Thread: Poll: are people okay with function/operator table redesign?
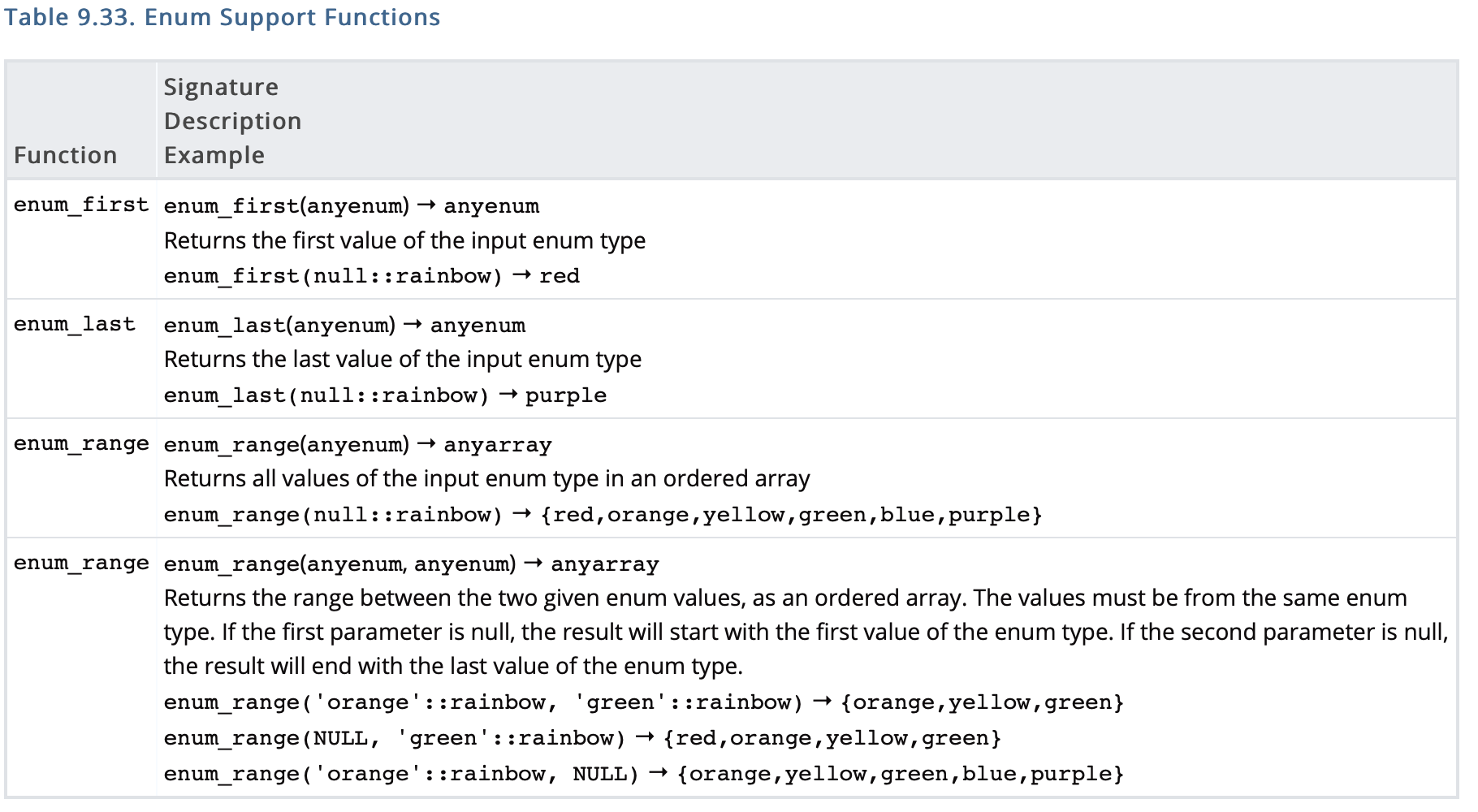
As discussed in the thread at [1], I've been working on redesigning the tables we use to present SQL functions and operators. The first installment of that is now up; see tables 9.30 and 9.31 at https://www.postgresql.org/docs/devel/functions-datetime.html and table 9.33 at https://www.postgresql.org/docs/devel/functions-enum.html Before I spend more time on this, I want to make sure that people are happy with this line of attack. Comparing these tables to the way they look in v12, they clearly take more vertical space; but at least to my eye they're less cluttered and more readable. They definitely scale a lot better for cases where a long function description is needed, or where we'd like to have more than one example. Does anyone prefer the old way, or have a better idea? I know that the table headings are a bit weirdly laid out; hopefully that can be resolved [2]. regards, tom lane [1] https://www.postgresql.org/message-id/flat/9326.1581457869%40sss.pgh.pa.us [2] https://www.postgresql.org/message-id/6169.1586794603%40sss.pgh.pa.us
On Mon, Apr 13, 2020 at 1:13 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > As discussed in the thread at [1], I've been working on redesigning > the tables we use to present SQL functions and operators. The > first installment of that is now up; see tables 9.30 and 9.31 at > > https://www.postgresql.org/docs/devel/functions-datetime.html > > and table 9.33 at > > https://www.postgresql.org/docs/devel/functions-enum.html > > Before I spend more time on this, I want to make sure that people > are happy with this line of attack. Comparing these tables to > the way they look in v12, they clearly take more vertical space; > but at least to my eye they're less cluttered and more readable. > They definitely scale a lot better for cases where a long function > description is needed, or where we'd like to have more than one > example. Does anyone prefer the old way, or have a better idea? I find the new way quite hard to read. I prefer the old way. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2020-04-13 19:13, Tom Lane wrote: > As discussed in the thread at [1], I've been working on redesigning > the tables we use to present SQL functions and operators. The > first installment of that is now up; see tables 9.30 and 9.31 at > > https://www.postgresql.org/docs/devel/functions-datetime.html > > and table 9.33 at > > https://www.postgresql.org/docs/devel/functions-enum.html > > Before I spend more time on this, I want to make sure that people > are happy with this line of attack. Comparing these tables to > the way they look in v12, they clearly take more vertical space; > but at least to my eye they're less cluttered and more readable. > They definitely scale a lot better for cases where a long function > description is needed, or where we'd like to have more than one > example. Does anyone prefer the old way, or have a better idea? > +1 In the pdf it is a big improvement; and the html is better too.
On Mon, 13 Apr 2020 at 13:13, Tom Lane <tgl@sss.pgh.pa.us> wrote:
As discussed in the thread at [1], I've been working on redesigning
the tables we use to present SQL functions and operators. The
first installment of that is now up; see tables 9.30 and 9.31 at
https://www.postgresql.org/docs/devel/functions-datetime.html
and table 9.33 at
https://www.postgresql.org/docs/devel/functions-enum.html
Before I spend more time on this, I want to make sure that people
are happy with this line of attack. Comparing these tables to
the way they look in v12, they clearly take more vertical space;
but at least to my eye they're less cluttered and more readable.
They definitely scale a lot better for cases where a long function
description is needed, or where we'd like to have more than one
example. Does anyone prefer the old way, or have a better idea?
I honestly don’t know. My initial reaction is a combination of “that’s weird” and “that’s cool”. So a few comments, which shouldn’t be taken as indicating a definite preference:
- showing the signature like this is interesting. For a moment I was wondering why it doesn’t say, for example, "interval → interval → interval” then I remembered this is Postgres, not Haskell. On the one hand, I like putting the signature like this; on the other, I don’t like that the return type is in a different place in each one. Could it be split into the same two columns as the example(s); first column inputs, second column results?
- another possibility for the parameters: list each one on a separate line, together with default (if applicable). Maybe that would be excessively tall, but it would sure make completely clear just exactly how many parameters there are and never wrap (well, maybe on a phone, but we can only do so much).
- for the various current-time-related functions (age, current_time, etc.), rather than saying “variable”, could it be the actual result with “now” being taken to be a specific fixed time within the year in which the documentation was generated? This would be really helpful for example with being clear that current_time is only the time of day with no date.
- the specific fixed time should be something like (current year)-06-30 18:45:54. I’ve deliberately chosen all values to be outside of the range of values with smaller ranges. For example, the hour is >12, the limit of the month field.
- I think there should be much more distinctive lines between the different functions. As it is the fact that the table is groups of 3 lines doesn’t jump out at the eye.
On 2020-Apr-13, Tom Lane wrote: > As discussed in the thread at [1], I've been working on redesigning > the tables we use to present SQL functions and operators. The > first installment of that is now up; see tables 9.30 and 9.31 at > > https://www.postgresql.org/docs/devel/functions-datetime.html > > and table 9.33 at > > https://www.postgresql.org/docs/devel/functions-enum.html > > Before I spend more time on this, I want to make sure that people > are happy with this line of attack. Comparing these tables to > the way they look in v12, they clearly take more vertical space; > but at least to my eye they're less cluttered and more readable. > They definitely scale a lot better for cases where a long function > description is needed, or where we'd like to have more than one > example. I am torn. On the one side, I think this new format is so much better than the old one that we should definitely use it for all tables. On the other side, I also think this format is slightly more complicated to read, so perhaps it would be sensible to keep using the old format for the simplest tables. One argument for the first of those positions is that if this new table layout is everywhere, it'll take less total time to get used to it. One improvement (that I don't know is possible in docbook) would be to have the inter-logical-row line be slightly thicker than the intra-logical-row one. That'd make each entry visually more obvious. I think you already mentioned the PDF issue that these multi-row entries are sometimes split across pages. I cannot believe docbook is so stupid not to have a solution to that problem, but I don't know what that solution would be. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Isaac Morland <isaac.morland@gmail.com> writes:
> - showing the signature like this is interesting. For a moment I was
> wondering why it doesn’t say, for example, "interval → interval → interval”
> then I remembered this is Postgres, not Haskell. On the one hand, I like
> putting the signature like this; on the other, I don’t like that the return
> type is in a different place in each one. Could it be split into the same
> two columns as the example(s); first column inputs, second column results?
We tried that in an earlier iteration (see the referenced thread). It
doesn't work very well because you end up having to allocate the max
amount of space for any result type or example result on every line.
Giving up the separate cell for return type is a lot of what makes this
workable.
> - another possibility for the parameters: list each one on a separate line,
> together with default (if applicable). Maybe that would be excessively
> tall, but it would sure make completely clear just exactly how many
> parameters there are and never wrap (well, maybe on a phone, but we can
> only do so much).
Since so few built-in functions have default parameters, that's going to
waste an awful lot of space in most cases. I actually ended up removing
the explicit "default" clauses from make_interval (which is the only
function with defaults that I dealt with so far) and instead explained
that they all default to zero in the text description, because that took
way less space.
> - for the various current-time-related functions (age, current_time, etc.),
> rather than saying “variable”, could it be the actual result with “now”
> being taken to be a specific fixed time within the year in which the
> documentation was generated? This would be really helpful for example with
> being clear that current_time is only the time of day with no date.
Yeah, I've been waffling about that. On the one hand, we regularly get
docs complaints from people who say "I tried this example and I didn't
get the claimed result". On the other hand you could figure that
everybody should understand that current_timestamp won't work like that
... but the first such example in the table is age() for which that
automatic understanding might not apply.
The examples down in 9.9.4 use a specific time, which is looking pretty
long in the tooth right now, and no one has complained --- but that's
in a context where it's absolutely plain that every mentioned function
is going to have a time-varying result.
On the whole I'm kind of leaning to going back to using a specific time.
But that's a detail that's not very relevant to the bigger picture here.
(No, I'm not going to try to make it update every year; too much work
for too little reward.)
> - I think there should be much more distinctive lines between the different
> functions. As it is the fact that the table is groups of 3 lines doesn’t
> jump out at the eye.
I don't know any easy way to do that. We do already have the grouping
visible in the first column...
regards, tom lane
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> One improvement (that I don't know is possible in docbook) would be to
> have the inter-logical-row line be slightly thicker than the
> intra-logical-row one. That'd make each entry visually more obvious.
Yeah, I don't see any way to do that :-(. We could suppress the row
lines entirely between the members of the logical group, but that'd
almost surely look worse.
(I tried to implement this to see, and couldn't get rowsep="0" in
a <spanspec> to render the way I expected, so there may be toolchain
bugs in the way of it anyway.)
We could leave an entirely empty row between logical groups, but
that would be really wasteful of vertical space.
Another possibility, which'd only help in HTML, would be to render
some of the cells with a slightly different background color.
That's beyond my docbook/css skills, but it might be possible.
regards, tom lane
On Mon, Apr 13, 2020 at 2:47 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Another possibility, which'd only help in HTML, would be to render > some of the cells with a slightly different background color. > That's beyond my docbook/css skills, but it might be possible. I think some visual distinction would be really helpful, if we can get it. I just wonder if there's too much clutter here. Like, line 1: date - interval → timestamp OK, gotcha. Line 2: Subtract an interval from a date Well, is that really adding anything non-obvious? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 4/13/20 1:13 PM, Tom Lane wrote: > As discussed in the thread at [1], I've been working on redesigning > the tables we use to present SQL functions and operators. The > first installment of that is now up; see tables 9.30 and 9.31 at > > https://www.postgresql.org/docs/devel/functions-datetime.html > > and table 9.33 at > > https://www.postgresql.org/docs/devel/functions-enum.html > > Before I spend more time on this, I want to make sure that people > are happy with this line of attack. Comparing these tables to > the way they look in v12, they clearly take more vertical space; > but at least to my eye they're less cluttered and more readable. > They definitely scale a lot better for cases where a long function > description is needed, or where we'd like to have more than one > example. Does anyone prefer the old way, or have a better idea? > > I know that the table headings are a bit weirdly laid out; hopefully > that can be resolved [2]. > > regards, tom lane > > [1] https://www.postgresql.org/message-id/flat/9326.1581457869%40sss.pgh.pa.us > [2] https://www.postgresql.org/message-id/6169.1586794603%40sss.pgh.pa.us > Gotta say I'm not a huge fan. I appreciate the effort, and I get the problem, but I'm not sure we have a net improvement here. One thing that did occur to me is that the function/operator name is essentially redundant, as it's in the signature anyway. Not sure if that helps us any though. Maybe we're just trying to shoehorn too much information into a single table. cheers andrew -- Andrew Dunstan https://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Robert Haas <robertmhaas@gmail.com> writes:
> I just wonder if there's too much clutter here. Like, line 1:
> date - interval → timestamp
> OK, gotcha. Line 2:
> Subtract an interval from a date
> Well, is that really adding anything non-obvious?
Yeah, back in the other thread I said
>>> I decided to try converting the date/time operators table too, to
>>> see how well this works for that. It's bulkier than before, but
>>> also (I think) more precise. I realized that this table actually
>>> had three examples already for float8 * interval, but it wasn't
>>> at all obvious that they were the same operator. So that aspect
>>> is a lot nicer here. On the other hand, it seems like the text
>>> descriptions are only marginally useful here. I can imagine that
>>> they would be useful in some other operator tables, such as
>>> geometric operators, but I'm a bit tempted to leave them out
>>> in this particular table. The format would adapt to that easily.
I wouldn't be averse to dropping the text descriptions for operators
in places where they seem obvious ... but who decides what is obvious?
Indeed, we've gotten more than one complaint in the past that some of the
geometric and JSON operators require a longer explanation than they've
got. So one of the points here was to have a format that could adapt to
that. But in this particular table I agree they're marginal.
regards, tom lane
On Mon, Apr 13, 2020 at 11:27 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
Isaac Morland <isaac.morland@gmail.com> writes:
> - I think there should be much more distinctive lines between the different
> functions. As it is the fact that the table is groups of 3 lines doesn’t
> jump out at the eye.
I don't know any easy way to do that. We do already have the grouping
visible in the first column...
Can we lightly background color every other rowgroup (i.e., "greenbar")?
I don't think having a separate Result column helps. The additional horizontal whitespace distances all relevant context information (at least on a wide monitor). Having the example rows mirror the Signature row seems like an easier to consume choice.
e.g.,
enum_first(null::rainbow) → red
date '2001-09-28' + 7 → 2001-10-05
Its also removes the left alignment in a fixed width column which draws unwanted visual attention.
David J.
Andrew Dunstan <andrew.dunstan@2ndquadrant.com> writes:
> One thing that did occur to me is that the function/operator name is
> essentially redundant, as it's in the signature anyway. Not sure if that
> helps us any though.
Hm, you have a point there. However, if we drop the lefthand column
then there really isn't any visual distinction between the row(s)
associated with one function and those of the next. Unless we can
find another fix for that aspect (as already discussed in this thread)
I doubt it'd be an improvement.
> Maybe we're just trying to shoehorn too much information into a single
> table.
Yeah, back at the beginning of this exercise, Alvaro wondered aloud
if we should go to something other than tables altogether. I dunno
what that'd look like though.
regards, tom lane
"David G. Johnston" <david.g.johnston@gmail.com> writes:
> Can we lightly background color every other rowgroup (i.e., "greenbar")?
If you know how to do that at all, let alone in a maintainable way (ie
one where inserting a new function doesn't require touching the entries
for the ones after), let's see it. I agree it'd be a nice solution,
if we could make it work, but I don't see how. I'd been imagining
instead that we could give a different background color to the first
line of each group; which I don't know how to do but it at least seems
plausible that a style could be attached to a <spanspec>.
> I don't think having a separate Result column helps. The additional
> horizontal whitespace distances all relevant context information (at least
> on a wide monitor). Having the example rows mirror the Signature row seems
> like an easier to consume choice.
Interesting idea. I'm afraid that it would not look so great in cases
where the example-plus-result overflows one line, which would inevitably
happen in PDF format. Still, maybe that would be rare enough to not be
a huge problem. In most places it'd be a win to not have to separately
allocate example and result space.
regards, tom lane
I wrote: > "David G. Johnston" <david.g.johnston@gmail.com> writes: >> I don't think having a separate Result column helps. The additional >> horizontal whitespace distances all relevant context information (at least >> on a wide monitor). Having the example rows mirror the Signature row seems >> like an easier to consume choice. > Interesting idea. I'm afraid that it would not look so great in cases > where the example-plus-result overflows one line, which would inevitably > happen in PDF format. Still, maybe that would be rare enough to not be > a huge problem. In most places it'd be a win to not have to separately > allocate example and result space. Actually ... if we did it like that, then it would be possible to treat the signature + description + example(s) as one big table cell with line breaks rather than row-separator bars. That would help address the inadequate-visual-separation-between-groups issue, but on the other hand maybe we'd end up with too little visual separation between the elements of a function description. A quick google search turned up this suggestion about how to force line breaks in docbook table cells: http://www.sagehill.net/docbookxsl/LineBreaks.html which seems pretty hacky but it should work. Anyone know a better way? regards, tom lane
On Mon, Apr 13, 2020 at 1:41 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
"David G. Johnston" <david.g.johnston@gmail.com> writes:
> Can we lightly background color every other rowgroup (i.e., "greenbar")?
If you know how to do that at all, let alone in a maintainable way (ie
one where inserting a new function doesn't require touching the entries
for the ones after), let's see it.
The nth-child({odd|even}) CSS Selector should provide the desired functionality, at least for HTML, but the structure will need to modified so that there is some single element that represents a single rowgroup. I tried (not too hard) to key off of the presence of the "rowspan" attribute but that does not seem possible.
David J.
On Mon, Apr 13, 2020 at 1:57 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
Actually ... if we did it like that, then it would be possible to treat
the signature + description + example(s) as one big table cell with line
breaks rather than row-separator bars.
That would help address the
inadequate-visual-separation-between-groups issue, but on the other hand
maybe we'd end up with too little visual separation between the elements
of a function description.
Speaking in terms of HTML if we use <hr /> instead of <br /> we would get the best of both worlds.
David J.
On 4/13/20 1:13 PM, Tom Lane wrote: > As discussed in the thread at [1], I've been working on redesigning > the tables we use to present SQL functions and operators. The > first installment of that is now up; see tables 9.30 and 9.31 at > > https://www.postgresql.org/docs/devel/functions-datetime.html > > and table 9.33 at > > https://www.postgresql.org/docs/devel/functions-enum.html > > Before I spend more time on this, I want to make sure that people > are happy with this line of attack. Comparing these tables to > the way they look in v12, they clearly take more vertical space; > but at least to my eye they're less cluttered and more readable. > They definitely scale a lot better for cases where a long function > description is needed, or where we'd like to have more than one > example. Does anyone prefer the old way, or have a better idea? > > I know that the table headings are a bit weirdly laid out; hopefully > that can be resolved [2]. > [2] https://www.postgresql.org/message-id/6169.1586794603%40sss.pgh.pa.us When evaluating [2], I will admit at first I was very confused about the layout and wasn't exactly sure what you were saying was incorrect in that note. After fixing [2] on my local copy, I started to look at it again. For positives, I do think it's an improvement for readability on mobile. Flow/content aside, it was easier to read and follow what was going on and there was less side scrolling. I think one thing that was throwing me off was having the function signature before the description. I would recommend flipping them: have the function description first, followed by signature, followed be examples. I think that follows the natural flow more of what one is doing when they look up the function. I think that would also benefit larger tables too: instead of having to scroll up to understand how things are laid out, it'd follow said flow. There are probably some things we can do with shading on the pgweb side to make items more distinguishable, I don't think that would be too terrible to add. Thinking out loud, it'd also be great if we could add in some anchors as well, so perhaps in the future on the pgweb side we could add in some discoverable links that other documentation has -- which in turn people could click / link to others directly to the function name. Anyway, change is hard. I'm warming up to it. Jonathan
Attachment
Thinking out loud, it'd also be great if we could add in some anchors as
well, so perhaps in the future on the pgweb side we could add in some
discoverable links that other documentation has -- which in turn people
could click / link to others directly to the function name.
+1
"David G. Johnston" <david.g.johnston@gmail.com> writes:
> On Mon, Apr 13, 2020 at 1:57 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Actually ... if we did it like that, then it would be possible to treat
>> the signature + description + example(s) as one big table cell with line
>> breaks rather than row-separator bars.
>> That would help address the
>> inadequate-visual-separation-between-groups issue, but on the other hand
>> maybe we'd end up with too little visual separation between the elements
>> of a function description.
> Speaking in terms of HTML if we use <hr /> instead of <br /> we would get
> the best of both worlds.
Hm. I quickly hacked up table 9.33 to use this approach. Attached
are a patch for that, as well as screenshots of HTML and PDF output.
(To get the equivalent of HTML-hr.png, use <hr/> not <br/> in the
stylesheet.)
I don't think I like the <hr/> version better than <br/> --- it adds
quite a bit of vertical space, more than I was expecting really. The
documentation I could find with Google suggests that <hr/> can be
rendered with quite a bit of variation by different agents, so other
people might get different results. (This is with Safari.) It seems
like the font differentiation between the description and the other
parts is almost, but perhaps not quite, enough separation already.
I don't know how to get the equivalent of <hr/> in PDF output, so
that version just does line breaks. It seems like the vertical
spacing in the examples is a bit wonky, but otherwise it's not awful.
Note that the PDF rendering shows the header and function name
alignment as I intended them; the HTML renderings are wrong due to
website stylesheet issues.
regards, tom lane
diff --git a/doc/src/sgml/func.sgml b/doc/src/sgml/func.sgml
index 7a270eb..497c125 100644
--- a/doc/src/sgml/func.sgml
+++ b/doc/src/sgml/func.sgml
@@ -8645,103 +8645,89 @@ CREATE TYPE rainbow AS ENUM ('red', 'orange', 'yellow', 'green', 'blue', 'purple
<table id="functions-enum-table">
<title>Enum Support Functions</title>
- <tgroup cols="3">
- <colspec colname="col1" colwidth="0.5*"/>
- <colspec colname="col2" colwidth="1*"/>
- <colspec colname="col3" colwidth="1*"/>
- <spanspec spanname="name" namest="col1" nameend="col1" align="left"/>
- <spanspec spanname="sig" namest="col2" nameend="col3" align="left"/>
- <spanspec spanname="desc" namest="col2" nameend="col3" align="left"/>
- <spanspec spanname="example" namest="col2" nameend="col2" align="left"/>
- <spanspec spanname="exresult" namest="col3" nameend="col3" align="left"/>
+ <tgroup cols="2">
+ <colspec colname="col1" colwidth="0.5*" align="left"/>
+ <colspec colname="col2" colwidth="1*" align="left"/>
<thead>
<row>
- <entry spanname="name" align="center" valign="middle" morerows="2">Function</entry>
- <entry spanname="sig" align="center">Signature</entry>
- </row>
- <row>
- <entry spanname="desc" align="center">Description</entry>
- </row>
- <row>
- <entry spanname="example" align="center">Example</entry>
- <entry spanname="exresult" align="center">Example Result</entry>
+ <entry align="center" valign="middle">Function</entry>
+ <entry align="center">Signature<?br?>Description<?br?>Example</entry>
</row>
</thead>
<tbody>
<row>
- <entry spanname="name" morerows="2">
+ <entry valign="middle">
<indexterm>
<primary>enum_first</primary>
</indexterm>
<function>enum_first</function>
</entry>
- <entry spanname="sig"><function>enum_first</function>(<type>anyenum</type>)
<returnvalue>anyenum</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Returns the first value of the input enum type</entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_first(&zwsp;null::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>red</literal></entry>
+ <entry>
+ <function>enum_first</function>(<type>anyenum</type>)
+ <returnvalue>anyenum</returnvalue>
+ <?br?>
+ Returns the first value of the input enum type
+ <?br?>
+ <literal>enum_first(&zwsp;null::rainbow)</literal>
+ <returnvalue>red</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2">
+ <entry valign="middle">
<indexterm>
<primary>enum_last</primary>
</indexterm>
<function>enum_last</function>
</entry>
- <entry spanname="sig"><function>enum_last</function>(<type>anyenum</type>)
<returnvalue>anyenum</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Returns the last value of the input enum type</entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_last(&zwsp;null::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>purple</literal></entry>
+ <entry>
+ <function>enum_last</function>(<type>anyenum</type>)
+ <returnvalue>anyenum</returnvalue>
+ <?br?>
+ Returns the last value of the input enum type
+ <?br?>
+ <literal>enum_last(&zwsp;null::rainbow)</literal>
+ <returnvalue>purple</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2">
+ <entry valign="middle">
<indexterm>
<primary>enum_range</primary>
</indexterm>
<function>enum_range</function>
</entry>
- <entry spanname="sig"><function>enum_range</function>(<type>anyenum</type>)
<returnvalue>anyarray</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Returns all values of the input enum type in an ordered array</entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_range(&zwsp;null::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>{red,orange,yellow,&zwsp;green,blue,purple}</literal></entry>
- </row>
- <row>
- <entry spanname="name" morerows="4"><function>enum_range</function></entry>
- <entry spanname="sig"><function>enum_range</function>(<type>anyenum</type>, <type>anyenum</type>)
<returnvalue>anyarray</returnvalue></entry>
+ <entry>
+ <function>enum_range</function>(<type>anyenum</type>)
+ <returnvalue>anyarray</returnvalue>
+ <?br?>
+ Returns all values of the input enum type in an ordered array
+ <?br?>
+ <literal>enum_range(&zwsp;null::rainbow)</literal>
+ <returnvalue>{red,orange,yellow,&zwsp;green,blue,purple}</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="desc">
+ <entry valign="middle"><function>enum_range</function></entry>
+ <entry><function>enum_range</function>(<type>anyenum</type>, <type>anyenum</type>)
+ <returnvalue>anyarray</returnvalue>
+ <?br?>
Returns the range between the two given enum values, as an ordered
array. The values must be from the same enum type. If the first
parameter is null, the result will start with the first value of
the enum type.
If the second parameter is null, the result will end with the last
value of the enum type.
+ <?br?>
+ <literal>enum_range(&zwsp;'orange'::rainbow, 'green'::rainbow)</literal>
+ <returnvalue>{orange,yellow,green}</returnvalue>
+ <?br?>
+ <literal>enum_range(NULL, 'green'::rainbow)</literal>
+ <returnvalue>{red,orange,&zwsp;yellow,green}</returnvalue>
+ <?br?>
+ <literal>enum_range(&zwsp;'orange'::rainbow, NULL)</literal>
+ <returnvalue>{orange,yellow,green,&zwsp;blue,purple}</returnvalue>
</entry>
</row>
- <row>
- <entry spanname="example"><literal>enum_range(&zwsp;'orange'::rainbow, 'green'::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>{orange,yellow,green}</literal></entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_range(NULL, 'green'::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>{red,orange,yellow,&zwsp;green}</literal></entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_range(&zwsp;'orange'::rainbow, NULL)</literal></entry>
- <entry spanname="exresult"><literal>{orange,yellow,green,&zwsp;blue,purple}</literal></entry>
- </row>
</tbody>
</tgroup>
</table>
diff --git a/doc/src/sgml/stylesheet-common.xsl b/doc/src/sgml/stylesheet-common.xsl
index a13565e..105ed1c 100644
--- a/doc/src/sgml/stylesheet-common.xsl
+++ b/doc/src/sgml/stylesheet-common.xsl
@@ -103,4 +103,11 @@
<xsl:apply-templates select="." mode="xref"/>
</xsl:template>
+
+<!-- Support for explicit line breaks <?br?> within table cells -->
+
+<xsl:template match="processing-instruction('br')">
+ <br/>
+</xsl:template>
+
</xsl:stylesheet>
diff --git a/doc/src/sgml/stylesheet-fo.xsl b/doc/src/sgml/stylesheet-fo.xsl
index 2aaae82..713159d 100644
--- a/doc/src/sgml/stylesheet-fo.xsl
+++ b/doc/src/sgml/stylesheet-fo.xsl
@@ -70,6 +70,11 @@
<xsl:call-template name="inline.monoseq"/>
</xsl:template>
+<!-- overrides stylesheet-common.xsl -->
+<xsl:template match="processing-instruction('br')">
+ <fo:block/>
+</xsl:template>
+
<!-- bug fix from <https://sourceforge.net/p/docbook/bugs/1360/#831b> -->
<xsl:template match="varlistentry/term" mode="xref-to">
Attachment
{kind=link}
{kind=link}
{kind=link}
Yeah, back at the beginning of this exercise, Alvaro wondered aloud
if we should go to something other than tables altogether. I dunno
what that'd look like though.
It would probably look like our acronyms and glossary pages.
Maybe the return example and return values get replaced with a programlisting?
"Jonathan S. Katz" <jkatz@postgresql.org> writes:
> I think one thing that was throwing me off was having the function
> signature before the description. I would recommend flipping them: have
> the function description first, followed by signature, followed be
> examples. I think that follows the natural flow more of what one is
> doing when they look up the function.
The trouble with that is it doesn't work very well when we have
multiple similarly-named functions with different signatures.
Consider what the two enum_range() entries in 9.33 will look like,
for example. I think we need the signature to establish which function
we're talking about.
> There are probably some things we can do with shading on the pgweb side
> to make items more distinguishable, I don't think that would be too
> terrible to add.
Per David's earlier comment, it seems like alternating backgrounds might
be feasible if we can get it down to one <row> per function, as the
version I just posted has.
regards, tom lane
On 4/13/20 6:51 PM, Tom Lane wrote: > "Jonathan S. Katz" <jkatz@postgresql.org> writes: >> I think one thing that was throwing me off was having the function >> signature before the description. I would recommend flipping them: have >> the function description first, followed by signature, followed be >> examples. I think that follows the natural flow more of what one is >> doing when they look up the function. > > The trouble with that is it doesn't work very well when we have > multiple similarly-named functions with different signatures. > Consider what the two enum_range() entries in 9.33 will look like, > for example. I think we need the signature to establish which function > we're talking about. I get that, I just find I'm doing too much thinking looking at it. Perhaps a counterproposal: We eliminate the content in the leftmost "function column, but leave that there to allow the function name / signature to span the full 3 columns. Then the rest of the info goes below. This will also compress the table height down a bit. >> There are probably some things we can do with shading on the pgweb side >> to make items more distinguishable, I don't think that would be too >> terrible to add. > > Per David's earlier comment, it seems like alternating backgrounds might > be feasible if we can get it down to one <row> per function, as the > version I just posted has. or a classname on the "<tr>" when a new function starts or the like. Easy enough to get the CSS to work off of that :) Jonathan
Attachment
On 4/13/20 7:02 PM, Jonathan S. Katz wrote: > On 4/13/20 6:51 PM, Tom Lane wrote: >> "Jonathan S. Katz" <jkatz@postgresql.org> writes: >>> I think one thing that was throwing me off was having the function >>> signature before the description. I would recommend flipping them: have >>> the function description first, followed by signature, followed be >>> examples. I think that follows the natural flow more of what one is >>> doing when they look up the function. >> >> The trouble with that is it doesn't work very well when we have >> multiple similarly-named functions with different signatures. >> Consider what the two enum_range() entries in 9.33 will look like, >> for example. I think we need the signature to establish which function >> we're talking about. > > I get that, I just find I'm doing too much thinking looking at it. > > Perhaps a counterproposal: We eliminate the content in the leftmost > "function column, but leave that there to allow the function name / > signature to span the full 3 columns. Then the rest of the info goes > below. This will also compress the table height down a bit. An attempt at a "POC" of what I'm describing (attached image). I'm not sure if I 100% like it, but it does reduce the amount of information we're displaying but conveys all the details (and matches what we have in the previous version). The alignment could be adjusted if need be, too. Jonathan
Attachment
{kind=link}
I wrote:
> I don't think I like the <hr/> version better than <br/> --- it adds
> quite a bit of vertical space, more than I was expecting really.
Actually, after staring more at HTML-hr.png, what's *really* bothering
me about that rendering is that the lines made by <hr/> are actually
wider than the inter-table-cell lines. Surely we want the opposite
relationship. Presumably that could be fixed with some css-level
adjustments; and maybe the spacing could be tightened up a bit too?
I do like having that visual separation, it just needs to be toned
down compared to the table cell separators.
Reproducing the effect in the PDF build remains an issue, too.
regards, tom lane
On 2020-Apr-13, Jonathan S. Katz wrote: > On 4/13/20 7:02 PM, Jonathan S. Katz wrote: > > Perhaps a counterproposal: We eliminate the content in the leftmost > > "function column, but leave that there to allow the function name / > > signature to span the full 3 columns. Then the rest of the info goes > > below. This will also compress the table height down a bit. > > An attempt at a "POC" of what I'm describing (attached image). > > I'm not sure if I 100% like it, but it does reduce the amount of > information we're displaying but conveys all the details (and matches > what we have in the previous version). Ooh, this seems a nice idea -- the indentation seems to be sufficient to tell apart entries from each other. Your point about information reduction refers to the fact that we no longer keep the unadorned name but only the signature, right? That seems an improvement to me now that I look at it. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
"Jonathan S. Katz" <jkatz@postgresql.org> writes:
> On 4/13/20 7:02 PM, Jonathan S. Katz wrote:
>> Perhaps a counterproposal: We eliminate the content in the leftmost
>> "function column, but leave that there to allow the function name /
>> signature to span the full 3 columns. Then the rest of the info goes
>> below. This will also compress the table height down a bit.
> An attempt at a "POC" of what I'm describing (attached image).
Hmm ... what is determining the width of the left-hand column?
It doesn't seem to have any content, since the function entries
are being spanned across the whole table.
I think the main practical problem though is that it wouldn't
work nicely for operators, since the key "name" you'd be looking
for would not be at the left of the signature line. I suppose we
don't necessarily have to have the same layout for operators as
for functions, but it feels like it'd be jarringly inconsistent.
regards, tom lane
Hello Tom, > Before I spend more time on this, I want to make sure that people > are happy with this line of attack. +1 I like it this way, because the structure is quite readable, which is the point. My 0.02€: Maybe column heander "Example Result" should be simply "Result", because it is already on the same line as "Example" on its left, and "Example | Example Result" looks redundant. Maybe the signature and description lines could be exchanged: I'm more interested and the description first, and the signature just above the example would make sense. I'm wondering whether the function/operator name should be vertically centered in its cell? I'd left it left justified. -- Fabien.
On 4/13/20 7:55 PM, Tom Lane wrote: > "Jonathan S. Katz" <jkatz@postgresql.org> writes: >> On 4/13/20 7:02 PM, Jonathan S. Katz wrote: >>> Perhaps a counterproposal: We eliminate the content in the leftmost >>> "function column, but leave that there to allow the function name / >>> signature to span the full 3 columns. Then the rest of the info goes >>> below. This will also compress the table height down a bit. >> An attempt at a "POC" of what I'm describing (attached image). > Hmm ... what is determining the width of the left-hand column? > It doesn't seem to have any content, since the function entries > are being spanned across the whole table. > > I think the main practical problem though is that it wouldn't > work nicely for operators, since the key "name" you'd be looking > for would not be at the left of the signature line. I suppose we > don't necessarily have to have the same layout for operators as > for functions, but it feels like it'd be jarringly inconsistent. > > Maybe highlight the item by bolding or colour? cheers andrew -- Andrew Dunstan https://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 4/13/20 7:13 PM, Tom Lane wrote: > As discussed in the thread at [1], I've been working on redesigning > the tables we use to present SQL functions and operators. The > first installment of that is now up; see tables 9.30 and 9.31 at > > https://www.postgresql.org/docs/devel/functions-datetime.html > > and table 9.33 at > > https://www.postgresql.org/docs/devel/functions-enum.html > > Before I spend more time on this, I want to make sure that people > are happy with this line of attack. Comparing these tables to > the way they look in v12, they clearly take more vertical space; > but at least to my eye they're less cluttered and more readable. > They definitely scale a lot better for cases where a long function > description is needed, or where we'd like to have more than one > example. Does anyone prefer the old way, or have a better idea? > > I know that the table headings are a bit weirdly laid out; hopefully > that can be resolved [2]. I prefer the old way since I find it very hard to see which fields belong to which function in the new way. I think what confuses my eyes is how some rows are split in half while others are not, especially for those functions where there is only one example output. I do not have any issue reading those with many example outputs. For the old tables I can at least just make the browser window ridiculously wide ro read them. Andreas
Andreas Karlsson <andreas@proxel.se> writes:
> For the old tables I can at least just make the browser window
> ridiculously wide ro read them.
A large part of the point here is to make the tables usable
when you don't have that option, as for example in PDF output.
Even with a wide window, though, some of our function tables are
monstrously ugly.
regards, tom lane
On 4/14/20 4:29 PM, Tom Lane wrote: > Andreas Karlsson <andreas@proxel.se> writes: >> For the old tables I can at least just make the browser window >> ridiculously wide ro read them. > > A large part of the point here is to make the tables usable > when you don't have that option, as for example in PDF output. > > Even with a wide window, though, some of our function tables are > monstrously ugly. Sure, but I wager the number of people using the HTML version of our documentation on laptops and desktop computers are the biggest group of users. That said, I agree with that quite many of our tables right now are ugly, but I prefer ugly to hard to read. For me the mix of having every third row split into two fields makes the tables very hard to read. I have a hard time seeing which rows belong to which function. Andreas
Andreas Karlsson <andreas@proxel.se> writes:
> That said, I agree with that quite many of our tables right now are
> ugly, but I prefer ugly to hard to read. For me the mix of having every
> third row split into two fields makes the tables very hard to read. I
> have a hard time seeing which rows belong to which function.
Did you look at the variants without that discussed downthread?
regards, tom lane
On Mon, Apr 13, 2020 at 4:29 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > I wouldn't be averse to dropping the text descriptions for operators > in places where they seem obvious ... but who decides what is obvious? Well, we do. We're smart, right? I don't think it's a good idea to add clutter to table A just because table B needs more details. What matters is whether table A needs more details. The v12 version of the "Table 9.30. Date/Time Operators" is not that wide, and is really quite clear. The new version takes 3 lines per operator where the old one took one. That's because you've added (1) a description of the fact that + does addition and - does subtraction, repeated for each operator, and (2) explicit information about the input and result types. I don't think either add much, in this case. The former doesn't really need to be explained, and the latter was clear enough from the way the examples were presented - everything had explicit types. For more complicated cases, one thing we could do is ditch the table and use a <variablelist> with a separate <varlistentry> for each operator. So you could have something like: <varlistentry> <term><literal>date + date &arrow; timestamp</literal></term> <listentry> Lengthy elocution, including an example. </listentry> </varlistentry> But I would only advocate for this style in cases where there is substantial explaining to be done. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> The v12 version of the "Table 9.30. Date/Time Operators" is not that
> wide, and is really quite clear.
Well, no it isn't. The main nit I would pick in that claim is that
it's far from obvious that the three examples of float8 * interval
are all talking about the same operator; in fact, a reader would
be very likely to draw the false conclusion that there is an
integer * interval operator.
This is an aspect of the general problem that we don't have a nice
way to deal with multiple examples in the tables. Somebody kluged
their way around it here in this particular way, but I'd really like
a clearer way, because we need more examples.
I would also point out that this table is quite out of step with
the rest of the docs in its practice of showing the results as
though they were typed literals. Most places that show results
just show what you'd expect to see in a psql output column, making
it necessary to show the result data type somewhere else.
> The new version takes 3 lines per
> operator where the old one took one. That's because you've added (1) a
> description of the fact that + does addition and - does subtraction,
> repeated for each operator, and (2) explicit information about the
> input and result types. I don't think either add much, in this case.
As I already said, I agree about the text descriptions being of marginal
value in this case. I disagree about the explicit datatypes, because the
float8 * interval cases already show a hole in that argument, and surely
we don't want to require every example to use explicitly-typed literals
and nothing but. Besides, what will you do for operators that take
anyarray or the like?
> For more complicated cases, one thing we could do is ditch the table
> and use a <variablelist> with a separate <varlistentry> for each
> operator. So you could have something like:
> ...
> But I would only advocate for this style in cases where there is
> substantial explaining to be done.
I'd like to have more consistency, not less. I do not think it helps
readers to have each page in Chapter 9 have its own idiosyncratic way of
presenting operators/functions. The operator tables are actually almost
that bad, right now --- compare section 9.1 (hasn't even bothered with
a formal <table>) with tables 9.1, 9.4, 9.9, 9.12, 9.14, 9.30, 9.34,
9.37, 9.41, 9.44. The variation in level of detail and precision is
striking, and not in a good way.
regards, tom lane
On Tue, Apr 14, 2020 at 11:26 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Well, no it isn't. The main nit I would pick in that claim is that > it's far from obvious that the three examples of float8 * interval > are all talking about the same operator; in fact, a reader would > be very likely to draw the false conclusion that there is an > integer * interval operator. I agree that's not great. I think that could possibly be fixed by showing all three examples in the same cell, and maybe by revising the choice of examples. > I'd like to have more consistency, not less. I do not think it helps > readers to have each page in Chapter 9 have its own idiosyncratic way of > presenting operators/functions. The operator tables are actually almost > that bad, right now --- compare section 9.1 (hasn't even bothered with > a formal <table>) with tables 9.1, 9.4, 9.9, 9.12, 9.14, 9.30, 9.34, > 9.37, 9.41, 9.44. The variation in level of detail and precision is > striking, and not in a good way. Well, I don't know. Having two or even three formats is not the same as having infinitely many formats, and may be justified if the needs are sufficiently different from each other. At any rate, if the price of more clarity and more examples is that the tables become three times as long and harder to read, I am somewhat inclined to think that the cure is worse than the disease. I can readily see how something like table 9.10 (Other String Functions) might be a mess on a narrow screen or in PDF format, but it's an extremely useful table on a normal-size screen in HTML format, and part of what makes it useful is that it's compact. Almost anything we do is going to remove some of that compactness to save horizontal space. Maybe that's OK, but it's sure not great. It's nice to be able to see more on one screen. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> At any rate, if the price of more clarity and more examples is that
> the tables become three times as long and harder to read, I am
> somewhat inclined to think that the cure is worse than the disease. I
> can readily see how something like table 9.10 (Other String Functions)
> might be a mess on a narrow screen or in PDF format, but it's an
> extremely useful table on a normal-size screen in HTML format, and
> part of what makes it useful is that it's compact. Almost anything we
> do is going to remove some of that compactness to save horizontal
> space. Maybe that's OK, but it's sure not great. It's nice to be able
> to see more on one screen.
I dunno, it doesn't look to me like 9.10 is some paragon of efficient
use of screen space, even with a wide window. (And my goodness it
looks bad if I try a window about half my usual web-browsing width.)
Maybe I should go convert that one to see what it looks like in one of
the other layouts being discussed.
regards, tom lane
On Mon, Apr 13, 2020 at 10:13 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
As discussed in the thread at [1], I've been working on redesigning
the tables we use to present SQL functions and operators. The
first installment of that is now up; see tables 9.30 and 9.31 at
https://www.postgresql.org/docs/devel/functions-datetime.html
and table 9.33 at
https://www.postgresql.org/docs/devel/functions-enum.html
As I write this the enum headers are centered horizontally while the datetime ones are left aligned. The centering doesn't do it for me. To much gap and the data itself is not centered so there is a large disconnected between the header and the value.
The run-on aspect of the left-aligned setup is of some concern but maybe just adding some left padding to the second column - and right padding to the first - can provide the desired negative space without adding so much as to break usability.
(gonna use embedded images here...)


David J.
Attachment
Hi all, Sorry I'm very new on this discussion. A colleague of mine told me I could probably give my opinion on this thread. I'm sorry in advance if I'm off topic. I just wanted to mention that from Tom's proposal I played a bit with the generated HTML in order to try to make things easier to read without thinking about technical issues for now. The first big issue (that may have already been mentioned) in my opinion is that different elements are difficult to distinguish. It's difficult for example to know what is the return type, what is the description, etc. I think that if the idea is to get rid of the columns, you need to make sure that it's easy to know which is which. With a very short amount of time, the user should be able to find what he's looking for. The best way to achieve this is to use some styling (font style and color). Attached you will find two different options I worked on very quickly. I would be happy to give more hints on how I did this of course and why I chose some options. Please let me know. Kind regards, Le 13/04/2020 à 19:13, Tom Lane a écrit : > As discussed in the thread at [1], I've been working on redesigning > the tables we use to present SQL functions and operators. The > first installment of that is now up; see tables 9.30 and 9.31 at > > https://www.postgresql.org/docs/devel/functions-datetime.html > > and table 9.33 at > > https://www.postgresql.org/docs/devel/functions-enum.html > > Before I spend more time on this, I want to make sure that people > are happy with this line of attack. Comparing these tables to > the way they look in v12, they clearly take more vertical space; > but at least to my eye they're less cluttered and more readable. > They definitely scale a lot better for cases where a long function > description is needed, or where we'd like to have more than one > example. Does anyone prefer the old way, or have a better idea? > > I know that the table headings are a bit weirdly laid out; hopefully > that can be resolved [2]. > > regards, tom lane > > [1] https://www.postgresql.org/message-id/flat/9326.1581457869%40sss.pgh.pa.us > [2] https://www.postgresql.org/message-id/6169.1586794603%40sss.pgh.pa.us > >
Attachment
{kind=link}
{kind=link}
On Wed, 15 Apr 2020 at 11:26, Pierre Giraud <pierre.giraud@dalibo.com> wrote:
The best way to achieve this is to use some styling (font style and color).
Attached you will find two different options I worked on very quickly.
I really like the first. Just a couple of suggestions I would make:
- leave a space between the function name and (. Regardless of opinions on what source code should look like, your documentation has space between each parameter and the next one, and between the ) and the -> and the ->. and the return type so it seems crowded not to have space between the function name and the (.
- At this point it's not really a table any more; I would get rid of the lines, maybe tweak the spacing, and possibly use <dl> <dt> <dd> (definition list) rather than table-related HTML elements. See https://developer.mozilla.org/en-US/docs/Web/HTML/Element/dl.
I think the bolding really makes stand out the crucial parts one needs to find.
st 15. 4. 2020 v 17:43 odesílatel Isaac Morland <isaac.morland@gmail.com> napsal:
On Wed, 15 Apr 2020 at 11:26, Pierre Giraud <pierre.giraud@dalibo.com> wrote:The best way to achieve this is to use some styling (font style and color).
Attached you will find two different options I worked on very quickly.I really like the first. Just a couple of suggestions I would make:
yes, it is very well readable
Pavel
- leave a space between the function name and (. Regardless of opinions on what source code should look like, your documentation has space between each parameter and the next one, and between the ) and the -> and the ->. and the return type so it seems crowded not to have space between the function name and the (.- At this point it's not really a table any more; I would get rid of the lines, maybe tweak the spacing, and possibly use <dl> <dt> <dd> (definition list) rather than table-related HTML elements. See https://developer.mozilla.org/en-US/docs/Web/HTML/Element/dl.I think the bolding really makes stand out the crucial parts one needs to find.
On Wed, Apr 15, 2020 at 11:54 AM Pavel Stehule <pavel.stehule@gmail.com> wrote: > st 15. 4. 2020 v 17:43 odesílatel Isaac Morland <isaac.morland@gmail.com> napsal: >> On Wed, 15 Apr 2020 at 11:26, Pierre Giraud <pierre.giraud@dalibo.com> wrote: >>> The best way to achieve this is to use some styling (font style and color). >>> >>> Attached you will find two different options I worked on very quickly. >> >> I really like the first. Just a couple of suggestions I would make: > > yes, it is very well readable +1. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Is there a way to get a heavier line between each function? It would be helpful to have a clearer demarcation of what belongs to each function.
On Wed, Apr 15, 2020 at 9:04 AM Robert Haas <robertmhaas@gmail.com> wrote:
On Wed, Apr 15, 2020 at 11:54 AM Pavel Stehule <pavel.stehule@gmail.com> wrote:
> st 15. 4. 2020 v 17:43 odesílatel Isaac Morland <isaac.morland@gmail.com> napsal:
>> On Wed, 15 Apr 2020 at 11:26, Pierre Giraud <pierre.giraud@dalibo.com> wrote:
>>> The best way to achieve this is to use some styling (font style and color).
>>>
>>> Attached you will find two different options I worked on very quickly.
>>
>> I really like the first. Just a couple of suggestions I would make:
>
> yes, it is very well readable
+1.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Steven Pousty <steve.pousty@gmail.com> writes: > Is there a way to get a heavier line between each function? It would be > helpful to have a clearer demarcation of what belongs to each function. The first alternative I posted at https://www.postgresql.org/message-id/31833.1586817876%40sss.pgh.pa.us seems like it would accomplish that pretty well, by having lines *only* between functions. The last couple of things that have been posted seem way more cluttered than that one. regards, tom lane
On Mon, Apr 13, 2020 at 10:13 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
As discussed in the thread at [1], I've been working on redesigning
the tables we use to present SQL functions and operators. The
first installment of that is now up; see tables 9.30 and 9.31 at
https://www.postgresql.org/docs/devel/functions-datetime.html
and table 9.33 at
https://www.postgresql.org/docs/devel/functions-enum.html
The run-on aspect of the left-aligned setup is of some concern but maybe just adding some left padding to the second column - and right padding to the first - can provide the desired negative space without adding so much as to break usability.
David J.
As I threatened to do earlier, I made a pass at converting table 9.10
to a couple of the styles under discussion. (This is just a
draft-quality patch, so it might have some minor bugs --- the point
is just to see what these styles look like.)
I've concluded after looking around that the ideas involving not having
a <table> at all, but just a <variablelist> or the like, are not very
well-advised. That would eliminate, or at least greatly degrade, the
visual distinction between the per-function material and the surrounding
commentary. Which does not seem like a winner to me; for example it
would make it quite hard to skip over the detailed material when you're
just trying to skim the docs.
We did have a number of people suggesting that just reordering things as
"description, signature, examples" might be a good idea, so I gave that
a try; attached is a rendition of a portion of 9.10 in that style (the
"v1" image). It's not bad, but there's still going to be a lot of
wasted whitespace in tables that include even one long function name.
(9.10's longest is "regexp_split_to_array", so it's showing this problem
significantly.)
I also experimented with Jonathan's idea of dropping the separate
function name and allowing the function signature to span left into
that column -- see "v2" images. This actually works really well,
and would work even better (IMO) if we could get rid of the inter-row
and inter-column rules within a function entry. I failed to
accomplish that with rowsep/colsep annotations, but from remarks
upthread I suppose there might be a CSS way to accomplish it. (But
the rowsep/colsep annotations *do* work in PDF output, so I kept them;
that means we only need a CSS fix and not some kind of flow-object
magic for PDF.)
To allow direct comparison of these 9.10 images against the situation
in HEAD, I've also attached an extract of 9.10 as rendered by my
browser with "STYLE=website". As you can see this is *not* quite
identical to how it renders on postgresql.org, so there is still some
unexplained differential in font or margins or something. But if you
look at those three PNGs you can see that either v1 or v2 has a pretty
substantial advantage over HEAD in terms of the amount of space
needed. v2 would be even further ahead if we could eliminate some of
the vertical space around the intra-function row split, which again
might be doable with CSS magic.
The main disadvantage I can see to the v2 design is that we're back
to having two <rows> per function, which is inevitably going to result
in PDF builds putting page breaks between those rows. But you can't
have everything ... and maybe we could find a way to discourage such
breaks if we tried.
Another issue is that v2 won't adapt real well to operator tables;
the operator name won't be at the left. I don't have a lot of faith
in the proposal to fix that with font tricks. Maybe we could stick
to something close to the layout that table 9.30 has in HEAD (ie
repeating the operator name in column 1), since we won't have long
operator names messing up the format. Again, CSS'ing our way
out of the internal lines and extra vertical space within a single
logical table cell would make that layout look nicer.
On balance I quite like the v2 layout and would prefer to move forward
with that, assuming we can solve the remaining issues via CSS or style
sheets.
In addition to screenshots, I've attached patches against HEAD that
convert both tables 9.10 and 9.33 into v1 and v2 styles.
regards, tom lane
diff --git a/doc/src/sgml/func.sgml b/doc/src/sgml/func.sgml
index 7a270eb..84a7e57 100644
--- a/doc/src/sgml/func.sgml
+++ b/doc/src/sgml/func.sgml
@@ -1798,243 +1798,276 @@
<table id="functions-string-other">
<title>Other String Functions</title>
- <tgroup cols="5">
+ <tgroup cols="2">
+ <colspec colname="col1" align="left" colwidth="0.25*"/>
+ <colspec colname="col2" align="left" colwidth="1*"/>
<thead>
<row>
<entry>Function</entry>
- <entry>Return Type</entry>
- <entry>Description</entry>
- <entry>Example</entry>
- <entry>Result</entry>
+ <entry>Description<?br?>Signature<?br?>Example(s)</entry>
</row>
</thead>
<tbody>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>ascii</primary>
</indexterm>
- <literal><function>ascii(<parameter>string</parameter>)</function></literal>
+ <function>ascii</function>
</entry>
- <entry><type>int</type></entry>
<entry>
- <acronym>ASCII</acronym> code of the first character of the
- argument. For <acronym>UTF8</acronym> returns the Unicode code
- point of the character. For other multibyte encodings, the
- argument must be an <acronym>ASCII</acronym> character.
+ Returns the numeric code of the first character of the argument.
+ In <acronym>UTF8</acronym> encoding, returns the Unicode code point
+ of the character. In other multibyte encodings, the argument must
+ be an <acronym>ASCII</acronym> character.
+ <?br?>
+ <function>ascii</function> ( <type>text</type> )
+ <returnvalue>integer</returnvalue>
+ <?br?>
+ <literal>ascii('x')</literal>
+ <returnvalue>120</returnvalue>
</entry>
- <entry><literal>ascii('x')</literal></entry>
- <entry><literal>120</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>btrim</primary>
</indexterm>
- <literal><function>btrim(<parameter>string</parameter> <type>text</type>
- <optional>, <parameter>characters</parameter> <type>text</type></optional>)</function></literal>
+ <function>btrim</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Remove the longest string consisting only of characters
+ Removes the longest string consisting only of characters
in <parameter>characters</parameter> (a space by default)
- from the start and end of <parameter>string</parameter>
+ from the start and end of <parameter>string</parameter>.
+ <?br?>
+ <function>btrim</function> ( <parameter>string</parameter> <type>text</type>
+ <optional>, <parameter>characters</parameter> <type>text</type> </optional> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>btrim('xyxtrimyyx', 'xyz')</literal>
+ <returnvalue>trim</returnvalue>
</entry>
- <entry><literal>btrim('xyxtrimyyx', 'xyz')</literal></entry>
- <entry><literal>trim</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>chr</primary>
</indexterm>
- <literal><function>chr(<type>int</type>)</function></literal>
+ <function>chr</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Character with the given code. For <acronym>UTF8</acronym> the
- argument is treated as a Unicode code point. For other multibyte
- encodings the argument must designate an
- <acronym>ASCII</acronym> character. The NULL (0) character is not
- allowed because text data types cannot store such bytes.
+ Returns the character with the given
+ code. In <acronym>UTF8</acronym> encoding the argument is treated as
+ a Unicode code point. In other multibyte encodings the argument must
+ designate an <acronym>ASCII</acronym> character. The NULL (0)
+ character is not allowed because text data types cannot store such
+ bytes.
+ <?br?>
+ <function>chr</function> ( <type>integer</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>chr(65)</literal>
+ <returnvalue>A</returnvalue>
</entry>
- <entry><literal>chr(65)</literal></entry>
- <entry><literal>A</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>concat</primary>
</indexterm>
- <literal><function>concat(<parameter>str</parameter> <type>"any"</type>
- [, <parameter>str</parameter> <type>"any"</type> [, ...] ])</function></literal>
+ <function>concat</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Concatenate the text representations of all the arguments.
+ Concatenates the text representations of all the arguments.
NULL arguments are ignored.
+ <?br?>
+ <function>concat</function> ( <parameter>val</parameter> <type>"any"</type>
+ [, <parameter>val</parameter> <type>"any"</type> [, ...] ] )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>concat('abcde', 2, NULL, 22)</literal>
+ <returnvalue>abcde222</returnvalue>
</entry>
- <entry><literal>concat('abcde', 2, NULL, 22)</literal></entry>
- <entry><literal>abcde222</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>concat_ws</primary>
</indexterm>
- <literal><function>concat_ws(<parameter>sep</parameter> <type>text</type>,
- <parameter>str</parameter> <type>"any"</type>
- [, <parameter>str</parameter> <type>"any"</type> [, ...] ])</function></literal>
+ <function>concat_ws</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Concatenate all but the first argument with separators. The first
+ Concatenates all but the first argument, with separators. The first
argument is used as the separator string. NULL arguments are ignored.
+ <?br?>
+ <function>concat_ws</function> ( <parameter>sep</parameter> <type>text</type>,
+ <parameter>val</parameter> <type>"any"</type>
+ [, <parameter>val</parameter> <type>"any"</type> [, ...] ] )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>concat_ws(',', 'abcde', 2, NULL, 22)</literal>
+ <returnvalue>abcde,2,22</returnvalue>
</entry>
- <entry><literal>concat_ws(',', 'abcde', 2, NULL, 22)</literal></entry>
- <entry><literal>abcde,2,22</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>format</primary>
</indexterm>
- <literal><function>format</function>(<parameter>formatstr</parameter> <type>text</type>
- [, <parameter>formatarg</parameter> <type>"any"</type> [, ...] ])</literal>
+ <function>format</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Format arguments according to a format string.
+ Formats arguments according to a format string;
+ see <xref linkend="functions-string-format"/>.
This function is similar to the C function <function>sprintf</function>.
- See <xref linkend="functions-string-format"/>.
+ <?br?>
+ <function>format</function> ( <parameter>formatstr</parameter> <type>text</type>
+ [, <parameter>formatarg</parameter> <type>"any"</type> [, ...] ] )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>format('Hello %s, %1$s', 'World')</literal>
+ <returnvalue>Hello World, World</returnvalue>
</entry>
- <entry><literal>format('Hello %s, %1$s', 'World')</literal></entry>
- <entry><literal>Hello World, World</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>initcap</primary>
</indexterm>
- <literal><function>initcap(<parameter>string</parameter>)</function></literal>
+ <function>initcap</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Convert the first letter of each word to upper case and the
+ Converts the first letter of each word to upper case and the
rest to lower case. Words are sequences of alphanumeric
characters separated by non-alphanumeric characters.
+ <?br?>
+ <function>initcap</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>initcap('hi THOMAS')</literal>
+ <returnvalue>Hi Thomas</returnvalue>
</entry>
- <entry><literal>initcap('hi THOMAS')</literal></entry>
- <entry><literal>Hi Thomas</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>left</primary>
</indexterm>
- <literal><function>left(<parameter>string</parameter> <type>text</type>,
- <parameter>n</parameter> <type>int</type>)</function></literal>
+ <function>left</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Return first <replaceable>n</replaceable> characters in the
- string, or when <replaceable>n</replaceable> is negative, return
- all but last |<replaceable>n</replaceable>| characters
- </entry>
- <entry><literal>left('abcde', 2)</literal></entry>
- <entry><literal>ab</literal></entry>
+ Returns first <replaceable>n</replaceable> characters in the
+ string, or when <replaceable>n</replaceable> is negative, returns
+ all but last |<replaceable>n</replaceable>| characters.
+ <?br?>
+ <function>left</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>n</parameter> <type>integer</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>left('abcde', 2)</literal>
+ <returnvalue>ab</returnvalue>
+ </entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>length</primary>
</indexterm>
- <literal><function>length(<parameter>string</parameter>)</function></literal>
+ <function>length</function>
</entry>
- <entry><type>int</type></entry>
<entry>
- Number of characters in <parameter>string</parameter>
+ Returns the number of characters in the string.
+ <?br?>
+ <function>length</function> ( <type>text</type> )
+ <returnvalue>integer</returnvalue>
+ <?br?>
+ <literal>length('jose')</literal>
+ <returnvalue>4</returnvalue>
</entry>
- <entry><literal>length('jose')</literal></entry>
- <entry><literal>4</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>lpad</primary>
</indexterm>
- <literal><function>lpad(<parameter>string</parameter> <type>text</type>,
- <parameter>length</parameter> <type>int</type>
- <optional>, <parameter>fill</parameter> <type>text</type></optional>)</function></literal>
+ <function>lpad</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Extend the <parameter>string</parameter> to length
+ Extends the <parameter>string</parameter> to length
<parameter>length</parameter> by prepending the characters
<parameter>fill</parameter> (a space by default). If the
<parameter>string</parameter> is already longer than
- <parameter>length</parameter> then it is truncated (on the
- right).
+ <parameter>length</parameter> then it is truncated (on the right).
+ <?br?>
+ <function>lpad</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>length</parameter> <type>integer</type>
+ <optional>, <parameter>fill</parameter> <type>text</type> </optional> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>lpad('hi', 5, 'xy')</literal>
+ <returnvalue>xyxhi</returnvalue>
</entry>
- <entry><literal>lpad('hi', 5, 'xy')</literal></entry>
- <entry><literal>xyxhi</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>ltrim</primary>
</indexterm>
- <literal><function>ltrim(<parameter>string</parameter> <type>text</type>
- <optional>, <parameter>characters</parameter> <type>text</type></optional>)</function></literal>
+ <function>ltrim</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Remove the longest string containing only characters from
+ Removes the longest string containing only characters from
<parameter>characters</parameter> (a space by default) from the start of
- <parameter>string</parameter>
+ <parameter>string</parameter>.
+ <?br?>
+ <function>ltrim</function> ( <parameter>string</parameter> <type>text</type>
+ <optional>, <parameter>characters</parameter> <type>text</type> </optional> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>ltrim('zzzytest', 'xyz')</literal>
+ <returnvalue>test</returnvalue>
</entry>
- <entry><literal>ltrim('zzzytest', 'xyz')</literal></entry>
- <entry><literal>test</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>md5</primary>
</indexterm>
- <literal><function>md5(<parameter>string</parameter>)</function></literal>
+ <function>md5</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- MD5 <link linkend="functions-hash-note">hash</link>, with
- the result written in hexadecimal
+ Computes MD5 <link linkend="functions-hash-note">hash</link>, with
+ the result written in hexadecimal.
+ <?br?>
+ <function>md5</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>md5('abc')</literal>
+ <returnvalue>900150983cd24fb0&zwsp;d6963f7d28e17f72</returnvalue>
</entry>
- <entry><literal>md5('abc')</literal></entry>
- <entry><literal>900150983cd24fb0 d6963f7d28e17f72</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>parse_ident</primary>
</indexterm>
- <literal><function>parse_ident(<parameter>qualified_identifier</parameter> <type>text</type>
- [, <parameter>strictmode</parameter> <type>boolean</type> DEFAULT true ] )</function></literal>
+ <function>parse_ident</function>
</entry>
- <entry><type>text[]</type></entry>
<entry>
- Split <parameter>qualified_identifier</parameter> into an array of
+ Splits <parameter>qualified_identifier</parameter> into an array of
identifiers, removing any quoting of individual identifiers. By
default, extra characters after the last identifier are considered an
error; but if the second parameter is <literal>false</literal>, then such
@@ -2042,417 +2075,513 @@
names for objects like functions.) Note that this function does not
truncate over-length identifiers. If you want truncation you can cast
the result to <type>name[]</type>.
+ <?br?>
+ <function>parse_ident</function> ( <parameter>qualified_identifier</parameter> <type>text</type>
+ [, <parameter>strictmode</parameter> <type>boolean</type> <literal>DEFAULT</literal> <literal>true</literal> ]
)
+ <returnvalue>text[]</returnvalue>
+ <?br?>
+ <literal>parse_ident('"SomeSchema".someTable')</literal>
+ <returnvalue>{SomeSchema,sometable}</returnvalue>
</entry>
- <entry><literal>parse_ident('"SomeSchema".someTable')</literal></entry>
- <entry><literal>{SomeSchema,sometable}</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>pg_client_encoding</primary>
</indexterm>
- <literal><function>pg_client_encoding()</function></literal>
+ <function>pg_client_encoding</function>
</entry>
- <entry><type>name</type></entry>
<entry>
- Current client encoding name
+ Returns current client encoding name.
+ <?br?>
+ <function>pg_client_encoding</function> ( )
+ <returnvalue>name</returnvalue>
+ <?br?>
+ <literal>pg_client_encoding()</literal>
+ <returnvalue>SQL_ASCII</returnvalue>
</entry>
- <entry><literal>pg_client_encoding()</literal></entry>
- <entry><literal>SQL_ASCII</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>quote_ident</primary>
</indexterm>
- <literal><function>quote_ident(<parameter>string</parameter> <type>text</type>)</function></literal>
+ <function>quote_ident</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Return the given string suitably quoted to be used as an identifier
+ Returns the given string suitably quoted to be used as an identifier
in an <acronym>SQL</acronym> statement string.
Quotes are added only if necessary (i.e., if the string contains
non-identifier characters or would be case-folded).
Embedded quotes are properly doubled.
See also <xref linkend="plpgsql-quote-literal-example"/>.
+ <?br?>
+ <function>quote_ident</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>quote_ident('Foo bar')</literal>
+ <returnvalue>"Foo bar"</returnvalue>
</entry>
- <entry><literal>quote_ident('Foo bar')</literal></entry>
- <entry><literal>"Foo bar"</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>quote_literal</primary>
</indexterm>
- <literal><function>quote_literal(<parameter>string</parameter> <type>text</type>)</function></literal>
+ <function>quote_literal</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Return the given string suitably quoted to be used as a string literal
+ Returns the given string suitably quoted to be used as a string literal
in an <acronym>SQL</acronym> statement string.
Embedded single-quotes and backslashes are properly doubled.
Note that <function>quote_literal</function> returns null on null
input; if the argument might be null,
<function>quote_nullable</function> is often more suitable.
See also <xref linkend="plpgsql-quote-literal-example"/>.
+ <?br?>
+ <function>quote_literal</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>quote_literal(E'O\'Reilly')</literal>
+ <returnvalue>'O''Reilly'</returnvalue>
</entry>
- <entry><literal>quote_literal(E'O\'Reilly')</literal></entry>
- <entry><literal>'O''Reilly'</literal></entry>
</row>
<row>
- <entry><literal><function>quote_literal(<parameter>value</parameter>
<type>anyelement</type>)</function></literal></entry>
- <entry><type>text</type></entry>
+ <entry valign="top"><function>quote_literal</function></entry>
<entry>
- Coerce the given value to text and then quote it as a literal.
+ Coerces the given value to text and then quotes it as a literal.
Embedded single-quotes and backslashes are properly doubled.
+ <?br?>
+ <function>quote_literal</function> ( <type>anyelement</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>quote_literal(42.5)</literal>
+ <returnvalue>'42.5'</returnvalue>
</entry>
- <entry><literal>quote_literal(42.5)</literal></entry>
- <entry><literal>'42.5'</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>quote_nullable</primary>
</indexterm>
- <literal><function>quote_nullable(<parameter>string</parameter> <type>text</type>)</function></literal>
+ <function>quote_nullable</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Return the given string suitably quoted to be used as a string literal
+ Returns the given string suitably quoted to be used as a string literal
in an <acronym>SQL</acronym> statement string; or, if the argument
- is null, return <literal>NULL</literal>.
+ is null, returns <literal>NULL</literal>.
Embedded single-quotes and backslashes are properly doubled.
See also <xref linkend="plpgsql-quote-literal-example"/>.
+ <?br?>
+ <function>quote_nullable</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>quote_nullable(NULL)</literal>
+ <returnvalue>NULL</returnvalue>
</entry>
- <entry><literal>quote_nullable(NULL)</literal></entry>
- <entry><literal>NULL</literal></entry>
</row>
<row>
- <entry><literal><function>quote_nullable(<parameter>value</parameter>
<type>anyelement</type>)</function></literal></entry>
- <entry><type>text</type></entry>
+ <entry valign="top"><function>quote_nullable</function></entry>
<entry>
- Coerce the given value to text and then quote it as a literal;
- or, if the argument is null, return <literal>NULL</literal>.
+ Coerces the given value to text and then quotes it as a literal;
+ or, if the argument is null, returns <literal>NULL</literal>.
Embedded single-quotes and backslashes are properly doubled.
+ <?br?>
+ <function>quote_nullable</function> ( <type>anyelement</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>quote_nullable(42.5)</literal>
+ <returnvalue>'42.5'</returnvalue>
</entry>
- <entry><literal>quote_nullable(42.5)</literal></entry>
- <entry><literal>'42.5'</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>regexp_match</primary>
</indexterm>
- <literal><function>regexp_match(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter>
<type>text</type>])</function></literal>
+ <function>regexp_match</function>
</entry>
- <entry><type>text[]</type></entry>
<entry>
- Return captured substring(s) resulting from the first match of a POSIX
- regular expression to the <parameter>string</parameter> (see
- <xref linkend="functions-posix-regexp"/> for more information)
+ Returns captured substring(s) resulting from the first match of a POSIX
+ regular expression to the <parameter>string</parameter>; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <function>regexp_match</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type> ] )
+ <returnvalue>text[]</returnvalue>
+ <?br?>
+ <literal>regexp_match('foobarbequebaz', '(bar)(beque)')</literal>
+ <returnvalue>{bar,beque}</returnvalue>
</entry>
- <entry><literal>regexp_match('foobarbequebaz', '(bar)(beque)')</literal></entry>
- <entry><literal>{bar,beque}</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>regexp_matches</primary>
</indexterm>
- <literal><function>regexp_matches(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter>
<type>text</type>])</function></literal>
+ <function>regexp_matches</function>
</entry>
- <entry><type>setof text[]</type></entry>
<entry>
- Return captured substring(s) resulting from matching a POSIX regular
- expression to the <parameter>string</parameter> (see
- <xref linkend="functions-posix-regexp"/> for more information)
+ Returns captured substring(s) resulting from matching a POSIX regular
+ expression to the <parameter>string</parameter>; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <function>regexp_matches</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type> ] )
+ <returnvalue>setof text[]</returnvalue>
+ <?br?>
+ <literal>regexp_matches('foobarbequebaz', 'ba.', 'g')</literal>
+ <returnvalue>{bar}<?br?>{baz}</returnvalue><?br?>(2 rows)
</entry>
- <entry><literal>regexp_matches('foobarbequebaz', 'ba.', 'g')</literal></entry>
- <entry><literal>{bar}</literal><para><literal>{baz}</literal></para> (2 rows)</entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>regexp_replace</primary>
</indexterm>
- <literal><function>regexp_replace(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type>, <parameter>replacement</parameter> <type>text</type> [,
<parameter>flags</parameter><type>text</type>])</function></literal>
+ <function>regexp_replace</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Replace substring(s) matching a POSIX regular expression (see
- <xref linkend="functions-posix-regexp"/> for more information)
+ Replaces substring(s) matching a POSIX regular expression; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <function>regexp_replace</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type>, <parameter>replacement</parameter> <type>text</type> [,
<parameter>flags</parameter><type>text</type> ] )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>regexp_replace('Thomas', '.[mN]a.', 'M')</literal>
+ <returnvalue>ThM</returnvalue>
</entry>
- <entry><literal>regexp_replace('Thomas', '.[mN]a.', 'M')</literal></entry>
- <entry><literal>ThM</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>regexp_split_to_array</primary>
</indexterm>
- <literal><function>regexp_split_to_array(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type>
])</function></literal>
+ <function>regexp_split_to_array</function>
</entry>
- <entry><type>text[]</type></entry>
<entry>
- Split <parameter>string</parameter> using a POSIX regular expression as
- the delimiter (see <xref linkend="functions-posix-regexp"/> for more
- information)
+ Splits <parameter>string</parameter> using a POSIX regular
+ expression as the delimiter; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <function>regexp_split_to_array</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type> ] )
+ <returnvalue>text[]</returnvalue>
+ <?br?>
+ <literal>regexp_split_to_array('hello world', '\s+')</literal>
+ <returnvalue>{hello,world}</returnvalue>
</entry>
- <entry><literal>regexp_split_to_array('hello world', '\s+')</literal></entry>
- <entry><literal>{hello,world}</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>regexp_split_to_table</primary>
</indexterm>
- <literal><function>regexp_split_to_table(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter>
<type>text</type>])</function></literal>
+ <function>regexp_split_to_table</function>
</entry>
- <entry><type>setof text</type></entry>
<entry>
- Split <parameter>string</parameter> using a POSIX regular expression as
- the delimiter (see <xref linkend="functions-posix-regexp"/> for more
- information)
+ Splits <parameter>string</parameter> using a POSIX regular
+ expression as the delimiter; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <function>regexp_split_to_table</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type> ] )
+ <returnvalue>setof text</returnvalue>
+ <?br?>
+ <literal>regexp_split_to_table('hello world', '\s+')</literal>
+ <returnvalue>hello<?br?>world</returnvalue><?br?>(2 rows)
</entry>
- <entry><literal>regexp_split_to_table('hello world', '\s+')</literal></entry>
- <entry><literal>hello</literal><para><literal>world</literal></para> (2 rows)</entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>repeat</primary>
</indexterm>
- <literal><function>repeat(<parameter>string</parameter> <type>text</type>, <parameter>number</parameter>
<type>int</type>)</function></literal>
+ <function>repeat</function>
+ </entry>
+ <entry>
+ Repeats <parameter>string</parameter> the specified
+ <parameter>number</parameter> of times.
+ <?br?>
+ <function>repeat</function> ( <parameter>string</parameter> <type>text</type>, <parameter>number</parameter>
<type>integer</type>)
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>repeat('Pg', 4)</literal>
+ <returnvalue>PgPgPgPg</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>Repeat <parameter>string</parameter> the specified
- <parameter>number</parameter> of times</entry>
- <entry><literal>repeat('Pg', 4)</literal></entry>
- <entry><literal>PgPgPgPg</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>replace</primary>
</indexterm>
- <literal><function>replace(<parameter>string</parameter> <type>text</type>,
- <parameter>from</parameter> <type>text</type>,
- <parameter>to</parameter> <type>text</type>)</function></literal>
+ <function>replace</function>
</entry>
- <entry><type>text</type></entry>
- <entry>Replace all occurrences in <parameter>string</parameter> of substring
- <parameter>from</parameter> with substring <parameter>to</parameter>
+ <entry>
+ Replaces all occurrences in <parameter>string</parameter> of
+ substring <parameter>from</parameter> with
+ substring <parameter>to</parameter>.
+ <?br?>
+ <function>replace</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>from</parameter> <type>text</type>,
+ <parameter>to</parameter> <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>replace('abcdefabcdef', 'cd', 'XX')</literal>
+ <returnvalue>abXXefabXXef</returnvalue>
</entry>
- <entry><literal>replace('abcdefabcdef', 'cd', 'XX')</literal></entry>
- <entry><literal>abXXefabXXef</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>reverse</primary>
</indexterm>
- <literal><function>reverse(<parameter>str</parameter>)</function></literal>
+ <function>reverse</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Reverse the order of the characters in <parameter>string</parameter>
+ Reverses the order of the characters in the string.
+ <?br?>
+ <function>reverse</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>reverse('abcde')</literal>
+ <returnvalue>edcba</returnvalue>
</entry>
- <entry><literal>reverse('abcde')</literal></entry>
- <entry><literal>edcba</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>right</primary>
</indexterm>
- <literal><function>right(<parameter>string</parameter> <type>text</type>,
- <parameter>n</parameter> <type>int</type>)</function></literal>
+ <function>right</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Return last <replaceable>n</replaceable> characters in the string,
- or when <replaceable>n</replaceable> is negative, return all but
- first |<replaceable>n</replaceable>| characters
+ Returns last <replaceable>n</replaceable> characters in the string,
+ or when <replaceable>n</replaceable> is negative, returns all but
+ first |<replaceable>n</replaceable>| characters.
+ <?br?>
+ <function>right</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>n</parameter> <type>integer</type> )
+<type></type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>right('abcde', 2)</literal>
+ <returnvalue>de</returnvalue>
</entry>
- <entry><literal>right('abcde', 2)</literal></entry>
- <entry><literal>de</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>rpad</primary>
</indexterm>
- <literal><function>rpad(<parameter>string</parameter> <type>text</type>,
- <parameter>length</parameter> <type>int</type>
- <optional>, <parameter>fill</parameter> <type>text</type></optional>)</function></literal>
+ <function>rpad</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Extend the <parameter>string</parameter> to length
+ Extends the <parameter>string</parameter> to length
<parameter>length</parameter> by appending the characters
<parameter>fill</parameter> (a space by default). If the
<parameter>string</parameter> is already longer than
<parameter>length</parameter> then it is truncated.
+ <?br?>
+ <function>rpad</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>length</parameter> <type>integer</type>
+ <optional>, <parameter>fill</parameter> <type>text</type> </optional> )
+<type></type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>rpad('hi', 5, 'xy')</literal>
+ <returnvalue>hixyx</returnvalue>
</entry>
- <entry><literal>rpad('hi', 5, 'xy')</literal></entry>
- <entry><literal>hixyx</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>rtrim</primary>
</indexterm>
- <literal><function>rtrim(<parameter>string</parameter> <type>text</type>
- <optional>, <parameter>characters</parameter> <type>text</type></optional>)</function></literal>
+ <function>rtrim</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Remove the longest string containing only characters from
+ Removes the longest string containing only characters from
<parameter>characters</parameter> (a space by default) from the end of
- <parameter>string</parameter>
+ <parameter>string</parameter>.
+ <?br?>
+ <function>rtrim</function> ( <parameter>string</parameter> <type>text</type>
+ <optional>, <parameter>characters</parameter> <type>text</type> </optional> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>rtrim('testxxzx', 'xyz')</literal>
+ <returnvalue>test</returnvalue>
</entry>
- <entry><literal>rtrim('testxxzx', 'xyz')</literal></entry>
- <entry><literal>test</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>split_part</primary>
</indexterm>
- <literal><function>split_part(<parameter>string</parameter> <type>text</type>,
- <parameter>delimiter</parameter> <type>text</type>,
- <parameter>field</parameter> <type>int</type>)</function></literal>
+ <function>split_part</function>
</entry>
- <entry><type>text</type></entry>
- <entry>Split <parameter>string</parameter> on <parameter>delimiter</parameter>
- and return the given field (counting from one)
+ <entry>
+ Splits <parameter>string</parameter> on <parameter>delimiter</parameter>
+ and returns the <parameter>n</parameter>'th field (counting from one).
+ <?br?>
+ <function>split_part</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>delimiter</parameter> <type>text</type>,
+ <parameter>n</parameter> <type>integer</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>split_part('abc~@~def~@~ghi', '~@~', 2)</literal>
+ <returnvalue>def</returnvalue>
</entry>
- <entry><literal>split_part('abc~@~def~@~ghi', '~@~', 2)</literal></entry>
- <entry><literal>def</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>strpos</primary>
</indexterm>
- <literal><function>strpos(<parameter>string</parameter>,
<parameter>substring</parameter>)</function></literal>
+ <function>strpos</function>
</entry>
- <entry><type>int</type></entry>
<entry>
- Location of specified substring (same as
- <literal>position(<parameter>substring</parameter> in
- <parameter>string</parameter>)</literal>, but note the reversed
- argument order)
+ Returns location of specified <parameter>substring</parameter>
+ within <parameter>string</parameter>, or zero if it's not present.
+ (Same as <literal>position(<parameter>substring</parameter> in
+ <parameter>string</parameter>)</literal>, but note the reversed
+ argument order.)
+ <?br?>
+ <function>strpos</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>substring</parameter><type>text</type> )
+ <returnvalue>integer</returnvalue>
+ <?br?>
+ <literal>strpos('high', 'ig')</literal>
+ <returnvalue>2</returnvalue>
</entry>
- <entry><literal>strpos('high', 'ig')</literal></entry>
- <entry><literal>2</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>substr</primary>
</indexterm>
- <literal><function>substr(<parameter>string</parameter>, <parameter>from</parameter> <optional>,
<parameter>count</parameter></optional>)</function></literal>
+ <function>substr</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Extract substring (same as
- <literal>substring(<parameter>string</parameter> from <parameter>from</parameter> for
<parameter>count</parameter>)</literal>)
+ Extracts substring starting at index <parameter>start</parameter>,
+ and extending for <parameter>count</parameter> characters if that is
+ specified. (Same
+ as <literal>substring(<parameter>string</parameter>
+ from <parameter>start</parameter>
+ for <parameter>count</parameter>)</literal>.)
+ <?br?>
+ <function>substr</function> ( <parameter>string</parameter> <type>text</type>, <parameter>start</parameter>
<type>integer</type><optional>, <parameter>count</parameter> <type>integer</type> </optional> )
+<type></type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>substr('alphabet', 3, 2)</literal>
+ <returnvalue>ph</returnvalue>
</entry>
- <entry><literal>substr('alphabet', 3, 2)</literal></entry>
- <entry><literal>ph</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>starts_with</primary>
</indexterm>
- <literal><function>starts_with(<parameter>string</parameter>,
<parameter>prefix</parameter>)</function></literal>
+ <function>starts_with</function>
</entry>
- <entry><type>bool</type></entry>
<entry>
- Return true if <parameter>string</parameter> starts
- with <parameter>prefix</parameter>
+ Returns true if <parameter>string</parameter> starts
+ with <parameter>prefix</parameter>.
+ <?br?>
+ <function>starts_with</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>prefix</parameter><type>text</type> )
+ <returnvalue>boolean</returnvalue>
+ <?br?>
+ <literal>starts_with('alphabet', 'alph')</literal>
+ <returnvalue>t</returnvalue>
</entry>
- <entry><literal>starts_with('alphabet', 'alph')</literal></entry>
- <entry><literal>t</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>to_ascii</primary>
</indexterm>
- <literal><function>to_ascii(<parameter>string</parameter> <type>text</type>
- <optional>, <parameter>encoding</parameter> <type>text</type></optional>)</function></literal>
+ <function>to_ascii</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Convert <parameter>string</parameter> to <acronym>ASCII</acronym> from another encoding
- (only supports conversion from <literal>LATIN1</literal>, <literal>LATIN2</literal>,
<literal>LATIN9</literal>,
- and <literal>WIN1250</literal> encodings)
+ Converts <parameter>string</parameter> to <acronym>ASCII</acronym>
+ from another encoding, which may be identified by name or number;
+ if <parameter>encoding</parameter> is omitted the database encoding
+ is assumed. The conversion consists primarily of dropping accents.
+ Conversion is only supported
+ from <literal>LATIN1</literal>, <literal>LATIN2</literal>,
+ <literal>LATIN9</literal>, and <literal>WIN1250</literal> encodings.
+ <?br?>
+ <function>to_ascii</function> ( <parameter>string</parameter> <type>text</type>
+ <optional>, <parameter>encoding</parameter> <type>name</type> or <type>integer</type> </optional> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>to_ascii('Karél')</literal>
+ <returnvalue>Karel</returnvalue>
</entry>
- <entry><literal>to_ascii('Karel')</literal></entry>
- <entry><literal>Karel</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>to_hex</primary>
</indexterm>
- <literal><function>to_hex(<parameter>number</parameter> <type>int</type>
- or <type>bigint</type>)</function></literal>
+ <function>to_hex</function>
</entry>
- <entry><type>text</type></entry>
- <entry>Convert <parameter>number</parameter> to its equivalent hexadecimal
- representation
+ <entry>
+ Converts <parameter>number</parameter> to its equivalent hexadecimal
+ representation.
+ <?br?>
+ <function>to_hex</function> ( <parameter>number</parameter>
+ <type>integer</type>
+ or <type>bigint</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>to_hex(2147483647)</literal>
+ <returnvalue>7fffffff</returnvalue>
</entry>
- <entry><literal>to_hex(2147483647)</literal></entry>
- <entry><literal>7fffffff</literal></entry>
</row>
<row>
- <entry>
+ <entry valign="top">
<indexterm>
<primary>translate</primary>
</indexterm>
- <literal><function>translate(<parameter>string</parameter> <type>text</type>,
- <parameter>from</parameter> <type>text</type>,
- <parameter>to</parameter> <type>text</type>)</function></literal>
+ <function>translate</function>
</entry>
- <entry><type>text</type></entry>
<entry>
- Any character in <parameter>string</parameter> that matches a
- character in the <parameter>from</parameter> set is replaced by
- the corresponding character in the <parameter>to</parameter>
+ Replaces each character in <parameter>string</parameter> that
+ matches a character in the <parameter>from</parameter> set with the
+ corresponding character in the <parameter>to</parameter>
set. If <parameter>from</parameter> is longer than
<parameter>to</parameter>, occurrences of the extra characters in
- <parameter>from</parameter> are removed.
+ <parameter>from</parameter> are deleted.
+ <?br?>
+ <function>translate</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>from</parameter> <type>text</type>,
+ <parameter>to</parameter> <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ <literal>translate('12345', '143', 'ax')</literal>
+ <returnvalue>a2x5</returnvalue>
</entry>
- <entry><literal>translate('12345', '143', 'ax')</literal></entry>
- <entry><literal>a2x5</literal></entry>
</row>
</tbody>
@@ -8645,103 +8774,90 @@ CREATE TYPE rainbow AS ENUM ('red', 'orange', 'yellow', 'green', 'blue', 'purple
<table id="functions-enum-table">
<title>Enum Support Functions</title>
- <tgroup cols="3">
- <colspec colname="col1" colwidth="0.5*"/>
- <colspec colname="col2" colwidth="1*"/>
- <colspec colname="col3" colwidth="1*"/>
- <spanspec spanname="name" namest="col1" nameend="col1" align="left"/>
- <spanspec spanname="sig" namest="col2" nameend="col3" align="left"/>
- <spanspec spanname="desc" namest="col2" nameend="col3" align="left"/>
- <spanspec spanname="example" namest="col2" nameend="col2" align="left"/>
- <spanspec spanname="exresult" namest="col3" nameend="col3" align="left"/>
+ <tgroup cols="2">
+ <colspec colname="col1" align="left" colwidth="0.25*"/>
+ <colspec colname="col2" align="left" colwidth="1*"/>
<thead>
<row>
- <entry spanname="name" align="center" valign="middle" morerows="2">Function</entry>
- <entry spanname="sig" align="center">Signature</entry>
- </row>
- <row>
- <entry spanname="desc" align="center">Description</entry>
- </row>
- <row>
- <entry spanname="example" align="center">Example</entry>
- <entry spanname="exresult" align="center">Example Result</entry>
+ <entry>Function</entry>
+ <entry>Description<?br?>Signature<?br?>Example(s)</entry>
</row>
</thead>
<tbody>
<row>
- <entry spanname="name" morerows="2">
+ <entry valign="top">
<indexterm>
<primary>enum_first</primary>
</indexterm>
<function>enum_first</function>
</entry>
- <entry spanname="sig"><function>enum_first</function>(<type>anyenum</type>)
<returnvalue>anyenum</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Returns the first value of the input enum type</entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_first(&zwsp;null::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>red</literal></entry>
+ <entry>
+ Returns the first value of the input enum type.
+ <?br?>
+ <function>enum_first</function> ( <type>anyenum</type> )
+ <returnvalue>anyenum</returnvalue>
+ <?br?>
+ <literal>enum_first(&zwsp;null::rainbow)</literal>
+ <returnvalue>red</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2">
+ <entry valign="top">
<indexterm>
<primary>enum_last</primary>
</indexterm>
<function>enum_last</function>
</entry>
- <entry spanname="sig"><function>enum_last</function>(<type>anyenum</type>)
<returnvalue>anyenum</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Returns the last value of the input enum type</entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_last(&zwsp;null::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>purple</literal></entry>
+ <entry>
+ Returns the last value of the input enum type.
+ <?br?>
+ <function>enum_last</function> ( <type>anyenum</type> )
+ <returnvalue>anyenum</returnvalue>
+ <?br?>
+ <literal>enum_last(&zwsp;null::rainbow)</literal>
+ <returnvalue>purple</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2">
+ <entry valign="top">
<indexterm>
<primary>enum_range</primary>
</indexterm>
<function>enum_range</function>
</entry>
- <entry spanname="sig"><function>enum_range</function>(<type>anyenum</type>)
<returnvalue>anyarray</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Returns all values of the input enum type in an ordered array</entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_range(&zwsp;null::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>{red,orange,yellow,&zwsp;green,blue,purple}</literal></entry>
- </row>
- <row>
- <entry spanname="name" morerows="4"><function>enum_range</function></entry>
- <entry spanname="sig"><function>enum_range</function>(<type>anyenum</type>, <type>anyenum</type>)
<returnvalue>anyarray</returnvalue></entry>
+ <entry>
+ Returns all values of the input enum type in an ordered array.
+ <?br?>
+ <function>enum_range</function> ( <type>anyenum</type> )
+ <returnvalue>anyarray</returnvalue>
+ <?br?>
+ <literal>enum_range(&zwsp;null::rainbow)</literal>
+ <returnvalue>{red,orange,yellow,&zwsp;green,blue,purple}</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="desc">
+ <entry valign="top"><function>enum_range</function></entry>
+ <entry>
Returns the range between the two given enum values, as an ordered
array. The values must be from the same enum type. If the first
parameter is null, the result will start with the first value of
the enum type.
If the second parameter is null, the result will end with the last
value of the enum type.
+ <?br?>
+ <function>enum_range</function> ( <type>anyenum</type>, <type>anyenum</type> )
+ <returnvalue>anyarray</returnvalue>
+ <?br?>
+ <literal>enum_range(&zwsp;'orange'::rainbow, 'green'::rainbow)</literal>
+ <returnvalue>{orange,yellow,green}</returnvalue>
+ <?br?>
+ <literal>enum_range(NULL, 'green'::rainbow)</literal>
+ <returnvalue>{red,orange,&zwsp;yellow,green}</returnvalue>
+ <?br?>
+ <literal>enum_range(&zwsp;'orange'::rainbow, NULL)</literal>
+ <returnvalue>{orange,yellow,green,&zwsp;blue,purple}</returnvalue>
</entry>
</row>
- <row>
- <entry spanname="example"><literal>enum_range(&zwsp;'orange'::rainbow, 'green'::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>{orange,yellow,green}</literal></entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_range(NULL, 'green'::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>{red,orange,yellow,&zwsp;green}</literal></entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_range(&zwsp;'orange'::rainbow, NULL)</literal></entry>
- <entry spanname="exresult"><literal>{orange,yellow,green,&zwsp;blue,purple}</literal></entry>
- </row>
</tbody>
</tgroup>
</table>
diff --git a/doc/src/sgml/stylesheet-common.xsl b/doc/src/sgml/stylesheet-common.xsl
index a13565e..105ed1c 100644
--- a/doc/src/sgml/stylesheet-common.xsl
+++ b/doc/src/sgml/stylesheet-common.xsl
@@ -103,4 +103,11 @@
<xsl:apply-templates select="." mode="xref"/>
</xsl:template>
+
+<!-- Support for explicit line breaks <?br?> within table cells -->
+
+<xsl:template match="processing-instruction('br')">
+ <br/>
+</xsl:template>
+
</xsl:stylesheet>
diff --git a/doc/src/sgml/stylesheet-fo.xsl b/doc/src/sgml/stylesheet-fo.xsl
index 2aaae82..713159d 100644
--- a/doc/src/sgml/stylesheet-fo.xsl
+++ b/doc/src/sgml/stylesheet-fo.xsl
@@ -70,6 +70,11 @@
<xsl:call-template name="inline.monoseq"/>
</xsl:template>
+<!-- overrides stylesheet-common.xsl -->
+<xsl:template match="processing-instruction('br')">
+ <fo:block/>
+</xsl:template>
+
<!-- bug fix from <https://sourceforge.net/p/docbook/bugs/1360/#831b> -->
<xsl:template match="varlistentry/term" mode="xref-to">
diff --git a/doc/src/sgml/func.sgml b/doc/src/sgml/func.sgml
index 7a270eb..fef21bb 100644
--- a/doc/src/sgml/func.sgml
+++ b/doc/src/sgml/func.sgml
@@ -1798,243 +1798,282 @@
<table id="functions-string-other">
<title>Other String Functions</title>
- <tgroup cols="5">
+ <tgroup cols="2">
+ <colspec colname="c1" align="left" colwidth="1*" colsep="0"/>
+ <colspec colname="c2" align="left" colwidth="7*"/>
+ <spanspec spanname="sig" namest="c1" nameend="c2" align="left" rowsep="0"/>
+ <spanspec spanname="desc" namest="c2" nameend="c2" align="left"/>
<thead>
<row>
- <entry>Function</entry>
- <entry>Return Type</entry>
- <entry>Description</entry>
- <entry>Example</entry>
- <entry>Result</entry>
+ <entry valign="top">Function</entry>
+ <entry>Signature<?br?>Description<?br?>Example(s)</entry>
</row>
</thead>
<tbody>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>ascii</primary>
</indexterm>
- <literal><function>ascii(<parameter>string</parameter>)</function></literal>
+ <function>ascii</function> ( <type>text</type> )
+ <returnvalue>integer</returnvalue>
</entry>
- <entry><type>int</type></entry>
- <entry>
- <acronym>ASCII</acronym> code of the first character of the
- argument. For <acronym>UTF8</acronym> returns the Unicode code
- point of the character. For other multibyte encodings, the
- argument must be an <acronym>ASCII</acronym> character.
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns the numeric code of the first character of the argument.
+ In <acronym>UTF8</acronym> encoding, returns the Unicode code point
+ of the character. In other multibyte encodings, the argument must
+ be an <acronym>ASCII</acronym> character.
+ <?br?>
+ <literal>ascii('x')</literal>
+ <returnvalue>120</returnvalue>
</entry>
- <entry><literal>ascii('x')</literal></entry>
- <entry><literal>120</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>btrim</primary>
</indexterm>
- <literal><function>btrim(<parameter>string</parameter> <type>text</type>
- <optional>, <parameter>characters</parameter> <type>text</type></optional>)</function></literal>
+ <function>btrim</function> ( <parameter>string</parameter> <type>text</type>
+ <optional>, <parameter>characters</parameter> <type>text</type> </optional> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Remove the longest string consisting only of characters
+ </row>
+ <row>
+ <entry spanname="desc">
+ Removes the longest string consisting only of characters
in <parameter>characters</parameter> (a space by default)
- from the start and end of <parameter>string</parameter>
+ from the start and end of <parameter>string</parameter>.
+ <?br?>
+ <literal>btrim('xyxtrimyyx', 'xyz')</literal>
+ <returnvalue>trim</returnvalue>
</entry>
- <entry><literal>btrim('xyxtrimyyx', 'xyz')</literal></entry>
- <entry><literal>trim</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>chr</primary>
</indexterm>
- <literal><function>chr(<type>int</type>)</function></literal>
+ <function>chr</function> ( <type>integer</type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Character with the given code. For <acronym>UTF8</acronym> the
- argument is treated as a Unicode code point. For other multibyte
- encodings the argument must designate an
- <acronym>ASCII</acronym> character. The NULL (0) character is not
- allowed because text data types cannot store such bytes.
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns the character with the given
+ code. In <acronym>UTF8</acronym> encoding the argument is treated as
+ a Unicode code point. In other multibyte encodings the argument must
+ designate an <acronym>ASCII</acronym> character. The NULL (0)
+ character is not allowed because text data types cannot store such
+ bytes.
+ <?br?>
+ <literal>chr(65)</literal>
+ <returnvalue>A</returnvalue>
</entry>
- <entry><literal>chr(65)</literal></entry>
- <entry><literal>A</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>concat</primary>
</indexterm>
- <literal><function>concat(<parameter>str</parameter> <type>"any"</type>
- [, <parameter>str</parameter> <type>"any"</type> [, ...] ])</function></literal>
+ <function>concat</function> ( <parameter>val</parameter> <type>"any"</type>
+ [, <parameter>val</parameter> <type>"any"</type> [, ...] ] )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Concatenate the text representations of all the arguments.
+ </row>
+ <row>
+ <entry spanname="desc">
+ Concatenates the text representations of all the arguments.
NULL arguments are ignored.
+ <?br?>
+ <literal>concat('abcde', 2, NULL, 22)</literal>
+ <returnvalue>abcde222</returnvalue>
</entry>
- <entry><literal>concat('abcde', 2, NULL, 22)</literal></entry>
- <entry><literal>abcde222</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>concat_ws</primary>
</indexterm>
- <literal><function>concat_ws(<parameter>sep</parameter> <type>text</type>,
- <parameter>str</parameter> <type>"any"</type>
- [, <parameter>str</parameter> <type>"any"</type> [, ...] ])</function></literal>
+ <function>concat_ws</function> ( <parameter>sep</parameter> <type>text</type>,
+ <parameter>val</parameter> <type>"any"</type>
+ [, <parameter>val</parameter> <type>"any"</type> [, ...] ] )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Concatenate all but the first argument with separators. The first
+ </row>
+ <row>
+ <entry spanname="desc">
+ Concatenates all but the first argument, with separators. The first
argument is used as the separator string. NULL arguments are ignored.
+ <?br?>
+ <literal>concat_ws(',', 'abcde', 2, NULL, 22)</literal>
+ <returnvalue>abcde,2,22</returnvalue>
</entry>
- <entry><literal>concat_ws(',', 'abcde', 2, NULL, 22)</literal></entry>
- <entry><literal>abcde,2,22</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>format</primary>
</indexterm>
- <literal><function>format</function>(<parameter>formatstr</parameter> <type>text</type>
- [, <parameter>formatarg</parameter> <type>"any"</type> [, ...] ])</literal>
+ <function>format</function> ( <parameter>formatstr</parameter> <type>text</type>
+ [, <parameter>formatarg</parameter> <type>"any"</type> [, ...] ] )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Format arguments according to a format string.
+ </row>
+ <row>
+ <entry spanname="desc">
+ Formats arguments according to a format string;
+ see <xref linkend="functions-string-format"/>.
This function is similar to the C function <function>sprintf</function>.
- See <xref linkend="functions-string-format"/>.
+ <?br?>
+ <literal>format('Hello %s, %1$s', 'World')</literal>
+ <returnvalue>Hello World, World</returnvalue>
</entry>
- <entry><literal>format('Hello %s, %1$s', 'World')</literal></entry>
- <entry><literal>Hello World, World</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>initcap</primary>
</indexterm>
- <literal><function>initcap(<parameter>string</parameter>)</function></literal>
+ <function>initcap</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Convert the first letter of each word to upper case and the
+ </row>
+ <row>
+ <entry spanname="desc">
+ Converts the first letter of each word to upper case and the
rest to lower case. Words are sequences of alphanumeric
characters separated by non-alphanumeric characters.
+ <?br?>
+ <literal>initcap('hi THOMAS')</literal>
+ <returnvalue>Hi Thomas</returnvalue>
</entry>
- <entry><literal>initcap('hi THOMAS')</literal></entry>
- <entry><literal>Hi Thomas</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>left</primary>
</indexterm>
- <literal><function>left(<parameter>string</parameter> <type>text</type>,
- <parameter>n</parameter> <type>int</type>)</function></literal>
+ <function>left</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>n</parameter> <type>integer</type> )
+ <returnvalue>text</returnvalue>
+ </entry>
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns first <replaceable>n</replaceable> characters in the
+ string, or when <replaceable>n</replaceable> is negative, returns
+ all but last |<replaceable>n</replaceable>| characters.
+ <?br?>
+ <literal>left('abcde', 2)</literal>
+ <returnvalue>ab</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Return first <replaceable>n</replaceable> characters in the
- string, or when <replaceable>n</replaceable> is negative, return
- all but last |<replaceable>n</replaceable>| characters
- </entry>
- <entry><literal>left('abcde', 2)</literal></entry>
- <entry><literal>ab</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>length</primary>
</indexterm>
- <literal><function>length(<parameter>string</parameter>)</function></literal>
+ <function>length</function> ( <type>text</type> )
+ <returnvalue>integer</returnvalue>
</entry>
- <entry><type>int</type></entry>
- <entry>
- Number of characters in <parameter>string</parameter>
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns the number of characters in the string.
+ <?br?>
+ <literal>length('jose')</literal>
+ <returnvalue>4</returnvalue>
</entry>
- <entry><literal>length('jose')</literal></entry>
- <entry><literal>4</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>lpad</primary>
</indexterm>
- <literal><function>lpad(<parameter>string</parameter> <type>text</type>,
- <parameter>length</parameter> <type>int</type>
- <optional>, <parameter>fill</parameter> <type>text</type></optional>)</function></literal>
+ <function>lpad</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>length</parameter> <type>integer</type>
+ <optional>, <parameter>fill</parameter> <type>text</type> </optional> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Extend the <parameter>string</parameter> to length
+ </row>
+ <row>
+ <entry spanname="desc">
+ Extends the <parameter>string</parameter> to length
<parameter>length</parameter> by prepending the characters
<parameter>fill</parameter> (a space by default). If the
<parameter>string</parameter> is already longer than
- <parameter>length</parameter> then it is truncated (on the
- right).
+ <parameter>length</parameter> then it is truncated (on the right).
+ <?br?>
+ <literal>lpad('hi', 5, 'xy')</literal>
+ <returnvalue>xyxhi</returnvalue>
</entry>
- <entry><literal>lpad('hi', 5, 'xy')</literal></entry>
- <entry><literal>xyxhi</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>ltrim</primary>
</indexterm>
- <literal><function>ltrim(<parameter>string</parameter> <type>text</type>
- <optional>, <parameter>characters</parameter> <type>text</type></optional>)</function></literal>
+ <function>ltrim</function> ( <parameter>string</parameter> <type>text</type>
+ <optional>, <parameter>characters</parameter> <type>text</type> </optional> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Remove the longest string containing only characters from
+ </row>
+ <row>
+ <entry spanname="desc">
+ Removes the longest string containing only characters from
<parameter>characters</parameter> (a space by default) from the start of
- <parameter>string</parameter>
+ <parameter>string</parameter>.
+ <?br?>
+ <literal>ltrim('zzzytest', 'xyz')</literal>
+ <returnvalue>test</returnvalue>
</entry>
- <entry><literal>ltrim('zzzytest', 'xyz')</literal></entry>
- <entry><literal>test</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>md5</primary>
</indexterm>
- <literal><function>md5(<parameter>string</parameter>)</function></literal>
+ <function>md5</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- MD5 <link linkend="functions-hash-note">hash</link>, with
- the result written in hexadecimal
+ </row>
+ <row>
+ <entry spanname="desc">
+ Computes MD5 <link linkend="functions-hash-note">hash</link>, with
+ the result written in hexadecimal.
+ <?br?>
+ <literal>md5('abc')</literal>
+ <returnvalue>900150983cd24fb0&zwsp;d6963f7d28e17f72</returnvalue>
</entry>
- <entry><literal>md5('abc')</literal></entry>
- <entry><literal>900150983cd24fb0 d6963f7d28e17f72</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>parse_ident</primary>
</indexterm>
- <literal><function>parse_ident(<parameter>qualified_identifier</parameter> <type>text</type>
- [, <parameter>strictmode</parameter> <type>boolean</type> DEFAULT true ] )</function></literal>
+ <function>parse_ident</function> ( <parameter>qualified_identifier</parameter> <type>text</type>
+ [, <parameter>strictmode</parameter> <type>boolean</type> <literal>DEFAULT</literal> <literal>true</literal> ]
)
+ <returnvalue>text[]</returnvalue>
</entry>
- <entry><type>text[]</type></entry>
- <entry>
- Split <parameter>qualified_identifier</parameter> into an array of
+ </row>
+ <row>
+ <entry spanname="desc">
+ Splits <parameter>qualified_identifier</parameter> into an array of
identifiers, removing any quoting of individual identifiers. By
default, extra characters after the last identifier are considered an
error; but if the second parameter is <literal>false</literal>, then such
@@ -2042,417 +2081,513 @@
names for objects like functions.) Note that this function does not
truncate over-length identifiers. If you want truncation you can cast
the result to <type>name[]</type>.
+ <?br?>
+ <literal>parse_ident('"SomeSchema".someTable')</literal>
+ <returnvalue>{SomeSchema,sometable}</returnvalue>
</entry>
- <entry><literal>parse_ident('"SomeSchema".someTable')</literal></entry>
- <entry><literal>{SomeSchema,sometable}</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>pg_client_encoding</primary>
</indexterm>
- <literal><function>pg_client_encoding()</function></literal>
+ <function>pg_client_encoding</function> ( )
+ <returnvalue>name</returnvalue>
</entry>
- <entry><type>name</type></entry>
- <entry>
- Current client encoding name
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns current client encoding name.
+ <?br?>
+ <literal>pg_client_encoding()</literal>
+ <returnvalue>SQL_ASCII</returnvalue>
</entry>
- <entry><literal>pg_client_encoding()</literal></entry>
- <entry><literal>SQL_ASCII</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>quote_ident</primary>
</indexterm>
- <literal><function>quote_ident(<parameter>string</parameter> <type>text</type>)</function></literal>
+ <function>quote_ident</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Return the given string suitably quoted to be used as an identifier
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns the given string suitably quoted to be used as an identifier
in an <acronym>SQL</acronym> statement string.
Quotes are added only if necessary (i.e., if the string contains
non-identifier characters or would be case-folded).
Embedded quotes are properly doubled.
See also <xref linkend="plpgsql-quote-literal-example"/>.
+ <?br?>
+ <literal>quote_ident('Foo bar')</literal>
+ <returnvalue>"Foo bar"</returnvalue>
</entry>
- <entry><literal>quote_ident('Foo bar')</literal></entry>
- <entry><literal>"Foo bar"</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>quote_literal</primary>
</indexterm>
- <literal><function>quote_literal(<parameter>string</parameter> <type>text</type>)</function></literal>
+ <function>quote_literal</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Return the given string suitably quoted to be used as a string literal
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns the given string suitably quoted to be used as a string literal
in an <acronym>SQL</acronym> statement string.
Embedded single-quotes and backslashes are properly doubled.
Note that <function>quote_literal</function> returns null on null
input; if the argument might be null,
<function>quote_nullable</function> is often more suitable.
See also <xref linkend="plpgsql-quote-literal-example"/>.
+ <?br?>
+ <literal>quote_literal(E'O\'Reilly')</literal>
+ <returnvalue>'O''Reilly'</returnvalue>
</entry>
- <entry><literal>quote_literal(E'O\'Reilly')</literal></entry>
- <entry><literal>'O''Reilly'</literal></entry>
</row>
<row>
- <entry><literal><function>quote_literal(<parameter>value</parameter>
<type>anyelement</type>)</function></literal></entry>
- <entry><type>text</type></entry>
- <entry>
- Coerce the given value to text and then quote it as a literal.
+ <entry spanname="sig">
+ <function>quote_literal</function> ( <type>anyelement</type> )
+ <returnvalue>text</returnvalue>
+ </entry>
+ </row>
+ <row>
+ <entry spanname="desc">
+ Coerces the given value to text and then quotes it as a literal.
Embedded single-quotes and backslashes are properly doubled.
+ <?br?>
+ <literal>quote_literal(42.5)</literal>
+ <returnvalue>'42.5'</returnvalue>
</entry>
- <entry><literal>quote_literal(42.5)</literal></entry>
- <entry><literal>'42.5'</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>quote_nullable</primary>
</indexterm>
- <literal><function>quote_nullable(<parameter>string</parameter> <type>text</type>)</function></literal>
+ <function>quote_nullable</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Return the given string suitably quoted to be used as a string literal
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns the given string suitably quoted to be used as a string literal
in an <acronym>SQL</acronym> statement string; or, if the argument
- is null, return <literal>NULL</literal>.
+ is null, returns <literal>NULL</literal>.
Embedded single-quotes and backslashes are properly doubled.
See also <xref linkend="plpgsql-quote-literal-example"/>.
+ <?br?>
+ <literal>quote_nullable(NULL)</literal>
+ <returnvalue>NULL</returnvalue>
</entry>
- <entry><literal>quote_nullable(NULL)</literal></entry>
- <entry><literal>NULL</literal></entry>
</row>
<row>
- <entry><literal><function>quote_nullable(<parameter>value</parameter>
<type>anyelement</type>)</function></literal></entry>
- <entry><type>text</type></entry>
- <entry>
- Coerce the given value to text and then quote it as a literal;
- or, if the argument is null, return <literal>NULL</literal>.
+ <entry spanname="sig">
+ <function>quote_nullable</function> ( <type>anyelement</type> )
+ <returnvalue>text</returnvalue>
+ </entry>
+ </row>
+ <row>
+ <entry spanname="desc">
+ Coerces the given value to text and then quotes it as a literal;
+ or, if the argument is null, returns <literal>NULL</literal>.
Embedded single-quotes and backslashes are properly doubled.
+ <?br?>
+ <literal>quote_nullable(42.5)</literal>
+ <returnvalue>'42.5'</returnvalue>
</entry>
- <entry><literal>quote_nullable(42.5)</literal></entry>
- <entry><literal>'42.5'</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>regexp_match</primary>
</indexterm>
- <literal><function>regexp_match(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter>
<type>text</type>])</function></literal>
+ <function>regexp_match</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type> ] )
+ <returnvalue>text[]</returnvalue>
</entry>
- <entry><type>text[]</type></entry>
- <entry>
- Return captured substring(s) resulting from the first match of a POSIX
- regular expression to the <parameter>string</parameter> (see
- <xref linkend="functions-posix-regexp"/> for more information)
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns captured substring(s) resulting from the first match of a POSIX
+ regular expression to the <parameter>string</parameter>; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <literal>regexp_match('foobarbequebaz', '(bar)(beque)')</literal>
+ <returnvalue>{bar,beque}</returnvalue>
</entry>
- <entry><literal>regexp_match('foobarbequebaz', '(bar)(beque)')</literal></entry>
- <entry><literal>{bar,beque}</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>regexp_matches</primary>
</indexterm>
- <literal><function>regexp_matches(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter>
<type>text</type>])</function></literal>
+ <function>regexp_matches</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type> ] )
+ <returnvalue>setof text[]</returnvalue>
</entry>
- <entry><type>setof text[]</type></entry>
- <entry>
- Return captured substring(s) resulting from matching a POSIX regular
- expression to the <parameter>string</parameter> (see
- <xref linkend="functions-posix-regexp"/> for more information)
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns captured substring(s) resulting from matching a POSIX regular
+ expression to the <parameter>string</parameter>; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <literal>regexp_matches('foobarbequebaz', 'ba.', 'g')</literal>
+ <returnvalue>{bar}<?br?>{baz}</returnvalue><?br?>(2 rows)
</entry>
- <entry><literal>regexp_matches('foobarbequebaz', 'ba.', 'g')</literal></entry>
- <entry><literal>{bar}</literal><para><literal>{baz}</literal></para> (2 rows)</entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>regexp_replace</primary>
</indexterm>
- <literal><function>regexp_replace(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type>, <parameter>replacement</parameter> <type>text</type> [,
<parameter>flags</parameter><type>text</type>])</function></literal>
+ <function>regexp_replace</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type>, <parameter>replacement</parameter> <type>text</type> [,
<parameter>flags</parameter><type>text</type> ] )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Replace substring(s) matching a POSIX regular expression (see
- <xref linkend="functions-posix-regexp"/> for more information)
+ </row>
+ <row>
+ <entry spanname="desc">
+ Replaces substring(s) matching a POSIX regular expression; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <literal>regexp_replace('Thomas', '.[mN]a.', 'M')</literal>
+ <returnvalue>ThM</returnvalue>
</entry>
- <entry><literal>regexp_replace('Thomas', '.[mN]a.', 'M')</literal></entry>
- <entry><literal>ThM</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>regexp_split_to_array</primary>
</indexterm>
- <literal><function>regexp_split_to_array(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type>
])</function></literal>
+ <function>regexp_split_to_array</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type> ] )
+ <returnvalue>text[]</returnvalue>
</entry>
- <entry><type>text[]</type></entry>
- <entry>
- Split <parameter>string</parameter> using a POSIX regular expression as
- the delimiter (see <xref linkend="functions-posix-regexp"/> for more
- information)
+ </row>
+ <row>
+ <entry spanname="desc">
+ Splits <parameter>string</parameter> using a POSIX regular
+ expression as the delimiter; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <literal>regexp_split_to_array('hello world', '\s+')</literal>
+ <returnvalue>{hello,world}</returnvalue>
</entry>
- <entry><literal>regexp_split_to_array('hello world', '\s+')</literal></entry>
- <entry><literal>{hello,world}</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>regexp_split_to_table</primary>
</indexterm>
- <literal><function>regexp_split_to_table(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter>
<type>text</type>])</function></literal>
+ <function>regexp_split_to_table</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type> ] )
+ <returnvalue>setof text</returnvalue>
</entry>
- <entry><type>setof text</type></entry>
- <entry>
- Split <parameter>string</parameter> using a POSIX regular expression as
- the delimiter (see <xref linkend="functions-posix-regexp"/> for more
- information)
+ </row>
+ <row>
+ <entry spanname="desc">
+ Splits <parameter>string</parameter> using a POSIX regular
+ expression as the delimiter; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <literal>regexp_split_to_table('hello world', '\s+')</literal>
+ <returnvalue>hello<?br?>world</returnvalue><?br?>(2 rows)
</entry>
- <entry><literal>regexp_split_to_table('hello world', '\s+')</literal></entry>
- <entry><literal>hello</literal><para><literal>world</literal></para> (2 rows)</entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>repeat</primary>
</indexterm>
- <literal><function>repeat(<parameter>string</parameter> <type>text</type>, <parameter>number</parameter>
<type>int</type>)</function></literal>
+ <function>repeat</function> ( <parameter>string</parameter> <type>text</type>, <parameter>number</parameter>
<type>integer</type>)
+ <returnvalue>text</returnvalue>
+ </entry>
+ </row>
+ <row>
+ <entry spanname="desc">
+ Repeats <parameter>string</parameter> the specified
+ <parameter>number</parameter> of times.
+ <?br?>
+ <literal>repeat('Pg', 4)</literal>
+ <returnvalue>PgPgPgPg</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>Repeat <parameter>string</parameter> the specified
- <parameter>number</parameter> of times</entry>
- <entry><literal>repeat('Pg', 4)</literal></entry>
- <entry><literal>PgPgPgPg</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>replace</primary>
</indexterm>
- <literal><function>replace(<parameter>string</parameter> <type>text</type>,
+ <function>replace</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>from</parameter> <type>text</type>,
- <parameter>to</parameter> <type>text</type>)</function></literal>
+ <parameter>to</parameter> <type>text</type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>Replace all occurrences in <parameter>string</parameter> of substring
- <parameter>from</parameter> with substring <parameter>to</parameter>
+ </row>
+ <row>
+ <entry spanname="desc">
+ Replaces all occurrences in <parameter>string</parameter> of
+ substring <parameter>from</parameter> with
+ substring <parameter>to</parameter>.
+ <?br?>
+ <literal>replace('abcdefabcdef', 'cd', 'XX')</literal>
+ <returnvalue>abXXefabXXef</returnvalue>
</entry>
- <entry><literal>replace('abcdefabcdef', 'cd', 'XX')</literal></entry>
- <entry><literal>abXXefabXXef</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>reverse</primary>
</indexterm>
- <literal><function>reverse(<parameter>str</parameter>)</function></literal>
+ <function>reverse</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Reverse the order of the characters in <parameter>string</parameter>
+ </row>
+ <row>
+ <entry spanname="desc">
+ Reverses the order of the characters in the string.
+ <?br?>
+ <literal>reverse('abcde')</literal>
+ <returnvalue>edcba</returnvalue>
</entry>
- <entry><literal>reverse('abcde')</literal></entry>
- <entry><literal>edcba</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>right</primary>
</indexterm>
- <literal><function>right(<parameter>string</parameter> <type>text</type>,
- <parameter>n</parameter> <type>int</type>)</function></literal>
+ <function>right</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>n</parameter> <type>integer</type> )
+<type></type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Return last <replaceable>n</replaceable> characters in the string,
- or when <replaceable>n</replaceable> is negative, return all but
- first |<replaceable>n</replaceable>| characters
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns last <replaceable>n</replaceable> characters in the string,
+ or when <replaceable>n</replaceable> is negative, returns all but
+ first |<replaceable>n</replaceable>| characters.
+ <?br?>
+ <literal>right('abcde', 2)</literal>
+ <returnvalue>de</returnvalue>
</entry>
- <entry><literal>right('abcde', 2)</literal></entry>
- <entry><literal>de</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>rpad</primary>
</indexterm>
- <literal><function>rpad(<parameter>string</parameter> <type>text</type>,
- <parameter>length</parameter> <type>int</type>
- <optional>, <parameter>fill</parameter> <type>text</type></optional>)</function></literal>
+ <function>rpad</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>length</parameter> <type>integer</type>
+ <optional>, <parameter>fill</parameter> <type>text</type> </optional> )
+<type></type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Extend the <parameter>string</parameter> to length
+ </row>
+ <row>
+ <entry spanname="desc">
+ Extends the <parameter>string</parameter> to length
<parameter>length</parameter> by appending the characters
<parameter>fill</parameter> (a space by default). If the
<parameter>string</parameter> is already longer than
<parameter>length</parameter> then it is truncated.
+ <?br?>
+ <literal>rpad('hi', 5, 'xy')</literal>
+ <returnvalue>hixyx</returnvalue>
</entry>
- <entry><literal>rpad('hi', 5, 'xy')</literal></entry>
- <entry><literal>hixyx</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>rtrim</primary>
</indexterm>
- <literal><function>rtrim(<parameter>string</parameter> <type>text</type>
- <optional>, <parameter>characters</parameter> <type>text</type></optional>)</function></literal>
+ <function>rtrim</function> ( <parameter>string</parameter> <type>text</type>
+ <optional>, <parameter>characters</parameter> <type>text</type> </optional> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Remove the longest string containing only characters from
+ </row>
+ <row>
+ <entry spanname="desc">
+ Removes the longest string containing only characters from
<parameter>characters</parameter> (a space by default) from the end of
- <parameter>string</parameter>
+ <parameter>string</parameter>.
+ <?br?>
+ <literal>rtrim('testxxzx', 'xyz')</literal>
+ <returnvalue>test</returnvalue>
</entry>
- <entry><literal>rtrim('testxxzx', 'xyz')</literal></entry>
- <entry><literal>test</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>split_part</primary>
</indexterm>
- <literal><function>split_part(<parameter>string</parameter> <type>text</type>,
+ <function>split_part</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>delimiter</parameter> <type>text</type>,
- <parameter>field</parameter> <type>int</type>)</function></literal>
+ <parameter>n</parameter> <type>integer</type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>Split <parameter>string</parameter> on <parameter>delimiter</parameter>
- and return the given field (counting from one)
+ </row>
+ <row>
+ <entry spanname="desc">
+ Splits <parameter>string</parameter> on <parameter>delimiter</parameter>
+ and returns the <parameter>n</parameter>'th field (counting from one).
+ <?br?>
+ <literal>split_part('abc~@~def~@~ghi', '~@~', 2)</literal>
+ <returnvalue>def</returnvalue>
</entry>
- <entry><literal>split_part('abc~@~def~@~ghi', '~@~', 2)</literal></entry>
- <entry><literal>def</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>strpos</primary>
</indexterm>
- <literal><function>strpos(<parameter>string</parameter>,
<parameter>substring</parameter>)</function></literal>
+ <function>strpos</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>substring</parameter><type>text</type> )
+ <returnvalue>integer</returnvalue>
</entry>
- <entry><type>int</type></entry>
- <entry>
- Location of specified substring (same as
- <literal>position(<parameter>substring</parameter> in
- <parameter>string</parameter>)</literal>, but note the reversed
- argument order)
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns location of specified <parameter>substring</parameter>
+ within <parameter>string</parameter>, or zero if it's not present.
+ (Same as <literal>position(<parameter>substring</parameter> in
+ <parameter>string</parameter>)</literal>, but note the reversed
+ argument order.)
+ <?br?>
+ <literal>strpos('high', 'ig')</literal>
+ <returnvalue>2</returnvalue>
</entry>
- <entry><literal>strpos('high', 'ig')</literal></entry>
- <entry><literal>2</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>substr</primary>
</indexterm>
- <literal><function>substr(<parameter>string</parameter>, <parameter>from</parameter> <optional>,
<parameter>count</parameter></optional>)</function></literal>
+ <function>substr</function> ( <parameter>string</parameter> <type>text</type>, <parameter>start</parameter>
<type>integer</type><optional>, <parameter>count</parameter> <type>integer</type> </optional> )
+<type></type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Extract substring (same as
- <literal>substring(<parameter>string</parameter> from <parameter>from</parameter> for
<parameter>count</parameter>)</literal>)
+ </row>
+ <row>
+ <entry spanname="desc">
+ Extracts substring starting at index <parameter>start</parameter>,
+ and extending for <parameter>count</parameter> characters if that is
+ specified. (Same
+ as <literal>substring(<parameter>string</parameter>
+ from <parameter>start</parameter>
+ for <parameter>count</parameter>)</literal>.)
+ <?br?>
+ <literal>substr('alphabet', 3, 2)</literal>
+ <returnvalue>ph</returnvalue>
</entry>
- <entry><literal>substr('alphabet', 3, 2)</literal></entry>
- <entry><literal>ph</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>starts_with</primary>
</indexterm>
- <literal><function>starts_with(<parameter>string</parameter>,
<parameter>prefix</parameter>)</function></literal>
+ <function>starts_with</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>prefix</parameter><type>text</type> )
+ <returnvalue>boolean</returnvalue>
</entry>
- <entry><type>bool</type></entry>
- <entry>
- Return true if <parameter>string</parameter> starts
- with <parameter>prefix</parameter>
+ </row>
+ <row>
+ <entry spanname="desc">
+ Returns true if <parameter>string</parameter> starts
+ with <parameter>prefix</parameter>.
+ <?br?>
+ <literal>starts_with('alphabet', 'alph')</literal>
+ <returnvalue>t</returnvalue>
</entry>
- <entry><literal>starts_with('alphabet', 'alph')</literal></entry>
- <entry><literal>t</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>to_ascii</primary>
</indexterm>
- <literal><function>to_ascii(<parameter>string</parameter> <type>text</type>
- <optional>, <parameter>encoding</parameter> <type>text</type></optional>)</function></literal>
+ <function>to_ascii</function> ( <parameter>string</parameter> <type>text</type>
+ <optional>, <parameter>encoding</parameter> <type>name</type> or <type>integer</type> </optional> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Convert <parameter>string</parameter> to <acronym>ASCII</acronym> from another encoding
- (only supports conversion from <literal>LATIN1</literal>, <literal>LATIN2</literal>,
<literal>LATIN9</literal>,
- and <literal>WIN1250</literal> encodings)
+ </row>
+ <row>
+ <entry spanname="desc">
+ Converts <parameter>string</parameter> to <acronym>ASCII</acronym>
+ from another encoding, which may be identified by name or number;
+ if <parameter>encoding</parameter> is omitted the database encoding
+ is assumed. The conversion consists primarily of dropping accents.
+ Conversion is only supported
+ from <literal>LATIN1</literal>, <literal>LATIN2</literal>,
+ <literal>LATIN9</literal>, and <literal>WIN1250</literal> encodings.
+ <?br?>
+ <literal>to_ascii('Karél')</literal>
+ <returnvalue>Karel</returnvalue>
</entry>
- <entry><literal>to_ascii('Karel')</literal></entry>
- <entry><literal>Karel</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>to_hex</primary>
</indexterm>
- <literal><function>to_hex(<parameter>number</parameter> <type>int</type>
- or <type>bigint</type>)</function></literal>
+ <function>to_hex</function> ( <parameter>number</parameter>
+ <type>integer</type>
+ or <type>bigint</type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>Convert <parameter>number</parameter> to its equivalent hexadecimal
- representation
+ </row>
+ <row>
+ <entry spanname="desc">
+ Converts <parameter>number</parameter> to its equivalent hexadecimal
+ representation.
+ <?br?>
+ <literal>to_hex(2147483647)</literal>
+ <returnvalue>7fffffff</returnvalue>
</entry>
- <entry><literal>to_hex(2147483647)</literal></entry>
- <entry><literal>7fffffff</literal></entry>
</row>
<row>
- <entry>
+ <entry spanname="sig">
<indexterm>
<primary>translate</primary>
</indexterm>
- <literal><function>translate(<parameter>string</parameter> <type>text</type>,
+ <function>translate</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>from</parameter> <type>text</type>,
- <parameter>to</parameter> <type>text</type>)</function></literal>
+ <parameter>to</parameter> <type>text</type> )
+ <returnvalue>text</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Any character in <parameter>string</parameter> that matches a
- character in the <parameter>from</parameter> set is replaced by
- the corresponding character in the <parameter>to</parameter>
+ </row>
+ <row>
+ <entry spanname="desc">
+ Replaces each character in <parameter>string</parameter> that
+ matches a character in the <parameter>from</parameter> set with the
+ corresponding character in the <parameter>to</parameter>
set. If <parameter>from</parameter> is longer than
<parameter>to</parameter>, occurrences of the extra characters in
- <parameter>from</parameter> are removed.
+ <parameter>from</parameter> are deleted.
+ <?br?>
+ <literal>translate('12345', '143', 'ax')</literal>
+ <returnvalue>a2x5</returnvalue>
</entry>
- <entry><literal>translate('12345', '143', 'ax')</literal></entry>
- <entry><literal>a2x5</literal></entry>
</row>
</tbody>
@@ -8645,80 +8780,74 @@ CREATE TYPE rainbow AS ENUM ('red', 'orange', 'yellow', 'green', 'blue', 'purple
<table id="functions-enum-table">
<title>Enum Support Functions</title>
- <tgroup cols="3">
- <colspec colname="col1" colwidth="0.5*"/>
- <colspec colname="col2" colwidth="1*"/>
- <colspec colname="col3" colwidth="1*"/>
- <spanspec spanname="name" namest="col1" nameend="col1" align="left"/>
- <spanspec spanname="sig" namest="col2" nameend="col3" align="left"/>
- <spanspec spanname="desc" namest="col2" nameend="col3" align="left"/>
- <spanspec spanname="example" namest="col2" nameend="col2" align="left"/>
- <spanspec spanname="exresult" namest="col3" nameend="col3" align="left"/>
+ <tgroup cols="2">
+ <colspec colname="c1" align="left" colwidth="1*" colsep="0"/>
+ <colspec colname="c2" align="left" colwidth="7*"/>
+ <spanspec spanname="sig" namest="c1" nameend="c2" align="left" rowsep="0"/>
+ <spanspec spanname="desc" namest="c2" nameend="c2" align="left"/>
<thead>
<row>
- <entry spanname="name" align="center" valign="middle" morerows="2">Function</entry>
- <entry spanname="sig" align="center">Signature</entry>
- </row>
- <row>
- <entry spanname="desc" align="center">Description</entry>
- </row>
- <row>
- <entry spanname="example" align="center">Example</entry>
- <entry spanname="exresult" align="center">Example Result</entry>
+ <entry valign="top">Function</entry>
+ <entry>Signature<?br?>Description<?br?>Example(s)</entry>
</row>
</thead>
<tbody>
<row>
- <entry spanname="name" morerows="2">
+ <entry spanname="sig">
<indexterm>
<primary>enum_first</primary>
</indexterm>
- <function>enum_first</function>
+ <function>enum_first</function> ( <type>anyenum</type> )
+ <returnvalue>anyenum</returnvalue>
</entry>
- <entry spanname="sig"><function>enum_first</function>(<type>anyenum</type>)
<returnvalue>anyenum</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Returns the first value of the input enum type</entry>
</row>
<row>
- <entry spanname="example"><literal>enum_first(&zwsp;null::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>red</literal></entry>
+ <entry spanname="desc">
+ Returns the first value of the input enum type.
+ <?br?>
+ <literal>enum_first(null::rainbow)</literal>
+ <returnvalue>red</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2">
+ <entry spanname="sig">
<indexterm>
<primary>enum_last</primary>
</indexterm>
- <function>enum_last</function>
+ <function>enum_last</function> ( <type>anyenum</type> )
+ <returnvalue>anyenum</returnvalue>
</entry>
- <entry spanname="sig"><function>enum_last</function>(<type>anyenum</type>)
<returnvalue>anyenum</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Returns the last value of the input enum type</entry>
</row>
<row>
- <entry spanname="example"><literal>enum_last(&zwsp;null::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>purple</literal></entry>
+ <entry spanname="desc">
+ Returns the last value of the input enum type.
+ <?br?>
+ <literal>enum_last(null::rainbow)</literal>
+ <returnvalue>purple</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2">
+ <entry spanname="sig">
<indexterm>
<primary>enum_range</primary>
</indexterm>
- <function>enum_range</function>
+ <function>enum_range</function> ( <type>anyenum</type> )
+ <returnvalue>anyarray</returnvalue>
</entry>
- <entry spanname="sig"><function>enum_range</function>(<type>anyenum</type>)
<returnvalue>anyarray</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Returns all values of the input enum type in an ordered array</entry>
</row>
<row>
- <entry spanname="example"><literal>enum_range(&zwsp;null::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>{red,orange,yellow,&zwsp;green,blue,purple}</literal></entry>
+ <entry spanname="desc">
+ Returns all values of the input enum type in an ordered array.
+ <?br?>
+ <literal>enum_range(null::rainbow)</literal>
+ <returnvalue>{red,orange,yellow,&zwsp;green,blue,purple}</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="4"><function>enum_range</function></entry>
- <entry spanname="sig"><function>enum_range</function>(<type>anyenum</type>, <type>anyenum</type>)
<returnvalue>anyarray</returnvalue></entry>
+ <entry spanname="sig">
+ <function>enum_range</function> ( <type>anyenum</type>, <type>anyenum</type> )
+ <returnvalue>anyarray</returnvalue>
+ </entry>
</row>
<row>
<entry spanname="desc">
@@ -8728,20 +8857,17 @@ CREATE TYPE rainbow AS ENUM ('red', 'orange', 'yellow', 'green', 'blue', 'purple
the enum type.
If the second parameter is null, the result will end with the last
value of the enum type.
+ <?br?>
+ <literal>enum_range('orange'::rainbow, 'green'::rainbow)</literal>
+ <returnvalue>{orange,yellow,green}</returnvalue>
+ <?br?>
+ <literal>enum_range(NULL, 'green'::rainbow)</literal>
+ <returnvalue>{red,orange,&zwsp;yellow,green}</returnvalue>
+ <?br?>
+ <literal>enum_range('orange'::rainbow, NULL)</literal>
+ <returnvalue>{orange,yellow,green,&zwsp;blue,purple}</returnvalue>
</entry>
</row>
- <row>
- <entry spanname="example"><literal>enum_range(&zwsp;'orange'::rainbow, 'green'::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>{orange,yellow,green}</literal></entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_range(NULL, 'green'::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>{red,orange,yellow,&zwsp;green}</literal></entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_range(&zwsp;'orange'::rainbow, NULL)</literal></entry>
- <entry spanname="exresult"><literal>{orange,yellow,green,&zwsp;blue,purple}</literal></entry>
- </row>
</tbody>
</tgroup>
</table>
diff --git a/doc/src/sgml/stylesheet-common.xsl b/doc/src/sgml/stylesheet-common.xsl
index a13565e..105ed1c 100644
--- a/doc/src/sgml/stylesheet-common.xsl
+++ b/doc/src/sgml/stylesheet-common.xsl
@@ -103,4 +103,11 @@
<xsl:apply-templates select="." mode="xref"/>
</xsl:template>
+
+<!-- Support for explicit line breaks <?br?> within table cells -->
+
+<xsl:template match="processing-instruction('br')">
+ <br/>
+</xsl:template>
+
</xsl:stylesheet>
diff --git a/doc/src/sgml/stylesheet-fo.xsl b/doc/src/sgml/stylesheet-fo.xsl
index 2aaae82..713159d 100644
--- a/doc/src/sgml/stylesheet-fo.xsl
+++ b/doc/src/sgml/stylesheet-fo.xsl
@@ -70,6 +70,11 @@
<xsl:call-template name="inline.monoseq"/>
</xsl:template>
+<!-- overrides stylesheet-common.xsl -->
+<xsl:template match="processing-instruction('br')">
+ <fo:block/>
+</xsl:template>
+
<!-- bug fix from <https://sourceforge.net/p/docbook/bugs/1360/#831b> -->
<xsl:template match="varlistentry/term" mode="xref-to">
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
At Wed, 15 Apr 2020 12:04:34 -0400, Robert Haas <robertmhaas@gmail.com> wrote in > On Wed, Apr 15, 2020 at 11:54 AM Pavel Stehule <pavel.stehule@gmail.com> wrote: > > st 15. 4. 2020 v 17:43 odesílatel Isaac Morland <isaac.morland@gmail.com> napsal: > >> On Wed, 15 Apr 2020 at 11:26, Pierre Giraud <pierre.giraud@dalibo.com> wrote: > >>> The best way to achieve this is to use some styling (font style and color). > >>> > >>> Attached you will find two different options I worked on very quickly. > >> > >> I really like the first. Just a couple of suggestions I would make: > > > > yes, it is very well readable > > +1. +1. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
Le 16/04/2020 à 00:18, Tom Lane a écrit : > As I threatened to do earlier, I made a pass at converting table 9.10 > to a couple of the styles under discussion. (This is just a > draft-quality patch, so it might have some minor bugs --- the point > is just to see what these styles look like.) > > I've concluded after looking around that the ideas involving not having > a <table> at all, but just a <variablelist> or the like, are not very > well-advised. That would eliminate, or at least greatly degrade, the > visual distinction between the per-function material and the surrounding > commentary. Which does not seem like a winner to me; for example it > would make it quite hard to skip over the detailed material when you're > just trying to skim the docs. > > We did have a number of people suggesting that just reordering things as > "description, signature, examples" might be a good idea, so I gave that > a try; attached is a rendition of a portion of 9.10 in that style (the > "v1" image). It's not bad, but there's still going to be a lot of > wasted whitespace in tables that include even one long function name. > (9.10's longest is "regexp_split_to_array", so it's showing this problem > significantly.) > > I also experimented with Jonathan's idea of dropping the separate > function name and allowing the function signature to span left into > that column -- see "v2" images. This actually works really well, > and would work even better (IMO) if we could get rid of the inter-row > and inter-column rules within a function entry. I failed to > accomplish that with rowsep/colsep annotations, but from remarks > upthread I suppose there might be a CSS way to accomplish it. (But > the rowsep/colsep annotations *do* work in PDF output, so I kept them; > that means we only need a CSS fix and not some kind of flow-object > magic for PDF.) > > To allow direct comparison of these 9.10 images against the situation > in HEAD, I've also attached an extract of 9.10 as rendered by my > browser with "STYLE=website". As you can see this is *not* quite > identical to how it renders on postgresql.org, so there is still some > unexplained differential in font or margins or something. But if you > look at those three PNGs you can see that either v1 or v2 has a pretty > substantial advantage over HEAD in terms of the amount of space > needed. v2 would be even further ahead if we could eliminate some of > the vertical space around the intra-function row split, which again > might be doable with CSS magic. > > The main disadvantage I can see to the v2 design is that we're back > to having two <rows> per function, which is inevitably going to result > in PDF builds putting page breaks between those rows. But you can't > have everything ... and maybe we could find a way to discourage such > breaks if we tried. What about putting everything into one <table row> and use a block with some left padding/margin for description + example. This would solve the PDF page break issue as well as the column separation border one. The screenshot attached uses a <dl> tag for the descrition/example block. > > Another issue is that v2 won't adapt real well to operator tables; > the operator name won't be at the left. I don't have a lot of faith > in the proposal to fix that with font tricks. Maybe we could stick > to something close to the layout that table 9.30 has in HEAD (ie > repeating the operator name in column 1), since we won't have long > operator names messing up the format. Again, CSS'ing our way > out of the internal lines and extra vertical space within a single > logical table cell would make that layout look nicer. > > On balance I quite like the v2 layout and would prefer to move forward > with that, assuming we can solve the remaining issues via CSS or style > sheets. > > In addition to screenshots, I've attached patches against HEAD that > convert both tables 9.10 and 9.33 into v1 and v2 styles. > > regards, tom lane >
Attachment
{kind=link}
Pierre Giraud <pierre.giraud@dalibo.com> writes:
> Le 16/04/2020 à 00:18, Tom Lane a écrit :
>> The main disadvantage I can see to the v2 design is that we're back
>> to having two <rows> per function, which is inevitably going to result
>> in PDF builds putting page breaks between those rows. But you can't
>> have everything ... and maybe we could find a way to discourage such
>> breaks if we tried.
Further experimentation shows that the PDF toolchain is perfectly willing
to put a page break *within* a multi-line <row>; if there is any
preference to break between rows instead, it's pretty weak. So that
argument is a red herring and we shouldn't waste time chasing it.
However, there'd still be some advantage in not being dependent on CSS
hackery to make it look nice in HTML.
What we're down to wanting, at this point, is basically a para with
hanging indent.
> What about putting everything into one <table row> and use a block with
> some left padding/margin for description + example.
> This would solve the PDF page break issue as well as the column
> separation border one.
> The screenshot attached uses a <dl> tag for the descrition/example block.
That looks about right, perhaps, but could you be a little clearer about
how you accomplished that?
regards, tom lane
Le 16/04/2020 à 16:43, Tom Lane a écrit : > Pierre Giraud <pierre.giraud@dalibo.com> writes: >> Le 16/04/2020 à 00:18, Tom Lane a écrit : >>> The main disadvantage I can see to the v2 design is that we're back >>> to having two <rows> per function, which is inevitably going to result >>> in PDF builds putting page breaks between those rows. But you can't >>> have everything ... and maybe we could find a way to discourage such >>> breaks if we tried. > > Further experimentation shows that the PDF toolchain is perfectly willing > to put a page break *within* a multi-line <row>; if there is any > preference to break between rows instead, it's pretty weak. So that > argument is a red herring and we shouldn't waste time chasing it. > However, there'd still be some advantage in not being dependent on CSS > hackery to make it look nice in HTML. > > What we're down to wanting, at this point, is basically a para with > hanging indent. > >> What about putting everything into one <table row> and use a block with >> some left padding/margin for description + example. >> This would solve the PDF page break issue as well as the column >> separation border one. >> The screenshot attached uses a <dl> tag for the descrition/example block. > > That looks about right, perhaps, but could you be a little clearer about > how you accomplished that? Attached you will find the HTML structure with associated styles. Sorry I haven't tried to do this from the DocBook sources. I hope this helps though. Regards
Attachment
Pierre Giraud <pierre.giraud@dalibo.com> writes:
> Le 16/04/2020 à 16:43, Tom Lane a écrit :
>> Pierre Giraud <pierre.giraud@dalibo.com> writes:
>>> The screenshot attached uses a <dl> tag for the descrition/example block.
>> That looks about right, perhaps, but could you be a little clearer about
>> how you accomplished that?
> Attached you will find the HTML structure with associated styles.
> Sorry I haven't tried to do this from the DocBook sources.
> I hope this helps though.
After a bit of poking at it, I couldn't find another way to do that
than using a <variablelist> structure. Which is an annoying amount
of markup to be adding to each table cell, but I guess we could live
with it. A bigger problem is that docbook applies styles to the
<dl> structure that, at least by default, add a LOT of vertical space.
Doesn't seem real workable unless we can undo that.
regards, tom lane
On 4/14/20 4:52 PM, Tom Lane wrote: > Andreas Karlsson <andreas@proxel.se> writes: >> That said, I agree with that quite many of our tables right now are >> ugly, but I prefer ugly to hard to read. For me the mix of having every >> third row split into two fields makes the tables very hard to read. I >> have a hard time seeing which rows belong to which function. > > Did you look at the variants without that discussed downthread? Yeah, I did some of them are quite readable, for example your latest two screenshots of table 9.10. Andreas
v1 is good. I like your v2 even better. If it becomes possible to remove or soften the "inter-row" horizontal line with CSS tricks afterwards, that would be swell, but even without that, I cast my vote to using this table format. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> I like your v2 even better. If it becomes possible to remove or soften
> the "inter-row" horizontal line with CSS tricks afterwards, that would
> be swell, but even without that, I cast my vote to using this table
> format.
I eventually figured out that the approved way to do per-table-entry
customization is to attach "role" properties to the DocBook elements,
and then key off the role names in applying formatting changes in
the customization layer. So attached is a v3 that handles the desired
formatting changes by applying a hanging indent to table <entry>
contents if the entry is marked with role="functableentry". It may
well be possible to do this in a cleaner fashion, but this seems
good enough for discussion.
I changed table 9.30 (Date/Time Operators) to this style, doing it
exactly the same way as functions, just to see what it'd look like.
I'm not sure if this is OK or if we want a separate column with
just the operator name at the left --- it seems a little bit hard
to spot the operator you want, but not impossible. Thoughts?
Attached are screenshots of the same segment of table 9.10 as before
and of the initial portion of 9.30, the patch against HEAD to produce
these, and a hacky patch on the website's main.css to get it to go
along. Without the last you just get all the subsidiary stuff
left-justified if you build with STYLE=website, which isn't impossibly
unreadable but it's not the desired presentation.
I didn't include any screenshots of the PDF rendering, but it looks
fine.
regards, tom lane
diff --git a/doc/src/sgml/func.sgml b/doc/src/sgml/func.sgml
index 7a270eb..1924e06 100644
--- a/doc/src/sgml/func.sgml
+++ b/doc/src/sgml/func.sgml
@@ -1798,243 +1798,240 @@
<table id="functions-string-other">
<title>Other String Functions</title>
- <tgroup cols="5">
+ <tgroup cols="1">
<thead>
<row>
- <entry>Function</entry>
- <entry>Return Type</entry>
- <entry>Description</entry>
- <entry>Example</entry>
- <entry>Result</entry>
+ <entry role="functableentry">
+ Function<?br?>Description<?br?>Example(s)
+ </entry>
</row>
</thead>
<tbody>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>ascii</primary>
</indexterm>
- <literal><function>ascii(<parameter>string</parameter>)</function></literal>
+ <function>ascii</function> ( <type>text</type> )
+ <returnvalue>integer</returnvalue>
+ <?br?>
+ Returns the numeric code of the first character of the argument.
+ In <acronym>UTF8</acronym> encoding, returns the Unicode code point
+ of the character. In other multibyte encodings, the argument must
+ be an <acronym>ASCII</acronym> character.
+ <?br?>
+ <literal>ascii('x')</literal>
+ <returnvalue>120</returnvalue>
</entry>
- <entry><type>int</type></entry>
- <entry>
- <acronym>ASCII</acronym> code of the first character of the
- argument. For <acronym>UTF8</acronym> returns the Unicode code
- point of the character. For other multibyte encodings, the
- argument must be an <acronym>ASCII</acronym> character.
- </entry>
- <entry><literal>ascii('x')</literal></entry>
- <entry><literal>120</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>btrim</primary>
</indexterm>
- <literal><function>btrim(<parameter>string</parameter> <type>text</type>
- <optional>, <parameter>characters</parameter> <type>text</type></optional>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Remove the longest string consisting only of characters
+ <function>btrim</function> ( <parameter>string</parameter> <type>text</type>
+ <optional>, <parameter>characters</parameter> <type>text</type> </optional> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Removes the longest string consisting only of characters
in <parameter>characters</parameter> (a space by default)
- from the start and end of <parameter>string</parameter>
+ from the start and end of <parameter>string</parameter>.
+ <?br?>
+ <literal>btrim('xyxtrimyyx', 'xyz')</literal>
+ <returnvalue>trim</returnvalue>
</entry>
- <entry><literal>btrim('xyxtrimyyx', 'xyz')</literal></entry>
- <entry><literal>trim</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>chr</primary>
</indexterm>
- <literal><function>chr(<type>int</type>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Character with the given code. For <acronym>UTF8</acronym> the
- argument is treated as a Unicode code point. For other multibyte
- encodings the argument must designate an
- <acronym>ASCII</acronym> character. The NULL (0) character is not
- allowed because text data types cannot store such bytes.
+ <function>chr</function> ( <type>integer</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Returns the character with the given
+ code. In <acronym>UTF8</acronym> encoding the argument is treated as
+ a Unicode code point. In other multibyte encodings the argument must
+ designate an <acronym>ASCII</acronym> character. The NULL (0)
+ character is not allowed because text data types cannot store such
+ bytes.
+ <?br?>
+ <literal>chr(65)</literal>
+ <returnvalue>A</returnvalue>
</entry>
- <entry><literal>chr(65)</literal></entry>
- <entry><literal>A</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>concat</primary>
</indexterm>
- <literal><function>concat(<parameter>str</parameter> <type>"any"</type>
- [, <parameter>str</parameter> <type>"any"</type> [, ...] ])</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Concatenate the text representations of all the arguments.
+ <function>concat</function> ( <parameter>val</parameter> <type>"any"</type>
+ [, <parameter>val</parameter> <type>"any"</type> [, ...] ] )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Concatenates the text representations of all the arguments.
NULL arguments are ignored.
+ <?br?>
+ <literal>concat('abcde', 2, NULL, 22)</literal>
+ <returnvalue>abcde222</returnvalue>
</entry>
- <entry><literal>concat('abcde', 2, NULL, 22)</literal></entry>
- <entry><literal>abcde222</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>concat_ws</primary>
</indexterm>
- <literal><function>concat_ws(<parameter>sep</parameter> <type>text</type>,
- <parameter>str</parameter> <type>"any"</type>
- [, <parameter>str</parameter> <type>"any"</type> [, ...] ])</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Concatenate all but the first argument with separators. The first
+ <function>concat_ws</function> ( <parameter>sep</parameter> <type>text</type>,
+ <parameter>val</parameter> <type>"any"</type>
+ [, <parameter>val</parameter> <type>"any"</type> [, ...] ] )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Concatenates all but the first argument, with separators. The first
argument is used as the separator string. NULL arguments are ignored.
+ <?br?>
+ <literal>concat_ws(',', 'abcde', 2, NULL, 22)</literal>
+ <returnvalue>abcde,2,22</returnvalue>
</entry>
- <entry><literal>concat_ws(',', 'abcde', 2, NULL, 22)</literal></entry>
- <entry><literal>abcde,2,22</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>format</primary>
</indexterm>
- <literal><function>format</function>(<parameter>formatstr</parameter> <type>text</type>
- [, <parameter>formatarg</parameter> <type>"any"</type> [, ...] ])</literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Format arguments according to a format string.
+ <function>format</function> ( <parameter>formatstr</parameter> <type>text</type>
+ [, <parameter>formatarg</parameter> <type>"any"</type> [, ...] ] )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Formats arguments according to a format string;
+ see <xref linkend="functions-string-format"/>.
This function is similar to the C function <function>sprintf</function>.
- See <xref linkend="functions-string-format"/>.
+ <?br?>
+ <literal>format('Hello %s, %1$s', 'World')</literal>
+ <returnvalue>Hello World, World</returnvalue>
</entry>
- <entry><literal>format('Hello %s, %1$s', 'World')</literal></entry>
- <entry><literal>Hello World, World</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>initcap</primary>
</indexterm>
- <literal><function>initcap(<parameter>string</parameter>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Convert the first letter of each word to upper case and the
+ <function>initcap</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Converts the first letter of each word to upper case and the
rest to lower case. Words are sequences of alphanumeric
characters separated by non-alphanumeric characters.
+ <?br?>
+ <literal>initcap('hi THOMAS')</literal>
+ <returnvalue>Hi Thomas</returnvalue>
</entry>
- <entry><literal>initcap('hi THOMAS')</literal></entry>
- <entry><literal>Hi Thomas</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>left</primary>
</indexterm>
- <literal><function>left(<parameter>string</parameter> <type>text</type>,
- <parameter>n</parameter> <type>int</type>)</function></literal>
+ <function>left</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>n</parameter> <type>integer</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Returns first <replaceable>n</replaceable> characters in the
+ string, or when <replaceable>n</replaceable> is negative, returns
+ all but last |<replaceable>n</replaceable>| characters.
+ <?br?>
+ <literal>left('abcde', 2)</literal>
+ <returnvalue>ab</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Return first <replaceable>n</replaceable> characters in the
- string, or when <replaceable>n</replaceable> is negative, return
- all but last |<replaceable>n</replaceable>| characters
- </entry>
- <entry><literal>left('abcde', 2)</literal></entry>
- <entry><literal>ab</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>length</primary>
</indexterm>
- <literal><function>length(<parameter>string</parameter>)</function></literal>
- </entry>
- <entry><type>int</type></entry>
- <entry>
- Number of characters in <parameter>string</parameter>
+ <function>length</function> ( <type>text</type> )
+ <returnvalue>integer</returnvalue>
+ <?br?>
+ Returns the number of characters in the string.
+ <?br?>
+ <literal>length('jose')</literal>
+ <returnvalue>4</returnvalue>
</entry>
- <entry><literal>length('jose')</literal></entry>
- <entry><literal>4</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>lpad</primary>
</indexterm>
- <literal><function>lpad(<parameter>string</parameter> <type>text</type>,
- <parameter>length</parameter> <type>int</type>
- <optional>, <parameter>fill</parameter> <type>text</type></optional>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Extend the <parameter>string</parameter> to length
+ <function>lpad</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>length</parameter> <type>integer</type>
+ <optional>, <parameter>fill</parameter> <type>text</type> </optional> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Extends the <parameter>string</parameter> to length
<parameter>length</parameter> by prepending the characters
<parameter>fill</parameter> (a space by default). If the
<parameter>string</parameter> is already longer than
- <parameter>length</parameter> then it is truncated (on the
- right).
+ <parameter>length</parameter> then it is truncated (on the right).
+ <?br?>
+ <literal>lpad('hi', 5, 'xy')</literal>
+ <returnvalue>xyxhi</returnvalue>
</entry>
- <entry><literal>lpad('hi', 5, 'xy')</literal></entry>
- <entry><literal>xyxhi</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>ltrim</primary>
</indexterm>
- <literal><function>ltrim(<parameter>string</parameter> <type>text</type>
- <optional>, <parameter>characters</parameter> <type>text</type></optional>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Remove the longest string containing only characters from
+ <function>ltrim</function> ( <parameter>string</parameter> <type>text</type>
+ <optional>, <parameter>characters</parameter> <type>text</type> </optional> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Removes the longest string containing only characters from
<parameter>characters</parameter> (a space by default) from the start of
- <parameter>string</parameter>
+ <parameter>string</parameter>.
+ <?br?>
+ <literal>ltrim('zzzytest', 'xyz')</literal>
+ <returnvalue>test</returnvalue>
</entry>
- <entry><literal>ltrim('zzzytest', 'xyz')</literal></entry>
- <entry><literal>test</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>md5</primary>
</indexterm>
- <literal><function>md5(<parameter>string</parameter>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- MD5 <link linkend="functions-hash-note">hash</link>, with
- the result written in hexadecimal
+ <function>md5</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Computes MD5 <link linkend="functions-hash-note">hash</link>, with
+ the result written in hexadecimal.
+ <?br?>
+ <literal>md5('abc')</literal>
+ <returnvalue>900150983cd24fb0&zwsp;d6963f7d28e17f72</returnvalue>
</entry>
- <entry><literal>md5('abc')</literal></entry>
- <entry><literal>900150983cd24fb0 d6963f7d28e17f72</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>parse_ident</primary>
</indexterm>
- <literal><function>parse_ident(<parameter>qualified_identifier</parameter> <type>text</type>
- [, <parameter>strictmode</parameter> <type>boolean</type> DEFAULT true ] )</function></literal>
- </entry>
- <entry><type>text[]</type></entry>
- <entry>
- Split <parameter>qualified_identifier</parameter> into an array of
+ <function>parse_ident</function> ( <parameter>qualified_identifier</parameter> <type>text</type>
+ [, <parameter>strictmode</parameter> <type>boolean</type> <literal>DEFAULT</literal> <literal>true</literal> ]
)
+ <returnvalue>text[]</returnvalue>
+ <?br?>
+ Splits <parameter>qualified_identifier</parameter> into an array of
identifiers, removing any quoting of individual identifiers. By
default, extra characters after the last identifier are considered an
error; but if the second parameter is <literal>false</literal>, then such
@@ -2042,417 +2039,441 @@
names for objects like functions.) Note that this function does not
truncate over-length identifiers. If you want truncation you can cast
the result to <type>name[]</type>.
+ <?br?>
+ <literal>parse_ident('"SomeSchema".someTable')</literal>
+ <returnvalue>{SomeSchema,sometable}</returnvalue>
</entry>
- <entry><literal>parse_ident('"SomeSchema".someTable')</literal></entry>
- <entry><literal>{SomeSchema,sometable}</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>pg_client_encoding</primary>
</indexterm>
- <literal><function>pg_client_encoding()</function></literal>
- </entry>
- <entry><type>name</type></entry>
- <entry>
- Current client encoding name
+ <function>pg_client_encoding</function> ( )
+ <returnvalue>name</returnvalue>
+ <?br?>
+ Returns current client encoding name.
+ <?br?>
+ <literal>pg_client_encoding()</literal>
+ <returnvalue>SQL_ASCII</returnvalue>
</entry>
- <entry><literal>pg_client_encoding()</literal></entry>
- <entry><literal>SQL_ASCII</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>quote_ident</primary>
</indexterm>
- <literal><function>quote_ident(<parameter>string</parameter> <type>text</type>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Return the given string suitably quoted to be used as an identifier
+ <function>quote_ident</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Returns the given string suitably quoted to be used as an identifier
in an <acronym>SQL</acronym> statement string.
Quotes are added only if necessary (i.e., if the string contains
non-identifier characters or would be case-folded).
Embedded quotes are properly doubled.
See also <xref linkend="plpgsql-quote-literal-example"/>.
+ <?br?>
+ <literal>quote_ident('Foo bar')</literal>
+ <returnvalue>"Foo bar"</returnvalue>
</entry>
- <entry><literal>quote_ident('Foo bar')</literal></entry>
- <entry><literal>"Foo bar"</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>quote_literal</primary>
</indexterm>
- <literal><function>quote_literal(<parameter>string</parameter> <type>text</type>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Return the given string suitably quoted to be used as a string literal
+ <function>quote_literal</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Returns the given string suitably quoted to be used as a string literal
in an <acronym>SQL</acronym> statement string.
Embedded single-quotes and backslashes are properly doubled.
Note that <function>quote_literal</function> returns null on null
input; if the argument might be null,
<function>quote_nullable</function> is often more suitable.
See also <xref linkend="plpgsql-quote-literal-example"/>.
+ <?br?>
+ <literal>quote_literal(E'O\'Reilly')</literal>
+ <returnvalue>'O''Reilly'</returnvalue>
</entry>
- <entry><literal>quote_literal(E'O\'Reilly')</literal></entry>
- <entry><literal>'O''Reilly'</literal></entry>
</row>
<row>
- <entry><literal><function>quote_literal(<parameter>value</parameter>
<type>anyelement</type>)</function></literal></entry>
- <entry><type>text</type></entry>
- <entry>
- Coerce the given value to text and then quote it as a literal.
+ <entry role="functableentry">
+ <function>quote_literal</function> ( <type>anyelement</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Coerces the given value to text and then quotes it as a literal.
Embedded single-quotes and backslashes are properly doubled.
+ <?br?>
+ <literal>quote_literal(42.5)</literal>
+ <returnvalue>'42.5'</returnvalue>
</entry>
- <entry><literal>quote_literal(42.5)</literal></entry>
- <entry><literal>'42.5'</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>quote_nullable</primary>
</indexterm>
- <literal><function>quote_nullable(<parameter>string</parameter> <type>text</type>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Return the given string suitably quoted to be used as a string literal
+ <function>quote_nullable</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Returns the given string suitably quoted to be used as a string literal
in an <acronym>SQL</acronym> statement string; or, if the argument
- is null, return <literal>NULL</literal>.
+ is null, returns <literal>NULL</literal>.
Embedded single-quotes and backslashes are properly doubled.
See also <xref linkend="plpgsql-quote-literal-example"/>.
+ <?br?>
+ <literal>quote_nullable(NULL)</literal>
+ <returnvalue>NULL</returnvalue>
</entry>
- <entry><literal>quote_nullable(NULL)</literal></entry>
- <entry><literal>NULL</literal></entry>
</row>
<row>
- <entry><literal><function>quote_nullable(<parameter>value</parameter>
<type>anyelement</type>)</function></literal></entry>
- <entry><type>text</type></entry>
- <entry>
- Coerce the given value to text and then quote it as a literal;
- or, if the argument is null, return <literal>NULL</literal>.
+ <entry role="functableentry">
+ <function>quote_nullable</function> ( <type>anyelement</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Coerces the given value to text and then quotes it as a literal;
+ or, if the argument is null, returns <literal>NULL</literal>.
Embedded single-quotes and backslashes are properly doubled.
+ <?br?>
+ <literal>quote_nullable(42.5)</literal>
+ <returnvalue>'42.5'</returnvalue>
</entry>
- <entry><literal>quote_nullable(42.5)</literal></entry>
- <entry><literal>'42.5'</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>regexp_match</primary>
</indexterm>
- <literal><function>regexp_match(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter>
<type>text</type>])</function></literal>
- </entry>
- <entry><type>text[]</type></entry>
- <entry>
- Return captured substring(s) resulting from the first match of a POSIX
- regular expression to the <parameter>string</parameter> (see
- <xref linkend="functions-posix-regexp"/> for more information)
+ <function>regexp_match</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type> ] )
+ <returnvalue>text[]</returnvalue>
+ <?br?>
+ Returns captured substring(s) resulting from the first match of a POSIX
+ regular expression to the <parameter>string</parameter>; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <literal>regexp_match('foobarbequebaz', '(bar)(beque)')</literal>
+ <returnvalue>{bar,beque}</returnvalue>
</entry>
- <entry><literal>regexp_match('foobarbequebaz', '(bar)(beque)')</literal></entry>
- <entry><literal>{bar,beque}</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>regexp_matches</primary>
</indexterm>
- <literal><function>regexp_matches(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter>
<type>text</type>])</function></literal>
- </entry>
- <entry><type>setof text[]</type></entry>
- <entry>
- Return captured substring(s) resulting from matching a POSIX regular
- expression to the <parameter>string</parameter> (see
- <xref linkend="functions-posix-regexp"/> for more information)
+ <function>regexp_matches</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type> ] )
+ <returnvalue>setof text[]</returnvalue>
+ <?br?>
+ Returns captured substring(s) resulting from matching a POSIX regular
+ expression to the <parameter>string</parameter>; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <literal>regexp_matches('foobarbequebaz', 'ba.', 'g')</literal>
+ <returnvalue>{bar}<?br?>{baz}</returnvalue><?br?>(2 rows)
</entry>
- <entry><literal>regexp_matches('foobarbequebaz', 'ba.', 'g')</literal></entry>
- <entry><literal>{bar}</literal><para><literal>{baz}</literal></para> (2 rows)</entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>regexp_replace</primary>
</indexterm>
- <literal><function>regexp_replace(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type>, <parameter>replacement</parameter> <type>text</type> [,
<parameter>flags</parameter><type>text</type>])</function></literal>
+ <function>regexp_replace</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type>, <parameter>replacement</parameter> <type>text</type> [,
<parameter>flags</parameter><type>text</type> ] )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Replaces substring(s) matching a POSIX regular expression; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <literal>regexp_replace('Thomas', '.[mN]a.', 'M')</literal>
+ <returnvalue>ThM</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Replace substring(s) matching a POSIX regular expression (see
- <xref linkend="functions-posix-regexp"/> for more information)
- </entry>
- <entry><literal>regexp_replace('Thomas', '.[mN]a.', 'M')</literal></entry>
- <entry><literal>ThM</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>regexp_split_to_array</primary>
</indexterm>
- <literal><function>regexp_split_to_array(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type>
])</function></literal>
- </entry>
- <entry><type>text[]</type></entry>
- <entry>
- Split <parameter>string</parameter> using a POSIX regular expression as
- the delimiter (see <xref linkend="functions-posix-regexp"/> for more
- information)
+ <function>regexp_split_to_array</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type> ] )
+ <returnvalue>text[]</returnvalue>
+ <?br?>
+ Splits <parameter>string</parameter> using a POSIX regular
+ expression as the delimiter; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <literal>regexp_split_to_array('hello world', '\s+')</literal>
+ <returnvalue>{hello,world}</returnvalue>
</entry>
- <entry><literal>regexp_split_to_array('hello world', '\s+')</literal></entry>
- <entry><literal>{hello,world}</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>regexp_split_to_table</primary>
</indexterm>
- <literal><function>regexp_split_to_table(<parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter>
<type>text</type>])</function></literal>
- </entry>
- <entry><type>setof text</type></entry>
- <entry>
- Split <parameter>string</parameter> using a POSIX regular expression as
- the delimiter (see <xref linkend="functions-posix-regexp"/> for more
- information)
+ <function>regexp_split_to_table</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>pattern</parameter><type>text</type> [, <parameter>flags</parameter> <type>text</type> ] )
+ <returnvalue>setof text</returnvalue>
+ <?br?>
+ Splits <parameter>string</parameter> using a POSIX regular
+ expression as the delimiter; see
+ <xref linkend="functions-posix-regexp"/>.
+ <?br?>
+ <literal>regexp_split_to_table('hello world', '\s+')</literal>
+ <returnvalue>hello<?br?>world</returnvalue><?br?>(2 rows)
</entry>
- <entry><literal>regexp_split_to_table('hello world', '\s+')</literal></entry>
- <entry><literal>hello</literal><para><literal>world</literal></para> (2 rows)</entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>repeat</primary>
</indexterm>
- <literal><function>repeat(<parameter>string</parameter> <type>text</type>, <parameter>number</parameter>
<type>int</type>)</function></literal>
+ <function>repeat</function> ( <parameter>string</parameter> <type>text</type>, <parameter>number</parameter>
<type>integer</type>)
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Repeats <parameter>string</parameter> the specified
+ <parameter>number</parameter> of times.
+ <?br?>
+ <literal>repeat('Pg', 4)</literal>
+ <returnvalue>PgPgPgPg</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>Repeat <parameter>string</parameter> the specified
- <parameter>number</parameter> of times</entry>
- <entry><literal>repeat('Pg', 4)</literal></entry>
- <entry><literal>PgPgPgPg</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>replace</primary>
</indexterm>
- <literal><function>replace(<parameter>string</parameter> <type>text</type>,
+ <function>replace</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>from</parameter> <type>text</type>,
- <parameter>to</parameter> <type>text</type>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>Replace all occurrences in <parameter>string</parameter> of substring
- <parameter>from</parameter> with substring <parameter>to</parameter>
+ <parameter>to</parameter> <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Replaces all occurrences in <parameter>string</parameter> of
+ substring <parameter>from</parameter> with
+ substring <parameter>to</parameter>.
+ <?br?>
+ <literal>replace('abcdefabcdef', 'cd', 'XX')</literal>
+ <returnvalue>abXXefabXXef</returnvalue>
</entry>
- <entry><literal>replace('abcdefabcdef', 'cd', 'XX')</literal></entry>
- <entry><literal>abXXefabXXef</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>reverse</primary>
</indexterm>
- <literal><function>reverse(<parameter>str</parameter>)</function></literal>
+ <function>reverse</function> ( <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Reverses the order of the characters in the string.
+ <?br?>
+ <literal>reverse('abcde')</literal>
+ <returnvalue>edcba</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Reverse the order of the characters in <parameter>string</parameter>
- </entry>
- <entry><literal>reverse('abcde')</literal></entry>
- <entry><literal>edcba</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>right</primary>
</indexterm>
- <literal><function>right(<parameter>string</parameter> <type>text</type>,
- <parameter>n</parameter> <type>int</type>)</function></literal>
+ <function>right</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>n</parameter> <type>integer</type> )
+<type></type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Returns last <replaceable>n</replaceable> characters in the string,
+ or when <replaceable>n</replaceable> is negative, returns all but
+ first |<replaceable>n</replaceable>| characters.
+ <?br?>
+ <literal>right('abcde', 2)</literal>
+ <returnvalue>de</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Return last <replaceable>n</replaceable> characters in the string,
- or when <replaceable>n</replaceable> is negative, return all but
- first |<replaceable>n</replaceable>| characters
- </entry>
- <entry><literal>right('abcde', 2)</literal></entry>
- <entry><literal>de</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>rpad</primary>
</indexterm>
- <literal><function>rpad(<parameter>string</parameter> <type>text</type>,
- <parameter>length</parameter> <type>int</type>
- <optional>, <parameter>fill</parameter> <type>text</type></optional>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Extend the <parameter>string</parameter> to length
+ <function>rpad</function> ( <parameter>string</parameter> <type>text</type>,
+ <parameter>length</parameter> <type>integer</type>
+ <optional>, <parameter>fill</parameter> <type>text</type> </optional> )
+<type></type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Extends the <parameter>string</parameter> to length
<parameter>length</parameter> by appending the characters
<parameter>fill</parameter> (a space by default). If the
<parameter>string</parameter> is already longer than
<parameter>length</parameter> then it is truncated.
+ <?br?>
+ <literal>rpad('hi', 5, 'xy')</literal>
+ <returnvalue>hixyx</returnvalue>
</entry>
- <entry><literal>rpad('hi', 5, 'xy')</literal></entry>
- <entry><literal>hixyx</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>rtrim</primary>
</indexterm>
- <literal><function>rtrim(<parameter>string</parameter> <type>text</type>
- <optional>, <parameter>characters</parameter> <type>text</type></optional>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Remove the longest string containing only characters from
+ <function>rtrim</function> ( <parameter>string</parameter> <type>text</type>
+ <optional>, <parameter>characters</parameter> <type>text</type> </optional> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Removes the longest string containing only characters from
<parameter>characters</parameter> (a space by default) from the end of
- <parameter>string</parameter>
+ <parameter>string</parameter>.
+ <?br?>
+ <literal>rtrim('testxxzx', 'xyz')</literal>
+ <returnvalue>test</returnvalue>
</entry>
- <entry><literal>rtrim('testxxzx', 'xyz')</literal></entry>
- <entry><literal>test</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>split_part</primary>
</indexterm>
- <literal><function>split_part(<parameter>string</parameter> <type>text</type>,
+ <function>split_part</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>delimiter</parameter> <type>text</type>,
- <parameter>field</parameter> <type>int</type>)</function></literal>
+ <parameter>n</parameter> <type>integer</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Splits <parameter>string</parameter> on <parameter>delimiter</parameter>
+ and returns the <parameter>n</parameter>'th field (counting from one).
+ <?br?>
+ <literal>split_part('abc~@~def~@~ghi', '~@~', 2)</literal>
+ <returnvalue>def</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>Split <parameter>string</parameter> on <parameter>delimiter</parameter>
- and return the given field (counting from one)
- </entry>
- <entry><literal>split_part('abc~@~def~@~ghi', '~@~', 2)</literal></entry>
- <entry><literal>def</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>strpos</primary>
</indexterm>
- <literal><function>strpos(<parameter>string</parameter>,
<parameter>substring</parameter>)</function></literal>
- </entry>
- <entry><type>int</type></entry>
- <entry>
- Location of specified substring (same as
- <literal>position(<parameter>substring</parameter> in
- <parameter>string</parameter>)</literal>, but note the reversed
- argument order)
+ <function>strpos</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>substring</parameter><type>text</type> )
+ <returnvalue>integer</returnvalue>
+ <?br?>
+ Returns location of specified <parameter>substring</parameter>
+ within <parameter>string</parameter>, or zero if it's not present.
+ (Same as <literal>position(<parameter>substring</parameter> in
+ <parameter>string</parameter>)</literal>, but note the reversed
+ argument order.)
+ <?br?>
+ <literal>strpos('high', 'ig')</literal>
+ <returnvalue>2</returnvalue>
</entry>
- <entry><literal>strpos('high', 'ig')</literal></entry>
- <entry><literal>2</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>substr</primary>
</indexterm>
- <literal><function>substr(<parameter>string</parameter>, <parameter>from</parameter> <optional>,
<parameter>count</parameter></optional>)</function></literal>
+ <function>substr</function> ( <parameter>string</parameter> <type>text</type>, <parameter>start</parameter>
<type>integer</type><optional>, <parameter>count</parameter> <type>integer</type> </optional> )
+<type></type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Extracts substring starting at index <parameter>start</parameter>,
+ and extending for <parameter>count</parameter> characters if that is
+ specified. (Same
+ as <literal>substring(<parameter>string</parameter>
+ from <parameter>start</parameter>
+ for <parameter>count</parameter>)</literal>.)
+ <?br?>
+ <literal>substr('alphabet', 3, 2)</literal>
+ <returnvalue>ph</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Extract substring (same as
- <literal>substring(<parameter>string</parameter> from <parameter>from</parameter> for
<parameter>count</parameter>)</literal>)
- </entry>
- <entry><literal>substr('alphabet', 3, 2)</literal></entry>
- <entry><literal>ph</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>starts_with</primary>
</indexterm>
- <literal><function>starts_with(<parameter>string</parameter>,
<parameter>prefix</parameter>)</function></literal>
+ <function>starts_with</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>prefix</parameter><type>text</type> )
+ <returnvalue>boolean</returnvalue>
+ <?br?>
+ Returns true if <parameter>string</parameter> starts
+ with <parameter>prefix</parameter>.
+ <?br?>
+ <literal>starts_with('alphabet', 'alph')</literal>
+ <returnvalue>t</returnvalue>
</entry>
- <entry><type>bool</type></entry>
- <entry>
- Return true if <parameter>string</parameter> starts
- with <parameter>prefix</parameter>
- </entry>
- <entry><literal>starts_with('alphabet', 'alph')</literal></entry>
- <entry><literal>t</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>to_ascii</primary>
</indexterm>
- <literal><function>to_ascii(<parameter>string</parameter> <type>text</type>
- <optional>, <parameter>encoding</parameter> <type>text</type></optional>)</function></literal>
+ <function>to_ascii</function> ( <parameter>string</parameter> <type>text</type>
+ <optional>, <parameter>encoding</parameter> <type>name</type> or <type>integer</type> </optional> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Converts <parameter>string</parameter> to <acronym>ASCII</acronym>
+ from another encoding, which may be identified by name or number;
+ if <parameter>encoding</parameter> is omitted the database encoding
+ is assumed. The conversion consists primarily of dropping accents.
+ Conversion is only supported
+ from <literal>LATIN1</literal>, <literal>LATIN2</literal>,
+ <literal>LATIN9</literal>, and <literal>WIN1250</literal> encodings.
+ <?br?>
+ <literal>to_ascii('Karél')</literal>
+ <returnvalue>Karel</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>
- Convert <parameter>string</parameter> to <acronym>ASCII</acronym> from another encoding
- (only supports conversion from <literal>LATIN1</literal>, <literal>LATIN2</literal>,
<literal>LATIN9</literal>,
- and <literal>WIN1250</literal> encodings)
- </entry>
- <entry><literal>to_ascii('Karel')</literal></entry>
- <entry><literal>Karel</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>to_hex</primary>
</indexterm>
- <literal><function>to_hex(<parameter>number</parameter> <type>int</type>
- or <type>bigint</type>)</function></literal>
+ <function>to_hex</function> ( <parameter>number</parameter>
+ <type>integer</type>
+ or <type>bigint</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Converts <parameter>number</parameter> to its equivalent hexadecimal
+ representation.
+ <?br?>
+ <literal>to_hex(2147483647)</literal>
+ <returnvalue>7fffffff</returnvalue>
</entry>
- <entry><type>text</type></entry>
- <entry>Convert <parameter>number</parameter> to its equivalent hexadecimal
- representation
- </entry>
- <entry><literal>to_hex(2147483647)</literal></entry>
- <entry><literal>7fffffff</literal></entry>
</row>
<row>
- <entry>
+ <entry role="functableentry">
<indexterm>
<primary>translate</primary>
</indexterm>
- <literal><function>translate(<parameter>string</parameter> <type>text</type>,
+ <function>translate</function> ( <parameter>string</parameter> <type>text</type>,
<parameter>from</parameter> <type>text</type>,
- <parameter>to</parameter> <type>text</type>)</function></literal>
- </entry>
- <entry><type>text</type></entry>
- <entry>
- Any character in <parameter>string</parameter> that matches a
- character in the <parameter>from</parameter> set is replaced by
- the corresponding character in the <parameter>to</parameter>
+ <parameter>to</parameter> <type>text</type> )
+ <returnvalue>text</returnvalue>
+ <?br?>
+ Replaces each character in <parameter>string</parameter> that
+ matches a character in the <parameter>from</parameter> set with the
+ corresponding character in the <parameter>to</parameter>
set. If <parameter>from</parameter> is longer than
<parameter>to</parameter>, occurrences of the extra characters in
- <parameter>from</parameter> are removed.
+ <parameter>from</parameter> are deleted.
+ <?br?>
+ <literal>translate('12345', '143', 'ax')</literal>
+ <returnvalue>a2x5</returnvalue>
</entry>
- <entry><literal>translate('12345', '143', 'ax')</literal></entry>
- <entry><literal>a2x5</literal></entry>
</row>
</tbody>
@@ -6743,257 +6764,224 @@ SELECT regexp_match('abc01234xyz', '(?:(.*?)(\d+)(.*)){1,1}');
<table id="operators-datetime-table">
<title>Date/Time Operators</title>
- <tgroup cols="3">
- <colspec colname="col1" colwidth="0.25*"/>
- <colspec colname="col2" colwidth="1*"/>
- <colspec colname="col3" colwidth="1*"/>
- <spanspec spanname="name" namest="col1" nameend="col1" align="left"/>
- <spanspec spanname="sig" namest="col2" nameend="col3" align="left"/>
- <spanspec spanname="desc" namest="col2" nameend="col3" align="left"/>
- <spanspec spanname="example" namest="col2" nameend="col2" align="left"/>
- <spanspec spanname="exresult" namest="col3" nameend="col3" align="left"/>
+ <tgroup cols="1">
<thead>
<row>
- <entry spanname="name" align="center" valign="middle" morerows="2">Operator</entry>
- <entry spanname="sig" align="center">Signature</entry>
- </row>
- <row>
- <entry spanname="desc" align="center">Description</entry>
- </row>
- <row>
- <entry spanname="example" align="center">Example</entry>
- <entry spanname="exresult" align="center">Example Result</entry>
+ <entry role="functableentry">
+ Operator<?br?>Description<?br?>Example(s)
+ </entry>
</row>
</thead>
<tbody>
<row>
- <entry spanname="name" morerows="2"> <literal>+</literal> </entry>
- <entry spanname="sig"><type>date</type> <literal>+</literal> <type>integer</type>
- <returnvalue>date</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Add a number of days to a date</entry>
- </row>
- <row>
- <entry spanname="example"><literal>date '2001-09-28' + 7</literal></entry>
- <entry spanname="exresult"><literal>2001-10-05</literal></entry>
+ <entry role="functableentry">
+ <type>date</type> <literal>+</literal> <type>integer</type>
+ <returnvalue>date</returnvalue>
+ <?br?>
+ Add a number of days to a date
+ <?br?>
+ <literal>date '2001-09-28' + 7</literal>
+ <returnvalue>2001-10-05</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>+</literal> </entry>
- <entry spanname="sig"><type>date</type> <literal>+</literal> <type>interval</type>
- <returnvalue>timestamp</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Add an interval to a date</entry>
- </row>
- <row>
- <entry spanname="example"><literal>date '2001-09-28' + interval '1 hour'</literal></entry>
- <entry spanname="exresult"><literal>2001-09-28 01:00:00</literal></entry>
+ <entry role="functableentry">
+ <type>date</type> <literal>+</literal> <type>interval</type>
+ <returnvalue>timestamp</returnvalue>
+ <?br?>
+ Add an interval to a date
+ <?br?>
+ <literal>date '2001-09-28' + interval '1 hour'</literal>
+ <returnvalue>2001-09-28 01:00:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>+</literal> </entry>
- <entry spanname="sig"><type>date</type> <literal>+</literal> <type>time</type>
- <returnvalue>timestamp</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Add a time-of-day to a date</entry>
- </row>
- <row>
- <entry spanname="example"><literal>date '2001-09-28' + time '03:00'</literal></entry>
- <entry spanname="exresult"><literal>2001-09-28 03:00:00</literal></entry>
+ <entry role="functableentry">
+ <type>date</type> <literal>+</literal> <type>time</type>
+ <returnvalue>timestamp</returnvalue>
+ <?br?>
+ Add a time-of-day to a date
+ <?br?>
+ <literal>date '2001-09-28' + time '03:00'</literal>
+ <returnvalue>2001-09-28 03:00:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>+</literal> </entry>
- <entry spanname="sig"><type>interval</type> <literal>+</literal> <type>interval</type>
- <returnvalue>interval</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Add intervals</entry>
- </row>
- <row>
- <entry spanname="example"><literal>interval '1 day' + interval '1 hour'</literal></entry>
- <entry spanname="exresult"><literal>1 day 01:00:00</literal></entry>
+ <entry role="functableentry">
+ <type>interval</type> <literal>+</literal> <type>interval</type>
+ <returnvalue>interval</returnvalue>
+ <?br?>
+ Add intervals
+ <?br?>
+ <literal>interval '1 day' + interval '1 hour'</literal>
+ <returnvalue>1 day 01:00:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>+</literal> </entry>
- <entry spanname="sig"><type>timestamp</type> <literal>+</literal> <type>interval</type>
- <returnvalue>timestamp</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Add an interval to a timestamp</entry>
- </row>
- <row>
- <entry spanname="example"><literal>timestamp '2001-09-28 01:00' + interval '23 hours'</literal></entry>
- <entry spanname="exresult"><literal>2001-09-29 00:00:00</literal></entry>
+ <entry role="functableentry">
+ <type>timestamp</type> <literal>+</literal> <type>interval</type>
+ <returnvalue>timestamp</returnvalue>
+ <?br?>
+ Add an interval to a timestamp
+ <?br?>
+ <literal>timestamp '2001-09-28 01:00' + interval '23 hours'</literal>
+ <returnvalue>2001-09-29 00:00:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>+</literal> </entry>
- <entry spanname="sig"><type>time</type> <literal>+</literal> <type>interval</type>
- <returnvalue>time</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Add an interval to a time</entry>
- </row>
- <row>
- <entry spanname="example"><literal>time '01:00' + interval '3 hours'</literal></entry>
- <entry spanname="exresult"><literal>04:00:00</literal></entry>
+ <entry role="functableentry">
+ <type>time</type> <literal>+</literal> <type>interval</type>
+ <returnvalue>time</returnvalue>
+ <?br?>
+ Add an interval to a time
+ <?br?>
+ <literal>time '01:00' + interval '3 hours'</literal>
+ <returnvalue>04:00:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>-</literal> </entry>
- <entry spanname="sig"><literal>-</literal> <type>interval</type>
- <returnvalue>interval</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Negate an interval</entry>
- </row>
- <row>
- <entry spanname="example"><literal>- interval '23 hours'</literal></entry>
- <entry spanname="exresult"><literal>-23:00:00</literal></entry>
+ <entry role="functableentry">
+ <literal>-</literal> <type>interval</type>
+ <returnvalue>interval</returnvalue>
+ <?br?>
+ Negate an interval
+ <?br?>
+ <literal>- interval '23 hours'</literal>
+ <returnvalue>-23:00:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>-</literal> </entry>
- <entry spanname="sig"><type>date</type> <literal>-</literal> <type>date</type>
- <returnvalue>integer</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Subtract dates</entry>
- </row>
- <row>
- <entry spanname="example"><literal>date '2001-10-01' - date '2001-09-28'</literal></entry>
- <entry spanname="exresult"><literal>3</literal></entry>
+ <entry role="functableentry">
+ <type>date</type> <literal>-</literal> <type>date</type>
+ <returnvalue>integer</returnvalue>
+ <?br?>
+ Subtract dates
+ <?br?>
+ <literal>date '2001-10-01' - date '2001-09-28'</literal>
+ <returnvalue>3</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>-</literal> </entry>
- <entry spanname="sig"><type>date</type> <literal>-</literal> <type>integer</type>
- <returnvalue>date</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Subtract a number of days from a date</entry>
- </row>
- <row>
- <entry spanname="example"><literal>date '2001-10-01' - 7</literal></entry>
- <entry spanname="exresult"><literal>2001-09-24</literal></entry>
+ <entry role="functableentry">
+ <type>date</type> <literal>-</literal> <type>integer</type>
+ <returnvalue>date</returnvalue>
+ <?br?>
+ Subtract a number of days from a date
+ <?br?>
+ <literal>date '2001-10-01' - 7</literal>
+ <returnvalue>2001-09-24</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>-</literal> </entry>
- <entry spanname="sig"><type>date</type> <literal>-</literal> <type>interval</type>
- <returnvalue>timestamp</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Subtract an interval from a date</entry>
- </row>
- <row>
- <entry spanname="example"><literal>date '2001-09-28' - interval '1 hour'</literal></entry>
- <entry spanname="exresult"><literal>2001-09-27 23:00:00</literal></entry>
+ <entry role="functableentry">
+ <type>date</type> <literal>-</literal> <type>interval</type>
+ <returnvalue>timestamp</returnvalue>
+ <?br?>
+ Subtract an interval from a date
+ <?br?>
+ <literal>date '2001-09-28' - interval '1 hour'</literal>
+ <returnvalue>2001-09-27 23:00:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>-</literal> </entry>
- <entry spanname="sig"><type>time</type> <literal>-</literal> <type>time</type>
- <returnvalue>interval</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Subtract times</entry>
- </row>
- <row>
- <entry spanname="example"><literal>time '05:00' - time '03:00'</literal></entry>
- <entry spanname="exresult"><literal>02:00:00</literal></entry>
+ <entry role="functableentry">
+ <type>time</type> <literal>-</literal> <type>time</type>
+ <returnvalue>interval</returnvalue>
+ <?br?>
+ Subtract times
+ <?br?>
+ <literal>time '05:00' - time '03:00'</literal>
+ <returnvalue>02:00:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>-</literal> </entry>
- <entry spanname="sig"><type>time</type> <literal>-</literal> <type>interval</type>
- <returnvalue>time</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Subtract an interval from a time</entry>
- </row>
- <row>
- <entry spanname="example"><literal>time '05:00' - interval '2 hours'</literal></entry>
- <entry spanname="exresult"><literal>03:00:00</literal></entry>
+ <entry role="functableentry">
+ <type>time</type> <literal>-</literal> <type>interval</type>
+ <returnvalue>time</returnvalue>
+ <?br?>
+ Subtract an interval from a time
+ <?br?>
+ <literal>time '05:00' - interval '2 hours'</literal>
+ <returnvalue>03:00:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>-</literal> </entry>
- <entry spanname="sig"><type>timestamp</type> <literal>-</literal> <type>interval</type>
- <returnvalue>timestamp</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Subtract an interval from a timestamp</entry>
- </row>
- <row>
- <entry spanname="example"><literal>timestamp '2001-09-28 23:00' - interval '23 hours'</literal></entry>
- <entry spanname="exresult"><literal>2001-09-28 00:00:00</literal></entry>
+ <entry role="functableentry">
+ <type>timestamp</type> <literal>-</literal> <type>interval</type>
+ <returnvalue>timestamp</returnvalue>
+ <?br?>
+ Subtract an interval from a timestamp
+ <?br?>
+ <literal>timestamp '2001-09-28 23:00' - interval '23 hours'</literal>
+ <returnvalue>2001-09-28 00:00:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>-</literal> </entry>
- <entry spanname="sig"><type>interval</type> <literal>-</literal> <type>interval</type>
- <returnvalue>interval</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Subtract intervals</entry>
- </row>
- <row>
- <entry spanname="example"><literal>interval '1 day' - interval '1 hour'</literal></entry>
- <entry spanname="exresult"><literal>1 day -01:00:00</literal></entry>
+ <entry role="functableentry">
+ <type>interval</type> <literal>-</literal> <type>interval</type>
+ <returnvalue>interval</returnvalue>
+ <?br?>
+ Subtract intervals
+ <?br?>
+ <literal>interval '1 day' - interval '1 hour'</literal>
+ <returnvalue>1 day -01:00:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>-</literal> </entry>
- <entry spanname="sig"><type>timestamp</type> <literal>-</literal> <type>timestamp</type>
- <returnvalue>interval</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Subtract timestamps</entry>
- </row>
- <row>
- <entry spanname="example"><literal>timestamp '2001-09-29 03:00' - timestamp '2001-09-27
12:00'</literal></entry>
- <entry spanname="exresult"><literal>1 day 15:00:00</literal></entry>
+ <entry role="functableentry">
+ <type>timestamp</type> <literal>-</literal> <type>timestamp</type>
+ <returnvalue>interval</returnvalue>
+ <?br?>
+ Subtract timestamps
+ <?br?>
+ <literal>timestamp '2001-09-29 03:00' - timestamp '2001-09-27 12:00'</literal>
+ <returnvalue>1 day 15:00:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="4"> <literal>*</literal> </entry>
- <entry spanname="sig"><type>double precision</type> <literal>*</literal> <type>interval</type>
- <returnvalue>interval</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Multiply an interval by a scalar</entry>
- </row>
- <row>
- <entry spanname="example"><literal>900 * interval '1 second'</literal></entry>
- <entry spanname="exresult"><literal>00:15:00</literal></entry>
- </row>
- <row>
- <entry spanname="example"><literal>21 * interval '1 day'</literal></entry>
- <entry spanname="exresult"><literal>21 days</literal></entry>
- </row>
- <row>
- <entry spanname="example"><literal>3.5 * interval '1 hour'</literal></entry>
- <entry spanname="exresult"><literal>03:30:00</literal></entry>
+ <entry role="functableentry">
+ <type>interval</type> <literal>*</literal> <type>double precision</type>
+ <returnvalue>interval</returnvalue>
+ <?br?>
+ Multiply an interval by a scalar
+ <?br?>
+ <literal>interval '1 second' * 900</literal>
+ <returnvalue>00:15:00</returnvalue>
+ <?br?>
+ <literal>interval '1 day' * 21</literal>
+ <returnvalue>21 days</returnvalue>
+ <?br?>
+ <literal>interval '1 hour' * 3.5</literal>
+ <returnvalue>03:30:00</returnvalue>
+ </entry>
</row>
<row>
- <entry spanname="name" morerows="2"> <literal>/</literal> </entry>
- <entry spanname="sig"><type>interval</type> <literal>/</literal> <type>double precision</type>
- <returnvalue>interval</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Divide an interval by a scalar</entry>
- </row>
- <row>
- <entry spanname="example"><literal>interval '1 hour' / 1.5</literal></entry>
- <entry spanname="exresult"><literal>00:40:00</literal></entry>
+ <entry role="functableentry">
+ <type>interval</type> <literal>/</literal> <type>double precision</type>
+ <returnvalue>interval</returnvalue>
+ <?br?>
+ Divide an interval by a scalar
+ <?br?>
+ <literal>interval '1 hour' / 1.5</literal>
+ <returnvalue>00:40:00</returnvalue>
+ </entry>
</row>
</tbody>
</tgroup>
@@ -8645,103 +8633,79 @@ CREATE TYPE rainbow AS ENUM ('red', 'orange', 'yellow', 'green', 'blue', 'purple
<table id="functions-enum-table">
<title>Enum Support Functions</title>
- <tgroup cols="3">
- <colspec colname="col1" colwidth="0.5*"/>
- <colspec colname="col2" colwidth="1*"/>
- <colspec colname="col3" colwidth="1*"/>
- <spanspec spanname="name" namest="col1" nameend="col1" align="left"/>
- <spanspec spanname="sig" namest="col2" nameend="col3" align="left"/>
- <spanspec spanname="desc" namest="col2" nameend="col3" align="left"/>
- <spanspec spanname="example" namest="col2" nameend="col2" align="left"/>
- <spanspec spanname="exresult" namest="col3" nameend="col3" align="left"/>
+ <tgroup cols="1">
<thead>
<row>
- <entry spanname="name" align="center" valign="middle" morerows="2">Function</entry>
- <entry spanname="sig" align="center">Signature</entry>
- </row>
- <row>
- <entry spanname="desc" align="center">Description</entry>
- </row>
- <row>
- <entry spanname="example" align="center">Example</entry>
- <entry spanname="exresult" align="center">Example Result</entry>
+ <entry role="functableentry">
+ Function<?br?>Description<?br?>Example(s)
+ </entry>
</row>
</thead>
<tbody>
<row>
- <entry spanname="name" morerows="2">
+ <entry role="functableentry">
<indexterm>
<primary>enum_first</primary>
</indexterm>
- <function>enum_first</function>
+ <function>enum_first</function> ( <type>anyenum</type> )
+ <returnvalue>anyenum</returnvalue>
+ <?br?>
+ Returns the first value of the input enum type.
+ <?br?>
+ <literal>enum_first(null::rainbow)</literal>
+ <returnvalue>red</returnvalue>
</entry>
- <entry spanname="sig"><function>enum_first</function>(<type>anyenum</type>)
<returnvalue>anyenum</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Returns the first value of the input enum type</entry>
</row>
<row>
- <entry spanname="example"><literal>enum_first(&zwsp;null::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>red</literal></entry>
- </row>
- <row>
- <entry spanname="name" morerows="2">
+ <entry role="functableentry">
<indexterm>
<primary>enum_last</primary>
</indexterm>
- <function>enum_last</function>
+ <function>enum_last</function> ( <type>anyenum</type> )
+ <returnvalue>anyenum</returnvalue>
+ <?br?>
+ Returns the last value of the input enum type.
+ <?br?>
+ <literal>enum_last(null::rainbow)</literal>
+ <returnvalue>purple</returnvalue>
</entry>
- <entry spanname="sig"><function>enum_last</function>(<type>anyenum</type>)
<returnvalue>anyenum</returnvalue></entry>
</row>
<row>
- <entry spanname="desc">Returns the last value of the input enum type</entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_last(&zwsp;null::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>purple</literal></entry>
- </row>
- <row>
- <entry spanname="name" morerows="2">
+ <entry role="functableentry">
<indexterm>
<primary>enum_range</primary>
</indexterm>
- <function>enum_range</function>
+ <function>enum_range</function> ( <type>anyenum</type> )
+ <returnvalue>anyarray</returnvalue>
+ <?br?>
+ Returns all values of the input enum type in an ordered array.
+ <?br?>
+ <literal>enum_range(null::rainbow)</literal>
+ <returnvalue>{red,orange,yellow,&zwsp;green,blue,purple}</returnvalue>
</entry>
- <entry spanname="sig"><function>enum_range</function>(<type>anyenum</type>)
<returnvalue>anyarray</returnvalue></entry>
- </row>
- <row>
- <entry spanname="desc">Returns all values of the input enum type in an ordered array</entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_range(&zwsp;null::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>{red,orange,yellow,&zwsp;green,blue,purple}</literal></entry>
- </row>
- <row>
- <entry spanname="name" morerows="4"><function>enum_range</function></entry>
- <entry spanname="sig"><function>enum_range</function>(<type>anyenum</type>, <type>anyenum</type>)
<returnvalue>anyarray</returnvalue></entry>
</row>
<row>
- <entry spanname="desc">
+ <entry role="functableentry">
+ <function>enum_range</function> ( <type>anyenum</type>, <type>anyenum</type> )
+ <returnvalue>anyarray</returnvalue>
+ <?br?>
Returns the range between the two given enum values, as an ordered
array. The values must be from the same enum type. If the first
parameter is null, the result will start with the first value of
the enum type.
If the second parameter is null, the result will end with the last
value of the enum type.
+ <?br?>
+ <literal>enum_range('orange'::rainbow, 'green'::rainbow)</literal>
+ <returnvalue>{orange,yellow,green}</returnvalue>
+ <?br?>
+ <literal>enum_range(NULL, 'green'::rainbow)</literal>
+ <returnvalue>{red,orange,&zwsp;yellow,green}</returnvalue>
+ <?br?>
+ <literal>enum_range('orange'::rainbow, NULL)</literal>
+ <returnvalue>{orange,yellow,green,&zwsp;blue,purple}</returnvalue>
</entry>
</row>
- <row>
- <entry spanname="example"><literal>enum_range(&zwsp;'orange'::rainbow, 'green'::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>{orange,yellow,green}</literal></entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_range(NULL, 'green'::rainbow)</literal></entry>
- <entry spanname="exresult"><literal>{red,orange,yellow,&zwsp;green}</literal></entry>
- </row>
- <row>
- <entry spanname="example"><literal>enum_range(&zwsp;'orange'::rainbow, NULL)</literal></entry>
- <entry spanname="exresult"><literal>{orange,yellow,green,&zwsp;blue,purple}</literal></entry>
- </row>
</tbody>
</tgroup>
</table>
diff --git a/doc/src/sgml/stylesheet-common.xsl b/doc/src/sgml/stylesheet-common.xsl
index a13565e..105ed1c 100644
--- a/doc/src/sgml/stylesheet-common.xsl
+++ b/doc/src/sgml/stylesheet-common.xsl
@@ -103,4 +103,11 @@
<xsl:apply-templates select="." mode="xref"/>
</xsl:template>
+
+<!-- Support for explicit line breaks <?br?> within table cells -->
+
+<xsl:template match="processing-instruction('br')">
+ <br/>
+</xsl:template>
+
</xsl:stylesheet>
diff --git a/doc/src/sgml/stylesheet-fo.xsl b/doc/src/sgml/stylesheet-fo.xsl
index 2aaae82..cf6a420 100644
--- a/doc/src/sgml/stylesheet-fo.xsl
+++ b/doc/src/sgml/stylesheet-fo.xsl
@@ -63,6 +63,31 @@
</fo:inline>
</xsl:template>
+<!-- overrides built-in DocBook template -->
+<xsl:template name="table.cell.block.properties">
+ <!-- highlight this entry? -->
+ <xsl:choose>
+ <xsl:when test="ancestor::thead or ancestor::tfoot">
+ <xsl:attribute name="font-weight">bold</xsl:attribute>
+ </xsl:when>
+ <!-- Make row headers bold too -->
+ <xsl:when test="ancestor::tbody and
+ (ancestor::table[@rowheader = 'firstcol'] or
+ ancestor::informaltable[@rowheader = 'firstcol']) and
+ ancestor-or-self::entry[1][count(preceding-sibling::entry) = 0]">
+ <xsl:attribute name="font-weight">bold</xsl:attribute>
+ </xsl:when>
+ </xsl:choose>
+ <!-- Postgres additions start here -->
+ <xsl:choose>
+ <xsl:when test="self::entry[@role='functableentry']">
+ <xsl:attribute name="margin-left">5em</xsl:attribute>
+ <xsl:attribute name="text-indent">-5em</xsl:attribute>
+ <xsl:attribute name="text-align">left</xsl:attribute>
+ </xsl:when>
+ </xsl:choose>
+</xsl:template>
+
<!-- overrides stylesheet-common.xsl -->
<!-- FOP needs us to be explicit about the font to use for right arrow -->
<xsl:template match="returnvalue">
@@ -70,6 +95,11 @@
<xsl:call-template name="inline.monoseq"/>
</xsl:template>
+<!-- overrides stylesheet-common.xsl -->
+<xsl:template match="processing-instruction('br')">
+ <fo:block/>
+</xsl:template>
+
<!-- bug fix from <https://sourceforge.net/p/docbook/bugs/1360/#831b> -->
<xsl:template match="varlistentry/term" mode="xref-to">
diff --git a/doc/src/sgml/stylesheet.css b/doc/src/sgml/stylesheet.css
index 1a66c78..7951881 100644
--- a/doc/src/sgml/stylesheet.css
+++ b/doc/src/sgml/stylesheet.css
@@ -76,6 +76,20 @@ div.example {
margin: 0.5ex;
}
+/* formatting for entries in tables of functions: indent all but first line */
+
+th.functableentry {
+ padding-left: 5em;
+ text-indent: -5em;
+ text-align: left;
+}
+
+td.functableentry {
+ padding-left: 5em;
+ text-indent: -5em;
+ text-align: left;
+}
+
/* Put these here instead of inside the HTML (see unsetting of
admon.style in XSL) so that the web site stylesheet can set its own
style. */
--- main.css.orig 2020-04-16 18:46:26.040658279 -0400
+++ main.css 2020-04-16 19:18:15.689371719 -0400
@@ -791,6 +791,20 @@
word-break: unset;
}
+/* formatting for entries in tables of functions: indent all but first line */
+
+#docContent table.table th.functableentry {
+ padding-left: 5em;
+ text-indent: -5em;
+ text-align: left;
+}
+
+#docContent table.table td.functableentry {
+ padding-left: 5em;
+ text-indent: -5em;
+ text-align: left;
+}
+
/**
* Titles, Navigation
*/
Attachment
{kind=link}
{kind=link}
On Thu, Apr 16, 2020 at 8:25 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Attached are screenshots of the same segment of table 9.10 as before > and of the initial portion of 9.30, the patch against HEAD to produce > these, and a hacky patch on the website's main.css to get it to go > along. Without the last you just get all the subsidiary stuff > left-justified if you build with STYLE=website, which isn't impossibly > unreadable but it's not the desired presentation. These seem very nice, and way more readable than the version with which you started the thread. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Thu, Apr 16, 2020 at 8:25 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Attached are screenshots of the same segment of table 9.10 as before
>> and of the initial portion of 9.30, the patch against HEAD to produce
>> these, and a hacky patch on the website's main.css to get it to go
>> along. Without the last you just get all the subsidiary stuff
>> left-justified if you build with STYLE=website, which isn't impossibly
>> unreadable but it's not the desired presentation.
> These seem very nice, and way more readable than the version with
> which you started the thread.
Glad you like 'em ;-). Do you have an opinion about what to do
with the operator tables --- ie do we need a column with the operator
name at the left?
regards, tom lane
On Fri, Apr 17, 2020 at 2:38 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Glad you like 'em ;-). Do you have an opinion about what to do > with the operator tables --- ie do we need a column with the operator > name at the left? Well, if the first row says date + date -> date, then I don't think we also need another column to say that we're talking about + Seems redundant. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Fri, Apr 17, 2020 at 2:38 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Glad you like 'em ;-). Do you have an opinion about what to do
>> with the operator tables --- ie do we need a column with the operator
>> name at the left?
> Well, if the first row says date + date -> date, then I don't think we
> also need another column to say that we're talking about +
> Seems redundant.
Well, sure it's redundant, the same way an index is redundant.
Question is whether it makes it easier to find what you're after.
Comparing this to what is in table 9.30 as of HEAD [1], it does
seem like the operator column in the latter is a bit busy/redundant.
Perhaps it'd be less so if we used the morerows trick to have only
one occurrence of each operator name in the first column. But that
would be a little bit of a pain to maintain, so I'm not sure it's
worth the trouble.
Another advantage of handling functions and operators in exactly
the same format is that we won't need to do something weird for
tables 9.9 and 9.11, which include both.
For the moment I'll press on without including that column; we can
add it later without a huge amount of pain if we decide we want it.
On the other point of dispute about the operator tables: for the
moment I'm leaning towards keeping the text descriptions. Surveying
the existing tables, the *only* two that lack text descriptions now
are this one and the as-yet-unnumbered table in 9.1 for AND/OR/NOT.
(Actually, that one calls itself a truth table not an operator
definition table, so maybe we should leave it alone.) While there
is a reasonable argument that 9.1 Comparison Operators' descriptions
are all obvious, it's hard to make that argument for any other tables.
So I think the fact that 9.30 lacked such up to now is an aberration
not a good principle to follow. Even in 9.30, the fact that, say,
date + integer interprets the integer as so-many-days isn't really
so blindingly obvious that it doesn't need documented. In another
universe we might've made that count as seconds and had the result
type be timestamp, the way it works for date + interval.
regards, tom lane
[1] https://www.postgresql.org/docs/devel/functions-datetime.html
On Fri, Apr 17, 2020 at 3:58 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > On the other point of dispute about the operator tables: for the > moment I'm leaning towards keeping the text descriptions. I mostly suggested nuking them just to try to make the table more readable. But since you've found another (and better) solution to that problem, I withdraw that suggestion. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Fri, Apr 17, 2020 at 3:58 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> On the other point of dispute about the operator tables: for the
>> moment I'm leaning towards keeping the text descriptions.
> I mostly suggested nuking them just to try to make the table more
> readable. But since you've found another (and better) solution to that
> problem, I withdraw that suggestion.
Cool, then we're all on the same page. I shall press forward.
regards, tom lane
On Fri, Apr 17, 2020 at 11:38 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
Robert Haas <robertmhaas@gmail.com> writes:
> On Thu, Apr 16, 2020 at 8:25 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Attached are screenshots of the same segment of table 9.10 as before
>> and of the initial portion of 9.30, the patch against HEAD to produce
>> these, and a hacky patch on the website's main.css to get it to go
>> along. Without the last you just get all the subsidiary stuff
>> left-justified if you build with STYLE=website, which isn't impossibly
>> unreadable but it's not the desired presentation.
> These seem very nice, and way more readable than the version with
> which you started the thread.
I too like the layout result.
Glad you like 'em ;-). Do you have an opinion about what to do
with the operator tables --- ie do we need a column with the operator
name at the left?
I feel like writing them as:
+ (date, integer) -> date
makes more sense as they are mainly sorted on the operator symbol as opposed to the left operand.
I think the description line is beneficial, and easy enough to skim over for the trained eye just looking for a refresher on the example syntax.
David J.
"David G. Johnston" <david.g.johnston@gmail.com> writes:
> I feel like writing them as:
> + (date, integer) -> date
> makes more sense as they are mainly sorted on the operator symbol as
> opposed to the left operand.
Hmm ... we do use that syntax in some fairly-obscure places like
ALTER OPERATOR, but I'm afraid that novice users would just be
completely befuddled. Maybe the examples would be enough to clarify,
but I'm not convinced. Especially not for unary operators, where
ALTER OPERATOR would have us write "- (NONE, integer)".
regards, tom lane
On Fri, Apr 17, 2020 at 4:04 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
Especially not for unary operators, where
ALTER OPERATOR would have us write "- (NONE, integer)".
I'd drop the parens for unary and just write "- integer"
It is a bit geeky but then again SQL writers are not typically computer language novices so operators should be comfortable for them and this isn't that off-the-wall. But I agree with the concern.
David J.
"David G. Johnston" <david.g.johnston@gmail.com> writes:
> On Fri, Apr 17, 2020 at 4:04 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Especially not for unary operators, where
>> ALTER OPERATOR would have us write "- (NONE, integer)".
> I'd drop the parens for unary and just write "- integer"
We do have some postfix operators still ... although it looks like
there's only one in core. In any case, the signature line is *the*
thing that is supposed to specify what the syntax is, so I'm not
too pleased with using an ambiguous notation for it.
regards, tom lane
On Fri, Apr 17, 2020 at 4:17 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
"David G. Johnston" <david.g.johnston@gmail.com> writes:
> On Fri, Apr 17, 2020 at 4:04 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Especially not for unary operators, where
>> ALTER OPERATOR would have us write "- (NONE, integer)".
> I'd drop the parens for unary and just write "- integer"
We do have some postfix operators still ... although it looks like
there's only one in core. In any case, the signature line is *the*
thing that is supposed to specify what the syntax is, so I'm not
too pleased with using an ambiguous notation for it.
Neither:
- (NONE, integer)
nor
! (integer, NONE)
seem bad, and do make very obvious how they are different.
The left margin scanning ability for the symbol (hey, I have an expression here that uses @>, what does that do?) seems worth the bit of novelty required.
David J.
"David G. Johnston" <david.g.johnston@gmail.com> writes:
> On Fri, Apr 17, 2020 at 4:17 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> We do have some postfix operators still ... although it looks like
>> there's only one in core. In any case, the signature line is *the*
>> thing that is supposed to specify what the syntax is, so I'm not
>> too pleased with using an ambiguous notation for it.
> Neither:
> - (NONE, integer)
> nor
> ! (integer, NONE)
> seem bad, and do make very obvious how they are different.
> The left margin scanning ability for the symbol (hey, I have an expression
> here that uses @>, what does that do?) seems worth the bit of novelty
> required.
Meh. If we're worried about that, personally I'd much rather put
back the separate left-hand column with just the operator name.
We could also experiment with bold-facing the operator names,
as somebody suggested upthread.
regards, tom lane
On Fri, Apr 17, 2020 at 6:30 PM David G. Johnston <david.g.johnston@gmail.com> wrote: > I feel like writing them as: > > + (date, integer) -> date > > makes more sense as they are mainly sorted on the operator symbol as opposed to the left operand. I thought about that, too, but I think the way Tom did it is better. It's much more natural to see it using the syntax with which it will actually be invoked. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Fri, Apr 17, 2020 at 6:30 PM David G. Johnston
> <david.g.johnston@gmail.com> wrote:
>> I feel like writing them as:
>> + (date, integer) -> date
>> makes more sense as they are mainly sorted on the operator symbol as opposed to the left operand.
> I thought about that, too, but I think the way Tom did it is better.
> It's much more natural to see it using the syntax with which it will
> actually be invoked.
Just for the record, I experimented with putting back an "operator name"
column, as attached. I think it could be argued either way whether this
is an improvement or not.
Some notes:
* The column seems annoyingly wide, but the only way to make it narrower
is to narrow or eliminate the column title, which could be confusing.
Also, if there's not a fair amount of whitespace, it looks as if the
initial name is part of the signature, which is *really* confusing,
cf second screenshot. (I'm not sure why the vertical rule is rendered
so much more weakly in this case, but it is.)
* I also tried it with valign="middle" to center the operator name among
its entries. This was *not* an improvement, it largely breaks the
ability to see which entries belong to the name.
regards, tom lane
Attachment
{kind=link}
{kind=link}
so 18. 4. 2020 v 22:36 odesílatel Tom Lane <tgl@sss.pgh.pa.us> napsal:
Robert Haas <robertmhaas@gmail.com> writes:
> On Fri, Apr 17, 2020 at 6:30 PM David G. Johnston
> <david.g.johnston@gmail.com> wrote:
>> I feel like writing them as:
>> + (date, integer) -> date
>> makes more sense as they are mainly sorted on the operator symbol as opposed to the left operand.
> I thought about that, too, but I think the way Tom did it is better.
> It's much more natural to see it using the syntax with which it will
> actually be invoked.
Just for the record, I experimented with putting back an "operator name"
column, as attached. I think it could be argued either way whether this
is an improvement or not.
Some notes:
* The column seems annoyingly wide, but the only way to make it narrower
is to narrow or eliminate the column title, which could be confusing.
Also, if there's not a fair amount of whitespace, it looks as if the
initial name is part of the signature, which is *really* confusing,
cf second screenshot. (I'm not sure why the vertical rule is rendered
so much more weakly in this case, but it is.)
* I also tried it with valign="middle" to center the operator name among
its entries. This was *not* an improvement, it largely breaks the
ability to see which entries belong to the name.
first variant looks better, because column with operator is wider.
Maybe it can look better if a content will be places to mid point. In left upper corner it is less readable.
Regards
Pavel
regards, tom lane
On 2020-04-13 22:33, Tom Lane wrote: >> Maybe we're just trying to shoehorn too much information into a single >> table. > Yeah, back at the beginning of this exercise, Alvaro wondered aloud > if we should go to something other than tables altogether. I dunno > what that'd look like though. Yeah, after reading all this, my conclusion is also, probably tables are not the right solution. A variablelist/definition list would be the next thing to try in my mind. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2020-04-16 08:26, Pierre Giraud wrote: > The screenshot attached uses a <dl> tag for the descrition/example block. I like this better, but then you don't really need the table because you can just make the whole thing a definition list. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2020-04-17 02:25, Tom Lane wrote:
> I eventually figured out that the approved way to do per-table-entry
> customization is to attach "role" properties to the DocBook elements,
> and then key off the role names in applying formatting changes in
> the customization layer. So attached is a v3 that handles the desired
> formatting changes by applying a hanging indent to table <entry>
> contents if the entry is marked with role="functableentry". It may
> well be possible to do this in a cleaner fashion, but this seems
> good enough for discussion.
This scares me in terms of maintainability of both the toolchain and the
markup. Table formatting is already incredibly fragile, and here we
just keep poking it until it looks a certain way instead of thinking
about semantic markup.
A good old definition list of the kind
synopsis
explanation
example or two
would be much easier to maintain on all fronts. And we could for
example link directly to a function, which is currently not really possible.
If we want to draw a box around this and change the spacing, we can do
that with CSS.
--
Peter Eisentraut http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Peter Eisentraut <peter.eisentraut@2ndquadrant.com> writes:
> This scares me in terms of maintainability of both the toolchain and the
> markup. Table formatting is already incredibly fragile, and here we
> just keep poking it until it looks a certain way instead of thinking
> about semantic markup.
That's a fair criticism, but ...
> A good old definition list of the kind
> synopsis
> explanation
> example or two
> would be much easier to maintain on all fronts. And we could for
> example link directly to a function, which is currently not really possible.
> If we want to draw a box around this and change the spacing, we can do
> that with CSS.
... "we can fix it with CSS" is just as much reliance on toolchain.
In any case, I reject the idea that we should just drop the table
markup altogether and use inline variablelists. In most of these
sections there is a very clear separation between the table contents
(with per-function or per-operator details) and the surrounding
commentary, which deals with more general concerns. That's a useful
separation for both readers and authors, so we need to preserve it
in some form, but the standard rendering of variablelists won't.
(Our existing major use of variablelists, in the GUC chapter, works
around this basically by not having any "surrounding commentary"
... but that solution doesn't work here.)
There is also value in being able to say things like "see Table m.n
for the available operators for type foo".
If somebody's got an idea how to obtain this painfully-agreed-to
visual appearance from more robust markup, I'm all ears. This
stuff is a bit outside my skill set, so I don't claim to have
found the best possible implementation.
regards, tom lane
On Sun, 19 Apr 2020 at 09:23, Tom Lane <tgl@sss.pgh.pa.us> wrote:
In any case, I reject the idea that we should just drop the table
markup altogether and use inline variablelists. In most of these
sections there is a very clear separation between the table contents
(with per-function or per-operator details) and the surrounding
commentary, which deals with more general concerns. That's a useful
separation for both readers and authors, so we need to preserve it
in some form, but the standard rendering of variablelists won't.
(Our existing major use of variablelists, in the GUC chapter, works
around this basically by not having any "surrounding commentary"
... but that solution doesn't work here.)
There is also value in being able to say things like "see Table m.n
for the available operators for type foo".
The HTML definition list under discussion looks like this:
<dl>
<dt> term 1 </dt>
<dd> description 1 </dd>
<dt> term 2 </dt>
<dd> description 2a </dd>
<dd> description 2b </dd>
</dl>
So the enclosing <dl> element has the same role in the overall document as the <table>, and could be styled to set it apart from the main text and make it clear that it is a single unit (and at least in principle could be included in the "table" numbering). In the function/operator listing use case, there would be one <dd> for the description and a <dd> for each example. See:
If we were only concerned with HTML output then based on the desired semantics and appearance I would recommend <dl> without hesitation. Because of the need to produce PDF as well and my lack of knowledge of the Postgres documentation build process, I can't be so certain but I still suspect <dl> to be the best approach.
Isaac Morland <isaac.morland@gmail.com> writes:
> If we were only concerned with HTML output then based on the desired
> semantics and appearance I would recommend <dl> without hesitation. Because
> of the need to produce PDF as well and my lack of knowledge of the Postgres
> documentation build process, I can't be so certain but I still suspect <dl>
> to be the best approach.
Yeah ... so a part of this problem is to persuade DocBook to generate
that.
As I mentioned upthread, I did experiment with putting a single-item
<variablelist> in each table cell. That works out to an annoying amount
of markup overhead, since variablelist is a rather overengineered
construct, but I imagine we could live with it. The real problem was
the amount of whitespace it wanted to add. We could probably hack our
way out of that with CSS for HTML output, but it was quite unclear whether
the PDF toolchain could be made to render it reasonably.
A desirable solution, perhaps, would be a <variablelist> corresponding to
the entire table with rendering customization that produces table-like
dividing lines around <varlistentry>s. I'm not volunteering to figure
out how to do that though, especially not for PDF.
In the meantime I plan to push forward with the markup approach we've
got. The editorial content should still work if we find a better
markup answer, and I'm willing to do the work of replacing the markup
as long as somebody else figures out what it should be.
regards, tom lane
вс, 19 апр. 2020 г. в 20:00, Tom Lane <tgl@sss.pgh.pa.us>:
In the meantime I plan to push forward with the markup approach we've
got. The editorial content should still work if we find a better
markup answer, and I'm willing to do the work of replacing the markup
as long as somebody else figures out what it should be.
I am following this thread as a frequent documentation user.
While table 9.5 with functions looks quite nice, I quite dislike 9.4 with operators.
Previously, I could lookup operator in the leftmost column and read on. Right now I have to look through the whole table (well, not really, but still) to find the operator.
Victor Yegorov
Victor Yegorov <vyegorov@gmail.com> writes:
> While table 9.5 with functions looks quite nice, I quite dislike 9.4 with
> operators.
> Previously, I could lookup operator in the leftmost column and read on.
> Right now I have to look through the whole table (well, not really, but
> still) to find the operator.
Aside from the alternatives already discussed, the only other idea
that's come to my mind is to write operator entries in a style like
|| as in: text || text → text
Concatenates the two strings.
'Post' || 'greSQL' → PostgreSQL
Not sure that that's any better, but it is another alternative.
regards, tom lane
Victor Yegorov <vyegorov@gmail.com> writes:
> While table 9.5 with functions looks quite nice, I quite dislike 9.4 with
> operators.
BTW, I think a big part of the problem with table 9.4 as it's being
rendered in the web style right now is that the type placeholders
(numeric_type etc) are being rendered in a ridiculously overemphasized
fashion, causing them to overwhelm all else. Do we really want
<replaceable> to be rendered that way? I'd think plain italic,
comparable to the rendering of <parameter>, would be more appropriate.
I could make this page use <parameter> for that purpose of course,
but it seems like semantically the wrong thing.
regards, tom lane
On 2020-Apr-20, Tom Lane wrote: > Victor Yegorov <vyegorov@gmail.com> writes: > > While table 9.5 with functions looks quite nice, I quite dislike 9.4 with > > operators. > > Previously, I could lookup operator in the leftmost column and read on. > > Right now I have to look through the whole table (well, not really, but > > still) to find the operator. > > Aside from the alternatives already discussed, There's one with a separate column for the operator, without types, at the left (the "with names" example at https://postgr.es/m/14380.1587242177@sss.pgh.pa.us ). That seemed pretty promising -- not sure why it was discarded. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera <alvherre@2ndquadrant.com> writes: > There's one with a separate column for the operator, without types, at > the left (the "with names" example at > https://postgr.es/m/14380.1587242177@sss.pgh.pa.us ). That seemed > pretty promising -- not sure why it was discarded. Well, I wouldn't say it was discarded --- but there sure wasn't a groundswell of support. Looking at it again, I'd be inclined not to bother with the morerows trick but just to have an operator name entry in each row. This table is a bit of an outlier anyway, I'm finding --- very few of the operator tables have multiple entries per operator name. regards, tom lane
On 2020-Apr-20, Tom Lane wrote: > Alvaro Herrera <alvherre@2ndquadrant.com> writes: > > There's one with a separate column for the operator, without types, at > > the left (the "with names" example at > > https://postgr.es/m/14380.1587242177@sss.pgh.pa.us ). That seemed > > pretty promising -- not sure why it was discarded. > > Well, I wouldn't say it was discarded --- but there sure wasn't > a groundswell of support. Ah. > Looking at it again, I'd be inclined not to bother with the > morerows trick but just to have an operator name entry in each row. > This table is a bit of an outlier anyway, I'm finding --- very few > of the operator tables have multiple entries per operator name. No disagreement here. 'morerows' attribs are always a messy business. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2020-04-19 15:23, Tom Lane wrote: > If somebody's got an idea how to obtain this painfully-agreed-to > visual appearance from more robust markup, I'm all ears. This > stuff is a bit outside my skill set, so I don't claim to have > found the best possible implementation. I've played with this a bit, and there are certainly a lot of interesting things that you can do with CSS nowadays that would preserve some semblance of semantic markup on both the DocBook side and the HTML side. We haven't even considered what this new markup would do to non-visual consumers. But my conclusion is that this new direction is bad and the old way was much better. My vote is to keep what we had in PG12. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Peter Eisentraut <peter.eisentraut@2ndquadrant.com> writes:
> I've played with this a bit, and there are certainly a lot of
> interesting things that you can do with CSS nowadays that would preserve
> some semblance of semantic markup on both the DocBook side and the HTML
> side.
As I said, I'm happy to do the legwork of improving the markup if someone
will point me in the right direction. But I know next to zip about CSS,
so it would not be productive for me to do the basic design there ---
it would take too long and there would probably still be lots to criticize
in whatever I came up with.
(I note ruefully that my original design in e894c6183 *was* pretty decent
semantic markup, especially if you're willing to accept spanspec
identifiers as semantic annotation. But people didn't like the visual
result, so now we have better visuals and uglier markup.)
> But my conclusion is that this new direction is bad and the old way was
> much better. My vote is to keep what we had in PG12.
I'm not willing to accept that conclusion. Why are we even bothering
to support PDF output, if lots of critical information is going to be
illegible? (And even if you figure PDFs should go the way of the dodo,
almost any narrow-window presentation has got problems with these tables.)
Also, as I've been going through this, I've realized that there are many
places in chapter 9 where the documentation is well south of adequate, if
not flat-out wrong. Some of it is just that nobody's gone through this
material in decades, and some of it is that the existing table layout is
so unfriendly to writing more than a couple words of explanation per item.
But I'm not willing to abandon the work I've done so far and just hope
that in another twenty years somebody will be brave or foolish enough to
try again.
regards, tom lane
On Thu, Apr 23, 2020 at 12:04:01PM -0400, Tom Lane wrote: > Peter Eisentraut <peter.eisentraut@2ndquadrant.com> writes: > > I've played with this a bit, and there are certainly a lot of > > interesting things that you can do with CSS nowadays that would preserve > > some semblance of semantic markup on both the DocBook side and the HTML > > side. > > As I said, I'm happy to do the legwork of improving the markup if someone > will point me in the right direction. But I know next to zip about CSS, > so it would not be productive for me to do the basic design there --- > it would take too long and there would probably still be lots to criticize > in whatever I came up with. I can do the CSS if you tell me what you want. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
Bruce Momjian <bruce@momjian.us> writes:
> On Thu, Apr 23, 2020 at 12:04:01PM -0400, Tom Lane wrote:
>> As I said, I'm happy to do the legwork of improving the markup if someone
>> will point me in the right direction. But I know next to zip about CSS,
>> so it would not be productive for me to do the basic design there ---
>> it would take too long and there would probably still be lots to criticize
>> in whatever I came up with.
> I can do the CSS if you tell me what you want.
I think the existing visual appearance is more or less agreed to, so
what we want is to reproduce that as closely as possible from some
saner markup. The first problem is to agree on what "saner markup"
is exactly.
We could possibly use margin and vertical-space CSS adjustments starting
from just using several <para>s within each table cell (one <para> for
signature, one for description, one for each example). I'm not sure
whether that meets Peter's desire for "semantic" markup though. It's not
any worse than the old way with otherwise-unlabeled <entry>s, but it's not
better either. Do we want, say, to distinguish descriptions from examples
in the markup? If so, will paras with a role attribute do, or does it
need to be something else?
I'm also not sure whether or not Peter is objecting to the way I used
<returnvalue>. That seems reasonably semantically-based to me, but since
he hasn't stated what his criteria are, I don't know if he thinks so.
(I'll admit that it's a bit of an abuse to use that for both function
return types and example results.) If that's out then we need some other
design for getting the right arrows into place.
regards, tom lane
If we're doing nicer markup+CSS for this, then it might make sense to
find a better solution for this kind of entry with multiple signatures
(which was already an issue in the previous version):
text || anynonarray or anynonarray || text → text
Converts the non-string input to text, then concatenates the two
strings. (The non-string input cannot be of an array type, because that
would create ambiguity with the array || operators. If you want to
concatenate an array's text equivalent, cast it to text explicitly.)
'Value: ' || 42 → Value: 42
I think it would make sense to split the first line to put each of the
two signatures on their own line. So it would look like this:
text || anynonarray
anynonarray || text → text
Converts the non-string input to text, then concatenates the two
strings. (The non-string input cannot be of an array type, because that
would create ambiguity with the array || operators. If you want to
concatenate an array's text equivalent, cast it to text explicitly.)
'Value: ' || 42 → Value: 42
Another example:
to_ascii ( string text [, encoding name or integer ] ) → text
should be (I think):
to_ascii ( string text [, encoding name ] ) → text
to_ascii ( string text [, integer ] ) → text
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> If we're doing nicer markup+CSS for this, then it might make sense to
> find a better solution for this kind of entry with multiple signatures
> (which was already an issue in the previous version):
Yeah, agreed. I would like to be able to have multiple signature blocks
in one table cell, which the current hack can't handle. There aren't
quite enough cases to make this mandatory, but it would be nicer.
It seems do-able if we explicitly mark signature blocks with their
own role, say
<entry role="functableentry">
<para role="funcsignature">
text || anynonarray → text
</para>
<para role="funcsignature">
anynonarray || text → text
</para>
<para>
description ...
Then the CSS can key off of the role to decide what indentation to apply
to the para. While I mostly see how that would work, I'm not very sure
about whether we can make it work in the PDF chain too.
Not sure whether it'd be worth inventing additional roles to apply to
description and example paras, or whether that's just inducing carpal
tunnel syndrome to no purpose. We'd want to keep the role label on the
<entry>s anyway I think, and that context should be enough as long as
we don't need different formatting for descriptions and examples.
But maybe Peter's notion of "semantic markup" requires it anyway.
regards, tom lane
I wrote:
> Alvaro Herrera <alvherre@2ndquadrant.com> writes:
>> If we're doing nicer markup+CSS for this, then it might make sense to
>> find a better solution for this kind of entry with multiple signatures
>> (which was already an issue in the previous version):
> Yeah, agreed. I would like to be able to have multiple signature blocks
> in one table cell, which the current hack can't handle. There aren't
> quite enough cases to make this mandatory, but it would be nicer.
> It seems do-able if we explicitly mark signature blocks with their
> own role, say ...
Hearing no comments, I went ahead and experimented with that.
Attached is a POC patch that changes just the header and first few
entries in table 9.9, just to see what it'd look like. This does
nicely reproduce the existing visual appearance. (With the margin
parameters I used, there is a teensy bit more vertical space, but
I think it looks better this way. That could be adjusted either
way of course.)
There is a small problem with getting this to work in the webstyle
HTML: somebody decided it would be a great idea to have a global
override on paragraph margin-bottom settings. For the purposes of
this test I just deleted that from main.css, but I suppose we want
some more-nuanced solution in reality.
<digression>
One thing I couldn't help noticing while fooling with this is what
seems to be a bug in the PDF toolchain: any place you try to put
an <indexterm>, you get extra whitespace. Not a lot, but once you
see it, you can't un-see it. It's particularly obvious if one of
two adjacent lines has the extra indentation and the other doesn't.
In the attached, I added an <indexterm> to one of the signature
entries for "text || anynonarray", and you can see what I'm unhappy
about in the PDF screenshot. The problem already exists in our
previous markup, at least in places where people put indexterms
inside function-table entries, but it'll be more obvious anyplace
we choose to have two signature entries in one table cell.
I tried putting the <indexterm>s outside the <para> elements, but
that makes it worse not better: instead of a little bit of extra
horizontal whitespace, you get a lot of extra vertical whitespace.
The only "fix" I've found is to place the <indexterm> at the end
of the signature <para> instead of the beginning. That's not included
in the attached but it does hide the existence of the extra space
quite effectively. I'm not sure though whether it might result in
odd behavior of cross-reference links to the function entry.
In any case it feels like a hack.
</digression>
It seems to me that this way is better than the markup I've been
using --- one thing I've observed is that Emacs' sgml mode is a
bit confused by the <?br?> hacks, and it's happier with this.
But it's not clear to me whether this is sufficient to resolve
Peter's unhappiness.
regards, tom lane
diff --git a/doc/src/sgml/func.sgml b/doc/src/sgml/func.sgml
index b0afaeb..ffcb0ae 100644
--- a/doc/src/sgml/func.sgml
+++ b/doc/src/sgml/func.sgml
@@ -2067,48 +2067,64 @@ repeat('Pg', 4) <returnvalue>PgPgPgPg</returnvalue>
<tgroup cols="1">
<thead>
<row>
- <entry role="functableentry">
- Function/Operator<?br?>Description<?br?>Example(s)
- </entry>
+ <entry role="func_table_entry"><para role="func_signature">
+ Function/Operator
+ </para>
+ <para>
+ Description
+ </para>
+ <para>
+ Example(s)
+ </para></entry>
</row>
</thead>
<tbody>
<row>
- <entry role="functableentry">
+ <entry role="func_table_entry"><para role="func_signature">
<indexterm>
<primary>character string</primary>
<secondary>concatenation</secondary>
</indexterm>
<type>text</type> <literal>||</literal> <type>text</type>
<returnvalue>text</returnvalue>
- <?br?>
+ </para>
+ <para>
Concatenates the two strings.
- <?br?>
+ </para>
+ <para>
<literal>'Post' || 'greSQL'</literal>
<returnvalue>PostgreSQL</returnvalue>
- </entry>
+ </para></entry>
</row>
<row>
- <entry role="functableentry">
+ <entry role="func_table_entry"><para role="func_signature">
+<indexterm>
+ <primary>character string test</primary>
+</indexterm>
<type>text</type> <literal>||</literal> <type>anynonarray</type>
- or <type>anynonarray</type> <literal>||</literal> <type>text</type>
<returnvalue>text</returnvalue>
- <?br?>
+ </para>
+ <para role="func_signature">
+ <type>anynonarray</type> <literal>||</literal> <type>text</type>
+ <returnvalue>text</returnvalue>
+ </para>
+ <para>
Converts the non-string input to text, then concatenates the two
strings. (The non-string input cannot be of an array type, because
that would create ambiguity with the array <literal>||</literal>
operators. If you want to concatenate an array's text equivalent,
cast it to <type>text</type> explicitly.)
- <?br?>
+ </para>
+ <para>
<literal>'Value: ' || 42</literal>
<returnvalue>Value: 42</returnvalue>
- </entry>
+ </para></entry>
</row>
<row>
- <entry role="functableentry">
+ <entry role="func_table_entry"><para role="func_signature">
<indexterm>
<primary>normalized</primary>
</indexterm>
@@ -2117,7 +2133,8 @@ repeat('Pg', 4) <returnvalue>PgPgPgPg</returnvalue>
</indexterm>
<type>text</type> <literal>IS</literal> <optional><literal>NOT</literal></optional>
<optional><parameter>form</parameter></optional><literal>NORMALIZED</literal>
<returnvalue>boolean</returnvalue>
- <?br?>
+ </para>
+ <para>
Checks whether the string is in the specified Unicode normalization
form. The optional <parameter>form</parameter> key word specifies the
form: <literal>NFC</literal> (the default), <literal>NFD</literal>,
@@ -2125,10 +2142,11 @@ repeat('Pg', 4) <returnvalue>PgPgPgPg</returnvalue>
only be used when the server encoding is <literal>UTF8</literal>. Note
that checking for normalization using this expression is often faster
than normalizing possibly already normalized strings.
- <?br?>
+ </para>
+ <para>
<literal>U&'\0061\0308bc' IS NFD NORMALIZED</literal>
<returnvalue>t</returnvalue>
- </entry>
+ </para></entry>
</row>
<row>
diff --git a/doc/src/sgml/stylesheet-fo.xsl b/doc/src/sgml/stylesheet-fo.xsl
index 6797e06..e923b00 100644
--- a/doc/src/sgml/stylesheet-fo.xsl
+++ b/doc/src/sgml/stylesheet-fo.xsl
@@ -89,6 +89,16 @@
</xsl:choose>
</xsl:template>
+<!-- formatting for entries in tables of functions -->
+<xsl:template match="entry[@role='func_table_entry']/para">
+ <fo:block margin-left="4em" text-align="left">
+ <xsl:if test="self::para[@role='func_signature']">
+ <xsl:attribute name="text-indent">-3.5em</xsl:attribute>
+ </xsl:if>
+ <xsl:apply-templates/>
+ </fo:block>
+</xsl:template>
+
<!-- overrides stylesheet-common.xsl -->
<!-- FOP needs us to be explicit about the font to use for right arrow -->
<xsl:template match="returnvalue">
diff --git a/doc/src/sgml/stylesheet.css b/doc/src/sgml/stylesheet.css
index f369e12..d28cec4 100644
--- a/doc/src/sgml/stylesheet.css
+++ b/doc/src/sgml/stylesheet.css
@@ -85,6 +85,18 @@ td.functableentry {
text-align: left;
}
+th.func_table_entry p,
+td.func_table_entry p {
+ margin-top: 0.1em;
+ margin-bottom: 0.1em;
+ padding-left: 4em;
+ text-align: left;
+}
+
+p.func_signature {
+ text-indent: -3.5em;
+}
+
/* Put these here instead of inside the HTML (see unsetting of
admon.style in XSL) so that the web site stylesheet can set its own
style. */
--- main.css~ 2020-04-26 12:45:29.646286775 -0400
+++ main.css 2020-04-26 12:54:04.605046657 -0400
@@ -624,9 +624,11 @@
margin-top: 1rem;
}
+/*
#docContent p {
margin-bottom: 1rem !important;
}
+*/
#docContent hr {
margin: 0 0 0.5em 0;
@@ -799,6 +801,18 @@
text-align: left;
}
+#docContent table.table th.func_table_entry p,
+#docContent table.table td.func_table_entry p {
+ margin-top: 0.1em;
+ margin-bottom: 0.1em;
+ padding-left: 4em;
+ text-align: left;
+}
+
+#docContent table.table p.func_signature {
+ text-indent: -3.5em;
+}
+
/**
* Titles, Navigation
*/
Attachment
{kind=link}
{kind=link}
{kind=link}
On 4/26/20 1:40 PM, Tom Lane wrote: > I wrote: >> Alvaro Herrera <alvherre@2ndquadrant.com> writes: > There is a small problem with getting this to work in the webstyle > HTML: somebody decided it would be a great idea to have a global > override on paragraph margin-bottom settings. For the purposes of > this test I just deleted that from main.css, but I suppose we want > some more-nuanced solution in reality. I have to see why that is. I traced it back to the original "bring doc styles up to modern website" patch (66798351) and there is missing context. Anyway, I'd like to test it before a wholesale removal (there is often a strong correlation between "!important" and "hack", so I'll want to further dive into it). I'll have some time to play around with the CSS tonight. Jonathan
Attachment
On 4/26/20 3:21 PM, Jonathan S. Katz wrote:
> On 4/26/20 1:40 PM, Tom Lane wrote:
>> I wrote:
>>> Alvaro Herrera <alvherre@2ndquadrant.com> writes:
>
>> There is a small problem with getting this to work in the webstyle
>> HTML: somebody decided it would be a great idea to have a global
>> override on paragraph margin-bottom settings. For the purposes of
>> this test I just deleted that from main.css, but I suppose we want
>> some more-nuanced solution in reality.
>
> I have to see why that is. I traced it back to the original "bring doc
> styles up to modern website" patch (66798351) and there is missing
> context. Anyway, I'd like to test it before a wholesale removal (there
> is often a strong correlation between "!important" and "hack", so I'll
> want to further dive into it).
>
> I'll have some time to play around with the CSS tonight.
Can you try
#docContent p {
- margin-bottom: 1rem !important;
+ margin-bottom: 1rem;
}
and see how it looks?
Jonathan
Attachment
"Jonathan S. Katz" <jkatz@postgresql.org> writes:
> Can you try
> #docContent p {
> - margin-bottom: 1rem !important;
> + margin-bottom: 1rem;
> }
> and see how it looks?
In some desultory looking around, I couldn't find anyplace in the
existing text that that changes at all. And it does make the
revised table markup render the way I want ... so +1.
regards, tom lane
On 4/26/20 9:44 PM, Tom Lane wrote:
> "Jonathan S. Katz" <jkatz@postgresql.org> writes:
>> Can you try
>
>> #docContent p {
>> - margin-bottom: 1rem !important;
>> + margin-bottom: 1rem;
>> }
>
>> and see how it looks?
>
> In some desultory looking around, I couldn't find anyplace in the
> existing text that that changes at all. And it does make the
> revised table markup render the way I want ... so +1.
Great. I do want to do a bit more desultory testing in the older
versions of the docs, but it can be committed whenever the -docs side is
ready.
Thanks,
Jonathan
Attachment
"Jonathan S. Katz" <jkatz@postgresql.org> writes:
> Great. I do want to do a bit more desultory testing in the older
> versions of the docs, but it can be committed whenever the -docs side is
> ready.
Other than that point, the main.css patch as I presented it just adds
some rules that aren't used yet, so it could be pushed as soon as you're
satisfied about the !important change. It'd probably make sense to
push it in advance of making the markup changes, so we don't have an
interval of near-unreadable devel docs.
Still waiting to hear whether this markup approach satisfies
Peter's concerns, though.
regards, tom lane
On 4/27/20 8:49 AM, Tom Lane wrote: > "Jonathan S. Katz" <jkatz@postgresql.org> writes: >> Great. I do want to do a bit more desultory testing in the older >> versions of the docs, but it can be committed whenever the -docs side is >> ready. > > Other than that point, the main.css patch as I presented it just adds > some rules that aren't used yet, so it could be pushed as soon as you're > satisfied about the !important change. It'd probably make sense to > push it in advance of making the markup changes, so we don't have an > interval of near-unreadable devel docs. *nods* I'll ensure to test again and hopefully commit later today. I forget what I was looking at, but I did see a similar pattern in some other modern software docs, so it seems like this is trending in the right direction. Looking forward to the rollout! Jonathan
Attachment
"Jonathan S. Katz" <jkatz@postgresql.org> writes:
> On 4/27/20 8:49 AM, Tom Lane wrote:
>> Other than that point, the main.css patch as I presented it just adds
>> some rules that aren't used yet, so it could be pushed as soon as you're
>> satisfied about the !important change. It'd probably make sense to
>> push it in advance of making the markup changes, so we don't have an
>> interval of near-unreadable devel docs.
> *nods* I'll ensure to test again and hopefully commit later today.
After looking at the JSON function tables, I've concluded that the
ability to have more than one function signature per table cell is
really rather essential not optional. So I'm going to go ahead and
convert all the existing markup to the <para>-based style I proposed
on Sunday. Please push the main.css change when you can.
regards, tom lane
I wrote:
> One thing I couldn't help noticing while fooling with this is what
> seems to be a bug in the PDF toolchain: any place you try to put
> an <indexterm>, you get extra whitespace. Not a lot, but once you
> see it, you can't un-see it. It's particularly obvious if one of
> two adjacent lines has the extra indentation and the other doesn't.
> ...
> The only "fix" I've found is to place the <indexterm> at the end
> of the signature <para> instead of the beginning.
I spent some more time experimenting with this today, and determined
that there's no way to fix it by messing with FO layout attributes.
The basic problem seems to be that if you write
<entry role="func_table_entry"><para role="func_signature">
<indexterm>
<primary>ceiling</primary>
</indexterm>
<function>ceiling</function> ( <type>numeric</type> )
then what you get in the .fo file is
<fo:table-cell padding-start="2pt" padding-end="2pt" padding-top="2pt" padding-bottom="2pt"
border-bottom-width="0.5pt"border-bottom-style="solid" border-bottom-color="black"><fo:block><fo:block
margin-left="4em"text-align="left" text-indent="-3.5em">
<fo:wrapper id="id-1.5.8.9.6.2.2.4.1.1.1"><!--ceiling--></fo:wrapper>
<fo:inline font-family="monospace">ceiling</fo:inline> ( <fo:inline font-family="monospace">numeric</fo:inline>
)
where the <fo:wrapper> apparently is used as a cross-reference anchor.
The trouble with this is that the rules for collapsing adjacent whitespace
don't work across the <fo:wrapper>, so no matter what you do you will end
up with two spaces not one before the visible text "ceiling". The only
way to hide the effects of that with layout attributes is to set
whitespace to be ignored altogether within the block, which is quite
undesirable.
The fix I'm currently considering is to eliminate the extra whitespace
run(s) by formatting <indexterm>s within tables this way:
<row>
<entry role="func_table_entry"><para role="func_signature"><indexterm>
<primary>char_length</primary>
</indexterm><indexterm>
<primary>character string</primary>
<secondary>length</secondary>
</indexterm><indexterm>
<primary>length</primary>
<secondary sortas="character string">of a character string</secondary>
<see>character string, length</see>
</indexterm>
<function>char_length</function> ( <type>text</type> )
<returnvalue>integer</returnvalue>
</para>
Perhaps it's only worth being anal about this in table cells with multiple
function signatures and/or multiple <indexterm>s; in other places the
whitespace variation just isn't that noticeable. On the other hand,
there's something to be said for having uniform layout of the XML source,
which'd suggest having a uniform rule "no whitespace before an <indexterm>
within a table cell".
Or we could put the <indexterm>s at the end. Or just ignore it, reasoning
that the PDF output is never going to look all that great anyway.
Thoughts?
regards, tom lane
After further fooling with this issue, I've determined that
(1) I need to be able to use <programlisting> environments within the
func_table_entry cells and have them render more-or-less normally.
There doesn't seem to be any other good way to render multiline
example results for set-returning functions ... but marking such
environments up to the extent that the website style normally does
is very distracting.
(2) I found that adding !important to the func_table_entry rules
is enough to override less-general !important rules. So it'd be
possible to leave all the existing CSS rules alone, if that makes
you feel more comfortable.
The attached updated patch reflects both of these conclusions.
We could take out some of the !important annotations here if
you're willing to delete !important annotations in more-global
rules for <p> and/or <pre>, but maybe that's something to fool
with later. I'd like to get this done sooner ...
regards, tom lane
--- main.css.orig 2020-04-29 17:19:24.089511785 -0400
+++ main.css 2020-04-29 19:18:28.082138095 -0400
@@ -799,6 +799,27 @@
text-align: left;
}
+#docContent table.table th.func_table_entry p,
+#docContent table.table td.func_table_entry p {
+ margin-top: 0.1em;
+ margin-bottom: 0.1em !important;
+ padding-left: 4em;
+ text-align: left;
+}
+
+#docContent table.table p.func_signature {
+ text-indent: -3.5em;
+}
+
+#docContent table.table td.func_table_entry pre.programlisting {
+ margin-top: 0.1em !important;
+ margin-bottom: 0.1em !important;
+ padding: 0 !important;
+ padding-left: 4em !important;
+ background-color: inherit !important;
+ border: 0;
+}
+
/**
* Titles, Navigation
*/
On 4/29/20 7:29 PM, Tom Lane wrote: > After further fooling with this issue, I've determined that > > (1) I need to be able to use <programlisting> environments within the > func_table_entry cells and have them render more-or-less normally. > There doesn't seem to be any other good way to render multiline > example results for set-returning functions ... but marking such > environments up to the extent that the website style normally does > is very distracting. > > (2) I found that adding !important to the func_table_entry rules > is enough to override less-general !important rules. So it'd be > possible to leave all the existing CSS rules alone, if that makes > you feel more comfortable. > > The attached updated patch reflects both of these conclusions. > We could take out some of the !important annotations here if > you're willing to delete !important annotations in more-global > rules for <p> and/or <pre>, but maybe that's something to fool > with later. I'd like to get this done sooner ... My preference would be to figure out the CSS rules that are causing you to rely on !important at the table level and just fix that up, rather than hacking in too many !important. I'll compromise on the temporary importants, but first I want to see what's causing the need for it. Do you have a suggestion on a page to test? Jonathan
Attachment
On 4/29/20 7:40 PM, Jonathan S. Katz wrote: > On 4/29/20 7:29 PM, Tom Lane wrote: >> After further fooling with this issue, I've determined that >> >> (1) I need to be able to use <programlisting> environments within the >> func_table_entry cells and have them render more-or-less normally. >> There doesn't seem to be any other good way to render multiline >> example results for set-returning functions ... but marking such >> environments up to the extent that the website style normally does >> is very distracting. >> >> (2) I found that adding !important to the func_table_entry rules >> is enough to override less-general !important rules. So it'd be >> possible to leave all the existing CSS rules alone, if that makes >> you feel more comfortable. >> >> The attached updated patch reflects both of these conclusions. >> We could take out some of the !important annotations here if >> you're willing to delete !important annotations in more-global >> rules for <p> and/or <pre>, but maybe that's something to fool >> with later. I'd like to get this done sooner ... > > My preference would be to figure out the CSS rules that are causing you > to rely on !important at the table level and just fix that up, rather > than hacking in too many !important. > > I'll compromise on the temporary importants, but first I want to see > what's causing the need for it. Do you have a suggestion on a page to test? From real quick I got it to here. With the latest copy of the doc builds it appears to still work as expected, but I need a section with the new "pre" block to test. I think the "background-color: inherit !important" is a bit odd, and would like to trace that one down a bit more, but I did not see anything obvious on my glance through it. How does it look on your end? Jonathan
Attachment
"Jonathan S. Katz" <jkatz@postgresql.org> writes:
> On 4/29/20 7:40 PM, Jonathan S. Katz wrote:
>> I'll compromise on the temporary importants, but first I want to see
>> what's causing the need for it. Do you have a suggestion on a page to test?
I haven't yet pushed anything dependent on the new markup, but
attached is a draft revision for the JSON section; if you look at
the SRFs such as json_array_elements you'll see the issue.
> From real quick I got it to here. With the latest copy of the doc builds
> it appears to still work as expected, but I need a section with the new
> "pre" block to test.
Yeah, I see you found the same <p> and <pre> settings I did.
> I think the "background-color: inherit !important" is a bit odd, and
> would like to trace that one down a bit more, but I did not see anything
> obvious on my glance through it.
I think it's coming from this bit at about main.css:660:
pre,
code,
#docContent kbd,
#docContent tt.LITERAL,
#docContent tt.REPLACEABLE {
font-size: 0.9rem !important;
color: inherit !important;
background-color: #f8f9fa !important;
border-radius: .25rem;
margin: .6rem 0;
font-weight: 300;
}
I had to override most of that.
regards, tom lane
diff --git a/doc/src/sgml/func.sgml b/doc/src/sgml/func.sgml
index 68c08c5..1d3c281 100644
--- a/doc/src/sgml/func.sgml
+++ b/doc/src/sgml/func.sgml
@@ -14368,1461 +14423,2322 @@ table2-mapping
<xref linkend="functions-json-op-table"/> shows the operators that
are available for use with JSON data types (see <xref
linkend="datatype-json"/>).
- </para>
-
- <table id="functions-json-op-table">
- <title><type>json</type> and <type>jsonb</type> Operators</title>
- <tgroup cols="6">
- <thead>
- <row>
- <entry>Operator</entry>
- <entry>Right Operand Type</entry>
- <entry>Return type</entry>
- <entry>Description</entry>
- <entry>Example</entry>
- <entry>Example Result</entry>
- </row>
- </thead>
- <tbody>
- <row>
- <entry><literal>-></literal></entry>
- <entry><type>int</type></entry>
- <entry><type>json</type> or <type>jsonb</type></entry>
- <entry>Get JSON array element (indexed from zero, negative
- integers count from the end)</entry>
- <entry><literal>'[{"a":"foo"},{"b":"bar"},{"c":"baz"}]'::json->2</literal></entry>
- <entry><literal>{"c":"baz"}</literal></entry>
- </row>
- <row>
- <entry><literal>-></literal></entry>
- <entry><type>text</type></entry>
- <entry><type>json</type> or <type>jsonb</type></entry>
- <entry>Get JSON object field by key</entry>
- <entry><literal>'{"a": {"b":"foo"}}'::json->'a'</literal></entry>
- <entry><literal>{"b":"foo"}</literal></entry>
- </row>
- <row>
- <entry><literal>->></literal></entry>
- <entry><type>int</type></entry>
- <entry><type>text</type></entry>
- <entry>Get JSON array element as <type>text</type></entry>
- <entry><literal>'[1,2,3]'::json->>2</literal></entry>
- <entry><literal>3</literal></entry>
- </row>
- <row>
- <entry><literal>->></literal></entry>
- <entry><type>text</type></entry>
- <entry><type>text</type></entry>
- <entry>Get JSON object field as <type>text</type></entry>
- <entry><literal>'{"a":1,"b":2}'::json->>'b'</literal></entry>
- <entry><literal>2</literal></entry>
- </row>
- <row>
- <entry><literal>#></literal></entry>
- <entry><type>text[]</type></entry>
- <entry><type>json</type> or <type>jsonb</type></entry>
- <entry>Get JSON object at the specified path</entry>
- <entry><literal>'{"a": {"b":{"c": "foo"}}}'::json#>'{a,b}'</literal></entry>
- <entry><literal>{"c": "foo"}</literal></entry>
- </row>
- <row>
- <entry><literal>#>></literal></entry>
- <entry><type>text[]</type></entry>
- <entry><type>text</type></entry>
- <entry>Get JSON object at the specified path as <type>text</type></entry>
- <entry><literal>'{"a":[1,2,3],"b":[4,5,6]}'::json#>>'{a,2}'</literal></entry>
- <entry><literal>3</literal></entry>
- </row>
- </tbody>
- </tgroup>
- </table>
-
- <note>
- <para>
- There are parallel variants of these operators for both the
- <type>json</type> and <type>jsonb</type> types.
- The field/element/path extraction operators
- return the same type as their left-hand input (either <type>json</type>
- or <type>jsonb</type>), except for those specified as
- returning <type>text</type>, which coerce the value to text.
- The field/element/path extraction operators return NULL, rather than
- failing, if the JSON input does not have the right structure to match
- the request; for example if no such element exists. The
- field/element/path extraction operators that accept integer JSON
- array subscripts all support negative subscripting from the end of
- arrays.
- </para>
- </note>
- <para>
- The standard comparison operators shown in <xref
+ In addition, the usual comparison operators shown in <xref
linkend="functions-comparison-op-table"/> are available for
- <type>jsonb</type>, but not for <type>json</type>. They follow the
- ordering rules for B-tree operations outlined at <xref
- linkend="json-indexing"/>.
- </para>
- <para>
- Some further operators also exist only for <type>jsonb</type>, as shown
- in <xref linkend="functions-jsonb-op-table"/>.
- Many of these operators can be indexed by
- <type>jsonb</type> operator classes. For a full description of
- <type>jsonb</type> containment and existence semantics, see <xref
- linkend="json-containment"/>. <xref linkend="json-indexing"/>
- describes how these operators can be used to effectively index
- <type>jsonb</type> data.
- </para>
- <table id="functions-jsonb-op-table">
- <title>Additional <type>jsonb</type> Operators</title>
- <tgroup cols="4">
- <thead>
- <row>
- <entry>Operator</entry>
- <entry>Right Operand Type</entry>
- <entry>Description</entry>
- <entry>Example</entry>
- </row>
- </thead>
- <tbody>
- <row>
- <entry><literal>@></literal></entry>
- <entry><type>jsonb</type></entry>
- <entry>Does the left JSON value contain the right JSON
- path/value entries at the top level?</entry>
- <entry><literal>'{"a":1, "b":2}'::jsonb @> '{"b":2}'::jsonb</literal></entry>
- </row>
- <row>
- <entry><literal><@</literal></entry>
- <entry><type>jsonb</type></entry>
- <entry>Are the left JSON path/value entries contained at the top level within
- the right JSON value?</entry>
- <entry><literal>'{"b":2}'::jsonb <@ '{"a":1, "b":2}'::jsonb</literal></entry>
- </row>
- <row>
- <entry><literal>?</literal></entry>
- <entry><type>text</type></entry>
- <entry>Does the <emphasis>string</emphasis> exist as a top-level
- key within the JSON value?</entry>
- <entry><literal>'{"a":1, "b":2}'::jsonb ? 'b'</literal></entry>
- </row>
- <row>
- <entry><literal>?|</literal></entry>
- <entry><type>text[]</type></entry>
- <entry>Do any of these array <emphasis>strings</emphasis>
- exist as top-level keys?</entry>
- <entry><literal>'{"a":1, "b":2, "c":3}'::jsonb ?| array['b', 'c']</literal></entry>
- </row>
- <row>
- <entry><literal>?&</literal></entry>
- <entry><type>text[]</type></entry>
- <entry>Do all of these array <emphasis>strings</emphasis> exist
- as top-level keys?</entry>
- <entry><literal>'["a", "b"]'::jsonb ?& array['a', 'b']</literal></entry>
- </row>
- <row>
- <entry><literal>||</literal></entry>
- <entry><type>jsonb</type></entry>
- <entry>Concatenate two <type>jsonb</type> values into a new <type>jsonb</type> value</entry>
- <entry><literal>'["a", "b"]'::jsonb || '["c", "d"]'::jsonb</literal></entry>
- </row>
- <row>
- <entry><literal>-</literal></entry>
- <entry><type>text</type></entry>
- <entry>Delete key/value pair or <emphasis>string</emphasis>
- element from left operand. Key/value pairs are matched based
- on their key value.</entry>
- <entry><literal>'{"a": "b"}'::jsonb - 'a' </literal></entry>
- </row>
- <row>
- <entry><literal>-</literal></entry>
- <entry><type>text[]</type></entry>
- <entry>Delete multiple key/value pairs or <emphasis>string</emphasis>
- elements from left operand. Key/value pairs are matched based
- on their key value.</entry>
- <entry><literal>'{"a": "b", "c": "d"}'::jsonb - '{a,c}'::text[] </literal></entry>
- </row>
- <row>
- <entry><literal>-</literal></entry>
- <entry><type>integer</type></entry>
- <entry>Delete the array element with specified index (Negative
- integers count from the end). Throws an error if top level
- container is not an array.</entry>
- <entry><literal>'["a", "b"]'::jsonb - 1 </literal></entry>
- </row>
- <row>
- <entry><literal>#-</literal></entry>
- <entry><type>text[]</type></entry>
- <entry>Delete the field or element with specified path (for
- JSON arrays, negative integers count from the end)</entry>
- <entry><literal>'["a", {"b":1}]'::jsonb #- '{1,b}'</literal></entry>
- </row>
- <row>
- <entry><literal>@?</literal></entry>
- <entry><type>jsonpath</type></entry>
- <entry>Does JSON path return any item for the specified JSON value?</entry>
- <entry><literal>'{"a":[1,2,3,4,5]}'::jsonb @? '$.a[*] ? (@ > 2)'</literal></entry>
- </row>
- <row>
- <entry><literal>@@</literal></entry>
- <entry><type>jsonpath</type></entry>
- <entry>Returns the result of JSON path predicate check for the specified JSON value.
- Only the first item of the result is taken into account. If the
- result is not Boolean, then <literal>null</literal> is returned.</entry>
- <entry><literal>'{"a":[1,2,3,4,5]}'::jsonb @@ '$.a[*] > 2'</literal></entry>
- </row>
- </tbody>
- </tgroup>
- </table>
-
- <note>
- <para>
- The <literal>||</literal> operator concatenates the elements at the top level of
- each of its operands. It does not operate recursively. For example, if
- both operands are objects with a common key field name, the value of the
- field in the result will just be the value from the right hand operand.
- </para>
- </note>
-
- <note>
- <para>
- The <literal>@?</literal> and <literal>@@</literal> operators suppress
- the following errors: lacking object field or array element, unexpected
- JSON item type, datetime and numeric errors.
- This behavior might be helpful while searching over JSON document
- collections of varying structure.
- </para>
- </note>
-
- <para>
- <xref linkend="functions-json-creation-table"/> shows the functions that are
- available for creating <type>json</type> and <type>jsonb</type> values.
- (There are no equivalent functions for <type>jsonb</type>, of the <literal>row_to_json</literal>
- and <literal>array_to_json</literal> functions. However, the <literal>to_jsonb</literal>
- function supplies much the same functionality as these functions would.)
+ <type>jsonb</type>, though not for <type>json</type>. The comparison
+ operators follow the ordering rules for B-tree operations outlined in
+ <xref linkend="json-indexing"/>.
</para>
- <indexterm>
- <primary>to_json</primary>
- </indexterm>
- <indexterm>
- <primary>array_to_json</primary>
- </indexterm>
- <indexterm>
- <primary>row_to_json</primary>
- </indexterm>
- <indexterm>
- <primary>json_build_array</primary>
- </indexterm>
- <indexterm>
- <primary>json_build_object</primary>
- </indexterm>
- <indexterm>
- <primary>json_object</primary>
- </indexterm>
- <indexterm>
- <primary>to_jsonb</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_build_array</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_build_object</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_object</primary>
- </indexterm>
-
- <table id="functions-json-creation-table">
- <title>JSON Creation Functions</title>
- <tgroup cols="4">
+ <table id="functions-json-op-table">
+ <title><type>json</type> and <type>jsonb</type> Operators</title>
+ <tgroup cols="1">
<thead>
<row>
- <entry>Function</entry>
- <entry>Description</entry>
- <entry>Example</entry>
- <entry>Example Result</entry>
+ <entry role="func_table_entry"><para role="func_signature">
+ Operator
+ </para>
+ <para>
+ Description
+ </para>
+ <para>
+ Example(s)
+ </para></entry>
</row>
</thead>
+
<tbody>
<row>
- <entry><para><literal>to_json(anyelement)</literal>
- </para><para><literal>to_jsonb(anyelement)</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>json</type> <literal>-></literal> <type>integer</type>
+ <returnvalue>json</returnvalue>
+ </para>
+ <para role="func_signature">
+ <type>jsonb</type> <literal>-></literal> <type>integer</type>
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Extracts <replaceable>n</replaceable>'th element of JSON array
+ (array elements are indexed from zero, but negative integers count
+ from the end).
+ </para>
+ <para>
+ <literal>'[{"a":"foo"},{"b":"bar"},{"c":"baz"}]'::json -> 2</literal>
+ <returnvalue>{"c":"baz"}</returnvalue>
+ </para>
+ <para>
+ <literal>'[{"a":"foo"},{"b":"bar"},{"c":"baz"}]'::json -> -3</literal>
+ <returnvalue>{"a":"foo"}</returnvalue>
</para></entry>
- <entry>
- Returns the value as <type>json</type> or <type>jsonb</type>.
- Arrays and composites are converted
- (recursively) to arrays and objects; otherwise, if there is a cast
- from the type to <type>json</type>, the cast function will be used to
- perform the conversion; otherwise, a scalar value is produced.
- For any scalar type other than a number, a Boolean, or a null value,
- the text representation will be used, in such a fashion that it is a
- valid <type>json</type> or <type>jsonb</type> value.
- </entry>
- <entry><literal>to_json('Fred said "Hi."'::text)</literal></entry>
- <entry><literal>"Fred said \"Hi.\""</literal></entry>
- </row>
- <row>
- <entry>
- <literal>array_to_json(anyarray [, pretty_bool])</literal>
- </entry>
- <entry>
- Returns the array as a JSON array. A PostgreSQL multidimensional array
- becomes a JSON array of arrays. Line feeds will be added between
- dimension-1 elements if <parameter>pretty_bool</parameter> is true.
- </entry>
- <entry><literal>array_to_json('{{1,5},{99,100}}'::int[])</literal></entry>
- <entry><literal>[[1,5],[99,100]]</literal></entry>
</row>
+
<row>
- <entry>
- <literal>row_to_json(record [, pretty_bool])</literal>
- </entry>
- <entry>
- Returns the row as a JSON object. Line feeds will be added between
- level-1 elements if <parameter>pretty_bool</parameter> is true.
- </entry>
- <entry><literal>row_to_json(row(1,'foo'))</literal></entry>
- <entry><literal>{"f1":1,"f2":"foo"}</literal></entry>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>json</type> <literal>-></literal> <type>text</type>
+ <returnvalue>json</returnvalue>
+ </para>
+ <para role="func_signature">
+ <type>jsonb</type> <literal>-></literal> <type>text</type>
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Extracts JSON object field with the given key.
+ </para>
+ <para>
+ <literal>'{"a": {"b":"foo"}}'::json -> 'a'</literal>
+ <returnvalue>{"b":"foo"}</returnvalue>
+ </para></entry>
</row>
+
<row>
- <entry><para><literal>json_build_array(VARIADIC "any")</literal>
- </para><para><literal>jsonb_build_array(VARIADIC "any")</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>json</type> <literal>->></literal> <type>integer</type>
+ <returnvalue>text</returnvalue>
+ </para>
+ <para role="func_signature">
+ <type>jsonb</type> <literal>->></literal> <type>integer</type>
+ <returnvalue>text</returnvalue>
+ </para>
+ <para>
+ Extracts <replaceable>n</replaceable>'th element of JSON array,
+ as <type>text</type>.
+ </para>
+ <para>
+ <literal>'[1,2,3]'::json ->> 2</literal>
+ <returnvalue>3</returnvalue>
</para></entry>
- <entry>
- Builds a possibly-heterogeneously-typed JSON array out of a variadic
- argument list.
- </entry>
- <entry><literal>json_build_array(1,2,'3',4,5)</literal></entry>
- <entry><literal>[1, 2, "3", 4, 5]</literal></entry>
</row>
+
<row>
- <entry><para><literal>json_build_object(VARIADIC "any")</literal>
- </para><para><literal>jsonb_build_object(VARIADIC "any")</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>json</type> <literal>->></literal> <type>text</type>
+ <returnvalue>text</returnvalue>
+ </para>
+ <para role="func_signature">
+ <type>jsonb</type> <literal>->></literal> <type>text</type>
+ <returnvalue>text</returnvalue>
+ </para>
+ <para>
+ Extracts JSON object field with the given key, as <type>text</type>.
+ </para>
+ <para>
+ <literal>'{"a":1,"b":2}'::json ->> 'b'</literal>
+ <returnvalue>2</returnvalue>
</para></entry>
- <entry>
- Builds a JSON object out of a variadic argument list. By
- convention, the argument list consists of alternating
- keys and values.
- </entry>
- <entry><literal>json_build_object('foo',1,'bar',2)</literal></entry>
- <entry><literal>{"foo": 1, "bar": 2}</literal></entry>
</row>
+
<row>
- <entry><para><literal>json_object(text[])</literal>
- </para><para><literal>jsonb_object(text[])</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>json</type> <literal>#></literal> <type>text[]</type>
+ <returnvalue>json</returnvalue>
+ </para>
+ <para role="func_signature">
+ <type>jsonb</type> <literal>#></literal> <type>text[]</type>
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Extracts JSON sub-object at the specified path, where path elements
+ can be either field keys or array indexes.
+ </para>
+ <para>
+ <literal>'{"a": {"b": ["foo","bar"]}}'::json #> '{a,b,1}'</literal>
+ <returnvalue>"bar"</returnvalue>
</para></entry>
- <entry>
- Builds a JSON object out of a text array. The array must have either
- exactly one dimension with an even number of members, in which case
- they are taken as alternating key/value pairs, or two dimensions
- such that each inner array has exactly two elements, which
- are taken as a key/value pair.
- </entry>
- <entry><para><literal>json_object('{a, 1, b, "def", c, 3.5}')</literal></para>
- <para><literal>json_object('{{a, 1},{b, "def"},{c, 3.5}}')</literal></para></entry>
- <entry><literal>{"a": "1", "b": "def", "c": "3.5"}</literal></entry>
</row>
+
<row>
- <entry><para><literal>json_object(keys text[], values text[])</literal>
- </para><para><literal>jsonb_object(keys text[], values text[])</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>json</type> <literal>#>></literal> <type>text[]</type>
+ <returnvalue>text</returnvalue>
+ </para>
+ <para role="func_signature">
+ <type>jsonb</type> <literal>#>></literal> <type>text[]</type>
+ <returnvalue>text</returnvalue>
+ </para>
+ <para>
+ Extracts JSON sub-object at the specified path as <type>text</type>.
+ </para>
+ <para>
+ <literal>'{"a": {"b": ["foo","bar"]}}'::json #>> '{a,b,1}'</literal>
+ <returnvalue>bar</returnvalue>
</para></entry>
- <entry>
- This form of <function>json_object</function> takes keys and values pairwise from two separate
- arrays. In all other respects it is identical to the one-argument form.
- </entry>
- <entry><literal>json_object('{a, b}', '{1,2}')</literal></entry>
- <entry><literal>{"a": "1", "b": "2"}</literal></entry>
</row>
</tbody>
</tgroup>
</table>
<note>
- <para>
- <function>array_to_json</function> and <function>row_to_json</function> have the same
- behavior as <function>to_json</function> except for offering a pretty-printing
- option. The behavior described for <function>to_json</function> likewise applies
- to each individual value converted by the other JSON creation functions.
- </para>
- </note>
-
- <note>
- <para>
- The <xref linkend="hstore"/> extension has a cast
- from <type>hstore</type> to <type>json</type>, so that
- <type>hstore</type> values converted via the JSON creation functions
- will be represented as JSON objects, not as primitive string values.
- </para>
+ <para>
+ The field/element/path extraction operators return NULL, rather than
+ failing, if the JSON input does not have the right structure to match
+ the request; for example if no such key or array element exists.
+ </para>
</note>
<para>
- <xref linkend="functions-json-processing-table"/> shows the functions that
- are available for processing <type>json</type> and <type>jsonb</type> values.
+ Some further operators exist only for <type>jsonb</type>, as shown
+ in <xref linkend="functions-jsonb-op-table"/>.
+ <xref linkend="json-indexing"/>
+ describes how these operators can be used to effectively search indexed
+ <type>jsonb</type> data.
</para>
- <indexterm>
- <primary>json_array_length</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_array_length</primary>
- </indexterm>
- <indexterm>
- <primary>json_each</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_each</primary>
- </indexterm>
- <indexterm>
- <primary>json_each_text</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_each_text</primary>
- </indexterm>
- <indexterm>
- <primary>json_extract_path</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_extract_path</primary>
- </indexterm>
- <indexterm>
- <primary>json_extract_path_text</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_extract_path_text</primary>
- </indexterm>
- <indexterm>
- <primary>json_object_keys</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_object_keys</primary>
- </indexterm>
- <indexterm>
- <primary>json_populate_record</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_populate_record</primary>
- </indexterm>
- <indexterm>
- <primary>json_populate_recordset</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_populate_recordset</primary>
- </indexterm>
- <indexterm>
- <primary>json_array_elements</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_array_elements</primary>
- </indexterm>
- <indexterm>
- <primary>json_array_elements_text</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_array_elements_text</primary>
- </indexterm>
- <indexterm>
- <primary>json_typeof</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_typeof</primary>
- </indexterm>
- <indexterm>
- <primary>json_to_record</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_to_record</primary>
- </indexterm>
- <indexterm>
- <primary>json_to_recordset</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_to_recordset</primary>
- </indexterm>
- <indexterm>
- <primary>json_strip_nulls</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_strip_nulls</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_set</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_set_lax</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_insert</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_pretty</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_path_exists</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_path_exists_tz</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_path_match</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_path_match_tz</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_path_query</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_path_query_tz</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_path_query_array</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_path_query_array_tz</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_path_query_first</primary>
- </indexterm>
- <indexterm>
- <primary>jsonb_path_query_first_tz</primary>
- </indexterm>
-
- <table id="functions-json-processing-table">
- <title>JSON Processing Functions</title>
- <tgroup cols="5">
+ <table id="functions-jsonb-op-table">
+ <title>Additional <type>jsonb</type> Operators</title>
+ <tgroup cols="1">
<thead>
<row>
- <entry>Function</entry>
- <entry>Return Type</entry>
- <entry>Description</entry>
- <entry>Example</entry>
- <entry>Example Result</entry>
+ <entry role="func_table_entry"><para role="func_signature">
+ Operator
+ </para>
+ <para>
+ Description
+ </para>
+ <para>
+ Example(s)
+ </para></entry>
</row>
</thead>
+
<tbody>
<row>
- <entry><para><literal>json_array_length(json)</literal>
- </para><para><literal>jsonb_array_length(jsonb)</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>jsonb</type> <literal>@></literal> <type>jsonb</type>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Does the first JSON value contain the second?
+ (See <xref linkend="json-containment"/> for details about containment.)
+ </para>
+ <para>
+ <literal>'{"a":1, "b":2}'::jsonb @> '{"b":2}'::jsonb</literal>
+ <returnvalue>t</returnvalue>
</para></entry>
- <entry><type>int</type></entry>
- <entry>
- Returns the number of elements in the outermost JSON array.
- </entry>
- <entry><literal>json_array_length('[1,2,3,{"f1":1,"f2":[5,6]},4]')</literal></entry>
- <entry><literal>5</literal></entry>
</row>
+
<row>
- <entry><para><literal>json_each(json)</literal>
- </para><para><literal>jsonb_each(jsonb)</literal>
- </para></entry>
- <entry><para><literal>setof key text, value json</literal>
- </para><para><literal>setof key text, value jsonb</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>jsonb</type> <literal><@</literal> <type>jsonb</type>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Is the first JSON value contained in the second?
+ </para>
+ <para>
+ <literal>'{"b":2}'::jsonb <@ '{"a":1, "b":2}'::jsonb</literal>
+ <returnvalue>t</returnvalue>
</para></entry>
- <entry>
- Expands the outermost JSON object into a set of key/value pairs.
- </entry>
- <entry><literal>select * from json_each('{"a":"foo", "b":"bar"}')</literal></entry>
- <entry>
-<programlisting>
- key | value
------+-------
- a | "foo"
- b | "bar"
-</programlisting>
- </entry>
</row>
+
<row>
- <entry><para><literal>json_each_text(json)</literal>
- </para><para><literal>jsonb_each_text(jsonb)</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>jsonb</type> <literal>?</literal> <type>text</type>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Does the text string exist as a top-level key or array element within
+ the JSON value?
+ </para>
+ <para>
+ <literal>'{"a":1, "b":2}'::jsonb ? 'b'</literal>
+ <returnvalue>t</returnvalue>
+ </para>
+ <para>
+ <literal>'["a", "b", "c"]'::jsonb ? 'b'</literal>
+ <returnvalue>t</returnvalue>
</para></entry>
- <entry><type>setof key text, value text</type></entry>
- <entry>
- Expands the outermost JSON object into a set of key/value pairs. The
- returned values will be of type <type>text</type>.
- </entry>
- <entry><literal>select * from json_each_text('{"a":"foo", "b":"bar"}')</literal></entry>
- <entry>
-<programlisting>
- key | value
------+-------
- a | foo
- b | bar
-</programlisting>
- </entry>
</row>
+
<row>
- <entry><para><literal>json_extract_path(from_json json, VARIADIC path_elems text[])</literal>
- </para><para><literal>jsonb_extract_path(from_json jsonb, VARIADIC path_elems text[])</literal>
- </para></entry>
- <entry><para><type>json</type></para><para><type>jsonb</type>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>jsonb</type> <literal>?|</literal> <type>text[]</type>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Do any of the strings in the text array exist as top-level keys or
+ array elements?
+ </para>
+ <para>
+ <literal>'{"a":1, "b":2, "c":3}'::jsonb ?| array['b', 'd']</literal>
+ <returnvalue>t</returnvalue>
</para></entry>
- <entry>
- Returns JSON value pointed to by <replaceable>path_elems</replaceable>
- (equivalent to <literal>#></literal> operator).
- </entry>
- <entry><literal>json_extract_path('{"f2":{"f3":1},"f4":{"f5":99,"f6":"foo"}}','f4')</literal></entry>
- <entry><literal>{"f5":99,"f6":"foo"}</literal></entry>
</row>
+
<row>
- <entry><para><literal>json_extract_path_text(from_json json, VARIADIC path_elems text[])</literal>
- </para><para><literal>jsonb_extract_path_text(from_json jsonb, VARIADIC path_elems text[])</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>jsonb</type> <literal>?&</literal> <type>text[]</type>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Do all of the strings in the text array exist as top-level keys or
+ array elements?
+ </para>
+ <para>
+ <literal>'["a", "b", "c"]'::jsonb ?& array['a', 'b']</literal>
+ <returnvalue>t</returnvalue>
</para></entry>
- <entry><type>text</type></entry>
- <entry>
- Returns JSON value pointed to by <replaceable>path_elems</replaceable>
- as <type>text</type>
- (equivalent to <literal>#>></literal> operator).
- </entry>
- <entry><literal>json_extract_path_text('{"f2":{"f3":1},"f4":{"f5":99,"f6":"foo"}}','f4',
'f6')</literal></entry>
- <entry><literal>foo</literal></entry>
</row>
+
<row>
- <entry><para><literal>json_object_keys(json)</literal>
- </para><para><literal>jsonb_object_keys(jsonb)</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>jsonb</type> <literal>||</literal> <type>jsonb</type>
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Concatenates two <type>jsonb</type> values.
+ Concatenating two objects generates an object with the union of their
+ keys, taking the second object's value when there are duplicate keys.
+ Does not operate recursively: only the top-level array or object
+ structure is merged.
+ </para>
+ <para>
+ <literal>'["a", "b"]'::jsonb || '["a", "d"]'::jsonb</literal>
+ <returnvalue>["a", "b", "a", "d"]</returnvalue>
+ </para>
+ <para>
+ <literal>'{"a": "b"}'::jsonb || '{"c": "d"}'::jsonb</literal>
+ <returnvalue>{"a": "b", "c": "d"}</returnvalue>
</para></entry>
- <entry><type>setof text</type></entry>
- <entry>
- Returns set of keys in the outermost JSON object.
- </entry>
- <entry><literal>json_object_keys('{"f1":"abc","f2":{"f3":"a", "f4":"b"}}')</literal></entry>
- <entry>
-<programlisting>
- json_object_keys
-------------------
- f1
- f2
-</programlisting>
- </entry>
</row>
+
<row>
- <entry><para><literal>json_populate_record(base anyelement, from_json json)</literal>
- </para><para><literal>jsonb_populate_record(base anyelement, from_json jsonb)</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>jsonb</type> <literal>-</literal> <type>text</type>
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Deletes a key (and its value) from a JSON object, or matching string
+ value(s) from a JSON array.
+ </para>
+ <para>
+ <literal>'{"a": "b", "c": "d"}'::jsonb - 'a'</literal>
+ <returnvalue>{"c": "d"}</returnvalue>
+ </para>
+ <para>
+ <literal>'["a", "b", "c", "b"]'::jsonb - 'b'</literal>
+ <returnvalue>["a", "c"]</returnvalue>
</para></entry>
- <entry><type>anyelement</type></entry>
- <entry>
- Expands the object in <replaceable>from_json</replaceable> to a row
- whose columns match the record type defined by <replaceable>base</replaceable>
- (see note below).
- </entry>
- <entry><literal>select * from json_populate_record(null::myrowtype, '{"a": 1, "b": ["2", "a b"], "c": {"d": 4,
"e":"a b c"}}')</literal></entry>
- <entry>
-<programlisting>
- a | b | c
----+-----------+-------------
- 1 | {2,"a b"} | (4,"a b c")
-</programlisting>
- </entry>
</row>
+
<row>
- <entry><para><literal>json_populate_recordset(base anyelement, from_json json)</literal>
- </para><para><literal>jsonb_populate_recordset(base anyelement, from_json jsonb)</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>jsonb</type> <literal>-</literal> <type>text[]</type>
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Deletes all matching keys or array elements from the left operand.
+ </para>
+ <para>
+ <literal>'{"a": "b", "c": "d"}'::jsonb - '{a,c}'::text[]</literal>
+ <returnvalue>{}</returnvalue>
</para></entry>
- <entry><type>setof anyelement</type></entry>
- <entry>
- Expands the outermost array of objects
- in <replaceable>from_json</replaceable> to a set of rows whose
- columns match the record type defined by <replaceable>base</replaceable> (see
- note below).
- </entry>
- <entry><literal>select * from json_populate_recordset(null::myrowtype,
'[{"a":1,"b":2},{"a":3,"b":4}]')</literal></entry>
- <entry>
-<programlisting>
- a | b
----+---
- 1 | 2
- 3 | 4
-</programlisting>
- </entry>
</row>
+
<row>
- <entry><para><literal>json_array_elements(json)</literal>
- </para><para><literal>jsonb_array_elements(jsonb)</literal>
- </para></entry>
- <entry><para><type>setof json</type>
- </para><para><type>setof jsonb</type>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>jsonb</type> <literal>-</literal> <type>integer</type>
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Deletes the array element with specified index (negative
+ integers count from the end). Throws an error if JSON value
+ is not an array.
+ </para>
+ <para>
+ <literal>'["a", "b"]'::jsonb - 1 </literal>
+ <returnvalue>["a"]</returnvalue>
</para></entry>
- <entry>
- Expands a JSON array to a set of JSON values.
- </entry>
- <entry><literal>select * from json_array_elements('[1,true, [2,false]]')</literal></entry>
- <entry>
-<programlisting>
- value
------------
- 1
- true
- [2,false]
-</programlisting>
- </entry>
</row>
+
<row>
- <entry><para><literal>json_array_elements_text(json)</literal>
- </para><para><literal>jsonb_array_elements_text(jsonb)</literal>
- </para></entry>
- <entry><type>setof text</type></entry>
- <entry>
- Expands a JSON array to a set of <type>text</type> values.
- </entry>
- <entry><literal>select * from json_array_elements_text('["foo", "bar"]')</literal></entry>
- <entry>
-<programlisting>
- value
------------
- foo
- bar
-</programlisting>
- </entry>
- </row>
- <row>
- <entry><para><literal>json_typeof(json)</literal>
- </para><para><literal>jsonb_typeof(jsonb)</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>jsonb</type> <literal>#-</literal> <type>text[]</type>
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Deletes the field or array element at the specified path, where path
+ elements can be either field keys or array indexes.
+ </para>
+ <para>
+ <literal>'["a", {"b":1}]'::jsonb #- '{1,b}'</literal>
+ <returnvalue>["a", {}]</returnvalue>
</para></entry>
- <entry><type>text</type></entry>
- <entry>
- Returns the type of the outermost JSON value as a text string.
- Possible types are
- <literal>object</literal>, <literal>array</literal>, <literal>string</literal>, <literal>number</literal>,
- <literal>boolean</literal>, and <literal>null</literal>.
- </entry>
- <entry><literal>json_typeof('-123.4')</literal></entry>
- <entry><literal>number</literal></entry>
</row>
+
<row>
- <entry><para><literal>json_to_record(json)</literal>
- </para><para><literal>jsonb_to_record(jsonb)</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>jsonb</type> <literal>@?</literal> <type>jsonpath</type>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Does JSON path return any item for the specified JSON value?
+ </para>
+ <para>
+ <literal>'{"a":[1,2,3,4,5]}'::jsonb @? '$.a[*] ? (@ > 2)'</literal>
+ <returnvalue>t</returnvalue>
</para></entry>
- <entry><type>record</type></entry>
- <entry>
- Builds an arbitrary record from a JSON object (see note below). As
- with all functions returning <type>record</type>, the caller must
- explicitly define the structure of the record with an <literal>AS</literal>
- clause.
- </entry>
- <entry><literal>select * from json_to_record('{"a":1,"b":[1,2,3],"c":[1,2,3],"e":"bar","r": {"a": 123, "b": "a
bc"}}') as x(a int, b text, c int[], d text, r myrowtype) </literal></entry>
- <entry>
-<programlisting>
- a | b | c | d | r
----+---------+---------+---+---------------
- 1 | [1,2,3] | {1,2,3} | | (123,"a b c")
-</programlisting>
- </entry>
</row>
+
<row>
- <entry><para><literal>json_to_recordset(json)</literal>
- </para><para><literal>jsonb_to_recordset(jsonb)</literal>
+ <entry role="func_table_entry"><para role="func_signature">
+ <type>jsonb</type> <literal>@@</literal> <type>jsonpath</type>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Returns the result of a JSON path predicate check for the
+ specified JSON value. Only the first item of the result is taken into
+ account. If the result is not Boolean, then <literal>NULL</literal>
+ is returned.
+ </para>
+ <para>
+ <literal>'{"a":[1,2,3,4,5]}'::jsonb @@ '$.a[*] > 2'</literal>
+ <returnvalue>t</returnvalue>
</para></entry>
- <entry><type>setof record</type></entry>
- <entry>
- Builds an arbitrary set of records from a JSON array of objects (see
- note below). As with all functions returning <type>record</type>, the
- caller must explicitly define the structure of the record with
- an <literal>AS</literal> clause.
- </entry>
- <entry><literal>select * from json_to_recordset('[{"a":1,"b":"foo"},{"a":"2","c":"bar"}]') as x(a int, b
text);</literal></entry>
- <entry>
-<programlisting>
- a | b
----+-----
- 1 | foo
- 2 |
-</programlisting>
- </entry>
</row>
- <row>
- <entry><para><literal>json_strip_nulls(from_json json)</literal>
- </para><para><literal>jsonb_strip_nulls(from_json jsonb)</literal>
- </para></entry>
- <entry><para><type>json</type></para><para><type>jsonb</type></para></entry>
- <entry>
- Returns <replaceable>from_json</replaceable>
- with all object fields that have null values omitted. Other null values
- are untouched.
- </entry>
- <entry><literal>json_strip_nulls('[{"f1":1,"f2":null},2,null,3]')</literal></entry>
- <entry><literal>[{"f1":1},2,null,3]</literal></entry>
- </row>
- <row>
- <entry><para><literal>jsonb_set(target jsonb, path text[], new_value jsonb <optional>, create_missing
boolean</optional>)</literal>
- </para></entry>
- <entry><para><type>jsonb</type></para></entry>
- <entry>
- Returns <replaceable>target</replaceable>
- with the section designated by <replaceable>path</replaceable>
- replaced by <replaceable>new_value</replaceable>, or with
- <replaceable>new_value</replaceable> added if
- <replaceable>create_missing</replaceable> is true (default is
- <literal>true</literal>) and the item
- designated by <replaceable>path</replaceable> does not exist.
- As with the path oriented operators, negative integers that
- appear in <replaceable>path</replaceable> count from the end
- of JSON arrays.
- </entry>
- <entry><para><literal>jsonb_set('[{"f1":1,"f2":null},2,null,3]', '{0,f1}','[2,3,4]', false)</literal>
- </para><para><literal>jsonb_set('[{"f1":1,"f2":null},2]', '{0,f3}','[2,3,4]')</literal>
- </para></entry>
- <entry><para><literal>[{"f1":[2,3,4],"f2":null},2,null,3]</literal>
- </para><para><literal>[{"f1": 1, "f2": null, "f3": [2, 3, 4]}, 2]</literal>
- </para></entry>
- </row>
- <row>
- <entry><para><literal>jsonb_set_lax(target jsonb, path text[], new_value jsonb <optional>, create_missing
boolean</optional><optional>, null_value_treatment text</optional>)</literal>
- </para></entry>
- <entry><para><type>jsonb</type></para></entry>
- <entry>
- If <replaceable>new_value</replaceable> is not <literal>null</literal>,
- behaves identically to <literal>jsonb_set</literal>. Otherwise behaves
- according to the value of <replaceable>null_value_treatment</replaceable>
- which must be one of <literal>'raise_exception'</literal>,
- <literal>'use_json_null'</literal>, <literal>'delete_key'</literal>, or
- <literal>'return_target'</literal>. The default is
- <literal>'use_json_null'</literal>.
- </entry>
- <entry><para><literal>jsonb_set_lax('[{"f1":1,"f2":null},2,null,3]', '{0,f1}',null)</literal>
- </para><para><literal>jsonb_set_lax('[{"f1":99,"f2":null},2]', '{0,f3}',null, true,
'return_target')</literal>
- </para></entry>
- <entry><para><literal>[{"f1":null,"f2":null},2,null,3]</literal>
- </para><para><literal>[{"f1": 99, "f2": null}, 2]</literal>
- </para></entry>
- </row>
- <row>
- <entry>
- <para><literal>
- jsonb_insert(target jsonb, path text[], new_value jsonb <optional>, insert_after boolean</optional>)
- </literal></para>
- </entry>
- <entry><para><type>jsonb</type></para></entry>
- <entry>
- Returns <replaceable>target</replaceable> with
- <replaceable>new_value</replaceable> inserted. If
- <replaceable>target</replaceable> section designated by
- <replaceable>path</replaceable> is in a JSONB array,
- <replaceable>new_value</replaceable> will be inserted before target or
- after if <replaceable>insert_after</replaceable> is true (default is
- <literal>false</literal>). If <replaceable>target</replaceable> section
- designated by <replaceable>path</replaceable> is in JSONB object,
- <replaceable>new_value</replaceable> will be inserted only if
- <replaceable>target</replaceable> does not exist. As with the path
- oriented operators, negative integers that appear in
- <replaceable>path</replaceable> count from the end of JSON arrays.
- </entry>
- <entry>
- <para><literal>
- jsonb_insert('{"a": [0,1,2]}', '{a, 1}', '"new_value"')
- </literal></para>
- <para><literal>
- jsonb_insert('{"a": [0,1,2]}', '{a, 1}', '"new_value"', true)
- </literal></para>
- </entry>
- <entry><para><literal>{"a": [0, "new_value", 1, 2]}</literal>
- </para><para><literal>{"a": [0, 1, "new_value", 2]}</literal>
- </para></entry>
- </row>
- <row>
- <entry><para><literal>jsonb_pretty(from_json jsonb)</literal>
- </para></entry>
- <entry><para><type>text</type></para></entry>
- <entry>
- Returns <replaceable>from_json</replaceable>
- as indented JSON text.
- </entry>
- <entry><literal>jsonb_pretty('[{"f1":1,"f2":null},2,null,3]')</literal></entry>
- <entry>
-<programlisting>
-[
- {
- "f1": 1,
- "f2": null
- },
- 2,
- null,
- 3
-]
-</programlisting>
- </entry>
- </row>
- <row>
- <entry>
- <para><literal>
- jsonb_path_exists(target jsonb, path jsonpath <optional>, vars jsonb <optional>, silent
bool</optional></optional>)
- </literal></para>
- <para><literal>
- jsonb_path_exists_tz(target jsonb, path jsonpath <optional>, vars jsonb <optional>, silent
bool</optional></optional>)
- </literal></para>
- </entry>
- <entry><type>boolean</type></entry>
- <entry>
- Checks whether JSON path returns any item for the specified JSON
- value.
- </entry>
- <entry>
- <para><literal>
- jsonb_path_exists('{"a":[1,2,3,4,5]}', '$.a[*] ? (@ >= $min && @ <= $max)', '{"min":2,"max":4}')
- </literal></para>
- </entry>
- <entry>
- <para><literal>true</literal></para>
- </entry>
- </row>
- <row>
- <entry>
- <para><literal>
- jsonb_path_match(target jsonb, path jsonpath <optional>, vars jsonb <optional>, silent
bool</optional></optional>)
- </literal></para>
- <para><literal>
- jsonb_path_match_tz(target jsonb, path jsonpath <optional>, vars jsonb <optional>, silent
bool</optional></optional>)
- </literal></para>
- </entry>
- <entry><type>boolean</type></entry>
- <entry>
- Returns the result of JSON path predicate check for the specified JSON value.
- Only the first item of the result is taken into account. If the
- result is not Boolean, then <literal>null</literal> is returned.
- </entry>
- <entry>
- <para><literal>
- jsonb_path_match('{"a":[1,2,3,4,5]}', 'exists($.a[*] ? (@ >= $min && @ <= $max))',
'{"min":2,"max":4}')
- </literal></para>
- </entry>
- <entry>
- <para><literal>true</literal></para>
- </entry>
- </row>
- <row>
- <entry>
- <para><literal>
- jsonb_path_query(target jsonb, path jsonpath <optional>, vars jsonb <optional>, silent
bool</optional></optional>)
- </literal></para>
- <para><literal>
- jsonb_path_query_tz(target jsonb, path jsonpath <optional>, vars jsonb <optional>, silent
bool</optional></optional>)
- </literal></para>
- </entry>
- <entry><type>setof jsonb</type></entry>
- <entry>
- Gets all JSON items returned by JSON path for the specified JSON
- value.
- </entry>
- <entry>
- <para><literal>
- select * from jsonb_path_query('{"a":[1,2,3,4,5]}', '$.a[*] ? (@ >= $min && @ <= $max)',
'{"min":2,"max":4}');
- </literal></para>
- </entry>
- <entry>
- <para>
-<programlisting>
- jsonb_path_query
-------------------
- 2
- 3
- 4
-</programlisting>
- </para>
- </entry>
- </row>
- <row>
- <entry>
- <para><literal>
- jsonb_path_query_array(target jsonb, path jsonpath <optional>, vars jsonb <optional>, silent
bool</optional></optional>)
- </literal></para>
- <para><literal>
- jsonb_path_query_array_tz(target jsonb, path jsonpath <optional>, vars jsonb <optional>, silent
bool</optional></optional>)
- </literal></para>
- </entry>
- <entry><type>jsonb</type></entry>
- <entry>
- Gets all JSON items returned by JSON path for the specified JSON
- value and wraps result into an array.
- </entry>
- <entry>
- <para><literal>
- jsonb_path_query_array('{"a":[1,2,3,4,5]}', '$.a[*] ? (@ >= $min && @ <= $max)',
'{"min":2,"max":4}')
- </literal></para>
- </entry>
- <entry>
- <para><literal>[2, 3, 4]</literal></para>
- </entry>
- </row>
- <row>
- <entry>
- <para><literal>
- jsonb_path_query_first(target jsonb, path jsonpath <optional>, vars jsonb <optional>, silent
bool</optional></optional>)
- </literal></para>
- <para><literal>
- jsonb_path_query_first_tz(target jsonb, path jsonpath <optional>, vars jsonb <optional>, silent
bool</optional></optional>)
- </literal></para>
- </entry>
- <entry><type>jsonb</type></entry>
- <entry>
- Gets the first JSON item returned by JSON path for the specified JSON
- value. Returns <literal>NULL</literal> on no results.
- </entry>
- <entry>
- <para><literal>
- jsonb_path_query_first('{"a":[1,2,3,4,5]}', '$.a[*] ? (@ >= $min && @ <= $max)',
'{"min":2,"max":4}')
- </literal></para>
- </entry>
- <entry>
- <para><literal>2</literal></para>
- </entry>
- </row>
</tbody>
</tgroup>
</table>
<note>
- <para>
- Many of these functions and operators will convert Unicode escapes in
- JSON strings to the appropriate single character. This is a non-issue
- if the input is type <type>jsonb</type>, because the conversion was already
- done; but for <type>json</type> input, this may result in throwing an error,
- as noted in <xref linkend="datatype-json"/>.
- </para>
- </note>
-
- <note>
- <para>
- The functions
- <function>json[b]_populate_record</function>,
- <function>json[b]_populate_recordset</function>,
- <function>json[b]_to_record</function> and
- <function>json[b]_to_recordset</function>
- operate on a JSON object, or array of objects, and extract the values
- associated with keys whose names match column names of the output row
- type.
- Object fields that do not correspond to any output column name are
- ignored, and output columns that do not match any object field will be
- filled with nulls.
- To convert a JSON value to the SQL type of an output column, the
- following rules are applied in sequence:
- <itemizedlist spacing="compact">
- <listitem>
- <para>
- A JSON null value is converted to a SQL null in all cases.
- </para>
- </listitem>
- <listitem>
- <para>
- If the output column is of type <type>json</type>
- or <type>jsonb</type>, the JSON value is just reproduced exactly.
- </para>
- </listitem>
- <listitem>
- <para>
- If the output column is a composite (row) type, and the JSON value is
- a JSON object, the fields of the object are converted to columns of
- the output row type by recursive application of these rules.
- </para>
- </listitem>
- <listitem>
- <para>
- Likewise, if the output column is an array type and the JSON value is
- a JSON array, the elements of the JSON array are converted to elements
- of the output array by recursive application of these rules.
- </para>
- </listitem>
- <listitem>
- <para>
- Otherwise, if the JSON value is a string literal, the contents of the
- string are fed to the input conversion function for the column's data
- type.
- </para>
- </listitem>
- <listitem>
- <para>
- Otherwise, the ordinary text representation of the JSON value is fed
- to the input conversion function for the column's data type.
- </para>
- </listitem>
- </itemizedlist>
- </para>
-
- <para>
- While the examples for these functions use constants, the typical use
- would be to reference a table in the <literal>FROM</literal> clause
- and use one of its <type>json</type> or <type>jsonb</type> columns
- as an argument to the function. Extracted key values can then be
- referenced in other parts of the query, like <literal>WHERE</literal>
- clauses and target lists. Extracting multiple values in this
- way can improve performance over extracting them separately with
- per-key operators.
- </para>
- </note>
-
- <note>
- <para>
- All the items of the <literal>path</literal> parameter of <literal>jsonb_set</literal>
- as well as <literal>jsonb_insert</literal> except the last item must be present
- in the <literal>target</literal>. If <literal>create_missing</literal> is false, all
- items of the <literal>path</literal> parameter of <literal>jsonb_set</literal> must be
- present. If these conditions are not met the <literal>target</literal> is
- returned unchanged.
- </para>
- <para>
- If the last path item is an object key, it will be created if it
- is absent and given the new value. If the last path item is an array
- index, if it is positive the item to set is found by counting from
- the left, and if negative by counting from the right - <literal>-1</literal>
- designates the rightmost element, and so on.
- If the item is out of the range -array_length .. array_length -1,
- and create_missing is true, the new value is added at the beginning
- of the array if the item is negative, and at the end of the array if
- it is positive.
- </para>
- </note>
-
- <note>
- <para>
- The <literal>json_typeof</literal> function's <literal>null</literal> return value
- should not be confused with a SQL NULL. While
- calling <literal>json_typeof('null'::json)</literal> will
- return <literal>null</literal>, calling <literal>json_typeof(NULL::json)</literal>
- will return a SQL NULL.
- </para>
- </note>
-
- <note>
- <para>
- If the argument to <literal>json_strip_nulls</literal> contains duplicate
- field names in any object, the result could be semantically somewhat
- different, depending on the order in which they occur. This is not an
- issue for <literal>jsonb_strip_nulls</literal> since <type>jsonb</type> values never have
- duplicate object field names.
- </para>
- </note>
-
- <note>
- <para>
- The <literal>jsonb_path_*</literal> functions have optional
- <literal>vars</literal> and <literal>silent</literal> arguments.
- </para>
- <para>
- If the <parameter>vars</parameter> argument is specified, it provides an
- object containing named variables to be substituted into a
- <literal>jsonpath</literal> expression.
- </para>
- <para>
- If the <parameter>silent</parameter> argument is specified and has the
- <literal>true</literal> value, these functions suppress the same errors
- as the <literal>@?</literal> and <literal>@@</literal> operators.
- </para>
- </note>
-
- <note>
<para>
- Some of the <literal>jsonb_path_*</literal> functions have a
- <literal>_tz</literal> suffix. These functions have been implemented to
- support comparison of date/time values that involves implicit
- timezone-aware casts. Since operations with time zones are not immutable,
- these functions are qualified as stable. Their counterparts without the
- suffix do not support such casts, so they are immutable and can be used for
- such use-cases as expression indexes
- (see <xref linkend="indexes-expressional"/>). There is no difference
- between these functions for other <type>jsonpath</type> operations.
+ The <type>jsonpath</type> operators <literal>@?</literal>
+ and <literal>@@</literal> suppress the following errors: missing object
+ field or array element, unexpected JSON item type, datetime and numeric
+ errors. The <type>jsonpath</type>-related functions described below can
+ also be told to suppress these types of errors. This behavior might be
+ helpful when searching JSON document collections of varying structure.
</para>
</note>
<para>
- See also <xref linkend="functions-aggregate"/> for the aggregate
- function <function>json_agg</function> which aggregates record
- values as JSON, and the aggregate function
- <function>json_object_agg</function> which aggregates pairs of values
- into a JSON object, and their <type>jsonb</type> equivalents,
- <function>jsonb_agg</function> and <function>jsonb_object_agg</function>.
+ <xref linkend="functions-json-creation-table"/> shows the functions that are
+ available for constructing <type>json</type> and <type>jsonb</type> values.
</para>
- </sect2>
-
- <sect2 id="functions-sqljson-path">
- <title>The SQL/JSON Path Language</title>
- <indexterm zone="functions-sqljson-path">
- <primary>SQL/JSON path language</primary>
- </indexterm>
+ <table id="functions-json-creation-table">
+ <title>JSON Creation Functions</title>
+ <tgroup cols="1">
+ <thead>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ Function
+ </para>
+ <para>
+ Description
+ </para>
+ <para>
+ Example(s)
+ </para></entry>
+ </row>
+ </thead>
- <para>
- SQL/JSON path expressions specify the items to be retrieved
- from the JSON data, similar to XPath expressions used
- for SQL access to XML. In <productname>PostgreSQL</productname>,
- path expressions are implemented as the <type>jsonpath</type>
- data type and can use any elements described in
- <xref linkend="datatype-jsonpath"/>.
- </para>
+ <tbody>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>to_json</primary>
+ </indexterm>
+ <function>to_json</function> ( <type>anyelement</type> )
+ <returnvalue>json</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>to_jsonb</primary>
+ </indexterm>
+ <function>to_jsonb</function> ( <type>anyelement</type> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Converts any SQL value to <type>json</type> or <type>jsonb</type>.
+ Arrays and composites are converted recursively to arrays and
+ objects (multidimensional arrays become arrays of arrays in JSON).
+ Otherwise, if there is a cast from the SQL data type
+ to <type>json</type>, the cast function will be used to perform the
+ conversion;<footnote>
+ <para>
+ For example, the <xref linkend="hstore"/> extension has a cast
+ from <type>hstore</type> to <type>json</type>, so that
+ <type>hstore</type> values converted via the JSON creation functions
+ will be represented as JSON objects, not as primitive string values.
+ </para>
+ </footnote>
+ otherwise, a scalar JSON value is produced. For any scalar other than
+ a number, a Boolean, or a null value, the text representation will be
+ used, with escaping as necessary to make it a valid JSON string value.
+ </para>
+ <para>
+ <literal>to_json('Fred said "Hi."'::text)</literal>
+ <returnvalue>"Fred said \"Hi.\""</returnvalue>
+ </para>
+ <para>
+ <literal>to_jsonb(row(42, 'Fred said "Hi."'::text))</literal>
+ <returnvalue>{"f1": 42, "f2": "Fred said \"Hi.\""}</returnvalue>
+ </para></entry>
+ </row>
- <para>JSON query functions and operators
- pass the provided path expression to the <firstterm>path engine</firstterm>
- for evaluation. If the expression matches the queried JSON data,
- the corresponding SQL/JSON item is returned.
- Path expressions are written in the SQL/JSON path language
- and can also include arithmetic expressions and functions.
- Query functions treat the provided expression as a
- text string, so it must be enclosed in single quotes.
- </para>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>array_to_json</primary>
+ </indexterm>
+ <function>array_to_json</function> ( <type>anyarray</type> <optional>, <type>boolean</type> </optional> )
+ <returnvalue>json</returnvalue>
+ </para>
+ <para>
+ Converts a SQL array to a JSON array. The behavior is the same
+ as <function>to_json</function> except that line feeds will be added
+ between top-level array elements if the optional boolean parameter is
+ true.
+ </para>
+ <para>
+ <literal>array_to_json('{{1,5},{99,100}}'::int[])</literal>
+ <returnvalue>[[1,5],[99,100]]</returnvalue>
+ </para></entry>
+ </row>
- <para>
- A path expression consists of a sequence of elements allowed
- by the <type>jsonpath</type> data type.
- The path expression is evaluated from left to right, but
- you can use parentheses to change the order of operations.
- If the evaluation is successful, a sequence of SQL/JSON items
- (<firstterm>SQL/JSON sequence</firstterm>) is produced,
- and the evaluation result is returned to the JSON query function
- that completes the specified computation.
- </para>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>row_to_json</primary>
+ </indexterm>
+ <function>row_to_json</function> ( <type>record</type> <optional>, <type>boolean</type> </optional> )
+ <returnvalue>json</returnvalue>
+ </para>
+ <para>
+ Converts a SQL composite value to a JSON object. The behavior is the
+ same as <function>to_json</function> except that line feeds will be
+ added between top-level elements if the optional boolean parameter is
+ true.
+ </para>
+ <para>
+ <literal>row_to_json(row(1,'foo'))</literal>
+ <returnvalue>{"f1":1,"f2":"foo"}</returnvalue>
+ </para></entry>
+ </row>
- <para>
- To refer to the JSON data to be queried (the
- <firstterm>context item</firstterm>), use the <literal>$</literal> sign
- in the path expression. It can be followed by one or more
- <link linkend="type-jsonpath-accessors">accessor operators</link>,
- which go down the JSON structure level by level to retrieve the
- content of context item. Each operator that follows deals with the
- result of the previous evaluation step.
- </para>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_build_array</primary>
+ </indexterm>
+ <function>json_build_array</function> ( <literal>VARIADIC</literal> <type>"any"</type> )
+ <returnvalue>json</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_build_array</primary>
+ </indexterm>
+ <function>jsonb_build_array</function> ( <literal>VARIADIC</literal> <type>"any"</type> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Builds a possibly-heterogeneously-typed JSON array out of a variadic
+ argument list. Each argument is converted as
+ per <function>to_json</function> or <function>to_jsonb</function>.
+ </para>
+ <para>
+ <literal>json_build_array(1,2,'foo',4,5)</literal>
+ <returnvalue>[1, 2, "foo", 4, 5]</returnvalue>
+ </para></entry>
+ </row>
- <para>
- For example, suppose you have some JSON data from a GPS tracker that you
- would like to parse, such as:
-<programlisting>
-{
- "track": {
- "segments": [
- {
- "location": [ 47.763, 13.4034 ],
- "start time": "2018-10-14 10:05:14",
- "HR": 73
- },
- {
- "location": [ 47.706, 13.2635 ],
- "start time": "2018-10-14 10:39:21",
- "HR": 135
- }
- ]
- }
-}
-</programlisting>
- </para>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_build_object</primary>
+ </indexterm>
+ <function>json_build_object</function> ( <literal>VARIADIC</literal> <type>"any"</type> )
+ <returnvalue>json</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_build_object</primary>
+ </indexterm>
+ <function>jsonb_build_object</function> ( <literal>VARIADIC</literal> <type>"any"</type> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Builds a JSON object out of a variadic argument list. By convention,
+ the argument list consists of alternating keys and values. Key
+ arguments are coerced to text; value arguments are converted as
+ per <function>to_json</function> or <function>to_jsonb</function>.
+ </para>
+ <para>
+ <literal>json_build_object('foo',1,2,row(3,'bar'))</literal>
+ <returnvalue>{"foo" : 1, "2" : {"f1":3,"f2":"bar"}}</returnvalue>
+ </para></entry>
+ </row>
- <para>
- To retrieve the available track segments, you need to use the
- <literal>.<replaceable>key</replaceable></literal> accessor
- operator for all the preceding JSON objects:
-<programlisting>
-'$.track.segments'
-</programlisting>
- </para>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_object</primary>
+ </indexterm>
+ <function>json_object</function> ( <type>text[]</type> )
+ <returnvalue>json</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_object</primary>
+ </indexterm>
+ <function>jsonb_object</function> ( <type>text[]</type> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Builds a JSON object out of a text array. The array must have either
+ exactly one dimension with an even number of members, in which case
+ they are taken as alternating key/value pairs, or two dimensions
+ such that each inner array has exactly two elements, which
+ are taken as a key/value pair. All values are converted to JSON
+ strings.
+ </para>
+ <para>
+ <literal>json_object('{a, 1, b, "def", c, 3.5}')</literal>
+ <returnvalue>{"a" : "1", "b" : "def", "c" : "3.5"}</returnvalue>
+ </para>
+ <para><literal>json_object('{{a, 1},{b, "def"},{c, 3.5}}')</literal>
+ <returnvalue>{"a" : "1", "b" : "def", "c" : "3.5"}</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <function>json_object</function> ( <replaceable>keys</replaceable> <type>text[]</type>,
<replaceable>values</replaceable><type>text[]</type> )
+ <returnvalue>json</returnvalue>
+ </para>
+ <para role="func_signature">
+ <function>jsonb_object</function> ( <replaceable>keys</replaceable> <type>text[]</type>,
<replaceable>values</replaceable><type>text[]</type> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ This form of <function>json_object</function> takes keys and values
+ pairwise from separate text arrays. Otherwise it is identical to
+ the one-argument form.
+ </para>
+ <para>
+ <literal>json_object('{a, b}', '{1,2}')</literal>
+ <returnvalue>{"a": "1", "b": "2"}</returnvalue>
+ </para></entry>
+ </row>
+ </tbody>
+ </tgroup>
+ </table>
<para>
- If the item to retrieve is an element of an array, you have
- to unnest this array using the <literal>[*]</literal> operator. For example,
- the following path will return location coordinates for all
- the available track segments:
-<programlisting>
-'$.track.segments[*].location'
-</programlisting>
+ <xref linkend="functions-json-processing-table"/> shows the functions that
+ are available for processing <type>json</type> and <type>jsonb</type> values.
</para>
- <para>
- To return the coordinates of the first segment only, you can
- specify the corresponding subscript in the <literal>[]</literal>
- accessor operator. Note that the SQL/JSON arrays are 0-relative:
+ <table id="functions-json-processing-table">
+ <title>JSON Processing Functions</title>
+ <tgroup cols="1">
+ <thead>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ Function
+ </para>
+ <para>
+ Description
+ </para>
+ <para>
+ Example(s)
+ </para></entry>
+ </row>
+ </thead>
+
+ <tbody>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_array_elements</primary>
+ </indexterm>
+ <function>json_array_elements</function> ( <type>json</type> )
+ <returnvalue>setof json</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_array_elements</primary>
+ </indexterm>
+ <function>jsonb_array_elements</function> ( <type>jsonb</type> )
+ <returnvalue>setof jsonb</returnvalue>
+ </para>
+ <para>
+ Expands the top-level JSON array into a set of JSON values.
+ </para>
+ <para>
+ <literal>select * from json_array_elements('[1,true, [2,false]]')</literal>
+ <returnvalue></returnvalue>
<programlisting>
-'$.track.segments[0].location'
+ value
+-----------
+ 1
+ true
+ [2,false]
</programlisting>
- </para>
+ </para></entry>
+ </row>
- <para>
- The result of each path evaluation step can be processed
- by one or more <type>jsonpath</type> operators and methods
- listed in <xref linkend="functions-sqljson-path-operators"/>.
- Each method name must be preceded by a dot. For example,
- you can get an array size:
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_array_elements_text</primary>
+ </indexterm>
+ <function>json_array_elements_text</function> ( <type>json</type> )
+ <returnvalue>setof text</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_array_elements_text</primary>
+ </indexterm>
+ <function>jsonb_array_elements_text</function> ( <type>jsonb</type> )
+ <returnvalue>setof text</returnvalue>
+ </para>
+ <para>
+ Expands the top-level JSON array into a set of <type>text</type> values.
+ </para>
+ <para>
+ <literal>select * from json_array_elements_text('["foo", "bar"]')</literal>
+ <returnvalue></returnvalue>
<programlisting>
-'$.track.segments.size()'
+ value
+-----------
+ foo
+ bar
</programlisting>
- For more examples of using <type>jsonpath</type> operators
- and methods within path expressions, see
- <xref linkend="functions-sqljson-path-operators"/>.
- </para>
+ </para></entry>
+ </row>
- <para>
- When defining the path, you can also use one or more
- <firstterm>filter expressions</firstterm> that work similar to the
- <literal>WHERE</literal> clause in SQL. A filter expression begins with
- a question mark and provides a condition in parentheses:
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_array_length</primary>
+ </indexterm>
+ <function>json_array_length</function> ( <type>json</type> )
+ <returnvalue>integer</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_array_length</primary>
+ </indexterm>
+ <function>jsonb_array_length</function> ( <type>jsonb</type> )
+ <returnvalue>integer</returnvalue>
+ </para>
+ <para>
+ Returns the number of elements in the top-level JSON array.
+ </para>
+ <para>
+ <literal>json_array_length('[1,2,3,{"f1":1,"f2":[5,6]},4]')</literal>
+ <returnvalue>5</returnvalue>
+ </para></entry>
+ </row>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_each</primary>
+ </indexterm>
+ <function>json_each</function> ( <type>json</type> )
+ <returnvalue>setof <replaceable>key</replaceable> text,
+ <replaceable>value</replaceable> json</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_each</primary>
+ </indexterm>
+ <function>jsonb_each</function> ( <type>jsonb</type> )
+ <returnvalue>setof <replaceable>key</replaceable> text,
+ <replaceable>value</replaceable> jsonb</returnvalue>
+ </para>
+ <para>
+ Expands the top-level JSON object into a set of key/value pairs.
+ </para>
+ <para>
+ <literal>select * from json_each('{"a":"foo", "b":"bar"}')</literal>
+ <returnvalue></returnvalue>
<programlisting>
-? (<replaceable>condition</replaceable>)
+ key | value
+-----+-------
+ a | "foo"
+ b | "bar"
</programlisting>
- </para>
-
- <para>
- Filter expressions must be specified right after the path evaluation step
- to which they are applied. The result of this step is filtered to include
- only those items that satisfy the provided condition. SQL/JSON defines
- three-valued logic, so the condition can be <literal>true</literal>, <literal>false</literal>,
- or <literal>unknown</literal>. The <literal>unknown</literal> value
- plays the same role as SQL <literal>NULL</literal> and can be tested
- for with the <literal>is unknown</literal> predicate. Further path
- evaluation steps use only those items for which filter expressions
- return <literal>true</literal>.
- </para>
-
- <para>
- Functions and operators that can be used in filter expressions are listed
- in <xref linkend="functions-sqljson-filter-ex-table"/>. The path
- evaluation result to be filtered is denoted by the <literal>@</literal>
- variable. To refer to a JSON element stored at a lower nesting level,
- add one or more accessor operators after <literal>@</literal>.
- </para>
+ </para></entry>
+ </row>
- <para>
- Suppose you would like to retrieve all heart rate values higher
- than 130. You can achieve this using the following expression:
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_each_text</primary>
+ </indexterm>
+ <function>json_each_text</function> ( <type>json</type> )
+ <returnvalue>setof <replaceable>key</replaceable> text,
+ <replaceable>value</replaceable> text</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_each_text</primary>
+ </indexterm>
+ <function>jsonb_each_text</function> ( <type>jsonb</type> )
+ <returnvalue>setof <replaceable>key</replaceable> text,
+ <replaceable>value</replaceable> text</returnvalue>
+ </para>
+ <para>
+ Expands the top-level JSON object into a set of key/value pairs.
+ The returned <replaceable>value</replaceable>s will be of
+ type <type>text</type>.
+ </para>
+ <para>
+ <literal>select * from json_each_text('{"a":"foo", "b":"bar"}')</literal>
+ <returnvalue></returnvalue>
<programlisting>
-'$.track.segments[*].HR ? (@ > 130)'
+ key | value
+-----+-------
+ a | foo
+ b | bar
</programlisting>
- </para>
+ </para></entry>
+ </row>
- <para>
- To get the start time of segments with such values instead, you have to
- filter out irrelevant segments before returning the start time, so the
- filter expression is applied to the previous step, and the path used
- in the condition is different:
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_extract_path</primary>
+ </indexterm>
+ <function>json_extract_path</function> ( <replaceable>from_json</replaceable> <type>json</type>,
<literal>VARIADIC</literal><replaceable>path_elems</replaceable> <type>text[]</type> )
+ <returnvalue>json</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_extract_path</primary>
+ </indexterm>
+ <function>jsonb_extract_path</function> ( <replaceable>from_json</replaceable> <type>jsonb</type>,
<literal>VARIADIC</literal><replaceable>path_elems</replaceable> <type>text[]</type> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Extracts JSON sub-object at the specified path.
+ (This is functionally equivalent to the <literal>#></literal>
+ operator, but writing the path out as a variadic list can be more
+ convenient in some cases.)
+ </para>
+ <para>
+ <literal>json_extract_path('{"f2":{"f3":1},"f4":{"f5":99,"f6":"foo"}}', 'f4', 'f6')</literal>
+ <returnvalue>"foo"</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_extract_path_text</primary>
+ </indexterm>
+ <function>json_extract_path_text</function> ( <replaceable>from_json</replaceable> <type>json</type>,
<literal>VARIADIC</literal><replaceable>path_elems</replaceable> <type>text[]</type> )
+ <returnvalue>text</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_extract_path_text</primary>
+ </indexterm>
+ <function>jsonb_extract_path_text</function> ( <replaceable>from_json</replaceable> <type>jsonb</type>,
<literal>VARIADIC</literal><replaceable>path_elems</replaceable> <type>text[]</type> )
+ <returnvalue>text</returnvalue>
+ </para>
+ <para>
+ Extracts JSON sub-object at the specified path as <type>text</type>.
+ (This is functionally equivalent to the <literal>#>></literal>
+ operator.)
+ </para>
+ <para>
+ <literal>json_extract_path_text('{"f2":{"f3":1},"f4":{"f5":99,"f6":"foo"}}', 'f4', 'f6')</literal>
+ <returnvalue>foo</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_object_keys</primary>
+ </indexterm>
+ <function>json_object_keys</function> ( <type>json</type> )
+ <returnvalue>setof text</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_object_keys</primary>
+ </indexterm>
+ <function>jsonb_object_keys</function> ( <type>jsonb</type> )
+ <returnvalue>setof text</returnvalue>
+ </para>
+ <para>
+ Returns the set of keys in the top-level JSON object.
+ </para>
+ <para>
+ <literal>select * from json_object_keys('{"f1":"abc","f2":{"f3":"a", "f4":"b"}}')</literal>
+ <returnvalue></returnvalue>
<programlisting>
-'$.track.segments[*] ? (@.HR > 130)."start time"'
+ json_object_keys
+------------------
+ f1
+ f2
</programlisting>
- </para>
+ </para></entry>
+ </row>
- <para>
- You can use several filter expressions on the same nesting level, if
- required. For example, the following expression selects all segments
- that contain locations with relevant coordinates and high heart rate values:
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_populate_record</primary>
+ </indexterm>
+ <function>json_populate_record</function> ( <replaceable>base</replaceable> <type>anyelement</type>,
<replaceable>from_json</replaceable><type>json</type> )
+ <returnvalue>anyelement</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_populate_record</primary>
+ </indexterm>
+ <function>jsonb_populate_record</function> ( <replaceable>base</replaceable> <type>anyelement</type>,
<replaceable>from_json</replaceable><type>jsonb</type> )
+ <returnvalue>anyelement</returnvalue>
+ </para>
+ <para>
+ Expands the top-level JSON object to a row having the composite type
+ of the <replaceable>base</replaceable> argument. The JSON object
+ is scanned for fields whose names match column names of the output row
+ type, and their values are inserted into those columns of the output.
+ (Fields that do not correspond to any output column name are ignored.)
+ In typical use, the value of <replaceable>base</replaceable> is just
+ <literal>NULL</literal>, which means that any output columns that do
+ not match any object field will be filled with nulls. However,
+ if <replaceable>base</replaceable> isn't <literal>NULL</literal> then
+ the values it contains will be used for unmatched columns.
+ </para>
+ <para>
+ To convert a JSON value to the SQL type of an output column, the
+ following rules are applied in sequence:
+ <itemizedlist spacing="compact">
+ <listitem>
+ <para>
+ A JSON null value is converted to a SQL null in all cases.
+ </para>
+ </listitem>
+ <listitem>
+ <para>
+ If the output column is of type <type>json</type>
+ or <type>jsonb</type>, the JSON value is just reproduced exactly.
+ </para>
+ </listitem>
+ <listitem>
+ <para>
+ If the output column is a composite (row) type, and the JSON value
+ is a JSON object, the fields of the object are converted to columns
+ of the output row type by recursive application of these rules.
+ </para>
+ </listitem>
+ <listitem>
+ <para>
+ Likewise, if the output column is an array type and the JSON value
+ is a JSON array, the elements of the JSON array are converted to
+ elements of the output array by recursive application of these
+ rules.
+ </para>
+ </listitem>
+ <listitem>
+ <para>
+ Otherwise, if the JSON value is a string, the contents of the
+ string are fed to the input conversion function for the column's
+ data type.
+ </para>
+ </listitem>
+ <listitem>
+ <para>
+ Otherwise, the ordinary text representation of the JSON value is
+ fed to the input conversion function for the column's data type.
+ </para>
+ </listitem>
+ </itemizedlist>
+ </para>
+ <para>
+ While the example below uses a constant JSON value, typical use would
+ be to reference a <type>json</type> or <type>jsonb</type> column
+ laterally from another table in the query's <literal>FROM</literal>
+ clause. Writing <function>json_populate_record</function> in
+ the <literal>FROM</literal> clause is good practice, since all of the
+ extracted columns are available for use without duplicate function
+ calls.
+ </para>
+ <para>
+ <literal>select * from json_populate_record(null::myrowtype, '{"a": 1, "b": ["2", "a b"], "c": {"d": 4, "e":
"a b c"}}')</literal>
+ <returnvalue></returnvalue>
<programlisting>
-'$.track.segments[*] ? (@.location[1] < 13.4) ? (@.HR > 130)."start time"'
+ a | b | c
+---+-----------+-------------
+ 1 | {2,"a b"} | (4,"a b c")
</programlisting>
- </para>
+ </para></entry>
+ </row>
- <para>
- Using filter expressions at different nesting levels is also allowed.
- The following example first filters all segments by location, and then
- returns high heart rate values for these segments, if available:
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_populate_recordset</primary>
+ </indexterm>
+ <function>json_populate_recordset</function> ( <replaceable>base</replaceable> <type>anyelement</type>,
<replaceable>from_json</replaceable><type>json</type> )
+ <returnvalue>setof anyelement</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_populate_recordset</primary>
+ </indexterm>
+ <function>jsonb_populate_recordset</function> ( <replaceable>base</replaceable> <type>anyelement</type>,
<replaceable>from_json</replaceable><type>jsonb</type> )
+ <returnvalue>setof anyelement</returnvalue>
+ </para>
+ <para>
+ Expands the top-level JSON array of objects to a set of rows having
+ the composite type of the <replaceable>base</replaceable> argument.
+ Each element of the JSON array is processed as described above
+ for <function>json[b]_populate_record</function>.
+ </para>
+ <para>
+ <literal>select * from json_populate_recordset(null::myrowtype, '[{"a":1,"b":2},{"a":3,"b":4}]')</literal>
+ <returnvalue></returnvalue>
<programlisting>
-'$.track.segments[*] ? (@.location[1] < 13.4).HR ? (@ > 130)'
+ a | b
+---+---
+ 1 | 2
+ 3 | 4
</programlisting>
- </para>
+ </para></entry>
+ </row>
- <para>
- You can also nest filter expressions within each other:
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_to_record</primary>
+ </indexterm>
+ <function>json_to_record</function> ( <type>json</type> )
+ <returnvalue>record</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_to_record</primary>
+ </indexterm>
+ <function>jsonb_to_record</function> ( <type>jsonb</type> )
+ <returnvalue>record</returnvalue>
+ </para>
+ <para>
+ Expands the top-level JSON object to a row having the composite type
+ defined by an <literal>AS</literal> clause. (As with all functions
+ returning <type>record</type>, the calling query must explicitly
+ define the structure of the record with an <literal>AS</literal>
+ clause.) The output record is filled from fields of the JSON object,
+ in the same way as described above
+ for <function>json[b]_populate_record</function>. Since there is no
+ input record value, unmatched columns are always filled with nulls.
+ </para>
+ <para>
+ <literal>select * from json_to_record('{"a":1,"b":[1,2,3],"c":[1,2,3],"e":"bar","r": {"a": 123, "b": "a b
c"}}')as x(a int, b text, c int[], d text, r myrowtype) </literal>
+ <returnvalue></returnvalue>
<programlisting>
-'$.track ? (exists(@.segments[*] ? (@.HR > 130))).segments.size()'
+ a | b | c | d | r
+---+---------+---------+---+---------------
+ 1 | [1,2,3] | {1,2,3} | | (123,"a b c")
</programlisting>
- This expression returns the size of the track if it contains any
- segments with high heart rate values, or an empty sequence otherwise.
- </para>
-
- <para>
- <productname>PostgreSQL</productname>'s implementation of SQL/JSON path
- language has the following deviations from the SQL/JSON standard:
- </para>
+ </para></entry>
+ </row>
- <itemizedlist>
- <listitem>
- <para>
- A path expression can be a Boolean predicate, although the SQL/JSON
- standard allows predicates only in filters. This is necessary for
- implementation of the <literal>@@</literal> operator. For example,
- the following <type>jsonpath</type> expression is valid in
- <productname>PostgreSQL</productname>:
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_to_recordset</primary>
+ </indexterm>
+ <function>json_to_recordset</function> ( <type>json</type> )
+ <returnvalue>setof record</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_to_recordset</primary>
+ </indexterm>
+ <function>jsonb_to_recordset</function> ( <type>jsonb</type> )
+ <returnvalue>setof record</returnvalue>
+ </para>
+ <para>
+ Expands the top-level JSON array of objects to a set of rows having
+ the composite type defined by an <literal>AS</literal> clause. (As
+ with all functions returning <type>record</type>, the calling query
+ must explicitly define the structure of the record with
+ an <literal>AS</literal> clause.) Each element of the JSON array is
+ processed as described above
+ for <function>json[b]_populate_record</function>.
+ </para>
+ <para>
+ <literal>select * from json_to_recordset('[{"a":1,"b":"foo"},{"a":"2","c":"bar"}]') as x(a int, b
text)</literal>
+ <returnvalue></returnvalue>
<programlisting>
-'$.track.segments[*].HR < 70'
+ a | b
+---+-----
+ 1 | foo
+ 2 |
</programlisting>
- </para>
- </listitem>
+ </para></entry>
+ </row>
- <listitem>
- <para>
- There are minor differences in the interpretation of regular
- expression patterns used in <literal>like_regex</literal> filters, as
- described in <xref linkend="jsonpath-regular-expressions"/>.
- </para>
- </listitem>
- </itemizedlist>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>jsonb_set</primary>
+ </indexterm>
+ <function>jsonb_set</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>text[]</type>, <replaceable>new_value</replaceable> <type>jsonb</type> <optional>,
<replaceable>create_if_missing</replaceable><type>boolean</type> </optional> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Returns <replaceable>target</replaceable>
+ with the item designated by <replaceable>path</replaceable>
+ replaced by <replaceable>new_value</replaceable>, or with
+ <replaceable>new_value</replaceable> added if
+ <replaceable>create_if_missing</replaceable> is true (which is the
+ default) and the item designated by <replaceable>path</replaceable>
+ does not exist.
+ All earlier steps in the path must exist, or
+ the <replaceable>target</replaceable> is returned unchanged.
+ As with the path oriented operators, negative integers that
+ appear in the <replaceable>path</replaceable> count from the end
+ of JSON arrays.
+ If the last path step is an array index that is out of range,
+ and <replaceable>create_if_missing</replaceable> is true, the new
+ value is added at the beginning of the array if the index is negative,
+ or at the end of the array if it is positive.
+ </para>
+ <para>
+ <literal>jsonb_set('[{"f1":1,"f2":null},2,null,3]', '{0,f1}','[2,3,4]', false)</literal>
+ <returnvalue>[{"f1": [2, 3, 4], "f2": null}, 2, null, 3]</returnvalue>
+ </para>
+ <para>
+ <literal>jsonb_set('[{"f1":1,"f2":null},2]', '{0,f3}','[2,3,4]')</literal>
+ <returnvalue>[{"f1": 1, "f2": null, "f3": [2, 3, 4]}, 2]</returnvalue>
+ </para></entry>
+ </row>
- <sect3 id="strict-and-lax-modes">
- <title>Strict and Lax Modes</title>
- <para>
- When you query JSON data, the path expression may not match the
- actual JSON data structure. An attempt to access a non-existent
- member of an object or element of an array results in a
- structural error. SQL/JSON path expressions have two modes
- of handling structural errors:
- </para>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>jsonb_set_lax</primary>
+ </indexterm>
+ <function>jsonb_set_lax</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>text[]</type>, <replaceable>new_value</replaceable> <type>jsonb</type> <optional>,
<replaceable>create_if_missing</replaceable><type>boolean</type> <optional>,
<replaceable>null_value_treatment</replaceable><type>text</type> </optional></optional> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ If <replaceable>new_value</replaceable> is not <literal>null</literal>,
+ behaves identically to <literal>jsonb_set</literal>. Otherwise behaves
+ according to the value
+ of <replaceable>null_value_treatment</replaceable> which must be one
+ of <literal>'raise_exception'</literal>,
+ <literal>'use_json_null'</literal>, <literal>'delete_key'</literal>, or
+ <literal>'return_target'</literal>. The default is
+ <literal>'use_json_null'</literal>.
+ </para>
+ <para>
+ <literal>jsonb_set_lax('[{"f1":1,"f2":null},2,null,3]', '{0,f1}',null)</literal>
+ <returnvalue>[{"f1":null,"f2":null},2,null,3]</returnvalue>
+ </para>
+ <para>
+ <literal>jsonb_set_lax('[{"f1":99,"f2":null},2]', '{0,f3}',null, true, 'return_target')</literal>
+ <returnvalue>[{"f1": 99, "f2": null}, 2]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>jsonb_insert</primary>
+ </indexterm>
+ <function>jsonb_insert</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>text[]</type>, <replaceable>new_value</replaceable> <type>jsonb</type> <optional>,
<replaceable>insert_after</replaceable><type>boolean</type> </optional> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Returns <replaceable>target</replaceable>
+ with <replaceable>new_value</replaceable> inserted. If the item
+ designated by the <replaceable>path</replaceable> is an array
+ element, <replaceable>new_value</replaceable> will be inserted before
+ that item if <replaceable>insert_after</replaceable> is false (which
+ is the default), or after it
+ if <replaceable>insert_after</replaceable> is true. If the item
+ designated by the <replaceable>path</replaceable> is an object
+ field, <replaceable>new_value</replaceable> will be inserted only if
+ the object does not already contain that key.
+ All earlier steps in the path must exist, or
+ the <replaceable>target</replaceable> is returned unchanged.
+ As with the path oriented operators, negative integers that
+ appear in the <replaceable>path</replaceable> count from the end
+ of JSON arrays.
+ If the last path step is an array index that is out of range, the new
+ value is added at the beginning of the array if the index is negative,
+ or at the end of the array if it is positive.
+ </para>
+ <para>
+ <literal>jsonb_insert('{"a": [0,1,2]}', '{a, 1}', '"new_value"')</literal>
+ <returnvalue>{"a": [0, "new_value", 1, 2]}</returnvalue>
+ </para>
+ <para>
+ <literal>jsonb_insert('{"a": [0,1,2]}', '{a, 1}', '"new_value"', true)</literal>
+ <returnvalue>{"a": [0, 1, "new_value", 2]}</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_strip_nulls</primary>
+ </indexterm>
+ <function>json_strip_nulls</function> ( <type>json</type> )
+ <returnvalue>json</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_strip_nulls</primary>
+ </indexterm>
+ <function>jsonb_strip_nulls</function> ( <type>jsonb</type> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Deletes all object fields that have null values from the given JSON
+ value, recursively. Null values that are not object fields are
+ untouched.
+ </para>
+ <para>
+ <literal>json_strip_nulls('[{"f1":1,"f2":null},2,null,3]')</literal>
+ <returnvalue>[{"f1":1},2,null,3]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>jsonb_path_exists</primary>
+ </indexterm>
+ <function>jsonb_path_exists</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>jsonpath</type> <optional>, <replaceable>vars</replaceable> <type>jsonb</type>
<optional>,<replaceable>silent</replaceable> <type>boolean</type> </optional></optional> )
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Checks whether the JSON path returns any item for the specified JSON
+ value.
+ If the <replaceable>vars</replaceable> argument is specified, it must
+ be a JSON object, and its fields provide named values to be
+ substituted into the <type>jsonpath</type> expression.
+ If the <replaceable>silent</replaceable> argument is specified and
+ is <literal>true</literal>, the function suppresses the same errors
+ as the <literal>@?</literal> and <literal>@@</literal> operators do.
+ </para>
+ <para>
+ <literal>jsonb_path_exists('{"a":[1,2,3,4,5]}', '$.a[*] ? (@ >= $min && @ <= $max)',
'{"min":2,"max":4}')</literal>
+ <returnvalue>t</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>jsonb_path_match</primary>
+ </indexterm>
+ <function>jsonb_path_match</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>jsonpath</type> <optional>, <replaceable>vars</replaceable> <type>jsonb</type>
<optional>,<replaceable>silent</replaceable> <type>boolean</type> </optional></optional> )
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Returns the result of a JSON path predicate check for the specified
+ JSON value. Only the first item of the result is taken into account.
+ If the result is not Boolean, then <literal>NULL</literal> is returned.
+ The optional <replaceable>vars</replaceable>
+ and <replaceable>silent</replaceable> arguments act the same as
+ for <function>jsonb_path_exists</function>.
+ </para>
+ <para>
+ <literal>jsonb_path_match('{"a":[1,2,3,4,5]}', 'exists($.a[*] ? (@ >= $min && @ <= $max))',
'{"min":2,"max":4}')</literal>
+ <returnvalue>t</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>jsonb_path_query</primary>
+ </indexterm>
+ <function>jsonb_path_query</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>jsonpath</type> <optional>, <replaceable>vars</replaceable> <type>jsonb</type>
<optional>,<replaceable>silent</replaceable> <type>boolean</type> </optional></optional> )
+ <returnvalue>setof jsonb</returnvalue>
+ </para>
+ <para>
+ Returns all JSON items returned by the JSON path for the specified
+ JSON value.
+ The optional <replaceable>vars</replaceable>
+ and <replaceable>silent</replaceable> arguments act the same as
+ for <function>jsonb_path_exists</function>.
+ </para>
+ <para>
+ <literal>select * from jsonb_path_query('{"a":[1,2,3,4,5]}', '$.a[*] ? (@ >= $min && @ <= $max)',
'{"min":2,"max":4}')</literal>
+ <returnvalue></returnvalue>
+<programlisting>
+ jsonb_path_query
+------------------
+ 2
+ 3
+ 4
+</programlisting>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>jsonb_path_query_array</primary>
+ </indexterm>
+ <function>jsonb_path_query_array</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>jsonpath</type> <optional>, <replaceable>vars</replaceable> <type>jsonb</type>
<optional>,<replaceable>silent</replaceable> <type>boolean</type> </optional></optional> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Returns all JSON items returned by the JSON path for the specified
+ JSON value, as a JSON array.
+ The optional <replaceable>vars</replaceable>
+ and <replaceable>silent</replaceable> arguments act the same as
+ for <function>jsonb_path_exists</function>.
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('{"a":[1,2,3,4,5]}', '$.a[*] ? (@ >= $min && @ <= $max)',
'{"min":2,"max":4}')</literal>
+ <returnvalue>[2, 3, 4]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>jsonb_path_query_first</primary>
+ </indexterm>
+ <function>jsonb_path_query_first</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>jsonpath</type> <optional>, <replaceable>vars</replaceable> <type>jsonb</type>
<optional>,<replaceable>silent</replaceable> <type>boolean</type> </optional></optional> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ Returns the first JSON item returned by the JSON path for the
+ specified JSON value. Returns <literal>NULL</literal> if there are no
+ results.
+ The optional <replaceable>vars</replaceable>
+ and <replaceable>silent</replaceable> arguments act the same as
+ for <function>jsonb_path_exists</function>.
+ </para>
+ <para>
+ <literal>jsonb_path_query_first('{"a":[1,2,3,4,5]}', '$.a[*] ? (@ >= $min && @ <= $max)',
'{"min":2,"max":4}')</literal>
+ <returnvalue>2</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>jsonb_path_exists_tz</primary>
+ </indexterm>
+ <function>jsonb_path_exists_tz</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>jsonpath</type> <optional>, <replaceable>vars</replaceable> <type>jsonb</type>
<optional>,<replaceable>silent</replaceable> <type>boolean</type> </optional></optional> )
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_path_match_tz</primary>
+ </indexterm>
+ <function>jsonb_path_match_tz</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>jsonpath</type> <optional>, <replaceable>vars</replaceable> <type>jsonb</type>
<optional>,<replaceable>silent</replaceable> <type>boolean</type> </optional></optional> )
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_path_query_tz</primary>
+ </indexterm>
+ <function>jsonb_path_query_tz</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>jsonpath</type> <optional>, <replaceable>vars</replaceable> <type>jsonb</type>
<optional>,<replaceable>silent</replaceable> <type>boolean</type> </optional></optional> )
+ <returnvalue>setof jsonb</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_path_query_array_tz</primary>
+ </indexterm>
+ <function>jsonb_path_query_array_tz</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>jsonpath</type> <optional>, <replaceable>vars</replaceable> <type>jsonb</type>
<optional>,<replaceable>silent</replaceable> <type>boolean</type> </optional></optional> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_path_query_first_tz</primary>
+ </indexterm>
+ <function>jsonb_path_query_first_tz</function> ( <replaceable>target</replaceable> <type>jsonb</type>,
<replaceable>path</replaceable><type>jsonpath</type> <optional>, <replaceable>vars</replaceable> <type>jsonb</type>
<optional>,<replaceable>silent</replaceable> <type>boolean</type> </optional></optional> )
+ <returnvalue>jsonb</returnvalue>
+ </para>
+ <para>
+ These functions act like their counterparts described above without
+ the <literal>_tz</literal> suffix, except that these functions support
+ comparisons of date/time values that require timezone-aware
+ conversions. The example below requires interpretation of the
+ date-only value <literal>2015-08-02</literal> as a timestamp with time
+ zone, so the result depends on the current
+ <xref linkend="guc-timezone"/> setting. Due to this dependency, these
+ functions are marked as stable, which means these functions cannot be
+ used in indexes. Their counterparts are immutable, and so can be used
+ in indexes; but they will throw errors if asked to make such
+ comparisons.
+ </para>
+ <para>
+ <literal>jsonb_path_exists_tz('["2015-08-01 12:00:00 -05"]', '$[*] ? (@.datetime() <
"2015-08-02".datetime())')</literal>
+ <returnvalue>t</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>jsonb_pretty</primary>
+ </indexterm>
+ <function>jsonb_pretty</function> ( <type>jsonb</type> )
+ <returnvalue>text</returnvalue>
+ </para>
+ <para>
+ Converts the given JSON value to pretty-printed, indented text.
+ </para>
+ <para>
+ <literal>jsonb_pretty('[{"f1":1,"f2":null},2]')</literal>
+ <returnvalue></returnvalue>
+<programlisting>
+[
+ {
+ "f1": 1,
+ "f2": null
+ },
+ 2
+]
+</programlisting>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>json_typeof</primary>
+ </indexterm>
+ <function>json_typeof</function> ( <type>json</type> )
+ <returnvalue>text</returnvalue>
+ </para>
+ <para role="func_signature">
+ <indexterm>
+ <primary>jsonb_typeof</primary>
+ </indexterm>
+ <function>jsonb_typeof</function> ( <type>jsonb</type> )
+ <returnvalue>text</returnvalue>
+ </para>
+ <para>
+ Returns the type of the top-level JSON value as a text string.
+ Possible types are
+ <literal>object</literal>, <literal>array</literal>,
+ <literal>string</literal>, <literal>number</literal>,
+ <literal>boolean</literal>, and <literal>null</literal>.
+ (The <literal>null</literal> result should not be confused
+ with a SQL NULL; see the examples.)
+ </para>
+ <para>
+ <literal>json_typeof('-123.4')</literal>
+ <returnvalue>number</returnvalue>
+ </para>
+ <para>
+ <literal>json_typeof('null'::json)</literal>
+ <returnvalue>null</returnvalue>
+ </para>
+ <para>
+ <literal>json_typeof(NULL::json) IS NULL</literal>
+ <returnvalue>t</returnvalue>
+ </para></entry>
+ </row>
+ </tbody>
+ </tgroup>
+ </table>
+
+ <para>
+ See also <xref linkend="functions-aggregate"/> for the aggregate
+ function <function>json_agg</function> which aggregates record
+ values as JSON, the aggregate function
+ <function>json_object_agg</function> which aggregates pairs of values
+ into a JSON object, and their <type>jsonb</type> equivalents,
+ <function>jsonb_agg</function> and <function>jsonb_object_agg</function>.
+ </para>
+ </sect2>
+
+ <sect2 id="functions-sqljson-path">
+ <title>The SQL/JSON Path Language</title>
+
+ <indexterm zone="functions-sqljson-path">
+ <primary>SQL/JSON path language</primary>
+ </indexterm>
+
+ <para>
+ SQL/JSON path expressions specify the items to be retrieved
+ from the JSON data, similar to XPath expressions used
+ for SQL access to XML. In <productname>PostgreSQL</productname>,
+ path expressions are implemented as the <type>jsonpath</type>
+ data type and can use any elements described in
+ <xref linkend="datatype-jsonpath"/>.
+ </para>
+
+ <para>
+ JSON query functions and operators
+ pass the provided path expression to the <firstterm>path engine</firstterm>
+ for evaluation. If the expression matches the queried JSON data,
+ the corresponding JSON item, or set of items, is returned.
+ Path expressions are written in the SQL/JSON path language
+ and can include arithmetic expressions and functions.
+ </para>
+
+ <para>
+ A path expression consists of a sequence of elements allowed
+ by the <type>jsonpath</type> data type.
+ The path expression is normally evaluated from left to right, but
+ you can use parentheses to change the order of operations.
+ If the evaluation is successful, a sequence of JSON items is produced,
+ and the evaluation result is returned to the JSON query function
+ that completes the specified computation.
+ </para>
+
+ <para>
+ To refer to the JSON value being queried (the
+ <firstterm>context item</firstterm>), use the <literal>$</literal> variable
+ in the path expression. It can be followed by one or more
+ <link linkend="type-jsonpath-accessors">accessor operators</link>,
+ which go down the JSON structure level by level to retrieve sub-items
+ of the context item. Each operator that follows deals with the
+ result of the previous evaluation step.
+ </para>
+
+ <para>
+ For example, suppose you have some JSON data from a GPS tracker that you
+ would like to parse, such as:
+<programlisting>
+{
+ "track": {
+ "segments": [
+ {
+ "location": [ 47.763, 13.4034 ],
+ "start time": "2018-10-14 10:05:14",
+ "HR": 73
+ },
+ {
+ "location": [ 47.706, 13.2635 ],
+ "start time": "2018-10-14 10:39:21",
+ "HR": 135
+ }
+ ]
+ }
+}
+</programlisting>
+ </para>
+
+ <para>
+ To retrieve the available track segments, you need to use the
+ <literal>.<replaceable>key</replaceable></literal> accessor
+ operator to descend through surrounding JSON objects:
+<programlisting>
+$.track.segments
+</programlisting>
+ </para>
+
+ <para>
+ To retrieve the contents of an array, you typically use the
+ <literal>[*]</literal> operator. For example,
+ the following path will return the location coordinates for all
+ the available track segments:
+<programlisting>
+$.track.segments[*].location
+</programlisting>
+ </para>
+
+ <para>
+ To return the coordinates of the first segment only, you can
+ specify the corresponding subscript in the <literal>[]</literal>
+ accessor operator. Recall that JSON array indexes are 0-relative:
+<programlisting>
+$.track.segments[0].location
+</programlisting>
+ </para>
+
+ <para>
+ The result of each path evaluation step can be processed
+ by one or more <type>jsonpath</type> operators and methods
+ listed in <xref linkend="functions-sqljson-path-operators"/>.
+ Each method name must be preceded by a dot. For example,
+ you can get the size of an array:
+<programlisting>
+$.track.segments.size()
+</programlisting>
+ More examples of using <type>jsonpath</type> operators
+ and methods within path expressions appear below in
+ <xref linkend="functions-sqljson-path-operators"/>.
+ </para>
+
+ <para>
+ When defining a path, you can also use one or more
+ <firstterm>filter expressions</firstterm> that work similarly to the
+ <literal>WHERE</literal> clause in SQL. A filter expression begins with
+ a question mark and provides a condition in parentheses:
+
+<programlisting>
+? (<replaceable>condition</replaceable>)
+</programlisting>
+ </para>
+
+ <para>
+ Filter expressions must be written just after the path evaluation step
+ to which they should apply. The result of that step is filtered to include
+ only those items that satisfy the provided condition. SQL/JSON defines
+ three-valued logic, so the condition can be <literal>true</literal>, <literal>false</literal>,
+ or <literal>unknown</literal>. The <literal>unknown</literal> value
+ plays the same role as SQL <literal>NULL</literal> and can be tested
+ for with the <literal>is unknown</literal> predicate. Further path
+ evaluation steps use only those items for which the filter expression
+ returned <literal>true</literal>.
+ </para>
+
+ <para>
+ The functions and operators that can be used in filter expressions are
+ listed in <xref linkend="functions-sqljson-filter-ex-table"/>. Within a
+ filter expression, the <literal>@</literal> variable denotes the value
+ being filtered (i.e., one result of the preceding path step). You can
+ write accessor operators after <literal>@</literal> to retrieve component
+ items.
+ </para>
+
+ <para>
+ For example, suppose you would like to retrieve all heart rate values higher
+ than 130. You can achieve this using the following expression:
+<programlisting>
+$.track.segments[*].HR ? (@ > 130)
+</programlisting>
+ </para>
+
+ <para>
+ To get the start times of segments with such values, you have to
+ filter out irrelevant segments before returning the start times, so the
+ filter expression is applied to the previous step, and the path used
+ in the condition is different:
+<programlisting>
+$.track.segments[*] ? (@.HR > 130)."start time"
+</programlisting>
+ </para>
+
+ <para>
+ You can use several filter expressions in sequence, if required. For
+ example, the following expression selects start times of all segments that
+ contain locations with relevant coordinates and high heart rate values:
+<programlisting>
+$.track.segments[*] ? (@.location[1] < 13.4) ? (@.HR > 130)."start time"
+</programlisting>
+ </para>
+
+ <para>
+ Using filter expressions at different nesting levels is also allowed.
+ The following example first filters all segments by location, and then
+ returns high heart rate values for these segments, if available:
+<programlisting>
+$.track.segments[*] ? (@.location[1] < 13.4).HR ? (@ > 130)
+</programlisting>
+ </para>
+
+ <para>
+ You can also nest filter expressions within each other:
+<programlisting>
+$.track ? (exists(@.segments[*] ? (@.HR > 130))).segments.size()
+</programlisting>
+ This expression returns the size of the track if it contains any
+ segments with high heart rate values, or an empty sequence otherwise.
+ </para>
+
+ <para>
+ <productname>PostgreSQL</productname>'s implementation of the SQL/JSON path
+ language has the following deviations from the SQL/JSON standard:
+ </para>
+
+ <itemizedlist>
+ <listitem>
+ <para>
+ A path expression can be a Boolean predicate, although the SQL/JSON
+ standard allows predicates only in filters. This is necessary for
+ implementation of the <literal>@@</literal> operator. For example,
+ the following <type>jsonpath</type> expression is valid in
+ <productname>PostgreSQL</productname>:
+<programlisting>
+$.track.segments[*].HR < 70
+</programlisting>
+ </para>
+ </listitem>
+
+ <listitem>
+ <para>
+ There are minor differences in the interpretation of regular
+ expression patterns used in <literal>like_regex</literal> filters, as
+ described in <xref linkend="jsonpath-regular-expressions"/>.
+ </para>
+ </listitem>
+ </itemizedlist>
+
+ <sect3 id="strict-and-lax-modes">
+ <title>Strict and Lax Modes</title>
+ <para>
+ When you query JSON data, the path expression may not match the
+ actual JSON data structure. An attempt to access a non-existent
+ member of an object or element of an array results in a
+ structural error. SQL/JSON path expressions have two modes
+ of handling structural errors:
+ </para>
+
+ <itemizedlist>
+ <listitem>
+ <para>
+ lax (default) — the path engine implicitly adapts
+ the queried data to the specified path.
+ Any remaining structural errors are suppressed and converted
+ to empty SQL/JSON sequences.
+ </para>
+ </listitem>
+ <listitem>
+ <para>
+ strict — if a structural error occurs, an error is raised.
+ </para>
+ </listitem>
+ </itemizedlist>
+
+ <para>
+ The lax mode facilitates matching of a JSON document structure and path
+ expression if the JSON data does not conform to the expected schema.
+ If an operand does not match the requirements of a particular operation,
+ it can be automatically wrapped as an SQL/JSON array or unwrapped by
+ converting its elements into an SQL/JSON sequence before performing
+ this operation. Besides, comparison operators automatically unwrap their
+ operands in the lax mode, so you can compare SQL/JSON arrays
+ out-of-the-box. An array of size 1 is considered equal to its sole element.
+ Automatic unwrapping is not performed only when:
+ <itemizedlist>
+ <listitem>
+ <para>
+ The path expression contains <literal>type()</literal> or
+ <literal>size()</literal> methods that return the type
+ and the number of elements in the array, respectively.
+ </para>
+ </listitem>
+ <listitem>
+ <para>
+ The queried JSON data contain nested arrays. In this case, only
+ the outermost array is unwrapped, while all the inner arrays
+ remain unchanged. Thus, implicit unwrapping can only go one
+ level down within each path evaluation step.
+ </para>
+ </listitem>
+ </itemizedlist>
+ </para>
+
+ <para>
+ For example, when querying the GPS data listed above, you can
+ abstract from the fact that it stores an array of segments
+ when using the lax mode:
+<programlisting>
+lax $.track.segments.location
+</programlisting>
+ </para>
+
+ <para>
+ In the strict mode, the specified path must exactly match the structure of
+ the queried JSON document to return an SQL/JSON item, so using this
+ path expression will cause an error. To get the same result as in
+ the lax mode, you have to explicitly unwrap the
+ <literal>segments</literal> array:
+<programlisting>
+strict $.track.segments[*].location
+</programlisting>
+ </para>
+
+ </sect3>
+
+ <sect3 id="functions-sqljson-path-operators">
+ <title>SQL/JSON Path Operators and Methods</title>
+
+ <para>
+ <xref linkend="functions-sqljson-op-table"/> shows the operators and
+ methods available in <type>jsonpath</type>. Note that while the unary
+ operators and methods can be applied to multiple values resulting from a
+ preceding path step, the binary operators (addition etc.) can only be
+ applied to single values.
+ </para>
+
+ <table id="functions-sqljson-op-table">
+ <title><type>jsonpath</type> Operators and Methods</title>
+ <tgroup cols="1">
+ <thead>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ Operator/Method
+ </para>
+ <para>
+ Description
+ </para>
+ <para>
+ Example(s)
+ </para></entry>
+ </row>
+ </thead>
+
+ <tbody>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>number</replaceable> <literal>+</literal> <replaceable>number</replaceable>
+ <returnvalue><replaceable>number</replaceable></returnvalue>
+ </para>
+ <para>
+ Addition
+ </para>
+ <para>
+ <literal>jsonb_path_query('[2]', '$[0] + 3')</literal>
+ <returnvalue>5</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <literal>+</literal> <replaceable>number</replaceable>
+ <returnvalue><replaceable>number</replaceable></returnvalue>
+ </para>
+ <para>
+ Unary plus (no operation); unlike addition, this can iterate over
+ multiple values
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('{"x": [2,3,4]}', '+ $.x')</literal>
+ <returnvalue>[2, 3, 4]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>number</replaceable> <literal>-</literal> <replaceable>number</replaceable>
+ <returnvalue><replaceable>number</replaceable></returnvalue>
+ </para>
+ <para>
+ Subtraction
+ </para>
+ <para>
+ <literal>jsonb_path_query('[2]', '7 - $[0]')</literal>
+ <returnvalue>5</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <literal>-</literal> <replaceable>number</replaceable>
+ <returnvalue><replaceable>number</replaceable></returnvalue>
+ </para>
+ <para>
+ Negation; unlike subtraction, this can iterate over
+ multiple values
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('{"x": [2,3,4]}', '- $.x')</literal>
+ <returnvalue>[-2, -3, -4]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>number</replaceable> <literal>*</literal> <replaceable>number</replaceable>
+ <returnvalue><replaceable>number</replaceable></returnvalue>
+ </para>
+ <para>
+ Multiplication
+ </para>
+ <para>
+ <literal>jsonb_path_query('[4]', '2 * $[0]')</literal>
+ <returnvalue>8</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>number</replaceable> <literal>/</literal> <replaceable>number</replaceable>
+ <returnvalue><replaceable>number</replaceable></returnvalue>
+ </para>
+ <para>
+ Division
+ </para>
+ <para>
+ <literal>jsonb_path_query('[8.5]', '$[0] / 2')</literal>
+ <returnvalue>4.2500000000000000</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>number</replaceable> <literal>%</literal> <replaceable>number</replaceable>
+ <returnvalue><replaceable>number</replaceable></returnvalue>
+ </para>
+ <para>
+ Modulo (remainder)
+ </para>
+ <para>
+ <literal>jsonb_path_query('[32]', '$[0] % 10')</literal>
+ <returnvalue>2</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>value</replaceable> <literal>.</literal> <literal>type()</literal>
+ <returnvalue><replaceable>string</replaceable></returnvalue>
+ </para>
+ <para>
+ Type of the JSON item (see <function>json_typeof</function>)
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('[1, "2", {}]', '$[*].type()')</literal>
+ <returnvalue>["number", "string", "object"]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>value</replaceable> <literal>.</literal> <literal>size()</literal>
+ <returnvalue><replaceable>number</replaceable></returnvalue>
+ </para>
+ <para>
+ Size of the JSON item (number of array elements, or 1 if not an
+ array)
+ </para>
+ <para>
+ <literal>jsonb_path_query('{"m": [11, 15]}', '$.m.size()')</literal>
+ <returnvalue>2</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>value</replaceable> <literal>.</literal> <literal>double()</literal>
+ <returnvalue><replaceable>number</replaceable></returnvalue>
+ </para>
+ <para>
+ Approximate floating-point number converted from a JSON number or
+ string
+ </para>
+ <para>
+ <literal>jsonb_path_query('{"len": "1.9"}', '$.len.double() * 2')</literal>
+ <returnvalue>3.8</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>number</replaceable> <literal>.</literal> <literal>ceiling()</literal>
+ <returnvalue><replaceable>number</replaceable></returnvalue>
+ </para>
+ <para>
+ Nearest integer greater than or equal to the given number
+ </para>
+ <para>
+ <literal>jsonb_path_query('{"h": 1.3}', '$.h.ceiling()')</literal>
+ <returnvalue>2</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>number</replaceable> <literal>.</literal> <literal>floor()</literal>
+ <returnvalue><replaceable>number</replaceable></returnvalue>
+ </para>
+ <para>
+ Nearest integer less than or equal to the given number
+ </para>
+ <para>
+ <literal>jsonb_path_query('{"h": 1.7}', '$.h.floor()')</literal>
+ <returnvalue>1</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>number</replaceable> <literal>.</literal> <literal>abs()</literal>
+ <returnvalue><replaceable>number</replaceable></returnvalue>
+ </para>
+ <para>
+ Absolute value of the given number
+ </para>
+ <para>
+ <literal>jsonb_path_query('{"z": -0.3}', '$.z.abs()')</literal>
+ <returnvalue>0.3</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>string</replaceable> <literal>.</literal> <literal>datetime()</literal>
+ <returnvalue><replaceable>datetime_type</replaceable></returnvalue>
+ (see note)
+ </para>
+ <para>
+ Date/time value converted from a string
+ </para>
+ <para>
+ <literal>jsonb_path_query('["2015-8-1", "2015-08-12"]', '$[*] ? (@.datetime() <
"2015-08-2".datetime())')</literal>
+ <returnvalue>"2015-8-1"</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>string</replaceable> <literal>.</literal>
<literal>datetime(<replaceable>template</replaceable>)</literal>
+ <returnvalue><replaceable>datetime_type</replaceable></returnvalue>
+ (see note)
+ </para>
+ <para>
+ Date/time value converted from a string using the
+ specified <function>to_timestamp</function> template
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('["12:30", "18:40"]', '$[*].datetime("HH24:MI")')</literal>
+ <returnvalue>["12:30:00", "18:40:00"]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>object</replaceable> <literal>.</literal> <literal>keyvalue()</literal>
+ <returnvalue><replaceable>array</replaceable></returnvalue>
+ </para>
+ <para>
+ The object's key-value pairs, represented as an array of objects
+ containing three fields: <literal>"key"</literal>,
+ <literal>"value"</literal>, and <literal>"id"</literal>;
+ <literal>"id"</literal> is a unique identifier of the object the
+ key-value pair belongs to
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('{"x": "20", "y": 32}', '$.keyvalue()')</literal>
+ <returnvalue>[{"id": 0, "key": "x", "value": "20"}, {"id": 0, "key": "y", "value": 32}]</returnvalue>
+ </para></entry>
+ </row>
+ </tbody>
+ </tgroup>
+ </table>
+
+ <note>
+ <para>
+ The result type of the <literal>datetime()</literal> and
+ <literal>datetime(<replaceable>template</replaceable>)</literal>
+ methods can be <type>date</type>, <type>timetz</type>, <type>time</type>,
+ <type>timestamptz</type>, or <type>timestamp</type>.
+ Both methods determine their result type dynamically.
+ </para>
+ <para>
+ The <literal>datetime()</literal> method sequentially tries to
+ match its input string to the ISO formats
+ for <type>date</type>, <type>timetz</type>, <type>time</type>,
+ <type>timestamptz</type>, and <type>timestamp</type>. It stops on
+ the first matching format and emits the corresponding data type.
+ </para>
+ <para>
+ The <literal>datetime(<replaceable>template</replaceable>)</literal>
+ method determines the result type according to the fields used in the
+ provided template string.
+ </para>
+ <para>
+ The <literal>datetime()</literal> and
+ <literal>datetime(<replaceable>template</replaceable>)</literal> methods
+ use the same parsing rules as the <literal>to_timestamp</literal> SQL
+ function does (see <xref linkend="functions-formatting"/>), with three
+ exceptions. First, these methods don't allow unmatched template
+ patterns. Second, only the following separators are allowed in the
+ template string: minus sign, period, solidus (slash), comma, apostrophe,
+ semicolon, colon and space. Third, separators in the template string
+ must exactly match the input string.
+ </para>
+ <para>
+ If different date/time types need to be compared, an implicit cast is
+ applied. A <type>date</type> value can be cast to <type>timestamp</type>
+ or <type>timestamptz</type>, <type>timestamp</type> can be cast to
+ <type>timestamptz</type>, and <type>time</type> to <type>timetz</type>.
+ However, all but the first of these conversions depend on the current
+ <xref linkend="guc-timezone"/> setting, and thus can only be performed
+ within timezone-aware <type>jsonpath</type> functions.
+ </para>
+ </note>
+
+ <para>
+ <xref linkend="functions-sqljson-filter-ex-table"/> shows the available
+ filter expression elements.
+ </para>
+
+ <table id="functions-sqljson-filter-ex-table">
+ <title><type>jsonpath</type> Filter Expression Elements</title>
+ <tgroup cols="1">
+ <thead>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ Predicate/Value
+ </para>
+ <para>
+ Description
+ </para>
+ <para>
+ Example(s)
+ </para></entry>
+ </row>
+ </thead>
+
+ <tbody>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>value</replaceable> <literal>==</literal> <replaceable>value</replaceable>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Equality comparison (this, and the other comparison operators, work on
+ all JSON scalar values)
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('[1, "a", 1, 3]', '$[*] ? (@ == 1)')</literal>
+ <returnvalue>[1, 1]</returnvalue>
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('[1, "a", 1, 3]', '$[*] ? (@ == "a")')</literal>
+ <returnvalue>["a"]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>value</replaceable> <literal>!=</literal> <replaceable>value</replaceable>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para role="func_signature">
+ <replaceable>value</replaceable> <literal><></literal> <replaceable>value</replaceable>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Non-equality comparison
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('[1, 2, 1, 3]', '$[*] ? (@ != 1)')</literal>
+ <returnvalue>[2, 3]</returnvalue>
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('["a", "b", "c"]', '$[*] ? (@ <> "b")')</literal>
+ <returnvalue>["a", "c"]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>value</replaceable> <literal><</literal> <replaceable>value</replaceable>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Less-than comparison
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('[1, 2, 3]', '$[*] ? (@ < 2)')</literal>
+ <returnvalue>[1]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>value</replaceable> <literal><=</literal> <replaceable>value</replaceable>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Less-than-or-equal-to comparison
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('["a", "b", "c"]', '$[*] ? (@ <= "b")')</literal>
+ <returnvalue>["a", "b"]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>value</replaceable> <literal>></literal> <replaceable>value</replaceable>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Greater-than comparison
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('[1, 2, 3]', '$[*] ? (@ > 2)')</literal>
+ <returnvalue>[3]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>value</replaceable> <literal>>=</literal> <replaceable>value</replaceable>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Greater-than-or-equal-to comparison
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('[1, 2, 3]', '$[*] ? (@ >= 2)')</literal>
+ <returnvalue>[2, 3]</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <literal>true</literal>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ JSON constant <literal>true</literal>
+ </para>
+ <para>
+ <literal>jsonb_path_query('[{"name": "John", "parent": false}, {"name": "Chris", "parent": true}]', '$[*] ?
(@.parent== true)')</literal>
+ <returnvalue>{"name": "Chris", "parent": true}</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <literal>false</literal>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ JSON constant <literal>false</literal>
+ </para>
+ <para>
+ <literal>jsonb_path_query('[{"name": "John", "parent": false}, {"name": "Chris", "parent": true}]', '$[*] ?
(@.parent== false)')</literal>
+ <returnvalue>{"name": "John", "parent": false}</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <literal>null</literal>
+ <returnvalue><replaceable>value</replaceable></returnvalue>
+ </para>
+ <para>
+ JSON constant <literal>null</literal> (note that, unlike in SQL,
+ comparison to <literal>null</literal> works normally)
+ </para>
+ <para>
+ <literal>jsonb_path_query('[{"name": "Mary", "job": null}, {"name": "Michael", "job": "driver"}]', '$[*] ?
(@.job== null) .name')</literal>
+ <returnvalue>"Mary"</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>boolean</replaceable> <literal>&&</literal> <replaceable>boolean</replaceable>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Boolean AND
+ </para>
+ <para>
+ <literal>jsonb_path_query('[1, 3, 7]', '$[*] ? (@ > 1 && @ < 5)')</literal>
+ <returnvalue>3</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>boolean</replaceable> <literal>||</literal> <replaceable>boolean</replaceable>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Boolean OR
+ </para>
+ <para>
+ <literal>jsonb_path_query('[1, 3, 7]', '$[*] ? (@ < 1 || @ > 5)')</literal>
+ <returnvalue>7</returnvalue>
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <literal>!</literal> <replaceable>boolean</replaceable>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Boolean NOT
+ </para>
+ <para>
+ <literal>jsonb_path_query('[1, 3, 7]', '$[*] ? (!(@ < 5))')</literal>
+ <returnvalue>7</returnvalue>
+ </para></entry>
+ </row>
- <itemizedlist>
- <listitem>
- <para>
- lax (default) — the path engine implicitly adapts
- the queried data to the specified path.
- Any remaining structural errors are suppressed and converted
- to empty SQL/JSON sequences.
- </para>
- </listitem>
- <listitem>
- <para>
- strict — if a structural error occurs, an error is raised.
- </para>
- </listitem>
- </itemizedlist>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>boolean</replaceable> <literal>is unknown</literal>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Tests whether a Boolean condition is <literal>unknown</literal>.
+ </para>
+ <para>
+ <literal>jsonb_path_query('[-1, 2, 7, "foo"]', '$[*] ? ((@ > 0) is unknown)')</literal>
+ <returnvalue>"foo"</returnvalue>
+ </para></entry>
+ </row>
- <para>
- The lax mode facilitates matching of a JSON document structure and path
- expression if the JSON data does not conform to the expected schema.
- If an operand does not match the requirements of a particular operation,
- it can be automatically wrapped as an SQL/JSON array or unwrapped by
- converting its elements into an SQL/JSON sequence before performing
- this operation. Besides, comparison operators automatically unwrap their
- operands in the lax mode, so you can compare SQL/JSON arrays
- out-of-the-box. An array of size 1 is considered equal to its sole element.
- Automatic unwrapping is not performed only when:
- <itemizedlist>
- <listitem>
- <para>
- The path expression contains <literal>type()</literal> or
- <literal>size()</literal> methods that return the type
- and the number of elements in the array, respectively.
- </para>
- </listitem>
- <listitem>
- <para>
- The queried JSON data contain nested arrays. In this case, only
- the outermost array is unwrapped, while all the inner arrays
- remain unchanged. Thus, implicit unwrapping can only go one
- level down within each path evaluation step.
- </para>
- </listitem>
- </itemizedlist>
- </para>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>string</replaceable> <literal>like_regex</literal> <replaceable>string</replaceable> <optional>
<literal>flag</literal><replaceable>string</replaceable> </optional>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Tests whether the first operand matches the regular expression
+ given by the second operand, optionally with modifications
+ described by a string of <literal>flag</literal> characters (see
+ <xref linkend="jsonpath-regular-expressions"/>).
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('["abc", "abd", "aBdC", "abdacb", "babc"]', '$[*] ? (@ like_regex
"^ab.*c")')</literal>
+ <returnvalue>["abc", "abdacb"]</returnvalue>
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('["abc", "abd", "aBdC", "abdacb", "babc"]', '$[*] ? (@ like_regex "^ab.*c"
flag"i")')</literal>
+ <returnvalue>["abc", "aBdC", "abdacb"]</returnvalue>
+ </para></entry>
+ </row>
- <para>
- For example, when querying the GPS data listed above, you can
- abstract from the fact that it stores an array of segments
- when using the lax mode:
-<programlisting>
-'lax $.track.segments.location'
-</programlisting>
- </para>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <replaceable>string</replaceable> <literal>starts with</literal> <replaceable>string</replaceable>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Tests whether the second operand is an initial substring of the first
+ operand.
+ </para>
+ <para>
+ <literal>jsonb_path_query('["John Smith", "Mary Stone", "Bob Johnson"]', '$[*] ? (@ starts with
"John")')</literal>
+ <returnvalue>"John Smith"</returnvalue>
+ </para></entry>
+ </row>
- <para>
- In the strict mode, the specified path must exactly match the structure of
- the queried JSON document to return an SQL/JSON item, so using this
- path expression will cause an error. To get the same result as in
- the lax mode, you have to explicitly unwrap the
- <literal>segments</literal> array:
-<programlisting>
-'strict $.track.segments[*].location'
-</programlisting>
- </para>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <literal>exists</literal> <literal>(</literal> <replaceable>path_expression</replaceable> <literal>)</literal>
+ <returnvalue>boolean</returnvalue>
+ </para>
+ <para>
+ Tests whether a path expression matches at least one SQL/JSON item.
+ Returns <literal>unknown</literal> if the path expression would result
+ in an error; the second example uses this to avoid a no-such-key error
+ in strict mode.
+ </para>
+ <para>
+ <literal>jsonb_path_query('{"x": [1, 2], "y": [2, 4]}', 'strict $.* ? (exists (@ ? (@[*] > 2)))')</literal>
+ <returnvalue>[2, 4]</returnvalue>
+ </para>
+ <para>
+ <literal>jsonb_path_query_array('{"value": 41}', 'strict $ ? (exists (@.name)) .name')</literal>
+ <returnvalue>[]</returnvalue>
+ </para></entry>
+ </row>
+ </tbody>
+ </tgroup>
+ </table>
</sect3>
<sect3 id="jsonpath-regular-expressions">
- <title>Regular Expressions</title>
+ <title>SQL/JSON Regular Expressions</title>
<indexterm zone="jsonpath-regular-expressions">
<primary><literal>LIKE_REGEX</literal></primary>
@@ -15835,7 +16751,7 @@ table2-mapping
following SQL/JSON path query would case-insensitively match all
strings in an array that start with an English vowel:
<programlisting>
-'$[*] ? (@ like_regex "^[aeiou]" flag "i")'
+$[*] ? (@ like_regex "^[aeiou]" flag "i")
</programlisting>
</para>
@@ -15872,340 +16788,9 @@ table2-mapping
backslashes you want to use in the regular expression must be doubled.
For example, to match strings that contain only digits:
<programlisting>
-'$ ? (@ like_regex "^\\d+$")'
+$ ? (@ like_regex "^\\d+$")
</programlisting>
</para>
-
- </sect3>
-
- <sect3 id="functions-sqljson-path-operators">
- <title>SQL/JSON Path Operators and Methods</title>
-
- <para>
- <xref linkend="functions-sqljson-op-table"/> shows the operators and
- methods available in <type>jsonpath</type>. <xref
- linkend="functions-sqljson-filter-ex-table"/> shows the available filter
- expression elements.
- </para>
-
- <table id="functions-sqljson-op-table">
- <title><type>jsonpath</type> Operators and Methods</title>
- <tgroup cols="5">
- <thead>
- <row>
- <entry>Operator/Method</entry>
- <entry>Description</entry>
- <entry>Example JSON</entry>
- <entry>Example Query</entry>
- <entry>Result</entry>
- </row>
- </thead>
- <tbody>
- <row>
- <entry><literal>+</literal> (unary)</entry>
- <entry>Plus operator that iterates over the SQL/JSON sequence</entry>
- <entry><literal>{"x": [2.85, -14.7, -9.4]}</literal></entry>
- <entry><literal>+ $.x.floor()</literal></entry>
- <entry><literal>2, -15, -10</literal></entry>
- </row>
- <row>
- <entry><literal>-</literal> (unary)</entry>
- <entry>Minus operator that iterates over the SQL/JSON sequence</entry>
- <entry><literal>{"x": [2.85, -14.7, -9.4]}</literal></entry>
- <entry><literal>- $.x.floor()</literal></entry>
- <entry><literal>-2, 15, 10</literal></entry>
- </row>
- <row>
- <entry><literal>+</literal> (binary)</entry>
- <entry>Addition</entry>
- <entry><literal>[2]</literal></entry>
- <entry><literal>2 + $[0]</literal></entry>
- <entry><literal>4</literal></entry>
- </row>
- <row>
- <entry><literal>-</literal> (binary)</entry>
- <entry>Subtraction</entry>
- <entry><literal>[2]</literal></entry>
- <entry><literal>4 - $[0]</literal></entry>
- <entry><literal>2</literal></entry>
- </row>
- <row>
- <entry><literal>*</literal></entry>
- <entry>Multiplication</entry>
- <entry><literal>[4]</literal></entry>
- <entry><literal>2 * $[0]</literal></entry>
- <entry><literal>8</literal></entry>
- </row>
- <row>
- <entry><literal>/</literal></entry>
- <entry>Division</entry>
- <entry><literal>[8]</literal></entry>
- <entry><literal>$[0] / 2</literal></entry>
- <entry><literal>4</literal></entry>
- </row>
- <row>
- <entry><literal>%</literal></entry>
- <entry>Modulus</entry>
- <entry><literal>[32]</literal></entry>
- <entry><literal>$[0] % 10</literal></entry>
- <entry><literal>2</literal></entry>
- </row>
- <row>
- <entry><literal>type()</literal></entry>
- <entry>Type of the SQL/JSON item</entry>
- <entry><literal>[1, "2", {}]</literal></entry>
- <entry><literal>$[*].type()</literal></entry>
- <entry><literal>"number", "string", "object"</literal></entry>
- </row>
- <row>
- <entry><literal>size()</literal></entry>
- <entry>Size of the SQL/JSON item</entry>
- <entry><literal>{"m": [11, 15]}</literal></entry>
- <entry><literal>$.m.size()</literal></entry>
- <entry><literal>2</literal></entry>
- </row>
- <row>
- <entry><literal>double()</literal></entry>
- <entry>Approximate floating-point number converted from an SQL/JSON number or a string</entry>
- <entry><literal>{"len": "1.9"}</literal></entry>
- <entry><literal>$.len.double() * 2</literal></entry>
- <entry><literal>3.8</literal></entry>
- </row>
- <row>
- <entry><literal>ceiling()</literal></entry>
- <entry>Nearest integer greater than or equal to the SQL/JSON number</entry>
- <entry><literal>{"h": 1.3}</literal></entry>
- <entry><literal>$.h.ceiling()</literal></entry>
- <entry><literal>2</literal></entry>
- </row>
- <row>
- <entry><literal>floor()</literal></entry>
- <entry>Nearest integer less than or equal to the SQL/JSON number</entry>
- <entry><literal>{"h": 1.3}</literal></entry>
- <entry><literal>$.h.floor()</literal></entry>
- <entry><literal>1</literal></entry>
- </row>
- <row>
- <entry><literal>abs()</literal></entry>
- <entry>Absolute value of the SQL/JSON number</entry>
- <entry><literal>{"z": -0.3}</literal></entry>
- <entry><literal>$.z.abs()</literal></entry>
- <entry><literal>0.3</literal></entry>
- </row>
- <row>
- <entry><literal>datetime()</literal></entry>
- <entry>Date/time value converted from a string</entry>
- <entry><literal>["2015-8-1", "2015-08-12"]</literal></entry>
- <entry><literal>$[*] ? (@.datetime() < "2015-08-2". datetime())</literal></entry>
- <entry><literal>2015-8-1</literal></entry>
- </row>
- <row>
- <entry><literal>datetime(<replaceable>template</replaceable>)</literal></entry>
- <entry>Date/time value converted from a string using the specified template</entry>
- <entry><literal>["12:30", "18:40"]</literal></entry>
- <entry><literal>$[*].datetime("HH24:MI")</literal></entry>
- <entry><literal>"12:30:00", "18:40:00"</literal></entry>
- </row>
- <row>
- <entry><literal>keyvalue()</literal></entry>
- <entry>
- Sequence of object's key-value pairs represented as array of items
- containing three fields (<literal>"key"</literal>,
- <literal>"value"</literal>, and <literal>"id"</literal>).
- <literal>"id"</literal> is a unique identifier of the object
- key-value pair belongs to.
- </entry>
- <entry><literal>{"x": "20", "y": 32}</literal></entry>
- <entry><literal>$.keyvalue()</literal></entry>
- <entry><literal>{"key": "x", "value": "20", "id": 0}, {"key": "y", "value": 32, "id": 0}</literal></entry>
- </row>
- </tbody>
- </tgroup>
- </table>
-
- <note>
- <para>
- The result type of <literal>datetime()</literal> and
- <literal>datetime(<replaceable>template</replaceable>)</literal>
- methods can be <type>date</type>, <type>timetz</type>, <type>time</type>,
- <type>timestamptz</type>, or <type>timestamp</type>.
- Both methods determine the result type dynamically.
- </para>
- <para>
- The <literal>datetime()</literal> method sequentially tries ISO formats
- for <type>date</type>, <type>timetz</type>, <type>time</type>,
- <type>timestamptz</type>, and <type>timestamp</type>. It stops on
- the first matching format and the corresponding data type.
- </para>
- <para>
- The <literal>datetime(<replaceable>template</replaceable>)</literal>
- method determines the result type by the provided template string.
- </para>
- <para>
- The <literal>datetime()</literal> and
- <literal>datetime(<replaceable>template</replaceable>)</literal> methods
- use the same parsing rules as the <literal>to_timestamp</literal> SQL
- function does (see <xref linkend="functions-formatting"/>), with three
- exceptions. First, these methods don't allow unmatched template
- patterns. Second, only the following separators are allowed in the
- template string: minus sign, period, solidus (slash), comma, apostrophe,
- semicolon, colon and space. Third, separators in the template string
- must exactly match the input string.
- </para>
- </note>
-
- <table id="functions-sqljson-filter-ex-table">
- <title><type>jsonpath</type> Filter Expression Elements</title>
- <tgroup cols="5">
- <thead>
- <row>
- <entry>Value/Predicate</entry>
- <entry>Description</entry>
- <entry>Example JSON</entry>
- <entry>Example Query</entry>
- <entry>Result</entry>
- </row>
- </thead>
- <tbody>
- <row>
- <entry><literal>==</literal></entry>
- <entry>Equality operator</entry>
- <entry><literal>[1, 2, 1, 3]</literal></entry>
- <entry><literal>$[*] ? (@ == 1)</literal></entry>
- <entry><literal>1, 1</literal></entry>
- </row>
- <row>
- <entry><literal>!=</literal></entry>
- <entry>Non-equality operator</entry>
- <entry><literal>[1, 2, 1, 3]</literal></entry>
- <entry><literal>$[*] ? (@ != 1)</literal></entry>
- <entry><literal>2, 3</literal></entry>
- </row>
- <row>
- <entry><literal><></literal></entry>
- <entry>Non-equality operator (same as <literal>!=</literal>)</entry>
- <entry><literal>[1, 2, 1, 3]</literal></entry>
- <entry><literal>$[*] ? (@ <> 1)</literal></entry>
- <entry><literal>2, 3</literal></entry>
- </row>
- <row>
- <entry><literal><</literal></entry>
- <entry>Less-than operator</entry>
- <entry><literal>[1, 2, 3]</literal></entry>
- <entry><literal>$[*] ? (@ < 2)</literal></entry>
- <entry><literal>1</literal></entry>
- </row>
- <row>
- <entry><literal><=</literal></entry>
- <entry>Less-than-or-equal-to operator</entry>
- <entry><literal>[1, 2, 3]</literal></entry>
- <entry><literal>$[*] ? (@ <= 2)</literal></entry>
- <entry><literal>1, 2</literal></entry>
- </row>
- <row>
- <entry><literal>></literal></entry>
- <entry>Greater-than operator</entry>
- <entry><literal>[1, 2, 3]</literal></entry>
- <entry><literal>$[*] ? (@ > 2)</literal></entry>
- <entry><literal>3</literal></entry>
- </row>
- <row>
- <entry><literal>>=</literal></entry>
- <entry>Greater-than-or-equal-to operator</entry>
- <entry><literal>[1, 2, 3]</literal></entry>
- <entry><literal>$[*] ? (@ >= 2)</literal></entry>
- <entry><literal>2, 3</literal></entry>
- </row>
- <row>
- <entry><literal>true</literal></entry>
- <entry>Value used to perform comparison with JSON <literal>true</literal> literal</entry>
- <entry><literal>[{"name": "John", "parent": false},
- {"name": "Chris", "parent": true}]</literal></entry>
- <entry><literal>$[*] ? (@.parent == true)</literal></entry>
- <entry><literal>{"name": "Chris", "parent": true}</literal></entry>
- </row>
- <row>
- <entry><literal>false</literal></entry>
- <entry>Value used to perform comparison with JSON <literal>false</literal> literal</entry>
- <entry><literal>[{"name": "John", "parent": false},
- {"name": "Chris", "parent": true}]</literal></entry>
- <entry><literal>$[*] ? (@.parent == false)</literal></entry>
- <entry><literal>{"name": "John", "parent": false}</literal></entry>
- </row>
- <row>
- <entry><literal>null</literal></entry>
- <entry>Value used to perform comparison with JSON <literal>null</literal> value</entry>
- <entry><literal>[{"name": "Mary", "job": null},
- {"name": "Michael", "job": "driver"}]</literal></entry>
- <entry><literal>$[*] ? (@.job == null) .name</literal></entry>
- <entry><literal>"Mary"</literal></entry>
- </row>
- <row>
- <entry><literal>&&</literal></entry>
- <entry>Boolean AND</entry>
- <entry><literal>[1, 3, 7]</literal></entry>
- <entry><literal>$[*] ? (@ > 1 && @ < 5)</literal></entry>
- <entry><literal>3</literal></entry>
- </row>
- <row>
- <entry><literal>||</literal></entry>
- <entry>Boolean OR</entry>
- <entry><literal>[1, 3, 7]</literal></entry>
- <entry><literal>$[*] ? (@ < 1 || @ > 5)</literal></entry>
- <entry><literal>7</literal></entry>
- </row>
- <row>
- <entry><literal>!</literal></entry>
- <entry>Boolean NOT</entry>
- <entry><literal>[1, 3, 7]</literal></entry>
- <entry><literal>$[*] ? (!(@ < 5))</literal></entry>
- <entry><literal>7</literal></entry>
- </row>
- <row>
- <entry><literal>like_regex</literal></entry>
- <entry>
- Tests whether the first operand matches the regular expression
- given by the second operand, optionally with modifications
- described by a string of <literal>flag</literal> characters (see
- <xref linkend="jsonpath-regular-expressions"/>)
- </entry>
- <entry><literal>["abc", "abd", "aBdC", "abdacb", "babc"]</literal></entry>
- <entry><literal>$[*] ? (@ like_regex "^ab.*c" flag "i")</literal></entry>
- <entry><literal>"abc", "aBdC", "abdacb"</literal></entry>
- </row>
- <row>
- <entry><literal>starts with</literal></entry>
- <entry>Tests whether the second operand is an initial substring of the first operand</entry>
- <entry><literal>["John Smith", "Mary Stone", "Bob Johnson"]</literal></entry>
- <entry><literal>$[*] ? (@ starts with "John")</literal></entry>
- <entry><literal>"John Smith"</literal></entry>
- </row>
- <row>
- <entry><literal>exists</literal></entry>
- <entry>Tests whether a path expression matches at least one SQL/JSON item</entry>
- <entry><literal>{"x": [1, 2], "y": [2, 4]}</literal></entry>
- <entry><literal>strict $.* ? (exists (@ ? (@[*] > 2)))</literal></entry>
- <entry><literal>2, 4</literal></entry>
- </row>
- <row>
- <entry><literal>is unknown</literal></entry>
- <entry>Tests whether a Boolean condition is <literal>unknown</literal></entry>
- <entry><literal>[-1, 2, 7, "infinity"]</literal></entry>
- <entry><literal>$[*] ? ((@ > 0) is unknown)</literal></entry>
- <entry><literal>"infinity"</literal></entry>
- </row>
- </tbody>
- </tgroup>
- </table>
-
- <note>
- <para>
- When different date/time values are compared, an implicit cast is
- applied. A <type>date</type> value can be cast to <type>timestamp</type>
- or <type>timestamptz</type>, <type>timestamp</type> can be cast to
- <type>timestamptz</type>, and <type>time</type> — to <type>timetz</type>.
- </para>
- </note>
</sect3>
</sect2>
</sect1>
On 4/29/20 8:15 PM, Tom Lane wrote:
> "Jonathan S. Katz" <jkatz@postgresql.org> writes:
>> On 4/29/20 7:40 PM, Jonathan S. Katz wrote:
>>> I'll compromise on the temporary importants, but first I want to see
>>> what's causing the need for it. Do you have a suggestion on a page to test?
>
> I haven't yet pushed anything dependent on the new markup, but
> attached is a draft revision for the JSON section; if you look at
> the SRFs such as json_array_elements you'll see the issue.
>
>> From real quick I got it to here. With the latest copy of the doc builds
>> it appears to still work as expected, but I need a section with the new
>> "pre" block to test.
>
> Yeah, I see you found the same <p> and <pre> settings I did.
>
>> I think the "background-color: inherit !important" is a bit odd, and
>> would like to trace that one down a bit more, but I did not see anything
>> obvious on my glance through it.
>
> I think it's coming from this bit at about main.css:660:
>
> pre,
> code,
> #docContent kbd,
> #docContent tt.LITERAL,
> #docContent tt.REPLACEABLE {
> font-size: 0.9rem !important;
> color: inherit !important;
> background-color: #f8f9fa !important;
> border-radius: .25rem;
> margin: .6rem 0;
> font-weight: 300;
> }
>
> I had to override most of that.
Yeah, I had started toying with that and saw no differences, but I would
need to test against anything in particular. I'm pretty confident we can
remove those importants, based on my desultory testing.
I'll try and get the patch built + docs loaded, and see if we can safely
remove those.
Jonathan
Attachment
On 4/29/20 9:22 PM, Jonathan S. Katz wrote:
> On 4/29/20 8:15 PM, Tom Lane wrote:
>> "Jonathan S. Katz" <jkatz@postgresql.org> writes:
>>> On 4/29/20 7:40 PM, Jonathan S. Katz wrote:
>>>> I'll compromise on the temporary importants, but first I want to see
>>>> what's causing the need for it. Do you have a suggestion on a page to test?
>>
>> I haven't yet pushed anything dependent on the new markup, but
>> attached is a draft revision for the JSON section; if you look at
>> the SRFs such as json_array_elements you'll see the issue.
^ This was super helpful. Built locally, and made it really easy to
test. Thanks!
>>> From real quick I got it to here. With the latest copy of the doc builds
>>> it appears to still work as expected, but I need a section with the new
>>> "pre" block to test.
>>
>> Yeah, I see you found the same <p> and <pre> settings I did.
>>
>>> I think the "background-color: inherit !important" is a bit odd, and
>>> would like to trace that one down a bit more, but I did not see anything
>>> obvious on my glance through it.
>>
>> I think it's coming from this bit at about main.css:660:
>>
>> pre,
>> code,
>> #docContent kbd,
>> #docContent tt.LITERAL,
>> #docContent tt.REPLACEABLE {
>> font-size: 0.9rem !important;
>> color: inherit !important;
>> background-color: #f8f9fa !important;
>> border-radius: .25rem;
>> margin: .6rem 0;
>> font-weight: 300;
>> }
>>
>> I had to override most of that.
>
> Yeah, I had started toying with that and saw no differences, but I would
> need to test against anything in particular. I'm pretty confident we can
> remove those importants, based on my desultory testing.
>
> I'll try and get the patch built + docs loaded, and see if we can safely
> remove those.
Please see latest attached. I've eliminated the !important, condensed
the CSS, and the desultory (yes, my word of the week) testing did not
find issues in devel or earlier versions.
Please let me know if this works for you. If it does, I'll push it up to
pgweb.
Jonathan
Attachment
"Jonathan S. Katz" <jkatz@postgresql.org> writes:
> Please see latest attached. I've eliminated the !important, condensed
> the CSS, and the desultory (yes, my word of the week) testing did not
> find issues in devel or earlier versions.
> Please let me know if this works for you. If it does, I'll push it up to
> pgweb.
NAK ... that does *not* work for me.
It looks to me like you are expecting that "margin" with four parameters
will override an outer-level setting of margin-bottom, but that is not
how my browser is responding. ISTM you need to explicitly set the very
same parameters in the more-specific rule as in the less-specific rule
that you want to override.
I get reasonable results with these settings, but not with
anything more abbreviated:
#docContent table.table th.func_table_entry p,
#docContent table.table td.func_table_entry p {
margin-top: 0.1em;
margin-bottom: 0.1em;
padding-left: 4em;
text-align: left;
}
#docContent table.table p.func_signature {
text-indent: -3.5em;
}
#docContent table.table td.func_table_entry pre.programlisting {
background-color: inherit;
border: 0;
margin-top: 0.1em;
margin-bottom: 0.1em;
padding: 0;
padding-left: 4em;
}
In particular, it might look like the multiple padding settings
in the pre.programlisting rule are redundant ... but they are not, at
least not with Safari.
regards, tom lane
On 4/29/20 10:38 PM, Tom Lane wrote: > "Jonathan S. Katz" <jkatz@postgresql.org> writes: >> Please see latest attached. I've eliminated the !important, condensed >> the CSS, and the desultory (yes, my word of the week) testing did not >> find issues in devel or earlier versions. > >> Please let me know if this works for you. If it does, I'll push it up to >> pgweb. > > NAK ... that does *not* work for me. Learned a new acronym... > It looks to me like you are expecting that "margin" with four parameters > will override an outer-level setting of margin-bottom, but that is not > how my browser is responding. ISTM you need to explicitly set the very > same parameters in the more-specific rule as in the less-specific rule > that you want to override. > > I get reasonable results with these settings, but not with > anything more abbreviated: > In particular, it might look like the multiple padding settings > in the pre.programlisting rule are redundant ... but they are not, at > least not with Safari. Clearly I was caught doing a single browser test (Chrome). Reverted back to the verbose way sans !important, attached, which appears to be the consensus. If you can ACK this, I'll commit. Thanks, Jonathan
Attachment
"Jonathan S. Katz" <jkatz@postgresql.org> writes:
> Clearly I was caught doing a single browser test (Chrome).
Well, I've not tested anything but Safari, either ...
> Reverted back to the verbose way sans !important, attached, which
> appears to be the consensus. If you can ACK this, I'll commit.
This one works for me.
regards, tom lane
On 4/29/20 11:26 PM, Tom Lane wrote: > "Jonathan S. Katz" <jkatz@postgresql.org> writes: >> Clearly I was caught doing a single browser test (Chrome). > > Well, I've not tested anything but Safari, either ... > >> Reverted back to the verbose way sans !important, attached, which >> appears to be the consensus. If you can ACK this, I'll commit. > > This one works for me. Pushed. Thanks! Jonathan
Attachment
I've now completed updating chapter 9 for the new layout, and the results are visible at https://www.postgresql.org/docs/devel/functions.html There is more to do --- for instance, various contrib modules have function/operator tables that should be synced with this design. But this seemed like a good place to pause and reflect. After working through the whole chapter, the only aspect of the new markup that really doesn't seem to work so well is the use of <returnvalue> for function result types and example results. While I don't think that that's broken in concept, DocBook has restrictions on the contents of <returnvalue> that are problematic: * It won't let you put any verbatim-layout environment, such as <programlisting>, inside <returnvalue>. This is an issue for examples for set-returning functions in particular. I've done those like this: <para> <literal>regexp_matches('foobarbequebaz', 'ba.', 'g')</literal> <returnvalue></returnvalue> <programlisting> {bar} {baz} </programlisting> (2 rows in result) </para> where the empty <returnvalue> environment is just serving to generate a right arrow. It looks all right, but it's hardly semantically-based markup. * <returnvalue> is also quite sticky about inserting other sorts of font-changing environments inside it. As an example, it'll let you include <replaceable> but not <type>, which seems pretty weird to me. This is problematic in some places where it's desirable to have text rather than just a type name, for example <function>stddev</function> ( <replaceable>numeric_type</replaceable> ) <returnvalue></returnvalue> <type>double precision</type> for <type>real</type> or <type>double precision</type>, otherwise <type>numeric</type> Now I could have done this example by spelling out all six varieties of stddev() separately, and maybe I should've, but it seemed overly bulky that way. So again <returnvalue> is just generating the right arrow. * After experimenting with a few different ways to handle functions with multiple OUT parameters, I settled on doing it like this: <function>pg_partition_tree</function> ( <type>regclass</type> ) <returnvalue>setof record</returnvalue> ( <parameter>relid</parameter> <type>regclass</type>, <parameter>parentrelid</parameter> <type>regclass</type>, <parameter>isleaf</parameter> <type>boolean</type>, <parameter>level</parameter> <type>integer</type> ) This looks nice and I think it's much more intelligible than other things I tried --- in particular, including the OUT parameters in the function signature seems to me to be mostly confusing. But, once again, it's abusing the concept that <returnvalue> contains the result type. Ideally the output-column list would be inside the <returnvalue> environment, but DocBook won't allow that because of the <type> tags. So at this point I'm tempted to abandon <returnvalue> and go back to using a custom entity to generate the right arrow, so that the markup would just look like, say, <function>stddev</function> ( <replaceable>numeric_type</replaceable> ) &returns; <type>double precision</type> for <type>real</type> or <type>double precision</type>, otherwise <type>numeric</type> Does anyone have a preference on that, or a better alternative? regards, tom lane
On 5/4/20 5:22 PM, Tom Lane wrote: > I've now completed updating chapter 9 for the new layout, > and the results are visible at > https://www.postgresql.org/docs/devel/functions.html > There is more to do --- for instance, various contrib modules > have function/operator tables that should be synced with this > design. But this seemed like a good place to pause and reflect. This is already much better. I've skimmed through a few of the pages, I can say that the aggregates page[1] is WAY easier to read. Yay! > > After working through the whole chapter, the only aspect of the > new markup that really doesn't seem to work so well is the use > of <returnvalue> for function result types and example results. > While I don't think that that's broken in concept, DocBook has > restrictions on the contents of <returnvalue> that are problematic: > > * It won't let you put any verbatim-layout environment, such > as <programlisting>, inside <returnvalue>. This is an issue for > examples for set-returning functions in particular. I've done > those like this: > > <para> > <literal>regexp_matches('foobarbequebaz', 'ba.', 'g')</literal> > <returnvalue></returnvalue> > <programlisting> > {bar} > {baz} > </programlisting> > (2 rows in result) > </para> > > where the empty <returnvalue> environment is just serving to generate a > right arrow. It looks all right, but it's hardly semantically-based > markup. We could apply some CSS on the pgweb front perhaps to help distinguish at least the results? For the above example, it would be great to capture the program listing + "2 rows in result" output and format them similarly, though it appears the "(2 rows in result)" is in its own block. Anyway, likely not that hard to apply some CSS and make it appear a bit more distinguished, if that's the general idea. > * <returnvalue> is also quite sticky about inserting other sorts > of font-changing environments inside it. As an example, it'll let > you include <replaceable> but not <type>, which seems pretty weird > to me. This is problematic in some places where it's desirable to > have text rather than just a type name, for example > > <function>stddev</function> ( <replaceable>numeric_type</replaceable> ) > <returnvalue></returnvalue> <type>double precision</type> > for <type>real</type> or <type>double precision</type>, > otherwise <type>numeric</type> > > Now I could have done this example by spelling out all six varieties of > stddev() separately, and maybe I should've, but it seemed overly bulky > that way. So again <returnvalue> is just generating the right arrow. > > * After experimenting with a few different ways to handle functions with > multiple OUT parameters, I settled on doing it like this: > > <function>pg_partition_tree</function> ( <type>regclass</type> ) > <returnvalue>setof record</returnvalue> > ( <parameter>relid</parameter> <type>regclass</type>, > <parameter>parentrelid</parameter> <type>regclass</type>, > <parameter>isleaf</parameter> <type>boolean</type>, > <parameter>level</parameter> <type>integer</type> ) > > This looks nice and I think it's much more intelligible than other > things I tried --- in particular, including the OUT parameters in > the function signature seems to me to be mostly confusing. But, > once again, it's abusing the concept that <returnvalue> contains > the result type. Ideally the output-column list would be inside > the <returnvalue> environment, but DocBook won't allow that > because of the <type> tags. It does look better, but things look a bit smushed together on the pgweb front. It seems like there's enough structure where one can make some not-too-zany CSS rules to put a bit more space between elements, but perhaps wait to hear the decision on the rest of the structural questions. > So at this point I'm tempted to abandon <returnvalue> and go back > to using a custom entity to generate the right arrow, so that > the markup would just look like, say, > > <function>stddev</function> ( <replaceable>numeric_type</replaceable> ) > &returns; <type>double precision</type> > for <type>real</type> or <type>double precision</type>, > otherwise <type>numeric</type> > > Does anyone have a preference on that, or a better alternative? As long as we can properly style without zany CSS rules, I'm +0 :) Jonathan [1] https://www.postgresql.org/docs/devel/functions-aggregate.html
Attachment
"Jonathan S. Katz" <jkatz@postgresql.org> writes: > On 5/4/20 5:22 PM, Tom Lane wrote: >> I've now completed updating chapter 9 for the new layout, >> and the results are visible at >> https://www.postgresql.org/docs/devel/functions.html > This is already much better. I've skimmed through a few of the pages, I > can say that the aggregates page[1] is WAY easier to read. Yay! Thanks! >> * After experimenting with a few different ways to handle functions with >> multiple OUT parameters, I settled on doing it like this: >> <function>pg_partition_tree</function> ( <type>regclass</type> ) >> <returnvalue>setof record</returnvalue> >> ( <parameter>relid</parameter> <type>regclass</type>, >> <parameter>parentrelid</parameter> <type>regclass</type>, >> <parameter>isleaf</parameter> <type>boolean</type>, >> <parameter>level</parameter> <type>integer</type> ) >> >> This looks nice and I think it's much more intelligible than other >> things I tried --- in particular, including the OUT parameters in >> the function signature seems to me to be mostly confusing. But, >> once again, it's abusing the concept that <returnvalue> contains >> the result type. Ideally the output-column list would be inside >> the <returnvalue> environment, but DocBook won't allow that >> because of the <type> tags. > It does look better, but things look a bit smushed together on the pgweb > front. Yeah. There's less smushing of function signatures when building the docs without STYLE=website, so there's something specific to the website style. I think you'd mentioned that we were intentionally crimping the space and/or font size within tables? Maybe that could get un-done now. I hadn't bothered to worry about such details until we had a reasonable sample of cases to look at, but now would be a good time. Another rendering oddity that I'd not bothered to chase down is the appearance of <itemizedlist> environments within table cells. We have a few of those now as a result of migration of material that had been out-of-line into the table cells; one example is in json_populate_record, about halfway down this page: https://www.postgresql.org/docs/devel/functions-json.html The text of the list items seems to be getting indented to the same extent as a not-in-a-table <itemizedlist> list does --- but the bullets aren't indented nearly as much, making for weird spacing. (There's a short <itemizedlist> at the top of the same page that you can compare to.) The same weird spacing is visible in a non STYLE=website build, so I think this might be less a CSS issue and more a DocBook issue. On the other hand, it looks fine in the PDF build. So I'm not sure where to look for the cause. regards, tom lane
On 5/4/20 6:39 PM, Tom Lane wrote: > "Jonathan S. Katz" <jkatz@postgresql.org> writes: >> On 5/4/20 5:22 PM, Tom Lane wrote: >> It does look better, but things look a bit smushed together on the pgweb >> front. > > Yeah. There's less smushing of function signatures when building the > docs without STYLE=website, so there's something specific to the > website style. I think you'd mentioned that we were intentionally > crimping the space and/or font size within tables? Maybe that could > get un-done now. I hadn't bothered to worry about such details until > we had a reasonable sample of cases to look at, but now would be a > good time. IIRC this was the monospace issue[1], but there are some other things I'm seeing (e.g. the italics) that may be pushing things closer together htan not. Now that round 1 of commits are in, I can take a whack at tightening it up this week. > Another rendering oddity that I'd not bothered to chase down is > the appearance of <itemizedlist> environments within table cells. > We have a few of those now as a result of migration of material > that had been out-of-line into the table cells; one example is > in json_populate_record, about halfway down this page: > > https://www.postgresql.org/docs/devel/functions-json.html > > The text of the list items seems to be getting indented to the > same extent as a not-in-a-table <itemizedlist> list does --- > but the bullets aren't indented nearly as much, making for > weird spacing. (There's a short <itemizedlist> at the top of > the same page that you can compare to.) Looking at the code, I believe this is a pretty straightforward adjustment. I can include it with the aforementioned changes. Jonathan [1] https://www.postgresql.org/message-id/3f8560a6-9044-bdb8-6b3b-68842570db18@postgresql.org
Attachment
On Mon, 4 May 2020 at 22:22, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > * <returnvalue> is also quite sticky about inserting other sorts > of font-changing environments inside it. As an example, it'll let > you include <replaceable> but not <type>, which seems pretty weird > to me. This is problematic in some places where it's desirable to > have text rather than just a type name, for example > > <function>stddev</function> ( <replaceable>numeric_type</replaceable> ) > <returnvalue></returnvalue> <type>double precision</type> > for <type>real</type> or <type>double precision</type>, > otherwise <type>numeric</type> > > Now I could have done this example by spelling out all six varieties of > stddev() separately, and maybe I should've, but it seemed overly bulky > that way. FWIW, I prefer having each variety spelled out separately. For example, I really like the new way that aggregates like sum() and avg() are displayed. To me, having all the types listed like that is much more readable than having to read and interpret a piece of free text. Similarly, for other functions like gcd(), lcm() and mod(). I think it would be better to get rid of numeric_type, and just list all the variants of each function. Regards, Dean
On Mon, May 4, 2020 at 11:22 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
I've now completed updating chapter 9 for the new layout,
and the results are visible at
https://www.postgresql.org/docs/devel/functions.html
There is more to do --- for instance, various contrib modules
have function/operator tables that should be synced with this
design. But this seemed like a good place to pause and reflect.
Would it be premature to complain about the not-that-great look of Table 9.1 now?
Compare the two attached images: the screenshot from
vs the GIMP-assisted pipe dream of mine to align it to the right edge of the table cell.
I don't have the faintest idea how to achieve that using SGML at the moment, but it just looks so much nicer to me. ;-)
Regards,
--
Alex
Attachment
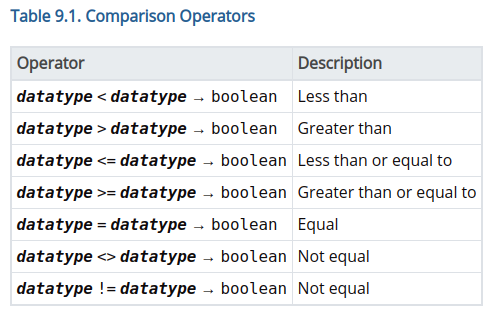{kind=link}
{kind=link}
Dean Rasheed <dean.a.rasheed@gmail.com> writes:
> On Mon, 4 May 2020 at 22:22, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Now I could have done this example by spelling out all six varieties of
>> stddev() separately, and maybe I should've, but it seemed overly bulky
>> that way.
> FWIW, I prefer having each variety spelled out separately. For
> example, I really like the new way that aggregates like sum() and
> avg() are displayed. To me, having all the types listed like that is
> much more readable than having to read and interpret a piece of free
> text.
> Similarly, for other functions like gcd(), lcm() and mod(). I think it
> would be better to get rid of numeric_type, and just list all the
> variants of each function.
I had had the same idea to start with, but it didn't survive first contact
with table 9.4 (Mathematical Operators). It's not really reasonable to
spell out all the variants of + ... especially not if you want to be
precise, because then you'd have to list the cross-type variants too.
If I counted correctly, there are fourteen variants of binary + that
would have to be listed in that table, never mind the other common
operators.
max() and min() have a similar sort of problem --- the list of variants
is just dauntingly long, and it's not that interesting either.
I wrote out sum() and avg() the way I did because they have a somewhat
irregular mapping from input to output types, so it seemed better to
just list the alternatives explicitly.
I don't object too much to spelling out the variants of stddev()
and variance(), if there's a consensus for that. But getting rid
of "numeric_type" entirely seems impractical.
regards, tom lane
Oleksandr Shulgin <oleksandr.shulgin@zalando.de> writes: > Would it be premature to complain about the not-that-great look of Table > 9.1 now? > Compare the two attached images: the screenshot from > https://www.postgresql.org/docs/devel/functions-comparison.html > vs the GIMP-assisted pipe dream of mine to align it to the right edge of > the table cell. Hmph. I experimented with the attached patch, but at least in my browser it only reduces the spacing inconsistency, it doesn't eliminate it. And from a semantic standpoint, this is not nice markup. Doing better would require substantial foolery with sub-columns and I'm not even sure that it's possible to fix that way. (We don't have huge control over inter-column spacing, I don't think.) On the whole, if this is our worst table problem, I'm happy ;-) regards, tom lane diff --git a/doc/src/sgml/func.sgml b/doc/src/sgml/func.sgml index d9b3598..557a3ac 100644 --- a/doc/src/sgml/func.sgml +++ b/doc/src/sgml/func.sgml @@ -222,7 +222,7 @@ repeat('Pg', 4) <returnvalue>PgPgPgPg</returnvalue> <tbody> <row> <entry> - <replaceable>datatype</replaceable> <literal><</literal> <replaceable>datatype</replaceable> + <replaceable>datatype</replaceable> <literal>< </literal> <replaceable>datatype</replaceable> <returnvalue>boolean</returnvalue> </entry> <entry>Less than</entry> @@ -230,7 +230,7 @@ repeat('Pg', 4) <returnvalue>PgPgPgPg</returnvalue> <row> <entry> - <replaceable>datatype</replaceable> <literal>></literal> <replaceable>datatype</replaceable> + <replaceable>datatype</replaceable> <literal>> </literal> <replaceable>datatype</replaceable> <returnvalue>boolean</returnvalue> </entry> <entry>Greater than</entry> @@ -254,7 +254,7 @@ repeat('Pg', 4) <returnvalue>PgPgPgPg</returnvalue> <row> <entry> - <replaceable>datatype</replaceable> <literal>=</literal> <replaceable>datatype</replaceable> + <replaceable>datatype</replaceable> <literal>= </literal> <replaceable>datatype</replaceable> <returnvalue>boolean</returnvalue> </entry> <entry>Equal</entry>