RE: Perform streaming logical transactions by background workers and parallel apply - Mailing list pgsql-hackers
| From | houzj.fnst@fujitsu.com |
|---|---|
| Subject | RE: Perform streaming logical transactions by background workers and parallel apply |
| Date | |
| Msg-id | OS0PR01MB57160DFDEF5B1C4668346B7D94E99@OS0PR01MB5716.jpnprd01.prod.outlook.com Whole thread Raw |
| In response to | Perform streaming logical transactions by background workers and parallel apply (Amit Kapila <amit.kapila16@gmail.com>) |
| Responses |
RE: Perform streaming logical transactions by background workers and parallel apply
Re: Perform streaming logical transactions by background workers and parallel apply Re: Perform streaming logical transactions by background workers and parallel apply |
| List | pgsql-hackers |
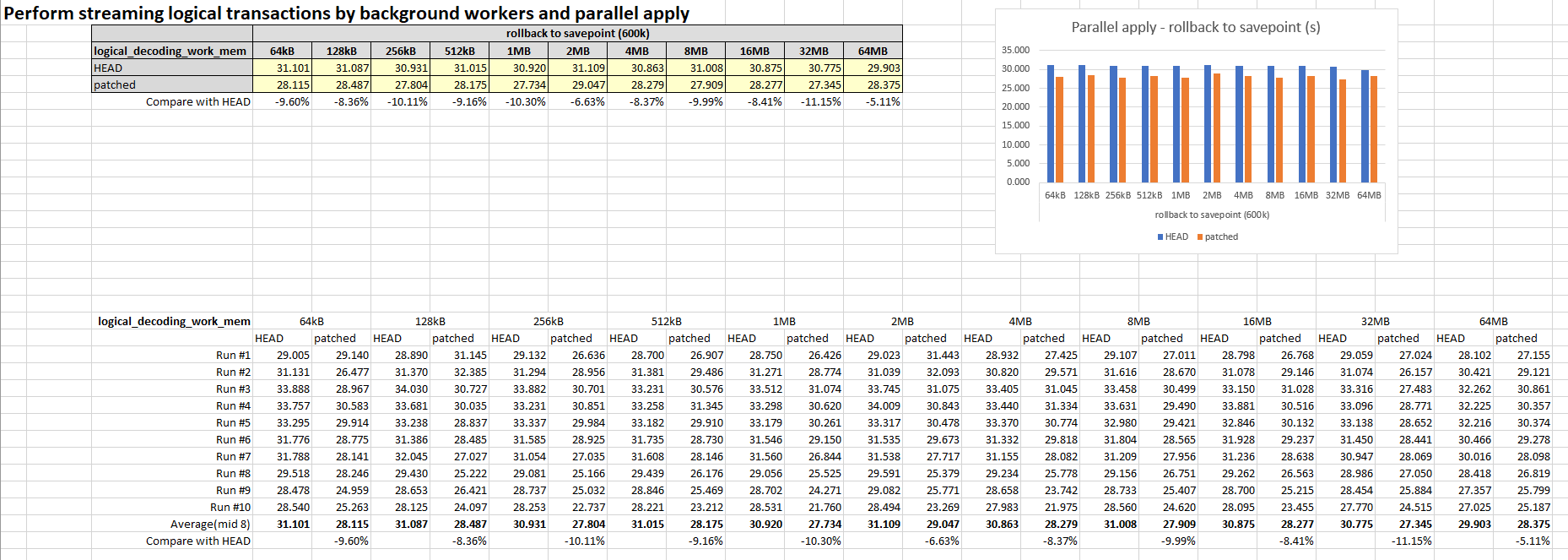
On Wednesday, April 6, 2022 1:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > In this email, I would like to discuss allowing streaming logical > transactions (large in-progress transactions) by background workers > and parallel apply in general. The goal of this work is to improve the > performance of the apply work in logical replication. > > Currently, for large transactions, the publisher sends the data in > multiple streams (changes divided into chunks depending upon > logical_decoding_work_mem), and then on the subscriber-side, the apply > worker writes the changes into temporary files and once it receives > the commit, it read from the file and apply the entire transaction. To > improve the performance of such transactions, we can instead allow > them to be applied via background workers. There could be multiple > ways to achieve this: > > Approach-1: Assign a new bgworker (if available) as soon as the xact's > first stream came and the main apply worker will send changes to this > new worker via shared memory. We keep this worker assigned till the > transaction commit came and also wait for the worker to finish at > commit. This preserves commit ordering and avoid writing to and > reading from file in most cases. We still need to spill if there is no > worker available. We also need to allow stream_stop to complete by the > background worker to finish it to avoid deadlocks because T-1's > current stream of changes can update rows in conflicting order with > T-2's next stream of changes. > Attach the POC patch for the Approach-1 of "Perform streaming logical transactions by background workers". The patch is still a WIP patch as there are serval TODO items left, including: * error handling for bgworker * support for SKIP the transaction in bgworker * handle the case when there is no more worker available (might need spill the data to the temp file in this case) * some potential bugs The original patch is borrowed from an old thread[1] and was rebased and extended/cleaned by me. Comments and suggestions are welcome. [1] https://www.postgresql.org/message-id/8eda5118-2dd0-79a1-4fe9-eec7e334de17%40postgrespro.ru Here are some performance results of the patch shared by Shi Yu off-list. The performance was tested by varying logical_decoding_work_mem, which include two cases: 1) bulk insert. 2) create savepoint and rollback to savepoint. I used synchronous logical replication in the test, compared SQL execution times before and after applying the patch. The results are as follows. The bar charts and the details of the test are Attached as well. RESULT - bulk insert (5kk) ---------------------------------- logical_decoding_work_mem 64kB 128kB 256kB 512kB 1MB 2MB 4MB 8MB 16MB 32MB 64MB HEAD 51.673 51.199 51.166 50.259 52.898 50.651 51.156 51.210 50.678 51.256 51.138 patched 36.198 35.123 34.223 29.198 28.712 29.090 29.709 29.408 34.367 34.716 35.439 RESULT - rollback to savepoint (600k) ---------------------------------- logical_decoding_work_mem 64kB 128kB 256kB 512kB 1MB 2MB 4MB 8MB 16MB 32MB 64MB HEAD 31.101 31.087 30.931 31.015 30.920 31.109 30.863 31.008 30.875 30.775 29.903 patched 28.115 28.487 27.804 28.175 27.734 29.047 28.279 27.909 28.277 27.345 28.375 Summary: 1) bulk insert For different logical_decoding_work_mem size, it takes about 30% ~ 45% less time, which looks good to me. After applying this patch, it seems that the performance is better when logical_decoding_work_mem is between 512kB and 8MB. 2) rollback to savepoint There is an improvement of about 5% ~ 10% after applying this patch. In this case, the patch spend less time handling the part that is not rolled back, because it saves the time writing the changes into a temporary file and reading the file. And for the part that is rolled back, it would spend more time than HEAD, because it takes more time to write to filesystem and rollback than writing a temporary file and truncating the file. Overall, the results looks good. Best regards, Hou zj
Attachment
{kind=link}
{kind=link}
pgsql-hackers by date: