Re: [HACKERS] Custom compression methods - Mailing list pgsql-hackers
| From | Tomas Vondra |
|---|---|
| Subject | Re: [HACKERS] Custom compression methods |
| Date | |
| Msg-id | 9a0745ab-5b62-d81f-3a6d-ec0929a4a99d@2ndquadrant.com Whole thread Raw |
| In response to | Re: [HACKERS] Custom compression methods (Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru>) |
| Responses |
Re: [HACKERS] Custom compression methods
Re: [HACKERS] Custom compression methods |
| List | pgsql-hackers |
On 11/28/2017 02:29 PM, Ildus Kurbangaliev wrote:
> On Mon, 27 Nov 2017 18:20:12 +0100
> Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
>
>> I guess the trick might be -DRANDOMIZE_ALLOCATED_MEMORY (I first
>> tried without it, and it seemed working fine). If that's the case,
>> I bet there is a palloc that should have been palloc0, or something
>> like that.
>
> Thanks, that was it. I've been able to reproduce this bug. The
> attached patch should fix this bug and I've also added recompression
> when tuples moved to the relation with the compressed attribute.
>
I've done many tests with fulltext search on the mail archive, using
different compression algorithm, and this time it worked fine. So I can
confirm v7 fixes the issue.
Let me elaborate a bit about the benchmarking I did. I realize the patch
is meant to provide only an "API" for custom compression methods, and so
benchmarking of existing general-purpose algorithms (replacing the
built-in pglz) may seem a bit irrelevant. But I'll draw some conclusions
from that, so please bear with me. Or just skip the next section.
------------------ benchmark / start ------------------
I was curious how much better we could do than the built-in compression,
so I've whipped together a bunch of extensions for a few common
general-purpose compression algorithms (lz4, gz, bz2, zstd, brotli and
snappy), loaded the community mailing list archives using "archie" [1]
and ran a bunch of real-world full-text queries on it. I've used
"default" (or "medium") compression levels for all algorithms.
For the loads, the results look like this:
seconds size
-------------------------
pglz 1631 9786
zstd 1844 7102
lz4 1582 9537
bz2 2382 7670
gz 1703 7067
snappy 1587 12288
brotli 10973 6180
According to those results the algorithms seem quite comparable, with
the exception of snappy and brotli. Snappy supposedly aims for fast
compression and not compression ratio, but it's about as fast as the
other algorithms and compression ratio is almost 2x worse. Brotli is
much slower, although it gets better compression ratio.
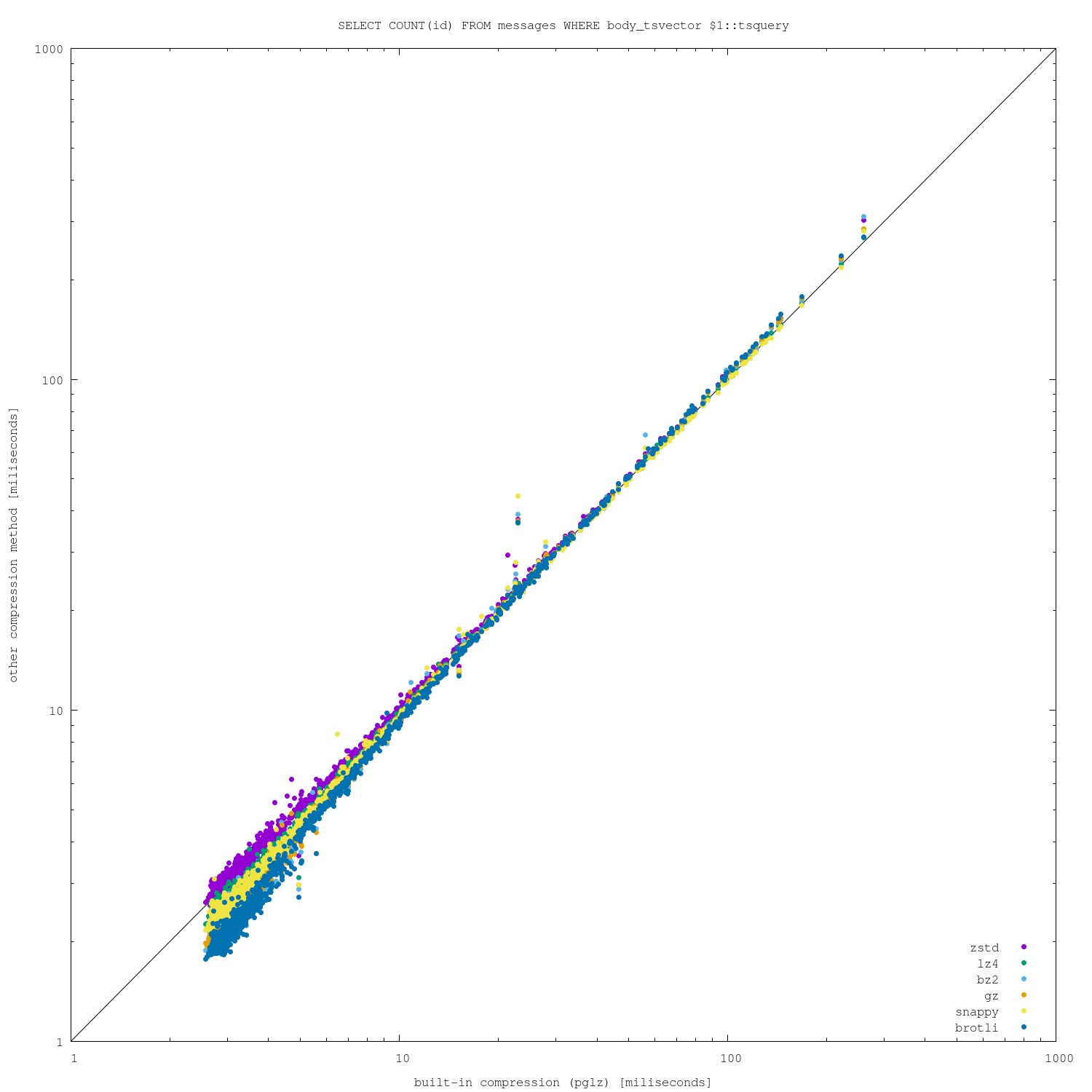
For the queries, I ran about 33k of real-world queries (executed on the
community mailing lists in the past). Firstly, a simple
-- unsorted
SELECT COUNT(id) FROM messages WHERE body_tsvector @@ $1::tsquery
and then
-- sorted
SELECT id FROM messages WHERE body_tsvector @@ $1::tsquery
ORDER BY ts_rank(body_tsvector, $1::tsquery) DESC LIMIT 100;
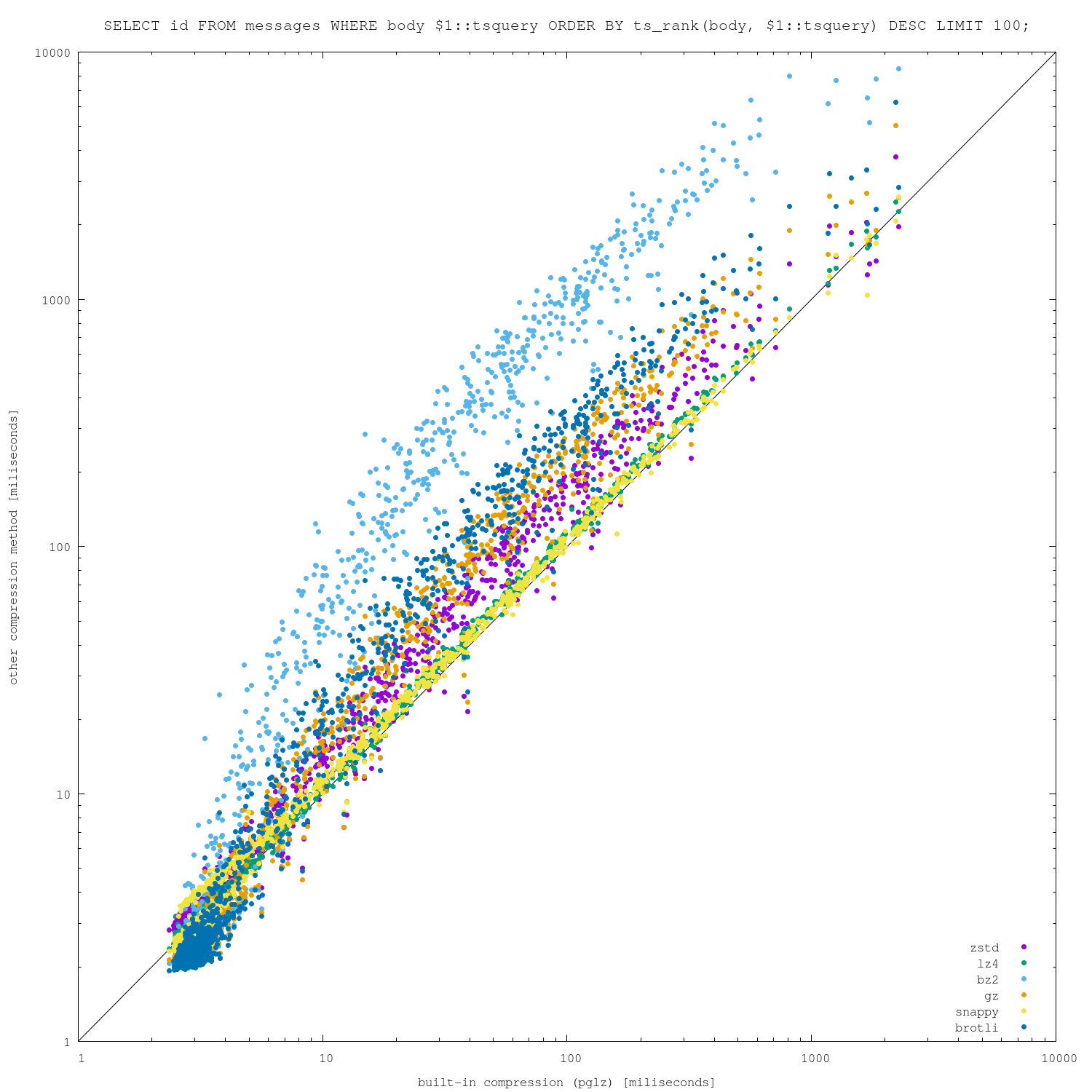
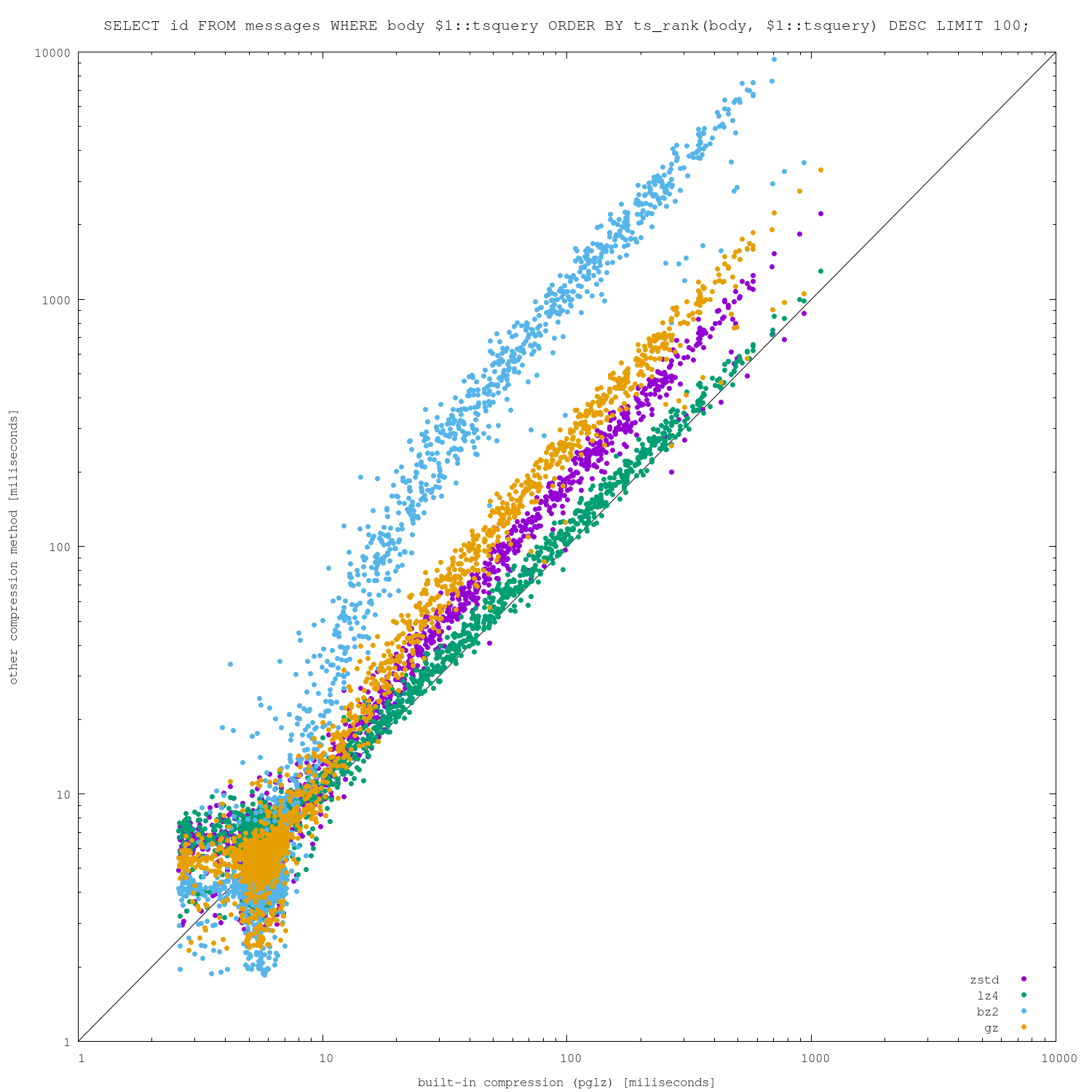
Attached are 4 different charts, plotting pglz on x-axis and the other
algorithms on y-axis (so below diagonal => new algorithm is faster,
above diagonal => pglz is faster). I did this on two different machines,
one with only 8GB of RAM (so the dataset does not fit) and one much
larger (so everything fits into RAM).
I'm actually surprised how well the built-in pglz compression fares,
both on compression ratio and (de)compression speed. There is a bit of
noise for the fastest queries, when the alternative algorithms perform
better in non-trivial number of cases.
I suspect those cases may be due to not implementing anything like
PGLZ_strategy_default->min_comp_rate (requiring 25% size reduction), but
I'm not sure about it.
For more expensive queries, pglz pretty much wins. Of course, increasing
compression level might change the results a bit, but it will also make
the data loads slower.
------------------ benchmark / end ------------------
While the results may look differently for other datasets, my conclusion
is that it's unlikely we'll find another general-purpose algorithm
beating pglz (enough for people to switch to it, as they'll need to
worry about testing, deployment of extensions etc).
That doesn't necessarily mean supporting custom compression algorithms
is pointless, of course, but I think people will be much more interested
in exploiting known features of the data (instead of treating the values
as opaque arrays of bytes).
For example, I see the patch implements a special compression method for
tsvector values (used in the tests), exploiting from knowledge of
internal structure. I haven't tested if that is an improvement (either
in compression/decompression speed or compression ratio), though.
I can imagine other interesting use cases - for example values in JSONB
columns often use the same "schema" (keys, nesting, ...), so can I
imagine building a "dictionary" of JSON keys for the whole column ...
Ildus, is this a use case you've been aiming for, or were you aiming to
use the new API in a different way?
I wonder if the patch can be improved to handle this use case better.
For example, it requires knowledge the actual data type, instead of
treating it as opaque varlena / byte array. I see tsvector compression
does that by checking typeid in the handler.
But that fails for example with this example
db=# create domain x as tsvector;
CREATE DOMAIN
db=# create table t (a x compressed ts1);
ERROR: unexpected type 28198672 for tsvector compression handler
which means it's a few brick shy to properly support domains. But I
wonder if this should be instead specified in CREATE COMPRESSION METHOD
instead. I mean, something like
CREATE COMPRESSION METHOD ts1 HANDLER tsvector_compression_handler
TYPE tsvector;
When type is no specified, it applies to all varlena values. Otherwise
only to that type. Also, why not to allow setting the compression as the
default method for a data type, e.g.
CREATE COMPRESSION METHOD ts1 HANDLER tsvector_compression_handler
TYPE tsvector DEFAULT;
would automatically add 'COMPRESSED ts1' to all tsvector columns in new
CREATE TABLE commands.
BTW do you expect the tsvector compression to be generally useful, or is
it meant to be used only by the tests? If generally useful, perhaps it
should be created in pg_compression by default. If only for tests, maybe
it should be implemented in an extension in contrib (thus also serving
as example how to implement new methods).
I haven't thought about the JSONB use case very much, but I suppose that
could be done using the configure/drop methods. I mean, allocating the
dictionary somewhere (e.g. in a table created by an extension?). The
configure method gets the Form_pg_attribute record, so that should be
enough I guess.
But the patch is not testing those two methods at all, which seems like
something that needs to be addresses before commit. I don't expect a
full-fledged JSONB compression extension, but something simple that
actually exercises those methods in a meaningful way.
Similarly for the compression options - we need to test that the WITH
part is handled correctly (tsvector does not provide configure method).
Which reminds me I'm confused by pg_compression_opt. Consider this:
CREATE COMPRESSION METHOD ts1 HANDLER tsvector_compression_handler;
CREATE TABLE t (a tsvector COMPRESSED ts1);
db=# select * from pg_compression_opt ;
cmoptoid | cmname | cmhandler | cmoptions
----------+--------+------------------------------+-----------
28198689 | ts1 | tsvector_compression_handler |
(1 row)
DROP TABLE t;
db=# select * from pg_compression_opt ;
cmoptoid | cmname | cmhandler | cmoptions
----------+--------+------------------------------+-----------
28198689 | ts1 | tsvector_compression_handler |
(1 row)
db=# DROP COMPRESSION METHOD ts1;
ERROR: cannot drop compression method ts1 because other objects
depend on it
DETAIL: compression options for ts1 depends on compression method
ts1
HINT: Use DROP ... CASCADE to drop the dependent objects too.
I believe the pg_compression_opt is actually linked to pg_attribute, in
which case it should include (attrelid,attnum), and should be dropped
when the table is dropped.
I suppose it was done this way to work around the lack of recompression
(i.e. the compressed value might have ended in other table), but that is
no longer true.
A few more comments:
1) The patch makes optionListToArray (in foreigncmds.c) non-static, but
it's not used anywhere. So this seems like change that is no longer
necessary.
2) I see we add two un-reserved keywords in gram.y - COMPRESSION and
COMPRESSED. Perhaps COMPRESSION would be enough? I mean, we could do
CREATE TABLE t (c TEXT COMPRESSION cm1);
ALTER ... SET COMPRESSION name ...
ALTER ... SET COMPRESSION none;
Although I agree the "SET COMPRESSION none" is a bit strange.
3) heap_prepare_insert uses this chunk of code
+ else if (HeapTupleHasExternal(tup)
+ || RelationGetDescr(relation)->tdflags & TD_ATTR_CUSTOM_COMPRESSED
+ || HeapTupleHasCustomCompressed(tup)
+ || tup->t_len > TOAST_TUPLE_THRESHOLD)
Shouldn't that be rather
+ else if (HeapTupleHasExternal(tup)
+ || (RelationGetDescr(relation)->tdflags & TD_ATTR_CUSTOM_COMPRESSED
+ && HeapTupleHasCustomCompressed(tup))
+ || tup->t_len > TOAST_TUPLE_THRESHOLD)
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: