Re: [HACKERS] Custom compression methods - Mailing list pgsql-hackers
| From | Oleg Bartunov |
|---|---|
| Subject | Re: [HACKERS] Custom compression methods |
| Date | |
| Msg-id | CAF4Au4z-7_Ya4qO=PBK37dyY-Up+CqT0v_ucqXUV8Zanu4eNLw@mail.gmail.com Whole thread |
| In response to | Re: [HACKERS] Custom compression methods (Tomas Vondra <tomas.vondra@2ndquadrant.com>) |
| List | pgsql-hackers |
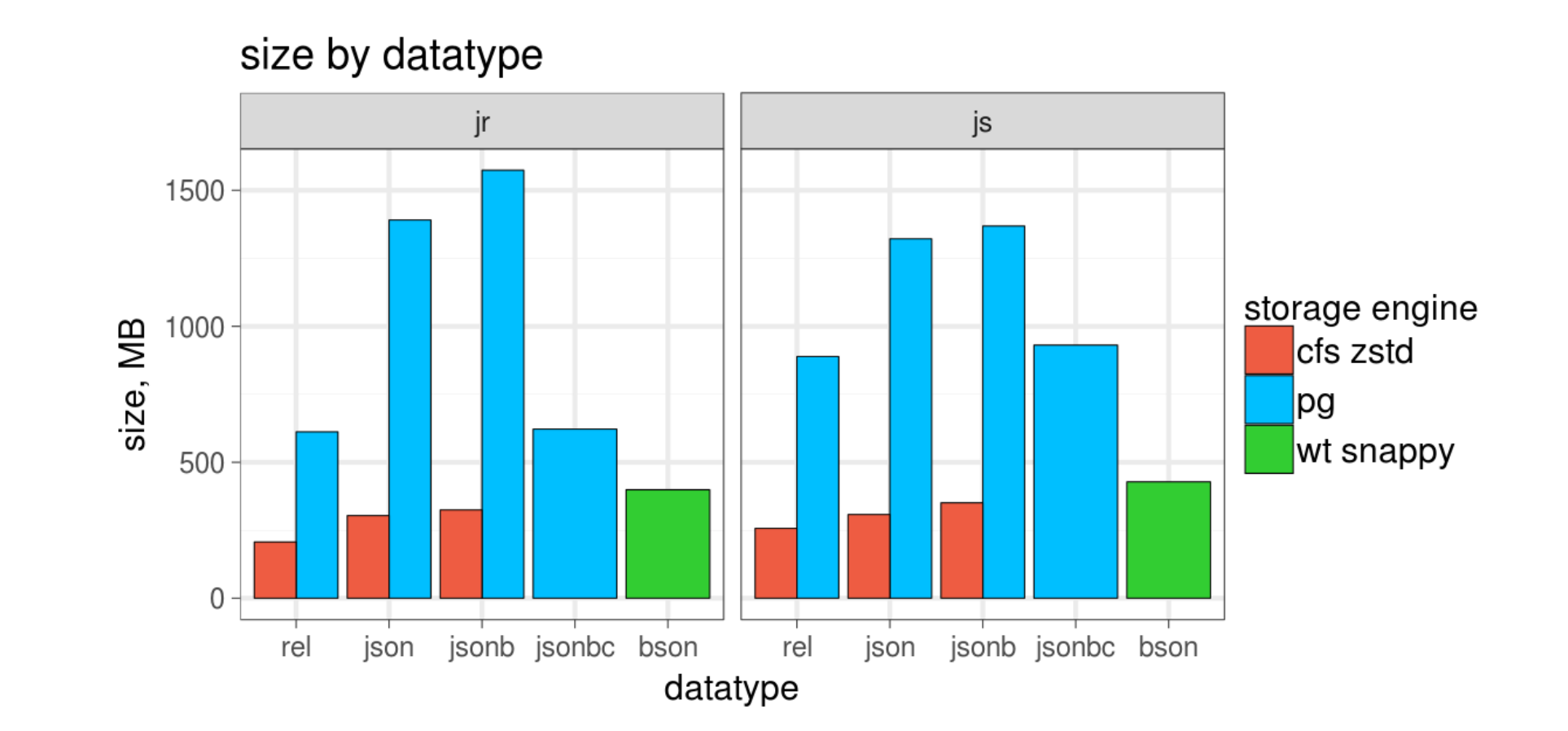
On Sat, Dec 2, 2017 at 6:04 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 12/01/2017 10:52 PM, Andres Freund wrote: >> On 2017-12-01 16:14:58 -0500, Robert Haas wrote: >>> Honestly, if we can give everybody a 4% space reduction by >>> switching to lz4, I think that's totally worth doing -- but let's >>> not make people choose it, let's make it the default going forward, >>> and keep pglz support around so we don't break pg_upgrade >>> compatibility (and so people can continue to choose it if for some >>> reason it works better in their use case). That kind of improvement >>> is nothing special in a specific workload, but TOAST is a pretty >>> general-purpose mechanism. I have become, through a few bitter >>> experiences, a strong believer in the value of trying to reduce our >>> on-disk footprint, and knocking 4% off the size of every TOAST >>> table in the world does not sound worthless to me -- even though >>> context-aware compression can doubtless do a lot better. >> >> +1. It's also a lot faster, and I've seen way way to many workloads >> with 50%+ time spent in pglz. >> > > TBH the 4% figure is something I mostly made up (I'm fake news!). On the > mailing list archive (which I believe is pretty compressible) I observed > something like 2.5% size reduction with lz4 compared to pglz, at least > with the compression levels I've used ... Nikita Glukhove tested compression on real json data: Delicious bookmarks (js): json 1322MB jsonb 1369MB jsonbc 931MB 1.5x jsonb+lz4d 404MB 3.4x Citus customer reviews (jr): json 1391MB jsonb 1574MB jsonbc 622MB 2.5x jsonb+lz4d 601MB 2.5x I also attached a plot with wired tiger size (zstd compression) in Mongodb. Nikita has more numbers about compression. > > Other algorithms (e.g. zstd) got significantly better compression (25%) > compared to pglz, but in exchange for longer compression. I'm sure we > could lower compression level to make it faster, but that will of course > hurt the compression ratio. > > I don't think switching to a different compression algorithm is a way > forward - it was proposed and explored repeatedly in the past, and every > time it failed for a number of reasons, most of which are still valid. > > > Firstly, it's going to be quite hard (or perhaps impossible) to find an > algorithm that is "universally better" than pglz. Some algorithms do > work better for text documents, some for binary blobs, etc. I don't > think there's a win-win option. > > Sure, there are workloads where pglz performs poorly (I've seen such > cases too), but IMHO that's more an argument for the custom compression > method approach. pglz gives you good default compression in most cases, > and you can change it for columns where it matters, and where a > different space/time trade-off makes sense. > > > Secondly, all the previous attempts ran into some legal issues, i.e. > licensing and/or patents. Maybe the situation changed since then (no > idea, haven't looked into that), but in the past the "pluggable" > approach was proposed as a way to address this. I don't think so. Pluggable means that now we have more data types, which don't fit to the old compression scheme of TOAST and we need better flexibility. I see in future we could avoid decompression of the whole toast just to get on key from document, so we first slice data and compress each slice separately. > > > regards > > -- > Tomas Vondra http://www.2ndQuadrant.com > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services >
Attachment
{kind=link}
pgsql-hackers by date: