Thread: Perform streaming logical transactions by background workers and parallel apply
Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
In this email, I would like to discuss allowing streaming logical transactions (large in-progress transactions) by background workers and parallel apply in general. The goal of this work is to improve the performance of the apply work in logical replication. Currently, for large transactions, the publisher sends the data in multiple streams (changes divided into chunks depending upon logical_decoding_work_mem), and then on the subscriber-side, the apply worker writes the changes into temporary files and once it receives the commit, it read from the file and apply the entire transaction. To improve the performance of such transactions, we can instead allow them to be applied via background workers. There could be multiple ways to achieve this: Approach-1: Assign a new bgworker (if available) as soon as the xact's first stream came and the main apply worker will send changes to this new worker via shared memory. We keep this worker assigned till the transaction commit came and also wait for the worker to finish at commit. This preserves commit ordering and avoid writing to and reading from file in most cases. We still need to spill if there is no worker available. We also need to allow stream_stop to complete by the background worker to finish it to avoid deadlocks because T-1's current stream of changes can update rows in conflicting order with T-2's next stream of changes. Approach-2: Assign another worker to spill the changes and only allow to apply at the commit time by the same or another worker. Now, to preserve, the commit order, we need to wait at commit so that the assigned respective workers can finish. This won't avoid spilling to disk and reading back at commit time but can help in receiving and processing more data than we are doing currently but not sure if this can win over Approach-1 because we still need to write and read from the file and we need to probably use share memory queue to send the data to other background workers to process it. We need to change error handling to allow the above parallelization. The current model for apply is such that if any error occurs while applying we will simply report the error in server logs and the apply worker will exit. On the restart, it will again get the transaction data which previously failed and it will try to apply it again. Now, in the new approach (say Approach-1), we need to ensure that all the active workers that are applying in-progress transactions should also exit before the main apply worker exit to allow rollback of currently applied transactions and re-apply them as we get the data again. This is required to avoid losing transactions if any later transaction got committed and updated the replication origin as in such cases the earlier transactions won't be resent. This won't be much different than what we do now, where say two transactions, t-1, and t-2 have multiple streams overlapped. Now, if the error happened before one of those is completed via commit or rollback, all the data needs to be resent by the server and processed again by the apply worker. The next step in this area is to parallelize apply of all possible transactions. I think the main things we need to care about to allow this are: 1. Transaction dependency: We can't simply allow dependent transactions to perform in parallel as that can lead to inconsistency. Say, if we insert a row in the first transaction and update it in the second transaction and allow both transactions to apply in parallel, the insert-one may occur later and the update will fail. 2. Deadlocks: It can happen because now the transactions will be applied in parallel. Say transaction T-1 updates row-2 and row-3 and transaction T-2 updates row-3 and row-2, if we allow in parallel then there is a chance of deadlock whereas there is no such risk in serial execution where the commit order is preserved. We can solve both problems if we allow only independent xacts to be parallelized. The transactions would be considered dependent if they operate on the same set of rows from the same table. Now apart from this, there could be other cases where determining transaction dependency won't be straightforward, so we can disallow those transactions to participate in parallel apply. Those are the cases where we can use functions in the table definition expressions. We can think of identifying safe functions like all built-in functions, and any immutable functions (and probably stable functions). We need to check safety for cases such as (a) trigger functions, (b) column default value expressions (as those can call functions), (c) constraint expressions, (d) foreign keys, (e) operations on partitioned tables (especially those performed via publish_via_partition_root option) as we need to check for expressions on all partitions. The transactions that operate on the same set of tables and are performing truncate can lead to deadlock, so we need to consider such transactions as a dependent. The basic idea is that for each running xact we can maintain the table oid, row id(pkey or replica identity), and xid in the hash table in apply worker. For any new xact, we need to check if it doesn't conflict with one of the previous running xacts and only then allow it to be applied parallelly. We can collect all the changes of a transaction in the in-memory buffer while checking its dependency and then allow it to perform by one of the available workers at commit. If the rows for a particular transaction exceed a certain threshold then we need to escalate to a table-level strategy which means any other transaction operating on the same table will be considered dependent. For very large transactions that didn't fit in the in-memory buffer, either we need to spill those to disk or just decide to not parallelize them. We need to remove rows from the hash table once the transaction is applied completely. The other thing we need to ensure while parallelizing independent transactions is to preserve the commit order of transactions. This is to ensure that in case of errors, we won't get replicas out of sync. Say, if we allow the commit order to be changed then it is possible that some later transaction has updated the replication_origin LSN to a later value than the transaction for which the apply is in progress. Now, if the error occurs for such an in-progress transaction, the server won't send the changes for such a transaction as the replication_origin's LSN would have moved ahead. Even though we are preserving commit order there will be a benefit of doing parallel apply as we should be able to parallelize most of the writes in the transactions. Thoughts? Thanks to Hou-San and Shi-San for helping me to investigate these ideas. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
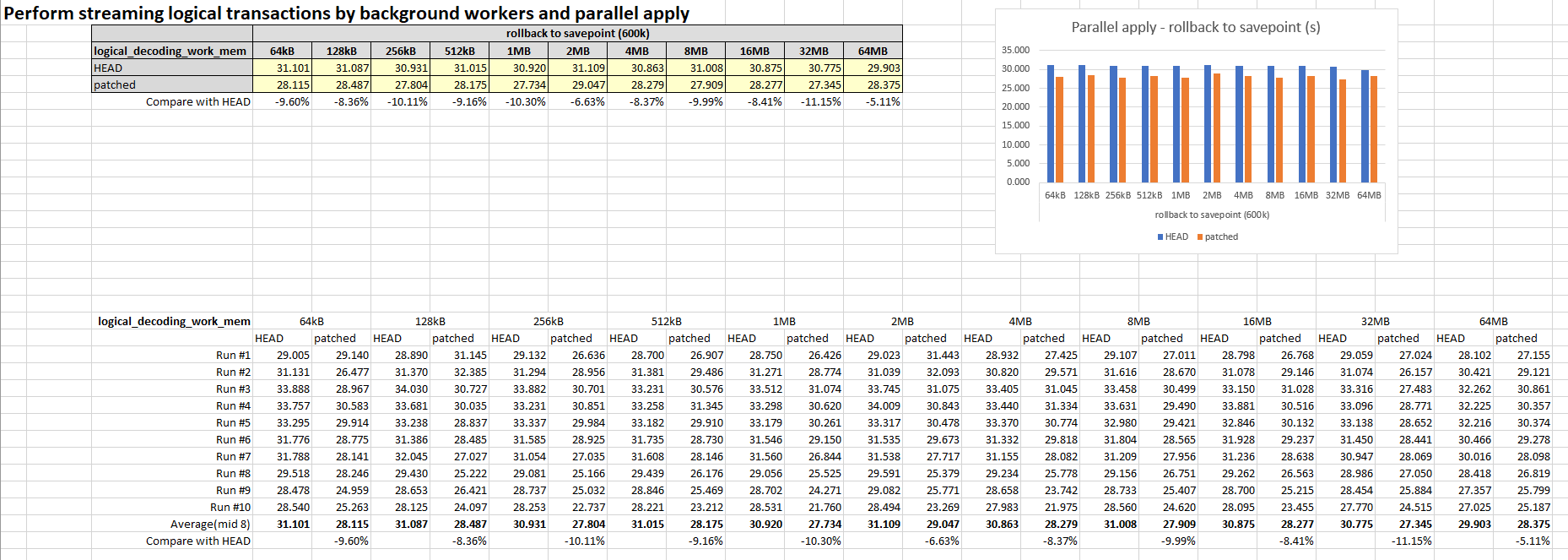
On Wednesday, April 6, 2022 1:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > In this email, I would like to discuss allowing streaming logical > transactions (large in-progress transactions) by background workers > and parallel apply in general. The goal of this work is to improve the > performance of the apply work in logical replication. > > Currently, for large transactions, the publisher sends the data in > multiple streams (changes divided into chunks depending upon > logical_decoding_work_mem), and then on the subscriber-side, the apply > worker writes the changes into temporary files and once it receives > the commit, it read from the file and apply the entire transaction. To > improve the performance of such transactions, we can instead allow > them to be applied via background workers. There could be multiple > ways to achieve this: > > Approach-1: Assign a new bgworker (if available) as soon as the xact's > first stream came and the main apply worker will send changes to this > new worker via shared memory. We keep this worker assigned till the > transaction commit came and also wait for the worker to finish at > commit. This preserves commit ordering and avoid writing to and > reading from file in most cases. We still need to spill if there is no > worker available. We also need to allow stream_stop to complete by the > background worker to finish it to avoid deadlocks because T-1's > current stream of changes can update rows in conflicting order with > T-2's next stream of changes. > Attach the POC patch for the Approach-1 of "Perform streaming logical transactions by background workers". The patch is still a WIP patch as there are serval TODO items left, including: * error handling for bgworker * support for SKIP the transaction in bgworker * handle the case when there is no more worker available (might need spill the data to the temp file in this case) * some potential bugs The original patch is borrowed from an old thread[1] and was rebased and extended/cleaned by me. Comments and suggestions are welcome. [1] https://www.postgresql.org/message-id/8eda5118-2dd0-79a1-4fe9-eec7e334de17%40postgrespro.ru Here are some performance results of the patch shared by Shi Yu off-list. The performance was tested by varying logical_decoding_work_mem, which include two cases: 1) bulk insert. 2) create savepoint and rollback to savepoint. I used synchronous logical replication in the test, compared SQL execution times before and after applying the patch. The results are as follows. The bar charts and the details of the test are Attached as well. RESULT - bulk insert (5kk) ---------------------------------- logical_decoding_work_mem 64kB 128kB 256kB 512kB 1MB 2MB 4MB 8MB 16MB 32MB 64MB HEAD 51.673 51.199 51.166 50.259 52.898 50.651 51.156 51.210 50.678 51.256 51.138 patched 36.198 35.123 34.223 29.198 28.712 29.090 29.709 29.408 34.367 34.716 35.439 RESULT - rollback to savepoint (600k) ---------------------------------- logical_decoding_work_mem 64kB 128kB 256kB 512kB 1MB 2MB 4MB 8MB 16MB 32MB 64MB HEAD 31.101 31.087 30.931 31.015 30.920 31.109 30.863 31.008 30.875 30.775 29.903 patched 28.115 28.487 27.804 28.175 27.734 29.047 28.279 27.909 28.277 27.345 28.375 Summary: 1) bulk insert For different logical_decoding_work_mem size, it takes about 30% ~ 45% less time, which looks good to me. After applying this patch, it seems that the performance is better when logical_decoding_work_mem is between 512kB and 8MB. 2) rollback to savepoint There is an improvement of about 5% ~ 10% after applying this patch. In this case, the patch spend less time handling the part that is not rolled back, because it saves the time writing the changes into a temporary file and reading the file. And for the part that is rolled back, it would spend more time than HEAD, because it takes more time to write to filesystem and rollback than writing a temporary file and truncating the file. Overall, the results looks good. Best regards, Hou zj
Attachment
{kind=link}
{kind=link}
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, April 8, 2022 5:14 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > On Wednesday, April 6, 2022 1:20 PM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > In this email, I would like to discuss allowing streaming logical > > transactions (large in-progress transactions) by background workers > > and parallel apply in general. The goal of this work is to improve the > > performance of the apply work in logical replication. > > > > Currently, for large transactions, the publisher sends the data in > > multiple streams (changes divided into chunks depending upon > > logical_decoding_work_mem), and then on the subscriber-side, the apply > > worker writes the changes into temporary files and once it receives > > the commit, it read from the file and apply the entire transaction. To > > improve the performance of such transactions, we can instead allow > > them to be applied via background workers. There could be multiple > > ways to achieve this: > > > > Approach-1: Assign a new bgworker (if available) as soon as the xact's > > first stream came and the main apply worker will send changes to this > > new worker via shared memory. We keep this worker assigned till the > > transaction commit came and also wait for the worker to finish at > > commit. This preserves commit ordering and avoid writing to and > > reading from file in most cases. We still need to spill if there is no > > worker available. We also need to allow stream_stop to complete by the > > background worker to finish it to avoid deadlocks because T-1's > > current stream of changes can update rows in conflicting order with > > T-2's next stream of changes. > > > > Attach the POC patch for the Approach-1 of "Perform streaming logical > transactions by background workers". The patch is still a WIP patch as > there are serval TODO items left, including: > > * error handling for bgworker > * support for SKIP the transaction in bgworker > * handle the case when there is no more worker available > (might need spill the data to the temp file in this case) > * some potential bugs > > The original patch is borrowed from an old thread[1] and was rebased and > extended/cleaned by me. Comments and suggestions are welcome. Attach a new version patch which improved the error handling and handled the case when there is no more worker available (will spill the data to the temp file in this case). Currently, it still doesn't support skip the streamed transaction in bgworker, because in this approach, we don't know the last lsn for the streamed transaction being applied, so cannot get the lsn to SKIP. I will think more about it and keep testing the patch. Best regards, Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Apr 14, 2022 at 9:12 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Friday, April 8, 2022 5:14 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > Attach a new version patch which improved the error handling and handled the case > when there is no more worker available (will spill the data to the temp file in this case). > > Currently, it still doesn't support skip the streamed transaction in bgworker, because > in this approach, we don't know the last lsn for the streamed transaction being applied, > so cannot get the lsn to SKIP. I will think more about it and keep testing the patch. > I think we can avoid performing the streaming transaction by bgworker if skip_lsn is set. This needs some more thought but anyway I see another problem in this patch. I think we won't be able to make the decision whether to apply the change for a relation that is not in the 'READY' state (see should_apply_changes_for_rel) as we won't know 'remote_final_lsn' by that time for streaming transactions. I think what we can do here is that before assigning the transaction to bgworker, we can check if any of the rels is not in the 'READY' state, we can make the transaction spill the changes as we are doing now. Even if we do such a check, it is still possible that some rel on which this transaction is performing operation can appear to be in 'non-ready' state after starting bgworker and for such a case I think we need to give error and restart the transaction as we have no way to know whether we need to perform an operation on the 'rel'. This is possible if the user performs REFRESH PUBLICATION in parallel to this transaction as that can add a new rel to the pg_subscription_rel. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, April 19, 2022 2:58 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Apr 14, 2022 at 9:12 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Friday, April 8, 2022 5:14 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > Attach a new version patch which improved the error handling and handled
> the case
> > when there is no more worker available (will spill the data to the temp file in
> this case).
> >
> > Currently, it still doesn't support skip the streamed transaction in bgworker,
> because
> > in this approach, we don't know the last lsn for the streamed transaction
> being applied,
> > so cannot get the lsn to SKIP. I will think more about it and keep testing the
> patch.
> >
>
> I think we can avoid performing the streaming transaction by bgworker
> if skip_lsn is set. This needs some more thought but anyway I see
> another problem in this patch. I think we won't be able to make the
> decision whether to apply the change for a relation that is not in the
> 'READY' state (see should_apply_changes_for_rel) as we won't know
> 'remote_final_lsn' by that time for streaming transactions. I think
> what we can do here is that before assigning the transaction to
> bgworker, we can check if any of the rels is not in the 'READY' state,
> we can make the transaction spill the changes as we are doing now.
> Even if we do such a check, it is still possible that some rel on
> which this transaction is performing operation can appear to be in
> 'non-ready' state after starting bgworker and for such a case I think
> we need to give error and restart the transaction as we have no way to
> know whether we need to perform an operation on the 'rel'. This is
> possible if the user performs REFRESH PUBLICATION in parallel to this
> transaction as that can add a new rel to the pg_subscription_rel.
Changed as suggested.
Attach the new version patch which cleanup some code and fix above problem. For
now, it won't apply streaming transaction in bgworker if skiplsn is set or any
table is not in 'READY' state.
Besides, extent the subscription streaming option to ('on/off/apply(apply in
bgworker)/spool(spool to file)') so that user can control whether to apply The
transaction in a bgworker.
Best regards,
Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, April 20, 2022 4:57 PM houzj.fnst@fujitsu.com wrote:
>
> On Tuesday, April 19, 2022 2:58 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > On Thu, Apr 14, 2022 at 9:12 AM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Friday, April 8, 2022 5:14 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > Attach a new version patch which improved the error handling and
> > > handled
> > the case
> > > when there is no more worker available (will spill the data to the
> > > temp file in
> > this case).
> > >
> > > Currently, it still doesn't support skip the streamed transaction in
> > > bgworker,
> > because
> > > in this approach, we don't know the last lsn for the streamed
> > > transaction
> > being applied,
> > > so cannot get the lsn to SKIP. I will think more about it and keep
> > > testing the
> > patch.
> > >
> >
> > I think we can avoid performing the streaming transaction by bgworker
> > if skip_lsn is set. This needs some more thought but anyway I see
> > another problem in this patch. I think we won't be able to make the
> > decision whether to apply the change for a relation that is not in the
> > 'READY' state (see should_apply_changes_for_rel) as we won't know
> > 'remote_final_lsn' by that time for streaming transactions. I think
> > what we can do here is that before assigning the transaction to
> > bgworker, we can check if any of the rels is not in the 'READY' state,
> > we can make the transaction spill the changes as we are doing now.
> > Even if we do such a check, it is still possible that some rel on
> > which this transaction is performing operation can appear to be in
> > 'non-ready' state after starting bgworker and for such a case I think
> > we need to give error and restart the transaction as we have no way to
> > know whether we need to perform an operation on the 'rel'. This is
> > possible if the user performs REFRESH PUBLICATION in parallel to this
> > transaction as that can add a new rel to the pg_subscription_rel.
>
> Changed as suggested.
>
> Attach the new version patch which cleanup some code and fix above problem.
> For now, it won't apply streaming transaction in bgworker if skiplsn is set or any
> table is not in 'READY' state.
>
> Besides, extent the subscription streaming option to ('on/off/apply(apply in
> bgworker)/spool(spool to file)') so that user can control whether to apply The
> transaction in a bgworker.
Sorry, there was a miss in the pg_dump testcase which cause failure in CFbot.
Attach a new version patch which fix that.
Best regards,
Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Hello Hou-san. Here are my review comments for v4-0001. Sorry, there
are so many of them (it is a big patch); some are trivial, and others
you might easily dismiss due to my misunderstanding of the code. But
hopefully, there are at least some comments that can be helpful in
improving the patch quality.
======
1. General comment - terms
Needs to be more consistent about what exactly you will call this new
worker. Sometimes called "locally apply worker"; sometimes "bgworker";
sometimes "subworker", sometimes "BGW", sometimes other variations etc
… Need to pick ONE good name then update all the references/comments
in the patch to use that name consistently throughout.
~~~
2. General comment - option values
I felt the "streaming" option values ought to be different from what
this patch proposes so it affected some of my following review
comments. (Later I give example what I thought the values should be).
~~~
3. General comment - bool option change to enum
This option change for "streaming" is similar to the options change
for "copy_data=force" that Vignesh is doing for his "infinite
recursion" patch v9-0002 [1]. Yet they seem implemented differently
(i.e. char versus enum). I think you should discuss the 2 approaches
with Vignesh and then code these option changes in a consistent way.
~~~
4. General comment - worker.c globals
There seems a growing number of global variables in the worker.c code.
I was wondering is it really necessary? because the logic becomes more
intricate now if you have to know that some global was set up as a
side-effect of some other function call. E.g maybe if you could do a
few more HTAB lookups to identify the bgworker then might not need to
rely on the globals so much?
======
5. Commit message - typo
and then on the subscriber-side, the apply worker writes the changes into
temporary files and once it receives the commit, it read from the file and
apply the entire transaction. To improve the performance of such transactions,
typo: "read" -> "reads"
typo: "apply" -> "applies"
~~~
6. Commit message - wording
In this approach, we assign a new bgworker (if available) as soon as the xact's
first stream came and the main apply worker will send changes to this new
worker via shared memory. The bgworker will directly apply the change instead
of writing it to temporary files. We keep this worker assigned till the
transaction commit came and also wait for the worker to finish at commit. This
wording: "came" -> "is received" (2x)
~~~
7. Commit message - terms
(this is the same point as comment #1)
I think there is too much changing of terminology. IMO it will be
easier if you always just call the current main apply workers the
"apply worker" and always call this new worker the "bgworker" (or some
better name). But never just call it the "worker".
~~~
8. Commit message - typo
transaction commit came and also wait for the worker to finish at commit. This
preserves commit ordering and avoid writing to and reading from file in most
cases. We still need to spill if there is no worker available. We also need to
typo: "avoid" -> "avoids"
~~~
9. Commit message - wording/typo
Also extend the subscription streaming option so that user can control whether
apply the streaming transaction in a bgworker or spill the change to disk. User
wording: "Also extend" -> "This patch also extends"
typo: "whether apply" -> "whether to apply"
~~~
10. Commit message - option values
apply the streaming transaction in a bgworker or spill the change to disk. User
can set the streaming option to 'on/off', 'apply', 'spool'. For now, 'on' and
Those values do not really seem intuitive to me. E.g. if you set
"apply" then you already said above that sometimes it might have to
spool anyway if there were no bgworkers available. Why not just name
them like "on/off/parallel"?
(I have written more about this in a later comment #14)
======
11. doc/src/sgml/catalogs.sgml - wording
+ Controls in which modes we handle the streaming of in-progress
transactions.
+ <literal>f</literal> = disallow streaming of in-progress transactions
wording: "Controls in which modes we handle..." -> "Controls how to handle..."
~~~
12. doc/src/sgml/catalogs.sgml - wording
+ <literal>a</literal> = apply changes directly in background worker
wording: "in background worker" -> "using a background worker"
~~~
13. doc/src/sgml/catalogs.sgml - option values
Anyway, all this page will be different if I can persuade you to
change the option values (see comment #14)
======
14. doc/src/sgml/ref/create_subscription.sgml - option values
Since the default value is "off" I felt these options would be
better/simpler if they are just like "off/on/parallel". E.g.
Specifically, I think the "on" should behave the same as the current
code does, so the user should deliberately choose to use this new
bgworker approach.
e.g.
- "off" = off, same as current PG15
- "on" = on, same as current PG15
- "parallel" = try to use the new bgworker to apply stream
======
15. src/backend/commands/subscriptioncmds.c - SubOpts
Vignesh uses similar code for his "infinite recursion" patch being
developed [1] but he used an enum but here you use a char. I think you
should discuss together both decide to use either enum or char for the
member so there is a consistency.
~~~
16. src/backend/commands/subscriptioncmds.c - combine conditions
+ /*
+ * The set of strings accepted here should match up with the
+ * grammar's opt_boolean_or_string production.
+ */
+ if (pg_strcasecmp(sval, "true") == 0)
+ return SUBSTREAM_APPLY;
+ if (pg_strcasecmp(sval, "false") == 0)
+ return SUBSTREAM_OFF;
+ if (pg_strcasecmp(sval, "on") == 0)
+ return SUBSTREAM_APPLY;
+ if (pg_strcasecmp(sval, "off") == 0)
+ return SUBSTREAM_OFF;
+ if (pg_strcasecmp(sval, "spool") == 0)
+ return SUBSTREAM_SPOOL;
+ if (pg_strcasecmp(sval, "apply") == 0)
+ return SUBSTREAM_APPLY;
Because I think the possible option values should be different to
these I can’t comment much on this code, except to suggest IMO the if
conditions should be combined where the options are considered to be
equivalent.
======
17. src/backend/replication/logical/launcher.c - stop_worker
@@ -72,6 +72,7 @@ static void logicalrep_launcher_onexit(int code, Datum arg);
static void logicalrep_worker_onexit(int code, Datum arg);
static void logicalrep_worker_detach(void);
static void logicalrep_worker_cleanup(LogicalRepWorker *worker);
+static void stop_worker(LogicalRepWorker *worker);
The function name does not seem consistent with the other similar static funcs.
~~~
18. src/backend/replication/logical/launcher.c - change if
@@ -225,7 +226,7 @@ logicalrep_worker_find(Oid subid, Oid relid, bool
only_running)
LogicalRepWorker *w = &LogicalRepCtx->workers[i];
if (w->in_use && w->subid == subid && w->relid == relid &&
- (!only_running || w->proc))
+ (!only_running || w->proc) && !w->subworker)
{
Maybe code would be easier (and then you can comment it) if you do like:
/* TODO: comment here */
if (w->subworker)
continue;
~~~
19. src/backend/replication/logical/launcher.c -
logicalrep_worker_launch comment
@@ -262,9 +263,9 @@ logicalrep_workers_find(Oid subid, bool only_running)
/*
* Start new apply background worker, if possible.
*/
-void
+bool
logicalrep_worker_launch(Oid dbid, Oid subid, const char *subname, Oid userid,
- Oid relid)
+ Oid relid, dsm_handle subworker_dsm)
Saying "start new apply..." comment feels a bit misleading. E.g. this
is also called to start the sync worker. And also for the main apply
worker (which we are not really calling a "background worker" in other
places). So this is the same kind of terminology problem as my review
comment #1.
~~~
20. src/backend/replication/logical/launcher.c - asserts?
I thought maybe there should be some assertions in this code upfront.
E.g. cannot have OidIsValid(relid) and subworker_dsm valid at the same
time.
~~~
21. src/backend/replication/logical/launcher.c - terms
+ else
+ snprintf(bgw.bgw_name, BGW_MAXLEN,
+ "logical replication apply worker for subscription %u", subid);
I think the names of all these workers is a bit vague still in the
messages – e.g. "logical replication worker" versus "logical
replication apply worker" sounds too similar to me. So this is kind of
same as my review comment #1.
~~~
22. src/backend/replication/logical/launcher.c -
logicalrep_worker_stop double unlock?
@@ -450,6 +465,18 @@ logicalrep_worker_stop(Oid subid, Oid relid)
return;
}
+ stop_worker(worker);
+
+ LWLockRelease(LogicalRepWorkerLock);
+}
IIUC, sometimes it seems that stop_worker() function might already
release the lock before it returns. In that case won’t this other
explicit lock release be a problem?
~~~
23. src/backend/replication/logical/launcher.c - logicalrep_worker_detach
@@ -600,6 +625,28 @@ logicalrep_worker_attach(int slot)
static void
logicalrep_worker_detach(void)
{
+ /*
+ * If we are the main apply worker, stop all the sub apply workers we
+ * started before.
+ */
+ if (!MyLogicalRepWorker->subworker)
+ {
+ List *workers;
+ ListCell *lc;
+
+ LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
+
+ workers = logicalrep_workers_find(MyLogicalRepWorker->subid, true);
+ foreach(lc, workers)
+ {
+ LogicalRepWorker *w = (LogicalRepWorker *) lfirst(lc);
+ if (w->subworker)
+ stop_worker(w);
+ }
+
+ LWLockRelease(LogicalRepWorkerLock);
Can this have the same double-unlock problem as I described in the
previous review comment #22?
~~~
24. src/backend/replication/logical/launcher.c - ApplyLauncherMain
@@ -869,7 +917,7 @@ ApplyLauncherMain(Datum main_arg)
wait_time = wal_retrieve_retry_interval;
logicalrep_worker_launch(sub->dbid, sub->oid, sub->name,
- sub->owner, InvalidOid);
+ sub->owner, InvalidOid, DSM_HANDLE_INVALID);
}
Now that the logicalrep_worker_launch is retuning a bool, should this
call be checking the return value and taking appropriate action if it
failed?
======
25. src/backend/replication/logical/origin.c - acquire comment
+ /*
+ * We allow the apply worker to get the slot which is acquired by its
+ * leader process.
+ */
+ else if (curstate->acquired_by != 0 && acquire)
The comment was not very clear to me. Does the term "apply worker" in
the comment make sense, or should that say "bgworker"? This might be
another example of my review comment #1.
~~~
26. src/backend/replication/logical/origin.c - acquire code
+ /*
+ * We allow the apply worker to get the slot which is acquired by its
+ * leader process.
+ */
+ else if (curstate->acquired_by != 0 && acquire)
{
ereport(ERROR,
I somehow felt that this param would be better called 'skip_acquire',
so all the callers would have to use the opposite boolean and then
this code would say like below (which seemed easier to me). YMMV.
else if (curstate->acquired_by != 0 && !skip_acquire)
{
ereport(ERROR,
=====
27. src/backend/replication/logical/tablesync.c
@@ -568,7 +568,8 @@ process_syncing_tables_for_apply(XLogRecPtr current_lsn)
MySubscription->oid,
MySubscription->name,
MyLogicalRepWorker->userid,
- rstate->relid);
+ rstate->relid,
+ DSM_HANDLE_INVALID);
hentry->last_start_time = now;
Now that the logicalrep_worker_launch is returning a bool, should this
call be checking that the launch was successful before it changes the
last_start_time?
======
28. src/backend/replication/logical/worker.c - file comment
+ * 1) Separate background workers
+ *
+ * Assign a new bgworker (if available) as soon as the xact's first stream came
+ * and the main apply worker will send changes to this new worker via shared
+ * memory. We keep this worker assigned till the transaction commit came and
+ * also wait for the worker to finish at commit. This preserves commit ordering
+ * and avoid writing to and reading from file in most cases. We still need to
+ * spill if there is no worker available. We also need to allow stream_stop to
+ * complete by the background worker to finish it to avoid deadlocks because
+ * T-1's current stream of changes can update rows in conflicting order with
+ * T-2's next stream of changes.
This comment fragment looks the same as the commit message so the
typos/wording reported already for the commit message are applicable
here too.
~~~
29. src/backend/replication/logical/worker.c - file comment
+ * If no worker is available to handle streamed transaction, we write the data
* to temporary files and then applied at once when the final commit arrives.
wording: "we write the data" -> "the data is written"
~~~
30. src/backend/replication/logical/worker.c - ParallelState
+typedef struct ParallelState
Add to typedefs.list
~~~
31. src/backend/replication/logical/worker.c - ParallelState flags
+typedef struct ParallelState
+{
+ slock_t mutex;
+ bool attached;
+ bool ready;
+ bool finished;
+ bool failed;
+ Oid subid;
+ TransactionId stream_xid;
+ uint32 n;
+} ParallelState;
Those bool states look independent to me. Should they be one enum
member instead of lots of bool members?
~~~
32. src/backend/replication/logical/worker.c - ParallelState comments
+typedef struct ParallelState
+{
+ slock_t mutex;
+ bool attached;
+ bool ready;
+ bool finished;
+ bool failed;
+ Oid subid;
+ TransactionId stream_xid;
+ uint32 n;
+} ParallelState;
Needs some comments. Some might be self-evident but some are not -
e.g. what is 'n'?
~~~
33. src/backend/replication/logical/worker.c - WorkerState
+typedef struct WorkerState
Add to typedefs.list
~~~
34. src/backend/replication/logical/worker.c - WorkerEntry
+typedef struct WorkerEntry
Add to typedefs.list
~~~
35. src/backend/replication/logical/worker.c - static function names
+/* Worker setup and interactions */
+static void setup_dsm(WorkerState *wstate);
+static WorkerState *setup_background_worker(void);
+static void wait_for_worker_ready(WorkerState *wstate, bool notify);
+static void wait_for_transaction_finish(WorkerState *wstate);
+static void send_data_to_worker(WorkerState *wstate, Size nbytes,
+ const void *data);
+static WorkerState *find_or_start_worker(TransactionId xid, bool start);
+static void free_stream_apply_worker(void);
+static bool transaction_applied_in_bgworker(TransactionId xid);
+static void check_workers_status(void);
All these new functions have random-looking names. Since they all are
new to this feature I thought they should all be named similarly...
e.g. something like
bgworker_setup
bgworker_check_status
bgworker_wait_for_ready
etc.
~~~
36. src/backend/replication/logical/worker.c - nchanges
+
+static uint32 nchanges = 0;
+
What is this? Needs a comment.
~~~
37. src/backend/replication/logical/worker.c - handle_streamed_transaction
static bool
handle_streamed_transaction(LogicalRepMsgType action, StringInfo s)
{
- TransactionId xid;
+ TransactionId current_xid = InvalidTransactionId;
/* not in streaming mode */
- if (!in_streamed_transaction)
+ if (!in_streamed_transaction && !isLogicalApplyWorker)
return false;
Is it correct to be testing the isLogicalApplyWorker here?
e.g. What if the streaming code is not using bgworkers at all?
At least maybe that comment (/* not in streaming mode */) should be updated?
~~~
38. src/backend/replication/logical/worker.c - handle_streamed_transaction
+ if (current_xid != stream_xid &&
+ !list_member_int(subxactlist, (int) current_xid))
+ {
+ MemoryContext oldctx;
+ char *spname = (char *) palloc(64 * sizeof(char));
+ sprintf(spname, "savepoint_for_xid_%u", current_xid);
Can't the name just be a char[64] on the stack?
~~~
39. src/backend/replication/logical/worker.c - handle_streamed_transaction
+ /*
+ * XXX The publisher side don't always send relation update message
+ * after the streaming transaction, so update the relation in main
+ * worker here.
+ */
typo: "don't" -> "doesn't" ?
~~~
40. src/backend/replication/logical/worker.c - apply_handle_commit_prepared
@@ -976,30 +1116,51 @@ apply_handle_commit_prepared(StringInfo s)
char gid[GIDSIZE];
logicalrep_read_commit_prepared(s, &prepare_data);
+
set_apply_error_context_xact(prepare_data.xid, prepare_data.commit_lsn);
Spurious whitespace?
~~~
41. src/backend/replication/logical/worker.c - apply_handle_commit_prepared
+ /* Check if we have prepared transaction in another bgworker */
+ if (transaction_applied_in_bgworker(prepare_data.xid))
+ {
+ elog(DEBUG1, "received commit for streamed transaction %u", prepare_data.xid);
- /* There is no transaction when COMMIT PREPARED is called */
- begin_replication_step();
+ /* Send commit message */
+ send_data_to_worker(stream_apply_worker, s->len, s->data);
It seems a bit complex/tricky that the code is always relying on all
the side-effects that the global stream_apply_worker will be set.
I am not sure if it is possible to remove the global and untangle
everything. E.g. Why not change the transaction_applied_in_bgworker to
return the bgworker (instead of return bool) and then can assign it to
a local var in this function.
Or can’t you do HTAB lookup in a few more places instead of carrying
around the knowledge of some global var that was initialized in some
other place?
It would be easier if you can eliminate having to be aware of
side-effects happening behind the scenes.
~~~
42. src/backend/replication/logical/worker.c - apply_handle_rollback_prepared
@@ -1019,35 +1180,51 @@ apply_handle_rollback_prepared(StringInfo s)
char gid[GIDSIZE];
logicalrep_read_rollback_prepared(s, &rollback_data);
+
set_apply_error_context_xact(rollback_data.xid,
rollback_data.rollback_end_lsn);
Spurious whitespace?
~~~
43. src/backend/replication/logical/worker.c - apply_handle_rollback_prepared
+ /* Check if we are processing the prepared transaction in a bgworker */
+ if (transaction_applied_in_bgworker(rollback_data.xid))
+ {
+ send_data_to_worker(stream_apply_worker, s->len, s->data);
Same as previous comment #41. Relies on the side effect of something
setting the global stream_apply_worker.
~~~
44. src/backend/replication/logical/worker.c - find_or_start_worker
+ /*
+ * For streaming transactions that is being applied in bgworker, we cannot
+ * decide whether to apply the change for a relation that is not in the
+ * READY state (see should_apply_changes_for_rel) as we won't know
+ * remote_final_lsn by that time. So, we don't start new bgworker in this
+ * case.
+ */
typo: "that is" -> "that are"
~~~
45. src/backend/replication/logical/worker.c - find_or_start_worker
+ if (MySubscription->stream != SUBSTREAM_APPLY)
+ return NULL;
...
+ else if (start && !XLogRecPtrIsInvalid(MySubscription->skiplsn))
+ return NULL;
...
+ else if (start && !AllTablesyncsReady())
+ return NULL;
+ else if (!start && ApplyWorkersHash == NULL)
+ return NULL;
I am not sure but I think most of that rejection if/else can probably
just be "if" (not "else if") because otherwise, the code would have
returned anyhow, right? Removing all the "else" might make the code
more readable.
~~~
46. src/backend/replication/logical/worker.c - find_or_start_worker
+ if (wstate == NULL)
+ {
+ /*
+ * If there is no more worker can be launched here, remove the
+ * entry in hash table.
+ */
+ hash_search(ApplyWorkersHash, &xid, HASH_REMOVE, &found);
+ return NULL;
+ }
wording: "If there is no more worker can be launched here, remove" ->
"If the bgworker cannot be launched, remove..."
~~~
47. src/backend/replication/logical/worker.c - free_stream_apply_worker
+/*
+ * Add the worker to the freelist and remove the entry from hash table.
+ */
+static void
+free_stream_apply_worker(void)
IMO it might be better to pass the bgworker here instead of silently
working with the global stream_apply_worker.
~~~
48. src/backend/replication/logical/worker.c - free_stream_apply_worker
+ elog(LOG, "adding finished apply worker #%u for xid %u to the idle list",
+ stream_apply_worker->pstate->n, stream_apply_worker->pstate->stream_xid);
Should the be an Assert here to check the bgworker state really was FINISHED?
~~~
49. src/backend/replication/logical/worker.c - serialize_stream_prepare
+static void
+serialize_stream_prepare(LogicalRepPreparedTxnData *prepare_data)
Missing function comment.
~~~
50. src/backend/replication/logical/worker.c - serialize_stream_start
-/*
- * Handle STREAM START message.
- */
static void
-apply_handle_stream_start(StringInfo s)
+serialize_stream_start(bool first_segment)
Missing function comment.
~~~
51. src/backend/replication/logical/worker.c - serialize_stream_stop
+static void
+serialize_stream_stop()
+{
Missing function comment.
~~~
52. src/backend/replication/logical/worker.c - general serialize_XXXX
I can see now that you have created many serialize_XXX functions which
seem to only be called one time. It looks like the only purpose is to
encapsulate the code to make the handler function shorter? But it
seems a bit uneven that you did this only for the serialize cases. If
you really want these separate functions then perhaps there ought to
also be the equivalent bgworker functions too. There seem to be always
3 scenarios:
i.e
1. Worker is the bgworker
2. Worker is Main Apply but a bgworker exists
3. Worker is Main apply and bgworker does not exist.
Perhaps every handler function should have THREE other little
functions that it calls appropriately?
~~~
53. src/backend/replication/logical/worker.c - serialize_stream_abort
+
+static void
+serialize_stream_abort(TransactionId xid, TransactionId subxid)
+{
Missing function comment.
~~~
54. src/backend/replication/logical/worker.c - apply_handle_stream_abort
+ if (isLogicalApplyWorker)
+ {
+ ereport(LOG,
+ (errcode_for_file_access(),
+ errmsg("[Apply BGW #%u] aborting current transaction xid=%u, subxid=%u",
+ MyParallelState->n, GetCurrentTransactionIdIfAny(),
GetCurrentSubTransactionId())));
Why is the errcode using errcode_for_file_access? (2x)
~~~
55. src/backend/replication/logical/worker.c - apply_handle_stream_abort
+ /*
+ * OK, so it's a subxact. Rollback to the savepoint.
+ *
+ * We also need to read the subxactlist, determine the offset
+ * tracked for the subxact, and truncate the list.
+ */
+ int i;
+ bool found = false;
+ char *spname = (char *) palloc(64 * sizeof(char));
Can that just be char[64] on the stack?
~~~
56. src/backend/replication/logical/worker.c - apply_dispatch
@@ -2511,6 +3061,7 @@ apply_dispatch(StringInfo s)
break;
case LOGICAL_REP_MSG_STREAM_START:
+ elog(LOG, "LOGICAL_REP_MSG_STREAM_START");
apply_handle_stream_start(s);
break;
I guess this is just for debugging purposes so you should put some
FIXME comment here as a reminder to get rid of it later?
~~~
57. src/backend/replication/logical/worker.c - store_flush_position,
isLogicalApplyWorker
@@ -2618,6 +3169,10 @@ store_flush_position(XLogRecPtr remote_lsn)
{
FlushPosition *flushpos;
+ /* We only need to collect the LSN in main apply worker */
+ if (isLogicalApplyWorker)
+ return;
+
This comment is not specific to this function, but for global
isLogicalApplyWorker IMO this should be implemented to look more like
the inline function am_tablesync_worker().
e.g. I think you should replace this global with something like
am_apply_bgworker()
Maybe it should do something like check the value of
MyLogicalRepWorker->subworker?
~~~
58. src/backend/replication/logical/worker.c - LogicalRepApplyLoop
@@ -3467,6 +4025,7 @@ TwoPhaseTransactionGid(Oid subid, TransactionId
xid, char *gid, int szgid)
snprintf(gid, szgid, "pg_gid_%u_%u", subid, xid);
}
+
/*
* Execute the initial sync with error handling. Disable the subscription,
* if it's required.
Spurious whitespace
~~~
59. src/backend/replication/logical/worker.c - ApplyWorkerMain
@@ -3733,7 +4292,7 @@ ApplyWorkerMain(Datum main_arg)
options.proto.logical.publication_names = MySubscription->publications;
options.proto.logical.binary = MySubscription->binary;
- options.proto.logical.streaming = MySubscription->stream;
+ options.proto.logical.streaming = (MySubscription->stream != SUBSTREAM_OFF);
options.proto.logical.twophase = false;
I was not sure why this is converting from an enum to a boolean? Is it right?
~~~
60. src/backend/replication/logical/worker.c - LogicalApplyBgwLoop
+ shmq_res = shm_mq_receive(mqh, &len, &data, false);
+
+ if (shmq_res != SHM_MQ_SUCCESS)
+ break;
Should this log some more error information here?
~~~
61. src/backend/replication/logical/worker.c - LogicalApplyBgwLoop
+ if (len == 0)
+ {
+ elog(LOG, "[Apply BGW #%u] got zero-length message, stopping", pst->n);
+ break;
+ }
+ else
+ {
+ XLogRecPtr start_lsn;
+ XLogRecPtr end_lsn;
+ TimestampTz send_time;
Maybe the "else" is not needed here, and if you remove it then it will
get rid of all the unnecessary indentation.
~~~
62. src/backend/replication/logical/worker.c - LogicalApplyBgwLoop
+ /*
+ * We use first byte of message for additional communication between
+ * main Logical replication worker and Apply BGWorkers, so if it
+ * differs from 'w', then process it first.
+ */
I was thinking maybe this switch should include
case 'w':
break;
because then for the "default" case you should give ERROR because
something unexpected arrived.
~~~
63. src/backend/replication/logical/worker.c - ApplyBgwShutdown
+static void
+ApplyBgwShutdown(int code, Datum arg)
+{
+ SpinLockAcquire(&MyParallelState->mutex);
+ MyParallelState->failed = true;
+ SpinLockRelease(&MyParallelState->mutex);
+
+ dsm_detach((dsm_segment *) DatumGetPointer(arg));
+}
Should this do detach first and set the flag last?
~~~
64. src/backend/replication/logical/worker.c - LogicalApplyBgwMain
+ /*
+ * Acquire a worker number.
+ *
+ * By convention, the process registering this background worker should
+ * have stored the control structure at key 0. We look up that key to
+ * find it. Our worker number gives our identity: there may be just one
+ * worker involved in this parallel operation, or there may be many.
+ */
Maybe there should be another elog closer to this comment? So as soon
as you know the BGW number log something?
e.g.
elog(LOG, "[Apply BGW #%u] starting", pst->n);
~~~
65. src/backend/replication/logical/worker.c - setup_background_worker
+/*
+ * Register background workers.
+ */
+static WorkerState *
+setup_background_worker(void)
I think that comment needs some more info because it is doing more
than just registering... it is successfully launching the worker
first.
~~~
66. src/backend/replication/logical/worker.c - setup_background_worker
+ if (launched)
+ {
+ /* Wait for worker to become ready. */
+ wait_for_worker_ready(wstate, false);
+
+ ApplyWorkersList = lappend(ApplyWorkersList, wstate);
+ nworkers += 1;
+ }
Do you really need to carry around this global 'nworkers' variable?
Can’t you just check the length of the ApplyWorkerList to get this
number?
~~~
67. src/backend/replication/logical/worker.c - send_data_to_worker
+/*
+ * Send the data to worker via shared-memory queue.
+ */
+static void
+send_data_to_worker(WorkerState *wstate, Size nbytes, const void *data)
wording: "to worker" -> "to the specified apply bgworker"
This is just another example of my comment #1.
~~~
68. src/backend/replication/logical/worker.c - send_data_to_worker
+ if (result != SHM_MQ_SUCCESS)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("could not send tuple to shared-memory queue")));
+}
typo: is "tuples" the right word here?
~~~
69. src/backend/replication/logical/worker.c - wait_for_worker_ready
+
+static void
+wait_for_worker_ready(WorkerState *wstate, bool notify)
+{
Missing function comment.
~~~
70. src/backend/replication/logical/worker.c - wait_for_worker_ready
+
+static void
+wait_for_worker_ready(WorkerState *wstate, bool notify)
+{
'notify' seems a bit of a poor name here. And this param seems a bit
of a strange side-effect for something called wait_for_worker_ready.
If really need to do this way maybe name it something more verbose
like 'notify_received_stream_stop'?
~~~
71. src/backend/replication/logical/worker.c - wait_for_worker_ready
+ if (!result)
+ ereport(ERROR,
+ (errcode(ERRCODE_INSUFFICIENT_RESOURCES),
+ errmsg("one or more background workers failed to start")));
Is the ERROR code reachable? IIUC there is no escape from the previous
for (;;) loop except when the result is set to true.
~~~
72. src/backend/replication/logical/worker.c - wait_for_transaction_finish
+
+static void
+wait_for_transaction_finish(WorkerState *wstate)
+{
Missing function comment.
~~~
73. src/backend/replication/logical/worker.c - wait_for_transaction_finish
+ if (finished)
+ {
+ break;
+ }
The brackets are not needed for 1 statement.
~~~
74. src/backend/replication/logical/worker.c - transaction_applied_in_bgworker
+static bool
+transaction_applied_in_bgworker(TransactionId xid)
Instead of side-effect assigning the global variable, why not return
the bgworker (or NULL) and let the caller work with the result?
~~~
75. src/backend/replication/logical/worker.c - check_workers_status
+/*
+ * Check the status of workers and report an error if any bgworker exit
+ * unexpectedly.
wording: -> "... if any bgworker has exited unexpectedly ..."
~~~
76. src/backend/replication/logical/worker.c - check_workers_status
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("Background worker %u exited unexpectedly",
+ wstate->pstate->n)));
Should that message also give more identifying info about the
*current* worker doing the ERROR - e.g.the one which found this the
other bgworker was failed? Or is that just the PIC in the log message
good enough?
~~~
77. src/backend/replication/logical/worker.c - check_workers_status
+ if (!AllTablesyncsReady() && nfreeworkers != list_length(ApplyWorkersList))
+ {
I did not really understand this code, but isn't there a possibility
that it will cause many restarts if the tablesyncs are taking a long
time to complete?
======
78. src/include/catalog/pg_subscription.
@@ -122,6 +122,18 @@ typedef struct Subscription
List *publications; /* List of publication names to subscribe to */
} Subscription;
+/* Disallow streaming in-progress transactions */
+#define SUBSTREAM_OFF 'f'
+
+/*
+ * Streaming transactions are written to a temporary file and applied only
+ * after the transaction is committed on upstream.
+ */
+#define SUBSTREAM_SPOOL 's'
+
+/* Streaming transactions are appied immediately via a background worker */
+#define SUBSTREAM_APPLY 'a'
IIRC Vignesh had a similar options requirement for his "infinite
recursion" patch [1], except he was using enums instead of #define for
char. Maybe discuss with Vignesh (and either he should change or you
should change) so there is a consistent code style for the options.
======
79. src/include/replication/logicalproto.h - old extern
@@ -243,8 +243,10 @@ extern TransactionId
logicalrep_read_stream_start(StringInfo in,
extern void logicalrep_write_stream_stop(StringInfo out);
extern void logicalrep_write_stream_commit(StringInfo out,
ReorderBufferTXN *txn,
XLogRecPtr commit_lsn);
-extern TransactionId logicalrep_read_stream_commit(StringInfo out,
+extern TransactionId logicalrep_read_stream_commit_old(StringInfo out,
LogicalRepCommitData *commit_data);
Is anybody still using this "old" function? Maybe I missed it.
======
80. src/include/replication/logicalworker.h
@@ -13,6 +13,7 @@
#define LOGICALWORKER_H
extern void ApplyWorkerMain(Datum main_arg);
+extern void LogicalApplyBgwMain(Datum main_arg);
The new name seems inconsistent with the old one. What about calling
it ApplyBgworkerMain?
======
81. src/test/regress/expected/subscription.out
Isn't this missing some test cases for the new options added? E.g. I
never see streaming value is set to 's'.
======
82. src/test/subscription/t/029_on_error.pl
If options values were changed how I suggested (review comment #14)
then I think a change such as this would not be necessary because
everything would be backward compatible.
------
[1] https://www.postgresql.org/message-id/CALDaNm2Fe%3Dg4Tx-DhzwD6NU0VRAfaPedXwWO01maNU7_OfS8fw%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, April 22, 2022 12:12 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hello Hou-san. Here are my review comments for v4-0001. Sorry, there
> are so many of them (it is a big patch); some are trivial, and others
> you might easily dismiss due to my misunderstanding of the code. But
> hopefully, there are at least some comments that can be helpful in
> improving the patch quality.
Thanks for the comments !
I think most of the comments make sense and here are explanations for
some of them.
> 24. src/backend/replication/logical/launcher.c - ApplyLauncherMain
>
> @@ -869,7 +917,7 @@ ApplyLauncherMain(Datum main_arg)
> wait_time = wal_retrieve_retry_interval;
>
> logicalrep_worker_launch(sub->dbid, sub->oid, sub->name,
> - sub->owner, InvalidOid);
> + sub->owner, InvalidOid, DSM_HANDLE_INVALID);
> }
> Now that the logicalrep_worker_launch is retuning a bool, should this
> call be checking the return value and taking appropriate action if it
> failed?
Not sure we can change the logic of existing caller. I think only the new
caller in the patch is necessary to check this.
> 26. src/backend/replication/logical/origin.c - acquire code
>
> + /*
> + * We allow the apply worker to get the slot which is acquired by its
> + * leader process.
> + */
> + else if (curstate->acquired_by != 0 && acquire)
> {
> ereport(ERROR,
>
> I somehow felt that this param would be better called 'skip_acquire',
> so all the callers would have to use the opposite boolean and then
> this code would say like below (which seemed easier to me). YMMV.
>
> else if (curstate->acquired_by != 0 && !skip_acquire)
> {
> ereport(ERROR,
Not sure about this.
> 59. src/backend/replication/logical/worker.c - ApplyWorkerMain
>
> @@ -3733,7 +4292,7 @@ ApplyWorkerMain(Datum main_arg)
>
> options.proto.logical.publication_names = MySubscription->publications;
> options.proto.logical.binary = MySubscription->binary;
> - options.proto.logical.streaming = MySubscription->stream;
> + options.proto.logical.streaming = (MySubscription->stream != SUBSTREAM_OFF);
> options.proto.logical.twophase = false;
>
> I was not sure why this is converting from an enum to a boolean? Is it right?
I think it's ok, the "logical.streaming" is used in publisher which don't need
to know the exact type of the streaming(it only need to know whether the
streaming is enabled for now)
> 63. src/backend/replication/logical/worker.c - ApplyBgwShutdown
>
> +static void
> +ApplyBgwShutdown(int code, Datum arg)
> +{
> + SpinLockAcquire(&MyParallelState->mutex);
> + MyParallelState->failed = true;
> + SpinLockRelease(&MyParallelState->mutex);
> +
> + dsm_detach((dsm_segment *) DatumGetPointer(arg));
> +}
>
> Should this do detach first and set the flag last?
Not sure about this. I think it's fine to detach this at the end.
> 76. src/backend/replication/logical/worker.c - check_workers_status
>
> + ereport(ERROR,
> + (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("Background worker %u exited unexpectedly",
> + wstate->pstate->n)));
>
> Should that message also give more identifying info about the
> *current* worker doing the ERROR - e.g.the one which found this the
> other bgworker was failed? Or is that just the PIC in the log message
> good enough?
Currently, only the main apply worker should report this error, so not sure do
we need to report the current worker.
> 77. src/backend/replication/logical/worker.c - check_workers_status
>
> + if (!AllTablesyncsReady() && nfreeworkers != list_length(ApplyWorkersList))
> + {
>
> I did not really understand this code, but isn't there a possibility
> that it will cause many restarts if the tablesyncs are taking a long
> time to complete?
I think it's ok, after restarting, we won't start bgworker until all the table
is READY.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
vignesh C
Date:
On Fri, Apr 8, 2022 at 2:44 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, April 6, 2022 1:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > In this email, I would like to discuss allowing streaming logical > > transactions (large in-progress transactions) by background workers > > and parallel apply in general. The goal of this work is to improve the > > performance of the apply work in logical replication. > > > > Currently, for large transactions, the publisher sends the data in > > multiple streams (changes divided into chunks depending upon > > logical_decoding_work_mem), and then on the subscriber-side, the apply > > worker writes the changes into temporary files and once it receives > > the commit, it read from the file and apply the entire transaction. To > > improve the performance of such transactions, we can instead allow > > them to be applied via background workers. There could be multiple > > ways to achieve this: > > > > Approach-1: Assign a new bgworker (if available) as soon as the xact's > > first stream came and the main apply worker will send changes to this > > new worker via shared memory. We keep this worker assigned till the > > transaction commit came and also wait for the worker to finish at > > commit. This preserves commit ordering and avoid writing to and > > reading from file in most cases. We still need to spill if there is no > > worker available. We also need to allow stream_stop to complete by the > > background worker to finish it to avoid deadlocks because T-1's > > current stream of changes can update rows in conflicting order with > > T-2's next stream of changes. > > > > Attach the POC patch for the Approach-1 of "Perform streaming logical > transactions by background workers". The patch is still a WIP patch as > there are serval TODO items left, including: > > * error handling for bgworker > * support for SKIP the transaction in bgworker > * handle the case when there is no more worker available > (might need spill the data to the temp file in this case) > * some potential bugs > > The original patch is borrowed from an old thread[1] and was rebased and > extended/cleaned by me. Comments and suggestions are welcome. > > [1] https://www.postgresql.org/message-id/8eda5118-2dd0-79a1-4fe9-eec7e334de17%40postgrespro.ru > > Here are some performance results of the patch shared by Shi Yu off-list. > > The performance was tested by varying > logical_decoding_work_mem, which include two cases: > > 1) bulk insert. > 2) create savepoint and rollback to savepoint. > > I used synchronous logical replication in the test, compared SQL execution > times before and after applying the patch. > > The results are as follows. The bar charts and the details of the test are > Attached as well. > > RESULT - bulk insert (5kk) > ---------------------------------- > logical_decoding_work_mem 64kB 128kB 256kB 512kB 1MB 2MB 4MB 8MB 16MB 32MB 64MB > HEAD 51.673 51.199 51.166 50.259 52.898 50.651 51.156 51.210 50.678 51.256 51.138 > patched 36.198 35.123 34.223 29.198 28.712 29.090 29.709 29.408 34.367 34.716 35.439 > > RESULT - rollback to savepoint (600k) > ---------------------------------- > logical_decoding_work_mem 64kB 128kB 256kB 512kB 1MB 2MB 4MB 8MB 16MB 32MB 64MB > HEAD 31.101 31.087 30.931 31.015 30.920 31.109 30.863 31.008 30.875 30.775 29.903 > patched 28.115 28.487 27.804 28.175 27.734 29.047 28.279 27.909 28.277 27.345 28.375 > > > Summary: > 1) bulk insert > > For different logical_decoding_work_mem size, it takes about 30% ~ 45% less > time, which looks good to me. After applying this patch, it seems that the > performance is better when logical_decoding_work_mem is between 512kB and 8MB. > > 2) rollback to savepoint > > There is an improvement of about 5% ~ 10% after applying this patch. > > In this case, the patch spend less time handling the part that is not > rolled back, because it saves the time writing the changes into a temporary file > and reading the file. And for the part that is rolled back, it would spend more > time than HEAD, because it takes more time to write to filesystem and rollback > than writing a temporary file and truncating the file. Overall, the results looks > good. One comment on the design: We should have a strategy to release the workers which have completed applying the transactions, else even though there are some idle workers for one of the subscriptions, it cannot be used by other subscriptions. Like in the following case: Let's say max_logical_replication_workers is set to 10, if subscription sub_1 uses all the 10 workers to apply the transactions and all the 10 workers have finished applying the transactions and then subscription sub_2 requests some workers for applying transactions, subscription sub_2 will not get any workers. Maybe if the workers have completed applying the transactions, subscription sub_2 should be able to get these workers in this case. Regards, Vignesh
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, April 25, 2022 4:35 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > On Friday, April 22, 2022 12:12 PM Peter Smith <smithpb2250@gmail.com> > wrote: > > > > Hello Hou-san. Here are my review comments for v4-0001. Sorry, there > > are so many of them (it is a big patch); some are trivial, and others > > you might easily dismiss due to my misunderstanding of the code. But > > hopefully, there are at least some comments that can be helpful in > > improving the patch quality. > > Thanks for the comments ! > I think most of the comments make sense and here are explanations for some > of them. Hi, I addressed the rest of Peter's comments and here is a new version patch. The naming of the newly introduced option and worker might need more thought, so I haven't change all of them. I will think over and change it later. One comment I didn't address: > 3. General comment - bool option change to enum > > This option change for "streaming" is similar to the options change > for "copy_data=force" that Vignesh is doing for his "infinite > recursion" patch v9-0002 [1]. Yet they seem implemented differently > (i.e. char versus enum). I think you should discuss the 2 approaches > with Vignesh and then code these option changes in a consistent way. > > [1] https://www.postgresql.org/message-id/CALDaNm2Fe%3Dg4Tx-DhzwD6NU0VRAfaPedXwWO01maNU7_OfS8fw%40mail.gmail.> com I think the "streaming" option is a bit different from the "copy_data" option. Because the "streaming" is a column of the system table (pg_subscription) which should use "char" type to represent different values in this case(For example: pg_class.relkind/pg_class.relpersistence/pg_class.relreplident ...). And the "copy_data" option is not a system table column and I think it's fine to use Enum for it. Best regards, Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"shiy.fnst@fujitsu.com"
Date:
On Fri, Apr 29, 2022 10:07 AM Hou, Zhijie/侯 志杰 <houzj.fnst@fujitsu.com> wrote: > > I addressed the rest of Peter's comments and here is a new version patch. > Thanks for your patch. The patch modified streaming option in logical replication, it can be set to 'on', 'off' and 'apply'. The new option 'apply' haven't been tested in the tap test. Attach a patch which modified the subscription tap test to cover both 'on' and 'apply' option. (The main patch is also attached to make cfbot happy.) Besides, I noticed that for two-phase commit transactions, if the transaction is prepared by a background worker, the background worker would be asked to handle the message about commit/rollback this transaction. Is it possible that the messages about commit/rollback prepared transaction are handled by apply worker directly? Regards, Shi yu
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Fri, Apr 8, 2022 at 6:14 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, April 6, 2022 1:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > In this email, I would like to discuss allowing streaming logical > > transactions (large in-progress transactions) by background workers > > and parallel apply in general. The goal of this work is to improve the > > performance of the apply work in logical replication. > > > > Currently, for large transactions, the publisher sends the data in > > multiple streams (changes divided into chunks depending upon > > logical_decoding_work_mem), and then on the subscriber-side, the apply > > worker writes the changes into temporary files and once it receives > > the commit, it read from the file and apply the entire transaction. To > > improve the performance of such transactions, we can instead allow > > them to be applied via background workers. There could be multiple > > ways to achieve this: > > > > Approach-1: Assign a new bgworker (if available) as soon as the xact's > > first stream came and the main apply worker will send changes to this > > new worker via shared memory. We keep this worker assigned till the > > transaction commit came and also wait for the worker to finish at > > commit. This preserves commit ordering and avoid writing to and > > reading from file in most cases. We still need to spill if there is no > > worker available. We also need to allow stream_stop to complete by the > > background worker to finish it to avoid deadlocks because T-1's > > current stream of changes can update rows in conflicting order with > > T-2's next stream of changes. > > > > Attach the POC patch for the Approach-1 of "Perform streaming logical > transactions by background workers". The patch is still a WIP patch as > there are serval TODO items left, including: > > * error handling for bgworker > * support for SKIP the transaction in bgworker > * handle the case when there is no more worker available > (might need spill the data to the temp file in this case) > * some potential bugs Are you planning to support "Transaction dependency" Amit mentioned in his first mail in this patch? IIUC since the background apply worker applies the streamed changes as soon as receiving them from the main apply worker, a conflict that doesn't happen in the current streaming logical replication could happen. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, May 2, 2022 at 11:47 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Fri, Apr 8, 2022 at 6:14 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Wednesday, April 6, 2022 1:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > In this email, I would like to discuss allowing streaming logical > > > transactions (large in-progress transactions) by background workers > > > and parallel apply in general. The goal of this work is to improve the > > > performance of the apply work in logical replication. > > > > > > Currently, for large transactions, the publisher sends the data in > > > multiple streams (changes divided into chunks depending upon > > > logical_decoding_work_mem), and then on the subscriber-side, the apply > > > worker writes the changes into temporary files and once it receives > > > the commit, it read from the file and apply the entire transaction. To > > > improve the performance of such transactions, we can instead allow > > > them to be applied via background workers. There could be multiple > > > ways to achieve this: > > > > > > Approach-1: Assign a new bgworker (if available) as soon as the xact's > > > first stream came and the main apply worker will send changes to this > > > new worker via shared memory. We keep this worker assigned till the > > > transaction commit came and also wait for the worker to finish at > > > commit. This preserves commit ordering and avoid writing to and > > > reading from file in most cases. We still need to spill if there is no > > > worker available. We also need to allow stream_stop to complete by the > > > background worker to finish it to avoid deadlocks because T-1's > > > current stream of changes can update rows in conflicting order with > > > T-2's next stream of changes. > > > > > > > Attach the POC patch for the Approach-1 of "Perform streaming logical > > transactions by background workers". The patch is still a WIP patch as > > there are serval TODO items left, including: > > > > * error handling for bgworker > > * support for SKIP the transaction in bgworker > > * handle the case when there is no more worker available > > (might need spill the data to the temp file in this case) > > * some potential bugs > > Are you planning to support "Transaction dependency" Amit mentioned in > his first mail in this patch? IIUC since the background apply worker > applies the streamed changes as soon as receiving them from the main > apply worker, a conflict that doesn't happen in the current streaming > logical replication could happen. > This patch seems to be waiting for stream_stop to finish, so I don't see how the issues related to "Transaction dependency" can arise? What type of conflict/issues you have in mind? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, May 2, 2022 at 6:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Mon, May 2, 2022 at 11:47 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Fri, Apr 8, 2022 at 6:14 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Wednesday, April 6, 2022 1:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > >
> > > > In this email, I would like to discuss allowing streaming logical
> > > > transactions (large in-progress transactions) by background workers
> > > > and parallel apply in general. The goal of this work is to improve the
> > > > performance of the apply work in logical replication.
> > > >
> > > > Currently, for large transactions, the publisher sends the data in
> > > > multiple streams (changes divided into chunks depending upon
> > > > logical_decoding_work_mem), and then on the subscriber-side, the apply
> > > > worker writes the changes into temporary files and once it receives
> > > > the commit, it read from the file and apply the entire transaction. To
> > > > improve the performance of such transactions, we can instead allow
> > > > them to be applied via background workers. There could be multiple
> > > > ways to achieve this:
> > > >
> > > > Approach-1: Assign a new bgworker (if available) as soon as the xact's
> > > > first stream came and the main apply worker will send changes to this
> > > > new worker via shared memory. We keep this worker assigned till the
> > > > transaction commit came and also wait for the worker to finish at
> > > > commit. This preserves commit ordering and avoid writing to and
> > > > reading from file in most cases. We still need to spill if there is no
> > > > worker available. We also need to allow stream_stop to complete by the
> > > > background worker to finish it to avoid deadlocks because T-1's
> > > > current stream of changes can update rows in conflicting order with
> > > > T-2's next stream of changes.
> > > >
> > >
> > > Attach the POC patch for the Approach-1 of "Perform streaming logical
> > > transactions by background workers". The patch is still a WIP patch as
> > > there are serval TODO items left, including:
> > >
> > > * error handling for bgworker
> > > * support for SKIP the transaction in bgworker
> > > * handle the case when there is no more worker available
> > > (might need spill the data to the temp file in this case)
> > > * some potential bugs
> >
> > Are you planning to support "Transaction dependency" Amit mentioned in
> > his first mail in this patch? IIUC since the background apply worker
> > applies the streamed changes as soon as receiving them from the main
> > apply worker, a conflict that doesn't happen in the current streaming
> > logical replication could happen.
> >
>
> This patch seems to be waiting for stream_stop to finish, so I don't
> see how the issues related to "Transaction dependency" can arise? What
> type of conflict/issues you have in mind?
Suppose we set both publisher and subscriber:
On publisher:
create table test (i int);
insert into test values (0);
create publication test_pub for table test;
On subscriber:
create table test (i int primary key);
create subscription test_sub connection '...' publication test_pub; --
value 0 is replicated via initial sync
Now, both 'test' tables have value 0.
And suppose two concurrent transactions are executed on the publisher
in following order:
TX-1:
begin;
insert into test select generate_series(0, 10000); -- changes will be streamed;
TX-2:
begin;
delete from test where c = 0;
commit;
TX-1:
commit;
With the current streaming logical replication, these changes will be
applied successfully since the deletion is applied before the
(streamed) insertion. Whereas with the apply bgworker, it fails due to
an unique constraint violation since the insertion is applied first.
I've confirmed that it happens with v5 patch.
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, May 2, 2022 at 5:06 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Mon, May 2, 2022 at 6:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Mon, May 2, 2022 at 11:47 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > > Are you planning to support "Transaction dependency" Amit mentioned in > > > his first mail in this patch? IIUC since the background apply worker > > > applies the streamed changes as soon as receiving them from the main > > > apply worker, a conflict that doesn't happen in the current streaming > > > logical replication could happen. > > > > > > > This patch seems to be waiting for stream_stop to finish, so I don't > > see how the issues related to "Transaction dependency" can arise? What > > type of conflict/issues you have in mind? > > Suppose we set both publisher and subscriber: > > On publisher: > create table test (i int); > insert into test values (0); > create publication test_pub for table test; > > On subscriber: > create table test (i int primary key); > create subscription test_sub connection '...' publication test_pub; -- > value 0 is replicated via initial sync > > Now, both 'test' tables have value 0. > > And suppose two concurrent transactions are executed on the publisher > in following order: > > TX-1: > begin; > insert into test select generate_series(0, 10000); -- changes will be streamed; > > TX-2: > begin; > delete from test where c = 0; > commit; > > TX-1: > commit; > > With the current streaming logical replication, these changes will be > applied successfully since the deletion is applied before the > (streamed) insertion. Whereas with the apply bgworker, it fails due to > an unique constraint violation since the insertion is applied first. > I've confirmed that it happens with v5 patch. > Good point but I am not completely sure if doing transaction dependency tracking for such cases is really worth it. I feel for such concurrent cases users can anyway now also get conflicts, it is just a matter of timing. One more thing to check transaction dependency, we might need to spill the data for streaming transactions in which case we might lose all the benefits of doing it via a background worker. Do we see any simple way to avoid this? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Tue, May 3, 2022 at 2:15 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, May 2, 2022 at 5:06 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Mon, May 2, 2022 at 6:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Mon, May 2, 2022 at 11:47 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > > > > > Are you planning to support "Transaction dependency" Amit mentioned in > > > > his first mail in this patch? IIUC since the background apply worker > > > > applies the streamed changes as soon as receiving them from the main > > > > apply worker, a conflict that doesn't happen in the current streaming > > > > logical replication could happen. > > > > > > > > > > This patch seems to be waiting for stream_stop to finish, so I don't > > > see how the issues related to "Transaction dependency" can arise? What > > > type of conflict/issues you have in mind? > > > > Suppose we set both publisher and subscriber: > > > > On publisher: > > create table test (i int); > > insert into test values (0); > > create publication test_pub for table test; > > > > On subscriber: > > create table test (i int primary key); > > create subscription test_sub connection '...' publication test_pub; -- > > value 0 is replicated via initial sync > > > > Now, both 'test' tables have value 0. > > > > And suppose two concurrent transactions are executed on the publisher > > in following order: > > > > TX-1: > > begin; > > insert into test select generate_series(0, 10000); -- changes will be streamed; > > > > TX-2: > > begin; > > delete from test where c = 0; > > commit; > > > > TX-1: > > commit; > > > > With the current streaming logical replication, these changes will be > > applied successfully since the deletion is applied before the > > (streamed) insertion. Whereas with the apply bgworker, it fails due to > > an unique constraint violation since the insertion is applied first. > > I've confirmed that it happens with v5 patch. > > > > Good point but I am not completely sure if doing transaction > dependency tracking for such cases is really worth it. I feel for such > concurrent cases users can anyway now also get conflicts, it is just a > matter of timing. One more thing to check transaction dependency, we > might need to spill the data for streaming transactions in which case > we might lose all the benefits of doing it via a background worker. Do > we see any simple way to avoid this? > Avoiding unexpected differences like this is why I suggested the option should have to be explicitly enabled instead of being on by default as it is in the current patch. See my review comment #14 [1]. It means the user won't have to change their existing code as a workaround. ------ [1] https://www.postgresql.org/message-id/CAHut%2BPuqYP5eD5wcSCtk%3Da6KuMjat2UCzqyGoE7sieCaBsVskQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Tue, May 3, 2022 at 5:16 PM Peter Smith <smithpb2250@gmail.com> wrote: > ... > Avoiding unexpected differences like this is why I suggested the > option should have to be explicitly enabled instead of being on by > default as it is in the current patch. See my review comment #14 [1]. > It means the user won't have to change their existing code as a > workaround. > > ------ > [1] https://www.postgresql.org/message-id/CAHut%2BPuqYP5eD5wcSCtk%3Da6KuMjat2UCzqyGoE7sieCaBsVskQ%40mail.gmail.com > Sorry I was wrong above. It seems this behaviour was already changed in the latest patch v5 so now the option value 'on' means what it always did. Thanks! ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, May 3, 2022 at 9:45 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, May 2, 2022 at 5:06 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Mon, May 2, 2022 at 6:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Mon, May 2, 2022 at 11:47 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > > > > > Are you planning to support "Transaction dependency" Amit mentioned in > > > > his first mail in this patch? IIUC since the background apply worker > > > > applies the streamed changes as soon as receiving them from the main > > > > apply worker, a conflict that doesn't happen in the current streaming > > > > logical replication could happen. > > > > > > > > > > This patch seems to be waiting for stream_stop to finish, so I don't > > > see how the issues related to "Transaction dependency" can arise? What > > > type of conflict/issues you have in mind? > > > > Suppose we set both publisher and subscriber: > > > > On publisher: > > create table test (i int); > > insert into test values (0); > > create publication test_pub for table test; > > > > On subscriber: > > create table test (i int primary key); > > create subscription test_sub connection '...' publication test_pub; -- > > value 0 is replicated via initial sync > > > > Now, both 'test' tables have value 0. > > > > And suppose two concurrent transactions are executed on the publisher > > in following order: > > > > TX-1: > > begin; > > insert into test select generate_series(0, 10000); -- changes will be streamed; > > > > TX-2: > > begin; > > delete from test where c = 0; > > commit; > > > > TX-1: > > commit; > > > > With the current streaming logical replication, these changes will be > > applied successfully since the deletion is applied before the > > (streamed) insertion. Whereas with the apply bgworker, it fails due to > > an unique constraint violation since the insertion is applied first. > > I've confirmed that it happens with v5 patch. > > > > Good point but I am not completely sure if doing transaction > dependency tracking for such cases is really worth it. I feel for such > concurrent cases users can anyway now also get conflicts, it is just a > matter of timing. One more thing to check transaction dependency, we > might need to spill the data for streaming transactions in which case > we might lose all the benefits of doing it via a background worker. Do > we see any simple way to avoid this? > I think the other kind of problem that can happen here is delete followed by an insert. If in the example provided by you, TX-1 performs delete (say it is large enough to cause streaming) and TX-2 performs insert then I think it will block the apply worker because insert will start waiting infinitely. Currently, I think it will lead to conflict due to insert but that is still solvable by allowing users to remove conflicting rows. It seems both these problems are due to the reason that the table on publisher and subscriber has different constraints otherwise, we would have seen the same behavior on the publisher as well. There could be a few ways to avoid these and similar problems: a. detect the difference in constraints between publisher and subscribers like primary key and probably others (like whether there is any volatile function present in index expression) when applying the change and then we give ERROR to the user that she must change the streaming mode to 'spill' instead of 'apply' (aka parallel apply). b. Same as (a) but instead of ERROR just LOG this information and change the mode to spill for the transactions that operate on that particular relation. I think we can cache this information in LogicalRepRelMapEntry. Thoughts? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for v5-0001.
I will take a look at the v5-0002 (TAP) patch another time.
======
1. Commit message
The message still refers to "apply background". Should that say "apply
background worker"?
Other parts just call this the "worker". Personally, I think it might
be better to coin some new term for this thing (e.g. "apply-bgworker"
or something like that of your choosing) so then you can just
concisely *always* refer to that everywhere without any ambiguity. e.g
same applies to every comment and every message in this patch. They
should all use identical terminology (e.g. "apply-bgworker").
~~~
2. Commit message
"We also need to allow stream_stop to complete by the apply background
to finish it to..."
Wording: ???
~~~
3. Commit message
This patch also extends the subscription streaming option so that user
can control whether apply the streaming transaction in a apply
background or spill the change to disk.
Wording: "user" -> "the user"
Typo: "whether apply" -> "whether to apply"
Typo: "a apply" -> "an apply"
~~~
4. Commit message
User can set the streaming option to 'on/off', 'apply'. For now,
'apply' means the streaming will be applied via a apply background if
available. 'on' means the streaming transaction will be spilled to
disk.
I think "apply" might not be the best choice of values for this
meaning, but I think Hou-san already said [1] that this was being
reconsidered.
~~~
5. doc/src/sgml/catalogs.sgml - formatting
@@ -7863,11 +7863,15 @@ SCRAM-SHA-256$<replaceable><iteration
count></replaceable>:<replaceable>&l
<row>
<entry role="catalog_table_entry"><para role="column_definition">
- <structfield>substream</structfield> <type>bool</type>
+ <structfield>substream</structfield> <type>char</type>
</para>
<para>
- If true, the subscription will allow streaming of in-progress
- transactions
+ Controls how to handle the streaming of in-progress transactions.
+ <literal>f</literal> = disallow streaming of in-progress transactions
+ <literal>o</literal> = spill the changes of in-progress transactions to
+ disk and apply at once after the transaction is committed on the
+ publisher.
+ <literal>a</literal> = apply changes directly using a background worker
</para></entry>
</row>
Needs to be consistent with other value lists on this page.
5a. The first sentence to end with ":"
5b. List items to end with ","
~~~
6. doc/src/sgml/ref/create_subscription.sgml
+ <para>
+ If set to <literal>apply</literal> incoming
+ changes are directly applied via one of the background worker, if
+ available. If no background worker is free to handle streaming
+ transaction then the changes are written to a file and applied after
+ the transaction is committed. Note that if error happen when applying
+ changes in background worker, it might not report the finish LSN of
+ the remote transaction in server log.
</para>
6a. Typo: "one of the background worker," -> "one of the background workers,"
6b. Wording
BEFORE
Note that if error happen when applying changes in background worker,
it might not report the finish LSN of the remote transaction in server
log.
SUGGESTION
Note that if an error happens when applying changes in a background
worker, it might not report the finish LSN of the remote transaction
in the server log.
~~~
7. src/backend/commands/subscriptioncmds.c - defGetStreamingMode
+static char
+defGetStreamingMode(DefElem *def)
+{
+ /*
+ * If no parameter given, assume "true" is meant.
+ */
+ if (def->arg == NULL)
+ return SUBSTREAM_ON;
But is that right? IIUC all the docs said that the default is OFF.
~~~
8. src/backend/commands/subscriptioncmds.c - defGetStreamingMode
+ /*
+ * The set of strings accepted here should match up with the
+ * grammar's opt_boolean_or_string production.
+ */
+ if (pg_strcasecmp(sval, "true") == 0 ||
+ pg_strcasecmp(sval, "on") == 0)
+ return SUBSTREAM_ON;
+ if (pg_strcasecmp(sval, "apply") == 0)
+ return SUBSTREAM_APPLY;
+ if (pg_strcasecmp(sval, "false") == 0 ||
+ pg_strcasecmp(sval, "off") == 0)
+ return SUBSTREAM_OFF;
Perhaps should re-order these OFF/ON/APPLY to be consistent with the
T_Integer case above here.
~~~
9. src/backend/replication/logical/launcher.c - logicalrep_worker_launch
The "start new apply background worker ..." function comment feels a
bit misleading now that seems what you are calling this new kind of
worker. E.g. this is also called to start the sync worker. And also
for the apply worker (which we are not really calling a "background
worker" in other places). This comment is the same as [PSv4] #19.
~~~
10. src/backend/replication/logical/launcher.c - logicalrep_worker_launch
@@ -275,6 +280,9 @@ logicalrep_worker_launch(Oid dbid, Oid subid,
const char *subname, Oid userid,
int nsyncworkers;
TimestampTz now;
+ /* We don't support table sync in subworker */
+ Assert(!((subworker_dsm != DSM_HANDLE_INVALID) && OidIsValid(relid)));
I think you should declare a new variable like:
bool is_subworker = subworker_dsm != DSM_HANDLE_INVALID;
Then this Assert can be simplified, and also you can re-use the
'is_subworker' later multiple times in this same function to simplify
lots of other code also.
~~~
11. src/backend/replication/logical/launcher.c - logicalrep_worker_stop_internal
+/*
+ * Workhorse for logicalrep_worker_stop() and logicalrep_worker_detach(). Stop
+ * the worker and wait for wait for it to die.
+ */
+static void
+logicalrep_worker_stop_internal(LogicalRepWorker *worker)
Typo: "wait for" is repeated 2x.
~~~
12. src/backend/replication/logical/origin.c - replorigin_session_setup
@@ -1110,7 +1110,11 @@ replorigin_session_setup(RepOriginId node)
if (curstate->roident != node)
continue;
- else if (curstate->acquired_by != 0)
+ /*
+ * We allow the apply worker to get the slot which is acquired by its
+ * leader process.
+ */
+ else if (curstate->acquired_by != 0 && acquire)
I still feel this is overly-cofusing. Shouldn't comment say "Allow the
apply bgworker to get the slot...".
Also the parameter name 'acquire' is hard to reconcile with the
comment. E.g. I feel all this would be easier to understand if the
param was was refactored with a name like 'bgworker' and the code was
changed to:
else if (curstate->acquired_by != 0 && !bgworker)
Of course, the value true/false would need to be flipped on calls too.
This is the same as my previous comment [PSv4] #26.
~~~
13. src/backend/replication/logical/proto.c
@@ -1138,14 +1138,11 @@ logicalrep_write_stream_commit(StringInfo out,
ReorderBufferTXN *txn,
/*
* Read STREAM COMMIT from the output stream.
*/
-TransactionId
+void
logicalrep_read_stream_commit(StringInfo in, LogicalRepCommitData *commit_data)
{
- TransactionId xid;
uint8 flags;
- xid = pq_getmsgint(in, 4);
-
/* read flags (unused for now) */
flags = pq_getmsgbyte(in);
There is something incompatible with the read/write functions here.
The write writes the txid before the flags, but the read_commit does
not read it at all – if only reads the flags (???) if this is really
correct then I think there need to be some comments to explain WHY it
is correct.
NOTE: See also review comment 28 where I proposed another way to write
this code.
~~~
14. src/backend/replication/logical/worker.c - comment
The whole comment is similar to the commit message so any changes
there should be made here also.
~~~
15. src/backend/replication/logical/worker.c - ParallelState
+/*
+ * Shared information among apply workers.
+ */
+typedef struct ParallelState
It looks like there is already another typedef called "ParallelState"
because it is already in the typedefs.list. Maybe this name should be
changed or maybe make it static or something?
~~~
16. src/backend/replication/logical/worker.c - defines
+/*
+ * States for apply background worker.
+ */
+#define APPLY_BGWORKER_ATTACHED 'a'
+#define APPLY_BGWORKER_READY 'r'
+#define APPLY_BGWORKER_BUSY 'b'
+#define APPLY_BGWORKER_FINISHED 'f'
+#define APPLY_BGWORKER_EXIT 'e'
Those char states all look independent. So wouldn’t this be
represented better as an enum to reinforce that fact?
~~~
17. src/backend/replication/logical/worker.c - functions
+/* Worker setup and interactions */
+static WorkerState *apply_bgworker_setup(void);
+static WorkerState *find_or_start_apply_bgworker(TransactionId xid,
+ bool start);
Maybe rename to apply_bgworker_find_or_start() to match the pattern of
the others?
~~~
18. src/backend/replication/logical/worker.c - macros
+#define am_apply_bgworker() (MyLogicalRepWorker->subworker)
+#define applying_changes_in_bgworker() (in_streamed_transaction &&
stream_apply_worker != NULL)
18a. Somehow I felt these are not in the best place.
- Maybe am_apply_bgworker() should be in worker_internal.h?
- Maybe the applying_changes_in_bgworker() should be nearby the
stream_apply_worker declaration
18b. Maybe applying_changes_in_bgworker should be renamed to something
else to match the pattern of the others (e.g. "apply_bgworker_active"
or something)
~~~
19. src/backend/replication/logical/worker.c - handle_streamed_transaction
+ /*
+ * If we decided to apply the changes of this transaction in a apply
+ * background worker, pass the data to the worker.
+ */
Typo: "in a apply" -> "in an apply"
~~~
20. src/backend/replication/logical/worker.c - handle_streamed_transaction
+ /*
+ * XXX The publisher side doesn't always send relation update message
+ * after the streaming transaction, so update the relation in main
+ * apply worker here.
+ */
Wording: "doesn't always send relation update message" -> "doesn't
always send relation update messages" ??
~~~
21. src/backend/replication/logical/worker.c - apply_handle_commit_prepared
+ apply_bgworker_set_state(APPLY_BGWORKER_FINISHED);
It seems somewhat confusing to see calls to apply_bgworker_set_state()
when we may or may not even be an apply bgworker.
I know it adds more code, but I somehow feel it is more readable if
all these calls were changed to look below. Please consider it.
SUGGESTION
if (am_bgworker())
apply_bgworker_set_state(XXX);
Then you can also change the apply_bgworker_set_state to
Assert(am_apply_bgworker());
~~~
22. src/backend/replication/logical/worker.c - find_or_start_apply_bgworker
+
+ if (!start && ApplyWorkersHash == NULL)
+ return NULL;
+
IIUC maybe this extra check is not really necessary. I see no harm to
create the HashTable even if was called in this state. If the 'start'
flag is false then nothing is going to be found anyway, so it will
return NULL. e.g. Might as well make the code a few lines
shorter/simpler by removing this check.
~~~
23. src/backend/replication/logical/worker.c - apply_bgworker_free
+/*
+ * Add the worker to the freelist and remove the entry from hash table.
+ */
+static void
+apply_bgworker_free(WorkerState *wstate)
+{
+ bool found;
+ MemoryContext oldctx;
+ TransactionId xid = wstate->pstate->stream_xid;
If you are not going to check the value of 'found' then why bother to
pass this param at all? Can't you just pass NULL?
~~~
24. src/backend/replication/logical/worker.c - apply_bgworker_free
Should there be an Assert that the bgworker state really was FINISHED?
I think I asked this already [PSv4] #48.
~~~
24. src/backend/replication/logical/worker.c - apply_handle_stream_start
@@ -1088,24 +1416,71 @@ apply_handle_stream_prepare(StringInfo s)
logicalrep_read_stream_prepare(s, &prepare_data);
set_apply_error_context_xact(prepare_data.xid, prepare_data.prepare_lsn);
- elog(DEBUG1, "received prepare for streamed transaction %u",
prepare_data.xid);
+ /*
+ * If we are in a bgworker, just prepare the transaction.
+ */
+ if (am_apply_bgworker())
Don’t need to say "If we are..." because the am_apply_worker()
condition makes it clear this is true.
~~~
25. src/backend/replication/logical/worker.c - apply_handle_stream_start
- if (MyLogicalRepWorker->stream_fileset == NULL)
+ stream_apply_worker = find_or_start_apply_bgworker(stream_xid, first_segment);
+
+ if (applying_changes_in_bgworker())
{
IIUC this condition seems overkill. I think you can just say if
(stream_apply_worker)
~~~
26. src/backend/replication/logical/worker.c - apply_handle_stream_abort
+ if (found)
+ {
+ elog(LOG, "rolled back to savepoint %s", spname);
+ RollbackToSavepoint(spname);
+ CommitTransactionCommand();
+ subxactlist = list_truncate(subxactlist, i + 1);
+ }
Should that elog use the "[Apply BGW #%u]" format like the others for BGW?
~~~
27. src/backend/replication/logical/worker.c - apply_handle_stream_abort
Should this function be setting stream_apply_worker = NULL somewhere
when all is done?
~~~
28. src/backend/replication/logical/worker.c - apply_handle_stream_commit
+/*
+ * Handle STREAM COMMIT message.
+ */
+static void
+apply_handle_stream_commit(StringInfo s)
+{
+ LogicalRepCommitData commit_data;
+ TransactionId xid;
+
+ if (in_streamed_transaction)
+ ereport(ERROR,
+ (errcode(ERRCODE_PROTOCOL_VIOLATION),
+ errmsg_internal("STREAM COMMIT message without STREAM STOP")));
+
+ xid = pq_getmsgint(s, 4);
+ logicalrep_read_stream_commit(s, &commit_data);
+ set_apply_error_context_xact(xid, commit_data.commit_lsn);
There is something a bit odd about this code. I think the
logicalrep_read_stream_commit() should take another param and the Txid
be extracted/read only INSIDE that logicalrep_read_stream_commit
function. See also review comment #13.
~~~
29. src/backend/replication/logical/worker.c - apply_handle_stream_commit
I am unsure, but should something be setting the stream_apply_worker =
NULL somewhere when all is done?
~~~
30. src/backend/replication/logical/worker.c - LogicalApplyBgwLoop
30a.
+ if (shmq_res != SHM_MQ_SUCCESS)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("lost connection to the main apply worker")));
30b.
+ default:
+ elog(ERROR, "unexpected message");
+ break;
Should both those error messages have the "[Apply BGW #%u]" prefix
like the other BGW messages?
~~~
31. src/backend/replication/logical/worker.c - ApplyBgwShutdown
+/*
+ * Set the failed flag so that the main apply worker can realize we have
+ * shutdown.
+ */
+static void
+ApplyBgwShutdown(int code, Datum arg)
The comment does not seem to be in sync with the code. E.g.
Wording: "failed flag" -> "exit state" ??
~~~
32. src/backend/replication/logical/worker.c - ApplyBgwShutdown
+/*
+ * Set the failed flag so that the main apply worker can realize we have
+ * shutdown.
+ */
+static void
+ApplyBgwShutdown(int code, Datum arg)
If the 'code' param is deliberately unused it might be better to say
so in the comment...
~~~
33. src/backend/replication/logical/worker.c - LogicalApplyBgwMain
33a.
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("unable to map dynamic shared memory segment")));
33b.
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("bad magic number in dynamic shared memory segment")));
+
33c.
+ ereport(LOG,
+ (errmsg("logical replication apply worker for subscription %u will not "
+ "start because the subscription was removed during startup",
+ MyLogicalRepWorker->subid)));
Should all these messages have "[Apply BGW ?]" prefix even though they
are not yet attached?
~~~
34. src/backend/replication/logical/worker.c - setup_dsm
+ * We need one key to register the location of the header, and we need
+ * nworkers keys to track the locations of the message queues.
+ */
This comment about 'nworkers' seems stale because that variable no
longer exists.
~~~
35. src/backend/replication/logical/worker.c - apply_bgworker_setup
+/*
+ * Start apply worker background worker process and allocat shared memory for
+ * it.
+ */
+static WorkerState *
+apply_bgworker_setup(void)
typo: "allocat" -> "allocate"
~~~
36. src/backend/replication/logical/worker.c - apply_bgworker_setup
+ elog(LOG, "setting up apply worker #%u", list_length(ApplyWorkersList) + 1)
Should this message have the standard "[Apply BGW %u]" pattern?
~~~
37. src/backend/replication/logical/worker.c - apply_bgworker_setup
+ if (launched)
+ {
+ /* Wait for worker to become ready. */
+ apply_bgworker_wait_for(wstate, APPLY_BGWORKER_ATTACHED);
+
+ ApplyWorkersList = lappend(ApplyWorkersList, wstate);
+ }
Since there is a state APPLY_BGWORKER_READY I think either this
comment is wrong or this passed parameter ATTACHED must be wrong.
~~~
38. src/backend/replication/logical/worker.c - apply_bgworker_send_data
+ if (result != SHM_MQ_SUCCESS)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("could not send tuples to shared-memory queue")));
+}
Wording: Is it right to ocall these "tuples" or better just say
"data"? I am not sure. Already asked this in [PSv4] #68
~~~
39. src/backend/replication/logical/worker.c - apply_bgworker_wait_for
+/*
+ * Wait until the state of apply background worker reach the 'wait_for_state'
+ */
+static void
+apply_bgworker_wait_for(WorkerState *wstate, char wait_for_state)
typo: "reach" -> "reaches"
~~~
40. src/backend/replication/logical/worker.c - apply_bgworker_wait_for
+ /* If the worker is ready, we have succeeded. */
+ SpinLockAcquire(&wstate->pstate->mutex);
+ status = wstate->pstate->state;
+ SpinLockRelease(&wstate->pstate->mutex);
+
+ if (status == wait_for_state)
+ break;
40a. What does this mention "ready". This function might be waiting
for a different state to that.
40b. Anyway, I think this comment should be a few lines lower, above
the if (status == wait_for_state)
~~~
41. src/backend/replication/logical/worker.c - apply_bgworker_wait_for
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("Background worker %u failed to apply transaction %u",
+ wstate->pstate->n, wstate->pstate->stream_xid)));
Should this message have the standard "[Apply BGW %u]" pattern?
~~~
42. src/backend/replication/logical/worker.c - check_workers_status
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("Background worker %u exited unexpectedly",
+ wstate->pstate->n)));
Should this message have the standard "[Apply BGW %u]" pattern? Or if
this is just from Apply worker maybe it should be clearer like "Apply
worker detected apply bgworker %u exited unexpectedly".
~~~
43. src/backend/replication/logical/worker.c - check_workers_status
+ ereport(LOG,
+ (errmsg("logical replication apply workers for subscription \"%s\"
will restart",
+ MySubscription->name),
+ errdetail("Cannot start table synchronization while bgworkers are "
+ "handling streamed replication transaction")));
I am not sure, but isn't the message backwards? e.g. Should it say more like:
"Cannot handle streamed transactions using bgworkers while table
synchronization is still in progress".
~~~
44. src/backend/replication/logical/worker.c - apply_bgworker_set_state
+ elog(LOG, "[Apply BGW #%u] set state to %c",
+ MyParallelState->n, state);
The line wrapping seemed overkill here.
~~~
45. src/backend/utils/activity/wait_event.c
@@ -388,6 +388,9 @@ pgstat_get_wait_ipc(WaitEventIPC w)
case WAIT_EVENT_HASH_GROW_BUCKETS_REINSERT:
event_name = "HashGrowBucketsReinsert";
break;
+ case WAIT_EVENT_LOGICAL_APPLY_WORKER_READY:
+ event_name = "LogicalApplyWorkerReady";
+ break;
I am not sure this is the best name for this event since the only
place it is used (in apply_bgworker_wait_for) is not only waiting for
READY state. Maybe a name like WAIT_EVENT_LOGICAL_APPLY_BGWORKER or
WAIT_EVENT_LOGICAL_APPLY_WORKER_SYNC would be more appropriate? Need
to change the wait_event.h also.
~~~
46. src/include/catalog/pg_subscription.h
+/* Disallow streaming in-progress transactions */
+#define SUBSTREAM_OFF 'f'
+
+/*
+ * Streaming transactions are written to a temporary file and applied only
+ * after the transaction is committed on upstream.
+ */
+#define SUBSTREAM_ON 'o'
+
+/* Streaming transactions are appied immediately via a background worker */
+#define SUBSTREAM_APPLY 'a'
46a. There is not really any overarching comment that associates these
#defines back to the new 'stream' field so you are just supposed to
guess that's what they are for?
46b. I also feel that using 'o' for ON is not consistent with the 'f'
of OFF. IMO better to use 't/f' for true/false instead of 'o/f'. Also
don't forget update docs, pg_dump.c etc.
46c. Typo: "appied" -> "applied"
~~~~
47. src/test/regress/expected/subscription.out - missting test
Missing some test cases for all new option values? E.g. Where is the
test using streaming value is set to 'apply'. Same comment as [PSv4]
#81
------
[1]
https://www.postgresql.org/message-id/OS0PR01MB5716E8D536552467EFB512EF94FC9%40OS0PR01MB5716.jpnprd01.prod.outlook.com
[PSv4] https://www.postgresql.org/message-id/CAHut%2BPuqYP5eD5wcSCtk%3Da6KuMjat2UCzqyGoE7sieCaBsVskQ%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Fri, Apr 29, 2022 at 3:22 PM shiy.fnst@fujitsu.com
<shiy.fnst@fujitsu.com> wrote:
...
> Thanks for your patch.
>
> The patch modified streaming option in logical replication, it can be set to
> 'on', 'off' and 'apply'. The new option 'apply' haven't been tested in the tap test.
> Attach a patch which modified the subscription tap test to cover both 'on' and
> 'apply' option. (The main patch is also attached to make cfbot happy.)
>
Here are my review comments for v5-0002 (TAP tests)
Your changes followed a similar pattern of refactoring so most of my
comments below is repeated for all the files.
======
1. Commit message
For the tap tests about streaming option in logical replication, test both
'on' and 'apply' option.
SUGGESTION
Change all TAP tests using the PUBLICATION "streaming" option, so they
now test both 'on' and 'apply' values.
~~~
2. src/test/subscription/t/015_stream.pl
+sub test_streaming
+{
I think the function should have a comment to say that its purpose is
to encapsulate all the common (stream related) test steps so the same
code can be run both for the streaming=on and streaming=apply cases.
~~~
3. src/test/subscription/t/015_stream.pl
+
+# Test streaming mode on
+# Test streaming mode apply
These comments fell too small. IMO they should both be more prominent like:
################################
# Test using streaming mode 'on'
################################
###################################
# Test using streaming mode 'apply'
###################################
~~~
4. src/test/subscription/t/015_stream.pl
+# Test streaming mode apply
+$node_publisher->safe_psql('postgres', "DELETE FROM test_tab WHERE (a > 2)");
$node_publisher->wait_for_catchup($appname);
I think those 2 lines do not really belong after the "# Test streaming
mode apply" comment. IIUC they are really just doing cleanup from the
prior test part so I think they should
a) be *above* this comment (and say "# cleanup the test data") or
b) maybe it is best to put all the cleanup lines actually inside the
'test_streaming' function so that the last thing the function does is
clean up after itself.
option b seems tidier to me.
~~~
5. src/test/subscription/t/016_stream_subxact.pl
sub test_streaming should be commented. (same as comment #2)
~~~
6. src/test/subscription/t/016_stream_subxact.pl
The comments for the different streaming nodes should be more
prominent. (same as comment #3)
~~~
7. src/test/subscription/t/016_stream_subxact.pl
+# Test streaming mode apply
+$node_publisher->safe_psql('postgres', "DELETE FROM test_tab WHERE (a > 2)");
$node_publisher->wait_for_catchup($appname);
These don't seem to belong here. They are clean up from the prior
test. (same as comment #4)
~~~
8. src/test/subscription/t/017_stream_ddl.pl
sub test_streaming should be commented. (same as comment #2)
~~~
9. src/test/subscription/t/017_stream_ddl.pl
The comments for the different streaming nodes should be more
prominent. (same as comment #3)
~~~
10. src/test/subscription/t/017_stream_ddl.pl
+# Test streaming mode apply
$node_publisher->safe_psql(
'postgres', q{
-BEGIN;
-INSERT INTO test_tab VALUES (2001, md5(2001::text), -2001, 2*2001);
-ALTER TABLE test_tab ADD COLUMN e INT;
-SAVEPOINT s1;
-INSERT INTO test_tab VALUES (2002, md5(2002::text), -2002, 2*2002, -3*2002);
-COMMIT;
+DELETE FROM test_tab WHERE (a > 2);
+ALTER TABLE test_tab DROP COLUMN c, DROP COLUMN d, DROP COLUMN e,
DROP COLUMN f;
});
$node_publisher->wait_for_catchup($appname);
These don't seem to belong here. They are clean up from the prior
test. (same as comment #4)
~~~
11. .../t/018_stream_subxact_abort.pl
sub test_streaming should be commented. (same as comment #2)
~~~
12. .../t/018_stream_subxact_abort.pl
The comments for the different streaming nodes should be more
prominent. (same as comment #3)
~~~
13. .../t/018_stream_subxact_abort.pl
+# Test streaming mode apply
+$node_publisher->safe_psql('postgres', "DELETE FROM test_tab WHERE (a > 2)");
$node_publisher->wait_for_catchup($appname);
These don't seem to belong here. They are clean up from the prior
test. (same as comment #4)
~~~
14. .../t/019_stream_subxact_ddl_abort.pl
sub test_streaming should be commented. (same as comment #2)
~~~
15. .../t/019_stream_subxact_ddl_abort.pl
The comments for the different streaming nodes should be more
prominent. (same as comment #3)
~~~
16. .../t/019_stream_subxact_ddl_abort.pl
+test_streaming($node_publisher, $node_subscriber, $appname);
+
+# Test streaming mode apply
$node_publisher->safe_psql(
'postgres', q{
-BEGIN;
-INSERT INTO test_tab SELECT i, md5(i::text) FROM generate_series(3,500) s(i);
-ALTER TABLE test_tab ADD COLUMN c INT;
-SAVEPOINT s1;
-INSERT INTO test_tab SELECT i, md5(i::text), -i FROM
generate_series(501,1000) s(i);
-ALTER TABLE test_tab ADD COLUMN d INT;
-SAVEPOINT s2;
-INSERT INTO test_tab SELECT i, md5(i::text), -i, 2*i FROM
generate_series(1001,1500) s(i);
-ALTER TABLE test_tab ADD COLUMN e INT;
-SAVEPOINT s3;
-INSERT INTO test_tab SELECT i, md5(i::text), -i, 2*i, -3*i FROM
generate_series(1501,2000) s(i);
+DELETE FROM test_tab WHERE (a > 2);
ALTER TABLE test_tab DROP COLUMN c;
-ROLLBACK TO s1;
-INSERT INTO test_tab SELECT i, md5(i::text), i FROM
generate_series(501,1000) s(i);
-COMMIT;
});
-
$node_publisher->wait_for_catchup($appname);
These don't seem to belong here. They are clean up from the prior
test. (same as comment #4)
~~~
17. .../subscription/t/022_twophase_cascade.
+# ---------------------
+# 2PC + STREAMING TESTS
+# ---------------------
+sub test_streaming
+{
I think maybe that 2PC comment should not have been moved. IMO it
belongs in the main test body...
~~~
18. .../subscription/t/022_twophase_cascade.
sub test_streaming should be commented. (same as comment #2)
~~~
19. .../subscription/t/022_twophase_cascade.
+sub test_streaming
+{
+ my ($node_A, $node_B, $node_C, $appname_B, $appname_C, $streaming) = @_;
If you called that '$streaming' param something more like
'$streaming_mode' it would read better I think.
~~~
20. .../subscription/t/023_twophase_stream.pl
sub test_streaming should be commented. (same as comment #2)
~~~
21. .../subscription/t/023_twophase_stream.pl
The comments for the different streaming nodes should be more
prominent. (same as comment #3)
~~~
22. .../subscription/t/023_twophase_stream.pl
+# Test streaming mode apply
$node_publisher->safe_psql('postgres', "DELETE FROM test_tab WHERE a > 2;");
-
-# Then insert, update and delete enough rows to exceed the 64kB limit.
-$node_publisher->safe_psql('postgres', q{
- BEGIN;
- INSERT INTO test_tab SELECT i, md5(i::text) FROM generate_series(3,
5000) s(i);
- UPDATE test_tab SET b = md5(b) WHERE mod(a,2) = 0;
- DELETE FROM test_tab WHERE mod(a,3) = 0;
- PREPARE TRANSACTION 'test_prepared_tab';});
-
-$node_publisher->wait_for_catchup($appname);
-
-# check that transaction is in prepared state on subscriber
-$result = $node_subscriber->safe_psql('postgres', "SELECT count(*)
FROM pg_prepared_xacts;");
-is($result, qq(1), 'transaction is prepared on subscriber');
-
-# 2PC transaction gets aborted
-$node_publisher->safe_psql('postgres', "ROLLBACK PREPARED
'test_prepared_tab';");
-
$node_publisher->wait_for_catchup($appname);
These don't seem to belong here. They are clean up from the prior
test. (same as comment #4)
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, May 4, 2022 at 12:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, May 3, 2022 at 9:45 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Mon, May 2, 2022 at 5:06 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > On Mon, May 2, 2022 at 6:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > On Mon, May 2, 2022 at 11:47 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > > > > > > > > Are you planning to support "Transaction dependency" Amit mentioned in > > > > > his first mail in this patch? IIUC since the background apply worker > > > > > applies the streamed changes as soon as receiving them from the main > > > > > apply worker, a conflict that doesn't happen in the current streaming > > > > > logical replication could happen. > > > > > > > > > > > > > This patch seems to be waiting for stream_stop to finish, so I don't > > > > see how the issues related to "Transaction dependency" can arise? What > > > > type of conflict/issues you have in mind? > > > > > > Suppose we set both publisher and subscriber: > > > > > > On publisher: > > > create table test (i int); > > > insert into test values (0); > > > create publication test_pub for table test; > > > > > > On subscriber: > > > create table test (i int primary key); > > > create subscription test_sub connection '...' publication test_pub; -- > > > value 0 is replicated via initial sync > > > > > > Now, both 'test' tables have value 0. > > > > > > And suppose two concurrent transactions are executed on the publisher > > > in following order: > > > > > > TX-1: > > > begin; > > > insert into test select generate_series(0, 10000); -- changes will be streamed; > > > > > > TX-2: > > > begin; > > > delete from test where c = 0; > > > commit; > > > > > > TX-1: > > > commit; > > > > > > With the current streaming logical replication, these changes will be > > > applied successfully since the deletion is applied before the > > > (streamed) insertion. Whereas with the apply bgworker, it fails due to > > > an unique constraint violation since the insertion is applied first. > > > I've confirmed that it happens with v5 patch. > > > > > > > Good point but I am not completely sure if doing transaction > > dependency tracking for such cases is really worth it. I feel for such > > concurrent cases users can anyway now also get conflicts, it is just a > > matter of timing. One more thing to check transaction dependency, we > > might need to spill the data for streaming transactions in which case > > we might lose all the benefits of doing it via a background worker. Do > > we see any simple way to avoid this? > > I agree that it is just a matter of timing. I think new issues that haven't happened on the current streaming logical replication depending on the timing could happen with this feature and vice versa. > > I think the other kind of problem that can happen here is delete > followed by an insert. If in the example provided by you, TX-1 > performs delete (say it is large enough to cause streaming) and TX-2 > performs insert then I think it will block the apply worker because > insert will start waiting infinitely. Currently, I think it will lead > to conflict due to insert but that is still solvable by allowing users > to remove conflicting rows. > > It seems both these problems are due to the reason that the table on > publisher and subscriber has different constraints otherwise, we would > have seen the same behavior on the publisher as well. > > There could be a few ways to avoid these and similar problems: > a. detect the difference in constraints between publisher and > subscribers like primary key and probably others (like whether there > is any volatile function present in index expression) when applying > the change and then we give ERROR to the user that she must change the > streaming mode to 'spill' instead of 'apply' (aka parallel apply). > b. Same as (a) but instead of ERROR just LOG this information and > change the mode to spill for the transactions that operate on that > particular relation. Given that it doesn't introduce a new kind of problem I don't think we need special treatment for that at least in this feature. If we want such modes we can discuss it separately. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, May 4, 2022 at 8:44 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Tue, May 3, 2022 at 5:16 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > ... > > > Avoiding unexpected differences like this is why I suggested the > > option should have to be explicitly enabled instead of being on by > > default as it is in the current patch. See my review comment #14 [1]. > > It means the user won't have to change their existing code as a > > workaround. > > > > ------ > > [1] https://www.postgresql.org/message-id/CAHut%2BPuqYP5eD5wcSCtk%3Da6KuMjat2UCzqyGoE7sieCaBsVskQ%40mail.gmail.com > > > > Sorry I was wrong above. It seems this behaviour was already changed > in the latest patch v5 so now the option value 'on' means what it > always did. Thanks! Having it optional seems a good idea. BTW can the user configure how many apply bgworkers can be used per subscription or in the whole system? Like max_sync_workers_per_subscription, is it better to have a configuration parameter or a subscription option for that? If so, setting it to 0 probably means to disable the parallel apply feature. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, May 10, 2022 at 10:39 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Wed, May 4, 2022 at 8:44 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Tue, May 3, 2022 at 5:16 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > ... > > > > > Avoiding unexpected differences like this is why I suggested the > > > option should have to be explicitly enabled instead of being on by > > > default as it is in the current patch. See my review comment #14 [1]. > > > It means the user won't have to change their existing code as a > > > workaround. > > > > > > ------ > > > [1] https://www.postgresql.org/message-id/CAHut%2BPuqYP5eD5wcSCtk%3Da6KuMjat2UCzqyGoE7sieCaBsVskQ%40mail.gmail.com > > > > > > > Sorry I was wrong above. It seems this behaviour was already changed > > in the latest patch v5 so now the option value 'on' means what it > > always did. Thanks! > > Having it optional seems a good idea. BTW can the user configure how > many apply bgworkers can be used per subscription or in the whole > system? Like max_sync_workers_per_subscription, is it better to have a > configuration parameter or a subscription option for that? If so, > setting it to 0 probably means to disable the parallel apply feature. > Yeah, that might be useful but we are already giving an option while creating a subscription whether to allow parallelism, so will it be useful to give one more way to disable this feature? OTOH, having something like max_parallel_apply_workers/max_bg_apply_workers at the system level can give better control for how much parallelism the user wishes to allow for apply work. If we have such a new parameter then I think max_logical_replication_workers should include apply workers, parallel apply workers, and table synchronization? In such a case, don't we need to think of increasing the default value of max_logical_replication_workers? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, May 10, 2022 at 10:35 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Wed, May 4, 2022 at 12:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, May 3, 2022 at 9:45 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Mon, May 2, 2022 at 5:06 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > On Mon, May 2, 2022 at 6:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > > On Mon, May 2, 2022 at 11:47 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > > > > > > > > > > > Are you planning to support "Transaction dependency" Amit mentioned in > > > > > > his first mail in this patch? IIUC since the background apply worker > > > > > > applies the streamed changes as soon as receiving them from the main > > > > > > apply worker, a conflict that doesn't happen in the current streaming > > > > > > logical replication could happen. > > > > > > > > > > > > > > > > This patch seems to be waiting for stream_stop to finish, so I don't > > > > > see how the issues related to "Transaction dependency" can arise? What > > > > > type of conflict/issues you have in mind? > > > > > > > > Suppose we set both publisher and subscriber: > > > > > > > > On publisher: > > > > create table test (i int); > > > > insert into test values (0); > > > > create publication test_pub for table test; > > > > > > > > On subscriber: > > > > create table test (i int primary key); > > > > create subscription test_sub connection '...' publication test_pub; -- > > > > value 0 is replicated via initial sync > > > > > > > > Now, both 'test' tables have value 0. > > > > > > > > And suppose two concurrent transactions are executed on the publisher > > > > in following order: > > > > > > > > TX-1: > > > > begin; > > > > insert into test select generate_series(0, 10000); -- changes will be streamed; > > > > > > > > TX-2: > > > > begin; > > > > delete from test where c = 0; > > > > commit; > > > > > > > > TX-1: > > > > commit; > > > > > > > > With the current streaming logical replication, these changes will be > > > > applied successfully since the deletion is applied before the > > > > (streamed) insertion. Whereas with the apply bgworker, it fails due to > > > > an unique constraint violation since the insertion is applied first. > > > > I've confirmed that it happens with v5 patch. > > > > > > > > > > Good point but I am not completely sure if doing transaction > > > dependency tracking for such cases is really worth it. I feel for such > > > concurrent cases users can anyway now also get conflicts, it is just a > > > matter of timing. One more thing to check transaction dependency, we > > > might need to spill the data for streaming transactions in which case > > > we might lose all the benefits of doing it via a background worker. Do > > > we see any simple way to avoid this? > > > > > I agree that it is just a matter of timing. I think new issues that > haven't happened on the current streaming logical replication > depending on the timing could happen with this feature and vice versa. > Here by vice versa, do you mean some problems that can happen with current code won't happen after new implementation? If so, can you give one such example? > > > > I think the other kind of problem that can happen here is delete > > followed by an insert. If in the example provided by you, TX-1 > > performs delete (say it is large enough to cause streaming) and TX-2 > > performs insert then I think it will block the apply worker because > > insert will start waiting infinitely. Currently, I think it will lead > > to conflict due to insert but that is still solvable by allowing users > > to remove conflicting rows. > > > > It seems both these problems are due to the reason that the table on > > publisher and subscriber has different constraints otherwise, we would > > have seen the same behavior on the publisher as well. > > > > There could be a few ways to avoid these and similar problems: > > a. detect the difference in constraints between publisher and > > subscribers like primary key and probably others (like whether there > > is any volatile function present in index expression) when applying > > the change and then we give ERROR to the user that she must change the > > streaming mode to 'spill' instead of 'apply' (aka parallel apply). > > b. Same as (a) but instead of ERROR just LOG this information and > > change the mode to spill for the transactions that operate on that > > particular relation. > > Given that it doesn't introduce a new kind of problem I don't think we > need special treatment for that at least in this feature. > Isn't the problem related to infinite wait by insert as explained in my previous email (in the above-quoted text) a new kind of problem that won't exist in the current implementation? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Tue, May 10, 2022 at 6:10 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, May 10, 2022 at 10:35 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Wed, May 4, 2022 at 12:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Tue, May 3, 2022 at 9:45 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > On Mon, May 2, 2022 at 5:06 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > > > On Mon, May 2, 2022 at 6:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > > > > On Mon, May 2, 2022 at 11:47 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > > > > > > > > > > > > > > Are you planning to support "Transaction dependency" Amit mentioned in > > > > > > > his first mail in this patch? IIUC since the background apply worker > > > > > > > applies the streamed changes as soon as receiving them from the main > > > > > > > apply worker, a conflict that doesn't happen in the current streaming > > > > > > > logical replication could happen. > > > > > > > > > > > > > > > > > > > This patch seems to be waiting for stream_stop to finish, so I don't > > > > > > see how the issues related to "Transaction dependency" can arise? What > > > > > > type of conflict/issues you have in mind? > > > > > > > > > > Suppose we set both publisher and subscriber: > > > > > > > > > > On publisher: > > > > > create table test (i int); > > > > > insert into test values (0); > > > > > create publication test_pub for table test; > > > > > > > > > > On subscriber: > > > > > create table test (i int primary key); > > > > > create subscription test_sub connection '...' publication test_pub; -- > > > > > value 0 is replicated via initial sync > > > > > > > > > > Now, both 'test' tables have value 0. > > > > > > > > > > And suppose two concurrent transactions are executed on the publisher > > > > > in following order: > > > > > > > > > > TX-1: > > > > > begin; > > > > > insert into test select generate_series(0, 10000); -- changes will be streamed; > > > > > > > > > > TX-2: > > > > > begin; > > > > > delete from test where c = 0; > > > > > commit; > > > > > > > > > > TX-1: > > > > > commit; > > > > > > > > > > With the current streaming logical replication, these changes will be > > > > > applied successfully since the deletion is applied before the > > > > > (streamed) insertion. Whereas with the apply bgworker, it fails due to > > > > > an unique constraint violation since the insertion is applied first. > > > > > I've confirmed that it happens with v5 patch. > > > > > > > > > > > > > Good point but I am not completely sure if doing transaction > > > > dependency tracking for such cases is really worth it. I feel for such > > > > concurrent cases users can anyway now also get conflicts, it is just a > > > > matter of timing. One more thing to check transaction dependency, we > > > > might need to spill the data for streaming transactions in which case > > > > we might lose all the benefits of doing it via a background worker. Do > > > > we see any simple way to avoid this? > > > > > > > > I agree that it is just a matter of timing. I think new issues that > > haven't happened on the current streaming logical replication > > depending on the timing could happen with this feature and vice versa. > > > > Here by vice versa, do you mean some problems that can happen with > current code won't happen after new implementation? If so, can you > give one such example? > > > > > > > I think the other kind of problem that can happen here is delete > > > followed by an insert. If in the example provided by you, TX-1 > > > performs delete (say it is large enough to cause streaming) and TX-2 > > > performs insert then I think it will block the apply worker because > > > insert will start waiting infinitely. Currently, I think it will lead > > > to conflict due to insert but that is still solvable by allowing users > > > to remove conflicting rows. > > > > > > It seems both these problems are due to the reason that the table on > > > publisher and subscriber has different constraints otherwise, we would > > > have seen the same behavior on the publisher as well. > > > > > > There could be a few ways to avoid these and similar problems: > > > a. detect the difference in constraints between publisher and > > > subscribers like primary key and probably others (like whether there > > > is any volatile function present in index expression) when applying > > > the change and then we give ERROR to the user that she must change the > > > streaming mode to 'spill' instead of 'apply' (aka parallel apply). > > > b. Same as (a) but instead of ERROR just LOG this information and > > > change the mode to spill for the transactions that operate on that > > > particular relation. > > > > Given that it doesn't introduce a new kind of problem I don't think we > > need special treatment for that at least in this feature. > > > > Isn't the problem related to infinite wait by insert as explained in > my previous email (in the above-quoted text) a new kind of problem > that won't exist in the current implementation? > Sorry I had completely missed the point that the commit order won't be changed. I agree that this new implementation would introduce a new kind of issue as you mentioned above, and the opposite is not true. Regarding the case you explained in the previous email I also think it will happen with the parallel apply feature. The apply worker will be blocked until the conflict is resolved. I'm not sure how to avoid that. It would be not easy to compare constraints between publisher and subscribers when replicating partitioning tables. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Tue, May 10, 2022 at 5:59 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, May 10, 2022 at 10:39 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Wed, May 4, 2022 at 8:44 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > On Tue, May 3, 2022 at 5:16 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > ... > > > > > > > Avoiding unexpected differences like this is why I suggested the > > > > option should have to be explicitly enabled instead of being on by > > > > default as it is in the current patch. See my review comment #14 [1]. > > > > It means the user won't have to change their existing code as a > > > > workaround. > > > > > > > > ------ > > > > [1] https://www.postgresql.org/message-id/CAHut%2BPuqYP5eD5wcSCtk%3Da6KuMjat2UCzqyGoE7sieCaBsVskQ%40mail.gmail.com > > > > > > > > > > Sorry I was wrong above. It seems this behaviour was already changed > > > in the latest patch v5 so now the option value 'on' means what it > > > always did. Thanks! > > > > Having it optional seems a good idea. BTW can the user configure how > > many apply bgworkers can be used per subscription or in the whole > > system? Like max_sync_workers_per_subscription, is it better to have a > > configuration parameter or a subscription option for that? If so, > > setting it to 0 probably means to disable the parallel apply feature. > > > > Yeah, that might be useful but we are already giving an option while > creating a subscription whether to allow parallelism, so will it be > useful to give one more way to disable this feature? OTOH, having > something like max_parallel_apply_workers/max_bg_apply_workers at the > system level can give better control for how much parallelism the user > wishes to allow for apply work. Or we can have something like max_parallel_apply_workers_per_subscription that controls how many parallel apply workers can launch per subscription. That also gives better control for the number of parallel apply workers. > If we have such a new parameter then I > think max_logical_replication_workers should include apply workers, > parallel apply workers, and table synchronization? Agreed. > In such a case, > don't we need to think of increasing the default value of > max_logical_replication_workers? I think we would need to think about that if the parallel apply is enabled by default but given that it's disabled by default I'm fine with the current default value. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, May 11, 2022 at 9:17 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Tue, May 10, 2022 at 6:10 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, May 10, 2022 at 10:35 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > On Wed, May 4, 2022 at 12:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > > > > I think the other kind of problem that can happen here is delete > > > > followed by an insert. If in the example provided by you, TX-1 > > > > performs delete (say it is large enough to cause streaming) and TX-2 > > > > performs insert then I think it will block the apply worker because > > > > insert will start waiting infinitely. Currently, I think it will lead > > > > to conflict due to insert but that is still solvable by allowing users > > > > to remove conflicting rows. > > > > > > > > It seems both these problems are due to the reason that the table on > > > > publisher and subscriber has different constraints otherwise, we would > > > > have seen the same behavior on the publisher as well. > > > > > > > > There could be a few ways to avoid these and similar problems: > > > > a. detect the difference in constraints between publisher and > > > > subscribers like primary key and probably others (like whether there > > > > is any volatile function present in index expression) when applying > > > > the change and then we give ERROR to the user that she must change the > > > > streaming mode to 'spill' instead of 'apply' (aka parallel apply). > > > > b. Same as (a) but instead of ERROR just LOG this information and > > > > change the mode to spill for the transactions that operate on that > > > > particular relation. > > > > > > Given that it doesn't introduce a new kind of problem I don't think we > > > need special treatment for that at least in this feature. > > > > > > > Isn't the problem related to infinite wait by insert as explained in > > my previous email (in the above-quoted text) a new kind of problem > > that won't exist in the current implementation? > > > > Sorry I had completely missed the point that the commit order won't be > changed. I agree that this new implementation would introduce a new > kind of issue as you mentioned above, and the opposite is not true. > > Regarding the case you explained in the previous email I also think it > will happen with the parallel apply feature. The apply worker will be > blocked until the conflict is resolved. I'm not sure how to avoid > that. It would be not easy to compare constraints between publisher > and subscribers when replicating partitioning tables. > I agree that partitioned tables need some more thought but in some simple cases where replication happens via individual partition tables (default), we can detect as we do for normal tables. OTOH, when replication happens via root (publish_via_partition_root) it could be tricky as the partitions could be different on both sides. I think the cases where we can't safely identify the constraint difference won't be considered for apply via a new bg worker. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, May 11, 2022 at 9:35 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Tue, May 10, 2022 at 5:59 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, May 10, 2022 at 10:39 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > Having it optional seems a good idea. BTW can the user configure how > > > many apply bgworkers can be used per subscription or in the whole > > > system? Like max_sync_workers_per_subscription, is it better to have a > > > configuration parameter or a subscription option for that? If so, > > > setting it to 0 probably means to disable the parallel apply feature. > > > > > > > Yeah, that might be useful but we are already giving an option while > > creating a subscription whether to allow parallelism, so will it be > > useful to give one more way to disable this feature? OTOH, having > > something like max_parallel_apply_workers/max_bg_apply_workers at the > > system level can give better control for how much parallelism the user > > wishes to allow for apply work. > > Or we can have something like > max_parallel_apply_workers_per_subscription that controls how many > parallel apply workers can launch per subscription. That also gives > better control for the number of parallel apply workers. > I think we can go either way in this matter as both have their pros and cons. I feel limiting the parallel workers per subscription gives better control but OTOH, it may not allow max usage of parallelism because some quota from other subscriptions might remain unused. Let us see what Hou-San or others think on this matter? -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, May 5, 2022 1:46 PM Peter Smith <smithpb2250@gmail.com> wrote: > Here are my review comments for v5-0001. > I will take a look at the v5-0002 (TAP) patch another time. Thanks for the comments ! > 4. Commit message > > User can set the streaming option to 'on/off', 'apply'. For now, > 'apply' means the streaming will be applied via a apply background if > available. 'on' means the streaming transaction will be spilled to > disk. > > > I think "apply" might not be the best choice of values for this > meaning, but I think Hou-san already said [1] that this was being > reconsidered. Yes, I am thinking over this along with some other related stuff[1] posted by Amit and sawada. Will change this in next version. [1] https://www.postgresql.org/message-id/flat/CAA4eK1%2B7D4qAQUQEE8zzQ0fGCqeBWd3rzTaY5N0jVs-VXFc_Xw%40mail.gmail.com > 7. src/backend/commands/subscriptioncmds.c - defGetStreamingMode > > +static char > +defGetStreamingMode(DefElem *def) > +{ > + /* > + * If no parameter given, assume "true" is meant. > + */ > + if (def->arg == NULL) > + return SUBSTREAM_ON; > > But is that right? IIUC all the docs said that the default is OFF. I think it's right. "arg == NULL" means user specify the streaming option without the value. Like CREATE SUBSCRIPTION xxx WITH(streaming). The value should be 'on' in this case. > 12. src/backend/replication/logical/origin.c - replorigin_session_setup > > @@ -1110,7 +1110,11 @@ replorigin_session_setup(RepOriginId node) > if (curstate->roident != node) > continue; > > - else if (curstate->acquired_by != 0) > + /* > + * We allow the apply worker to get the slot which is acquired by its > + * leader process. > + */ > + else if (curstate->acquired_by != 0 && acquire) > > I still feel this is overly-cofusing. Shouldn't comment say "Allow the > apply bgworker to get the slot...". > > Also the parameter name 'acquire' is hard to reconcile with the > comment. E.g. I feel all this would be easier to understand if the > param was was refactored with a name like 'bgworker' and the code was > changed to: > else if (curstate->acquired_by != 0 && !bgworker) > > Of course, the value true/false would need to be flipped on calls too. > This is the same as my previous comment [PSv4] #26. I feel it's not good idea to mention bgworker in origin.c. I have remove this comment and add some other comments in worker.c. > 26. src/backend/replication/logical/worker.c - apply_handle_stream_abort > > + if (found) > + { > + elog(LOG, "rolled back to savepoint %s", spname); > + RollbackToSavepoint(spname); > + CommitTransactionCommand(); > + subxactlist = list_truncate(subxactlist, i + 1); > + } > > Should that elog use the "[Apply BGW #%u]" format like the others for BGW? I feel the "[Apply BGW #%u]" is a bit hacky and some of them comes from the old patchset. I will recheck these logs and adjust them and change some log level in next version. > 27. src/backend/replication/logical/worker.c - apply_handle_stream_abort > > Should this function be setting stream_apply_worker = NULL somewhere > when all is done? > 29. src/backend/replication/logical/worker.c - apply_handle_stream_commit > > I am unsure, but should something be setting the stream_apply_worker = > NULL somewhere when all is done? I think the worker already be set to NULL in apply_handle_stream_stop. > 32. src/backend/replication/logical/worker.c - ApplyBgwShutdown > > +/* > + * Set the failed flag so that the main apply worker can realize we have > + * shutdown. > + */ > +static void > +ApplyBgwShutdown(int code, Datum arg) > > If the 'code' param is deliberately unused it might be better to say > so in the comment... Not sure about this. After searching the codes, I think most of the callback functions doesn't use and add comments for the 'code' param. > 45. src/backend/utils/activity/wait_event.c > > @@ -388,6 +388,9 @@ pgstat_get_wait_ipc(WaitEventIPC w) > case WAIT_EVENT_HASH_GROW_BUCKETS_REINSERT: > event_name = "HashGrowBucketsReinsert"; > break; > + case WAIT_EVENT_LOGICAL_APPLY_WORKER_READY: > + event_name = "LogicalApplyWorkerReady"; > + break; > > I am not sure this is the best name for this event since the only > place it is used (in apply_bgworker_wait_for) is not only waiting for > READY state. Maybe a name like WAIT_EVENT_LOGICAL_APPLY_BGWORKER or > WAIT_EVENT_LOGICAL_APPLY_WORKER_SYNC would be more appropriate? Need > to change the wait_event.h also. I noticed a similar named "WAIT_EVENT_LOGICAL_SYNC_STATE_CHANGE", so I changed this to WAIT_EVENT_LOGICAL_APPLY_WORKER_STATE_CHANGE. > 47. src/test/regress/expected/subscription.out - missting test > > Missing some test cases for all new option values? E.g. Where is the > test using streaming value is set to 'apply'. Same comment as [PSv4] > #81 The new option is tested in the second patch posted by Shi yu. I addressed other comments from Peter and the 2PC related comment from Shi. Here is the version patch. Best regards, Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, May 11, 2022 1:10 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, May 11, 2022 at 9:35 AM Masahiko Sawada > <sawada.mshk@gmail.com> wrote: > > > > On Tue, May 10, 2022 at 5:59 PM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > > > > On Tue, May 10, 2022 at 10:39 AM Masahiko Sawada > <sawada.mshk@gmail.com> wrote: > > > > > > > > Having it optional seems a good idea. BTW can the user configure > > > > how many apply bgworkers can be used per subscription or in the > > > > whole system? Like max_sync_workers_per_subscription, is it better > > > > to have a configuration parameter or a subscription option for > > > > that? If so, setting it to 0 probably means to disable the parallel apply > feature. > > > > > > > > > > Yeah, that might be useful but we are already giving an option while > > > creating a subscription whether to allow parallelism, so will it be > > > useful to give one more way to disable this feature? OTOH, having > > > something like max_parallel_apply_workers/max_bg_apply_workers at > > > the system level can give better control for how much parallelism > > > the user wishes to allow for apply work. > > > > Or we can have something like > > max_parallel_apply_workers_per_subscription that controls how many > > parallel apply workers can launch per subscription. That also gives > > better control for the number of parallel apply workers. > > > > I think we can go either way in this matter as both have their pros and cons. I > feel limiting the parallel workers per subscription gives better control but > OTOH, it may not allow max usage of parallelism because some quota from > other subscriptions might remain unused. Let us see what Hou-San or others > think on this matter? Thanks for Amit and Sawada-san's comments ! I will think over these approaches and reply soon. Best regards, Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"shiy.fnst@fujitsu.com"
Date:
On Fri, May 6, 2022 4:56 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are my review comments for v5-0002 (TAP tests)
>
> Your changes followed a similar pattern of refactoring so most of my
> comments below is repeated for all the files.
>
Thanks for your comments.
> ======
>
> 1. Commit message
>
> For the tap tests about streaming option in logical replication, test both
> 'on' and 'apply' option.
>
> SUGGESTION
> Change all TAP tests using the PUBLICATION "streaming" option, so they
> now test both 'on' and 'apply' values.
>
OK. But "streaming" is a subscription option, so I modified it to:
Change all TAP tests using the SUBSCRIPTION "streaming" option, so they
now test both 'on' and 'apply' values.
> ~~~
>
> 4. src/test/subscription/t/015_stream.pl
>
> +# Test streaming mode apply
> +$node_publisher->safe_psql('postgres', "DELETE FROM test_tab WHERE (a > 2)");
> $node_publisher->wait_for_catchup($appname);
>
> I think those 2 lines do not really belong after the "# Test streaming
> mode apply" comment. IIUC they are really just doing cleanup from the
> prior test part so I think they should
>
> a) be *above* this comment (and say "# cleanup the test data") or
> b) maybe it is best to put all the cleanup lines actually inside the
> 'test_streaming' function so that the last thing the function does is
> clean up after itself.
>
> option b seems tidier to me.
>
I also think option b seems better, so I put them inside test_streaming().
The rest of the comments are fixed as suggested.
Besides, I noticed that we didn't free the background worker after preparing a
transaction in the main patch, so made some small changes to fix it.
Attach the updated patches.
Regards,
Shi yu
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
"Here are my review comments for v6-0001.
======
1. General
I saw that now in most places you are referring to the new kind of
worker as the "apply background worker". But there are a few comments
remaining that still refer to "bgworker". Please search the entire
patch for "bgworker" in the comments and replace them with "apply
background worker".
======
2. Commit message
We also need to allow stream_stop to complete by the
apply background worker to finish it to avoid deadlocks because T-1's current
stream of changes can update rows in conflicting order with T-2's next stream
of changes.
Something is not right with this wording: "to complete by the apply
background worker to finish it...".
Maybe just omit the words "to finish it" (??).
~~~
3. Commit message
This patch also extends the subscription streaming option so that...
SUGGESTION
This patch also extends the SUBSCRIPTION 'streaming' option so that...
======
4. src/backend/commands/subscriptioncmds.c - defGetStreamingMode
+/*
+ * Extract the streaming mode value from a DefElem. This is like
+ * defGetBoolean() but also accepts the special value and "apply".
+ */
+static char
+defGetStreamingMode(DefElem *def)
Typo: "special value and..." -> "special value of..."
======
5. src/backend/replication/logical/launcher.c - logicalrep_worker_launch
+
+ if (subworker_dsm == DSM_HANDLE_INVALID)
+ snprintf(bgw.bgw_function_name, BGW_MAXLEN, "ApplyWorkerMain");
+ else
+ snprintf(bgw.bgw_function_name, BGW_MAXLEN, "ApplyBgworkerMain");
+
+
5a.
This condition should be using the new 'is_subworker' bool
5b.
Double blank lines?
~~~
6. src/backend/replication/logical/launcher.c - logicalrep_worker_launch
- else
+ else if (subworker_dsm == DSM_HANDLE_INVALID)
snprintf(bgw.bgw_name, BGW_MAXLEN,
"logical replication worker for subscription %u", subid);
+ else
+ snprintf(bgw.bgw_name, BGW_MAXLEN,
+ "logical replication apply worker for subscription %u", subid);
snprintf(bgw.bgw_type, BGW_MAXLEN, "logical replication worker");
This condition also should be using the new 'is_subworker' bool
~~~
7. src/backend/replication/logical/launcher.c - logicalrep_worker_stop_internal
+
+ Assert(LWLockHeldByMe(LogicalRepWorkerLock));
+
I think there should be a comment here to say that this lock is
required/expected to be released by the caller of this function.
======
8. src/backend/replication/logical/origin.c - replorigin_session_setup
@@ -1068,7 +1068,7 @@ ReplicationOriginExitCleanup(int code, Datum arg)
* with replorigin_session_reset().
*/
void
-replorigin_session_setup(RepOriginId node)
+replorigin_session_setup(RepOriginId node, bool acquire)
{
This function has been problematic for several reviews. I saw that you
removed the previously confusing comment but I still feel some kind of
explanation is needed for the vague 'acquire' parameter. OTOH perhaps
if you just change the param name to 'must_acquire' then I think it
would be self-explanatory.
======
9. src/backend/replication/logical/worker.c - General
Some of the logs have a prefix "[Apply BGW #%u]" and some do not; I
did not really understand how you decided to prefix or not so I did
not comment about them individually. Are they all OK? Perhaps if you
can explain the reason for the choices I can review it better next
time.
~~~
10. src/backend/replication/logical/worker.c - General
There are multiple places in the code where there is code checking
if/else for bgworker or normal apply worker. And in those places,
there is often a comment like:
"If we are in main apply worker..."
But it is redundant to say "If we are" because we know we are.
Instead, those cases should say a comment at the top of the else like:
/* This is the main apply worker. */
And then the "If we are in main apply worker" text can be removed from
the comment. There are many examples in the patch like this. Please
search and modify all of them.
~~~
11. src/backend/replication/logical/worker.c - file header comment
The whole comment is similar to the commit message so any changes made
there (for #2, #3) should be made here also.
~~~
12. src/backend/replication/logical/worker.c
+typedef struct WorkerEntry
+{
+ TransactionId xid;
+ WorkerState *wstate;
+} WorkerEntry;
Missing comment for this structure
~~~
13. src/backend/replication/logical/worker.c
WorkerState
WorkerEntry
I felt that these struct names seem too generic - shouldn't they be
something more like ApplyBgworkerState, ApplyBgworkerEntry
~~~
14. src/backend/replication/logical/worker.c
+static List *ApplyWorkersIdleList = NIL;
IMO maybe ApplyWorkersFreeList is a better name than IdleList for
this. "Idle" sounds just like it is paused rather than available for
someone else to use. If you change this then please search the rest of
the patch for mentions in log messages etc
~~~
15. src/backend/replication/logical/worker.c
+static WorkerState *stream_apply_worker = NULL;
+
+/* check if we apply transaction in apply bgworker */
+#define apply_bgworker_active() (in_streamed_transaction &&
stream_apply_worker != NULL)
Wording: "if we apply transaction" -> "if we are applying the transaction"
~~~
16. src/backend/replication/logical/worker.c - handle_streamed_transaction
+ * For the main apply worker, if in streaming mode (receiving a block of
+ * streamed transaction), we send the data to the apply background worker.
+ *
+ * For the apply background worker, define a savepoint if new subtransaction
+ * was started.
*
* Returns true for streamed transactions, false otherwise (regular mode).
*/
static bool
handle_streamed_transaction(LogicalRepMsgType action, StringInfo s)
16a.
Typo: "if new subtransaction" -> "if a new subtransaction"
16b.
That "regular mode" comment seems not quite right because IIUC it also
returns false also for a bgworker (which hardly seems like a "regular
mode")
~~~
17. src/backend/replication/logical/worker.c - handle_streamed_transaction
- /* not in streaming mode */
- if (!in_streamed_transaction)
+ /*
+ * Return if we are not in streaming mode and are not in an apply
+ * background worker.
+ */
+ if (!in_streamed_transaction && !am_apply_bgworker())
return false;
Somehow I found this condition confusing, the comment is not helpful
either because it just says exactly what the code says. Can you give a
better explanatory comment?
e.g.
Maybe the comment should be:
"Return if not in streaming mode (unless this is an apply background worker)"
e.g.
Maybe condition is easier to understand if written as:
if (!(in_streamed_transaction || am_apply_bgworker()))
~~~
18. src/backend/replication/logical/worker.c - handle_streamed_transaction
+ if (action == LOGICAL_REP_MSG_RELATION)
+ {
+ LogicalRepRelation *rel = logicalrep_read_rel(s);
+ logicalrep_relmap_update(rel);
+ }
+
+ }
+ else
+ {
+ /* Add the new subxact to the array (unless already there). */
+ subxact_info_add(current_xid);
Unnecessary blank line.
~~~
19. src/backend/replication/logical/worker.c - find_or_start_apply_bgworker
+ if (found)
+ {
+ entry->wstate->pstate->state = APPLY_BGWORKER_BUSY;
+ return entry->wstate;
+ }
+ else if (!start)
+ return NULL;
+
+ /* If there is at least one worker in the idle list, then take one. */
+ if (list_length(ApplyWorkersIdleList) > 0)
I felt that there should be a comment (after the return NULL) that says:
/*
* Start a new apply background worker
*/
~~~
20. src/backend/replication/logical/worker.c - apply_bgworker_free
+/*
+ * Add the worker to the freelist and remove the entry from hash table.
+ */
+static void
+apply_bgworker_free(WorkerState *wstate)
20a.
Typo: "freelist" -> "free list"
20b.
Elsewhere (and in the log message) this is called the idle list (but
actually I prefer "free list" like in this comment). See also comment
#14.
~~~
21. src/backend/replication/logical/worker.c - apply_bgworker_free
+ hash_search(ApplyWorkersHash, &xid,
+ HASH_REMOVE, &found);
21a.
If you are not going to check the value of ‘found’ then why bother to
pass this param at all; can’t you just pass NULL? (I think I asked the
same question in a previous review)
21b.
The wrapping over 2 lines seems unnecessary here.
~~~
22. src/backend/replication/logical/worker.c - apply_handle_stream_start
/*
- * Initialize the worker's stream_fileset if we haven't yet. This will be
- * used for the entire duration of the worker so create it in a permanent
- * context. We create this on the very first streaming message from any
- * transaction and then use it for this and other streaming transactions.
- * Now, we could create a fileset at the start of the worker as well but
- * then we won't be sure that it will ever be used.
+ * If we are in main apply worker, check if there is any free bgworker
+ * we can use to process this transaction.
*/
- if (MyLogicalRepWorker->stream_fileset == NULL)
+ stream_apply_worker = apply_bgworker_find_or_start(stream_xid, first_segment);
22a.
Typo: "in main apply worker" -> "in the main apply worker"
22b.
Since this is not if/else code, it might be better to put
Assert(!am_apply_bgworker()); above this just to make it more clear.
~~~
23. src/backend/replication/logical/worker.c - apply_handle_stream_start
+ /*
+ * If we have free worker or we already started to apply this
+ * transaction in bgworker, we pass the data to worker.
+ */
SUGGESTION
If we have found a free worker or if we are already applying this
transaction in an apply background worker, then we pass the data to
that worker.
~~~
24. src/backend/replication/logical/worker.c - apply_handle_stream_abort
+apply_handle_stream_abort(StringInfo s)
{
- StringInfoData s2;
- int nchanges;
- char path[MAXPGPATH];
- char *buffer = NULL;
- MemoryContext oldcxt;
- BufFile *fd;
+ TransactionId xid;
+ TransactionId subxid;
- maybe_start_skipping_changes(lsn);
+ if (in_streamed_transaction)
+ ereport(ERROR,
+ (errcode(ERRCODE_PROTOCOL_VIOLATION),
+ errmsg_internal("STREAM COMMIT message without STREAM STOP")));
Typo?
Shouldn't that errmsg say "STREAM ABORT message..." instead of "STREAM
COMMIT message..."
~~~
25. src/backend/replication/logical/worker.c - apply_handle_stream_abort
+ for(i = list_length(subxactlist) - 1; i >= 0; i--)
+ {
Missing space after "for"
~~~
26. src/backend/replication/logical/worker.c - apply_handle_stream_abort
+ if (found)
+ {
+ elog(LOG, "rolled back to savepoint %s", spname);
+ RollbackToSavepoint(spname);
+ CommitTransactionCommand();
+ subxactlist = list_truncate(subxactlist, i + 1);
+ }
Does this need to log anything if nothing was found? Or is it ok to
leave as-is and silently ignore it?
~~~
27. src/backend/replication/logical/worker.c - LogicalApplyBgwLoop
+ if (len == 0)
+ {
+ elog(LOG, "[Apply BGW #%u] got zero-length message, stopping", pst->n);
+ break;
+ }
Maybe it is unnecessary to say "stopping" because it will say that in
the next log anyway when it breaks out of the main loop.
~~~
28. src/backend/replication/logical/worker.c - LogicalApplyBgwLoop
+ default:
+ elog(ERROR, "unexpected message");
+ break;
Perhaps the switch byte should be in a variable so then you can log
what was the unexpected byte code received. e.g. Similar to
apply_handle_tuple_routing function.
~~~
29. src/backend/replication/logical/worker.c - LogicalApplyBgwMain
+ /*
+ * The apply bgworker don't need to monopolize this replication origin
+ * which was already acquired by its leader process.
+ */
+ replorigin_session_setup(originid, false);
+ replorigin_session_origin = originid;
+ CommitTransactionCommand();
Typo: The apply bgworker don't need ..."
-> "The apply background workers don't need ..."
or -> "The apply background worker doesn't need ..."
~~~
30. src/backend/replication/logical/worker.c - apply_bgworker_setup
+/*
+ * Start apply worker background worker process and allocate shared memory for
+ * it.
+ */
+static WorkerState *
+apply_bgworker_setup(void)
Typo: "apply worker background worker process" -> "apply background
worker process"
~~~
31. src/backend/replication/logical/worker.c - apply_bgworker_wait_for
+ /* If any workers (or the postmaster) have died, we have failed. */
+ if (status == APPLY_BGWORKER_EXIT)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("Background worker %u failed to apply transaction %u",
+ wstate->pstate->n, wstate->pstate->stream_xid)));
The errmsg should start with a lowercase letter.
~~~
32. src/backend/replication/logical/worker.c - check_workers_status
+ /*
+ * We don't lock here as in the worst case we will just detect the
+ * failure of worker a bit later.
+ */
+ if (wstate->pstate->state == APPLY_BGWORKER_EXIT)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("Background worker %u exited unexpectedly",
+ wstate->pstate->n)));
The errmsg should start with a lowercase letter.
~~~
33. src/backend/replication/logical/worker.c - check_workers_status
+/* Set the state of apply background worker */
+static void
+apply_bgworker_set_state(char state)
Maybe OK, or perhaps choose from one of:
- "Set the state of an apply background worker"
- "Set the apply background worker state"
======
34. src/bin/pg_dump/pg_dump.c - getSubscriptions
@@ -4450,7 +4450,7 @@ getSubscriptions(Archive *fout)
if (fout->remoteVersion >= 140000)
appendPQExpBufferStr(query, " s.substream,\n");
else
- appendPQExpBufferStr(query, " false AS substream,\n");
+ appendPQExpBufferStr(query, " 'f' AS substream,\n");
Is that logic right? Before this patch the attribute was bool; now it
is char. So doesn't there need to be some conversion/mapping here for
when you read from >= 140000 but it was still bool so you need to
convert 'false' -> 'f' and 'true' -> 't'?
======
35. src/include/replication/origin.h
@@ -53,7 +53,7 @@ extern XLogRecPtr
replorigin_get_progress(RepOriginId node, bool flush);
extern void replorigin_session_advance(XLogRecPtr remote_commit,
XLogRecPtr local_commit);
-extern void replorigin_session_setup(RepOriginId node);
+extern void replorigin_session_setup(RepOriginId node, bool acquire);
As previously suggested in comment #8 maybe the 2nd parm should be
'must_acquire'.
======
36. src/include/replication/worker_internal.h
@@ -60,6 +60,8 @@ typedef struct LogicalRepWorker
*/
FileSet *stream_fileset;
+ bool subworker;
+
Probably this new member deserves a comment.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for v6-0002.
======
1. src/test/subscription/t/015_stream.pl
+################################
+# Test using streaming mode 'on'
+################################
$node_subscriber->safe_psql('postgres',
"CREATE SUBSCRIPTION tap_sub CONNECTION '$publisher_connstr
application_name=$appname' PUBLICATION tap_pub WITH (streaming = on)"
);
-
$node_publisher->wait_for_catchup($appname);
-
# Also wait for initial table sync to finish
my $synced_query =
"SELECT count(1) = 0 FROM pg_subscription_rel WHERE srsubstate NOT
IN ('r', 's');";
$node_subscriber->poll_query_until('postgres', $synced_query)
or die "Timed out while waiting for subscriber to synchronize data";
-
my $result =
$node_subscriber->safe_psql('postgres',
"SELECT count(*), count(c), count(d = 999) FROM test_tab");
is($result, qq(2|2|2), 'check initial data was copied to subscriber');
1a.
Several whitespace lines became removed by the patch. IMO it was
better (e.g. less squishy) how it looked originally.
1b.
Maybe some more blank lines should be added to the 'apply' test part
too, to match 1a.
~~~
2. src/test/subscription/t/015_stream.pl
+$node_publisher->poll_query_until('postgres',
+ "SELECT pid != $oldpid FROM pg_stat_replication WHERE
application_name = '$appname' AND state = 'streaming';"
+) or die "Timed out while waiting for apply to restart after changing
PUBLICATION";
Should that say "... after changing SUBSCRIPTION"?
~~~
3. src/test/subscription/t/016_stream_subxact.pl
+$node_publisher->poll_query_until('postgres',
+ "SELECT pid != $oldpid FROM pg_stat_replication WHERE
application_name = '$appname' AND state = 'streaming';"
+) or die "Timed out while waiting for apply to restart after changing
PUBLICATION";
+
Should that say "... after changing SUBSCRIPTION"?
~~~
4. src/test/subscription/t/017_stream_ddl.pl
+$node_publisher->poll_query_until('postgres',
+ "SELECT pid != $oldpid FROM pg_stat_replication WHERE
application_name = '$appname' AND state = 'streaming';"
+) or die "Timed out while waiting for apply to restart after changing
PUBLICATION";
+
Should that say "... after changing SUBSCRIPTION"?
~~~
5. .../t/018_stream_subxact_abort.pl
+$node_publisher->poll_query_until('postgres',
+ "SELECT pid != $oldpid FROM pg_stat_replication WHERE
application_name = '$appname' AND state = 'streaming';"
+) or die "Timed out while waiting for apply to restart after changing
PUBLICATION";
Should that say "... after changing SUBSCRIPTION" ?
~~~
6. .../t/019_stream_subxact_ddl_abort.pl
+$node_publisher->poll_query_until('postgres',
+ "SELECT pid != $oldpid FROM pg_stat_replication WHERE
application_name = '$appname' AND state = 'streaming';"
+) or die "Timed out while waiting for apply to restart after changing
PUBLICATION";
+
Should that say "... after changing SUBSCRIPTION"?
~~~
7. .../subscription/t/023_twophase_stream.pl
###############################
# Check initial data was copied to subscriber
###############################
Perhaps the above comment now looks a bit out-of-place with the extra #####.
Looks better now as just:
# Check initial data was copied to the subscriber
~~~
8. .../subscription/t/023_twophase_stream.pl
+$node_publisher->poll_query_until('postgres',
+ "SELECT pid != $oldpid FROM pg_stat_replication WHERE
application_name = '$appname' AND state = 'streaming';"
+) or die "Timed out while waiting for apply to restart after changing
PUBLICATION";
Should that say "... after changing SUBSCRIPTION"?
------
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Fri, May 13, 2022 4:53 PM houzj.fnst@fujitsu.com wrote:
> On Wednesday, May 11, 2022 1:10 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > On Wed, May 11, 2022 at 9:35 AM Masahiko Sawada
> > <sawada.mshk@gmail.com> wrote:
> > >
> > > On Tue, May 10, 2022 at 5:59 PM Amit Kapila <amit.kapila16@gmail.com>
> > wrote:
> > > >
> > > > On Tue, May 10, 2022 at 10:39 AM Masahiko Sawada
> > <sawada.mshk@gmail.com> wrote:
> > > > >
> > > > > Having it optional seems a good idea. BTW can the user configure
> > > > > how many apply bgworkers can be used per subscription or in the
> > > > > whole system? Like max_sync_workers_per_subscription, is it better
> > > > > to have a configuration parameter or a subscription option for
> > > > > that? If so, setting it to 0 probably means to disable the parallel apply
> > feature.
> > > > >
> > > >
> > > > Yeah, that might be useful but we are already giving an option while
> > > > creating a subscription whether to allow parallelism, so will it be
> > > > useful to give one more way to disable this feature? OTOH, having
> > > > something like max_parallel_apply_workers/max_bg_apply_workers at
> > > > the system level can give better control for how much parallelism
> > > > the user wishes to allow for apply work.
> > >
> > > Or we can have something like
> > > max_parallel_apply_workers_per_subscription that controls how many
> > > parallel apply workers can launch per subscription. That also gives
> > > better control for the number of parallel apply workers.
> > >
> >
> > I think we can go either way in this matter as both have their pros and cons. I
> > feel limiting the parallel workers per subscription gives better control but
> > OTOH, it may not allow max usage of parallelism because some quota from
> > other subscriptions might remain unused. Let us see what Hou-San or others
> > think on this matter?
>
> Thanks for Amit and Sawada-san's comments !
> I will think over these approaches and reply soon.
After reading the thread, I wrote two patches for these comments.
The first patch (see v6-0003):
Improve the feature as suggested in [1].
For the issue mentioned by Amit-san (there is a block problem in the case
mentioned by Sawada-san), after investigating, I think this issue is caused by
unique index. So I added a check to make sure the unique columns are the same
between publisher and subscriber.
For other cases, I added the check that if there is any non-immutable function
present in expression in subscriber's relation. Check from the following 3
items:
a. The function in triggers;
b. Column default value expressions and domain constraints;
c. Constraint expressions.
BTW, I do not add partitioned table related code. I think this part needs other
additional modifications. I will add this later when these modifications are
finished.
The second patch (see v6-0004):
Improve the feature as suggested in [2].
Add a GUC "max_apply_bgworkers_per_subscription" to control parallelism. This
GUC controls how many apply background workers can be launched per
subscription. I set its default value to 3 and do not change the default value
of other GUCs.
[1] - https://www.postgresql.org/message-id/CAA4eK1JwahU_WuP3S%2B7POqta%3DPhm_3gxZeVmJuuoUq1NV%3DkrXA%40mail.gmail.com
[2] - https://www.postgresql.org/message-id/CAA4eK1%2B7D4qAQUQEE8zzQ0fGCqeBWd3rzTaY5N0jVs-VXFc_Xw%40mail.gmail.com
Attach the patches. (Did not change v6-0001 and v6-0002.)
Regards,
Wang wei
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"osumi.takamichi@fujitsu.com"
Date:
On Wednesday, May 25, 2022 11:25 AM wangw.fnst@fujitsu.com <wangw.fnst@fujitsu.com> wrote:
> Attach the patches. (Did not change v6-0001 and v6-0002.)
Hi,
Some review comments on the new patches from v6-0001 to v6-0004.
<v6-0001>
(1) create_subscription.sgml
+ the transaction is committed. Note that if an error happens when
+ applying changes in a background worker, it might not report the
+ finish LSN of the remote transaction in the server log.
I suggest to add a couple of sentences like below
to the section of logical-replication-conflicts in logical-replication.sgml.
"
Setting streaming mode to 'apply' can export invalid LSN as
finish LSN of failed transaction. Changing the streaming mode and
making the same conflict writes the finish LSN of the
failed transaction in the server log if required.
"
(2) ApplyBgworkerMain
+ PG_TRY();
+ {
+ LogicalApplyBgwLoop(mqh, pst);
+ }
+ PG_CATCH();
+ {
...
+ pgstat_report_subscription_error(MySubscription->oid, false);
+
+ PG_RE_THROW();
+ }
+ PG_END_TRY();
When I stream a transaction in-progress and it causes an error(duplication error),
seemingly the subscription stats (values in pg_stat_subscription_stats) don't
get updated properly. The 2nd argument should be true for apply error.
Also, I observe that both apply_error_count and sync_error_count
get updated together by error. I think we need to check this point as well.
<v6-0003>
(3) logicalrep_write_attrs
+ if (rel->rd_rel->relhasindex)
+ {
+ List *indexoidlist = RelationGetIndexList(rel);
+ ListCell *indexoidscan;
+ foreach(indexoidscan, indexoidlist)
and
+ if (indexRel->rd_index->indisunique)
+ {
+ int i;
+ /* Add referenced attributes to idindexattrs */
+ for (i = 0; i < indexRel->rd_index->indnatts; i++)
We don't have each blank line after variable declarations.
There might be some other codes where this point can be applied.
Please check.
(4)
+ /*
+ * If any unique index exist, check that they are same as remoterel.
+ */
+ if (!rel->sameunique)
+ ereport(ERROR,
+ (errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
+ errmsg("cannot replicate relation with different unique index"),
+ errhint("Please change the streaming option to 'on' instead of 'apply'.")));
When I create a logical replication setup with different constraints
and let streaming of in-progress transaction run,
I keep getting this error.
This should be documented as a restriction or something,
to let users know the replication progress can't go forward by
any differences written like in the commit-message in v6-0003.
Also, it would be preferable to test this as well, if we
don't dislike having TAP tests for this.
Best Regards,
Takamichi Osumi
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Wed, May 18, 2022 3:11 PM Peter Smith <smithpb2250@gmail.com> wrote:
> "Here are my review comments for v6-0001.
Thanks for your comments.
> 7. src/backend/replication/logical/launcher.c - logicalrep_worker_stop_internal
>
> +
> + Assert(LWLockHeldByMe(LogicalRepWorkerLock));
> +
>
> I think there should be a comment here to say that this lock is
> required/expected to be released by the caller of this function.
IMHO, it maybe not a problem to read code here.
In addition, keep consistent with other places where invoke this function in
the same file. So I did not change this.
> 9. src/backend/replication/logical/worker.c - General
>
> Some of the logs have a prefix "[Apply BGW #%u]" and some do not; I
> did not really understand how you decided to prefix or not so I did
> not comment about them individually. Are they all OK? Perhaps if you
> can explain the reason for the choices I can review it better next
> time.
I think most of these logs should be logged in debug mode. So I changed them to
"DEBUG1" level.
And I added the prefix to all messages logged by apply background worker and
deleted some logs that I think maybe not very helpful.
> 11. src/backend/replication/logical/worker.c - file header comment
>
> The whole comment is similar to the commit message so any changes made
> there (for #2, #3) should be made here also.
Improve the comments as suggested in #2.
Sorry but I did not find same message as #2 here.
> 13. src/backend/replication/logical/worker.c
>
> WorkerState
> WorkerEntry
>
> I felt that these struct names seem too generic - shouldn't they be
> something more like ApplyBgworkerState, ApplyBgworkerEntry
>
> ~~~
I think we have used "ApplyBgworkerState" in the patch. So I improved this with
the following modifications:
```
ApplyBgworkerState -> ApplyBgworkerStatus
WorkerState -> ApplyBgworkerState
WorkerEntry -> ApplyBgworkerEntry
```
BTW, I also modified the relevant comments and variable names.
> 16. src/backend/replication/logical/worker.c - handle_streamed_transaction
>
> + * For the main apply worker, if in streaming mode (receiving a block of
> + * streamed transaction), we send the data to the apply background worker.
> + *
> + * For the apply background worker, define a savepoint if new subtransaction
> + * was started.
> *
> * Returns true for streamed transactions, false otherwise (regular mode).
> */
> static bool
> handle_streamed_transaction(LogicalRepMsgType action, StringInfo s)
>
> 16a.
> Typo: "if new subtransaction" -> "if a new subtransaction"
>
> 16b.
> That "regular mode" comment seems not quite right because IIUC it also
> returns false also for a bgworker (which hardly seems like a "regular
> mode")
16a. Improved it as suggested.
16b. Changed the comment as follows:
From:
```
* Returns true for streamed transactions, false otherwise (regular mode).
```
To:
```
* For non-streamed transactions, returns false;
* For streamed transactions, returns true if in main apply worker, false
* otherwise.
```
> 19. src/backend/replication/logical/worker.c - find_or_start_apply_bgworker
>
> + if (found)
> + {
> + entry->wstate->pstate->state = APPLY_BGWORKER_BUSY;
> + return entry->wstate;
> + }
> + else if (!start)
> + return NULL;
> +
> + /* If there is at least one worker in the idle list, then take one. */
> + if (list_length(ApplyWorkersIdleList) > 0)
>
> I felt that there should be a comment (after the return NULL) that says:
>
> /*
> * Start a new apply background worker
> */
>
> ~~~
Improve this comment here.
After the code that you mentioned, it will try to get a apply background
worker (try to start one or take one from idle list). So I change the comment
as follows:
From:
```
/* If there is at least one worker in the idle list, then take one. */
```
To:
```
/*
* Now, we try to get a apply background worker.
* If there is at least one worker in the idle list, then take one.
* Otherwise, we try to start a new apply background worker.
*/
```
> 22. src/backend/replication/logical/worker.c - apply_handle_stream_start
>
> /*
> - * Initialize the worker's stream_fileset if we haven't yet. This will be
> - * used for the entire duration of the worker so create it in a permanent
> - * context. We create this on the very first streaming message from any
> - * transaction and then use it for this and other streaming transactions.
> - * Now, we could create a fileset at the start of the worker as well but
> - * then we won't be sure that it will ever be used.
> + * If we are in main apply worker, check if there is any free bgworker
> + * we can use to process this transaction.
> */
> - if (MyLogicalRepWorker->stream_fileset == NULL)
> + stream_apply_worker = apply_bgworker_find_or_start(stream_xid,
> first_segment);
>
> 22a.
> Typo: "in main apply worker" -> "in the main apply worker"
>
> 22b.
> Since this is not if/else code, it might be better to put
> Assert(!am_apply_bgworker()); above this just to make it more clear.
22a. Improved it as suggested.
22b.
IMHO, since we have `if (am_apply_bgworker())` above and it will return in this
if-condition, so I just think Assert() might be a bit redundant here.
So I did not change this.
> 26. src/backend/replication/logical/worker.c - apply_handle_stream_abort
>
> + if (found)
> + {
> + elog(LOG, "rolled back to savepoint %s", spname);
> + RollbackToSavepoint(spname);
> + CommitTransactionCommand();
> + subxactlist = list_truncate(subxactlist, i + 1);
> + }
>
> Does this need to log anything if nothing was found? Or is it ok to
> leave as-is and silently ignore it?
Yes, I think it is okay.
> 33. src/backend/replication/logical/worker.c - check_workers_status
>
> +/* Set the state of apply background worker */
> +static void
> +apply_bgworker_set_state(char state)
>
> Maybe OK, or perhaps choose from one of:
> - "Set the state of an apply background worker"
> - "Set the apply background worker state"
Improve it by using the second one.
> 34. src/bin/pg_dump/pg_dump.c - getSubscriptions
>
> @@ -4450,7 +4450,7 @@ getSubscriptions(Archive *fout)
> if (fout->remoteVersion >= 140000)
> appendPQExpBufferStr(query, " s.substream,\n");
> else
> - appendPQExpBufferStr(query, " false AS substream,\n");
> + appendPQExpBufferStr(query, " 'f' AS substream,\n");
>
>
> Is that logic right? Before this patch the attribute was bool; now it
> is char. So doesn't there need to be some conversion/mapping here for
> when you read from >= 140000 but it was still bool so you need to
> convert 'false' -> 'f' and 'true' -> 't'?
Yes, I think it is right.
We could handle the input of option "streaming" : on/true/off/false/apply.
The rest of the comments are improved as suggested.
And thanks for Shi Yu to improve the patch 0002 by addressing the comments in
[1].
Attach the new patches(only changed 0001 and 0002)
[1] - https://www.postgresql.org/message-id/CAHut%2BPv_0nfUxriwxBQnZTOF5dy5nfG5NtWMr8e00mPrt2Vjzw%40mail.gmail.com
Regards,
Wang wei
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, May 30, 2022 at 2:22 PM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> Attach the new patches(only changed 0001 and 0002)
>
Few comments/suggestions for 0001 and 0003
=====================================
0001
--------
1.
+ else
+ snprintf(bgw.bgw_name, BGW_MAXLEN,
+ "logical replication apply worker for subscription %u", subid);
Can we slightly change the message to: "logical replication background
apply worker for subscription %u"?
2. Can we think of separating the new logic for applying the xact by
bgworker into a new file like applybgwroker or applyparallel? We have
previously done the same in the case of vacuum (see vacuumparallel.c).
3.
+ /*
+ * XXX The publisher side doesn't always send relation update messages
+ * after the streaming transaction, so update the relation in main
+ * apply worker here.
+ */
+ if (action == LOGICAL_REP_MSG_RELATION)
+ {
+ LogicalRepRelation *rel = logicalrep_read_rel(s);
+ logicalrep_relmap_update(rel);
+ }
I think the publisher side won't send the relation update message
after streaming transaction only if it has already been sent for a
non-streaming transaction in which case we don't need to update the
local cache here. This is as per my understanding of
maybe_send_schema(), do let me know if I am missing something? If my
understanding is correct then we don't need this change.
4.
+ * For the main apply worker, if in streaming mode (receiving a block of
+ * streamed transaction), we send the data to the apply background worker.
*
- * If in streaming mode (receiving a block of streamed transaction), we
- * simply redirect it to a file for the proper toplevel transaction.
This comment is slightly confusing. Can we change it to something
like: "In streaming case (receiving a block of streamed transaction),
for SUBSTREAM_ON mode, we simply redirect it to a file for the proper
toplevel transaction, and for SUBSTREAM_APPLY mode, we send the
changes to background apply worker."?
5.
+apply_handle_stream_abort(StringInfo s)
{
...
...
+ /*
+ * If the two XIDs are the same, it's in fact abort of toplevel xact,
+ * so just free the subxactlist.
+ */
+ if (subxid == xid)
+ {
+ set_apply_error_context_xact(subxid, InvalidXLogRecPtr);
- fd = BufFileOpenFileSet(MyLogicalRepWorker->stream_fileset, path, O_RDONLY,
- false);
+ AbortCurrentTransaction();
- buffer = palloc(BLCKSZ);
+ EndTransactionBlock(false);
+ CommitTransactionCommand();
+
+ in_remote_transaction = false;
...
...
}
Here, can we update the replication origin as we are doing in
apply_handle_rollback_prepared? Currently, we don't do it because we
are just cleaning up temporary files for which we don't even have a
transaction. Also, we don't have the required infrastructure to
advance origins for aborts as we have for abort prepared. See commits
[1eb6d6527a][8a812e5106]. If we think it is a good idea then I think
we need to send abort_lsn and abort_time from the publisher and we
need to be careful to make it work with lower subscriber versions that
don't have the facility to process these additional values.
0003
--------
6.
+ /*
+ * If any unique index exist, check that they are same as remoterel.
+ */
+ if (!rel->sameunique)
+ ereport(ERROR,
+ (errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
+ errmsg("cannot replicate relation with different unique index"),
+ errhint("Please change the streaming option to 'on' instead of 'apply'.")));
I think we can do better here. Instead of simply erroring out and
asking the user to change streaming mode, we can remember this in the
system catalog probably in pg_subscription, and then on restart, we
can change the streaming mode to 'on', perform the transaction, and
again change the streaming mode to apply. I am not sure whether we
want to do it in the first version or not, so if you agree with this,
developing it as a separate patch would be a good idea.
Also, please update comments here as to why we don't handle such cases.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, May 30, 2022 at 5:08 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Mon, May 30, 2022 at 2:22 PM wangw.fnst@fujitsu.com
> <wangw.fnst@fujitsu.com> wrote:
> >
> > Attach the new patches(only changed 0001 and 0002)
> >
>
This patch allows the same replication origin to be used by the main
apply worker and the bgworker that uses it to apply streaming
transactions. See the changes [1] in the patch. I am not completely
sure whether that is a good idea even though I could not spot or think
of problems that can't be fixed in your patch. I see that currently
both the main apply worker and bgworker will assign MyProcPid to the
assigned origin slot, this can create the problem because
ReplicationOriginExitCleanup() can clean it up even though the main
apply worker or another bgworker is still using that origin slot. Now,
one way to fix is that we assign only the main apply worker's
MyProcPid to session_replication_state->acquired_by. I have tried to
think about the concurrency issues as multiple workers could now point
to the same replication origin state. I think it is safe because the
patch maintains the commit order by allowing only one process to
commit at a time, so no two workers will be operating on the same
origin at the same time. Even, though there is no case where the patch
will try to advance the session's origin concurrently, it appears safe
to do so as we change/advance the session_origin LSNs under
replicate_state LWLock.
Another idea could be that we allow multiple replication origins (one
for each bgworker and one for the main apply worker) for the apply
workers corresponding to a subscription. Then on restart, we can find
the highest LSN among all the origins for a subscription. This should
work primarily because we will maintain the commit order. Now, for
this to work we need to somehow map all the origins for a subscription
and one possibility is that we have a subscription id in each of the
origin names. Currently we use ("pg_%u", MySubscription->oid) as
origin_name. We can probably append some unique identifier number for
each worker to allow each origin to have a subscription id. We need to
drop all origins for a particular subscription on DROP SUBSCRIPTION. I
think having multiple origins for the same subscription will have some
additional work when we try to filter changes based on origin.
The advantage of the first idea is that it won't increase the need to
have more origins per subscription but it is quite possible that I am
missing something and there are problems due to which we can't use
that approach.
Thoughts?
[1]:
-replorigin_session_setup(RepOriginId node)
+replorigin_session_setup(RepOriginId node, bool acquire)
{
static bool registered_cleanup;
int i;
@@ -1110,7 +1110,7 @@ replorigin_session_setup(RepOriginId node)
if (curstate->roident != node)
continue;
- else if (curstate->acquired_by != 0)
+ else if (curstate->acquired_by != 0 && acquire)
{
...
...
+ /*
+ * The apply bgworker don't need to monopolize this replication origin
+ * which was already acquired by its leader process.
+ */
+ replorigin_session_setup(originid, false);
+ replorigin_session_origin = originid;
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Tue, May 31, 2022 at 5:53 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Mon, May 30, 2022 at 5:08 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Mon, May 30, 2022 at 2:22 PM wangw.fnst@fujitsu.com
> > <wangw.fnst@fujitsu.com> wrote:
> > >
> > > Attach the new patches(only changed 0001 and 0002)
> > >
> >
>
> This patch allows the same replication origin to be used by the main
> apply worker and the bgworker that uses it to apply streaming
> transactions. See the changes [1] in the patch. I am not completely
> sure whether that is a good idea even though I could not spot or think
> of problems that can't be fixed in your patch. I see that currently
> both the main apply worker and bgworker will assign MyProcPid to the
> assigned origin slot, this can create the problem because
> ReplicationOriginExitCleanup() can clean it up even though the main
> apply worker or another bgworker is still using that origin slot.
Good point.
> Now,
> one way to fix is that we assign only the main apply worker's
> MyProcPid to session_replication_state->acquired_by. I have tried to
> think about the concurrency issues as multiple workers could now point
> to the same replication origin state. I think it is safe because the
> patch maintains the commit order by allowing only one process to
> commit at a time, so no two workers will be operating on the same
> origin at the same time. Even, though there is no case where the patch
> will try to advance the session's origin concurrently, it appears safe
> to do so as we change/advance the session_origin LSNs under
> replicate_state LWLock.
Right. That way, the cleanup is done only by the main apply worker.
Probably the bgworker can check if the origin is already acquired by
its (leader) main apply worker process for safety.
>
> Another idea could be that we allow multiple replication origins (one
> for each bgworker and one for the main apply worker) for the apply
> workers corresponding to a subscription. Then on restart, we can find
> the highest LSN among all the origins for a subscription. This should
> work primarily because we will maintain the commit order. Now, for
> this to work we need to somehow map all the origins for a subscription
> and one possibility is that we have a subscription id in each of the
> origin names. Currently we use ("pg_%u", MySubscription->oid) as
> origin_name. We can probably append some unique identifier number for
> each worker to allow each origin to have a subscription id. We need to
> drop all origins for a particular subscription on DROP SUBSCRIPTION. I
> think having multiple origins for the same subscription will have some
> additional work when we try to filter changes based on origin.
It also seems to work but need additional work and resource.
> The advantage of the first idea is that it won't increase the need to
> have more origins per subscription but it is quite possible that I am
> missing something and there are problems due to which we can't use
> that approach.
I prefer the first idea as it's simpler than the second one. I don't
see any concurrency problem so far unless I'm not missing something.
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Jun 1, 2022 at 7:30 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Tue, May 31, 2022 at 5:53 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Mon, May 30, 2022 at 5:08 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > >
> > > On Mon, May 30, 2022 at 2:22 PM wangw.fnst@fujitsu.com
> > > <wangw.fnst@fujitsu.com> wrote:
> > > >
> > > > Attach the new patches(only changed 0001 and 0002)
> > > >
> > >
> >
> > This patch allows the same replication origin to be used by the main
> > apply worker and the bgworker that uses it to apply streaming
> > transactions. See the changes [1] in the patch. I am not completely
> > sure whether that is a good idea even though I could not spot or think
> > of problems that can't be fixed in your patch. I see that currently
> > both the main apply worker and bgworker will assign MyProcPid to the
> > assigned origin slot, this can create the problem because
> > ReplicationOriginExitCleanup() can clean it up even though the main
> > apply worker or another bgworker is still using that origin slot.
>
> Good point.
>
> > Now,
> > one way to fix is that we assign only the main apply worker's
> > MyProcPid to session_replication_state->acquired_by. I have tried to
> > think about the concurrency issues as multiple workers could now point
> > to the same replication origin state. I think it is safe because the
> > patch maintains the commit order by allowing only one process to
> > commit at a time, so no two workers will be operating on the same
> > origin at the same time. Even, though there is no case where the patch
> > will try to advance the session's origin concurrently, it appears safe
> > to do so as we change/advance the session_origin LSNs under
> > replicate_state LWLock.
>
> Right. That way, the cleanup is done only by the main apply worker.
> Probably the bgworker can check if the origin is already acquired by
> its (leader) main apply worker process for safety.
>
Yeah, that makes sense.
> >
> > Another idea could be that we allow multiple replication origins (one
> > for each bgworker and one for the main apply worker) for the apply
> > workers corresponding to a subscription. Then on restart, we can find
> > the highest LSN among all the origins for a subscription. This should
> > work primarily because we will maintain the commit order. Now, for
> > this to work we need to somehow map all the origins for a subscription
> > and one possibility is that we have a subscription id in each of the
> > origin names. Currently we use ("pg_%u", MySubscription->oid) as
> > origin_name. We can probably append some unique identifier number for
> > each worker to allow each origin to have a subscription id. We need to
> > drop all origins for a particular subscription on DROP SUBSCRIPTION. I
> > think having multiple origins for the same subscription will have some
> > additional work when we try to filter changes based on origin.
>
> It also seems to work but need additional work and resource.
>
> > The advantage of the first idea is that it won't increase the need to
> > have more origins per subscription but it is quite possible that I am
> > missing something and there are problems due to which we can't use
> > that approach.
>
> I prefer the first idea as it's simpler than the second one. I don't
> see any concurrency problem so far unless I'm not missing something.
>
Thanks for evaluating it and sharing your opinion.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Wed, Jun 1, 2022 1:19 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Wed, Jun 1, 2022 at 7:30 AM Masahiko Sawada <sawada.mshk@gmail.com>
> wrote:
> >
> > On Tue, May 31, 2022 at 5:53 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> > >
> > > On Mon, May 30, 2022 at 5:08 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> > > >
> > > > On Mon, May 30, 2022 at 2:22 PM wangw.fnst@fujitsu.com
> > > > <wangw.fnst@fujitsu.com> wrote:
> > > > >
> > > > > Attach the new patches(only changed 0001 and 0002)
> > > > >
> > > >
> > >
> > > This patch allows the same replication origin to be used by the main
> > > apply worker and the bgworker that uses it to apply streaming
> > > transactions. See the changes [1] in the patch. I am not completely
> > > sure whether that is a good idea even though I could not spot or think
> > > of problems that can't be fixed in your patch. I see that currently
> > > both the main apply worker and bgworker will assign MyProcPid to the
> > > assigned origin slot, this can create the problem because
> > > ReplicationOriginExitCleanup() can clean it up even though the main
> > > apply worker or another bgworker is still using that origin slot.
> >
> > Good point.
> >
> > > Now,
> > > one way to fix is that we assign only the main apply worker's
> > > MyProcPid to session_replication_state->acquired_by. I have tried to
> > > think about the concurrency issues as multiple workers could now point
> > > to the same replication origin state. I think it is safe because the
> > > patch maintains the commit order by allowing only one process to
> > > commit at a time, so no two workers will be operating on the same
> > > origin at the same time. Even, though there is no case where the patch
> > > will try to advance the session's origin concurrently, it appears safe
> > > to do so as we change/advance the session_origin LSNs under
> > > replicate_state LWLock.
> >
> > Right. That way, the cleanup is done only by the main apply worker.
> > Probably the bgworker can check if the origin is already acquired by
> > its (leader) main apply worker process for safety.
> >
>
> Yeah, that makes sense.
>
> > >
> > > Another idea could be that we allow multiple replication origins (one
> > > for each bgworker and one for the main apply worker) for the apply
> > > workers corresponding to a subscription. Then on restart, we can find
> > > the highest LSN among all the origins for a subscription. This should
> > > work primarily because we will maintain the commit order. Now, for
> > > this to work we need to somehow map all the origins for a subscription
> > > and one possibility is that we have a subscription id in each of the
> > > origin names. Currently we use ("pg_%u", MySubscription->oid) as
> > > origin_name. We can probably append some unique identifier number for
> > > each worker to allow each origin to have a subscription id. We need to
> > > drop all origins for a particular subscription on DROP SUBSCRIPTION. I
> > > think having multiple origins for the same subscription will have some
> > > additional work when we try to filter changes based on origin.
> >
> > It also seems to work but need additional work and resource.
> >
> > > The advantage of the first idea is that it won't increase the need to
> > > have more origins per subscription but it is quite possible that I am
> > > missing something and there are problems due to which we can't use
> > > that approach.
> >
> > I prefer the first idea as it's simpler than the second one. I don't
> > see any concurrency problem so far unless I'm not missing something.
> >
>
> Thanks for evaluating it and sharing your opinion.
Thanks for your comments and opinions.
I fixed this problem by following the first suggestion. I also added the
relevant checks and changed the relevant comments.
Thanks for Shi Yu to add some tests as suggested by Osumi-san in [1].#4 and
improve the 0002 patch by adding some checks to see if the apply background
worker starts.
Attach the new patches.
1. Add some descriptions related to "apply" mode to logical-replication.sgml
and create_subscription.sgml.(suggested by Osumi-san in [1].#1,#4)
2. Fix the problem that values in pg_stat_subscription_stats are not updated
properly. (suggested by Osumi-san in [1].#2)
3. Improve the code formatting of the patches. (suggested by Osumi-san in [1].#3)
4. Add some tests in 0003 patch. And improve some tests by adding some checks
to see if the apply background worker starts in 0002 patch. (suggested by
Osumi-san in [1].#4 and Shi Yu)
5. Improve the log message. (suggested by Amit-san in [2].#1)
6. Separate the new logic related to apply background worker to new file
applybgwroker.c. (suggested by Amit-san in [2].#2)
7. Improve function handle_streamed_transaction. (suggested by Amit-san in[2].#3)
8. Improve some comments. (suggested by Amit-san in [2].#4,#6 and me)
9. Fix the problem that the structure member "acquired_by" is incorrectly set
when apply background worker tries to get replication origin.
(suggested by Amit-san in [3])
[1] -
https://www.postgresql.org/message-id/TYCPR01MB83735AEE38370254ED495B06EDDA9%40TYCPR01MB8373.jpnprd01.prod.outlook.com
[2] - https://www.postgresql.org/message-id/CAA4eK1Jt08SYbRt_-rbSWNg%3DX9-m8%2BRdP5PosfnQgyF-z8bkxQ%40mail.gmail.com
[3] - https://www.postgresql.org/message-id/CAA4eK1%2BZ6ahpTQK2KzkvQ1kN-urVS9-N_RDM11MS%2BbtqaB8Bpw%40mail.gmail.com
Regards,
Wang wei
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Mon, May 30, 2022 7:38 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> Few comments/suggestions for 0001 and 0003
> =====================================
> 0001
> --------
Thanks for your comments.
> 1.
> + else
> + snprintf(bgw.bgw_name, BGW_MAXLEN,
> + "logical replication apply worker for subscription %u", subid);
>
> Can we slightly change the message to: "logical replication background
> apply worker for subscription %u"?
Improve the message as suggested.
> 2. Can we think of separating the new logic for applying the xact by
> bgworker into a new file like applybgwroker or applyparallel? We have
> previously done the same in the case of vacuum (see vacuumparallel.c).
Improve the patch as suggested. I separated the new logic related to apply
background worker to new file src/backend/replication/logical/applybgwroker.c.
> 3.
> + /*
> + * XXX The publisher side doesn't always send relation update messages
> + * after the streaming transaction, so update the relation in main
> + * apply worker here.
> + */
> + if (action == LOGICAL_REP_MSG_RELATION)
> + {
> + LogicalRepRelation *rel = logicalrep_read_rel(s);
> + logicalrep_relmap_update(rel);
> + }
>
> I think the publisher side won't send the relation update message
> after streaming transaction only if it has already been sent for a
> non-streaming transaction in which case we don't need to update the
> local cache here. This is as per my understanding of
> maybe_send_schema(), do let me know if I am missing something? If my
> understanding is correct then we don't need this change.
I think we need this change because the publisher will invoke function
cleanup_rel_sync_cache when committing a streaming transaction, then it will
set "schema_sent" to true for related entry. Later, publisher may not send this
schema in function maybe_send_schema because we already sent this schema
(schema_sent = true).
If we do not have this change, It would cause an error in the following case:
Suppose that after walsender worker starts, first we commit a streaming
transaction. Walsender sends relation update message, and only apply background
worker can update relation map cache by this message. After this, if we commit
a non-streamed transaction that contains same replicated table, walsender will
not send relation update message, so main apply worker would not get relation
update message.
I think we need this change to update relation map cache not only in apply
background worker but also in apply main worker.
In addition, we should also handle the LOGICAL_REP_MSG_TYPE message just like
LOGICAL_REP_MSG_RELATION. So improve the code you mentioned. BTW, I simplify
the function handle_streamed_transaction().
> 4.
> + * For the main apply worker, if in streaming mode (receiving a block of
> + * streamed transaction), we send the data to the apply background worker.
> *
> - * If in streaming mode (receiving a block of streamed transaction), we
> - * simply redirect it to a file for the proper toplevel transaction.
>
> This comment is slightly confusing. Can we change it to something
> like: "In streaming case (receiving a block of streamed transaction),
> for SUBSTREAM_ON mode, we simply redirect it to a file for the proper
> toplevel transaction, and for SUBSTREAM_APPLY mode, we send the
> changes to background apply worker."?
Improve the comments as suggested.
> 5.
> +apply_handle_stream_abort(StringInfo s)
> {
> ...
> ...
> + /*
> + * If the two XIDs are the same, it's in fact abort of toplevel xact,
> + * so just free the subxactlist.
> + */
> + if (subxid == xid)
> + {
> + set_apply_error_context_xact(subxid, InvalidXLogRecPtr);
>
> - fd = BufFileOpenFileSet(MyLogicalRepWorker->stream_fileset, path,
> O_RDONLY,
> - false);
> + AbortCurrentTransaction();
>
> - buffer = palloc(BLCKSZ);
> + EndTransactionBlock(false);
> + CommitTransactionCommand();
> +
> + in_remote_transaction = false;
> ...
> ...
> }
>
> Here, can we update the replication origin as we are doing in
> apply_handle_rollback_prepared? Currently, we don't do it because we
> are just cleaning up temporary files for which we don't even have a
> transaction. Also, we don't have the required infrastructure to
> advance origins for aborts as we have for abort prepared. See commits
> [1eb6d6527a][8a812e5106]. If we think it is a good idea then I think
> we need to send abort_lsn and abort_time from the publisher and we
> need to be careful to make it work with lower subscriber versions that
> don't have the facility to process these additional values.
I think it is a good idea. I will consider this and add this part in next
version.
> 0003
> --------
> 6.
> + /*
> + * If any unique index exist, check that they are same as remoterel.
> + */
> + if (!rel->sameunique)
> + ereport(ERROR,
> + (errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
> + errmsg("cannot replicate relation with different unique index"),
> + errhint("Please change the streaming option to 'on' instead of 'apply'.")));
>
> I think we can do better here. Instead of simply erroring out and
> asking the user to change streaming mode, we can remember this in the
> system catalog probably in pg_subscription, and then on restart, we
> can change the streaming mode to 'on', perform the transaction, and
> again change the streaming mode to apply. I am not sure whether we
> want to do it in the first version or not, so if you agree with this,
> developing it as a separate patch would be a good idea.
>
> Also, please update comments here as to why we don't handle such cases.
Yes, I think it is a good idea. I will develop it as a separate patch later.
And I added the comments atop function apply_bgworker_relation_check as
below:
```
* Although we maintains the commit order by allowing only one process to
* commit at a time, our access order to the relation has changed.
* This could cause unexpected problems if the unique column on the replicated
* table is inconsistent with the publisher-side or contains non-immutable
* functions when applying transactions in the apply background worker.
```
I also made some other changes. The new patches and the modification details
were attached in [1].
[1] -
https://www.postgresql.org/message-id/OS3PR01MB62758A881FF3240171B7B21B9EDE9%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Sun, May 29, 2022 8:25 PM osumi.takamichi@fujitsu.com <osumi.takamichi@fujitsu.com> wrote:
> Hi,
>
>
> Some review comments on the new patches from v6-0001 to v6-0004.
Thanks for your comments.
> <v6-0001>
>
> (1) create_subscription.sgml
>
> + the transaction is committed. Note that if an error happens when
> + applying changes in a background worker, it might not report the
> + finish LSN of the remote transaction in the server log.
>
> I suggest to add a couple of sentences like below
> to the section of logical-replication-conflicts in logical-replication.sgml.
>
> "
> Setting streaming mode to 'apply' can export invalid LSN as
> finish LSN of failed transaction. Changing the streaming mode and
> making the same conflict writes the finish LSN of the
> failed transaction in the server log if required.
> "
Add the sentences as suggested.
> (2) ApplyBgworkerMain
>
>
> + PG_TRY();
> + {
> + LogicalApplyBgwLoop(mqh, pst);
> + }
> + PG_CATCH();
> + {
>
> ...
>
> + pgstat_report_subscription_error(MySubscription->oid, false);
> +
> + PG_RE_THROW();
> + }
> + PG_END_TRY();
>
>
> When I stream a transaction in-progress and it causes an error(duplication error),
> seemingly the subscription stats (values in pg_stat_subscription_stats) don't
> get updated properly. The 2nd argument should be true for apply error.
>
> Also, I observe that both apply_error_count and sync_error_count
> get updated together by error. I think we need to check this point as well.
Yes, we should input "true" to 2nd argument here to log "apply error".
And after checking the second point you mentioned, I think it is caused by the
first point you mentioned and another reason:
With the patch v6 (or v7) and we specify option "apply", when a streamed
transaction causes an error (duplication error), the function
pgstat_report_subscription_error is invoke twice (in main apply worker and
apply background worker, see function ApplyWorkerMain()->start_apply() and
ApplyBgworkerMain). This means for one same error, we will send twice stats
message.
So to fix this, I removed the code that you mentioned and then, just invoke
function LogicalApplyBgwLoop here.
> <v6-0003>
>
>
> (3) logicalrep_write_attrs
>
> + if (rel->rd_rel->relhasindex)
> + {
> + List *indexoidlist = RelationGetIndexList(rel);
> + ListCell *indexoidscan;
> + foreach(indexoidscan, indexoidlist)
>
> and
>
> + if (indexRel->rd_index->indisunique)
> + {
> + int i;
> + /* Add referenced attributes to idindexattrs */
> + for (i = 0; i < indexRel->rd_index->indnatts; i++)
>
> We don't have each blank line after variable declarations.
> There might be some other codes where this point can be applied.
> Please check.
Improve the formatting as you suggested. And I run pgindent for new patches.
> (4)
>
> + /*
> + * If any unique index exist, check that they are same as remoterel.
> + */
> + if (!rel->sameunique)
> + ereport(ERROR,
> + (errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
> + errmsg("cannot replicate relation with different unique index"),
> + errhint("Please change the streaming option to 'on' instead of
> 'apply'.")));
>
>
> When I create a logical replication setup with different constraints
> and let streaming of in-progress transaction run,
> I keep getting this error.
>
> This should be documented as a restriction or something,
> to let users know the replication progress can't go forward by
> any differences written like in the commit-message in v6-0003.
>
> Also, it would be preferable to test this as well, if we
> don't dislike having TAP tests for this.
Yes, you are right. Thank for your reminder.
I added this in the paragraph introducing value "apply" in
create_subscription.sgml:
```
To run in this mode, there are following two requirements. The first
is that the unique column should be the same between publisher and
subscriber; the second is that there should not be any non-immutable
function in subscriber-side replicated table.
```
Also added the related tests. (refer to 032_streaming_apply.pl in v8-0003)
I also made some other changes. The new patches and the modification details
were attached in [1].
[1] -
https://www.postgresql.org/message-id/OS3PR01MB62758A881FF3240171B7B21B9EDE9%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Thur, Jun 2, 2022 6:02 PM I wrote: > Attach the new patches. I tried to improve the patches by following 2 points: 1. Improved the patch as suggested by Amit-san that I mentioned in [1]. When publisher sends a "STREAM ABORT" message to subscriber, add the lsn and time of this abort to this message.(see function logicalrep_write_stream_abort) When subscriber receives this message, it will update the replication origin. (see function apply_handle_stream_abort and function RecordTransactionAbort) 2. Fixed missing settings for two GUCs (session_replication_role and search_path) in apply background worker in patch 0001 and improved checking of trigger functions in patch 0003. Thanks to Hou Zhi Jie for adding the aborts message related infrastructure for the first point. Thanks to Shi Yu for pointing out the second point. Attach the new patches.(only changed 0001 and 0003) [1] - https://www.postgresql.org/message-id/OS3PR01MB6275FBD9359F8ED0EDE7E5459EDE9%40OS3PR01MB6275.jpnprd01.prod.outlook.com Regards, Wang wei
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Wed, Jun 8, 2022 3:13 PM I wrote: > Attach the new patches.(only changed 0001 and 0003) I tried to improve the patches by following points: 1. Initialize variable include_abort_lsn to false. It reports a warning in cfbot. (see patch v10-0001) BTW, I merged the patch that added the new GUC (see v9-0004) into patch 0001. 2. Because of the improvement #2 in [1], the foreign key could not be detected when checking trigger function. So added additional checks for the foreign key. (see patch 0004) 3. Adding a check for the partition table when trying to apply changes in the apply background worker. (see patch 0004) In additional, the partition cache map on subscriber have several bugs (see thread [2]). Because patch 0004 is developed based on the patches in [2], so I merged the patches(v4-0001~v4-0003) in [2] into a temporary patch 0003 here. After the patches in [2] is committed, I will delete patch 0003 and rebase patch 0004. 4. Improve constraint checking in a separate patch as suggested by Amit-san in [3] #6.(see patch 0005) I added a new field "bool subretry" in catalog pg_subscription. I use this field to indicate whether the transaction that we are going to process has failed before. If apply worker/bgworker was exit with an error, this field will be set to true; If we successfully apply a transaction, this field will be set to false. If we retry to apply a streaming transaction, whether the user sets the streaming option to "on" or "apply", we will apply the transaction in the apply worker. Attach the new patches. Only changed patches 0001, 0004 and added new separate patch 0005. [1] - https://www.postgresql.org/message-id/OS3PR01MB6275208A2F8ED832710F65E09EA49%40OS3PR01MB6275.jpnprd01.prod.outlook.com [2] - https://www.postgresql.org/message-id/flat/OSZPR01MB6310F46CD425A967E4AEF736FDA49%40OSZPR01MB6310.jpnprd01.prod.outlook.com [3] - https://www.postgresql.org/message-id/CAA4eK1Jt08SYbRt_-rbSWNg%3DX9-m8%2BRdP5PosfnQgyF-z8bkxQ%40mail.gmail.com Regards, Wang wei
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Tues, Jun 14, 2022 11:17 AM I wrote: > Attach the new patches. > ...... > 3. Adding a check for the partition table when trying to apply changes in the > apply background worker. (see patch 0004) > In additional, the partition cache map on subscriber have several bugs (see > thread [2]). Because patch 0004 is developed based on the patches in [2], so I > merged the patches(v4-0001~v4-0003) in [2] into a temporary patch 0003 here. > After the patches in [2] is committed, I will delete patch 0003 and rebase > patch 0004. I added some test cases for this (see patch 0004). In patch 0005, I made corresponding adjustments according to these test cases. I also slightly modified the comments about the check for unique index. (see patch 0004) Also rebased the temporary patch 0003 because the first patch in thread [1] is committed (see commit 5a97b132 in HEAD) . Attach the new patches. Only changed patches 0004, 0005. [1] - https://www.postgresql.org/message-id/OSZPR01MB6310F46CD425A967E4AEF736FDA49%40OSZPR01MB6310.jpnprd01.prod.outlook.com Regards, Wang wei
Attachment
- v11-0001-Perform-streaming-logical-transactions-by-backgr.patch
- v11-0002-Test-streaming-apply-option-in-tap-test.patch
- v11-0003-A-temporary-patch-that-includes-patches-in-anoth.patch
- v11-0004-Add-some-checks-before-using-apply-background-wo.patch
- v11-0005-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Jun 14, 2022 at 9:07 AM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
>
> Attach the new patches.
> Only changed patches 0001, 0004 and added new separate patch 0005.
>
Few questions/comments on 0001
===========================
1.
In the commit message, I see: "We also need to allow stream_stop to
complete by the apply background worker to avoid deadlocks because
T-1's current stream of changes can update rows in conflicting order
with T-2's next stream of changes."
Thinking about this, won't the T-1 and T-2 deadlock on the publisher
node as well if the above statement is true?
2.
+ <para>
+ The apply background workers are taken from the pool defined by
+ <varname>max_logical_replication_workers</varname>.
+ </para>
+ <para>
+ The default value is 3. This parameter can only be set in the
+ <filename>postgresql.conf</filename> file or on the server command
+ line.
+ </para>
Is there a reason to choose this number as 3? Why not 2 similar to
max_sync_workers_per_subscription?
3.
+
+ <para>
+ Setting streaming mode to <literal>apply</literal> could export invalid LSN
+ as finish LSN of failed transaction. Changing the streaming mode and making
+ the same conflict writes the finish LSN of the failed transaction in the
+ server log if required.
+ </para>
How will the user identify that this is an invalid LSN value and she
shouldn't use it to SKIP the transaction? Can we change the second
sentence to: "User should change the streaming mode to 'on' if they
would instead wish to see the finish LSN on error. Users can use
finish LSN to SKIP applying the transaction." I think we can give
reference to docs where the SKIP feature is explained.
4.
+ * This file contains routines that are intended to support setting up, using,
+ * and tearing down a ApplyBgworkerState.
+ * Refer to the comments in file header of logical/worker.c to see more
+ * informations about apply background worker.
Typo. /informations/information.
Consider having an empty line between the above two lines.
5.
+ApplyBgworkerState *
+apply_bgworker_find_or_start(TransactionId xid, bool start)
{
...
...
+ if (!TransactionIdIsValid(xid))
+ return NULL;
+
+ /*
+ * We don't start new background worker if we are not in streaming apply
+ * mode.
+ */
+ if (MySubscription->stream != SUBSTREAM_APPLY)
+ return NULL;
+
+ /*
+ * We don't start new background worker if user has set skiplsn as it's
+ * possible that user want to skip the streaming transaction. For
+ * streaming transaction, we need to spill the transaction to disk so that
+ * we can get the last LSN of the transaction to judge whether to skip
+ * before starting to apply the change.
+ */
+ if (start && !XLogRecPtrIsInvalid(MySubscription->skiplsn))
+ return NULL;
+
+ /*
+ * For streaming transactions that are being applied in apply background
+ * worker, we cannot decide whether to apply the change for a relation
+ * that is not in the READY state (see should_apply_changes_for_rel) as we
+ * won't know remote_final_lsn by that time. So, we don't start new apply
+ * background worker in this case.
+ */
+ if (start && !AllTablesyncsReady())
+ return NULL;
...
...
}
Can we move some of these starting checks to a separate function like
canstartapplybgworker()?
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Wed, Jun 15, 2022 at 8:13 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> Few questions/comments on 0001
> ===========================
Thanks for your comments.
> 1.
> In the commit message, I see: "We also need to allow stream_stop to
> complete by the apply background worker to avoid deadlocks because
> T-1's current stream of changes can update rows in conflicting order
> with T-2's next stream of changes."
>
> Thinking about this, won't the T-1 and T-2 deadlock on the publisher
> node as well if the above statement is true?
Yes, I think so.
I think if table's unique index/constraint of the publisher and the subscriber
are consistent, the deadlock will occur on the publisher-side.
If it is inconsistent, deadlock may only occur in the subscriber. But since we
added the check for these (see patch 0004), so it seems okay to not handle this
at STREAM_STOP.
BTW, I made the following improvements to the code (#a, #c are improved in 0004
patch, #b, #d and #e are improved in 0001 patch.) :
a.
I added some comments in the function apply_handle_stream_stop to explain why
we do not need to allow stream_stop to complete by the apply background worker.
b.
I deleted related commit message in 0001 patch and the related comments in file
header (worker.c).
c.
Renamed the function logicalrep_rel_mark_apply_bgworker to
logicalrep_rel_mark_safe_in_apply_bgworker. Also did some slight improvements
in this function.
d.
When apply worker sends stream xact messages to apply background worker, only
wait for apply background worker to complete when commit, prepare and abort of
toplevel xact.
e.
The state setting of apply background worker was not very accurate before, so
improved this (see the invocations to function pgstat_report_activity in
function LogicalApplyBgwLoop, apply_handle_stream_start and
apply_handle_stream_abort).
> 2.
> + <para>
> + The apply background workers are taken from the pool defined by
> + <varname>max_logical_replication_workers</varname>.
> + </para>
> + <para>
> + The default value is 3. This parameter can only be set in the
> + <filename>postgresql.conf</filename> file or on the server command
> + line.
> + </para>
>
> Is there a reason to choose this number as 3? Why not 2 similar to
> max_sync_workers_per_subscription?
Improved the default as suggested.
> 3.
> +
> + <para>
> + Setting streaming mode to <literal>apply</literal> could export invalid LSN
> + as finish LSN of failed transaction. Changing the streaming mode and making
> + the same conflict writes the finish LSN of the failed transaction in the
> + server log if required.
> + </para>
>
> How will the user identify that this is an invalid LSN value and she
> shouldn't use it to SKIP the transaction? Can we change the second
> sentence to: "User should change the streaming mode to 'on' if they
> would instead wish to see the finish LSN on error. Users can use
> finish LSN to SKIP applying the transaction." I think we can give
> reference to docs where the SKIP feature is explained.
Improved the sentence as suggested.
And I added the reference after the statement in your suggestion.
It looks like:
```
... Users can use finish LSN to SKIP applying the transaction by running <link
linkend="sql-altersubscription"><command>ALTER SUBSCRIPTION ...
SKIP</command></link>.
```
> 4.
> + * This file contains routines that are intended to support setting up, using,
> + * and tearing down a ApplyBgworkerState.
> + * Refer to the comments in file header of logical/worker.c to see more
> + * informations about apply background worker.
>
> Typo. /informations/information.
>
> Consider having an empty line between the above two lines.
Improved the message as suggested.
> 5.
> +ApplyBgworkerState *
> +apply_bgworker_find_or_start(TransactionId xid, bool start)
> {
> ...
> ...
> + if (!TransactionIdIsValid(xid))
> + return NULL;
> +
> + /*
> + * We don't start new background worker if we are not in streaming apply
> + * mode.
> + */
> + if (MySubscription->stream != SUBSTREAM_APPLY)
> + return NULL;
> +
> + /*
> + * We don't start new background worker if user has set skiplsn as it's
> + * possible that user want to skip the streaming transaction. For
> + * streaming transaction, we need to spill the transaction to disk so that
> + * we can get the last LSN of the transaction to judge whether to skip
> + * before starting to apply the change.
> + */
> + if (start && !XLogRecPtrIsInvalid(MySubscription->skiplsn))
> + return NULL;
> +
> + /*
> + * For streaming transactions that are being applied in apply background
> + * worker, we cannot decide whether to apply the change for a relation
> + * that is not in the READY state (see should_apply_changes_for_rel) as we
> + * won't know remote_final_lsn by that time. So, we don't start new apply
> + * background worker in this case.
> + */
> + if (start && !AllTablesyncsReady())
> + return NULL;
> ...
> ...
> }
>
> Can we move some of these starting checks to a separate function like
> canstartapplybgworker()?
Improved as suggested.
BTW, I rebased the temporary patch 0003 because one patch in thread [1] is
committed (see commit b7658c24c7 in HEAD).
Attach the new patches.
Only changed patches 0001, 0004.
Regards,
Wang wei
Attachment
- v12-0001-Perform-streaming-logical-transactions-by-backgr.patch
- v12-0002-Test-streaming-apply-option-in-tap-test.patch
- v12-0003-A-temporary-patch-that-includes-patch-in-another.patch
- v12-0004-Add-some-checks-before-using-apply-background-wo.patch
- v12-0005-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Jun 17, 2022 at 12:47 PM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> Attach the new patches.
> Only changed patches 0001, 0004.
>
Few more comments on the previous version of patch:
===========================================
1.
+/*
+ * Count the number of registered (not necessarily running) apply background
+ * worker for a subscription.
+ */
/worker/workers
2.
+static void
+apply_bgworker_setup_dsm(ApplyBgworkerState *wstate)
+{
...
...
+ int64 queue_size = 160000000; /* 16 MB for now */
I think it would be better to use define for this rather than a
hard-coded value.
3.
+/*
+ * Status for apply background worker.
+ */
+typedef enum ApplyBgworkerStatus
+{
+ APPLY_BGWORKER_ATTACHED = 0,
+ APPLY_BGWORKER_READY,
+ APPLY_BGWORKER_BUSY,
+ APPLY_BGWORKER_FINISHED,
+ APPLY_BGWORKER_EXIT
+} ApplyBgworkerStatus;
It would be better if you can add comments to explain each of these states.
4.
+ /* Set up one message queue per worker, plus one. */
+ mq = shm_mq_create(shm_toc_allocate(toc, (Size) queue_size),
+ (Size) queue_size);
+ shm_toc_insert(toc, APPLY_BGWORKER_KEY_MQ, mq);
+ shm_mq_set_sender(mq, MyProc);
I don't understand the meaning of 'plus one' in the above comment as
the patch seems to be setting up just one queue here?
5.
+
+ /* Attach the queues. */
+ wstate->mq_handle = shm_mq_attach(mq, seg, NULL);
Similar to above. If there is only one queue then the comment should
say queue instead of queues.
6.
snprintf(bgw.bgw_name, BGW_MAXLEN,
"logical replication worker for subscription %u", subid);
+ else
+ snprintf(bgw.bgw_name, BGW_MAXLEN,
+ "logical replication background apply worker for subscription %u ", subid);
No need for extra space after %u in the above code.
7.
+ launched = logicalrep_worker_launch(MyLogicalRepWorker->dbid,
+ MySubscription->oid,
+ MySubscription->name,
+ MyLogicalRepWorker->userid,
+ InvalidOid,
+ dsm_segment_handle(wstate->dsm_seg));
+
+ if (launched)
+ {
+ /* Wait for worker to attach. */
+ apply_bgworker_wait_for(wstate, APPLY_BGWORKER_ATTACHED);
In logicalrep_worker_launch(), we already seem to be waiting for
workers to attach via WaitForReplicationWorkerAttach(), so it is not
clear to me why we need to wait again? If there is a genuine reason
then it is better to add some comments to explain it. I think in some
way, we need to know if the worker is successfully attached and we may
not get that via WaitForReplicationWorkerAttach, so there needs to be
some way to know that but this doesn't sound like a very good idea. If
that understanding is correct then can we think of a better way?
8. I think we can simplify apply_bgworker_find_or_start by having
separate APIs for find and start. Most of the places need to use find
API except for the first stream. If we do that then I think you don't
need to make a hash entry unless we established ApplyBgworkerState
which currently looks odd as you need to remove the entry if we fail
to allocate the state.
9.
+ /*
+ * TO IMPROVE: Do we need to display the apply background worker's
+ * information in pg_stat_replication ?
+ */
+ UpdateWorkerStats(last_received, send_time, false);
In this do you mean to say pg_stat_subscription? If so, then to decide
whether we need to update stats here we should see what additional
information we can update here which is not possible via the main
apply worker?
10.
ApplyBgworkerMain
{
...
+ /* Load the subscription into persistent memory context. */
+ ApplyContext = AllocSetContextCreate(TopMemoryContext,
...
This comment seems to be copied from ApplyWorkerMain but doesn't apply here.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Jun 17, 2022 at 12:47 PM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> On Wed, Jun 15, 2022 at 8:13 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > Few questions/comments on 0001
> > ===========================
> Thanks for your comments.
>
> > 1.
> > In the commit message, I see: "We also need to allow stream_stop to
> > complete by the apply background worker to avoid deadlocks because
> > T-1's current stream of changes can update rows in conflicting order
> > with T-2's next stream of changes."
> >
> > Thinking about this, won't the T-1 and T-2 deadlock on the publisher
> > node as well if the above statement is true?
> Yes, I think so.
> I think if table's unique index/constraint of the publisher and the subscriber
> are consistent, the deadlock will occur on the publisher-side.
> If it is inconsistent, deadlock may only occur in the subscriber. But since we
> added the check for these (see patch 0004), so it seems okay to not handle this
> at STREAM_STOP.
>
> BTW, I made the following improvements to the code (#a, #c are improved in 0004
> patch, #b, #d and #e are improved in 0001 patch.) :
> a.
> I added some comments in the function apply_handle_stream_stop to explain why
> we do not need to allow stream_stop to complete by the apply background worker.
>
I have improved the comments in this and other related sections of the
patch. See attached.
>
>
> > 3.
> > +
> > + <para>
> > + Setting streaming mode to <literal>apply</literal> could export invalid LSN
> > + as finish LSN of failed transaction. Changing the streaming mode and making
> > + the same conflict writes the finish LSN of the failed transaction in the
> > + server log if required.
> > + </para>
> >
> > How will the user identify that this is an invalid LSN value and she
> > shouldn't use it to SKIP the transaction? Can we change the second
> > sentence to: "User should change the streaming mode to 'on' if they
> > would instead wish to see the finish LSN on error. Users can use
> > finish LSN to SKIP applying the transaction." I think we can give
> > reference to docs where the SKIP feature is explained.
> Improved the sentence as suggested.
>
You haven't answered first part of the comment: "How will the user
identify that this is an invalid LSN value and she shouldn't use it to
SKIP the transaction?". Have you checked what value it displays? For
example, in one of the case in apply_error_callback as shown in below
code, we don't even display finish LSN if it is invalid.
else if (XLogRecPtrIsInvalid(errarg->finish_lsn))
errcontext("processing remote data for replication origin \"%s\"
during \"%s\" in transaction %u",
errarg->origin_name,
logicalrep_message_type(errarg->command),
errarg->remote_xid);
--
With Regards,
Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for the v11-0001 patch.
(I will review the remaining patches 0002-0005 and post any comments later)
======
1. General
I still feel that 'apply' seems like a meaningless enum value for this
feature because from a user point-of-view every replicated change gets
"applied". IMO something like 'streaming = parallel' or 'streaming =
background' (etc) might have more meaning for a user.
======
2. Commit message
We also need to allow stream_stop to complete by the
apply background worker to avoid deadlocks because T-1's current stream of
changes can update rows in conflicting order with T-2's next stream of changes.
Did this mean to say?
"allow stream_stop to complete by" -> "allow stream_stop to be performed by"
~~~
3. Commit message
This patch also extends the SUBSCRIPTION 'streaming' option so that the user
can control whether to apply the streaming transaction in an apply background
worker or spill the change to disk. User can set the streaming option to
'on/off', 'apply'. For now, 'apply' means the streaming will be applied via a
apply background worker if available. 'on' means the streaming transaction will
be spilled to disk.
3a.
"option" -> "parameter" (2x)
3b.
"User can" -> "The user can"
3c.
I think this part should also mention that the stream parameter
default is unchanged...
======
4. doc/src/sgml/config.sgml
+ <para>
+ Maximum number of apply background workers per subscription. This
+ parameter controls the amount of parallelism of the streaming of
+ in-progress transactions if we set subscription option
+ <literal>streaming</literal> to <literal>apply</literal>.
+ </para>
"if we set subscription option <literal>streaming</literal> to
<literal>apply</literal>." -> "when subscription parameter
<literal>streaming = apply</literal>.
======
5. doc/src/sgml/config.sgml
+ <para>
+ Setting streaming mode to <literal>apply</literal> could export invalid LSN
+ as finish LSN of failed transaction. Changing the streaming mode and making
+ the same conflict writes the finish LSN of the failed transaction in the
+ server log if required.
+ </para>
This text made no sense to me. Can you reword it?
IIUC it means something like this:
When the streaming mode is 'apply', the finish LSN of failed
transactions may not be logged. In that case, it may be necessary to
change the streaming mode and cause the same conflicts again so the
finish LSN of the failed transaction will be written to the server
log.
======
6. doc/src/sgml/protocol.sgml
Since there are protocol changes made here, shouldn’t there also be
some corresponding LOGICALREP_PROTO_XXX constants and special checking
added in the worker.c?
======
7. doc/src/sgml/ref/create_subscription.sgml
+ for this subscription. The default value is <literal>off</literal>,
+ all transactions are fully decoded on the publisher and only then
+ sent to the subscriber as a whole.
+ </para>
SUGGESTION
The default value is off, meaning all transactions are fully decoded
on the publisher and only then sent to the subscriber as a whole.
~~~
8. doc/src/sgml/ref/create_subscription.sgml
+ <para>
+ If set to <literal>on</literal>, the changes of transaction are
+ written to temporary files and then applied at once after the
+ transaction is committed on the publisher.
+ </para>
SUGGESTION
If set to on, the incoming changes are written to a temporary file and
then applied only after the transaction is committed on the publisher.
~~~
9. doc/src/sgml/ref/create_subscription.sgml
+ <para>
+ If set to <literal>apply</literal> incoming
+ changes are directly applied via one of the background workers, if
+ available. If no background worker is free to handle streaming
+ transaction then the changes are written to a file and applied after
+ the transaction is committed. Note that if an error happens when
+ applying changes in a background worker, it might not report the
+ finish LSN of the remote transaction in the server log.
</para>
SUGGESTION
If set to apply, the incoming changes are directly applied via one of
the apply background workers, if available. If no background worker is
free to handle streaming transactions then the changes are written to
a file and applied after the transaction is committed. Note that if an
error happens when applying changes in a background worker, the finish
LSN of the remote transaction might not be reported in the server log.
======
10. src/backend/access/transam/xact.c
@@ -1741,6 +1742,13 @@ RecordTransactionAbort(bool isSubXact)
elog(PANIC, "cannot abort transaction %u, it was already committed",
xid);
+ /*
+ * Are we using the replication origins feature? Or, in other words,
+ * are we replaying remote actions?
+ */
+ replorigin = (replorigin_session_origin != InvalidRepOriginId &&
+ replorigin_session_origin != DoNotReplicateId);
+
/* Fetch the data we need for the abort record */
nrels = smgrGetPendingDeletes(false, &rels);
nchildren = xactGetCommittedChildren(&children);
@@ -1765,6 +1773,11 @@ RecordTransactionAbort(bool isSubXact)
MyXactFlags, InvalidTransactionId,
NULL);
+ if (replorigin)
+ /* Move LSNs forward for this replication origin */
+ replorigin_session_advance(replorigin_session_origin_lsn,
+ XactLastRecEnd);
+
I did not see any reason why the code assigning the 'replorigin' and
the code checking the 'replorigin' are separated like they are. I
thought these 2 new code fragments should be kept together. Perhaps it
was decided this assignment must be outside the critical section? But
if that’s the case maybe a comment explaining so would be good.
~~~
11. src/backend/access/transam/xact.c
+ if (replorigin)
+ /* Move LSNs forward for this replication origin */
+ replorigin_session_advance(replorigin_session_origin_lsn,
+
The positioning of that comment is unusual. Maybe better before the check?
======
12. src/backend/commands/subscriptioncmds.c - defGetStreamingMode
+ /*
+ * If no parameter given, assume "true" is meant.
+ */
+ if (def->arg == NULL)
+ return SUBSTREAM_ON;
SUGGESTION for comment
If the streaming parameter is given but no parameter value is
specified, then assume "true" is meant.
~~~
13. src/backend/commands/subscriptioncmds.c - defGetStreamingMode
+ /*
+ * Allow 0, 1, "true", "false", "on", "off" or "apply".
+ */
IMO these should be in a order consistent with the code.
SUGGESTION
Allow 0, 1, “false”, "true", “off”, "on", or "apply".
======
14. src/backend/replication/logical/Makefile
- worker.o
+ worker.o \
+ applybgwroker.o
typo "applybgwroker" -> "applybgworker"
======
15. .../replication/logical/applybgwroker.c
+/*-------------------------------------------------------------------------
+ * applybgwroker.c
+ * Support routines for applying xact by apply background worker
+ *
+ * Copyright (c) 2016-2022, PostgreSQL Global Development Group
+ *
+ * IDENTIFICATION
+ * src/backend/replication/logical/applybgwroker.c
15a.
Typo in filename: "applybgwroker" -> "applybgworker"
15b.
Typo in file header comment: "applybgwroker" -> "applybgworker"
~~~
16. .../replication/logical/applybgwroker.c
+/*
+ * entry for a hash table we use to map from xid to our apply background worker
+ * state.
+ */
+typedef struct ApplyBgworkerEntry
Comment should start uppercase.
~~~
17. .../replication/logical/applybgwroker.c
+/*
+ * Fields to record the share informations between main apply worker and apply
+ * background worker.
+ */
SUGGESTION
Information shared between main apply worker and apply background worker.
~~~
18. .../replication/logical/applybgwroker.c
+/* apply background worker setup */
+static ApplyBgworkerState *apply_bgworker_setup(void);
+static void apply_bgworker_setup_dsm(ApplyBgworkerState *wstate);
IMO there was not really any need for this comment – these are just
function forward declares.
~~~
19. .../replication/logical/applybgwroker.c - find_or_start_apply_bgworker
+ if (found)
+ {
+ entry->wstate->pstate->status = APPLY_BGWORKER_BUSY;
+ return entry->wstate;
+ }
+ else if (!start)
+ return NULL;
I felt this might be more readable without the else:
if (found)
{
entry->wstate->pstate->status = APPLY_BGWORKER_BUSY;
return entry->wstate;
}
Assert(!found)
if (!start)
return NULL;
~~~
20. .../replication/logical/applybgwroker.c - find_or_start_apply_bgworker
+ /*
+ * Now, we try to get a apply background worker. If there is at least one
+ * worker in the idle list, then take one. Otherwise, we try to start a
+ * new apply background worker.
+ */
20a.
"a apply" -> "an apply"
20b.
IMO it's better to call this the free list (not the idle list)
~~~
21. .../replication/logical/applybgwroker.c - find_or_start_apply_bgworker
+ /*
+ * If the apply background worker cannot be launched, remove entry
+ * in hash table.
+ */
"remove entry in hash table" -> "remove the entry from the hash table"
~~~
22. .../replication/logical/applybgwroker.c - apply_bgworker_free
+/*
+ * Add the worker to the free list and remove the entry from hash table.
+ */
"from hash table" -> "from the hash table"
~~~
23. .../replication/logical/applybgwroker.c - apply_bgworker_free
+ elog(DEBUG1, "adding finished apply worker #%u for xid %u to the idle list",
+ wstate->pstate->n, wstate->pstate->stream_xid);
IMO it's better to call this the free list (not the idle list)
~~~
24. .../replication/logical/applybgwroker.c - LogicalApplyBgwLoop
+/* Apply Background Worker main loop */
+static void
+LogicalApplyBgwLoop(shm_mq_handle *mqh, volatile ApplyBgworkerShared *pst)
Why is the name incosistent with other function names in the file?
Should it be apply_bgworker_loop?
~~~
25. .../replication/logical/applybgwroker.c - LogicalApplyBgwLoop
+ /*
+ * Push apply error context callback. Fields will be filled during
+ * applying a change.
+ */
"during" -> "when"
~~~
26. .../replication/logical/applybgwroker.c - LogicalApplyBgwLoop
+ /*
+ * We use first byte of message for additional communication between
+ * main Logical replication worker and apply bgworkers, so if it
+ * differs from 'w', then process it first.
+ */
"bgworkers" -> "background workers"
~~~
27. .../replication/logical/applybgwroker.c - ApplyBgwShutdown
For consistency should it be called apply_bgworker_shutdown?
~~~
28. .../replication/logical/applybgwroker.c - LogicalApplyBgwMain
For consistency should it be called apply_bgworker_main?
~~~
29. .../replication/logical/applybgwroker.c - apply_bgworker_check_status
+ errdetail("Cannot handle streamed replication transaction by apply "
+ "bgworkers until all tables are synchronized")));
"bgworkers" -> "background workers"
======
30. src/backend/replication/logical/decode.c
@@ -651,9 +651,10 @@ DecodeCommit(LogicalDecodingContext *ctx,
XLogRecordBuffer *buf,
{
for (i = 0; i < parsed->nsubxacts; i++)
{
- ReorderBufferForget(ctx->reorder, parsed->subxacts[i], buf->origptr);
+ ReorderBufferForget(ctx->reorder, parsed->subxacts[i], buf->origptr,
+ commit_time);
}
- ReorderBufferForget(ctx->reorder, xid, buf->origptr);
+ ReorderBufferForget(ctx->reorder, xid, buf->origptr, commit_time);
ReorderBufferForget was declared with 'abort_time' param. So it makes
these calls a bit confusing looking to be passing 'commit_time'
Maybe better to do like below and pass 'forget_time' (inside that
'if') along with an explanatory comment:
TimestampTz forget_time = commit_time;
======
31. src/backend/replication/logical/launcher.c - logicalrep_worker_find
+ /* We only need main apply worker or table sync worker here */
"need" -> "are interested in the"
~~~
32. src/backend/replication/logical/launcher.c - logicalrep_worker_launch
+ if (!is_subworker)
+ snprintf(bgw.bgw_function_name, BGW_MAXLEN, "ApplyWorkerMain");
+ else
+ snprintf(bgw.bgw_function_name, BGW_MAXLEN, "ApplyBgworkerMain");
IMO better to reverse this and express the condition as 'if (is_subworker)'
~~~
33. src/backend/replication/logical/launcher.c - logicalrep_worker_launch
+ else if (!is_subworker)
snprintf(bgw.bgw_name, BGW_MAXLEN,
"logical replication worker for subscription %u", subid);
+ else
+ snprintf(bgw.bgw_name, BGW_MAXLEN,
+ "logical replication background apply worker for subscription %u ", subid);
33a.
Ditto. IMO better to reverse this and express the condition as 'if
(is_subworker)'
33b.
"background apply worker" -> "apply background worker"
~~~
34. src/backend/replication/logical/launcher.c - logicalrep_worker_stop
IMO this code logic should be rewritten to be simpler to have a common
LWLockRelease. This also makes the code more like
logicalrep_worker_detach, which seems like a good thing.
SUGGESTION
logicalrep_worker_stop(Oid subid, Oid relid)
{
LogicalRepWorker *worker;
LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
worker = logicalrep_worker_find(subid, relid, false);
if (worker)
logicalrep_worker_stop_internal(worker);
LWLockRelease(LogicalRepWorkerLock);
}
~~~
35. src/backend/replication/logical/launcher.c -
logicalrep_apply_background_worker_count
+/*
+ * Count the number of registered (not necessarily running) apply background
+ * worker for a subscription.
+ */
"worker" -> "workers"
~~~
36. src/backend/replication/logical/launcher.c -
logicalrep_apply_background_worker_count
+ int res = 0;
+
A better variable name here would be 'count', or even 'n'.
======
36. src/backend/replication/logical/origin.c
+ * However, If must_acquire is false, we allow process to get the slot which is
+ * already acquired by other process.
SUGGESTION
However, if the function parameter 'must_acquire' is false, we allow
the process to use the same slot already acquired by another process.
~~~
37. src/backend/replication/logical/origin.c
+ ereport(ERROR,
+ (errcode(ERRCODE_CONFIGURATION_LIMIT_EXCEEDED),
+ errmsg("could not find correct replication state slot for
replication origin with OID %u for apply background worker",
+ node),
+ errhint("There is no replication state slot set by its main apply worker.")));
37a.
Somehow, I felt the errmsg and the errhint could be clearer. Maybe like this?
" apply background worker could not find replication state slot for
replication origin with OID %u",
"There is no replication state slot set by the main apply worker."
37b.
Also, I think thet generally the 'errhint' informs some advice or some
action that the user can take to fix the problem. But is this errhint
actually saying anything useful for the user? Perhaps you meant to say
'errdetail' here?
======
38. src/backend/replication/logical/proto.c - logicalrep_read_stream_abort
+ /*
+ * If the version of the publisher is lower than the version of the
+ * subscriber, it may not support sending these two fields, so only take
+ * these fields when include_abort_lsn is true.
+ */
+ if (include_abort_lsn)
+ {
+ abort_data->abort_lsn = pq_getmsgint64(in);
+ abort_data->abort_time = pq_getmsgint64(in);
+ }
+ else
+ {
+ abort_data->abort_lsn = InvalidXLogRecPtr;
+ abort_data->abort_time = 0;
+ }
This comment is documenting a decision that was made elsewhere.
But it somehow feels wrong to me that the decision to read or not read
the abort time/lsn is made by the caller of this function. IMO it
might make more sense if the server version was simply passed as a
param and then this function can be in control of its own destiny and
make the decision does it need to read those extra fields or not. An
extra member flag can be added to LogicalRepStreamAbortData to
indicate if abort_data read these values or not.
======
39. src/backend/replication/logical/worker.c
* Streamed transactions (large transactions exceeding a memory limit on the
- * upstream) are not applied immediately, but instead, the data is written
- * to temporary files and then applied at once when the final commit arrives.
+ * upstream) are applied via one of two approaches.
"via" -> "using"
~~~
40. src/backend/replication/logical/worker.c
+ * Assign a new apply background worker (if available) as soon as the xact's
+ * first stream is received and the main apply worker will send changes to this
+ * new worker via shared memory. We keep this worker assigned till the
+ * transaction commit is received and also wait for the worker to finish at
+ * commit. This preserves commit ordering and avoids writing to and reading
+ * from file in most cases. We still need to spill if there is no worker
+ * available. We also need to allow stream_stop to complete by the background
+ * worker to avoid deadlocks because T-1's current stream of changes can update
+ * rows in conflicting order with T-2's next stream of changes.
40a.
"and the main apply -> ". The main apply"
40b.
"and avoids writing to and reading from file in most cases." -> "and
avoids file I/O in most cases."
40c.
"We still need to spill if" -> "We still need to spill to a file if"
40d.
"We also need to allow stream_stop to complete by the background
worker" -> "We also need to allow stream_stop to be performed by the
background worker"
~~~
41. src/backend/replication/logical/worker.c
-static ApplyErrorCallbackArg apply_error_callback_arg =
+ApplyErrorCallbackArg apply_error_callback_arg =
{
.command = 0,
.rel = NULL,
@@ -242,7 +246,7 @@ static ApplyErrorCallbackArg apply_error_callback_arg =
.origin_name = NULL,
};
Maybe it is still a good idea to at least keep the old comment here:
/* Struct for saving and restoring apply errcontext information */
~~
42. src/backend/replication/logical/worker.c
+/* check if we are applying the transaction in apply background worker */
+#define apply_bgworker_active() (in_streamed_transaction &&
stream_apply_worker != NULL)
42a.
Uppercase comment.
42b.
"in apply background worker" -> "in apply background worker"
~~~
43. src/backend/replication/logical/worker.c - handle_streamed_transaction
@@ -426,41 +437,76 @@ end_replication_step(void)
}
/*
- * Handle streamed transactions.
+ * Handle streamed transactions for both main apply worker and apply background
+ * worker.
*
- * If in streaming mode (receiving a block of streamed transaction), we
- * simply redirect it to a file for the proper toplevel transaction.
+ * In streaming case (receiving a block of streamed transaction), for
+ * SUBSTREAM_ON mode, we simply redirect it to a file for the proper toplevel
+ * transaction, and for SUBSTREAM_APPLY mode, we send the changes to background
+ * apply worker (LOGICAL_REP_MSG_RELATION or LOGICAL_REP_MSG_TYPE changes will
+ * also be applied in main apply worker).
*
- * Returns true for streamed transactions, false otherwise (regular mode).
+ * For non-streamed transactions, returns false;
+ * For streamed transactions, returns true if in main apply worker (except we
+ * apply streamed transaction in "apply" mode and address
+ * LOGICAL_REP_MSG_RELATION or LOGICAL_REP_MSG_TYPE changes), false otherwise.
*/
Maybe it is accurate (I don’t know), but this header comment seems
excessively complicated with so many quirks about when to return
true/false. Can it be reworded into plainer language?
~~~
44. src/backend/replication/logical/worker.c - handle_streamed_transaction
Because there are so many returns for each of these conditions,
consider refactoring the logic to change all the if/else to just be
"if" and then you can comment each separate cases better. I think it
may be clearer.
SUGGESTION
/* This is the apply background worker */
if (am_apply_bgworker())
{
...
return false;
}
/* This is the main apply, but there is an apply background worker */
if (apply_bgworker_active())
{
...
return true;
}
/* This is the main apply, and there is no apply background worker */
...
return true;
~~~
45. src/backend/replication/logical/worker.c - apply_handle_stream_prepare
+ /*
+ * This is the main apply worker. Check if we are processing this
+ * transaction in a apply background worker.
+ */
+ if (wstate)
I think the part that says "This is the main apply worker" should be
at the top of the 'else'
~~~
46. src/backend/replication/logical/worker.c - apply_handle_stream_prepare
+ /*
+ * This is the main apply worker and the transaction has been
+ * serialized to file, replay all the spooled operations.
+ */
SUGGESTION
The transaction has been serialized to file. Replay all the spooled operations.
~~~
47. src/backend/replication/logical/worker.c - apply_handle_stream_prepare
+ /* unlink the files with serialized changes and subxact info. */
+ stream_cleanup_files(MyLogicalRepWorker->subid, prepare_data.xid);
Start comment with capital letter.
~~~
48. src/backend/replication/logical/worker.c - apply_handle_stream_start
+ /* If we are in a apply background worker, begin the transaction */
+ AcceptInvalidationMessages();
+ maybe_reread_subscription();
The "if we are" part of the comment is not needed because the fact the
code is inside am_apply_bgworker() makes this obvious anyway/
~~~
49. src/backend/replication/logical/worker.c - apply_handle_stream_start
+ /* open the spool file for this transaction */
+ stream_open_file(MyLogicalRepWorker->subid, stream_xid, first_segment);
+
Start the comment uppercase.
+ /* if this is not the first segment, open existing subxact file */
+ if (!first_segment)
+ subxact_info_read(MyLogicalRepWorker->subid, stream_xid);
Start the comment uppercase.
~~~
50. src/backend/replication/logical/worker.c - apply_handle_stream_abort
+ /* Check whether the publisher sends abort_lsn and abort_time. */
+ if (am_apply_bgworker())
+ include_abort_lsn = MyParallelState->server_version >= 150000;
+
+ logicalrep_read_stream_abort(s, &abort_data, include_abort_lsn);
Here is where I felt maybe just the server version could be passed so
the logicalrep_read_stream_abort could decide itself what message
parts needed to be read. Basically it seems strange that the message
contain parts which might not be read. I felt it is better to always
read the whole message then later you can choose what parts you are
interested in.
~~~
51. src/backend/replication/logical/worker.c - apply_handle_stream_abort
+ /*
+ * This is the main apply worker. Check if we are processing this
+ * transaction in a apply background worker.
+ */
+ /*
+ * We are in main apply worker and the transaction has been serialized
+ * to file.
+ */
51a.
I thought the "This is the main apply worker" and "We are in main
apply worker" should just be be a comment top of this "else"
51b.
"a apply worker" -> "an apply worker"
51c.
There seemed to be some missing comment to say this logic is telling
the bgworker to abort and then waiting for it to do so.
~~~
52. src/backend/replication/logical/worker.c - apply_handle_stream_commit
I did not really understand why the patch relocates this function to
another place in the file. Can't it be left in the same place?
~~~
53. src/backend/replication/logical/worker.c - apply_handle_stream_commit
+ /*
+ * This is the main apply worker. Check if we are processing this
+ * transaction in an apply background worker.
+ */
I thought the top of the else should just say "This is the main apply worker."
Then the if (wstate) part should say “Check if we are processing this
transaction in an apply background worker, and if so tell it to
comment the message”/
~~~
54. src/backend/replication/logical/worker.c - apply_handle_stream_commit
+ /*
+ * This is the main apply worker and the transaction has been
+ * serialized to file, replay all the spooled operations.
+ */
SUGGESTION
The transaction has been serialized to file, so replay all the spooled
operations.
~~~
55. src/backend/replication/logical/worker.c - apply_handle_stream_commit
+ /* unlink the files with serialized changes and subxact info */
+ stream_cleanup_files(MyLogicalRepWorker->subid, xid);
Uppercase comment.
======
56. src/backend/utils/misc/guc.c
@@ -3220,6 +3220,18 @@ static struct config_int ConfigureNamesInt[] =
NULL, NULL, NULL
},
+ {
+ {"max_apply_bgworkers_per_subscription",
+ PGC_SIGHUP,
+ REPLICATION_SUBSCRIBERS,
+ gettext_noop("Maximum number of apply backgrand workers per subscription."),
+ NULL,
+ },
+ &max_apply_bgworkers_per_subscription,
+ 3, 0, MAX_BACKENDS,
+ NULL, NULL, NULL
+ },
+
"backgrand" -> "background"
======
57. src/include/catalog/pg_subscription.h
@@ -109,7 +110,7 @@ typedef struct Subscription
bool enabled; /* Indicates if the subscription is enabled */
bool binary; /* Indicates if the subscription wants data in
* binary format */
- bool stream; /* Allow streaming in-progress transactions. */
+ char stream; /* Allow streaming in-progress transactions. */
char twophasestate; /* Allow streaming two-phase transactions */
bool disableonerr; /* Indicates if the subscription should be
* automatically disabled if a worker error
I felt probably this 'stream' comment should be the same as for 'substream'.
======
58. src/include/replication/worker_internal.h
+/*
+ * Shared information among apply workers.
+ */
+typedef struct ApplyBgworkerShared
SUGGESTION (maybe you can do better than this)
Struct for sharing information between apply main and apply background workers.
~~~
59. src/include/replication/worker_internal.h
+ /* Status for apply background worker. */
+ ApplyBgworkerStatus status;
"Status for" -> "Status of"
~~~
60. src/include/replication/worker_internal.h
+extern PGDLLIMPORT MemoryContext ApplyMessageContext;
+
+extern PGDLLIMPORT ApplyErrorCallbackArg apply_error_callback_arg;
+
+extern PGDLLIMPORT bool MySubscriptionValid;
+
+extern PGDLLIMPORT volatile ApplyBgworkerShared *MyParallelState;
+extern PGDLLIMPORT List *subxactlist;
+
I did not recognise the significance why are the last 2 externs
grouped togeth but the others are not.
~~~
61. src/include/replication/worker_internal.h
+/* prototype needed because of stream_commit */
+extern void apply_dispatch(StringInfo s);
61a.
I was unsure if this comment is useful to anyone...
61b.
If you decide to keep it, please use uppercase.
~~~
62. src/include/replication/worker_internal.h
+/* apply background worker setup and interactions */
+extern ApplyBgworkerState *apply_bgworker_find_or_start(TransactionId xid,
+ bool start);
Uppercase comment.
======
63.
I also did a quick check of all the new debug logging added. Here is
everyhing from patch v11-0001.
apply_bgworker_free:
+ elog(DEBUG1, "adding finished apply worker #%u for xid %u to the idle list",
+ wstate->pstate->n, wstate->pstate->stream_xid);
LogicalApplyBgwLoop:
+ elog(DEBUG1, "[Apply BGW #%u] ended processing streaming chunk,"
+ "waiting on shm_mq_receive", pst->n);
+ elog(DEBUG1, "[Apply BGW #%u] exiting", pst->n);
ApplyBgworkerMain:
+ elog(DEBUG1, "[Apply BGW #%u] started", pst->n);
apply_bgworker_setup:
+ elog(DEBUG1, "setting up apply worker #%u",
list_length(ApplyWorkersList) + 1);
apply_bgworker_set_status:
+ elog(DEBUG1, "[Apply BGW #%u] set status to %d", MyParallelState->n, status);
apply_bgworker_subxact_info_add:
+ elog(DEBUG1, "[Apply BGW #%u] defining savepoint %s",
+ MyParallelState->n, spname);
apply_handle_stream_prepare:
+ elog(DEBUG1, "received prepare for streamed transaction %u",
+ prepare_data.xid);
apply_handle_stream_start:
+ elog(DEBUG1, "starting streaming of xid %u", stream_xid);
apply_handle_stream_stop:
+ elog(DEBUG1, "stopped streaming of xid %u, %u changes streamed",
stream_xid, nchanges);
apply_handle_stream_abort:
+ elog(DEBUG1, "[Apply BGW #%u] aborting current transaction xid=%u, subxid=%u",
+ MyParallelState->n, GetCurrentTransactionIdIfAny(),
+ GetCurrentSubTransactionId());
+ elog(DEBUG1, "[Apply BGW #%u] rolling back to savepoint %s",
+ MyParallelState->n, spname);
apply_handle_stream_commit:
+ elog(DEBUG1, "received commit for streamed transaction %u", xid);
Observations:
63a.
Every new introduced message is at level DEBUG1 (not DEBUG). AFAIK
this is OK, because the messages are all protocol related and every
other existing debug message of the current replication worker.c was
also at the same DEBUG1 level.
63b.
The prefix "[Apply BGW #%u]" is used to indicate the bgworker is
executing the code, but it does not seem to be used 100% consistently
- e.g. there are some apply_bgworker_XXX functions not using this
prefix. Is that OK or a mistake?
------
Kind Regards,
Peter Smith.
Fujitsu Austrlia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Jun 21, 2022 at 7:11 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Here are some review comments for the v11-0001 patch. > > (I will review the remaining patches 0002-0005 and post any comments later) > > ====== > > 1. General > > I still feel that 'apply' seems like a meaningless enum value for this > feature because from a user point-of-view every replicated change gets > "applied". IMO something like 'streaming = parallel' or 'streaming = > background' (etc) might have more meaning for a user. > +1. I would prefer 'streaming = parallel' as that suits here because we allow streams (set of changes) of a transaction to be applied in parallel to other transactions or in parallel to a stream of changes from another streaming transaction. > ====== > > 10. src/backend/access/transam/xact.c > > @@ -1741,6 +1742,13 @@ RecordTransactionAbort(bool isSubXact) > elog(PANIC, "cannot abort transaction %u, it was already committed", > xid); > > + /* > + * Are we using the replication origins feature? Or, in other words, > + * are we replaying remote actions? > + */ > + replorigin = (replorigin_session_origin != InvalidRepOriginId && > + replorigin_session_origin != DoNotReplicateId); > + > /* Fetch the data we need for the abort record */ > nrels = smgrGetPendingDeletes(false, &rels); > nchildren = xactGetCommittedChildren(&children); > @@ -1765,6 +1773,11 @@ RecordTransactionAbort(bool isSubXact) > MyXactFlags, InvalidTransactionId, > NULL); > > + if (replorigin) > + /* Move LSNs forward for this replication origin */ > + replorigin_session_advance(replorigin_session_origin_lsn, > + XactLastRecEnd); > + > > I did not see any reason why the code assigning the 'replorigin' and > the code checking the 'replorigin' are separated like they are. I > thought these 2 new code fragments should be kept together. Perhaps it > was decided this assignment must be outside the critical section? But > if that’s the case maybe a comment explaining so would be good. > I also don't see any particular reason for this apart from being similar to RecordTransactionCommit(). I think it should be fine either way. > ~~~ > > 11. src/backend/access/transam/xact.c > > + if (replorigin) > + /* Move LSNs forward for this replication origin */ > + replorigin_session_advance(replorigin_session_origin_lsn, > + > > The positioning of that comment is unusual. Maybe better before the check? > This again seems to be due to a similar code in RecordTransactionCommit(). I would suggest let's keep the code consistent. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
FYI - the latest patch set v12* on this thread no longer applies. [postgres@CentOS7-x64 oss_postgres_misc]$ git apply v12-0003-A-temporary-patch-that-includes-patch-in-another.patch error: patch failed: src/backend/replication/logical/relation.c:307 error: src/backend/replication/logical/relation.c: patch does not apply error: patch failed: src/backend/replication/logical/worker.c:2358 error: src/backend/replication/logical/worker.c: patch does not apply error: patch failed: src/test/subscription/t/013_partition.pl:868 error: src/test/subscription/t/013_partition.pl: patch does not apply [postgres@CentOS7-x64 oss_postgres_misc]$ ~~ I know the v12-0003 was meant just a temporary patch for something that may now already be pushed, but it cannot be just skipped either because then v12-0004 will also fail. [postgres@CentOS7-x64 oss_postgres_misc]$ git apply v12-0004-Add-some-checks-before-using-apply-background-wo.patch error: patch failed: src/backend/replication/logical/relation.c:433 error: src/backend/replication/logical/relation.c: patch does not apply error: patch failed: src/backend/replication/logical/worker.c:2403 error: src/backend/replication/logical/worker.c: patch does not apply [postgres@CentOS7-x64 oss_postgres_misc]$ ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for v12-0002 ====== 1. Commit message "streaming" option -> "streaming" parameter ~~~ 2. General (every file in this patch) "streaming" option -> "streaming" parameter ~~~ 3. .../subscription/t/022_twophase_cascade.pl For every test file in this patch the new function is passed $is_apply = 0/1 to indicate to use 'on' or 'apply' parameter value. But in this test file the parameter is passed as $streaming_mode = 'on'/'apply'. I was wondering if (for the sake of consistency) it might be better to use the same parameter kind for all of the test files. Actually, I don't care if you choose to do nothing and leave this as-is; I am just posting this review comment in case it was not a deliberate decision to implement them differently. e.g. + my ($node_publisher, $node_subscriber, $appname, $is_apply) = @_; versus + my ($node_A, $node_B, $node_C, $appname_B, $appname_C, $streaming_mode) = + @_; ------ Kind Regards, Peter Smith. Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Mon, Jun 20, 2022 at 11:00 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
> I have improved the comments in this and other related sections of the
> patch. See attached.
Thanks for your comments and patch!
Improved the comments as you suggested.
> > > 3.
> > > +
> > > + <para>
> > > + Setting streaming mode to <literal>apply</literal> could export invalid
> LSN
> > > + as finish LSN of failed transaction. Changing the streaming mode and
> making
> > > + the same conflict writes the finish LSN of the failed transaction in the
> > > + server log if required.
> > > + </para>
> > >
> > > How will the user identify that this is an invalid LSN value and she
> > > shouldn't use it to SKIP the transaction? Can we change the second
> > > sentence to: "User should change the streaming mode to 'on' if they
> > > would instead wish to see the finish LSN on error. Users can use
> > > finish LSN to SKIP applying the transaction." I think we can give
> > > reference to docs where the SKIP feature is explained.
> > Improved the sentence as suggested.
> >
>
> You haven't answered first part of the comment: "How will the user
> identify that this is an invalid LSN value and she shouldn't use it to
> SKIP the transaction?". Have you checked what value it displays? For
> example, in one of the case in apply_error_callback as shown in below
> code, we don't even display finish LSN if it is invalid.
> else if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> errcontext("processing remote data for replication origin \"%s\"
> during \"%s\" in transaction %u",
> errarg->origin_name,
> logicalrep_message_type(errarg->command),
> errarg->remote_xid);
I am sorry that I missed something in my previous reply.
The invalid LSN value here is to say InvalidXLogRecPtr (0/0).
Here is an example :
```
2022-06-23 14:30:11.343 CST [822333] logical replication worker CONTEXT: processing remote data for replication origin
"pg_16389"during "INSERT" for replication target relation "public.tab" in transaction 727 finished at 0/0
```
So I try to improve the sentence in pg-doc by changing from
```
Setting streaming mode to <literal>apply</literal> could export invalid LSN as
finish LSN of failed transaction.
```
to
```
Setting streaming mode to <literal>apply</literal> could export invalid LSN
(0/0) as finish LSN of failed transaction.
```
I also improved the patches as you suggested in [1]:
> 1.
> +/*
> + * Count the number of registered (not necessarily running) apply background
> + * worker for a subscription.
> + */
>
> /worker/workers
Improved as suggested.
> 2.
> +static void
> +apply_bgworker_setup_dsm(ApplyBgworkerState *wstate)
> +{
> ...
> ...
> + int64 queue_size = 160000000; /* 16 MB for now */
>
> I think it would be better to use define for this rather than a
> hard-coded value.
Improved as suggested.
Added a macro like this:
```
/* queue size of DSM, 16 MB for now. */
#define DSM_QUEUE_SIZE 160000000
```
> 3.
> +/*
> + * Status for apply background worker.
> + */
> +typedef enum ApplyBgworkerStatus
> +{
> + APPLY_BGWORKER_ATTACHED = 0,
> + APPLY_BGWORKER_READY,
> + APPLY_BGWORKER_BUSY,
> + APPLY_BGWORKER_FINISHED,
> + APPLY_BGWORKER_EXIT
> +} ApplyBgworkerStatus;
>
> It would be better if you can add comments to explain each of these states.
Improved as suggested.
Added the comments like below:
```
APPLY_BGWORKER_BUSY = 0, /* assigned to a transaction */
APPLY_BGWORKER_FINISHED, /* transaction is completed */
APPLY_BGWORKER_EXIT /* exit */
```
In addition, after improving the point #7 as you suggested, I removed
"APPLY_BGWORKER_ATTACHED". And I removed "APPLY_BGWORKER_READY" in v12.
> 4.
> + /* Set up one message queue per worker, plus one. */
> + mq = shm_mq_create(shm_toc_allocate(toc, (Size) queue_size),
> + (Size) queue_size);
> + shm_toc_insert(toc, APPLY_BGWORKER_KEY_MQ, mq);
> + shm_mq_set_sender(mq, MyProc);
>
>
> I don't understand the meaning of 'plus one' in the above comment as
> the patch seems to be setting up just one queue here?
Yes, you are right. Improved as below:
```
/* Set up message queue for the worker. */
```
> 5.
> +
> + /* Attach the queues. */
> + wstate->mq_handle = shm_mq_attach(mq, seg, NULL);
>
> Similar to above. If there is only one queue then the comment should
> say queue instead of queues.
Improved as suggested.
> 6.
> snprintf(bgw.bgw_name, BGW_MAXLEN,
> "logical replication worker for subscription %u", subid);
> + else
> + snprintf(bgw.bgw_name, BGW_MAXLEN,
> + "logical replication background apply worker for subscription %u ", subid);
>
> No need for extra space after %u in the above code.
Improved as suggested.
> 7.
> + launched = logicalrep_worker_launch(MyLogicalRepWorker->dbid,
> + MySubscription->oid,
> + MySubscription->name,
> + MyLogicalRepWorker->userid,
> + InvalidOid,
> + dsm_segment_handle(wstate->dsm_seg));
> +
> + if (launched)
> + {
> + /* Wait for worker to attach. */
> + apply_bgworker_wait_for(wstate, APPLY_BGWORKER_ATTACHED);
>
> In logicalrep_worker_launch(), we already seem to be waiting for
> workers to attach via WaitForReplicationWorkerAttach(), so it is not
> clear to me why we need to wait again? If there is a genuine reason
> then it is better to add some comments to explain it. I think in some
> way, we need to know if the worker is successfully attached and we may
> not get that via WaitForReplicationWorkerAttach, so there needs to be
> some way to know that but this doesn't sound like a very good idea. If
> that understanding is correct then can we think of a better way?
Improved the related logic.
The reason we wait again here in previous version is to wait for apply bgworker
to attach the memory queue, but function WaitForReplicationWorkerAttach could
not do that.
Now to improve this, we invoke the function logicalrep_worker_attach after the
attaching the memory queue instead of before.
Also to make sure worker has not die due to error or some reasons, I modified
the function logicalrep_worker_launch and function
WaitForReplicationWorkerAttach. And then, we could judge whether the worker
started successfully or died according to the return value of the function
logicalrep_worker_launch.
> 8. I think we can simplify apply_bgworker_find_or_start by having
> separate APIs for find and start. Most of the places need to use find
> API except for the first stream. If we do that then I think you don't
> need to make a hash entry unless we established ApplyBgworkerState
> which currently looks odd as you need to remove the entry if we fail
> to allocate the state.
Improved as suggested.
> 9.
> + /*
> + * TO IMPROVE: Do we need to display the apply background worker's
> + * information in pg_stat_replication ?
> + */
> + UpdateWorkerStats(last_received, send_time, false);
>
> In this do you mean to say pg_stat_subscription? If so, then to decide
> whether we need to update stats here we should see what additional
> information we can update here which is not possible via the main
> apply worker?
Yes, it should be pg_stat_subscription. I think we do not need to update these
statistics here.
I think the messages received in function LogicalApplyBgwLoop in apply bgworker
have handled in function LogicalRepApplyLoop in apply worker, these statistics
have been updated. (see function LogicalRepApplyLoop)
> 10.
> ApplyBgworkerMain
> {
> ...
> + /* Load the subscription into persistent memory context. */
> + ApplyContext = AllocSetContextCreate(TopMemoryContext,
> ...
>
> This comment seems to be copied from ApplyWorkerMain but doesn't apply
> here.
Yes, you are right. Improved as below:
```
/* Init the memory context for the apply background worker to work in. */
```
In addition, I also tried to improve the patches by following points:
a.
In the function apply_handle_stream_abort, when invoking the function
set_apply_error_context_xact, I forgot to change the second input parameter.
So changed "InvalidXLogRecPtr" to "abort_lsn".
b.
Improved the function name from "canstartapplybgworker" to
"apply_bgworker_can_start".
c.
Detach the dsm segment if we fail to launch a apply bgworker. (see function
apply_bgworker_setup)
BTW, I deleted the temporary patch 0003 (v12) and rebased patches because the
commit 26b3455afa and ac0e2d387a in HEAD.
And now, I am improving the patches as suggested by Peter-san in [3]. I will
send new patches soon.
Attach the new patches.
[1] - https://www.postgresql.org/message-id/CAA4eK1%2BQQHGb0afmM_Cf2qu%3DUJoCnvs3VcZ%2B1xTiySx205fU1w%40mail.gmail.com
[2] -
https://www.postgresql.org/message-id/OS3PR01MB6275208A2F8ED832710F65E09EA49%40OS3PR01MB6275.jpnprd01.prod.outlook.com
[3] - https://www.postgresql.org/message-id/CAHut%2BPtu_eWOVWAKrwkUFdTAh_r-RZsbDFkFmKwEAmxws%3DSh5w%40mail.gmail.com
Regards,
Wang wei
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Jun 23, 2022 at 12:51 PM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> On Mon, Jun 20, 2022 at 11:00 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > I have improved the comments in this and other related sections of the
> > patch. See attached.
> Thanks for your comments and patch!
> Improved the comments as you suggested.
>
> > > > 3.
> > > > +
> > > > + <para>
> > > > + Setting streaming mode to <literal>apply</literal> could export invalid
> > LSN
> > > > + as finish LSN of failed transaction. Changing the streaming mode and
> > making
> > > > + the same conflict writes the finish LSN of the failed transaction in the
> > > > + server log if required.
> > > > + </para>
> > > >
> > > > How will the user identify that this is an invalid LSN value and she
> > > > shouldn't use it to SKIP the transaction? Can we change the second
> > > > sentence to: "User should change the streaming mode to 'on' if they
> > > > would instead wish to see the finish LSN on error. Users can use
> > > > finish LSN to SKIP applying the transaction." I think we can give
> > > > reference to docs where the SKIP feature is explained.
> > > Improved the sentence as suggested.
> > >
> >
> > You haven't answered first part of the comment: "How will the user
> > identify that this is an invalid LSN value and she shouldn't use it to
> > SKIP the transaction?". Have you checked what value it displays? For
> > example, in one of the case in apply_error_callback as shown in below
> > code, we don't even display finish LSN if it is invalid.
> > else if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> > errcontext("processing remote data for replication origin \"%s\"
> > during \"%s\" in transaction %u",
> > errarg->origin_name,
> > logicalrep_message_type(errarg->command),
> > errarg->remote_xid);
> I am sorry that I missed something in my previous reply.
> The invalid LSN value here is to say InvalidXLogRecPtr (0/0).
> Here is an example :
> ```
> 2022-06-23 14:30:11.343 CST [822333] logical replication worker CONTEXT: processing remote data for replication
origin"pg_16389" during "INSERT" for replication target relation "public.tab" in transaction 727 finished at 0/0
> ```
>
I don't think it is a good idea to display invalid values. We can mask
this as we are doing in other cases in function apply_error_callback.
The ideal way is that we provide a view/system table for users to
check these errors but that is a matter of another patch. So users
probably need to check Logs to see if the error is from a background
apply worker to decide whether or not to switch streaming mode.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Thu, Jun 23, 2022 at 16:44 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Thu, Jun 23, 2022 at 12:51 PM wangw.fnst@fujitsu.com
> <wangw.fnst@fujitsu.com> wrote:
> >
> > On Mon, Jun 20, 2022 at 11:00 AM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> > > I have improved the comments in this and other related sections of the
> > > patch. See attached.
> > Thanks for your comments and patch!
> > Improved the comments as you suggested.
> >
> > > > > 3.
> > > > > +
> > > > > + <para>
> > > > > + Setting streaming mode to <literal>apply</literal> could export invalid
> > > LSN
> > > > > + as finish LSN of failed transaction. Changing the streaming mode and
> > > making
> > > > > + the same conflict writes the finish LSN of the failed transaction in the
> > > > > + server log if required.
> > > > > + </para>
> > > > >
> > > > > How will the user identify that this is an invalid LSN value and she
> > > > > shouldn't use it to SKIP the transaction? Can we change the second
> > > > > sentence to: "User should change the streaming mode to 'on' if they
> > > > > would instead wish to see the finish LSN on error. Users can use
> > > > > finish LSN to SKIP applying the transaction." I think we can give
> > > > > reference to docs where the SKIP feature is explained.
> > > > Improved the sentence as suggested.
> > > >
> > >
> > > You haven't answered first part of the comment: "How will the user
> > > identify that this is an invalid LSN value and she shouldn't use it to
> > > SKIP the transaction?". Have you checked what value it displays? For
> > > example, in one of the case in apply_error_callback as shown in below
> > > code, we don't even display finish LSN if it is invalid.
> > > else if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> > > errcontext("processing remote data for replication origin \"%s\"
> > > during \"%s\" in transaction %u",
> > > errarg->origin_name,
> > > logicalrep_message_type(errarg->command),
> > > errarg->remote_xid);
> > I am sorry that I missed something in my previous reply.
> > The invalid LSN value here is to say InvalidXLogRecPtr (0/0).
> > Here is an example :
> > ```
> > 2022-06-23 14:30:11.343 CST [822333] logical replication worker CONTEXT:
> processing remote data for replication origin "pg_16389" during "INSERT" for
> replication target relation "public.tab" in transaction 727 finished at 0/0
> > ```
> >
>
> I don't think it is a good idea to display invalid values. We can mask
> this as we are doing in other cases in function apply_error_callback.
> The ideal way is that we provide a view/system table for users to
> check these errors but that is a matter of another patch. So users
> probably need to check Logs to see if the error is from a background
> apply worker to decide whether or not to switch streaming mode.
Thanks for your comments.
I improved it as you suggested. I mask the LSN if it is invalid LSN(0/0).
Also, I improved the related pg-doc as following:
```
When the streaming mode is <literal>parallel</literal>, the finish LSN of
failed transactions may not be logged. In that case, it may be necessary to
change the streaming mode to <literal>on</literal> and cause the same
conflicts again so the finish LSN of the failed transaction will be written
to the server log. For the usage of finish LSN, please refer to <link
linkend="sql-altersubscription"><command>ALTER SUBSCRIPTION ...
SKIP</command></link>.
```
After improving this (mask invalid LSN), I found that this improvement and
parallel apply patch do not seem to have a strong correlation. Would it be
better to improve and commit in another separate patch?
I also improved patches as suggested by Peter-san in [1] and [2].
Thanks for Shi Yu to improve the patches by addressing the comments in [2].
Attach the new patches.
[1] - https://www.postgresql.org/message-id/CAHut%2BPtu_eWOVWAKrwkUFdTAh_r-RZsbDFkFmKwEAmxws%3DSh5w%40mail.gmail.com
[2] - https://www.postgresql.org/message-id/CAHut%2BPsDzRu6PD1uSRkftRXef-KwrOoYrcq7Cm0v4otisi5M%2Bg%40mail.gmail.com
Regards,
Wang wei
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Mon, Jun 21, 2022 at 9:41 AM Peter Smith <smithpb2250@gmail.com> wrote:
> Here are some review comments for the v11-0001 patch.
>
> (I will review the remaining patches 0002-0005 and post any comments later)
>
Thanks for your comments.
> 6. doc/src/sgml/protocol.sgml
>
> Since there are protocol changes made here, shouldn’t there also be
> some corresponding LOGICALREP_PROTO_XXX constants and special checking
> added in the worker.c?
I think it is okay not to add new macro. Because we just expanded the existing
options ("streaming"). And we added a check for version in function
apply_handle_stream_abort.
> 8. doc/src/sgml/ref/create_subscription.sgml
>
> + <para>
> + If set to <literal>on</literal>, the changes of transaction are
> + written to temporary files and then applied at once after the
> + transaction is committed on the publisher.
> + </para>
>
> SUGGESTION
> If set to on, the incoming changes are written to a temporary file and
> then applied only after the transaction is committed on the publisher.
In "on" mode, there may be more than one temporary file for one streaming
transaction. (see the invocation of function BufFileCreateFileSet in function
stream_open_file and function subxact_info_write)
So I think the existing description might be better.
If you feel this sentence is not clear, I will try to improve it later.
> 10. src/backend/access/transam/xact.c
>
> @@ -1741,6 +1742,13 @@ RecordTransactionAbort(bool isSubXact)
> elog(PANIC, "cannot abort transaction %u, it was already committed",
> xid);
>
> + /*
> + * Are we using the replication origins feature? Or, in other words,
> + * are we replaying remote actions?
> + */
> + replorigin = (replorigin_session_origin != InvalidRepOriginId &&
> + replorigin_session_origin != DoNotReplicateId);
> +
> /* Fetch the data we need for the abort record */
> nrels = smgrGetPendingDeletes(false, &rels);
> nchildren = xactGetCommittedChildren(&children);
> @@ -1765,6 +1773,11 @@ RecordTransactionAbort(bool isSubXact)
> MyXactFlags, InvalidTransactionId,
> NULL);
>
> + if (replorigin)
> + /* Move LSNs forward for this replication origin */
> + replorigin_session_advance(replorigin_session_origin_lsn,
> + XactLastRecEnd);
> +
>
> I did not see any reason why the code assigning the 'replorigin' and
> the code checking the 'replorigin' are separated like they are. I
> thought these 2 new code fragments should be kept together. Perhaps it
> was decided this assignment must be outside the critical section? But
> if that’s the case maybe a comment explaining so would be good.
>
> ~~~
>
> 11. src/backend/access/transam/xact.c
>
> + if (replorigin)
> + /* Move LSNs forward for this replication origin */
> + replorigin_session_advance(replorigin_session_origin_lsn,
> +
>
> The positioning of that comment is unusual. Maybe better before the check?
As Amit-san said in [1], this is just for consistency with the code in the
function RecordTransactionCommit.
> 12. src/backend/commands/subscriptioncmds.c - defGetStreamingMode
>
> + /*
> + * If no parameter given, assume "true" is meant.
> + */
> + if (def->arg == NULL)
> + return SUBSTREAM_ON;
>
> SUGGESTION for comment
> If the streaming parameter is given but no parameter value is
> specified, then assume "true" is meant.
I think it might be better to be consistent with the function defGetBoolean
here.
> 24. .../replication/logical/applybgwroker.c - LogicalApplyBgwLoop
>
> +/* Apply Background Worker main loop */
> +static void
> +LogicalApplyBgwLoop(shm_mq_handle *mqh, volatile ApplyBgworkerShared
> *pst)
>
> Why is the name incosistent with other function names in the file?
> Should it be apply_bgworker_loop?
I think this function name would be better to be consistent with the function
LogicalRepApplyLoop.
> 28. .../replication/logical/applybgwroker.c - LogicalApplyBgwMain
>
> For consistency should it be called apply_bgworker_main?
I think this function name would be better to be consistent with the function
ApplyWorkerMain.
> 30. src/backend/replication/logical/decode.c
>
> @@ -651,9 +651,10 @@ DecodeCommit(LogicalDecodingContext *ctx,
> XLogRecordBuffer *buf,
> {
> for (i = 0; i < parsed->nsubxacts; i++)
> {
> - ReorderBufferForget(ctx->reorder, parsed->subxacts[i], buf->origptr);
> + ReorderBufferForget(ctx->reorder, parsed->subxacts[i], buf->origptr,
> + commit_time);
> }
> - ReorderBufferForget(ctx->reorder, xid, buf->origptr);
> + ReorderBufferForget(ctx->reorder, xid, buf->origptr, commit_time);
>
> ReorderBufferForget was declared with 'abort_time' param. So it makes
> these calls a bit confusing looking to be passing 'commit_time'
>
> Maybe better to do like below and pass 'forget_time' (inside that
> 'if') along with an explanatory comment:
>
> TimestampTz forget_time = commit_time;
I did not change this. I am just not sure how much this will help.
> 36. src/backend/replication/logical/launcher.c -
> logicalrep_apply_background_worker_count
>
> + int res = 0;
> +
>
> A better variable name here would be 'count', or even 'n'.
I think this variable name would be better to be consistent with the function
logicalrep_sync_worker_count.
> 38. src/backend/replication/logical/proto.c - logicalrep_read_stream_abort
>
> + /*
> + * If the version of the publisher is lower than the version of the
> + * subscriber, it may not support sending these two fields, so only take
> + * these fields when include_abort_lsn is true.
> + */
> + if (include_abort_lsn)
> + {
> + abort_data->abort_lsn = pq_getmsgint64(in);
> + abort_data->abort_time = pq_getmsgint64(in);
> + }
> + else
> + {
> + abort_data->abort_lsn = InvalidXLogRecPtr;
> + abort_data->abort_time = 0;
> + }
>
> This comment is documenting a decision that was made elsewhere.
>
> But it somehow feels wrong to me that the decision to read or not read
> the abort time/lsn is made by the caller of this function. IMO it
> might make more sense if the server version was simply passed as a
> param and then this function can be in control of its own destiny and
> make the decision does it need to read those extra fields or not. An
> extra member flag can be added to LogicalRepStreamAbortData to
> indicate if abort_data read these values or not.
I understand what you mean. But I am not sure if it is appropriate to introduce
version information in the file proto.c just for the STREAM_ABORT message. And
I think it might complicate the file proto.c if introducing version
information. Also, I think it might not be a good idea to add a flag to
LogicalRepStreamAbortData (There is no similar flag in structure
LogicalRep.*Data).
So, I just introduce a flag to decide whether we should read these fields from
the STREAM_ABORT message.
> 41. src/backend/replication/logical/worker.c
>
> -static ApplyErrorCallbackArg apply_error_callback_arg =
> +ApplyErrorCallbackArg apply_error_callback_arg =
> {
> .command = 0,
> .rel = NULL,
> @@ -242,7 +246,7 @@ static ApplyErrorCallbackArg apply_error_callback_arg =
> .origin_name = NULL,
> };
>
> Maybe it is still a good idea to at least keep the old comment here:
> /* Struct for saving and restoring apply errcontext information */
I think the old comment looks like it was for the structure
ApplyErrorCallbackArg, not the variable apply_error_callback_arg.
So I did not add new comments here for variable apply_error_callback_arg.
> 42. src/backend/replication/logical/worker.c
>
> +/* check if we are applying the transaction in apply background worker */
> +#define apply_bgworker_active() (in_streamed_transaction &&
> stream_apply_worker != NULL)
>
> 42a.
> Uppercase comment.
>
> 42b.
> "in apply background worker" -> "in apply background worker"
=> 42a.
improved as suggested.
=> 42b.
Sorry, I am not sure what you mean.
> 43. src/backend/replication/logical/worker.c - handle_streamed_transaction
>
> @@ -426,41 +437,76 @@ end_replication_step(void)
> }
>
> /*
> - * Handle streamed transactions.
> + * Handle streamed transactions for both main apply worker and apply
> background
> + * worker.
> *
> - * If in streaming mode (receiving a block of streamed transaction), we
> - * simply redirect it to a file for the proper toplevel transaction.
> + * In streaming case (receiving a block of streamed transaction), for
> + * SUBSTREAM_ON mode, we simply redirect it to a file for the proper toplevel
> + * transaction, and for SUBSTREAM_APPLY mode, we send the changes to
> background
> + * apply worker (LOGICAL_REP_MSG_RELATION or LOGICAL_REP_MSG_TYPE
> changes will
> + * also be applied in main apply worker).
> *
> - * Returns true for streamed transactions, false otherwise (regular mode).
> + * For non-streamed transactions, returns false;
> + * For streamed transactions, returns true if in main apply worker (except we
> + * apply streamed transaction in "apply" mode and address
> + * LOGICAL_REP_MSG_RELATION or LOGICAL_REP_MSG_TYPE changes), false
> otherwise.
> */
>
> Maybe it is accurate (I don’t know), but this header comment seems
> excessively complicated with so many quirks about when to return
> true/false. Can it be reworded into plainer language?
Improved the comments like below:
```
* For non-streamed transactions, returns false;
* For streamed transactions, returns true if in main apply worker, false
* otherwise.
*
* But there are two exceptions: If we apply streamed transaction in main apply
* worker with parallel mode, it will return false when we address
* LOGICAL_REP_MSG_RELATION or LOGICAL_REP_MSG_TYPE changes.
```
> 46. src/backend/replication/logical/worker.c - apply_handle_stream_prepare
>
> + /*
> + * This is the main apply worker and the transaction has been
> + * serialized to file, replay all the spooled operations.
> + */
>
> SUGGESTION
> The transaction has been serialized to file. Replay all the spooled operations.
Both #46 and #54 seem to try to improve on the same comment. Personally I
prefer the improvement in #54. So improved this as suggested in #54.
> 50. src/backend/replication/logical/worker.c - apply_handle_stream_abort
>
> + /* Check whether the publisher sends abort_lsn and abort_time. */
> + if (am_apply_bgworker())
> + include_abort_lsn = MyParallelState->server_version >= 150000;
> +
> + logicalrep_read_stream_abort(s, &abort_data, include_abort_lsn);
>
> Here is where I felt maybe just the server version could be passed so
> the logicalrep_read_stream_abort could decide itself what message
> parts needed to be read. Basically it seems strange that the message
> contain parts which might not be read. I felt it is better to always
> read the whole message then later you can choose what parts you are
> interested in.
Please refer to the reply to #38.
In addition, we do not always read these two new fields from STREAM_ABORT
message. Because if the subscriber's version is higher than the publisher's
version, it may try to read data that in the invalid area.
I think this is not a correct behaviour.
> 63.
>
> I also did a quick check of all the new debug logging added. Here is
> everyhing from patch v11-0001.
>
> apply_bgworker_free:
> + elog(DEBUG1, "adding finished apply worker #%u for xid %u to the idle list",
> + wstate->pstate->n, wstate->pstate->stream_xid);
>
> LogicalApplyBgwLoop:
> + elog(DEBUG1, "[Apply BGW #%u] ended processing streaming chunk,"
> + "waiting on shm_mq_receive", pst->n);
>
> + elog(DEBUG1, "[Apply BGW #%u] exiting", pst->n);
>
> ApplyBgworkerMain:
> + elog(DEBUG1, "[Apply BGW #%u] started", pst->n);
>
> apply_bgworker_setup:
> + elog(DEBUG1, "setting up apply worker #%u",
> list_length(ApplyWorkersList) + 1);
>
> apply_bgworker_set_status:
> + elog(DEBUG1, "[Apply BGW #%u] set status to %d", MyParallelState->n,
> status);
>
> apply_bgworker_subxact_info_add:
> + elog(DEBUG1, "[Apply BGW #%u] defining savepoint %s",
> + MyParallelState->n, spname);
>
> apply_handle_stream_prepare:
> + elog(DEBUG1, "received prepare for streamed transaction %u",
> + prepare_data.xid);
>
> apply_handle_stream_start:
> + elog(DEBUG1, "starting streaming of xid %u", stream_xid);
>
> apply_handle_stream_stop:
> + elog(DEBUG1, "stopped streaming of xid %u, %u changes streamed",
> stream_xid, nchanges);
>
> apply_handle_stream_abort:
> + elog(DEBUG1, "[Apply BGW #%u] aborting current transaction xid=%u,
> subxid=%u",
> + MyParallelState->n, GetCurrentTransactionIdIfAny(),
> + GetCurrentSubTransactionId());
>
> + elog(DEBUG1, "[Apply BGW #%u] rolling back to savepoint %s",
> + MyParallelState->n, spname);
>
> apply_handle_stream_commit:
> + elog(DEBUG1, "received commit for streamed transaction %u", xid);
>
>
> Observations:
>
> 63a.
> Every new introduced message is at level DEBUG1 (not DEBUG). AFAIK
> this is OK, because the messages are all protocol related and every
> other existing debug message of the current replication worker.c was
> also at the same DEBUG1 level.
>
> 63b.
> The prefix "[Apply BGW #%u]" is used to indicate the bgworker is
> executing the code, but it does not seem to be used 100% consistently
> - e.g. there are some apply_bgworker_XXX functions not using this
> prefix. Is that OK or a mistake?
Thanks for your check. I confirm this point in v13. And there are 5 functions
do not use the prefix "[Apply BGW #%u]":
```
apply_bgworker_free
apply_bgworker_setup
apply_bgworker_send_data
apply_bgworker_wait_for
apply_bgworker_check_status
```
These 5 functions do not use this prefix because they only output logs in apply
worker. So I think it is okay.
The rest of the comments are improved as suggested.
The new patches were attached in [2].
[1] - https://www.postgresql.org/message-id/CAA4eK1J9_jcLNVqmxt_d28uGi6hAV31wjYdgmg1p8BGuEctNpw%40mail.gmail.com
[2] -
https://www.postgresql.org/message-id/OS3PR01MB62758DBE8FA12BA72A43AC819EB89%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Thu, Jun 23, 2022 at 9:41 AM Peter Smith <smithpb2250@gmail.com> wrote: > Here are some review comments for v12-0002 Thanks for your comments. > 3. .../subscription/t/022_twophase_cascade.pl > > For every test file in this patch the new function is passed $is_apply > = 0/1 to indicate to use 'on' or 'apply' parameter value. But in this > test file the parameter is passed as $streaming_mode = 'on'/'apply'. > > I was wondering if (for the sake of consistency) it might be better to > use the same parameter kind for all of the test files. Actually, I > don't care if you choose to do nothing and leave this as-is; I am just > posting this review comment in case it was not a deliberate decision > to implement them differently. > > e.g. > + my ($node_publisher, $node_subscriber, $appname, $is_apply) = @_; > > versus > + my ($node_A, $node_B, $node_C, $appname_B, $appname_C, > $streaming_mode) = > + @_; This is because in 022_twophase_cascade.pl, altering subscription streaming mode is inside test_streaming(), it would be more convenient to pass which streaming mode we use (on or apply), we can directly use that in alter subscription command. In other files, we need to get the option because we only check the log in apply mode, so I think it is sufficient to pass 'is_apply' (whose value is 0 or 1). Because of these differences, I did not change it. The rest of the comments are improved as suggested. The new patches were attached in [1]. [1] - https://www.postgresql.org/message-id/OS3PR01MB62758DBE8FA12BA72A43AC819EB89%40OS3PR01MB6275.jpnprd01.prod.outlook.com Regards, Wang wei
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Jun 28, 2022 at 8:51 AM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> On Thu, Jun 23, 2022 at 16:44 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > On Thu, Jun 23, 2022 at 12:51 PM wangw.fnst@fujitsu.com
> > <wangw.fnst@fujitsu.com> wrote:
> > >
> > > On Mon, Jun 20, 2022 at 11:00 AM Amit Kapila <amit.kapila16@gmail.com>
> > wrote:
> > > > I have improved the comments in this and other related sections of the
> > > > patch. See attached.
> > > Thanks for your comments and patch!
> > > Improved the comments as you suggested.
> > >
> > > > > > 3.
> > > > > > +
> > > > > > + <para>
> > > > > > + Setting streaming mode to <literal>apply</literal> could export invalid
> > > > LSN
> > > > > > + as finish LSN of failed transaction. Changing the streaming mode and
> > > > making
> > > > > > + the same conflict writes the finish LSN of the failed transaction in the
> > > > > > + server log if required.
> > > > > > + </para>
> > > > > >
> > > > > > How will the user identify that this is an invalid LSN value and she
> > > > > > shouldn't use it to SKIP the transaction? Can we change the second
> > > > > > sentence to: "User should change the streaming mode to 'on' if they
> > > > > > would instead wish to see the finish LSN on error. Users can use
> > > > > > finish LSN to SKIP applying the transaction." I think we can give
> > > > > > reference to docs where the SKIP feature is explained.
> > > > > Improved the sentence as suggested.
> > > > >
> > > >
> > > > You haven't answered first part of the comment: "How will the user
> > > > identify that this is an invalid LSN value and she shouldn't use it to
> > > > SKIP the transaction?". Have you checked what value it displays? For
> > > > example, in one of the case in apply_error_callback as shown in below
> > > > code, we don't even display finish LSN if it is invalid.
> > > > else if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> > > > errcontext("processing remote data for replication origin \"%s\"
> > > > during \"%s\" in transaction %u",
> > > > errarg->origin_name,
> > > > logicalrep_message_type(errarg->command),
> > > > errarg->remote_xid);
> > > I am sorry that I missed something in my previous reply.
> > > The invalid LSN value here is to say InvalidXLogRecPtr (0/0).
> > > Here is an example :
> > > ```
> > > 2022-06-23 14:30:11.343 CST [822333] logical replication worker CONTEXT:
> > processing remote data for replication origin "pg_16389" during "INSERT" for
> > replication target relation "public.tab" in transaction 727 finished at 0/0
> > > ```
> > >
> >
> > I don't think it is a good idea to display invalid values. We can mask
> > this as we are doing in other cases in function apply_error_callback.
> > The ideal way is that we provide a view/system table for users to
> > check these errors but that is a matter of another patch. So users
> > probably need to check Logs to see if the error is from a background
> > apply worker to decide whether or not to switch streaming mode.
>
> Thanks for your comments.
> I improved it as you suggested. I mask the LSN if it is invalid LSN(0/0).
> Also, I improved the related pg-doc as following:
> ```
> When the streaming mode is <literal>parallel</literal>, the finish LSN of
> failed transactions may not be logged. In that case, it may be necessary to
> change the streaming mode to <literal>on</literal> and cause the same
> conflicts again so the finish LSN of the failed transaction will be written
> to the server log. For the usage of finish LSN, please refer to <link
> linkend="sql-altersubscription"><command>ALTER SUBSCRIPTION ...
> SKIP</command></link>.
> ```
> After improving this (mask invalid LSN), I found that this improvement and
> parallel apply patch do not seem to have a strong correlation. Would it be
> better to improve and commit in another separate patch?
>
Is there any other case where we can hit this code path (mask
invalidLSN) without this patch?
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Tues, Jun 28, 2022 at 12:15 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Tue, Jun 28, 2022 at 8:51 AM wangw.fnst@fujitsu.com
> <wangw.fnst@fujitsu.com> wrote:
> >
> > On Thu, Jun 23, 2022 at 16:44 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> > > On Thu, Jun 23, 2022 at 12:51 PM wangw.fnst@fujitsu.com
> > > <wangw.fnst@fujitsu.com> wrote:
> > > >
> > > > On Mon, Jun 20, 2022 at 11:00 AM Amit Kapila <amit.kapila16@gmail.com>
> > > wrote:
> > > > > I have improved the comments in this and other related sections of the
> > > > > patch. See attached.
> > > > Thanks for your comments and patch!
> > > > Improved the comments as you suggested.
> > > >
> > > > > > > 3.
> > > > > > > +
> > > > > > > + <para>
> > > > > > > + Setting streaming mode to <literal>apply</literal> could export
> invalid
> > > > > LSN
> > > > > > > + as finish LSN of failed transaction. Changing the streaming mode
> and
> > > > > making
> > > > > > > + the same conflict writes the finish LSN of the failed transaction in
> the
> > > > > > > + server log if required.
> > > > > > > + </para>
> > > > > > >
> > > > > > > How will the user identify that this is an invalid LSN value and she
> > > > > > > shouldn't use it to SKIP the transaction? Can we change the second
> > > > > > > sentence to: "User should change the streaming mode to 'on' if they
> > > > > > > would instead wish to see the finish LSN on error. Users can use
> > > > > > > finish LSN to SKIP applying the transaction." I think we can give
> > > > > > > reference to docs where the SKIP feature is explained.
> > > > > > Improved the sentence as suggested.
> > > > > >
> > > > >
> > > > > You haven't answered first part of the comment: "How will the user
> > > > > identify that this is an invalid LSN value and she shouldn't use it to
> > > > > SKIP the transaction?". Have you checked what value it displays? For
> > > > > example, in one of the case in apply_error_callback as shown in below
> > > > > code, we don't even display finish LSN if it is invalid.
> > > > > else if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> > > > > errcontext("processing remote data for replication origin \"%s\"
> > > > > during \"%s\" in transaction %u",
> > > > > errarg->origin_name,
> > > > > logicalrep_message_type(errarg->command),
> > > > > errarg->remote_xid);
> > > > I am sorry that I missed something in my previous reply.
> > > > The invalid LSN value here is to say InvalidXLogRecPtr (0/0).
> > > > Here is an example :
> > > > ```
> > > > 2022-06-23 14:30:11.343 CST [822333] logical replication worker CONTEXT:
> > > processing remote data for replication origin "pg_16389" during "INSERT" for
> > > replication target relation "public.tab" in transaction 727 finished at 0/0
> > > > ```
> > > >
> > >
> > > I don't think it is a good idea to display invalid values. We can mask
> > > this as we are doing in other cases in function apply_error_callback.
> > > The ideal way is that we provide a view/system table for users to
> > > check these errors but that is a matter of another patch. So users
> > > probably need to check Logs to see if the error is from a background
> > > apply worker to decide whether or not to switch streaming mode.
> >
> > Thanks for your comments.
> > I improved it as you suggested. I mask the LSN if it is invalid LSN(0/0).
> > Also, I improved the related pg-doc as following:
> > ```
> > When the streaming mode is <literal>parallel</literal>, the finish LSN of
> > failed transactions may not be logged. In that case, it may be necessary to
> > change the streaming mode to <literal>on</literal> and cause the same
> > conflicts again so the finish LSN of the failed transaction will be written
> > to the server log. For the usage of finish LSN, please refer to <link
> > linkend="sql-altersubscription"><command>ALTER SUBSCRIPTION ...
> > SKIP</command></link>.
> > ```
> > After improving this (mask invalid LSN), I found that this improvement and
> > parallel apply patch do not seem to have a strong correlation. Would it be
> > better to improve and commit in another separate patch?
> >
>
> Is there any other case where we can hit this code path (mask
> invalidLSN) without this patch?
I realized that there is no normal case that could hit this code path in HEAD.
If we want to hit this code path, we must set apply_error_callback_arg.rel to
valid relation and set finish LSN to InvalidXLogRecPtr.
But now in HEAD, we only set apply_error_callback_arg.rel to valid relation
after setting finish LSN to valid LSN.
So it seems fine change this along with the parallel apply patch.
Regards,
Wang wei
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Below are some review comments for patches v14-0001, and v14-0002:
========
v14-0001
========
1.1 Commit message
For now, 'parallel' means the streaming will be applied
via a apply background worker if available. 'on' means the streaming
transaction will be spilled to disk. By the way, we do not change the default
behaviour.
SUGGESTION (minor tweaks)
The parameter value 'parallel' means the streaming will be applied via
an apply background worker, if available. The parameter value 'on'
means the streaming transaction will be spilled to disk. The default
value is 'off' (same as current behaviour).
======
1.2 doc/src/sgml/protocol.sgml - Protocol constants
Previously I wrote that since there are protocol changes here,
shouldn’t there also be some corresponding LOGICALREP_PROTO_XXX
constants and special checking added in the worker.c?
But you said [1 comment #6] you think it is OK because...
IMO, I still disagree with the reply. The fact is that the protocol
*has* been changed, so IIUC that is precisely the reason for having
those protocol constants.
e.g I am guessing you might assign the new one somewhere here:
--
server_version = walrcv_server_version(LogRepWorkerWalRcvConn);
options.proto.logical.proto_version =
server_version >= 150000 ? LOGICALREP_PROTO_TWOPHASE_VERSION_NUM :
server_version >= 140000 ? LOGICALREP_PROTO_STREAM_VERSION_NUM :
LOGICALREP_PROTO_VERSION_NUM;
--
And then later you would refer to this new protocol version (instead
of the server version) when calling to the apply_handle_stream_abort
function.
======
1.3 doc/src/sgml/ref/create_subscription.sgml
+ <para>
+ If set to <literal>on</literal>, the changes of transaction are
+ written to temporary files and then applied at once after the
+ transaction is committed on the publisher.
+ </para>
Previously I suggested changing some text but it was rejected [1
comment #8] because you said there may be *multiple* files, not just
one. That is fair enough, but there were some other changes to that
suggested text unrelated to the number of files.
SUGGESTION #2
If set to on, the incoming changes are written to temporary files and
then applied only after the transaction is committed on the publisher.
~~~
1.4
+ <para>
+ If set to <literal>parallel</literal>, incoming changes are directly
+ applied via one of the apply background workers, if available. If no
+ background worker is free to handle streaming transaction then the
+ changes are written to a file and applied after the transaction is
+ committed. Note that if an error happens when applying changes in a
+ background worker, the finish LSN of the remote transaction might
+ not be reported in the server log.
</para>
Should this also say "written to temporary files" instead of "written
to a file"?
======
1.5 src/backend/commands/subscriptioncmds.c
+ /*
+ * If no parameter given, assume "true" is meant.
+ */
Previously I suggested an update for this comment, but it was rejected
[1 comment #12] saying you wanted consistency with defGetBoolean.
Sure, that is one point of view. Another one is that "two wrongs don't
make a right". IIUC that comment as it currently stands is incorrect
because in this case there *is* a parameter given - it is just the
parameter *value* that is missing. Maybe see what other people think?
======
1.6. src/backend/replication/logical/Makefile
It seems to me like these files were intended to be listed in
alphabetical order, so you should move this new file accordingly.
======
1.7 .../replication/logical/applybgworker.c
+/* queue size of DSM, 16 MB for now. */
+#define DSM_QUEUE_SIZE 160000000
The comment should start uppercase.
~~~
1.8 .../replication/logical/applybgworker.c - apply_bgworker_can_start
Maybe this is just my opinion but it sounds a bit strange to over-use
"we" in all the comments.
1.8.a
+/*
+ * Confirm if we can try to start a new apply background worker.
+ */
+static bool
+apply_bgworker_can_start(TransactionId xid)
SUGGESTION
Check if starting a new apply background worker is allowed.
1.8.b
+ /*
+ * We don't start new background worker if we are not in streaming parallel
+ * mode.
+ */
SUGGESTION
Don't start a new background worker if not in streaming parallel mode.
1.8.c
+ /*
+ * We don't start new background worker if user has set skiplsn as it's
+ * possible that user want to skip the streaming transaction. For
+ * streaming transaction, we need to spill the transaction to disk so that
+ * we can get the last LSN of the transaction to judge whether to skip
+ * before starting to apply the change.
+ */
SUGGESTION
Don't start a new background worker if...
~~~
1.9 .../replication/logical/applybgworker.c - apply_bgworker_start
+/*
+ * Try to start worker inside ApplyWorkersHash for requested xid.
+ */
+ApplyBgworkerState *
+apply_bgworker_start(TransactionId xid)
The comment seems not quite right.
SUGGESTION
Try to start an apply background worker and, if successful, cache it
in ApplyWorkersHash keyed by the specified xid.
~~~
1.10 .../replication/logical/applybgworker.c - apply_bgworker_find
+ /*
+ * Find entry for requested transaction.
+ */
+ entry = hash_search(ApplyWorkersHash, &xid, HASH_FIND, &found);
+ if (found)
+ {
+ entry->wstate->pstate->status = APPLY_BGWORKER_BUSY;
+ return entry->wstate;
+ }
+ else
+ return NULL;
+}
IMO it is an unexpected side-effect for the function called "find" to
be also modifying the thing that it found. IMO this setting BUSY
should either be done by the caller, or else this function name should
be renamed to make it obvious that this is doing more than just
"finding" something.
~~~
1.11 .../replication/logical/applybgworker.c - LogicalApplyBgwLoop
+ /*
+ * Push apply error context callback. Fields will be filled applying
+ * applying a change.
+ */
Typo: "applying applying"
~~~
1.12 .../replication/logical/applybgworker.c - apply_bgworker_setup
+ if (launched)
+ ApplyWorkersList = lappend(ApplyWorkersList, wstate);
+ else
+ {
+ shm_mq_detach(wstate->mq_handle);
+ dsm_detach(wstate->dsm_seg);
+ pfree(wstate);
+
+ wstate->mq_handle = NULL;
+ wstate->dsm_seg = NULL;
+ wstate = NULL;
+ }
I am not sure what those first 2 NULL assignments are trying to
achieve. Nothing AFAICT. In any case, it looks like a bug to deference
the 'wstate' after you already pfree-d it in the line above.
~~~
1.13 .../replication/logical/applybgworker.c - apply_bgworker_check_status
+ * Exit if any relation is not in the READY state and if any worker is handling
+ * the streaming transaction at the same time. Because for streaming
+ * transactions that is being applied in apply background worker, we cannot
+ * decide whether to apply the change for a relation that is not in the READY
+ * state (see should_apply_changes_for_rel) as we won't know remote_final_lsn
+ * by that time.
+ */
+void
+apply_bgworker_check_status(void)
Somehow, I felt that this "Exit if..." comment really belonged at the
appropriate place in the function body, instead of in the function
header.
======
1.14 src/backend/replication/logical/launcher.c - WaitForReplicationWorkerAttach
@@ -151,8 +153,10 @@ get_subscription_list(void)
*
* This is only needed for cleaning up the shared memory in case the worker
* fails to attach.
+ *
+ * Returns false if the attach fails. Otherwise return true.
*/
-static void
+static bool
WaitForReplicationWorkerAttach(LogicalRepWorker *worker,
Comment should say either "Return" or "returns"; not one of each.
~~~
1.15. src/backend/replication/logical/launcher.c -
WaitForReplicationWorkerAttach
+ return worker->in_use ? true : false;
Same as just:
return worker->in_use;
~~~
1.16. src/backend/replication/logical/launcher.c - logicalrep_worker_launch
+ bool is_subworker = (subworker_dsm != DSM_HANDLE_INVALID);
+
+ /* We don't support table sync in subworker */
+ Assert(!(is_subworker && OidIsValid(relid)));
I'm not sure the comment is good. It sounds like it is something that
might be possible but is just current "not supported". In fact, I
thought this is really just a sanity check because the combination of
those params is just plain wrong isn't it? Maybe a better comment is
just:
/* Sanity check */
======
1.17 src/backend/replication/logical/proto.c
+ /*
+ * If the version of the publisher is lower than the version of the
+ * subscriber, it may not support sending these two fields. So these
+ * fields are only taken if they are included.
+ */
+ if (include_abort_lsn)
1.17a
I thought that the comment about "versions of publishers lower than
version of subscribers..." is bogus. Perhaps you have in mind just
thinking about versions prior to PG16 but that is not what the comment
is saying. E.g. sometime in the future, the publisher may be PG18 and
the subscriber might be PG25. So that might work fine (even though the
publisher is a lower version), but this comment will be completely
misleading. BTW this is another reason I think code needs to be using
protocol versions (not server versions). [See other comment #1.2]
1.17b.
Anyway, I felt that any comment describing the meaning of the the
'include_abort_lsn' param would be better in the function header
comment, instead of in the function body.
======
1.18 src/backend/replication/logical/worker.c - file header comment
+ * 1) Separate background workers
+ *
+ * Assign a new apply background worker (if available) as soon as the xact's...
Somehow this long comment did not ever mention that this mode is
selected by the user using the 'streaming=parallel'. I thought
probably it should say that somewhere here.
~~~
1.19. src/backend/replication/logical/worker.c -
ApplyErrorCallbackArg apply_error_callback_arg =
{
.command = 0,
.rel = NULL,
.remote_attnum = -1,
.remote_xid = InvalidTransactionId,
.finish_lsn = InvalidXLogRecPtr,
.origin_name = NULL,
};
I still thought that the above initialization deserves some sort of
comment, even if you don't want to use the comment text previously
suggested [1 comment #41]
~~~
1.20 src/backend/replication/logical/worker.c -
@@ -251,27 +258,38 @@ static MemoryContext LogicalStreamingContext = NULL;
WalReceiverConn *LogRepWorkerWalRcvConn = NULL;
Subscription *MySubscription = NULL;
-static bool MySubscriptionValid = false;
+bool MySubscriptionValid = false;
bool in_remote_transaction = false;
static XLogRecPtr remote_final_lsn = InvalidXLogRecPtr;
/* fields valid only when processing streamed transaction */
-static bool in_streamed_transaction = false;
+bool in_streamed_transaction = false;
The tab alignment here looks wrong. IMO it's not worth trying to align
these at all. I think the tabs are leftover from before when the vars
used to be static.
~~~
1.21 src/backend/replication/logical/worker.c - apply_bgworker_active
+/* Check if we are applying the transaction in apply background worker */
+#define apply_bgworker_active() (in_streamed_transaction &&
stream_apply_worker != NULL)
Sorry [1 comment #42b], I had meant to write "in apply background
worker" -> "in an apply background worker".
~~~
1.22 src/backend/replication/logical/worker.c - skip_xact_finish_lsn
/*
* We enable skipping all data modification changes (INSERT, UPDATE, etc.) for
* the subscription if the remote transaction's finish LSN matches
the subskiplsn.
* Once we start skipping changes, we don't stop it until we skip all
changes of
* the transaction even if pg_subscription is updated and
MySubscription->skiplsn
- * gets changed or reset during that. Also, in streaming transaction cases, we
- * don't skip receiving and spooling the changes since we decide whether or not
+ * gets changed or reset during that. Also, in streaming transaction
cases (streaming = on),
+ * we don't skip receiving and spooling the changes since we decide
whether or not
* to skip applying the changes when starting to apply changes. The
subskiplsn is
* cleared after successfully skipping the transaction or applying non-empty
* transaction. The latter prevents the mistakenly specified subskiplsn from
- * being left.
+ * being left. Note that we cannot skip the streaming transaction in parallel
+ * mode, because we cannot get the finish LSN before applying the changes.
*/
"in parallel mode, because" -> "in 'streaming = parallel' mode, because"
~~~
1.23 src/backend/replication/logical/worker.c - handle_streamed_transaction
1.23a
/*
- * Handle streamed transactions.
+ * Handle streamed transactions for both main apply worker and apply background
+ * worker.
SUGGESTION
Handle streamed transactions for both the main apply worker and the
apply background workers.
1.23b
+ * In streaming case (receiving a block of streamed transaction), for
+ * SUBSTREAM_ON mode, we simply redirect it to a file for the proper toplevel
+ * transaction, and for SUBSTREAM_PARALLEL mode, we send the changes to
+ * background apply worker (LOGICAL_REP_MSG_RELATION or LOGICAL_REP_MSG_TYPE
+ * changes will also be applied in main apply worker).
"background apply worker" -> "apply background workers"
Also, I think you don't need to say "we" everywhere:
"we simply redirect it" -> "simply redirect it"
"we send the changes" -> "send the changes"
1.23c.
+ * But there are two exceptions: If we apply streamed transaction in main apply
+ * worker with parallel mode, it will return false when we address
+ * LOGICAL_REP_MSG_RELATION or LOGICAL_REP_MSG_TYPE changes.
SUGGESTION
Exception: When parallel mode is applying streamed transaction in the
main apply worker, (e.g. when addressing
LOGICAL_REP_MSG_RELATION or LOGICAL_REP_MSG_TYPE changes), then return false.
~~~
1.24 src/backend/replication/logical/worker.c - handle_streamed_transaction
1.24a.
/* not in streaming mode */
- if (!in_streamed_transaction)
+ if (!(in_streamed_transaction || am_apply_bgworker()))
return false;
Uppercase comment
1.24b
+ /* define a savepoint for a subxact if needed. */
+ apply_bgworker_subxact_info_add(current_xid);
Uppercase comment
~~~
1.25 src/backend/replication/logical/worker.c - handle_streamed_transaction
+ /*
+ * This is the main apply worker, and there is an apply background
+ * worker. So we apply the changes of this transaction in an apply
+ * background worker. Pass the data to the worker.
+ */
SUGGESTION (to be more consistent with the next comment)
This is the main apply worker, but there is an apply background
worker, so apply the changes of this transaction in that background
worker. Pass the data to the worker.
~~~
1.26 src/backend/replication/logical/worker.c - handle_streamed_transaction
+ /*
+ * This is the main apply worker, but there is no apply background
+ * worker. So we write to temporary files and apply when the final
+ * commit arrives.
SUGGESTION
This is the main apply worker, but there is no apply background
worker, so write to temporary files and apply when the final commit
arrives.
~~~
1.27 src/backend/replication/logical/worker.c - apply_handle_stream_prepare
+ /*
+ * Check if we are processing this transaction in an apply background
+ * worker.
+ */
SUGGESTION:
Check if we are processing this transaction in an apply background
worker and if so, send the changes to that worker.
~~~
1.28 src/backend/replication/logical/worker.c - apply_handle_stream_prepare
+ if (wstate)
+ {
+ apply_bgworker_send_data(wstate, s->len, s->data);
+
+ /*
+ * Wait for apply background worker to finish. This is required to
+ * maintain commit order which avoids failures due to transaction
+ * dependencies and deadlocks.
+ */
+ apply_bgworker_wait_for(wstate, APPLY_BGWORKER_FINISHED);
+ apply_bgworker_free(wstate);
I think maybe the comment can be changed slightly, and then it can
move up one line to the top of this code block (above the 3
statements). I think it will become more readable.
SUGGESTION
After sending the data to the apply background worker, wait for that
worker to finish. This is necessary to maintain commit order which
avoids failures due to transaction dependencies and deadlocks.
~~~
1.29 src/backend/replication/logical/worker.c - apply_handle_stream_start
+ /*
+ * If no worker is available for the first stream start, we start to
+ * serialize all the changes of the transaction.
+ */
+ else
+ {
1.29a.
I felt that this comment should be INSIDE the else { block to be more readable.
1.29b.
The comment can also be simplified a bit
SUGGESTION:
Since no apply background worker is available for the first stream
start, serialize all the changes of the transaction.
~~~
1.30 src/backend/replication/logical/worker.c - apply_handle_stream_start
+ /* if this is not the first segment, open existing subxact file */
+ if (!first_segment)
+ subxact_info_read(MyLogicalRepWorker->subid, stream_xid);
Uppercase comment
~~~
1.31. src/backend/replication/logical/worker.c - apply_handle_stream_stop
+ if (apply_bgworker_active())
+ {
+ char action = LOGICAL_REP_MSG_STREAM_STOP;
Are all the tabs before the variable needed?
~~~
1.32. src/backend/replication/logical/worker.c - apply_handle_stream_abort
+ /* Check whether the publisher sends abort_lsn and abort_time. */
+ if (am_apply_bgworker())
+ include_abort_lsn = MyParallelState->server_version >= 150000;
Previously I already reported about this [1 comment #50]
I just do not trust this code to do the correct thing. E.g. what if
streaming=parallel but all bgworkers are exhausted then IIUC the
am_apply_bgworker() will not be true. But then with both PG15 servers
for pub/sub you will WRITE something but then you will not READ it.
Won't the stream IO will get out of step and everything will fall
apart?
Perhaps the include_abort_lsn assignment should be unconditionally
set, and I think this should be a protocol version check instead of a
server version check shouldn’t it (see my earlier comment 1.2)
~~~
1.32 src/backend/replication/logical/worker.c - apply_handle_stream_abort
BTW, I think the PG16devel is now stamped in the GitHub HEAD so
perhaps all of your 150000 checks should be now changed to say 160000?
~~~
1.33 src/backend/replication/logical/worker.c - apply_handle_stream_abort
+ /*
+ * We are in main apply worker and the transaction has been serialized
+ * to file.
+ */
+ else
+ serialize_stream_abort(xid, subxid);
I think this will be more readable if written like:
else
{
/* put comment here... */
serialize_stream_abort(xid, subxid);
}
~~~
1.34 src/backend/replication/logical/worker.c - apply_dispatch
-
/*
* Logical replication protocol message dispatcher.
*/
-static void
+void
apply_dispatch(StringInfo s)
Maybe removing the whitespace is not really needed as part of this patch?
======
1.35 src/include/catalog/pg_subscription.h
+/* Disallow streaming in-progress transactions */
+#define SUBSTREAM_OFF 'f'
+
+/*
+ * Streaming transactions are written to a temporary file and applied only
+ * after the transaction is committed on upstream.
+ */
+#define SUBSTREAM_ON 't'
+
+/* Streaming transactions are applied immediately via a background worker */
+#define SUBSTREAM_PARALLEL 'p'
+
1.35a
Should all these "Streaming transactions" be called "Streaming
in-progress transactions"?
1.35b.
Either align the values or don’t. Currently, they seem half-aligned.
1.35c.
SUGGESTION (modify the 1st comment to be more consistent with the others)
Streaming in-progress transactions are disallowed.
======
1.36 src/include/replication/worker_internal.h
extern int logicalrep_sync_worker_count(Oid subid);
+extern int logicalrep_apply_background_worker_count(Oid subid);
Just wondering if this should be called
"logicalrep_apply_bgworker_count(Oid subid);" for consistency with the
other function naming.
========
v14-0002
========
2.1 Commit message
Change all TAP tests using the SUBSCRIPTION "streaming" option, so they
now test both 'on' and 'parallel' values.
"option" -> "parameter"
------
[1]
https://www.postgresql.org/message-id/OS3PR01MB6275DCCDF35B3BBD52CA02CC9EB89%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Jul 1, 2022 at 12:13 PM Peter Smith <smithpb2250@gmail.com> wrote: > > ====== > > 1.2 doc/src/sgml/protocol.sgml - Protocol constants > > Previously I wrote that since there are protocol changes here, > shouldn’t there also be some corresponding LOGICALREP_PROTO_XXX > constants and special checking added in the worker.c? > > But you said [1 comment #6] you think it is OK because... > > IMO, I still disagree with the reply. The fact is that the protocol > *has* been changed, so IIUC that is precisely the reason for having > those protocol constants. > > e.g I am guessing you might assign the new one somewhere here: > -- > server_version = walrcv_server_version(LogRepWorkerWalRcvConn); > options.proto.logical.proto_version = > server_version >= 150000 ? LOGICALREP_PROTO_TWOPHASE_VERSION_NUM : > server_version >= 140000 ? LOGICALREP_PROTO_STREAM_VERSION_NUM : > LOGICALREP_PROTO_VERSION_NUM; > -- > > And then later you would refer to this new protocol version (instead > of the server version) when calling to the apply_handle_stream_abort > function. > > ====== > One point related to this that occurred to me is how it will behave if the publisher is of version >=16 whereas the subscriber is of versions <=15? Won't in that case publisher sends the new fields but subscribers won't be reading those which may cause some problems. > ====== > > 1.5 src/backend/commands/subscriptioncmds.c > > + /* > + * If no parameter given, assume "true" is meant. > + */ > > Previously I suggested an update for this comment, but it was rejected > [1 comment #12] saying you wanted consistency with defGetBoolean. > > Sure, that is one point of view. Another one is that "two wrongs don't > make a right". IIUC that comment as it currently stands is incorrect > because in this case there *is* a parameter given - it is just the > parameter *value* that is missing. > You have a point but if we see this function in the vicinity then the proposed comment also makes sense. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Below are some review comments for patch v14-0003:
========
v14-0003
========
3.1 Commit message
If any of the following checks are violated, an error will be reported.
1. The unique columns between publisher and subscriber are difference.
2. There is any non-immutable function present in expression in
subscriber's relation. Check from the following 4 items:
a. The function in triggers;
b. Column default value expressions and domain constraints;
c. Constraint expressions.
d. The foreign keys.
SUGGESTION (rewording to match the docs and the code).
Add some checks before using apply background worker to apply changes.
streaming=parallel mode has two requirements:
1) The unique columns must be the same between publisher and subscriber
2) There cannot be any non-immutable functions in the subscriber-side
replicated table. Look for functions in the following places:
* a. Trigger functions
* b. Column default value expressions and domain constraints
* c. Constraint expressions
* d. Foreign keys
======
3.2 doc/src/sgml/ref/create_subscription.sgml
+ To run in this mode, there are following two requirements. The first
+ is that the unique column should be the same between publisher and
+ subscriber; the second is that there should not be any non-immutable
+ function in subscriber-side replicated table.
SUGGESTION
Parallel mode has two requirements: 1) the unique columns must be the
same between publisher and subscriber; 2) there cannot be any
non-immutable functions in the subscriber-side replicated table.
======
3.3 .../replication/logical/applybgworker.c - apply_bgworker_relation_check
+ * Check if changes on this logical replication relation can be applied by
+ * apply background worker.
SUGGESTION
Check if changes on this relation can be applied by an apply background worker.
~~~
3.4
+ * Although we maintains the commit order by allowing only one process to
+ * commit at a time, our access order to the relation has changed.
SUGGESTION
Although the commit order is maintained only allowing one process to
commit at a time, the access order to the relation has changed.
~~~
3.5
+ /* Check only we are in apply bgworker. */
+ if (!am_apply_bgworker())
+ return;
SUGGESTION
/* Skip check if not an apply background worker. */
~~~
3.6
+ /*
+ * If it is a partitioned table, we do not check it, we will check its
+ * partition later.
+ */
This comment is lacking useful details:
/* Partition table checks are done later in (?????) */
~~~
3.7
+ if (!rel->sameunique)
+ ereport(ERROR,
+ (errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
+ errmsg("cannot replicate relation with different unique index"),
+ errhint("Please change the streaming option to 'on' instead of
'parallel'.")));
Maybe the first message should change slightly so it is worded
consistently with the other one.
SUGGESTION
errmsg("cannot replicate relation. Unique indexes must be the same"),
======
3.8 src/backend/replication/logical/proto.c
-#define LOGICALREP_IS_REPLICA_IDENTITY 1
+#define LOGICALREP_IS_REPLICA_IDENTITY 0x0001
+#define LOGICALREP_IS_UNIQUE 0x0002
I think these constants should named differently to reflect that they
are just attribute flags. They should should use similar bitset styles
to the other nearby constants.
SUGGESTION
#define ATTR_IS_REPLICA_IDENTITY (1 << 0)
#define ATTR_IS_UNIQUE (1 << 1)
~~~
3.9 src/backend/replication/logical/proto.c - logicalrep_write_attrs
This big slab of new code to get the BMS looks very similar to
RelationGetIdentityKeyBitmap. So perhaps this code should be
encapsulated in another function like that one (in relcache.c?) and
then just called from logicalrep_write_attrs
======
3.10 src/backend/replication/logical/relation.c -
logicalrep_relmap_reset_volatility_cb
+/*
+ * Reset the flag volatility of all existing entry in the relation map cache.
+ */
+static void
+logicalrep_relmap_reset_volatility_cb(Datum arg, int cacheid, uint32 hashvalue)
SUGGESTION
Reset the volatility flag of all entries in the relation map cache.
~~~
3.11 src/backend/replication/logical/relation.c -
logicalrep_rel_mark_safe_in_apply_bgworker
+/*
+ * Check if unique index/constraint matches and mark sameunique and volatility
+ * flag.
+ *
+ * Don't throw any error here just mark the relation entry as not sameunique or
+ * FUNCTION_NONIMMUTABLE as we only check these in apply background worker.
+ */
+static void
+logicalrep_rel_mark_safe_in_apply_bgworker(LogicalRepRelMapEntry *entry)
SUGGESTION
Check if unique index/constraint matches and assign 'sameunique' flag.
Check if there are any non-immutable functions and assign the
'volatility' flag. Note: Don't throw any error here - these flags will
be checked in the apply background worker.
~~~
3.12 src/backend/replication/logical/relation.c -
logicalrep_rel_mark_safe_in_apply_bgworker
I did not really understand why you used an enum for one flag
(volatility) but not the other one (sameunique); shouldn’t both of
these be tri-values: unknown/yes/no?
For E.g. there is a quick exit from this function if the
FUNCTION_UNKNOWN, but there is no equivalent quick exit for the
sameunique? It seems inconsistent.
~~~
3.13 src/backend/replication/logical/relation.c -
logicalrep_rel_mark_safe_in_apply_bgworker
+ /*
+ * Check whether there is any non-immutable function in the local table.
+ *
+ * a. The function in triggers;
+ * b. Column default value expressions and domain constraints;
+ * c. Constraint expressions;
+ * d. Foreign keys.
+ */
SUGGESTION
* Check if there is any non-immutable function in the local table.
* Look for functions in the following places:
* a. trigger functions
* b. Column default value expressions and domain constraints
* c. Constraint expressions
* d. Foreign keys
~~~
3.14 src/backend/replication/logical/relation.c -
logicalrep_rel_mark_safe_in_apply_bgworker
There are lots of places setting FUNCTION_NONIMMUTABLE, so I think
this code might be tidier if you just have a single return at the end
of this function and 'goto' it.
e.g.
if (...)
goto function_not_immutable;
...
return;
function_not_immutable:
entry->volatility = FUNCTION_NONIMMUTABLE;
======
3.15 src/backend/replication/logical/worker.c - apply_handle_stream_stop
+ /*
+ * Unlike stream_commit, we don't need to wait here for stream_stop to
+ * finish. Allowing the other transaction to be applied before stream_stop
+ * is finished can only lead to failures if the unique index/constraint is
+ * different between publisher and subscriber. But for such cases, we don't
+ * allow streamed transactions to be applied in parallel. See
+ * apply_bgworker_relation_check.
+ */
"can only lead to failures" -> "can lead to failures"
~~~
3.16 src/backend/replication/logical/worker.c - apply_handle_tuple_routing
@@ -2534,13 +2548,14 @@ apply_handle_tuple_routing(ApplyExecutionData *edata,
}
MemoryContextSwitchTo(oldctx);
+ part_entry = logicalrep_partition_open(relmapentry, partrel,
+ attrmap);
+
+ apply_bgworker_relation_check(part_entry);
+
/* Check if we can do the update or delete on the leaf partition. */
if (operation == CMD_UPDATE || operation == CMD_DELETE)
- {
- part_entry = logicalrep_partition_open(relmapentry, partrel,
- attrmap);
check_relation_updatable(part_entry);
- }
Perhaps the apply_bgworker_relation_check(part_entry); should be done
AFTER the CMD_UPDATE/CMD_DELETE check because then it will not change
the existing errors for those cases.
======
3.17 src/backend/utils/cache/typcache.c
+/*
+ * GetDomainConstraints --- get DomainConstraintState list of
specified domain type
+ */
+List *
+GetDomainConstraints(Oid type_id)
This is an unusual-looking function header comment, with the function
name and the "---".
======
3.18 src/include/replication/logicalrelation.h
+/*
+ * States to determine volatility of the function in expressions in one
+ * relation.
+ */
+typedef enum RelFuncVolatility
+{
+ FUNCTION_UNKNOWN = 0, /* initializing */
+ FUNCTION_IMMUTABLE, /* all functions are immutable function */
+ FUNCTION_NONIMMUTABLE /* at least one non-immutable function */
+} RelFuncVolatility;
+
I think the comments can be improved, and also the values can be more
self-explanatory. e.g.
typedef enum RelFuncVolatility
{
FUNCTION_UNKNOWN_IMMUATABLE, /* unknown */
FUNCTION_ALL_MUTABLE, /* all functions are immutable */
FUNCTION_NOT_ALL_IMMUTABLE /* not all functions are immuatble */
} RelFuncVolatility;
~~~
3.18
RelFuncVolatility should be added to typedefs.list
~~~
3.19
@@ -31,6 +42,11 @@ typedef struct LogicalRepRelMapEntry
Relation localrel; /* relcache entry (NULL when closed) */
AttrMap *attrmap; /* map of local attributes to remote ones */
bool updatable; /* Can apply updates/deletes? */
+ bool sameunique; /* Are all unique columns of the local
+ relation contained by the unique columns in
+ remote? */
(This is similar to review comment 3.12)
I felt it was inconsistent for this to be a boolean but for the
'volatility' member to be an enum. AFAIK these 2 flags are similar
kinds – e.g. essentially tri-state flags unknown/true/false so I
thought they should be treated the same. E.g. both enums?
~~~
3.20
+ RelFuncVolatility volatility; /* all functions in localrel are
+ immutable function? */
SUGGESTION
/* Indicator of local relation function volatility */
======
3.21 .../subscription/t/022_twophase_cascade.pl
+ if ($streaming_mode eq 'parallel')
+ {
+ $node_C->safe_psql(
+ 'postgres', "
+ ALTER TABLE test_tab ALTER c DROP DEFAULT");
+ }
+
Indentation of the ALTER does not seem right.
======
3.22 .../subscription/t/032_streaming_apply.pl
3.22.a
+# Setup structure on publisher
"structure"?
3.22.b
+# Setup structure on subscriber
"structure"?
~~~
3.23
+# Check that a background worker starts if "streaming" option is specified as
+# "parallel". We have to look for the DEBUG1 log messages about that, so
+# temporarily bump up the log verbosity.
+$node_subscriber->append_conf('postgresql.conf', "log_min_messages = debug1");
+$node_subscriber->reload;
+
+$node_publisher->safe_psql('postgres',
+ "INSERT INTO test_tab SELECT i, md5(i::text) FROM generate_series(1,
5000) s(i)"
+);
+
+$node_subscriber->wait_for_log(qr/\[Apply BGW #\d+\] started/, 0);
+$node_subscriber->append_conf('postgresql.conf',
+ "log_min_messages = warning");
+$node_subscriber->reload;
I didn't really think it was necessary to bump this log level, and to
verify that the bgworker is started, because this test is anyway going
to ensure that the ERROR "cannot replicate relation with different
unique index" happens, so that is already implicitly ensuring the
bgworker was used.
~~~
3.24
+# Then we check the unique index on partition table.
+$node_subscriber->safe_psql(
+ 'postgres', qq{
+CREATE TRIGGER insert_trig
+BEFORE INSERT ON test_tab_partition
+FOR EACH ROW EXECUTE PROCEDURE trigger_func();
+ALTER TABLE test_tab_partition ENABLE REPLICA TRIGGER insert_trig;
+});
Looks like the wrong comment. I think it should say something like
"Check the trigger on the partition table."
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Below are some review comments for patch v14-0004:
========
v14-0004
========
4.0 General.
This comment is an after-thought but as I write this mail I am
wondering if most of this 0004 patch is even necessary at all? Instead
of introducing a new column and all the baggage that goes with it,
can't the same functionality be achieved just by toggling the
streaming mode 'substream' value from 'p' (parallel) to 't' (on)
whenever an error occurs causing a retry? Anyway, if you do change it
this way then most of the following comments can be disregarded.
======
4.1 Commit message
Patch needs an explanatory commit message. Currently, there is nothing.
======
4.2 doc/src/sgml/catalogs.sgml
+ <row>
+ <entry role="catalog_table_entry"><para role="column_definition">
+ <structfield>subretry</structfield> <type>bool</type>
+ </para>
+ <para>
+ If true, the subscription will not try to apply streaming transaction
+ in <literal>parallel</literal> mode. See
+ <xref linkend="sql-createsubscription"/> for more information.
+ </para></entry>
+ </row>
I think it is overkill to mention anything about the
streaming=parallel here because IIUC it is nothing to do with this
field at all. I thought you really only need to say something brief
like:
SUGGESTION:
True if the previous apply change failed and a retry was required.
======
4.3 doc/src/sgml/ref/create_subscription.sgml
@@ -244,6 +244,10 @@ CREATE SUBSCRIPTION <replaceable
class="parameter">subscription_name</replaceabl
is that the unique column should be the same between publisher and
subscriber; the second is that there should not be any non-immutable
function in subscriber-side replicated table.
+ When applying a streaming transaction, if either requirement is not
+ met, the background worker will exit with an error. And when retrying
+ later, we will try to apply this transaction in <literal>on</literal>
+ mode.
</para>
I did not think it is good to say "we" in the docs.
SUGGESTION
When applying a streaming transaction, if either requirement is not
met, the background worker will exit with an error. Parallel mode is
disregarded when retrying; instead the transaction will be applied
using <literal>streaming = on</literal>.
======
4.4 .../replication/logical/applybgworker.c
+ /*
+ * We don't start new background worker if retry was set as it's possible
+ * that the last time we tried to apply a transaction in background worker
+ * and the check failed (see function apply_bgworker_relation_check). So
+ * we will try to apply this transaction in apply worker.
+ */
SUGGESTION (simplified, and remove "we")
Don't use apply background workers for retries, because it is possible
that the last time we tried to apply a transaction using an apply
background worker the checks failed (see function
apply_bgworker_relation_check).
~~~
4.5
+ elog(DEBUG1, "retry to apply an streaming transaction in apply "
+ "background worker");
IMO the log message is too confusing
SUGGESTION
"apply background workers are not used for retries"
======
4.6 src/backend/replication/logical/worker.c
4.6.a - apply_handle_commit
+ /* Set the flag that we will not retry later. */
+ set_subscription_retry(false);
But the comment is wrong, isn't it? Shouldn’t it just say that we are
not *currently* retrying? And can’t this just anyway be redundant if
only the catalog column has a DEFAULT value of false?
4.6.b - apply_handle_prepare
Ditto
4.6.c - apply_handle_commit_prepared
Ditto
4.6.d - apply_handle_rollback_prepared
Ditto
4.6.e - apply_handle_stream_prepare
Ditto
4.6.f - apply_handle_stream_abort
Ditto
4.6.g - apply_handle_stream_commit
Ditto
~~~
4.7 src/backend/replication/logical/worker.c
4.7.a - start_table_sync
@@ -3894,6 +3917,9 @@ start_table_sync(XLogRecPtr *origin_startpos,
char **myslotname)
}
PG_CATCH();
{
+ /* Set the flag that we will retry later. */
+ set_subscription_retry(true);
Maybe this should say more like "Flag that the next apply will be the
result of a retry"
4.7.b - start_apply
Ditto
~~~
4.8 src/backend/replication/logical/worker.c - set_subscription_retry
+
+/*
+ * Set subretry of pg_subscription catalog.
+ *
+ * If retry is true, subscriber is about to exit with an error. Otherwise, it
+ * means that the changes was applied successfully.
+ */
+static void
+set_subscription_retry(bool retry)
"changes" -> "change" ?
~~~
4.8 src/backend/replication/logical/worker.c - set_subscription_retry
Isn't this flag only every used when streaming=parallel? But it does
not seem ot be checking that anywhere before potentiall executing all
this code when maybe will never be used.
======
4.9 src/include/catalog/pg_subscription.h
@@ -76,6 +76,8 @@ CATALOG(pg_subscription,6100,SubscriptionRelationId)
BKI_SHARED_RELATION BKI_ROW
bool subdisableonerr; /* True if a worker error should cause the
* subscription to be disabled */
+ bool subretry; /* True if the previous apply change failed. */
I was wondering if you can give this column a DEFAULT value of false,
because then perhaps most of the patch code from worker.c may be able
to be eliminated.
======
4.10 .../subscription/t/032_streaming_apply.pl
I felt that the test cases all seem to blend together. IMO it will be
more readable if the main text parts are visually separated
e.g using a comment like:
# =================================================
------
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"shiy.fnst@fujitsu.com"
Date:
On Tue, Jun 28, 2022 11:22 AM Wang, Wei/王 威 <wangw.fnst@fujitsu.com> wrote:
>
> I also improved patches as suggested by Peter-san in [1] and [2].
> Thanks for Shi Yu to improve the patches by addressing the comments in [2].
>
> Attach the new patches.
>
Thanks for updating the patch.
Here are some comments.
0001 patch
==============
1.
+ /* Check If there are free worker slot(s) */
+ LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
I think "Check If" should be "Check if".
0003 patch
==============
1.
Should we call apply_bgworker_relation_check() in apply_handle_truncate()?
0004 patch
==============
1.
@@ -3932,6 +3958,9 @@ start_apply(XLogRecPtr origin_startpos)
}
PG_CATCH();
{
+ /* Set the flag that we will retry later. */
+ set_subscription_retry(true);
+
if (MySubscription->disableonerr)
DisableSubscriptionAndExit();
Else
I think we need to emit the error and recover from the error state before
setting the retry flag, like what we do in DisableSubscriptionAndExit().
Otherwise if an error is detected when setting the retry flag, we won't get the
error message reported by the apply worker.
Regards,
Shi yu
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Fri, Jul 1, 2022 at 14:43 PM Peter Smith <smithpb2250@gmail.com> wrote:
> Below are some review comments for patches v14-0001, and v14-0002:
Thanks for your comments.
> 1.10 .../replication/logical/applybgworker.c - apply_bgworker_find
>
> + /*
> + * Find entry for requested transaction.
> + */
> + entry = hash_search(ApplyWorkersHash, &xid, HASH_FIND, &found);
> + if (found)
> + {
> + entry->wstate->pstate->status = APPLY_BGWORKER_BUSY;
> + return entry->wstate;
> + }
> + else
> + return NULL;
> +}
>
> IMO it is an unexpected side-effect for the function called "find" to
> be also modifying the thing that it found. IMO this setting BUSY
> should either be done by the caller, or else this function name should
> be renamed to make it obvious that this is doing more than just
> "finding" something.
Since we set the state to BUSY in the function apply_bgworker_start and the
state is not modified (set to FINISHED) until the transaction completes, I
think we do not need to set this state to BUSY again in the function
apply_bgworker_find during applying the transaction.
So I removed it and invoked function Assert.
I also invoked function Assert in function apply_bgworker_start.
> 1.16. src/backend/replication/logical/launcher.c - logicalrep_worker_launch
>
> + bool is_subworker = (subworker_dsm != DSM_HANDLE_INVALID);
> +
> + /* We don't support table sync in subworker */
> + Assert(!(is_subworker && OidIsValid(relid)));
>
> I'm not sure the comment is good. It sounds like it is something that
> might be possible but is just current "not supported". In fact, I
> thought this is really just a sanity check because the combination of
> those params is just plain wrong isn't it? Maybe a better comment is
> just:
> /* Sanity check */
Improved this comment as following:
```
/* Sanity check : we don't support table sync in subworker. */
```
> 1.22 src/backend/replication/logical/worker.c - skip_xact_finish_lsn
>
> /*
> * We enable skipping all data modification changes (INSERT, UPDATE, etc.) for
> * the subscription if the remote transaction's finish LSN matches
> the subskiplsn.
> * Once we start skipping changes, we don't stop it until we skip all
> changes of
> * the transaction even if pg_subscription is updated and
> MySubscription->skiplsn
> - * gets changed or reset during that. Also, in streaming transaction cases, we
> - * don't skip receiving and spooling the changes since we decide whether or not
> + * gets changed or reset during that. Also, in streaming transaction
> cases (streaming = on),
> + * we don't skip receiving and spooling the changes since we decide
> whether or not
> * to skip applying the changes when starting to apply changes. The
> subskiplsn is
> * cleared after successfully skipping the transaction or applying non-empty
> * transaction. The latter prevents the mistakenly specified subskiplsn from
> - * being left.
> + * being left. Note that we cannot skip the streaming transaction in parallel
> + * mode, because we cannot get the finish LSN before applying the changes.
> */
>
> "in parallel mode, because" -> "in 'streaming = parallel' mode, because"
Not sure about this.
> 1.28 src/backend/replication/logical/worker.c - apply_handle_stream_prepare
>
> + if (wstate)
> + {
> + apply_bgworker_send_data(wstate, s->len, s->data);
> +
> + /*
> + * Wait for apply background worker to finish. This is required to
> + * maintain commit order which avoids failures due to transaction
> + * dependencies and deadlocks.
> + */
> + apply_bgworker_wait_for(wstate, APPLY_BGWORKER_FINISHED);
> + apply_bgworker_free(wstate);
>
> I think maybe the comment can be changed slightly, and then it can
> move up one line to the top of this code block (above the 3
> statements). I think it will become more readable.
>
> SUGGESTION
> After sending the data to the apply background worker, wait for that
> worker to finish. This is necessary to maintain commit order which
> avoids failures due to transaction dependencies and deadlocks.
I think it might be better to add a new comment before invoking function
apply_bgworker_send_data. Improve the comments as you suggested.
I improved this point in function apply_handle_stream_prepare,
apply_handle_stream_abort and apply_handle_stream_commit. What do you think
about changing it like this:
```
/* Send STREAM PREPARE message to the apply background worker. */
apply_bgworker_send_data(wstate, s->len, s->data);
/*
* After sending the data to the apply background worker, wait for
* that worker to finish. This is necessary to maintain commit
* order which avoids failures due to transaction dependencies and
* deadlocks.
*/
apply_bgworker_wait_for(wstate, APPLY_BGWORKER_FINISHED);
```
> 1.34 src/backend/replication/logical/worker.c - apply_dispatch
>
> -
> /*
> * Logical replication protocol message dispatcher.
> */
> -static void
> +void
> apply_dispatch(StringInfo s)
>
> Maybe removing the whitespace is not really needed as part of this patch?
Yes, this change is not necessary for this patch.
But since this change does not involve the modification of comments and actual
code, it just adjusts the blank line between the function modified by this
patch and the previous function, so I think it is okay in this patch.
> 2.1 Commit message
>
> Change all TAP tests using the SUBSCRIPTION "streaming" option, so they
> now test both 'on' and 'parallel' values.
>
> "option" -> "parameter"
Sorry I missed this point when I was merging the patches. I merged this change
in v15.
Attach the new patches.
Also improved the patches as suggested in [1], [2] and [3].
[1] - https://www.postgresql.org/message-id/CAA4eK1KgovaRcbSuzzWki1HVso6oLAdZ2aPr1nWxX1x%3DVDBQJg%40mail.gmail.com
[2] - https://www.postgresql.org/message-id/CAHut%2BPtRNAOwFtBp_TnDWdC7UpcTxPJzQnrm%3DNytN7cVBt5zRQ%40mail.gmail.com
[3] - https://www.postgresql.org/message-id/CAHut%2BPvrw%2BtgCEYGxv%2BnKrqg-zbJdYEXee6o4irPAsYoXcuUcw%40mail.gmail.com
Regards,
Wang wei
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Fri, Jul 1, 2022 at 17:44 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > Thanks for your comments. > On Fri, Jul 1, 2022 at 12:13 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > ====== > > > > 1.2 doc/src/sgml/protocol.sgml - Protocol constants > > > > Previously I wrote that since there are protocol changes here, > > shouldn’t there also be some corresponding LOGICALREP_PROTO_XXX > > constants and special checking added in the worker.c? > > > > But you said [1 comment #6] you think it is OK because... > > > > IMO, I still disagree with the reply. The fact is that the protocol > > *has* been changed, so IIUC that is precisely the reason for having > > those protocol constants. > > > > e.g I am guessing you might assign the new one somewhere here: > > -- > > server_version = walrcv_server_version(LogRepWorkerWalRcvConn); > > options.proto.logical.proto_version = > > server_version >= 150000 ? > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM : > > server_version >= 140000 ? > LOGICALREP_PROTO_STREAM_VERSION_NUM : > > LOGICALREP_PROTO_VERSION_NUM; > > -- > > > > And then later you would refer to this new protocol version (instead > > of the server version) when calling to the apply_handle_stream_abort > > function. > > > > ====== > > > > One point related to this that occurred to me is how it will behave if > the publisher is of version >=16 whereas the subscriber is of versions > <=15? Won't in that case publisher sends the new fields but > subscribers won't be reading those which may cause some problems. Makes sense. Fixed this point. As Peter-san suggested, I added a new protocol macro LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM. This new macro marks the version that supports apply background worker (it means we will read abort_lsn and abort_time). And the publisher sends abort_lsn and abort_time fields only if subscriber will read them. (see function logicalrep_write_stream_abort) The new patches were attached in [1]. [1] - https://www.postgresql.org/message-id/OS3PR01MB62755C6C9A75EB09F7218B589E839%40OS3PR01MB6275.jpnprd01.prod.outlook.com Regards, Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Mon, Jul 4, 2022 at 12:12 AM Peter Smith <smithpb2250@gmail.com> wrote:
> Below are some review comments for patch v14-0003:
Thanks for your comments.
> 3.1 Commit message
>
> If any of the following checks are violated, an error will be reported.
> 1. The unique columns between publisher and subscriber are difference.
> 2. There is any non-immutable function present in expression in
> subscriber's relation. Check from the following 4 items:
> a. The function in triggers;
> b. Column default value expressions and domain constraints;
> c. Constraint expressions.
> d. The foreign keys.
>
> SUGGESTION (rewording to match the docs and the code).
>
> Add some checks before using apply background worker to apply changes.
> streaming=parallel mode has two requirements:
> 1) The unique columns must be the same between publisher and subscriber
> 2) There cannot be any non-immutable functions in the subscriber-side
> replicated table. Look for functions in the following places:
> * a. Trigger functions
> * b. Column default value expressions and domain constraints
> * c. Constraint expressions
> * d. Foreign keys
>
> ======
>
> 3.2 doc/src/sgml/ref/create_subscription.sgml
>
> + To run in this mode, there are following two requirements. The first
> + is that the unique column should be the same between publisher and
> + subscriber; the second is that there should not be any non-immutable
> + function in subscriber-side replicated table.
>
> SUGGESTION
> Parallel mode has two requirements: 1) the unique columns must be the
> same between publisher and subscriber; 2) there cannot be any
> non-immutable functions in the subscriber-side replicated table.
I did not write clearly enough before. So I made some slight modifications to
the first requirement you suggested. Like this:
```
1) The unique column in the relation on the subscriber-side should also be the
unique column on the publisher-side;
```
> 3.9 src/backend/replication/logical/proto.c - logicalrep_write_attrs
>
> This big slab of new code to get the BMS looks very similar to
> RelationGetIdentityKeyBitmap. So perhaps this code should be
> encapsulated in another function like that one (in relcache.c?) and
> then just called from logicalrep_write_attrs
I think the file relcache.c should contain cache-build operations, and the code
I added doesn't have this operation. So I didn't change.
> 3.12 src/backend/replication/logical/relation.c -
> logicalrep_rel_mark_safe_in_apply_bgworker
>
> I did not really understand why you used an enum for one flag
> (volatility) but not the other one (sameunique); shouldn’t both of
> these be tri-values: unknown/yes/no?
>
> For E.g. there is a quick exit from this function if the
> FUNCTION_UNKNOWN, but there is no equivalent quick exit for the
> sameunique? It seems inconsistent.
After rethinking patch 0003, I think we only need one flag. So I merged flags
'volatility' and 'sameunique' into a new flag 'parallel'. It is a tri-state
flag. And I also made some related modifications.
> 3.14 src/backend/replication/logical/relation.c -
> logicalrep_rel_mark_safe_in_apply_bgworker
>
> There are lots of places setting FUNCTION_NONIMMUTABLE, so I think
> this code might be tidier if you just have a single return at the end
> of this function and 'goto' it.
>
> e.g.
> if (...)
> goto function_not_immutable;
>
> ...
>
> return;
>
> function_not_immutable:
> entry->volatility = FUNCTION_NONIMMUTABLE;
Personally, I do not like to use the `goto` syntax if it is not necessary,
because the `goto` syntax will forcibly change the flow of code execution.
> 3.17 src/backend/utils/cache/typcache.c
>
> +/*
> + * GetDomainConstraints --- get DomainConstraintState list of
> specified domain type
> + */
> +List *
> +GetDomainConstraints(Oid type_id)
>
> This is an unusual-looking function header comment, with the function
> name and the "---".
Not sure about this. Please refer to function lookup_rowtype_tupdesc_internal.
> 3.19
>
> @@ -31,6 +42,11 @@ typedef struct LogicalRepRelMapEntry
> Relation localrel; /* relcache entry (NULL when closed) */
> AttrMap *attrmap; /* map of local attributes to remote ones */
> bool updatable; /* Can apply updates/deletes? */
> + bool sameunique; /* Are all unique columns of the local
> + relation contained by the unique columns in
> + remote? */
>
> (This is similar to review comment 3.12)
>
> I felt it was inconsistent for this to be a boolean but for the
> 'volatility' member to be an enum. AFAIK these 2 flags are similar
> kinds – e.g. essentially tri-state flags unknown/true/false so I
> thought they should be treated the same. E.g. both enums?
Please refer to the reply to #3.12.
> 3.22 .../subscription/t/032_streaming_apply.pl
>
> 3.22.a
> +# Setup structure on publisher
>
> "structure"?
>
> 3.22.b
> +# Setup structure on subscriber
>
> "structure"?
Just refer to other subscription test.
> 3.23
>
> +# Check that a background worker starts if "streaming" option is specified as
> +# "parallel". We have to look for the DEBUG1 log messages about that, so
> +# temporarily bump up the log verbosity.
> +$node_subscriber->append_conf('postgresql.conf', "log_min_messages =
> debug1");
> +$node_subscriber->reload;
> +
> +$node_publisher->safe_psql('postgres',
> + "INSERT INTO test_tab SELECT i, md5(i::text) FROM generate_series(1,
> 5000) s(i)"
> +);
> +
> +$node_subscriber->wait_for_log(qr/\[Apply BGW #\d+\] started/, 0);
> +$node_subscriber->append_conf('postgresql.conf',
> + "log_min_messages = warning");
> +$node_subscriber->reload;
>
> I didn't really think it was necessary to bump this log level, and to
> verify that the bgworker is started, because this test is anyway going
> to ensure that the ERROR "cannot replicate relation with different
> unique index" happens, so that is already implicitly ensuring the
> bgworker was used.
Since it takes almost no time, I think a more detailed confirmation is fine.
The rest of the comments are improved as suggested.
The new patches were attached in [1].
[1] -
https://www.postgresql.org/message-id/OS3PR01MB62755C6C9A75EB09F7218B589E839%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Mon, Jul 4, 2022 at 14:47 AM Peter Smith <smithpb2250@gmail.com> wrote:
> Below are some review comments for patch v14-0004:
Thanks for your comments.
> 4.0 General.
>
> This comment is an after-thought but as I write this mail I am
> wondering if most of this 0004 patch is even necessary at all? Instead
> of introducing a new column and all the baggage that goes with it,
> can't the same functionality be achieved just by toggling the
> streaming mode 'substream' value from 'p' (parallel) to 't' (on)
> whenever an error occurs causing a retry? Anyway, if you do change it
> this way then most of the following comments can be disregarded.
In the approach that you mentioned, after retrying, the transaction will always
be applied in "on" mode. This will change the user's setting.
That is to say, in most cases, user needs to manually reset option "streaming"
to "parallel". I think it might not be very friendly.
> 4.6 src/backend/replication/logical/worker.c
>
> 4.6.a - apply_handle_commit
>
> + /* Set the flag that we will not retry later. */
> + set_subscription_retry(false);
>
> But the comment is wrong, isn't it? Shouldn’t it just say that we are
> not *currently* retrying? And can’t this just anyway be redundant if
> only the catalog column has a DEFAULT value of false?
>
> 4.6.b - apply_handle_prepare
> Ditto
>
> 4.6.c - apply_handle_commit_prepared
> Ditto
>
> 4.6.d - apply_handle_rollback_prepared
> Ditto
>
> 4.6.e - apply_handle_stream_prepare
> Ditto
>
> 4.6.f - apply_handle_stream_abort
> Ditto
>
> 4.6.g - apply_handle_stream_commit
> Ditto
Set default value of the field "subretry" to "false" as you suggested.
We need to reset this field to false after retrying to apply a streaming
transaction in main apply worker ("on" mode).
I think this comment is not clear. So I change it to
```
Reset the retry flag.
```
> 4.7 src/backend/replication/logical/worker.c
>
> 4.7.a - start_table_sync
>
> @@ -3894,6 +3917,9 @@ start_table_sync(XLogRecPtr *origin_startpos,
> char **myslotname)
> }
> PG_CATCH();
> {
> + /* Set the flag that we will retry later. */
> + set_subscription_retry(true);
>
> Maybe this should say more like "Flag that the next apply will be the
> result of a retry"
>
> 4.7.b - start_apply
> Ditto
Similar to the reply in #4.6, I changed it to `Set the retry flag.`.
> 4.8 src/backend/replication/logical/worker.c - set_subscription_retry
>
> +
> +/*
> + * Set subretry of pg_subscription catalog.
> + *
> + * If retry is true, subscriber is about to exit with an error. Otherwise, it
> + * means that the changes was applied successfully.
> + */
> +static void
> +set_subscription_retry(bool retry)
>
> "changes" -> "change" ?
I did not make it clear before.
I modified "changes" to "transaction".
> 4.8 src/backend/replication/logical/worker.c - set_subscription_retry
>
> Isn't this flag only every used when streaming=parallel? But it does
> not seem ot be checking that anywhere before potentiall executing all
> this code when maybe will never be used.
Yes, currently this field is only checked by apply background worker.
> 4.9 src/include/catalog/pg_subscription.h
>
> @@ -76,6 +76,8 @@ CATALOG(pg_subscription,6100,SubscriptionRelationId)
> BKI_SHARED_RELATION BKI_ROW
> bool subdisableonerr; /* True if a worker error should cause the
> * subscription to be disabled */
>
> + bool subretry; /* True if the previous apply change failed. */
>
> I was wondering if you can give this column a DEFAULT value of false,
> because then perhaps most of the patch code from worker.c may be able
> to be eliminated.
Please refer to the reply to #4.6.
The rest of the comments are improved as suggested.
The new patches were attached in [1].
[1] -
https://www.postgresql.org/message-id/OS3PR01MB62755C6C9A75EB09F7218B589E839%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Fri, Jul 7, 2022 at 11:44 AM I wrote: > Attach the new patches. I found a failure on CFbot [1], which after investigation I think is due to my previous modification (see response to #1.10 in [2]). For a streaming transaction, if we failed in the first chunk of streamed changes for this transaction in the apply background worker, we will set the status of this apply background worker to APPLY_BGWORKER_EXIT. And at the same time, main apply worker obtains apply background worker in the function apply_bgworker_find when processing the second chunk of streamed changes for this transaction, the status of apply background worker is APPLY_BGWORKER_EXIT. So the following assertion will fail: ``` Assert(status == APPLY_BGWORKER_BUSY); ``` To fix this, before invoking function assert, I try to detect the failure of apply background worker. If the status is APPLY_BGWORKER_EXIT, then exit with an error. I also made some other small improvements. Attach the new patches. [1] - https://cirrus-ci.com/task/6383178511286272?logs=test_world#L2636 [2] - https://www.postgresql.org/message-id/OS3PR01MB62755C6C9A75EB09F7218B589E839%40OS3PR01MB6275.jpnprd01.prod.outlook.com Regards, Wang wei
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Below are my review comments for the v16* patch set:
========
v16-0001
========
1.0 <general>
There are places (comments, docs, errmsgs, etc) in the patch referring
to "parallel mode". I think every one of those references should be
found and renamed to "parallel streaming mode" or "streaming=parallel"
or at the very least match sure that "streaming" is in the same
sentence. IMO it's too vague just saying "parallel" without also
saying the context is for the "streaming" parameter.
I have commented on some of those examples below, but please search
everything anyway (including the docs) to catch the ones I haven't
explicitly mentioned.
======
1.1 src/backend/commands/subscriptioncmds.c
+defGetStreamingMode(DefElem *def)
+{
+ /*
+ * If no value given, assume "true" is meant.
+ */
Please fix this comment to identical to this pushed patch [1]
======
1.2 .../replication/logical/applybgworker.c - apply_bgworker_start
+ if (list_length(ApplyWorkersFreeList) > 0)
+ {
+ wstate = (ApplyBgworkerState *) llast(ApplyWorkersFreeList);
+ ApplyWorkersFreeList = list_delete_last(ApplyWorkersFreeList);
+ Assert(wstate->pstate->status == APPLY_BGWORKER_FINISHED);
+ }
The Assert that the entries in the free-list are FINISHED seems like
unnecessary checking. IIUC, code is already doing the Assert that
entries are FINISHED before allowing them into the free-list in the
first place.
~~~
1.3 .../replication/logical/applybgworker.c - apply_bgworker_find
+ if (found)
+ {
+ char status = entry->wstate->pstate->status;
+
+ /* If any workers (or the postmaster) have died, we have failed. */
+ if (status == APPLY_BGWORKER_EXIT)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("background worker %u failed to apply transaction %u",
+ entry->wstate->pstate->n,
+ entry->wstate->pstate->stream_xid)));
+
+ Assert(status == APPLY_BGWORKER_BUSY);
+
+ return entry->wstate;
+ }
Why not remove that Assert but change the condition to be:
if (status != APPLY_BGWORKER_BUSY)
ereport(...)
======
1.4 src/backend/replication/logical/proto.c - logicalrep_write_stream_abort
@@ -1163,31 +1163,56 @@ logicalrep_read_stream_commit(StringInfo in,
LogicalRepCommitData *commit_data)
/*
* Write STREAM ABORT to the output stream. Note that xid and subxid will be
* same for the top-level transaction abort.
+ *
+ * If write_abort_lsn is true, send the abort_lsn and abort_time fields.
+ * Otherwise not.
*/
"Otherwise not." -> ", otherwise don't."
~~~
1.5 src/backend/replication/logical/proto.c - logicalrep_read_stream_abort
+ *
+ * If read_abort_lsn is true, try to read the abort_lsn and abort_time fields.
+ * Otherwise not.
*/
void
-logicalrep_read_stream_abort(StringInfo in, TransactionId *xid,
- TransactionId *subxid)
+logicalrep_read_stream_abort(StringInfo in,
+ LogicalRepStreamAbortData *abort_data,
+ bool read_abort_lsn)
"Otherwise not." -> ", otherwise don't."
======
1.6 src/backend/replication/logical/worker.c - file comment
+ * If streaming = parallel, We assign a new apply background worker (if
+ * available) as soon as the xact's first stream is received. The main apply
"We" -> "we" ... or maybe better just remove it completely.
~~~
1.7 src/backend/replication/logical/worker.c - apply_handle_stream_prepare
+ /*
+ * After sending the data to the apply background worker, wait for
+ * that worker to finish. This is necessary to maintain commit
+ * order which avoids failures due to transaction dependencies and
+ * deadlocks.
+ */
+ apply_bgworker_send_data(wstate, s->len, s->data);
+ apply_bgworker_wait_for(wstate, APPLY_BGWORKER_FINISHED);
+ apply_bgworker_free(wstate);
The comment should be changed how you had suggested [2], so that it
will be formatted the same way as a couple of other similar comments.
~~~
1.8 src/backend/replication/logical/worker.c - apply_handle_stream_abort
+ /* Check whether the publisher sends abort_lsn and abort_time. */
+ if (am_apply_bgworker())
+ read_abort_lsn = MyParallelState->server_version >= 160000;
This is handling decisions about read/write of the protocol bytes. I
think feel like it will be better to be checking the server *protocol*
version (not the server postgres version) to make this decision – e.g.
this code should be using the new macro you introduced so it will end
up looking much like how the pgoutput_stream_abort code is doing it.
~~~
1.9 src/backend/replication/logical/worker.c - store_flush_position
@@ -2636,6 +2999,10 @@ store_flush_position(XLogRecPtr remote_lsn)
{
FlushPosition *flushpos;
+ /* We only need to collect the LSN in main apply worker */
+ if (am_apply_bgworker())
+ return;
+
SUGGESTION
/* Skip if not the main apply worker */
======
1.10 src/backend/replication/pgoutput/pgoutput.c
@@ -1820,6 +1820,8 @@ pgoutput_stream_abort(struct LogicalDecodingContext *ctx,
XLogRecPtr abort_lsn)
{
ReorderBufferTXN *toptxn;
+ bool write_abort_lsn = false;
+ PGOutputData *data = (PGOutputData *) ctx->output_plugin_private;
/*
* The abort should happen outside streaming block, even for streamed
@@ -1832,8 +1834,13 @@ pgoutput_stream_abort(struct LogicalDecodingContext *ctx,
Assert(rbtxn_is_streamed(toptxn));
+ /* We only send abort_lsn and abort_time if the subscriber needs them. */
+ if (data->protocol_version >= LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM)
+ write_abort_lsn = true;
+
IMO it's simpler to remove the declaration default assignment, and
instead this code can be written as:
write_abort_lsn = data->protocol_version >=
LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM;
======
1.11 src/include/replication/logicalproto.h
+ *
+ * LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM is the minimum protocol version
+ * with support for streaming large transactions in apply background worker.
+ * Introduced in PG16.
"in apply background worker" -> "using apply background workers"
~~~
1.12
+extern void logicalrep_read_stream_abort(StringInfo in,
+ LogicalRepStreamAbortData *abort_data,
+ bool include_abort_lsn);
I think the "include_abort_lsn" is now renamed to "include_abort_lsn".
========
v16-0002
========
No comments.
========
v16-0003
========
3.0 <general>
Same comment about "parallel mode" as in comment #1.0
======
3.1 doc/src/sgml/ref/create_subscription.sgml
+ the publisher-side; 2) there cannot be any non-immutable functions
+ in the subscriber-side replicated table.
The functions are not table data so maybe it's better to say
"functions in the ..." -> "functions used by the ...". If you change
this then there are equivalent comments and commit messages that
should change to match it.
======
3.2 .../replication/logical/applybgworker.c - apply_bgworker_relation_check
+ ereport(ERROR,
+ (errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
+ errmsg("cannot replicate target relation \"%s.%s\" in parallel "
+ "mode", rel->remoterel.nspname, rel->remoterel.relname),
+ errdetail("The unique column on subscriber is not the unique "
+ "column on publisher or there is at least one "
+ "non-immutable function."),
+ errhint("Please change the streaming option to 'on' instead of
'parallel'.")));
3.2a
SUGGESTED errmsg
"cannot replicate target relation \"%s.%s\" using subscription
parameter streaming=parallel"
3.2b
SUGGESTED errhint
"Please change to use subscription parameter streaming=on"
3.3
The errcode seems the wrong one. Perhaps it should be
ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE.
======
3.4 src/backend/replication/logical/proto.c - logicalrep_write_attrs
In [3] you wrote:
I think the file relcache.c should contain cache-build operations, and the code
I added doesn't have this operation. So I didn't change.
But I only gave relcache.c as an example. It can also be a new static
function in this same file, but anyway I still think this big slab of
code might be better if not done inline in logicalrep_write_attrs.
~~~
3.5 src/backend/replication/logical/proto.c - logicalrep_read_attrs
@@ -1012,11 +1062,14 @@ logicalrep_read_attrs(StringInfo in,
LogicalRepRelation *rel)
{
uint8 flags;
- /* Check for replica identity column */
+ /* Check for replica identity and unique column */
flags = pq_getmsgbyte(in);
- if (flags & LOGICALREP_IS_REPLICA_IDENTITY)
+ if (flags & ATTR_IS_REPLICA_IDENTITY)
attkeys = bms_add_member(attkeys, i);
+ if (flags & ATTR_IS_UNIQUE)
+ attunique = bms_add_member(attunique, i);
The code comment really applies to all 3 statements so maybe better
not to have the blank line here.
======
3.6 src/backend/replication/logical/relation.c - logicalrep_rel_mark_parallel
3.6.a
+ /* Fast path if we marked 'parallel' flag. */
+ if (entry->parallel != PARALLEL_APPLY_UNKNOWN)
+ return;
SUGGESTED
Fast path if 'parallel' flag is already known.
~
3.6.b
+ /* Initialize the flag. */
+ entry->parallel = PARALLEL_APPLY_SAFE;
I think it makes more sense if assigning SAFE is the very *last* thing
this function does – not the first thing.
~
3.6.c
+ /*
+ * First, we check if the unique column in the relation on the
+ * subscriber-side is also the unique column on the publisher-side.
+ */
"First, we check..." -> "First, check..."
~
3.6.d
+ /*
+ * Then, We check if there is any non-immutable function in the local
+ * table. Look for functions in the following places:
"Then, We check..." -> "Then, check"
~~~
3.7 src/backend/replication/logical/relation.c - logicalrep_rel_mark_parallel
From [3] you wrote:
Personally, I do not like to use the `goto` syntax if it is not necessary,
because the `goto` syntax will forcibly change the flow of code execution.
Yes, but OTOH readability is a major consideration too, and in this
function by simply saying goto parallel_unsafe; you can have 3 returns
instead of 7 returns, and it will take ~10 lines less code to do the
same functionality.
======
3.8 src/include/replication/logicalrelation.h
+/*
+ * States to determine if changes on one relation can be applied by an apply
+ * background worker.
+ */
+typedef enum RelParallel
+{
+ PARALLEL_APPLY_UNKNOWN = 0, /* unknown */
+ PARALLEL_APPLY_SAFE, /* Can apply changes in an apply background
+ worker */
+ PARALLEL_APPLY_UNSAFE /* Can not apply changes in an apply background
+ worker */
+} RelParallel;
3.8a
"can be applied by an apply background worker." -> "can be applied
using an apply background worker."
~
3.8b
The enum is described, and IMO the enum values are self-explanatory
now. So commenting them individually is not adding any useful
information. I think those comments can be removed.
~
3.8c
The RelParallel name does not have much meaning to it - there is
nothing really about that name that says it is related to validation
states. Maybe "ParallelSafety" or "ParalleApplySafety" or something
similar?
~~~
3.9 src/include/replication/logicalrelation.h
+ RelParallel parallel; /* Can apply changes in an apply
+ background worker? */
This comment is like #3.8c.
IMO the member name 'parallel' doesn't really have enough meaning.
What about something like 'parallel_apply', or 'parallel_ok', or
'parallel_safe', or something similar.
======
3.10 .../subscription/t/032_streaming_apply.pl
In [3] you wrote:
Since it takes almost no time, I think a more detailed confirmation is fine.
Yes, but I think a confirmation is a confirmation regardless - the
test will either pass/fail and this additional code won't change the
result. e.g. Maybe the extra code does not hurt much, but AFAIK having
a "detailed confirmation" doesn't really achieve anything useful
either. I previously suggested to removed it simply because it means
less test code to maintain.
========
v16-0004
========
4.0 <general>
Same comment about "parallel mode" as in comment #1.0
======
4.1 Commit message
If the user sets the subscription_parameter "streaming" to "parallel", when
applying a streaming transaction, we will try to apply this transaction in
apply background worker. However, when the changes in this transaction cannot
be applied in apply background worker, the background worker will exit with an
error. In this case, we can retry applying this streaming transaction in "on"
mode. In this way, we may avoid blocking logical replication here.
So we introduce field "subretry" in catalog "pg_subscription". When the
subscriber exit with an error, we will try to set this flag to true, and when
the transaction is applied successfully, we will try to set this flag to false.
Then when we try to apply a streaming transaction in apply background worker,
we can see if this transaction has failed before based on the "subretry" field.
~
I reworded above to remove most of the "we" this and "we" that...
SUGGESTION
When the subscription parameter is set streaming=parallel, the logic
tries to apply the streaming transaction using an apply background
worker. If this fails the background worker exits with an error.
In this case, retry applying the streaming transaction using the
normal streaming=on mode. This is done to avoid getting caught in a
loop of the same retry errors.
A new flag field "subretry" has been introduced to catalog
"pg_subscription". If the subscriber exits with an error, this flag
will be set true, and whenever the transaction is applied
successfully, this flag is reset false. Now, when deciding how to
apply a streaming transaction, the logic can know if this transaction
has previously failed or not (by checking the "subretry" field).
======
4.2 doc/src/sgml/catalogs.sgml
+ <para>
+ True if the previous apply change failed and a retry was required.
+ </para></entry>
"was" required? "will be required"? It is a bit vague what tense to use...
SUGGESTION 1
True if the previous apply change failed, necessitating a retry
SUGGESTION 2
True if the previous apply change failed
======
4.3 doc/src/sgml/ref/create_subscription.sgml
+ <literal>parallel</literal> mode is disregarded when retrying;
+ instead the transaction will be applied using <literal>on</literal>
+ mode.
"on mode" etc sounds strange.
SUGGESTION
During the retry the streaming=parallel mode is ignored. The retried
transaction will be applied using streaming=on mode.
======
4.4 src/backend/replication/logical/worker.c - set_subscription_retry
+ if (MySubscription->retry == retry ||
+ am_apply_bgworker())
+ return;
+
Somehow I feel that this quick exit condition is not quite what it
seems. IIUC the purpose of this is really to avoid doing the tuple
updates if it is not necessary to do them. So if retry was already set
true then there is no need to update tuple to true again. So if retry
was already set false then there is no need to update the tuple to
false. But I just don't see how the (hypothetical) code below can work
as expected, because where is the code updating the value of
MySubscription->retry ???
set_subscription_retry(true);
set_subscription_retry(true);
I think at least there needs to be some detailed comments explaining
what this quick exit is really doing because my guess is that
currently it is not quite working as expected.
~~~
4.5
+ /* reset subretry */
Uppercase comment
------
[1] https://github.com/postgres/postgres/commit/8445f5a21d40b969673ca03918c74b4fbc882bf4
[2]
https://www.postgresql.org/message-id/OS3PR01MB62755C6C9A75EB09F7218B589E839%40OS3PR01MB6275.jpnprd01.prod.outlook.com
[3]
https://www.postgresql.org/message-id/OS3PR01MB6275120502A4730AB9932FCA9E839%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Fri, Jul 7, 2022 at 11:32 AM Shi, Yu/侍 雨 <shiy.fnst@cn.fujitsu.com> wrote:
> Thanks for updating the patch.
>
> Here are some comments.
Thanks for your comments.
> 0001 patch
> ==============
> 1.
> + /* Check If there are free worker slot(s) */
> + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
>
> I think "Check If" should be "Check if".
Fixed.
> 0003 patch
> ==============
> 1.
> Should we call apply_bgworker_relation_check() in apply_handle_truncate()?
Because TRUNCATE blocks all other operations on the table, I think that when
two transactions on the publisher-side operate on the same table, at least one
of them will be blocked. So I think for this case the blocking will happen on
the publisher-side.
> 0004 patch
> ==============
> 1.
> @@ -3932,6 +3958,9 @@ start_apply(XLogRecPtr origin_startpos)
> }
> PG_CATCH();
> {
> + /* Set the flag that we will retry later. */
> + set_subscription_retry(true);
> +
> if (MySubscription->disableonerr)
> DisableSubscriptionAndExit();
> Else
>
> I think we need to emit the error and recover from the error state before
> setting the retry flag, like what we do in DisableSubscriptionAndExit().
> Otherwise if an error is detected when setting the retry flag, we won't get the
> error message reported by the apply worker.
You are right.
I fixed this point as you suggested. (I moved the operations you mentioned from
the function DisableSubscriptionAndExit to before setting the retry flag.)
I also made a similar modification in the function start_table_sync.
Attach the news patches.
Regards,
Wang wei
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Wed, Jul 13, 2022 at 13:49 PM Peter Smith <smithpb2250@gmail.com> wrote:
> Below are my review comments for the v16* patch set:
Thanks for your comments.
> ========
> v16-0001
> ========
>
> 1.0 <general>
>
> There are places (comments, docs, errmsgs, etc) in the patch referring
> to "parallel mode". I think every one of those references should be
> found and renamed to "parallel streaming mode" or "streaming=parallel"
> or at the very least match sure that "streaming" is in the same
> sentence. IMO it's too vague just saying "parallel" without also
> saying the context is for the "streaming" parameter.
>
> I have commented on some of those examples below, but please search
> everything anyway (including the docs) to catch the ones I haven't
> explicitly mentioned.
I checked all places in the patch where the word "parallel" is used (case
insensitive), and I think it is clear that the description is related to stream
transactions. So I am not so sure. Could you please give me some examples? I
will improve them later.
> 1.2 .../replication/logical/applybgworker.c - apply_bgworker_start
>
> + if (list_length(ApplyWorkersFreeList) > 0)
> + {
> + wstate = (ApplyBgworkerState *) llast(ApplyWorkersFreeList);
> + ApplyWorkersFreeList = list_delete_last(ApplyWorkersFreeList);
> + Assert(wstate->pstate->status == APPLY_BGWORKER_FINISHED);
> + }
>
> The Assert that the entries in the free-list are FINISHED seems like
> unnecessary checking. IIUC, code is already doing the Assert that
> entries are FINISHED before allowing them into the free-list in the
> first place.
Just for robustness.
> 1.3 .../replication/logical/applybgworker.c - apply_bgworker_find
>
> + if (found)
> + {
> + char status = entry->wstate->pstate->status;
> +
> + /* If any workers (or the postmaster) have died, we have failed. */
> + if (status == APPLY_BGWORKER_EXIT)
> + ereport(ERROR,
> + (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("background worker %u failed to apply transaction %u",
> + entry->wstate->pstate->n,
> + entry->wstate->pstate->stream_xid)));
> +
> + Assert(status == APPLY_BGWORKER_BUSY);
> +
> + return entry->wstate;
> + }
>
> Why not remove that Assert but change the condition to be:
>
> if (status != APPLY_BGWORKER_BUSY)
> ereport(...)
When I check "APPLY_BGWORKER_EXIT", I use the function "ereport" to report the
error, because "APPLY_BGWORKER_EXIT" is a possible use case.
But for "APPLY_BGWORKER_BUSY", this use case should not happen here. So I think
it's fine to only check this for developers when the compile option
"--enable-cassert" is specified.
> ========
> v16-0003
> ========
>
> 3.0 <general>
>
> Same comment about "parallel mode" as in comment #1.0
>
> ======
Please refer to the reply to #1.0.
> 3.5 src/backend/replication/logical/proto.c - logicalrep_read_attrs
>
> @@ -1012,11 +1062,14 @@ logicalrep_read_attrs(StringInfo in,
> LogicalRepRelation *rel)
> {
> uint8 flags;
>
> - /* Check for replica identity column */
> + /* Check for replica identity and unique column */
> flags = pq_getmsgbyte(in);
> - if (flags & LOGICALREP_IS_REPLICA_IDENTITY)
> + if (flags & ATTR_IS_REPLICA_IDENTITY)
> attkeys = bms_add_member(attkeys, i);
>
> + if (flags & ATTR_IS_UNIQUE)
> + attunique = bms_add_member(attunique, i);
>
> The code comment really applies to all 3 statements so maybe better
> not to have the blank line here.
I think it looks a bit messy without the blank line.
So I tried to improve it to the following:
```
/* Check for replica identity column */
flags = pq_getmsgbyte(in);
if (flags & ATTR_IS_REPLICA_IDENTITY)
attkeys = bms_add_member(attkeys, i);
/* Check for unique column */
if (flags & ATTR_IS_UNIQUE)
attunique = bms_add_member(attunique, i);
```
> 3.6 src/backend/replication/logical/relation.c - logicalrep_rel_mark_parallel
>
> 3.6.a
> + /* Fast path if we marked 'parallel' flag. */
> + if (entry->parallel != PARALLEL_APPLY_UNKNOWN)
> + return;
>
> SUGGESTED
> Fast path if 'parallel' flag is already known.
>
> ~
>
> 3.6.b
> + /* Initialize the flag. */
> + entry->parallel = PARALLEL_APPLY_SAFE;
>
> I think it makes more sense if assigning SAFE is the very *last* thing
> this function does – not the first thing.
>
> ~
>
> 3.6.c
> + /*
> + * First, we check if the unique column in the relation on the
> + * subscriber-side is also the unique column on the publisher-side.
> + */
>
> "First, we check..." -> "First, check..."
>
> ~
>
> 3.6.d
> + /*
> + * Then, We check if there is any non-immutable function in the local
> + * table. Look for functions in the following places:
>
>
> "Then, We check..." -> "Then, check"
=>3.6.a
=>3.6.c
=>3.6.d
Improved as suggested.
=>3.6.b
Not sure about this.
> 3.7 src/backend/replication/logical/relation.c - logicalrep_rel_mark_parallel
>
> From [3] you wrote:
> Personally, I do not like to use the `goto` syntax if it is not necessary,
> because the `goto` syntax will forcibly change the flow of code execution.
>
> Yes, but OTOH readability is a major consideration too, and in this
> function by simply saying goto parallel_unsafe; you can have 3 returns
> instead of 7 returns, and it will take ~10 lines less code to do the
> same functionality.
I am still not sure about this, I think I will change this if some more people
think `goto` is better here.
> 4.3 doc/src/sgml/ref/create_subscription.sgml
>
> + <literal>parallel</literal> mode is disregarded when retrying;
> + instead the transaction will be applied using <literal>on</literal>
> + mode.
>
> "on mode" etc sounds strange.
>
> SUGGESTION
> During the retry the streaming=parallel mode is ignored. The retried
> transaction will be applied using streaming=on mode.
Since it's part of the streaming option document. I think it's fine to directly
say "<literal>parallel</literal> mode"
> 4.4 src/backend/replication/logical/worker.c - set_subscription_retry
>
> + if (MySubscription->retry == retry ||
> + am_apply_bgworker())
> + return;
> +
>
> Somehow I feel that this quick exit condition is not quite what it
> seems. IIUC the purpose of this is really to avoid doing the tuple
> updates if it is not necessary to do them. So if retry was already set
> true then there is no need to update tuple to true again. So if retry
> was already set false then there is no need to update the tuple to
> false. But I just don't see how the (hypothetical) code below can work
> as expected, because where is the code updating the value of
> MySubscription->retry ???
>
> set_subscription_retry(true);
> set_subscription_retry(true);
>
> I think at least there needs to be some detailed comments explaining
> what this quick exit is really doing because my guess is that
> currently it is not quite working as expected.
The subscription cache is be updated in maybe_reread_subscription() and is
invoked at every transaction. And we reset the retry flag at transaction end,
so it should be fine. And I think the quick exit check code is similar to
clear_subscription_skip_lsn.
Attach the news patches.
[1] - https://www.postgresql.org/message-id/CAHut%2BPv0yWynWTmp4o34s0d98xVubys9fy%3Dp0YXsZ5_sUcNnMw%40mail.gmail.com
Regards,
Wang wei
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Tues, Jul 19, 2022 at 10:29 AM I wrote: > Attach the news patches. Not able to apply patches cleanly because the change in HEAD (366283961a). Therefore, I rebased the patch based on the changes in HEAD. Attach the new patches. Regards, Wang wei
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Jul 22, 2022 at 8:26 AM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> On Tues, Jul 19, 2022 at 10:29 AM I wrote:
> > Attach the news patches.
>
> Not able to apply patches cleanly because the change in HEAD (366283961a).
> Therefore, I rebased the patch based on the changes in HEAD.
>
> Attach the new patches.
>
Few comments on 0001:
======================
1.
- <structfield>substream</structfield> <type>bool</type>
+ <structfield>substream</structfield> <type>char</type>
</para>
<para>
- If true, the subscription will allow streaming of in-progress
- transactions
+ Controls how to handle the streaming of in-progress transactions:
+ <literal>f</literal> = disallow streaming of in-progress transactions,
+ <literal>t</literal> = spill the changes of in-progress transactions to
+ disk and apply at once after the transaction is committed on the
+ publisher,
+ <literal>p</literal> = apply changes directly using a background worker
Shouldn't the description of 'p' be something like: apply changes
directly using a background worker, if available, otherwise, it
behaves the same as 't'
2.
Note that if an error happens when
+ applying changes in a background worker, the finish LSN of the
+ remote transaction might not be reported in the server log.
Is there any case where finish LSN can be reported when applying via
background worker, if not, then we should use 'won't' instead of
'might not'?
3.
+#define PG_LOGICAL_APPLY_SHM_MAGIC 0x79fb2447 // TODO Consider change
It is better to change this as the same magic number is used by
PG_TEST_SHM_MQ_MAGIC
4.
+ /* Ignore statistics fields that have been updated. */
+ s.cursor += IGNORE_SIZE_IN_MESSAGE;
Can we change the comment to: "Ignore statistics fields that have been
updated by the main apply worker."? Will it be better to name the
define as "SIZE_STATS_MESSAGE"?
5.
+/* Apply Background Worker main loop */
+static void
+LogicalApplyBgwLoop(shm_mq_handle *mqh, volatile ApplyBgworkerShared *shared)
{
...
...
+ apply_dispatch(&s);
+
+ if (ConfigReloadPending)
+ {
+ ConfigReloadPending = false;
+ ProcessConfigFile(PGC_SIGHUP);
+ }
+
+ MemoryContextSwitchTo(oldctx);
+ MemoryContextReset(ApplyMessageContext);
We should not process the config file under ApplyMessageContext. You
should switch context before processing the config file. See other
similar usages in the code.
6.
+/* Apply Background Worker main loop */
+static void
+LogicalApplyBgwLoop(shm_mq_handle *mqh, volatile ApplyBgworkerShared *shared)
{
...
...
+ MemoryContextSwitchTo(oldctx);
+ MemoryContextReset(ApplyMessageContext);
+ }
+
+ MemoryContextSwitchTo(TopMemoryContext);
+ MemoryContextReset(ApplyContext);
...
}
I don't see the need to reset ApplyContext here as we don't do
anything in that context here.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Fri, Jul 22, 2022 at 8:27 AM wangw.fnst@fujitsu.com <wangw.fnst@fujitsu.com> wrote: > > On Tues, Jul 19, 2022 at 10:29 AM I wrote: > > Attach the news patches. > > Not able to apply patches cleanly because the change in HEAD (366283961a). > Therefore, I rebased the patch based on the changes in HEAD. > > Attach the new patches. + /* Check the foreign keys. */ + fkeys = RelationGetFKeyList(entry->localrel); + if (fkeys) + entry->parallel_apply = PARALLEL_APPLY_UNSAFE; So if there is a foreign key on any of the tables which are parts of a subscription then we do not allow changes for that subscription to be applied in parallel? I think this is a big limitation because having foreign key on the table is very normal right? I agree that if we allow them then there could be failure due to out of order apply right? but IMHO we should not put the restriction instead let it fail if there is ever such conflict. Because if there is a conflict the transaction will be sent again. Do we see that there could be wrong or inconsistent results if we allow such things to be executed in parallel. If not then IMHO just to avoid some corner case failure we are restricting very normal cases. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Tue, Jul 26, 2022 at 2:30 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Fri, Jul 22, 2022 at 8:27 AM wangw.fnst@fujitsu.com > <wangw.fnst@fujitsu.com> wrote: > > > > On Tues, Jul 19, 2022 at 10:29 AM I wrote: > > > Attach the news patches. > > > > Not able to apply patches cleanly because the change in HEAD (366283961a). > > Therefore, I rebased the patch based on the changes in HEAD. > > > > Attach the new patches. > > + /* Check the foreign keys. */ > + fkeys = RelationGetFKeyList(entry->localrel); > + if (fkeys) > + entry->parallel_apply = PARALLEL_APPLY_UNSAFE; > > So if there is a foreign key on any of the tables which are parts of a > subscription then we do not allow changes for that subscription to be > applied in parallel? I think this is a big limitation because having > foreign key on the table is very normal right? I agree that if we > allow them then there could be failure due to out of order apply > right? but IMHO we should not put the restriction instead let it fail > if there is ever such conflict. Because if there is a conflict the > transaction will be sent again. Do we see that there could be wrong > or inconsistent results if we allow such things to be executed in > parallel. If not then IMHO just to avoid some corner case failure we > are restricting very normal cases. some more comments.. 1. + /* + * If we have found a free worker or if we are already applying this + * transaction in an apply background worker, then we pass the data to + * that worker. + */ + if (first_segment) + apply_bgworker_send_data(stream_apply_worker, s->len, s->data); Comment says that if we have found a free worker or we are already applying in the worker then pass the changes to the worker but actually as per the code here we are only passing in case of first_segment? I think what you are trying to say is that if it is first segment then send the 2. + /* + * This is the main apply worker. Check if there is any free apply + * background worker we can use to process this transaction. + */ + if (first_segment) + stream_apply_worker = apply_bgworker_start(stream_xid); + else + stream_apply_worker = apply_bgworker_find(stream_xid); So currently, whenever we get a new streamed transaction we try to start a new background worker for that. Why do we need to start/close the background apply worker every time we get a new streamed transaction. I mean we can keep the worker in the pool for time being and if there is a new transaction looking for a worker then we can find from that. Starting a worker is costly operation and since we are using parallelism for this mean we are expecting that there would be frequent streamed transaction needing parallel apply worker so why not to let it wait for a certain amount of time so that if load is low it will anyway stop and if the load is high it will be reused for next streamed transaction. 3. Why are we restricting parallel apply workers only for the streamed transactions, because streaming depends upon the size of the logical decoding work mem so making steaming and parallel apply tightly coupled seems too restrictive to me. Do we see some obvious problems in applying other transactions in parallel? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comment for patch v19-0001:
======
1.1 Missing docs for protocol version
Since you bumped the logical replication protocol version for this
patch, now there is some missing documentation to describe this new
protocol version. e.g. See here [1]
======
1.2 doc/src/sgml/config.sgml
+ <para>
+ Maximum number of apply background workers per subscription. This
+ parameter controls the amount of parallelism of the streaming of
+ in-progress transactions when subscription parameter
+ <literal>streaming = parallel</literal>.
+ </para>
SUGGESTION
Maximum number of apply background workers per subscription. This
parameter controls the amount of parallelism for streaming of
in-progress transactions with subscription parameter
<literal>streaming = parallel</literal>.
======
1.3 src/sgml/protocol.sgml
@@ -6809,6 +6809,25 @@ psql "dbname=postgres replication=database" -c
"IDENTIFY_SYSTEM;"
</listitem>
</varlistentry>
+ <varlistentry>
+ <term>Int64 (XLogRecPtr)</term>
+ <listitem>
+ <para>
+ The LSN of the abort.
+ </para>
+ </listitem>
+ </varlistentry>
+
+ <varlistentry>
+ <term>Int64 (TimestampTz)</term>
+ <listitem>
+ <para>
+ Abort timestamp of the transaction. The value is in number
+ of microseconds since PostgreSQL epoch (2000-01-01).
+ </para>
+ </listitem>
+ </varlistentry>
There are missing notes on these new fields. They both should says
something like "This field is available since protocol version 4."
(See similar examples on the same docs page)
======
1.4 src/backend/replication/logical/applybgworker.c - apply_bgworker_start
Previously [1] I wrote:
> The Assert that the entries in the free-list are FINISHED seems like
> unnecessary checking. IIUC, code is already doing the Assert that
> entries are FINISHED before allowing them into the free-list in the
> first place.
IMO this Assert just causes unnecessary doubts, but if you really want
to keep it then I think it belongs logically *above* the
list_delete_last.
~~~
1.5 src/backend/replication/logical/applybgworker.c - apply_bgworker_start
+ server_version = walrcv_server_version(LogRepWorkerWalRcvConn);
+ wstate->shared->server_version =
+ server_version >= 160000 ? LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM :
+ server_version >= 150000 ? LOGICALREP_PROTO_TWOPHASE_VERSION_NUM :
+ server_version >= 140000 ? LOGICALREP_PROTO_STREAM_VERSION_NUM :
+ LOGICALREP_PROTO_VERSION_NUM;
It makes no sense to assign a protocol version to a server_version.
Perhaps it is just a simple matter of a poorly named struct member.
e.g Maybe everything is OK if it said something like
wstate->shared->proto_version.
~~~
1.6 src/backend/replication/logical/applybgworker.c - LogicalApplyBgwLoop
+/* Apply Background Worker main loop */
+static void
+LogicalApplyBgwLoop(shm_mq_handle *mqh, volatile ApplyBgworkerShared *shared)
'shared' seems a very vague param name. Maybe can be 'bgw_shared' or
'parallel_shared' or something better?
~~~
1.7 src/backend/replication/logical/applybgworker.c - ApplyBgworkerMain
+/*
+ * Apply Background Worker entry point
+ */
+void
+ApplyBgworkerMain(Datum main_arg)
+{
+ volatile ApplyBgworkerShared *shared;
'shared' seems a very vague var name. Maybe can be 'bgw_shared' or
'parallel_shared' or something better?
~~~
1.8 src/backend/replication/logical/applybgworker.c - apply_bgworker_setup_dsm
+static void
+apply_bgworker_setup_dsm(ApplyBgworkerState *wstate)
+{
+ shm_toc_estimator e;
+ Size segsize;
+ dsm_segment *seg;
+ shm_toc *toc;
+ ApplyBgworkerShared *shared;
+ shm_mq *mq;
'shared' seems a very vague var name. Maybe can be 'bgw_shared' or
'parallel_shared' or something better?
~~~
1.9 src/backend/replication/logical/applybgworker.c - apply_bgworker_setup_dsm
+ server_version = walrcv_server_version(LogRepWorkerWalRcvConn);
+ shared->server_version =
+ server_version >= 160000 ? LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM :
+ server_version >= 150000 ? LOGICALREP_PROTO_TWOPHASE_VERSION_NUM :
+ server_version >= 140000 ? LOGICALREP_PROTO_STREAM_VERSION_NUM :
+ LOGICALREP_PROTO_VERSION_NUM;
Same as earlier review comment #1.5
======
1.10 src/backend/replication/logical/worker.c
@@ -22,8 +22,28 @@
* STREAMED TRANSACTIONS
* ---------------------
* Streamed transactions (large transactions exceeding a memory limit on the
- * upstream) are not applied immediately, but instead, the data is written
- * to temporary files and then applied at once when the final commit arrives.
+ * upstream) are applied using one of two approaches.
+ *
+ * 1) Separate background workers
"two approaches." --> "two approaches:"
~~~
1.11 src/backend/replication/logical/worker.c - apply_handle_stream_abort
+ /* Check whether the publisher sends abort_lsn and abort_time. */
+ if (am_apply_bgworker())
+ read_abort_lsn = MyParallelShared->server_version >=
+ LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM;
IMO makes no sense to compare a server version with a protocol
version. Same as review comment #1.5
======
1.12 src/include/replication/worker_internal.h
+typedef struct ApplyBgworkerShared
+{
+ slock_t mutex;
+
+ /* Status of apply background worker. */
+ ApplyBgworkerStatus status;
+
+ /* server version of publisher. */
+ uint32 server_version;
+
+ TransactionId stream_xid;
+ uint32 n; /* id of apply background worker */
+} ApplyBgworkerShared;
AFAICT you only ever used 'server_version' for storing the *protocol*
version, so really this member should be called something like
'proto_version'. Please see earlier review comment #1.5 and others.
------
[1] https://www.postgresql.org/message-id/CAHut%2BPvN7fwtUE%3DbidzrsOUXSt%2BJpnkJztZ-Jn5t86moofaZ6g%40mail.gmail.com
[2] https://www.postgresql.org/docs/devel/protocol-logical-replication.html
Kind Reagrds,
Peter Smith.
Fujitsu Australia.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for patch v19-0003:
======
3.1 doc/src/sgml/ref/create_subscription.sgml
@@ -240,6 +240,10 @@ CREATE SUBSCRIPTION <replaceable
class="parameter">subscription_name</replaceabl
transaction is committed. Note that if an error happens when
applying changes in a background worker, the finish LSN of the
remote transaction might not be reported in the server log.
+ <literal>parallel</literal> mode has two requirements: 1) the unique
+ column in the relation on the subscriber-side should also be the
+ unique column on the publisher-side; 2) there cannot be any
+ non-immutable functions used by the subscriber-side replicated table.
</para>
3.1a.
It looked a bit strange starting the sentence with the enum
"<literal>parallel</literal> mode". Maybe reword it something like:
"This mode has two requirements: ..."
or
"There are two requirements for using <literal>parallel</literal> mode: ..."
3.1b.
Point 1) says "relation", but point 2) says "table". I think the
consistent term should be used.
======
3.2 <general>
For consistency, please search all this patch and replace every:
"... applied by an apply background worker" -> "... applied using an
apply background worker"
And also search/replace every:
"... in the apply background worker: -> "... using an apply background worker"
======
3.3 .../replication/logical/applybgworker.c
@@ -800,3 +800,47 @@ apply_bgworker_subxact_info_add(TransactionId current_xid)
MemoryContextSwitchTo(oldctx);
}
}
+
+/*
+ * Check if changes on this relation can be applied by an apply background
+ * worker.
+ *
+ * Although the commit order is maintained only allowing one process to commit
+ * at a time, the access order to the relation has changed. This could cause
+ * unexpected problems if the unique column on the replicated table is
+ * inconsistent with the publisher-side or contains non-immutable functions
+ * when applying transactions in the apply background worker.
+ */
+void
+apply_bgworker_relation_check(LogicalRepRelMapEntry *rel)
"only allowing" -> "by only allowing" (I think you mean this, right?)
~~~
3.4
+ /*
+ * Return if changes on this relation can be applied by an apply background
+ * worker.
+ */
+ if (rel->parallel_apply == PARALLEL_APPLY_SAFE)
+ return;
+
+ /* We are in error mode and should give user correct error. */
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("cannot replicate target relation \"%s.%s\" using "
+ "subscription parameter streaming=parallel",
+ rel->remoterel.nspname, rel->remoterel.relname),
+ errdetail("The unique column on subscriber is not the unique "
+ "column on publisher or there is at least one "
+ "non-immutable function."),
+ errhint("Please change to use subscription parameter "
+ "streaming=on.")));
3.4a.
Of course, the code should give the user the "correct error" if there
is an error (!), but having a comment explicitly saying so does not
serve any purpose.
3.4b.
The logic might be simplified if it was written differently like:
+ if (rel->parallel_apply != PARALLEL_APPLY_SAFE)
+ ereport(ERROR, ...
======
3.5 src/backend/replication/logical/proto.c
@@ -40,6 +41,68 @@ static void logicalrep_read_tuple(StringInfo in,
LogicalRepTupleData *tuple);
static void logicalrep_write_namespace(StringInfo out, Oid nspid);
static const char *logicalrep_read_namespace(StringInfo in);
+static Bitmapset *RelationGetUniqueKeyBitmap(Relation rel);
+
+/*
+ * RelationGetUniqueKeyBitmap -- get a bitmap of unique attribute numbers
+ *
+ * This is similar to RelationGetIdentityKeyBitmap(), but returns a bitmap of
+ * index attribute numbers for all unique indexes.
+ */
+static Bitmapset *
+RelationGetUniqueKeyBitmap(Relation rel)
Why is the forward declaration needed when the static function
immediately follows it?
======
3.6 src/backend/replication/logical/relation.c -
logicalrep_relmap_reset_parallel_cb
@@ -91,6 +98,26 @@ logicalrep_relmap_invalidate_cb(Datum arg, Oid reloid)
}
}
+/*
+ * Relcache invalidation callback to reset parallel flag.
+ */
+static void
+logicalrep_relmap_reset_parallel_cb(Datum arg, int cacheid, uint32 hashvalue)
"reset parallel flag" -> "reset parallel_apply flag"
~~~
3.7 src/backend/replication/logical/relation.c -
logicalrep_rel_mark_parallel_apply
+ * There are two requirements for applying changes in an apply background
+ * worker: 1) The unique column in the relation on the subscriber-side should
+ * also be the unique column on the publisher-side; 2) There cannot be any
+ * non-immutable functions used by the subscriber-side.
This comment should exactly match the help text. See review comment #3.1
~~~
3.8
+ /* Initialize the flag. */
+ entry->parallel_apply = PARALLEL_APPLY_SAFE;
I previously suggested [1] (#3.6b) to move this. Consider, that you
cannot logically flag the entry as "safe" until you are certain that
it is safe. And you cannot be sure of that until you've passed all the
checks this function is doing. Therefore IMO the assignment to
PARALLEL_APPLY_SAFE should be the last line of the function.
~~~
3.9
+ /*
+ * Then, check if there is any non-immutable function used by the local
+ * table. Look for functions in the following places:
+ * a. trigger functions;
+ * b. Column default value expressions and domain constraints;
+ * c. Constraint expressions;
+ * d. Foreign keys.
+ */
"used by the local table" -> "used by the subscriber-side relation"
(reworded so that it is consistent with the First comment)
~~~
3.10
I previously suggested [1] (#3.7) to use goto in this function to
avoid the excessive number of returns. IMO there is nothing inherently
evil about gotos, so long as they are used with care - sometimes they
are the best option. Anyway, I attached some BEFORE/AFTER example code
to this post - others can judge which way is preferable.
======
3.11 src/backend/utils/cache/typcache.c - GetDomainConstraints
@@ -2540,6 +2540,23 @@ compare_values_of_enum(TypeCacheEntry *tcache,
Oid arg1, Oid arg2)
return 0;
}
+/*
+ * GetDomainConstraints --- get DomainConstraintState list of
specified domain type
+ */
+List *
+GetDomainConstraints(Oid type_id)
+{
+ TypeCacheEntry *typentry;
+ List *constraints = NIL;
+
+ typentry = lookup_type_cache(type_id, TYPECACHE_DOMAIN_CONSTR_INFO);
+
+ if(typentry->domainData != NULL)
+ constraints = typentry->domainData->constraints;
+
+ return constraints;
+}
This function can be simplified (if you want). e.g.
List *
GetDomainConstraints(Oid type_id)
{
TypeCacheEntry *typentry;
typentry = lookup_type_cache(type_id, TYPECACHE_DOMAIN_CONSTR_INFO);
return typentry->domainData ? typentry->domainData->constraints : NIL;
}
======
3.12 src/include/replication/logicalrelation.h
@@ -15,6 +15,19 @@
#include "access/attmap.h"
#include "replication/logicalproto.h"
+/*
+ * States to determine if changes on one relation can be applied using an
+ * apply background worker.
+ */
+typedef enum ParalleApplySafety
+{
+ PARALLEL_APPLY_UNKNOWN = 0, /* unknown */
+ PARALLEL_APPLY_SAFE, /* Can apply changes in an apply background
+ worker */
+ PARALLEL_APPLY_UNSAFE /* Can not apply changes in an apply background
+ worker */
+} ParalleApplySafety;
+
3.12a
Typo in enum and typedef names:
"ParalleApplySafety" -> "ParallelApplySafety"
3.12b
I think the values are quite self-explanatory now. Commenting on each
of them separately is not really adding anything useful.
3.12c.
New enum missing from typedefs.list?
======
3.13 typdefs.list
Should include the new typedef. See comment #3.12c.
------
[1]
https://www.postgresql.org/message-id/OS3PR01MB62758A6AAED27B3A848CEB7A9E8F9%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Jul 26, 2022 at 2:30 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Fri, Jul 22, 2022 at 8:27 AM wangw.fnst@fujitsu.com > <wangw.fnst@fujitsu.com> wrote: > > > > On Tues, Jul 19, 2022 at 10:29 AM I wrote: > > > Attach the news patches. > > > > Not able to apply patches cleanly because the change in HEAD (366283961a). > > Therefore, I rebased the patch based on the changes in HEAD. > > > > Attach the new patches. > > + /* Check the foreign keys. */ > + fkeys = RelationGetFKeyList(entry->localrel); > + if (fkeys) > + entry->parallel_apply = PARALLEL_APPLY_UNSAFE; > > So if there is a foreign key on any of the tables which are parts of a > subscription then we do not allow changes for that subscription to be > applied in parallel? > I think the above check will just prevent the parallelism for a xact operating on the corresponding relation not the relations of the entire subscription. Your statement sounds like you are saying that it will prevent parallelism for all the other tables in the subscription which has a table with FK. > I think this is a big limitation because having > foreign key on the table is very normal right? I agree that if we > allow them then there could be failure due to out of order apply > right? > What kind of failure do you have in mind and how it can occur? The one way it can fail is if the publisher doesn't have a corresponding foreign key on the table because then the publisher could have allowed an insert into a table (insert into FK table without having the corresponding key in PK table) which may not be allowed on the subscriber. However, I don't see any check that could prevent this because for this we need to compare the FK list for a table from the publisher with the corresponding one on the subscriber. I am not really sure if due to the risk of such conflicts we should block parallelism of transactions operating on tables with FK because those conflicts can occur even without parallelism, it is just a matter of timing. But, I could be missing something due to which the above check can be useful? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Wed, Jul 27, 2022 at 10:06 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Tue, Jul 26, 2022 at 2:30 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> >
> > On Fri, Jul 22, 2022 at 8:27 AM wangw.fnst@fujitsu.com
> > <wangw.fnst@fujitsu.com> wrote:
> > >
> > > On Tues, Jul 19, 2022 at 10:29 AM I wrote:
> > > > Attach the news patches.
> > >
> > > Not able to apply patches cleanly because the change in HEAD (366283961a).
> > > Therefore, I rebased the patch based on the changes in HEAD.
> > >
> > > Attach the new patches.
> >
> > + /* Check the foreign keys. */
> > + fkeys = RelationGetFKeyList(entry->localrel);
> > + if (fkeys)
> > + entry->parallel_apply = PARALLEL_APPLY_UNSAFE;
> >
> > So if there is a foreign key on any of the tables which are parts of a
> > subscription then we do not allow changes for that subscription to be
> > applied in parallel?
> >
>
> I think the above check will just prevent the parallelism for a xact
> operating on the corresponding relation not the relations of the
> entire subscription. Your statement sounds like you are saying that it
> will prevent parallelism for all the other tables in the subscription
> which has a table with FK.
Okay, got it. I thought we are disallowing parallelism for the entire
subscription.
> > I think this is a big limitation because having
> > foreign key on the table is very normal right? I agree that if we
> > allow them then there could be failure due to out of order apply
> > right?
> >
>
> What kind of failure do you have in mind and how it can occur? The one
> way it can fail is if the publisher doesn't have a corresponding
> foreign key on the table because then the publisher could have allowed
> an insert into a table (insert into FK table without having the
> corresponding key in PK table) which may not be allowed on the
> subscriber. However, I don't see any check that could prevent this
> because for this we need to compare the FK list for a table from the
> publisher with the corresponding one on the subscriber. I am not
> really sure if due to the risk of such conflicts we should block
> parallelism of transactions operating on tables with FK because those
> conflicts can occur even without parallelism, it is just a matter of
> timing. But, I could be missing something due to which the above check
> can be useful?
Actually, my question starts with this check[1][2], from this it
appears that if this relation is having a foreign key then we are
marking it parallel unsafe[2] and later in [1] while the worker is
applying changes for that relation and if it was marked parallel
unsafe then we are throwing error. So my question was why we are
putting this restriction? Although this error is only talking about
unique and non-immutable functions this is also giving an error if the
target table had a foreign key. So my question was do we really need
to restrict this? I mean why we are restricting this case?
[1]
+apply_bgworker_relation_check(LogicalRepRelMapEntry *rel)
+{
+ /* Skip check if not an apply background worker. */
+ if (!am_apply_bgworker())
+ return;
+
+ /*
+ * Partition table checks are done later in function
+ * apply_handle_tuple_routing.
+ */
+ if (rel->localrel->rd_rel->relkind == RELKIND_PARTITIONED_TABLE)
+ return;
+
+ /*
+ * Return if changes on this relation can be applied by an apply background
+ * worker.
+ */
+ if (rel->parallel_apply == PARALLEL_APPLY_SAFE)
+ return;
+
+ /* We are in error mode and should give user correct error. */
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("cannot replicate target relation \"%s.%s\" using "
+ "subscription parameter streaming=parallel",
+ rel->remoterel.nspname, rel->remoterel.relname),
+ errdetail("The unique column on subscriber is not the unique "
+ "column on publisher or there is at least one "
+ "non-immutable function."),
+ errhint("Please change to use subscription parameter "
+ "streaming=on.")));
+}
[2]
> > + /* Check the foreign keys. */
> > + fkeys = RelationGetFKeyList(entry->localrel);
> > + if (fkeys)
> > + entry->parallel_apply = PARALLEL_APPLY_UNSAFE;
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, July 27, 2022 1:29 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Wed, Jul 27, 2022 at 10:06 AM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > On Tue, Jul 26, 2022 at 2:30 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> > >
> > > On Fri, Jul 22, 2022 at 8:27 AM wangw.fnst@fujitsu.com
> > > <wangw.fnst@fujitsu.com> wrote:
> > > >
> > > > On Tues, Jul 19, 2022 at 10:29 AM I wrote:
> > > > > Attach the news patches.
> > > >
> > > > Not able to apply patches cleanly because the change in HEAD
> (366283961a).
> > > > Therefore, I rebased the patch based on the changes in HEAD.
> > > >
> > > > Attach the new patches.
> > >
> > > + /* Check the foreign keys. */
> > > + fkeys = RelationGetFKeyList(entry->localrel);
> > > + if (fkeys)
> > > + entry->parallel_apply = PARALLEL_APPLY_UNSAFE;
> > >
> > > So if there is a foreign key on any of the tables which are parts of
> > > a subscription then we do not allow changes for that subscription to
> > > be applied in parallel?
> > >
> >
> > I think the above check will just prevent the parallelism for a xact
> > operating on the corresponding relation not the relations of the
> > entire subscription. Your statement sounds like you are saying that it
> > will prevent parallelism for all the other tables in the subscription
> > which has a table with FK.
>
> Okay, got it. I thought we are disallowing parallelism for the entire subscription.
>
> > > I think this is a big limitation because having foreign key on the
> > > table is very normal right? I agree that if we allow them then
> > > there could be failure due to out of order apply right?
> > >
> >
> > What kind of failure do you have in mind and how it can occur? The one
> > way it can fail is if the publisher doesn't have a corresponding
> > foreign key on the table because then the publisher could have allowed
> > an insert into a table (insert into FK table without having the
> > corresponding key in PK table) which may not be allowed on the
> > subscriber. However, I don't see any check that could prevent this
> > because for this we need to compare the FK list for a table from the
> > publisher with the corresponding one on the subscriber. I am not
> > really sure if due to the risk of such conflicts we should block
> > parallelism of transactions operating on tables with FK because those
> > conflicts can occur even without parallelism, it is just a matter of
> > timing. But, I could be missing something due to which the above check
> > can be useful?
>
> Actually, my question starts with this check[1][2], from this it
> appears that if this relation is having a foreign key then we are
> marking it parallel unsafe[2] and later in [1] while the worker is
> applying changes for that relation and if it was marked parallel
> unsafe then we are throwing error. So my question was why we are
> putting this restriction? Although this error is only talking about
> unique and non-immutable functions this is also giving an error if the
> target table had a foreign key. So my question was do we really need
> to restrict this? I mean why we are restricting this case?
>
Hi,
I think the foreign key check is used to prevent the apply worker from waiting
indefinitely which is caused by foreign key difference between publisher and
subscriber, Like the following example:
-------------------------------------
Publisher:
-- both table are published
CREATE TABLE PKTABLE ( ptest1 int);
CREATE TABLE FKTABLE ( ftest1 int);
-- initial data
INSERT INTO PKTABLE VALUES(1);
Subcriber:
CREATE TABLE PKTABLE ( ptest1 int PRIMARY KEY);
CREATE TABLE FKTABLE ( ftest1 int REFERENCES PKTABLE);
-- Execute the following transactions on publisher
Tx1:
INSERT ... -- make enough changes to start streaming mode
DELETE FROM PKTABLE;
Tx2:
INSERT ITNO FKTABLE VALUES(1);
COMMIT;
COMMIT;
-------------------------------------
The subcriber's apply worker will wait indefinitely, because the main apply worker is
waiting for the streaming transaction to finish which is in another apply
bgworker.
BTW, I think the foreign key won't take effect in subscriber's apply worker by
default. Because we set session_replication_role to 'replica' in apply worker
which prevent the FK trigger function to be executed(only the trigger with
FIRES_ON_REPLICA flag will be executed in this mode). User can only alter the
trigger to enable it on replica mode to make the foreign key work. So, ISTM, we
won't hit this ERROR frequently.
And based on this, another comment about the patch is that it seems unnecessary
to directly check the FK returned by RelationGetFKeyList. Checking the actual FK
trigger function seems enough.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for the patch v19-0004:
======
1. doc/src/sgml/ref/create_subscription.sgml
@@ -244,6 +244,11 @@ CREATE SUBSCRIPTION <replaceable
class="parameter">subscription_name</replaceabl
column in the relation on the subscriber-side should also be the
unique column on the publisher-side; 2) there cannot be any
non-immutable functions used by the subscriber-side replicated table.
+ When applying a streaming transaction, if either requirement is not
+ met, the background worker will exit with an error.
+ <literal>parallel</literal> mode is disregarded when retrying;
+ instead the transaction will be applied using <literal>on</literal>
+ mode.
</para>
That last sentence starting with lowercase seems odd - that's why I
thought saying "The parallel mode..." might be better. IMO "on mode"
seems strange too. Hence my previous [1] (#4.3) suggestion for this
SUGGESTION
The <literal>parallel</literal> mode is disregarded when retrying;
instead the transaction will be applied using <literal>streaming =
on</literal>.
======
2. src/backend/replication/logical/worker.c - start_table_sync
@@ -3902,20 +3925,28 @@ start_table_sync(XLogRecPtr *origin_startpos,
char **myslotname)
}
PG_CATCH();
{
+ /*
+ * Emit the error message, and recover from the error state to an idle
+ * state
+ */
+ HOLD_INTERRUPTS();
+
+ EmitErrorReport();
+ AbortOutOfAnyTransaction();
+ FlushErrorState();
+
+ RESUME_INTERRUPTS();
+
+ /* Report the worker failed during table synchronization */
+ pgstat_report_subscription_error(MySubscription->oid, false);
+
+ /* Set the retry flag. */
+ set_subscription_retry(true);
+
if (MySubscription->disableonerr)
DisableSubscriptionAndExit();
- else
- {
- /*
- * Report the worker failed during table synchronization. Abort
- * the current transaction so that the stats message is sent in an
- * idle state.
- */
- AbortOutOfAnyTransaction();
- pgstat_report_subscription_error(MySubscription->oid, false);
- PG_RE_THROW();
- }
+ proc_exit(0);
}
But is it correct to set the 'retry' flag even if the
MySubscription->disableonerr is true? Won’t that mean even after the
user corrects the problem and then re-enabled the subscription it
still won't let the streaming=parallel work, because that retry flag
is set?
Also, Something seems wrong to me here - IIUC the patch changed this
code because of the potential risk of an error within the
set_subscription_retry function, but now if such an error happens the
current code will bypass even getting to DisableSubscriptionAndExit,
so the subscription won't have a chance to get disabled as the user
might have wanted.
~~~
3. src/backend/replication/logical/worker.c - start_apply
@@ -3940,20 +3971,27 @@ start_apply(XLogRecPtr origin_startpos)
}
PG_CATCH();
{
+ /*
+ * Emit the error message, and recover from the error state to an idle
+ * state
+ */
+ HOLD_INTERRUPTS();
+
+ EmitErrorReport();
+ AbortOutOfAnyTransaction();
+ FlushErrorState();
+
+ RESUME_INTERRUPTS();
+
+ /* Report the worker failed while applying changes */
+ pgstat_report_subscription_error(MySubscription->oid,
+ !am_tablesync_worker());
+
+ /* Set the retry flag. */
+ set_subscription_retry(true);
+
if (MySubscription->disableonerr)
DisableSubscriptionAndExit();
- else
- {
- /*
- * Report the worker failed while applying changes. Abort the
- * current transaction so that the stats message is sent in an
- * idle state.
- */
- AbortOutOfAnyTransaction();
- pgstat_report_subscription_error(MySubscription->oid, !am_tablesync_worker());
-
- PG_RE_THROW();
- }
}
(Same as previous review comment #2)
But is it correct to set the 'retry' flag even if the
MySubscription->disableonerr is true? Won’t that mean even after the
user corrects the problem and then re-enabled the subscription it
still won't let the streaming=parallel work, because that retry flag
is set?
Also, Something seems wrong to me here - IIUC the patch changed this
code because of the potential risk of an error within the
set_subscription_retry function, but now if such an error happens the
current code will bypass even getting to DisableSubscriptionAndExit,
so the subscription won't have a chance to get disabled as the user
might have wanted.
~~~
4. src/backend/replication/logical/worker.c - DisableSubscriptionAndExit
/*
- * After error recovery, disable the subscription in a new transaction
- * and exit cleanly.
+ * Disable the subscription in a new transaction.
*/
static void
DisableSubscriptionAndExit(void)
{
- /*
- * Emit the error message, and recover from the error state to an idle
- * state
- */
- HOLD_INTERRUPTS();
-
- EmitErrorReport();
- AbortOutOfAnyTransaction();
- FlushErrorState();
-
- RESUME_INTERRUPTS();
-
- /* Report the worker failed during either table synchronization or apply */
- pgstat_report_subscription_error(MyLogicalRepWorker->subid,
- !am_tablesync_worker());
-
/* Disable the subscription */
StartTransactionCommand();
DisableSubscription(MySubscription->oid);
@@ -4231,8 +4252,6 @@ DisableSubscriptionAndExit(void)
ereport(LOG,
errmsg("logical replication subscription \"%s\" has been disabled
due to an error",
MySubscription->name));
-
- proc_exit(0);
}
4a.
Hmm, I think it is a bad idea to remove the "exiting" code from the
function but still leave the function name the same as before saying
"AndExit".
4b.
Also, now the patch is unconditionally doing proc_exit(0) in the
calling code where previously it would do PG_RE_THROW. So it's a
subtle difference from the path the code used to take for worker
errors..
~~~
5. src/backend/replication/logical/worker.c - set_subscription_retry
@@ -4467,3 +4486,63 @@ reset_apply_error_context_info(void)
apply_error_callback_arg.remote_attnum = -1;
set_apply_error_context_xact(InvalidTransactionId, InvalidXLogRecPtr);
}
+
+/*
+ * Set subretry of pg_subscription catalog.
+ *
+ * If retry is true, subscriber is about to exit with an error. Otherwise, it
+ * means that the transaction was applied successfully.
+ */
+static void
+set_subscription_retry(bool retry)
+{
+ Relation rel;
+ HeapTuple tup;
+ bool started_tx = false;
+ bool nulls[Natts_pg_subscription];
+ bool replaces[Natts_pg_subscription];
+ Datum values[Natts_pg_subscription];
+
+ if (MySubscription->retry == retry ||
+ am_apply_bgworker())
+ return;
Currently, I think this new 'subretry' field is only used to decide
whether a retry can use an apply background worker or not. I think all
this logic is *only* used when streaming=parallel. But AFAICT the
logic for setting/clearing the retry flag is executed *always*
regardless of the streaming mode.
So for all the times when the user did not ask for streaming=parallel
doesn't this just cause unnecessary overhead for every transaction?
------
[1]
https://www.postgresql.org/message-id/OS3PR01MB62758A6AAED27B3A848CEB7A9E8F9%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, July 26, 2022 5:34 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > On Tue, Jul 26, 2022 at 2:30 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Fri, Jul 22, 2022 at 8:27 AM wangw.fnst@fujitsu.com > > <wangw.fnst@fujitsu.com> wrote: > > > > > > On Tues, Jul 19, 2022 at 10:29 AM I wrote: > > > > Attach the news patches. > > > > > > Not able to apply patches cleanly because the change in HEAD > (366283961a). > > > Therefore, I rebased the patch based on the changes in HEAD. > > > > > > Attach the new patches. > > > > + /* Check the foreign keys. */ > > + fkeys = RelationGetFKeyList(entry->localrel); > > + if (fkeys) > > + entry->parallel_apply = PARALLEL_APPLY_UNSAFE; > > > > So if there is a foreign key on any of the tables which are parts of a > > subscription then we do not allow changes for that subscription to be > > applied in parallel? I think this is a big limitation because having > > foreign key on the table is very normal right? I agree that if we > > allow them then there could be failure due to out of order apply > > right? but IMHO we should not put the restriction instead let it fail > > if there is ever such conflict. Because if there is a conflict the > > transaction will be sent again. Do we see that there could be wrong > > or inconsistent results if we allow such things to be executed in > > parallel. If not then IMHO just to avoid some corner case failure we > > are restricting very normal cases. > > some more comments.. > 1. > + /* > + * If we have found a free worker or if we are already > applying this > + * transaction in an apply background worker, then we > pass the data to > + * that worker. > + */ > + if (first_segment) > + apply_bgworker_send_data(stream_apply_worker, s->len, > + s->data); > > Comment says that if we have found a free worker or we are already applying in > the worker then pass the changes to the worker but actually as per the code > here we are only passing in case of first_segment? > > I think what you are trying to say is that if it is first segment then send the > > 2. > + /* > + * This is the main apply worker. Check if there is any free apply > + * background worker we can use to process this transaction. > + */ > + if (first_segment) > + stream_apply_worker = apply_bgworker_start(stream_xid); > + else > + stream_apply_worker = apply_bgworker_find(stream_xid); > > So currently, whenever we get a new streamed transaction we try to start a new > background worker for that. Why do we need to start/close the background > apply worker every time we get a new streamed transaction. I mean we can > keep the worker in the pool for time being and if there is a new transaction > looking for a worker then we can find from that. Starting a worker is costly > operation and since we are using parallelism for this mean we are expecting > that there would be frequent streamed transaction needing parallel apply > worker so why not to let it wait for a certain amount of time so that if load is low > it will anyway stop and if the load is high it will be reused for next streamed > transaction. It seems the function name was a bit mislead. Currently, the started apply bgworker won't exit after applying the transaction. And the apply_bgworker_start will first try to choose a free worker. It will start a new worker only if no free worker is available. > 3. > Why are we restricting parallel apply workers only for the streamed > transactions, because streaming depends upon the size of the logical decoding > work mem so making steaming and parallel apply tightly coupled seems too > restrictive to me. Do we see some obvious problems in applying other > transactions in parallel? We thought there could be some conflict failure and deadlock if we parallel apply normal transaction which need transaction dependency check[1]. But I will do some more research for this and share the result soon. [1] https://www.postgresql.org/message-id/CAA4eK1%2BwyN6zpaHUkCLorEWNx75MG0xhMwcFhvjqm2KURZEAGw%40mail.gmail.com Best regards, Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Wang-san,
Hi, I'm also interested in the patch and I started to review this.
Followings are comments about 0001.
1. terminology
In your patch a new worker "apply background worker" has been introduced,
but I thought it might be confused because PostgreSQL has already the worker "background worker".
Both of apply worker and apply bworker are categolized as bgworker.
Do you have any reasons not to use "apply parallel worker" or "apply streaming worker"?
(Note that I'm not native English speaker)
2. logicalrep_worker_stop()
```
- /* No worker, nothing to do. */
- if (!worker)
- {
- LWLockRelease(LogicalRepWorkerLock);
- return;
- }
+ if (worker)
+ logicalrep_worker_stop_internal(worker);
+
+ LWLockRelease(LogicalRepWorkerLock);
+}
```
I thought you could add a comment the meaning of if-statement, like "No main apply worker, nothing to do"
3. logicalrep_workers_find()
I thought you could add a description about difference between this and logicalrep_worker_find() at the top of the
function.
IIUC logicalrep_workers_find() counts subworker, but logicalrep_worker_find() does not focus such type of workers.
4. logicalrep_worker_detach()
```
static void
logicalrep_worker_detach(void)
{
+ /*
+ * If we are the main apply worker, stop all the apply background workers
+ * we started before.
+ *
```
I thought "we are" should be "This is", based on other comments.
5. applybgworker.c
```
+/* Apply background workers hash table (initialized on first use) */
+static HTAB *ApplyWorkersHash = NULL;
+static List *ApplyWorkersFreeList = NIL;
+static List *ApplyWorkersList = NIL;
```
I thought they should be ApplyBgWorkersXXX, because they stores information only related with apply bgworkers.
6. ApplyBgworkerShared
```
+ TransactionId stream_xid;
+ uint32 n; /* id of apply background worker */
+} ApplyBgworkerShared;
```
I thought the field "n" is too general, how about "proc_id" or "worker_id"?
7. apply_bgworker_wait_for()
```
+ /* If any workers (or the postmaster) have died, we have failed. */
+ if (status == APPLY_BGWORKER_EXIT)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("background worker %u failed to apply transaction %u",
+ wstate->shared->n, wstate->shared->stream_xid)))
```
7.a
I thought we should not mention about PM death here, because in this case
apply worker will exit at WaitLatch().
7.b
The error message should be "apply background worker %u...".
8. apply_bgworker_check_status()
```
+ errmsg("background worker %u exited unexpectedly",
+ wstate->shared->n)));
```
The error message should be "apply background worker %u...".
9. apply_bgworker_send_data()
```
+ if (result != SHM_MQ_SUCCESS)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("could not send tuples to shared-memory queue")));
```
I thought the error message should be "could not send data to..."
because sent data might not be tuples. For example, in case of STEAM PREPARE, I thit does not contain tuple.
10. wait_event.h
```
WAIT_EVENT_HASH_GROW_BUCKETS_REINSERT,
+ WAIT_EVENT_LOGICAL_APPLY_WORKER_STATE_CHANGE,
WAIT_EVENT_LOGICAL_SYNC_DATA,
```
I thought the event should be WAIT_EVENT_LOGICAL_APPLY_BG_WORKER_STATE_CHANGE,
because this is used when apply worker waits until the status of bgworker changes.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Wang, I found further comments about the test code. 11. src/test/regress/sql/subscription.sql ``` -- fail - streaming must be boolean CREATE SUBSCRIPTION regress_testsub CONNECTION 'dbname=regress_doesnotexist' PUBLICATION testpub WITH (connect = false, streaming= foo); ``` The comment is no longer correct: should be "streaming must be boolean or 'parallel'" 12. src/test/regress/sql/subscription.sql ``` -- now it works CREATE SUBSCRIPTION regress_testsub CONNECTION 'dbname=regress_doesnotexist' PUBLICATION testpub WITH (connect = false, streaming= true); ``` I think we should test the case of streaming = 'parallel'. 13. 015_stream.pl I could not find test about TRUNCATE. IIUC apply bgworker works well even if it gets LOGICAL_REP_MSG_TRUNCATE message from main worker. Can you add the case? Best Regards, Hayato Kuroda FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Jul 27, 2022 at 1:27 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, July 27, 2022 1:29 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Wed, Jul 27, 2022 at 10:06 AM Amit Kapila <amit.kapila16@gmail.com> > > > > > > What kind of failure do you have in mind and how it can occur? The one > > > way it can fail is if the publisher doesn't have a corresponding > > > foreign key on the table because then the publisher could have allowed > > > an insert into a table (insert into FK table without having the > > > corresponding key in PK table) which may not be allowed on the > > > subscriber. However, I don't see any check that could prevent this > > > because for this we need to compare the FK list for a table from the > > > publisher with the corresponding one on the subscriber. I am not > > > really sure if due to the risk of such conflicts we should block > > > parallelism of transactions operating on tables with FK because those > > > conflicts can occur even without parallelism, it is just a matter of > > > timing. But, I could be missing something due to which the above check > > > can be useful? > > > > Actually, my question starts with this check[1][2], from this it > > appears that if this relation is having a foreign key then we are > > marking it parallel unsafe[2] and later in [1] while the worker is > > applying changes for that relation and if it was marked parallel > > unsafe then we are throwing error. So my question was why we are > > putting this restriction? Although this error is only talking about > > unique and non-immutable functions this is also giving an error if the > > target table had a foreign key. So my question was do we really need > > to restrict this? I mean why we are restricting this case? > > > > Hi, > > I think the foreign key check is used to prevent the apply worker from waiting > indefinitely which is caused by foreign key difference between publisher and > subscriber, Like the following example: > > ------------------------------------- > Publisher: > -- both table are published > CREATE TABLE PKTABLE ( ptest1 int); > CREATE TABLE FKTABLE ( ftest1 int); > > -- initial data > INSERT INTO PKTABLE VALUES(1); > > Subcriber: > CREATE TABLE PKTABLE ( ptest1 int PRIMARY KEY); > CREATE TABLE FKTABLE ( ftest1 int REFERENCES PKTABLE); > > -- Execute the following transactions on publisher > > Tx1: > INSERT ... -- make enough changes to start streaming mode > DELETE FROM PKTABLE; > Tx2: > INSERT ITNO FKTABLE VALUES(1); > COMMIT; > COMMIT; > ------------------------------------- > > The subcriber's apply worker will wait indefinitely, because the main apply worker is > waiting for the streaming transaction to finish which is in another apply > bgworker. > IIUC, here the problem will be that TX2 (Insert in FK table) performed by the apply worker will wait for a parallel worker doing streaming transaction TX1 which has performed Delete from PK table. This wait is required because we can't decide if Insert will be successful or not till TX1 is either committed or Rollback. This is similar to the problem related to primary/unique keys mentioned earlier [1]. If so, then, we should try to forbid this in some way to avoid subscribers from being stuck. Dilip, does this reason sounds sufficient to you for such a check, or do you still think we don't need any check for FK's? > > BTW, I think the foreign key won't take effect in subscriber's apply worker by > default. Because we set session_replication_role to 'replica' in apply worker > which prevent the FK trigger function to be executed(only the trigger with > FIRES_ON_REPLICA flag will be executed in this mode). User can only alter the > trigger to enable it on replica mode to make the foreign key work. So, ISTM, we > won't hit this ERROR frequently. > > And based on this, another comment about the patch is that it seems unnecessary > to directly check the FK returned by RelationGetFKeyList. Checking the actual FK > trigger function seems enough. > That is correct. I think it would have been better if we can detect that publisher doesn't have FK but the subscriber has FK as it can occur only in that scenario. If that requires us to send more information from the publisher, we can leave it for now (as this doesn't seem to be a frequent scenario) and keep a simpler check based on subscriber schema. I think we should add a test as mentioned by you above so that if tomorrow one tries to remove the FK check, we have a way to know. Also, please add comments and tests for additional checks related to constraints in the patch. [1] - https://www.postgresql.org/message-id/CAA4eK1JwahU_WuP3S%2B7POqta%3DPhm_3gxZeVmJuuoUq1NV%3DkrXA%40mail.gmail.com -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, July 27, 2022 4:22 PM houzj.fnst@fujitsu.com wrote: > > On Tuesday, July 26, 2022 5:34 PM Dilip Kumar <dilipbalaut@gmail.com> > wrote: > > > 3. > > Why are we restricting parallel apply workers only for the streamed > > transactions, because streaming depends upon the size of the logical > > decoding work mem so making steaming and parallel apply tightly > > coupled seems too restrictive to me. Do we see some obvious problems > > in applying other transactions in parallel? > > We thought there could be some conflict failure and deadlock if we parallel > apply normal transaction which need transaction dependency check[1]. But I > will do some more research for this and share the result soon. After thinking about this, I confirmed that it would be easy to cause deadlock error if we don't have additional dependency analysis and COMMIT order preserve handling for parallel apply normal transaction. Because the basic idea to parallel apply normal transaction in the first version is that: the main apply worker will receive data from pub and pass them to apply bgworker without applying by itself. And only before the apply bgworker apply the final COMMIT command, it need to wait for any previous transaction to finish to preserve the commit order. It means we could pass the next transaction's data to another apply bgworker before the previous transaction is committed in the first apply bgworker. In this approach, we have to do the dependency analysis because it's easy to cause dead lock error when applying DMLs in parallel(See the attachment for the examples where the dead lock could happen). So, it's a bit different from streaming transaction. We could apply the next transaction only after the first transaction is committed in which approach we don't need the dependency analysis, but it would not bring noticeable performance improvement even if we start serval apply workers to do that because the actual DMLs are not performed in parallel. Based on above, we plan to first introduce the patch to perform streaming logical transactions by background workers, and then introduce parallel apply normal transaction which design is different and need some additional handling. Best regards, Hou zj > [1] > https://www.postgresql.org/message-id/CAA4eK1%2BwyN6zpaHUkCLorEW > Nx75MG0xhMwcFhvjqm2KURZEAGw%40mail.gmail.com
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Aug 2, 2022 at 5:16 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, July 27, 2022 4:22 PM houzj.fnst@fujitsu.com wrote: > > > > On Tuesday, July 26, 2022 5:34 PM Dilip Kumar <dilipbalaut@gmail.com> > > wrote: > > > > > 3. > > > Why are we restricting parallel apply workers only for the streamed > > > transactions, because streaming depends upon the size of the logical > > > decoding work mem so making steaming and parallel apply tightly > > > coupled seems too restrictive to me. Do we see some obvious problems > > > in applying other transactions in parallel? > > > > We thought there could be some conflict failure and deadlock if we parallel > > apply normal transaction which need transaction dependency check[1]. But I > > will do some more research for this and share the result soon. > > After thinking about this, I confirmed that it would be easy to cause deadlock > error if we don't have additional dependency analysis and COMMIT order preserve > handling for parallel apply normal transaction. > > Because the basic idea to parallel apply normal transaction in the first > version is that: the main apply worker will receive data from pub and pass them > to apply bgworker without applying by itself. And only before the apply > bgworker apply the final COMMIT command, it need to wait for any previous > transaction to finish to preserve the commit order. It means we could pass the > next transaction's data to another apply bgworker before the previous > transaction is committed in the first apply bgworker. > > In this approach, we have to do the dependency analysis because it's easy to > cause dead lock error when applying DMLs in parallel(See the attachment for the > examples where the dead lock could happen). So, it's a bit different from > streaming transaction. > > We could apply the next transaction only after the first transaction is > committed in which approach we don't need the dependency analysis, but it would > not bring noticeable performance improvement even if we start serval apply > workers to do that because the actual DMLs are not performed in parallel. > I agree that for short transactions it may not bring noticeable performance improvement but somewhat larger transactions could still benefit from parallelism where we won't start to operate on new transactions without waiting for the previous transaction's commit. Having said that, I think we can enable parallelism for non-streaming transactions as a separate patch. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Thurs, Jul 28, 2022 at 21:32 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > Thanks for your comments and opinions. > On Wed, Jul 27, 2022 at 1:27 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > BTW, I think the foreign key won't take effect in subscriber's apply worker by > > default. Because we set session_replication_role to 'replica' in apply worker > > which prevent the FK trigger function to be executed(only the trigger with > > FIRES_ON_REPLICA flag will be executed in this mode). User can only alter the > > trigger to enable it on replica mode to make the foreign key work. So, ISTM, > we > > won't hit this ERROR frequently. > > > > And based on this, another comment about the patch is that it seems > unnecessary > > to directly check the FK returned by RelationGetFKeyList. Checking the actual > FK > > trigger function seems enough. > > > > That is correct. I think it would have been better if we can detect > that publisher doesn't have FK but the subscriber has FK as it can > occur only in that scenario. If that requires us to send more > information from the publisher, we can leave it for now (as this > doesn't seem to be a frequent scenario) and keep a simpler check based > on subscriber schema. > > I think we should add a test as mentioned by you above so that if > tomorrow one tries to remove the FK check, we have a way to know. > Also, please add comments and tests for additional checks related to > constraints in the patch. > > [1] - https://www.postgresql.org/message- > id/CAA4eK1JwahU_WuP3S%2B7POqta%3DPhm_3gxZeVmJuuoUq1NV%3DkrXA > %40mail.gmail.com I added some test cases that cause indefinite waits without additional checks related to constraints. (please see file 032_streaming_apply.pl in 0003-patch) I also added some comments for FK check and why we need these checks. In addition, I found another two scenarios that could cause infinite waits, so I made the following changes: 1. I check the default values for the columns that only in subscriber-side. (Previous versions only checked for columns that existed in both publisher-side and subscriber-side.) 2. When using an apply background worker, the check needs to be performed not only in the apply background worker, but also in the main apply worker. I also did some other improvements based on the suggestions posted in this thread. Attach the new patches. Regards, Wang wei
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Thurs, Jul 28, 2022 at 13:20 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote:
>
> Dear Wang-san,
>
> Hi, I'm also interested in the patch and I started to review this.
> Followings are comments about 0001.
Thanks for your kindly review and comments.
To avoid making this thread too long, I will reply to all of your comments
(#1~#13) in this email.
> 1. terminology
>
> In your patch a new worker "apply background worker" has been introduced,
> but I thought it might be confused because PostgreSQL has already the worker
> "background worker".
> Both of apply worker and apply bworker are categolized as bgworker.
> Do you have any reasons not to use "apply parallel worker" or "apply streaming
> worker"?
> (Note that I'm not native English speaker)
Since we will later consider applying non-streamed transactions in parallel, I
think "apply streaming worker" might not be very suitable. I think PostgreSQL
also has the worker "parallel worker", so for "apply parallel worker" and
"apply background worker", I feel that "apply background worker" will make the
relationship between workers more clear. ("[main] apply worker" and "apply
background worker")
> 2. logicalrep_worker_stop()
>
> ```
> - /* No worker, nothing to do. */
> - if (!worker)
> - {
> - LWLockRelease(LogicalRepWorkerLock);
> - return;
> - }
> + if (worker)
> + logicalrep_worker_stop_internal(worker);
> +
> + LWLockRelease(LogicalRepWorkerLock);
> +}
> ```
>
> I thought you could add a comment the meaning of if-statement, like "No main
> apply worker, nothing to do"
Since the processing in the if statement is reversed from before, I added the
following comment based on your suggestion:
```
Found the main worker, then try to stop it.
```
> 3. logicalrep_workers_find()
>
> I thought you could add a description about difference between this and
> logicalrep_worker_find() at the top of the function.
> IIUC logicalrep_workers_find() counts subworker, but logicalrep_worker_find()
> does not focus such type of workers.
I think it is fine to keep the comment because the comment says "returns list
of *all workers* for the subscription".
Also, we have added the comment "We are only interested in the main apply
worker or table sync worker here" in the function logicalrep_worker_find.
> 5. applybgworker.c
>
> ```
> +/* Apply background workers hash table (initialized on first use) */
> +static HTAB *ApplyWorkersHash = NULL;
> +static List *ApplyWorkersFreeList = NIL;
> +static List *ApplyWorkersList = NIL;
> ```
>
> I thought they should be ApplyBgWorkersXXX, because they stores information
> only related with apply bgworkers.
I improved them to ApplyBgworkersXXX just for the consistency with other names.
> 6. ApplyBgworkerShared
>
> ```
> + TransactionId stream_xid;
> + uint32 n; /* id of apply background worker */
> +} ApplyBgworkerShared;
> ```
>
> I thought the field "n" is too general, how about "proc_id" or "worker_id"?
I think "worker_id" seems better, so I improved "n" to "worker_id".
> 10. wait_event.h
>
> ```
> WAIT_EVENT_HASH_GROW_BUCKETS_REINSERT,
> + WAIT_EVENT_LOGICAL_APPLY_WORKER_STATE_CHANGE,
> WAIT_EVENT_LOGICAL_SYNC_DATA,
> ```
>
> I thought the event should be
> WAIT_EVENT_LOGICAL_APPLY_BG_WORKER_STATE_CHANGE,
> because this is used when apply worker waits until the status of bgworker
> changes.
I improved them to "WAIT_EVENT_LOGICAL_APPLY_BGWORKER_STATE_CHANGE" just for
the consistency with other names.
> 13. 015_stream.pl
>
> I could not find test about TRUNCATE. IIUC apply bgworker works well
> even if it gets LOGICAL_REP_MSG_TRUNCATE message from main worker.
> Can you add the case?
I modified the test cases in "032_streaming_apply.pl" this time, the use case
you mentioned is covered now.
The rest of the comments are improved as suggested.
The new patches were attached in [1].
[1] -
https://www.postgresql.org/message-id/OS3PR01MB6275D64BE7726B0221B15F389E9F9%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Wed, Jul 27, 2022 at 16:03 PM Peter Smith <smithpb2250@gmail.com> wrote:
> Here are some review comments for the patch v19-0004:
Thanks for your kindly review and comments.
To avoid making this thread too long, I will reply to all of your comments
(0001-patch ~ 0004-patch) in this email.
In addition, in order not to confuse the replies, I added the following serial
number above your comments on 0004-patch:
```
4.2 && 4.3
4.4
4.5
```
> 1.6 src/backend/replication/logical/applybgworker.c - LogicalApplyBgwLoop
>
> +/* Apply Background Worker main loop */
> +static void
> +LogicalApplyBgwLoop(shm_mq_handle *mqh, volatile ApplyBgworkerShared
> *shared)
>
> 'shared' seems a very vague param name. Maybe can be 'bgw_shared' or
> 'parallel_shared' or something better?
>
> ~~~
>
> 1.7 src/backend/replication/logical/applybgworker.c - ApplyBgworkerMain
>
> +/*
> + * Apply Background Worker entry point
> + */
> +void
> +ApplyBgworkerMain(Datum main_arg)
> +{
> + volatile ApplyBgworkerShared *shared;
>
> 'shared' seems a very vague var name. Maybe can be 'bgw_shared' or
> 'parallel_shared' or something better?
>
> ~~~
>
> 1.8 src/backend/replication/logical/applybgworker.c -
> apply_bgworker_setup_dsm
>
> +static void
> +apply_bgworker_setup_dsm(ApplyBgworkerState *wstate)
> +{
> + shm_toc_estimator e;
> + Size segsize;
> + dsm_segment *seg;
> + shm_toc *toc;
> + ApplyBgworkerShared *shared;
> + shm_mq *mq;
>
> 'shared' seems a very vague var name. Maybe can be 'bgw_shared' or
> 'parallel_shared' or something better?
>
> ~~~
Not sure about this.
> 3.3 .../replication/logical/applybgworker.c
>
> @@ -800,3 +800,47 @@ apply_bgworker_subxact_info_add(TransactionId
> current_xid)
> MemoryContextSwitchTo(oldctx);
> }
> }
> +
> +/*
> + * Check if changes on this relation can be applied by an apply background
> + * worker.
> + *
> + * Although the commit order is maintained only allowing one process to
> commit
> + * at a time, the access order to the relation has changed. This could cause
> + * unexpected problems if the unique column on the replicated table is
> + * inconsistent with the publisher-side or contains non-immutable functions
> + * when applying transactions in the apply background worker.
> + */
> +void
> +apply_bgworker_relation_check(LogicalRepRelMapEntry *rel)
>
> "only allowing" -> "by only allowing" (I think you mean this, right?)
Since I'm not a native English speaker, I'm not quite sure which of the two
descriptions you suggested is better. See #3.4 in [1]. Now I overwrite your
last suggestion with your suggestion this time.
> 3.4
>
> + /*
> + * Return if changes on this relation can be applied by an apply background
> + * worker.
> + */
> + if (rel->parallel_apply == PARALLEL_APPLY_SAFE)
> + return;
> +
> + /* We are in error mode and should give user correct error. */
> + ereport(ERROR,
> + (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("cannot replicate target relation \"%s.%s\" using "
> + "subscription parameter streaming=parallel",
> + rel->remoterel.nspname, rel->remoterel.relname),
> + errdetail("The unique column on subscriber is not the unique "
> + "column on publisher or there is at least one "
> + "non-immutable function."),
> + errhint("Please change to use subscription parameter "
> + "streaming=on.")));
>
> 3.4a.
> Of course, the code should give the user the "correct error" if there
> is an error (!), but having a comment explicitly saying so does not
> serve any purpose.
>
> 3.4b.
> The logic might be simplified if it was written differently like:
>
> + if (rel->parallel_apply != PARALLEL_APPLY_SAFE)
> + ereport(ERROR, ...
Just to keep the style consistent with the function
apply_bgworker_relation_check.
> 3.8
>
> + /* Initialize the flag. */
> + entry->parallel_apply = PARALLEL_APPLY_SAFE;
>
> I previously suggested [1] (#3.6b) to move this. Consider, that you
> cannot logically flag the entry as "safe" until you are certain that
> it is safe. And you cannot be sure of that until you've passed all the
> checks this function is doing. Therefore IMO the assignment to
> PARALLEL_APPLY_SAFE should be the last line of the function.
Not sure about this.
> 3.11 src/backend/utils/cache/typcache.c - GetDomainConstraints
>
> @@ -2540,6 +2540,23 @@ compare_values_of_enum(TypeCacheEntry *tcache,
> Oid arg1, Oid arg2)
> return 0;
> }
>
> +/*
> + * GetDomainConstraints --- get DomainConstraintState list of
> specified domain type
> + */
> +List *
> +GetDomainConstraints(Oid type_id)
> +{
> + TypeCacheEntry *typentry;
> + List *constraints = NIL;
> +
> + typentry = lookup_type_cache(type_id,
> TYPECACHE_DOMAIN_CONSTR_INFO);
> +
> + if(typentry->domainData != NULL)
> + constraints = typentry->domainData->constraints;
> +
> + return constraints;
> +}
>
> This function can be simplified (if you want). e.g.
>
> List *
> GetDomainConstraints(Oid type_id)
> {
> TypeCacheEntry *typentry;
>
> typentry = lookup_type_cache(type_id, TYPECACHE_DOMAIN_CONSTR_INFO);
>
> return typentry->domainData ? typentry->domainData->constraints : NIL;
> }
I just think the former one looks clearer.
4.2 && 4.3
> 2. src/backend/replication/logical/worker.c - start_table_sync
>
> @@ -3902,20 +3925,28 @@ start_table_sync(XLogRecPtr *origin_startpos,
> char **myslotname)
> }
> PG_CATCH();
> {
> + /*
> + * Emit the error message, and recover from the error state to an idle
> + * state
> + */
> + HOLD_INTERRUPTS();
> +
> + EmitErrorReport();
> + AbortOutOfAnyTransaction();
> + FlushErrorState();
> +
> + RESUME_INTERRUPTS();
> +
> + /* Report the worker failed during table synchronization */
> + pgstat_report_subscription_error(MySubscription->oid, false);
> +
> + /* Set the retry flag. */
> + set_subscription_retry(true);
> +
> if (MySubscription->disableonerr)
> DisableSubscriptionAndExit();
> - else
> - {
> - /*
> - * Report the worker failed during table synchronization. Abort
> - * the current transaction so that the stats message is sent in an
> - * idle state.
> - */
> - AbortOutOfAnyTransaction();
> - pgstat_report_subscription_error(MySubscription->oid, false);
>
> - PG_RE_THROW();
> - }
> + proc_exit(0);
> }
>
> But is it correct to set the 'retry' flag even if the
> MySubscription->disableonerr is true? Won’t that mean even after the
> user corrects the problem and then re-enabled the subscription it
> still won't let the streaming=parallel work, because that retry flag
> is set?
>
> Also, Something seems wrong to me here - IIUC the patch changed this
> code because of the potential risk of an error within the
> set_subscription_retry function, but now if such an error happens the
> current code will bypass even getting to DisableSubscriptionAndExit,
> so the subscription won't have a chance to get disabled as the user
> might have wanted.
> 3. src/backend/replication/logical/worker.c - start_apply
>
> @@ -3940,20 +3971,27 @@ start_apply(XLogRecPtr origin_startpos)
> }
> PG_CATCH();
> {
> + /*
> + * Emit the error message, and recover from the error state to an idle
> + * state
> + */
> + HOLD_INTERRUPTS();
> +
> + EmitErrorReport();
> + AbortOutOfAnyTransaction();
> + FlushErrorState();
> +
> + RESUME_INTERRUPTS();
> +
> + /* Report the worker failed while applying changes */
> + pgstat_report_subscription_error(MySubscription->oid,
> + !am_tablesync_worker());
> +
> + /* Set the retry flag. */
> + set_subscription_retry(true);
> +
> if (MySubscription->disableonerr)
> DisableSubscriptionAndExit();
> - else
> - {
> - /*
> - * Report the worker failed while applying changes. Abort the
> - * current transaction so that the stats message is sent in an
> - * idle state.
> - */
> - AbortOutOfAnyTransaction();
> - pgstat_report_subscription_error(MySubscription-
> >oid, !am_tablesync_worker());
> -
> - PG_RE_THROW();
> - }
> }
>
> (Same as previous review comment #2)
>
> But is it correct to set the 'retry' flag even if the
> MySubscription->disableonerr is true? Won’t that mean even after the
> user corrects the problem and then re-enabled the subscription it
> still won't let the streaming=parallel work, because that retry flag
> is set?
>
> Also, Something seems wrong to me here - IIUC the patch changed this
> code because of the potential risk of an error within the
> set_subscription_retry function, but now if such an error happens the
> current code will bypass even getting to DisableSubscriptionAndExit,
> so the subscription won't have a chance to get disabled as the user
> might have wanted.
=>4.2.a
=>4.3.a
I think this is the expected behavior.
=>4.2.b
=>4.3.b
Fixed this point. (Invoke function set_subscription_retry after handling the
"disableonerr" parameter.)
4.4
> 4. src/backend/replication/logical/worker.c - DisableSubscriptionAndExit
>
> /*
> - * After error recovery, disable the subscription in a new transaction
> - * and exit cleanly.
> + * Disable the subscription in a new transaction.
> */
> static void
> DisableSubscriptionAndExit(void)
> {
> - /*
> - * Emit the error message, and recover from the error state to an idle
> - * state
> - */
> - HOLD_INTERRUPTS();
> -
> - EmitErrorReport();
> - AbortOutOfAnyTransaction();
> - FlushErrorState();
> -
> - RESUME_INTERRUPTS();
> -
> - /* Report the worker failed during either table synchronization or apply */
> - pgstat_report_subscription_error(MyLogicalRepWorker->subid,
> - !am_tablesync_worker());
> -
> /* Disable the subscription */
> StartTransactionCommand();
> DisableSubscription(MySubscription->oid);
> @@ -4231,8 +4252,6 @@ DisableSubscriptionAndExit(void)
> ereport(LOG,
> errmsg("logical replication subscription \"%s\" has been disabled
> due to an error",
> MySubscription->name));
> -
> - proc_exit(0);
> }
>
> 4a.
> Hmm, I think it is a bad idea to remove the "exiting" code from the
> function but still leave the function name the same as before saying
> "AndExit".
>
> 4b.
> Also, now the patch is unconditionally doing proc_exit(0) in the
> calling code where previously it would do PG_RE_THROW. So it's a
> subtle difference from the path the code used to take for worker
> errors..
=>4.a
Fixed as suggested.
=>4.b
I think function PG_RE_THROW will try to report the error and go away (see
function StartBackgroundWorker). So I think that since the error has been
reported at the beginning, it is fine to invoke function proc_exit to go away
at the end.
4.5
> 5. src/backend/replication/logical/worker.c - set_subscription_retry
>
> @@ -4467,3 +4486,63 @@ reset_apply_error_context_info(void)
> apply_error_callback_arg.remote_attnum = -1;
> set_apply_error_context_xact(InvalidTransactionId, InvalidXLogRecPtr);
> }
> +
> +/*
> + * Set subretry of pg_subscription catalog.
> + *
> + * If retry is true, subscriber is about to exit with an error. Otherwise, it
> + * means that the transaction was applied successfully.
> + */
> +static void
> +set_subscription_retry(bool retry)
> +{
> + Relation rel;
> + HeapTuple tup;
> + bool started_tx = false;
> + bool nulls[Natts_pg_subscription];
> + bool replaces[Natts_pg_subscription];
> + Datum values[Natts_pg_subscription];
> +
> + if (MySubscription->retry == retry ||
> + am_apply_bgworker())
> + return;
>
> Currently, I think this new 'subretry' field is only used to decide
> whether a retry can use an apply background worker or not. I think all
> this logic is *only* used when streaming=parallel. But AFAICT the
> logic for setting/clearing the retry flag is executed *always*
> regardless of the streaming mode.
>
> So for all the times when the user did not ask for streaming=parallel
> doesn't this just cause unnecessary overhead for every transaction?
I think it is fine. Because for one transaction, only the first time the
transaction is applied with failure and the first time it is successfully
retried, the catalog pg_subscription will be really modified.
The rest of the comments are improved as suggested.
The new patches were attached in [2].
[1] - https://www.postgresql.org/message-id/CAHut%2BPtRNAOwFtBp_TnDWdC7UpcTxPJzQnrm%3DNytN7cVBt5zRQ%40mail.gmail.com
[2] -
https://www.postgresql.org/message-id/OS3PR01MB6275D64BE7726B0221B15F389E9F9%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Mon, Jul 25, 2022 at 21:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> Few comments on 0001:
> ======================
Thanks for your comments.
> 1.
> - <structfield>substream</structfield> <type>bool</type>
> + <structfield>substream</structfield> <type>char</type>
> </para>
> <para>
> - If true, the subscription will allow streaming of in-progress
> - transactions
> + Controls how to handle the streaming of in-progress transactions:
> + <literal>f</literal> = disallow streaming of in-progress transactions,
> + <literal>t</literal> = spill the changes of in-progress transactions to
> + disk and apply at once after the transaction is committed on the
> + publisher,
> + <literal>p</literal> = apply changes directly using a background worker
>
> Shouldn't the description of 'p' be something like: apply changes
> directly using a background worker, if available, otherwise, it
> behaves the same as 't'
Improved as suggested.
> 2.
> Note that if an error happens when
> + applying changes in a background worker, the finish LSN of the
> + remote transaction might not be reported in the server log.
>
> Is there any case where finish LSN can be reported when applying via
> background worker, if not, then we should use 'won't' instead of
> 'might not'?
Yes, I think the use case you mentioned exists. (The finish LSN can be reported
when applying via background worker). So I do not change this.
For example, in the function apply_handle_stream_commit , if an error occurs
after invoking the function set_apply_error_context_xact, I think the error
message will contain the finish LSN.
> 3.
> +#define PG_LOGICAL_APPLY_SHM_MAGIC 0x79fb2447 // TODO Consider
> change
>
> It is better to change this as the same magic number is used by
> PG_TEST_SHM_MQ_MAGIC
Improved as suggested. I changed it to a random magic number (0x787ca067) that
doesn't duplicate in the HEAD.
> 4.
> + /* Ignore statistics fields that have been updated. */
> + s.cursor += IGNORE_SIZE_IN_MESSAGE;
>
> Can we change the comment to: "Ignore statistics fields that have been
> updated by the main apply worker."? Will it be better to name the
> define as "SIZE_STATS_MESSAGE"?
Improved the comments and the macro name as suggested.
> 5.
> +/* Apply Background Worker main loop */
> +static void
> +LogicalApplyBgwLoop(shm_mq_handle *mqh, volatile ApplyBgworkerShared
> *shared)
> {
> ...
> ...
>
> + apply_dispatch(&s);
> +
> + if (ConfigReloadPending)
> + {
> + ConfigReloadPending = false;
> + ProcessConfigFile(PGC_SIGHUP);
> + }
> +
> + MemoryContextSwitchTo(oldctx);
> + MemoryContextReset(ApplyMessageContext);
>
> We should not process the config file under ApplyMessageContext. You
> should switch context before processing the config file. See other
> similar usages in the code.
Fixed as suggested.
In addition, the apply bgworker misses switching "CurrentMemoryContext" back to
oldctx when it receives a "STOP" message. This will make oldctx lose track of
"TopMemoryContext". Fixed this by invoking `MemoryContextSwitchTo(oldctx);`
when processing the "STOP" message.
> 6.
> +/* Apply Background Worker main loop */
> +static void
> +LogicalApplyBgwLoop(shm_mq_handle *mqh, volatile ApplyBgworkerShared
> *shared)
> {
> ...
> ...
> + MemoryContextSwitchTo(oldctx);
> + MemoryContextReset(ApplyMessageContext);
> + }
> +
> + MemoryContextSwitchTo(TopMemoryContext);
> + MemoryContextReset(ApplyContext);
> ...
> }
>
> I don't see the need to reset ApplyContext here as we don't do
> anything in that context here.
Improved as suggested.
Removed the invocation of function MemoryContextReset(ApplyContext).
The new patches were attached in [1].
[1] -
https://www.postgresql.org/message-id/OS3PR01MB6275D64BE7726B0221B15F389E9F9%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"shiy.fnst@fujitsu.com"
Date:
On Thu, Aug 4, 2022 2:36 PM Wang, Wei/王 威 <wangw.fnst@fujitsu.com> wrote:
>
> I also did some other improvements based on the suggestions posted in this
> thread. Attach the new patches.
>
Thanks for updating the patch. Here are some comments on v20-0001 patch.
1.
+typedef struct ApplyBgworkerShared
+{
+ slock_t mutex;
+
+ /* Status of apply background worker. */
+ ApplyBgworkerStatus status;
+
+ /* proto version of publisher. */
+ uint32 proto_version;
+
+ TransactionId stream_xid;
+
+ /* id of apply background worker */
+ uint32 worker_id;
+} ApplyBgworkerShared;
Would it be better to modify the comment of "proto_version" to "Logical protocol
version"?
2. commnent of handle_streamed_transaction()
+ * Exception: When the main apply worker is applying streaming transactions in
+ * parallel mode (e.g. when addressing LOGICAL_REP_MSG_RELATION or
+ * LOGICAL_REP_MSG_TYPE changes), then return false.
This comment doesn't look very clear, could we change it to:
Exception: In SUBSTREAM_PARALLEL mode, if the message type is
LOGICAL_REP_MSG_RELATION or LOGICAL_REP_MSG_TYPE, return false even if this is
the main apply worker.
3.
+/*
+ * There are three fields in message: start_lsn, end_lsn and send_time. Because
+ * we have updated these statistics in apply worker, we could ignore these
+ * fields in apply background worker. (see function LogicalRepApplyLoop)
+ */
+#define SIZE_STATS_MESSAGE (3 * sizeof(uint64))
updated these statistics in apply worker
->
updated these statistics in main apply worker
4.
+static void
+LogicalApplyBgwLoop(shm_mq_handle *mqh, volatile ApplyBgworkerShared *shared)
+{
+ shm_mq_result shmq_res;
+ PGPROC *registrant;
+ ErrorContextCallback errcallback;
I think we can define "shmq_res" in the for loop.
5.
+ /*
+ * We use first byte of message for additional communication between
+ * main Logical replication worker and apply background workers, so if
+ * it differs from 'w', then process it first.
+ */
between main Logical replication worker and apply background workers
->
between main apply worker and apply background workers
Regards,
Shi yu
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Tue, Aug 2, 2022 at 5:16 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, July 27, 2022 4:22 PM houzj.fnst@fujitsu.com wrote: > > > > On Tuesday, July 26, 2022 5:34 PM Dilip Kumar <dilipbalaut@gmail.com> > > wrote: > > > > > 3. > > > Why are we restricting parallel apply workers only for the streamed > > > transactions, because streaming depends upon the size of the logical > > > decoding work mem so making steaming and parallel apply tightly > > > coupled seems too restrictive to me. Do we see some obvious problems > > > in applying other transactions in parallel? > > > > We thought there could be some conflict failure and deadlock if we parallel > > apply normal transaction which need transaction dependency check[1]. But I > > will do some more research for this and share the result soon. > > After thinking about this, I confirmed that it would be easy to cause deadlock > error if we don't have additional dependency analysis and COMMIT order preserve > handling for parallel apply normal transaction. > > Because the basic idea to parallel apply normal transaction in the first > version is that: the main apply worker will receive data from pub and pass them > to apply bgworker without applying by itself. And only before the apply > bgworker apply the final COMMIT command, it need to wait for any previous > transaction to finish to preserve the commit order. It means we could pass the > next transaction's data to another apply bgworker before the previous > transaction is committed in the first apply bgworker. > > In this approach, we have to do the dependency analysis because it's easy to > cause dead lock error when applying DMLs in parallel(See the attachment for the > examples where the dead lock could happen). So, it's a bit different from > streaming transaction. > > We could apply the next transaction only after the first transaction is > committed in which approach we don't need the dependency analysis, but it would > not bring noticeable performance improvement even if we start serval apply > workers to do that because the actual DMLs are not performed in parallel. > > Based on above, we plan to first introduce the patch to perform streaming > logical transactions by background workers, and then introduce parallel apply > normal transaction which design is different and need some additional handling. Yeah I think that makes sense. Since the streamed transactions are sent to standby interleaved so we can take advantage of parallelism and along with that we can also avoid the I/O so that will also speedup. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Mon, Aug 8, 2022 at 10:18 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> > Based on above, we plan to first introduce the patch to perform streaming
> > logical transactions by background workers, and then introduce parallel apply
> > normal transaction which design is different and need some additional handling.
>
> Yeah I think that makes sense. Since the streamed transactions are
> sent to standby interleaved so we can take advantage of parallelism
> and along with that we can also avoid the I/O so that will also
> speedup.
Some review comments on the latest version of the patch.
1.
+/* Queue size of DSM, 16 MB for now. */
+#define DSM_QUEUE_SIZE 160000000
Why don't we directly use 16 *1024 * 1024, that would be exactly 16 MB
so it will match with comments and also it would be more readable.
2.
+/*
+ * There are three fields in message: start_lsn, end_lsn and send_time. Because
+ * we have updated these statistics in apply worker, we could ignore these
+ * fields in apply background worker. (see function LogicalRepApplyLoop)
+ */
+#define SIZE_STATS_MESSAGE (3 * sizeof(uint64))
Instead of assuming you have 3 uint64 why don't directly add 2 *
sizeof(XLogRecPtr) + sizeof(TimestampTz) so that if this data type
ever changes
we don't need to track that we will have to change this as well.
3.
+/*
+ * Entry for a hash table we use to map from xid to our apply background worker
+ * state.
+ */
+typedef struct ApplyBgworkerEntry
+{
+ TransactionId xid;
+ ApplyBgworkerState *wstate;
+} ApplyBgworkerEntry;
Mention in the comment of the structure or for the member that xid is
the key of the hash. Refer to other such structures for the
reference.
I am doing a more detailed review but this is what I got so far.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Mon, Aug 8, 2022 at 11:41 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Mon, Aug 8, 2022 at 10:18 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> >
> > > Based on above, we plan to first introduce the patch to perform streaming
> > > logical transactions by background workers, and then introduce parallel apply
> > > normal transaction which design is different and need some additional handling.
> >
> > Yeah I think that makes sense. Since the streamed transactions are
> > sent to standby interleaved so we can take advantage of parallelism
> > and along with that we can also avoid the I/O so that will also
> > speedup.
>
> Some review comments on the latest version of the patch.
>
> 1.
> +/* Queue size of DSM, 16 MB for now. */
> +#define DSM_QUEUE_SIZE 160000000
>
> Why don't we directly use 16 *1024 * 1024, that would be exactly 16 MB
> so it will match with comments and also it would be more readable.
>
> 2.
> +/*
> + * There are three fields in message: start_lsn, end_lsn and send_time. Because
> + * we have updated these statistics in apply worker, we could ignore these
> + * fields in apply background worker. (see function LogicalRepApplyLoop)
> + */
> +#define SIZE_STATS_MESSAGE (3 * sizeof(uint64))
>
> Instead of assuming you have 3 uint64 why don't directly add 2 *
> sizeof(XLogRecPtr) + sizeof(TimestampTz) so that if this data type
> ever changes
> we don't need to track that we will have to change this as well.
>
> 3.
> +/*
> + * Entry for a hash table we use to map from xid to our apply background worker
> + * state.
> + */
> +typedef struct ApplyBgworkerEntry
> +{
> + TransactionId xid;
> + ApplyBgworkerState *wstate;
> +} ApplyBgworkerEntry;
>
> Mention in the comment of the structure or for the member that xid is
> the key of the hash. Refer to other such structures for the
> reference.
>
> I am doing a more detailed review but this is what I got so far.
Some more comments
+ /*
+ * Exit if any relation is not in the READY state and if any worker is
+ * handling the streaming transaction at the same time. Because for
+ * streaming transactions that is being applied in apply background
+ * worker, we cannot decide whether to apply the change for a relation
+ * that is not in the READY state (see should_apply_changes_for_rel) as we
+ * won't know remote_final_lsn by that time.
+ */
+ if (list_length(ApplyBgworkersFreeList) !=
list_length(ApplyBgworkersList) &&
+ !AllTablesyncsReady())
+ {
+ ereport(LOG,
+ (errmsg("logical replication apply workers for
subscription \"%s\" will restart",
+ MySubscription->name),
+ errdetail("Cannot handle streamed replication
transaction by apply "
+ "background workers until all tables are
synchronized")));
+
+ proc_exit(0);
+ }
How this situation can occur? I mean while starting a background
worker itself we can check whether all tables are sync ready or not
right?
+ /* Check the status of apply background worker if any. */
+ apply_bgworker_check_status();
+
What is the need to checking each worker status on every commit? I
mean if there are a lot of small transactions along with some
steamiing transactions
then it will affect the apply performance for those small transactions?
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Wang,
Thanks for updating patch sets! Followings are comments about v20-0001.
1. config.sgml
```
<para>
Specifies maximum number of logical replication workers. This includes
both apply workers and table synchronization workers.
</para>
```
I think you can add a description in the above paragraph, like
" This includes apply main workers, apply background workers, and table synchronization workers."
2. logical-replication.sgml
2.a Configuration Settings
```
<varname>max_logical_replication_workers</varname> must be set to at least
the number of subscriptions, again plus some reserve for the table
synchronization.
```
I think you can add a description in the above paragraph, like
"... the number of subscriptions, plus some reserve for the table synchronization
and the streaming transaction."
2.b Monitoring
```
<para>
Normally, there is a single apply process running for an enabled
subscription. A disabled subscription or a crashed subscription will have
zero rows in this view. If the initial data synchronization of any
table is in progress, there will be additional workers for the tables
being synchronized.
</para>
```
I think you can add a sentence in the above paragraph, like
"... synchronized. Moreover, if the streaming transaction is applied parallelly,
there will be additional workers"
3. launcher.c
```
+ /* Sanity check : we don't support table sync in subworker. */
```
I think "Sanity check :" should be "Sanity check:", per other files.
4. worker.c
4.a handle_streamed_transaction()
```
- /* not in streaming mode */
- if (!in_streamed_transaction)
+ /* Not in streaming mode */
+ if (!(in_streamed_transaction || am_apply_bgworker()))
```
I think the comment should also mention about apply background worker case.
4.b handle_streamed_transaction()
```
- Assert(stream_fd != NULL);
```
I think this assersion seems reasonable in case of stream='on'.
Could you revive it and move to later part in the function, like after subxact_info_add(current_xid)?
4.c apply_handle_prepare_internal()
```
* BeginTransactionBlock is necessary to balance the EndTransactionBlock
* called within the PrepareTransactionBlock below.
*/
- BeginTransactionBlock();
+ if (!IsTransactionBlock())
+ BeginTransactionBlock();
+
```
I think the comment should be "We must be in transaction block to balance...".
4.d apply_handle_stream_prepare()
```
- *
- * Logic is in two parts:
- * 1. Replay all the spooled operations
- * 2. Mark the transaction as prepared
*/
static void
apply_handle_stream_prepare(StringInfo s)
```
I think these comments are useful when stream='on',
so it should be moved to later part.
5. applybgworker.c
5.a apply_bgworker_setup()
```
+ elog(DEBUG1, "setting up apply worker #%u", list_length(ApplyBgworkersList) + 1);
```
"apply worker" should be "apply background worker".
5.b LogicalApplyBgwLoop()
```
+ elog(DEBUG1, "[Apply BGW #%u] ended processing streaming chunk,"
+ "waiting on shm_mq_receive", shared->worker_id);
```
A blank is needed after comma. I checked serverlog, and the message outputed like:
```
[Apply BGW #1] ended processing streaming chunk,waiting on shm_mq_receive
```
6.
When I started up the apply background worker and did `SELECT * from pg_stat_subscription`, I got following lines:
```
postgres=# select * from pg_stat_subscription;
subid | subname | pid | relid | received_lsn | last_msg_send_time | last_msg_receipt_time |
latest_end_lsn| latest_end
_time
-------+---------+-------+-------+--------------+-------------------------------+-------------------------------+----------------+------------------
-------------
16400 | sub | 22383 | | | -infinity | -infinity |
| -infinity
16400 | sub | 22312 | | 0/6734740 | 2022-08-09 07:40:19.367676+00 | 2022-08-09 07:40:19.375455+00 |
0/6734740 | 2022-08-09 07:40:
19.367676+00
(2 rows)
```
6.a
It seems that the upper line represents the apply background worker, but I think last_msg_send_time and
last_msg_receipt_timeshould be null.
Is it like initialization mistake?
```
$ ps aux | grep 22383
... postgres: logical replication apply background worker for subscription 16400
```
6.b
Currently, the documentation doesn't clarify the method to determine the type of logical replication workers.
Could you add descriptions about it?
I think adding a column "subworker" is an alternative approach.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Aug 4, 2022 at 12:10 PM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> On Mon, Jul 25, 2022 at 21:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > Few comments on 0001:
> > ======================
>
> Thanks for your comments.
>
Review comments on v20-0001-Perform-streaming-logical-transactions-by-backgr
===============================================================
1.
+ <para>
+ If set to <literal>on</literal>, the incoming changes are written to
+ temporary files and then applied only after the transaction is
+ committed on the publisher.
It is not very clear that the transaction is applied when the commit
is received by the subscriber. Can we slightly change it to: "If set
to <literal>on</literal>, the incoming changes are written to
temporary files and then applied only after the transaction is
committed on the publisher and received by the subscriber."
2.
/* First time through, initialize apply workers hashtable */
+ if (ApplyBgworkersHash == NULL)
+ {
+ HASHCTL ctl;
+
+ MemSet(&ctl, 0, sizeof(ctl));
+ ctl.keysize = sizeof(TransactionId);
+ ctl.entrysize = sizeof(ApplyBgworkerEntry);
+ ctl.hcxt = ApplyContext;
+
+ ApplyBgworkersHash = hash_create("logical apply workers hash", 8, &ctl,
+ HASH_ELEM | HASH_BLOBS | HASH_CONTEXT);
I think it would be better if we start with probably 16 element hash
table, 8 seems to be on the lower side.
3.
+/*
+ * Try to look up worker assigned before (see function apply_bgworker_get_free)
+ * inside ApplyBgworkersHash for requested xid.
+ */
+ApplyBgworkerState *
+apply_bgworker_find(TransactionId xid)
The above comment is not very clear. There doesn't seem to be any
function named apply_bgworker_get_free in the patch. Can we write this
comment as: "Find the previously assigned worker for the given
transaction, if any."
4.
/*
+ * Push apply error context callback. Fields will be filled applying a
+ * change.
+ */
/Fields will be filled applying a change./Fields will be filled while
applying a change.
5.
+void
+ApplyBgworkerMain(Datum main_arg)
+{
...
...
+ StartTransactionCommand();
+ oldcontext = MemoryContextSwitchTo(ApplyContext);
+
+ MySubscription = GetSubscription(MyLogicalRepWorker->subid, true);
+ if (!MySubscription)
+ {
+ ereport(LOG,
+ (errmsg("logical replication apply worker for subscription %u will not "
+ "start because the subscription was removed during startup",
+ MyLogicalRepWorker->subid)));
+ proc_exit(0);
+ }
+
+ MySubscriptionValid = true;
+ MemoryContextSwitchTo(oldcontext);
+
+ /* Setup synchronous commit according to the user's wishes */
+ SetConfigOption("synchronous_commit", MySubscription->synccommit,
+ PGC_BACKEND, PGC_S_OVERRIDE);
+
+ /* Keep us informed about subscription changes. */
+ CacheRegisterSyscacheCallback(SUBSCRIPTIONOID,
+ subscription_change_cb,
+ (Datum) 0);
+
+ CommitTransactionCommand();
...
This part appears of the code appears to be the same as we have in
ApplyWorkerMain() except that the patch doesn't check whether the
subscription is enabled. Is there a reason to not have that check here
as well? Then in ApplyWorkerMain(), we do LOG the type of worker that
is also missing here. Unless there is a specific reason to have a
different code here, we should move this part to a common function and
call it both from ApplyWorkerMain() and ApplyBgworkerMain().
6. I think the code in ApplyBgworkerMain() to set
session_replication_role, search_path, and connect to the database
also appears to be the same in ApplyWorkerMain(). If so, that can also
be moved to the common function mentioned in the previous point.
7. I think we need to register for subscription rel map invalidation
(invalidate_syncing_table_states) in ApplyBgworkerMain similar to
ApplyWorkerMain. The reason is that we check the table state after
processing a commit or similar change record via a call to
process_syncing_tables.
8. In apply_bgworker_setup_dsm(), we should have handling related to
dsm_create failure due to max_segments reached as we have in
InitializeParallelDSM(). We can follow the regular path of streaming
transactions in case we are not able to create DSM instead of
parallelizing it.
9.
+ shm_toc_initialize_estimator(&e);
+ shm_toc_estimate_chunk(&e, sizeof(ApplyBgworkerShared));
+ shm_toc_estimate_chunk(&e, (Size) queue_size);
+
+ shm_toc_estimate_keys(&e, 1 + 1);
Here, you can directly write 2 instead of (1 + 1) stuff. It is quite
clear that we need two keys here.
10.
apply_bgworker_wait_for()
{
...
+ /* Wait to be signalled. */
+ WaitLatch(MyLatch, WL_LATCH_SET | WL_EXIT_ON_PM_DEATH, 0,
+ WAIT_EVENT_LOGICAL_APPLY_BGWORKER_STATE_CHANGE);
...
}
Typecast with the void, if we don't care for the return value.
11.
+static void
+apply_bgworker_shutdown(int code, Datum arg)
+{
+ SpinLockAcquire(&MyParallelShared->mutex);
+ MyParallelShared->status = APPLY_BGWORKER_EXIT;
+ SpinLockRelease(&MyParallelShared->mutex);
Is there a reason to not use apply_bgworker_set_status() directly?
12.
+ * Special case is if the first change comes from subtransaction, then
+ * we check that current_xid differs from stream_xid.
+ */
+void
+apply_bgworker_subxact_info_add(TransactionId current_xid)
+{
+ if (current_xid != stream_xid &&
+ !list_member_int(subxactlist, (int) current_xid))
...
...
I don't understand the above comment. Does that mean we don't need to
define a savepoint if the first change is from a subtransaction? Also,
keep an empty line before the above comment.
13.
+void
+apply_bgworker_subxact_info_add(TransactionId current_xid)
+{
+ if (current_xid != stream_xid &&
+ !list_member_int(subxactlist, (int) current_xid))
+ {
+ MemoryContext oldctx;
+ char spname[MAXPGPATH];
+
+ snprintf(spname, MAXPGPATH, "savepoint_for_xid_%u", current_xid);
To uniquely generate the savepoint name, it is better to append the
subscription id as well? Something like pg_sp_<subid>_<xid>.
14. The CommitTransactionCommand() call in
apply_bgworker_subxact_info_add looks a bit odd as that function
neither seems to be starting the transaction command nor has any
comments explaining it. Shall we do it in caller where it is more
apparent to do the same?
15.
else
snprintf(bgw.bgw_name, BGW_MAXLEN,
"logical replication worker for subscription %u", subid);
+
snprintf(bgw.bgw_type, BGW_MAXLEN, "logical replication worker");
Spurious new line
16.
@@ -1153,7 +1162,14 @@ replorigin_session_setup(RepOriginId node)
Assert(session_replication_state->roident != InvalidRepOriginId);
- session_replication_state->acquired_by = MyProcPid;
+ if (must_acquire)
+ session_replication_state->acquired_by = MyProcPid;
+ else if (session_replication_state->acquired_by == 0)
+ ereport(ERROR,
+ (errcode(ERRCODE_CONFIGURATION_LIMIT_EXCEEDED),
+ errmsg("apply background worker could not find replication state
slot for replication origin with OID %u",
+ node),
+ errdetail("There is no replication state slot set by its main apply
worker.")));
It is not a good idea to give apply workers specific messages from
this API because I don't think we can assume this is used by only
apply workers. It seems to me that if 'must_acquire' is false, then we
should either give elog(ERROR, ..) or there should be an Assert for
the same. I am not completely sure but maybe we can request the caller
to supply the PID (which already has acquired this origin) in case
must_acquire is false and then use it in Assert/elog to ensure the
correct usage of API. What do you think?
17. The commit message can explain the abort-related new information
this patch sends to the subscribers.
18.
+ * In streaming case (receiving a block of streamed transaction), for
+ * SUBSTREAM_ON mode, simply redirect it to a file for the proper toplevel
+ * transaction, and for SUBSTREAM_PARALLEL mode, send the changes to apply
+ * background workers (LOGICAL_REP_MSG_RELATION or LOGICAL_REP_MSG_TYPE changes
+ * will also be applied in main apply worker).
In this, part of the comment "(LOGICAL_REP_MSG_RELATION or
LOGICAL_REP_MSG_TYPE changes will also be applied in main apply
worker)" is not very clear. Do you mean to say that these messages are
applied by both main and background apply workers, if so, then please
state the same explicitly?
19.
- /* not in streaming mode */
- if (!in_streamed_transaction)
+ /* Not in streaming mode */
+ if (!(in_streamed_transaction || am_apply_bgworker()))
...
...
- /* write the change to the current file */
+ /* Write the change to the current file */
stream_write_change(action, s);
I don't see the need to change the above comments.
20.
static bool
handle_streamed_transaction(LogicalRepMsgType action, StringInfo s)
{
...
...
+ if (am_apply_bgworker())
+ {
+ /* Define a savepoint for a subxact if needed. */
+ apply_bgworker_subxact_info_add(current_xid);
+
+ return false;
+ }
+
+ if (apply_bgworker_active())
Isn't it better to use else if in the above code and probably else for
the remaining part of code in this function?
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Aug 9, 2022 at 11:09 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> Some more comments
>
> + /*
> + * Exit if any relation is not in the READY state and if any worker is
> + * handling the streaming transaction at the same time. Because for
> + * streaming transactions that is being applied in apply background
> + * worker, we cannot decide whether to apply the change for a relation
> + * that is not in the READY state (see should_apply_changes_for_rel) as we
> + * won't know remote_final_lsn by that time.
> + */
> + if (list_length(ApplyBgworkersFreeList) !=
> list_length(ApplyBgworkersList) &&
> + !AllTablesyncsReady())
> + {
> + ereport(LOG,
> + (errmsg("logical replication apply workers for
> subscription \"%s\" will restart",
> + MySubscription->name),
> + errdetail("Cannot handle streamed replication
> transaction by apply "
> + "background workers until all tables are
> synchronized")));
> +
> + proc_exit(0);
> + }
>
> How this situation can occur? I mean while starting a background
> worker itself we can check whether all tables are sync ready or not
> right?
>
We are already checking at the start in apply_bgworker_can_start() but
I think it is required to check at the later point of time as well
because the new rels can be added to pg_subscription_rel via Alter
Subscription ... Refresh. I feel if that reasoning is correct then we
can probably expand comments to make it clear.
> + /* Check the status of apply background worker if any. */
> + apply_bgworker_check_status();
> +
>
> What is the need to checking each worker status on every commit? I
> mean if there are a lot of small transactions along with some
> steamiing transactions
> then it will affect the apply performance for those small transactions?
>
I don't think performance will be a concern because this won't do any
costly operation unless invalidation happens in which case it will
access system catalogs. However, if my above understanding is correct
that new tables can be added during the apply process then not sure
doing it at commit time is sufficient/correct because it can change
even during the transaction.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Hi Wang,
> 6.a
>
> It seems that the upper line represents the apply background worker, but I think
> last_msg_send_time and last_msg_receipt_time should be null.
> Is it like initialization mistake?
I checked again about the issue.
Attributes worker->last_send_time, worker->last_recv_time, and worker->reply_time
are initialized in logicalrep_worker_launch():
```
...
TIMESTAMP_NOBEGIN(worker->last_send_time);
TIMESTAMP_NOBEGIN(worker->last_recv_time);
worker->reply_lsn = InvalidXLogRecPtr;
TIMESTAMP_NOBEGIN(worker->reply_time);
...
```
And the macro is defined in timestamp.h, and it seems that the values are initialized as PG_INT64_MIN.
```
#define DT_NOBEGIN PG_INT64_MIN
#define DT_NOEND PG_INT64_MAX
#define TIMESTAMP_NOBEGIN(j) \
do {(j) = DT_NOBEGIN;} while (0)
```
However, in pg_stat_get_subscription(), these values are regarded as null if they are zero.
```
if (worker.last_send_time == 0)
nulls[4] = true;
else
values[4] = TimestampTzGetDatum(worker.last_send_time);
if (worker.last_recv_time == 0)
nulls[5] = true;
else
values[5] = TimestampTzGetDatum(worker.last_recv_time);
```
I think above lines are wrong, these values should be compared with PG_INT64_MIN.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Aug 9, 2022 at 5:39 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Tue, Aug 9, 2022 at 11:09 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> >
> > Some more comments
> >
> > + /*
> > + * Exit if any relation is not in the READY state and if any worker is
> > + * handling the streaming transaction at the same time. Because for
> > + * streaming transactions that is being applied in apply background
> > + * worker, we cannot decide whether to apply the change for a relation
> > + * that is not in the READY state (see should_apply_changes_for_rel) as we
> > + * won't know remote_final_lsn by that time.
> > + */
> > + if (list_length(ApplyBgworkersFreeList) !=
> > list_length(ApplyBgworkersList) &&
> > + !AllTablesyncsReady())
> > + {
> > + ereport(LOG,
> > + (errmsg("logical replication apply workers for
> > subscription \"%s\" will restart",
> > + MySubscription->name),
> > + errdetail("Cannot handle streamed replication
> > transaction by apply "
> > + "background workers until all tables are
> > synchronized")));
> > +
> > + proc_exit(0);
> > + }
> >
> > How this situation can occur? I mean while starting a background
> > worker itself we can check whether all tables are sync ready or not
> > right?
> >
>
> We are already checking at the start in apply_bgworker_can_start() but
> I think it is required to check at the later point of time as well
> because the new rels can be added to pg_subscription_rel via Alter
> Subscription ... Refresh. I feel if that reasoning is correct then we
> can probably expand comments to make it clear.
>
> > + /* Check the status of apply background worker if any. */
> > + apply_bgworker_check_status();
> > +
> >
> > What is the need to checking each worker status on every commit? I
> > mean if there are a lot of small transactions along with some
> > steamiing transactions
> > then it will affect the apply performance for those small transactions?
> >
>
> I don't think performance will be a concern because this won't do any
> costly operation unless invalidation happens in which case it will
> access system catalogs. However, if my above understanding is correct
> that new tables can be added during the apply process then not sure
> doing it at commit time is sufficient/correct because it can change
> even during the transaction.
>
One idea that may handle it cleanly is to check for
SUBREL_STATE_SYNCDONE state in should_apply_changes_for_rel() and
error out for apply_bg_worker(). For the SUBREL_STATE_READY state, it
should return true and for any other state, it can return false. The
one advantage of this approach could be that the parallel apply worker
will give an error only if the corresponding transaction has performed
any operation on the relation that has reached the SYNCDONE state.
OTOH, checking at each transaction end can also lead to erroring out
of workers even if the parallel apply transaction doesn't perform any
operation on the relation which is not in the READY state.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for the patch v20-0001:
======
1. doc/src/sgml/catalogs.sgml
+ <literal>p</literal> = apply changes directly using a background
+ worker, if available, otherwise, it behaves the same as 't'
The different char values 'f','t','p' are separated by comma (,) in
the list, which is normal for the pgdocs AFAIK. However, because of
this I don't think it is a good idea to use those other commas within
the description for 'p', I suggest you remove those ones to avoid
ambiguity with the separators.
======
2. doc/src/sgml/protocol.sgml
@@ -3096,7 +3096,7 @@ psql "dbname=postgres replication=database" -c
"IDENTIFY_SYSTEM;"
<listitem>
<para>
Protocol version. Currently versions <literal>1</literal>,
<literal>2</literal>,
- and <literal>3</literal> are supported.
+ <literal>3</literal> and <literal>4</literal> are supported.
</para>
Put a comma after the penultimate value like it had before.
======
3. src/backend/replication/logical/applybgworker.c - <general>
There are multiple function comments and other code comments in this
file that are missing a terminating period (.)
======
4. src/backend/replication/logical/applybgworker.c - apply_bgworker_start
+/*
+ * Try to get a free apply background worker.
+ *
+ * If there is at least one worker in the free list, then take one. Otherwise,
+ * try to start a new apply background worker. If successful, cache it in
+ * ApplyBgworkersHash keyed by the specified xid.
+ */
+ApplyBgworkerState *
+apply_bgworker_start(TransactionId xid)
SUGGESTION (for function comment)
Return the apply background worker that will be used for the specified xid.
If an apply background worker is found in the free list then re-use
it, otherwise start a fresh one. Cache the worker ApplyBgworkersHash
keyed by the specified xid.
~~~
5.
+ /* Try to get a free apply background worker */
+ if (list_length(ApplyBgworkersFreeList) > 0)
if (list_length(ApplyBgworkersFreeList) > 0)
AFAIK a non-empty list is guaranteed to be not NIL, and an empty list
is guaranteed to be NIL. So if you want to the above can simply be
written as:
if (ApplyBgworkersFreeList)
~~~
6. src/backend/replication/logical/applybgworker.c - apply_bgworker_find
+/*
+ * Try to look up worker assigned before (see function apply_bgworker_get_free)
+ * inside ApplyBgworkersHash for requested xid.
+ */
+ApplyBgworkerState *
+apply_bgworker_find(TransactionId xid)
SUGGESTION (for function comment)
Find the worker previously assigned/cached for this xid. (see function
apply_bgworker_start)
~~~
7.
+ Assert(status == APPLY_BGWORKER_BUSY);
+
+ return entry->wstate;
+ }
+ else
+ return NULL;
IMO here it is better to just remove that 'else' and unconditionally
return NULL at the end of this function.
~~~
8. src/backend/replication/logical/applybgworker.c -
apply_bgworker_subxact_info_add
+ * Inside apply background worker we can figure out that new subtransaction was
+ * started if new change arrived with different xid. In that case we can define
+ * named savepoint, so that we were able to commit/rollback it separately
+ * later.
+ * Special case is if the first change comes from subtransaction, then
+ * we check that current_xid differs from stream_xid.
+ */
+void
+apply_bgworker_subxact_info_add(TransactionId current_xid)
It is not quite English. Can you improve it a bit?
SUGGESTION (maybe like this?)
The apply background worker can figure out if a new subtransaction was
started by checking if the new change arrived with different xid. In
that case define a named savepoint, so that we are able to
commit/rollback it separately later. A special case is when the first
change comes from subtransaction – this is determined by checking if
the current_xid differs from stream_xid.
======
9. src/backend/replication/logical/launcher.c - WaitForReplicationWorkerAttach
+ *
+ * Return false if the attach fails. Otherwise return true.
*/
-static void
+static bool
WaitForReplicationWorkerAttach(LogicalRepWorker *worker,
Why not just say "Return whether the attach was successful."
~~~
10. src/backend/replication/logical/launcher.c - logicalrep_worker_stop
+ /* Found the main worker, then try to stop it. */
+ if (worker)
+ logicalrep_worker_stop_internal(worker);
IMO the comment is kind of pointless because it only says what the
code is clearly doing. If you really wanted to reinforce this worker
is a main apply worker then you can do that with code like:
if (worker)
{
Assert(!worker->subworker);
logicalrep_worker_stop_internal(worker);
}
~~~
11. src/backend/replication/logical/launcher.c - logicalrep_worker_detach
@@ -599,6 +632,29 @@ logicalrep_worker_attach(int slot)
static void
logicalrep_worker_detach(void)
{
+ /*
+ * This is the main apply worker, stop all the apply background workers we
+ * started before.
+ */
+ if (!MyLogicalRepWorker->subworker)
SUGGESTION (for comment)
This is the main apply worker. Stop all apply background workers
previously started from here.
~~~
12 src/backend/replication/logical/launcher.c - logicalrep_apply_bgworker_count
+/*
+ * Count the number of registered (not necessarily running) apply background
+ * workers for a subscription.
+ */
+int
+logicalrep_apply_bgworker_count(Oid subid)
SUGGESTION
Count the number of registered (but not necessarily running) apply
background workers for a subscription.
~~~
13.
+ /* Search for attached worker for a given subscription id. */
+ for (i = 0; i < max_logical_replication_workers; i++)
SUGGESTION
Scan all attached apply background workers, only counting those which
have the given subscription id.
======
14. src/backend/replication/logical/worker.c - apply_error_callback
+ {
+ if (errarg->remote_attnum < 0)
+ {
+ if (XLogRecPtrIsInvalid(errarg->finish_lsn))
+ errcontext("processing remote data for replication origin \"%s\"
during \"%s\" for replication target relation \"%s.%s\" in transaction
%u",
+ errarg->origin_name,
+ logicalrep_message_type(errarg->command),
+ errarg->rel->remoterel.nspname,
+ errarg->rel->remoterel.relname,
+ errarg->remote_xid);
+ else
+ errcontext("processing remote data for replication origin \"%s\"
during \"%s\" for replication target relation \"%s.%s\" in transaction
%u finished at %X/%X",
+ errarg->origin_name,
+ logicalrep_message_type(errarg->command),
+ errarg->rel->remoterel.nspname,
+ errarg->rel->remoterel.relname,
+ errarg->remote_xid,
+ LSN_FORMAT_ARGS(errarg->finish_lsn));
+ }
+ else
+ {
+ if (XLogRecPtrIsInvalid(errarg->finish_lsn))
+ errcontext("processing remote data for replication origin \"%s\"
during \"%s\" for replication target relation \"%s.%s\" column \"%s\"
in transaction %u",
+ errarg->origin_name,
+ logicalrep_message_type(errarg->command),
+ errarg->rel->remoterel.nspname,
+ errarg->rel->remoterel.relname,
+ errarg->rel->remoterel.attnames[errarg->remote_attnum],
+ errarg->remote_xid);
+ else
+ errcontext("processing remote data for replication origin \"%s\"
during \"%s\" for replication target relation \"%s.%s\" column \"%s\"
in transaction %u finished at %X/%X",
+ errarg->origin_name,
+ logicalrep_message_type(errarg->command),
+ errarg->rel->remoterel.nspname,
+ errarg->rel->remoterel.relname,
+ errarg->rel->remoterel.attnames[errarg->remote_attnum],
+ errarg->remote_xid,
+ LSN_FORMAT_ARGS(errarg->finish_lsn));
+ }
+ }
There is quite a lot of common code here:
"processing remote data for replication origin \"%s\" during \"%s\"
for replication target relation \"%s.%s\"
errarg->origin_name,
logicalrep_message_type(errarg->command),
errarg->rel->remoterel.nspname,
errarg->rel->remoterel.relname,
Is it worth trying to extract that common part to keep this code
shorter? E.g. It could be easily done just with some #defines
======
15. src/include/replication/worker_internal.h
+ /* proto version of publisher. */
+ uint32 proto_version;
SUGGESTION
Protocol version of publisher
~~~
16.
+ /* id of apply background worker */
+ uint32 worker_id;
Uppercase comment
~~~
17.
+/*
+ * Struct for maintaining an apply background worker.
+ */
+typedef struct ApplyBgworkerState
I'm not sure what this comment means. Perhaps there are some words missing?
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Aug 4, 2022 at 12:07 PM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> On Thurs, Jul 28, 2022 at 13:20 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote:
> >
> > Dear Wang-san,
> >
> > Hi, I'm also interested in the patch and I started to review this.
> > Followings are comments about 0001.
>
> Thanks for your kindly review and comments.
> To avoid making this thread too long, I will reply to all of your comments
> (#1~#13) in this email.
>
> > 1. terminology
> >
> > In your patch a new worker "apply background worker" has been introduced,
> > but I thought it might be confused because PostgreSQL has already the worker
> > "background worker".
> > Both of apply worker and apply bworker are categolized as bgworker.
> > Do you have any reasons not to use "apply parallel worker" or "apply streaming
> > worker"?
> > (Note that I'm not native English speaker)
>
> Since we will later consider applying non-streamed transactions in parallel, I
> think "apply streaming worker" might not be very suitable. I think PostgreSQL
> also has the worker "parallel worker", so for "apply parallel worker" and
> "apply background worker", I feel that "apply background worker" will make the
> relationship between workers more clear. ("[main] apply worker" and "apply
> background worker")
>
But, on similar lines, we do have vacuumparallel.c for parallelizing
index vacuum. I agree with Kuroda-San on this point that the currently
proposed terminology doesn't sound to be very clear. The other options
that come to my mind are "apply streaming transaction worker", "apply
parallel worker" and file name could be applystreamworker.c,
applyparallel.c, applyparallelworker.c, etc. I see the point why you
are hesitant in calling it "apply parallel worker" but it is quite
possible that even for non-streamed xacts, we will share quite some
part of this code.
Thoughts?
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, August 9, 2022 7:00 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Aug 4, 2022 at 12:10 PM wangw.fnst@fujitsu.com
> <wangw.fnst@fujitsu.com> wrote:
> >
> > On Mon, Jul 25, 2022 at 21:50 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> > > Few comments on 0001:
> > > ======================
> >
> > Thanks for your comments.
> >
>
> Review comments on
> v20-0001-Perform-streaming-logical-transactions-by-backgr
> ===================================================
> ============
> 1.
> + <para>
> + If set to <literal>on</literal>, the incoming changes are written to
> + temporary files and then applied only after the transaction is
> + committed on the publisher.
>
> It is not very clear that the transaction is applied when the commit is received
> by the subscriber. Can we slightly change it to: "If set to <literal>on</literal>,
> the incoming changes are written to temporary files and then applied only after
> the transaction is committed on the publisher and received by the subscriber."
Changed.
> 2.
> /* First time through, initialize apply workers hashtable */
> + if (ApplyBgworkersHash == NULL)
> + {
> + HASHCTL ctl;
> +
> + MemSet(&ctl, 0, sizeof(ctl));
> + ctl.keysize = sizeof(TransactionId);
> + ctl.entrysize = sizeof(ApplyBgworkerEntry); ctl.hcxt = ApplyContext;
> +
> + ApplyBgworkersHash = hash_create("logical apply workers hash", 8, &ctl,
> + HASH_ELEM | HASH_BLOBS | HASH_CONTEXT);
>
> I think it would be better if we start with probably 16 element hash table, 8
> seems to be on the lower side.
Changed.
> 3.
> +/*
> + * Try to look up worker assigned before (see function
> +apply_bgworker_get_free)
> + * inside ApplyBgworkersHash for requested xid.
> + */
> +ApplyBgworkerState *
> +apply_bgworker_find(TransactionId xid)
>
> The above comment is not very clear. There doesn't seem to be any function
> named apply_bgworker_get_free in the patch. Can we write this comment as:
> "Find the previously assigned worker for the given transaction, if any."
Changed the comments.
> 4.
> /*
> + * Push apply error context callback. Fields will be filled applying a
> + * change.
> + */
>
> /Fields will be filled applying a change./Fields will be filled while applying a
> change.
Changed.
> 5.
> +void
> +ApplyBgworkerMain(Datum main_arg)
> +{
> ...
> ...
> + StartTransactionCommand();
> + oldcontext = MemoryContextSwitchTo(ApplyContext);
> +
> + MySubscription = GetSubscription(MyLogicalRepWorker->subid, true); if
> + (!MySubscription) { ereport(LOG, (errmsg("logical replication apply
> + worker for subscription %u will not "
> + "start because the subscription was removed during startup",
> + MyLogicalRepWorker->subid)));
> + proc_exit(0);
> + }
> +
> + MySubscriptionValid = true;
> + MemoryContextSwitchTo(oldcontext);
> +
> + /* Setup synchronous commit according to the user's wishes */
> + SetConfigOption("synchronous_commit", MySubscription->synccommit,
> + PGC_BACKEND, PGC_S_OVERRIDE);
> +
> + /* Keep us informed about subscription changes. */
> + CacheRegisterSyscacheCallback(SUBSCRIPTIONOID,
> + subscription_change_cb,
> + (Datum) 0);
> +
> + CommitTransactionCommand();
> ...
>
> This part appears of the code appears to be the same as we have in
> ApplyWorkerMain() except that the patch doesn't check whether the
> subscription is enabled. Is there a reason to not have that check here as well?
> Then in ApplyWorkerMain(), we do LOG the type of worker that is also missing
> here. Unless there is a specific reason to have a different code here, we should
> move this part to a common function and call it both from ApplyWorkerMain()
> and ApplyBgworkerMain().
> 6. I think the code in ApplyBgworkerMain() to set session_replication_role,
> search_path, and connect to the database also appears to be the same in
> ApplyWorkerMain(). If so, that can also be moved to the common function
> mentioned in the previous point.
>
> 7. I think we need to register for subscription rel map invalidation
> (invalidate_syncing_table_states) in ApplyBgworkerMain similar to
> ApplyWorkerMain. The reason is that we check the table state after processing
> a commit or similar change record via a call to process_syncing_tables.
Agreed and changed.
> 8. In apply_bgworker_setup_dsm(), we should have handling related to
> dsm_create failure due to max_segments reached as we have in
> InitializeParallelDSM(). We can follow the regular path of streaming
> transactions in case we are not able to create DSM instead of parallelizing it.
Changed.
> 9.
> + shm_toc_initialize_estimator(&e);
> + shm_toc_estimate_chunk(&e, sizeof(ApplyBgworkerShared));
> + shm_toc_estimate_chunk(&e, (Size) queue_size);
> +
> + shm_toc_estimate_keys(&e, 1 + 1);
>
> Here, you can directly write 2 instead of (1 + 1) stuff. It is quite clear that we
> need two keys here.
Changed.
> 10.
> apply_bgworker_wait_for()
> {
> ...
> + /* Wait to be signalled. */
> + WaitLatch(MyLatch, WL_LATCH_SET | WL_EXIT_ON_PM_DEATH, 0,
> + WAIT_EVENT_LOGICAL_APPLY_BGWORKER_STATE_CHANGE);
> ...
> }
>
> Typecast with the void, if we don't care for the return value.
Changed.
> 11.
> +static void
> +apply_bgworker_shutdown(int code, Datum arg) {
> +SpinLockAcquire(&MyParallelShared->mutex);
> + MyParallelShared->status = APPLY_BGWORKER_EXIT;
> + SpinLockRelease(&MyParallelShared->mutex);
>
> Is there a reason to not use apply_bgworker_set_status() directly?
No, changed to use that function.
> 12.
> + * Special case is if the first change comes from subtransaction, then
> + * we check that current_xid differs from stream_xid.
> + */
> +void
> +apply_bgworker_subxact_info_add(TransactionId current_xid) { if
> +(current_xid != stream_xid && !list_member_int(subxactlist, (int)
> +current_xid))
> ...
> ...
>
> I don't understand the above comment. Does that mean we don't need to
> define a savepoint if the first change is from a subtransaction? Also, keep an
> empty line before the above comment.
After checking, I think this comment is not very clear and have removed it
and improve other comments.
> 13.
> +void
> +apply_bgworker_subxact_info_add(TransactionId current_xid) { if
> +(current_xid != stream_xid && !list_member_int(subxactlist, (int)
> +current_xid)) { MemoryContext oldctx; char spname[MAXPGPATH];
> +
> + snprintf(spname, MAXPGPATH, "savepoint_for_xid_%u", current_xid);
>
> To uniquely generate the savepoint name, it is better to append the
> subscription id as well? Something like pg_sp_<subid>_<xid>.
Changed.
> 14. The CommitTransactionCommand() call in
> apply_bgworker_subxact_info_add looks a bit odd as that function neither
> seems to be starting the transaction command nor has any comments
> explaining it. Shall we do it in caller where it is more apparent to do the same?
I think the CommitTransactionCommand here is used to cooperate the
DefineSavepoint because we need to invoke CommitTransactionCommand to
start a new subtransaction. I tried to add some comments to explain the same.
> 15.
> else
> snprintf(bgw.bgw_name, BGW_MAXLEN,
> "logical replication worker for subscription %u", subid);
> +
> snprintf(bgw.bgw_type, BGW_MAXLEN, "logical replication worker");
>
> Spurious new line
Removed.
> 16.
> @@ -1153,7 +1162,14 @@ replorigin_session_setup(RepOriginId node)
>
> Assert(session_replication_state->roident != InvalidRepOriginId);
>
> - session_replication_state->acquired_by = MyProcPid;
> + if (must_acquire)
> + session_replication_state->acquired_by = MyProcPid; else if
> + (session_replication_state->acquired_by == 0) ereport(ERROR,
> + (errcode(ERRCODE_CONFIGURATION_LIMIT_EXCEEDED),
> + errmsg("apply background worker could not find replication state
> slot for replication origin with OID %u",
> + node),
> + errdetail("There is no replication state slot set by its main apply
> worker.")));
>
> It is not a good idea to give apply workers specific messages from this API
> because I don't think we can assume this is used by only apply workers. It seems
> to me that if 'must_acquire' is false, then we should either give elog(ERROR, ..)
> or there should be an Assert for the same. I am not completely sure but maybe
> we can request the caller to supply the PID (which already has acquired this
> origin) in case must_acquire is false and then use it in Assert/elog to ensure the
> correct usage of API. What do you think?
Agreed. I think we can replace the 'must_acquire' with the pid of worker which
acquired this origin(called 'acquired_by'). We can use this pid to check and
report the error if needed.
> 17. The commit message can explain the abort-related new information this
> patch sends to the subscribers.
Added.
> 18.
> + * In streaming case (receiving a block of streamed transaction), for
> + * SUBSTREAM_ON mode, simply redirect it to a file for the proper
> + toplevel
> + * transaction, and for SUBSTREAM_PARALLEL mode, send the changes to
> + apply
> + * background workers (LOGICAL_REP_MSG_RELATION or
> LOGICAL_REP_MSG_TYPE
> + changes
> + * will also be applied in main apply worker).
>
> In this, part of the comment "(LOGICAL_REP_MSG_RELATION or
> LOGICAL_REP_MSG_TYPE changes will also be applied in main apply worker)" is
> not very clear. Do you mean to say that these messages are applied by both
> main and background apply workers, if so, then please state the same
> explicitly?
Changed.
> 19.
> - /* not in streaming mode */
> - if (!in_streamed_transaction)
> + /* Not in streaming mode */
> + if (!(in_streamed_transaction || am_apply_bgworker()))
> ...
> ...
> - /* write the change to the current file */
> + /* Write the change to the current file */
> stream_write_change(action, s);
>
> I don't see the need to change the above comments.
Remove the changes.
> 20.
> static bool
> handle_streamed_transaction(LogicalRepMsgType action, StringInfo s) { ...
> ...
> + if (am_apply_bgworker())
> + {
> + /* Define a savepoint for a subxact if needed. */
> + apply_bgworker_subxact_info_add(current_xid);
> +
> + return false;
> + }
> +
> + if (apply_bgworker_active())
>
> Isn't it better to use else if in the above code and probably else for the
> remaining part of code in this function?
Changed.
Attach new version(v21) patch set which addressed all the comments received so far.
Best regards,
Hou zj
Attachment
- v21-0003-Add-some-checks-before-using-apply-background-wo.patch
- v21-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v21-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v21-0001-Perform-streaming-logical-transactions-by-backgr.patch
- v21-0002-Test-streaming-parallel-option-in-tap-test.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, August 10, 2022 11:39 AM Amit Kapila <amit.kapila16@gmail.com>wrote:
>
> On Tue, Aug 9, 2022 at 5:39 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Tue, Aug 9, 2022 at 11:09 AM Dilip Kumar <dilipbalaut@gmail.com>
> wrote:
> > >
> > > Some more comments
> > >
> > > + /*
> > > + * Exit if any relation is not in the READY state and if any worker is
> > > + * handling the streaming transaction at the same time. Because for
> > > + * streaming transactions that is being applied in apply background
> > > + * worker, we cannot decide whether to apply the change for a
> relation
> > > + * that is not in the READY state (see should_apply_changes_for_rel) as
> we
> > > + * won't know remote_final_lsn by that time.
> > > + */
> > > + if (list_length(ApplyBgworkersFreeList) !=
> > > list_length(ApplyBgworkersList) &&
> > > + !AllTablesyncsReady())
> > > + {
> > > + ereport(LOG,
> > > + (errmsg("logical replication apply workers for
> > > subscription \"%s\" will restart",
> > > + MySubscription->name),
> > > + errdetail("Cannot handle streamed replication
> > > transaction by apply "
> > > + "background workers until all tables are
> > > synchronized")));
> > > +
> > > + proc_exit(0);
> > > + }
> > >
> > > How this situation can occur? I mean while starting a background
> > > worker itself we can check whether all tables are sync ready or not
> > > right?
> > >
> >
> > We are already checking at the start in apply_bgworker_can_start() but
> > I think it is required to check at the later point of time as well
> > because the new rels can be added to pg_subscription_rel via Alter
> > Subscription ... Refresh. I feel if that reasoning is correct then we
> > can probably expand comments to make it clear.
> >
> > > + /* Check the status of apply background worker if any. */
> > > + apply_bgworker_check_status();
> > > +
> > >
> > > What is the need to checking each worker status on every commit? I
> > > mean if there are a lot of small transactions along with some
> > > steamiing transactions then it will affect the apply performance for
> > > those small transactions?
> > >
> >
> > I don't think performance will be a concern because this won't do any
> > costly operation unless invalidation happens in which case it will
> > access system catalogs. However, if my above understanding is correct
> > that new tables can be added during the apply process then not sure
> > doing it at commit time is sufficient/correct because it can change
> > even during the transaction.
> >
>
> One idea that may handle it cleanly is to check for SUBREL_STATE_SYNCDONE
> state in should_apply_changes_for_rel() and error out for apply_bg_worker().
> For the SUBREL_STATE_READY state, it should return true and for any other
> state, it can return false. The one advantage of this approach could be that the
> parallel apply worker will give an error only if the corresponding transaction
> has performed any operation on the relation that has reached the SYNCDONE
> state.
> OTOH, checking at each transaction end can also lead to erroring out of
> workers even if the parallel apply transaction doesn't perform any operation on
> the relation which is not in the READY state.
I agree that it would be better to check at should_apply_changes_for_rel().
In addition, I think we should report an error if the table is not in READY state,
otherwise return true. Currently(on HEAD), if the table state is NOT READY, we
will skip all the changes related to the relation in a transaction because we
invoke process_syncing_tables only at transaction end which means the state of
table won't be changed during applying a transaction.
But while the apply bgworker is applying the streaming transaction, the
main apply worker could have applied serval normal transaction which could
change the state of table serval times(FROM INIT -> READY). So, to prevent the
risk case that we skip part of changes before state comes to READY and then
start to apply the changes after READY during on transaction, we'd better error
out if the table is not in READY state and restart without apply background
worker.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, August 9, 2022 4:49 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote: > Dear Wang, > > Thanks for updating patch sets! Followings are comments about v20-0001. > > 1. config.sgml > > ``` > <para> > Specifies maximum number of logical replication workers. This includes > both apply workers and table synchronization workers. > </para> > ``` > > I think you can add a description in the above paragraph, like > " This includes apply main workers, apply background workers, and table > synchronization workers." Changed. > 2. logical-replication.sgml > > 2.a Configuration Settings > > ``` > <varname>max_logical_replication_workers</varname> must be set to at > least > the number of subscriptions, again plus some reserve for the table > synchronization. > ``` > > I think you can add a description in the above paragraph, like > "... the number of subscriptions, plus some reserve for the table > synchronization > and the streaming transaction." I think it's not a must to add the number of streaming transactions here as it also works even if no worker is available for apply bgworker as explained in the document of streaming option. > 2.b Monitoring > > ``` > <para> > Normally, there is a single apply process running for an enabled > subscription. A disabled subscription or a crashed subscription will have > zero rows in this view. If the initial data synchronization of any > table is in progress, there will be additional workers for the tables > being synchronized. > </para> > ``` > > I think you can add a sentence in the above paragraph, like > "... synchronized. Moreover, if the streaming transaction is applied parallelly, > there will be additional workers" Added > 3. launcher.c > > ``` > + /* Sanity check : we don't support table sync in subworker. */ > ``` > > I think "Sanity check :" should be "Sanity check:", per other files. Changed. > 4. worker.c > > 4.a handle_streamed_transaction() > > ``` > - /* not in streaming mode */ > - if (!in_streamed_transaction) > + /* Not in streaming mode */ > + if (!(in_streamed_transaction || am_apply_bgworker())) > ``` > > I think the comment should also mention about apply background worker case. Added. > 4.b handle_streamed_transaction() > > ``` > - Assert(stream_fd != NULL); > ``` > > I think this assersion seems reasonable in case of stream='on'. > Could you revive it and move to later part in the function, like after > subxact_info_add(current_xid)? Added. > 4.c apply_handle_prepare_internal() > > ``` > * BeginTransactionBlock is necessary to balance the > EndTransactionBlock > * called within the PrepareTransactionBlock below. > */ > - BeginTransactionBlock(); > + if (!IsTransactionBlock()) > + BeginTransactionBlock(); > + > ``` > > I think the comment should be "We must be in transaction block to balance...". Changed. > 4.d apply_handle_stream_prepare() > > ``` > - * > - * Logic is in two parts: > - * 1. Replay all the spooled operations > - * 2. Mark the transaction as prepared > */ > static void > apply_handle_stream_prepare(StringInfo s) > ``` > > I think these comments are useful when stream='on', > so it should be moved to later part. I think we already have similar comments in later part. > 5. applybgworker.c > > 5.a apply_bgworker_setup() > > ``` > + elog(DEBUG1, "setting up apply worker #%u", > list_length(ApplyBgworkersList) + 1); > ``` > > "apply worker" should be "apply background worker". > > 5.b LogicalApplyBgwLoop() > > ``` > + elog(DEBUG1, "[Apply BGW #%u] ended > processing streaming chunk," > + "waiting on shm_mq_receive", > shared->worker_id); > ``` > > A blank is needed after comma. I checked serverlog, and the message > outputed like: > > ``` > [Apply BGW #1] ended processing streaming chunk,waiting on > shm_mq_receive > ``` Changed. > 6. > > When I started up the apply background worker and did `SELECT * from > pg_stat_subscription`, I got following lines: > > ``` > postgres=# select * from pg_stat_subscription; > subid | subname | pid | relid | received_lsn | last_msg_send_time > | last_msg_receipt_time | latest_end_lsn | latest_end > _time > -------+---------+-------+-------+--------------+---------------------------- > ---+-------------------------------+----------------+------------------ > ------------- > 16400 | sub | 22383 | | | -infinity | > -infinity | | -infinity > 16400 | sub | 22312 | | 0/6734740 | 2022-08-09 > 07:40:19.367676+00 | 2022-08-09 07:40:19.375455+00 | 0/6734740 | > 2022-08-09 07:40: > 19.367676+00 > (2 rows) > ``` > > > 6.a > > It seems that the upper line represents the apply background worker, but I > think last_msg_send_time and last_msg_receipt_time should be null. > Is it like initialization mistake? Changed. > ``` > $ ps aux | grep 22383 > ... postgres: logical replication apply background worker for subscription > 16400 > ``` > > 6.b > > Currently, the documentation doesn't clarify the method to determine the type > of logical replication workers. > Could you add descriptions about it? > I think adding a column "subworker" is an alternative approach. I am quite sure about whether it's necessary, But I tried to add a new column(main_apply_pid) in a separate patch(0005). Best regards, Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, August 11, 2022 3:48 PM houzj.fnst@fujitsu.com wrote: > > On Tuesday, August 9, 2022 7:00 PM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > > > > Review comments on > > v20-0001-Perform-streaming-logical-transactions-by-backgr > > Attach new version(v21) patch set which addressed all the comments received > so far. > Sorry, I didn't include the documentation changes. Here is the complete patch set. Best regards, Hou zj
Attachment
- v21-0003-Add-some-checks-before-using-apply-background-wo.patch
- v21-0001-Perform-streaming-logical-transactions-by-backgr.patch
- v21-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v21-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v21-0002-Test-streaming-parallel-option-in-tap-test.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, August 10, 2022 5:40 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are some review comments for the patch v20-0001:
> ======
>
> 1. doc/src/sgml/catalogs.sgml
>
> + <literal>p</literal> = apply changes directly using a background
> + worker, if available, otherwise, it behaves the same as 't'
>
> The different char values 'f','t','p' are separated by comma (,) in
> the list, which is normal for the pgdocs AFAIK. However, because of
> this I don't think it is a good idea to use those other commas within
> the description for 'p', I suggest you remove those ones to avoid
> ambiguity with the separators.
Changed.
> ======
>
> 2. doc/src/sgml/protocol.sgml
>
> @@ -3096,7 +3096,7 @@ psql "dbname=postgres replication=database" -c
> "IDENTIFY_SYSTEM;"
> <listitem>
> <para>
> Protocol version. Currently versions <literal>1</literal>,
> <literal>2</literal>,
> - and <literal>3</literal> are supported.
> + <literal>3</literal> and <literal>4</literal> are supported.
> </para>
>
> Put a comma after the penultimate value like it had before.
>
Changed.
> ======
>
> 3. src/backend/replication/logical/applybgworker.c - <general>
>
> There are multiple function comments and other code comments in this
> file that are missing a terminating period (.)
>
> ======
>
Changed.
> 4. src/backend/replication/logical/applybgworker.c - apply_bgworker_start
>
> +/*
> + * Try to get a free apply background worker.
> + *
> + * If there is at least one worker in the free list, then take one. Otherwise,
> + * try to start a new apply background worker. If successful, cache it in
> + * ApplyBgworkersHash keyed by the specified xid.
> + */
> +ApplyBgworkerState *
> +apply_bgworker_start(TransactionId xid)
>
> SUGGESTION (for function comment)
> Return the apply background worker that will be used for the specified xid.
>
> If an apply background worker is found in the free list then re-use
> it, otherwise start a fresh one. Cache the worker ApplyBgworkersHash
> keyed by the specified xid.
>
> ~~~
>
Changed.
> 5.
>
> + /* Try to get a free apply background worker */
> + if (list_length(ApplyBgworkersFreeList) > 0)
>
> if (list_length(ApplyBgworkersFreeList) > 0)
>
> AFAIK a non-empty list is guaranteed to be not NIL, and an empty list
> is guaranteed to be NIL. So if you want to the above can simply be
> written as:
>
> if (ApplyBgworkersFreeList)
>
Both ways are fine to me, so I kept the current style.
> ~~~
>
> 6. src/backend/replication/logical/applybgworker.c - apply_bgworker_find
>
> +/*
> + * Try to look up worker assigned before (see function
> apply_bgworker_get_free)
> + * inside ApplyBgworkersHash for requested xid.
> + */
> +ApplyBgworkerState *
> +apply_bgworker_find(TransactionId xid)
>
> SUGGESTION (for function comment)
> Find the worker previously assigned/cached for this xid. (see function
> apply_bgworker_start)
>
Changed.
> ~~~
>
> 7.
>
> + Assert(status == APPLY_BGWORKER_BUSY);
> +
> + return entry->wstate;
> + }
> + else
> + return NULL;
>
> IMO here it is better to just remove that 'else' and unconditionally
> return NULL at the end of this function.
>
Changed.
> ~~~
>
> 8. src/backend/replication/logical/applybgworker.c -
> apply_bgworker_subxact_info_add
>
> + * Inside apply background worker we can figure out that new subtransaction
> was
> + * started if new change arrived with different xid. In that case we can define
> + * named savepoint, so that we were able to commit/rollback it separately
> + * later.
> + * Special case is if the first change comes from subtransaction, then
> + * we check that current_xid differs from stream_xid.
> + */
> +void
> +apply_bgworker_subxact_info_add(TransactionId current_xid)
>
> It is not quite English. Can you improve it a bit?
>
> SUGGESTION (maybe like this?)
> The apply background worker can figure out if a new subtransaction was
> started by checking if the new change arrived with different xid. In
> that case define a named savepoint, so that we are able to
> commit/rollback it separately later. A special case is when the first
> change comes from subtransaction – this is determined by checking if
> the current_xid differs from stream_xid.
>
Changed.
> ======
>
> 9. src/backend/replication/logical/launcher.c -
> WaitForReplicationWorkerAttach
>
> + *
> + * Return false if the attach fails. Otherwise return true.
> */
> -static void
> +static bool
> WaitForReplicationWorkerAttach(LogicalRepWorker *worker,
>
> Why not just say "Return whether the attach was successful."
>
Changed.
> ~~~
>
> 10. src/backend/replication/logical/launcher.c - logicalrep_worker_stop
>
> + /* Found the main worker, then try to stop it. */
> + if (worker)
> + logicalrep_worker_stop_internal(worker);
>
> IMO the comment is kind of pointless because it only says what the
> code is clearly doing. If you really wanted to reinforce this worker
> is a main apply worker then you can do that with code like:
>
> if (worker)
> {
> Assert(!worker->subworker);
> logicalrep_worker_stop_internal(worker);
> }
>
Changed.
> ~~~
>
> 11. src/backend/replication/logical/launcher.c - logicalrep_worker_detach
>
> @@ -599,6 +632,29 @@ logicalrep_worker_attach(int slot)
> static void
> logicalrep_worker_detach(void)
> {
> + /*
> + * This is the main apply worker, stop all the apply background workers we
> + * started before.
> + */
> + if (!MyLogicalRepWorker->subworker)
>
> SUGGESTION (for comment)
> This is the main apply worker. Stop all apply background workers
> previously started from here.
>
Changed.
> ~~~
>
> 12 src/backend/replication/logical/launcher.c -
> logicalrep_apply_bgworker_count
>
> +/*
> + * Count the number of registered (not necessarily running) apply background
> + * workers for a subscription.
> + */
> +int
> +logicalrep_apply_bgworker_count(Oid subid)
>
> SUGGESTION
> Count the number of registered (but not necessarily running) apply
> background workers for a subscription.
>
Changed.
> ~~~
>
> 13.
>
> + /* Search for attached worker for a given subscription id. */
> + for (i = 0; i < max_logical_replication_workers; i++)
>
> SUGGESTION
> Scan all attached apply background workers, only counting those which
> have the given subscription id.
>
Changed.
> ======
>
> 14. src/backend/replication/logical/worker.c - apply_error_callback
>
> + {
> + if (errarg->remote_attnum < 0)
> + {
> + if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> + errcontext("processing remote data for replication origin \"%s\"
> during \"%s\" for replication target relation \"%s.%s\" in transaction
> %u",
> + errarg->origin_name,
> + logicalrep_message_type(errarg->command),
> + errarg->rel->remoterel.nspname,
> + errarg->rel->remoterel.relname,
> + errarg->remote_xid);
> + else
> + errcontext("processing remote data for replication origin \"%s\"
> during \"%s\" for replication target relation \"%s.%s\" in transaction
> %u finished at %X/%X",
> + errarg->origin_name,
> + logicalrep_message_type(errarg->command),
> + errarg->rel->remoterel.nspname,
> + errarg->rel->remoterel.relname,
> + errarg->remote_xid,
> + LSN_FORMAT_ARGS(errarg->finish_lsn));
> + }
> + else
> + {
> + if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> + errcontext("processing remote data for replication origin \"%s\"
> during \"%s\" for replication target relation \"%s.%s\" column \"%s\"
> in transaction %u",
> + errarg->origin_name,
> + logicalrep_message_type(errarg->command),
> + errarg->rel->remoterel.nspname,
> + errarg->rel->remoterel.relname,
> + errarg->rel->remoterel.attnames[errarg->remote_attnum],
> + errarg->remote_xid);
> + else
> + errcontext("processing remote data for replication origin \"%s\"
> during \"%s\" for replication target relation \"%s.%s\" column \"%s\"
> in transaction %u finished at %X/%X",
> + errarg->origin_name,
> + logicalrep_message_type(errarg->command),
> + errarg->rel->remoterel.nspname,
> + errarg->rel->remoterel.relname,
> + errarg->rel->remoterel.attnames[errarg->remote_attnum],
> + errarg->remote_xid,
> + LSN_FORMAT_ARGS(errarg->finish_lsn));
> + }
> + }
>
> There is quite a lot of common code here:
>
> "processing remote data for replication origin \"%s\" during \"%s\"
> for replication target relation \"%s.%s\"
>
> errarg->origin_name,
> logicalrep_message_type(errarg->command),
> errarg->rel->remoterel.nspname,
> errarg->rel->remoterel.relname,
>
> Is it worth trying to extract that common part to keep this code
> shorter? E.g. It could be easily done just with some #defines
>
I am not sure do we have a clean way to change this, any suggestions ?
> ======
>
> 15. src/include/replication/worker_internal.h
>
> + /* proto version of publisher. */
> + uint32 proto_version;
>
> SUGGESTION
> Protocol version of publisher
>
> ~~~
>
Changed.
> 16.
>
> + /* id of apply background worker */
> + uint32 worker_id;
>
> Uppercase comment
>
Changed.
>
> 17.
>
> +/*
> + * Struct for maintaining an apply background worker.
> + */
> +typedef struct ApplyBgworkerState
>
> I'm not sure what this comment means. Perhaps there are some words missing?
>
I renamed the struct to ApplyBgworkerInfo which sounds better to me and changed the comments.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for v20-0003:
(Sorry - the reviews are time consuming, so I am lagging slightly
behind the latest posted version)
======
1. <General>
1a.
There are a few comment modifications in this patch (e.g. changing
FROM "in an apply background worker" TO "using an apply background
worker"). e.g. I noticed lots of these in worker.c but they might be
in other files too.
Although these are good changes, these are just tweaks to new comments
introduced by patch 0001, so IMO such changes belong in that patch,
not in this one.
1b.
Actually, there are still some comments says "by an apply background
worker///" and some saying "using an apply background worker..." and
some saying "in the apply background worker...". Maybe they are all
OK, but it will be better if all such can be searched and made to have
consistent wording
======
2. Commit message
2a.
Without these restrictions, the following scenario may occur:
The apply background worker lock a row when processing a streaming transaction,
after that the main apply worker tries to lock the same row when processing
another transaction. At this time, the main apply worker waits for the
streaming transaction to complete and the lock to be released, it won't send
subsequent data of the streaming transaction to the apply background worker;
the apply background worker waits to receive the rest of streaming transaction
and can't finish this transaction. Then the main apply worker will wait
indefinitely.
"background worker lock a row" -> "background worker locks a row"
"Then the main apply worker will wait indefinitely." -> really, you
already said the main apply worker is waiting, so I think this
sentence only needs to say: "Now a deadlock has occurred, so both
workers will wait indefinitely."
2b.
Text fragments are all common between:
i. This commit message
ii. Text in pgdocs CREATE SUBSCRIPTION
iii. Function comment for 'logicalrep_rel_mark_parallel_apply' in relation.c
After addressing other review comments please make sure all those 3
parts are worded same.
======
3. doc/src/sgml/ref/create_subscription.sgml
+ There are two requirements for using <literal>parallel</literal>
+ mode: 1) the unique column in the table on the subscriber-side should
+ also be the unique column on the publisher-side; 2) there cannot be
+ any non-immutable functions used by the subscriber-side replicated
+ table.
3a.
I am not sure – is "requirements" the correct word here, or maybe it
should be "prerequisites".
3b.
Is it correct to say "should also be", or should that say "must also be"?
======
4. src/backend/replication/logical/applybgworker.c -
apply_bgworker_relation_check
+ /*
+ * Skip check if not using apply background workers.
+ *
+ * If any worker is handling the streaming transaction, this check needs to
+ * be performed not only in the apply background worker, but also in the
+ * main apply worker. This is because without these restrictions, main
+ * apply worker may block apply background worker, which will cause
+ * infinite waits.
+ */
+ if (!am_apply_bgworker() &&
+ (list_length(ApplyBgworkersFreeList) == list_length(ApplyBgworkersList)))
+ return;
I struggled a bit to reconcile the comment with the condition. Is the
!am_apply_bgworker() part of this even needed – isn't the
list_length() check enough?
~~~
5.
+ /* We are in error mode and should give user correct error. */
I still [1, #3.4a] don't see the value in saying "should give correct
error" (e.g. what's the alternative?).
Maybe instead of that comment it can just say:
rel->parallel_apply = PARALLEL_APPLY_UNSAFE;
======
6. src/backend/replication/logical/proto.c - RelationGetUniqueKeyBitmap
+ /* Add referenced attributes to idindexattrs */
+ for (i = 0; i < indexRel->rd_index->indnatts; i++)
+ {
+ int attrnum = indexRel->rd_index->indkey.values[i];
+
+ /*
+ * We don't include non-key columns into idindexattrs
+ * bitmaps. See RelationGetIndexAttrBitmap.
+ */
+ if (attrnum != 0)
+ {
+ if (i < indexRel->rd_index->indnkeyatts &&
+ !bms_is_member(attrnum - FirstLowInvalidHeapAttributeNumber, attunique))
+ attunique = bms_add_member(attunique,
+ attrnum - FirstLowInvalidHeapAttributeNumber);
+ }
+ }
There are 2x comments in that code that are referring to
'idindexattrs' but I think it is a cut/paste problem because that
variable name does not even exist in this copied function.
======
7. src/backend/replication/logical/relation.c -
logicalrep_rel_mark_parallel_apply
+ /* Initialize the flag. */
+ entry->parallel_apply = PARALLEL_APPLY_SAFE;
I have unsuccessfully repeated the same review comment several times
[1 #3.8] suggesting that this flag should not be initialized to SAFE.
IMO the state should remain as UNKNOWN until you are either sure it is
SAFE, or sure it is UNSAFE. Anyway, I'll give up on this point now;
let's see what other people think.
======
8. src/include/replication/logicalrelation.h
+/*
+ * States to determine if changes on one relation can be applied using an
+ * apply background worker.
+ */
+typedef enum ParallelApplySafety
+{
+ PARALLEL_APPLY_UNKNOWN = 0, /* unknown */
+ PARALLEL_APPLY_SAFE, /* Can apply changes using an apply background
+ worker */
+ PARALLEL_APPLY_UNSAFE /* Can not apply changes using an apply
+ background worker */
+} ParallelApplySafety;
+
I think the values are self-explanatory so the comments for every
value add nothing here, particularly since the enum itself has a
comment saying the same thing. I'm not sure if you accidentally missed
my previous comment [1, #3.12b] about this, or just did not agree with
it.
======
9. .../subscription/t/015_stream.pl
+# "streaming = parallel" does not support non-immutable functions, so change
+# the function in the defult expression of column "c".
+$node_subscriber->safe_psql(
+ 'postgres', qq{
+ALTER TABLE test_tab ALTER COLUMN c SET DEFAULT to_timestamp(1284352323);
+ALTER SUBSCRIPTION tap_sub SET(streaming = parallel, binary = off);
+});
9a.
typo "defult"
9b.
The problem with to_timestamp(1284352323) is that it looks like it
must be some special value, but in fact AFAIK you don't care at all
what value timestamp this is. I think it would be better here to just
use to_timestamp(0) or to_timestamp(999) or similar so the number is
obviously not something of importance.
======
10. .../subscription/t/016_stream.pl
+# "streaming = parallel" does not support non-immutable functions, so change
+# the function in the defult expression of column "c".
+$node_subscriber->safe_psql(
+ 'postgres', qq{
+ALTER TABLE test_tab ALTER COLUMN c SET DEFAULT to_timestamp(1284352323);
+ALTER SUBSCRIPTION tap_sub SET(streaming = parallel);
+});
10a. Ditto 9a.
10b. Ditto 9b.
======
11. .../subscription/t/022_twophase_cascade.pl
+# "streaming = parallel" does not support non-immutable functions, so change
+# the function in the defult expression of column "c".
+$node_B->safe_psql(
+ 'postgres', "ALTER TABLE test_tab ALTER COLUMN c SET DEFAULT
to_timestamp(1284352323);");
+$node_C->safe_psql(
+ 'postgres', "ALTER TABLE test_tab ALTER COLUMN c SET DEFAULT
to_timestamp(1284352323);");
+
11a. Ditto 9a.
11b. Ditto 9b.
======
12. .../subscription/t/023_twophase_stream.pl
+# "streaming = parallel" does not support non-immutable functions, so change
+# the function in the defult expression of column "c".
+$node_subscriber->safe_psql(
+ 'postgres', qq{
+ALTER TABLE test_tab ALTER COLUMN c SET DEFAULT to_timestamp(1284352323);
+ALTER SUBSCRIPTION tap_sub SET(streaming = parallel);
+});
12a. Ditto 9a.
12b. Ditto 9b.
======
13. .../subscription/t/032_streaming_apply.pl
+# Drop default value on the subscriber, now it works.
+$node_subscriber->safe_psql('postgres',
+ "ALTER TABLE test_tab1 ALTER COLUMN b DROP DEFAULT");
Maybe for these tests like this it would be better to test if it works
OK using an immutable DEFAULT function instead of just completely
removing the bad function to make it work.
I think maybe the same was done for TRIGGER tests. There was a test
for a trigger with a bad function, and then the trigger was removed.
What about including a test for the trigger with a good function?
------
[1] https://www.postgresql.org/message-id/CAHut%2BPv9cKurDQHtk-ygYp45-8LYdE%3D4sMZY-8UmbeDTGgECVg%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for v20-0004:
(This completes my reviews of the v20* patch set. Sorry, the reviews
are time consuming, so I am lagging slightly behind the latest posted
version)
======
1. doc/src/sgml/ref/create_subscription.sgml
@@ -245,6 +245,11 @@ CREATE SUBSCRIPTION <replaceable
class="parameter">subscription_name</replaceabl
also be the unique column on the publisher-side; 2) there cannot be
any non-immutable functions used by the subscriber-side replicated
table.
+ When applying a streaming transaction, if either requirement is not
+ met, the background worker will exit with an error.
+ The <literal>parallel</literal> mode is disregarded when retrying;
+ instead the transaction will be applied using <literal>on</literal>
+ mode.
</para>
The "on mode" still sounds strange to me. Maybe it's just my personal
opinion, but I don’t really consider 'on' and 'off' to be "modes".
Anyway I already posted the same comment several times before [1,
#4.3]. Let's see what others think.
SUGGESTION
"using on mode" -> "using streaming = on"
======
2. src/backend/replication/logical/worker.c - start_table_sync
@@ -3902,20 +3925,28 @@ start_table_sync(XLogRecPtr *origin_startpos,
char **myslotname)
}
PG_CATCH();
{
+ /*
+ * Emit the error message, and recover from the error state to an idle
+ * state
+ */
+ HOLD_INTERRUPTS();
+
+ EmitErrorReport();
+ AbortOutOfAnyTransaction();
+ FlushErrorState();
+
+ RESUME_INTERRUPTS();
+
+ /* Report the worker failed during table synchronization */
+ pgstat_report_subscription_error(MySubscription->oid, false);
+
if (MySubscription->disableonerr)
- DisableSubscriptionAndExit();
- else
- {
- /*
- * Report the worker failed during table synchronization. Abort
- * the current transaction so that the stats message is sent in an
- * idle state.
- */
- AbortOutOfAnyTransaction();
- pgstat_report_subscription_error(MySubscription->oid, false);
+ DisableSubscriptionOnError();
- PG_RE_THROW();
- }
+ /* Set the retry flag. */
+ set_subscription_retry(true);
+
+ proc_exit(0);
}
PG_END_TRY();
Perhaps current code is OK, but I am not 100% sure if we should set
the retry flag when the disable_on_error is set, because the
subscription is not going to be retried (because it is disabled). And
later, if/when the user does enable the subscription, presumably that
will be after they have already addressed the problem that caused the
error/disablement in the first place.
~~~
3. src/backend/replication/logical/worker.c - start_apply
PG_CATCH();
{
+ /*
+ * Emit the error message, and recover from the error state to an idle
+ * state
+ */
+ HOLD_INTERRUPTS();
+
+ EmitErrorReport();
+ AbortOutOfAnyTransaction();
+ FlushErrorState();
+
+ RESUME_INTERRUPTS();
+
+ /* Report the worker failed while applying changes */
+ pgstat_report_subscription_error(MySubscription->oid,
+ !am_tablesync_worker());
+
if (MySubscription->disableonerr)
- DisableSubscriptionAndExit();
- else
- {
- /*
- * Report the worker failed while applying changes. Abort the
- * current transaction so that the stats message is sent in an
- * idle state.
- */
- AbortOutOfAnyTransaction();
- pgstat_report_subscription_error(MySubscription->oid, !am_tablesync_worker());
+ DisableSubscriptionOnError();
- PG_RE_THROW();
- }
+ /* Set the retry flag. */
+ set_subscription_retry(true);
}
PG_END_TRY();
}
3a.
Same comment as #2
3b.
This PG_CATCH used to leave by either proc_exit(0) or PG_RE_THROW but
what does it do now? My first impression is there is a bug here due to
some missing code, because AFAICT the exception is caught and gobbled
up and then what...?
~~~
4. src/backend/replication/logical/worker.c - set_subscription_retry
+ if (MySubscription->retry == retry ||
+ am_apply_bgworker())
+ return;
4a.
I this this quick exit can be split and given some appropriate comments
SUGGESTION (for example)
/* Fast path - if no state change then nothing to do */
if (MySubscription->retry == retry)
return;
/* Fast path - skip for apply background workers */
if (am_apply_bgworker())
return;
======
5. .../subscription/t/032_streaming_apply.pl
@@ -78,9 +78,13 @@ my $timer =
IPC::Run::timeout($PostgreSQL::Test::Utils::timeout_default);
my $h = $node_publisher->background_psql('postgres', \$in, \$out, $timer,
on_error_stop => 0);
+# ============================================================================
All those comment highlighting lines like "# ==============" really
belong in the earlier patch (0003 ?) when this TAP test file was
introduced.
------
[1] https://www.postgresql.org/message-id/CAHut%2BPvrw%2BtgCEYGxv%2BnKrqg-zbJdYEXee6o4irPAsYoXcuUcw%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Fri, August 12, 2022 12:46 PM Peter Smith <smithpb2250@gmail.com> wrote:
> Here are some review comments for v20-0003:
>
> (Sorry - the reviews are time consuming, so I am lagging slightly
> behind the latest posted version)
Thanks for your comments.
> 1. <General>
>
> 1a.
> There are a few comment modifications in this patch (e.g. changing
> FROM "in an apply background worker" TO "using an apply background
> worker"). e.g. I noticed lots of these in worker.c but they might be
> in other files too.
>
> Although these are good changes, these are just tweaks to new comments
> introduced by patch 0001, so IMO such changes belong in that patch,
> not in this one.
>
> 1b.
> Actually, there are still some comments says "by an apply background
> worker///" and some saying "using an apply background worker..." and
> some saying "in the apply background worker...". Maybe they are all
> OK, but it will be better if all such can be searched and made to have
> consistent wording
Improved.
> 2. Commit message
>
> 2a.
>
> Without these restrictions, the following scenario may occur:
> The apply background worker lock a row when processing a streaming
> transaction,
> after that the main apply worker tries to lock the same row when processing
> another transaction. At this time, the main apply worker waits for the
> streaming transaction to complete and the lock to be released, it won't send
> subsequent data of the streaming transaction to the apply background worker;
> the apply background worker waits to receive the rest of streaming transaction
> and can't finish this transaction. Then the main apply worker will wait
> indefinitely.
>
> "background worker lock a row" -> "background worker locks a row"
>
> "Then the main apply worker will wait indefinitely." -> really, you
> already said the main apply worker is waiting, so I think this
> sentence only needs to say: "Now a deadlock has occurred, so both
> workers will wait indefinitely."
>
> 2b.
>
> Text fragments are all common between:
>
> i. This commit message
> ii. Text in pgdocs CREATE SUBSCRIPTION
> iii. Function comment for 'logicalrep_rel_mark_parallel_apply' in relation.c
>
> After addressing other review comments please make sure all those 3
> parts are worded same.
Improved.
> 3. doc/src/sgml/ref/create_subscription.sgml
>
> + There are two requirements for using <literal>parallel</literal>
> + mode: 1) the unique column in the table on the subscriber-side should
> + also be the unique column on the publisher-side; 2) there cannot be
> + any non-immutable functions used by the subscriber-side replicated
> + table.
>
> 3a.
> I am not sure – is "requirements" the correct word here, or maybe it
> should be "prerequisites".
>
> 3b.
> Is it correct to say "should also be", or should that say "must also be"?
Improved.
> 4. src/backend/replication/logical/applybgworker.c -
> apply_bgworker_relation_check
>
> + /*
> + * Skip check if not using apply background workers.
> + *
> + * If any worker is handling the streaming transaction, this check needs to
> + * be performed not only in the apply background worker, but also in the
> + * main apply worker. This is because without these restrictions, main
> + * apply worker may block apply background worker, which will cause
> + * infinite waits.
> + */
> + if (!am_apply_bgworker() &&
> + (list_length(ApplyBgworkersFreeList) == list_length(ApplyBgworkersList)))
> + return;
>
> I struggled a bit to reconcile the comment with the condition. Is the
> !am_apply_bgworker() part of this even needed – isn't the
> list_length() check enough?
We need to check this for apply bgworker. (Both lists are "NIL" in apply
bgworker.)
> 5.
>
> + /* We are in error mode and should give user correct error. */
>
> I still [1, #3.4a] don't see the value in saying "should give correct
> error" (e.g. what's the alternative?).
>
> Maybe instead of that comment it can just say:
> rel->parallel_apply = PARALLEL_APPLY_UNSAFE;
I changed if-statement to report the error:
If 'parallel_apply' isn't 'PARALLEL_APPLY_SAFE', then report the error.
> 6. src/backend/replication/logical/proto.c - RelationGetUniqueKeyBitmap
>
> + /* Add referenced attributes to idindexattrs */
> + for (i = 0; i < indexRel->rd_index->indnatts; i++)
> + {
> + int attrnum = indexRel->rd_index->indkey.values[i];
> +
> + /*
> + * We don't include non-key columns into idindexattrs
> + * bitmaps. See RelationGetIndexAttrBitmap.
> + */
> + if (attrnum != 0)
> + {
> + if (i < indexRel->rd_index->indnkeyatts &&
> + !bms_is_member(attrnum - FirstLowInvalidHeapAttributeNumber, attunique))
> + attunique = bms_add_member(attunique,
> + attrnum - FirstLowInvalidHeapAttributeNumber);
> + }
> + }
>
> There are 2x comments in that code that are referring to
> 'idindexattrs' but I think it is a cut/paste problem because that
> variable name does not even exist in this copied function.
Fixed the comments.
> 7. src/backend/replication/logical/relation.c -
> logicalrep_rel_mark_parallel_apply
>
> + /* Initialize the flag. */
> + entry->parallel_apply = PARALLEL_APPLY_SAFE;
>
> I have unsuccessfully repeated the same review comment several times
> [1 #3.8] suggesting that this flag should not be initialized to SAFE.
> IMO the state should remain as UNKNOWN until you are either sure it is
> SAFE, or sure it is UNSAFE. Anyway, I'll give up on this point now;
> let's see what other people think.
Okay, I will follow the relevant comments later.
> 8. src/include/replication/logicalrelation.h
>
> +/*
> + * States to determine if changes on one relation can be applied using an
> + * apply background worker.
> + */
> +typedef enum ParallelApplySafety
> +{
> + PARALLEL_APPLY_UNKNOWN = 0, /* unknown */
> + PARALLEL_APPLY_SAFE, /* Can apply changes using an apply background
> + worker */
> + PARALLEL_APPLY_UNSAFE /* Can not apply changes using an apply
> + background worker */
> +} ParallelApplySafety;
> +
>
> I think the values are self-explanatory so the comments for every
> value add nothing here, particularly since the enum itself has a
> comment saying the same thing. I'm not sure if you accidentally missed
> my previous comment [1, #3.12b] about this, or just did not agree with
> it.
Changed.
> 9. .../subscription/t/015_stream.pl
>
> +# "streaming = parallel" does not support non-immutable functions, so change
> +# the function in the defult expression of column "c".
> +$node_subscriber->safe_psql(
> + 'postgres', qq{
> +ALTER TABLE test_tab ALTER COLUMN c SET DEFAULT
> to_timestamp(1284352323);
> +ALTER SUBSCRIPTION tap_sub SET(streaming = parallel, binary = off);
> +});
>
> 9a.
> typo "defult"
>
> 9b.
> The problem with to_timestamp(1284352323) is that it looks like it
> must be some special value, but in fact AFAIK you don't care at all
> what value timestamp this is. I think it would be better here to just
> use to_timestamp(0) or to_timestamp(999) or similar so the number is
> obviously not something of importance.
>
> ======
>
> 10. .../subscription/t/016_stream.pl
>
> +# "streaming = parallel" does not support non-immutable functions, so change
> +# the function in the defult expression of column "c".
> +$node_subscriber->safe_psql(
> + 'postgres', qq{
> +ALTER TABLE test_tab ALTER COLUMN c SET DEFAULT
> to_timestamp(1284352323);
> +ALTER SUBSCRIPTION tap_sub SET(streaming = parallel);
> +});
>
> 10a. Ditto 9a.
> 10b. Ditto 9b.
>
> ======
>
> 11. .../subscription/t/022_twophase_cascade.pl
>
> +# "streaming = parallel" does not support non-immutable functions, so change
> +# the function in the defult expression of column "c".
> +$node_B->safe_psql(
> + 'postgres', "ALTER TABLE test_tab ALTER COLUMN c SET DEFAULT
> to_timestamp(1284352323);");
> +$node_C->safe_psql(
> + 'postgres', "ALTER TABLE test_tab ALTER COLUMN c SET DEFAULT
> to_timestamp(1284352323);");
> +
>
> 11a. Ditto 9a.
> 11b. Ditto 9b.
>
> ======
>
> 12. .../subscription/t/023_twophase_stream.pl
>
> +# "streaming = parallel" does not support non-immutable functions, so change
> +# the function in the defult expression of column "c".
> +$node_subscriber->safe_psql(
> + 'postgres', qq{
> +ALTER TABLE test_tab ALTER COLUMN c SET DEFAULT
> to_timestamp(1284352323);
> +ALTER SUBSCRIPTION tap_sub SET(streaming = parallel);
> +});
>
> 12a. Ditto 9a.
> 12b. Ditto 9b.
Improved.
> 13. .../subscription/t/032_streaming_apply.pl
>
> +# Drop default value on the subscriber, now it works.
> +$node_subscriber->safe_psql('postgres',
> + "ALTER TABLE test_tab1 ALTER COLUMN b DROP DEFAULT");
>
> Maybe for these tests like this it would be better to test if it works
> OK using an immutable DEFAULT function instead of just completely
> removing the bad function to make it work.
>
> I think maybe the same was done for TRIGGER tests. There was a test
> for a trigger with a bad function, and then the trigger was removed.
> What about including a test for the trigger with a good function?
Improved.
Attach the new patches.
Regards,
Wang wei
Attachment
- v22-0001-Perform-streaming-logical-transactions-by-backgr.patch
- v22-0002-Test-streaming-parallel-option-in-tap-test.patch
- v22-0003-Add-some-checks-before-using-apply-background-wo.patch
- v22-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v22-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Fri, August 12, 2022 17:22 PM Peter Smith <smithpb2250@gmail.com> wrote:
> Here are some review comments for v20-0004:
>
> (This completes my reviews of the v20* patch set. Sorry, the reviews
> are time consuming, so I am lagging slightly behind the latest posted
> version)
Thanks for your comments.
> 1. doc/src/sgml/ref/create_subscription.sgml
>
> @@ -245,6 +245,11 @@ CREATE SUBSCRIPTION <replaceable
> class="parameter">subscription_name</replaceabl
> also be the unique column on the publisher-side; 2) there cannot be
> any non-immutable functions used by the subscriber-side replicated
> table.
> + When applying a streaming transaction, if either requirement is not
> + met, the background worker will exit with an error.
> + The <literal>parallel</literal> mode is disregarded when retrying;
> + instead the transaction will be applied using <literal>on</literal>
> + mode.
> </para>
>
> The "on mode" still sounds strange to me. Maybe it's just my personal
> opinion, but I don’t really consider 'on' and 'off' to be "modes".
> Anyway I already posted the same comment several times before [1,
> #4.3]. Let's see what others think.
>
> SUGGESTION
> "using on mode" -> "using streaming = on"
Okay, I will follow the relevant comments later.
> 2. src/backend/replication/logical/worker.c - start_table_sync
>
> @@ -3902,20 +3925,28 @@ start_table_sync(XLogRecPtr *origin_startpos,
> char **myslotname)
> }
> PG_CATCH();
> {
> + /*
> + * Emit the error message, and recover from the error state to an idle
> + * state
> + */
> + HOLD_INTERRUPTS();
> +
> + EmitErrorReport();
> + AbortOutOfAnyTransaction();
> + FlushErrorState();
> +
> + RESUME_INTERRUPTS();
> +
> + /* Report the worker failed during table synchronization */
> + pgstat_report_subscription_error(MySubscription->oid, false);
> +
> if (MySubscription->disableonerr)
> - DisableSubscriptionAndExit();
> - else
> - {
> - /*
> - * Report the worker failed during table synchronization. Abort
> - * the current transaction so that the stats message is sent in an
> - * idle state.
> - */
> - AbortOutOfAnyTransaction();
> - pgstat_report_subscription_error(MySubscription->oid, false);
> + DisableSubscriptionOnError();
>
> - PG_RE_THROW();
> - }
> + /* Set the retry flag. */
> + set_subscription_retry(true);
> +
> + proc_exit(0);
> }
> PG_END_TRY();
>
> Perhaps current code is OK, but I am not 100% sure if we should set
> the retry flag when the disable_on_error is set, because the
> subscription is not going to be retried (because it is disabled). And
> later, if/when the user does enable the subscription, presumably that
> will be after they have already addressed the problem that caused the
> error/disablement in the first place.
I think it is okay. Because even after addressing the problem, it is also
*retrying* to apply the failed transaction. And, in the worst case, it just
applies the first failed streaming transaction using "on" mode instead of
"parallel" mode.
> 3. src/backend/replication/logical/worker.c - start_apply
>
> PG_CATCH();
> {
> + /*
> + * Emit the error message, and recover from the error state to an idle
> + * state
> + */
> + HOLD_INTERRUPTS();
> +
> + EmitErrorReport();
> + AbortOutOfAnyTransaction();
> + FlushErrorState();
> +
> + RESUME_INTERRUPTS();
> +
> + /* Report the worker failed while applying changes */
> + pgstat_report_subscription_error(MySubscription->oid,
> + !am_tablesync_worker());
> +
> if (MySubscription->disableonerr)
> - DisableSubscriptionAndExit();
> - else
> - {
> - /*
> - * Report the worker failed while applying changes. Abort the
> - * current transaction so that the stats message is sent in an
> - * idle state.
> - */
> - AbortOutOfAnyTransaction();
> - pgstat_report_subscription_error(MySubscription-
> >oid, !am_tablesync_worker());
> + DisableSubscriptionOnError();
>
> - PG_RE_THROW();
> - }
> + /* Set the retry flag. */
> + set_subscription_retry(true);
> }
> PG_END_TRY();
> }
>
> 3a.
> Same comment as #2
>
> 3b.
> This PG_CATCH used to leave by either proc_exit(0) or PG_RE_THROW but
> what does it do now? My first impression is there is a bug here due to
> some missing code, because AFAICT the exception is caught and gobbled
> up and then what...?
=>3a.
See the reply to #2.
=>3b.
The function `proc_exit(0)` is invoked after invoking function start_apply. See
function ApplyWorkerMain.
> 4. src/backend/replication/logical/worker.c - set_subscription_retry
>
> + if (MySubscription->retry == retry ||
> + am_apply_bgworker())
> + return;
>
> 4a.
> I this this quick exit can be split and given some appropriate comments
>
> SUGGESTION (for example)
> /* Fast path - if no state change then nothing to do */
> if (MySubscription->retry == retry)
> return;
>
> /* Fast path - skip for apply background workers */
> if (am_apply_bgworker())
> return;
Changed.
> 5. .../subscription/t/032_streaming_apply.pl
>
> @@ -78,9 +78,13 @@ my $timer =
> IPC::Run::timeout($PostgreSQL::Test::Utils::timeout_default);
> my $h = $node_publisher->background_psql('postgres', \$in, \$out, $timer,
> on_error_stop => 0);
>
> +#
> =============================================================
> ===============
>
> All those comment highlighting lines like "# ==============" really
> belong in the earlier patch (0003 ?) when this TAP test file was
> introduced.
Changed.
The new patches were attached in [1].
[1] -
https://www.postgresql.org/message-id/OS3PR01MB6275739E73E8BEC5D13FB6739E6B9%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Tues, August 16, 2022 15:33 PM I wrote: > Attach the new patches. I found that cfbot has a failure. After investigation, I think it is because the worker's exit state is not set correctly. So I made some slight modifications. Attach the new patches. Regards, Wang wei
Attachment
- v23-0001-Perform-streaming-logical-transactions-by-backgr.patch
- v23-0002-Test-streaming-parallel-option-in-tap-test.patch
- v23-0003-Add-some-checks-before-using-apply-background-wo.patch
- v23-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v23-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"shiy.fnst@fujitsu.com"
Date:
On Wed, Aug 17, 2022 2:28 PM Wang, Wei/王 威 <wangw.fnst@fujitsu.com> wrote:
>
> On Tues, August 16, 2022 15:33 PM I wrote:
> > Attach the new patches.
>
> I found that cfbot has a failure.
> After investigation, I think it is because the worker's exit state is not set
> correctly. So I made some slight modifications.
>
> Attach the new patches.
>
Thanks for updating the patch. Here are some comments.
0003 patch
==============
1. src/backend/replication/logical/applybgworker.c
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("cannot replicate target relation \"%s.%s\" using "
+ "subscription parameter streaming=parallel",
+ rel->remoterel.nspname, rel->remoterel.relname),
+ errdetail("The unique column on subscriber is not the unique "
+ "column on publisher or there is at least one "
+ "non-immutable function."),
+ errhint("Please change to use subscription parameter "
+ "streaming=on.")));
Should we use "%s" instead of "streaming=parallel" and "streaming=on"?
2. src/backend/replication/logical/applybgworker.c
+ * If any worker is handling the streaming transaction, this check needs to
+ * be performed not only using the apply background worker, but also in the
+ * main apply worker. This is because without these restrictions, main
this check needs to be performed not only using the apply background worker, but
also in the main apply worker.
->
this check not only needs to be performed by apply background worker, but also
by the main apply worker
3. src/backend/replication/logical/relation.c
+ if (ukey)
+ {
+ i = -1;
+ while ((i = bms_next_member(ukey, i)) >= 0)
+ {
+ attnum = AttrNumberGetAttrOffset(i + FirstLowInvalidHeapAttributeNumber);
+
+ if (entry->attrmap->attnums[attnum] < 0 ||
+ !bms_is_member(entry->attrmap->attnums[attnum], entry->remoterel.attunique))
+ {
+ entry->parallel_apply = PARALLEL_APPLY_UNSAFE;
+ return;
+ }
+ }
+
+ bms_free(ukey);
It looks we need to call bms_free() before return, right?
4. src/backend/replication/logical/relation.c
+ /* We don't need info for dropped or generated attributes */
+ if (att->attisdropped || att->attgenerated)
+ continue;
Would it be better to change the comment to:
We don't check dropped or generated attributes
5. src/test/subscription/t/032_streaming_apply.pl
+$node_publisher->wait_for_catchup($appname);
+
+# Then we check the foreign key on partition table.
+$node_publisher->wait_for_catchup($appname);
Here, wait_for_catchup() is called twice, we can remove the second one.
6. src/backend/replication/logical/applybgworker.c
+ /* If any workers (or the postmaster) have died, we have failed. */
+ if (status == APPLY_BGWORKER_EXIT)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("background worker %u failed to apply transaction %u",
+ entry->wstate->shared->worker_id,
+ entry->wstate->shared->stream_xid)));
Should we change the error message to "apply background worker %u failed to
apply transaction %u" ? To be consistent with the error message in
apply_bgworker_wait_for().
0004 patch
==============
1.
I saw that the commit message says:
If the subscriber exits with an error, this flag will be set true, and
whenever the transaction is applied successfully, this flag is reset false.
"subretry" is set to false if a transaction is applied successfully, it looks
similar to what clear_subscription_skip_lsn() does, so maybe we should remove
the following change in apply_handle_stream_abort()? Or only call
set_subscription_retry() when rollbacking the toplevel transaction.
@@ -1671,6 +1688,9 @@ apply_handle_stream_abort(StringInfo s)
*/
serialize_stream_abort(xid, subxid);
}
+
+ /* Reset the retry flag. */
+ set_subscription_retry(false);
}
reset_apply_error_context_info();
2. src/backend/replication/logical/worker.c
+ /* Reset subretry */
+ values[Anum_pg_subscription_subretry - 1] = BoolGetDatum(retry);
+ replaces[Anum_pg_subscription_subretry - 1] = true;
/* Reset subretry */
->
/* Set subretry */
3.
+# Insert dependent data on the publisher, now it works.
+$node_subscriber->safe_psql('postgres', "INSERT INTO test_tab2 VALUES(1)");
In the case that the DELETE change from publisher has not been applied yet when
executing the INSERT, the INSERT will fail.
0005 patch
==============
1.
+ <para>
+ Process ID of the main apply worker, if this process is a apply
+ background worker. NULL if this process is a main apply worker or a
+ synchronization worker.
+ </para></entry>
a apply background worker
->
an apply background worker
Regards,
Shi yu
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for patch v21-0001:
Note - There are some "general" comments which will result in lots of
smaller changes. The subsequent "detailed" review comments have some
overlap with these general comments but I expect some will be missed
so please search/replace to fix all code related to those general
comments.
======
1. GENERAL - main_worker_pid and replorigin_session_setup
Quite a few of my subsequent review comments below are related to the
somewhat tricky (IMO) change to the code for this area. Here is a
summary of some things that can be done to clean/simplify this logic.
1a.
Make the existing replorigin_session_setup function just be a wrapper
that delegates to the other function passing the acquired_by as 0.
This is because in every case but one (in the apply bg worker main) we
are always passing 0, and IMO there is no need to spread the messy
extra param to places that do not use it.
1b.
'main_worker_pid' is a confusing member name given the way it gets
used - e.g. not even set when you actually *are* the main apply
worker? You can still keep all the same logic, but just change the
name to something more like 'apply_leader_pid' - then the code can
make sense because the main apply workers have no "apply leader" but
the apply background workers do.
1c.
IMO it will be much better to use pid_t and InvalidPid for the type
and the unset values of this member.
1d.
The checks/Asserts for main_worker_pid are confusing to read. (e.g.
Assert(worker->main_worker_pid != 0) means the worker is a apply
background worker. IMO there should be convenient macros for these -
then code can be readable again.
e.g.
#define isApplyMainWorker(worker) (worker->apply_leader_pid == InvalidPid)
#define isApplyBgWorker(worker) (worker->apply_leader_pid != InvalidPid)
======
2. GENERAL - ApplyBgworkerInfo
I like that the struct ApplyBgworkerState was renamed to the more
appropriate name ApplyBgworkerInfo. But now all the old variable names
(e.g. 'wstate') and parameters must be updated as well. Please
search/replace them all in code and comments.
e.g.
ApplyBgworkerInfo *wstate
should now be something like:
ApplyBgworkerInfo *winfo;
======
3. GENERAL - ApplyBgWorkerStatus --> ApplyBgworkerState
IMO the enum should be changed to ApplyBgWorkerState because the
values all represent the discrete state that the bgworker is at. See
the top StackOverflow answer here [1] which is the same as the point I
am trying to make with this comment.
This is a simple mechanical exercise rename to fix the reliability
but it will impact lots of variables, parameters, function names, and
comments. Please search/replace to get them all.
======
4. Commit message
In addition, the patch extends the logical replication STREAM_ABORT message so
that abort_time and abort_lsn can also be sent which can be used to update the
replication origin in apply background worker when the streaming transaction is
aborted.
4a.
Should this para also mention something about the introduction of
protocol version 4?
4b.
Should this para also mention that these extensions are not strictly
mandatory for the parallel streaming to still work?
======
5. doc/src/sgml/catalogs.sgml
<para>
- If true, the subscription will allow streaming of in-progress
- transactions
+ Controls how to handle the streaming of in-progress transactions:
+ <literal>f</literal> = disallow streaming of in-progress transactions,
+ <literal>t</literal> = spill the changes of in-progress transactions to
+ disk and apply at once after the transaction is committed on the
+ publisher,
+ <literal>p</literal> = apply changes directly using a background
+ worker if available(same as 't' if no worker is available)
</para></entry>
Missing whitespace before '('
======
6. doc/src/sgml/logical-replication.sgml
@@ -1334,7 +1344,8 @@ CONTEXT: processing remote data for replication
origin "pg_16395" during "INSER
subscription. A disabled subscription or a crashed subscription will have
zero rows in this view. If the initial data synchronization of any
table is in progress, there will be additional workers for the tables
- being synchronized.
+ being synchronized. Moreover, if the streaming transaction is applied
+ parallelly, there will be additional workers.
</para>
"applied parallelly" sounds a bit strange.
SUGGESTION-1
Moreover, if the streaming transaction is applied in parallel, there
will be additional workers.
SUGGESTION-2
Moreover, if the streaming transaction is applied using 'parallel'
mode, there will be additional workers.
======
7. doc/src/sgml/protocol.sgml
@@ -3106,6 +3106,11 @@ psql "dbname=postgres replication=database" -c
"IDENTIFY_SYSTEM;"
Version <literal>3</literal> is supported only for server version 15
and above, and it allows streaming of two-phase commits.
</para>
+ <para>
+ Version <literal>4</literal> is supported only for server version 16
+ and above, and it allows applying stream of large in-progress
+ transactions in parallel.
+ </para>
7a.
"applying stream of" -> "applying streams of"
7b.
Actually, I'm not sure that this description is strictly correct even
to say "it allows ..." because IIUC the streaming=parallel can still
work anyway without protocol 4 – it is just some of the extended
STREAM_ABORT message members will be missing, right?
======
8. doc/src/sgml/ref/create_subscription.sgml
+ <para>
+ If set to <literal>parallel</literal>, incoming changes are directly
+ applied via one of the apply background workers, if available. If no
+ background worker is free to handle streaming transaction then the
+ changes are written to temporary files and applied after the
+ transaction is committed. Note that if an error happens when
+ applying changes in a background worker, the finish LSN of the
+ remote transaction might not be reported in the server log.
</para>
"is free to handle streaming transaction"
-> "is free to handle streaming transactions"
or -> "is free to handle the streaming transaction"
======
9. src/backend/replication/logical/applybgworker.c - general
Some of the messages refer to the "worker #%u" and some refer to the
"worker %u" (without the '#'). All the messages should have a
consistent format.
~~~
10. src/backend/replication/logical/applybgworker.c - general
Search/replace all 'wstate' and change to 'winfo' or similar. See comment #2
~~~
11. src/backend/replication/logical/applybgworker.c - define
+/* Queue size of DSM, 16 MB for now. */
+#define DSM_QUEUE_SIZE (16*1024*1024)
Missing whitespace between operators
~~~
12. src/backend/replication/logical/applybgworker.c - define
+/*
+ * There are three fields in message: start_lsn, end_lsn and send_time. Because
+ * we have updated these statistics in apply worker, we could ignore these
+ * fields in apply background worker. (see function LogicalRepApplyLoop).
+ */
+#define SIZE_STATS_MESSAGE (2*sizeof(XLogRecPtr)+sizeof(TimestampTz))
12a.
"worker." -> "worker" (since the sentence already has a period at the end)
12b.
Missing whitespace between operators
~~~
13. src/backend/replication/logical/applybgworker.c - ApplyBgworkerEntry
+/*
+ * Entry for a hash table we use to map from xid to our apply background worker
+ * state.
+ */
+typedef struct ApplyBgworkerEntry
"our" -> "the"
~~~
14. src/backend/replication/logical/applybgworker.c - apply_bgworker_can_start
+ /*
+ * For streaming transactions that are being applied in apply background
+ * worker, we cannot decide whether to apply the change for a relation
+ * that is not in the READY state (see should_apply_changes_for_rel) as we
+ * won't know remote_final_lsn by that time. So, we don't start new apply
+ * background worker in this case.
+ */
14a.
"applied in apply background worker" -> "applied using an apply
background worker"
14b.
"we don't start new apply" -> "we don't start the new apply"
~~~
15. src/backend/replication/logical/applybgworker.c - apply_bgworker_start
+/*
+ * Return the apply background worker that will be used for the specified xid.
+ *
+ * If an apply background worker is found in the free list then re-use it,
+ * otherwise start a fresh one. Cache the worker ApplyBgworkersHash keyed by
+ * the specified xid.
+ */
+ApplyBgworkerInfo *
+apply_bgworker_start(TransactionId xid)
"Cache the worker ApplyBgworkersHash" -> "Cache the worker in
ApplyBgworkersHash"
~~~
16.
+ /* Try to get a free apply background worker. */
+ if (list_length(ApplyBgworkersFreeList) > 0)
Please refer to the recent push [2] of my other patch. This code should say
if (ApplyBgworkersFreeList !- NIL)
~~~
17. src/backend/replication/logical/applybgworker.c - LogicalApplyBgworkerMain
+ MyLogicalRepWorker->last_send_time = MyLogicalRepWorker->last_recv_time =
+ MyLogicalRepWorker->reply_time = 0;
+
+ InitializeApplyWorker();
Lots of things happen within InitializeApplyWorker(). I think this
call deserves at least some comment to say it does lots of common
initialization. And same for the other caller or this in the apply
main worker.
~~~
18. src/backend/replication/logical/applybgworker.c - apply_bgworker_setup_dsm
+/*
+ * Set up a dynamic shared memory segment.
+ *
+ * We set up a control region that contains a ApplyBgworkerShared,
+ * plus one region per message queue. There are as many message queues as
+ * the number of workers.
+ */
+static bool
+apply_bgworker_setup_dsm(ApplyBgworkerInfo *wstate)
This function is now returning a bool, so it would be better for the
function comment to describe the meaning of the return value.
~~~
19.
+ /* Create the shared memory segment and establish a table of contents. */
+ seg = dsm_create(shm_toc_estimate(&e), 0);
+
+ if (seg == NULL)
+ return false;
+
+ toc = shm_toc_create(PG_LOGICAL_APPLY_SHM_MAGIC, dsm_segment_address(seg),
+ segsize);
This code is similar but inconsistent with other code in the function
LogicalApplyBgworkerMain
19a.
I think the whitespace should be the same as in the other fucntion
19b.
Shouldn't the 'toc' result be checked like it was in the other function?
~~~
20. src/backend/replication/logical/applybgworker.c - apply_bgworker_setup
I think this function could be refactored to be cleaner and share more
common logic.
SUGGESTION
/* Setup shared memory, and attempt launch. */
if (apply_bgworker_setup_dsm(wstate))
{
bool launched;
launched = logicalrep_worker_launch(MyLogicalRepWorker->dbid,
MySubscription->oid,
MySubscription->name,
MyLogicalRepWorker->userid,
InvalidOid,
dsm_segment_handle(wstate->dsm_seg));
if (launched)
{
ApplyBgworkersList = lappend(ApplyBgworkersList, wstate);
MemoryContextSwitchTo(oldcontext);
return wstate;
}
else
{
dsm_detach(wstate->dsm_seg);
wstate->dsm_seg = NULL;
}
}
pfree(wstate);
MemoryContextSwitchTo(oldcontext);
return NULL;
~~~
21. src/backend/replication/logical/applybgworker.c -
apply_bgworker_check_status
+apply_bgworker_check_status(void)
+{
+ ListCell *lc;
+
+ if (am_apply_bgworker() || MySubscription->stream != SUBSTREAM_PARALLEL)
+ return;
IMO it makes more sense logically for the condition to be reordered:
if (MySubscription->stream != SUBSTREAM_PARALLEL || am_apply_bgworker())
~~~
22.
This function should be renamed to 'apply_bgworker_check_state'. See
review comment #3
~~~
23. src/backend/replication/logical/applybgworker.c - apply_bgworker_set_status
This function should be renamed to 'apply_bgworker_set_state'. See
review comment #3
~~~
24. src/backend/replication/logical/applybgworker.c -
apply_bgworker_subxact_info_add
+ /*
+ * CommitTransactionCommand is needed to start a subtransaction after
+ * issuing a SAVEPOINT inside a transaction block(see
+ * StartSubTransaction()).
+ */
Missing whitespace before '('
~~~
25. src/backend/replication/logical/applybgworker.c -
apply_bgworker_savepoint_name
+/*
+ * Form the savepoint name for streaming transaction.
+ *
+ * Return the name in the supplied buffer.
+ */
+void
+apply_bgworker_savepoint_name(Oid suboid, TransactionId xid,
"name for streaming" -> "name for the streaming"
======
26. src/backend/replication/logical/launcher.c - logicalrep_worker_find
@@ -223,6 +227,13 @@ logicalrep_worker_find(Oid subid, Oid relid, bool
only_running)
{
LogicalRepWorker *w = &LogicalRepCtx->workers[i];
+ /*
+ * We are only interested in the main apply worker or table sync worker
+ * here.
+ */
+ if (w->main_worker_pid != 0)
+ continue;
+
IMO the comment is not very well aligned with what the code is doing.
26a.
That comment saying "We are only interested in the main apply worker
or table sync worker here." is a general statement that I think
belongs outside this loop.
26b.
And the comment just for this condition should be like the below:
SUGGESTION
Skip apply background workers.
26c.
Also, code readability would be better if it used the earlier
suggested macros. See comment #1d.
SUGGESTION
/* Skip apply background workers. */
if (isApplyBgWorker(w))
continue;
~~~
27. src/backend/replication/logical/launcher.c - logicalrep_worker_launch
@@ -259,11 +270,11 @@ logicalrep_workers_find(Oid subid, bool only_running)
}
/*
- * Start new apply background worker, if possible.
+ * Start new background worker, if possible.
*/
-void
+bool
logicalrep_worker_launch(Oid dbid, Oid subid, const char *subname, Oid userid,
- Oid relid)
+ Oid relid, dsm_handle subworker_dsm)
This function now returns bool so the function comment probably should
describe the meaning of that return value.
~~~
28.
+ worker->main_worker_pid = is_subworker ? MyProcPid : 0;
Here is an example where I think code would benefit from the
suggestions of comments #1b, #1c.
SUGGESTION
worker->apply_leader_pid = is_subworker ? MyProcPid : InvalidPid;
~~~
29. src/backend/replication/logical/launcher.c - logicalrep_worker_stop
+ Assert(worker->main_worker_pid == 0);
Here is an example where I think code readability would benefit from
comment #1d.
Assert(isApplyMainWorker(worker));
~~~
30. src/backend/replication/logical/launcher.c - logicalrep_worker_detach
+ /*
+ * This is the main apply worker, stop all the apply background workers
+ * previously started from here.
+ */
"worker, stop" -> "worker; stop"
~~~
31.
+ if (w->main_worker_pid != 0)
+ logicalrep_worker_stop_internal(w);
See comment #1d.
SUGGESTION:
if (isApplyBgWorker(w)) ...
~~~
32. src/backend/replication/logical/launcher.c - logicalrep_worker_cleanup
@@ -621,6 +678,7 @@ logicalrep_worker_cleanup(LogicalRepWorker *worker)
worker->userid = InvalidOid;
worker->subid = InvalidOid;
worker->relid = InvalidOid;
+ worker->main_worker_pid = 0;
}
See Comment #1c.
SUGGESTION:
worker->apply_leader_pid = InvalidPid;
~~~
33. src/backend/replication/logical/launcher.c - logicalrep_apply_bgworker_count
+ if (w->subid == subid && w->main_worker_pid != 0)
+ res++;
See comment #1d.
SUGGESTION
if (w->subid == subid && isApplyBgWorker(w))
======
34. src/backend/replication/logical/origin.c - replorigin_session_setup
@@ -1075,12 +1075,21 @@ ReplicationOriginExitCleanup(int code, Datum arg)
* array doesn't have to be searched when calling
* replorigin_session_advance().
*
- * Obviously only one such cached origin can exist per process and the current
+ * Normally only one such cached origin can exist per process and the current
* cached value can only be set again after the previous value is torn down
* with replorigin_session_reset().
+ *
+ * However, if the function parameter 'acquired_by' is not 0, we allow the
+ * process to use the same slot already acquired by another process. It's safe
+ * because 1) The only caller (apply background workers) will maintain the
+ * commit order by allowing only one process to commit at a time, so no two
+ * workers will be operating on the same origin at the same time (see comments
+ * in logical/worker.c). 2) Even though we try to advance the session's origin
+ * concurrently, it's safe to do so as we change/advance the session_origin
+ * LSNs under replicate_state LWLock.
*/
void
-replorigin_session_setup(RepOriginId node)
+replorigin_session_setup(RepOriginId node, int acquired_by)
34a.
The comment does not actually say that acquired_by is the PID of the
owning process. It should say that.
34b.
IMO better to change the int acquired_by to type pid_t.
~~~
35.
See comment #1a.
I suggest existing replorigin_session_setup should just now be a
wrapper function that delegates to this new function and it can pass
the 'acquired_by' as 0.
e.g.
void
replorigin_session_setup(RepOriginId node)
{
replorigin_session_setup_acquired(node, 0)
}
~~
- session_replication_state->acquired_by = MyProcPid;
+ if (acquired_by == 0)
+ session_replication_state->acquired_by = MyProcPid;
+ else if (session_replication_state->acquired_by == 0)
+ elog(ERROR, "could not find replication state slot for replication"
+ "origin with OID %u which was acquired by %d", node, acquired_by);
Is that right to compare == 0?
Shouldn't this really be checking the owner is the passed 'acquired_by' slot?
e.g.
else if (session_replication_state->acquired_by != acquired_by)
======
36. src/backend/replication/logical/tablesync.c - process_syncing_tables
@@ -589,6 +590,9 @@ process_syncing_tables_for_apply(XLogRecPtr current_lsn)
void
process_syncing_tables(XLogRecPtr current_lsn)
{
+ if (am_apply_bgworker())
+ return;
+
Perhaps should be a comment to describe why process_syncing_tables
should be skipped for the apply background worker?
======
37. src/backend/replication/logical/worker.c - file comment
+ * 2) Write to temporary files and apply when the final commit arrives
+ *
+ * If no worker is available to handle streamed transaction, the data is
+ * written to temporary files and then applied at once when the final commit
+ * arrives.
"streamed transaction" -> "the streamed transaction"
~~~
38. src/backend/replication/logical/worker.c - should_apply_changes_for_rel
+ *
+ * Note that for streaming transactions that is being applied in apply
+ * background worker, we disallow applying changes on a table that is not in
+ * the READY state, because we cannot decide whether to apply the change as we
+ * won't know remote_final_lsn by that time.
+ *
+ * We already checked this in apply_bgworker_can_start() before assigning the
+ * streaming transaction to the background worker, but it also needs to be
+ * checked here because if the user executes ALTER SUBSCRIPTION ... REFRESH
+ * PUBLICATION in parallel, the new table can be added to pg_subscription_rel
+ * in parallel to this transaction.
*/
static bool
should_apply_changes_for_rel(LogicalRepRelMapEntry *rel)
38a.
"transactions that is being applied" -> "transactions that are being applied"
38b.
It is a bit confusing to keep using the word "parallel" here in the
comments (which is nothing to do with streaming=parallel mode – you
just mean *simultaneously* or *concurrently*). Perhaps the code
comment can be slightly reworded? Also, "in parallel to" doesn't sound
right.
~~~
39. src/backend/replication/logical/worker.c - handle_streamed_transaction
+ /* Not in streaming mode and not in apply background worker. */
+ if (!(in_streamed_transaction || am_apply_bgworker()))
return false;
IMO if you wanted to write the comment in that way then the code
should have matched it more closely like:
if (!in_streamed_transaction && !am_apply_bgworker())
OTOH, if you want to keep the code as-is then the comment should be
worded slightly differently.
~~~
40.
The coding styles do not seem particularly consistent. For example,
this function (handle_streamed_transaction) uses if/else and assigns
var 'res' to be a common return. But the previous function
(should_apply_changes_for_rel) uses if/else but returns directly from
every block. If possible, I think it's better to stick to the same
pattern instead of flip/flopping coding styles for no apparent reason.
~~~
41. src/backend/replication/logical/worker.c - apply_handle_prepare_internal
/*
- * BeginTransactionBlock is necessary to balance the EndTransactionBlock
+ * We must be in transaction block to balance the EndTransactionBlock
* called within the PrepareTransactionBlock below.
*/
I'm not sure what this comment changes saying that is any different to
the original HEAD comment.
And even if it must be kept the grammar is wrong.
~~~
42. src/backend/replication/logical/worker.c - apply_handle_stream_commit
@@ -1468,8 +1793,8 @@ apply_spooled_messages(TransactionId xid, XLogRecPtr lsn)
static void
apply_handle_stream_commit(StringInfo s)
{
- TransactionId xid;
LogicalRepCommitData commit_data;
+ TransactionId xid;
This change is just switching the order of declarations? If not
needed, remove it.
~~~
43.
+ else
+ {
+ /* This is the main apply worker. */
+ ApplyBgworkerInfo *wstate = apply_bgworker_find(xid);
- /* unlink the files with serialized changes and subxact info */
- stream_cleanup_files(MyLogicalRepWorker->subid, xid);
+ elog(DEBUG1, "received commit for streamed transaction %u", xid);
+
+ /*
+ * Check if we are processing this transaction in an apply background
+ * worker and if so, send the changes to that worker.
+ */
+ if (wstate)
+ {
+ /* Send STREAM COMMIT message to the apply background worker. */
+ apply_bgworker_send_data(wstate, s->len, s->data);
+
+ /*
+ * After sending the data to the apply background worker, wait for
+ * that worker to finish. This is necessary to maintain commit
+ * order which avoids failures due to transaction dependencies and
+ * deadlocks.
+ */
+ apply_bgworker_wait_for(wstate, APPLY_BGWORKER_FINISHED);
+
+ pgstat_report_stat(false);
+ store_flush_position(commit_data.end_lsn);
+ stop_skipping_changes();
+
+ apply_bgworker_free(wstate);
+
+ /*
+ * The transaction is either non-empty or skipped, so we clear the
+ * subskiplsn.
+ */
+ clear_subscription_skip_lsn(commit_data.commit_lsn);
+ }
+ else
+ {
+ /*
+ * The transaction has been serialized to file, so replay all the
+ * spooled operations.
+ */
+ apply_spooled_messages(xid, commit_data.commit_lsn);
+
+ apply_handle_commit_internal(&commit_data);
+
+ /* Unlink the files with serialized changes and subxact info. */
+ stream_cleanup_files(MyLogicalRepWorker->subid, xid);
+ }
+ }
+
+ /* Check the status of apply background worker if any. */
+ apply_bgworker_check_status();
/* Process any tables that are being synchronized in parallel. */
process_syncing_tables(commit_data.end_lsn);
43a.
AFAIK apply_bgworker_check_status() does nothing if am_apply_worker –
so can this call be moved into the code block where you already know
it is the main apply worker?
43b.
Similarly, AFAIK process_syncing_tables() does nothing if
am_apply_worker – so can this call can be moved into the code block
where you already know it is the main apply worker?
~~~
44. src/backend/replication/logical/worker.c - InitializeApplyWorker
+/*
+ * Initialize the databse connection, in-memory subscription and necessary
+ * config options.
+ */
void
-ApplyWorkerMain(Datum main_arg)
+InitializeApplyWorker(void)
{
44a.
typo "databse"
44b.
Should there be some more explanation in this comment to say that this
is common code for both the appl main workers and apply background
workers?
44c.
Following on from #44b, consider renaming this to something like
CommonApplyWorkerInit() to emphasize it is called from multiple
places?
~~~
45. src/backend/replication/logical/worker.c - ApplyWorkerMain
- replorigin_session_setup(originid);
+ replorigin_session_setup(originid, 0);
See #1a. Then this change won't be necessary.
~~~
46. src/backend/replication/logical/worker.c - apply_error_callback
+ if (errarg->remote_attnum < 0)
+ {
+ if (XLogRecPtrIsInvalid(errarg->finish_lsn))
+ errcontext("processing remote data for replication origin \"%s\"
during \"%s\" for replication target relation \"%s.%s\" in transaction
%u",
+ errarg->origin_name,
+ logicalrep_message_type(errarg->command),
+ errarg->rel->remoterel.nspname,
+ errarg->rel->remoterel.relname,
+ errarg->remote_xid);
+ else
+ errcontext("processing remote data for replication origin \"%s\"
during \"%s\" for replication target relation \"%s.%s\" in transaction
%u finished at %X/%X",
+ errarg->origin_name,
+ logicalrep_message_type(errarg->command),
+ errarg->rel->remoterel.nspname,
+ errarg->rel->remoterel.relname,
+ errarg->remote_xid,
+ LSN_FORMAT_ARGS(errarg->finish_lsn));
+ }
+ else
+ {
+ if (XLogRecPtrIsInvalid(errarg->finish_lsn))
+ errcontext("processing remote data for replication origin \"%s\"
during \"%s\" for replication target relation \"%s.%s\" column \"%s\"
in transaction %u",
+ errarg->origin_name,
+ logicalrep_message_type(errarg->command),
+ errarg->rel->remoterel.nspname,
+ errarg->rel->remoterel.relname,
+ errarg->rel->remoterel.attnames[errarg->remote_attnum],
+ errarg->remote_xid);
+ else
+ errcontext("processing remote data for replication origin \"%s\"
during \"%s\" for replication target relation \"%s.%s\" column \"%s\"
in transaction %u finished at %X/%X",
+ errarg->origin_name,
+ logicalrep_message_type(errarg->command),
+ errarg->rel->remoterel.nspname,
+ errarg->rel->remoterel.relname,
+ errarg->rel->remoterel.attnames[errarg->remote_attnum],
+ errarg->remote_xid,
+ LSN_FORMAT_ARGS(errarg->finish_lsn));
+ }
+ }
Hou-san had asked [3](comment #14) me how the above code can be
shortened. Below is one idea, but maybe you won't like it ;-)
#define MSG_O_T_S_R "processing remote data for replication origin
\"%s\" during \"%s\" for replication target relation \"%s.%s\" "
#define O_T_S_R\
errarg->origin_name,\
logicalrep_message_type(errarg->command),\
errarg->rel->remoterel.nspname,\
errarg->rel->remoterel.relname
if (errarg->remote_attnum < 0)
{
if (XLogRecPtrIsInvalid(errarg->finish_lsn))
errcontext(MSG_O_T_S_R "in transaction %u",
O_T_S_R,
errarg->remote_xid);
else
errcontext(MSG_O_T_S_R "in transaction %u finished at %X/%X",
O_T_S_R,
errarg->remote_xid,
LSN_FORMAT_ARGS(errarg->finish_lsn));
}
else
{
if (XLogRecPtrIsInvalid(errarg->finish_lsn))
errcontext(MSG_O_T_S_R "column \"%s\" in transaction %u",
O_T_S_R,
errarg->rel->remoterel.attnames[errarg->remote_attnum],
errarg->remote_xid);
else
errcontext(MSG_O_T_S_R "column \"%s\" in transaction %u finished at %X/%X",
O_T_S_R,
errarg->rel->remoterel.attnames[errarg->remote_attnum],
errarg->remote_xid,
LSN_FORMAT_ARGS(errarg->finish_lsn));
}
#undef O_T_S_R
#undef MSG_O_T_S_R
======
47. src/include/replication/logicalproto.h
@@ -32,12 +32,17 @@
*
* LOGICALREP_PROTO_TWOPHASE_VERSION_NUM is the minimum protocol version with
* support for two-phase commit decoding (at prepare time). Introduced in PG15.
+ *
+ * LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM is the minimum protocol version
+ * with support for streaming large transactions using apply background
+ * workers. Introduced in PG16.
*/
#define LOGICALREP_PROTO_MIN_VERSION_NUM 1
#define LOGICALREP_PROTO_VERSION_NUM 1
#define LOGICALREP_PROTO_STREAM_VERSION_NUM 2
#define LOGICALREP_PROTO_TWOPHASE_VERSION_NUM 3
-#define LOGICALREP_PROTO_MAX_VERSION_NUM LOGICALREP_PROTO_TWOPHASE_VERSION_NUM
+#define LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM 4
+#define LOGICALREP_PROTO_MAX_VERSION_NUM
LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM
47a.
I don't think that comment is strictly true. IIUC the new protocol
version 4 is currently only affecting the *extra* STREAM_ABORT members
– but in fact streaming=parallel is still functional without using
those extra members, isn't it? So maybe this description needed to be
modified a bit to be more accurate?
47b.
And perhaps the entire constant should be renamed to something like
LOGICALREP_PROTO_PARALLEL_STREAM_ABORT_VERSION_NUM?
======
48. src/include/replication/origin.h
-extern void replorigin_session_setup(RepOriginId node);
+extern void replorigin_session_setup(RepOriginId node, int acquired_by);
See comment #1a, #35.
IMO original should be left as-is and a new "wrapped" function added
with pid_t param.
======
49. src/include/replication/worker_internal.h
@@ -60,6 +63,12 @@ typedef struct LogicalRepWorker
*/
FileSet *stream_fileset;
+ /*
+ * PID of main apply worker if this slot is used for an apply background
+ * worker.
+ */
+ int main_worker_pid;
+
/* Stats. */
XLogRecPtr last_lsn;
TimestampTz last_send_time;
@@ -68,8 +77,70 @@ typedef struct LogicalRepWorker
TimestampTz reply_time;
} LogicalRepWorker;
49a.
See my general comments #1b, #1b, #1c about this.
49b.
Also, the comment should describe both cases.
SUGGESTION
/*
* For apply background worker - 'apply_leader_pid' is the PID of the main
* apply worker that launched the apply background worker.
*
* For main apply worker - 'apply_leader_pid' is InvalidPid.
*/
pid_t apply_leader_pid;
49c.
Here is where some helpful worker macros (mentioned in comment #1d)
can be defined.
SUGGESTION
#define isApplyMainWorker(worker) (worker->apply_leader_pid == InvalidPid)
#define isApplyBgWorker(worker) (worker->apply_leader_pid != InvalidPid)
~~~
50.
+/*
+ * Status of apply background worker.
+ */
+typedef enum ApplyBgworkerStatus
+{
+ APPLY_BGWORKER_BUSY = 0, /* assigned to a transaction */
+ APPLY_BGWORKER_FINISHED, /* transaction is completed */
+ APPLY_BGWORKER_EXIT /* exit */
+} ApplyBgworkerStatus;
50a.
See general comment #3 why this enum should be renamed to ApplyBgworkerState
50b.
The comment "/* exit */" is pretty meaningless. Maybe "worker has
shutdown/exited" or similar?
50c.
In fact, I think the enum value should be APPLY_BGWORKER_EXITED
50d.
There seems no reason to explicitly assign APPLY_BGWORKER_BUSY enum value to 0.
SUGGESTION
/*
* Apply background worker states.
*/
typedef enum ApplyBgworkerState
{
APPLY_BGWORKER_BUSY, /* assigned to a transaction */
APPLY_BGWORKER_FINISHED, /* transaction is completed */
APPLY_BGWORKER_EXITED /* worker has shutdown/exited */
} ApplyBgworkerState;
~~~
51.
+typedef struct ApplyBgworkerShared
+{
+ slock_t mutex;
+
+ /* Status of apply background worker. */
+ ApplyBgworkerStatus status;
+
+ /* Logical protocol version. */
+ uint32 proto_version;
+
+ TransactionId stream_xid;
+
+ /* Id of apply background worker */
+ uint32 worker_id;
+} ApplyBgworkerShared;
51a.
+ /* Status of apply background worker. */
+ ApplyBgworkerStatus status;
See review comment #3.
SUGGESTION:
/* Current state of the apply background worker c. */
ApplyBgworkerState worker_state;
51b.
+ /* Id of apply background worker */
"Id" -> "ID" might be more usual.
~~~
52.
+/* Apply background worker setup and interactions */
+extern ApplyBgworkerInfo *apply_bgworker_start(TransactionId xid);
+extern ApplyBgworkerInfo *apply_bgworker_find(TransactionId xid);
+extern void apply_bgworker_wait_for(ApplyBgworkerInfo *wstate,
+ ApplyBgworkerStatus wait_for_status);
+extern void apply_bgworker_send_data(ApplyBgworkerInfo *wstate, Size nbytes,
+ const void *data);
+extern void apply_bgworker_free(ApplyBgworkerInfo *wstate);
+extern void apply_bgworker_check_status(void);
+extern void apply_bgworker_set_status(ApplyBgworkerStatus status);
+extern void apply_bgworker_subxact_info_add(TransactionId current_xid);
+extern void apply_bgworker_savepoint_name(Oid suboid, Oid relid,
+ char *spname, int szsp);
This big block of similarly named externs might as well be in
alphabetical order instead of apparently random.
~~~
53.
+static inline bool
+am_apply_bgworker(void)
+{
+ return MyLogicalRepWorker->main_worker_pid != 0;
+}
This can be simplified/improved using the new macros as previously
suggested in #1d.
SUGGESTION
static inline bool
am_apply_bgworker(void)
{
return isApplyBgWorker(MyLogicalRepWorker);
}
====
54. src/tools/pgindent/typedefs.list
AppendState
+ApplyBgworkerEntry
+ApplyBgworkerShared
+ApplyBgworkerInfo
+ApplyBgworkerStatus
ApplyErrorCallbackArg
Please rearrange these into alphabetical order.
------
[1]
https://softwareengineering.stackexchange.com/questions/219351/state-or-status-when-should-a-variable-name-contain-the-word-state-and-w#:~:text=status%20is%20used%20to%20describe,(e.g.%20pending%2Fdispatched)
[2] https://github.com/postgres/postgres/commit/efd0c16becbf45e3b0215e124fde75fee8fcbce4
[3]
https://www.postgresql.org/message-id/OS0PR01MB57169AEA399C6DC370EAF23B94649%40OS0PR01MB5716.jpnprd01.prod.outlook.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Hi Wang-san, FYI, I also checked the latest patch v23-0001 but found that the v21-0001/v23-0001 differences are minimal, so all my v21* review comments are still applicable for the patch v23-0001. ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Aug 18, 2022 at 11:59 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are my review comments for patch v21-0001:
>
> 4. Commit message
>
> In addition, the patch extends the logical replication STREAM_ABORT message so
> that abort_time and abort_lsn can also be sent which can be used to update the
> replication origin in apply background worker when the streaming transaction is
> aborted.
>
> 4a.
> Should this para also mention something about the introduction of
> protocol version 4?
>
> 4b.
> Should this para also mention that these extensions are not strictly
> mandatory for the parallel streaming to still work?
>
Without parallel streaming/apply, we don't need to send this extra
message. So, I don't think it will be correct to say that.
>
> 46. src/backend/replication/logical/worker.c - apply_error_callback
>
> + if (errarg->remote_attnum < 0)
> + {
> + if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> + errcontext("processing remote data for replication origin \"%s\"
> during \"%s\" for replication target relation \"%s.%s\" in transaction
> %u",
> + errarg->origin_name,
> + logicalrep_message_type(errarg->command),
> + errarg->rel->remoterel.nspname,
> + errarg->rel->remoterel.relname,
> + errarg->remote_xid);
> + else
> + errcontext("processing remote data for replication origin \"%s\"
> during \"%s\" for replication target relation \"%s.%s\" in transaction
> %u finished at %X/%X",
> + errarg->origin_name,
> + logicalrep_message_type(errarg->command),
> + errarg->rel->remoterel.nspname,
> + errarg->rel->remoterel.relname,
> + errarg->remote_xid,
> + LSN_FORMAT_ARGS(errarg->finish_lsn));
> + }
> + else
> + {
> + if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> + errcontext("processing remote data for replication origin \"%s\"
> during \"%s\" for replication target relation \"%s.%s\" column \"%s\"
> in transaction %u",
> + errarg->origin_name,
> + logicalrep_message_type(errarg->command),
> + errarg->rel->remoterel.nspname,
> + errarg->rel->remoterel.relname,
> + errarg->rel->remoterel.attnames[errarg->remote_attnum],
> + errarg->remote_xid);
> + else
> + errcontext("processing remote data for replication origin \"%s\"
> during \"%s\" for replication target relation \"%s.%s\" column \"%s\"
> in transaction %u finished at %X/%X",
> + errarg->origin_name,
> + logicalrep_message_type(errarg->command),
> + errarg->rel->remoterel.nspname,
> + errarg->rel->remoterel.relname,
> + errarg->rel->remoterel.attnames[errarg->remote_attnum],
> + errarg->remote_xid,
> + LSN_FORMAT_ARGS(errarg->finish_lsn));
> + }
> + }
>
> Hou-san had asked [3](comment #14) me how the above code can be
> shortened. Below is one idea, but maybe you won't like it ;-)
>
> #define MSG_O_T_S_R "processing remote data for replication origin
> \"%s\" during \"%s\" for replication target relation \"%s.%s\" "
> #define O_T_S_R\
> errarg->origin_name,\
> logicalrep_message_type(errarg->command),\
> errarg->rel->remoterel.nspname,\
> errarg->rel->remoterel.relname
>
> if (errarg->remote_attnum < 0)
> {
> if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> errcontext(MSG_O_T_S_R "in transaction %u",
> O_T_S_R,
> errarg->remote_xid);
> else
> errcontext(MSG_O_T_S_R "in transaction %u finished at %X/%X",
> O_T_S_R,
> errarg->remote_xid,
> LSN_FORMAT_ARGS(errarg->finish_lsn));
> }
> else
> {
> if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> errcontext(MSG_O_T_S_R "column \"%s\" in transaction %u",
> O_T_S_R,
> errarg->rel->remoterel.attnames[errarg->remote_attnum],
> errarg->remote_xid);
> else
> errcontext(MSG_O_T_S_R "column \"%s\" in transaction %u finished at %X/%X",
> O_T_S_R,
> errarg->rel->remoterel.attnames[errarg->remote_attnum],
> errarg->remote_xid,
> LSN_FORMAT_ARGS(errarg->finish_lsn));
> }
> #undef O_T_S_R
> #undef MSG_O_T_S_R
>
> ======
>
I don't like this much. I think this reduces readability.
> 47. src/include/replication/logicalproto.h
>
> @@ -32,12 +32,17 @@
> *
> * LOGICALREP_PROTO_TWOPHASE_VERSION_NUM is the minimum protocol version with
> * support for two-phase commit decoding (at prepare time). Introduced in PG15.
> + *
> + * LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM is the minimum protocol version
> + * with support for streaming large transactions using apply background
> + * workers. Introduced in PG16.
> */
> #define LOGICALREP_PROTO_MIN_VERSION_NUM 1
> #define LOGICALREP_PROTO_VERSION_NUM 1
> #define LOGICALREP_PROTO_STREAM_VERSION_NUM 2
> #define LOGICALREP_PROTO_TWOPHASE_VERSION_NUM 3
> -#define LOGICALREP_PROTO_MAX_VERSION_NUM LOGICALREP_PROTO_TWOPHASE_VERSION_NUM
> +#define LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM 4
> +#define LOGICALREP_PROTO_MAX_VERSION_NUM
> LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM
>
> 47a.
> I don't think that comment is strictly true. IIUC the new protocol
> version 4 is currently only affecting the *extra* STREAM_ABORT members
> – but in fact streaming=parallel is still functional without using
> those extra members, isn't it? So maybe this description needed to be
> modified a bit to be more accurate?
>
The reason for sending this extra abort members is to ensure that
after aborting the transaction, if the subscriber/apply worker
restarts, it doesn't need to request the transaction again. Do you
have suggestions for improving this comment?
>
> 52.
>
> +/* Apply background worker setup and interactions */
> +extern ApplyBgworkerInfo *apply_bgworker_start(TransactionId xid);
> +extern ApplyBgworkerInfo *apply_bgworker_find(TransactionId xid);
> +extern void apply_bgworker_wait_for(ApplyBgworkerInfo *wstate,
> + ApplyBgworkerStatus wait_for_status);
> +extern void apply_bgworker_send_data(ApplyBgworkerInfo *wstate, Size nbytes,
> + const void *data);
> +extern void apply_bgworker_free(ApplyBgworkerInfo *wstate);
> +extern void apply_bgworker_check_status(void);
> +extern void apply_bgworker_set_status(ApplyBgworkerStatus status);
> +extern void apply_bgworker_subxact_info_add(TransactionId current_xid);
> +extern void apply_bgworker_savepoint_name(Oid suboid, Oid relid,
> + char *spname, int szsp);
>
> This big block of similarly named externs might as well be in
> alphabetical order instead of apparently random.
>
I think it is better to order them based on related functionality if
they are not already instead of using alphabetical order.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Thu, Aug 18, 2022 at 6:57 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Aug 18, 2022 at 11:59 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > Here are my review comments for patch v21-0001:
> >
> > 4. Commit message
> >
> > In addition, the patch extends the logical replication STREAM_ABORT message so
> > that abort_time and abort_lsn can also be sent which can be used to update the
> > replication origin in apply background worker when the streaming transaction is
> > aborted.
> >
> > 4a.
> > Should this para also mention something about the introduction of
> > protocol version 4?
> >
> > 4b.
> > Should this para also mention that these extensions are not strictly
> > mandatory for the parallel streaming to still work?
> >
>
> Without parallel streaming/apply, we don't need to send this extra
> message. So, I don't think it will be correct to say that.
See my reply to 47a below.
>
> >
> > 46. src/backend/replication/logical/worker.c - apply_error_callback
> >
> > + if (errarg->remote_attnum < 0)
> > + {
> > + if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> > + errcontext("processing remote data for replication origin \"%s\"
> > during \"%s\" for replication target relation \"%s.%s\" in transaction
> > %u",
> > + errarg->origin_name,
> > + logicalrep_message_type(errarg->command),
> > + errarg->rel->remoterel.nspname,
> > + errarg->rel->remoterel.relname,
> > + errarg->remote_xid);
> > + else
> > + errcontext("processing remote data for replication origin \"%s\"
> > during \"%s\" for replication target relation \"%s.%s\" in transaction
> > %u finished at %X/%X",
> > + errarg->origin_name,
> > + logicalrep_message_type(errarg->command),
> > + errarg->rel->remoterel.nspname,
> > + errarg->rel->remoterel.relname,
> > + errarg->remote_xid,
> > + LSN_FORMAT_ARGS(errarg->finish_lsn));
> > + }
> > + else
> > + {
> > + if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> > + errcontext("processing remote data for replication origin \"%s\"
> > during \"%s\" for replication target relation \"%s.%s\" column \"%s\"
> > in transaction %u",
> > + errarg->origin_name,
> > + logicalrep_message_type(errarg->command),
> > + errarg->rel->remoterel.nspname,
> > + errarg->rel->remoterel.relname,
> > + errarg->rel->remoterel.attnames[errarg->remote_attnum],
> > + errarg->remote_xid);
> > + else
> > + errcontext("processing remote data for replication origin \"%s\"
> > during \"%s\" for replication target relation \"%s.%s\" column \"%s\"
> > in transaction %u finished at %X/%X",
> > + errarg->origin_name,
> > + logicalrep_message_type(errarg->command),
> > + errarg->rel->remoterel.nspname,
> > + errarg->rel->remoterel.relname,
> > + errarg->rel->remoterel.attnames[errarg->remote_attnum],
> > + errarg->remote_xid,
> > + LSN_FORMAT_ARGS(errarg->finish_lsn));
> > + }
> > + }
> >
> > Hou-san had asked [3](comment #14) me how the above code can be
> > shortened. Below is one idea, but maybe you won't like it ;-)
> >
> > #define MSG_O_T_S_R "processing remote data for replication origin
> > \"%s\" during \"%s\" for replication target relation \"%s.%s\" "
> > #define O_T_S_R\
> > errarg->origin_name,\
> > logicalrep_message_type(errarg->command),\
> > errarg->rel->remoterel.nspname,\
> > errarg->rel->remoterel.relname
> >
> > if (errarg->remote_attnum < 0)
> > {
> > if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> > errcontext(MSG_O_T_S_R "in transaction %u",
> > O_T_S_R,
> > errarg->remote_xid);
> > else
> > errcontext(MSG_O_T_S_R "in transaction %u finished at %X/%X",
> > O_T_S_R,
> > errarg->remote_xid,
> > LSN_FORMAT_ARGS(errarg->finish_lsn));
> > }
> > else
> > {
> > if (XLogRecPtrIsInvalid(errarg->finish_lsn))
> > errcontext(MSG_O_T_S_R "column \"%s\" in transaction %u",
> > O_T_S_R,
> > errarg->rel->remoterel.attnames[errarg->remote_attnum],
> > errarg->remote_xid);
> > else
> > errcontext(MSG_O_T_S_R "column \"%s\" in transaction %u finished at %X/%X",
> > O_T_S_R,
> > errarg->rel->remoterel.attnames[errarg->remote_attnum],
> > errarg->remote_xid,
> > LSN_FORMAT_ARGS(errarg->finish_lsn));
> > }
> > #undef O_T_S_R
> > #undef MSG_O_T_S_R
> >
> > ======
> >
>
> I don't like this much. I think this reduces readability.
I agree. That wasn't a very serious suggestion :-)
>
> > 47. src/include/replication/logicalproto.h
> >
> > @@ -32,12 +32,17 @@
> > *
> > * LOGICALREP_PROTO_TWOPHASE_VERSION_NUM is the minimum protocol version with
> > * support for two-phase commit decoding (at prepare time). Introduced in PG15.
> > + *
> > + * LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM is the minimum protocol version
> > + * with support for streaming large transactions using apply background
> > + * workers. Introduced in PG16.
> > */
> > #define LOGICALREP_PROTO_MIN_VERSION_NUM 1
> > #define LOGICALREP_PROTO_VERSION_NUM 1
> > #define LOGICALREP_PROTO_STREAM_VERSION_NUM 2
> > #define LOGICALREP_PROTO_TWOPHASE_VERSION_NUM 3
> > -#define LOGICALREP_PROTO_MAX_VERSION_NUM LOGICALREP_PROTO_TWOPHASE_VERSION_NUM
> > +#define LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM 4
> > +#define LOGICALREP_PROTO_MAX_VERSION_NUM
> > LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM
> >
> > 47a.
> > I don't think that comment is strictly true. IIUC the new protocol
> > version 4 is currently only affecting the *extra* STREAM_ABORT members
> > – but in fact streaming=parallel is still functional without using
> > those extra members, isn't it? So maybe this description needed to be
> > modified a bit to be more accurate?
> >
>
> The reason for sending this extra abort members is to ensure that
> after aborting the transaction, if the subscriber/apply worker
> restarts, it doesn't need to request the transaction again. Do you
> have suggestions for improving this comment?
>
I gave three review comments for v21-0001 that were all related to
this same point:
i- #4b (commit message)
ii- #7 (protocol pgdocs)
iii- #47a (code comment)
The point was:
AFAIK protocol 4 is only to let the parallel streaming logic behave
*better* in how it can handle restarts after aborts. But that does not
mean that protocol 4 is a *pre-requisite* for "allowing"
streaming=parallel to work in the first place. I thought that a PG15
publisher and PG16 subscriber can still work using streaming=parallel
even with protocol 3, but it just won't be quite as clever for
handling restarts after abort as protocol 4 (PG16 -> PG16) would be.
If the above is correct, then the code comment can be changed to
something like this:
BEFORE
LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM is the minimum protocol
version with support for streaming large transactions using apply
background workers. Introduced in PG16.
AFTER
LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM improves how subscription
parameter streaming=parallel (introduced in PG16) will handle restarts
after aborts. Introduced in PG16.
~
The protocol pgdocs might be changed similarly...
BEFORE
Version <literal>4</literal> is supported only for server version 16
and above, and it allows applying stream of large in-progress
transactions in parallel.
AFTER
Version <literal>4</literal> is supported only for server version 16
and above, and it improves how subscription parameter
streaming=parallel (introduced in PG16) will handle restarts after
aborts.
~~
And similar text again for the commit message...
------
Kind Regards,
Peter Smith.
Fujitsu Australia.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Aug 18, 2022 at 3:40 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Thu, Aug 18, 2022 at 6:57 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > 47. src/include/replication/logicalproto.h > > > > > > @@ -32,12 +32,17 @@ > > > * > > > * LOGICALREP_PROTO_TWOPHASE_VERSION_NUM is the minimum protocol version with > > > * support for two-phase commit decoding (at prepare time). Introduced in PG15. > > > + * > > > + * LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM is the minimum protocol version > > > + * with support for streaming large transactions using apply background > > > + * workers. Introduced in PG16. > > > */ > > > #define LOGICALREP_PROTO_MIN_VERSION_NUM 1 > > > #define LOGICALREP_PROTO_VERSION_NUM 1 > > > #define LOGICALREP_PROTO_STREAM_VERSION_NUM 2 > > > #define LOGICALREP_PROTO_TWOPHASE_VERSION_NUM 3 > > > -#define LOGICALREP_PROTO_MAX_VERSION_NUM LOGICALREP_PROTO_TWOPHASE_VERSION_NUM > > > +#define LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM 4 > > > +#define LOGICALREP_PROTO_MAX_VERSION_NUM > > > LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM > > > > > > 47a. > > > I don't think that comment is strictly true. IIUC the new protocol > > > version 4 is currently only affecting the *extra* STREAM_ABORT members > > > – but in fact streaming=parallel is still functional without using > > > those extra members, isn't it? So maybe this description needed to be > > > modified a bit to be more accurate? > > > > > > > The reason for sending this extra abort members is to ensure that > > after aborting the transaction, if the subscriber/apply worker > > restarts, it doesn't need to request the transaction again. Do you > > have suggestions for improving this comment? > > > > I gave three review comments for v21-0001 that were all related to > this same point: > i- #4b (commit message) > ii- #7 (protocol pgdocs) > iii- #47a (code comment) > > The point was: > AFAIK protocol 4 is only to let the parallel streaming logic behave > *better* in how it can handle restarts after aborts. But that does not > mean that protocol 4 is a *pre-requisite* for "allowing" > streaming=parallel to work in the first place. I thought that a PG15 > publisher and PG16 subscriber can still work using streaming=parallel > even with protocol 3, but it just won't be quite as clever for > handling restarts after abort as protocol 4 (PG16 -> PG16) would be. > It is not only that it makes it better but one can say that it is a break of a replication protocol that after the client (subscriber) has applied some transaction, it requests the same transaction again. So, I think it is better to make the parallelism work only when the server version is also 16. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Aug 17, 2022 at 11:58 AM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> Attach the new patches.
>
Few comments on v23-0001
=======================
1.
+ /*
+ * Attach to the dynamic shared memory segment for the parallel query, and
+ * find its table of contents.
+ *
+ * Note: at this point, we have not created any ResourceOwner in this
+ * process. This will result in our DSM mapping surviving until process
+ * exit, which is fine. If there were a ResourceOwner, it would acquire
+ * ownership of the mapping, but we have no need for that.
+ */
In the first sentence, instead of a parallel query, you need to use
parallel apply. I think we don't need to repeat the entire note as we
have in ParallelWorkerMain. You can say something like: "Like parallel
query, we don't need resource owner by this time. See
ParallelWorkerMain"
2.
+/*
+ * There are three fields in message: start_lsn, end_lsn and send_time. Because
+ * we have updated these statistics in apply worker, we could ignore these
+ * fields in apply background worker. (see function LogicalRepApplyLoop).
+ */
+#define SIZE_STATS_MESSAGE (2*sizeof(XLogRecPtr)+sizeof(TimestampTz))
The first sentence in the above comment isn't clear about which
message it talks about. I think it is about any message received by
this apply bgworker, if so, can we change it to: "There are three
fields in each message received by apply worker: start_lsn, end_lsn,
and send_time."
3.
+/*
+ * Return the apply background worker that will be used for the specified xid.
+ *
+ * If an apply background worker is found in the free list then re-use it,
+ * otherwise start a fresh one. Cache the worker ApplyBgworkersHash keyed by
+ * the specified xid.
+ */
+ApplyBgworkerInfo *
+apply_bgworker_start(TransactionId xid)
The first sentence should say apply background worker info. Can we
change the cache-related sentence in the above comment to "Cache the
worker info in ApplyBgworkersHash keyed by the specified xid."?
4.
/*
+ * We use first byte of message for additional communication between
+ * main Logical replication worker and apply background workers, so if
+ * it differs from 'w', then process it first.
+ */
+ c = pq_getmsgbyte(&s);
+ switch (c)
+ {
+ /* End message of streaming chunk */
+ case LOGICAL_REP_MSG_STREAM_STOP:
+ elog(DEBUG1, "[Apply BGW #%u] ended processing streaming chunk, "
+ "waiting on shm_mq_receive", shared->worker_id);
+
Why do we need special handling of LOGICAL_REP_MSG_STREAM_STOP message
here? Instead, why not let it get handled via apply_dispatch path? You
will require special handling for apply_bg_worker but I see other
messages do have similar handling.
5.
+ /*
+ * Now, we have initialized DSM. Attach to slot.
+ */
+ logicalrep_worker_attach(worker_slot);
Can we change this comment to something like: "Primary initialization
is complete. Now, we can attach to our slot.". IIRC, we have done it
after initialization to avoid some race conditions among leader apply
worker and this parallel apply worker. If so, can we explain the same
in the comments?
6.
+/*
+ * Set up a dynamic shared memory segment.
+ *
+ * We set up a control region that contains a ApplyBgworkerShared,
+ * plus one region per message queue. There are as many message queues as
+ * the number of workers.
+ */
+static bool
+apply_bgworker_setup_dsm(ApplyBgworkerInfo *wstate)
I think the part of the comment: "There are as many message queues as
the number of workers." doesn't seem to fit atop this function as this
has nothing to do with the number of workers. It would be a good idea
to write something about what all is communicated via DSM in the
description you have written about apply bg workers in worker.c.
7.
+ /* Check if there are free worker slot(s). */
+ LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
+ napplyworkers = logicalrep_apply_bgworker_count(MyLogicalRepWorker->subid);
+ LWLockRelease(LogicalRepWorkerLock);
+
+ if (napplyworkers >= max_apply_bgworkers_per_subscription)
+ return NULL;
Won't it be better to check this restriction in
logicalrep_worker_launch() as we do for tablesync workers? That way
all similar restrictions will be in one place.
8.
+ if (rel->state != SUBREL_STATE_READY)
+ ereport(ERROR,
+ (errmsg("logical replication apply workers for subscription \"%s\"
will restart",
+ MySubscription->name),
+ errdetail("Cannot handle streamed replication transaction by apply "
+ "background workers until all tables are synchronized")));
errdetail messages always end with a full stop.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Hi Wang-san, Here is some more information about my v21-0001 review [2] posted yesterday. ~~ If the streaming=parallel will be disallowed for publishers not using protocol 4 (see Amit's post [1]), then please ignore all my previous review comments about the protocol descriptions (see [2] comments #4b, #7b, #47a, #47b). ~~ Also, I was having second thoughts about the name replacement for the 'main_worker_pid' member (see [2] comments #1b, #49). Previously I suggested 'apply_leader_pid', but now I think something like 'apply_bgworker_leader_pid' would be better. (It's a bit verbose, but now it gives the proper understanding that only an apply bgworker can have a valid value for this member). ------ [1] https://www.postgresql.org/message-id/CAA4eK1JR2GR9jjaz9T1ZxzgLVS0h089EE8ZB%3DF2EsVHbM_5sfA%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAHut%2BPuxEQ88PDhFcBftnNY1BAjdj_9G8FYhTvPHKjP8yfacaQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Aug 19, 2022 at 4:36 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Hi Wang-san, > > Here is some more information about my v21-0001 review [2] posted yesterday. > > ~~ > > If the streaming=parallel will be disallowed for publishers not using > protocol 4 (see Amit's post [1]), then please ignore all my previous > review comments about the protocol descriptions (see [2] comments #4b, > #7b, #47a, #47b). > > ~~ > > Also, I was having second thoughts about the name replacement for the > 'main_worker_pid' member (see [2] comments #1b, #49). Previously I > suggested 'apply_leader_pid', but now I think something like > 'apply_bgworker_leader_pid' would be better. (It's a bit verbose, but > now it gives the proper understanding that only an apply bgworker can > have a valid value for this member). > I find your previous suggestion to name it 'apply_leader_pid' better. According to me, it conveys the meaning. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for the patch v23-0003:
======
3.1. src/backend/replication/logical/applybgworker.c -
apply_bgworker_relation_check
+ * Although the commit order is maintained by only allowing one process to
+ * commit at a time, the access order to the relation has changed. This could
+ * cause unexpected problems if the unique column on the replicated table is
+ * inconsistent with the publisher-side or contains non-immutable functions
+ * when applying transactions using an apply background worker.
+ */
+void
+apply_bgworker_relation_check(LogicalRepRelMapEntry *rel)
I’m not sure, but should that second sentence be rearranged as follows?
SUGGESTION
This could cause unexpected problems when applying transactions using
an apply background worker if the unique column on the replicated
table is inconsistent with the publisher-side, or if the relation
contains non-immutable functions.
~~~
3.2.
+ if (!am_apply_bgworker() &&
+ (list_length(ApplyBgworkersFreeList) == list_length(ApplyBgworkersList)))
+ return;
Previously I posted I was struggling to understand the above
condition, and then it was explained (see [1] comment #4) that:
> We need to check this for apply bgworker. (Both lists are "NIL" in apply bgworker.)
I think that information should be included in the code comment.
======
3.3. src/include/replication/logicalrelation.h
+/*
+ * States to determine if changes on one relation can be applied using an
+ * apply background worker.
+ */
+typedef enum ParallelApplySafety
+{
+ PARALLEL_APPLY_UNKNOWN = 0,
+ PARALLEL_APPLY_SAFE,
+ PARALLEL_APPLY_UNSAFE
+} ParallelApplySafety;
+
3.3a.
The enum value PARALLEL_APPLY_UNKNOWN doesn't really mean anything.
Maybe naming it PARALLEL_APPLY_SAFETY_UNKNOWN gives it the intended
meaning.
3.3b.
+ PARALLEL_APPLY_UNKNOWN = 0,
I didn't see any reason to explicitly assign this to 0.
~~~
3.4. src/include/replication/logicalrelation.h
@@ -31,6 +42,8 @@ typedef struct LogicalRepRelMapEntry
Relation localrel; /* relcache entry (NULL when closed) */
AttrMap *attrmap; /* map of local attributes to remote ones */
bool updatable; /* Can apply updates/deletes? */
+ ParallelApplySafety parallel_apply; /* Can apply changes in an apply
+
(Similar to above comment #3.3a)
The member name 'parallel_apply' doesn't really mean anything. Perhaps
renaming this to 'parallel_apply_safe' or 'parallel_safe' etc will
give it the intended meaning.
------
[1]
https://www.postgresql.org/message-id/OS3PR01MB6275739E73E8BEC5D13FB6739E6B9%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for the patch v23-0004: ====== 4.1 src/test/subscription/t/032_streaming_apply.pl This test file was introduced in patch 0003, but I think there are a few changes in this 0004 patch which are really have nothing to do with 0004 and should have been included in the original 0003. e.g. There are multiple comments like below - these belong back in the 0003 patch # Wait for this streaming transaction to be applied in the apply worker. # Wait for this streaming transaction to be applied in the apply worker. # Wait for this streaming transaction to be applied in the apply worker. # Wait for this streaming transaction to be applied in the apply worker. # Wait for this streaming transaction to be applied in the apply worker. # Wait for this streaming transaction to be applied in the apply worker. # Wait for this streaming transaction to be applied in the apply worker. # Wait for this streaming transaction to be applied in the apply worker. # Wait for this streaming transaction to be applied in the apply worker. # Wait for this streaming transaction to be applied in the apply worker. # Wait for this streaming transaction to be applied in the apply worker. ~~~ 4.2 @@ -166,17 +175,6 @@ CREATE TRIGGER tri_tab1_unsafe BEFORE INSERT ON public.test_tab1 FOR EACH ROW EXECUTE PROCEDURE trigger_func_tab1_unsafe(); ALTER TABLE test_tab1 ENABLE REPLICA TRIGGER tri_tab1_unsafe; - -CREATE FUNCTION trigger_func_tab1_safe() RETURNS TRIGGER AS \$\$ - BEGIN - RAISE NOTICE 'test for safe trigger function'; - RETURN NEW; - END -\$\$ language plpgsql; -ALTER FUNCTION trigger_func_tab1_safe IMMUTABLE; -CREATE TRIGGER tri_tab1_safe -BEFORE INSERT ON public.test_tab1 -FOR EACH ROW EXECUTE PROCEDURE trigger_func_tab1_safe(); }); I didn't understand why all this trigger_func_tab1_safe which was added in patch 0003 is now getting removed in patch 0004. Maybe there is some good reason, but it doesn't seem right to be adding code in one patch and then removing it again in the next patch. ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Aug 18, 2022 at 5:14 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Aug 17, 2022 at 11:58 AM wangw.fnst@fujitsu.com
> <wangw.fnst@fujitsu.com> wrote:
> >
> > Attach the new patches.
> >
>
> Few comments on v23-0001
> =======================
>
Some more comments on v23-0001
============================
1.
static bool
handle_streamed_transaction(LogicalRepMsgType action, StringInfo s)
{
...
- /* not in streaming mode */
- if (!in_streamed_transaction)
+ /* Not in streaming mode and not in apply background worker. */
+ if (!(in_streamed_transaction || am_apply_bgworker()))
return false;
This check appears a bit strange because ideally in bgworker
in_streamed_transaction should be false. I think we should set
in_streamed_transaction to true in apply_handle_stream_start() only
when we are going to write to file. Is there a reason for not doing
the same?
2.
+ {
+ /* This is the main apply worker. */
+ ApplyBgworkerInfo *wstate = apply_bgworker_find(xid);
+
+ /*
+ * Check if we are processing this transaction using an apply
+ * background worker and if so, send the changes to that worker.
+ */
+ if (wstate)
+ {
+ /* Send STREAM ABORT message to the apply background worker. */
+ apply_bgworker_send_data(wstate, s->len, s->data);
Why at some places the patch needs to separately fetch
ApplyBgworkerInfo whereas at other places it directly uses
stream_apply_worker to pass the data to bgworker.
3. Why apply_handle_stream_abort() or apply_handle_stream_prepare()
doesn't use apply_bgworker_active() to identify whether it needs to
send the information to bgworker?
4. In apply_handle_stream_prepare(), apply_handle_stream_abort(), and
some other similar functions, the patch handles three cases (a) apply
background worker, (b) sending data to bgworker, (c) handling for
streamed transaction in apply worker. I think the code will look
better if you move the respective code for all three cases into
separate functions. Surely, if the code to deal with each of the cases
is less then we don't need to move it to a separate function.
5.
@@ -1088,24 +1177,78 @@ apply_handle_stream_prepare(StringInfo s)
{
...
+ in_remote_transaction = false;
+
+ /* Unlink the files with serialized changes and subxact info. */
+ stream_cleanup_files(MyLogicalRepWorker->subid, prepare_data.xid);
+ }
+ }
in_remote_transaction = false;
...
We don't need to in_remote_transaction to false in multiple places.
6.
@@ -1177,36 +1311,93 @@ apply_handle_stream_start(StringInfo s)
{
...
...
+ if (am_apply_bgworker())
{
- MemoryContext oldctx;
-
- oldctx = MemoryContextSwitchTo(ApplyContext);
+ /*
+ * Make sure the handle apply_dispatch methods are aware we're in a
+ * remote transaction.
+ */
+ in_remote_transaction = true;
- MyLogicalRepWorker->stream_fileset = palloc(sizeof(FileSet));
- FileSetInit(MyLogicalRepWorker->stream_fileset);
+ /* Begin the transaction. */
+ AcceptInvalidationMessages();
+ maybe_reread_subscription();
- MemoryContextSwitchTo(oldctx);
+ StartTransactionCommand();
+ BeginTransactionBlock();
+ CommitTransactionCommand();
}
...
Why do we need to start a transaction here? Why can't it be done via
begin_replication_step() during the first operation apply? Is it
because we may need to define a save point in bgworker and we don't
that information beforehand? If so, then also, can't it be handled by
begin_replication_step() either by explicitly passing the information
or checking it there and then starting a transaction block? In any
case, please add a few comments to explain why this separate handling
is required for bgworker?
7. When we are already setting bgworker status as APPLY_BGWORKER_BUSY
in apply_bgworker_setup_dsm() then why do we need to set it again in
apply_bgworker_start()?
8. It is not clear to me how APPLY_BGWORKER_EXIT status is used. Is it
required for the cases where bgworker exists due to some error and
then apply worker uses it to detect that and exits? How other
bgworkers would notice this, is it done via
apply_bgworker_check_status()?
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for the v23-0005 patch: ====== Commit Message says: main_worker_pid is Process ID of the main apply worker, if this process is a apply background worker. NULL if this process is a main apply worker or a synchronization worker. The new column can make it easier to distinguish main apply worker and apply background worker. -- Having a column called ‘main_worker_pid’ which is defined to be NULL if the process *is* the main apply worker does not make any sense to me. IMO it feels hacky trying to squeeze meaning out of the 'main_worker_pid' member of the LogicalRepWorker like this. If the intention really is to make it easier to distinguish the different kinds of subscription workers then surely there are much better ways to achieve that. For example, why not introduce a new 'type' enum member of the LogicalRepWorker (e.g. WORKER_TYPE_TABLESYNC='t', WORKER_TYPE_APPLY='a', WORKER_TYPE_PARALLEL_APPLY='p'), then use some char column to expose it? As a bonus, I think the other code (i.e.patch 0001) will also be improved if a 'type' member is added. ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Aug 19, 2022 at 2:36 PM Peter Smith <smithpb2250@gmail.com> wrote: > > Here are my review comments for the v23-0005 patch: > > ====== > > Commit Message says: > main_worker_pid is Process ID of the main apply worker, if this process is a > apply background worker. NULL if this process is a main apply worker or a > synchronization worker. > The new column can make it easier to distinguish main apply worker and apply > background worker. > > -- > > Having a column called ‘main_worker_pid’ which is defined to be NULL > if the process *is* the main apply worker does not make any sense to > me. > I haven't read this part of a patch but it seems to me we have something similar for parallel query workers. Refer 'leader_pid' column in pg_stat_activity. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Fri, Aug 19, 2022 at 7:10 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Aug 19, 2022 at 2:36 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Here are my review comments for the v23-0005 patch: > > > > ====== > > > > Commit Message says: > > main_worker_pid is Process ID of the main apply worker, if this process is a > > apply background worker. NULL if this process is a main apply worker or a > > synchronization worker. > > The new column can make it easier to distinguish main apply worker and apply > > background worker. > > > > -- > > > > Having a column called ‘main_worker_pid’ which is defined to be NULL > > if the process *is* the main apply worker does not make any sense to > > me. > > > > I haven't read this part of a patch but it seems to me we have > something similar for parallel query workers. Refer 'leader_pid' > column in pg_stat_activity. > IIUC (from the patch 0005 commit message) the intention is to be able to easily distinguish the worker types. I thought using a leader PID (by whatever name) seemed a poor way to achieve that in this case because the PID is either NULL or not NULL, but there are 3 kinds of subscription workers, not 2. ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Aug 19, 2022 at 3:05 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Fri, Aug 19, 2022 at 7:10 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Fri, Aug 19, 2022 at 2:36 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > Here are my review comments for the v23-0005 patch: > > > > > > ====== > > > > > > Commit Message says: > > > main_worker_pid is Process ID of the main apply worker, if this process is a > > > apply background worker. NULL if this process is a main apply worker or a > > > synchronization worker. > > > The new column can make it easier to distinguish main apply worker and apply > > > background worker. > > > > > > -- > > > > > > Having a column called ‘main_worker_pid’ which is defined to be NULL > > > if the process *is* the main apply worker does not make any sense to > > > me. > > > > > > > I haven't read this part of a patch but it seems to me we have > > something similar for parallel query workers. Refer 'leader_pid' > > column in pg_stat_activity. > > > > IIUC (from the patch 0005 commit message) the intention is to be able > to easily distinguish the worker types. > I think it is only to distinguish between leader apply worker and background apply workers. The tablesync worker can be distinguished based on relid field. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Fri, Aug 19, 2022 at 7:55 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Aug 19, 2022 at 3:05 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Fri, Aug 19, 2022 at 7:10 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Fri, Aug 19, 2022 at 2:36 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > Here are my review comments for the v23-0005 patch: > > > > > > > > ====== > > > > > > > > Commit Message says: > > > > main_worker_pid is Process ID of the main apply worker, if this process is a > > > > apply background worker. NULL if this process is a main apply worker or a > > > > synchronization worker. > > > > The new column can make it easier to distinguish main apply worker and apply > > > > background worker. > > > > > > > > -- > > > > > > > > Having a column called ‘main_worker_pid’ which is defined to be NULL > > > > if the process *is* the main apply worker does not make any sense to > > > > me. > > > > > > > > > > I haven't read this part of a patch but it seems to me we have > > > something similar for parallel query workers. Refer 'leader_pid' > > > column in pg_stat_activity. > > > > > > > IIUC (from the patch 0005 commit message) the intention is to be able > > to easily distinguish the worker types. > > > > I think it is only to distinguish between leader apply worker and > background apply workers. The tablesync worker can be distinguished > based on relid field. > Right. But that's the reason for my question in the first place - why implement the patch so that the user still has to jump through hoops just to know the worker type information? e.g. Option 1 (patch) - if there is a non-NULL relid field then the worker type must be a tablesyc worker, otherwise if there is non-NULL a leader_pid field then the worker type must be an apply background worker, otherwise the worker type must be an apply main worker. versus Option 2 - new worker_type field (values 't','p','a') ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Aug 22, 2022 at 4:42 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Fri, Aug 19, 2022 at 7:55 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Fri, Aug 19, 2022 at 3:05 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > On Fri, Aug 19, 2022 at 7:10 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > On Fri, Aug 19, 2022 at 2:36 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > > > Here are my review comments for the v23-0005 patch: > > > > > > > > > > ====== > > > > > > > > > > Commit Message says: > > > > > main_worker_pid is Process ID of the main apply worker, if this process is a > > > > > apply background worker. NULL if this process is a main apply worker or a > > > > > synchronization worker. > > > > > The new column can make it easier to distinguish main apply worker and apply > > > > > background worker. > > > > > > > > > > -- > > > > > > > > > > Having a column called ‘main_worker_pid’ which is defined to be NULL > > > > > if the process *is* the main apply worker does not make any sense to > > > > > me. > > > > > > > > > > > > > I haven't read this part of a patch but it seems to me we have > > > > something similar for parallel query workers. Refer 'leader_pid' > > > > column in pg_stat_activity. > > > > > > > > > > IIUC (from the patch 0005 commit message) the intention is to be able > > > to easily distinguish the worker types. > > > > > > > I think it is only to distinguish between leader apply worker and > > background apply workers. The tablesync worker can be distinguished > > based on relid field. > > > > Right. But that's the reason for my question in the first place - why > implement the patch so that the user still has to jump through hoops > just to know the worker type information? > I think it is not only to judge worker type but also to know the pid of each of the workers during parallel apply. Isn't it better to have both main apply worker pid and parallel apply worker pid as we have for the parallel query system? -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Wang,
Thank you for updating the patch! Followings are comments about v23-0001 and v23-0005.
v23-0001
01. logical-replication.sgml
+ <para>
+ When the streaming mode is <literal>parallel</literal>, the finish LSN of
+ failed transactions may not be logged. In that case, it may be necessary to
+ change the streaming mode to <literal>on</literal> and cause the same
+ conflicts again so the finish LSN of the failed transaction will be written
+ to the server log. For the usage of finish LSN, please refer to <link
+ linkend="sql-altersubscription"><command>ALTER SUBSCRIPTION ...
+ SKIP</command></link>.
+ </para>
I was not sure about streaming='off' mode. Is there any reasons that only ON mode is focused?
02. protocol.sgml
+ <varlistentry>
+ <term>Int64 (XLogRecPtr)</term>
+ <listitem>
+ <para>
+ The LSN of the abort. This field is available since protocol version
+ 4.
+ </para>
+ </listitem>
+ </varlistentry>
+
+ <varlistentry>
+ <term>Int64 (TimestampTz)</term>
+ <listitem>
+ <para>
+ Abort timestamp of the transaction. The value is in number
+ of microseconds since PostgreSQL epoch (2000-01-01). This field is
+ available since protocol version 4.
+ </para>
+ </listitem>
+ </varlistentry>
+
It seems that changes are in the variablelist for stream commit.
I think these are included in the stream abort message, so it should be moved.
03. decode.c
- ReorderBufferForget(ctx->reorder, parsed->subxacts[i], buf->origptr);
+ ReorderBufferForget(ctx->reorder, parsed->subxacts[i], buf->origptr,
+ commit_time);
}
- ReorderBufferForget(ctx->reorder, xid, buf->origptr);
+ ReorderBufferForget(ctx->reorder, xid, buf->origptr, commit_time);
'commit_time' has been passed as argument 'abort_time', I think it may be confusing.
How about adding a comment above, like:
"In case of streamed transactions, they are regarded as being aborted at commit_time"
04. launcher.c
04.a
+ worker->main_worker_pid = is_subworker ? MyProcPid : 0;
You can use InvalidPid instead of 0.
(I thought pid should be represented by the datatype pid_t, but in some codes it is defined as int...)
04.b
+ worker->main_worker_pid = 0;
You can use InvalidPid instead of 0, same as above.
05. origin.c
void
-replorigin_session_setup(RepOriginId node)
+replorigin_session_setup(RepOriginId node, int acquired_by)
IIUC the same slot can be used only when the apply main worker has already acquired the slot
and the subworker for the same subscription tries to acquire, but it cannot understand from comments.
How about adding comments, or an assertion that acquired_by is same as session_replication_state->acquired_by ?
Moreover acquired_by should be compared with InvalidPid, based on above comments.
06. proto.c
void
logicalrep_write_stream_abort(StringInfo out, TransactionId xid,
- TransactionId subxid)
+ ReorderBufferTXN *txn, XLogRecPtr abort_lsn,
+ bool write_abort_lsn
I think write_abort_lsn may be not needed,
because abort_lsn can be used for controlling whether abort_XXX fields should be filled or not.
07. worker.c
+/*
+ * The number of changes during one streaming block (only for apply background
+ * workers)
+ */
+static uint32 nchanges = 0;
This variable is used only by the main apply worker, so the comment seems not correct.
How about "...(only for SUBSTREAM_PARALLEL case)"?
v23-0005
08. monitoring.sgml
I cannot decide which option proposed in [1] is better, but followings descriptions are needed in both cases.
(In [2] I had intended to propose something like option 2)
08.a
You can add a description that the field 'relid' will be NULL even for apply background worker.
08.b
You can add a description that fields 'received_lsn', 'last_msg_send_time', 'last_msg_receipt_time',
'latest_end_lsn', 'latest_end_time' will be NULL for apply background worker.
[1]:
https://www.postgresql.org/message-id/CAHut%2BPuPwdwZqXBJjtU%2BR9NULbOpxMG%3Di2hmqgg%2B7p0rmK0hrw%40mail.gmail.com
[2]:
https://www.postgresql.org/message-id/TYAPR01MB58660B4732E7F80B322174A3F5629%40TYAPR01MB5866.jpnprd01.prod.outlook.com
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Mon, Aug 22, 2022 at 7:01 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Aug 22, 2022 at 4:42 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Fri, Aug 19, 2022 at 7:55 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Fri, Aug 19, 2022 at 3:05 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > On Fri, Aug 19, 2022 at 7:10 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > > On Fri, Aug 19, 2022 at 2:36 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > > > > > Here are my review comments for the v23-0005 patch: > > > > > > > > > > > > ====== > > > > > > > > > > > > Commit Message says: > > > > > > main_worker_pid is Process ID of the main apply worker, if this process is a > > > > > > apply background worker. NULL if this process is a main apply worker or a > > > > > > synchronization worker. > > > > > > The new column can make it easier to distinguish main apply worker and apply > > > > > > background worker. > > > > > > > > > > > > -- > > > > > > > > > > > > Having a column called ‘main_worker_pid’ which is defined to be NULL > > > > > > if the process *is* the main apply worker does not make any sense to > > > > > > me. > > > > > > > > > > > > > > > > I haven't read this part of a patch but it seems to me we have > > > > > something similar for parallel query workers. Refer 'leader_pid' > > > > > column in pg_stat_activity. > > > > > > > > > > > > > IIUC (from the patch 0005 commit message) the intention is to be able > > > > to easily distinguish the worker types. > > > > > > > > > > I think it is only to distinguish between leader apply worker and > > > background apply workers. The tablesync worker can be distinguished > > > based on relid field. > > > > > > > Right. But that's the reason for my question in the first place - why > > implement the patch so that the user still has to jump through hoops > > just to know the worker type information? > > > > I think it is not only to judge worker type but also to know the pid > of each of the workers during parallel apply. Isn't it better to have > both main apply worker pid and parallel apply worker pid as we have > for the parallel query system? > OK, thanks for pointing me to that other view. Now that I see the existing pg_stat_activity already has 'pid' and 'leader_pid' [1], it suddenly seems more reasonable to do similar for this pg_stat_subscription. This background information needs to be conveyed better in the patch 0005 commit message. The current commit message said nothing about trying to be consistent with the existing stats views; it only says this field was added to distinguish more easily between the types of apply workers. ------ [1] https://www.postgresql.org/docs/devel/monitoring-stats.html Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Mon, Aug 22, 2022 at 10:49 PM kuroda.hayato@fujitsu.com <kuroda.hayato@fujitsu.com> wrote: > > 04. launcher.c > > 04.a > > + worker->main_worker_pid = is_subworker ? MyProcPid : 0; > > You can use InvalidPid instead of 0. > (I thought pid should be represented by the datatype pid_t, but in some codes it is defined as int...) > > 04.b > > + worker->main_worker_pid = 0; > > You can use InvalidPid instead of 0, same as above. > > 05. origin.c > > void > -replorigin_session_setup(RepOriginId node) > +replorigin_session_setup(RepOriginId node, int acquired_by) > > IIUC the same slot can be used only when the apply main worker has already acquired the slot > and the subworker for the same subscription tries to acquire, but it cannot understand from comments. > How about adding comments, or an assertion that acquired_by is same as session_replication_state->acquired_by ? > Moreover acquired_by should be compared with InvalidPid, based on above comments. > In general I agree, and I also suggested to use pid_t and InvalidPid (at least for all the new code) In practice, please be aware that InvalidPid is -1 (not 0), so replacing any existing code (e.g. in replorigin_session_setup) that was already checking for 0 has to be done with lots of care. ------ Kind Regards, Peter Smith. Fujitsu Australia.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Wang,
Followings are my comments about v23-0003. Currently I do not have any comments about 0002 and 0004.
09. general
It seems that logicalrep_rel_mark_parallel_apply() is always called when relations are opened on the subscriber-side,
but is it really needed? There checks are required only for streaming parallel apply,
so it may be not needed in case of streaming = 'on' or 'off'.
10. commit message
2) There cannot be any non-immutable functions used by the subscriber-side
replicated table. Look for functions in the following places:
* a. Trigger functions
* b. Column default value expressions and domain constraints
* c. Constraint expressions
* d. Foreign keys
"Foreign key" should not be listed here because it is not related with the mutability. I think it should be listed as
3),not d..
11. create_subscription.sgml
The constraint about foreign key should be described here.
11. relation.c
11.a
+ CacheRegisterSyscacheCallback(PROCOID,
+ logicalrep_relmap_reset_parallel_cb,
+ (Datum) 0);
Isn't it needed another syscache callback for pg_type?
Users can add any constraints via ALTER DOMAIN command, but the added constraint may be not checked.
I checked AlterDomainAddConstraint(), and it invalidates only the relcache for pg_type.
11.b
+ /*
+ * If the column is of a DOMAIN type, determine whether
+ * that domain has any CHECK expressions that are not
+ * immutable.
+ */
+ if (get_typtype(att->atttypid) == TYPTYPE_DOMAIN)
+ {
I think the default value of *domain* must be also checked here.
I tested like followings.
===
1. created a domain that has a default value
CREATE DOMAIN tmp INT DEFAULT 1 CHECK (VALUE > 0);
2. created a table
CREATE TABLE foo (id tmp PRIMARY KEY);
3. checked pg_attribute and pg_class
select oid, relname, attname, atthasdef from pg_attribute, pg_class where pg_attribute.attrelid = pg_class.oid and
pg_class.relname= 'foo' and attname = 'id';
oid | relname | attname | atthasdef
-------+---------+---------+-----------
16394 | foo | id | f
(1 row)
Tt meant that functions might be not checked because the if-statement `if (att->atthasdef)` became false.
===
12. 015_stream.pl, 016_stream_subxact.pl, 022_twophase_cascade.pl, 023_twophase_stream.pl
- my ($node_publisher, $node_subscriber, $appname, $is_parallel) = @_;
+ my ($node_publisher, $node_subscriber, $appname) = @_;
Why the parameter is removed? I think the test that waits the output
from the apply background worker is meaningful.
13. 032_streaming_apply.pl
The filename seems too general because apply background workers are tested in above tests.
How about "streaming_apply_constraint" or something?
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, August 19, 2022 4:49 PM Amit Kapila <amit.kapila16@gmail.com>
>
> On Thu, Aug 18, 2022 at 5:14 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > On Wed, Aug 17, 2022 at 11:58 AM wangw.fnst@fujitsu.com
> > <wangw.fnst@fujitsu.com> wrote:
> > >
> > > Attach the new patches.
> > >
> >
> > Few comments on v23-0001
> > =======================
> >
>
> Some more comments on v23-0001
> ============================
> 1.
> static bool
> handle_streamed_transaction(LogicalRepMsgType action, StringInfo s) { ...
> - /* not in streaming mode */
> - if (!in_streamed_transaction)
> + /* Not in streaming mode and not in apply background worker. */ if
> + (!(in_streamed_transaction || am_apply_bgworker()))
> return false;
>
> This check appears a bit strange because ideally in bgworker
> in_streamed_transaction should be false. I think we should set
> in_streamed_transaction to true in apply_handle_stream_start() only when we
> are going to write to file. Is there a reason for not doing the same?
No, I removed this.
> 2.
> + {
> + /* This is the main apply worker. */
> + ApplyBgworkerInfo *wstate = apply_bgworker_find(xid);
> +
> + /*
> + * Check if we are processing this transaction using an apply
> + * background worker and if so, send the changes to that worker.
> + */
> + if (wstate)
> + {
> + /* Send STREAM ABORT message to the apply background worker. */
> + apply_bgworker_send_data(wstate, s->len, s->data);
>
> Why at some places the patch needs to separately fetch ApplyBgworkerInfo
> whereas at other places it directly uses stream_apply_worker to pass the data
> to bgworker.
> 3. Why apply_handle_stream_abort() or apply_handle_stream_prepare()
> doesn't use apply_bgworker_active() to identify whether it needs to send the
> information to bgworker?
I think stream_apply_worker is only valid between STREAM_START and STREAM_END,
But it seems it's not clear from the code. So I added some comments and slightly refactor
the code.
> 4. In apply_handle_stream_prepare(), apply_handle_stream_abort(), and some
> other similar functions, the patch handles three cases (a) apply background
> worker, (b) sending data to bgworker, (c) handling for streamed transaction in
> apply worker. I think the code will look better if you move the respective code
> for all three cases into separate functions. Surely, if the code to deal with each
> of the cases is less then we don't need to move it to a separate function.
Refactored and simplified.
> 5.
> @@ -1088,24 +1177,78 @@ apply_handle_stream_prepare(StringInfo s) { ...
> + in_remote_transaction = false;
> +
> + /* Unlink the files with serialized changes and subxact info. */
> + stream_cleanup_files(MyLogicalRepWorker->subid, prepare_data.xid); } }
>
> in_remote_transaction = false;
> ...
>
> We don't need to in_remote_transaction to false in multiple places.
Removed.
> 6.
> @@ -1177,36 +1311,93 @@ apply_handle_stream_start(StringInfo s) { ...
> ...
> + if (am_apply_bgworker())
> {
> - MemoryContext oldctx;
> -
> - oldctx = MemoryContextSwitchTo(ApplyContext);
> + /*
> + * Make sure the handle apply_dispatch methods are aware we're in a
> + * remote transaction.
> + */
> + in_remote_transaction = true;
>
> - MyLogicalRepWorker->stream_fileset = palloc(sizeof(FileSet));
> - FileSetInit(MyLogicalRepWorker->stream_fileset);
> + /* Begin the transaction. */
> + AcceptInvalidationMessages();
> + maybe_reread_subscription();
>
> - MemoryContextSwitchTo(oldctx);
> + StartTransactionCommand();
> + BeginTransactionBlock();
> + CommitTransactionCommand();
> }
> ...
>
> Why do we need to start a transaction here? Why can't it be done via
> begin_replication_step() during the first operation apply? Is it because we may
> need to define a save point in bgworker and we don't that information
> beforehand? If so, then also, can't it be handled by
> begin_replication_step() either by explicitly passing the information or
> checking it there and then starting a transaction block? In any case, please add
> a few comments to explain why this separate handling is required for
> bgworker?
The transaction block is used to define the savepoint and I moved these
codes to the place where the savepoint is defined which looks better now.
> 7. When we are already setting bgworker status as APPLY_BGWORKER_BUSY in
> apply_bgworker_setup_dsm() then why do we need to set it again in
> apply_bgworker_start()?
Removed.
> 8. It is not clear to me how APPLY_BGWORKER_EXIT status is used. Is it required
> for the cases where bgworker exists due to some error and then apply worker
> uses it to detect that and exits? How other bgworkers would notice this, is it
> done via apply_bgworker_check_status()?
It was used to detect the unexpected exit of bgworker and I have changed the design
of this which is now similar to what we have in parallel query.
Attach the new version patch set(v24) which address above comments.
Besides, I added some logic which try to stop the bgworker at transaction end
if there are enough workers in the pool.
Best regards,
Hou zj
Attachment
- v24-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v24-0001-Perform-streaming-logical-transactions-by-backgr.patch
- v24-0002-Test-streaming-parallel-option-in-tap-test.patch
- v24-0003-Add-some-checks-before-using-apply-background-wo.patch
- v24-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Mon, Aug 22, 2022 20:50 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote: > Dear Wang, > > Thank you for updating the patch! Followings are comments about > v23-0001 and v23-0005. Thanks for your comments. > v23-0001 > > 01. logical-replication.sgml > > + <para> > + When the streaming mode is <literal>parallel</literal>, the finish LSN of > + failed transactions may not be logged. In that case, it may be necessary to > + change the streaming mode to <literal>on</literal> and cause the same > + conflicts again so the finish LSN of the failed transaction will be written > + to the server log. For the usage of finish LSN, please refer to <link > + linkend="sql-altersubscription"><command>ALTER SUBSCRIPTION ... > + SKIP</command></link>. > + </para> > > I was not sure about streaming='off' mode. Is there any reasons that > only ON mode is focused? Added off. > 02. protocol.sgml > > + <varlistentry> > + <term>Int64 (XLogRecPtr)</term> > + <listitem> > + <para> > + The LSN of the abort. This field is available since protocol version > + 4. > + </para> > + </listitem> > + </varlistentry> > + > + <varlistentry> > + <term>Int64 (TimestampTz)</term> > + <listitem> > + <para> > + Abort timestamp of the transaction. The value is in number > + of microseconds since PostgreSQL epoch (2000-01-01). This field is > + available since protocol version 4. > + </para> > + </listitem> > + </varlistentry> > + > > It seems that changes are in the variablelist for stream commit. > I think these are included in the stream abort message, so it should be moved. Fixed. > 03. decode.c > > - ReorderBufferForget(ctx->reorder, parsed->subxacts[i], buf- > >origptr); > + ReorderBufferForget(ctx->reorder, > + parsed->subxacts[i], buf- > >origptr, > + > + commit_time); > } > - ReorderBufferForget(ctx->reorder, xid, buf->origptr); > + ReorderBufferForget(ctx->reorder, xid, buf->origptr, > + commit_time); > > 'commit_time' has been passed as argument 'abort_time', I think it may > be confusing. > How about adding a comment above, like: > "In case of streamed transactions, they are regarded as being aborted > at commit_time" IIRC, I free the comment above the loop might be more clear about this, but I will think about it again. > 04. launcher.c > > 04.a > > + worker->main_worker_pid = is_subworker ? MyProcPid : 0; > > You can use InvalidPid instead of 0. > (I thought pid should be represented by the datatype pid_t, but in > some codes it is defined as int...) > > 04.b > > + worker->main_worker_pid = 0; > > You can use InvalidPid instead of 0, same as above. Improved > 05. origin.c > > void > -replorigin_session_setup(RepOriginId node) > +replorigin_session_setup(RepOriginId node, int acquired_by) > > IIUC the same slot can be used only when the apply main worker has > already acquired the slot and the subworker for the same subscription > tries to acquire, but it cannot understand from comments. > How about adding comments, or an assertion that acquired_by is same as > session_replication_state->acquired_by ? > Moreover acquired_by should be compared with InvalidPid, based on > above comments. I think we have tried to check if 'acquired_by' and acquired_by of slot are equal inside this function. I am not sure if it's a good idea to use InvalidPid here ,as we set session_replication_state->acquired_by(int) to 0(instead of -1) to indicate that no worker acquire it. > 06. proto.c > > void > logicalrep_write_stream_abort(StringInfo out, TransactionId xid, > - TransactionId subxid) > + ReorderBufferTXN *txn, XLogRecPtr abort_lsn, > + bool > + write_abort_lsn > > I think write_abort_lsn may be not needed, because abort_lsn can be > used for controlling whether abort_XXX fields should be filled or not. I think if the subscriber's version is lower than 16 (which won't handle the abort_XXX fields), then we don't need to send the abort_XXX fields either. > 07. worker.c > > +/* > + * The number of changes during one streaming block (only for apply > background > + * workers) > + */ > +static uint32 nchanges = 0; > > This variable is used only by the main apply worker, so the comment > seems not correct. > How about "...(only for SUBSTREAM_PARALLEL case)"? The previous comments seemed a bit confusing. I tried to improve this comments to this: ``` The number of changes sent to apply background workers during one streaming block. ``` > v23-0005 > > 08. monitoring.sgml > > I cannot decide which option proposed in [1] is better, but followings > descriptions are needed in both cases. > (In [2] I had intended to propose something like option 2) > > 08.a > > You can add a description that the field 'relid' will be NULL even for > apply background worker. > > 08.b > > You can add a description that fields 'received_lsn', > 'last_msg_send_time', 'last_msg_receipt_time', 'latest_end_lsn', > 'latest_end_time' will be NULL for apply background worker. Improved Regards, Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thur, Aug 18, 2022 11:44 AM Peter Smith <smithpb2250@gmail.com> wrote:
> Here are my review comments for patch v21-0001:
>
> Note - There are some "general" comments which will result in lots of
> smaller changes. The subsequent "detailed" review comments have some
> overlap with these general comments but I expect some will be missed
> so please search/replace to fix all code related to those general
> comments.
Thanks for your comments.
> 1. GENERAL - main_worker_pid and replorigin_session_setup
>
> Quite a few of my subsequent review comments below are related to the
> somewhat tricky (IMO) change to the code for this area. Here is a
> summary of some things that can be done to clean/simplify this logic.
>
> 1a.
> Make the existing replorigin_session_setup function just be a wrapper
> that delegates to the other function passing the acquired_by as 0.
> This is because in every case but one (in the apply bg worker main) we
> are always passing 0, and IMO there is no need to spread the messy
> extra param to places that do not use it.
Not sure about this. I feel interface change should
be fine in major release.
> 17. src/backend/replication/logical/applybgworker.c -
> LogicalApplyBgworkerMain
>
> + MyLogicalRepWorker->last_send_time = MyLogicalRepWorker-
> >last_recv_time =
> + MyLogicalRepWorker->reply_time = 0;
> +
> + InitializeApplyWorker();
>
> Lots of things happen within InitializeApplyWorker(). I think this
> call deserves at least some comment to say it does lots of common
> initialization. And same for the other caller or this in the apply
> main worker.
I feel we can refer to the comments above/in the function InitializeApplyWorker.
> 19.
> + toc = shm_toc_create(PG_LOGICAL_APPLY_SHM_MAGIC,
> dsm_segment_address(seg),
> + segsize);
Since toc is just same as the input address which I think should not be NULL.
I think it's fine to skip the check here like what we did in other codes.
shm_toc_create(uint64 magic, void *address, Size nbytes)
{
shm_toc *toc = (shm_toc *) address;
> 20. src/backend/replication/logical/applybgworker.c -
> apply_bgworker_setup
>
> I think this function could be refactored to be cleaner and share more
> common logic.
>
> SUGGESTION
>
> /* Setup shared memory, and attempt launch. */ if
> (apply_bgworker_setup_dsm(wstate))
> {
> bool launched;
> launched = logicalrep_worker_launch(MyLogicalRepWorker->dbid,
> MySubscription->oid,
> MySubscription->name,
> MyLogicalRepWorker->userid,
> InvalidOid,
> dsm_segment_handle(wstate->dsm_seg));
> if (launched)
> {
> ApplyBgworkersList = lappend(ApplyBgworkersList, wstate);
> MemoryContextSwitchTo(oldcontext);
> return wstate;
> }
> else
> {
> dsm_detach(wstate->dsm_seg);
> wstate->dsm_seg = NULL;
> }
> }
>
> pfree(wstate);
> MemoryContextSwitchTo(oldcontext);
> return NULL;
Not sure about this.
> 36. src/backend/replication/logical/tablesync.c -
> process_syncing_tables
>
> @@ -589,6 +590,9 @@ process_syncing_tables_for_apply(XLogRecPtr
> current_lsn)
> void
> process_syncing_tables(XLogRecPtr current_lsn) {
> + if (am_apply_bgworker())
> + return;
> +
>
> Perhaps should be a comment to describe why process_syncing_tables
> should be skipped for the apply background worker?
I might refactor this function soon, so didn't change for now.
But I will consider it.
> 39. src/backend/replication/logical/worker.c -
> handle_streamed_transaction
>
> + /* Not in streaming mode and not in apply background worker. */ if
> + (!(in_streamed_transaction || am_apply_bgworker()))
> return false;
> IMO if you wanted to write the comment in that way then the code
> should have matched it more closely like:
> if (!in_streamed_transaction && !am_apply_bgworker())
>
> OTOH, if you want to keep the code as-is then the comment should be
> worded slightly differently.
I feel both the in_streamed_transaction flag and in bgworker indicate that
we are in streaming mode. So it seems the original /* Not in streaming mode */
Should be fine.
> 44. src/backend/replication/logical/worker.c - InitializeApplyWorker
>
>
> +/*
> + * Initialize the databse connection, in-memory subscription and
> +necessary
> + * config options.
> + */
> void
> -ApplyWorkerMain(Datum main_arg)
> 44b.
> Should there be some more explanation in this comment to say that this
> is common code for both the appl main workers and apply background
> workers?
>
> 44c.
> Following on from #44b, consider renaming this to something like
> CommonApplyWorkerInit() to emphasize it is called from multiple
> places?
Not sure about this. if we change the bgworker name to parallel
apply worker in the future, it might be worth emphasizing this. So
I will consider this.
> 52.
>
> +/* Apply background worker setup and interactions */ extern
> +ApplyBgworkerInfo *apply_bgworker_start(TransactionId xid); extern
> +ApplyBgworkerInfo *apply_bgworker_find(TransactionId xid); extern
> +void apply_bgworker_wait_for(ApplyBgworkerInfo *wstate,
> +ApplyBgworkerStatus wait_for_status); extern void
> +apply_bgworker_send_data(ApplyBgworkerInfo *wstate, Size
> nbytes,
> + const void *data);
> +extern void apply_bgworker_free(ApplyBgworkerInfo *wstate); extern
> +void apply_bgworker_check_status(void);
> +extern void apply_bgworker_set_status(ApplyBgworkerStatus status);
> +extern void apply_bgworker_subxact_info_add(TransactionId
> +current_xid); extern void apply_bgworker_savepoint_name(Oid suboid, Oid relid,
> + char *spname, int szsp);
>
> This big block of similarly named externs might as well be in
> alphabetical order instead of apparently random.
I think Amit has a good idea in [2].
So I tried to reorder these based on related functionality.
The reply to your comments #4.2 for patch 0004 in [3]:
> 4.2
>
> @@ -166,17 +175,6 @@ CREATE TRIGGER tri_tab1_unsafe BEFORE INSERT ON
> public.test_tab1 FOR EACH ROW EXECUTE PROCEDURE
> trigger_func_tab1_unsafe(); ALTER TABLE test_tab1 ENABLE REPLICA
> TRIGGER tri_tab1_unsafe;
> -
> -CREATE FUNCTION trigger_func_tab1_safe() RETURNS TRIGGER AS \$\$
> - BEGIN
> - RAISE NOTICE 'test for safe trigger function';
> - RETURN NEW;
> - END
> -\$\$ language plpgsql;
> -ALTER FUNCTION trigger_func_tab1_safe IMMUTABLE; -CREATE TRIGGER
> tri_tab1_safe -BEFORE INSERT ON public.test_tab1 -FOR EACH ROW EXECUTE
> PROCEDURE trigger_func_tab1_safe(); });
>
> I didn't understand why all this trigger_func_tab1_safe which was
> added in patch 0003 is now getting removed in patch 0004. Maybe there
> is some good reason, but it doesn't seem right to be adding code in
> one patch and then removing it again in the next patch.
Because in 0003 we need to manually do something to let the test recover
from the constraint failure, while in 0004 it can automatically retry.
The rest of your comments are improved as suggested.
[1] - https://www.postgresql.org/message-id/CAHut%2BPuAxW57fowiMrn%3D3%3D53sagmehiTSW0o1Q52MpR3phUmyw%40mail.gmail.com
[2] - https://www.postgresql.org/message-id/CAA4eK1KpuQAk_fiqVXy16WkDrKPBwA9E61VpvLfkse-o31NNVA%40mail.gmail.com
[3] - https://www.postgresql.org/message-id/CAHut%2BPtCRkTT_KNaqA5Fn6_T38BXtFn4Eb3Ct-AbNko91s-cjQ%40mail.gmail.com
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, August 24, 2022 9:47 PM houzj.fnst@fujitsu.com wrote:
>
> On Friday, August 19, 2022 4:49 PM Amit Kapila <amit.kapila16@gmail.com>
> >
> > On Thu, Aug 18, 2022 at 5:14 PM Amit Kapila <amit.kapila16@gmail.com>
> > wrote:
> > >
> > > On Wed, Aug 17, 2022 at 11:58 AM wangw.fnst@fujitsu.com
> > > <wangw.fnst@fujitsu.com> wrote:
> > > >
> > > > Attach the new patches.
> > > >
> > >
> > > Few comments on v23-0001
> > > =======================
> > >
> >
> > Some more comments on v23-0001
> > ============================
> > 1.
> > static bool
> > handle_streamed_transaction(LogicalRepMsgType action, StringInfo s) { ...
> > - /* not in streaming mode */
> > - if (!in_streamed_transaction)
> > + /* Not in streaming mode and not in apply background worker. */ if
> > + (!(in_streamed_transaction || am_apply_bgworker()))
> > return false;
> >
> > This check appears a bit strange because ideally in bgworker
> > in_streamed_transaction should be false. I think we should set
> > in_streamed_transaction to true in apply_handle_stream_start() only
> > when we are going to write to file. Is there a reason for not doing the same?
>
> No, I removed this.
>
> > 2.
> > + {
> > + /* This is the main apply worker. */ ApplyBgworkerInfo *wstate =
> > + apply_bgworker_find(xid);
> > +
> > + /*
> > + * Check if we are processing this transaction using an apply
> > + * background worker and if so, send the changes to that worker.
> > + */
> > + if (wstate)
> > + {
> > + /* Send STREAM ABORT message to the apply background worker. */
> > + apply_bgworker_send_data(wstate, s->len, s->data);
> >
> > Why at some places the patch needs to separately fetch
> > ApplyBgworkerInfo whereas at other places it directly uses
> > stream_apply_worker to pass the data to bgworker.
> > 3. Why apply_handle_stream_abort() or apply_handle_stream_prepare()
> > doesn't use apply_bgworker_active() to identify whether it needs to
> > send the information to bgworker?
>
> I think stream_apply_worker is only valid between STREAM_START and
> STREAM_END, But it seems it's not clear from the code. So I added some
> comments and slightly refactor the code.
>
>
> > 4. In apply_handle_stream_prepare(), apply_handle_stream_abort(), and
> > some other similar functions, the patch handles three cases (a) apply
> > background worker, (b) sending data to bgworker, (c) handling for
> > streamed transaction in apply worker. I think the code will look
> > better if you move the respective code for all three cases into
> > separate functions. Surely, if the code to deal with each of the cases is less then
> we don't need to move it to a separate function.
>
> Refactored and simplified.
>
> > 5.
> > @@ -1088,24 +1177,78 @@ apply_handle_stream_prepare(StringInfo s) { ...
> > + in_remote_transaction = false;
> > +
> > + /* Unlink the files with serialized changes and subxact info. */
> > + stream_cleanup_files(MyLogicalRepWorker->subid, prepare_data.xid); }
> > + }
> >
> > in_remote_transaction = false;
> > ...
> >
> > We don't need to in_remote_transaction to false in multiple places.
>
> Removed.
>
> > 6.
> > @@ -1177,36 +1311,93 @@ apply_handle_stream_start(StringInfo s) { ...
> > ...
> > + if (am_apply_bgworker())
> > {
> > - MemoryContext oldctx;
> > -
> > - oldctx = MemoryContextSwitchTo(ApplyContext);
> > + /*
> > + * Make sure the handle apply_dispatch methods are aware we're in a
> > + * remote transaction.
> > + */
> > + in_remote_transaction = true;
> >
> > - MyLogicalRepWorker->stream_fileset = palloc(sizeof(FileSet));
> > - FileSetInit(MyLogicalRepWorker->stream_fileset);
> > + /* Begin the transaction. */
> > + AcceptInvalidationMessages();
> > + maybe_reread_subscription();
> >
> > - MemoryContextSwitchTo(oldctx);
> > + StartTransactionCommand();
> > + BeginTransactionBlock();
> > + CommitTransactionCommand();
> > }
> > ...
> >
> > Why do we need to start a transaction here? Why can't it be done via
> > begin_replication_step() during the first operation apply? Is it
> > because we may need to define a save point in bgworker and we don't
> > that information beforehand? If so, then also, can't it be handled by
> > begin_replication_step() either by explicitly passing the information
> > or checking it there and then starting a transaction block? In any
> > case, please add a few comments to explain why this separate handling
> > is required for bgworker?
>
> The transaction block is used to define the savepoint and I moved these codes to
> the place where the savepoint is defined which looks better now.
>
> > 7. When we are already setting bgworker status as APPLY_BGWORKER_BUSY
> > in
> > apply_bgworker_setup_dsm() then why do we need to set it again in
> > apply_bgworker_start()?
>
> Removed.
>
> > 8. It is not clear to me how APPLY_BGWORKER_EXIT status is used. Is it
> > required for the cases where bgworker exists due to some error and
> > then apply worker uses it to detect that and exits? How other
> > bgworkers would notice this, is it done via apply_bgworker_check_status()?
>
> It was used to detect the unexpected exit of bgworker and I have changed the
> design of this which is now similar to what we have in parallel query.
>
> Attach the new version patch set(v24) which address above comments.
> Besides, I added some logic which try to stop the bgworker at transaction end if
> there are enough workers in the pool.
Also attach the result of performance test based on v23 patch.
This test used synchronous logical replication, and compared SQL execution
times before and after applying the patch. This is tested by varying
logical_decoding_work_mem.
The test was performed ten times, and the average of the middle eight was taken.
The results are as follows. The bar chart and the details of the test are attached.
RESULT - bulk insert (5kk)
----------------------------------
logical_decoding_work_mem 64kB 128kB 256kB 512kB 1MB 2MB 4MB 8MB 16MB 32MB 64MB
HEAD 46.940 46.428 46.663 46.373 46.339 46.838 50.346 50.536 50.452 50.582 47.491
patched 33.942 33.780 30.760 30.760 29.992 30.076 30.827 33.420 33.966 34.133 31.096
For different logical_decoding_work_mem size, it takes
about 30% ~ 40% less time, which looks good.
Some other tests are still in progress, might share them later.
Best regards,
Hou zj
Attachment
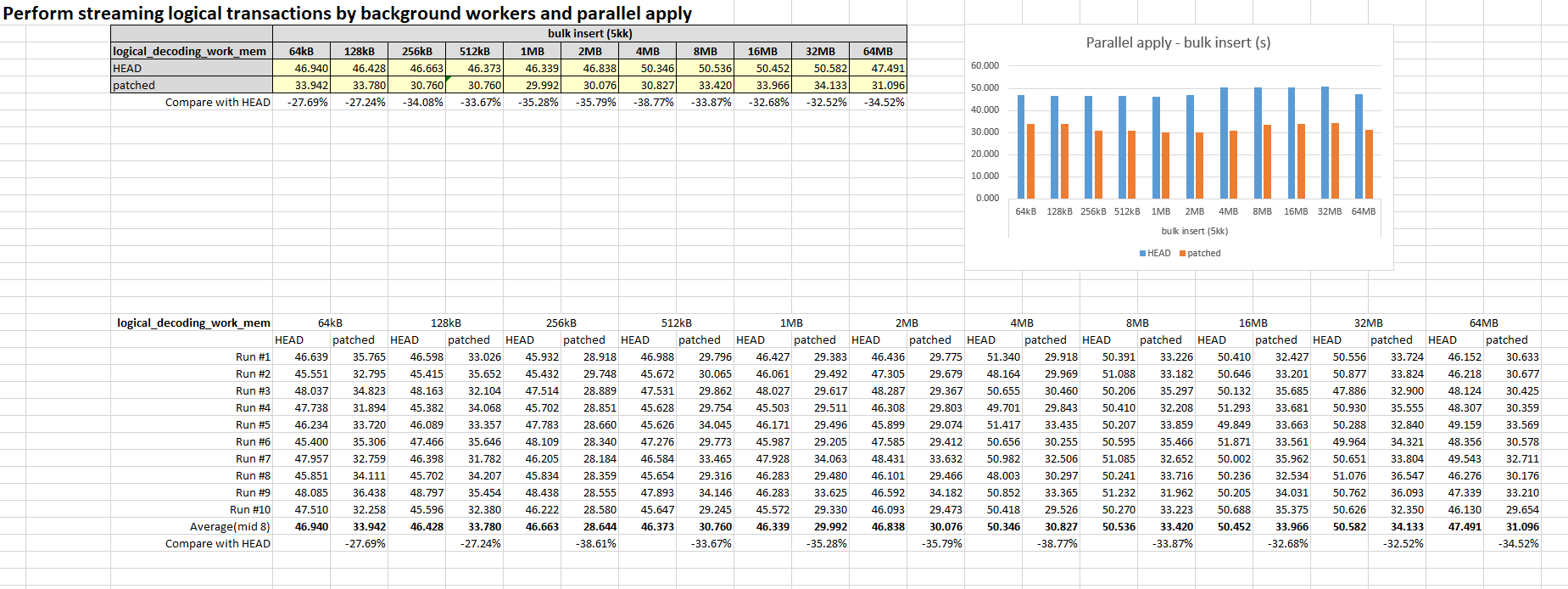{kind=link}
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Aug 24, 2022 at 7:17 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Friday, August 19, 2022 4:49 PM Amit Kapila <amit.kapila16@gmail.com>
> >
>
> > 8. It is not clear to me how APPLY_BGWORKER_EXIT status is used. Is it required
> > for the cases where bgworker exists due to some error and then apply worker
> > uses it to detect that and exits? How other bgworkers would notice this, is it
> > done via apply_bgworker_check_status()?
>
> It was used to detect the unexpected exit of bgworker and I have changed the design
> of this which is now similar to what we have in parallel query.
>
Thanks, this looks better.
> Attach the new version patch set(v24) which address above comments.
> Besides, I added some logic which try to stop the bgworker at transaction end
> if there are enough workers in the pool.
>
I think this deserves an explanation in worker.c under the title:
"Separate background workers" in the patch.
Review comments for v24-0001
=========================
1.
+ * cost of searhing the hash table
/searhing/searching
2.
+/*
+ * Apply background worker states.
+ */
+typedef enum ApplyBgworkerState
+{
+ APPLY_BGWORKER_BUSY, /* assigned to a transaction */
+ APPLY_BGWORKER_FINISHED /* transaction is completed */
+} ApplyBgworkerState;
Now, that there are just two states, can we think to represent them
via a flag ('available'/'in_use') or do you see a downside with that
as compared to the current approach?
3.
-replorigin_session_setup(RepOriginId node)
+replorigin_session_setup(RepOriginId node, int apply_leader_pid)
I have mentioned previously that we don't need anything specific to
apply worker/leader in this API, so why this change? The other idea
that occurred to me is that can we use replorigin_session_reset()
before sending the commit message to bgworker and then do the session
setup in bgworker only to handle the commit/abort/prepare message. We
also need to set it again for the leader apply worker after the leader
worker completes the wait for bgworker to finish the commit handling.
4. Unlike parallel query, here we seem to be creating separate DSM for
each worker, and probably the difference is due to the fact that here
we don't know upfront how many workers will actually be required. If
so, can we write some comments for the same in worker.c where you have
explained about parallel bgwroker stuff?
5.
/*
- * Handle streamed transactions.
+ * Handle streamed transactions for both the main apply worker and the apply
+ * background workers.
Shall we use leader apply worker in the above comment? Also, check
other places in the patch for similar changes.
6.
+ else
+ {
- /* open the spool file for this transaction */
- stream_open_file(MyLogicalRepWorker->subid, stream_xid, first_segment);
+ /* notify handle methods we're processing a remote transaction */
+ in_streamed_transaction = true;
There is a spurious line after else {. Also, the comment could be
slightly improved: "/* notify handle methods we're processing a remote
in-progress transaction */"
7. The checks in various apply_handle_stream_* functions have improved
as compared to the previous version but I think we can still improve
those. One idea could be to use a separate function to decide the
action we want to take and then based on it, the caller can take
appropriate action. Using a similar idea, we can improve the checks in
handle_streamed_transaction() as well.
8.
+ else if ((winfo = apply_bgworker_find(xid)))
+ {
+ /* Send STREAM ABORT message to the apply background worker. */
+ apply_bgworker_send_data(winfo, s->len, s->data);
+
+ /*
+ * After sending the data to the apply background worker, wait for
+ * that worker to finish. This is necessary to maintain commit
+ * order which avoids failures due to transaction dependencies and
+ * deadlocks.
+ */
+ if (subxid == xid)
+ {
+ apply_bgworker_wait_for(winfo, APPLY_BGWORKER_FINISHED);
+ apply_bgworker_free(winfo);
+ }
+ }
+ else
+ /*
+ * We are in main apply worker and the transaction has been
+ * serialized to file.
+ */
+ serialize_stream_abort(xid, subxid);
In the last else block, you can use {} to make it consistent with
other if, else checks.
9.
+void
+ApplyBgworkerMain(Datum main_arg)
+{
+ volatile ApplyBgworkerShared *shared;
+
+ dsm_handle handle;
Is there a need to keep this empty line between the above two declarations?
10.
+ /*
+ * Attach to the message queue.
+ */
+ mq = shm_toc_lookup(toc, APPLY_BGWORKER_KEY_ERROR_QUEUE, false);
Here, we should say error queue in the comments.
11.
+ /*
+ * Attach to the message queue.
+ */
+ mq = shm_toc_lookup(toc, APPLY_BGWORKER_KEY_ERROR_QUEUE, false);
+ shm_mq_set_sender(mq, MyProc);
+ error_mqh = shm_mq_attach(mq, seg, NULL);
+ pq_redirect_to_shm_mq(seg, error_mqh);
+
+ /*
+ * Now, we have initialized DSM. Attach to slot.
+ */
+ logicalrep_worker_attach(worker_slot);
+ MyParallelShared->logicalrep_worker_generation =
MyLogicalRepWorker->generation;
+ MyParallelShared->logicalrep_worker_slot_no = worker_slot;
+
+ pq_set_parallel_leader(MyLogicalRepWorker->apply_leader_pid,
+ InvalidBackendId);
Is there a reason to set parallel_leader immediately after
pq_redirect_to_shm_mq() as we are doing parallel.c?
12.
if (pq_mq_parallel_leader_pid != 0)
+ {
SendProcSignal(pq_mq_parallel_leader_pid,
PROCSIG_PARALLEL_MESSAGE,
pq_mq_parallel_leader_backend_id);
+ /*
+ * XXX maybe we can reuse the PROCSIG_PARALLEL_MESSAGE instead of
+ * introducing a new signal reason.
+ */
+ SendProcSignal(pq_mq_parallel_leader_pid,
+ PROCSIG_APPLY_BGWORKER_MESSAGE,
+ pq_mq_parallel_leader_backend_id);
+ }
I think we don't need to send both signals. Here, we can check if this
is a parallel worker (IsParallelWorker), then send
PROCSIG_PARALLEL_MESSAGE, otherwise, send
PROCSIG_APPLY_BGWORKER_MESSAGE message. In the else part, we can have
an assert to ensure it is an apply bgworker.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Thu, Aug 11, 2022 at 12:13 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > Since we will later consider applying non-streamed transactions in parallel, I
> > think "apply streaming worker" might not be very suitable. I think PostgreSQL
> > also has the worker "parallel worker", so for "apply parallel worker" and
> > "apply background worker", I feel that "apply background worker" will make the
> > relationship between workers more clear. ("[main] apply worker" and "apply
> > background worker")
> >
>
> But, on similar lines, we do have vacuumparallel.c for parallelizing
> index vacuum. I agree with Kuroda-San on this point that the currently
> proposed terminology doesn't sound to be very clear. The other options
> that come to my mind are "apply streaming transaction worker", "apply
> parallel worker" and file name could be applystreamworker.c,
> applyparallel.c, applyparallelworker.c, etc. I see the point why you
> are hesitant in calling it "apply parallel worker" but it is quite
> possible that even for non-streamed xacts, we will share quite some
> part of this code.
I think the "apply streaming transaction worker" is a good option
w.r.t. what we are currently doing but then in the future, if we want
to apply normal transactions in parallel then we will have to again
change the name. So I think "apply parallel worker" might look
better and the file name could be "applyparallelworker.c" or just
"parallelworker.c". Although "parallelworker.c" file name is a bit
generic but we already have worker.c so w.r.t that "parallelworker.c"
should just look fine. At least that is what I think.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Aug 26, 2022 at 9:30 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Thu, Aug 11, 2022 at 12:13 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > > Since we will later consider applying non-streamed transactions in parallel, I
> > > think "apply streaming worker" might not be very suitable. I think PostgreSQL
> > > also has the worker "parallel worker", so for "apply parallel worker" and
> > > "apply background worker", I feel that "apply background worker" will make the
> > > relationship between workers more clear. ("[main] apply worker" and "apply
> > > background worker")
> > >
> >
> > But, on similar lines, we do have vacuumparallel.c for parallelizing
> > index vacuum. I agree with Kuroda-San on this point that the currently
> > proposed terminology doesn't sound to be very clear. The other options
> > that come to my mind are "apply streaming transaction worker", "apply
> > parallel worker" and file name could be applystreamworker.c,
> > applyparallel.c, applyparallelworker.c, etc. I see the point why you
> > are hesitant in calling it "apply parallel worker" but it is quite
> > possible that even for non-streamed xacts, we will share quite some
> > part of this code.
>
> I think the "apply streaming transaction worker" is a good option
> w.r.t. what we are currently doing but then in the future, if we want
> to apply normal transactions in parallel then we will have to again
> change the name. So I think "apply parallel worker" might look
> better and the file name could be "applyparallelworker.c" or just
> "parallelworker.c". Although "parallelworker.c" file name is a bit
> generic but we already have worker.c so w.r.t that "parallelworker.c"
> should just look fine.
>
Yeah based on that theory, we can go with parallelworker.c but my vote
is to go with applyparallelworker.c among the above as that is more
clear. I feel worker.c is already not a very good name where we are
doing the work related to apply, so it won't be advisable to go down
that path further.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, August 25, 2022 7:33 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Aug 24, 2022 at 7:17 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Friday, August 19, 2022 4:49 PM Amit Kapila <amit.kapila16@gmail.com>
> > >
> >
> > > 8. It is not clear to me how APPLY_BGWORKER_EXIT status is used. Is it
> required
> > > for the cases where bgworker exists due to some error and then apply
> worker
> > > uses it to detect that and exits? How other bgworkers would notice this, is
> it
> > > done via apply_bgworker_check_status()?
> >
> > It was used to detect the unexpected exit of bgworker and I have changed
> the design
> > of this which is now similar to what we have in parallel query.
> >
>
> Thanks, this looks better.
>
> > Attach the new version patch set(v24) which address above comments.
> > Besides, I added some logic which try to stop the bgworker at transaction
> end
> > if there are enough workers in the pool.
> >
>
> I think this deserves an explanation in worker.c under the title:
> "Separate background workers" in the patch.
>
> Review comments for v24-0001
Thanks for the comments.
> =========================
> 1.
> + * cost of searhing the hash table
>
> /searhing/searching
Fixed.
> 2.
> +/*
> + * Apply background worker states.
> + */
> +typedef enum ApplyBgworkerState
> +{
> + APPLY_BGWORKER_BUSY, /* assigned to a transaction */
> + APPLY_BGWORKER_FINISHED /* transaction is completed */
> +} ApplyBgworkerState;
>
> Now, that there are just two states, can we think to represent them
> via a flag ('available'/'in_use') or do you see a downside with that
> as compared to the current approach?
Changed to in_use.
> 3.
> -replorigin_session_setup(RepOriginId node)
> +replorigin_session_setup(RepOriginId node, int apply_leader_pid)
>
> I have mentioned previously that we don't need anything specific to
> apply worker/leader in this API, so why this change? The other idea
> that occurred to me is that can we use replorigin_session_reset()
> before sending the commit message to bgworker and then do the session
> setup in bgworker only to handle the commit/abort/prepare message. We
> also need to set it again for the leader apply worker after the leader
> worker completes the wait for bgworker to finish the commit handling.
I have reverted the changes related to replorigin_session_setup and used
the suggested approach. I also did some simple performance tests for this approach
and didn't see some obvious overhead as the replorigin_session_setup is invoked
per streaming transaction.
> 4. Unlike parallel query, here we seem to be creating separate DSM for
> each worker, and probably the difference is due to the fact that here
> we don't know upfront how many workers will actually be required. If
> so, can we write some comments for the same in worker.c where you have
> explained about parallel bgwroker stuff?
Added.
> 5.
> /*
> - * Handle streamed transactions.
> + * Handle streamed transactions for both the main apply worker and the apply
> + * background workers.
>
> Shall we use leader apply worker in the above comment? Also, check
> other places in the patch for similar changes.
Changed.
> 6.
> + else
> + {
>
> - /* open the spool file for this transaction */
> - stream_open_file(MyLogicalRepWorker->subid, stream_xid, first_segment);
> + /* notify handle methods we're processing a remote transaction */
> + in_streamed_transaction = true;
>
> There is a spurious line after else {. Also, the comment could be
> slightly improved: "/* notify handle methods we're processing a remote
> in-progress transaction */"
Changed.
> 7. The checks in various apply_handle_stream_* functions have improved
> as compared to the previous version but I think we can still improve
> those. One idea could be to use a separate function to decide the
> action we want to take and then based on it, the caller can take
> appropriate action. Using a similar idea, we can improve the checks in
> handle_streamed_transaction() as well.
Improved as suggested.
> 8.
> + else if ((winfo = apply_bgworker_find(xid)))
> + {
> + /* Send STREAM ABORT message to the apply background worker. */
> + apply_bgworker_send_data(winfo, s->len, s->data);
> +
> + /*
> + * After sending the data to the apply background worker, wait for
> + * that worker to finish. This is necessary to maintain commit
> + * order which avoids failures due to transaction dependencies and
> + * deadlocks.
> + */
> + if (subxid == xid)
> + {
> + apply_bgworker_wait_for(winfo, APPLY_BGWORKER_FINISHED);
> + apply_bgworker_free(winfo);
> + }
> + }
> + else
> + /*
> + * We are in main apply worker and the transaction has been
> + * serialized to file.
> + */
> + serialize_stream_abort(xid, subxid);
>
> In the last else block, you can use {} to make it consistent with
> other if, else checks.
>
> 9.
> +void
> +ApplyBgworkerMain(Datum main_arg)
> +{
> + volatile ApplyBgworkerShared *shared;
> +
> + dsm_handle handle;
>
> Is there a need to keep this empty line between the above two declarations?
Removed.
> 10.
> + /*
> + * Attach to the message queue.
> + */
> + mq = shm_toc_lookup(toc, APPLY_BGWORKER_KEY_ERROR_QUEUE, false);
>
> Here, we should say error queue in the comments.
Fixed.
> 11.
> + /*
> + * Attach to the message queue.
> + */
> + mq = shm_toc_lookup(toc, APPLY_BGWORKER_KEY_ERROR_QUEUE, false);
> + shm_mq_set_sender(mq, MyProc);
> + error_mqh = shm_mq_attach(mq, seg, NULL);
> + pq_redirect_to_shm_mq(seg, error_mqh);
> +
> + /*
> + * Now, we have initialized DSM. Attach to slot.
> + */
> + logicalrep_worker_attach(worker_slot);
> + MyParallelShared->logicalrep_worker_generation =
> MyLogicalRepWorker->generation;
> + MyParallelShared->logicalrep_worker_slot_no = worker_slot;
> +
> + pq_set_parallel_leader(MyLogicalRepWorker->apply_leader_pid,
> + InvalidBackendId);
>
> Is there a reason to set parallel_leader immediately after
> pq_redirect_to_shm_mq() as we are doing parallel.c?
Moved the code.
> 12.
> if (pq_mq_parallel_leader_pid != 0)
> + {
> SendProcSignal(pq_mq_parallel_leader_pid,
> PROCSIG_PARALLEL_MESSAGE,
> pq_mq_parallel_leader_backend_id);
>
> + /*
> + * XXX maybe we can reuse the PROCSIG_PARALLEL_MESSAGE instead of
> + * introducing a new signal reason.
> + */
> + SendProcSignal(pq_mq_parallel_leader_pid,
> + PROCSIG_APPLY_BGWORKER_MESSAGE,
> + pq_mq_parallel_leader_backend_id);
> + }
>
> I think we don't need to send both signals. Here, we can check if this
> is a parallel worker (IsParallelWorker), then send
> PROCSIG_PARALLEL_MESSAGE, otherwise, send
> PROCSIG_APPLY_BGWORKER_MESSAGE message. In the else part, we can have
> an assert to ensure it is an apply bgworker.
Changed.
Attach the new version patch set which addressed the above comments
and comments from Amit[1] and Kuroda-san[2].
As discussed, I also renamed all the "apply background worker" and
related stuff to "apply parallel worker".
[1] https://www.postgresql.org/message-id/CAA4eK1%2B_oHZHoDooAR7QcYD2CeTUWNSwkqVcLWC2iQijAJC4Cg%40mail.gmail.com
[2]
https://www.postgresql.org/message-id/TYAPR01MB58666A97D40AB8919D106AD5F5709%40TYAPR01MB5866.jpnprd01.prod.outlook.com
Best regards,
Hou zj
Attachment
- v25-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v25-0001-Perform-streaming-logical-transactions-by-parall.patch
- v25-0002-Test-streaming-parallel-option-in-tap-test.patch
- v25-0003-Add-some-checks-before-using-apply-parallel-work.patch
- v25-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tues, Aug 24, 2022 16:41 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote:
> Dear Wang,
>
> Followings are my comments about v23-0003. Currently I do not have any
> comments about 0002 and 0004.
Thanks for your comments.
> 09. general
>
> It seems that logicalrep_rel_mark_parallel_apply() is always called
> when relations are opened on the subscriber-side, but is it really
> needed? There checks are required only for streaming parallel apply,
> so it may be not needed in case of streaming = 'on' or 'off'.
Improved.
This check is only performed when using apply background workers.
> 10. commit message
>
> 2) There cannot be any non-immutable functions used by the subscriber-side
> replicated table. Look for functions in the following places:
> * a. Trigger functions
> * b. Column default value expressions and domain constraints
> * c. Constraint expressions
> * d. Foreign keys
>
> "Foreign key" should not be listed here because it is not related with
> the mutability. I think it should be listed as 3), not d..
Improved.
> 11. create_subscription.sgml
>
> The constraint about foreign key should be described here.
>
> 11. relation.c
>
> 11.a
>
> + CacheRegisterSyscacheCallback(PROCOID,
> + logicalrep_relmap_reset_parallel_cb,
> +
> + (Datum) 0);
>
> Isn't it needed another syscache callback for pg_type?
> Users can add any constraints via ALTER DOMAIN command, but the added
> constraint may be not checked.
> I checked AlterDomainAddConstraint(), and it invalidates only the
> relcache for pg_type.
>
> 11.b
>
> + /*
> + * If the column is of a DOMAIN type, determine whether
> + * that domain has any CHECK expressions that are not
> + * immutable.
> + */
> + if (get_typtype(att->atttypid) == TYPTYPE_DOMAIN)
> + {
>
> I think the default value of *domain* must be also checked here.
> I tested like followings.
>
> ===
> 1. created a domain that has a default value CREATE DOMAIN tmp INT
> DEFAULT 1 CHECK (VALUE > 0);
>
> 2. created a table
> CREATE TABLE foo (id tmp PRIMARY KEY);
>
> 3. checked pg_attribute and pg_class
> select oid, relname, attname, atthasdef from pg_attribute, pg_class
> where pg_attribute.attrelid = pg_class.oid and pg_class.relname =
> 'foo' and attname = 'id';
> oid | relname | attname | atthasdef
> -------+---------+---------+-----------
> 16394 | foo | id | f
> (1 row)
>
> Tt meant that functions might be not checked because the if-statement
> `if (att-
> >atthasdef)` became false.
> ===
Fixed.
In addition, to reduce duplicate validation, only the flag "parallel_apply_safe" is reset when pg_proc and pg_type
changes.
> 12. 015_stream.pl, 016_stream_subxact.pl, 022_twophase_cascade.pl,
> 023_twophase_stream.pl
>
> - my ($node_publisher, $node_subscriber, $appname, $is_parallel) = @_;
> + my ($node_publisher, $node_subscriber, $appname) = @_;
>
> Why the parameter is removed? I think the test that waits the output
> from the apply background worker is meaningful.
Revert this change.
In addition, made some modifications to the logs confirmed in these test files to
ensure the streamed transactions complete as expected using apply background worker.
> 13. 032_streaming_apply.pl
>
> The filename seems too general because apply background workers are
> tested in above tests.
> How about "streaming_apply_constraint" or something?
Renamed to 032_streaming_parallel_safety.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Aug 29, 2022 at 5:01 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Thursday, August 25, 2022 7:33 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
>
> > 11.
> > + /*
> > + * Attach to the message queue.
> > + */
> > + mq = shm_toc_lookup(toc, APPLY_BGWORKER_KEY_ERROR_QUEUE, false);
> > + shm_mq_set_sender(mq, MyProc);
> > + error_mqh = shm_mq_attach(mq, seg, NULL);
> > + pq_redirect_to_shm_mq(seg, error_mqh);
> > +
> > + /*
> > + * Now, we have initialized DSM. Attach to slot.
> > + */
> > + logicalrep_worker_attach(worker_slot);
> > + MyParallelShared->logicalrep_worker_generation =
> > MyLogicalRepWorker->generation;
> > + MyParallelShared->logicalrep_worker_slot_no = worker_slot;
> > +
> > + pq_set_parallel_leader(MyLogicalRepWorker->apply_leader_pid,
> > + InvalidBackendId);
> >
> > Is there a reason to set parallel_leader immediately after
> > pq_redirect_to_shm_mq() as we are doing parallel.c?
>
> Moved the code.
>
Sorry, if I was not clear but what I wanted was something like the below:
diff --git a/src/backend/replication/logical/applyparallelworker.c
b/src/backend/replication/logical/applyparallelworker.c
index 832e99cd48..6646e00658 100644
--- a/src/backend/replication/logical/applyparallelworker.c
+++ b/src/backend/replication/logical/applyparallelworker.c
@@ -480,6 +480,9 @@ ApplyParallelWorkerMain(Datum main_arg)
mq = shm_toc_lookup(toc, PARALLEL_APPLY_KEY_ERROR_QUEUE, false);
shm_mq_set_sender(mq, MyProc);
error_mqh = shm_mq_attach(mq, seg, NULL);
+ pq_redirect_to_shm_mq(seg, error_mqh);
+ pq_set_parallel_leader(MyLogicalRepWorker->apply_leader_pid,
+ InvalidBackendId);
/*
* Primary initialization is complete. Now, we can attach to
our slot. This
@@ -490,10 +493,6 @@ ApplyParallelWorkerMain(Datum main_arg)
MyParallelShared->logicalrep_worker_generation =
MyLogicalRepWorker->generation;
MyParallelShared->logicalrep_worker_slot_no = worker_slot;
- pq_redirect_to_shm_mq(seg, error_mqh);
- pq_set_parallel_leader(MyLogicalRepWorker->apply_leader_pid,
- InvalidBackendId);
-
MyLogicalRepWorker->last_send_time =
MyLogicalRepWorker->last_recv_time =
MyLogicalRepWorker->reply_time = 0;
Few other comments on v25-0001*
============================
1.
+ {
+ {"max_apply_parallel_workers_per_subscription",
+ PGC_SIGHUP,
+ REPLICATION_SUBSCRIBERS,
+ gettext_noop("Maximum number of apply parallel workers per subscription."),
+ NULL,
+ },
+ &max_apply_parallel_workers_per_subscription,
Let's model this to max_parallel_workers_per_gather and name this
max_parallel_apply_workers_per_subscription.
+typedef struct ApplyParallelWorkerEntry
+{
+ TransactionId xid; /* Hash key -- must be first */
+ ApplyParallelWorkerInfo *winfo;
+} ApplyParallelWorkerEntry;
+
+/* Apply parallel workers hash table (initialized on first use). */
+static HTAB *ApplyParallelWorkersHash = NULL;
+static List *ApplyParallelWorkersFreeList = NIL;
+static List *ApplyParallelWorkersList = NIL;
Similarly, for above let's name them as ParallelApply*. I think in
comments/doc changes it is better to refer as parallel apply worker.
we can keep filename as it is.
2.
+ * If there are enough apply parallel workers(reache half of the
+ * max_apply_parallel_workers_per_subscription)
/reache/reached. There should be a space before (.
3.
+ * The dynamic shared memory segment will contain (1) a shm_mq that can be used
+ * to transport errors (and other messages reported via elog/ereport) from the
+ * apply parallel worker to leader apply worker (2) another shm_mq that can
+ * be used to transport changes in the transaction from leader apply worker to
+ * apply parallel worker (3) necessary information to be shared among apply
+ * parallel workers to leader apply worker
I think it is better to use send instead of transport in above
paragraph. In (3), /apply parallel workers to leader apply
worker/apply parallel workers and leader apply worker
4.
handle_streamed_transaction(LogicalRepMsgType action, StringInfo s)
{
...
...
+ else if (apply_action == TA_SEND_TO_PARALLEL_WORKER)
+ {
+ parallel_apply_send_data(winfo, s->len, s->data);
It is better to have an Assert for winfo being non-null here and other
similar usages.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Aug 30, 2022 at 12:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> Few other comments on v25-0001*
> ============================
>
Some more comments on v25-0001*:
=============================
1.
+static void
+apply_handle_stream_abort(StringInfo s)
...
...
+ else if (apply_action == TA_SEND_TO_PARALLEL_WORKER)
+ {
+ if (subxid == xid)
+ parallel_apply_replorigin_reset();
+
+ /* Send STREAM ABORT message to the apply parallel worker. */
+ parallel_apply_send_data(winfo, s->len, s->data);
+
+ /*
+ * After sending the data to the apply parallel worker, wait for
+ * that worker to finish. This is necessary to maintain commit
+ * order which avoids failures due to transaction dependencies and
+ * deadlocks.
+ */
+ if (subxid == xid)
+ {
+ parallel_apply_wait_for_free(winfo);
...
...
From this code, it appears that we are waiting for rollbacks to finish
but not doing the same in the rollback to savepoint cases. Is there a
reason for the same? I think we need to wait for rollbacks to avoid
transaction dependency and deadlock issues. Consider the below case:
Consider table t1 (c1 primary key, c2, c3) has a row (1, 2, 3) on both
publisher and subscriber.
Publisher
Session-1
==========
Begin;
...
Delete from t1 where c1 = 1;
Session-2
Begin;
...
insert into t1 values(1, 4, 5); --This will wait for Session-1's
Delete to finish.
Session-1
Rollback;
Session-2
-- The wait will be finished and the insert will be successful.
Commit;
Now, assume both these transactions get streamed and if we didn't wait
for rollback/rollback to savepoint, it is possible that the insert
gets executed before and leads to a constraint violation. This won't
happen in non-parallel mode, so we should wait for rollbacks to
finish.
2. I think we don't need to wait at Rollback Prepared/Commit Prepared
because we wait for prepare to finish in *_stream_prepare function.
That will ensure all the operations in that transaction have happened
in the subscriber, so no concurrent transaction can create deadlock or
transaction dependency issues. If so, I think it is better to explain
this in the comments.
3.
+/* What action to take for the transaction. */
+typedef enum
{
- LogicalRepMsgType command; /* 0 if invalid */
- LogicalRepRelMapEntry *rel;
+ /* The action for non-streaming transactions. */
+ TA_APPLY_IN_LEADER_WORKER,
- /* Remote node information */
- int remote_attnum; /* -1 if invalid */
- TransactionId remote_xid;
- XLogRecPtr finish_lsn;
- char *origin_name;
-} ApplyErrorCallbackArg;
+ /* Actions for streaming transactions. */
+ TA_SERIALIZE_TO_FILE,
+ TA_APPLY_IN_PARALLEL_WORKER,
+ TA_SEND_TO_PARALLEL_WORKER
+} TransactionApplyAction;
I think each action needs explanation atop this enum typedef.
4.
@@ -1149,24 +1315,14 @@ static void
apply_handle_stream_start(StringInfo s)
{
...
+ else if (apply_action == TA_SERIALIZE_TO_FILE)
+ {
+ /*
+ * For the first stream start, check if there is any free apply
+ * parallel worker we can use to process this transaction.
+ */
+ if (first_segment)
+ winfo = parallel_apply_start_worker(stream_xid);
- /* open the spool file for this transaction */
- stream_open_file(MyLogicalRepWorker->subid, stream_xid, first_segment);
+ if (winfo)
+ {
+ /*
+ * If we have found a free worker, then we pass the data to that
+ * worker.
+ */
+ parallel_apply_send_data(winfo, s->len, s->data);
- /* if this is not the first segment, open existing subxact file */
- if (!first_segment)
- subxact_info_read(MyLogicalRepWorker->subid, stream_xid);
+ nchanges = 0;
- pgstat_report_activity(STATE_RUNNING, NULL);
+ /* Cache the apply parallel worker for this transaction. */
+ stream_apply_worker = winfo;
+ }
...
This looks odd to me in the sense that even if the action is
TA_SERIALIZE_TO_FILE, we still send the information to the parallel
worker. Won't it be better if we call parallel_apply_start_worker()
for first_segment before checking apply_action with
get_transaction_apply_action(). That way we can avoid this special
case handling.
5.
+/*
+ * Struct for sharing information between apply leader apply worker and apply
+ * parallel workers.
+ */
+typedef struct ApplyParallelWorkerShared
+{
+ slock_t mutex;
+
+ bool in_use;
+
+ /* Logical protocol version. */
+ uint32 proto_version;
+
+ TransactionId stream_xid;
Are we using stream_xid passed by the leader in parallel worker? If
so, how? If not, then can we do without this?
6.
+void
+HandleParallelApplyMessages(void)
{
...
+ /* OK to process messages. Reset the flag saying there are more to do. */
+ ParallelApplyMessagePending = false;
I don't understand the meaning of the second part of the comment.
Shouldn't we say: "Reset the flag saying there is nothing more to
do."? I know you have copied from the other part of the code but there
also I am not sure if it is correct.
7.
+static List *ApplyParallelWorkersFreeList = NIL;
+static List *ApplyParallelWorkersList = NIL;
Do we really need to maintain two different workers' lists? If so,
what is the advantage? I think there won't be many parallel apply
workers, so even if maintain one list and search it, there shouldn't
be any performance impact. I feel maintaining two lists for this
purpose is a bit complex and has more chances of bugs, so we should
try to avoid it if possible.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, August 30, 2022 7:51 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Tue, Aug 30, 2022 at 12:12 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > Few other comments on v25-0001*
> > ============================
> >
>
> Some more comments on v25-0001*:
> =============================
> 1.
> +static void
> +apply_handle_stream_abort(StringInfo s)
> ...
> ...
> + else if (apply_action == TA_SEND_TO_PARALLEL_WORKER) { if (subxid ==
> + xid) parallel_apply_replorigin_reset();
> +
> + /* Send STREAM ABORT message to the apply parallel worker. */
> + parallel_apply_send_data(winfo, s->len, s->data);
> +
> + /*
> + * After sending the data to the apply parallel worker, wait for
> + * that worker to finish. This is necessary to maintain commit
> + * order which avoids failures due to transaction dependencies and
> + * deadlocks.
> + */
> + if (subxid == xid)
> + {
> + parallel_apply_wait_for_free(winfo);
> ...
> ...
>
> From this code, it appears that we are waiting for rollbacks to finish but not
> doing the same in the rollback to savepoint cases. Is there a reason for the
> same? I think we need to wait for rollbacks to avoid transaction dependency
> and deadlock issues. Consider the below case:
>
> Consider table t1 (c1 primary key, c2, c3) has a row (1, 2, 3) on both publisher and
> subscriber.
>
> Publisher
> Session-1
> ==========
> Begin;
> ...
> Delete from t1 where c1 = 1;
>
> Session-2
> Begin;
> ...
> insert into t1 values(1, 4, 5); --This will wait for Session-1's Delete to finish.
>
> Session-1
> Rollback;
>
> Session-2
> -- The wait will be finished and the insert will be successful.
> Commit;
>
> Now, assume both these transactions get streamed and if we didn't wait for
> rollback/rollback to savepoint, it is possible that the insert gets executed
> before and leads to a constraint violation. This won't happen in non-parallel
> mode, so we should wait for rollbacks to finish.
Agreed and changed.
> 2. I think we don't need to wait at Rollback Prepared/Commit Prepared
> because we wait for prepare to finish in *_stream_prepare function.
> That will ensure all the operations in that transaction have happened in the
> subscriber, so no concurrent transaction can create deadlock or transaction
> dependency issues. If so, I think it is better to explain this in the comments.
Added some comments about this.
> 3.
> +/* What action to take for the transaction. */ typedef enum
> {
> - LogicalRepMsgType command; /* 0 if invalid */
> - LogicalRepRelMapEntry *rel;
> + /* The action for non-streaming transactions. */
> + TA_APPLY_IN_LEADER_WORKER,
>
> - /* Remote node information */
> - int remote_attnum; /* -1 if invalid */
> - TransactionId remote_xid;
> - XLogRecPtr finish_lsn;
> - char *origin_name;
> -} ApplyErrorCallbackArg;
> + /* Actions for streaming transactions. */ TA_SERIALIZE_TO_FILE,
> +TA_APPLY_IN_PARALLEL_WORKER, TA_SEND_TO_PARALLEL_WORKER }
> +TransactionApplyAction;
>
> I think each action needs explanation atop this enum typedef.
Added.
> 4.
> @@ -1149,24 +1315,14 @@ static void
> apply_handle_stream_start(StringInfo s) { ...
> + else if (apply_action == TA_SERIALIZE_TO_FILE) {
> + /*
> + * For the first stream start, check if there is any free apply
> + * parallel worker we can use to process this transaction.
> + */
> + if (first_segment)
> + winfo = parallel_apply_start_worker(stream_xid);
>
> - /* open the spool file for this transaction */
> - stream_open_file(MyLogicalRepWorker->subid, stream_xid, first_segment);
> + if (winfo)
> + {
> + /*
> + * If we have found a free worker, then we pass the data to that
> + * worker.
> + */
> + parallel_apply_send_data(winfo, s->len, s->data);
>
> - /* if this is not the first segment, open existing subxact file */
> - if (!first_segment)
> - subxact_info_read(MyLogicalRepWorker->subid, stream_xid);
> + nchanges = 0;
>
> - pgstat_report_activity(STATE_RUNNING, NULL);
> + /* Cache the apply parallel worker for this transaction. */
> + stream_apply_worker = winfo; }
> ...
>
> This looks odd to me in the sense that even if the action is
> TA_SERIALIZE_TO_FILE, we still send the information to the parallel
> worker. Won't it be better if we call parallel_apply_start_worker()
> for first_segment before checking apply_action with
> get_transaction_apply_action(). That way we can avoid this special
> case handling.
Changed as suggested.
> 5.
> +/*
> + * Struct for sharing information between apply leader apply worker and apply
> + * parallel workers.
> + */
> +typedef struct ApplyParallelWorkerShared
> +{
> + slock_t mutex;
> +
> + bool in_use;
> +
> + /* Logical protocol version. */
> + uint32 proto_version;
> +
> + TransactionId stream_xid;
>
> Are we using stream_xid passed by the leader in parallel worker? If
> so, how? If not, then can we do without this?
No, it seems we don't need this. Removed.
> 6.
> +void
> +HandleParallelApplyMessages(void)
> {
> ...
> + /* OK to process messages. Reset the flag saying there are more to do. */
> + ParallelApplyMessagePending = false;
>
> I don't understand the meaning of the second part of the comment.
> Shouldn't we say: "Reset the flag saying there is nothing more to
> do."? I know you have copied from the other part of the code but there
> also I am not sure if it is correct.
I feel the comment here is not very helpful, so I removed this.
> 7.
> +static List *ApplyParallelWorkersFreeList = NIL;
> +static List *ApplyParallelWorkersList = NIL;
>
> Do we really need to maintain two different workers' lists? If so,
> what is the advantage? I think there won't be many parallel apply
> workers, so even if maintain one list and search it, there shouldn't
> be any performance impact. I feel maintaining two lists for this
> purpose is a bit complex and has more chances of bugs, so we should
> try to avoid it if possible.
Agreed, I removed the ApplyParallelWorkersList and reused
ApplyParallelWorkersList in other places.
Attach the new version patch set which addressed above comments
and comments from[1].
[1] https://www.postgresql.org/message-id/CAA4eK1%2Be8JsiC8uMZPU25xQRyxNvVS24M4%3DZy-xD18jzX%2BvrmA%40mail.gmail.com
Best regards,
Hou zj
Attachment
- v26-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v26-0001-Perform-streaming-logical-transactions-by-parall.patch
- v26-0002-Test-streaming-parallel-option-in-tap-test.patch
- v26-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v26-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, August 31, 2022 5:56 PM houzj.fnst@fujitsu.com wrote:
>
> On Tuesday, August 30, 2022 7:51 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > On Tue, Aug 30, 2022 at 12:12 PM Amit Kapila <amit.kapila16@gmail.com>
> > wrote:
> > >
> > > Few other comments on v25-0001*
> > > ============================
> > >
> >
> > Some more comments on v25-0001*:
> > =============================
> > 1.
> > +static void
> > +apply_handle_stream_abort(StringInfo s)
> > ...
> > ...
> > + else if (apply_action == TA_SEND_TO_PARALLEL_WORKER) { if (subxid ==
> > + xid) parallel_apply_replorigin_reset();
> > +
> > + /* Send STREAM ABORT message to the apply parallel worker. */
> > + parallel_apply_send_data(winfo, s->len, s->data);
> > +
> > + /*
> > + * After sending the data to the apply parallel worker, wait for
> > + * that worker to finish. This is necessary to maintain commit
> > + * order which avoids failures due to transaction dependencies and
> > + * deadlocks.
> > + */
> > + if (subxid == xid)
> > + {
> > + parallel_apply_wait_for_free(winfo);
> > ...
> > ...
> >
> > From this code, it appears that we are waiting for rollbacks to finish
> > but not doing the same in the rollback to savepoint cases. Is there a
> > reason for the same? I think we need to wait for rollbacks to avoid
> > transaction dependency and deadlock issues. Consider the below case:
> >
> > Consider table t1 (c1 primary key, c2, c3) has a row (1, 2, 3) on both
> > publisher and subscriber.
> >
> > Publisher
> > Session-1
> > ==========
> > Begin;
> > ...
> > Delete from t1 where c1 = 1;
> >
> > Session-2
> > Begin;
> > ...
> > insert into t1 values(1, 4, 5); --This will wait for Session-1's Delete to finish.
> >
> > Session-1
> > Rollback;
> >
> > Session-2
> > -- The wait will be finished and the insert will be successful.
> > Commit;
> >
> > Now, assume both these transactions get streamed and if we didn't wait
> > for rollback/rollback to savepoint, it is possible that the insert
> > gets executed before and leads to a constraint violation. This won't
> > happen in non-parallel mode, so we should wait for rollbacks to finish.
>
> Agreed and changed.
>
> > 2. I think we don't need to wait at Rollback Prepared/Commit Prepared
> > because we wait for prepare to finish in *_stream_prepare function.
> > That will ensure all the operations in that transaction have happened
> > in the subscriber, so no concurrent transaction can create deadlock or
> > transaction dependency issues. If so, I think it is better to explain this in the
> comments.
>
> Added some comments about this.
>
> > 3.
> > +/* What action to take for the transaction. */ typedef enum
> > {
> > - LogicalRepMsgType command; /* 0 if invalid */
> > - LogicalRepRelMapEntry *rel;
> > + /* The action for non-streaming transactions. */
> > + TA_APPLY_IN_LEADER_WORKER,
> >
> > - /* Remote node information */
> > - int remote_attnum; /* -1 if invalid */
> > - TransactionId remote_xid;
> > - XLogRecPtr finish_lsn;
> > - char *origin_name;
> > -} ApplyErrorCallbackArg;
> > + /* Actions for streaming transactions. */ TA_SERIALIZE_TO_FILE,
> > +TA_APPLY_IN_PARALLEL_WORKER, TA_SEND_TO_PARALLEL_WORKER }
> > +TransactionApplyAction;
> >
> > I think each action needs explanation atop this enum typedef.
>
> Added.
>
> > 4.
> > @@ -1149,24 +1315,14 @@ static void
> > apply_handle_stream_start(StringInfo s) { ...
> > + else if (apply_action == TA_SERIALIZE_TO_FILE) {
> > + /*
> > + * For the first stream start, check if there is any free apply
> > + * parallel worker we can use to process this transaction.
> > + */
> > + if (first_segment)
> > + winfo = parallel_apply_start_worker(stream_xid);
> >
> > - /* open the spool file for this transaction */
> > - stream_open_file(MyLogicalRepWorker->subid, stream_xid,
> > first_segment);
> > + if (winfo)
> > + {
> > + /*
> > + * If we have found a free worker, then we pass the data to that
> > + * worker.
> > + */
> > + parallel_apply_send_data(winfo, s->len, s->data);
> >
> > - /* if this is not the first segment, open existing subxact file */
> > - if (!first_segment)
> > - subxact_info_read(MyLogicalRepWorker->subid, stream_xid);
> > + nchanges = 0;
> >
> > - pgstat_report_activity(STATE_RUNNING, NULL);
> > + /* Cache the apply parallel worker for this transaction. */
> > + stream_apply_worker = winfo; }
> > ...
> >
> > This looks odd to me in the sense that even if the action is
> > TA_SERIALIZE_TO_FILE, we still send the information to the parallel
> > worker. Won't it be better if we call parallel_apply_start_worker()
> > for first_segment before checking apply_action with
> > get_transaction_apply_action(). That way we can avoid this special
> > case handling.
>
> Changed as suggested.
>
> > 5.
> > +/*
> > + * Struct for sharing information between apply leader apply worker
> > +and apply
> > + * parallel workers.
> > + */
> > +typedef struct ApplyParallelWorkerShared { slock_t mutex;
> > +
> > + bool in_use;
> > +
> > + /* Logical protocol version. */
> > + uint32 proto_version;
> > +
> > + TransactionId stream_xid;
> >
> > Are we using stream_xid passed by the leader in parallel worker? If
> > so, how? If not, then can we do without this?
>
> No, it seems we don't need this. Removed.
>
> > 6.
> > +void
> > +HandleParallelApplyMessages(void)
> > {
> > ...
> > + /* OK to process messages. Reset the flag saying there are more to
> > + do. */ ParallelApplyMessagePending = false;
> >
> > I don't understand the meaning of the second part of the comment.
> > Shouldn't we say: "Reset the flag saying there is nothing more to
> > do."? I know you have copied from the other part of the code but there
> > also I am not sure if it is correct.
>
> I feel the comment here is not very helpful, so I removed this.
>
> > 7.
> > +static List *ApplyParallelWorkersFreeList = NIL; static List
> > +*ApplyParallelWorkersList = NIL;
> >
> > Do we really need to maintain two different workers' lists? If so,
> > what is the advantage? I think there won't be many parallel apply
> > workers, so even if maintain one list and search it, there shouldn't
> > be any performance impact. I feel maintaining two lists for this
> > purpose is a bit complex and has more chances of bugs, so we should
> > try to avoid it if possible.
>
> Agreed, I removed the ApplyParallelWorkersList and reused
> ApplyParallelWorkersList in other places.
>
> Attach the new version patch set which addressed above comments and
> comments from[1].
>
> [1]
> https://www.postgresql.org/message-id/CAA4eK1%2Be8JsiC8uMZPU25xQRy
> xNvVS24M4%3DZy-xD18jzX%2BvrmA%40mail.gmail.com
Attach a new version patch set which fixes some typos and some cosmetic things.
Best regards,
Hou zj
Attachment
- v27-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v27-0001-Perform-streaming-logical-transactions-by-parall.patch
- v27-0002-Test-streaming-parallel-option-in-tap-test.patch
- v27-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v27-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Sep 1, 2022 at 4:53 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
Review of v27-0001*:
================
1. I feel the usage of in_remote_transaction and in_use flags is
slightly complex. IIUC, the patch uses in_use flag to ensure commit
ordering by waiting for it to become false before proceeding in
transaction finish commands in leader apply worker. If so, I think it
is better to name it in_parallel_apply_xact and set it to true only
when we start applying xact in parallel apply worker and set it to
false when we finish the xact in parallel apply worker. It can be
initialized to false while setting up DSM. Also, accordingly change
the function parallel_apply_wait_for_free() to
parallel_apply_wait_for_xact_finish and parallel_apply_set_idle to
parallel_apply_set_xact_finish. We can change the name of the
in_remote_transaction flag to in_use.
Please explain about these flags in the struct where they are declared.
2. The worker_id in ParallelApplyWorkerShared struct could have wrong
information after the worker is reused from the pool. Because we could
have removed some other worker from the ParallelApplyWorkersList which
will make the value of worker_id wrong. For error/debug messages, we
can probably use LSN if available or can oid of subscription if
required. I thought of using xid as well but I think it is better to
avoid that in messages as it can wraparound. See, if the patch uses
xid in other messages, it is better to either use it along with LSN or
try to use only LSN.
3.
elog(ERROR, "[Parallel Apply Worker #%u] unexpected message \"%c\"",
+ shared->worker_id, c);
Also, I am not sure whether the above style (use of []) of messages is
good. Did you follow the usage from some other place?
4.
apply_handle_stream_stop(StringInfo s)
{
...
+ if (apply_action == TA_APPLY_IN_PARALLEL_WORKER)
+ {
+ elog(DEBUG1, "[Parallel Apply Worker #%u] ended processing streaming chunk, "
+ "waiting on shm_mq_receive", MyParallelShared->worker_id);
...
I don't understand the relevance of "waiting on shm_mq_receive" in the
above message because AFAICS, here we are not waiting on any receive
call.
5. I suggest you please go through all the ERROR/LOG/DEBUG messages in
the patch and try to improve them based on the above comments.
6.
+ * The dynamic shared memory segment will contain (1) a shm_mq that can be used
+ * to send errors (and other messages reported via elog/ereport) from the
+ * parallel apply worker to leader apply worker (2) another shm_mq that can be
+ * used to send changes in the transaction from leader apply worker to parallel
+ * apply worker
Here, it would be better to switch (1) and (2). I feel it is better to
explain first about how the main apply information is exchanged among
workers.
7.
+ /* Try to get a free parallel apply worker. */
+ foreach(lc, ParallelApplyWorkersList)
+ {
+ ParallelApplyWorkerInfo *tmp_winfo;
+
+ tmp_winfo = (ParallelApplyWorkerInfo *) lfirst(lc);
+
+ if (tmp_winfo->error_mq_handle == NULL)
+ {
+ /*
+ * Release the worker information and try next one if the parallel
+ * apply worker exited cleanly.
+ */
+ ParallelApplyWorkersList =
foreach_delete_current(ParallelApplyWorkersList, lc);
+ shm_mq_detach(tmp_winfo->mq_handle);
+ dsm_detach(tmp_winfo->dsm_seg);
+ pfree(tmp_winfo);
+
+ continue;
+ }
+
+ if (!tmp_winfo->in_remote_transaction)
+ {
+ winfo = tmp_winfo;
+ break;
+ }
+ }
Can we write it as if ... else if? If so, then we don't need to
continue in the first loop. And, can we add some more comments to
explain these cases?
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, September 2, 2022 2:10 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Sep 1, 2022 at 4:53 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
>
> Review of v27-0001*:
Thanks for the comments.
> ================
> 1. I feel the usage of in_remote_transaction and in_use flags is slightly complex.
> IIUC, the patch uses in_use flag to ensure commit ordering by waiting for it to
> become false before proceeding in transaction finish commands in leader
> apply worker. If so, I think it is better to name it in_parallel_apply_xact and set it
> to true only when we start applying xact in parallel apply worker and set it to
> false when we finish the xact in parallel apply worker. It can be initialized to false
> while setting up DSM. Also, accordingly change the function
> parallel_apply_wait_for_free() to parallel_apply_wait_for_xact_finish and
> parallel_apply_set_idle to parallel_apply_set_xact_finish. We can change the
> name of the in_remote_transaction flag to in_use.
Agreed. One thing I found when addressing this is that there could be a race
condition if we want to set the flag in parallel apply worker:
where the leader has already started waiting for the parallel apply worker to
finish processing the transaction(set the in_parallel_apply_xact to false)
while the child process has not yet processed the first STREAM_START and has
not set the in_parallel_apply_xact to true.
> Please explain about these flags in the struct where they are declared.
>
> 2. The worker_id in ParallelApplyWorkerShared struct could have wrong
> information after the worker is reused from the pool. Because we could have
> removed some other worker from the ParallelApplyWorkersList which will
> make the value of worker_id wrong. For error/debug messages, we can
> probably use LSN if available or can oid of subscription if required. I thought of
> using xid as well but I think it is better to avoid that in messages as it can
> wraparound. See, if the patch uses xid in other messages, it is better to either
> use it along with LSN or try to use only LSN.
> 3.
> elog(ERROR, "[Parallel Apply Worker #%u] unexpected message \"%c\"",
> + shared->worker_id, c);
>
> Also, I am not sure whether the above style (use of []) of messages is good. Did
> you follow the usage from some other place?
> 4.
> apply_handle_stream_stop(StringInfo s)
> {
> ...
> + if (apply_action == TA_APPLY_IN_PARALLEL_WORKER) { elog(DEBUG1,
> + "[Parallel Apply Worker #%u] ended processing streaming chunk, "
> + "waiting on shm_mq_receive", MyParallelShared->worker_id);
> ...
>
> I don't understand the relevance of "waiting on shm_mq_receive" in the
> above message because AFAICS, here we are not waiting on any receive
> call.
>
> 5. I suggest you please go through all the ERROR/LOG/DEBUG messages in
> the patch and try to improve them based on the above comments.
I removed the worker_id and also removed and improved some DEBUG/ERROR
messages which I think is not clear or we don't have similar message in existing code.
> 6.
> + * The dynamic shared memory segment will contain (1) a shm_mq that can be
> used
> + * to send errors (and other messages reported via elog/ereport) from the
> + * parallel apply worker to leader apply worker (2) another shm_mq that can
> be
> + * used to send changes in the transaction from leader apply worker to parallel
> + * apply worker
>
> Here, it would be better to switch (1) and (2). I feel it is better to
> explain first about how the main apply information is exchanged among
> workers.
Exchanged.
> 7.
> + /* Try to get a free parallel apply worker. */
> + foreach(lc, ParallelApplyWorkersList)
> + {
> + ParallelApplyWorkerInfo *tmp_winfo;
> +
> + tmp_winfo = (ParallelApplyWorkerInfo *) lfirst(lc);
> +
> + if (tmp_winfo->error_mq_handle == NULL)
> + {
> + /*
> + * Release the worker information and try next one if the parallel
> + * apply worker exited cleanly.
> + */
> + ParallelApplyWorkersList =
> foreach_delete_current(ParallelApplyWorkersList, lc);
> + shm_mq_detach(tmp_winfo->mq_handle);
> + dsm_detach(tmp_winfo->dsm_seg);
> + pfree(tmp_winfo);
> +
> + continue;
> + }
> +
> + if (!tmp_winfo->in_remote_transaction)
> + {
> + winfo = tmp_winfo;
> + break;
> + }
> + }
>
> Can we write it as if ... else if? If so, then we don't need to
> continue in the first loop. And, can we add some more comments to
> explain these cases?
Changed.
Attach the new version patch set which addressed above comments and
also fixed another problem while subscriber to a low version publisher.
Best regards,
Hou zj
Attachment
- v28-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v28-0001-Perform-streaming-logical-transactions-by-parall.patch
- v28-0002-Test-streaming-parallel-option-in-tap-test.patch
- v28-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v28-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, September 5, 2022 8:41 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Friday, September 2, 2022 2:10 PM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > > On Thu, Sep 1, 2022 at 4:53 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > Review of v27-0001*: > > Thanks for the comments. > > > ================ > > 1. I feel the usage of in_remote_transaction and in_use flags is slightly complex. > > IIUC, the patch uses in_use flag to ensure commit ordering by waiting > > for it to become false before proceeding in transaction finish > > commands in leader apply worker. If so, I think it is better to name > > it in_parallel_apply_xact and set it to true only when we start > > applying xact in parallel apply worker and set it to false when we > > finish the xact in parallel apply worker. It can be initialized to > > false while setting up DSM. Also, accordingly change the function > > parallel_apply_wait_for_free() to parallel_apply_wait_for_xact_finish > > and parallel_apply_set_idle to parallel_apply_set_xact_finish. We can > > change the name of the in_remote_transaction flag to in_use. > > Agreed. One thing I found when addressing this is that there could be a race > condition if we want to set the flag in parallel apply worker: > > where the leader has already started waiting for the parallel apply worker to > finish processing the transaction(set the in_parallel_apply_xact to false) while the > child process has not yet processed the first STREAM_START and has not set the > in_parallel_apply_xact to true. Sorry, I didn’t complete this sentence. I meant it's safer to set this flag in apply leader, So I changed the code like that and added some comments to explain the same. ... > > Attach the new version patch set which addressed above comments and also > fixed another problem while subscriber to a low version publisher. Attach the correct patch set this time. Best regards, Hou zj
Attachment
- v28-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v28-0001-Perform-streaming-logical-transactions-by-parall.patch
- v28-0002-Test-streaming-parallel-option-in-tap-test.patch
- v28-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v28-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Sep 5, 2022 at 6:34 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > Attach the correct patch set this time. > Few comments on v28-0001*: ======================= 1. + /* Whether the worker is processing a transaction. */ + bool in_use; I think this same comment applies to in_parallel_apply_xact flag as well. How about: "Indicates whether the worker is available to be used for parallel apply transaction?"? 2. + /* + * Set this flag in the leader instead of the parallel apply worker to + * avoid the race condition where the leader has already started waiting + * for the parallel apply worker to finish processing the transaction(set + * the in_parallel_apply_xact to false) while the child process has not yet + * processed the first STREAM_START and has not set the + * in_parallel_apply_xact to true. I think part of this comment "(set the in_parallel_apply_xact to false)" is not necessary. It will be clear without that. 3. + /* Create entry for requested transaction. */ + entry = hash_search(ParallelApplyWorkersHash, &xid, HASH_ENTER, &found); + if (found) + elog(ERROR, "hash table corrupted"); ... ... + hash_search(ParallelApplyWorkersHash, &xid, HASH_REMOVE, NULL); It is better to have a similar elog for HASH_REMOVE case as well. We normally seem to have such elog for HASH_REMOVE. 4. * Parallel apply is not supported when subscribing to a publisher which + * cannot provide the abort_time, abort_lsn and the column information used + * to verify the parallel apply safety. In this comment, which column information are you referring to? 5. + /* + * Set in_parallel_apply_xact to true again as we only aborted the + * subtransaction and the top transaction is still in progress. No + * need to lock here because currently only the apply leader are + * accessing this flag. + */ + winfo->shared->in_parallel_apply_xact = true; This theory sounds good to me but I think it is better to update/read this flag under spinlock as the patch is doing at a few other places. I think that will make the code easier to follow without worrying too much about such special cases. There are a few asserts as well which read this without lock, it would be better to change those as well. 6. + * LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM is the minimum protocol version + * with support for streaming large transactions using parallel apply + * workers. Introduced in PG16. How about changing it to something like: "LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM is the minimum protocol version where we support applying large streaming transactions in parallel. Introduced in PG16." 7. + PGOutputData *data = (PGOutputData *) ctx->output_plugin_private; + bool write_abort_lsn = (data->protocol_version >= + LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM); /* * The abort should happen outside streaming block, even for streamed @@ -1856,7 +1859,8 @@ pgoutput_stream_abort(struct LogicalDecodingContext *ctx, Assert(rbtxn_is_streamed(toptxn)); OutputPluginPrepareWrite(ctx, true); - logicalrep_write_stream_abort(ctx->out, toptxn->xid, txn->xid); + logicalrep_write_stream_abort(ctx->out, toptxn->xid, txn, abort_lsn, + write_abort_lsn); I think we need to send additional information if the client has used the parallel streaming option. Also, let's keep sending subxid as we were doing previously and add additional parameters required. It may be better to name write_abort_lsn as abort_info. 8. + /* + * Check whether the publisher sends abort_lsn and abort_time. + * + * Note that the paralle apply worker is only started when the publisher + * sends abort_lsn and abort_time. + */ + if (am_parallel_apply_worker() || + walrcv_server_version(LogRepWorkerWalRcvConn) >= 160000) + read_abort_lsn = true; + + logicalrep_read_stream_abort(s, &abort_data, read_abort_lsn); This check should match with the check for the write operation where we are checking the protocol version as well. There is a typo as well in the comments (/paralle/parallel). -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Sep 8, 2022 at 12:21 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Sep 5, 2022 at 6:34 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > Attach the correct patch set this time. > > > > Few comments on v28-0001*: > ======================= > Some suggestions for comments in v28-0001* 1. +/* + * Entry for a hash table we use to map from xid to the parallel apply worker + * state. + */ +typedef struct ParallelApplyWorkerEntry Let's change this comment to: "Hash table entry to map xid to the parallel apply worker state." 2. +/* + * List that stores the information of parallel apply workers that were + * started. Newly added worker information will be removed from the list at the + * end of the transaction when there are enough workers in the pool. Besides, + * exited workers will be removed from the list after being detected. + */ +static List *ParallelApplyWorkersList = NIL; Can we change this to: "A list to maintain the active parallel apply workers. The information for the new worker is added to the list after successfully launching it. The list entry is removed at the end of the transaction if there are already enough workers in the worker pool. For more information about the worker pool, see comments atop worker.c. We also remove the entry from the list if the worker is exited due to some error." Apart from this, I have added/changed a few other comments in v28-0001*. Kindly check the attached, if you are fine with it then please include it in the next version. -- With Regards, Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for the v28-0001 patch:
(There may be some overlap with other people's review comments and/or
some fixes already made).
======
1. Commit Message
In addition, the patch extends the logical replication STREAM_ABORT message so
that abort_time and abort_lsn can also be sent which can be used to update the
replication origin in parallel apply worker when the streaming transaction is
aborted.
~
Should this also mention that because this message extension is needed
to support parallel streaming, meaning that parallel streaming is not
supported for publications on servers < PG16?
======
2. doc/src/sgml/config.sgml
<para>
Specifies maximum number of logical replication workers. This includes
- both apply workers and table synchronization workers.
+ apply leader workers, parallel apply workers, and table synchronization
+ workers.
</para>
"apply leader workers" -> "leader apply workers"
~~~
3.
max_logical_replication_workers (integer)
Specifies maximum number of logical replication workers. This
includes apply leader workers, parallel apply workers, and table
synchronization workers.
Logical replication workers are taken from the pool defined by
max_worker_processes.
The default value is 4. This parameter can only be set at server start.
~
I did not really understand why the default is 4. Because the default
tablesync workers is 2, and the default parallel workers is 2, but
what about accounting for the apply worker? Therefore, shouldn't
max_logical_replication_workers default be 5 instead of 4?
======
4. src/backend/commands/subscriptioncmds.c - defGetStreamingMode
+ }
+ ereport(ERROR,
+ (errcode(ERRCODE_SYNTAX_ERROR),
+ errmsg("%s requires a Boolean value or \"parallel\"",
+ def->defname)));
+ return SUBSTREAM_OFF; /* keep compiler quiet */
+}
Some whitespace before the ereport and the return might be tidier.
======
5. src/backend/libpq/pqmq.c
+ {
+ if (IsParallelWorker())
+ SendProcSignal(pq_mq_parallel_leader_pid,
+ PROCSIG_PARALLEL_MESSAGE,
+ pq_mq_parallel_leader_backend_id);
+ else
+ {
+ Assert(IsLogicalParallelApplyWorker());
+ SendProcSignal(pq_mq_parallel_leader_pid,
+ PROCSIG_PARALLEL_APPLY_MESSAGE,
+ pq_mq_parallel_leader_backend_id);
+ }
+ }
This code can be simplified if you want to. For example,
{
ProcSignalReason reason;
Assert(IsParallelWorker() || IsLogicalParallelApplyWorker());
reason = IsParallelWorker() ? PROCSIG_PARALLEL_MESSAGE :
PROCSIG_PARALLEL_APPLY_MESSAGE;
SendProcSignal(pq_mq_parallel_leader_pid, reason,
pq_mq_parallel_leader_backend_id);
}
======
6. src/backend/replication/logical/applyparallelworker.c
Is there a reason why this file is called applyparallelworker.c
instead of parallelapplyworker.c? Now this name is out of step with
names of all the new typedefs etc.
~~~
7.
+/*
+ * There are three fields in each message received by parallel apply worker:
+ * start_lsn, end_lsn and send_time. Because we have updated these statistics
+ * in leader apply worker, we could ignore these fields in parallel apply
+ * worker (see function LogicalRepApplyLoop).
+ */
+#define SIZE_STATS_MESSAGE (2 * sizeof(XLogRecPtr) + sizeof(TimestampTz))
SUGGESTION (Just dded word "the" and change "could" -> "can")
There are three fields in each message received by the parallel apply
worker: start_lsn, end_lsn and send_time. Because we have updated
these statistics in the leader apply worker, we can ignore these
fields in the parallel apply worker (see function
LogicalRepApplyLoop).
~~~
8.
+/*
+ * List that stores the information of parallel apply workers that were
+ * started. Newly added worker information will be removed from the list at the
+ * end of the transaction when there are enough workers in the pool. Besides,
+ * exited workers will be removed from the list after being detected.
+ */
+static List *ParallelApplyWorkersList = NIL;
Perhaps this comment can give more explanation of what is meant by the
part that says "when there are enough workers in the pool".
~~~
9. src/backend/replication/logical/applyparallelworker.c -
parallel_apply_can_start
+ /*
+ * Don't start a new parallel worker if not in streaming parallel mode.
+ */
+ if (MySubscription->stream != SUBSTREAM_PARALLEL)
+ return false;
"streaming parallel mode." -> "parallel streaming mode."
~~~
10.
+ /*
+ * For streaming transactions that are being applied using parallel apply
+ * worker, we cannot decide whether to apply the change for a relation that
+ * is not in the READY state (see should_apply_changes_for_rel) as we won't
+ * know remote_final_lsn by that time. So, we don't start the new parallel
+ * apply worker in this case.
+ */
+ if (!AllTablesyncsReady())
+ return false;
"using parallel apply worker" -> "using a parallel apply worker"
~~~
11.
+ /*
+ * Do not allow parallel apply worker to be started in the parallel apply
+ * worker.
+ */
+ if (am_parallel_apply_worker())
+ return false;
I guess the comment is valid but it sounds strange.
SUGGESTION
Only leader apply workers can start parallel apply workers.
~~~
12.
+ if (am_parallel_apply_worker())
+ return false;
Maybe this code should be earlier in this function, because surely
this is a less costly test than the test for !AllTablesyncsReady()?
~~~
13. src/backend/replication/logical/applyparallelworker.c -
parallel_apply_start_worker
+/*
+ * Start a parallel apply worker that will be used for the specified xid.
+ *
+ * If a parallel apply worker is not in use then re-use it, otherwise start a
+ * fresh one. Cache the worker information in ParallelApplyWorkersHash keyed by
+ * the specified xid.
+ */
"is not in use" -> "is found but not in use" ?
~~~
14.
+ /* Failed to start a new parallel apply worker. */
+ if (winfo == NULL)
+ return;
There seem to be quite a lot of places (like this example) where
something may go wrong and the behaviour apparently will just silently
fall-back to using the non-parallel streaming. Maybe that is OK, but I
am just wondering how can the user ever know this has happened? Maybe
the docs can mention that this could happen and give some description
of what processes users can look for (or some other strategy) so they
can just confirm that the parallel streaming is really working like
they assume it to be?
~~~
15.
+ * Set this flag in the leader instead of the parallel apply worker to
+ * avoid the race condition where the leader has already started waiting
+ * for the parallel apply worker to finish processing the transaction(set
+ * the in_parallel_apply_xact to false) while the child process has not yet
+ * processed the first STREAM_START and has not set the
+ * in_parallel_apply_xact to true.
Missing whitespace before "("
~~~
16. src/backend/replication/logical/applyparallelworker.c -
parallel_apply_find_worker
+ /* Return the cached parallel apply worker if valid. */
+ if (stream_apply_worker != NULL)
+ return stream_apply_worker;
Perhaps 'cur_stream_parallel_apply_winfo' is a better name for this var?
~~~
17. src/backend/replication/logical/applyparallelworker.c -
parallel_apply_free_worker
+/*
+ * Remove the parallel apply worker entry from the hash table. And stop the
+ * worker if there are enough workers in the pool.
+ */
+void
+parallel_apply_free_worker(ParallelApplyWorkerInfo *winfo, TransactionId xid)
I think the reason for doing the "enough workers in the pool" logic
needs some more explanation.
~~~
18.
+ if (napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
+ {
+ logicalrep_worker_stop_by_slot(winfo->shared->logicalrep_worker_slot_no,
+ winfo->shared->logicalrep_worker_generation);
+
+ ParallelApplyWorkersList = list_delete_ptr(ParallelApplyWorkersList, winfo);
+
+ shm_mq_detach(winfo->mq_handle);
+ shm_mq_detach(winfo->error_mq_handle);
+ dsm_detach(winfo->dsm_seg);
+ pfree(winfo);
+ }
+ else
+ winfo->in_use = false;
Maybe it is easier to remove this "else" and just unconditionally set
winfo->in_use = false BEFORE the check to free the entire winfo.
~~~
19. src/backend/replication/logical/applyparallelworker.c -
LogicalParallelApplyLoop
+ ApplyMessageContext = AllocSetContextCreate(ApplyContext,
+ "ApplyMessageContext",
+ ALLOCSET_DEFAULT_SIZES);
Should the name of this context be "ParallelApplyMessageContext"?
~~~
20. src/backend/replication/logical/applyparallelworker.c -
HandleParallelApplyMessage
+ default:
+ {
+ elog(ERROR, "unrecognized message type received from parallel apply
worker: %c (message length %d bytes)",
+ msgtype, msg->len);
+ }
"received from" -> "received by"
~~~
21. src/backend/replication/logical/applyparallelworker.c -
HandleParallelApplyMessages
+/*
+ * Handle any queued protocol messages received from parallel apply workers.
+ */
+void
+HandleParallelApplyMessages(void)
21a.
"received from" -> "received by"
~
21b.
I wonder if this comment should give some credit to the function in
parallel.c - because this seems almost a copy of all that code.
~~~
22. src/backend/replication/logical/applyparallelworker.c -
parallel_apply_set_xact_finish
+/*
+ * Set the in_parallel_apply_xact flag for the current parallel apply worker.
+ */
+void
+parallel_apply_set_xact_finish(void)
Should that "Set" really be saying "Reset" or "Clear"?
======
23. src/backend/replication/logical/launcher.c - logicalrep_worker_launch
+ nparallelapplyworkers = logicalrep_parallel_apply_worker_count(subid);
+
+ /*
+ * Return silently if the number of parallel apply workers reached the
+ * limit per subscription.
+ */
+ if (is_subworker && nparallelapplyworkers >=
max_parallel_apply_workers_per_subscription)
+ {
+ LWLockRelease(LogicalRepWorkerLock);
+ return false;
}
I’m not sure if this is a good idea to be so silent. How will the user
know if they should increase the GUC parameter or not if it never
tells them that the value is too low?
~~~
24.
/* Now wait until it attaches. */
- WaitForReplicationWorkerAttach(worker, generation, bgw_handle);
+ return WaitForReplicationWorkerAttach(worker, generation, bgw_handle);
The comment feels a tiny bit misleading, because there is a chance
that this might not attach at all and return false if something goes
wrong.
~~~
25. src/backend/replication/logical/launcher.c - logicalrep_worker_stop
+void
+logicalrep_worker_stop_by_slot(int slot_no, uint16 generation)
+{
+ LogicalRepWorker *worker = &LogicalRepCtx->workers[slot_no];
+
+ LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
+
+ /* Return if the generation doesn't match or the worker is not alive. */
+ if (worker->generation != generation ||
+ worker->proc == NULL)
+ return;
+
+ logicalrep_worker_stop_internal(worker);
+
+ LWLockRelease(LogicalRepWorkerLock);
+}
I think this condition should be changed and reversed, otherwise you
might return before releasing the lock (??)
SUGGESTION
{
LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
/* Stop only if the worker is alive and the generation matches. */
if (worker && worker->proc && worker->generation == generation)
logicalrep_worker_stop_internal(worker);
LWLockRelease(LogicalRepWorkerLock);
}
~~~
26 src/backend/replication/logical/launcher.c - logicalrep_worker_stop_internal
+/*
+ * Workhorse for logicalrep_worker_stop() and logicalrep_worker_detach(). Stop
+ * the worker and wait for it to die.
+ */
... and logicalrep_worker_stop_by_slot()
~~~
27. src/backend/replication/logical/launcher.c - logicalrep_worker_detach
+ /*
+ * This is the leader apply worker; stop all the parallel apply workers
+ * previously started from here.
+ */
+ if (!isParallelApplyWorker(MyLogicalRepWorker))
27a.
The comment does not match the code. If this *is* the leader apply
worker then why do we have the condition to check that?
Maybe only needs a comment update like
SUGGESTION
If this is the leader apply worker then stop all the parallel...
~
27b.
Code seems also assuming it cannot be a tablesync worker but it is not
checking that. I am wondering if it will be better to have yet another
macro/inline to do isLeaderApplyWorker() that will make sure this
really is the leader apply worker. (This review comment suggestion is
repeated later below).
======
28. src/backend/replication/logical/worker.c - STREAMED TRANSACTIONS comment
+ * If no worker is available to handle the streamed transaction, the data is
+ * written to temporary files and then applied at once when the final commit
+ * arrives.
SUGGESTION
If streaming = true, or if streaming = parallel but there are not
parallel apply workers available to handle the streamed transaction,
the data is written to...
~~~
29. src/backend/replication/logical/worker.c - TransactionApplyAction
/*
* What action to take for the transaction.
*
* TA_APPLY_IN_LEADER_WORKER means that we are in the leader apply worker and
* changes of the transaction are applied directly in the worker.
*
* TA_SERIALIZE_TO_FILE means that we are in leader apply worker and changes
* are written to temporary files and then applied when the final commit
* arrives.
*
* TA_APPLY_IN_PARALLEL_WORKER means that we are in the parallel apply worker
* and changes of the transaction are applied directly in the worker.
*
* TA_SEND_TO_PARALLEL_WORKER means that we are in the leader apply worker and
* need to send the changes to the parallel apply worker.
*/
typedef enum
{
/* The action for non-streaming transactions. */
TA_APPLY_IN_LEADER_WORKER,
/* Actions for streaming transactions. */
TA_SERIALIZE_TO_FILE,
TA_APPLY_IN_PARALLEL_WORKER,
TA_SEND_TO_PARALLEL_WORKER
} TransactionApplyAction;
~
29a.
I think if you change all those enum names slightly (e.g. like below)
then they can be more self-explanatory:
TA_NOT_STREAMING_LEADER_APPLY
TA_STREAMING_LEADER_SERIALIZE
TA_STREAMING_LEADER_SEND_TO_PARALLEL
TA_STREAMING_PARALLEL_APPLY
~
29b.
* TA_APPLY_IN_LEADER_WORKER means that we are in the leader apply worker and
* changes of the transaction are applied directly in the worker.
Maybe that should mention this is for the non-streaming case, or if
you change all the enums names like in 29a. then there is no need
because it is more self-explanatory.
~~~
30. src/backend/replication/logical/worker.c - should_apply_changes_for_rel
* Note that for streaming transactions that are being applied in parallel
+ * apply worker, we disallow applying changes on a table that is not in
+ * the READY state, because we cannot decide whether to apply the change as we
+ * won't know remote_final_lsn by that time.
"applied in parallel apply worker" -> "applied in the parallel apply worker"
~~~
31.
+ errdetail("Cannot handle streamed replication transaction by parallel "
+ "apply workers until all tables are synchronized.")));
"by parallel apply workers" -> "using parallel apply workers" (?)
~~~
32. src/backend/replication/logical/worker.c - handle_streamed_transaction
Now that there is an apply_action enum I felt it is better for this
code to be using a switch instead of all the if/else. Furthermore, it
might be better to put the switch case in a logical order (e.g. same
as the suggested enums value order of #29a).
~~~
33. src/backend/replication/logical/worker.c - apply_handle_stream_prepare
(same as comment #32)
Now that there is an apply_action enum I felt it is better for this
code to be using a switch instead of all the if/else. Furthermore, it
might be better to put the switch case in a logical order (e.g. same
as the suggested enums value order of #29a).
~~~
34. src/backend/replication/logical/worker.c - apply_handle_stream_start
(same as comment #32)
Now that there is an apply_action enum I felt it is better for this
code to be using a switch instead of all the if/else. Furthermore, it
might be better to put the switch case in a logical order (e.g. same
as the suggested enums value order of #29a).
~~~
35.
+ else if (apply_action == TA_SERIALIZE_TO_FILE)
+ {
+ /*
+ * Notify handle methods we're processing a remote in-progress
+ * transaction.
+ */
+ in_streamed_transaction = true;
+
+ /*
+ * Since no parallel apply worker is available for the first
+ * stream start, serialize all the changes of the transaction.
+ *
"Since no parallel apply worker is available".
I don't think the comment is quite correct. Maybe it is doing the
serialization because the user simply did not request to use the
parallel mode at all?
~~~
36. src/backend/replication/logical/worker.c - apply_handle_stream_stop
(same as comment #32)
Now that there is an apply_action enum I felt it is better for this
code to be using a switch instead of all the if/else. Furthermore, it
might be better to put the switch case in a logical order (e.g. same
as the suggested enums value order of #29a).
~~~
37. src/backend/replication/logical/worker.c - apply_handle_stream_abort
+ /*
+ * Check whether the publisher sends abort_lsn and abort_time.
+ *
+ * Note that the paralle apply worker is only started when the publisher
+ * sends abort_lsn and abort_time.
+ */
typo "paralle"
~~~
38.
(same as comment #32)
Now that there is an apply_action enum I felt it is better for this
code to be using a switch instead of all the if/else. Furthermore, it
might be better to put the switch case in a logical order (e.g. same
as the suggested enums value order of #29a).
~~~
39.
+ /*
+ * Set in_parallel_apply_xact to true again as we only aborted the
+ * subtransaction and the top transaction is still in progress. No
+ * need to lock here because currently only the apply leader are
+ * accessing this flag.
+ */
"are accessing" -> "is accessing"
~~~
40. src/backend/replication/logical/worker.c - apply_handle_stream_commit
(same as comment #32)
Now that there is an apply_action enum I felt it is better for this
code to be using a switch instead of all the if/else. Furthermore, it
might be better to put the switch case in a logical order (e.g. same
as the suggested enums value order of #29a).
~~~
41. src/backend/replication/logical/worker.c - store_flush_position
+ /* Skip if not the leader apply worker */
+ if (am_parallel_apply_worker())
+ return;
+
Code might be better to implement/use a new function so it can check
something like !am_leader_apply_worker()
~~~
42. src/backend/replication/logical/worker.c - InitializeApplyWorker
+/*
+ * Initialize the database connection, in-memory subscription and necessary
+ * config options.
+ */
I still think this should mention that this is common initialization
code for "both leader apply workers, and parallel apply workers"
~~~
43. src/backend/replication/logical/worker.c - ApplyWorkerMain
- /* This is main apply worker */
+ /* This is leader apply worker */
"is leader" -> "is the leader"
~~~
44. src/backend/replication/logical/worker.c - IsLogicalParallelApplyWorker
+/*
+ * Is current process a logical replication parallel apply worker?
+ */
+bool
+IsLogicalParallelApplyWorker(void)
+{
+ return am_parallel_apply_worker();
+}
+
It seems a bit strange to have this function
IsLogicalParallelApplyWorker, and also am_parallel_apply_worker()
which are basically identical except one of them is static and one is
not.
I wonder if there should be just one function. And if you really do
need 2 names for consistency then you can just define a synonym like
#define am_parallel_apply_worker IsLogicalParallelApplyWorker
~~~
45. src/backend/replication/logical/worker.c - get_transaction_apply_action
+/*
+ * Return the action to take for the given transaction. Also return the
+ * parallel apply worker information if the action is
+ * TA_SEND_TO_PARALLEL_WORKER.
+ */
+static TransactionApplyAction
+get_transaction_apply_action(TransactionId xid,
ParallelApplyWorkerInfo **winfo)
I think this should be slightly more clear to say that *winfo is
assigned to the destination parallel worker info (if the action is
TA_SEND_TO_PARALLEL_WORKER), otherwise *winfo is assigned NULL (see
also #46 below)
~~~
46.
+static TransactionApplyAction
+get_transaction_apply_action(TransactionId xid,
ParallelApplyWorkerInfo **winfo)
+{
+ if (am_parallel_apply_worker())
+ return TA_APPLY_IN_PARALLEL_WORKER;
+ else if (in_remote_transaction)
+ return TA_APPLY_IN_LEADER_WORKER;
+
+ /*
+ * Check if we are processing this transaction using a parallel apply
+ * worker and if so, send the changes to that worker.
+ */
+ else if ((*winfo = parallel_apply_find_worker(xid)))
+ return TA_SEND_TO_PARALLEL_WORKER;
+ else
+ return TA_SERIALIZE_TO_FILE;
+}
The code is a bit quirky at the moment because sometimes the *winfo
will be assigned NULL and sometimes it will be assigned valid value,
and sometimes it will still be unassigned.
I suggest always assigning it either NULL or valid.
SUGGESTIONS
static TransactionApplyAction
get_transaction_apply_action(TransactionId xid, ParallelApplyWorkerInfo **winfo)
{
*winfo = NULL; <== add this default assignment
...
======
47. src/backend/storage/ipc/procsignal.c - procsignal_sigusr1_handler
@@ -657,6 +658,9 @@ procsignal_sigusr1_handler(SIGNAL_ARGS)
if (CheckProcSignal(PROCSIG_LOG_MEMORY_CONTEXT))
HandleLogMemoryContextInterrupt();
+ if (CheckProcSignal(PROCSIG_PARALLEL_APPLY_MESSAGE))
+ HandleParallelApplyMessageInterrupt();
+
I wasn’t sure about the placement of this new code because those
CheckProcSignal don’t seem to have any particular order. I think this
belongs adjacent to the PROCSIG_PARALLEL_MESSAGE since it has the most
in common with that one.
======
48. src/backend/tcop/postgres.c
@@ -3377,6 +3377,9 @@ ProcessInterrupts(void)
if (LogMemoryContextPending)
ProcessLogMemoryContextInterrupt();
+
+ if (ParallelApplyMessagePending)
+ HandleParallelApplyMessages();
(like #47)
I think this belongs adjacent to the ParallelMessagePending check
since it has most in common with that one.
======
49. src/include/replication/worker_internal.h
@@ -60,6 +64,12 @@ typedef struct LogicalRepWorker
*/
FileSet *stream_fileset;
+ /*
+ * PID of leader apply worker if this slot is used for a parallel apply
+ * worker, InvalidPid otherwise.
+ */
+ pid_t apply_leader_pid;
+
/* Stats. */
XLogRecPtr last_lsn;
TimestampTz last_send_time;
Whitespace indent of the new member ok?
~~~
50.
+typedef struct ParallelApplyWorkerShared
+{
+ slock_t mutex;
+
+ /*
+ * Flag used to ensure commit ordering.
+ *
+ * The parallel apply worker will set it to false after handling the
+ * transaction finish commands while the apply leader will wait for it to
+ * become false before proceeding in transaction finish commands (e.g.
+ * STREAM_COMMIT/STREAM_ABORT/STREAM_PREPARE).
+ */
+ bool in_parallel_apply_xact;
+
+ /* Information from the corresponding LogicalRepWorker slot. */
+ uint16 logicalrep_worker_generation;
+
+ int logicalrep_worker_slot_no;
+} ParallelApplyWorkerShared;
Whitespace indents of the new members ok?
~~~
51.
/* Main memory context for apply worker. Permanent during worker lifetime. */
extern PGDLLIMPORT MemoryContext ApplyContext;
+extern PGDLLIMPORT MemoryContext ApplyMessageContext;
Maybe there should be a blank line between those externs, because the
comment applies only to the first one, right? Alternatively modify the
comment.
~~~
52. src/include/replication/worker_internal.h - am_parallel_apply_worker
I thought it might be worthwhile to also add another function like
am_leader_apply_worker(). I noticed at least one place in this patch
where it could have been called.
SUGGESTION
static inline bool
am_parallel_apply_worker(void)
{
return !isParallelApplyWorker(MyLogicalRepWorker) && !am_tablesync_worker();
}
======
53. src/include/storage/procsignal.h
@@ -35,6 +35,7 @@ typedef enum
PROCSIG_WALSND_INIT_STOPPING, /* ask walsenders to prepare for shutdown */
PROCSIG_BARRIER, /* global barrier interrupt */
PROCSIG_LOG_MEMORY_CONTEXT, /* ask backend to log the memory contexts */
+ PROCSIG_PARALLEL_APPLY_MESSAGE, /* Message from parallel apply workers */
(like #47)
I think this new enum belongs adjacent to the PROCSIG_PARALLEL_MESSAGE
since it has most in common with that one
======
54. src/tools/pgindent/typedefs.list
Missing TransactionApplyAction?
------
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, September 9, 2022 3:02 PM Peter Smith <smithpb2250@gmail.com> wrote: > > Here are my review comments for the v28-0001 patch: > > (There may be some overlap with other people's review comments and/or > some fixes already made). > Thanks for the comments. > 3. > > max_logical_replication_workers (integer) > Specifies maximum number of logical replication workers. This > includes apply leader workers, parallel apply workers, and table > synchronization workers. > Logical replication workers are taken from the pool defined by > max_worker_processes. > The default value is 4. This parameter can only be set at server start. > > ~ > > I did not really understand why the default is 4. Because the default > tablesync workers is 2, and the default parallel workers is 2, but > what about accounting for the apply worker? Therefore, shouldn't > max_logical_replication_workers default be 5 instead of 4? The parallel apply is disabled by default, so it's not a must to increase this global default value as discussed[1] [1] https://www.postgresql.org/message-id/CAD21AoCwaU8SqjmC7UkKWNjDg3Uz4FDGurMpis3zw5SEC%2B27jQ%40mail.gmail.com > 6. src/backend/replication/logical/applyparallelworker.c > > Is there a reason why this file is called applyparallelworker.c > instead of parallelapplyworker.c? Now this name is out of step with > names of all the new typedefs etc. It was suggested which is consistent with the "vacuumparallel.c", but I am fine with either name. I can change this if more people think parallelapplyworker.c is better. > 16. src/backend/replication/logical/applyparallelworker.c - > parallel_apply_find_worker > > + /* Return the cached parallel apply worker if valid. */ > + if (stream_apply_worker != NULL) > + return stream_apply_worker; > > Perhaps 'cur_stream_parallel_apply_winfo' is a better name for this var? This looks a bit long to me. > /* Now wait until it attaches. */ > - WaitForReplicationWorkerAttach(worker, generation, bgw_handle); > + return WaitForReplicationWorkerAttach(worker, generation, bgw_handle); > > The comment feels a tiny bit misleading, because there is a chance > that this might not attach at all and return false if something goes > wrong. I feel it might be better to fix this via a separate patch. > Now that there is an apply_action enum I felt it is better for this > code to be using a switch instead of all the if/else. Furthermore, it > might be better to put the switch case in a logical order (e.g. same > as the suggested enums value order of #29a). I'm not sure whether switch case is better than if/else here. But if more people prefer, I can change this. > 23. src/backend/replication/logical/launcher.c - logicalrep_worker_launch > > + nparallelapplyworkers = logicalrep_parallel_apply_worker_count(subid); > + > + /* > + * Return silently if the number of parallel apply workers reached the > + * limit per subscription. > + */ > + if (is_subworker && nparallelapplyworkers >= > max_parallel_apply_workers_per_subscription) > + { > + LWLockRelease(LogicalRepWorkerLock); > + return false; > } > I’m not sure if this is a good idea to be so silent. How will the user > know if they should increase the GUC parameter or not if it never > tells them that the value is too low ? It's like what we do for table sync worker. Besides, I think user is likely to intentionally limit the parallel apply worker number to leave free workers for other purposes. And we do report a WARNING later if there is no free worker slots errmsg("out of logical replication worker slots"). > 41. src/backend/replication/logical/worker.c - store_flush_position > > + /* Skip if not the leader apply worker */ > + if (am_parallel_apply_worker()) > + return; > + > > Code might be better to implement/use a new function so it can check > something like !am_leader_apply_worker() Based on the existing code, both leader and table sync worker could enter this function. Using !am_leader_apply_worker() seems will disallow table sync worker to enter this function which might be not good although . > 47. src/backend/storage/ipc/procsignal.c - procsignal_sigusr1_handler > > @@ -657,6 +658,9 @@ procsignal_sigusr1_handler(SIGNAL_ARGS) > if (CheckProcSignal(PROCSIG_LOG_MEMORY_CONTEXT)) > HandleLogMemoryContextInterrupt(); > > + if (CheckProcSignal(PROCSIG_PARALLEL_APPLY_MESSAGE)) > + HandleParallelApplyMessageInterrupt(); > + > > I wasn’t sure about the placement of this new code because those > CheckProcSignal don’t seem to have any particular order. I think this > belongs adjacent to the PROCSIG_PARALLEL_MESSAGE since it has the most > in common with that one. I'm not very sure, I just followed the way we used to add new SignalReason (e.g. add the new reason at the last but before the Recovery conflict reasons). And the parallel apply is not very similar to parallel query in detail. > I thought it might be worthwhile to also add another function like > am_leader_apply_worker(). I noticed at least one place in this patch > where it could have been called. It seems a bit unnecessary to introduce a new macro where we already can use am_parallel_apply_worker to check. Best regards, Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Hou-san,
Thank you for updating the patch! Followings are comments for v28-0001.
I will dig your patch more, but I send partially to keep the activity of the thread.
===
For applyparallelworker.c
01. filename
The word-ordering of filename seems not good
because you defined the new worker as "parallel apply worker".
02. global variable
```
+/* Parallel apply workers hash table (initialized on first use). */
+static HTAB *ParallelApplyWorkersHash = NULL;
+
+/*
+ * List that stores the information of parallel apply workers that were
+ * started. Newly added worker information will be removed from the list at the
+ * end of the transaction when there are enough workers in the pool. Besides,
+ * exited workers will be removed from the list after being detected.
+ */
+static List *ParallelApplyWorkersList = NIL;
```
Could you add descriptions about difference between the list and hash table?
IIUC the Hash stores the parallel workers that
are assigned to transacitons, and the list stores all alive ones.
03. parallel_apply_find_worker
```
+ /* Return the cached parallel apply worker if valid. */
+ if (stream_apply_worker != NULL)
+ return stream_apply_worker;
```
This is just a question -
Why the given xid and the assigned xid to the worker are not checked here?
Is there chance to find wrong worker?
04. parallel_apply_start_worker
```
+/*
+ * Start a parallel apply worker that will be used for the specified xid.
+ *
+ * If a parallel apply worker is not in use then re-use it, otherwise start a
+ * fresh one. Cache the worker information in ParallelApplyWorkersHash keyed by
+ * the specified xid.
+ */
+void
+parallel_apply_start_worker(TransactionId xid)
```
"parallel_apply_start_worker" should be "start_parallel_apply_worker", I think
05. parallel_apply_stream_abort
```
for (i = list_length(subxactlist) - 1; i >= 0; i--)
{
xid = list_nth_xid(subxactlist, i);
if (xid == subxid)
{
found = true;
break;
}
}
```
Please not reuse the xid, declare and use another variable in the else block or something.
06. parallel_apply_free_worker
```
+ if (napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
+ {
```
Please add a comment like: "Do we have enough workers in the pool?" or something.
===
For worker.c
07. general
In many lines if-else statement is used for apply_action, but I think they should rewrite as switch-case statement.
08. global variable
```
-static bool in_streamed_transaction = false;
+bool in_streamed_transaction = false;
```
a.
It seems that in_streamed_transaction is used only in the worker.c, so we can change to stati variable.
b.
That flag is set only when an apply worker spill the transaction to the disk.
How about "in_streamed_transaction" -> "in_spilled_transaction"?
09. apply_handle_stream_prepare
```
- elog(DEBUG1, "received prepare for streamed transaction %u", prepare_data.xid);
```
I think this debug message is still useful.
10. apply_handle_stream_stop
```
+ if (apply_action == TA_APPLY_IN_PARALLEL_WORKER)
+ {
+ pgstat_report_activity(STATE_IDLEINTRANSACTION, NULL);
+ }
+ else if (apply_action == TA_SEND_TO_PARALLEL_WORKER)
+ {
```
The ordering of the STREAM {STOP, START} is checked only when an apply worker spill the transaction to the disk.
(This is done via in_streamed_transaction)
I think checks should be added here, like if (!stream_apply_worker) or something.
11. apply_handle_stream_abort
```
+ if (in_streamed_transaction)
+ ereport(ERROR,
+ (errcode(ERRCODE_PROTOCOL_VIOLATION),
+ errmsg_internal("STREAM ABORT message without STREAM STOP")));
```
I think the check by stream_apply_worker should be added.
12. apply_handle_stream_commit
a.
```
if (in_streamed_transaction)
ereport(ERROR,
(errcode(ERRCODE_PROTOCOL_VIOLATION),
errmsg_internal("STREAM COMMIT message without STREAM STOP")));
```
I think the check by stream_apply_worker should be added.
b.
```
- elog(DEBUG1, "received commit for streamed transaction %u", xid);
```
I think this debug message is still useful.
===
For launcher.c
13. logicalrep_worker_stop_by_slot
```
+ LogicalRepWorker *worker = &LogicalRepCtx->workers[slot_no];
+
+ LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
+
+ /* Return if the generation doesn't match or the worker is not alive. */
+ if (worker->generation != generation ||
+ worker->proc == NULL)
+ return;
+
```
a.
LWLockAcquire(LogicalRepWorkerLock) is needed before reading slots.
b.
LWLockRelease(LogicalRepWorkerLock) is needed even if worker is not found.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Sep 9, 2022 at 2:31 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Friday, September 9, 2022 3:02 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > 3. > > > > max_logical_replication_workers (integer) > > Specifies maximum number of logical replication workers. This > > includes apply leader workers, parallel apply workers, and table > > synchronization workers. > > Logical replication workers are taken from the pool defined by > > max_worker_processes. > > The default value is 4. This parameter can only be set at server start. > > > > ~ > > > > I did not really understand why the default is 4. Because the default > > tablesync workers is 2, and the default parallel workers is 2, but > > what about accounting for the apply worker? Therefore, shouldn't > > max_logical_replication_workers default be 5 instead of 4? > > The parallel apply is disabled by default, so it's not a must to increase this > global default value as discussed[1] > > [1] https://www.postgresql.org/message-id/CAD21AoCwaU8SqjmC7UkKWNjDg3Uz4FDGurMpis3zw5SEC%2B27jQ%40mail.gmail.com > Okay, but can we document to increase this value when the parallel apply is enabled? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Sep 9, 2022 at 12:32 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> 29. src/backend/replication/logical/worker.c - TransactionApplyAction
>
> /*
> * What action to take for the transaction.
> *
> * TA_APPLY_IN_LEADER_WORKER means that we are in the leader apply worker and
> * changes of the transaction are applied directly in the worker.
> *
> * TA_SERIALIZE_TO_FILE means that we are in leader apply worker and changes
> * are written to temporary files and then applied when the final commit
> * arrives.
> *
> * TA_APPLY_IN_PARALLEL_WORKER means that we are in the parallel apply worker
> * and changes of the transaction are applied directly in the worker.
> *
> * TA_SEND_TO_PARALLEL_WORKER means that we are in the leader apply worker and
> * need to send the changes to the parallel apply worker.
> */
> typedef enum
> {
> /* The action for non-streaming transactions. */
> TA_APPLY_IN_LEADER_WORKER,
>
> /* Actions for streaming transactions. */
> TA_SERIALIZE_TO_FILE,
> TA_APPLY_IN_PARALLEL_WORKER,
> TA_SEND_TO_PARALLEL_WORKER
> } TransactionApplyAction;
>
> ~
>
> 29a.
> I think if you change all those enum names slightly (e.g. like below)
> then they can be more self-explanatory:
>
> TA_NOT_STREAMING_LEADER_APPLY
> TA_STREAMING_LEADER_SERIALIZE
> TA_STREAMING_LEADER_SEND_TO_PARALLEL
> TA_STREAMING_PARALLEL_APPLY
>
> ~
>
I also think we can improve naming but adding streaming in the names
makes them slightly difficult to read. As you have suggested, it will
be better to add comments for streaming and non-streaming cases. How
about naming them as below:
typedef enum
{
TRANS_LEADER_APPLY
TRANS_LEADER_SERIALIZE
TRANS_LEADER_SEND_TO_PARALLEL
TRANS_PARALLEL_APPLY
} TransApplyAction;
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Sep 12, 2022 at 4:27 PM kuroda.hayato@fujitsu.com <kuroda.hayato@fujitsu.com> wrote: > > Dear Hou-san, > > Thank you for updating the patch! Followings are comments for v28-0001. > I will dig your patch more, but I send partially to keep the activity of the thread. > > === > For applyparallelworker.c > > 01. filename > The word-ordering of filename seems not good > because you defined the new worker as "parallel apply worker". > I think in the future we may have more files for apply work (like applyddl.c for DDL apply work), so it seems okay to name all apply related files in a similar way. > > === > For worker.c > > 07. general > > In many lines if-else statement is used for apply_action, but I think they should rewrite as switch-case statement. > Sounds reasonable to me. > 08. global variable > > ``` > -static bool in_streamed_transaction = false; > +bool in_streamed_transaction = false; > ``` > > a. > > It seems that in_streamed_transaction is used only in the worker.c, so we can change to stati variable. > Yeah, I don't know why it has been changed in the first place. > b. > > That flag is set only when an apply worker spill the transaction to the disk. > How about "in_streamed_transaction" -> "in_spilled_transaction"? > Isn't this an existing variable? If so, it doesn't seem like a good idea to change the name unless we are changing its meaning. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Hou-san,
> I will dig your patch more, but I send partially to keep the activity of the thread.
More minor comments about v28.
===
About 0002
For 015_stream.pl
14. check_parallel_log
```
+# Check the log that the streamed transaction was completed successfully
+# reported by parallel apply worker.
+sub check_parallel_log
+{
+ my ($node_subscriber, $offset, $is_parallel)= @_;
+ my $parallel_message = 'finished processing the transaction finish command';
+
+ if ($is_parallel)
+ {
+ $node_subscriber->wait_for_log(qr/$parallel_message/, $offset);
+ }
+}
```
I think check_parallel_log() should be called only when streaming = 'parallel' and if-statement is not needed
===
For 016_stream_subxact.pl
15. test_streaming
```
+ INSERT INTO test_tab SELECT i, md5(i::text) FROM generate_series( 3, 500) s(i);
```
" 3" should be "3".
===
About 0003
For applyparallelworker.c
16. parallel_apply_relation_check()
```
+ if (rel->parallel_apply_safe == PARALLEL_APPLY_SAFETY_UNKNOWN)
+ logicalrep_rel_mark_parallel_apply(rel);
```
I was not clear when logicalrep_rel_mark_parallel_apply() is called here.
IIUC parallel_apply_relation_check() is called when parallel apply worker handles changes,
but before that relation is opened via logicalrep_rel_open() and parallel_apply_safe is set here.
If it guards some protocol violation, we may use Assert().
===
For create_subscription.sgml
17.
The restriction about foreign key does not seem to be documented.
===
About 0004
For 015_stream.pl
18. check_parallel_log
I heard that the removal has been reverted, but in the patch
check_parallel_log() is removed again... :-(
===
About throughout
I checked the test coverage via `make coverage`. About appluparallelworker.c and worker.c, both function coverage is
100%,and
line coverages are 86.2 % and 94.5 %. Generally it's good.
But I read the report and following parts seems not tested.
In parallel_apply_start_worker():
```
if (tmp_winfo->error_mq_handle == NULL)
{
/*
* Release the worker information and try next one if the parallel
* apply worker exited cleanly.
*/
ParallelApplyWorkersList = foreach_delete_current(ParallelApplyWorkersList, lc);
shm_mq_detach(tmp_winfo->mq_handle);
dsm_detach(tmp_winfo->dsm_seg);
pfree(tmp_winfo);
}
```
In HandleParallelApplyMessage():
```
case 'X': /* Terminate, indicating clean exit */
{
shm_mq_detach(winfo->error_mq_handle);
winfo->error_mq_handle = NULL;
break;
}
```
Does it mean that we do not test the termination of parallel apply worker? If so I think it should be tested.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Hi, > > 01. filename > > The word-ordering of filename seems not good > > because you defined the new worker as "parallel apply worker". > > > > I think in the future we may have more files for apply work (like > applyddl.c for DDL apply work), so it seems okay to name all apply > related files in a similar way. > > That flag is set only when an apply worker spill the transaction to the disk. > > How about "in_streamed_transaction" -> "in_spilled_transaction"? > > > > Isn't this an existing variable? If so, it doesn't seem like a good > idea to change the name unless we are changing its meaning. Both of you said are reasonable. They do not have to be modified. Best Regards, Hayato Kuroda FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Thur, Sep 8, 2022 at 14:52 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > On Mon, Sep 5, 2022 at 6:34 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > Attach the correct patch set this time. > > > > Few comments on v28-0001*: Thanks for your comments. > 1. > + /* Whether the worker is processing a transaction. */ > + bool in_use; > > I think this same comment applies to in_parallel_apply_xact flag as > well. How about: "Indicates whether the worker is available to be used > for parallel apply transaction?"? > > 2. > + /* > + * Set this flag in the leader instead of the parallel apply worker to > + * avoid the race condition where the leader has already started waiting > + * for the parallel apply worker to finish processing the transaction(set > + * the in_parallel_apply_xact to false) while the child process has not yet > + * processed the first STREAM_START and has not set the > + * in_parallel_apply_xact to true. > > I think part of this comment "(set the in_parallel_apply_xact to > false)" is not necessary. It will be clear without that. > > 3. > + /* Create entry for requested transaction. */ > + entry = hash_search(ParallelApplyWorkersHash, &xid, HASH_ENTER, &found); > + if (found) > + elog(ERROR, "hash table corrupted"); > ... > ... > + hash_search(ParallelApplyWorkersHash, &xid, HASH_REMOVE, NULL); > > It is better to have a similar elog for HASH_REMOVE case as well. We > normally seem to have such elog for HASH_REMOVE. > > 4. > * Parallel apply is not supported when subscribing to a publisher which > + * cannot provide the abort_time, abort_lsn and the column information > used > + * to verify the parallel apply safety. > > > In this comment, which column information are you referring to? > > 5. > + /* > + * Set in_parallel_apply_xact to true again as we only aborted the > + * subtransaction and the top transaction is still in progress. No > + * need to lock here because currently only the apply leader are > + * accessing this flag. > + */ > + winfo->shared->in_parallel_apply_xact = true; > > This theory sounds good to me but I think it is better to update/read > this flag under spinlock as the patch is doing at a few other places. > I think that will make the code easier to follow without worrying too > much about such special cases. There are a few asserts as well which > read this without lock, it would be better to change those as well. > > 6. > + * LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM is the minimum > protocol version > + * with support for streaming large transactions using parallel apply > + * workers. Introduced in PG16. > > How about changing it to something like: > "LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM is the minimum > protocol > version where we support applying large streaming transactions in > parallel. Introduced in PG16." > > 7. > + PGOutputData *data = (PGOutputData *) ctx->output_plugin_private; > + bool write_abort_lsn = (data->protocol_version >= > + LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM); > > /* > * The abort should happen outside streaming block, even for streamed > @@ -1856,7 +1859,8 @@ pgoutput_stream_abort(struct > LogicalDecodingContext *ctx, > Assert(rbtxn_is_streamed(toptxn)); > > OutputPluginPrepareWrite(ctx, true); > - logicalrep_write_stream_abort(ctx->out, toptxn->xid, txn->xid); > + logicalrep_write_stream_abort(ctx->out, toptxn->xid, txn, abort_lsn, > + write_abort_lsn); > > I think we need to send additional information if the client has used > the parallel streaming option. Also, let's keep sending subxid as we > were doing previously and add additional parameters required. It may > be better to name write_abort_lsn as abort_info. > > 8. > + /* > + * Check whether the publisher sends abort_lsn and abort_time. > + * > + * Note that the paralle apply worker is only started when the publisher > + * sends abort_lsn and abort_time. > + */ > + if (am_parallel_apply_worker() || > + walrcv_server_version(LogRepWorkerWalRcvConn) >= 160000) > + read_abort_lsn = true; > + > + logicalrep_read_stream_abort(s, &abort_data, read_abort_lsn); > > This check should match with the check for the write operation where > we are checking the protocol version as well. There is a typo as well > in the comments (/paralle/parallel). Improved as suggested. Attach the new patch set. Regards, Wang wei
Attachment
- v29-0001-Perform-streaming-logical-transactions-by-parall.patch
- v29-0002-Test-streaming-parallel-option-in-tap-test.patch
- v29-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v29-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v29-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Thur, Sep 8, 2022 at 19:25 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > On Thu, Sep 8, 2022 at 12:21 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Mon, Sep 5, 2022 at 6:34 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > Attach the correct patch set this time. > > > > > > > Few comments on v28-0001*: > > ======================= > > > > Some suggestions for comments in v28-0001* Thanks for your comments and patch! > 1. > +/* > + * Entry for a hash table we use to map from xid to the parallel apply worker > + * state. > + */ > +typedef struct ParallelApplyWorkerEntry > > Let's change this comment to: "Hash table entry to map xid to the > parallel apply worker state." > > 2. > +/* > + * List that stores the information of parallel apply workers that were > + * started. Newly added worker information will be removed from the list at > the > + * end of the transaction when there are enough workers in the pool. Besides, > + * exited workers will be removed from the list after being detected. > + */ > +static List *ParallelApplyWorkersList = NIL; > > Can we change this to: "A list to maintain the active parallel apply > workers. The information for the new worker is added to the list after > successfully launching it. The list entry is removed at the end of the > transaction if there are already enough workers in the worker pool. > For more information about the worker pool, see comments atop > worker.c. We also remove the entry from the list if the worker is > exited due to some error." > > Apart from this, I have added/changed a few other comments in > v28-0001*. Kindly check the attached, if you are fine with it then > please include it in the next version. Improved as suggested. The new patches were attached in [1]. [1] - https://www.postgresql.org/message-id/OS3PR01MB6275F145878B4A44586C46CE9E499%40OS3PR01MB6275.jpnprd01.prod.outlook.com Regards, Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Fri, Sep 9, 2022 at 15:02 PM Peter Smith <smithpb2250@gmail.com> wrote:
> Here are my review comments for the v28-0001 patch:
>
> (There may be some overlap with other people's review comments and/or
> some fixes already made).
Thanks for your comments.
> 5. src/backend/libpq/pqmq.c
>
> + {
> + if (IsParallelWorker())
> + SendProcSignal(pq_mq_parallel_leader_pid,
> + PROCSIG_PARALLEL_MESSAGE,
> + pq_mq_parallel_leader_backend_id);
> + else
> + {
> + Assert(IsLogicalParallelApplyWorker());
> + SendProcSignal(pq_mq_parallel_leader_pid,
> + PROCSIG_PARALLEL_APPLY_MESSAGE,
> + pq_mq_parallel_leader_backend_id);
> + }
> + }
>
> This code can be simplified if you want to. For example,
>
> {
> ProcSignalReason reason;
> Assert(IsParallelWorker() || IsLogicalParallelApplyWorker());
> reason = IsParallelWorker() ? PROCSIG_PARALLEL_MESSAGE :
> PROCSIG_PARALLEL_APPLY_MESSAGE;
> SendProcSignal(pq_mq_parallel_leader_pid, reason,
> pq_mq_parallel_leader_backend_id);
> }
Not sure this would be better.
> 14.
>
> + /* Failed to start a new parallel apply worker. */
> + if (winfo == NULL)
> + return;
>
> There seem to be quite a lot of places (like this example) where
> something may go wrong and the behaviour apparently will just silently
> fall-back to using the non-parallel streaming. Maybe that is OK, but I
> am just wondering how can the user ever know this has happened? Maybe
> the docs can mention that this could happen and give some description
> of what processes users can look for (or some other strategy) so they
> can just confirm that the parallel streaming is really working like
> they assume it to be?
I think user could refer to the view pg_stat_subscription to check if the
parallel apply worker started.
BTW, we have documented the case if no parallel worker are available.
> 17. src/backend/replication/logical/applyparallelworker.c -
> parallel_apply_free_worker
>
> +/*
> + * Remove the parallel apply worker entry from the hash table. And stop the
> + * worker if there are enough workers in the pool.
> + */
> +void
> +parallel_apply_free_worker(ParallelApplyWorkerInfo *winfo, TransactionId
> xid)
>
> I think the reason for doing the "enough workers in the pool" logic
> needs some more explanation.
Because the process is always running, So stop it to reduce waste of resources.
> 19. src/backend/replication/logical/applyparallelworker.c -
> LogicalParallelApplyLoop
>
> + ApplyMessageContext = AllocSetContextCreate(ApplyContext,
> + "ApplyMessageContext",
> + ALLOCSET_DEFAULT_SIZES);
>
> Should the name of this context be "ParallelApplyMessageContext"?
I think it is okay to use "ApplyMessageContext" here just like "ApplyContext".
I will change this if more people have the same idea as you.
> 20. src/backend/replication/logical/applyparallelworker.c -
> HandleParallelApplyMessage
>
> + default:
> + {
> + elog(ERROR, "unrecognized message type received from parallel apply
> worker: %c (message length %d bytes)",
> + msgtype, msg->len);
> + }
>
> "received from" -> "received by"
>
> ~~~
>
>
> 21. src/backend/replication/logical/applyparallelworker.c -
> HandleParallelApplyMessages
>
> +/*
> + * Handle any queued protocol messages received from parallel apply workers.
> + */
> +void
> +HandleParallelApplyMessages(void)
>
> 21a.
> "received from" -> "received by"
>
> ~
>
> 21b.
> I wonder if this comment should give some credit to the function in
> parallel.c - because this seems almost a copy of all that code.
Since the message is from parallel apply worker to main apply worker, I think
"from" looks a little better.
> 27. src/backend/replication/logical/launcher.c - logicalrep_worker_detach
>
> + /*
> + * This is the leader apply worker; stop all the parallel apply workers
> + * previously started from here.
> + */
> + if (!isParallelApplyWorker(MyLogicalRepWorker))
>
> 27a.
> The comment does not match the code. If this *is* the leader apply
> worker then why do we have the condition to check that?
>
> Maybe only needs a comment update like
>
> SUGGESTION
> If this is the leader apply worker then stop all the parallel...
>
> ~
>
> 27b.
> Code seems also assuming it cannot be a tablesync worker but it is not
> checking that. I am wondering if it will be better to have yet another
> macro/inline to do isLeaderApplyWorker() that will make sure this
> really is the leader apply worker. (This review comment suggestion is
> repeated later below).
=>27a.
Improved as suggested.
=>27b.
Changed the if-statement to
`if (!am_parallel_apply_worker() && !am_tablesync_worker())`.
> 42. src/backend/replication/logical/worker.c - InitializeApplyWorker
>
> +/*
> + * Initialize the database connection, in-memory subscription and necessary
> + * config options.
> + */
>
> I still think this should mention that this is common initialization
> code for "both leader apply workers, and parallel apply workers"
I'm not sure about this. I will change this if more people have the same idea
as you.
> 44. src/backend/replication/logical/worker.c - IsLogicalParallelApplyWorker
>
> +/*
> + * Is current process a logical replication parallel apply worker?
> + */
> +bool
> +IsLogicalParallelApplyWorker(void)
> +{
> + return am_parallel_apply_worker();
> +}
> +
>
> It seems a bit strange to have this function
> IsLogicalParallelApplyWorker, and also am_parallel_apply_worker()
> which are basically identical except one of them is static and one is
> not.
>
> I wonder if there should be just one function. And if you really do
> need 2 names for consistency then you can just define a synonym like
>
> #define am_parallel_apply_worker IsLogicalParallelApplyWorker
I am not sure whether this will be better. But I can change this if more people
prefer.
> 49. src/include/replication/worker_internal.h
>
> @@ -60,6 +64,12 @@ typedef struct LogicalRepWorker
> */
> FileSet *stream_fileset;
>
> + /*
> + * PID of leader apply worker if this slot is used for a parallel apply
> + * worker, InvalidPid otherwise.
> + */
> + pid_t apply_leader_pid;
> +
> /* Stats. */
> XLogRecPtr last_lsn;
> TimestampTz last_send_time;
> Whitespace indent of the new member ok?
I will run pgindent later.
The rest of the comments are changed as suggested.
The new patches were attached in [1].
[1] -
https://www.postgresql.org/message-id/OS3PR01MB6275F145878B4A44586C46CE9E499%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Mon, Sep 12, 2022 at 18:58 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote:
> Dear Hou-san,
>
> Thank you for updating the patch! Followings are comments for v28-0001.
> I will dig your patch more, but I send partially to keep the activity of the thread.
Thanks for your comments.
> ===
> For applyparallelworker.c
>
> 01. filename
> The word-ordering of filename seems not good
> because you defined the new worker as "parallel apply worker".
As the Amit said, keep it consistent with other file name format.
> 02. global variable
>
> ```
> +/* Parallel apply workers hash table (initialized on first use). */
> +static HTAB *ParallelApplyWorkersHash = NULL;
> +
> +/*
> + * List that stores the information of parallel apply workers that were
> + * started. Newly added worker information will be removed from the list at
> the
> + * end of the transaction when there are enough workers in the pool. Besides,
> + * exited workers will be removed from the list after being detected.
> + */
> +static List *ParallelApplyWorkersList = NIL;
> ```
>
> Could you add descriptions about difference between the list and hash table?
> IIUC the Hash stores the parallel workers that
> are assigned to transacitons, and the list stores all alive ones.
Did some modifications to the comments above ParallelApplyWorkersList.
And I think we could know the difference between these two variables by
referring to the functions parallel_apply_start_worker and
parallel_apply_free_worker.
> 03. parallel_apply_find_worker
>
> ```
> + /* Return the cached parallel apply worker if valid. */
> + if (stream_apply_worker != NULL)
> + return stream_apply_worker;
> ```
>
> This is just a question -
> Why the given xid and the assigned xid to the worker are not checked here?
> Is there chance to find wrong worker?
I think it is okay to not check the worker's xid here.
Please refer to the comments above `stream_apply_worker`.
"stream_apply_worker" will only be returned during a stream block, which means
the xid is the same as the xid in the STREAM_START message.
> 04. parallel_apply_start_worker
>
> ```
> +/*
> + * Start a parallel apply worker that will be used for the specified xid.
> + *
> + * If a parallel apply worker is not in use then re-use it, otherwise start a
> + * fresh one. Cache the worker information in ParallelApplyWorkersHash
> keyed by
> + * the specified xid.
> + */
> +void
> +parallel_apply_start_worker(TransactionId xid)
> ```
>
> "parallel_apply_start_worker" should be "start_parallel_apply_worker", I think
For code readability, similar functions are named in this format:
`parallel_apply_.*_worker`.
> 05. parallel_apply_stream_abort
>
> ```
> for (i = list_length(subxactlist) - 1; i >= 0; i--)
> {
> xid = list_nth_xid(subxactlist, i);
> if (xid == subxid)
> {
> found = true;
> break;
> }
> }
> ```
>
> Please not reuse the xid, declare and use another variable in the else block or
> something.
Added a temporary variable "xid_tmp" inside the for-statement.
> 06. parallel_apply_free_worker
>
> ```
> + if (napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
> + {
> ```
>
> Please add a comment like: "Do we have enough workers in the pool?" or
> something.
Added the following comment according to your suggestion:
`Are there enough workers in the pool?`
> For worker.c
>
> 07. general
>
> In many lines if-else statement is used for apply_action, but I think they should
> rewrite as switch-case statement.
Changed.
> 08. global variable
>
> ```
> -static bool in_streamed_transaction = false;
> +bool in_streamed_transaction = false;
> ```
>
> a.
>
> It seems that in_streamed_transaction is used only in the worker.c, so we can
> change to stati variable.
>
> b.
>
> That flag is set only when an apply worker spill the transaction to the disk.
> How about "in_streamed_transaction" -> "in_spilled_transaction"?
=>8a.
Improved.
=>8b.
I am not sure if we could rename this existing variable for this. So I kept the
name.
> 09. apply_handle_stream_prepare
>
> ```
> - elog(DEBUG1, "received prepare for streamed transaction %u",
> prepare_data.xid);
> ```
>
> I think this debug message is still useful.
Since I think it is not appropriate to log the xid here, added back the
following message: `finished processing the transaction finish command`.
> 10. apply_handle_stream_stop
>
> ```
> + if (apply_action == TA_APPLY_IN_PARALLEL_WORKER)
> + {
> + pgstat_report_activity(STATE_IDLEINTRANSACTION, NULL);
> + }
> + else if (apply_action == TA_SEND_TO_PARALLEL_WORKER)
> + {
> ```
>
> The ordering of the STREAM {STOP, START} is checked only when an apply
> worker spill the transaction to the disk.
> (This is done via in_streamed_transaction)
> I think checks should be added here, like if (!stream_apply_worker) or
> something.
>
> 11. apply_handle_stream_abort
>
> ```
> + if (in_streamed_transaction)
> + ereport(ERROR,
> + (errcode(ERRCODE_PROTOCOL_VIOLATION),
> + errmsg_internal("STREAM ABORT message without STREAM
> STOP")));
> ```
>
> I think the check by stream_apply_worker should be added.
Because "in_streamed_transaction" is only used for non-parallel apply.
So I used stream_apply_worker to confirm the ordering of the STREAM {STOP,
START}.
BTW, I move the reset of in_streamed_transaction into the block of
`else if (apply_action == TA_SERIALIZE_TO_FILE)`.
> 12. apply_handle_stream_commit
>
> a.
>
> ```
> if (in_streamed_transaction)
> ereport(ERROR,
> (errcode(ERRCODE_PROTOCOL_VIOLATION),
> errmsg_internal("STREAM COMMIT message
> without STREAM STOP")));
> ```
>
> I think the check by stream_apply_worker should be added.
>
> b.
>
> ```
> - elog(DEBUG1, "received commit for streamed transaction %u", xid);
> ```
>
> I think this debug message is still useful.
=>12a.
See the reply to #10 && #11.
=>12b.
See the reply to #09.
> ===
> For launcher.c
>
> 13. logicalrep_worker_stop_by_slot
>
> ```
> + LogicalRepWorker *worker = &LogicalRepCtx->workers[slot_no];
> +
> + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> +
> + /* Return if the generation doesn't match or the worker is not alive. */
> + if (worker->generation != generation ||
> + worker->proc == NULL)
> + return;
> +
> ```
>
> a.
>
> LWLockAcquire(LogicalRepWorkerLock) is needed before reading slots.
>
> b.
>
> LWLockRelease(LogicalRepWorkerLock) is needed even if worker is not found.
Fixed.
The new patches were attached in [1].
[1] -
https://www.postgresql.org/message-id/OS3PR01MB6275F145878B4A44586C46CE9E499%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Tues, Sep 13, 2022 at 17:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > Thanks for your comments. > On Fri, Sep 9, 2022 at 2:31 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Friday, September 9, 2022 3:02 PM Peter Smith <smithpb2250@gmail.com> > wrote: > > > > > > > > 3. > > > > > > max_logical_replication_workers (integer) > > > Specifies maximum number of logical replication workers. This > > > includes apply leader workers, parallel apply workers, and table > > > synchronization workers. > > > Logical replication workers are taken from the pool defined by > > > max_worker_processes. > > > The default value is 4. This parameter can only be set at server start. > > > > > > ~ > > > > > > I did not really understand why the default is 4. Because the default > > > tablesync workers is 2, and the default parallel workers is 2, but > > > what about accounting for the apply worker? Therefore, shouldn't > > > max_logical_replication_workers default be 5 instead of 4? > > > > The parallel apply is disabled by default, so it's not a must to increase this > > global default value as discussed[1] > > > > [1] https://www.postgresql.org/message- > id/CAD21AoCwaU8SqjmC7UkKWNjDg3Uz4FDGurMpis3zw5SEC%2B27jQ%40mail > .gmail.com > > > > Okay, but can we document to increase this value when the parallel > apply is enabled? Add the following sentence in the chapter [31.10. Configuration Settings]: ``` In addition, if the subscription parameter <literal>streaming</literal> is set to <literal>parallel</literal>, please increase <literal>max_logical_replication_workers</literal> according to the desired number of parallel apply workers. ``` The new patches were attached in [1]. [1] - https://www.postgresql.org/message-id/OS3PR01MB6275F145878B4A44586C46CE9E499%40OS3PR01MB6275.jpnprd01.prod.outlook.com Regards, Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Wed, Sep 13, 2022 at 18:26 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
Thanks for your comments.
> On Fri, Sep 9, 2022 at 12:32 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > 29. src/backend/replication/logical/worker.c - TransactionApplyAction
> >
> > /*
> > * What action to take for the transaction.
> > *
> > * TA_APPLY_IN_LEADER_WORKER means that we are in the leader apply
> worker and
> > * changes of the transaction are applied directly in the worker.
> > *
> > * TA_SERIALIZE_TO_FILE means that we are in leader apply worker and
> changes
> > * are written to temporary files and then applied when the final commit
> > * arrives.
> > *
> > * TA_APPLY_IN_PARALLEL_WORKER means that we are in the parallel apply
> worker
> > * and changes of the transaction are applied directly in the worker.
> > *
> > * TA_SEND_TO_PARALLEL_WORKER means that we are in the leader apply
> worker and
> > * need to send the changes to the parallel apply worker.
> > */
> > typedef enum
> > {
> > /* The action for non-streaming transactions. */
> > TA_APPLY_IN_LEADER_WORKER,
> >
> > /* Actions for streaming transactions. */
> > TA_SERIALIZE_TO_FILE,
> > TA_APPLY_IN_PARALLEL_WORKER,
> > TA_SEND_TO_PARALLEL_WORKER
> > } TransactionApplyAction;
> >
> > ~
> >
> > 29a.
> > I think if you change all those enum names slightly (e.g. like below)
> > then they can be more self-explanatory:
> >
> > TA_NOT_STREAMING_LEADER_APPLY
> > TA_STREAMING_LEADER_SERIALIZE
> > TA_STREAMING_LEADER_SEND_TO_PARALLEL
> > TA_STREAMING_PARALLEL_APPLY
> >
> > ~
> >
>
> I also think we can improve naming but adding streaming in the names
> makes them slightly difficult to read. As you have suggested, it will
> be better to add comments for streaming and non-streaming cases. How
> about naming them as below:
>
> typedef enum
> {
> TRANS_LEADER_APPLY
> TRANS_LEADER_SERIALIZE
> TRANS_LEADER_SEND_TO_PARALLEL
> TRANS_PARALLEL_APPLY
> } TransApplyAction;
I think your suggestion looks good.
Improved as suggested.
The new patches were attached in [1].
[1] -
https://www.postgresql.org/message-id/OS3PR01MB6275F145878B4A44586C46CE9E499%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Tues, Sep 13, 2022 at 20:02 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote:
> Dear Hou-san,
>
> > I will dig your patch more, but I send partially to keep the activity of the thread.
>
> More minor comments about v28.
Thanks for your comments.
> ===
> About 0002
>
> For 015_stream.pl
>
> 14. check_parallel_log
>
> ```
> +# Check the log that the streamed transaction was completed successfully
> +# reported by parallel apply worker.
> +sub check_parallel_log
> +{
> + my ($node_subscriber, $offset, $is_parallel)= @_;
> + my $parallel_message = 'finished processing the transaction finish
> command';
> +
> + if ($is_parallel)
> + {
> + $node_subscriber->wait_for_log(qr/$parallel_message/, $offset);
> + }
> +}
> ```
>
> I think check_parallel_log() should be called only when streaming = 'parallel' and
> if-statement is not needed
I wanted to make the function test_streaming look simpler, so I put the
checking of the streaming option inside the function check_parallel_log.
> For 016_stream_subxact.pl
>
> 15. test_streaming
>
> ```
> + INSERT INTO test_tab SELECT i, md5(i::text) FROM generate_series( 3,
> 500) s(i);
> ```
>
> " 3" should be "3".
Improved.
> About 0003
>
> For applyparallelworker.c
>
> 16. parallel_apply_relation_check()
>
> ```
> + if (rel->parallel_apply_safe == PARALLEL_APPLY_SAFETY_UNKNOWN)
> + logicalrep_rel_mark_parallel_apply(rel);
> ```
>
> I was not clear when logicalrep_rel_mark_parallel_apply() is called here.
> IIUC parallel_apply_relation_check() is called when parallel apply worker
> handles changes,
> but before that relation is opened via logicalrep_rel_open() and
> parallel_apply_safe is set here.
> If it guards some protocol violation, we may use Assert().
Compared with the flag "localrelvalid", we also need to additionally reset the
flag "safety" when function and type are changed (see function
logicalrep_relmap_init). So I think for these two cases, we just need to reset
the flag "safety" to avoid rebuilding too much cache (see function
logicalrep_relmap_reset_parallel_cb).
> For create_subscription.sgml
>
> 17.
> The restriction about foreign key does not seem to be documented.
I removed the check for the foreign key.
Since foreign key does not take effect in the subscriber's apply worker by
default, it seems that foreign key does not hit this ERROR frequently.
If we set foreign key related trigger to "REPLICA", then, I think this flag
will be set to "unsafety" when checking non-immutable function uesd by trigger.
BTW, I only document this reason in the commit message and keep the foreign key
related tests.
> ===
> About 0004
>
> For 015_stream.pl
>
> 18. check_parallel_log
>
> I heard that the removal has been reverted, but in the patch
> check_parallel_log() is removed again... :-(
Yes, I removed it.
I think this will make the test unstable. Because after applying patch
0004, we could not sure whether the transaction is completed in a parallel
apply worker. If any unexpected error occurs, the test will fail because the
log cannot be found, even if the transaction completed successfully.
> ===
> About throughout
>
> I checked the test coverage via `make coverage`. About appluparallelworker.c
> and worker.c, both function coverage is 100%, and
> line coverages are 86.2 % and 94.5 %. Generally it's good.
> But I read the report and following parts seems not tested.
>
> In parallel_apply_start_worker():
>
> ```
> if (tmp_winfo->error_mq_handle == NULL)
> {
> /*
> * Release the worker information and try next one if
> the parallel
> * apply worker exited cleanly.
> */
> ParallelApplyWorkersList =
> foreach_delete_current(ParallelApplyWorkersList, lc);
> shm_mq_detach(tmp_winfo->mq_handle);
> dsm_detach(tmp_winfo->dsm_seg);
> pfree(tmp_winfo);
> }
> ```
>
> In HandleParallelApplyMessage():
>
> ```
> case 'X': /* Terminate, indicating
> clean exit */
> {
> shm_mq_detach(winfo->error_mq_handle);
> winfo->error_mq_handle = NULL;
> break;
> }
> ```
>
> Does it mean that we do not test the termination of parallel apply worker? If so I
> think it should be tested.
Since this is an unexpected situation that cannot be reproduced 100%, we did
not add tests related to this part of the code to improve coverage.
The new patches were attached in [1].
[1] -
https://www.postgresql.org/message-id/OS3PR01MB6275F145878B4A44586C46CE9E499%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"shiy.fnst@fujitsu.com"
Date:
On Thu, Sep 15, 2022 1:15 PM Wang, Wei/王 威 <wangw.fnst@fujitsu.com> wrote: > > Attach the new patch set. > Hi, I did some performance tests for "rollback to savepoint" cases, based on v28 patch. This test used synchronous logical replication, and compared SQL execution times before and after applying the patch. It tested different percentage of changes in the transaction are rolled back (use "rollback to savepoint"), when using different logical_decoding_work_mem. The test was performed ten times, and the average of the middle eight was taken. The results are as follows. The bar charts and the scripts of the test are attached. The steps to reproduce performance test are at the beginning of `start_pub.sh`. RESULT - rollback 10% (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 43.752 43.463 42.667 patched 32.646 30.941 31.491 Compare with HEAD -25.39% -28.81% -26.19% RESULT - rollback 20% (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 40.974 40.214 39.930 patched 28.114 28.055 27.550 Compare with HEAD -31.39% -30.23% -31.00% RESULT - rollback 30% (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 37.648 37.785 36.969 patched 29.554 29.389 27.398 Compare with HEAD -21.50% -22.22% -25.89% RESULT - rollback 50% (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 32.312 32.201 32.533 patched 30.238 30.244 27.903 Compare with HEAD -6.42% -6.08% -14.23% (If "Compare with HEAD" is a positive number, it means worse than HEAD; if it is a negative number, it means better than HEAD.) Summary: In general, when using "rollback to savepoint", the more the amount of data we need to rollback, the smaller the improvement compared to HEAD. But as such cases won't be often, this should be okay. Regards, Shi yu
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Sep 15, 2022 at 10:45 AM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> Attach the new patch set.
>
Review of v29-0001*
==================
1.
+parallel_apply_find_worker(TransactionId xid)
{
...
+ entry = hash_search(ParallelApplyWorkersHash, &xid, HASH_FIND, &found);
+ if (found)
+ {
+ /* If any workers (or the postmaster) have died, we have failed. */
+ if (entry->winfo->error_mq_handle == NULL)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("lost connection to parallel apply worker")));
...
}
I think the above comment is incorrect because if the postmaster would
have died then you wouldn't have found the entry in the hash table.
How about something like: "We can't proceed if the parallel streaming
worker has already exited."
2.
+/*
+ * Find the previously assigned worker for the given transaction, if any.
+ */
+ParallelApplyWorkerInfo *
+parallel_apply_find_worker(TransactionId xid)
No need to use word 'previously' in the above sentence.
3.
+ * We need one key to register the location of the header, and we need
+ * another key to track the location of the message queue.
+ */
+ shm_toc_initialize_estimator(&e);
+ shm_toc_estimate_chunk(&e, sizeof(ParallelApplyWorkerShared));
+ shm_toc_estimate_chunk(&e, queue_size);
+ shm_toc_estimate_chunk(&e, error_queue_size);
+
+ shm_toc_estimate_keys(&e, 3);
Overall, three keys are used but the comment indicates two. You forgot
to mention about error_queue.
4.
+ if (launched)
+ ParallelApplyWorkersList = lappend(ParallelApplyWorkersList, winfo);
+ else
+ {
+ shm_mq_detach(winfo->mq_handle);
+ shm_mq_detach(winfo->error_mq_handle);
+ dsm_detach(winfo->dsm_seg);
+ pfree(winfo);
+
+ winfo = NULL;
+ }
A. The code used in the else part to free worker info is the same as
what is used in parallel_apply_free_worker. Can we move this to a
separate function say parallel_apply_free_worker_info()?
B. I think it will be better if you use {} for if branch to make it
look consistent with else branch.
5.
+ * case define a named savepoint, so that we are able to commit/rollback it
+ * separately later.
+ */
+void
+parallel_apply_subxact_info_add(TransactionId current_xid)
I don't see the need of commit in the above message. So, we can
slightly modify it to: "... so that we are able to rollback to it
separately later."
6.
+ for (i = list_length(subxactlist) - 1; i >= 0; i--)
+ {
+ xid = list_nth_xid(subxactlist, i);
...
...
+/*
+ * Return the TransactionId value contained in the n'th element of the
+ * specified list.
+ */
+static inline TransactionId
+list_nth_xid(const List *list, int n)
+{
+ Assert(IsA(list, XidList));
+ return lfirst_xid(list_nth_cell(list, n));
+}
I am not really sure that we need a new list function to use for this
place. Can't we directly use lfirst_xid(list_nth_cell) instead?
7.
+void
+parallel_apply_replorigin_setup(void)
+{
+ RepOriginId originid;
+ char originname[NAMEDATALEN];
+ bool started_tx = false;
+
+ /* This function might be called inside or outside of transaction. */
+ if (!IsTransactionState())
+ {
+ StartTransactionCommand();
+ started_tx = true;
+ }
Is there a place in the patch where this function will be called
without having an active transaction state? If so, then this coding is
fine but if not, then I suggest keeping an assert for transaction
state here. The same thing applies to
parallel_apply_replorigin_reset() as well.
8.
+ *
+ * If write_abort_lsn is true, send the abort_lsn and abort_time fields,
+ * otherwise don't.
*/
void
logicalrep_write_stream_abort(StringInfo out, TransactionId xid,
- TransactionId subxid)
+ TransactionId subxid, XLogRecPtr abort_lsn,
+ TimestampTz abort_time, bool abort_info)
In the comment, the name of the variable needs to be updated.
9.
+TransactionId stream_xid = InvalidTransactionId;
-static TransactionId stream_xid = InvalidTransactionId;
...
...
+void
+parallel_apply_subxact_info_add(TransactionId current_xid)
+{
+ if (current_xid != stream_xid &&
+ !list_member_xid(subxactlist, current_xid))
It seems you have changed the scope of stream_xid to use it in
parallel_apply_subxact_info_add(). Won't it be better to pass it as a
parameter (say top_xid)?
10.
--- a/src/backend/replication/libpqwalreceiver/libpqwalreceiver.c
+++ b/src/backend/replication/libpqwalreceiver/libpqwalreceiver.c
@@ -20,6 +20,7 @@
#include <sys/time.h>
#include "access/xlog.h"
+#include "catalog/pg_subscription.h"
#include "catalog/pg_type.h"
#include "common/connect.h"
#include "funcapi.h"
@@ -443,9 +444,14 @@ libpqrcv_startstreaming(WalReceiverConn *conn,
appendStringInfo(&cmd, "proto_version '%u'",
options->proto.logical.proto_version);
- if (options->proto.logical.streaming &&
- PQserverVersion(conn->streamConn) >= 140000)
- appendStringInfoString(&cmd, ", streaming 'on'");
+ if (options->proto.logical.streaming != SUBSTREAM_OFF)
+ {
+ if (PQserverVersion(conn->streamConn) >= 160000 &&
+ options->proto.logical.streaming == SUBSTREAM_PARALLEL)
+ appendStringInfoString(&cmd, ", streaming 'parallel'");
+ else if (PQserverVersion(conn->streamConn) >= 140000)
+ appendStringInfoString(&cmd, ", streaming 'on'");
+ }
It doesn't seem like a good idea to expose subscription options here.
Can we think of having char *streaming_option instead of the current
streaming parameter which is filled by the caller and used here
directly?
11. The error message used in pgoutput_startup() seems to be better
than the current messages used in that function but it is better to be
consistent with other messages. There is a discussion in the email
thread [1] on improving those messages, so kindly suggest there.
12. In addition to the above, I have changed/added a few comments in
the attached patch.
[1] - https://www.postgresql.org/message-id/20220914.111507.13049297635620898.horikyota.ntt%40gmail.com
--
With Regards,
Amit Kapila.
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Thu, Sep 15, 2022 at 19:40 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Thu, Sep 15, 2022 at 10:45 AM wangw.fnst@fujitsu.com
> <wangw.fnst@fujitsu.com> wrote:
> >
> > Attach the new patch set.
> >
>
> Review of v29-0001*
Thanks for your comments and patch!
> ==================
> 1.
> +parallel_apply_find_worker(TransactionId xid)
> {
> ...
> + entry = hash_search(ParallelApplyWorkersHash, &xid, HASH_FIND, &found);
> + if (found)
> + {
> + /* If any workers (or the postmaster) have died, we have failed. */
> + if (entry->winfo->error_mq_handle == NULL)
> + ereport(ERROR,
> + (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("lost connection to parallel apply worker")));
> ...
> }
>
> I think the above comment is incorrect because if the postmaster would
> have died then you wouldn't have found the entry in the hash table.
> How about something like: "We can't proceed if the parallel streaming
> worker has already exited."
Fixed.
> 2.
> +/*
> + * Find the previously assigned worker for the given transaction, if any.
> + */
> +ParallelApplyWorkerInfo *
> +parallel_apply_find_worker(TransactionId xid)
>
> No need to use word 'previously' in the above sentence.
Improved.
> 3.
> + * We need one key to register the location of the header, and we need
> + * another key to track the location of the message queue.
> + */
> + shm_toc_initialize_estimator(&e);
> + shm_toc_estimate_chunk(&e, sizeof(ParallelApplyWorkerShared));
> + shm_toc_estimate_chunk(&e, queue_size);
> + shm_toc_estimate_chunk(&e, error_queue_size);
> +
> + shm_toc_estimate_keys(&e, 3);
>
> Overall, three keys are used but the comment indicates two. You forgot
> to mention about error_queue.
Fixed.
> 4.
> + if (launched)
> + ParallelApplyWorkersList = lappend(ParallelApplyWorkersList, winfo);
> + else
> + {
> + shm_mq_detach(winfo->mq_handle);
> + shm_mq_detach(winfo->error_mq_handle);
> + dsm_detach(winfo->dsm_seg);
> + pfree(winfo);
> +
> + winfo = NULL;
> + }
>
> A. The code used in the else part to free worker info is the same as
> what is used in parallel_apply_free_worker. Can we move this to a
> separate function say parallel_apply_free_worker_info()?
> B. I think it will be better if you use {} for if branch to make it
> look consistent with else branch.
Improved.
> 5.
> + * case define a named savepoint, so that we are able to commit/rollback it
> + * separately later.
> + */
> +void
> +parallel_apply_subxact_info_add(TransactionId current_xid)
>
> I don't see the need of commit in the above message. So, we can
> slightly modify it to: "... so that we are able to rollback to it
> separately later."
Improved.
> 6.
> + for (i = list_length(subxactlist) - 1; i >= 0; i--)
> + {
> + xid = list_nth_xid(subxactlist, i);
> ...
> ...
>
> +/*
> + * Return the TransactionId value contained in the n'th element of the
> + * specified list.
> + */
> +static inline TransactionId
> +list_nth_xid(const List *list, int n)
> +{
> + Assert(IsA(list, XidList));
> + return lfirst_xid(list_nth_cell(list, n));
> +}
>
> I am not really sure that we need a new list function to use for this
> place. Can't we directly use lfirst_xid(list_nth_cell) instead?
Improved.
> 7.
> +void
> +parallel_apply_replorigin_setup(void)
> +{
> + RepOriginId originid;
> + char originname[NAMEDATALEN];
> + bool started_tx = false;
> +
> + /* This function might be called inside or outside of transaction. */
> + if (!IsTransactionState())
> + {
> + StartTransactionCommand();
> + started_tx = true;
> + }
>
> Is there a place in the patch where this function will be called
> without having an active transaction state? If so, then this coding is
> fine but if not, then I suggest keeping an assert for transaction
> state here. The same thing applies to
> parallel_apply_replorigin_reset() as well.
When using parallel apply, only the parallel apply worker is in a transaction
while the leader apply worker is not. So when invoking function
parallel_apply_replorigin_setup() in the leader apply worker, we need to start
a transaction block.
> 8.
> + *
> + * If write_abort_lsn is true, send the abort_lsn and abort_time fields,
> + * otherwise don't.
> */
> void
> logicalrep_write_stream_abort(StringInfo out, TransactionId xid,
> - TransactionId subxid)
> + TransactionId subxid, XLogRecPtr abort_lsn,
> + TimestampTz abort_time, bool abort_info)
>
> In the comment, the name of the variable needs to be updated.
Fixed.
> 9.
> +TransactionId stream_xid = InvalidTransactionId;
>
> -static TransactionId stream_xid = InvalidTransactionId;
> ...
> ...
> +void
> +parallel_apply_subxact_info_add(TransactionId current_xid)
> +{
> + if (current_xid != stream_xid &&
> + !list_member_xid(subxactlist, current_xid))
>
> It seems you have changed the scope of stream_xid to use it in
> parallel_apply_subxact_info_add(). Won't it be better to pass it as a
> parameter (say top_xid)?
Improved.
> 10.
> --- a/src/backend/replication/libpqwalreceiver/libpqwalreceiver.c
> +++ b/src/backend/replication/libpqwalreceiver/libpqwalreceiver.c
> @@ -20,6 +20,7 @@
> #include <sys/time.h>
>
> #include "access/xlog.h"
> +#include "catalog/pg_subscription.h"
> #include "catalog/pg_type.h"
> #include "common/connect.h"
> #include "funcapi.h"
> @@ -443,9 +444,14 @@ libpqrcv_startstreaming(WalReceiverConn *conn,
> appendStringInfo(&cmd, "proto_version '%u'",
> options->proto.logical.proto_version);
>
> - if (options->proto.logical.streaming &&
> - PQserverVersion(conn->streamConn) >= 140000)
> - appendStringInfoString(&cmd, ", streaming 'on'");
> + if (options->proto.logical.streaming != SUBSTREAM_OFF)
> + {
> + if (PQserverVersion(conn->streamConn) >= 160000 &&
> + options->proto.logical.streaming == SUBSTREAM_PARALLEL)
> + appendStringInfoString(&cmd, ", streaming 'parallel'");
> + else if (PQserverVersion(conn->streamConn) >= 140000)
> + appendStringInfoString(&cmd, ", streaming 'on'");
> + }
>
> It doesn't seem like a good idea to expose subscription options here.
> Can we think of having char *streaming_option instead of the current
> streaming parameter which is filled by the caller and used here
> directly?
Improved.
> 11. The error message used in pgoutput_startup() seems to be better
> than the current messages used in that function but it is better to be
> consistent with other messages. There is a discussion in the email
> thread [1] on improving those messages, so kindly suggest there.
Okay, I will try to modify the two messages and share them in the thread you
mentioned.
> 12. In addition to the above, I have changed/added a few comments in
> the attached patch.
Improved as suggested.
Regards,
Wang wei
Attachment
- v30-0001-Perform-streaming-logical-transactions-by-parall.patch
- v30-0002-Test-streaming-parallel-option-in-tap-test.patch
- v30-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v30-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v30-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"shiy.fnst@fujitsu.com"
Date:
On Mon, Sept 19, 2022 11:26 AM Wang, Wei/王 威 <wangw.fnst@fujitsu.com> wrote:
>
>
> Improved as suggested.
>
Thanks for updating the patch. Here are some comments on 0001 patch.
1.
+ case TRANS_LEADER_SERIALIZE:
- oldctx = MemoryContextSwitchTo(ApplyContext);
+ /*
+ * Notify handle methods we're processing a remote in-progress
+ * transaction.
+ */
+ in_streamed_transaction = true;
- MyLogicalRepWorker->stream_fileset = palloc(sizeof(FileSet));
- FileSetInit(MyLogicalRepWorker->stream_fileset);
+ /*
+ * Since no parallel apply worker is used for the first stream
+ * start, serialize all the changes of the transaction.
+ *
+ * Start a transaction on stream start, this transaction will be
It seems that the following comment can be removed after using switch case.
+ * Since no parallel apply worker is used for the first stream
+ * start, serialize all the changes of the transaction.
2.
+ switch (apply_action)
+ {
+ case TRANS_LEADER_SERIALIZE:
+ if (!in_streamed_transaction)
+ ereport(ERROR,
+ (errcode(ERRCODE_PROTOCOL_VIOLATION),
+ errmsg_internal("STREAM STOP message without STREAM START")));
In apply_handle_stream_stop(), I think we can move this check to the beginning of
this function, to be consistent to other functions.
3. I think the some of the changes in 0005 patch can be merged to 0001 patch,
0005 patch can only contain the changes about new column 'apply_leader_pid'.
4.
+ * ParallelApplyWorkersList. After successfully, launching a new worker it's
+ * information is added to the ParallelApplyWorkersList. Once the worker
Should `it's` be `its` ?
Regards
Shi yu
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
FYI - The latest patch 30-0001 fails to apply, it seems due to a recent commit [1]. [postgres@CentOS7-x64 oss_postgres_misc]$ git apply ../patches_misc/v30-0001-Perform-streaming-logical-transactions-by-parall.patch error: patch failed: src/include/replication/logicalproto.h:246 error: src/include/replication/logicalproto.h: patch does not apply ------ [1] https://github.com/postgres/postgres/commit/bfcf1b34805f70df48eedeec237230d0cc1154a6 Kind Regards, Peter Smith. Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Tues, Sep 20, 2022 at 11:41 AM Shi, Yu/侍 雨 <shiy.fnst@cn.fujitsu.com> wrote:
> On Mon, Sept 19, 2022 11:26 AM Wang, Wei/王 威 <wangw.fnst@fujitsu.com>
> wrote:
> >
> >
> > Improved as suggested.
> >
>
> Thanks for updating the patch. Here are some comments on 0001 patch.
Thanks for your comments.
> 1.
> + case TRANS_LEADER_SERIALIZE:
>
> - oldctx = MemoryContextSwitchTo(ApplyContext);
> + /*
> + * Notify handle methods we're processing a remote in-
> progress
> + * transaction.
> + */
> + in_streamed_transaction = true;
>
> - MyLogicalRepWorker->stream_fileset = palloc(sizeof(FileSet));
> - FileSetInit(MyLogicalRepWorker->stream_fileset);
> + /*
> + * Since no parallel apply worker is used for the first
> stream
> + * start, serialize all the changes of the transaction.
> + *
> + * Start a transaction on stream start, this transaction will
> be
>
>
> It seems that the following comment can be removed after using switch case.
> + * Since no parallel apply worker is used for the first
> stream
> + * start, serialize all the changes of the transaction.
Removed.
> 2.
> + switch (apply_action)
> + {
> + case TRANS_LEADER_SERIALIZE:
> + if (!in_streamed_transaction)
> + ereport(ERROR,
> +
> (errcode(ERRCODE_PROTOCOL_VIOLATION),
> + errmsg_internal("STREAM STOP
> message without STREAM START")));
>
> In apply_handle_stream_stop(), I think we can move this check to the beginning
> of
> this function, to be consistent to other functions.
Improved as suggested.
> 3. I think the some of the changes in 0005 patch can be merged to 0001 patch,
> 0005 patch can only contain the changes about new column 'apply_leader_pid'.
Merged changes not related to 'apply_leader_pid' into patch 0001.
> 4.
> + * ParallelApplyWorkersList. After successfully, launching a new worker it's
> + * information is added to the ParallelApplyWorkersList. Once the worker
>
> Should `it's` be `its` ?
Fixed.
Attach the new patch set.
Regards,
Wang wei
Attachment
- v31-0001-Perform-streaming-logical-transactions-by-parall.patch
- v31-0002-Test-streaming-parallel-option-in-tap-test.patch
- v31-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v31-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v31-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
> FYI - > > The latest patch 30-0001 fails to apply, it seems due to a recent commit [1]. > > [postgres@CentOS7-x64 oss_postgres_misc]$ git apply > ../patches_misc/v30-0001-Perform-streaming-logical-transactions-by- > parall.patch > error: patch failed: src/include/replication/logicalproto.h:246 > error: src/include/replication/logicalproto.h: patch does not apply Thanks for your kindly reminder. I rebased the patch set and attached them in [1]. [1] - https://www.postgresql.org/message-id/OS3PR01MB6275298521AE1BBEF5A055EE9E4F9%40OS3PR01MB6275.jpnprd01.prod.outlook.com Regards, Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Wed, Sep 21, 2022 at 10:09 AM Wang, Wei/王 威 <wangw.fnst@fujitsu.com> wrote: > Attach the new patch set. Because of the changes in HEAD (a932824), the patch set could not be applied cleanly, so I rebase them. Attach the new patch set. Regards, Wang wei
Attachment
- v32-0001-Perform-streaming-logical-transactions-by-parall.patch
- v32-0002-Test-streaming-parallel-option-in-tap-test.patch
- v32-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v32-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v32-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for patch v30-0001.
======
1. Commit message
In addition, the patch extends the logical replication STREAM_ABORT message so
that abort_time and abort_lsn can also be sent which can be used to update the
replication origin in parallel apply worker when the streaming transaction is
aborted. Because this message extension is needed to support parallel
streaming, meaning that parallel streaming is not supported for publications on
servers < PG16.
"meaning that parallel streaming is not supported" -> "parallel
streaming is not supported"
======
2. doc/src/sgml/logical-replication.sgml
@@ -1611,8 +1622,12 @@ CONTEXT: processing remote data for
replication origin "pg_16395" during "INSER
to the subscriber, plus some reserve for table synchronization.
<varname>max_logical_replication_workers</varname> must be set to at least
the number of subscriptions, again plus some reserve for the table
- synchronization. Additionally the <varname>max_worker_processes</varname>
- may need to be adjusted to accommodate for replication workers, at least
+ synchronization. In addition, if the subscription parameter
+ <literal>streaming</literal> is set to <literal>parallel</literal>, please
+ increase <literal>max_logical_replication_workers</literal> according to
+ the desired number of parallel apply workers. Additionally the
+ <varname>max_worker_processes</varname> may need to be adjusted to
+ accommodate for replication workers, at least
(<varname>max_logical_replication_workers</varname>
+ <literal>1</literal>). Note that some extensions and parallel queries
also take worker slots from <varname>max_worker_processes</varname>.
IMO it looks a bit strange to have "In addition" followed by "Additionally".
Also, "to accommodate for replication workers"? seems like a typo (but
it is not caused by your patch)
BEFORE
In addition, if the subscription parameter streaming is set to
parallel, please increase max_logical_replication_workers according to
the desired number of parallel apply workers.
AFTER (???)
If the subscription parameter streaming is set to parallel,
max_logical_replication_workers should be increased according to the
desired number of parallel apply workers.
======
3. .../replication/logical/applyparallelworker.c - parallel_apply_can_start
+/*
+ * Returns true, if it is allowed to start a parallel apply worker, false,
+ * otherwise.
+ */
+static bool
+parallel_apply_can_start(TransactionId xid)
Seems a slightly complicated comment for a simple boolean function.
SUGGESTION
Returns true/false if it is OK to start a parallel apply worker.
======
4. .../replication/logical/applyparallelworker.c - parallel_apply_free_worker
+ winfo->in_use = false;
+
+ /* Are there enough workers in the pool? */
+ if (napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
+ {
I felt the comment/logic about "enough" needs a bit more description.
At least it should say to refer to the more detailed explanation atop
worker.c
======
5. .../replication/logical/applyparallelworker.c - parallel_apply_setup_dsm
+ /*
+ * Estimate how much shared memory we need.
+ *
+ * Because the TOC machinery may choose to insert padding of oddly-sized
+ * requests, we must estimate each chunk separately.
+ *
+ * We need one key to register the location of the header, and we need two
+ * other keys to track of the locations of the message queue and the error
+ * message queue.
+ */
"track of" -> "keep track of" ?
======
6. src/backend/replication/logical/launcher.c - logicalrep_worker_detach
logicalrep_worker_detach(void)
{
+ /* Stop the parallel apply workers. */
+ if (!am_parallel_apply_worker() && !am_tablesync_worker())
+ {
+ List *workers;
+ ListCell *lc;
The condition is not very obvious. This is why I previously suggested
adding another macro/function like 'isLeaderApplyWorker'. In the
absence of that, then I think the comment needs to be more
descriptive.
SUGGESTION
If this is the leader apply worker then stop the parallel apply workers.
======
7. src/backend/replication/logical/proto.c - logicalrep_read_stream_abort
void
logicalrep_write_stream_abort(StringInfo out, TransactionId xid,
- TransactionId subxid)
+ TransactionId subxid, XLogRecPtr abort_lsn,
+ TimestampTz abort_time, bool abort_info)
{
pq_sendbyte(out, LOGICAL_REP_MSG_STREAM_ABORT);
@@ -1175,19 +1179,40 @@ logicalrep_write_stream_abort(StringInfo out,
TransactionId xid,
/* transaction ID */
pq_sendint32(out, xid);
pq_sendint32(out, subxid);
+
+ if (abort_info)
+ {
+ pq_sendint64(out, abort_lsn);
+ pq_sendint64(out, abort_time);
+ }
The new param name 'abort_info' seems misleading.
Maybe a name like 'write_abort_info' is better?
~~~
8. src/backend/replication/logical/proto.c - logicalrep_read_stream_abort
+logicalrep_read_stream_abort(StringInfo in,
+ LogicalRepStreamAbortData *abort_data,
+ bool read_abort_lsn)
{
- Assert(xid && subxid);
+ Assert(abort_data);
+
+ abort_data->xid = pq_getmsgint(in, 4);
+ abort_data->subxid = pq_getmsgint(in, 4);
- *xid = pq_getmsgint(in, 4);
- *subxid = pq_getmsgint(in, 4);
+ if (read_abort_lsn)
+ {
+ abort_data->abort_lsn = pq_getmsgint64(in);
+ abort_data->abort_time = pq_getmsgint64(in);
+ }
This name 'read_abort_lsn' is inconsistent with the 'abort_info' of
the logicalrep_write_stream_abort.
I suggest change these to 'read_abort_info/write_abort_info'
======
9. src/backend/replication/logical/worker.c - file header comment
+ * information is added to the ParallelApplyWorkersList. Once the worker
+ * finishes applying the transaction, we mark it available for use. Now,
+ * before starting a new worker to apply the streaming transaction, we check
+ * the list and use any worker, if available. Note that we maintain a maximum
9a.
"available for use." -> "available for re-use."
~
9b.
"we check the list and use any worker, if available" -> "we check the
list for any available worker"
~~~
10. src/backend/replication/logical/worker.c - handle_streamed_transaction
+ /* write the change to the current file */
+ stream_write_change(action, s);
+ return true;
Uppercase the comment.
~~~
11. src/backend/replication/logical/worker.c - apply_handle_stream_abort
+static void
+apply_handle_stream_abort(StringInfo s)
+{
+ TransactionId xid;
+ TransactionId subxid;
+ LogicalRepStreamAbortData abort_data;
+ bool read_abort_lsn = false;
+ ParallelApplyWorkerInfo *winfo = NULL;
+ TransApplyAction apply_action;
The variable 'read_abort_lsn' name ought to be changed to match
consistently the parameter name.
======
12. src/backend/replication/pgoutput/pgoutput.c - pgoutput_stream_abort
@@ -1843,6 +1850,8 @@ pgoutput_stream_abort(struct LogicalDecodingContext *ctx,
XLogRecPtr abort_lsn)
{
ReorderBufferTXN *toptxn;
+ PGOutputData *data = (PGOutputData *) ctx->output_plugin_private;
+ bool abort_info = (data->streaming == SUBSTREAM_PARALLEL);
The variable 'abort_info' name ought to be changed to be
'write_abort_info' (as suggested above) to match consistently the
parameter name.
======
13. src/include/replication/worker_internal.h
+ /*
+ * Indicates whether the worker is available to be used for parallel apply
+ * transaction?
+ */
+ bool in_use;
This comment seems backward for this member's name.
SUGGESTION (something like...)
Indicates whether this ParallelApplyWorkerInfo is currently being used
by a parallel apply worker processing a transaction. (If this flag is
false then it means the ParallelApplyWorkerInfo is available for
re-use by another parallel apply worker.)
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Sep 21, 2022 at 2:55 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> ======
>
> 3. .../replication/logical/applyparallelworker.c - parallel_apply_can_start
>
> +/*
> + * Returns true, if it is allowed to start a parallel apply worker, false,
> + * otherwise.
> + */
> +static bool
> +parallel_apply_can_start(TransactionId xid)
>
> Seems a slightly complicated comment for a simple boolean function.
>
> SUGGESTION
> Returns true/false if it is OK to start a parallel apply worker.
>
I think this is the style followed at some other places as well. So,
we can leave it.
>
> 6. src/backend/replication/logical/launcher.c - logicalrep_worker_detach
>
> logicalrep_worker_detach(void)
> {
> + /* Stop the parallel apply workers. */
> + if (!am_parallel_apply_worker() && !am_tablesync_worker())
> + {
> + List *workers;
> + ListCell *lc;
>
> The condition is not very obvious. This is why I previously suggested
> adding another macro/function like 'isLeaderApplyWorker'.
>
How about having function a function am_leader_apply_worker() { ...
return OidIsValid(MyLogicalRepWorker->relid) &&
(MyLogicalRepWorker->apply_leader_pid == InvalidPid) ...}?
>
> 13. src/include/replication/worker_internal.h
>
> + /*
> + * Indicates whether the worker is available to be used for parallel apply
> + * transaction?
> + */
> + bool in_use;
>
> This comment seems backward for this member's name.
>
> SUGGESTION (something like...)
> Indicates whether this ParallelApplyWorkerInfo is currently being used
> by a parallel apply worker processing a transaction. (If this flag is
> false then it means the ParallelApplyWorkerInfo is available for
> re-use by another parallel apply worker.)
>
I am not sure if this is an improvement over the current. The current
comment appears reasonable to me as it is easy to follow.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Wed, Sep 21, 2022 at 17:25 PM Peter Smith <smithpb2250@gmail.com> wrote:
> Here are some review comments for patch v30-0001.
Thanks for your comments.
> ======
>
> 1. Commit message
>
> In addition, the patch extends the logical replication STREAM_ABORT message
> so
> that abort_time and abort_lsn can also be sent which can be used to update the
> replication origin in parallel apply worker when the streaming transaction is
> aborted. Because this message extension is needed to support parallel
> streaming, meaning that parallel streaming is not supported for publications on
> servers < PG16.
>
> "meaning that parallel streaming is not supported" -> "parallel
> streaming is not supported"
Improved as suggested.
> ======
>
> 2. doc/src/sgml/logical-replication.sgml
>
> @@ -1611,8 +1622,12 @@ CONTEXT: processing remote data for
> replication origin "pg_16395" during "INSER
> to the subscriber, plus some reserve for table synchronization.
> <varname>max_logical_replication_workers</varname> must be set to at
> least
> the number of subscriptions, again plus some reserve for the table
> - synchronization. Additionally the
> <varname>max_worker_processes</varname>
> - may need to be adjusted to accommodate for replication workers, at least
> + synchronization. In addition, if the subscription parameter
> + <literal>streaming</literal> is set to <literal>parallel</literal>, please
> + increase <literal>max_logical_replication_workers</literal> according to
> + the desired number of parallel apply workers. Additionally the
> + <varname>max_worker_processes</varname> may need to be adjusted to
> + accommodate for replication workers, at least
> (<varname>max_logical_replication_workers</varname>
> + <literal>1</literal>). Note that some extensions and parallel queries
> also take worker slots from <varname>max_worker_processes</varname>.
>
> IMO it looks a bit strange to have "In addition" followed by "Additionally".
>
> Also, "to accommodate for replication workers"? seems like a typo (but
> it is not caused by your patch)
>
> BEFORE
> In addition, if the subscription parameter streaming is set to
> parallel, please increase max_logical_replication_workers according to
> the desired number of parallel apply workers.
>
> AFTER (???)
> If the subscription parameter streaming is set to parallel,
> max_logical_replication_workers should be increased according to the
> desired number of parallel apply workers.
=> Reword
Improved as suggested.
=> typo?
Sorry, I am not sure. Do you mean
s/replication workers/workers for subscriptions/ or something else?
I think we should improve it in a new thread.
> ======
>
> 4. .../replication/logical/applyparallelworker.c - parallel_apply_free_worker
>
> + winfo->in_use = false;
> +
> + /* Are there enough workers in the pool? */
> + if (napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
> + {
>
> I felt the comment/logic about "enough" needs a bit more description.
> At least it should say to refer to the more detailed explanation atop
> worker.c
Added related comment atop this function.
> ======
>
> 5. .../replication/logical/applyparallelworker.c - parallel_apply_setup_dsm
>
> + /*
> + * Estimate how much shared memory we need.
> + *
> + * Because the TOC machinery may choose to insert padding of oddly-sized
> + * requests, we must estimate each chunk separately.
> + *
> + * We need one key to register the location of the header, and we need two
> + * other keys to track of the locations of the message queue and the error
> + * message queue.
> + */
>
> "track of" -> "keep track of" ?
Improved.
> ======
>
> 6. src/backend/replication/logical/launcher.c - logicalrep_worker_detach
>
> logicalrep_worker_detach(void)
> {
> + /* Stop the parallel apply workers. */
> + if (!am_parallel_apply_worker() && !am_tablesync_worker())
> + {
> + List *workers;
> + ListCell *lc;
>
> The condition is not very obvious. This is why I previously suggested
> adding another macro/function like 'isLeaderApplyWorker'. In the
> absence of that, then I think the comment needs to be more
> descriptive.
>
> SUGGESTION
> If this is the leader apply worker then stop the parallel apply workers.
Added the new function am_leader_apply_worker.
> ======
>
> 7. src/backend/replication/logical/proto.c - logicalrep_read_stream_abort
>
> void
> logicalrep_write_stream_abort(StringInfo out, TransactionId xid,
> - TransactionId subxid)
> + TransactionId subxid, XLogRecPtr abort_lsn,
> + TimestampTz abort_time, bool abort_info)
> {
> pq_sendbyte(out, LOGICAL_REP_MSG_STREAM_ABORT);
>
> @@ -1175,19 +1179,40 @@ logicalrep_write_stream_abort(StringInfo out,
> TransactionId xid,
> /* transaction ID */
> pq_sendint32(out, xid);
> pq_sendint32(out, subxid);
> +
> + if (abort_info)
> + {
> + pq_sendint64(out, abort_lsn);
> + pq_sendint64(out, abort_time);
> + }
>
>
> The new param name 'abort_info' seems misleading.
>
> Maybe a name like 'write_abort_info' is better?
Improved as suggested.
> ~~~
>
> 8. src/backend/replication/logical/proto.c - logicalrep_read_stream_abort
>
> +logicalrep_read_stream_abort(StringInfo in,
> + LogicalRepStreamAbortData *abort_data,
> + bool read_abort_lsn)
> {
> - Assert(xid && subxid);
> + Assert(abort_data);
> +
> + abort_data->xid = pq_getmsgint(in, 4);
> + abort_data->subxid = pq_getmsgint(in, 4);
>
> - *xid = pq_getmsgint(in, 4);
> - *subxid = pq_getmsgint(in, 4);
> + if (read_abort_lsn)
> + {
> + abort_data->abort_lsn = pq_getmsgint64(in);
> + abort_data->abort_time = pq_getmsgint64(in);
> + }
>
> This name 'read_abort_lsn' is inconsistent with the 'abort_info' of
> the logicalrep_write_stream_abort.
>
> I suggest change these to 'read_abort_info/write_abort_info'
Improved as suggested.
> ======
>
> 9. src/backend/replication/logical/worker.c - file header comment
>
> + * information is added to the ParallelApplyWorkersList. Once the worker
> + * finishes applying the transaction, we mark it available for use. Now,
> + * before starting a new worker to apply the streaming transaction, we check
> + * the list and use any worker, if available. Note that we maintain a maximum
>
> 9a.
> "available for use." -> "available for re-use."
>
> ~
>
> 9b.
> "we check the list and use any worker, if available" -> "we check the
> list for any available worker"
Improved as suggested.
> ~~~
>
> 10. src/backend/replication/logical/worker.c - handle_streamed_transaction
>
> + /* write the change to the current file */
> + stream_write_change(action, s);
> + return true;
>
> Uppercase the comment.
Improved as suggested.
> ~~~
>
> 11. src/backend/replication/logical/worker.c - apply_handle_stream_abort
>
> +static void
> +apply_handle_stream_abort(StringInfo s)
> +{
> + TransactionId xid;
> + TransactionId subxid;
> + LogicalRepStreamAbortData abort_data;
> + bool read_abort_lsn = false;
> + ParallelApplyWorkerInfo *winfo = NULL;
> + TransApplyAction apply_action;
>
> The variable 'read_abort_lsn' name ought to be changed to match
> consistently the parameter name.
Improved as suggested.
> ======
>
> 12. src/backend/replication/pgoutput/pgoutput.c - pgoutput_stream_abort
>
> @@ -1843,6 +1850,8 @@ pgoutput_stream_abort(struct
> LogicalDecodingContext *ctx,
> XLogRecPtr abort_lsn)
> {
> ReorderBufferTXN *toptxn;
> + PGOutputData *data = (PGOutputData *) ctx->output_plugin_private;
> + bool abort_info = (data->streaming == SUBSTREAM_PARALLEL);
>
> The variable 'abort_info' name ought to be changed to be
> 'write_abort_info' (as suggested above) to match consistently the
> parameter name.
Improved as suggested.
Attach the new patch set.
Regards,
Wang wei
Attachment
- v33-0001-Perform-streaming-logical-transactions-by-parall.patch
- v33-0002-Test-streaming-parallel-option-in-tap-test.patch
- v33-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v33-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v33-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Wang,
Thanks for updating the patch! Followings are comments for v33-0001.
===
libpqwalreceiver.c
01. inclusion
```
+#include "catalog/pg_subscription.h"
```
We don't have to include it because the analysis of parameters is done at caller.
===
launcher.c
02. logicalrep_worker_launch()
```
+ /*
+ * Return silently if the number of parallel apply workers reached the
+ * limit per subscription.
+ */
+ if (is_subworker && nparallelapplyworkers >= max_parallel_apply_workers_per_subscription)
```
a.
I felt that it might be kind if we output some debug messages.
b.
The if statement seems to be more than 80 characters. You can move to new line around "nparallelapplyworkers >= ...".
===
applyparallelworker.c
03. declaration
```
+/*
+ * Is there a message pending in parallel apply worker which we need to
+ * receive?
+ */
+volatile bool ParallelApplyMessagePending = false;
```
I checked other flags that are set by signal handlers, their datatype seemed to be sig_atomic_t.
Is there any reasons that you use normal bool? It should be changed if not.
04. HandleParallelApplyMessages()
```
+ if (winfo->error_mq_handle == NULL)
+ continue;
```
a.
I was not sure when the cell should be cleaned. Currently we clean up ParallelApplyWorkersList() only in the
parallel_apply_start_worker(),
but we have chances to remove such a cell like HandleParallelApplyMessages() or HandleParallelApplyMessage(). How do
youthink?
b.
Comments should be added even if we keep this, like "exited worker, skipped".
```
+ else
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("lost connection to the leader apply worker")));
```
c.
This function is called on the leader apply worker, so the hint should be "lost connection to the parallel apply
worker".
05. parallel_apply_setup_worker()
``
+ if (launched)
+ {
+ ParallelApplyWorkersList = lappend(ParallelApplyWorkersList, winfo);
+ }
```
{} should be removed.
06. parallel_apply_wait_for_xact_finish()
```
+ /* If any workers have died, we have failed. */
```
This function checked only about a parallel apply worker, so the comment should be "if worker has..."?
===
worker.c
07. handle_streamed_transaction()
```
+ * For non-streamed transactions, returns false;
```
"returns false;" -> "returns false"
apply_handle_commit_prepared(), apply_handle_abort_prepared()
These functions are not expected that parallel worker calls
so I think Assert() should be added.
08. UpdateWorkerStats()
```
-static void
+void
UpdateWorkerStats(XLogRecPtr last_lsn, TimestampTz send_time, bool reply)
```
This function is called only in worker.c, should be static.
09. subscription_change_cb()
```
-static void
+void
subscription_change_cb(Datum arg, int cacheid, uint32 hashvalue)
```
This function is called only in worker.c, should be static.
10. InitializeApplyWorker()
```
+/*
+ * Initialize the database connection, in-memory subscription and necessary
+ * config options.
+ */
void
-ApplyWorkerMain(Datum main_arg)
+InitializeApplyWorker(void)
```
Some comments should be added about this is a common part of leader and parallel apply worker.
===
logicalrepworker.h
11. declaration
```
extern PGDLLIMPORT volatile bool ParallelApplyMessagePending;
```
Please refer above comment.
===
guc_tables.c
12. ConfigureNamesInt
```
+ {
+ {"max_parallel_apply_workers_per_subscription",
+ PGC_SIGHUP,
+ REPLICATION_SUBSCRIBERS,
+ gettext_noop("Maximum number of parallel apply workers per subscription."),
+ NULL,
+ },
+ &max_parallel_apply_workers_per_subscription,
+ 2, 0, MAX_BACKENDS,
+ NULL, NULL, NULL
+ },
```
This parameter can be changed by pg_ctl reload, so the following corner case may be occurred.
Should we add a assign hook to handle this? Or, can we ignore it?
1. set max_parallel_apply_workers_per_subscription to 4.
2. start replicating two streaming transactions.
3. commit transactions
=== Two parallel workers will be remained ===
4. change max_parallel_apply_workers_per_subscription to 3
5. We expected that only one worker remains, but two parallel workers remained.
It will be not stopped until another streamed transaction is started and committed.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, September 22, 2022 4:08 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote:
>
> Thanks for updating the patch! Followings are comments for v33-0001.
Thanks for the comments.
> 04. HandleParallelApplyMessages()
>
> ```
> + if (winfo->error_mq_handle == NULL)
> + continue;
> ```
>
> a.
> I was not sure when the cell should be cleaned. Currently we clean up
> ParallelApplyWorkersList() only in the parallel_apply_start_worker(), but we
> have chances to remove such a cell like HandleParallelApplyMessages() or
> HandleParallelApplyMessage(). How do you think?
HandleParallelApplyxx functions are signal callback functions which I think
are unsafe to cleanup the list cells that may be in use before entering
these signal callback functions.
>
> 05. parallel_apply_setup_worker()
>
> ``
> + if (launched)
> + {
> + ParallelApplyWorkersList = lappend(ParallelApplyWorkersList,
> winfo);
> + }
> ```
>
> {} should be removed.
I think this style is fine and this was also suggested to be consistent with the
else{} part.
>
> 06. parallel_apply_wait_for_xact_finish()
>
> ```
> + /* If any workers have died, we have failed. */
> ```
>
> This function checked only about a parallel apply worker, so the comment
> should be "if worker has..."?
The comments seem clear to me as it's a general comment.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Sep 22, 2022 at 1:37 PM kuroda.hayato@fujitsu.com
<kuroda.hayato@fujitsu.com> wrote:
>
> ===
> applyparallelworker.c
>
> 03. declaration
>
> ```
> +/*
> + * Is there a message pending in parallel apply worker which we need to
> + * receive?
> + */
> +volatile bool ParallelApplyMessagePending = false;
> ```
>
> I checked other flags that are set by signal handlers, their datatype seemed to be sig_atomic_t.
> Is there any reasons that you use normal bool? It should be changed if not.
>
It follows the logic similar to ParallelMessagePending. Do you see any
problem with it?
> 04. HandleParallelApplyMessages()
>
> ```
> + if (winfo->error_mq_handle == NULL)
> + continue;
> ```
>
> a.
> I was not sure when the cell should be cleaned. Currently we clean up ParallelApplyWorkersList() only in the
parallel_apply_start_worker(),
> but we have chances to remove such a cell like HandleParallelApplyMessages() or HandleParallelApplyMessage(). How do
youthink?
>
Note that HandleParallelApply* are invoked during interrupt handling,
so it may not be advisable to remove it there.
>
> 12. ConfigureNamesInt
>
> ```
> + {
> + {"max_parallel_apply_workers_per_subscription",
> + PGC_SIGHUP,
> + REPLICATION_SUBSCRIBERS,
> + gettext_noop("Maximum number of parallel apply workers per subscription."),
> + NULL,
> + },
> + &max_parallel_apply_workers_per_subscription,
> + 2, 0, MAX_BACKENDS,
> + NULL, NULL, NULL
> + },
> ```
>
> This parameter can be changed by pg_ctl reload, so the following corner case may be occurred.
> Should we add a assign hook to handle this? Or, can we ignore it?
>
I think we can ignore this as it will eventually start respecting the threshold.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Sep 22, 2022 at 8:59 AM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
Few comments on v33-0001
=======================
1.
+ else if (data->streaming == SUBSTREAM_PARALLEL &&
+ data->protocol_version < LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM)
+ ereport(ERROR,
+ (errcode(ERRCODE_INVALID_PARAMETER_VALUE),
+ errmsg("requested proto_version=%d does not support
streaming=parallel mode, need %d or higher",
+ data->protocol_version, LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM)));
I think we can improve this error message as: "requested
proto_version=%d does not support parallel streaming mode, need %d or
higher".
2.
--- a/doc/src/sgml/monitoring.sgml
+++ b/doc/src/sgml/monitoring.sgml
@@ -3184,7 +3184,7 @@ SELECT pid, wait_event_type, wait_event FROM
pg_stat_activity WHERE wait_event i
</para>
<para>
OID of the relation that the worker is synchronizing; null for the
- main apply worker
+ main apply worker and the apply parallel worker
</para></entry>
</row>
This and other changes in monitoring.sgml refers the workers as "apply
parallel worker". Isn't it better to use parallel apply worker as we
are using at other places in the patch? But, I have another question,
do we really need to display entries for parallel apply workers in
pg_stat_subscription if it doesn't have any meaningful information? I
think we can easily avoid it in pg_stat_get_subscription by checking
apply_leader_pid.
3.
ApplyWorkerMain()
{
...
...
+
+ if (server_version >= 160000 &&
+ MySubscription->stream == SUBSTREAM_PARALLEL)
+ options.proto.logical.streaming = pstrdup("parallel");
After deciding here whether the parallel streaming mode is enabled or
not, we recheck the same thing in apply_handle_stream_abort() and
parallel_apply_can_start(). In parallel_apply_can_start(), we do it
via two different checks. How about storing this information say in
structure MyLogicalRepWorker in ApplyWorkerMain() and then use it at
other places?
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Hi Amit,
> > I checked other flags that are set by signal handlers, their datatype seemed to
> be sig_atomic_t.
> > Is there any reasons that you use normal bool? It should be changed if not.
> >
>
> It follows the logic similar to ParallelMessagePending. Do you see any
> problem with it?
Hmm, one consideration is:
what will happen if the signal handler HandleParallelApplyMessageInterrupt() is fired during
"ParallelApplyMessagePending= false;"?
IIUC sig_atomic_t has been needed to avoid writing to same data at the same time.
According to C99 standard(I grepped draft version [1]), the behavior seems to be undefined if the signal handler
attaches to not "volatile sig_atomic_t" data.
...But I'm not sure whether this is really problematic in the current system, sorry...
```
If the signal occurs other than as the result of calling the abort or raise function,
the behavior is undefined if the signal handler refers to any object with static storage duration other than by
assigninga value to an object declared as volatile sig_atomic_t,
or the signal handler calls any function in the standard library other than the abort function,
the _Exit function, or the signal function with the first argument equal to the signal number corresponding to the
signalthat caused the invocation of the handler.
```
> > a.
> > I was not sure when the cell should be cleaned. Currently we clean up
> ParallelApplyWorkersList() only in the parallel_apply_start_worker(),
> > but we have chances to remove such a cell like HandleParallelApplyMessages()
> or HandleParallelApplyMessage(). How do you think?
> >
>
> Note that HandleParallelApply* are invoked during interrupt handling,
> so it may not be advisable to remove it there.
>
> >
> > 12. ConfigureNamesInt
> >
> > ```
> > + {
> > + {"max_parallel_apply_workers_per_subscription",
> > + PGC_SIGHUP,
> > + REPLICATION_SUBSCRIBERS,
> > + gettext_noop("Maximum number of parallel apply
> workers per subscription."),
> > + NULL,
> > + },
> > + &max_parallel_apply_workers_per_subscription,
> > + 2, 0, MAX_BACKENDS,
> > + NULL, NULL, NULL
> > + },
> > ```
> >
> > This parameter can be changed by pg_ctl reload, so the following corner case
> may be occurred.
> > Should we add a assign hook to handle this? Or, can we ignore it?
> >
>
> I think we can ignore this as it will eventually start respecting the threshold.
Both of you said are reasonable for me.
[1]: https://www.open-std.org/JTC1/SC22/WG14/www/docs/n1256.pdf
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Sep 22, 2022 at 4:50 PM kuroda.hayato@fujitsu.com <kuroda.hayato@fujitsu.com> wrote: > > Hi Amit, > > > > I checked other flags that are set by signal handlers, their datatype seemed to > > be sig_atomic_t. > > > Is there any reasons that you use normal bool? It should be changed if not. > > > > > > > It follows the logic similar to ParallelMessagePending. Do you see any > > problem with it? > > Hmm, one consideration is: > what will happen if the signal handler HandleParallelApplyMessageInterrupt() is fired during "ParallelApplyMessagePending= false;"? > IIUC sig_atomic_t has been needed to avoid writing to same data at the same time. > But we do call HOLD_INTERRUPTS() before we do "ParallelApplyMessagePending = false;", so that should not happen. However, I think it would be better to use sig_atomic_t here for the sake of consistency. I think you can start a separate thread to check if we can change ParallelMessagePending to make it consistent with other such variables. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Sep 22, 2022 at 3:41 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Sep 22, 2022 at 8:59 AM wangw.fnst@fujitsu.com
> <wangw.fnst@fujitsu.com> wrote:
> >
>
> Few comments on v33-0001
> =======================
>
Some more comments on v33-0001
=============================
1.
+ /* Information from the corresponding LogicalRepWorker slot. */
+ uint16 logicalrep_worker_generation;
+
+ int logicalrep_worker_slot_no;
+} ParallelApplyWorkerShared;
Both these variables are read/changed by leader/parallel workers
without using any lock (mutex). It seems currently there is no problem
because of the way the patch is using in_parallel_apply_xact but I
think it won't be a good idea to rely on it. I suggest using mutex to
operate on these variables and also check if the slot_no is in a valid
range after reading it in parallel_apply_free_worker, otherwise error
out using elog.
2.
static void
apply_handle_stream_stop(StringInfo s)
{
- if (!in_streamed_transaction)
+ ParallelApplyWorkerInfo *winfo = NULL;
+ TransApplyAction apply_action;
+
+ if (!am_parallel_apply_worker() &&
+ (!in_streamed_transaction && !stream_apply_worker))
ereport(ERROR,
(errcode(ERRCODE_PROTOCOL_VIOLATION),
errmsg_internal("STREAM STOP message without STREAM START")));
This check won't be able to detect missing stream start messages for
parallel apply workers apart from the first pair of start/stop. I
thought of adding in_remote_transaction check along with
am_parallel_apply_worker() to detect the same but that also won't work
because the parallel worker doesn't reset it at the stop message.
Another possibility is to introduce yet another variable for this but
that doesn't seem worth it. I would like to keep this check simple.
Can you think of any better way?
3. I think we can skip sending start/stop messages from the leader to
the parallel worker because unlike apply worker it will process only
one transaction-at-a-time. However, it is not clear whether that is
worth the effort because it is sent after logical_decoding_work_mem
changes. For now, I have added a comment for this in the attached
patch but let me if I am missing something or if I am wrong.
4.
postgres=# select pid, leader_pid, application_name, backend_type from
pg_stat_activity;
pid | leader_pid | application_name | backend_type
-------+------------+------------------+------------------------------
27624 | | | logical replication launcher
17336 | | psql | client backend
26312 | | | logical replication worker
26376 | | psql | client backend
14004 | | | logical replication worker
Here, the second worker entry is for the parallel worker. Isn't it
better if we distinguish this by keeping type as a logical replication
parallel worker? I think for this you need to change bgw_type in
logicalrep_worker_launch().
5. Can we name parallel_apply_subxact_info_add() as
parallel_apply_start_subtrans()?
Apart from the above, I have added/edited a few comments and made a
few other cosmetic changes in the attached.
--
With Regards,
Amit Kapila.
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Thur, Sep 22, 2022 at 16:08 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote:
> Dear Wang,
>
> Thanks for updating the patch! Followings are comments for v33-0001.
Thanks for your comments.
> ===
> libpqwalreceiver.c
>
> 01. inclusion
>
> ```
> +#include "catalog/pg_subscription.h"
> ```
>
> We don't have to include it because the analysis of parameters is done at caller.
>
> ===
> launcher.c
Improved.
> 02. logicalrep_worker_launch()
>
> ```
> + /*
> + * Return silently if the number of parallel apply workers reached the
> + * limit per subscription.
> + */
> + if (is_subworker && nparallelapplyworkers >=
> max_parallel_apply_workers_per_subscription)
> ```
>
> a.
> I felt that it might be kind if we output some debug messages.
>
> b.
> The if statement seems to be more than 80 characters. You can move to new
> line around "nparallelapplyworkers >= ...".
Improved.
> ===
> applyparallelworker.c
>
> 03. declaration
>
> ```
> +/*
> + * Is there a message pending in parallel apply worker which we need to
> + * receive?
> + */
> +volatile bool ParallelApplyMessagePending = false;
> ```
>
> I checked other flags that are set by signal handlers, their datatype seemed to
> be sig_atomic_t.
> Is there any reasons that you use normal bool? It should be changed if not.
Improved.
> 04. HandleParallelApplyMessages()
>
> ```
> + if (winfo->error_mq_handle == NULL)
> + continue;
> ```
>
> a.
> I was not sure when the cell should be cleaned. Currently we clean up
> ParallelApplyWorkersList() only in the parallel_apply_start_worker(),
> but we have chances to remove such a cell like HandleParallelApplyMessages()
> or HandleParallelApplyMessage(). How do you think?
>
> b.
> Comments should be added even if we keep this, like "exited worker, skipped".
>
> ```
> + else
> + ereport(ERROR,
> +
> (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("lost connection to the leader apply worker")));
> ```
>
> c.
> This function is called on the leader apply worker, so the hint should be "lost
> connection to the parallel apply worker".
=>b.
Added the following comment according to your suggestion.
`Skip if worker has exited`
=>c.
Fixed.
> ===
> worker.c
>
> 07. handle_streamed_transaction()
>
> ```
> + * For non-streamed transactions, returns false;
> ```
>
> "returns false;" -> "returns false"
Improved. I changed the semicolon to a period
> apply_handle_commit_prepared(), apply_handle_abort_prepared()
>
> These functions are not expected that parallel worker calls
> so I think Assert() should be added.
I am not sure if this modification is necessary since we do not modify the
non-streamed transaction related message like "COMMIT PREPARED" or "ROLLBACK
PREPARED".
> 08. UpdateWorkerStats()
>
> ```
> -static void
> +void
> UpdateWorkerStats(XLogRecPtr last_lsn, TimestampTz send_time, bool reply)
> ```
>
> This function is called only in worker.c, should be static.
>
> 09. subscription_change_cb()
>
> ```
> -static void
> +void
> subscription_change_cb(Datum arg, int cacheid, uint32 hashvalue)
> ```
>
> This function is called only in worker.c, should be static.
Improved.
> 10. InitializeApplyWorker()
>
> ```
> +/*
> + * Initialize the database connection, in-memory subscription and necessary
> + * config options.
> + */
> void
> -ApplyWorkerMain(Datum main_arg)
> +InitializeApplyWorker(void)
> ```
>
> Some comments should be added about this is a common part of leader and
> parallel apply worker.
Added the following comment:
`The common initialization for leader apply worker and parallel apply worker.`
> ===
> logicalrepworker.h
>
> 11. declaration
>
> ```
> extern PGDLLIMPORT volatile bool ParallelApplyMessagePending;
> ```
>
> Please refer above comment.
>
> ===
> guc_tables.c
Improved.
Also rebased the patch set based on the changes in HEAD (26f7802).
Attach the new patch set.
Regards,
Wang wei
Attachment
- v34-0001-Perform-streaming-logical-transactions-by-parall.patch
- v34-0002-Test-streaming-parallel-option-in-tap-test.patch
- v34-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v34-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v34-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Thur, Sep 22, 2022 at 18:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> Few comments on v33-0001
> =======================
Thanks for your comments.
> 1.
> + else if (data->streaming == SUBSTREAM_PARALLEL &&
> + data->protocol_version <
> LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM)
> + ereport(ERROR,
> + (errcode(ERRCODE_INVALID_PARAMETER_VALUE),
> + errmsg("requested proto_version=%d does not support
> streaming=parallel mode, need %d or higher",
> + data->protocol_version,
> LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM)));
>
> I think we can improve this error message as: "requested
> proto_version=%d does not support parallel streaming mode, need %d or
> higher".
Improved.
> 2.
> --- a/doc/src/sgml/monitoring.sgml
> +++ b/doc/src/sgml/monitoring.sgml
> @@ -3184,7 +3184,7 @@ SELECT pid, wait_event_type, wait_event FROM
> pg_stat_activity WHERE wait_event i
> </para>
> <para>
> OID of the relation that the worker is synchronizing; null for the
> - main apply worker
> + main apply worker and the apply parallel worker
> </para></entry>
> </row>
>
> This and other changes in monitoring.sgml refers the workers as "apply
> parallel worker". Isn't it better to use parallel apply worker as we
> are using at other places in the patch? But, I have another question,
> do we really need to display entries for parallel apply workers in
> pg_stat_subscription if it doesn't have any meaningful information? I
> think we can easily avoid it in pg_stat_get_subscription by checking
> apply_leader_pid.
Make sense. Improved as suggested.
Do not display parallel apply worker related information in this view after
applying 0001 patch. But display entries for parallel apply worker after
applying 0005 patch.
> 3.
> ApplyWorkerMain()
> {
> ...
> ...
> +
> + if (server_version >= 160000 &&
> + MySubscription->stream == SUBSTREAM_PARALLEL)
> + options.proto.logical.streaming = pstrdup("parallel");
>
> After deciding here whether the parallel streaming mode is enabled or
> not, we recheck the same thing in apply_handle_stream_abort() and
> parallel_apply_can_start(). In parallel_apply_can_start(), we do it
> via two different checks. How about storing this information say in
> structure MyLogicalRepWorker in ApplyWorkerMain() and then use it at
> other places?
Improved as suggested.
Added a new flag "in_parallel_apply" to structure MyLogicalRepWorker.
Because the patch set could not be applied cleanly, I rebased and shared them
for review.
I have not addressed the comment you posted in [1]. I will share the new patch
set when I finish them.
The new patches were attached in [2].
[1] - https://www.postgresql.org/message-id/CAA4eK1KjGNA8T8O77rRhkv6bRT6OsdQaEy--2hNrJFCc80bN0A%40mail.gmail.com
[2] -
https://www.postgresql.org/message-id/OS3PR01MB6275F4A7CA186412E2FF2ED29E529%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Wang, Thanks for updating patch!... but cfbot says that it cannot be accepted [1]. I thought the header <signal.h> should be included, like miscadmin.h. [1]: https://cirrus-ci.com/task/5909508684775424 Best Regards, Hayato Kuroda FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Sep 26, 2022 at 8:41 AM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> On Thur, Sep 22, 2022 at 18:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> > 3.
> > ApplyWorkerMain()
> > {
> > ...
> > ...
> > +
> > + if (server_version >= 160000 &&
> > + MySubscription->stream == SUBSTREAM_PARALLEL)
> > + options.proto.logical.streaming = pstrdup("parallel");
> >
> > After deciding here whether the parallel streaming mode is enabled or
> > not, we recheck the same thing in apply_handle_stream_abort() and
> > parallel_apply_can_start(). In parallel_apply_can_start(), we do it
> > via two different checks. How about storing this information say in
> > structure MyLogicalRepWorker in ApplyWorkerMain() and then use it at
> > other places?
>
> Improved as suggested.
> Added a new flag "in_parallel_apply" to structure MyLogicalRepWorker.
>
Can we name the variable in_parallel_apply as parallel_apply and set
it in logicalrep_worker_launch() instead of in
ParallelApplyWorkerMain()?
Few other comments:
==================
1.
+ if (is_subworker &&
+ nparallelapplyworkers >= max_parallel_apply_workers_per_subscription)
+ {
+ LWLockRelease(LogicalRepWorkerLock);
+
+ ereport(DEBUG1,
+ (errcode(ERRCODE_CONFIGURATION_LIMIT_EXCEEDED),
+ errmsg("out of parallel apply workers"),
+ errhint("You might need to increase
max_parallel_apply_workers_per_subscription.")));
I think it is better to keep the level of this as LOG. Similar
messages at other places use WARNING or LOG. Here, I prefer LOG
because the system can still proceed without blocking anything.
2.
+/* Reset replication origin tracking. */
+void
+parallel_apply_replorigin_reset(void)
+{
+ bool started_tx = false;
+
+ /* This function might be called inside or outside of transaction. */
+ if (!IsTransactionState())
+ {
+ StartTransactionCommand();
+ started_tx = true;
+ }
Why do we need a transaction in this function?
3. Few suggestions to improve in the patch:
diff --git a/src/backend/replication/logical/worker.c
b/src/backend/replication/logical/worker.c
index 1623c9e2fa..d9c519dfab 100644
--- a/src/backend/replication/logical/worker.c
+++ b/src/backend/replication/logical/worker.c
@@ -1264,6 +1264,10 @@ apply_handle_stream_prepare(StringInfo s)
case TRANS_LEADER_SEND_TO_PARALLEL:
Assert(winfo);
+ /*
+ * The origin can be active only in one process. See
+ * apply_handle_stream_commit.
+ */
parallel_apply_replorigin_reset();
/* Send STREAM PREPARE message to the parallel apply worker. */
@@ -1623,12 +1627,7 @@ apply_handle_stream_abort(StringInfo s)
(errcode(ERRCODE_PROTOCOL_VIOLATION),
errmsg_internal("STREAM ABORT message without STREAM STOP")));
- /*
- * Check whether the publisher sends abort_lsn and abort_time.
- *
- * Note that the parallel apply worker is only started when the publisher
- * sends abort_lsn and abort_time.
- */
+ /* We receive abort information only when we can apply in parallel. */
if (MyLogicalRepWorker->in_parallel_apply)
read_abort_info = true;
@@ -1656,7 +1655,13 @@ apply_handle_stream_abort(StringInfo s)
Assert(winfo);
if (subxid == xid)
+ {
+ /*
+ * The origin can be active only in one process. See
+ * apply_handle_stream_commit.
+ */
parallel_apply_replorigin_reset();
+ }
/* Send STREAM ABORT message to the parallel apply worker. */
parallel_apply_send_data(winfo, s->len, s->data);
@@ -1858,6 +1863,12 @@ apply_handle_stream_commit(StringInfo s)
case TRANS_LEADER_SEND_TO_PARALLEL:
Assert(winfo);
+ /*
+ * We need to reset the replication origin before sending the commit
+ * message and set it up again after confirming that parallel worker
+ * has processed the message. This is required because origin can be
+ * active only in one process at-a-time.
+ */
parallel_apply_replorigin_reset();
/* Send STREAM COMMIT message to the parallel apply worker. */
diff --git a/src/include/replication/worker_internal.h
b/src/include/replication/worker_internal.h
index 4cbfb43492..2bd9664f86 100644
--- a/src/include/replication/worker_internal.h
+++ b/src/include/replication/worker_internal.h
@@ -70,11 +70,7 @@ typedef struct LogicalRepWorker
*/
pid_t apply_leader_pid;
- /*
- * Indicates whether to use parallel apply workers.
- *
- * Determined based on streaming parameter and publisher version.
- */
+ /* Indicates whether apply can be performed parallelly. */
bool in_parallel_apply;
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Wang,
Followings are comments for your patchset.
====
0001
01. launcher.c - logicalrep_worker_stop_internal()
```
+
+ Assert(LWLockHeldByMe(LogicalRepWorkerLock));
+
```
I think it should be Assert(LWLockHeldByMeInMode(LogicalRepWorkerLock, LW_SHARED))
because the lock is released one and acquired again as LW_SHARED.
If newer function has been acquired lock as LW_EXCLUSIVE and call logicalrep_worker_stop_internal(),
its lock may become weaker after calling it.
02. launcher.c - apply_handle_stream_start()
```
+ /*
+ * Notify handle methods we're processing a remote in-progress
+ * transaction.
+ */
+ in_streamed_transaction = true;
- MyLogicalRepWorker->stream_fileset = palloc(sizeof(FileSet));
- FileSetInit(MyLogicalRepWorker->stream_fileset);
+ /*
+ * Start a transaction on stream start, this transaction will be
+ * committed on the stream stop unless it is a tablesync worker in
+ * which case it will be committed after processing all the
+ * messages. We need the transaction for handling the buffile,
+ * used for serializing the streaming data and subxact info.
+ */
+ begin_replication_step();
```
Previously in_streamed_transaction was set after the begin_replication_step(),
but the ordering is modified. Maybe we don't have to modify it if there is no particular reason.
03. launcher.c - apply_handle_stream_stop()
```
+ /* Commit the per-stream transaction */
+ CommitTransactionCommand();
+
+ /* Reset per-stream context */
+ MemoryContextReset(LogicalStreamingContext);
+
+ pgstat_report_activity(STATE_IDLE, NULL);
+
+ in_streamed_transaction = false;
```
Previously in_streamed_transaction was set after the MemoryContextReset(), but the ordering is modified.
Maybe we don't have to modify it if there is no particular reason.
04. applyparallelworker.c - LogicalParallelApplyLoop()
```
+ shmq_res = shm_mq_receive(mqh, &len, &data, false);
...
+ if (ConfigReloadPending)
+ {
+ ConfigReloadPending = false;
+ ProcessConfigFile(PGC_SIGHUP);
+ }
```
Here the parallel apply worker waits to receive messages and after dispatching it ProcessConfigFile() is called.
It means that .conf will be not read until the parallel apply worker receives new messages and apply them.
It may be problematic when users change log_min_message to debugXXX for debugging but the streamed transaction rarely
come.
They expected that detailed description appears on the log from next streaming chunk, but it does not.
This does not occur in leader worker when it waits messages from publisher, because it uses libpqrcv_receive(), which
worksasynchronously.
I 'm not sure whether it should be documented that the evaluation of GUCs may be delayed, how do you think?
===
0004
05. logical-replication.sgml
```
...
In that case, it may be necessary to change the streaming mode to on or off and cause
the same conflicts again so the finish LSN of the failed transaction will be written to the server log.
...
```
Above sentence is added by 0001, but it is not modified by 0004.
Such transactions will be retried as streaming=on mode, so some descriptions related with it should be added.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Saturday, September 24, 2022 7:40 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Sep 22, 2022 at 3:41 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > On Thu, Sep 22, 2022 at 8:59 AM wangw.fnst@fujitsu.com
> > <wangw.fnst@fujitsu.com> wrote:
> > >
> >
> > Few comments on v33-0001
> > =======================
> >
>
> Some more comments on v33-0001
> =============================
> 1.
> + /* Information from the corresponding LogicalRepWorker slot. */
> + uint16 logicalrep_worker_generation;
> +
> + int logicalrep_worker_slot_no;
> +} ParallelApplyWorkerShared;
>
> Both these variables are read/changed by leader/parallel workers without
> using any lock (mutex). It seems currently there is no problem because of the
> way the patch is using in_parallel_apply_xact but I think it won't be a good idea
> to rely on it. I suggest using mutex to operate on these variables and also check
> if the slot_no is in a valid range after reading it in parallel_apply_free_worker,
> otherwise error out using elog.
Changed.
> 2.
> static void
> apply_handle_stream_stop(StringInfo s)
> {
> - if (!in_streamed_transaction)
> + ParallelApplyWorkerInfo *winfo = NULL; TransApplyAction apply_action;
> +
> + if (!am_parallel_apply_worker() &&
> + (!in_streamed_transaction && !stream_apply_worker))
> ereport(ERROR,
> (errcode(ERRCODE_PROTOCOL_VIOLATION),
> errmsg_internal("STREAM STOP message without STREAM START")));
>
> This check won't be able to detect missing stream start messages for parallel
> apply workers apart from the first pair of start/stop. I thought of adding
> in_remote_transaction check along with
> am_parallel_apply_worker() to detect the same but that also won't work
> because the parallel worker doesn't reset it at the stop message.
> Another possibility is to introduce yet another variable for this but that doesn't
> seem worth it. I would like to keep this check simple.
> Can you think of any better way?
I feel we can reuse the in_streamed_transaction in parallel apply worker to
simplify the check there. I tried to set this flag in parallel apply worker
when stream starts and reset it when stream stop so that we can directly check
this flag for duplicate stream start message and other related things.
> 3. I think we can skip sending start/stop messages from the leader to the
> parallel worker because unlike apply worker it will process only one
> transaction-at-a-time. However, it is not clear whether that is worth the effort
> because it is sent after logical_decoding_work_mem changes. For now, I have
> added a comment for this in the attached patch but let me if I am missing
> something or if I am wrong.
I the suggested comments look good.
> 4.
> postgres=# select pid, leader_pid, application_name, backend_type from
> pg_stat_activity;
> pid | leader_pid | application_name | backend_type
> -------+------------+------------------+------------------------------
> 27624 | | | logical replication launcher
> 17336 | | psql | client backend
> 26312 | | | logical replication worker
> 26376 | | psql | client backend
> 14004 | | | logical replication worker
>
> Here, the second worker entry is for the parallel worker. Isn't it better if we
> distinguish this by keeping type as a logical replication parallel worker? I think
> for this you need to change bgw_type in logicalrep_worker_launch().
Changed.
> 5. Can we name parallel_apply_subxact_info_add() as
> parallel_apply_start_subtrans()?
>
> Apart from the above, I have added/edited a few comments and made a few
> other cosmetic changes in the attached.
Changed.
Best regards,
Hou zj
Attachment
- v35-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v35-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v35-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v35-0001-Perform-streaming-logical-transactions-by-parall.patch
- v35-0002-Test-streaming-parallel-option-in-tap-test.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, September 26, 2022 6:58 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Mon, Sep 26, 2022 at 8:41 AM wangw.fnst@fujitsu.com
> <wangw.fnst@fujitsu.com> wrote:
> >
> > On Thur, Sep 22, 2022 at 18:12 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > > 3.
> > > ApplyWorkerMain()
> > > {
> > > ...
> > > ...
> > > +
> > > + if (server_version >= 160000 &&
> > > + MySubscription->stream == SUBSTREAM_PARALLEL)
> > > + options.proto.logical.streaming = pstrdup("parallel");
> > >
> > > After deciding here whether the parallel streaming mode is enabled
> > > or not, we recheck the same thing in apply_handle_stream_abort() and
> > > parallel_apply_can_start(). In parallel_apply_can_start(), we do it
> > > via two different checks. How about storing this information say in
> > > structure MyLogicalRepWorker in ApplyWorkerMain() and then use it at
> > > other places?
> >
> > Improved as suggested.
> > Added a new flag "in_parallel_apply" to structure MyLogicalRepWorker.
> >
>
> Can we name the variable in_parallel_apply as parallel_apply and set it in
> logicalrep_worker_launch() instead of in ParallelApplyWorkerMain()?
Changed.
> Few other comments:
> ==================
> 1.
> + if (is_subworker &&
> + nparallelapplyworkers >= max_parallel_apply_workers_per_subscription)
> + {
> + LWLockRelease(LogicalRepWorkerLock);
> +
> + ereport(DEBUG1,
> + (errcode(ERRCODE_CONFIGURATION_LIMIT_EXCEEDED),
> + errmsg("out of parallel apply workers"), errhint("You might need to
> + increase
> max_parallel_apply_workers_per_subscription.")));
>
> I think it is better to keep the level of this as LOG. Similar messages at other
> places use WARNING or LOG. Here, I prefer LOG because the system can still
> proceed without blocking anything.
Changed.
> 2.
> +/* Reset replication origin tracking. */ void
> +parallel_apply_replorigin_reset(void)
> +{
> + bool started_tx = false;
> +
> + /* This function might be called inside or outside of transaction. */
> + if (!IsTransactionState()) { StartTransactionCommand(); started_tx =
> + true; }
>
> Why do we need a transaction in this function?
I think we don't need it and removed this in the new version patch.
> 3. Few suggestions to improve in the patch:
> diff --git a/src/backend/replication/logical/worker.c
> b/src/backend/replication/logical/worker.c
> index 1623c9e2fa..d9c519dfab 100644
> --- a/src/backend/replication/logical/worker.c
> +++ b/src/backend/replication/logical/worker.c
> @@ -1264,6 +1264,10 @@ apply_handle_stream_prepare(StringInfo s)
> case TRANS_LEADER_SEND_TO_PARALLEL:
> Assert(winfo);
>
> + /*
> + * The origin can be active only in one process. See
> + * apply_handle_stream_commit.
> + */
> parallel_apply_replorigin_reset();
>
> /* Send STREAM PREPARE message to the parallel apply worker. */ @@
> -1623,12 +1627,7 @@ apply_handle_stream_abort(StringInfo s)
> (errcode(ERRCODE_PROTOCOL_VIOLATION),
> errmsg_internal("STREAM ABORT message without STREAM STOP")));
>
> - /*
> - * Check whether the publisher sends abort_lsn and abort_time.
> - *
> - * Note that the parallel apply worker is only started when the publisher
> - * sends abort_lsn and abort_time.
> - */
> + /* We receive abort information only when we can apply in parallel. */
> if (MyLogicalRepWorker->in_parallel_apply)
> read_abort_info = true;
>
> @@ -1656,7 +1655,13 @@ apply_handle_stream_abort(StringInfo s)
> Assert(winfo);
>
> if (subxid == xid)
> + {
> + /*
> + * The origin can be active only in one process. See
> + * apply_handle_stream_commit.
> + */
> parallel_apply_replorigin_reset();
> + }
>
> /* Send STREAM ABORT message to the parallel apply worker. */
> parallel_apply_send_data(winfo, s->len, s->data); @@ -1858,6 +1863,12 @@
> apply_handle_stream_commit(StringInfo s)
> case TRANS_LEADER_SEND_TO_PARALLEL:
> Assert(winfo);
>
> + /*
> + * We need to reset the replication origin before sending the commit
> + * message and set it up again after confirming that parallel worker
> + * has processed the message. This is required because origin can be
> + * active only in one process at-a-time.
> + */
> parallel_apply_replorigin_reset();
>
> /* Send STREAM COMMIT message to the parallel apply worker. */ diff --git
> a/src/include/replication/worker_internal.h
> b/src/include/replication/worker_internal.h
> index 4cbfb43492..2bd9664f86 100644
> --- a/src/include/replication/worker_internal.h
> +++ b/src/include/replication/worker_internal.h
> @@ -70,11 +70,7 @@ typedef struct LogicalRepWorker
> */
> pid_t apply_leader_pid;
>
> - /*
> - * Indicates whether to use parallel apply workers.
> - *
> - * Determined based on streaming parameter and publisher version.
> - */
> + /* Indicates whether apply can be performed parallelly. */
> bool in_parallel_apply;
>
Merged, thanks.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, September 27, 2022 2:32 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com>
>
> Dear Wang,
>
> Followings are comments for your patchset.
Thanks for the comments.
> ====
> 0001
>
>
> 01. launcher.c - logicalrep_worker_stop_internal()
>
> ```
> +
> + Assert(LWLockHeldByMe(LogicalRepWorkerLock));
> +
> ```
Changed.
> I think it should be Assert(LWLockHeldByMeInMode(LogicalRepWorkerLock,
> LW_SHARED)) because the lock is released one and acquired again as
> LW_SHARED.
> If newer function has been acquired lock as LW_EXCLUSIVE and call
> logicalrep_worker_stop_internal(),
> its lock may become weaker after calling it.
>
> 02. launcher.c - apply_handle_stream_start()
>
> ```
> + /*
> + * Notify handle methods we're processing a remote
> in-progress
> + * transaction.
> + */
> + in_streamed_transaction = true;
>
> - MyLogicalRepWorker->stream_fileset = palloc(sizeof(FileSet));
> - FileSetInit(MyLogicalRepWorker->stream_fileset);
> + /*
> + * Start a transaction on stream start, this transaction
> will be
> + * committed on the stream stop unless it is a
> tablesync worker in
> + * which case it will be committed after processing all
> the
> + * messages. We need the transaction for handling the
> buffile,
> + * used for serializing the streaming data and subxact
> info.
> + */
> + begin_replication_step();
> ```
>
> Previously in_streamed_transaction was set after the begin_replication_step(),
> but the ordering is modified. Maybe we don't have to modify it if there is no
> particular reason.
>
> 03. launcher.c - apply_handle_stream_stop()
>
> ```
> + /* Commit the per-stream transaction */
> + CommitTransactionCommand();
> +
> + /* Reset per-stream context */
> + MemoryContextReset(LogicalStreamingContext);
> +
> + pgstat_report_activity(STATE_IDLE, NULL);
> +
> + in_streamed_transaction = false;
> ```
>
> Previously in_streamed_transaction was set after the MemoryContextReset(),
> but the ordering is modified.
> Maybe we don't have to modify it if there is no particular reason.
I adjusted the position of this due to some other improvements this time.
>
> 04. applyparallelworker.c - LogicalParallelApplyLoop()
>
> ```
> + shmq_res = shm_mq_receive(mqh, &len, &data, false);
> ...
> + if (ConfigReloadPending)
> + {
> + ConfigReloadPending = false;
> + ProcessConfigFile(PGC_SIGHUP);
> + }
> ```
>
>
> Here the parallel apply worker waits to receive messages and after dispatching
> it ProcessConfigFile() is called.
> It means that .conf will be not read until the parallel apply worker receives new
> messages and apply them.
>
> It may be problematic when users change log_min_message to debugXXX for
> debugging but the streamed transaction rarely come.
> They expected that detailed description appears on the log from next
> streaming chunk, but it does not.
>
> This does not occur in leader worker when it waits messages from publisher,
> because it uses libpqrcv_receive(), which works asynchronously.
>
> I 'm not sure whether it should be documented that the evaluation of GUCs may
> be delayed, how do you think?
I changed the shm_mq_receive to asynchronous mode which is also consistent with
what we did for Gather node when reading data from parallel query workers.
>
> ===
> 0004
>
> 05. logical-replication.sgml
>
> ```
> ...
> In that case, it may be necessary to change the streaming mode to on or off and
> cause the same conflicts again so the finish LSN of the failed transaction will be
> written to the server log.
> ...
> ```
>
> Above sentence is added by 0001, but it is not modified by 0004.
> Such transactions will be retried as streaming=on mode, so some descriptions
> related with it should be added.
Added.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Hou,
Thanks for updating patch. I will review yours soon, but I reply to your comment.
> > 04. applyparallelworker.c - LogicalParallelApplyLoop()
> >
> > ```
> > + shmq_res = shm_mq_receive(mqh, &len, &data, false);
> > ...
> > + if (ConfigReloadPending)
> > + {
> > + ConfigReloadPending = false;
> > + ProcessConfigFile(PGC_SIGHUP);
> > + }
> > ```
> >
> >
> > Here the parallel apply worker waits to receive messages and after dispatching
> > it ProcessConfigFile() is called.
> > It means that .conf will be not read until the parallel apply worker receives new
> > messages and apply them.
> >
> > It may be problematic when users change log_min_message to debugXXX for
> > debugging but the streamed transaction rarely come.
> > They expected that detailed description appears on the log from next
> > streaming chunk, but it does not.
> >
> > This does not occur in leader worker when it waits messages from publisher,
> > because it uses libpqrcv_receive(), which works asynchronously.
> >
> > I 'm not sure whether it should be documented that the evaluation of GUCs may
> > be delayed, how do you think?
>
> I changed the shm_mq_receive to asynchronous mode which is also consistent
> with
> what we did for Gather node when reading data from parallel query workers.
I checked your implementation, but it seemed that the parallel apply worker will not sleep
even if there are no messages or signals. It might be very inefficient.
In gather node - gather_readnext(), the same way is used, but I think there is a premise
that the wait-time is short because it is related with only one gather node.
In terms of parallel apply worker, however, we cannot predict the wait-time because
it is related with the streamed transactions. If such transactions rarely come, parallel apply workers may spend many
CPUtime.
I think we should wait during short time or until leader notifies, if shmq_res == SHM_MQ_WOULD_BLOCK.
How do you think?
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for the v35-0001 patch:
======
1. Commit message
Currently, for large transactions, the publisher sends the data in multiple
streams (changes divided into chunks depending upon logical_decoding_work_mem),
and then on the subscriber-side, the apply worker writes the changes into
temporary files and once it receives the commit, it reads from the file and
applies the entire transaction.
~
There is a mix of plural and singular.
"reads from the file" -> "reads from those files" ?
~~~
2.
This preserves commit ordering and avoids
writing to and reading from file in most cases. We still need to spill if there
is no worker available.
2a.
"file" => "files"
2b.
"in most cases. We still need to spill" -> "in most cases, although we
still need to spill"
======
3. GENERAL
(this comment was written after I wrote all the other ones below so
there might be some unintended overlaps...)
I found the mixed use of the same member names having different
meanings to be quite confusing.
e.g.1
PGOutputData 'streaming' is now a single char internal representation
the subscription parameter streaming mode ('f','t','p')
- bool streaming;
+ char streaming;
e.g.2
WalRcvStreamOptions 'streaming' is a C string version of the
subscription streaming mode ("on", "parallel")
- bool streaming; /* Streaming of large transactions */
+ char *streaming; /* Streaming of large transactions */
e.g.3
SubOpts 'streaming' is again like the first example - a single char
for the mode.
- bool streaming;
+ char streaming;
IMO everything would become much simpler if you did:
3a.
Rename "char streaming;" -> "char streaming_mode;"
3b.
Re-designed the "char *streaming;" code to also use the single char
notation, then also call that member 'streaming_mode'. Then everything
will be consistent.
======
doc/src/sgml/config.sgml
4. - max_parallel_apply_workers_per_subscription
+ <varlistentry
id="guc-max-parallel-apply-workers-per-subscription"
xreflabel="max_parallel_apply_workers_per_subscription">
+ <term><varname>max_parallel_apply_workers_per_subscription</varname>
(<type>integer</type>)
+ <indexterm>
+ <primary><varname>max_parallel_apply_workers_per_subscription</varname>
configuration parameter</primary>
+ </indexterm>
+ </term>
+ <listitem>
+ <para>
+ Maximum number of parallel apply workers per subscription. This
+ parameter controls the amount of parallelism for streaming of
+ in-progress transactions with subscription parameter
+ <literal>streaming = parallel</literal>.
+ </para>
+ <para>
+ The parallel apply workers are taken from the pool defined by
+ <varname>max_logical_replication_workers</varname>.
+ </para>
+ <para>
+ The default value is 2. This parameter can only be set in the
+ <filename>postgresql.conf</filename> file or on the server command
+ line.
+ </para>
+ </listitem>
+ </varlistentry>
I felt that maybe this should also xref to the
doc/src/sgml/logical-replication.sgml section where you say about
"max_logical_replication_workers should be increased according to the
desired number of parallel apply workers."
=====
5. doc/src/sgml/protocol.sgml
+ <para>
+ Version <literal>4</literal> is supported only for server version 16
+ and above, and it allows applying streams of large in-progress
+ transactions in parallel.
+ </para>
SUGGESTION
... and it allows streams of large in-progress transactions to be
applied in parallel.
======
6. doc/src/sgml/ref/create_subscription.sgml
+ <para>
+ If set to <literal>parallel</literal>, incoming changes are directly
+ applied via one of the parallel apply workers, if available. If no
+ parallel worker is free to handle streaming transactions then the
+ changes are written to temporary files and applied after the
+ transaction is committed. Note that if an error happens when
+ applying changes in a parallel worker, the finish LSN of the
+ remote transaction might not be reported in the server log.
</para>
6a.
"parallel worker is free" -> "parallel apply worker is free"
~
6b.
"Note that if an error happens when applying changes in a parallel
worker," --> "Note that if an error happens in a parallel apply
worker,"
======
7. src/backend/access/transam/xact.c - RecordTransactionAbort
+ /*
+ * Are we using the replication origins feature? Or, in other words, are
+ * we replaying remote actions?
+ */
+ replorigin = (replorigin_session_origin != InvalidRepOriginId &&
+ replorigin_session_origin != DoNotReplicateId);
"Or, in other words," -> "In other words,"
======
src/backend/replication/logical/applyparallelworker.c
8. - file header comment
+ * Refer to the comments in file header of logical/worker.c to see more
+ * information about parallel apply worker.
8a.
"in file header" -> "in the file header"
~
8b.
"about parallel apply worker." -> "about parallel apply workers."
~~~
9. - parallel_apply_can_start
+/*
+ * Returns true, if it is allowed to start a parallel apply worker, false,
+ * otherwise.
+ */
+static bool
+parallel_apply_can_start(TransactionId xid)
(The commas are strange)
SUGGESTION
Returns true if it is OK to start a parallel apply worker, false otherwise.
or just SUGGESTION
Returns true if it is OK to start a parallel apply worker.
~~~
10.
+ /*
+ * Don't start a new parallel worker if not in parallel streaming mode or
+ * the publisher does not support parallel apply.
+ */
+ if (!MyLogicalRepWorker->parallel_apply)
+ return false;
10a.
SUGGESTION
Don't start a new parallel apply worker if the subscription is not
using parallel streaming mode, or if the publisher does not support
parallel apply.
~
10b.
IMO this flag might be better to be called 'parallel_apply_enabled' or
something similar.
(see also review comment #55b.)
~~~
11. - parallel_apply_start_worker
+ /* Try to start a new parallel apply worker. */
+ if (winfo == NULL)
+ winfo = parallel_apply_setup_worker();
+
+ /* Failed to start a new parallel apply worker. */
+ if (winfo == NULL)
+ return;
IMO might be cleaner to write that code like below. And now the 2nd
comment is not really adding anything so it can be removed too.
SUGGESTION
if (winfo == NULL)
{
/* Try to start a new parallel apply worker. */
winfo = parallel_apply_setup_worker();
if (winfo == NULL)
return;
}
~~~
12. - parallel_apply_free_worker
+ SpinLockAcquire(&winfo->shared->mutex);
+ slot_no = winfo->shared->logicalrep_worker_slot_no;
+ generation = winfo->shared->logicalrep_worker_generation;
+ SpinLockRelease(&winfo->shared->mutex);
I know there are not many places doing this, but do you think it might
be worth introducing some new set/get function to encapsulate the
set/get of the generation/slot so it does the mutex spin-locks in
common code?
~~~
13. - LogicalParallelApplyLoop
+ /*
+ * Init the ApplyMessageContext which we clean up after each replication
+ * protocol message.
+ */
+ ApplyMessageContext = AllocSetContextCreate(ApplyContext,
+ "ApplyMessageContext",
+ ALLOCSET_DEFAULT_SIZES);
Because this is in the parallel apply worker should the name (e.g. the
2nd param) be changed to "ParallelApplyMessageContext"?
~~~
14.
+ else if (shmq_res == SHM_MQ_DETACHED)
+ {
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("lost connection to the leader apply worker")));
+ }
+ /* SHM_MQ_WOULD_BLOCK is purposefully ignored */
Instead of that comment sort of floating in space I wonder if this
code would be better written as a switch, so then you can write this
comment in the 'default' case.
OR, maybe the "else if (shmq_res == SHM_MQ_DETACHED)" should be changed to
SUGGESTION
else if (shmq_res != SHM_MQ_WOULD_BLOCK)
OR, just having an empty code block would be better than just a code
comment all by itself.
SUGGESTION
else
{
/* SHM_MQ_WOULD_BLOCK is purposefully ignored */
}
~~~
15. - ParallelApplyWorkerMain
+ /*
+ * Allocate the origin name in long-lived context for error context
+ * message.
+ */
+ snprintf(originname, sizeof(originname), "pg_%u", MySubscription->oid);
15a.
"in long-lived" -> "in a long-lived"
~
15b.
Please watch my other thread [1] where I am hoping to push a patch to
will replace these snprintf's with a common function to do the same.
If/when my patch is pushed then this code needs to be changed to call
that new function.
~~~
16. - HandleParallelApplyMessages
+ res = shm_mq_receive(winfo->error_mq_handle, &nbytes,
+ &data, true);
Seems to have unnecessary wrapping.
~~~
17. - parallel_apply_setup_dsm
+/*
+ * Set up a dynamic shared memory segment.
+ *
+ * We set up a control region that contains a fixed worker info
+ * (ParallelApplyWorkerShared), a message queue, and an error queue.
+ *
+ * Returns true on success, false on failure.
+ */
+static bool
+parallel_apply_setup_dsm(ParallelApplyWorkerInfo *winfo)
"fixed worker info" -> "fixed size worker info" ?
~~~
18.
+ * We need one key to register the location of the header, and we need two
+ * other keys to track the locations of the message queue and the error
+ * message queue.
"and we need two other" -> "and two other"
~~~
19. - parallel_apply_wait_for_xact_finish
+void
+parallel_apply_wait_for_xact_finish(ParallelApplyWorkerInfo *winfo)
+{
+ for (;;)
+ {
+ if (!parallel_apply_get_in_xact(winfo->shared))
+ break;
Should that condition have a comment? All the others do.
~~~
20. - parallel_apply_savepoint_name
The only callers that I could find are from
parallel_apply_start_subtrans and parallel_apply_stream_abort so...
20a.
Why is there an extern in worker_internal.h?
~
20b.
Why is this not declared static?
~~~
21.
The callers to parallel_apply_start_subtrans are both allocating a
name buffer size like:
char spname[MAXPGPATH];
Is that right?
I thought that PG names were limited by NAMEDATALEN.
~~~
22. - parallel_apply_replorigin_setup
+ snprintf(originname, sizeof(originname), "pg_%u", MySubscription->oid);
Please watch my other thread [1] where I am hoping to push a patch to
will replace these snprintf's with a common function to do the same.
If/when my patch is pushed then this code needs to be changed to call
that new function.
======
src/backend/replication/logical/launcher.c
23. - GUCs
@@ -54,6 +54,7 @@
int max_logical_replication_workers = 4;
int max_sync_workers_per_subscription = 2;
+int max_parallel_apply_workers_per_subscription = 2;
Please watch my other thread [2] where I am hoping to push a patch to
clean up some of these GUV C variable declarations. It is not really
recommended to assign default values to the C variable like this -
they are kind of misleading because they will be overwritten by the
GUC default value when the GUC mechanism starts up.
~~~
24. - logicalrep_worker_launch
+ /* Sanity check: we don't support table sync in subworker. */
+ Assert(!(is_subworker && OidIsValid(relid)));
IMO "we don't support" makes it sound like this is something that
maybe is intended for the future. In fact, I think just this
combination is not possible so it is just a plain sanity check. I
think might be better just say like below
/* Sanity check - tablesync worker cannot be a subworker */
~~~
25.
+ worker->parallel_apply = is_subworker;
It seems kind of strange to assign one boolean to about but they have
completely different names. I wondered if 'is_subworker' should be
called 'is_parallel_apply_worker'?
~~~
26.
if (OidIsValid(relid))
snprintf(bgw.bgw_name, BGW_MAXLEN,
"logical replication worker for subscription %u sync %u", subid, relid);
+ else if (is_subworker)
+ snprintf(bgw.bgw_name, BGW_MAXLEN,
+ "logical replication parallel apply worker for subscription %u", subid);
else
snprintf(bgw.bgw_name, BGW_MAXLEN,
"logical replication worker for subscription %u", subid);
I think that *last* text now be changed like below:
BEFORE
"logical replication worker for subscription %u"
AFTER
"logical replication apply worker for subscription %u"
~~~
27. - logicalrep_worker_stop_internal
+/*
+ * Workhorse for logicalrep_worker_stop(), logicalrep_worker_detach() and
+ * logicalrep_worker_stop_by_slot(). Stop the worker and wait for it to die.
+ */
+static void
+logicalrep_worker_stop_internal(LogicalRepWorker *worker)
IMO it would be better to define this static function *before* all the
callers of it.
~~~
28. - logicalrep_worker_detach
+ /* Stop the parallel apply workers. */
+ if (am_leader_apply_worker())
+ {
Should that comment rather say like below?
/* If this is the leader apply worker then stop all of its parallel
apply workers. */
~~~
29. - pg_stat_get_subscription
+ /* Skip if this is parallel apply worker */
+ if (worker.apply_leader_pid != InvalidPid)
+ continue;
29a.
"is parallel apply" -> "is a parallel apply"
~
29b.
IMO this condition should be using your macro isParallelApplyWorker(worker).
======
30. src/backend/replication/logical/proto.c - logicalrep_read_stream_abort
+ *
+ * If read_abort_info is true, try to read the abort_lsn and abort_time fields,
+ * otherwise don't.
*/
void
-logicalrep_read_stream_abort(StringInfo in, TransactionId *xid,
- TransactionId *subxid)
+logicalrep_read_stream_abort(StringInfo in,
+ LogicalRepStreamAbortData *abort_data,
+ bool read_abort_info)
"try to read" -> "read"
======
31. src/backend/replication/logical/tablesync.c - process_syncing_tables
process_syncing_tables(XLogRecPtr current_lsn)
{
+ if (am_parallel_apply_worker())
+ return;
+
Maybe should have some comment here like:
/* Skip for parallel apply workers. */
======
src/backend/replication/logical/worker.c
32. - file header comment
+ * the list for any available worker. Note that we maintain a maximum of half
+ * the max_parallel_apply_workers_per_subscription workers in the pool and
+ * after that, we simply exit the worker after applying the transaction. This
+ * worker pool threshold is a bit arbitrary and we can provide a guc for this
+ * in the future if required.
IMO that sentence beginning with "This worker pool" should be written
as an XXX-style comment.
Also "guc" -> "GUC variable"
e.g.
* the list for any available worker. Note that we maintain a maximum of half
* the max_parallel_apply_workers_per_subscription workers in the pool and
* after that, we simply exit the worker after applying the transaction.
*
* XXX This worker pool threshold is a bit arbitrary and we can provide a GUC
* variable for this in the future if required.
~~~
33.
* we cannot count how many workers will be started. It may be possible to
* allocate enough shared memory in one segment based on the maximum number of
* parallel apply workers
(max_parallel_apply_workers_per_subscription), but this
* may waste some memory if no process is actually started.
"may waste some memory" -> "would waste memory"
~~~
34.
+ * In case, no worker is available to handle the streamed transaction, we
+ * follow approach 2.
SUGGESTION
If no parallel apply worker is available to handle the streamed
transaction we follow approach 2.
~~~
35. - TransApplyAction
+ * TRANS_LEADER_SERIALIZE means that we are in leader apply worker and changes
+ * are written to temporary files and then applied when the final commit
+ * arrives.
"in leader apply" -> "in the leader apply"
~~~
36 - should_apply_changes_for_rel
should_apply_changes_for_rel(LogicalRepRelMapEntry *rel)
{
if (am_tablesync_worker())
return MyLogicalRepWorker->relid == rel->localreloid;
+ else if (am_parallel_apply_worker())
+ {
+ if (rel->state != SUBREL_STATE_READY)
+ ereport(ERROR,
+ (errmsg("logical replication apply workers for subscription \"%s\"
will restart",
+ MySubscription->name),
+ errdetail("Cannot handle streamed replication transaction using parallel "
+ "apply workers until all tables are synchronized.")));
+
+ return true;
+ }
else
return (rel->state == SUBREL_STATE_READY ||
(rel->state == SUBREL_STATE_SYNCDONE &&
@@ -427,43 +519,87 @@ end_replication_step(void)
This function can be made tidier just by removing all the 'else' ...
SUGGESTION
if (am_tablesync_worker())
return ...
if (am_parallel_apply_worker())
{
...
return true;
}
Assert(am_leader_apply_worker());
return ...
~~~
37. - handle_streamed_transaction
+ /*
+ * XXX The publisher side doesn't always send relation/type update
+ * messages after the streaming transaction, so also update the
+ * relation/type in leader apply worker here. See function
+ * cleanup_rel_sync_cache.
+ */
+ if (action == LOGICAL_REP_MSG_RELATION ||
+ action == LOGICAL_REP_MSG_TYPE)
+ return false;
+ return true;
37.
"so also update the relation/type in leader apply worker here"
Is that comment worded correctly? There is nothing being updated "here".
~
37.
That code is the same as:
return (action != LOGICAL_REP_MSG_RELATION && action != LOGICAL_REP_MSG_TYPE);
~~~
38. - apply_handle_commit_prepared
+ *
+ * Note that we don't need to wait here if the transaction was prepared in a
+ * parallel apply worker. Because we have already waited for the prepare to
+ * finish in apply_handle_stream_prepare() which will ensure all the operations
+ * in that transaction have happened in the subscriber and no concurrent
+ * transaction can create deadlock or transaction dependency issues.
*/
static void
apply_handle_commit_prepared(StringInfo s)
"worker. Because" -> "worker because"
~~~
39. - apply_handle_rollback_prepared
+ *
+ * Note that we don't need to wait here if the transaction was prepared in a
+ * parallel apply worker. Because we have already waited for the prepare to
+ * finish in apply_handle_stream_prepare() which will ensure all the operations
+ * in that transaction have happened in the subscriber and no concurrent
+ * transaction can create deadlock or transaction dependency issues.
*/
static void
apply_handle_rollback_prepared(StringInfo s)
See previous review comment #38 above.
~~~
40. - apply_handle_stream_prepare
+ case TRANS_LEADER_SERIALIZE:
- /* Mark the transaction as prepared. */
- apply_handle_prepare_internal(&prepare_data);
+ /*
+ * The transaction has been serialized to file, so replay all the
+ * spooled operations.
+ */
Spurious blank line after the 'case'.
FYI - this same blank line is also in all the other switch/case that
looked like this one, so if you will fix it then please check all
those other places too...
~~~
41. - apply_handle_stream_start
+ *
+ * XXX We can avoid sending pair of the START/STOP messages to the parallel
+ * worker because unlike apply worker it will process only one
+ * transaction-at-a-time. However, it is not clear whether that is worth the
+ * effort because it is sent after logical_decoding_work_mem changes.
*/
static void
apply_handle_stream_start(StringInfo s)
"sending pair" -> "sending pairs"
~~~
42.
- /* notify handle methods we're processing a remote transaction */
+ /* Notify handle methods we're processing a remote transaction. */
in_streamed_transaction = true;
Changing this comment seemed unrelated to this patch, so maybe don't do this.
~~~
43.
/*
- * Initialize the worker's stream_fileset if we haven't yet. This will be
- * used for the entire duration of the worker so create it in a permanent
- * context. We create this on the very first streaming message from any
- * transaction and then use it for this and other streaming transactions.
- * Now, we could create a fileset at the start of the worker as well but
- * then we won't be sure that it will ever be used.
+ * For the first stream start, check if there is any free parallel apply
+ * worker we can use to process this transaction.
*/
- if (MyLogicalRepWorker->stream_fileset == NULL)
+ if (first_segment)
+ parallel_apply_start_worker(stream_xid);
This comment update seems misleading. The
parallel_apply_start_worker() isn't just checking if there is a free
worker. All that free worker logic stuff is *inside* the
parallel_apply_start_worker() function, so maybe no need to mention
about it here at the caller.
~~~
44.
+ case TRANS_PARALLEL_APPLY:
+ break;
Should this include a comment explaining why there is nothing to do?
~~~
39. - apply_handle_stream_abort
+ /* We receive abort information only when we can apply in parallel. */
+ if (MyLogicalRepWorker->parallel_apply)
+ read_abort_info = true;
44a.
SUGGESTION
We receive abort information only when the publisher can support parallel apply.
~
44b.
Why not remove the assignment in the declaration, and just write this code as:
read_abort_info = MyLogicalRepWorker->parallel_apply;
~~~
45.
+ /*
+ * We are in leader apply worker and the transaction has been
+ * serialized to file.
+ */
+ serialize_stream_abort(xid, subxid);
"in leader apply worker" -> "in the leader apply worker"
~~~
46. - store_flush_position
/* Skip if not the leader apply worker */
if (am_parallel_apply_worker())
return;
I previously wrote something about this and Hou-san gave a reason [3]
why not to change the condition.
But the comment still does not match the code, because a tablesync
worker would get past here.
Maybe the comment is wrong?
~~~
47. - InitializeApplyWorker
+/*
+ * The common initialization for leader apply worker and parallel apply worker.
+ *
+ * Initialize the database connection, in-memory subscription and necessary
+ * config options.
+ */
void
-ApplyWorkerMain(Datum main_arg)
+InitializeApplyWorker(void)
"The common initialization" -> "Common initialization"
~~~
48. - ApplyWorkerMain
+/* Logical Replication Apply worker entry point */
+void
+ApplyWorkerMain(Datum main_arg)
"Apply worker" -> "apply worker"
~~~
49.
+ /*
+ * We don't currently need any ResourceOwner in a walreceiver process, but
+ * if we did, we could call CreateAuxProcessResourceOwner here.
+ */
I think this comment should have "XXX" prefix.
~~~
50.
+ if (server_version >= 160000 &&
+ MySubscription->stream == SUBSTREAM_PARALLEL)
+ {
+ options.proto.logical.streaming = pstrdup("parallel");
+ MyLogicalRepWorker->parallel_apply = true;
+ }
+ else if (server_version >= 140000 &&
+ MySubscription->stream != SUBSTREAM_OFF)
+ options.proto.logical.streaming = pstrdup("on");
+ else
+ options.proto.logical.streaming = NULL;
IMO it might make more sense for these conditions to be checking the
'options.proto.logical.proto_version' here instead of checking the
hardwired server versions. Also, I suggest may be better (for clarity)
to always assign the parallel_apply member.
SUGGESTION
if (options.proto.logical.proto_version >=
LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM &&
MySubscription->stream == SUBSTREAM_PARALLEL)
{
options.proto.logical.streaming = pstrdup("parallel");
MyLogicalRepWorker->parallel_apply = true;
}
else if (options.proto.logical.proto_version >=
LOGICALREP_PROTO_STREAM_VERSION_NUM &&
MySubscription->stream != SUBSTREAM_OFF)
{
options.proto.logical.streaming = pstrdup("on");
MyLogicalRepWorker->parallel_apply = false;
}
else
{
options.proto.logical.streaming = NULL;
MyLogicalRepWorker->parallel_apply = false;
}
~~~
51. - clear_subscription_skip_lsn
- if (likely(XLogRecPtrIsInvalid(myskiplsn)))
+ if (likely(XLogRecPtrIsInvalid(myskiplsn)) ||
+ am_parallel_apply_worker())
return;
Unnecessary wrapping.
~~~
52. - get_transaction_apply_action
+static TransApplyAction
+get_transaction_apply_action(TransactionId xid,
ParallelApplyWorkerInfo **winfo)
+{
+ *winfo = NULL;
+
+ if (am_parallel_apply_worker())
+ {
+ return TRANS_PARALLEL_APPLY;
+ }
+ else if (in_remote_transaction)
+ {
+ return TRANS_LEADER_APPLY;
+ }
+
+ /*
+ * Check if we are processing this transaction using a parallel apply
+ * worker and if so, send the changes to that worker.
+ */
+ else if ((*winfo = parallel_apply_find_worker(xid)))
+ {
+ return TRANS_LEADER_SEND_TO_PARALLEL;
+ }
+ else
+ {
+ return TRANS_LEADER_SERIALIZE;
+ }
+}
52a.
All these if/else and code blocks seem excessive. It can be simplified
as follows:
SUGGESTION
static TransApplyAction
get_transaction_apply_action(TransactionId xid, ParallelApplyWorkerInfo **winfo)
{
*winfo = NULL;
if (am_parallel_apply_worker())
return TRANS_PARALLEL_APPLY;
if (in_remote_transaction)
return TRANS_LEADER_APPLY;
/*
* Check if we are processing this transaction using a parallel apply
* worker and if so, send the changes to that worker.
*/
if ((*winfo = parallel_apply_find_worker(xid)))
return TRANS_LEADER_SEND_TO_PARALLEL;
return TRANS_LEADER_SERIALIZE;
}
~
52b.
Can a tablesync worker ever get here? It might be better to
Assert(!am_tablesync_worker()); at top of this function?
======
src/backend/replication/pgoutput/pgoutput.c
53. - pgoutput_startup
ereport(ERROR,
(errcode(ERRCODE_INVALID_PARAMETER_VALUE),
errmsg("requested proto_version=%d does not support streaming, need
%d or higher",
data->protocol_version, LOGICALREP_PROTO_STREAM_VERSION_NUM)));
+ else if (data->streaming == SUBSTREAM_PARALLEL &&
+ data->protocol_version < LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM)
+ ereport(ERROR,
+ (errcode(ERRCODE_INVALID_PARAMETER_VALUE),
+ errmsg("requested proto_version=%d does not support parallel
streaming mode, need %d or higher",
+ data->protocol_version, LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM)));
The previous error message just says "streamimg", not "streaming mode"
so for consistency better to remove that word "mode" IMO.
~~~
54. - pgoutput_stream_abort
- logicalrep_write_stream_abort(ctx->out, toptxn->xid, txn->xid);
+ logicalrep_write_stream_abort(ctx->out, toptxn->xid, txn->xid,
abort_lsn, txn->xact_time.abort_time, write_abort_info);
+
Wrapping is needed here.
======
src/include/replication/worker_internal.h
55. - LogicalRepWorker
+ /* Indicates whether apply can be performed parallelly. */
+ bool parallel_apply;
+
55a.
"parallelly" - ?? is there a better way to phrase this? IMO that is an
uncommon word.
~
55b.
IMO this member name should be named slightly different to give a
better feel for what it really means.
Maybe something like one of:
"parallel_apply_ok"
"parallel_apply_enabled"
"use_parallel_apply"
etc?
~~~
56. - ParallelApplyWorkerInfo
+ /*
+ * Indicates whether the worker is available to be used for parallel apply
+ * transaction?
+ */
+ bool in_use;
As previously posted [4], this member comment is describing the
opposite of the member name. (e.g. the comment would be correct if the
member was called 'is_available', but it isn't)
SUGGESTION
True if the worker is being used to process a parallel apply
transaction. False indicates this worker is available for re-use.
~~~
57. - am_leader_apply_worker
+static inline bool
+am_leader_apply_worker(void)
+{
+ return (!OidIsValid(MyLogicalRepWorker->relid) &&
+ !isParallelApplyWorker(MyLogicalRepWorker));
+}
I wondered if it would be tidier/easier to define this function like
below. The others are inline functions anyhow so it should end up as
the same thing, right?
static inline bool
am_leader_apply_worker(void)
{
return (!am_tablesync_worker() && !am_parallel_apply_worker);
}
======
58.
--- fail - streaming must be boolean
+-- fail - streaming must be boolean or 'parallel'
CREATE SUBSCRIPTION regress_testsub CONNECTION
'dbname=regress_doesnotexist' PUBLICATION testpub WITH (connect =
false, streaming = foo);
I think there are tests already for explicitly create/set the
subscription parameter streaming = on/off/parallel
But what about when there is no value explicitly specified? Shouldn't
there also be tests like below to check that *implied* boolean true
still works for this enum?
CREATE SUBSCRIPTION ... WITH (streaming)
ALTER SUBSCRIPTION ... SET (streaming)
------
[1] My patch snprintfs -
https://www.postgresql.org/message-id/flat/CAHut%2BPsB9hEEU-JHqTUBL3bv--vesUvThYr1-95ZyG5PkF9PQQ%40mail.gmail.com#17abe65e826f48d3d5a1cf5b83ce5271
[2] My patch GUC C vars -
https://www.postgresql.org/message-id/flat/CAHut%2BPsWxJgmrAvPsw9smFVAvAoyWstO7ttAkAq8NKDhsVNa3Q%40mail.gmail.com#1526a180383a3374ae4d701f25799926
[3] Houz reply comment #41 -
https://www.postgresql.org/message-id/OS0PR01MB5716E7E5798625AE9437CD6F94439%40OS0PR01MB5716.jpnprd01.prod.outlook.com
[4] Previous review comment #13 -
https://www.postgresql.org/message-id/CAHut%2BPuVjRgGr4saN7qwq0oB8DANHVR7UfDiciB1Q3cYN54F6A%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Tue, Sep 27, 2022 at 9:26 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Saturday, September 24, 2022 7:40 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Thu, Sep 22, 2022 at 3:41 PM Amit Kapila <amit.kapila16@gmail.com>
> > wrote:
> > >
> > > On Thu, Sep 22, 2022 at 8:59 AM wangw.fnst@fujitsu.com
> > > <wangw.fnst@fujitsu.com> wrote:
> > > >
> > >
> > > Few comments on v33-0001
> > > =======================
> > >
> >
> > Some more comments on v33-0001
> > =============================
> > 1.
> > + /* Information from the corresponding LogicalRepWorker slot. */
> > + uint16 logicalrep_worker_generation;
> > +
> > + int logicalrep_worker_slot_no;
> > +} ParallelApplyWorkerShared;
> >
> > Both these variables are read/changed by leader/parallel workers without
> > using any lock (mutex). It seems currently there is no problem because of the
> > way the patch is using in_parallel_apply_xact but I think it won't be a good idea
> > to rely on it. I suggest using mutex to operate on these variables and also check
> > if the slot_no is in a valid range after reading it in parallel_apply_free_worker,
> > otherwise error out using elog.
>
> Changed.
>
> > 2.
> > static void
> > apply_handle_stream_stop(StringInfo s)
> > {
> > - if (!in_streamed_transaction)
> > + ParallelApplyWorkerInfo *winfo = NULL; TransApplyAction apply_action;
> > +
> > + if (!am_parallel_apply_worker() &&
> > + (!in_streamed_transaction && !stream_apply_worker))
> > ereport(ERROR,
> > (errcode(ERRCODE_PROTOCOL_VIOLATION),
> > errmsg_internal("STREAM STOP message without STREAM START")));
> >
> > This check won't be able to detect missing stream start messages for parallel
> > apply workers apart from the first pair of start/stop. I thought of adding
> > in_remote_transaction check along with
> > am_parallel_apply_worker() to detect the same but that also won't work
> > because the parallel worker doesn't reset it at the stop message.
> > Another possibility is to introduce yet another variable for this but that doesn't
> > seem worth it. I would like to keep this check simple.
> > Can you think of any better way?
>
> I feel we can reuse the in_streamed_transaction in parallel apply worker to
> simplify the check there. I tried to set this flag in parallel apply worker
> when stream starts and reset it when stream stop so that we can directly check
> this flag for duplicate stream start message and other related things.
>
> > 3. I think we can skip sending start/stop messages from the leader to the
> > parallel worker because unlike apply worker it will process only one
> > transaction-at-a-time. However, it is not clear whether that is worth the effort
> > because it is sent after logical_decoding_work_mem changes. For now, I have
> > added a comment for this in the attached patch but let me if I am missing
> > something or if I am wrong.
>
> I the suggested comments look good.
>
> > 4.
> > postgres=# select pid, leader_pid, application_name, backend_type from
> > pg_stat_activity;
> > pid | leader_pid | application_name | backend_type
> > -------+------------+------------------+------------------------------
> > 27624 | | | logical replication launcher
> > 17336 | | psql | client backend
> > 26312 | | | logical replication worker
> > 26376 | | psql | client backend
> > 14004 | | | logical replication worker
> >
> > Here, the second worker entry is for the parallel worker. Isn't it better if we
> > distinguish this by keeping type as a logical replication parallel worker? I think
> > for this you need to change bgw_type in logicalrep_worker_launch().
>
> Changed.
>
> > 5. Can we name parallel_apply_subxact_info_add() as
> > parallel_apply_start_subtrans()?
> >
> > Apart from the above, I have added/edited a few comments and made a few
> > other cosmetic changes in the attached.
>
While looking at v35 patch, I realized that there are some cases where
the logical replication gets stuck depending on partitioned table
structure. For instance, there are following tables, publication, and
subscription:
* On publisher
create table p (c int) partition by list (c);
create table c1 partition of p for values in (1);
create table c2 (c int);
create publication test_pub for table p, c1, c2 with
(publish_via_partition_root = 'true');
* On subscriber
create table p (c int) partition by list (c);
create table c1 partition of p for values In (2);
create table c2 partition of p for values In (1);
create subscription test_sub connection 'port=5551 dbname=postgres'
publication test_pub with (streaming = 'parallel', copy_data =
'false');
Note that while both the publisher and the subscriber have the same
name tables the partition structure is different and rows go to a
different table on the subscriber (eg, row c=1 will go to c2 table on
the subscriber). If two current transactions are executed as follows,
the apply worker (ig, the leader apply worker) waits for a lock on c2
held by its parallel apply worker:
* TX-1
BEGIN;
INSERT INTO p SELECT 1 FROM generate_series(1, 10000); --- changes are streamed
* TX-2
BEGIN;
TRUNCATE c2; --- wait for a lock on c2
* TX-1
INSERT INTO p SELECT 1 FROM generate_series(1, 10000);
COMMIT;
This might not be a common case in practice but it could mean that
there is a restriction on how partitioned tables should be structured
on the publisher and the subscriber when using streaming = 'parallel'.
When this happens, since the logical replication cannot move forward
the users need to disable parallel-apply mode or increase
logical_decoding_work_mem. We could describe this limitation in the
doc but it would be hard for users to detect problematic table
structure.
BTW, when the leader apply worker waits for a lock on c2 in the above
example, the parallel apply worker is in a busy-loop, which should be
fixed.
Regards,
--
Masahiko Sawada
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Sep 29, 2022 at 3:20 PM kuroda.hayato@fujitsu.com
<kuroda.hayato@fujitsu.com> wrote:
>
> Dear Hou,
>
> Thanks for updating patch. I will review yours soon, but I reply to your comment.
>
> > > 04. applyparallelworker.c - LogicalParallelApplyLoop()
> > >
> > > ```
> > > + shmq_res = shm_mq_receive(mqh, &len, &data, false);
> > > ...
> > > + if (ConfigReloadPending)
> > > + {
> > > + ConfigReloadPending = false;
> > > + ProcessConfigFile(PGC_SIGHUP);
> > > + }
> > > ```
> > >
> > >
> > > Here the parallel apply worker waits to receive messages and after dispatching
> > > it ProcessConfigFile() is called.
> > > It means that .conf will be not read until the parallel apply worker receives new
> > > messages and apply them.
> > >
> > > It may be problematic when users change log_min_message to debugXXX for
> > > debugging but the streamed transaction rarely come.
> > > They expected that detailed description appears on the log from next
> > > streaming chunk, but it does not.
> > >
> > > This does not occur in leader worker when it waits messages from publisher,
> > > because it uses libpqrcv_receive(), which works asynchronously.
> > >
> > > I 'm not sure whether it should be documented that the evaluation of GUCs may
> > > be delayed, how do you think?
> >
> > I changed the shm_mq_receive to asynchronous mode which is also consistent
> > with
> > what we did for Gather node when reading data from parallel query workers.
>
> I checked your implementation, but it seemed that the parallel apply worker will not sleep
> even if there are no messages or signals. It might be very inefficient.
>
> In gather node - gather_readnext(), the same way is used, but I think there is a premise
> that the wait-time is short because it is related with only one gather node.
> In terms of parallel apply worker, however, we cannot predict the wait-time because
> it is related with the streamed transactions. If such transactions rarely come, parallel apply workers may spend many
CPUtime.
>
> I think we should wait during short time or until leader notifies, if shmq_res == SHM_MQ_WOULD_BLOCK.
> How do you think?
>
Can't we use WaitLatch in the case of SHM_MQ_WOULD_BLOCK as we are
using it for the same case at some other place in the code? We can use
the same nap time as we are using in the leader apply worker.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Amit, > Can't we use WaitLatch in the case of SHM_MQ_WOULD_BLOCK as we are > using it for the same case at some other place in the code? We can use > the same nap time as we are using in the leader apply worker. I'm not sure whether such a short nap time is needed or not. Because unlike leader apply worker, parallel apply workers do not have timeout like wal_receiver_timeout, so they do not have to check so frequently and send feedback to publisher. But basically I agree that we can use same logic as leader. Best Regards, Hayato Kuroda FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Sep 30, 2022 at 1:56 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are my review comments for the v35-0001 patch:
>
> ======
>
> 3. GENERAL
>
> (this comment was written after I wrote all the other ones below so
> there might be some unintended overlaps...)
>
> I found the mixed use of the same member names having different
> meanings to be quite confusing.
>
> e.g.1
> PGOutputData 'streaming' is now a single char internal representation
> the subscription parameter streaming mode ('f','t','p')
> - bool streaming;
> + char streaming;
>
> e.g.2
> WalRcvStreamOptions 'streaming' is a C string version of the
> subscription streaming mode ("on", "parallel")
> - bool streaming; /* Streaming of large transactions */
> + char *streaming; /* Streaming of large transactions */
>
> e.g.3
> SubOpts 'streaming' is again like the first example - a single char
> for the mode.
> - bool streaming;
> + char streaming;
>
>
> IMO everything would become much simpler if you did:
>
> 3a.
> Rename "char streaming;" -> "char streaming_mode;"
>
> 3b.
> Re-designed the "char *streaming;" code to also use the single char
> notation, then also call that member 'streaming_mode'. Then everything
> will be consistent.
>
Won't this impact the previous version publisher which already uses
on/off? We may need to maintain multiple values which would be
confusing.
>
> 9. - parallel_apply_can_start
>
> +/*
> + * Returns true, if it is allowed to start a parallel apply worker, false,
> + * otherwise.
> + */
> +static bool
> +parallel_apply_can_start(TransactionId xid)
>
> (The commas are strange)
>
> SUGGESTION
> Returns true if it is OK to start a parallel apply worker, false otherwise.
>
+1 for this.
>
> 28. - logicalrep_worker_detach
>
> + /* Stop the parallel apply workers. */
> + if (am_leader_apply_worker())
> + {
>
> Should that comment rather say like below?
>
> /* If this is the leader apply worker then stop all of its parallel
> apply workers. */
>
I think this would be just saying what is apparent from the code, so
not sure if it is an improvement.
>
> 38. - apply_handle_commit_prepared
>
> + *
> + * Note that we don't need to wait here if the transaction was prepared in a
> + * parallel apply worker. Because we have already waited for the prepare to
> + * finish in apply_handle_stream_prepare() which will ensure all the operations
> + * in that transaction have happened in the subscriber and no concurrent
> + * transaction can create deadlock or transaction dependency issues.
> */
> static void
> apply_handle_commit_prepared(StringInfo s)
>
> "worker. Because" -> "worker because"
>
I think this will make this line too long. Can we think of breaking it
in some way?
>
> 43.
>
> /*
> - * Initialize the worker's stream_fileset if we haven't yet. This will be
> - * used for the entire duration of the worker so create it in a permanent
> - * context. We create this on the very first streaming message from any
> - * transaction and then use it for this and other streaming transactions.
> - * Now, we could create a fileset at the start of the worker as well but
> - * then we won't be sure that it will ever be used.
> + * For the first stream start, check if there is any free parallel apply
> + * worker we can use to process this transaction.
> */
> - if (MyLogicalRepWorker->stream_fileset == NULL)
> + if (first_segment)
> + parallel_apply_start_worker(stream_xid);
>
> This comment update seems misleading. The
> parallel_apply_start_worker() isn't just checking if there is a free
> worker. All that free worker logic stuff is *inside* the
> parallel_apply_start_worker() function, so maybe no need to mention
> about it here at the caller.
>
It will be good to have some comments here instead of completely removing it.
>
> 39. - apply_handle_stream_abort
>
> + /* We receive abort information only when we can apply in parallel. */
> + if (MyLogicalRepWorker->parallel_apply)
> + read_abort_info = true;
>
> 44a.
> SUGGESTION
> We receive abort information only when the publisher can support parallel apply.
>
The existing comment seems better to me in this case.
>
> 55. - LogicalRepWorker
>
> + /* Indicates whether apply can be performed parallelly. */
> + bool parallel_apply;
> +
>
> 55a.
> "parallelly" - ?? is there a better way to phrase this? IMO that is an
> uncommon word.
>
How about ".. can be performed in parallel."?
> ~
>
> 55b.
> IMO this member name should be named slightly different to give a
> better feel for what it really means.
>
> Maybe something like one of:
> "parallel_apply_ok"
> "parallel_apply_enabled"
> "use_parallel_apply"
> etc?
>
The extra word doesn't seem to be useful here.
> 58.
>
> --- fail - streaming must be boolean
> +-- fail - streaming must be boolean or 'parallel'
> CREATE SUBSCRIPTION regress_testsub CONNECTION
> 'dbname=regress_doesnotexist' PUBLICATION testpub WITH (connect =
> false, streaming = foo);
>
> I think there are tests already for explicitly create/set the
> subscription parameter streaming = on/off/parallel
>
> But what about when there is no value explicitly specified? Shouldn't
> there also be tests like below to check that *implied* boolean true
> still works for this enum?
>
> CREATE SUBSCRIPTION ... WITH (streaming)
> ALTER SUBSCRIPTION ... SET (streaming)
>
I think before adding new tests for this, please check if we have any
similar tests for other boolean options.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
> -----Original Message-----
> From: Masahiko Sawada <sawada.mshk@gmail.com>
> Sent: Thursday, October 6, 2022 4:07 PM
> To: Hou, Zhijie/侯 志杰 <houzj.fnst@fujitsu.com>
> Cc: Amit Kapila <amit.kapila16@gmail.com>; Wang, Wei/王 威
> <wangw.fnst@fujitsu.com>; Peter Smith <smithpb2250@gmail.com>; Dilip
> Kumar <dilipbalaut@gmail.com>; Shi, Yu/侍 雨 <shiy.fnst@fujitsu.com>;
> PostgreSQL Hackers <pgsql-hackers@lists.postgresql.org>
> Subject: Re: Perform streaming logical transactions by background workers and
> parallel apply
>
> On Tue, Sep 27, 2022 at 9:26 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Saturday, September 24, 2022 7:40 PM Amit Kapila
> <amit.kapila16@gmail.com> wrote:
> > >
> > > On Thu, Sep 22, 2022 at 3:41 PM Amit Kapila <amit.kapila16@gmail.com>
> > > wrote:
> > > >
> > > > On Thu, Sep 22, 2022 at 8:59 AM wangw.fnst@fujitsu.com
> > > > <wangw.fnst@fujitsu.com> wrote:
> > > > >
> > > >
> > > > Few comments on v33-0001
> > > > =======================
> > > >
> > >
> > > Some more comments on v33-0001
> > > =============================
> > > 1.
> > > + /* Information from the corresponding LogicalRepWorker slot. */
> > > + uint16 logicalrep_worker_generation;
> > > +
> > > + int logicalrep_worker_slot_no;
> > > +} ParallelApplyWorkerShared;
> > >
> > > Both these variables are read/changed by leader/parallel workers without
> > > using any lock (mutex). It seems currently there is no problem because of
> the
> > > way the patch is using in_parallel_apply_xact but I think it won't be a good
> idea
> > > to rely on it. I suggest using mutex to operate on these variables and also
> check
> > > if the slot_no is in a valid range after reading it in parallel_apply_free_worker,
> > > otherwise error out using elog.
> >
> > Changed.
> >
> > > 2.
> > > static void
> > > apply_handle_stream_stop(StringInfo s)
> > > {
> > > - if (!in_streamed_transaction)
> > > + ParallelApplyWorkerInfo *winfo = NULL; TransApplyAction apply_action;
> > > +
> > > + if (!am_parallel_apply_worker() &&
> > > + (!in_streamed_transaction && !stream_apply_worker))
> > > ereport(ERROR,
> > > (errcode(ERRCODE_PROTOCOL_VIOLATION),
> > > errmsg_internal("STREAM STOP message without STREAM START")));
> > >
> > > This check won't be able to detect missing stream start messages for parallel
> > > apply workers apart from the first pair of start/stop. I thought of adding
> > > in_remote_transaction check along with
> > > am_parallel_apply_worker() to detect the same but that also won't work
> > > because the parallel worker doesn't reset it at the stop message.
> > > Another possibility is to introduce yet another variable for this but that
> doesn't
> > > seem worth it. I would like to keep this check simple.
> > > Can you think of any better way?
> >
> > I feel we can reuse the in_streamed_transaction in parallel apply worker to
> > simplify the check there. I tried to set this flag in parallel apply worker
> > when stream starts and reset it when stream stop so that we can directly check
> > this flag for duplicate stream start message and other related things.
> >
> > > 3. I think we can skip sending start/stop messages from the leader to the
> > > parallel worker because unlike apply worker it will process only one
> > > transaction-at-a-time. However, it is not clear whether that is worth the
> effort
> > > because it is sent after logical_decoding_work_mem changes. For now, I have
> > > added a comment for this in the attached patch but let me if I am missing
> > > something or if I am wrong.
> >
> > I the suggested comments look good.
> >
> > > 4.
> > > postgres=# select pid, leader_pid, application_name, backend_type from
> > > pg_stat_activity;
> > > pid | leader_pid | application_name | backend_type
> > > -------+------------+------------------+------------------------------
> > > 27624 | | | logical replication launcher
> > > 17336 | | psql | client backend
> > > 26312 | | | logical replication worker
> > > 26376 | | psql | client backend
> > > 14004 | | | logical replication worker
> > >
> > > Here, the second worker entry is for the parallel worker. Isn't it better if we
> > > distinguish this by keeping type as a logical replication parallel worker? I
> think
> > > for this you need to change bgw_type in logicalrep_worker_launch().
> >
> > Changed.
> >
> > > 5. Can we name parallel_apply_subxact_info_add() as
> > > parallel_apply_start_subtrans()?
> > >
> > > Apart from the above, I have added/edited a few comments and made a few
> > > other cosmetic changes in the attached.
> >
>
> While looking at v35 patch, I realized that there are some cases where
> the logical replication gets stuck depending on partitioned table
> structure. For instance, there are following tables, publication, and
> subscription:
>
> * On publisher
> create table p (c int) partition by list (c);
> create table c1 partition of p for values in (1);
> create table c2 (c int);
> create publication test_pub for table p, c1, c2 with
> (publish_via_partition_root = 'true');
>
> * On subscriber
> create table p (c int) partition by list (c);
> create table c1 partition of p for values In (2);
> create table c2 partition of p for values In (1);
> create subscription test_sub connection 'port=5551 dbname=postgres'
> publication test_pub with (streaming = 'parallel', copy_data =
> 'false');
>
> Note that while both the publisher and the subscriber have the same
> name tables the partition structure is different and rows go to a
> different table on the subscriber (eg, row c=1 will go to c2 table on
> the subscriber). If two current transactions are executed as follows,
> the apply worker (ig, the leader apply worker) waits for a lock on c2
> held by its parallel apply worker:
>
> * TX-1
> BEGIN;
> INSERT INTO p SELECT 1 FROM generate_series(1, 10000); --- changes are
> streamed
>
> * TX-2
> BEGIN;
> TRUNCATE c2; --- wait for a lock on c2
>
> * TX-1
> INSERT INTO p SELECT 1 FROM generate_series(1, 10000);
> COMMIT;
>
> This might not be a common case in practice but it could mean that
> there is a restriction on how partitioned tables should be structured
> on the publisher and the subscriber when using streaming = 'parallel'.
> When this happens, since the logical replication cannot move forward
> the users need to disable parallel-apply mode or increase
> logical_decoding_work_mem. We could describe this limitation in the
> doc but it would be hard for users to detect problematic table
> structure.
Thanks for testing this!
I think the root reason for this kind of deadlock problems is the table
structure difference between publisher and subscriber(similar to the unique
difference reported earlier[1]). So, I think we'd better disallow this case. For
example to avoid the reported problem, we could only support parallel apply if
pubviaroot is false on publisher and replicated tables' types(relkind) are the
same between publisher and subscriber.
Although it might restrict some use cases, but I think it only restrict the
cases when the partitioned table's structure is different between publisher and
subscriber. User can still use parallel apply for cases when the table
structure is the same between publisher and subscriber which seems acceptable
to me. And we can also document that the feature is expected to be used for the
case when tables' structure are the same. Thoughts ?
BTW, to achieve this, we could send the publisher's relkind along with the
RELATION message and compare it with relkind on subscriber. We could report an
error if publisher's or subscriber's table is a partitioned table.
> BTW, when the leader apply worker waits for a lock on c2 in the above
> example, the parallel apply worker is in a busy-loop, which should be
> fixed.
Yeah, It seems we used async mode when receiving message which caused this,
I plan to improve that part soon.
[1] https://www.postgresql.org/message-id/CAD21AoDPHstj%2BjD3ODS-bd1uM%2BZE%3DcpDKf8npeNFZD%2BYdM28fA%40mail.gmail.com
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, October 6, 2022 6:54 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote: > > Dear Amit, > > > Can't we use WaitLatch in the case of SHM_MQ_WOULD_BLOCK as we are > > using it for the same case at some other place in the code? We can use > > the same nap time as we are using in the leader apply worker. > > I'm not sure whether such a short nap time is needed or not. > Because unlike leader apply worker, parallel apply workers do not have timeout > like wal_receiver_timeout, so they do not have to check so frequently and send > feedback to publisher. > But basically I agree that we can use same logic as leader. Thanks for the suggestion. I tried to add a WaitLatch, but it seems affect the performance because the Latch might not be set when leader send some message to parallel apply worker which means it will wait until timeout. I feel we'd better change it back to sync mode and do the ProcessConfigFile() after receiving the message and before applying the change which seems also address the problem. Best regards, Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Hou,
I put comments for v35-0001.
01. catalog.sgml
```
+ Controls how to handle the streaming of in-progress transactions:
+ <literal>f</literal> = disallow streaming of in-progress transactions,
+ <literal>t</literal> = spill the changes of in-progress transactions to
+ disk and apply at once after the transaction is committed on the
+ publisher,
+ <literal>p</literal> = apply changes directly using a parallel apply
+ worker if available (same as 't' if no worker is available)
```
I'm not sure why 't' means "spill the changes to file". Is it compatibility issue?
~~~
02. applyworker.c - parallel_apply_stream_abort
The argument abort_data is not modified in the function. Maybe "const" modifier should be added.
(Other functions should be also checked...)
~~~
03. applyparallelworker.c - parallel_apply_find_worker
```
+ ParallelApplyWorkerEntry *entry = NULL;
```
This may not have to be initialized here.
~~~
04. applyparallelworker.c - HandleParallelApplyMessages
```
+ static MemoryContext hpm_context = NULL;
```
I think "hpm" means "handle parallel message", so it should be "hpam".
~~~
05. launcher.c - logicalrep_worker_launch()
```
if (is_subworker)
snprintf(bgw.bgw_type, BGW_MAXLEN, "logical replication parallel worker");
else
snprintf(bgw.bgw_type, BGW_MAXLEN, "logical replication worker");
```
I'm not sure why there are only bgw_type even if there are three types of apply workers. Is it for compatibility?
~~~
06. launcher.c - logicalrep_worker_stop_by_slot
An assertion like Assert(slot_no >=0 && slot_no < max_logical_replication_workers) should be added at the top of this
function.
~~~
07. launcher.c - logicalrep_worker_stop_internal
```
+/*
+ * Workhorse for logicalrep_worker_stop(), logicalrep_worker_detach() and
+ * logicalrep_worker_stop_by_slot(). Stop the worker and wait for it to die.
+ */
+static void
+logicalrep_worker_stop_internal(LogicalRepWorker *worker)
```
I think logicalrep_worker_stop_internal() may be not "Workhorse" for logicalrep_worker_detach(). In the function
internalfunction is called for parallel apply worker, and it does not main part of the detach function.
~~~
08. worker.c - handle_streamed_transaction()
```
+ TransactionId current_xid = InvalidTransactionId;
```
This initialization is not needed. This is not used in non-streaming mode, otherwise it is substituted before used.
~~~
09. worker.c - handle_streamed_transaction()
```
+ case TRANS_PARALLEL_APPLY:
+ /* Define a savepoint for a subxact if needed. */
+ parallel_apply_start_subtrans(current_xid, stream_xid);
+ return false;
```
Based on other case-block, Assert(am_parallel_apply_worker()) may be added at the top of this part.
This suggestion can be said for other swith-case statements.
~~~
10. worker.c - apply_handle_stream_start
```
+ *
+ * XXX We can avoid sending pair of the START/STOP messages to the parallel
+ * worker because unlike apply worker it will process only one
+ * transaction-at-a-time. However, it is not clear whether that is worth the
+ * effort because it is sent after logical_decoding_work_mem changes.
```
I can understand that START message is not needed, but is STOP really removable? If leader does not send STOP to its
child,does it lose a chance to change the worker-state to IDLE_IN_TRANSACTION?
~~~
11. worker.c - apply_handle_stream_start
Currently the number of received chunks have not counted, but it can do if a variable "nchunks" is defined and
incrementedin apply_handle_stream_start(). This this info may be useful to determine appropriate
logical_decoding_work_memfor workloads. How do you think?
~~~
12. worker.c - get_transaction_apply_action
{} are not needed.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Hou, > Thanks for the suggestion. > > I tried to add a WaitLatch, but it seems affect the performance > because the Latch might not be set when leader send some > message to parallel apply worker which means it will wait until > timeout. Yes, currently it leader does not notify anything. To handle that leader must set a latch in parallel_apply_send_data(). It can be done if leader accesses to winfo->shared-> logicalrep_worker_slot_no, and sets a latch for LogicalRepCtxStruct->worker[slot_no]. Best Regards, Hayato Kuroda FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, October 6, 2022 9:00 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote: > > Dear Hou, > > > Thanks for the suggestion. > > > > I tried to add a WaitLatch, but it seems affect the performance > > because the Latch might not be set when leader send some message to > > parallel apply worker which means it will wait until timeout. > > Yes, currently it leader does not notify anything. > To handle that leader must set a latch in parallel_apply_send_data(). > It can be done if leader accesses to winfo->shared-> logicalrep_worker_slot_no, > and sets a latch for LogicalRepCtxStruct->worker[slot_no]. Thanks for the suggestion. I think we could do that, but I feel it's not great to set latch frequently. Besides, to access the LogicalRepCtxStruct->worker[] we would need to hold a lock which might also bring some overhead. Best regards, Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Thu, Oct 6, 2022 at 10:38 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Fri, Sep 30, 2022 at 1:56 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > Here are my review comments for the v35-0001 patch:
> >
> > ======
> >
> > 3. GENERAL
> >
> > (this comment was written after I wrote all the other ones below so
> > there might be some unintended overlaps...)
> >
> > I found the mixed use of the same member names having different
> > meanings to be quite confusing.
> >
> > e.g.1
> > PGOutputData 'streaming' is now a single char internal representation
> > the subscription parameter streaming mode ('f','t','p')
> > - bool streaming;
> > + char streaming;
> >
> > e.g.2
> > WalRcvStreamOptions 'streaming' is a C string version of the
> > subscription streaming mode ("on", "parallel")
> > - bool streaming; /* Streaming of large transactions */
> > + char *streaming; /* Streaming of large transactions */
> >
> > e.g.3
> > SubOpts 'streaming' is again like the first example - a single char
> > for the mode.
> > - bool streaming;
> > + char streaming;
> >
> >
> > IMO everything would become much simpler if you did:
> >
> > 3a.
> > Rename "char streaming;" -> "char streaming_mode;"
> >
> > 3b.
> > Re-designed the "char *streaming;" code to also use the single char
> > notation, then also call that member 'streaming_mode'. Then everything
> > will be consistent.
> >
>
> Won't this impact the previous version publisher which already uses
> on/off? We may need to maintain multiple values which would be
> confusing.
>
I only meant that the *internal* struct member names mentioned could
change - not anything exposed as user-visible parameter names or
column names etc. Or were you referring to it as causing unnecessary
troubles for back-patching? Anyway, the main point of this review
comment was #3b. Unless I am mistaken, there is no reason why that one
cannot be changed to use 'char' instead of 'char *', for consistency
across all the same named members.
> >
> > 9. - parallel_apply_can_start
> >
> > +/*
> > + * Returns true, if it is allowed to start a parallel apply worker, false,
> > + * otherwise.
> > + */
> > +static bool
> > +parallel_apply_can_start(TransactionId xid)
> >
> > (The commas are strange)
> >
> > SUGGESTION
> > Returns true if it is OK to start a parallel apply worker, false otherwise.
> >
>
> +1 for this.
> >
> > 28. - logicalrep_worker_detach
> >
> > + /* Stop the parallel apply workers. */
> > + if (am_leader_apply_worker())
> > + {
> >
> > Should that comment rather say like below?
> >
> > /* If this is the leader apply worker then stop all of its parallel
> > apply workers. */
> >
>
> I think this would be just saying what is apparent from the code, so
> not sure if it is an improvement.
>
> >
> > 38. - apply_handle_commit_prepared
> >
> > + *
> > + * Note that we don't need to wait here if the transaction was prepared in a
> > + * parallel apply worker. Because we have already waited for the prepare to
> > + * finish in apply_handle_stream_prepare() which will ensure all the operations
> > + * in that transaction have happened in the subscriber and no concurrent
> > + * transaction can create deadlock or transaction dependency issues.
> > */
> > static void
> > apply_handle_commit_prepared(StringInfo s)
> >
> > "worker. Because" -> "worker because"
> >
>
> I think this will make this line too long. Can we think of breaking it
> in some way?
OK, how about below:
Note that we don't need to wait here if the transaction was prepared
in a parallel apply worker. In that case, we have already waited for
the prepare to finish in apply_handle_stream_prepare() which will
ensure all the operations in that transaction have happened in the
subscriber, so no concurrent transaction can cause deadlock or
transaction dependency issues.
>
> >
> > 43.
> >
> > /*
> > - * Initialize the worker's stream_fileset if we haven't yet. This will be
> > - * used for the entire duration of the worker so create it in a permanent
> > - * context. We create this on the very first streaming message from any
> > - * transaction and then use it for this and other streaming transactions.
> > - * Now, we could create a fileset at the start of the worker as well but
> > - * then we won't be sure that it will ever be used.
> > + * For the first stream start, check if there is any free parallel apply
> > + * worker we can use to process this transaction.
> > */
> > - if (MyLogicalRepWorker->stream_fileset == NULL)
> > + if (first_segment)
> > + parallel_apply_start_worker(stream_xid);
> >
> > This comment update seems misleading. The
> > parallel_apply_start_worker() isn't just checking if there is a free
> > worker. All that free worker logic stuff is *inside* the
> > parallel_apply_start_worker() function, so maybe no need to mention
> > about it here at the caller.
> >
>
> It will be good to have some comments here instead of completely removing it.
>
> >
> > 39. - apply_handle_stream_abort
> >
> > + /* We receive abort information only when we can apply in parallel. */
> > + if (MyLogicalRepWorker->parallel_apply)
> > + read_abort_info = true;
> >
> > 44a.
> > SUGGESTION
> > We receive abort information only when the publisher can support parallel apply.
> >
>
> The existing comment seems better to me in this case.
>
> >
> > 55. - LogicalRepWorker
> >
> > + /* Indicates whether apply can be performed parallelly. */
> > + bool parallel_apply;
> > +
> >
> > 55a.
> > "parallelly" - ?? is there a better way to phrase this? IMO that is an
> > uncommon word.
> >
>
> How about ".. can be performed in parallel."?
>
> > ~
> >
> > 55b.
> > IMO this member name should be named slightly different to give a
> > better feel for what it really means.
> >
> > Maybe something like one of:
> > "parallel_apply_ok"
> > "parallel_apply_enabled"
> > "use_parallel_apply"
> > etc?
> >
>
> The extra word doesn't seem to be useful here.
>
> > 58.
> >
> > --- fail - streaming must be boolean
> > +-- fail - streaming must be boolean or 'parallel'
> > CREATE SUBSCRIPTION regress_testsub CONNECTION
> > 'dbname=regress_doesnotexist' PUBLICATION testpub WITH (connect =
> > false, streaming = foo);
> >
> > I think there are tests already for explicitly create/set the
> > subscription parameter streaming = on/off/parallel
> >
> > But what about when there is no value explicitly specified? Shouldn't
> > there also be tests like below to check that *implied* boolean true
> > still works for this enum?
> >
> > CREATE SUBSCRIPTION ... WITH (streaming)
> > ALTER SUBSCRIPTION ... SET (streaming)
> >
>
> I think before adding new tests for this, please check if we have any
> similar tests for other boolean options.
IMO this one is a bit different because it's not really a boolean
option anymore - it's a kind of a hybrid boolean/enum. That's why I
thought this ought to be tested regardless if there are existing tests
for the (normal) boolean options.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Thu, Oct 6, 2022 at 9:04 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
>
>
> > -----Original Message-----
> > From: Masahiko Sawada <sawada.mshk@gmail.com>
> > Sent: Thursday, October 6, 2022 4:07 PM
> > To: Hou, Zhijie/侯 志杰 <houzj.fnst@fujitsu.com>
> > Cc: Amit Kapila <amit.kapila16@gmail.com>; Wang, Wei/王 威
> > <wangw.fnst@fujitsu.com>; Peter Smith <smithpb2250@gmail.com>; Dilip
> > Kumar <dilipbalaut@gmail.com>; Shi, Yu/侍 雨 <shiy.fnst@fujitsu.com>;
> > PostgreSQL Hackers <pgsql-hackers@lists.postgresql.org>
> > Subject: Re: Perform streaming logical transactions by background workers and
> > parallel apply
> >
> > On Tue, Sep 27, 2022 at 9:26 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Saturday, September 24, 2022 7:40 PM Amit Kapila
> > <amit.kapila16@gmail.com> wrote:
> > > >
> > > > On Thu, Sep 22, 2022 at 3:41 PM Amit Kapila <amit.kapila16@gmail.com>
> > > > wrote:
> > > > >
> > > > > On Thu, Sep 22, 2022 at 8:59 AM wangw.fnst@fujitsu.com
> > > > > <wangw.fnst@fujitsu.com> wrote:
> > > > > >
> > > > >
> > > > > Few comments on v33-0001
> > > > > =======================
> > > > >
> > > >
> > > > Some more comments on v33-0001
> > > > =============================
> > > > 1.
> > > > + /* Information from the corresponding LogicalRepWorker slot. */
> > > > + uint16 logicalrep_worker_generation;
> > > > +
> > > > + int logicalrep_worker_slot_no;
> > > > +} ParallelApplyWorkerShared;
> > > >
> > > > Both these variables are read/changed by leader/parallel workers without
> > > > using any lock (mutex). It seems currently there is no problem because of
> > the
> > > > way the patch is using in_parallel_apply_xact but I think it won't be a good
> > idea
> > > > to rely on it. I suggest using mutex to operate on these variables and also
> > check
> > > > if the slot_no is in a valid range after reading it in parallel_apply_free_worker,
> > > > otherwise error out using elog.
> > >
> > > Changed.
> > >
> > > > 2.
> > > > static void
> > > > apply_handle_stream_stop(StringInfo s)
> > > > {
> > > > - if (!in_streamed_transaction)
> > > > + ParallelApplyWorkerInfo *winfo = NULL; TransApplyAction apply_action;
> > > > +
> > > > + if (!am_parallel_apply_worker() &&
> > > > + (!in_streamed_transaction && !stream_apply_worker))
> > > > ereport(ERROR,
> > > > (errcode(ERRCODE_PROTOCOL_VIOLATION),
> > > > errmsg_internal("STREAM STOP message without STREAM START")));
> > > >
> > > > This check won't be able to detect missing stream start messages for parallel
> > > > apply workers apart from the first pair of start/stop. I thought of adding
> > > > in_remote_transaction check along with
> > > > am_parallel_apply_worker() to detect the same but that also won't work
> > > > because the parallel worker doesn't reset it at the stop message.
> > > > Another possibility is to introduce yet another variable for this but that
> > doesn't
> > > > seem worth it. I would like to keep this check simple.
> > > > Can you think of any better way?
> > >
> > > I feel we can reuse the in_streamed_transaction in parallel apply worker to
> > > simplify the check there. I tried to set this flag in parallel apply worker
> > > when stream starts and reset it when stream stop so that we can directly check
> > > this flag for duplicate stream start message and other related things.
> > >
> > > > 3. I think we can skip sending start/stop messages from the leader to the
> > > > parallel worker because unlike apply worker it will process only one
> > > > transaction-at-a-time. However, it is not clear whether that is worth the
> > effort
> > > > because it is sent after logical_decoding_work_mem changes. For now, I have
> > > > added a comment for this in the attached patch but let me if I am missing
> > > > something or if I am wrong.
> > >
> > > I the suggested comments look good.
> > >
> > > > 4.
> > > > postgres=# select pid, leader_pid, application_name, backend_type from
> > > > pg_stat_activity;
> > > > pid | leader_pid | application_name | backend_type
> > > > -------+------------+------------------+------------------------------
> > > > 27624 | | | logical replication launcher
> > > > 17336 | | psql | client backend
> > > > 26312 | | | logical replication worker
> > > > 26376 | | psql | client backend
> > > > 14004 | | | logical replication worker
> > > >
> > > > Here, the second worker entry is for the parallel worker. Isn't it better if we
> > > > distinguish this by keeping type as a logical replication parallel worker? I
> > think
> > > > for this you need to change bgw_type in logicalrep_worker_launch().
> > >
> > > Changed.
> > >
> > > > 5. Can we name parallel_apply_subxact_info_add() as
> > > > parallel_apply_start_subtrans()?
> > > >
> > > > Apart from the above, I have added/edited a few comments and made a few
> > > > other cosmetic changes in the attached.
> > >
> >
> > While looking at v35 patch, I realized that there are some cases where
> > the logical replication gets stuck depending on partitioned table
> > structure. For instance, there are following tables, publication, and
> > subscription:
> >
> > * On publisher
> > create table p (c int) partition by list (c);
> > create table c1 partition of p for values in (1);
> > create table c2 (c int);
> > create publication test_pub for table p, c1, c2 with
> > (publish_via_partition_root = 'true');
> >
> > * On subscriber
> > create table p (c int) partition by list (c);
> > create table c1 partition of p for values In (2);
> > create table c2 partition of p for values In (1);
> > create subscription test_sub connection 'port=5551 dbname=postgres'
> > publication test_pub with (streaming = 'parallel', copy_data =
> > 'false');
> >
> > Note that while both the publisher and the subscriber have the same
> > name tables the partition structure is different and rows go to a
> > different table on the subscriber (eg, row c=1 will go to c2 table on
> > the subscriber). If two current transactions are executed as follows,
> > the apply worker (ig, the leader apply worker) waits for a lock on c2
> > held by its parallel apply worker:
> >
> > * TX-1
> > BEGIN;
> > INSERT INTO p SELECT 1 FROM generate_series(1, 10000); --- changes are
> > streamed
> >
> > * TX-2
> > BEGIN;
> > TRUNCATE c2; --- wait for a lock on c2
> >
> > * TX-1
> > INSERT INTO p SELECT 1 FROM generate_series(1, 10000);
> > COMMIT;
> >
> > This might not be a common case in practice but it could mean that
> > there is a restriction on how partitioned tables should be structured
> > on the publisher and the subscriber when using streaming = 'parallel'.
> > When this happens, since the logical replication cannot move forward
> > the users need to disable parallel-apply mode or increase
> > logical_decoding_work_mem. We could describe this limitation in the
> > doc but it would be hard for users to detect problematic table
> > structure.
>
> Thanks for testing this!
>
> I think the root reason for this kind of deadlock problems is the table
> structure difference between publisher and subscriber(similar to the unique
> difference reported earlier[1]). So, I think we'd better disallow this case. For
> example to avoid the reported problem, we could only support parallel apply if
> pubviaroot is false on publisher and replicated tables' types(relkind) are the
> same between publisher and subscriber.
>
> Although it might restrict some use cases, but I think it only restrict the
> cases when the partitioned table's structure is different between publisher and
> subscriber. User can still use parallel apply for cases when the table
> structure is the same between publisher and subscriber which seems acceptable
> to me. And we can also document that the feature is expected to be used for the
> case when tables' structure are the same. Thoughts ?
I'm concerned that it could be a big restriction for users. Having
different partitioned table's structures on the publisher and the
subscriber is quite common use cases.
From the feature perspective, the root cause seems to be the fact that
the apply worker does both receiving and applying changes. Since it
cannot receive the subsequent messages while waiting for a lock on a
table, the parallel apply worker also cannot move forward. If we have
a dedicated receiver process, it can off-load the messages to the
worker while another process waiting for a lock. So I think that
separating receiver and apply worker could be a building block for
parallel-apply.
Regards,
--
Masahiko Sawada
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Oct 7, 2022 at 8:47 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Thu, Oct 6, 2022 at 9:04 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > I think the root reason for this kind of deadlock problems is the table > > structure difference between publisher and subscriber(similar to the unique > > difference reported earlier[1]). So, I think we'd better disallow this case. For > > example to avoid the reported problem, we could only support parallel apply if > > pubviaroot is false on publisher and replicated tables' types(relkind) are the > > same between publisher and subscriber. > > > > Although it might restrict some use cases, but I think it only restrict the > > cases when the partitioned table's structure is different between publisher and > > subscriber. User can still use parallel apply for cases when the table > > structure is the same between publisher and subscriber which seems acceptable > > to me. And we can also document that the feature is expected to be used for the > > case when tables' structure are the same. Thoughts ? > > I'm concerned that it could be a big restriction for users. Having > different partitioned table's structures on the publisher and the > subscriber is quite common use cases. > > From the feature perspective, the root cause seems to be the fact that > the apply worker does both receiving and applying changes. Since it > cannot receive the subsequent messages while waiting for a lock on a > table, the parallel apply worker also cannot move forward. If we have > a dedicated receiver process, it can off-load the messages to the > worker while another process waiting for a lock. So I think that > separating receiver and apply worker could be a building block for > parallel-apply. > I think the disadvantage that comes to mind is the overhead of passing messages between receiver and applier processes even for non-parallel cases. Now, I don't think it is advisable to have separate handling for non-parallel cases. The other thing is that we need to someway deal with feedback messages which helps to move synchronous replicas and update subscriber's progress which in turn helps to keep the restart point updated. These messages also act as heartbeat messages between walsender and walapply process. To deal with this, one idea is that we can have two connections to walsender process, one with walreceiver and the other with walapply process which according to me could lead to a big increase in resource consumption and it will bring another set of complexities in the system. Now, in this, I think we have two possibilities, (a) The first one is that we pass all messages to the leader apply worker and then it decides whether to execute serially or pass it to the parallel apply worker. However, that can again deadlock in the truncate scenario we discussed because the main apply worker won't be able to receive new messages once it is blocked at the truncate command. (b) The second one is walreceiver process itself takes care of passing streaming transactions to parallel apply workers but if we do that then walreceiver needs to wait at the transaction end to maintain commit order which means it can also lead to deadlock in case the truncate happens in a streaming xact. The other alternative is that we allow walreceiver process to wait for apply process to finish transaction and send the feedback but that seems to be again an overhead if we have to do it even for small transactions, especially it can delay sync replication cases. Even, if we don't consider overhead, it can still lead to a deadlock because walreceiver won't be able to move in the scenario we are discussing. About your point that having different partition structures for publisher and subscriber, I don't know how common it will be once we have DDL replication. Also, the default value of publish_via_partition_root is false which doesn't seem to indicate that this is a quite common case. We have fixed quite a few issues in this area in the last release or two which were found during development, so not sure if these are used quite often in the field but it could just be a coincidence. Also, it will only matter if there are large transactions that perform on such tables which I don't think will be easy to predict whether those are common or not. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Oct 7, 2022 at 8:38 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Thu, Oct 6, 2022 at 10:38 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Fri, Sep 30, 2022 at 1:56 PM Peter Smith <smithpb2250@gmail.com> wrote:
> > >
> > > Here are my review comments for the v35-0001 patch:
> > >
> > > ======
> > >
> > > 3. GENERAL
> > >
> > > (this comment was written after I wrote all the other ones below so
> > > there might be some unintended overlaps...)
> > >
> > > I found the mixed use of the same member names having different
> > > meanings to be quite confusing.
> > >
> > > e.g.1
> > > PGOutputData 'streaming' is now a single char internal representation
> > > the subscription parameter streaming mode ('f','t','p')
> > > - bool streaming;
> > > + char streaming;
> > >
> > > e.g.2
> > > WalRcvStreamOptions 'streaming' is a C string version of the
> > > subscription streaming mode ("on", "parallel")
> > > - bool streaming; /* Streaming of large transactions */
> > > + char *streaming; /* Streaming of large transactions */
> > >
> > > e.g.3
> > > SubOpts 'streaming' is again like the first example - a single char
> > > for the mode.
> > > - bool streaming;
> > > + char streaming;
> > >
> > >
> > > IMO everything would become much simpler if you did:
> > >
> > > 3a.
> > > Rename "char streaming;" -> "char streaming_mode;"
> > >
> > > 3b.
> > > Re-designed the "char *streaming;" code to also use the single char
> > > notation, then also call that member 'streaming_mode'. Then everything
> > > will be consistent.
> > >
> >
> > Won't this impact the previous version publisher which already uses
> > on/off? We may need to maintain multiple values which would be
> > confusing.
> >
>
> I only meant that the *internal* struct member names mentioned could
> change - not anything exposed as user-visible parameter names or
> column names etc. Or were you referring to it as causing unnecessary
> troubles for back-patching? Anyway, the main point of this review
> comment was #3b.
>
My response was for 3b only.
> Unless I am mistaken, there is no reason why that one
> cannot be changed to use 'char' instead of 'char *', for consistency
> across all the same named members.
>
I feel this will bring more complexity to the code if you have to keep
it working with old-version publishers.
> > >
> > > 9. - parallel_apply_can_start
> > >
> > > +/*
> > > + * Returns true, if it is allowed to start a parallel apply worker, false,
> > > + * otherwise.
> > > + */
> > > +static bool
> > > +parallel_apply_can_start(TransactionId xid)
> > >
> > > (The commas are strange)
> > >
> > > SUGGESTION
> > > Returns true if it is OK to start a parallel apply worker, false otherwise.
> > >
> >
> > +1 for this.
> > >
> > > 28. - logicalrep_worker_detach
> > >
> > > + /* Stop the parallel apply workers. */
> > > + if (am_leader_apply_worker())
> > > + {
> > >
> > > Should that comment rather say like below?
> > >
> > > /* If this is the leader apply worker then stop all of its parallel
> > > apply workers. */
> > >
> >
> > I think this would be just saying what is apparent from the code, so
> > not sure if it is an improvement.
> >
> > >
> > > 38. - apply_handle_commit_prepared
> > >
> > > + *
> > > + * Note that we don't need to wait here if the transaction was prepared in a
> > > + * parallel apply worker. Because we have already waited for the prepare to
> > > + * finish in apply_handle_stream_prepare() which will ensure all the operations
> > > + * in that transaction have happened in the subscriber and no concurrent
> > > + * transaction can create deadlock or transaction dependency issues.
> > > */
> > > static void
> > > apply_handle_commit_prepared(StringInfo s)
> > >
> > > "worker. Because" -> "worker because"
> > >
> >
> > I think this will make this line too long. Can we think of breaking it
> > in some way?
>
> OK, how about below:
>
> Note that we don't need to wait here if the transaction was prepared
> in a parallel apply worker. In that case, we have already waited for
> the prepare to finish in apply_handle_stream_prepare() which will
> ensure all the operations in that transaction have happened in the
> subscriber, so no concurrent transaction can cause deadlock or
> transaction dependency issues.
>
Yeah, this looks better.
> >
> > > 58.
> > >
> > > --- fail - streaming must be boolean
> > > +-- fail - streaming must be boolean or 'parallel'
> > > CREATE SUBSCRIPTION regress_testsub CONNECTION
> > > 'dbname=regress_doesnotexist' PUBLICATION testpub WITH (connect =
> > > false, streaming = foo);
> > >
> > > I think there are tests already for explicitly create/set the
> > > subscription parameter streaming = on/off/parallel
> > >
> > > But what about when there is no value explicitly specified? Shouldn't
> > > there also be tests like below to check that *implied* boolean true
> > > still works for this enum?
> > >
> > > CREATE SUBSCRIPTION ... WITH (streaming)
> > > ALTER SUBSCRIPTION ... SET (streaming)
> > >
> >
> > I think before adding new tests for this, please check if we have any
> > similar tests for other boolean options.
>
> IMO this one is a bit different because it's not really a boolean
> option anymore - it's a kind of a hybrid boolean/enum. That's why I
> thought this ought to be tested regardless if there are existing tests
> for the (normal) boolean options.
>
I am not really sure if adding such tests are valuable but if Hou-San
and you feel it is good to have it then I am fine with it.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, October 6, 2022 8:40 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote:
>
> Dear Hou,
>
> I put comments for v35-0001.
Thanks for the comments.
> 01. catalog.sgml
>
> ```
> + Controls how to handle the streaming of in-progress transactions:
> + <literal>f</literal> = disallow streaming of in-progress transactions,
> + <literal>t</literal> = spill the changes of in-progress transactions to
> + disk and apply at once after the transaction is committed on the
> + publisher,
> + <literal>p</literal> = apply changes directly using a parallel apply
> + worker if available (same as 't' if no worker is available)
> ```
>
> I'm not sure why 't' means "spill the changes to file". Is it compatibility issue?
Yes, I think it would be better to be consistent with previous version.
> ~~~
> 02. applyworker.c - parallel_apply_stream_abort
>
> The argument abort_data is not modified in the function. Maybe "const"
> modifier should be added.
> (Other functions should be also checked...)
I am not sure is it necessary to add the const here as I didn’t
find many similar style codes.
> ~~~
> 03. applyparallelworker.c - parallel_apply_find_worker
>
> ```
> + ParallelApplyWorkerEntry *entry = NULL;
> ```
>
> This may not have to be initialized here.
Fixed.
> ~~~
> 04. applyparallelworker.c - HandleParallelApplyMessages
>
> ```
> + static MemoryContext hpm_context = NULL;
> ```
>
> I think "hpm" means "handle parallel message", so it should be "hpam".
Fixed.
> ~~~
> 05. launcher.c - logicalrep_worker_launch()
>
> ```
> if (is_subworker)
> snprintf(bgw.bgw_type, BGW_MAXLEN, "logical replication
> parallel worker");
> else
> snprintf(bgw.bgw_type, BGW_MAXLEN, "logical replication
> worker"); ```
>
> I'm not sure why there are only bgw_type even if there are three types of apply
> workers. Is it for compatibility?
Yeah, It's for compatibility.
> ~~~
> 06. launcher.c - logicalrep_worker_stop_by_slot
>
> An assertion like Assert(slot_no >=0 && slot_no <
> max_logical_replication_workers) should be added at the top of this function.
>
Fixed.
> ~~~
> 07. launcher.c - logicalrep_worker_stop_internal
>
> ```
> +/*
> + * Workhorse for logicalrep_worker_stop(), logicalrep_worker_detach()
> +and
> + * logicalrep_worker_stop_by_slot(). Stop the worker and wait for it to die.
> + */
> +static void
> +logicalrep_worker_stop_internal(LogicalRepWorker *worker)
> ```
>
> I think logicalrep_worker_stop_internal() may be not "Workhorse" for
> logicalrep_worker_detach(). In the function internal function is called for
> parallel apply worker, and it does not main part of the detach function.
>
> ~~~
> 08. worker.c - handle_streamed_transaction()
>
> ```
> + TransactionId current_xid = InvalidTransactionId;
> ```
>
> This initialization is not needed. This is not used in non-streaming mode,
> otherwise it is substituted before used.
Fixed.
> ~~~
> 09. worker.c - handle_streamed_transaction()
>
> ```
> + case TRANS_PARALLEL_APPLY:
> + /* Define a savepoint for a subxact if needed. */
> + parallel_apply_start_subtrans(current_xid, stream_xid);
> + return false;
> ```
>
> Based on other case-block, Assert(am_parallel_apply_worker()) may be added
> at the top of this part.
> This suggestion can be said for other swith-case statements.
I feel the apply_action is returned by the nearby
get_transaction_apply_action() function call which means it can only be in
parallel apply worker here. So, I am not sure if the assert is necessary or not.
> ~~~
> 10. worker.c - apply_handle_stream_start
>
> ```
> + *
> + * XXX We can avoid sending pair of the START/STOP messages to the
> + parallel
> + * worker because unlike apply worker it will process only one
> + * transaction-at-a-time. However, it is not clear whether that is
> + worth the
> + * effort because it is sent after logical_decoding_work_mem changes.
> ```
>
> I can understand that START message is not needed, but is STOP really
> removable? If leader does not send STOP to its child, does it lose a chance to
> change the worker-state to IDLE_IN_TRANSACTION?
Fixed.
> ~~~
> 11. worker.c - apply_handle_stream_start
>
> Currently the number of received chunks have not counted, but it can do if a
> variable "nchunks" is defined and incremented in apply_handle_stream_start().
> This this info may be useful to determine appropriate
> logical_decoding_work_mem for workloads. How do you think?
Since we don't have similar DEBUG message for "streaming=on" mode, so I feel
maybe we can leave this for now and add them later as a separate patch if needed.
> ~~~
> 12. worker.c - get_transaction_apply_action
>
> {} are not needed.
I am fine with either style here, so I didn’t change this.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, September 30, 2022 4:27 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are my review comments for the v35-0001 patch:
Thanks for the comments.
> 3. GENERAL
> I found the mixed use of the same member names having different meanings to be quite confusing.
>
> e.g.1
> PGOutputData 'streaming' is now a single char internal representation the subscription parameter streaming mode
('f','t','p')
> - bool streaming;
> + char streaming;
>
> e.g.2
> WalRcvStreamOptions 'streaming' is a C string version of the subscription streaming mode ("on", "parallel")
> - bool streaming; /* Streaming of large transactions */
> + char *streaming; /* Streaming of large transactions */
>
> e.g.3
> SubOpts 'streaming' is again like the first example - a single char for the mode.
> - bool streaming;
> + char streaming;
>
>
> IMO everything would become much simpler if you did:
>
> 3a.
> Rename "char streaming;" -> "char streaming_mode;"
The word 'streaming' is the same as the actual option name, so personally I think it's fine.
But if others also agreed that the name can be improved, I can change it.
>
> 3b. Re-designed the "char *streaming;" code to also use the single char
> notation, then also call that member 'streaming_mode'. Then everything will
> be > consistent.
If we use single byte(char) here we would need to compare it with the standard
streaming option value in libpqwalreceiver.c which was suggested not to do[1].
> 4. - max_parallel_apply_workers_per_subscription
> + </para>
> + <para>
> + The parallel apply workers are taken from the pool defined by
> + <varname>max_logical_replication_workers</varname>.
> + </para>
> + <para>
> + The default value is 2. This parameter can only be set in the
> + <filename>postgresql.conf</filename> file or on the server command
> + line.
> + </para>
> + </listitem>
> + </varlistentry>
>
> I felt that maybe this should also xref to the
> doc/src/sgml/logical-replication.sgml section where you say about
> "max_logical_replication_workers should be increased according to the
> desired number of parallel apply workers."
Not sure about this as we don't have similar thing in the document of
max_logical_replication_workers and max_sync_workers_per_subscription.
> ======
>
> 7. src/backend/access/transam/xact.c - RecordTransactionAbort
>
>
> + /*
> + * Are we using the replication origins feature? Or, in other words,
> + are
> + * we replaying remote actions?
> + */
> + replorigin = (replorigin_session_origin != InvalidRepOriginId &&
> + replorigin_session_origin != DoNotReplicateId);
>
> "Or, in other words," -> "In other words,"
I think it is better to keep consistent with the comments in function
RecordTransactionCommit.
> 10b.
> IMO this flag might be better to be called 'parallel_apply_enabled' or something similar.
> (see also review comment #55b.)
Not sure about this.
> 12. - parallel_apply_free_worker
>
> + SpinLockAcquire(&winfo->shared->mutex);
> + slot_no = winfo->shared->logicalrep_worker_slot_no;
> + generation = winfo->shared->logicalrep_worker_generation;
> + SpinLockRelease(&winfo->shared->mutex);
>
> I know there are not many places doing this, but do you think it might be
> worth introducing some new set/get function to encapsulate the set/get of the
> >generation/slot so it does the mutex spin-locks in common code?
Not sure about this.
> 13. - LogicalParallelApplyLoop
>
> + /*
> + * Init the ApplyMessageContext which we clean up after each
> + replication
> + * protocol message.
> + */
> + ApplyMessageContext = AllocSetContextCreate(ApplyContext,
> + "ApplyMessageContext",
> + ALLOCSET_DEFAULT_SIZES);
>
> Because this is in the parallel apply worker should the name (e.g. the 2nd
> param) be changed to "ParallelApplyMessageContext"?
Not sure about this, because ApplyMessageContext is used in both worker.c and
applyparallelworker.c.
> + else if (is_subworker)
> + snprintf(bgw.bgw_name, BGW_MAXLEN,
> + "logical replication parallel apply worker for subscription %u",
> + subid);
> else
> snprintf(bgw.bgw_name, BGW_MAXLEN,
> "logical replication worker for subscription %u", subid);
>
> I think that *last* text now be changed like below:
>
> BEFORE
> "logical replication worker for subscription %u"
> AFTER
> "logical replication apply worker for subscription %u"
I am not sure if it's a good idea to change existing process description.
> 36 - should_apply_changes_for_rel
> should_apply_changes_for_rel(LogicalRepRelMapEntry *rel) {
> if (am_tablesync_worker())
> return MyLogicalRepWorker->relid == rel->localreloid;
> + else if (am_parallel_apply_worker())
> + {
> + if (rel->state != SUBREL_STATE_READY)
> + ereport(ERROR,
> + (errmsg("logical replication apply workers for subscription \"%s\"
> will restart",
> + MySubscription->name),
> + errdetail("Cannot handle streamed replication transaction using parallel "
> + "apply workers until all tables are synchronized.")));
> +
> + return true;
> + }
> else
> return (rel->state == SUBREL_STATE_READY ||
> (rel->state == SUBREL_STATE_SYNCDONE && @@ -427,43 +519,87 @@ end_replication_step(void)
>
> This function can be made tidier just by removing all the 'else' ...
I feel the current style looks better.
> 40. - apply_handle_stream_prepare
>
> + case TRANS_LEADER_SERIALIZE:
>
> - /* Mark the transaction as prepared. */
> - apply_handle_prepare_internal(&prepare_data);
> + /*
> + * The transaction has been serialized to file, so replay all the
> + * spooled operations.
> + */
>
> Spurious blank line after the 'case'.
Personally, I think this style is fine.
> 48. - ApplyWorkerMain
>
> +/* Logical Replication Apply worker entry point */ void
> +ApplyWorkerMain(Datum main_arg)
>
> "Apply worker" -> "apply worker"
Since it's the existing comment, I feel we can leave this.
> + /*
> + * We don't currently need any ResourceOwner in a walreceiver process,
> + but
> + * if we did, we could call CreateAuxProcessResourceOwner here.
> + */
>
> I think this comment should have "XXX" prefix.
I am not sure as this comment is just a reminder.
> 50.
>
> + if (server_version >= 160000 &&
> + MySubscription->stream == SUBSTREAM_PARALLEL)
> + {
> + options.proto.logical.streaming = pstrdup("parallel");
> + MyLogicalRepWorker->parallel_apply = true;
> + }
> + else if (server_version >= 140000 &&
> + MySubscription->stream != SUBSTREAM_OFF)
> + options.proto.logical.streaming = pstrdup("on"); else
> + options.proto.logical.streaming = NULL;
>
> IMO it might make more sense for these conditions to be checking the
> 'options.proto.logical.proto_version' here instead of checking the hardwired
> server > versions. Also, I suggest may be better (for clarity) to always
> assign the parallel_apply member.
Currently, the proto_version is only checked at publisher, I am not sure if
it's a good idea to check it here.
> 52. - get_transaction_apply_action
>
> + /*
> + * Check if we are processing this transaction using a parallel apply
> + * worker and if so, send the changes to that worker.
> + */
> + else if ((*winfo = parallel_apply_find_worker(xid))) { return
> +TRANS_LEADER_SEND_TO_PARALLEL; } else { return
> +TRANS_LEADER_SERIALIZE; } }
>
> 52a.
> All these if/else and code blocks seem excessive. It can be simplified as follows:
I feel this style is fine.
> 52b.
> Can a tablesync worker ever get here? It might be better to
> Assert(!am_tablesync_worker()); at top of this function?
Not sure if it's necessary or not.
> 55b.
> IMO this member name should be named slightly different to give a better feel
> for what it really means.
>
> Maybe something like one of:
> "parallel_apply_ok"
> "parallel_apply_enabled"
> "use_parallel_apply"
> etc?
I feel the current name is fine. But if others also feel the same, I can try to
rename it.
> 57. - am_leader_apply_worker
>
> +static inline bool
> +am_leader_apply_worker(void)
> +{
> + return (!OidIsValid(MyLogicalRepWorker->relid) &&
> +!isParallelApplyWorker(MyLogicalRepWorker));
> +}
>
> I wondered if it would be tidier/easier to define this function like below.
> The others are inline functions anyhow so it should end up as the same >
> thing, right?
>
> static inline bool
> am_leader_apply_worker(void)
> {
> return (!am_tablesync_worker() && !am_parallel_apply_worker); }
I feel the current style is fine.
>--- fail - streaming must be boolean
>+-- fail - streaming must be boolean or 'parallel'
> CREATE SUBSCRIPTION regress_testsub CONNECTION 'dbname=regress_doesnotexist' PUBLICATION testpub WITH (connect =
>false,streaming = foo);
>
>I think there are tests already for explicitly create/set the subscription
>parameter streaming = on/off/parallel
>
>But what about when there is no value explicitly specified? Shouldn't there
>also be tests like below to check that *implied* boolean true still works for
>this enum?
I didn't find similar tests for no value explicitly specified cases, so I didn't add this
for now.
Attach the new version patch set which addressed most of the comments.
[1] https://www.postgresql.org/message-id/CAA4eK1LMVdS6uM7Tw7ANL0BetAd76TKkmAXNNQa0haTe2tax6g%40mail.gmail.com
Best regards,
Hou zj
Attachment
- v36-0002-Test-streaming-parallel-option-in-tap-test.patch
- v36-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v36-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v36-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v36-0001-Perform-streaming-logical-transactions-by-parall.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Fri, Oct 7, 2022 at 2:00 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Oct 7, 2022 at 8:47 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Thu, Oct 6, 2022 at 9:04 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > I think the root reason for this kind of deadlock problems is the table > > > structure difference between publisher and subscriber(similar to the unique > > > difference reported earlier[1]). So, I think we'd better disallow this case. For > > > example to avoid the reported problem, we could only support parallel apply if > > > pubviaroot is false on publisher and replicated tables' types(relkind) are the > > > same between publisher and subscriber. > > > > > > Although it might restrict some use cases, but I think it only restrict the > > > cases when the partitioned table's structure is different between publisher and > > > subscriber. User can still use parallel apply for cases when the table > > > structure is the same between publisher and subscriber which seems acceptable > > > to me. And we can also document that the feature is expected to be used for the > > > case when tables' structure are the same. Thoughts ? > > > > I'm concerned that it could be a big restriction for users. Having > > different partitioned table's structures on the publisher and the > > subscriber is quite common use cases. > > > > From the feature perspective, the root cause seems to be the fact that > > the apply worker does both receiving and applying changes. Since it > > cannot receive the subsequent messages while waiting for a lock on a > > table, the parallel apply worker also cannot move forward. If we have > > a dedicated receiver process, it can off-load the messages to the > > worker while another process waiting for a lock. So I think that > > separating receiver and apply worker could be a building block for > > parallel-apply. > > > > I think the disadvantage that comes to mind is the overhead of passing > messages between receiver and applier processes even for non-parallel > cases. Now, I don't think it is advisable to have separate handling > for non-parallel cases. The other thing is that we need to someway > deal with feedback messages which helps to move synchronous replicas > and update subscriber's progress which in turn helps to keep the > restart point updated. These messages also act as heartbeat messages > between walsender and walapply process. > > To deal with this, one idea is that we can have two connections to > walsender process, one with walreceiver and the other with walapply > process which according to me could lead to a big increase in resource > consumption and it will bring another set of complexities in the > system. Now, in this, I think we have two possibilities, (a) The first > one is that we pass all messages to the leader apply worker and then > it decides whether to execute serially or pass it to the parallel > apply worker. However, that can again deadlock in the truncate > scenario we discussed because the main apply worker won't be able to > receive new messages once it is blocked at the truncate command. (b) > The second one is walreceiver process itself takes care of passing > streaming transactions to parallel apply workers but if we do that > then walreceiver needs to wait at the transaction end to maintain > commit order which means it can also lead to deadlock in case the > truncate happens in a streaming xact. I imagined (b) but I had missed the point of preserving the commit order. Separating the receiver and apply worker cannot resolve this problem. > > The other alternative is that we allow walreceiver process to wait for > apply process to finish transaction and send the feedback but that > seems to be again an overhead if we have to do it even for small > transactions, especially it can delay sync replication cases. Even, if > we don't consider overhead, it can still lead to a deadlock because > walreceiver won't be able to move in the scenario we are discussing. > > About your point that having different partition structures for > publisher and subscriber, I don't know how common it will be once we > have DDL replication. Also, the default value of > publish_via_partition_root is false which doesn't seem to indicate > that this is a quite common case. So how can we consider these concurrent issues that could happen only when streaming = 'parallel'? Can we restrict some use cases to avoid the problem or can we have a safeguard against these conflicts? We could find a new problematic scenario in the future and if it happens, logical replication gets stuck, it cannot be resolved only by apply workers themselves. Regards, -- Masahiko Sawada PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Fri, Oct 7, 2022 at 14:18 PM Hou, Zhijie/侯 志杰 <houzj.fnst@cn.fujitsu.com> wrote: > Attach the new version patch set which addressed most of the comments. Rebased the patch set because the new change in HEAD (776e1c8). Attach the new patch set. Regards, Wang wei
Attachment
- v37-0001-Perform-streaming-logical-transactions-by-parall.patch
- v37-0002-Test-streaming-parallel-option-in-tap-test.patch
- v37-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v37-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v37-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Oct 11, 2022 at 5:52 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Fri, Oct 7, 2022 at 2:00 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > About your point that having different partition structures for > > publisher and subscriber, I don't know how common it will be once we > > have DDL replication. Also, the default value of > > publish_via_partition_root is false which doesn't seem to indicate > > that this is a quite common case. > > So how can we consider these concurrent issues that could happen only > when streaming = 'parallel'? Can we restrict some use cases to avoid > the problem or can we have a safeguard against these conflicts? > Yeah, right now the strategy is to disallow parallel apply for such cases as you can see in *0003* patch. > We > could find a new problematic scenario in the future and if it happens, > logical replication gets stuck, it cannot be resolved only by apply > workers themselves. > I think users can change streaming option to on/off and internally the parallel apply worker can detect and restart to allow replication to proceed. Having said that, I think that would be a bug in the code and we should try to fix it. We may need to disable parallel apply in the problematic case. The other ideas that occurred to me in this regard are (a) provide a reloption (say parallel_apply) at table level and we can use that to bypass various checks like different Unique Key between publisher/subscriber, constraints/expressions having mutable functions, Foreign Key (when enabled on subscriber), operations on Partitioned Table. We can't detect whether those are safe or not (primarily because of a different structure in publisher and subscriber) so we prohibit parallel apply but if users use this option, we can allow it even in those cases. (b) While enabling the parallel option in the subscription, we can try to match all the table(s) information of the publisher/subscriber. It will be tricky to make this work because say even if match some trigger function name, we won't be able to match the function body. The other thing is when at a later point the table definition is changed on the subscriber, we need to again validate the information between publisher and subscriber which I think would be difficult as we would be already in between processing some message and getting information from the publisher at that stage won't be possible. Thoughts? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for v36-0001.
======
1. GENERAL
Houzj wrote ([1] #3a):
The word 'streaming' is the same as the actual option name, so
personally I think it's fine. But if others also agreed that the name
can be improved, I can change it.
~
Sure, I was not really complaining that the name is "wrong". Only I
did not think it was a good idea to have multiple struct members
called 'streaming' when they don't have the same meaning. e.g. one is
the internal character mode equivalent of the parameter, and one is
the parameter value as a string. That's why I thought they should be
different names. e.g. Make the 2nd one 'streaming_valstr' or
something.
======
2. doc/src/sgml/config.sgml
Previously I suggested there should be xrefsto the "Configuration
Settings" page but Houzj wrote ([1] #4):
Not sure about this as we don't have similar thing in the document of
max_logical_replication_workers and max_sync_workers_per_subscription.
~
Fair enough, but IMO perhaps all those others should also xref to the
"Configuration Settings" chapter. So if such a change does not belong
in this patch, then how about if I make another independent thread to
post this suggestion?
======
.../replication/logical/applyparallelworker.c
3. parallel_apply_find_worker
+parallel_apply_find_worker(TransactionId xid)
+{
+ bool found;
+ ParallelApplyWorkerEntry *entry = NULL;
+
+ if (!TransactionIdIsValid(xid))
+ return NULL;
+
+ if (ParallelApplyWorkersHash == NULL)
+ return NULL;
+
+ /* Return the cached parallel apply worker if valid. */
+ if (stream_apply_worker != NULL)
+ return stream_apply_worker;
+
+ /*
+ * Find entry for requested transaction.
+ */
+ entry = hash_search(ParallelApplyWorkersHash, &xid, HASH_FIND, &found);
In function parallel_apply_start_worker() you removed the entry
assignment to NULL because it is never needed. Can do the same here
too.
~~~
4. parallel_apply_free_worker
+/*
+ * Remove the parallel apply worker entry from the hash table. And stop the
+ * worker if there are enough workers in the pool. For more information about
+ * the worker pool, see comments atop worker.c.
+ */
+void
+parallel_apply_free_worker(ParallelApplyWorkerInfo *winfo, TransactionId xid)
"And stop" -> "Stop"
~~~
5. parallel_apply_free_worker
+ * Although some error messages may be lost in rare scenarios, but
+ * since the parallel apply worker has finished processing the
+ * transaction, and error messages may be lost even if we detach the
+ * error queue after terminating the process. So it should be ok.
+ */
SUGGESTION (minor rewording)
Some error messages may be lost in rare scenarios, but it should be OK
because the parallel apply worker has finished processing the
transaction, and error messages may be lost even if we detached the
error queue after terminating the process.
~~~
6. LogicalParallelApplyLoop
+ for (;;)
+ {
+ void *data;
+ Size len;
+ int c;
+ StringInfoData s;
+ MemoryContext oldctx;
+
+ CHECK_FOR_INTERRUPTS();
+
+ /* Ensure we are reading the data into our memory context. */
+ oldctx = MemoryContextSwitchTo(ApplyMessageContext);
+
...
+
+ MemoryContextSwitchTo(oldctx);
+ MemoryContextReset(ApplyMessageContext);
+ }
Do those memory context switches need to happen inside the for(;;)
loop like that? I thought perhaps those can be done *outside* of the
loop instead of always switching and switching back on the next
iteration.
~~~
7. LogicalParallelApplyLoop
Previous I suggested maybe the name (e.g. the 2nd param) should be
changed to "ParallelApplyMessageContext"? Houzj wrote ([1] #13): Not
sure about this, because ApplyMessageContext is used in both worker.c
and applyparallelworker.c.
~
But I thought those are completely independent ApplyMessageContext's
in different processes that happen to have the same name. Shouldn't
they have a name appropriate to who owns them?
~~~
8. ParallelApplyWorkerMain
+ /*
+ * Allocate the origin name in a long-lived context for error context
+ * message.
+ */
+ snprintf(originname, sizeof(originname), "pg_%u", MySubscription->oid);
Now that ReplicationOriginNameForLogicalRep patch is pushed [2] please
make use of this common function.
~~~
9. HandleParallelApplyMessage
+ case 'X': /* Terminate, indicating clean exit */
+ {
+ shm_mq_detach(winfo->error_mq_handle);
+ winfo->error_mq_handle = NULL;
+ break;
+ }
+
+ /*
+ * Don't need to do anything about NoticeResponse and
+ * NotifyResponse as the logical replication worker doesn't need
+ * to send messages to the client.
+ */
+ case 'N':
+ case 'A':
+ break;
+ default:
+ {
+ elog(ERROR, "unrecognized message type received from parallel apply
worker: %c (message length %d bytes)",
+ msgtype, msg->len);
+ }
9a. case 'X':
There are no variable declarations here so the statement block {} is not needed
~
9b. default:
There are no variable declarations here so the statement block {} is not needed
~~~
10. parallel_apply_stream_abort
+ int i;
+ bool found = false;
+ char spname[MAXPGPATH];
+
+ parallel_apply_savepoint_name(MySubscription->oid, subxid, spname,
+ sizeof(spname));
I posted about using NAMEDATALEN in a previous review ([3] #21) but I
think only one place was fixed and this one was missed.
~~~
11. parallel_apply_replorigin_setup
+ snprintf(originname, sizeof(originname), "pg_%u", MySubscription->oid);
+ originid = replorigin_by_name(originname, false);
+ replorigin_session_setup(originid);
+ replorigin_session_origin = originid;
Same as #8. Please call the new ReplicationOriginNameForLogicalRep function.
======
src/backend/replication/logical/launcher.c
12. logicalrep_worker_launch
Previously I suggested may the apply process name should change
FROM
"logical replication worker for subscription %u"
TO
"logical replication apply worker for subscription %u"
and Houz wrote ([1] #13)
I am not sure if it's a good idea to change existing process description.
~
But that seems inconsistent to me because elsewhere this patch is
already exposing the name to the user (like when it says "logical
replication apply worker for subscription \"%s\" has started".
Shouldn’t the process name match these logs?
======
src/backend/replication/logical/worker.c
13. apply_handle_stream_start
+ *
+ * XXX We can avoid sending pairs of the START messages to the parallel worker
+ * because unlike apply worker it will process only one transaction-at-a-time.
+ * However, it is not clear whether that is worth the effort because it is sent
+ * after logical_decoding_work_mem changes.
*/
static void
apply_handle_stream_start(StringInfo s)
13a.
"transaction-at-a-time." -> "transaction at a time."
~
13b.
I was not sure what does that last sentence mean? Does it mean something like:
"However, it is not clear whether doing this is worth the effort
because pairs of START messages occur only after
logical_decoding_work_mem changes."
~~~
14. apply_handle_stream_start
+ ParallelApplyWorkerInfo *winfo = NULL;
The declaration *winfo assignment to NULL is not needed because
get_transaction_apply_action will always do this anyway.
~~~
15. apply_handle_stream_start
+
+ case TRANS_PARALLEL_APPLY:
+ break;
I had previously suggested this include a comment explaining why there
is nothing to do ([3] #44), but I think there was no reply.
~~~
16. apply_handle_stream_stop
apply_handle_stream_stop(StringInfo s)
{
+ ParallelApplyWorkerInfo *winfo = NULL;
+ TransApplyAction apply_action
The declaration *winfo assignment to NULL is not needed because
get_transaction_apply_action will always do this anyway.
~~~
17. serialize_stream_abort
+ ParallelApplyWorkerInfo *winfo = NULL;
+ TransApplyAction apply_action;
The declaration *winfo assignment to NULL is not needed because
get_transaction_apply_action will always do this anyway.
~~~
18. apply_handle_stream_commit
LogicalRepCommitData commit_data;
+ ParallelApplyWorkerInfo *winfo = NULL;
+ TransApplyAction apply_action;
The declaration *winfo assignment to NULL is not needed because
get_transaction_apply_action will always do this anyway.
~~~
19. ApplyWorkerMain
+
+/* Logical Replication Apply worker entry point */
+void
+ApplyWorkerMain(Datum main_arg)
Previously I suugested changing "Apply worker" to "apply worker", and
Houzj ([1] #48) replied:
Since it's the existing comment, I feel we can leave this.
~
Normally I agree don't change the original code unrelated to the
patch, but in practice, I think no patch would be accepted that just
changes just "A" to "a", so if you don't change it here in this patch
to be consistent then it will never happen. That's why I think should
be part of this patch.
~~~
20. ApplyWorkerMain
+ /*
+ * We don't currently need any ResourceOwner in a walreceiver process, but
+ * if we did, we could call CreateAuxProcessResourceOwner here.
+ */
Previously I suggested prefixing this as "XXX" and Houzj replied ([1] #48):
I am not sure as this comment is just a reminder.
~
OK, then maybe since it is a reminder "Note" then it should be changed:
"We don't currently..." -> "Note: We don't currently..."
~~~
21. ApplyWorkerMain
+ if (server_version >= 160000 &&
+ MySubscription->stream == SUBSTREAM_PARALLEL)
+ {
+ options.proto.logical.streaming = pstrdup("parallel");
+ MyLogicalRepWorker->parallel_apply = true;
+ }
+ else if (server_version >= 140000 &&
+ MySubscription->stream != SUBSTREAM_OFF)
+ {
+ options.proto.logical.streaming = pstrdup("on");
+ MyLogicalRepWorker->parallel_apply = false;
+ }
+ else
+ {
+ options.proto.logical.streaming = NULL;
+ MyLogicalRepWorker->parallel_apply = false;
+ }
I think the block of if/else is only for assigning the
streaming/parallel members so should have some comment to say that:
SUGGESTION
Assign the appropriate streaming flag according to the 'streaming'
mode and the publisher's ability to support that mode.
~~~
22. get_transaction_apply_action
+static TransApplyAction
+get_transaction_apply_action(TransactionId xid,
ParallelApplyWorkerInfo **winfo)
+{
+ *winfo = NULL;
+
+ if (am_parallel_apply_worker())
+ {
+ return TRANS_PARALLEL_APPLY;
+ }
+ else if (in_remote_transaction)
+ {
+ return TRANS_LEADER_APPLY;
+ }
+
+ /*
+ * Check if we are processing this transaction using a parallel apply
+ * worker and if so, send the changes to that worker.
+ */
+ else if ((*winfo = parallel_apply_find_worker(xid)))
+ {
+ return TRANS_LEADER_SEND_TO_PARALLEL;
+ }
+ else
+ {
+ return TRANS_LEADER_SERIALIZE;
+ }
+}
22a.
Previously I suggested the statement blocks are overkill and all the
{} should be removed, and Houzj ([1] #52a) wrote:
I feel this style is fine.
~
Sure, it is fine, but FWIW I thought it is not the normal PG coding
convention to use unnecessary {} unless it would seem strange to omit
them.
~~
22b.
Also previously I had suggested
> Can a tablesync worker ever get here? It might be better to
> Assert(!am_tablesync_worker()); at top of this function?
and Houzj ([1] #52b) replied:
Not sure if it's necessary or not.
~
OTOH you could say no Assert is ever really necessary, but IMO adding
one here would at least be a sanity check and help to document the
function better.
======
23. src/test/regress/sql/subscription.sql
Previously I mentioned testing the 'streaming' option with no value.
Houzj replied ([1]
I didn't find similar tests for no value explicitly specified cases,
so I didn't add this for now.
But as I also responded ([4] #58) already to Amit:
IMO this one is a bit different because it's not really a boolean
option anymore - it's a kind of a hybrid boolean/enum. That's why I
thought this ought to be tested regardless if there are existing tests
for the (normal) boolean options.
Anyway, you can decide what you want.
------
[1] Houzj replies to my v35 review
https://www.postgresql.org/message-id/OS0PR01MB5716B400CD81565E868616DB945F9%40OS0PR01MB5716.jpnprd01.prod.outlook.com
[2] ReplicationOriginNameForLogicalRep
https://github.com/postgres/postgres/commit/776e1c8a5d1494e345e5e1b16a5eba5e98aaddca
[3] My review v35
https://www.postgresql.org/message-id/CAHut%2BPvFENKb5fcMko5HHtNEAaZyNwGhu3PASrcBt%2BHFoFL%3DFw%40mail.gmail.com
[4] Explaining some v35 review comments
https://www.postgresql.org/message-id/CAHut%2BPscac%2BipFSFx89ACmacjPe4Dn%3DqVq8T0V%3DnQkv38QgnBw%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Oct 6, 2022 at 6:09 PM kuroda.hayato@fujitsu.com <kuroda.hayato@fujitsu.com> wrote: > > ~~~ > 10. worker.c - apply_handle_stream_start > > ``` > + * > + * XXX We can avoid sending pair of the START/STOP messages to the parallel > + * worker because unlike apply worker it will process only one > + * transaction-at-a-time. However, it is not clear whether that is worth the > + * effort because it is sent after logical_decoding_work_mem changes. > ``` > > I can understand that START message is not needed, but is STOP really removable? If leader does not send STOP to its child,does it lose a chance to change the worker-state to IDLE_IN_TRANSACTION? > I think if we want we can set that state before we went to sleep in parallel apply worker. So, I guess ideally we don't need both of these messages but for now, it is fine as mentioned in the comments. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Oct 12, 2022 at 3:41 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are some review comments for v36-0001.
>
>
> 6. LogicalParallelApplyLoop
>
> + for (;;)
> + {
> + void *data;
> + Size len;
> + int c;
> + StringInfoData s;
> + MemoryContext oldctx;
> +
> + CHECK_FOR_INTERRUPTS();
> +
> + /* Ensure we are reading the data into our memory context. */
> + oldctx = MemoryContextSwitchTo(ApplyMessageContext);
> +
> ...
> +
> + MemoryContextSwitchTo(oldctx);
> + MemoryContextReset(ApplyMessageContext);
> + }
>
> Do those memory context switches need to happen inside the for(;;)
> loop like that? I thought perhaps those can be done *outside* of the
> loop instead of always switching and switching back on the next
> iteration.
>
I think we need to reset the ApplyMessageContext each time after
processing a message and also don't want to process the config file in
the applymessagecontext.
> ======
>
> src/backend/replication/logical/launcher.c
>
> 12. logicalrep_worker_launch
>
> Previously I suggested may the apply process name should change
>
> FROM
> "logical replication worker for subscription %u"
> TO
> "logical replication apply worker for subscription %u"
>
> and Houz wrote ([1] #13)
> I am not sure if it's a good idea to change existing process description.
>
> ~
>
> But that seems inconsistent to me because elsewhere this patch is
> already exposing the name to the user (like when it says "logical
> replication apply worker for subscription \"%s\" has started".
> Shouldn’t the process name match these logs?
>
I think it is okay to change the name here for the sake of consistency.
>
> 19. ApplyWorkerMain
>
> +
> +/* Logical Replication Apply worker entry point */
> +void
> +ApplyWorkerMain(Datum main_arg)
>
> Previously I suugested changing "Apply worker" to "apply worker", and
> Houzj ([1] #48) replied:
> Since it's the existing comment, I feel we can leave this.
>
> ~
>
> Normally I agree don't change the original code unrelated to the
> patch, but in practice, I think no patch would be accepted that just
> changes just "A" to "a", so if you don't change it here in this patch
> to be consistent then it will never happen. That's why I think should
> be part of this patch.
>
Hmm, I think one might then extend this to many other similar cosmetic
stuff in the nearby areas. It sometimes distracts the reviewer if
there are unrelated changes, so better to avoid it.
>
> 22. get_transaction_apply_action
>
> +static TransApplyAction
> +get_transaction_apply_action(TransactionId xid,
> ParallelApplyWorkerInfo **winfo)
> +{
> + *winfo = NULL;
> +
> + if (am_parallel_apply_worker())
> + {
> + return TRANS_PARALLEL_APPLY;
> + }
> + else if (in_remote_transaction)
> + {
> + return TRANS_LEADER_APPLY;
> + }
> +
> + /*
> + * Check if we are processing this transaction using a parallel apply
> + * worker and if so, send the changes to that worker.
> + */
> + else if ((*winfo = parallel_apply_find_worker(xid)))
> + {
> + return TRANS_LEADER_SEND_TO_PARALLEL;
> + }
> + else
> + {
> + return TRANS_LEADER_SERIALIZE;
> + }
> +}
>
> 22a.
>
> Previously I suggested the statement blocks are overkill and all the
> {} should be removed, and Houzj ([1] #52a) wrote:
> I feel this style is fine.
>
> ~
>
> Sure, it is fine, but FWIW I thought it is not the normal PG coding
> convention to use unnecessary {} unless it would seem strange to omit
> them.
>
Yeah, but here we are using comments in between the else if construct
due to which using {} makes it look better. I agree that this is
mostly a question of personal preference and we can go either way but
my preference would be to use the style patch has currently used.
>
> 23. src/test/regress/sql/subscription.sql
>
> Previously I mentioned testing the 'streaming' option with no value.
> Houzj replied ([1]
> I didn't find similar tests for no value explicitly specified cases,
> so I didn't add this for now.
>
> But as I also responded ([4] #58) already to Amit:
> IMO this one is a bit different because it's not really a boolean
> option anymore - it's a kind of a hybrid boolean/enum. That's why I
> thought this ought to be tested regardless if there are existing tests
> for the (normal) boolean options.
>
I still feel this is not required. I think we have to be cautious
about not adding too many tests in this area that are of less or no
value.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Oct 12, 2022 at 7:41 AM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> On Fri, Oct 7, 2022 at 14:18 PM Hou, Zhijie/侯 志杰 <houzj.fnst@cn.fujitsu.com> wrote:
> > Attach the new version patch set which addressed most of the comments.
>
> Rebased the patch set because the new change in HEAD (776e1c8).
>
> Attach the new patch set.
>
+static void
+HandleParallelApplyMessage(ParallelApplyWorkerInfo *winfo, StringInfo msg)
{
...
+ case 'X': /* Terminate, indicating clean exit */
+ {
+ shm_mq_detach(winfo->error_mq_handle);
+ winfo->error_mq_handle = NULL;
+ break;
+ }
...
}
I don't see the use of this message in the patch. If this is not
required by the latest version then we can remove it and its
corresponding handling in parallel_apply_start_worker(). I am
referring to the below code in parallel_apply_start_worker():
+ if (tmp_winfo->error_mq_handle == NULL)
+ {
+ /*
+ * Release the worker information and try next one if the parallel
+ * apply worker exited cleanly.
+ */
+ ParallelApplyWorkersList =
foreach_delete_current(ParallelApplyWorkersList, lc);
+ shm_mq_detach(tmp_winfo->mq_handle);
+ dsm_detach(tmp_winfo->dsm_seg);
+ pfree(tmp_winfo);
+ }
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, October 14, 2022 12:30 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Oct 12, 2022 at 7:41 AM wangw.fnst@fujitsu.com
> <wangw.fnst@fujitsu.com> wrote:
> >
> > On Fri, Oct 7, 2022 at 14:18 PM Hou, Zhijie/侯 志杰
> <houzj.fnst@cn.fujitsu.com> wrote:
> > > Attach the new version patch set which addressed most of the comments.
> >
> > Rebased the patch set because the new change in HEAD (776e1c8).
> >
> > Attach the new patch set.
> >
>
> +static void
> +HandleParallelApplyMessage(ParallelApplyWorkerInfo *winfo, StringInfo
> +msg)
> {
> ...
> + case 'X': /* Terminate, indicating clean exit */ {
> + shm_mq_detach(winfo->error_mq_handle);
> + winfo->error_mq_handle = NULL;
> + break;
> + }
> ...
> }
>
> I don't see the use of this message in the patch. If this is not required by the
> latest version then we can remove it and its corresponding handling in
> parallel_apply_start_worker(). I am referring to the below code in
> parallel_apply_start_worker():
Thanks for the comments, I removed these codes in the new version patch set.
I also did the following changes in the new version patch:
[0001]
* Teach the parallel apply worker to catch the subscription parameter change in
the main loop so that user can change the streaming option to "on" to stop
the parallel apply workers in case the leader apply workers get stuck because of
some deadlock problems discussed in [1].
* Some cosmetic changes.
* Address comments from Peter[2].
[0004]
* Disallow replicating from or to a partitioned table in parallel streaming
mode. This is to avoid the deadlock cases when the partitioned table's
inheritance structure is different between publisher and subscriber as
discussed [1].
[1] https://www.postgresql.org/message-id/CAA4eK1JYFXEoFhJAvg1qU%3DnZrZLw_87X%3D2YWQGFBbcBGirAUwA%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAHut%2BPvxL8tJ2ZUpEjkbRFe6qKSH%2Br54BQ7wM8p%3D335tUbuXbg%40mail.gmail.com
Best regards,
Hou zj
Attachment
- v38-0006-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v38-0001-Perform-streaming-logical-transactions-by-parall.patch
- v38-0004-Retrict-parallel-for-partitioned-table.patch
- v38-0002-Test-streaming-parallel-option-in-tap-test.patch
- v38-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v38-0005-Retry-to-apply-streaming-xact-only-in-apply-work.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wed, Oct 12, 2022 at 18:11 PM Peter Smith <smithpb2250@gmail.com> wrote:
> Here are some review comments for v36-0001.
Thanks for your comments.
> ======
>
> 1. GENERAL
>
> Houzj wrote ([1] #3a):
> The word 'streaming' is the same as the actual option name, so
> personally I think it's fine. But if others also agreed that the name
> can be improved, I can change it.
>
> ~
>
> Sure, I was not really complaining that the name is "wrong". Only I
> did not think it was a good idea to have multiple struct members
> called 'streaming' when they don't have the same meaning. e.g. one is
> the internal character mode equivalent of the parameter, and one is
> the parameter value as a string. That's why I thought they should be
> different names. e.g. Make the 2nd one 'streaming_valstr' or
> something.
Changed.
> ======
>
> 2. doc/src/sgml/config.sgml
>
> Previously I suggested there should be xrefsto the "Configuration
> Settings" page but Houzj wrote ([1] #4):
> Not sure about this as we don't have similar thing in the document of
> max_logical_replication_workers and max_sync_workers_per_subscription.
>
> ~
>
> Fair enough, but IMO perhaps all those others should also xref to the
> "Configuration Settings" chapter. So if such a change does not belong
> in this patch, then how about if I make another independent thread to
> post this suggestion?
Sure, I feel it would be better to do it in a separate thread.
> ======
>
> .../replication/logical/applyparallelworker.c
>
>
> 3. parallel_apply_find_worker
>
> +parallel_apply_find_worker(TransactionId xid) { bool found;
> +ParallelApplyWorkerEntry *entry = NULL;
> +
> + if (!TransactionIdIsValid(xid))
> + return NULL;
> +
> + if (ParallelApplyWorkersHash == NULL) return NULL;
> +
> + /* Return the cached parallel apply worker if valid. */ if
> + (stream_apply_worker != NULL) return stream_apply_worker;
> +
> + /*
> + * Find entry for requested transaction.
> + */
> + entry = hash_search(ParallelApplyWorkersHash, &xid, HASH_FIND,
> + &found);
>
> In function parallel_apply_start_worker() you removed the entry
> assignment to NULL because it is never needed. Can do the same here
> too.
Changed.
> 4. parallel_apply_free_worker
>
> +/*
> + * Remove the parallel apply worker entry from the hash table. And
> +stop the
> + * worker if there are enough workers in the pool. For more
> +information about
> + * the worker pool, see comments atop worker.c.
> + */
> +void
> +parallel_apply_free_worker(ParallelApplyWorkerInfo *winfo,
> +TransactionId
> xid)
>
> "And stop" -> "Stop"
Changed.
> 5. parallel_apply_free_worker
>
> + * Although some error messages may be lost in rare scenarios, but
> + * since the parallel apply worker has finished processing the
> + * transaction, and error messages may be lost even if we detach the
> + * error queue after terminating the process. So it should be ok.
> + */
>
> SUGGESTION (minor rewording)
> Some error messages may be lost in rare scenarios, but it should be OK
> because the parallel apply worker has finished processing the
> transaction, and error messages may be lost even if we detached the
> error queue after terminating the process.
Changed.
> ~~~
>
> 7. LogicalParallelApplyLoop
>
> Previous I suggested maybe the name (e.g. the 2nd param) should be
> changed to "ParallelApplyMessageContext"? Houzj wrote ([1] #13): Not
> sure about this, because ApplyMessageContext is used in both worker.c
> and applyparallelworker.c.
>
> ~
>
> But I thought those are completely independent ApplyMessageContext's
> in different processes that happen to have the same name. Shouldn't
> they have a name appropriate to who owns them?
ApplyMessageContext is used by the begin_replication_step() function which will
be invoked in both leader and parallel apply worker. So, we need to name the
memory context the same as ApplyMessageContext, otherwise we would need to
modify the logic of begin_replication_step() to use another memory context if
in parallel apply worker.
> ~~~
>
> 8. ParallelApplyWorkerMain
>
> + /*
> + * Allocate the origin name in a long-lived context for error context
> + * message.
> + */
> + snprintf(originname, sizeof(originname), "pg_%u",
> + MySubscription->oid);
>
> Now that ReplicationOriginNameForLogicalRep patch is pushed [2] please
> make use of this common function.
Changed.
> ~~~
>
> 9. HandleParallelApplyMessage
>
> + case 'X': /* Terminate, indicating clean exit */ {
> + shm_mq_detach(winfo->error_mq_handle);
> + winfo->error_mq_handle = NULL;
> + break;
> + }
> +
> + /*
> + * Don't need to do anything about NoticeResponse and
> + * NotifyResponse as the logical replication worker doesn't need
> + * to send messages to the client.
> + */
> + case 'N':
> + case 'A':
> + break;
> + default:
> + {
> + elog(ERROR, "unrecognized message type received from parallel apply
> worker: %c (message length %d bytes)",
> + msgtype, msg->len);
> + }
>
> 9a. case 'X':
> There are no variable declarations here so the statement block {} is
> not needed
>
> ~
>
> 9b. default:
> There are no variable declarations here so the statement block {} is
> not needed
Changed.
> ~~~
>
> 10. parallel_apply_stream_abort
>
> + int i;
> + bool found = false;
> + char spname[MAXPGPATH];
> +
> + parallel_apply_savepoint_name(MySubscription->oid, subxid, spname,
> + sizeof(spname));
>
> I posted about using NAMEDATALEN in a previous review ([3] #21) but I
> think only one place was fixed and this one was missed.
Changed.
> ======
>
> src/backend/replication/logical/launcher.c
>
> 12. logicalrep_worker_launch
>
> Previously I suggested may the apply process name should change
>
> FROM
> "logical replication worker for subscription %u"
> TO
> "logical replication apply worker for subscription %u"
>
> and Houz wrote ([1] #13)
> I am not sure if it's a good idea to change existing process description.
>
> ~
>
> But that seems inconsistent to me because elsewhere this patch is
> already exposing the name to the user (like when it says "logical
> replication apply worker for subscription \"%s\" has started".
> Shouldn’t the process name match these logs?
Changed.
> ======
>
> src/backend/replication/logical/worker.c
>
> 13. apply_handle_stream_start
>
> + *
> + * XXX We can avoid sending pairs of the START messages to the
> + parallel
> worker
> + * because unlike apply worker it will process only one transaction-at-a-time.
> + * However, it is not clear whether that is worth the effort because
> + it is sent
> + * after logical_decoding_work_mem changes.
> */
> static void
> apply_handle_stream_start(StringInfo s)
>
> 13a.
> "transaction-at-a-time." -> "transaction at a time."
>
> ~
>
> 13b.
> I was not sure what does that last sentence mean? Does it mean something like:
> "However, it is not clear whether doing this is worth the effort
> because pairs of START messages occur only after
> logical_decoding_work_mem changes."
=>13a.
Changed.
> ~~~
>
> 14. apply_handle_stream_start
>
> + ParallelApplyWorkerInfo *winfo = NULL;
>
> The declaration *winfo assignment to NULL is not needed because
> get_transaction_apply_action will always do this anyway.
Changed.
> ~~~
>
> 15. apply_handle_stream_start
>
> +
> + case TRANS_PARALLEL_APPLY:
> + break;
>
> I had previously suggested this include a comment explaining why there
> is nothing to do ([3] #44), but I think there was no reply.
The parallel apply worker doesn't need special handling for STREAM START,
it only needs to run some common code path that is shared by leader.
I added a small comment about this.
> ~~~
>
> 20. ApplyWorkerMain
>
> + /*
> + * We don't currently need any ResourceOwner in a walreceiver
> + process, but
> + * if we did, we could call CreateAuxProcessResourceOwner here.
> + */
>
> Previously I suggested prefixing this as "XXX" and Houzj replied ([1] #48):
> I am not sure as this comment is just a reminder.
>
> ~
>
> OK, then maybe since it is a reminder "Note" then it should be changed:
> "We don't currently..." -> "Note: We don't currently..."
I feel it's fine to leave the comment as that's the existing comment
in ApplyWorkerMain().
> ~~~
>
> 21. ApplyWorkerMain
>
> + if (server_version >= 160000 &&
> + MySubscription->stream == SUBSTREAM_PARALLEL)
> + {
> + options.proto.logical.streaming = pstrdup("parallel");
> + MyLogicalRepWorker->parallel_apply = true;
> + }
> + else if (server_version >= 140000 &&
> + MySubscription->stream != SUBSTREAM_OFF)
> + {
> + options.proto.logical.streaming = pstrdup("on");
> + MyLogicalRepWorker->parallel_apply = false;
> + }
> + else
> + {
> + options.proto.logical.streaming = NULL;
> + MyLogicalRepWorker->parallel_apply = false;
> + }
>
> I think the block of if/else is only for assigning the
> streaming/parallel members so should have some comment to say that:
>
> SUGGESTION
> Assign the appropriate streaming flag according to the 'streaming'
> mode and the publisher's ability to support that mode.
Added the comments as suggested.
> ~~~
>
> 22. get_transaction_apply_action
>
> +static TransApplyAction
> +get_transaction_apply_action(TransactionId xid,
> ParallelApplyWorkerInfo **winfo)
> +{
> + *winfo = NULL;
> +
> + if (am_parallel_apply_worker())
> + {
> + return TRANS_PARALLEL_APPLY;
> + }
> + else if (in_remote_transaction)
> + {
> + return TRANS_LEADER_APPLY;
> + }
> +
> + /*
> + * Check if we are processing this transaction using a parallel apply
> + * worker and if so, send the changes to that worker.
> + */
> + else if ((*winfo = parallel_apply_find_worker(xid))) { return
> +TRANS_LEADER_SEND_TO_PARALLEL; } else { return
> +TRANS_LEADER_SERIALIZE; } }
>
> 22b.
> Also previously I had suggested
>
> > Can a tablesync worker ever get here? It might be better to
> > Assert(!am_tablesync_worker()); at top of this function?
>
> and Houzj ([1] #52b) replied:
> Not sure if it's necessary or not.
>
> ~
>
> OTOH you could say no Assert is ever really necessary, but IMO adding
> one here would at least be a sanity check and help to document the
> function better.
get_transaction_apply_action might also be invoked in table sync worker in some
rare cases when some streaming transaction comes while doing the table sync.
And the function works fine in that case, so I don't think we should add the
Assert() here.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Hi, here are my review comments for patch v38-0001.
======
.../replication/logical/applyparallelworker.c
1. parallel_apply_start_worker
+ /* Try to get a free parallel apply worker. */
+ foreach(lc, ParallelApplyWorkersList)
+ {
+ ParallelApplyWorkerInfo *tmp_winfo;
+
+ tmp_winfo = (ParallelApplyWorkerInfo *) lfirst(lc);
+
+ if (!tmp_winfo->in_use)
+ {
+ /* Found a worker that has not been assigned a transaction. */
+ winfo = tmp_winfo;
+ break;
+ }
+ }
The "Found a worker..." comment seems redundant because it's already
clear from the prior comment and the 'in_use' member what this code is
doing.
~~~
2. LogicalParallelApplyLoop
+ void *data;
+ Size len;
+ int c;
+ int rc;
+ StringInfoData s;
+ MemoryContext oldctx;
Several of these vars (like 'c', 'rc', 's') can be declared deeper -
e.g. only in the scope where they are actually used.
~~~
3.
+ /* Ensure we are reading the data into our memory context. */
+ oldctx = MemoryContextSwitchTo(ApplyMessageContext);
Doesn't something need to switch back to this 'oldctx' prior to
breaking out of the for(;;) loop?
~~~
4.
+ apply_dispatch(&s);
+
+ MemoryContextReset(ApplyMessageContext);
Isn't this broken now? Since you've removed the
MemoryContextSwitchTo(oldctx), so next iteration will switch to
ApplyMessageContext again which will overwrite and lose knowledge of
the original 'oldctx' (??)
~~
5.
Maybe this is a silly idea, I'm not sure. Because this is an infinite
loop, then instead of the multiple calls to
MemoryContextReset(ApplyMessageContext) maybe there can be just a
single call to it immediately before you switch to that context in the
first place. The effect will be the same, won't it?
e.g.
+ /* Ensure we are reading the data into our memory context. */
+ MemoryContextReset(ApplyMessageContext); <=== THIS
+ oldctx = MemoryContextSwitchTo(ApplyMessageContext);
~~~
6.
The code logic keeps flip-flopping for several versions. I think if
you are going to check all the return types of shm_mq_receive then
using a switch(shmq_res) might be a better way than having multiple
if/else with some Asserts.
======
src/backend/replication/logical/launcher.c
7. logicalrep_worker_launch
Previously I'd suggested ([1] #12) that the process name should change
for consistency, and AFAIK Amit also said [2] that would be OK, but
this change is still not done in the current patch.
======
src/backend/replication/logical/worker.c
8. should_apply_changes_for_rel
* Should this worker apply changes for given relation.
*
* This is mainly needed for initial relation data sync as that runs in
* separate worker process running in parallel and we need some way to skip
* changes coming to the main apply worker during the sync of a table.
This existing comment refers to the "main apply worker". IMO it should
say "leader apply worker" to keep all the terminology consistent.
~~~
9. apply_handle_stream_start
+ *
+ * XXX We can avoid sending pairs of the START/STOP messages to the parallel
+ * worker because unlike apply worker it will process only one transaction at a
+ * time. However, it is not clear whether that is worth the effort because it
+ * is sent after logical_decoding_work_mem changes.
*/
static void
apply_handle_stream_start(StringInfo s)
As previously mentioned ([1] #13b) it's not obvious to me what that
last sentence means. e.g. "because it is sent" - what is "it"?
~~~
10. ApplyWorkerMain
else
{
/* This is main apply worker */
RepOriginId originid;
TimeLineID startpointTLI;
char *err;
Same as #8. IMO it should now say "leader apply worker" to keep all
the terminology consistent.
~~~
11.
+ /*
+ * Assign the appropriate streaming flag according to the 'streaming' mode
+ * and the publisher's ability to support that mode.
+ */
Maybe "streaming flag" -> "streaming string/flag". (sorry, it was my
bad suggestion last time)
~~~
12. get_transaction_apply_action
I still felt like there should be some tablesync checks/comments in
this function, just for sanity, even if it works as-is now.
For example, are you saying ([3] #22b) that there might be rare cases
where a Tablesync would call to parallel_apply_find_worker? That seems
strange, given that "for streaming transactions that are being applied
in the parallel ... we disallow applying changes on a table that is
not in the READY state".
------
[1] My v36 review -
https://www.postgresql.org/message-id/CAHut%2BPvxL8tJ2ZUpEjkbRFe6qKSH%2Br54BQ7wM8p%3D335tUbuXbg%40mail.gmail.com
[2] Amit's feedback for my v36 review -
https://www.postgresql.org/message-id/CAA4eK1%2BOyQ8-psruZZ0sYff5KactTHZneR-cfsHd%2Bn%2BN7khEKQ%40mail.gmail.com
[3] Hou's feedback for my v36 review -
https://www.postgresql.org/message-id/OS0PR01MB57162232BF51A09F4BD13C7594249%40OS0PR01MB5716.jpnprd01.prod.outlook.com
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, October 18, 2022 10:36 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Hi, here are my review comments for patch v38-0001. Thanks for the comments. > ~~~ > > 12. get_transaction_apply_action > > I still felt like there should be some tablesync checks/comments in > this function, just for sanity, even if it works as-is now. > > For example, are you saying ([3] #22b) that there might be rare cases > where a Tablesync would call to parallel_apply_find_worker? That seems > strange, given that "for streaming transactions that are being applied > in the parallel ... we disallow applying changes on a table that is > not in the READY state". > > ------ I think because we won't try to start parallel apply worker in table sync worker(see the check in parallel_apply_can_start()), so we won't find any worker in parallel_apply_find_worker() which means get_transaction_apply_action will return TRANS_LEADER_SERIALIZE. And get_transaction_apply_action is a function which can be invoked for all kinds of workers(same is true for all apply_handle_xxx functions), so not sure if table sync check/comment is necessary. Best regards, Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Oct 18, 2022 at 8:06 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Hi, here are my review comments for patch v38-0001. > > 3. > > + /* Ensure we are reading the data into our memory context. */ > + oldctx = MemoryContextSwitchTo(ApplyMessageContext); > > Doesn't something need to switch back to this 'oldctx' prior to > breaking out of the for(;;) loop? > > ~~~ > > 4. > > + apply_dispatch(&s); > + > + MemoryContextReset(ApplyMessageContext); > > Isn't this broken now? Since you've removed the > MemoryContextSwitchTo(oldctx), so next iteration will switch to > ApplyMessageContext again which will overwrite and lose knowledge of > the original 'oldctx' (??) > > ~~ > > 5. > > Maybe this is a silly idea, I'm not sure. Because this is an infinite > loop, then instead of the multiple calls to > MemoryContextReset(ApplyMessageContext) maybe there can be just a > single call to it immediately before you switch to that context in the > first place. The effect will be the same, won't it? > I think so but I think it will look a bit odd, especially for the first time. If the purpose is to just do it once, won't it be better to do it at the end of for loop? > > 9. apply_handle_stream_start > > + * > + * XXX We can avoid sending pairs of the START/STOP messages to the parallel > + * worker because unlike apply worker it will process only one transaction at a > + * time. However, it is not clear whether that is worth the effort because it > + * is sent after logical_decoding_work_mem changes. > */ > static void > apply_handle_stream_start(StringInfo s) > > As previously mentioned ([1] #13b) it's not obvious to me what that > last sentence means. e.g. "because it is sent" - what is "it"? > Here, it refers to START/STOP messages, so I think we should say "... because these messages are sent .." instead of "... because it is sent ...". Does that makes sense to you? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Thu, Oct 6, 2022 at 1:37 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > While looking at v35 patch, I realized that there are some cases where > the logical replication gets stuck depending on partitioned table > structure. For instance, there are following tables, publication, and > subscription: > > * On publisher > create table p (c int) partition by list (c); > create table c1 partition of p for values in (1); > create table c2 (c int); > create publication test_pub for table p, c1, c2 with > (publish_via_partition_root = 'true'); > > * On subscriber > create table p (c int) partition by list (c); > create table c1 partition of p for values In (2); > create table c2 partition of p for values In (1); > create subscription test_sub connection 'port=5551 dbname=postgres' > publication test_pub with (streaming = 'parallel', copy_data = > 'false'); > > Note that while both the publisher and the subscriber have the same > name tables the partition structure is different and rows go to a > different table on the subscriber (eg, row c=1 will go to c2 table on > the subscriber). If two current transactions are executed as follows, > the apply worker (ig, the leader apply worker) waits for a lock on c2 > held by its parallel apply worker: > > * TX-1 > BEGIN; > INSERT INTO p SELECT 1 FROM generate_series(1, 10000); --- changes are streamed > > * TX-2 > BEGIN; > TRUNCATE c2; --- wait for a lock on c2 > > * TX-1 > INSERT INTO p SELECT 1 FROM generate_series(1, 10000); > COMMIT; > > This might not be a common case in practice but it could mean that > there is a restriction on how partitioned tables should be structured > on the publisher and the subscriber when using streaming = 'parallel'. > When this happens, since the logical replication cannot move forward > the users need to disable parallel-apply mode or increase > logical_decoding_work_mem. We could describe this limitation in the > doc but it would be hard for users to detect problematic table > structure. Interesting case. So I think the root of the problem is the same as what we have for a column is marked unique to the subscriber but not to the publisher. In short, two transactions which are independent of each other on the publisher are dependent on each other on the subscriber side because table definition is different on the subscriber. So can't we handle this case in the same way by marking this table unsafe for parallel-apply? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Oct 18, 2022 at 5:22 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Thu, Oct 6, 2022 at 1:37 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > While looking at v35 patch, I realized that there are some cases where > > the logical replication gets stuck depending on partitioned table > > structure. For instance, there are following tables, publication, and > > subscription: > > > > * On publisher > > create table p (c int) partition by list (c); > > create table c1 partition of p for values in (1); > > create table c2 (c int); > > create publication test_pub for table p, c1, c2 with > > (publish_via_partition_root = 'true'); > > > > * On subscriber > > create table p (c int) partition by list (c); > > create table c1 partition of p for values In (2); > > create table c2 partition of p for values In (1); > > create subscription test_sub connection 'port=5551 dbname=postgres' > > publication test_pub with (streaming = 'parallel', copy_data = > > 'false'); > > > > Note that while both the publisher and the subscriber have the same > > name tables the partition structure is different and rows go to a > > different table on the subscriber (eg, row c=1 will go to c2 table on > > the subscriber). If two current transactions are executed as follows, > > the apply worker (ig, the leader apply worker) waits for a lock on c2 > > held by its parallel apply worker: > > > > * TX-1 > > BEGIN; > > INSERT INTO p SELECT 1 FROM generate_series(1, 10000); --- changes are streamed > > > > * TX-2 > > BEGIN; > > TRUNCATE c2; --- wait for a lock on c2 > > > > * TX-1 > > INSERT INTO p SELECT 1 FROM generate_series(1, 10000); > > COMMIT; > > > > This might not be a common case in practice but it could mean that > > there is a restriction on how partitioned tables should be structured > > on the publisher and the subscriber when using streaming = 'parallel'. > > When this happens, since the logical replication cannot move forward > > the users need to disable parallel-apply mode or increase > > logical_decoding_work_mem. We could describe this limitation in the > > doc but it would be hard for users to detect problematic table > > structure. > > Interesting case. So I think the root of the problem is the same as > what we have for a column is marked unique to the subscriber but not > to the publisher. In short, two transactions which are independent of > each other on the publisher are dependent on each other on the > subscriber side because table definition is different on the > subscriber. So can't we handle this case in the same way by marking > this table unsafe for parallel-apply? > Yes, we can do that. I think Hou-San has already dealt that way in his latest patch [1]. See his response in the email [1]: "Disallow replicating from or to a partitioned table in parallel streaming mode". [1] - https://www.postgresql.org/message-id/OS0PR01MB57160760B34E1655718F4D1994249%40OS0PR01MB5716.jpnprd01.prod.outlook.com -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, October 18, 2022 10:36 AM Peter Smith <smithpb2250@gmail.com> wrote:
> Hi, here are my review comments for patch v38-0001.
Thanks for your comments.
> ======
>
> .../replication/logical/applyparallelworker.c
>
> 1. parallel_apply_start_worker
>
> + /* Try to get a free parallel apply worker. */ foreach(lc,
> + ParallelApplyWorkersList) { ParallelApplyWorkerInfo *tmp_winfo;
> +
> + tmp_winfo = (ParallelApplyWorkerInfo *) lfirst(lc);
> +
> + if (!tmp_winfo->in_use)
> + {
> + /* Found a worker that has not been assigned a transaction. */ winfo
> + = tmp_winfo; break; } }
>
> The "Found a worker..." comment seems redundant because it's already
> clear from the prior comment and the 'in_use' member what this code is
> doing.
Removed.
> ~~~
>
> 2. LogicalParallelApplyLoop
>
> + void *data;
> + Size len;
> + int c;
> + int rc;
> + StringInfoData s;
> + MemoryContext oldctx;
>
> Several of these vars (like 'c', 'rc', 's') can be declared deeper -
> e.g. only in the scope where they are actually used.
Changed.
> ~~~
>
> 3.
>
> + /* Ensure we are reading the data into our memory context. */ oldctx
> + = MemoryContextSwitchTo(ApplyMessageContext);
>
> Doesn't something need to switch back to this 'oldctx' prior to
> breaking out of the for(;;) loop?
>
> ~~~
>
> 4.
>
> + apply_dispatch(&s);
> +
> + MemoryContextReset(ApplyMessageContext);
>
> Isn't this broken now? Since you've removed the
> MemoryContextSwitchTo(oldctx), so next iteration will switch to
> ApplyMessageContext again which will overwrite and lose knowledge of
> the original 'oldctx' (??)
Sorry for the miss, fixed.
> ~~
>
> 5.
>
> Maybe this is a silly idea, I'm not sure. Because this is an infinite
> loop, then instead of the multiple calls to
> MemoryContextReset(ApplyMessageContext) maybe there can be just a
> single call to it immediately before you switch to that context in the
> first place. The effect will be the same, won't it?
>
> e.g.
> + /* Ensure we are reading the data into our memory context. */
> + MemoryContextReset(ApplyMessageContext); <=== THIS oldctx =
> + MemoryContextSwitchTo(ApplyMessageContext);
In SHM_MQ_WOULD_BLOCK branch, we would invoke WaitLatch, so I feel we'd better
reset the memory context before waiting to avoid keeping no longer useful
memory context for more time (although it doesn’t matter too much in practice).
So, I didn't change this for now.
> ~~~
>
> 6.
>
> The code logic keeps flip-flopping for several versions. I think if
> you are going to check all the return types of shm_mq_receive then
> using a switch(shmq_res) might be a better way than having multiple
> if/else with some Asserts.
Changed.
> ======
>
> src/backend/replication/logical/launcher.c
>
> 7. logicalrep_worker_launch
>
> Previously I'd suggested ([1] #12) that the process name should change
> for consistency, and AFAIK Amit also said [2] that would be OK, but
> this change is still not done in the current patch.
Changed.
> ======
>
> src/backend/replication/logical/worker.c
>
> 8. should_apply_changes_for_rel
>
> * Should this worker apply changes for given relation.
> *
> * This is mainly needed for initial relation data sync as that runs
> in
> * separate worker process running in parallel and we need some way to
> skip
> * changes coming to the main apply worker during the sync of a table.
>
> This existing comment refers to the "main apply worker". IMO it should
> say "leader apply worker" to keep all the terminology consistent.
Changed.
> ~~~
>
> 9. apply_handle_stream_start
>
> + *
> + * XXX We can avoid sending pairs of the START/STOP messages to the
> + parallel
> + * worker because unlike apply worker it will process only one
> + transaction at a
> + * time. However, it is not clear whether that is worth the effort
> + because it
> + * is sent after logical_decoding_work_mem changes.
> */
> static void
> apply_handle_stream_start(StringInfo s)
>
> As previously mentioned ([1] #13b) it's not obvious to me what that
> last sentence means. e.g. "because it is sent" - what is "it"?
Changed as Amit's suggestion in [1].
> ~~~
>
> 11.
>
> + /*
> + * Assign the appropriate streaming flag according to the 'streaming'
> + mode
> + * and the publisher's ability to support that mode.
> + */
>
> Maybe "streaming flag" -> "streaming string/flag". (sorry, it was my
> bad suggestion last time)
Improved.
Attach the version patch set.
[1] - https://www.postgresql.org/message-id/CAA4eK1%2BqwbD419%3DKgRTLRVj5zQhbM%3Dbfi-cvWG3HkORktb4-YA%40mail.gmail.com
Best Regards
Hou Zhijie
Attachment
- v39-0001-Perform-streaming-logical-transactions-by-parall.patch
- v39-0002-Test-streaming-parallel-option-in-tap-test.patch
- v39-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v39-0004-Retrict-parallel-for-partitioned-table.patch
- v39-0005-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v39-0006-Add-a-main_worker_pid-to-pg_stat_subscription.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"kuroda.hayato@fujitsu.com"
Date:
Dear Hou,
Thanks for updating the patch! Followings are my comments.
===
01. applyparallelworker.c - SIZE_STATS_MESSAGE
```
/*
* There are three fields in each message received by the parallel apply
* worker: start_lsn, end_lsn and send_time. Because we have updated these
* statistics in the leader apply worker, we can ignore these fields in the
* parallel apply worker (see function LogicalRepApplyLoop).
*/
#define SIZE_STATS_MESSAGE (2 * sizeof(XLogRecPtr) + sizeof(TimestampTz))
```
According to other comment styles, it seems that the first sentence of the comment should
represent the datatype and usage, not the detailed reason.
For example, about ParallelApplyWorkersList, you said "A list ...". How about adding like following message:
The message size that can be skipped by parallel apply worker
~~~
02. applyparallelworker.c - parallel_apply_start_subtrans
```
if (current_xid != top_xid &&
!list_member_xid(subxactlist, current_xid))
```
A macro TransactionIdEquals is defined in access/transam.h. Should we use it, or is it too trivial?
~~~
03. applyparallelwprker.c - LogicalParallelApplyLoop
```
case SHM_MQ_WOULD_BLOCK:
{
int rc;
if (!in_streamed_transaction)
{
/*
* If we didn't get any transactions for a while there might be
* unconsumed invalidation messages in the queue, consume them
* now.
*/
AcceptInvalidationMessages();
maybe_reread_subscription();
}
MemoryContextReset(ApplyMessageContext);
```
Is MemoryContextReset() needed? IIUC no one uses ApplyMessageContext if we reach here.
~~~
04. applyparallelwprker.c - HandleParallelApplyMessages
```
else if (res == SHM_MQ_SUCCESS)
{
StringInfoData msg;
initStringInfo(&msg);
appendBinaryStringInfo(&msg, data, nbytes);
HandleParallelApplyMessage(winfo, &msg);
pfree(msg.data);
}
```
In LogicalParallelApplyLoop(), appendBinaryStringInfo() is not used
but initialized StringInfoData directly initialized. Why there is a difrerence?
The function will do repalloc() and memcpy(), so it may be inefficient.
~~~
05. applyparallelwprker.c - parallel_apply_send_data
```
if (result != SHM_MQ_SUCCESS)
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
errmsg("could not send data to shared-memory queue")));
```
I checked the enumeration of shm_mq_result, and I felt that shm_mq_send(nowait = false) failed
only when the opposite process has been exited.
How about add a hint or detailed message like "lost connection to parallel apply worker"?
===
06. worker.c - nchanges
```
/*
* The number of changes sent to parallel apply workers during one streaming
* block.
*/
static uint32 nchanges = 0;
```
I found that the name "nchanges" has been already used in apply_spooled_messages().
It works well because the local variable is always used
when name collision between local and global variables is occurred, but I think it may be confused.
~~~
07. worker.c - apply_handle_commit_internal
I think we can add an assertion like Assert(replorigin_session_origin_lsn != InvalidXLogRecPtr &&
replorigin_session_origin= InvalidRepOriginId),
to avoid missing replorigin_session_setup. Previously it was set at the entry point at never reset.
~~~
08. worker.c - apply_handle_prepare_internal
Same as above.
~~~
09. worker.c - maybe_reread_subscription
```
/*
* Exit if any parameter that affects the remote connection was changed.
* The launcher will start a new worker.
*/
if (strcmp(newsub->conninfo, MySubscription->conninfo) != 0 ||
strcmp(newsub->name, MySubscription->name) != 0 ||
strcmp(newsub->slotname, MySubscription->slotname) != 0 ||
newsub->binary != MySubscription->binary ||
newsub->stream != MySubscription->stream ||
strcmp(newsub->origin, MySubscription->origin) != 0 ||
newsub->owner != MySubscription->owner ||
!equal(newsub->publications, MySubscription->publications))
{
ereport(LOG,
(errmsg("logical replication apply worker for subscription \"%s\" will restart because of a parameter
change",
MySubscription->name)));
proc_exit(0);
}
```
When the parallel apply worker has been launched and then the subscription option has been modified,
the same message will appear twice.
But if the option "streaming" is changed from "parallel" to "on", one of them will not restart again.
Should we modify message?
===
10. general
IIUC parallel apply workers could not detect the deadlock automatically, right?
I thought we might be able to use the heartbeat protocol between a leader worker and parallel workers.
You have already implemented a mechanism to send and receive messages between workers.
My idea is that each parallel apply worker records a timestamp that gets a message from the leader
and if a certain time (30s?) has passed it sends a heartbeat message like 'H'.
The leader consumes 'H' and sends a reply like LOGICAL_REP_MSG_KEEPALIVE in HandleParallelApplyMessage().
If the parallel apply worker does not receive any message for more than one minute,
it regards that the deadlock has occurred and can change the retry flag to on and exit.
The above assumes that the leader cannot reply to the message while waiting for the lock.
Moreover, it may have notable overhead and we must use a new logical replication message type.
How do you think? Have you already considered about it?
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Tue, Oct 18, 2022 at 6:25 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > Interesting case. So I think the root of the problem is the same as > > what we have for a column is marked unique to the subscriber but not > > to the publisher. In short, two transactions which are independent of > > each other on the publisher are dependent on each other on the > > subscriber side because table definition is different on the > > subscriber. So can't we handle this case in the same way by marking > > this table unsafe for parallel-apply? > > > > Yes, we can do that. I think Hou-San has already dealt that way in his > latest patch [1]. See his response in the email [1]: "Disallow > replicating from or to a partitioned table in parallel streaming > mode". > > [1] - https://www.postgresql.org/message-id/OS0PR01MB57160760B34E1655718F4D1994249%40OS0PR01MB5716.jpnprd01.prod.outlook.com Okay, somehow I missed the latest email. I will look into it soon. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Hi, here are my review comments for the patch v39-0001
======
src/backend/libpq/pqmq.c
1. mq_putmessage
+ if (IsParallelWorker())
+ SendProcSignal(pq_mq_parallel_leader_pid,
+ PROCSIG_PARALLEL_MESSAGE,
+ pq_mq_parallel_leader_backend_id);
+ else
+ {
+ Assert(IsLogicalParallelApplyWorker());
+ SendProcSignal(pq_mq_parallel_leader_pid,
+ PROCSIG_PARALLEL_APPLY_MESSAGE,
+ pq_mq_parallel_leader_backend_id);
+ }
The generically named macro (IsParallelWorker) makes it seem like a
parallel apply worker is NOT a kind of parallel worker (e.g. it is in
the 'else'), which seems odd. But I am not sure what you can do to
improve this... e.g. reversing the if/else might look logically saner,
but might also be less efficient for the IsParallelWorker case (??)
======
.../replication/logical/applyparallelworker.c
2. LogicalParallelApplyLoop
+ /* Ensure we are reading the data into our memory context. */
+ (void) MemoryContextSwitchTo(ApplyMessageContext);
Why did you use the (void) cast for this MemoryContextSwitchTo but not
for the next one later in the same function?
~~~
3.
+ if (len == 0)
+ break;
As mentioned in my previous review ([1] #3), we are still in the
ApplyMessageContext here. Shouldn't the code be switching to the
previous context before escaping from the loop?
~~~
4.
+ switch (shmq_res)
+ {
+ case SHM_MQ_SUCCESS:
+ {
+ StringInfoData s;
+ int c;
+
+ if (len == 0)
+ break;
I think this introduces a subtle bug.
IIUC the intent of the "break" when len == 0 is to escape from the
loop. But now, this will only break from the switch case. So, it looks
like you need some kind of loop "done" flag, or maybe have to revert
back to using if/else to fix this.
~~~
5.
+ /*
+ * The first byte of message for additional communication between
+ * leader apply worker and parallel apply workers can only be 'w'.
+ */
+ c = pq_getmsgbyte(&s);
Why does it refer to "additional communication"? Isn’t it enough just
to say something like below:
SUGGESTION
The first byte of messages sent from leader apply worker to parallel
apply workers can only be 'w'.
~~~
src/backend/replication/logical/worker.c
6. apply_handle_stream_start
+ *
+ * XXX We can avoid sending pairs of the START/STOP messages to the parallel
+ * worker because unlike apply worker it will process only one transaction at a
+ * time. However, it is not clear whether that is worth the effort because
+ * these messages are sent after logical_decoding_work_mem changes.
*/
static void
apply_handle_stream_start(StringInfo s)
I don't know what the "changes" part means. IIUC, the meaning of the
last sentence is like below:
SUGGESTION
However, it is not clear whether any optimization is worthwhile
because these messages are sent only when the
logical_decoding_work_mem threshold is exceeded.
~~~
7. get_transaction_apply_action
> 12. get_transaction_apply_action
>
> I still felt like there should be some tablesync checks/comments in
> this function, just for sanity, even if it works as-is now.
>
> For example, are you saying ([3] #22b) that there might be rare cases
> where a Tablesync would call to parallel_apply_find_worker? That seems
> strange, given that "for streaming transactions that are being applied
> in the parallel ... we disallow applying changes on a table that is
> not in the READY state".
>
> ------
Houz wrote [2] -
I think because we won't try to start parallel apply worker in table sync
worker(see the check in parallel_apply_can_start()), so we won't find any
worker in parallel_apply_find_worker() which means get_transaction_apply_action
will return TRANS_LEADER_SERIALIZE. And get_transaction_apply_action is a
function which can be invoked for all kinds of workers(same is true for all
apply_handle_xxx functions), so not sure if table sync check/comment is
necessary.
~
Sure, and I believe you when you say it all works OK - but IMO there
is something still not quite right with this current code. For
example,
e.g.1 the functional will return TRANS_LEADER_SERIALIZE for Tablesync
worker, and yet the comment for TRANS_LEADER_SERIALIZE says "means
that we are in the leader apply worker" (except we are not)
e.g.2 we know for a fact that Tablesync workers cannot start their own
parallel apply workers, so then why do we even let the Tablesync
worker make a call to parallel_apply_find_worker() looking for
something we know will not be found?
------
[1] My review of v38-0001 -
https://www.postgresql.org/message-id/CAHut%2BPsY0aevdVqeCUJOrRQMrwpg5Wz3-Mo%2BbU%3DmCxW2%2B9EBTg%40mail.gmail.com
[2] Houz reply for my review v38 -
https://www.postgresql.org/message-id/OS0PR01MB5716D738A8F27968806957B194289%40OS0PR01MB5716.jpnprd01.prod.outlook.com
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, October 19, 2022 8:50 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote:
Thanks for the comments.
> 03. applyparallelwprker.c - LogicalParallelApplyLoop
>
> ```
> case SHM_MQ_WOULD_BLOCK:
> {
> int rc;
>
> if (!in_streamed_transaction)
> {
> /*
> * If we didn't get any transactions for a while there might be
> * unconsumed invalidation messages in the queue, consume them
> * now.
> */
> AcceptInvalidationMessages();
> maybe_reread_subscription();
> }
>
> MemoryContextReset(ApplyMessageContext);
> ```
>
> Is MemoryContextReset() needed? IIUC no one uses ApplyMessageContext if we reach here.
I was concerned that some code in deeper level might allocate some memory as
there are lots of codes and functions could be invoked in the loop(For example,
the functions in ProcessInterrupts()). Although It might not matter in
practice, but I think it might be better to reset here to make it robust. Besides,
the code seems consistent with the logic in LogicalRepApplyLoop.
> 04. applyparallelwprker.c - HandleParallelApplyMessages
>
> ```
> else if (res == SHM_MQ_SUCCESS)
> {
> StringInfoData msg;
>
> initStringInfo(&msg);
> appendBinaryStringInfo(&msg, data, nbytes);
> HandleParallelApplyMessage(winfo, &msg);
> pfree(msg.data);
> }
> ```
>
> In LogicalParallelApplyLoop(), appendBinaryStringInfo() is not used but
> initialized StringInfoData directly initialized. Why there is a difrerence? The
> function will do repalloc() and memcpy(), so it may be inefficient.
I think both styles are fine, the code in HandleParallelApplyMessages is to keep
consistent with the similar function HandleParallelMessages() which is not a
performance sensitive function.
> 05. applyparallelwprker.c - parallel_apply_send_data
>
> ```
> if (result != SHM_MQ_SUCCESS)
> ereport(ERROR,
> (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> errmsg("could not send data to shared-memory queue")));
>
> ```
>
> I checked the enumeration of shm_mq_result, and I felt that shm_mq_send(nowait
> = false) failed only when the opposite process has been exited. How about add a
> hint or detailed message like "lost connection to parallel apply worker"?
Thanks for analyzing, but I am not sure if "lost connection to xx worker" is a
appropriate errhint or detail. The current error message looks clear to me.
> 07. worker.c - apply_handle_commit_internal
>
> I think we can add an assertion like Assert(replorigin_session_origin_lsn !=
> InvalidXLogRecPtr && replorigin_session_origin = InvalidRepOriginId), to
> avoid missing replorigin_session_setup. Previously it was set at the entry
> point at never reset.
I feel addding the assert for replorigin_session_origin is fine here. For
replorigin_session_origin_lsn, I am not sure if looks better to check here as
we need to distingush the case for streaming=on and streaming=parallel if we
want to check that.
> 10. general
>
> IIUC parallel apply workers could not detect the deadlock automatically,
> right? I thought we might be able to use the heartbeat protocol between a
> leader worker and parallel workers.
>
> You have already implemented a mechanism to send and receive messages between
> workers. My idea is that each parallel apply worker records a timestamp that
> gets a message from the leader and if a certain time (30s?) has passed it
> sends a heartbeat message like 'H'. The leader consumes 'H' and sends a reply
> like LOGICAL_REP_MSG_KEEPALIVE in HandleParallelApplyMessage(). If the
> parallel apply worker does not receive any message for more than one minute,
> it regards that the deadlock has occurred and can change the retry flag to on
> and exit.
>
> The above assumes that the leader cannot reply to the message while waiting
> for the lock. Moreover, it may have notable overhead and we must use a new
> logical replication message type.
>
> How do you think? Have you already considered about it?
Thanks for the suggestion. But we are trying to detect this kind of problem before
this problematic case happens and disallow parallelism in these cases by
checking the unique/constr/partitioned... in 0003/0004 patch.
About the keepalive design. We could do that, but the leader could also be
blocked by some other user backend, so this design might cause the worker to
error out in some unexpected cases which seems not great.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Oct 20, 2022 at 2:08 PM Peter Smith <smithpb2250@gmail.com> wrote: > > 7. get_transaction_apply_action > > > 12. get_transaction_apply_action > > > > I still felt like there should be some tablesync checks/comments in > > this function, just for sanity, even if it works as-is now. > > > > For example, are you saying ([3] #22b) that there might be rare cases > > where a Tablesync would call to parallel_apply_find_worker? That seems > > strange, given that "for streaming transactions that are being applied > > in the parallel ... we disallow applying changes on a table that is > > not in the READY state". > > > > ------ > > Houz wrote [2] - > > I think because we won't try to start parallel apply worker in table sync > worker(see the check in parallel_apply_can_start()), so we won't find any > worker in parallel_apply_find_worker() which means get_transaction_apply_action > will return TRANS_LEADER_SERIALIZE. And get_transaction_apply_action is a > function which can be invoked for all kinds of workers(same is true for all > apply_handle_xxx functions), so not sure if table sync check/comment is > necessary. > > ~ > > Sure, and I believe you when you say it all works OK - but IMO there > is something still not quite right with this current code. For > example, > > e.g.1 the functional will return TRANS_LEADER_SERIALIZE for Tablesync > worker, and yet the comment for TRANS_LEADER_SERIALIZE says "means > that we are in the leader apply worker" (except we are not) > > e.g.2 we know for a fact that Tablesync workers cannot start their own > parallel apply workers, so then why do we even let the Tablesync > worker make a call to parallel_apply_find_worker() looking for > something we know will not be found? > I don't see much benefit in adding an additional check for tablesync workers here. It will unnecessarily make this part of the code look bit ugly. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, October 19, 2022 8:50 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote:
>
> ===
> 01. applyparallelworker.c - SIZE_STATS_MESSAGE
>
> ```
> /*
> * There are three fields in each message received by the parallel apply
> * worker: start_lsn, end_lsn and send_time. Because we have updated these
> * statistics in the leader apply worker, we can ignore these fields in the
> * parallel apply worker (see function LogicalRepApplyLoop).
> */
> #define SIZE_STATS_MESSAGE (2 * sizeof(XLogRecPtr) + sizeof(TimestampTz))
> ```
>
> According to other comment styles, it seems that the first sentence of the
> comment should represent the datatype and usage, not the detailed reason.
> For example, about ParallelApplyWorkersList, you said "A list ...". How about
> adding like following message:
> The message size that can be skipped by parallel apply worker
Thanks for the comments, but the current description seems enough to me.
> ~~~
> 02. applyparallelworker.c - parallel_apply_start_subtrans
>
> ```
> if (current_xid != top_xid &&
> !list_member_xid(subxactlist, current_xid)) ```
>
> A macro TransactionIdEquals is defined in access/transam.h. Should we use it,
> or is it too trivial?
I checked the existing codes, it seems both style are being used.
Maybe we can post a separate patch to replace them later.
> ~~~
> 08. worker.c - apply_handle_prepare_internal
>
> Same as above.
>
>
> ~~~
> 09. worker.c - maybe_reread_subscription
>
> ```
> /*
> * Exit if any parameter that affects the remote connection was
> changed.
> * The launcher will start a new worker.
> */
> if (strcmp(newsub->conninfo, MySubscription->conninfo) != 0 ||
> strcmp(newsub->name, MySubscription->name) != 0 ||
> strcmp(newsub->slotname, MySubscription->slotname) != 0 ||
> newsub->binary != MySubscription->binary ||
> newsub->stream != MySubscription->stream ||
> strcmp(newsub->origin, MySubscription->origin) != 0 ||
> newsub->owner != MySubscription->owner ||
> !equal(newsub->publications, MySubscription->publications))
> {
> ereport(LOG,
> (errmsg("logical replication apply worker for
> subscription \"%s\" will restart because of a parameter change",
> MySubscription->name)));
>
> proc_exit(0);
> }
> ```
>
> When the parallel apply worker has been launched and then the subscription
> option has been modified, the same message will appear twice.
> But if the option "streaming" is changed from "parallel" to "on", one of them
> will not restart again.
> Should we modify message?
Thanks, it seems a timing problem, if the leader catch the change first and stop
the parallel workers, the message will only appear once. But I agree we'd
better make the message clear. I changed the message in parallel apply worker.
While on it, I also adjusted some other message to include "parallel apply
worker" if they are in parallel apply worker.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, October 20, 2022 5:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > On Thu, Oct 20, 2022 at 2:08 PM Peter Smith <smithpb2250@gmail.com> > wrote: > > > > 7. get_transaction_apply_action > > > > > 12. get_transaction_apply_action > > > > > > I still felt like there should be some tablesync checks/comments in > > > this function, just for sanity, even if it works as-is now. > > > > > > For example, are you saying ([3] #22b) that there might be rare > > > cases where a Tablesync would call to parallel_apply_find_worker? > > > That seems strange, given that "for streaming transactions that are > > > being applied in the parallel ... we disallow applying changes on a > > > table that is not in the READY state". > > > > > > ------ > > > > Houz wrote [2] - > > > > I think because we won't try to start parallel apply worker in table > > sync worker(see the check in parallel_apply_can_start()), so we won't > > find any worker in parallel_apply_find_worker() which means > > get_transaction_apply_action will return TRANS_LEADER_SERIALIZE. And > > get_transaction_apply_action is a function which can be invoked for > > all kinds of workers(same is true for all apply_handle_xxx functions), > > so not sure if table sync check/comment is necessary. > > > > ~ > > > > Sure, and I believe you when you say it all works OK - but IMO there > > is something still not quite right with this current code. For > > example, > > > > e.g.1 the functional will return TRANS_LEADER_SERIALIZE for Tablesync > > worker, and yet the comment for TRANS_LEADER_SERIALIZE says "means > > that we are in the leader apply worker" (except we are not) > > > > e.g.2 we know for a fact that Tablesync workers cannot start their own > > parallel apply workers, so then why do we even let the Tablesync > > worker make a call to parallel_apply_find_worker() looking for > > something we know will not be found? > > > > I don't see much benefit in adding an additional check for tablesync workers > here. It will unnecessarily make this part of the code look bit ugly. Thanks for the review, here is the new version patch set which addressed Peter[1] and Kuroda-san[2]'s comments. [1] https://www.postgresql.org/message-id/CAHut%2BPs0HXawMD%3DzQ5YUncc9kjGy%2Bmd_39Y4Fdf%3DsKjt-LE92g%40mail.gmail.com [2] https://www.postgresql.org/message-id/TYAPR01MB586674C1EE91C06DBACE7728F52B9%40TYAPR01MB5866.jpnprd01.prod.outlook.com Best regards, Hou zj
Attachment
- v40-0006-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v40-0001-Perform-streaming-logical-transactions-by-parall.patch
- v40-0002-Test-streaming-parallel-option-in-tap-test.patch
- v40-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v40-0004-Retrict-parallel-for-partitioned-table.patch
- v40-0005-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for v40-0001.
======
src/backend/replication/logical/worker.c
1. should_apply_changes_for_rel
+ else if (am_parallel_apply_worker())
+ {
+ if (rel->state != SUBREL_STATE_READY)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("logical replication parallel apply worker for subscription
\"%s\" will stop",
+ MySubscription->name),
+ errdetail("Cannot handle streamed replication transaction using parallel "
+ "apply workers until all tables are synchronized.")));
1a.
"transaction" -> "transactions"
1b.
"are synchronized" -> "have been synchronized."
e.g. "Cannot handle streamed replication transactions using parallel
apply workers until all tables have been synchronized."
~~~
2. maybe_reread_subscription
+ if (am_parallel_apply_worker())
+ ereport(LOG,
+ (errmsg("logical replication parallel apply worker for subscription
\"%s\" will "
+ "stop because the subscription was removed",
+ MySubscription->name)));
+ else
+ ereport(LOG,
+ (errmsg("logical replication apply worker for subscription \"%s\" will "
+ "stop because the subscription was removed",
+ MySubscription->name)));
Maybe there is an easier way to code this instead of if/else and
cut/paste message text:
SUGGESTION
ereport(LOG,
(errmsg("logical replication %s for subscription \"%s\" will stop
because the subscription was removed",
am_parallel_apply_worker() ? "parallel apply worker" : "apply worker",
MySubscription->name)));
~~~
3.
+ if (am_parallel_apply_worker())
+ ereport(LOG,
+ (errmsg("logical replication parallel apply worker for subscription
\"%s\" will "
+ "stop because the subscription was disabled",
+ MySubscription->name)));
+ else
+ ereport(LOG,
+ (errmsg("logical replication apply worker for subscription \"%s\" will "
+ "stop because the subscription was disabled",
+ MySubscription->name)));
These can be combined like comment #2 above
SUGGESTION
ereport(LOG,
(errmsg("logical replication %s for subscription \"%s\" will stop
because the subscription was disabled",
am_parallel_apply_worker() ? "parallel apply worker" : "apply worker",
MySubscription->name)));
~~~
4.
+ if (am_parallel_apply_worker())
+ ereport(LOG,
+ (errmsg("logical replication parallel apply worker for subscription
\"%s\" will stop because of a parameter change",
+ MySubscription->name)));
+ else
+ ereport(LOG,
+ (errmsg("logical replication apply worker for subscription \"%s\"
will restart because of a parameter change",
+ MySubscription->name)));
These can be combined like comment #2 above
SUGGESTION
ereport(LOG,
(errmsg("logical replication %s for subscription \"%s\" will restart
because of a parameter change",
am_parallel_apply_worker() ? "parallel apply worker" : "apply worker",
MySubscription->name)));
~~~~
4. InitializeApplyWorker
+ if (am_parallel_apply_worker())
+ ereport(LOG,
+ (errmsg("logical replication parallel apply worker for subscription
%u will not "
+ "start because the subscription was removed during startup",
+ MyLogicalRepWorker->subid)));
+ else
+ ereport(LOG,
+ (errmsg("logical replication apply worker for subscription %u will not "
+ "start because the subscription was removed during startup",
+ MyLogicalRepWorker->subid)));
These can be combined like comment #2 above
SUGGESTION
ereport(LOG,
(errmsg("logical replication %s for subscription %u will not start
because the subscription was removed during startup",
am_parallel_apply_worker() ? "parallel apply worker" : "apply worker",
MyLogicalRepWorker->subid)));
~~~
5.
+ else if (am_parallel_apply_worker())
+ ereport(LOG,
+ (errmsg("logical replication parallel apply worker for subscription
\"%s\" has started",
+ MySubscription->name)));
else
ereport(LOG,
(errmsg("logical replication apply worker for subscription \"%s\"
has started",
MySubscription->name)));
The last if/else can be combined same as comment #2 above
SUGGESTION
else
ereport(LOG,
(errmsg("logical replication %s for subscription \"%s\" has started",
am_parallel_apply_worker() ? "parallel apply worker" : "apply worker",
MySubscription->name)));
~~~
6. IsLogicalParallelApplyWorker
+bool
+IsLogicalParallelApplyWorker(void)
+{
+ return IsLogicalWorker() && am_parallel_apply_worker();
+}
Patch v40 added the IsLogicalWorker() to the condition, but why is
that extra check necessary?
======
7. src/include/replication/worker_internal.h
+typedef struct ParallelApplyWorkerInfo
+{
+ shm_mq_handle *mq_handle;
+
+ /*
+ * The queue used to transfer messages from the parallel apply worker to
+ * the leader apply worker.
+ */
+ shm_mq_handle *error_mq_handle;
In patch v40 the comment about the NULL error_mq_handle is removed,
but since the code still explicitly set/checks NULL in different
places isn't it still better to have some comment here to describe
what NULL means?
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Oct 21, 2022 at 3:02 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
Few comments on the 0001 and 0003 patches:
v40-0001*
==========
1.
+ /*
+ * The queue used to transfer messages from the parallel apply worker to
+ * the leader apply worker.
+ */
+ shm_mq_handle *error_mq_handle;
Shall we say error messages instead of messages?
2.
+/*
+ * Is there a message pending in parallel apply worker which we need to
+ * receive?
+ */
+volatile sig_atomic_t ParallelApplyMessagePending = false;
Can we slightly change above comment to: "Is there a message sent by
parallel apply worker which we need to receive?"
3.
+
+ ThrowErrorData(&edata);
+
+ /* Should not reach here after rethrowing an error. */
+ error_context_stack = save_error_context_stack;
Should we instead do Assert(false) after ThrowErrorData?
4.
+ * apply worker (c) necessary information to be shared among parallel apply
+ * workers and leader apply worker (i.e. in_parallel_apply_xact flag and the
+ * corresponding LogicalRepWorker slot information).
I don't think here the comment needs to exactly say which variables
are shared. necessary information to synchronize between parallel
apply workers and leader apply worker.
5.
+ * The dynamic shared memory segment will contain (a) a shm_mq that can be
+ * used to send changes in the transaction from leader apply worker to parallel
+ * apply worker (b) another shm_mq that can be used to send errors
In both (a) and (b), instead of "can be", we can use "is".
6.
Note that we cannot skip the streaming transactions when using
+ * parallel apply workers because we cannot get the finish LSN before
+ * applying the changes.
This comment is unclear about the action of parallel apply worker when
finish LSN is set. We can add something like: "So, we don't start
parallel apply worker when finish LSN is set by the user."
v40-0003
==========
7. The function RelationGetUniqueKeyBitmap() should be defined in
relcache.c next to RelationGetIdentityKeyBitmap().
8.
+RelationGetUniqueKeyBitmap(Relation rel)
{
...
+ if (!rel->rd_rel->relhasindex)
+ return NULL;
It would be better to use "if
(!RelationGetForm(relation)->relhasindex)" so as to be consistent with
similar usage in RelationGetUniqueKeyBitmap.
9. In RelationGetUniqueKeyBitmap(), we must assert here that the
historic snapshot is set as we are not taking a lock on index rels.
The same is already ensured in RelationGetIdentityKeyBitmap(), is
there a reason to be different here?
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, Oct 12, 2022 at 3:04 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Oct 11, 2022 at 5:52 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Fri, Oct 7, 2022 at 2:00 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > About your point that having different partition structures for > > > publisher and subscriber, I don't know how common it will be once we > > > have DDL replication. Also, the default value of > > > publish_via_partition_root is false which doesn't seem to indicate > > > that this is a quite common case. > > > > So how can we consider these concurrent issues that could happen only > > when streaming = 'parallel'? Can we restrict some use cases to avoid > > the problem or can we have a safeguard against these conflicts? > > > > Yeah, right now the strategy is to disallow parallel apply for such > cases as you can see in *0003* patch. Tightening the restrictions could work in some cases but there might still be coner cases and it could reduce the usability. I'm not really sure that we can ensure such a deadlock won't happen with the current restrictions. I think we need something safeguard just in case. For example, if the leader apply worker is waiting for a lock acquired by its parallel worker, it cancels the parallel worker's transaction, commits its transaction, and restarts logical replication. Or the leader can log the deadlock to let the user know. > > > We > > could find a new problematic scenario in the future and if it happens, > > logical replication gets stuck, it cannot be resolved only by apply > > workers themselves. > > > > I think users can change streaming option to on/off and internally the > parallel apply worker can detect and restart to allow replication to > proceed. Having said that, I think that would be a bug in the code and > we should try to fix it. We may need to disable parallel apply in the > problematic case. > > The other ideas that occurred to me in this regard are (a) provide a > reloption (say parallel_apply) at table level and we can use that to > bypass various checks like different Unique Key between > publisher/subscriber, constraints/expressions having mutable > functions, Foreign Key (when enabled on subscriber), operations on > Partitioned Table. We can't detect whether those are safe or not > (primarily because of a different structure in publisher and > subscriber) so we prohibit parallel apply but if users use this > option, we can allow it even in those cases. The parallel apply worker is assigned per transaction, right? If so, how can we know which tables are modified in the transaction in advance? and what if two tables whose reloptions are true and false are modified in the same transaction? > (b) While enabling the > parallel option in the subscription, we can try to match all the > table(s) information of the publisher/subscriber. It will be tricky to > make this work because say even if match some trigger function name, > we won't be able to match the function body. The other thing is when > at a later point the table definition is changed on the subscriber, we > need to again validate the information between publisher and > subscriber which I think would be difficult as we would be already in > between processing some message and getting information from the > publisher at that stage won't be possible. Indeed. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Oct 24, 2022 at 11:41 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are my review comments for v40-0001.
>
> ======
>
> src/backend/replication/logical/worker.c
>
>
> 1. should_apply_changes_for_rel
>
> + else if (am_parallel_apply_worker())
> + {
> + if (rel->state != SUBREL_STATE_READY)
> + ereport(ERROR,
> + (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("logical replication parallel apply worker for subscription
> \"%s\" will stop",
> + MySubscription->name),
> + errdetail("Cannot handle streamed replication transaction using parallel "
> + "apply workers until all tables are synchronized.")));
>
> 1a.
> "transaction" -> "transactions"
>
> 1b.
> "are synchronized" -> "have been synchronized."
>
> e.g. "Cannot handle streamed replication transactions using parallel
> apply workers until all tables have been synchronized."
>
> ~~~
>
> 2. maybe_reread_subscription
>
> + if (am_parallel_apply_worker())
> + ereport(LOG,
> + (errmsg("logical replication parallel apply worker for subscription
> \"%s\" will "
> + "stop because the subscription was removed",
> + MySubscription->name)));
> + else
> + ereport(LOG,
> + (errmsg("logical replication apply worker for subscription \"%s\" will "
> + "stop because the subscription was removed",
> + MySubscription->name)));
>
> Maybe there is an easier way to code this instead of if/else and
> cut/paste message text:
>
> SUGGESTION
>
> ereport(LOG,
> (errmsg("logical replication %s for subscription \"%s\" will stop
> because the subscription was removed",
> am_parallel_apply_worker() ? "parallel apply worker" : "apply worker",
> MySubscription->name)));
> ~~~
>
If we want to go this way then it may be better to record the
appropriate string beforehand and use that here.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Fri, Oct 21, 2022 at 6:32 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Thursday, October 20, 2022 5:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Oct 20, 2022 at 2:08 PM Peter Smith <smithpb2250@gmail.com> > > wrote: > > > > > > 7. get_transaction_apply_action > > > > > > > 12. get_transaction_apply_action > > > > > > > > I still felt like there should be some tablesync checks/comments in > > > > this function, just for sanity, even if it works as-is now. > > > > > > > > For example, are you saying ([3] #22b) that there might be rare > > > > cases where a Tablesync would call to parallel_apply_find_worker? > > > > That seems strange, given that "for streaming transactions that are > > > > being applied in the parallel ... we disallow applying changes on a > > > > table that is not in the READY state". > > > > > > > > ------ > > > > > > Houz wrote [2] - > > > > > > I think because we won't try to start parallel apply worker in table > > > sync worker(see the check in parallel_apply_can_start()), so we won't > > > find any worker in parallel_apply_find_worker() which means > > > get_transaction_apply_action will return TRANS_LEADER_SERIALIZE. And > > > get_transaction_apply_action is a function which can be invoked for > > > all kinds of workers(same is true for all apply_handle_xxx functions), > > > so not sure if table sync check/comment is necessary. > > > > > > ~ > > > > > > Sure, and I believe you when you say it all works OK - but IMO there > > > is something still not quite right with this current code. For > > > example, > > > > > > e.g.1 the functional will return TRANS_LEADER_SERIALIZE for Tablesync > > > worker, and yet the comment for TRANS_LEADER_SERIALIZE says "means > > > that we are in the leader apply worker" (except we are not) > > > > > > e.g.2 we know for a fact that Tablesync workers cannot start their own > > > parallel apply workers, so then why do we even let the Tablesync > > > worker make a call to parallel_apply_find_worker() looking for > > > something we know will not be found? > > > > > > > I don't see much benefit in adding an additional check for tablesync workers > > here. It will unnecessarily make this part of the code look bit ugly. > > Thanks for the review, here is the new version patch set which addressed Peter[1] > and Kuroda-san[2]'s comments. I've started to review this patch. I tested v40-0001 patch and have one question: IIUC even when most of the changes in the transaction are filtered out in pgoutput (eg., by relation filter or row filter), the walsender sends STREAM_START. This means that the subscriber could end up launching parallel apply workers also for almost empty (and streamed) transactions. For example, I created three subscriptions each of which subscribes to a different table. When I loaded a large amount of data into one table, all three (leader) apply workers received START_STREAM and launched their parallel apply workers. However, two of them finished without applying any data. I think this behaviour looks problematic since it wastes workers and rather decreases the apply performance if the changes are not large. Is it worth considering a way to delay launching a parallel apply worker until we find out the amount of changes is actually large? For example, the leader worker writes the streamed changes to files as usual and launches a parallel worker if the amount of changes exceeds a threshold or the leader receives the second segment. After that, the leader worker switches to send the streamed changes to parallel workers via shm_mq instead of files. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
FYI - After a recent push, the v40-0001 patch no longer applies on the latest HEAD. [postgres@CentOS7-x64 oss_postgres_misc]$ git apply ../patches_misc/v40-0001-Perform-streaming-logical-transactions-by-parall.patch error: patch failed: src/backend/replication/logical/launcher.c:54 error: src/backend/replication/logical/launcher.c: patch does not apply ------ Kind Regards, Peter Smith. Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Tues, Oct 25, 2022 at 14:28 PM Peter Smith <smithpb2250@gmail.com> wrote: > FYI - After a recent push, the v40-0001 patch no longer applies on the > latest HEAD. > > [postgres@CentOS7-x64 oss_postgres_misc]$ git apply > ../patches_misc/v40-0001-Perform-streaming-logical-transactions-by- > parall.patch > error: patch failed: src/backend/replication/logical/launcher.c:54 > error: src/backend/replication/logical/launcher.c: patch does not apply Thanks for your reminder. I just rebased the patch set for review. The new patch set will be shared later when the comments in this thread are addressed. Regards, Wang wei
Attachment
- v41-0001-Perform-streaming-logical-transactions-by-parall.patch
- v41-0002-Test-streaming-parallel-option-in-tap-test.patch
- v41-0003-Add-some-checks-before-using-parallel-apply-work.patch
- v41-0004-Retrict-parallel-for-partitioned-table.patch
- v41-0005-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v41-0006-Add-a-main_worker_pid-to-pg_stat_subscription.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Oct 25, 2022 at 8:38 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Fri, Oct 21, 2022 at 6:32 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > I've started to review this patch. I tested v40-0001 patch and have > one question: > > IIUC even when most of the changes in the transaction are filtered out > in pgoutput (eg., by relation filter or row filter), the walsender > sends STREAM_START. This means that the subscriber could end up > launching parallel apply workers also for almost empty (and streamed) > transactions. For example, I created three subscriptions each of which > subscribes to a different table. When I loaded a large amount of data > into one table, all three (leader) apply workers received START_STREAM > and launched their parallel apply workers. > The apply workers will be launched just the first time then we maintain a pool so that we don't need to restart them. > However, two of them > finished without applying any data. I think this behaviour looks > problematic since it wastes workers and rather decreases the apply > performance if the changes are not large. Is it worth considering a > way to delay launching a parallel apply worker until we find out the > amount of changes is actually large? > I think even if changes are less there may not be much difference because we have observed that the performance improvement comes from not writing to file. > For example, the leader worker > writes the streamed changes to files as usual and launches a parallel > worker if the amount of changes exceeds a threshold or the leader > receives the second segment. After that, the leader worker switches to > send the streamed changes to parallel workers via shm_mq instead of > files. > I think writing to file won't be a good idea as that can hamper the performance benefit in some cases and not sure if it is worth. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"shiy.fnst@fujitsu.com"
Date:
On Wed, Oct 26, 2022 7:19 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Oct 25, 2022 at 8:38 AM Masahiko Sawada > <sawada.mshk@gmail.com> wrote: > > > > On Fri, Oct 21, 2022 at 6:32 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > I've started to review this patch. I tested v40-0001 patch and have > > one question: > > > > IIUC even when most of the changes in the transaction are filtered out > > in pgoutput (eg., by relation filter or row filter), the walsender > > sends STREAM_START. This means that the subscriber could end up > > launching parallel apply workers also for almost empty (and streamed) > > transactions. For example, I created three subscriptions each of which > > subscribes to a different table. When I loaded a large amount of data > > into one table, all three (leader) apply workers received START_STREAM > > and launched their parallel apply workers. > > > > The apply workers will be launched just the first time then we > maintain a pool so that we don't need to restart them. > > > However, two of them > > finished without applying any data. I think this behaviour looks > > problematic since it wastes workers and rather decreases the apply > > performance if the changes are not large. Is it worth considering a > > way to delay launching a parallel apply worker until we find out the > > amount of changes is actually large? > > > > I think even if changes are less there may not be much difference > because we have observed that the performance improvement comes from > not writing to file. > > > For example, the leader worker > > writes the streamed changes to files as usual and launches a parallel > > worker if the amount of changes exceeds a threshold or the leader > > receives the second segment. After that, the leader worker switches to > > send the streamed changes to parallel workers via shm_mq instead of > > files. > > > > I think writing to file won't be a good idea as that can hamper the > performance benefit in some cases and not sure if it is worth. > I tried to test some cases that only a small part of the transaction or an empty transaction is sent to subscriber, to see if using streaming parallel will bring performance degradation. The test was performed ten times, and the average was taken. The results are as follows. The details and the script of the test is attached. 10% of rows are sent ---------------------------------- HEAD 24.4595 patched 18.4545 5% of rows are sent ---------------------------------- HEAD 21.244 patched 17.9655 0% of rows are sent ---------------------------------- HEAD 18.0605 patched 17.893 It shows that when only 5% or 10% of rows are sent to subscriber, using parallel apply takes less time than HEAD, and even if all rows are filtered there's no performance degradation. Regards Shi yu
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Thu, Oct 27, 2022 at 11:34 AM shiy.fnst@fujitsu.com <shiy.fnst@fujitsu.com> wrote: > > On Wed, Oct 26, 2022 7:19 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, Oct 25, 2022 at 8:38 AM Masahiko Sawada > > <sawada.mshk@gmail.com> wrote: > > > > > > On Fri, Oct 21, 2022 at 6:32 PM houzj.fnst@fujitsu.com > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > I've started to review this patch. I tested v40-0001 patch and have > > > one question: > > > > > > IIUC even when most of the changes in the transaction are filtered out > > > in pgoutput (eg., by relation filter or row filter), the walsender > > > sends STREAM_START. This means that the subscriber could end up > > > launching parallel apply workers also for almost empty (and streamed) > > > transactions. For example, I created three subscriptions each of which > > > subscribes to a different table. When I loaded a large amount of data > > > into one table, all three (leader) apply workers received START_STREAM > > > and launched their parallel apply workers. > > > > > > > The apply workers will be launched just the first time then we > > maintain a pool so that we don't need to restart them. > > > > > However, two of them > > > finished without applying any data. I think this behaviour looks > > > problematic since it wastes workers and rather decreases the apply > > > performance if the changes are not large. Is it worth considering a > > > way to delay launching a parallel apply worker until we find out the > > > amount of changes is actually large? > > > > > > > I think even if changes are less there may not be much difference > > because we have observed that the performance improvement comes from > > not writing to file. > > > > > For example, the leader worker > > > writes the streamed changes to files as usual and launches a parallel > > > worker if the amount of changes exceeds a threshold or the leader > > > receives the second segment. After that, the leader worker switches to > > > send the streamed changes to parallel workers via shm_mq instead of > > > files. > > > > > > > I think writing to file won't be a good idea as that can hamper the > > performance benefit in some cases and not sure if it is worth. > > > > I tried to test some cases that only a small part of the transaction or an empty > transaction is sent to subscriber, to see if using streaming parallel will bring > performance degradation. > > The test was performed ten times, and the average was taken. > The results are as follows. The details and the script of the test is attached. > > 10% of rows are sent > ---------------------------------- > HEAD 24.4595 > patched 18.4545 > > 5% of rows are sent > ---------------------------------- > HEAD 21.244 > patched 17.9655 > > 0% of rows are sent > ---------------------------------- > HEAD 18.0605 > patched 17.893 > > > It shows that when only 5% or 10% of rows are sent to subscriber, using parallel > apply takes less time than HEAD, and even if all rows are filtered there's no > performance degradation. Thank you for the testing! I think this performance improvement comes from both applying changes in parallel to receiving changes and avoiding writing a file. I'm happy to know there is also a benefit also for small streaming transactions. I've also measured the overhead when processing streaming empty transactions and confirmed the overhead is negligible. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"shiy.fnst@fujitsu.com"
Date:
On Tue, Oct 25, 2022 2:56 PM Wang, Wei/王 威 <wangw.fnst@fujitsu.com> wrote: > > On Tues, Oct 25, 2022 at 14:28 PM Peter Smith <smithpb2250@gmail.com> > wrote: > > FYI - After a recent push, the v40-0001 patch no longer applies on the > > latest HEAD. > > > > [postgres@CentOS7-x64 oss_postgres_misc]$ git apply > > ../patches_misc/v40-0001-Perform-streaming-logical-transactions-by- > > parall.patch > > error: patch failed: src/backend/replication/logical/launcher.c:54 > > error: src/backend/replication/logical/launcher.c: patch does not apply > > Thanks for your reminder. > > I just rebased the patch set for review. > The new patch set will be shared later when the comments in this thread are > addressed. > I tried to write a draft patch to force streaming every change instead of waiting until logical_decoding_work_mem is exceeded, which could help to test streaming parallel. Attach the patch. This is based on v41-0001 patch. With this patch, I saw a problem that the subscription option "origin" doesn't work when using streaming parallel. That's because when the parallel apply worker writing the WAL for the changes, replorigin_session_origin is InvalidRepOriginId. In current patch, origin can be active only in one process at-a-time. To fix it, maybe we need to remove this restriction, like what we did in the old version of patch. Regards Shi yu
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Oct 28, 2022 at 3:04 PM shiy.fnst@fujitsu.com <shiy.fnst@fujitsu.com> wrote: > > On Tue, Oct 25, 2022 2:56 PM Wang, Wei/王 威 <wangw.fnst@fujitsu.com> wrote: > > I tried to write a draft patch to force streaming every change instead of > waiting until logical_decoding_work_mem is exceeded, which could help to test > streaming parallel. Attach the patch. This is based on v41-0001 patch. > Thanks, I think this is quite useful for testing. > With this patch, I saw a problem that the subscription option "origin" doesn't > work when using streaming parallel. That's because when the parallel apply > worker writing the WAL for the changes, replorigin_session_origin is > InvalidRepOriginId. In current patch, origin can be active only in one process > at-a-time. > > To fix it, maybe we need to remove this restriction, like what we did in the old > version of patch. > Agreed, we need to allow using origins for writing all the changes by the parallel worker. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, Oct 24, 2022 at 8:42 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Wed, Oct 12, 2022 at 3:04 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Tue, Oct 11, 2022 at 5:52 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > >
> > > On Fri, Oct 7, 2022 at 2:00 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > > >
> > > > About your point that having different partition structures for
> > > > publisher and subscriber, I don't know how common it will be once we
> > > > have DDL replication. Also, the default value of
> > > > publish_via_partition_root is false which doesn't seem to indicate
> > > > that this is a quite common case.
> > >
> > > So how can we consider these concurrent issues that could happen only
> > > when streaming = 'parallel'? Can we restrict some use cases to avoid
> > > the problem or can we have a safeguard against these conflicts?
> > >
> >
> > Yeah, right now the strategy is to disallow parallel apply for such
> > cases as you can see in *0003* patch.
>
> Tightening the restrictions could work in some cases but there might
> still be coner cases and it could reduce the usability. I'm not really
> sure that we can ensure such a deadlock won't happen with the current
> restrictions. I think we need something safeguard just in case. For
> example, if the leader apply worker is waiting for a lock acquired by
> its parallel worker, it cancels the parallel worker's transaction,
> commits its transaction, and restarts logical replication. Or the
> leader can log the deadlock to let the user know.
>
As another direction, we could make the parallel apply feature robust
if we can detect deadlocks that happen among the leader worker and
parallel workers. I'd like to summarize the idea discussed off-list
(with Amit, Hou-San, and Kuroda-San) for discussion. The basic idea is
that when the leader worker or parallel worker needs to wait for
something (eg. transaction completion, messages) we use lmgr
functionality so that we can create wait-for edges and detect
deadlocks in lmgr.
For example, a scenario where a deadlock occurs is the following:
[Publisher]
create table tab1(a int);
create publication pub for table tab1;
[Subcriber]
creat table tab1(a int primary key);
create subscription sub connection 'port=10000 dbname=postgres'
publication pub with (streaming = parallel);
TX1:
BEGIN;
INSERT INTO tab1 SELECT i FROM generate_series(1, 5000) s(i); -- streamed
Tx2:
BEGIN;
INSERT INTO tab1 SELECT i FROM generate_series(1, 5000) s(i); -- streamed
COMMIT;
COMMIT;
Suppose a parallel apply worker (PA-1) is executing TX-1 and the
leader apply worker (LA) is executing TX-2 concurrently on the
subscriber. Now, LA is waiting for PA-1 because of the unique key of
tab1 while PA-1 is waiting for LA to send further messages. There is a
deadlock between PA-1 and LA but lmgr cannot detect it.
One idea to resolve this issue is that we have LA acquire a session
lock on a shared object (by LockSharedObjectForSession()) and have
PA-1 wait on the lock before trying to receive messages. IOW, LA
acquires the lock before sending STREAM_STOP and releases it if
already acquired before sending STREAM_START, STREAM_PREPARE and
STREAM_COMMIT. For PA-1, it always needs to acquire the lock after
processing STREAM_STOP and then release immediately after acquiring
it. That way, when PA-1 is waiting for LA, we can have a wait-edge
from PA-1 to LA in lmgr, which will make a deadlock in lmgr like:
LA (waiting to acquire lock) -> PA-1 (waiting to acquire the shared
object) -> LA
We would need the shared objects per parallel apply worker.
After detecting a deadlock, we can restart logical replication with
temporarily disabling the parallel apply, which is done by 0005 patch.
Another scenario is similar to the previous case but TX-1 and TX-2 are
executed by two parallel apply workers (PA-1 and PA-2 respectively).
In this scenario, PA-2 is waiting for PA-1 to complete its transaction
while PA-1 is waiting for subsequent input from LA. Also, LA is
waiting for PA-2 to complete its transaction in order to preserve the
commit order. There is a deadlock among three processes but it cannot
be detected in lmgr because the fact that LA is waiting for PA-2 to
complete its transaction doesn't appear in lmgr (see
parallel_apply_wait_for_xact_finish()). To fix it, we can use
XactLockTableWait() instead.
However, since XactLockTableWait() considers PREPARED TRANSACTION as
still in progress, probably we need a similar trick as above in case
where a transaction is prepared. For example, suppose that TX-2 was
prepared instead of committed in the above scenario, PA-2 acquires
another shared lock at START_STREAM and releases it at
STREAM_COMMIT/PREPARE. LA can wait on the lock.
Yet another scenario where LA has to wait is the case where the shm_mq
buffer is full. In the above scenario (ie. PA-1 and PA-2 are executing
transactions concurrently), if the shm_mq buffer between LA and PA-2
is full, LA has to wait to send messages, and this wait doesn't appear
in lmgr. To fix it, probably we have to use non-blocking write and
wait with a timeout. If timeout is exceeded, the LA will write to file
and indicate PA-2 that it needs to read file for remaining messages.
Then LA will start waiting for commit which will detect deadlock if
any.
If we can detect deadlocks by having such a functionality or some
other way then we don't need to tighten the restrictions of subscribed
tables' schemas etc.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, November 2, 2022 10:50 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Mon, Oct 24, 2022 at 8:42 PM Masahiko Sawada > <sawada.mshk@gmail.com> wrote: > > > > On Wed, Oct 12, 2022 at 3:04 PM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > > > > On Tue, Oct 11, 2022 at 5:52 AM Masahiko Sawada > <sawada.mshk@gmail.com> wrote: > > > > > > > > On Fri, Oct 7, 2022 at 2:00 PM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > > > > > > > > About your point that having different partition structures for > > > > > publisher and subscriber, I don't know how common it will be once we > > > > > have DDL replication. Also, the default value of > > > > > publish_via_partition_root is false which doesn't seem to indicate > > > > > that this is a quite common case. > > > > > > > > So how can we consider these concurrent issues that could happen only > > > > when streaming = 'parallel'? Can we restrict some use cases to avoid > > > > the problem or can we have a safeguard against these conflicts? > > > > > > > > > > Yeah, right now the strategy is to disallow parallel apply for such > > > cases as you can see in *0003* patch. > > > > Tightening the restrictions could work in some cases but there might > > still be coner cases and it could reduce the usability. I'm not really > > sure that we can ensure such a deadlock won't happen with the current > > restrictions. I think we need something safeguard just in case. For > > example, if the leader apply worker is waiting for a lock acquired by > > its parallel worker, it cancels the parallel worker's transaction, > > commits its transaction, and restarts logical replication. Or the > > leader can log the deadlock to let the user know. > > > > As another direction, we could make the parallel apply feature robust > if we can detect deadlocks that happen among the leader worker and > parallel workers. I'd like to summarize the idea discussed off-list > (with Amit, Hou-San, and Kuroda-San) for discussion. The basic idea is > that when the leader worker or parallel worker needs to wait for > something (eg. transaction completion, messages) we use lmgr > functionality so that we can create wait-for edges and detect > deadlocks in lmgr. > > For example, a scenario where a deadlock occurs is the following: > > [Publisher] > create table tab1(a int); > create publication pub for table tab1; > > [Subcriber] > creat table tab1(a int primary key); > create subscription sub connection 'port=10000 dbname=postgres' > publication pub with (streaming = parallel); > > TX1: > BEGIN; > INSERT INTO tab1 SELECT i FROM generate_series(1, 5000) s(i); -- streamed > Tx2: > BEGIN; > INSERT INTO tab1 SELECT i FROM generate_series(1, 5000) s(i); -- streamed > COMMIT; > COMMIT; > > Suppose a parallel apply worker (PA-1) is executing TX-1 and the > leader apply worker (LA) is executing TX-2 concurrently on the > subscriber. Now, LA is waiting for PA-1 because of the unique key of > tab1 while PA-1 is waiting for LA to send further messages. There is a > deadlock between PA-1 and LA but lmgr cannot detect it. > > One idea to resolve this issue is that we have LA acquire a session > lock on a shared object (by LockSharedObjectForSession()) and have > PA-1 wait on the lock before trying to receive messages. IOW, LA > acquires the lock before sending STREAM_STOP and releases it if > already acquired before sending STREAM_START, STREAM_PREPARE and > STREAM_COMMIT. For PA-1, it always needs to acquire the lock after > processing STREAM_STOP and then release immediately after acquiring > it. That way, when PA-1 is waiting for LA, we can have a wait-edge > from PA-1 to LA in lmgr, which will make a deadlock in lmgr like: > > LA (waiting to acquire lock) -> PA-1 (waiting to acquire the shared > object) -> LA > > We would need the shared objects per parallel apply worker. > > After detecting a deadlock, we can restart logical replication with > temporarily disabling the parallel apply, which is done by 0005 patch. > > Another scenario is similar to the previous case but TX-1 and TX-2 are > executed by two parallel apply workers (PA-1 and PA-2 respectively). > In this scenario, PA-2 is waiting for PA-1 to complete its transaction > while PA-1 is waiting for subsequent input from LA. Also, LA is > waiting for PA-2 to complete its transaction in order to preserve the > commit order. There is a deadlock among three processes but it cannot > be detected in lmgr because the fact that LA is waiting for PA-2 to > complete its transaction doesn't appear in lmgr (see > parallel_apply_wait_for_xact_finish()). To fix it, we can use > XactLockTableWait() instead. > > However, since XactLockTableWait() considers PREPARED TRANSACTION as > still in progress, probably we need a similar trick as above in case > where a transaction is prepared. For example, suppose that TX-2 was > prepared instead of committed in the above scenario, PA-2 acquires > another shared lock at START_STREAM and releases it at > STREAM_COMMIT/PREPARE. LA can wait on the lock. > > Yet another scenario where LA has to wait is the case where the shm_mq > buffer is full. In the above scenario (ie. PA-1 and PA-2 are executing > transactions concurrently), if the shm_mq buffer between LA and PA-2 > is full, LA has to wait to send messages, and this wait doesn't appear > in lmgr. To fix it, probably we have to use non-blocking write and > wait with a timeout. If timeout is exceeded, the LA will write to file > and indicate PA-2 that it needs to read file for remaining messages. > Then LA will start waiting for commit which will detect deadlock if > any. > > If we can detect deadlocks by having such a functionality or some > other way then we don't need to tighten the restrictions of subscribed > tables' schemas etc. Thanks for the analysis and summary ! I tried to implement the above idea and here is the patch set. I have done some basic tests for the new codes and it work fine. But I am going to test some conner cases to make sure all the codes work fine. I removed the old 0003 patch which was used to check the parallel apply safety because now we can detect the deadlock problem. Besides, there are few tasks left which I will handle soon and update the patch set: * Address previous comment from Amit[1], Shi-san[2] and Peter[3] (Already done but haven't merged them). * Rebase the original 0005 patch which is "retry to apply streaming xact only in leader apply worker". * Adjust some comments and documentation related to new codes. [1] https://www.postgresql.org/message-id/CAA4eK1Lsn%3D_gz1-3LqZ-wEDQDmChUsOX8LvHS8WV39wC1iRR%3DQ%40mail.gmail.com [2] https://www.postgresql.org/message-id/OSZPR01MB631042582805A8E8615BC413FD329%40OSZPR01MB6310.jpnprd01.prod.outlook.com [3] https://www.postgresql.org/message-id/CAHut%2BPsJWHRoRzXtMrJ1RaxmkS2LkiMR_4S2pSionxXmYsyOww%40mail.gmail.com Best regards, Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Hou,
Thank you for updating the patch!
While testing yours, I found that the leader apply worker has been crashed in the following case.
I will dig the failure more, but I reported here for records.
1. Change macros for forcing to write a temporary file.
```
-#define CHANGES_THRESHOLD 1000
-#define SHM_SEND_TIMEOUT_MS 10000
+#define CHANGES_THRESHOLD 10
+#define SHM_SEND_TIMEOUT_MS 100
```
2. Set logical_decoding_work_mem to 64kB on publisher
3. Insert huge data on publisher
```
publisher=# \d tbl
Table "public.tbl"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
c | integer | | |
Publications:
"pub"
publisher=# BEGIN;
BEGIN
publisher=*# INSERT INTO tbl SELECT i FROM generate_series(1, 5000000) s(i);
INSERT 0 5000000
publisher=*# COMMIT;
```
-> LA crashes on subscriber! Followings are the backtrace.
```
(gdb) bt
#0 0x00007f2663ae4387 in raise () from /lib64/libc.so.6
#1 0x00007f2663ae5a78 in abort () from /lib64/libc.so.6
#2 0x0000000000ad0a95 in ExceptionalCondition (conditionName=0xcabdd0 "mqh->mqh_partial_bytes <= nbytes",
fileName=0xcabc30 "../src/backend/storage/ipc/shm_mq.c", lineNumber=420) at ../src/backend/utils/error/assert.c:66
#3 0x00000000008eaeb7 in shm_mq_sendv (mqh=0x271ebd8, iov=0x7ffc664a2690, iovcnt=1, nowait=false, force_flush=true)
at ../src/backend/storage/ipc/shm_mq.c:420
#4 0x00000000008eac5a in shm_mq_send (mqh=0x271ebd8, nbytes=1, data=0x271f3c0, nowait=false, force_flush=true)
at ../src/backend/storage/ipc/shm_mq.c:338
#5 0x0000000000880e18 in parallel_apply_free_worker (winfo=0x271f270, xid=735, stop_worker=true)
at ../src/backend/replication/logical/applyparallelworker.c:368
#6 0x00000000008a3638 in apply_handle_stream_commit (s=0x7ffc664a2790) at
../src/backend/replication/logical/worker.c:2081
#7 0x00000000008a54da in apply_dispatch (s=0x7ffc664a2790) at ../src/backend/replication/logical/worker.c:3195
#8 0x00000000008a5a76 in LogicalRepApplyLoop (last_received=378674872) at
../src/backend/replication/logical/worker.c:3431
#9 0x00000000008a72ac in start_apply (origin_startpos=0) at ../src/backend/replication/logical/worker.c:4245
#10 0x00000000008a7d77 in ApplyWorkerMain (main_arg=0) at ../src/backend/replication/logical/worker.c:4555
#11 0x000000000084983c in StartBackgroundWorker () at ../src/backend/postmaster/bgworker.c:861
#12 0x0000000000854192 in do_start_bgworker (rw=0x26c0d20) at ../src/backend/postmaster/postmaster.c:5801
#13 0x000000000085457c in maybe_start_bgworkers () at ../src/backend/postmaster/postmaster.c:6025
#14 0x000000000085350b in sigusr1_handler (postgres_signal_arg=10) at ../src/backend/postmaster/postmaster.c:5182
#15 <signal handler called>
#16 0x00007f2663ba3b23 in __select_nocancel () from /lib64/libc.so.6
#17 0x000000000084edbc in ServerLoop () at ../src/backend/postmaster/postmaster.c:1768
#18 0x000000000084e737 in PostmasterMain (argc=3, argv=0x2690f60) at ../src/backend/postmaster/postmaster.c:1476
#19 0x000000000074adfb in main (argc=3, argv=0x2690f60) at ../src/backend/main/main.c:197
```
PSA the script that can reproduce the failure on my environment.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Nov 3, 2022 at 6:36 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Thanks for the analysis and summary !
>
> I tried to implement the above idea and here is the patch set.
>
Few comments on v42-0001
===========================
1.
+ /*
+ * Set the xact_state flag in the leader instead of the
+ * parallel apply worker to avoid the race condition where the leader has
+ * already started waiting for the parallel apply worker to finish
+ * processing the transaction while the child process has not yet
+ * processed the first STREAM_START and has not set the
+ * xact_state to true.
+ */
+ SpinLockAcquire(&winfo->shared->mutex);
+ winfo->shared->xact_state = PARALLEL_TRANS_UNKNOWN;
The comments and code for xact_state doesn't seem to match.
2.
+ * progress. This could happend as we don't wait for transaction rollback
+ * to finish.
+ */
/happend/happen
3.
+/* Helper function to release a lock with lockid */
+void
+parallel_apply_lock(uint16 lockid)
...
...
+/* Helper function to take a lock with lockid */
+void
+parallel_apply_unlock(uint16 lockid)
Here, the comments seems to be reversed.
4.
+parallel_apply_lock(uint16 lockid)
+{
+ MemoryContext oldcontext;
+
+ if (list_member_int(ParallelApplyLockids, lockid))
+ return;
+
+ LockSharedObjectForSession(SubscriptionRelationId, MySubscription->oid,
+ lockid, am_leader_apply_worker() ?
+ AccessExclusiveLock:
+ AccessShareLock);
This appears odd to me because this forecloses the option the parallel
apply worker can ever acquire this lock in exclusive mode. I think it
would be better to have lock_mode as one of the parameters in this
API.
5.
+ * Inintialize fileset if not yet and open the file.
+ */
+void
+serialize_stream_start(TransactionId xid, bool first_segment)
Typo. /Inintialize/Initialize
6.
parallel_apply_setup_dsm()
{
...
+ shared->xact_state = false;
xact_state should be set with one of the values of ParallelTransState.
7.
/*
+ * Don't use SharedFileSet here because the fileset is shared by the leader
+ * worker and the fileset in leader need to survive after releasing the
+ * shared memory
This comment seems a bit unclear to me. Should there be and between
leader worker? If so, then the following 'and' won't make sense.
8.
+apply_handle_stream_stop(StringInfo s)
{
...
+ case TRANS_PARALLEL_APPLY:
+
+ /*
+ * If there is no message left, wait for the leader to release the
+ * lock and send more messages.
+ */
+ if (pg_atomic_sub_fetch_u32(&(MyParallelShared->left_message), 1) == 0)
+ parallel_apply_lock(MyParallelShared->stream_lock_id);
As per Sawada-San's email [1], this lock should be released
immediately after we acquire it. If we do so, then we don't need to
unlock separately in apply_handle_stream_start() in the below code and
at similar places in stream_prepare, stream_commit, and stream_abort.
Is there a reason for doing it differently?
apply_handle_stream_start(StringInfo s)
{
...
+ case TRANS_PARALLEL_APPLY:
...
+ /*
+ * Unlock the shared object lock so that the leader apply worker
+ * can continue to send changes.
+ */
+ parallel_apply_unlock(MyParallelShared->stream_lock_id);
9.
+parallel_apply_spooled_messages(void)
{
...
+ if (fileset_valid)
+ {
+ in_streamed_transaction = false;
+
+ parallel_apply_lock(MyParallelShared->transaction_lock_id);
Is there a reason to acquire this lock here if the parallel apply
worker will acquire it at stream_start?
10.
+ winfo->shared->stream_lock_id = parallel_apply_get_unique_id();
+ winfo->shared->transaction_lock_id = parallel_apply_get_unique_id();
Why can't we use xid (remote_xid) for one of these and local_xid (one
generated by parallel apply) for the other? I was a bit worried about
the local_xid because it will be generated only after applying the
first message but the patch already seems to be waiting for it in
parallel_apply_wait_for_xact_finish as seen in the below code.
+void
+parallel_apply_wait_for_xact_finish(ParallelApplyWorkerShared *wshared)
+{
+ /*
+ * Wait until the parallel apply worker handles the first message and
+ * set the flag to true.
+ */
+ parallel_apply_wait_for_in_xact(wshared, PARALLEL_TRANS_STARTED);
+
+ /* Wait for the transaction lock to be released. */
+ parallel_apply_lock(wshared->transaction_lock_id);
[1] - https://www.postgresql.org/message-id/CAD21AoCWovvhGBD2uKcQqbk6px6apswuBrs6dR9%2BWhP1j2LdsQ%40mail.gmail.com
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
> While testing yours, I found that the leader apply worker has been crashed in the > following case. > I will dig the failure more, but I reported here for records. I found a reason why the leader apply worker crasehes. In parallel_apply_free_worker() the leader sends the pending message to parallel apply worker: ``` + /* + * Resend the pending message to parallel apply worker to cleanup the + * queue. Note that parallel apply worker will just ignore this message + * as it has already handled this message while applying spooled + * messages. + */ + result = shm_mq_send(winfo->mq_handle, strlen(winfo->pending_msg), + winfo->pending_msg, false, true); ``` ...but the message length should not be calucarete by strlen() because the logicalrep message has '\0'. PSA the patch to fix it. It can be applied on v42 patch set. Best Regards, Hayato Kuroda FUJITSU LIMITED
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Nov 4, 2022 at 1:36 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Nov 3, 2022 at 6:36 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > Thanks for the analysis and summary !
> >
> > I tried to implement the above idea and here is the patch set.
> >
>
> Few comments on v42-0001
> ===========================
>
Few more comments on v42-0001
===============================
1. In parallel_apply_send_data(), it seems winfo->serialize_changes
and switching_to_serialize are set to indicate that we have changed
parallel to serialize mode. Isn't using just the
switching_to_serialize sufficient? Also, it would be better to name
switching_to_serialize as parallel_to_serialize or something like
that.
2. In parallel_apply_send_data(), the patch has already initialized
the fileset, and then again in apply_handle_stream_start(), it will do
the same if we fail while sending stream_start message to the parallel
worker. It seems we don't need to initialize fileset again for
TRANS_LEADER_PARTIAL_SERIALIZE state in apply_handle_stream_start()
unless I am missing something.
3.
apply_handle_stream_start(StringInfo s)
{
...
+ if (!first_segment)
+ {
+ /*
+ * Unlock the shared object lock so that parallel apply worker
+ * can continue to receive and apply changes.
+ */
+ parallel_apply_unlock(winfo->shared->stream_lock_id);
...
}
Can we have an assert before this unlock call that the lock must be
held? Similarly, if there are other places then we can have assert
there as well.
4. It is not very clear to me how maintaining ParallelApplyLockids
list is helpful.
5.
/*
+ * Handle STREAM START message when the transaction was spilled to disk.
+ *
+ * Inintialize fileset if not yet and open the file.
+ */
+void
+serialize_stream_start(TransactionId xid, bool first_segment)
+{
+ /*
+ * Start a transaction on stream start,
This function's name and comments seem to indicate that it is to
handle stream_start message. Is that really the case? It is being
called from parallel_apply_send_data() which made me think it can be
used from other places as well.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, November 4, 2022 4:07 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Nov 3, 2022 at 6:36 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > Thanks for the analysis and summary !
> >
> > I tried to implement the above idea and here is the patch set.
> >
>
> Few comments on v42-0001
> ===========================
Thanks for the comments.
>
> 10.
> + winfo->shared->stream_lock_id = parallel_apply_get_unique_id();
> + winfo->shared->transaction_lock_id = parallel_apply_get_unique_id();
>
> Why can't we use xid (remote_xid) for one of these and local_xid (one generated
> by parallel apply) for the other? I was a bit worried about the local_xid because it
> will be generated only after applying the first message but the patch already
> seems to be waiting for it in parallel_apply_wait_for_xact_finish as seen in the
> below code.
>
> +void
> +parallel_apply_wait_for_xact_finish(ParallelApplyWorkerShared *wshared)
> +{
> + /*
> + * Wait until the parallel apply worker handles the first message and
> + * set the flag to true.
> + */
> + parallel_apply_wait_for_in_xact(wshared, PARALLEL_TRANS_STARTED);
> +
> + /* Wait for the transaction lock to be released. */
> + parallel_apply_lock(wshared->transaction_lock_id);
I also considered using xid for these locks, but it seems the objsubid for the
shared object lock is 16bit while xid is 32 bit. So, I tried to generate a unique 16bit id
here. I will think more on this and maybe I need to add some comments to
explain this.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Nov 4, 2022 at 7:35 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Friday, November 4, 2022 4:07 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Thu, Nov 3, 2022 at 6:36 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > Thanks for the analysis and summary ! > > > > > > I tried to implement the above idea and here is the patch set. > > > > > > > Few comments on v42-0001 > > =========================== > > Thanks for the comments. > > > > > 10. > > + winfo->shared->stream_lock_id = parallel_apply_get_unique_id(); > > + winfo->shared->transaction_lock_id = parallel_apply_get_unique_id(); > > > > Why can't we use xid (remote_xid) for one of these and local_xid (one generated > > by parallel apply) for the other? ... ... > > I also considered using xid for these locks, but it seems the objsubid for the > shared object lock is 16bit while xid is 32 bit. So, I tried to generate a unique 16bit id > here. > Okay, I see your point. Can we think of having a new lock tag for this with classid, objid, objsubid for the first three fields of locktag field? We can use a new macro SET_LOCKTAG_APPLY_TRANSACTION and a common function to set the tag and acquire the lock. One more point related to this is that I am suggesting classid by referring to SET_LOCKTAG_OBJECT as that is used in the current patch but do you think we need it for our purpose, won't subscription id and xid can uniquely identify the tag? -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Saturday, November 5, 2022 1:43 PM Amit Kapila <amit.kapila16@gmail.com> > > On Fri, Nov 4, 2022 at 7:35 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Friday, November 4, 2022 4:07 PM Amit Kapila > <amit.kapila16@gmail.com> wrote: > > > > > > On Thu, Nov 3, 2022 at 6:36 PM houzj.fnst@fujitsu.com > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > Thanks for the analysis and summary ! > > > > > > > > I tried to implement the above idea and here is the patch set. > > > > > > > > > > Few comments on v42-0001 > > > =========================== > > > > Thanks for the comments. > > > > > > > > 10. > > > + winfo->shared->stream_lock_id = parallel_apply_get_unique_id(); > > > + winfo->shared->transaction_lock_id = > > > + winfo->shared->parallel_apply_get_unique_id(); > > > > > > Why can't we use xid (remote_xid) for one of these and local_xid > > > (one generated by parallel apply) for the other? > ... > ... > > > > I also considered using xid for these locks, but it seems the objsubid > > for the shared object lock is 16bit while xid is 32 bit. So, I tried > > to generate a unique 16bit id here. > > > > Okay, I see your point. Can we think of having a new lock tag for this with classid, > objid, objsubid for the first three fields of locktag field? We can use a new > macro SET_LOCKTAG_APPLY_TRANSACTION and a common function to set the > tag and acquire the lock. One more point related to this is that I am suggesting > classid by referring to SET_LOCKTAG_OBJECT as that is used in the current > patch but do you think we need it for our purpose, won't subscription id and > xid can uniquely identify the tag? I agree that it could be better to have a new lock tag. Another point is that the remote xid and Local xid could be the same in some rare cases, so I think we might need to add another identifier to make it unique. Maybe : locktag_field1 : subscription oid locktag_field2 : xid(remote or local) locktag_field3 : 0(lock for stream block)/1(lock for transaction) Best regards, Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Sun, Nov 6, 2022 at 3:40 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Saturday, November 5, 2022 1:43 PM Amit Kapila <amit.kapila16@gmail.com> > > > > On Fri, Nov 4, 2022 at 7:35 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > On Friday, November 4, 2022 4:07 PM Amit Kapila > > <amit.kapila16@gmail.com> wrote: > > > > > > > > On Thu, Nov 3, 2022 at 6:36 PM houzj.fnst@fujitsu.com > > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > > > Thanks for the analysis and summary ! > > > > > > > > > > I tried to implement the above idea and here is the patch set. > > > > > > > > > > > > > Few comments on v42-0001 > > > > =========================== > > > > > > Thanks for the comments. > > > > > > > > > > > 10. > > > > + winfo->shared->stream_lock_id = parallel_apply_get_unique_id(); > > > > + winfo->shared->transaction_lock_id = > > > > + winfo->shared->parallel_apply_get_unique_id(); > > > > > > > > Why can't we use xid (remote_xid) for one of these and local_xid > > > > (one generated by parallel apply) for the other? > > ... > > ... > > > > > > I also considered using xid for these locks, but it seems the objsubid > > > for the shared object lock is 16bit while xid is 32 bit. So, I tried > > > to generate a unique 16bit id here. > > > > > > > Okay, I see your point. Can we think of having a new lock tag for this with classid, > > objid, objsubid for the first three fields of locktag field? We can use a new > > macro SET_LOCKTAG_APPLY_TRANSACTION and a common function to set the > > tag and acquire the lock. One more point related to this is that I am suggesting > > classid by referring to SET_LOCKTAG_OBJECT as that is used in the current > > patch but do you think we need it for our purpose, won't subscription id and > > xid can uniquely identify the tag? > > I agree that it could be better to have a new lock tag. Another point is that > the remote xid and Local xid could be the same in some rare cases, so I think > we might need to add another identifier to make it unique. > > Maybe : > locktag_field1 : subscription oid > locktag_field2 : xid(remote or local) > locktag_field3 : 0(lock for stream block)/1(lock for transaction) Or I think we can use locktag_field2 for remote xid and locktag_field3 for local xid. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Nov 7, 2022 at 8:26 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Sun, Nov 6, 2022 at 3:40 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Saturday, November 5, 2022 1:43 PM Amit Kapila <amit.kapila16@gmail.com> > > > > > > On Fri, Nov 4, 2022 at 7:35 PM houzj.fnst@fujitsu.com > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > On Friday, November 4, 2022 4:07 PM Amit Kapila > > > <amit.kapila16@gmail.com> wrote: > > > > > > > > > > On Thu, Nov 3, 2022 at 6:36 PM houzj.fnst@fujitsu.com > > > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > > > > > Thanks for the analysis and summary ! > > > > > > > > > > > > I tried to implement the above idea and here is the patch set. > > > > > > > > > > > > > > > > Few comments on v42-0001 > > > > > =========================== > > > > > > > > Thanks for the comments. > > > > > > > > > > > > > > 10. > > > > > + winfo->shared->stream_lock_id = parallel_apply_get_unique_id(); > > > > > + winfo->shared->transaction_lock_id = > > > > > + winfo->shared->parallel_apply_get_unique_id(); > > > > > > > > > > Why can't we use xid (remote_xid) for one of these and local_xid > > > > > (one generated by parallel apply) for the other? > > > ... > > > ... > > > > > > > > I also considered using xid for these locks, but it seems the objsubid > > > > for the shared object lock is 16bit while xid is 32 bit. So, I tried > > > > to generate a unique 16bit id here. > > > > > > > > > > Okay, I see your point. Can we think of having a new lock tag for this with classid, > > > objid, objsubid for the first three fields of locktag field? We can use a new > > > macro SET_LOCKTAG_APPLY_TRANSACTION and a common function to set the > > > tag and acquire the lock. One more point related to this is that I am suggesting > > > classid by referring to SET_LOCKTAG_OBJECT as that is used in the current > > > patch but do you think we need it for our purpose, won't subscription id and > > > xid can uniquely identify the tag? > > > > I agree that it could be better to have a new lock tag. Another point is that > > the remote xid and Local xid could be the same in some rare cases, so I think > > we might need to add another identifier to make it unique. > > > > Maybe : > > locktag_field1 : subscription oid > > locktag_field2 : xid(remote or local) > > locktag_field3 : 0(lock for stream block)/1(lock for transaction) > > Or I think we can use locktag_field2 for remote xid and locktag_field3 > for local xid. > We can do that way as well but OTOH, I think for the local transactions we don't need subscription oid, so field1 could be InvalidOid and field2 will be xid of local xact. Won't that be better? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, Nov 7, 2022 at 12:58 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Nov 7, 2022 at 8:26 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Sun, Nov 6, 2022 at 3:40 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > On Saturday, November 5, 2022 1:43 PM Amit Kapila <amit.kapila16@gmail.com> > > > > > > > > On Fri, Nov 4, 2022 at 7:35 PM houzj.fnst@fujitsu.com > > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > > > On Friday, November 4, 2022 4:07 PM Amit Kapila > > > > <amit.kapila16@gmail.com> wrote: > > > > > > > > > > > > On Thu, Nov 3, 2022 at 6:36 PM houzj.fnst@fujitsu.com > > > > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > > > > > > > Thanks for the analysis and summary ! > > > > > > > > > > > > > > I tried to implement the above idea and here is the patch set. > > > > > > > > > > > > > > > > > > > Few comments on v42-0001 > > > > > > =========================== > > > > > > > > > > Thanks for the comments. > > > > > > > > > > > > > > > > > 10. > > > > > > + winfo->shared->stream_lock_id = parallel_apply_get_unique_id(); > > > > > > + winfo->shared->transaction_lock_id = > > > > > > + winfo->shared->parallel_apply_get_unique_id(); > > > > > > > > > > > > Why can't we use xid (remote_xid) for one of these and local_xid > > > > > > (one generated by parallel apply) for the other? > > > > ... > > > > ... > > > > > > > > > > I also considered using xid for these locks, but it seems the objsubid > > > > > for the shared object lock is 16bit while xid is 32 bit. So, I tried > > > > > to generate a unique 16bit id here. > > > > > > > > > > > > > Okay, I see your point. Can we think of having a new lock tag for this with classid, > > > > objid, objsubid for the first three fields of locktag field? We can use a new > > > > macro SET_LOCKTAG_APPLY_TRANSACTION and a common function to set the > > > > tag and acquire the lock. One more point related to this is that I am suggesting > > > > classid by referring to SET_LOCKTAG_OBJECT as that is used in the current > > > > patch but do you think we need it for our purpose, won't subscription id and > > > > xid can uniquely identify the tag? > > > > > > I agree that it could be better to have a new lock tag. Another point is that > > > the remote xid and Local xid could be the same in some rare cases, so I think > > > we might need to add another identifier to make it unique. > > > > > > Maybe : > > > locktag_field1 : subscription oid > > > locktag_field2 : xid(remote or local) > > > locktag_field3 : 0(lock for stream block)/1(lock for transaction) > > > > Or I think we can use locktag_field2 for remote xid and locktag_field3 > > for local xid. > > > > We can do that way as well but OTOH, I think for the local > transactions we don't need subscription oid, so field1 could be > InvalidOid and field2 will be xid of local xact. Won't that be better? This would work. But I'm a bit concerned that we cannot identify which subscriptions the lock belongs to when checking pg_locks view. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Nov 7, 2022 at 10:02 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Mon, Nov 7, 2022 at 12:58 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > I agree that it could be better to have a new lock tag. Another point is that > > > > the remote xid and Local xid could be the same in some rare cases, so I think > > > > we might need to add another identifier to make it unique. > > > > > > > > Maybe : > > > > locktag_field1 : subscription oid > > > > locktag_field2 : xid(remote or local) > > > > locktag_field3 : 0(lock for stream block)/1(lock for transaction) > > > > > > Or I think we can use locktag_field2 for remote xid and locktag_field3 > > > for local xid. > > > > > > > We can do that way as well but OTOH, I think for the local > > transactions we don't need subscription oid, so field1 could be > > InvalidOid and field2 will be xid of local xact. Won't that be better? > > This would work. But I'm a bit concerned that we cannot identify which > subscriptions the lock belongs to when checking pg_locks view. > Fair point. I think if the user wants, she can join with pg_stat_subscription based on PID and find the corresponding subscription. However, if we want to identify everything via pg_locks then I think we should also mention classid or database id as field1. So, it would look like: field1: (pg_subscription's oid or current db id); field2: OID of subscription in pg_subscription; field3: local or remote xid; field4: 0/1 to differentiate between remote and local xid. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for v42-0001
======
1. General.
Please take the time to process all new code comments using a
grammar/spelling checker (e.g. simply cut/paste them into MSWord or
Grammarly or any other tool of your choice as a quick double-check)
*before* posting the patches; too many of my review comments are about
code comments and it's taking a long time to keep cycling through
reporting/fixing/confirming comments for every patch version -
whereas it probably would take hardly any time to make the same
spelling/grammar corrections up-front.
======
.../replication/logical/applyparallelworker.c
2. ParallelApplyLockids
This seems like a bogus name. Code is using this in a way that means
the subset of lockED ids. Not the list of all the lock ids.
OTHO, having another list of ALL lock-ids might be useful (for
detecting unique ids) if you are able to maintain such a list safely.
~~~
3. parallel_apply_can_start
+
+ if (switching_to_serialize)
+ return false;
This should have an explanatory comment.
~~~
4. parallel_apply_start_worker
+ /* Check if the transaction in that worker has been finished. */
+ xact_state = parallel_apply_get_xact_state(tmp_winfo->shared);
+ if (xact_state == PARALLEL_TRANS_FINISHED)
"has been finished." -> "has finished."
~~~
5.
+ /*
+ * Set the xact_state flag in the leader instead of the
+ * parallel apply worker to avoid the race condition where the leader has
+ * already started waiting for the parallel apply worker to finish
+ * processing the transaction while the child process has not yet
+ * processed the first STREAM_START and has not set the
+ * xact_state to true.
+ */
+ SpinLockAcquire(&winfo->shared->mutex);
+ winfo->shared->xact_state = PARALLEL_TRANS_UNKNOWN;
+ winfo->shared->xid = xid;
+ winfo->shared->fileset_valid = false;
+ winfo->shared->partial_sent_message = false;
+ SpinLockRelease(&winfo->shared->mutex);
This code comment is stale, because xact_state is no longer a "flag",
nor does "set the xact_state to true." make sense anymore.
~~~
6. parallel_apply_free_worker
+ /*
+ * Don't free the worker if the transaction in the worker is still in
+ * progress. This could happend as we don't wait for transaction rollback
+ * to finish.
+ */
+ if (parallel_apply_get_xact_state(winfo->shared) < PARALLEL_TRANS_FINISHED)
+ return;
6a.
typo "happend"
~
6b.
Saying "< PARALLEL_TRANS_FINISHED" seems kind of risky because not it
is assuming a specific ordering of those enums which has never been
mentioned before. I think it will be safer to say "!=
PARALLEL_TRANS_FINISHED" instead. Alternatively, if the enum order is
important then it must be documented with the typedef so that nobody
changes it.
~~~
7.
+ ParallelApplyWorkersList = list_delete_ptr(ParallelApplyWorkersList,
+ winfo);
Unnecessary wrapping
~~~
8.
+ /*
+ * Resend the pending message to parallel apply worker to cleanup the
+ * queue. Note that parallel apply worker will just ignore this message
+ * as it has already handled this message while applying spooled
+ * messages.
+ */
+ result = shm_mq_send(winfo->mq_handle, strlen(winfo->pending_msg),
+ winfo->pending_msg, false, true);
If I understand this logic it seems a bit hacky. From the comment, it
seems you are resending a message that you know/expect to be ignored
simply to make it disappear. (??). Isn't there some other way to clear
the pending message without requiring a bogus send?
~~~
9. parallel_apply_spooled_messages
+
+static void
+parallel_apply_spooled_messages(void)
Missing function comment
~~~
10.
+parallel_apply_spooled_messages(void)
+{
+ bool fileset_valid = false;
+
+ /*
+ * Check if changes has been serialized to disk. if so, read and
+ * apply them.
+ */
+ SpinLockAcquire(&MyParallelShared->mutex);
+ fileset_valid = MyParallelShared->fileset_valid;
+ SpinLockRelease(&MyParallelShared->mutex);
The variable assignment in the declaration seems unnecessary.
~~~
11.
+ /*
+ * Check if changes has been serialized to disk. if so, read and
+ * apply them.
+ */
+ SpinLockAcquire(&MyParallelShared->mutex);
+ fileset_valid = MyParallelShared->fileset_valid;
+ SpinLockRelease(&MyParallelShared->mutex);
"has been" -> "have been"
~~~
12.
+ apply_spooled_messages(&MyParallelShared->fileset,
+ MyParallelShared->xid,
+ InvalidXLogRecPtr);
+ parallel_apply_set_fileset(MyParallelShared, false);
parallel_apply_set_fileset() is a confusing function name. IMO this
logic would be better split into 2 smaller functions:
- parallel_apply_set_fileset_valid()
- parallel_apply_set_fileset_invalid()
~~~
13. parallel_apply_get_unique_id
+/*
+ * Returns the unique id among all parallel apply workers in the subscriber.
+ */
+static uint16
+parallel_apply_get_unique_id()
The meaning of that comment and the purpose of this function are not
entirely clear... e.g. I had to read the code to figure out what the
comment is describing.
~~~
14.
The function seems to be written in some way that scans all known ids
looking for one that does not match. I wonder if it might be easier to
just assign some auto-incrementing static instead of having to scan
for uniqueness always. Since the pool of apply workers is limited is
that kind of ID ever going to come close to running out?
Alternatively, see also comment #2 for a different way to know what
lockids are present.
~~~
15.
winfo->shared->stream_lock_id = parallel_apply_get_unique_id();
winfo->shared->transaction_lock_id = parallel_apply_get_unique_id();
It somehow feels clunky to be calling this
parallel_apply_get_unique_id() like this to scan all the same things 2
times. If you are going to keep this scanning logic then at least the
function should be changed to return a PAIR of lock-ids so you only;y
need to do 1x scan instead of 2x scan.
~~~
16. parallel_apply_send_data
+/*
+ * Send the data to the specified parallel apply worker via
shared-memory queue.
+ */
+void
+parallel_apply_send_data(ParallelApplyWorkerInfo *winfo, Size nbytes,
+ const void *data)
The function comment needs more detail to explain the purpose of, and
how the thresholds work.
~~~
17. parallel_apply_wait_for_xact_finish
+/*
+ * Wait until the parallel apply worker's transaction finishes.
+ */
+void
+parallel_apply_wait_for_xact_finish(ParallelApplyWorkerShared *wshared)
I think this comment needs lots more details because the
implementation seems to be doing a lot more than just waiting for the
start to become "finished" - e.g. it seems to be waiting for it to
transition through the other stages as well...
~~~
18.
The boolean flag was changed to enum states so all these comments
mentioning "flag" are stale and need to be reworded/rewritten.
18a.
+ /*
+ * Wait until the parallel apply worker handles the first message and
+ * set the flag to true.
+ */
Update this comment
~
18b.
+ /*
+ * Wait until the flag becomes false in case the lock was released because
+ * of failure while applying.
+ */
Update this comment
~~~
19. parallel_apply_wait_for_in_xact
+/*
+ * Wait until the parallel apply worker's xact_state flag becomes
+ * the same as in_xact.
+ */
+static void
+parallel_apply_wait_for_in_xact(ParallelApplyWorkerShared *wshared,
+ ParallelTransState xact_state)
SUGGESTION
Wait until the parallel apply worker's transaction state becomes the
same as in_xact.
~~~
20.
+ /* Stop if the flag becomes the same as in_xact. */
+ if (parallel_apply_get_xact_state(wshared) >= xact_state)
+ break;
20a.
"flag" -> "transaction state",
~
20b.
This code uses >= comparison which means a strict order of the enum
values is assumed. So this order MUST be documented in the enum
typedef.
~~~
21. parallel_apply_set_xact_state
+/*
+ * Set the xact_state flag for the given parallel apply worker.
+ */
+void
+parallel_apply_set_xact_state(ParallelApplyWorkerShared *wshared,
+ ParallelTransState xact_state)
SUGGESTION
Set an enum indicating the transaction state for the given parallel
apply worker.
~~~
22. parallel_apply_get_xact_state
/*
* Get the xact_state flag for the given parallel apply worker.
*/
static ParallelTransState
parallel_apply_get_xact_state(ParallelApplyWorkerShared *wshared)
SUGGESTION
Get an enum indicating the transaction state for the given parallel
apply worker.
~~~
23. parallel_apply_set_fileset
+/*
+ * Set the fileset_valid flag and fileset for the given parallel apply worker.
+ */
+void
+parallel_apply_set_fileset(ParallelApplyWorkerShared *wshared, bool
fileset_valid)
As mentioned elsewhere (#12 above) I think would be better to split
this into 2 functions.
~~~
24. parallel_apply_lock/unlock
24a.
+/* Helper function to release a lock with lockid */
SUGGESTION
Helper function to release a lock identified by lockid.
~
24b.
+/* Helper function to take a lock with lockid */
SUGGESTION
Helper function to acquire a lock identified by lockid.
~
24c.
+/* Helper function to release a lock with lockid */
+void
+parallel_apply_lock(uint16 lockid)
...
+/* Helper function to take a lock with lockid */
+void
+parallel_apply_unlock(uint16 lockid)
Aren't those function comments around the wrong way?
======
src/backend/replication/logical/worker.c
25. File header comment
+ * The dynamic shared memory segment will contain (a) a shm_mq that can be used
+ * to send changes in the transaction from leader apply worker to parallel
+ * apply worker (b) another shm_mq that can be used to send errors (and other
+ * messages reported via elog/ereport) from the parallel apply worker to leader
+ * apply worker (c) necessary information to be shared among parallel apply
+ * workers and leader apply worker (i.e. the member in
+ * ParallelApplyWorkerShared).
"the member in ParallelApplyWorkerShared" -> "the members of
ParallelApplyWorkerShared"
~~~
26.
Shouldn't that comment have something to say about the
deadlock-detection design?
~~~
27. TransApplyAction
+typedef enum
{
- LogicalRepMsgType command; /* 0 if invalid */
- LogicalRepRelMapEntry *rel;
-
- /* Remote node information */
- int remote_attnum; /* -1 if invalid */
- TransactionId remote_xid;
- XLogRecPtr finish_lsn;
- char *origin_name;
-} ApplyErrorCallbackArg;
-
-static ApplyErrorCallbackArg apply_error_callback_arg =
+ /* The action for non-streaming transactions. */
+ TRANS_LEADER_APPLY,
+
+ /* Actions for streaming transactions. */
+ TRANS_LEADER_SERIALIZE,
+ TRANS_LEADER_PARTIAL_SERIALIZE,
+ TRANS_LEADER_SEND_TO_PARALLEL,
+ TRANS_PARALLEL_APPLY
+} TransApplyAction;
27a.
A new enum TRANS_LEADER_PARTIAL_SERIALIZE was added, but the
explanatory comment for it is missing
~
27b.
In fact, this new TRANS_LEADER_PARTIAL_SERIALIZE is used in many
places with no comments to explain what it is for.
~~~
28. handle_streamed_transaction
static bool
handle_streamed_transaction(LogicalRepMsgType action, StringInfo s)
{
- TransactionId xid;
+ TransactionId current_xid;
+ ParallelApplyWorkerInfo *winfo;
+ TransApplyAction apply_action;
+ StringInfoData origin_msg;
+
+ apply_action = get_transaction_apply_action(stream_xid, &winfo);
/* not in streaming mode */
- if (!in_streamed_transaction)
+ if (apply_action == TRANS_LEADER_APPLY)
return false;
- Assert(stream_fd != NULL);
Assert(TransactionIdIsValid(stream_xid));
+ origin_msg = *s;
28a.
There are no comments explaining what this
TRANS_LEADER_PARTIAL_SERIALIZE is doing. SO I cannot tell if
'origin_msg' is a meaningful name, or does that mean to say
'original_msg' ?
~
28b.
Why not assign it at the declaration, the same as
apply_handle_stream_prepare does?
~~~
29. apply_handle_stream_prepare
+ case TRANS_LEADER_PARTIAL_SERIALIZE:
Seems like there is a missing explanation of what this partial
serialize logic is doing.
~~~
30.
+ case TRANS_PARALLEL_APPLY:
+ parallel_apply_replorigin_setup();
+
+ /* Unlock all the shared object lock at transaction end. */
+ parallel_apply_unlock(MyParallelShared->stream_lock_id);
+
+ if (stream_fd)
+ BufFileClose(stream_fd);
Should be some explanatory comment, on what's going on here with the
stream_fd. E.g. how does it get to be non-NULL and why you do not set
it again to NULL after the BufFileClose.
~~~
31.
/*
+ * Handle STREAM START message when the transaction was spilled to disk.
+ *
+ * Inintialize fileset if not yet and open the file.
+ */
+void
+serialize_stream_start(TransactionId xid, bool first_segment)
Typo "Inintialize" -> "Initialize"
Looks like missing words in the comment.
SUGGESTION
Initialize fileset (if not already done), and open the file.
~~~
32. apply_handle_stream_start
- if (in_streamed_transaction)
+ if (!switching_to_serialize && in_streamed_transaction)
ereport(ERROR,
(errcode(ERRCODE_PROTOCOL_VIOLATION),
errmsg_internal("duplicate STREAM START message")));
Somehow, I think this condition seems more natural if written the
other way around:
SUGGESTION
if (in_streamed_transaction && !switching_to_serialize)
~~~
33.
+ /*
+ * Increment the number of message waiting to be processed by
+ * parallel apply worker.
+ */
+ pg_atomic_add_fetch_u32(&(winfo->shared->left_message), 1);
33a.
"of message" -> "of messages".
~
33b.
The extra &() parens are not useful.
This same syntax is repeated in all the calls to that atomic function
so please search/fix all the others too...
~
33c.
The member name 'left_message' seems not a very good name. How about
'pending_message_count' or 'n_unprocessed_messages' or
'n_messages_remaining' or anything else more informative?
~~~
34. apply_handle_stream_abort
+static void
+apply_handle_stream_abort(StringInfo s)
+{
+ TransactionId xid;
+ TransactionId subxid;
+ LogicalRepStreamAbortData abort_data;
+ ParallelApplyWorkerInfo *winfo;
+ TransApplyAction apply_action;
+ StringInfoData origin_msg = *s;
I'm unsure about that 'origin_msg' variable. Should that be called
'original_msg'?
~~~
35.
+ if (subxid == xid)
There are multiple parts of this logic that are doing (subxid == xid),
so it might be better to assign that to a meaningful variable name
instead of the repeated comparisons.
36.
+ * The file was deleted if aborted the whole transaction, so
+ * create it again in this case.
English? Missing words?
~~~
37.
+ /*
+ * Increment the number of message waiting to be processed by
+ * parallel apply worker.
+ */
"message" -> "messages"
~~~
38.
+ /*
+ * If there is no message left, wait for the leader to release the
+ * lock and send more messages.
+ */
+ if (xid != subxid &&
+ pg_atomic_sub_fetch_u32(&(MyParallelShared->left_message), 1) == 0)
+ parallel_apply_lock(MyParallelShared->stream_lock_id);
The comment says "wait for the leader"... but the comment seems
misleading - there is no waiting happening here.
~~~
39. apply_spooled_messages
+
/*
* Common spoolfile processing.
*/
-static void
-apply_spooled_messages(TransactionId xid, XLogRecPtr lsn)
+void
+apply_spooled_messages(FileSet *stream_fileset, TransactionId xid,
+ XLogRecPtr lsn)
Spurious extra blank line above this function.
~~~
40.
- fd = BufFileOpenFileSet(MyLogicalRepWorker->stream_fileset, path, O_RDONLY,
+ fd = BufFileOpenFileSet(stream_fileset, path, O_RDONLY,
false);
Unnecessary wrapping.
~~~
41.
+ fd = BufFileOpenFileSet(stream_fileset, path, O_RDONLY,
false);
+ stream_fd = fd;
Is it still meaningful to have the local 'fd' variable? Might as well
just use 'stream_fd' instead now, right?
~~~
42.
+ /*
+ * Break the loop if parallel apply worker have finished applying the
+ * transaction. The parallel apply worker should have close the file
+ * before committing.
+ */
English?
"if parallel" -> "if the parallel"
"have finished" -> "has finished"
"should have close" -> "should have closed"
~~~
43. apply_handle_stream_commit
LogicalRepCommitData commit_data;
+ ParallelApplyWorkerInfo *winfo;
+ TransApplyAction apply_action;
+ StringInfoData origin_msg = *s
I'm unsure about that 'origin_msg' variable. Should that be called
'original_msg' ?
~~~
44. stream_write_message
+ * stream_write_message
+ * Serialize the message that are not in a streaming block to a file.
+ */
+static void
+stream_write_message(TransactionId xid, char action, StringInfo s,
+ bool create_file)
44a.
This logic seems new, but the function comment sounds strange
(English/typos?) and it is not giving enough details about when is
this file, and for what purpose are we writing to it?
~
44b.
If this is always written to a file, then wouldn't a better function
name be something including the word "serialize" - e.g.
serialize_message()?
======
src/backend/replication/logical/launcher.c
45. logicalrep_worker_onexit
+ /*
+ * Release all the session level lock that could be held in parallel apply
+ * mode.
+ */
+ LockReleaseAll(DEFAULT_LOCKMETHOD, true);
"the session level lock" -> "session level locks"
======
src/include/replication/worker_internal.h
46. ParallelApplyWorkerShared
+ /*
+ * Flag used to ensure commit ordering.
+ *
+ * The parallel apply worker will set it to false after handling the
+ * transaction finish commands while the apply leader will wait for it to
+ * become false before proceeding in transaction finish commands (e.g.
+ * STREAM_COMMIT/STREAM_ABORT/STREAM_PREPARE).
+ */
+ ParallelTransState xact_state;
The comment has gone stale because this member is not a boolean flag
anymore, so saying "will set it to false" is wrong...
~~~
47.
+ /* Unique identifiers in the current subscription that used to lock. */
+ uint16 stream_lock_id;
+ uint16 transaction_lock_id;
Comment English?
~~~
48.
+ pg_atomic_uint32 left_message;
Needs explanatory comment.
~~~
49.
+ /* Whether there is partially sent message left in the queue. */
+ bool partial_sent_message;
Comment English?
~~~
50.
+ /*
+ * Don't use SharedFileSet here because the fileset is shared by the leader
+ * worker and the fileset in leader need to survive after releasing the
+ * shared memory so that the leader can re-use the fileset for next
+ * streaming transaction.
+ */
+ bool fileset_valid;
+ FileSet fileset;
The comment here seems to need some more work because it is saying
more about what it *isn't*, rather than what it *is*.
Something like:
The 'fileset' is used for....
The 'fileset' is only valid to use when the accompanying fileset_valid
flag is true...
NOTE - We cannot use a SharedFileSet here because....
Also, fix typos "need to survive" -> "needs to survive".
Also, it may be better to refer to the "leader apply worker" by its
full name instead of just "leader".
~~~
51. typedef struct ParallelApplyWorkerInfo
+ bool serialize_changes;
Needs explanatory comment.
~~
52.
+ /*
+ * Used to save the message that was only partially sent to parallel apply
+ * worker.
+ */
+ char *pending_msg;
Some information seems missing because this comment does not have
enough detail to know what it means - e.g. what is a partially sent
message?
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Thu, Nov 3, 2022 at 10:06 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Wednesday, November 2, 2022 10:50 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Mon, Oct 24, 2022 at 8:42 PM Masahiko Sawada
> > <sawada.mshk@gmail.com> wrote:
> > >
> > > On Wed, Oct 12, 2022 at 3:04 PM Amit Kapila <amit.kapila16@gmail.com>
> > wrote:
> > > >
> > > > On Tue, Oct 11, 2022 at 5:52 AM Masahiko Sawada
> > <sawada.mshk@gmail.com> wrote:
> > > > >
> > > > > On Fri, Oct 7, 2022 at 2:00 PM Amit Kapila <amit.kapila16@gmail.com>
> > wrote:
> > > > > >
> > > > > > About your point that having different partition structures for
> > > > > > publisher and subscriber, I don't know how common it will be once we
> > > > > > have DDL replication. Also, the default value of
> > > > > > publish_via_partition_root is false which doesn't seem to indicate
> > > > > > that this is a quite common case.
> > > > >
> > > > > So how can we consider these concurrent issues that could happen only
> > > > > when streaming = 'parallel'? Can we restrict some use cases to avoid
> > > > > the problem or can we have a safeguard against these conflicts?
> > > > >
> > > >
> > > > Yeah, right now the strategy is to disallow parallel apply for such
> > > > cases as you can see in *0003* patch.
> > >
> > > Tightening the restrictions could work in some cases but there might
> > > still be coner cases and it could reduce the usability. I'm not really
> > > sure that we can ensure such a deadlock won't happen with the current
> > > restrictions. I think we need something safeguard just in case. For
> > > example, if the leader apply worker is waiting for a lock acquired by
> > > its parallel worker, it cancels the parallel worker's transaction,
> > > commits its transaction, and restarts logical replication. Or the
> > > leader can log the deadlock to let the user know.
> > >
> >
> > As another direction, we could make the parallel apply feature robust
> > if we can detect deadlocks that happen among the leader worker and
> > parallel workers. I'd like to summarize the idea discussed off-list
> > (with Amit, Hou-San, and Kuroda-San) for discussion. The basic idea is
> > that when the leader worker or parallel worker needs to wait for
> > something (eg. transaction completion, messages) we use lmgr
> > functionality so that we can create wait-for edges and detect
> > deadlocks in lmgr.
> >
> > For example, a scenario where a deadlock occurs is the following:
> >
> > [Publisher]
> > create table tab1(a int);
> > create publication pub for table tab1;
> >
> > [Subcriber]
> > creat table tab1(a int primary key);
> > create subscription sub connection 'port=10000 dbname=postgres'
> > publication pub with (streaming = parallel);
> >
> > TX1:
> > BEGIN;
> > INSERT INTO tab1 SELECT i FROM generate_series(1, 5000) s(i); -- streamed
> > Tx2:
> > BEGIN;
> > INSERT INTO tab1 SELECT i FROM generate_series(1, 5000) s(i); -- streamed
> > COMMIT;
> > COMMIT;
> >
> > Suppose a parallel apply worker (PA-1) is executing TX-1 and the
> > leader apply worker (LA) is executing TX-2 concurrently on the
> > subscriber. Now, LA is waiting for PA-1 because of the unique key of
> > tab1 while PA-1 is waiting for LA to send further messages. There is a
> > deadlock between PA-1 and LA but lmgr cannot detect it.
> >
> > One idea to resolve this issue is that we have LA acquire a session
> > lock on a shared object (by LockSharedObjectForSession()) and have
> > PA-1 wait on the lock before trying to receive messages. IOW, LA
> > acquires the lock before sending STREAM_STOP and releases it if
> > already acquired before sending STREAM_START, STREAM_PREPARE and
> > STREAM_COMMIT. For PA-1, it always needs to acquire the lock after
> > processing STREAM_STOP and then release immediately after acquiring
> > it. That way, when PA-1 is waiting for LA, we can have a wait-edge
> > from PA-1 to LA in lmgr, which will make a deadlock in lmgr like:
> >
> > LA (waiting to acquire lock) -> PA-1 (waiting to acquire the shared
> > object) -> LA
> >
> > We would need the shared objects per parallel apply worker.
> >
> > After detecting a deadlock, we can restart logical replication with
> > temporarily disabling the parallel apply, which is done by 0005 patch.
> >
> > Another scenario is similar to the previous case but TX-1 and TX-2 are
> > executed by two parallel apply workers (PA-1 and PA-2 respectively).
> > In this scenario, PA-2 is waiting for PA-1 to complete its transaction
> > while PA-1 is waiting for subsequent input from LA. Also, LA is
> > waiting for PA-2 to complete its transaction in order to preserve the
> > commit order. There is a deadlock among three processes but it cannot
> > be detected in lmgr because the fact that LA is waiting for PA-2 to
> > complete its transaction doesn't appear in lmgr (see
> > parallel_apply_wait_for_xact_finish()). To fix it, we can use
> > XactLockTableWait() instead.
> >
> > However, since XactLockTableWait() considers PREPARED TRANSACTION as
> > still in progress, probably we need a similar trick as above in case
> > where a transaction is prepared. For example, suppose that TX-2 was
> > prepared instead of committed in the above scenario, PA-2 acquires
> > another shared lock at START_STREAM and releases it at
> > STREAM_COMMIT/PREPARE. LA can wait on the lock.
> >
> > Yet another scenario where LA has to wait is the case where the shm_mq
> > buffer is full. In the above scenario (ie. PA-1 and PA-2 are executing
> > transactions concurrently), if the shm_mq buffer between LA and PA-2
> > is full, LA has to wait to send messages, and this wait doesn't appear
> > in lmgr. To fix it, probably we have to use non-blocking write and
> > wait with a timeout. If timeout is exceeded, the LA will write to file
> > and indicate PA-2 that it needs to read file for remaining messages.
> > Then LA will start waiting for commit which will detect deadlock if
> > any.
> >
> > If we can detect deadlocks by having such a functionality or some
> > other way then we don't need to tighten the restrictions of subscribed
> > tables' schemas etc.
>
> Thanks for the analysis and summary !
>
> I tried to implement the above idea and here is the patch set. I have done some
> basic tests for the new codes and it work fine.
Thank you for updating the patches!
Here are comments on v42-0001:
We have the following three similar name functions regarding to
starting a new parallel apply worker:
parallel_apply_start_worker()
parallel_apply_setup_worker()
parallel_apply_setup_dsm()
It seems to me that we can somewhat merge them since
parallel_apply_setup_worker() and parallel_apply_setup_dsm() have only
one caller.
---
+/*
+ * Extract the streaming mode value from a DefElem. This is like
+ * defGetBoolean() but also accepts the special value of "parallel".
+ */
+char
+defGetStreamingMode(DefElem *def)
It's a bit unnatural to have this function in define.c since other
functions in this file for primitive data types. How about having it
in subscription.c?
---
/*
* Exit if any parameter that affects the remote connection
was changed.
- * The launcher will start a new worker.
+ * The launcher will start a new worker, but note that the
parallel apply
+ * worker may or may not restart depending on the value of
the streaming
+ * option and whether there will be a streaming transaction.
In which case does the parallel apply worker don't restart even if the
streaming option has been changed?
---
I think we should explain somewhere the idea of using locks for
synchronization between leader and worker. Maybe can we do that with
sample workload in new README file?
---
in parallel_apply_send_data():
+ result = shm_mq_send(winfo->mq_handle, nbytes, data,
true, true);
+
+ if (result == SHM_MQ_SUCCESS)
+ break;
+ else if (result == SHM_MQ_DETACHED)
+ ereport(ERROR,
+
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("could not send data
to shared-memory queue")))
+
+ Assert(result == SHM_MQ_WOULD_BLOCK);
+
+ if (++retry >= CHANGES_THRESHOLD)
+ {
+ MemoryContext oldcontext;
+ StringInfoData msg;
+ TimestampTz now = GetCurrentTimestamp();
+
+ if (startTime == 0)
+ startTime = now;
+
+ if (!TimestampDifferenceExceeds(startTime,
now, SHM_SEND_TIMEOUT_MS))
+ continue;
IIUC since the parallel worker retries to send data without waits the
'retry' will get larger than CHANGES_THRESHOLD in a very short time.
But the worker waits at least for SHM_SEND_TIMEOUT_MS to spool data
regardless of 'retry' count. Don't we need to nap somewhat and why do
we need CHANGES_THRESHOLD?
---
+/*
+ * Wait until the parallel apply worker's xact_state flag becomes
+ * the same as in_xact.
+ */
+static void
+parallel_apply_wait_for_in_xact(ParallelApplyWorkerShared *wshared,
+
ParallelTransState xact_state)
+{
+ for (;;)
+ {
+ /* Stop if the flag becomes the same as in_xact. */
What do you mean by 'in_xact' here?
---
I got the error "ERROR: invalid logical replication message type ""
with the following scenario:
1. Stop the PA by sending SIGSTOP signal.
2. Stream a large transaction so that the LA spools changes to the file for PA.
3. Resume the PA by sending SIGCONT signal.
4. Stream another large transaction.
---
* On publisher (with logical_decoding_work_mem = 64kB)
begin;
insert into t select generate_series(1, 1000);
rollback;
begin;
insert into t select generate_series(1, 1000);
rollback;
I got the following error:
ERROR: hash table corrupted
CONTEXT: processing remote data for replication origin "pg_16393"
during message type "STREAM START" in transaction 734
---
IIUC the changes for worker.c in 0001 patch includes both changes:
1. apply worker takes action based on the apply_action returned by
get_transaction_apply_action() per message (or streamed chunk).
2. apply worker supports handling parallel apply workers.
It seems to me that (1) is a rather refactoring patch, so probably we
can do that in a separate patch so that we can make the patches
smaller.
---
postgres(1:2831190)=# \dRs+ test_sub1
List of subscriptions
-[ RECORD 1 ]------+--------------------------
Name | test_sub1
Owner | masahiko
Enabled | t
Publication | {test_pub1}
Binary | f
Streaming | p
Two-phase commit | d
Disable on error | f
Origin | any
Synchronous commit | off
Conninfo | port=5551 dbname=postgres
Skip LSN | 0/0
It's better to show 'on', 'off' or 'streaming' rather than one character.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Hou,
The followings are my comments. I want to consider the patch more, but I sent it once.
===
worker.c
01. typedef enum TransApplyAction
```
/*
* What action to take for the transaction.
*
* TRANS_LEADER_APPLY means that we are in the leader apply worker and changes
* of the transaction are applied directly in the worker.
*
* TRANS_LEADER_SERIALIZE means that we are in the leader apply worker or table
* sync worker. Changes are written to temporary files and then applied when
* the final commit arrives.
*
* TRANS_LEADER_SEND_TO_PARALLEL means that we are in the leader apply worker
* and need to send the changes to the parallel apply worker.
*
* TRANS_PARALLEL_APPLY means that we are in the parallel apply worker and
* changes of the transaction are applied directly in the worker.
*/
```
TRANS_LEADER_PARTIAL_SERIALIZE should be listed in.
02. handle_streamed_transaction()
```
+ StringInfoData origin_msg;
...
+ origin_msg = *s;
...
+ /* Write the change to the current file */
+ stream_write_change(action,
+ apply_action == TRANS_LEADER_SERIALIZE ?
+ s : &origin_msg);
```
I'm not sure why origin_msg is needed. Can we remove the conditional operator?
03. apply_handle_stream_start()
```
+ * XXX We can avoid sending pairs of the START/STOP messages to the parallel
+ * worker because unlike apply worker it will process only one transaction at a
+ * time. However, it is not clear whether any optimization is worthwhile
+ * because these messages are sent only when the logical_decoding_work_mem
+ * threshold is exceeded.
```
This comment should be modified because PA must acquire and release locks at that time.
04. apply_handle_stream_prepare()
```
+ /*
+ * After sending the data to the parallel apply worker, wait for
+ * that worker to finish. This is necessary to maintain commit
+ * order which avoids failures due to transaction dependencies and
+ * deadlocks.
+ */
+ parallel_apply_wait_for_xact_finish(winfo->shared);
```
Here seems not to be correct. LA may not send data but spill changes to file.
05. apply_handle_stream_commit()
```
+ if (apply_action == TRANS_LEADER_PARTIAL_SERIALIZE)
+ stream_cleanup_files(MyLogicalRepWorker->subid, xid);
```
I'm not sure whether the stream files should be removed by LA or PAs. Could you tell me the reason why you choose LA?
===
applyparallelworker.c
05. parallel_apply_can_start()
```
+ if (switching_to_serialize)
+ return false;
```
Could you add a comment like:
Don't start a new parallel apply worker if the leader apply worker has been spilling changes to the disk temporarily.
06. parallel_apply_start_worker()
```
+ /*
+ * Set the xact_state flag in the leader instead of the
+ * parallel apply worker to avoid the race condition where the leader has
+ * already started waiting for the parallel apply worker to finish
+ * processing the transaction while the child process has not yet
+ * processed the first STREAM_START and has not set the
+ * xact_state to true.
+ */
```
I thinkg the word "flag" should be used for boolean, so the comment should be modified.
(There are so many such code-comments, all of them should be modified.)
07. parallel_apply_get_unique_id()
```
+/*
+ * Returns the unique id among all parallel apply workers in the subscriber.
+ */
+static uint16
+parallel_apply_get_unique_id()
```
I think this function is inefficient: the computational complexity will be increased linearly when the number of PAs is
increased.I think the Bitmapset data structure may be used.
08. parallel_apply_send_data()
```
#define CHANGES_THRESHOLD 1000
#define SHM_SEND_TIMEOUT_MS 10000
```
I think the timeout may be too long. Could you tell me the background about it?
09. parallel_apply_send_data()
```
/*
* Close the stream file if not in a streaming block, the file will
* be reopened later.
*/
if (!stream_apply_worker)
serialize_stream_stop(winfo->shared->xid);
```
a.
IIUC the timings when LA tries to send data but stream_apply_worker is NULL are:
* apply_handle_stream_prepare,
* apply_handle_stream_start,
* apply_handle_stream_abort, and
* apply_handle_stream_commit.
And at that time the state of TransApplyAction may be TRANS_LEADER_SEND_TO_PARALLEL. When should be close the file?
b.
Even if this is needed, I think the name of the called function should be modified. Here LA may not handle STREAM_STOP
message.close_stream_file() or something?
10. parallel_apply_send_data()
```
/* Initialize the stream fileset. */
serialize_stream_start(winfo->shared->xid, true);
```
I think the name of the called function should be modified. Here LA may not handle STREAM_START message.
open_stream_file()or something?
11. parallel_apply_send_data()
```
if (++retry >= CHANGES_THRESHOLD)
{
MemoryContext oldcontext;
StringInfoData msg;
...
initStringInfo(&msg);
appendBinaryStringInfo(&msg, data, nbytes);
...
switching_to_serialize = true;
apply_dispatch(&msg);
switching_to_serialize = false;
break;
}
```
pfree(msg.data) may be needed.
===
12. worker_internal.h
```
+ pg_atomic_uint32 left_message;
```
ParallelApplyWorkerShared has been already controlled by mutex locks. Why did you add an atomic variable to the data
structure?
===
13. typedefs.list
ParallelTransState should be added.
===
14. General
I have already said old about it directly, but I point it out to notify other members again.
I have caused a deadlock with two PAs. Indeed it could be solved by the lmgr, but the output seemed not to be kind.
Followingswere copied from the log and we could see that commands executed by apply workers were not output. Can we
extendit, or is it the out of scope?
```
2022-11-07 11:11:27.449 UTC [11262] ERROR: deadlock detected
2022-11-07 11:11:27.449 UTC [11262] DETAIL: Process 11262 waits for AccessExclusiveLock on object 16393 of class 6100
ofdatabase 0; blocked by process 11320.
Process 11320 waits for ShareLock on transaction 742; blocked by process 11266.
Process 11266 waits for AccessShareLock on object 16393 of class 6100 of database 0; blocked by process 11262.
Process 11262: <command string not enabled>
Process 11320: <command string not enabled>
Process 11266: <command string not enabled>
```
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, November 4, 2022 7:45 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Fri, Nov 4, 2022 at 1:36 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Thu, Nov 3, 2022 at 6:36 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > Thanks for the analysis and summary !
> > >
> > > I tried to implement the above idea and here is the patch set.
> > >
> >
> > Few comments on v42-0001
> > ===========================
> >
Thanks for the comments.
> Few more comments on v42-0001
> ===============================
> 1. In parallel_apply_send_data(), it seems winfo->serialize_changes
> and switching_to_serialize are set to indicate that we have changed
> parallel to serialize mode. Isn't using just the
> switching_to_serialize sufficient? Also, it would be better to name
> switching_to_serialize as parallel_to_serialize or something like
> that.
I slightly change the logic to let serialize the message directly when timeout
instead of invoking apply_dispatch again so that we don't need the
switching_to_serialize.
>
> 2. In parallel_apply_send_data(), the patch has already initialized
> the fileset, and then again in apply_handle_stream_start(), it will do
> the same if we fail while sending stream_start message to the parallel
> worker. It seems we don't need to initialize fileset again for
> TRANS_LEADER_PARTIAL_SERIALIZE state in apply_handle_stream_start()
> unless I am missing something.
Fixed.
> 3.
> apply_handle_stream_start(StringInfo s)
> {
> ...
> + if (!first_segment)
> + {
> + /*
> + * Unlock the shared object lock so that parallel apply worker
> + * can continue to receive and apply changes.
> + */
> + parallel_apply_unlock(winfo->shared->stream_lock_id);
> ...
> }
>
> Can we have an assert before this unlock call that the lock must be
> held? Similarly, if there are other places then we can have assert
> there as well.
It seems we don't have a standard API can be used without a transaction.
Maybe we can use the list ParallelApplyLockids to check that ?
> 4. It is not very clear to me how maintaining ParallelApplyLockids
> list is helpful.
I will think about this and remove this in next version list if possible.
>
> 5.
> /*
> + * Handle STREAM START message when the transaction was spilled to disk.
> + *
> + * Inintialize fileset if not yet and open the file.
> + */
> +void
> +serialize_stream_start(TransactionId xid, bool first_segment)
> +{
> + /*
> + * Start a transaction on stream start,
>
> This function's name and comments seem to indicate that it is to
> handle stream_start message. Is that really the case? It is being
> called from parallel_apply_send_data() which made me think it can be
> used from other places as well.
Adjusted the comment.
Here is the new version patch set which addressed comments as of last Friday.
I also added some comments for the newly introduced codes in this version.
And thanks a lot for the comments that Sawada-san, Peter and Kuroda-san posted today.
I will handle them in next version soon.
Best regards,
Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
> Fair point. I think if the user wants, she can join with > pg_stat_subscription based on PID and find the corresponding > subscription. However, if we want to identify everything via pg_locks > then I think we should also mention classid or database id as field1. > So, it would look like: field1: (pg_subscription's oid or current db > id); field2: OID of subscription in pg_subscription; field3: local or > remote xid; field4: 0/1 to differentiate between remote and local xid. Sorry I missed the discussion related with LOCKTAG. +1 for adding a new tag like LOCKTAG_PARALLEL_APPLY, and I prefer field1 should be dbid because it is more useful for reporting a lock in DescribeLockTag(). Best Regards, Hayato Kuroda FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, November 7, 2022 9:19 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
>
> On Friday, November 4, 2022 7:45 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > On Fri, Nov 4, 2022 at 1:36 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> > >
> > > On Thu, Nov 3, 2022 at 6:36 PM houzj.fnst@fujitsu.com
> > > <houzj.fnst@fujitsu.com> wrote:
> > > >
> > > > Thanks for the analysis and summary !
> > > >
> > > > I tried to implement the above idea and here is the patch set.
> > > >
> > >
> > > Few comments on v42-0001
> > > ===========================
> > >
>
> Thanks for the comments.
>
> > Few more comments on v42-0001
> > ===============================
> > 1. In parallel_apply_send_data(), it seems winfo->serialize_changes
> > and switching_to_serialize are set to indicate that we have changed
> > parallel to serialize mode. Isn't using just the
> > switching_to_serialize sufficient? Also, it would be better to name
> > switching_to_serialize as parallel_to_serialize or something like
> > that.
>
> I slightly change the logic to let serialize the message directly when timeout
> instead of invoking apply_dispatch again so that we don't need the
> switching_to_serialize.
>
> >
> > 2. In parallel_apply_send_data(), the patch has already initialized
> > the fileset, and then again in apply_handle_stream_start(), it will do
> > the same if we fail while sending stream_start message to the parallel
> > worker. It seems we don't need to initialize fileset again for
> > TRANS_LEADER_PARTIAL_SERIALIZE state in apply_handle_stream_start()
> > unless I am missing something.
>
> Fixed.
>
> > 3.
> > apply_handle_stream_start(StringInfo s) { ...
> > + if (!first_segment)
> > + {
> > + /*
> > + * Unlock the shared object lock so that parallel apply worker
> > + * can continue to receive and apply changes.
> > + */
> > + parallel_apply_unlock(winfo->shared->stream_lock_id);
> > ...
> > }
> >
> > Can we have an assert before this unlock call that the lock must be
> > held? Similarly, if there are other places then we can have assert
> > there as well.
>
> It seems we don't have a standard API can be used without a transaction.
> Maybe we can use the list ParallelApplyLockids to check that ?
>
> > 4. It is not very clear to me how maintaining ParallelApplyLockids
> > list is helpful.
>
> I will think about this and remove this in next version list if possible.
>
> >
> > 5.
> > /*
> > + * Handle STREAM START message when the transaction was spilled to disk.
> > + *
> > + * Inintialize fileset if not yet and open the file.
> > + */
> > +void
> > +serialize_stream_start(TransactionId xid, bool first_segment) {
> > + /*
> > + * Start a transaction on stream start,
> >
> > This function's name and comments seem to indicate that it is to
> > handle stream_start message. Is that really the case? It is being
> > called from parallel_apply_send_data() which made me think it can be
> > used from other places as well.
>
> Adjusted the comment.
>
> Here is the new version patch set which addressed comments as of last Friday.
> I also added some comments for the newly introduced codes in this version.
>
Sorry, I posted the wrong patch for V43 which lack some changes.
Attach the correct patch set here.
Best regards,
Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Nov 7, 2022 at 6:49 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Friday, November 4, 2022 7:45 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > 3.
> > apply_handle_stream_start(StringInfo s)
> > {
> > ...
> > + if (!first_segment)
> > + {
> > + /*
> > + * Unlock the shared object lock so that parallel apply worker
> > + * can continue to receive and apply changes.
> > + */
> > + parallel_apply_unlock(winfo->shared->stream_lock_id);
> > ...
> > }
> >
> > Can we have an assert before this unlock call that the lock must be
> > held? Similarly, if there are other places then we can have assert
> > there as well.
>
> It seems we don't have a standard API can be used without a transaction.
> Maybe we can use the list ParallelApplyLockids to check that ?
>
Yeah, that occurred to me as well but I am not sure if it is a good
idea to maintain this list just for assertion but if it turns out that
we need to maintain it for a different purpose then we can probably
use it for assert as well.
Few other comments/questions:
=========================
1.
apply_handle_stream_start(StringInfo s)
{
...
+ case TRANS_PARALLEL_APPLY:
...
...
+ /*
+ * Unlock the shared object lock so that the leader apply worker
+ * can continue to send changes.
+ */
+ parallel_apply_unlock(MyParallelShared->stream_lock_id, AccessShareLock);
As per the design in the email [1], this lock needs to be released by
the leader worker during stream start which means it should be
released under the state TRANS_LEADER_SEND_TO_PARALLEL. From the
comments as well, it is not clear to me why at this time leader is
supposed to be blocked. Is there a reason for doing differently than
what is proposed in the original design?
2. Similar to above, it is not clear why the parallel worker needs to
release the stream_lock_id lock at stream_commit and stream_prepare?
3. Am, I understanding correctly that you need to lock/unlock in
apply_handle_stream_abort() for the parallel worker because after
rollback to savepoint, there could be another set of stream or
transaction end commands for which you want to wait? If so, maybe an
additional comment would serve the purpose.
4.
The leader may have sent multiple streaming blocks in the queue
+ * When the child is processing a streaming block. So only try to
+ * lock if there is no message left in the queue.
Let's slightly reword this to: "By the time child is processing the
changes in the current streaming block, the leader may have sent
multiple streaming blocks. So, try to lock only if there is no message
left in the queue."
5.
+parallel_apply_unlock(uint16 lockid, LOCKMODE lockmode)
+{
+ if (!list_member_int(ParallelApplyLockids, lockid))
+ return;
+
+ UnlockSharedObjectForSession(SubscriptionRelationId, MySubscription->oid,
+ lockid, am_leader_apply_worker() ?
+ AccessExclusiveLock:
+ AccessShareLock);
This function should use lockmode argument passed rather than deciding
based on am_leader_apply_worker. I think this is anyway going to
change if we start using a different locktag as discussed in one of
the above emails.
6.
+
/*
* Common spoolfile processing.
*/
-static void
-apply_spooled_messages(TransactionId xid, XLogRecPtr lsn)
+void
+apply_spooled_messages(FileSet *stream_fileset, TransactionId xid,
Seems like a spurious line addition.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Hi all, I have tested the patch set in two cases, so I want to share the result. ==== Case 1. deadlock caused by leader worker, parallel worker, and backend. Case 2. deadlock caused by non-immutable trigger === It has worked well in both cases. PSA reports what I did. I want to investigate more if anymore wants to check. Best Regards, Hayato Kuroda FUJITSU LIMITED
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Nov 7, 2022 at 1:46 PM Peter Smith <smithpb2250@gmail.com> wrote: > > Here are my review comments for v42-0001 ... ... > > 8. > > + /* > + * Resend the pending message to parallel apply worker to cleanup the > + * queue. Note that parallel apply worker will just ignore this message > + * as it has already handled this message while applying spooled > + * messages. > + */ > + result = shm_mq_send(winfo->mq_handle, strlen(winfo->pending_msg), > + winfo->pending_msg, false, true); > > If I understand this logic it seems a bit hacky. From the comment, it > seems you are resending a message that you know/expect to be ignored > simply to make it disappear. (??). Isn't there some other way to clear > the pending message without requiring a bogus send? > IIUC, this handling is required for the case when we are not able to send a message to parallel apply worker and switch to serialize mode (write remaining data to file). Basically, it is possible that the message is only partially sent and there is no way clean the queue. I feel we can directly free the worker in this case even if there is a space in the worker pool. The other idea could be that we detach from shm_mq and then invent a way to re-attach it after we try to reuse the same worker. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, November 7, 2022 6:18 PM Masahiko Sawada <sawada.mshk@gmail.com>
>
> On Thu, Nov 3, 2022 at 10:06 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Wednesday, November 2, 2022 10:50 AM Masahiko Sawada
> <sawada.mshk@gmail.com> wrote:
> > >
> > > On Mon, Oct 24, 2022 at 8:42 PM Masahiko Sawada
> > > <sawada.mshk@gmail.com> wrote:
> > > >
> > > > On Wed, Oct 12, 2022 at 3:04 PM Amit Kapila <amit.kapila16@gmail.com>
> > > wrote:
> > > > >
> > > > > On Tue, Oct 11, 2022 at 5:52 AM Masahiko Sawada
> > > <sawada.mshk@gmail.com> wrote:
> > > > > >
> > > > > > On Fri, Oct 7, 2022 at 2:00 PM Amit Kapila <amit.kapila16@gmail.com>
> > > wrote:
> > > > > > >
> > > > > > > About your point that having different partition structures for
> > > > > > > publisher and subscriber, I don't know how common it will be once
> we
> > > > > > > have DDL replication. Also, the default value of
> > > > > > > publish_via_partition_root is false which doesn't seem to indicate
> > > > > > > that this is a quite common case.
> > > > > >
> > > > > > So how can we consider these concurrent issues that could happen
> only
> > > > > > when streaming = 'parallel'? Can we restrict some use cases to avoid
> > > > > > the problem or can we have a safeguard against these conflicts?
> > > > > >
> > > > >
> > > > > Yeah, right now the strategy is to disallow parallel apply for such
> > > > > cases as you can see in *0003* patch.
> > > >
> > > > Tightening the restrictions could work in some cases but there might
> > > > still be coner cases and it could reduce the usability. I'm not really
> > > > sure that we can ensure such a deadlock won't happen with the current
> > > > restrictions. I think we need something safeguard just in case. For
> > > > example, if the leader apply worker is waiting for a lock acquired by
> > > > its parallel worker, it cancels the parallel worker's transaction,
> > > > commits its transaction, and restarts logical replication. Or the
> > > > leader can log the deadlock to let the user know.
> > > >
> > >
> > > As another direction, we could make the parallel apply feature robust
> > > if we can detect deadlocks that happen among the leader worker and
> > > parallel workers. I'd like to summarize the idea discussed off-list
> > > (with Amit, Hou-San, and Kuroda-San) for discussion. The basic idea is
> > > that when the leader worker or parallel worker needs to wait for
> > > something (eg. transaction completion, messages) we use lmgr
> > > functionality so that we can create wait-for edges and detect
> > > deadlocks in lmgr.
> > >
> > > For example, a scenario where a deadlock occurs is the following:
> > >
> > > [Publisher]
> > > create table tab1(a int);
> > > create publication pub for table tab1;
> > >
> > > [Subcriber]
> > > creat table tab1(a int primary key);
> > > create subscription sub connection 'port=10000 dbname=postgres'
> > > publication pub with (streaming = parallel);
> > >
> > > TX1:
> > > BEGIN;
> > > INSERT INTO tab1 SELECT i FROM generate_series(1, 5000) s(i); -- streamed
> > > Tx2:
> > > BEGIN;
> > > INSERT INTO tab1 SELECT i FROM generate_series(1, 5000) s(i); --
> streamed
> > > COMMIT;
> > > COMMIT;
> > >
> > > Suppose a parallel apply worker (PA-1) is executing TX-1 and the
> > > leader apply worker (LA) is executing TX-2 concurrently on the
> > > subscriber. Now, LA is waiting for PA-1 because of the unique key of
> > > tab1 while PA-1 is waiting for LA to send further messages. There is a
> > > deadlock between PA-1 and LA but lmgr cannot detect it.
> > >
> > > One idea to resolve this issue is that we have LA acquire a session
> > > lock on a shared object (by LockSharedObjectForSession()) and have
> > > PA-1 wait on the lock before trying to receive messages. IOW, LA
> > > acquires the lock before sending STREAM_STOP and releases it if
> > > already acquired before sending STREAM_START, STREAM_PREPARE and
> > > STREAM_COMMIT. For PA-1, it always needs to acquire the lock after
> > > processing STREAM_STOP and then release immediately after acquiring
> > > it. That way, when PA-1 is waiting for LA, we can have a wait-edge
> > > from PA-1 to LA in lmgr, which will make a deadlock in lmgr like:
> > >
> > > LA (waiting to acquire lock) -> PA-1 (waiting to acquire the shared
> > > object) -> LA
> > >
> > > We would need the shared objects per parallel apply worker.
> > >
> > > After detecting a deadlock, we can restart logical replication with
> > > temporarily disabling the parallel apply, which is done by 0005 patch.
> > >
> > > Another scenario is similar to the previous case but TX-1 and TX-2 are
> > > executed by two parallel apply workers (PA-1 and PA-2 respectively).
> > > In this scenario, PA-2 is waiting for PA-1 to complete its transaction
> > > while PA-1 is waiting for subsequent input from LA. Also, LA is
> > > waiting for PA-2 to complete its transaction in order to preserve the
> > > commit order. There is a deadlock among three processes but it cannot
> > > be detected in lmgr because the fact that LA is waiting for PA-2 to
> > > complete its transaction doesn't appear in lmgr (see
> > > parallel_apply_wait_for_xact_finish()). To fix it, we can use
> > > XactLockTableWait() instead.
> > >
> > > However, since XactLockTableWait() considers PREPARED TRANSACTION as
> > > still in progress, probably we need a similar trick as above in case
> > > where a transaction is prepared. For example, suppose that TX-2 was
> > > prepared instead of committed in the above scenario, PA-2 acquires
> > > another shared lock at START_STREAM and releases it at
> > > STREAM_COMMIT/PREPARE. LA can wait on the lock.
> > >
> > > Yet another scenario where LA has to wait is the case where the shm_mq
> > > buffer is full. In the above scenario (ie. PA-1 and PA-2 are executing
> > > transactions concurrently), if the shm_mq buffer between LA and PA-2
> > > is full, LA has to wait to send messages, and this wait doesn't appear
> > > in lmgr. To fix it, probably we have to use non-blocking write and
> > > wait with a timeout. If timeout is exceeded, the LA will write to file
> > > and indicate PA-2 that it needs to read file for remaining messages.
> > > Then LA will start waiting for commit which will detect deadlock if
> > > any.
> > >
> > > If we can detect deadlocks by having such a functionality or some
> > > other way then we don't need to tighten the restrictions of subscribed
> > > tables' schemas etc.
> >
> > Thanks for the analysis and summary !
> >
> > I tried to implement the above idea and here is the patch set. I have done some
> > basic tests for the new codes and it work fine.
>
> Thank you for updating the patches!
>
> Here are comments on v42-0001:
Thanks for the comments.
> We have the following three similar name functions regarding to
> starting a new parallel apply worker:
>
> parallel_apply_start_worker()
> parallel_apply_setup_worker()
> parallel_apply_setup_dsm()
>
> It seems to me that we can somewhat merge them since
> parallel_apply_setup_worker() and parallel_apply_setup_dsm() have only
> one caller.
Since these functions are doing different tasks(external function, Launch, DSM), so I
personally feel it's OK to split them. But if others also feel it's unnecessary I will
merge them.
> ---
> +/*
> + * Extract the streaming mode value from a DefElem. This is like
> + * defGetBoolean() but also accepts the special value of "parallel".
> + */
> +char
> +defGetStreamingMode(DefElem *def)
>
> It's a bit unnatural to have this function in define.c since other
> functions in this file for primitive data types. How about having it
> in subscription.c?
Changed.
> ---
> /*
> * Exit if any parameter that affects the remote connection
> was changed.
> - * The launcher will start a new worker.
> + * The launcher will start a new worker, but note that the
> parallel apply
> + * worker may or may not restart depending on the value of
> the streaming
> + * option and whether there will be a streaming transaction.
>
> In which case does the parallel apply worker don't restart even if the
> streaming option has been changed?
>
> ---
> I think we should explain somewhere the idea of using locks for
> synchronization between leader and worker. Maybe can we do that with
> sample workload in new README file?
Having a README sounds like a good idea. I think not only the lock design, we might
need to also move some other existing design comments atop worker.c into that. So, maybe
better do that as a separate patch ? For now, I added comments atop applyparallelworker.c.
> ---
> in parallel_apply_send_data():
>
> + result = shm_mq_send(winfo->mq_handle, nbytes, data,
> true, true);
> +
> + if (result == SHM_MQ_SUCCESS)
> + break;
> + else if (result == SHM_MQ_DETACHED)
> + ereport(ERROR,
> +
> (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("could not send data
> to shared-memory queue")))
> +
> + Assert(result == SHM_MQ_WOULD_BLOCK);
> +
> + if (++retry >= CHANGES_THRESHOLD)
> + {
> + MemoryContext oldcontext;
> + StringInfoData msg;
> + TimestampTz now = GetCurrentTimestamp();
> +
> + if (startTime == 0)
> + startTime = now;
> +
> + if (!TimestampDifferenceExceeds(startTime,
> now, SHM_SEND_TIMEOUT_MS))
> + continue;
>
> IIUC since the parallel worker retries to send data without waits the
> 'retry' will get larger than CHANGES_THRESHOLD in a very short time.
> But the worker waits at least for SHM_SEND_TIMEOUT_MS to spool data
> regardless of 'retry' count. Don't we need to nap somewhat and why do
> we need CHANGES_THRESHOLD?
Oh, I intended to only check for timeout after continuously retrying XX times to
reduce the cost of getting the system time and calculating the time difference.
I added some comments in the code.
> ---
> +/*
> + * Wait until the parallel apply worker's xact_state flag becomes
> + * the same as in_xact.
> + */
> +static void
> +parallel_apply_wait_for_in_xact(ParallelApplyWorkerShared *wshared,
> +
> ParallelTransState xact_state)
> +{
> + for (;;)
> + {
> + /* Stop if the flag becomes the same as in_xact. */
>
> What do you mean by 'in_xact' here?
Changed.
> ---
> I got the error "ERROR: invalid logical replication message type ""
> with the following scenario:
>
> 1. Stop the PA by sending SIGSTOP signal.
> 2. Stream a large transaction so that the LA spools changes to the file for PA.
> 3. Resume the PA by sending SIGCONT signal.
> 4. Stream another large transaction.
>
> ---
> * On publisher (with logical_decoding_work_mem = 64kB)
> begin;
> insert into t select generate_series(1, 1000);
> rollback;
> begin;
> insert into t select generate_series(1, 1000);
> rollback;
>
> I got the following error:
>
> ERROR: hash table corrupted
> CONTEXT: processing remote data for replication origin "pg_16393"
> during message type "STREAM START" in transaction 734
Thanks! I think I have fixed them in the new version.
> ---
> IIUC the changes for worker.c in 0001 patch includes both changes:
>
> 1. apply worker takes action based on the apply_action returned by
> get_transaction_apply_action() per message (or streamed chunk).
> 2. apply worker supports handling parallel apply workers.
>
> It seems to me that (1) is a rather refactoring patch, so probably we
> can do that in a separate patch so that we can make the patches
> smaller.
I tried it, but it seems the code size of the apply_action is quite small,
Because we only have two action(LEADER_APPLY/LEADER_SERIALIZE) on HEAD branch
and only handle_streamed_transaction use it. I will think if there are other
ways to split the patch.
> ---
> postgres(1:2831190)=# \dRs+ test_sub1
> List of subscriptions
> -[ RECORD 1 ]------+--------------------------
> Name | test_sub1
> Owner | masahiko
> Enabled | t
> Publication | {test_pub1}
> Binary | f
> Streaming | p
> Two-phase commit | d
> Disable on error | f
> Origin | any
> Synchronous commit | off
> Conninfo | port=5551 dbname=postgres
> Skip LSN | 0/0
>
> It's better to show 'on', 'off' or 'streaming' rather than one character.
Changed.
Best regards,
Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, November 7, 2022 7:43 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote:
>
> Dear Hou,
>
> The followings are my comments. I want to consider the patch more, but I sent
> it once.
Thanks for the comments.
>
> ===
> worker.c
>
> 01. typedef enum TransApplyAction
>
> ```
> /*
> * What action to take for the transaction.
> *
> * TRANS_LEADER_APPLY means that we are in the leader apply worker and
> changes
> * of the transaction are applied directly in the worker.
> *
> * TRANS_LEADER_SERIALIZE means that we are in the leader apply worker or
> table
> * sync worker. Changes are written to temporary files and then applied when
> * the final commit arrives.
> *
> * TRANS_LEADER_SEND_TO_PARALLEL means that we are in the leader apply
> worker
> * and need to send the changes to the parallel apply worker.
> *
> * TRANS_PARALLEL_APPLY means that we are in the parallel apply worker and
> * changes of the transaction are applied directly in the worker.
> */
> ```
>
> TRANS_LEADER_PARTIAL_SERIALIZE should be listed in.
>
Added.
> 02. handle_streamed_transaction()
>
> ```
> + StringInfoData origin_msg;
> ...
> + origin_msg = *s;
> ...
> + /* Write the change to the current file */
> + stream_write_change(action,
> +
> apply_action == TRANS_LEADER_SERIALIZE ?
> +
> + s : &origin_msg);
> ```
>
> I'm not sure why origin_msg is needed. Can we remove the conditional
> operator?
Currently, the parallel apply worker would need the transaction xid of this change to
define savepoint. So, it need to write the original message to file.
>
> 03. apply_handle_stream_start()
>
> ```
> + * XXX We can avoid sending pairs of the START/STOP messages to the
> + parallel
> + * worker because unlike apply worker it will process only one
> + transaction at a
> + * time. However, it is not clear whether any optimization is
> + worthwhile
> + * because these messages are sent only when the
> + logical_decoding_work_mem
> + * threshold is exceeded.
> ```
>
> This comment should be modified because PA must acquire and release locks at
> that time.
>
>
> 04. apply_handle_stream_prepare()
>
> ```
> + /*
> + * After sending the data to the parallel apply worker,
> wait for
> + * that worker to finish. This is necessary to maintain
> commit
> + * order which avoids failures due to transaction
> dependencies and
> + * deadlocks.
> + */
> +
> + parallel_apply_wait_for_xact_finish(winfo->shared);
> ```
>
> Here seems not to be correct. LA may not send data but spill changes to file.
Changed.
> 05. apply_handle_stream_commit()
>
> ```
> + if (apply_action ==
> TRANS_LEADER_PARTIAL_SERIALIZE)
> +
> + stream_cleanup_files(MyLogicalRepWorker->subid, xid);
> ```
>
> I'm not sure whether the stream files should be removed by LA or PAs. Could
> you tell me the reason why you choose LA?
I think the logic would be natural that only LA can write/delete/create the file and
PA only need to read from it.
> ===
> applyparallelworker.c
>
> 05. parallel_apply_can_start()
>
> ```
> + if (switching_to_serialize)
> + return false;
> ```
>
> Could you add a comment like:
> Don't start a new parallel apply worker if the leader apply worker has been
> spilling changes to the disk temporarily.
These codes have been removed.
> 06. parallel_apply_start_worker()
>
> ```
> + /*
> + * Set the xact_state flag in the leader instead of the
> + * parallel apply worker to avoid the race condition where the leader
> has
> + * already started waiting for the parallel apply worker to finish
> + * processing the transaction while the child process has not yet
> + * processed the first STREAM_START and has not set the
> + * xact_state to true.
> + */
> ```
>
> I thinkg the word "flag" should be used for boolean, so the comment should be
> modified.
> (There are so many such code-comments, all of them should be modified.)
Changed.
>
> 07. parallel_apply_get_unique_id()
>
> ```
> +/*
> + * Returns the unique id among all parallel apply workers in the subscriber.
> + */
> +static uint16
> +parallel_apply_get_unique_id()
> ```
>
> I think this function is inefficient: the computational complexity will be increased
> linearly when the number of PAs is increased. I think the Bitmapset data
> structure may be used.
This function is removed.
> 08. parallel_apply_send_data()
>
> ```
> #define CHANGES_THRESHOLD 1000
> #define SHM_SEND_TIMEOUT_MS 10000
> ```
>
> I think the timeout may be too long. Could you tell me the background about it?
Serializing data to file would affect the performance, so I tried to make it difficult to happen unless the
PA is really blocked by another PA or BA.
> 09. parallel_apply_send_data()
>
> ```
> /*
> * Close the stream file if not in a streaming block, the
> file will
> * be reopened later.
> */
> if (!stream_apply_worker)
> serialize_stream_stop(winfo->shared->xid);
> ```
>
> a.
> IIUC the timings when LA tries to send data but stream_apply_worker is NULL
> are:
> * apply_handle_stream_prepare,
> * apply_handle_stream_start,
> * apply_handle_stream_abort, and
> * apply_handle_stream_commit.
> And at that time the state of TransApplyAction may be
> TRANS_LEADER_SEND_TO_PARALLEL. When should be close the file?
Changed to use another condition to check.
> b.
> Even if this is needed, I think the name of the called function should be modified.
> Here LA may not handle STREAM_STOP message. close_stream_file() or
> something?
>
>
> 10. parallel_apply_send_data()
>
> ```
> /* Initialize the stream fileset. */
> serialize_stream_start(winfo->shared->xid, true); ```
>
> I think the name of the called function should be modified. Here LA may not
> handle STREAM_START message. open_stream_file() or something?
>
> 11. parallel_apply_send_data()
>
> ```
> if (++retry >= CHANGES_THRESHOLD)
> {
> MemoryContext oldcontext;
> StringInfoData msg;
> ...
> initStringInfo(&msg);
> appendBinaryStringInfo(&msg, data, nbytes); ...
> switching_to_serialize = true;
> apply_dispatch(&msg);
> switching_to_serialize = false;
>
> break;
> }
> ```
>
> pfree(msg.data) may be needed.
>
> ===
> 12. worker_internal.h
>
> ```
> + pg_atomic_uint32 left_message;
> ```
>
>
> ParallelApplyWorkerShared has been already controlled by mutex locks. Why
> did you add an atomic variable to the data structure?
I personally feel this value is modified more frequently, so use an atomic
variable here.
> ===
> 13. typedefs.list
>
> ParallelTransState should be added.
Added.
> ===
> 14. General
>
> I have already said old about it directly, but I point it out to notify other members
> again.
> I have caused a deadlock with two PAs. Indeed it could be solved by the lmgr, but
> the output seemed not to be kind. Followings were copied from the log and we
> could see that commands executed by apply workers were not output. Can we
> extend it, or is it the out of scope?
>
>
> ```
> 2022-11-07 11:11:27.449 UTC [11262] ERROR: deadlock detected
> 2022-11-07 11:11:27.449 UTC [11262] DETAIL: Process 11262 waits for
> AccessExclusiveLock on object 16393 of class 6100 of database 0; blocked by
> process 11320.
> Process 11320 waits for ShareLock on transaction 742; blocked by
> process 11266.
> Process 11266 waits for AccessShareLock on object 16393 of class 6100 of
> database 0; blocked by process 11262.
> Process 11262: <command string not enabled>
> Process 11320: <command string not enabled>
> Process 11266: <command string not enabled> ```
On HEAD, a apply worker could also cause a deadlock with a user backend. Like:
Tx1 (backend)
begin;
insert into tbl1 values (100);
Tx2 (replaying streaming transaction)
begin;
insert into tbl1 values (1);
delete from tbl2;
insert into tbl1 values (1);
insert into tbl1 values (100);
logical replication worker ERROR: deadlock detected
logical replication worker DETAIL: Process 2158391 waits for ShareLock on transaction 749; blocked by process
2158410.
Process 2158410 waits for ShareLock on transaction 750; blocked by process 2158391.
Process 2158391: <command string not enabled>
Process 2158410: insert into tbl1 values (1);
So, it looks like the existing behavior. I agree that it would be better to
show something, but maybe we can do that as a separate patch.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, November 7, 2022 4:17 PM Peter Smith <smithpb2250@gmail.com>
>
> Here are my review comments for v42-0001
Thanks for the comments.
> ======
>
> 28. handle_streamed_transaction
>
> static bool
> handle_streamed_transaction(LogicalRepMsgType action, StringInfo s) {
> - TransactionId xid;
> + TransactionId current_xid;
> + ParallelApplyWorkerInfo *winfo;
> + TransApplyAction apply_action;
> + StringInfoData origin_msg;
> +
> + apply_action = get_transaction_apply_action(stream_xid, &winfo);
>
> /* not in streaming mode */
> - if (!in_streamed_transaction)
> + if (apply_action == TRANS_LEADER_APPLY)
> return false;
>
> - Assert(stream_fd != NULL);
> Assert(TransactionIdIsValid(stream_xid));
>
> + origin_msg = *s;
>
> ~
>
> 28b.
> Why not assign it at the declaration, the same as apply_handle_stream_prepare
> does?
The assignment is unnecessary for non-streaming transaction, so I delayed it.
> ~
>
> 44b.
> If this is always written to a file, then wouldn't a better function name be
> something including the word "serialize" - e.g.
> serialize_message()?
I feel it would be better to be consistent with the existing style stream_xxx_xx().
I think I have addressed all the comments, but since quite a few logics are
changed in the new version so I might missed something. And dome code wrapping need to
be adjusted, I plan to run pg_indent for next version.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, November 8, 2022 7:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Mon, Nov 7, 2022 at 6:49 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Friday, November 4, 2022 7:45 PM Amit Kapila
> <amit.kapila16@gmail.com> wrote:
> > > 3.
> > > apply_handle_stream_start(StringInfo s) { ...
> > > + if (!first_segment)
> > > + {
> > > + /*
> > > + * Unlock the shared object lock so that parallel apply worker
> > > + * can continue to receive and apply changes.
> > > + */
> > > + parallel_apply_unlock(winfo->shared->stream_lock_id);
> > > ...
> > > }
> > >
> > > Can we have an assert before this unlock call that the lock must be
> > > held? Similarly, if there are other places then we can have assert
> > > there as well.
> >
> > It seems we don't have a standard API can be used without a transaction.
> > Maybe we can use the list ParallelApplyLockids to check that ?
> >
>
> Yeah, that occurred to me as well but I am not sure if it is a good
> idea to maintain this list just for assertion but if it turns out that
> we need to maintain it for a different purpose then we can probably
> use it for assert as well.
>
> Few other comments/questions:
> =========================
> 1.
> apply_handle_stream_start(StringInfo s)
> {
> ...
>
> + case TRANS_PARALLEL_APPLY:
> ...
> ...
> + /*
> + * Unlock the shared object lock so that the leader apply worker
> + * can continue to send changes.
> + */
> + parallel_apply_unlock(MyParallelShared->stream_lock_id,
> AccessShareLock);
>
> As per the design in the email [1], this lock needs to be released by
> the leader worker during stream start which means it should be
> released under the state TRANS_LEADER_SEND_TO_PARALLEL. From the
> comments as well, it is not clear to me why at this time leader is
> supposed to be blocked. Is there a reason for doing differently than
> what is proposed in the original design?
> 2. Similar to above, it is not clear why the parallel worker needs to
> release the stream_lock_id lock at stream_commit and stream_prepare?
Sorry, these were due to my miss. Changed.
> 3. Am, I understanding correctly that you need to lock/unlock in
> apply_handle_stream_abort() for the parallel worker because after
> rollback to savepoint, there could be another set of stream or
> transaction end commands for which you want to wait? If so, maybe an
> additional comment would serve the purpose.
I think you are right. I will think about this in case I missed something and
add some comments in next version.
> 4.
> The leader may have sent multiple streaming blocks in the queue
> + * When the child is processing a streaming block. So only try to
> + * lock if there is no message left in the queue.
>
> Let's slightly reword this to: "By the time child is processing the
> changes in the current streaming block, the leader may have sent
> multiple streaming blocks. So, try to lock only if there is no message
> left in the queue."
Changed.
> 5.
> +parallel_apply_unlock(uint16 lockid, LOCKMODE lockmode)
> +{
> + if (!list_member_int(ParallelApplyLockids, lockid))
> + return;
> +
> + UnlockSharedObjectForSession(SubscriptionRelationId,
> MySubscription->oid,
> + lockid, am_leader_apply_worker() ?
> + AccessExclusiveLock:
> + AccessShareLock);
>
> This function should use lockmode argument passed rather than deciding
> based on am_leader_apply_worker. I think this is anyway going to
> change if we start using a different locktag as discussed in one of
> the above emails.
Changed.
> 6.
> +
> /*
> * Common spoolfile processing.
> */
> -static void
> -apply_spooled_messages(TransactionId xid, XLogRecPtr lsn)
> +void
> +apply_spooled_messages(FileSet *stream_fileset, TransactionId xid,
>
> Seems like a spurious line addition.
Removed.
> Fair point. I think if the user wants, she can join with pg_stat_subscription
> based on PID and find the corresponding subscription. However, if we want to
> identify everything via pg_locks then I think we should also mention classid
> or database id as field1. So, it would look like: field1: (pg_subscription's
> oid or current db id); field2: OID of subscription in pg_subscription;
> field3: local or remote xid; field4: 0/1 to differentiate between remote and
> local xid.
I tried to use local xid to lock the transaction, but we currently can only get
the local xid after applying the first change. And it's possible that the first
change in parallel apply worker is blocked by other parallel apply worker which
means the parallel apply worker might not have a chance to share the local xid
with the leader.
To resolve this, I tried to use remote_xid for both stream and transaction lock
and use field4: 0/1 to differentiate between stream and transaction lock. Like:
field1: (current db id); field2: OID of subscription in pg_subscription;
field3: remote xid; field4: 0/1 to differentiate between stream_lock and
transaction_lock.
> IIUC, this handling is required for the case when we are not able to send a
> message to parallel apply worker and switch to serialize mode (write
> remaining data to file). Basically, it is possible that the message is only
> partially sent and there is no way clean the queue. I feel we can directly
> free the worker in this case even if there is a space in the worker pool. The
> other idea could be that we detach from shm_mq and then invent a way to
> re-attach it after we try to reuse the same worker.
For now, I directly stop the worker in this case. But I will think more about
this.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, November 7, 2022 6:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Thu, Nov 3, 2022 at 10:06 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Wednesday, November 2, 2022 10:50 AM Masahiko Sawada > <sawada.mshk@gmail.com> wrote: > > > > > > On Mon, Oct 24, 2022 at 8:42 PM Masahiko Sawada > > > <sawada.mshk@gmail.com> wrote: > > > > > > > > On Wed, Oct 12, 2022 at 3:04 PM Amit Kapila > <amit.kapila16@gmail.com> > > > wrote: > > > > > > > > > > On Tue, Oct 11, 2022 at 5:52 AM Masahiko Sawada > > > <sawada.mshk@gmail.com> wrote: > > > > > > > > > > > > On Fri, Oct 7, 2022 at 2:00 PM Amit Kapila > <amit.kapila16@gmail.com> > > > wrote: > > > > > > > > > > > > > > About your point that having different partition structures for > > > > > > > publisher and subscriber, I don't know how common it will be once > we > > > > > > > have DDL replication. Also, the default value of > > > > > > > publish_via_partition_root is false which doesn't seem to indicate > > > > > > > that this is a quite common case. > > > > > > > > > > > > So how can we consider these concurrent issues that could happen > only > > > > > > when streaming = 'parallel'? Can we restrict some use cases to avoid > > > > > > the problem or can we have a safeguard against these conflicts? > > > > > > > > > > > > > > > > Yeah, right now the strategy is to disallow parallel apply for such > > > > > cases as you can see in *0003* patch. > > > > > > > > Tightening the restrictions could work in some cases but there might > > > > still be coner cases and it could reduce the usability. I'm not really > > > > sure that we can ensure such a deadlock won't happen with the current > > > > restrictions. I think we need something safeguard just in case. For > > > > example, if the leader apply worker is waiting for a lock acquired by > > > > its parallel worker, it cancels the parallel worker's transaction, > > > > commits its transaction, and restarts logical replication. Or the > > > > leader can log the deadlock to let the user know. > > > > > > > > > > As another direction, we could make the parallel apply feature robust > > > if we can detect deadlocks that happen among the leader worker and > > > parallel workers. I'd like to summarize the idea discussed off-list > > > (with Amit, Hou-San, and Kuroda-San) for discussion. The basic idea is > > > that when the leader worker or parallel worker needs to wait for > > > something (eg. transaction completion, messages) we use lmgr > > > functionality so that we can create wait-for edges and detect > > > deadlocks in lmgr. > > > > > > For example, a scenario where a deadlock occurs is the following: > > > > > > [Publisher] > > > create table tab1(a int); > > > create publication pub for table tab1; > > > > > > [Subcriber] > > > creat table tab1(a int primary key); > > > create subscription sub connection 'port=10000 dbname=postgres' > > > publication pub with (streaming = parallel); > > > > > > TX1: > > > BEGIN; > > > INSERT INTO tab1 SELECT i FROM generate_series(1, 5000) s(i); -- streamed > > > Tx2: > > > BEGIN; > > > INSERT INTO tab1 SELECT i FROM generate_series(1, 5000) s(i); -- > streamed > > > COMMIT; > > > COMMIT; > > > > > > Suppose a parallel apply worker (PA-1) is executing TX-1 and the > > > leader apply worker (LA) is executing TX-2 concurrently on the > > > subscriber. Now, LA is waiting for PA-1 because of the unique key of > > > tab1 while PA-1 is waiting for LA to send further messages. There is a > > > deadlock between PA-1 and LA but lmgr cannot detect it. > > > > > > One idea to resolve this issue is that we have LA acquire a session > > > lock on a shared object (by LockSharedObjectForSession()) and have > > > PA-1 wait on the lock before trying to receive messages. IOW, LA > > > acquires the lock before sending STREAM_STOP and releases it if > > > already acquired before sending STREAM_START, STREAM_PREPARE and > > > STREAM_COMMIT. For PA-1, it always needs to acquire the lock after > > > processing STREAM_STOP and then release immediately after acquiring > > > it. That way, when PA-1 is waiting for LA, we can have a wait-edge > > > from PA-1 to LA in lmgr, which will make a deadlock in lmgr like: > > > > > > LA (waiting to acquire lock) -> PA-1 (waiting to acquire the shared > > > object) -> LA > > > > > > We would need the shared objects per parallel apply worker. > > > > > > After detecting a deadlock, we can restart logical replication with > > > temporarily disabling the parallel apply, which is done by 0005 patch. > > > > > > Another scenario is similar to the previous case but TX-1 and TX-2 are > > > executed by two parallel apply workers (PA-1 and PA-2 respectively). > > > In this scenario, PA-2 is waiting for PA-1 to complete its transaction > > > while PA-1 is waiting for subsequent input from LA. Also, LA is > > > waiting for PA-2 to complete its transaction in order to preserve the > > > commit order. There is a deadlock among three processes but it cannot > > > be detected in lmgr because the fact that LA is waiting for PA-2 to > > > complete its transaction doesn't appear in lmgr (see > > > parallel_apply_wait_for_xact_finish()). To fix it, we can use > > > XactLockTableWait() instead. > > > > > > However, since XactLockTableWait() considers PREPARED TRANSACTION > as > > > still in progress, probably we need a similar trick as above in case > > > where a transaction is prepared. For example, suppose that TX-2 was > > > prepared instead of committed in the above scenario, PA-2 acquires > > > another shared lock at START_STREAM and releases it at > > > STREAM_COMMIT/PREPARE. LA can wait on the lock. > > > > > > Yet another scenario where LA has to wait is the case where the shm_mq > > > buffer is full. In the above scenario (ie. PA-1 and PA-2 are executing > > > transactions concurrently), if the shm_mq buffer between LA and PA-2 > > > is full, LA has to wait to send messages, and this wait doesn't appear > > > in lmgr. To fix it, probably we have to use non-blocking write and > > > wait with a timeout. If timeout is exceeded, the LA will write to file > > > and indicate PA-2 that it needs to read file for remaining messages. > > > Then LA will start waiting for commit which will detect deadlock if > > > any. > > > > > > If we can detect deadlocks by having such a functionality or some > > > other way then we don't need to tighten the restrictions of subscribed > > > tables' schemas etc. > > > > Thanks for the analysis and summary ! > > > > I tried to implement the above idea and here is the patch set. I have done > some > > basic tests for the new codes and it work fine. > > Thank you for updating the patches! > > Here are comments on v42-0001: > > We have the following three similar name functions regarding to > starting a new parallel apply worker: > --- > /* > * Exit if any parameter that affects the remote connection > was changed. > - * The launcher will start a new worker. > + * The launcher will start a new worker, but note that the > parallel apply > + * worker may or may not restart depending on the value of > the streaming > + * option and whether there will be a streaming transaction. > > In which case does the parallel apply worker don't restart even if the > streaming option has been changed? Sorry, I forgot to reply to this comment. If user change the streaming option from 'parallel' to 'on' or 'off', the parallel apply workers won't be restarted. Best regards, Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Nov 11, 2022 at 7:57 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Monday, November 7, 2022 6:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > Here are comments on v42-0001:
> >
> > We have the following three similar name functions regarding to
> > starting a new parallel apply worker:
> > ---
> > /*
> > * Exit if any parameter that affects the remote connection
> > was changed.
> > - * The launcher will start a new worker.
> > + * The launcher will start a new worker, but note that the
> > parallel apply
> > + * worker may or may not restart depending on the value of
> > the streaming
> > + * option and whether there will be a streaming transaction.
> >
> > In which case does the parallel apply worker don't restart even if the
> > streaming option has been changed?
>
> Sorry, I forgot to reply to this comment. If user change the streaming option from
> 'parallel' to 'on' or 'off', the parallel apply workers won't be restarted.
>
How about something like the below so as to be more explicit about
this in the comments?
diff --git a/src/backend/replication/logical/worker.c
b/src/backend/replication/logical/worker.c
index bfe326bf0c..74cd5565bd 100644
--- a/src/backend/replication/logical/worker.c
+++ b/src/backend/replication/logical/worker.c
@@ -3727,9 +3727,10 @@ maybe_reread_subscription(void)
/*
* Exit if any parameter that affects the remote connection was changed.
- * The launcher will start a new worker, but note that the
parallel apply
- * worker may or may not restart depending on the value of the streaming
- * option and whether there will be a streaming transaction.
+ * The launcher will start a new worker but note that the parallel apply
+ * worker won't restart if the streaming option's value is changed from
+ * 'parallel' to any other value or the server decides not to stream the
+ * in-progress transaction.
*/
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
Hi, I noticed a CFbot failure and here is the new version patch set which should fix that. I also ran pgindent and made some cosmetic changes in the new version patch. Best regards, Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Nov 10, 2022 at 8:41 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Monday, November 7, 2022 6:18 PM Masahiko Sawada <sawada.mshk@gmail.com>
> >
> > Here are comments on v42-0001:
>
> Thanks for the comments.
>
> > We have the following three similar name functions regarding to
> > starting a new parallel apply worker:
> >
> > parallel_apply_start_worker()
> > parallel_apply_setup_worker()
> > parallel_apply_setup_dsm()
> >
> > It seems to me that we can somewhat merge them since
> > parallel_apply_setup_worker() and parallel_apply_setup_dsm() have only
> > one caller.
>
> Since these functions are doing different tasks(external function, Launch, DSM), so I
> personally feel it's OK to split them. But if others also feel it's unnecessary I will
> merge them.
>
I think it is fine either way but if you want to keep the
functionality of parallel_apply_setup_worker() separate then let's
name it to something like parallel_apply_init_and_launch_worker which
will make the function name bit long but it will be clear. I am
thinking that instead of using parallel_apply infront of each
function, shall we use PA? Then we can name this function as
PAInitializeAndLaunchWorker().
I feel you can even move the functionality to get the worker from pool
in parallel_apply_start_worker() to a separate function.
Another related comment:
+ /* Try to get a free parallel apply worker. */
+ foreach(lc, ParallelApplyWorkersList)
+ {
+ ParallelApplyWorkerInfo *tmp_winfo;
+
+ tmp_winfo = (ParallelApplyWorkerInfo *) lfirst(lc);
+
+ /* Check if the transaction in the worker has finished. */
+ if (parallel_apply_free_worker(tmp_winfo, tmp_winfo->shared->xid, false))
+ {
+ /*
+ * Clean up the woker information if the parallel apply woker has
+ * been stopped.
+ */
+ ParallelApplyWorkersList =
foreach_delete_current(ParallelApplyWorkersList, lc);
+ parallel_apply_free_worker_info(tmp_winfo);
+ continue;
+ }
I find it bit odd that even parallel_apply_free_worker() has the
functionality to free the worker info, still, we are doing it outside.
Is there a specific reason for the same? I think we can add a comment
atop parallel_apply_free_worker() that on success, it will free the
passed winfo. In addition to that, we can write some comments before
trying to free worker suggesting that it would be possible for
rollback cases because after rollback we don't wait for workers to
finish so can't perform the cleanup.
> > ---
> > in parallel_apply_send_data():
> >
> > + result = shm_mq_send(winfo->mq_handle, nbytes, data,
> > true, true);
> > +
> > + if (result == SHM_MQ_SUCCESS)
> > + break;
> > + else if (result == SHM_MQ_DETACHED)
> > + ereport(ERROR,
> > +
> > (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> > + errmsg("could not send data
> > to shared-memory queue")))
> > +
> > + Assert(result == SHM_MQ_WOULD_BLOCK);
> > +
> > + if (++retry >= CHANGES_THRESHOLD)
> > + {
> > + MemoryContext oldcontext;
> > + StringInfoData msg;
> > + TimestampTz now = GetCurrentTimestamp();
> > +
> > + if (startTime == 0)
> > + startTime = now;
> > +
> > + if (!TimestampDifferenceExceeds(startTime,
> > now, SHM_SEND_TIMEOUT_MS))
> > + continue;
> >
> > IIUC since the parallel worker retries to send data without waits the
> > 'retry' will get larger than CHANGES_THRESHOLD in a very short time.
> > But the worker waits at least for SHM_SEND_TIMEOUT_MS to spool data
> > regardless of 'retry' count. Don't we need to nap somewhat and why do
> > we need CHANGES_THRESHOLD?
>
> Oh, I intended to only check for timeout after continuously retrying XX times to
> reduce the cost of getting the system time and calculating the time difference.
> I added some comments in the code.
>
Sure, but the patch assumes that immediate retry will help which I am
not sure is correct. IIUC, the patch has overall wait time 10s, if so,
I guess you can retry after 1s, that will amiliorate the cost of
getting the system time.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Nov 11, 2022 at 2:12 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
Few comments on v46-0001:
======================
1.
+static void
+apply_handle_stream_abort(StringInfo s)
{
...
+ /* Send STREAM ABORT message to the parallel apply worker. */
+ parallel_apply_send_data(winfo, s->len, s->data);
+
+ if (abort_toplevel_transaction)
+ {
+ parallel_apply_unlock_stream(xid, AccessExclusiveLock);
Shouldn't we need to release this lock before sending the message as
we are doing for streap_prepare and stream_commit? If there is a
reason for doing it differently here then let's add some comments for
the same.
2. It seems once the patch makes the file state as busy
(LEADER_FILESET_BUSY), it will only be accessible after the leader
apply worker receives a transaction end message like stream_commit. Is
my understanding correct? If yes, then why can't we make it accessible
after the stream_stop message? Are you worried about the concurrency
handling for reading and writing the file? If so, we can probably deal
with it via some lock for reading and writing to file for each change.
I think after this we may not need additional stream level lock/unlock
in parallel_apply_spooled_messages. I understand that you probably
want to keep the code simple so I am not suggesting changing it
immediately but just wanted to know whether you have considered
alternatives here.
3. Don't we need to release the transaction lock at stream_abort in
parallel apply worker? I understand that we are not waiting for it in
the leader worker but still parallel apply worker should release it if
acquired at stream_start by it.
4. A minor comment change as below:
diff --git a/src/backend/replication/logical/worker.c
b/src/backend/replication/logical/worker.c
index 43f09b7e9a..c771851d1f 100644
--- a/src/backend/replication/logical/worker.c
+++ b/src/backend/replication/logical/worker.c
@@ -1851,6 +1851,9 @@ apply_handle_stream_abort(StringInfo s)
parallel_apply_stream_abort(&abort_data);
/*
+ * We need to wait after processing rollback
to savepoint for the next set
+ * of changes.
+ *
* By the time parallel apply worker is
processing the changes in
* the current streaming block, the leader
apply worker may have
* sent multiple streaming blocks. So, try to
lock only if there
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Saturday, November 12, 2022 7:06 PM Amit Kapila <amit.kapila16@gmail.com>
>
> On Fri, Nov 11, 2022 at 2:12 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
>
> Few comments on v46-0001:
> ======================
>
Thanks for the comments.
> 1.
> +static void
> +apply_handle_stream_abort(StringInfo s)
> {
> ...
> + /* Send STREAM ABORT message to the parallel apply worker. */
> + parallel_apply_send_data(winfo, s->len, s->data);
> +
> + if (abort_toplevel_transaction)
> + {
> + parallel_apply_unlock_stream(xid, AccessExclusiveLock);
>
> Shouldn't we need to release this lock before sending the message as
> we are doing for streap_prepare and stream_commit? If there is a
> reason for doing it differently here then let's add some comments for
> the same.
Changed.
> 2. It seems once the patch makes the file state as busy
> (LEADER_FILESET_BUSY), it will only be accessible after the leader
> apply worker receives a transaction end message like stream_commit. Is
> my understanding correct? If yes, then why can't we make it accessible
> after the stream_stop message? Are you worried about the concurrency
> handling for reading and writing the file? If so, we can probably deal
> with it via some lock for reading and writing to file for each change.
> I think after this we may not need additional stream level lock/unlock
> in parallel_apply_spooled_messages. I understand that you probably
> want to keep the code simple so I am not suggesting changing it
> immediately but just wanted to know whether you have considered
> alternatives here.
I thought about this, but it seems the current buffile design doesn't allow two
processes to open the same buffile at the same time(refer to the comment atop
of BufFileOpenFileSet()). This means the LA needs to make sure the PA has
closed the buffile before writing more changes into it. Although we could let
the LA wait for that, but it could cause another kind of deadlock. Suppose the
PA opened the file and is blocked when applying the just read change. And the
LA starts to wait when trying to write the next set of streaming changes into
file because the file is still opened by PA. Then the lock edge is like:
LA (wait for file to be closed) -> PA1 (wait for unique lock in PA2) -> PA2
(wait for stream lock held in LA)
We could introduce another lock for this, but that seems not very great as we
already had two kinds of locks here.
Another solution could be we create different filename for each streaming block
so that the leader don't need to reopen the same file after writing changes
into it, but that seems largely increase the number of temp files and looks a
bit hacky. Or we could let PA open the file, then read and close the file for
each change, but it seems bring some overhead of opening and closing file.
Another solution which doesn't need a new lock could be that we create
different filename for each streaming block so that the leader doesn't need to
reopen the same file after writing changes into it, but that seems largely
increase the number of temp files and looks a bit hacky. Or we could let PA
open the file, then read and close the file for each change, but it seems bring
some overhead of opening and closing file.
Based on above, how about keep the current approach ?(i.e. PA
will open the file only after the leader apply worker receives a transaction
end message like stream_commit). Ideally, it will enter partial serialize mode
only when PA is blocked by a backend or another PA which seems not that common.
> 3. Don't we need to release the transaction lock at stream_abort in
> parallel apply worker? I understand that we are not waiting for it in
> the leader worker but still parallel apply worker should release it if
> acquired at stream_start by it.
I thought that the lock will be automatically released on rollback. But after testing, I find
It’s possible that the lock won't be released if it's a empty streaming transaction. So, I
add the code to release the lock in the new version patch.
>
> 4. A minor comment change as below:
> diff --git a/src/backend/replication/logical/worker.c
> b/src/backend/replication/logical/worker.c
> index 43f09b7e9a..c771851d1f 100644
> --- a/src/backend/replication/logical/worker.c
> +++ b/src/backend/replication/logical/worker.c
> @@ -1851,6 +1851,9 @@ apply_handle_stream_abort(StringInfo s)
> parallel_apply_stream_abort(&abort_data);
>
> /*
> + * We need to wait after processing rollback
> to savepoint for the next set
> + * of changes.
> + *
> * By the time parallel apply worker is
> processing the changes in
> * the current streaming block, the leader
> apply worker may have
> * sent multiple streaming blocks. So, try to
> lock only if there
Merged.
Attach the new version patch set which addressed above comments and comments from [1].
In the new version patch, I renamed parallel_apply_xxx functions to pa_xxx to
make the name shorter according to the suggestion in [1]. Besides, I split the
codes related to partial serialize to 0002 patch to make the patch easier to
review.
[1] https://www.postgresql.org/message-id/CAA4eK1LGyQ%2BS-jCMnYSz_hvoqiNA0Of%3D%2BMksY%3DXTUaRc5XzXJQ%40mail.gmail.com
Best regards,
Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, November 15, 2022 7:58 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
>
> On Saturday, November 12, 2022 7:06 PM Amit Kapila
> <amit.kapila16@gmail.com>
> >
> > On Fri, Nov 11, 2022 at 2:12 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> >
> > Few comments on v46-0001:
> > ======================
> >
>
> Thanks for the comments.
>
> > 1.
> > +static void
> > +apply_handle_stream_abort(StringInfo s)
> > {
> > ...
> > + /* Send STREAM ABORT message to the parallel apply worker. */
> > + parallel_apply_send_data(winfo, s->len, s->data);
> > +
> > + if (abort_toplevel_transaction)
> > + {
> > + parallel_apply_unlock_stream(xid, AccessExclusiveLock);
> >
> > Shouldn't we need to release this lock before sending the message as
> > we are doing for streap_prepare and stream_commit? If there is a
> > reason for doing it differently here then let's add some comments for
> > the same.
>
> Changed.
>
> > 2. It seems once the patch makes the file state as busy
> > (LEADER_FILESET_BUSY), it will only be accessible after the leader
> > apply worker receives a transaction end message like stream_commit. Is
> > my understanding correct? If yes, then why can't we make it accessible
> > after the stream_stop message? Are you worried about the concurrency
> > handling for reading and writing the file? If so, we can probably deal
> > with it via some lock for reading and writing to file for each change.
> > I think after this we may not need additional stream level lock/unlock
> > in parallel_apply_spooled_messages. I understand that you probably
> > want to keep the code simple so I am not suggesting changing it
> > immediately but just wanted to know whether you have considered
> > alternatives here.
>
> I thought about this, but it seems the current buffile design doesn't allow two
> processes to open the same buffile at the same time(refer to the comment
> atop of BufFileOpenFileSet()). This means the LA needs to make sure the PA has
> closed the buffile before writing more changes into it. Although we could let
> the LA wait for that, but it could cause another kind of deadlock. Suppose the
> PA opened the file and is blocked when applying the just read change. And the
> LA starts to wait when trying to write the next set of streaming changes into file
> because the file is still opened by PA. Then the lock edge is like:
>
> LA (wait for file to be closed) -> PA1 (wait for unique lock in PA2) -> PA2 (wait
> for stream lock held in LA)
>
> We could introduce another lock for this, but that seems not very great as we
> already had two kinds of locks here.
>
> Another solution could be we create different filename for each streaming
> block so that the leader don't need to reopen the same file after writing
> changes into it, but that seems largely increase the number of temp files and
> looks a bit hacky. Or we could let PA open the file, then read and close the file
> for each change, but it seems bring some overhead of opening and closing file.
>
> Another solution which doesn't need a new lock could be that we create
> different filename for each streaming block so that the leader doesn't need to
> reopen the same file after writing changes into it, but that seems largely
> increase the number of temp files and looks a bit hacky. Or we could let PA
> open the file, then read and close the file for each change, but it seems bring
> some overhead of opening and closing file.
>
> Based on above, how about keep the current approach ?(i.e. PA will open the
> file only after the leader apply worker receives a transaction end message like
> stream_commit). Ideally, it will enter partial serialize mode only when PA is
> blocked by a backend or another PA which seems not that common.
>
> > 3. Don't we need to release the transaction lock at stream_abort in
> > parallel apply worker? I understand that we are not waiting for it in
> > the leader worker but still parallel apply worker should release it if
> > acquired at stream_start by it.
>
> I thought that the lock will be automatically released on rollback. But after
> testing, I find It’s possible that the lock won't be released if it's a empty
> streaming transaction. So, I add the code to release the lock in the new version
> patch.
>
> >
> > 4. A minor comment change as below:
> > diff --git a/src/backend/replication/logical/worker.c
> > b/src/backend/replication/logical/worker.c
> > index 43f09b7e9a..c771851d1f 100644
> > --- a/src/backend/replication/logical/worker.c
> > +++ b/src/backend/replication/logical/worker.c
> > @@ -1851,6 +1851,9 @@ apply_handle_stream_abort(StringInfo s)
> > parallel_apply_stream_abort(&abort_data);
> >
> > /*
> > + * We need to wait after processing rollback
> > to savepoint for the next set
> > + * of changes.
> > + *
> > * By the time parallel apply worker is
> > processing the changes in
> > * the current streaming block, the leader
> > apply worker may have
> > * sent multiple streaming blocks. So, try to
> > lock only if there
>
> Merged.
>
> Attach the new version patch set which addressed above comments and
> comments from [1].
>
> In the new version patch, I renamed parallel_apply_xxx functions to pa_xxx to
> make the name shorter according to the suggestion in [1]. Besides, I split the
> codes related to partial serialize to 0002 patch to make the patch easier to
> review.
>
> [1]
> https://www.postgresql.org/message-id/CAA4eK1LGyQ%2BS-jCMnYSz_hvoq
> iNA0Of%3D%2BMksY%3DXTUaRc5XzXJQ%40mail.gmail.com
I noticed that I didn't add CHECK_FOR_INTERRUPTS while retrying send message.
So, attach the new version which adds that. Also attach the 0004 patch that
restarts logical replication with temporarily disabling the parallel apply if
failed to apply a transaction in parallel apply worker.
Best regards,
Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Tue, Nov 15, 2022 at 8:57 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Saturday, November 12, 2022 7:06 PM Amit Kapila <amit.kapila16@gmail.com>
> >
> > On Fri, Nov 11, 2022 at 2:12 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> >
> > Few comments on v46-0001:
> > ======================
> >
>
> Thanks for the comments.
>
> > 1.
> > +static void
> > +apply_handle_stream_abort(StringInfo s)
> > {
> > ...
> > + /* Send STREAM ABORT message to the parallel apply worker. */
> > + parallel_apply_send_data(winfo, s->len, s->data);
> > +
> > + if (abort_toplevel_transaction)
> > + {
> > + parallel_apply_unlock_stream(xid, AccessExclusiveLock);
> >
> > Shouldn't we need to release this lock before sending the message as
> > we are doing for streap_prepare and stream_commit? If there is a
> > reason for doing it differently here then let's add some comments for
> > the same.
>
> Changed.
>
> > 2. It seems once the patch makes the file state as busy
> > (LEADER_FILESET_BUSY), it will only be accessible after the leader
> > apply worker receives a transaction end message like stream_commit. Is
> > my understanding correct? If yes, then why can't we make it accessible
> > after the stream_stop message? Are you worried about the concurrency
> > handling for reading and writing the file? If so, we can probably deal
> > with it via some lock for reading and writing to file for each change.
> > I think after this we may not need additional stream level lock/unlock
> > in parallel_apply_spooled_messages. I understand that you probably
> > want to keep the code simple so I am not suggesting changing it
> > immediately but just wanted to know whether you have considered
> > alternatives here.
>
> I thought about this, but it seems the current buffile design doesn't allow two
> processes to open the same buffile at the same time(refer to the comment atop
> of BufFileOpenFileSet()). This means the LA needs to make sure the PA has
> closed the buffile before writing more changes into it. Although we could let
> the LA wait for that, but it could cause another kind of deadlock. Suppose the
> PA opened the file and is blocked when applying the just read change. And the
> LA starts to wait when trying to write the next set of streaming changes into
> file because the file is still opened by PA. Then the lock edge is like:
>
> LA (wait for file to be closed) -> PA1 (wait for unique lock in PA2) -> PA2
> (wait for stream lock held in LA)
>
> We could introduce another lock for this, but that seems not very great as we
> already had two kinds of locks here.
>
> Another solution could be we create different filename for each streaming block
> so that the leader don't need to reopen the same file after writing changes
> into it, but that seems largely increase the number of temp files and looks a
> bit hacky. Or we could let PA open the file, then read and close the file for
> each change, but it seems bring some overhead of opening and closing file.
>
> Another solution which doesn't need a new lock could be that we create
> different filename for each streaming block so that the leader doesn't need to
> reopen the same file after writing changes into it, but that seems largely
> increase the number of temp files and looks a bit hacky. Or we could let PA
> open the file, then read and close the file for each change, but it seems bring
> some overhead of opening and closing file.
>
> Based on above, how about keep the current approach ?(i.e. PA
> will open the file only after the leader apply worker receives a transaction
> end message like stream_commit). Ideally, it will enter partial serialize mode
> only when PA is blocked by a backend or another PA which seems not that common.
+1. We can improve this area later in a separate patch.
Here are review comments on v47-0001 and v47-0002 patches:
When the parallel apply worker exited, I got the following server log.
I think this log is not appropriate since the worker was not
terminated by administrator command but exited by itself. Also,
probably it should exit with exit code 0?
FATAL: terminating logical replication worker due to administrator command
LOG: background worker "logical replication parallel worker" (PID
3594918) exited with exit code 1
---
/*
* Stop the worker if there are enough workers in the pool or the leader
* apply worker serialized part of the transaction data to a file due to
* send timeout.
*/
if (winfo->serialize_changes ||
napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
Why do we need to stop the worker if the leader serializes changes?
---
+ /*
+ * Release all session level locks that could be held in parallel apply
+ * mode.
+ */
+ LockReleaseAll(DEFAULT_LOCKMETHOD, true);
+
I think we call LockReleaseAll() at the process exit (in ProcKill()),
but do we really need to do LockReleaseAll() here too?
---
+ elog(ERROR, "could not find replication state slot
for replication"
+ "origin with OID %u which was acquired by
%d", node, acquired_by);
Let's not break the error log message in the middle so that the user
can search the message by grep easily.
---
+ {
+ {"max_parallel_apply_workers_per_subscription",
+ PGC_SIGHUP,
+ REPLICATION_SUBSCRIBERS,
+ gettext_noop("Maximum number of parallel
apply workers per subscription."),
+ NULL,
+ },
+ &max_parallel_apply_workers_per_subscription,
+ 2, 0, MAX_BACKENDS,
+ NULL, NULL, NULL
+ },
+
I think we should use MAX_PARALLEL_WORKER_LIMIT as the max value
instead. MAX_BACKENDS is too high.
---
+ /*
+ * Indicates whether there are pending messages in the queue.
The parallel
+ * apply worker will check it before starting to wait.
+ */
+ pg_atomic_uint32 pending_message_count;
The "pending messages" sounds like individual logical replication
messages such as LOGICAL_REP_MSG_INSERT. But IIUC what this value
actually shows is how many streamed chunks are pending to process,
right?
---
The streaming parameter has the new value "parallel" for "streaming"
option to enable the parallel apply. It fits so far but I think the
parallel apply feature doesn't necessarily need to be tied up with
streaming replication. For example, we might want to support parallel
apply also for non-streaming transactions in the future. It might be
better to have another option, say "parallel", to control parallel
apply behavior. The "parallel" option can be a boolean option and
setting parallel = on requires streaming = on.
Another variant is to have a new subscription parameter for example
"parallel_workers" parameter that specifies the number of parallel
workers. That way, users can specify the number of parallel workers
per subscription.
---
When the parallel apply worker raises an error, I got the same error
twice from the leader worker and parallel worker as follows. Can we
suppress either one?
2022-11-17 17:30:23.490 JST [3814552] LOG: logical replication
parallel apply worker for subscription "test_sub1" has started
2022-11-17 17:30:23.490 JST [3814552] ERROR: duplicate key value
violates unique constraint "test1_c_idx"
2022-11-17 17:30:23.490 JST [3814552] DETAIL: Key (c)=(1) already exists.
2022-11-17 17:30:23.490 JST [3814552] CONTEXT: processing remote data
for replication origin "pg_16390" during message type "INSERT" for
replication target relatio
n "public.test1" in transaction 731
2022-11-17 17:30:23.490 JST [3814550] ERROR: duplicate key value
violates unique constraint "test1_c_idx"
2022-11-17 17:30:23.490 JST [3814550] DETAIL: Key (c)=(1) already exists.
2022-11-17 17:30:23.490 JST [3814550] CONTEXT: processing remote data
for replication origin "pg_16390" during message type "INSERT" for
replication target relatio
n "public.test1" in transaction 731
parallel apply worker
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Nov 16, 2022 at 1:50 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Tuesday, November 15, 2022 7:58 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
>
> I noticed that I didn't add CHECK_FOR_INTERRUPTS while retrying send message.
> So, attach the new version which adds that. Also attach the 0004 patch that
> restarts logical replication with temporarily disabling the parallel apply if
> failed to apply a transaction in parallel apply worker.
>
Few comments on v48-0001
======================
1. The variable name pending_message_count seems to indicate a number
of pending messages but normally it is pending start/stop streams
except for probably rollback to savepoint case. Shall we name it
pending_stream_count and change the comments accordingly?
2. The variable name abort_toplevel_transaction seems unnecessarily
long. Shall we rename it to toplevel_xact or something like that?
3.
+ /*
+ * Increment the number of messages waiting to be processed by
+ * parallel apply worker.
+ */
+ if (!abort_toplevel_transaction)
+ pg_atomic_add_fetch_u32(&(winfo->shared->pending_message_count), 1);
+ else
+ pa_unlock_stream(xid, AccessExclusiveLock);
It is better to explain here why different actions are required for
subtransaction and transaction rather than the current comment.
4.
+
+ if (abort_toplevel_transaction)
+ {
+ (void) pa_free_worker(winfo, xid);
+ }
{} is not required here.
5.
/*
+ * Although the lock can be automatically released during transaction
+ * rollback, but we still release the lock here as we may not in a
+ * transaction.
+ */
+ pa_unlock_transaction(xid, AccessShareLock);
+
It is better to explain for which case (I think it is for empty xacts)
it will be useful to release it explicitly.
6.
+ *
+ * XXX We can avoid sending pairs of the START/STOP messages to the parallel
+ * worker because unlike apply worker it will process only one transaction at a
+ * time. However, it is not clear whether any optimization is worthwhile
+ * because these messages are sent only when the logical_decoding_work_mem
+ * threshold is exceeded.
*/
static void
apply_handle_stream_start(StringInfo s)
I think this comment is no longer valid as now we need to wait for the
next stream at stream_stop message and also need to acquire the lock
in stream_start message. So, I think it is better to remove it unless
I am missing something.
7. I am able to compile applyparallelworker.c by commenting few of the
header includes. Please check if those are really required.
#include "libpq/pqformat.h"
#include "libpq/pqmq.h"
//#include "mb/pg_wchar.h"
#include "pgstat.h"
#include "postmaster/interrupt.h"
#include "replication/logicallauncher.h"
//#include "replication/logicalworker.h"
#include "replication/origin.h"
//#include "replication/walreceiver.h"
#include "replication/worker_internal.h"
#include "storage/ipc.h"
#include "storage/lmgr.h"
//#include "storage/procarray.h"
#include "tcop/tcopprot.h"
#include "utils/inval.h"
#include "utils/memutils.h"
//#include "utils/resowner.h"
#include "utils/syscache.h"
8.
+/*
+ * Is there a message sent by parallel apply worker which we need to receive?
+ */
+volatile sig_atomic_t ParallelApplyMessagePending = false;
This comment and variable are placed in applyparallelworker.c, so 'we'
in the above sentence is not clear. I think you need to use leader
apply worker instead.
9.
+static ParallelApplyWorkerInfo *pa_get_free_worker(void);
Will it be better if we name this function pa_get_available_worker()?
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Fri, Nov 18, 2022 at 11:36 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > ... > --- > The streaming parameter has the new value "parallel" for "streaming" > option to enable the parallel apply. It fits so far but I think the > parallel apply feature doesn't necessarily need to be tied up with > streaming replication. For example, we might want to support parallel > apply also for non-streaming transactions in the future. It might be > better to have another option, say "parallel", to control parallel > apply behavior. The "parallel" option can be a boolean option and > setting parallel = on requires streaming = on. > FWIW, I tend to agree with this idea but for a different reason. In this patch, the 'streaming' parameter had become a kind of hybrid boolean/enum. AFAIK there are no other parameters anywhere that use a hybrid pattern like this so I was thinking it may be better not to be different. But I didn't think that parallel_apply=on should *require* streaming=on. It might be better for parallel_apply=on is just the *default*, but it simply achieves nothing unless streaming=on too. That way users would not need to change anything at all to get the benefits of parallel streaming. > Another variant is to have a new subscription parameter for example > "parallel_workers" parameter that specifies the number of parallel > workers. That way, users can specify the number of parallel workers > per subscription. > ------ Kind Regards, Peter Smith. Fujitsu Australia.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Nov 18, 2022 at 8:01 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Fri, Nov 18, 2022 at 11:36 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > ... > > --- > > The streaming parameter has the new value "parallel" for "streaming" > > option to enable the parallel apply. It fits so far but I think the > > parallel apply feature doesn't necessarily need to be tied up with > > streaming replication. For example, we might want to support parallel > > apply also for non-streaming transactions in the future. It might be > > better to have another option, say "parallel", to control parallel > > apply behavior. The "parallel" option can be a boolean option and > > setting parallel = on requires streaming = on. > > If we do that then how will the user be able to use streaming serialize mode (write to file for streaming transactions) as we have now? Because after we introduce parallelism for non-streaming transactions, the user would want parallel = on irrespective of the streaming mode. Also, users may wish to only parallelize large transactions because of additional overhead for non-streaming transactions for transaction dependency tracking, etc. So, the user may wish to have a separate knob for large transactions as the patch has now. > > FWIW, I tend to agree with this idea but for a different reason. In > this patch, the 'streaming' parameter had become a kind of hybrid > boolean/enum. AFAIK there are no other parameters anywhere that use a > hybrid pattern like this so I was thinking it may be better not to be > different. > I think we have a similar pattern for GUC parameters like constraint_exclusion (see constraint_exclusion_options), backslash_quote (see backslash_quote_options), etc. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Fri, Nov 18, 2022 at 1:47 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Nov 18, 2022 at 8:01 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Fri, Nov 18, 2022 at 11:36 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > ... > > > --- > > > The streaming parameter has the new value "parallel" for "streaming" > > > option to enable the parallel apply. It fits so far but I think the > > > parallel apply feature doesn't necessarily need to be tied up with > > > streaming replication. For example, we might want to support parallel > > > apply also for non-streaming transactions in the future. It might be > > > better to have another option, say "parallel", to control parallel > > > apply behavior. The "parallel" option can be a boolean option and > > > setting parallel = on requires streaming = on. > > > > > If we do that then how will the user be able to use streaming > serialize mode (write to file for streaming transactions) as we have > now? Because after we introduce parallelism for non-streaming > transactions, the user would want parallel = on irrespective of the > streaming mode. Also, users may wish to only parallelize large > transactions because of additional overhead for non-streaming > transactions for transaction dependency tracking, etc. So, the user > may wish to have a separate knob for large transactions as the patch > has now. One idea for that would be to make it enum. For example, setting parallel = "streaming" works for that. > > > > > FWIW, I tend to agree with this idea but for a different reason. In > > this patch, the 'streaming' parameter had become a kind of hybrid > > boolean/enum. AFAIK there are no other parameters anywhere that use a > > hybrid pattern like this so I was thinking it may be better not to be > > different. > > > > I think we have a similar pattern for GUC parameters like > constraint_exclusion (see constraint_exclusion_options), > backslash_quote (see backslash_quote_options), etc. Right. vacuum_index_cleanup and buffering storage parameters that accept 'on', 'off', or 'auto') are other examples. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Nov 18, 2022 at 10:31 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Fri, Nov 18, 2022 at 1:47 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Fri, Nov 18, 2022 at 8:01 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > On Fri, Nov 18, 2022 at 11:36 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > ... > > > > --- > > > > The streaming parameter has the new value "parallel" for "streaming" > > > > option to enable the parallel apply. It fits so far but I think the > > > > parallel apply feature doesn't necessarily need to be tied up with > > > > streaming replication. For example, we might want to support parallel > > > > apply also for non-streaming transactions in the future. It might be > > > > better to have another option, say "parallel", to control parallel > > > > apply behavior. The "parallel" option can be a boolean option and > > > > setting parallel = on requires streaming = on. > > > > > > > > If we do that then how will the user be able to use streaming > > serialize mode (write to file for streaming transactions) as we have > > now? Because after we introduce parallelism for non-streaming > > transactions, the user would want parallel = on irrespective of the > > streaming mode. Also, users may wish to only parallelize large > > transactions because of additional overhead for non-streaming > > transactions for transaction dependency tracking, etc. So, the user > > may wish to have a separate knob for large transactions as the patch > > has now. > > One idea for that would be to make it enum. For example, setting > parallel = "streaming" works for that. > Yeah, but then we will have two different parameters (parallel and streaming) to control streaming behavior. This will be confusing say when the user says parallel = 'streaming' and streaming = off, we need to probably disallow such settings but not sure if it would be any better than allowing parallelism for large xacts by streaming parameter. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for v47-0001
(This review is a WIP - I will post more comments for this patch next week)
======
.../replication/logical/applyparallelworker.c
1.
+ * Copyright (c) 2022, PostgreSQL Global Development Group
+ *
+ * IDENTIFICATION src/backend/replication/logical/applyparallelworker.c
+ *
This IDENTIFICATION should be on 2 lines like it previously was
instead of wrapped into one line. For consistency with all other file
headers.
~~~
2. File header comment
+ * Since the database structure (schema of subscription tables, etc.) of
+ * publisher and subscriber may be different.
Incomplete sentence?
~~~
3.
+ * When the following two scenarios occur, a deadlock occurs.
Actually, you described three scenarios in this comment. Not two.
SUGGESTION
The following scenarios can cause a deadlock.
~~~
4.
+ * LA (waiting to acquire the local transaction lock) -> PA1 (waiting to
+ * acquire the lock on the unique index) -> PA2 (waiting to acquire the lock on
+ * the remote transaction) -> LA
"PA1" -> "PA-1"
"PA2" -> "PA-2"
~~~
5.
+ * To resolve this issue, we use non-blocking write and wait with a timeout. If
+ * timeout is exceeded, the LA report an error and restart logical replication.
"report" --> "reports"
"restart" -> "restarts"
OR
"LA report" -> "LA will report"
~~~
6. pa_wait_for_xact_state
+/*
+ * Wait until the parallel apply worker's transaction state reach or exceed the
+ * given xact_state.
+ */
+static void
+pa_wait_for_xact_state(ParallelApplyWorkerShared *wshared,
+ ParallelTransState xact_state)
"reach or exceed" -> "reaches or exceeds"
~~~
7. pa_stream_abort
+ /*
+ * Although the lock can be automatically released during transaction
+ * rollback, but we still release the lock here as we may not in a
+ * transaction.
+ */
+ pa_unlock_transaction(xid, AccessShareLock);
"but we still" -> "we still"
"we may not in a" -> "we may not be in a"
~~~
8.
+ pa_savepoint_name(MySubscription->oid, subxid, spname,
+ sizeof(spname));
+
Unnecessary wrapping
~~~
9.
+ for (i = list_length(subxactlist) - 1; i >= 0; i--)
+ {
+ TransactionId xid_tmp = lfirst_xid(list_nth_cell(subxactlist, i));
+
+ if (xid_tmp == subxid)
+ {
+ found = true;
+ break;
+ }
+ }
+
+ if (found)
+ {
+ RollbackToSavepoint(spname);
+ CommitTransactionCommand();
+ subxactlist = list_truncate(subxactlist, i + 1);
+ }
This code logic does not seem to require the 'found' flag. You can do
the RollbackToSavepoint/CommitTransactionCommand/list_truncate before
the break.
~~~
10. pa_lock/unlock _stream/_transaction
+/*
+ * Helper functions to acquire and release a lock for each stream block.
+ *
+ * Set locktag_field4 to 0 to indicate that it's a stream lock.
+ */
+/*
+ * Helper functions to acquire and release a lock for each local transaction.
+ *
+ * Set locktag_field4 to 1 to indicate that it's a transaction lock.
Should constants/defines/enums replace those magic numbers 0 and 1?
~~~
11. pa_lock_transaction
+ * Note that all the callers are passing remote transaction ID instead of local
+ * transaction ID as xid. This is because the local transaction ID will only be
+ * assigned while applying the first change in the parallel apply, but it's
+ * possible that the first change in parallel apply worker is blocked by a
+ * concurrently executing transaction in another parallel apply worker causing
+ * the leader cannot get local transaction ID.
"causing the leader cannot" -> "which means the leader cannot" (??)
======
src/backend/replication/logical/worker.c
12. TransApplyAction
+/*
+ * What action to take for the transaction.
+ *
+ * TRANS_LEADER_APPLY:
+ * The action means that we are in the leader apply worker and changes of the
+ * transaction are applied directly in the worker.
+ *
+ * TRANS_LEADER_SERIALIZE:
+ * It means that we are in the leader apply worker or table sync worker.
+ * Changes are written to temporary files and then applied when the final
+ * commit arrives.
+ *
+ * TRANS_LEADER_SEND_TO_PARALLEL:
+ * The action means that we are in the leader apply worker and need to send the
+ * changes to the parallel apply worker.
+ *
+ * TRANS_PARALLEL_APPLY:
+ * The action that we are in the parallel apply worker and changes of the
+ * transaction are applied directly in the worker.
+ */
+typedef enum
12a
Too many various ways of saying the same thing:
"The action means that we..."
"It means that we..."
"The action that we..." (typo?)
Please word all these comments consistently
~
12b.
"directly in the worker" -> "directly by the worker" (??) 2x
~~~
13. get_worker_name
+/*
+ * Return the name of the logical replication worker.
+ */
+static const char *
+get_worker_name(void)
+{
+ if (am_tablesync_worker())
+ return _("logical replication table synchronization worker");
+ else if (am_parallel_apply_worker())
+ return _("logical replication parallel apply worker");
+ else
+ return _("logical replication apply worker");
+}
This function belongs nearer the top of the module (above all the
error messages that are using it).
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Nov 18, 2022 at 7:56 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Nov 16, 2022 at 1:50 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Tuesday, November 15, 2022 7:58 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
> >
> > I noticed that I didn't add CHECK_FOR_INTERRUPTS while retrying send message.
> > So, attach the new version which adds that. Also attach the 0004 patch that
> > restarts logical replication with temporarily disabling the parallel apply if
> > failed to apply a transaction in parallel apply worker.
> >
>
> Few comments on v48-0001
> ======================
>
I have made quite a few changes in the comments, added some new
comments, and made other cosmetic changes in the attached patch. The
is atop v48-0001*. If these look okay to you, please include them in
the next version. Apart from these, I have a few more comments on
v48-0001*
1.
+static bool
+pa_can_start(TransactionId xid)
+{
+ if (!TransactionIdIsValid(xid))
+ return false;
The caller (see caller of pa_start_worker) already has a check that
xid passed here is valid, so I think this should be an Assert unless I
am missing something in which case it is better to add a comment here.
2. Will it be better to rename pa_start_worker() as
pa_allocate_worker() because it sometimes gets the worker from the
pool and also allocate the hash entry for worker info? That will even
match the corresponding pa_free_worker().
3.
+pa_start_subtrans(TransactionId current_xid, TransactionId top_xid)
{
...
+
+ oldctx = MemoryContextSwitchTo(ApplyContext);
+ subxactlist = lappend_xid(subxactlist, current_xid);
+ MemoryContextSwitchTo(oldctx);
...
Why do we need to allocate this list in a permanent context? IIUC, we
need to use this to maintain subxacts so that it can be later used to
find the given subxact at the time of rollback to savepoint in the
current in-progress transaction, so why do we need it beyond the
transaction being applied? If there is a reason for the same, it would
be better to add some comments for the same.
4.
+pa_stream_abort(LogicalRepStreamAbortData *abort_data)
{
...
+
+ for (i = list_length(subxactlist) - 1; i >= 0; i--)
+ {
+ TransactionId xid_tmp = lfirst_xid(list_nth_cell(subxactlist, i));
+
+ if (xid_tmp == subxid)
+ {
+ found = true;
+ break;
+ }
+ }
+
+ if (found)
+ {
+ RollbackToSavepoint(spname);
+ CommitTransactionCommand();
+ subxactlist = list_truncate(subxactlist, i + 1);
+ }
I was thinking whether we can have an Assert(false) for the not found
case but it seems if all the changes of a subxact have been skipped
then probably subxid corresponding to "rollback to savepoint" won't be
found in subxactlist and we don't need to do anything for it. If that
is the case, then probably adding a comment for it would be a good
idea, otherwise, we can probably have Assert(false) in the else case.
--
With Regards,
Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Fri, Nov 18, 2022 at 6:03 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are some review comments for v47-0001
>
> (This review is a WIP - I will post more comments for this patch next week)
>
Here are the rest of my comments for v47-0001
======
doc/src/sgml/monitoring.
1.
@@ -1851,6 +1851,11 @@ postgres 27093 0.0 0.0 30096 2752 ?
Ss 11:34 0:00 postgres: ser
<entry>Waiting to acquire an advisory user lock.</entry>
</row>
<row>
+ <entry><literal>applytransaction</literal></entry>
+ <entry>Waiting to acquire acquire a lock on a remote transaction being
+ applied on the subscriber side.</entry>
+ </row>
+ <row>
1a.
Typo "acquire acquire"
~
1b.
Maybe "on the subscriber side" does not mean much without any context.
Maybe better to word it as below.
SUGGESTION
Waiting to acquire a lock on a remote transaction being applied by a
logical replication subscriber.
======
doc/src/sgml/system-views.sgml
2.
@@ -1361,8 +1361,9 @@
<literal>virtualxid</literal>,
<literal>spectoken</literal>,
<literal>object</literal>,
- <literal>userlock</literal>, or
- <literal>advisory</literal>.
+ <literal>userlock</literal>,
+ <literal>advisory</literal> or
+ <literal>applytransaction</literal>.
This change removed the Oxford comma that was there before. I assume
it was unintended.
======
.../replication/logical/applyparallelworker.c
3. globals
The parallel_apply_XXX functions were all shortened to pa_XXX.
I wondered if the same simplification should be done also to the
global statics...
e.g.
ParallelApplyWorkersHash -> PAWorkerHash
ParallelApplyWorkersList -> PAWorkerList
ParallelApplyMessagePending -> PAMessagePending
etc...
~~~
4. pa_get_free_worker
+ foreach(lc, active_workers)
+ {
+ ParallelApplyWorkerInfo *winfo = NULL;
+
+ winfo = (ParallelApplyWorkerInfo *) lfirst(lc);
No need to assign NULL because the next line just overwrites that anyhow.
~
5.
+ /*
+ * Try to free the worker first, because we don't wait for the rollback
+ * command to finish so the worker may not be freed at the end of the
+ * transaction.
+ */
+ if (pa_free_worker(winfo, winfo->shared->xid))
+ continue;
+
+ if (!winfo->in_use)
+ return winfo;
Shouldn't the (!winfo->in_use) check be done first as well -- e.g. why
are we trying to free a worker which is maybe not even in_use?
SUGGESTION (this will need some comment to explain what it is doing)
if (!winfo->in_use || !pa_free_worker(winfo, winfo->shared->xid) &&
!winfo->in_use)
return winfo;
~~~
6. pa_free_worker
+/*
+ * Remove the parallel apply worker entry from the hash table. Stop the work if
+ * there are enough workers in the pool.
+ *
Typo? "work" -> "worker"
~
7.
+ /* Are there enough workers in the pool? */
+ if (napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
+ {
IMO that comment should be something more like "Don't detach/stop the
worker unless..."
~~~
8. pa_send_data
+ /*
+ * Retry after 1s to reduce the cost of getting the system time and
+ * calculating the time difference.
+ */
+ (void) WaitLatch(MyLatch,
+ WL_LATCH_SET | WL_TIMEOUT | WL_EXIT_ON_PM_DEATH,
+ 1000L,
+ WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE);
8a.
I am not sure you need to explain the reason in the comment. Just
saying "Wait before retrying." seems sufficient to me.
~
8b.
Instead of the hardwired "1s" in the comment, and 1000L in the code,
maybe better to just have another constant.
SUGGESTION
#define SHM_SEND_RETRY_INTERVAL_MS 1000
#define SHM_SEND_TIMEOUT_MS 10000
~
9.
+ if (startTime == 0)
+ startTime = GetCurrentTimestamp();
+ else if (TimestampDifferenceExceeds(startTime, GetCurrentTimestamp(),
IMO the initial startTime should be at top of the function otherwise
the timeout calculation seems wrong.
======
src/backend/replication/logical/worker.c
10. handle_streamed_transaction
+ * In streaming case (receiving a block of streamed transaction), for
+ * SUBSTREAM_ON mode, simply redirect it to a file for the proper toplevel
+ * transaction, and for SUBSTREAM_PARALLEL mode, send the changes to parallel
+ * apply workers (LOGICAL_REP_MSG_RELATION or LOGICAL_REP_MSG_TYPE changes
+ * will be applied by both leader apply worker and parallel apply workers).
I'm not sure this function comment should be referring to SUBSTREAM_ON
and SUBSTREAM_PARALLEL because the function body does not use those
anywhere in the logic.
~~~
11. apply_handle_stream_start
+ /*
+ * Increment the number of messages waiting to be processed by
+ * parallel apply worker.
+ */
+ pg_atomic_add_fetch_u32(&(winfo->shared->pending_message_count), 1);
+
The &() parens are not needed. Just write &winfo->shared->pending_message_count.
Also, search/replace others like this -- there are a few of them.
~~~
12. apply_handle_stream_stop
+ if (!abort_toplevel_transaction &&
+ pg_atomic_sub_fetch_u32(&(MyParallelShared->pending_message_count), 1) == 0)
+ {
+ pa_lock_stream(MyParallelShared->xid, AccessShareLock);
+ pa_unlock_stream(MyParallelShared->xid, AccessShareLock);
+ }
That lock/unlock seems like it is done just as a way of
testing/waiting for an exclusive lock held on the xid to be released.
But the code is too tricky -- IMO it needs a big comment saying how
this trick works, or maybe better to have a wrapper function for this
for clarity. e.g. pa_wait_nolock_stream(xid); (or some better name)
~~~
13. apply_handle_stream_abort
+ if (abort_toplevel_transaction)
+ {
+ (void) pa_free_worker(winfo, xid);
+ }
Unnecessary { }
~~~
14. maybe_reread_subscription
@@ -3083,8 +3563,9 @@ maybe_reread_subscription(void)
if (!newsub)
{
ereport(LOG,
- (errmsg("logical replication apply worker for subscription \"%s\" will "
- "stop because the subscription was removed",
+ /* translator: first %s is the name of logical replication worker */
+ (errmsg("%s for subscription \"%s\" will stop because the "
+ "subscription was removed", get_worker_name(),
MySubscription->name)));
proc_exit(0);
@@ -3094,8 +3575,9 @@ maybe_reread_subscription(void)
if (!newsub->enabled)
{
ereport(LOG,
- (errmsg("logical replication apply worker for subscription \"%s\" will "
- "stop because the subscription was disabled",
+ /* translator: first %s is the name of logical replication worker */
+ (errmsg("%s for subscription \"%s\" will stop because the "
+ "subscription was disabled", get_worker_name(),
MySubscription->name)));
IMO better to avoid splitting the string literals over multiple line like this.
Please check the rest of the patch too -- there may be many more just like this.
~~~
15. ApplyWorkerMain
@@ -3726,7 +4236,7 @@ ApplyWorkerMain(Datum main_arg)
}
else
{
- /* This is main apply worker */
+ /* This is leader apply worker */
RepOriginId originid;
"This is leader" -> "This is the leader"
======
src/bin/psql/describe.c
16. describeSubscriptions
+ if (pset.sversion >= 160000)
+ appendPQExpBuffer(&buf,
+ ", (CASE substream\n"
+ " WHEN 'f' THEN 'off'\n"
+ " WHEN 't' THEN 'on'\n"
+ " WHEN 'p' THEN 'parallel'\n"
+ " END) AS \"%s\"\n",
+ gettext_noop("Streaming"));
+ else
+ appendPQExpBuffer(&buf,
+ ", substream AS \"%s\"\n",
+ gettext_noop("Streaming"));
I'm not sure it is an improvement to change the output "t/f/p" to
"on/off/parallel"
IMO "t/f/parallel" would be better. Then the t/f is consistent with
- how it used to display, and
- all the other boolean fields
======
src/include/replication/worker_internal.h
17. ParallelTransState
+/*
+ * State of the transaction in parallel apply worker.
+ *
+ * These enum values are ordered by the order of transaction state changes in
+ * parallel apply worker.
+ */
+typedef enum ParallelTransState
"ordered by the order" ??
SUGGESTION
The enum values must have the same order as the transaction state transitions.
======
src/include/storage/lock.h
18.
@@ -149,10 +149,12 @@ typedef enum LockTagType
LOCKTAG_SPECULATIVE_TOKEN, /* speculative insertion Xid and token */
LOCKTAG_OBJECT, /* non-relation database object */
LOCKTAG_USERLOCK, /* reserved for old contrib/userlock code */
- LOCKTAG_ADVISORY /* advisory user locks */
+ LOCKTAG_ADVISORY, /* advisory user locks */
+ LOCKTAG_APPLY_TRANSACTION /* transaction being applied on the subscriber
+ * side */
} LockTagType;
-#define LOCKTAG_LAST_TYPE LOCKTAG_ADVISORY
+#define LOCKTAG_LAST_TYPE LOCKTAG_APPLY_TRANSACTION
extern PGDLLIMPORT const char *const LockTagTypeNames[];
@@ -278,6 +280,17 @@ typedef struct LOCKTAG
(locktag).locktag_type = LOCKTAG_ADVISORY, \
(locktag).locktag_lockmethodid = USER_LOCKMETHOD)
+/*
+ * ID info for a remote transaction on the subscriber side is:
+ * DB OID + SUBSCRIPTION OID + TRANSACTION ID + OBJID
+ */
+#define SET_LOCKTAG_APPLY_TRANSACTION(locktag,dboid,suboid,xid,objid) \
+ ((locktag).locktag_field1 = (dboid), \
+ (locktag).locktag_field2 = (suboid), \
+ (locktag).locktag_field3 = (xid), \
+ (locktag).locktag_field4 = (objid), \
+ (locktag).locktag_type = LOCKTAG_APPLY_TRANSACTION, \
+ (locktag).locktag_lockmethodid = DEFAULT_LOCKMETHOD)
Maybe "on the subscriber side" (2 places above) has no meaning here
because there is no context this is talking about logical replication.
Maybe those comments need to say something more like "on a logical
replication subscriber"
------
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Saturday, November 19, 2022 6:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Fri, Nov 18, 2022 at 7:56 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Wed, Nov 16, 2022 at 1:50 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Tuesday, November 15, 2022 7:58 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> > >
> > > I noticed that I didn't add CHECK_FOR_INTERRUPTS while retrying send
> message.
> > > So, attach the new version which adds that. Also attach the 0004
> > > patch that restarts logical replication with temporarily disabling
> > > the parallel apply if failed to apply a transaction in parallel apply worker.
> > >
> >
> > Few comments on v48-0001
Thanks for the comments !
> > ======================
> >
>
> I have made quite a few changes in the comments, added some new comments,
> and made other cosmetic changes in the attached patch. The is atop v48-0001*.
> If these look okay to you, please include them in the next version. Apart from
> these, I have a few more comments on
> v48-0001*
Thanks, I have checked and merge them.
> 1.
> +static bool
> +pa_can_start(TransactionId xid)
> +{
> + if (!TransactionIdIsValid(xid))
> + return false;
>
> The caller (see caller of pa_start_worker) already has a check that xid passed
> here is valid, so I think this should be an Assert unless I am missing something in
> which case it is better to add a comment here.
Changed to an Assert().
> 2. Will it be better to rename pa_start_worker() as
> pa_allocate_worker() because it sometimes gets the worker from the pool and
> also allocate the hash entry for worker info? That will even match the
> corresponding pa_free_worker().
Agreed and changed.
> 3.
> +pa_start_subtrans(TransactionId current_xid, TransactionId top_xid)
> {
> ...
> +
> + oldctx = MemoryContextSwitchTo(ApplyContext);
> + subxactlist = lappend_xid(subxactlist, current_xid);
> + MemoryContextSwitchTo(oldctx);
> ...
>
> Why do we need to allocate this list in a permanent context? IIUC, we need to
> use this to maintain subxacts so that it can be later used to find the given
> subxact at the time of rollback to savepoint in the current in-progress
> transaction, so why do we need it beyond the transaction being applied? If
> there is a reason for the same, it would be better to add some comments for
> the same.
I think you are right, I changed to use TopTransactionContext here.
> 4.
> +pa_stream_abort(LogicalRepStreamAbortData *abort_data)
> {
> ...
> +
> + for (i = list_length(subxactlist) - 1; i >= 0; i--) { TransactionId
> + xid_tmp = lfirst_xid(list_nth_cell(subxactlist, i));
> +
> + if (xid_tmp == subxid)
> + {
> + found = true;
> + break;
> + }
> + }
> +
> + if (found)
> + {
> + RollbackToSavepoint(spname);
> + CommitTransactionCommand();
> + subxactlist = list_truncate(subxactlist, i + 1); }
>
> I was thinking whether we can have an Assert(false) for the not found case but it
> seems if all the changes of a subxact have been skipped then probably subxid
> corresponding to "rollback to savepoint" won't be found in subxactlist and we
> don't need to do anything for it. If that is the case, then probably adding a
> comment for it would be a good idea, otherwise, we can probably have
> Assert(false) in the else case.
Yes, we might not find the xid for an empty subtransaction. I added some comments
here for the same.
Apart from above, I also addressed the comments in [1] and fixed a bug that
parallel worker exits silently while the leader cannot detect that. In the
latest patch, the parallel apply worker will send a notify('X') message to
leader so that leader can detect the exit.
Here is the new version patch.
[1] https://www.postgresql.org/message-id/CAA4eK1KWgReYbpwEMh1H1ohHoYirv4Aa%3D6v13MutCF9NvHTc5A%40mail.gmail.com
Best regards,
Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, November 18, 2022 8:36 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> Here are review comments on v47-0001 and v47-0002 patches:
Thanks for the comments!
> When the parallel apply worker exited, I got the following server log.
> I think this log is not appropriate since the worker was not terminated by
> administrator command but exited by itself. Also, probably it should exit with
> exit code 0?
>
> FATAL: terminating logical replication worker due to administrator command
> LOG: background worker "logical replication parallel worker" (PID
> 3594918) exited with exit code 1
Changed to report a LOG and exited with code 0.
> ---
> /*
> * Stop the worker if there are enough workers in the pool or the leader
> * apply worker serialized part of the transaction data to a file due to
> * send timeout.
> */
> if (winfo->serialize_changes ||
> napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
>
> Why do we need to stop the worker if the leader serializes changes?
Because there might be partial sent message left in memory queue if send timeout.
And we need to either re-send the same message until success or detach from the memory
queue. To make the logic simple, the patch directly stop the worker in this case.
> ---
> + /*
> + * Release all session level locks that could be held in parallel apply
> + * mode.
> + */
> + LockReleaseAll(DEFAULT_LOCKMETHOD, true);
> +
>
> I think we call LockReleaseAll() at the process exit (in ProcKill()), but do we
> really need to do LockReleaseAll() here too?
If we don't release locks before ProcKill, we might break an Assert check at
the beginning of ProcKill which is used to ensure all the locks are released.
And It seems ProcKill doesn't release session level locks after the assert
check. So I think we'd better release them here.
> ---
>
> + elog(ERROR, "could not find replication state slot
> for replication"
> + "origin with OID %u which was acquired by
> %d", node, acquired_by);
>
> Let's not break the error log message in the middle so that the user can search
> the message by grep easily.
Changed.
> ---
> + {
> + {"max_parallel_apply_workers_per_subscription",
> + PGC_SIGHUP,
> + REPLICATION_SUBSCRIBERS,
> + gettext_noop("Maximum number of parallel
> apply workers per subscription."),
> + NULL,
> + },
> + &max_parallel_apply_workers_per_subscription,
> + 2, 0, MAX_BACKENDS,
> + NULL, NULL, NULL
> + },
> +
>
> I think we should use MAX_PARALLEL_WORKER_LIMIT as the max value instead.
> MAX_BACKENDS is too high.
Changed.
> ---
> + /*
> + * Indicates whether there are pending messages in the queue.
> The parallel
> + * apply worker will check it before starting to wait.
> + */
> + pg_atomic_uint32 pending_message_count;
>
> The "pending messages" sounds like individual logical replication messages
> such as LOGICAL_REP_MSG_INSERT. But IIUC what this value actually shows is
> how many streamed chunks are pending to process, right?
Yes, renamed this.
> ---
> When the parallel apply worker raises an error, I got the same error twice from
> the leader worker and parallel worker as follows. Can we suppress either one?
>
> 2022-11-17 17:30:23.490 JST [3814552] LOG: logical replication parallel apply
> worker for subscription "test_sub1" has started
> 2022-11-17 17:30:23.490 JST [3814552] ERROR: duplicate key value violates
> unique constraint "test1_c_idx"
> 2022-11-17 17:30:23.490 JST [3814552] DETAIL: Key (c)=(1) already exists.
> 2022-11-17 17:30:23.490 JST [3814552] CONTEXT: processing remote data for
> replication origin "pg_16390" during message type "INSERT" for replication
> target relatio n "public.test1" in transaction 731
> 2022-11-17 17:30:23.490 JST [3814550] ERROR: duplicate key value violates
> unique constraint "test1_c_idx"
> 2022-11-17 17:30:23.490 JST [3814550] DETAIL: Key (c)=(1) already exists.
> 2022-11-17 17:30:23.490 JST [3814550] CONTEXT: processing remote data for
> replication origin "pg_16390" during message type "INSERT" for replication
> target relatio n "public.test1" in transaction 731
> parallel apply worker
It seems similar to the behavior of parallel query which will report the same
error twice. But I agree it might be better for the leader to report something
different. So, I changed the error message reported by leader in the new
version patch.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, November 21, 2022 2:26 PM Peter Smith <smithpb2250@gmail.com> wrote:
> On Fri, Nov 18, 2022 at 6:03 PM Peter Smith <smithpb2250@gmail.com>
> wrote:
> >
> > Here are some review comments for v47-0001
> >
> > (This review is a WIP - I will post more comments for this patch next
> > week)
> >
>
> Here are the rest of my comments for v47-0001
Thanks for the comments!
> ======
>
> doc/src/sgml/monitoring.
>
> 1.
>
> @@ -1851,6 +1851,11 @@ postgres 27093 0.0 0.0 30096 2752 ?
> Ss 11:34 0:00 postgres: ser
> <entry>Waiting to acquire an advisory user lock.</entry>
> </row>
> <row>
> + <entry><literal>applytransaction</literal></entry>
> + <entry>Waiting to acquire acquire a lock on a remote transaction being
> + applied on the subscriber side.</entry>
> + </row>
> + <row>
>
> 1a.
> Typo "acquire acquire"
Fixed.
> ~
>
> 1b.
> Maybe "on the subscriber side" does not mean much without any context.
> Maybe better to word it as below.
>
> SUGGESTION
> Waiting to acquire a lock on a remote transaction being applied by a logical
> replication subscriber.
Changed.
> ======
>
> doc/src/sgml/system-views.sgml
>
> 2.
>
> @@ -1361,8 +1361,9 @@
> <literal>virtualxid</literal>,
> <literal>spectoken</literal>,
> <literal>object</literal>,
> - <literal>userlock</literal>, or
> - <literal>advisory</literal>.
> + <literal>userlock</literal>,
> + <literal>advisory</literal> or
> + <literal>applytransaction</literal>.
>
> This change removed the Oxford comma that was there before. I assume it was
> unintended.
Changed.
> ======
>
> .../replication/logical/applyparallelworker.c
>
> 3. globals
>
> The parallel_apply_XXX functions were all shortened to pa_XXX.
>
> I wondered if the same simplification should be done also to the global
> statics...
>
> e.g.
> ParallelApplyWorkersHash -> PAWorkerHash ParallelApplyWorkersList ->
> PAWorkerList ParallelApplyMessagePending -> PAMessagePending etc...
I personally feel these names looks fine to me.
> ~~~
>
> 4. pa_get_free_worker
>
> + foreach(lc, active_workers)
> + {
> + ParallelApplyWorkerInfo *winfo = NULL;
> +
> + winfo = (ParallelApplyWorkerInfo *) lfirst(lc);
>
> No need to assign NULL because the next line just overwrites that anyhow.
Changed.
> ~
>
> 5.
>
> + /*
> + * Try to free the worker first, because we don't wait for the rollback
> + * command to finish so the worker may not be freed at the end of the
> + * transaction.
> + */
> + if (pa_free_worker(winfo, winfo->shared->xid)) continue;
> +
> + if (!winfo->in_use)
> + return winfo;
>
> Shouldn't the (!winfo->in_use) check be done first as well -- e.g. why are we
> trying to free a worker which is maybe not even in_use?
>
> SUGGESTION (this will need some comment to explain what it is doing) if
> (!winfo->in_use || !pa_free_worker(winfo, winfo->shared->xid) &&
> !winfo->in_use)
> return winfo;
Since the pa_free_worker will check the in_use flag as well and
the current style looks clean to me. So I didn't change this.
But it seems we need to first call pa_free_worker for every worker and then
choose a free a free, otherwise a stopped worker info(shared memory or ...)
might be left for a long time. I will think about this and try to fix it in
next version.
> ~~~
>
> 6. pa_free_worker
>
> +/*
> + * Remove the parallel apply worker entry from the hash table. Stop the
> +work if
> + * there are enough workers in the pool.
> + *
>
> Typo? "work" -> "worker"
>
Fixed.
>
> 7.
>
> + /* Are there enough workers in the pool? */ if (napplyworkers >
> + (max_parallel_apply_workers_per_subscription / 2)) {
>
> IMO that comment should be something more like "Don't detach/stop the
> worker unless..."
>
Improved.
>
> 8. pa_send_data
>
> + /*
> + * Retry after 1s to reduce the cost of getting the system time and
> + * calculating the time difference.
> + */
> + (void) WaitLatch(MyLatch,
> + WL_LATCH_SET | WL_TIMEOUT | WL_EXIT_ON_PM_DEATH, 1000L,
> + WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE);
>
> 8a.
> I am not sure you need to explain the reason in the comment. Just saying "Wait
> before retrying." seems sufficient to me.
Changed.
> ~
>
> 8b.
> Instead of the hardwired "1s" in the comment, and 1000L in the code, maybe
> better to just have another constant.
>
> SUGGESTION
> #define SHM_SEND_RETRY_INTERVAL_MS 1000
> #define SHM_SEND_TIMEOUT_MS 10000
Changed.
> ~
>
> 9.
>
> + if (startTime == 0)
> + startTime = GetCurrentTimestamp();
> + else if (TimestampDifferenceExceeds(startTime, GetCurrentTimestamp(),
>
> IMO the initial startTime should be at top of the function otherwise the timeout
> calculation seems wrong.
Setting startTime at beginning will bring unnecessary cost if we don't need to retry.
And start counting from the first failure looks fine to me.
> ======
>
> src/backend/replication/logical/worker.c
>
> 10. handle_streamed_transaction
>
> + * In streaming case (receiving a block of streamed transaction), for
> + * SUBSTREAM_ON mode, simply redirect it to a file for the proper
> + toplevel
> + * transaction, and for SUBSTREAM_PARALLEL mode, send the changes to
> + parallel
> + * apply workers (LOGICAL_REP_MSG_RELATION or LOGICAL_REP_MSG_TYPE
> + changes
> + * will be applied by both leader apply worker and parallel apply workers).
>
> I'm not sure this function comment should be referring to SUBSTREAM_ON
> and SUBSTREAM_PARALLEL because the function body does not use those
> anywhere in the logic.
Improved.
> ~~~
>
> 11. apply_handle_stream_start
>
> + /*
> + * Increment the number of messages waiting to be processed by
> + * parallel apply worker.
> + */
> + pg_atomic_add_fetch_u32(&(winfo->shared->pending_message_count), 1);
> +
>
> The &() parens are not needed. Just write
> &winfo->shared->pending_message_count.
>
> Also, search/replace others like this -- there are a few of them.
Changed.
> ~~~
>
> 12. apply_handle_stream_stop
>
> + if (!abort_toplevel_transaction &&
> + pg_atomic_sub_fetch_u32(&(MyParallelShared->pending_message_count),
> 1)
> + == 0) { pa_lock_stream(MyParallelShared->xid, AccessShareLock);
> + pa_unlock_stream(MyParallelShared->xid, AccessShareLock); }
>
> That lock/unlock seems like it is done just as a way of testing/waiting for an
> exclusive lock held on the xid to be released.
> But the code is too tricky -- IMO it needs a big comment saying how this trick
> works, or maybe better to have a wrapper function for this for clarity. e.g.
> pa_wait_nolock_stream(xid); (or some better name)
I think the comments atop applyparallelworker.c explained the usage of
stream/transaction lock.
```
...
* In order for lmgr to detect this, we have LA acquire a session lock on the
* remote transaction (by pa_lock_stream()) and have PA wait on the lock before
* trying to receive messages. In other words, LA acquires the lock before
* sending STREAM_STOP and releases it if already acquired before sending
* STREAM_START, STREAM_ABORT(for toplevel transaction), STREAM_PREPARE and
* STREAM_COMMIT. For PA, it always needs to acquire the lock after processing
* STREAM_STOP and then release immediately after acquiring it. That way, when
* PA is waiting for LA, we can have a wait-edge from PA to LA in lmgr, which
* will make a deadlock in lmgr like:
...
```
> ~~~
>
> 13. apply_handle_stream_abort
>
> + if (abort_toplevel_transaction)
> + {
> + (void) pa_free_worker(winfo, xid);
> + }
>
> Unnecessary { }
Removed.
> ~~~
>
> 14. maybe_reread_subscription
>
> @@ -3083,8 +3563,9 @@ maybe_reread_subscription(void)
> if (!newsub)
> {
> ereport(LOG,
> - (errmsg("logical replication apply worker for subscription \"%s\" will "
> - "stop because the subscription was removed",
> + /* translator: first %s is the name of logical replication worker */
> + (errmsg("%s for subscription \"%s\" will stop because the "
> + "subscription was removed", get_worker_name(),
> MySubscription->name)));
>
> proc_exit(0);
> @@ -3094,8 +3575,9 @@ maybe_reread_subscription(void)
> if (!newsub->enabled)
> {
> ereport(LOG,
> - (errmsg("logical replication apply worker for subscription \"%s\" will "
> - "stop because the subscription was disabled",
> + /* translator: first %s is the name of logical replication worker */
> + (errmsg("%s for subscription \"%s\" will stop because the "
> + "subscription was disabled", get_worker_name(),
> MySubscription->name)));
>
> IMO better to avoid splitting the string literals over multiple line like this.
>
> Please check the rest of the patch too -- there may be many more just like this.
Changed.
> ~~~
>
> 15. ApplyWorkerMain
>
> @@ -3726,7 +4236,7 @@ ApplyWorkerMain(Datum main_arg)
> }
> else
> {
> - /* This is main apply worker */
> + /* This is leader apply worker */
> RepOriginId originid;
> "This is leader" -> "This is the leader"
Changed.
> ======
>
> src/bin/psql/describe.c
>
> 16. describeSubscriptions
>
> + if (pset.sversion >= 160000)
> + appendPQExpBuffer(&buf,
> + ", (CASE substream\n"
> + " WHEN 'f' THEN 'off'\n"
> + " WHEN 't' THEN 'on'\n"
> + " WHEN 'p' THEN 'parallel'\n"
> + " END) AS \"%s\"\n",
> + gettext_noop("Streaming"));
> + else
> + appendPQExpBuffer(&buf,
> + ", substream AS \"%s\"\n",
> + gettext_noop("Streaming"));
>
> I'm not sure it is an improvement to change the output "t/f/p" to
> "on/off/parallel"
>
> IMO "t/f/parallel" would be better. Then the t/f is consistent with
> - how it used to display, and
> - all the other boolean fields
I think the current style is consistent with the " Synchronous commit" parameter which
also shows "on/off/remote_apply/...", so didn't change this.
Name | ... | Synchronous commit
------+-----+-------------------
sub | ... | on
> ======
>
> src/include/replication/worker_internal.h
>
> 17. ParallelTransState
>
> +/*
> + * State of the transaction in parallel apply worker.
> + *
> + * These enum values are ordered by the order of transaction state
> +changes in
> + * parallel apply worker.
> + */
> +typedef enum ParallelTransState
>
> "ordered by the order" ??
>
> SUGGESTION
> The enum values must have the same order as the transaction state transitions.
Changed.
> ======
>
> src/include/storage/lock.h
>
> 18.
>
> @@ -149,10 +149,12 @@ typedef enum LockTagType
> LOCKTAG_SPECULATIVE_TOKEN, /* speculative insertion Xid and token */
> LOCKTAG_OBJECT, /* non-relation database object */
> LOCKTAG_USERLOCK, /* reserved for old contrib/userlock code */
> - LOCKTAG_ADVISORY /* advisory user locks */
> + LOCKTAG_ADVISORY, /* advisory user locks */
> LOCKTAG_APPLY_TRANSACTION
> + /* transaction being applied on the subscriber
> + * side */
> } LockTagType;
>
> -#define LOCKTAG_LAST_TYPE LOCKTAG_ADVISORY
> +#define LOCKTAG_LAST_TYPE LOCKTAG_APPLY_TRANSACTION
>
> extern PGDLLIMPORT const char *const LockTagTypeNames[];
>
> @@ -278,6 +280,17 @@ typedef struct LOCKTAG
> (locktag).locktag_type = LOCKTAG_ADVISORY, \
> (locktag).locktag_lockmethodid = USER_LOCKMETHOD)
>
> +/*
> + * ID info for a remote transaction on the subscriber side is:
> + * DB OID + SUBSCRIPTION OID + TRANSACTION ID + OBJID */ #define
> +SET_LOCKTAG_APPLY_TRANSACTION(locktag,dboid,suboid,xid,objid) \
> + ((locktag).locktag_field1 = (dboid), \
> + (locktag).locktag_field2 = (suboid), \
> + (locktag).locktag_field3 = (xid), \
> + (locktag).locktag_field4 = (objid), \
> + (locktag).locktag_type = LOCKTAG_APPLY_TRANSACTION, \
> +(locktag).locktag_lockmethodid = DEFAULT_LOCKMETHOD)
>
> Maybe "on the subscriber side" (2 places above) has no meaning here because
> there is no context this is talking about logical replication.
> Maybe those comments need to say something more like "on a logical
> replication subscriber"
>
Changed.
I also addressed all the comments from [1]
[1] https://www.postgresql.org/message-id/CAHut%2BPs7TzqqDnuH8r_ct1W_zSBCnuo3wodMt4Y8_Gw7rSRAaw%40mail.gmail.com
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, November 21, 2022 8:34 PMhouzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
>
> On Saturday, November 19, 2022 6:49 PM Amit Kapila
> <amit.kapila16@gmail.com> wrote:
> >
> > On Fri, Nov 18, 2022 at 7:56 AM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> > >
> > > On Wed, Nov 16, 2022 at 1:50 PM houzj.fnst@fujitsu.com
> > > <houzj.fnst@fujitsu.com> wrote:
> > > >
> > > > On Tuesday, November 15, 2022 7:58 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > > >
> > > > I noticed that I didn't add CHECK_FOR_INTERRUPTS while retrying
> > > > send
> > message.
> > > > So, attach the new version which adds that. Also attach the 0004
> > > > patch that restarts logical replication with temporarily disabling
> > > > the parallel apply if failed to apply a transaction in parallel apply worker.
> > > >
> > >
> > > Few comments on v48-0001
>
> Thanks for the comments !
>
> > > ======================
> > >
> >
> > I have made quite a few changes in the comments, added some new
> > comments, and made other cosmetic changes in the attached patch. The is
> atop v48-0001*.
> > If these look okay to you, please include them in the next version.
> > Apart from these, I have a few more comments on
> > v48-0001*
>
> Thanks, I have checked and merge them.
>
> > 1.
> > +static bool
> > +pa_can_start(TransactionId xid)
> > +{
> > + if (!TransactionIdIsValid(xid))
> > + return false;
> >
> > The caller (see caller of pa_start_worker) already has a check that
> > xid passed here is valid, so I think this should be an Assert unless I
> > am missing something in which case it is better to add a comment here.
>
> Changed to an Assert().
>
> > 2. Will it be better to rename pa_start_worker() as
> > pa_allocate_worker() because it sometimes gets the worker from the
> > pool and also allocate the hash entry for worker info? That will even
> > match the corresponding pa_free_worker().
>
> Agreed and changed.
>
> > 3.
> > +pa_start_subtrans(TransactionId current_xid, TransactionId top_xid)
> > {
> > ...
> > +
> > + oldctx = MemoryContextSwitchTo(ApplyContext);
> > + subxactlist = lappend_xid(subxactlist, current_xid);
> > + MemoryContextSwitchTo(oldctx);
> > ...
> >
> > Why do we need to allocate this list in a permanent context? IIUC, we
> > need to use this to maintain subxacts so that it can be later used to
> > find the given subxact at the time of rollback to savepoint in the
> > current in-progress transaction, so why do we need it beyond the
> > transaction being applied? If there is a reason for the same, it would
> > be better to add some comments for the same.
>
> I think you are right, I changed to use TopTransactionContext here.
>
> > 4.
> > +pa_stream_abort(LogicalRepStreamAbortData *abort_data)
> > {
> > ...
> > +
> > + for (i = list_length(subxactlist) - 1; i >= 0; i--) { TransactionId
> > + xid_tmp = lfirst_xid(list_nth_cell(subxactlist, i));
> > +
> > + if (xid_tmp == subxid)
> > + {
> > + found = true;
> > + break;
> > + }
> > + }
> > +
> > + if (found)
> > + {
> > + RollbackToSavepoint(spname);
> > + CommitTransactionCommand();
> > + subxactlist = list_truncate(subxactlist, i + 1); }
> >
> > I was thinking whether we can have an Assert(false) for the not found
> > case but it seems if all the changes of a subxact have been skipped
> > then probably subxid corresponding to "rollback to savepoint" won't be
> > found in subxactlist and we don't need to do anything for it. If that
> > is the case, then probably adding a comment for it would be a good
> > idea, otherwise, we can probably have
> > Assert(false) in the else case.
>
> Yes, we might not find the xid for an empty subtransaction. I added some
> comments here for the same.
>
> Apart from above, I also addressed the comments in [1] and fixed a bug that
> parallel worker exits silently while the leader cannot detect that. In the latest
> patch, the parallel apply worker will send a notify('X') message to leader so that
> leader can detect the exit.
>
> Here is the new version patch.
I noticed that I missed a header file causing CFbot to complain.
Attach a new version patch set which fix that.
Best regards,
Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Thanks for addressing my review comments on v47-0001.
Here are my review comments for v49-0001.
======
src/backend/replication/logical/applyparallelworker.c
1. GENERAL - NULL checks
There is inconsistent NULL checking in the patch.
Sometimes it is like (!winfo)
Sometimes explicit NULL checks like (winfo->mq_handle != NULL)
(That is just one example -- there are differences in many places)
It would be better to use a consistent style everywhere.
~
2. GENERAL - Error message worker name
2a.
In worker.c all the messages are now "logical replication apply
worker" or "logical replication parallel apply worker" etc, but in the
applyparallel.c sometimes the "logical replication" part is missing.
IMO all the messages in this patch should be consistently worded.
I've reported some of them in the following comment below, but please
search the whole patch for any I might have missed.
2b.
Consider if maybe all of these ought to be calling get_worker_name()
which is currently static in worker.c. Doing this means any future
changes to get_worker_name won't cause more inconsistencies.
~~~
3. File header comment
+ * IDENTIFICATION src/backend/replication/logical/applyparallelworker.c
The word "IDENTIFICATION" should be on a separate line (for
consistency with every other PG source file)
~
4.
+ * In order for lmgr to detect this, we have LA acquire a session lock on the
+ * remote transaction (by pa_lock_stream()) and have PA wait on the lock before
+ * trying to receive messages. In other words, LA acquires the lock before
+ * sending STREAM_STOP and releases it if already acquired before sending
+ * STREAM_START, STREAM_ABORT(for toplevel transaction), STREAM_PREPARE and
+ * STREAM_COMMIT. For PA, it always needs to acquire the lock after processing
+ * STREAM_STOP and STREAM_ABORT(for subtransaction) and then release
+ * immediately after acquiring it. That way, when PA is waiting for LA, we can
+ * have a wait-edge from PA to LA in lmgr, which will make a deadlock in lmgr
+ * like:
Missing spaces before '(' deliberate?
~~~
5. globals
+/*
+ * Is there a message sent by parallel apply worker which the leader apply
+ * worker need to receive?
+ */
+volatile sig_atomic_t ParallelApplyMessagePending = false;
SUGGESTION
Is there a message sent by a parallel apply worker that the leader
apply worker needs to receive?
~~~
6. pa_get_available_worker
+/*
+ * get an available parallel apply worker from the worker pool.
+ */
+static ParallelApplyWorkerInfo *
+pa_get_available_worker(void)
Uppercase comment
~
7.
+ /*
+ * We first try to free the worker to improve our chances of getting
+ * the worker. Normally, we free the worker after ensuring that the
+ * transaction is committed by parallel worker but for rollbacks, we
+ * don't wait for the transaction to finish so can't free the worker
+ * information immediately.
+ */
7a.
"We first try to free the worker to improve our chances of getting the worker."
SUGGESTION
We first try to free the worker to improve our chances of finding one
that is not in use.
~
7b.
"parallel worker" -> "the parallel worker"
~~~
8. pa_allocate_worker
+ /* Try to get a free parallel apply worker. */
+ winfo = pa_get_available_worker();
+
SUGGESTION
First, try to get a parallel apply worker from the pool.
~~~
9. pa_free_worker
+ * This removes the parallel apply worker entry from the hash table so that it
+ * can't be used. This either stops the worker and free the corresponding info,
+ * if there are enough workers in the pool or just marks it available for
+ * reuse.
BEFORE
This either stops the worker and free the corresponding info, if there
are enough workers in the pool or just marks it available for reuse.
SUGGESTION
If there are enough workers in the pool it stops the worker and frees
the corresponding info, otherwise it just marks the worker as
available for reuse.
~
10.
+ /* Free the corresponding info if the worker exited cleanly. */
+ if (winfo->error_mq_handle == NULL)
+ {
+ pa_free_worker_info(winfo);
+ return true;
+ }
Is it correct that this bypasses the removal from the hash table?
~
11.
+
+ /* Worker is already available for reuse. */
+ if (!winfo->in_use)
+ return false;
Should this quick-exit check for in_use come first?
~~
12. HandleParallelApplyMessage
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("parallel apply worker exited abnormally"),
+ errcontext("%s", edata.context)));
Maybe "parallel apply worker" -> "logical replication parallel apply
worker" (for consistency with the other error messages)
~
13.
+ default:
+ elog(ERROR, "unrecognized message type received from parallel apply
worker: %c (message length %d bytes)",
+ msgtype, msg->len);
+ }
ditto #12 above.
~
14.
+ case 'X': /* Terminate, indicating clean exit. */
+ {
+ shm_mq_detach(winfo->error_mq_handle);
+ winfo->error_mq_handle = NULL;
+ break;
+ }
+ default:
No need for the { } here.
~~~
15. HandleParallelApplyMessage
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("lost connection to the parallel apply worker")));
+ }
"parallel apply worker" -> "logical replication parallel apply worker"
~~~
16. pa_init_and_launch_worker
+ /* Setup shared memory. */
+ if (!pa_setup_dsm(winfo))
+ {
+ MemoryContextSwitchTo(oldcontext);
+ pfree(winfo);
+ return NULL;
+ }
Wouldn't it be better to do the pfree before switching back to the oldcontext?
~~~
17. pa_send_data
+ /* Wait before retrying. */
+ rc = WaitLatch(MyLatch,
+ WL_LATCH_SET | WL_TIMEOUT | WL_EXIT_ON_PM_DEATH,
+ SHM_SEND_RETRY_INTERVAL_MS,
+ WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE);
+
+ if (rc & WL_LATCH_SET)
+ {
+ ResetLatch(MyLatch);
+ CHECK_FOR_INTERRUPTS();
+ }
Instead of CHECK_FOR_INTERRUPTS, should this be calling your new
function ProcessParallelApplyInterrupts?
~
18.
+ if (startTime == 0)
+ startTime = GetCurrentTimestamp();
+ else if (TimestampDifferenceExceeds(startTime, GetCurrentTimestamp(),
+ SHM_SEND_TIMEOUT_MS))
+ ereport(ERROR,
+ (errcode(ERRCODE_CONNECTION_FAILURE),
+ errmsg("terminating logical replication parallel apply worker due to
timeout")));
I'd previously commented that the timeout calculation seemed wrong.
Hou-san replied [1,#9] "start counting from the first failure looks
fine to me." but I am not so sure - e.g. If the timeout is 10s then I
expect it to fail ~10s after the function is called, not 11s after. I
know it's pedantic, but where's the harm in making the calculation
right instead of just nearly right?
IMO probably an easy fix for this is like:
#define SHM_SEND_RETRY_INTERVAL_MS 1000
#define SHM_SEND_TIMEOUT_MS (10000 - SHM_SEND_RETRY_INTERVAL_MS)
~~~
19. pa_wait_for_xact_state
+ /* An interrupt may have occurred while we were waiting. */
+ CHECK_FOR_INTERRUPTS();
Instead of CHECK_FOR_INTERRUPTS, should this be calling your new
function ProcessParallelApplyInterrupts?
~~~
20. pa_savepoint_name
+static void
+pa_savepoint_name(Oid suboid, TransactionId xid, char *spname,
+ Size szsp)
Unnecessary wrapping?
======
src/backend/replication/logical/origin.c
21. replorigin_session_setup
+ * However, we do allow multiple processes to point to the same origin slot
+ * if requested by the caller by passing PID of the process that has already
+ * acquired it. This is to allow using the same origin by multiple parallel
+ * apply processes the provided they maintain commit order, for example, by
+ * allowing only one process to commit at a time.
21a.
I thought the comment should mention this is optional and the special
value acquired_by=0 means don't do this.
~
21b.
"the provided they" ?? typo?
======
src/backend/replication/logical/tablesync.c
22. process_syncing_tables
process_syncing_tables(XLogRecPtr current_lsn)
{
+ /*
+ * Skip for parallel apply workers as they don't operate on tables that
+ * are not in ready state. See pa_can_start() and
+ * should_apply_changes_for_rel().
+ */
+ if (am_parallel_apply_worker())
+ return;
SUGGESTION (remove the double negative)
Skip for parallel apply workers because they only operate on tables
that are in a READY state. See pa_can_start() and
should_apply_changes_for_rel().
======
src/backend/replication/logical/worker.c
23. apply_handle_stream_stop
Previously I suggested that this lock/unlock seems too tricky and
needed a comment. The reply [1,#12] was that this is already described
atop parallelapplyworker.c. OK, but in that case maybe here the
comment can just refer to that explanation:
SUGGESTION
Refer to the comments atop applyparallelworker.c for what this lock
and immediate unlock is doing.
~~~
24. apply_handle_stream_abort
+ if (pg_atomic_sub_fetch_u32(&(MyParallelShared->pending_stream_count),
1) == 0)
+ {
+ pa_lock_stream(MyParallelShared->xid, AccessShareLock);
+ pa_unlock_stream(MyParallelShared->xid, AccessShareLock);
+ }
ditto comment #23
~~~
25. apply_worker_clean_exit
+void
+apply_worker_clean_exit(void)
+{
+ /* Notify the leader apply worker that we have exited cleanly. */
+ if (am_parallel_apply_worker())
+ pq_putmessage('X', NULL, 0);
+
+ proc_exit(0);
+}
Somehow it doesn't seem right that the PA worker sending 'X' is here
in worker.c, while the LA worker receipt of this 'X' is in the other
applyparallelworker.c module. Maybe that other function
HandleParallelApplyMessage should also be here in worker.c?
======
src/backend/utils/misc/guc_tables.c
26.
@@ -2957,6 +2957,18 @@ struct config_int ConfigureNamesInt[] =
NULL,
},
&max_sync_workers_per_subscription,
+ 2, 0, MAX_PARALLEL_WORKER_LIMIT,
+ NULL, NULL, NULL
+ },
+
+ {
+ {"max_parallel_apply_workers_per_subscription",
+ PGC_SIGHUP,
+ REPLICATION_SUBSCRIBERS,
+ gettext_noop("Maximum number of parallel apply workers per subscription."),
+ NULL,
+ },
+ &max_parallel_apply_workers_per_subscription,
2, 0, MAX_BACKENDS,
NULL, NULL, NULL
Is this correct? Did you mean to change
max_sync_workers_per_subscription, My 1st impression is that there has
been some mixup with the MAX_PARALLEL_WORKER_LIMIT and MAX_BACKENDS or
that this change was accidentally made to the wrong GUC.
======
src/include/replication/worker_internal.h
27. ParallelApplyWorkerShared
+ /*
+ * Indicates whether there are pending streaming blocks in the queue. The
+ * parallel apply worker will check it before starting to wait.
+ */
+ pg_atomic_uint32 pending_stream_count;
A better name might be 'n_pending_stream_blocks'.
~
28. function names
extern void logicalrep_worker_stop(Oid subid, Oid relid);
+extern void logicalrep_parallel_apply_worker_stop(int slot_no, uint16
generation);
extern void logicalrep_worker_wakeup(Oid subid, Oid relid);
extern void logicalrep_worker_wakeup_ptr(LogicalRepWorker *worker);
extern int logicalrep_sync_worker_count(Oid subid);
+extern int logicalrep_parallel_apply_worker_count(Oid subid);
Would it be better to call those new functions using similar shorter
names as done elsewhere?
logicalrep_parallel_apply_worker_stop -> logicalrep_pa_worker_stop
logicalrep_parallel_apply_worker_count -> logicalrep_pa_worker_count
------
[1] Hou-san's reply to my review v47-0001.
https://www.postgresql.org/message-id/OS0PR01MB571680391393F3CB63469F3E940A9%40OS0PR01MB5716.jpnprd01.prod.outlook.com
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tues, November 22, 2022 13:20 PM Peter Smith <smithpb2250@gmail.com> wrote:
> Thanks for addressing my review comments on v47-0001.
>
> Here are my review comments for v49-0001.
Thanks for your comments.
> ======
>
> src/backend/replication/logical/applyparallelworker.c
>
> 1. GENERAL - NULL checks
>
> There is inconsistent NULL checking in the patch.
>
> Sometimes it is like (!winfo)
> Sometimes explicit NULL checks like (winfo->mq_handle != NULL)
>
> (That is just one example -- there are differences in many places)
>
> It would be better to use a consistent style everywhere.
Changed.
> ~
>
> 2. GENERAL - Error message worker name
>
> 2a.
> In worker.c all the messages are now "logical replication apply
> worker" or "logical replication parallel apply worker" etc, but in the
> applyparallel.c sometimes the "logical replication" part is missing.
> IMO all the messages in this patch should be consistently worded.
>
> I've reported some of them in the following comment below, but please
> search the whole patch for any I might have missed.
Rename LA and PA to the following styles:
```
LA -> logical replication apply worker
PA -> logical replication parallel apply worker ```
> 2b.
> Consider if maybe all of these ought to be calling get_worker_name()
> which is currently static in worker.c. Doing this means any future
> changes to get_worker_name won't cause more inconsistencies.
The most error message in applyparallelxx.c can only use "xx parallel worker",
so I think it's fine not to call get_worker_name
> ~~~
>
> 3. File header comment
>
> + * IDENTIFICATION
> + src/backend/replication/logical/applyparallelworker.c
>
> The word "IDENTIFICATION" should be on a separate line (for
> consistency with every other PG source file)
Fixed.
> ~
>
> 4.
>
> + * In order for lmgr to detect this, we have LA acquire a session
> + lock on the
> + * remote transaction (by pa_lock_stream()) and have PA wait on the
> + lock
> before
> + * trying to receive messages. In other words, LA acquires the lock
> + before
> + * sending STREAM_STOP and releases it if already acquired before
> + sending
> + * STREAM_START, STREAM_ABORT(for toplevel transaction),
> STREAM_PREPARE and
> + * STREAM_COMMIT. For PA, it always needs to acquire the lock after
> processing
> + * STREAM_STOP and STREAM_ABORT(for subtransaction) and then release
> + * immediately after acquiring it. That way, when PA is waiting for
> + LA, we can
> + * have a wait-edge from PA to LA in lmgr, which will make a deadlock
> + in lmgr
> + * like:
>
> Missing spaces before '(' deliberate?
Added.
> ~~~
>
> 5. globals
>
> +/*
> + * Is there a message sent by parallel apply worker which the leader
> +apply
> + * worker need to receive?
> + */
> +volatile sig_atomic_t ParallelApplyMessagePending = false;
>
> SUGGESTION
> Is there a message sent by a parallel apply worker that the leader
> apply worker needs to receive?
Changed.
> ~~~
>
> 6. pa_get_available_worker
>
> +/*
> + * get an available parallel apply worker from the worker pool.
> + */
> +static ParallelApplyWorkerInfo *
> +pa_get_available_worker(void)
>
> Uppercase comment
Changed.
> ~
>
> 7.
>
> + /*
> + * We first try to free the worker to improve our chances of getting
> + * the worker. Normally, we free the worker after ensuring that the
> + * transaction is committed by parallel worker but for rollbacks, we
> + * don't wait for the transaction to finish so can't free the worker
> + * information immediately.
> + */
>
> 7a.
> "We first try to free the worker to improve our chances of getting the worker."
>
> SUGGESTION
> We first try to free the worker to improve our chances of finding one
> that is not in use.
>
> ~
>
> 7b.
> "parallel worker" -> "the parallel worker"
Changed.
> ~~~
>
> 8. pa_allocate_worker
>
> + /* Try to get a free parallel apply worker. */ winfo =
> + pa_get_available_worker();
> +
>
> SUGGESTION
> First, try to get a parallel apply worker from the pool.
Changed.
> ~~~
>
> 9. pa_free_worker
>
> + * This removes the parallel apply worker entry from the hash table
> + so that it
> + * can't be used. This either stops the worker and free the
> + corresponding info,
> + * if there are enough workers in the pool or just marks it available
> + for
> + * reuse.
>
> BEFORE
> This either stops the worker and free the corresponding info, if there
> are enough workers in the pool or just marks it available for reuse.
>
> SUGGESTION
> If there are enough workers in the pool it stops the worker and frees
> the corresponding info, otherwise it just marks the worker as
> available for reuse.
Changed.
> ~
>
> 10.
>
> + /* Free the corresponding info if the worker exited cleanly. */ if
> + (winfo->error_mq_handle == NULL) { pa_free_worker_info(winfo);
> + return true; }
>
> Is it correct that this bypasses the removal from the hash table?
I rethink about this, it seems unnecessary to free the information here as
we don't expect the worker to stop unless the leader as them to stop.
So, I temporarily remove this and will think about this in next version.
> ~
>
> 14.
>
> + case 'X': /* Terminate, indicating clean exit. */ {
> + shm_mq_detach(winfo->error_mq_handle);
> + winfo->error_mq_handle = NULL;
> + break;
> + }
> + default:
>
>
> No need for the { } here.
Changed.
> ~~~
>
> 16. pa_init_and_launch_worker
>
> + /* Setup shared memory. */
> + if (!pa_setup_dsm(winfo))
> + {
> + MemoryContextSwitchTo(oldcontext);
> + pfree(winfo);
> + return NULL;
> + }
>
>
> Wouldn't it be better to do the pfree before switching back to the oldcontext?
I think either style seems fine.
> ~~~
>
> 17. pa_send_data
>
> + /* Wait before retrying. */
> + rc = WaitLatch(MyLatch,
> + WL_LATCH_SET | WL_TIMEOUT | WL_EXIT_ON_PM_DEATH,
> + SHM_SEND_RETRY_INTERVAL_MS,
> + WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE);
> +
> + if (rc & WL_LATCH_SET)
> + {
> + ResetLatch(MyLatch);
> + CHECK_FOR_INTERRUPTS();
> + }
>
>
> Instead of CHECK_FOR_INTERRUPTS, should this be calling your new
> function ProcessParallelApplyInterrupts?
I thought the ProcessParallelApplyInterrupts is intended to be invoked only in main
loop(LogicalParallelApplyLoop) to make the parallel apply worker exit cleanly.
> ~
>
> 18.
>
> + if (startTime == 0)
> + startTime = GetCurrentTimestamp();
> + else if (TimestampDifferenceExceeds(startTime,
> + GetCurrentTimestamp(),
> + SHM_SEND_TIMEOUT_MS))
> + ereport(ERROR,
> + (errcode(ERRCODE_CONNECTION_FAILURE),
> + errmsg("terminating logical replication parallel apply worker due to
> timeout")));
>
>
> I'd previously commented that the timeout calculation seemed wrong.
> Hou-san replied [1,#9] "start counting from the first failure looks
> fine to me." but I am not so sure - e.g. If the timeout is 10s then I
> expect it to fail ~10s after the function is called, not 11s after. I
> know it's pedantic, but where's the harm in making the calculation
> right instead of just nearly right?
>
> IMO probably an easy fix for this is like:
>
> #define SHM_SEND_RETRY_INTERVAL_MS 1000 #define SHM_SEND_TIMEOUT_MS
> (10000 - SHM_SEND_RETRY_INTERVAL_MS)
OK, I moved the place of setting startTime before the WaitLatch.
> ~~~
>
> 20. pa_savepoint_name
>
> +static void
> +pa_savepoint_name(Oid suboid, TransactionId xid, char *spname,
> + Size szsp)
>
> Unnecessary wrapping?
Changed.
> ======
>
> src/backend/replication/logical/origin.c
>
> 21. replorigin_session_setup
>
> + * However, we do allow multiple processes to point to the same
> + origin slot
> + * if requested by the caller by passing PID of the process that has
> + already
> + * acquired it. This is to allow using the same origin by multiple
> + parallel
> + * apply processes the provided they maintain commit order, for
> + example, by
> + * allowing only one process to commit at a time.
>
> 21a.
> I thought the comment should mention this is optional and the special
> value acquired_by=0 means don't do this.
Added.
> ~
>
> 21b.
> "the provided they" ?? typo?
Changed.
> ======
>
> src/backend/replication/logical/tablesync.c
>
> 22. process_syncing_tables
>
> process_syncing_tables(XLogRecPtr current_lsn) {
> + /*
> + * Skip for parallel apply workers as they don't operate on tables
> + that
> + * are not in ready state. See pa_can_start() and
> + * should_apply_changes_for_rel().
> + */
> + if (am_parallel_apply_worker())
> + return;
>
> SUGGESTION (remove the double negative) Skip for parallel apply
> workers because they only operate on tables that are in a READY state.
> See pa_can_start() and should_apply_changes_for_rel().
Changed.
> ======
>
> src/backend/replication/logical/worker.c
>
> 23. apply_handle_stream_stop
>
>
> Previously I suggested that this lock/unlock seems too tricky and
> needed a comment. The reply [1,#12] was that this is already described
> atop parallelapplyworker.c. OK, but in that case maybe here the
> comment can just refer to that explanation:
>
> SUGGESTION
> Refer to the comments atop applyparallelworker.c for what this lock
> and immediate unlock is doing.
>
> ~~~
>
> 24. apply_handle_stream_abort
>
> + if
> + (pg_atomic_sub_fetch_u32(&(MyParallelShared->pending_stream_count),
> 1) == 0)
> + {
> + pa_lock_stream(MyParallelShared->xid, AccessShareLock);
> + pa_unlock_stream(MyParallelShared->xid, AccessShareLock); }
>
> ditto comment #23
I feel the place atop the definition of pa_lock_xxx function is a better place to
put the comments, so added there. User can check it when reading the lock
functions.
> ~~~
>
> 25. apply_worker_clean_exit
>
> +void
> +apply_worker_clean_exit(void)
> +{
> + /* Notify the leader apply worker that we have exited cleanly. */
> +if (am_parallel_apply_worker()) pq_putmessage('X', NULL, 0);
> +
> + proc_exit(0);
> +}
>
> Somehow it doesn't seem right that the PA worker sending 'X' is here
> in worker.c, while the LA worker receipt of this 'X' is in the other
> applyparallelworker.c module. Maybe that other function
> HandleParallelApplyMessage should also be here in worker.c?
I thought the function apply_worker_clean_exit is widely used in worker.c and
is a common function for both leader/parallel apply workers, so I put it in
worker.c. But HandleParallelApplyMessage is a function only for parallel
worker, so it would be better to put it in applyparallelworker.c.
> ======
>
> src/backend/utils/misc/guc_tables.c
>
> 26.
>
> @@ -2957,6 +2957,18 @@ struct config_int ConfigureNamesInt[] =
> NULL,
> },
> &max_sync_workers_per_subscription,
> + 2, 0, MAX_PARALLEL_WORKER_LIMIT,
> + NULL, NULL, NULL
> + },
> +
> + {
> + {"max_parallel_apply_workers_per_subscription",
> + PGC_SIGHUP,
> + REPLICATION_SUBSCRIBERS,
> + gettext_noop("Maximum number of parallel apply workers per
> + subscription."), NULL, },
> + &max_parallel_apply_workers_per_subscription,
> 2, 0, MAX_BACKENDS,
> NULL, NULL, NULL
>
> Is this correct? Did you mean to change
> max_sync_workers_per_subscription, My 1st impression is that there has
> been some mixup with the MAX_PARALLEL_WORKER_LIMIT and MAX_BACKENDS or
> that this change was accidentally made to the wrong GUC.
Fixed.
> ======
>
> src/include/replication/worker_internal.h
>
> 27. ParallelApplyWorkerShared
>
> + /*
> + * Indicates whether there are pending streaming blocks in the queue.
> + The
> + * parallel apply worker will check it before starting to wait.
> + */
> + pg_atomic_uint32 pending_stream_count;
>
> A better name might be 'n_pending_stream_blocks'.
I am not sure if the name looks better, so didn’t change this.
> ~
>
> 28. function names
>
> extern void logicalrep_worker_stop(Oid subid, Oid relid);
> +extern void logicalrep_parallel_apply_worker_stop(int slot_no, uint16
> generation);
> extern void logicalrep_worker_wakeup(Oid subid, Oid relid); extern
> void logicalrep_worker_wakeup_ptr(LogicalRepWorker *worker);
>
> extern int logicalrep_sync_worker_count(Oid subid);
> +extern int logicalrep_parallel_apply_worker_count(Oid subid);
>
> Would it be better to call those new functions using similar shorter
> names as done elsewhere?
>
> logicalrep_parallel_apply_worker_stop -> logicalrep_pa_worker_stop
> logicalrep_parallel_apply_worker_count -> logicalrep_pa_worker_count
Changed.
Attach new version patch which also fixed an invalid shared memory access bug
in 0002 patch reported by Kuroda-San offlist.
Best regards,
Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Hou,
Thanks for updating the patch!
I tested the case whether the deadlock caused by foreign key constraint could be
detected, and it worked well.
Followings are my review comments. They are basically related with 0001, but
some contents may be not. It takes time to understand 0002 correctly...
01. typedefs.list
LeaderFileSetState should be added to typedefs.list.
02. 032_streaming_parallel_apply.pl
As I said in [1]: the test name may be not matched. Do you have reasons to
revert the change?
03. 032_streaming_parallel_apply.pl
The test does not cover the case that the backend process relates with the
deadlock. IIUC this is another motivation to use a stream/transaction lock.
I think it should be added.
04. log output
While being applied spooled changes by PA, there are so many messages like
"replayed %d changes from file..." and "applied %u changes...". They comes from
apply_handle_stream_stop() and apply_spooled_messages(). They have same meaning,
so I think one of them can be removed.
05. system_views.sql
In the previous version you modified pg_stat_subscription system view. Why do you revert that?
06. interrupt.c - SignalHandlerForShutdownRequest()
In the comment atop SignalHandlerForShutdownRequest(), some processes that assign the function
except SIGTERM are clarified. We may be able to add the parallel apply worker.
07. proto.c - logicalrep_write_stream_abort()
We may able to add assertions for abort_lsn and abort_time, like xid and subxid.
08. guc_tables.c - ConfigureNamesInt
```
&max_sync_workers_per_subscription,
+ 2, 0, MAX_PARALLEL_WORKER_LIMIT,
+ NULL, NULL, NULL
+ },
```
The upper limit for max_sync_workers_per_subscription seems to be wrong, it should
be used for max_parallel_apply_workers_per_subscription.
10. worker.c - maybe_reread_subscription()
```
+ if (am_parallel_apply_worker())
+ ereport(LOG,
+ /* translator: first %s is the name of logical replication worker */
+ (errmsg("%s for subscription \"%s\" will stop because of a parameter change",
+ get_worker_name(), MySubscription->name)));
```
I was not sure get_worker_name() is needed. I think "logical replication apply worker"
should be embedded.
11. worker.c - ApplyWorkerMain()
```
+ (errmsg_internal("%s for subscription \"%s\" two_phase is %s",
+ get_worker_name(),
```
The message for translator is needed.
[1]:
https://www.postgresql.org/message-id/TYAPR01MB58666A97D40AB8919D106AD5F5709%40TYAPR01MB5866.jpnprd01.prod.outlook.com
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Nov 22, 2022 at 7:23 PM Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com> wrote: > > > 07. proto.c - logicalrep_write_stream_abort() > > We may able to add assertions for abort_lsn and abort_time, like xid and subxid. > If you see logicalrep_write_stream_commit(), we have an assertion for xid but not for LSN and other parameters. I think the current coding in the patch is consistent with that. > > 08. guc_tables.c - ConfigureNamesInt > > ``` > &max_sync_workers_per_subscription, > + 2, 0, MAX_PARALLEL_WORKER_LIMIT, > + NULL, NULL, NULL > + }, > ``` > > The upper limit for max_sync_workers_per_subscription seems to be wrong, it should > be used for max_parallel_apply_workers_per_subscription. > Right, I don't know why this needs to be changed in the first place. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Nov 22, 2022 at 7:30 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
Few minor comments and questions:
============================
1.
+static void
+LogicalParallelApplyLoop(shm_mq_handle *mqh)
{
+ for (;;)
+ {
+ void *data;
+ Size len;
+
+ ProcessParallelApplyInterrupts();
...
...
+ if (rc & WL_LATCH_SET)
+ {
+ ResetLatch(MyLatch);
+ ProcessParallelApplyInterrupts();
+ }
...
}
Why ProcessParallelApplyInterrupts() is called twice in
LogicalParallelApplyLoop()?
2.
+ * This scenario is similar to the first case but TX-1 and TX-2 are executed by
+ * two parallel apply workers (PA-1 and PA-2 respectively). In this scenario,
+ * PA-2 is waiting for PA-1 to complete its transaction while PA-1 is waiting
+ * for subsequent input from LA. Also, LA is waiting for PA-2 to complete its
+ * transaction in order to preserve the commit order. There is a deadlock among
+ * three processes.
+ *
...
...
+ *
+ * LA (waiting to acquire the local transaction lock) -> PA-1 (waiting to
+ * acquire the lock on the unique index) -> PA-2 (waiting to acquire the lock
+ * on the remote transaction) -> LA
+ *
Isn't the order of PA-1 and PA-2 different in the second paragraph as
compared to the first one.
3.
+ * Deadlock-detection
+ * ------------------
It may be better to keep the title of this section as Locking Considerations.
4. In the section mentioned in Point 3, it would be better to
separately explain why we need session-level locks instead of
transaction level.
5. Add the below comments in the code:
diff --git a/src/backend/replication/logical/applyparallelworker.c
b/src/backend/replication/logical/applyparallelworker.c
index 9385afb6d2..56f00defcf 100644
--- a/src/backend/replication/logical/applyparallelworker.c
+++ b/src/backend/replication/logical/applyparallelworker.c
@@ -431,6 +431,9 @@ pa_free_worker_info(ParallelApplyWorkerInfo *winfo)
if (winfo->dsm_seg != NULL)
dsm_detach(winfo->dsm_seg);
+ /*
+ * Ensure this worker information won't be reused during
worker allocation.
+ */
ParallelApplyWorkersList = list_delete_ptr(ParallelApplyWorkersList,
winfo);
@@ -762,6 +765,10 @@
HandleParallelApplyMessage(ParallelApplyWorkerInfo *winfo, StringInfo
msg)
*/
error_context_stack = apply_error_context_stack;
+ /*
+ * The actual error must be already
reported by parallel apply
+ * worker.
+ */
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
errmsg("parallel
apply worker exited abnormally"),
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for v51-0001.
======
.../replication/logical/applyparallelworker.c
1. General - Error messages, get_worker_name()
I previously wrote a comment to ask if the get_worker_name() should be
used in more places but the reply [1, #2b] was:
> 2b.
> Consider if maybe all of these ought to be calling get_worker_name()
> which is currently static in worker.c. Doing this means any future
> changes to get_worker_name won't cause more inconsistencies.
The most error message in applyparallelxx.c can only use "xx parallel
worker", so I think it's fine not to call get_worker_name
~
I thought the reply missed the point I was trying to make -- I meant
if it was arranged now so *every* message would go via
get_worker_name() then in future somebody wanted to change the names
(e.g. from "logical replication parallel apply worker" to "LR PA
worker") then it would only need to be changed in one central place
instead of hunting down every hardwired error message.
Anyway, you can do it how you want -- I just was not sure you'd got my
original point.
~~~
2. HandleParallelApplyMessage
+ case 'X': /* Terminate, indicating clean exit. */
+ shm_mq_detach(winfo->error_mq_handle);
+ winfo->error_mq_handle = NULL;
+ break;
+ default:
+ elog(ERROR, "unrecognized message type received from logical
replication parallel apply worker: %c (message length %d bytes)",
+ msgtype, msg->len);
The case 'X' code indentation is too much.
======
src/backend/replication/logical/origin.c
3. replorigin_session_setup(RepOriginId node, int acquired_by)
@@ -1075,12 +1075,20 @@ ReplicationOriginExitCleanup(int code, Datum arg)
* array doesn't have to be searched when calling
* replorigin_session_advance().
*
- * Obviously only one such cached origin can exist per process and the current
+ * Normally only one such cached origin can exist per process and the current
* cached value can only be set again after the previous value is torn down
* with replorigin_session_reset().
+ *
+ * However, we do allow multiple processes to point to the same origin slot if
+ * requested by the caller by passing PID of the process that has already
+ * acquired it as acquired_by. This is to allow multiple parallel apply
+ * processes to use the same origin, provided they maintain commit order, for
+ * example, by allowing only one process to commit at a time. For the first
+ * process requesting this origin, the acquired_by parameter needs to be set to
+ * 0.
*/
void
-replorigin_session_setup(RepOriginId node)
+replorigin_session_setup(RepOriginId node, int acquired_by)
I think the meaning of the acquired_by=0 is not fully described here:
"For the first process requesting this origin, the acquired_by
parameter needs to be set to 0."
IMO that seems to be describing it only from POV that you are always
going to want to allow multiple processes. But really this is an
optional feature so you might pass acquired_by=0, not just because
this is the first of multiple, but also because you *never* want to
allow multiple at all. The comment does not convey this meaning.
Maybe something worded like below is better?
SUGGESTION
Normally only one such cached origin can exist per process so the
cached value can only be set again after the previous value is torn
down with replorigin_session_reset(). For this normal case pass
acquired_by=0 (meaning the slot is not allowed to be already acquired
by another process).
However, sometimes multiple processes can safely re-use the same
origin slot (for example, multiple parallel apply processes can safely
use the same origin, provided they maintain commit order by allowing
only one process to commit at a time). For this case the first process
must pass acquired_by=0, and then the other processes sharing that
same origin can pass acquired_by=PID of the first process.
======
src/backend/replication/logical/worker.c
4. GENERAL - get_worker_name()
If you decide it is OK to hardwire some error messages instead of
unconditionally calling the get_worker_name() -- see my #1 review
comment in this post -- then there are some other messages in this
file that also seem like they can be also hardwired because the type
of worker is already known.
Here are some examples:
4a.
+ else if (am_parallel_apply_worker())
+ {
+ if (rel->state != SUBREL_STATE_READY)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ /* translator: first %s is the name of logical replication worker */
+ errmsg("%s for subscription \"%s\" will stop",
+ get_worker_name(), MySubscription->name),
+ errdetail("Cannot handle streamed replication transactions using
parallel apply workers until all tables have been synchronized.")));
+
+ return true;
+ }
In the above code from should_apply_changes_for_rel we already know
this is a parallel apply worker.
~
4b.
+ if (am_parallel_apply_worker())
+ ereport(LOG,
+ /* translator: first %s is the name of logical replication worker */
+ (errmsg("%s for subscription \"%s\" will stop because of a parameter change",
+ get_worker_name(), MySubscription->name)));
+ else
In the above code from maybe_reread_subscription we already know this
is a parallel apply worker.
4c.
if (am_tablesync_worker())
ereport(LOG,
- (errmsg("logical replication table synchronization worker for
subscription \"%s\", table \"%s\" has started",
- MySubscription->name, get_rel_name(MyLogicalRepWorker->relid))));
+ /* translator: first %s is the name of logical replication worker */
+ (errmsg("%s for subscription \"%s\", table \"%s\" has started",
+ get_worker_name(), MySubscription->name,
+ get_rel_name(MyLogicalRepWorker->relid))));
In the above code from ApplyWorkerMain we already know this is a
tablesync worker
~~~
5. get_transaction_apply_action
+
+/*
+ * Return the action to take for the given transaction. *winfo is assigned to
+ * the destination parallel worker info (if the action is
+ * TRANS_LEADER_SEND_TO_PARALLEL, otherwise *winfo is assigned NULL.
+ */
+static TransApplyAction
+get_transaction_apply_action(TransactionId xid,
ParallelApplyWorkerInfo **winfo)
There is no closing ')' in the function comment.
~~~
6. apply_worker_clean_exit
+ /* Notify the leader apply worker that we have exited cleanly. */
+ if (am_parallel_apply_worker())
+ pq_putmessage('X', NULL, 0);
IMO the comment would be better inside the if block
SUGGESTION
if (am_parallel_apply_worker())
{
/* Notify the leader apply worker that we have exited cleanly. */
pq_putmessage('X', NULL, 0);
}
------
[1] Hou-san's reply to my v49-0001 review.
https://www.postgresql.org/message-id/OS0PR01MB5716339FF7CB759E751492CB940D9%40OS0PR01MB5716.jpnprd01.prod.outlook.com
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, November 23, 2022 9:40 PM Amit Kapila <amit.kapila16@gmail.com>
>
> On Tue, Nov 22, 2022 at 7:30 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
>
> Few minor comments and questions:
> ============================
> 1.
> +static void
> +LogicalParallelApplyLoop(shm_mq_handle *mqh)
> {
> + for (;;)
> + {
> + void *data;
> + Size len;
> +
> + ProcessParallelApplyInterrupts();
> ...
> ...
> + if (rc & WL_LATCH_SET)
> + {
> + ResetLatch(MyLatch);
> + ProcessParallelApplyInterrupts();
> + }
> ...
> }
>
> Why ProcessParallelApplyInterrupts() is called twice in
> LogicalParallelApplyLoop()?
I think the second call is unnecessary, so removed it.
> 2.
> + * This scenario is similar to the first case but TX-1 and TX-2 are
> + executed by
> + * two parallel apply workers (PA-1 and PA-2 respectively). In this
> + scenario,
> + * PA-2 is waiting for PA-1 to complete its transaction while PA-1 is
> + waiting
> + * for subsequent input from LA. Also, LA is waiting for PA-2 to
> + complete its
> + * transaction in order to preserve the commit order. There is a
> + deadlock among
> + * three processes.
> + *
> ...
> ...
> + *
> + * LA (waiting to acquire the local transaction lock) -> PA-1 (waiting
> + to
> + * acquire the lock on the unique index) -> PA-2 (waiting to acquire
> + the lock
> + * on the remote transaction) -> LA
> + *
>
> Isn't the order of PA-1 and PA-2 different in the second paragraph as compared
> to the first one.
Fixed.
> 3.
> + * Deadlock-detection
> + * ------------------
>
> It may be better to keep the title of this section as Locking Considerations.
>
> 4. In the section mentioned in Point 3, it would be better to separately explain
> why we need session-level locks instead of transaction level.
Added.
> 5. Add the below comments in the code:
> diff --git a/src/backend/replication/logical/applyparallelworker.c
> b/src/backend/replication/logical/applyparallelworker.c
> index 9385afb6d2..56f00defcf 100644
> --- a/src/backend/replication/logical/applyparallelworker.c
> +++ b/src/backend/replication/logical/applyparallelworker.c
> @@ -431,6 +431,9 @@ pa_free_worker_info(ParallelApplyWorkerInfo *winfo)
> if (winfo->dsm_seg != NULL)
> dsm_detach(winfo->dsm_seg);
>
> + /*
> + * Ensure this worker information won't be reused during
> worker allocation.
> + */
> ,
>
> winfo);
>
> @@ -762,6 +765,10 @@
> HandleParallelApplyMessage(ParallelApplyWorkerInfo *winfo, StringInfo
> msg)
> */
> error_context_stack =
> apply_error_context_stack;
>
> + /*
> + * The actual error must be already
> reported by parallel apply
> + * worker.
> + */
> ereport(ERROR,
>
> (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> errmsg("parallel apply worker
> exited abnormally"),
Added.
Attach the new version patch which addressed all comments so far.
Besides, I let the PA send a different message to LA when it exits due to
subscription information change. The LA will report a more meaningful message
and restart replication after catching new message to prevent the LA from
sending message to exited PA.
Best regards,
Hou zj
Attachment
- v52-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v52-0002-Serialize-partial-changes-to-disk-if-the-shm_mq-.patch
- v52-0001-Perform-streaming-logical-transactions-by-parall.patch
- v52-0003-Test-streaming-parallel-option-in-tap-test.patch
- v52-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, November 25, 2022 10:54 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are some review comments for v51-0001.
Thanks for the comments!
> ======
>
> .../replication/logical/applyparallelworker.c
>
> 1. General - Error messages, get_worker_name()
>
> I previously wrote a comment to ask if the get_worker_name() should be used
> in more places but the reply [1, #2b] was:
>
> > 2b.
> > Consider if maybe all of these ought to be calling get_worker_name()
> > which is currently static in worker.c. Doing this means any future
> > changes to get_worker_name won't cause more inconsistencies.
>
> The most error message in applyparallelxx.c can only use "xx parallel worker",
> so I think it's fine not to call get_worker_name
>
> ~
>
> I thought the reply missed the point I was trying to make -- I meant if it was
> arranged now so *every* message would go via
> get_worker_name() then in future somebody wanted to change the names (e.g.
> from "logical replication parallel apply worker" to "LR PA
> worker") then it would only need to be changed in one central place instead of
> hunting down every hardwired error message.
>
Thanks for the suggestion. I understand your point, but I feel that using
get_worker_name() at some places where the worker type is decided could make
developer think that all kind of worker can enter this code which I am not sure
is better. So I didn't change this.
>
> 2. HandleParallelApplyMessage
>
> + case 'X': /* Terminate, indicating clean exit. */
> + shm_mq_detach(winfo->error_mq_handle);
> + winfo->error_mq_handle = NULL;
> + break;
> + default:
> + elog(ERROR, "unrecognized message type received from logical
> replication parallel apply worker: %c (message length %d bytes)",
> + msgtype, msg->len);
>
> The case 'X' code indentation is too much.
Changed.
> ======
>
> src/backend/replication/logical/origin.c
>
> 3. replorigin_session_setup(RepOriginId node, int acquired_by)
>
> @@ -1075,12 +1075,20 @@ ReplicationOriginExitCleanup(int code, Datum arg)
> * array doesn't have to be searched when calling
> * replorigin_session_advance().
> *
> - * Obviously only one such cached origin can exist per process and the current
> + * Normally only one such cached origin can exist per process and the
> + current
> * cached value can only be set again after the previous value is torn down
> * with replorigin_session_reset().
> + *
> + * However, we do allow multiple processes to point to the same origin
> + slot if
> + * requested by the caller by passing PID of the process that has
> + already
> + * acquired it as acquired_by. This is to allow multiple parallel apply
> + * processes to use the same origin, provided they maintain commit
> + order, for
> + * example, by allowing only one process to commit at a time. For the
> + first
> + * process requesting this origin, the acquired_by parameter needs to
> + be set to
> + * 0.
> */
> void
> -replorigin_session_setup(RepOriginId node)
> +replorigin_session_setup(RepOriginId node, int acquired_by)
>
> I think the meaning of the acquired_by=0 is not fully described here:
> "For the first process requesting this origin, the acquired_by parameter needs
> to be set to 0."
> IMO that seems to be describing it only from POV that you are always going to
> want to allow multiple processes. But really this is an optional feature so you
> might pass acquired_by=0, not just because this is the first of multiple, but also
> because you *never* want to allow multiple at all. The comment does not
> convey this meaning.
>
> Maybe something worded like below is better?
>
> SUGGESTION
> Normally only one such cached origin can exist per process so the cached value
> can only be set again after the previous value is torn down with
> replorigin_session_reset(). For this normal case pass
> acquired_by=0 (meaning the slot is not allowed to be already acquired by
> another process).
>
> However, sometimes multiple processes can safely re-use the same origin slot
> (for example, multiple parallel apply processes can safely use the same origin,
> provided they maintain commit order by allowing only one process to commit
> at a time). For this case the first process must pass acquired_by=0, and then the
> other processes sharing that same origin can pass acquired_by=PID of the first
> process.
Changes as suggested.
> ======
>
> src/backend/replication/logical/worker.c
>
> 4. GENERAL - get_worker_name()
>
> If you decide it is OK to hardwire some error messages instead of
> unconditionally calling the get_worker_name() -- see my #1 review comment in
> this post -- then there are some other messages in this file that also seem like
> they can be also hardwired because the type of worker is already known.
>
> Here are some examples:
>
> 4a.
>
> + else if (am_parallel_apply_worker())
> + {
> + if (rel->state != SUBREL_STATE_READY)
> + ereport(ERROR,
> + (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + /* translator: first %s is the name of logical replication worker */
> + errmsg("%s for subscription \"%s\" will stop", get_worker_name(),
> + MySubscription->name), errdetail("Cannot handle streamed replication
> + transactions using
> parallel apply workers until all tables have been synchronized.")));
> +
> + return true;
> + }
>
> In the above code from should_apply_changes_for_rel we already know this is a
> parallel apply worker.
>
> ~
>
> 4b.
>
> + if (am_parallel_apply_worker())
> + ereport(LOG,
> + /* translator: first %s is the name of logical replication worker */
> + (errmsg("%s for subscription \"%s\" will stop because of a parameter
> + change", get_worker_name(), MySubscription->name))); else
>
> In the above code from maybe_reread_subscription we already know this is a
> parallel apply worker.
>
> 4c.
>
> if (am_tablesync_worker())
> ereport(LOG,
> - (errmsg("logical replication table synchronization worker for subscription
> \"%s\", table \"%s\" has started",
> - MySubscription->name, get_rel_name(MyLogicalRepWorker->relid))));
> + /* translator: first %s is the name of logical replication worker */
> + (errmsg("%s for subscription \"%s\", table \"%s\" has started",
> + get_worker_name(), MySubscription->name,
> + get_rel_name(MyLogicalRepWorker->relid))));
>
> In the above code from ApplyWorkerMain we already know this is a tablesync
> worker
Thanks for checking these, changed.
> ~~~
>
> 5. get_transaction_apply_action
>
> +
> +/*
> + * Return the action to take for the given transaction. *winfo is
> +assigned to
> + * the destination parallel worker info (if the action is
> + * TRANS_LEADER_SEND_TO_PARALLEL, otherwise *winfo is assigned NULL.
> + */
> +static TransApplyAction
> +get_transaction_apply_action(TransactionId xid,
> ParallelApplyWorkerInfo **winfo)
>
> There is no closing ')' in the function comment.
Added.
> ~~~
>
> 6. apply_worker_clean_exit
>
> + /* Notify the leader apply worker that we have exited cleanly. */ if
> + (am_parallel_apply_worker()) pq_putmessage('X', NULL, 0);
>
> IMO the comment would be better inside the if block
>
> SUGGESTION
> if (am_parallel_apply_worker())
> {
> /* Notify the leader apply worker that we have exited cleanly. */
> pq_putmessage('X', NULL, 0);
> }
Changed.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, November 22, 2022 9:53 PM Kuroda, Hayato <kuroda.hayato@fujitsu.com> wroteL
>
> Thanks for updating the patch!
> I tested the case whether the deadlock caused by foreign key constraint could
> be detected, and it worked well.
>
> Followings are my review comments. They are basically related with 0001, but
> some contents may be not. It takes time to understand 0002 correctly...
Thanks for the comments!
> 01. typedefs.list
>
> LeaderFileSetState should be added to typedefs.list.
>
>
> 02. 032_streaming_parallel_apply.pl
>
> As I said in [1]: the test name may be not matched. Do you have reasons to
> revert the change?
The original parallel safety check has been removed, so I changed the name.
After rethinking about this, I named it to stream_parallel_conflict.
>
> 03. 032_streaming_parallel_apply.pl
>
> The test does not cover the case that the backend process relates with the
> deadlock. IIUC this is another motivation to use a stream/transaction lock.
> I think it should be added.
The main deadlock cases that stream/transaction lock can detect is 1) LA->PA 2)
LA->PA->PA as explained atop applyparallelworker.c. So I think backend process
related one is a variant which I think have been covered by the existing
tests in the patch.
> 04. log output
>
> While being applied spooled changes by PA, there are so many messages like
> "replayed %d changes from file..." and "applied %u changes...". They comes
> from
> apply_handle_stream_stop() and apply_spooled_messages(). They have same
> meaning, so I think one of them can be removed.
Changed.
> 05. system_views.sql
>
> In the previous version you modified pg_stat_subscription system view. Why
> do you revert that?
I was not sure should we include that in the main patch set.
I added a top-up patch that change the view.
> 06. interrupt.c - SignalHandlerForShutdownRequest()
>
> In the comment atop SignalHandlerForShutdownRequest(), some processes
> that assign the function except SIGTERM are clarified. We may be able to add
> the parallel apply worker.
Changed
> 08. guc_tables.c - ConfigureNamesInt
>
> ```
> &max_sync_workers_per_subscription,
> + 2, 0, MAX_PARALLEL_WORKER_LIMIT,
> + NULL, NULL, NULL
> + },
> ```
>
> The upper limit for max_sync_workers_per_subscription seems to be wrong, it
> should be used for max_parallel_apply_workers_per_subscription.
That's my miss, sorry for that.
> 10. worker.c - maybe_reread_subscription()
>
>
> ```
> + if (am_parallel_apply_worker())
> + ereport(LOG,
> + /* translator: first %s is the name of logical replication
> worker */
> + (errmsg("%s for subscription \"%s\"
> will stop because of a parameter change",
> +
> + get_worker_name(), MySubscription->name)));
> ```
>
> I was not sure get_worker_name() is needed. I think "logical replication apply
> worker"
> should be embedded.
Changed.
>
> 11. worker.c - ApplyWorkerMain()
>
> ```
> + (errmsg_internal("%s for subscription \"%s\"
> two_phase is %s",
> +
> + get_worker_name(),
> ```
Changed
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for patch v51-0002
======
1.
GENERAL - terminology: spool/serialize and data/changes/message
The terminology seems to be used at random. IMO it might be worthwhile
rechecking at least that terms are used consistently in all the
comments. e.g "serialize message data to disk" ... and later ...
"apply the spooled messages".
Also for places where it says "Write the message to file" maybe
consider using consistent terminology like "serialize the message to a
file".
Also, try to standardize the way things are described by using
consistent (if they really are the same) terminology for "writing
data" VS "writing data" VS "writing messages" etc. It is confusing
trying to know if the different wording has some intended meaning or
is it just random.
======
Commit message
2.
When the leader apply worker times out while sending a message to the parallel
apply worker. Instead of erroring out, switch to partial serialize mode and let
the leader serialize all remaining changes to the file and notify the parallel
apply workers to read and apply them at the end of the transaction.
~
The first sentence seems incomplete
SUGGESTION.
In patch 0001 if the leader apply worker times out while attempting to
send a message to the parallel apply worker it results in an ERROR.
This patch (0002) modifies that behaviour, so instead of erroring it
will switch to "partial serialize" mode - in this mode the leader
serializes all remaining changes to a file and notifies the parallel
apply workers to read and apply them at the end of the transaction.
~~~
3.
This patch 0002 is called “Serialize partial changes to disk if the
shm_mq buffer is full”, but the commit message is saying nothing about
the buffer filling up. I think the Commit message should be mentioning
something that makes the commit patch name more relevant. Otherwise
change the patch name.
======
.../replication/logical/applyparallelworker.c
4. File header comment
+ * timeout is exceeded, the LA will write to file and indicate PA-2 that it
+ * needs to read file for remaining messages. Then LA will start waiting for
+ * commit which will detect deadlock if any. (See pa_send_data() and typedef
+ * enum TransApplyAction)
"needs to read file for remaining messages" -> "needs to read that
file for the remaining messages"
~~~
5. pa_free_worker
+ /*
+ * Stop the worker if there are enough workers in the pool.
+ *
+ * XXX we also need to stop the worker if the leader apply worker
+ * serialized part of the transaction data to a file due to send timeout.
+ * This is because the message could be partially written to the queue due
+ * to send timeout and there is no way to clean the queue other than
+ * resending the message until it succeeds. To avoid complexity, we
+ * directly stop the worker in this case.
+ */
+ if (winfo->serialize_changes ||
+ napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
5a.
+ * XXX we also need to stop the worker if the leader apply worker
+ * serialized part of the transaction data to a file due to send timeout.
SUGGESTION
XXX The worker is also stopped if the leader apply worker needed to
serialize part of the transaction data due to a send timeout.
~
5b.
+ /* Unlink the files with serialized changes. */
+ if (winfo->serialize_changes)
+ stream_cleanup_files(MyLogicalRepWorker->subid, winfo->shared->xid);
A better comment might be
SUGGESTION
Unlink any files that were needed to serialize partial changes.
~~~
6. pa_spooled_messages
/*
* Replay the spooled messages in the parallel apply worker if leader apply
* worker has finished serializing changes to the file.
*/
static void
pa_spooled_messages(void)
6a.
IMO a better name for this function would be pa_apply_spooled_messages();
~
6b.
"if leader apply" -> "if the leader apply"
~
7.
+ /*
+ * Acquire the stream lock if the leader apply worker is serializing
+ * changes to the file, because the parallel apply worker will no longer
+ * have a chance to receive a STREAM_STOP and acquire the lock until the
+ * leader serialize all changes to the file.
+ */
+ if (fileset_state == LEADER_FILESET_BUSY)
+ {
+ pa_lock_stream(MyParallelShared->xid, AccessShareLock);
+ pa_unlock_stream(MyParallelShared->xid, AccessShareLock);
+ }
SUGGESTION (rearranged comment - please check, I am not sure if I got
this right)
If the leader apply worker is still (busy) serializing partial changes
then the parallel apply worker acquires the stream lock now.
Otherwise, it would not have a chance to receive a STREAM_STOP (and
acquire the stream lock) until the leader had serialized all changes.
~~~
8. pa_send_data
+ *
+ * When sending data times out, data will be serialized to disk. And the
+ * current streaming transaction will enter PARTIAL_SERIALIZE mode, which means
+ * that subsequent data will also be serialized to disk.
*/
void
pa_send_data(ParallelApplyWorkerInfo *winfo, Size nbytes, const void *data)
SUGGESTION (minor comment change)
If the attempt to send data via shared memory times out, then we will
switch to "PARTIAL_SERIALIZE mode" for the current transaction. This
means that the current data and any subsequent data for this
transaction will be serialized to disk.
~
9.
Assert(!IsTransactionState());
+ Assert(!winfo->serialize_changes);
How about also asserting that this must be the LA worker?
~
10.
+ /*
+ * The parallel apply worker might be stuck for some reason, so
+ * stop sending data to parallel worker and start to serialize
+ * data to files.
+ */
+ winfo->serialize_changes = true;
SUGGESTION (minor reword)
The parallel apply worker might be stuck for some reason, so stop
sending data directly to it and start to serialize data to files
instead.
~
11.
+ /* Skip first byte and statistics fields. */
+ msg.cursor += SIZE_STATS_MESSAGE + 1;
IMO it would be better for the comment order and the code calculation
order to be the same.
SUGGESTION
/* Skip first byte and statistics fields. */
msg.cursor += 1 + SIZE_STATS_MESSAGE;
~
12. pa_stream_abort
+ /*
+ * If the parallel apply worker is applying the spooled
+ * messages, we save the current file position and close the
+ * file to prevent the file from being accidentally closed on
+ * rollback.
+ */
+ if (stream_fd)
+ {
+ BufFileTell(stream_fd, &fileno, &offset);
+ BufFileClose(stream_fd);
+ reopen_stream_fd = true;
+ }
+
RollbackToSavepoint(spname);
CommitTransactionCommand();
subxactlist = list_truncate(subxactlist, i + 1);
+
+ /*
+ * Reopen the file and set the file position to the saved
+ * position.
+ */
+ if (reopen_stream_fd)
It seems a bit vague to just refer to "close the file" and "reopen the
file" in these comments. IMO it would be better to call this file by a
name like "the message spool file" or similar. Please check all other
similar comments.
~~~
13. pa_set_fileset_state
/*
+ * Set the fileset_state flag for the given parallel apply worker. The
+ * stream_fileset of the leader apply worker will be written into the shared
+ * memory if the fileset_state is LEADER_FILESET_ACCESSIBLE.
+ */
+void
+pa_set_fileset_state(ParallelApplyWorkerShared *wshared,
+ LeaderFileSetState fileset_state)
+{
13a.
It is an enum -- not a "flag", so:
"fileset_state flag" -> "fileste state"
~~
13b.
It seemed strange to me that the comment/code says this state is only
written to shm when it is "ACCESSIBLE".... IIUC this same filestate
lingers around to be reused for other workers so I expected the state
should *always* be written whenever the LA changes it. (I mean even if
the PA is not needing to look at this member, I still think it should
have the current/correct value in it).
======
src/backend/replication/logical/worker.c
14. TRANS_LEADER_SEND_TO_PARALLEL
+ * TRANS_LEADER_PARTIAL_SERIALIZE:
+ * The action means that we are in the leader apply worker and have sent some
+ * changes to the parallel apply worker, but the remaining changes need to be
+ * serialized to disk due to timeout while sending data, and the parallel apply
+ * worker will apply these changes when the final commit arrives.
+ *
+ * One might think we can use LEADER_SERIALIZE directly. But in partial
+ * serialize mode, in addition to serializing changes to file, the leader
+ * worker needs to write the STREAM_XXX message to disk, and needs to wait for
+ * parallel apply worker to finish the transaction when processing the
+ * transaction finish command. So a new action was introduced to make the logic
+ * clearer.
+ *
* TRANS_LEADER_SEND_TO_PARALLEL:
SUGGESTION (Minor wording changes)
The action means that we are in the leader apply worker and have sent
some changes directly to the parallel apply worker, due to timeout
while sending data the remaining changes need to be serialized to
disk. The parallel apply worker will apply these serialized changes
when the final commit arrives.
LEADER_SERIALIZE could not be used for this case because, in addition
to serializing changes, the leader worker also needs to write the
STREAM_XXX message to disk, and wait for the parallel apply worker to
finish the transaction when processing the transaction finish command.
So this new action was introduced to make the logic clearer.
~
15.
/* Actions for streaming transactions. */
TRANS_LEADER_SERIALIZE,
+ TRANS_LEADER_PARTIAL_SERIALIZE,
TRANS_LEADER_SEND_TO_PARALLEL,
TRANS_PARALLEL_APPLY
Although it makes no difference I felt it would be better to put
TRANS_LEADER_PARTIAL_SERIALIZE *after* TRANS_LEADER_SEND_TO_PARALLEL
because that would be the order that these mode changes occur in the
logic...
~~~
16.
@@ -375,7 +388,7 @@ typedef struct ApplySubXactData
static ApplySubXactData subxact_data = {0, 0, InvalidTransactionId, NULL};
static inline void subxact_filename(char *path, Oid subid, TransactionId xid);
-static inline void changes_filename(char *path, Oid subid, TransactionId xid);
+inline void changes_filename(char *path, Oid subid, TransactionId xid);
IIUC (see [1]) when this function was made non-static the "inline"
should have been put into the header file.
~
17.
@@ -388,10 +401,9 @@ static inline void cleanup_subxact_info(void);
/*
* Serialize and deserialize changes for a toplevel transaction.
*/
-static void stream_cleanup_files(Oid subid, TransactionId xid);
static void stream_open_file(Oid subid, TransactionId xid,
bool first_segment);
-static void stream_write_change(char action, StringInfo s);
+static void stream_write_message(TransactionId xid, char action, StringInfo s);
static void stream_close_file(void);
17a.
I felt just saying "file/files" is too vague. All the references to
the file should be consistent, so IMO everything would be better named
like:
"stream_cleanup_files" -> "stream_msg_spoolfile_cleanup()"
"stream_open_file" -> "stream_msg_spoolfile_open()"
"stream_close_file" -> "stream_msg_spoolfile_close()"
"stream_write_message" -> "stream_msg_spoolfile_write_msg()"
~
17b.
IMO there is not enough distinction here between function names
stream_write_message and stream_write_change. e.g. You cannot really
tell from their names what might be the difference.
~~~
18.
@@ -586,6 +595,7 @@ handle_streamed_transaction(LogicalRepMsgType
action, StringInfo s)
TransactionId current_xid;
ParallelApplyWorkerInfo *winfo;
TransApplyAction apply_action;
+ StringInfoData original_msg;
apply_action = get_transaction_apply_action(stream_xid, &winfo);
@@ -595,6 +605,8 @@ handle_streamed_transaction(LogicalRepMsgType
action, StringInfo s)
Assert(TransactionIdIsValid(stream_xid));
+ original_msg = *s;
+
/*
* We should have received XID of the subxact as the first part of the
* message, so extract it.
@@ -618,10 +630,14 @@ handle_streamed_transaction(LogicalRepMsgType
action, StringInfo s)
stream_write_change(action, s);
return true;
+ case TRANS_LEADER_PARTIAL_SERIALIZE:
case TRANS_LEADER_SEND_TO_PARALLEL:
Assert(winfo);
- pa_send_data(winfo, s->len, s->data);
+ if (apply_action == TRANS_LEADER_SEND_TO_PARALLEL)
+ pa_send_data(winfo, s->len, s->data);
+ else
+ stream_write_change(action, &original_msg);
The original_msg is not used except for TRANS_LEADER_PARTIAL_SERIALIZE
case so I think it should only be declared/assigned in the scope of
that 'else'
~~
19. apply_handle_stream_prepare
@@ -1316,13 +1335,21 @@ apply_handle_stream_prepare(StringInfo s)
pa_unlock_stream(winfo->shared->xid, AccessExclusiveLock);
/* Send STREAM PREPARE message to the parallel apply worker. */
- pa_send_data(winfo, s->len, s->data);
+ if (apply_action == TRANS_LEADER_SEND_TO_PARALLEL)
+ pa_send_data(winfo, s->len, s->data);
+ else
+ stream_write_message(prepare_data.xid,
+ LOGICAL_REP_MSG_STREAM_PREPARE,
+ &original_msg);
The original_msg is not used except for TRANS_LEADER_PARTIAL_SERIALIZE
case so I think it should only be declared/assigned in the scope of
that 'else'
~
20.
+ /*
+ * Close the file before committing if the parallel apply is
+ * applying spooled changes.
+ */
+ if (stream_fd)
+ BufFileClose(stream_fd);
I found this a bit confusing because there is already a
stream_close_file() wrapper function which does almost the same as
this. So either this code should be calling that function, or the
comment here should be explaining why this code is NOT calling that
function.
~~~
21. serialize_stream_start
+/*
+ * Initialize fileset (if not already done).
+ *
+ * Create a new file when first_segment is true, otherwise open the existing
+ * file.
+ */
+void
+serialize_stream_start(TransactionId xid, bool first_segment)
IMO this function should be called stream_msg_spoolfile_init() or
stream_msg_spoolfile_begin() to match the pattern for function names
of the message spool file that I previously suggested. (see review
comment #17a)
~
22.
+ /*
+ * Initialize the worker's stream_fileset if we haven't yet. This will be
+ * used for the entire duration of the worker so create it in a permanent
+ * context. We create this on the very first streaming message from any
+ * transaction and then use it for this and other streaming transactions.
+ * Now, we could create a fileset at the start of the worker as well but
+ * then we won't be sure that it will ever be used.
+ */
+ if (!MyLogicalRepWorker->stream_fileset)
I assumed this is a typo "Now," --> "Note," ?
~~~
23. apply_handle_stream_start
@@ -1404,6 +1478,7 @@ apply_handle_stream_start(StringInfo s)
bool first_segment;
ParallelApplyWorkerInfo *winfo;
TransApplyAction apply_action;
+ StringInfoData original_msg = *s;
The original_msg is not used except for TRANS_LEADER_PARTIAL_SERIALIZE
case so I think it should only be declared/assigned in the scope of
that 'else'
~
24.
/*
- * Start a transaction on stream start, this transaction will be
- * committed on the stream stop unless it is a tablesync worker in
- * which case it will be committed after processing all the
- * messages. We need the transaction for handling the buffile,
- * used for serializing the streaming data and subxact info.
+ * serialize_stream_start will start a transaction, this
+ * transaction will be committed on the stream stop unless it is a
+ * tablesync worker in which case it will be committed after
+ * processing all the messages. We need the transaction for
+ * handling the buffile, used for serializing the streaming data
+ * and subxact info.
*/
- begin_replication_step();
+ serialize_stream_start(stream_xid, first_segment);
+ break;
Make the comment a bit more natural.
SUGGESTION
Function serialize_stream_start starts a transaction. This transaction
will be committed on the stream stop unless it is a tablesync worker
in which case it will be committed after processing all the messages.
We need this transaction for handling the BufFile, used for
serializing the streaming data and subxact info.
~
25.
+ case TRANS_LEADER_PARTIAL_SERIALIZE:
/*
- * Initialize the worker's stream_fileset if we haven't yet. This
- * will be used for the entire duration of the worker so create it
- * in a permanent context. We create this on the very first
- * streaming message from any transaction and then use it for this
- * and other streaming transactions. Now, we could create a
- * fileset at the start of the worker as well but then we won't be
- * sure that it will ever be used.
+ * The file should have been created when entering
+ * PARTIAL_SERIALIZE mode so no need to create it again. The
+ * transaction started in serialize_stream_start will be committed
+ * on the stream stop.
*/
- if (!MyLogicalRepWorker->stream_fileset)
BEFORE
The file should have been created when entering PARTIAL_SERIALIZE mode
so no need to create it again.
SUGGESTION
The message spool file was already created when entering PARTIAL_SERIALIZE mode.
~~~
26. serialize_stream_stop
/*
+ * Update the information about subxacts and close the file.
+ *
+ * This function should be called when the serialize_stream_start function has
+ * been called.
+ */
+void
+serialize_stream_stop(TransactionId xid)
Maybe 2nd part of that comment should be something more like
SUGGESTION
This function ends what was started by the function serialize_stream_start().
~
27.
+ /*
+ * Close the file with serialized changes, and serialize information about
+ * subxacts for the toplevel transaction.
+ */
+ subxact_info_write(MyLogicalRepWorker->subid, xid);
+ stream_close_file();
Should the comment and the code be in the same order?
SUGGESTION
Serialize information about subxacts for the toplevel transaction,
then close the stream messages spool file.
~~~
28. handle_stream_abort
+ case TRANS_LEADER_PARTIAL_SERIALIZE:
+ Assert(winfo);
+
+ /*
+ * Parallel apply worker might have applied some changes, so write
+ * the STREAM_ABORT message so that the parallel apply worker can
+ * rollback the subtransaction if needed.
+ */
+ stream_write_message(xid, LOGICAL_REP_MSG_STREAM_ABORT,
+ &original_msg);
+
28a.
The original_msg is not used except for TRANS_LEADER_PARTIAL_SERIALIZE
case so I think it should only be declared/assigned in the scope of
that case.
~
28b.
"so that the parallel apply worker can" -> "so that it can"
~~~
29. apply_spooled_messages
+void
+apply_spooled_messages(FileSet *stream_fileset, TransactionId xid,
+ XLogRecPtr lsn)
{
StringInfoData s2;
int nchanges;
char path[MAXPGPATH];
char *buffer = NULL;
MemoryContext oldcxt;
- BufFile *fd;
- maybe_start_skipping_changes(lsn);
+ if (!am_parallel_apply_worker())
+ maybe_start_skipping_changes(lsn);
/* Make sure we have an open transaction */
begin_replication_step();
@@ -1810,8 +1913,8 @@ apply_spooled_messages(TransactionId xid, XLogRecPtr lsn)
changes_filename(path, MyLogicalRepWorker->subid, xid);
elog(DEBUG1, "replaying changes from file \"%s\"", path);
- fd = BufFileOpenFileSet(MyLogicalRepWorker->stream_fileset, path, O_RDONLY,
- false);
+ stream_fd = BufFileOpenFileSet(stream_fileset, path, O_RDONLY, false);
+ stream_xid = xid;
IMO it seems strange to me that the fileset is passed as a parameter
but then the resulting fd is always assigned to a single global
variable (regardless of what the fileset was passed).
~
30.
- BufFileClose(fd);
-
+ BufFileClose(stream_fd);
pfree(buffer);
pfree(s2.data);
+done:
+ stream_fd = NULL;
+ stream_xid = InvalidTransactionId;
+
This code fragment seems to be doing almost the same as what function
stream_close_file() is doing. Should you just call that instead?
~~~
31. apply_handle_stream_commit
+ if (apply_action == TRANS_LEADER_SEND_TO_PARALLEL)
+ pa_send_data(winfo, s->len, s->data);
+ else
+ stream_write_message(xid, LOGICAL_REP_MSG_STREAM_COMMIT,
+ &original_msg);
The original_msg is not used except for TRANS_LEADER_PARTIAL_SERIALIZE
case so I think it should only be declared/assigned in the scope of
that 'else'
~
32.
case TRANS_PARALLEL_APPLY:
+
+ /*
+ * Close the file before committing if the parallel apply is
+ * applying spooled changes.
+ */
+ if (stream_fd)
+ BufFileClose(stream_fd);
(Same as earlier review comment #20)
IMO this is confusing because there is already a stream_close_file()
wrapper function that does almost the same. So either this code should
be calling that function, or the comment here should explain why this
code is NOT calling that function.
======
src/include/replication/worker_internal.h
33. LeaderFileSetState
+/* State of fileset in leader apply worker. */
+typedef enum LeaderFileSetState
+{
+ LEADER_FILESET_UNKNOWN,
+ LEADER_FILESET_BUSY,
+ LEADER_FILESET_ACCESSIBLE
+} LeaderFileSetState;
33a.
Missing from typedefs.list?
~
33b.
I thought some more explanatory comments for the meaning of
BUSY/ACCESSIBLE should be here.
~
33c.
READY might be a better value than ACCESSIBLE
~
33d.
I'm not sure what usefulness does the "LEADER_" and "Leader" prefixes
give here. Maybe a name like PartialFileSetStat is more meaningful?
e.g. like this?
typedef enum PartialFileSetState
{
FS_UNKNOWN,
FS_BUSY,
FS_READY
} PartialFileSetState;
~
~~~
34. ParallelApplyWorkerShared
+ /*
+ * The leader apply worker will serialize changes to the file after
+ * entering PARTIAL_SERIALIZE mode and share the fileset with the parallel
+ * apply worker when processing the transaction finish command. And then
+ * the parallel apply worker will apply all the spooled messages.
+ *
+ * Don't use SharedFileSet here as we need the fileset to survive after
+ * releasing the shared memory so that the leader apply worker can re-use
+ * the fileset for next streaming transaction.
+ */
+ LeaderFileSetState fileset_state;
+ FileSet fileset;
Minor rewording of that comment
SUGGESTION
After entering PARTIAL_SERIALIZE mode, the leader apply worker will
serialize changes to the file, and share the fileset with the parallel
apply worker when processing the transaction finish command. Then the
parallel apply worker will apply all the spooled messages.
FileSet is used here instead of SharedFileSet because we need it to
survive after releasing the shared memory so that the leader apply
worker can re-use the same fileset for the next streaming transaction.
~~~
35. globals
/*
+ * Indicates whether the leader apply worker needs to serialize the
+ * remaining changes to disk due to timeout when sending data to the
+ * parallel apply worker.
+ */
+ bool serialize_changes;
35a.
I wonder if the comment would be better to also mention "via shared memory".
SUGGESTION
Indicates whether the leader apply worker needs to serialize the
remaining changes to disk due to timeout when attempting to send data
to the parallel apply worker via shared memory.
~
35b.
I wonder if a more informative variable name might be
serialize_remaining_changes?
------
[1] https://stackoverflow.com/questions/17504316/what-happens-with-an-extern-inline-function
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Sun, Nov 27, 2022 at 9:43 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Attach the new version patch which addressed all comments so far.
>
Few comments on v52-0001*
========================
1.
pa_free_worker()
{
...
+ /* Free the worker information if the worker exited cleanly. */
+ if (!winfo->error_mq_handle)
+ {
+ pa_free_worker_info(winfo);
+
+ if (winfo->in_use &&
+ !hash_search(ParallelApplyWorkersHash, &xid, HASH_REMOVE, NULL))
+ elog(ERROR, "hash table corrupted");
pa_free_worker_info() pfrees the winfo, so how is it legal to
winfo->in_use in the above check?
Also, why is this check (!winfo->error_mq_handle) required in the
first place in the patch? The worker exits cleanly only when the
leader apply worker sends a SIGINT signal and in that case, we already
detach from the error queue and clean up other worker information.
2.
+HandleParallelApplyMessages(void)
+{
...
...
+ foreach(lc, ParallelApplyWorkersList)
+ {
+ shm_mq_result res;
+ Size nbytes;
+ void *data;
+ ParallelApplyWorkerInfo *winfo = (ParallelApplyWorkerInfo *) lfirst(lc);
+
+ if (!winfo->error_mq_handle)
+ continue;
Similar to the previous comment, it is not clear whether we need this
check. If required, can we add a comment to indicate the case where it
happens to be true?
Note, there is a similar check for winfo->error_mq_handle in
pa_wait_for_xact_state(). Please add some comments if that is
required.
3. Why is there apply_worker_clean_exit() at the end of
ParallelApplyWorkerMain()? Normally either the leader worker stops
parallel apply, or parallel apply gets stopped because of a parameter
change, or exits because of error, and in none of those cases it can
hit this code path unless I am missing something.
Additionally, I think in LogicalParallelApplyLoop, we will never
receive zero-length messages so that is also wrong and should be
converted to elog(ERROR,..).
4. I think in logicalrep_worker_detach(), we should detach from the
shm error queue so that the parallel apply worker won't try to send a
termination message back to the leader worker.
5.
pa_send_data()
{
...
+ if (startTime == 0)
+ startTime = GetCurrentTimestamp();
...
What is the use of getting the current timestamp before waitlatch
logic, if it is not used before that? It seems that is for the time
logic to look correct. We can probably reduce the 10s interval to 9s
for that.
In this function, we need to add some comments to indicate why the
current logic is used, and also probably we can refer to the comments
atop this file.
6. I think it will be better if we keep stream_apply_worker local to
applyparallelworker.c by exposing functions to cache/resetting the
required info.
7. Apart from the above, I have made a few changes in the comments and
some miscellaneous cosmetic changes in the attached. Kindly include
these in the next version unless you see a problem with any change.
--
With Regards,
Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Nov 28, 2022 at 12:49 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
...
>
> 17.
> @@ -388,10 +401,9 @@ static inline void cleanup_subxact_info(void);
> /*
> * Serialize and deserialize changes for a toplevel transaction.
> */
> -static void stream_cleanup_files(Oid subid, TransactionId xid);
> static void stream_open_file(Oid subid, TransactionId xid,
> bool first_segment);
> -static void stream_write_change(char action, StringInfo s);
> +static void stream_write_message(TransactionId xid, char action, StringInfo s);
> static void stream_close_file(void);
>
> 17a.
>
> I felt just saying "file/files" is too vague. All the references to
> the file should be consistent, so IMO everything would be better named
> like:
>
> "stream_cleanup_files" -> "stream_msg_spoolfile_cleanup()"
> "stream_open_file" -> "stream_msg_spoolfile_open()"
> "stream_close_file" -> "stream_msg_spoolfile_close()"
> "stream_write_message" -> "stream_msg_spoolfile_write_msg()"
>
> ~
>
> 17b.
> IMO there is not enough distinction here between function names
> stream_write_message and stream_write_change. e.g. You cannot really
> tell from their names what might be the difference.
>
> ~~~
>
I think the only new function needed by this patch is
stream_write_message so don't see why to change all others for that. I
see two possibilities to make name better (a) name function as
stream_open_and_write_change, or (b) pass a new argument (boolean
open) to stream_write_change
...
>
> src/include/replication/worker_internal.h
>
> 33. LeaderFileSetState
>
> +/* State of fileset in leader apply worker. */
> +typedef enum LeaderFileSetState
> +{
> + LEADER_FILESET_UNKNOWN,
> + LEADER_FILESET_BUSY,
> + LEADER_FILESET_ACCESSIBLE
> +} LeaderFileSetState;
>
> 33a.
>
> Missing from typedefs.list?
>
> ~
>
> 33b.
>
> I thought some more explanatory comments for the meaning of
> BUSY/ACCESSIBLE should be here.
>
> ~
>
> 33c.
>
> READY might be a better value than ACCESSIBLE
>
> ~
>
> 33d.
> I'm not sure what usefulness does the "LEADER_" and "Leader" prefixes
> give here. Maybe a name like PartialFileSetStat is more meaningful?
>
> e.g. like this?
>
> typedef enum PartialFileSetState
> {
> FS_UNKNOWN,
> FS_BUSY,
> FS_READY
> } PartialFileSetState;
>
> ~
>
All your suggestions in this point look good to me.
>
> ~~~
>
>
> 35. globals
>
> /*
> + * Indicates whether the leader apply worker needs to serialize the
> + * remaining changes to disk due to timeout when sending data to the
> + * parallel apply worker.
> + */
> + bool serialize_changes;
>
> 35a.
> I wonder if the comment would be better to also mention "via shared memory".
>
> SUGGESTION
>
> Indicates whether the leader apply worker needs to serialize the
> remaining changes to disk due to timeout when attempting to send data
> to the parallel apply worker via shared memory.
>
> ~
>
I think the comment should say " .. the leader apply worker serialized
remaining changes ..."
> 35b.
> I wonder if a more informative variable name might be
> serialize_remaining_changes?
>
I think this needlessly makes the variable name long.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Mon, November 28, 2022 20:26 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Sun, Nov 27, 2022 at 9:43 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > Attach the new version patch which addressed all comments so far.
> >
>
> Few comments on v52-0001*
> ========================
> 1.
> pa_free_worker()
> {
> ...
> + /* Free the worker information if the worker exited cleanly. */ if
> + (!winfo->error_mq_handle) { pa_free_worker_info(winfo);
> +
> + if (winfo->in_use &&
> + !hash_search(ParallelApplyWorkersHash, &xid, HASH_REMOVE, NULL))
> + elog(ERROR, "hash table corrupted");
>
> pa_free_worker_info() pfrees the winfo, so how is it legal to
> winfo->in_use in the above check?
>
> Also, why is this check (!winfo->error_mq_handle) required in the
> first place in the patch? The worker exits cleanly only when the
> leader apply worker sends a SIGINT signal and in that case, we already
> detach from the error queue and clean up other worker information.
It was intended for the case when a user send a signal, but it seems not standard way to do that.
So, I removed this check (!winfo->error_mq_handle).
> 2.
> +HandleParallelApplyMessages(void)
> +{
> ...
> ...
> + foreach(lc, ParallelApplyWorkersList) { shm_mq_result res; Size
> + nbytes;
> + void *data;
> + ParallelApplyWorkerInfo *winfo = (ParallelApplyWorkerInfo *)
> + lfirst(lc);
> +
> + if (!winfo->error_mq_handle)
> + continue;
>
> Similar to the previous comment, it is not clear whether we need this
> check. If required, can we add a comment to indicate the case where it
> happens to be true?
> Note, there is a similar check for winfo->error_mq_handle in
> pa_wait_for_xact_state(). Please add some comments if that is
> required.
Removed this check in these two functions.
> 3. Why is there apply_worker_clean_exit() at the end of
> ParallelApplyWorkerMain()? Normally either the leader worker stops
> parallel apply, or parallel apply gets stopped because of a parameter
> change, or exits because of error, and in none of those cases it can
> hit this code path unless I am missing something.
>
> Additionally, I think in LogicalParallelApplyLoop, we will never
> receive zero-length messages so that is also wrong and should be
> converted to elog(ERROR,..).
Agreed and changed.
> 4. I think in logicalrep_worker_detach(), we should detach from the
> shm error queue so that the parallel apply worker won't try to send a
> termination message back to the leader worker.
Agreed and changed.
> 5.
> pa_send_data()
> {
> ...
> + if (startTime == 0)
> + startTime = GetCurrentTimestamp();
> ...
>
> What is the use of getting the current timestamp before waitlatch
> logic, if it is not used before that? It seems that is for the time
> logic to look correct. We can probably reduce the 10s interval to 9s
> for that.
Changed.
> In this function, we need to add some comments to indicate why the
> current logic is used, and also probably we can refer to the comments
> atop this file.
Added some comments.
> 6. I think it will be better if we keep stream_apply_worker local to
> applyparallelworker.c by exposing functions to cache/resetting the
> required info.
Agree. Added a new function to set the stream_apply_worker.
> 7. Apart from the above, I have made a few changes in the comments and
> some miscellaneous cosmetic changes in the attached. Kindly include
> these in the next version unless you see a problem with any change.
Thanks, I have checked and merge them.
Attach the new version patch which addressed all comments.
Best regards,
Hou zj
Attachment
- v53-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v53-0001-Perform-streaming-logical-transactions-by-parall.patch
- v53-0002-Serialize-partial-changes-to-a-file-when-the-att.patch
- v53-0003-Test-streaming-parallel-option-in-tap-test.patch
- v53-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Mon, November 28, 2022 15:19 PM Peter Smith <smithpb2250@gmail.com> wrote:
> Here are some review comments for patch v51-0002
Thanks for your comments!
> ======
>
> 1.
>
> GENERAL - terminology: spool/serialize and data/changes/message
>
> The terminology seems to be used at random. IMO it might be worthwhile
> rechecking at least that terms are used consistently in all the
> comments. e.g "serialize message data to disk" ... and later ...
> "apply the spooled messages".
>
> Also for places where it says "Write the message to file" maybe
> consider using consistent terminology like "serialize the message to a
> file".
>
> Also, try to standardize the way things are described by using
> consistent (if they really are the same) terminology for "writing
> data" VS "writing data" VS "writing messages" etc. It is confusing
> trying to know if the different wording has some intended meaning or
> is it just random.
I changes some of them, but I think there some things left which I will recheck in next version.
And I think we'd better not change comments that refer to existing comments or functions or variables.
For example, it’s fine for comments that refer to apply_spooled_message to use "spool" "message".
> ======
>
> Commit message
>
> 2.
> When the leader apply worker times out while sending a message to the
> parallel apply worker. Instead of erroring out, switch to partial
> serialize mode and let the leader serialize all remaining changes to
> the file and notify the parallel apply workers to read and apply them at the end of the transaction.
>
> ~
>
> The first sentence seems incomplete
>
> SUGGESTION.
> In patch 0001 if the leader apply worker times out while attempting to
> send a message to the parallel apply worker it results in an ERROR.
>
> This patch (0002) modifies that behaviour, so instead of erroring it
> will switch to "partial serialize" mode - in this mode the leader
> serializes all remaining changes to a file and notifies the parallel
> apply workers to read and apply them at the end of the transaction.
>
> ~~~
>
> 3.
>
> This patch 0002 is called “Serialize partial changes to disk if the
> shm_mq buffer is full”, but the commit message is saying nothing about
> the buffer filling up. I think the Commit message should be mentioning
> something that makes the commit patch name more relevant. Otherwise
> change the patch name.
Changed.
> ======
>
> .../replication/logical/applyparallelworker.c
>
> 4. File header comment
>
> + * timeout is exceeded, the LA will write to file and indicate PA-2
> + that it
> + * needs to read file for remaining messages. Then LA will start
> + waiting for
> + * commit which will detect deadlock if any. (See pa_send_data() and
> + typedef
> + * enum TransApplyAction)
>
> "needs to read file for remaining messages" -> "needs to read that
> file for the remaining messages"
Changed.
> ~~~
>
> 5. pa_free_worker
>
> + /*
> + * Stop the worker if there are enough workers in the pool.
> + *
> + * XXX we also need to stop the worker if the leader apply worker
> + * serialized part of the transaction data to a file due to send timeout.
> + * This is because the message could be partially written to the
> + queue due
> + * to send timeout and there is no way to clean the queue other than
> + * resending the message until it succeeds. To avoid complexity, we
> + * directly stop the worker in this case.
> + */
> + if (winfo->serialize_changes ||
> + napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
>
> 5a.
>
> + * XXX we also need to stop the worker if the leader apply worker
> + * serialized part of the transaction data to a file due to send timeout.
>
> SUGGESTION
> XXX The worker is also stopped if the leader apply worker needed to
> serialize part of the transaction data due to a send timeout.
>
> ~
>
> 5b.
>
> + /* Unlink the files with serialized changes. */ if
> + (winfo->serialize_changes)
> + stream_cleanup_files(MyLogicalRepWorker->subid, winfo->shared->xid);
>
> A better comment might be
>
> SUGGESTION
> Unlink any files that were needed to serialize partial changes.
Changed.
> ~~~
>
> 6. pa_spooled_messages
>
> /*
> * Replay the spooled messages in the parallel apply worker if leader
> apply
> * worker has finished serializing changes to the file.
> */
> static void
> pa_spooled_messages(void)
>
> 6a.
> IMO a better name for this function would be
> pa_apply_spooled_messages();
Not sure about this.
> ~
>
> 6b.
> "if leader apply" -> "if the leader apply"
Changed.
> ~
>
> 7.
>
> + /*
> + * Acquire the stream lock if the leader apply worker is serializing
> + * changes to the file, because the parallel apply worker will no
> + longer
> + * have a chance to receive a STREAM_STOP and acquire the lock until
> + the
> + * leader serialize all changes to the file.
> + */
> + if (fileset_state == LEADER_FILESET_BUSY) {
> + pa_lock_stream(MyParallelShared->xid, AccessShareLock);
> + pa_unlock_stream(MyParallelShared->xid, AccessShareLock); }
>
> SUGGESTION (rearranged comment - please check, I am not sure if I got
> this right)
>
> If the leader apply worker is still (busy) serializing partial changes
> then the parallel apply worker acquires the stream lock now.
> Otherwise, it would not have a chance to receive a STREAM_STOP (and
> acquire the stream lock) until the leader had serialized all changes.
Changed.
> ~~~
>
> 8. pa_send_data
>
> + *
> + * When sending data times out, data will be serialized to disk. And
> + the
> + * current streaming transaction will enter PARTIAL_SERIALIZE mode,
> + which
> means
> + * that subsequent data will also be serialized to disk.
> */
> void
> pa_send_data(ParallelApplyWorkerInfo *winfo, Size nbytes, const void
> *data)
>
> SUGGESTION (minor comment change)
>
> If the attempt to send data via shared memory times out, then we will
> switch to "PARTIAL_SERIALIZE mode" for the current transaction. This
> means that the current data and any subsequent data for this
> transaction will be serialized to disk.
Changed.
> ~
>
> 9.
>
> Assert(!IsTransactionState());
> + Assert(!winfo->serialize_changes);
>
> How about also asserting that this must be the LA worker?
Not sure about this as I think the parallel apply worker won't have a winfo.
> ~
>
> 10.
>
> + /*
> + * The parallel apply worker might be stuck for some reason, so
> + * stop sending data to parallel worker and start to serialize
> + * data to files.
> + */
> + winfo->serialize_changes = true;
>
> SUGGESTION (minor reword)
> The parallel apply worker might be stuck for some reason, so stop
> sending data directly to it and start to serialize data to files
> instead.
Changed.
> ~
>
> 11.
> + /* Skip first byte and statistics fields. */ msg.cursor +=
> + SIZE_STATS_MESSAGE + 1;
>
> IMO it would be better for the comment order and the code calculation
> order to be the same.
>
> SUGGESTION
> /* Skip first byte and statistics fields. */ msg.cursor += 1 +
> SIZE_STATS_MESSAGE;
Changed.
> ~
>
> 12. pa_stream_abort
>
> + /*
> + * If the parallel apply worker is applying the spooled
> + * messages, we save the current file position and close the
> + * file to prevent the file from being accidentally closed on
> + * rollback.
> + */
> + if (stream_fd)
> + {
> + BufFileTell(stream_fd, &fileno, &offset); BufFileClose(stream_fd);
> + reopen_stream_fd = true; }
> +
> RollbackToSavepoint(spname);
> CommitTransactionCommand();
> subxactlist = list_truncate(subxactlist, i + 1);
> +
> + /*
> + * Reopen the file and set the file position to the saved
> + * position.
> + */
> + if (reopen_stream_fd)
>
> It seems a bit vague to just refer to "close the file" and "reopen the
> file" in these comments. IMO it would be better to call this file by a
> name like "the message spool file" or similar. Please check all other
> similar comments.
Changed.
> ~~~
>
> 13. pa_set_fileset_state
>
> /*
> + * Set the fileset_state flag for the given parallel apply worker.
> +The
> + * stream_fileset of the leader apply worker will be written into the
> +shared
> + * memory if the fileset_state is LEADER_FILESET_ACCESSIBLE.
> + */
> +void
> +pa_set_fileset_state(ParallelApplyWorkerShared *wshared,
> +LeaderFileSetState fileset_state) {
>
> 13a.
>
> It is an enum -- not a "flag", so:
>
> "fileset_state flag" -> "fileste state"
Changed.
> ~~
>
> 13b.
>
> It seemed strange to me that the comment/code says this state is only
> written to shm when it is "ACCESSIBLE".... IIUC this same filestate
> lingers around to be reused for other workers so I expected the state
> should *always* be written whenever the LA changes it. (I mean even if
> the PA is not needing to look at this member, I still think it should
> have the current/correct value in it).
I think we will always change the state.
Or do you mean the fileset is only written(not the state) when it is ACCESSIBLE?
The fileset cannot be used before it's READY, so I didn't write that fileset into
shared memory before that.
> ======
>
> src/backend/replication/logical/worker.c
>
> 14. TRANS_LEADER_SEND_TO_PARALLEL
>
> + * TRANS_LEADER_PARTIAL_SERIALIZE:
> + * The action means that we are in the leader apply worker and have
> + sent
> some
> + * changes to the parallel apply worker, but the remaining changes
> + need to be
> + * serialized to disk due to timeout while sending data, and the
> + parallel apply
> + * worker will apply these changes when the final commit arrives.
> + *
> + * One might think we can use LEADER_SERIALIZE directly. But in
> + partial
> + * serialize mode, in addition to serializing changes to file, the
> + leader
> + * worker needs to write the STREAM_XXX message to disk, and needs to
> + wait
> for
> + * parallel apply worker to finish the transaction when processing
> + the
> + * transaction finish command. So a new action was introduced to make
> + the
> logic
> + * clearer.
> + *
> * TRANS_LEADER_SEND_TO_PARALLEL:
>
>
> SUGGESTION (Minor wording changes)
> The action means that we are in the leader apply worker and have sent
> some changes directly to the parallel apply worker, due to timeout
> while sending data the remaining changes need to be serialized to
> disk. The parallel apply worker will apply these serialized changes
> when the final commit arrives.
>
> LEADER_SERIALIZE could not be used for this case because, in addition
> to serializing changes, the leader worker also needs to write the
> STREAM_XXX message to disk, and wait for the parallel apply worker to
> finish the transaction when processing the transaction finish command.
> So this new action was introduced to make the logic clearer.
Changed.
> ~
>
> 15.
> /* Actions for streaming transactions. */
> TRANS_LEADER_SERIALIZE,
> + TRANS_LEADER_PARTIAL_SERIALIZE,
> TRANS_LEADER_SEND_TO_PARALLEL,
> TRANS_PARALLEL_APPLY
>
> Although it makes no difference I felt it would be better to put
> TRANS_LEADER_PARTIAL_SERIALIZE *after* TRANS_LEADER_SEND_TO_PARALLEL
> because that would be the order that these mode changes occur in the
> logic...
I thought that it is fine as it follows LEADER_SERIALIZE which is similar to
LEADER_PARTIAL_SERIALIZE.
> ~~~
>
> 16.
>
> @@ -375,7 +388,7 @@ typedef struct ApplySubXactData static
> ApplySubXactData subxact_data = {0, 0, InvalidTransactionId, NULL};
>
> static inline void subxact_filename(char *path, Oid subid,
> TransactionId xid); -static inline void changes_filename(char *path,
> Oid subid, TransactionId xid);
> +inline void changes_filename(char *path, Oid subid, TransactionId
> +xid);
>
> IIUC (see [1]) when this function was made non-static the "inline"
> should have been put into the header file.
Changed this function from "inline void" to "void" as I am not sure is it better to put
this function's definition on header file.
> ~
>
> 17.
> @@ -388,10 +401,9 @@ static inline void cleanup_subxact_info(void);
> /*
> * Serialize and deserialize changes for a toplevel transaction.
> */
> -static void stream_cleanup_files(Oid subid, TransactionId xid);
> static void stream_open_file(Oid subid, TransactionId xid,
> bool first_segment);
> -static void stream_write_change(char action, StringInfo s);
> +static void stream_write_message(TransactionId xid, char action,
> +StringInfo s);
> static void stream_close_file(void);
>
> 17a.
>
> I felt just saying "file/files" is too vague. All the references to
> the file should be consistent, so IMO everything would be better named
> like:
>
> "stream_cleanup_files" -> "stream_msg_spoolfile_cleanup()"
> "stream_open_file" -> "stream_msg_spoolfile_open()"
> "stream_close_file" -> "stream_msg_spoolfile_close()"
> "stream_write_message" -> "stream_msg_spoolfile_write_msg()"
Renamed the function stream_write_message to stream_open_and_write_change.
> ~
>
> 17b.
> IMO there is not enough distinction here between function names
> stream_write_message and stream_write_change. e.g. You cannot really
> tell from their names what might be the difference.
Changed the name.
> ~~~
>
> 18.
>
> @@ -586,6 +595,7 @@ handle_streamed_transaction(LogicalRepMsgType
> action, StringInfo s)
> TransactionId current_xid;
> ParallelApplyWorkerInfo *winfo;
> TransApplyAction apply_action;
> + StringInfoData original_msg;
>
> apply_action = get_transaction_apply_action(stream_xid, &winfo);
>
> @@ -595,6 +605,8 @@ handle_streamed_transaction(LogicalRepMsgType
> action, StringInfo s)
>
> Assert(TransactionIdIsValid(stream_xid));
>
> + original_msg = *s;
> +
> /*
> * We should have received XID of the subxact as the first part of the
> * message, so extract it.
> @@ -618,10 +630,14 @@ handle_streamed_transaction(LogicalRepMsgType
> action, StringInfo s)
> stream_write_change(action, s);
> return true;
>
> + case TRANS_LEADER_PARTIAL_SERIALIZE:
> case TRANS_LEADER_SEND_TO_PARALLEL:
> Assert(winfo);
>
> - pa_send_data(winfo, s->len, s->data);
> + if (apply_action == TRANS_LEADER_SEND_TO_PARALLEL)
> + pa_send_data(winfo, s->len, s->data); else
> + stream_write_change(action, &original_msg);
>
> The original_msg is not used except for TRANS_LEADER_PARTIAL_SERIALIZE
> case so I think it should only be declared/assigned in the scope of
> that 'else'
The member 'cursor' of 's' is changed after invoking the function pq_getmsgint.
So 'original_msg' is assigned before invoking the function pq_getmsgint.
> ~
>
> 20.
>
> + /*
> + * Close the file before committing if the parallel apply is
> + * applying spooled changes.
> + */
> + if (stream_fd)
> + BufFileClose(stream_fd);
>
> I found this a bit confusing because there is already a
> stream_close_file() wrapper function which does almost the same as
> this. So either this code should be calling that function, or the
> comment here should be explaining why this code is NOT calling that
> function.
Changed.
> ~~~
>
> 21. serialize_stream_start
>
> +/*
> + * Initialize fileset (if not already done).
> + *
> + * Create a new file when first_segment is true, otherwise open the
> +existing
> + * file.
> + */
> +void
> +serialize_stream_start(TransactionId xid, bool first_segment)
>
> IMO this function should be called stream_msg_spoolfile_init() or
> stream_msg_spoolfile_begin() to match the pattern for function names
> of the message spool file that I previously suggested. (see review
> comment #17a)
I am not sure about the name is better. I will think over this and adjust in next version.
> ~
>
> 22.
>
> + /*
> + * Initialize the worker's stream_fileset if we haven't yet. This
> + will be
> + * used for the entire duration of the worker so create it in a
> + permanent
> + * context. We create this on the very first streaming message from
> + any
> + * transaction and then use it for this and other streaming transactions.
> + * Now, we could create a fileset at the start of the worker as well
> + but
> + * then we won't be sure that it will ever be used.
> + */
> + if (!MyLogicalRepWorker->stream_fileset)
>
> I assumed this is a typo "Now," --> "Note," ?
That seems the existing comments, I am not sure it's a typo or not.
> ~
>
> 24.
>
> /*
> - * Start a transaction on stream start, this transaction will be
> - * committed on the stream stop unless it is a tablesync worker in
> - * which case it will be committed after processing all the
> - * messages. We need the transaction for handling the buffile,
> - * used for serializing the streaming data and subxact info.
> + * serialize_stream_start will start a transaction, this
> + * transaction will be committed on the stream stop unless it is a
> + * tablesync worker in which case it will be committed after
> + * processing all the messages. We need the transaction for
> + * handling the buffile, used for serializing the streaming data
> + * and subxact info.
> */
> - begin_replication_step();
> + serialize_stream_start(stream_xid, first_segment); break;
>
> Make the comment a bit more natural.
>
> SUGGESTION
>
> Function serialize_stream_start starts a transaction. This transaction
> will be committed on the stream stop unless it is a tablesync worker
> in which case it will be committed after processing all the messages.
> We need this transaction for handling the BufFile, used for
> serializing the streaming data and subxact info.
Changed.
> ~
>
> 25.
>
> + case TRANS_LEADER_PARTIAL_SERIALIZE:
> /*
> - * Initialize the worker's stream_fileset if we haven't yet. This
> - * will be used for the entire duration of the worker so create it
> - * in a permanent context. We create this on the very first
> - * streaming message from any transaction and then use it for this
> - * and other streaming transactions. Now, we could create a
> - * fileset at the start of the worker as well but then we won't be
> - * sure that it will ever be used.
> + * The file should have been created when entering
> + * PARTIAL_SERIALIZE mode so no need to create it again. The
> + * transaction started in serialize_stream_start will be committed
> + * on the stream stop.
> */
> - if (!MyLogicalRepWorker->stream_fileset)
>
> BEFORE
> The file should have been created when entering PARTIAL_SERIALIZE mode
> so no need to create it again.
>
> SUGGESTION
> The message spool file was already created when entering
> PARTIAL_SERIALIZE mode.
Changed.
> ~~~
>
> 26. serialize_stream_stop
>
> /*
> + * Update the information about subxacts and close the file.
> + *
> + * This function should be called when the serialize_stream_start
> +function has
> + * been called.
> + */
> +void
> +serialize_stream_stop(TransactionId xid)
>
> Maybe 2nd part of that comment should be something more like
>
> SUGGESTION
> This function ends what was started by the function serialize_stream_start().
I am thinking about a new function name and will adjust this in next version.
> ~
>
> 27.
>
> + /*
> + * Close the file with serialized changes, and serialize information
> + about
> + * subxacts for the toplevel transaction.
> + */
> + subxact_info_write(MyLogicalRepWorker->subid, xid);
> + stream_close_file();
>
> Should the comment and the code be in the same order?
>
> SUGGESTION
> Serialize information about subxacts for the toplevel transaction,
> then close the stream messages spool file.
Changed.
> ~~~
>
> 28. handle_stream_abort
>
> + case TRANS_LEADER_PARTIAL_SERIALIZE:
> + Assert(winfo);
> +
> + /*
> + * Parallel apply worker might have applied some changes, so write
> + * the STREAM_ABORT message so that the parallel apply worker can
> + * rollback the subtransaction if needed.
> + */
> + stream_write_message(xid, LOGICAL_REP_MSG_STREAM_ABORT,
> + &original_msg);
> +
>
> 28a.
> The original_msg is not used except for TRANS_LEADER_PARTIAL_SERIALIZE
> case so I think it should only be declared/assigned in the scope of
> that case.
>
> ~
>
> 28b.
> "so that the parallel apply worker can" -> "so that it can"
Changed.
> ~~~
>
> 29. apply_spooled_messages
>
> +void
> +apply_spooled_messages(FileSet *stream_fileset, TransactionId xid,
> + XLogRecPtr lsn)
> {
> StringInfoData s2;
> int nchanges;
> char path[MAXPGPATH];
> char *buffer = NULL;
> MemoryContext oldcxt;
> - BufFile *fd;
>
> - maybe_start_skipping_changes(lsn);
> + if (!am_parallel_apply_worker())
> + maybe_start_skipping_changes(lsn);
>
> /* Make sure we have an open transaction */
> begin_replication_step();
> @@ -1810,8 +1913,8 @@ apply_spooled_messages(TransactionId xid,
> XLogRecPtr lsn)
> changes_filename(path, MyLogicalRepWorker->subid, xid);
> elog(DEBUG1, "replaying changes from file \"%s\"", path);
>
> - fd = BufFileOpenFileSet(MyLogicalRepWorker->stream_fileset, path,
> O_RDONLY,
> - false);
> + stream_fd = BufFileOpenFileSet(stream_fileset, path, O_RDONLY,
> + false); stream_xid = xid;
>
> IMO it seems strange to me that the fileset is passed as a parameter
> but then the resulting fd is always assigned to a single global
> variable (regardless of what the fileset was passed).
I am not sure about this as we already have similar code in stream_open_file().
> ~
>
> 30.
>
> - BufFileClose(fd);
> -
> + BufFileClose(stream_fd);
> pfree(buffer);
> pfree(s2.data);
>
> +done:
> + stream_fd = NULL;
> + stream_xid = InvalidTransactionId;
> +
>
> This code fragment seems to be doing almost the same as what function
> stream_close_file() is doing. Should you just call that instead?
Changed.
> ======
>
> src/include/replication/worker_internal.h
>
> 33. LeaderFileSetState
>
> +/* State of fileset in leader apply worker. */ typedef enum
> +LeaderFileSetState { LEADER_FILESET_UNKNOWN, LEADER_FILESET_BUSY,
> +LEADER_FILESET_ACCESSIBLE } LeaderFileSetState;
>
> 33a.
>
> Missing from typedefs.list?
>
> ~
>
> 33b.
>
> I thought some more explanatory comments for the meaning of
> BUSY/ACCESSIBLE should be here.
>
> ~
>
> 33c.
>
> READY might be a better value than ACCESSIBLE
>
> ~
>
> 33d.
> I'm not sure what usefulness does the "LEADER_" and "Leader" prefixes
> give here. Maybe a name like PartialFileSetStat is more meaningful?
>
> e.g. like this?
>
> typedef enum PartialFileSetState
> {
> FS_UNKNOWN,
> FS_BUSY,
> FS_READY
> } PartialFileSetState;
Changed.
> ~~~
>
> 34. ParallelApplyWorkerShared
>
> + /*
> + * The leader apply worker will serialize changes to the file after
> + * entering PARTIAL_SERIALIZE mode and share the fileset with the
> + parallel
> + * apply worker when processing the transaction finish command. And
> + then
> + * the parallel apply worker will apply all the spooled messages.
> + *
> + * Don't use SharedFileSet here as we need the fileset to survive
> + after
> + * releasing the shared memory so that the leader apply worker can
> + re-use
> + * the fileset for next streaming transaction.
> + */
> + LeaderFileSetState fileset_state;
> + FileSet fileset;
>
> Minor rewording of that comment
>
> SUGGESTION
> After entering PARTIAL_SERIALIZE mode, the leader apply worker will
> serialize changes to the file, and share the fileset with the parallel
> apply worker when processing the transaction finish command. Then the
> parallel apply worker will apply all the spooled messages.
>
> FileSet is used here instead of SharedFileSet because we need it to
> survive after releasing the shared memory so that the leader apply
> worker can re-use the same fileset for the next streaming transaction.
Changed.
> ~~~
>
> 35. globals
>
> /*
> + * Indicates whether the leader apply worker needs to serialize the
> + * remaining changes to disk due to timeout when sending data to the
> + * parallel apply worker.
> + */
> + bool serialize_changes;
>
> 35a.
> I wonder if the comment would be better to also mention "via shared memory".
>
> SUGGESTION
>
> Indicates whether the leader apply worker needs to serialize the
> remaining changes to disk due to timeout when attempting to send data
> to the parallel apply worker via shared memory.
Changed.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Nov 29, 2022 at 10:18 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Attach the new version patch which addressed all comments.
>
Review comments on v53-0001*
==========================
1.
Subscription *MySubscription = NULL;
-static bool MySubscriptionValid = false;
+bool MySubscriptionValid = false;
It seems still this variable is used in worker.c, so why it's scope changed?
2.
/* fields valid only when processing streamed transaction */
-static bool in_streamed_transaction = false;
+bool in_streamed_transaction = false;
Is it really required to change the scope of this variable? Can we
think of exposing a macro or inline function to check it in
applyparallelworker.c?
3.
should_apply_changes_for_rel(LogicalRepRelMapEntry *rel)
{
if (am_tablesync_worker())
return MyLogicalRepWorker->relid == rel->localreloid;
+ else if (am_parallel_apply_worker())
+ {
+ if (rel->state != SUBREL_STATE_READY)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("logical replication parallel apply worker for subscription
\"%s\" will stop",
Is this check sufficient? What if the rel->state is
SUBREL_STATE_UNKNOWN? I think that will be possible when the refresh
publication has not been yet performed after adding a new relation to
the publication. If that is true then won't we need to simply ignore
that change and continue instead of erroring out? Can you please once
test and check this case?
4.
+
+ case TRANS_PARALLEL_APPLY:
+ list_free(subxactlist);
+ subxactlist = NIL;
+
+ apply_handle_commit_internal(&commit_data);
I don't think we need to retail pfree subxactlist as this is allocated
in TopTransactionContext and will be freed at commit/prepare. This way
freeing looks a bit adhoc to me and you need to expose this list
outside applyparallelworker.c which doesn't seem like a good idea to
me either.
5.
+ apply_handle_commit_internal(&commit_data);
+
+ pa_set_xact_state(MyParallelShared, PARALLEL_TRANS_FINISHED);
+ pa_unlock_transaction(xid, AccessShareLock);
+
+ elog(DEBUG1, "finished processing the transaction finish command");
I think in this and similar DEBUG logs, we can tell the exact command
instead of writing 'finish'.
6.
apply_handle_stream_commit()
{
...
+ /*
+ * After sending the data to the parallel apply worker, wait for
+ * that worker to finish. This is necessary to maintain commit
+ * order which avoids failures due to transaction dependencies and
+ * deadlocks.
+ */
+ pa_wait_for_xact_finish(winfo);
+
+ pgstat_report_stat(false);
+ store_flush_position(commit_data.end_lsn);
+ stop_skipping_changes();
+
+ (void) pa_free_worker(winfo, xid);
...
}
apply_handle_stream_prepare(StringInfo s)
{
+
+ /*
+ * After sending the data to the parallel apply worker, wait for
+ * that worker to finish. This is necessary to maintain commit
+ * order which avoids failures due to transaction dependencies and
+ * deadlocks.
+ */
+ pa_wait_for_xact_finish(winfo);
+ (void) pa_free_worker(winfo, prepare_data.xid);
- /* unlink the files with serialized changes and subxact info. */
- stream_cleanup_files(MyLogicalRepWorker->subid, prepare_data.xid);
+ in_remote_transaction = false;
+
+ store_flush_position(prepare_data.end_lsn);
In both of the above functions, we should be consistent in calling
pa_free_worker() function which I think should be immediately after
pa_wait_for_xact_finish(). Is there a reason for not being consistent
here?
7.
+ res = shm_mq_receive(winfo->error_mq_handle, &nbytes, &data, true);
+
+ /*
+ * The leader will detach from the error queue and set it to NULL
+ * before preparing to stop all parallel apply workers, so we don't
+ * need to handle error messages anymore.
+ */
+ if (!winfo->error_mq_handle)
+ continue;
This check must be done before calling shm_mq_receive. So, changed it
in the attached patch.
8.
@@ -2675,6 +3156,10 @@ store_flush_position(XLogRecPtr remote_lsn)
{
FlushPosition *flushpos;
+ /* Skip for parallel apply workers. */
+ if (am_parallel_apply_worker())
+ return;
It is okay to always update the flush position by leader apply worker
but I think the leader won't have updated value for XactLastCommitEnd
as the local transaction is committed by parallel apply worker.
9.
@@ -3831,11 +4366,11 @@ ApplyWorkerMain(Datum main_arg)
ereport(DEBUG1,
(errmsg_internal("logical replication apply worker for subscription
\"%s\" two_phase is %s",
- MySubscription->name,
- MySubscription->twophasestate == LOGICALREP_TWOPHASE_STATE_DISABLED
? "DISABLED" :
- MySubscription->twophasestate == LOGICALREP_TWOPHASE_STATE_PENDING ?
"PENDING" :
- MySubscription->twophasestate == LOGICALREP_TWOPHASE_STATE_ENABLED ?
"ENABLED" :
- "?")));
+ MySubscription->name,
+ MySubscription->twophasestate == LOGICALREP_TWOPHASE_STATE_DISABLED
? "DISABLED" :
+ MySubscription->twophasestate == LOGICALREP_TWOPHASE_STATE_PENDING ?
"PENDING" :
+ MySubscription->twophasestate == LOGICALREP_TWOPHASE_STATE_ENABLED ?
"ENABLED" :
+ "?")));
Is this change related to this patch?
10. What is the reason to expose ApplyErrorCallbackArg via worker_internal.h?
11. The order to declare pa_set_stream_apply_worker() in
worker_internal.h and define in applyparallelworker.c is not the same.
Similarly, please check all other functions.
12. Apart from the above, I have made a few changes in the comments
and some other cosmetic changes in the attached patch.
--
With Regards,
Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Nov 29, 2022 at 6:03 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > 12. Apart from the above, I have made a few changes in the comments > and some other cosmetic changes in the attached patch. > I have made some additional changes in the comments at various places. Kindly check the attached and let me know your thoughts. -- With Regards, Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Nov 29, 2022 at 10:18 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Attach the new version patch which addressed all comments.
>
Some comments on v53-0002*
========================
1. I think testing the scenario where the shm_mq buffer is full
between the leader and parallel apply worker would require a large
amount of data and then also there is no guarantee. How about having a
developer GUC [1] force_apply_serialize which allows us to serialize
the changes and only after commit the parallel apply worker would be
allowed to apply it?
I am not sure if we can reliably test the serialization of partial
changes (like some changes have been already sent to parallel apply
worker and then serialization happens) but at least we can test the
serialization of complete xacts and their execution via parallel apply
worker.
2.
+ /*
+ * The stream lock is released when processing changes in a
+ * streaming block, so the leader needs to acquire the lock here
+ * before entering PARTIAL_SERIALIZE mode to ensure that the
+ * parallel apply worker will wait for the leader to release the
+ * stream lock.
+ */
+ if (in_streamed_transaction &&
+ action != LOGICAL_REP_MSG_STREAM_STOP)
+ {
+ pa_lock_stream(winfo->shared->xid, AccessExclusiveLock);
This comment is not completely correct because we can even acquire the
lock for the very streaming chunk. This check will work but doesn't
appear future-proof or at least not very easy to understand though I
don't have a better suggestion at this stage. Can we think of a better
check here?
3. I have modified a few comments in v53-0002* patch and the
incremental patch for the same is attached.
[1] - https://www.postgresql.org/docs/devel/runtime-config-developer.html
--
With Regards,
Amit Kapila.
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear hackers, > 1. I think testing the scenario where the shm_mq buffer is full > between the leader and parallel apply worker would require a large > amount of data and then also there is no guarantee. How about having a > developer GUC [1] force_apply_serialize which allows us to serialize > the changes and only after commit the parallel apply worker would be > allowed to apply it? > > I am not sure if we can reliably test the serialization of partial > changes (like some changes have been already sent to parallel apply > worker and then serialization happens) but at least we can test the > serialization of complete xacts and their execution via parallel apply > worker. I agreed for adding the developer options, because the part that LA serialize changes and PAs read and apply them might be complex. I have reported some bugs around here. One idea: A threshold(integer) can be introduced as the developer GUC. LA skips to send data or jumps to serialization part to PA via shm_mq_send() when it has sent more than (threshold) times. This may be able to test the partial-serialization case. Default(-1) means no-op, and 0 means all changes must be serialized. Best Regards, Hayato Kuroda FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, November 29, 2022 8:34 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Tue, Nov 29, 2022 at 10:18 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > Attach the new version patch which addressed all comments.
> >
>
> Review comments on v53-0001*
Thanks for the comments!
> ==========================
> 1.
> Subscription *MySubscription = NULL;
> -static bool MySubscriptionValid = false;
> +bool MySubscriptionValid = false;
>
> It seems still this variable is used in worker.c, so why it's scope changed?
I think it's not needed. Removed.
> 2.
> /* fields valid only when processing streamed transaction */ -static bool
> in_streamed_transaction = false;
> +bool in_streamed_transaction = false;
>
> Is it really required to change the scope of this variable? Can we think of
> exposing a macro or inline function to check it in applyparallelworker.c?
Introduced a new function.
> 3.
> should_apply_changes_for_rel(LogicalRepRelMapEntry *rel) {
> if (am_tablesync_worker())
> return MyLogicalRepWorker->relid == rel->localreloid;
> + else if (am_parallel_apply_worker())
> + {
> + if (rel->state != SUBREL_STATE_READY)
> + ereport(ERROR,
> + (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("logical replication parallel apply worker for subscription
> \"%s\" will stop",
>
> Is this check sufficient? What if the rel->state is SUBREL_STATE_UNKNOWN? I
> think that will be possible when the refresh publication has not been yet
> performed after adding a new relation to the publication. If that is true then
> won't we need to simply ignore that change and continue instead of erroring
> out? Can you please once test and check this case?
You are right. Changed to not report an ERROR for SUBREL_STATE_UNKNOWN.
> 4.
> +
> + case TRANS_PARALLEL_APPLY:
> + list_free(subxactlist);
> + subxactlist = NIL;
> +
> + apply_handle_commit_internal(&commit_data);
>
> I don't think we need to retail pfree subxactlist as this is allocated in
> TopTransactionContext and will be freed at commit/prepare. This way freeing
> looks a bit adhoc to me and you need to expose this list outside
> applyparallelworker.c which doesn't seem like a good idea to me either.
Removed the list_free.
> 5.
> + apply_handle_commit_internal(&commit_data);
> +
> + pa_set_xact_state(MyParallelShared, PARALLEL_TRANS_FINISHED);
> + pa_unlock_transaction(xid, AccessShareLock);
> +
> + elog(DEBUG1, "finished processing the transaction finish command");
>
> I think in this and similar DEBUG logs, we can tell the exact command instead of
> writing 'finish'.
Changed.
> 6.
> apply_handle_stream_commit()
> {
> ...
> + /*
> + * After sending the data to the parallel apply worker, wait for
> + * that worker to finish. This is necessary to maintain commit
> + * order which avoids failures due to transaction dependencies and
> + * deadlocks.
> + */
> + pa_wait_for_xact_finish(winfo);
> +
> + pgstat_report_stat(false);
> + store_flush_position(commit_data.end_lsn);
> + stop_skipping_changes();
> +
> + (void) pa_free_worker(winfo, xid);
> ...
> }
> apply_handle_stream_prepare(StringInfo s) {
> +
> + /*
> + * After sending the data to the parallel apply worker, wait for
> + * that worker to finish. This is necessary to maintain commit
> + * order which avoids failures due to transaction dependencies and
> + * deadlocks.
> + */
> + pa_wait_for_xact_finish(winfo);
> + (void) pa_free_worker(winfo, prepare_data.xid);
>
> - /* unlink the files with serialized changes and subxact info. */
> - stream_cleanup_files(MyLogicalRepWorker->subid, prepare_data.xid);
> + in_remote_transaction = false;
> +
> + store_flush_position(prepare_data.end_lsn);
>
>
> In both of the above functions, we should be consistent in calling
> pa_free_worker() function which I think should be immediately after
> pa_wait_for_xact_finish(). Is there a reason for not being consistent here?
Changed the order to make them consistent.
> 7.
> + res = shm_mq_receive(winfo->error_mq_handle, &nbytes, &data, true);
> +
> + /*
> + * The leader will detach from the error queue and set it to NULL
> + * before preparing to stop all parallel apply workers, so we don't
> + * need to handle error messages anymore.
> + */
> + if (!winfo->error_mq_handle)
> + continue;
>
> This check must be done before calling shm_mq_receive. So, changed it in the
> attached patch.
Thanks, merged.
> 8.
> @@ -2675,6 +3156,10 @@ store_flush_position(XLogRecPtr remote_lsn) {
> FlushPosition *flushpos;
>
> + /* Skip for parallel apply workers. */ if (am_parallel_apply_worker())
> + return;
>
> It is okay to always update the flush position by leader apply worker but I think
> the leader won't have updated value for XactLastCommitEnd as the local
> transaction is committed by parallel apply worker.
I added a field in shared memory so that the parallel apply worker can pass
the XactLastCommitEnd to leader and then the leader will store that.
> 9.
> @@ -3831,11 +4366,11 @@ ApplyWorkerMain(Datum main_arg)
>
> ereport(DEBUG1,
> (errmsg_internal("logical replication apply worker for subscription \"%s\"
> two_phase is %s",
> - MySubscription->name,
> - MySubscription->twophasestate ==
> LOGICALREP_TWOPHASE_STATE_DISABLED
> ? "DISABLED" :
> - MySubscription->twophasestate ==
> LOGICALREP_TWOPHASE_STATE_PENDING ?
> "PENDING" :
> - MySubscription->twophasestate ==
> LOGICALREP_TWOPHASE_STATE_ENABLED ?
> "ENABLED" :
> - "?")));
> + MySubscription->name,
> + MySubscription->twophasestate ==
> LOGICALREP_TWOPHASE_STATE_DISABLED
> ? "DISABLED" :
> + MySubscription->twophasestate ==
> LOGICALREP_TWOPHASE_STATE_PENDING ?
> "PENDING" :
> + MySubscription->twophasestate ==
> LOGICALREP_TWOPHASE_STATE_ENABLED ?
> "ENABLED" :
> + "?")));
>
> Is this change related to this patch?
I think accidentally changed due to pgident. Reverted.
> 10. What is the reason to expose ApplyErrorCallbackArg via worker_internal.h?
The parallel apply worker need to set the origin name into this. I introduced another function
to set this.
> 11. The order to declare pa_set_stream_apply_worker() in worker_internal.h and
> define in applyparallelworker.c is not the same.
> Similarly, please check all other functions.
Changed.
> 12. Apart from the above, I have made a few changes in the comments and
> some other cosmetic changes in the attached patch.
Thanks, I have checked and merged them.
Attach the new version patch set.
I haven't addressed comment #1 and #2 from [1], I need to think about it and
will handle it soon. Besides, I haven't renamed serialize_stream_start/stop and
haven't finished the word consistency check for comments, I think I will handle
them soon.
[1] https://www.postgresql.org/message-id/CAA4eK1LGKYUDFZ_jFPrU497wQf2HNvt5a%2BtCTpqSeWSG6kfpSA%40mail.gmail.com
Best regards,
Hou zj
Attachment
- v54-0001-Perform-streaming-logical-transactions-by-parall.patch
- v54-0002-Serialize-partial-changes-to-a-file-when-the-att.patch
- v54-0003-Test-streaming-parallel-option-in-tap-test.patch
- v54-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v54-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, November 30, 2022 9:41 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Tuesday, November 29, 2022 8:34 PM Amit Kapila > > Review comments on v53-0001* > > Attach the new version patch set. Sorry, there were some mistakes in the previous patch set. Here is the correct V54 patch set. I also ran pgindent for the patch set. Best regards, Hou zj
Attachment
- v54-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v54-0002-Serialize-partial-changes-to-a-file-when-the-att.patch
- v54-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v54-0001-Perform-streaming-logical-transactions-by-parall.patch
- v54-0003-Test-streaming-parallel-option-in-tap-test.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, Nov 30, 2022 at 7:54 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Nov 29, 2022 at 10:18 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > Attach the new version patch which addressed all comments. > > > > Some comments on v53-0002* > ======================== > 1. I think testing the scenario where the shm_mq buffer is full > between the leader and parallel apply worker would require a large > amount of data and then also there is no guarantee. How about having a > developer GUC [1] force_apply_serialize which allows us to serialize > the changes and only after commit the parallel apply worker would be > allowed to apply it? +1 The code coverage report shows that we don't cover the partial serialization codes. This GUC would improve the code coverage. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, Nov 30, 2022 at 10:51 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Wednesday, November 30, 2022 9:41 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
> >
> > On Tuesday, November 29, 2022 8:34 PM Amit Kapila
> > > Review comments on v53-0001*
> >
> > Attach the new version patch set.
>
> Sorry, there were some mistakes in the previous patch set.
> Here is the correct V54 patch set. I also ran pgindent for the patch set.
>
Thank you for updating the patches. Here are random review comments
for 0001 and 0002 patches.
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
errmsg("logical replication parallel apply worker
exited abnormally"),
errcontext("%s", edata.context)));
and
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
errmsg("logical replication parallel apply worker
exited because of subscription information change")));
I'm not sure ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE is appropriate
here. Given that parallel apply worker has already reported the error
message with the error code, I think we don't need to set the
errorcode for the logs from the leader process.
Also, I'm not sure the term "exited abnormally" is appropriate since
we use it when the server crashes for example. I think ERRORs reported
here don't mean that in general.
---
if (am_parallel_apply_worker() && on_subinfo_change)
{
/*
* If a parallel apply worker exits due to the subscription
* information change, we notify the leader apply worker so that the
* leader can report more meaningful message in time and restart the
* logical replication.
*/
pq_putmessage('X', NULL, 0);
}
and
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
errmsg("logical replication parallel apply worker
exited because of subscription information change")));
Do we really need an additional message in case of 'X'? When we call
apply_worker_clean_exit with on_subinfo_change = true, we have
reported the error message such as:
ereport(LOG,
(errmsg("logical replication parallel apply worker for
subscription \"%s\" will stop because of a parameter change",
MySubscription->name)));
I think that reporting a similar message from the leader might not be
meaningful for users.
---
- if (options->proto.logical.streaming &&
- PQserverVersion(conn->streamConn) >= 140000)
- appendStringInfoString(&cmd, ", streaming 'on'");
+ if (options->proto.logical.streaming_str)
+ appendStringInfo(&cmd, ", streaming '%s'",
+
options->proto.logical.streaming_str);
and
+ /*
+ * Assign the appropriate option value for streaming option
according to
+ * the 'streaming' mode and the publisher's ability to
support that mode.
+ */
+ if (server_version >= 160000 &&
+ MySubscription->stream == SUBSTREAM_PARALLEL)
+ {
+ options.proto.logical.streaming_str = pstrdup("parallel");
+ MyLogicalRepWorker->parallel_apply = true;
+ }
+ else if (server_version >= 140000 &&
+ MySubscription->stream != SUBSTREAM_OFF)
+ {
+ options.proto.logical.streaming_str = pstrdup("on");
+ MyLogicalRepWorker->parallel_apply = false;
+ }
+ else
+ {
+ options.proto.logical.streaming_str = NULL;
+ MyLogicalRepWorker->parallel_apply = false;
+ }
This change moves the code of adjustment of the streaming option based
on the publisher server version from libpqwalreceiver.c to worker.c.
On the other hand, the similar logic for other parameters such as
"two_phase" and "origin" are still done in libpqwalreceiver.c. How
about passing MySubscription->stream via WalRcvStreamOptions and
constructing a streaming option string in libpqrcv_startstreaming()?
In ApplyWorkerMain(), we just need to set
MyLogicalRepWorker->parallel_apply = true if (server_version >= 160000
&& MySubscription->stream == SUBSTREAM_PARALLEL). We won't need
pstrdup for "parallel" and "on", and it's more consistent with other
parameters.
---
+ * We maintain a worker pool to avoid restarting workers for each streaming
+ * transaction. We maintain each worker's information in the
Do we need to describe the pool in the doc?
---
+ * in AccessExclusive mode at transaction finish commands (STREAM_COMMIT and
+ * STREAM_PREAPRE) and release it immediately.
typo, s/STREAM_PREAPRE/STREAM_PREPARE/
---
+/* Parallel apply workers hash table (initialized on first use). */
+static HTAB *ParallelApplyWorkersHash = NULL;
+
+/*
+ * A list to maintain the active parallel apply workers. The information for
+ * the new worker is added to the list after successfully launching it. The
+ * list entry is removed if there are already enough workers in the worker
+ * pool either at the end of the transaction or while trying to find a free
+ * worker for applying the transaction. For more information about the worker
+ * pool, see comments atop this file.
+ */
+static List *ParallelApplyWorkersList = NIL;
The names ParallelApplyWorkersHash and ParallelWorkersList are very
similar but the usages are completely different. Probably we can find
better names such as ParallelApplyTxnHash and ParallelApplyWorkerPool.
And probably we can add more comments for ParallelApplyWorkersHash.
---
if (winfo->serialize_changes ||
napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
{
int slot_no;
uint16 generation;
SpinLockAcquire(&winfo->shared->mutex);
generation = winfo->shared->logicalrep_worker_generation;
slot_no = winfo->shared->logicalrep_worker_slot_no;
SpinLockRelease(&winfo->shared->mutex);
logicalrep_pa_worker_stop(slot_no, generation);
pa_free_worker_info(winfo);
return true;
}
/* Unlink any files that were needed to serialize partial changes. */
if (winfo->serialize_changes)
stream_cleanup_files(MyLogicalRepWorker->subid, winfo->shared->xid);
If winfo->serialize_changes is true, we return true in the first if
statement. So stream_cleanup_files in the second if statement is never
executed.
---
+ /*
+ * First, try to get a parallel apply worker from the pool,
if available.
+ * Otherwise, try to start a new parallel apply worker.
+ */
+ winfo = pa_get_available_worker();
+ if (!winfo)
+ {
+ winfo = pa_init_and_launch_worker();
+ if (!winfo)
+ return;
+ }
I think we don't necessarily need to separate two functions for
getting a worker from the pool and launching a new worker. It seems to
reduce the readability. Instead, I think that we can have one function
that returns winfo if there is a free worker in the worker pool or it
launches a worker. That way, we can simply do like:
winfo = pg_launch_parallel_worker()
if (!winfo)
return;
---
+ /* Setup replication origin tracking. */
+ StartTransactionCommand();
+ ReplicationOriginNameForLogicalRep(MySubscription->oid, InvalidOid,
+
originname, sizeof(originname));
+ originid = replorigin_by_name(originname, true);
+ if (!OidIsValid(originid))
+ originid = replorigin_create(originname);
This code looks to allow parallel workers to use different origins in
cases where the origin doesn't exist, but is that okay? Shouldn't we
pass miassing_ok = false in this case?
---
cfbot seems to fails:
https://cirrus-ci.com/task/6264595342426112
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Dec 1, 2022 at 11:44 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Wed, Nov 30, 2022 at 7:54 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, Nov 29, 2022 at 10:18 AM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > Attach the new version patch which addressed all comments. > > > > > > > Some comments on v53-0002* > > ======================== > > 1. I think testing the scenario where the shm_mq buffer is full > > between the leader and parallel apply worker would require a large > > amount of data and then also there is no guarantee. How about having a > > developer GUC [1] force_apply_serialize which allows us to serialize > > the changes and only after commit the parallel apply worker would be > > allowed to apply it? > > +1 > > The code coverage report shows that we don't cover the partial > serialization codes. This GUC would improve the code coverage. > Shall we keep it as a boolean or an integer? Keeping it as an integer as suggested by Kuroda-San [1] would have an added advantage that we can easily test the cases where serialization would be triggered after sending some changes. [1] - https://www.postgresql.org/message-id/TYAPR01MB5866160DE81FA2D88B8F22DEF5159%40TYAPR01MB5866.jpnprd01.prod.outlook.com -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, December 1, 2022 3:58 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Wed, Nov 30, 2022 at 10:51 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Wednesday, November 30, 2022 9:41 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Tuesday, November 29, 2022 8:34 PM Amit Kapila
> > > > Review comments on v53-0001*
> > >
> > > Attach the new version patch set.
> >
> > Sorry, there were some mistakes in the previous patch set.
> > Here is the correct V54 patch set. I also ran pgindent for the patch set.
> >
>
> Thank you for updating the patches. Here are random review comments for
> 0001 and 0002 patches.
Thanks for the comments!
>
> ereport(ERROR,
> (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> errmsg("logical replication parallel apply worker exited
> abnormally"),
> errcontext("%s", edata.context))); and
>
> ereport(ERROR,
> (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> errmsg("logical replication parallel apply worker exited
> because of subscription information change")));
>
> I'm not sure ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE is appropriate
> here. Given that parallel apply worker has already reported the error message
> with the error code, I think we don't need to set the errorcode for the logs
> from the leader process.
>
> Also, I'm not sure the term "exited abnormally" is appropriate since we use it
> when the server crashes for example. I think ERRORs reported here don't mean
> that in general.
How about reporting "xxx worker exited due to error" ?
> ---
> if (am_parallel_apply_worker() && on_subinfo_change) {
> /*
> * If a parallel apply worker exits due to the subscription
> * information change, we notify the leader apply worker so that the
> * leader can report more meaningful message in time and restart the
> * logical replication.
> */
> pq_putmessage('X', NULL, 0);
> }
>
> and
>
> ereport(ERROR,
> (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> errmsg("logical replication parallel apply worker exited
> because of subscription information change")));
>
> Do we really need an additional message in case of 'X'? When we call
> apply_worker_clean_exit with on_subinfo_change = true, we have reported the
> error message such as:
>
> ereport(LOG,
> (errmsg("logical replication parallel apply worker for subscription
> \"%s\" will stop because of a parameter change",
> MySubscription->name)));
>
> I think that reporting a similar message from the leader might not be
> meaningful for users.
The intention is to let leader report more meaningful message if a worker
exited due to subinfo change. Otherwise, the leader is likely to report an
error like " lost connection ... to parallel apply worker" when trying to send
data via shared memory if the worker exited. What do you think ?
> ---
> - if (options->proto.logical.streaming &&
> - PQserverVersion(conn->streamConn) >= 140000)
> - appendStringInfoString(&cmd, ", streaming 'on'");
> + if (options->proto.logical.streaming_str)
> + appendStringInfo(&cmd, ", streaming '%s'",
> +
> options->proto.logical.streaming_str);
>
> and
>
> + /*
> + * Assign the appropriate option value for streaming option
> according to
> + * the 'streaming' mode and the publisher's ability to
> support that mode.
> + */
> + if (server_version >= 160000 &&
> + MySubscription->stream == SUBSTREAM_PARALLEL)
> + {
> + options.proto.logical.streaming_str = pstrdup("parallel");
> + MyLogicalRepWorker->parallel_apply = true;
> + }
> + else if (server_version >= 140000 &&
> + MySubscription->stream != SUBSTREAM_OFF)
> + {
> + options.proto.logical.streaming_str = pstrdup("on");
> + MyLogicalRepWorker->parallel_apply = false;
> + }
> + else
> + {
> + options.proto.logical.streaming_str = NULL;
> + MyLogicalRepWorker->parallel_apply = false;
> + }
>
> This change moves the code of adjustment of the streaming option based on
> the publisher server version from libpqwalreceiver.c to worker.c.
> On the other hand, the similar logic for other parameters such as "two_phase"
> and "origin" are still done in libpqwalreceiver.c. How about passing
> MySubscription->stream via WalRcvStreamOptions and constructing a
> streaming option string in libpqrcv_startstreaming()?
> In ApplyWorkerMain(), we just need to set
> MyLogicalRepWorker->parallel_apply = true if (server_version >= 160000
> && MySubscription->stream == SUBSTREAM_PARALLEL). We won't need
> pstrdup for "parallel" and "on", and it's more consistent with other parameters.
Thanks for the suggestion. I thought about the same idea before, but it seems
we would weed to introduce " pg_subscription.h " into libpqwalreceiver.c. The
libpqwalreceiver.c looks a like a common place. So I am not sure is it looks
better to expose the detail of streaming option to it.
> ---
> + * We maintain a worker pool to avoid restarting workers for each
> + streaming
> + * transaction. We maintain each worker's information in the
>
> Do we need to describe the pool in the doc?
I thought the worker pool is kind of internal information.
Maybe we can add it later if receive some feedback about this
after pushing the main patch.
> ---
> + * in AccessExclusive mode at transaction finish commands
> + (STREAM_COMMIT and
> + * STREAM_PREAPRE) and release it immediately.
>
> typo, s/STREAM_PREAPRE/STREAM_PREPARE/
Will change.
> ---
> +/* Parallel apply workers hash table (initialized on first use). */
> +static HTAB *ParallelApplyWorkersHash = NULL;
> +
> +/*
> + * A list to maintain the active parallel apply workers. The
> +information for
> + * the new worker is added to the list after successfully launching it.
> +The
> + * list entry is removed if there are already enough workers in the
> +worker
> + * pool either at the end of the transaction or while trying to find a
> +free
> + * worker for applying the transaction. For more information about the
> +worker
> + * pool, see comments atop this file.
> + */
> +static List *ParallelApplyWorkersList = NIL;
>
> The names ParallelApplyWorkersHash and ParallelWorkersList are very similar
> but the usages are completely different. Probably we can find better names
> such as ParallelApplyTxnHash and ParallelApplyWorkerPool.
> And probably we can add more comments for ParallelApplyWorkersHash.
Will change.
> ---
> if (winfo->serialize_changes ||
> napplyworkers > (max_parallel_apply_workers_per_subscription / 2)) {
> int slot_no;
> uint16 generation;
>
> SpinLockAcquire(&winfo->shared->mutex);
> generation = winfo->shared->logicalrep_worker_generation;
> slot_no = winfo->shared->logicalrep_worker_slot_no;
> SpinLockRelease(&winfo->shared->mutex);
>
> logicalrep_pa_worker_stop(slot_no, generation);
>
> pa_free_worker_info(winfo);
>
> return true;
> }
>
> /* Unlink any files that were needed to serialize partial changes. */ if
> (winfo->serialize_changes)
> stream_cleanup_files(MyLogicalRepWorker->subid, winfo->shared->xid);
>
> If winfo->serialize_changes is true, we return true in the first if statement. So
> stream_cleanup_files in the second if statement is never executed.
pa_free_worker_info will also cleanup the fileset. But I think I can move that
stream_cleanup_files before the "... napplyworkers >
(max_parallel_apply_workers_per_subscription / 2))" check so that it would be
more clear.
> ---
> + /*
> + * First, try to get a parallel apply worker from the pool,
> if available.
> + * Otherwise, try to start a new parallel apply worker.
> + */
> + winfo = pa_get_available_worker();
> + if (!winfo)
> + {
> + winfo = pa_init_and_launch_worker();
> + if (!winfo)
> + return;
> + }
>
> I think we don't necessarily need to separate two functions for getting a worker
> from the pool and launching a new worker. It seems to reduce the readability.
> Instead, I think that we can have one function that returns winfo if there is a free
> worker in the worker pool or it launches a worker. That way, we can simply do
> like:
>
> winfo = pg_launch_parallel_worker()
> if (!winfo)
> return;
Will change
> ---
> + /* Setup replication origin tracking. */
> + StartTransactionCommand();
> + ReplicationOriginNameForLogicalRep(MySubscription->oid,
> + InvalidOid,
> +
> originname, sizeof(originname));
> + originid = replorigin_by_name(originname, true);
> + if (!OidIsValid(originid))
> + originid = replorigin_create(originname);
>
> This code looks to allow parallel workers to use different origins in cases where
> the origin doesn't exist, but is that okay? Shouldn't we pass miassing_ok = false
> in this case?
>
Will change
> ---
> cfbot seems to fails:
>
> https://cirrus-ci.com/task/6264595342426112
Thanks for reporting, it's due to a testcase problem, I will fix that test soon.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Nov 30, 2022 at 4:23 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> 2.
> + /*
> + * The stream lock is released when processing changes in a
> + * streaming block, so the leader needs to acquire the lock here
> + * before entering PARTIAL_SERIALIZE mode to ensure that the
> + * parallel apply worker will wait for the leader to release the
> + * stream lock.
> + */
> + if (in_streamed_transaction &&
> + action != LOGICAL_REP_MSG_STREAM_STOP)
> + {
> + pa_lock_stream(winfo->shared->xid, AccessExclusiveLock);
>
> This comment is not completely correct because we can even acquire the
> lock for the very streaming chunk. This check will work but doesn't
> appear future-proof or at least not very easy to understand though I
> don't have a better suggestion at this stage. Can we think of a better
> check here?
>
One idea is that we acquire this lock every time and callers like
stream_commit are responsible to release it. Also, we can handle the
close of stream file in the respective callers. I think that will make
this part of the patch easier to follow.
Some other comments:
=====================
1. The handling of buffile inside pa_stream_abort() looks bit ugly to
me. I think you primarily required it because the buffile opened by
parallel apply worker is in CurrentResourceOwner. Can we think of
having a new resource owner to apply spooled messages? I think that
will avoid the need to have a special purpose code to handle buffiles
in parallel apply worker.
2.
@@ -564,6 +571,7 @@ handle_streamed_transaction(LogicalRepMsgType
action, StringInfo s)
TransactionId current_xid;
ParallelApplyWorkerInfo *winfo;
TransApplyAction apply_action;
+ StringInfoData original_msg;
apply_action = get_transaction_apply_action(stream_xid, &winfo);
@@ -573,6 +581,8 @@ handle_streamed_transaction(LogicalRepMsgType
action, StringInfo s)
Assert(TransactionIdIsValid(stream_xid));
+ original_msg = *s;
+
/*
* We should have received XID of the subxact as the first part of the
* message, so extract it.
@@ -596,10 +606,14 @@ handle_streamed_transaction(LogicalRepMsgType
action, StringInfo s)
stream_write_change(action, s);
return true;
+ case TRANS_LEADER_PARTIAL_SERIALIZE:
case TRANS_LEADER_SEND_TO_PARALLEL:
Assert(winfo);
- pa_send_data(winfo, s->len, s->data);
+ if (apply_action == TRANS_LEADER_SEND_TO_PARALLEL)
+ pa_send_data(winfo, s->len, s->data);
+ else
+ stream_write_change(action, &original_msg);
Please add the comment to specify the reason to remember the original string.
3.
@@ -1797,8 +1907,8 @@ apply_spooled_messages(TransactionId xid, XLogRecPtr lsn)
changes_filename(path, MyLogicalRepWorker->subid, xid);
elog(DEBUG1, "replaying changes from file \"%s\"", path);
- fd = BufFileOpenFileSet(MyLogicalRepWorker->stream_fileset, path, O_RDONLY,
- false);
+ stream_fd = BufFileOpenFileSet(stream_fileset, path, O_RDONLY, false);
+ stream_xid = xid;
Why do we need stream_xid here? I think we can avoid having global
stream_fd if the comment #1 is feasible.
4.
+ * TRANS_LEADER_APPLY:
+ * The action means that we
/The/This. Please make a similar change for other actions.
5. Apart from the above, please find a few changes to the comments for
0001 and 0002 patches in the attached patches.
--
With Regards,
Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Dec 2, 2022 at 2:29 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> 3. pa_setup_dsm
>
> +/*
> + * Set up a dynamic shared memory segment.
> + *
> + * We set up a control region that contains a fixed-size worker info
> + * (ParallelApplyWorkerShared), a message queue, and an error queue.
> + *
> + * Returns true on success, false on failure.
> + */
> +static bool
> +pa_setup_dsm(ParallelApplyWorkerInfo *winfo)
>
> IMO that's confusing to say "fixed-sized worker info" when it's
> referring to the ParallelApplyWorkerShared structure and not the other
> ParallelApplyWorkerInfo.
>
> Might be better to say:
>
> "a fixed-size worker info (ParallelApplyWorkerShared)" -> "a
> fixed-size struct (ParallelApplyWorkerShared)"
>
> ~~~
>
I find the existing wording better than what you are proposing. We can
remove the structure name if you think that is better but IMO, current
wording is good.
>
> 6. pa_free_worker_info
>
> + /*
> + * Ensure this worker information won't be reused during worker
> + * allocation.
> + */
> + ParallelApplyWorkersList = list_delete_ptr(ParallelApplyWorkersList,
> + winfo);
>
> SUGGESTION 1
> Removing from the worker pool ensures this information won't be reused
> during worker allocation.
>
> SUGGESTION 2 (more simply)
> Remove from the worker pool.
>
+1 for the second suggestion.
> ~~~
>
> 7. HandleParallelApplyMessage
>
> + /*
> + * The actual error must have been reported by the parallel
> + * apply worker.
> + */
> + ereport(ERROR,
> + (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("logical replication parallel apply worker exited abnormally"),
> + errcontext("%s", edata.context)));
>
> Maybe it's better to remove the comment, but replace it with an
> errhint that tells the user "For the cause of this error see the error
> logged by the logical replication parallel apply worker."
>
I am not sure if such an errhint is a good idea, anyway, I think both
the errors will be adjacent in the LOGs unless there is some other
error in the short span.
> ~~~
>
> 17. apply_handle_stream_stop
>
> + case TRANS_PARALLEL_APPLY:
> + elog(DEBUG1, "applied %u changes in the streaming chunk",
> + parallel_stream_nchanges);
> +
> + /*
> + * By the time parallel apply worker is processing the changes in
> + * the current streaming block, the leader apply worker may have
> + * sent multiple streaming blocks. This can lead to parallel apply
> + * worker start waiting even when there are more chunk of streams
> + * in the queue. So, try to lock only if there is no message left
> + * in the queue. See Locking Considerations atop
> + * applyparallelworker.c.
> + */
>
> SUGGESTION (minor rewording)
>
> By the time the parallel apply worker is processing the changes in the
> current streaming block, the leader apply worker may have sent
> multiple streaming blocks. To the parallel apply from waiting
> unnecessarily, try to lock only if there is no message left in the
> queue. See Locking Considerations atop applyparallelworker.c.
>
I have proposed the additional line (This can lead to parallel apply
worker start waiting even when there are more chunk of streams in the
queue.) because it took me some time to understand this particular
scenario.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Hou,
Thanks for making the patch. Followings are my comments for v54-0003 and 0004.
0003
pa_free_worker()
+ /* Unlink any files that were needed to serialize partial changes. */
+ if (winfo->serialize_changes)
+ stream_cleanup_files(MyLogicalRepWorker->subid, winfo->shared->xid);
+
I think this part is not needed, because the LA cannot reach here if winfo->serialize_changes is true. Moreover
stream_cleanup_files()is done in pa_free_worker_info().
LogicalParallelApplyLoop()
The parallel apply worker wakes up every 0.1s even if we are in the PARTIAL_SERIALIZE mode. Do you have idea to reduce
that?
```
+ pa_spooled_messages();
```
Comments are needed here, like "Changes may be serialize...".
pa_stream_abort()
```
+ /*
+ * Reopen the file and set the file position to the saved
+ * position.
+ */
+ if (reopen_stream_fd)
+ {
+ char path[MAXPGPATH];
+
+ changes_filename(path, MyLogicalRepWorker->subid, xid);
+ stream_fd = BufFileOpenFileSet(&MyParallelShared->fileset,
+ path, O_RDONLY,
false);
+ BufFileSeek(stream_fd, fileno, offset, SEEK_SET);
+ }
```
MyParallelShared->serialize_changes may be used instead of reopen_stream_fd.
worker.c
```
-#include "storage/buffile.h"
```
I think this include should not be removed.
handle_streamed_transaction()
```
+ if (apply_action == TRANS_LEADER_SEND_TO_PARALLEL)
+ pa_send_data(winfo, s->len, s->data);
+ else
+ stream_write_change(action, &original_msg);
```
Comments are needed here, 0001 has that bu removed in 0002.
There are some similar lines.
```
+ /*
+ * It is possible that while sending this change to parallel apply
+ * worker we need to switch to serialize mode.
+ */
+ if (winfo->serialize_changes)
+ pa_set_fileset_state(winfo->shared, FS_READY);
```
There are three same parts in the code, can we combine them to common part?
apply_spooled_messages()
```
+ /*
+ * Break the loop if the parallel apply worker has finished applying
+ * the transaction. The parallel apply worker should have closed the
+ * file before committing.
+ */
+ if (am_parallel_apply_worker() &&
+ MyParallelShared->xact_state == PARALLEL_TRANS_FINISHED)
+ goto done;
```
I thnk pfree(buffer) and pfree(s2.data) should not be skippied.
And this part should be at below "nchanges++;"
0004
set_subscription_retry()
```
+ LockSharedObject(SubscriptionRelationId, MySubscription->oid, 0,
+ AccessShareLock);
+
```
I think AccessExclusiveLock should be aquired instead of AccessShareLock.
In AlterSubscription(), LockSharedObject(AccessExclusiveLock) seems to be used.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Dec 2, 2022 at 4:57 PM Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com> wrote: > > handle_streamed_transaction() > > ``` > + if (apply_action == TRANS_LEADER_SEND_TO_PARALLEL) > + pa_send_data(winfo, s->len, s->data); > + else > + stream_write_change(action, &original_msg); > ``` > > Comments are needed here, 0001 has that bu removed in 0002. > There are some similar lines. > I have suggested removing it because they were just saying what is evident from the code and doesn't seem to be adding any value. I would say they were rather confusing. -- With Regards, Amit Kapila.
Fwd: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
---------- Forwarded message --------- From: Peter Smith <smithpb2250@gmail.com> Date: Sat, Dec 3, 2022 at 8:03 AM Subject: Re: Perform streaming logical transactions by background workers and parallel apply To: Amit Kapila <amit.kapila16@gmail.com> On Fri, Dec 2, 2022 at 8:57 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Dec 2, 2022 at 2:29 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > 3. pa_setup_dsm > > > > +/* > > + * Set up a dynamic shared memory segment. > > + * > > + * We set up a control region that contains a fixed-size worker info > > + * (ParallelApplyWorkerShared), a message queue, and an error queue. > > + * > > + * Returns true on success, false on failure. > > + */ > > +static bool > > +pa_setup_dsm(ParallelApplyWorkerInfo *winfo) > > > > IMO that's confusing to say "fixed-sized worker info" when it's > > referring to the ParallelApplyWorkerShared structure and not the other > > ParallelApplyWorkerInfo. > > > > Might be better to say: > > > > "a fixed-size worker info (ParallelApplyWorkerShared)" -> "a > > fixed-size struct (ParallelApplyWorkerShared)" > > > > ~~~ > > > > I find the existing wording better than what you are proposing. We can > remove the structure name if you think that is better but IMO, current > wording is good. > Including the structure name was helpful, but "worker info" made me wrongly think it was talking about ParallelApplyWorkerInfo (e.g. "worker info" was too much like WorkerInfo). So any different way to say "worker info" might avoid that confusion. ------ Kind Regards, Peter Smith. Fujitsu Australia
Fwd: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
(Resending this because somehow my previous post did not appear in the
mail archives)
---------- Forwarded message ---------
From: Peter Smith <smithpb2250@gmail.com>
Date: Fri, Dec 2, 2022 at 7:59 PM
Subject: Re: Perform streaming logical transactions by background
workers and parallel apply
To: houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com>
Cc: Amit Kapila <amit.kapila16@gmail.com>, Masahiko Sawada
<sawada.mshk@gmail.com>, wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com>, Dilip Kumar <dilipbalaut@gmail.com>,
shiy.fnst@fujitsu.com <shiy.fnst@fujitsu.com>, PostgreSQL Hackers
<pgsql-hackers@lists.postgresql.org>
Here are my review comments for patch v54-0001.
======
FILE: .../replication/logical/applyparallelworker.c
1. File header comment
1a.
+ * This file contains the code to launch, set up, and teardown parallel apply
+ * worker which receives the changes from the leader worker and
invokes routines
+ * to apply those on the subscriber database.
"parallel apply worker" -> "a parallel apply worker"
~
1b.
+ *
+ * This file contains routines that are intended to support setting up, using
+ * and tearing down a ParallelApplyWorkerInfo which is required to communicate
+ * among leader and parallel apply workers.
"that are intended to support" -> "for"
"required to communicate among leader and parallel apply workers." ->
"required so the leader worker and parallel apply workers can
communicate with each other."
~
1c.
+ *
+ * The parallel apply workers are assigned (if available) as soon as xact's
+ * first stream is received for subscriptions that have set their 'streaming'
+ * option as parallel. The leader apply worker will send changes to this new
+ * worker via shared memory. We keep this worker assigned till the transaction
+ * commit is received and also wait for the worker to finish at commit. This
+ * preserves commit ordering and avoid file I/O in most cases, although we
+ * still need to spill to a file if there is no worker available. See comments
+ * atop logical/worker to know more about streamed xacts whose changes are
+ * spilled to disk. It is important to maintain commit order to avoid failures
+ * due to (a) transaction dependencies, say if we insert a row in the first
+ * transaction and update it in the second transaction on publisher then
+ * allowing the subscriber to apply both in parallel can lead to failure in the
+ * update. (b) deadlocks, allowing transactions that update the same set of
+ * rows/tables in the opposite order to be applied in parallel can lead to
+ * deadlocks.
"due to (a)" -> "due to: "
"(a) transaction dependencies, " -> "(a) transaction dependencies - "
". (b) deadlocks, " => "; (b) deadlocks - "
~
1d.
+ *
+ * We maintain a worker pool to avoid restarting workers for each streaming
+ * transaction. We maintain each worker's information in the
+ * ParallelApplyWorkersList. After successfully launching a new worker, its
+ * information is added to the ParallelApplyWorkersList. Once the worker
+ * finishes applying the transaction, we mark it available for re-use. Now,
+ * before starting a new worker to apply the streaming transaction, we check
+ * the list for any available worker. Note that we maintain a maximum of half
+ * the max_parallel_apply_workers_per_subscription workers in the pool and
+ * after that, we simply exit the worker after applying the transaction.
+ *
"We maintain a worker pool" -> "A worker pool is used"
"We maintain each worker's information" -> "We maintain each worker's
information (ParallelApplyWorkerInfo)"
"we mark it available for re-use" -> "it is marked as available for re-use"
"Note that we maintain a maximum of half" -> "Note that we retain a
maximum of half"
~
1e.
+ * XXX This worker pool threshold is a bit arbitrary and we can provide a GUC
+ * variable for this in the future if required.
"a bit arbitrary" -> "arbitrary"
~
1f.
+ *
+ * The leader apply worker will create a separate dynamic shared memory segment
+ * when each parallel apply worker starts. The reason for this design is that
+ * we cannot count how many workers will be started. It may be possible to
+ * allocate enough shared memory in one segment based on the maximum number of
+ * parallel apply workers (max_parallel_apply_workers_per_subscription), but
+ * this would waste memory if no process is actually started.
+ *
"we cannot count how many workers will be started." -> "we cannot
predict how many workers will be needed."
~
1g.
+ * The dynamic shared memory segment will contain (a) a shm_mq that is used to
+ * send changes in the transaction from leader apply worker to parallel apply
+ * worker (b) another shm_mq that is used to send errors (and other messages
+ * reported via elog/ereport) from the parallel apply worker to leader apply
+ * worker (c) necessary information to be shared among parallel apply workers
+ * and leader apply worker (i.e. members of ParallelApplyWorkerShared).
"will contain (a)" => "contains: (a)"
"worker (b)" -> "worker; (b)
"worker (c)" -> "worker; (c)"
"and leader apply worker" -> "and the leader apply worker"
~
1h.
+ *
+ * Locking Considerations
+ * ----------------------
+ * Since the database structure (schema of subscription tables, constraints,
+ * etc.) of the publisher and subscriber could be different, applying
+ * transactions in parallel mode on the subscriber side can cause some
+ * deadlocks that do not occur on the publisher side which is expected and can
+ * happen even without parallel mode. In order to detect the deadlocks among
+ * leader and parallel apply workers, we need to ensure that we wait using lmgr
+ * locks, otherwise, such deadlocks won't be detected. The other approach was
+ * to not allow parallelism when the schema of tables is different between the
+ * publisher and subscriber but that would be too restrictive and would require
+ * the publisher to send much more information than it is currently sending.
+ *
"side which is expected and can happen even without parallel mode." =>
"side. This can happen even without parallel mode."
", otherwise, such deadlocks won't be detected." -> remove this
because the beginning of the sentence says the same thing.
"The other approach was to not allow" -> "An alternative approach
could be to not allow"
~
1i.
+ *
+ * 4) Lock types
+ *
+ * Both the stream lock and the transaction lock mentioned above are
+ * session-level locks because both locks could be acquired outside the
+ * transaction, and the stream lock in the leader need to persist across
+ * transaction boundaries i.e. until the end of the streaming transaction.
+ *-------------------------------------------------------------------------
+ */
"need to persist" -> "needs to persist"
~~~
2. ParallelApplyWorkersList
+/*
+ * A list to maintain the active parallel apply workers. The information for
+ * the new worker is added to the list after successfully launching it. The
+ * list entry is removed if there are already enough workers in the worker
+ * pool either at the end of the transaction or while trying to find a free
+ * worker for applying the transaction. For more information about the worker
+ * pool, see comments atop this file.
+ */
+static List *ParallelApplyWorkersList = NIL;
"A list to maintain the active parallel apply workers." -> "A list
(pool) of active parallel apply workers."
~~~
3. pa_setup_dsm
+/*
+ * Set up a dynamic shared memory segment.
+ *
+ * We set up a control region that contains a fixed-size worker info
+ * (ParallelApplyWorkerShared), a message queue, and an error queue.
+ *
+ * Returns true on success, false on failure.
+ */
+static bool
+pa_setup_dsm(ParallelApplyWorkerInfo *winfo)
IMO that's confusing to say "fixed-sized worker info" when it's
referring to the ParallelApplyWorkerShared structure and not the other
ParallelApplyWorkerInfo.
Might be better to say:
"a fixed-size worker info (ParallelApplyWorkerShared)" -> "a
fixed-size struct (ParallelApplyWorkerShared)"
~~~
4. pa_init_and_launch_worker
+ /*
+ * The worker info can be used for the entire duration of the worker so
+ * create it in a permanent context.
+ */
+ oldcontext = MemoryContextSwitchTo(ApplyContext);
SUGGESTION
The worker info can be used for the lifetime of the worker process, so
create it in a permanent context.
~~~
5. pa_allocate_worker
+ /*
+ * First, try to get a parallel apply worker from the pool, if available.
+ * Otherwise, try to start a new parallel apply worker.
+ */
+ winfo = pa_get_available_worker();
+ if (!winfo)
+ {
+ winfo = pa_init_and_launch_worker();
+ if (!winfo)
+ return;
+ }
SUGGESTION
Try to get a parallel apply worker from the pool. If none is available
then start a new one.
~~~
6. pa_free_worker_info
+ /*
+ * Ensure this worker information won't be reused during worker
+ * allocation.
+ */
+ ParallelApplyWorkersList = list_delete_ptr(ParallelApplyWorkersList,
+ winfo);
SUGGESTION 1
Removing from the worker pool ensures this information won't be reused
during worker allocation.
SUGGESTION 2 (more simply)
Remove from the worker pool.
~~~
7. HandleParallelApplyMessage
+ /*
+ * The actual error must have been reported by the parallel
+ * apply worker.
+ */
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("logical replication parallel apply worker exited abnormally"),
+ errcontext("%s", edata.context)));
Maybe it's better to remove the comment, but replace it with an
errhint that tells the user "For the cause of this error see the error
logged by the logical replication parallel apply worker."
~
8.
+ case 'X':
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("logical replication parallel apply worker exited because of
subscription information change")));
+ break; /* Silence compiler warning. */
+ default:
Add a blank line before the default:
~
9.
+ /*
+ * Don't need to do anything about NoticeResponse and
+ * NotifyResponse as the logical replication worker doesn't need
+ * to send messages to the client.
+ */
+ case 'N':
+ case 'A':
+ break;
+
+ /*
+ * Restart replication if a parallel apply worker exited because
+ * of subscription information change.
+ */
+ case 'X':
IMO the comments describing the logic to take for each case should be
*inside* the case. The comment above (if any) should only say what the
messagetype means means.
SUGGESTION
/* Notification, NotifyResponse. */
case 'N':
case 'A':
/*
* Don't need to do anything about these message types as the logical replication
* worker doesn't need to send messages to the client.
*/
break;
/* Parallel apply worker exited because of subscription information change. */
case 'X':
/* Restart replication */
~~~
10. pa_send_data
+ /*
+ * If the attempt to send data via shared memory times out, we restart
+ * the logical replication to prevent possible deadlocks with another
+ * parallel apply worker. Refer to the comments atop
+ * applyparallelworker.c for details.
+ */
+ if (startTime == 0)
+ startTime = GetCurrentTimestamp();
Sometimes (like here) you say "Refer to the comments atop
applyparallelworker.c". In other places, the comments say "Refer to
the comments atop this file.". IMO the wording should be consistent
everywhere.
~~~
11. pa_set_stream_apply_worker
+/*
+ * Set the worker that required for applying the current streaming transaction.
+ */
+void
+pa_set_stream_apply_worker(ParallelApplyWorkerInfo *winfo)
+{
+ stream_apply_worker = winfo;
+}
"the worker that required for" ?? English ??
~~~
12. pa_clean_subtrans
+/* Reset the list that maintains subtransactions. */
+void
+pa_clean_subtrans(void)
+{
+ subxactlist = NIL;
+}
Maybe a more informative function name would be pa_reset_subxactlist()?
~~~
13. pa_stream_abort
+ subxactlist = NIL;
Since you created a new function pa_clean_subtrans which does exactly
this same NIL assignment I was not expecting to see this global being
explicitly set like this in other code -- It's confusing to have
multiple ways to do the same thing.
Please check the rest of the patch in case the same is done elsewhere.
======
FILE: src/backend/replication/logical/launcher.c
14. logicalrep_worker_detach
+ /*
+ * Detach from the error_mq_handle for all parallel apply workers
+ * before terminating them to prevent the leader apply worker from
+ * receiving the worker termination messages and sending it to logs
+ * when the same is already done by individual parallel worker.
+ */
+ pa_detach_all_error_mq();
"before terminating them to prevent" -> "before terminating them. This prevents"
"termination messages" -> "termination message"
"by individual" -> "by the"
======
FILE: src/backend/replication/logical/worker.c
15. File header comment
+ * 1) Write to temporary files and apply when the final commit arrives
+ *
+ * This approach is used when user has set subscription's streaming option as
+ * on.
"when user has set" -> "when the user has set the"
~
16.
+ * 2) Parallel apply workers.
+ *
+ * This approach is used when user has set subscription's streaming option as
+ * parallel. See logical/applyparallelworker.c for information about this
+ * approach.
"when user has set" -> "when the user has set the "
~~~
17. apply_handle_stream_stop
+ case TRANS_PARALLEL_APPLY:
+ elog(DEBUG1, "applied %u changes in the streaming chunk",
+ parallel_stream_nchanges);
+
+ /*
+ * By the time parallel apply worker is processing the changes in
+ * the current streaming block, the leader apply worker may have
+ * sent multiple streaming blocks. This can lead to parallel apply
+ * worker start waiting even when there are more chunk of streams
+ * in the queue. So, try to lock only if there is no message left
+ * in the queue. See Locking Considerations atop
+ * applyparallelworker.c.
+ */
SUGGESTION (minor rewording)
By the time the parallel apply worker is processing the changes in the
current streaming block, the leader apply worker may have sent
multiple streaming blocks. To the parallel apply from waiting
unnecessarily, try to lock only if there is no message left in the
queue. See Locking Considerations atop applyparallelworker.c.
~~~
18. apply_handle_stream_abort
+ case TRANS_PARALLEL_APPLY:
+ pa_stream_abort(&abort_data);
+
+ /*
+ * We need to wait after processing rollback to savepoint for the
+ * next set of changes.
+ *
+ * By the time parallel apply worker is processing the changes in
+ * the current streaming block, the leader apply worker may have
+ * sent multiple streaming blocks. This can lead to parallel apply
+ * worker start waiting even when there are more chunk of streams
+ * in the queue. So, try to lock only if there is no message left
+ * in the queue. See Locking Considerations atop
+ * applyparallelworker.c.
+ */
Second paragraph ("By the time...") same review comment as the
previous one (#17)
~~~
19. store_flush_position
+ /*
+ * Skip for parallel apply workers. The leader apply worker will ensure to
+ * update it as the lsn_mapping is maintained by it.
+ */
+ if (am_parallel_apply_worker())
+ return;
SUGGESTION (comment multiple "it" was confusing)
Skip for parallel apply workers, because the lsn_mapping is maintained
by the leader apply worker.
~~~
20. set_apply_error_context_origin
+
+/* Set the origin name of apply error callback. */
+void
+set_apply_error_context_origin(char *originname)
+{
+ /*
+ * Allocate the origin name in long-lived context for error context
+ * message.
+ */
+ apply_error_callback_arg.origin_name = MemoryContextStrdup(ApplyContext,
+ originname);
+}
IMO that "Allocate ..." comment should just replace the function header comment.
~~~
21. apply_worker_clean_exit
I wasn't sure if calling this a 'clean' exit meant anything much.
How about:
- apply_worker_proc_exit, or
- apply_worker_exit
~
22.
+apply_worker_clean_exit(bool on_subinfo_change)
+{
+ if (am_parallel_apply_worker() && on_subinfo_change)
+ {
+ /*
+ * If a parallel apply worker exits due to the subscription
+ * information change, we notify the leader apply worker so that the
+ * leader can report more meaningful message in time and restart the
+ * logical replication.
+ */
+ pq_putmessage('X', NULL, 0);
+ }
+
+ proc_exit(0);
+}
SUGGESTION (for comment)
If this is a parallel apply worker exiting due to a subscription
information change, we notify the leader apply worker so that it can
report a more meaningful message before restarting the logical
replication.
======
FILE: src/include/commands/subscriptioncmds.h
23. externs
@@ -26,4 +26,6 @@ extern void DropSubscription(DropSubscriptionStmt
*stmt, bool isTopLevel);
extern ObjectAddress AlterSubscriptionOwner(const char *name, Oid newOwnerId);
extern void AlterSubscriptionOwner_oid(Oid subid, Oid newOwnerId);
+extern char defGetStreamingMode(DefElem *def);
The extern is not in the same order as the functions of subscriptioncmds.c
======
FILE: src/include/replication/worker_internal.h
24. externs
24a.
+extern void apply_dispatch(StringInfo s);
+
+extern void InitializeApplyWorker(void);
+
+extern void maybe_reread_subscription(void);
The above externs are not in the same order as the functions of worker.c
~
24b.
+extern void pa_lock_stream(TransactionId xid, LOCKMODE lockmode);
+extern void pa_lock_transaction(TransactionId xid, LOCKMODE lockmode);
+
+extern void pa_unlock_stream(TransactionId xid, LOCKMODE lockmode);
+extern void pa_unlock_transaction(TransactionId xid, LOCKMODE lockmode);
The above externs are not in the same order as the functions of
applyparallelworker.c
------
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
Thursday, December 1, 2022 8:40 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Nov 30, 2022 at 4:23 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > 2.
> > + /*
> > + * The stream lock is released when processing changes in a
> > + * streaming block, so the leader needs to acquire the lock here
> > + * before entering PARTIAL_SERIALIZE mode to ensure that the
> > + * parallel apply worker will wait for the leader to release the
> > + * stream lock.
> > + */
> > + if (in_streamed_transaction &&
> > + action != LOGICAL_REP_MSG_STREAM_STOP) {
> > + pa_lock_stream(winfo->shared->xid, AccessExclusiveLock);
> >
> > This comment is not completely correct because we can even acquire the
> > lock for the very streaming chunk. This check will work but doesn't
> > appear future-proof or at least not very easy to understand though I
> > don't have a better suggestion at this stage. Can we think of a better
> > check here?
> >
>
> One idea is that we acquire this lock every time and callers like stream_commit
> are responsible to release it. Also, we can handle the close of stream file in the
> respective callers. I think that will make this part of the patch easier to follow.
Changed.
> Some other comments:
> =====================
> 1. The handling of buffile inside pa_stream_abort() looks bit ugly to me. I think
> you primarily required it because the buffile opened by parallel apply worker is
> in CurrentResourceOwner.
Changed to use toplevel transaction's resource.
> Can we think of having a new resource owner to
> apply spooled messages? I think that will avoid the need to have a special
> purpose code to handle buffiles in parallel apply worker.
I am thinking about this and will address this in next version.
> 2.
> @@ -564,6 +571,7 @@ handle_streamed_transaction(LogicalRepMsgType
> action, StringInfo s)
> TransactionId current_xid;
> ParallelApplyWorkerInfo *winfo;
> TransApplyAction apply_action;
> + StringInfoData original_msg;
>
> apply_action = get_transaction_apply_action(stream_xid, &winfo);
>
> @@ -573,6 +581,8 @@ handle_streamed_transaction(LogicalRepMsgType
> action, StringInfo s)
>
> Assert(TransactionIdIsValid(stream_xid));
>
> + original_msg = *s;
> +
> /*
> * We should have received XID of the subxact as the first part of the
> * message, so extract it.
> @@ -596,10 +606,14 @@ handle_streamed_transaction(LogicalRepMsgType
> action, StringInfo s)
> stream_write_change(action, s);
> return true;
>
> + case TRANS_LEADER_PARTIAL_SERIALIZE:
> case TRANS_LEADER_SEND_TO_PARALLEL:
> Assert(winfo);
>
> - pa_send_data(winfo, s->len, s->data);
> + if (apply_action == TRANS_LEADER_SEND_TO_PARALLEL) pa_send_data(winfo,
> + s->len, s->data); else stream_write_change(action, &original_msg);
>
> Please add the comment to specify the reason to remember the original string.
Added.
> 3.
> @@ -1797,8 +1907,8 @@ apply_spooled_messages(TransactionId xid,
> XLogRecPtr lsn)
> changes_filename(path, MyLogicalRepWorker->subid, xid);
> elog(DEBUG1, "replaying changes from file \"%s\"", path);
>
> - fd = BufFileOpenFileSet(MyLogicalRepWorker->stream_fileset, path,
> O_RDONLY,
> - false);
> + stream_fd = BufFileOpenFileSet(stream_fileset, path, O_RDONLY, false);
> + stream_xid = xid;
>
> Why do we need stream_xid here? I think we can avoid having global stream_fd
> if the comment #1 is feasible.
I think we don't need it anymore, I have removed it.
> 4.
> + * TRANS_LEADER_APPLY:
> + * The action means that we
>
> /The/This. Please make a similar change for other actions.
>
> 5. Apart from the above, please find a few changes to the comments for
> 0001 and 0002 patches in the attached patches.
Merged.
Attach the new version patch set which addressed most of the comments received so
far except some comments being discussed[1].
[1]
https://www.postgresql.org/message-id/OS0PR01MB57167BF64FC0891734C8E81A94149%40OS0PR01MB5716.jpnprd01.prod.outlook.com
Best regards,
Hou zj
Attachment
- v55-0003-Test-streaming-parallel-option-in-tap-test.patch
- v55-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v55-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v55-0001-Perform-streaming-logical-transactions-by-parall.patch
- v55-0002-Serialize-partial-changes-to-a-file-when-the-att.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, December 2, 2022 7:27 PM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wroteL
>
> Dear Hou,
>
> Thanks for making the patch. Followings are my comments for v54-0003 and
> 0004.
Thanks for the comments!
>
> 0003
>
> pa_free_worker()
>
> + /* Unlink any files that were needed to serialize partial changes. */
> + if (winfo->serialize_changes)
> + stream_cleanup_files(MyLogicalRepWorker->subid,
> winfo->shared->xid);
> +
>
> I think this part is not needed, because the LA cannot reach here if
> winfo->serialize_changes is true. Moreover stream_cleanup_files() is done in
> pa_free_worker_info().
Removed.
> LogicalParallelApplyLoop()
>
> The parallel apply worker wakes up every 0.1s even if we are in the
> PARTIAL_SERIALIZE mode. Do you have idea to reduce that?
The parallel apply worker usually will wait on the stream lock after entering
PARTIAL_SERIALIZE mode.
> ```
> + pa_spooled_messages();
> ```
>
> Comments are needed here, like "Changes may be serialize...".
Added.
> pa_stream_abort()
>
> ```
> + /*
> + * Reopen the file and set the file position to
> the saved
> + * position.
> + */
> + if (reopen_stream_fd)
> + {
> + char path[MAXPGPATH];
> +
> + changes_filename(path,
> MyLogicalRepWorker->subid, xid);
> + stream_fd =
> BufFileOpenFileSet(&MyParallelShared->fileset,
> +
> path, O_RDONLY, false);
> + BufFileSeek(stream_fd, fileno, offset,
> SEEK_SET);
> + }
> ```
>
> MyParallelShared->serialize_changes may be used instead of reopen_stream_fd.
These codes have been removed.
>
> ```
> + /*
> + * It is possible that while sending this change to
> parallel apply
> + * worker we need to switch to serialize mode.
> + */
> + if (winfo->serialize_changes)
> + pa_set_fileset_state(winfo->shared,
> FS_READY);
> ```
>
> There are three same parts in the code, can we combine them to common part?
These codes have been slightly refactored.
> apply_spooled_messages()
>
> ```
> + /*
> + * Break the loop if the parallel apply worker has finished
> applying
> + * the transaction. The parallel apply worker should have closed
> the
> + * file before committing.
> + */
> + if (am_parallel_apply_worker() &&
> + MyParallelShared->xact_state ==
> PARALLEL_TRANS_FINISHED)
> + goto done;
> ```
>
> I thnk pfree(buffer) and pfree(s2.data) should not be skippied.
> And this part should be at below "nchanges++;"
buffer, s2.data were allocated in the toplevel transaction's context and it
will be automatically freed soon when handling STREAM COMMIT.
>
> 0004
>
> set_subscription_retry()
>
> ```
> + LockSharedObject(SubscriptionRelationId, MySubscription->oid, 0,
> + AccessShareLock);
> +
> ```
>
> I think AccessExclusiveLock should be aquired instead of AccessShareLock.
> In AlterSubscription(), LockSharedObject(AccessExclusiveLock) seems to be
> used.
Changed.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, December 2, 2022 4:59 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are my review comments for patch v54-0001.
Thanks for the comments!
> ======
>
> FILE: .../replication/logical/applyparallelworker.c
>
> 1b.
>
> + *
> + * This file contains routines that are intended to support setting up,
> + using
> + * and tearing down a ParallelApplyWorkerInfo which is required to
> + communicate
> + * among leader and parallel apply workers.
>
> "that are intended to support" -> "for"
I find the current word is consistent with the comments atop vacuumparallel.c and
execParallel.c. So didn't change this one.
> 3. pa_setup_dsm
>
> +/*
> + * Set up a dynamic shared memory segment.
> + *
> + * We set up a control region that contains a fixed-size worker info
> + * (ParallelApplyWorkerShared), a message queue, and an error queue.
> + *
> + * Returns true on success, false on failure.
> + */
> +static bool
> +pa_setup_dsm(ParallelApplyWorkerInfo *winfo)
>
> IMO that's confusing to say "fixed-sized worker info" when it's referring to the
> ParallelApplyWorkerShared structure and not the other
> ParallelApplyWorkerInfo.
>
> Might be better to say:
>
> "a fixed-size worker info (ParallelApplyWorkerShared)" -> "a fixed-size struct
> (ParallelApplyWorkerShared)"
The ParallelApplyWorkerShared is also kind of information that shared
between workers. So, I am fine with current word. Or maybe just "fixed-size info" ?
> ~~~
>
> 12. pa_clean_subtrans
>
> +/* Reset the list that maintains subtransactions. */ void
> +pa_clean_subtrans(void)
> +{
> + subxactlist = NIL;
> +}
>
> Maybe a more informative function name would be pa_reset_subxactlist()?
I thought the current name is more consistent with pa_start_subtrans.
> ~~~
>
> 17. apply_handle_stream_stop
>
> + case TRANS_PARALLEL_APPLY:
> + elog(DEBUG1, "applied %u changes in the streaming chunk",
> + parallel_stream_nchanges);
> +
> + /*
> + * By the time parallel apply worker is processing the changes in
> + * the current streaming block, the leader apply worker may have
> + * sent multiple streaming blocks. This can lead to parallel apply
> + * worker start waiting even when there are more chunk of streams
> + * in the queue. So, try to lock only if there is no message left
> + * in the queue. See Locking Considerations atop
> + * applyparallelworker.c.
> + */
>
> SUGGESTION (minor rewording)
>
> By the time the parallel apply worker is processing the changes in the current
> streaming block, the leader apply worker may have sent multiple streaming
> blocks. To the parallel apply from waiting unnecessarily, try to lock only if there
> is no message left in the queue. See Locking Considerations atop
> applyparallelworker.c.
>
Didn't change this one according to Amit's comment.
>
> 21. apply_worker_clean_exit
>
> I wasn't sure if calling this a 'clean' exit meant anything much.
>
> How about:
> - apply_worker_proc_exit, or
> - apply_worker_exit
I thought the clean means the exit number is 0(proc_exit(0)) and is
not due to any ERROR, I am not sure If proc_exit or exit is better.
I have addressed other comments in the new version patch.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Sunday, December 4, 2022 7:17 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> > > Thursday, December 1, 2022 8:40 PM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > Some other comments: > ... > Attach the new version patch set which addressed most of the comments > received so far except some comments being discussed[1]. > [1] https://www.postgresql.org/message-id/OS0PR01MB57167BF64FC0891734C8E81A94149%40OS0PR01MB5716.jpnprd01.prod.outlook.com Attach a new version patch set which fixed a testcase failure on CFbot. Best regards, Hou zj
Attachment
- v56-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v56-0001-Perform-streaming-logical-transactions-by-parall.patch
- v56-0002-Serialize-partial-changes-to-a-file-when-the-att.patch
- v56-0003-Test-streaming-parallel-option-in-tap-test.patch
- v56-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Sun, Dec 4, 2022 at 4:48 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Friday, December 2, 2022 4:59 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
>
> > ~~~
> >
> > 12. pa_clean_subtrans
> >
> > +/* Reset the list that maintains subtransactions. */ void
> > +pa_clean_subtrans(void)
> > +{
> > + subxactlist = NIL;
> > +}
> >
> > Maybe a more informative function name would be pa_reset_subxactlist()?
>
> I thought the current name is more consistent with pa_start_subtrans.
>
Then how about changing the name to pg_reset_subtrans()?
>
> >
> > 21. apply_worker_clean_exit
> >
> > I wasn't sure if calling this a 'clean' exit meant anything much.
> >
> > How about:
> > - apply_worker_proc_exit, or
> > - apply_worker_exit
>
> I thought the clean means the exit number is 0(proc_exit(0)) and is
> not due to any ERROR, I am not sure If proc_exit or exit is better.
>
> I have addressed other comments in the new version patch.
>
+1 for apply_worker_exit.
One minor suggestion for a recent change in v56-0001*:
/*
- * A hash table used to cache streaming transactions being applied and the
- * parallel application workers required to apply transactions.
+ * A hash table used to cache the state of streaming transactions being
+ * applied by the parallel apply workers.
*/
static HTAB *ParallelApplyTxnHash = NULL;
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for patch v55-0002
======
.../replication/logical/applyparallelworker.c
1. pa_can_start
@@ -276,9 +278,9 @@ pa_can_start(TransactionId xid)
/*
* Don't start a new parallel worker if user has set skiplsn as it's
* possible that user want to skip the streaming transaction. For
- * streaming transaction, we need to spill the transaction to disk so that
- * we can get the last LSN of the transaction to judge whether to skip
- * before starting to apply the change.
+ * streaming transaction, we need to serialize the transaction to a file
+ * so that we can get the last LSN of the transaction to judge whether to
+ * skip before starting to apply the change.
*/
if (!XLogRecPtrIsInvalid(MySubscription->skiplsn))
return false;
I think the wording change may belong in patch 0001 because it has
nothing to do with partial serializing.
~~~
2. pa_free_worker
+ /*
+ * Stop the worker if there are enough workers in the pool.
+ *
+ * XXX The worker is also stopped if the leader apply worker needed to
+ * serialize part of the transaction data due to a send timeout. This is
+ * because the message could be partially written to the queue due to send
+ * timeout and there is no way to clean the queue other than resending the
+ * message until it succeeds. To avoid complexity, we directly stop the
+ * worker in this case.
+ */
+ if (winfo->serialize_changes ||
+ napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
Don't need to say "due to send timeout" 2 times in 2 sentences.
SUGGESTION
XXX The worker is also stopped if the leader apply worker needed to
serialize part of the transaction data due to a send timeout. This is
because the message could be partially written to the queue but there
is no way to clean the queue other than resending the message until it
succeeds. Directly stopping the worker avoids needing this complexity.
~~~
3. pa_spooled_messages
Previously I suggested this function name should be changed but that
was rejected (see [1] #6a)
> 6a.
> IMO a better name for this function would be
> pa_apply_spooled_messages();
Not sure about this.
~
FYI the reason for the previous suggestion is because there is no verb
in the current function name, so the reader is left thinking
pa_spooled_messages "what"?
It means the caller has to have extra comments like:
/* Check if changes have been serialized to a file. */
pa_spooled_messages();
OTOH, if the function was called something better -- e.g.
pa_check_for_spooled_messages() or similar -- then it would be
self-explanatory.
~
4.
/*
+ * Replay the spooled messages in the parallel apply worker if the leader apply
+ * worker has finished serializing changes to the file.
+ */
+static void
+pa_spooled_messages(void)
I'm not 100% sure of the logic, so IMO maybe the comment should say a
bit more about how this works:
Specifically, let's say there was some timeout and the LA needed to
write the spool file, then let's say the PA timed out and found itself
inside this function. Now, let's say the LA is still busy writing the
file -- so what happens next?
Does this function simply return, then the main PA loop waits again,
then the times out again, then PA finds itself back inside this
function again... and that keeps happening over and over until
eventually the spool file is found FS_READY? Some explanatory comments
might help.
~
5.
+ /*
+ * Check if changes have been serialized to a file. if so, read and apply
+ * them.
+ */
+ SpinLockAcquire(&MyParallelShared->mutex);
+ fileset_state = MyParallelShared->fileset_state;
+ SpinLockRelease(&MyParallelShared->mutex);
"if so" -> "If so"
~~~
6. pa_send_data
+ *
+ * If the attempt to send data via shared memory times out, then we will switch
+ * to "PARTIAL_SERIALIZE mode" for the current transaction to prevent possible
+ * deadlocks with another parallel apply worker (refer to the comments atop
+ * applyparallelworker.c for details). This means that the current data and any
+ * subsequent data for this transaction will be serialized to a file.
*/
void
pa_send_data(ParallelApplyWorkerInfo *winfo, Size nbytes, const void *data)
SUGGESTION (minor comment rearranging)
If the attempt to send data via shared memory times out, then we will
switch to "PARTIAL_SERIALIZE mode" for the current transaction -- this
means that the current data and any subsequent data for this
transaction will be serialized to a file. This is done to prevent
possible deadlocks with another parallel apply worker (refer to the
comments atop applyparallelworker.c for details).
~
7.
+ /*
+ * Take the stream lock to make sure that the parallel apply worker
+ * will wait for the leader to release the stream lock until the
+ * end of the transaction.
+ */
+ pa_lock_stream(winfo->shared->xid, AccessExclusiveLock);
The comment doesn't sound right.
"until the end" -> "at the end" (??)
~~~
8. pa_stream_abort
@@ -1374,6 +1470,7 @@ pa_stream_abort(LogicalRepStreamAbortData *abort_data)
RollbackToSavepoint(spname);
CommitTransactionCommand();
subxactlist = list_truncate(subxactlist, i + 1);
+
break;
}
}
Spurious whitespace unrelated to this patch?
======
src/backend/replication/logical/worker.c
9. handle_streamed_transaction
/*
+ * The parallel apply worker needs the xid in this message to decide
+ * whether to define a savepoint, so save the original message that has not
+ * moved the cursor after the xid. We will serailize this message to a file
+ * in PARTIAL_SERIALIZE mode.
+ */
+ original_msg = *s;
"serailize" -> "serialize"
~~~
10. apply_handle_stream_prepare
@@ -1245,6 +1265,7 @@ apply_handle_stream_prepare(StringInfo s)
LogicalRepPreparedTxnData prepare_data;
ParallelApplyWorkerInfo *winfo;
TransApplyAction apply_action;
+ StringInfoData original_msg = *s;
Should this include a longer explanation of why this copy is needed
(same as was done in handle_streamed_transaction)?
~
11.
case TRANS_PARALLEL_APPLY:
+
+ /*
+ * Close the file before committing if the parallel apply worker
+ * is applying spooled messages.
+ */
+ if (stream_fd)
+ stream_close_file();
11a.
This comment seems worded backwards.
SUGGESTION
If the parallel apply worker is applying spooled messages then close
the file before committing.
~
11b.
I'm confused - isn't there code doing exactly this (close file before
commit) already in the apply_handle_stream_commit
TRANS_PARALLEL_APPLY?
~~~
12. apply_handle_stream_start
@@ -1383,6 +1493,7 @@ apply_handle_stream_start(StringInfo s)
bool first_segment;
ParallelApplyWorkerInfo *winfo;
TransApplyAction apply_action;
+ StringInfoData original_msg = *s;
Should this include a longer explanation of why this copy is needed
(same as was done in handle_streamed_transaction)?
~
13.
+ serialize_stream_start(stream_xid, false);
+ stream_write_change(LOGICAL_REP_MSG_STREAM_START, &original_msg);
- end_replication_step();
break;
A spurious blank line is left before the break;
~~~
14. serialize_stream_stop
+ /* We must be in a valid transaction state */
+ Assert(IsTransactionState());
The comment seems redundant. The code says the same.
~~~
15. apply_handle_stream_abort
@@ -1676,6 +1794,7 @@ apply_handle_stream_abort(StringInfo s)
LogicalRepStreamAbortData abort_data;
ParallelApplyWorkerInfo *winfo;
TransApplyAction apply_action;
+ StringInfoData original_msg = *s;
bool toplevel_xact;
Should this include a longer explanation of why this copy is needed
(same as was done in handle_streamed_transaction)?
~~~
16. apply_spooled_messages
+ stream_fd = BufFileOpenFileSet(stream_fileset, path, O_RDONLY, false);
Something still seems a bit odd about this to me (previously also
mentioned in review [1] #29) but I cannot quite put my finger on it...
AFAIK the 'stream_fd' is the global the LA is using to remember the
single stream spool file; It corresponds to the LogicalRepWorker's
'stream_fileset'. So using that same global on the PA side somehow
seemed strange to me. The fileset at PA comes from a different place
(MyParallelShared->fileset).
Basically, I felt that whenever use are using 'stream_fd' and
'stream_fileset' etc. then it should be safe to assume you are looking
at the worker.c from the leader apply worker POV. Otherwise, IMO it
should just use some fd/fs passed around as parameters. Sure, there
might be a few places like stream_close_file (etc) which need some
small refactoring to pass as a parameter instead of always using
'stream_fd' but IMO the end result will be tidier.
~
17.
+ /*
+ * No need to output the DEBUG message here in the parallel apply
+ * worker as similar messages will be output when handling STREAM_STOP
+ * message.
+ */
+ if (!am_parallel_apply_worker() && nchanges % 1000 == 0)
elog(DEBUG1, "replayed %d changes from file \"%s\"",
nchanges, path);
Instead of saying what you are not doing ("No need to... in output
apply worker") wouldn't it make more sense to reverse it and say what
you are doing ("Only log DEBUG messages for the leader apply worker
because ...") and then the condition also becomes positive:
if (am_leader_apply_worker())
{
...
}
~
18.
+ if (am_parallel_apply_worker() &&
+ MyParallelShared->xact_state == PARALLEL_TRANS_FINISHED)
+ goto done;
+
+ /*
+ * No need to output the DEBUG message here in the parallel apply
+ * worker as similar messages will be output when handling STREAM_STOP
+ * message.
+ */
+ if (!am_parallel_apply_worker() && nchanges % 1000 == 0)
elog(DEBUG1, "replayed %d changes from file \"%s\"",
nchanges, path);
}
- BufFileClose(fd);
-
+ stream_close_file();
pfree(buffer);
pfree(s2.data);
+done:
elog(DEBUG1, "replayed %d (all) changes from file \"%s\"",
nchanges, path);
Shouldn't that "done:" label be *above* the pfree's. Otherwise, those
are going to be skipped over by the "goto done;".
~~~
19. apply_handle_stream_commit
@@ -1898,6 +2072,7 @@ apply_handle_stream_commit(StringInfo s)
LogicalRepCommitData commit_data;
ParallelApplyWorkerInfo *winfo;
TransApplyAction apply_action;
+ StringInfoData original_msg = *s;
Should this include a longer explanation of why this copy is needed
(same as was done in handle_streamed_transaction)?
~
20.
+ /*
+ * Close the file before committing if the parallel apply worker
+ * is applying spooled messages.
+ */
+ if (stream_fd)
+ stream_close_file();
(same as previous review comment - see #11)
This comment seems worded backwards.
SUGGESTION
If the parallel apply worker is applying spooled messages then close
the file before committing.
======
src/include/replication/worker_internal.h
21. PartialFileSetState
+ * State of fileset in leader apply worker.
+ *
+ * FS_BUSY means that the leader is serializing changes to the file. FS_READY
+ * means that the leader has serialized all changes to the file and the file is
+ * ready to be read by a parallel apply worker.
+ */
+typedef enum PartialFileSetState
"ready to be read" sounded a bit strange.
SUGGESTION
... to the file so it is now OK for a parallel apply worker to read it.
------
[1] Houz reply to my review v51-0002 --
https://www.postgresql.org/message-id/OS0PR01MB5716350729D8C67AA8CE333194129%40OS0PR01MB5716.jpnprd01.prod.outlook.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Dec 6, 2022 at 5:27 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Here are my review comments for patch v55-0002 > ... > > 3. pa_spooled_messages > > Previously I suggested this function name should be changed but that > was rejected (see [1] #6a) > > > 6a. > > IMO a better name for this function would be > > pa_apply_spooled_messages(); > Not sure about this. > > ~ > > FYI the reason for the previous suggestion is because there is no verb > in the current function name, so the reader is left thinking > pa_spooled_messages "what"? > > It means the caller has to have extra comments like: > /* Check if changes have been serialized to a file. */ > pa_spooled_messages(); > > OTOH, if the function was called something better -- e.g. > pa_check_for_spooled_messages() or similar -- then it would be > self-explanatory. > I think pa_check_for_spooled_messages() could be misleading because we do apply the changes in that function, so probably a comment as suggested by you is a better option. > ~ > > 4. > > /* > + * Replay the spooled messages in the parallel apply worker if the leader apply > + * worker has finished serializing changes to the file. > + */ > +static void > +pa_spooled_messages(void) > > I'm not 100% sure of the logic, so IMO maybe the comment should say a > bit more about how this works: > > Specifically, let's say there was some timeout and the LA needed to > write the spool file, then let's say the PA timed out and found itself > inside this function. Now, let's say the LA is still busy writing the > file -- so what happens next? > > Does this function simply return, then the main PA loop waits again, > then the times out again, then PA finds itself back inside this > function again... and that keeps happening over and over until > eventually the spool file is found FS_READY? Some explanatory comments > might help. > No, PA will simply wait for LA to finish. See the code handling for FS_BUSY state. We might want to slightly improve part of the current comment to: "If the leader apply worker is busy serializing the partial changes then acquire the stream lock now and wait for the leader worker to finish serializing the changes". > > 16. apply_spooled_messages > > + stream_fd = BufFileOpenFileSet(stream_fileset, path, O_RDONLY, false); > > Something still seems a bit odd about this to me (previously also > mentioned in review [1] #29) but I cannot quite put my finger on it... > > AFAIK the 'stream_fd' is the global the LA is using to remember the > single stream spool file; It corresponds to the LogicalRepWorker's > 'stream_fileset'. So using that same global on the PA side somehow > seemed strange to me. The fileset at PA comes from a different place > (MyParallelShared->fileset). > I think 'stream_fd' is specific to apply module which can be used by apply, tablesync, or parallel worker. Unfortunately, now, the code in worker.c is a mix of worker and apply module. At some point, we should separate apply logic to a separate file. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Dec 5, 2022 at 9:59 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > Attach a new version patch set which fixed a testcase failure on CFbot. > Few comments: ============ 1. + /* + * Break the loop if the parallel apply worker has finished applying + * the transaction. The parallel apply worker should have closed the + * file before committing. + */ + if (am_parallel_apply_worker() && + MyParallelShared->xact_state == PARALLEL_TRANS_FINISHED) + goto done; This looks hackish to me because ideally, this API should exit after reading and applying all the messages in the spool file. This check is primarily based on the knowledge that once we reach some state, the file won't have more data. I think it would be better to explicitly ensure the same. 2. + /* + * No need to output the DEBUG message here in the parallel apply + * worker as similar messages will be output when handling STREAM_STOP + * message. + */ + if (!am_parallel_apply_worker() && nchanges % 1000 == 0) elog(DEBUG1, "replayed %d changes from file \"%s\"", nchanges, path); } I think this check appeared a bit ugly to me. I think it is okay to get a similar DEBUG message at another place (on stream_stop) because (a) this is logged every 1000 messages whereas stream_stop can be after many more messages, so there doesn't appear to be a direct correlation; (b) due to this, we can identify whether it is due to spooled messages or due to direct apply; ideally we can use another DEBUG message to differentiate but this doesn't appear bad to me. 3. The function names for serialize_stream_start(), serialize_stream_stop(), and serialize_stream_abort() don't seem to match the functionality they provide because none of these write/serialize changes to the file. Can we rename these? Some possible options could be stream_start_internal or stream_start_guts. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Tue, Dec 6, 2022 at 2:51 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Dec 6, 2022 at 5:27 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Here are my review comments for patch v55-0002 > > > ... > > 4. > > > > /* > > + * Replay the spooled messages in the parallel apply worker if the leader apply > > + * worker has finished serializing changes to the file. > > + */ > > +static void > > +pa_spooled_messages(void) > > > > I'm not 100% sure of the logic, so IMO maybe the comment should say a > > bit more about how this works: > > > > Specifically, let's say there was some timeout and the LA needed to > > write the spool file, then let's say the PA timed out and found itself > > inside this function. Now, let's say the LA is still busy writing the > > file -- so what happens next? > > > > Does this function simply return, then the main PA loop waits again, > > then the times out again, then PA finds itself back inside this > > function again... and that keeps happening over and over until > > eventually the spool file is found FS_READY? Some explanatory comments > > might help. > > > > No, PA will simply wait for LA to finish. See the code handling for > FS_BUSY state. We might want to slightly improve part of the current > comment to: "If the leader apply worker is busy serializing the > partial changes then acquire the stream lock now and wait for the > leader worker to finish serializing the changes". > Sure, "PA will simply wait for LA to finish". Except I think it's not quite that simple because IIUC when LA *does* finish, the PA (this function) will continue and just drop out the bottom -- it cannot apply those spooled messages yet until it cycles all the way back around the main loop and times out again and gets back into pa_spooled_messages function again to get to the FS_READY block of code where it can finally call the 'apply_spooled_messages'... If my understanding is correct, then It's that extra looping that I thought maybe warrants some mention in a comment here. ------ Kind Regards, Peter Smith. Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, December 6, 2022 3:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Dec 5, 2022 at 9:59 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > Attach a new version patch set which fixed a testcase failure on CFbot. > > > > Few comments: > ============ > 1. > + /* > + * Break the loop if the parallel apply worker has finished applying > + * the transaction. The parallel apply worker should have closed the > + * file before committing. > + */ > + if (am_parallel_apply_worker() && > + MyParallelShared->xact_state == PARALLEL_TRANS_FINISHED) > + goto done; > > This looks hackish to me because ideally, this API should exit after reading and > applying all the messages in the spool file. This check is primarily based on the > knowledge that once we reach some state, the file won't have more data. I > think it would be better to explicitly ensure the same. I added a function to ensure that there is no message left after committing the transaction. > 2. > + /* > + * No need to output the DEBUG message here in the parallel apply > + * worker as similar messages will be output when handling STREAM_STOP > + * message. > + */ > + if (!am_parallel_apply_worker() && nchanges % 1000 == 0) > elog(DEBUG1, "replayed %d changes from file \"%s\"", > nchanges, path); > } > > I think this check appeared a bit ugly to me. I think it is okay to get a similar > DEBUG message at another place (on stream_stop) because > (a) this is logged every 1000 messages whereas stream_stop can be after many > more messages, so there doesn't appear to be a direct correlation; (b) due to > this, we can identify whether it is due to spooled messages or due to direct > apply; ideally we can use another DEBUG message to differentiate but this > doesn't appear bad to me. OK, I removed this check. > 3. The function names for serialize_stream_start(), serialize_stream_stop(), and > serialize_stream_abort() don't seem to match the functionality they provide > because none of these write/serialize changes to the file. Can we rename > these? Some possible options could be stream_start_internal or > stream_start_guts. Renamed to stream_start_internal(). Attach the new version patch set which addressed above comments. I also attach a new patch to force stream change(provided by Shi-san) and another one that introduce a GUC stream_serialize_threshold (provided by Kuroda-san and Shi-san) which can help testing the patch set. Besides, I fixed a bug where there could still be messages left in memory queue and the PA has started to apply spooled message. Best regards, Hou zj
Attachment
- v57-0007-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v57-0002-Serialize-partial-changes-to-a-file-when-the-att.patch
- v57-0001-Perform-streaming-logical-transactions-by-parall.patch
- v57-0003-Test-streaming-parallel-option-in-tap-test.patch
- v57-0004-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v57-0005-Allow-streaming-every-change-without-waiting-til.patch
- v57-0006-Retry-to-apply-streaming-xact-only-in-apply-work.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tue, Dec 6, 2022 7:57 AM Peter Smith <smithpb2250@gmail.com> wrote:
> Here are my review comments for patch v55-0002
Thansk for your comments.
> ======
>
> .../replication/logical/applyparallelworker.c
>
> 1. pa_can_start
>
> @@ -276,9 +278,9 @@ pa_can_start(TransactionId xid)
> /*
> * Don't start a new parallel worker if user has set skiplsn as it's
> * possible that user want to skip the streaming transaction. For
> - * streaming transaction, we need to spill the transaction to disk so
> that
> - * we can get the last LSN of the transaction to judge whether to
> skip
> - * before starting to apply the change.
> + * streaming transaction, we need to serialize the transaction to a
> + file
> + * so that we can get the last LSN of the transaction to judge
> + whether to
> + * skip before starting to apply the change.
> */
> if (!XLogRecPtrIsInvalid(MySubscription->skiplsn))
> return false;
>
> I think the wording change may belong in patch 0001 because it has
> nothing to do with partial serializing.
Changed.
> ~~~
>
> 2. pa_free_worker
>
> + /*
> + * Stop the worker if there are enough workers in the pool.
> + *
> + * XXX The worker is also stopped if the leader apply worker needed
> + to
> + * serialize part of the transaction data due to a send timeout. This
> + is
> + * because the message could be partially written to the queue due to
> + send
> + * timeout and there is no way to clean the queue other than
> + resending the
> + * message until it succeeds. To avoid complexity, we directly stop
> + the
> + * worker in this case.
> + */
> + if (winfo->serialize_changes ||
> + napplyworkers > (max_parallel_apply_workers_per_subscription / 2))
>
> Don't need to say "due to send timeout" 2 times in 2 sentences.
>
> SUGGESTION
> XXX The worker is also stopped if the leader apply worker needed to
> serialize part of the transaction data due to a send timeout. This is
> because the message could be partially written to the queue but there
> is no way to clean the queue other than resending the message until it
> succeeds. Directly stopping the worker avoids needing this complexity.
Changed.
> 4.
>
> /*
> + * Replay the spooled messages in the parallel apply worker if the
> +leader apply
> + * worker has finished serializing changes to the file.
> + */
> +static void
> +pa_spooled_messages(void)
>
> I'm not 100% sure of the logic, so IMO maybe the comment should say a
> bit more about how this works:
>
> Specifically, let's say there was some timeout and the LA needed to
> write the spool file, then let's say the PA timed out and found itself
> inside this function. Now, let's say the LA is still busy writing the
> file -- so what happens next?
>
> Does this function simply return, then the main PA loop waits again,
> then the times out again, then PA finds itself back inside this
> function again... and that keeps happening over and over until
> eventually the spool file is found FS_READY? Some explanatory comments
> might help.
Slightly changed the logic and comment here.
> ~
>
> 5.
>
> + /*
> + * Check if changes have been serialized to a file. if so, read and
> + apply
> + * them.
> + */
> + SpinLockAcquire(&MyParallelShared->mutex);
> + fileset_state = MyParallelShared->fileset_state;
> + SpinLockRelease(&MyParallelShared->mutex);
>
> "if so" -> "If so"
Changed.
> ~~~
>
>
> 6. pa_send_data
>
> + *
> + * If the attempt to send data via shared memory times out, then we
> + will
> switch
> + * to "PARTIAL_SERIALIZE mode" for the current transaction to prevent
> possible
> + * deadlocks with another parallel apply worker (refer to the
> + comments atop
> + * applyparallelworker.c for details). This means that the current
> + data and any
> + * subsequent data for this transaction will be serialized to a file.
> */
> void
> pa_send_data(ParallelApplyWorkerInfo *winfo, Size nbytes, const void
> *data)
>
> SUGGESTION (minor comment rearranging)
>
> If the attempt to send data via shared memory times out, then we will
> switch to "PARTIAL_SERIALIZE mode" for the current transaction -- this
> means that the current data and any subsequent data for this
> transaction will be serialized to a file. This is done to prevent
> possible deadlocks with another parallel apply worker (refer to the
> comments atop applyparallelworker.c for details).
Changed.
> ~
>
> 7.
>
> + /*
> + * Take the stream lock to make sure that the parallel apply worker
> + * will wait for the leader to release the stream lock until the
> + * end of the transaction.
> + */
> + pa_lock_stream(winfo->shared->xid, AccessExclusiveLock);
>
> The comment doesn't sound right.
>
> "until the end" -> "at the end" (??)
I think it means "PA wait ... until the end of transaction".
> ~~~
>
> 8. pa_stream_abort
>
> @@ -1374,6 +1470,7 @@ pa_stream_abort(LogicalRepStreamAbortData
> *abort_data)
> RollbackToSavepoint(spname);
> CommitTransactionCommand();
> subxactlist = list_truncate(subxactlist, i + 1);
> +
> break;
> }
> }
> Spurious whitespace unrelated to this patch?
Changed.
> ======
>
> src/backend/replication/logical/worker.c
>
> 9. handle_streamed_transaction
>
> /*
> + * The parallel apply worker needs the xid in this message to decide
> + * whether to define a savepoint, so save the original message that
> + has not
> + * moved the cursor after the xid. We will serailize this message to
> + a file
> + * in PARTIAL_SERIALIZE mode.
> + */
> + original_msg = *s;
>
> "serailize" -> "serialize"
Changed.
> ~~~
>
> 10. apply_handle_stream_prepare
>
> @@ -1245,6 +1265,7 @@ apply_handle_stream_prepare(StringInfo s)
> LogicalRepPreparedTxnData prepare_data;
> ParallelApplyWorkerInfo *winfo;
> TransApplyAction apply_action;
> + StringInfoData original_msg = *s;
>
> Should this include a longer explanation of why this copy is needed
> (same as was done in handle_streamed_transaction)?
Added the blow comment atop this variable.
```
Save the message before it is consumed.
```
> ~
>
> 11.
>
> case TRANS_PARALLEL_APPLY:
> +
> + /*
> + * Close the file before committing if the parallel apply worker
> + * is applying spooled messages.
> + */
> + if (stream_fd)
> + stream_close_file();
>
> 11a.
>
> This comment seems worded backwards.
>
> SUGGESTION
> If the parallel apply worker is applying spooled messages then close
> the file before committing.
Changed.
> ~
>
> 11b.
>
> I'm confused - isn't there code doing exactly this (close file before
> commit) already in the apply_handle_stream_commit
> TRANS_PARALLEL_APPLY?
I think here is a typo.
Changed the action in the comment. (committing -> preparing)
> ~
>
> 13.
>
> + serialize_stream_start(stream_xid, false);
> + stream_write_change(LOGICAL_REP_MSG_STREAM_START, &original_msg);
>
> - end_replication_step();
> break;
>
> A spurious blank line is left before the break;
Changed.
> ~~~
>
> 14. serialize_stream_stop
>
> + /* We must be in a valid transaction state */
> + Assert(IsTransactionState());
>
> The comment seems redundant. The code says the same.
Changed.
> ~
>
> 17.
>
> + /*
> + * No need to output the DEBUG message here in the parallel apply
> + * worker as similar messages will be output when handling
> + STREAM_STOP
> + * message.
> + */
> + if (!am_parallel_apply_worker() && nchanges % 1000 == 0)
> elog(DEBUG1, "replayed %d changes from file \"%s\"",
> nchanges, path);
>
> Instead of saying what you are not doing ("No need to... in output
> apply worker") wouldn't it make more sense to reverse it and say what
> you are doing ("Only log DEBUG messages for the leader apply worker
> because ...") and then the condition also becomes positive:
>
> if (am_leader_apply_worker())
> {
> ...
> }
Removed this condition according to Amit's comment.
> ~
>
> 18.
>
> + if (am_parallel_apply_worker() &&
> + MyParallelShared->xact_state == PARALLEL_TRANS_FINISHED)
> + goto done;
> +
> + /*
> + * No need to output the DEBUG message here in the parallel apply
> + * worker as similar messages will be output when handling
> + STREAM_STOP
> + * message.
> + */
> + if (!am_parallel_apply_worker() && nchanges % 1000 == 0)
> elog(DEBUG1, "replayed %d changes from file \"%s\"",
> nchanges, path);
> }
>
> - BufFileClose(fd);
> -
> + stream_close_file();
> pfree(buffer);
> pfree(s2.data);
>
> +done:
> elog(DEBUG1, "replayed %d (all) changes from file \"%s\"",
> nchanges, path);
>
> Shouldn't that "done:" label be *above* the pfree's. Otherwise, those
> are going to be skipped over by the "goto done;".
After reconsidering, I think there is no need to 'pfree' these two variables here,
because they are allocated in toplevel transaction's context and will be freed very soon.
So, I just removed these pfree().
> ======
>
> src/include/replication/worker_internal.h
>
> 21. PartialFileSetState
>
>
> + * State of fileset in leader apply worker.
> + *
> + * FS_BUSY means that the leader is serializing changes to the file.
> +FS_READY
> + * means that the leader has serialized all changes to the file and
> +the file is
> + * ready to be read by a parallel apply worker.
> + */
> +typedef enum PartialFileSetState
>
> "ready to be read" sounded a bit strange.
>
> SUGGESTION
> ... to the file so it is now OK for a parallel apply worker to read it.
Changed.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Thu, Dec 1, 2022 at 7:17 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Thursday, December 1, 2022 3:58 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Wed, Nov 30, 2022 at 10:51 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Wednesday, November 30, 2022 9:41 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > > >
> > > > On Tuesday, November 29, 2022 8:34 PM Amit Kapila
> > > > > Review comments on v53-0001*
> > > >
> > > > Attach the new version patch set.
> > >
> > > Sorry, there were some mistakes in the previous patch set.
> > > Here is the correct V54 patch set. I also ran pgindent for the patch set.
> > >
> >
> > Thank you for updating the patches. Here are random review comments for
> > 0001 and 0002 patches.
>
> Thanks for the comments!
>
> >
> > ereport(ERROR,
> > (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> > errmsg("logical replication parallel apply worker exited
> > abnormally"),
> > errcontext("%s", edata.context))); and
> >
> > ereport(ERROR,
> > (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> > errmsg("logical replication parallel apply worker exited
> > because of subscription information change")));
> >
> > I'm not sure ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE is appropriate
> > here. Given that parallel apply worker has already reported the error message
> > with the error code, I think we don't need to set the errorcode for the logs
> > from the leader process.
> >
> > Also, I'm not sure the term "exited abnormally" is appropriate since we use it
> > when the server crashes for example. I think ERRORs reported here don't mean
> > that in general.
>
> How about reporting "xxx worker exited due to error" ?
Sounds better to me.
>
> > ---
> > if (am_parallel_apply_worker() && on_subinfo_change) {
> > /*
> > * If a parallel apply worker exits due to the subscription
> > * information change, we notify the leader apply worker so that the
> > * leader can report more meaningful message in time and restart the
> > * logical replication.
> > */
> > pq_putmessage('X', NULL, 0);
> > }
> >
> > and
> >
> > ereport(ERROR,
> > (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> > errmsg("logical replication parallel apply worker exited
> > because of subscription information change")));
> >
> > Do we really need an additional message in case of 'X'? When we call
> > apply_worker_clean_exit with on_subinfo_change = true, we have reported the
> > error message such as:
> >
> > ereport(LOG,
> > (errmsg("logical replication parallel apply worker for subscription
> > \"%s\" will stop because of a parameter change",
> > MySubscription->name)));
> >
> > I think that reporting a similar message from the leader might not be
> > meaningful for users.
>
> The intention is to let leader report more meaningful message if a worker
> exited due to subinfo change. Otherwise, the leader is likely to report an
> error like " lost connection ... to parallel apply worker" when trying to send
> data via shared memory if the worker exited. What do you think ?
Agreed. But do we need to have the leader exit with an error in spite
of the fact that the worker cleanly exits? If the leader exits with an
error, the subscription will be disabled if disable_on_error is true,
right?
And what do you think about the error code?
>
> > ---
> > - if (options->proto.logical.streaming &&
> > - PQserverVersion(conn->streamConn) >= 140000)
> > - appendStringInfoString(&cmd, ", streaming 'on'");
> > + if (options->proto.logical.streaming_str)
> > + appendStringInfo(&cmd, ", streaming '%s'",
> > +
> > options->proto.logical.streaming_str);
> >
> > and
> >
> > + /*
> > + * Assign the appropriate option value for streaming option
> > according to
> > + * the 'streaming' mode and the publisher's ability to
> > support that mode.
> > + */
> > + if (server_version >= 160000 &&
> > + MySubscription->stream == SUBSTREAM_PARALLEL)
> > + {
> > + options.proto.logical.streaming_str = pstrdup("parallel");
> > + MyLogicalRepWorker->parallel_apply = true;
> > + }
> > + else if (server_version >= 140000 &&
> > + MySubscription->stream != SUBSTREAM_OFF)
> > + {
> > + options.proto.logical.streaming_str = pstrdup("on");
> > + MyLogicalRepWorker->parallel_apply = false;
> > + }
> > + else
> > + {
> > + options.proto.logical.streaming_str = NULL;
> > + MyLogicalRepWorker->parallel_apply = false;
> > + }
> >
> > This change moves the code of adjustment of the streaming option based on
> > the publisher server version from libpqwalreceiver.c to worker.c.
> > On the other hand, the similar logic for other parameters such as "two_phase"
> > and "origin" are still done in libpqwalreceiver.c. How about passing
> > MySubscription->stream via WalRcvStreamOptions and constructing a
> > streaming option string in libpqrcv_startstreaming()?
> > In ApplyWorkerMain(), we just need to set
> > MyLogicalRepWorker->parallel_apply = true if (server_version >= 160000
> > && MySubscription->stream == SUBSTREAM_PARALLEL). We won't need
> > pstrdup for "parallel" and "on", and it's more consistent with other parameters.
>
> Thanks for the suggestion. I thought about the same idea before, but it seems
> we would weed to introduce " pg_subscription.h " into libpqwalreceiver.c. The
> libpqwalreceiver.c looks a like a common place. So I am not sure is it looks
> better to expose the detail of streaming option to it.
Right. It means that all enum parameters of WalRcvStreamOptions needs
to be handled in the caller (e.g. worker.c etc) whereas other
parameters are handled in libpqwalreceiver.c. It's not elegant but I
have no better idea for that.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Dec 7, 2022 at 9:00 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Thu, Dec 1, 2022 at 7:17 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > > ---
> > > if (am_parallel_apply_worker() && on_subinfo_change) {
> > > /*
> > > * If a parallel apply worker exits due to the subscription
> > > * information change, we notify the leader apply worker so that the
> > > * leader can report more meaningful message in time and restart the
> > > * logical replication.
> > > */
> > > pq_putmessage('X', NULL, 0);
> > > }
> > >
> > > and
> > >
> > > ereport(ERROR,
> > > (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> > > errmsg("logical replication parallel apply worker exited
> > > because of subscription information change")));
> > >
> > > Do we really need an additional message in case of 'X'? When we call
> > > apply_worker_clean_exit with on_subinfo_change = true, we have reported the
> > > error message such as:
> > >
> > > ereport(LOG,
> > > (errmsg("logical replication parallel apply worker for subscription
> > > \"%s\" will stop because of a parameter change",
> > > MySubscription->name)));
> > >
> > > I think that reporting a similar message from the leader might not be
> > > meaningful for users.
> >
> > The intention is to let leader report more meaningful message if a worker
> > exited due to subinfo change. Otherwise, the leader is likely to report an
> > error like " lost connection ... to parallel apply worker" when trying to send
> > data via shared memory if the worker exited. What do you think ?
>
> Agreed. But do we need to have the leader exit with an error in spite
> of the fact that the worker cleanly exits? If the leader exits with an
> error, the subscription will be disabled if disable_on_error is true,
> right?
>
Right, but the leader will anyway exit at some point either due to an
ERROR like "lost connection ... to parallel worker" or with a LOG
like: "... will restart because of a parameter change" but I see your
point. So, will it be better if we have a LOG message here and then
proc_exit()? Do you have something else in mind for this?
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, Dec 7, 2022 at 1:29 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Dec 7, 2022 at 9:00 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Thu, Dec 1, 2022 at 7:17 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > > ---
> > > > if (am_parallel_apply_worker() && on_subinfo_change) {
> > > > /*
> > > > * If a parallel apply worker exits due to the subscription
> > > > * information change, we notify the leader apply worker so that the
> > > > * leader can report more meaningful message in time and restart the
> > > > * logical replication.
> > > > */
> > > > pq_putmessage('X', NULL, 0);
> > > > }
> > > >
> > > > and
> > > >
> > > > ereport(ERROR,
> > > > (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> > > > errmsg("logical replication parallel apply worker exited
> > > > because of subscription information change")));
> > > >
> > > > Do we really need an additional message in case of 'X'? When we call
> > > > apply_worker_clean_exit with on_subinfo_change = true, we have reported the
> > > > error message such as:
> > > >
> > > > ereport(LOG,
> > > > (errmsg("logical replication parallel apply worker for subscription
> > > > \"%s\" will stop because of a parameter change",
> > > > MySubscription->name)));
> > > >
> > > > I think that reporting a similar message from the leader might not be
> > > > meaningful for users.
> > >
> > > The intention is to let leader report more meaningful message if a worker
> > > exited due to subinfo change. Otherwise, the leader is likely to report an
> > > error like " lost connection ... to parallel apply worker" when trying to send
> > > data via shared memory if the worker exited. What do you think ?
> >
> > Agreed. But do we need to have the leader exit with an error in spite
> > of the fact that the worker cleanly exits? If the leader exits with an
> > error, the subscription will be disabled if disable_on_error is true,
> > right?
> >
>
> Right, but the leader will anyway exit at some point either due to an
> ERROR like "lost connection ... to parallel worker" or with a LOG
> like: "... will restart because of a parameter change" but I see your
> point. So, will it be better if we have a LOG message here and then
> proc_exit()? Do you have something else in mind for this?
No, I was thinking that too. It's better to write a LOG message and do
proc_exit().
Regarding the error "lost connection ... to parallel worker", it could
still happen depending on the timing even if the parallel worker
cleanly exits due to parameter changes, right? If so, I'm concerned
that it could lead to disable the subscription unexpectedly if
disable_on_error is enabled.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Dec 7, 2022 at 10:10 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Wed, Dec 7, 2022 at 1:29 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > Right, but the leader will anyway exit at some point either due to an > > ERROR like "lost connection ... to parallel worker" or with a LOG > > like: "... will restart because of a parameter change" but I see your > > point. So, will it be better if we have a LOG message here and then > > proc_exit()? Do you have something else in mind for this? > > No, I was thinking that too. It's better to write a LOG message and do > proc_exit(). > > Regarding the error "lost connection ... to parallel worker", it could > still happen depending on the timing even if the parallel worker > cleanly exits due to parameter changes, right? If so, I'm concerned > that it could lead to disable the subscription unexpectedly if > disable_on_error is enabled. > If we want to avoid this then I think we have the following options (a) parallel apply skips checking parameter change (b) parallel worker won't exit on parameter change but will silently absorb the parameter and continue its processing; anyway, the leader will detect it and stop the worker for the parameter change Among these, the advantage of (b) is that it will allow reflecting the parameter change (that doesn't need restart) in the parallel worker. Do you have any better idea to deal with this? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Dec 7, 2022 at 8:28 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Besides, I fixed a bug where there could still be messages left in memory
> queue and the PA has started to apply spooled message.
>
Few comments on the recent changes in the patch:
========================================
1. It seems you need to set FS_SERIALIZE_DONE in
stream_prepare/commit/abort. They are still directly setting the state
as READY. Am, I missing something or you forgot to change it?
2.
case TRANS_PARALLEL_APPLY:
pa_stream_abort(&abort_data);
+ /*
+ * Reset the stream_fd after aborting the toplevel transaction in
+ * case the parallel apply worker is applying spooled messages
+ */
+ if (toplevel_xact)
+ stream_fd = NULL;
I think we can keep the handling of stream file the same in
abort/commit/prepare code path.
3. It is already pointed out by Peter that it is better to add some
comments in pa_spooled_messages() function that we won't be
immediately able to apply changes after the lock is released, it will
be done in the next cycle.
4. Shall we rename FS_SERIALIZE as FS_SERIALIZE_IN_PROGRESS? That will
appear consistent with FS_SERIALIZE_DONE.
5. Comment improvements:
diff --git a/src/backend/replication/logical/worker.c
b/src/backend/replication/logical/worker.c
index b26d587ae4..921d973863 100644
--- a/src/backend/replication/logical/worker.c
+++ b/src/backend/replication/logical/worker.c
@@ -1934,8 +1934,7 @@ apply_handle_stream_abort(StringInfo s)
}
/*
- * Check if the passed fileno and offset are the last fileno and position of
- * the fileset, and report an ERROR if not.
+ * Ensure that the passed location is fileset's end.
*/
static void
ensure_last_message(FileSet *stream_fileset, TransactionId xid, int fileno,
@@ -2084,9 +2083,9 @@ apply_spooled_messages(FileSet *stream_fileset,
TransactionId xid,
nchanges++;
/*
- * Break the loop if stream_fd is set to NULL which
means the parallel
- * apply worker has finished applying the transaction.
The parallel
- * apply worker should have closed the file before committing.
+ * It is possible the file has been closed because we
have processed
+ * some transaction end message like stream_commit in
which case that
+ * must be the last message.
*/
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, Dec 5, 2022 at 1:29 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Sunday, December 4, 2022 7:17 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> > > > > Thursday, December 1, 2022 8:40 PM Amit Kapila <amit.kapila16@gmail.com> > > wrote: > > > Some other comments: > > ... > > Attach the new version patch set which addressed most of the comments > > received so far except some comments being discussed[1]. > > [1] https://www.postgresql.org/message-id/OS0PR01MB57167BF64FC0891734C8E81A94149%40OS0PR01MB5716.jpnprd01.prod.outlook.com > > Attach a new version patch set which fixed a testcase failure on CFbot. Here are some comments on v56 0001, 0002 patches. Please ignore comments if you already incorporated them in v57. +static void +ProcessParallelApplyInterrupts(void) +{ + CHECK_FOR_INTERRUPTS(); + + if (ShutdownRequestPending) + { + ereport(LOG, + (errmsg("logical replication parallel apply worker for subscrip tion \"%s\" has finished", + MySubscription->name))); + + apply_worker_clean_exit(false); + } + + if (ConfigReloadPending) + { + ConfigReloadPending = false; + ProcessConfigFile(PGC_SIGHUP); + } +} I personally think that we don't need to have a function to do only these few things. --- +/* Disallow streaming in-progress transactions. */ +#define SUBSTREAM_OFF 'f' + +/* + * Streaming in-progress transactions are written to a temporary file and + * applied only after the transaction is committed on upstream. + */ +#define SUBSTREAM_ON 't' + +/* + * Streaming in-progress transactions are applied immediately via a parallel + * apply worker. + */ +#define SUBSTREAM_PARALLEL 'p' + While these names look good to me, we already have the following existing values: */ #define LOGICALREP_TWOPHASE_STATE_DISABLED 'd' #define LOGICALREP_TWOPHASE_STATE_PENDING 'p' #define LOGICALREP_TWOPHASE_STATE_ENABLED 'e' /* * The subscription will request the publisher to * have any origin. */ #define LOGICALREP_ORIGIN_NONE "none" /* * The subscription will request the publisher to * of their origin. */ #define LOGICALREP_ORIGIN_ANY "any" Should we change the names to something like LOGICALREP_STREAM_PARALLEL? --- + * The lock graph for the above example will look as follows: + * LA (waiting to acquire the lock on the unique index) -> PA (waiting to + * acquire the lock on the remote transaction) -> LA and + * The lock graph for the above example will look as follows: + * LA (waiting to acquire the transaction lock) -> PA-2 (waiting to acquire the + * lock due to unique index constraint) -> PA-1 (waiting to acquire the stream + * lock) -> LA "(waiting to acquire the lock on the remote transaction)" in the first example and "(waiting to acquire the stream lock)" in the second example is the same meaning, right? If so, I think we should use either term for consistency. --- + bool write_abort_info = (data->streaming == SUBSTREAM_PARALLEL); I think that instead of setting write_abort_info every time when pgoutput_stream_abort() is called, we can set it once, probably in PGOutputData, at startup. --- server_version = walrcv_server_version(LogRepWorkerWalRcvConn); options.proto.logical.proto_version = + server_version >= 160000 ? LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM : server_version >= 150000 ? LOGICALREP_PROTO_TWOPHASE_VERSION_NUM : server_version >= 140000 ? LOGICALREP_PROTO_STREAM_VERSION_NUM : LOGICALREP_PROTO_VERSION_NUM; Instead of always using the new protocol version, I think we can use LOGICALREP_PROTO_TWOPHASE_VERSION_NUM if the streaming is not 'parallel'. That way, we don't need to change protocl version check logic in pgoutput.c and don't need to expose defGetStreamingMode(). What do you think? --- When max_parallel_apply_workers_per_subscription is changed to a value lower than the number of parallel worker running at that time, do we need to stop extra workers? --- If a value of max_parallel_apply_workers_per_subscription is not sufficient, we get the LOG "out of parallel apply workers" every time when the apply worker doesn't launch a worker. But do we really need this log? It seems not consistent with max_sync_workers_per_subscription behavior. I think we can check if the number of running parallel workers is less than max_parallel_apply_workers_per_subscription before calling logicalrep_worker_launch(). What do you think? --- + if (server_version >= 160000 && + MySubscription->stream == SUBSTREAM_PARALLEL) + { + options.proto.logical.streaming_str = pstrdup("parallel"); + MyLogicalRepWorker->parallel_apply = true; + } + else if (server_version >= 140000 && + MySubscription->stream != SUBSTREAM_OFF) + { + options.proto.logical.streaming_str = pstrdup("on"); + MyLogicalRepWorker->parallel_apply = false; + } I think we don't need to use pstrdup(). --- - BeginTransactionBlock(); - CommitTransactionCommand(); /* Completes the preceding Begin command. */ + if (!IsTransactionBlock()) + { + BeginTransactionBlock(); + CommitTransactionCommand(); /* Completes the preceding Begin command. */ + } Do we need this change? In my environment, 'make check-world' passes without this change. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, Dec 7, 2022 at 4:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Dec 7, 2022 at 10:10 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Wed, Dec 7, 2022 at 1:29 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > Right, but the leader will anyway exit at some point either due to an > > > ERROR like "lost connection ... to parallel worker" or with a LOG > > > like: "... will restart because of a parameter change" but I see your > > > point. So, will it be better if we have a LOG message here and then > > > proc_exit()? Do you have something else in mind for this? > > > > No, I was thinking that too. It's better to write a LOG message and do > > proc_exit(). > > > > Regarding the error "lost connection ... to parallel worker", it could > > still happen depending on the timing even if the parallel worker > > cleanly exits due to parameter changes, right? If so, I'm concerned > > that it could lead to disable the subscription unexpectedly if > > disable_on_error is enabled. > > > > If we want to avoid this then I think we have the following options > (a) parallel apply skips checking parameter change (b) parallel worker > won't exit on parameter change but will silently absorb the parameter > and continue its processing; anyway, the leader will detect it and > stop the worker for the parameter change > > Among these, the advantage of (b) is that it will allow reflecting the > parameter change (that doesn't need restart) in the parallel worker. > Do you have any better idea to deal with this? I think (b) is better. We need to reflect the synchronous_commit parameter also in parallel workers in the worker pool. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, December 7, 2022 7:51 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Mon, Dec 5, 2022 at 1:29 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Sunday, December 4, 2022 7:17 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> > > > > > > Thursday, December 1, 2022 8:40 PM Amit Kapila > <amit.kapila16@gmail.com> > > > wrote: > > > > Some other comments: > > > ... > > > Attach the new version patch set which addressed most of the comments > > > received so far except some comments being discussed[1]. > > > [1] > https://www.postgresql.org/message-id/OS0PR01MB57167BF64FC0891734C > 8E81A94149%40OS0PR01MB5716.jpnprd01.prod.outlook.com > > > > Attach a new version patch set which fixed a testcase failure on CFbot. > > Here are some comments on v56 0001, 0002 patches. Please ignore > comments if you already incorporated them in v57. Thanks for the comments! > +static void > +ProcessParallelApplyInterrupts(void) > +{ > + CHECK_FOR_INTERRUPTS(); > + > + if (ShutdownRequestPending) > + { > + ereport(LOG, > + (errmsg("logical replication parallel > apply worker for subscrip > tion \"%s\" has finished", > + MySubscription->name))); > + > + apply_worker_clean_exit(false); > + } > + > + if (ConfigReloadPending) > + { > + ConfigReloadPending = false; > + ProcessConfigFile(PGC_SIGHUP); > + } > +} > > I personally think that we don't need to have a function to do only > these few things. I thought that introduce a new function make the handling of worker specific Interrupts logic similar to other existing ones. Like: ProcessWalRcvInterrupts () in walreceiver.c and HandlePgArchInterrupts() in pgarch.c ... > > Should we change the names to something like > LOGICALREP_STREAM_PARALLEL? Agreed, will change. > --- > + * The lock graph for the above example will look as follows: > + * LA (waiting to acquire the lock on the unique index) -> PA (waiting to > + * acquire the lock on the remote transaction) -> LA > > and > > + * The lock graph for the above example will look as follows: > + * LA (waiting to acquire the transaction lock) -> PA-2 (waiting to acquire the > + * lock due to unique index constraint) -> PA-1 (waiting to acquire the stream > + * lock) -> LA > > "(waiting to acquire the lock on the remote transaction)" in the first > example and "(waiting to acquire the stream lock)" in the second > example is the same meaning, right? If so, I think we should use > either term for consistency. Will change. > --- > + bool write_abort_info = (data->streaming == > SUBSTREAM_PARALLEL); > > I think that instead of setting write_abort_info every time when > pgoutput_stream_abort() is called, we can set it once, probably in > PGOutputData, at startup. I thought that since we already have a "stream" flag in PGOutputData, I am not sure if it would be better to introduce another flag for the same option. > --- > server_version = walrcv_server_version(LogRepWorkerWalRcvConn); > options.proto.logical.proto_version = > + server_version >= 160000 ? > LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM : > server_version >= 150000 ? > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM : > server_version >= 140000 ? > LOGICALREP_PROTO_STREAM_VERSION_NUM : > LOGICALREP_PROTO_VERSION_NUM; > > Instead of always using the new protocol version, I think we can use > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM if the streaming is not > 'parallel'. That way, we don't need to change protocl version check > logic in pgoutput.c and don't need to expose defGetStreamingMode(). > What do you think? I think that some user can also use the new version number when trying to get changes (via pg_logical_slot_peek_binary_changes or other functions), so I feel leave the check for new version number seems fine. Besides, I feel even if we don't use new version number, we still need to use defGetStreamingMode to check if parallel mode in used as we need to send abort_lsn when parallel is in used. I might be missing something, sorry for that. Can you please explain the idea a bit ? > --- > When max_parallel_apply_workers_per_subscription is changed to a value > lower than the number of parallel worker running at that time, do we > need to stop extra workers? I think we can do this, like adding a check in the main loop of leader worker, and check every time after reloading the conf. OTOH, we will also stop the worker after finishing a transaction, so I am slightly not sure do we need to add another check logic here. But I am fine to add it if you think it would be better. > --- > If a value of max_parallel_apply_workers_per_subscription is not > sufficient, we get the LOG "out of parallel apply workers" every time > when the apply worker doesn't launch a worker. But do we really need > this log? It seems not consistent with > max_sync_workers_per_subscription behavior. I think we can check if > the number of running parallel workers is less than > max_parallel_apply_workers_per_subscription before calling > logicalrep_worker_launch(). What do you think? > > --- > + if (server_version >= 160000 && > + MySubscription->stream == SUBSTREAM_PARALLEL) > + { > + options.proto.logical.streaming_str = pstrdup("parallel"); > + MyLogicalRepWorker->parallel_apply = true; > + } > + else if (server_version >= 140000 && > + MySubscription->stream != SUBSTREAM_OFF) > + { > + options.proto.logical.streaming_str = pstrdup("on"); > + MyLogicalRepWorker->parallel_apply = false; > + } > > I think we don't need to use pstrdup(). Will remove. > --- > - BeginTransactionBlock(); > - CommitTransactionCommand(); /* Completes the preceding Begin > command. */ > + if (!IsTransactionBlock()) > + { > + BeginTransactionBlock(); > + CommitTransactionCommand(); /* Completes the preceding > Begin command. */ > + } > > Do we need this change? In my environment, 'make check-world' passes > without this change. We will start a transaction block when defining the savepoint and we will get a warning[1] if enter this function later. I think there would be some WARNs in the log of " 022_twophase_cascade" test if we remove this check. [1] WARN: there is already a transaction in progress" Best regards, Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, December 7, 2022 7:51 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Mon, Dec 5, 2022 at 1:29 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Sunday, December 4, 2022 7:17 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> > > > > > > Thursday, December 1, 2022 8:40 PM Amit Kapila > <amit.kapila16@gmail.com> > > > wrote: > > > > Some other comments: > > > ... > > > Attach the new version patch set which addressed most of the comments > > > received so far except some comments being discussed[1]. > > > [1] > https://www.postgresql.org/message-id/OS0PR01MB57167BF64FC0891734C > 8E81A94149%40OS0PR01MB5716.jpnprd01.prod.outlook.com > > > > Attach a new version patch set which fixed a testcase failure on CFbot. > > --- > If a value of max_parallel_apply_workers_per_subscription is not > sufficient, we get the LOG "out of parallel apply workers" every time > when the apply worker doesn't launch a worker. But do we really need > this log? It seems not consistent with > max_sync_workers_per_subscription behavior. I think we can check if > the number of running parallel workers is less than > max_parallel_apply_workers_per_subscription before calling > logicalrep_worker_launch(). What do you think? (Sorry, I missed this comment in last email) I personally feel giving a hint might help user to realize that the max_parallel_applyxxx is not enough for the current workload and then they can adjust the parameter. Otherwise, user might have an easy way to check if more workers are needed. Best regards, Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Dec 7, 2022 at 6:33 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, December 7, 2022 7:51 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > --- > > When max_parallel_apply_workers_per_subscription is changed to a value > > lower than the number of parallel worker running at that time, do we > > need to stop extra workers? > > I think we can do this, like adding a check in the main loop of leader worker, and > check every time after reloading the conf. OTOH, we will also stop the worker after > finishing a transaction, so I am slightly not sure do we need to add another check logic here. > But I am fine to add it if you think it would be better. > I think this is tricky because it is possible that all active workers are busy with long-running transactions, so, I think stopping them doesn't make sense. I think as long as we are freeing them after use it seems okay to me. OTOH, each time after finishing the transaction, we can stop the workers, if the workers in the free pool exceed 'max_parallel_apply_workers_per_subscription'. I don't know if it is worth. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, December 7, 2022 6:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Dec 7, 2022 at 8:28 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > Besides, I fixed a bug where there could still be messages left in > > memory queue and the PA has started to apply spooled message. > > > > Few comments on the recent changes in the patch: > ======================================== > 1. It seems you need to set FS_SERIALIZE_DONE in > stream_prepare/commit/abort. They are still directly setting the state as > READY. Am, I missing something or you forgot to change it? It's my miss, changed. > 2. > case TRANS_PARALLEL_APPLY: > pa_stream_abort(&abort_data); > > + /* > + * Reset the stream_fd after aborting the toplevel transaction in > + * case the parallel apply worker is applying spooled messages */ if > + (toplevel_xact) stream_fd = NULL; > > I think we can keep the handling of stream file the same in > abort/commit/prepare code path. Changed. > 3. It is already pointed out by Peter that it is better to add some comments in > pa_spooled_messages() function that we won't be immediately able to apply > changes after the lock is released, it will be done in the next cycle. Added. > 4. Shall we rename FS_SERIALIZE as FS_SERIALIZE_IN_PROGRESS? That will > appear consistent with FS_SERIALIZE_DONE. Agreed, changed. > 5. Comment improvements: > diff --git a/src/backend/replication/logical/worker.c > b/src/backend/replication/logical/worker.c > index b26d587ae4..921d973863 100644 > --- a/src/backend/replication/logical/worker.c > +++ b/src/backend/replication/logical/worker.c > @@ -1934,8 +1934,7 @@ apply_handle_stream_abort(StringInfo s) } > > /* > - * Check if the passed fileno and offset are the last fileno and position of > - * the fileset, and report an ERROR if not. > + * Ensure that the passed location is fileset's end. > */ > static void > ensure_last_message(FileSet *stream_fileset, TransactionId xid, int fileno, @@ > -2084,9 +2083,9 @@ apply_spooled_messages(FileSet *stream_fileset, > TransactionId xid, > nchanges++; > > /* > - * Break the loop if stream_fd is set to NULL which > means the parallel > - * apply worker has finished applying the transaction. > The parallel > - * apply worker should have closed the file before committing. > + * It is possible the file has been closed because we > have processed > + * some transaction end message like stream_commit in > which case that > + * must be the last message. > */ Merged, thanks. Attach the new version patch which addressed all above comments and part of comments from[1] except some comments that are being discussed. Apart from above, according to the comment from Amit and Sawada-san[2], the new version patch won't stop the parallel worker due to subscription parameter change, it will absorb the change instead, and the leader will anyway detect the parameter change and stop all workers later. Based on this, I also removed the maybe_reread_subscription() call in parallel apply worker's main loop, because we need to make sure we won't update the local subscription parameter in the middle of the transaction. And we will call maybe_reread_subscription() before starting a transaction in parallel apply worker anyway(in maybe_reread_subscription()), so remove that check is fine and can save some codes. [1] https://www.postgresql.org/message-id/CAD21AoCZ3i9w1Rz-81Lv1QB%2BJGP60Ypiom4%2BwM9eP3aQTx0STQ%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAD21AoAzYstJVM0nMVnXZoeYamqD2j92DkWVH%3DYbGtA4yzy19A%40mail.gmail.com Best regards, Hou zj
Attachment
- v58-0007-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v58-0002-Serialize-partial-changes-to-a-file-when-the-att.patch
- v58-0001-Perform-streaming-logical-transactions-by-parall.patch
- v58-0003-Test-streaming-parallel-option-in-tap-test.patch
- v58-0004-Allow-streaming-every-change-without-waiting-til.patch
- v58-0005-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v58-0006-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Thu, Dec 8, 2022 at 1:52 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Dec 7, 2022 at 6:33 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Wednesday, December 7, 2022 7:51 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > --- > > > When max_parallel_apply_workers_per_subscription is changed to a value > > > lower than the number of parallel worker running at that time, do we > > > need to stop extra workers? > > > > I think we can do this, like adding a check in the main loop of leader worker, and > > check every time after reloading the conf. OTOH, we will also stop the worker after > > finishing a transaction, so I am slightly not sure do we need to add another check logic here. > > But I am fine to add it if you think it would be better. > > > > I think this is tricky because it is possible that all active workers > are busy with long-running transactions, so, I think stopping them > doesn't make sense. Right, we should not stop running parallel workers. > I think as long as we are freeing them after use > it seems okay to me. OTOH, each time after finishing the transaction, > we can stop the workers, if the workers in the free pool exceed > 'max_parallel_apply_workers_per_subscription'. Or the apply leader worker can check that after reloading the config file. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, Dec 7, 2022 at 10:03 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, December 7, 2022 7:51 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Mon, Dec 5, 2022 at 1:29 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > On Sunday, December 4, 2022 7:17 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> > > > > > > > > Thursday, December 1, 2022 8:40 PM Amit Kapila > > <amit.kapila16@gmail.com> > > > > wrote: > > > > > Some other comments: > > > > ... > > > > Attach the new version patch set which addressed most of the comments > > > > received so far except some comments being discussed[1]. > > > > [1] > > https://www.postgresql.org/message-id/OS0PR01MB57167BF64FC0891734C > > 8E81A94149%40OS0PR01MB5716.jpnprd01.prod.outlook.com > > > > > > Attach a new version patch set which fixed a testcase failure on CFbot. > > > > Here are some comments on v56 0001, 0002 patches. Please ignore > > comments if you already incorporated them in v57. > > Thanks for the comments! > > > +static void > > +ProcessParallelApplyInterrupts(void) > > +{ > > + CHECK_FOR_INTERRUPTS(); > > + > > + if (ShutdownRequestPending) > > + { > > + ereport(LOG, > > + (errmsg("logical replication parallel > > apply worker for subscrip > > tion \"%s\" has finished", > > + MySubscription->name))); > > + > > + apply_worker_clean_exit(false); > > + } > > + > > + if (ConfigReloadPending) > > + { > > + ConfigReloadPending = false; > > + ProcessConfigFile(PGC_SIGHUP); > > + } > > +} > > > > I personally think that we don't need to have a function to do only > > these few things. > > I thought that introduce a new function make the handling of worker specific > Interrupts logic similar to other existing ones. Like: > ProcessWalRcvInterrupts () in walreceiver.c and HandlePgArchInterrupts() in > pgarch.c ... I think the difference from them is that there is only one place to call ProcessParallelApplyInterrupts(). > > > > > Should we change the names to something like > > LOGICALREP_STREAM_PARALLEL? > > Agreed, will change. > > > --- > > + * The lock graph for the above example will look as follows: > > + * LA (waiting to acquire the lock on the unique index) -> PA (waiting to > > + * acquire the lock on the remote transaction) -> LA > > > > and > > > > + * The lock graph for the above example will look as follows: > > + * LA (waiting to acquire the transaction lock) -> PA-2 (waiting to acquire the > > + * lock due to unique index constraint) -> PA-1 (waiting to acquire the stream > > + * lock) -> LA > > > > "(waiting to acquire the lock on the remote transaction)" in the first > > example and "(waiting to acquire the stream lock)" in the second > > example is the same meaning, right? If so, I think we should use > > either term for consistency. > > Will change. > > > --- > > + bool write_abort_info = (data->streaming == > > SUBSTREAM_PARALLEL); > > > > I think that instead of setting write_abort_info every time when > > pgoutput_stream_abort() is called, we can set it once, probably in > > PGOutputData, at startup. > > I thought that since we already have a "stream" flag in PGOutputData, I am not > sure if it would be better to introduce another flag for the same option. I see your point. Another way is to have it as a static variable like publish_no_origin. But since It's trivial change I'm fine also with the current code. > > > --- > > server_version = walrcv_server_version(LogRepWorkerWalRcvConn); > > options.proto.logical.proto_version = > > + server_version >= 160000 ? > > LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM : > > server_version >= 150000 ? > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM : > > server_version >= 140000 ? > > LOGICALREP_PROTO_STREAM_VERSION_NUM : > > LOGICALREP_PROTO_VERSION_NUM; > > > > Instead of always using the new protocol version, I think we can use > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM if the streaming is not > > 'parallel'. That way, we don't need to change protocl version check > > logic in pgoutput.c and don't need to expose defGetStreamingMode(). > > What do you think? > > I think that some user can also use the new version number when trying to get > changes (via pg_logical_slot_peek_binary_changes or other functions), so I feel > leave the check for new version number seems fine. > > Besides, I feel even if we don't use new version number, we still need to use > defGetStreamingMode to check if parallel mode in used as we need to send > abort_lsn when parallel is in used. I might be missing something, sorry for > that. Can you please explain the idea a bit ? My idea is that we use LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM if (server_version >= 160000 && MySubscription->stream == SUBSTREAM_PARALLEL). If the stream is SUBSTREAM_ON, we use LOGICALREP_PROTO_TWOPHASE_VERSION_NUM even if server_version is 160000. That way, in pgoutput.c, we can send abort_lsn if the protocol version is LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM. We don't need to send "streaming = parallel" to the publisher since the publisher can decide whether or not to send abort_lsn based on the protocol version (still needs to send "streaming = on" though). I might be missing something. My question came from the fact that the difference between LOGICALREP_PROTO_TWOPHASE_VERSION_NUM and LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM is just whether or not to send abort_lsn and there are two knobs to control that. IIUC even if we use the new protocol version, the data actually sent during logical replication are the same as the previous protocol version if streaming is not 'parallel'. So I thought that we do either not send 'parallel' to the publisher (i.e., send abort_lsn based on the protocol version) or not introduce a new protocol version (i.e. send abort_lsn based on the streaming option). > > > --- > > When max_parallel_apply_workers_per_subscription is changed to a value > > lower than the number of parallel worker running at that time, do we > > need to stop extra workers? > > I think we can do this, like adding a check in the main loop of leader worker, and > check every time after reloading the conf. OTOH, we will also stop the worker after > finishing a transaction, so I am slightly not sure do we need to add another check logic here. > But I am fine to add it if you think it would be better. > > > > --- > > If a value of max_parallel_apply_workers_per_subscription is not > > sufficient, we get the LOG "out of parallel apply workers" every time > > when the apply worker doesn't launch a worker. But do we really need > > this log? It seems not consistent with > > max_sync_workers_per_subscription behavior. I think we can check if > > the number of running parallel workers is less than > > max_parallel_apply_workers_per_subscription before calling > > logicalrep_worker_launch(). What do you think? > > > > --- > > + if (server_version >= 160000 && > > + MySubscription->stream == SUBSTREAM_PARALLEL) > > + { > > + options.proto.logical.streaming_str = pstrdup("parallel"); > > + MyLogicalRepWorker->parallel_apply = true; > > + } > > + else if (server_version >= 140000 && > > + MySubscription->stream != SUBSTREAM_OFF) > > + { > > + options.proto.logical.streaming_str = pstrdup("on"); > > + MyLogicalRepWorker->parallel_apply = false; > > + } > > > > I think we don't need to use pstrdup(). > > Will remove. > > > --- > > - BeginTransactionBlock(); > > - CommitTransactionCommand(); /* Completes the preceding Begin > > command. */ > > + if (!IsTransactionBlock()) > > + { > > + BeginTransactionBlock(); > > + CommitTransactionCommand(); /* Completes the preceding > > Begin command. */ > > + } > > > > Do we need this change? In my environment, 'make check-world' passes > > without this change. > > We will start a transaction block when defining the savepoint and we will get > a warning[1] if enter this function later. I think there would be some WARNs in > the log of " 022_twophase_cascade" test if we remove this check. Thanks, I understood. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Dec 8, 2022 at 12:42 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Wed, Dec 7, 2022 at 10:03 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> >
> > > +static void
> > > +ProcessParallelApplyInterrupts(void)
> > > +{
> > > + CHECK_FOR_INTERRUPTS();
> > > +
> > > + if (ShutdownRequestPending)
> > > + {
> > > + ereport(LOG,
> > > + (errmsg("logical replication parallel
> > > apply worker for subscrip
> > > tion \"%s\" has finished",
> > > + MySubscription->name)));
> > > +
> > > + apply_worker_clean_exit(false);
> > > + }
> > > +
> > > + if (ConfigReloadPending)
> > > + {
> > > + ConfigReloadPending = false;
> > > + ProcessConfigFile(PGC_SIGHUP);
> > > + }
> > > +}
> > >
> > > I personally think that we don't need to have a function to do only
> > > these few things.
> >
> > I thought that introduce a new function make the handling of worker specific
> > Interrupts logic similar to other existing ones. Like:
> > ProcessWalRcvInterrupts () in walreceiver.c and HandlePgArchInterrupts() in
> > pgarch.c ...
>
> I think the difference from them is that there is only one place to
> call ProcessParallelApplyInterrupts().
>
But I feel it is better to isolate this code in a separate function.
What if we decide to extend it further by having some logic to stop
workers after reloading of config?
> >
> > > ---
> > > server_version = walrcv_server_version(LogRepWorkerWalRcvConn);
> > > options.proto.logical.proto_version =
> > > + server_version >= 160000 ?
> > > LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM :
> > > server_version >= 150000 ?
> > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM :
> > > server_version >= 140000 ?
> > > LOGICALREP_PROTO_STREAM_VERSION_NUM :
> > > LOGICALREP_PROTO_VERSION_NUM;
> > >
> > > Instead of always using the new protocol version, I think we can use
> > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM if the streaming is not
> > > 'parallel'. That way, we don't need to change protocl version check
> > > logic in pgoutput.c and don't need to expose defGetStreamingMode().
> > > What do you think?
> >
> > I think that some user can also use the new version number when trying to get
> > changes (via pg_logical_slot_peek_binary_changes or other functions), so I feel
> > leave the check for new version number seems fine.
> >
> > Besides, I feel even if we don't use new version number, we still need to use
> > defGetStreamingMode to check if parallel mode in used as we need to send
> > abort_lsn when parallel is in used. I might be missing something, sorry for
> > that. Can you please explain the idea a bit ?
>
> My idea is that we use LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM if
> (server_version >= 160000 && MySubscription->stream ==
> SUBSTREAM_PARALLEL). If the stream is SUBSTREAM_ON, we use
> LOGICALREP_PROTO_TWOPHASE_VERSION_NUM even if server_version is
> 160000. That way, in pgoutput.c, we can send abort_lsn if the protocol
> version is LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM. We don't need
> to send "streaming = parallel" to the publisher since the publisher
> can decide whether or not to send abort_lsn based on the protocol
> version (still needs to send "streaming = on" though). I might be
> missing something.
>
What if we decide to send some more additional information as part of
another patch like we are discussing in the thread [1]? Now, we won't
be able to decide the version number based on just the streaming
option. Also, in such a case, even for
LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM, it may not be a good
idea to send additional abort information unless the user has used the
streaming=parallel option.
[1] - https://www.postgresql.org/message-id/CAGPVpCRWEVhXa7ovrhuSQofx4to7o22oU9iKtrOgAOtz_%3DY6vg%40mail.gmail.com
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Thu, Dec 8, 2022 at 4:42 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Dec 8, 2022 at 12:42 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Wed, Dec 7, 2022 at 10:03 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > >
> > > > +static void
> > > > +ProcessParallelApplyInterrupts(void)
> > > > +{
> > > > + CHECK_FOR_INTERRUPTS();
> > > > +
> > > > + if (ShutdownRequestPending)
> > > > + {
> > > > + ereport(LOG,
> > > > + (errmsg("logical replication parallel
> > > > apply worker for subscrip
> > > > tion \"%s\" has finished",
> > > > + MySubscription->name)));
> > > > +
> > > > + apply_worker_clean_exit(false);
> > > > + }
> > > > +
> > > > + if (ConfigReloadPending)
> > > > + {
> > > > + ConfigReloadPending = false;
> > > > + ProcessConfigFile(PGC_SIGHUP);
> > > > + }
> > > > +}
> > > >
> > > > I personally think that we don't need to have a function to do only
> > > > these few things.
> > >
> > > I thought that introduce a new function make the handling of worker specific
> > > Interrupts logic similar to other existing ones. Like:
> > > ProcessWalRcvInterrupts () in walreceiver.c and HandlePgArchInterrupts() in
> > > pgarch.c ...
> >
> > I think the difference from them is that there is only one place to
> > call ProcessParallelApplyInterrupts().
> >
>
> But I feel it is better to isolate this code in a separate function.
> What if we decide to extend it further by having some logic to stop
> workers after reloading of config?
I think we can separate the function at that time. But let's keep the
current code as you and Hou agree with the current code. I'm not going
to insist on that.
>
> > >
> > > > ---
> > > > server_version = walrcv_server_version(LogRepWorkerWalRcvConn);
> > > > options.proto.logical.proto_version =
> > > > + server_version >= 160000 ?
> > > > LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM :
> > > > server_version >= 150000 ?
> > > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM :
> > > > server_version >= 140000 ?
> > > > LOGICALREP_PROTO_STREAM_VERSION_NUM :
> > > > LOGICALREP_PROTO_VERSION_NUM;
> > > >
> > > > Instead of always using the new protocol version, I think we can use
> > > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM if the streaming is not
> > > > 'parallel'. That way, we don't need to change protocl version check
> > > > logic in pgoutput.c and don't need to expose defGetStreamingMode().
> > > > What do you think?
> > >
> > > I think that some user can also use the new version number when trying to get
> > > changes (via pg_logical_slot_peek_binary_changes or other functions), so I feel
> > > leave the check for new version number seems fine.
> > >
> > > Besides, I feel even if we don't use new version number, we still need to use
> > > defGetStreamingMode to check if parallel mode in used as we need to send
> > > abort_lsn when parallel is in used. I might be missing something, sorry for
> > > that. Can you please explain the idea a bit ?
> >
> > My idea is that we use LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM if
> > (server_version >= 160000 && MySubscription->stream ==
> > SUBSTREAM_PARALLEL). If the stream is SUBSTREAM_ON, we use
> > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM even if server_version is
> > 160000. That way, in pgoutput.c, we can send abort_lsn if the protocol
> > version is LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM. We don't need
> > to send "streaming = parallel" to the publisher since the publisher
> > can decide whether or not to send abort_lsn based on the protocol
> > version (still needs to send "streaming = on" though). I might be
> > missing something.
> >
>
> What if we decide to send some more additional information as part of
> another patch like we are discussing in the thread [1]? Now, we won't
> be able to decide the version number based on just the streaming
> option. Also, in such a case, even for
> LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM, it may not be a good
> idea to send additional abort information unless the user has used the
> streaming=parallel option.
If we're going to send the additional information, it makes sense to
send streaming=parallel. But the next question came to me is why do we
need to increase the protocol version for parallel apply feature? If
sending the additional information is also controlled by an option
like "streaming", we can decide what we send based on these options,
no?
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Thu, Dec 8, 2022 at 7:43 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Thu, Dec 8, 2022 at 4:42 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Thu, Dec 8, 2022 at 12:42 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > >
> > > On Wed, Dec 7, 2022 at 10:03 PM houzj.fnst@fujitsu.com
> > > <houzj.fnst@fujitsu.com> wrote:
> > > >
> > > >
> > > > > +static void
> > > > > +ProcessParallelApplyInterrupts(void)
> > > > > +{
> > > > > + CHECK_FOR_INTERRUPTS();
> > > > > +
> > > > > + if (ShutdownRequestPending)
> > > > > + {
> > > > > + ereport(LOG,
> > > > > + (errmsg("logical replication parallel
> > > > > apply worker for subscrip
> > > > > tion \"%s\" has finished",
> > > > > + MySubscription->name)));
> > > > > +
> > > > > + apply_worker_clean_exit(false);
> > > > > + }
> > > > > +
> > > > > + if (ConfigReloadPending)
> > > > > + {
> > > > > + ConfigReloadPending = false;
> > > > > + ProcessConfigFile(PGC_SIGHUP);
> > > > > + }
> > > > > +}
> > > > >
> > > > > I personally think that we don't need to have a function to do only
> > > > > these few things.
> > > >
> > > > I thought that introduce a new function make the handling of worker specific
> > > > Interrupts logic similar to other existing ones. Like:
> > > > ProcessWalRcvInterrupts () in walreceiver.c and HandlePgArchInterrupts() in
> > > > pgarch.c ...
> > >
> > > I think the difference from them is that there is only one place to
> > > call ProcessParallelApplyInterrupts().
> > >
> >
> > But I feel it is better to isolate this code in a separate function.
> > What if we decide to extend it further by having some logic to stop
> > workers after reloading of config?
>
> I think we can separate the function at that time. But let's keep the
> current code as you and Hou agree with the current code. I'm not going
> to insist on that.
>
> >
> > > >
> > > > > ---
> > > > > server_version = walrcv_server_version(LogRepWorkerWalRcvConn);
> > > > > options.proto.logical.proto_version =
> > > > > + server_version >= 160000 ?
> > > > > LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM :
> > > > > server_version >= 150000 ?
> > > > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM :
> > > > > server_version >= 140000 ?
> > > > > LOGICALREP_PROTO_STREAM_VERSION_NUM :
> > > > > LOGICALREP_PROTO_VERSION_NUM;
> > > > >
> > > > > Instead of always using the new protocol version, I think we can use
> > > > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM if the streaming is not
> > > > > 'parallel'. That way, we don't need to change protocl version check
> > > > > logic in pgoutput.c and don't need to expose defGetStreamingMode().
> > > > > What do you think?
> > > >
> > > > I think that some user can also use the new version number when trying to get
> > > > changes (via pg_logical_slot_peek_binary_changes or other functions), so I feel
> > > > leave the check for new version number seems fine.
> > > >
> > > > Besides, I feel even if we don't use new version number, we still need to use
> > > > defGetStreamingMode to check if parallel mode in used as we need to send
> > > > abort_lsn when parallel is in used. I might be missing something, sorry for
> > > > that. Can you please explain the idea a bit ?
> > >
> > > My idea is that we use LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM if
> > > (server_version >= 160000 && MySubscription->stream ==
> > > SUBSTREAM_PARALLEL). If the stream is SUBSTREAM_ON, we use
> > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM even if server_version is
> > > 160000. That way, in pgoutput.c, we can send abort_lsn if the protocol
> > > version is LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM. We don't need
> > > to send "streaming = parallel" to the publisher since the publisher
> > > can decide whether or not to send abort_lsn based on the protocol
> > > version (still needs to send "streaming = on" though). I might be
> > > missing something.
> > >
> >
> > What if we decide to send some more additional information as part of
> > another patch like we are discussing in the thread [1]? Now, we won't
> > be able to decide the version number based on just the streaming
> > option. Also, in such a case, even for
> > LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM, it may not be a good
> > idea to send additional abort information unless the user has used the
> > streaming=parallel option.
>
> If we're going to send the additional information, it makes sense to
> send streaming=parallel. But the next question came to me is why do we
> need to increase the protocol version for parallel apply feature? If
> sending the additional information is also controlled by an option
> like "streaming", we can decide what we send based on these options,
> no?
>
AFAIK the protocol version defines what protocol message bytes are
transmitted on the wire. So I thought the protocol version should
*always* be updated whenever the message format changes. In other
words, I don't think we ought to be transmitting different protocol
message formats unless it is a different protocol version.
Whether the pub/sub implementation actually needs to check that
protocol version or whether we happen to have some alternative knob we
can check doesn't change what the protocol version is supposed to
mean. And the PGDOCS [1] and [2] currently have clear field notes
about when those fields are present (e.g. "This field is available
since protocol version XXX"), but if hypothetically you don't change
the protocol version for some new fields then now the message format
becomes tied to the built-in implementation of pub/sub -- now what
field note will you say instead to explain that?
------
[1] https://www.postgresql.org/docs/current/protocol-logical-replication.html
[2] https://www.postgresql.org/docs/current/protocol-logicalrep-message-formats.html
Kind Regards,
Peter Smith.
Fujitsu Australia.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Dec 9, 2022 at 7:45 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Thu, Dec 8, 2022 at 7:43 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Thu, Dec 8, 2022 at 4:42 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > >
> > > On Thu, Dec 8, 2022 at 12:42 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > > >
> > > > On Wed, Dec 7, 2022 at 10:03 PM houzj.fnst@fujitsu.com
> > > > <houzj.fnst@fujitsu.com> wrote:
> > > > >
> > > > >
> > > > > > +static void
> > > > > > +ProcessParallelApplyInterrupts(void)
> > > > > > +{
> > > > > > + CHECK_FOR_INTERRUPTS();
> > > > > > +
> > > > > > + if (ShutdownRequestPending)
> > > > > > + {
> > > > > > + ereport(LOG,
> > > > > > + (errmsg("logical replication parallel
> > > > > > apply worker for subscrip
> > > > > > tion \"%s\" has finished",
> > > > > > + MySubscription->name)));
> > > > > > +
> > > > > > + apply_worker_clean_exit(false);
> > > > > > + }
> > > > > > +
> > > > > > + if (ConfigReloadPending)
> > > > > > + {
> > > > > > + ConfigReloadPending = false;
> > > > > > + ProcessConfigFile(PGC_SIGHUP);
> > > > > > + }
> > > > > > +}
> > > > > >
> > > > > > I personally think that we don't need to have a function to do only
> > > > > > these few things.
> > > > >
> > > > > I thought that introduce a new function make the handling of worker specific
> > > > > Interrupts logic similar to other existing ones. Like:
> > > > > ProcessWalRcvInterrupts () in walreceiver.c and HandlePgArchInterrupts() in
> > > > > pgarch.c ...
> > > >
> > > > I think the difference from them is that there is only one place to
> > > > call ProcessParallelApplyInterrupts().
> > > >
> > >
> > > But I feel it is better to isolate this code in a separate function.
> > > What if we decide to extend it further by having some logic to stop
> > > workers after reloading of config?
> >
> > I think we can separate the function at that time. But let's keep the
> > current code as you and Hou agree with the current code. I'm not going
> > to insist on that.
> >
> > >
> > > > >
> > > > > > ---
> > > > > > server_version = walrcv_server_version(LogRepWorkerWalRcvConn);
> > > > > > options.proto.logical.proto_version =
> > > > > > + server_version >= 160000 ?
> > > > > > LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM :
> > > > > > server_version >= 150000 ?
> > > > > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM :
> > > > > > server_version >= 140000 ?
> > > > > > LOGICALREP_PROTO_STREAM_VERSION_NUM :
> > > > > > LOGICALREP_PROTO_VERSION_NUM;
> > > > > >
> > > > > > Instead of always using the new protocol version, I think we can use
> > > > > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM if the streaming is not
> > > > > > 'parallel'. That way, we don't need to change protocl version check
> > > > > > logic in pgoutput.c and don't need to expose defGetStreamingMode().
> > > > > > What do you think?
> > > > >
> > > > > I think that some user can also use the new version number when trying to get
> > > > > changes (via pg_logical_slot_peek_binary_changes or other functions), so I feel
> > > > > leave the check for new version number seems fine.
> > > > >
> > > > > Besides, I feel even if we don't use new version number, we still need to use
> > > > > defGetStreamingMode to check if parallel mode in used as we need to send
> > > > > abort_lsn when parallel is in used. I might be missing something, sorry for
> > > > > that. Can you please explain the idea a bit ?
> > > >
> > > > My idea is that we use LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM if
> > > > (server_version >= 160000 && MySubscription->stream ==
> > > > SUBSTREAM_PARALLEL). If the stream is SUBSTREAM_ON, we use
> > > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM even if server_version is
> > > > 160000. That way, in pgoutput.c, we can send abort_lsn if the protocol
> > > > version is LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM. We don't need
> > > > to send "streaming = parallel" to the publisher since the publisher
> > > > can decide whether or not to send abort_lsn based on the protocol
> > > > version (still needs to send "streaming = on" though). I might be
> > > > missing something.
> > > >
> > >
> > > What if we decide to send some more additional information as part of
> > > another patch like we are discussing in the thread [1]? Now, we won't
> > > be able to decide the version number based on just the streaming
> > > option. Also, in such a case, even for
> > > LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM, it may not be a good
> > > idea to send additional abort information unless the user has used the
> > > streaming=parallel option.
> >
> > If we're going to send the additional information, it makes sense to
> > send streaming=parallel. But the next question came to me is why do we
> > need to increase the protocol version for parallel apply feature? If
> > sending the additional information is also controlled by an option
> > like "streaming", we can decide what we send based on these options,
> > no?
> >
>
> AFAIK the protocol version defines what protocol message bytes are
> transmitted on the wire. So I thought the protocol version should
> *always* be updated whenever the message format changes. In other
> words, I don't think we ought to be transmitting different protocol
> message formats unless it is a different protocol version.
>
> Whether the pub/sub implementation actually needs to check that
> protocol version or whether we happen to have some alternative knob we
> can check doesn't change what the protocol version is supposed to
> mean. And the PGDOCS [1] and [2] currently have clear field notes
> about when those fields are present (e.g. "This field is available
> since protocol version XXX"), but if hypothetically you don't change
> the protocol version for some new fields then now the message format
> becomes tied to the built-in implementation of pub/sub -- now what
> field note will you say instead to explain that?
>
I think the protocol version acts as a backstop to not send some
information which clients don't understand. Now, the other way is to
believe the client when it sends a particular option (say streaming =
on (aka allow sending in-progress transactions)) that it will
understand additional information for that feature but the protocol
version acts as a backstop in that case. As Peter mentioned, it will
be easier to explain the additional information we are sending across
different versions without relying on additional options for pub/sub.
Having said that, we can send additional required information based on
just the new option but I felt it is better to bump the protocol
version along with it unless we see any downside to it. What do you
think?
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Dec 8, 2022 at 12:37 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > Review comments ============== 1. Currently, we don't release the stream lock in LA (leade apply worker) for "rollback to savepoint" and the reason is mentioned in comments of apply_handle_stream_abort() in the patch. But, today, while testing, I found that can lead to deadlock which otherwise, won't happen on the publisher. The key point is rollback to savepoint releases the locks acquired by the particular subtransaction, so parallel apply worker should also do the same. Consider the following example where the transaction in session-1 is being performed by the parallel apply worker and the transaction in session-2 is being performed by the leader apply worker. I have simulated it by using GUC force_stream_mode. Publisher ========== Session-1 postgres=# begin; BEGIN postgres=*# savepoint s1; SAVEPOINT postgres=*# truncate t1; TRUNCATE TABLE Session-2 postgres=# begin; BEGIN postgres=*# insert into t1 values(4); Session-1 postgres=*# rollback to savepoint s1; ROLLBACK Session-2 Commit; With or without commit of Session-2, this scenario will lead to deadlock on the subscriber because PA (parallel apply worker) is waiting for LA to send the next command, and LA is blocked by Exclusive of PA. There is no deadlock on the publisher because rollback to savepoint will release the lock acquired by truncate. To solve this, How about if we do three things before sending abort of sub-transaction (a) unlock the stream lock, (b) increment pending_stream_count, (c) take the stream lock again? Now, if the PA is not already waiting on the stop, it will not wait at stream_stop but will wait after applying abort of sub-transaction and if it is already waiting at stream_stop, the wait will be released. If this works then probably we should try to do (b) before (a) to match the steps with stream_start. 2. There seems to be another general problem in the way the patch waits for stream_stop in PA (parallel apply worker). Currently, PA checks, if there are no more pending streams then it tries to wait for the next stream by waiting on a stream lock. However, it is possible after PA checks there is no pending stream and before it actually starts waiting on a lock, the LA sends another stream for which even stream_stop is sent, in this case, PA will start waiting for the next stream whereas there is actually a pending stream available. In this case, it won't lead to any problem apart from delay in applying the changes in such cases but for the case mentioned in the previous point (Pont 1), it can lead to deadlock even after we implement the solution proposed to solve it. 3. The other point to consider is that for stream_commit/prepare/abort, in LA, we release the stream lock after sending the message whereas for stream_start we release it before sending the message. I think for the earlier cases (stream_commit/prepare/abort), the patch has done like this because pa_send_data() may need to require the lock again when it times out and start serializing, so there will be no sense in first releasing it, then re-acquiring it, and then again releasing it. Can't we also release the lock for stream_start after pa_send_data() only if it is not switched to serialize mode? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Fri, Dec 9, 2022 at 3:05 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Fri, Dec 9, 2022 at 7:45 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > On Thu, Dec 8, 2022 at 7:43 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > >
> > > On Thu, Dec 8, 2022 at 4:42 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > > >
> > > > On Thu, Dec 8, 2022 at 12:42 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > > > >
> > > > > On Wed, Dec 7, 2022 at 10:03 PM houzj.fnst@fujitsu.com
> > > > > <houzj.fnst@fujitsu.com> wrote:
> > > > > >
> > > > > >
> > > > > > > +static void
> > > > > > > +ProcessParallelApplyInterrupts(void)
> > > > > > > +{
> > > > > > > + CHECK_FOR_INTERRUPTS();
> > > > > > > +
> > > > > > > + if (ShutdownRequestPending)
> > > > > > > + {
> > > > > > > + ereport(LOG,
> > > > > > > + (errmsg("logical replication parallel
> > > > > > > apply worker for subscrip
> > > > > > > tion \"%s\" has finished",
> > > > > > > + MySubscription->name)));
> > > > > > > +
> > > > > > > + apply_worker_clean_exit(false);
> > > > > > > + }
> > > > > > > +
> > > > > > > + if (ConfigReloadPending)
> > > > > > > + {
> > > > > > > + ConfigReloadPending = false;
> > > > > > > + ProcessConfigFile(PGC_SIGHUP);
> > > > > > > + }
> > > > > > > +}
> > > > > > >
> > > > > > > I personally think that we don't need to have a function to do only
> > > > > > > these few things.
> > > > > >
> > > > > > I thought that introduce a new function make the handling of worker specific
> > > > > > Interrupts logic similar to other existing ones. Like:
> > > > > > ProcessWalRcvInterrupts () in walreceiver.c and HandlePgArchInterrupts() in
> > > > > > pgarch.c ...
> > > > >
> > > > > I think the difference from them is that there is only one place to
> > > > > call ProcessParallelApplyInterrupts().
> > > > >
> > > >
> > > > But I feel it is better to isolate this code in a separate function.
> > > > What if we decide to extend it further by having some logic to stop
> > > > workers after reloading of config?
> > >
> > > I think we can separate the function at that time. But let's keep the
> > > current code as you and Hou agree with the current code. I'm not going
> > > to insist on that.
> > >
> > > >
> > > > > >
> > > > > > > ---
> > > > > > > server_version = walrcv_server_version(LogRepWorkerWalRcvConn);
> > > > > > > options.proto.logical.proto_version =
> > > > > > > + server_version >= 160000 ?
> > > > > > > LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM :
> > > > > > > server_version >= 150000 ?
> > > > > > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM :
> > > > > > > server_version >= 140000 ?
> > > > > > > LOGICALREP_PROTO_STREAM_VERSION_NUM :
> > > > > > > LOGICALREP_PROTO_VERSION_NUM;
> > > > > > >
> > > > > > > Instead of always using the new protocol version, I think we can use
> > > > > > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM if the streaming is not
> > > > > > > 'parallel'. That way, we don't need to change protocl version check
> > > > > > > logic in pgoutput.c and don't need to expose defGetStreamingMode().
> > > > > > > What do you think?
> > > > > >
> > > > > > I think that some user can also use the new version number when trying to get
> > > > > > changes (via pg_logical_slot_peek_binary_changes or other functions), so I feel
> > > > > > leave the check for new version number seems fine.
> > > > > >
> > > > > > Besides, I feel even if we don't use new version number, we still need to use
> > > > > > defGetStreamingMode to check if parallel mode in used as we need to send
> > > > > > abort_lsn when parallel is in used. I might be missing something, sorry for
> > > > > > that. Can you please explain the idea a bit ?
> > > > >
> > > > > My idea is that we use LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM if
> > > > > (server_version >= 160000 && MySubscription->stream ==
> > > > > SUBSTREAM_PARALLEL). If the stream is SUBSTREAM_ON, we use
> > > > > LOGICALREP_PROTO_TWOPHASE_VERSION_NUM even if server_version is
> > > > > 160000. That way, in pgoutput.c, we can send abort_lsn if the protocol
> > > > > version is LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM. We don't need
> > > > > to send "streaming = parallel" to the publisher since the publisher
> > > > > can decide whether or not to send abort_lsn based on the protocol
> > > > > version (still needs to send "streaming = on" though). I might be
> > > > > missing something.
> > > > >
> > > >
> > > > What if we decide to send some more additional information as part of
> > > > another patch like we are discussing in the thread [1]? Now, we won't
> > > > be able to decide the version number based on just the streaming
> > > > option. Also, in such a case, even for
> > > > LOGICALREP_PROTO_STREAM_PARALLEL_VERSION_NUM, it may not be a good
> > > > idea to send additional abort information unless the user has used the
> > > > streaming=parallel option.
> > >
> > > If we're going to send the additional information, it makes sense to
> > > send streaming=parallel. But the next question came to me is why do we
> > > need to increase the protocol version for parallel apply feature? If
> > > sending the additional information is also controlled by an option
> > > like "streaming", we can decide what we send based on these options,
> > > no?
> > >
> >
> > AFAIK the protocol version defines what protocol message bytes are
> > transmitted on the wire. So I thought the protocol version should
> > *always* be updated whenever the message format changes. In other
> > words, I don't think we ought to be transmitting different protocol
> > message formats unless it is a different protocol version.
> >
> > Whether the pub/sub implementation actually needs to check that
> > protocol version or whether we happen to have some alternative knob we
> > can check doesn't change what the protocol version is supposed to
> > mean. And the PGDOCS [1] and [2] currently have clear field notes
> > about when those fields are present (e.g. "This field is available
> > since protocol version XXX"), but if hypothetically you don't change
> > the protocol version for some new fields then now the message format
> > becomes tied to the built-in implementation of pub/sub -- now what
> > field note will you say instead to explain that?
> >
>
> I think the protocol version acts as a backstop to not send some
> information which clients don't understand. Now, the other way is to
> believe the client when it sends a particular option (say streaming =
> on (aka allow sending in-progress transactions)) that it will
> understand additional information for that feature but the protocol
> version acts as a backstop in that case.
Yeah, it seems that this is how the logical replication protocol has
been working. New logical replication protocol versions have backward
compatibility. I was thinking that the protocol version needs to bump
if there is no compatibility, i.g. if most clients need to change to
support new protocols.
> As Peter mentioned, it will
> be easier to explain the additional information we are sending across
> different versions without relying on additional options for pub/sub.
> Having said that, we can send additional required information based on
> just the new option but I felt it is better to bump the protocol
> version along with it unless we see any downside to it. What do you
> think?
I agree to bump the protocol version.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, December 9, 2022 3:14 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Dec 8, 2022 at 12:37 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > Review comments Thanks for the comments! > ============== > 1. Currently, we don't release the stream lock in LA (leade apply > worker) for "rollback to savepoint" and the reason is mentioned in comments of > apply_handle_stream_abort() in the patch. But, today, while testing, I found that > can lead to deadlock which otherwise, won't happen on the publisher. The key > point is rollback to savepoint releases the locks acquired by the particular > subtransaction, so parallel apply worker should also do the same. Consider the > following example where the transaction in session-1 is being performed by the > parallel apply worker and the transaction in session-2 is being performed by the > leader apply worker. I have simulated it by using GUC force_stream_mode. > Publisher > ========== > Session-1 > postgres=# begin; > BEGIN > postgres=*# savepoint s1; > SAVEPOINT > postgres=*# truncate t1; > TRUNCATE TABLE > > Session-2 > postgres=# begin; > BEGIN > postgres=*# insert into t1 values(4); > > Session-1 > postgres=*# rollback to savepoint s1; > ROLLBACK > > Session-2 > Commit; > > With or without commit of Session-2, this scenario will lead to deadlock on the > subscriber because PA (parallel apply worker) is waiting for LA to send the next > command, and LA is blocked by Exclusive of PA. There is no deadlock on the > publisher because rollback to savepoint will release the lock acquired by > truncate. > > To solve this, How about if we do three things before sending abort of > sub-transaction (a) unlock the stream lock, (b) increment pending_stream_count, > (c) take the stream lock again? > > Now, if the PA is not already waiting on the stop, it will not wait at stream_stop > but will wait after applying abort of sub-transaction and if it is already waiting at > stream_stop, the wait will be released. If this works then probably we should try > to do (b) before (a) to match the steps with stream_start. The solution works for me, I have changed the code as suggested. > 2. There seems to be another general problem in the way the patch waits for > stream_stop in PA (parallel apply worker). Currently, PA checks, if there are no > more pending streams then it tries to wait for the next stream by waiting on a > stream lock. However, it is possible after PA checks there is no pending stream > and before it actually starts waiting on a lock, the LA sends another stream for > which even stream_stop is sent, in this case, PA will start waiting for the next > stream whereas there is actually a pending stream available. In this case, it won't > lead to any problem apart from delay in applying the changes in such cases but > for the case mentioned in the previous point (Pont 1), it can lead to deadlock > even after we implement the solution proposed to solve it. Thanks for reporting, I have introduced another flag in shared memory and use it to prevent the leader from incrementing the pending_stream_count if the parallel apply worker is trying to lock the stream lock. > 3. The other point to consider is that for stream_commit/prepare/abort, in LA, we > release the stream lock after sending the message whereas for stream_start we > release it before sending the message. I think for the earlier cases > (stream_commit/prepare/abort), the patch has done like this because > pa_send_data() may need to require the lock again when it times out and start > serializing, so there will be no sense in first releasing it, then re-acquiring it, and > then again releasing it. Can't we also release the lock for stream_start after > pa_send_data() only if it is not switched to serialize mode? Changed. Attach the new version patch set which addressed above comments. Besides, the new version patch will try to stop extra parallel workers if user sets the max_parallel_apply_workers_per_subscription to a lower number. Best regards, Hou zj
Attachment
- v59-0003-Test-streaming-parallel-option-in-tap-test.patch
- v59-0006-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v59-0002-Serialize-partial-changes-to-a-file-when-the-att.patch
- v59-0004-Allow-streaming-every-change-without-waiting-til.patch
- v59-0005-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v59-0007-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v59-0001-Perform-streaming-logical-transactions-by-parall.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
FYI - a rebase is needed. This patch is currently failing in cfbot [1], probably due to recent logical replication documentation updates [2]. ------ [1] cfbot failing for v59 - http://cfbot.cputube.org/patch_41_3621.log [2] PGDOCS updated - https://github.com/postgres/postgres/commit/a8500750ca0acf6bb95cf9d1ac7f421749b22db7 Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Some minor review comments for v58-0001
======
.../replication/logical/applyparallelworker.c
1. pa_can_start
+ /*
+ * Don't start a new parallel worker if user has set skiplsn as it's
+ * possible that user want to skip the streaming transaction. For streaming
+ * transaction, we need to serialize the transaction to a file so that we
+ * can get the last LSN of the transaction to judge whether to skip before
+ * starting to apply the change.
+ */
+ if (!XLogRecPtrIsInvalid(MySubscription->skiplsn))
+ return false;
"that user want" -> "that they want"
"For streaming transaction," -> "For streaming transactions,"
~~~
2. pa_free_worker_info
+ /* Remove from the worker pool. */
+ ParallelApplyWorkerPool = list_delete_ptr(ParallelApplyWorkerPool,
+ winfo);
Unnecessary wrapping
~~~
3. pa_set_stream_apply_worker
+/*
+ * Set the worker that required to apply the current streaming transaction.
+ */
+void
+pa_set_stream_apply_worker(ParallelApplyWorkerInfo *winfo)
+{
+ stream_apply_worker = winfo;
+}
Comment wording seems wrong.
======
src/include/replication/worker_internal.h
4. ParallelApplyWorkerShared
+ * XactLastCommitEnd from the parallel apply worker. This is required to
+ * update the lsn_mappings by leader worker.
+ */
+ XLogRecPtr last_commit_end;
+} ParallelApplyWorkerShared;
"This is required to update the lsn_mappings by leader worker." -->
did you mean "This is required by the leader worker so it can update
the lsn_mappings." ??
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Dec 13, 2022 at 4:36 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> ~~~
>
> 3. pa_set_stream_apply_worker
>
> +/*
> + * Set the worker that required to apply the current streaming transaction.
> + */
> +void
> +pa_set_stream_apply_worker(ParallelApplyWorkerInfo *winfo)
> +{
> + stream_apply_worker = winfo;
> +}
>
> Comment wording seems wrong.
>
I think something like "Cache the parallel apply worker information."
may be more suitable here.
Few more similar cosmetic comments:
1.
+ /*
+ * Unlock the shared object lock so that the parallel apply worker
+ * can continue to receive changes.
+ */
+ if (!first_segment)
+ pa_unlock_stream(winfo->shared->xid, AccessExclusiveLock);
This comment is missing in the new (0002) patch.
2.
+ if (!winfo->serialize_changes)
+ {
+ if (!first_segment)
+ pa_unlock_stream(winfo->shared->xid, AccessExclusiveLock);
I think we should write some comments on why we are not unlocking when
serializing changes.
3. Please add a comment like below in the patch to make it clear why
in stream_abort case we perform locking before sending the message.
--- a/src/backend/replication/logical/worker.c
+++ b/src/backend/replication/logical/worker.c
@@ -1858,6 +1858,13 @@ apply_handle_stream_abort(StringInfo s)
* worker will wait on the lock for the next
set of changes after
* processing the STREAM_ABORT message if it
is not already waiting
* for STREAM_STOP message.
+ *
+ * It is important to perform this locking
before sending the
+ * STREAM_ABORT message so that the leader can
hold the lock first
+ * and the parallel apply worker will wait for
the leader to release
+ * the lock. This is the same as what we do in
+ * apply_handle_stream_stop. See Locking
Considerations atop
+ * applyparallelworker.c.
*/
if (!toplevel_xact)
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, December 13, 2022 6:41 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Tue, Dec 13, 2022 at 4:36 AM Peter Smith <smithpb2250@gmail.com>
> wrote:
> >
> > ~~~
> >
> > 3. pa_set_stream_apply_worker
> >
> > +/*
> > + * Set the worker that required to apply the current streaming transaction.
> > + */
> > +void
> > +pa_set_stream_apply_worker(ParallelApplyWorkerInfo *winfo) {
> > +stream_apply_worker = winfo; }
> >
> > Comment wording seems wrong.
> >
>
> I think something like "Cache the parallel apply worker information."
> may be more suitable here.
Changed.
> Few more similar cosmetic comments:
> 1.
> + /*
> + * Unlock the shared object lock so that the parallel apply worker
> + * can continue to receive changes.
> + */
> + if (!first_segment)
> + pa_unlock_stream(winfo->shared->xid, AccessExclusiveLock);
>
> This comment is missing in the new (0002) patch.
Added.
> 2.
> + if (!winfo->serialize_changes)
> + {
> + if (!first_segment)
> + pa_unlock_stream(winfo->shared->xid, AccessExclusiveLock);
>
> I think we should write some comments on why we are not unlocking when
> serializing changes.
Added.
> 3. Please add a comment like below in the patch to make it clear why in
> stream_abort case we perform locking before sending the message.
> --- a/src/backend/replication/logical/worker.c
> +++ b/src/backend/replication/logical/worker.c
> @@ -1858,6 +1858,13 @@ apply_handle_stream_abort(StringInfo s)
> * worker will wait on the lock for the next set of
> changes after
> * processing the STREAM_ABORT message if it is not
> already waiting
> * for STREAM_STOP message.
> + *
> + * It is important to perform this locking
> before sending the
> + * STREAM_ABORT message so that the leader can
> hold the lock first
> + * and the parallel apply worker will wait for
> the leader to release
> + * the lock. This is the same as what we do in
> + * apply_handle_stream_stop. See Locking
> Considerations atop
> + * applyparallelworker.c.
> */
> if (!toplevel_xact)
Merged.
Attach the new version patch which addressed above comments.
I also slightly refactored logic related to pa_spooled_messages() so that
It doesn't need to wait for a timeout if there are pending spooled messages.
Best regards,
Hou zj
Attachment
- v60-0007-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v60-0002-Serialize-partial-changes-to-a-file-when-the-att.patch
- v60-0001-Perform-streaming-logical-transactions-by-parall.patch
- v60-0003-Test-streaming-parallel-option-in-tap-test.patch
- v60-0004-Allow-streaming-every-change-without-waiting-til.patch
- v60-0005-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v60-0006-Retry-to-apply-streaming-xact-only-in-apply-work.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tue, Dec 13, 2022 7:06 AM Peter Smith <smithpb2250@gmail.com> wrote:
> Some minor review comments for v58-0001
Thanks for your comments.
> ======
>
> .../replication/logical/applyparallelworker.c
>
> 1. pa_can_start
>
> + /*
> + * Don't start a new parallel worker if user has set skiplsn as it's
> + * possible that user want to skip the streaming transaction. For
> + streaming
> + * transaction, we need to serialize the transaction to a file so
> + that we
> + * can get the last LSN of the transaction to judge whether to skip
> + before
> + * starting to apply the change.
> + */
> + if (!XLogRecPtrIsInvalid(MySubscription->skiplsn))
> + return false;
>
>
> "that user want" -> "that they want"
>
> "For streaming transaction," -> "For streaming transactions,"
Changed.
> ~~~
>
> 2. pa_free_worker_info
>
> + /* Remove from the worker pool. */
> + ParallelApplyWorkerPool = list_delete_ptr(ParallelApplyWorkerPool,
> + winfo);
>
> Unnecessary wrapping
Changed.
> ~~~
>
> 3. pa_set_stream_apply_worker
>
> +/*
> + * Set the worker that required to apply the current streaming transaction.
> + */
> +void
> +pa_set_stream_apply_worker(ParallelApplyWorkerInfo *winfo) {
> +stream_apply_worker = winfo; }
>
> Comment wording seems wrong.
Tried to improve this comment.
> ======
>
> src/include/replication/worker_internal.h
>
> 4. ParallelApplyWorkerShared
>
> + * XactLastCommitEnd from the parallel apply worker. This is required
> +to
> + * update the lsn_mappings by leader worker.
> + */
> + XLogRecPtr last_commit_end;
> +} ParallelApplyWorkerShared;
>
>
> "This is required to update the lsn_mappings by leader worker." -->
> did you mean "This is required by the leader worker so it can update
> the lsn_mappings." ??
Changed.
Also thanks for the kind reminder in [1], rebased the patch set.
Attach the new patch set.
[1] - https://www.postgresql.org/message-id/CAHut%2BPt4qv7xfJUmwdn6Vy47L5mqzKtkPr31%3DDmEayJWXetvYg%40mail.gmail.com
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Sun, Dec 11, 2022 at 8:45 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Friday, December 9, 2022 3:14 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Thu, Dec 8, 2022 at 12:37 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> >
> > Review comments
>
> Thanks for the comments!
>
> > ==============
> > 1. Currently, we don't release the stream lock in LA (leade apply
> > worker) for "rollback to savepoint" and the reason is mentioned in comments of
> > apply_handle_stream_abort() in the patch. But, today, while testing, I found that
> > can lead to deadlock which otherwise, won't happen on the publisher. The key
> > point is rollback to savepoint releases the locks acquired by the particular
> > subtransaction, so parallel apply worker should also do the same. Consider the
> > following example where the transaction in session-1 is being performed by the
> > parallel apply worker and the transaction in session-2 is being performed by the
> > leader apply worker. I have simulated it by using GUC force_stream_mode.
> > Publisher
> > ==========
> > Session-1
> > postgres=# begin;
> > BEGIN
> > postgres=*# savepoint s1;
> > SAVEPOINT
> > postgres=*# truncate t1;
> > TRUNCATE TABLE
> >
> > Session-2
> > postgres=# begin;
> > BEGIN
> > postgres=*# insert into t1 values(4);
> >
> > Session-1
> > postgres=*# rollback to savepoint s1;
> > ROLLBACK
> >
> > Session-2
> > Commit;
> >
> > With or without commit of Session-2, this scenario will lead to deadlock on the
> > subscriber because PA (parallel apply worker) is waiting for LA to send the next
> > command, and LA is blocked by Exclusive of PA. There is no deadlock on the
> > publisher because rollback to savepoint will release the lock acquired by
> > truncate.
> >
> > To solve this, How about if we do three things before sending abort of
> > sub-transaction (a) unlock the stream lock, (b) increment pending_stream_count,
> > (c) take the stream lock again?
> >
> > Now, if the PA is not already waiting on the stop, it will not wait at stream_stop
> > but will wait after applying abort of sub-transaction and if it is already waiting at
> > stream_stop, the wait will be released. If this works then probably we should try
> > to do (b) before (a) to match the steps with stream_start.
>
> The solution works for me, I have changed the code as suggested.
>
>
> > 2. There seems to be another general problem in the way the patch waits for
> > stream_stop in PA (parallel apply worker). Currently, PA checks, if there are no
> > more pending streams then it tries to wait for the next stream by waiting on a
> > stream lock. However, it is possible after PA checks there is no pending stream
> > and before it actually starts waiting on a lock, the LA sends another stream for
> > which even stream_stop is sent, in this case, PA will start waiting for the next
> > stream whereas there is actually a pending stream available. In this case, it won't
> > lead to any problem apart from delay in applying the changes in such cases but
> > for the case mentioned in the previous point (Pont 1), it can lead to deadlock
> > even after we implement the solution proposed to solve it.
>
> Thanks for reporting, I have introduced another flag in shared memory and use it to
> prevent the leader from incrementing the pending_stream_count if the parallel
> apply worker is trying to lock the stream lock.
>
>
> > 3. The other point to consider is that for stream_commit/prepare/abort, in LA, we
> > release the stream lock after sending the message whereas for stream_start we
> > release it before sending the message. I think for the earlier cases
> > (stream_commit/prepare/abort), the patch has done like this because
> > pa_send_data() may need to require the lock again when it times out and start
> > serializing, so there will be no sense in first releasing it, then re-acquiring it, and
> > then again releasing it. Can't we also release the lock for stream_start after
> > pa_send_data() only if it is not switched to serialize mode?
>
> Changed.
>
> Attach the new version patch set which addressed above comments.
Here are comments on v59 0001, 0002 patches:
+void
+pa_increment_stream_block(ParallelApplyWorkerShared *wshared)
+{
+ while (1)
+ {
+ SpinLockAcquire(&wshared->mutex);
+
+ /*
+ * Don't try to increment the count if the parallel
apply worker is
+ * taking the stream lock. Otherwise, there would be
a race condition
+ * that the parallel apply worker checks there is no
pending streaming
+ * block and before it actually starts waiting on a
lock, the leader
+ * sends another streaming block and take the stream
lock again. In
+ * this case, the parallel apply worker will start
waiting for the next
+ * streaming block whereas there is actually a
pending streaming block
+ * available.
+ */
+ if (!wshared->pa_wait_for_stream)
+ {
+ wshared->pending_stream_count++;
+ SpinLockRelease(&wshared->mutex);
+ break;
+ }
+
+ SpinLockRelease(&wshared->mutex);
+ }
+}
I think we should add an assertion to check if we don't hold the stream lock.
I think that waiting for pa_wait_for_stream to be false in a busy loop
is not a good idea. It's not interruptible and there is not guarantee
that we can break from this loop in a short time. For instance, if PA
executes pa_decr_and_wait_stream_block() a bit earlier than LA
executes pa_increment_stream_block(), LA has to wait for PA to acquire
and release the stream lock in a busy loop. It should not be long in
normal cases but the duration LA needs to wait for PA depends on PA,
which could be long. Also what if PA raises an error in
pa_lock_stream() due to some reasons? I think LA won't be able to
detect the failure.
I think we should at least make it interruptible and maybe need to add
some sleep. Or perhaps we can use the condition variable for this
case.
---
In worker.c, we have the following common pattern:
case TRANS_LEADER_PARTIAL_SERIALIZE:
write change to the file;
do some work;
break;
case TRANS_LEADER_SEND_TO_PARALLEL:
pa_send_data();
if (winfo->serialize_changes)
{
do some worker required after writing changes to the file.
}
:
break;
IIUC there are two different paths for partial serialization: (a)
where apply_action is TRANS_LEADER_PARTIAL_SERIALIZE, and (b) where
apply_action is TRANS_LEADER_PARTIAL_SERIALIZE and
winfo->serialize_changes became true. And we need to match what we do
in (a) and (b). Rather than having two different paths for the same
case, how about falling through TRANS_LEADER_PARTIAL_SERIALIZE when we
could not send the changes? That is, pa_send_data() just returns false
when the timeout exceeds and we need to switch to serialize changes,
otherwise returns true. If it returns false, we prepare for switching
to serialize changes such as initializing fileset, and fall through
TRANS_LEADER_PARTIAL_SERIALIZE case. The code would be like:
case TRANS_LEADER_SEND_TO_PARALLEL:
ret = pa_send_data();
if (ret)
{
do work for sending changes to PA.
break;
}
/* prepare for switching to serialize changes */
winfo->serialize_changes = true;
initialize fileset;
acquire stream lock if necessary;
/* FALLTHROUGH */
case TRANS_LEADER_PARTIAL_SERIALIZE:
do work for serializing changes;
break;
---
/*
- * Unlock the shared object lock so that
parallel apply worker can
- * continue to receive and apply changes.
+ * Parallel apply worker might have applied
some changes, so write
+ * the STREAM_ABORT message so that it can rollback the
+ * subtransaction if needed.
*/
- pa_unlock_stream(xid, AccessExclusiveLock);
+ stream_open_and_write_change(xid,
LOGICAL_REP_MSG_STREAM_ABORT,
+
&original_msg);
+
+ if (toplevel_xact)
+ {
+ pa_unlock_stream(xid, AccessExclusiveLock);
+ pa_set_fileset_state(winfo->shared,
FS_SERIALIZE_DONE);
+ (void) pa_free_worker(winfo, xid);
+ }
At every place except for the above code, we set the fileset state
FS_SERIALIZE_DONE first then unlock the stream lock. Is there any
reason for that?
---
+ case TRANS_LEADER_SEND_TO_PARALLEL:
+ Assert(winfo);
+
+ /*
+ * Unlock the shared object lock so that
parallel apply worker can
+ * continue to receive and apply changes.
+ */
+ pa_unlock_stream(xid, AccessExclusiveLock);
+
+ /*
+ * For the case of aborting the
subtransaction, we increment the
+ * number of streaming blocks and take the
lock again before
+ * sending the STREAM_ABORT to ensure that the
parallel apply
+ * worker will wait on the lock for the next
set of changes after
+ * processing the STREAM_ABORT message if it
is not already waiting
+ * for STREAM_STOP message.
+ */
+ if (!toplevel_xact)
+ {
+ pa_increment_stream_block(winfo->shared);
+ pa_lock_stream(xid, AccessExclusiveLock);
+ }
+
+ /* Send STREAM ABORT message to the parallel
apply worker. */
+ pa_send_data(winfo, s->len, s->data);
+
+ if (toplevel_xact)
+ (void) pa_free_worker(winfo, xid);
+
+ break;
In apply_handle_stream_abort(), it's better to add the comment why we
don't need to wait for PA to finish.
Also, given that we don't wait for PA to finish in this case, does it
really make sense to call pa_free_worker() immediately after sending
STREAM_ABORT?
---
PA acquires the transaction lock in AccessShare mode whereas LA
acquires it in AccessExclusiveMode. Is it better to do the opposite?
Like a backend process acquires a lock on its XID in Exclusive mode,
we can have PA acquire the lock on its XID in Exclusive mode whereas
other attempts to acquire it in Share mode to wait.
---
void
pa_lock_stream(TransactionId xid, LOCKMODE lockmode)
{
LockApplyTransactionForSession(MyLogicalRepWorker->subid, xid,
PARALLEL_APPLY_LOCK_STREAM, lockmode);
}
I think since we don't need to let the caller to specify the lock mode
but need only shared and exclusive modes, we can make it simple by
having a boolean argument say shared instead of lockmode.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, December 13, 2022 11:25 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Sun, Dec 11, 2022 at 8:45 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Friday, December 9, 2022 3:14 PM Amit Kapila
> <amit.kapila16@gmail.com> wrote:
> > >
> > > On Thu, Dec 8, 2022 at 12:37 PM houzj.fnst@fujitsu.com
> > > <houzj.fnst@fujitsu.com> wrote:
> > > >
> > >
> > > Review comments
> >
> > Thanks for the comments!
> >
> > > ==============
> > > 1. Currently, we don't release the stream lock in LA (leade apply
> > > worker) for "rollback to savepoint" and the reason is mentioned in
> > > comments of
> > > apply_handle_stream_abort() in the patch. But, today, while testing,
> > > I found that can lead to deadlock which otherwise, won't happen on
> > > the publisher. The key point is rollback to savepoint releases the
> > > locks acquired by the particular subtransaction, so parallel apply
> > > worker should also do the same. Consider the following example where
> > > the transaction in session-1 is being performed by the parallel
> > > apply worker and the transaction in session-2 is being performed by the
> leader apply worker. I have simulated it by using GUC force_stream_mode.
> > > Publisher
> > > ==========
> > > Session-1
> > > postgres=# begin;
> > > BEGIN
> > > postgres=*# savepoint s1;
> > > SAVEPOINT
> > > postgres=*# truncate t1;
> > > TRUNCATE TABLE
> > >
> > > Session-2
> > > postgres=# begin;
> > > BEGIN
> > > postgres=*# insert into t1 values(4);
> > >
> > > Session-1
> > > postgres=*# rollback to savepoint s1; ROLLBACK
> > >
> > > Session-2
> > > Commit;
> > >
> > > With or without commit of Session-2, this scenario will lead to
> > > deadlock on the subscriber because PA (parallel apply worker) is
> > > waiting for LA to send the next command, and LA is blocked by
> > > Exclusive of PA. There is no deadlock on the publisher because
> > > rollback to savepoint will release the lock acquired by truncate.
> > >
> > > To solve this, How about if we do three things before sending abort
> > > of sub-transaction (a) unlock the stream lock, (b) increment
> > > pending_stream_count,
> > > (c) take the stream lock again?
> > >
> > > Now, if the PA is not already waiting on the stop, it will not wait
> > > at stream_stop but will wait after applying abort of sub-transaction
> > > and if it is already waiting at stream_stop, the wait will be
> > > released. If this works then probably we should try to do (b) before (a) to
> match the steps with stream_start.
> >
> > The solution works for me, I have changed the code as suggested.
> >
> >
> > > 2. There seems to be another general problem in the way the patch
> > > waits for stream_stop in PA (parallel apply worker). Currently, PA
> > > checks, if there are no more pending streams then it tries to wait
> > > for the next stream by waiting on a stream lock. However, it is
> > > possible after PA checks there is no pending stream and before it
> > > actually starts waiting on a lock, the LA sends another stream for
> > > which even stream_stop is sent, in this case, PA will start waiting
> > > for the next stream whereas there is actually a pending stream
> > > available. In this case, it won't lead to any problem apart from
> > > delay in applying the changes in such cases but for the case mentioned in
> the previous point (Pont 1), it can lead to deadlock even after we implement the
> solution proposed to solve it.
> >
> > Thanks for reporting, I have introduced another flag in shared memory
> > and use it to prevent the leader from incrementing the
> > pending_stream_count if the parallel apply worker is trying to lock the stream
> lock.
> >
> >
> > > 3. The other point to consider is that for
> > > stream_commit/prepare/abort, in LA, we release the stream lock after
> > > sending the message whereas for stream_start we release it before
> > > sending the message. I think for the earlier cases
> > > (stream_commit/prepare/abort), the patch has done like this because
> > > pa_send_data() may need to require the lock again when it times out
> > > and start serializing, so there will be no sense in first releasing
> > > it, then re-acquiring it, and then again releasing it. Can't we also
> > > release the lock for stream_start after
> > > pa_send_data() only if it is not switched to serialize mode?
> >
> > Changed.
> >
> > Attach the new version patch set which addressed above comments.
>
> Here are comments on v59 0001, 0002 patches:
Thanks for the comments!
> +void
> +pa_increment_stream_block(ParallelApplyWorkerShared *wshared) {
> + while (1)
> + {
> + SpinLockAcquire(&wshared->mutex);
> +
> + /*
> + * Don't try to increment the count if the parallel
> apply worker is
> + * taking the stream lock. Otherwise, there would be
> a race condition
> + * that the parallel apply worker checks there is no
> pending streaming
> + * block and before it actually starts waiting on a
> lock, the leader
> + * sends another streaming block and take the stream
> lock again. In
> + * this case, the parallel apply worker will start
> waiting for the next
> + * streaming block whereas there is actually a
> pending streaming block
> + * available.
> + */
> + if (!wshared->pa_wait_for_stream)
> + {
> + wshared->pending_stream_count++;
> + SpinLockRelease(&wshared->mutex);
> + break;
> + }
> +
> + SpinLockRelease(&wshared->mutex);
> + }
> +}
>
> I think we should add an assertion to check if we don't hold the stream lock.
>
> I think that waiting for pa_wait_for_stream to be false in a busy loop is not a
> good idea. It's not interruptible and there is not guarantee that we can break
> from this loop in a short time. For instance, if PA executes
> pa_decr_and_wait_stream_block() a bit earlier than LA executes
> pa_increment_stream_block(), LA has to wait for PA to acquire and release the
> stream lock in a busy loop. It should not be long in normal cases but the
> duration LA needs to wait for PA depends on PA, which could be long. Also
> what if PA raises an error in
> pa_lock_stream() due to some reasons? I think LA won't be able to detect the
> failure.
>
> I think we should at least make it interruptible and maybe need to add some
> sleep. Or perhaps we can use the condition variable for this case.
Thanks for the analysis, I will research this part.
> ---
> In worker.c, we have the following common pattern:
>
> case TRANS_LEADER_PARTIAL_SERIALIZE:
> write change to the file;
> do some work;
> break;
>
> case TRANS_LEADER_SEND_TO_PARALLEL:
> pa_send_data();
>
> if (winfo->serialize_changes)
> {
> do some worker required after writing changes to the file.
> }
> :
> break;
>
> IIUC there are two different paths for partial serialization: (a) where
> apply_action is TRANS_LEADER_PARTIAL_SERIALIZE, and (b) where
> apply_action is TRANS_LEADER_PARTIAL_SERIALIZE and
> winfo->serialize_changes became true. And we need to match what we do
> in (a) and (b). Rather than having two different paths for the same case, how
> about falling through TRANS_LEADER_PARTIAL_SERIALIZE when we could not
> send the changes? That is, pa_send_data() just returns false when the timeout
> exceeds and we need to switch to serialize changes, otherwise returns true. If it
> returns false, we prepare for switching to serialize changes such as initializing
> fileset, and fall through TRANS_LEADER_PARTIAL_SERIALIZE case. The code
> would be like:
>
> case TRANS_LEADER_SEND_TO_PARALLEL:
> ret = pa_send_data();
>
> if (ret)
> {
> do work for sending changes to PA.
> break;
> }
>
> /* prepare for switching to serialize changes */
> winfo->serialize_changes = true;
> initialize fileset;
> acquire stream lock if necessary;
>
> /* FALLTHROUGH */
> case TRANS_LEADER_PARTIAL_SERIALIZE:
> do work for serializing changes;
> break;
I think that the suggestion is to extract the code that switch to serialize
mode out of the pa_send_data(), and then we need to add that logic in all the
functions which call pa_send_data(), I am not sure if it looks better as it
might introduce some more codes in each handling function.
> ---
> /*
> - * Unlock the shared object lock so that
> parallel apply worker can
> - * continue to receive and apply changes.
> + * Parallel apply worker might have applied
> some changes, so write
> + * the STREAM_ABORT message so that it can rollback
> the
> + * subtransaction if needed.
> */
> - pa_unlock_stream(xid, AccessExclusiveLock);
> + stream_open_and_write_change(xid,
> LOGICAL_REP_MSG_STREAM_ABORT,
> +
> &original_msg);
> +
> + if (toplevel_xact)
> + {
> + pa_unlock_stream(xid, AccessExclusiveLock);
> + pa_set_fileset_state(winfo->shared,
> FS_SERIALIZE_DONE);
> + (void) pa_free_worker(winfo, xid);
> + }
>
> At every place except for the above code, we set the fileset state
> FS_SERIALIZE_DONE first then unlock the stream lock. Is there any reason for
> that?
No, I think we should make them consistent, will change this.
> ---
> + case TRANS_LEADER_SEND_TO_PARALLEL:
> + Assert(winfo);
> +
> + /*
> + * Unlock the shared object lock so that
> parallel apply worker can
> + * continue to receive and apply changes.
> + */
> + pa_unlock_stream(xid, AccessExclusiveLock);
> +
> + /*
> + * For the case of aborting the
> subtransaction, we increment the
> + * number of streaming blocks and take the
> lock again before
> + * sending the STREAM_ABORT to ensure that the
> parallel apply
> + * worker will wait on the lock for the next
> set of changes after
> + * processing the STREAM_ABORT message if it
> is not already waiting
> + * for STREAM_STOP message.
> + */
> + if (!toplevel_xact)
> + {
> + pa_increment_stream_block(winfo->shared);
> + pa_lock_stream(xid, AccessExclusiveLock);
> + }
> +
> + /* Send STREAM ABORT message to the parallel
> apply worker. */
> + pa_send_data(winfo, s->len, s->data);
> +
> + if (toplevel_xact)
> + (void) pa_free_worker(winfo, xid);
> +
> + break;
>
> In apply_handle_stream_abort(), it's better to add the comment why we don't
> need to wait for PA to finish.
Will add.
>
> Also, given that we don't wait for PA to finish in this case, does it really make
> sense to call pa_free_worker() immediately after sending STREAM_ABORT?
I think it's possible that the PA finish the ROLLBACK quickly and the LA can
free the worker here in time.
> ---
> PA acquires the transaction lock in AccessShare mode whereas LA acquires it in
> AccessExclusiveMode. Is it better to do the opposite?
> Like a backend process acquires a lock on its XID in Exclusive mode, we can
> have PA acquire the lock on its XID in Exclusive mode whereas other attempts
> to acquire it in Share mode to wait.
Agreed, will improve.
> ---
> void
> pa_lock_stream(TransactionId xid, LOCKMODE lockmode) {
> LockApplyTransactionForSession(MyLogicalRepWorker->subid, xid,
> PARALLEL_APPLY_LOCK_STREAM,
> lockmode); }
>
> I think since we don't need to let the caller to specify the lock mode but need
> only shared and exclusive modes, we can make it simple by having a boolean
> argument say shared instead of lockmode.
I personally think passing the lockmode would make the code more clear
than passing a Boolean value.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"shiy.fnst@fujitsu.com"
Date:
Hi, I did some performance tests for this patch, based on v59-0001 and v59-0002 patch. This test used synchronous logical replication, and compared SQL execution times before and after applying the patch. Two cases are tested by varying logical_decoding_work_mem: a) Bulk insert. b) Rollback to savepoint. (Different percentage of changes in the transaction are rolled back). The test was performed ten times, and the average of the middle eight was taken. The results are as follows. The bar charts are attached. (The steps are the same as before.[1]) RESULT - bulk insert (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 51.655 51.694 51.262 patched 31.104 31.234 31.711 Compare with HEAD -39.79% -39.58% -38.14% RESULT - rollback 10% (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 43.908 43.358 42.874 patched 31.924 31.343 29.102 Compare with HEAD -27.29% -27.71% -32.12% RESULT - rollback 20% (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 40.561 40.599 40.015 patched 31.562 32.116 29.680 Compare with HEAD -22.19% -20.89% -25.83% RESULT - rollback 30% (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 38.092 37.756 37.142 patched 31.631 31.236 28.783 Compare with HEAD -16.96% -17.27% -22.50% RESULT - rollback 50% (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 33.387 33.056 32.638 patched 31.272 31.279 29.876 Compare with HEAD -6.34% -5.38% -8.46% (If "Compare with HEAD" is a positive number, it means worse than HEAD; if it is a negative number, it means better than HEAD.) Summary: In the case of bulk insert, it takes about 30% ~ 40% less time, which looks good to me. In the case of rollback to savepoint, the larger the amount of data rolled back, the smaller the improvement compared to HEAD. But as such cases won't be often, this should be okay. [1] https://www.postgresql.org/message-id/OSZPR01MB63103AA97349BBB858E27DEAFD499%40OSZPR01MB6310.jpnprd01.prod.outlook.com Regards, Shi yu
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Dec 14, 2022 at 9:50 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Tuesday, December 13, 2022 11:25 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > Here are comments on v59 0001, 0002 patches:
>
> Thanks for the comments!
>
> > +void
> > +pa_increment_stream_block(ParallelApplyWorkerShared *wshared) {
> > + while (1)
> > + {
> > + SpinLockAcquire(&wshared->mutex);
> > +
> > + /*
> > + * Don't try to increment the count if the parallel
> > apply worker is
> > + * taking the stream lock. Otherwise, there would be
> > a race condition
> > + * that the parallel apply worker checks there is no
> > pending streaming
> > + * block and before it actually starts waiting on a
> > lock, the leader
> > + * sends another streaming block and take the stream
> > lock again. In
> > + * this case, the parallel apply worker will start
> > waiting for the next
> > + * streaming block whereas there is actually a
> > pending streaming block
> > + * available.
> > + */
> > + if (!wshared->pa_wait_for_stream)
> > + {
> > + wshared->pending_stream_count++;
> > + SpinLockRelease(&wshared->mutex);
> > + break;
> > + }
> > +
> > + SpinLockRelease(&wshared->mutex);
> > + }
> > +}
> >
> > I think we should add an assertion to check if we don't hold the stream lock.
> >
> > I think that waiting for pa_wait_for_stream to be false in a busy loop is not a
> > good idea. It's not interruptible and there is not guarantee that we can break
> > from this loop in a short time. For instance, if PA executes
> > pa_decr_and_wait_stream_block() a bit earlier than LA executes
> > pa_increment_stream_block(), LA has to wait for PA to acquire and release the
> > stream lock in a busy loop. It should not be long in normal cases but the
> > duration LA needs to wait for PA depends on PA, which could be long. Also
> > what if PA raises an error in
> > pa_lock_stream() due to some reasons? I think LA won't be able to detect the
> > failure.
> >
> > I think we should at least make it interruptible and maybe need to add some
> > sleep. Or perhaps we can use the condition variable for this case.
>
Or we can leave this while (true) logic altogether for the first
version and have a comment to explain this race. Anyway, after
restarting, it will probably be solved. We can always change this part
of the code later if this really turns out to be problematic.
> Thanks for the analysis, I will research this part.
>
> > ---
> > In worker.c, we have the following common pattern:
> >
> > case TRANS_LEADER_PARTIAL_SERIALIZE:
> > write change to the file;
> > do some work;
> > break;
> >
> > case TRANS_LEADER_SEND_TO_PARALLEL:
> > pa_send_data();
> >
> > if (winfo->serialize_changes)
> > {
> > do some worker required after writing changes to the file.
> > }
> > :
> > break;
> >
> > IIUC there are two different paths for partial serialization: (a) where
> > apply_action is TRANS_LEADER_PARTIAL_SERIALIZE, and (b) where
> > apply_action is TRANS_LEADER_PARTIAL_SERIALIZE and
> > winfo->serialize_changes became true. And we need to match what we do
> > in (a) and (b). Rather than having two different paths for the same case, how
> > about falling through TRANS_LEADER_PARTIAL_SERIALIZE when we could not
> > send the changes? That is, pa_send_data() just returns false when the timeout
> > exceeds and we need to switch to serialize changes, otherwise returns true. If it
> > returns false, we prepare for switching to serialize changes such as initializing
> > fileset, and fall through TRANS_LEADER_PARTIAL_SERIALIZE case. The code
> > would be like:
> >
> > case TRANS_LEADER_SEND_TO_PARALLEL:
> > ret = pa_send_data();
> >
> > if (ret)
> > {
> > do work for sending changes to PA.
> > break;
> > }
> >
> > /* prepare for switching to serialize changes */
> > winfo->serialize_changes = true;
> > initialize fileset;
> > acquire stream lock if necessary;
> >
> > /* FALLTHROUGH */
> > case TRANS_LEADER_PARTIAL_SERIALIZE:
> > do work for serializing changes;
> > break;
>
> I think that the suggestion is to extract the code that switch to serialize
> mode out of the pa_send_data(), and then we need to add that logic in all the
> functions which call pa_send_data(), I am not sure if it looks better as it
> might introduce some more codes in each handling function.
>
How about extracting the common code from apply_handle_stream_commit
and apply_handle_stream_prepare to a separate function say
pa_xact_finish_common()? I see there is a lot of common code (unlock
the stream, wait for the finish, store flush location, free worker
info) in both the functions for TRANS_LEADER_PARTIAL_SERIALIZE and
TRANS_LEADER_SEND_TO_PARALLEL cases.
>
> > ---
> > void
> > pa_lock_stream(TransactionId xid, LOCKMODE lockmode) {
> > LockApplyTransactionForSession(MyLogicalRepWorker->subid, xid,
> > PARALLEL_APPLY_LOCK_STREAM,
> > lockmode); }
> >
> > I think since we don't need to let the caller to specify the lock mode but need
> > only shared and exclusive modes, we can make it simple by having a boolean
> > argument say shared instead of lockmode.
>
> I personally think passing the lockmode would make the code more clear
> than passing a Boolean value.
>
+1.
I have made a few changes in the newly added comments and function
name in the attached patch. Kindly include this if you find the
changes okay.
--
With Regards,
Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, Dec 14, 2022 at 1:20 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Tuesday, December 13, 2022 11:25 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Sun, Dec 11, 2022 at 8:45 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Friday, December 9, 2022 3:14 PM Amit Kapila
> > <amit.kapila16@gmail.com> wrote:
> > > >
> > > > On Thu, Dec 8, 2022 at 12:37 PM houzj.fnst@fujitsu.com
> > > > <houzj.fnst@fujitsu.com> wrote:
> > > > >
> > > >
> > > > Review comments
> > >
> > > Thanks for the comments!
> > >
> > > > ==============
> > > > 1. Currently, we don't release the stream lock in LA (leade apply
> > > > worker) for "rollback to savepoint" and the reason is mentioned in
> > > > comments of
> > > > apply_handle_stream_abort() in the patch. But, today, while testing,
> > > > I found that can lead to deadlock which otherwise, won't happen on
> > > > the publisher. The key point is rollback to savepoint releases the
> > > > locks acquired by the particular subtransaction, so parallel apply
> > > > worker should also do the same. Consider the following example where
> > > > the transaction in session-1 is being performed by the parallel
> > > > apply worker and the transaction in session-2 is being performed by the
> > leader apply worker. I have simulated it by using GUC force_stream_mode.
> > > > Publisher
> > > > ==========
> > > > Session-1
> > > > postgres=# begin;
> > > > BEGIN
> > > > postgres=*# savepoint s1;
> > > > SAVEPOINT
> > > > postgres=*# truncate t1;
> > > > TRUNCATE TABLE
> > > >
> > > > Session-2
> > > > postgres=# begin;
> > > > BEGIN
> > > > postgres=*# insert into t1 values(4);
> > > >
> > > > Session-1
> > > > postgres=*# rollback to savepoint s1; ROLLBACK
> > > >
> > > > Session-2
> > > > Commit;
> > > >
> > > > With or without commit of Session-2, this scenario will lead to
> > > > deadlock on the subscriber because PA (parallel apply worker) is
> > > > waiting for LA to send the next command, and LA is blocked by
> > > > Exclusive of PA. There is no deadlock on the publisher because
> > > > rollback to savepoint will release the lock acquired by truncate.
> > > >
> > > > To solve this, How about if we do three things before sending abort
> > > > of sub-transaction (a) unlock the stream lock, (b) increment
> > > > pending_stream_count,
> > > > (c) take the stream lock again?
> > > >
> > > > Now, if the PA is not already waiting on the stop, it will not wait
> > > > at stream_stop but will wait after applying abort of sub-transaction
> > > > and if it is already waiting at stream_stop, the wait will be
> > > > released. If this works then probably we should try to do (b) before (a) to
> > match the steps with stream_start.
> > >
> > > The solution works for me, I have changed the code as suggested.
> > >
> > >
> > > > 2. There seems to be another general problem in the way the patch
> > > > waits for stream_stop in PA (parallel apply worker). Currently, PA
> > > > checks, if there are no more pending streams then it tries to wait
> > > > for the next stream by waiting on a stream lock. However, it is
> > > > possible after PA checks there is no pending stream and before it
> > > > actually starts waiting on a lock, the LA sends another stream for
> > > > which even stream_stop is sent, in this case, PA will start waiting
> > > > for the next stream whereas there is actually a pending stream
> > > > available. In this case, it won't lead to any problem apart from
> > > > delay in applying the changes in such cases but for the case mentioned in
> > the previous point (Pont 1), it can lead to deadlock even after we implement the
> > solution proposed to solve it.
> > >
> > > Thanks for reporting, I have introduced another flag in shared memory
> > > and use it to prevent the leader from incrementing the
> > > pending_stream_count if the parallel apply worker is trying to lock the stream
> > lock.
> > >
> > >
> > > > 3. The other point to consider is that for
> > > > stream_commit/prepare/abort, in LA, we release the stream lock after
> > > > sending the message whereas for stream_start we release it before
> > > > sending the message. I think for the earlier cases
> > > > (stream_commit/prepare/abort), the patch has done like this because
> > > > pa_send_data() may need to require the lock again when it times out
> > > > and start serializing, so there will be no sense in first releasing
> > > > it, then re-acquiring it, and then again releasing it. Can't we also
> > > > release the lock for stream_start after
> > > > pa_send_data() only if it is not switched to serialize mode?
> > >
> > > Changed.
> > >
> > > Attach the new version patch set which addressed above comments.
> >
> > Here are comments on v59 0001, 0002 patches:
>
> Thanks for the comments!
>
> > +void
> > +pa_increment_stream_block(ParallelApplyWorkerShared *wshared) {
> > + while (1)
> > + {
> > + SpinLockAcquire(&wshared->mutex);
> > +
> > + /*
> > + * Don't try to increment the count if the parallel
> > apply worker is
> > + * taking the stream lock. Otherwise, there would be
> > a race condition
> > + * that the parallel apply worker checks there is no
> > pending streaming
> > + * block and before it actually starts waiting on a
> > lock, the leader
> > + * sends another streaming block and take the stream
> > lock again. In
> > + * this case, the parallel apply worker will start
> > waiting for the next
> > + * streaming block whereas there is actually a
> > pending streaming block
> > + * available.
> > + */
> > + if (!wshared->pa_wait_for_stream)
> > + {
> > + wshared->pending_stream_count++;
> > + SpinLockRelease(&wshared->mutex);
> > + break;
> > + }
> > +
> > + SpinLockRelease(&wshared->mutex);
> > + }
> > +}
> >
> > I think we should add an assertion to check if we don't hold the stream lock.
> >
> > I think that waiting for pa_wait_for_stream to be false in a busy loop is not a
> > good idea. It's not interruptible and there is not guarantee that we can break
> > from this loop in a short time. For instance, if PA executes
> > pa_decr_and_wait_stream_block() a bit earlier than LA executes
> > pa_increment_stream_block(), LA has to wait for PA to acquire and release the
> > stream lock in a busy loop. It should not be long in normal cases but the
> > duration LA needs to wait for PA depends on PA, which could be long. Also
> > what if PA raises an error in
> > pa_lock_stream() due to some reasons? I think LA won't be able to detect the
> > failure.
> >
> > I think we should at least make it interruptible and maybe need to add some
> > sleep. Or perhaps we can use the condition variable for this case.
>
> Thanks for the analysis, I will research this part.
>
> > ---
> > In worker.c, we have the following common pattern:
> >
> > case TRANS_LEADER_PARTIAL_SERIALIZE:
> > write change to the file;
> > do some work;
> > break;
> >
> > case TRANS_LEADER_SEND_TO_PARALLEL:
> > pa_send_data();
> >
> > if (winfo->serialize_changes)
> > {
> > do some worker required after writing changes to the file.
> > }
> > :
> > break;
> >
> > IIUC there are two different paths for partial serialization: (a) where
> > apply_action is TRANS_LEADER_PARTIAL_SERIALIZE, and (b) where
> > apply_action is TRANS_LEADER_PARTIAL_SERIALIZE and
> > winfo->serialize_changes became true. And we need to match what we do
> > in (a) and (b). Rather than having two different paths for the same case, how
> > about falling through TRANS_LEADER_PARTIAL_SERIALIZE when we could not
> > send the changes? That is, pa_send_data() just returns false when the timeout
> > exceeds and we need to switch to serialize changes, otherwise returns true. If it
> > returns false, we prepare for switching to serialize changes such as initializing
> > fileset, and fall through TRANS_LEADER_PARTIAL_SERIALIZE case. The code
> > would be like:
> >
> > case TRANS_LEADER_SEND_TO_PARALLEL:
> > ret = pa_send_data();
> >
> > if (ret)
> > {
> > do work for sending changes to PA.
> > break;
> > }
> >
> > /* prepare for switching to serialize changes */
> > winfo->serialize_changes = true;
> > initialize fileset;
> > acquire stream lock if necessary;
> >
> > /* FALLTHROUGH */
> > case TRANS_LEADER_PARTIAL_SERIALIZE:
> > do work for serializing changes;
> > break;
>
> I think that the suggestion is to extract the code that switch to serialize
> mode out of the pa_send_data(), and then we need to add that logic in all the
> functions which call pa_send_data(), I am not sure if it looks better as it
> might introduce some more codes in each handling function.
I think we can have a common function to prepare for switching to
serialize changes. With the current code, I'm concerned that we have
to check if what we do in both cases are matched whenever we change
the code for the partial serialization case.
> > ---
> > void
> > pa_lock_stream(TransactionId xid, LOCKMODE lockmode) {
> > LockApplyTransactionForSession(MyLogicalRepWorker->subid, xid,
> > PARALLEL_APPLY_LOCK_STREAM,
> > lockmode); }
> >
> > I think since we don't need to let the caller to specify the lock mode but need
> > only shared and exclusive modes, we can make it simple by having a boolean
> > argument say shared instead of lockmode.
>
> I personally think passing the lockmode would make the code more clear
> than passing a Boolean value.
Okay, agreed.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, December 14, 2022 2:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Dec 14, 2022 at 9:50 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Tuesday, December 13, 2022 11:25 PM Masahiko Sawada
> <sawada.mshk@gmail.com> wrote:
> > >
> > > Here are comments on v59 0001, 0002 patches:
> >
> > Thanks for the comments!
> >
> > > +void
> > > +pa_increment_stream_block(ParallelApplyWorkerShared *wshared) {
> > > + while (1)
> > > + {
> > > + SpinLockAcquire(&wshared->mutex);
> > > +
> > > + /*
> > > + * Don't try to increment the count if the parallel
> > > apply worker is
> > > + * taking the stream lock. Otherwise, there would
> > > + be
> > > a race condition
> > > + * that the parallel apply worker checks there is
> > > + no
> > > pending streaming
> > > + * block and before it actually starts waiting on a
> > > lock, the leader
> > > + * sends another streaming block and take the
> > > + stream
> > > lock again. In
> > > + * this case, the parallel apply worker will start
> > > waiting for the next
> > > + * streaming block whereas there is actually a
> > > pending streaming block
> > > + * available.
> > > + */
> > > + if (!wshared->pa_wait_for_stream)
> > > + {
> > > + wshared->pending_stream_count++;
> > > + SpinLockRelease(&wshared->mutex);
> > > + break;
> > > + }
> > > +
> > > + SpinLockRelease(&wshared->mutex);
> > > + }
> > > +}
> > >
> > > I think we should add an assertion to check if we don't hold the stream lock.
> > >
> > > I think that waiting for pa_wait_for_stream to be false in a busy
> > > loop is not a good idea. It's not interruptible and there is not
> > > guarantee that we can break from this loop in a short time. For
> > > instance, if PA executes
> > > pa_decr_and_wait_stream_block() a bit earlier than LA executes
> > > pa_increment_stream_block(), LA has to wait for PA to acquire and
> > > release the stream lock in a busy loop. It should not be long in
> > > normal cases but the duration LA needs to wait for PA depends on PA,
> > > which could be long. Also what if PA raises an error in
> > > pa_lock_stream() due to some reasons? I think LA won't be able to
> > > detect the failure.
> > >
> > > I think we should at least make it interruptible and maybe need to
> > > add some sleep. Or perhaps we can use the condition variable for this case.
> >
>
> Or we can leave this while (true) logic altogether for the first version and have a
> comment to explain this race. Anyway, after restarting, it will probably be
> solved. We can always change this part of the code later if this really turns out
> to be problematic.
Agreed, and reverted this part.
>
> > Thanks for the analysis, I will research this part.
> >
> > > ---
> > > In worker.c, we have the following common pattern:
> > >
> > > case TRANS_LEADER_PARTIAL_SERIALIZE:
> > > write change to the file;
> > > do some work;
> > > break;
> > >
> > > case TRANS_LEADER_SEND_TO_PARALLEL:
> > > pa_send_data();
> > >
> > > if (winfo->serialize_changes)
> > > {
> > > do some worker required after writing changes to the file.
> > > }
> > > :
> > > break;
> > >
> > > IIUC there are two different paths for partial serialization: (a)
> > > where apply_action is TRANS_LEADER_PARTIAL_SERIALIZE, and (b) where
> > > apply_action is TRANS_LEADER_PARTIAL_SERIALIZE and
> > > winfo->serialize_changes became true. And we need to match what we
> > > winfo->do
> > > in (a) and (b). Rather than having two different paths for the same
> > > case, how about falling through TRANS_LEADER_PARTIAL_SERIALIZE when
> > > we could not send the changes? That is, pa_send_data() just returns
> > > false when the timeout exceeds and we need to switch to serialize
> > > changes, otherwise returns true. If it returns false, we prepare for
> > > switching to serialize changes such as initializing fileset, and
> > > fall through TRANS_LEADER_PARTIAL_SERIALIZE case. The code would be
> like:
> > >
> > > case TRANS_LEADER_SEND_TO_PARALLEL:
> > > ret = pa_send_data();
> > >
> > > if (ret)
> > > {
> > > do work for sending changes to PA.
> > > break;
> > > }
> > >
> > > /* prepare for switching to serialize changes */
> > > winfo->serialize_changes = true;
> > > initialize fileset;
> > > acquire stream lock if necessary;
> > >
> > > /* FALLTHROUGH */
> > > case TRANS_LEADER_PARTIAL_SERIALIZE:
> > > do work for serializing changes;
> > > break;
> >
> > I think that the suggestion is to extract the code that switch to
> > serialize mode out of the pa_send_data(), and then we need to add that
> > logic in all the functions which call pa_send_data(), I am not sure if
> > it looks better as it might introduce some more codes in each handling
> function.
> >
>
> How about extracting the common code from apply_handle_stream_commit
> and apply_handle_stream_prepare to a separate function say
> pa_xact_finish_common()? I see there is a lot of common code (unlock the
> stream, wait for the finish, store flush location, free worker
> info) in both the functions for TRANS_LEADER_PARTIAL_SERIALIZE and
> TRANS_LEADER_SEND_TO_PARALLEL cases.
Agreed, changed. I also addressed Sawada-san comment by extracting the
code that switch to serialize out of pa_send_data().
> >
> > > ---
> > > void
> > > pa_lock_stream(TransactionId xid, LOCKMODE lockmode) {
> > > LockApplyTransactionForSession(MyLogicalRepWorker->subid, xid,
> > > PARALLEL_APPLY_LOCK_STREAM,
> > > lockmode); }
> > >
> > > I think since we don't need to let the caller to specify the lock
> > > mode but need only shared and exclusive modes, we can make it simple
> > > by having a boolean argument say shared instead of lockmode.
> >
> > I personally think passing the lockmode would make the code more clear
> > than passing a Boolean value.
> >
>
> +1.
>
> I have made a few changes in the newly added comments and function name in
> the attached patch. Kindly include this if you find the changes okay.
Thanks, I have checked and merged it.
Attach the new version patch set which addressed all comments so far.
Best regards,
Hou zj
Attachment
- v61-0007-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v61-0001-Perform-streaming-logical-transactions-by-parall.patch
- v61-0002-Serialize-partial-changes-to-a-file-when-the-att.patch
- v61-0003-Test-streaming-parallel-option-in-tap-test.patch
- v61-0004-Allow-streaming-every-change-without-waiting-til.patch
- v61-0005-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v61-0006-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, Dec 14, 2022 at 3:48 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Dec 14, 2022 at 9:50 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Tuesday, December 13, 2022 11:25 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > >
> > > Here are comments on v59 0001, 0002 patches:
> >
> > Thanks for the comments!
> >
> > > +void
> > > +pa_increment_stream_block(ParallelApplyWorkerShared *wshared) {
> > > + while (1)
> > > + {
> > > + SpinLockAcquire(&wshared->mutex);
> > > +
> > > + /*
> > > + * Don't try to increment the count if the parallel
> > > apply worker is
> > > + * taking the stream lock. Otherwise, there would be
> > > a race condition
> > > + * that the parallel apply worker checks there is no
> > > pending streaming
> > > + * block and before it actually starts waiting on a
> > > lock, the leader
> > > + * sends another streaming block and take the stream
> > > lock again. In
> > > + * this case, the parallel apply worker will start
> > > waiting for the next
> > > + * streaming block whereas there is actually a
> > > pending streaming block
> > > + * available.
> > > + */
> > > + if (!wshared->pa_wait_for_stream)
> > > + {
> > > + wshared->pending_stream_count++;
> > > + SpinLockRelease(&wshared->mutex);
> > > + break;
> > > + }
> > > +
> > > + SpinLockRelease(&wshared->mutex);
> > > + }
> > > +}
> > >
> > > I think we should add an assertion to check if we don't hold the stream lock.
> > >
> > > I think that waiting for pa_wait_for_stream to be false in a busy loop is not a
> > > good idea. It's not interruptible and there is not guarantee that we can break
> > > from this loop in a short time. For instance, if PA executes
> > > pa_decr_and_wait_stream_block() a bit earlier than LA executes
> > > pa_increment_stream_block(), LA has to wait for PA to acquire and release the
> > > stream lock in a busy loop. It should not be long in normal cases but the
> > > duration LA needs to wait for PA depends on PA, which could be long. Also
> > > what if PA raises an error in
> > > pa_lock_stream() due to some reasons? I think LA won't be able to detect the
> > > failure.
> > >
> > > I think we should at least make it interruptible and maybe need to add some
> > > sleep. Or perhaps we can use the condition variable for this case.
> >
>
> Or we can leave this while (true) logic altogether for the first
> version and have a comment to explain this race. Anyway, after
> restarting, it will probably be solved. We can always change this part
> of the code later if this really turns out to be problematic.
>
+1. Thank you Hou-san for adding this comment in the latest version (v61) patch!
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Dec 15, 2022 at 8:58 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
Few minor comments:
=================
1.
+ for (i = list_length(subxactlist) - 1; i >= 0; i--)
+ {
+ TransactionId xid_tmp = lfirst_xid(list_nth_cell(subxactlist, i));
+
+ if (xid_tmp == subxid)
+ {
+ RollbackToSavepoint(spname);
+ CommitTransactionCommand();
+ subxactlist = list_truncate(subxactlist, i + 1);
I find that there is always one element extra in the list after
rollback to savepoint. Don't we need to truncate the list to 'i' as
shown in the diff below?
2.
* Note that If it's an empty sub-transaction then we will not find
* the subxid here.
If in above comment seems to be in wrong case. Anyway, I have slightly
modified it as you can see in the diff below.
$ git diff
diff --git a/src/backend/replication/logical/applyparallelworker.c
b/src/backend/replication/logical/applyparallelworker.c
index 11695c75fa..c809b1fd01 100644
--- a/src/backend/replication/logical/applyparallelworker.c
+++ b/src/backend/replication/logical/applyparallelworker.c
@@ -1516,8 +1516,8 @@ pa_stream_abort(LogicalRepStreamAbortData *abort_data)
* Search the subxactlist, determine the offset tracked for the
* subxact, and truncate the list.
*
- * Note that If it's an empty sub-transaction then we
will not find
- * the subxid here.
+ * Note that for an empty sub-transaction we won't
find the subxid
+ * here.
*/
for (i = list_length(subxactlist) - 1; i >= 0; i--)
{
@@ -1527,7 +1527,7 @@ pa_stream_abort(LogicalRepStreamAbortData *abort_data)
{
RollbackToSavepoint(spname);
CommitTransactionCommand();
- subxactlist = list_truncate(subxactlist, i + 1);
+ subxactlist = list_truncate(subxactlist, i);
break;
}
}
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Thu, Dec 15, 2022 at 12:28 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Wednesday, December 14, 2022 2:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> >
> > On Wed, Dec 14, 2022 at 9:50 AM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Tuesday, December 13, 2022 11:25 PM Masahiko Sawada
> > <sawada.mshk@gmail.com> wrote:
> > > >
> > > > Here are comments on v59 0001, 0002 patches:
> > >
> > > Thanks for the comments!
> > >
> > > > +void
> > > > +pa_increment_stream_block(ParallelApplyWorkerShared *wshared) {
> > > > + while (1)
> > > > + {
> > > > + SpinLockAcquire(&wshared->mutex);
> > > > +
> > > > + /*
> > > > + * Don't try to increment the count if the parallel
> > > > apply worker is
> > > > + * taking the stream lock. Otherwise, there would
> > > > + be
> > > > a race condition
> > > > + * that the parallel apply worker checks there is
> > > > + no
> > > > pending streaming
> > > > + * block and before it actually starts waiting on a
> > > > lock, the leader
> > > > + * sends another streaming block and take the
> > > > + stream
> > > > lock again. In
> > > > + * this case, the parallel apply worker will start
> > > > waiting for the next
> > > > + * streaming block whereas there is actually a
> > > > pending streaming block
> > > > + * available.
> > > > + */
> > > > + if (!wshared->pa_wait_for_stream)
> > > > + {
> > > > + wshared->pending_stream_count++;
> > > > + SpinLockRelease(&wshared->mutex);
> > > > + break;
> > > > + }
> > > > +
> > > > + SpinLockRelease(&wshared->mutex);
> > > > + }
> > > > +}
> > > >
> > > > I think we should add an assertion to check if we don't hold the stream lock.
> > > >
> > > > I think that waiting for pa_wait_for_stream to be false in a busy
> > > > loop is not a good idea. It's not interruptible and there is not
> > > > guarantee that we can break from this loop in a short time. For
> > > > instance, if PA executes
> > > > pa_decr_and_wait_stream_block() a bit earlier than LA executes
> > > > pa_increment_stream_block(), LA has to wait for PA to acquire and
> > > > release the stream lock in a busy loop. It should not be long in
> > > > normal cases but the duration LA needs to wait for PA depends on PA,
> > > > which could be long. Also what if PA raises an error in
> > > > pa_lock_stream() due to some reasons? I think LA won't be able to
> > > > detect the failure.
> > > >
> > > > I think we should at least make it interruptible and maybe need to
> > > > add some sleep. Or perhaps we can use the condition variable for this case.
> > >
> >
> > Or we can leave this while (true) logic altogether for the first version and have a
> > comment to explain this race. Anyway, after restarting, it will probably be
> > solved. We can always change this part of the code later if this really turns out
> > to be problematic.
>
> Agreed, and reverted this part.
>
> >
> > > Thanks for the analysis, I will research this part.
> > >
> > > > ---
> > > > In worker.c, we have the following common pattern:
> > > >
> > > > case TRANS_LEADER_PARTIAL_SERIALIZE:
> > > > write change to the file;
> > > > do some work;
> > > > break;
> > > >
> > > > case TRANS_LEADER_SEND_TO_PARALLEL:
> > > > pa_send_data();
> > > >
> > > > if (winfo->serialize_changes)
> > > > {
> > > > do some worker required after writing changes to the file.
> > > > }
> > > > :
> > > > break;
> > > >
> > > > IIUC there are two different paths for partial serialization: (a)
> > > > where apply_action is TRANS_LEADER_PARTIAL_SERIALIZE, and (b) where
> > > > apply_action is TRANS_LEADER_PARTIAL_SERIALIZE and
> > > > winfo->serialize_changes became true. And we need to match what we
> > > > winfo->do
> > > > in (a) and (b). Rather than having two different paths for the same
> > > > case, how about falling through TRANS_LEADER_PARTIAL_SERIALIZE when
> > > > we could not send the changes? That is, pa_send_data() just returns
> > > > false when the timeout exceeds and we need to switch to serialize
> > > > changes, otherwise returns true. If it returns false, we prepare for
> > > > switching to serialize changes such as initializing fileset, and
> > > > fall through TRANS_LEADER_PARTIAL_SERIALIZE case. The code would be
> > like:
> > > >
> > > > case TRANS_LEADER_SEND_TO_PARALLEL:
> > > > ret = pa_send_data();
> > > >
> > > > if (ret)
> > > > {
> > > > do work for sending changes to PA.
> > > > break;
> > > > }
> > > >
> > > > /* prepare for switching to serialize changes */
> > > > winfo->serialize_changes = true;
> > > > initialize fileset;
> > > > acquire stream lock if necessary;
> > > >
> > > > /* FALLTHROUGH */
> > > > case TRANS_LEADER_PARTIAL_SERIALIZE:
> > > > do work for serializing changes;
> > > > break;
> > >
> > > I think that the suggestion is to extract the code that switch to
> > > serialize mode out of the pa_send_data(), and then we need to add that
> > > logic in all the functions which call pa_send_data(), I am not sure if
> > > it looks better as it might introduce some more codes in each handling
> > function.
> > >
> >
> > How about extracting the common code from apply_handle_stream_commit
> > and apply_handle_stream_prepare to a separate function say
> > pa_xact_finish_common()? I see there is a lot of common code (unlock the
> > stream, wait for the finish, store flush location, free worker
> > info) in both the functions for TRANS_LEADER_PARTIAL_SERIALIZE and
> > TRANS_LEADER_SEND_TO_PARALLEL cases.
>
> Agreed, changed. I also addressed Sawada-san comment by extracting the
> code that switch to serialize out of pa_send_data().
>
> > >
> > > > ---
> > > > void
> > > > pa_lock_stream(TransactionId xid, LOCKMODE lockmode) {
> > > > LockApplyTransactionForSession(MyLogicalRepWorker->subid, xid,
> > > > PARALLEL_APPLY_LOCK_STREAM,
> > > > lockmode); }
> > > >
> > > > I think since we don't need to let the caller to specify the lock
> > > > mode but need only shared and exclusive modes, we can make it simple
> > > > by having a boolean argument say shared instead of lockmode.
> > >
> > > I personally think passing the lockmode would make the code more clear
> > > than passing a Boolean value.
> > >
> >
> > +1.
> >
> > I have made a few changes in the newly added comments and function name in
> > the attached patch. Kindly include this if you find the changes okay.
>
> Thanks, I have checked and merged it.
>
> Attach the new version patch set which addressed all comments so far.
Thank you for updating the patches! Here are some minor comments:
@@ -100,7 +100,6 @@ static void check_duplicates_in_publist(List
*publist, Datum *datums);
static List *merge_publications(List *oldpublist, List *newpublist,
bool addpub, const char *subname);
static void ReportSlotConnectionError(List *rstates, Oid subid, char
*slotname, char *err);
-
/*
* Common option parsing function for CREATE and ALTER SUBSCRIPTION commands.
*
Unnecessary line removal.
---
+ * Swtich to PARTIAL_SERIALIZE mode for the current transaction -- this means
typo
s/Swtich/Switch/
---
+pa_has_spooled_message_pending()
+{
+ PartialFileSetState fileset_state;
+
+ fileset_state = pa_get_fileset_state();
+
+ if (fileset_state != FS_UNKNOWN)
+ return true;
+ else
+ return false;
+}
I think we can simply do:
return (fileset_state != FS_UNKNOWN);
Or do we need this function in the first place? I think we can do in
LogicalParallelApplyLoop() like:
else if (shmq_res == SHM_MQ_WOULD_BLOCK)
{
/* Check if changes have been serialized to a file. */
if (pa_get_fileset_state != FS_UNKNOWN)
{
pa_spooled_messages();
}
Also, I think the name FS_UNKNOWN doesn't mean anything. It sounds
rather we don't expect this state but it's not true. How about
FS_INITIAL or FS_EMPTY? It sounds more understandable.
---
+/*
+ * Wait until the parallel apply worker's transaction finishes.
+ */
+void
+pa_wait_for_xact_finish(ParallelApplyWorkerInfo *winfo)
I think we no longer need to expose pa_wait_for_exact_finish().
---
+ active_workers = list_copy(ParallelApplyWorkerPool);
+
+ foreach(lc, active_workers)
+ {
+ int slot_no;
+ uint16 generation;
+ ParallelApplyWorkerInfo *winfo =
(ParallelApplyWorkerInfo *) lfirst(lc);
+
+ LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
+ napplyworkers =
logicalrep_pa_worker_count(MyLogicalRepWorker->subid);
+ LWLockRelease(LogicalRepWorkerLock);
+
+ if (napplyworkers <=
max_parallel_apply_workers_per_subscription / 2)
+ return;
+
Calling logicalrep_pa_worker_count() with lwlock for each worker seems
not efficient to me. I think we can get the number of workers once at
the top of this function and return if it's already lower than the
maximum pool size. Otherwise, we attempt to stop extra workers.
---
+bool
+pa_free_worker(ParallelApplyWorkerInfo *winfo, TransactionId xid)
+{
Is there any reason why this function has the XID as a separate
argument? It seems to me that since we always call this function with
'winfo' and 'winfo->shared->xid', we can remove xid from the function
argument.
---
+ /* Initialize shared memory area. */
+ SpinLockAcquire(&winfo->shared->mutex);
+ winfo->shared->xact_state = PARALLEL_TRANS_UNKNOWN;
+ winfo->shared->xid = xid;
+ SpinLockRelease(&winfo->shared->mutex);
It's practically no problem but is there any reason why some fields of
ParallelApplyWorkerInfo are initialized in pa_setup_dsm() whereas some
fields are done here?
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, December 16, 2022 3:08 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
>
>Here are some minor comments:
Thanks for the comments!
> ---
> +pa_has_spooled_message_pending()
> +{
> + PartialFileSetState fileset_state;
> +
> + fileset_state = pa_get_fileset_state();
> +
> + if (fileset_state != FS_UNKNOWN)
> + return true;
> + else
> + return false;
> +}
>
> I think we can simply do:
>
> return (fileset_state != FS_UNKNOWN);
Will change.
>
> Or do we need this function in the first place? I think we can do in
> LogicalParallelApplyLoop() like:
I was intended to not expose the file state in the main loop, so maybe better
to keep this function.
> ---
> + active_workers = list_copy(ParallelApplyWorkerPool);
> +
> + foreach(lc, active_workers)
> + {
> + int slot_no;
> + uint16 generation;
> + ParallelApplyWorkerInfo *winfo =
> (ParallelApplyWorkerInfo *) lfirst(lc);
> +
> + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> + napplyworkers =
> logicalrep_pa_worker_count(MyLogicalRepWorker->subid);
> + LWLockRelease(LogicalRepWorkerLock);
> +
> + if (napplyworkers <=
> max_parallel_apply_workers_per_subscription / 2)
> + return;
> +
>
> Calling logicalrep_pa_worker_count() with lwlock for each worker seems
> not efficient to me. I think we can get the number of workers once at
> the top of this function and return if it's already lower than the
> maximum pool size. Otherwise, we attempt to stop extra workers.
How about we directly check the length of worker pool list here which
seems simpler and don't need to lock ?
> ---
> +bool
> +pa_free_worker(ParallelApplyWorkerInfo *winfo, TransactionId xid)
> +{
>
>
> Is there any reason why this function has the XID as a separate
> argument? It seems to me that since we always call this function with
> 'winfo' and 'winfo->shared->xid', we can remove xid from the function
> argument.
>
> ---
> + /* Initialize shared memory area. */
> + SpinLockAcquire(&winfo->shared->mutex);
> + winfo->shared->xact_state = PARALLEL_TRANS_UNKNOWN;
> + winfo->shared->xid = xid;
> + SpinLockRelease(&winfo->shared->mutex);
>
> It's practically no problem but is there any reason why some fields of
> ParallelApplyWorkerInfo are initialized in pa_setup_dsm() whereas some
> fields are done here?
We could be using old worker in the pool here in which case we need to update
these fields with the new streaming transaction information.
I will address other comments except above ones which are being discussed.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Dec 15, 2022 at 6:29 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
I have noticed that the origin information of the rollback is not
restored after restart of the server. So, the apply worker will send
the old origin information in that case. It seems we need the below
change in XactLogAbortRecord(). What do you think?
diff --git a/src/backend/access/transam/xact.c
b/src/backend/access/transam/xact.c
index 419fac5d6f..1b047133db 100644
--- a/src/backend/access/transam/xact.c
+++ b/src/backend/access/transam/xact.c
@@ -5880,11 +5880,10 @@ XactLogAbortRecord(TimestampTz abort_time,
}
/*
- * Dump transaction origin information only for abort prepared. We need
- * this during recovery to update the replication origin progress.
+ * Dump transaction origin information. We need this during recovery to
+ * update the replication origin progress.
*/
- if ((replorigin_session_origin != InvalidRepOriginId) &&
- TransactionIdIsValid(twophase_xid))
+ if (replorigin_session_origin != InvalidRepOriginId)
{
xl_xinfo.xinfo |= XACT_XINFO_HAS_ORIGIN;
@@ -5941,8 +5940,8 @@ XactLogAbortRecord(TimestampTz abort_time,
if (xl_xinfo.xinfo & XACT_XINFO_HAS_ORIGIN)
XLogRegisterData((char *) (&xl_origin), sizeof(xl_xact_origin));
- if (TransactionIdIsValid(twophase_xid))
- XLogSetRecordFlags(XLOG_INCLUDE_ORIGIN);
+ /* include the replication origin */
+ XLogSetRecordFlags(XLOG_INCLUDE_ORIGIN);
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Dec 16, 2022 at 2:47 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> > ---
> > + active_workers = list_copy(ParallelApplyWorkerPool);
> > +
> > + foreach(lc, active_workers)
> > + {
> > + int slot_no;
> > + uint16 generation;
> > + ParallelApplyWorkerInfo *winfo =
> > (ParallelApplyWorkerInfo *) lfirst(lc);
> > +
> > + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> > + napplyworkers =
> > logicalrep_pa_worker_count(MyLogicalRepWorker->subid);
> > + LWLockRelease(LogicalRepWorkerLock);
> > +
> > + if (napplyworkers <=
> > max_parallel_apply_workers_per_subscription / 2)
> > + return;
> > +
> >
> > Calling logicalrep_pa_worker_count() with lwlock for each worker seems
> > not efficient to me. I think we can get the number of workers once at
> > the top of this function and return if it's already lower than the
> > maximum pool size. Otherwise, we attempt to stop extra workers.
>
> How about we directly check the length of worker pool list here which
> seems simpler and don't need to lock ?
>
I don't see any problem with that. Also, if such a check is safe then
can't we use the same in pa_free_worker() as well? BTW, shouldn't
pa_stop_idle_workers() try to free/stop workers unless the active
number reaches below max_parallel_apply_workers_per_subscription?
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Dec 16, 2022 at 4:34 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Fri, Dec 16, 2022 at 2:47 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > > ---
> > > + active_workers = list_copy(ParallelApplyWorkerPool);
> > > +
> > > + foreach(lc, active_workers)
> > > + {
> > > + int slot_no;
> > > + uint16 generation;
> > > + ParallelApplyWorkerInfo *winfo =
> > > (ParallelApplyWorkerInfo *) lfirst(lc);
> > > +
> > > + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> > > + napplyworkers =
> > > logicalrep_pa_worker_count(MyLogicalRepWorker->subid);
> > > + LWLockRelease(LogicalRepWorkerLock);
> > > +
> > > + if (napplyworkers <=
> > > max_parallel_apply_workers_per_subscription / 2)
> > > + return;
> > > +
> > >
> > > Calling logicalrep_pa_worker_count() with lwlock for each worker seems
> > > not efficient to me. I think we can get the number of workers once at
> > > the top of this function and return if it's already lower than the
> > > maximum pool size. Otherwise, we attempt to stop extra workers.
> >
> > How about we directly check the length of worker pool list here which
> > seems simpler and don't need to lock ?
> >
>
> I don't see any problem with that. Also, if such a check is safe then
> can't we use the same in pa_free_worker() as well? BTW, shouldn't
> pa_stop_idle_workers() try to free/stop workers unless the active
> number reaches below max_parallel_apply_workers_per_subscription?
>
BTW, can we move pa_stop_idle_workers() functionality to a later patch
(say into v61-0006*)? That way we can focus on it separately once the
main patch is committed.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Saturday, December 17, 2022 8:16 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Fri, Dec 16, 2022 at 4:34 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Fri, Dec 16, 2022 at 2:47 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > > ---
> > > > + active_workers = list_copy(ParallelApplyWorkerPool);
> > > > +
> > > > + foreach(lc, active_workers)
> > > > + {
> > > > + int slot_no;
> > > > + uint16 generation;
> > > > + ParallelApplyWorkerInfo *winfo =
> > > > (ParallelApplyWorkerInfo *) lfirst(lc);
> > > > +
> > > > + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> > > > + napplyworkers =
> > > > logicalrep_pa_worker_count(MyLogicalRepWorker->subid);
> > > > + LWLockRelease(LogicalRepWorkerLock);
> > > > +
> > > > + if (napplyworkers <=
> > > > max_parallel_apply_workers_per_subscription / 2)
> > > > + return;
> > > > +
> > > >
> > > > Calling logicalrep_pa_worker_count() with lwlock for each worker
> > > > seems not efficient to me. I think we can get the number of
> > > > workers once at the top of this function and return if it's
> > > > already lower than the maximum pool size. Otherwise, we attempt to stop
> extra workers.
> > >
> > > How about we directly check the length of worker pool list here
> > > which seems simpler and don't need to lock ?
> > >
> >
> > I don't see any problem with that. Also, if such a check is safe then
> > can't we use the same in pa_free_worker() as well? BTW, shouldn't
> > pa_stop_idle_workers() try to free/stop workers unless the active
> > number reaches below max_parallel_apply_workers_per_subscription?
> >
>
> BTW, can we move pa_stop_idle_workers() functionality to a later patch (say into
> v61-0006*)? That way we can focus on it separately once the main patch is
> committed.
Agreed. I have addressed all the comments and did some cosmetic changes.
Attach the new version patch set.
Best regards,
Hou zj
Attachment
- v62-0008-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v62-0002-Serialize-partial-changes-to-a-file-when-the-att.patch
- v62-0001-Perform-streaming-logical-transactions-by-parall.patch
- v62-0006-Stop-extra-worker-if-GUC-was-changed.patch
- v62-0003-Test-streaming-parallel-option-in-tap-test.patch
- v62-0004-Allow-streaming-every-change-without-waiting-til.patch
- v62-0005-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v62-0007-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Sat, Dec 17, 2022 at 7:34 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Agreed. I have addressed all the comments and did some cosmetic changes.
> Attach the new version patch set.
>
Few comments:
============
1.
+ if (fileset_state == FS_SERIALIZE_IN_PROGRESS)
+ {
+ pa_lock_stream(MyParallelShared->xid, AccessShareLock);
+ pa_unlock_stream(MyParallelShared->xid, AccessShareLock);
+ }
+
+ /*
+ * We cannot read the file immediately after the leader has serialized all
+ * changes to the file because there may still be messages in the memory
+ * queue. We will apply all spooled messages the next time we call this
+ * function, which should ensure that there are no messages left in the
+ * memory queue.
+ */
+ else if (fileset_state == FS_SERIALIZE_DONE)
+ {
Once we have waited in the FS_SERIALIZE_IN_PROGRESS, the file state
can be FS_SERIALIZE_DONE immediately after that. So, won't it be
better to have a separate if block for FS_SERIALIZE_DONE state? If you
agree to do so then we can probably remove the comment: "* XXX It is
possible that immediately after we have waited for a lock in ...".
2.
+void
+pa_decr_and_wait_stream_block(void)
+{
+ Assert(am_parallel_apply_worker());
+
+ if (pg_atomic_sub_fetch_u32(&MyParallelShared->pending_stream_count, 1) == 0)
I think here the count can go negative when we are in serialize mode
because we don't increase it for serialize mode. I can't see any
problem due to that but OTOH, this doesn't seem to be intended because
in the future if we decide to implement the functionality of switching
back to non-serialize mode, this could be a problem. Also, I guess we
don't even need to try locking/unlocking the stream lock in that case.
One idea to avoid this is to check if the pending count is zero then
if file_set in not available raise an error (elog ERROR), otherwise,
simply return from here.
3. In apply_handle_stream_stop(), we are setting backendstate as idle
for cases TRANS_LEADER_SEND_TO_PARALLEL and TRANS_PARALLEL_APPLY. For
other cases, it is set by stream_stop_internal. I think it would be
better to set the state explicitly for all cases to make the code look
consistent and remove it from stream_stop_internal(). The other reason
to remove setting the state from stream_stop_internal() is that when
that function is invoked from other places like
apply_handle_stream_commit(), it seems to be setting the idle before
actually we reach the idle state.
4. Apart from the above, I have made a few changes in the comments,
see attached.
--
With Regards,
Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Hi, I have done some testing for this patch. This post describes my tests so far and the results observed. Background - Testing multiple PA workers: --------------------------------------- The "parallel apply" feature allocates the PA workers (if it can) upon receiving STREAM_START replication protocol msg. This means that if there are replication messages for overlapping streaming transactions you should see multiple PA workers processing them (assuming the PA pool size is configured appropriately). But AFAIK the only way to cause replication protocol messages to arrive and be applied in a particular order is by manual testing (e.g use 2x psql sessions and manually arrange for there to be overlapping transactions for the published table). I have tried to make this kind of (regression) testing easier -- in order to test many overlapping combinations in a repeatable and semi-automated way I have posted a small enhancement to the isolationtester spec grammar [1]. Using this, now we can just press a button to test lots of different streaming transaction combinations and then observe the parallel apply message dispatching in action... Test message combinations (from specs/pub-sub.spec): ---------------------------------------------------- # single tx permutation ps1_begin ps1_ins ps1_commit ps1_sel ps2_sel sub_sleep sub_sel permutation ps2_begin ps2_ins ps2_commit ps1_sel ps2_sel sub_sleep sub_sel # rollback permutation ps1_begin ps1_ins ps1_rollback ps1_sel sub_sleep sub_sel # overlapping tx rollback and commit permutation ps1_begin ps1_ins ps2_begin ps2_ins ps1_rollback ps2_commit sub_sleep sub_sel permutation ps1_begin ps1_ins ps2_begin ps2_ins ps1_commit ps2_rollback sub_sleep sub_sel # overlapping tx commits permutation ps1_begin ps1_ins ps2_begin ps2_ins ps2_commit ps1_commit sub_sleep sub_sel permutation ps1_begin ps1_ins ps2_begin ps2_ins ps1_commit ps2_commit sub_sleep sub_sel permutation ps1_begin ps2_begin ps1_ins ps2_ins ps2_commit ps1_commit sub_sleep sub_sel permutation ps1_begin ps2_begin ps1_ins ps2_ins ps1_commit ps2_commit sub_sleep sub_sel permutation ps1_begin ps2_begin ps2_ins ps1_ins ps2_commit ps1_commit sub_sleep sub_sel permutation ps1_begin ps2_begin ps2_ins ps1_ins ps1_commit ps2_commit sub_sleep sub_sel Test setup: ----------- 1. Setup publisher and subscriber servers 1a. Publisher server is configured to use new GUC 'force_stream_mode = true' [2]. This means even single-row inserts cause replication STREAM_START messages which will trigger the PA workers. 1b. Subscriber server is configured to use new GUC 'max_parallel_apply_workers_per_subscription'. Set this value to change how many PA workers can be allocated. 2. isolation/specs/pub-test.spec (defines the publisher sessions being tested) How verified: ------------- 1. Running the isolationtester pub-sub.spec test gives the expected table results (so data was replicated OK) - any new permutations can be added as required. - more overlapping sessions (e.g. 3 or 4...) can be added as required. 2. Changing the publisher GUC 'force_stream_mode' to be true/false - we can see if PA workers being used or not being used -- (ps -eaf | grep 'logical replication') 3. Changing the subscriber GUC 'max_parallel_apply_workers_per_subscription' - set to high value or low value so we can see the PA worker (pool) being used or filling to capacity 4. I have also patched some temporary logging into code for both "LA" and "PA" workers - now the subscriber logfile leaves a trail of evidence about which worker did what (for apply_dispatch and for locking calls) Observed Results: ----------------- 1. From the user's POV everything is normal - data gets replicated as expected regardless of GUC settings (force_streaming / max_parallel_apply_workers_per_subscription). [postgres@CentOS7-x64 isolation]$ make check-pub-sub ... ============== creating temporary instance ============== ============== initializing database system ============== ============== starting postmaster ============== running on port 61696 with PID 11822 ============== creating database "isolation_regression" ============== CREATE DATABASE ALTER DATABASE ALTER DATABASE ALTER DATABASE ALTER DATABASE ALTER DATABASE ALTER DATABASE ============== running regression test queries ============== test pub-sub ... ok 33424 ms ============== shutting down postmaster ============== ============== removing temporary instance ============== ===================== All 1 tests passed. ===================== 2. Confirmation multiple PA workers were used (force_streaming=true / max_parallel_apply_workers_per_subscription=99) [postgres@CentOS7-x64 isolation]$ ps -eaf | grep 'logical replication' postgres 5298 5293 0 Dec19 ? 00:00:00 postgres: logical replication launcher postgres 5306 5301 0 Dec19 ? 00:00:00 postgres: logical replication launcher postgres 17301 5301 0 10:31 ? 00:00:00 postgres: logical replication parallel apply worker for subscription 16387 postgres 17524 5301 0 10:31 ? 00:00:00 postgres: logical replication parallel apply worker for subscription 16387 postgres 21134 5301 0 08:08 ? 00:00:01 postgres: logical replication apply worker for subscription 16387 postgres 22377 13260 0 10:34 pts/0 00:00:00 grep --color=auto logical replication 3. Confirmation no PA workers were used when not streaming (force_streaming=false / max_parallel_apply_workers_per_subscription=99) [postgres@CentOS7-x64 isolation]$ ps -eaf | grep 'logical replication' postgres 26857 26846 0 10:37 ? 00:00:00 postgres: logical replication launcher postgres 26875 26864 0 10:37 ? 00:00:00 postgres: logical replication launcher postgres 26889 26864 0 10:37 ? 00:00:00 postgres: logical replication apply worker for subscription 16387 postgres 29901 13260 0 10:39 pts/0 00:00:00 grep --color=auto logical replication 4. Confirmation only one PA worker gets used when the pool is limited (force_streaming=true / max_parallel_apply_workers_per_subscription=1) 4a. (processes) [postgres@CentOS7-x64 isolation]$ ps -eaf | grep 'logical replication' postgres 2484 13260 0 10:42 pts/0 00:00:00 grep --color=auto logical replication postgres 32500 32495 0 10:40 ? 00:00:00 postgres: logical replication launcher postgres 32508 32503 0 10:40 ? 00:00:00 postgres: logical replication launcher postgres 32514 32503 0 10:41 ? 00:00:00 postgres: logical replication apply worker for subscription 16387 4b. (logs) 2022-12-20 10:41:43.551 AEDT [32514] LOG: out of parallel apply workers 2022-12-20 10:41:43.551 AEDT [32514] HINT: You might need to increase max_parallel_apply_workers_per_subscription. 2022-12-20 10:41:43.551 AEDT [32514] CONTEXT: processing remote data for replication origin "pg_16387" during message type "STREAM START" in transaction 756 5. Confirmation no PA workers get used when there is none available (force_streaming=true / max_parallel_apply_workers_per_subscription=0) 5a. (processes) [postgres@CentOS7-x64 isolation]$ ps -eaf | grep 'logical replication' postgres 10026 10021 0 10:47 ? 00:00:00 postgres: logical replication launcher postgres 10034 10029 0 10:47 ? 00:00:00 postgres: logical replication launcher postgres 10041 10029 0 10:47 ? 00:00:00 postgres: logical replication apply worker for subscription 16387 postgres 13068 13260 0 10:48 pts/0 00:00:00 grep --color=auto logical replication 5b. (logs) 2022-12-20 10:47:50.216 AEDT [10041] LOG: out of parallel apply workers 2022-12-20 10:47:50.216 AEDT [10041] HINT: You might need to increase max_parallel_apply_workers_per_subscription. .. Also, there are no "PA" log messages present Summary ------- In summary, everything I have tested so far appeared to be working properly. In other words, for overlapping streamed transactions of different kinds, and regardless of whether zero/some/all of those transactions are getting processed by a PA worker, the resulting replicated data looked consistently OK. PSA some files - test_init.sh - sample test script for setup publisher/subscriber required by spec test. - spec/pub-sub.spec = spec combinations for causing overlapping streaming transactions - pub-sub.out = output from successful isolationtester (make check-pub-sub) run - SUB.log = subscriber logs augmented with my "LA" and "PA" extra logging for showing locking/dispatching. (I can also post my logging patch if anyone is interested to try using it to see the output like in SUB.log). NOTE - all testing described in this post above was using v58-0001 only. However, the point of implementing these as a .spec test was to be able to repeat these same regression tests on newer versions with minimal manual steps required. Later I plan to fetch/apply the most recent patch version and repeat these same tests. ------ [1] My isolationtester conninfo enhancement v2 - https://www.postgresql.org/message-id/CAHut%2BPv_1Mev0709uj_OjyNCzfBjENE3RD9%3Dd9RZYfcqUKfG%3DA%40mail.gmail.com [2] Shi-san's GUC 'force_streaming_mode' - https://www.postgresql.org/message-id/flat/OSZPR01MB63104E7449DBE41932DB19F1FD1B9%40OSZPR01MB6310.jpnprd01.prod.outlook.com Kind Regards, Peter Smith. Fujitsu Australia
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Dec 20, 2022 at 8:17 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Summary > ------- > > In summary, everything I have tested so far appeared to be working > properly. In other words, for overlapping streamed transactions of > different kinds, and regardless of whether zero/some/all of those > transactions are getting processed by a PA worker, the resulting > replicated data looked consistently OK. > Thanks for doing the detailed testing of this patch. I think the one area where we can focus more is the switch-to-serialization mode while sending changes to the parallel worker. > > NOTE - all testing described in this post above was using v58-0001 > only. However, the point of implementing these as a .spec test was to > be able to repeat these same regression tests on newer versions with > minimal manual steps required. Later I plan to fetch/apply the most > recent patch version and repeat these same tests. > That would be really helpful. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Tue, Dec 20, 2022 at 2:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Dec 20, 2022 at 8:17 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Summary > > ------- > > > > In summary, everything I have tested so far appeared to be working > > properly. In other words, for overlapping streamed transactions of > > different kinds, and regardless of whether zero/some/all of those > > transactions are getting processed by a PA worker, the resulting > > replicated data looked consistently OK. > > > > Thanks for doing the detailed testing of this patch. I think the one > area where we can focus more is the switch-to-serialization mode while > sending changes to the parallel worker. > > > > > NOTE - all testing described in this post above was using v58-0001 > > only. However, the point of implementing these as a .spec test was to > > be able to repeat these same regression tests on newer versions with > > minimal manual steps required. Later I plan to fetch/apply the most > > recent patch version and repeat these same tests. > > > > That would be really helpful. > FYI, my pub-sub.spec tests gave the same result (i.e. pass) when re-run against the latest v62-0001 (parallel apply base patch) and v62-0004 (GUC 'force_stream_mode' patch). ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Dec 19, 2022 at 6:17 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Sat, Dec 17, 2022 at 7:34 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > Agreed. I have addressed all the comments and did some cosmetic changes.
> > Attach the new version patch set.
> >
>
> Few comments:
> ============
>
Few more minor points:
1.
-static inline void
+void
changes_filename(char *path, Oid subid, TransactionId xid)
{
This function seems to be used only in worker.c. So, what is the need
to make it extern?
2. I have made a few changes in the comments. See attached. This is
atop my yesterday's top-up patch.
I think we should merge the 0001 and 0002 patches as they need to be
committed together.
--
With Regards,
Amit Kapila.
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, December 19, 2022 8:47 PMs Amit Kapila <amit.kapila16@gmail.com>:
>
> On Sat, Dec 17, 2022 at 7:34 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > Agreed. I have addressed all the comments and did some cosmetic changes.
> > Attach the new version patch set.
> >
>
> Few comments:
> ============
> 1.
> + if (fileset_state == FS_SERIALIZE_IN_PROGRESS) {
> + pa_lock_stream(MyParallelShared->xid, AccessShareLock);
> + pa_unlock_stream(MyParallelShared->xid, AccessShareLock); }
> +
> + /*
> + * We cannot read the file immediately after the leader has serialized
> + all
> + * changes to the file because there may still be messages in the
> + memory
> + * queue. We will apply all spooled messages the next time we call this
> + * function, which should ensure that there are no messages left in the
> + * memory queue.
> + */
> + else if (fileset_state == FS_SERIALIZE_DONE) {
>
> Once we have waited in the FS_SERIALIZE_IN_PROGRESS, the file state can be
> FS_SERIALIZE_DONE immediately after that. So, won't it be better to have a
> separate if block for FS_SERIALIZE_DONE state? If you agree to do so then we
> can probably remove the comment: "* XXX It is possible that immediately after
> we have waited for a lock in ...".
Changed and slightly adjust the comments.
> 2.
> +void
> +pa_decr_and_wait_stream_block(void)
> +{
> + Assert(am_parallel_apply_worker());
> +
> + if (pg_atomic_sub_fetch_u32(&MyParallelShared->pending_stream_count,
> + 1) == 0)
>
> I think here the count can go negative when we are in serialize mode because
> we don't increase it for serialize mode. I can't see any problem due to that but
> OTOH, this doesn't seem to be intended because in the future if we decide to
> implement the functionality of switching back to non-serialize mode, this could
> be a problem. Also, I guess we don't even need to try locking/unlocking the
> stream lock in that case.
> One idea to avoid this is to check if the pending count is zero then if file_set in
> not available raise an error (elog ERROR), otherwise, simply return from here.
Added the check.
>
> 3. In apply_handle_stream_stop(), we are setting backendstate as idle for cases
> TRANS_LEADER_SEND_TO_PARALLEL and TRANS_PARALLEL_APPLY. For other
> cases, it is set by stream_stop_internal. I think it would be better to set the state
> explicitly for all cases to make the code look consistent and remove it from
> stream_stop_internal(). The other reason to remove setting the state from
> stream_stop_internal() is that when that function is invoked from other places
> like apply_handle_stream_commit(), it seems to be setting the idle before
> actually we reach the idle state.
Changed. Besides, I notice that the pgstat_report_activity in pa_stream_abort
for sub transaction is unnecessary since the state should be consistent with the
state set at last stream_stop, so I have removed that as well.
>
> 4. Apart from the above, I have made a few changes in the comments, see
> attached.
Thanks, I have merged the patch.
Best regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, December 20, 2022 5:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Mon, Dec 19, 2022 at 6:17 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Sat, Dec 17, 2022 at 7:34 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > Agreed. I have addressed all the comments and did some cosmetic changes.
> > > Attach the new version patch set.
> > >
> >
> > Few comments:
> > ============
> >
>
> Few more minor points:
> 1.
> -static inline void
> +void
> changes_filename(char *path, Oid subid, TransactionId xid) {
>
> This function seems to be used only in worker.c. So, what is the need to make it
> extern?
Oh, I forgot to revert this change after removing the one caller outside of worker.c.
Changed.
>
> 2. I have made a few changes in the comments. See attached. This is atop my
> yesterday's top-up patch.
Thanks, I have checked and merged this.
> I think we should merge the 0001 and 0002 patches as they need to be
> committed together.
Merged and ran the pgident for the patch set.
Attach the new version patch set which addressed all comments so far.
Best regards,
Hou zj
Attachment
- v63-0001-Perform-streaming-logical-transactions-by-parall.patch
- v63-0002-Test-streaming-parallel-option-in-tap-test.patch
- v63-0003-Allow-streaming-every-change-without-waiting-til.patch
- v63-0004-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v63-0005-Stop-extra-worker-if-GUC-was-changed.patch
- v63-0006-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v63-0007-Add-a-main_worker_pid-to-pg_stat_subscription.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
FYI - applying v63-0001 using the latest master does not work. git apply ../patches_misc/v63-0001-Perform-streaming-logical-transactions-by-parall.patch error: patch failed: src/backend/replication/logical/meson.build:1 error: src/backend/replication/logical/meson.build: patch does not apply Looks like a recent commit [1] to add copyrights broke the patch ------ [1] https://github.com/postgres/postgres/commit/8284cf5f746f84303eda34d213e89c8439a83a42 Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Tue, Dec 20, 2022 at 5:22 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Tue, Dec 20, 2022 at 2:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, Dec 20, 2022 at 8:17 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > Summary > > > ------- > > > > > > In summary, everything I have tested so far appeared to be working > > > properly. In other words, for overlapping streamed transactions of > > > different kinds, and regardless of whether zero/some/all of those > > > transactions are getting processed by a PA worker, the resulting > > > replicated data looked consistently OK. > > > > > > > Thanks for doing the detailed testing of this patch. I think the one > > area where we can focus more is the switch-to-serialization mode while > > sending changes to the parallel worker. > > > > > > > > NOTE - all testing described in this post above was using v58-0001 > > > only. However, the point of implementing these as a .spec test was to > > > be able to repeat these same regression tests on newer versions with > > > minimal manual steps required. Later I plan to fetch/apply the most > > > recent patch version and repeat these same tests. > > > > > > > That would be really helpful. > > > FYI, my pub-sub.spec tests gave the same result (i.e. pass) when re-run with the latest v63 (0001,0002,0003) applied. ------ Kind Regards, Peter Smith. Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wed, Dec 21, 2022 9:07 AM Peter Smith <smithpb2250@gmail.com> wrote: > FYI - applying v63-0001 using the latest master does not work. > > git apply ../patches_misc/v63-0001-Perform-streaming-logical-transactions-by- > parall.patch > error: patch failed: src/backend/replication/logical/meson.build:1 > error: src/backend/replication/logical/meson.build: patch does not apply > > Looks like a recent commit [1] to add copyrights broke the patch Thanks for your reminder. Rebased the patch set. Attach the new patch set which also includes some cosmetic comment changes. Best regards, Hou zj
Attachment
- v64-0007-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v64-0001-Perform-streaming-logical-transactions-by-parall.patch
- v64-0002-Test-streaming-parallel-option-in-tap-test.patch
- v64-0003-Allow-streaming-every-change-without-waiting-til.patch
- v64-0004-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v64-0005-Stop-extra-worker-if-GUC-was-changed.patch
- v64-0006-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Dec 21, 2022 at 11:02 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
>
> Attach the new patch set which also includes some
> cosmetic comment changes.
>
I noticed one problem with the recent change in the patch.
+ * The fileset state should become FS_SERIALIZE_DONE once we have waited
+ * for a lock in the FS_SERIALIZE_IN_PROGRESS state, so we get the state
+ * again and recheck it later.
+ */
+ if (fileset_state == FS_SERIALIZE_IN_PROGRESS)
+ {
+ pa_lock_stream(MyParallelShared->xid, AccessShareLock);
+ pa_unlock_stream(MyParallelShared->xid, AccessShareLock);
+
+ fileset_state = pa_get_fileset_state();
+ Assert(fileset_state == FS_SERIALIZE_DONE);
This is not always true because say due to deadlock, this lock is
released by the leader worker, in that case, the file state will be
still in progress. So, I think we need a change like the below:
diff --git a/src/backend/replication/logical/applyparallelworker.c
b/src/backend/replication/logical/applyparallelworker.c
index 45faa74596..8076786f0d 100644
--- a/src/backend/replication/logical/applyparallelworker.c
+++ b/src/backend/replication/logical/applyparallelworker.c
@@ -686,8 +686,8 @@ pa_spooled_messages(void)
* the leader had serialized all changes which can lead to undetected
* deadlock.
*
- * The fileset state must be FS_SERIALIZE_DONE once the leader
worker has
- * finished serializing the changes.
+ * Note that the fileset state can be FS_SERIALIZE_DONE once the leader
+ * worker has finished serializing the changes.
*/
if (fileset_state == FS_SERIALIZE_IN_PROGRESS)
{
@@ -695,7 +695,6 @@ pa_spooled_messages(void)
pa_unlock_stream(MyParallelShared->xid, AccessShareLock);
fileset_state = pa_get_fileset_state();
- Assert(fileset_state == FS_SERIALIZE_DONE);
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, Dec 21, 2022 at 2:32 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Wed, Dec 21, 2022 9:07 AM Peter Smith <smithpb2250@gmail.com> wrote:
> > FYI - applying v63-0001 using the latest master does not work.
> >
> > git apply ../patches_misc/v63-0001-Perform-streaming-logical-transactions-by-
> > parall.patch
> > error: patch failed: src/backend/replication/logical/meson.build:1
> > error: src/backend/replication/logical/meson.build: patch does not apply
> >
> > Looks like a recent commit [1] to add copyrights broke the patch
>
> Thanks for your reminder.
> Rebased the patch set.
>
> Attach the new patch set which also includes some
> cosmetic comment changes.
>
Thank you for updating the patch. Here are some comments on v64 patches:
While testing the patch, I realized that if all streamed transactions
are handled by parallel workers, there is no chance for the leader to
call maybe_reread_subscription() except for when waiting for the next
message. Due to this, the leader didn't stop for a while even if the
subscription gets disabled. It's an extreme case since my test was
that pgbench runs 30 concurrent transactions and logical_decoding_mode
= 'immediate', but we might want to make sure to call
maybe_reread_subscription() at least after committing/preparing a
transaction.
---
+ if (pg_atomic_read_u32(&MyParallelShared->pending_stream_count) == 0)
+ {
+ if (pa_has_spooled_message_pending())
+ return;
+
+ elog(ERROR, "invalid pending streaming block number");
+ }
I think it's helpful if the error message shows the invalid block number.
---
On Wed, Dec 7, 2022 at 10:13 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Wednesday, December 7, 2022 7:51 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > ---
> > If a value of max_parallel_apply_workers_per_subscription is not
> > sufficient, we get the LOG "out of parallel apply workers" every time
> > when the apply worker doesn't launch a worker. But do we really need
> > this log? It seems not consistent with
> > max_sync_workers_per_subscription behavior. I think we can check if
> > the number of running parallel workers is less than
> > max_parallel_apply_workers_per_subscription before calling
> > logicalrep_worker_launch(). What do you think?
>
> (Sorry, I missed this comment in last email)
>
> I personally feel giving a hint might help user to realize that the
> max_parallel_applyxxx is not enough for the current workload and then they can
> adjust the parameter. Otherwise, user might have an easy way to check if more
> workers are needed.
>
Sorry, I missed this comment.
I think the number of concurrent transactions on the publisher could
be several hundreds, and the number of streamed transactions among
them could be several tens. I agree setting
max_parallel_apply_workers_per_subscription to a value high enough is
ideal but I'm not sure we want to inform users immediately that the
setting value is not enough. I think that with the default value
(i.e., 2), it will not be enough for many systems and the server logs
could be flood with the LOG "out of parallel apply workers". If we
want to give a hint to users, we can probably show the statistics on
pg_stat_subscription_stats view such as the number of streamed
transactions that are handled by the leader and parallel workers.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Dec 22, 2022 at 11:39 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> Thank you for updating the patch. Here are some comments on v64 patches:
>
> While testing the patch, I realized that if all streamed transactions
> are handled by parallel workers, there is no chance for the leader to
> call maybe_reread_subscription() except for when waiting for the next
> message. Due to this, the leader didn't stop for a while even if the
> subscription gets disabled. It's an extreme case since my test was
> that pgbench runs 30 concurrent transactions and logical_decoding_mode
> = 'immediate', but we might want to make sure to call
> maybe_reread_subscription() at least after committing/preparing a
> transaction.
>
Won't it be better to call it only if we handle the transaction by the
parallel worker?
> ---
> + if (pg_atomic_read_u32(&MyParallelShared->pending_stream_count) == 0)
> + {
> + if (pa_has_spooled_message_pending())
> + return;
> +
> + elog(ERROR, "invalid pending streaming block number");
> + }
>
> I think it's helpful if the error message shows the invalid block number.
>
+1. Additionally, I suggest changing the message to "invalid pending
streaming chunk"?
> ---
> On Wed, Dec 7, 2022 at 10:13 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Wednesday, December 7, 2022 7:51 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > > ---
> > > If a value of max_parallel_apply_workers_per_subscription is not
> > > sufficient, we get the LOG "out of parallel apply workers" every time
> > > when the apply worker doesn't launch a worker. But do we really need
> > > this log? It seems not consistent with
> > > max_sync_workers_per_subscription behavior. I think we can check if
> > > the number of running parallel workers is less than
> > > max_parallel_apply_workers_per_subscription before calling
> > > logicalrep_worker_launch(). What do you think?
> >
> > (Sorry, I missed this comment in last email)
> >
> > I personally feel giving a hint might help user to realize that the
> > max_parallel_applyxxx is not enough for the current workload and then they can
> > adjust the parameter. Otherwise, user might have an easy way to check if more
> > workers are needed.
> >
>
> Sorry, I missed this comment.
>
> I think the number of concurrent transactions on the publisher could
> be several hundreds, and the number of streamed transactions among
> them could be several tens. I agree setting
> max_parallel_apply_workers_per_subscription to a value high enough is
> ideal but I'm not sure we want to inform users immediately that the
> setting value is not enough. I think that with the default value
> (i.e., 2), it will not be enough for many systems and the server logs
> could be flood with the LOG "out of parallel apply workers".
>
It seems currently we give a similar message when the logical
replication worker slots are finished "out of logical replication
worker slots" or when we are not able to register background workers
"out of background worker slots". Now, OTOH, when we exceed the limit
of sync workers "max_sync_workers_per_subscription", we don't display
any message. Personally, I think if any user has used the streaming
option as "parallel" she wants all large transactions to be performed
in parallel and if the system is not able to deal with it, displaying
a LOG message will be useful for users. This is because the
performance difference for large transactions between parallel and
non-parallel is big (30-40%) and it is better for users to know as
soon as possible instead of expecting them to run some monitoring
query to notice the same.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Dec 21, 2022 at 11:02 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Attach the new patch set which also includes some
> cosmetic comment changes.
>
Few minor comments:
=================
1.
+ <literal>t</literal> = spill the changes of in-progress
transactions to+ disk and apply at once after the transaction is
committed on the+ publisher,
Can we change this description to: "spill the changes of in-progress
transactions to disk and apply at once after the transaction is
committed on the publisher and received by the subscriber,"
2.
table is in progress, there will be additional workers for the tables
- being synchronized.
+ being synchronized. Moreover, if the streaming transaction is applied in
+ parallel, there will be additional workers.
Do we need this change in the first patch? We skip parallel apply
workers from view for the first patch. Am, I missing something?
3.
I think we would need a catversion bump for parallel apply feature
because of below change:
@@ -7913,11 +7913,16 @@ SCRAM-SHA-256$<replaceable><iteration
count></replaceable>:<replaceable>&l
<row>
<entry role="catalog_table_entry"><para role="column_definition">
- <structfield>substream</structfield> <type>bool</type>
+ <structfield>substream</structfield> <type>char</type>
</para>
Am, I missing something? If not, then I think we can note that in the
commit message to avoid forgetting it before commit.
4. Kindly change the below comments:
diff --git a/src/backend/replication/logical/applyparallelworker.c
b/src/backend/replication/logical/applyparallelworker.c
index 97f4a3037c..02bb608188 100644
--- a/src/backend/replication/logical/applyparallelworker.c
+++ b/src/backend/replication/logical/applyparallelworker.c
@@ -9,11 +9,10 @@
*
* This file contains the code to launch, set up, and teardown a parallel apply
* worker which receives the changes from the leader worker and
invokes routines
- * to apply those on the subscriber database.
- *
- * This file contains routines that are intended to support setting up, using
- * and tearing down a ParallelApplyWorkerInfo which is required so the leader
- * worker and parallel apply workers can communicate with each other.
+ * to apply those on the subscriber database. Additionally, this file contains
+ * routines that are intended to support setting up, using, and tearing down a
+ * ParallelApplyWorkerInfo which is required so the leader worker and parallel
+ * apply workers can communicate with each other.
*
* The parallel apply workers are assigned (if available) as soon as xact's
* first stream is received for subscriptions that have set their 'streaming'
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Thu, Dec 22, 2022 at 7:04 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Dec 22, 2022 at 11:39 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > Thank you for updating the patch. Here are some comments on v64 patches:
> >
> > While testing the patch, I realized that if all streamed transactions
> > are handled by parallel workers, there is no chance for the leader to
> > call maybe_reread_subscription() except for when waiting for the next
> > message. Due to this, the leader didn't stop for a while even if the
> > subscription gets disabled. It's an extreme case since my test was
> > that pgbench runs 30 concurrent transactions and logical_decoding_mode
> > = 'immediate', but we might want to make sure to call
> > maybe_reread_subscription() at least after committing/preparing a
> > transaction.
> >
>
> Won't it be better to call it only if we handle the transaction by the
> parallel worker?
Agreed. And we won't need to do that after handling stream_prepare as
we don't do that now.
>
> > ---
> > + if (pg_atomic_read_u32(&MyParallelShared->pending_stream_count) == 0)
> > + {
> > + if (pa_has_spooled_message_pending())
> > + return;
> > +
> > + elog(ERROR, "invalid pending streaming block number");
> > + }
> >
> > I think it's helpful if the error message shows the invalid block number.
> >
>
> +1. Additionally, I suggest changing the message to "invalid pending
> streaming chunk"?
>
> > ---
> > On Wed, Dec 7, 2022 at 10:13 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Wednesday, December 7, 2022 7:51 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > > > ---
> > > > If a value of max_parallel_apply_workers_per_subscription is not
> > > > sufficient, we get the LOG "out of parallel apply workers" every time
> > > > when the apply worker doesn't launch a worker. But do we really need
> > > > this log? It seems not consistent with
> > > > max_sync_workers_per_subscription behavior. I think we can check if
> > > > the number of running parallel workers is less than
> > > > max_parallel_apply_workers_per_subscription before calling
> > > > logicalrep_worker_launch(). What do you think?
> > >
> > > (Sorry, I missed this comment in last email)
> > >
> > > I personally feel giving a hint might help user to realize that the
> > > max_parallel_applyxxx is not enough for the current workload and then they can
> > > adjust the parameter. Otherwise, user might have an easy way to check if more
> > > workers are needed.
> > >
> >
> > Sorry, I missed this comment.
> >
> > I think the number of concurrent transactions on the publisher could
> > be several hundreds, and the number of streamed transactions among
> > them could be several tens. I agree setting
> > max_parallel_apply_workers_per_subscription to a value high enough is
> > ideal but I'm not sure we want to inform users immediately that the
> > setting value is not enough. I think that with the default value
> > (i.e., 2), it will not be enough for many systems and the server logs
> > could be flood with the LOG "out of parallel apply workers".
> >
>
> It seems currently we give a similar message when the logical
> replication worker slots are finished "out of logical replication
> worker slots" or when we are not able to register background workers
> "out of background worker slots". Now, OTOH, when we exceed the limit
> of sync workers "max_sync_workers_per_subscription", we don't display
> any message. Personally, I think if any user has used the streaming
> option as "parallel" she wants all large transactions to be performed
> in parallel and if the system is not able to deal with it, displaying
> a LOG message will be useful for users. This is because the
> performance difference for large transactions between parallel and
> non-parallel is big (30-40%) and it is better for users to know as
> soon as possible instead of expecting them to run some monitoring
> query to notice the same.
I see your point. But looking at other parallel features such as
parallel queries, parallel vacuum and parallel index creation, we
don't give such messages even if the number of parallel workers
actually launched is lower than the ideal. They also bring a big
performance benefit.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Dec 22, 2022 at 6:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Thu, Dec 22, 2022 at 7:04 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Thu, Dec 22, 2022 at 11:39 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > Thank you for updating the patch. Here are some comments on v64 patches: > > > > > > While testing the patch, I realized that if all streamed transactions > > > are handled by parallel workers, there is no chance for the leader to > > > call maybe_reread_subscription() except for when waiting for the next > > > message. Due to this, the leader didn't stop for a while even if the > > > subscription gets disabled. It's an extreme case since my test was > > > that pgbench runs 30 concurrent transactions and logical_decoding_mode > > > = 'immediate', but we might want to make sure to call > > > maybe_reread_subscription() at least after committing/preparing a > > > transaction. > > > > > > > Won't it be better to call it only if we handle the transaction by the > > parallel worker? > > Agreed. And we won't need to do that after handling stream_prepare as > we don't do that now. > I think we do this for both prepare and non-prepare cases via begin_replication_step(). Here, in both cases, as the changes are sent to the parallel apply worker, we missed in both cases. So, I think it is better to do in both cases. > > > > It seems currently we give a similar message when the logical > > replication worker slots are finished "out of logical replication > > worker slots" or when we are not able to register background workers > > "out of background worker slots". Now, OTOH, when we exceed the limit > > of sync workers "max_sync_workers_per_subscription", we don't display > > any message. Personally, I think if any user has used the streaming > > option as "parallel" she wants all large transactions to be performed > > in parallel and if the system is not able to deal with it, displaying > > a LOG message will be useful for users. This is because the > > performance difference for large transactions between parallel and > > non-parallel is big (30-40%) and it is better for users to know as > > soon as possible instead of expecting them to run some monitoring > > query to notice the same. > > I see your point. But looking at other parallel features such as > parallel queries, parallel vacuum and parallel index creation, we > don't give such messages even if the number of parallel workers > actually launched is lower than the ideal. They also bring a big > performance benefit. > Fair enough. Let's remove this LOG message. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Fri, Dec 23, 2022 at 12:21 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Dec 22, 2022 at 6:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Thu, Dec 22, 2022 at 7:04 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Thu, Dec 22, 2022 at 11:39 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > Thank you for updating the patch. Here are some comments on v64 patches: > > > > > > > > While testing the patch, I realized that if all streamed transactions > > > > are handled by parallel workers, there is no chance for the leader to > > > > call maybe_reread_subscription() except for when waiting for the next > > > > message. Due to this, the leader didn't stop for a while even if the > > > > subscription gets disabled. It's an extreme case since my test was > > > > that pgbench runs 30 concurrent transactions and logical_decoding_mode > > > > = 'immediate', but we might want to make sure to call > > > > maybe_reread_subscription() at least after committing/preparing a > > > > transaction. > > > > > > > > > > Won't it be better to call it only if we handle the transaction by the > > > parallel worker? > > > > Agreed. And we won't need to do that after handling stream_prepare as > > we don't do that now. > > > > I think we do this for both prepare and non-prepare cases via > begin_replication_step(). Here, in both cases, as the changes are sent > to the parallel apply worker, we missed in both cases. So, I think it > is better to do in both cases. Agreed. I missed that we call maybe_reread_subscription() even in the prepare case. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, December 22, 2022 8:05 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Dec 21, 2022 at 11:02 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > Attach the new patch set which also includes some cosmetic comment > > changes. > > > > Few minor comments: > ================= > 1. > + <literal>t</literal> = spill the changes of in-progress > transactions to+ disk and apply at once after the transaction is > committed on the+ publisher, > > Can we change this description to: "spill the changes of in-progress transactions > to disk and apply at once after the transaction is committed on the publisher and > received by the subscriber," Changed. > 2. > table is in progress, there will be additional workers for the tables > - being synchronized. > + being synchronized. Moreover, if the streaming transaction is applied in > + parallel, there will be additional workers. > > Do we need this change in the first patch? We skip parallel apply workers from > view for the first patch. Am, I missing something? No, I moved this to 0007 which include parallel apply workers in the view. > 3. > I think we would need a catversion bump for parallel apply feature because of > below change: > @@ -7913,11 +7913,16 @@ SCRAM-SHA-256$<replaceable><iteration > count></replaceable>:<replaceable>&l > > <row> > <entry role="catalog_table_entry"><para role="column_definition"> > - <structfield>substream</structfield> <type>bool</type> > + <structfield>substream</structfield> <type>char</type> > </para> > > Am, I missing something? If not, then I think we can note that in the commit > message to avoid forgetting it before commit. Added. > > 4. Kindly change the below comments: > diff --git a/src/backend/replication/logical/applyparallelworker.c > b/src/backend/replication/logical/applyparallelworker.c > index 97f4a3037c..02bb608188 100644 > --- a/src/backend/replication/logical/applyparallelworker.c > +++ b/src/backend/replication/logical/applyparallelworker.c > @@ -9,11 +9,10 @@ > * > * This file contains the code to launch, set up, and teardown a parallel apply > * worker which receives the changes from the leader worker and invokes > routines > - * to apply those on the subscriber database. > - * > - * This file contains routines that are intended to support setting up, using > - * and tearing down a ParallelApplyWorkerInfo which is required so the leader > - * worker and parallel apply workers can communicate with each other. > + * to apply those on the subscriber database. Additionally, this file > + contains > + * routines that are intended to support setting up, using, and tearing > + down a > + * ParallelApplyWorkerInfo which is required so the leader worker and > + parallel > + * apply workers can communicate with each other. > * > * The parallel apply workers are assigned (if available) as soon as xact's > * first stream is received for subscriptions that have set their 'streaming' Merged. Besides, I also did the following changes: 1. Added maybe_reread_subscription_info in leader before assigning the transaction to parallel apply worker (Sawada-san's comments[1]) 2. Removed the "out of parallel apply workers" LOG ( Sawada-san's comments[1]) 3. Improved a elog message (Sawada-san's comments[1]). 4. Moved the testcases from 032_xx into existing 015_stream.pl which can save the initialization time. Since we introduced quite a few testcases in this patch set, so I did this to try to reduce the testing time that increased after applying these patches. [1] https://www.postgresql.org/message-id/CAD21AoDWd2pXau%2BpkYWOi87VGYrDD%3DOxakEDgOyUS%2BqV9XuAGA%40mail.gmail.com Best regards, Hou zj
Attachment
- v65-0007-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v65-0001-Perform-streaming-logical-transactions-by-parall.patch
- v65-0002-Test-streaming-parallel-option-in-tap-test.patch
- v65-0003-Allow-streaming-every-change-without-waiting-til.patch
- v65-0004-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v65-0005-Stop-extra-worker-if-GUC-was-changed.patch
- v65-0006-Retry-to-apply-streaming-xact-only-in-apply-work.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, December 23, 2022 1:52 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Thursday, December 22, 2022 8:05 PM Amit Kapila > <amit.kapila16@gmail.com> wrote: > > > > On Wed, Dec 21, 2022 at 11:02 AM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > Attach the new patch set which also includes some cosmetic comment > > > changes. > > > > > > > Few minor comments: > > ================= > > 1. > > + <literal>t</literal> = spill the changes of in-progress > > transactions to+ disk and apply at once after the transaction is > > committed on the+ publisher, > > > > Can we change this description to: "spill the changes of in-progress > > transactions to disk and apply at once after the transaction is > > committed on the publisher and received by the subscriber," > > Changed. > > > 2. > > table is in progress, there will be additional workers for the tables > > - being synchronized. > > + being synchronized. Moreover, if the streaming transaction is applied in > > + parallel, there will be additional workers. > > > > Do we need this change in the first patch? We skip parallel apply > > workers from view for the first patch. Am, I missing something? > > No, I moved this to 0007 which include parallel apply workers in the view. > > > 3. > > I think we would need a catversion bump for parallel apply feature > > because of below change: > > @@ -7913,11 +7913,16 @@ SCRAM-SHA-256$<replaceable><iteration > > count></replaceable>:<replaceable>&l > > > > <row> > > <entry role="catalog_table_entry"><para role="column_definition"> > > - <structfield>substream</structfield> <type>bool</type> > > + <structfield>substream</structfield> <type>char</type> > > </para> > > > > Am, I missing something? If not, then I think we can note that in the > > commit message to avoid forgetting it before commit. > > Added. > > > > > 4. Kindly change the below comments: > > diff --git a/src/backend/replication/logical/applyparallelworker.c > > b/src/backend/replication/logical/applyparallelworker.c > > index 97f4a3037c..02bb608188 100644 > > --- a/src/backend/replication/logical/applyparallelworker.c > > +++ b/src/backend/replication/logical/applyparallelworker.c > > @@ -9,11 +9,10 @@ > > * > > * This file contains the code to launch, set up, and teardown a parallel apply > > * worker which receives the changes from the leader worker and > > invokes routines > > - * to apply those on the subscriber database. > > - * > > - * This file contains routines that are intended to support setting > > up, using > > - * and tearing down a ParallelApplyWorkerInfo which is required so > > the leader > > - * worker and parallel apply workers can communicate with each other. > > + * to apply those on the subscriber database. Additionally, this file > > + contains > > + * routines that are intended to support setting up, using, and > > + tearing down a > > + * ParallelApplyWorkerInfo which is required so the leader worker and > > + parallel > > + * apply workers can communicate with each other. > > * > > * The parallel apply workers are assigned (if available) as soon as xact's > > * first stream is received for subscriptions that have set their 'streaming' > > Merged. > > Besides, I also did the following changes: > 1. Added maybe_reread_subscription_info in leader before assigning the > transaction to parallel apply worker (Sawada-san's comments[1]) 2. Removed > the "out of parallel apply workers" LOG ( Sawada-san's comments[1]) 3. > Improved a elog message (Sawada-san's comments[1]). > 4. Moved the testcases from 032_xx into existing 015_stream.pl which can save > the initialization time. Since we introduced quite a few testcases in this patch set, > so I did this to try to reduce the testing time that increased after applying these > patches. I noticed a CFbot failure in one of the new testcases in 015_stream.pl which comes from old 032_xx.pl. It's because I slightly adjusted the change size in a transaction in last version which cause the transaction's size not to exceed the decoding work mem, so the transaction is not being applied as expected as streaming transactions(it is applied as a non-stremaing transaction) which cause the failure. Attach the new version patch which fixed this miss. Best regards, Hou zj
Attachment
- v66-0007-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v66-0001-Perform-streaming-logical-transactions-by-parall.patch
- v66-0002-Test-streaming-parallel-option-in-tap-test.patch
- v66-0003-Allow-streaming-every-change-without-waiting-til.patch
- v66-0004-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v66-0005-Stop-extra-worker-if-GUC-was-changed.patch
- v66-0006-Retry-to-apply-streaming-xact-only-in-apply-work.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, December 23, 2022 5:20 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > I noticed a CFbot failure in one of the new testcases in 015_stream.pl which > comes from old 032_xx.pl. It's because I slightly adjusted the change size in a > transaction in last version which cause the transaction's size not to exceed the > decoding work mem, so the transaction is not being applied as expected as > streaming transactions(it is applied as a non-stremaing transaction) which cause > the failure. Attach the new version patch which fixed this miss. > Since the GUC used to force stream changes has been committed, I removed that patch from the patch set here and rebased the testcases based on that commit. Here is the rebased patch set. Best regards, Hou zj
Attachment
- v67-0006-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v67-0001-Perform-streaming-logical-transactions-by-parall.patch
- v67-0002-Test-streaming-parallel-option-in-tap-test.patch
- v67-0003-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v67-0004-Stop-extra-worker-if-GUC-was-changed.patch
- v67-0005-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Dec 26, 2022 at 9:52 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Friday, December 23, 2022 5:20 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
>
> Since the GUC used to force stream changes has been committed, I removed that
> patch from the patch set here and rebased the testcases based on that commit.
> Here is the rebased patch set.
>
Few comments on 0002 and 0001 patches
=================================
1.
+ if ($is_parallel)
+ {
+ $node_subscriber->append_conf('postgresql.conf',
+ "log_min_messages = debug1");
+ $node_subscriber->reload;
+ }
+
+ # Check the subscriber log from now on.
+ $offset = -s $node_subscriber->logfile;
+
+ $in .= q{
+ BEGIN;
+ INSERT INTO test_tab SELECT i, md5(i::text) FROM
generate_series(3, 5000) s(i);
How can we guarantee that reload would have taken place before this
next test? I see that 020_archive_status.pl is executing a query to
ensure the reload has been taken into consideration. Can we do the
same?
2. It is not very clear whether converting 017_stream_ddl and
019_stream_subxact_ddl_abort adds much value. They seem to be mostly
testing DDL/DML interaction of publisher side. We can probably check
the code coverage by removing the parallel version for these two files
and remove them unless it covers some extra code. If we decide to
remove parallel version for these two files then we can probably add a
comment atop these files indicating why we don't have a version that
parallel option for these tests.
3.
+# Drop the unique index on the subscriber, now it works.
+$node_subscriber->safe_psql('postgres', "DROP INDEX idx_tab");
+
+# Wait for this streaming transaction to be applied in the apply worker.
$node_publisher->wait_for_catchup($appname);
$result =
- $node_subscriber->safe_psql('postgres',
- "SELECT count(*), count(c), count(d = 999) FROM test_tab");
-is($result, qq(3334|3334|3334), 'check extra columns contain local defaults');
+ $node_subscriber->safe_psql('postgres', "SELECT count(*) FROM test_tab_2");
+is($result, qq(5001), 'data replicated to subscriber after dropping index');
-# Test the streaming in binary mode
+# Clean up test data from the environment.
+$node_publisher->safe_psql('postgres', "TRUNCATE TABLE test_tab_2");
+$node_publisher->wait_for_catchup($appname);
$node_subscriber->safe_psql('postgres',
- "ALTER SUBSCRIPTION tap_sub SET (binary = on)");
+ "CREATE UNIQUE INDEX idx_tab on test_tab_2(a)");
What is the need to first Drop the index and then recreate it after a few lines?
4. Attached, find some comment improvements atop v67-0002* patch.
Similar comments need to be changed in other test files.
5. Attached, find some comment improvements atop v67-0001* patch.
--
With Regards,
Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, Dec 26, 2022 at 1:22 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Friday, December 23, 2022 5:20 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
> >
> > I noticed a CFbot failure in one of the new testcases in 015_stream.pl which
> > comes from old 032_xx.pl. It's because I slightly adjusted the change size in a
> > transaction in last version which cause the transaction's size not to exceed the
> > decoding work mem, so the transaction is not being applied as expected as
> > streaming transactions(it is applied as a non-stremaing transaction) which cause
> > the failure. Attach the new version patch which fixed this miss.
> >
>
> Since the GUC used to force stream changes has been committed, I removed that
> patch from the patch set here and rebased the testcases based on that commit.
> Here is the rebased patch set.
>
Thank you for updating the patches. Here are some comments for 0001
and 0002 patches:
I think it'd be better to write logs when the leader enters the
serialization mode. It would be helpful for investigating issues.
---
+ if (!pa_can_start(xid))
+ return;
+
+ /* First time through, initialize parallel apply worker state
hashtable. */
+ if (!ParallelApplyTxnHash)
+ {
+ HASHCTL ctl;
+
+ MemSet(&ctl, 0, sizeof(ctl));
+ ctl.keysize = sizeof(TransactionId);
+ ctl.entrysize = sizeof(ParallelApplyWorkerEntry);
+ ctl.hcxt = ApplyContext;
+
+ ParallelApplyTxnHash = hash_create("logical
replication parallel apply workershash",
+
16, &ctl,
+
HASH_ELEM |HASH_BLOBS | HASH_CONTEXT);
+ }
+
+ /*
+ * It's necessary to reread the subscription information
before assigning
+ * the transaction to a parallel apply worker. Otherwise, the
leader may
+ * not be able to reread the subscription information if streaming
+ * transactions keep coming and are handled by parallel apply workers.
+ */
+ maybe_reread_subscription();
pa_can_start() checks if the skiplsn is an invalid xid or not, and
then maybe_reread_subscription() could update the skiplsn to a valid
value. As the comments in pa_can_start() says, it won't work. I think
we should call maybe_reread_subscription() in
apply_handle_stream_start() before calling pa_allocate_worker().
---
+static inline bool
+am_leader_apply_worker(void)
+{
+ return (!OidIsValid(MyLogicalRepWorker->relid) &&
+ !isParallelApplyWorker(MyLogicalRepWorker));
+}
How about using !am_tablesync_worker() instead of
!OidIsValid(MyLogicalRepWorker->relid) for better readability?
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Dec 26, 2022 at 6:33 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> ---
> + if (!pa_can_start(xid))
> + return;
> +
> + /* First time through, initialize parallel apply worker state
> hashtable. */
> + if (!ParallelApplyTxnHash)
> + {
> + HASHCTL ctl;
> +
> + MemSet(&ctl, 0, sizeof(ctl));
> + ctl.keysize = sizeof(TransactionId);
> + ctl.entrysize = sizeof(ParallelApplyWorkerEntry);
> + ctl.hcxt = ApplyContext;
> +
> + ParallelApplyTxnHash = hash_create("logical
> replication parallel apply workershash",
> +
> 16, &ctl,
> +
> HASH_ELEM |HASH_BLOBS | HASH_CONTEXT);
> + }
> +
> + /*
> + * It's necessary to reread the subscription information
> before assigning
> + * the transaction to a parallel apply worker. Otherwise, the
> leader may
> + * not be able to reread the subscription information if streaming
> + * transactions keep coming and are handled by parallel apply workers.
> + */
> + maybe_reread_subscription();
>
> pa_can_start() checks if the skiplsn is an invalid xid or not, and
> then maybe_reread_subscription() could update the skiplsn to a valid
> value. As the comments in pa_can_start() says, it won't work. I think
> we should call maybe_reread_subscription() in
> apply_handle_stream_start() before calling pa_allocate_worker().
>
But I think a similar thing can happen when we start the worker and
then before the transaction ends, we do maybe_reread_subscription(). I
think we should try to call maybe_reread_subscription() when we are
reasonably sure that we are going to enter parallel mode, otherwise,
anyway, it will be later called by the leader worker.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Mon, Dec 26, 2022 at 6:59 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > In the commit message, there is a statement like this "However, if the leader apply worker times out while attempting to send a message to the parallel apply worker, it will switch to "partial serialize" mode - in this mode the leader serializes all remaining changes to a file and notifies the parallel apply workers to read and apply them at the end of the transaction." I think it is a good idea to serialize the change to the file in this case to avoid deadlocks, but why does the parallel worker need to wait till the transaction commits to reading the file? I mean we can switch the serialize state and make a parallel worker pull changes from the file and if the parallel worker has caught up with the changes then it can again change the state to "share memory" and now the apply worker can again start sending through shared memory. I think generally streaming transactions are large and it is possible that the shared memory queue gets full because of a lot of changes for a particular transaction but later when the load switches to the other transactions then it would be quite common for the worker to catch up with the changes then it better to again take advantage of using memory. Otherwise, in this case, we are just wasting resources (worker/shared memory queue) but still writing in the file. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Dec 26, 2022 at 7:35 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > In the commit message, there is a statement like this > > "However, if the leader apply worker times out while attempting to > send a message to the > parallel apply worker, it will switch to "partial serialize" mode - in this > mode the leader serializes all remaining changes to a file and notifies the > parallel apply workers to read and apply them at the end of the transaction." > > I think it is a good idea to serialize the change to the file in this > case to avoid deadlocks, but why does the parallel worker need to wait > till the transaction commits to reading the file? I mean we can > switch the serialize state and make a parallel worker pull changes > from the file and if the parallel worker has caught up with the > changes then it can again change the state to "share memory" and now > the apply worker can again start sending through shared memory. > > I think generally streaming transactions are large and it is possible > that the shared memory queue gets full because of a lot of changes for > a particular transaction but later when the load switches to the other > transactions then it would be quite common for the worker to catch up > with the changes then it better to again take advantage of using > memory. Otherwise, in this case, we are just wasting resources > (worker/shared memory queue) but still writing in the file. > Note that there is a certain threshold timeout for which we wait before switching to serialize mode and normally it happens only when PA starts waiting on some lock acquired by the backend. Now, apart from that even if we decide to switch modes, the current BufFile mechanism doesn't have a good way for that. It doesn't allow two processes to open the same buffile at the same time which means we need to maintain multiple files to achieve the mode where we can switch back from serialize mode. We cannot let LA wait for PA to close the file as that could introduce another kind of deadlock. For details, see the discussion in the email [1]. The other problem is that we have no way to deal with partially sent data via a shared memory queue. Say, if we timeout while sending the data, we have to resend the same message until it succeeds which will be tricky because we can't keep retrying as that can lead to deadlock. I think if we try to build this new mode, it will be a lot of effort without equivalent returns. In common cases, we didn't see that we time out and switch to serialize mode. It is mostly in cases where PA starts to wait for the lock acquired by other backend or the machine is slow enough to deal with the number of parallel apply workers. So, it doesn't seem worth adding more complexity to the first version but we don't rule out the possibility of the same in the future if we really see such cases are common. [1] - https://www.postgresql.org/message-id/CAD21AoDScLvLT8JBfu5WaGCPQs_qhxsybMT%2BsMXJ%3DQrDMTyr9w%40mail.gmail.com -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Mon, Dec 26, 2022 19:51 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> Few comments on 0002 and 0001 patches
> =================================
Thanks for your comments.
> 1.
> + if ($is_parallel)
> + {
> + $node_subscriber->append_conf('postgresql.conf',
> + "log_min_messages = debug1");
> + $node_subscriber->reload;
> + }
> +
> + # Check the subscriber log from now on.
> + $offset = -s $node_subscriber->logfile;
> +
> + $in .= q{
> + BEGIN;
> + INSERT INTO test_tab SELECT i, md5(i::text) FROM
> generate_series(3, 5000) s(i);
>
> How can we guarantee that reload would have taken place before this
> next test? I see that 020_archive_status.pl is executing a query to
> ensure the reload has been taken into consideration. Can we do the
> same?
Agree. Improved as suggested.
> 2. It is not very clear whether converting 017_stream_ddl and
> 019_stream_subxact_ddl_abort adds much value. They seem to be mostly
> testing DDL/DML interaction of publisher side. We can probably check
> the code coverage by removing the parallel version for these two files
> and remove them unless it covers some extra code. If we decide to
> remove parallel version for these two files then we can probably add a
> comment atop these files indicating why we don't have a version that
> parallel option for these tests.
I have checked this and removed the parallel version for these two files.
Also added some comments atop these two test files to explain this.
> 3.
> +# Drop the unique index on the subscriber, now it works.
> +$node_subscriber->safe_psql('postgres', "DROP INDEX idx_tab");
> +
> +# Wait for this streaming transaction to be applied in the apply worker.
> $node_publisher->wait_for_catchup($appname);
>
> $result =
> - $node_subscriber->safe_psql('postgres',
> - "SELECT count(*), count(c), count(d = 999) FROM test_tab");
> -is($result, qq(3334|3334|3334), 'check extra columns contain local defaults');
> + $node_subscriber->safe_psql('postgres', "SELECT count(*) FROM
> test_tab_2");
> +is($result, qq(5001), 'data replicated to subscriber after dropping index');
>
> -# Test the streaming in binary mode
> +# Clean up test data from the environment.
> +$node_publisher->safe_psql('postgres', "TRUNCATE TABLE test_tab_2");
> +$node_publisher->wait_for_catchup($appname);
> $node_subscriber->safe_psql('postgres',
> - "ALTER SUBSCRIPTION tap_sub SET (binary = on)");
> + "CREATE UNIQUE INDEX idx_tab on test_tab_2(a)");
>
> What is the need to first Drop the index and then recreate it after a few lines?
Since we want the two transactions to complete normally without conflicts due
to the unique index, we temporarily delete the index.
I added some new comments to explain this.
> 4. Attached, find some comment improvements atop v67-0002* patch.
> Similar comments need to be changed in other test files.
Thanks, I have checked and merge them. And also changed similar comments in
other test files.
> 5. Attached, find some comment improvements atop v67-0001* patch.
Thanks, I have checked and merge them.
Attach the new version patch which addressed all above comments and part of
comments from [1] except one comment that are being discussed.
[1] - https://www.postgresql.org/message-id/CAD21AoDvT%2BTv3auBBShk19EkKLj6ByQtnAzfMjh49BhyT7f4Nw%40mail.gmail.com
Regards,
Wang wei
Attachment
- v68-0001-Perform-streaming-logical-transactions-by-parall.patch
- v68-0002-Test-streaming-parallel-option-in-tap-test.patch
- v68-0003-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v68-0004-Stop-extra-worker-if-GUC-was-changed.patch
- v68-0005-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v68-0006-Add-a-main_worker_pid-to-pg_stat_subscription.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Mon, Dec 26, 2022 21:02 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> Thank you for updating the patches. Here are some comments for 0001
> and 0002 patches:
Thanks for your comments.
> I think it'd be better to write logs when the leader enters the
> serialization mode. It would be helpful for investigating issues.
Agree. Added the log about this in the function pa_send_data().
> ---
> +static inline bool
> +am_leader_apply_worker(void)
> +{
> + return (!OidIsValid(MyLogicalRepWorker->relid) &&
> + !isParallelApplyWorker(MyLogicalRepWorker));
> +}
>
> How about using !am_tablesync_worker() instead of
> !OidIsValid(MyLogicalRepWorker->relid) for better readability?
Agree. Improved this as suggested.
The new patch set was attached in [1].
[1] -
https://www.postgresql.org/message-id/OS3PR01MB6275B61076717E4CE9E079D19EED9%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Regards,
Wang wei
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Tue, Dec 27, 2022 at 9:15 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Dec 26, 2022 at 7:35 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > In the commit message, there is a statement like this > > > > "However, if the leader apply worker times out while attempting to > > send a message to the > > parallel apply worker, it will switch to "partial serialize" mode - in this > > mode the leader serializes all remaining changes to a file and notifies the > > parallel apply workers to read and apply them at the end of the transaction." > > > > I think it is a good idea to serialize the change to the file in this > > case to avoid deadlocks, but why does the parallel worker need to wait > > till the transaction commits to reading the file? I mean we can > > switch the serialize state and make a parallel worker pull changes > > from the file and if the parallel worker has caught up with the > > changes then it can again change the state to "share memory" and now > > the apply worker can again start sending through shared memory. > > > > I think generally streaming transactions are large and it is possible > > that the shared memory queue gets full because of a lot of changes for > > a particular transaction but later when the load switches to the other > > transactions then it would be quite common for the worker to catch up > > with the changes then it better to again take advantage of using > > memory. Otherwise, in this case, we are just wasting resources > > (worker/shared memory queue) but still writing in the file. > > > > Note that there is a certain threshold timeout for which we wait > before switching to serialize mode and normally it happens only when > PA starts waiting on some lock acquired by the backend. Now, apart > from that even if we decide to switch modes, the current BufFile > mechanism doesn't have a good way for that. It doesn't allow two > processes to open the same buffile at the same time which means we > need to maintain multiple files to achieve the mode where we can > switch back from serialize mode. We cannot let LA wait for PA to close > the file as that could introduce another kind of deadlock. For > details, see the discussion in the email [1]. The other problem is > that we have no way to deal with partially sent data via a shared > memory queue. Say, if we timeout while sending the data, we have to > resend the same message until it succeeds which will be tricky because > we can't keep retrying as that can lead to deadlock. I think if we try > to build this new mode, it will be a lot of effort without equivalent > returns. In common cases, we didn't see that we time out and switch to > serialize mode. It is mostly in cases where PA starts to wait for the > lock acquired by other backend or the machine is slow enough to deal > with the number of parallel apply workers. So, it doesn't seem worth > adding more complexity to the first version but we don't rule out the > possibility of the same in the future if we really see such cases are > common. > > [1] - https://www.postgresql.org/message-id/CAD21AoDScLvLT8JBfu5WaGCPQs_qhxsybMT%2BsMXJ%3DQrDMTyr9w%40mail.gmail.com Okay, I see. And once we change to serialize mode we can't release the worker as well because we have already applied partial changes under some transaction from a PA so we can not apply remaining from the LA. I understand it might introduce a lot of complex design to change it back to parallel apply mode but my only worry is that in such cases we will be holding on to the parallel worker just to wait till commit to reading from the spool file. But as you said it should not be very common case so maybe this is fine. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Dec 27, 2022 at 10:36 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Dec 27, 2022 at 9:15 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Mon, Dec 26, 2022 at 7:35 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > > > In the commit message, there is a statement like this > > > > > > "However, if the leader apply worker times out while attempting to > > > send a message to the > > > parallel apply worker, it will switch to "partial serialize" mode - in this > > > mode the leader serializes all remaining changes to a file and notifies the > > > parallel apply workers to read and apply them at the end of the transaction." > > > > > > I think it is a good idea to serialize the change to the file in this > > > case to avoid deadlocks, but why does the parallel worker need to wait > > > till the transaction commits to reading the file? I mean we can > > > switch the serialize state and make a parallel worker pull changes > > > from the file and if the parallel worker has caught up with the > > > changes then it can again change the state to "share memory" and now > > > the apply worker can again start sending through shared memory. > > > > > > I think generally streaming transactions are large and it is possible > > > that the shared memory queue gets full because of a lot of changes for > > > a particular transaction but later when the load switches to the other > > > transactions then it would be quite common for the worker to catch up > > > with the changes then it better to again take advantage of using > > > memory. Otherwise, in this case, we are just wasting resources > > > (worker/shared memory queue) but still writing in the file. > > > > > > > Note that there is a certain threshold timeout for which we wait > > before switching to serialize mode and normally it happens only when > > PA starts waiting on some lock acquired by the backend. Now, apart > > from that even if we decide to switch modes, the current BufFile > > mechanism doesn't have a good way for that. It doesn't allow two > > processes to open the same buffile at the same time which means we > > need to maintain multiple files to achieve the mode where we can > > switch back from serialize mode. We cannot let LA wait for PA to close > > the file as that could introduce another kind of deadlock. For > > details, see the discussion in the email [1]. The other problem is > > that we have no way to deal with partially sent data via a shared > > memory queue. Say, if we timeout while sending the data, we have to > > resend the same message until it succeeds which will be tricky because > > we can't keep retrying as that can lead to deadlock. I think if we try > > to build this new mode, it will be a lot of effort without equivalent > > returns. In common cases, we didn't see that we time out and switch to > > serialize mode. It is mostly in cases where PA starts to wait for the > > lock acquired by other backend or the machine is slow enough to deal > > with the number of parallel apply workers. So, it doesn't seem worth > > adding more complexity to the first version but we don't rule out the > > possibility of the same in the future if we really see such cases are > > common. > > > > [1] - https://www.postgresql.org/message-id/CAD21AoDScLvLT8JBfu5WaGCPQs_qhxsybMT%2BsMXJ%3DQrDMTyr9w%40mail.gmail.com > > Okay, I see. And once we change to serialize mode we can't release > the worker as well because we have already applied partial changes > under some transaction from a PA so we can not apply remaining from > the LA. I understand it might introduce a lot of complex design to > change it back to parallel apply mode but my only worry is that in > such cases we will be holding on to the parallel worker just to wait > till commit to reading from the spool file. But as you said it should > not be very common case so maybe this is fine. > Right and as said previously if required (which is not clear at this stage) we can develop it in the later version as well. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, Dec 26, 2022 at 10:29 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Mon, Dec 26, 2022 at 6:33 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > ---
> > + if (!pa_can_start(xid))
> > + return;
> > +
> > + /* First time through, initialize parallel apply worker state
> > hashtable. */
> > + if (!ParallelApplyTxnHash)
> > + {
> > + HASHCTL ctl;
> > +
> > + MemSet(&ctl, 0, sizeof(ctl));
> > + ctl.keysize = sizeof(TransactionId);
> > + ctl.entrysize = sizeof(ParallelApplyWorkerEntry);
> > + ctl.hcxt = ApplyContext;
> > +
> > + ParallelApplyTxnHash = hash_create("logical
> > replication parallel apply workershash",
> > +
> > 16, &ctl,
> > +
> > HASH_ELEM |HASH_BLOBS | HASH_CONTEXT);
> > + }
> > +
> > + /*
> > + * It's necessary to reread the subscription information
> > before assigning
> > + * the transaction to a parallel apply worker. Otherwise, the
> > leader may
> > + * not be able to reread the subscription information if streaming
> > + * transactions keep coming and are handled by parallel apply workers.
> > + */
> > + maybe_reread_subscription();
> >
> > pa_can_start() checks if the skiplsn is an invalid xid or not, and
> > then maybe_reread_subscription() could update the skiplsn to a valid
> > value. As the comments in pa_can_start() says, it won't work. I think
> > we should call maybe_reread_subscription() in
> > apply_handle_stream_start() before calling pa_allocate_worker().
> >
>
> But I think a similar thing can happen when we start the worker and
> then before the transaction ends, we do maybe_reread_subscription().
Where do we do maybe_reread_subscription() in this case? IIUC if the
leader sends all changes to the worker, there is no chance for the
leader to do maybe_reread_subscription except for when waiting for the
input. On reflection, adding maybe_reread_subscription() to
apply_handle_stream_start() adds one extra call of it so it's not
good. Alternatively, we can do that in pa_can_start() before checking
the skiplsn. I think we do a similar thing in AllTablesyncsRead() --
update the information before the check if necessary.
> I think we should try to call maybe_reread_subscription() when we are
> reasonably sure that we are going to enter parallel mode, otherwise,
> anyway, it will be later called by the leader worker.
It isn't a big problem even if we update the skiplsn after launching a
worker since we will skip the transaction the next time. But it would
be more consistent with the current behavior. As I mentioned above,
doing it in pa_can_start() seems to be reasonable to me. What do you
think?
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Dec 27, 2022 at 11:28 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Mon, Dec 26, 2022 at 10:29 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Mon, Dec 26, 2022 at 6:33 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > >
> > > ---
> > > + if (!pa_can_start(xid))
> > > + return;
> > > +
> > > + /* First time through, initialize parallel apply worker state
> > > hashtable. */
> > > + if (!ParallelApplyTxnHash)
> > > + {
> > > + HASHCTL ctl;
> > > +
> > > + MemSet(&ctl, 0, sizeof(ctl));
> > > + ctl.keysize = sizeof(TransactionId);
> > > + ctl.entrysize = sizeof(ParallelApplyWorkerEntry);
> > > + ctl.hcxt = ApplyContext;
> > > +
> > > + ParallelApplyTxnHash = hash_create("logical
> > > replication parallel apply workershash",
> > > +
> > > 16, &ctl,
> > > +
> > > HASH_ELEM |HASH_BLOBS | HASH_CONTEXT);
> > > + }
> > > +
> > > + /*
> > > + * It's necessary to reread the subscription information
> > > before assigning
> > > + * the transaction to a parallel apply worker. Otherwise, the
> > > leader may
> > > + * not be able to reread the subscription information if streaming
> > > + * transactions keep coming and are handled by parallel apply workers.
> > > + */
> > > + maybe_reread_subscription();
> > >
> > > pa_can_start() checks if the skiplsn is an invalid xid or not, and
> > > then maybe_reread_subscription() could update the skiplsn to a valid
> > > value. As the comments in pa_can_start() says, it won't work. I think
> > > we should call maybe_reread_subscription() in
> > > apply_handle_stream_start() before calling pa_allocate_worker().
> > >
> >
> > But I think a similar thing can happen when we start the worker and
> > then before the transaction ends, we do maybe_reread_subscription().
>
> Where do we do maybe_reread_subscription() in this case? IIUC if the
> leader sends all changes to the worker, there is no chance for the
> leader to do maybe_reread_subscription except for when waiting for the
> input.
Yes, this is the point where it can happen. IT can happen when there
is some delay between different streaming chunks.
> On reflection, adding maybe_reread_subscription() to
> apply_handle_stream_start() adds one extra call of it so it's not
> good. Alternatively, we can do that in pa_can_start() before checking
> the skiplsn. I think we do a similar thing in AllTablesyncsRead() --
> update the information before the check if necessary.
>
> > I think we should try to call maybe_reread_subscription() when we are
> > reasonably sure that we are going to enter parallel mode, otherwise,
> > anyway, it will be later called by the leader worker.
>
> It isn't a big problem even if we update the skiplsn after launching a
> worker since we will skip the transaction the next time. But it would
> be more consistent with the current behavior. As I mentioned above,
> doing it in pa_can_start() seems to be reasonable to me. What do you
> think?
>
Okay, we can do it in pa_can_start but then let's do it before we
check the parallel_apply flag as that can also be changed if the
streaming mode is changed. Please see the changes in the attached
patch which is atop the 0001 and 0002 patches. I have made a few
comment improvements as well.
--
With Regards,
Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Dec 27, 2022 at 10:24 AM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> Attach the new version patch which addressed all above comments and part of
> comments from [1] except one comment that are being discussed.
>
1.
+# Test that the deadlock is detected among leader and parallel apply workers.
+
+$node_subscriber->append_conf('postgresql.conf', "deadlock_timeout = 1ms");
+$node_subscriber->reload;
+
A. I see that the other existing tests have deadlock_timeout set as
10ms, 100ms, 100s, etc. Is there a reason to keep so low here? Shall
we keep it as 10ms?
B. /among leader/among the leader
2. Can we leave having tests in 022_twophase_cascade to be covered by
parallel mode? The two-phase and parallel apply will be covered by
023_twophase_stream, so not sure if we get any extra coverage by
022_twophase_cascade.
3. Let's combine 0001 and 0002 as both have got reviewed independently.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Tue, Dec 27, 2022 19:37 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Tue, Dec 27, 2022 at 10:24 AM wangw.fnst@fujitsu.com
> <wangw.fnst@fujitsu.com> wrote:
> >
> > Attach the new version patch which addressed all above comments and part
> of
> > comments from [1] except one comment that are being discussed.
> >
Thanks for your comments.
> 1.
> +# Test that the deadlock is detected among leader and parallel apply workers.
> +
> +$node_subscriber->append_conf('postgresql.conf', "deadlock_timeout =
> 1ms");
> +$node_subscriber->reload;
> +
>
> A. I see that the other existing tests have deadlock_timeout set as
> 10ms, 100ms, 100s, etc. Is there a reason to keep so low here? Shall
> we keep it as 10ms?
No, I think you are right. Keep it as 10ms.
> B. /among leader/among the leader
Fixed.
> 2. Can we leave having tests in 022_twophase_cascade to be covered by
> parallel mode? The two-phase and parallel apply will be covered by
> 023_twophase_stream, so not sure if we get any extra coverage by
> 022_twophase_cascade.
Compared with 023_twophase_stream, there is "rollback a subtransaction" in
022_twophase_cascade, but since this part of the code can be covered by tests
in 018_stream_subxact_abort, I think we can remove parallel version for
022_twophase_cascade. So I reverted changes in 022_twophase_cascade for
parallel mode and added some comments atop this file.
> 3. Let's combine 0001 and 0002 as both have got reviewed independently.
Combined them into one patch.
And I also checked and merged the diff patch in [1].
Besides, also fixed the below problem:
In previous versions, we didn't wait for STREAM_ABORT transactions to complete.
But in extreme cases, this can cause problems if the STREAM_ABORT transaction
doesn't complete and xid wraparound occurs on the publisher-side. Fixed this by
waiting for the STREAM_ABORT transaction to complete.
Attach the new patch set.
[1] - https://www.postgresql.org/message-id/CAA4eK1%2B5gTjHzWovkbUj%2BxsQ9yO9jVcKsS-3c5ZXLFy8JmfT%3DA%40mail.gmail.com
Regards,
Wang wei
Attachment
- v69-0001-Perform-streaming-logical-transactions-by-parall.patch
- v69-0002-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v69-0003-Stop-extra-worker-if-GUC-was-changed.patch
- v69-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v69-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Dec 28, 2022 at 10:09 AM wangw.fnst@fujitsu.com <wangw.fnst@fujitsu.com> wrote: > I have made a number of changes in the comments, removed extra list copy in pa_launch_parallel_worker(), and removed unnecessary include in worker. Please see the attached and let me know what you think. Feel free to rebase and send the remaining patches. -- With Regards, Amit Kapila.
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Thur, Dec 29, 2022 21:25 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > On Wed, Dec 28, 2022 at 10:09 AM wangw.fnst@fujitsu.com > <wangw.fnst@fujitsu.com> wrote: > > > > I have made a number of changes in the comments, removed extra list > copy in pa_launch_parallel_worker(), and removed unnecessary include > in worker. Please see the attached and let me know what you think. > Feel free to rebase and send the remaining patches. Thanks for your improvement. I've checked it and it looks good to me. Rebased the other patches and ran the pgident for the patch set. Attach the new patch set. Regards, Wang wei
Attachment
- v70-0001-Perform-streaming-logical-transactions-by-parall.patch
- v70-0002-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v70-0003-Stop-extra-worker-if-GUC-was-changed.patch
- v70-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v70-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Dec 30, 2022 at 3:55 PM wangw.fnst@fujitsu.com <wangw.fnst@fujitsu.com> wrote: > > I've checked it and it looks good to me. > Rebased the other patches and ran the pgident for the patch set. > > Attach the new patch set. > I have added a few DEBUG messages and changed a few comments in the 0001 patch. With that v71-0001* looks good to me and I'll commit it later this week (by Thursday or Friday) unless there are any major comments or objections. -- With Regards, Amit Kapila.
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Mon, Jan 2, 2023 at 18:54 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > On Fri, Dec 30, 2022 at 3:55 PM wangw.fnst@fujitsu.com > <wangw.fnst@fujitsu.com> wrote: > > > > I've checked it and it looks good to me. > > Rebased the other patches and ran the pgident for the patch set. > > > > Attach the new patch set. > > > > I have added a few DEBUG messages and changed a few comments in the > 0001 patch. With that v71-0001* looks good to me and I'll commit it > later this week (by Thursday or Friday) unless there are any major > comments or objections. Thanks for your improvement. Rebased the patch set because the new change in HEAD (c8e1ba7). Attach the new patch set. Regards, Wang wei
Attachment
- v72-0001-Perform-apply-of-large-transactions-by-parallel-.patch
- v72-0002-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v72-0003-Stop-extra-worker-if-GUC-was-changed.patch
- v72-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
- v72-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
shveta malik
Date:
On Tue, Jan 3, 2023 at 11:10 AM wangw.fnst@fujitsu.com <wangw.fnst@fujitsu.com> wrote: > > On Mon, Jan 2, 2023 at 18:54 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Dec 30, 2022 at 3:55 PM wangw.fnst@fujitsu.com > > <wangw.fnst@fujitsu.com> wrote: > > > > > > I've checked it and it looks good to me. > > > Rebased the other patches and ran the pgident for the patch set. > > > > > > Attach the new patch set. > > > > > > > I have added a few DEBUG messages and changed a few comments in the > > 0001 patch. With that v71-0001* looks good to me and I'll commit it > > later this week (by Thursday or Friday) unless there are any major > > comments or objections. > > Thanks for your improvement. > > Rebased the patch set because the new change in HEAD (c8e1ba7). > Attach the new patch set. > > Regards, > Wang wei Hi, In continuation with [1] and [2], I did some performance testing on v70-0001 patch. This test used synchronous logical replication and compared SQL execution times before and after applying the patch. The following cases are tested by varying logical_decoding_work_mem: a) Bulk insert. b) Bulk delete c) Bulk update b) Rollback to savepoint. (different percentages of changes in the transaction are rolled back). The tests are performed ten times, and the average of the middle eight is taken. The scripts are the same as before [1]. The scripts for additional update and delete testing are attached. The results are as follows: RESULT - bulk insert (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 34.475 34.222 34.400 patched 20.168 20.181 20.510 Compare with HEAD -41.49% -41.029% -40.377% RESULT - bulk delete (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 40.286 41.312 41.312 patched 23.749 23.759 23.480 Compare with HEAD -41.04% -42.48% -43.16% RESULT - bulk update (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 63.650 65.260 65.459 patched 46.692 46.275 48.281 Compare with HEAD -26.64% -29.09% -26.24% RESULT - rollback 10% (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 33.386 33.213 31.990 patched 20.540 19.295 18.139 Compare with HEAD -38.47% -41.90% -43.29% RESULT - rollback 20% (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 32.150 31.871 30.825 patched 19.331 19.366 18.285 Compare with HEAD -39.87% -39.23% -40.68% RESULT - rollback 30% (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 28.611 30.139 29.433 patched 19.632 19.838 18.374 Compare with HEAD -31.38% -34.17% -37.57% RESULT - rollback 50% (5kk) --------------------------------------------------------------- logical_decoding_work_mem 64kB 256kB 64MB HEAD 27.410 27.167 25.990 patched 19.982 18.749 18.048 Compare with HEAD -27.099% -30.98% -30.55% (if "Compare with HEAD" is a positive number, it means worse than HEAD; if it is a negative number, it means better than HEAD.) Summary: Update shows 26-29% improvement, while insert and delete shows ~40% improvement. In the case of rollback, the improvement is somewhat between 27-42%. The improvement slightly decreases with larger amounts of data being rolled back. [1] https://www.postgresql.org/message-id/OSZPR01MB63103AA97349BBB858E27DEAFD499%40OSZPR01MB6310.jpnprd01.prod.outlook.com [2] https://www.postgresql.org/message-id/OSZPR01MB6310174063C9144D2081F657FDE09%40OSZPR01MB6310.jpnprd01.prod.outlook.com thanks Shveta
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Tue, Jan 3, 2023 at 2:40 PM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> On Mon, Jan 2, 2023 at 18:54 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > On Fri, Dec 30, 2022 at 3:55 PM wangw.fnst@fujitsu.com
> > <wangw.fnst@fujitsu.com> wrote:
> > >
> > > I've checked it and it looks good to me.
> > > Rebased the other patches and ran the pgident for the patch set.
> > >
> > > Attach the new patch set.
> > >
> >
> > I have added a few DEBUG messages and changed a few comments in the
> > 0001 patch. With that v71-0001* looks good to me and I'll commit it
> > later this week (by Thursday or Friday) unless there are any major
> > comments or objections.
>
> Thanks for your improvement.
>
> Rebased the patch set because the new change in HEAD (c8e1ba7).
> Attach the new patch set.
There are some unused parameters in v72 patches:
+static bool
+pa_can_start(TransactionId xid)
+{
+ Assert(TransactionIdIsValid(xid));
'xid' is used only for the assertion check but I don't think it's necessary.
---
+/*
+ * Make sure the leader apply worker tries to read from our error
queue one more
+ * time. This guards against the case where we exit uncleanly without sending
+ * an ErrorResponse, for example because some code calls proc_exit directly.
+ */
+static void
+pa_shutdown(int code, Datum arg)
Similarly, we don't use 'code' here.
---
+/*
+ * Handle a single protocol message received from a single parallel apply
+ * worker.
+ */
+static void
+HandleParallelApplyMessage(ParallelApplyWorkerInfo *winfo, StringInfo msg)
In addition, the same is true for 'winfo'.
The rest looks good to me.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, Jan 4, 2023 at 2:31 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Tue, Jan 3, 2023 at 2:40 PM wangw.fnst@fujitsu.com > <wangw.fnst@fujitsu.com> wrote: > > > > On Mon, Jan 2, 2023 at 18:54 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > On Fri, Dec 30, 2022 at 3:55 PM wangw.fnst@fujitsu.com > > > <wangw.fnst@fujitsu.com> wrote: > > > > > > > > I've checked it and it looks good to me. > > > > Rebased the other patches and ran the pgident for the patch set. > > > > > > > > Attach the new patch set. > > > > > > > > > > I have added a few DEBUG messages and changed a few comments in the > > > 0001 patch. With that v71-0001* looks good to me and I'll commit it > > > later this week (by Thursday or Friday) unless there are any major > > > comments or objections. > > > > Thanks for your improvement. > > > > Rebased the patch set because the new change in HEAD (c8e1ba7). > > Attach the new patch set. > > There are some unused parameters in v72 patches: > > --- > +/* > + * Make sure the leader apply worker tries to read from our error > queue one more > + * time. This guards against the case where we exit uncleanly without sending > + * an ErrorResponse, for example because some code calls proc_exit directly. > + */ > +static void > +pa_shutdown(int code, Datum arg) > > Similarly, we don't use 'code' here. This is necessary. Sorry for the noise. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wed, Jan 4, 2023 at 13:31 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> On Tue, Jan 3, 2023 at 2:40 PM wangw.fnst@fujitsu.com
> <wangw.fnst@fujitsu.com> wrote:
> >
> > On Mon, Jan 2, 2023 at 18:54 PM Amit Kapila
> > <amit.kapila16@gmail.com>
> wrote:
> > > On Fri, Dec 30, 2022 at 3:55 PM wangw.fnst@fujitsu.com
> > > <wangw.fnst@fujitsu.com> wrote:
> > > >
> > > > I've checked it and it looks good to me.
> > > > Rebased the other patches and ran the pgident for the patch set.
> > > >
> > > > Attach the new patch set.
> > > >
> > >
> > > I have added a few DEBUG messages and changed a few comments in
> > > the
> > > 0001 patch. With that v71-0001* looks good to me and I'll commit
> > > it later this week (by Thursday or Friday) unless there are any
> > > major comments or objections.
> >
> > Thanks for your improvement.
> >
> > Rebased the patch set because the new change in HEAD (c8e1ba7).
> > Attach the new patch set.
>
> There are some unused parameters in v72 patches:
Thanks for your comments!
> +static bool
> +pa_can_start(TransactionId xid)
> +{
> + Assert(TransactionIdIsValid(xid));
>
> 'xid' is used only for the assertion check but I don't think it's necessary.
Agree. Removed this check.
> ---
> +/*
> + * Handle a single protocol message received from a single parallel
> +apply
> + * worker.
> + */
> +static void
> +HandleParallelApplyMessage(ParallelApplyWorkerInfo *winfo, StringInfo
> +msg)
>
> In addition, the same is true for 'winfo'.
Agree. Removed this parameter.
Attach the new patch set.
Apart from addressing Sawada-San's comments, I also did some other minor
changes in the patch:
* Adjusted a testcase about crash restart in 023_twophase_stream.pl, I
skipped the check for DEBUG msg as the msg might not be output if the crash happens
before that.
* Adjusted the code in pg_lock_status() to make the fields of
applytransaction lock display in more appropriate places.
* Add a comment to explain why we unlock the transaction before aborting the
transaction in parallel apply worker.
Best regards,
Hou zj
Attachment
- v73-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v73-0001-Perform-apply-of-large-transactions-by-parallel-.patch
- v73-0002-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v73-0003-Stop-extra-worker-if-GUC-was-changed.patch
- v73-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Wed, Jan 4, 2023 at 4:25 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > Attach the new patch set. > Apart from addressing Sawada-San's comments, I also did some other minor > changes in the patch: I have done a high-level review of 0001, and later I will do a detailed review of this while reading through the patch I think some of the comments need some changes.. 1. + The deadlock can happen in + * the following ways: + * + * 4) Lock types + * + * Both the stream lock and the transaction lock mentioned above are + * session-level locks because both locks could be acquired outside the + * transaction, and the stream lock in the leader needs to persist across + * transaction boundaries i.e. until the end of the streaming transaction. I think the Lock types should not be listed with the number 4). Because point number 1,2 and 3 are explaining the way how deadlocks can happen but 4) doesn't fall under that category. 2. + * Since the database structure (schema of subscription tables, constraints, + * etc.) of the publisher and subscriber could be different, applying + * transactions in parallel mode on the subscriber side can cause some + * deadlocks that do not occur on the publisher side. I think this paragraph needs to be rephrased a bit. It is saying that some deadlock can occur on subscribers which did not occur on the publisher. I think what it should be conveying is that the deadlock can occur due to concurrently applying the conflicting/dependent transactions which are not conflicting/dependent on the publisher due to <explain reason>. Because if we create the same schema on the publisher it might not have ended up in a deadlock instead it would have been executed in sequence (due to lock waiting). So the main point we are conveying is that the transaction which was independent of each other on the publisher could be dependent on the subscriber and they can end up in deadlock due to parallel apply. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Jan 4, 2023 at 4:52 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > 2. > + * Since the database structure (schema of subscription tables, constraints, > + * etc.) of the publisher and subscriber could be different, applying > + * transactions in parallel mode on the subscriber side can cause some > + * deadlocks that do not occur on the publisher side. > > I think this paragraph needs to be rephrased a bit. It is saying that > some deadlock can occur on subscribers which did not occur on the > publisher. I think what it should be conveying is that the deadlock > can occur due to concurrently applying the conflicting/dependent > transactions which are not conflicting/dependent on the publisher due > to <explain reason>. Because if we create the same schema on the > publisher it might not have ended up in a deadlock instead it would > have been executed in sequence (due to lock waiting). So the main > point we are conveying is that the transaction which was independent > of each other on the publisher could be dependent on the subscriber > and they can end up in deadlock due to parallel apply. > How about changing it to: "We have a risk of deadlock due to parallelly applying the transactions that were independent on the publisher side but became dependent on the subscriber side due to the different database structures (like schema of subscription tables, constraints, etc.) on each side. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Wed, Jan 4, 2023 at 6:40 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Jan 4, 2023 at 4:52 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > 2. > > + * Since the database structure (schema of subscription tables, constraints, > > + * etc.) of the publisher and subscriber could be different, applying > > + * transactions in parallel mode on the subscriber side can cause some > > + * deadlocks that do not occur on the publisher side. > > > > I think this paragraph needs to be rephrased a bit. It is saying that > > some deadlock can occur on subscribers which did not occur on the > > publisher. I think what it should be conveying is that the deadlock > > can occur due to concurrently applying the conflicting/dependent > > transactions which are not conflicting/dependent on the publisher due > > to <explain reason>. Because if we create the same schema on the > > publisher it might not have ended up in a deadlock instead it would > > have been executed in sequence (due to lock waiting). So the main > > point we are conveying is that the transaction which was independent > > of each other on the publisher could be dependent on the subscriber > > and they can end up in deadlock due to parallel apply. > > > > How about changing it to: "We have a risk of deadlock due to > parallelly applying the transactions that were independent on the > publisher side but became dependent on the subscriber side due to the > different database structures (like schema of subscription tables, > constraints, etc.) on each side. I think this looks good to me. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, January 4, 2023 9:29 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Wed, Jan 4, 2023 at 6:40 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Wed, Jan 4, 2023 at 4:52 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > > > 2. > > > + * Since the database structure (schema of subscription tables, > > > + constraints, > > > + * etc.) of the publisher and subscriber could be different, > > > + applying > > > + * transactions in parallel mode on the subscriber side can cause > > > + some > > > + * deadlocks that do not occur on the publisher side. > > > > > > I think this paragraph needs to be rephrased a bit. It is saying > > > that some deadlock can occur on subscribers which did not occur on > > > the publisher. I think what it should be conveying is that the > > > deadlock can occur due to concurrently applying the > > > conflicting/dependent transactions which are not > > > conflicting/dependent on the publisher due to <explain reason>. > > > Because if we create the same schema on the publisher it might not > > > have ended up in a deadlock instead it would have been executed in > > > sequence (due to lock waiting). So the main point we are conveying > > > is that the transaction which was independent of each other on the > > > publisher could be dependent on the subscriber and they can end up in > deadlock due to parallel apply. > > > > > > > How about changing it to: "We have a risk of deadlock due to > > parallelly applying the transactions that were independent on the > > publisher side but became dependent on the subscriber side due to the > > different database structures (like schema of subscription tables, > > constraints, etc.) on each side. > > I think this looks good to me. Thanks for the comments. Attach the new version patch set which changed the comments as suggested. Best regards, Hou zj
Attachment
- v74-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v74-0001-Perform-apply-of-large-transactions-by-parallel-.patch
- v74-0002-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v74-0003-Stop-extra-worker-if-GUC-was-changed.patch
- v74-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Thu, Jan 5, 2023 at 9:07 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, January 4, 2023 9:29 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > I think this looks good to me. > > Thanks for the comments. > Attach the new version patch set which changed the comments as suggested. Thanks for the updated patch, while testing this I see one strange behavior which seems like bug to me, here is the step to reproduce 1. start 2 servers(config: logical_decoding_work_mem=64kB) ./pg_ctl -D data/ -c -l pub_logs start ./pg_ctl -D data1/ -c -l sub_logs start 2. Publisher: create table t(a int PRIMARY KEY ,b text); CREATE OR REPLACE FUNCTION large_val() RETURNS TEXT LANGUAGE SQL AS 'select array_agg(md5(g::text))::text from generate_series(1, 256) g'; create publication test_pub for table t with(PUBLISH='insert,delete,update,truncate'); alter table t replica identity FULL ; insert into t values (generate_series(1,2000),large_val()) ON CONFLICT (a) DO UPDATE SET a=EXCLUDED.a*300; 3. Subscription Server: create table t(a int,b text); create subscription test_sub CONNECTION 'host=localhost port=5432 dbname=postgres' PUBLICATION test_pub WITH ( slot_name = test_slot_sub1,streaming=parallel); 4. Publication Server: begin ; savepoint a; delete from t; savepoint b; insert into t values (generate_series(1,5000),large_val()) ON CONFLICT (a) DO UPDATE SET a=EXCLUDED.a*30000; -- (while executing this start publisher in 2-3 secs) Restart the publication server, while the transaction is still in an uncommitted state. ./pg_ctl -D data/ -c -l pub_logs stop -mi ./pg_ctl -D data/ -c -l pub_logs start -mi after this, the parallel apply worker stuck in waiting on stream lock forever (even after 10 mins) -- see below, from subscriber logs I can see one of the parallel apply worker [75677] started but never finished [no error], after that I have performed more operation [same insert] which got applied by new parallel apply worked which got started and finished within 1 second. dilipku+ 75660 1 0 13:39 ? 00:00:00 /home/dilipkumar/work/PG/install/bin/postgres -D data dilipku+ 75661 75660 0 13:39 ? 00:00:00 postgres: checkpointer dilipku+ 75662 75660 0 13:39 ? 00:00:00 postgres: background writer dilipku+ 75664 75660 0 13:39 ? 00:00:00 postgres: walwriter dilipku+ 75665 75660 0 13:39 ? 00:00:00 postgres: autovacuum launcher dilipku+ 75666 75660 0 13:39 ? 00:00:00 postgres: logical replication launcher dilipku+ 75675 75595 0 13:39 ? 00:00:00 postgres: logical replication apply worker for subscription 16389 dilipku+ 75676 75660 0 13:39 ? 00:00:00 postgres: walsender dilipkumar postgres ::1(42192) START_REPLICATION dilipku+ 75677 75595 0 13:39 ? 00:00:00 postgres: logical replication parallel apply worker for subscription 16389 waiting Subscriber logs: 2023-01-05 13:39:07.261 IST [75595] LOG: background worker "logical replication worker" (PID 75649) exited with exit code 1 2023-01-05 13:39:12.272 IST [75675] LOG: logical replication apply worker for subscription "test_sub" has started 2023-01-05 13:39:12.307 IST [75677] LOG: logical replication parallel apply worker for subscription "test_sub" has started 2023-01-05 13:43:31.003 IST [75596] LOG: checkpoint starting: time 2023-01-05 13:46:32.045 IST [76337] LOG: logical replication parallel apply worker for subscription "test_sub" has started 2023-01-05 13:46:35.214 IST [76337] LOG: logical replication parallel apply worker for subscription "test_sub" has finished 2023-01-05 13:46:50.241 IST [76384] LOG: logical replication parallel apply worker for subscription "test_sub" has started 2023-01-05 13:46:53.676 IST [76384] LOG: logical replication parallel apply worker for subscription "test_sub" has finished -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, January 5, 2023 4:22 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Thu, Jan 5, 2023 at 9:07 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Wednesday, January 4, 2023 9:29 PM Dilip Kumar > <dilipbalaut@gmail.com> wrote: > > > > I think this looks good to me. > > > > Thanks for the comments. > > Attach the new version patch set which changed the comments as > suggested. > > Thanks for the updated patch, while testing this I see one strange > behavior which seems like bug to me, here is the step to reproduce > > 1. start 2 servers(config: logical_decoding_work_mem=64kB) > ./pg_ctl -D data/ -c -l pub_logs start > ./pg_ctl -D data1/ -c -l sub_logs start > > 2. Publisher: > create table t(a int PRIMARY KEY ,b text); > CREATE OR REPLACE FUNCTION large_val() RETURNS TEXT LANGUAGE SQL AS > 'select array_agg(md5(g::text))::text from generate_series(1, 256) g'; > create publication test_pub for table t > with(PUBLISH='insert,delete,update,truncate'); > alter table t replica identity FULL ; > insert into t values (generate_series(1,2000),large_val()) ON CONFLICT > (a) DO UPDATE SET a=EXCLUDED.a*300; > > 3. Subscription Server: > create table t(a int,b text); > create subscription test_sub CONNECTION 'host=localhost port=5432 > dbname=postgres' PUBLICATION test_pub WITH ( slot_name = > test_slot_sub1,streaming=parallel); > > 4. Publication Server: > begin ; > savepoint a; > delete from t; > savepoint b; > insert into t values (generate_series(1,5000),large_val()) ON CONFLICT > (a) DO UPDATE SET a=EXCLUDED.a*30000; -- (while executing this start > publisher in 2-3 secs) > > Restart the publication server, while the transaction is still in an > uncommitted state. > ./pg_ctl -D data/ -c -l pub_logs stop -mi > ./pg_ctl -D data/ -c -l pub_logs start -mi > > after this, the parallel apply worker stuck in waiting on stream lock > forever (even after 10 mins) -- see below, from subscriber logs I can > see one of the parallel apply worker [75677] started but never > finished [no error], after that I have performed more operation [same > insert] which got applied by new parallel apply worked which got > started and finished within 1 second. > Thanks for reporting the problem. After analyzing the behavior, I think it's a bug on publisher side which is not directly related to parallel apply. I think the root reason is that we didn't try to send a stream end(stream abort) message to subscriber for the crashed transaction which was streamed before. The behavior is that, after restarting, the publisher will start to decode the transaction that aborted due to crash, and when try to stream the first change of that transaction, it will send a stream start message but then it realizes that the transaction was aborted, so it will enter the PG_CATCH block of ReorderBufferProcessTXN() and call ReorderBufferResetTXN() which send the stream stop message. And in this case, there would be a parallel apply worker started on subscriber waiting for stream end message which will never come. I think the same behavior happens for the non-parallel mode which will cause a stream file left on subscriber and will not be cleaned until the apply worker is restarted. To fix it, I think we need to send a stream abort message when we are cleaning up crashed transaction on publisher(e.g., in ReorderBufferAbortOld()). And here is a tiny patch which change the same. I have confirmed that the bug is fixed and all regression tests pass. What do you think ? I will start a new thread and try to write a testcase if possible after reaching a consensus. Best regards, Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Thu, Jan 5, 2023 at 5:03 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Thursday, January 5, 2023 4:22 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > Thanks for reporting the problem. > > After analyzing the behavior, I think it's a bug on publisher side which > is not directly related to parallel apply. > > I think the root reason is that we didn't try to send a stream end(stream > abort) message to subscriber for the crashed transaction which was streamed > before. > The behavior is that, after restarting, the publisher will start to decode the > transaction that aborted due to crash, and when try to stream the first change > of that transaction, it will send a stream start message but then it realizes > that the transaction was aborted, so it will enter the PG_CATCH block of > ReorderBufferProcessTXN() and call ReorderBufferResetTXN() which send the > stream stop message. And in this case, there would be a parallel apply worker > started on subscriber waiting for stream end message which will never come. I suspected it but didn't analyze this. > I think the same behavior happens for the non-parallel mode which will cause > a stream file left on subscriber and will not be cleaned until the apply worker is > restarted. > To fix it, I think we need to send a stream abort message when we are cleaning > up crashed transaction on publisher(e.g., in ReorderBufferAbortOld()). And here > is a tiny patch which change the same. I have confirmed that the bug is fixed > and all regression tests pass. > > What do you think ? > I will start a new thread and try to write a testcase if possible > after reaching a consensus. I think your analysis looks correct and we can raise this in a new thread. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, January 5, 2023 7:54 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Thu, Jan 5, 2023 at 5:03 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Thursday, January 5, 2023 4:22 PM Dilip Kumar <dilipbalaut@gmail.com> > wrote: > > > > > > Thanks for reporting the problem. > > > > After analyzing the behavior, I think it's a bug on publisher side > > which is not directly related to parallel apply. > > > > I think the root reason is that we didn't try to send a stream > > end(stream > > abort) message to subscriber for the crashed transaction which was > > streamed before. > > The behavior is that, after restarting, the publisher will start to > > decode the transaction that aborted due to crash, and when try to > > stream the first change of that transaction, it will send a stream > > start message but then it realizes that the transaction was aborted, > > so it will enter the PG_CATCH block of > > ReorderBufferProcessTXN() and call ReorderBufferResetTXN() which send > > the stream stop message. And in this case, there would be a parallel > > apply worker started on subscriber waiting for stream end message which > will never come. > > I suspected it but didn't analyze this. > > > I think the same behavior happens for the non-parallel mode which will > > cause a stream file left on subscriber and will not be cleaned until > > the apply worker is restarted. > > To fix it, I think we need to send a stream abort message when we are > > cleaning up crashed transaction on publisher(e.g., in > > ReorderBufferAbortOld()). And here is a tiny patch which change the > > same. I have confirmed that the bug is fixed and all regression tests pass. > > > > What do you think ? > > I will start a new thread and try to write a testcase if possible > > after reaching a consensus. > > I think your analysis looks correct and we can raise this in a new thread. Thanks, I have started another thread[1] Attach the parallel apply patch set here again. I didn't change the patch set, attach it here just to let the CFbot keep testing it. [1] https://www.postgresql.org/message-id/OS0PR01MB5716A773F46768A1B75BE24394FB9%40OS0PR01MB5716.jpnprd01.prod.outlook.com Best regards, Hou zj
Attachment
- v74-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v74-0001-Perform-apply-of-large-transactions-by-parallel-.patch
- v74-0002-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v74-0003-Stop-extra-worker-if-GUC-was-changed.patch
- v74-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Fri, Jan 6, 2023 at 9:37 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Thursday, January 5, 2023 7:54 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> Thanks, I have started another thread[1]
>
> Attach the parallel apply patch set here again. I didn't change the patch set,
> attach it here just to let the CFbot keep testing it.
I have completed the review and some basic testing and it mostly looks
fine to me. Here is my last set of comments/suggestions.
1.
/*
* Don't start a new parallel worker if user has set skiplsn as it's
* possible that they want to skip the streaming transaction. For
* streaming transactions, we need to serialize the transaction to a file
* so that we can get the last LSN of the transaction to judge whether to
* skip before starting to apply the change.
*/
if (!XLogRecPtrIsInvalid(MySubscription->skiplsn))
return false;
I think this is fine to block parallelism in this case, but it is also
possible to make it less restrictive, basically, only if the first lsn
of the transaction is <= skiplsn, then only it is possible that the
final_lsn might match with skiplsn otherwise that is not possible. And
if we want then we can allow parallelism in that case.
I understand that currently we do not have first_lsn of the
transaction in stream start message but I think that should be easy to
do? Although I am not sure if it is worth it, it's good to make a
note at least.
2.
+ * XXX Additionally, we also stop the worker if the leader apply worker
+ * serialize part of the transaction data due to a send timeout. This is
+ * because the message could be partially written to the queue and there
+ * is no way to clean the queue other than resending the message until it
+ * succeeds. Instead of trying to send the data which anyway would have
+ * been serialized and then letting the parallel apply worker deal with
+ * the spurious message, we stop the worker.
+ */
+ if (winfo->serialize_changes ||
+ list_length(ParallelApplyWorkerPool) >
+ (max_parallel_apply_workers_per_subscription / 2))
IMHO this reason (XXX Additionally, we also stop the worker if the
leader apply worker serialize part of the transaction data due to a
send timeout) for stopping the worker looks a bit hackish to me. It
may be a rare case so I am not talking about the performance but the
reasoning behind stopping is not good. Ideally we should be able to
clean up the message queue and reuse the worker.
3.
+ else if (shmq_res == SHM_MQ_WOULD_BLOCK)
+ {
+ /* Replay the changes from the file, if any. */
+ if (pa_has_spooled_message_pending())
+ {
+ pa_spooled_messages();
+ }
I think we do not need this pa_has_spooled_message_pending() function.
Because this function is just calling pa_get_fileset_state() which is
acquiring mutex and getting filestate then if the filestate is not
FS_EMPTY then we call pa_spooled_messages() that will again call
pa_get_fileset_state() which will again acquire mutex. I think when
the state is FS_SERIALIZE_IN_PROGRESS it will frequently call
pa_get_fileset_state() consecutively 2 times, and I think we can
easily achieve the same behavior with just one call.
4.
+ * leader, or when there there is an error. None of these cases will allow
+ * the code to reach here.
/when there there is an error/when there is an error
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Jan 6, 2023 at 11:24 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Fri, Jan 6, 2023 at 9:37 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Thursday, January 5, 2023 7:54 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> > Thanks, I have started another thread[1]
> >
> > Attach the parallel apply patch set here again. I didn't change the patch set,
> > attach it here just to let the CFbot keep testing it.
>
> I have completed the review and some basic testing and it mostly looks
> fine to me. Here is my last set of comments/suggestions.
>
> 1.
> /*
> * Don't start a new parallel worker if user has set skiplsn as it's
> * possible that they want to skip the streaming transaction. For
> * streaming transactions, we need to serialize the transaction to a file
> * so that we can get the last LSN of the transaction to judge whether to
> * skip before starting to apply the change.
> */
> if (!XLogRecPtrIsInvalid(MySubscription->skiplsn))
> return false;
>
>
> I think this is fine to block parallelism in this case, but it is also
> possible to make it less restrictive, basically, only if the first lsn
> of the transaction is <= skiplsn, then only it is possible that the
> final_lsn might match with skiplsn otherwise that is not possible. And
> if we want then we can allow parallelism in that case.
>
> I understand that currently we do not have first_lsn of the
> transaction in stream start message but I think that should be easy to
> do? Although I am not sure if it is worth it, it's good to make a
> note at least.
>
Yeah, I also don't think sending extra eight bytes with stream_start
message is worth it. But it is fine to mention the same in the
comments.
> 2.
>
> + * XXX Additionally, we also stop the worker if the leader apply worker
> + * serialize part of the transaction data due to a send timeout. This is
> + * because the message could be partially written to the queue and there
> + * is no way to clean the queue other than resending the message until it
> + * succeeds. Instead of trying to send the data which anyway would have
> + * been serialized and then letting the parallel apply worker deal with
> + * the spurious message, we stop the worker.
> + */
> + if (winfo->serialize_changes ||
> + list_length(ParallelApplyWorkerPool) >
> + (max_parallel_apply_workers_per_subscription / 2))
>
> IMHO this reason (XXX Additionally, we also stop the worker if the
> leader apply worker serialize part of the transaction data due to a
> send timeout) for stopping the worker looks a bit hackish to me. It
> may be a rare case so I am not talking about the performance but the
> reasoning behind stopping is not good. Ideally we should be able to
> clean up the message queue and reuse the worker.
>
TBH, I don't know what is the better way to deal with this with the
current infrastructure. I thought we can do this as a separate
enhancement in the future.
> 3.
> + else if (shmq_res == SHM_MQ_WOULD_BLOCK)
> + {
> + /* Replay the changes from the file, if any. */
> + if (pa_has_spooled_message_pending())
> + {
> + pa_spooled_messages();
> + }
>
> I think we do not need this pa_has_spooled_message_pending() function.
> Because this function is just calling pa_get_fileset_state() which is
> acquiring mutex and getting filestate then if the filestate is not
> FS_EMPTY then we call pa_spooled_messages() that will again call
> pa_get_fileset_state() which will again acquire mutex. I think when
> the state is FS_SERIALIZE_IN_PROGRESS it will frequently call
> pa_get_fileset_state() consecutively 2 times, and I think we can
> easily achieve the same behavior with just one call.
>
This is just to keep the code easy to follow. As this would be a rare
case, so thought of giving preference to code clarity.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Fri, Jan 6, 2023 at 12:05 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
>
> Yeah, I also don't think sending extra eight bytes with stream_start
> message is worth it. But it is fine to mention the same in the
> comments.
Right.
> > 2.
> >
> > + * XXX Additionally, we also stop the worker if the leader apply worker
> > + * serialize part of the transaction data due to a send timeout. This is
> > + * because the message could be partially written to the queue and there
> > + * is no way to clean the queue other than resending the message until it
> > + * succeeds. Instead of trying to send the data which anyway would have
> > + * been serialized and then letting the parallel apply worker deal with
> > + * the spurious message, we stop the worker.
> > + */
> > + if (winfo->serialize_changes ||
> > + list_length(ParallelApplyWorkerPool) >
> > + (max_parallel_apply_workers_per_subscription / 2))
> >
> > IMHO this reason (XXX Additionally, we also stop the worker if the
> > leader apply worker serialize part of the transaction data due to a
> > send timeout) for stopping the worker looks a bit hackish to me. It
> > may be a rare case so I am not talking about the performance but the
> > reasoning behind stopping is not good. Ideally we should be able to
> > clean up the message queue and reuse the worker.
> >
>
> TBH, I don't know what is the better way to deal with this with the
> current infrastructure. I thought we can do this as a separate
> enhancement in the future.
Okay.
> > 3.
> > + else if (shmq_res == SHM_MQ_WOULD_BLOCK)
> > + {
> > + /* Replay the changes from the file, if any. */
> > + if (pa_has_spooled_message_pending())
> > + {
> > + pa_spooled_messages();
> > + }
> >
> > I think we do not need this pa_has_spooled_message_pending() function.
> > Because this function is just calling pa_get_fileset_state() which is
> > acquiring mutex and getting filestate then if the filestate is not
> > FS_EMPTY then we call pa_spooled_messages() that will again call
> > pa_get_fileset_state() which will again acquire mutex. I think when
> > the state is FS_SERIALIZE_IN_PROGRESS it will frequently call
> > pa_get_fileset_state() consecutively 2 times, and I think we can
> > easily achieve the same behavior with just one call.
> >
>
> This is just to keep the code easy to follow. As this would be a rare
> case, so thought of giving preference to code clarity.
I think the code will be simpler with just one function no? I mean
instead of calling pa_has_spooled_message_pending() in if condition
what if we directly call pa_spooled_messages();, this is anyway
fetching the file_state and if the filestate is EMPTY then it can
return false, and if it returns false we can execute the code which is
there in else condition. We might need to change the name of the
function though.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Fri, Jan 6, 2023 at 12:59 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> > > 3.
> > > + else if (shmq_res == SHM_MQ_WOULD_BLOCK)
> > > + {
> > > + /* Replay the changes from the file, if any. */
> > > + if (pa_has_spooled_message_pending())
> > > + {
> > > + pa_spooled_messages();
> > > + }
> > >
> > > I think we do not need this pa_has_spooled_message_pending() function.
> > > Because this function is just calling pa_get_fileset_state() which is
> > > acquiring mutex and getting filestate then if the filestate is not
> > > FS_EMPTY then we call pa_spooled_messages() that will again call
> > > pa_get_fileset_state() which will again acquire mutex. I think when
> > > the state is FS_SERIALIZE_IN_PROGRESS it will frequently call
> > > pa_get_fileset_state() consecutively 2 times, and I think we can
> > > easily achieve the same behavior with just one call.
> > >
> >
> > This is just to keep the code easy to follow. As this would be a rare
> > case, so thought of giving preference to code clarity.
>
> I think the code will be simpler with just one function no? I mean
> instead of calling pa_has_spooled_message_pending() in if condition
> what if we directly call pa_spooled_messages();, this is anyway
> fetching the file_state and if the filestate is EMPTY then it can
> return false, and if it returns false we can execute the code which is
> there in else condition. We might need to change the name of the
> function though.
>
But anyway it is not a performance-critical path so if you think the
current way looks cleaner then I am fine with that too.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, January 6, 2023 3:29 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
Hi,
Thanks for your comments.
> On Fri, Jan 6, 2023 at 12:05 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
>
> >
> > Yeah, I also don't think sending extra eight bytes with stream_start
> > message is worth it. But it is fine to mention the same in the
> > comments.
>
> Right.
Added some comment.
>
> > > 2.
> > >
> > > + * XXX Additionally, we also stop the worker if the leader apply
> worker
> > > + * serialize part of the transaction data due to a send timeout. This is
> > > + * because the message could be partially written to the queue and
> there
> > > + * is no way to clean the queue other than resending the message
> until it
> > > + * succeeds. Instead of trying to send the data which anyway would
> have
> > > + * been serialized and then letting the parallel apply worker deal with
> > > + * the spurious message, we stop the worker.
> > > + */
> > > + if (winfo->serialize_changes ||
> > > + list_length(ParallelApplyWorkerPool) >
> > > + (max_parallel_apply_workers_per_subscription / 2))
> > >
> > > IMHO this reason (XXX Additionally, we also stop the worker if the
> > > leader apply worker serialize part of the transaction data due to a
> > > send timeout) for stopping the worker looks a bit hackish to me. It
> > > may be a rare case so I am not talking about the performance but the
> > > reasoning behind stopping is not good. Ideally we should be able to
> > > clean up the message queue and reuse the worker.
> > >
> >
> > TBH, I don't know what is the better way to deal with this with the
> > current infrastructure. I thought we can do this as a separate
> > enhancement in the future.
>
> Okay.
>
> > > 3.
> > > + else if (shmq_res == SHM_MQ_WOULD_BLOCK)
> > > + {
> > > + /* Replay the changes from the file, if any. */
> > > + if (pa_has_spooled_message_pending())
> > > + {
> > > + pa_spooled_messages();
> > > + }
> > >
> > > I think we do not need this pa_has_spooled_message_pending() function.
> > > Because this function is just calling pa_get_fileset_state() which
> > > is acquiring mutex and getting filestate then if the filestate is
> > > not FS_EMPTY then we call pa_spooled_messages() that will again call
> > > pa_get_fileset_state() which will again acquire mutex. I think when
> > > the state is FS_SERIALIZE_IN_PROGRESS it will frequently call
> > > pa_get_fileset_state() consecutively 2 times, and I think we can
> > > easily achieve the same behavior with just one call.
> > >
> >
> > This is just to keep the code easy to follow. As this would be a rare
> > case, so thought of giving preference to code clarity.
>
> I think the code will be simpler with just one function no? I mean instead of
> calling pa_has_spooled_message_pending() in if condition what if we directly
> call pa_spooled_messages();, this is anyway fetching the file_state and if the
> filestate is EMPTY then it can return false, and if it returns false we can execute
> the code which is there in else condition. We might need to change the name
> of the function though.
Changed as suggested.
I have addressed all the comments and here is the new version patch set.
I also added some documents about the new lock and fixed some typos.
Attach the new version patch set.
Best regards,
Hou zj
Attachment
- v75-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v75-0001-Perform-apply-of-large-transactions-by-parallel-.patch
- v75-0002-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v75-0003-Stop-extra-worker-if-GUC-was-changed.patch
- v75-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Fri, Jan 6, 2023 at 3:38 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > Looks good, but I feel in pa_process_spooled_messages_if_required() function after getting the filestate the first check should be if (filestate== FS_EMPTY) return false. I mean why to process through all the states if it is empty and we can directly exit. It is not a big deal so if you prefer the way it is then I have no objection to it. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Saturday, January 7, 2023 12:50 PM Dilip Kumar <dilipbalaut@gmail.com> > > On Fri, Jan 6, 2023 at 3:38 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> > wrote: > > > > Looks good, but I feel in pa_process_spooled_messages_if_required() > function after getting the filestate the first check should be if (filestate== > FS_EMPTY) return false. I mean why to process through all the states if it is > empty and we can directly exit. It is not a big deal so if you prefer the way it is > then I have no objection to it. I think your suggestion looks good, I have adjusted the code. I also rebase the patch set due to the recent commit c6e1f6. And here is the new version patch set. Best regards, Hou zj
Attachment
- v76-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v76-0001-Perform-apply-of-large-transactions-by-parallel-.patch
- v76-0002-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v76-0003-Stop-extra-worker-if-GUC-was-changed.patch
- v76-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Sat, Jan 7, 2023 at 11:13 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Saturday, January 7, 2023 12:50 PM Dilip Kumar <dilipbalaut@gmail.com> > > > > On Fri, Jan 6, 2023 at 3:38 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> > > wrote: > > > > > > > Looks good, but I feel in pa_process_spooled_messages_if_required() > > function after getting the filestate the first check should be if (filestate== > > FS_EMPTY) return false. I mean why to process through all the states if it is > > empty and we can directly exit. It is not a big deal so if you prefer the way it is > > then I have no objection to it. > > I think your suggestion looks good, I have adjusted the code. > I also rebase the patch set due to the recent commit c6e1f6. > And here is the new version patch set. > LGTM -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Sat, Jan 7, 2023 at 2:25 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > Today, I was analyzing this patch w.r.t recent commit c6e1f62e2c and found that pa_set_xact_state() should set the latch (wake up) for the leader worker as the leader could be waiting in pa_wait_for_xact_state(). What do you think? But otherwise, it should be okay w.r.t DDLs because this patch allows the leader worker to restart logical replication for subscription parameter change which will in turn stop/restart parallel workers if required. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Sunday, January 8, 2023 10:14 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Sat, Jan 7, 2023 at 2:25 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > Today, I was analyzing this patch w.r.t recent commit c6e1f62e2c and found that > pa_set_xact_state() should set the latch (wake up) for the leader worker as the > leader could be waiting in pa_wait_for_xact_state(). What do you think? But > otherwise, it should be okay w.r.t DDLs because this patch allows the leader > worker to restart logical replication for subscription parameter change which will > in turn stop/restart parallel workers if required. Thanks for the analysis. I agree that it would be better to signal the leader when setting the state to PARALLEL_TRANS_STARTED, otherwise it might slightly delay the timing of catch the state change in pa_wait_for_xact_state(), so I have updated the patch for the same. Besides, I also checked commit c6e1f62e2c, I think DDL operation doesn't need to wake up the parallel apply worker directly as the parallel apply worker doesn't start table sync and only communicate with the leader, so I didn't find some other places that need to be changed. Attach the updated patch set. Best regards, Hou zj
Attachment
- v77-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v77-0001-Perform-apply-of-large-transactions-by-parallel-.patch
- v77-0002-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v77-0003-Stop-extra-worker-if-GUC-was-changed.patch
- v77-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Sunday, January 8, 2023 11:59 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > On Sunday, January 8, 2023 10:14 AM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > > On Sat, Jan 7, 2023 at 2:25 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > > > > Today, I was analyzing this patch w.r.t recent commit c6e1f62e2c and > > found that > > pa_set_xact_state() should set the latch (wake up) for the leader > > worker as the leader could be waiting in pa_wait_for_xact_state(). > > What do you think? But otherwise, it should be okay w.r.t DDLs because > > this patch allows the leader worker to restart logical replication for > > subscription parameter change which will in turn stop/restart parallel workers > if required. > > Thanks for the analysis. I agree that it would be better to signal the leader when > setting the state to PARALLEL_TRANS_STARTED, otherwise it might slightly delay > the timing of catch the state change in pa_wait_for_xact_state(), so I have > updated the patch for the same. Besides, I also checked commit c6e1f62e2c, I > think DDL operation doesn't need to wake up the parallel apply worker directly > as the parallel apply worker doesn't start table sync and only communicate with > the leader, so I didn't find some other places that need to be changed. > > Attach the updated patch set. Sorry, the commit message of 0001 was accidentally deleted, just attach the same patch set again with commit message.
Attachment
- v77-0005-Add-a-main_worker_pid-to-pg_stat_subscription.patch
- v77-0001-Perform-apply-of-large-transactions-by-parallel-.patch
- v77-0002-Add-GUC-stream_serialize_threshold-and-test-seri.patch
- v77-0003-Stop-extra-worker-if-GUC-was-changed.patch
- v77-0004-Retry-to-apply-streaming-xact-only-in-apply-work.patch
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Sun, Jan 8, 2023 at 11:32 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Sunday, January 8, 2023 11:59 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > Attach the updated patch set. > > Sorry, the commit message of 0001 was accidentally deleted, just attach > the same patch set again with commit message. > Pushed the first (0001) patch. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Shinoda, Noriyoshi (PN Japan FSIP)"
Date:
Hi, Thanks for the great new feature. Applied patches include adding wait events LogicalParallelApplyMain, LogicalParallelApplyStateChange. However, it seems that monitoring.sgml only contains descriptions for pg_locks. The attached patch adds relevant wait eventinformation. Please update if you have a better description. Noriyoshi Shinoda -----Original Message----- From: Amit Kapila <amit.kapila16@gmail.com> Sent: Monday, January 9, 2023 5:51 PM To: houzj.fnst@fujitsu.com Cc: Masahiko Sawada <sawada.mshk@gmail.com>; wangw.fnst@fujitsu.com; Peter Smith <smithpb2250@gmail.com>; shiy.fnst@fujitsu.com;PostgreSQL Hackers <pgsql-hackers@lists.postgresql.org>; Dilip Kumar <dilipbalaut@gmail.com> Subject: Re: Perform streaming logical transactions by background workers and parallel apply On Sun, Jan 8, 2023 at 11:32 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Sunday, January 8, 2023 11:59 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > Attach the updated patch set. > > Sorry, the commit message of 0001 was accidentally deleted, just > attach the same patch set again with commit message. > Pushed the first (0001) patch. -- With Regards, Amit Kapila.
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, January 9, 2023 5:32 PM Shinoda, Noriyoshi (PN Japan FSIP) <noriyoshi.shinoda@hpe.com> wrote: > > Hi, Thanks for the great new feature. > > Applied patches include adding wait events LogicalParallelApplyMain, > LogicalParallelApplyStateChange. > However, it seems that monitoring.sgml only contains descriptions for > pg_locks. The attached patch adds relevant wait event information. > Please update if you have a better description. Thanks for reporting. I think for LogicalParallelApplyStateChange we'd better document it in a consistent style with LogicalSyncStateChange, so I have slightly adjusted the patch for the same. Best regards, Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Shinoda, Noriyoshi (PN Japan FSIP)"
Date:
Thanks for the reply. > Thanks for reporting. I think for LogicalParallelApplyStateChange we'd better document it in a consistent style with LogicalSyncStateChange, > so I have slightly adjusted the patch for the same. I think the description in the patch you attached is better. Regards, Noriyoshi Shinoda -----Original Message----- From: houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> Sent: Monday, January 9, 2023 7:15 PM To: Shinoda, Noriyoshi (PN Japan FSIP) <noriyoshi.shinoda@hpe.com>; Amit Kapila <amit.kapila16@gmail.com> Cc: Masahiko Sawada <sawada.mshk@gmail.com>; wangw.fnst@fujitsu.com; Peter Smith <smithpb2250@gmail.com>; shiy.fnst@fujitsu.com;PostgreSQL Hackers <pgsql-hackers@lists.postgresql.org>; Dilip Kumar <dilipbalaut@gmail.com> Subject: RE: Perform streaming logical transactions by background workers and parallel apply On Monday, January 9, 2023 5:32 PM Shinoda, Noriyoshi (PN Japan FSIP) <noriyoshi.shinoda@hpe.com> wrote: > > Hi, Thanks for the great new feature. > > Applied patches include adding wait events LogicalParallelApplyMain, > LogicalParallelApplyStateChange. > However, it seems that monitoring.sgml only contains descriptions for > pg_locks. The attached patch adds relevant wait event information. > Please update if you have a better description. Thanks for reporting. I think for LogicalParallelApplyStateChange we'd better document it in a consistent style with LogicalSyncStateChange,so I have slightly adjusted the patch for the same. Best regards, Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, January 9, 2023 4:51 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Sun, Jan 8, 2023 at 11:32 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Sunday, January 8, 2023 11:59 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > Attach the updated patch set. > > > > Sorry, the commit message of 0001 was accidentally deleted, just > > attach the same patch set again with commit message. > > > > Pushed the first (0001) patch. Thanks for pushing, here are the remaining patches. I reordered the patch number to put patches that are easier to commit in the front of others. Best regards, Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Kyotaro Horiguchi
Date:
Hello.
At Mon, 9 Jan 2023 14:21:03 +0530, Amit Kapila <amit.kapila16@gmail.com> wrote in
> Pushed the first (0001) patch.
It added the following error message.
+ seg = dsm_attach(handle);
+ if (!seg)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("unable to map dynamic shared memory segment")));
On the other hand we already have the following one in parallel.c
(another in pg_prewarm)
seg = dsm_attach(DatumGetUInt32(main_arg));
if (seg == NULL)
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
errmsg("could not map dynamic shared memory segment")));
Although I don't see a technical difference between the two, all the
other occurances including the just above (except test_shm_mq) use
"could not". A faint memory in my non-durable memory tells me that we
have a policy that we use "can/could not" than "unable".
(Mmm. I find ones in StartBackgroundWorker and sepgsql_client_auth.)
Shouldn't we use the latter than the former? If that's true, it seems
to me that test_shm_mq also needs the same amendment to avoid the same
mistake in future.
=====
index 2e5914d5d9..a2d7474ed4 100644
--- a/src/backend/replication/logical/applyparallelworker.c
+++ b/src/backend/replication/logical/applyparallelworker.c
@@ -891,7 +891,7 @@ ParallelApplyWorkerMain(Datum main_arg)
if (!seg)
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
- errmsg("unable to map dynamic shared memory segment")));
+ errmsg("could not map dynamic shared memory segment")));
toc = shm_toc_attach(PG_LOGICAL_APPLY_SHM_MAGIC, dsm_segment_address(seg));
if (!toc)
diff --git a/src/test/modules/test_shm_mq/worker.c b/src/test/modules/test_shm_mq/worker.c
index 8807727337..005b56023b 100644
--- a/src/test/modules/test_shm_mq/worker.c
+++ b/src/test/modules/test_shm_mq/worker.c
@@ -81,7 +81,7 @@ test_shm_mq_main(Datum main_arg)
if (seg == NULL)
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
- errmsg("unable to map dynamic shared memory segment")));
+ errmsg("could not map dynamic shared memory segment")));
toc = shm_toc_attach(PG_TEST_SHM_MQ_MAGIC, dsm_segment_address(seg));
if (toc == NULL)
ereport(ERROR,
=====
regards.
--
Kyotaro Horiguchi
NTT Open Source Software Center
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Jan 10, 2023 at 11:16 AM Kyotaro Horiguchi
<horikyota.ntt@gmail.com> wrote:
>
> At Mon, 9 Jan 2023 14:21:03 +0530, Amit Kapila <amit.kapila16@gmail.com> wrote in
> > Pushed the first (0001) patch.
>
> It added the following error message.
>
> + seg = dsm_attach(handle);
> + if (!seg)
> + ereport(ERROR,
> + (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("unable to map dynamic shared memory segment")));
>
> On the other hand we already have the following one in parallel.c
> (another in pg_prewarm)
>
> seg = dsm_attach(DatumGetUInt32(main_arg));
> if (seg == NULL)
> ereport(ERROR,
> (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> errmsg("could not map dynamic shared memory segment")));
>
> Although I don't see a technical difference between the two, all the
> other occurances including the just above (except test_shm_mq) use
> "could not". A faint memory in my non-durable memory tells me that we
> have a policy that we use "can/could not" than "unable".
>
Right, it is mentioned in docs [1] (see section "Tricky Words to Avoid").
> (Mmm. I find ones in StartBackgroundWorker and sepgsql_client_auth.)
>
> Shouldn't we use the latter than the former? If that's true, it seems
> to me that test_shm_mq also needs the same amendment to avoid the same
> mistake in future.
>
> =====
> index 2e5914d5d9..a2d7474ed4 100644
> --- a/src/backend/replication/logical/applyparallelworker.c
> +++ b/src/backend/replication/logical/applyparallelworker.c
> @@ -891,7 +891,7 @@ ParallelApplyWorkerMain(Datum main_arg)
> if (!seg)
> ereport(ERROR,
> (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> - errmsg("unable to map dynamic shared memory segment")));
> + errmsg("could not map dynamic shared memory segment")));
>
> toc = shm_toc_attach(PG_LOGICAL_APPLY_SHM_MAGIC, dsm_segment_address(seg));
> if (!toc)
> diff --git a/src/test/modules/test_shm_mq/worker.c b/src/test/modules/test_shm_mq/worker.c
> index 8807727337..005b56023b 100644
> --- a/src/test/modules/test_shm_mq/worker.c
> +++ b/src/test/modules/test_shm_mq/worker.c
> @@ -81,7 +81,7 @@ test_shm_mq_main(Datum main_arg)
> if (seg == NULL)
> ereport(ERROR,
> (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> - errmsg("unable to map dynamic shared memory segment")));
> + errmsg("could not map dynamic shared memory segment")));
> toc = shm_toc_attach(PG_TEST_SHM_MQ_MAGIC, dsm_segment_address(seg));
> if (toc == NULL)
> ereport(ERROR,
> =====
>
Can you please start a new thread and post these changes as we are
proposing to change existing message as well?
[1] - https://www.postgresql.org/docs/devel/error-style-guide.html
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Tue, Jan 10, 2023 at 10:26 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Monday, January 9, 2023 4:51 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Sun, Jan 8, 2023 at 11:32 AM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > On Sunday, January 8, 2023 11:59 AM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > Attach the updated patch set. > > > > > > Sorry, the commit message of 0001 was accidentally deleted, just > > > attach the same patch set again with commit message. > > > > > > > Pushed the first (0001) patch. > > Thanks for pushing, here are the remaining patches. > I reordered the patch number to put patches that are easier to > commit in the front of others. I was looking into 0001, IMHO the pid should continue to represent the main apply worker. So the pid will always show the main apply worker which is actually receiving all the changes for the subscription (in short working as logical receiver) and if it is applying changes through a parallel worker then it should put the parallel worker pid in a new column called 'parallel_worker_pid' or 'parallel_apply_worker_pid' otherwise NULL. Thoughts? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, January 10, 2023 7:48 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Tue, Jan 10, 2023 at 10:26 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Monday, January 9, 2023 4:51 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> > >
> > > On Sun, Jan 8, 2023 at 11:32 AM houzj.fnst@fujitsu.com
> > > <houzj.fnst@fujitsu.com> wrote:
> > > >
> > > > On Sunday, January 8, 2023 11:59 AM houzj.fnst@fujitsu.com
> > > <houzj.fnst@fujitsu.com> wrote:
> > > > > Attach the updated patch set.
> > > >
> > > > Sorry, the commit message of 0001 was accidentally deleted, just
> > > > attach the same patch set again with commit message.
> > > >
> > >
> > > Pushed the first (0001) patch.
> >
> > Thanks for pushing, here are the remaining patches.
> > I reordered the patch number to put patches that are easier to commit
> > in the front of others.
>
> I was looking into 0001, IMHO the pid should continue to represent the main
> apply worker. So the pid will always show the main apply worker which is
> actually receiving all the changes for the subscription (in short working as
> logical receiver) and if it is applying changes through a parallel worker then it
> should put the parallel worker pid in a new column called 'parallel_worker_pid'
> or 'parallel_apply_worker_pid' otherwise NULL. Thoughts?
Thanks for the comment.
IIRC, you mean something like following, right ?
(sorry if I misunderstood)
--
For parallel apply worker:
'pid' column shows the pid of the leader, new column parallel_worker_pid shows its own pid
For leader apply worker:
'pid' column shows its own pid, new column parallel_worker_pid shows 0
--
If so, I am not sure if the above is better, because it is changing the
existing column's('pid') meaning, the 'pid' will no longer represent the pid of
the worker itself. Besides, it seems not consistent with what we have for
parallel query workers in pg_stat_activity. What do you think ?
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Jan 11, 2023 at 9:34 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Tuesday, January 10, 2023 7:48 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> >
> > I was looking into 0001, IMHO the pid should continue to represent the main
> > apply worker. So the pid will always show the main apply worker which is
> > actually receiving all the changes for the subscription (in short working as
> > logical receiver) and if it is applying changes through a parallel worker then it
> > should put the parallel worker pid in a new column called 'parallel_worker_pid'
> > or 'parallel_apply_worker_pid' otherwise NULL. Thoughts?
>
> Thanks for the comment.
>
> IIRC, you mean something like following, right ?
> (sorry if I misunderstood)
> --
> For parallel apply worker:
> 'pid' column shows the pid of the leader, new column parallel_worker_pid shows its own pid
>
> For leader apply worker:
> 'pid' column shows its own pid, new column parallel_worker_pid shows 0
> --
>
> If so, I am not sure if the above is better, because it is changing the
> existing column's('pid') meaning, the 'pid' will no longer represent the pid of
> the worker itself. Besides, it seems not consistent with what we have for
> parallel query workers in pg_stat_activity. What do you think ?
>
+1. I think it makes sense to keep it similar to pg_stat_activity.
+ <para>
+ Process ID of the leader apply worker, if this process is a apply
+ parallel worker. NULL if this process is a leader apply worker or a
+ synchronization worker.
Can we change the above description to something like: "Process ID of
the leader apply worker, if this process is a parallel apply worker.
NULL if this process is a leader apply worker or does not participate
in parallel apply, or a synchronization worker."?
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Wed, Jan 11, 2023 at 9:34 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> > I was looking into 0001, IMHO the pid should continue to represent the main
> > apply worker. So the pid will always show the main apply worker which is
> > actually receiving all the changes for the subscription (in short working as
> > logical receiver) and if it is applying changes through a parallel worker then it
> > should put the parallel worker pid in a new column called 'parallel_worker_pid'
> > or 'parallel_apply_worker_pid' otherwise NULL. Thoughts?
>
> Thanks for the comment.
>
> IIRC, you mean something like following, right ?
> (sorry if I misunderstood)
> --
> For parallel apply worker:
> 'pid' column shows the pid of the leader, new column parallel_worker_pid shows its own pid
>
> For leader apply worker:
> 'pid' column shows its own pid, new column parallel_worker_pid shows 0
> --
>
> If so, I am not sure if the above is better, because it is changing the
> existing column's('pid') meaning, the 'pid' will no longer represent the pid of
> the worker itself. Besides, it seems not consistent with what we have for
> parallel query workers in pg_stat_activity. What do you think ?
Actually, I always imagined the pid is the process id of the worker
which is actually receiving the changes for the subscriber. Keeping
the pid to represent the leader makes more sense. But as you said,
that parallel worker for backend is already following the terminology
as you have in your patch to show the pid as the pid of the applying
worker so I am fine with the way you have.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Hi, here are some review comments for patch v78-0001.
======
General
1. (terminology)
AFAIK everywhere until now we’ve been referring everywhere
(docs/comments/code) to the parent apply worker as the "leader apply
worker". Not the "main apply worker". Not the "apply leader worker".
Not any other variations...
From this POV I think the worker member "apply_leader_pid" would be
better named "leader_apply_pid", but I see that this was already
committed to HEAD differently.
Maybe it is not possible (or you don't want) to change that internal
member name but IMO at least all the new code and docs should try to
be using consistent terminology (e.g. leader_apply_XXX) where
possible.
======
Commit message
2.
main_worker_pid is Process ID of the leader apply worker, if this process is a
apply parallel worker. NULL if this process is a leader apply worker or a
synchronization worker.
IIUC, this text is just cut/paste from the monitoring.sgml. In a
review comment below I suggest some changes to that text, so then this
commit message should also change to be the same.
~~
3.
The new column can make it easier to distinguish leader apply worker and apply
parallel worker which is also similar to the 'leader_pid' column in
pg_stat_activity.
SUGGESTION
The new column makes it easier to distinguish parallel apply workers
from other kinds of workers. It is implemented this way to be similar
to the 'leader_pid' column in pg_stat_activity.
======
doc/src/sgml/logical-replication.sgml
4.
+ being synchronized. Moreover, if the streaming transaction is applied in
+ parallel, there will be additional workers.
SUGGESTION
there will be additional workers -> there may be additional parallel
apply workers
======
doc/src/sgml/monitoring.sgml
5. pg_stat_subscription
@@ -3198,11 +3198,22 @@ SELECT pid, wait_event_type, wait_event FROM
pg_stat_activity WHERE wait_event i
<row>
<entry role="catalog_table_entry"><para role="column_definition">
+ <structfield>apply_leader_pid</structfield> <type>integer</type>
+ </para>
+ <para>
+ Process ID of the leader apply worker, if this process is a apply
+ parallel worker. NULL if this process is a leader apply worker or a
+ synchronization worker.
+ </para></entry>
+ </row>
+
+ <row>
+ <entry role="catalog_table_entry"><para role="column_definition">
<structfield>relid</structfield> <type>oid</type>
</para>
<para>
OID of the relation that the worker is synchronizing; null for the
- main apply worker
+ main apply worker and the parallel apply worker
</para></entry>
</row>
5a.
(Same as general comment #1 about terminology)
"apply_leader_pid" --> "leader_apply_pid"
~~
5b.
The current text feels awkward. I see it was copied from the similar
text of 'pg_stat_activity' but perhaps it can be simplified a bit.
SUGGESTION
Process ID of the leader apply worker if this process is a parallel
apply worker; otherwise NULL.
~~
5c.
BEFORE
null for the main apply worker and the parallel apply worker
AFTER
null for the leader apply worker and parallel apply workers
~~
5c.
<structfield>relid</structfield> <type>oid</type>
</para>
<para>
OID of the relation that the worker is synchronizing; null for the
- main apply worker
+ main apply worker and the parallel apply worker
</para></entry>
main apply worker -> leader apply worker
~~~
6.
@@ -3212,7 +3223,7 @@ SELECT pid, wait_event_type, wait_event FROM
pg_stat_activity WHERE wait_event i
</para>
<para>
Last write-ahead log location received, the initial value of
- this field being 0
+ this field being 0; null for the parallel apply worker
</para></entry>
</row>
BEFORE
null for the parallel apply worker
AFTER
null for parallel apply workers
~~~
7.
@@ -3221,7 +3232,8 @@ SELECT pid, wait_event_type, wait_event FROM
pg_stat_activity WHERE wait_event i
<structfield>last_msg_send_time</structfield> <type>timestamp
with time zone</type>
</para>
<para>
- Send time of last message received from origin WAL sender
+ Send time of last message received from origin WAL sender; null for the
+ parallel apply worker
</para></entry>
</row>
(same as #6)
BEFORE
null for the parallel apply worker
AFTER
null for parallel apply workers
~~~
8.
@@ -3230,7 +3242,8 @@ SELECT pid, wait_event_type, wait_event FROM
pg_stat_activity WHERE wait_event i
<structfield>last_msg_receipt_time</structfield>
<type>timestamp with time zone</type>
</para>
<para>
- Receipt time of last message received from origin WAL sender
+ Receipt time of last message received from origin WAL sender; null for
+ the parallel apply worker
</para></entry>
</row>
(same as #6)
BEFORE
null for the parallel apply worker
AFTER
null for parallel apply workers
~~~
9.
@@ -3239,7 +3252,8 @@ SELECT pid, wait_event_type, wait_event FROM
pg_stat_activity WHERE wait_event i
<structfield>latest_end_lsn</structfield> <type>pg_lsn</type>
</para>
<para>
- Last write-ahead log location reported to origin WAL sender
+ Last write-ahead log location reported to origin WAL sender; null for
+ the parallel apply worker
</para></entry>
</row>
(same as #6)
BEFORE
null for the parallel apply worker
AFTER
null for parallel apply workers
~~~
10.
@@ -3249,7 +3263,7 @@ SELECT pid, wait_event_type, wait_event FROM
pg_stat_activity WHERE wait_event i
</para>
<para>
Time of last write-ahead log location reported to origin WAL
- sender
+ sender; null for the parallel apply worker
</para></entry>
</row>
</tbody>
(same as #6)
BEFORE
null for the parallel apply worker
AFTER
null for parallel apply workers
======
src/backend/catalog/system_views.sql
11.
@@ -949,6 +949,7 @@ CREATE VIEW pg_stat_subscription AS
su.oid AS subid,
su.subname,
st.pid,
+ st.apply_leader_pid,
st.relid,
st.received_lsn,
st.last_msg_send_time,
(Same as general comment #1 about terminology)
"apply_leader_pid" --> "leader_apply_pid"
======
src/backend/replication/logical/launcher.c
12.
+ if (worker.apply_leader_pid == InvalidPid)
nulls[3] = true;
else
- values[3] = LSNGetDatum(worker.last_lsn);
- if (worker.last_send_time == 0)
+ values[3] = Int32GetDatum(worker.apply_leader_pid);
+
12a.
(Same as general comment #1 about terminology)
"apply_leader_pid" --> "leader_apply_pid"
~~
12b.
I wondered if here the code should be using the
isParallelApplyWorker(worker) macro here for readability.
e.g.
if (isParallelApplyWorker(worker))
values[3] = Int32GetDatum(worker.apply_leader_pid);
else
nulls[3] = true;
======
src/include/catalog/pg_proc.dat
13.
+ proallargtypes =>
'{oid,oid,oid,int4,int4,pg_lsn,timestamptz,timestamptz,pg_lsn,timestamptz}',
+ proargmodes => '{i,o,o,o,o,o,o,o,o,o}',
+ proargnames =>
'{subid,subid,relid,pid,apply_leader_pid,received_lsn,last_msg_send_time,last_msg_receipt_time,latest_end_lsn,latest_end_time}',
(Same as general comment #1 about terminology)
"apply_leader_pid" --> "leader_apply_pid"
======
src/test/regress/expected/rules.out
14.
@@ -2094,6 +2094,7 @@ pg_stat_ssl| SELECT s.pid,
pg_stat_subscription| SELECT su.oid AS subid,
su.subname,
st.pid,
+ st.apply_leader_pid,
st.relid,
st.received_lsn,
st.last_msg_send_time,
@@ -2101,7 +2102,7 @@ pg_stat_subscription| SELECT su.oid AS subid,
st.latest_end_lsn,
st.latest_end_time
FROM (pg_subscription su
- LEFT JOIN pg_stat_get_subscription(NULL::oid) st(subid, relid,
pid, received_lsn, last_msg_send_time, last_msg_receipt_time,
latest_end_lsn, latest_end_time) ON ((st.subid = su.oid)));
+ LEFT JOIN pg_stat_get_subscription(NULL::oid) st(subid, relid,
pid, apply_leader_pid, received_lsn, last_msg_send_time,
last_msg_receipt_time, latest_end_lsn, latest_end_time) ON ((st.subid
= su.oid)));
pg_stat_subscription_stats| SELECT ss.subid,
s.subname,
ss.apply_error_count,
(Same comment as elsewhere)
"apply_leader_pid" --> "leader_apply_pid"
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Jan 12, 2023 at 9:54 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > doc/src/sgml/monitoring.sgml > > 5. pg_stat_subscription > > @@ -3198,11 +3198,22 @@ SELECT pid, wait_event_type, wait_event FROM > pg_stat_activity WHERE wait_event i > > <row> > <entry role="catalog_table_entry"><para role="column_definition"> > + <structfield>apply_leader_pid</structfield> <type>integer</type> > + </para> > + <para> > + Process ID of the leader apply worker, if this process is a apply > + parallel worker. NULL if this process is a leader apply worker or a > + synchronization worker. > + </para></entry> > + </row> > + > + <row> > + <entry role="catalog_table_entry"><para role="column_definition"> > <structfield>relid</structfield> <type>oid</type> > </para> > <para> > OID of the relation that the worker is synchronizing; null for the > - main apply worker > + main apply worker and the parallel apply worker > </para></entry> > </row> > > 5a. > > (Same as general comment #1 about terminology) > > "apply_leader_pid" --> "leader_apply_pid" > How about naming this as just leader_pid? I think it could be helpful in the future if we decide to parallelize initial sync (aka parallel copy) because then we could use this for the leader PID of parallel sync workers as well. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
shveta malik
Date:
On Thu, Jan 12, 2023 at 10:34 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Jan 12, 2023 at 9:54 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > doc/src/sgml/monitoring.sgml > > > > 5. pg_stat_subscription > > > > @@ -3198,11 +3198,22 @@ SELECT pid, wait_event_type, wait_event FROM > > pg_stat_activity WHERE wait_event i > > > > <row> > > <entry role="catalog_table_entry"><para role="column_definition"> > > + <structfield>apply_leader_pid</structfield> <type>integer</type> > > + </para> > > + <para> > > + Process ID of the leader apply worker, if this process is a apply > > + parallel worker. NULL if this process is a leader apply worker or a > > + synchronization worker. > > + </para></entry> > > + </row> > > + > > + <row> > > + <entry role="catalog_table_entry"><para role="column_definition"> > > <structfield>relid</structfield> <type>oid</type> > > </para> > > <para> > > OID of the relation that the worker is synchronizing; null for the > > - main apply worker > > + main apply worker and the parallel apply worker > > </para></entry> > > </row> > > > > 5a. > > > > (Same as general comment #1 about terminology) > > > > "apply_leader_pid" --> "leader_apply_pid" > > > > How about naming this as just leader_pid? I think it could be helpful > in the future if we decide to parallelize initial sync (aka parallel > copy) because then we could use this for the leader PID of parallel > sync workers as well. > > -- I still prefer leader_apply_pid. leader_pid does not tell which 'operation' it belongs to. 'apply' gives the clarity that it is apply related process. The terms used in patch look very confusing. I had to read a few lines multiple times to understand it. 1. Summary says 'main_worker_pid' to be added but I do not see 'main_worker_pid' added in pg_stat_subscription, instead I see 'apply_leader_pid'. Am I missing something? Also, as stated above 'leader_apply_pid' makes more sense. it is better to correct it everywhere (apply leader-->leader apply). Once that is done, it can be reviewed again. thanks Shveta
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Jan 12, 2023 at 4:21 PM shveta malik <shveta.malik@gmail.com> wrote: > > On Thu, Jan 12, 2023 at 10:34 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Thu, Jan 12, 2023 at 9:54 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > > doc/src/sgml/monitoring.sgml > > > > > > 5. pg_stat_subscription > > > > > > @@ -3198,11 +3198,22 @@ SELECT pid, wait_event_type, wait_event FROM > > > pg_stat_activity WHERE wait_event i > > > > > > <row> > > > <entry role="catalog_table_entry"><para role="column_definition"> > > > + <structfield>apply_leader_pid</structfield> <type>integer</type> > > > + </para> > > > + <para> > > > + Process ID of the leader apply worker, if this process is a apply > > > + parallel worker. NULL if this process is a leader apply worker or a > > > + synchronization worker. > > > + </para></entry> > > > + </row> > > > + > > > + <row> > > > + <entry role="catalog_table_entry"><para role="column_definition"> > > > <structfield>relid</structfield> <type>oid</type> > > > </para> > > > <para> > > > OID of the relation that the worker is synchronizing; null for the > > > - main apply worker > > > + main apply worker and the parallel apply worker > > > </para></entry> > > > </row> > > > > > > 5a. > > > > > > (Same as general comment #1 about terminology) > > > > > > "apply_leader_pid" --> "leader_apply_pid" > > > > > > > How about naming this as just leader_pid? I think it could be helpful > > in the future if we decide to parallelize initial sync (aka parallel > > copy) because then we could use this for the leader PID of parallel > > sync workers as well. > > > > -- > > I still prefer leader_apply_pid. > leader_pid does not tell which 'operation' it belongs to. 'apply' > gives the clarity that it is apply related process. > But then do you suggest that tomorrow if we allow parallel sync workers then we have a separate column leader_sync_pid? I think that doesn't sound like a good idea and moreover one can refer to docs for clarification. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, January 12, 2023 7:08 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Jan 12, 2023 at 4:21 PM shveta malik <shveta.malik@gmail.com> wrote: > > > > On Thu, Jan 12, 2023 at 10:34 AM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > > > > On Thu, Jan 12, 2023 at 9:54 AM Peter Smith <smithpb2250@gmail.com> > wrote: > > > > > > > > > > > > doc/src/sgml/monitoring.sgml > > > > > > > > 5. pg_stat_subscription > > > > > > > > @@ -3198,11 +3198,22 @@ SELECT pid, wait_event_type, wait_event > > > > FROM pg_stat_activity WHERE wait_event i > > > > > > > > <row> > > > > <entry role="catalog_table_entry"><para > > > > role="column_definition"> > > > > + <structfield>apply_leader_pid</structfield> > <type>integer</type> > > > > + </para> > > > > + <para> > > > > + Process ID of the leader apply worker, if this process is a apply > > > > + parallel worker. NULL if this process is a leader apply worker or a > > > > + synchronization worker. > > > > + </para></entry> > > > > + </row> > > > > + > > > > + <row> > > > > + <entry role="catalog_table_entry"><para > > > > + role="column_definition"> > > > > <structfield>relid</structfield> <type>oid</type> > > > > </para> > > > > <para> > > > > OID of the relation that the worker is synchronizing; null for the > > > > - main apply worker > > > > + main apply worker and the parallel apply worker > > > > </para></entry> > > > > </row> > > > > > > > > 5a. > > > > > > > > (Same as general comment #1 about terminology) > > > > > > > > "apply_leader_pid" --> "leader_apply_pid" > > > > > > > > > > How about naming this as just leader_pid? I think it could be > > > helpful in the future if we decide to parallelize initial sync (aka > > > parallel > > > copy) because then we could use this for the leader PID of parallel > > > sync workers as well. > > > > > > -- > > > > I still prefer leader_apply_pid. > > leader_pid does not tell which 'operation' it belongs to. 'apply' > > gives the clarity that it is apply related process. > > > > But then do you suggest that tomorrow if we allow parallel sync workers then > we have a separate column leader_sync_pid? I think that doesn't sound like a > good idea and moreover one can refer to docs for clarification. I agree that leader_pid would be better not only for future parallel copy sync feature, but also it's more consistent with the leader_pid column in pg_stat_activity. And here is the version patch which addressed Peter's comments and renamed all the related stuff to leader_pid. Best Regards, Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, January 12, 2023 12:24 PM Peter Smith <smithpb2250@gmail.com> wrote: > > Hi, here are some review comments for patch v78-0001. Thanks for your comments. > ====== > > General > > 1. (terminology) > > AFAIK everywhere until now we’ve been referring everywhere > (docs/comments/code) to the parent apply worker as the "leader apply > worker". Not the "main apply worker". Not the "apply leader worker". > Not any other variations... > > From this POV I think the worker member "apply_leader_pid" would be better > named "leader_apply_pid", but I see that this was already committed to > HEAD differently. > > Maybe it is not possible (or you don't want) to change that internal member > name but IMO at least all the new code and docs should try to be using > consistent terminology (e.g. leader_apply_XXX) where possible. > > ====== > > Commit message > > 2. > > main_worker_pid is Process ID of the leader apply worker, if this process is a > apply parallel worker. NULL if this process is a leader apply worker or a > synchronization worker. > > IIUC, this text is just cut/paste from the monitoring.sgml. In a review comment > below I suggest some changes to that text, so then this commit message > should also change to be the same. Changed. > ~~ > > 3. > > The new column can make it easier to distinguish leader apply worker and > apply parallel worker which is also similar to the 'leader_pid' column in > pg_stat_activity. > > SUGGESTION > The new column makes it easier to distinguish parallel apply workers from > other kinds of workers. It is implemented this way to be similar to the > 'leader_pid' column in pg_stat_activity. Changed. > ====== > > doc/src/sgml/logical-replication.sgml > > 4. > > + being synchronized. Moreover, if the streaming transaction is applied in > + parallel, there will be additional workers. > > SUGGESTION > there will be additional workers -> there may be additional parallel apply > workers Changed. > ====== > > doc/src/sgml/monitoring.sgml > > 5. pg_stat_subscription > > @@ -3198,11 +3198,22 @@ SELECT pid, wait_event_type, wait_event FROM > pg_stat_activity WHERE wait_event i > > <row> > <entry role="catalog_table_entry"><para role="column_definition"> > + <structfield>apply_leader_pid</structfield> <type>integer</type> > + </para> > + <para> > + Process ID of the leader apply worker, if this process is a apply > + parallel worker. NULL if this process is a leader apply worker or a > + synchronization worker. > + </para></entry> > + </row> > + > + <row> > + <entry role="catalog_table_entry"><para role="column_definition"> > <structfield>relid</structfield> <type>oid</type> > </para> > <para> > OID of the relation that the worker is synchronizing; null for the > - main apply worker > + main apply worker and the parallel apply worker > </para></entry> > </row> > > 5a. > > (Same as general comment #1 about terminology) > > "apply_leader_pid" --> "leader_apply_pid" I changed this and all related stuff to "leader_pid" as I agree with Amit that this might be useful for future features and is more consistent with the leader_pid in pg_stat_activity. > > ~~ > > 5b. > > The current text feels awkward. I see it was copied from the similar text of > 'pg_stat_activity' but perhaps it can be simplified a bit. > > SUGGESTION > Process ID of the leader apply worker if this process is a parallel apply worker; > otherwise NULL. I slightly adjusted this according Amit's suggestion which I think would provide more information. "Process ID of the leader apply worker, if this process is a parallel apply worker. NULL if this process is a leader apply worker or does not participate in parallel apply, or a synchronization worker." " > ~~ > > 5c. > BEFORE > null for the main apply worker and the parallel apply worker > > AFTER > null for the leader apply worker and parallel apply workers Changed. > ~~ > > 5c. > > <structfield>relid</structfield> <type>oid</type> > </para> > <para> > OID of the relation that the worker is synchronizing; null for the > - main apply worker > + main apply worker and the parallel apply worker > </para></entry> > > > main apply worker -> leader apply worker > Changed. > ~~~ > > 6. > > @@ -3212,7 +3223,7 @@ SELECT pid, wait_event_type, wait_event FROM > pg_stat_activity WHERE wait_event i > </para> > <para> > Last write-ahead log location received, the initial value of > - this field being 0 > + this field being 0; null for the parallel apply worker > </para></entry> > </row> > > BEFORE > null for the parallel apply worker > > AFTER > null for parallel apply workers > Changed. > ~~~ > > 7. > > @@ -3221,7 +3232,8 @@ SELECT pid, wait_event_type, wait_event FROM > pg_stat_activity WHERE wait_event i > <structfield>last_msg_send_time</structfield> <type>timestamp > with time zone</type> > </para> > <para> > - Send time of last message received from origin WAL sender > + Send time of last message received from origin WAL sender; null for > the > + parallel apply worker > </para></entry> > </row> > > (same as #6) > > BEFORE > null for the parallel apply worker > > AFTER > null for parallel apply workers > Changed. > ~~~ > > 8. > > @@ -3230,7 +3242,8 @@ SELECT pid, wait_event_type, wait_event FROM > pg_stat_activity WHERE wait_event i > <structfield>last_msg_receipt_time</structfield> > <type>timestamp with time zone</type> > </para> > <para> > - Receipt time of last message received from origin WAL sender > + Receipt time of last message received from origin WAL sender; null for > + the parallel apply worker > </para></entry> > </row> > > (same as #6) > > BEFORE > null for the parallel apply worker > > AFTER > null for parallel apply workers > Changed. > ~~~ > > 9. > > @@ -3239,7 +3252,8 @@ SELECT pid, wait_event_type, wait_event FROM > pg_stat_activity WHERE wait_event i > <structfield>latest_end_lsn</structfield> <type>pg_lsn</type> > </para> > <para> > - Last write-ahead log location reported to origin WAL sender > + Last write-ahead log location reported to origin WAL sender; null for > + the parallel apply worker > </para></entry> > </row> > > (same as #6) > > BEFORE > null for the parallel apply worker > > AFTER > null for parallel apply workers > Changed. > ~~~ > > 10. > > @@ -3249,7 +3263,7 @@ SELECT pid, wait_event_type, wait_event FROM > pg_stat_activity WHERE wait_event i > </para> > <para> > Time of last write-ahead log location reported to origin WAL > - sender > + sender; null for the parallel apply worker > </para></entry> > </row> > </tbody> > > (same as #6) > > BEFORE > null for the parallel apply worker > > AFTER > null for parallel apply workers > Changed. > 12b. > > I wondered if here the code should be using the > isParallelApplyWorker(worker) macro here for readability. > > e.g. > > if (isParallelApplyWorker(worker)) > values[3] = Int32GetDatum(worker.apply_leader_pid); > else > nulls[3] = true; Changed. Best Regards, Hou Zhijie
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for v79-0001.
======
General
1.
When Amit suggested [1] changing the name just to "leader_pid" instead
of "leader_apply_pid" I thought he was only referring to changing the
view column name, not also the internal member names of the worker
structure. Maybe it is OK anyway, but please check if that was the
intention.
======
Commit message
2.
leader_pid is the process ID of the leader apply worker if this process is a
parallel apply worker. If this field is NULL, it indicates that the process is
a leader apply worker or does not participate in parallel apply, or a
synchronization worker.
~
This text is just cut/paste from the monitoring.sgml. In a review
comment below I suggest some changes to that text, so then this commit
message should also change to be the same.
======
doc/src/sgml/monitoring.sgml
3.
<entry role="catalog_table_entry"><para role="column_definition">
+ <structfield>leader_pid</structfield> <type>integer</type>
+ </para>
+ <para>
+ Process ID of the leader apply worker if this process is a parallel
+ apply worker; NULL if this process is a leader apply worker or does not
+ participate in parallel apply, or a synchronization worker
+ </para></entry>
I felt this change is giving too many details and ended up just
muddying the water.
E.g. Now this says basically "NULL if AAA or BBB, or CCC" but that
makes it sounds like there are 3 other things the process could be
instead of a parallel worker. But that is not not really true unless
you are making some distinction between the main "apply worker" which
is a leader versus a main apply worker which is not a leader. IMO we
should not be making any distinction at all - the leader apply worker
and the main (not leader) apply worker are one-and-the-same process.
So, I still prefer my previous suggestion (see [2] #5b]
======
src/backend/catalog/system_views.sql
4.
@@ -949,6 +949,7 @@ CREATE VIEW pg_stat_subscription AS
su.oid AS subid,
su.subname,
st.pid,
+ st.leader_pid,
st.relid,
st.received_lsn,
st.last_msg_send_time,
IMO it would be very useful to have an additional "kind" attribute for
this view. This will save the user from needing to do mental
gymnastics every time just to recognise what kind of process they are
looking at.
For example, I tried this:
CREATE VIEW pg_stat_subscription AS
SELECT
su.oid AS subid,
su.subname,
CASE
WHEN st.relid IS NOT NULL THEN 'tablesync'
WHEN st.leader_pid IS NOT NULL THEN 'parallel apply'
ELSE 'leader apply'
END AS kind,
st.pid,
st.leader_pid,
st.relid,
st.received_lsn,
st.last_msg_send_time,
st.last_msg_receipt_time,
st.latest_end_lsn,
st.latest_end_time
FROM pg_subscription su
LEFT JOIN pg_stat_get_subscription(NULL) st
ON (st.subid = su.oid);
and it results in much more readable output IMO:
test_sub=# select * from pg_stat_subscription;
subid | subname | kind | pid | leader_pid | relid |
received_lsn | last_msg_send_time |
last_msg_receipt_time | lat
est_end_lsn | latest_end_time
-------+---------+--------------+------+------------+-------+--------------+-------------------------------+-------------------------------+----
------------+-------------------------------
16388 | sub1 | leader apply | 5281 | | |
0/1901378 | 2023-01-13 12:39:03.984249+11 | 2023-01-13
12:39:03.986157+11 | 0/1
901378 | 2023-01-13 12:39:03.984249+11
(1 row)
Thoughts?
------
[1] Amit - https://www.postgresql.org/message-id/CAA4eK1KYUbnthSPyo4VjnhMygB0c1DZtp0XC-V2-GSETQ743ww%40mail.gmail.com
[2] My v78-0001 review -
https://www.postgresql.org/message-id/CAHut%2BPvA10Bp9Jaw9OS2%2BpuKHr7ry_xB3Tf2-bbv5gyxD5E_gw%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
shveta malik
Date:
On Thu, Jan 12, 2023 at 4:37 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > But then do you suggest that tomorrow if we allow parallel sync > workers then we have a separate column leader_sync_pid? I think that > doesn't sound like a good idea and moreover one can refer to docs for > clarification. > > -- okay, leader_pid is fine I think. thanks Shveta
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Jan 13, 2023 at 7:56 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Here are my review comments for v79-0001. > > ====== > > General > > 1. > > When Amit suggested [1] changing the name just to "leader_pid" instead > of "leader_apply_pid" I thought he was only referring to changing the > view column name, not also the internal member names of the worker > structure. Maybe it is OK anyway, but please check if that was the > intention. > Yes, that was the intention. > > 3. > > <entry role="catalog_table_entry"><para role="column_definition"> > + <structfield>leader_pid</structfield> <type>integer</type> > + </para> > + <para> > + Process ID of the leader apply worker if this process is a parallel > + apply worker; NULL if this process is a leader apply worker or does not > + participate in parallel apply, or a synchronization worker > + </para></entry> > > I felt this change is giving too many details and ended up just > muddying the water. > I see that we give a similar description for other parameters as well. For example leader_pid in pg_stat_activity, see client_dn, client_serial in pg_stat_ssl. It is better to be consistent here and this gives the reader a bit more information when the value is NULL for the new column. > > 4. > > @@ -949,6 +949,7 @@ CREATE VIEW pg_stat_subscription AS > su.oid AS subid, > su.subname, > st.pid, > + st.leader_pid, > st.relid, > st.received_lsn, > st.last_msg_send_time, > > IMO it would be very useful to have an additional "kind" attribute for > this view. This will save the user from needing to do mental > gymnastics every time just to recognise what kind of process they are > looking at. > This could be a separate enhancement as the same should be true for sync workers. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Jan 13, 2023 at 9:06 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Jan 13, 2023 at 7:56 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > 3. > > > > <entry role="catalog_table_entry"><para role="column_definition"> > > + <structfield>leader_pid</structfield> <type>integer</type> > > + </para> > > + <para> > > + Process ID of the leader apply worker if this process is a parallel > > + apply worker; NULL if this process is a leader apply worker or does not > > + participate in parallel apply, or a synchronization worker > > + </para></entry> > > > > I felt this change is giving too many details and ended up just > > muddying the water. > > > > I see that we give a similar description for other parameters as well. > For example leader_pid in pg_stat_activity, > BTW, shouldn't we update leader_pid column in pg_stat_activity as well to display apply leader PID for parallel apply workers? It will currently display for other parallel operations like a parallel vacuum, so I don't see a reason to not do the same for parallel apply workers. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Fri, Jan 13, 2023 at 1:28 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Jan 13, 2023 at 9:06 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Fri, Jan 13, 2023 at 7:56 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > > > > 3. > > > > > > <entry role="catalog_table_entry"><para role="column_definition"> > > > + <structfield>leader_pid</structfield> <type>integer</type> > > > + </para> > > > + <para> > > > + Process ID of the leader apply worker if this process is a parallel > > > + apply worker; NULL if this process is a leader apply worker or does not > > > + participate in parallel apply, or a synchronization worker > > > + </para></entry> > > > > > > I felt this change is giving too many details and ended up just > > > muddying the water. > > > > > > > I see that we give a similar description for other parameters as well. > > For example leader_pid in pg_stat_activity, > > > > BTW, shouldn't we update leader_pid column in pg_stat_activity as well > to display apply leader PID for parallel apply workers? It will > currently display for other parallel operations like a parallel > vacuum, so I don't see a reason to not do the same for parallel apply > workers. +1 The parallel apply workers have different properties than the parallel query workers since they execute different transactions and don't use group locking but it would be a good hint for users to show the leader and parallel apply worker processes are related. If users want to check only parallel query workers they can use the backend_type column. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Fri, Jan 13, 2023 at 2:37 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > 3. > > > > <entry role="catalog_table_entry"><para role="column_definition"> > > + <structfield>leader_pid</structfield> <type>integer</type> > > + </para> > > + <para> > > + Process ID of the leader apply worker if this process is a parallel > > + apply worker; NULL if this process is a leader apply worker or does not > > + participate in parallel apply, or a synchronization worker > > + </para></entry> > > > > I felt this change is giving too many details and ended up just > > muddying the water. > > > > I see that we give a similar description for other parameters as well. > For example leader_pid in pg_stat_activity, see client_dn, > client_serial in pg_stat_ssl. It is better to be consistent here and > this gives the reader a bit more information when the value is NULL > for the new column. > It is OK to give extra details as those other examples do, but my point -- where I wrote "the leader apply worker and the (not leader) apply worker are one-and-the-same process" -- was there are currently only 3 kinds of workers possible (leader apply, parallel apply, tablsync). If it is not a "parallel apply" worker then it can only be one of the other 2. So I think it is sufficient and less confusing to say: Process ID of the leader apply worker if this process is a parallel apply worker; NULL if this process is a leader apply worker or a synchronization worker. ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Thu, Jan 12, 2023 at 9:34 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Thursday, January 12, 2023 7:08 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Thu, Jan 12, 2023 at 4:21 PM shveta malik <shveta.malik@gmail.com> wrote:
> > >
> > > On Thu, Jan 12, 2023 at 10:34 AM Amit Kapila <amit.kapila16@gmail.com>
> > wrote:
> > > >
> > > > On Thu, Jan 12, 2023 at 9:54 AM Peter Smith <smithpb2250@gmail.com>
> > wrote:
> > > > >
> > > > >
> > > > > doc/src/sgml/monitoring.sgml
> > > > >
> > > > > 5. pg_stat_subscription
> > > > >
> > > > > @@ -3198,11 +3198,22 @@ SELECT pid, wait_event_type, wait_event
> > > > > FROM pg_stat_activity WHERE wait_event i
> > > > >
> > > > > <row>
> > > > > <entry role="catalog_table_entry"><para
> > > > > role="column_definition">
> > > > > + <structfield>apply_leader_pid</structfield>
> > <type>integer</type>
> > > > > + </para>
> > > > > + <para>
> > > > > + Process ID of the leader apply worker, if this process is a apply
> > > > > + parallel worker. NULL if this process is a leader apply worker or a
> > > > > + synchronization worker.
> > > > > + </para></entry>
> > > > > + </row>
> > > > > +
> > > > > + <row>
> > > > > + <entry role="catalog_table_entry"><para
> > > > > + role="column_definition">
> > > > > <structfield>relid</structfield> <type>oid</type>
> > > > > </para>
> > > > > <para>
> > > > > OID of the relation that the worker is synchronizing; null for the
> > > > > - main apply worker
> > > > > + main apply worker and the parallel apply worker
> > > > > </para></entry>
> > > > > </row>
> > > > >
> > > > > 5a.
> > > > >
> > > > > (Same as general comment #1 about terminology)
> > > > >
> > > > > "apply_leader_pid" --> "leader_apply_pid"
> > > > >
> > > >
> > > > How about naming this as just leader_pid? I think it could be
> > > > helpful in the future if we decide to parallelize initial sync (aka
> > > > parallel
> > > > copy) because then we could use this for the leader PID of parallel
> > > > sync workers as well.
> > > >
> > > > --
> > >
> > > I still prefer leader_apply_pid.
> > > leader_pid does not tell which 'operation' it belongs to. 'apply'
> > > gives the clarity that it is apply related process.
> > >
> >
> > But then do you suggest that tomorrow if we allow parallel sync workers then
> > we have a separate column leader_sync_pid? I think that doesn't sound like a
> > good idea and moreover one can refer to docs for clarification.
>
> I agree that leader_pid would be better not only for future parallel copy sync feature,
> but also it's more consistent with the leader_pid column in pg_stat_activity.
>
> And here is the version patch which addressed Peter's comments and renamed all
> the related stuff to leader_pid.
Here are two comments on v79-0003 patch.
+ /* Force to serialize messages if stream_serialize_threshold
is reached. */
+ if (stream_serialize_threshold != -1 &&
+ (stream_serialize_threshold == 0 ||
+ stream_serialize_threshold < parallel_stream_nchunks))
+ {
+ parallel_stream_nchunks = 0;
+ return false;
+ }
I think it would be better if we show the log message ""logical
replication apply worker will serialize the remaining changes of
remote transaction %u to a file" even in stream_serialize_threshold
case.
IIUC parallel_stream_nchunks won't be reset if pa_send_data() failed
due to the timeout.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for patch v79-0002.
======
General
1.
I saw that earlier in this thread Hou-san [1] and Amit [2] also seemed
to say there is not much point for this patch.
So I wanted to +1 that same opinion.
I feel this patch just adds more complexity for almost no gain:
- reducing the 'max_apply_workers_per_suibscription' seems not very
common in the first place.
- even when the GUC is reduced, at that point in time all the workers
might be in use so there may be nothing that can be immediately done.
- IIUC the excess workers (for a reduced GUC) are going to get freed
naturally anyway over time as more transactions are completed so the
pool size will reduce accordingly.
~
OTOH some refactoring parts of this patch (e.g. the new pa_stop_worker
function) look better to me. I would keep those ones but remove all
the pa_stop_idle_workers function/call.
*** NOTE: The remainder of these review comments are maybe only
relevant if you are going to keep this pa_stop_idle_workers
behaviour...
======
Commit message
2.
If the max_parallel_apply_workers_per_subscription is changed to a
lower value, try to stop free workers in the pool to keep the number of
workers lower than half of the max_parallel_apply_workers_per_subscription
SUGGESTION
If the GUC max_parallel_apply_workers_per_subscription is changed to a
lower value, try to stop unused workers to keep the pool size lower
than half of max_parallel_apply_workers_per_subscription.
======
.../replication/logical/applyparallelworker.c
3. pa_free_worker
if (winfo->serialize_changes ||
list_length(ParallelApplyWorkerPool) >
(max_parallel_apply_workers_per_subscription / 2))
{
pa_stop_worker(winfo);
return;
}
winfo->in_use = false;
winfo->serialize_changes = false;
~
IMO the above code can be more neatly written using if/else because
then there is only one return point, and there is a place to write the
explanatory comment about the else.
SUGGESTION
if (winfo->serialize_changes ||
list_length(ParallelApplyWorkerPool) >
(max_parallel_apply_workers_per_subscription / 2))
{
pa_stop_worker(winfo);
}
else
{
/* Don't stop the worker. Only mark it available for re-use. */
winfo->in_use = false;
winfo->serialize_changes = false;
}
======
src/backend/replication/logical/worker.c
4. pa_stop_idle_workers
/*
* Try to stop parallel apply workers that are not in use to keep the number of
* workers lower than half of the max_parallel_apply_workers_per_subscription.
*/
void
pa_stop_idle_workers(void)
{
List *active_workers;
ListCell *lc;
int max_applyworkers = max_parallel_apply_workers_per_subscription / 2;
if (list_length(ParallelApplyWorkerPool) <= max_applyworkers)
return;
active_workers = list_copy(ParallelApplyWorkerPool);
foreach(lc, active_workers)
{
ParallelApplyWorkerInfo *winfo = (ParallelApplyWorkerInfo *) lfirst(lc);
pa_stop_worker(winfo);
/* Recheck the number of workers. */
if (list_length(ParallelApplyWorkerPool) <= max_applyworkers)
break;
}
list_free(active_workers);
}
~
4a. function comment
SUGGESTION
Try to keep the worker pool size lower than half of the
max_parallel_apply_workers_per_subscription.
~
4b. function name
This is not stopping all idle workers, so maybe a more meaningful name
for this function is something more like "pa_reduce_workerpool"
~
4c.
IMO the "max_applyworkers" var is a misleading name. Maybe something
like "goal_poolsize" is better?
~
4d.
Maybe I misunderstand the logic for the pool, but shouldn't this be
checking the winfo->in_use flag before blindly stopping each worker?
======
src/backend/replication/logical/worker.c
5.
@@ -3630,6 +3630,13 @@ LogicalRepApplyLoop(XLogRecPtr last_received)
{
ConfigReloadPending = false;
ProcessConfigFile(PGC_SIGHUP);
+
+ /*
+ * Try to stop free workers in the pool in case the
+ * max_parallel_apply_workers_per_subscription is changed to a
+ * lower value.
+ */
+ pa_stop_idle_workers();
}
5a.
SUGGESTED COMMENT
If max_parallel_apply_workers_per_subscription is changed to a lower
value, try to reduce the worker pool to match.
~
5b.
Instead of unconditionally calling pa_stop_idle_workers, shouldn't
this code compare the value of
max_parallel_apply_workers_per_subscription before/after the
ProcessConfigFile so it only calls if the GUC was lowered?
------
[1] Hou-san -
https://www.postgresql.org/message-id/OS0PR01MB5716E527412A3481F90B4397941A9%40OS0PR01MB5716.jpnprd01.prod.outlook.com
[2] Amit -
https://www.postgresql.org/message-id/CAA4eK1J%3D9m-VNRMHCqeG8jpX0CTn3Ciad2o4H-ogrZMDJ3tn4w%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, January 13, 2023 1:02 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Fri, Jan 13, 2023 at 1:28 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Fri, Jan 13, 2023 at 9:06 AM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > > > > On Fri, Jan 13, 2023 at 7:56 AM Peter Smith <smithpb2250@gmail.com> > wrote: > > > > > > > > > > > > > > > 3. > > > > > > > > <entry role="catalog_table_entry"><para > > > > role="column_definition"> > > > > + <structfield>leader_pid</structfield> <type>integer</type> > > > > + </para> > > > > + <para> > > > > + Process ID of the leader apply worker if this process is a parallel > > > > + apply worker; NULL if this process is a leader apply worker or > does not > > > > + participate in parallel apply, or a synchronization worker > > > > + </para></entry> > > > > > > > > I felt this change is giving too many details and ended up just > > > > muddying the water. > > > > > > > > > > I see that we give a similar description for other parameters as well. > > > For example leader_pid in pg_stat_activity, > > > > > > > BTW, shouldn't we update leader_pid column in pg_stat_activity as well > > to display apply leader PID for parallel apply workers? It will > > currently display for other parallel operations like a parallel > > vacuum, so I don't see a reason to not do the same for parallel apply > > workers. > > +1 > > The parallel apply workers have different properties than the parallel query > workers since they execute different transactions and don't use group locking > but it would be a good hint for users to show the leader and parallel apply > worker processes are related. If users want to check only parallel query workers > they can use the backend_type column. Agreed, and changed as suggested. Attach the new version patch set which address the comments so far. Best Regards, Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, January 13, 2023 1:43 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> On Thu, Jan 12, 2023 at 9:34 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Thursday, January 12, 2023 7:08 PM Amit Kapila
> <amit.kapila16@gmail.com> wrote:
> > >
> > > On Thu, Jan 12, 2023 at 4:21 PM shveta malik <shveta.malik@gmail.com>
> wrote:
> > > >
> > > > On Thu, Jan 12, 2023 at 10:34 AM Amit Kapila
> > > > <amit.kapila16@gmail.com>
> > > wrote:
> > > > >
> > > > > On Thu, Jan 12, 2023 at 9:54 AM Peter Smith
> > > > > <smithpb2250@gmail.com>
> > > wrote:
> > > > > >
> > > > > >
> > > > > > doc/src/sgml/monitoring.sgml
> > > > > >
> > > > > > 5. pg_stat_subscription
> > > > > >
> > > > > > @@ -3198,11 +3198,22 @@ SELECT pid, wait_event_type,
> > > > > > wait_event FROM pg_stat_activity WHERE wait_event i
> > > > > >
> > > > > > <row>
> > > > > > <entry role="catalog_table_entry"><para
> > > > > > role="column_definition">
> > > > > > + <structfield>apply_leader_pid</structfield>
> > > <type>integer</type>
> > > > > > + </para>
> > > > > > + <para>
> > > > > > + Process ID of the leader apply worker, if this process is a
> apply
> > > > > > + parallel worker. NULL if this process is a leader apply worker
> or a
> > > > > > + synchronization worker.
> > > > > > + </para></entry>
> > > > > > + </row>
> > > > > > +
> > > > > > + <row>
> > > > > > + <entry role="catalog_table_entry"><para
> > > > > > + role="column_definition">
> > > > > > <structfield>relid</structfield> <type>oid</type>
> > > > > > </para>
> > > > > > <para>
> > > > > > OID of the relation that the worker is synchronizing; null for
> the
> > > > > > - main apply worker
> > > > > > + main apply worker and the parallel apply worker
> > > > > > </para></entry>
> > > > > > </row>
> > > > > >
> > > > > > 5a.
> > > > > >
> > > > > > (Same as general comment #1 about terminology)
> > > > > >
> > > > > > "apply_leader_pid" --> "leader_apply_pid"
> > > > > >
> > > > >
> > > > > How about naming this as just leader_pid? I think it could be
> > > > > helpful in the future if we decide to parallelize initial sync
> > > > > (aka parallel
> > > > > copy) because then we could use this for the leader PID of
> > > > > parallel sync workers as well.
> > > > >
> > > > > --
> > > >
> > > > I still prefer leader_apply_pid.
> > > > leader_pid does not tell which 'operation' it belongs to. 'apply'
> > > > gives the clarity that it is apply related process.
> > > >
> > >
> > > But then do you suggest that tomorrow if we allow parallel sync
> > > workers then we have a separate column leader_sync_pid? I think that
> > > doesn't sound like a good idea and moreover one can refer to docs for
> clarification.
> >
> > I agree that leader_pid would be better not only for future parallel
> > copy sync feature, but also it's more consistent with the leader_pid column in
> pg_stat_activity.
> >
> > And here is the version patch which addressed Peter's comments and
> > renamed all the related stuff to leader_pid.
>
> Here are two comments on v79-0003 patch.
Thanks for the comments.
>
> + /* Force to serialize messages if stream_serialize_threshold
> is reached. */
> + if (stream_serialize_threshold != -1 &&
> + (stream_serialize_threshold == 0 ||
> + stream_serialize_threshold < parallel_stream_nchunks))
> + {
> + parallel_stream_nchunks = 0;
> + return false;
> + }
>
> I think it would be better if we show the log message ""logical replication apply
> worker will serialize the remaining changes of remote transaction %u to a file"
> even in stream_serialize_threshold case.
Agreed and changed.
>
> IIUC parallel_stream_nchunks won't be reset if pa_send_data() failed due to the
> timeout.
Changed.
Best Regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, January 13, 2023 2:20 PM Peter Smith <smithpb2250@gmail.com> wrote: > > Here are some review comments for patch v79-0002. Thanks for your comments. > ====== > > General > > 1. > > I saw that earlier in this thread Hou-san [1] and Amit [2] also seemed to say > there is not much point for this patch. > > So I wanted to +1 that same opinion. > > I feel this patch just adds more complexity for almost no gain: > - reducing the 'max_apply_workers_per_suibscription' seems not very > common in the first place. > - even when the GUC is reduced, at that point in time all the workers might be in > use so there may be nothing that can be immediately done. > - IIUC the excess workers (for a reduced GUC) are going to get freed naturally > anyway over time as more transactions are completed so the pool size will > reduce accordingly. I need to think over it, and we can have detailed discussion after committing the first patch. So I didn't address the comments for 0002 for now. Best Regards, Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Jan 13, 2023 at 3:44 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Friday, January 13, 2023 1:43 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Thu, Jan 12, 2023 at 9:34 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: In GetLogicalLeaderApplyWorker(), we can use shared lock instead exclusive as we are just reading the workers array. Also, the function name looks a bit odd to me, so I changed it to GetLeaderApplyWorkerPid(). Also, it is better to use InvalidPid instead of 0 when there is no valid value for leader_pid in GetLeaderApplyWorkerPid(). Apart from that, I have made minor changes in the comments, docs, and commit message. I am planning to push this next week by Tuesday unless you or others have any major comments. -- With Regards, Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Tomas Vondra
Date:
Hi,
I think there's a bug in how get_transaction_apply_action() interacts
with handle_streamed_transaction() to decide whether the transaction is
streamed or not. Originally, the code was simply:
/* not in streaming mode */
if (!in_streamed_transaction)
return false;
But now this decision was moved to get_transaction_apply_action(), which
does this:
if (am_parallel_apply_worker())
{
return TRANS_PARALLEL_APPLY;
}
else if (in_remote_transaction)
{
return TRANS_LEADER_APPLY;
}
and handle_streamed_transaction() then uses the result like this:
/* not in streaming mode */
if (apply_action == TRANS_LEADER_APPLY)
return false;
Notice this is not equal to the original behavior, because the two flags
(in_remote_transaction and in_streamed_transaction) are not inverse.
That is,
in_remote_transaction=false
does not imply we're processing streamed transaction. It's allowed both
flags are false, i.e. a change may be "non-transactional" and not
streamed, though the only example of such thing in the protocol are
logical messages. Which are however ignored in the apply worker, so I'm
not surprised no existing test failed on this.
So I think get_transaction_apply_action() should do this:
if (am_parallel_apply_worker())
{
return TRANS_PARALLEL_APPLY;
}
else if (!in_streamed_transaction)
{
return TRANS_LEADER_APPLY;
}
FWIW I've noticed this after rebasing the sequence decoding patch, which
adds another type of protocol message with the transactional vs.
non-transactional behavior, similar to "logical messages" except that in
this case the worker does not ignore that.
Also, I think get_transaction_apply_action() would deserve better
comments explaining how/why it makes the decisions.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Re: Perform streaming logical transactions by background workers and parallel apply
From
Kyotaro Horiguchi
Date:
At Tue, 10 Jan 2023 12:01:43 +0530, Amit Kapila <amit.kapila16@gmail.com> wrote in > On Tue, Jan 10, 2023 at 11:16 AM Kyotaro Horiguchi > <horikyota.ntt@gmail.com> wrote: > > Although I don't see a technical difference between the two, all the > > other occurances including the just above (except test_shm_mq) use > > "could not". A faint memory in my non-durable memory tells me that we > > have a policy that we use "can/could not" than "unable". > > > > Right, it is mentioned in docs [1] (see section "Tricky Words to Avoid"). Thanks for confirmation. > Can you please start a new thread and post these changes as we are > proposing to change existing message as well? All right. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for v81-0001.
======
Commit Message
1.
Additionally, update the leader_pid column in pg_stat_activity as well to
display the PID of the leader apply worker for parallel apply workers.
~
Probably it should not say both "Additionally" and "as well" in the
same sentence.
======
src/backend/replication/logical/launcher.c
2.
/*
+ * Return the pid of the leader apply worker if the given pid is the pid of a
+ * parallel apply worker, otherwise return InvalidPid.
+ */
+pid_t
+GetLeaderApplyWorkerPid(pid_t pid)
+{
+ int leader_pid = InvalidPid;
+ int i;
+
+ LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
+
+ for (i = 0; i < max_logical_replication_workers; i++)
+ {
+ LogicalRepWorker *w = &LogicalRepCtx->workers[i];
+
+ if (isParallelApplyWorker(w) && w->proc && pid == w->proc->pid)
+ {
+ leader_pid = w->leader_pid;
+ break;
+ }
+ }
+
+ LWLockRelease(LogicalRepWorkerLock);
+
+ return leader_pid;
+}
2a.
IIUC the IsParallelApplyWorker macro does nothing except check that
the leader_pid is not InvalidPid anyway, so AFAIK this algorithm does
not benefit from using this macro because we will want to return
InvalidPid anyway if the given pid matches.
So the inner condition can just say:
if (w->proc && w->proc->pid == pid)
{
leader_pid = w->leader_pid;
break;
}
~
2b.
A possible alternative comment.
BEFORE
Return the pid of the leader apply worker if the given pid is the pid
of a parallel apply worker, otherwise return InvalidPid.
AFTER
If the given pid has a leader apply worker then return the leader pid,
otherwise, return InvalidPid.
======
src/backend/utils/adt/pgstatfuncs.c
3.
@@ -434,6 +435,16 @@ pg_stat_get_activity(PG_FUNCTION_ARGS)
values[28] = Int32GetDatum(leader->pid);
nulls[28] = false;
}
+ else
+ {
+ int leader_pid = GetLeaderApplyWorkerPid(beentry->st_procpid);
+
+ if (leader_pid != InvalidPid)
+ {
+ values[28] = Int32GetDatum(leader_pid);
+ nulls[28] = false;
+ }
+
3a.
There is an existing comment preceding this if/else but it refers only
to leaders of parallel groups. Should that comment be updated to
mention the leader apply worker too?
~
3b.
It may be unrelated to this patch, but it seems strange to me that the
nulls[28]/values[28] assignments are done where they are. Every other
nulls/values assignment of this function here is pretty much in the
correct numerical order except this one, so IMO this code ought to be
relocated to later in this same function.
------
Kind Regards,
Peter Smith.
Fujitsu Australia.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Sun, Jan 15, 2023 at 10:39 PM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
> I think there's a bug in how get_transaction_apply_action() interacts
> with handle_streamed_transaction() to decide whether the transaction is
> streamed or not. Originally, the code was simply:
>
> /* not in streaming mode */
> if (!in_streamed_transaction)
> return false;
>
> But now this decision was moved to get_transaction_apply_action(), which
> does this:
>
> if (am_parallel_apply_worker())
> {
> return TRANS_PARALLEL_APPLY;
> }
> else if (in_remote_transaction)
> {
> return TRANS_LEADER_APPLY;
> }
>
> and handle_streamed_transaction() then uses the result like this:
>
> /* not in streaming mode */
> if (apply_action == TRANS_LEADER_APPLY)
> return false;
>
> Notice this is not equal to the original behavior, because the two flags
> (in_remote_transaction and in_streamed_transaction) are not inverse.
> That is,
>
> in_remote_transaction=false
>
> does not imply we're processing streamed transaction. It's allowed both
> flags are false, i.e. a change may be "non-transactional" and not
> streamed, though the only example of such thing in the protocol are
> logical messages. Which are however ignored in the apply worker, so I'm
> not surprised no existing test failed on this.
>
Right, this is the reason we didn't catch it in our testing.
> So I think get_transaction_apply_action() should do this:
>
> if (am_parallel_apply_worker())
> {
> return TRANS_PARALLEL_APPLY;
> }
> else if (!in_streamed_transaction)
> {
> return TRANS_LEADER_APPLY;
> }
>
Yeah, something like this would work but some of the callers other
than handle_streamed_transaction() also need to be changed. See
attached.
> FWIW I've noticed this after rebasing the sequence decoding patch, which
> adds another type of protocol message with the transactional vs.
> non-transactional behavior, similar to "logical messages" except that in
> this case the worker does not ignore that.
>
> Also, I think get_transaction_apply_action() would deserve better
> comments explaining how/why it makes the decisions.
>
Okay, I have added the comments in get_transaction_apply_action() and
updated the comments to refer to the enum TransApplyAction where all
the actions are explained.
--
With Regards,
Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Jan 16, 2023 at 10:24 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> 2.
>
> /*
> + * Return the pid of the leader apply worker if the given pid is the pid of a
> + * parallel apply worker, otherwise return InvalidPid.
> + */
> +pid_t
> +GetLeaderApplyWorkerPid(pid_t pid)
> +{
> + int leader_pid = InvalidPid;
> + int i;
> +
> + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> +
> + for (i = 0; i < max_logical_replication_workers; i++)
> + {
> + LogicalRepWorker *w = &LogicalRepCtx->workers[i];
> +
> + if (isParallelApplyWorker(w) && w->proc && pid == w->proc->pid)
> + {
> + leader_pid = w->leader_pid;
> + break;
> + }
> + }
> +
> + LWLockRelease(LogicalRepWorkerLock);
> +
> + return leader_pid;
> +}
>
> 2a.
> IIUC the IsParallelApplyWorker macro does nothing except check that
> the leader_pid is not InvalidPid anyway, so AFAIK this algorithm does
> not benefit from using this macro because we will want to return
> InvalidPid anyway if the given pid matches.
>
> So the inner condition can just say:
>
> if (w->proc && w->proc->pid == pid)
> {
> leader_pid = w->leader_pid;
> break;
> }
>
Yeah, this should also work but I feel the current one is explicit and
more clear.
> ~
>
> 2b.
> A possible alternative comment.
>
> BEFORE
> Return the pid of the leader apply worker if the given pid is the pid
> of a parallel apply worker, otherwise return InvalidPid.
>
>
> AFTER
> If the given pid has a leader apply worker then return the leader pid,
> otherwise, return InvalidPid.
>
I don't think that is an improvement.
> ======
>
> src/backend/utils/adt/pgstatfuncs.c
>
> 3.
>
> @@ -434,6 +435,16 @@ pg_stat_get_activity(PG_FUNCTION_ARGS)
> values[28] = Int32GetDatum(leader->pid);
> nulls[28] = false;
> }
> + else
> + {
> + int leader_pid = GetLeaderApplyWorkerPid(beentry->st_procpid);
> +
> + if (leader_pid != InvalidPid)
> + {
> + values[28] = Int32GetDatum(leader_pid);
> + nulls[28] = false;
> + }
> +
>
> 3a.
> There is an existing comment preceding this if/else but it refers only
> to leaders of parallel groups. Should that comment be updated to
> mention the leader apply worker too?
>
Yeah, we can slightly adjust the comments. How about something like the below:
index 415e711729..7eb668634a 100644
--- a/src/backend/utils/adt/pgstatfuncs.c
+++ b/src/backend/utils/adt/pgstatfuncs.c
@@ -410,9 +410,9 @@ pg_stat_get_activity(PG_FUNCTION_ARGS)
/*
* If a PGPROC entry was retrieved, display
wait events and lock
- * group leader information if any. To avoid
extra overhead, no
- * extra lock is being held, so there is no guarantee of
- * consistency across multiple rows.
+ * group leader or apply leader information if
any. To avoid extra
+ * overhead, no extra lock is being held, so
there is no guarantee
+ * of consistency across multiple rows.
*/
if (proc != NULL)
{
@@ -428,7 +428,7 @@ pg_stat_get_activity(PG_FUNCTION_ARGS)
/*
* Show the leader only for active
parallel workers. This
* leaves the field as NULL for the
leader of a parallel
- * group.
+ * group or the leader of a parallel apply.
*/
if (leader && leader->pid !=
beentry->st_procpid)
> ~
>
> 3b.
> It may be unrelated to this patch, but it seems strange to me that the
> nulls[28]/values[28] assignments are done where they are. Every other
> nulls/values assignment of this function here is pretty much in the
> correct numerical order except this one, so IMO this code ought to be
> relocated to later in this same function.
>
This is not related to the current patch but I see there is merit in
the current coding as it is better to retrieve all the fields of proc
together.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Tomas Vondra
Date:
Hi Amit, Thanks for the patch, the changes seem reasonable to me and it does fix the issue in the sequence decoding patch. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Mon, Jan 16, 2023 at 5:41 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Mon, Jan 16, 2023 at 10:24 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > 2.
> >
> > /*
> > + * Return the pid of the leader apply worker if the given pid is the pid of a
> > + * parallel apply worker, otherwise return InvalidPid.
> > + */
> > +pid_t
> > +GetLeaderApplyWorkerPid(pid_t pid)
> > +{
> > + int leader_pid = InvalidPid;
> > + int i;
> > +
> > + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> > +
> > + for (i = 0; i < max_logical_replication_workers; i++)
> > + {
> > + LogicalRepWorker *w = &LogicalRepCtx->workers[i];
> > +
> > + if (isParallelApplyWorker(w) && w->proc && pid == w->proc->pid)
> > + {
> > + leader_pid = w->leader_pid;
> > + break;
> > + }
> > + }
> > +
> > + LWLockRelease(LogicalRepWorkerLock);
> > +
> > + return leader_pid;
> > +}
> >
> > 2a.
> > IIUC the IsParallelApplyWorker macro does nothing except check that
> > the leader_pid is not InvalidPid anyway, so AFAIK this algorithm does
> > not benefit from using this macro because we will want to return
> > InvalidPid anyway if the given pid matches.
> >
> > So the inner condition can just say:
> >
> > if (w->proc && w->proc->pid == pid)
> > {
> > leader_pid = w->leader_pid;
> > break;
> > }
> >
>
> Yeah, this should also work but I feel the current one is explicit and
> more clear.
OK.
But, I have one last comment about this function -- I saw there are
already other functions that iterate max_logical_replication_workers
like this looking for things:
- logicalrep_worker_find
- logicalrep_workers_find
- logicalrep_worker_launch
- logicalrep_sync_worker_count
So I felt this new function (currently called GetLeaderApplyWorkerPid)
ought to be named similarly to those ones. e.g. call it something like
"logicalrep_worker_find_pa_leader_pid".
>
> > ~
> >
> > 2b.
> > A possible alternative comment.
> >
> > BEFORE
> > Return the pid of the leader apply worker if the given pid is the pid
> > of a parallel apply worker, otherwise return InvalidPid.
> >
> >
> > AFTER
> > If the given pid has a leader apply worker then return the leader pid,
> > otherwise, return InvalidPid.
> >
>
> I don't think that is an improvement.
>
> > ======
> >
> > src/backend/utils/adt/pgstatfuncs.c
> >
> > 3.
> >
> > @@ -434,6 +435,16 @@ pg_stat_get_activity(PG_FUNCTION_ARGS)
> > values[28] = Int32GetDatum(leader->pid);
> > nulls[28] = false;
> > }
> > + else
> > + {
> > + int leader_pid = GetLeaderApplyWorkerPid(beentry->st_procpid);
> > +
> > + if (leader_pid != InvalidPid)
> > + {
> > + values[28] = Int32GetDatum(leader_pid);
> > + nulls[28] = false;
> > + }
> > +
> >
> > 3a.
> > There is an existing comment preceding this if/else but it refers only
> > to leaders of parallel groups. Should that comment be updated to
> > mention the leader apply worker too?
> >
>
> Yeah, we can slightly adjust the comments. How about something like the below:
> index 415e711729..7eb668634a 100644
> --- a/src/backend/utils/adt/pgstatfuncs.c
> +++ b/src/backend/utils/adt/pgstatfuncs.c
> @@ -410,9 +410,9 @@ pg_stat_get_activity(PG_FUNCTION_ARGS)
>
> /*
> * If a PGPROC entry was retrieved, display
> wait events and lock
> - * group leader information if any. To avoid
> extra overhead, no
> - * extra lock is being held, so there is no guarantee of
> - * consistency across multiple rows.
> + * group leader or apply leader information if
> any. To avoid extra
> + * overhead, no extra lock is being held, so
> there is no guarantee
> + * of consistency across multiple rows.
> */
> if (proc != NULL)
> {
> @@ -428,7 +428,7 @@ pg_stat_get_activity(PG_FUNCTION_ARGS)
> /*
> * Show the leader only for active
> parallel workers. This
> * leaves the field as NULL for the
> leader of a parallel
> - * group.
> + * group or the leader of a parallel apply.
> */
> if (leader && leader->pid !=
> beentry->st_procpid)
>
The updated comment LGTM.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, January 17, 2023 5:43 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Mon, Jan 16, 2023 at 5:41 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > On Mon, Jan 16, 2023 at 10:24 AM Peter Smith <smithpb2250@gmail.com>
> wrote:
> > >
> > > 2.
> > >
> > > /*
> > > + * Return the pid of the leader apply worker if the given pid is
> > > +the pid of a
> > > + * parallel apply worker, otherwise return InvalidPid.
> > > + */
> > > +pid_t
> > > +GetLeaderApplyWorkerPid(pid_t pid)
> > > +{
> > > + int leader_pid = InvalidPid;
> > > + int i;
> > > +
> > > + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> > > +
> > > + for (i = 0; i < max_logical_replication_workers; i++) {
> > > + LogicalRepWorker *w = &LogicalRepCtx->workers[i];
> > > +
> > > + if (isParallelApplyWorker(w) && w->proc && pid == w->proc->pid) {
> > > + leader_pid = w->leader_pid; break; } }
> > > +
> > > + LWLockRelease(LogicalRepWorkerLock);
> > > +
> > > + return leader_pid;
> > > +}
> > >
> > > 2a.
> > > IIUC the IsParallelApplyWorker macro does nothing except check that
> > > the leader_pid is not InvalidPid anyway, so AFAIK this algorithm
> > > does not benefit from using this macro because we will want to
> > > return InvalidPid anyway if the given pid matches.
> > >
> > > So the inner condition can just say:
> > >
> > > if (w->proc && w->proc->pid == pid)
> > > {
> > > leader_pid = w->leader_pid;
> > > break;
> > > }
> > >
> >
> > Yeah, this should also work but I feel the current one is explicit and
> > more clear.
>
> OK.
>
> But, I have one last comment about this function -- I saw there are already
> other functions that iterate max_logical_replication_workers like this looking
> for things:
> - logicalrep_worker_find
> - logicalrep_workers_find
> - logicalrep_worker_launch
> - logicalrep_sync_worker_count
>
> So I felt this new function (currently called GetLeaderApplyWorkerPid) ought
> to be named similarly to those ones. e.g. call it something like
> "logicalrep_worker_find_pa_leader_pid".
>
I am not sure we can use the name, because currently all the API name in launcher that
used by other module(not related to subscription) are like
AxxBxx style(see the functions in logicallauncher.h).
logicalrep_worker_xxx style functions are currently only declared in
worker_internal.h.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, Jan 16, 2023 at 3:19 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Sun, Jan 15, 2023 at 10:39 PM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
> >
> > I think there's a bug in how get_transaction_apply_action() interacts
> > with handle_streamed_transaction() to decide whether the transaction is
> > streamed or not. Originally, the code was simply:
> >
> > /* not in streaming mode */
> > if (!in_streamed_transaction)
> > return false;
> >
> > But now this decision was moved to get_transaction_apply_action(), which
> > does this:
> >
> > if (am_parallel_apply_worker())
> > {
> > return TRANS_PARALLEL_APPLY;
> > }
> > else if (in_remote_transaction)
> > {
> > return TRANS_LEADER_APPLY;
> > }
> >
> > and handle_streamed_transaction() then uses the result like this:
> >
> > /* not in streaming mode */
> > if (apply_action == TRANS_LEADER_APPLY)
> > return false;
> >
> > Notice this is not equal to the original behavior, because the two flags
> > (in_remote_transaction and in_streamed_transaction) are not inverse.
> > That is,
> >
> > in_remote_transaction=false
> >
> > does not imply we're processing streamed transaction. It's allowed both
> > flags are false, i.e. a change may be "non-transactional" and not
> > streamed, though the only example of such thing in the protocol are
> > logical messages. Which are however ignored in the apply worker, so I'm
> > not surprised no existing test failed on this.
> >
>
> Right, this is the reason we didn't catch it in our testing.
>
> > So I think get_transaction_apply_action() should do this:
> >
> > if (am_parallel_apply_worker())
> > {
> > return TRANS_PARALLEL_APPLY;
> > }
> > else if (!in_streamed_transaction)
> > {
> > return TRANS_LEADER_APPLY;
> > }
> >
>
> Yeah, something like this would work but some of the callers other
> than handle_streamed_transaction() also need to be changed. See
> attached.
>
> > FWIW I've noticed this after rebasing the sequence decoding patch, which
> > adds another type of protocol message with the transactional vs.
> > non-transactional behavior, similar to "logical messages" except that in
> > this case the worker does not ignore that.
> >
> > Also, I think get_transaction_apply_action() would deserve better
> > comments explaining how/why it makes the decisions.
> >
>
> Okay, I have added the comments in get_transaction_apply_action() and
> updated the comments to refer to the enum TransApplyAction where all
> the actions are explained.
Thank you for the patch.
@@ -1710,6 +1712,7 @@ apply_handle_stream_stop(StringInfo s)
}
in_streamed_transaction = false;
+ stream_xid = InvalidTransactionId;
We reset stream_xid also in stream_close_file() but probably it's no
longer necessary?
How about adding an assertion in apply_handle_stream_start() to make
sure the stream_xid is invalid?
---
It's not related to this issue but I realized that if the action
returned by get_transaction_apply_action() is not handled in the
switch statement, we do only Assert(false). Is it better to raise an
error like "unexpected apply action %d" just in case in order to
detect failure cases also in the production environment?
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Jan 17, 2023 at 8:35 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Mon, Jan 16, 2023 at 3:19 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > Okay, I have added the comments in get_transaction_apply_action() and > > updated the comments to refer to the enum TransApplyAction where all > > the actions are explained. > > Thank you for the patch. > > @@ -1710,6 +1712,7 @@ apply_handle_stream_stop(StringInfo s) > } > > in_streamed_transaction = false; > + stream_xid = InvalidTransactionId; > > We reset stream_xid also in stream_close_file() but probably it's no > longer necessary? > I think so. > How about adding an assertion in apply_handle_stream_start() to make > sure the stream_xid is invalid? > I think it would be better to add such an assert in apply_handle_begin/apply_handle_begin_prepare because there won't be a problem if we start_stream message even when stream_xid is valid. However, maybe it is better to add in all three functions (apply_handle_begin/apply_handle_begin_prepare/apply_handle_stream_start). What do you think? > --- > It's not related to this issue but I realized that if the action > returned by get_transaction_apply_action() is not handled in the > switch statement, we do only Assert(false). Is it better to raise an > error like "unexpected apply action %d" just in case in order to > detect failure cases also in the production environment? > Yeah, that may be better. Shall we do that as part of this patch only or as a separate patch? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Tue, Jan 17, 2023 at 1:21 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Tuesday, January 17, 2023 5:43 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > On Mon, Jan 16, 2023 at 5:41 PM Amit Kapila <amit.kapila16@gmail.com>
> > wrote:
> > >
> > > On Mon, Jan 16, 2023 at 10:24 AM Peter Smith <smithpb2250@gmail.com>
> > wrote:
> > > >
> > > > 2.
> > > >
> > > > /*
> > > > + * Return the pid of the leader apply worker if the given pid is
> > > > +the pid of a
> > > > + * parallel apply worker, otherwise return InvalidPid.
> > > > + */
> > > > +pid_t
> > > > +GetLeaderApplyWorkerPid(pid_t pid)
> > > > +{
> > > > + int leader_pid = InvalidPid;
> > > > + int i;
> > > > +
> > > > + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> > > > +
> > > > + for (i = 0; i < max_logical_replication_workers; i++) {
> > > > + LogicalRepWorker *w = &LogicalRepCtx->workers[i];
> > > > +
> > > > + if (isParallelApplyWorker(w) && w->proc && pid == w->proc->pid) {
> > > > + leader_pid = w->leader_pid; break; } }
> > > > +
> > > > + LWLockRelease(LogicalRepWorkerLock);
> > > > +
> > > > + return leader_pid;
> > > > +}
> > > >
> > > > 2a.
> > > > IIUC the IsParallelApplyWorker macro does nothing except check that
> > > > the leader_pid is not InvalidPid anyway, so AFAIK this algorithm
> > > > does not benefit from using this macro because we will want to
> > > > return InvalidPid anyway if the given pid matches.
> > > >
> > > > So the inner condition can just say:
> > > >
> > > > if (w->proc && w->proc->pid == pid)
> > > > {
> > > > leader_pid = w->leader_pid;
> > > > break;
> > > > }
> > > >
> > >
> > > Yeah, this should also work but I feel the current one is explicit and
> > > more clear.
> >
> > OK.
> >
> > But, I have one last comment about this function -- I saw there are already
> > other functions that iterate max_logical_replication_workers like this looking
> > for things:
> > - logicalrep_worker_find
> > - logicalrep_workers_find
> > - logicalrep_worker_launch
> > - logicalrep_sync_worker_count
> >
> > So I felt this new function (currently called GetLeaderApplyWorkerPid) ought
> > to be named similarly to those ones. e.g. call it something like
> > "logicalrep_worker_find_pa_leader_pid".
> >
>
> I am not sure we can use the name, because currently all the API name in launcher that
> used by other module(not related to subscription) are like
> AxxBxx style(see the functions in logicallauncher.h).
> logicalrep_worker_xxx style functions are currently only declared in
> worker_internal.h.
>
OK. I didn't know there was another header convention that you were
following. In that case, it is fine to leave the name as-is.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, January 17, 2023 11:32 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Tue, Jan 17, 2023 at 1:21 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Tuesday, January 17, 2023 5:43 AM Peter Smith
> <smithpb2250@gmail.com> wrote:
> > >
> > > On Mon, Jan 16, 2023 at 5:41 PM Amit Kapila
> > > <amit.kapila16@gmail.com>
> > > wrote:
> > > >
> > > > On Mon, Jan 16, 2023 at 10:24 AM Peter Smith
> > > > <smithpb2250@gmail.com>
> > > wrote:
> > > > >
> > > > > 2.
> > > > >
> > > > > /*
> > > > > + * Return the pid of the leader apply worker if the given pid
> > > > > +is the pid of a
> > > > > + * parallel apply worker, otherwise return InvalidPid.
> > > > > + */
> > > > > +pid_t
> > > > > +GetLeaderApplyWorkerPid(pid_t pid) { int leader_pid =
> > > > > +InvalidPid; int i;
> > > > > +
> > > > > + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> > > > > +
> > > > > + for (i = 0; i < max_logical_replication_workers; i++) {
> > > > > + LogicalRepWorker *w = &LogicalRepCtx->workers[i];
> > > > > +
> > > > > + if (isParallelApplyWorker(w) && w->proc && pid ==
> > > > > + w->proc->pid) { leader_pid = w->leader_pid; break; } }
> > > > > +
> > > > > + LWLockRelease(LogicalRepWorkerLock);
> > > > > +
> > > > > + return leader_pid;
> > > > > +}
> > > > >
> > > > > 2a.
> > > > > IIUC the IsParallelApplyWorker macro does nothing except check
> > > > > that the leader_pid is not InvalidPid anyway, so AFAIK this
> > > > > algorithm does not benefit from using this macro because we will
> > > > > want to return InvalidPid anyway if the given pid matches.
> > > > >
> > > > > So the inner condition can just say:
> > > > >
> > > > > if (w->proc && w->proc->pid == pid) { leader_pid =
> > > > > w->leader_pid; break; }
> > > > >
> > > >
> > > > Yeah, this should also work but I feel the current one is explicit
> > > > and more clear.
> > >
> > > OK.
> > >
> > > But, I have one last comment about this function -- I saw there are
> > > already other functions that iterate max_logical_replication_workers
> > > like this looking for things:
> > > - logicalrep_worker_find
> > > - logicalrep_workers_find
> > > - logicalrep_worker_launch
> > > - logicalrep_sync_worker_count
> > >
> > > So I felt this new function (currently called
> > > GetLeaderApplyWorkerPid) ought to be named similarly to those ones.
> > > e.g. call it something like "logicalrep_worker_find_pa_leader_pid".
> > >
> >
> > I am not sure we can use the name, because currently all the API name
> > in launcher that used by other module(not related to subscription) are
> > like AxxBxx style(see the functions in logicallauncher.h).
> > logicalrep_worker_xxx style functions are currently only declared in
> > worker_internal.h.
> >
>
> OK. I didn't know there was another header convention that you were following.
> In that case, it is fine to leave the name as-is.
Thanks for confirming!
Attach the new version 0001 patch which addressed all other comments.
Best regards,
Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Tue, Jan 17, 2023 at 2:37 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Tuesday, January 17, 2023 11:32 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > On Tue, Jan 17, 2023 at 1:21 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Tuesday, January 17, 2023 5:43 AM Peter Smith
> > <smithpb2250@gmail.com> wrote:
> > > >
> > > > On Mon, Jan 16, 2023 at 5:41 PM Amit Kapila
> > > > <amit.kapila16@gmail.com>
> > > > wrote:
> > > > >
> > > > > On Mon, Jan 16, 2023 at 10:24 AM Peter Smith
> > > > > <smithpb2250@gmail.com>
> > > > wrote:
> > > > > >
> > > > > > 2.
> > > > > >
> > > > > > /*
> > > > > > + * Return the pid of the leader apply worker if the given pid
> > > > > > +is the pid of a
> > > > > > + * parallel apply worker, otherwise return InvalidPid.
> > > > > > + */
> > > > > > +pid_t
> > > > > > +GetLeaderApplyWorkerPid(pid_t pid) { int leader_pid =
> > > > > > +InvalidPid; int i;
> > > > > > +
> > > > > > + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> > > > > > +
> > > > > > + for (i = 0; i < max_logical_replication_workers; i++) {
> > > > > > + LogicalRepWorker *w = &LogicalRepCtx->workers[i];
> > > > > > +
> > > > > > + if (isParallelApplyWorker(w) && w->proc && pid ==
> > > > > > + w->proc->pid) { leader_pid = w->leader_pid; break; } }
> > > > > > +
> > > > > > + LWLockRelease(LogicalRepWorkerLock);
> > > > > > +
> > > > > > + return leader_pid;
> > > > > > +}
> > > > > >
> > > > > > 2a.
> > > > > > IIUC the IsParallelApplyWorker macro does nothing except check
> > > > > > that the leader_pid is not InvalidPid anyway, so AFAIK this
> > > > > > algorithm does not benefit from using this macro because we will
> > > > > > want to return InvalidPid anyway if the given pid matches.
> > > > > >
> > > > > > So the inner condition can just say:
> > > > > >
> > > > > > if (w->proc && w->proc->pid == pid) { leader_pid =
> > > > > > w->leader_pid; break; }
> > > > > >
> > > > >
> > > > > Yeah, this should also work but I feel the current one is explicit
> > > > > and more clear.
> > > >
> > > > OK.
> > > >
> > > > But, I have one last comment about this function -- I saw there are
> > > > already other functions that iterate max_logical_replication_workers
> > > > like this looking for things:
> > > > - logicalrep_worker_find
> > > > - logicalrep_workers_find
> > > > - logicalrep_worker_launch
> > > > - logicalrep_sync_worker_count
> > > >
> > > > So I felt this new function (currently called
> > > > GetLeaderApplyWorkerPid) ought to be named similarly to those ones.
> > > > e.g. call it something like "logicalrep_worker_find_pa_leader_pid".
> > > >
> > >
> > > I am not sure we can use the name, because currently all the API name
> > > in launcher that used by other module(not related to subscription) are
> > > like AxxBxx style(see the functions in logicallauncher.h).
> > > logicalrep_worker_xxx style functions are currently only declared in
> > > worker_internal.h.
> > >
> >
> > OK. I didn't know there was another header convention that you were following.
> > In that case, it is fine to leave the name as-is.
>
> Thanks for confirming!
>
> Attach the new version 0001 patch which addressed all other comments.
>
OK. I checked the differences between patches v81-0001/v82-0001 and
found everything I was expecting to see.
I have no more review comments for v82-0001.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
shveta malik
Date:
On Tue, Jan 17, 2023 at 9:07 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Tuesday, January 17, 2023 11:32 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > On Tue, Jan 17, 2023 at 1:21 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Tuesday, January 17, 2023 5:43 AM Peter Smith
> > <smithpb2250@gmail.com> wrote:
> > > >
> > > > On Mon, Jan 16, 2023 at 5:41 PM Amit Kapila
> > > > <amit.kapila16@gmail.com>
> > > > wrote:
> > > > >
> > > > > On Mon, Jan 16, 2023 at 10:24 AM Peter Smith
> > > > > <smithpb2250@gmail.com>
> > > > wrote:
> > > > > >
> > > > > > 2.
> > > > > >
> > > > > > /*
> > > > > > + * Return the pid of the leader apply worker if the given pid
> > > > > > +is the pid of a
> > > > > > + * parallel apply worker, otherwise return InvalidPid.
> > > > > > + */
> > > > > > +pid_t
> > > > > > +GetLeaderApplyWorkerPid(pid_t pid) { int leader_pid =
> > > > > > +InvalidPid; int i;
> > > > > > +
> > > > > > + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> > > > > > +
> > > > > > + for (i = 0; i < max_logical_replication_workers; i++) {
> > > > > > + LogicalRepWorker *w = &LogicalRepCtx->workers[i];
> > > > > > +
> > > > > > + if (isParallelApplyWorker(w) && w->proc && pid ==
> > > > > > + w->proc->pid) { leader_pid = w->leader_pid; break; } }
> > > > > > +
> > > > > > + LWLockRelease(LogicalRepWorkerLock);
> > > > > > +
> > > > > > + return leader_pid;
> > > > > > +}
> > > > > >
> > > > > > 2a.
> > > > > > IIUC the IsParallelApplyWorker macro does nothing except check
> > > > > > that the leader_pid is not InvalidPid anyway, so AFAIK this
> > > > > > algorithm does not benefit from using this macro because we will
> > > > > > want to return InvalidPid anyway if the given pid matches.
> > > > > >
> > > > > > So the inner condition can just say:
> > > > > >
> > > > > > if (w->proc && w->proc->pid == pid) { leader_pid =
> > > > > > w->leader_pid; break; }
> > > > > >
> > > > >
> > > > > Yeah, this should also work but I feel the current one is explicit
> > > > > and more clear.
> > > >
> > > > OK.
> > > >
> > > > But, I have one last comment about this function -- I saw there are
> > > > already other functions that iterate max_logical_replication_workers
> > > > like this looking for things:
> > > > - logicalrep_worker_find
> > > > - logicalrep_workers_find
> > > > - logicalrep_worker_launch
> > > > - logicalrep_sync_worker_count
> > > >
> > > > So I felt this new function (currently called
> > > > GetLeaderApplyWorkerPid) ought to be named similarly to those ones.
> > > > e.g. call it something like "logicalrep_worker_find_pa_leader_pid".
> > > >
> > >
> > > I am not sure we can use the name, because currently all the API name
> > > in launcher that used by other module(not related to subscription) are
> > > like AxxBxx style(see the functions in logicallauncher.h).
> > > logicalrep_worker_xxx style functions are currently only declared in
> > > worker_internal.h.
> > >
> >
> > OK. I didn't know there was another header convention that you were following.
> > In that case, it is fine to leave the name as-is.
>
> Thanks for confirming!
>
> Attach the new version 0001 patch which addressed all other comments.
>
> Best regards,
> Hou zj
Hello Hou-san,
1. Do we need to extend test-cases to review the leader_pid column in
pg_stats tables?
2. Do we need to follow the naming convention for
'GetLeaderApplyWorkerPid' like other functions in the same file which
starts with 'logicalrep_'
thanks
Shveta
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Jan 17, 2023 at 8:59 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Jan 17, 2023 at 8:35 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Mon, Jan 16, 2023 at 3:19 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > Okay, I have added the comments in get_transaction_apply_action() and > > > updated the comments to refer to the enum TransApplyAction where all > > > the actions are explained. > > > > Thank you for the patch. > > > > @@ -1710,6 +1712,7 @@ apply_handle_stream_stop(StringInfo s) > > } > > > > in_streamed_transaction = false; > > + stream_xid = InvalidTransactionId; > > > > We reset stream_xid also in stream_close_file() but probably it's no > > longer necessary? > > > > I think so. > > > How about adding an assertion in apply_handle_stream_start() to make > > sure the stream_xid is invalid? > > > > I think it would be better to add such an assert in > apply_handle_begin/apply_handle_begin_prepare because there won't be a > problem if we start_stream message even when stream_xid is valid. > However, maybe it is better to add in all three functions > (apply_handle_begin/apply_handle_begin_prepare/apply_handle_stream_start). > What do you think? > > > --- > > It's not related to this issue but I realized that if the action > > returned by get_transaction_apply_action() is not handled in the > > switch statement, we do only Assert(false). Is it better to raise an > > error like "unexpected apply action %d" just in case in order to > > detect failure cases also in the production environment? > > > > Yeah, that may be better. Shall we do that as part of this patch only > or as a separate patch? > Please find attached the updated patches to address the above comments. I think we can combine and commit them as one patch as both are related. -- With Regards, Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Tue, Jan 17, 2023 at 1:55 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Jan 17, 2023 at 8:59 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, Jan 17, 2023 at 8:35 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > On Mon, Jan 16, 2023 at 3:19 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > Okay, I have added the comments in get_transaction_apply_action() and > > > > updated the comments to refer to the enum TransApplyAction where all > > > > the actions are explained. > > > > > > Thank you for the patch. > > > > > > @@ -1710,6 +1712,7 @@ apply_handle_stream_stop(StringInfo s) > > > } > > > > > > in_streamed_transaction = false; > > > + stream_xid = InvalidTransactionId; > > > > > > We reset stream_xid also in stream_close_file() but probably it's no > > > longer necessary? > > > > > > > I think so. > > > > > How about adding an assertion in apply_handle_stream_start() to make > > > sure the stream_xid is invalid? > > > > > > > I think it would be better to add such an assert in > > apply_handle_begin/apply_handle_begin_prepare because there won't be a > > problem if we start_stream message even when stream_xid is valid. > > However, maybe it is better to add in all three functions > > (apply_handle_begin/apply_handle_begin_prepare/apply_handle_stream_start). > > What do you think? > > > > > --- > > > It's not related to this issue but I realized that if the action > > > returned by get_transaction_apply_action() is not handled in the > > > switch statement, we do only Assert(false). Is it better to raise an > > > error like "unexpected apply action %d" just in case in order to > > > detect failure cases also in the production environment? > > > > > > > Yeah, that may be better. Shall we do that as part of this patch only > > or as a separate patch? > > > > Please find attached the updated patches to address the above > comments. I think we can combine and commit them as one patch as both > are related. Thank you for the patches! Looks good to me. And +1 to merge them. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, January 17, 2023 12:55 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Jan 17, 2023 at 8:59 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, Jan 17, 2023 at 8:35 AM Masahiko Sawada > <sawada.mshk@gmail.com> wrote: > > > > > > On Mon, Jan 16, 2023 at 3:19 PM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > > > > > > Okay, I have added the comments in get_transaction_apply_action() > > > > and updated the comments to refer to the enum TransApplyAction > > > > where all the actions are explained. > > > > > > Thank you for the patch. > > > > > > @@ -1710,6 +1712,7 @@ apply_handle_stream_stop(StringInfo s) > > > } > > > > > > in_streamed_transaction = false; > > > + stream_xid = InvalidTransactionId; > > > > > > We reset stream_xid also in stream_close_file() but probably it's no > > > longer necessary? > > > > > > > I think so. > > > > > How about adding an assertion in apply_handle_stream_start() to make > > > sure the stream_xid is invalid? > > > > > > > I think it would be better to add such an assert in > > apply_handle_begin/apply_handle_begin_prepare because there won't be a > > problem if we start_stream message even when stream_xid is valid. > > However, maybe it is better to add in all three functions > > > (apply_handle_begin/apply_handle_begin_prepare/apply_handle_stream_star > t). > > What do you think? > > > > > --- > > > It's not related to this issue but I realized that if the action > > > returned by get_transaction_apply_action() is not handled in the > > > switch statement, we do only Assert(false). Is it better to raise an > > > error like "unexpected apply action %d" just in case in order to > > > detect failure cases also in the production environment? > > > > > > > Yeah, that may be better. Shall we do that as part of this patch only > > or as a separate patch? > > > > Please find attached the updated patches to address the above comments. I > think we can combine and commit them as one patch as both are related. Thanks for fixing these. I have confirmed that all regression tests passed after applying the patches. And the patches look good to me. Best regards, Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Tue, Jan 17, 2023 at 12:37 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Tuesday, January 17, 2023 11:32 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > On Tue, Jan 17, 2023 at 1:21 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Tuesday, January 17, 2023 5:43 AM Peter Smith
> > <smithpb2250@gmail.com> wrote:
> > > >
> > > > On Mon, Jan 16, 2023 at 5:41 PM Amit Kapila
> > > > <amit.kapila16@gmail.com>
> > > > wrote:
> > > > >
> > > > > On Mon, Jan 16, 2023 at 10:24 AM Peter Smith
> > > > > <smithpb2250@gmail.com>
> > > > wrote:
> > > > > >
> > > > > > 2.
> > > > > >
> > > > > > /*
> > > > > > + * Return the pid of the leader apply worker if the given pid
> > > > > > +is the pid of a
> > > > > > + * parallel apply worker, otherwise return InvalidPid.
> > > > > > + */
> > > > > > +pid_t
> > > > > > +GetLeaderApplyWorkerPid(pid_t pid) { int leader_pid =
> > > > > > +InvalidPid; int i;
> > > > > > +
> > > > > > + LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
> > > > > > +
> > > > > > + for (i = 0; i < max_logical_replication_workers; i++) {
> > > > > > + LogicalRepWorker *w = &LogicalRepCtx->workers[i];
> > > > > > +
> > > > > > + if (isParallelApplyWorker(w) && w->proc && pid ==
> > > > > > + w->proc->pid) { leader_pid = w->leader_pid; break; } }
> > > > > > +
> > > > > > + LWLockRelease(LogicalRepWorkerLock);
> > > > > > +
> > > > > > + return leader_pid;
> > > > > > +}
> > > > > >
> > > > > > 2a.
> > > > > > IIUC the IsParallelApplyWorker macro does nothing except check
> > > > > > that the leader_pid is not InvalidPid anyway, so AFAIK this
> > > > > > algorithm does not benefit from using this macro because we will
> > > > > > want to return InvalidPid anyway if the given pid matches.
> > > > > >
> > > > > > So the inner condition can just say:
> > > > > >
> > > > > > if (w->proc && w->proc->pid == pid) { leader_pid =
> > > > > > w->leader_pid; break; }
> > > > > >
> > > > >
> > > > > Yeah, this should also work but I feel the current one is explicit
> > > > > and more clear.
> > > >
> > > > OK.
> > > >
> > > > But, I have one last comment about this function -- I saw there are
> > > > already other functions that iterate max_logical_replication_workers
> > > > like this looking for things:
> > > > - logicalrep_worker_find
> > > > - logicalrep_workers_find
> > > > - logicalrep_worker_launch
> > > > - logicalrep_sync_worker_count
> > > >
> > > > So I felt this new function (currently called
> > > > GetLeaderApplyWorkerPid) ought to be named similarly to those ones.
> > > > e.g. call it something like "logicalrep_worker_find_pa_leader_pid".
> > > >
> > >
> > > I am not sure we can use the name, because currently all the API name
> > > in launcher that used by other module(not related to subscription) are
> > > like AxxBxx style(see the functions in logicallauncher.h).
> > > logicalrep_worker_xxx style functions are currently only declared in
> > > worker_internal.h.
> > >
> >
> > OK. I didn't know there was another header convention that you were following.
> > In that case, it is fine to leave the name as-is.
>
> Thanks for confirming!
>
> Attach the new version 0001 patch which addressed all other comments.
>
Thank you for updating the patch. Here is one comment:
@@ -426,14 +427,24 @@ pg_stat_get_activity(PG_FUNCTION_ARGS)
/*
* Show the leader only for active
parallel workers. This
- * leaves the field as NULL for the
leader of a parallel
- * group.
+ * leaves the field as NULL for the
leader of a parallel group
+ * or the leader of parallel apply workers.
*/
if (leader && leader->pid !=
beentry->st_procpid)
{
values[28] = Int32GetDatum(leader->pid);
nulls[28] = false;
}
+ else
+ {
+ int
leader_pid = GetLeaderApplyWorkerPid(beentry->st_procpid);
+
+ if (leader_pid != InvalidPid)
+ {
+ values[28] =
Int32GetDatum(leader_pid);
+ nulls[28] = false;
+ }
+ }
}
I'm slightly concerned that there could be overhead of executing
GetLeaderApplyWorkerPid () for every backend process except for
parallel query workers. The number of such backends could be large and
GetLeaderApplyWorkerPid() acquires the lwlock. For example, does it
make sense to check (st_backendType == B_BG_WORKER) before calling
GetLeaderApplyWorkerPid()? Or it might not be a problem since it's
LogicalRepWorkerLock which is not likely to be contended.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, January 17, 2023 2:46 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Tue, Jan 17, 2023 at 12:37 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> > Attach the new version 0001 patch which addressed all other comments.
> >
>
> Thank you for updating the patch. Here is one comment:
>
> @@ -426,14 +427,24 @@ pg_stat_get_activity(PG_FUNCTION_ARGS)
>
> /*
> * Show the leader only for active parallel
> workers. This
> - * leaves the field as NULL for the
> leader of a parallel
> - * group.
> + * leaves the field as NULL for the
> leader of a parallel group
> + * or the leader of parallel apply workers.
> */
> if (leader && leader->pid !=
> beentry->st_procpid)
> {
> values[28] =
> Int32GetDatum(leader->pid);
> nulls[28] = false;
> }
> + else
> + {
> + int
> leader_pid = GetLeaderApplyWorkerPid(beentry->st_procpid);
> +
> + if (leader_pid != InvalidPid)
> + {
> + values[28] =
> Int32GetDatum(leader_pid);
> + nulls[28] = false;
> + }
> + }
> }
>
> I'm slightly concerned that there could be overhead of executing
> GetLeaderApplyWorkerPid () for every backend process except for parallel
> query workers. The number of such backends could be large and
> GetLeaderApplyWorkerPid() acquires the lwlock. For example, does it make
> sense to check (st_backendType == B_BG_WORKER) before calling
> GetLeaderApplyWorkerPid()? Or it might not be a problem since it's
> LogicalRepWorkerLock which is not likely to be contended.
Thanks for the comment and I think your suggestion makes sense.
I have added the check before getting the leader pid. Here is the new version patch.
Best regards,
Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, January 17, 2023 12:34 PM shveta malik <shveta.malik@gmail.com> wrote: > > On Tue, Jan 17, 2023 at 9:07 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Tuesday, January 17, 2023 11:32 AM Peter Smith > <smithpb2250@gmail.com> wrote: > > > OK. I didn't know there was another header convention that you were > > > following. > > > In that case, it is fine to leave the name as-is. > > > > Thanks for confirming! > > > > Attach the new version 0001 patch which addressed all other comments. > > > > Best regards, > > Hou zj > > Hello Hou-san, > > 1. Do we need to extend test-cases to review the leader_pid column in pg_stats > tables? Thanks for the comments. We currently don't have any tests for the view, so I feel we can extend them later as a separate patch. > 2. Do we need to follow the naming convention for > 'GetLeaderApplyWorkerPid' like other functions in the same file which starts > with 'logicalrep_' We have agreed [1] to follow the naming convention for functions in logicallauncher.h which are mainly used for other modules. [1] https://www.postgresql.org/message-id/CAHut%2BPtgj%3DDY8F1cMBRUxsZtq2-faW%3D%3D5-dSuHSPJGx1a_vBFQ%40mail.gmail.com Best regards, Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Tue, Jan 17, 2023 at 6:14 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Tuesday, January 17, 2023 2:46 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Tue, Jan 17, 2023 at 12:37 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > > Attach the new version 0001 patch which addressed all other comments.
> > >
> >
> > Thank you for updating the patch. Here is one comment:
> >
> > @@ -426,14 +427,24 @@ pg_stat_get_activity(PG_FUNCTION_ARGS)
> >
> > /*
> > * Show the leader only for active parallel
> > workers. This
> > - * leaves the field as NULL for the
> > leader of a parallel
> > - * group.
> > + * leaves the field as NULL for the
> > leader of a parallel group
> > + * or the leader of parallel apply workers.
> > */
> > if (leader && leader->pid !=
> > beentry->st_procpid)
> > {
> > values[28] =
> > Int32GetDatum(leader->pid);
> > nulls[28] = false;
> > }
> > + else
> > + {
> > + int
> > leader_pid = GetLeaderApplyWorkerPid(beentry->st_procpid);
> > +
> > + if (leader_pid != InvalidPid)
> > + {
> > + values[28] =
> > Int32GetDatum(leader_pid);
> > + nulls[28] = false;
> > + }
> > + }
> > }
> >
> > I'm slightly concerned that there could be overhead of executing
> > GetLeaderApplyWorkerPid () for every backend process except for parallel
> > query workers. The number of such backends could be large and
> > GetLeaderApplyWorkerPid() acquires the lwlock. For example, does it make
> > sense to check (st_backendType == B_BG_WORKER) before calling
> > GetLeaderApplyWorkerPid()? Or it might not be a problem since it's
> > LogicalRepWorkerLock which is not likely to be contended.
>
> Thanks for the comment and I think your suggestion makes sense.
> I have added the check before getting the leader pid. Here is the new version patch.
Thank you for updating the patch. Looks good to me.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Jan 17, 2023 at 8:07 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Tue, Jan 17, 2023 at 6:14 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Tuesday, January 17, 2023 2:46 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > On Tue, Jan 17, 2023 at 12:37 PM houzj.fnst@fujitsu.com > > > <houzj.fnst@fujitsu.com> wrote: > > > I'm slightly concerned that there could be overhead of executing > > > GetLeaderApplyWorkerPid () for every backend process except for parallel > > > query workers. The number of such backends could be large and > > > GetLeaderApplyWorkerPid() acquires the lwlock. For example, does it make > > > sense to check (st_backendType == B_BG_WORKER) before calling > > > GetLeaderApplyWorkerPid()? Or it might not be a problem since it's > > > LogicalRepWorkerLock which is not likely to be contended. > > > > Thanks for the comment and I think your suggestion makes sense. > > I have added the check before getting the leader pid. Here is the new version patch. > > Thank you for updating the patch. Looks good to me. > Pushed. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Wed, Jan 18, 2023 12:36 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > On Tue, Jan 17, 2023 at 8:07 PM Masahiko Sawada <sawada.mshk@gmail.com> > wrote: > > > > On Tue, Jan 17, 2023 at 6:14 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > On Tuesday, January 17, 2023 2:46 PM Masahiko Sawada > <sawada.mshk@gmail.com> wrote: > > > > > > > > On Tue, Jan 17, 2023 at 12:37 PM houzj.fnst@fujitsu.com > > > > <houzj.fnst@fujitsu.com> wrote: > > > > I'm slightly concerned that there could be overhead of executing > > > > GetLeaderApplyWorkerPid () for every backend process except for parallel > > > > query workers. The number of such backends could be large and > > > > GetLeaderApplyWorkerPid() acquires the lwlock. For example, does it > make > > > > sense to check (st_backendType == B_BG_WORKER) before calling > > > > GetLeaderApplyWorkerPid()? Or it might not be a problem since it's > > > > LogicalRepWorkerLock which is not likely to be contended. > > > > > > Thanks for the comment and I think your suggestion makes sense. > > > I have added the check before getting the leader pid. Here is the new > version patch. > > > > Thank you for updating the patch. Looks good to me. > > > > Pushed. Rebased and attach remaining patches for reviewing. Regards, Wang Wei
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Jan 13, 2023 at 11:50 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Here are some review comments for patch v79-0002. > So, this is about the latest v84-0001-Stop-extra-worker-if-GUC-was-changed. > ====== > > General > > 1. > > I saw that earlier in this thread Hou-san [1] and Amit [2] also seemed > to say there is not much point for this patch. > > So I wanted to +1 that same opinion. > > I feel this patch just adds more complexity for almost no gain: > - reducing the 'max_apply_workers_per_suibscription' seems not very > common in the first place. > - even when the GUC is reduced, at that point in time all the workers > might be in use so there may be nothing that can be immediately done. > - IIUC the excess workers (for a reduced GUC) are going to get freed > naturally anyway over time as more transactions are completed so the > pool size will reduce accordingly. > I am still not sure if it is worth pursuing this patch because of the above reasons. I don't think it would be difficult to add this even at a later point in time if we really see a use case for this. Sawada-San, IIRC, you raised this point. What do you think? The other point I am wondering is whether we can have a different way to test partial serialization apart from introducing another developer GUC (stream_serialize_threshold). One possibility could be that we can have a subscription option (parallel_send_timeout or something like that) with some default value (current_timeout used in the patch) which will be used only when streaming = parallel. Users may want to wait for more time before serialization starts depending on the workload (say when resource usage is high on a subscriber-side machine, or there are concurrent long-running transactions that can block parallel apply for a bit longer time). I know with this as well it may not be straightforward to test the functionality because we can't be sure how many changes would be required for a timeout to occur. This is just for brainstorming other options to test the partial serialization functionality. Thoughts? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Jan 18, 2023 at 12:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Jan 13, 2023 at 11:50 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Here are some review comments for patch v79-0002. > > > > So, this is about the latest v84-0001-Stop-extra-worker-if-GUC-was-changed. > > > > > I feel this patch just adds more complexity for almost no gain: > > - reducing the 'max_apply_workers_per_suibscription' seems not very > > common in the first place. > > - even when the GUC is reduced, at that point in time all the workers > > might be in use so there may be nothing that can be immediately done. > > - IIUC the excess workers (for a reduced GUC) are going to get freed > > naturally anyway over time as more transactions are completed so the > > pool size will reduce accordingly. > > > > I am still not sure if it is worth pursuing this patch because of the > above reasons. I don't think it would be difficult to add this even at > a later point in time if we really see a use case for this. > Sawada-San, IIRC, you raised this point. What do you think? > > The other point I am wondering is whether we can have a different way > to test partial serialization apart from introducing another developer > GUC (stream_serialize_threshold). One possibility could be that we can > have a subscription option (parallel_send_timeout or something like > that) with some default value (current_timeout used in the patch) > which will be used only when streaming = parallel. Users may want to > wait for more time before serialization starts depending on the > workload (say when resource usage is high on a subscriber-side > machine, or there are concurrent long-running transactions that can > block parallel apply for a bit longer time). I know with this as well > it may not be straightforward to test the functionality because we > can't be sure how many changes would be required for a timeout to > occur. This is just for brainstorming other options to test the > partial serialization functionality. > Apart from the above, we can also have a subscription option to specify parallel_shm_queue_size (queue_size used to determine the queue between the leader and parallel worker) and that can be used for this purpose. Basically, configuring it to a smaller value can help in reducing the test time but still, it will not eliminate the need for dependency on timing we have to wait before switching to partial serialize mode. I think this can be used in production as well to tune the performance depending on workload. Yet another way is to use the existing parameter logical_decode_mode [1]. If the value of logical_decoding_mode is 'immediate', then we can immediately switch to partial serialize mode. This will eliminate the dependency on timing. The one argument against using this is that it won't be as clear as a separate parameter like 'stream_serialize_threshold' proposed by the patch but OTOH we already have a few parameters that serve a different purpose when used on the subscriber. For example, 'max_replication_slots' is used to define the maximum number of replication slots on the publisher and the maximum number of origins on subscribers. Similarly, wal_retrieve_retry_interval' is used for different purposes on subscriber and standby nodes. [1] - https://www.postgresql.org/docs/devel/runtime-config-developer.html -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
shveta malik
Date:
On Thu, Jan 19, 2023 at 11:11 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Jan 18, 2023 at 12:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Fri, Jan 13, 2023 at 11:50 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > Here are some review comments for patch v79-0002. > > > > > > > So, this is about the latest v84-0001-Stop-extra-worker-if-GUC-was-changed. > > > > > > > > I feel this patch just adds more complexity for almost no gain: > > > - reducing the 'max_apply_workers_per_suibscription' seems not very > > > common in the first place. > > > - even when the GUC is reduced, at that point in time all the workers > > > might be in use so there may be nothing that can be immediately done. > > > - IIUC the excess workers (for a reduced GUC) are going to get freed > > > naturally anyway over time as more transactions are completed so the > > > pool size will reduce accordingly. > > > > > > > I am still not sure if it is worth pursuing this patch because of the > > above reasons. I don't think it would be difficult to add this even at > > a later point in time if we really see a use case for this. > > Sawada-San, IIRC, you raised this point. What do you think? > > > > The other point I am wondering is whether we can have a different way > > to test partial serialization apart from introducing another developer > > GUC (stream_serialize_threshold). One possibility could be that we can > > have a subscription option (parallel_send_timeout or something like > > that) with some default value (current_timeout used in the patch) > > which will be used only when streaming = parallel. Users may want to > > wait for more time before serialization starts depending on the > > workload (say when resource usage is high on a subscriber-side > > machine, or there are concurrent long-running transactions that can > > block parallel apply for a bit longer time). I know with this as well > > it may not be straightforward to test the functionality because we > > can't be sure how many changes would be required for a timeout to > > occur. This is just for brainstorming other options to test the > > partial serialization functionality. > > > > Apart from the above, we can also have a subscription option to > specify parallel_shm_queue_size (queue_size used to determine the > queue between the leader and parallel worker) and that can be used for > this purpose. Basically, configuring it to a smaller value can help in > reducing the test time but still, it will not eliminate the need for > dependency on timing we have to wait before switching to partial > serialize mode. I think this can be used in production as well to tune > the performance depending on workload. > > Yet another way is to use the existing parameter logical_decode_mode > [1]. If the value of logical_decoding_mode is 'immediate', then we can > immediately switch to partial serialize mode. This will eliminate the > dependency on timing. The one argument against using this is that it > won't be as clear as a separate parameter like > 'stream_serialize_threshold' proposed by the patch but OTOH we already > have a few parameters that serve a different purpose when used on the > subscriber. For example, 'max_replication_slots' is used to define the > maximum number of replication slots on the publisher and the maximum > number of origins on subscribers. Similarly, > wal_retrieve_retry_interval' is used for different purposes on > subscriber and standby nodes. > > [1] - https://www.postgresql.org/docs/devel/runtime-config-developer.html > > -- > With Regards, > Amit Kapila. Hi Amit, On rethinking the complete model, what I feel is that the name logical_decoding_mode is not something which defines modes of logical decoding. We, I think, picked it based on logical_decoding_work_mem. As per current implementation, the parameter 'logical_decoding_mode' tells what happens when work-memory used by logical decoding reaches its limit. So it is in-fact 'logicalrep_workmem_vacate_mode' or 'logicalrep_trans_eviction_mode'. So if it is set to immediate, meaning vacate the work-memory immediately or evict transactions immediately. Add buffered means the reverse (i.e. keep on buffering transactions until we reach a limit). Now coming to subscribers, we can reuse the same parameter. On subscriber as well, shared-memory queue could be considered as its workmem and thus the name 'logicalrep_workmem_vacate_mode' might look more relevant. On publisher: logicalrep_workmem_vacate_mode=immediate, buffered. On subscriber: logicalrep_workmem_vacate_mode=stream_serialize (or if we want to keep immediate here too, that will also be fine). Thoughts? And I am assuming it is possible to change the GUC name before the coming release. If not, please let me know, we can brainstorm other ideas. thanks Shveta
Re: Perform streaming logical transactions by background workers and parallel apply
From
shveta malik
Date:
On Thu, Jan 19, 2023 at 3:44 PM shveta malik <shveta.malik@gmail.com> wrote: > > On Thu, Jan 19, 2023 at 11:11 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Wed, Jan 18, 2023 at 12:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Fri, Jan 13, 2023 at 11:50 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > Here are some review comments for patch v79-0002. > > > > > > > > > > So, this is about the latest v84-0001-Stop-extra-worker-if-GUC-was-changed. > > > > > > > > > > > I feel this patch just adds more complexity for almost no gain: > > > > - reducing the 'max_apply_workers_per_suibscription' seems not very > > > > common in the first place. > > > > - even when the GUC is reduced, at that point in time all the workers > > > > might be in use so there may be nothing that can be immediately done. > > > > - IIUC the excess workers (for a reduced GUC) are going to get freed > > > > naturally anyway over time as more transactions are completed so the > > > > pool size will reduce accordingly. > > > > > > > > > > I am still not sure if it is worth pursuing this patch because of the > > > above reasons. I don't think it would be difficult to add this even at > > > a later point in time if we really see a use case for this. > > > Sawada-San, IIRC, you raised this point. What do you think? > > > > > > The other point I am wondering is whether we can have a different way > > > to test partial serialization apart from introducing another developer > > > GUC (stream_serialize_threshold). One possibility could be that we can > > > have a subscription option (parallel_send_timeout or something like > > > that) with some default value (current_timeout used in the patch) > > > which will be used only when streaming = parallel. Users may want to > > > wait for more time before serialization starts depending on the > > > workload (say when resource usage is high on a subscriber-side > > > machine, or there are concurrent long-running transactions that can > > > block parallel apply for a bit longer time). I know with this as well > > > it may not be straightforward to test the functionality because we > > > can't be sure how many changes would be required for a timeout to > > > occur. This is just for brainstorming other options to test the > > > partial serialization functionality. > > > > > > > Apart from the above, we can also have a subscription option to > > specify parallel_shm_queue_size (queue_size used to determine the > > queue between the leader and parallel worker) and that can be used for > > this purpose. Basically, configuring it to a smaller value can help in > > reducing the test time but still, it will not eliminate the need for > > dependency on timing we have to wait before switching to partial > > serialize mode. I think this can be used in production as well to tune > > the performance depending on workload. > > > > Yet another way is to use the existing parameter logical_decode_mode > > [1]. If the value of logical_decoding_mode is 'immediate', then we can > > immediately switch to partial serialize mode. This will eliminate the > > dependency on timing. The one argument against using this is that it > > won't be as clear as a separate parameter like > > 'stream_serialize_threshold' proposed by the patch but OTOH we already > > have a few parameters that serve a different purpose when used on the > > subscriber. For example, 'max_replication_slots' is used to define the > > maximum number of replication slots on the publisher and the maximum > > number of origins on subscribers. Similarly, > > wal_retrieve_retry_interval' is used for different purposes on > > subscriber and standby nodes. > > > > [1] - https://www.postgresql.org/docs/devel/runtime-config-developer.html > > > > -- > > With Regards, > > Amit Kapila. > > Hi Amit, > > On rethinking the complete model, what I feel is that the name > logical_decoding_mode is not something which defines modes of logical > decoding. We, I think, picked it based on logical_decoding_work_mem. > As per current implementation, the parameter 'logical_decoding_mode' > tells what happens when work-memory used by logical decoding reaches > its limit. So it is in-fact 'logicalrep_workmem_vacate_mode' or Minor correction in what I said earlier: As per current implementation, the parameter 'logical_decoding_mode' more or less tells how to deal with workmem i.e. to keep it buffering with txns until it reaches its limit or immediately vacate it. > 'logicalrep_trans_eviction_mode'. So if it is set to immediate, > meaning vacate the work-memory immediately or evict transactions > immediately. Add buffered means the reverse (i.e. keep on buffering > transactions until we reach a limit). Now coming to subscribers, we > can reuse the same parameter. On subscriber as well, shared-memory > queue could be considered as its workmem and thus the name > 'logicalrep_workmem_vacate_mode' might look more relevant. > > On publisher: > logicalrep_workmem_vacate_mode=immediate, buffered. > > On subscriber: > logicalrep_workmem_vacate_mode=stream_serialize (or if we want to > keep immediate here too, that will also be fine). > > Thoughts? > And I am assuming it is possible to change the GUC name before the > coming release. If not, please let me know, we can brainstorm other > ideas. > > thanks > Shveta thanks Shveta
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Thu, Jan 19, 2023 at 2:41 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Jan 18, 2023 at 12:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Fri, Jan 13, 2023 at 11:50 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > Here are some review comments for patch v79-0002. > > > > > > > So, this is about the latest v84-0001-Stop-extra-worker-if-GUC-was-changed. > > > > > > > > I feel this patch just adds more complexity for almost no gain: > > > - reducing the 'max_apply_workers_per_suibscription' seems not very > > > common in the first place. > > > - even when the GUC is reduced, at that point in time all the workers > > > might be in use so there may be nothing that can be immediately done. > > > - IIUC the excess workers (for a reduced GUC) are going to get freed > > > naturally anyway over time as more transactions are completed so the > > > pool size will reduce accordingly. > > > > > > > I am still not sure if it is worth pursuing this patch because of the > > above reasons. I don't think it would be difficult to add this even at > > a later point in time if we really see a use case for this. > > Sawada-San, IIRC, you raised this point. What do you think? > > > > The other point I am wondering is whether we can have a different way > > to test partial serialization apart from introducing another developer > > GUC (stream_serialize_threshold). One possibility could be that we can > > have a subscription option (parallel_send_timeout or something like > > that) with some default value (current_timeout used in the patch) > > which will be used only when streaming = parallel. Users may want to > > wait for more time before serialization starts depending on the > > workload (say when resource usage is high on a subscriber-side > > machine, or there are concurrent long-running transactions that can > > block parallel apply for a bit longer time). I know with this as well > > it may not be straightforward to test the functionality because we > > can't be sure how many changes would be required for a timeout to > > occur. This is just for brainstorming other options to test the > > partial serialization functionality. I can see parallel_send_timeout idea could be useful somewhat but I'm concerned users can tune this value properly. It's likely to indicate something abnormal or locking issues if LA waits to write data to the queue for more than 10s. Also, I think it doesn't make sense to allow users to set this timeout to a very low value. If switching to partial serialization mode early is useful in some cases, I think it's better to provide it as a new mode, such as streaming = 'parallel-file' etc. > > Apart from the above, we can also have a subscription option to > specify parallel_shm_queue_size (queue_size used to determine the > queue between the leader and parallel worker) and that can be used for > this purpose. Basically, configuring it to a smaller value can help in > reducing the test time but still, it will not eliminate the need for > dependency on timing we have to wait before switching to partial > serialize mode. I think this can be used in production as well to tune > the performance depending on workload. A parameter for the queue size is interesting but I agree it will not eliminate the need for dependency on timing. > > Yet another way is to use the existing parameter logical_decode_mode > [1]. If the value of logical_decoding_mode is 'immediate', then we can > immediately switch to partial serialize mode. This will eliminate the > dependency on timing. The one argument against using this is that it > won't be as clear as a separate parameter like > 'stream_serialize_threshold' proposed by the patch but OTOH we already > have a few parameters that serve a different purpose when used on the > subscriber. For example, 'max_replication_slots' is used to define the > maximum number of replication slots on the publisher and the maximum > number of origins on subscribers. Similarly, > wal_retrieve_retry_interval' is used for different purposes on > subscriber and standby nodes. Using the existing parameter makes sense to me. But if we use logical_decoding_mode also on the subscriber, as Shveta Malik also suggested, probably it's better to rename it so as not to confuse. For example, logical_replication_mode or something. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Jan 20, 2023 at 11:48 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > Yet another way is to use the existing parameter logical_decode_mode > > [1]. If the value of logical_decoding_mode is 'immediate', then we can > > immediately switch to partial serialize mode. This will eliminate the > > dependency on timing. The one argument against using this is that it > > won't be as clear as a separate parameter like > > 'stream_serialize_threshold' proposed by the patch but OTOH we already > > have a few parameters that serve a different purpose when used on the > > subscriber. For example, 'max_replication_slots' is used to define the > > maximum number of replication slots on the publisher and the maximum > > number of origins on subscribers. Similarly, > > wal_retrieve_retry_interval' is used for different purposes on > > subscriber and standby nodes. > > Using the existing parameter makes sense to me. But if we use > logical_decoding_mode also on the subscriber, as Shveta Malik also > suggested, probably it's better to rename it so as not to confuse. For > example, logical_replication_mode or something. > +1. Among the options discussed, this sounds better. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Dilip Kumar
Date:
On Mon, Jan 23, 2023 at 8:47 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Jan 20, 2023 at 11:48 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > Yet another way is to use the existing parameter logical_decode_mode > > > [1]. If the value of logical_decoding_mode is 'immediate', then we can > > > immediately switch to partial serialize mode. This will eliminate the > > > dependency on timing. The one argument against using this is that it > > > won't be as clear as a separate parameter like > > > 'stream_serialize_threshold' proposed by the patch but OTOH we already > > > have a few parameters that serve a different purpose when used on the > > > subscriber. For example, 'max_replication_slots' is used to define the > > > maximum number of replication slots on the publisher and the maximum > > > number of origins on subscribers. Similarly, > > > wal_retrieve_retry_interval' is used for different purposes on > > > subscriber and standby nodes. > > > > Using the existing parameter makes sense to me. But if we use > > logical_decoding_mode also on the subscriber, as Shveta Malik also > > suggested, probably it's better to rename it so as not to confuse. For > > example, logical_replication_mode or something. > > > > +1. Among the options discussed, this sounds better. Yeah, this looks better option with the parameter name 'logical_replication_mode'. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, January 23, 2023 11:17 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Jan 20, 2023 at 11:48 AM Masahiko Sawada <sawada.mshk@gmail.com> > wrote: > > > > > > > > Yet another way is to use the existing parameter logical_decode_mode > > > [1]. If the value of logical_decoding_mode is 'immediate', then we > > > can immediately switch to partial serialize mode. This will > > > eliminate the dependency on timing. The one argument against using > > > this is that it won't be as clear as a separate parameter like > > > 'stream_serialize_threshold' proposed by the patch but OTOH we > > > already have a few parameters that serve a different purpose when > > > used on the subscriber. For example, 'max_replication_slots' is used > > > to define the maximum number of replication slots on the publisher > > > and the maximum number of origins on subscribers. Similarly, > > > wal_retrieve_retry_interval' is used for different purposes on > > > subscriber and standby nodes. > > > > Using the existing parameter makes sense to me. But if we use > > logical_decoding_mode also on the subscriber, as Shveta Malik also > > suggested, probably it's better to rename it so as not to confuse. For > > example, logical_replication_mode or something. > > > > +1. Among the options discussed, this sounds better. OK, here is patch set which does the same. The first patch set only renames the GUC name, and the second patch uses the GUC to test the partial serialization. Best Regards, Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Hou,
Thank you for updating the patch! Followings are my comments.
1. guc_tables.c
```
static const struct config_enum_entry logical_decoding_mode_options[] = {
- {"buffered", LOGICAL_DECODING_MODE_BUFFERED, false},
- {"immediate", LOGICAL_DECODING_MODE_IMMEDIATE, false},
+ {"buffered", LOGICAL_REP_MODE_BUFFERED, false},
+ {"immediate", LOGICAL_REP_MODE_IMMEDIATE, false},
{NULL, 0, false}
};
```
This struct should be also modified.
2. guc_tables.c
```
- {"logical_decoding_mode", PGC_USERSET, DEVELOPER_OPTIONS,
+ {"logical_replication_mode", PGC_USERSET, DEVELOPER_OPTIONS,
gettext_noop("Allows streaming or serializing each change in logical decoding."),
NULL,
```
I felt the description seems not to be suitable for current behavior.
A short description should be like "Sets a behavior of logical replication", and
further descriptions can be added in lond description.
3. config.sgml
```
<para>
This parameter is intended to be used to test logical decoding and
replication of large transactions for which otherwise we need to
generate the changes till <varname>logical_decoding_work_mem</varname>
is reached.
</para>
```
I understood that this part described the usage of the parameter. How about adding
a statement like:
" Moreover, this can be also used to test the message passing between the leader
and parallel apply workers."
4. 015_stream.pl
```
+# Ensure that the messages are serialized.
```
In other parts "changes" are used instead of "messages". Can you change the word?
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for patch v86-0001.
======
General
1.
IIUC the GUC name was made generic 'logical_replication_mode' so that
multiple developer GUCs are not needed later.
But IMO those current option values (buffered/immediate) for that GUC
are maybe a bit too generic. Perhaps in future, we might want more
granular control than that allows. e.g. I can imagine there might be
multiple different meanings for what "buffered" means. If there is any
chance of the generic values being problematic later then maybe they
should be made more specific up-front.
e.g. maybe like:
logical_replication_mode = buffered_decoding
logical_replication_mode = immediate_decoding
Thoughts?
======
Commit message
2.
Since we may extend the developer option logical_decoding_mode to to test the
parallel apply of large transaction on subscriber, rename this option to
logical_replication_mode to make it easier to understand.
~
2a
typo "to to"
typo "large transaction on subscriber" --> "large transactions on the
subscriber"
~
2b.
IMO better to rephrase the whole paragraph like shown below.
SUGGESTION
Rename the developer option 'logical_decoding_mode' to the more
flexible name 'logical_replication_mode' because doing so will make it
easier to extend this option in future to help test other areas of
logical replication.
======
doc/src/sgml/config.sgml
3.
Allows streaming or serializing changes immediately in logical
decoding. The allowed values of logical_replication_mode are buffered
and immediate. When set to immediate, stream each change if streaming
option (see optional parameters set by CREATE SUBSCRIPTION) is
enabled, otherwise, serialize each change. When set to buffered, which
is the default, decoding will stream or serialize changes when
logical_decoding_work_mem is reached.
~
IMO it's more clear to say the default when the options are first
mentioned. So I suggested removing the "which is the default" part,
and instead saying:
BEFORE
The allowed values of logical_replication_mode are buffered and immediate.
AFTER
The allowed values of logical_replication_mode are buffered and
immediate. The default is buffered.
======
src/backend/utils/misc/guc_tables.c
4.
@@ -396,8 +396,8 @@ static const struct config_enum_entry
ssl_protocol_versions_info[] = {
};
static const struct config_enum_entry logical_decoding_mode_options[] = {
- {"buffered", LOGICAL_DECODING_MODE_BUFFERED, false},
- {"immediate", LOGICAL_DECODING_MODE_IMMEDIATE, false},
+ {"buffered", LOGICAL_REP_MODE_BUFFERED, false},
+ {"immediate", LOGICAL_REP_MODE_IMMEDIATE, false},
{NULL, 0, false}
};
I noticed this array is still called "logical_decoding_mode_options".
Was that deliberate?
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Jan 24, 2023 at 9:13 AM Peter Smith <smithpb2250@gmail.com> wrote: > > 1. > > IIUC the GUC name was made generic 'logical_replication_mode' so that > multiple developer GUCs are not needed later. > > But IMO those current option values (buffered/immediate) for that GUC > are maybe a bit too generic. Perhaps in future, we might want more > granular control than that allows. e.g. I can imagine there might be > multiple different meanings for what "buffered" means. If there is any > chance of the generic values being problematic later then maybe they > should be made more specific up-front. > > e.g. maybe like: > logical_replication_mode = buffered_decoding > logical_replication_mode = immediate_decoding > For now, it seems the meaning of buffered/immediate suits our debugging and test needs for publisher/subscriber. This is somewhat explained in Shveta's email [1]. I also think in the future this parameter could be extended for a different purpose but maybe it would be better to invent some new values at that time as things would be more clear. We could do what you are suggesting or in fact even use different values for publisher and subscriber but not really sure whether that will simplify the usage. [1] - https://www.postgresql.org/message-id/CAJpy0uDzddK_ZUsB2qBJUbW_ZODYGoUHTaS5pVcYE2tzATCVXQ%40mail.gmail.com -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are some review comments for v86-0002
======
Commit message
1.
Use the use the existing developer option logical_replication_mode to test the
parallel apply of large transaction on subscriber.
~
Typo “Use the use the”
SUGGESTION (rewritten)
Give additional functionality to the existing developer option
'logical_replication_mode' to help test parallel apply of large
transactions on the subscriber.
~~~
2.
Maybe that commit message should also say extra TAP tests that have
been added to exercise the serialization part of the parallel apply?
BTW – I can see the TAP tests are testing full serialization (when the
GUC is 'immediate') but I not sure how is "partial" serialization
(when it has to switch halfway from shmem to files) being tested.
======
doc/src/sgml/config.sgml
3.
Allows streaming or serializing changes immediately in logical
decoding. The allowed values of logical_replication_mode are buffered
and immediate. When set to immediate, stream each change if streaming
option (see optional parameters set by CREATE SUBSCRIPTION) is
enabled, otherwise, serialize each change. When set to buffered, which
is the default, decoding will stream or serialize changes when
logical_decoding_work_mem is reached.
On the subscriber side, if streaming option is set to parallel, this
parameter also allows the leader apply worker to send changes to the
shared memory queue or to serialize changes. When set to buffered, the
leader sends changes to parallel apply workers via shared memory
queue. When set to immediate, the leader serializes all changes to
files and notifies the parallel apply workers to read and apply them
at the end of the transaction.
~
Because now this same developer GUC affects both the publisher side
and the subscriber side differently IMO this whole description should
be re-structured accordingly.
SUGGESTION (something like)
The allowed values of logical_replication_mode are buffered and
immediate. The default is buffered.
On the publisher side, ...
On the subscriber side, ...
~~~
4.
This parameter is intended to be used to test logical decoding and
replication of large transactions for which otherwise we need to
generate the changes till logical_decoding_work_mem is reached.
~
Maybe this paragraph needs rewording or moving. e.g. Isn't that
misleading now? Although this might be an explanation for the
publisher side, it does not seem relevant to the subscriber side's
behaviour.
======
.../replication/logical/applyparallelworker.c
5.
@ -1149,6 +1149,9 @@ pa_send_data(ParallelApplyWorkerInfo *winfo, Size
nbytes, const void *data)
Assert(!IsTransactionState());
Assert(!winfo->serialize_changes);
+ if (logical_replication_mode == LOGICAL_REP_MODE_IMMEDIATE)
+ return false;
+
I felt that code should have some comment, even if it is just
something quite basic like "/* For developer testing */"
======
.../t/018_stream_subxact_abort.pl
6.
+# Clean up test data from the environment.
+$node_publisher->safe_psql('postgres', "TRUNCATE TABLE test_tab_2");
+$node_publisher->wait_for_catchup($appname);
Is it necessary to TRUNCATE the table here? If everything is working
shouldn't the data be rolled back anyway?
~~~
7.
+$node_publisher->safe_psql(
+ 'postgres', q{
+ BEGIN;
+ INSERT INTO test_tab_2 values(1);
+ SAVEPOINT sp;
+ INSERT INTO test_tab_2 values(1);
+ ROLLBACK TO sp;
+ COMMIT;
+ });
Perhaps this should insert 2 different values so then the verification
code can check the correct value remains instead of just checking
COUNT(*)?
------
Kind Regards,
Peter Smith.
Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, January 24, 2023 3:19 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are some review comments for v86-0002
>
> ======
> Commit message
>
> 1.
> Use the use the existing developer option logical_replication_mode to test the
> parallel apply of large transaction on subscriber.
>
> ~
>
> Typo “Use the use the”
>
> SUGGESTION (rewritten)
> Give additional functionality to the existing developer option
> 'logical_replication_mode' to help test parallel apply of large transactions on the
> subscriber.
Changed.
> ~~~
>
> 2.
> Maybe that commit message should also say extra TAP tests that have been
> added to exercise the serialization part of the parallel apply?
Added.
> BTW – I can see the TAP tests are testing full serialization (when the GUC is
> 'immediate') but I not sure how is "partial" serialization (when it has to switch
> halfway from shmem to files) being tested.
The new tests are intended to test most of new code patch for partial
serialization by doing it from the beginning. Later, if required, we can add
different tests for it.
>
> ======
> doc/src/sgml/config.sgml
>
> 3.
> Allows streaming or serializing changes immediately in logical decoding. The
> allowed values of logical_replication_mode are buffered and immediate. When
> set to immediate, stream each change if streaming option (see optional
> parameters set by CREATE SUBSCRIPTION) is enabled, otherwise, serialize each
> change. When set to buffered, which is the default, decoding will stream or
> serialize changes when logical_decoding_work_mem is reached.
> On the subscriber side, if streaming option is set to parallel, this parameter also
> allows the leader apply worker to send changes to the shared memory queue or
> to serialize changes. When set to buffered, the leader sends changes to parallel
> apply workers via shared memory queue. When set to immediate, the leader
> serializes all changes to files and notifies the parallel apply workers to read and
> apply them at the end of the transaction.
>
> ~
>
> Because now this same developer GUC affects both the publisher side and the
> subscriber side differently IMO this whole description should be re-structured
> accordingly.
>
> SUGGESTION (something like)
>
> The allowed values of logical_replication_mode are buffered and immediate. The
> default is buffered.
>
> On the publisher side, ...
>
> On the subscriber side, ...
Changed.
>
> ~~~
>
> 4.
> This parameter is intended to be used to test logical decoding and replication of
> large transactions for which otherwise we need to generate the changes till
> logical_decoding_work_mem is reached.
>
> ~
>
> Maybe this paragraph needs rewording or moving. e.g. Isn't that misleading
> now? Although this might be an explanation for the publisher side, it does not
> seem relevant to the subscriber side's behaviour.
Adjusted the description here.
>
> ======
> .../replication/logical/applyparallelworker.c
>
> 5.
> @ -1149,6 +1149,9 @@ pa_send_data(ParallelApplyWorkerInfo *winfo, Size
> nbytes, const void *data)
> Assert(!IsTransactionState());
> Assert(!winfo->serialize_changes);
>
> + if (logical_replication_mode == LOGICAL_REP_MODE_IMMEDIATE) return
> + false;
> +
>
> I felt that code should have some comment, even if it is just something quite
> basic like "/* For developer testing */"
Added.
>
> ======
> .../t/018_stream_subxact_abort.pl
>
> 6.
> +# Clean up test data from the environment.
> +$node_publisher->safe_psql('postgres', "TRUNCATE TABLE test_tab_2");
> +$node_publisher->wait_for_catchup($appname);
>
> Is it necessary to TRUNCATE the table here? If everything is working shouldn't
> the data be rolled back anyway?
I think it's unnecessary, so removed.
>
> ~~~
>
> 7.
> +$node_publisher->safe_psql(
> + 'postgres', q{
> + BEGIN;
> + INSERT INTO test_tab_2 values(1);
> + SAVEPOINT sp;
> + INSERT INTO test_tab_2 values(1);
> + ROLLBACK TO sp;
> + COMMIT;
> + });
>
> Perhaps this should insert 2 different values so then the verification code can
> check the correct value remains instead of just checking COUNT(*)?
I think testing the count should be ok as the nearby testcases are
also checking the count.
Best regards,
Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, January 24, 2023 11:43 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are my review comments for patch v86-0001.
Thanks for your comments.
>
>
> ======
> Commit message
>
> 2.
> Since we may extend the developer option logical_decoding_mode to to test the
> parallel apply of large transaction on subscriber, rename this option to
> logical_replication_mode to make it easier to understand.
>
> ~
>
> 2a
> typo "to to"
>
> typo "large transaction on subscriber" --> "large transactions on the subscriber"
>
> ~
>
> 2b.
> IMO better to rephrase the whole paragraph like shown below.
>
> SUGGESTION
>
> Rename the developer option 'logical_decoding_mode' to the more flexible
> name 'logical_replication_mode' because doing so will make it easier to extend
> this option in future to help test other areas of logical replication.
Changed.
> ======
> doc/src/sgml/config.sgml
>
> 3.
> Allows streaming or serializing changes immediately in logical decoding. The
> allowed values of logical_replication_mode are buffered and immediate. When
> set to immediate, stream each change if streaming option (see optional
> parameters set by CREATE SUBSCRIPTION) is enabled, otherwise, serialize each
> change. When set to buffered, which is the default, decoding will stream or
> serialize changes when logical_decoding_work_mem is reached.
>
> ~
>
> IMO it's more clear to say the default when the options are first mentioned. So I
> suggested removing the "which is the default" part, and instead saying:
>
> BEFORE
> The allowed values of logical_replication_mode are buffered and immediate.
>
> AFTER
> The allowed values of logical_replication_mode are buffered and immediate. The
> default is buffered.
I included this change in the 0002 patch.
> ======
> src/backend/utils/misc/guc_tables.c
>
> 4.
> @@ -396,8 +396,8 @@ static const struct config_enum_entry
> ssl_protocol_versions_info[] = { };
>
> static const struct config_enum_entry logical_decoding_mode_options[] = {
> - {"buffered", LOGICAL_DECODING_MODE_BUFFERED, false},
> - {"immediate", LOGICAL_DECODING_MODE_IMMEDIATE, false},
> + {"buffered", LOGICAL_REP_MODE_BUFFERED, false}, {"immediate",
> + LOGICAL_REP_MODE_IMMEDIATE, false},
> {NULL, 0, false}
> };
>
> I noticed this array is still called "logical_decoding_mode_options".
> Was that deliberate?
No, I didn't notice this one. Changed.
Best Regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, January 23, 2023 8:34 PM Kuroda, Hayato wrote:
>
> Followings are my comments.
Thanks for your comments.
>
> 1. guc_tables.c
>
> ```
> static const struct config_enum_entry logical_decoding_mode_options[] = {
> - {"buffered", LOGICAL_DECODING_MODE_BUFFERED, false},
> - {"immediate", LOGICAL_DECODING_MODE_IMMEDIATE, false},
> + {"buffered", LOGICAL_REP_MODE_BUFFERED, false},
> + {"immediate", LOGICAL_REP_MODE_IMMEDIATE, false},
> {NULL, 0, false}
> };
> ```
>
> This struct should be also modified.
Modified.
>
> 2. guc_tables.c
>
>
> ```
> - {"logical_decoding_mode", PGC_USERSET,
> DEVELOPER_OPTIONS,
> + {"logical_replication_mode", PGC_USERSET,
> + DEVELOPER_OPTIONS,
> gettext_noop("Allows streaming or serializing each
> change in logical decoding."),
> NULL,
> ```
>
> I felt the description seems not to be suitable for current behavior.
> A short description should be like "Sets a behavior of logical replication", and
> further descriptions can be added in lond description.
I adjusted the description here.
> 3. config.sgml
>
> ```
> <para>
> This parameter is intended to be used to test logical decoding and
> replication of large transactions for which otherwise we need to
> generate the changes till
> <varname>logical_decoding_work_mem</varname>
> is reached.
> </para>
> ```
>
> I understood that this part described the usage of the parameter. How about
> adding a statement like:
>
> " Moreover, this can be also used to test the message passing between the
> leader and parallel apply workers."
Added.
> 4. 015_stream.pl
>
> ```
> +# Ensure that the messages are serialized.
> ```
>
> In other parts "changes" are used instead of "messages". Can you change the
> word?
Changed.
Best Regards,
Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, January 24, 2023 8:47 PM Hou, Zhijie wrote: > > On Tuesday, January 24, 2023 3:19 PM Peter Smith <smithpb2250@gmail.com> > wrote: > > > > Here are some review comments for v86-0002 > > Sorry, the patch set was somehow attached twice. Here is the correct new version patch set which addressed all comments so far. Best Regards, Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Hou, > Sorry, the patch set was somehow attached twice. Here is the correct new version > patch set which addressed all comments so far. Thank you for updating the patch! I confirmed that All of my comments are addressed. One comment: In this test the rollback-prepared seems not to be executed. This is because serializations are finished while handling PREPARE message and the final state of transaction does not affect that, right? I think it may be helpful to add a one line comment. Best Regards, Hayato Kuroda FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Tue, Jan 24, 2023 at 11:49 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
...
>
> Sorry, the patch set was somehow attached twice. Here is the correct new version
> patch set which addressed all comments so far.
>
Here are my review comments for patch v87-0001.
======
src/backend/replication/logical/reorderbuffer.c
1.
@@ -210,7 +210,7 @@ int logical_decoding_work_mem;
static const Size max_changes_in_memory = 4096; /* XXX for restore only */
/* GUC variable */
-int logical_decoding_mode = LOGICAL_DECODING_MODE_BUFFERED;
+int logical_replication_mode = LOGICAL_REP_MODE_BUFFERED;
I noticed that the comment /* GUC variable */ is currently only above
the logical_replication_mode, but actually logical_decoding_work_mem
is a GUC variable too. Maybe this should be rearranged somehow then
change the comment "GUC variable" -> "GUC variables"?
======
src/backend/utils/misc/guc_tables.c
@@ -4908,13 +4908,13 @@ struct config_enum ConfigureNamesEnum[] =
},
{
- {"logical_decoding_mode", PGC_USERSET, DEVELOPER_OPTIONS,
+ {"logical_replication_mode", PGC_USERSET, DEVELOPER_OPTIONS,
gettext_noop("Allows streaming or serializing each change in logical
decoding."),
NULL,
GUC_NOT_IN_SAMPLE
},
- &logical_decoding_mode,
- LOGICAL_DECODING_MODE_BUFFERED, logical_decoding_mode_options,
+ &logical_replication_mode,
+ LOGICAL_REP_MODE_BUFFERED, logical_replication_mode_options,
NULL, NULL, NULL
},
That gettext_noop string seems incorrect. I think Kuroda-san
previously reported the same, but then you replied it has been fixed
already [1]
> I felt the description seems not to be suitable for current behavior.
> A short description should be like "Sets a behavior of logical replication", and
> further descriptions can be added in lond description.
I adjusted the description here.
But this doesn't look fixed to me. (??)
======
src/include/replication/reorderbuffer.h
3.
@@ -18,14 +18,14 @@
#include "utils/timestamp.h"
extern PGDLLIMPORT int logical_decoding_work_mem;
-extern PGDLLIMPORT int logical_decoding_mode;
+extern PGDLLIMPORT int logical_replication_mode;
Probably here should also be a comment to say "/* GUC variables */"
------
[1]
https://www.postgresql.org/message-id/OS0PR01MB5716AE9F095F9E7888987BC794C99%40OS0PR01MB5716.jpnprd01.prod.outlook.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for patch v87-0002.
======
doc/src/sgml/config.sgml
1.
<para>
- Allows streaming or serializing changes immediately in
logical decoding.
The allowed values of <varname>logical_replication_mode</varname> are
- <literal>buffered</literal> and <literal>immediate</literal>. When set
- to <literal>immediate</literal>, stream each change if
+ <literal>buffered</literal> and <literal>immediate</literal>.
The default
+ is <literal>buffered</literal>.
+ </para>
I didn't think it was necessary to say “of logical_replication_mode”.
IMO that much is already obvious because this is the first sentence of
the description for logical_replication_mode.
(see also review comment #4)
~~~
2.
+ <para>
+ On the publisher side, it allows streaming or serializing changes
+ immediately in logical decoding. When set to
+ <literal>immediate</literal>, stream each change if
<literal>streaming</literal> option (see optional parameters set by
<link linkend="sql-createsubscription"><command>CREATE
SUBSCRIPTION</command></link>)
is enabled, otherwise, serialize each change. When set to
- <literal>buffered</literal>, which is the default, decoding will stream
- or serialize changes when <varname>logical_decoding_work_mem</varname>
- is reached.
+ <literal>buffered</literal>, decoding will stream or serialize changes
+ when <varname>logical_decoding_work_mem</varname> is reached.
</para>
2a.
"it allows" --> "logical_replication_mode allows"
2b.
"decoding" --> "the decoding"
~~~
3.
+ <para>
+ On the subscriber side, if <literal>streaming</literal> option is set
+ to <literal>parallel</literal>, this parameter also allows the leader
+ apply worker to send changes to the shared memory queue or to serialize
+ changes. When set to <literal>buffered</literal>, the leader sends
+ changes to parallel apply workers via shared memory queue. When set to
+ <literal>immediate</literal>, the leader serializes all changes to
+ files and notifies the parallel apply workers to read and apply them at
+ the end of the transaction.
+ </para>
"this parameter also allows" --> "logical_replication_mode also allows"
~~~
4.
<para>
This parameter is intended to be used to test logical decoding and
replication of large transactions for which otherwise we need to
generate the changes till <varname>logical_decoding_work_mem</varname>
- is reached.
+ is reached. Moreover, this can also be used to test the transmission of
+ changes between the leader and parallel apply workers.
</para>
"Moreover, this can also" --> "It can also"
I am wondering would this sentence be better put at the top of the GUC
description. So then the first paragraph becomes like this:
SUGGESTION (I've also added another sentence "The effect of...")
The allowed values are buffered and immediate. The default is
buffered. This parameter is intended to be used to test logical
decoding and replication of large transactions for which otherwise we
need to generate the changes till logical_decoding_work_mem is
reached. It can also be used to test the transmission of changes
between the leader and parallel apply workers. The effect of
logical_replication_mode is different for the publisher and
subscriber:
On the publisher side...
On the subscriber side...
======
.../replication/logical/applyparallelworker.c
5.
+ /*
+ * In immeidate mode, directly return false so that we can switch to
+ * PARTIAL_SERIALIZE mode and serialize remaining changes to files.
+ */
+ if (logical_replication_mode == LOGICAL_REP_MODE_IMMEDIATE)
+ return false;
Typo "immediate"
Also, I felt "directly" is not needed. "return false" and "directly
return false" is the same.
SUGGESTION
Using ‘immediate’ mode returns false to cause a switch to
PARTIAL_SERIALIZE mode so that the remaining changes will be
serialized.
======
src/backend/utils/misc/guc_tables.c
6.
{
{"logical_replication_mode", PGC_USERSET, DEVELOPER_OPTIONS,
- gettext_noop("Allows streaming or serializing each change in logical
decoding."),
- NULL,
+ gettext_noop("Controls the behavior of logical replication publisher
and subscriber"),
+ gettext_noop("If set to immediate, on the publisher side, it "
+ "allows streaming or serializing each change in "
+ "logical decoding. On the subscriber side, in "
+ "parallel streaming mode, it allows the leader apply "
+ "worker to serialize changes to files and notifies "
+ "the parallel apply workers to read and apply them at "
+ "the end of the transaction."),
GUC_NOT_IN_SAMPLE
},
6a. short description
User PoV behaviour should be the same. Instead, maybe say "controls
the internal behavior" or something like that?
~
6b. long description
IMO the long description shouldn’t mention ‘immediate’ mode first as it does.
BEFORE
If set to immediate, on the publisher side, ...
AFTER
On the publisher side, ...
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Jan 25, 2023 at 3:15 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> 1.
> @@ -210,7 +210,7 @@ int logical_decoding_work_mem;
> static const Size max_changes_in_memory = 4096; /* XXX for restore only */
>
> /* GUC variable */
> -int logical_decoding_mode = LOGICAL_DECODING_MODE_BUFFERED;
> +int logical_replication_mode = LOGICAL_REP_MODE_BUFFERED;
>
>
> I noticed that the comment /* GUC variable */ is currently only above
> the logical_replication_mode, but actually logical_decoding_work_mem
> is a GUC variable too. Maybe this should be rearranged somehow then
> change the comment "GUC variable" -> "GUC variables"?
>
I think moving these variables together doesn't sound like a good idea
because logical_decoding_work_mem variable is defined with other
related variable. Also, if we are doing the last comment, I think that
will obviate the need for this.
> ======
> src/backend/utils/misc/guc_tables.c
>
> @@ -4908,13 +4908,13 @@ struct config_enum ConfigureNamesEnum[] =
> },
>
> {
> - {"logical_decoding_mode", PGC_USERSET, DEVELOPER_OPTIONS,
> + {"logical_replication_mode", PGC_USERSET, DEVELOPER_OPTIONS,
> gettext_noop("Allows streaming or serializing each change in logical
> decoding."),
> NULL,
> GUC_NOT_IN_SAMPLE
> },
> - &logical_decoding_mode,
> - LOGICAL_DECODING_MODE_BUFFERED, logical_decoding_mode_options,
> + &logical_replication_mode,
> + LOGICAL_REP_MODE_BUFFERED, logical_replication_mode_options,
> NULL, NULL, NULL
> },
>
> That gettext_noop string seems incorrect. I think Kuroda-san
> previously reported the same, but then you replied it has been fixed
> already [1]
>
> > I felt the description seems not to be suitable for current behavior.
> > A short description should be like "Sets a behavior of logical replication", and
> > further descriptions can be added in lond description.
> I adjusted the description here.
>
> But this doesn't look fixed to me. (??)
>
Okay, so, how about the following for the 0001 patch:
short desc: Controls when to replicate each change.
long desc: On the publisher, it allows streaming or serializing each
change in logical decoding.
Then we can extend it as follows for the 0002 patch:
Controls when to replicate or apply each change
On the publisher, it allows streaming or serializing each change in
logical decoding. On the subscriber, it allows serialization of all
changes to files and notifies the parallel apply workers to read and
apply them at the end of the transaction.
> ======
> src/include/replication/reorderbuffer.h
>
> 3.
> @@ -18,14 +18,14 @@
> #include "utils/timestamp.h"
>
> extern PGDLLIMPORT int logical_decoding_work_mem;
> -extern PGDLLIMPORT int logical_decoding_mode;
> +extern PGDLLIMPORT int logical_replication_mode;
>
> Probably here should also be a comment to say "/* GUC variables */"
>
Okay, we can do this.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Jan 25, 2023 at 10:05 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Jan 25, 2023 at 3:15 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > 1.
> > @@ -210,7 +210,7 @@ int logical_decoding_work_mem;
> > static const Size max_changes_in_memory = 4096; /* XXX for restore only */
> >
> > /* GUC variable */
> > -int logical_decoding_mode = LOGICAL_DECODING_MODE_BUFFERED;
> > +int logical_replication_mode = LOGICAL_REP_MODE_BUFFERED;
> >
> >
> > I noticed that the comment /* GUC variable */ is currently only above
> > the logical_replication_mode, but actually logical_decoding_work_mem
> > is a GUC variable too. Maybe this should be rearranged somehow then
> > change the comment "GUC variable" -> "GUC variables"?
> >
>
> I think moving these variables together doesn't sound like a good idea
> because logical_decoding_work_mem variable is defined with other
> related variable. Also, if we are doing the last comment, I think that
> will obviate the need for this.
>
> > ======
> > src/backend/utils/misc/guc_tables.c
> >
> > @@ -4908,13 +4908,13 @@ struct config_enum ConfigureNamesEnum[] =
> > },
> >
> > {
> > - {"logical_decoding_mode", PGC_USERSET, DEVELOPER_OPTIONS,
> > + {"logical_replication_mode", PGC_USERSET, DEVELOPER_OPTIONS,
> > gettext_noop("Allows streaming or serializing each change in logical
> > decoding."),
> > NULL,
> > GUC_NOT_IN_SAMPLE
> > },
> > - &logical_decoding_mode,
> > - LOGICAL_DECODING_MODE_BUFFERED, logical_decoding_mode_options,
> > + &logical_replication_mode,
> > + LOGICAL_REP_MODE_BUFFERED, logical_replication_mode_options,
> > NULL, NULL, NULL
> > },
> >
> > That gettext_noop string seems incorrect. I think Kuroda-san
> > previously reported the same, but then you replied it has been fixed
> > already [1]
> >
> > > I felt the description seems not to be suitable for current behavior.
> > > A short description should be like "Sets a behavior of logical replication", and
> > > further descriptions can be added in lond description.
> > I adjusted the description here.
> >
> > But this doesn't look fixed to me. (??)
> >
>
> Okay, so, how about the following for the 0001 patch:
> short desc: Controls when to replicate each change.
> long desc: On the publisher, it allows streaming or serializing each
> change in logical decoding.
>
I have updated the patch accordingly and it looks good to me. I'll
push this first patch early next week (Monday) unless there are more
comments.
--
With Regards,
Amit Kapila.
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Amit, > > I have updated the patch accordingly and it looks good to me. I'll > push this first patch early next week (Monday) unless there are more > comments. Thanks for updating. I checked v88-0001 and I have no objection. LGTM. Best Regards, Hayato Kuroda FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, January 25, 2023 7:30 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are my review comments for patch v87-0002.
Thanks for your comments.
> ======
> doc/src/sgml/config.sgml
>
> 1.
> <para>
> - Allows streaming or serializing changes immediately in
> logical decoding.
> The allowed values of
> <varname>logical_replication_mode</varname> are
> - <literal>buffered</literal> and <literal>immediate</literal>. When
> set
> - to <literal>immediate</literal>, stream each change if
> + <literal>buffered</literal> and <literal>immediate</literal>.
> The default
> + is <literal>buffered</literal>.
> + </para>
>
> I didn't think it was necessary to say “of logical_replication_mode”.
> IMO that much is already obvious because this is the first sentence of the
> description for logical_replication_mode.
>
Changed.
> ~~~
>
> 2.
> + <para>
> + On the publisher side, it allows streaming or serializing changes
> + immediately in logical decoding. When set to
> + <literal>immediate</literal>, stream each change if
> <literal>streaming</literal> option (see optional parameters set by
> <link linkend="sql-createsubscription"><command>CREATE
> SUBSCRIPTION</command></link>)
> is enabled, otherwise, serialize each change. When set to
> - <literal>buffered</literal>, which is the default, decoding will stream
> - or serialize changes when
> <varname>logical_decoding_work_mem</varname>
> - is reached.
> + <literal>buffered</literal>, decoding will stream or serialize changes
> + when <varname>logical_decoding_work_mem</varname> is
> reached.
> </para>
>
> 2a.
> "it allows" --> "logical_replication_mode allows"
>
> 2b.
> "decoding" --> "the decoding"
Changed.
> ~~~
>
> 3.
> + <para>
> + On the subscriber side, if <literal>streaming</literal> option is set
> + to <literal>parallel</literal>, this parameter also allows the leader
> + apply worker to send changes to the shared memory queue or to
> serialize
> + changes. When set to <literal>buffered</literal>, the leader sends
> + changes to parallel apply workers via shared memory queue. When
> set to
> + <literal>immediate</literal>, the leader serializes all changes to
> + files and notifies the parallel apply workers to read and apply them at
> + the end of the transaction.
> + </para>
>
> "this parameter also allows" --> "logical_replication_mode also allows"
Changed.
> ~~~
>
> 4.
> <para>
> This parameter is intended to be used to test logical decoding and
> replication of large transactions for which otherwise we need to
> generate the changes till
> <varname>logical_decoding_work_mem</varname>
> - is reached.
> + is reached. Moreover, this can also be used to test the transmission of
> + changes between the leader and parallel apply workers.
> </para>
>
> "Moreover, this can also" --> "It can also"
>
> I am wondering would this sentence be better put at the top of the GUC
> description. So then the first paragraph becomes like this:
>
>
> SUGGESTION (I've also added another sentence "The effect of...")
>
> The allowed values are buffered and immediate. The default is buffered. This
> parameter is intended to be used to test logical decoding and replication of large
> transactions for which otherwise we need to generate the changes till
> logical_decoding_work_mem is reached. It can also be used to test the
> transmission of changes between the leader and parallel apply workers. The
> effect of logical_replication_mode is different for the publisher and
> subscriber:
>
> On the publisher side...
>
> On the subscriber side...
I think your suggestion makes sense, so changed as suggested.
> ======
> .../replication/logical/applyparallelworker.c
>
> 5.
> + /*
> + * In immeidate mode, directly return false so that we can switch to
> + * PARTIAL_SERIALIZE mode and serialize remaining changes to files.
> + */
> + if (logical_replication_mode == LOGICAL_REP_MODE_IMMEDIATE) return
> + false;
>
> Typo "immediate"
>
> Also, I felt "directly" is not needed. "return false" and "directly return false" is the
> same.
>
> SUGGESTION
> Using ‘immediate’ mode returns false to cause a switch to PARTIAL_SERIALIZE
> mode so that the remaining changes will be serialized.
Changed.
> ======
> src/backend/utils/misc/guc_tables.c
>
> 6.
> {
> {"logical_replication_mode", PGC_USERSET, DEVELOPER_OPTIONS,
> - gettext_noop("Allows streaming or serializing each change in logical
> decoding."),
> - NULL,
> + gettext_noop("Controls the behavior of logical replication publisher
> and subscriber"),
> + gettext_noop("If set to immediate, on the publisher side, it "
> + "allows streaming or serializing each change in "
> + "logical decoding. On the subscriber side, in "
> + "parallel streaming mode, it allows the leader apply "
> + "worker to serialize changes to files and notifies "
> + "the parallel apply workers to read and apply them at "
> + "the end of the transaction."),
> GUC_NOT_IN_SAMPLE
> },
>
> 6a. short description
>
> User PoV behaviour should be the same. Instead, maybe say "controls the
> internal behavior" or something like that?
Changed to "internal behavior xxx"
> ~
>
> 6b. long description
>
> IMO the long description shouldn’t mention ‘immediate’ mode first as it does.
>
> BEFORE
> If set to immediate, on the publisher side, ...
>
> AFTER
> On the publisher side, ...
Changed.
Attach the new version patch set.
The 0001 patch is the same as the v88-0001 posted by Amit[1],
attach it here to make cfbot happy.
[1] https://www.postgresql.org/message-id/CAA4eK1JpWoaB63YULpQa1KDw_zBW-QoRMuNxuiP1KafPJzuVuw%40mail.gmail.com
Best Regards,
Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Hou, Thank you for updating the patch! Followings are comments. 1. config.sgml ``` + the changes till logical_decoding_work_mem is reached. It can also be ``` I think it should be sandwiched by <varname>. 2. config.sgml ``` + On the publisher side, <varname>logical_replication_mode</varname> allows + allows streaming or serializing changes immediately in logical decoding. ``` Typo "allows allows" -> "allows" 3. test general You confirmed that the leader started to serialize changes, but did not ensure the endpoint. IIUC the parallel apply worker exits after applying serialized changes, and it is not tested yet. Can we add polling the log somewhere? 4. 015_stream.pl ``` +is($result, qq(15000), 'all changes are replayed from file') ``` The statement may be unclear because changes can be also replicated when streaming = on. How about: "parallel apply worker replayed all changes from file"? Best Regards, Hayato Kuroda FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Wed, Jan 25, 2023 at 3:27 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Jan 25, 2023 at 10:05 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Wed, Jan 25, 2023 at 3:15 AM Peter Smith <smithpb2250@gmail.com> wrote:
> > >
> > > 1.
> > > @@ -210,7 +210,7 @@ int logical_decoding_work_mem;
> > > static const Size max_changes_in_memory = 4096; /* XXX for restore only */
> > >
> > > /* GUC variable */
> > > -int logical_decoding_mode = LOGICAL_DECODING_MODE_BUFFERED;
> > > +int logical_replication_mode = LOGICAL_REP_MODE_BUFFERED;
> > >
> > >
> > > I noticed that the comment /* GUC variable */ is currently only above
> > > the logical_replication_mode, but actually logical_decoding_work_mem
> > > is a GUC variable too. Maybe this should be rearranged somehow then
> > > change the comment "GUC variable" -> "GUC variables"?
> > >
> >
> > I think moving these variables together doesn't sound like a good idea
> > because logical_decoding_work_mem variable is defined with other
> > related variable. Also, if we are doing the last comment, I think that
> > will obviate the need for this.
> >
> > > ======
> > > src/backend/utils/misc/guc_tables.c
> > >
> > > @@ -4908,13 +4908,13 @@ struct config_enum ConfigureNamesEnum[] =
> > > },
> > >
> > > {
> > > - {"logical_decoding_mode", PGC_USERSET, DEVELOPER_OPTIONS,
> > > + {"logical_replication_mode", PGC_USERSET, DEVELOPER_OPTIONS,
> > > gettext_noop("Allows streaming or serializing each change in logical
> > > decoding."),
> > > NULL,
> > > GUC_NOT_IN_SAMPLE
> > > },
> > > - &logical_decoding_mode,
> > > - LOGICAL_DECODING_MODE_BUFFERED, logical_decoding_mode_options,
> > > + &logical_replication_mode,
> > > + LOGICAL_REP_MODE_BUFFERED, logical_replication_mode_options,
> > > NULL, NULL, NULL
> > > },
> > >
> > > That gettext_noop string seems incorrect. I think Kuroda-san
> > > previously reported the same, but then you replied it has been fixed
> > > already [1]
> > >
> > > > I felt the description seems not to be suitable for current behavior.
> > > > A short description should be like "Sets a behavior of logical replication", and
> > > > further descriptions can be added in lond description.
> > > I adjusted the description here.
> > >
> > > But this doesn't look fixed to me. (??)
> > >
> >
> > Okay, so, how about the following for the 0001 patch:
> > short desc: Controls when to replicate each change.
> > long desc: On the publisher, it allows streaming or serializing each
> > change in logical decoding.
> >
>
> I have updated the patch accordingly and it looks good to me. I'll
> push this first patch early next week (Monday) unless there are more
> comments.
The patch looks good to me too. Thank you for the patch.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Patch v88-0001 LGTM. Below are just some minor review comments about the commit message. ====== Commit message 1. We have discussed having this parameter as a subscription option but exposing a parameter that is primarily used for testing/debugging to users didn't seem advisable and there is no other such parameter. The other option we have discussed is to have a separate GUC for subscriber-side testing but it appears that for the current testing existing parameter is sufficient and avoids adding another GUC. SUGGESTION We discussed exposing this parameter as a subscription option, but it did not seem advisable since it is primarily used for testing/debugging and there is no other such developer option. We also discussed having separate GUCs for publisher/subscriber-side, but for current testing/debugging requirements, one GUC is sufficient. ~~ 2. Reviewed-by: Pater Smith, Kuroda Hayato, Amit Kapila "Pater" --> "Peter" ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Here are my review comments for v88-0002.
======
General
1.
The test cases are checking the log content but they are not checking
for debug logs or untranslated elogs -- they are expecting a normal
ereport LOG that might be translated. I’m not sure if that is OK, or
if it is a potential problem.
======
doc/src/sgml/config.sgml
2.
On the publisher side, logical_replication_mode allows allows
streaming or serializing changes immediately in logical decoding. When
set to immediate, stream each change if streaming option (see optional
parameters set by CREATE SUBSCRIPTION) is enabled, otherwise,
serialize each change. When set to buffered, the decoding will stream
or serialize changes when logical_decoding_work_mem is reached.
2a.
typo "allows allows" (Kuroda-san reported same)
2b.
"if streaming option" --> "if the streaming option"
~~~
3.
On the subscriber side, if streaming option is set to parallel,
logical_replication_mode also allows the leader apply worker to send
changes to the shared memory queue or to serialize changes.
SUGGESTION
On the subscriber side, if the streaming option is set to parallel,
logical_replication_mode can be used to direct the leader apply worker
to send changes to the shared memory queue or to serialize changes.
======
src/backend/utils/misc/guc_tables.c
4.
{
{"logical_replication_mode", PGC_USERSET, DEVELOPER_OPTIONS,
- gettext_noop("Controls when to replicate each change."),
- gettext_noop("On the publisher, it allows streaming or serializing
each change in logical decoding."),
+ gettext_noop("Controls the internal behavior of logical replication
publisher and subscriber"),
+ gettext_noop("On the publisher, it allows streaming or "
+ "serializing each change in logical decoding. On the "
+ "subscriber, in parallel streaming mode, it allows "
+ "the leader apply worker to serialize changes to "
+ "files and notifies the parallel apply workers to "
+ "read and apply them at the end of the transaction."),
GUC_NOT_IN_SAMPLE
},
Suggest re-wording the long description (subscriber part) to be more
like the documentation text.
BEFORE
On the subscriber, in parallel streaming mode, it allows the leader
apply worker to serialize changes to files and notifies the parallel
apply workers to read and apply them at the end of the transaction.
SUGGESTION
On the subscriber, if the streaming option is set to parallel, it
directs the leader apply worker to send changes to the shared memory
queue or to serialize changes and apply them at the end of the
transaction.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Jan 30, 2023 at 5:40 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Patch v88-0001 LGTM. > Pushed. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, January 30, 2023 12:13 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are my review comments for v88-0002.
Thanks for your comments.
>
> ======
> General
>
> 1.
> The test cases are checking the log content but they are not checking for
> debug logs or untranslated elogs -- they are expecting a normal ereport LOG
> that might be translated. I’m not sure if that is OK, or if it is a potential problem.
We have tests that check the ereport ERROR and ereport WARNING message(by
search for the ERROR or WARNING keyword for all the tap tests), so I think
checking the LOG should be fine.
> ======
> doc/src/sgml/config.sgml
>
> 2.
> On the publisher side, logical_replication_mode allows allows streaming or
> serializing changes immediately in logical decoding. When set to immediate,
> stream each change if streaming option (see optional parameters set by
> CREATE SUBSCRIPTION) is enabled, otherwise, serialize each change. When set
> to buffered, the decoding will stream or serialize changes when
> logical_decoding_work_mem is reached.
>
> 2a.
> typo "allows allows" (Kuroda-san reported same)
>
> 2b.
> "if streaming option" --> "if the streaming option"
Changed.
> ~~~
>
> 3.
> On the subscriber side, if streaming option is set to parallel,
> logical_replication_mode also allows the leader apply worker to send changes
> to the shared memory queue or to serialize changes.
>
> SUGGESTION
> On the subscriber side, if the streaming option is set to parallel,
> logical_replication_mode can be used to direct the leader apply worker to
> send changes to the shared memory queue or to serialize changes.
Changed.
> ======
> src/backend/utils/misc/guc_tables.c
>
> 4.
> {
> {"logical_replication_mode", PGC_USERSET, DEVELOPER_OPTIONS,
> - gettext_noop("Controls when to replicate each change."),
> - gettext_noop("On the publisher, it allows streaming or serializing each
> change in logical decoding."),
> + gettext_noop("Controls the internal behavior of logical replication
> publisher and subscriber"),
> + gettext_noop("On the publisher, it allows streaming or "
> + "serializing each change in logical decoding. On the "
> + "subscriber, in parallel streaming mode, it allows "
> + "the leader apply worker to serialize changes to "
> + "files and notifies the parallel apply workers to "
> + "read and apply them at the end of the transaction."),
> GUC_NOT_IN_SAMPLE
> },
> Suggest re-wording the long description (subscriber part) to be more like the
> documentation text.
>
> BEFORE
> On the subscriber, in parallel streaming mode, it allows the leader apply worker
> to serialize changes to files and notifies the parallel apply workers to read and
> apply them at the end of the transaction.
>
> SUGGESTION
> On the subscriber, if the streaming option is set to parallel, it directs the leader
> apply worker to send changes to the shared memory queue or to serialize
> changes and apply them at the end of the transaction.
>
Changed.
Attach the new version patch which addressed all comments so far (the v88-0001
has been committed, so we only have one remaining patch this time).
Best Regards,
Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Thursday, January 26, 2023 11:37 AM Kuroda, Hayato/黒田 隼人 <kuroda.hayato@fujitsu.com> wrote: > > Followings are comments. Thanks for the comments. > In this test the rollback-prepared seems not to be executed. This is because > serializations are finished while handling PREPARE message and the final > state of transaction does not affect that, right? I think it may be helpful > to add a one line comment. Yes, but I am slightly unsure if it would be helpful to add this as we only test basic cases(mainly for code coverage) for partial serialization. > > 1. config.sgml > > ``` > + the changes till logical_decoding_work_mem is reached. It can also > be > ``` > > I think it should be sandwiched by <varname>. Added. > > 2. config.sgml > > ``` > + On the publisher side, > <varname>logical_replication_mode</varname> allows > + allows streaming or serializing changes immediately in logical > decoding. > ``` > > Typo "allows allows" -> "allows" Fixed. > 3. test general > > You confirmed that the leader started to serialize changes, but did not ensure > the endpoint. > IIUC the parallel apply worker exits after applying serialized changes, and it is > not tested yet. > Can we add polling the log somewhere? I checked other tests and didn't find some examples where we test the exit of apply worker or table sync worker. And if the parallel apply worker doesn't stop in this case, we will fail anyway when reusing this worker to handle the next transaction because the queue is broken. So, I prefer to keep the tests short. > 4. 015_stream.pl > > ``` > +is($result, qq(15000), 'all changes are replayed from file') > ``` > > The statement may be unclear because changes can be also replicated when > streaming = on. > How about: "parallel apply worker replayed all changes from file"? Changed. Best regards, Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Hou, Thank you for updating the patch! I checked your replies and new patch, and it seems good. Currently I have no comments Best Regards, Hayato Kuroda FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, Jan 30, 2023 at 3:23 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Monday, January 30, 2023 12:13 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > Here are my review comments for v88-0002.
>
> Thanks for your comments.
>
> >
> > ======
> > General
> >
> > 1.
> > The test cases are checking the log content but they are not checking for
> > debug logs or untranslated elogs -- they are expecting a normal ereport LOG
> > that might be translated. I’m not sure if that is OK, or if it is a potential problem.
>
> We have tests that check the ereport ERROR and ereport WARNING message(by
> search for the ERROR or WARNING keyword for all the tap tests), so I think
> checking the LOG should be fine.
>
> > ======
> > doc/src/sgml/config.sgml
> >
> > 2.
> > On the publisher side, logical_replication_mode allows allows streaming or
> > serializing changes immediately in logical decoding. When set to immediate,
> > stream each change if streaming option (see optional parameters set by
> > CREATE SUBSCRIPTION) is enabled, otherwise, serialize each change. When set
> > to buffered, the decoding will stream or serialize changes when
> > logical_decoding_work_mem is reached.
> >
> > 2a.
> > typo "allows allows" (Kuroda-san reported same)
> >
> > 2b.
> > "if streaming option" --> "if the streaming option"
>
> Changed.
>
> > ~~~
> >
> > 3.
> > On the subscriber side, if streaming option is set to parallel,
> > logical_replication_mode also allows the leader apply worker to send changes
> > to the shared memory queue or to serialize changes.
> >
> > SUGGESTION
> > On the subscriber side, if the streaming option is set to parallel,
> > logical_replication_mode can be used to direct the leader apply worker to
> > send changes to the shared memory queue or to serialize changes.
>
> Changed.
>
> > ======
> > src/backend/utils/misc/guc_tables.c
> >
> > 4.
> > {
> > {"logical_replication_mode", PGC_USERSET, DEVELOPER_OPTIONS,
> > - gettext_noop("Controls when to replicate each change."),
> > - gettext_noop("On the publisher, it allows streaming or serializing each
> > change in logical decoding."),
> > + gettext_noop("Controls the internal behavior of logical replication
> > publisher and subscriber"),
> > + gettext_noop("On the publisher, it allows streaming or "
> > + "serializing each change in logical decoding. On the "
> > + "subscriber, in parallel streaming mode, it allows "
> > + "the leader apply worker to serialize changes to "
> > + "files and notifies the parallel apply workers to "
> > + "read and apply them at the end of the transaction."),
> > GUC_NOT_IN_SAMPLE
> > },
> > Suggest re-wording the long description (subscriber part) to be more like the
> > documentation text.
> >
> > BEFORE
> > On the subscriber, in parallel streaming mode, it allows the leader apply worker
> > to serialize changes to files and notifies the parallel apply workers to read and
> > apply them at the end of the transaction.
> >
> > SUGGESTION
> > On the subscriber, if the streaming option is set to parallel, it directs the leader
> > apply worker to send changes to the shared memory queue or to serialize
> > changes and apply them at the end of the transaction.
> >
>
> Changed.
>
> Attach the new version patch which addressed all comments so far (the v88-0001
> has been committed, so we only have one remaining patch this time).
>
I have one comment on v89 patch:
+ /*
+ * Using 'immediate' mode returns false to cause a switch to
+ * PARTIAL_SERIALIZE mode so that the remaining changes will
be serialized.
+ */
+ if (logical_replication_mode == LOGICAL_REP_MODE_IMMEDIATE)
+ return false;
+
Probably we might want to add unlikely() here since we could pass
through this path very frequently?
The rest looks good to me.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Mon, Jan 30, 2023 at 5:23 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Monday, January 30, 2023 12:13 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Here are my review comments for v88-0002. > > Thanks for your comments. > > > > > ====== > > General > > > > 1. > > The test cases are checking the log content but they are not checking for > > debug logs or untranslated elogs -- they are expecting a normal ereport LOG > > that might be translated. I’m not sure if that is OK, or if it is a potential problem. > > We have tests that check the ereport ERROR and ereport WARNING message(by > search for the ERROR or WARNING keyword for all the tap tests), so I think > checking the LOG should be fine. > > > ====== > > doc/src/sgml/config.sgml > > > > 2. > > On the publisher side, logical_replication_mode allows allows streaming or > > serializing changes immediately in logical decoding. When set to immediate, > > stream each change if streaming option (see optional parameters set by > > CREATE SUBSCRIPTION) is enabled, otherwise, serialize each change. When set > > to buffered, the decoding will stream or serialize changes when > > logical_decoding_work_mem is reached. > > > > 2a. > > typo "allows allows" (Kuroda-san reported same) > > > > 2b. > > "if streaming option" --> "if the streaming option" > > Changed. Although you replied "Changed" for the above, AFAICT my review comment #2b. was accidentally missed. Otherwise, the patch LGTM. ------ Kind Regards, Peter Smith. Fujitsu Australia
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, January 30, 2023 10:20 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > I have one comment on v89 patch: > > + /* > + * Using 'immediate' mode returns false to cause a switch to > + * PARTIAL_SERIALIZE mode so that the remaining changes will > be serialized. > + */ > + if (logical_replication_mode == LOGICAL_REP_MODE_IMMEDIATE) > + return false; > + > > Probably we might want to add unlikely() here since we could pass through this > path very frequently? I think your comment makes sense, thanks. I updated the patch for the same. Best Regards, Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, January 31, 2023 8:23 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Mon, Jan 30, 2023 at 5:23 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Monday, January 30, 2023 12:13 PM Peter Smith > <smithpb2250@gmail.com> wrote: > > > > > > Here are my review comments for v88-0002. > > > > Thanks for your comments. > > > > > > > > ====== > > > General > > > > > > 1. > > > The test cases are checking the log content but they are not > > > checking for debug logs or untranslated elogs -- they are expecting > > > a normal ereport LOG that might be translated. I’m not sure if that is OK, or > if it is a potential problem. > > > > We have tests that check the ereport ERROR and ereport WARNING > > message(by search for the ERROR or WARNING keyword for all the tap > > tests), so I think checking the LOG should be fine. > > > > > ====== > > > doc/src/sgml/config.sgml > > > > > > 2. > > > On the publisher side, logical_replication_mode allows allows > > > streaming or serializing changes immediately in logical decoding. > > > When set to immediate, stream each change if streaming option (see > > > optional parameters set by CREATE SUBSCRIPTION) is enabled, > > > otherwise, serialize each change. When set to buffered, the decoding > > > will stream or serialize changes when logical_decoding_work_mem is > reached. > > > > > > 2a. > > > typo "allows allows" (Kuroda-san reported same) > > > > > > 2b. > > > "if streaming option" --> "if the streaming option" > > > > Changed. > > Although you replied "Changed" for the above, AFAICT my review comment > #2b. was accidentally missed. Fixed. Best Regards, Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Thanks for the updates to address all of my previous review comments. Patch v90-0001 LGTM. ------ Kind Reagrds, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Jan 31, 2023 at 9:04 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > I think your comment makes sense, thanks. > I updated the patch for the same. > The patch looks mostly good to me. I have made a few changes in the comments and docs, see attached. -- With Regards, Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
Some minor review comments for v91-0001
======
doc/src/sgml/config.sgml
1.
<para>
- Allows streaming or serializing changes immediately in
logical decoding.
- The allowed values of <varname>logical_replication_mode</varname> are
- <literal>buffered</literal> and <literal>immediate</literal>. When set
- to <literal>immediate</literal>, stream each change if
+ The allowed values are <literal>buffered</literal> and
+ <literal>immediate</literal>. The default is
<literal>buffered</literal>.
+ This parameter is intended to be used to test logical decoding and
+ replication of large transactions for which otherwise we need
to generate
+ the changes till <varname>logical_decoding_work_mem</varname> is
+ reached. The effect of <varname>logical_replication_mode</varname> is
+ different for the publisher and subscriber:
+ </para>
The "for which otherwise..." part is only relevant for the
publisher-side. So it seemed slightly strange to give the reason why
to use the GUC for one side but not the other side.
Maybe we can just to remove that "for which otherwise..." part, since
the logical_decoding_work_mem gets mentioned later in the "On the
publisher side,..." paragraph anyway.
~~~
2.
<para>
- This parameter is intended to be used to test logical decoding and
- replication of large transactions for which otherwise we need to
- generate the changes till <varname>logical_decoding_work_mem</varname>
- is reached.
+ On the subscriber side, if the <literal>streaming</literal>
option is set to
+ <literal>parallel</literal>,
<varname>logical_replication_mode</varname>
+ can be used to direct the leader apply worker to send changes to the
+ shared memory queue or to serialize changes to the file. When set to
+ <literal>buffered</literal>, the leader sends changes to parallel apply
+ workers via a shared memory queue. When set to
+ <literal>immediate</literal>, the leader serializes all
changes to files
+ and notifies the parallel apply workers to read and apply them at the
+ end of the transaction.
</para>
"or serialize changes to the file." --> "or serialize all changes to
files." (just to use same wording as later in this same paragraph, and
also same wording as the GUC hint text).
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Thu, Feb 2, 2023 at 4:52 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Some minor review comments for v91-0001 > Pushed this yesterday after addressing your comments! -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Friday, February 3, 2023 11:04 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Feb 2, 2023 at 4:52 AM Peter Smith <smithpb2250@gmail.com> > wrote: > > > > Some minor review comments for v91-0001 > > > > Pushed this yesterday after addressing your comments! Thanks for pushing. Currently, we have two remaining patches which we are not sure whether it's worth committing for now. Just share them here for reference. 0001: Based on our discussion[1] on -hackers, it's not clear that if it's necessary to add the sub-feature to stop extra worker when max_apply_workers_per_suibscription is reduced. Because: - it's not clear whether reducing the 'max_apply_workers_per_suibscription' is very common. - even when the GUC is reduced, at that point in time all the workers might be in use so there may be nothing that can be immediately done. - IIUC the excess workers (for a reduced GUC) are going to get freed naturally anyway over time as more transactions are completed so the pool size will reduce accordingly. And given that the logic of this patch is simple, it would be easy to add this at a later point if we really see a use case for this. 0002: Since all the deadlock errors and other errors that caused by parallel streaming will be logged and user can check this kind of ERROR and disable the parallel streaming mode to resolve this. Besides, for this retry feature, It will be hard to distinguish whether the ERROR is caused by parallel streaming, and we might need to retry in serialize mode for all kinds of ERROR. So, it's not very clear if automatic use serialize mode to retry in case of any ERROR in parallel streaming is necessary or not. And we can also add this when we see a use case. [1] https://www.postgresql.org/message-id/CAA4eK1LotEuPsteuJMNpixxTj6R4B8k93q-6ruRmDzCxKzMNpA%40mail.gmail.com Best Regards, Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Fri, Feb 3, 2023 at 12:29 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Friday, February 3, 2023 11:04 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Thu, Feb 2, 2023 at 4:52 AM Peter Smith <smithpb2250@gmail.com> > > wrote: > > > > > > Some minor review comments for v91-0001 > > > > > > > Pushed this yesterday after addressing your comments! > > Thanks for pushing. > > Currently, we have two remaining patches which we are not sure whether it's worth > committing for now. Just share them here for reference. > > 0001: > > Based on our discussion[1] on -hackers, it's not clear that if it's necessary > to add the sub-feature to stop extra worker when > max_apply_workers_per_suibscription is reduced. Because: > > - it's not clear whether reducing the 'max_apply_workers_per_suibscription' is very > common. A use case I'm concerned about is a temporarily intensive data load, for example, a data loading batch job in a maintenance window. In this case, the user might want to temporarily increase max_parallel_workers_per_subscription in order to avoid a large replication lag, and revert the change back to normal after the job. If it's unlikely to stream the changes in the regular workload as logical_decoding_work_mem is big enough to handle the regular transaction data, the excess parallel workers won't exit. Another subscription might want to use parallel workers but there might not be free workers. That's why I thought we need to free the excess workers at some point. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Feb 3, 2023 at 1:28 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Fri, Feb 3, 2023 at 12:29 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Friday, February 3, 2023 11:04 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Thu, Feb 2, 2023 at 4:52 AM Peter Smith <smithpb2250@gmail.com> > > > wrote: > > > > > > > > Some minor review comments for v91-0001 > > > > > > > > > > Pushed this yesterday after addressing your comments! > > > > Thanks for pushing. > > > > Currently, we have two remaining patches which we are not sure whether it's worth > > committing for now. Just share them here for reference. > > > > 0001: > > > > Based on our discussion[1] on -hackers, it's not clear that if it's necessary > > to add the sub-feature to stop extra worker when > > max_apply_workers_per_suibscription is reduced. Because: > > > > - it's not clear whether reducing the 'max_apply_workers_per_suibscription' is very > > common. > > A use case I'm concerned about is a temporarily intensive data load, > for example, a data loading batch job in a maintenance window. In this > case, the user might want to temporarily increase > max_parallel_workers_per_subscription in order to avoid a large > replication lag, and revert the change back to normal after the job. > If it's unlikely to stream the changes in the regular workload as > logical_decoding_work_mem is big enough to handle the regular > transaction data, the excess parallel workers won't exit. > Won't in such a case, it would be better to just switch off the parallel option for a subscription? We need to think of a predictable way to test this path which may not be difficult. But I guess it would be better to wait for some feedback from the field about this feature before adding more to it and anyway it shouldn't be a big deal to add this later as well. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
Hi, while reading the code, I noticed that in pa_send_data() we set wait event to WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE while sending the message to the queue. Because this state is used in multiple places, user might not be able to distinguish what they are waiting for. So It seems we'd better to use WAIT_EVENT_MQ_SEND here which will be eaier to distinguish and understand. Here is a tiny patch for that. Best Regards, Hou zj
Attachment
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Hou, > while reading the code, I noticed that in pa_send_data() we set wait event > to WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE while sending > the > message to the queue. Because this state is used in multiple places, user might > not be able to distinguish what they are waiting for. So It seems we'd better > to use WAIT_EVENT_MQ_SEND here which will be eaier to distinguish and > understand. Here is a tiny patch for that. In LogicalParallelApplyLoop(), we introduced the new wait event WAIT_EVENT_LOGICAL_PARALLEL_APPLY_MAIN whereas it is practically waits a shared message queue and it seems to be same as WAIT_EVENT_MQ_RECEIVE. Do you have a policy to reuse the event instead of adding a new event? Best Regards, Hayato Kuroda FUJITSU LIMITED
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Monday, February 6, 2023 6:34 PM Kuroda, Hayato <kuroda.hayato@fujitsu.com> wrote: > > while reading the code, I noticed that in pa_send_data() we set wait > > event to WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE while > sending > > the message to the queue. Because this state is used in multiple > > places, user might not be able to distinguish what they are waiting > > for. So It seems we'd better to use WAIT_EVENT_MQ_SEND here which will > > be eaier to distinguish and understand. Here is a tiny patch for that. > > In LogicalParallelApplyLoop(), we introduced the new wait event > WAIT_EVENT_LOGICAL_PARALLEL_APPLY_MAIN whereas it is practically waits a > shared message queue and it seems to be same as WAIT_EVENT_MQ_RECEIVE. > Do you have a policy to reuse the event instead of adding a new event? I think PARALLEL_APPLY_MAIN waits for two kinds of event: 1) wait for new message from the queue 2) wait for the partial file state to be set. So, I think introducing a new general event for them is better and it is also consistent with the WAIT_EVENT_LOGICAL_APPLY_MAIN which is used in the main loop of leader apply worker(LogicalRepApplyLoop). But the event in pg_send_data() is only for message send, so it seems fine to use WAIT_EVENT_MQ_SEND, besides MQ_SEND is also unique in parallel apply worker and user can distinglish without adding new event. Best Regards, Hou zj
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Hou, > I think PARALLEL_APPLY_MAIN waits for two kinds of event: 1) wait for new > message from the queue 2) wait for the partial file state to be set. So, I > think introducing a new general event for them is better and it is also > consistent with the WAIT_EVENT_LOGICAL_APPLY_MAIN which is used in the > main > loop of leader apply worker(LogicalRepApplyLoop). But the event in > pg_send_data() is only for message send, so it seems fine to use > WAIT_EVENT_MQ_SEND, besides MQ_SEND is also unique in parallel apply > worker and > user can distinglish without adding new event. Thank you for your explanation. I think both of you said are reasonable. Best Regards, Hayato Kuroda FUJITSU LIMITED
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Feb 6, 2023 at 3:43 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > while reading the code, I noticed that in pa_send_data() we set wait event > to WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE while sending the > message to the queue. Because this state is used in multiple places, user might > not be able to distinguish what they are waiting for. So It seems we'd better > to use WAIT_EVENT_MQ_SEND here which will be eaier to distinguish and > understand. Here is a tiny patch for that. > Thanks for noticing this. The patch LGTM. I'll push this in some time. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Fri, Feb 3, 2023 at 6:44 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Feb 3, 2023 at 1:28 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Fri, Feb 3, 2023 at 12:29 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > On Friday, February 3, 2023 11:04 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > On Thu, Feb 2, 2023 at 4:52 AM Peter Smith <smithpb2250@gmail.com> > > > > wrote: > > > > > > > > > > Some minor review comments for v91-0001 > > > > > > > > > > > > > Pushed this yesterday after addressing your comments! > > > > > > Thanks for pushing. > > > > > > Currently, we have two remaining patches which we are not sure whether it's worth > > > committing for now. Just share them here for reference. > > > > > > 0001: > > > > > > Based on our discussion[1] on -hackers, it's not clear that if it's necessary > > > to add the sub-feature to stop extra worker when > > > max_apply_workers_per_suibscription is reduced. Because: > > > > > > - it's not clear whether reducing the 'max_apply_workers_per_suibscription' is very > > > common. > > > > A use case I'm concerned about is a temporarily intensive data load, > > for example, a data loading batch job in a maintenance window. In this > > case, the user might want to temporarily increase > > max_parallel_workers_per_subscription in order to avoid a large > > replication lag, and revert the change back to normal after the job. > > If it's unlikely to stream the changes in the regular workload as > > logical_decoding_work_mem is big enough to handle the regular > > transaction data, the excess parallel workers won't exit. > > > > Won't in such a case, it would be better to just switch off the > parallel option for a subscription? Not sure. Changing the parameter would be easier since it doesn't require restarts. > We need to think of a predictable > way to test this path which may not be difficult. But I guess it would > be better to wait for some feedback from the field about this feature > before adding more to it and anyway it shouldn't be a big deal to add > this later as well. Agreed to hear some feedback before adding it. It's not an urgent feature. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Feb 7, 2023 at 12:41 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Fri, Feb 3, 2023 at 6:44 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > We need to think of a predictable > > way to test this path which may not be difficult. But I guess it would > > be better to wait for some feedback from the field about this feature > > before adding more to it and anyway it shouldn't be a big deal to add > > this later as well. > > Agreed to hear some feedback before adding it. It's not an urgent feature. > Okay, Thanks! AFAIK, there is no pending patch left in this proposal. If so, I think it is better to close the corresponding CF entry. -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"wangw.fnst@fujitsu.com"
Date:
On Tue, Feb 7, 2023 15:37 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > On Tue, Feb 7, 2023 at 12:41 PM Masahiko Sawada <sawada.mshk@gmail.com> > wrote: > > > > On Fri, Feb 3, 2023 at 6:44 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > We need to think of a predictable > > > way to test this path which may not be difficult. But I guess it would > > > be better to wait for some feedback from the field about this feature > > > before adding more to it and anyway it shouldn't be a big deal to add > > > this later as well. > > > > Agreed to hear some feedback before adding it. It's not an urgent feature. > > > > Okay, Thanks! AFAIK, there is no pending patch left in this proposal. > If so, I think it is better to close the corresponding CF entry. Yes, I think so. Closed this CF entry. Regards, Wang Wei
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Tuesday, February 7, 2023 11:17 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Feb 6, 2023 at 3:43 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > while reading the code, I noticed that in pa_send_data() we set wait > > event to WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE while > sending > > the message to the queue. Because this state is used in multiple > > places, user might not be able to distinguish what they are waiting > > for. So It seems we'd better to use WAIT_EVENT_MQ_SEND here which will > > be eaier to distinguish and understand. Here is a tiny patch for that. > > As discussed[1], we'd better invent a new state for this purpose, so here is the patch that does the same. [1] https://www.postgresql.org/message-id/CAA4eK1LTud4FLRbS0QqdZ-pjSxwfFLHC1Dx%3D6Q7nyROCvvPSfw%40mail.gmail.com Best Regards, Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Fri, Feb 10, 2023 at 1:32 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Tuesday, February 7, 2023 11:17 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Mon, Feb 6, 2023 at 3:43 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > while reading the code, I noticed that in pa_send_data() we set wait > > > event to WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE while > > sending > > > the message to the queue. Because this state is used in multiple > > > places, user might not be able to distinguish what they are waiting > > > for. So It seems we'd better to use WAIT_EVENT_MQ_SEND here which will > > > be eaier to distinguish and understand. Here is a tiny patch for that. > > > > > As discussed[1], we'd better invent a new state for this purpose, so here is the patch > that does the same. > > [1] https://www.postgresql.org/message-id/CAA4eK1LTud4FLRbS0QqdZ-pjSxwfFLHC1Dx%3D6Q7nyROCvvPSfw%40mail.gmail.com > My first impression was the WAIT_EVENT_LOGICAL_PARALLEL_APPLY_SEND_DATA name seemed misleading because that makes it sound like the parallel apply worker is doing the sending, but IIUC it's really the opposite. And since WAIT_EVENT_LOGICAL_PARALLEL_APPLY_LEADER_SEND_DATA seems too verbose, how about shortening the prefix for both events? E.g. BEFORE WAIT_EVENT_LOGICAL_PARALLEL_APPLY_SEND_DATA, WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE, AFTER WAIT_EVENT_LOGICAL_PA_LEADER_SEND_DATA, WAIT_EVENT_LOGICAL_PA_STATE_CHANGE, ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Feb 10, 2023 at 8:56 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Fri, Feb 10, 2023 at 1:32 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Tuesday, February 7, 2023 11:17 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Mon, Feb 6, 2023 at 3:43 PM houzj.fnst@fujitsu.com > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > while reading the code, I noticed that in pa_send_data() we set wait > > > > event to WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE while > > > sending > > > > the message to the queue. Because this state is used in multiple > > > > places, user might not be able to distinguish what they are waiting > > > > for. So It seems we'd better to use WAIT_EVENT_MQ_SEND here which will > > > > be eaier to distinguish and understand. Here is a tiny patch for that. > > > > > > > > As discussed[1], we'd better invent a new state for this purpose, so here is the patch > > that does the same. > > > > [1] https://www.postgresql.org/message-id/CAA4eK1LTud4FLRbS0QqdZ-pjSxwfFLHC1Dx%3D6Q7nyROCvvPSfw%40mail.gmail.com > > > > My first impression was the > WAIT_EVENT_LOGICAL_PARALLEL_APPLY_SEND_DATA name seemed misleading > because that makes it sound like the parallel apply worker is doing > the sending, but IIUC it's really the opposite. > So, how about WAIT_EVENT_LOGICAL_APPLY_SEND_DATA? > And since WAIT_EVENT_LOGICAL_PARALLEL_APPLY_LEADER_SEND_DATA seems too > verbose, how about shortening the prefix for both events? E.g. > > BEFORE > WAIT_EVENT_LOGICAL_PARALLEL_APPLY_SEND_DATA, > WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE, > > AFTER > WAIT_EVENT_LOGICAL_PA_LEADER_SEND_DATA, > WAIT_EVENT_LOGICAL_PA_STATE_CHANGE, > I am not sure *_PA_LEADER_* is any better that what Hou-San has proposed. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
On Tue, Feb 14, 2023 at 5:04 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Feb 10, 2023 at 8:56 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Fri, Feb 10, 2023 at 1:32 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > On Tuesday, February 7, 2023 11:17 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > On Mon, Feb 6, 2023 at 3:43 PM houzj.fnst@fujitsu.com > > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > > > while reading the code, I noticed that in pa_send_data() we set wait > > > > > event to WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE while > > > > sending > > > > > the message to the queue. Because this state is used in multiple > > > > > places, user might not be able to distinguish what they are waiting > > > > > for. So It seems we'd better to use WAIT_EVENT_MQ_SEND here which will > > > > > be eaier to distinguish and understand. Here is a tiny patch for that. > > > > > > > > > > > As discussed[1], we'd better invent a new state for this purpose, so here is the patch > > > that does the same. > > > > > > [1] https://www.postgresql.org/message-id/CAA4eK1LTud4FLRbS0QqdZ-pjSxwfFLHC1Dx%3D6Q7nyROCvvPSfw%40mail.gmail.com > > > > > > > My first impression was the > > WAIT_EVENT_LOGICAL_PARALLEL_APPLY_SEND_DATA name seemed misleading > > because that makes it sound like the parallel apply worker is doing > > the sending, but IIUC it's really the opposite. > > > > So, how about WAIT_EVENT_LOGICAL_APPLY_SEND_DATA? > Yes, IIUC all the LR events are named WAIT_EVENT_LOGICAL_xxx. So names like the below seem correct format: a) WAIT_EVENT_LOGICAL_APPLY_SEND_DATA b) WAIT_EVENT_LOGICAL_LEADER_SEND_DATA c) WAIT_EVENT_LOGICAL_LEADER_APPLY_SEND_DATA Of those, I prefer option c) because saying LEADER_APPLY_xxx matches the name format of the existing WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE. ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Tue, Feb 14, 2023 at 3:58 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Tue, Feb 14, 2023 at 5:04 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Fri, Feb 10, 2023 at 8:56 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > On Fri, Feb 10, 2023 at 1:32 PM houzj.fnst@fujitsu.com > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > On Tuesday, February 7, 2023 11:17 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > > On Mon, Feb 6, 2023 at 3:43 PM houzj.fnst@fujitsu.com > > > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > > > > > while reading the code, I noticed that in pa_send_data() we set wait > > > > > > event to WAIT_EVENT_LOGICAL_PARALLEL_APPLY_STATE_CHANGE while > > > > > sending > > > > > > the message to the queue. Because this state is used in multiple > > > > > > places, user might not be able to distinguish what they are waiting > > > > > > for. So It seems we'd better to use WAIT_EVENT_MQ_SEND here which will > > > > > > be eaier to distinguish and understand. Here is a tiny patch for that. > > > > > > > > > > > > > > As discussed[1], we'd better invent a new state for this purpose, so here is the patch > > > > that does the same. > > > > > > > > [1] https://www.postgresql.org/message-id/CAA4eK1LTud4FLRbS0QqdZ-pjSxwfFLHC1Dx%3D6Q7nyROCvvPSfw%40mail.gmail.com > > > > > > > > > > My first impression was the > > > WAIT_EVENT_LOGICAL_PARALLEL_APPLY_SEND_DATA name seemed misleading > > > because that makes it sound like the parallel apply worker is doing > > > the sending, but IIUC it's really the opposite. > > > > > > > So, how about WAIT_EVENT_LOGICAL_APPLY_SEND_DATA? > > > > Yes, IIUC all the LR events are named WAIT_EVENT_LOGICAL_xxx. > > So names like the below seem correct format: > > a) WAIT_EVENT_LOGICAL_APPLY_SEND_DATA > b) WAIT_EVENT_LOGICAL_LEADER_SEND_DATA > c) WAIT_EVENT_LOGICAL_LEADER_APPLY_SEND_DATA Personally I'm fine even without "LEADER" in the wait event name since we don't have "who is waiting" in it. IIUC a row of pg_stat_activity shows who, and the wait event name shows "what the process is waiting". So I prefer (a). Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, Feb 14, 2023 at 7:45 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Tue, Feb 14, 2023 at 3:58 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Tue, Feb 14, 2023 at 5:04 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Fri, Feb 10, 2023 at 8:56 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > My first impression was the > > > > WAIT_EVENT_LOGICAL_PARALLEL_APPLY_SEND_DATA name seemed misleading > > > > because that makes it sound like the parallel apply worker is doing > > > > the sending, but IIUC it's really the opposite. > > > > > > > > > > So, how about WAIT_EVENT_LOGICAL_APPLY_SEND_DATA? > > > > > > > Yes, IIUC all the LR events are named WAIT_EVENT_LOGICAL_xxx. > > > > So names like the below seem correct format: > > > > a) WAIT_EVENT_LOGICAL_APPLY_SEND_DATA > > b) WAIT_EVENT_LOGICAL_LEADER_SEND_DATA > > c) WAIT_EVENT_LOGICAL_LEADER_APPLY_SEND_DATA > > Personally I'm fine even without "LEADER" in the wait event name since > we don't have "who is waiting" in it. IIUC a row of pg_stat_activity > shows who, and the wait event name shows "what the process is > waiting". So I prefer (a). > This logic makes sense to me. So, let's go with (a). -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"houzj.fnst@fujitsu.com"
Date:
On Wednesday, February 15, 2023 10:34 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Feb 14, 2023 at 7:45 PM Masahiko Sawada <sawada.mshk@gmail.com> > wrote: > > > > On Tue, Feb 14, 2023 at 3:58 PM Peter Smith <smithpb2250@gmail.com> > wrote: > > > > > > On Tue, Feb 14, 2023 at 5:04 PM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > > > > > > On Fri, Feb 10, 2023 at 8:56 AM Peter Smith <smithpb2250@gmail.com> > wrote: > > > > > > > > > > My first impression was the > > > > > WAIT_EVENT_LOGICAL_PARALLEL_APPLY_SEND_DATA name seemed > > > > > misleading because that makes it sound like the parallel apply > > > > > worker is doing the sending, but IIUC it's really the opposite. > > > > > > > > > > > > > So, how about WAIT_EVENT_LOGICAL_APPLY_SEND_DATA? > > > > > > > > > > Yes, IIUC all the LR events are named WAIT_EVENT_LOGICAL_xxx. > > > > > > So names like the below seem correct format: > > > > > > a) WAIT_EVENT_LOGICAL_APPLY_SEND_DATA > > > b) WAIT_EVENT_LOGICAL_LEADER_SEND_DATA > > > c) WAIT_EVENT_LOGICAL_LEADER_APPLY_SEND_DATA > > > > Personally I'm fine even without "LEADER" in the wait event name since > > we don't have "who is waiting" in it. IIUC a row of pg_stat_activity > > shows who, and the wait event name shows "what the process is > > waiting". So I prefer (a). > > > > This logic makes sense to me. So, let's go with (a). OK, here is patch that change the event name to WAIT_EVENT_LOGICAL_APPLY_SEND_DATA. Best Regard, Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Feb 15, 2023 at 8:55 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, February 15, 2023 10:34 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > > So names like the below seem correct format: > > > > > > > > a) WAIT_EVENT_LOGICAL_APPLY_SEND_DATA > > > > b) WAIT_EVENT_LOGICAL_LEADER_SEND_DATA > > > > c) WAIT_EVENT_LOGICAL_LEADER_APPLY_SEND_DATA > > > > > > Personally I'm fine even without "LEADER" in the wait event name since > > > we don't have "who is waiting" in it. IIUC a row of pg_stat_activity > > > shows who, and the wait event name shows "what the process is > > > waiting". So I prefer (a). > > > > > > > This logic makes sense to me. So, let's go with (a). > > OK, here is patch that change the event name to WAIT_EVENT_LOGICAL_APPLY_SEND_DATA. > LGTM. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Peter Smith
Date:
LGTM. My only comment is about the commit message. ====== Commit message d9d7fe6 reuse existing wait event when sending data in apply worker. But we should have invent a new wait state if we are waiting at a new place, so fix this. ~ SUGGESTION d9d7fe6 made use of an existing wait event when sending data from the apply worker, but we should have invented a new wait state since the code was waiting at a new place. This patch corrects the mistake by using a new wait state "LogicalApplySendData". ------ Kind Regards, Peter Smith. Fujitsu Australia
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, Jan 9, 2023 at 5:51 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Sun, Jan 8, 2023 at 11:32 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Sunday, January 8, 2023 11:59 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
> > > Attach the updated patch set.
> >
> > Sorry, the commit message of 0001 was accidentally deleted, just attach
> > the same patch set again with commit message.
> >
>
> Pushed the first (0001) patch.
While looking at the worker.c, I realized that we have the following
code in handle_streamed_transaction():
default:
Assert(false);
return false; / silence compiler warning /
I think it's better to do elog(ERROR) instead of Assert() as it ends
up returning false in non-assertion builds, which might cause a
problem. And it's more consistent with other codes in worker.c. Please
find an attached patch.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Kyotaro Horiguchi
Date:
At Mon, 24 Apr 2023 10:55:44 +0900, Masahiko Sawada <sawada.mshk@gmail.com> wrote in > While looking at the worker.c, I realized that we have the following > code in handle_streamed_transaction(): > > default: > Assert(false); > return false; / silence compiler warning / > > I think it's better to do elog(ERROR) instead of Assert() as it ends > up returning false in non-assertion builds, which might cause a > problem. And it's more consistent with other codes in worker.c. Please > find an attached patch. I concur that returning false is problematic. For assertion builds, Assert typically provides more detailed information than elog. However, in this case, it wouldn't matter much since the worker would repeatedly restart even after a server-restart for the same reason unless cosmic rays are involved. Moreover, the situation doesn't justify server-restaring, as it would unnecessarily involve other backends. In my opinion, it is fine to replace the Assert with an ERROR. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
Re: Perform streaming logical transactions by background workers and parallel apply
From
Kyotaro Horiguchi
Date:
At Mon, 24 Apr 2023 11:50:37 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in > I concur that returning false is problematic. > > For assertion builds, Assert typically provides more detailed > information than elog. However, in this case, it wouldn't matter much > since the worker would repeatedly restart even after a server-restart > for the same reason unless cosmic rays are involved. Moreover, the > situation doesn't justify server-restaring, as it would unnecessarily > involve other backends. Please disregard this part, as it's not relavant to non-assertion builds. > In my opinion, it is fine to replace the Assert with an ERROR. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
Re: Perform streaming logical transactions by background workers and parallel apply
From
Kyotaro Horiguchi
Date:
At Mon, 24 Apr 2023 11:50:37 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in > In my opinion, it is fine to replace the Assert with an ERROR. Sorry for posting multiple times in a row, but I'm a bit unceratin whether we should use FATAL or ERROR for this situation. The stream is not provided by user, and the session or process cannot continue. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Apr 24, 2023 at 8:40 AM Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote: > > At Mon, 24 Apr 2023 11:50:37 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in > > In my opinion, it is fine to replace the Assert with an ERROR. > > Sorry for posting multiple times in a row, but I'm a bit unceratin > whether we should use FATAL or ERROR for this situation. The stream is > not provided by user, and the session or process cannot continue. > I think ERROR should be fine here similar to other cases in worker.c. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Kyotaro Horiguchi
Date:
At Mon, 24 Apr 2023 08:59:07 +0530, Amit Kapila <amit.kapila16@gmail.com> wrote in > > Sorry for posting multiple times in a row, but I'm a bit unceratin > > whether we should use FATAL or ERROR for this situation. The stream is > > not provided by user, and the session or process cannot continue. > > > > I think ERROR should be fine here similar to other cases in worker.c. Sure, I don't have any issues with it. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, Apr 24, 2023 at 7:26 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > While looking at the worker.c, I realized that we have the following > code in handle_streamed_transaction(): > > default: > Assert(false); > return false; / silence compiler warning / > > I think it's better to do elog(ERROR) instead of Assert() as it ends > up returning false in non-assertion builds, which might cause a > problem. And it's more consistent with other codes in worker.c. Please > find an attached patch. > I haven't tested it but otherwise, the changes look good to me. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, Apr 24, 2023 at 2:24 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Apr 24, 2023 at 7:26 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > While looking at the worker.c, I realized that we have the following > > code in handle_streamed_transaction(): > > > > default: > > Assert(false); > > return false; / silence compiler warning / > > > > I think it's better to do elog(ERROR) instead of Assert() as it ends > > up returning false in non-assertion builds, which might cause a > > problem. And it's more consistent with other codes in worker.c. Please > > find an attached patch. > > > > I haven't tested it but otherwise, the changes look good to me. Thanks for checking! Pushed. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Alexander Lakhin
Date:
Hello hackers,
Please look at a new anomaly that can be observed starting from 216a7848.
The following script:
echo "CREATE SUBSCRIPTION testsub CONNECTION 'dbname=nodb' PUBLICATION testpub WITH (connect = false);
ALTER SUBSCRIPTION testsub ENABLE;" | psql
sleep 1
rm $PGINST/lib/libpqwalreceiver.so
sleep 15
pg_ctl -D "$PGDB" stop -m immediate
grep 'TRAP:' server.log
Leads to multiple assertion failures:
CREATE SUBSCRIPTION
ALTER SUBSCRIPTION
waiting for server to shut down.... done
server stopped
TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c", Line: 4439, PID: 2899323
TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c", Line: 4439, PID: 2899416
TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c", Line: 4439, PID: 2899427
TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c", Line: 4439, PID: 2899439
TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c", Line: 4439, PID: 2899538
TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c", Line: 4439, PID: 2899547
server.log contains:
2023-04-26 11:00:58.797 MSK [2899300] LOG: database system is ready to accept connections
2023-04-26 11:00:58.821 MSK [2899416] ERROR: could not access file "libpqwalreceiver": No such file or directory
TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c", Line: 4439, PID: 2899416
postgres: logical replication apply worker for subscription 16385 (ExceptionalCondition+0x69)[0x558b2ac06d41]
postgres: logical replication apply worker for subscription 16385 (VirtualXactLockTableCleanup+0xa4)[0x558b2aa9fd74]
postgres: logical replication apply worker for subscription 16385 (LockReleaseAll+0xbb)[0x558b2aa9fe7d]
postgres: logical replication apply worker for subscription 16385 (+0x4588c6)[0x558b2aa2a8c6]
postgres: logical replication apply worker for subscription 16385 (shmem_exit+0x6c)[0x558b2aa87eb1]
postgres: logical replication apply worker for subscription 16385 (+0x4b5faa)[0x558b2aa87faa]
postgres: logical replication apply worker for subscription 16385 (proc_exit+0xc)[0x558b2aa88031]
postgres: logical replication apply worker for subscription 16385 (StartBackgroundWorker+0x147)[0x558b2aa0b4d9]
postgres: logical replication apply worker for subscription 16385 (+0x43fdc1)[0x558b2aa11dc1]
postgres: logical replication apply worker for subscription 16385 (+0x43ff3d)[0x558b2aa11f3d]
postgres: logical replication apply worker for subscription 16385 (+0x440866)[0x558b2aa12866]
postgres: logical replication apply worker for subscription 16385 (+0x440e12)[0x558b2aa12e12]
postgres: logical replication apply worker for subscription 16385
(BackgroundWorkerInitializeConnection+0x0)[0x558b2aa14396]
postgres: logical replication apply worker for subscription 16385 (main+0x21a)[0x558b2a932e21]
I understand, that removing libpqwalreceiver.so (or whole pginst/) is not
what happens in a production environment every day, but nonetheless it's a
new failure mode and it can produce many coredumps when testing.
IIUC, that assert will fail in case of any error raised between
ApplyWorkerMain()->logicalrep_worker_attach()->before_shmem_exit() and
ApplyWorkerMain()->InitializeApplyWorker()->BackgroundWorkerInitializeConnectionByOid()->InitPostgres().
Best regards,
Alexander
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Zhijie Hou (Fujitsu)"
Date:
On Wednesday, April 26, 2023 5:00 PM Alexander Lakhin <exclusion@gmail.com> wrote:
> Please look at a new anomaly that can be observed starting from 216a7848.
>
> The following script:
> echo "CREATE SUBSCRIPTION testsub CONNECTION 'dbname=nodb'
> PUBLICATION testpub WITH (connect = false);
> ALTER SUBSCRIPTION testsub ENABLE;" | psql
>
> sleep 1
> rm $PGINST/lib/libpqwalreceiver.so
> sleep 15
> pg_ctl -D "$PGDB" stop -m immediate
> grep 'TRAP:' server.log
>
> Leads to multiple assertion failures:
> CREATE SUBSCRIPTION
> ALTER SUBSCRIPTION
> waiting for server to shut down.... done
> server stopped
> TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c",
> Line: 4439, PID: 2899323
> TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c",
> Line: 4439, PID: 2899416
> TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c",
> Line: 4439, PID: 2899427
> TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c",
> Line: 4439, PID: 2899439
> TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c",
> Line: 4439, PID: 2899538
> TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c",
> Line: 4439, PID: 2899547
>
> server.log contains:
> 2023-04-26 11:00:58.797 MSK [2899300] LOG: database system is ready to
> accept connections
> 2023-04-26 11:00:58.821 MSK [2899416] ERROR: could not access file
> "libpqwalreceiver": No such file or directory
> TRAP: failed Assert("MyProc->backendId != InvalidBackendId"), File: "lock.c",
> Line: 4439, PID: 2899416
> postgres: logical replication apply worker for subscription 16385
> (ExceptionalCondition+0x69)[0x558b2ac06d41]
> postgres: logical replication apply worker for subscription 16385
> (VirtualXactLockTableCleanup+0xa4)[0x558b2aa9fd74]
> postgres: logical replication apply worker for subscription 16385
> (LockReleaseAll+0xbb)[0x558b2aa9fe7d]
> postgres: logical replication apply worker for subscription 16385
> (+0x4588c6)[0x558b2aa2a8c6]
> postgres: logical replication apply worker for subscription 16385
> (shmem_exit+0x6c)[0x558b2aa87eb1]
> postgres: logical replication apply worker for subscription 16385
> (+0x4b5faa)[0x558b2aa87faa]
> postgres: logical replication apply worker for subscription 16385
> (proc_exit+0xc)[0x558b2aa88031]
> postgres: logical replication apply worker for subscription 16385
> (StartBackgroundWorker+0x147)[0x558b2aa0b4d9]
> postgres: logical replication apply worker for subscription 16385
> (+0x43fdc1)[0x558b2aa11dc1]
> postgres: logical replication apply worker for subscription 16385
> (+0x43ff3d)[0x558b2aa11f3d]
> postgres: logical replication apply worker for subscription 16385
> (+0x440866)[0x558b2aa12866]
> postgres: logical replication apply worker for subscription 16385
> (+0x440e12)[0x558b2aa12e12]
> postgres: logical replication apply worker for subscription 16385
> (BackgroundWorkerInitializeConnection+0x0)[0x558b2aa14396]
> postgres: logical replication apply worker for subscription 16385
> (main+0x21a)[0x558b2a932e21]
>
> I understand, that removing libpqwalreceiver.so (or whole pginst/) is not
> what happens in a production environment every day, but nonetheless it's a
> new failure mode and it can produce many coredumps when testing.
>
> IIUC, that assert will fail in case of any error raised between
> ApplyWorkerMain()->logicalrep_worker_attach()->before_shmem_exit() and
> ApplyWorkerMain()->InitializeApplyWorker()->BackgroundWorkerInitializeC
> onnectionByOid()->InitPostgres().
Thanks for reporting the issue.
I think the problem is that it tried to release locks in
logicalrep_worker_onexit() before the initialization of the process is complete
because this callback function was registered before the init phase. So I think we
can add a conditional statement before releasing locks. Please find an attached
patch.
Best Regards,
Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Apr 26, 2023 at 4:11 PM Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, April 26, 2023 5:00 PM Alexander Lakhin <exclusion@gmail.com> wrote: > > Thanks for reporting the issue. > > I think the problem is that it tried to release locks in > logicalrep_worker_onexit() before the initialization of the process is complete > because this callback function was registered before the init phase. So I think we > can add a conditional statement before releasing locks. Please find an attached > patch. > Yeah, this should work. Yet another possibility is to introduce a new variable 'InitializingApplyWorker' similar to 'InitializingParallelWorker' and use that to prevent releasing locks. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Wed, Apr 26, 2023 at 4:11 PM Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, April 26, 2023 5:00 PM Alexander Lakhin <exclusion@gmail.com> wrote: > > > > IIUC, that assert will fail in case of any error raised between > > ApplyWorkerMain()->logicalrep_worker_attach()->before_shmem_exit() and > > ApplyWorkerMain()->InitializeApplyWorker()->BackgroundWorkerInitializeC > > onnectionByOid()->InitPostgres(). > > Thanks for reporting the issue. > > I think the problem is that it tried to release locks in > logicalrep_worker_onexit() before the initialization of the process is complete > because this callback function was registered before the init phase. So I think we > can add a conditional statement before releasing locks. Please find an attached > patch. > Alexander, does the proposed patch fix the problem you are facing? Sawada-San, and others, do you see any better way to fix it than what has been proposed? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Alexander Lakhin
Date:
Hello Amit and Zhijie, 28.04.2023 05:51, Amit Kapila wrote: > On Wed, Apr 26, 2023 at 4:11 PM Zhijie Hou (Fujitsu) > <houzj.fnst@fujitsu.com> wrote: >> I think the problem is that it tried to release locks in >> logicalrep_worker_onexit() before the initialization of the process is complete >> because this callback function was registered before the init phase. So I think we >> can add a conditional statement before releasing locks. Please find an attached >> patch. > Alexander, does the proposed patch fix the problem you are facing? > Sawada-San, and others, do you see any better way to fix it than what > has been proposed? Yes, the patch definitely fixes it. Maybe some other onexit actions can be skipped in the non-normal mode, but the assert-triggering LockReleaseAll() not called now. Thank you! Best regards, Alexander
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Fri, Apr 28, 2023 at 11:51 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Apr 26, 2023 at 4:11 PM Zhijie Hou (Fujitsu)
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Wednesday, April 26, 2023 5:00 PM Alexander Lakhin <exclusion@gmail.com> wrote:
> > >
> > > IIUC, that assert will fail in case of any error raised between
> > > ApplyWorkerMain()->logicalrep_worker_attach()->before_shmem_exit() and
> > > ApplyWorkerMain()->InitializeApplyWorker()->BackgroundWorkerInitializeC
> > > onnectionByOid()->InitPostgres().
> >
> > Thanks for reporting the issue.
> >
> > I think the problem is that it tried to release locks in
> > logicalrep_worker_onexit() before the initialization of the process is complete
> > because this callback function was registered before the init phase. So I think we
> > can add a conditional statement before releasing locks. Please find an attached
> > patch.
> >
>
> Alexander, does the proposed patch fix the problem you are facing?
> Sawada-San, and others, do you see any better way to fix it than what
> has been proposed?
I'm concerned that the idea of relying on IsNormalProcessingMode()
might not be robust since if we change the meaning of
IsNormalProcessingMode() some day it would silently break again. So I
prefer using something like InitializingApplyWorker, or another idea
would be to do cleanup work (e.g., fileset deletion and lock release)
in a separate callback that is registered after connecting to the
database.
While investigating this issue, I've reviewed the code around
callbacks and worker termination etc and I found a problem.
A parallel apply worker calls the before_shmem_exit callbacks in the
following order:
1. ShutdownPostgres()
2. logicalrep_worker_onexit()
3. pa_shutdown()
Since the worker is detached during logicalrep_worker_onexit(),
MyLogicalReplication->leader_pid is an invalid when we call
pa_shutdown():
static void
pa_shutdown(int code, Datum arg)
{
Assert(MyLogicalRepWorker->leader_pid != InvalidPid);
SendProcSignal(MyLogicalRepWorker->leader_pid,
PROCSIG_PARALLEL_APPLY_MESSAGE,
InvalidBackendId);
Also, if the parallel apply worker fails shm_toc_lookup() during the
initialization, it raises an error (because of noError = false) but
ends up a SEGV as MyLogicalRepWorker is still NULL.
I think that we should not use MyLogicalRepWorker->leader_pid in
pa_shutdown() but instead store the leader's pid to a static variable
before registering pa_shutdown() callback. And probably we can
remember the backend id of the leader apply worker to speed up
SendProcSignal().
FWIW, we might need to be careful about the timing when we call
logicalrep_worker_detach() in the worker's termination process. Since
we rely on IsLogicalParallelApplyWorker() for the parallel apply
worker to send ERROR messages to the leader apply worker, if an ERROR
happens after logicalrep_worker_detach(), we will end up with the
assertion failure.
if (IsLogicalParallelApplyWorker())
SendProcSignal(pq_mq_parallel_leader_pid,
PROCSIG_PARALLEL_APPLY_MESSAGE,
pq_mq_parallel_leader_backend_id);
else
{
Assert(IsParallelWorker());
It normally would be a should-no-happen case, though.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Apr 28, 2023 at 11:48 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Fri, Apr 28, 2023 at 11:51 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Wed, Apr 26, 2023 at 4:11 PM Zhijie Hou (Fujitsu) > > <houzj.fnst@fujitsu.com> wrote: > > > > > > On Wednesday, April 26, 2023 5:00 PM Alexander Lakhin <exclusion@gmail.com> wrote: > > > > > > > > IIUC, that assert will fail in case of any error raised between > > > > ApplyWorkerMain()->logicalrep_worker_attach()->before_shmem_exit() and > > > > ApplyWorkerMain()->InitializeApplyWorker()->BackgroundWorkerInitializeC > > > > onnectionByOid()->InitPostgres(). > > > > > > Thanks for reporting the issue. > > > > > > I think the problem is that it tried to release locks in > > > logicalrep_worker_onexit() before the initialization of the process is complete > > > because this callback function was registered before the init phase. So I think we > > > can add a conditional statement before releasing locks. Please find an attached > > > patch. > > > > > > > Alexander, does the proposed patch fix the problem you are facing? > > Sawada-San, and others, do you see any better way to fix it than what > > has been proposed? > > I'm concerned that the idea of relying on IsNormalProcessingMode() > might not be robust since if we change the meaning of > IsNormalProcessingMode() some day it would silently break again. So I > prefer using something like InitializingApplyWorker, > I think if we change the meaning of IsNormalProcessingMode() then it could also break the other places the similar check is being used. However, I am fine with InitializingApplyWorker as that could be used at other places as well. I just want to avoid adding another variable by using IsNormalProcessingMode. > or another idea > would be to do cleanup work (e.g., fileset deletion and lock release) > in a separate callback that is registered after connecting to the > database. > Yeah, but not sure if it's worth having multiple callbacks for cleanup work. -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Fri, Apr 28, 2023 at 6:01 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Apr 28, 2023 at 11:48 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > On Fri, Apr 28, 2023 at 11:51 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Wed, Apr 26, 2023 at 4:11 PM Zhijie Hou (Fujitsu) > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > On Wednesday, April 26, 2023 5:00 PM Alexander Lakhin <exclusion@gmail.com> wrote: > > > > > > > > > > IIUC, that assert will fail in case of any error raised between > > > > > ApplyWorkerMain()->logicalrep_worker_attach()->before_shmem_exit() and > > > > > ApplyWorkerMain()->InitializeApplyWorker()->BackgroundWorkerInitializeC > > > > > onnectionByOid()->InitPostgres(). > > > > > > > > Thanks for reporting the issue. > > > > > > > > I think the problem is that it tried to release locks in > > > > logicalrep_worker_onexit() before the initialization of the process is complete > > > > because this callback function was registered before the init phase. So I think we > > > > can add a conditional statement before releasing locks. Please find an attached > > > > patch. > > > > > > > > > > Alexander, does the proposed patch fix the problem you are facing? > > > Sawada-San, and others, do you see any better way to fix it than what > > > has been proposed? > > > > I'm concerned that the idea of relying on IsNormalProcessingMode() > > might not be robust since if we change the meaning of > > IsNormalProcessingMode() some day it would silently break again. So I > > prefer using something like InitializingApplyWorker, > > > > I think if we change the meaning of IsNormalProcessingMode() then it > could also break the other places the similar check is being used. Right, but I think it's unclear the relationship between the processing modes and releasing session locks. If non-normal-processing mode means we're still in the process initialization phase, why we don't skip other cleanup works such as walrcv_disconnect() and FileSetDeleteAll()? > However, I am fine with InitializingApplyWorker as that could be used > at other places as well. I just want to avoid adding another variable > by using IsNormalProcessingMode. I think it's less confusing. > > > or another idea > > would be to do cleanup work (e.g., fileset deletion and lock release) > > in a separate callback that is registered after connecting to the > > database. > > > > Yeah, but not sure if it's worth having multiple callbacks for cleanup work. Fair point. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, Apr 28, 2023 at 11:48 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> While investigating this issue, I've reviewed the code around
> callbacks and worker termination etc and I found a problem.
>
> A parallel apply worker calls the before_shmem_exit callbacks in the
> following order:
>
> 1. ShutdownPostgres()
> 2. logicalrep_worker_onexit()
> 3. pa_shutdown()
>
> Since the worker is detached during logicalrep_worker_onexit(),
> MyLogicalReplication->leader_pid is an invalid when we call
> pa_shutdown():
>
> static void
> pa_shutdown(int code, Datum arg)
> {
> Assert(MyLogicalRepWorker->leader_pid != InvalidPid);
> SendProcSignal(MyLogicalRepWorker->leader_pid,
> PROCSIG_PARALLEL_APPLY_MESSAGE,
> InvalidBackendId);
>
> Also, if the parallel apply worker fails shm_toc_lookup() during the
> initialization, it raises an error (because of noError = false) but
> ends up a SEGV as MyLogicalRepWorker is still NULL.
>
> I think that we should not use MyLogicalRepWorker->leader_pid in
> pa_shutdown() but instead store the leader's pid to a static variable
> before registering pa_shutdown() callback.
>
Why not simply move the registration of pa_shutdown() to someplace
after logicalrep_worker_attach()? BTW, it seems we don't have access
to MyLogicalRepWorker->leader_pid till we attach to the worker slot
via logicalrep_worker_attach(), so we anyway need to do what you are
suggesting after attaching to the worker slot.
--
With Regards,
Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Zhijie Hou (Fujitsu)"
Date:
On Friday, April 28, 2023 2:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Fri, Apr 28, 2023 at 11:51 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Wed, Apr 26, 2023 at 4:11 PM Zhijie Hou (Fujitsu)
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Wednesday, April 26, 2023 5:00 PM Alexander Lakhin
> <exclusion@gmail.com> wrote:
> > > >
> > > > IIUC, that assert will fail in case of any error raised between
> > > >
> ApplyWorkerMain()->logicalrep_worker_attach()->before_shmem_exit() and
> > > >
> ApplyWorkerMain()->InitializeApplyWorker()->BackgroundWorkerInitializeC
> > > > onnectionByOid()->InitPostgres().
> > >
> > > Thanks for reporting the issue.
> > >
> > > I think the problem is that it tried to release locks in
> > > logicalrep_worker_onexit() before the initialization of the process is
> complete
> > > because this callback function was registered before the init phase. So I
> think we
> > > can add a conditional statement before releasing locks. Please find an
> attached
> > > patch.
> > >
> >
> > Alexander, does the proposed patch fix the problem you are facing?
> > Sawada-San, and others, do you see any better way to fix it than what
> > has been proposed?
>
> I'm concerned that the idea of relying on IsNormalProcessingMode()
> might not be robust since if we change the meaning of
> IsNormalProcessingMode() some day it would silently break again. So I
> prefer using something like InitializingApplyWorker, or another idea
> would be to do cleanup work (e.g., fileset deletion and lock release)
> in a separate callback that is registered after connecting to the
> database.
Thanks for the review. I agree that it’s better to use a new variable here.
Attach the patch for the same.
>
> FWIW, we might need to be careful about the timing when we call
> logicalrep_worker_detach() in the worker's termination process. Since
> we rely on IsLogicalParallelApplyWorker() for the parallel apply
> worker to send ERROR messages to the leader apply worker, if an ERROR
> happens after logicalrep_worker_detach(), we will end up with the
> assertion failure.
>
> if (IsLogicalParallelApplyWorker())
> SendProcSignal(pq_mq_parallel_leader_pid,
> PROCSIG_PARALLEL_APPLY_MESSAGE,
> pq_mq_parallel_leader_backend_id);
> else
> {
> Assert(IsParallelWorker());
>
> It normally would be a should-no-happen case, though.
Yes, I think currently PA sends ERROR message before exiting,
so the callback functions are always fired after the above code which
looks fine to me.
Best Regards,
Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, May 2, 2023 at 9:06 AM Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> wrote: > > On Friday, April 28, 2023 2:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > Alexander, does the proposed patch fix the problem you are facing? > > > Sawada-San, and others, do you see any better way to fix it than what > > > has been proposed? > > > > I'm concerned that the idea of relying on IsNormalProcessingMode() > > might not be robust since if we change the meaning of > > IsNormalProcessingMode() some day it would silently break again. So I > > prefer using something like InitializingApplyWorker, or another idea > > would be to do cleanup work (e.g., fileset deletion and lock release) > > in a separate callback that is registered after connecting to the > > database. > > Thanks for the review. I agree that it’s better to use a new variable here. > Attach the patch for the same. > + * + * However, if the worker is being initialized, there is no need to release + * locks. */ - LockReleaseAll(DEFAULT_LOCKMETHOD, true); + if (!InitializingApplyWorker) + LockReleaseAll(DEFAULT_LOCKMETHOD, true); Can we slightly reword this comment as: "The locks will be acquired once the worker is initialized."? -- With Regards, Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, May 2, 2023 at 9:46 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, May 2, 2023 at 9:06 AM Zhijie Hou (Fujitsu) > <houzj.fnst@fujitsu.com> wrote: > > > > On Friday, April 28, 2023 2:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > > > > > > > > Alexander, does the proposed patch fix the problem you are facing? > > > > Sawada-San, and others, do you see any better way to fix it than what > > > > has been proposed? > > > > > > I'm concerned that the idea of relying on IsNormalProcessingMode() > > > might not be robust since if we change the meaning of > > > IsNormalProcessingMode() some day it would silently break again. So I > > > prefer using something like InitializingApplyWorker, or another idea > > > would be to do cleanup work (e.g., fileset deletion and lock release) > > > in a separate callback that is registered after connecting to the > > > database. > > > > Thanks for the review. I agree that it’s better to use a new variable here. > > Attach the patch for the same. > > > > + * > + * However, if the worker is being initialized, there is no need to release > + * locks. > */ > - LockReleaseAll(DEFAULT_LOCKMETHOD, true); > + if (!InitializingApplyWorker) > + LockReleaseAll(DEFAULT_LOCKMETHOD, true); > > Can we slightly reword this comment as: "The locks will be acquired > once the worker is initialized."? > After making this modification, I pushed your patch. Thanks! -- With Regards, Amit Kapila.
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Zhijie Hou (Fujitsu)"
Date:
On Wednesday, May 3, 2023 3:17 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, May 2, 2023 at 9:46 AM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > > On Tue, May 2, 2023 at 9:06 AM Zhijie Hou (Fujitsu) > > <houzj.fnst@fujitsu.com> wrote: > > > > > > On Friday, April 28, 2023 2:18 PM Masahiko Sawada > <sawada.mshk@gmail.com> wrote: > > > > > > > > > > > > > > Alexander, does the proposed patch fix the problem you are facing? > > > > > Sawada-San, and others, do you see any better way to fix it than > > > > > what has been proposed? > > > > > > > > I'm concerned that the idea of relying on IsNormalProcessingMode() > > > > might not be robust since if we change the meaning of > > > > IsNormalProcessingMode() some day it would silently break again. > > > > So I prefer using something like InitializingApplyWorker, or > > > > another idea would be to do cleanup work (e.g., fileset deletion > > > > and lock release) in a separate callback that is registered after > > > > connecting to the database. > > > > > > Thanks for the review. I agree that it’s better to use a new variable here. > > > Attach the patch for the same. > > > > > > > + * > > + * However, if the worker is being initialized, there is no need to > > + release > > + * locks. > > */ > > - LockReleaseAll(DEFAULT_LOCKMETHOD, true); > > + if (!InitializingApplyWorker) > > + LockReleaseAll(DEFAULT_LOCKMETHOD, true); > > > > Can we slightly reword this comment as: "The locks will be acquired > > once the worker is initialized."? > > > > After making this modification, I pushed your patch. Thanks! Thanks for pushing. Attach another patch to fix the problem that pa_shutdown will access invalid MyLogicalRepWorker. I personally want to avoid introducing new static variable, so I only reorder the callback registration in this version. When testing this, I notice a rare case that the leader is possible to receive the worker termination message after the leader stops the parallel worker. This is unnecessary and have a risk that the leader would try to access the detached memory queue. This is more likely to happen and sometimes cause the failure in regression tests after the registration reorder patch because the dsm is detached earlier after applying the patch. So, put the patch that detach the error queue before stopping worker as 0001 and the registration reorder patch as 0002. Best Regards, Hou zj
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Tue, May 2, 2023 at 12:22 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Fri, Apr 28, 2023 at 11:48 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > While investigating this issue, I've reviewed the code around
> > callbacks and worker termination etc and I found a problem.
> >
> > A parallel apply worker calls the before_shmem_exit callbacks in the
> > following order:
> >
> > 1. ShutdownPostgres()
> > 2. logicalrep_worker_onexit()
> > 3. pa_shutdown()
> >
> > Since the worker is detached during logicalrep_worker_onexit(),
> > MyLogicalReplication->leader_pid is an invalid when we call
> > pa_shutdown():
> >
> > static void
> > pa_shutdown(int code, Datum arg)
> > {
> > Assert(MyLogicalRepWorker->leader_pid != InvalidPid);
> > SendProcSignal(MyLogicalRepWorker->leader_pid,
> > PROCSIG_PARALLEL_APPLY_MESSAGE,
> > InvalidBackendId);
> >
> > Also, if the parallel apply worker fails shm_toc_lookup() during the
> > initialization, it raises an error (because of noError = false) but
> > ends up a SEGV as MyLogicalRepWorker is still NULL.
> >
> > I think that we should not use MyLogicalRepWorker->leader_pid in
> > pa_shutdown() but instead store the leader's pid to a static variable
> > before registering pa_shutdown() callback.
> >
>
> Why not simply move the registration of pa_shutdown() to someplace
> after logicalrep_worker_attach()?
If we do that, the worker won't call dsm_detach() if it raises an
ERROR in logicalrep_worker_attach(), is that okay? It seems that it's
no practically problem since we call dsm_backend_shutdown() in
shmem_exit(), but if so why do we need to call it in pa_shutdown()?
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
RE: Perform streaming logical transactions by background workers and parallel apply
From
"Zhijie Hou (Fujitsu)"
Date:
On Monday, May 8, 2023 11:08 AM Masahiko Sawada <sawada.mshk@gmail.com>
Hi,
>
> On Tue, May 2, 2023 at 12:22 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > On Fri, Apr 28, 2023 at 11:48 AM Masahiko Sawada
> <sawada.mshk@gmail.com> wrote:
> > >
> > > While investigating this issue, I've reviewed the code around
> > > callbacks and worker termination etc and I found a problem.
> > >
> > > A parallel apply worker calls the before_shmem_exit callbacks in the
> > > following order:
> > >
> > > 1. ShutdownPostgres()
> > > 2. logicalrep_worker_onexit()
> > > 3. pa_shutdown()
> > >
> > > Since the worker is detached during logicalrep_worker_onexit(),
> > > MyLogicalReplication->leader_pid is an invalid when we call
> > > pa_shutdown():
> > >
> > > static void
> > > pa_shutdown(int code, Datum arg)
> > > {
> > > Assert(MyLogicalRepWorker->leader_pid != InvalidPid);
> > > SendProcSignal(MyLogicalRepWorker->leader_pid,
> > > PROCSIG_PARALLEL_APPLY_MESSAGE,
> > > InvalidBackendId);
> > >
> > > Also, if the parallel apply worker fails shm_toc_lookup() during the
> > > initialization, it raises an error (because of noError = false) but
> > > ends up a SEGV as MyLogicalRepWorker is still NULL.
> > >
> > > I think that we should not use MyLogicalRepWorker->leader_pid in
> > > pa_shutdown() but instead store the leader's pid to a static variable
> > > before registering pa_shutdown() callback.
> > >
> >
> > Why not simply move the registration of pa_shutdown() to someplace
> > after logicalrep_worker_attach()?
>
> If we do that, the worker won't call dsm_detach() if it raises an
> ERROR in logicalrep_worker_attach(), is that okay? It seems that it's
> no practically problem since we call dsm_backend_shutdown() in
> shmem_exit(), but if so why do we need to call it in pa_shutdown()?
I think the dsm_detach in pa_shutdown was intended to fire on_dsm_detach
callbacks to give callback a chance to report stat before the stat system is
shutdown, following what we do in ParallelWorkerShutdown() (e.g.
sharedfileset.c callbacks cause fd.c to do ReportTemporaryFileUsage(), so we
need to fire that earlier).
But for parallel apply, we currently only have one on_dsm_detach
callback(shm_mq_detach_callback) which doesn't report extra stats. So the
dsm_detach in pa_shutdown is only used to make it a bit future-proof in case
we add some other on_dsm_detach callbacks in the future which need to report
stats.
Best regards,
Hou zj
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, May 8, 2023 at 12:52 PM Zhijie Hou (Fujitsu)
<houzj.fnst@fujitsu.com> wrote:
>
> On Monday, May 8, 2023 11:08 AM Masahiko Sawada <sawada.mshk@gmail.com>
>
> Hi,
>
> >
> > On Tue, May 2, 2023 at 12:22 PM Amit Kapila <amit.kapila16@gmail.com>
> > wrote:
> > >
> > > On Fri, Apr 28, 2023 at 11:48 AM Masahiko Sawada
> > <sawada.mshk@gmail.com> wrote:
> > > >
> > > > While investigating this issue, I've reviewed the code around
> > > > callbacks and worker termination etc and I found a problem.
> > > >
> > > > A parallel apply worker calls the before_shmem_exit callbacks in the
> > > > following order:
> > > >
> > > > 1. ShutdownPostgres()
> > > > 2. logicalrep_worker_onexit()
> > > > 3. pa_shutdown()
> > > >
> > > > Since the worker is detached during logicalrep_worker_onexit(),
> > > > MyLogicalReplication->leader_pid is an invalid when we call
> > > > pa_shutdown():
> > > >
> > > > static void
> > > > pa_shutdown(int code, Datum arg)
> > > > {
> > > > Assert(MyLogicalRepWorker->leader_pid != InvalidPid);
> > > > SendProcSignal(MyLogicalRepWorker->leader_pid,
> > > > PROCSIG_PARALLEL_APPLY_MESSAGE,
> > > > InvalidBackendId);
> > > >
> > > > Also, if the parallel apply worker fails shm_toc_lookup() during the
> > > > initialization, it raises an error (because of noError = false) but
> > > > ends up a SEGV as MyLogicalRepWorker is still NULL.
> > > >
> > > > I think that we should not use MyLogicalRepWorker->leader_pid in
> > > > pa_shutdown() but instead store the leader's pid to a static variable
> > > > before registering pa_shutdown() callback.
> > > >
> > >
> > > Why not simply move the registration of pa_shutdown() to someplace
> > > after logicalrep_worker_attach()?
> >
> > If we do that, the worker won't call dsm_detach() if it raises an
> > ERROR in logicalrep_worker_attach(), is that okay? It seems that it's
> > no practically problem since we call dsm_backend_shutdown() in
> > shmem_exit(), but if so why do we need to call it in pa_shutdown()?
>
> I think the dsm_detach in pa_shutdown was intended to fire on_dsm_detach
> callbacks to give callback a chance to report stat before the stat system is
> shutdown, following what we do in ParallelWorkerShutdown() (e.g.
> sharedfileset.c callbacks cause fd.c to do ReportTemporaryFileUsage(), so we
> need to fire that earlier).
>
> But for parallel apply, we currently only have one on_dsm_detach
> callback(shm_mq_detach_callback) which doesn't report extra stats. So the
> dsm_detach in pa_shutdown is only used to make it a bit future-proof in case
> we add some other on_dsm_detach callbacks in the future which need to report
> stats.
Make sense . Given that it's possible that we add other callbacks that
report stats in the future, I think it's better not to move the
position to register pa_shutdown() callback.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Mon, May 8, 2023 at 11:08 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Mon, May 8, 2023 at 12:52 PM Zhijie Hou (Fujitsu)
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Monday, May 8, 2023 11:08 AM Masahiko Sawada <sawada.mshk@gmail.com>
> >
> > Hi,
> >
> > >
> > > On Tue, May 2, 2023 at 12:22 PM Amit Kapila <amit.kapila16@gmail.com>
> > > wrote:
> > > >
> > > > On Fri, Apr 28, 2023 at 11:48 AM Masahiko Sawada
> > > <sawada.mshk@gmail.com> wrote:
> > > > >
> > > > > While investigating this issue, I've reviewed the code around
> > > > > callbacks and worker termination etc and I found a problem.
> > > > >
> > > > > A parallel apply worker calls the before_shmem_exit callbacks in the
> > > > > following order:
> > > > >
> > > > > 1. ShutdownPostgres()
> > > > > 2. logicalrep_worker_onexit()
> > > > > 3. pa_shutdown()
> > > > >
> > > > > Since the worker is detached during logicalrep_worker_onexit(),
> > > > > MyLogicalReplication->leader_pid is an invalid when we call
> > > > > pa_shutdown():
> > > > >
> > > > > static void
> > > > > pa_shutdown(int code, Datum arg)
> > > > > {
> > > > > Assert(MyLogicalRepWorker->leader_pid != InvalidPid);
> > > > > SendProcSignal(MyLogicalRepWorker->leader_pid,
> > > > > PROCSIG_PARALLEL_APPLY_MESSAGE,
> > > > > InvalidBackendId);
> > > > >
> > > > > Also, if the parallel apply worker fails shm_toc_lookup() during the
> > > > > initialization, it raises an error (because of noError = false) but
> > > > > ends up a SEGV as MyLogicalRepWorker is still NULL.
> > > > >
> > > > > I think that we should not use MyLogicalRepWorker->leader_pid in
> > > > > pa_shutdown() but instead store the leader's pid to a static variable
> > > > > before registering pa_shutdown() callback.
> > > > >
> > > >
> > > > Why not simply move the registration of pa_shutdown() to someplace
> > > > after logicalrep_worker_attach()?
> > >
> > > If we do that, the worker won't call dsm_detach() if it raises an
> > > ERROR in logicalrep_worker_attach(), is that okay? It seems that it's
> > > no practically problem since we call dsm_backend_shutdown() in
> > > shmem_exit(), but if so why do we need to call it in pa_shutdown()?
> >
> > I think the dsm_detach in pa_shutdown was intended to fire on_dsm_detach
> > callbacks to give callback a chance to report stat before the stat system is
> > shutdown, following what we do in ParallelWorkerShutdown() (e.g.
> > sharedfileset.c callbacks cause fd.c to do ReportTemporaryFileUsage(), so we
> > need to fire that earlier).
> >
> > But for parallel apply, we currently only have one on_dsm_detach
> > callback(shm_mq_detach_callback) which doesn't report extra stats. So the
> > dsm_detach in pa_shutdown is only used to make it a bit future-proof in case
> > we add some other on_dsm_detach callbacks in the future which need to report
> > stats.
>
> Make sense . Given that it's possible that we add other callbacks that
> report stats in the future, I think it's better not to move the
> position to register pa_shutdown() callback.
>
Hmm, what kind of stats do we expect to be collected before we
register pa_shutdown? I think if required we can register such a
callback after pa_shutdown. I feel without reordering the callbacks,
the fix would be a bit complicated as explained in my previous email,
so I don't think it is worth complicating this code unless really
required.
--
With Regards,
Amit Kapila.
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Fri, May 5, 2023 at 9:14 AM Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> wrote: > > On Wednesday, May 3, 2023 3:17 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > Attach another patch to fix the problem that pa_shutdown will access invalid > MyLogicalRepWorker. I personally want to avoid introducing new static variable, > so I only reorder the callback registration in this version. > > When testing this, I notice a rare case that the leader is possible to receive > the worker termination message after the leader stops the parallel worker. This > is unnecessary and have a risk that the leader would try to access the detached > memory queue. This is more likely to happen and sometimes cause the failure in > regression tests after the registration reorder patch because the dsm is > detached earlier after applying the patch. > I think it is only possible for the leader apply can worker to try to receive the error message from an error queue after your 0002 patch. Because another place already detached from the queue before stopping the parallel apply workers. So, I combined both the patches and changed a few comments and a commit message. Let me know what you think of the attached. -- With Regards, Amit Kapila.
Attachment
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, May 8, 2023 at 3:34 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Mon, May 8, 2023 at 11:08 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Mon, May 8, 2023 at 12:52 PM Zhijie Hou (Fujitsu)
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Monday, May 8, 2023 11:08 AM Masahiko Sawada <sawada.mshk@gmail.com>
> > >
> > > Hi,
> > >
> > > >
> > > > On Tue, May 2, 2023 at 12:22 PM Amit Kapila <amit.kapila16@gmail.com>
> > > > wrote:
> > > > >
> > > > > On Fri, Apr 28, 2023 at 11:48 AM Masahiko Sawada
> > > > <sawada.mshk@gmail.com> wrote:
> > > > > >
> > > > > > While investigating this issue, I've reviewed the code around
> > > > > > callbacks and worker termination etc and I found a problem.
> > > > > >
> > > > > > A parallel apply worker calls the before_shmem_exit callbacks in the
> > > > > > following order:
> > > > > >
> > > > > > 1. ShutdownPostgres()
> > > > > > 2. logicalrep_worker_onexit()
> > > > > > 3. pa_shutdown()
> > > > > >
> > > > > > Since the worker is detached during logicalrep_worker_onexit(),
> > > > > > MyLogicalReplication->leader_pid is an invalid when we call
> > > > > > pa_shutdown():
> > > > > >
> > > > > > static void
> > > > > > pa_shutdown(int code, Datum arg)
> > > > > > {
> > > > > > Assert(MyLogicalRepWorker->leader_pid != InvalidPid);
> > > > > > SendProcSignal(MyLogicalRepWorker->leader_pid,
> > > > > > PROCSIG_PARALLEL_APPLY_MESSAGE,
> > > > > > InvalidBackendId);
> > > > > >
> > > > > > Also, if the parallel apply worker fails shm_toc_lookup() during the
> > > > > > initialization, it raises an error (because of noError = false) but
> > > > > > ends up a SEGV as MyLogicalRepWorker is still NULL.
> > > > > >
> > > > > > I think that we should not use MyLogicalRepWorker->leader_pid in
> > > > > > pa_shutdown() but instead store the leader's pid to a static variable
> > > > > > before registering pa_shutdown() callback.
> > > > > >
> > > > >
> > > > > Why not simply move the registration of pa_shutdown() to someplace
> > > > > after logicalrep_worker_attach()?
> > > >
> > > > If we do that, the worker won't call dsm_detach() if it raises an
> > > > ERROR in logicalrep_worker_attach(), is that okay? It seems that it's
> > > > no practically problem since we call dsm_backend_shutdown() in
> > > > shmem_exit(), but if so why do we need to call it in pa_shutdown()?
> > >
> > > I think the dsm_detach in pa_shutdown was intended to fire on_dsm_detach
> > > callbacks to give callback a chance to report stat before the stat system is
> > > shutdown, following what we do in ParallelWorkerShutdown() (e.g.
> > > sharedfileset.c callbacks cause fd.c to do ReportTemporaryFileUsage(), so we
> > > need to fire that earlier).
> > >
> > > But for parallel apply, we currently only have one on_dsm_detach
> > > callback(shm_mq_detach_callback) which doesn't report extra stats. So the
> > > dsm_detach in pa_shutdown is only used to make it a bit future-proof in case
> > > we add some other on_dsm_detach callbacks in the future which need to report
> > > stats.
> >
> > Make sense . Given that it's possible that we add other callbacks that
> > report stats in the future, I think it's better not to move the
> > position to register pa_shutdown() callback.
> >
>
> Hmm, what kind of stats do we expect to be collected before we
> register pa_shutdown? I think if required we can register such a
> callback after pa_shutdown. I feel without reordering the callbacks,
> the fix would be a bit complicated as explained in my previous email,
> so I don't think it is worth complicating this code unless really
> required.
Fair point. I agree that the issue can be resolved by carefully
ordering the callback registration.
Another thing I'm concerned about is that since both the leader worker
and parallel worker detach DSM before logicalrep_worker_onexit(),
cleaning up work that touches DSM cannot be done in
logicalrep_worker_onexit(). If we need to do something in the future,
we would need to have another callback called before detaching DSM.
But I'm fine as it's not a problem for now.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Masahiko Sawada
Date:
On Mon, May 8, 2023 at 8:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, May 5, 2023 at 9:14 AM Zhijie Hou (Fujitsu) > <houzj.fnst@fujitsu.com> wrote: > > > > On Wednesday, May 3, 2023 3:17 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > Attach another patch to fix the problem that pa_shutdown will access invalid > > MyLogicalRepWorker. I personally want to avoid introducing new static variable, > > so I only reorder the callback registration in this version. > > > > When testing this, I notice a rare case that the leader is possible to receive > > the worker termination message after the leader stops the parallel worker. This > > is unnecessary and have a risk that the leader would try to access the detached > > memory queue. This is more likely to happen and sometimes cause the failure in > > regression tests after the registration reorder patch because the dsm is > > detached earlier after applying the patch. > > > > I think it is only possible for the leader apply can worker to try to > receive the error message from an error queue after your 0002 patch. > Because another place already detached from the queue before stopping > the parallel apply workers. So, I combined both the patches and > changed a few comments and a commit message. Let me know what you > think of the attached. I have one comment on the detaching error queue part: + /* + * Detach from the error_mq_handle for the parallel apply worker before + * stopping it. This prevents the leader apply worker from trying to + * receive the message from the error queue that might already be detached + * by the parallel apply worker. + */ + shm_mq_detach(winfo->error_mq_handle); + winfo->error_mq_handle = NULL; In pa_detach_all_error_mq(), we try to detach error queues of all workers in the pool. I think we should check if the queue is already detached (i.e. is NULL) there. Otherwise, we will end up a SEGV if an error happens after detaching the error queue and before removing the worker from the pool. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Perform streaming logical transactions by background workers and parallel apply
From
Amit Kapila
Date:
On Tue, May 9, 2023 at 7:50 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Mon, May 8, 2023 at 8:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > I think it is only possible for the leader apply can worker to try to > > receive the error message from an error queue after your 0002 patch. > > Because another place already detached from the queue before stopping > > the parallel apply workers. So, I combined both the patches and > > changed a few comments and a commit message. Let me know what you > > think of the attached. > > I have one comment on the detaching error queue part: > > + /* > + * Detach from the error_mq_handle for the parallel apply worker before > + * stopping it. This prevents the leader apply worker from trying to > + * receive the message from the error queue that might already > be detached > + * by the parallel apply worker. > + */ > + shm_mq_detach(winfo->error_mq_handle); > + winfo->error_mq_handle = NULL; > > In pa_detach_all_error_mq(), we try to detach error queues of all > workers in the pool. I think we should check if the queue is already > detached (i.e. is NULL) there. Otherwise, we will end up a SEGV if an > error happens after detaching the error queue and before removing the > worker from the pool. > Agreed, I have made this change, added the same check at one other place for the sake of consistency, and pushed the patch. -- With Regards, Amit Kapila.