RE: Perform streaming logical transactions by background workers and parallel apply - Mailing list pgsql-hackers
| From | houzj.fnst@fujitsu.com |
|---|---|
| Subject | RE: Perform streaming logical transactions by background workers and parallel apply |
| Date | |
| Msg-id | OS3PR01MB57185B6066FF5C6808CF896294739@OS3PR01MB5718.jpnprd01.prod.outlook.com Whole thread Raw |
| In response to | RE: Perform streaming logical transactions by background workers and parallel apply ("houzj.fnst@fujitsu.com" <houzj.fnst@fujitsu.com>) |
| List | pgsql-hackers |
On Wednesday, August 24, 2022 9:47 PM houzj.fnst@fujitsu.com wrote:
>
> On Friday, August 19, 2022 4:49 PM Amit Kapila <amit.kapila16@gmail.com>
> >
> > On Thu, Aug 18, 2022 at 5:14 PM Amit Kapila <amit.kapila16@gmail.com>
> > wrote:
> > >
> > > On Wed, Aug 17, 2022 at 11:58 AM wangw.fnst@fujitsu.com
> > > <wangw.fnst@fujitsu.com> wrote:
> > > >
> > > > Attach the new patches.
> > > >
> > >
> > > Few comments on v23-0001
> > > =======================
> > >
> >
> > Some more comments on v23-0001
> > ============================
> > 1.
> > static bool
> > handle_streamed_transaction(LogicalRepMsgType action, StringInfo s) { ...
> > - /* not in streaming mode */
> > - if (!in_streamed_transaction)
> > + /* Not in streaming mode and not in apply background worker. */ if
> > + (!(in_streamed_transaction || am_apply_bgworker()))
> > return false;
> >
> > This check appears a bit strange because ideally in bgworker
> > in_streamed_transaction should be false. I think we should set
> > in_streamed_transaction to true in apply_handle_stream_start() only
> > when we are going to write to file. Is there a reason for not doing the same?
>
> No, I removed this.
>
> > 2.
> > + {
> > + /* This is the main apply worker. */ ApplyBgworkerInfo *wstate =
> > + apply_bgworker_find(xid);
> > +
> > + /*
> > + * Check if we are processing this transaction using an apply
> > + * background worker and if so, send the changes to that worker.
> > + */
> > + if (wstate)
> > + {
> > + /* Send STREAM ABORT message to the apply background worker. */
> > + apply_bgworker_send_data(wstate, s->len, s->data);
> >
> > Why at some places the patch needs to separately fetch
> > ApplyBgworkerInfo whereas at other places it directly uses
> > stream_apply_worker to pass the data to bgworker.
> > 3. Why apply_handle_stream_abort() or apply_handle_stream_prepare()
> > doesn't use apply_bgworker_active() to identify whether it needs to
> > send the information to bgworker?
>
> I think stream_apply_worker is only valid between STREAM_START and
> STREAM_END, But it seems it's not clear from the code. So I added some
> comments and slightly refactor the code.
>
>
> > 4. In apply_handle_stream_prepare(), apply_handle_stream_abort(), and
> > some other similar functions, the patch handles three cases (a) apply
> > background worker, (b) sending data to bgworker, (c) handling for
> > streamed transaction in apply worker. I think the code will look
> > better if you move the respective code for all three cases into
> > separate functions. Surely, if the code to deal with each of the cases is less then
> we don't need to move it to a separate function.
>
> Refactored and simplified.
>
> > 5.
> > @@ -1088,24 +1177,78 @@ apply_handle_stream_prepare(StringInfo s) { ...
> > + in_remote_transaction = false;
> > +
> > + /* Unlink the files with serialized changes and subxact info. */
> > + stream_cleanup_files(MyLogicalRepWorker->subid, prepare_data.xid); }
> > + }
> >
> > in_remote_transaction = false;
> > ...
> >
> > We don't need to in_remote_transaction to false in multiple places.
>
> Removed.
>
> > 6.
> > @@ -1177,36 +1311,93 @@ apply_handle_stream_start(StringInfo s) { ...
> > ...
> > + if (am_apply_bgworker())
> > {
> > - MemoryContext oldctx;
> > -
> > - oldctx = MemoryContextSwitchTo(ApplyContext);
> > + /*
> > + * Make sure the handle apply_dispatch methods are aware we're in a
> > + * remote transaction.
> > + */
> > + in_remote_transaction = true;
> >
> > - MyLogicalRepWorker->stream_fileset = palloc(sizeof(FileSet));
> > - FileSetInit(MyLogicalRepWorker->stream_fileset);
> > + /* Begin the transaction. */
> > + AcceptInvalidationMessages();
> > + maybe_reread_subscription();
> >
> > - MemoryContextSwitchTo(oldctx);
> > + StartTransactionCommand();
> > + BeginTransactionBlock();
> > + CommitTransactionCommand();
> > }
> > ...
> >
> > Why do we need to start a transaction here? Why can't it be done via
> > begin_replication_step() during the first operation apply? Is it
> > because we may need to define a save point in bgworker and we don't
> > that information beforehand? If so, then also, can't it be handled by
> > begin_replication_step() either by explicitly passing the information
> > or checking it there and then starting a transaction block? In any
> > case, please add a few comments to explain why this separate handling
> > is required for bgworker?
>
> The transaction block is used to define the savepoint and I moved these codes to
> the place where the savepoint is defined which looks better now.
>
> > 7. When we are already setting bgworker status as APPLY_BGWORKER_BUSY
> > in
> > apply_bgworker_setup_dsm() then why do we need to set it again in
> > apply_bgworker_start()?
>
> Removed.
>
> > 8. It is not clear to me how APPLY_BGWORKER_EXIT status is used. Is it
> > required for the cases where bgworker exists due to some error and
> > then apply worker uses it to detect that and exits? How other
> > bgworkers would notice this, is it done via apply_bgworker_check_status()?
>
> It was used to detect the unexpected exit of bgworker and I have changed the
> design of this which is now similar to what we have in parallel query.
>
> Attach the new version patch set(v24) which address above comments.
> Besides, I added some logic which try to stop the bgworker at transaction end if
> there are enough workers in the pool.
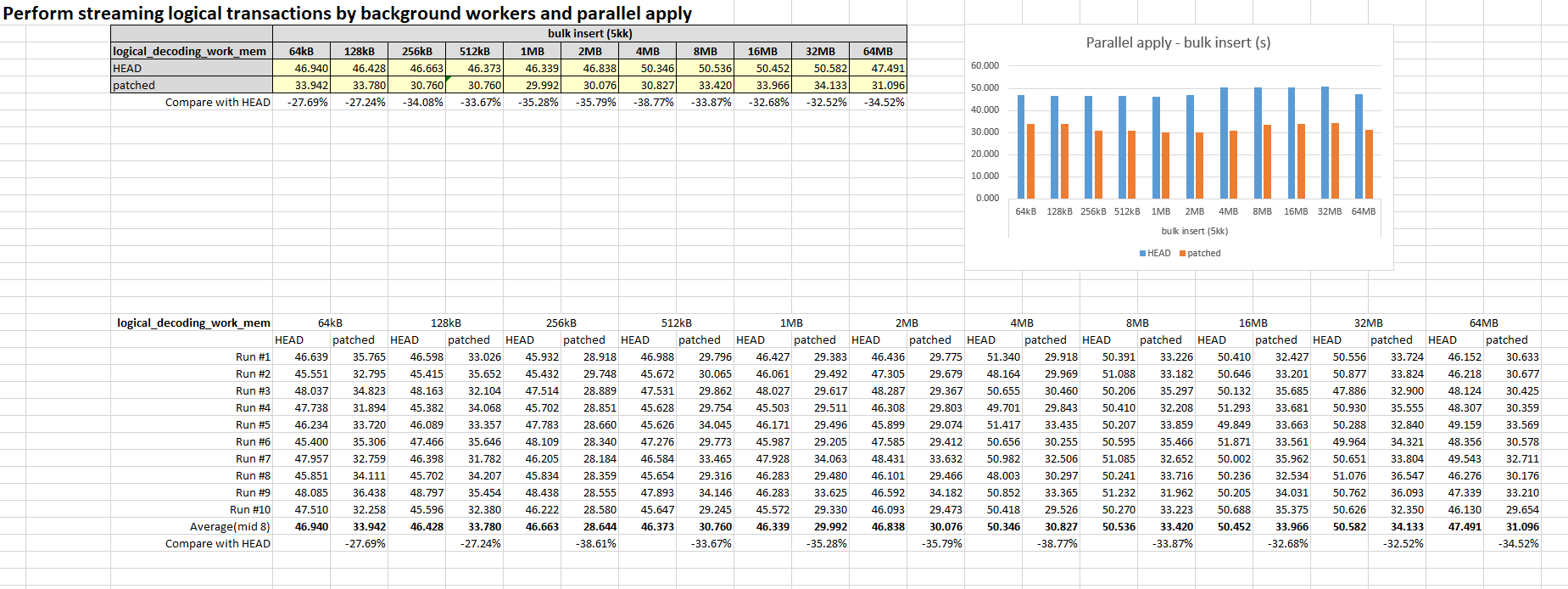
Also attach the result of performance test based on v23 patch.
This test used synchronous logical replication, and compared SQL execution
times before and after applying the patch. This is tested by varying
logical_decoding_work_mem.
The test was performed ten times, and the average of the middle eight was taken.
The results are as follows. The bar chart and the details of the test are attached.
RESULT - bulk insert (5kk)
----------------------------------
logical_decoding_work_mem 64kB 128kB 256kB 512kB 1MB 2MB 4MB 8MB 16MB 32MB 64MB
HEAD 46.940 46.428 46.663 46.373 46.339 46.838 50.346 50.536 50.452 50.582 47.491
patched 33.942 33.780 30.760 30.760 29.992 30.076 30.827 33.420 33.966 34.133 31.096
For different logical_decoding_work_mem size, it takes
about 30% ~ 40% less time, which looks good.
Some other tests are still in progress, might share them later.
Best regards,
Hou zj
Attachment
{kind=link}
pgsql-hackers by date: