason is that for >> building the tuple descriptor, we need to give the size of the fixed >> part (#define ATTRIBUTE_FIXED_PART_SIZE \ >> (offsetof(FormData_pg_attribute,attcompression) + sizeof(Oid))). But >> if we convert this to the oidvector then we don't know the size of the >> fixed part. Am I missing something? > >I could think of two solutions here >Sol1. >Make the first oid of the oidvector as part of the fixed size, like below >#define ATTRIBUTE_FIXED_PART_SIZE \ >(offsetof(FormData_pg_attribute, attcompression) + OidVectorSize(1)) > >Sol2: >Keep attcompression as oid only and for the preserve list, adds >another field in the variable part which will be of type oidvector. I >think most of the time we need to access the current compression >method and with this solution, we will be able to access that as part >of the tuple desc. > And is the oidvector actually needed? If we have the extra catalog, can't we track this simply using the regular dependencies? So we'd have the attcompression OID of the current compression method, and the preserved values would be tracked in pg_depend. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Oct 9, 2020 at 3:24 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > On Thu, Oct 08, 2020 at 02:38:27PM +0530, Dilip Kumar wrote: > >On Wed, Oct 7, 2020 at 5:00 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > >> > >> On Wed, Oct 7, 2020 at 10:26 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > >> > > >> > On Tue, Oct 6, 2020 at 10:21 PM Tomas Vondra > >> > <tomas.vondra@2ndquadrant.com> wrote: > >> > > > >> > > On Tue, Oct 06, 2020 at 11:00:55AM +0530, Dilip Kumar wrote: > >> > > >On Mon, Oct 5, 2020 at 9:34 PM Tomas Vondra > >> > > ><tomas.vondra@2ndquadrant.com> wrote: > >> > > >> > >> > > >> On Mon, Oct 05, 2020 at 07:57:41PM +0530, Dilip Kumar wrote: > >> > > >> >On Mon, Oct 5, 2020 at 5:53 PM Tomas Vondra > >> > > >> ><tomas.vondra@2ndquadrant.com> wrote: > >> > > >> >> > >> > > >> >> On Mon, Oct 05, 2020 at 11:17:28AM +0530, Dilip Kumar wrote: > >> > > >> >> >On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra > >> > > >> >> ><tomas.vondra@2ndquadrant.com> wrote: > >> > > >> >> > > >> > > >> >> >Thanks, Tomas for your feedback. > >> > > >> >> > > >> > > >> >> >> 9) attcompression ... > >> > > >> >> >> > >> > > >> >> >> The main issue I see is what the patch does with attcompression. Instead > >> > > >> >> >> of just using it to store a the compression method, it's also used to > >> > > >> >> >> store the preserved compression methods. And using NameData to store > >> > > >> >> >> this seems wrong too - if we really want to store this info, the correct > >> > > >> >> >> way is either using text[] or inventing charvector or similar. > >> > > >> >> > > >> > > >> >> >The reason for using the NameData is the get it in the fixed part of > >> > > >> >> >the data structure. > >> > > >> >> > > >> > > >> >> > >> > > >> >> Why do we need that? It's possible to have varlena fields with direct > >> > > >> >> access (see pg_index.indkey for example). > >> > > >> > > >> > > >> >I see. While making it NameData I was thinking whether we have an > >> > > >> >option to direct access the varlena. Thanks for pointing me there. I > >> > > >> >will change this. > >> > > >> > > >> > > >> > Adding NameData just to make > >> > > >> >> it fixed-length means we're always adding 64B even if we just need a > >> > > >> >> single byte, which means ~30% overhead for the FormData_pg_attribute. > >> > > >> >> That seems a bit unnecessary, and might be an issue with many attributes > >> > > >> >> (e.g. with many temp tables, etc.). > >> > > >> > > >> > > >> >You are right. Even I did not like to keep 64B for this, so I will change it. > >> > > >> > > >> > > >> >> > >> > > >> >> >> But to me this seems very much like a misuse of attcompression to track > >> > > >> >> >> dependencies on compression methods, necessary because we don't have a > >> > > >> >> >> separate catalog listing compression methods. If we had that, I think we > >> > > >> >> >> could simply add dependencies between attributes and that catalog. > >> > > >> >> > > >> > > >> >> >Basically, up to this patch, we are having only built-in compression > >> > > >> >> >methods and those can not be dropped so we don't need any dependency > >> > > >> >> >at all. We just want to know what is the current compression method > >> > > >> >> >and what is the preserve compression methods supported for this > >> > > >> >> >attribute. Maybe we can do it better instead of using the NameData > >> > > >> >> >but I don't think it makes sense to add a separate catalog? > >> > > >> >> > > >> > > >> >> > >> > > >> >> Sure, I understand what the goal was - all I'm saying is that it looks > >> > > >> >> very much like a workaround needed because we don't have the catalog. > >> > > >> >> > >> > > >> >> I don't quite understand how could we support custom compression methods > >> > > >> >> without listing them in some sort of catalog? > >> > > >> > > >> > > >> >Yeah for supporting custom compression we need some catalog. > >> > > >> > > >> > > >> >> >> Moreover, having the catalog would allow adding compression methods > >> > > >> >> >> (from extensions etc) instead of just having a list of hard-coded > >> > > >> >> >> compression methods. Which seems like a strange limitation, considering > >> > > >> >> >> this thread is called "custom compression methods". > >> > > >> >> > > >> > > >> >> >I think I forgot to mention while submitting the previous patch that > >> > > >> >> >the next patch I am planning to submit is, Support creating the custom > >> > > >> >> >compression methods wherein we can use pg_am catalog to insert the new > >> > > >> >> >compression method. And for dependency handling, we can create an > >> > > >> >> >attribute dependency on the pg_am row. Basically, we will create the > >> > > >> >> >attribute dependency on the current compression method AM as well as > >> > > >> >> >on the preserved compression methods AM. As part of this, we will > >> > > >> >> >add two build-in AMs for zlib and pglz, and the attcompression field > >> > > >> >> >will be converted to the oid_vector (first OID will be of the current > >> > > >> >> >compression method, followed by the preserved compression method's > >> > > >> >> >oids). > >> > > >> >> > > >> > > >> >> > >> > > >> >> Hmmm, ok. Not sure pg_am is the right place - compression methods don't > >> > > >> >> quite match what I though AMs are about, but maybe it's just my fault. > >> > > >> >> > >> > > >> >> FWIW it seems a bit strange to first do the attcompression magic and > >> > > >> >> then add the catalog later - I think we should start with the catalog > >> > > >> >> right away. The advantage is that if we end up committing only some of > >> > > >> >> the patches in this cycle, we already have all the infrastructure etc. > >> > > >> >> We can reorder that later, though. > >> > > >> > > >> > > >> >Hmm, yeah we can do this way as well that first create a new catalog > >> > > >> >table and add entries for these two built-in methods and the > >> > > >> >attcompression can store the oid vector. But if we only commit the > >> > > >> >build-in compression methods part then does it make sense to create an > >> > > >> >extra catalog or adding these build-in methods to the existing catalog > >> > > >> >(if we plan to use pg_am). Then in attcompression instead of using > >> > > >> >one byte for each preserve compression method, we need to use oid. So > >> > > >> >from Robert's mail[1], it appeared to me that he wants that the > >> > > >> >build-in compression methods part should be independently committable > >> > > >> >and if we think from that perspective then adding a catalog doesn't > >> > > >> >make much sense. But if we are planning to commit the custom method > >> > > >> >also then it makes more sense to directly start with the catalog > >> > > >> >because that way it will be easy to expand without much refactoring. > >> > > >> > > >> > > >> >[1] https://www.postgresql.org/message-id/CA%2BTgmobSDVgUage9qQ5P_%3DF_9jaMkCgyKxUQGtFQU7oN4kX-AA%40mail.gmail.com > >> > > >> > > >> > > >> > >> > > >> Hmmm. Maybe I'm missing something subtle, but I think that plan can be > >> > > >> interpreted in various ways - it does not really say whether the initial > >> > > >> list of built-in methods should be in some C array, or already in a proper > >> > > >> catalog. > >> > > >> > >> > > >> All I'm saying is it seems a bit weird to first implement dependencies > >> > > >> based on strange (mis)use of attcompression attribute, and then replace > >> > > >> it with a proper catalog. My understanding is those patches are expected > >> > > >> to be committable one by one, but the attcompression approach seems a > >> > > >> bit too hacky to me - not sure I'd want to commit that ... > >> > > > > >> > > >Okay, I will change this. So I will make create a new catalog > >> > > >pg_compression and add the entry for two built-in compression methods > >> > > >from the very first patch. > >> > > > > >> > > > >> > > OK. > >> > >> I have changed the first 2 patches, basically, now we are providing a > >> new catalog pg_compression and the pg_attribute is storing the oid of > >> the compression method. The patches still need some cleanup and there > >> is also one open comment that for index we should use its table > >> compression. > >> > >> I am still working on the preserve patch. For preserving the > >> compression method I am planning to convert the attcompression field > >> to the oidvector so that we can store the oid of the preserve method > >> also. I am not sure whether we can access this oidvector as a fixed > >> part of the FormData_pg_attribute or not. The reason is that for > >> building the tuple descriptor, we need to give the size of the fixed > >> part (#define ATTRIBUTE_FIXED_PART_SIZE \ > >> (offsetof(FormData_pg_attribute,attcompression) + sizeof(Oid))). But > >> if we convert this to the oidvector then we don't know the size of the > >> fixed part. Am I missing something? > > > >I could think of two solutions here > >Sol1. > >Make the first oid of the oidvector as part of the fixed size, like below > >#define ATTRIBUTE_FIXED_PART_SIZE \ > >(offsetof(FormData_pg_attribute, attcompression) + OidVectorSize(1)) > > > >Sol2: > >Keep attcompression as oid only and for the preserve list, adds > >another field in the variable part which will be of type oidvector. I > >think most of the time we need to access the current compression > >method and with this solution, we will be able to access that as part > >of the tuple desc. > > > > And is the oidvector actually needed? If we have the extra catalog, > can't we track this simply using the regular dependencies? So we'd have > the attcompression OID of the current compression method, and the > preserved values would be tracked in pg_depend. Right, we can do that as well. Actually, the preserved list need to be accessed only in case of ALTER TABLE SET COMPRESSION and INSERT INTO SELECT * FROM queries. So in such cases, I think it is okay to get the preserved compression oids from pg_depends. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Fri, Oct 9, 2020 at 3:01 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Fri, Oct 9, 2020 at 3:24 AM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: > > > > On Thu, Oct 08, 2020 at 02:38:27PM +0530, Dilip Kumar wrote: > > >On Wed, Oct 7, 2020 at 5:00 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > >> > > >> On Wed, Oct 7, 2020 at 10:26 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > >> > > > >> > On Tue, Oct 6, 2020 at 10:21 PM Tomas Vondra > > >> > <tomas.vondra@2ndquadrant.com> wrote: > > >> > > > > >> > > On Tue, Oct 06, 2020 at 11:00:55AM +0530, Dilip Kumar wrote: > > >> > > >On Mon, Oct 5, 2020 at 9:34 PM Tomas Vondra > > >> > > ><tomas.vondra@2ndquadrant.com> wrote: > > >> > > >> > > >> > > >> On Mon, Oct 05, 2020 at 07:57:41PM +0530, Dilip Kumar wrote: > > >> > > >> >On Mon, Oct 5, 2020 at 5:53 PM Tomas Vondra > > >> > > >> ><tomas.vondra@2ndquadrant.com> wrote: > > >> > > >> >> > > >> > > >> >> On Mon, Oct 05, 2020 at 11:17:28AM +0530, Dilip Kumar wrote: > > >> > > >> >> >On Mon, Oct 5, 2020 at 3:37 AM Tomas Vondra > > >> > > >> >> ><tomas.vondra@2ndquadrant.com> wrote: > > >> > > >> >> > > > >> > > >> >> >Thanks, Tomas for your feedback. > > >> > > >> >> > > > >> > > >> >> >> 9) attcompression ... > > >> > > >> >> >> > > >> > > >> >> >> The main issue I see is what the patch does with attcompression. Instead > > >> > > >> >> >> of just using it to store a the compression method, it's also used to > > >> > > >> >> >> store the preserved compression methods. And using NameData to store > > >> > > >> >> >> this seems wrong too - if we really want to store this info, the correct > > >> > > >> >> >> way is either using text[] or inventing charvector or similar. > > >> > > >> >> > > > >> > > >> >> >The reason for using the NameData is the get it in the fixed part of > > >> > > >> >> >the data structure. > > >> > > >> >> > > > >> > > >> >> > > >> > > >> >> Why do we need that? It's possible to have varlena fields with direct > > >> > > >> >> access (see pg_index.indkey for example). > > >> > > >> > > > >> > > >> >I see. While making it NameData I was thinking whether we have an > > >> > > >> >option to direct access the varlena. Thanks for pointing me there. I > > >> > > >> >will change this. > > >> > > >> > > > >> > > >> > Adding NameData just to make > > >> > > >> >> it fixed-length means we're always adding 64B even if we just need a > > >> > > >> >> single byte, which means ~30% overhead for the FormData_pg_attribute. > > >> > > >> >> That seems a bit unnecessary, and might be an issue with many attributes > > >> > > >> >> (e.g. with many temp tables, etc.). > > >> > > >> > > > >> > > >> >You are right. Even I did not like to keep 64B for this, so I will change it. > > >> > > >> > > > >> > > >> >> > > >> > > >> >> >> But to me this seems very much like a misuse of attcompression to track > > >> > > >> >> >> dependencies on compression methods, necessary because we don't have a > > >> > > >> >> >> separate catalog listing compression methods. If we had that, I think we > > >> > > >> >> >> could simply add dependencies between attributes and that catalog. > > >> > > >> >> > > > >> > > >> >> >Basically, up to this patch, we are having only built-in compression > > >> > > >> >> >methods and those can not be dropped so we don't need any dependency > > >> > > >> >> >at all. We just want to know what is the current compression method > > >> > > >> >> >and what is the preserve compression methods supported for this > > >> > > >> >> >attribute. Maybe we can do it better instead of using the NameData > > >> > > >> >> >but I don't think it makes sense to add a separate catalog? > > >> > > >> >> > > > >> > > >> >> > > >> > > >> >> Sure, I understand what the goal was - all I'm saying is that it looks > > >> > > >> >> very much like a workaround needed because we don't have the catalog. > > >> > > >> >> > > >> > > >> >> I don't quite understand how could we support custom compression methods > > >> > > >> >> without listing them in some sort of catalog? > > >> > > >> > > > >> > > >> >Yeah for supporting custom compression we need some catalog. > > >> > > >> > > > >> > > >> >> >> Moreover, having the catalog would allow adding compression methods > > >> > > >> >> >> (from extensions etc) instead of just having a list of hard-coded > > >> > > >> >> >> compression methods. Which seems like a strange limitation, considering > > >> > > >> >> >> this thread is called "custom compression methods". > > >> > > >> >> > > > >> > > >> >> >I think I forgot to mention while submitting the previous patch that > > >> > > >> >> >the next patch I am planning to submit is, Support creating the custom > > >> > > >> >> >compression methods wherein we can use pg_am catalog to insert the new > > >> > > >> >> >compression method. And for dependency handling, we can create an > > >> > > >> >> >attribute dependency on the pg_am row. Basically, we will create the > > >> > > >> >> >attribute dependency on the current compression method AM as well as > > >> > > >> >> >on the preserved compression methods AM. As part of this, we will > > >> > > >> >> >add two build-in AMs for zlib and pglz, and the attcompression field > > >> > > >> >> >will be converted to the oid_vector (first OID will be of the current > > >> > > >> >> >compression method, followed by the preserved compression method's > > >> > > >> >> >oids). > > >> > > >> >> > > > >> > > >> >> > > >> > > >> >> Hmmm, ok. Not sure pg_am is the right place - compression methods don't > > >> > > >> >> quite match what I though AMs are about, but maybe it's just my fault. > > >> > > >> >> > > >> > > >> >> FWIW it seems a bit strange to first do the attcompression magic and > > >> > > >> >> then add the catalog later - I think we should start with the catalog > > >> > > >> >> right away. The advantage is that if we end up committing only some of > > >> > > >> >> the patches in this cycle, we already have all the infrastructure etc. > > >> > > >> >> We can reorder that later, though. > > >> > > >> > > > >> > > >> >Hmm, yeah we can do this way as well that first create a new catalog > > >> > > >> >table and add entries for these two built-in methods and the > > >> > > >> >attcompression can store the oid vector. But if we only commit the > > >> > > >> >build-in compression methods part then does it make sense to create an > > >> > > >> >extra catalog or adding these build-in methods to the existing catalog > > >> > > >> >(if we plan to use pg_am). Then in attcompression instead of using > > >> > > >> >one byte for each preserve compression method, we need to use oid. So > > >> > > >> >from Robert's mail[1], it appeared to me that he wants that the > > >> > > >> >build-in compression methods part should be independently committable > > >> > > >> >and if we think from that perspective then adding a catalog doesn't > > >> > > >> >make much sense. But if we are planning to commit the custom method > > >> > > >> >also then it makes more sense to directly start with the catalog > > >> > > >> >because that way it will be easy to expand without much refactoring. > > >> > > >> > > > >> > > >> >[1] https://www.postgresql.org/message-id/CA%2BTgmobSDVgUage9qQ5P_%3DF_9jaMkCgyKxUQGtFQU7oN4kX-AA%40mail.gmail.com > > >> > > >> > > > >> > > >> > > >> > > >> Hmmm. Maybe I'm missing something subtle, but I think that plan can be > > >> > > >> interpreted in various ways - it does not really say whether the initial > > >> > > >> list of built-in methods should be in some C array, or already in a proper > > >> > > >> catalog. > > >> > > >> > > >> > > >> All I'm saying is it seems a bit weird to first implement dependencies > > >> > > >> based on strange (mis)use of attcompression attribute, and then replace > > >> > > >> it with a proper catalog. My understanding is those patches are expected > > >> > > >> to be committable one by one, but the attcompression approach seems a > > >> > > >> bit too hacky to me - not sure I'd want to commit that ... > > >> > > > > > >> > > >Okay, I will change this. So I will make create a new catalog > > >> > > >pg_compression and add the entry for two built-in compression methods > > >> > > >from the very first patch. > > >> > > > > > >> > > > > >> > > OK. > > >> > > >> I have changed the first 2 patches, basically, now we are providing a > > >> new catalog pg_compression and the pg_attribute is storing the oid of > > >> the compression method. The patches still need some cleanup and there > > >> is also one open comment that for index we should use its table > > >> compression. > > >> > > >> I am still working on the preserve patch. For preserving the > > >> compression method I am planning to convert the attcompression field > > >> to the oidvector so that we can store the oid of the preserve method > > >> also. I am not sure whether we can access this oidvector as a fixed > > >> part of the FormData_pg_attribute or not. The reason is that for > > >> building the tuple descriptor, we need to give the size of the fixed > > >> part (#define ATTRIBUTE_FIXED_PART_SIZE \ > > >> (offsetof(FormData_pg_attribute,attcompression) + sizeof(Oid))). But > > >> if we convert this to the oidvector then we don't know the size of the > > >> fixed part. Am I missing something? > > > > > >I could think of two solutions here > > >Sol1. > > >Make the first oid of the oidvector as part of the fixed size, like below > > >#define ATTRIBUTE_FIXED_PART_SIZE \ > > >(offsetof(FormData_pg_attribute, attcompression) + OidVectorSize(1)) > > > > > >Sol2: > > >Keep attcompression as oid only and for the preserve list, adds > > >another field in the variable part which will be of type oidvector. I > > >think most of the time we need to access the current compression > > >method and with this solution, we will be able to access that as part > > >of the tuple desc. > > > > > > > And is the oidvector actually needed? If we have the extra catalog, > > can't we track this simply using the regular dependencies? So we'd have > > the attcompression OID of the current compression method, and the > > preserved values would be tracked in pg_depend. > > Right, we can do that as well. Actually, the preserved list need to > be accessed only in case of ALTER TABLE SET COMPRESSION and INSERT > INTO SELECT * FROM queries. So in such cases, I think it is okay to > get the preserved compression oids from pg_depends. I have worked on this patch, so as discussed now I am maintaining the preserved compression methods using dependency. Still PRESERVE ALL syntax is not supported, I will work on that part. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Mon, Oct 12, 2020 at 02:28:43PM +0530, Dilip Kumar wrote: > >> ... > >I have worked on this patch, so as discussed now I am maintaining the >preserved compression methods using dependency. Still PRESERVE ALL >syntax is not supported, I will work on that part. > Cool, I'll take a look. What's your opinion on doing it this way? Do you think it's cleaner / more elegant, or is it something contrary to what the dependencies are meant to do? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Oct 12, 2020 at 7:32 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > On Mon, Oct 12, 2020 at 02:28:43PM +0530, Dilip Kumar wrote: > > > >> ... > > > >I have worked on this patch, so as discussed now I am maintaining the > >preserved compression methods using dependency. Still PRESERVE ALL > >syntax is not supported, I will work on that part. > > > > Cool, I'll take a look. What's your opinion on doing it this way? Do you > think it's cleaner / more elegant, or is it something contrary to what > the dependencies are meant to do? I think this looks much cleaner. Moreover, I feel that once we start supporting the custom compression methods then we anyway have to maintain the dependency so using that for finding the preserved compression method is good option. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Oct 13, 2020 at 10:30 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Mon, Oct 12, 2020 at 7:32 PM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: > > > > On Mon, Oct 12, 2020 at 02:28:43PM +0530, Dilip Kumar wrote: > > > > > >> ... > > > > > >I have worked on this patch, so as discussed now I am maintaining the > > >preserved compression methods using dependency. Still PRESERVE ALL > > >syntax is not supported, I will work on that part. > > > > > > > Cool, I'll take a look. What's your opinion on doing it this way? Do you > > think it's cleaner / more elegant, or is it something contrary to what > > the dependencies are meant to do? > > I think this looks much cleaner. Moreover, I feel that once we start > supporting the custom compression methods then we anyway have to > maintain the dependency so using that for finding the preserved > compression method is good option. I have also implemented the next set of patches. 0004 -> Provide a way to create custom compression methods 0005 -> Extention to implement lz4 as a custom compression method. A pending list of items: 1. Provide support for handling the compression option - As discussed up thread I will store the compression option of the latest compression method in a new field in pg_atrribute table 2. As of now I have kept zlib as the second built-in option and lz4 as a custom compression extension. In Offlist discussion with Robert, he suggested that we should keep lz4 as the built-in method and we can move zlib as an extension because lz4 is faster than zlib so better to keep that as the built-in method. So in the next version, I will change that. Any different opinion on this? 3. Improve the documentation, especially for create_compression_method. 4. By default support table compression method for the index. 5. Support the PRESERVE ALL option so that we can preserve all existing lists of compression methods without providing the whole list. 6. Cleanup of 0004 and 0005 as they are still WIP. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Sat, Oct 17, 2020 at 11:34 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Oct 13, 2020 at 10:30 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Mon, Oct 12, 2020 at 7:32 PM Tomas Vondra > > <tomas.vondra@2ndquadrant.com> wrote: > > > > > > On Mon, Oct 12, 2020 at 02:28:43PM +0530, Dilip Kumar wrote: > > > > > > > >> ... > > > > > > > >I have worked on this patch, so as discussed now I am maintaining the > > > >preserved compression methods using dependency. Still PRESERVE ALL > > > >syntax is not supported, I will work on that part. > > > > > > > > > > Cool, I'll take a look. What's your opinion on doing it this way? Do you > > > think it's cleaner / more elegant, or is it something contrary to what > > > the dependencies are meant to do? > > > > I think this looks much cleaner. Moreover, I feel that once we start > > supporting the custom compression methods then we anyway have to > > maintain the dependency so using that for finding the preserved > > compression method is good option. > > I have also implemented the next set of patches. > 0004 -> Provide a way to create custom compression methods > 0005 -> Extention to implement lz4 as a custom compression method. In the updated version I have worked on some of the listed items > A pending list of items: > 1. Provide support for handling the compression option > - As discussed up thread I will store the compression option of the > latest compression method in a new field in pg_atrribute table > 2. As of now I have kept zlib as the second built-in option and lz4 as > a custom compression extension. In Offlist discussion with Robert, he > suggested that we should keep lz4 as the built-in method and we can > move zlib as an extension because lz4 is faster than zlib so better to > keep that as the built-in method. So in the next version, I will > change that. Any different opinion on this? Done > 3. Improve the documentation, especially for create_compression_method. > 4. By default support table compression method for the index. Done > 5. Support the PRESERVE ALL option so that we can preserve all > existing lists of compression methods without providing the whole > list. 1,3,5 points are still pending. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Thu, Oct 8, 2020 at 5:54 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > And is the oidvector actually needed? If we have the extra catalog, > can't we track this simply using the regular dependencies? So we'd have > the attcompression OID of the current compression method, and the > preserved values would be tracked in pg_depend. If we go that route, we have to be sure that no such dependencies can exist for any other reason. Otherwise, there would be confusion about whether the dependency was there because values of that type were being preserved in the table, or whether it was for the hypothetical other reason. Now, admittedly, I can't quite think how that would happen. For example, if the attribute default expression somehow embedded a reference to a compression AM, that wouldn't cause this problem, because the dependency would be on the attribute default rather than the attribute itself. So maybe it's fine. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Oct 21, 2020 at 01:59:50PM +0530, Dilip Kumar wrote:
>On Sat, Oct 17, 2020 at 11:34 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>>
>> On Tue, Oct 13, 2020 at 10:30 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>> >
>> > On Mon, Oct 12, 2020 at 7:32 PM Tomas Vondra
>> > <tomas.vondra@2ndquadrant.com> wrote:
>> > >
>> > > On Mon, Oct 12, 2020 at 02:28:43PM +0530, Dilip Kumar wrote:
>> > > >
>> > > >> ...
>> > > >
>> > > >I have worked on this patch, so as discussed now I am maintaining the
>> > > >preserved compression methods using dependency. Still PRESERVE ALL
>> > > >syntax is not supported, I will work on that part.
>> > > >
>> > >
>> > > Cool, I'll take a look. What's your opinion on doing it this way? Do you
>> > > think it's cleaner / more elegant, or is it something contrary to what
>> > > the dependencies are meant to do?
>> >
>> > I think this looks much cleaner. Moreover, I feel that once we start
>> > supporting the custom compression methods then we anyway have to
>> > maintain the dependency so using that for finding the preserved
>> > compression method is good option.
>>
>> I have also implemented the next set of patches.
>> 0004 -> Provide a way to create custom compression methods
>> 0005 -> Extention to implement lz4 as a custom compression method.
>
>In the updated version I have worked on some of the listed items
>> A pending list of items:
>> 1. Provide support for handling the compression option
>> - As discussed up thread I will store the compression option of the
>> latest compression method in a new field in pg_atrribute table
>> 2. As of now I have kept zlib as the second built-in option and lz4 as
>> a custom compression extension. In Offlist discussion with Robert, he
>> suggested that we should keep lz4 as the built-in method and we can
>> move zlib as an extension because lz4 is faster than zlib so better to
>> keep that as the built-in method. So in the next version, I will
>> change that. Any different opinion on this?
>
>Done
>
>> 3. Improve the documentation, especially for create_compression_method.
>> 4. By default support table compression method for the index.
>
>Done
>
>> 5. Support the PRESERVE ALL option so that we can preserve all
>> existing lists of compression methods without providing the whole
>> list.
>
>1,3,5 points are still pending.
>
Thanks. I took a quick look at the patches and I think it seems fine. I
have one question, though - toast_compress_datum contains this code:
/* Call the actual compression function */
tmp = cmroutine->cmcompress((const struct varlena *) value);
if (!tmp)
return PointerGetDatum(NULL);
Shouldn't this really throw an error instead? I mean, if the compression
library returns NULL, isn't that an error?
regards
>--
>Regards,
>Dilip Kumar
>EnterpriseDB: http://www.enterprisedb.com
On Thu, Oct 22, 2020 at 2:11 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > On Wed, Oct 21, 2020 at 01:59:50PM +0530, Dilip Kumar wrote: > >On Sat, Oct 17, 2020 at 11:34 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > >> > >> On Tue, Oct 13, 2020 at 10:30 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > >> > > >> > On Mon, Oct 12, 2020 at 7:32 PM Tomas Vondra > >> > <tomas.vondra@2ndquadrant.com> wrote: > >> > > > >> > > On Mon, Oct 12, 2020 at 02:28:43PM +0530, Dilip Kumar wrote: > >> > > > > >> > > >> ... > >> > > > > >> > > >I have worked on this patch, so as discussed now I am maintaining the > >> > > >preserved compression methods using dependency. Still PRESERVE ALL > >> > > >syntax is not supported, I will work on that part. > >> > > > > >> > > > >> > > Cool, I'll take a look. What's your opinion on doing it this way? Do you > >> > > think it's cleaner / more elegant, or is it something contrary to what > >> > > the dependencies are meant to do? > >> > > >> > I think this looks much cleaner. Moreover, I feel that once we start > >> > supporting the custom compression methods then we anyway have to > >> > maintain the dependency so using that for finding the preserved > >> > compression method is good option. > >> > >> I have also implemented the next set of patches. > >> 0004 -> Provide a way to create custom compression methods > >> 0005 -> Extention to implement lz4 as a custom compression method. > > > >In the updated version I have worked on some of the listed items > >> A pending list of items: > >> 1. Provide support for handling the compression option > >> - As discussed up thread I will store the compression option of the > >> latest compression method in a new field in pg_atrribute table > >> 2. As of now I have kept zlib as the second built-in option and lz4 as > >> a custom compression extension. In Offlist discussion with Robert, he > >> suggested that we should keep lz4 as the built-in method and we can > >> move zlib as an extension because lz4 is faster than zlib so better to > >> keep that as the built-in method. So in the next version, I will > >> change that. Any different opinion on this? > > > >Done > > > >> 3. Improve the documentation, especially for create_compression_method. > >> 4. By default support table compression method for the index. > > > >Done > > > >> 5. Support the PRESERVE ALL option so that we can preserve all > >> existing lists of compression methods without providing the whole > >> list. > > > >1,3,5 points are still pending. > > > > Thanks. I took a quick look at the patches and I think it seems fine. I > have one question, though - toast_compress_datum contains this code: > > > /* Call the actual compression function */ > tmp = cmroutine->cmcompress((const struct varlena *) value); > if (!tmp) > return PointerGetDatum(NULL); > > > Shouldn't this really throw an error instead? I mean, if the compression > library returns NULL, isn't that an error? I don't think that we can throw an error here because pglz_compress might return -1 if it finds that it can not reduce the size of the data and we consider such data as "incompressible data" and return NULL. In such a case the caller will try to compress another attribute of the tuple. I think we can handle such cases in the specific handler functions. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Oct 21, 2020 at 8:51 PM Robert Haas <robertmhaas@gmail.com> wrote: > > On Thu, Oct 8, 2020 at 5:54 PM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: > > And is the oidvector actually needed? If we have the extra catalog, > > can't we track this simply using the regular dependencies? So we'd have > > the attcompression OID of the current compression method, and the > > preserved values would be tracked in pg_depend. > > If we go that route, we have to be sure that no such dependencies can > exist for any other reason. Otherwise, there would be confusion about > whether the dependency was there because values of that type were > being preserved in the table, or whether it was for the hypothetical > other reason. Now, admittedly, I can't quite think how that would > happen. For example, if the attribute default expression somehow > embedded a reference to a compression AM, that wouldn't cause this > problem, because the dependency would be on the attribute default > rather than the attribute itself. So maybe it's fine. Yeah, and moreover in the new patchset, we are storing the compression methods in the new catalog 'pg_compression' instead of merging with the pg_am. So I think only for the preserve purpose we will maintain the attribute -> pg_compression dependency so it should be fine. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Thu, Oct 22, 2020 at 10:41 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Thu, Oct 22, 2020 at 2:11 AM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: > > > > On Wed, Oct 21, 2020 at 01:59:50PM +0530, Dilip Kumar wrote: > > >On Sat, Oct 17, 2020 at 11:34 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > >> > > >> On Tue, Oct 13, 2020 at 10:30 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > >> > > > >> > On Mon, Oct 12, 2020 at 7:32 PM Tomas Vondra > > >> > <tomas.vondra@2ndquadrant.com> wrote: > > >> > > > > >> > > On Mon, Oct 12, 2020 at 02:28:43PM +0530, Dilip Kumar wrote: > > >> > > > > > >> > > >> ... > > >> > > > > > >> > > >I have worked on this patch, so as discussed now I am maintaining the > > >> > > >preserved compression methods using dependency. Still PRESERVE ALL > > >> > > >syntax is not supported, I will work on that part. > > >> > > > > > >> > > > > >> > > Cool, I'll take a look. What's your opinion on doing it this way? Do you > > >> > > think it's cleaner / more elegant, or is it something contrary to what > > >> > > the dependencies are meant to do? > > >> > > > >> > I think this looks much cleaner. Moreover, I feel that once we start > > >> > supporting the custom compression methods then we anyway have to > > >> > maintain the dependency so using that for finding the preserved > > >> > compression method is good option. > > >> > > >> I have also implemented the next set of patches. > > >> 0004 -> Provide a way to create custom compression methods > > >> 0005 -> Extention to implement lz4 as a custom compression method. > > > > > >In the updated version I have worked on some of the listed items > > >> A pending list of items: > > >> 1. Provide support for handling the compression option > > >> - As discussed up thread I will store the compression option of the > > >> latest compression method in a new field in pg_atrribute table > > >> 2. As of now I have kept zlib as the second built-in option and lz4 as > > >> a custom compression extension. In Offlist discussion with Robert, he > > >> suggested that we should keep lz4 as the built-in method and we can > > >> move zlib as an extension because lz4 is faster than zlib so better to > > >> keep that as the built-in method. So in the next version, I will > > >> change that. Any different opinion on this? > > > > > >Done > > > > > >> 3. Improve the documentation, especially for create_compression_method. > > >> 4. By default support table compression method for the index. > > > > > >Done > > > > > >> 5. Support the PRESERVE ALL option so that we can preserve all > > >> existing lists of compression methods without providing the whole > > >> list. > > > > > >1,3,5 points are still pending. > > > > > > > Thanks. I took a quick look at the patches and I think it seems fine. I > > have one question, though - toast_compress_datum contains this code: > > > > > > /* Call the actual compression function */ > > tmp = cmroutine->cmcompress((const struct varlena *) value); > > if (!tmp) > > return PointerGetDatum(NULL); > > > > > > Shouldn't this really throw an error instead? I mean, if the compression > > library returns NULL, isn't that an error? > > I don't think that we can throw an error here because pglz_compress > might return -1 if it finds that it can not reduce the size of the > data and we consider such data as "incompressible data" and return > NULL. In such a case the caller will try to compress another > attribute of the tuple. I think we can handle such cases in the > specific handler functions. I have added the compression failure error in lz4.c, please refer lz4_cmcompress in v9-0001 patch. Apart from that, I have also supported the PRESERVE ALL syntax to preserve all the existing compression methods. I have also rebased the patch on the current head. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Thu, Oct 22, 2020 at 5:56 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Thu, Oct 22, 2020 at 10:41 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Thu, Oct 22, 2020 at 2:11 AM Tomas Vondra > > <tomas.vondra@2ndquadrant.com> wrote: > > > > > > On Wed, Oct 21, 2020 at 01:59:50PM +0530, Dilip Kumar wrote: > > > >On Sat, Oct 17, 2020 at 11:34 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > >> > > > >> On Tue, Oct 13, 2020 at 10:30 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > >> > > > > >> > On Mon, Oct 12, 2020 at 7:32 PM Tomas Vondra > > > >> > <tomas.vondra@2ndquadrant.com> wrote: > > > >> > > > > > >> > > On Mon, Oct 12, 2020 at 02:28:43PM +0530, Dilip Kumar wrote: > > > >> > > > > > > >> > > >> ... > > > >> > > > > > > >> > > >I have worked on this patch, so as discussed now I am maintaining the > > > >> > > >preserved compression methods using dependency. Still PRESERVE ALL > > > >> > > >syntax is not supported, I will work on that part. > > > >> > > > > > > >> > > > > > >> > > Cool, I'll take a look. What's your opinion on doing it this way? Do you > > > >> > > think it's cleaner / more elegant, or is it something contrary to what > > > >> > > the dependencies are meant to do? > > > >> > > > > >> > I think this looks much cleaner. Moreover, I feel that once we start > > > >> > supporting the custom compression methods then we anyway have to > > > >> > maintain the dependency so using that for finding the preserved > > > >> > compression method is good option. > > > >> > > > >> I have also implemented the next set of patches. > > > >> 0004 -> Provide a way to create custom compression methods > > > >> 0005 -> Extention to implement lz4 as a custom compression method. > > > > > > > >In the updated version I have worked on some of the listed items > > > >> A pending list of items: > > > >> 1. Provide support for handling the compression option > > > >> - As discussed up thread I will store the compression option of the > > > >> latest compression method in a new field in pg_atrribute table > > > >> 2. As of now I have kept zlib as the second built-in option and lz4 as > > > >> a custom compression extension. In Offlist discussion with Robert, he > > > >> suggested that we should keep lz4 as the built-in method and we can > > > >> move zlib as an extension because lz4 is faster than zlib so better to > > > >> keep that as the built-in method. So in the next version, I will > > > >> change that. Any different opinion on this? > > > > > > > >Done > > > > > > > >> 3. Improve the documentation, especially for create_compression_method. > > > >> 4. By default support table compression method for the index. > > > > > > > >Done > > > > > > > >> 5. Support the PRESERVE ALL option so that we can preserve all > > > >> existing lists of compression methods without providing the whole > > > >> list. > > > > > > > >1,3,5 points are still pending. > > > > > > > > > > Thanks. I took a quick look at the patches and I think it seems fine. I > > > have one question, though - toast_compress_datum contains this code: > > > > > > > > > /* Call the actual compression function */ > > > tmp = cmroutine->cmcompress((const struct varlena *) value); > > > if (!tmp) > > > return PointerGetDatum(NULL); > > > > > > > > > Shouldn't this really throw an error instead? I mean, if the compression > > > library returns NULL, isn't that an error? > > > > I don't think that we can throw an error here because pglz_compress > > might return -1 if it finds that it can not reduce the size of the > > data and we consider such data as "incompressible data" and return > > NULL. In such a case the caller will try to compress another > > attribute of the tuple. I think we can handle such cases in the > > specific handler functions. > > I have added the compression failure error in lz4.c, please refer > lz4_cmcompress in v9-0001 patch. Apart from that, I have also > supported the PRESERVE ALL syntax to preserve all the existing > compression methods. I have also rebased the patch on the current > head. I have added the next patch to support the compression options. I am storing the compression options only for the latest compression method. Basically, based on this design we would be able to support the options which are used only for compressions. As of now, the compression option infrastructure is added and the compression options for inbuilt method pglz and the external method zlib are added. Next, I will work on adding the options for the lz4 method. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Tue, Oct 27, 2020 at 10:54 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Thu, Oct 22, 2020 at 5:56 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Thu, Oct 22, 2020 at 10:41 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > > > On Thu, Oct 22, 2020 at 2:11 AM Tomas Vondra > > > <tomas.vondra@2ndquadrant.com> wrote: > > > > > > > > On Wed, Oct 21, 2020 at 01:59:50PM +0530, Dilip Kumar wrote: > > > > >On Sat, Oct 17, 2020 at 11:34 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > >> > > > > >> On Tue, Oct 13, 2020 at 10:30 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > >> > > > > > >> > On Mon, Oct 12, 2020 at 7:32 PM Tomas Vondra > > > > >> > <tomas.vondra@2ndquadrant.com> wrote: > > > > >> > > > > > > >> > > On Mon, Oct 12, 2020 at 02:28:43PM +0530, Dilip Kumar wrote: > > > > >> > > > > > > > >> > > >> ... > > > > >> > > > > > > > >> > > >I have worked on this patch, so as discussed now I am maintaining the > > > > >> > > >preserved compression methods using dependency. Still PRESERVE ALL > > > > >> > > >syntax is not supported, I will work on that part. > > > > >> > > > > > > > >> > > > > > > >> > > Cool, I'll take a look. What's your opinion on doing it this way? Do you > > > > >> > > think it's cleaner / more elegant, or is it something contrary to what > > > > >> > > the dependencies are meant to do? > > > > >> > > > > > >> > I think this looks much cleaner. Moreover, I feel that once we start > > > > >> > supporting the custom compression methods then we anyway have to > > > > >> > maintain the dependency so using that for finding the preserved > > > > >> > compression method is good option. > > > > >> > > > > >> I have also implemented the next set of patches. > > > > >> 0004 -> Provide a way to create custom compression methods > > > > >> 0005 -> Extention to implement lz4 as a custom compression method. > > > > > > > > > >In the updated version I have worked on some of the listed items > > > > >> A pending list of items: > > > > >> 1. Provide support for handling the compression option > > > > >> - As discussed up thread I will store the compression option of the > > > > >> latest compression method in a new field in pg_atrribute table > > > > >> 2. As of now I have kept zlib as the second built-in option and lz4 as > > > > >> a custom compression extension. In Offlist discussion with Robert, he > > > > >> suggested that we should keep lz4 as the built-in method and we can > > > > >> move zlib as an extension because lz4 is faster than zlib so better to > > > > >> keep that as the built-in method. So in the next version, I will > > > > >> change that. Any different opinion on this? > > > > > > > > > >Done > > > > > > > > > >> 3. Improve the documentation, especially for create_compression_method. > > > > >> 4. By default support table compression method for the index. > > > > > > > > > >Done > > > > > > > > > >> 5. Support the PRESERVE ALL option so that we can preserve all > > > > >> existing lists of compression methods without providing the whole > > > > >> list. > > > > > > > > > >1,3,5 points are still pending. > > > > > > > > > > > > > Thanks. I took a quick look at the patches and I think it seems fine. I > > > > have one question, though - toast_compress_datum contains this code: > > > > > > > > > > > > /* Call the actual compression function */ > > > > tmp = cmroutine->cmcompress((const struct varlena *) value); > > > > if (!tmp) > > > > return PointerGetDatum(NULL); > > > > > > > > > > > > Shouldn't this really throw an error instead? I mean, if the compression > > > > library returns NULL, isn't that an error? > > > > > > I don't think that we can throw an error here because pglz_compress > > > might return -1 if it finds that it can not reduce the size of the > > > data and we consider such data as "incompressible data" and return > > > NULL. In such a case the caller will try to compress another > > > attribute of the tuple. I think we can handle such cases in the > > > specific handler functions. > > > > I have added the compression failure error in lz4.c, please refer > > lz4_cmcompress in v9-0001 patch. Apart from that, I have also > > supported the PRESERVE ALL syntax to preserve all the existing > > compression methods. I have also rebased the patch on the current > > head. > > I have added the next patch to support the compression options. I am > storing the compression options only for the latest compression > method. Basically, based on this design we would be able to support > the options which are used only for compressions. As of now, the > compression option infrastructure is added and the compression options > for inbuilt method pglz and the external method zlib are added. Next, > I will work on adding the options for the lz4 method. In the attached patch set I have also included the compression option support for lz4. As of now, I have only supported the acceleration for LZ4_compress_fast. There is also support for the dictionary-based compression but if we try to support that then we will need the dictionary for decompression also. Since we are only keeping the options for the current compression methods, we can not support dictionary-based options as of now. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Oct 28, 2020 at 01:16:31PM +0530, Dilip Kumar wrote: >> >> ... >> >> I have added the next patch to support the compression options. I am >> storing the compression options only for the latest compression >> method. Basically, based on this design we would be able to support >> the options which are used only for compressions. As of now, the >> compression option infrastructure is added and the compression options >> for inbuilt method pglz and the external method zlib are added. Next, >> I will work on adding the options for the lz4 method. > >In the attached patch set I have also included the compression option >support for lz4. As of now, I have only supported the acceleration >for LZ4_compress_fast. There is also support for the dictionary-based >compression but if we try to support that then we will need the >dictionary for decompression also. Since we are only keeping the >options for the current compression methods, we can not support >dictionary-based options as of now. > OK, thanks. Do you have any other plans to improve this patch series? I plan to do some testing and review, but if you're likely to post another version soon then I'd wait a bit. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Oct 29, 2020 at 12:31 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > On Wed, Oct 28, 2020 at 01:16:31PM +0530, Dilip Kumar wrote: > >> > >> ... > >> > >> I have added the next patch to support the compression options. I am > >> storing the compression options only for the latest compression > >> method. Basically, based on this design we would be able to support > >> the options which are used only for compressions. As of now, the > >> compression option infrastructure is added and the compression options > >> for inbuilt method pglz and the external method zlib are added. Next, > >> I will work on adding the options for the lz4 method. > > > >In the attached patch set I have also included the compression option > >support for lz4. As of now, I have only supported the acceleration > >for LZ4_compress_fast. There is also support for the dictionary-based > >compression but if we try to support that then we will need the > >dictionary for decompression also. Since we are only keeping the > >options for the current compression methods, we can not support > >dictionary-based options as of now. > > > > OK, thanks. Do you have any other plans to improve this patch series? I > plan to do some testing and review, but if you're likely to post another > version soon then I'd wait a bit. There was some issue in create_compression_method.sgml and the drop_compression_method.sgml was missing. I have fixed that in the attached patch. Now I am not planning to change anything soon so you can review. Thanks. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Thu, Oct 29, 2020 at 12:07 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Thu, Oct 29, 2020 at 12:31 AM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: > > > > On Wed, Oct 28, 2020 at 01:16:31PM +0530, Dilip Kumar wrote: > > >> > > >> ... > > >> > > >> I have added the next patch to support the compression options. I am > > >> storing the compression options only for the latest compression > > >> method. Basically, based on this design we would be able to support > > >> the options which are used only for compressions. As of now, the > > >> compression option infrastructure is added and the compression options > > >> for inbuilt method pglz and the external method zlib are added. Next, > > >> I will work on adding the options for the lz4 method. > > > > > >In the attached patch set I have also included the compression option > > >support for lz4. As of now, I have only supported the acceleration > > >for LZ4_compress_fast. There is also support for the dictionary-based > > >compression but if we try to support that then we will need the > > >dictionary for decompression also. Since we are only keeping the > > >options for the current compression methods, we can not support > > >dictionary-based options as of now. > > > > > > > OK, thanks. Do you have any other plans to improve this patch series? I > > plan to do some testing and review, but if you're likely to post another > > version soon then I'd wait a bit. > > There was some issue in create_compression_method.sgml and the > drop_compression_method.sgml was missing. I have fixed that in the > attached patch. Now I am not planning to change anything soon so you > can review. Thanks. The patches were not applying on the current head so I have re-based them. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Sun, Nov 8, 2020 at 4:29 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Thu, Oct 29, 2020 at 12:07 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Thu, Oct 29, 2020 at 12:31 AM Tomas Vondra > > <tomas.vondra@2ndquadrant.com> wrote: > > > > > > On Wed, Oct 28, 2020 at 01:16:31PM +0530, Dilip Kumar wrote: > > > >> > > > >> ... > > > >> > > > >> I have added the next patch to support the compression options. I am > > > >> storing the compression options only for the latest compression > > > >> method. Basically, based on this design we would be able to support > > > >> the options which are used only for compressions. As of now, the > > > >> compression option infrastructure is added and the compression options > > > >> for inbuilt method pglz and the external method zlib are added. Next, > > > >> I will work on adding the options for the lz4 method. > > > > > > > >In the attached patch set I have also included the compression option > > > >support for lz4. As of now, I have only supported the acceleration > > > >for LZ4_compress_fast. There is also support for the dictionary-based > > > >compression but if we try to support that then we will need the > > > >dictionary for decompression also. Since we are only keeping the > > > >options for the current compression methods, we can not support > > > >dictionary-based options as of now. > > > > > > > > > > OK, thanks. Do you have any other plans to improve this patch series? I > > > plan to do some testing and review, but if you're likely to post another > > > version soon then I'd wait a bit. > > > > There was some issue in create_compression_method.sgml and the > > drop_compression_method.sgml was missing. I have fixed that in the > > attached patch. Now I am not planning to change anything soon so you > > can review. Thanks. > > The patches were not applying on the current head so I have re-based them. There were a few problems in this rebased version, basically, the compression options were not passed while compressing values from the brin_form_tuple, so I have fixed this. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Nov 11, 2020 at 9:39 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> There were a few problems in this rebased version, basically, the
> compression options were not passed while compressing values from the
> brin_form_tuple, so I have fixed this.
Since the authorship history of this patch is complicated, it would be
nice if you would include authorship information and relevant
"Discussion" links in the patches.
Design level considerations and overall notes:
configure is autogenerated from configure.in, so the patch shouldn't
include changes only to the former.
Looking over the changes to src/include:
+ PGLZ_COMPRESSION_ID,
+ LZ4_COMPRESSION_ID
I think that it would be good to assign values to these explicitly.
+/* compresion handler routines */
Spelling.
+ /* compression routine for the compression method */
+ cmcompress_function cmcompress;
+
+ /* decompression routine for the compression method */
+ cmcompress_function cmdecompress;
Don't reuse cmcompress_function; that's confusing. Just have a typedef
per structure member, even if they end up being the same.
#define TOAST_COMPRESS_SET_RAWSIZE(ptr, len) \
- (((toast_compress_header *) (ptr))->rawsize = (len))
+do { \
+ Assert(len > 0 && len <= RAWSIZEMASK); \
+ ((toast_compress_header *) (ptr))->info = (len); \
+} while (0)
Indentation.
+#define TOAST_COMPRESS_SET_COMPRESSION_METHOD(ptr, cm_method) \
+ ((toast_compress_header *) (ptr))->info |= ((cm_method) << 30);
What about making TOAST_COMPRESS_SET_RAWSIZE() take another argument?
And possibly also rename it to TEST_COMPRESS_SET_SIZE_AND_METHOD() or
something? It seems not great to have separate functions each setting
part of a 4-byte quantity. Too much chance of failing to set both
parts. I guess you've got a function called
toast_set_compressed_datum_info() for that, but it's just a wrapper
around two macros that could just be combined, which would reduce
complexity overall.
+ T_CompressionRoutine, /* in access/compressionapi.h */
This looks misplaced. I guess it should go just after these:
T_FdwRoutine, /* in foreign/fdwapi.h */
T_IndexAmRoutine, /* in access/amapi.h */
T_TableAmRoutine, /* in access/tableam.h */
Looking over the regression test changes:
The tests at the top of create_cm.out that just test that we can
create tables with various storage types seem unrelated to the purpose
of the patch. And the file doesn't test creating a compression method
either, as the file name would suggest, so either the file name needs
to be changed (compression, compression_method?) or the tests don't go
here.
+-- check data is okdd
I guess whoever is responsible for this comment prefers vi to emacs.
I don't quite understand the purpose of all of these tests, and there
are some things that I feel like ought to be tested that seemingly
aren't. Like, you seem to test using an UPDATE to move a datum from a
table to another table with the same compression method, but not one
with a different compression method. Testing the former is nice and
everything, but that's the easy case: I think we also need to test the
latter. I think it would be good to verify not only that the data is
readable but that it's compressed the way we expect. I think it would
be a great idea to add a pg_column_compression() function in a similar
spirit to pg_column_size(). Perhaps it could return NULL when
compression is not in use or the data type is not varlena, and the
name of the compression method otherwise. That would allow for better
testing of this feature, and it would also be useful to users who are
switching methods, to see what data they still have that's using the
old method. It could be useful for debugging problems on customer
systems, too.
I wonder if we need a test that moves data between tables through an
intermediary. For instance, suppose a plpgsql function or DO block
fetches some data and stores it in a plpgsql variable and then uses
the variable to insert into another table. Hmm, maybe that would force
de-TOASTing. But perhaps there are other cases. Maybe a more general
way to approach the problem is: have you tried running a coverage
report and checked which parts of your code are getting exercised by
the existing tests and which parts are not? The stuff that isn't, we
should try to add more tests. It's easy to get corner cases wrong with
this kind of thing.
I notice that LIKE INCLUDING COMPRESSION doesn't seem to be tested, at
least not by 0001, which reinforces my feeling that the tests here are
not as thorough as they could be.
+NOTICE: pg_compression contains unpinned initdb-created object(s)
This seems wrong to me - why is it OK?
- result = (struct varlena *)
- palloc(TOAST_COMPRESS_RAWSIZE(attr) + VARHDRSZ);
- SET_VARSIZE(result, TOAST_COMPRESS_RAWSIZE(attr) + VARHDRSZ);
+ cmoid = GetCompressionOidFromCompressionId(TOAST_COMPRESS_METHOD(attr));
- if (pglz_decompress(TOAST_COMPRESS_RAWDATA(attr),
- TOAST_COMPRESS_SIZE(attr),
- VARDATA(result),
-
TOAST_COMPRESS_RAWSIZE(attr), true) < 0)
- elog(ERROR, "compressed data is corrupted");
+ /* get compression method handler routines */
+ cmroutine = GetCompressionRoutine(cmoid);
- return result;
+ return cmroutine->cmdecompress(attr);
I'm worried about how expensive this might be, and I think we could
make it cheaper. The reason why I think this might be expensive is:
currently, for every datum, you have a single direct function call.
Now, with this, you first have a direct function call to
GetCompressionOidFromCompressionId(). Then you have a call to
GetCompressionRoutine(), which does a syscache lookup and calls a
handler function, which is quite a lot more expensive than a single
function call. And the handler isn't even returning a statically
allocated structure, but is allocating new memory every time, which
involves more function calls and maybe memory leaks. Then you use the
results of all that to make an indirect function call.
I'm not sure exactly what combination of things we could use to make
this better, but it seems like there are a few possibilities:
(1) The handler function could return a pointer to the same
CompressionRoutine every time instead of constructing a new one every
time.
(2) The CompressionRoutine to which the handler function returns a
pointer could be statically allocated instead of being built at
runtime.
(3) GetCompressionRoutine could have an OID -> handler cache instead
of relying on syscache + calling the handler function all over again.
(4) For the compression types that have dedicated bit patterns in the
high bits of the compressed TOAST size, toast_compress_datum() could
just have hard-coded logic to use the correct handlers instead of
translating the bit pattern into an OID and then looking it up over
again.
(5) Going even further than #4 we could skip the handler layer
entirely for such methods, and just call the right function directly.
I think we should definitely do (1), and also (2) unless there's some
reason it's hard. (3) doesn't need to be part of this patch, but might
be something to consider later in the series. It's possible that it
doesn't have enough benefit to be worth the work, though. Also, I
think we should do either (4) or (5). I have a mild preference for (5)
unless it looks too ugly.
Note that I'm not talking about hard-coding a fast path for a
hard-coded list of OIDs - which would seem a little bit unprincipled -
but hard-coding a fast path for the bit patterns that are themselves
hard-coded. I don't think we lose anything in terms of extensibility
or even-handedness there; it's just avoiding a bunch of rigamarole
that doesn't really buy us anything.
All these points apply equally to toast_decompress_datum_slice() and
toast_compress_datum().
+ /* Fallback to default compression method, if not specified */
+ if (!OidIsValid(cmoid))
+ cmoid = DefaultCompressionOid;
I think that the caller should be required to specify a legal value,
and this should be an elog(ERROR) or an Assert().
The change to equalTupleDescs() makes me wonder. Like, can we specify
the compression method for a function parameter, or a function return
value? I would think not. But then how are the tuple descriptors set
up in that case? Under what circumstances do we actually need the
tuple descriptors to compare unequal?
lz4.c's header comment calls it cm_lz4.c, and the pathname is wrong too.
I wonder if we should try to adopt a convention for the names of these
files that isn't just the compression method name, like cmlz4 or
compress_lz4. I kind of like the latter one. I am a little worried
that just calling it lz4.c will result in name collisions later - not
in this directory, of course, but elsewhere in the system. It's not a
disaster if that happens, but for example verbose error reports print
the file name, so it's nice if it's unambiguous.
+ if (!IsBinaryUpgrade &&
+ (relkind == RELKIND_RELATION ||
+ relkind == RELKIND_PARTITIONED_TABLE))
+ attr->attcompression =
+
GetAttributeCompressionMethod(attr, colDef->compression);
+ else
+ attr->attcompression = InvalidOid;
Storing InvalidOid in the IsBinaryUpgrade case looks wrong. If
upgrading from pre-v14, we need to store PGLZ_COMPRESSION_OID.
Otherwise, we need to preserve whatever value was present in the old
version. Or am I confused here?
I think there should be tests for the way this interacts with
partitioning, and I think the intended interaction should be
documented. Perhaps it should behave like TABLESPACE, where the parent
property has no effect on what gets stored because the parent has no
storage, but is inherited by each new child.
I wonder in passing about TOAST tables and materialized views, which
are the other things that have storage. What gets stored for
attcompression? For a TOAST table it probably doesn't matter much
since TOAST table entries shouldn't ever be toasted themselves, so
anything that doesn't crash is fine (but maybe we should test that
trying to alter the compression properties of a TOAST table doesn't
crash, for example). For a materialized view it seems reasonable to
want to set column properties, but I'm not quite sure how that works
today for things like STORAGE anyway. If we do allow setting STORAGE
or COMPRESSION for materialized view columns then dump-and-reload
needs to preserve the values.
+ /*
+ * Use default compression method if the existing compression method is
+ * invalid but the new storage type is non plain storage.
+ */
+ if (!OidIsValid(attrtuple->attcompression) &&
+ (newstorage != TYPSTORAGE_PLAIN))
+ attrtuple->attcompression = DefaultCompressionOid;
You have a few too many parens in there.
I don't see a particularly good reason to treat plain and external
differently. More generally, I think there's a question here about
when we need an attribute to have a valid compression type and when we
don't. If typstorage is plan or external, then there's no point in
ever having a compression type and maybe we should even reject
attempts to set one (but I'm not sure). However, the attstorage is a
different case. Suppose the column is created with extended storage
and then later it's changed to plain. That's only a hint, so there may
still be toasted values in that column, so the compression setting
must endure. At any rate, we need to make sure we have clear and
sensible rules for when attcompression (a) must be valid, (b) may be
valid, and (c) must be invalid. And those rules need to at least be
documented in the comments, and maybe in the SGML docs.
I'm out of time for today, so I'll have to look at this more another
day. Hope this helps for a start.
--
Robert Haas
EDB: http://www.enterprisedb.com
On Sat, Nov 21, 2020 at 3:50 AM Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Wed, Nov 11, 2020 at 9:39 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> > There were a few problems in this rebased version, basically, the
> > compression options were not passed while compressing values from the
> > brin_form_tuple, so I have fixed this.
>
> Since the authorship history of this patch is complicated, it would be
> nice if you would include authorship information and relevant
> "Discussion" links in the patches.
>
> Design level considerations and overall notes:
>
> configure is autogenerated from configure.in, so the patch shouldn't
> include changes only to the former.
>
> Looking over the changes to src/include:
>
> + PGLZ_COMPRESSION_ID,
> + LZ4_COMPRESSION_ID
>
> I think that it would be good to assign values to these explicitly.
>
> +/* compresion handler routines */
>
> Spelling.
>
> + /* compression routine for the compression method */
> + cmcompress_function cmcompress;
> +
> + /* decompression routine for the compression method */
> + cmcompress_function cmdecompress;
>
> Don't reuse cmcompress_function; that's confusing. Just have a typedef
> per structure member, even if they end up being the same.
>
> #define TOAST_COMPRESS_SET_RAWSIZE(ptr, len) \
> - (((toast_compress_header *) (ptr))->rawsize = (len))
> +do { \
> + Assert(len > 0 && len <= RAWSIZEMASK); \
> + ((toast_compress_header *) (ptr))->info = (len); \
> +} while (0)
>
> Indentation.
>
> +#define TOAST_COMPRESS_SET_COMPRESSION_METHOD(ptr, cm_method) \
> + ((toast_compress_header *) (ptr))->info |= ((cm_method) << 30);
>
> What about making TOAST_COMPRESS_SET_RAWSIZE() take another argument?
> And possibly also rename it to TEST_COMPRESS_SET_SIZE_AND_METHOD() or
> something? It seems not great to have separate functions each setting
> part of a 4-byte quantity. Too much chance of failing to set both
> parts. I guess you've got a function called
> toast_set_compressed_datum_info() for that, but it's just a wrapper
> around two macros that could just be combined, which would reduce
> complexity overall.
>
> + T_CompressionRoutine, /* in access/compressionapi.h */
>
> This looks misplaced. I guess it should go just after these:
>
> T_FdwRoutine, /* in foreign/fdwapi.h */
> T_IndexAmRoutine, /* in access/amapi.h */
> T_TableAmRoutine, /* in access/tableam.h */
>
> Looking over the regression test changes:
>
> The tests at the top of create_cm.out that just test that we can
> create tables with various storage types seem unrelated to the purpose
> of the patch. And the file doesn't test creating a compression method
> either, as the file name would suggest, so either the file name needs
> to be changed (compression, compression_method?) or the tests don't go
> here.
>
> +-- check data is okdd
>
> I guess whoever is responsible for this comment prefers vi to emacs.
>
> I don't quite understand the purpose of all of these tests, and there
> are some things that I feel like ought to be tested that seemingly
> aren't. Like, you seem to test using an UPDATE to move a datum from a
> table to another table with the same compression method, but not one
> with a different compression method. Testing the former is nice and
> everything, but that's the easy case: I think we also need to test the
> latter. I think it would be good to verify not only that the data is
> readable but that it's compressed the way we expect. I think it would
> be a great idea to add a pg_column_compression() function in a similar
> spirit to pg_column_size(). Perhaps it could return NULL when
> compression is not in use or the data type is not varlena, and the
> name of the compression method otherwise. That would allow for better
> testing of this feature, and it would also be useful to users who are
> switching methods, to see what data they still have that's using the
> old method. It could be useful for debugging problems on customer
> systems, too.
>
> I wonder if we need a test that moves data between tables through an
> intermediary. For instance, suppose a plpgsql function or DO block
> fetches some data and stores it in a plpgsql variable and then uses
> the variable to insert into another table. Hmm, maybe that would force
> de-TOASTing. But perhaps there are other cases. Maybe a more general
> way to approach the problem is: have you tried running a coverage
> report and checked which parts of your code are getting exercised by
> the existing tests and which parts are not? The stuff that isn't, we
> should try to add more tests. It's easy to get corner cases wrong with
> this kind of thing.
>
> I notice that LIKE INCLUDING COMPRESSION doesn't seem to be tested, at
> least not by 0001, which reinforces my feeling that the tests here are
> not as thorough as they could be.
>
> +NOTICE: pg_compression contains unpinned initdb-created object(s)
>
> This seems wrong to me - why is it OK?
>
> - result = (struct varlena *)
> - palloc(TOAST_COMPRESS_RAWSIZE(attr) + VARHDRSZ);
> - SET_VARSIZE(result, TOAST_COMPRESS_RAWSIZE(attr) + VARHDRSZ);
> + cmoid = GetCompressionOidFromCompressionId(TOAST_COMPRESS_METHOD(attr));
>
> - if (pglz_decompress(TOAST_COMPRESS_RAWDATA(attr),
> - TOAST_COMPRESS_SIZE(attr),
> - VARDATA(result),
> -
> TOAST_COMPRESS_RAWSIZE(attr), true) < 0)
> - elog(ERROR, "compressed data is corrupted");
> + /* get compression method handler routines */
> + cmroutine = GetCompressionRoutine(cmoid);
>
> - return result;
> + return cmroutine->cmdecompress(attr);
>
> I'm worried about how expensive this might be, and I think we could
> make it cheaper. The reason why I think this might be expensive is:
> currently, for every datum, you have a single direct function call.
> Now, with this, you first have a direct function call to
> GetCompressionOidFromCompressionId(). Then you have a call to
> GetCompressionRoutine(), which does a syscache lookup and calls a
> handler function, which is quite a lot more expensive than a single
> function call. And the handler isn't even returning a statically
> allocated structure, but is allocating new memory every time, which
> involves more function calls and maybe memory leaks. Then you use the
> results of all that to make an indirect function call.
>
> I'm not sure exactly what combination of things we could use to make
> this better, but it seems like there are a few possibilities:
>
> (1) The handler function could return a pointer to the same
> CompressionRoutine every time instead of constructing a new one every
> time.
> (2) The CompressionRoutine to which the handler function returns a
> pointer could be statically allocated instead of being built at
> runtime.
> (3) GetCompressionRoutine could have an OID -> handler cache instead
> of relying on syscache + calling the handler function all over again.
> (4) For the compression types that have dedicated bit patterns in the
> high bits of the compressed TOAST size, toast_compress_datum() could
> just have hard-coded logic to use the correct handlers instead of
> translating the bit pattern into an OID and then looking it up over
> again.
> (5) Going even further than #4 we could skip the handler layer
> entirely for such methods, and just call the right function directly.
>
> I think we should definitely do (1), and also (2) unless there's some
> reason it's hard. (3) doesn't need to be part of this patch, but might
> be something to consider later in the series. It's possible that it
> doesn't have enough benefit to be worth the work, though. Also, I
> think we should do either (4) or (5). I have a mild preference for (5)
> unless it looks too ugly.
>
> Note that I'm not talking about hard-coding a fast path for a
> hard-coded list of OIDs - which would seem a little bit unprincipled -
> but hard-coding a fast path for the bit patterns that are themselves
> hard-coded. I don't think we lose anything in terms of extensibility
> or even-handedness there; it's just avoiding a bunch of rigamarole
> that doesn't really buy us anything.
>
> All these points apply equally to toast_decompress_datum_slice() and
> toast_compress_datum().
>
> + /* Fallback to default compression method, if not specified */
> + if (!OidIsValid(cmoid))
> + cmoid = DefaultCompressionOid;
>
> I think that the caller should be required to specify a legal value,
> and this should be an elog(ERROR) or an Assert().
>
> The change to equalTupleDescs() makes me wonder. Like, can we specify
> the compression method for a function parameter, or a function return
> value? I would think not. But then how are the tuple descriptors set
> up in that case? Under what circumstances do we actually need the
> tuple descriptors to compare unequal?
>
> lz4.c's header comment calls it cm_lz4.c, and the pathname is wrong too.
>
> I wonder if we should try to adopt a convention for the names of these
> files that isn't just the compression method name, like cmlz4 or
> compress_lz4. I kind of like the latter one. I am a little worried
> that just calling it lz4.c will result in name collisions later - not
> in this directory, of course, but elsewhere in the system. It's not a
> disaster if that happens, but for example verbose error reports print
> the file name, so it's nice if it's unambiguous.
>
> + if (!IsBinaryUpgrade &&
> + (relkind == RELKIND_RELATION ||
> + relkind == RELKIND_PARTITIONED_TABLE))
> + attr->attcompression =
> +
> GetAttributeCompressionMethod(attr, colDef->compression);
> + else
> + attr->attcompression = InvalidOid;
>
> Storing InvalidOid in the IsBinaryUpgrade case looks wrong. If
> upgrading from pre-v14, we need to store PGLZ_COMPRESSION_OID.
> Otherwise, we need to preserve whatever value was present in the old
> version. Or am I confused here?
>
> I think there should be tests for the way this interacts with
> partitioning, and I think the intended interaction should be
> documented. Perhaps it should behave like TABLESPACE, where the parent
> property has no effect on what gets stored because the parent has no
> storage, but is inherited by each new child.
>
> I wonder in passing about TOAST tables and materialized views, which
> are the other things that have storage. What gets stored for
> attcompression? For a TOAST table it probably doesn't matter much
> since TOAST table entries shouldn't ever be toasted themselves, so
> anything that doesn't crash is fine (but maybe we should test that
> trying to alter the compression properties of a TOAST table doesn't
> crash, for example). For a materialized view it seems reasonable to
> want to set column properties, but I'm not quite sure how that works
> today for things like STORAGE anyway. If we do allow setting STORAGE
> or COMPRESSION for materialized view columns then dump-and-reload
> needs to preserve the values.
>
> + /*
> + * Use default compression method if the existing compression method is
> + * invalid but the new storage type is non plain storage.
> + */
> + if (!OidIsValid(attrtuple->attcompression) &&
> + (newstorage != TYPSTORAGE_PLAIN))
> + attrtuple->attcompression = DefaultCompressionOid;
>
> You have a few too many parens in there.
>
> I don't see a particularly good reason to treat plain and external
> differently. More generally, I think there's a question here about
> when we need an attribute to have a valid compression type and when we
> don't. If typstorage is plan or external, then there's no point in
> ever having a compression type and maybe we should even reject
> attempts to set one (but I'm not sure). However, the attstorage is a
> different case. Suppose the column is created with extended storage
> and then later it's changed to plain. That's only a hint, so there may
> still be toasted values in that column, so the compression setting
> must endure. At any rate, we need to make sure we have clear and
> sensible rules for when attcompression (a) must be valid, (b) may be
> valid, and (c) must be invalid. And those rules need to at least be
> documented in the comments, and maybe in the SGML docs.
>
> I'm out of time for today, so I'll have to look at this more another
> day. Hope this helps for a start.
>
Thanks for the review Robert, I will work on these comments and
provide my analysis along with the updated patch in a couple of days.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Sat, Nov 21, 2020 at 3:50 AM Robert Haas <robertmhaas@gmail.com> wrote:
Most of the comments looks fine to me but I have a slightly different
opinion for one of the comment so replying only for that.
> I'm worried about how expensive this might be, and I think we could
> make it cheaper. The reason why I think this might be expensive is:
> currently, for every datum, you have a single direct function call.
> Now, with this, you first have a direct function call to
> GetCompressionOidFromCompressionId(). Then you have a call to
> GetCompressionRoutine(), which does a syscache lookup and calls a
> handler function, which is quite a lot more expensive than a single
> function call. And the handler isn't even returning a statically
> allocated structure, but is allocating new memory every time, which
> involves more function calls and maybe memory leaks. Then you use the
> results of all that to make an indirect function call.
>
> I'm not sure exactly what combination of things we could use to make
> this better, but it seems like there are a few possibilities:
>
> (1) The handler function could return a pointer to the same
> CompressionRoutine every time instead of constructing a new one every
> time.
> (2) The CompressionRoutine to which the handler function returns a
> pointer could be statically allocated instead of being built at
> runtime.
> (3) GetCompressionRoutine could have an OID -> handler cache instead
> of relying on syscache + calling the handler function all over again.
> (4) For the compression types that have dedicated bit patterns in the
> high bits of the compressed TOAST size, toast_compress_datum() could
> just have hard-coded logic to use the correct handlers instead of
> translating the bit pattern into an OID and then looking it up over
> again.
> (5) Going even further than #4 we could skip the handler layer
> entirely for such methods, and just call the right function directly.
>
> I think we should definitely do (1), and also (2) unless there's some
> reason it's hard. (3) doesn't need to be part of this patch, but might
> be something to consider later in the series. It's possible that it
> doesn't have enough benefit to be worth the work, though. Also, I
> think we should do either (4) or (5). I have a mild preference for (5)
> unless it looks too ugly.
>
> Note that I'm not talking about hard-coding a fast path for a
> hard-coded list of OIDs - which would seem a little bit unprincipled -
> but hard-coding a fast path for the bit patterns that are themselves
> hard-coded. I don't think we lose anything in terms of extensibility
> or even-handedness there; it's just avoiding a bunch of rigamarole
> that doesn't really buy us anything.
>
> All these points apply equally to toast_decompress_datum_slice() and
> toast_compress_datum().
I agree that (1) and (2) we shall definitely do as part of the first
patch and (3) we might do in later patches. I think from (4) and (5)
I am more inclined to do (4) for a couple of reasons
a) If we bypass the handler function and directly calls the
compression and decompression routines then we need to check whether
the current executable is compiled with this particular compression
library or not for example in 'lz4handler' we have this below check,
now if we don't have the handler function we either need to put this
in each compression/decompression functions or we need to put is in
each caller.
Datum
lz4handler(PG_FUNCTION_ARGS)
{
#ifndef HAVE_LIBLZ4
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("not built with lz4 support")));
#else
b) Another reason is that once we start supporting the compression
options (0006-Support-compression-methods-options.patch) then we also
need to call 'cminitstate_function' for parsing the compression
options and then calling the compression function, so we need to
hardcode multiple function calls.
I think b) is still okay but because of a) I am more inclined to do
(4), what is your opinion on this?
About (4), one option is that we directly call the correct handler
function for the built-in type directly from
toast_(de)compress(_slice) functions but in that case, we are
duplicating the code, another option is that we call the
GetCompressionRoutine() a common function and in that, for the
built-in type, we can directly call the corresponding handler function
and get the routine. The only thing is to avoid duplicating in
decompression routine we need to convert CompressionId to Oid before
calling GetCompressionRoutine(), but now we can avoid sys cache lookup
for the built-in type.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Tue, Nov 24, 2020 at 7:11 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> About (4), one option is that we directly call the correct handler
> function for the built-in type directly from
> toast_(de)compress(_slice) functions but in that case, we are
> duplicating the code, another option is that we call the
> GetCompressionRoutine() a common function and in that, for the
> built-in type, we can directly call the corresponding handler function
> and get the routine. The only thing is to avoid duplicating in
> decompression routine we need to convert CompressionId to Oid before
> calling GetCompressionRoutine(), but now we can avoid sys cache lookup
> for the built-in type.
Suppose that we have a variable lz4_methods (like heapam_methods) that
is always defined, whether or not lz4 support is present. It's defined
like this:
const CompressionAmRoutine lz4_compress_methods = {
.datum_compress = lz4_datum_compress,
.datum_decompress = lz4_datum_decompress,
.datum_decompress_slice = lz4_datum_decompress_slice
};
(It would be good, I think, to actually name things something like
this - in particular why would we have TableAmRoutine and
IndexAmRoutine but not include "Am" in the one for compression? In
general I think tableam is a good pattern to adhere to and we should
try to make this patch hew closely to it.)
Then those functions are contingent on #ifdef HAVE_LIBLZ4: they either
do their thing, or complain that lz4 compression is not supported.
Then in this function you can just say, well, if we have the 01 bit
pattern, handler = &lz4_compress_methods and proceed from there.
BTW, I think the "not supported" message should probably use the 'by
this build' language we use in some places i.e.
[rhaas pgsql]$ git grep errmsg.*'this build' | grep -vF .po:
contrib/pg_prewarm/pg_prewarm.c: errmsg("prefetch is not supported by
this build")));
src/backend/libpq/be-secure-openssl.c: (errmsg("\"%s\" setting \"%s\"
not supported by this build",
src/backend/libpq/be-secure-openssl.c: (errmsg("\"%s\" setting \"%s\"
not supported by this build",
src/backend/libpq/hba.c: errmsg("local connections are not supported
by this build"),
src/backend/libpq/hba.c: errmsg("hostssl record cannot match because
SSL is not supported by this build"),
src/backend/libpq/hba.c: errmsg("hostgssenc record cannot match
because GSSAPI is not supported by this build"),
src/backend/libpq/hba.c: errmsg("invalid authentication method \"%s\":
not supported by this build",
src/backend/utils/adt/pg_locale.c: errmsg("ICU is not supported in
this build"), \
src/backend/utils/misc/guc.c: GUC_check_errmsg("Bonjour is not
supported by this build");
src/backend/utils/misc/guc.c: GUC_check_errmsg("SSL is not supported
by this build");
--
Robert Haas
EDB: http://www.enterprisedb.com
On Tue, Nov 24, 2020 at 7:14 PM Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Tue, Nov 24, 2020 at 7:11 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> > About (4), one option is that we directly call the correct handler
> > function for the built-in type directly from
> > toast_(de)compress(_slice) functions but in that case, we are
> > duplicating the code, another option is that we call the
> > GetCompressionRoutine() a common function and in that, for the
> > built-in type, we can directly call the corresponding handler function
> > and get the routine. The only thing is to avoid duplicating in
> > decompression routine we need to convert CompressionId to Oid before
> > calling GetCompressionRoutine(), but now we can avoid sys cache lookup
> > for the built-in type.
>
> Suppose that we have a variable lz4_methods (like heapam_methods) that
> is always defined, whether or not lz4 support is present. It's defined
> like this:
>
> const CompressionAmRoutine lz4_compress_methods = {
> .datum_compress = lz4_datum_compress,
> .datum_decompress = lz4_datum_decompress,
> .datum_decompress_slice = lz4_datum_decompress_slice
> };
Yeah, this makes sense.
>
> (It would be good, I think, to actually name things something like
> this - in particular why would we have TableAmRoutine and
> IndexAmRoutine but not include "Am" in the one for compression? In
> general I think tableam is a good pattern to adhere to and we should
> try to make this patch hew closely to it.)
For the compression routine name, I did not include "Am" because
currently, we are storing the compression method in the new catalog
"pg_compression" not in the pg_am. So are you suggesting that we
should store the compression methods also in the pg_am instead of
creating a new catalog? IMHO, storing the compression methods in a
new catalog is a better option instead of storing them in pg_am
because actually, the compression methods are not the same as heap or
index AMs, I mean they are actually not the access methods. Am I
missing something?
> Then those functions are contingent on #ifdef HAVE_LIBLZ4: they either
> do their thing, or complain that lz4 compression is not supported.
> Then in this function you can just say, well, if we have the 01 bit
> pattern, handler = &lz4_compress_methods and proceed from there.
Okay
> BTW, I think the "not supported" message should probably use the 'by
> this build' language we use in some places i.e.
>
Okay
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Tue, Nov 24, 2020 at 10:47 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > For the compression routine name, I did not include "Am" because > currently, we are storing the compression method in the new catalog > "pg_compression" not in the pg_am. So are you suggesting that we > should store the compression methods also in the pg_am instead of > creating a new catalog? IMHO, storing the compression methods in a > new catalog is a better option instead of storing them in pg_am > because actually, the compression methods are not the same as heap or > index AMs, I mean they are actually not the access methods. Am I > missing something? Oh, I thought it had been suggested in previous discussions that these should be treated as access methods rather than inventing a whole new concept just for this, and it seemed like a good idea to me. I guess I missed the fact that the patch wasn't doing it that way. Hmm. -- Robert Haas EDB: http://www.enterprisedb.com
Robert Haas <robertmhaas@gmail.com> writes:
> On Tue, Nov 24, 2020 at 10:47 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>> For the compression routine name, I did not include "Am" because
>> currently, we are storing the compression method in the new catalog
>> "pg_compression" not in the pg_am. So are you suggesting that we
>> should store the compression methods also in the pg_am instead of
>> creating a new catalog? IMHO, storing the compression methods in a
>> new catalog is a better option instead of storing them in pg_am
>> because actually, the compression methods are not the same as heap or
>> index AMs, I mean they are actually not the access methods. Am I
>> missing something?
> Oh, I thought it had been suggested in previous discussions that these
> should be treated as access methods rather than inventing a whole new
> concept just for this, and it seemed like a good idea to me. I guess I
> missed the fact that the patch wasn't doing it that way. Hmm.
FWIW, I kind of agree with Robert's take on this. Heap and index AMs
are pretty fundamentally different animals, yet we don't have a problem
sticking them in the same catalog. I think anything that is related to
storage access could reasonably go into that catalog, rather than
inventing a new one.
regards, tom lane
On Tue, Nov 24, 2020 at 1:21 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > FWIW, I kind of agree with Robert's take on this. Heap and index AMs > are pretty fundamentally different animals, yet we don't have a problem > sticking them in the same catalog. I think anything that is related to > storage access could reasonably go into that catalog, rather than > inventing a new one. It's good to have your opinion on this since I wasn't totally sure what was best, but for the record, I can't take credit. Looks like it was Álvaro's suggestion originally: http://postgr.es/m/20171130205155.7mgq2cuqv6zxi25a@alvherre.pgsql -- Robert Haas EDB: http://www.enterprisedb.com
On 2020-Nov-24, Tom Lane wrote: > Robert Haas <robertmhaas@gmail.com> writes: > > Oh, I thought it had been suggested in previous discussions that these > > should be treated as access methods rather than inventing a whole new > > concept just for this, and it seemed like a good idea to me. I guess I > > missed the fact that the patch wasn't doing it that way. Hmm. > > FWIW, I kind of agree with Robert's take on this. Heap and index AMs > are pretty fundamentally different animals, yet we don't have a problem > sticking them in the same catalog. I think anything that is related to > storage access could reasonably go into that catalog, rather than > inventing a new one. Right -- Something like amname=lz4, amhandler=lz4handler, amtype=c. The core code must of course know how to instantiate an AM of type 'c' and what to use it for. https://postgr.es/m/20171213151818.75a20259@postgrespro.ru
On Wed, Nov 25, 2020 at 12:50 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2020-Nov-24, Tom Lane wrote: > > > Robert Haas <robertmhaas@gmail.com> writes: > > > > Oh, I thought it had been suggested in previous discussions that these > > > should be treated as access methods rather than inventing a whole new > > > concept just for this, and it seemed like a good idea to me. I guess I > > > missed the fact that the patch wasn't doing it that way. Hmm. > > > > FWIW, I kind of agree with Robert's take on this. Heap and index AMs > > are pretty fundamentally different animals, yet we don't have a problem > > sticking them in the same catalog. I think anything that is related to > > storage access could reasonably go into that catalog, rather than > > inventing a new one. > > Right -- Something like amname=lz4, amhandler=lz4handler, amtype=c. > The core code must of course know how to instantiate an AM of type > 'c' and what to use it for. > > https://postgr.es/m/20171213151818.75a20259@postgrespro.ru I have changed this, I agree that using the access method for creating compression has simplified the code. I will share the updated patch set after fixing other review comments by Robert. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Sat, Nov 21, 2020 at 3:50 AM Robert Haas <robertmhaas@gmail.com> wrote: While working on this comment I have doubts. > I wonder in passing about TOAST tables and materialized views, which > are the other things that have storage. What gets stored for > attcompression? For a TOAST table it probably doesn't matter much > since TOAST table entries shouldn't ever be toasted themselves, so > anything that doesn't crash is fine (but maybe we should test that > trying to alter the compression properties of a TOAST table doesn't > crash, for example). Yeah for the toast table it doesn't matter, but I am not sure what do you mean by altering the compression method for the toast table. Do you mean manually update the pg_attribute tuple for the toast table and set different compression methods? Or there is some direct way to alter the toast table? For a materialized view it seems reasonable to > want to set column properties, but I'm not quite sure how that works > today for things like STORAGE anyway. If we do allow setting STORAGE > or COMPRESSION for materialized view columns then dump-and-reload > needs to preserve the values. I see that we allow setting the STORAGE for the materialized view but I am not sure what is the use case. Basically, the tuples are directly getting selected from the host table and inserted in the materialized view without checking target and source storage type. The behavior is the same if you execute INSERT INTO dest_table SELECT * FROM source_table. Basically, if the source_table attribute has extended storage and the target table has plain storage, still the value will be inserted directly into the target table without any conversion. However, in the table, you can insert the new tuple and that will be stored as per the new storage method so that is still fine but I don't know any use case for the materialized view. Now I am thinking what should be the behavior for the materialized view? For the materialized view can we have the same behavior as storage? I think for the built-in compression method that might not be a problem but for the external compression method how can we handle the dependency, I mean when the materialized view has created the table was having an external compression method "cm1" and we have created the materialized view based on that now if we alter table and set the new compression method and force table rewrite then what will happen to the tuple inside the materialized view, I mean tuple is still compressed with "cm1" and there is no attribute is maintaining the dependency on "cm1" because the materialized view can point to any compression method. Now if we drop the cm1 it will be allowed to drop. So I think for the compression method we can consider the materialized view same as the table, I mean we can allow setting the compression method for the materialized view and we can always ensure that all the tuple in this view is compressed with the current or the preserved compression methods. So whenever we are inserting in the materialized view then we should compare the datum compression method with the target compression method. > + /* > + * Use default compression method if the existing compression method is > + * invalid but the new storage type is non plain storage. > + */ > + if (!OidIsValid(attrtuple->attcompression) && > + (newstorage != TYPSTORAGE_PLAIN)) > + attrtuple->attcompression = DefaultCompressionOid; > > You have a few too many parens in there. > > I don't see a particularly good reason to treat plain and external > differently. Yeah, I think they should be treated the same. More generally, I think there's a question here about > when we need an attribute to have a valid compression type and when we > don't. If typstorage is plan or external, then there's no point in > ever having a compression type and maybe we should even reject > attempts to set one (but I'm not sure). I agree. > However, the attstorage is a > different case. Suppose the column is created with extended storage > and then later it's changed to plain. That's only a hint, so there may > still be toasted values in that column, so the compression setting > must endure. At any rate, we need to make sure we have clear and > sensible rules for when attcompression (a) must be valid, (b) may be > valid, and (c) must be invalid. And those rules need to at least be > documented in the comments, and maybe in the SGML docs. IIUC, even if we change the attstorage the existing tuples are stored as it is without changing the tuple storage. So I think even if the attstorage is changed the attcompression should not have any change. After observing this behavior of storage I tend to think that for built-in compression methods also we should have the same behavior, I mean if the tuple is compressed with one of the built-in compression methods and if we are altering the compression method or we are doing INSERT INTO SELECT to the target field having a different compression method then we should not rewrite/decompress those tuples. Basically, I mean to say that the built-in compression methods can always be treated as PRESERVE because those can not be dropped. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Dec 1, 2020 at 4:50 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Sat, Nov 21, 2020 at 3:50 AM Robert Haas <robertmhaas@gmail.com> wrote: > > While working on this comment I have doubts. > > > I wonder in passing about TOAST tables and materialized views, which > > are the other things that have storage. What gets stored for > > attcompression? For a TOAST table it probably doesn't matter much > > since TOAST table entries shouldn't ever be toasted themselves, so > > anything that doesn't crash is fine (but maybe we should test that > > trying to alter the compression properties of a TOAST table doesn't > > crash, for example). > > Yeah for the toast table it doesn't matter, but I am not sure what do > you mean by altering the compression method for the toast table. Do you > mean manually update the pg_attribute tuple for the toast table and > set different compression methods? Or there is some direct way to > alter the toast table? > > For a materialized view it seems reasonable to > > want to set column properties, but I'm not quite sure how that works > > today for things like STORAGE anyway. If we do allow setting STORAGE > > or COMPRESSION for materialized view columns then dump-and-reload > > needs to preserve the values. > > I see that we allow setting the STORAGE for the materialized view but > I am not sure what is the use case. Basically, the tuples are > directly getting selected from the host table and inserted in the > materialized view without checking target and source storage type. > The behavior is the same if you execute INSERT INTO dest_table SELECT > * FROM source_table. Basically, if the source_table attribute has > extended storage and the target table has plain storage, still the > value will be inserted directly into the target table without any > conversion. However, in the table, you can insert the new tuple and > that will be stored as per the new storage method so that is still > fine but I don't know any use case for the materialized view. Now I am > thinking what should be the behavior for the materialized view? > > For the materialized view can we have the same behavior as storage? I > think for the built-in compression method that might not be a problem > but for the external compression method how can we handle the > dependency, I mean when the materialized view has created the table > was having an external compression method "cm1" and we have created > the materialized view based on that now if we alter table and set the > new compression method and force table rewrite then what will happen > to the tuple inside the materialized view, I mean tuple is still > compressed with "cm1" and there is no attribute is maintaining the > dependency on "cm1" because the materialized view can point to any > compression method. Now if we drop the cm1 it will be allowed to > drop. So I think for the compression method we can consider the > materialized view same as the table, I mean we can allow setting the > compression method for the materialized view and we can always ensure > that all the tuple in this view is compressed with the current or the > preserved compression methods. So whenever we are inserting in the > materialized view then we should compare the datum compression method > with the target compression method. > > > > + /* > > + * Use default compression method if the existing compression method is > > + * invalid but the new storage type is non plain storage. > > + */ > > + if (!OidIsValid(attrtuple->attcompression) && > > + (newstorage != TYPSTORAGE_PLAIN)) > > + attrtuple->attcompression = DefaultCompressionOid; > > > > You have a few too many parens in there. > > > > I don't see a particularly good reason to treat plain and external > > differently. > > Yeah, I think they should be treated the same. > > More generally, I think there's a question here about > > when we need an attribute to have a valid compression type and when we > > don't. If typstorage is plan or external, then there's no point in > > ever having a compression type and maybe we should even reject > > attempts to set one (but I'm not sure). > > I agree. > > > However, the attstorage is a > > different case. Suppose the column is created with extended storage > > and then later it's changed to plain. That's only a hint, so there may > > still be toasted values in that column, so the compression setting > > must endure. At any rate, we need to make sure we have clear and > > sensible rules for when attcompression (a) must be valid, (b) may be > > valid, and (c) must be invalid. And those rules need to at least be > > documented in the comments, and maybe in the SGML docs. > > IIUC, even if we change the attstorage the existing tuples are stored > as it is without changing the tuple storage. So I think even if the > attstorage is changed the attcompression should not have any change. > I have put some more thought into this and IMHO the rules should be as below 1. If attstorage is EXTENDED -> attcompression "must be valid" 2. if attstorage is PLAIN/EXTERNAL -> atttcompression "maybe valid" 3. if typstorage is PLAIN/EXTERNAL -> atttcompression "must be invalid" I am a little bit confused about (2), basically, it will be valid in the scenario u mentioned that change the atttstorege from EXTENDED to PLAIN/EXTERNAL. But I think in this case also we can just set the attcompression to invalid, however, we have to maintain the dependency between attribute and compression method so that the old methods using which we might have compressed a few tuples in the table doesn't get dropped. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Dec 1, 2020 at 9:15 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Dec 1, 2020 at 4:50 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Sat, Nov 21, 2020 at 3:50 AM Robert Haas <robertmhaas@gmail.com> wrote: > > > > While working on this comment I have doubts. > > > > > I wonder in passing about TOAST tables and materialized views, which > > > are the other things that have storage. What gets stored for > > > attcompression? For a TOAST table it probably doesn't matter much > > > since TOAST table entries shouldn't ever be toasted themselves, so > > > anything that doesn't crash is fine (but maybe we should test that > > > trying to alter the compression properties of a TOAST table doesn't > > > crash, for example). > > > > Yeah for the toast table it doesn't matter, but I am not sure what do > > you mean by altering the compression method for the toast table. Do you > > mean manually update the pg_attribute tuple for the toast table and > > set different compression methods? Or there is some direct way to > > alter the toast table? > > > > For a materialized view it seems reasonable to > > > want to set column properties, but I'm not quite sure how that works > > > today for things like STORAGE anyway. If we do allow setting STORAGE > > > or COMPRESSION for materialized view columns then dump-and-reload > > > needs to preserve the values. > > > > I see that we allow setting the STORAGE for the materialized view but > > I am not sure what is the use case. Basically, the tuples are > > directly getting selected from the host table and inserted in the > > materialized view without checking target and source storage type. > > The behavior is the same if you execute INSERT INTO dest_table SELECT > > * FROM source_table. Basically, if the source_table attribute has > > extended storage and the target table has plain storage, still the > > value will be inserted directly into the target table without any > > conversion. However, in the table, you can insert the new tuple and > > that will be stored as per the new storage method so that is still > > fine but I don't know any use case for the materialized view. Now I am > > thinking what should be the behavior for the materialized view? > > > > For the materialized view can we have the same behavior as storage? I > > think for the built-in compression method that might not be a problem > > but for the external compression method how can we handle the > > dependency, I mean when the materialized view has created the table > > was having an external compression method "cm1" and we have created > > the materialized view based on that now if we alter table and set the > > new compression method and force table rewrite then what will happen > > to the tuple inside the materialized view, I mean tuple is still > > compressed with "cm1" and there is no attribute is maintaining the > > dependency on "cm1" because the materialized view can point to any > > compression method. Now if we drop the cm1 it will be allowed to > > drop. So I think for the compression method we can consider the > > materialized view same as the table, I mean we can allow setting the > > compression method for the materialized view and we can always ensure > > that all the tuple in this view is compressed with the current or the > > preserved compression methods. So whenever we are inserting in the > > materialized view then we should compare the datum compression method > > with the target compression method. As per the offlist discussion with Robert, for materialized/table we will always compress the value as per the target attribute compression method. So if we are creating/refreshing the materialized view and the attcompression for the target attribute is different than the source table then we will decompress it and then compress it back as per the target table/view. > > > > > > > + /* > > > + * Use default compression method if the existing compression method is > > > + * invalid but the new storage type is non plain storage. > > > + */ > > > + if (!OidIsValid(attrtuple->attcompression) && > > > + (newstorage != TYPSTORAGE_PLAIN)) > > > + attrtuple->attcompression = DefaultCompressionOid; > > > > > > You have a few too many parens in there. > > > > > > I don't see a particularly good reason to treat plain and external > > > differently. > > > > Yeah, I think they should be treated the same. > > > > More generally, I think there's a question here about > > > when we need an attribute to have a valid compression type and when we > > > don't. If typstorage is plan or external, then there's no point in > > > ever having a compression type and maybe we should even reject > > > attempts to set one (but I'm not sure). > > > > I agree. > > > > > However, the attstorage is a > > > different case. Suppose the column is created with extended storage > > > and then later it's changed to plain. That's only a hint, so there may > > > still be toasted values in that column, so the compression setting > > > must endure. At any rate, we need to make sure we have clear and > > > sensible rules for when attcompression (a) must be valid, (b) may be > > > valid, and (c) must be invalid. And those rules need to at least be > > > documented in the comments, and maybe in the SGML docs. > > > > IIUC, even if we change the attstorage the existing tuples are stored > > as it is without changing the tuple storage. So I think even if the > > attstorage is changed the attcompression should not have any change. > > > > I have put some more thought into this and IMHO the rules should be as below > > 1. If attstorage is EXTENDED -> attcompression "must be valid" > 2. if attstorage is PLAIN/EXTERNAL -> atttcompression "maybe valid" > 3. if typstorage is PLAIN/EXTERNAL -> atttcompression "must be invalid" > > I am a little bit confused about (2), basically, it will be valid in > the scenario u mentioned that change the atttstorege from EXTENDED to > PLAIN/EXTERNAL. But I think in this case also we can just set the > attcompression to invalid, however, we have to maintain the dependency > between attribute and compression method so that the old methods using > which we might have compressed a few tuples in the table doesn't get > dropped. For this also I had an offlist discussion with Robert and we decided that it make sense to always have a valid compression method stored in the attribute if the attribute type is compressible irrespective of what is the current attribute storage. For example, if the attribute type is varchar then it will always have a valid compression method, it does not matter even if the att storage is plain or external. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Sat, Nov 21, 2020 at 3:50 AM Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Wed, Nov 11, 2020 at 9:39 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> > There were a few problems in this rebased version, basically, the
> > compression options were not passed while compressing values from the
> > brin_form_tuple, so I have fixed this.
>
> Since the authorship history of this patch is complicated, it would be
> nice if you would include authorship information and relevant
> "Discussion" links in the patches.
I have added that.
> Design level considerations and overall notes:
>
> configure is autogenerated from configure.in, so the patch shouldn't
> include changes only to the former.
Yeah, I missed those changes. Done now.
> Looking over the changes to src/include:
>
> + PGLZ_COMPRESSION_ID,
> + LZ4_COMPRESSION_ID
>
> I think that it would be good to assign values to these explicitly.
Done
> +/* compresion handler routines */
>
> Spelling.
Done
> + /* compression routine for the compression method */
> + cmcompress_function cmcompress;
> +
> + /* decompression routine for the compression method */
> + cmcompress_function cmdecompress;
>
> Don't reuse cmcompress_function; that's confusing. Just have a typedef
> per structure member, even if they end up being the same.
Fixed as suggested
> #define TOAST_COMPRESS_SET_RAWSIZE(ptr, len) \
> - (((toast_compress_header *) (ptr))->rawsize = (len))
> +do { \
> + Assert(len > 0 && len <= RAWSIZEMASK); \
> + ((toast_compress_header *) (ptr))->info = (len); \
> +} while (0)
>
> Indentation.
Done
> +#define TOAST_COMPRESS_SET_COMPRESSION_METHOD(ptr, cm_method) \
> + ((toast_compress_header *) (ptr))->info |= ((cm_method) << 30);
>
> What about making TOAST_COMPRESS_SET_RAWSIZE() take another argument?
> And possibly also rename it to TEST_COMPRESS_SET_SIZE_AND_METHOD() or
> something? It seems not great to have separate functions each setting
> part of a 4-byte quantity. Too much chance of failing to set both
> parts. I guess you've got a function called
> toast_set_compressed_datum_info() for that, but it's just a wrapper
> around two macros that could just be combined, which would reduce
> complexity overall.
Done that way
> + T_CompressionRoutine, /* in access/compressionapi.h */
>
> This looks misplaced. I guess it should go just after these:
>
> T_FdwRoutine, /* in foreign/fdwapi.h */
> T_IndexAmRoutine, /* in access/amapi.h */
> T_TableAmRoutine, /* in access/tableam.h */
Done
> Looking over the regression test changes:
>
> The tests at the top of create_cm.out that just test that we can
> create tables with various storage types seem unrelated to the purpose
> of the patch. And the file doesn't test creating a compression method
> either, as the file name would suggest, so either the file name needs
> to be changed (compression, compression_method?) or the tests don't go
> here.
Changed to "compression"
> +-- check data is okdd
>
> I guess whoever is responsible for this comment prefers vi to emacs.
Fixed
> I don't quite understand the purpose of all of these tests, and there
> are some things that I feel like ought to be tested that seemingly
> aren't. Like, you seem to test using an UPDATE to move a datum from a
> table to another table with the same compression method, but not one
> with a different compression method.
Added test for this, and some other tests to improve overall coverage.
Testing the former is nice and
> everything, but that's the easy case: I think we also need to test the
> latter. I think it would be good to verify not only that the data is
> readable but that it's compressed the way we expect. I think it would
> be a great idea to add a pg_column_compression() function in a similar
> spirit to pg_column_size(). Perhaps it could return NULL when
> compression is not in use or the data type is not varlena, and the
> name of the compression method otherwise. That would allow for better
> testing of this feature, and it would also be useful to users who are
> switching methods, to see what data they still have that's using the
> old method. It could be useful for debugging problems on customer
> systems, too.
This is a really great idea, I have added this function and used in my test.
> I wonder if we need a test that moves data between tables through an
> intermediary. For instance, suppose a plpgsql function or DO block
> fetches some data and stores it in a plpgsql variable and then uses
> the variable to insert into another table. Hmm, maybe that would force
> de-TOASTing. But perhaps there are other cases. Maybe a more general
> way to approach the problem is: have you tried running a coverage
> report and checked which parts of your code are getting exercised by
> the existing tests and which parts are not? The stuff that isn't, we
> should try to add more tests. It's easy to get corner cases wrong with
> this kind of thing.
>
> I notice that LIKE INCLUDING COMPRESSION doesn't seem to be tested, at
> least not by 0001, which reinforces my feeling that the tests here are
> not as thorough as they could be.
Added test for this as well.
> +NOTICE: pg_compression contains unpinned initdb-created object(s)
> This seems wrong to me - why is it OK?
Yeah, this is wrong, now fixed.
> - result = (struct varlena *)
> - palloc(TOAST_COMPRESS_RAWSIZE(attr) + VARHDRSZ);
> - SET_VARSIZE(result, TOAST_COMPRESS_RAWSIZE(attr) + VARHDRSZ);
> + cmoid = GetCompressionOidFromCompressionId(TOAST_COMPRESS_METHOD(attr));
>
> - if (pglz_decompress(TOAST_COMPRESS_RAWDATA(attr),
> - TOAST_COMPRESS_SIZE(attr),
> - VARDATA(result),
> -
> TOAST_COMPRESS_RAWSIZE(attr), true) < 0)
> - elog(ERROR, "compressed data is corrupted");
> + /* get compression method handler routines */
> + cmroutine = GetCompressionRoutine(cmoid);
>
> - return result;
> + return cmroutine->cmdecompress(attr);
>
> I'm worried about how expensive this might be, and I think we could
> make it cheaper. The reason why I think this might be expensive is:
> currently, for every datum, you have a single direct function call.
> Now, with this, you first have a direct function call to
> GetCompressionOidFromCompressionId(). Then you have a call to
> GetCompressionRoutine(), which does a syscache lookup and calls a
> handler function, which is quite a lot more expensive than a single
> function call. And the handler isn't even returning a statically
> allocated structure, but is allocating new memory every time, which
> involves more function calls and maybe memory leaks. Then you use the
> results of all that to make an indirect function call.
>
> I'm not sure exactly what combination of things we could use to make
> this better, but it seems like there are a few possibilities:
>
> (1) The handler function could return a pointer to the same
> CompressionRoutine every time instead of constructing a new one every
> time.
> (2) The CompressionRoutine to which the handler function returns a
> pointer could be statically allocated instead of being built at
> runtime.
> (3) GetCompressionRoutine could have an OID -> handler cache instead
> of relying on syscache + calling the handler function all over again.
> (4) For the compression types that have dedicated bit patterns in the
> high bits of the compressed TOAST size, toast_compress_datum() could
> just have hard-coded logic to use the correct handlers instead of
> translating the bit pattern into an OID and then looking it up over
> again.
> (5) Going even further than #4 we could skip the handler layer
> entirely for such methods, and just call the right function directly.
> I think we should definitely do (1), and also (2) unless there's some
> reason it's hard. (3) doesn't need to be part of this patch, but might
> be something to consider later in the series. It's possible that it
> doesn't have enough benefit to be worth the work, though. Also, I
> think we should do either (4) or (5). I have a mild preference for (5)
> unless it looks too ugly.
> Note that I'm not talking about hard-coding a fast path for a
> hard-coded list of OIDs - which would seem a little bit unprincipled -
> but hard-coding a fast path for the bit patterns that are themselves
> hard-coded. I don't think we lose anything in terms of extensibility
> or even-handedness there; it's just avoiding a bunch of rigamarole
> that doesn't really buy us anything.
>
> All these points apply equally to toast_decompress_datum_slice() and
> toast_compress_datum().
Fixed as discussed at [1]
> + /* Fallback to default compression method, if not specified */
> + if (!OidIsValid(cmoid))
> + cmoid = DefaultCompressionOid;
>
> I think that the caller should be required to specify a legal value,
> and this should be an elog(ERROR) or an Assert().
>
> The change to equalTupleDescs() makes me wonder. Like, can we specify
> the compression method for a function parameter, or a function return
> value? I would think not. But then how are the tuple descriptors set
> up in that case? Under what circumstances do we actually need the
> tuple descriptors to compare unequal?
If we alter the compression method then we check whether we need to
rebuild the tuple descriptor or not based on what value is changed so
if the attribute compression method is changed we need to rebuild the
compression method right. You might say that in the first patch we
are not allowing altering the compression method so we might move this
to the second patch but I thought since we added this field to
pg_attribute in this patch then better to add this check as well.
What am I missing?
> lz4.c's header comment calls it cm_lz4.c, and the pathname is wrong too.
>
> I wonder if we should try to adopt a convention for the names of these
> files that isn't just the compression method name, like cmlz4 or
> compress_lz4. I kind of like the latter one. I am a little worried
> that just calling it lz4.c will result in name collisions later - not
> in this directory, of course, but elsewhere in the system. It's not a
> disaster if that happens, but for example verbose error reports print
> the file name, so it's nice if it's unambiguous.
Changed to compress_lz4.
> + if (!IsBinaryUpgrade &&
> + (relkind == RELKIND_RELATION ||
> + relkind == RELKIND_PARTITIONED_TABLE))
> + attr->attcompression =
> +
> GetAttributeCompressionMethod(attr, colDef->compression);
> + else
> + attr->attcompression = InvalidOid;
>
> Storing InvalidOid in the IsBinaryUpgrade case looks wrong. If
> upgrading from pre-v14, we need to store PGLZ_COMPRESSION_OID.
> Otherwise, we need to preserve whatever value was present in the old
> version. Or am I confused here?
Okay, so I think we can simply remove the IsBinaryUpgrade check so it
will behave as expected. Basically, now it the compression method is
specified then it will take that compression method and if it is not
specified then it will take the PGLZ_COMPRESSION_OID.
> I think there should be tests for the way this interacts with
> partitioning, and I think the intended interaction should be
> documented. Perhaps it should behave like TABLESPACE, where the parent
> property has no effect on what gets stored because the parent has no
> storage, but is inherited by each new child.
I have added the test for this and also documented the same.
> I wonder in passing about TOAST tables and materialized views, which
> are the other things that have storage. What gets stored for
> attcompression?
I have changed this to store the Invalid compression method always.
For a TOAST table it probably doesn't matter much
> since TOAST table entries shouldn't ever be toasted themselves, so
> anything that doesn't crash is fine (but maybe we should test that
> trying to alter the compression properties of a TOAST table doesn't
> crash, for example).
You mean to update the pg_attribute table for the toasted field (e.g
chunk_data) and set the attcompression to something valid? Or there
is a better way to write this test?
For a materialized view it seems reasonable to
> want to set column properties, but I'm not quite sure how that works
> today for things like STORAGE anyway. If we do allow setting STORAGE
> or COMPRESSION for materialized view columns then dump-and-reload
> needs to preserve the values.
Fixed as described as [2]
> + /*
> + * Use default compression method if the existing compression method is
> + * invalid but the new storage type is non plain storage.
> + */
> + if (!OidIsValid(attrtuple->attcompression) &&
> + (newstorage != TYPSTORAGE_PLAIN))
> + attrtuple->attcompression = DefaultCompressionOid;
>
> You have a few too many parens in there.
Fixed
> I don't see a particularly good reason to treat plain and external
> differently. More generally, I think there's a question here about
> when we need an attribute to have a valid compression type and when we
> don't. If typstorage is plan or external, then there's no point in
> ever having a compression type and maybe we should even reject
> attempts to set one (but I'm not sure). However, the attstorage is a
> different case. Suppose the column is created with extended storage
> and then later it's changed to plain. That's only a hint, so there may
> still be toasted values in that column, so the compression setting
> must endure. At any rate, we need to make sure we have clear and
> sensible rules for when attcompression (a) must be valid, (b) may be
> valid, and (c) must be invalid. And those rules need to at least be
> documented in the comments, and maybe in the SGML docs.
>
> I'm out of time for today, so I'll have to look at this more another
> day. Hope this helps for a start.
Fixed as I have described at [2], and the rules are documented in
pg_attribute.h (atop attcompression field)
[1] https://www.postgresql.org/message-id/CA%2BTgmob3W8cnLgOQX%2BJQzeyGN3eKGmRrBkUY6WGfNyHa%2Bt_qEw%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAFiTN-tzTTT2oqWdRGLv1dvvS5MC1W%2BLE%2B3bqWPJUZj4GnHOJg%40mail.gmail.com
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Dec 9, 2020 at 5:37 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Sat, Nov 21, 2020 at 3:50 AM Robert Haas <robertmhaas@gmail.com> wrote:
> >
> > On Wed, Nov 11, 2020 at 9:39 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> > > There were a few problems in this rebased version, basically, the
> > > compression options were not passed while compressing values from the
> > > brin_form_tuple, so I have fixed this.
> >
> > Since the authorship history of this patch is complicated, it would be
> > nice if you would include authorship information and relevant
> > "Discussion" links in the patches.
>
> I have added that.
>
> > Design level considerations and overall notes:
> >
> > configure is autogenerated from configure.in, so the patch shouldn't
> > include changes only to the former.
>
> Yeah, I missed those changes. Done now.
>
> > Looking over the changes to src/include:
> >
> > + PGLZ_COMPRESSION_ID,
> > + LZ4_COMPRESSION_ID
> >
> > I think that it would be good to assign values to these explicitly.
>
> Done
>
> > +/* compresion handler routines */
> >
> > Spelling.
>
> Done
>
> > + /* compression routine for the compression method */
> > + cmcompress_function cmcompress;
> > +
> > + /* decompression routine for the compression method */
> > + cmcompress_function cmdecompress;
> >
> > Don't reuse cmcompress_function; that's confusing. Just have a typedef
> > per structure member, even if they end up being the same.
>
> Fixed as suggested
>
> > #define TOAST_COMPRESS_SET_RAWSIZE(ptr, len) \
> > - (((toast_compress_header *) (ptr))->rawsize = (len))
> > +do { \
> > + Assert(len > 0 && len <= RAWSIZEMASK); \
> > + ((toast_compress_header *) (ptr))->info = (len); \
> > +} while (0)
> >
> > Indentation.
>
> Done
>
> > +#define TOAST_COMPRESS_SET_COMPRESSION_METHOD(ptr, cm_method) \
> > + ((toast_compress_header *) (ptr))->info |= ((cm_method) << 30);
> >
> > What about making TOAST_COMPRESS_SET_RAWSIZE() take another argument?
> > And possibly also rename it to TEST_COMPRESS_SET_SIZE_AND_METHOD() or
> > something? It seems not great to have separate functions each setting
> > part of a 4-byte quantity. Too much chance of failing to set both
> > parts. I guess you've got a function called
> > toast_set_compressed_datum_info() for that, but it's just a wrapper
> > around two macros that could just be combined, which would reduce
> > complexity overall.
>
> Done that way
>
> > + T_CompressionRoutine, /* in access/compressionapi.h */
> >
> > This looks misplaced. I guess it should go just after these:
> >
> > T_FdwRoutine, /* in foreign/fdwapi.h */
> > T_IndexAmRoutine, /* in access/amapi.h */
> > T_TableAmRoutine, /* in access/tableam.h */
>
> Done
>
> > Looking over the regression test changes:
> >
> > The tests at the top of create_cm.out that just test that we can
> > create tables with various storage types seem unrelated to the purpose
> > of the patch. And the file doesn't test creating a compression method
> > either, as the file name would suggest, so either the file name needs
> > to be changed (compression, compression_method?) or the tests don't go
> > here.
>
> Changed to "compression"
>
> > +-- check data is okdd
> >
> > I guess whoever is responsible for this comment prefers vi to emacs.
>
> Fixed
>
> > I don't quite understand the purpose of all of these tests, and there
> > are some things that I feel like ought to be tested that seemingly
> > aren't. Like, you seem to test using an UPDATE to move a datum from a
> > table to another table with the same compression method, but not one
> > with a different compression method.
>
> Added test for this, and some other tests to improve overall coverage.
>
> Testing the former is nice and
> > everything, but that's the easy case: I think we also need to test the
> > latter. I think it would be good to verify not only that the data is
> > readable but that it's compressed the way we expect. I think it would
> > be a great idea to add a pg_column_compression() function in a similar
> > spirit to pg_column_size(). Perhaps it could return NULL when
> > compression is not in use or the data type is not varlena, and the
> > name of the compression method otherwise. That would allow for better
> > testing of this feature, and it would also be useful to users who are
> > switching methods, to see what data they still have that's using the
> > old method. It could be useful for debugging problems on customer
> > systems, too.
>
> This is a really great idea, I have added this function and used in my test.
>
> > I wonder if we need a test that moves data between tables through an
> > intermediary. For instance, suppose a plpgsql function or DO block
> > fetches some data and stores it in a plpgsql variable and then uses
> > the variable to insert into another table. Hmm, maybe that would force
> > de-TOASTing. But perhaps there are other cases. Maybe a more general
> > way to approach the problem is: have you tried running a coverage
> > report and checked which parts of your code are getting exercised by
> > the existing tests and which parts are not? The stuff that isn't, we
> > should try to add more tests. It's easy to get corner cases wrong with
> > this kind of thing.
> >
> > I notice that LIKE INCLUDING COMPRESSION doesn't seem to be tested, at
> > least not by 0001, which reinforces my feeling that the tests here are
> > not as thorough as they could be.
>
> Added test for this as well.
>
> > +NOTICE: pg_compression contains unpinned initdb-created object(s)
>
> > This seems wrong to me - why is it OK?
>
> Yeah, this is wrong, now fixed.
>
> > - result = (struct varlena *)
> > - palloc(TOAST_COMPRESS_RAWSIZE(attr) + VARHDRSZ);
> > - SET_VARSIZE(result, TOAST_COMPRESS_RAWSIZE(attr) + VARHDRSZ);
> > + cmoid = GetCompressionOidFromCompressionId(TOAST_COMPRESS_METHOD(attr));
> >
> > - if (pglz_decompress(TOAST_COMPRESS_RAWDATA(attr),
> > - TOAST_COMPRESS_SIZE(attr),
> > - VARDATA(result),
> > -
> > TOAST_COMPRESS_RAWSIZE(attr), true) < 0)
> > - elog(ERROR, "compressed data is corrupted");
> > + /* get compression method handler routines */
> > + cmroutine = GetCompressionRoutine(cmoid);
> >
> > - return result;
> > + return cmroutine->cmdecompress(attr);
> >
> > I'm worried about how expensive this might be, and I think we could
> > make it cheaper. The reason why I think this might be expensive is:
> > currently, for every datum, you have a single direct function call.
> > Now, with this, you first have a direct function call to
> > GetCompressionOidFromCompressionId(). Then you have a call to
> > GetCompressionRoutine(), which does a syscache lookup and calls a
> > handler function, which is quite a lot more expensive than a single
> > function call. And the handler isn't even returning a statically
> > allocated structure, but is allocating new memory every time, which
> > involves more function calls and maybe memory leaks. Then you use the
> > results of all that to make an indirect function call.
> >
> > I'm not sure exactly what combination of things we could use to make
> > this better, but it seems like there are a few possibilities:
> >
> > (1) The handler function could return a pointer to the same
> > CompressionRoutine every time instead of constructing a new one every
> > time.
> > (2) The CompressionRoutine to which the handler function returns a
> > pointer could be statically allocated instead of being built at
> > runtime.
> > (3) GetCompressionRoutine could have an OID -> handler cache instead
> > of relying on syscache + calling the handler function all over again.
> > (4) For the compression types that have dedicated bit patterns in the
> > high bits of the compressed TOAST size, toast_compress_datum() could
> > just have hard-coded logic to use the correct handlers instead of
> > translating the bit pattern into an OID and then looking it up over
> > again.
> > (5) Going even further than #4 we could skip the handler layer
> > entirely for such methods, and just call the right function directly.
> > I think we should definitely do (1), and also (2) unless there's some
> > reason it's hard. (3) doesn't need to be part of this patch, but might
> > be something to consider later in the series. It's possible that it
> > doesn't have enough benefit to be worth the work, though. Also, I
> > think we should do either (4) or (5). I have a mild preference for (5)
> > unless it looks too ugly.
> > Note that I'm not talking about hard-coding a fast path for a
> > hard-coded list of OIDs - which would seem a little bit unprincipled -
> > but hard-coding a fast path for the bit patterns that are themselves
> > hard-coded. I don't think we lose anything in terms of extensibility
> > or even-handedness there; it's just avoiding a bunch of rigamarole
> > that doesn't really buy us anything.
> >
> > All these points apply equally to toast_decompress_datum_slice() and
> > toast_compress_datum().
>
> Fixed as discussed at [1]
>
> > + /* Fallback to default compression method, if not specified */
> > + if (!OidIsValid(cmoid))
> > + cmoid = DefaultCompressionOid;
> >
> > I think that the caller should be required to specify a legal value,
> > and this should be an elog(ERROR) or an Assert().
> >
> > The change to equalTupleDescs() makes me wonder. Like, can we specify
> > the compression method for a function parameter, or a function return
> > value? I would think not. But then how are the tuple descriptors set
> > up in that case? Under what circumstances do we actually need the
> > tuple descriptors to compare unequal?
>
> If we alter the compression method then we check whether we need to
> rebuild the tuple descriptor or not based on what value is changed so
> if the attribute compression method is changed we need to rebuild the
> compression method right. You might say that in the first patch we
> are not allowing altering the compression method so we might move this
> to the second patch but I thought since we added this field to
> pg_attribute in this patch then better to add this check as well.
> What am I missing?
>
> > lz4.c's header comment calls it cm_lz4.c, and the pathname is wrong too.
> >
> > I wonder if we should try to adopt a convention for the names of these
> > files that isn't just the compression method name, like cmlz4 or
> > compress_lz4. I kind of like the latter one. I am a little worried
> > that just calling it lz4.c will result in name collisions later - not
> > in this directory, of course, but elsewhere in the system. It's not a
> > disaster if that happens, but for example verbose error reports print
> > the file name, so it's nice if it's unambiguous.
>
> Changed to compress_lz4.
>
> > + if (!IsBinaryUpgrade &&
> > + (relkind == RELKIND_RELATION ||
> > + relkind == RELKIND_PARTITIONED_TABLE))
> > + attr->attcompression =
> > +
> > GetAttributeCompressionMethod(attr, colDef->compression);
> > + else
> > + attr->attcompression = InvalidOid;
> >
> > Storing InvalidOid in the IsBinaryUpgrade case looks wrong. If
> > upgrading from pre-v14, we need to store PGLZ_COMPRESSION_OID.
> > Otherwise, we need to preserve whatever value was present in the old
> > version. Or am I confused here?
>
> Okay, so I think we can simply remove the IsBinaryUpgrade check so it
> will behave as expected. Basically, now it the compression method is
> specified then it will take that compression method and if it is not
> specified then it will take the PGLZ_COMPRESSION_OID.
>
> > I think there should be tests for the way this interacts with
> > partitioning, and I think the intended interaction should be
> > documented. Perhaps it should behave like TABLESPACE, where the parent
> > property has no effect on what gets stored because the parent has no
> > storage, but is inherited by each new child.
>
> I have added the test for this and also documented the same.
>
> > I wonder in passing about TOAST tables and materialized views, which
> > are the other things that have storage. What gets stored for
> > attcompression?
>
> I have changed this to store the Invalid compression method always.
>
> For a TOAST table it probably doesn't matter much
> > since TOAST table entries shouldn't ever be toasted themselves, so
> > anything that doesn't crash is fine (but maybe we should test that
> > trying to alter the compression properties of a TOAST table doesn't
> > crash, for example).
>
> You mean to update the pg_attribute table for the toasted field (e.g
> chunk_data) and set the attcompression to something valid? Or there
> is a better way to write this test?
>
> For a materialized view it seems reasonable to
> > want to set column properties, but I'm not quite sure how that works
> > today for things like STORAGE anyway. If we do allow setting STORAGE
> > or COMPRESSION for materialized view columns then dump-and-reload
> > needs to preserve the values.
>
> Fixed as described as [2]
>
> > + /*
> > + * Use default compression method if the existing compression method is
> > + * invalid but the new storage type is non plain storage.
> > + */
> > + if (!OidIsValid(attrtuple->attcompression) &&
> > + (newstorage != TYPSTORAGE_PLAIN))
> > + attrtuple->attcompression = DefaultCompressionOid;
> >
> > You have a few too many parens in there.
>
> Fixed
>
> > I don't see a particularly good reason to treat plain and external
> > differently. More generally, I think there's a question here about
> > when we need an attribute to have a valid compression type and when we
> > don't. If typstorage is plan or external, then there's no point in
> > ever having a compression type and maybe we should even reject
> > attempts to set one (but I'm not sure). However, the attstorage is a
> > different case. Suppose the column is created with extended storage
> > and then later it's changed to plain. That's only a hint, so there may
> > still be toasted values in that column, so the compression setting
> > must endure. At any rate, we need to make sure we have clear and
> > sensible rules for when attcompression (a) must be valid, (b) may be
> > valid, and (c) must be invalid. And those rules need to at least be
> > documented in the comments, and maybe in the SGML docs.
> >
> > I'm out of time for today, so I'll have to look at this more another
> > day. Hope this helps for a start.
>
> Fixed as I have described at [2], and the rules are documented in
> pg_attribute.h (atop attcompression field)
>
> [1] https://www.postgresql.org/message-id/CA%2BTgmob3W8cnLgOQX%2BJQzeyGN3eKGmRrBkUY6WGfNyHa%2Bt_qEw%40mail.gmail.com
> [2] https://www.postgresql.org/message-id/CAFiTN-tzTTT2oqWdRGLv1dvvS5MC1W%2BLE%2B3bqWPJUZj4GnHOJg%40mail.gmail.com
>
I was working on analyzing the behavior of how the attribute merging
should work for the compression method for an inherited child so for
that, I was analyzing the behavior for the storage method. I found
some behavior that doesn't seem right. Basically, while creating the
inherited child we don't allow the storage to be different than the
parent attribute's storage but later we are allowed to alter that, is
that correct behavior.
Here is the test case to demonstrate this.
postgres[12546]=# create table t (a varchar);
postgres[12546]=# alter table t ALTER COLUMN a SET STORAGE plain;
postgres[12546]=# create table t1 (a varchar);
postgres[12546]=# alter table t1 ALTER COLUMN a SET STORAGE external;
/* Not allowing to set the external because parent attribute has plain */
postgres[12546]=# create table t2 (LIKE t1 INCLUDING STORAGE) INHERITS ( t);
NOTICE: 00000: merging column "a" with inherited definition
LOCATION: MergeAttributes, tablecmds.c:2685
ERROR: 42804: column "a" has a storage parameter conflict
DETAIL: PLAIN versus EXTERNAL
LOCATION: MergeAttributes, tablecmds.c:2730
postgres[12546]=# create table t2 (LIKE t1 ) INHERITS (t);
/* But you can alter now */
postgres[12546]=# alter TABLE t2 ALTER COLUMN a SET STORAGE EXTERNAL ;
postgres[12546]=# \d+ t
Table "public.t"
Column | Type | Collation | Nullable | Default | Storage
| Compression | Stats target | Description
--------+-------------------+-----------+----------+---------+---------+-------------+--------------+-------------
a | character varying | | |
| plain | pglz | |
Child tables: t2
Access method: heap
postgres[12546]=# \d+ t2
Table "public.t2"
Column | Type | Collation | Nullable | Default | Storage
| Compression | Stats target | Description
--------+-------------------+-----------+----------+---------+----------+-------------+--------------+-------------
a | character varying | | |
| external | pglz | |
Inherits: t
Access method: heap
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Thu, Dec 17, 2020 at 10:55 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Wed, Dec 9, 2020 at 5:37 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> >
> > On Sat, Nov 21, 2020 at 3:50 AM Robert Haas <robertmhaas@gmail.com> wrote:
> > >
> > > On Wed, Nov 11, 2020 at 9:39 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> > > > There were a few problems in this rebased version, basically, the
> > > > compression options were not passed while compressing values from the
> > > > brin_form_tuple, so I have fixed this.
> > >
> > > Since the authorship history of this patch is complicated, it would be
> > > nice if you would include authorship information and relevant
> > > "Discussion" links in the patches.
> >
> > I have added that.
> >
> > > Design level considerations and overall notes:
> > >
> > > configure is autogenerated from configure.in, so the patch shouldn't
> > > include changes only to the former.
> >
> > Yeah, I missed those changes. Done now.
> >
> > > Looking over the changes to src/include:
> > >
> > > + PGLZ_COMPRESSION_ID,
> > > + LZ4_COMPRESSION_ID
> > >
> > > I think that it would be good to assign values to these explicitly.
> >
> > Done
> >
> > > +/* compresion handler routines */
> > >
> > > Spelling.
> >
> > Done
> >
> > > + /* compression routine for the compression method */
> > > + cmcompress_function cmcompress;
> > > +
> > > + /* decompression routine for the compression method */
> > > + cmcompress_function cmdecompress;
> > >
> > > Don't reuse cmcompress_function; that's confusing. Just have a typedef
> > > per structure member, even if they end up being the same.
> >
> > Fixed as suggested
> >
> > > #define TOAST_COMPRESS_SET_RAWSIZE(ptr, len) \
> > > - (((toast_compress_header *) (ptr))->rawsize = (len))
> > > +do { \
> > > + Assert(len > 0 && len <= RAWSIZEMASK); \
> > > + ((toast_compress_header *) (ptr))->info = (len); \
> > > +} while (0)
> > >
> > > Indentation.
> >
> > Done
> >
> > > +#define TOAST_COMPRESS_SET_COMPRESSION_METHOD(ptr, cm_method) \
> > > + ((toast_compress_header *) (ptr))->info |= ((cm_method) << 30);
> > >
> > > What about making TOAST_COMPRESS_SET_RAWSIZE() take another argument?
> > > And possibly also rename it to TEST_COMPRESS_SET_SIZE_AND_METHOD() or
> > > something? It seems not great to have separate functions each setting
> > > part of a 4-byte quantity. Too much chance of failing to set both
> > > parts. I guess you've got a function called
> > > toast_set_compressed_datum_info() for that, but it's just a wrapper
> > > around two macros that could just be combined, which would reduce
> > > complexity overall.
> >
> > Done that way
> >
> > > + T_CompressionRoutine, /* in access/compressionapi.h */
> > >
> > > This looks misplaced. I guess it should go just after these:
> > >
> > > T_FdwRoutine, /* in foreign/fdwapi.h */
> > > T_IndexAmRoutine, /* in access/amapi.h */
> > > T_TableAmRoutine, /* in access/tableam.h */
> >
> > Done
> >
> > > Looking over the regression test changes:
> > >
> > > The tests at the top of create_cm.out that just test that we can
> > > create tables with various storage types seem unrelated to the purpose
> > > of the patch. And the file doesn't test creating a compression method
> > > either, as the file name would suggest, so either the file name needs
> > > to be changed (compression, compression_method?) or the tests don't go
> > > here.
> >
> > Changed to "compression"
> >
> > > +-- check data is okdd
> > >
> > > I guess whoever is responsible for this comment prefers vi to emacs.
> >
> > Fixed
> >
> > > I don't quite understand the purpose of all of these tests, and there
> > > are some things that I feel like ought to be tested that seemingly
> > > aren't. Like, you seem to test using an UPDATE to move a datum from a
> > > table to another table with the same compression method, but not one
> > > with a different compression method.
> >
> > Added test for this, and some other tests to improve overall coverage.
> >
> > Testing the former is nice and
> > > everything, but that's the easy case: I think we also need to test the
> > > latter. I think it would be good to verify not only that the data is
> > > readable but that it's compressed the way we expect. I think it would
> > > be a great idea to add a pg_column_compression() function in a similar
> > > spirit to pg_column_size(). Perhaps it could return NULL when
> > > compression is not in use or the data type is not varlena, and the
> > > name of the compression method otherwise. That would allow for better
> > > testing of this feature, and it would also be useful to users who are
> > > switching methods, to see what data they still have that's using the
> > > old method. It could be useful for debugging problems on customer
> > > systems, too.
> >
> > This is a really great idea, I have added this function and used in my test.
> >
> > > I wonder if we need a test that moves data between tables through an
> > > intermediary. For instance, suppose a plpgsql function or DO block
> > > fetches some data and stores it in a plpgsql variable and then uses
> > > the variable to insert into another table. Hmm, maybe that would force
> > > de-TOASTing. But perhaps there are other cases. Maybe a more general
> > > way to approach the problem is: have you tried running a coverage
> > > report and checked which parts of your code are getting exercised by
> > > the existing tests and which parts are not? The stuff that isn't, we
> > > should try to add more tests. It's easy to get corner cases wrong with
> > > this kind of thing.
> > >
> > > I notice that LIKE INCLUDING COMPRESSION doesn't seem to be tested, at
> > > least not by 0001, which reinforces my feeling that the tests here are
> > > not as thorough as they could be.
> >
> > Added test for this as well.
> >
> > > +NOTICE: pg_compression contains unpinned initdb-created object(s)
> >
> > > This seems wrong to me - why is it OK?
> >
> > Yeah, this is wrong, now fixed.
> >
> > > - result = (struct varlena *)
> > > - palloc(TOAST_COMPRESS_RAWSIZE(attr) + VARHDRSZ);
> > > - SET_VARSIZE(result, TOAST_COMPRESS_RAWSIZE(attr) + VARHDRSZ);
> > > + cmoid = GetCompressionOidFromCompressionId(TOAST_COMPRESS_METHOD(attr));
> > >
> > > - if (pglz_decompress(TOAST_COMPRESS_RAWDATA(attr),
> > > - TOAST_COMPRESS_SIZE(attr),
> > > - VARDATA(result),
> > > -
> > > TOAST_COMPRESS_RAWSIZE(attr), true) < 0)
> > > - elog(ERROR, "compressed data is corrupted");
> > > + /* get compression method handler routines */
> > > + cmroutine = GetCompressionRoutine(cmoid);
> > >
> > > - return result;
> > > + return cmroutine->cmdecompress(attr);
> > >
> > > I'm worried about how expensive this might be, and I think we could
> > > make it cheaper. The reason why I think this might be expensive is:
> > > currently, for every datum, you have a single direct function call.
> > > Now, with this, you first have a direct function call to
> > > GetCompressionOidFromCompressionId(). Then you have a call to
> > > GetCompressionRoutine(), which does a syscache lookup and calls a
> > > handler function, which is quite a lot more expensive than a single
> > > function call. And the handler isn't even returning a statically
> > > allocated structure, but is allocating new memory every time, which
> > > involves more function calls and maybe memory leaks. Then you use the
> > > results of all that to make an indirect function call.
> > >
> > > I'm not sure exactly what combination of things we could use to make
> > > this better, but it seems like there are a few possibilities:
> > >
> > > (1) The handler function could return a pointer to the same
> > > CompressionRoutine every time instead of constructing a new one every
> > > time.
> > > (2) The CompressionRoutine to which the handler function returns a
> > > pointer could be statically allocated instead of being built at
> > > runtime.
> > > (3) GetCompressionRoutine could have an OID -> handler cache instead
> > > of relying on syscache + calling the handler function all over again.
> > > (4) For the compression types that have dedicated bit patterns in the
> > > high bits of the compressed TOAST size, toast_compress_datum() could
> > > just have hard-coded logic to use the correct handlers instead of
> > > translating the bit pattern into an OID and then looking it up over
> > > again.
> > > (5) Going even further than #4 we could skip the handler layer
> > > entirely for such methods, and just call the right function directly.
> > > I think we should definitely do (1), and also (2) unless there's some
> > > reason it's hard. (3) doesn't need to be part of this patch, but might
> > > be something to consider later in the series. It's possible that it
> > > doesn't have enough benefit to be worth the work, though. Also, I
> > > think we should do either (4) or (5). I have a mild preference for (5)
> > > unless it looks too ugly.
> > > Note that I'm not talking about hard-coding a fast path for a
> > > hard-coded list of OIDs - which would seem a little bit unprincipled -
> > > but hard-coding a fast path for the bit patterns that are themselves
> > > hard-coded. I don't think we lose anything in terms of extensibility
> > > or even-handedness there; it's just avoiding a bunch of rigamarole
> > > that doesn't really buy us anything.
> > >
> > > All these points apply equally to toast_decompress_datum_slice() and
> > > toast_compress_datum().
> >
> > Fixed as discussed at [1]
> >
> > > + /* Fallback to default compression method, if not specified */
> > > + if (!OidIsValid(cmoid))
> > > + cmoid = DefaultCompressionOid;
> > >
> > > I think that the caller should be required to specify a legal value,
> > > and this should be an elog(ERROR) or an Assert().
> > >
> > > The change to equalTupleDescs() makes me wonder. Like, can we specify
> > > the compression method for a function parameter, or a function return
> > > value? I would think not. But then how are the tuple descriptors set
> > > up in that case? Under what circumstances do we actually need the
> > > tuple descriptors to compare unequal?
> >
> > If we alter the compression method then we check whether we need to
> > rebuild the tuple descriptor or not based on what value is changed so
> > if the attribute compression method is changed we need to rebuild the
> > compression method right. You might say that in the first patch we
> > are not allowing altering the compression method so we might move this
> > to the second patch but I thought since we added this field to
> > pg_attribute in this patch then better to add this check as well.
> > What am I missing?
> >
> > > lz4.c's header comment calls it cm_lz4.c, and the pathname is wrong too.
> > >
> > > I wonder if we should try to adopt a convention for the names of these
> > > files that isn't just the compression method name, like cmlz4 or
> > > compress_lz4. I kind of like the latter one. I am a little worried
> > > that just calling it lz4.c will result in name collisions later - not
> > > in this directory, of course, but elsewhere in the system. It's not a
> > > disaster if that happens, but for example verbose error reports print
> > > the file name, so it's nice if it's unambiguous.
> >
> > Changed to compress_lz4.
> >
> > > + if (!IsBinaryUpgrade &&
> > > + (relkind == RELKIND_RELATION ||
> > > + relkind == RELKIND_PARTITIONED_TABLE))
> > > + attr->attcompression =
> > > +
> > > GetAttributeCompressionMethod(attr, colDef->compression);
> > > + else
> > > + attr->attcompression = InvalidOid;
> > >
> > > Storing InvalidOid in the IsBinaryUpgrade case looks wrong. If
> > > upgrading from pre-v14, we need to store PGLZ_COMPRESSION_OID.
> > > Otherwise, we need to preserve whatever value was present in the old
> > > version. Or am I confused here?
> >
> > Okay, so I think we can simply remove the IsBinaryUpgrade check so it
> > will behave as expected. Basically, now it the compression method is
> > specified then it will take that compression method and if it is not
> > specified then it will take the PGLZ_COMPRESSION_OID.
> >
> > > I think there should be tests for the way this interacts with
> > > partitioning, and I think the intended interaction should be
> > > documented. Perhaps it should behave like TABLESPACE, where the parent
> > > property has no effect on what gets stored because the parent has no
> > > storage, but is inherited by each new child.
> >
> > I have added the test for this and also documented the same.
> >
> > > I wonder in passing about TOAST tables and materialized views, which
> > > are the other things that have storage. What gets stored for
> > > attcompression?
> >
> > I have changed this to store the Invalid compression method always.
> >
> > For a TOAST table it probably doesn't matter much
> > > since TOAST table entries shouldn't ever be toasted themselves, so
> > > anything that doesn't crash is fine (but maybe we should test that
> > > trying to alter the compression properties of a TOAST table doesn't
> > > crash, for example).
> >
> > You mean to update the pg_attribute table for the toasted field (e.g
> > chunk_data) and set the attcompression to something valid? Or there
> > is a better way to write this test?
> >
> > For a materialized view it seems reasonable to
> > > want to set column properties, but I'm not quite sure how that works
> > > today for things like STORAGE anyway. If we do allow setting STORAGE
> > > or COMPRESSION for materialized view columns then dump-and-reload
> > > needs to preserve the values.
> >
> > Fixed as described as [2]
> >
> > > + /*
> > > + * Use default compression method if the existing compression method is
> > > + * invalid but the new storage type is non plain storage.
> > > + */
> > > + if (!OidIsValid(attrtuple->attcompression) &&
> > > + (newstorage != TYPSTORAGE_PLAIN))
> > > + attrtuple->attcompression = DefaultCompressionOid;
> > >
> > > You have a few too many parens in there.
> >
> > Fixed
> >
> > > I don't see a particularly good reason to treat plain and external
> > > differently. More generally, I think there's a question here about
> > > when we need an attribute to have a valid compression type and when we
> > > don't. If typstorage is plan or external, then there's no point in
> > > ever having a compression type and maybe we should even reject
> > > attempts to set one (but I'm not sure). However, the attstorage is a
> > > different case. Suppose the column is created with extended storage
> > > and then later it's changed to plain. That's only a hint, so there may
> > > still be toasted values in that column, so the compression setting
> > > must endure. At any rate, we need to make sure we have clear and
> > > sensible rules for when attcompression (a) must be valid, (b) may be
> > > valid, and (c) must be invalid. And those rules need to at least be
> > > documented in the comments, and maybe in the SGML docs.
> > >
> > > I'm out of time for today, so I'll have to look at this more another
> > > day. Hope this helps for a start.
> >
> > Fixed as I have described at [2], and the rules are documented in
> > pg_attribute.h (atop attcompression field)
> >
> > [1]
https://www.postgresql.org/message-id/CA%2BTgmob3W8cnLgOQX%2BJQzeyGN3eKGmRrBkUY6WGfNyHa%2Bt_qEw%40mail.gmail.com
> > [2] https://www.postgresql.org/message-id/CAFiTN-tzTTT2oqWdRGLv1dvvS5MC1W%2BLE%2B3bqWPJUZj4GnHOJg%40mail.gmail.com
> >
>
> I was working on analyzing the behavior of how the attribute merging
> should work for the compression method for an inherited child so for
> that, I was analyzing the behavior for the storage method. I found
> some behavior that doesn't seem right. Basically, while creating the
> inherited child we don't allow the storage to be different than the
> parent attribute's storage but later we are allowed to alter that, is
> that correct behavior.
>
> Here is the test case to demonstrate this.
>
> postgres[12546]=# create table t (a varchar);
> postgres[12546]=# alter table t ALTER COLUMN a SET STORAGE plain;
> postgres[12546]=# create table t1 (a varchar);
> postgres[12546]=# alter table t1 ALTER COLUMN a SET STORAGE external;
>
> /* Not allowing to set the external because parent attribute has plain */
> postgres[12546]=# create table t2 (LIKE t1 INCLUDING STORAGE) INHERITS ( t);
> NOTICE: 00000: merging column "a" with inherited definition
> LOCATION: MergeAttributes, tablecmds.c:2685
> ERROR: 42804: column "a" has a storage parameter conflict
> DETAIL: PLAIN versus EXTERNAL
> LOCATION: MergeAttributes, tablecmds.c:2730
On further analysis, IMHO the reason for this error is not that it can
not allow different storage methods for inherited child's attributes
but it is reporting error because of conflicting storage between child
and parent. For example, if we inherit a child from two-parent who
have the same attribute name with a different storage type then also
it will conflict. I know that if it conflicts between parent and
child we might give preference to the child's storage but I don't see
much problem with the current behavior also. So as of now, I have
kept the same behavior for the compression as well. I have added a
test case for the same.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Attachment
> 25 дек. 2020 г., в 14:34, Dilip Kumar <dilipbalaut@gmail.com> написал(а): > > <v16-0002-alter-table-set-compression.patch> <v16-0004-Create-custom-compression-methods.patch> <v16-0005-new-compression-method-extension-for-zlib.patch><v16-0001-Built-in-compression-method.patch> <v16-0003-Add-support-for-PRESERVE.patch><v16-0006-Support-compression-methods-options.patch> Maybe add Lz4\Zlib WAL FPI compression on top of this patchset? I'm not insisting on anything, it just would be so cool tohave it... BTW currently there are Oid collisions in original patchset. Best regards, Andrey Borodin.
Attachment
On Sun, Dec 27, 2020 at 12:40 PM Andrey Borodin <x4mmm@yandex-team.ru> wrote: > > > > > 25 дек. 2020 г., в 14:34, Dilip Kumar <dilipbalaut@gmail.com> написал(а): > > > > <v16-0002-alter-table-set-compression.patch> <v16-0004-Create-custom-compression-methods.patch> <v16-0005-new-compression-method-extension-for-zlib.patch><v16-0001-Built-in-compression-method.patch> <v16-0003-Add-support-for-PRESERVE.patch><v16-0006-Support-compression-methods-options.patch> > > Maybe add Lz4\Zlib WAL FPI compression on top of this patchset? I'm not insisting on anything, it just would be so coolto have it... > > BTW currently there are Oid collisions in original patchset. Thanks for the patch. Maybe we can allow setting custom compression methods for wal compression as well. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
> 28 дек. 2020 г., в 10:20, Dilip Kumar <dilipbalaut@gmail.com> написал(а): > > On Sun, Dec 27, 2020 at 12:40 PM Andrey Borodin <x4mmm@yandex-team.ru> wrote: >> >> >> >>> 25 дек. 2020 г., в 14:34, Dilip Kumar <dilipbalaut@gmail.com> написал(а): >>> >>> <v16-0002-alter-table-set-compression.patch> <v16-0004-Create-custom-compression-methods.patch> <v16-0005-new-compression-method-extension-for-zlib.patch><v16-0001-Built-in-compression-method.patch> <v16-0003-Add-support-for-PRESERVE.patch><v16-0006-Support-compression-methods-options.patch> >> >> Maybe add Lz4\Zlib WAL FPI compression on top of this patchset? I'm not insisting on anything, it just would be so coolto have it... >> >> BTW currently there are Oid collisions in original patchset. > > Thanks for the patch. Maybe we can allow setting custom compression > methods for wal compression as well. No, unfortunately, we can't use truly custom methods. Custom compression handlers are WAL-logged. So we can use only staticset of hardcoded compression methods. Thanks! Best regards, Andrey Borodin.
> 28 дек. 2020 г., в 11:14, Andrey Borodin <x4mmm@yandex-team.ru> написал(а): > >> Thanks for the patch. Maybe we can allow setting custom compression >> methods for wal compression as well. > > No, unfortunately, we can't use truly custom methods. Custom compression handlers are WAL-logged. So we can use only staticset of hardcoded compression methods. So, I've made some very basic benchmarks on my machine [0]. With pglz after checkpoint I observe 1146 and 1225 tps. With lz4 I observe 1485 and 1524 tps. Without wal_compression I see 1529 tps. These observations can be explained with plain statement: pglz is bottleneck on my machine, lz4 is not. While this effect can be reached with other means [1] I believe having lz4 for WAL FPIs would be much more CPU efficient. FPA lz4 for WAL FPI patch v17. Changes: fixed some frontend issues, added some comments. Best regards, Andrey Borodin. [0] https://yadi.sk/d/6y5YiROXQRkoEw [1] https://www.postgresql.org/message-id/flat/25991595-1848-4178-AA57-872B10309DA2%40yandex-team.ru#e7bb0e048358bcff281011dcf115ad42
Attachment
On Mon, Jan 4, 2021 at 6:52 AM Justin Pryzby <pryzby@telsasoft.com> wrote:
>
> The most recent patch doesn't compile --without-lz4:
>
> compress_lz4.c:191:17: error: ‘lz4_cmcheck’ undeclared here (not in a function)
> .datum_check = lz4_cmcheck,
> ...
>
> And fails pg_upgrade check, apparently losing track of the compression (?)
>
> CREATE TABLE public.cmdata2 (
> - f1 text COMPRESSION lz4
> + f1 text
> );
>
> You added pg_dump --no-compression, but the --help isn't updated. I think
> there should also be an option for pg_restore, like --no-tablespaces. And I
> think there should be a GUC for default_compression, like
> default_table_access_method, so one can restore into an alternate compression
> by setting PGOPTIONS=-cdefault_compression=lz4.
>
> I'd like to be able to make all compressible columns of a table use a
> non-default compression (except those which cannot), without having to use
> \gexec... We have tables with up to 1600 columns. So a GUC would allow that.
>
> Previously (on separate threads) I wondered whether pg_dump
> --no-table-access-method was needed - maybe that be sufficient for this case,
> too, but I think it should be possible to separately avoid restoring
> compression AM and AM "proper". So maybe it'd be like --no-tableam=compress
> --no-tableam=storage or --no-tableam-all.
>
> Some language fixes:
>
> Subject: [PATCH v16 1/6] Built-in compression method
>
> +++ b/doc/src/sgml/ddl.sgml
> @@ -3762,6 +3762,8 @@ CREATE TABLE measurement (
> <productname>PostgreSQL</productname>
> tables (or, possibly, foreign tables). It is possible to specify a
> tablespace and storage parameters for each partition separately.
> + Partitions inherits the compression method of the parent for each column
> + however we can set different compression method for each partition.
>
> Should say:
> + By default, each column in a partition inherits the compression method from its parent table,
> + however a different compression method can be set for each partition.
>
> +++ b/doc/src/sgml/ref/create_table.sgml
>
> + <varlistentry>
> + <term><literal>INCLUDING COMPRESSION</literal></term>
> + <listitem>
> + <para>
> + Compression method of the columns will be coppied. The default
> + behavior is to exclude compression method, resulting in the copied
> + column will have the default compression method if the column type is
> + compressible.
>
> Say:
> + Compression method of the columns will be copied. The default
> + behavior is to exclude compression methods, resulting in the
> + columns having the default compression method.
>
> + <varlistentry>
> + <term><literal>COMPRESSION <replaceable class="parameter">compression_method</replaceable></literal></term>
> + <listitem>
> + <para>
> + This clause adds the compression method to a column. Compression method
> + can be set from the available built-in compression methods. The available
> + options are <literal>pglz</literal> and <literal>lz4</literal>. If the
> + compression method is not sepcified for the compressible type then it will
> + have the default compression method. The default compression method is
> + <literal>pglz</literal>.
>
> Say "The compression method can be set from available compression methods" (or
> remove this sentence).
> Say "The available BUILT-IN methods are ..."
> sepcified => specified
>
> +
> + /*
> + * No point in wasting a palloc cycle if value size is out of the allowed
> + * range for compression
>
> say "outside the allowed range"
>
> + if (pset.sversion >= 120000 &&
> + if (pset.sversion >= 120000 &&
>
> A couple places that need to say >= 14
>
> Subject: [PATCH v16 2/6] alter table set compression
>
> + <literal>SET COMPRESSION <replaceable class="parameter">compression_method</replaceable></literal>
> + This clause adds compression to a column. Compression method can be set
> + from available built-in compression methods. The available built-in
> + methods are <literal>pglz</literal> and <literal>lz4</literal>.
>
> Should say "The compression method can be set to any available method. The
> built in methods are >PGLZ< or >LZ<"
> That fixes grammar, and correction that it's possible to set to an available
> method other than what's "built-in".
>
> +++ b/src/include/commands/event_trigger.h
> @@ -32,7 +32,7 @@ typedef struct EventTriggerData
> #define AT_REWRITE_ALTER_PERSISTENCE 0x01
> #define AT_REWRITE_DEFAULT_VAL 0x02
> #define AT_REWRITE_COLUMN_REWRITE 0x04
> -
> +#define AT_REWRITE_ALTER_COMPRESSION 0x08
> /*
>
> This is losing a useful newline.
>
> Subject: [PATCH v16 4/6] Create custom compression methods
>
> + This clause adds compression to a column. Compression method
> + could be created with <xref linkend="sql-create-access-method"/> or it can
> + be set from the available built-in compression methods. The available
> + built-in methods are <literal>pglz</literal> and <literal>lz4</literal>.
> + The PRESERVE list contains list of compression methods used on the column
> + and determines which of them should be kept on the column. Without
> + PRESERVE or if all the previous compression methods are not preserved then
> + the table will be rewritten. If PRESERVE ALL is specified then all the
> + previous methods will be preserved and the table will not be rewritten.
> </para>
> </listitem>
> </varlistentry>
>
> diff --git a/doc/src/sgml/ref/create_table.sgml b/doc/src/sgml/ref/create_table.sgml
> index f404dd1088..ade3989d75 100644
> --- a/doc/src/sgml/ref/create_table.sgml
> +++ b/doc/src/sgml/ref/create_table.sgml
> @@ -999,11 +999,12 @@ WITH ( MODULUS <replaceable class="parameter">numeric_literal</replaceable>, REM
> + could be created with <xref linkend="sql-create-access-method"/> or it can
> + be set from the available built-in compression methods. The available
>
> remove this first "built-in" ?
>
> + built-in methods are <literal>pglz</literal> and <literal>lz4</literal>.
>
>
> +GetCompressionAmRoutineByAmId(Oid amoid)
> ...
> + /* Check if it's an index access method as opposed to some other AM */
> + if (amform->amtype != AMTYPE_COMPRESSION)
> + ereport(ERROR,
> + (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("access method \"%s\" is not of type %s",
> + NameStr(amform->amname), "INDEX")));
> ...
> + errmsg("index access method \"%s\" does not have a handler",
>
> In 3 places, the comment and code should say "COMPRESSION" right ?
>
> Subject: [PATCH v16 6/6] Support compression methods options
>
> + If compression method has options they could be specified with
> + <literal>WITH</literal> parameter.
>
> If *the* compression method has options, they *can* be specified with *the* ...
>
> @@ -1004,7 +1004,9 @@ WITH ( MODULUS <replaceable class="parameter">numeric_literal</replaceable>, REM
> + method is <literal>pglz</literal>. If the compression method has options
> + they could be specified by <literal>WITH</literal>
> + parameter.
>
> same
>
> +static void *
> +lz4_cminitstate(List *options)
> +{
> + int32 *acceleration = palloc(sizeof(int32));
> +
> + /* initialize with the default acceleration */
> + *acceleration = 1;
> +
> + if (list_length(options) > 0)
> + {
> + ListCell *lc;
> +
> + foreach(lc, options)
> + {
> + DefElem *def = (DefElem *) lfirst(lc);
> +
> + if (strcmp(def->defname, "acceleration") == 0)
> + *acceleration = pg_atoi(defGetString(def), sizeof(int32), 0);
>
> Don't you need to say "else: error: unknown compression option" ?
>
> + /*
> + * Compression option must be only valid if we are updating the compression
> + * method.
> + */
> + Assert(DatumGetPointer(acoptions) == NULL || OidIsValid(newcompression));
> +
>
> should say "need be valid only if .."
>
Thanks for the review, I will work on these and respond along with the
updated patches.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Mon, Jan 4, 2021 at 6:52 AM Justin Pryzby <pryzby@telsasoft.com> wrote:
>
> The most recent patch doesn't compile --without-lz4:
>
> compress_lz4.c:191:17: error: ‘lz4_cmcheck’ undeclared here (not in a function)
> .datum_check = lz4_cmcheck,
> ...
>
My bad, fixed this.
> And fails pg_upgrade check, apparently losing track of the compression (?)
>
> CREATE TABLE public.cmdata2 (
> - f1 text COMPRESSION lz4
> + f1 text
> );
I did not get this? pg_upgrade check is passing for me.
> You added pg_dump --no-compression, but the --help isn't updated.
Fixed.
I think
> there should also be an option for pg_restore, like --no-tablespaces. And I
> think there should be a GUC for default_compression, like
> default_table_access_method, so one can restore into an alternate compression
> by setting PGOPTIONS=-cdefault_compression=lz4.
>
> I'd like to be able to make all compressible columns of a table use a
> non-default compression (except those which cannot), without having to use
> \gexec... We have tables with up to 1600 columns. So a GUC would allow that.
>
> Previously (on separate threads) I wondered whether pg_dump
> --no-table-access-method was needed - maybe that be sufficient for this case,
> too, but I think it should be possible to separately avoid restoring
> compression AM and AM "proper". So maybe it'd be like --no-tableam=compress
> --no-tableam=storage or --no-tableam-all.
I will put more thought into this and respond separately.
> Some language fixes:
>
> Subject: [PATCH v16 1/6] Built-in compression method
>
> +++ b/doc/src/sgml/ddl.sgml
> @@ -3762,6 +3762,8 @@ CREATE TABLE measurement (
> <productname>PostgreSQL</productname>
> tables (or, possibly, foreign tables). It is possible to specify a
> tablespace and storage parameters for each partition separately.
> + Partitions inherits the compression method of the parent for each column
> + however we can set different compression method for each partition.
>
> Should say:
> + By default, each column in a partition inherits the compression method from its parent table,
> + however a different compression method can be set for each partition.
Done
> +++ b/doc/src/sgml/ref/create_table.sgml
>
> + <varlistentry>
> + <term><literal>INCLUDING COMPRESSION</literal></term>
> + <listitem>
> + <para>
> + Compression method of the columns will be coppied. The default
> + behavior is to exclude compression method, resulting in the copied
> + column will have the default compression method if the column type is
> + compressible.
>
> Say:
> + Compression method of the columns will be copied. The default
> + behavior is to exclude compression methods, resulting in the
> + columns having the default compression method.
Done
> + <varlistentry>
> + <term><literal>COMPRESSION <replaceable class="parameter">compression_method</replaceable></literal></term>
> + <listitem>
> + <para>
> + This clause adds the compression method to a column. Compression method
> + can be set from the available built-in compression methods. The available
> + options are <literal>pglz</literal> and <literal>lz4</literal>. If the
> + compression method is not sepcified for the compressible type then it will
> + have the default compression method. The default compression method is
> + <literal>pglz</literal>.
>
> Say "The compression method can be set from available compression methods" (or
> remove this sentence).
> Say "The available BUILT-IN methods are ..."
> sepcified => specified
Done
> +
> + /*
> + * No point in wasting a palloc cycle if value size is out of the allowed
> + * range for compression
>
> say "outside the allowed range"
>
> + if (pset.sversion >= 120000 &&
> + if (pset.sversion >= 120000 &&
>
> A couple places that need to say >= 14
Fixed
> Subject: [PATCH v16 2/6] alter table set compression
>
> + <literal>SET COMPRESSION <replaceable class="parameter">compression_method</replaceable></literal>
> + This clause adds compression to a column. Compression method can be set
> + from available built-in compression methods. The available built-in
> + methods are <literal>pglz</literal> and <literal>lz4</literal>.
>
> Should say "The compression method can be set to any available method. The
> built in methods are >PGLZ< or >LZ<"
> That fixes grammar, and correction that it's possible to set to an available
> method other than what's "built-in".
Done
> +++ b/src/include/commands/event_trigger.h
> @@ -32,7 +32,7 @@ typedef struct EventTriggerData
> #define AT_REWRITE_ALTER_PERSISTENCE 0x01
> #define AT_REWRITE_DEFAULT_VAL 0x02
> #define AT_REWRITE_COLUMN_REWRITE 0x04
> -
> +#define AT_REWRITE_ALTER_COMPRESSION 0x08
> /*
>
> This is losing a useful newline.
Fixed
> Subject: [PATCH v16 4/6] Create custom compression methods
>
> + This clause adds compression to a column. Compression method
> + could be created with <xref linkend="sql-create-access-method"/> or it can
> + be set from the available built-in compression methods. The available
> + built-in methods are <literal>pglz</literal> and <literal>lz4</literal>.
> + The PRESERVE list contains list of compression methods used on the column
> + and determines which of them should be kept on the column. Without
> + PRESERVE or if all the previous compression methods are not preserved then
> + the table will be rewritten. If PRESERVE ALL is specified then all the
> + previous methods will be preserved and the table will not be rewritten.
> </para>
> </listitem>
> </varlistentry>
>
> diff --git a/doc/src/sgml/ref/create_table.sgml b/doc/src/sgml/ref/create_table.sgml
> index f404dd1088..ade3989d75 100644
> --- a/doc/src/sgml/ref/create_table.sgml
> +++ b/doc/src/sgml/ref/create_table.sgml
> @@ -999,11 +999,12 @@ WITH ( MODULUS <replaceable class="parameter">numeric_literal</replaceable>, REM
> + could be created with <xref linkend="sql-create-access-method"/> or it can
> + be set from the available built-in compression methods. The available
>
> remove this first "built-in" ?
Done
> + built-in methods are <literal>pglz</literal> and <literal>lz4</literal>.
>
>
> +GetCompressionAmRoutineByAmId(Oid amoid)
> ...
> + /* Check if it's an index access method as opposed to some other AM */
> + if (amform->amtype != AMTYPE_COMPRESSION)
> + ereport(ERROR,
> + (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("access method \"%s\" is not of type %s",
> + NameStr(amform->amname), "INDEX")));
> ...
> + errmsg("index access method \"%s\" does not have a handler",
>
> In 3 places, the comment and code should say "COMPRESSION" right ?
Fixed, along with some other refactoring around this code.
> Subject: [PATCH v16 6/6] Support compression methods options
>
> + If compression method has options they could be specified with
> + <literal>WITH</literal> parameter.
>
> If *the* compression method has options, they *can* be specified with *the* ...
Done
> @@ -1004,7 +1004,9 @@ WITH ( MODULUS <replaceable class="parameter">numeric_literal</replaceable>, REM
> + method is <literal>pglz</literal>. If the compression method has options
> + they could be specified by <literal>WITH</literal>
> + parameter.
>
> same
Done
> +static void *
> +lz4_cminitstate(List *options)
> +{
> + int32 *acceleration = palloc(sizeof(int32));
> +
> + /* initialize with the default acceleration */
> + *acceleration = 1;
> +
> + if (list_length(options) > 0)
> + {
> + ListCell *lc;
> +
> + foreach(lc, options)
> + {
> + DefElem *def = (DefElem *) lfirst(lc);
> +
> + if (strcmp(def->defname, "acceleration") == 0)
> + *acceleration = pg_atoi(defGetString(def), sizeof(int32), 0);
>
> Don't you need to say "else: error: unknown compression option" ?
Done
> + /*
> + * Compression option must be only valid if we are updating the compression
> + * method.
> + */
> + Assert(DatumGetPointer(acoptions) == NULL || OidIsValid(newcompression));
> +
>
> should say "need be valid only if .."
Changed.
Apart from this, I have also done some refactoring and comment improvement.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Attachment
On Mon, Jan 04, 2021 at 04:57:16PM +0530, Dilip Kumar wrote: > On Mon, Jan 4, 2021 at 6:52 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > > And fails pg_upgrade check, apparently losing track of the compression (?) > > > > CREATE TABLE public.cmdata2 ( > > - f1 text COMPRESSION lz4 > > + f1 text > > ); > > I did not get this? pg_upgrade check is passing for me. I realized that this was failing in your v16 patch sent Dec 25. It's passing on current patches because they do "DROP TABLE cmdata2", but that's only masking the error. I think this patch needs to be specifically concerned with pg_upgrade, so I suggest to not drop your tables and MVs, to allow the pg_upgrade test to check them. That exposes this issue: pg_dump: error: Error message from server: ERROR: cache lookup failed for access method 36447 pg_dump: error: The command was: COPY public.cmdata (f1) TO stdout; pg_dumpall: error: pg_dump failed on database "regression", exiting waiting for server to shut down.... done server stopped pg_dumpall of post-upgrade database cluster failed I found that's the AM's OID in the old clsuter: regression=# SELECT * FROM pg_am WHERE oid=36447; oid | amname | amhandler | amtype -------+--------+-------------+-------- 36447 | pglz2 | pglzhandler | c But in the new cluster, the OID has changed. Since that's written into table data, I think you have to ensure that the compression OIDs are preserved on upgrade: 16755 | pglz2 | pglzhandler | c In my brief attempt to inspect it, I got this crash: $ tmp_install/usr/local/pgsql/bin/postgres -D src/bin/pg_upgrade/tmp_check/data & regression=# SELECT pg_column_compression(f1) FROM cmdata a; server closed the connection unexpectedly Thread 1 "postgres" received signal SIGSEGV, Segmentation fault. __strlen_sse2 () at ../sysdeps/x86_64/multiarch/../strlen.S:120 120 ../sysdeps/x86_64/multiarch/../strlen.S: No such file or directory. (gdb) bt #0 __strlen_sse2 () at ../sysdeps/x86_64/multiarch/../strlen.S:120 #1 0x000055c6049fde62 in cstring_to_text (s=0x0) at varlena.c:193 #2 pg_column_compression () at varlena.c:5335 (gdb) up #2 pg_column_compression () at varlena.c:5335 5335 PG_RETURN_TEXT_P(cstring_to_text(get_am_name( (gdb) l 5333 varvalue = (struct varlena *) DatumGetPointer(value); 5334 5335 PG_RETURN_TEXT_P(cstring_to_text(get_am_name( 5336 toast_get_compression_oid(varvalue)))); I guess a missing AM here is a "shouldn't happen" case, but I'd prefer it to be caught with an elog() (maybe in get_am_name()) or at least an Assert. -- Justin
On Sun, Jan 10, 2021 at 10:59 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > On Mon, Jan 04, 2021 at 04:57:16PM +0530, Dilip Kumar wrote: > > On Mon, Jan 4, 2021 at 6:52 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > And fails pg_upgrade check, apparently losing track of the compression (?) > > > > > > CREATE TABLE public.cmdata2 ( > > > - f1 text COMPRESSION lz4 > > > + f1 text > > > ); > > > > I did not get this? pg_upgrade check is passing for me. > > I realized that this was failing in your v16 patch sent Dec 25. > It's passing on current patches because they do "DROP TABLE cmdata2", but > that's only masking the error. > > I think this patch needs to be specifically concerned with pg_upgrade, so I > suggest to not drop your tables and MVs, to allow the pg_upgrade test to check > them. That exposes this issue: Thanks for the suggestion I will try this. > pg_dump: error: Error message from server: ERROR: cache lookup failed for access method 36447 > pg_dump: error: The command was: COPY public.cmdata (f1) TO stdout; > pg_dumpall: error: pg_dump failed on database "regression", exiting > waiting for server to shut down.... done > server stopped > pg_dumpall of post-upgrade database cluster failed > > I found that's the AM's OID in the old clsuter: > regression=# SELECT * FROM pg_am WHERE oid=36447; > oid | amname | amhandler | amtype > -------+--------+-------------+-------- > 36447 | pglz2 | pglzhandler | c > > But in the new cluster, the OID has changed. Since that's written into table > data, I think you have to ensure that the compression OIDs are preserved on > upgrade: > > 16755 | pglz2 | pglzhandler | c Yeah, basically we are storing am oid in the compressed data so Oid must be preserved. I will look into this and fix it. > In my brief attempt to inspect it, I got this crash: > > $ tmp_install/usr/local/pgsql/bin/postgres -D src/bin/pg_upgrade/tmp_check/data & > regression=# SELECT pg_column_compression(f1) FROM cmdata a; > server closed the connection unexpectedly > > Thread 1 "postgres" received signal SIGSEGV, Segmentation fault. > __strlen_sse2 () at ../sysdeps/x86_64/multiarch/../strlen.S:120 > 120 ../sysdeps/x86_64/multiarch/../strlen.S: No such file or directory. > (gdb) bt > #0 __strlen_sse2 () at ../sysdeps/x86_64/multiarch/../strlen.S:120 > #1 0x000055c6049fde62 in cstring_to_text (s=0x0) at varlena.c:193 > #2 pg_column_compression () at varlena.c:5335 > > (gdb) up > #2 pg_column_compression () at varlena.c:5335 > 5335 PG_RETURN_TEXT_P(cstring_to_text(get_am_name( > (gdb) l > 5333 varvalue = (struct varlena *) DatumGetPointer(value); > 5334 > 5335 PG_RETURN_TEXT_P(cstring_to_text(get_am_name( > 5336 toast_get_compression_oid(varvalue)))); > > I guess a missing AM here is a "shouldn't happen" case, but I'd prefer it to be > caught with an elog() (maybe in get_am_name()) or at least an Assert. Yeah, this makes sense. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Jan 11, 2021 at 11:00 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Sun, Jan 10, 2021 at 10:59 PM Justin Pryzby <pryzby@telsasoft.com> wrote:
> >
> > On Mon, Jan 04, 2021 at 04:57:16PM +0530, Dilip Kumar wrote:
> > > On Mon, Jan 4, 2021 at 6:52 AM Justin Pryzby <pryzby@telsasoft.com> wrote:
> > > > And fails pg_upgrade check, apparently losing track of the compression (?)
> > > >
> > > > CREATE TABLE public.cmdata2 (
> > > > - f1 text COMPRESSION lz4
> > > > + f1 text
> > > > );
> > >
> > > I did not get this? pg_upgrade check is passing for me.
> >
> > I realized that this was failing in your v16 patch sent Dec 25.
> > It's passing on current patches because they do "DROP TABLE cmdata2", but
> > that's only masking the error.
I tested specifically pg_upgrade by removing all the DROP table and MV
and it is passing. I don't see the reason why should it fail. I mean
after the upgrade why COMPRESSION lz4 is missing?
> > I think this patch needs to be specifically concerned with pg_upgrade, so I
> > suggest to not drop your tables and MVs, to allow the pg_upgrade test to check
> > them. That exposes this issue:
>
> Thanks for the suggestion I will try this.
>
> > pg_dump: error: Error message from server: ERROR: cache lookup failed for access method 36447
> > pg_dump: error: The command was: COPY public.cmdata (f1) TO stdout;
> > pg_dumpall: error: pg_dump failed on database "regression", exiting
> > waiting for server to shut down.... done
> > server stopped
> > pg_dumpall of post-upgrade database cluster failed
> >
> > I found that's the AM's OID in the old clsuter:
> > regression=# SELECT * FROM pg_am WHERE oid=36447;
> > oid | amname | amhandler | amtype
> > -------+--------+-------------+--------
> > 36447 | pglz2 | pglzhandler | c
> >
> > But in the new cluster, the OID has changed. Since that's written into table
> > data, I think you have to ensure that the compression OIDs are preserved on
> > upgrade:
> >
> > 16755 | pglz2 | pglzhandler | c
>
> Yeah, basically we are storing am oid in the compressed data so Oid
> must be preserved. I will look into this and fix it.
On further analysis, if we are dumping and restoring then we will
compress the data back while inserting it so why would we need to old
OID. I mean in the new cluster we are inserting data again so it will
be compressed again and now it will store the new OID. Am I missing
something here?
> > In my brief attempt to inspect it, I got this crash:
> >
> > $ tmp_install/usr/local/pgsql/bin/postgres -D src/bin/pg_upgrade/tmp_check/data &
> > regression=# SELECT pg_column_compression(f1) FROM cmdata a;
> > server closed the connection unexpectedly
I tried to test this after the upgrade but I can get the proper value.
Laptop309pnin:bin dilipkumar$ ./pg_ctl -D
/Users/dilipkumar/Documents/PG/custom_compression/src/bin/pg_upgrade/tmp_check/data.old/
start
waiting for server to start....2021-01-11 11:53:28.153 IST [43412]
LOG: starting PostgreSQL 14devel on x86_64-apple-darwin19.6.0,
compiled by Apple clang version 11.0.3 (clang-1103.0.32.62), 64-bit
2021-01-11 11:53:28.170 IST [43412] LOG: database system is ready to
accept connections
done
server started
Laptop309pnin:bin dilipkumar$ ./psql -d regression
regression[43421]=# SELECT pg_column_compression(f1) FROM cmdata a;
pg_column_compression
-----------------------
lz4
lz4
pglz2
(3 rows)
Manual test: (dump and load on the new cluster)
---------------
postgres[43903]=# CREATE ACCESS METHOD pglz2 TYPE COMPRESSION HANDLER
pglzhandler;
CREATE ACCESS METHOD
postgres[43903]=# select oid from pg_am where amname='pglz2';
oid
-------
16384
(1 row)
postgres[43903]=# CREATE TABLE cmdata_test(f1 text COMPRESSION pglz2);
CREATE TABLE
postgres[43903]=# INSERT INTO cmdata_test
VALUES(repeat('1234567890',1000));
INSERT 0 1
postgres[43903]=# SELECT pg_column_compression(f1) FROM cmdata_test;
pg_column_compression
-----------------------
pglz2
(1 row)
Laptop309pnin:bin dilipkumar$ ./pg_dump -d postgres > 1.sql
—restore on new cluster—
postgres[44030]=# select oid from pg_am where amname='pglz2';
oid
-------
16385
(1 row)
postgres[44030]=# SELECT pg_column_compression(f1) FROM cmdata_test;
pg_column_compression
-----------------------
pglz2
(1 row)
You can see on the new cluster the OID of the pglz2 is changed but
there is no issue. Is it possible for you to give me a
self-contained test case to reproduce the issue or a theory that why
it should fail?
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Mon, Jan 11, 2021 at 12:11:54PM +0530, Dilip Kumar wrote: > On Mon, Jan 11, 2021 at 11:00 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Sun, Jan 10, 2021 at 10:59 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > > > On Mon, Jan 04, 2021 at 04:57:16PM +0530, Dilip Kumar wrote: > > > > On Mon, Jan 4, 2021 at 6:52 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > > And fails pg_upgrade check, apparently losing track of the compression (?) > > > > > > > > > > CREATE TABLE public.cmdata2 ( > > > > > - f1 text COMPRESSION lz4 > > > > > + f1 text > > > > > ); > > > > > > > > I did not get this? pg_upgrade check is passing for me. > > > > > > I realized that this was failing in your v16 patch sent Dec 25. > > > It's passing on current patches because they do "DROP TABLE cmdata2", but > > > that's only masking the error. > > I tested specifically pg_upgrade by removing all the DROP table and MV > and it is passing. I don't see the reason why should it fail. I mean > after the upgrade why COMPRESSION lz4 is missing? How did you test it ? I'm not completely clear how this is intended to work... has it been tested before ? According to the comments, in binary upgrade mode, there's an ALTER which is supposed to SET COMPRESSION, but that's evidently not happening. > > > I found that's the AM's OID in the old clsuter: > > > regression=# SELECT * FROM pg_am WHERE oid=36447; > > > oid | amname | amhandler | amtype > > > -------+--------+-------------+-------- > > > 36447 | pglz2 | pglzhandler | c > > > > > > But in the new cluster, the OID has changed. Since that's written into table > > > data, I think you have to ensure that the compression OIDs are preserved on > > > upgrade: > > > > > > 16755 | pglz2 | pglzhandler | c > > > > Yeah, basically we are storing am oid in the compressed data so Oid > > must be preserved. I will look into this and fix it. > > On further analysis, if we are dumping and restoring then we will > compress the data back while inserting it so why would we need to old > OID. I mean in the new cluster we are inserting data again so it will > be compressed again and now it will store the new OID. Am I missing > something here? I'm referring to pg_upgrade which uses pg_dump, but does *not* re-insert data, but rather recreates catalogs only and then links to the old tables (either with copy, link, or clone). Test with make -C src/bin/pg_upgrade (which is included in make check-world). -- Justin
On Mon, Jan 11, 2021 at 12:21 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > On Mon, Jan 11, 2021 at 12:11:54PM +0530, Dilip Kumar wrote: > > On Mon, Jan 11, 2021 at 11:00 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > On Sun, Jan 10, 2021 at 10:59 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > > > > > On Mon, Jan 04, 2021 at 04:57:16PM +0530, Dilip Kumar wrote: > > > > > On Mon, Jan 4, 2021 at 6:52 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > > > And fails pg_upgrade check, apparently losing track of the compression (?) > > > > > > > > > > > > CREATE TABLE public.cmdata2 ( > > > > > > - f1 text COMPRESSION lz4 > > > > > > + f1 text > > > > > > ); > > > > > > > > > > I did not get this? pg_upgrade check is passing for me. > > > > > > > > I realized that this was failing in your v16 patch sent Dec 25. > > > > It's passing on current patches because they do "DROP TABLE cmdata2", but > > > > that's only masking the error. > > > > I tested specifically pg_upgrade by removing all the DROP table and MV > > and it is passing. I don't see the reason why should it fail. I mean > > after the upgrade why COMPRESSION lz4 is missing? > > How did you test it ? > > I'm not completely clear how this is intended to work... has it been tested > before ? According to the comments, in binary upgrade mode, there's an ALTER > which is supposed to SET COMPRESSION, but that's evidently not happening. I am able to reproduce this issue, If I run pg_dump with binary_upgrade mode then I can see the issue (./pg_dump --binary-upgrade -d Postgres). Yes you are right that for fixing this there should be an ALTER..SET COMPRESSION method. > > > > I found that's the AM's OID in the old clsuter: > > > > regression=# SELECT * FROM pg_am WHERE oid=36447; > > > > oid | amname | amhandler | amtype > > > > -------+--------+-------------+-------- > > > > 36447 | pglz2 | pglzhandler | c > > > > > > > > But in the new cluster, the OID has changed. Since that's written into table > > > > data, I think you have to ensure that the compression OIDs are preserved on > > > > upgrade: > > > > > > > > 16755 | pglz2 | pglzhandler | c > > > > > > Yeah, basically we are storing am oid in the compressed data so Oid > > > must be preserved. I will look into this and fix it. > > > > On further analysis, if we are dumping and restoring then we will > > compress the data back while inserting it so why would we need to old > > OID. I mean in the new cluster we are inserting data again so it will > > be compressed again and now it will store the new OID. Am I missing > > something here? > > I'm referring to pg_upgrade which uses pg_dump, but does *not* re-insert data, > but rather recreates catalogs only and then links to the old tables (either > with copy, link, or clone). Test with make -C src/bin/pg_upgrade (which is > included in make check-world). Got this as well. I will fix these two issues and post the updated patch by tomorrow. Thanks for your findings. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Jan 11, 2021 at 3:40 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Mon, Jan 11, 2021 at 12:21 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > On Mon, Jan 11, 2021 at 12:11:54PM +0530, Dilip Kumar wrote: > > > On Mon, Jan 11, 2021 at 11:00 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Sun, Jan 10, 2021 at 10:59 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > > > > > > > On Mon, Jan 04, 2021 at 04:57:16PM +0530, Dilip Kumar wrote: > > > > > > On Mon, Jan 4, 2021 at 6:52 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > > > > And fails pg_upgrade check, apparently losing track of the compression (?) > > > > > > > > > > > > > > CREATE TABLE public.cmdata2 ( > > > > > > > - f1 text COMPRESSION lz4 > > > > > > > + f1 text > > > > > > > ); > > > > > > > > > > > > I did not get this? pg_upgrade check is passing for me. > > > > > > > > > > I realized that this was failing in your v16 patch sent Dec 25. > > > > > It's passing on current patches because they do "DROP TABLE cmdata2", but > > > > > that's only masking the error. > > > > > > I tested specifically pg_upgrade by removing all the DROP table and MV > > > and it is passing. I don't see the reason why should it fail. I mean > > > after the upgrade why COMPRESSION lz4 is missing? > > > > How did you test it ? > > > > I'm not completely clear how this is intended to work... has it been tested > > before ? According to the comments, in binary upgrade mode, there's an ALTER > > which is supposed to SET COMPRESSION, but that's evidently not happening. > > I am able to reproduce this issue, If I run pg_dump with > binary_upgrade mode then I can see the issue (./pg_dump > --binary-upgrade -d Postgres). Yes you are right that for fixing > this there should be an ALTER..SET COMPRESSION method. > > > > > > I found that's the AM's OID in the old clsuter: > > > > > regression=# SELECT * FROM pg_am WHERE oid=36447; > > > > > oid | amname | amhandler | amtype > > > > > -------+--------+-------------+-------- > > > > > 36447 | pglz2 | pglzhandler | c > > > > > > > > > > But in the new cluster, the OID has changed. Since that's written into table > > > > > data, I think you have to ensure that the compression OIDs are preserved on > > > > > upgrade: > > > > > > > > > > 16755 | pglz2 | pglzhandler | c > > > > > > > > Yeah, basically we are storing am oid in the compressed data so Oid > > > > must be preserved. I will look into this and fix it. > > > > > > On further analysis, if we are dumping and restoring then we will > > > compress the data back while inserting it so why would we need to old > > > OID. I mean in the new cluster we are inserting data again so it will > > > be compressed again and now it will store the new OID. Am I missing > > > something here? > > > > I'm referring to pg_upgrade which uses pg_dump, but does *not* re-insert data, > > but rather recreates catalogs only and then links to the old tables (either > > with copy, link, or clone). Test with make -C src/bin/pg_upgrade (which is > > included in make check-world). > > Got this as well. > > I will fix these two issues and post the updated patch by tomorrow. > > Thanks for your findings. I have fixed this issue in the v18 version, please test and let me know your thoughts. There is one more issue pending from an upgrade perspective in v18-0003, basically, for the preserved method we need to restore the dependency as well. I will work on this part and shared the next version soon. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Jan 13, 2021 at 2:14 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Mon, Jan 11, 2021 at 3:40 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Mon, Jan 11, 2021 at 12:21 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > > > On Mon, Jan 11, 2021 at 12:11:54PM +0530, Dilip Kumar wrote: > > > > On Mon, Jan 11, 2021 at 11:00 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > > On Sun, Jan 10, 2021 at 10:59 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > > > > > > > > > On Mon, Jan 04, 2021 at 04:57:16PM +0530, Dilip Kumar wrote: > > > > > > > On Mon, Jan 4, 2021 at 6:52 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > > > > > And fails pg_upgrade check, apparently losing track of the compression (?) > > > > > > > > > > > > > > > > CREATE TABLE public.cmdata2 ( > > > > > > > > - f1 text COMPRESSION lz4 > > > > > > > > + f1 text > > > > > > > > ); > > > > > > > > > > > > > > I did not get this? pg_upgrade check is passing for me. > > > > > > > > > > > > I realized that this was failing in your v16 patch sent Dec 25. > > > > > > It's passing on current patches because they do "DROP TABLE cmdata2", but > > > > > > that's only masking the error. > > > > > > > > I tested specifically pg_upgrade by removing all the DROP table and MV > > > > and it is passing. I don't see the reason why should it fail. I mean > > > > after the upgrade why COMPRESSION lz4 is missing? > > > > > > How did you test it ? > > > > > > I'm not completely clear how this is intended to work... has it been tested > > > before ? According to the comments, in binary upgrade mode, there's an ALTER > > > which is supposed to SET COMPRESSION, but that's evidently not happening. > > > > I am able to reproduce this issue, If I run pg_dump with > > binary_upgrade mode then I can see the issue (./pg_dump > > --binary-upgrade -d Postgres). Yes you are right that for fixing > > this there should be an ALTER..SET COMPRESSION method. > > > > > > > > I found that's the AM's OID in the old clsuter: > > > > > > regression=# SELECT * FROM pg_am WHERE oid=36447; > > > > > > oid | amname | amhandler | amtype > > > > > > -------+--------+-------------+-------- > > > > > > 36447 | pglz2 | pglzhandler | c > > > > > > > > > > > > But in the new cluster, the OID has changed. Since that's written into table > > > > > > data, I think you have to ensure that the compression OIDs are preserved on > > > > > > upgrade: > > > > > > > > > > > > 16755 | pglz2 | pglzhandler | c > > > > > > > > > > Yeah, basically we are storing am oid in the compressed data so Oid > > > > > must be preserved. I will look into this and fix it. > > > > > > > > On further analysis, if we are dumping and restoring then we will > > > > compress the data back while inserting it so why would we need to old > > > > OID. I mean in the new cluster we are inserting data again so it will > > > > be compressed again and now it will store the new OID. Am I missing > > > > something here? > > > > > > I'm referring to pg_upgrade which uses pg_dump, but does *not* re-insert data, > > > but rather recreates catalogs only and then links to the old tables (either > > > with copy, link, or clone). Test with make -C src/bin/pg_upgrade (which is > > > included in make check-world). > > > > Got this as well. > > > > I will fix these two issues and post the updated patch by tomorrow. > > > > Thanks for your findings. > > I have fixed this issue in the v18 version, please test and let me > know your thoughts. There is one more issue pending from an upgrade > perspective in v18-0003, basically, for the preserved method we need > to restore the dependency as well. I will work on this part and > shared the next version soon. Now I have added support for handling the preserved method in the binary upgrade, please find the updated patch set. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Jan 20, 2021 at 12:37 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > > Thanks for updating the patch. Thanks for the review > On Mon, Jan 4, 2021 at 6:52 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > > The most recent patch doesn't compile --without-lz4: > On Tue, Jan 05, 2021 at 11:19:33AM +0530, Dilip Kumar wrote: > > On Mon, Jan 4, 2021 at 10:08 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > I think I first saw it on cfbot and I reproduced it locally, too. > > > http://cfbot.cputube.org/dilip-kumar.html > > > > > > I think you'll have to make --without-lz4 the default until the build > > > environments include it, otherwise the patch checker will show red :( > > > > Oh ok, but if we make by default --without-lz4 then the test cases > > will start failing which is using lz4 compression. Am I missing > > something? > > The CIs are failing like this: > > http://cfbot.cputube.org/dilip-kumar.html > |checking for LZ4_compress in -llz4... no > |configure: error: lz4 library not found > |If you have lz4 already installed, see config.log for details on the > |failure. It is possible the compiler isn't looking in the proper directory. > |Use --without-lz4 to disable lz4 support. > > I thought that used to work (except for windows). I don't see that anything > changed in the configure tests... Is it because the CI moved off travis 2 > weeks ago ? I don't' know whether the travis environment had liblz4, and I > don't remember if the build was passing or if it was failing for some other > reason. I'm guessing historic logs from travis are not available, if they ever > were. > > I'm not sure how to deal with that, but maybe you'd need: > 1) A separate 0001 patch *allowing* LZ4 to be enabled/disabled; > 2) Current patchset needs to compile with/without LZ4, and pass tests in both > cases - maybe you can use "alternate test" output [0] to handle the "without" > case. Okay, let me think about how to deal with this. > 3) Eventually, the CI and build environments may have LZ4 installed, and then > we can have a separate debate about whether to enable it by default. > > [0] cp -iv src/test/regress/results/compression.out src/test/regress/expected/compression_1.out > > On Tue, Jan 05, 2021 at 02:20:26PM +0530, Dilip Kumar wrote: > > On Tue, Jan 5, 2021 at 11:19 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > On Mon, Jan 4, 2021 at 10:08 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > I see the windows build is failing: > > > > https://ci.appveyor.com/project/postgresql-cfbot/postgresql/build/1.0.123730 > > > > |undefined symbol: HAVE_LIBLZ4 at src/include/pg_config.h line 350 at src/tools/msvc/Mkvcbuild.pm line 852. > > > > This needs to be patched: src/tools/msvc/Solution.pm > > > > You can see my zstd/pg_dump patch for an example, if needed (actually I'm not > > > > 100% sure it's working yet, since the windows build failed for another reason). > > > > > > Okay, I will check that. > > This still needs help. > perl ./src/tools/msvc/mkvcbuild.pl > ... > undefined symbol: HAVE_LIBLZ4 at src/include/pg_config.h line 350 at /home/pryzbyj/src/postgres/src/tools/msvc/Mkvcbuild.pmline 852. > > Fix like: > > + HAVE_LIBLZ4 => $self->{options}->{zlib} ? 1 : undef, I will do that. > Some more language fixes: > > commit 3efafee52414503a87332fa6070541a3311a408c > Author: dilipkumar <dilipbalaut@gmail.com> > Date: Tue Sep 8 15:24:33 2020 +0530 > > Built-in compression method > > + If the compression method is not specified for the compressible type then > + it will have the default compression method. The default compression > > I think this should say: > If no compression method is specified, then compressible types will have the > default compression method (pglz). > > + * > + * Since version 11 TOAST_COMPRESS_SET_RAWSIZE also marks compressed > > Should say v14 ?? > > diff --git a/src/include/catalog/pg_attribute.h b/src/include/catalog/pg_attribute.h > index 059dec3647..e4df6bc5c1 100644 > --- a/src/include/catalog/pg_attribute.h > +++ b/src/include/catalog/pg_attribute.h > @@ -156,6 +156,14 @@ CATALOG(pg_attribute,1249,AttributeRelationId) BKI_BOOTSTRAP BKI_ROWTYPE_OID(75, > /* attribute's collation */ > Oid attcollation; > > + /* > + * Oid of the compression method that will be used for compressing the value > + * for this attribute. For the compressible atttypid this must always be a > > say "For compressible types, ..." > > + * valid Oid irrespective of what is the current value of the attstorage. > + * And for the incompressible atttypid this must always be an invalid Oid. > > say "must be InvalidOid" > > @@ -685,6 +686,7 @@ typedef enum TableLikeOption > CREATE_TABLE_LIKE_INDEXES = 1 << 5, > CREATE_TABLE_LIKE_STATISTICS = 1 << 6, > CREATE_TABLE_LIKE_STORAGE = 1 << 7, > + CREATE_TABLE_LIKE_COMPRESSION = 1 << 8, > > This is interesting... > I have a patch to implement LIKE .. (INCLUDING ACCESS METHOD). > I guess I should change it to say LIKE .. (TABLE ACCESS METHOD), right ? > https://commitfest.postgresql.org/31/2865/ > > Your first patch is large due to updating a large number of test cases to > include the "compression" column in \d+ output. Maybe that column should be > hidden when HIDE_TABLEAM is set by pg_regress ? I think that would allow > testing with alternate, default compression. > > commit ddcae4095e36e94e3e7080e2ab5a8d42cc2ca843 > Author: dilipkumar <dilipbalaut@gmail.com> > Date: Tue Jan 19 15:10:14 2021 +0530 > > Support compression methods options > > + * we don't need do it again in cminitstate function. > > need *to* do it again > > + * Fetch atttributes compression options > > attribute's :) > > commit b7946eda581230424f73f23d90843f4c2db946c2 > Author: dilipkumar <dilipbalaut@gmail.com> > Date: Wed Jan 13 12:14:40 2021 +0530 > > Create custom compression methods > > + * compression header otherwise, directly translate the buil-in compression > > built-in > > commit 0746a4d7a14209ebf62fe0dc1d12999ded879cfd > Author: dilipkumar <dilipbalaut@gmail.com> > Date: Mon Jan 4 15:15:20 2021 +0530 > > Add support for PRESERVE > > --- a/src/backend/catalog/objectaddress.c > +++ b/src/backend/catalog/objectaddress.c > @@ -15,6 +15,7 @@ > > #include "postgres.h" > > +#include "access/compressamapi.h" > > Unnecessary change to this file ? > > + * ... Collect the list of access method > + * oids on which this attribute has a dependency upon. > > "upon" is is redundant. Say "on which this attribute has a dependency". > > + * Check whether the given compression method oid is supported by > + * the target attribue. > > attribute > > + * In binary upgrade mode just create the dependency for all preserve > + * list compression method as a dependecy. > > dependency > I think you could say: "In binary upgrade mode, just create a dependency on all > preserved methods". I will work on other comments and send the updated patch in a day or two. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Hi,
I have been testing the patches for a while , below is the code coverage observed on the v19 patches.
| Sr No | File name | Code Coverage | ||||||
| Before | After | |||||||
| Line % | Function % | Line % | Function % | |||||
| 1 | src/backend/access/brin/brin_tuple.c | 96.7 | 100 | 96.7 | 100 | |||
| 2 | src/backend/access/common/detoast.c | 88 | 100 | 88.6 | 100 | |||
| 3 | src/backend/access/common/indextuple.c | 97.1 | 100 | 97.1 | 100 | |||
| 4 | src/backend/access/common/toast_internals.c | 88.8 | 88.9 | 88.6 | 88.9 | |||
| 5 | src/backend/access/common/tupdesc.c | 97.2 | 100 | 97.2 | 100 | |||
| 6 | src/backend/access/compression/compress_lz4.c | NA | NA | 93.5 | 100 | |||
| 7 | src/backend/access/compression/compress_pglz.c | NA | NA | 82.2 | 100 | |||
| 8 | src/backend/access/compression/compressamapi.c | NA | NA | 78.3 | 100 | |||
| 9 | src/backend/access/index/amapi.c | 73.5 | 100 | 74.5 | 100 | |||
| 10 | src/backend/access/table/toast_helper.c | 97.5 | 100 | 97.5 | 100 | |||
| 11 | src/backend/access/common/reloptions.c | 90.6 | 83.3 | 89.7 | 81.6 | |||
| 12 | src/backend/bootstrap/bootparse.y | 84.2 | 100 | 84.2 | 100 | |||
| 13 | src/backend/bootstrap/bootstrap.c | 66.4 | 100 | 66.4 | 100 | |||
| 14 | src/backend/commands/cluster.c | 90.4 | 100 | 90.4 | 100 | |||
| 15 | src/backend/catalog/heap.c | 97.3 | 100 | 97.3 | 100 | |||
| 16 | src/backend/catalog/index.c | 93.8 | 94.6 | 93.8 | 94.6 | |||
| 17 | src/backend/catalog/toasting.c | 96.7 | 100 | 96.8 | 100 | |||
| 18 | src/backend/catalog/objectaddress.c | 89.7 | 95.9 | 89.7 | 95.9 | |||
| 19 | src/backend/catalog/pg_depend.c | 98.6 | 100 | 98.6 | 100 | |||
| 20 | src/backend/commands/foreigncmds.c | 95.7 | 95.5 | 95.6 | 95.2 | |||
| 21 | src/backend/commands/compressioncmds.c | NA | NA | 97.2 | 100 | |||
| 22 | src/backend/commands/amcmds.c | 92.1 | 100 | 90.1 | 100 | |||
| 23 | src/backend/commands/createas.c | 96.8 | 90 | 96.8 | 90 | |||
| 24 | src/backend/commands/matview.c | 92.5 | 85.7 | 92.6 | 85.7 | |||
| 25 | src/backend/commands/tablecmds.c | 93.6 | 98.5 | 93.7 | 98.5 | |||
| 26 | src/backend/executor/nodeModifyTable.c | 93.8 | 92.9 | 93.7 | 92.9 | |||
| 27 | src/backend/nodes/copyfuncs.c | 79.1 | 78.7 | 79.2 | 78.8 | |||
| 28 | src/backend/nodes/equalfuncs.c | 28.8 | 23.9 | 28.7 | 23.8 | |||
| 29 | src/backend/nodes/nodeFuncs.c | 80.4 | 100 | 80.3 | 100 | |||
| 30 | src/backend/nodes/outfuncs.c | 38.2 | 38.1 | 38.1 | 38 | |||
| 31 | src/backend/parser/gram.y | 87.6 | 100 | 87.7 | 100 | |||
| 32 | src/backend/parser/parse_utilcmd.c | 91.6 | 100 | 91.6 | 100 | |||
| 33 | src/backend/replication/logical/reorderbuffer.c | 94.1 | 97 | 94.1 | 97 | |||
| 34 | src/backend/utils/adt/pg_upgrade_support.c | 56.2 | 83.3 | 58.4 | 84.6 | |||
| 35 | src/backend/utils/adt/pseudotypes.c | 18.5 | 11.3 | 18.3 | 10.9 | |||
| 36 | src/backend/utils/adt/varlena.c | 86.5 | 89 | 86.6 | 89.1 | |||
| 37 | src/bin/pg_dump/pg_dump.c | 89.4 | 97.4 | 89.5 | 97.4 | |||
| 38 | src/bin/psql/tab-complete.c | 50.8 | 57.7 | 50.8 | 57.7 | |||
| 39 | src/bin/psql/describe.c | 60.7 | 55.1 | 60.6 | 54.2 | |||
| 40 | contrib/cmzlib/cmzlib.c | NA | NA | 74.7 | 87.5 | |||
Thanks.
--
--
Regards,
Neha Sharma
On Wed, Jan 20, 2021 at 10:18 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
On Wed, Jan 20, 2021 at 12:37 AM Justin Pryzby <pryzby@telsasoft.com> wrote:
>
> Thanks for updating the patch.
Thanks for the review
> On Mon, Jan 4, 2021 at 6:52 AM Justin Pryzby <pryzby@telsasoft.com> wrote:
> > The most recent patch doesn't compile --without-lz4:
> On Tue, Jan 05, 2021 at 11:19:33AM +0530, Dilip Kumar wrote:
> > On Mon, Jan 4, 2021 at 10:08 PM Justin Pryzby <pryzby@telsasoft.com> wrote:
> > > I think I first saw it on cfbot and I reproduced it locally, too.
> > > http://cfbot.cputube.org/dilip-kumar.html
> > >
> > > I think you'll have to make --without-lz4 the default until the build
> > > environments include it, otherwise the patch checker will show red :(
> >
> > Oh ok, but if we make by default --without-lz4 then the test cases
> > will start failing which is using lz4 compression. Am I missing
> > something?
>
> The CIs are failing like this:
>
> http://cfbot.cputube.org/dilip-kumar.html
> |checking for LZ4_compress in -llz4... no
> |configure: error: lz4 library not found
> |If you have lz4 already installed, see config.log for details on the
> |failure. It is possible the compiler isn't looking in the proper directory.
> |Use --without-lz4 to disable lz4 support.
>
> I thought that used to work (except for windows). I don't see that anything
> changed in the configure tests... Is it because the CI moved off travis 2
> weeks ago ? I don't' know whether the travis environment had liblz4, and I
> don't remember if the build was passing or if it was failing for some other
> reason. I'm guessing historic logs from travis are not available, if they ever
> were.
>
> I'm not sure how to deal with that, but maybe you'd need:
> 1) A separate 0001 patch *allowing* LZ4 to be enabled/disabled;
> 2) Current patchset needs to compile with/without LZ4, and pass tests in both
> cases - maybe you can use "alternate test" output [0] to handle the "without"
> case.
Okay, let me think about how to deal with this.
> 3) Eventually, the CI and build environments may have LZ4 installed, and then
> we can have a separate debate about whether to enable it by default.
>
> [0] cp -iv src/test/regress/results/compression.out src/test/regress/expected/compression_1.out
>
> On Tue, Jan 05, 2021 at 02:20:26PM +0530, Dilip Kumar wrote:
> > On Tue, Jan 5, 2021 at 11:19 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> > > On Mon, Jan 4, 2021 at 10:08 PM Justin Pryzby <pryzby@telsasoft.com> wrote:
> > > > I see the windows build is failing:
> > > > https://ci.appveyor.com/project/postgresql-cfbot/postgresql/build/1.0.123730
> > > > |undefined symbol: HAVE_LIBLZ4 at src/include/pg_config.h line 350 at src/tools/msvc/Mkvcbuild.pm line 852.
> > > > This needs to be patched: src/tools/msvc/Solution.pm
> > > > You can see my zstd/pg_dump patch for an example, if needed (actually I'm not
> > > > 100% sure it's working yet, since the windows build failed for another reason).
> > >
> > > Okay, I will check that.
>
> This still needs help.
> perl ./src/tools/msvc/mkvcbuild.pl
> ...
> undefined symbol: HAVE_LIBLZ4 at src/include/pg_config.h line 350 at /home/pryzbyj/src/postgres/src/tools/msvc/Mkvcbuild.pm line 852.
>
> Fix like:
>
> + HAVE_LIBLZ4 => $self->{options}->{zlib} ? 1 : undef,
I will do that.
> Some more language fixes:
>
> commit 3efafee52414503a87332fa6070541a3311a408c
> Author: dilipkumar <dilipbalaut@gmail.com>
> Date: Tue Sep 8 15:24:33 2020 +0530
>
> Built-in compression method
>
> + If the compression method is not specified for the compressible type then
> + it will have the default compression method. The default compression
>
> I think this should say:
> If no compression method is specified, then compressible types will have the
> default compression method (pglz).
>
> + *
> + * Since version 11 TOAST_COMPRESS_SET_RAWSIZE also marks compressed
>
> Should say v14 ??
>
> diff --git a/src/include/catalog/pg_attribute.h b/src/include/catalog/pg_attribute.h
> index 059dec3647..e4df6bc5c1 100644
> --- a/src/include/catalog/pg_attribute.h
> +++ b/src/include/catalog/pg_attribute.h
> @@ -156,6 +156,14 @@ CATALOG(pg_attribute,1249,AttributeRelationId) BKI_BOOTSTRAP BKI_ROWTYPE_OID(75,
> /* attribute's collation */
> Oid attcollation;
>
> + /*
> + * Oid of the compression method that will be used for compressing the value
> + * for this attribute. For the compressible atttypid this must always be a
>
> say "For compressible types, ..."
>
> + * valid Oid irrespective of what is the current value of the attstorage.
> + * And for the incompressible atttypid this must always be an invalid Oid.
>
> say "must be InvalidOid"
>
> @@ -685,6 +686,7 @@ typedef enum TableLikeOption
> CREATE_TABLE_LIKE_INDEXES = 1 << 5,
> CREATE_TABLE_LIKE_STATISTICS = 1 << 6,
> CREATE_TABLE_LIKE_STORAGE = 1 << 7,
> + CREATE_TABLE_LIKE_COMPRESSION = 1 << 8,
>
> This is interesting...
> I have a patch to implement LIKE .. (INCLUDING ACCESS METHOD).
> I guess I should change it to say LIKE .. (TABLE ACCESS METHOD), right ?
> https://commitfest.postgresql.org/31/2865/
>
> Your first patch is large due to updating a large number of test cases to
> include the "compression" column in \d+ output. Maybe that column should be
> hidden when HIDE_TABLEAM is set by pg_regress ? I think that would allow
> testing with alternate, default compression.
>
> commit ddcae4095e36e94e3e7080e2ab5a8d42cc2ca843
> Author: dilipkumar <dilipbalaut@gmail.com>
> Date: Tue Jan 19 15:10:14 2021 +0530
>
> Support compression methods options
>
> + * we don't need do it again in cminitstate function.
>
> need *to* do it again
>
> + * Fetch atttributes compression options
>
> attribute's :)
>
> commit b7946eda581230424f73f23d90843f4c2db946c2
> Author: dilipkumar <dilipbalaut@gmail.com>
> Date: Wed Jan 13 12:14:40 2021 +0530
>
> Create custom compression methods
>
> + * compression header otherwise, directly translate the buil-in compression
>
> built-in
>
> commit 0746a4d7a14209ebf62fe0dc1d12999ded879cfd
> Author: dilipkumar <dilipbalaut@gmail.com>
> Date: Mon Jan 4 15:15:20 2021 +0530
>
> Add support for PRESERVE
>
> --- a/src/backend/catalog/objectaddress.c
> +++ b/src/backend/catalog/objectaddress.c
> @@ -15,6 +15,7 @@
>
> #include "postgres.h"
>
> +#include "access/compressamapi.h"
>
> Unnecessary change to this file ?
>
> + * ... Collect the list of access method
> + * oids on which this attribute has a dependency upon.
>
> "upon" is is redundant. Say "on which this attribute has a dependency".
>
> + * Check whether the given compression method oid is supported by
> + * the target attribue.
>
> attribute
>
> + * In binary upgrade mode just create the dependency for all preserve
> + * list compression method as a dependecy.
>
> dependency
> I think you could say: "In binary upgrade mode, just create a dependency on all
> preserved methods".
I will work on other comments and send the updated patch in a day or two.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Fri, Jan 29, 2021 at 9:47 AM Neha Sharma <neha.sharma@enterprisedb.com> wrote: > > Hi, > > I have been testing the patches for a while , below is the code coverage observed on the v19 patches. > > Sr NoFile nameCode Coverage > BeforeAfter > Line %Function %Line %Function % > 1src/backend/access/brin/brin_tuple.c96.710096.7100 > 2src/backend/access/common/detoast.c8810088.6100 > 3src/backend/access/common/indextuple.c97.110097.1100 > 4src/backend/access/common/toast_internals.c88.888.988.688.9 > 5src/backend/access/common/tupdesc.c97.210097.2100 > 6src/backend/access/compression/compress_lz4.cNANA93.5100 > 7src/backend/access/compression/compress_pglz.cNANA82.2100 > 8src/backend/access/compression/compressamapi.cNANA78.3100 > 9src/backend/access/index/amapi.c73.510074.5100 > 10src/backend/access/table/toast_helper.c97.510097.5100 > 11src/backend/access/common/reloptions.c90.683.389.781.6 > 12src/backend/bootstrap/bootparse.y84.210084.2100 > 13src/backend/bootstrap/bootstrap.c66.410066.4100 > 14src/backend/commands/cluster.c90.410090.4100 > 15src/backend/catalog/heap.c97.310097.3100 > 16src/backend/catalog/index.c93.894.693.894.6 > 17src/backend/catalog/toasting.c96.710096.8100 > 18src/backend/catalog/objectaddress.c89.795.989.795.9 > 19src/backend/catalog/pg_depend.c98.610098.6100 > 20src/backend/commands/foreigncmds.c95.795.595.695.2 > 21src/backend/commands/compressioncmds.cNANA97.2100 > 22src/backend/commands/amcmds.c92.110090.1100 > 23src/backend/commands/createas.c96.89096.890 > 24src/backend/commands/matview.c92.585.792.685.7 > 25src/backend/commands/tablecmds.c93.698.593.798.5 > 26src/backend/executor/nodeModifyTable.c93.892.993.792.9 > 27src/backend/nodes/copyfuncs.c79.178.779.278.8 > 28src/backend/nodes/equalfuncs.c28.823.928.723.8 > 29src/backend/nodes/nodeFuncs.c80.410080.3100 > 30src/backend/nodes/outfuncs.c38.238.138.138 > 31src/backend/parser/gram.y87.610087.7100 > 32src/backend/parser/parse_utilcmd.c91.610091.6100 > 33src/backend/replication/logical/reorderbuffer.c94.19794.197 > 34src/backend/utils/adt/pg_upgrade_support.c56.283.358.484.6 > 35src/backend/utils/adt/pseudotypes.c18.511.318.310.9 > 36src/backend/utils/adt/varlena.c86.58986.689.1 > 37src/bin/pg_dump/pg_dump.c89.497.489.597.4 > 38src/bin/psql/tab-complete.c50.857.750.857.7 > 39src/bin/psql/describe.c60.755.160.654.2 > 40contrib/cmzlib/cmzlib.cNANA74.787.5 > Thanks, Neha for testing this, overall coverage looks good to me except compress_pglz.c, compressamapi.c and cmzlib.c. I will analyze this and see if we can improve coverage for these files or not. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Jan 20, 2021 at 12:37 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > > Thanks for updating the patch. > > On Mon, Jan 4, 2021 at 6:52 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > > The most recent patch doesn't compile --without-lz4: > On Tue, Jan 05, 2021 at 11:19:33AM +0530, Dilip Kumar wrote: > > On Mon, Jan 4, 2021 at 10:08 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > I think I first saw it on cfbot and I reproduced it locally, too. > > > http://cfbot.cputube.org/dilip-kumar.html > > > > > > I think you'll have to make --without-lz4 the default until the build > > > environments include it, otherwise the patch checker will show red :( > > > > Oh ok, but if we make by default --without-lz4 then the test cases > > will start failing which is using lz4 compression. Am I missing > > something? > > The CIs are failing like this: > > http://cfbot.cputube.org/dilip-kumar.html > |checking for LZ4_compress in -llz4... no > |configure: error: lz4 library not found > |If you have lz4 already installed, see config.log for details on the > |failure. It is possible the compiler isn't looking in the proper directory. > |Use --without-lz4 to disable lz4 support. > > I thought that used to work (except for windows). I don't see that anything > changed in the configure tests... Is it because the CI moved off travis 2 > weeks ago ? I don't' know whether the travis environment had liblz4, and I > don't remember if the build was passing or if it was failing for some other > reason. I'm guessing historic logs from travis are not available, if they ever > were. > > I'm not sure how to deal with that, but maybe you'd need: > 1) A separate 0001 patch *allowing* LZ4 to be enabled/disabled; > 2) Current patchset needs to compile with/without LZ4, and pass tests in both > cases - maybe you can use "alternate test" output [0] to handle the "without" > case. > 3) Eventually, the CI and build environments may have LZ4 installed, and then > we can have a separate debate about whether to enable it by default. > > [0] cp -iv src/test/regress/results/compression.out src/test/regress/expected/compression_1.out I have done that so now default will be --without-lz4 > On Tue, Jan 05, 2021 at 02:20:26PM +0530, Dilip Kumar wrote: > > On Tue, Jan 5, 2021 at 11:19 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > On Mon, Jan 4, 2021 at 10:08 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > I see the windows build is failing: > > > > https://ci.appveyor.com/project/postgresql-cfbot/postgresql/build/1.0.123730 > > > > |undefined symbol: HAVE_LIBLZ4 at src/include/pg_config.h line 350 at src/tools/msvc/Mkvcbuild.pm line 852. > > > > This needs to be patched: src/tools/msvc/Solution.pm > > > > You can see my zstd/pg_dump patch for an example, if needed (actually I'm not > > > > 100% sure it's working yet, since the windows build failed for another reason). > > > > > > Okay, I will check that. > > This still needs help. > perl ./src/tools/msvc/mkvcbuild.pl > ... > undefined symbol: HAVE_LIBLZ4 at src/include/pg_config.h line 350 at /home/pryzbyj/src/postgres/src/tools/msvc/Mkvcbuild.pmline 852. > > Fix like: > > + HAVE_LIBLZ4 => $self->{options}->{zlib} ? 1 : undef, I added HAVE_LIBLZ4 undef, but I haven't yet tested on windows as I don't have a windows system. Later I will check this and fix if it doesn't work. > Some more language fixes: > > commit 3efafee52414503a87332fa6070541a3311a408c > Author: dilipkumar <dilipbalaut@gmail.com> > Date: Tue Sep 8 15:24:33 2020 +0530 > > Built-in compression method > > + If the compression method is not specified for the compressible type then > + it will have the default compression method. The default compression > > I think this should say: > If no compression method is specified, then compressible types will have the > default compression method (pglz). > > + * > + * Since version 11 TOAST_COMPRESS_SET_RAWSIZE also marks compressed > > Should say v14 ?? > > diff --git a/src/include/catalog/pg_attribute.h b/src/include/catalog/pg_attribute.h > index 059dec3647..e4df6bc5c1 100644 > --- a/src/include/catalog/pg_attribute.h > +++ b/src/include/catalog/pg_attribute.h > @@ -156,6 +156,14 @@ CATALOG(pg_attribute,1249,AttributeRelationId) BKI_BOOTSTRAP BKI_ROWTYPE_OID(75, > /* attribute's collation */ > Oid attcollation; > > + /* > + * Oid of the compression method that will be used for compressing the value > + * for this attribute. For the compressible atttypid this must always be a > > say "For compressible types, ..." > > + * valid Oid irrespective of what is the current value of the attstorage. > + * And for the incompressible atttypid this must always be an invalid Oid. > > say "must be InvalidOid" > > @@ -685,6 +686,7 @@ typedef enum TableLikeOption > CREATE_TABLE_LIKE_INDEXES = 1 << 5, > CREATE_TABLE_LIKE_STATISTICS = 1 << 6, > CREATE_TABLE_LIKE_STORAGE = 1 << 7, > + CREATE_TABLE_LIKE_COMPRESSION = 1 << 8, > > This is interesting... > I have a patch to implement LIKE .. (INCLUDING ACCESS METHOD). > I guess I should change it to say LIKE .. (TABLE ACCESS METHOD), right ? > https://commitfest.postgresql.org/31/2865/ > > Your first patch is large due to updating a large number of test cases to > include the "compression" column in \d+ output. Maybe that column should be > hidden when HIDE_TABLEAM is set by pg_regress ? I think that would allow > testing with alternate, default compression. I am not sure whether we should hide the compression method when HIDE_TABLEAM is set. I agree that it is actually an access method but it is not the same right? Because we are using it for compression not for storing data. > commit ddcae4095e36e94e3e7080e2ab5a8d42cc2ca843 > Author: dilipkumar <dilipbalaut@gmail.com> > Date: Tue Jan 19 15:10:14 2021 +0530 > > Support compression methods options > > + * we don't need do it again in cminitstate function. > > need *to* do it again Fixed > + * Fetch atttributes compression options > > attribute's :) Fixed > commit b7946eda581230424f73f23d90843f4c2db946c2 > Author: dilipkumar <dilipbalaut@gmail.com> > Date: Wed Jan 13 12:14:40 2021 +0530 > > Create custom compression methods > > + * compression header otherwise, directly translate the buil-in compression > > built-in Fixed > commit 0746a4d7a14209ebf62fe0dc1d12999ded879cfd > Author: dilipkumar <dilipbalaut@gmail.com> > Date: Mon Jan 4 15:15:20 2021 +0530 > > Add support for PRESERVE > > --- a/src/backend/catalog/objectaddress.c > +++ b/src/backend/catalog/objectaddress.c > @@ -15,6 +15,7 @@ > > #include "postgres.h" > > +#include "access/compressamapi.h" > > Unnecessary change to this file ? Fixed > > + * ... Collect the list of access method > + * oids on which this attribute has a dependency upon. > > "upon" is is redundant. Say "on which this attribute has a dependency". Changed > + * Check whether the given compression method oid is supported by > + * the target attribue. > > attribute Fixed > > + * In binary upgrade mode just create the dependency for all preserve > + * list compression method as a dependecy. > > dependency > I think you could say: "In binary upgrade mode, just create a dependency on all > preserved methods". Fixed -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
Some more review comments: 'git am' barfs on v0001 because it's got a whitespace error. VARFLAGS_4B_C() doesn't seem to be used in any of the patches. I'm OK with keeping it even if it's not used just because maybe someone will need it later but, uh, don't we need to use it someplace? To avoid moving the goalposts for a basic install, I suggest that --with-lz4 should default to disabled. Maybe we'll want to rethink that at some point, but since we're just getting started with this whole thing, I don't think now is the time. The change to ddl.sgml doesn't seem to make sense to me. There might be someplace where we want to explain how properties are inherited in partitioning hierarchies, but I don't think this is the right place, and I don't think this explanation is particularly clear. + This clause adds the compression method to a column. The Compression + method can be set from available compression methods. The built-in + methods are <literal>pglz</literal> and <literal>lz4</literal>. + If no compression method is specified, then compressible types will have + the default compression method <literal>pglz</literal>. Suggest: This sets the compression method for a column. The supported compression methods are <literal>pglz</literal> and <literal>lz4</literal>. <literal>lz4</literal> is available only if <literal>--with-lz4</literal> was used when building <productname>PostgreSQL</productname>. The default is <literal>pglz</literal>. We should make sure, if you haven't already, that trying to create a column with LZ4 compression fails at table creation time if the build does not support LZ4. But, someone could also create a table using a build that has LZ4 support and then switch to a different set of binaries that do not have it, so we need the runtime checks also. However, those runtime checks shouldn't fail simplify from trying to access a table that is set to use LZ4 compression; they should only fail if we actually need to decompress an LZ4'd value. Since indexes don't have TOAST tables, it surprises me that brin_form_tuple() thinks it can TOAST anything. But I guess that's not this patch's problem, if it's a problem at all. I like the fact that you changed the message "compressed data is corrupt" to indicate the compression method, but I think the resulting message doesn't follow style guidelines because I don't believe we normally put something with a colon prefix at the beginning of a primary error message. So instead of saying "pglz: compressed data is corrupt" I think you should say something like "compressed pglz data is corrupt". Also, I suggest that we take this opportunity to switch to ereport() rather than elog() and set errcode(ERRCODE_DATA_CORRUPTED). What testing have you done for performance impacts? Does the patch slow things down noticeably with pglz? (Hopefully not.) Can you measure a performance improvement with pglz? (Hopefully so.) Is it likely to hurt performance that there's no minimum size for lz4 compression as we have for pglz? Seems like that could result in a lot of wasted cycles trying to compress short strings. pglz_cmcompress() cancels compression if the resulting value would be larger than the original one, but it looks like lz4_cmcompress() will just store the enlarged value. That seems bad. pglz_cmcompress() doesn't need to pfree(tmp) before elog(ERROR). CompressionOidToId(), CompressionIdToOid() and maybe other places need to remember the message style guidelines. Primary error messages are not capitalized. Why should we now have to include toast_internals.h in reorderbuffer.c, which has no other changes? That definitely shouldn't be necessary. If something in another header file now requires something from toast_internals.h, then that header file would be obliged to include toast_internals.h itself. But actually that shouldn't happen, because the whole point of toast_internals.h is that it should not be included in very many places at all. If we're adding stuff there that is going to be broadly needed, we're adding it in the wrong place. varlena.c shouldn't need toast_internals.h either, and if it did, it should be in alphabetical order. -- Robert Haas EDB: http://www.enterprisedb.com
Even more review comments, still looking mostly at 0001:
If there's a reason why parallel_schedule is arranging to run the
compression test in parallel with nothing else, the comment in that
file should explain the reason. If there isn't, it should be added to
a parallel group that doesn't have the maximum number of tests yet,
probably the last such group in the file.
serial_schedule should add the test in a position that roughly
corresponds to where it appears in parallel_schedule.
I believe it's relatively standard practice to put variable
declarations at the top of the file. compress_lz4.c and
compress_pglz.c instead put those declarations nearer to the point of
use.
compressamapi.c has an awful lot of #include directives for the code
it actually contains. I believe that we should cut that down to what
is required by 0001, and other patches can add more later as required.
In fact, it's tempting to just get rid of this .c file altogether and
make the two functions it contains static inline functions in the
header, but I'm not 100% sure that's a good idea.
The copyright dates in a number of the file headers are out of date.
binary_upgrade_next_pg_am_oid and the related changes to
CreateAccessMethod don't belong in 0001, because it doesn't support
non-built-in compression methods. These changes and the related
pg_dump change should be moved to the patch that adds support for
that.
The comments added to dumpTableSchema() say that "compression is
assigned by ALTER" but don't give a reason. I think they should. I
don't know how much they need to explain about what the code does, but
they definitely need to explain why it does it. Also, isn't this bad?
If we create the column with the wrong compression setting initially
and then ALTER it, we have to rewrite the table. If it's empty, that's
cheap, but it'd still be better not to do it at all.
I'm not sure it's a good idea for dumpTableSchema() to leave out
specifying the compression method if it happens to be pglz. I think we
definitely shouldn't do it in binary-upgrade mode. What if we changed
the default in a future release? For that matter, even 0002 could make
the current approach unsafe.... I think, anyway.
The changes to pg_dump.h look like they haven't had a visit from
pgindent. You should probably try to do that for the whole patch,
though it's a bit annoying since you'll have to manually remove
unrelated changes to the same files that are being modified by the
patch. Also, why the extra blank line here?
GetAttributeCompression() is hard to understand. I suggest changing
the comment to "resolve column compression specification to an OID"
and somehow rejigger the code so that you aren't using one not-NULL
test and one NULL test on the same variable. Like maybe change the
first part to if (!IsStorageCompressible(typstorage)) { if
(compression == NULL) return InvalidOid; ereport(ERROR, ...); }
It puzzles me that CompareCompressionMethodAndDecompress() calls
slot_getallattrs() just before clearing the slot. It seems like this
ought to happen before we loop over the attributes, so that we don't
need to call slot_getattr() every time. See the comment for that
function. But even if we didn't do that for some reason, why would we
do it here? If it's already been done, it shouldn't do anything, and
if it hasn't been done, it might overwrite some of the values we just
poked into tts_values. It also seems suspicious that we can get away
with clearing the slot and then again marking it valid. I'm not sure
it really works like that. Like, can't clearing the slot invalidate
pointers stored in tts_values[]? For instance, if they are pointers
into an in-memory heap tuple, tts_heap_clear() is going to free the
tuple; if they are pointers into a buffer, tts_buffer_heap_clear() is
going to unpin it. I think the supported procedure for this sort of
thing is to have a second slot, set tts_values, tts_isnull etc. and
then materialize the slot. After materializing the new slot, it's
independent of the old slot, which can then be cleared. See for
example tts_virtual_materialize(). The whole approach you've taken
here might need to be rethought a bit. I think you are right to want
to avoid copying everything over into a new slot if nothing needs to
be done, and I think we should definitely keep that optimization, but
I think if you need to copy stuff, you have to do the above procedure
and then continue using the other slot instead of the original one.
Some places I think we have functions that return either the original
slot or a different one depending on how it goes; that might be a
useful idea here. But, you also can't just spam-create slots; it's
important that whatever ones we end up with get reused for every
tuple.
Doesn't the change to describeOneTableDetails() require declaring
changing the declaration of char *headers[11] to char *headers[12]?
How does this not fail Assert(cols <= lengthof(headers))?
Why does describeOneTableDetais() arrange to truncate the printed
value? We don't seem to do that for the other column properties, and
it's not like this one is particularly long.
Perhaps the changes to pg_am.dat shouldn't remove the blank line?
I think the comment to pg_attribute.h could be rephrased to stay
something like: "OID of compression AM. Must be InvalidOid if and only
if typstorage is 'a' or 'b'," replacing 'a' and 'b' with whatever the
right letters are. This would be shorter and I think also clearer than
what you have
The first comment change in postgres.h is wrong. You changed
va_extsize to "size in va_extinfo" but the associated structure
definition is unchanged, so the comment shouldn't be changed either.
In toast_internals.h, you end using 30 as a constant several times but
have no #define for it. You do have a #define for RAWSIZEMASK, but
that's really a derived value from 30. Also, it's not a great name
because it's kind of generic. So how about something like:
#define TOAST_RAWSIZE_BITS 30
#define TOAST_RAWSIZE_MASK ((1 << (TOAST_RAW_SIZE_BITS + 1)) - 1)
But then again on second thought, this 30 seems to be the same 30 that
shows up in the changes to postgres.h, and there again 0x3FFFFFFF
shows up too. So maybe we should actually be defining these constants
there, using names like VARLENA_RAWSIZE_BITS and VARLENA_RAWSIZE_MASK
and then having toast_internals.h use those constants as well.
Taken with the email I sent yesterday, I think this is a more or less
complete review of 0001. Although there are a bunch of things to fix
here still, I don't think this is that far from being committable. I
don't at this point see too much in terms of big design problems.
Probably the CompareCompressionMethodAndDecompress() is the closest to
a design-level problem, and certainly something needs to be done about
it, but even that is a fairly localized problem in the context of the
entire patch.
--
Robert Haas
EDB: http://www.enterprisedb.com
On Wed, Feb 3, 2021 at 2:07 AM Robert Haas <robertmhaas@gmail.com> wrote:
>
> Even more review comments, still looking mostly at 0001:
>
> If there's a reason why parallel_schedule is arranging to run the
> compression test in parallel with nothing else, the comment in that
> file should explain the reason. If there isn't, it should be added to
> a parallel group that doesn't have the maximum number of tests yet,
> probably the last such group in the file.
>
> serial_schedule should add the test in a position that roughly
> corresponds to where it appears in parallel_schedule.
>
> I believe it's relatively standard practice to put variable
> declarations at the top of the file. compress_lz4.c and
> compress_pglz.c instead put those declarations nearer to the point of
> use.
>
> compressamapi.c has an awful lot of #include directives for the code
> it actually contains. I believe that we should cut that down to what
> is required by 0001, and other patches can add more later as required.
> In fact, it's tempting to just get rid of this .c file altogether and
> make the two functions it contains static inline functions in the
> header, but I'm not 100% sure that's a good idea.
>
> The copyright dates in a number of the file headers are out of date.
>
> binary_upgrade_next_pg_am_oid and the related changes to
> CreateAccessMethod don't belong in 0001, because it doesn't support
> non-built-in compression methods. These changes and the related
> pg_dump change should be moved to the patch that adds support for
> that.
>
> The comments added to dumpTableSchema() say that "compression is
> assigned by ALTER" but don't give a reason. I think they should. I
> don't know how much they need to explain about what the code does, but
> they definitely need to explain why it does it. Also, isn't this bad?
> If we create the column with the wrong compression setting initially
> and then ALTER it, we have to rewrite the table. If it's empty, that's
> cheap, but it'd still be better not to do it at all.
>
> I'm not sure it's a good idea for dumpTableSchema() to leave out
> specifying the compression method if it happens to be pglz. I think we
> definitely shouldn't do it in binary-upgrade mode. What if we changed
> the default in a future release? For that matter, even 0002 could make
> the current approach unsafe.... I think, anyway.
>
> The changes to pg_dump.h look like they haven't had a visit from
> pgindent. You should probably try to do that for the whole patch,
> though it's a bit annoying since you'll have to manually remove
> unrelated changes to the same files that are being modified by the
> patch. Also, why the extra blank line here?
>
> GetAttributeCompression() is hard to understand. I suggest changing
> the comment to "resolve column compression specification to an OID"
> and somehow rejigger the code so that you aren't using one not-NULL
> test and one NULL test on the same variable. Like maybe change the
> first part to if (!IsStorageCompressible(typstorage)) { if
> (compression == NULL) return InvalidOid; ereport(ERROR, ...); }
>
> It puzzles me that CompareCompressionMethodAndDecompress() calls
> slot_getallattrs() just before clearing the slot. It seems like this
> ought to happen before we loop over the attributes, so that we don't
> need to call slot_getattr() every time. See the comment for that
> function. But even if we didn't do that for some reason, why would we
> do it here? If it's already been done, it shouldn't do anything, and
> if it hasn't been done, it might overwrite some of the values we just
> poked into tts_values. It also seems suspicious that we can get away
> with clearing the slot and then again marking it valid. I'm not sure
> it really works like that. Like, can't clearing the slot invalidate
> pointers stored in tts_values[]? For instance, if they are pointers
> into an in-memory heap tuple, tts_heap_clear() is going to free the
> tuple; if they are pointers into a buffer, tts_buffer_heap_clear() is
> going to unpin it. I think the supported procedure for this sort of
> thing is to have a second slot, set tts_values, tts_isnull etc. and
> then materialize the slot. After materializing the new slot, it's
> independent of the old slot, which can then be cleared. See for
> example tts_virtual_materialize(). The whole approach you've taken
> here might need to be rethought a bit. I think you are right to want
> to avoid copying everything over into a new slot if nothing needs to
> be done, and I think we should definitely keep that optimization, but
> I think if you need to copy stuff, you have to do the above procedure
> and then continue using the other slot instead of the original one.
> Some places I think we have functions that return either the original
> slot or a different one depending on how it goes; that might be a
> useful idea here. But, you also can't just spam-create slots; it's
> important that whatever ones we end up with get reused for every
> tuple.
>
> Doesn't the change to describeOneTableDetails() require declaring
> changing the declaration of char *headers[11] to char *headers[12]?
> How does this not fail Assert(cols <= lengthof(headers))?
>
> Why does describeOneTableDetais() arrange to truncate the printed
> value? We don't seem to do that for the other column properties, and
> it's not like this one is particularly long.
>
> Perhaps the changes to pg_am.dat shouldn't remove the blank line?
>
> I think the comment to pg_attribute.h could be rephrased to stay
> something like: "OID of compression AM. Must be InvalidOid if and only
> if typstorage is 'a' or 'b'," replacing 'a' and 'b' with whatever the
> right letters are. This would be shorter and I think also clearer than
> what you have
>
> The first comment change in postgres.h is wrong. You changed
> va_extsize to "size in va_extinfo" but the associated structure
> definition is unchanged, so the comment shouldn't be changed either.
>
> In toast_internals.h, you end using 30 as a constant several times but
> have no #define for it. You do have a #define for RAWSIZEMASK, but
> that's really a derived value from 30. Also, it's not a great name
> because it's kind of generic. So how about something like:
>
> #define TOAST_RAWSIZE_BITS 30
> #define TOAST_RAWSIZE_MASK ((1 << (TOAST_RAW_SIZE_BITS + 1)) - 1)
>
> But then again on second thought, this 30 seems to be the same 30 that
> shows up in the changes to postgres.h, and there again 0x3FFFFFFF
> shows up too. So maybe we should actually be defining these constants
> there, using names like VARLENA_RAWSIZE_BITS and VARLENA_RAWSIZE_MASK
> and then having toast_internals.h use those constants as well.
>
> Taken with the email I sent yesterday, I think this is a more or less
> complete review of 0001. Although there are a bunch of things to fix
> here still, I don't think this is that far from being committable. I
> don't at this point see too much in terms of big design problems.
> Probably the CompareCompressionMethodAndDecompress() is the closest to
> a design-level problem, and certainly something needs to be done about
> it, but even that is a fairly localized problem in the context of the
> entire patch.
Thanks, Robert for the detailed review. I will work on these comments
and post the updated patch.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Wed, Feb 3, 2021 at 2:07 AM Robert Haas <robertmhaas@gmail.com> wrote: While going through your comments, I need some suggestions about the one except this all other comments looks fine to me. > > It puzzles me that CompareCompressionMethodAndDecompress() calls > slot_getallattrs() just before clearing the slot. It seems like this > ought to happen before we loop over the attributes, so that we don't > need to call slot_getattr() every time. Yeah, actually, I thought I would avoid calling slot_getallattrs if none of the attributes got decompress. I agree if we call this before we can avoid calling slot_getattr but slot_getattr is only called for the attribute which has attlen -1. I agree that if we call slot_getattr for attnum n then it will deform all the attributes before that. But then slot_getallattrs only need to deform the remaining attributes not all. But maybe we can call the slot_getallattrs as soon as we see the first attribute with attlen -1 and then avoid calling subsequent slot_getattr, maybe that is better than compared to what I have because we will avoid calling slot_getattr for many attributes, especially when there are many verlena. See the comment for that > function. But even if we didn't do that for some reason, why would we > do it here? If it's already been done, it shouldn't do anything, and > if it hasn't been done, it might overwrite some of the values we just > poked into tts_values. It will not overwrite those values because slot_getallattrs will only fetch the values for "attnum > slot->tts_nvalid" so whatever we already fetched will not be overwritten. Just did that at the end to optimize the normal cases where we are not doing "insert into select * from" so that those can get away without calling slot_getallattrs at all. However, maybe calling slot_getattr for each varlena might cost us extra so I am okay to call slot_getallattrs this early. It also seems suspicious that we can get away > with clearing the slot and then again marking it valid. I'm not sure > it really works like that. Like, can't clearing the slot invalidate > pointers stored in tts_values[]? For instance, if they are pointers > into an in-memory heap tuple, tts_heap_clear() is going to free the > tuple; if they are pointers into a buffer, tts_buffer_heap_clear() is > going to unpin it. Yeah, that's completely wrong. I think I missed that part. One solution can be that we can just detach the tuple from the slot and then materialize so it will form the tuple with new values and then we can clear the old tuple. But that seems a bit hacky. I think the supported procedure for this sort of > thing is to have a second slot, set tts_values, tts_isnull etc. and > then materialize the slot. After materializing the new slot, it's > independent of the old slot, which can then be cleared. See for > example tts_virtual_materialize(). Okay, so if we take a new slot then we need to set this slot reference in the ScanState also otherwise that might point to the old slot. I haven't yet analyzed where all we might be keeping the reference to that old slot. Or I am missing something. Anyway, I will get a better idea once I try to implement this. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Thu, Feb 4, 2021 at 11:39 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > Yeah, actually, I thought I would avoid calling slot_getallattrs if > none of the attributes got decompress. I agree if we call this before > we can avoid calling slot_getattr but slot_getattr > is only called for the attribute which has attlen -1. I agree that if > we call slot_getattr for attnum n then it will deform all the > attributes before that. But then slot_getallattrs only need to deform > the remaining attributes not all. But maybe we can call the > slot_getallattrs as soon as we see the first attribute with attlen -1 > and then avoid calling subsequent slot_getattr, maybe that is better > than compared to what I have because we will avoid calling > slot_getattr for many attributes, especially when there are many > verlena. I think that if we need to deform at all, we need to deform all attributes, right? So there's no point in considering e.g. slot_getsomeattrs(). But just slot_getallattrs() as soon as we know we need to do it might be worthwhile. Could even have two loops: one that just figures out whether we need to deform; if not, return. Then slot_getallattrs(). Then another loop to do the work. > I think the supported procedure for this sort of > > thing is to have a second slot, set tts_values, tts_isnull etc. and > > then materialize the slot. After materializing the new slot, it's > > independent of the old slot, which can then be cleared. See for > > example tts_virtual_materialize(). > > Okay, so if we take a new slot then we need to set this slot reference > in the ScanState also otherwise that might point to the old slot. I > haven't yet analyzed where all we might be keeping the reference to > that old slot. Or I am missing something. My guess is you want to leave the ScanState alone so that we keep fetching into the same slot as before and have an extra slot on the side someplace. -- Robert Haas EDB: http://www.enterprisedb.com
On Fri, Feb 5, 2021 at 3:51 AM Robert Haas <robertmhaas@gmail.com> wrote: > > On Thu, Feb 4, 2021 at 11:39 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > Yeah, actually, I thought I would avoid calling slot_getallattrs if > > none of the attributes got decompress. I agree if we call this before > > we can avoid calling slot_getattr but slot_getattr > > is only called for the attribute which has attlen -1. I agree that if > > we call slot_getattr for attnum n then it will deform all the > > attributes before that. But then slot_getallattrs only need to deform > > the remaining attributes not all. But maybe we can call the > > slot_getallattrs as soon as we see the first attribute with attlen -1 > > and then avoid calling subsequent slot_getattr, maybe that is better > > than compared to what I have because we will avoid calling > > slot_getattr for many attributes, especially when there are many > > verlena. > > I think that if we need to deform at all, we need to deform all > attributes, right? IMHO that is not true, because we might need to deform the attribute just to check its stored compression. So for example the first attribute is varchar and the remaining 100 attributes are interger. So we just need to deform the first attribute and if the compression method of that is the same as the target attribute then we are done and not need to deform the remaining and we can just continue with the original slot and tuple. I am not saying this is a very practical example and we have to do it like this, but I am just making a point that it is not true that if we deform at all then we have to deform all. However, if we decompress any then we have to deform all because we need to materialize the tuple again. So there's no point in considering e.g. > slot_getsomeattrs(). But just slot_getallattrs() as soon as we know we > need to do it might be worthwhile. Could even have two loops: one that > just figures out whether we need to deform; if not, return. Then > slot_getallattrs(). Then another loop to do the work. > > > I think the supported procedure for this sort of > > > thing is to have a second slot, set tts_values, tts_isnull etc. and > > > then materialize the slot. After materializing the new slot, it's > > > independent of the old slot, which can then be cleared. See for > > > example tts_virtual_materialize(). > > > > Okay, so if we take a new slot then we need to set this slot reference > > in the ScanState also otherwise that might point to the old slot. I > > haven't yet analyzed where all we might be keeping the reference to > > that old slot. Or I am missing something. > > My guess is you want to leave the ScanState alone so that we keep > fetching into the same slot as before and have an extra slot on the > side someplace. Okay, got your point. Thanks. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Feb 3, 2021 at 2:07 AM Robert Haas <robertmhaas@gmail.com> wrote:
>
> Even more review comments, still looking mostly at 0001:
>
> If there's a reason why parallel_schedule is arranging to run the
> compression test in parallel with nothing else, the comment in that
> file should explain the reason. If there isn't, it should be added to
> a parallel group that doesn't have the maximum number of tests yet,
> probably the last such group in the file.
>
> serial_schedule should add the test in a position that roughly
> corresponds to where it appears in parallel_schedule.
Done
> I believe it's relatively standard practice to put variable
> declarations at the top of the file. compress_lz4.c and
> compress_pglz.c instead put those declarations nearer to the point of
> use.
Do you mean pglz_compress_methods and lz4_compress_methods ? I
followed that style from
heapam_handler.c. If you think that doesn't look good then I can move it up.
> compressamapi.c has an awful lot of #include directives for the code
> it actually contains. I believe that we should cut that down to what
> is required by 0001, and other patches can add more later as required.
> In fact, it's tempting to just get rid of this .c file altogether and
> make the two functions it contains static inline functions in the
> header, but I'm not 100% sure that's a good idea.
I think it looks better to move them to compressamapi.h so done that.
> The copyright dates in a number of the file headers are out of date.
Fixed
> binary_upgrade_next_pg_am_oid and the related changes to
> CreateAccessMethod don't belong in 0001, because it doesn't support
> non-built-in compression methods. These changes and the related
> pg_dump change should be moved to the patch that adds support for
> that.
Fixed
> The comments added to dumpTableSchema() say that "compression is
> assigned by ALTER" but don't give a reason. I think they should. I
> don't know how much they need to explain about what the code does, but
> they definitely need to explain why it does it. Also, isn't this bad?
> If we create the column with the wrong compression setting initially
> and then ALTER it, we have to rewrite the table. If it's empty, that's
> cheap, but it'd still be better not to do it at all.
Yeah, actually that part should go in 0003 patch where we implement
the custom compression method.
in that patch we need to alter and set because we want to keep the
preserved method as well
So I will add it there
> I'm not sure it's a good idea for dumpTableSchema() to leave out
> specifying the compression method if it happens to be pglz. I think we
> definitely shouldn't do it in binary-upgrade mode. What if we changed
> the default in a future release? For that matter, even 0002 could make
> the current approach unsafe.... I think, anyway.
Fixed
> The changes to pg_dump.h look like they haven't had a visit from
> pgindent. You should probably try to do that for the whole patch,
> though it's a bit annoying since you'll have to manually remove
> unrelated changes to the same files that are being modified by the
> patch. Also, why the extra blank line here?
Fixed, ran pgindent for other files as well.
> GetAttributeCompression() is hard to understand. I suggest changing
> the comment to "resolve column compression specification to an OID"
> and somehow rejigger the code so that you aren't using one not-NULL
> test and one NULL test on the same variable. Like maybe change the
> first part to if (!IsStorageCompressible(typstorage)) { if
> (compression == NULL) return InvalidOid; ereport(ERROR, ...); }
Done
> It puzzles me that CompareCompressionMethodAndDecompress() calls
> slot_getallattrs() just before clearing the slot. It seems like this
> ought to happen before we loop over the attributes, so that we don't
> need to call slot_getattr() every time. See the comment for that
> function. But even if we didn't do that for some reason, why would we
> do it here? If it's already been done, it shouldn't do anything, and
> if it hasn't been done, it might overwrite some of the values we just
> poked into tts_values. It also seems suspicious that we can get away
> with clearing the slot and then again marking it valid. I'm not sure
> it really works like that. Like, can't clearing the slot invalidate
> pointers stored in tts_values[]? For instance, if they are pointers
> into an in-memory heap tuple, tts_heap_clear() is going to free the
> tuple; if they are pointers into a buffer, tts_buffer_heap_clear() is
> going to unpin it. I think the supported procedure for this sort of
> thing is to have a second slot, set tts_values, tts_isnull etc. and
> then materialize the slot. After materializing the new slot, it's
> independent of the old slot, which can then be cleared. See for
> example tts_virtual_materialize(). The whole approach you've taken
> here might need to be rethought a bit. I think you are right to want
> to avoid copying everything over into a new slot if nothing needs to
> be done, and I think we should definitely keep that optimization, but
> I think if you need to copy stuff, you have to do the above procedure
> and then continue using the other slot instead of the original one.
> Some places I think we have functions that return either the original
> slot or a different one depending on how it goes; that might be a
> useful idea here. But, you also can't just spam-create slots; it's
> important that whatever ones we end up with get reused for every
> tuple.
I have changed this algorithm, so now if we have to decompress
anything we will use the new slot and we will stick that new slot to
the ModifyTableState, DR_transientrel for matviews and DR_intorel for
CTAS. Does this looks okay or we need to do something else? If this
logic looks fine then maybe we can think of some more optimization and
cleanup in this function.
> Doesn't the change to describeOneTableDetails() require declaring
> changing the declaration of char *headers[11] to char *headers[12]?
> How does this not fail Assert(cols <= lengthof(headers))?
Fixed
> Why does describeOneTableDetais() arrange to truncate the printed
> value? We don't seem to do that for the other column properties, and
> it's not like this one is particularly long.
Not required, fixed.
> Perhaps the changes to pg_am.dat shouldn't remove the blank line?
Fixed
> I think the comment to pg_attribute.h could be rephrased to stay
> something like: "OID of compression AM. Must be InvalidOid if and only
> if typstorage is 'a' or 'b'," replacing 'a' and 'b' with whatever the
> right letters are. This would be shorter and I think also clearer than
> what you have
Fixed
> The first comment change in postgres.h is wrong. You changed
> va_extsize to "size in va_extinfo" but the associated structure
> definition is unchanged, so the comment shouldn't be changed either.
Yup, not required.
> In toast_internals.h, you end using 30 as a constant several times but
> have no #define for it. You do have a #define for RAWSIZEMASK, but
> that's really a derived value from 30. Also, it's not a great name
> because it's kind of generic. So how about something like:
>
> #define TOAST_RAWSIZE_BITS 30
> #define TOAST_RAWSIZE_MASK ((1 << (TOAST_RAW_SIZE_BITS + 1)) - 1)
>
> But then again on second thought, this 30 seems to be the same 30 that
> shows up in the changes to postgres.h, and there again 0x3FFFFFFF
> shows up too. So maybe we should actually be defining these constants
> there, using names like VARLENA_RAWSIZE_BITS and VARLENA_RAWSIZE_MASK
> and then having toast_internals.h use those constants as well.
Done, IMHO it should be
#define VARLENA_RAWSIZE_BITS 30
#define VARLENA_RAWSIZE_MASK ((1 << VARLENA_RAWSIZE_BITS) -1 )
> Taken with the email I sent yesterday, I think this is a more or less
> complete review of 0001. Although there are a bunch of things to fix
> here still, I don't think this is that far from being committable. I
> don't at this point see too much in terms of big design problems.
> Probably the CompareCompressionMethodAndDecompress() is the closest to
> a design-level problem, and certainly something needs to be done about
> it, but even that is a fairly localized problem in the context of the
> entire patch.
0001 is attached, now pending parts are
- Confirm the new design of CompareCompressionMethodAndDecompress
- Performance test, especially lz4 with small varlena
- Rebase other patches atop this patch
- comment in ddl.sgml
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Attachment
On Tue, Feb 2, 2021 at 2:45 AM Robert Haas <robertmhaas@gmail.com> wrote: > > Some more review comments: > > 'git am' barfs on v0001 because it's got a whitespace error. Fixed > VARFLAGS_4B_C() doesn't seem to be used in any of the patches. I'm OK > with keeping it even if it's not used just because maybe someone will > need it later but, uh, don't we need to use it someplace? Actually I was using TOAST_COMPRESS_METHOD and that required inclusion of toast_internal.h so now I have used VARFLAGS_4B_C and with that we are able to remove the inclusion of toast_internal.h in unwanted places. > To avoid moving the goalposts for a basic install, I suggest that > --with-lz4 should default to disabled. Maybe we'll want to rethink > that at some point, but since we're just getting started with this > whole thing, I don't think now is the time. Done > The change to ddl.sgml doesn't seem to make sense to me. There might > be someplace where we want to explain how properties are inherited in > partitioning hierarchies, but I don't think this is the right place, > and I don't think this explanation is particularly clear. Not yet done, I thought at the same place we are describing the storage relationship with the partition so that is the place for the compression also. Maybe I will have to read ddl.sgml file and find out the most suitable place. So I kept is as pending. > + This clause adds the compression method to a column. The Compression > + method can be set from available compression methods. The built-in > + methods are <literal>pglz</literal> and <literal>lz4</literal>. > + If no compression method is specified, then compressible types will have > + the default compression method <literal>pglz</literal>. > > Suggest: This sets the compression method for a column. The supported > compression methods are <literal>pglz</literal> and > <literal>lz4</literal>. <literal>lz4</literal> is available only if > <literal>--with-lz4</literal> was used when building > <productname>PostgreSQL</productname>. The default is > <literal>pglz</literal>. Done > We should make sure, if you haven't already, that trying to create a > column with LZ4 compression fails at table creation time if the build > does not support LZ4. But, someone could also create a table using a > build that has LZ4 support and then switch to a different set of > binaries that do not have it, so we need the runtime checks also. > However, those runtime checks shouldn't fail simplify from trying to > access a table that is set to use LZ4 compression; they should only > fail if we actually need to decompress an LZ4'd value. Done, I have cheched the compression method Oid if it LZ4 and if the lz4 library is not install then error out. We can also use the handler sepcific check function but I am not sure does that make sense to add extra routine for that. In later patch 0006 we have an check function to verify the option so during that we can error out and no need to check this outside. > Since indexes don't have TOAST tables, it surprises me that > brin_form_tuple() thinks it can TOAST anything. But I guess that's not > this patch's problem, if it's a problem at all. it is just trying to compress it not externalize. > I like the fact that you changed the message "compressed data is > corrupt" to indicate the compression method, but I think the resulting > message doesn't follow style guidelines because I don't believe we > normally put something with a colon prefix at the beginning of a > primary error message. So instead of saying "pglz: compressed data is > corrupt" I think you should say something like "compressed pglz data > is corrupt". Also, I suggest that we take this opportunity to switch > to ereport() rather than elog() and set > errcode(ERRCODE_DATA_CORRUPTED). Done > > What testing have you done for performance impacts? Does the patch > slow things down noticeably with pglz? (Hopefully not.) Can you > measure a performance improvement with pglz? (Hopefully so.) Is it > likely to hurt performance that there's no minimum size for lz4 > compression as we have for pglz? Seems like that could result in a lot > of wasted cycles trying to compress short strings. Not sure what to do about this, I will check the performance with small varlenas and see. > pglz_cmcompress() cancels compression if the resulting value would be > larger than the original one, but it looks like lz4_cmcompress() will > just store the enlarged value. That seems bad. you mean lz4_cmcompress, Done > pglz_cmcompress() doesn't need to pfree(tmp) before elog(ERROR). Done > CompressionOidToId(), CompressionIdToOid() and maybe other places need > to remember the message style guidelines. Primary error messages are > not capitalized. Fixed > Why should we now have to include toast_internals.h in > reorderbuffer.c, which has no other changes? That definitely shouldn't > be necessary. If something in another header file now requires > something from toast_internals.h, then that header file would be > obliged to include toast_internals.h itself. But actually that > shouldn't happen, because the whole point of toast_internals.h is that > it should not be included in very many places at all. If we're adding > stuff there that is going to be broadly needed, we're adding it in the > wrong place. Done > varlena.c shouldn't need toast_internals.h either, and if it did, it > should be in alphabetical order. > It was the wrong usage, fixed now. Please refer to the latest patch at https://www.postgresql.org/message-id/CAFiTN-v9Cs1MORnp-3bGZ5QBwr5v3VarSvfaDizHi1acXES5xQ%40mail.gmail.com -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Fri, Feb 5, 2021 at 10:56 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > Could you comment on the patch I sent on Jan 30 ? I think it would be squished > into 0001. I don't see why we have to do that. Seems fine to have it as a separate patch. > Also, what about the idea to add HIDE_COMPRESSAM ? Right now, your patch > changes a great many regression tests, and I doubt many people are going to try > to look closely to verify the differences, now, or when setting a non-default > compression method. Personally, my preference is to just update the test outputs. It's not important whether many people look closely to verify the differences; we just need to look them over on a one-time basis to see if they seem OK. After that it's 0 effort, vs. having to maintain HIDE_COMPRESSAM forever. > Also, I think we may want to make enable-lz4 the default *for testing > purposes*, now that the linux and BSD environments include that. My guess was that would annoy some hackers whose build environments got broken. If everyone thinks otherwise I'm willing to be persuaded, but it's going to take more than 1 vote... -- Robert Haas EDB: http://www.enterprisedb.com
On Fri, Feb 5, 2021 at 11:07 AM Robert Haas <robertmhaas@gmail.com> wrote:
> Personally, my preference is to just update the test outputs. It's not
> important whether many people look closely to verify the differences;
> we just need to look them over on a one-time basis to see if they seem
> OK. After that it's 0 effort, vs. having to maintain HIDE_COMPRESSAM
> forever.
Oh, I guess you're thinking about the case where someone wants to run
the tests with a different default. That might be a good reason to
have this. But then those changes should go in 0002.
Regarding 0002, I'm not feeling very excited about having every call
to TupleDescInitEntry() do an extra syscache lookup. It's going to be
the same lookup every time forever to get the same value every time
forever. Now maybe that function can never get hot enough for it to
matter, but can't we find a way to be smarter about this? Like,
suppose we cache the OID in a global variable the first time we look
it up, and then use CacheRegisterSyscacheCallback() to have it zeroed
out if pg_am is updated?
Taking that idea a bit further, suppose you get rid of all the places
where you do get_compression_am_oid(default_toast_compression, false)
and change them to get_default_compression_am_oid(), which is defined
thus:
static Oid
get_default_compression_am_oid(void)
{
if (unlikely(!OidIsValid(cached_default_compression_oid))
// figure it out;
return cached_default_compression_oid;
}
Also, how about removing the debugging leftovers from syscache.c?
--
Robert Haas
EDB: http://www.enterprisedb.com
On Fri, Feb 5, 2021 at 8:11 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Wed, Feb 3, 2021 at 2:07 AM Robert Haas <robertmhaas@gmail.com> wrote:
> >
> > Even more review comments, still looking mostly at 0001:
> >
> > If there's a reason why parallel_schedule is arranging to run the
> > compression test in parallel with nothing else, the comment in that
> > file should explain the reason. If there isn't, it should be added to
> > a parallel group that doesn't have the maximum number of tests yet,
> > probably the last such group in the file.
> >
> > serial_schedule should add the test in a position that roughly
> > corresponds to where it appears in parallel_schedule.
>
> Done
>
> > I believe it's relatively standard practice to put variable
> > declarations at the top of the file. compress_lz4.c and
> > compress_pglz.c instead put those declarations nearer to the point of
> > use.
>
> Do you mean pglz_compress_methods and lz4_compress_methods ? I
> followed that style from
> heapam_handler.c. If you think that doesn't look good then I can move it up.
>
> > compressamapi.c has an awful lot of #include directives for the code
> > it actually contains. I believe that we should cut that down to what
> > is required by 0001, and other patches can add more later as required.
> > In fact, it's tempting to just get rid of this .c file altogether and
> > make the two functions it contains static inline functions in the
> > header, but I'm not 100% sure that's a good idea.
>
> I think it looks better to move them to compressamapi.h so done that.
>
> > The copyright dates in a number of the file headers are out of date.
>
> Fixed
>
> > binary_upgrade_next_pg_am_oid and the related changes to
> > CreateAccessMethod don't belong in 0001, because it doesn't support
> > non-built-in compression methods. These changes and the related
> > pg_dump change should be moved to the patch that adds support for
> > that.
>
> Fixed
>
> > The comments added to dumpTableSchema() say that "compression is
> > assigned by ALTER" but don't give a reason. I think they should. I
> > don't know how much they need to explain about what the code does, but
> > they definitely need to explain why it does it. Also, isn't this bad?
> > If we create the column with the wrong compression setting initially
> > and then ALTER it, we have to rewrite the table. If it's empty, that's
> > cheap, but it'd still be better not to do it at all.
>
> Yeah, actually that part should go in 0003 patch where we implement
> the custom compression method.
> in that patch we need to alter and set because we want to keep the
> preserved method as well
> So I will add it there
>
> > I'm not sure it's a good idea for dumpTableSchema() to leave out
> > specifying the compression method if it happens to be pglz. I think we
> > definitely shouldn't do it in binary-upgrade mode. What if we changed
> > the default in a future release? For that matter, even 0002 could make
> > the current approach unsafe.... I think, anyway.
>
> Fixed
>
>
> > The changes to pg_dump.h look like they haven't had a visit from
> > pgindent. You should probably try to do that for the whole patch,
> > though it's a bit annoying since you'll have to manually remove
> > unrelated changes to the same files that are being modified by the
> > patch. Also, why the extra blank line here?
>
> Fixed, ran pgindent for other files as well.
>
> > GetAttributeCompression() is hard to understand. I suggest changing
> > the comment to "resolve column compression specification to an OID"
> > and somehow rejigger the code so that you aren't using one not-NULL
> > test and one NULL test on the same variable. Like maybe change the
> > first part to if (!IsStorageCompressible(typstorage)) { if
> > (compression == NULL) return InvalidOid; ereport(ERROR, ...); }
>
> Done
>
> > It puzzles me that CompareCompressionMethodAndDecompress() calls
> > slot_getallattrs() just before clearing the slot. It seems like this
> > ought to happen before we loop over the attributes, so that we don't
> > need to call slot_getattr() every time. See the comment for that
> > function. But even if we didn't do that for some reason, why would we
> > do it here? If it's already been done, it shouldn't do anything, and
> > if it hasn't been done, it might overwrite some of the values we just
> > poked into tts_values. It also seems suspicious that we can get away
> > with clearing the slot and then again marking it valid. I'm not sure
> > it really works like that. Like, can't clearing the slot invalidate
> > pointers stored in tts_values[]? For instance, if they are pointers
> > into an in-memory heap tuple, tts_heap_clear() is going to free the
> > tuple; if they are pointers into a buffer, tts_buffer_heap_clear() is
> > going to unpin it. I think the supported procedure for this sort of
> > thing is to have a second slot, set tts_values, tts_isnull etc. and
> > then materialize the slot. After materializing the new slot, it's
> > independent of the old slot, which can then be cleared. See for
> > example tts_virtual_materialize(). The whole approach you've taken
> > here might need to be rethought a bit. I think you are right to want
> > to avoid copying everything over into a new slot if nothing needs to
> > be done, and I think we should definitely keep that optimization, but
> > I think if you need to copy stuff, you have to do the above procedure
> > and then continue using the other slot instead of the original one.
> > Some places I think we have functions that return either the original
> > slot or a different one depending on how it goes; that might be a
> > useful idea here. But, you also can't just spam-create slots; it's
> > important that whatever ones we end up with get reused for every
> > tuple.
>
> I have changed this algorithm, so now if we have to decompress
> anything we will use the new slot and we will stick that new slot to
> the ModifyTableState, DR_transientrel for matviews and DR_intorel for
> CTAS. Does this looks okay or we need to do something else? If this
> logic looks fine then maybe we can think of some more optimization and
> cleanup in this function.
>
>
> > Doesn't the change to describeOneTableDetails() require declaring
> > changing the declaration of char *headers[11] to char *headers[12]?
> > How does this not fail Assert(cols <= lengthof(headers))?
>
> Fixed
>
> > Why does describeOneTableDetais() arrange to truncate the printed
> > value? We don't seem to do that for the other column properties, and
> > it's not like this one is particularly long.
>
> Not required, fixed.
>
> > Perhaps the changes to pg_am.dat shouldn't remove the blank line?
>
> Fixed
>
> > I think the comment to pg_attribute.h could be rephrased to stay
> > something like: "OID of compression AM. Must be InvalidOid if and only
> > if typstorage is 'a' or 'b'," replacing 'a' and 'b' with whatever the
> > right letters are. This would be shorter and I think also clearer than
> > what you have
>
> Fixed
>
> > The first comment change in postgres.h is wrong. You changed
> > va_extsize to "size in va_extinfo" but the associated structure
> > definition is unchanged, so the comment shouldn't be changed either.
>
> Yup, not required.
>
> > In toast_internals.h, you end using 30 as a constant several times but
> > have no #define for it. You do have a #define for RAWSIZEMASK, but
> > that's really a derived value from 30. Also, it's not a great name
> > because it's kind of generic. So how about something like:
> >
> > #define TOAST_RAWSIZE_BITS 30
> > #define TOAST_RAWSIZE_MASK ((1 << (TOAST_RAW_SIZE_BITS + 1)) - 1)
> >
> > But then again on second thought, this 30 seems to be the same 30 that
> > shows up in the changes to postgres.h, and there again 0x3FFFFFFF
> > shows up too. So maybe we should actually be defining these constants
> > there, using names like VARLENA_RAWSIZE_BITS and VARLENA_RAWSIZE_MASK
> > and then having toast_internals.h use those constants as well.
>
> Done, IMHO it should be
> #define VARLENA_RAWSIZE_BITS 30
> #define VARLENA_RAWSIZE_MASK ((1 << VARLENA_RAWSIZE_BITS) -1 )
>
>
> > Taken with the email I sent yesterday, I think this is a more or less
> > complete review of 0001. Although there are a bunch of things to fix
> > here still, I don't think this is that far from being committable. I
> > don't at this point see too much in terms of big design problems.
> > Probably the CompareCompressionMethodAndDecompress() is the closest to
> > a design-level problem, and certainly something needs to be done about
> > it, but even that is a fairly localized problem in the context of the
> > entire patch.
>
> 0001 is attached, now pending parts are
>
> - Confirm the new design of CompareCompressionMethodAndDecompress
> - Performance test, especially lz4 with small varlena
I have tested the performance, pglz vs lz4
Test1: With a small simple string, pglz doesn't select compression but
lz4 select as no min limit
Table: 100 varchar column
Test: Insert 1000 tuple, each column of 25 bytes string (32 is min
limit for pglz)
Result:
pglz: 1030 ms (doesn't attempt compression so externalize),
lz4: 212 ms
Test2: With small incompressible string, pglz don't select compression
lz4 select but can not compress
Table: 100 varchar column
Test: Insert 1000 tuple, each column of 25 bytes string (32 is min
limit for pglz)
Result:
pglz: 1030 ms (doesn't attempt compression so externalize),
lz4: 1090 ms (attempt to compress but externalize):
Test3: Test a few columns with large random data
Table: 3 varchar column
Test: Insert 1000 tuple 3 columns size(3500 byes, 4200 bytes, 4900bytes)
pglz: 150 ms (compression ratio: 3.02%),
lz4: 30 ms (compression ratio : 2.3%)
Test4: Test3 with different large random slighly compressible, need to
compress + externalize:
Table: 3 varchar column
Insert: Insert 1000 tuple 3 columns size(8192, 8192, 8192)
CREATE OR REPLACE FUNCTION large_val() RETURNS TEXT LANGUAGE SQL AS
'select array_agg(md5(g::text))::text from generate_series(1, 256) g';
Test: insert into t1 select large_val(), large_val(), large_val() from
generate_series(1,1000);
pglz: 2000 ms
lz4: 1500 ms
Conclusion:
1. In most cases lz4 is faster and doing better compression as well.
2. In Test2 when small data is incompressible then lz4 tries to
compress whereas pglz doesn't try so there is some performance loss.
But if we want we can fix
it by setting some minimum limit of size for lz4 as well, maybe the
same size as pglz?
> - Rebase other patches atop this patch
> - comment in ddl.sgml
Other changes in patch:
- Now we are dumping the default compression method in the
binary-upgrade mode so the pg_dump test needed some change, fixed
that.
- in compress_pglz.c and compress_lz4.c, we were using
toast_internal.h macros so I removed and used varlena macros instead.
While testing, I noticed that if the compressed data are externalized
then pg_column_compression(), doesn't fetch the compression method
from the toast chunk, I think we should do that. I will analyze this
and fix it in the next version.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Attachment
On Sun, Feb 7, 2021 at 5:15 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Fri, Feb 5, 2021 at 8:11 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> >
> > On Wed, Feb 3, 2021 at 2:07 AM Robert Haas <robertmhaas@gmail.com> wrote:
> > >
> > > Even more review comments, still looking mostly at 0001:
> > >
> > > If there's a reason why parallel_schedule is arranging to run the
> > > compression test in parallel with nothing else, the comment in that
> > > file should explain the reason. If there isn't, it should be added to
> > > a parallel group that doesn't have the maximum number of tests yet,
> > > probably the last such group in the file.
> > >
> > > serial_schedule should add the test in a position that roughly
> > > corresponds to where it appears in parallel_schedule.
> >
> > Done
> >
> > > I believe it's relatively standard practice to put variable
> > > declarations at the top of the file. compress_lz4.c and
> > > compress_pglz.c instead put those declarations nearer to the point of
> > > use.
> >
> > Do you mean pglz_compress_methods and lz4_compress_methods ? I
> > followed that style from
> > heapam_handler.c. If you think that doesn't look good then I can move it up.
> >
> > > compressamapi.c has an awful lot of #include directives for the code
> > > it actually contains. I believe that we should cut that down to what
> > > is required by 0001, and other patches can add more later as required.
> > > In fact, it's tempting to just get rid of this .c file altogether and
> > > make the two functions it contains static inline functions in the
> > > header, but I'm not 100% sure that's a good idea.
> >
> > I think it looks better to move them to compressamapi.h so done that.
> >
> > > The copyright dates in a number of the file headers are out of date.
> >
> > Fixed
> >
> > > binary_upgrade_next_pg_am_oid and the related changes to
> > > CreateAccessMethod don't belong in 0001, because it doesn't support
> > > non-built-in compression methods. These changes and the related
> > > pg_dump change should be moved to the patch that adds support for
> > > that.
> >
> > Fixed
> >
> > > The comments added to dumpTableSchema() say that "compression is
> > > assigned by ALTER" but don't give a reason. I think they should. I
> > > don't know how much they need to explain about what the code does, but
> > > they definitely need to explain why it does it. Also, isn't this bad?
> > > If we create the column with the wrong compression setting initially
> > > and then ALTER it, we have to rewrite the table. If it's empty, that's
> > > cheap, but it'd still be better not to do it at all.
> >
> > Yeah, actually that part should go in 0003 patch where we implement
> > the custom compression method.
> > in that patch we need to alter and set because we want to keep the
> > preserved method as well
> > So I will add it there
> >
> > > I'm not sure it's a good idea for dumpTableSchema() to leave out
> > > specifying the compression method if it happens to be pglz. I think we
> > > definitely shouldn't do it in binary-upgrade mode. What if we changed
> > > the default in a future release? For that matter, even 0002 could make
> > > the current approach unsafe.... I think, anyway.
> >
> > Fixed
> >
> >
> > > The changes to pg_dump.h look like they haven't had a visit from
> > > pgindent. You should probably try to do that for the whole patch,
> > > though it's a bit annoying since you'll have to manually remove
> > > unrelated changes to the same files that are being modified by the
> > > patch. Also, why the extra blank line here?
> >
> > Fixed, ran pgindent for other files as well.
> >
> > > GetAttributeCompression() is hard to understand. I suggest changing
> > > the comment to "resolve column compression specification to an OID"
> > > and somehow rejigger the code so that you aren't using one not-NULL
> > > test and one NULL test on the same variable. Like maybe change the
> > > first part to if (!IsStorageCompressible(typstorage)) { if
> > > (compression == NULL) return InvalidOid; ereport(ERROR, ...); }
> >
> > Done
> >
> > > It puzzles me that CompareCompressionMethodAndDecompress() calls
> > > slot_getallattrs() just before clearing the slot. It seems like this
> > > ought to happen before we loop over the attributes, so that we don't
> > > need to call slot_getattr() every time. See the comment for that
> > > function. But even if we didn't do that for some reason, why would we
> > > do it here? If it's already been done, it shouldn't do anything, and
> > > if it hasn't been done, it might overwrite some of the values we just
> > > poked into tts_values. It also seems suspicious that we can get away
> > > with clearing the slot and then again marking it valid. I'm not sure
> > > it really works like that. Like, can't clearing the slot invalidate
> > > pointers stored in tts_values[]? For instance, if they are pointers
> > > into an in-memory heap tuple, tts_heap_clear() is going to free the
> > > tuple; if they are pointers into a buffer, tts_buffer_heap_clear() is
> > > going to unpin it. I think the supported procedure for this sort of
> > > thing is to have a second slot, set tts_values, tts_isnull etc. and
> > > then materialize the slot. After materializing the new slot, it's
> > > independent of the old slot, which can then be cleared. See for
> > > example tts_virtual_materialize(). The whole approach you've taken
> > > here might need to be rethought a bit. I think you are right to want
> > > to avoid copying everything over into a new slot if nothing needs to
> > > be done, and I think we should definitely keep that optimization, but
> > > I think if you need to copy stuff, you have to do the above procedure
> > > and then continue using the other slot instead of the original one.
> > > Some places I think we have functions that return either the original
> > > slot or a different one depending on how it goes; that might be a
> > > useful idea here. But, you also can't just spam-create slots; it's
> > > important that whatever ones we end up with get reused for every
> > > tuple.
> >
> > I have changed this algorithm, so now if we have to decompress
> > anything we will use the new slot and we will stick that new slot to
> > the ModifyTableState, DR_transientrel for matviews and DR_intorel for
> > CTAS. Does this looks okay or we need to do something else? If this
> > logic looks fine then maybe we can think of some more optimization and
> > cleanup in this function.
> >
> >
> > > Doesn't the change to describeOneTableDetails() require declaring
> > > changing the declaration of char *headers[11] to char *headers[12]?
> > > How does this not fail Assert(cols <= lengthof(headers))?
> >
> > Fixed
> >
> > > Why does describeOneTableDetais() arrange to truncate the printed
> > > value? We don't seem to do that for the other column properties, and
> > > it's not like this one is particularly long.
> >
> > Not required, fixed.
> >
> > > Perhaps the changes to pg_am.dat shouldn't remove the blank line?
> >
> > Fixed
> >
> > > I think the comment to pg_attribute.h could be rephrased to stay
> > > something like: "OID of compression AM. Must be InvalidOid if and only
> > > if typstorage is 'a' or 'b'," replacing 'a' and 'b' with whatever the
> > > right letters are. This would be shorter and I think also clearer than
> > > what you have
> >
> > Fixed
> >
> > > The first comment change in postgres.h is wrong. You changed
> > > va_extsize to "size in va_extinfo" but the associated structure
> > > definition is unchanged, so the comment shouldn't be changed either.
> >
> > Yup, not required.
> >
> > > In toast_internals.h, you end using 30 as a constant several times but
> > > have no #define for it. You do have a #define for RAWSIZEMASK, but
> > > that's really a derived value from 30. Also, it's not a great name
> > > because it's kind of generic. So how about something like:
> > >
> > > #define TOAST_RAWSIZE_BITS 30
> > > #define TOAST_RAWSIZE_MASK ((1 << (TOAST_RAW_SIZE_BITS + 1)) - 1)
> > >
> > > But then again on second thought, this 30 seems to be the same 30 that
> > > shows up in the changes to postgres.h, and there again 0x3FFFFFFF
> > > shows up too. So maybe we should actually be defining these constants
> > > there, using names like VARLENA_RAWSIZE_BITS and VARLENA_RAWSIZE_MASK
> > > and then having toast_internals.h use those constants as well.
> >
> > Done, IMHO it should be
> > #define VARLENA_RAWSIZE_BITS 30
> > #define VARLENA_RAWSIZE_MASK ((1 << VARLENA_RAWSIZE_BITS) -1 )
> >
> >
> > > Taken with the email I sent yesterday, I think this is a more or less
> > > complete review of 0001. Although there are a bunch of things to fix
> > > here still, I don't think this is that far from being committable. I
> > > don't at this point see too much in terms of big design problems.
> > > Probably the CompareCompressionMethodAndDecompress() is the closest to
> > > a design-level problem, and certainly something needs to be done about
> > > it, but even that is a fairly localized problem in the context of the
> > > entire patch.
> >
> > 0001 is attached, now pending parts are
> >
> > - Confirm the new design of CompareCompressionMethodAndDecompress
> > - Performance test, especially lz4 with small varlena
>
> I have tested the performance, pglz vs lz4
>
> Test1: With a small simple string, pglz doesn't select compression but
> lz4 select as no min limit
> Table: 100 varchar column
> Test: Insert 1000 tuple, each column of 25 bytes string (32 is min
> limit for pglz)
> Result:
> pglz: 1030 ms (doesn't attempt compression so externalize),
> lz4: 212 ms
>
> Test2: With small incompressible string, pglz don't select compression
> lz4 select but can not compress
> Table: 100 varchar column
> Test: Insert 1000 tuple, each column of 25 bytes string (32 is min
> limit for pglz)
> Result:
> pglz: 1030 ms (doesn't attempt compression so externalize),
> lz4: 1090 ms (attempt to compress but externalize):
>
> Test3: Test a few columns with large random data
> Table: 3 varchar column
> Test: Insert 1000 tuple 3 columns size(3500 byes, 4200 bytes, 4900bytes)
> pglz: 150 ms (compression ratio: 3.02%),
> lz4: 30 ms (compression ratio : 2.3%)
>
> Test4: Test3 with different large random slighly compressible, need to
> compress + externalize:
> Table: 3 varchar column
> Insert: Insert 1000 tuple 3 columns size(8192, 8192, 8192)
> CREATE OR REPLACE FUNCTION large_val() RETURNS TEXT LANGUAGE SQL AS
> 'select array_agg(md5(g::text))::text from generate_series(1, 256) g';
> Test: insert into t1 select large_val(), large_val(), large_val() from
> generate_series(1,1000);
> pglz: 2000 ms
> lz4: 1500 ms
>
> Conclusion:
> 1. In most cases lz4 is faster and doing better compression as well.
> 2. In Test2 when small data is incompressible then lz4 tries to
> compress whereas pglz doesn't try so there is some performance loss.
> But if we want we can fix
> it by setting some minimum limit of size for lz4 as well, maybe the
> same size as pglz?
>
> > - Rebase other patches atop this patch
> > - comment in ddl.sgml
>
> Other changes in patch:
> - Now we are dumping the default compression method in the
> binary-upgrade mode so the pg_dump test needed some change, fixed
> that.
> - in compress_pglz.c and compress_lz4.c, we were using
> toast_internal.h macros so I removed and used varlena macros instead.
>
> While testing, I noticed that if the compressed data are externalized
> then pg_column_compression(), doesn't fetch the compression method
> from the toast chunk, I think we should do that. I will analyze this
> and fix it in the next version.
While trying to fix this, I have realized this problem exists in
CompareCompressionMethodAndDecompress
see below code.
---
+ new_value = (struct varlena *)
+ DatumGetPointer(slot->tts_values[attnum - 1]);
+
+ /* nothing to be done, if it is not compressed */
+ if (!VARATT_IS_COMPRESSED(new_value))
+ continue;
---
Basically, we are just checking whether the stored value is compressed
or not, but we are clearly ignoring the fact that it might be
compressed and stored externally on disk. So basically if the value
is stored externally we can not know whether the external data were
compressed or not without fetching the values from the toast table, I
think instead of fetching the complete data from toast we can just
fetch the header using 'toast_fetch_datum_slice'.
Any other thoughts on this?
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Tue, Feb 9, 2021 at 2:08 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Sun, Feb 7, 2021 at 5:15 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> >
> > On Fri, Feb 5, 2021 at 8:11 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> > >
> > > On Wed, Feb 3, 2021 at 2:07 AM Robert Haas <robertmhaas@gmail.com> wrote:
> > > >
> > > > Even more review comments, still looking mostly at 0001:
> > > >
> > > > If there's a reason why parallel_schedule is arranging to run the
> > > > compression test in parallel with nothing else, the comment in that
> > > > file should explain the reason. If there isn't, it should be added to
> > > > a parallel group that doesn't have the maximum number of tests yet,
> > > > probably the last such group in the file.
> > > >
> > > > serial_schedule should add the test in a position that roughly
> > > > corresponds to where it appears in parallel_schedule.
> > >
> > > Done
> > >
> > > > I believe it's relatively standard practice to put variable
> > > > declarations at the top of the file. compress_lz4.c and
> > > > compress_pglz.c instead put those declarations nearer to the point of
> > > > use.
> > >
> > > Do you mean pglz_compress_methods and lz4_compress_methods ? I
> > > followed that style from
> > > heapam_handler.c. If you think that doesn't look good then I can move it up.
> > >
> > > > compressamapi.c has an awful lot of #include directives for the code
> > > > it actually contains. I believe that we should cut that down to what
> > > > is required by 0001, and other patches can add more later as required.
> > > > In fact, it's tempting to just get rid of this .c file altogether and
> > > > make the two functions it contains static inline functions in the
> > > > header, but I'm not 100% sure that's a good idea.
> > >
> > > I think it looks better to move them to compressamapi.h so done that.
> > >
> > > > The copyright dates in a number of the file headers are out of date.
> > >
> > > Fixed
> > >
> > > > binary_upgrade_next_pg_am_oid and the related changes to
> > > > CreateAccessMethod don't belong in 0001, because it doesn't support
> > > > non-built-in compression methods. These changes and the related
> > > > pg_dump change should be moved to the patch that adds support for
> > > > that.
> > >
> > > Fixed
> > >
> > > > The comments added to dumpTableSchema() say that "compression is
> > > > assigned by ALTER" but don't give a reason. I think they should. I
> > > > don't know how much they need to explain about what the code does, but
> > > > they definitely need to explain why it does it. Also, isn't this bad?
> > > > If we create the column with the wrong compression setting initially
> > > > and then ALTER it, we have to rewrite the table. If it's empty, that's
> > > > cheap, but it'd still be better not to do it at all.
> > >
> > > Yeah, actually that part should go in 0003 patch where we implement
> > > the custom compression method.
> > > in that patch we need to alter and set because we want to keep the
> > > preserved method as well
> > > So I will add it there
> > >
> > > > I'm not sure it's a good idea for dumpTableSchema() to leave out
> > > > specifying the compression method if it happens to be pglz. I think we
> > > > definitely shouldn't do it in binary-upgrade mode. What if we changed
> > > > the default in a future release? For that matter, even 0002 could make
> > > > the current approach unsafe.... I think, anyway.
> > >
> > > Fixed
> > >
> > >
> > > > The changes to pg_dump.h look like they haven't had a visit from
> > > > pgindent. You should probably try to do that for the whole patch,
> > > > though it's a bit annoying since you'll have to manually remove
> > > > unrelated changes to the same files that are being modified by the
> > > > patch. Also, why the extra blank line here?
> > >
> > > Fixed, ran pgindent for other files as well.
> > >
> > > > GetAttributeCompression() is hard to understand. I suggest changing
> > > > the comment to "resolve column compression specification to an OID"
> > > > and somehow rejigger the code so that you aren't using one not-NULL
> > > > test and one NULL test on the same variable. Like maybe change the
> > > > first part to if (!IsStorageCompressible(typstorage)) { if
> > > > (compression == NULL) return InvalidOid; ereport(ERROR, ...); }
> > >
> > > Done
> > >
> > > > It puzzles me that CompareCompressionMethodAndDecompress() calls
> > > > slot_getallattrs() just before clearing the slot. It seems like this
> > > > ought to happen before we loop over the attributes, so that we don't
> > > > need to call slot_getattr() every time. See the comment for that
> > > > function. But even if we didn't do that for some reason, why would we
> > > > do it here? If it's already been done, it shouldn't do anything, and
> > > > if it hasn't been done, it might overwrite some of the values we just
> > > > poked into tts_values. It also seems suspicious that we can get away
> > > > with clearing the slot and then again marking it valid. I'm not sure
> > > > it really works like that. Like, can't clearing the slot invalidate
> > > > pointers stored in tts_values[]? For instance, if they are pointers
> > > > into an in-memory heap tuple, tts_heap_clear() is going to free the
> > > > tuple; if they are pointers into a buffer, tts_buffer_heap_clear() is
> > > > going to unpin it. I think the supported procedure for this sort of
> > > > thing is to have a second slot, set tts_values, tts_isnull etc. and
> > > > then materialize the slot. After materializing the new slot, it's
> > > > independent of the old slot, which can then be cleared. See for
> > > > example tts_virtual_materialize(). The whole approach you've taken
> > > > here might need to be rethought a bit. I think you are right to want
> > > > to avoid copying everything over into a new slot if nothing needs to
> > > > be done, and I think we should definitely keep that optimization, but
> > > > I think if you need to copy stuff, you have to do the above procedure
> > > > and then continue using the other slot instead of the original one.
> > > > Some places I think we have functions that return either the original
> > > > slot or a different one depending on how it goes; that might be a
> > > > useful idea here. But, you also can't just spam-create slots; it's
> > > > important that whatever ones we end up with get reused for every
> > > > tuple.
> > >
> > > I have changed this algorithm, so now if we have to decompress
> > > anything we will use the new slot and we will stick that new slot to
> > > the ModifyTableState, DR_transientrel for matviews and DR_intorel for
> > > CTAS. Does this looks okay or we need to do something else? If this
> > > logic looks fine then maybe we can think of some more optimization and
> > > cleanup in this function.
> > >
> > >
> > > > Doesn't the change to describeOneTableDetails() require declaring
> > > > changing the declaration of char *headers[11] to char *headers[12]?
> > > > How does this not fail Assert(cols <= lengthof(headers))?
> > >
> > > Fixed
> > >
> > > > Why does describeOneTableDetais() arrange to truncate the printed
> > > > value? We don't seem to do that for the other column properties, and
> > > > it's not like this one is particularly long.
> > >
> > > Not required, fixed.
> > >
> > > > Perhaps the changes to pg_am.dat shouldn't remove the blank line?
> > >
> > > Fixed
> > >
> > > > I think the comment to pg_attribute.h could be rephrased to stay
> > > > something like: "OID of compression AM. Must be InvalidOid if and only
> > > > if typstorage is 'a' or 'b'," replacing 'a' and 'b' with whatever the
> > > > right letters are. This would be shorter and I think also clearer than
> > > > what you have
> > >
> > > Fixed
> > >
> > > > The first comment change in postgres.h is wrong. You changed
> > > > va_extsize to "size in va_extinfo" but the associated structure
> > > > definition is unchanged, so the comment shouldn't be changed either.
> > >
> > > Yup, not required.
> > >
> > > > In toast_internals.h, you end using 30 as a constant several times but
> > > > have no #define for it. You do have a #define for RAWSIZEMASK, but
> > > > that's really a derived value from 30. Also, it's not a great name
> > > > because it's kind of generic. So how about something like:
> > > >
> > > > #define TOAST_RAWSIZE_BITS 30
> > > > #define TOAST_RAWSIZE_MASK ((1 << (TOAST_RAW_SIZE_BITS + 1)) - 1)
> > > >
> > > > But then again on second thought, this 30 seems to be the same 30 that
> > > > shows up in the changes to postgres.h, and there again 0x3FFFFFFF
> > > > shows up too. So maybe we should actually be defining these constants
> > > > there, using names like VARLENA_RAWSIZE_BITS and VARLENA_RAWSIZE_MASK
> > > > and then having toast_internals.h use those constants as well.
> > >
> > > Done, IMHO it should be
> > > #define VARLENA_RAWSIZE_BITS 30
> > > #define VARLENA_RAWSIZE_MASK ((1 << VARLENA_RAWSIZE_BITS) -1 )
> > >
> > >
> > > > Taken with the email I sent yesterday, I think this is a more or less
> > > > complete review of 0001. Although there are a bunch of things to fix
> > > > here still, I don't think this is that far from being committable. I
> > > > don't at this point see too much in terms of big design problems.
> > > > Probably the CompareCompressionMethodAndDecompress() is the closest to
> > > > a design-level problem, and certainly something needs to be done about
> > > > it, but even that is a fairly localized problem in the context of the
> > > > entire patch.
> > >
> > > 0001 is attached, now pending parts are
> > >
> > > - Confirm the new design of CompareCompressionMethodAndDecompress
> > > - Performance test, especially lz4 with small varlena
> >
> > I have tested the performance, pglz vs lz4
> >
> > Test1: With a small simple string, pglz doesn't select compression but
> > lz4 select as no min limit
> > Table: 100 varchar column
> > Test: Insert 1000 tuple, each column of 25 bytes string (32 is min
> > limit for pglz)
> > Result:
> > pglz: 1030 ms (doesn't attempt compression so externalize),
> > lz4: 212 ms
> >
> > Test2: With small incompressible string, pglz don't select compression
> > lz4 select but can not compress
> > Table: 100 varchar column
> > Test: Insert 1000 tuple, each column of 25 bytes string (32 is min
> > limit for pglz)
> > Result:
> > pglz: 1030 ms (doesn't attempt compression so externalize),
> > lz4: 1090 ms (attempt to compress but externalize):
> >
> > Test3: Test a few columns with large random data
> > Table: 3 varchar column
> > Test: Insert 1000 tuple 3 columns size(3500 byes, 4200 bytes, 4900bytes)
> > pglz: 150 ms (compression ratio: 3.02%),
> > lz4: 30 ms (compression ratio : 2.3%)
> >
> > Test4: Test3 with different large random slighly compressible, need to
> > compress + externalize:
> > Table: 3 varchar column
> > Insert: Insert 1000 tuple 3 columns size(8192, 8192, 8192)
> > CREATE OR REPLACE FUNCTION large_val() RETURNS TEXT LANGUAGE SQL AS
> > 'select array_agg(md5(g::text))::text from generate_series(1, 256) g';
> > Test: insert into t1 select large_val(), large_val(), large_val() from
> > generate_series(1,1000);
> > pglz: 2000 ms
> > lz4: 1500 ms
> >
> > Conclusion:
> > 1. In most cases lz4 is faster and doing better compression as well.
> > 2. In Test2 when small data is incompressible then lz4 tries to
> > compress whereas pglz doesn't try so there is some performance loss.
> > But if we want we can fix
> > it by setting some minimum limit of size for lz4 as well, maybe the
> > same size as pglz?
> >
> > > - Rebase other patches atop this patch
> > > - comment in ddl.sgml
> >
> > Other changes in patch:
> > - Now we are dumping the default compression method in the
> > binary-upgrade mode so the pg_dump test needed some change, fixed
> > that.
> > - in compress_pglz.c and compress_lz4.c, we were using
> > toast_internal.h macros so I removed and used varlena macros instead.
> >
> > While testing, I noticed that if the compressed data are externalized
> > then pg_column_compression(), doesn't fetch the compression method
> > from the toast chunk, I think we should do that. I will analyze this
> > and fix it in the next version.
>
> While trying to fix this, I have realized this problem exists in
> CompareCompressionMethodAndDecompress
> see below code.
> ---
> + new_value = (struct varlena *)
> + DatumGetPointer(slot->tts_values[attnum - 1]);
> +
> + /* nothing to be done, if it is not compressed */
> + if (!VARATT_IS_COMPRESSED(new_value))
> + continue;
> ---
>
> Basically, we are just checking whether the stored value is compressed
> or not, but we are clearly ignoring the fact that it might be
> compressed and stored externally on disk. So basically if the value
> is stored externally we can not know whether the external data were
> compressed or not without fetching the values from the toast table, I
> think instead of fetching the complete data from toast we can just
> fetch the header using 'toast_fetch_datum_slice'.
>
> Any other thoughts on this?
I think I was partially wrong here. Basically, there is a way to know
whether the external data are compressed or not using
VARATT_EXTERNAL_IS_COMPRESSED macro. However, if it is compressed
then we will have to fetch the toast slice of size
toast_compress_header, to know the compression method.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Please remember to trim unnecessary quoted material. On Sun, Feb 7, 2021 at 6:45 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > [ a whole lot of quoted stuff ] > > I have tested the performance, pglz vs lz4 > > Test1: With a small simple string, pglz doesn't select compression but > lz4 select as no min limit > Table: 100 varchar column > Test: Insert 1000 tuple, each column of 25 bytes string (32 is min > limit for pglz) > Result: > pglz: 1030 ms (doesn't attempt compression so externalize), > lz4: 212 ms > > Test2: With small incompressible string, pglz don't select compression > lz4 select but can not compress > Table: 100 varchar column > Test: Insert 1000 tuple, each column of 25 bytes string (32 is min > limit for pglz) > Result: > pglz: 1030 ms (doesn't attempt compression so externalize), > lz4: 1090 ms (attempt to compress but externalize): > > Test3: Test a few columns with large random data > Table: 3 varchar column > Test: Insert 1000 tuple 3 columns size(3500 byes, 4200 bytes, 4900bytes) > pglz: 150 ms (compression ratio: 3.02%), > lz4: 30 ms (compression ratio : 2.3%) > > Test4: Test3 with different large random slighly compressible, need to > compress + externalize: > Table: 3 varchar column > Insert: Insert 1000 tuple 3 columns size(8192, 8192, 8192) > CREATE OR REPLACE FUNCTION large_val() RETURNS TEXT LANGUAGE SQL AS > 'select array_agg(md5(g::text))::text from generate_series(1, 256) g'; > Test: insert into t1 select large_val(), large_val(), large_val() from > generate_series(1,1000); > pglz: 2000 ms > lz4: 1500 ms > > Conclusion: > 1. In most cases lz4 is faster and doing better compression as well. > 2. In Test2 when small data is incompressible then lz4 tries to > compress whereas pglz doesn't try so there is some performance loss. > But if we want we can fix > it by setting some minimum limit of size for lz4 as well, maybe the > same size as pglz? So my conclusion here is that perhaps there's no real problem. It looks like externalizing is so expensive compared to compression that it's worth trying to compress even though it may not always pay off. If, by trying to compress, we avoid externalizing, it's a huge win (~5x). If we try to compress and don't manage to avoid externalizing, it's a small loss (~6%). It's probably reasonable to expect that compressible data is more common than incompressible data, so not only is the win a lot bigger than the loss, but we should be able to expect it to happen a lot more often. It's not impossible that somebody could get bitten, but it doesn't feel like a huge risk to me. One thing that does occur to me is that it might be a good idea to skip compression if it doesn't change the number of chunks that will be stored into the TOAST table. If we compress the value but still need to externalize it, and the compression didn't save enough to reduce the number of chunks, I suppose we ideally would externalize the uncompressed version. That would save decompression time later, without really costing anything. However, I suppose that would be a separate improvement from this patch. Maybe the possibility of compressing smaller values makes it slightly more important, but I'm not sure that it's worth getting excited about. If anyone feels otherwise on either point, it'd be good to hear about it. -- Robert Haas EDB: http://www.enterprisedb.com
On Tue, Feb 9, 2021 at 3:37 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > I think you misunderstood: I mean that the WIP patch should default to > --enable-lz4, to exercise on a few CI. It's hardly useful to run CI with the > feature disabled. I assume that the patch would be committed with default > --disable-lz4. Oh, I see. I guess we could do that. > Right, it's not one-time, it's also whenever setting a non-default compression > method. I say it should go into 0001 to avoid a whole bunch of churn in > src/test/regress, and then more churn (and rebase conflicts in other patches) > while adding HIDE_COMPRESSAM in 0002. Hmm, I guess that makes some sense, too. I'm not sure either one is completely critical, but it does make sense to me now. -- Robert Haas EDB: http://www.enterprisedb.com
On Wed, Feb 10, 2021 at 1:42 AM Robert Haas <robertmhaas@gmail.com> wrote: > > Please remember to trim unnecessary quoted material. Okay, I will. > On Sun, Feb 7, 2021 at 6:45 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > [ a whole lot of quoted stuff ] > > > > Conclusion: > > 1. In most cases lz4 is faster and doing better compression as well. > > 2. In Test2 when small data is incompressible then lz4 tries to > > compress whereas pglz doesn't try so there is some performance loss. > > But if we want we can fix > > it by setting some minimum limit of size for lz4 as well, maybe the > > same size as pglz? > > So my conclusion here is that perhaps there's no real problem. It > looks like externalizing is so expensive compared to compression that > it's worth trying to compress even though it may not always pay off. > If, by trying to compress, we avoid externalizing, it's a huge win > (~5x). If we try to compress and don't manage to avoid externalizing, > it's a small loss (~6%). It's probably reasonable to expect that > compressible data is more common than incompressible data, so not only > is the win a lot bigger than the loss, but we should be able to expect > it to happen a lot more often. It's not impossible that somebody could > get bitten, but it doesn't feel like a huge risk to me. I agree with this. That said maybe we could test the performance of pglz also by lowering/removing the min compression limit but maybe that should be an independent change. > One thing that does occur to me is that it might be a good idea to > skip compression if it doesn't change the number of chunks that will > be stored into the TOAST table. If we compress the value but still > need to externalize it, and the compression didn't save enough to > reduce the number of chunks, I suppose we ideally would externalize > the uncompressed version. That would save decompression time later, > without really costing anything. However, I suppose that would be a > separate improvement from this patch. Yeah, this seems like a good idea and we can work on that in a different thread. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Feb 9, 2021 at 6:14 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > Basically, we are just checking whether the stored value is compressed > > or not, but we are clearly ignoring the fact that it might be > > compressed and stored externally on disk. So basically if the value > > is stored externally we can not know whether the external data were > > compressed or not without fetching the values from the toast table, I > > think instead of fetching the complete data from toast we can just > > fetch the header using 'toast_fetch_datum_slice'. > > > > Any other thoughts on this? > > I think I was partially wrong here. Basically, there is a way to know > whether the external data are compressed or not using > VARATT_EXTERNAL_IS_COMPRESSED macro. However, if it is compressed > then we will have to fetch the toast slice of size > toast_compress_header, to know the compression method. I have fixed this issue, so now we will be able to detect the compression method of the externalized compressed data as well. I have also added a test case for this. I have rebased other patches also on top of this patch. I have fixed the doc compilation issue in patch 0004 raised by Justin. I still could not figure out what is the right place for inheriting the compression method related change in the "ddl.sgml" so that is still there, any suggestions on that? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Feb 10, 2021 at 9:52 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> [ new patches ]
I think that in both varattrib_4b and toast_internals.h it would be
better to pick a less generic field name. In toast_internals.h it's
just info; in postgres.h it's va_info. But:
[rhaas pgsql]$ git grep info | wc -l
24552
There are no references in the current source tree to va_info, so at
least that one is greppable, but it's still not very descriptive. I
suggest info -> tcinfo and va_info -> va_tcinfo, where "tc" stands for
"TOAST compression". Looking through 24552 references to info to find
the ones that pertain to this feature might take longer than searching
the somewhat shorter list of references to tcinfo, which prepatch is
just:
[rhaas pgsql]$ git grep tcinfo | wc -l
0
I don't see why we should allow for datum_decompress to be optional,
as toast_decompress_datum_slice does. Likely every serious compression
method will support that anyway. If not, the compression AM can deal
with the problem, rather than having the core code do it. That will
save some tiny amount of performance, too.
src/backend/access/compression/Makefile is missing a copyright header.
It's really sad that lz4_cmdecompress_slice allocates
VARRAWSIZE_4B_C(value) + VARHDRSZ rather than slicelength + VARHDRSZ
as pglz_cmdecompress_slice() does. Is that a mistake, or is that
necessary for some reason? If it's a mistake, let's fix it. If it's
necessary, let's add a comment about why, probably starting with
"Unfortunately, ....".
I think you have a fairly big problem with row types. Consider this example:
create table t1 (a int, b text compression pglz);
create table t2 (a int, b text compression lz4);
create table t3 (x t1);
insert into t1 values (1, repeat('foo', 1000));
insert into t2 values (1, repeat('foo', 1000));
insert into t3 select t1 from t1;
insert into t3 select row(a, b)::t1 from t2;
rhaas=# select pg_column_compression((t3.x).b) from t3;
pg_column_compression
-----------------------
pglz
lz4
(2 rows)
That's not good, because now
--
Robert Haas
EDB: http://www.enterprisedb.com
On Wed, Feb 10, 2021 at 3:06 PM Robert Haas <robertmhaas@gmail.com> wrote:
> I think you have a fairly big problem with row types. Consider this example:
>
> create table t1 (a int, b text compression pglz);
> create table t2 (a int, b text compression lz4);
> create table t3 (x t1);
> insert into t1 values (1, repeat('foo', 1000));
> insert into t2 values (1, repeat('foo', 1000));
> insert into t3 select t1 from t1;
> insert into t3 select row(a, b)::t1 from t2;
>
> rhaas=# select pg_column_compression((t3.x).b) from t3;
> pg_column_compression
> -----------------------
> pglz
> lz4
> (2 rows)
>
> That's not good, because now
...because now I hit send too soon. Also, because now column b has
implicit dependencies on both compression AMs and the rest of the
system has no idea. I think we probably should have a rule that
nothing except pglz is allowed inside of a record, just to keep it
simple. The record overall can be toasted so it's not clear why we
should also be toasting the original columns at all, but I think
precedent probably argues for continuing to allow PGLZ, as it can
already be like that on disk and pg_upgrade is a thing. The same kind
of issue probably exists for arrays and range types.
I poked around a bit trying to find ways of getting data compressed
with one compression method into a column that was marked with another
compression method, but wasn't able to break it.
In CompareCompressionMethodAndDecompress, I think this is still
playing a bit fast and loose with the rules around slots. I think we
can do better. Suppose that at the point where we discover that we
need to decompress at least one attribute, we create the new slot
right then, and also memcpy tts_values and tts_isnull. Then, for that
attribute and any future attributes that need decompression, we reset
tts_values in the *new* slot, leaving the old one untouched. Then,
after finishing all the attributes, the if (decompressed_any) block,
you just have a lot less stuff to do. The advantage of this is that
you haven't tainted the old slot; it's still got whatever contents it
had before, and is in a clean state, which seems better to me.
It's unclear to me whether this function actually needs to
ExecMaterializeSlot(newslot). It definitely does need to
ExecStoreVirtualTuple(newslot) and I think it's a very good idea, if
not absolutely mandatory, for it not to modify anything about the old
slot. But what's the argument that the new slot needs to be
materialized at this point? It may be needed, if the old slot would've
had to be materialized at this point. But it's something to think
about.
The CREATE TABLE documentation says that COMPRESSION is a kind of
column constraint, but that's wrong. For example, you can't write
CREATE TABLE a (b int4 CONSTRAINT thunk COMPRESSION lz4), for example,
contrary to what the syntax summary implies. When you fix this so that
the documentation matches the grammar change, you may also need to
move the longer description further up in create_table.sgml so the
order matches.
The use of VARHDRSZ_COMPRESS in toast_get_compression_oid() appears to
be incorrect. VARHDRSZ_COMPRESS is offsetof(varattrib_4b,
va_compressed.va_data). But what gets externalized in the case of a
compressed datum is just VARDATA(dval), which excludes the length
word, unlike VARHDRSZ_COMPRESS, which does not. This has no
consequences since we're only going to fetch 1 chunk either way, but I
think we should make it correct.
TOAST_COMPRESS_SET_SIZE_AND_METHOD() could Assert something about cm_method.
Small delta patch with a few other suggested changes attached.
--
Robert Haas
EDB: http://www.enterprisedb.com
Attachment
On Thu, Feb 11, 2021 at 3:26 AM Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Wed, Feb 10, 2021 at 3:06 PM Robert Haas <robertmhaas@gmail.com> wrote:
> > I think you have a fairly big problem with row types. Consider this example:
> >
> > create table t1 (a int, b text compression pglz);
> > create table t2 (a int, b text compression lz4);
> > create table t3 (x t1);
> > insert into t1 values (1, repeat('foo', 1000));
> > insert into t2 values (1, repeat('foo', 1000));
> > insert into t3 select t1 from t1;
> > insert into t3 select row(a, b)::t1 from t2;
> >
> > rhaas=# select pg_column_compression((t3.x).b) from t3;
> > pg_column_compression
> > -----------------------
> > pglz
> > lz4
> > (2 rows)
> >
> > That's not good, because now
Yeah, that's really bad.
> ...because now I hit send too soon. Also, because now column b has
> implicit dependencies on both compression AMs and the rest of the
> system has no idea. I think we probably should have a rule that
> nothing except pglz is allowed inside of a record, just to keep it
> simple. The record overall can be toasted so it's not clear why we
> should also be toasting the original columns at all, but I think
> precedent probably argues for continuing to allow PGLZ, as it can
> already be like that on disk and pg_upgrade is a thing. The same kind
> of issue probably exists for arrays and range types.
While constructing a row type from the tuple we flatten the external
data I think that would be the place to decompress the data if they
are not compressed with PGLZ. For array-type, we are already
detoasting/decompressing the source attribute see "construct_md_array"
so the array type doesn't have this problem. I haven't yet checked
the range type. Based on my analysis it appeared that the different
data types are getting constructed at different paths so maybe we
should find some centralized place or we need to make some function
call in all such places so that we can decompress the attribute if
required before forming the tuple for the composite type.
I have quickly hacked the code and after that, your test case is working fine.
postgres[55841]=# select pg_column_compression((t3.x).b) from t3;
pg_column_compression
-----------------------
pglz
(2 rows)
-> now the attribute 'b' inside the second tuple is decompressed
(because it was not compressed with PGLZ) so the compression method of
b is NULL
postgres[55841]=# select pg_column_compression((t3.x)) from t3;
pg_column_compression
-----------------------
pglz
(2 rows)
--> but the second row itself is compressed back using the local
compression method of t3
W.R.T the attached patch, In HeapTupleHeaderGetDatum, we don't even
attempt to detoast if there is no external field in the tuple, in POC
I have got rid of that check, but I think we might need to do better.
Maybe we can add a flag in infomask to detect whether the tuple has
any compressed data or not as we have for detecting the external data
(HEAP_HASEXTERNAL).
So I will do some more analysis in this area and try to come up with a
clean solution.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Attachment
On Thu, Feb 11, 2021 at 7:36 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > W.R.T the attached patch, In HeapTupleHeaderGetDatum, we don't even > attempt to detoast if there is no external field in the tuple, in POC > I have got rid of that check, but I think we might need to do better. > Maybe we can add a flag in infomask to detect whether the tuple has > any compressed data or not as we have for detecting the external data > (HEAP_HASEXTERNAL). No. This feature isn't close to being important enough to justify consuming an infomask bit. I don't really see why we need it anyway. If array construction already categorically detoasts, why can't we do the same thing here? Would it really cost that much? In what case? Having compressed values in a record we're going to store on disk actually seems like a pretty dumb idea. We might end up trying to recompress something parts of which have already been compressed. -- Robert Haas EDB: http://www.enterprisedb.com
On Thu, Feb 11, 2021 at 8:17 PM Robert Haas <robertmhaas@gmail.com> wrote: > > On Thu, Feb 11, 2021 at 7:36 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > W.R.T the attached patch, In HeapTupleHeaderGetDatum, we don't even > > attempt to detoast if there is no external field in the tuple, in POC > > I have got rid of that check, but I think we might need to do better. > > Maybe we can add a flag in infomask to detect whether the tuple has > > any compressed data or not as we have for detecting the external data > > (HEAP_HASEXTERNAL). > > No. This feature isn't close to being important enough to justify > consuming an infomask bit. Okay, > I don't really see why we need it anyway. If array construction > already categorically detoasts, why can't we do the same thing here? > Would it really cost that much? In what case? Having compressed values > in a record we're going to store on disk actually seems like a pretty > dumb idea. We might end up trying to recompress something parts of > which have already been compressed. > If we refer the comments atop function "toast_flatten_tuple_to_datum" --------------- * We have a general rule that Datums of container types (rows, arrays, * ranges, etc) must not contain any external TOAST pointers. Without * this rule, we'd have to look inside each Datum when preparing a tuple * for storage, which would be expensive and would fail to extend cleanly * to new sorts of container types. * * However, we don't want to say that tuples represented as HeapTuples * can't contain toasted fields, so instead this routine should be called * when such a HeapTuple is being converted into a Datum. * * While we're at it, we decompress any compressed fields too. This is not * necessary for correctness, but reflects an expectation that compression * will be more effective if applied to the whole tuple not individual * fields. We are not so concerned about that that we want to deconstruct * and reconstruct tuples just to get rid of compressed fields, however. * So callers typically won't call this unless they see that the tuple has * at least one external field. ---------------- It appears that the general rule we want to follow is that while creating the composite type we want to flatten any external pointer, but while doing that we also decompress any compressed field with the assumption that compressing the whole row/array will be a better idea instead of keeping them compressed individually. However, if there are no external toast pointers then we don't want to make an effort to just decompress the compressed data. Having said that I don't think this rule is followed throughout the code for example 1. "ExecEvalRow" is calling HeapTupleHeaderGetDatum only if there is any external field and which is calling "toast_flatten_tuple_to_datum" so this is following the rule. 2. "ExecEvalWholeRowVar" is calling "toast_build_flattened_tuple", but this is just flattening the external toast pointer but not doing anything to the compressed data. 3. "ExecEvalArrayExpr" is calling "construct_md_array", which will detoast the attribute if attlen is -1, so this will decompress any compressed data even though there is no external toast pointer. So in 1 we are following the rule but in 2 and 3 we are not. IMHO, for the composite data types we should make common a rule and we should follow that everywhere. As you said it will be good if we can always detoast any external/compressed data, that will help in getting better compression as well as fetching the data will be faster because we can avoid multi level detoasting/decompression. I will analyse this further and post a patch for the same. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Feb 15, 2021 at 1:58 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > > On Sun, Feb 14, 2021 at 12:49:40PM -0600, Justin Pryzby wrote: > > On Wed, Feb 10, 2021 at 04:56:17PM -0500, Robert Haas wrote: > > > Small delta patch with a few other suggested changes attached. > > > > Robert's fixup patch caused the CI to fail, since it 1) was called *.patch; > > and, 2) didn't include the previous patches. > > > > This includes a couple proposals of mine as separate patches. > > CIs failed on BSD and linux due to a test in contrib/, but others passed. > https://ci.appveyor.com/project/postgresql-cfbot/postgresql/build/1.0.127551 > https://cirrus-ci.com/task/6087701947482112 > https://cirrus-ci.com/task/6650651900903424 > https://cirrus-ci.com/task/5524751994060800 > > Resending with fixes to configure.ac and missed autoconf run. I think this is > expected to fail on mac, due to missing LZ4. > > BTW, compressamapi.h doesn't need to be included in any of these, at least in > the 0001 patch: > > src/backend/access/common/indextuple.c | 2 +- > src/backend/catalog/heap.c | 2 +- > src/backend/catalog/index.c | 2 +- > src/backend/parser/parse_utilcmd.c | 2 +- > > It's pretty unfriendly that this requires quoting the integer to be > syntactically valid: > > |postgres=# create table j(q text compression pglz with (level 1) ); > |2021-01-30 01:26:33.554 CST [31814] ERROR: syntax error at or near "1" at character 52 > |2021-01-30 01:26:33.554 CST [31814] STATEMENT: create table j(q text compression pglz with (level 1) ); > |ERROR: syntax error at or near "1" > |LINE 1: create table j(q text compression pglz with (level 1) ); Thanks for the review and patch for HIDE_COMPRESSAM, I will merge this into the main patch. And work on other comments after fixing the issue related to compressed data in composite types. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Sat, Feb 13, 2021 at 8:14 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Thu, Feb 11, 2021 at 8:17 PM Robert Haas <robertmhaas@gmail.com> wrote: > > > > On Thu, Feb 11, 2021 at 7:36 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > W.R.T the attached patch, In HeapTupleHeaderGetDatum, we don't even > > > attempt to detoast if there is no external field in the tuple, in POC > > > I have got rid of that check, but I think we might need to do better. > > > Maybe we can add a flag in infomask to detect whether the tuple has > > > any compressed data or not as we have for detecting the external data > > > (HEAP_HASEXTERNAL). > > > > No. This feature isn't close to being important enough to justify > > consuming an infomask bit. > > Okay, > > > I don't really see why we need it anyway. If array construction > > already categorically detoasts, why can't we do the same thing here? > > Would it really cost that much? In what case? Having compressed values > > in a record we're going to store on disk actually seems like a pretty > > dumb idea. We might end up trying to recompress something parts of > > which have already been compressed. > > > > If we refer the comments atop function "toast_flatten_tuple_to_datum" > > --------------- > * We have a general rule that Datums of container types (rows, arrays, > * ranges, etc) must not contain any external TOAST pointers. Without > * this rule, we'd have to look inside each Datum when preparing a tuple > * for storage, which would be expensive and would fail to extend cleanly > * to new sorts of container types. > * > * However, we don't want to say that tuples represented as HeapTuples > * can't contain toasted fields, so instead this routine should be called > * when such a HeapTuple is being converted into a Datum. > * > * While we're at it, we decompress any compressed fields too. This is not > * necessary for correctness, but reflects an expectation that compression > * will be more effective if applied to the whole tuple not individual > * fields. We are not so concerned about that that we want to deconstruct > * and reconstruct tuples just to get rid of compressed fields, however. > * So callers typically won't call this unless they see that the tuple has > * at least one external field. > ---------------- > > It appears that the general rule we want to follow is that while > creating the composite type we want to flatten any external pointer, > but while doing that we also decompress any compressed field with the > assumption that compressing the whole row/array will be a better idea > instead of keeping them compressed individually. However, if there > are no external toast pointers then we don't want to make an effort to > just decompress the compressed data. > > Having said that I don't think this rule is followed throughout the > code for example > > 1. "ExecEvalRow" is calling HeapTupleHeaderGetDatum only if there is > any external field and which is calling "toast_flatten_tuple_to_datum" > so this is following the rule. > 2. "ExecEvalWholeRowVar" is calling "toast_build_flattened_tuple", but > this is just flattening the external toast pointer but not doing > anything to the compressed data. > 3. "ExecEvalArrayExpr" is calling "construct_md_array", which will > detoast the attribute if attlen is -1, so this will decompress any > compressed data even though there is no external toast pointer. > > So in 1 we are following the rule but in 2 and 3 we are not. > > IMHO, for the composite data types we should make common a rule and we > should follow that everywhere. As you said it will be good if we can > always detoast any external/compressed data, that will help in getting > better compression as well as fetching the data will be faster because > we can avoid multi level detoasting/decompression. I will analyse > this further and post a patch for the same. I have done further analysis of this issue and came up with the attached patch. So with this patch, like external toast posiners we will not allow any compressed data also in the composite types. The problem is that now we will be processing all the tuple while forming the composite type irrespective of the source of the tuple, I mean if user is directly inserting into the array type and not selecting from another table then there will not be any compressed data so now checking each field of tuple for compressed data is unnecessary but I am not sure how to distinguish between those cases. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Fri, Feb 19, 2021 at 2:43 AM Justin Pryzby <pryzby@telsasoft.com> wrote:
I had an off list discussion with Robert and based on his suggestion
and a poc patch, I have come up with an updated version for handling
the composite type. Basically, the problem was that ExecEvalRow we
are first forming the tuple and then we are calling
HeapTupleHeaderGetDatum and then we again need to deform to find any
compressed data so that can cause huge performance penalty in all
unrelated paths which don't even contain any compressed data. So
Robert's idea was to check for the compressed/external data even
before forming the tuple. I have implemented that and I can see we
are not seeing any performance penalty.
Test setup:
----------------
create table t1 (f1 int, f2 text, f3 text, f4 text, f5 text, f6
text,f7 text, f8 text, f9 text);
create table t2 (f1 int, f2 text, f3 text, f4 text, f5 text, f6
text,f7 text, f8 text, f9 text);
create table t3(x t1);
pgbench custom script for all test:
------------------------------------------------
\set x random(1, 10000)
select row(f1,f2,f3,f4,f5,f6,f7,f8,f9)::t1 from t2 where f1=:x;
test1:
Objective: Just select on data and form row, data contain no
compressed/external (should not create regression on unrelated paths)
data: insert into t2 select i, repeat('f1',
10),repeat('f2',10),repeat('f3', 10),repeat('f4', 10),repeat('f5',
10),repeat('f6',10),repeat('f7', 10),repeat('f8', 10) from
generate_series(1,10000) as i;
Result(TPS): Head: 1509.79 Patch: 1509.67
test2: data contains 1 compressed filed no external data
data: insert into t2 select i, repeat('f2',
10),repeat('f3',10000),repeat('f3', 10),repeat('f5', 10),repeat('f6',
4000),repeat('f7',10),repeat('f8', 10),repeat('f9', 10) from
generate_series(1,10000) as i;
Result(TPS): Head: 1088.08 Patch: 1071.48
test4: data contains 1 compressed/1 external field
(alter table t2 alter COLUMN f2 set storage external;)
data: (insert into t2 select i, repeat('f2',
10000),repeat('f3',10000),repeat('f3', 10),repeat('f5',
10),repeat('f6', 4000),repeat('f7',10),repeat('f8', 10),repeat('f9',
10) from generate_series(1,10000) as i;)
Result(TPS): Head: 1459.28 Patch: 1459.37
test5: where head need not decompress but patch needs to:
data: insert into t2 select i, repeat('f2',
10),repeat('f3',6000),repeat('f34', 5000),repeat('f5',
10),repeat('f6', 4000),repeat('f7',10),repeat('f8', 10),repeat('f9',
10) from generate_series(1,10000) as I;
--pgbench script
\set x random(1, 10000)
insert into t3 select row(f1,f2,f3,f4,f5,f6,f7,f8,f9)::t1 from t2 where f1=:x;
Result(TPS): Head: 562.36 Patch: 469.91
Summary: It seems like in most of the unrelated cases we are not
creating any regression with the attached patch. There is only some
performance loss when there is only the compressed data in such cases
with the patch we have to decompress whereas in head we don't. But, I
think it is not a overall loss because eventually if we have to fetch
the data multiple time then with patch we just have to decompress once
as whole row is compressed whereas on head we have to decompress field
by field, so I don't think this can be considered as a regression.
I also had to put the handling in the extended record so that it can
decompress any compressed data in the extended record. I think I need
to put some more effort into cleaning up this code. I have put a very
localized fix in ER_get_flat_size, basically this will ignore the
ER_FLAG_HAVE_EXTERNAL flag and it will always process the record. I
think the handling might not be perfect but I posted it to get the
feedback on the idea.
Other changes:
- I have fixed other pending comments from Robert. I will reply to
individual comments in a separate mail.
- Merge HIDE_COMPRESSAM with 0001.
Pending work:
- Cleanup 0001, especially for extended records.
- Rebased other patches.
- Review default compression method guc from Justin
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Attachment
On Thu, Feb 11, 2021 at 1:37 AM Robert Haas <robertmhaas@gmail.com> wrote: > > On Wed, Feb 10, 2021 at 9:52 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > [ new patches ] > > I think that in both varattrib_4b and toast_internals.h it would be > better to pick a less generic field name. In toast_internals.h it's > just info; in postgres.h it's va_info. But: > > [rhaas pgsql]$ git grep info | wc -l > 24552 > > There are no references in the current source tree to va_info, so at > least that one is greppable, but it's still not very descriptive. I > suggest info -> tcinfo and va_info -> va_tcinfo, where "tc" stands for > "TOAST compression". Looking through 24552 references to info to find > the ones that pertain to this feature might take longer than searching > the somewhat shorter list of references to tcinfo, which prepatch is > just: > > [rhaas pgsql]$ git grep tcinfo | wc -l > 0 Done as suggested > > I don't see why we should allow for datum_decompress to be optional, > as toast_decompress_datum_slice does. Likely every serious compression > method will support that anyway. If not, the compression AM can deal > with the problem, rather than having the core code do it. That will > save some tiny amount of performance, too. Done > src/backend/access/compression/Makefile is missing a copyright header. Fixed > It's really sad that lz4_cmdecompress_slice allocates > VARRAWSIZE_4B_C(value) + VARHDRSZ rather than slicelength + VARHDRSZ > as pglz_cmdecompress_slice() does. Is that a mistake, or is that > necessary for some reason? If it's a mistake, let's fix it. If it's > necessary, let's add a comment about why, probably starting with > "Unfortunately, ....". In older versions of the lz4 there was a problem that the decompressed data size could be bigger than the slicelength which is resolved now so we can allocate slicelength + VARHDRSZ, I have fixed it. Please refer the latest patch at https://www.postgresql.org/message-id/CAFiTN-u2pyXDDDwZXJ-fVUwbLhJSe9TbrVR6rfW_rhdyL1A5bg%40mail.gmail.com -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Thu, Feb 11, 2021 at 3:26 AM Robert Haas <robertmhaas@gmail.com> wrote: > > In CompareCompressionMethodAndDecompress, I think this is still > playing a bit fast and loose with the rules around slots. I think we > can do better. Suppose that at the point where we discover that we > need to decompress at least one attribute, we create the new slot > right then, and also memcpy tts_values and tts_isnull. Then, for that > attribute and any future attributes that need decompression, we reset > tts_values in the *new* slot, leaving the old one untouched. Then, > after finishing all the attributes, the if (decompressed_any) block, > you just have a lot less stuff to do. The advantage of this is that > you haven't tainted the old slot; it's still got whatever contents it > had before, and is in a clean state, which seems better to me. Fixed > > It's unclear to me whether this function actually needs to > ExecMaterializeSlot(newslot). It definitely does need to > ExecStoreVirtualTuple(newslot) and I think it's a very good idea, if > not absolutely mandatory, for it not to modify anything about the old > slot. But what's the argument that the new slot needs to be > materialized at this point? It may be needed, if the old slot would've > had to be materialized at this point. But it's something to think > about. I think if the original slot was materialized then materialing the new slot make more sense to me so done that way. > > The CREATE TABLE documentation says that COMPRESSION is a kind of > column constraint, but that's wrong. For example, you can't write > CREATE TABLE a (b int4 CONSTRAINT thunk COMPRESSION lz4), for example, > contrary to what the syntax summary implies. When you fix this so that > the documentation matches the grammar change, you may also need to > move the longer description further up in create_table.sgml so the > order matches. Fixed > The use of VARHDRSZ_COMPRESS in toast_get_compression_oid() appears to > be incorrect. VARHDRSZ_COMPRESS is offsetof(varattrib_4b, > va_compressed.va_data). But what gets externalized in the case of a > compressed datum is just VARDATA(dval), which excludes the length > word, unlike VARHDRSZ_COMPRESS, which does not. This has no > consequences since we're only going to fetch 1 chunk either way, but I > think we should make it correct. Fixed > TOAST_COMPRESS_SET_SIZE_AND_METHOD() could Assert something about cm_method. While replying to the comments, I realised that I have missed it. I will fix it in the next version. > Small delta patch with a few other suggested changes attached. Merged -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Hi, On 2021-03-15 15:29:05 -0400, Robert Haas wrote: > On Mon, Mar 15, 2021 at 8:14 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > In the attached patches I have changed this, ... > > OK, so just looking over this patch series, here's what I think: > > - 0001 and 0002 are now somewhat independent of the rest of this work, > and could be dropped, but I think they're a good idea, so I'd like to > commit them. I went over 0001 carefully this morning and didn't find > any problems. I still need to do some more review of 0002. I don't particularly like PG_RETURN_HEAPTUPLEHEADER_RAW(). What is "raw" about it? It also seems to me like there needs to at least be a sentence or two explaining when to use which of the functions. I think heap_copy_tuple_as_raw_datum() should grow an assert checking there are no external columns? The commit messages could use a bit more explanation about motivation. I'm don't like that after 0002 ExecEvalRow(), ExecEvalFieldStoreForm() contain a nearly identical copy of the same code. And make_tuple_from_row() also is similar. It seem that there should be a heap_form_tuple() version doing this for us? > - 0003 through 0005 are the core of this patch set. I'd like to get > them into this release, but I think we're likely to run out of time. Comments about 0003: - why is HIDE_TOAST_COMPRESSION useful? Doesn't quite seem to be comparable to HIDE_TABLEAM? - (you comment on this later): toast_get_compression_method() needing to fetch some of the data to figure out the compression method is pretty painful. Especially because it then goes and throws away that data! - Adding all these indirect function calls via toast_compression[] just for all of two builtin methods isn't fun either. - I guess NO_LZ4_SUPPORT() is a macro so it shows the proper file/function name? - I wonder if adding compression to the equalTupleDesc() is really necessary / won't cause problems (thinking of cases like the equalTupleDesc() call in pg_proc.c). - Is nodeModifyTable.c really the right place for the logic around CompareCompressionMethodAndDecompress()? And is doing it in every place that does "user initiated" inserts really the right way? Why isn't this done on the tuptoasting level? - CompareCompressionMethodAndDecompress() is pretty deeply indented. Perhaps rewrite a few more of the conditions to be continue;? Comments about 0005: - I'm personally not really convinced tracking the compression type in pg_attribute the way you do is really worth it (. Especially given that it's right now only about new rows anyway. Seems like it'd be easier to just treat it as a default for new rows, and dispense with all the logic around mismatching compression types etc? > The biggest thing that jumps out at me while looking at this with > fresh eyes is that the patch doesn't touch varatt_external.va_extsize > at all. In a varatt_external, we can't use the va_rawsize to indicate > the compression method, because there are no bits free, because the 2 > bits not required to store the size are used to indicate what type of > varlena we've got. Once you get to varatt_external, you could also just encode it via vartag_external... > But, that means that the size of a varlena is limited to 1GB, so there > are 2 bits free in varatt_external.va_extsize, just like there are in > va_compressed.va_rawsize. We could store the same two bits in > varatt_external.va_extsize that we're storing in > va_compressed.va_rawsize aka va_tcinfo. That's a big deal, because > then toast_get_compression_method() doesn't have to call > toast_fetch_datum_slice() any more, which is a rather large savings. > If it's only impacting pg_column_compression() then whatever, but > that's not the case: we've got calls to > CompareCompressionMethodAndDecompress in places like intorel_receive() > and ExecModifyTable() that look pretty performance-critical. Yea, I agree, that does seem problematic. > There's another, rather brute-force approach to this problem, too. We > could just decide that lz4 will only be used for external data, and > that there's no such thing as an inline-compressed lz4 varlena. > deotast_fetch_datum() would just notice that the value is lz4'd and > de-lz4 it before returning it, since a compressed lz4 datum is > impossible. That seems fairly terrible. > I'm open to being convinced that we don't need to do either of these > things, and that the cost of iterating over all varlenas in the tuple > is not so bad as to preclude doing things as you have them here. But, > I'm afraid it's going to be too expensive. I mean, I would just define several of those places away by not caring about tuples in a different compressino formation ending up in a table... Greetings, Andres Freund
On Wed, Mar 17, 2021 at 7:41 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > 0002: > - Wrapper over heap_form_tuple and used in ExecEvalRow() and > ExecEvalFieldStoreForm() Instead of having heap_form_flattened_tuple(), how about heap_flatten_values(tupleDesc, values, isnull) that is documented to modify the values array? Then instead of replacing the heap_form_tuple() calls with a call to heap_form_flattened_tuple(), you just insert a call to heap_flatten_values() before the call to heap_form_tuple(). I think that might be easier for people looking at this code in the future to understand what's happening. -- Robert Haas EDB: http://www.enterprisedb.com
Hi, On 2021-03-17 13:31:14 -0400, Robert Haas wrote: > On Wed, Mar 17, 2021 at 7:41 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > 0002: > > - Wrapper over heap_form_tuple and used in ExecEvalRow() and > > ExecEvalFieldStoreForm() > > Instead of having heap_form_flattened_tuple(), how about > heap_flatten_values(tupleDesc, values, isnull) that is documented to > modify the values array? Then instead of replacing the > heap_form_tuple() calls with a call to heap_form_flattened_tuple(), > you just insert a call to heap_flatten_values() before the call to > heap_form_tuple(). I think that might be easier for people looking at > this code in the future to understand what's happening. OTOH heap_form_flattened_tuple() has the advantage that we can optimize it further (e.g. to do the conversion to flattened values in fill_val()) without changing the outside API. Greetings, Andres Freund
On Wed, Mar 17, 2021 at 2:17 PM Andres Freund <andres@anarazel.de> wrote: > OTOH heap_form_flattened_tuple() has the advantage that we can optimize > it further (e.g. to do the conversion to flattened values in fill_val()) > without changing the outside API. Well, in my view, that does change the outside API, because either the input values[] array is going to get scribbled on, or it's not. We should either decide we're not OK with it and just do the fill_val() thing now, or we should decide that we are and not worry about doing the fill_val() thing later. IMHO, anyway. -- Robert Haas EDB: http://www.enterprisedb.com
).On Mon, Mar 15, 2021 at 6:58 PM Andres Freund <andres@anarazel.de> wrote: > - Adding all these indirect function calls via toast_compression[] just > for all of two builtin methods isn't fun either. Yeah, it feels like this has too many layers of indirection now. Like, toast_decompress_datum() first gets TOAST_COMPRESS_METHOD(attr). Then it calls CompressionIdToMethod to convert one constant (like TOAST_PGLZ_COMPRESSION_ID) to another constant with a slightly different name (like TOAST_PGLZ_COMPRESSION). Then it calls GetCompressionRoutines() to get hold of the function pointers. Then it does an indirect functional call. That seemed like a pretty reasonable idea when we were trying to support arbitrary compression AMs without overly privileging the stuff that was built into core, but if we're just doing stuff that's built into core, then we could just switch (TOAST_COMPRESS_METHOD(attr)) and call the correct function. In fact, we could even move the stuff from toast_compression.c into detoast.c, which would allow the compiler to optimize better (e.g. by inlining, if it wants). The same applies to toast_decompress_datum_slice(). There's a similar issue in toast_get_compression_method() and the only caller, pg_column_compression(). Here the multiple mapping layers and the indirect function call are split across those two functions rather than all in the same one, but here again one could presumably find a place to just switch on TOAST_COMPRESS_METHOD(attr) or VARATT_EXTERNAL_GET_COMPRESSION(attr) and return "pglz" or "lz4" directly. In toast_compress_datum(), I think we could have a switch that invokes the appropriate compressor based on cmethod and sets a variable to the value to be passed as the final argument of TOAST_COMPRESS_SET_SIZE_AND_METHOD(). Likewise, I suppose CompressionNameToMethod could at least be simplified to use constant strings rather than stuff like toast_compression[TOAST_PGLZ_COMPRESSION_ID].cmname. > - why is HIDE_TOAST_COMPRESSION useful? Doesn't quite seem to be > comparable to HIDE_TABLEAM? Andres, what do you mean by this exactly? It's exactly the same issue: without this, if you change the default compression method, every test that uses \d+ breaks. If you want to be able to run the whole test suite with either compression method and get the same results, you need this. Now, maybe you don't, because perhaps that doesn't seem so important with compression methods as with table AMs. I think that's a defensible position. But, it is at the underlying level, the same thing. -- Robert Haas EDB: http://www.enterprisedb.com
Hi, On 2021-03-17 16:01:58 -0400, Robert Haas wrote: > > - why is HIDE_TOAST_COMPRESSION useful? Doesn't quite seem to be > > comparable to HIDE_TABLEAM? > > Andres, what do you mean by this exactly? It's exactly the same issue: > without this, if you change the default compression method, every test > that uses \d+ breaks. If you want to be able to run the whole test > suite with either compression method and get the same results, you > need this. Now, maybe you don't, because perhaps that doesn't seem so > important with compression methods as with table AMs. I think that latter part is why I wasn't sure such an option is warranted. Given it's a builtin feature, I didn't really forsee a need to be able to run all the tests with a different compression method. And it looked a like it could just have been copied from the tableam logic, without a clear need. But if it's useful, then ... Greetings, Andres Freund
On Thu, Mar 18, 2021 at 1:32 AM Robert Haas <robertmhaas@gmail.com> wrote: > > ).On Mon, Mar 15, 2021 at 6:58 PM Andres Freund <andres@anarazel.de> wrote: > > - Adding all these indirect function calls via toast_compression[] just > > for all of two builtin methods isn't fun either. > > Yeah, it feels like this has too many layers of indirection now. Like, > toast_decompress_datum() first gets TOAST_COMPRESS_METHOD(attr). Then > it calls CompressionIdToMethod to convert one constant (like > TOAST_PGLZ_COMPRESSION_ID) to another constant with a slightly > different name (like TOAST_PGLZ_COMPRESSION). Then it calls > GetCompressionRoutines() to get hold of the function pointers. Then it > does an indirect functional call. That seemed like a pretty reasonable > idea when we were trying to support arbitrary compression AMs without > overly privileging the stuff that was built into core, but if we're > just doing stuff that's built into core, then we could just switch > (TOAST_COMPRESS_METHOD(attr)) and call the correct function. In fact, > we could even move the stuff from toast_compression.c into detoast.c, > which would allow the compiler to optimize better (e.g. by inlining, > if it wants). > > The same applies to toast_decompress_datum_slice(). Changed this, but I have still kept the functions in toast_compression.c. I think keeping compression related functionality in a separate file looks much cleaner. Please have a look and let me know that whether you still feel we should move it ti detoast.c. If the reason is that we can inline, then I feel we are already paying cost of compression/decompression and compare to that in lining a function will not make much difference. > There's a similar issue in toast_get_compression_method() and the only > caller, pg_column_compression(). Here the multiple mapping layers and > the indirect function call are split across those two functions rather > than all in the same one, but here again one could presumably find a > place to just switch on TOAST_COMPRESS_METHOD(attr) or > VARATT_EXTERNAL_GET_COMPRESSION(attr) and return "pglz" or "lz4" > directly. I have simplified that, only one level of function call from pg_column_compression, I have kept a toast_get_compression_id function because in later patch 0005, we will be using that for getting the compression id from the compressed data. > In toast_compress_datum(), I think we could have a switch that invokes > the appropriate compressor based on cmethod and sets a variable to the > value to be passed as the final argument of > TOAST_COMPRESS_SET_SIZE_AND_METHOD(). Done > Likewise, I suppose CompressionNameToMethod could at least be > simplified to use constant strings rather than stuff like > toast_compression[TOAST_PGLZ_COMPRESSION_ID].cmname. Done Other changes: - As suggested by Andres, remove compression method comparision from eualTupleDesc, because it is not required now. - I found one problem in existing patch, the problem was in detoast_attr_slice, if externally stored data is compressed then we compute max possible compressed size to fetch based on the slice length, for that we were using pglz_maximum_compressed_size, which is not correct for lz4. For lz4, I think we need to fetch the complete compressed data. We might think that for lz4 we might compute lie Min(LZ4_compressBound(slicelength, total_compressed_size); But IMHO, we can not do that and the reason is same that why we should not use PGLZ_MAX_OUTPUT for pglz (explained in the comment atop pglz_maximum_compressed_size). -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Thu, Mar 18, 2021 at 4:40 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: I just realized that in the last patch (0003) I forgot to remove 2 unused functions, CompressionMethodToId and CompressionIdToMethod. Removed in the latest patch. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Thu, Mar 18, 2021 at 10:22 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > I just realized that in the last patch (0003) I forgot to remove 2 > unused functions, CompressionMethodToId and CompressionIdToMethod. > Removed in the latest patch. I spent a little time polishing 0001 and here's what I came up with. I adjusted some comments, added documentation, fixed up the commit message, etc. I still don't quite like the approach in 0002. I feel that the function should not construct the tuple but modify the caller's arrays as a side effect. And if we're absolutely committed to the design where it does that, the comments need to call it out clearly, which they don't. Regarding 0003: I think it might make sense to change the names of the compression and decompression functions to match the names of the callers more closely. Like, toast_decompress_datum() calls either pglz_cmdecompress() or lz4_cmdecompress(). But, why not pglz_decompress_datum() or lz4_decompress_datum()? The "cm" thing doesn't really mean anything, and because the varlena is allocated by that function itself rather than the caller, this can't be used for anything other than TOAST. In toast_compress_datum(), if (tmp == NULL) return PointerGetDatum(NULL) is duplicated. It would be better to move it after the switch. Instead of "could not compress data with lz4" I suggest "lz4 compression failed". In catalogs.sgml, you shouldn't mention InvalidCompressionMethod, but you should explain what the actual possible values mean. Look at the way attidentity and attgenerated are documented and do it like that. In pg_column_compression() it might be a bit more elegant to add a char *result variable or similar, and have the switch cases just set it, and then do PG_RETURN_TEXT_P(cstring_to_text(result)) at the bottom. In getTableAttrs(), if the remoteVersion is new, the column gets a different alias than if the column is old. In dumpTableSchema(), the condition tbinfo->attcompression[j] means exactly the thing as the condition tbinfo->attcompression[j] != '\0', so it can't be right to test both. I think that there's some confusion here about the data type of tbinfo->attcompression[j]. It seems to be char *. Maybe you intended to test the first character in that second test, but that's not what this does. But you don't need to test that anyway because the switch already takes care of it. So I suggest (a) removing tbinfo->attcompression[j] != '\0' from this if-statement and (b) adding != NULL to the previous line for clarity. I would also suggest concluding the switch with a break just for symmetry. The patch removes 11 references to va_extsize and leaves behind 4. None of those 4 look like things that should have been left. The comment which says "When fetching a prefix of a compressed external datum, account for the rawsize tracking amount of raw data, which is stored at the beginning as an int32 value)" is no longer 100% accurate. I suggest changing it to say something like "When fetching a prefix of a compressed external datum, account for the space required by va_tcinfo" and leave out the rest. In describeOneTableDetails, the comment "compresssion info" needs to be compressed by removing one "s". It seems a little unfortunate that we need to include access/toast_compression.h in detoast.h. It seems like the reason we need to do that is because otherwise we won't have ToastCompressionId defined and so we won't be able to prototype toast_get_compression_id. But I think we should solve that problem by moving that file to toast_compression.c. (I'm OK if you want to keep the files separate, or if you want to reverse course and combine them I'm OK with that too, but the extra header dependency is clearly a sign of a problem with the split.) Regarding 0005: I think ApplyChangesToIndexes() should be renamed to something like SetIndexStorageProperties(). It's too generic right now. I think 0004 and 0005 should just be merged into 0003. I can't see committing them separately. I know I was the one who made you split the patch up in the first place, but those patches are quite small and simple now, so it makes more sense to me to combine them. -- Robert Haas EDB: http://www.enterprisedb.com
Attachment
On Fri, Mar 19, 2021 at 1:27 AM Robert Haas <robertmhaas@gmail.com> wrote: > > On Thu, Mar 18, 2021 at 10:22 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > I just realized that in the last patch (0003) I forgot to remove 2 > > unused functions, CompressionMethodToId and CompressionIdToMethod. > > Removed in the latest patch. > > I spent a little time polishing 0001 and here's what I came up with. I > adjusted some comments, added documentation, fixed up the commit > message, etc. Thanks, the changes looks fine to me. > > I still don't quite like the approach in 0002. I feel that the > function should not construct the tuple but modify the caller's arrays > as a side effect. And if we're absolutely committed to the design > where it does that, the comments need to call it out clearly, which > they don't. Added comment for the same. > Regarding 0003: > > I think it might make sense to change the names of the compression and > decompression functions to match the names of the callers more > closely. Like, toast_decompress_datum() calls either > pglz_cmdecompress() or lz4_cmdecompress(). But, why not > pglz_decompress_datum() or lz4_decompress_datum()? The "cm" thing > doesn't really mean anything, and because the varlena is allocated by > that function itself rather than the caller, this can't be used for > anything other than TOAST. Done > In toast_compress_datum(), if (tmp == NULL) return > PointerGetDatum(NULL) is duplicated. It would be better to move it > after the switch. Done > Instead of "could not compress data with lz4" I suggest "lz4 > compression failed". Done > In catalogs.sgml, you shouldn't mention InvalidCompressionMethod, but > you should explain what the actual possible values mean. Look at the > way attidentity and attgenerated are documented and do it like that. Done > In pg_column_compression() it might be a bit more elegant to add a > char *result variable or similar, and have the switch cases just set > it, and then do PG_RETURN_TEXT_P(cstring_to_text(result)) at the > bottom. Done > In getTableAttrs(), if the remoteVersion is new, the column gets a > different alias than if the column is old. Fixed > In dumpTableSchema(), the condition tbinfo->attcompression[j] means > exactly the thing as the condition tbinfo->attcompression[j] != '\0', > so it can't be right to test both. I think that there's some confusion > here about the data type of tbinfo->attcompression[j]. It seems to be > char *. Maybe you intended to test the first character in that second > test, but that's not what this does. But you don't need to test that > anyway because the switch already takes care of it. So I suggest (a) > removing tbinfo->attcompression[j] != '\0' from this if-statement and > (b) adding != NULL to the previous line for clarity. I would also > suggest concluding the switch with a break just for symmetry. Fixed > The patch removes 11 references to va_extsize and leaves behind 4. > None of those 4 look like things that should have been left. Fixed > The comment which says "When fetching a prefix of a compressed > external datum, account for the rawsize tracking amount of raw data, > which is stored at the beginning as an int32 value)" is no longer 100% > accurate. I suggest changing it to say something like "When fetching a > prefix of a compressed external datum, account for the space required > by va_tcinfo" and leave out the rest. Done > In describeOneTableDetails, the comment "compresssion info" needs to > be compressed by removing one "s". Done > It seems a little unfortunate that we need to include > access/toast_compression.h in detoast.h. It seems like the reason we > need to do that is because otherwise we won't have ToastCompressionId > defined and so we won't be able to prototype toast_get_compression_id. > But I think we should solve that problem by moving that file to > toast_compression.c. (I'm OK if you want to keep the files separate, > or if you want to reverse course and combine them I'm OK with that > too, but the extra header dependency is clearly a sign of a problem > with the split.) Moved to toast_compression.c > Regarding 0005: > > I think ApplyChangesToIndexes() should be renamed to something like > SetIndexStorageProperties(). It's too generic right now. Done > I think 0004 and 0005 should just be merged into 0003. I can't see > committing them separately. I know I was the one who made you split > the patch up in the first place, but those patches are quite small and > simple now, so it makes more sense to me to combine them. Done Also added a test case for vacuum full to recompress the data. One question, like storage should we apply the alter set compression changes recursively to the inherited children (I have attached a separate patch for this )? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
I sent offlist a couple of times but notice that the latest patch is missing
this bit around AC_CHECK_HEADERS, which apparently can sometimes cause
warnings on mac.
ac_save_CPPFLAGS=$CPPFLAGS
CPPFLAGS="$LZ4_CFLAGS $CPPFLAGS"
AC_CHECK_HEADERS(lz4/lz4.h, [],
[AC_CHECK_HEADERS(lz4.h, [], [AC_MSG_ERROR([lz4.h header file is required for LZ4])])])
CPPFLAGS=$ac_save_CPPFLAGS
> diff --git a/configure.ac b/configure.ac
> index 2f1585a..54efbb2 100644
> --- a/configure.ac
> +++ b/configure.ac
> @@ -1410,6 +1425,11 @@ failure. It is possible the compiler isn't looking in the proper directory.
> Use --without-zlib to disable zlib support.])])
> fi
>
> +if test "$with_lz4" = yes; then
> + AC_CHECK_HEADERS(lz4/lz4.h, [],
> + [AC_CHECK_HEADERS(lz4.h, [], [AC_MSG_ERROR([lz4.h header file is required for LZ4])])])
> +fi
> +
> if test "$with_gssapi" = yes ; then
> AC_CHECK_HEADERS(gssapi/gssapi.h, [],
> [AC_CHECK_HEADERS(gssapi.h, [], [AC_MSG_ERROR([gssapi.h header file is required for GSSAPI])])])
On Fri, Mar 19, 2021 at 12:35 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > I sent offlist a couple of times but notice that the latest patch is missing > this bit around AC_CHECK_HEADERS, which apparently can sometimes cause > warnings on mac. > > ac_save_CPPFLAGS=$CPPFLAGS > CPPFLAGS="$LZ4_CFLAGS $CPPFLAGS" > AC_CHECK_HEADERS(lz4/lz4.h, [], > [AC_CHECK_HEADERS(lz4.h, [], [AC_MSG_ERROR([lz4.h header file is required for LZ4])])]) > CPPFLAGS=$ac_save_CPPFLAGS Hmm, it's working for me on macOS Catalina without this. Why do we need it? Can you provide a patch that inserts it in the exact place you think it needs to go? -- Robert Haas EDB: http://www.enterprisedb.com
On Fri, Mar 19, 2021 at 1:44 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > Working with one of Andrey's patches on another thread, he reported offlist > getting this message, resolved by this patch. Do you see this warning during > ./configure ? The latest CI is of a single patch without the LZ4 stuff, so I > can't check its log. > > configure: WARNING: lz4.h: accepted by the compiler, rejected by the preprocessor! > configure: WARNING: lz4.h: proceeding with the compiler's result No, I don't see this. I wonder whether this could possibly be an installation issue on Andrey's machine? If not, it must be version-dependent or installation-dependent in some way. -- Robert Haas EDB: http://www.enterprisedb.com
On Fri, Mar 19, 2021 at 10:11 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > Also added a test case for vacuum full to recompress the data. I committed the core patch (0003) with a bit more editing. Let's see what the buildfarm thinks. -- Robert Haas EDB: http://www.enterprisedb.com
Robert Haas <robertmhaas@gmail.com> writes:
> I committed the core patch (0003) with a bit more editing. Let's see
> what the buildfarm thinks.
Since no animals will be using --with-lz4, I'd expect vast silence.
regards, tom lane
I wrote:
> Since no animals will be using --with-lz4, I'd expect vast silence.
Nope ... crake's displeased with your assumption that it's OK to
clutter dumps with COMPRESSION clauses. As am I: that is going to
be utterly fatal for cross-version transportation of dumps.
regards, tom lane
Hmm, if I use configure --with-lz4, I get this:
checking whether to build with LZ4 support... yes
checking for liblz4... no
configure: error: Package requirements (liblz4) were not met:
No package 'liblz4' found
Consider adjusting the PKG_CONFIG_PATH environment variable if you
installed software in a non-standard prefix.
Alternatively, you may set the environment variables LZ4_CFLAGS
and LZ4_LIBS to avoid the need to call pkg-config.
See the pkg-config man page for more details.
running CONFIG_SHELL=/bin/bash /bin/bash /pgsql/source/master/configure --enable-debug --enable-depend
--enable-cassert--enable-nls --cache-file=/home/alvherre/run/pgconfig.master.cache --enable-thread-safety --with-python
--with-perl--with-tcl --with-openssl --with-libxml --enable-tap-tests --with-tclconfig=/usr/lib/tcl8.6
PYTHON=/usr/bin/python3--with-llvm --prefix=/pgsql/install/master --with-pgport=55432 --no-create --no-recursion
...
I find this behavior confusing; I'd rather have configure error out if
it can't find the package support I requested, than continuing with a
set of configure options different from what I gave.
--
Álvaro Herrera 39°49'30"S 73°17'W
"Postgres is bloatware by design: it was built to house
PhD theses." (Joey Hellerstein, SIGMOD annual conference 2002)
On Fri, Mar 19, 2021 at 4:20 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> Nope ... crake's displeased with your assumption that it's OK to
> clutter dumps with COMPRESSION clauses. As am I: that is going to
> be utterly fatal for cross-version transportation of dumps.
Yes, and prion's got this concerning diff:
Column | Type | Collation | Nullable | Default | Storage |
Compression | Stats target | Description
--------+---------+-----------+----------+---------+---------+-------------+--------------+-------------
- f1 | integer | | | | plain |
| |
+ f1 | integer | | | | plain | pglz
| |
Since the column is not a varlena, it shouldn't have a compression
method configured, yet on that machine it does, possibly because that
machine uses -DRELCACHE_FORCE_RELEASE -DCATCACHE_FORCE_RELEASE.
Regarding your point, that does look like clutter. We don't annotate
the dump with a storage clause unless it's non-default, so probably we
should do the same thing here. I think I gave Dilip bad advice here...
--
Robert Haas
EDB: http://www.enterprisedb.com
On 2021-03-19 17:35:58 -0300, Alvaro Herrera wrote: > I find this behavior confusing; I'd rather have configure error out if > it can't find the package support I requested, than continuing with a > set of configure options different from what I gave. +1
On 3/19/21 9:40 PM, Andres Freund wrote:
> On 2021-03-19 17:35:58 -0300, Alvaro Herrera wrote:
>> I find this behavior confusing; I'd rather have configure error out if
>> it can't find the package support I requested, than continuing with a
>> set of configure options different from what I gave.
>
> +1
>
Yeah. And why does it even require pkg-config, unlike any other library
that I'm aware of?
checking for liblz4... no
configure: error: in `/home/ubuntu/postgres':
configure: error: The pkg-config script could not be found or is too
old. Make sure it
is in your PATH or set the PKG_CONFIG environment variable to the full
path to pkg-config.
Alternatively, you may set the environment variables LZ4_CFLAGS
and LZ4_LIBS to avoid the need to call pkg-config.
See the pkg-config man page for more details.
To get pkg-config, see <http://pkg-config.freedesktop.org/>.
See `config.log' for more details
I see xml2 also mentions pkg-config in configure (next to XML2_CFLAGS),
but works fine without it.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 2021-03-19 22:19:49 +0100, Tomas Vondra wrote: > Yeah. And why does it even require pkg-config, unlike any other library > that I'm aware of? IMO it's fine to require pkg-config to simplify the configure code. Especially for new optional features. Adding multiple alternative ways to discover libraries for something like this makes configure slower, without a comensurate benefit.
On Fri, Mar 19, 2021 at 4:38 PM Robert Haas <robertmhaas@gmail.com> wrote: > Yes, and prion's got this concerning diff: > > Column | Type | Collation | Nullable | Default | Storage | > Compression | Stats target | Description > --------+---------+-----------+----------+---------+---------+-------------+--------------+------------- > - f1 | integer | | | | plain | > | | > + f1 | integer | | | | plain | pglz > | | > > Since the column is not a varlena, it shouldn't have a compression > method configured, yet on that machine it does, possibly because that > machine uses -DRELCACHE_FORCE_RELEASE -DCATCACHE_FORCE_RELEASE. I could reproduce the problem with those flags. I pushed a fix. > Regarding your point, that does look like clutter. We don't annotate > the dump with a storage clause unless it's non-default, so probably we > should do the same thing here. I think I gave Dilip bad advice here... Here's a patch for that. It's a little strange because you're going to skip dumping the toast compression based on the default value on the source system, but that might not be the default on the system where the dump is being restored, so you could fail to recreate the state you had. That is avoidable if you understand how things work, but some people might not. I don't have a better idea, though, so let me know what you think of this. -- Robert Haas EDB: http://www.enterprisedb.com
Attachment
On Fri, Mar 19, 2021 at 5:29 PM Andres Freund <andres@anarazel.de> wrote: > On 2021-03-19 22:19:49 +0100, Tomas Vondra wrote: > > Yeah. And why does it even require pkg-config, unlike any other library > > that I'm aware of? > > IMO it's fine to require pkg-config to simplify the configure > code. Especially for new optional features. Adding multiple alternative > ways to discover libraries for something like this makes configure > slower, without a comensurate benefit. So, would anyone like to propose a patch to revise the logic in a way that they like better? Here's one from me that tries to make the handling of the LZ4 stuff more like what we already do for zlib, but I'm not sure if it's correct, or if it's what everyone wants. Thoughts? -- Robert Haas EDB: http://www.enterprisedb.com
Attachment
On 2021-Mar-19, Robert Haas wrote: > > Regarding your point, that does look like clutter. We don't annotate > > the dump with a storage clause unless it's non-default, so probably we > > should do the same thing here. I think I gave Dilip bad advice here... > > Here's a patch for that. It's a little strange because you're going to > skip dumping the toast compression based on the default value on the > source system, but that might not be the default on the system where > the dump is being restored, so you could fail to recreate the state > you had. That is avoidable if you understand how things work, but some > people might not. I don't have a better idea, though, so let me know > what you think of this. Do you mean the column storage strategy, attstorage? I don't think that's really related, because the difference there is not a GUC setting but a compiled-in default for the type. In the case of compression, I'm not sure it makes sense to do it like that, but I can see the clutter argument: if we dump compression for all columns, it's going to be super noisy. (At least, for binary upgrade surely you must make sure to apply the correct setting regardless of defaults on either system). Maybe it makes sense to dump the compression clause if it is different from pglz, regardless of the default on the source server. Then, if the target server has chosen lz4 as default, *all* columns are going to end up as lz4, and if it hasn't, then only the ones that were lz4 in the source server are going to. That seems reasonable behavior. Also, if some columns are lz4 in source, and target does not have lz4, then everything is going to work out to not-lz4 with just a bunch of errors in the output. -- Álvaro Herrera 39°49'30"S 73°17'W
On 2021-Mar-19, Robert Haas wrote: > On Fri, Mar 19, 2021 at 10:11 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > Also added a test case for vacuum full to recompress the data. > > I committed the core patch (0003) with a bit more editing. Let's see > what the buildfarm thinks. I updated the coverage script to use --with-lz4; results are updated. While eyeballing the results I noticed this bit in lz4_decompress_datum_slice(): + /* slice decompression not supported prior to 1.8.3 */ + if (LZ4_versionNumber() < 10803) + return lz4_decompress_datum(value); which I read as returning the complete decompressed datum if slice decompression is not supported. I thought that was a bug, but looking at the caller I realize that this isn't really a problem, since it's detoast_attr_slice's responsibility to slice the result further -- no bug, it's just wasteful. I suggest to add comments to this effect, perhaps as the attached (feel free to reword, I think mine is awkward.) -- Álvaro Herrera 39°49'30"S 73°17'W Si no sabes adonde vas, es muy probable que acabes en otra parte.
Attachment
On 2021-Mar-19, Robert Haas wrote: > Here's one from me that tries to make the handling of the LZ4 stuff > more like what we already do for zlib, but I'm not sure if it's > correct, or if it's what everyone wants. This one seems to behave as expected (Debian 10, with and without liblz4-dev). -- Álvaro Herrera Valdivia, Chile "Just treat us the way you want to be treated + some extra allowance for ignorance." (Michael Brusser)
On Fri, Mar 19, 2021 at 6:22 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > Do you mean the column storage strategy, attstorage? I don't think > that's really related, because the difference there is not a GUC setting > but a compiled-in default for the type. In the case of compression, I'm > not sure it makes sense to do it like that, but I can see the clutter > argument: if we dump compression for all columns, it's going to be super > noisy. I agree. > (At least, for binary upgrade surely you must make sure to apply the > correct setting regardless of defaults on either system). It's not critical from a system integrity point of view; the catalog state just dictates what happens to new data. You could argue that if, in a future release, we change the default to lz4, it's good for pg_upgrade to migrate users to a set of column definitions that will use that for new data. > Maybe it makes sense to dump the compression clause if it is different > from pglz, regardless of the default on the source server. Then, if the > target server has chosen lz4 as default, *all* columns are going to end > up as lz4, and if it hasn't, then only the ones that were lz4 in the > source server are going to. That seems reasonable behavior. Also, if > some columns are lz4 in source, and target does not have lz4, then > everything is going to work out to not-lz4 with just a bunch of errors > in the output. Well, I really do hope that some day in the bright future, pglz will no longer be the thing we're shipping as the postgresql.conf default. So we'd just be postponing the noise until then. I think we need a better idea than that. -- Robert Haas EDB: http://www.enterprisedb.com
On 2021-Mar-19, Robert Haas wrote: > On Fri, Mar 19, 2021 at 6:22 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > (At least, for binary upgrade surely you must make sure to apply the > > correct setting regardless of defaults on either system). > > It's not critical from a system integrity point of view; the catalog > state just dictates what happens to new data. Oh, okay. > You could argue that if, in a future release, we change the default to > lz4, it's good for pg_upgrade to migrate users to a set of column > definitions that will use that for new data. Agreed, that seems a worthy goal. > > Maybe it makes sense to dump the compression clause if it is different > > from pglz, regardless of the default on the source server. > > Well, I really do hope that some day in the bright future, pglz will > no longer be the thing we're shipping as the postgresql.conf default. > So we'd just be postponing the noise until then. I think we need a > better idea than that. Hmm, why? In that future, we can just change the pg_dump behavior to no longer dump the compression clause if it's lz4 or whatever better algorithm we choose. So I think I'm clarifying my proposal to be "dump the compression clause if it's different from the compiled-in default" rather than "different from the GUC default". -- Álvaro Herrera Valdivia, Chile "Para tener más hay que desear menos"
On 2021-03-19 15:44:34 -0400, Robert Haas wrote: > I committed the core patch (0003) with a bit more editing. Let's see > what the buildfarm thinks. Congrats Dilip, Robert, All. The slow toast compression has been a significant issue for a long time.
On Fri, Mar 19, 2021 at 04:38:03PM -0400, Robert Haas wrote: > On Fri, Mar 19, 2021 at 4:20 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Nope ... crake's displeased with your assumption that it's OK to > > clutter dumps with COMPRESSION clauses. As am I: that is going to > > be utterly fatal for cross-version transportation of dumps. > > Regarding your point, that does look like clutter. We don't annotate > the dump with a storage clause unless it's non-default, so probably we > should do the same thing here. I think I gave Dilip bad advice here... On Fri, Mar 19, 2021 at 05:49:37PM -0400, Robert Haas wrote: > Here's a patch for that. It's a little strange because you're going to > skip dumping the toast compression based on the default value on the > source system, but that might not be the default on the system where > the dump is being restored, so you could fail to recreate the state > you had. That is avoidable if you understand how things work, but some > people might not. I don't have a better idea, though, so let me know > what you think of this. On Fri, Mar 19, 2021 at 07:22:42PM -0300, Alvaro Herrera wrote: > Do you mean the column storage strategy, attstorage? I don't think > that's really related, because the difference there is not a GUC setting > but a compiled-in default for the type. In the case of compression, I'm > not sure it makes sense to do it like that, but I can see the clutter > argument: if we dump compression for all columns, it's going to be super > noisy. > > (At least, for binary upgrade surely you must make sure to apply the > correct setting regardless of defaults on either system). > > Maybe it makes sense to dump the compression clause if it is different > from pglz, regardless of the default on the source server. Then, if the > target server has chosen lz4 as default, *all* columns are going to end > up as lz4, and if it hasn't, then only the ones that were lz4 in the > source server are going to. That seems reasonable behavior. Also, if > some columns are lz4 in source, and target does not have lz4, then > everything is going to work out to not-lz4 with just a bunch of errors > in the output. I think what's missing is dumping the GUC value itself, and then also dump any columns that differ from the GUC's setting. An early version of the GUC patch actually had an "XXX" comment about pg_dump support, and I was waiting for a review before polishing it. This was modelled after default_tablespace and default_table_access_method - I've mentioned that before that there's no pg_restore --no-table-am, and I have an unpublished patch to add it. That may be how I missed this until now. Then, this will output COMPRESSION on "a" (x)or "b" depending on the current default: | CREATE TABLE a(a text compression lz4, b text compression pglz); When we restore it, we set the default before restoring columns. I think it may be a good idea to document that dumps of columns with non-default compression aren't portable to older server versions, or servers --without-lz4. This is a consequence of the CREATE command being a big text blob, so pg_restore can't reasonably elide the COMPRESSION clause. While looking at this, I realized that someone added the GUC to postgresql.conf.sample, but not to doc/ - this was a separate patch until yesterday. I think since we're not doing catalog access for "pluggable" compression, this should just be an enum GUC, with #ifdef LZ4. Then we don't need a hook to validate it. ALTER and CREATE are silently accepting bogus compression names. I can write patches for these later. -- Justin
On 3/19/21 8:00 PM, Andres Freund wrote: > On 2021-03-19 15:44:34 -0400, Robert Haas wrote: >> I committed the core patch (0003) with a bit more editing. Let's see >> what the buildfarm thinks. > > Congrats Dilip, Robert, All. The slow toast compression has been a > significant issue for a long time. Yes, congratulations! This is a terrific improvement. Plus, now that lz4 is part of configure it lowers the bar for other features that want to use it. I'm guessing there will be a few. Thanks! -- -David david@pgmasters.net
Alvaro Herrera <alvherre@alvh.no-ip.org> writes:
> On 2021-Mar-19, Robert Haas wrote:
>> Well, I really do hope that some day in the bright future, pglz will
>> no longer be the thing we're shipping as the postgresql.conf default.
>> So we'd just be postponing the noise until then. I think we need a
>> better idea than that.
> Hmm, why? In that future, we can just change the pg_dump behavior to no
> longer dump the compression clause if it's lz4 or whatever better
> algorithm we choose. So I think I'm clarifying my proposal to be "dump
> the compression clause if it's different from the compiled-in default"
> rather than "different from the GUC default".
Extrapolating from the way we've dealt with similar issues
in the past, I think the structure of pg_dump's output ought to be:
1. SET default_toast_compression = 'source system's value'
in among the existing passel of SETs at the top. Doesn't
matter whether or not that is the compiled-in value.
2. No mention of compression in any CREATE TABLE command.
3. For any column having a compression option different from
the default, emit ALTER TABLE SET ... to set that option after
the CREATE TABLE. (You did implement such a SET, I trust.)
This minimizes the chatter for the normal case where all or most
columns have the same setting, and more importantly it allows the
dump to be read by older PG systems (or non-PG systems, or newer
systems built without --with-lz4) that would fail altogether
if the CREATE TABLE commands contained compression options.
To use the dump that way, you do have to be willing to ignore
errors from the SET and the ALTERs ... but that beats the heck
out of having to manually edit the dump script to get rid of
embedded COMPRESSION clauses.
I'm not sure whether we'd still need to mess around beyond
that to make the buildfarm's existing upgrade tests happy.
But we *must* do this much in any case, because as it stands
this patch has totally destroyed some major use-cases for
pg_dump.
There might be scope for a dump option to suppress mention
of compression altogether (comparable to, eg, --no-tablespaces).
But I think that's optional. In any case, we don't want
to put people in a position where they should have used such
an option and now they have no good way to recover their
dump to the system they want to recover to.
regards, tom lane
On 3/19/21 8:25 PM, Tom Lane wrote: > Alvaro Herrera <alvherre@alvh.no-ip.org> writes: >> On 2021-Mar-19, Robert Haas wrote: >>> Well, I really do hope that some day in the bright future, pglz will >>> no longer be the thing we're shipping as the postgresql.conf default. >>> So we'd just be postponing the noise until then. I think we need a >>> better idea than that. >> Hmm, why? In that future, we can just change the pg_dump behavior to no >> longer dump the compression clause if it's lz4 or whatever better >> algorithm we choose. So I think I'm clarifying my proposal to be "dump >> the compression clause if it's different from the compiled-in default" >> rather than "different from the GUC default". > Extrapolating from the way we've dealt with similar issues > in the past, I think the structure of pg_dump's output ought to be: > > 1. SET default_toast_compression = 'source system's value' > in among the existing passel of SETs at the top. Doesn't > matter whether or not that is the compiled-in value. > > 2. No mention of compression in any CREATE TABLE command. > > 3. For any column having a compression option different from > the default, emit ALTER TABLE SET ... to set that option after > the CREATE TABLE. (You did implement such a SET, I trust.) > > This minimizes the chatter for the normal case where all or most > columns have the same setting, and more importantly it allows the > dump to be read by older PG systems (or non-PG systems, or newer > systems built without --with-lz4) that would fail altogether > if the CREATE TABLE commands contained compression options. > To use the dump that way, you do have to be willing to ignore > errors from the SET and the ALTERs ... but that beats the heck > out of having to manually edit the dump script to get rid of > embedded COMPRESSION clauses. > > I'm not sure whether we'd still need to mess around beyond > that to make the buildfarm's existing upgrade tests happy. > But we *must* do this much in any case, because as it stands > this patch has totally destroyed some major use-cases for > pg_dump. > > There might be scope for a dump option to suppress mention > of compression altogether (comparable to, eg, --no-tablespaces). > But I think that's optional. In any case, we don't want > to put people in a position where they should have used such > an option and now they have no good way to recover their > dump to the system they want to recover to. > > I'm fairly sure this prescription would satisfy the buildfarm. It sounds pretty sane to me - I'd independently come to a very similar conclusion before reading the above. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
On Fri, Mar 19, 2021 at 8:25 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Extrapolating from the way we've dealt with similar issues > in the past, I think the structure of pg_dump's output ought to be: > > 1. SET default_toast_compression = 'source system's value' > in among the existing passel of SETs at the top. Doesn't > matter whether or not that is the compiled-in value. > > 2. No mention of compression in any CREATE TABLE command. > > 3. For any column having a compression option different from > the default, emit ALTER TABLE SET ... to set that option after > the CREATE TABLE. (You did implement such a SET, I trust.) Actually, *I* didn't implement any of this. But ALTER TABLE sometab ALTER somecol SET COMPRESSION somealgo works. This sounds like a reasonable approach. > There might be scope for a dump option to suppress mention > of compression altogether (comparable to, eg, --no-tablespaces). > But I think that's optional. In any case, we don't want > to put people in a position where they should have used such > an option and now they have no good way to recover their > dump to the system they want to recover to. The patch already has --no-toast-compression. -- Robert Haas EDB: http://www.enterprisedb.com
On Fri, Mar 19, 2021 at 6:38 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > I suggest to add comments to this effect, > perhaps as the attached (feel free to reword, I think mine is awkward.) It's not bad, although "the decompressed version of the full datum" might be a little better. I'd probably say instead: "This method might decompress the entire datum rather than just a slice, if slicing is not supported." or something of to that effect. Feel free to commit something you like. -- Robert Haas EDB: http://www.enterprisedb.com
On Sat, Mar 20, 2021 at 8:11 AM Robert Haas <robertmhaas@gmail.com> wrote: > > On Fri, Mar 19, 2021 at 8:25 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Extrapolating from the way we've dealt with similar issues > > in the past, I think the structure of pg_dump's output ought to be: > > > > 1. SET default_toast_compression = 'source system's value' > > in among the existing passel of SETs at the top. Doesn't > > matter whether or not that is the compiled-in value. > > > > 2. No mention of compression in any CREATE TABLE command. > > > > 3. For any column having a compression option different from > > the default, emit ALTER TABLE SET ... to set that option after > > the CREATE TABLE. (You did implement such a SET, I trust.) > > Actually, *I* didn't implement any of this. But ALTER TABLE sometab > ALTER somecol SET COMPRESSION somealgo works. > > This sounds like a reasonable approach. The attached patch implements that. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Sat, Mar 20, 2021 at 1:22 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Sat, Mar 20, 2021 at 8:11 AM Robert Haas <robertmhaas@gmail.com> wrote: > > > > On Fri, Mar 19, 2021 at 8:25 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > > Extrapolating from the way we've dealt with similar issues > > > in the past, I think the structure of pg_dump's output ought to be: > > > > > > 1. SET default_toast_compression = 'source system's value' > > > in among the existing passel of SETs at the top. Doesn't > > > matter whether or not that is the compiled-in value. > > > > > > 2. No mention of compression in any CREATE TABLE command. > > > > > > 3. For any column having a compression option different from > > > the default, emit ALTER TABLE SET ... to set that option after > > > the CREATE TABLE. (You did implement such a SET, I trust.) > > > > Actually, *I* didn't implement any of this. But ALTER TABLE sometab > > ALTER somecol SET COMPRESSION somealgo works. > > > > This sounds like a reasonable approach. > > The attached patch implements that. After sending this, just saw Justin also included patches for this. I think the ALTER ..SET COMPRESSION is more or less similar, I just fetched it from the older version of the patch set. But SET default_toast_compression are slightly different. I will look into your version and provide my opinion on which one looks better and we can commit that and feel free to share your thoughts. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Hi,
I think this bit in brin_tuple.c is wrong:
...
Form_pg_attribute att = TupleDescAttr(brdesc->bd_tupdesc,
keyno);
Datum cvalue = toast_compress_datum(value,
att->attcompression);
The problem is that this is looking at the index descriptor (i.e. what
types are indexed) instead of the stored type. For BRIN those may be
only loosely related, which is why the code does this a couple lines above:
/* We must look at the stored type, not at the index descriptor. */
TypeCacheEntry *atttype
= brdesc->bd_info[keyno]->oi_typcache[datumno];
For the built-in BRIN opclasses this happens to work, because e.g.
minmax stores two values of the original type. But it may not work for
other out-of-core opclasses, and it certainly doesn't work for the new
BRIN opclasses (bloom and minmax-multi).
Unfortunately, the only thing we have here is the type OID, so I guess
the only option is using GetDefaultToastCompression(). Perhaps we might
include that into BrinOpcInfo too, in the future.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Sat, Mar 20, 2021 at 3:05 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > Hi, > > I think this bit in brin_tuple.c is wrong: > > ... > Form_pg_attribute att = TupleDescAttr(brdesc->bd_tupdesc, > keyno); > Datum cvalue = toast_compress_datum(value, > att->attcompression); > > The problem is that this is looking at the index descriptor (i.e. what > types are indexed) instead of the stored type. For BRIN those may be > only loosely related, which is why the code does this a couple lines above: > > /* We must look at the stored type, not at the index descriptor. */ > TypeCacheEntry *atttype > = brdesc->bd_info[keyno]->oi_typcache[datumno]; Ok, I was not aware of this. > For the built-in BRIN opclasses this happens to work, because e.g. > minmax stores two values of the original type. But it may not work for > other out-of-core opclasses, and it certainly doesn't work for the new > BRIN opclasses (bloom and minmax-multi). Okay > Unfortunately, the only thing we have here is the type OID, so I guess > the only option is using GetDefaultToastCompression(). Perhaps we might > include that into BrinOpcInfo too, in the future. Right, I think for now we can use default compression for this case. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On 3/20/21 11:18 AM, Dilip Kumar wrote: > On Sat, Mar 20, 2021 at 3:05 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> Hi, >> >> I think this bit in brin_tuple.c is wrong: >> >> ... >> Form_pg_attribute att = TupleDescAttr(brdesc->bd_tupdesc, >> keyno); >> Datum cvalue = toast_compress_datum(value, >> att->attcompression); >> >> The problem is that this is looking at the index descriptor (i.e. what >> types are indexed) instead of the stored type. For BRIN those may be >> only loosely related, which is why the code does this a couple lines above: >> >> /* We must look at the stored type, not at the index descriptor. */ >> TypeCacheEntry *atttype >> = brdesc->bd_info[keyno]->oi_typcache[datumno]; > > Ok, I was not aware of this. > Yeah, the BRIN internal structure is not obvious, and the fact that all the built-in BRIN variants triggers the issue makes it harder to spot. >> For the built-in BRIN opclasses this happens to work, because e.g. >> minmax stores two values of the original type. But it may not work for >> other out-of-core opclasses, and it certainly doesn't work for the new >> BRIN opclasses (bloom and minmax-multi). > > Okay > >> Unfortunately, the only thing we have here is the type OID, so I guess >> the only option is using GetDefaultToastCompression(). Perhaps we might >> include that into BrinOpcInfo too, in the future. > > Right, I think for now we can use default compression for this case. > Good. I wonder if we might have "per type" preferred compression in the future, which would address this. But for now just using the default compression seems fine. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Mar 20, 2021 at 1:14 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > See attached. I have looked into your patches - 0001 to 0005 and 0007 look fine to me so maybe you can merge them all and create a fixup patch. Thanks for fixing this, these were some silly mistakes I made in my patch. - 0006 is fine but not sure what is the advantage over what we have today? - And, 0008 and 0009, I think my 0001-Fixup-dump-toast-compression-method.patch[1] is doing this in a much simpler way, please have a look and let me know if you think that has any problems and we need to do the way you are doing here? [1] https://www.postgresql.org/message-id/CAFiTN-v7EULPqVJ-6J%3DzH6n0%2BkO%3DYFtgpte%2BFTre%3DWrwcWBBTA%40mail.gmail.com -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On 3/20/21 11:45 AM, Tomas Vondra wrote: > > > On 3/20/21 11:18 AM, Dilip Kumar wrote: >> On Sat, Mar 20, 2021 at 3:05 PM Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >>> >>> Hi, >>> >>> I think this bit in brin_tuple.c is wrong: >>> >>> ... >>> Form_pg_attribute att = TupleDescAttr(brdesc->bd_tupdesc, >>> keyno); >>> Datum cvalue = toast_compress_datum(value, >>> att->attcompression); >>> >>> The problem is that this is looking at the index descriptor (i.e. what >>> types are indexed) instead of the stored type. For BRIN those may be >>> only loosely related, which is why the code does this a couple lines above: >>> >>> /* We must look at the stored type, not at the index descriptor. */ >>> TypeCacheEntry *atttype >>> = brdesc->bd_info[keyno]->oi_typcache[datumno]; >> >> Ok, I was not aware of this. >> > > Yeah, the BRIN internal structure is not obvious, and the fact that all > the built-in BRIN variants triggers the issue makes it harder to spot. > >>> For the built-in BRIN opclasses this happens to work, because e.g. >>> minmax stores two values of the original type. But it may not work for >>> other out-of-core opclasses, and it certainly doesn't work for the new >>> BRIN opclasses (bloom and minmax-multi). >> >> Okay >> >>> Unfortunately, the only thing we have here is the type OID, so I guess >>> the only option is using GetDefaultToastCompression(). Perhaps we might >>> include that into BrinOpcInfo too, in the future. >> >> Right, I think for now we can use default compression for this case. >> > > Good. I wonder if we might have "per type" preferred compression in the > future, which would address this. But for now just using the default > compression seems fine. > Actually, we can be a bit smarter - when the data types match, we can use the compression method defined for the attribute. That works fine for all built-in BRIN opclasses, and it seems quite reasonable - if the user picked a particular compression method for a column, it's likely because the data compress better with that method. So why not use that for the BRIN summary, when possible (even though the BRIN indexes tend to be tiny). Attached is a patch doing this. Barring objection I'll push that soon, so that I can push the BRIN index improvements (bloom etc.). regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
Justin Pryzby <pryzby@telsasoft.com> writes:
> On Sat, Mar 20, 2021 at 04:37:53PM +0530, Dilip Kumar wrote:
>> - And, 0008 and 0009, I think my
>> 0001-Fixup-dump-toast-compression-method.patch[1] is doing this in a
>> much simpler way, please have a look and let me know if you think that
>> has any problems and we need to do the way you are doing here?
> I tested and saw that your patch doesn't output "SET default_toast_compression"
> in non-text dumps (pg_dump -Fc).
Yeah, _doSetFixedOutputState is the wrong place: that runs on the
pg_restore side of the fence, and would not have access to the
necessary info in a separated dump/restore run.
It might be necessary to explicitly pass the state through in a TOC item,
as we do for things like the standard_conforming_strings setting.
regards, tom lane
I wrote:
> Yeah, _doSetFixedOutputState is the wrong place: that runs on the
> pg_restore side of the fence, and would not have access to the
> necessary info in a separated dump/restore run.
> It might be necessary to explicitly pass the state through in a TOC item,
> as we do for things like the standard_conforming_strings setting.
Ah, now that I read your patch I see that's exactly what you did.
I fixed up some issues in 0008/0009 (mostly cosmetic, except that
you forgot a server version check in dumpToastCompression) and
pushed that, so we can see if it makes crake happy.
regards, tom lane
On 3/20/21 3:03 PM, Tom Lane wrote:
> I wrote:
>> Yeah, _doSetFixedOutputState is the wrong place: that runs on the
>> pg_restore side of the fence, and would not have access to the
>> necessary info in a separated dump/restore run.
>> It might be necessary to explicitly pass the state through in a TOC item,
>> as we do for things like the standard_conforming_strings setting.
> Ah, now that I read your patch I see that's exactly what you did.
>
> I fixed up some issues in 0008/0009 (mostly cosmetic, except that
> you forgot a server version check in dumpToastCompression) and
> pushed that, so we can see if it makes crake happy.
>
>
It's still produced a significant amount more difference between the
dumps. For now I've increased the fuzz factor a bit like this:
diff --git a/PGBuild/Modules/TestUpgradeXversion.pm
b/PGBuild/Modules/TestUpgradeXversion.pm
index 1d1d313..567d7cb 100644
--- a/PGBuild/Modules/TestUpgradeXversion.pm
+++ b/PGBuild/Modules/TestUpgradeXversion.pm
@@ -621,7 +621,7 @@ sub test_upgrade ## no critic
(Subroutines::ProhibitManyArgs)
# generally from reordering of larg object output.
# If not we heuristically allow up to 2000 lines of diffs
- if ( ($oversion ne $this_branch && $difflines < 2000)
+ if ( ($oversion ne $this_branch && $difflines < 2700)
|| ($oversion eq $this_branch) && $difflines < 50)
{
return 1;
I'll try to come up with something better. Maybe just ignore lines like
SET default_toast_compression = 'pglz';
when taking the diff.
cheers
andrew
--
Andrew Dunstan
EDB: https://www.enterprisedb.com
I wrote: > I fixed up some issues in 0008/0009 (mostly cosmetic, except that > you forgot a server version check in dumpToastCompression) and > pushed that, so we can see if it makes crake happy. crake was still unhappy with that: https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=crake&dt=2021-03-20%2019%3A03%3A56 but I see it just went green ... did you do something to adjust the expected output? regards, tom lane
Andrew Dunstan <andrew@dunslane.net> writes:
> On 3/20/21 3:03 PM, Tom Lane wrote:
>> I fixed up some issues in 0008/0009 (mostly cosmetic, except that
>> you forgot a server version check in dumpToastCompression) and
>> pushed that, so we can see if it makes crake happy.
> It's still produced a significant amount more difference between the
> dumps. For now I've increased the fuzz factor a bit like this:
Ah, our emails crossed.
> I'll try to come up with something better. Maybe just ignore lines like
> SET default_toast_compression = 'pglz';
> when taking the diff.
I noticed that there were a fair number of other diffs besides those.
Seems like we need some better comparison technology, really, but I'm
not certain what.
regards, tom lane
Justin Pryzby <pryzby@telsasoft.com> writes:
> On Fri, Mar 19, 2021 at 05:35:58PM -0300, Alvaro Herrera wrote:
>> I find this behavior confusing; I'd rather have configure error out if
>> it can't find the package support I requested, than continuing with a
>> set of configure options different from what I gave.
> That's clearly wrong, but that's not the behavior I see:
Yeah, it errors out as-expected for me too, on a couple of different
machines (see sifaka's latest run for documentation).
regards, tom lane
Justin Pryzby <pryzby@telsasoft.com> writes:
> On Fri, Mar 19, 2021 at 02:07:31PM -0400, Robert Haas wrote:
>> On Fri, Mar 19, 2021 at 1:44 PM Justin Pryzby <pryzby@telsasoft.com> wrote:
>>> configure: WARNING: lz4.h: accepted by the compiler, rejected by the preprocessor!
>>> configure: WARNING: lz4.h: proceeding with the compiler's result
>> No, I don't see this. I wonder whether this could possibly be an
>> installation issue on Andrey's machine? If not, it must be
>> version-dependent or installation-dependent in some way.
> Andrey, can you check if latest HEAD (bbe0a81db) has these ./configure warnings ?
FWIW, I also saw that, when building HEAD against MacPorts' version
of liblz4 on an M1 Mac. config.log has
configure:13536: checking lz4.h usability
configure:13536: ccache clang -c -I/opt/local/include -Wall -Wmissing-prototype\
s -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmi\
ssing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -Wno-unus\
ed-command-line-argument -g -O2 -isysroot /Applications/Xcode.app/Contents/Deve\
loper/Platforms/MacOSX.platform/Developer/SDKs/MacOSX11.1.sdk conftest.c >&5
configure:13536: $? = 0
configure:13536: result: yes
configure:13536: checking lz4.h presence
configure:13536: ccache clang -E -isysroot /Applications/Xcode.app/Contents/Dev\
eloper/Platforms/MacOSX.platform/Developer/SDKs/MacOSX11.1.sdk conftest.c
conftest.c:67:10: fatal error: 'lz4.h' file not found
#include <lz4.h>
^~~~~~~
1 error generated.
configure:13536: $? = 1
Digging around, it looks like the "-I/opt/local/include" bit came
from LZ4_CFLAGS, which we then stuck into CFLAGS, but it needed
to be put in CPPFLAGS in order to make this test work.
regards, tom lane
On 3/20/21 4:21 PM, Justin Pryzby wrote:
> On Sat, Mar 20, 2021 at 04:13:47PM +0100, Tomas Vondra wrote:
>> +++ b/src/backend/access/brin/brin_tuple.c
>> @@ -213,10 +213,20 @@ brin_form_tuple(BrinDesc *brdesc, BlockNumber blkno, BrinMemTuple *tuple,
>> (atttype->typstorage == TYPSTORAGE_EXTENDED ||
>> atttype->typstorage == TYPSTORAGE_MAIN))
>> {
>> + Datum cvalue;
>> + char compression = GetDefaultToastCompression();
>> Form_pg_attribute att = TupleDescAttr(brdesc->bd_tupdesc,
>> keyno);
>> - Datum cvalue = toast_compress_datum(value,
>> - att->attcompression);
>> +
>> + /*
>> + * If the BRIN summary and indexed attribute use the same data
>> + * type, we can the same compression method. Otherwise we have
>
> can *use ?
>
>> + * to use the default method.
>> + */
>> + if (att->atttypid == atttype->type_id)
>> + compression = att->attcompression;
>
> It would be more obvious to me if this said here:
> | else: compression = GetDefaultToastCompression
>
Thanks. I've pushed a patch tweaked per your feedback.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Justin Pryzby <pryzby@telsasoft.com> writes:
> On Sat, Mar 20, 2021 at 05:37:07PM -0400, Tom Lane wrote:
>> Digging around, it looks like the "-I/opt/local/include" bit came
>> from LZ4_CFLAGS, which we then stuck into CFLAGS, but it needed
>> to be put in CPPFLAGS in order to make this test work.
> If it's the same as the issue Andrey reported, then it causes a ./configure
> WARNING, which is resolved by the ac_save hack, which I copied from ICU.
I think probably what we need to do, rather than shove the pkg-config
results willy-nilly into our flags, is to disassemble them like we do
with the same results for xml2. If you ask me, the way we are handling
ICU flags is a poor precedent that is going to blow up at some point;
the only reason it hasn't is that people aren't building --with-icu that
much yet.
regards, tom lane
BTW, I tried doing "make installcheck" after having adjusted
default_toast_compression to be "lz4". The compression test
itself fails because it's expecting the other setting; that
ought to be made more robust. Also, I see some diffs in the
indirect_toast test, which seems perhaps worthy of investigation.
(The diffs look to be just row ordering, but why?)
regards, tom lane
On Sun, Mar 21, 2021 at 7:03 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > BTW, I tried doing "make installcheck" after having adjusted > default_toast_compression to be "lz4". The compression test > itself fails because it's expecting the other setting; that > ought to be made more robust. Yeah, we need to set the default_toast_compression in the beginning of the test as attached. Also, I see some diffs in the > indirect_toast test, which seems perhaps worthy of investigation. > (The diffs look to be just row ordering, but why?) I will look into this. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Sun, Mar 21, 2021 at 9:10 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Sun, Mar 21, 2021 at 7:03 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > > > BTW, I tried doing "make installcheck" after having adjusted > > default_toast_compression to be "lz4". The compression test > > itself fails because it's expecting the other setting; that > > ought to be made more robust. > > Yeah, we need to set the default_toast_compression in the beginning of > the test as attached. In the last patch, I did not adjust the compression_1.out so fixed that in the attached patch. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Sun, Mar 21, 2021 at 7:03 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> Also, I see some diffs in the
> indirect_toast test, which seems perhaps worthy of investigation.
> (The diffs look to be just row ordering, but why?)
I have investigated that, actually in the below insert, after
compression the data size of (repeat('1234567890',50000)) is 1980
bytes with the lz4 whereas with pglz it is 5737 bytes. So with lz4,
the compressed data are stored inline whereas with pglz those are
getting externalized. Due to this for one of the update statements
followed by an insert, there was no space on the first page as data
are stored inline so the new tuple is stored on the next page and that
is what affecting the order. I hope this makes sense.
INSERT INTO indtoasttest(descr, f1, f2) VALUES('one-toasted,one-null',
NULL, repeat('1234567890',50000));
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Dilip Kumar <dilipbalaut@gmail.com> writes:
>> Yeah, we need to set the default_toast_compression in the beginning of
>> the test as attached.
> In the last patch, I did not adjust the compression_1.out so fixed
> that in the attached patch.
Pushed that; however, while testing that it works as expected,
I saw a new and far more concerning regression diff:
diff -U3 /home/postgres/pgsql/src/test/regress/expected/strings.out
/home/postgres/pgsql/src/test/regress/results/strings.out
--- /home/postgres/pgsql/src/test/regress/expected/strings.out 2021-02-18 10:34:58.190304138 -0500
+++ /home/postgres/pgsql/src/test/regress/results/strings.out 2021-03-21 16:27:22.029402834 -0400
@@ -1443,10 +1443,10 @@
-- If start plus length is > string length, the result is truncated to
-- string length
SELECT substr(f1, 99995, 10) from toasttest;
- substr
---------
- 567890
- 567890
+ substr
+------------------------
+ 567890\x7F\x7F\x7F\x7F
+ 567890\x7F\x7F\x7F\x7F
567890
567890
(4 rows)
@@ -1520,10 +1520,10 @@
-- If start plus length is > string length, the result is truncated to
-- string length
SELECT substr(f1, 99995, 10) from toasttest;
- substr
---------
- 567890
- 567890
+ substr
+------------------------
+ 567890\177\177\177\177
+ 567890\177\177\177\177
567890
567890
(4 rows)
This seems somewhat repeatable (three identical failures in three
attempts). Not sure why I did not see it yesterday; but anyway,
there is something wrong with partial detoasting for LZ4.
regards, tom lane
On Sun, Mar 21, 2021 at 04:32:31PM -0400, Tom Lane wrote: > This seems somewhat repeatable (three identical failures in three > attempts). Not sure why I did not see it yesterday; but anyway, > there is something wrong with partial detoasting for LZ4. With what version of LZ4 ? -- Justin
Justin Pryzby <pryzby@telsasoft.com> writes:
> On Sun, Mar 21, 2021 at 04:32:31PM -0400, Tom Lane wrote:
>> This seems somewhat repeatable (three identical failures in three
>> attempts). Not sure why I did not see it yesterday; but anyway,
>> there is something wrong with partial detoasting for LZ4.
> With what version of LZ4 ?
RHEL8's, which is
lz4-1.8.3-2.el8.x86_64
regards, tom lane
Justin Pryzby <pryzby@telsasoft.com> writes:
> Rebased on HEAD.
> 0005 forgot to update compression_1.out.
> Included changes to ./configure.ac and some other patches, but not Tomas's,
> since it'll make CFBOT get mad as soon as that's pushed.
I pushed a version of the configure fixes that passes my own sanity
checks, and removes the configure warning with MacPorts. That
obsoletes your 0006. Of the rest, I prefer the 0009 approach
(make the GUC an enum) to 0008, and the others seem sane but I haven't
studied the code, so I'll leave it to Robert to handle them.
regards, tom lane
... btw, now that I look at this, why are we expending a configure
probe for <lz4/lz4.h> ? If we need to cater for that spelling of
the header name, the C code proper is not ready for it.
regards, tom lane
I wrote: > Justin Pryzby <pryzby@telsasoft.com> writes: >> On Sun, Mar 21, 2021 at 04:32:31PM -0400, Tom Lane wrote: >>> This seems somewhat repeatable (three identical failures in three >>> attempts). Not sure why I did not see it yesterday; but anyway, >>> there is something wrong with partial detoasting for LZ4. >> With what version of LZ4 ? > RHEL8's, which is > lz4-1.8.3-2.el8.x86_64 I hate to be the bearer of bad news, but this suggests that LZ4_decompress_safe_partial is seriously broken in 1.9.2 as well: https://github.com/lz4/lz4/issues/783 Maybe we cannot rely on that function for a few more years yet. Also, I don't really understand why this code: /* slice decompression not supported prior to 1.8.3 */ if (LZ4_versionNumber() < 10803) return lz4_decompress_datum(value); It seems likely to me that we'd get a flat out build failure from library versions lacking LZ4_decompress_safe_partial, and thus that this run-time test is dead code and we should better be using a configure probe if we intend to allow old liblz4 versions. Though that might be moot. regards, tom lane
On Sun, Mar 21, 2021 at 07:11:50PM -0400, Tom Lane wrote: > I wrote: > > Justin Pryzby <pryzby@telsasoft.com> writes: > >> On Sun, Mar 21, 2021 at 04:32:31PM -0400, Tom Lane wrote: > >>> This seems somewhat repeatable (three identical failures in three > >>> attempts). Not sure why I did not see it yesterday; but anyway, > >>> there is something wrong with partial detoasting for LZ4. > > >> With what version of LZ4 ? > > > RHEL8's, which is > > lz4-1.8.3-2.el8.x86_64 > > I hate to be the bearer of bad news, but this suggests that > LZ4_decompress_safe_partial is seriously broken in 1.9.2 > as well: > > https://github.com/lz4/lz4/issues/783 Ouch > Maybe we cannot rely on that function for a few more years yet. > > Also, I don't really understand why this code: > > /* slice decompression not supported prior to 1.8.3 */ > if (LZ4_versionNumber() < 10803) > return lz4_decompress_datum(value); > > It seems likely to me that we'd get a flat out build failure > from library versions lacking LZ4_decompress_safe_partial, > and thus that this run-time test is dead code and we should > better be using a configure probe if we intend to allow old > liblz4 versions. Though that might be moot. The function existed before 1.8.3, but didn't handle slicing. https://github.com/lz4/lz4/releases/tag/v1.8.3 |Finally, an existing function, LZ4_decompress_safe_partial(), has been enhanced to make it possible to decompress only thebeginning of an LZ4 block, up to a specified number of bytes. Partial decoding can be useful to save CPU time and memory,when the objective is to extract a limited portion from a larger block. Possibly we could allow v >= 1.9.3 || (ver >= 1.8.3 && ver < 1.9.2). Or maybe not: the second half apparently worked "by accident", and we shouldn't need to have intimate knowledge of someone else's patchlevel releases, -- Justin
Justin Pryzby <pryzby@telsasoft.com> writes: > On Sun, Mar 21, 2021 at 07:11:50PM -0400, Tom Lane wrote: >> I hate to be the bearer of bad news, but this suggests that >> LZ4_decompress_safe_partial is seriously broken in 1.9.2 >> as well: >> https://github.com/lz4/lz4/issues/783 > Ouch Actually, after reading that closer, the problem only affects the case where the compressed-data-length passed to the function is a lie. So it shouldn't be a problem for our usage. Also, after studying the documentation for LZ4_decompress_safe and LZ4_decompress_safe_partial, I realized that liblz4 is also counting on the *output* buffer size to not be a lie. So we cannot pass it a number larger than the chunk's true decompressed size. The attached patch resolves the issue I'm seeing. regards, tom lane diff --git a/src/backend/access/common/toast_compression.c b/src/backend/access/common/toast_compression.c index 00af1740cf..74e449992a 100644 --- a/src/backend/access/common/toast_compression.c +++ b/src/backend/access/common/toast_compression.c @@ -220,6 +220,10 @@ lz4_decompress_datum_slice(const struct varlena *value, int32 slicelength) if (LZ4_versionNumber() < 10803) return lz4_decompress_datum(value); + /* liblz4 assumes that slicelength is not an overestimate */ + if (slicelength >= VARRAWSIZE_4B_C(value)) + return lz4_decompress_datum(value); + /* allocate memory for the uncompressed data */ result = (struct varlena *) palloc(slicelength + VARHDRSZ);
On Mon, Mar 22, 2021 at 5:22 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> Actually, after reading that closer, the problem only affects the
> case where the compressed-data-length passed to the function is
> a lie. So it shouldn't be a problem for our usage.
>
> Also, after studying the documentation for LZ4_decompress_safe
> and LZ4_decompress_safe_partial, I realized that liblz4 is also
> counting on the *output* buffer size to not be a lie. So we
> cannot pass it a number larger than the chunk's true decompressed
> size. The attached patch resolves the issue I'm seeing.
Okay, the fix makes sense. In fact, IMHO, in general also this fix
looks like an optimization, I mean when slicelength >=
VARRAWSIZE_4B_C(value), then why do we need to allocate extra memory
even in the case of pglz. So shall we put this check directly in
toast_decompress_datum_slice instead of handling it at the lz4 level?
Like this.
diff --git a/src/backend/access/common/detoast.c
b/src/backend/access/common/detoast.c
index bed50e8..099ac15 100644
--- a/src/backend/access/common/detoast.c
+++ b/src/backend/access/common/detoast.c
@@ -506,6 +506,10 @@ toast_decompress_datum_slice(struct varlena
*attr, int32 slicelength)
Assert(VARATT_IS_COMPRESSED(attr));
+ /* liblz4 assumes that slicelength is not an overestimate */
+ if (slicelength >= VARRAWSIZE_4B_C(attr))
+ return toast_decompress_datum(attr);
+
/*
* Fetch the compression method id stored in the compression header and
* decompress the data slice using the appropriate
decompression routine.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Mon, Mar 22, 2021 at 5:25 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > > On Sat, Mar 20, 2021 at 06:20:39PM -0500, Justin Pryzby wrote: > > Rebased on HEAD. > > 0005 forgot to update compression_1.out. > > Included changes to ./configure.ac and some other patches, but not Tomas's, > > since it'll make CFBOT get mad as soon as that's pushed. > > Rebased again. > Renamed "t" to a badcompresstbl to avoid name conflicts. > Polish the enum GUC patch some. > > I noticed that TOAST_INVALID_COMPRESSION_ID was unused ... but then I found a > use for it. Yeah, it is used in toast_compress_datum, toast_get_compression_id, reform_and_rewrite_tuple and pg_column_compression function. Your patches look fine to me. I agree that v3-0006 also makes sense as it is simplifying the GUC handling. Thanks for fixing these. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Sun, Mar 21, 2021 at 7:55 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > Rebased again. Thanks, Justin. I committed 0003 and 0004 together as 226e2be3876d0bda3dc33d16dfa0bed246b7b74f. I also committed 0001 and 0002 together as 24f0e395ac5892cd12e8914646fe921fac5ba23d, but with some revisions, because your text was not clear that this is setting the default for new tables, not new values; it also implied that this only affects out-of-line compression, which is not true. In lieu of trying to explain how TOAST works here, I added a link. It looks, though, like that documentation also needs to be patched for this change. I'll look into that, and your remaining patches, next. -- Robert Haas EDB: http://www.enterprisedb.com
Dilip Kumar <dilipbalaut@gmail.com> writes:
> On Mon, Mar 22, 2021 at 5:22 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Also, after studying the documentation for LZ4_decompress_safe
>> and LZ4_decompress_safe_partial, I realized that liblz4 is also
>> counting on the *output* buffer size to not be a lie. So we
>> cannot pass it a number larger than the chunk's true decompressed
>> size. The attached patch resolves the issue I'm seeing.
> Okay, the fix makes sense. In fact, IMHO, in general also this fix
> looks like an optimization, I mean when slicelength >=
> VARRAWSIZE_4B_C(value), then why do we need to allocate extra memory
> even in the case of pglz. So shall we put this check directly in
> toast_decompress_datum_slice instead of handling it at the lz4 level?
Yeah, I thought about that too, but do we want to assume that
VARRAWSIZE_4B_C is the correct way to get the decompressed size
for all compression methods?
(If so, I think it would be better style to have a less opaque macro
name for the purpose.)
regards, tom lane
On Mon, Mar 22, 2021 at 10:44 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > Thanks. I just realized that if you also push the GUC change, then the docs > should change from <string> to <enum> > > doc/src/sgml/config.sgml: <term><varname>default_toast_compression</varname> (<type>string</type>) I've now also committed your 0005. As for 0006, aside from the note above, which is a good one, is there any particular reason why this patch is labelled as WIP? I think this change makes sense and we should just do it unless there's some problem with it. -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Mar 22, 2021 at 8:11 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Dilip Kumar <dilipbalaut@gmail.com> writes: > > On Mon, Mar 22, 2021 at 5:22 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> Also, after studying the documentation for LZ4_decompress_safe > >> and LZ4_decompress_safe_partial, I realized that liblz4 is also > >> counting on the *output* buffer size to not be a lie. So we > >> cannot pass it a number larger than the chunk's true decompressed > >> size. The attached patch resolves the issue I'm seeing. > > > Okay, the fix makes sense. In fact, IMHO, in general also this fix > > looks like an optimization, I mean when slicelength >= > > VARRAWSIZE_4B_C(value), then why do we need to allocate extra memory > > even in the case of pglz. So shall we put this check directly in > > toast_decompress_datum_slice instead of handling it at the lz4 level? > > Yeah, I thought about that too, but do we want to assume that > VARRAWSIZE_4B_C is the correct way to get the decompressed size > for all compression methods? Yeah, VARRAWSIZE_4B_C is the macro getting the rawsize of the data stored in the compressed varlena. > (If so, I think it would be better style to have a less opaque macro > name for the purpose.) Okay, I have added another macro that is less opaque and came up with this patch. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Mon, Mar 22, 2021 at 10:41 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Okay, the fix makes sense. In fact, IMHO, in general also this fix > > looks like an optimization, I mean when slicelength >= > > VARRAWSIZE_4B_C(value), then why do we need to allocate extra memory > > even in the case of pglz. So shall we put this check directly in > > toast_decompress_datum_slice instead of handling it at the lz4 level? > > Yeah, I thought about that too, but do we want to assume that > VARRAWSIZE_4B_C is the correct way to get the decompressed size > for all compression methods? I think it's OK to assume this. If and when we add a third compression method, it seems certain to just grab one of the two remaining bit patterns. Now, things get a bit more complicated if and when we want to add a fourth method, because at that point you've got to ask yourself how comfortable you feel about stealing the last bit pattern for your feature. But, if the solution to that problem were to decide that whenever that last bit pattern is used, we will add an extra byte (or word) after va_tcinfo indicating the real compression method, then using VARRAWSIZE_4B_C here would still be correct. To imagine this decision being wrong, you have to posit a world in which one of the two remaining bit patterns for the high 2 bits cause the low 30 bits to be interpreted as something other than the size, which I guess is not totally impossible, but my first reaction is to think that such a design would be (1) hard to make work and (2) unnecessarily painful. > (If so, I think it would be better style to have a less opaque macro > name for the purpose.) Complaining about the name of one particular TOAST-related macro name seems a bit like complaining about the greenhouse gasses emitted by one particular car. They're pretty uniformly terrible. Does anyone really know when to use VARATT_IS_1B_E or VARATT_IS_4B_U or any of that cruft? Like, who decided that "is this varatt 1B E?" would be a perfectly reasonable way of asking "is this varlena is TOAST pointer?". While I'm complaining, it's hard to say enough bad things about the fact that we have 12 consecutive completely obscure macro definitions for which the only comments are (a) that they are endian-dependent - which isn't even true for all of them - and (b) that they are "considered internal." Apparently, they're SO internal that they don't even need to be understandable to other developers. Anyway, this particular macro name was chosen, it seems, for symmetry with VARDATA_4B_C, but if you want to change it to something else, I'm OK with that, too. -- Robert Haas EDB: http://www.enterprisedb.com
Robert Haas <robertmhaas@gmail.com> writes:
> On Mon, Mar 22, 2021 at 10:41 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Yeah, I thought about that too, but do we want to assume that
>> VARRAWSIZE_4B_C is the correct way to get the decompressed size
>> for all compression methods?
> I think it's OK to assume this.
OK, cool.
>> (If so, I think it would be better style to have a less opaque macro
>> name for the purpose.)
> Complaining about the name of one particular TOAST-related macro name
> seems a bit like complaining about the greenhouse gasses emitted by
> one particular car.
Maybe, but that's not a reason to make it worse. Anyway, my understanding
of that is that the really opaque names are *only* meant to be used in
this very stretch of postgres.h, ie they are just intermediate steps on
the way to the macros below them. As an example, the only use of
VARDATA_1B_E() is in VARDATA_EXTERNAL().
> Anyway, this particular macro name was chosen, it seems, for symmetry
> with VARDATA_4B_C, but if you want to change it to something else, I'm
> OK with that, too.
After looking at postgres.h for a bit, I'm thinking that what these
should have been symmetric with is the considerably-less-terrible
names used for the corresponding VARATT_EXTERNAL cases. Thus,
something like
s/VARRAWSIZE_4B_C/VARDATA_COMPRESSED_GET_RAWSIZE/
s/VARCOMPRESS_4B_C/VARDATA_COMPRESSED_GET_COMPRESSION/
Possibly the former names should survive and the latter become
wrappers around them, not sure. But we shouldn't be using the "4B"
terminology anyplace except this part of postgres.h.
regards, tom lane
On Mon, Mar 22, 2021 at 11:48 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Anyway, this particular macro name was chosen, it seems, for symmetry > > with VARDATA_4B_C, but if you want to change it to something else, I'm > > OK with that, too. > > After looking at postgres.h for a bit, I'm thinking that what these > should have been symmetric with is the considerably-less-terrible > names used for the corresponding VARATT_EXTERNAL cases. Thus, > something like > > s/VARRAWSIZE_4B_C/VARDATA_COMPRESSED_GET_RAWSIZE/ > s/VARCOMPRESS_4B_C/VARDATA_COMPRESSED_GET_COMPRESSION/ Works for me. > Possibly the former names should survive and the latter become > wrappers around them, not sure. But we shouldn't be using the "4B" > terminology anyplace except this part of postgres.h. I would argue that it shouldn't be used any place at all, and that we ought to go the other direction and get rid of the existing macros - e.g. change #define VARATT_IS_1B_E to #define VARATT_IS_EXTERNAL instead of defining the latter as a no-value-added wrapper around the former. Maybe at one time somebody thought that the test for VARATT_IS_EXTERNAL might someday have more cases than just VARATT_IS_1B_E, but that's not looking like a good bet in 2021. -- Robert Haas EDB: http://www.enterprisedb.com
Robert Haas <robertmhaas@gmail.com> writes:
> On Mon, Mar 22, 2021 at 11:48 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Possibly the former names should survive and the latter become
>> wrappers around them, not sure. But we shouldn't be using the "4B"
>> terminology anyplace except this part of postgres.h.
> I would argue that it shouldn't be used any place at all, and that we
> ought to go the other direction and get rid of the existing macros -
> e.g. change #define VARATT_IS_1B_E to #define VARATT_IS_EXTERNAL
> instead of defining the latter as a no-value-added wrapper around the
> former. Maybe at one time somebody thought that the test for
> VARATT_IS_EXTERNAL might someday have more cases than just
> VARATT_IS_1B_E, but that's not looking like a good bet in 2021.
Maybe. I think the original idea was exactly what the comment says,
to have a layer of macros that'd deal with endianness issues and no more.
That still seems like a reasonable plan to me, though perhaps it wasn't
executed very well.
regards, tom lane
On Mon, Mar 22, 2021 at 11:13 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > The first iteration was pretty rough, and there's still some question in my > mind about where default_toast_compression_options[] should be defined. If > it's in the header file, then I could use lengthof() - but then it probably > gets multiply defined. What do you want to use lengthof() for? > In the latest patch, there's multiple "externs". Maybe > guc.c doesn't need the extern, since it includes toast_compression.h. But then > it's the only "struct config_enum_entry" which has an "extern" outside of > guc.c. Oh, yeah, we certainly shouldn't have an extern in guc.c itself, if we've already got it in the header file. As to the more general question of where to put stuff, I don't think there's any conceptual problem with putting it in a header file rather than in guc.c. It's not very scalable to just keeping inventing new GUCs and sticking all their accoutrement into guc.c. That might have kind of made sense when guc.c was invented, since there were probably fewer settings there and guc.c itself was new, but at this point it's a well-established part of the infrastructure and having other subsystems cater to what it needs rather than the other way around seems logical. However, it's not great to have "utils/guc.h" included in "access/toast_compression.h", because then anything that includes "access/toast_compression.h" or "access/toast_internals.h" sucks in "utils/guc.h" even though it's not really topically related to what they intended to include. We can't avoid that just by choosing to put this enum in guc.c, because GetDefaultToastCompression() also uses it. But, what about giving the default_toast_compression_method GUC an assign hook that sets a global variable of type "char" to the appropriate value? Then GetDefaultToastCompression() goes away entirely. That might be worth exploring. > Also, it looks like you added default_toast_compression out of order, so maybe > you'd fix that at the same time. You know, I looked at where you had it and said to myself, "surely this is a silly place to put this, it would make much more sense to move this up a bit." Now I feel dumb. -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Mar 22, 2021 at 12:16 PM Robert Haas <robertmhaas@gmail.com> wrote: > But, what about giving the default_toast_compression_method GUC an > assign hook that sets a global variable of type "char" to the > appropriate value? Then GetDefaultToastCompression() goes away > entirely. That might be worth exploring. Actually, we can do even better. We should just make the values actually assigned to the GUC be TOAST_PGLZ_COMPRESSION etc. rather than TOAST_PGLZ_COMPRESSION_ID etc. Then a whole lot of complexity just goes away. I added some comments explaining why using TOAST_PGLZ_COMPRESSION is the wrong thing anyway. Then I got hacking and rearranged a few other things. So the attached patch does these thing: - Changes default_toast_compression to an enum, as in your patch, but now with values that are the same as what ultimately gets stored in attcompression. - Adds a comment warning against incautious use of TOAST_PGLZ_COMPRESSION_ID, etc. - Moves default_toast_compression_options to guc.c. - After doing the above two things, we can remove the #include of utils/guc.h into access/toast_compression.h, so the patch does that. - Moves NO_LZ4_SUPPORT, GetCompressionMethodName, and CompressionNameToMethod to guc.c. Making these inline functions doesn't save anything meaningful; it's more important not to export a bunch of random identifiers. - Removes an unnecessary cast to bool from the definition of CompressionMethodIsValid. I think this is significantly cleaner than what we have now, and I also prefer it to your proposal. Comments? -- Robert Haas EDB: http://www.enterprisedb.com
Attachment
Robert Haas <robertmhaas@gmail.com> writes:
> I think this is significantly cleaner than what we have now, and I
> also prefer it to your proposal.
+1 in general. However, I suspect that you did not try to compile
this without --with-lz4, because if you had you'd have noticed the
other uses of NO_LZ4_SUPPORT() that you broke. I think you need
to leave that macro where it is. Also, it's not nice for GUC check
functions to throw ereport(ERROR); we prefer the caller to be able
to decide if it's a hard error or not. That usage should be using
GUC_check_errdetail() or a cousin, so it can't share the macro anyway.
regards, tom lane
On Mon, Mar 22, 2021 at 2:10 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: > > I think this is significantly cleaner than what we have now, and I > > also prefer it to your proposal. > > +1 in general. However, I suspect that you did not try to compile > this without --with-lz4, because if you had you'd have noticed the > other uses of NO_LZ4_SUPPORT() that you broke. I think you need > to leave that macro where it is. You're correct that I hadn't tried this without --with-lz4, but I did grep for other uses of NO_LZ4_SUPPORT() and found none. I also just tried it without --with-lz4 just now, and it worked fine. > Also, it's not nice for GUC check > functions to throw ereport(ERROR); we prefer the caller to be able > to decide if it's a hard error or not. That usage should be using > GUC_check_errdetail() or a cousin, so it can't share the macro anyway. I agree that these are valid points about GUC check functions in general, but the patch I sent adds 0 GUC check functions and removes 1, and it didn't do the stuff you describe here anyway. Are you sure you're looking at the patch I sent, toast-compression-guc-rmh.patch? I can't help wondering if you applied it to a dirty source tree or got the wrong file or something, because otherwise I don't understand why you're seeing things that I'm not seeing. -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Mar 22, 2021 at 1:58 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > guc.c should not longer define this as extern: > default_toast_compression_options Fixed. > I think you should comment that default_toast_compression is an int as far as > guc.c is concerned, but storing one of the char value of TOAST_*_COMPRESSION Done. > Shouldn't varlena.c pg_column_compression() call GetCompressionMethodName () ? > I guess it should already have done that. It has a 0-3 integer, not a char value. > Maybe pg_dump.c can't use those constants, though (?) Hmm, toast_compression.h might actually be safe for frontend code now, or if necessary we could add #ifdef FRONTEND stanzas to make it so. I don't know if that is really this patch's job, but I guess it could be. A couple of other things: - Upon further reflection, I think the NO_LZ4_SUPPORT() message is kinda not great. I'm thinking we should change it to say "LZ4 is not supported by this build" instead of "unsupported LZ4 compression method" and drop the hint and detail. That seems more like how we've handled other such cases. - It is not very nice that the three possible values of attcompression are TOAST_PGLZ_COMPRESSION, TOAST_LZ4_COMPRESSION, and InvalidCompressionMethod. One of those three identifiers looks very little like the other two, and there's no real good reason for that. I think we should try to standardize on something, but I'm not sure what it should be. It would also be nice if these names were more visually distinct from the related but very different enum values TOAST_PGLZ_COMPRESSION_ID and TOAST_LZ4_COMPRESSION_ID. Really, as the comments I added explain, we want to minimize the amount of code that knows about the 0-3 "ID" values, and use the char values whenever we can. -- Robert Haas EDB: http://www.enterprisedb.com
Attachment
On Mon, Mar 22, 2021 at 4:33 PM Robert Haas <robertmhaas@gmail.com> wrote: > On Mon, Mar 22, 2021 at 1:58 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > guc.c should not longer define this as extern: > > default_toast_compression_options > > Fixed. Fixed some more. -- Robert Haas EDB: http://www.enterprisedb.com
Attachment
On Mon, Mar 22, 2021 at 03:47:58PM -0400, Robert Haas wrote:
> On Mon, Mar 22, 2021 at 2:10 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> > Robert Haas <robertmhaas@gmail.com> writes:
> > > I think this is significantly cleaner than what we have now, and I
> > > also prefer it to your proposal.
> >
> > +1 in general. However, I suspect that you did not try to compile
> > this without --with-lz4, because if you had you'd have noticed the
> > other uses of NO_LZ4_SUPPORT() that you broke. I think you need
> > to leave that macro where it is.
>
> You're correct that I hadn't tried this without --with-lz4, but I did
> grep for other uses of NO_LZ4_SUPPORT() and found none. I also just
> tried it without --with-lz4 just now, and it worked fine.
>
> > Also, it's not nice for GUC check
> > functions to throw ereport(ERROR); we prefer the caller to be able
> > to decide if it's a hard error or not. That usage should be using
> > GUC_check_errdetail() or a cousin, so it can't share the macro anyway.
>
> I agree that these are valid points about GUC check functions in
> general, but the patch I sent adds 0 GUC check functions and removes
> 1, and it didn't do the stuff you describe here anyway.
>
> Are you sure you're looking at the patch I sent,
> toast-compression-guc-rmh.patch? I can't help wondering if you applied
> it to a dirty source tree or got the wrong file or something, because
> otherwise I don't understand why you're seeing things that I'm not
> seeing.
I'm guessing Tom read this hunk as being changes to
check_default_toast_compression() rather than removing the function ?
- * Validate a new value for the default_toast_compression GUC.
+ * CompressionNameToMethod - Get compression method from compression name
+ *
+ * Search in the available built-in methods. If the compression not found
+ * in the built-in methods then return InvalidCompressionMethod.
*/
-bool
-check_default_toast_compression(char **newval, void **extra, GucSource source)
+char
+CompressionNameToMethod(const char *compression)
{
- if (**newval == '\0')
+ if (strcmp(compression, "pglz") == 0)
+ return TOAST_PGLZ_COMPRESSION;
+ else if (strcmp(compression, "lz4") == 0)
{
- GUC_check_errdetail("%s cannot be empty.",
- "default_toast_compression");
- return false;
+#ifndef USE_LZ4
+ NO_LZ4_SUPPORT();
+#endif
+ return TOAST_LZ4_COMPRESSION;
--
Justin
Justin Pryzby <pryzby@telsasoft.com> writes:
> On Mon, Mar 22, 2021 at 03:47:58PM -0400, Robert Haas wrote:
>> Are you sure you're looking at the patch I sent,
>> toast-compression-guc-rmh.patch? I can't help wondering if you applied
>> it to a dirty source tree or got the wrong file or something, because
>> otherwise I don't understand why you're seeing things that I'm not
>> seeing.
> I'm guessing Tom read this hunk as being changes to
> check_default_toast_compression() rather than removing the function ?
Yeah, after looking closer, the diff looks like
check_default_toast_compression is being modified in-place,
whereas actually it's getting replaced by CompressionNameToMethod
which does something entirely different. I'd also not looked
closely enough at where NO_LZ4_SUPPORT() was being moved to.
My apologies --- I can only plead -ENOCAFFEINE.
regards, tom lane
On Fri, Mar 19, 2021 at 2:44 PM Robert Haas <robertmhaas@gmail.com> wrote: > > I committed the core patch (0003) with a bit more editing. Let's see > what the buildfarm thinks. > I think this is bbe0a81db69bd10bd166907c3701492a29aca294, right? This introduced a new assert failure, steps to reproduce: """ create table t1 (col1 text, col2 text); create unique index on t1 ((col1 || col2)); insert into t1 values((select array_agg(md5(g::text))::text from generate_series(1, 256) g), version()); """ Attached is a backtrace from current HEAD -- Jaime Casanova Director de Servicios Profesionales SYSTEMGUARDS - Consultores de PostgreSQL
Attachment
On Wed, Mar 24, 2021 at 1:22 PM Jaime Casanova <jcasanov@systemguards.com.ec> wrote: > > On Fri, Mar 19, 2021 at 2:44 PM Robert Haas <robertmhaas@gmail.com> wrote: > > > > I committed the core patch (0003) with a bit more editing. Let's see > > what the buildfarm thinks. > > > > I think this is bbe0a81db69bd10bd166907c3701492a29aca294, right? > This introduced a new assert failure, steps to reproduce: > > """ > create table t1 (col1 text, col2 text); > create unique index on t1 ((col1 || col2)); > insert into t1 values((select array_agg(md5(g::text))::text from > generate_series(1, 256) g), version()); > """ > > Attached is a backtrace from current HEAD Thanks for reporting this issue. Actually, I missed setting the attcompression for the expression index and that is causing this assert. I will send a patch in some time. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Mar 24, 2021 at 1:43 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > """ > > create table t1 (col1 text, col2 text); > > create unique index on t1 ((col1 || col2)); > > insert into t1 values((select array_agg(md5(g::text))::text from > > generate_series(1, 256) g), version()); > > """ > > > > Attached is a backtrace from current HEAD > > Thanks for reporting this issue. Actually, I missed setting the > attcompression for the expression index and that is causing this > assert. I will send a patch in some time. PFA, patch to fix the issue. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Mar 24, 2021 at 2:49 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > On Wed, Mar 24, 2021 at 02:24:41PM +0530, Dilip Kumar wrote: > > On Wed, Mar 24, 2021 at 1:43 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > create table t1 (col1 text, col2 text); > > > > create unique index on t1 ((col1 || col2)); > > > > insert into t1 values((select array_agg(md5(g::text))::text from > > > > generate_series(1, 256) g), version()); > > > > > > > > Attached is a backtrace from current HEAD > > > > > > Thanks for reporting this issue. Actually, I missed setting the > > > attcompression for the expression index and that is causing this > > > assert. I will send a patch in some time. > > > > PFA, patch to fix the issue. > > Could you include a test case exercizing this code path ? > Like Jaime's reproducer. I will do that. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Mar 24, 2021 at 3:10 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Wed, Mar 24, 2021 at 2:49 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > > On Wed, Mar 24, 2021 at 02:24:41PM +0530, Dilip Kumar wrote: > > > On Wed, Mar 24, 2021 at 1:43 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > > create table t1 (col1 text, col2 text); > > > > > create unique index on t1 ((col1 || col2)); > > > > > insert into t1 values((select array_agg(md5(g::text))::text from > > > > > generate_series(1, 256) g), version()); > > > > > > > > > > Attached is a backtrace from current HEAD > > > > > > > > Thanks for reporting this issue. Actually, I missed setting the > > > > attcompression for the expression index and that is causing this > > > > assert. I will send a patch in some time. > > > > > > PFA, patch to fix the issue. > > > > Could you include a test case exercizing this code path ? > > Like Jaime's reproducer. > > I will do that. 0001 ->shows compression method for the index attribute in index describe 0002 -> fix the reported bug (test case included) Apart from this, I was thinking that currently, we are allowing to ALTER SET COMPRESSION only for the table and matview, IMHO it makes sense to allow to alter the compression method for the index column as well? I mean it is just a one-line change, but just wanted to know the opinion from others. It is not required for the storage because indexes can not have a toast table but index attributes can be compressed so it makes sense to allow to alter the compression method. Thought? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Mar 24, 2021 at 3:40 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > 0001 ->shows compression method for the index attribute in index describe > 0002 -> fix the reported bug (test case included) > > Apart from this, I was thinking that currently, we are allowing to > ALTER SET COMPRESSION only for the table and matview, IMHO it makes > sense to allow to alter the compression method for the index column as > well? I mean it is just a one-line change, but just wanted to know > the opinion from others. It is not required for the storage because > indexes can not have a toast table but index attributes can be > compressed so it makes sense to allow to alter the compression method. > Thought? I have anyway created a patch for this as well. Including all three patches so we don't lose track. 0001 ->shows compression method for the index attribute in index describe 0002 -> fix the reported bug (test case included) (optional) 0003-> Alter set compression for index column -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Mar 24, 2021 at 7:45 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > I have anyway created a patch for this as well. Including all three > patches so we don't lose track. > > 0001 ->shows compression method for the index attribute in index describe > 0002 -> fix the reported bug (test case included) > (optional) 0003-> Alter set compression for index column As I understand it, the design idea here up until now has been that the index's attcompression values are irrelevant and ignored and that any compression which happens for index attributes is based either on the table attribute's assigned attcompression value, or the default. If that's the idea, then all of these patches are wrong. Now, a possible alternative design would be that the index's attcompression controls compression for the index same as a table's does for the table. But in that case, it seems to me that these patches are insufficient, because then we'd also need to, for example, dump and restore the setting, which I don't think anything in these patches or the existing code will do. My vote, as of now, is for the first design, in which case you need to forget about trying to get pg_attribute to have the right contents - in fact, I think we should set all the values there to InvalidCompressionMethod to make sure we're not relying on them anywhere. And then you need to make sure that everything that tries to compress an index value uses the setting from the table column or the default, not the setting on the index column. -- Robert Haas EDB: http://www.enterprisedb.com
On Wed, Mar 24, 2021 at 8:41 PM Robert Haas <robertmhaas@gmail.com> wrote: > > On Wed, Mar 24, 2021 at 7:45 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > I have anyway created a patch for this as well. Including all three > > patches so we don't lose track. > > > > 0001 ->shows compression method for the index attribute in index describe > > 0002 -> fix the reported bug (test case included) > > (optional) 0003-> Alter set compression for index column > > As I understand it, the design idea here up until now has been that > the index's attcompression values are irrelevant and ignored and that > any compression which happens for index attributes is based either on > the table attribute's assigned attcompression value, or the default. > If that's the idea, then all of these patches are wrong. The current design is that whenever we create an index, the index's attribute copies the attcompression from the table's attribute. And, while compressing the index tuple we will use the attcompression from the index attribute. > Now, a possible alternative design would be that the index's > attcompression controls compression for the index same as a table's > does for the table. But in that case, it seems to me that these > patches are insufficient, because then we'd also need to, for example, > dump and restore the setting, which I don't think anything in these > patches or the existing code will do. Yeah, you are right. > My vote, as of now, is for the first design, in which case you need to > forget about trying to get pg_attribute to have the right contents - > in fact, I think we should set all the values there to > InvalidCompressionMethod to make sure we're not relying on them > anywhere. And then you need to make sure that everything that tries to > compress an index value uses the setting from the table column or the > default, not the setting on the index column. Okay, that sounds like a reasonable design idea. But the problem is that in index_form_tuple we only have index tuple descriptor, not the heap tuple descriptor. Maybe we will have to pass the heap tuple descriptor as a parameter to index_form_tuple. I will think more about this that how can we do that. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Andrew Dunstan <andrew@dunslane.net> writes:
> On 3/20/21 3:03 PM, Tom Lane wrote:
>> I fixed up some issues in 0008/0009 (mostly cosmetic, except that
>> you forgot a server version check in dumpToastCompression) and
>> pushed that, so we can see if it makes crake happy.
> It's still produced a significant amount more difference between the
> dumps. For now I've increased the fuzz factor a bit like this:
> - if ( ($oversion ne $this_branch && $difflines < 2000)
> + if ( ($oversion ne $this_branch && $difflines < 2700)
> I'll try to come up with something better. Maybe just ignore lines like
> SET default_toast_compression = 'pglz';
> when taking the diff.
I see that some other buildfarm animals besides your own critters
are still failing the xversion tests, presumably because they lack
this hack :-(.
On reflection, though, I wonder if we've made pg_dump do the right
thing anyway. There is a strong case to be made for the idea that
when dumping from a pre-14 server, it should emit
SET default_toast_compression = 'pglz';
rather than omitting any mention of the variable, which is what
I made it do in aa25d1089. If we changed that, I think all these
diffs would go away. Am I right in thinking that what's being
compared here is new pg_dump's dump from old server versus new
pg_dump's dump from new server?
The "strong case" goes like this: initdb a v14 cluster, change
default_toast_compression to lz4 in its postgresql.conf, then
try to pg_upgrade from an old server. If the dump script doesn't
set default_toast_compression = 'pglz' then the upgrade will
do the wrong thing because all the tables will be recreated with
a different behavior than they had before. IIUC, this wouldn't
result in broken data, but it still seems to me to be undesirable.
dump/restore ought to do its best to preserve the old DB state,
unless you explicitly tell it --no-toast-compression or the like.
regards, tom lane
On Wed, Mar 24, 2021 at 11:41 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > Okay, that sounds like a reasonable design idea. But the problem is > that in index_form_tuple we only have index tuple descriptor, not the > heap tuple descriptor. Maybe we will have to pass the heap tuple > descriptor as a parameter to index_form_tuple. I will think more > about this that how can we do that. Another option might be to decide that the pg_attribute tuples for the index columns always have to match the corresponding table columns. So, if you alter with ALTER TABLE, it runs around and updates all of the indexes to match. For expression index columns, we could store InvalidCompressionMethod, causing index_form_tuple() to substitute the run-time default. That kinda sucks, because it's a significant impediment to ever reducing the lock level for ALTER TABLE .. ALTER COLUMN .. SET COMPRESSION, but I'm not sure we have the luxury of worrying about that problem right now. -- Robert Haas EDB: http://www.enterprisedb.com
On Wed, Mar 24, 2021 at 9:32 PM Robert Haas <robertmhaas@gmail.com> wrote: > > On Wed, Mar 24, 2021 at 11:41 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > Okay, that sounds like a reasonable design idea. But the problem is > > that in index_form_tuple we only have index tuple descriptor, not the > > heap tuple descriptor. Maybe we will have to pass the heap tuple > > descriptor as a parameter to index_form_tuple. I will think more > > about this that how can we do that. > > Another option might be to decide that the pg_attribute tuples for the > index columns always have to match the corresponding table columns. > So, if you alter with ALTER TABLE, it runs around and updates all of > the indexes to match. For expression index columns, we could store > InvalidCompressionMethod, causing index_form_tuple() to substitute the > run-time default. That kinda sucks, because it's a significant > impediment to ever reducing the lock level for ALTER TABLE .. ALTER > COLUMN .. SET COMPRESSION, but I'm not sure we have the luxury of > worrying about that problem right now. Actually, we are already doing this, I mean ALTER TABLE .. ALTER COLUMN .. SET COMPRESSION is already updating the compression method of the index attribute. So 0003 doesn't make sense, sorry for the noise. However, 0001 and 0002 are still valid, or do you think that we don't want 0001 also? If we don't need 0001 also then we need to update the test output for 0002 slightly. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Mar 24, 2021 at 11:42 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > On reflection, though, I wonder if we've made pg_dump do the right > thing anyway. There is a strong case to be made for the idea that > when dumping from a pre-14 server, it should emit > SET default_toast_compression = 'pglz'; > rather than omitting any mention of the variable, which is what > I made it do in aa25d1089. If we changed that, I think all these > diffs would go away. Am I right in thinking that what's being > compared here is new pg_dump's dump from old server versus new > pg_dump's dump from new server? > > The "strong case" goes like this: initdb a v14 cluster, change > default_toast_compression to lz4 in its postgresql.conf, then > try to pg_upgrade from an old server. If the dump script doesn't > set default_toast_compression = 'pglz' then the upgrade will > do the wrong thing because all the tables will be recreated with > a different behavior than they had before. IIUC, this wouldn't > result in broken data, but it still seems to me to be undesirable. > dump/restore ought to do its best to preserve the old DB state, > unless you explicitly tell it --no-toast-compression or the like. This feels a bit like letting the tail wag the dog, because one might reasonably guess that the user's intention in such a case was to switch to using LZ4, and we've subverted that intention by deciding that we know better. I wouldn't blame someone for thinking that using --no-toast-compression with a pre-v14 server ought to have no effect, but with your proposal here, it would. Furthermore, IIUC, the user has no way of passing --no-toast-compression through to pg_upgrade, so they're just going to have to do the upgrade and then fix everything manually afterward to the state that they intended to have all along. Now, on the other hand, if they wanted to make practically any other kind of change while upgrading, they'd have to do something like that anyway, so I guess this is no worse. But also ... aren't we just doing this to work around a test case that isn't especially good in the first place? Counting the number of lines in the diff between A and B is an extremely crude proxy for "they're similar enough that we probably haven't broken anything." -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Mar 22, 2021 at 4:57 PM Robert Haas <robertmhaas@gmail.com> wrote: > > Fixed. > > Fixed some more. Committed. -- Robert Haas EDB: http://www.enterprisedb.com
Robert Haas <robertmhaas@gmail.com> writes:
> On Wed, Mar 24, 2021 at 11:42 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> On reflection, though, I wonder if we've made pg_dump do the right
>> thing anyway. There is a strong case to be made for the idea that
>> when dumping from a pre-14 server, it should emit
>> SET default_toast_compression = 'pglz';
>> rather than omitting any mention of the variable, which is what
>> I made it do in aa25d1089.
> But also ... aren't we just doing this to work around a test case that
> isn't especially good in the first place? Counting the number of lines
> in the diff between A and B is an extremely crude proxy for "they're
> similar enough that we probably haven't broken anything."
I wouldn't be proposing this if the xversion failures were the only
reason; making them go away is just a nice side-effect. The core
point is that the charter of pg_dump is to reproduce the source
database's state, and as things stand we're failing to ensure we
do that.
(But yeah, we really need a better way of making this check in
the xversion tests. I don't like the arbitrary "n lines of diff
is probably OK" business one bit.)
regards, tom lane
On Wed, Mar 24, 2021 at 12:45 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > I wouldn't be proposing this if the xversion failures were the only > reason; making them go away is just a nice side-effect. The core > point is that the charter of pg_dump is to reproduce the source > database's state, and as things stand we're failing to ensure we > do that. Well, that state is just a mental construct, right? In reality, there is no such state stored anywhere in the old database. You're choosing to attribute to it an implicit state that matches what would need to be configured in the newer version to get the same behavior, which is a reasonable thing to do, but it is an interpretive choice rather than a bare fact. I don't care very much if you want to change this, but to me it seems slightly worse than the status quo. It's hard to imagine that someone is going to create a new cluster, set the default to lz4, run pg_upgrade, and then complain that the new columns ended up with lz4 as the default. It seems much more likely that they're going to complain if the new columns *don't* end up with lz4 as the default. And I also can't see any other scenario where imagining that the TOAST compression property of the old database simply does not exist, rather than being pglz implicitly, is worse. But I could be wrong, and even if I'm right it's not a hill upon which I wish to die. -- Robert Haas EDB: http://www.enterprisedb.com
On Wed, Mar 24, 2021 at 12:24:38PM -0400, Robert Haas wrote: > On Wed, Mar 24, 2021 at 11:42 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > On reflection, though, I wonder if we've made pg_dump do the right > > thing anyway. There is a strong case to be made for the idea that > > when dumping from a pre-14 server, it should emit > > SET default_toast_compression = 'pglz'; > > rather than omitting any mention of the variable, which is what > > I made it do in aa25d1089. If we changed that, I think all these > > diffs would go away. Am I right in thinking that what's being > > compared here is new pg_dump's dump from old server versus new > > pg_dump's dump from new server? > > > > The "strong case" goes like this: initdb a v14 cluster, change > > default_toast_compression to lz4 in its postgresql.conf, then > > try to pg_upgrade from an old server. If the dump script doesn't > > set default_toast_compression = 'pglz' then the upgrade will > > do the wrong thing because all the tables will be recreated with > > a different behavior than they had before. IIUC, this wouldn't > > result in broken data, but it still seems to me to be undesirable. > > dump/restore ought to do its best to preserve the old DB state, > > unless you explicitly tell it --no-toast-compression or the like. > > This feels a bit like letting the tail wag the dog, because one might > reasonably guess that the user's intention in such a case was to > switch to using LZ4, and we've subverted that intention by deciding > that we know better. I wouldn't blame someone for thinking that using > --no-toast-compression with a pre-v14 server ought to have no effect, > but with your proposal here, it would. Furthermore, IIUC, the user has > no way of passing --no-toast-compression through to pg_upgrade, so > they're just going to have to do the upgrade and then fix everything > manually afterward to the state that they intended to have all along. > Now, on the other hand, if they wanted to make practically any other > kind of change while upgrading, they'd have to do something like that > anyway, so I guess this is no worse. I think it's not specific to pg_upgrade, but any pg_dump |pg_restore. The analogy with tablespaces is restoring from a cluster where the tablespace is named "vast" to one where it's named "huge". I do this by running PGOPTIONS=-cdefault_tablespace=huge pg_restore --no-tablespaces So I thinks as long as --no-toast-compression does the corresponding thing, the "restore with alternate compression" case is handled fine. -- Justin
On Wed, Mar 24, 2021 at 12:14 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > Actually, we are already doing this, I mean ALTER TABLE .. ALTER > COLUMN .. SET COMPRESSION is already updating the compression method > of the index attribute. So 0003 doesn't make sense, sorry for the > noise. However, 0001 and 0002 are still valid, or do you think that > we don't want 0001 also? If we don't need 0001 also then we need to > update the test output for 0002 slightly. It seems to me that 0002 is still not right. We can't fix the attcompression to whatever the default is at the time the index is created, because the default can be changed later, and there's no way to fix index afterward. I mean, it would be fine to do it that way if we were going to go with the other model, where the index state is separate from the table state, either can be changed independently, and it all gets dumped and restored. But, as it is, I think we should be deciding how to compress new values for an expression column based on the default_toast_compression setting at the time of compression, not the time of index creation. -- Robert Haas EDB: http://www.enterprisedb.com
On Wed, Mar 24, 2021 at 1:24 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > I think it's not specific to pg_upgrade, but any pg_dump |pg_restore. > > The analogy with tablespaces is restoring from a cluster where the tablespace > is named "vast" to one where it's named "huge". I do this by running > PGOPTIONS=-cdefault_tablespace=huge pg_restore --no-tablespaces > > So I thinks as long as --no-toast-compression does the corresponding thing, the > "restore with alternate compression" case is handled fine. I think you might be missing the point. If you're using pg_dump and pg_restore, you can pass --no-toast-compression if you want. But if you're using pg_upgrade, and it's internally calling pg_dump --binary-upgrade, then you don't have control over what options get passed. So --no-toast-compression is just fine for people who are dumping and restoring, but it's no help at all if you want to switch TOAST compression methods while doing a pg_upgrade. However, what does help with that is sticking with what Tom committed before rather than changing to what he's proposing now. If you like his current proposal, that's fine with me, as long as we're on the same page about what happens if we adopt it. -- Robert Haas EDB: http://www.enterprisedb.com
Justin Pryzby <pryzby@telsasoft.com> writes:
> On Wed, Mar 24, 2021 at 01:30:26PM -0400, Robert Haas wrote:
>> ... So --no-toast-compression is just fine for people who are
>> dumping and restoring, but it's no help at all if you want to switch
>> TOAST compression methods while doing a pg_upgrade. However, what does
>> help with that is sticking with what Tom committed before rather than
>> changing to what he's proposing now.
> I don't know what/any other cases support using pg_upgrade to change stuff like
> the example (changing to lz4). The way to do it is to make the changes either
> before or after. It seems weird to think that pg_upgrade would handle that.
Yeah; I think the charter of pg_upgrade is to reproduce the old database
state. If you try to twiddle the process to incorporate some changes
in that state, maybe it will work, but if it breaks you get to keep both
pieces. I surely don't wish to consider such shenanigans as supported.
But let's ignore the case of pg_upgrade and just consider a dump/restore.
I'd still say that unless you give --no-toast-compression then I would
expect the dump/restore to preserve the tables' old compression behavior.
Robert's argument that the pre-v14 database had no particular compression
behavior seems nonsensical to me. We know exactly which compression
behavior it has.
regards, tom lane
On Wed, Mar 24, 2021 at 10:57 PM Robert Haas <robertmhaas@gmail.com> wrote: > > On Wed, Mar 24, 2021 at 12:14 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > Actually, we are already doing this, I mean ALTER TABLE .. ALTER > > COLUMN .. SET COMPRESSION is already updating the compression method > > of the index attribute. So 0003 doesn't make sense, sorry for the > > noise. However, 0001 and 0002 are still valid, or do you think that > > we don't want 0001 also? If we don't need 0001 also then we need to > > update the test output for 0002 slightly. > > It seems to me that 0002 is still not right. We can't fix the > attcompression to whatever the default is at the time the index is > created, because the default can be changed later, and there's no way > to fix index afterward. I mean, it would be fine to do it that way if > we were going to go with the other model, where the index state is > separate from the table state, either can be changed independently, > and it all gets dumped and restored. But, as it is, I think we should > be deciding how to compress new values for an expression column based > on the default_toast_compression setting at the time of compression, > not the time of index creation. > Okay got it. Fixed as suggested. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Mar 24, 2021 at 2:15 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > But let's ignore the case of pg_upgrade and just consider a dump/restore. > I'd still say that unless you give --no-toast-compression then I would > expect the dump/restore to preserve the tables' old compression behavior. > Robert's argument that the pre-v14 database had no particular compression > behavior seems nonsensical to me. We know exactly which compression > behavior it has. I said that it didn't have a state, not that it didn't have a behavior. That's not exactly the same thing. But I don't want to argue about it, either. It's a judgement call what's best here, and I don't pretend to have all the answers. If you're sure you've got it right ... great! -- Robert Haas EDB: http://www.enterprisedb.com
On Thu, Mar 25, 2021 at 5:44 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > Okay got it. Fixed as suggested. Committed with a bit of editing of the comments. -- Robert Haas EDB: http://www.enterprisedb.com
On 3/24/21 12:45 PM, Tom Lane wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Wed, Mar 24, 2021 at 11:42 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> On reflection, though, I wonder if we've made pg_dump do the right >>> thing anyway. There is a strong case to be made for the idea that >>> when dumping from a pre-14 server, it should emit >>> SET default_toast_compression = 'pglz'; >>> rather than omitting any mention of the variable, which is what >>> I made it do in aa25d1089. >> But also ... aren't we just doing this to work around a test case that >> isn't especially good in the first place? Counting the number of lines >> in the diff between A and B is an extremely crude proxy for "they're >> similar enough that we probably haven't broken anything." > I wouldn't be proposing this if the xversion failures were the only > reason; making them go away is just a nice side-effect. The core > point is that the charter of pg_dump is to reproduce the source > database's state, and as things stand we're failing to ensure we > do that. > > (But yeah, we really need a better way of making this check in > the xversion tests. I don't like the arbitrary "n lines of diff > is probably OK" business one bit.) > > Well, I ran this module for years privately and used to have a matrix of the exact number of diff lines expected for each combination of source and target branch. If I didn't get that exact number of lines I reported an error on stderr. That was fine when we weren't reporting the results on the server, and I just sent an email to -hackers if I found an error. I kept this matrix by examining the diffs to make sure they were all benign. That was a pretty laborious process. So I decided to try a heuristic approach instead, and by trial and error came up with this 2000 lines measurement. When this appeared to be working and stable the module was released into the wild for other buildfarm owners to deploy. Nothing is hidden here - the diffs are reported, see for example <https://buildfarm.postgresql.org/cgi-bin/show_stage_log.pl?nm=crake&dt=2021-03-28%2015%3A37%3A07&stg=xversion-upgrade-REL9_4_STABLE-HEAD> What we're comparing here is target pg_dumpall against the original source vs target pg_dumpall against the upgraded source. If someone wants to come up with a better rule for detecting that nothing has gone wrong, I'll be happy to implement it. I don't particularly like the current rule either, it's there faute de mieux. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
On Sun, Mar 28, 2021 at 04:48:29PM -0400, Andrew Dunstan wrote: > Nothing is hidden here - the diffs are reported, see for example > <https://buildfarm.postgresql.org/cgi-bin/show_stage_log.pl?nm=crake&dt=2021-03-28%2015%3A37%3A07&stg=xversion-upgrade-REL9_4_STABLE-HEAD> > What we're comparing here is target pg_dumpall against the original > source vs target pg_dumpall against the upgraded source. The command being run is: https://github.com/PGBuildFarm/client-code/blob/master/PGBuild/Modules/TestUpgradeXversion.pm#L610 system( "diff -I '^-- ' -u $upgrade_loc/origin-$oversion.sql " . "$upgrade_loc/converted-$oversion-to-$this_branch.sql " . "> $upgrade_loc/dumpdiff-$oversion 2>&1"); ... my $difflines = `wc -l < $upgrade_loc/dumpdiff-$oversion`; where -I means: --ignore-matching-lines=RE I think wc -l should actually be grep -c '^[-+]' otherwise context lines count for as much as diff lines. You could write that with diff -U0 |wc -l, except the context is useful to humans. With some more effort, the number of lines of diff can be very small, allowing a smaller fudge factor. For upgrade from v10: time make -C src/bin/pg_upgrade check oldsrc=`pwd`/10 oldbindir=`pwd`/10/tmp_install/usr/local/pgsql/bin $ diff -u src/bin/pg_upgrade/tmp_check/dump1.sql src/bin/pg_upgrade/tmp_check/dump2.sql |wc -l 622 Without context: $ diff -u src/bin/pg_upgrade/tmp_check/dump1.sql src/bin/pg_upgrade/tmp_check/dump2.sql |grep -c '^[-+]' 142 Without comments: $ diff -I '^-- ' -u src/bin/pg_upgrade/tmp_check/dump1.sql src/bin/pg_upgrade/tmp_check/dump2.sql |grep -c '^[-+]' 130 Without SET default stuff: diff -I '^$' -I "SET default_table_access_method = heap;" -I "^SET default_toast_compression = 'pglz';$" -I '^-- ' -u /home/pryzbyj/src/postgres/src/bin/pg_upgrade/tmp_check/dump1.sql /home/pryzbyj/src/postgres/src/bin/pg_upgrade/tmp_check/dump2.sql|less |grep -c '^[-+]' 117 Without trigger function call noise: diff -I "^CREATE TRIGGER [_[:alnum:]]\+ .* FOR EACH \(ROW\|STATEMENT\) EXECUTE \(PROCEDURE\|FUNCTION\)" -I '^$' -I "SET default_table_access_method= heap;" -I "^SET default_toast_compression = 'pglz';$" -I '^-- ' -u /home/pryzbyj/src/postgres/src/bin/pg_upgrade/tmp_check/dump1.sql /home/pryzbyj/src/postgres/src/bin/pg_upgrade/tmp_check/dump2.sql|grep -c '^[-+]' 11 Maybe it's important not to totally ignore that, and instead perhaps clean up the known/accepted changes like s/FUNCTION/PROCEDURE/: </home/pryzbyj/src/postgres/src/bin/pg_upgrade/tmp_check/dump2.sql sed '/^CREATE TRIGGER/s/FUNCTION/PROCEDURE/' |diff -I'^$' -I "SET default_table_access_method = heap;" -I "^SET default_toast_compression = 'pglz';$" -I '^-- ' -u /home/pryzbyj/src/postgres/src/bin/pg_upgrade/tmp_check/dump1.sql- |grep -c '^[-+]' 11 It seems weird that we don't quote "heap" but we quote tablespaces and not toast compression methods. -- Justin
Robert Haas <robertmhaas@gmail.com> writes:
> On Wed, Mar 24, 2021 at 2:15 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> But let's ignore the case of pg_upgrade and just consider a dump/restore.
>> I'd still say that unless you give --no-toast-compression then I would
>> expect the dump/restore to preserve the tables' old compression behavior.
>> Robert's argument that the pre-v14 database had no particular compression
>> behavior seems nonsensical to me. We know exactly which compression
>> behavior it has.
> I said that it didn't have a state, not that it didn't have a
> behavior. That's not exactly the same thing. But I don't want to argue
> about it, either. It's a judgement call what's best here, and I don't
> pretend to have all the answers. If you're sure you've got it right
> ... great!
I've not heard any other comments about this, but I'm pretty sure that
preserving a table's old toast behavior is in line with what we'd normally
expect pg_dump to do --- especially in light of the fact that we did not
provide any --preserve-toast-compression switch to tell it to do so.
So I'm going to go change it.
regards, tom lane
On 3/30/21 10:30 AM, Tom Lane wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Wed, Mar 24, 2021 at 2:15 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> But let's ignore the case of pg_upgrade and just consider a dump/restore. >>> I'd still say that unless you give --no-toast-compression then I would >>> expect the dump/restore to preserve the tables' old compression behavior. >>> Robert's argument that the pre-v14 database had no particular compression >>> behavior seems nonsensical to me. We know exactly which compression >>> behavior it has. > >> I said that it didn't have a state, not that it didn't have a >> behavior. That's not exactly the same thing. But I don't want to argue >> about it, either. It's a judgement call what's best here, and I don't >> pretend to have all the answers. If you're sure you've got it right >> ... great! > > I've not heard any other comments about this, but I'm pretty sure that > preserving a table's old toast behavior is in line with what we'd normally > expect pg_dump to do --- especially in light of the fact that we did not > provide any --preserve-toast-compression switch to tell it to do so. > So I'm going to go change it. It looks like this CF entry should have been marked as committed so I did that. Regards, -- -David david@pgmasters.net
On Thu, Apr 8, 2021 at 11:32 AM David Steele <david@pgmasters.net> wrote: > It looks like this CF entry should have been marked as committed so I > did that. Thanks. Here's a patch for the doc update which was mentioned as an open item upthread. -- Robert Haas EDB: http://www.enterprisedb.com
Attachment
On Thu, Apr 8, 2021 at 3:38 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > It looks like this should not remove the word "data" ? Oh, yes, right. > The compression technique used for either in-line or out-of-line compressed > -data is a fairly simple and very fast member > -of the LZ family of compression techniques. See > -<filename>src/common/pg_lzcompress.c</filename> for the details. > +can be selected using the <literal>COMPRESSION</literal> option on a per-column > +basis when creating a table. The default for columns with no explicit setting > +is taken from the value of <xref linkend="guc-default-toast-compression" />. > > I thought this patch would need to update parts about borrowing 2 spare bits, > but maybe that's the wrong header..before. We're not borrowing any more bits from the places where we were borrowing 2 bits before. We are borrowing 2 bits from places that don't seem to be discussed in detail here, where no bits were borrowed before. -- Robert Haas EDB: http://www.enterprisedb.com