Thread: Patch: Write Amplification Reduction Method (WARM)
Hi All,
As previously discussed [1], WARM is a technique to reduce write amplification when an indexed column of a table is updated. HOT fails to handle such updates and ends up inserting a new index entry in all indexes of the table, irrespective of whether the index key has changed or not for a specific index. The problem was highlighted by Uber's blog post [2], but it was a well known problem and affects many workloads.
Simon brought up the idea originally within 2ndQuadrant and I developed it further with inputs from my other colleagues and community members.
There were two important problems identified during the earlier discussion. This patch addresses those issues in a simplified way. There are other complex ideas to solve those issues, but as the results demonstrate, even a simple approach will go far way in improving performance characteristics of many workloads, yet keeping the code complexity to relatively low.
Two problems have so far been identified with the WARM design.
“Duplicate Scan” - Claudio Freire brought up a design flaw which may lead an IndexScan to return same tuple twice or more, thus impacting the correctness of the solution.
“Root Pointer Search” - Andres raised the point that it could be inefficient to find the root line pointer for a tuple in the HOT or WARM chain since it may require us to scan through the entire page.
The Duplicate Scan problem has correctness issues so could block WARM completely. We propose the following solution:
We discussed a few ideas to address the "Duplicate Scan" problem. For example, we can teach Index AMs to discard any duplicate (key, CTID) insert requests. Or we could guarantee uniqueness by either only allowing updates in one lexical order. While the former is a more complete solution to avoid duplicate entries, searching through large number of keys for non-unique indexes could be a drag on performance. The latter approach may not be sufficient for many workloads. Also tracking increment/decrement for many indexes will be non-trivial.
There is another problem with allowing many index entries pointing to the same WARM chain. It will be non-trivial to know how many index entries are currently pointing to the WARM chain and index/heap vacuum will throw up more challenges.
Instead, what I would like to propose and the patch currently implements is to restrict WARM update to once per chain. So the first non-HOT update to a tuple or a HOT chain can be a WARM update. The chain can further be HOT updated any number of times. But it can no further be WARM updated. This might look too restrictive, but it can still bring down the number of regular updates by almost 50%. Further, if we devise a strategy to convert a WARM chain back to HOT chain, it can again be WARM updated. (This part is currently not implemented). A good side effect of this simple strategy is that we know there can maximum two index entries pointing to any given WARM chain.
The other problem Andres brought up can be solved by storing the root line pointer offset in the t_ctid field of the last tuple in the update chain. Barring some aborted update case, usually it's the last tuple in the update chain that will be updated, hence it seems logical and sufficient if we can find the root line pointer while accessing that tuple. Note that the t_ctid field in the latest tuple is usually useless and is made to point to itself. Instead, I propose to use a bit from t_infomask2 to identify the LATEST tuple in the chain and use OffsetNumber field in t_ctid to store root line pointer offset. For rare aborted update case, we can scan the heap page and find root line pointer is a hard way.
Index Recheck
--------------------
As the original proposal explains, while doing index scan we must recheck if the heap tuple matches the index keys. This has to be done only when the chain is marked as a WARM chain. Currently we do that by setting the last free bit in t_infomask2 to HEAP_WARM_TUPLE. The bit is set on the tuple that gets WARM updated and all subsequent tuples in the chain. But the information can subsequently be copied to root line pointer when it's converted to a LP_REDIRECT line pointer.
Since each index AM has its own view of the index tuples, each AM must implement its "amrecheck" routine. This routine to used to confirm that a tuple returned from a WARM chain indeed satisfies the index keys. If the index AM does not implement "amrecheck" routine, WARM update is disabled on a table which uses such an index. The patch currently implements "amrecheck" routines for hash and btree indexes. Hence a table with GiST or GIN index will not honour WARM updates.
Results
----------
We used a customised pgbench workload to test the feature. In particular, the pgbench_accounts table was widened to include many more columns and indexes. We also added an index on "abalance" field which gets updated in every transaction. This replicates a workload where there are many indexes on a table and an update changes just one index key.
CREATE TABLE pgbench_accounts (
aid bigint,
bid bigint,
abalance bigint,
filler1 text DEFAULT md5(random()::text),
filler2 text DEFAULT md5(random()::text),
filler3 text DEFAULT md5(random()::text),
filler4 text DEFAULT md5(random()::text),
filler5 text DEFAULT md5(random()::text),
filler6 text DEFAULT md5(random()::text),
filler7 text DEFAULT md5(random()::text),
filler8 text DEFAULT md5(random()::text),
filler9 text DEFAULT md5(random()::text),
filler10 text DEFAULT md5(random()::text),
filler11 text DEFAULT md5(random()::text),
filler12 text DEFAULT md5(random()::text)
);
CREATE UNIQUE INDEX pgb_a_aid ON pgbench_accounts(aid);
CREATE INDEX pgb_a_abalance ON pgbench_accounts(abalance);
CREATE INDEX pgb_a_filler1 ON pgbench_accounts(filler1);
CREATE INDEX pgb_a_filler2 ON pgbench_accounts(filler2);
CREATE INDEX pgb_a_filler3 ON pgbench_accounts(filler3);
CREATE INDEX pgb_a_filler4 ON pgbench_accounts(filler4);
These tests are run on c3.4xlarge AWS instances, with 30GB of RAM, 16 vCPU and 2x160GB SSD. Data and WAL were mounted on a separate SSD.
The scale factor of 700 was chosen to ensure that the database does not fit in memory and implications of additional write activity is evident.
The actual transactional tests would just update the pgbench_accounts table:
\set aid random(1, 100000 * :scale)
\set delta random(-5000, 5000)
BEGIN;
UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
END;
The tests were run for a long duration of 16 hrs each with 16 pgbench clients to ensure that effects of the patch are captured correctly.
Headline TPS numbers:
Master:
transaction type: update.sql
scaling factor: 700
query mode: simple
number of clients: 16
number of threads: 8
duration: 57600 s
number of transactions actually processed: 65552986
latency average: 14.059 ms
tps = 1138.072117 (including connections establishing)
tps = 1138.072156 (excluding connections establishing)
WARM:
transaction type: update.sql
scaling factor: 700
query mode: simple
number of clients: 16
number of threads: 8
duration: 57600 s
number of transactions actually processed: 116168454
latency average: 7.933 ms
tps = 2016.812924 (including connections establishing)
tps = 2016.812997 (excluding connections establishing)
So WARM shows about 77% increase in TPS. Note that these are fairly long running tests with nearly 100M transactions and the tests show a steady performance.
We also measured the amount of WAL generated by Master and WARM per transaction. While master generated 34967 bytes of WAL per transaction, WARM generated 18421 bytes of WAL per transaction.
We plotted a moving average of TPS against time and also against the percentage of WARM updates. Clearly higher the number of WARM updates, higher is the TPS. A graph showing percentage of WARM updates is also plotted and it shows a steady convergence to 50% mark with time.
We repeated the same tests starting with 90% heap fill factor such that there are many more WARM updates. Since with 90% fill factor and in combination with HOT pruning, most initial updates will be WARM updates and that impacts TPS positively. WARM shows nearly 150% increase in TPS for that workload.
Master:
transaction type: update.sql
scaling factor: 700
query mode: simple
number of clients: 16
number of threads: 8
duration: 57600 s
number of transactions actually processed: 78134617
latency average: 11.795 ms
tps = 1356.503629 (including connections establishing)
tps = 1356.503679 (excluding connections establishing)
WARM:
transaction type: update.sql
scaling factor: 700
query mode: simple
number of clients: 16
number of threads: 8
duration: 57600 s
number of transactions actually processed: 196782770
latency average: 4.683 ms
tps = 3416.364822 (including connections establishing)
tps = 3416.364949 (excluding connections establishing)
In this case, master produced ~49000 bytes of WAL per transaction where as WARM produced ~14000 bytes of WAL per transaction.
I concede that we haven't yet done many tests to measure overhead of the technique, especially in circumstances where WARM may not be very useful. What I have in mind are couple of tests:
- With many indexes and a good percentage of them requiring update
- A mix of read-write workload
Any other ideas to do that are welcome.
Concerns:
--------------
The additional heap recheck may have negative impact on performance. We tried to measure this by running a SELECT only workload for 1hr after 16hr test finished. But the TPS did not show any negative impact. The impact could be more if the update changes many index keys, something these tests don't test.
The patch also changes things such that index tuples are always returned because they may be needed for recheck. It's not clear if this is something to be worried about, but we could try to further fine tune this change.
There seems to be some modularity violations since index AM needs to access some of the executor stuff to form index datums. If that's a real concern, we can look at improving amrecheck signature so that it gets index datums from the caller.
The patch uses remaining 2 free bits in t_infomask, thus closing any further improvements which may need to use heap tuple flags. During the patch development we tried several other approaches such as reusing 3-higher order bits in OffsetNumber since the current max BLCKSZ limits the MaxOffsetNumber to 8192 and that can be represented in 13 bits. We finally reverted that change to keep the patch simple. But there is clearly a way to free up more bits if required.
Converting WARM chains back to HOT chains (VACUUM ?)
---------------------------------------------------------------------------------
The current implementation of WARM allows only one WARM update per chain. This
simplifies the design and addresses certain issues around duplicate scans. But
this also implies that the benefit of WARM will be no more than 50%, which is
still significant, but if we could return WARM chains back to normal status, we
could do far more WARM updates.
A distinct property of a WARM chain is that at least one index has more than
one live index entries pointing to the root of the chain. In other words, if we
can remove duplicate entry from every index or conclusively prove that there
are no duplicate index entries for the root line pointer, the chain can again
be marked as HOT.
Here is one idea, but more thoughts/suggestions are most welcome.
A WARM chain has two parts, separated by the tuple that caused WARM update. All
tuples in each part has matching index keys, but certain index keys may not
match between these two parts. Lets say we mark heap tuples in each part with a
special Red-Blue flag. The same flag is replicated in the index tuples. For
example, when new rows are inserted in a table, they are marked with Blue flag
and the index entries associated with those rows are also marked with Blue
flag. When a row is WARM updated, the new version is marked with Red flag and
the new index entry created by the update is also marked with Red flag.
Heap chain: lp [1] [2] [3] [4]
[aaaa, 1111]B -> [aaaa, 1111]B -> [bbbb, 1111]R -> [bbbb, 1111]R
Index1: (aaaa)B points to 1 (satisfies only tuples marked with B)
(bbbb)R points to 1 (satisfies only tuples marked with R)
Index2: (1111)B points to 1 (satisfies both B and R tuples)
It's clear that for indexes with Red and Blue pointers, a heap tuple with Blue
flag will be reachable from Blue pointer and that with Red flag will be
reachable from Red pointer. But for indexes which did not create a new entry,
both Blue and Red tuples will be reachable from Blue pointer (there is no Red
pointer in such indexes). So, as a side note, matching Red and Blue flags is
not enough from index scan perspective.
During first heap scan of VACUUM, we look for tuples with HEAP_WARM_TUPLE set.
If all live tuples in the chain are either marked with Blue flag or Red flag
(but no mix of Red and Blue), then the chain is a candidate for HOT conversion.
We remember the root line pointer and Red-Blue flag of the WARM chain in a
separate array.
If we have a Red WARM chain, then our goal is to remove Blue pointers and vice
versa. But there is a catch. For Index2 above, there is only Blue pointer
and that must not be removed. IOW we should remove Blue pointer iff a Red
pointer exists. Since index vacuum may visit Red and Blue pointers in any
order, I think we will need another index pass to remove dead
index pointers. So in the first index pass we check which WARM candidates have
2 index pointers. In the second pass, we remove the dead pointer and reset Red
flag is the surviving index pointer is Red.
During the second heap scan, we fix WARM chain by clearing HEAP_WARM_TUPLE flag
and also reset Red flag to Blue.
There are some more problems around aborted vacuums. For example, if vacuum
aborts after changing Red index flag to Blue but before removing the other Blue
pointer, we will end up with two Blue pointers to a Red WARM chain. But since
the HEAP_WARM_TUPLE flag on the heap tuple is still set, further WARM updates
to the chain will be blocked. I guess we will need some special handling for
case with multiple Blue pointers. We can either leave these WARM chains alone
and let them die with a subsequent non-WARM update or must apply heap-recheck
logic during index vacuum to find the dead pointer. Given that vacuum-aborts
are not common, I am inclined to leave this case unhandled. We must still check
for presence of multiple Blue pointers and ensure that we don't accidently
remove any of the Blue pointers and not clear WARM chains either.
Of course, the idea requires one bit each in index and heap tuple. There is already a free bit in index tuple and I've some ideas to free up additional bits in heap tuple (as mentioned above).
Further Work
------------------
1.The patch currently disables WARM updates on system relations. This is mostly to keep the patch simple, but in theory we should be able to support WARM updates on system tables too. It's not clear if its worth the complexity though.
2. AFAICS both CREATE INDEX and CIC should just work fine, but need validation for that.
3. GiST and GIN indexes are currently disabled for WARM. I don't see a fundamental reason why they won't work once we implement "amrecheck" method, but I don't understand those indexes well enough.
4. There are some modularity invasions I am worried about (is amrecheck signature ok?). There are also couple of hacks around to get access to index tuples during scans and I hope to get them correct during review process, with some feedback.
5. Patch does not implement machinery to convert WARM chains into HOT chains. I would give it go unless someone finds a problem with the idea or has a better idea.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
{kind=link}
{kind=link}
{kind=link}
On Wed, Aug 31, 2016 at 1:45 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
We discussed a few ideas to address the "Duplicate Scan" problem. For example, we can teach Index AMs to discard any duplicate (key, CTID) insert requests. Or we could guarantee uniqueness by either only allowing updates in one lexical order. While the former is a more complete solution to avoid duplicate entries, searching through large number of keys for non-unique indexes could be a drag on performance. The latter approach may not be sufficient for many workloads. Also tracking increment/decrement for many indexes will be non-trivial.There is another problem with allowing many index entries pointing to the same WARM chain. It will be non-trivial to know how many index entries are currently pointing to the WARM chain and index/heap vacuum will throw up more challenges.Instead, what I would like to propose and the patch currently implements is to restrict WARM update to once per chain. So the first non-HOT update to a tuple or a HOT chain can be a WARM update. The chain can further be HOT updated any number of times. But it can no further be WARM updated. This might look too restrictive, but it can still bring down the number of regular updates by almost 50%. Further, if we devise a strategy to convert a WARM chain back to HOT chain, it can again be WARM updated. (This part is currently not implemented). A good side effect of this simple strategy is that we know there can maximum two index entries pointing to any given WARM chain.
We should probably think about coordinating with my btree patch.
From the description above, the strategy is quite readily "upgradable" to one in which the indexam discards duplicate (key,ctid) pairs and that would remove the limitation of only one WARM update... right?
On Wed, Aug 31, 2016 at 10:38 PM, Claudio Freire <klaussfreire@gmail.com> wrote:
On Wed, Aug 31, 2016 at 1:45 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:We discussed a few ideas to address the "Duplicate Scan" problem. For example, we can teach Index AMs to discard any duplicate (key, CTID) insert requests. Or we could guarantee uniqueness by either only allowing updates in one lexical order. While the former is a more complete solution to avoid duplicate entries, searching through large number of keys for non-unique indexes could be a drag on performance. The latter approach may not be sufficient for many workloads. Also tracking increment/decrement for many indexes will be non-trivial.There is another problem with allowing many index entries pointing to the same WARM chain. It will be non-trivial to know how many index entries are currently pointing to the WARM chain and index/heap vacuum will throw up more challenges.Instead, what I would like to propose and the patch currently implements is to restrict WARM update to once per chain. So the first non-HOT update to a tuple or a HOT chain can be a WARM update. The chain can further be HOT updated any number of times. But it can no further be WARM updated. This might look too restrictive, but it can still bring down the number of regular updates by almost 50%. Further, if we devise a strategy to convert a WARM chain back to HOT chain, it can again be WARM updated. (This part is currently not implemented). A good side effect of this simple strategy is that we know there can maximum two index entries pointing to any given WARM chain.We should probably think about coordinating with my btree patch.From the description above, the strategy is quite readily "upgradable" to one in which the indexam discards duplicate (key,ctid) pairs and that would remove the limitation of only one WARM update... right?
Yes, we should be able to add further optimisations on lines you're working on, but what I like about the current approach is that a) it reduces complexity of the patch and b) having thought about cleaning up WARM chains, limiting number of index entries per root chain to a small number will simplify that aspect too.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Aug 31, 2016 at 10:15 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
Hi All,As previously discussed [1], WARM is a technique to reduce write amplification when an indexed column of a table is updated. HOT fails to handle such updates and ends up inserting a new index entry in all indexes of the table, irrespective of whether the index key has changed or not for a specific index. The problem was highlighted by Uber's blog post [2], but it was a well known problem and affects many workloads.
I realised that the patches were bit-rotten because of 8e1e3f958fb. Rebased patches on the current master are attached. I also took this opportunity to correct some white space errors and improve formatting of the README.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Wed, Aug 31, 2016 at 10:15:33PM +0530, Pavan Deolasee wrote: > Instead, what I would like to propose and the patch currently implements is to > restrict WARM update to once per chain. So the first non-HOT update to a tuple > or a HOT chain can be a WARM update. The chain can further be HOT updated any > number of times. But it can no further be WARM updated. This might look too > restrictive, but it can still bring down the number of regular updates by > almost 50%. Further, if we devise a strategy to convert a WARM chain back to > HOT chain, it can again be WARM updated. (This part is currently not > implemented). A good side effect of this simple strategy is that we know there > can maximum two index entries pointing to any given WARM chain. I like the simplified approach, as long as it doesn't block further improvements. > Headline TPS numbers: > > Master: > > transaction type: update.sql > scaling factor: 700 > query mode: simple > number of clients: 16 > number of threads: 8 > duration: 57600 s > number of transactions actually processed: 65552986 > latency average: 14.059 ms > tps = 1138.072117 (including connections establishing) > tps = 1138.072156 (excluding connections establishing) > > > WARM: > > transaction type: update.sql > scaling factor: 700 > query mode: simple > number of clients: 16 > number of threads: 8 > duration: 57600 s > number of transactions actually processed: 116168454 > latency average: 7.933 ms > tps = 2016.812924 (including connections establishing) > tps = 2016.812997 (excluding connections establishing) These are very impressive results. > Converting WARM chains back to HOT chains (VACUUM ?) > --------------------------------------------------------------------------------- > > The current implementation of WARM allows only one WARM update per chain. This > simplifies the design and addresses certain issues around duplicate scans. But > this also implies that the benefit of WARM will be no more than 50%, which is > still significant, but if we could return WARM chains back to normal status, we > could do far more WARM updates. > > A distinct property of a WARM chain is that at least one index has more than > one live index entries pointing to the root of the chain. In other words, if we > can remove duplicate entry from every index or conclusively prove that there > are no duplicate index entries for the root line pointer, the chain can again > be marked as HOT. I had not thought of how to convert from WARM to HOT yet. > Here is one idea, but more thoughts/suggestions are most welcome. > > A WARM chain has two parts, separated by the tuple that caused WARM update. All > tuples in each part has matching index keys, but certain index keys may not > match between these two parts. Lets say we mark heap tuples in each part with a > special Red-Blue flag. The same flag is replicated in the index tuples. For > example, when new rows are inserted in a table, they are marked with Blue flag > and the index entries associated with those rows are also marked with Blue > flag. When a row is WARM updated, the new version is marked with Red flag and > the new index entry created by the update is also marked with Red flag. > > > Heap chain: lp [1] [2] [3] [4] > [aaaa, 1111]B -> [aaaa, 1111]B -> [bbbb, 1111]R -> [bbbb, 1111]R > > Index1: (aaaa)B points to 1 (satisfies only tuples marked with B) > (bbbb)R points to 1 (satisfies only tuples marked with R) > > Index2: (1111)B points to 1 (satisfies both B and R tuples) > > > It's clear that for indexes with Red and Blue pointers, a heap tuple with Blue > flag will be reachable from Blue pointer and that with Red flag will be > reachable from Red pointer. But for indexes which did not create a new entry, > both Blue and Red tuples will be reachable from Blue pointer (there is no Red > pointer in such indexes). So, as a side note, matching Red and Blue flags is > not enough from index scan perspective. > > During first heap scan of VACUUM, we look for tuples with HEAP_WARM_TUPLE set. > If all live tuples in the chain are either marked with Blue flag or Red flag > (but no mix of Red and Blue), then the chain is a candidate for HOT conversion. Uh, if the chain is all blue, then there is are WARM entries so it already a HOT chain, so there is nothing to do, right? > We remember the root line pointer and Red-Blue flag of the WARM chain in a > separate array. > > If we have a Red WARM chain, then our goal is to remove Blue pointers and vice > versa. But there is a catch. For Index2 above, there is only Blue pointer > and that must not be removed. IOW we should remove Blue pointer iff a Red > pointer exists. Since index vacuum may visit Red and Blue pointers in any > order, I think we will need another index pass to remove dead > index pointers. So in the first index pass we check which WARM candidates have > 2 index pointers. In the second pass, we remove the dead pointer and reset Red > flag is the surviving index pointer is Red. Why not just remember the tid of chains converted from WARM to HOT, then use "amrecheck" on an index entry matching that tid to see if the index matches one of the entries in the chain. (It will match all of them or none of them, because they are all red.) I don't see a point in coloring the index entries as reds as later you would have to convert to blue in the WARM-to-HOT conversion, and a vacuum crash could lead to inconsistencies. Consider that you can just call "amrecheck" on the few chains that have converted from WARM to HOT. I believe this is more crash-safe too. However, if you have converted WARM to HOT in the heap, but crash durin the index entry removal, you could potentially have duplicates in the index later, which is bad. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Wed, Aug 31, 2016 at 04:03:29PM -0400, Bruce Momjian wrote: > Why not just remember the tid of chains converted from WARM to HOT, then > use "amrecheck" on an index entry matching that tid to see if the index > matches one of the entries in the chain. (It will match all of them or > none of them, because they are all red.) I don't see a point in > coloring the index entries as reds as later you would have to convert to > blue in the WARM-to-HOT conversion, and a vacuum crash could lead to > inconsistencies. Consider that you can just call "amrecheck" on the few > chains that have converted from WARM to HOT. I believe this is more > crash-safe too. However, if you have converted WARM to HOT in the heap, > but crash during the index entry removal, you could potentially have > duplicates in the index later, which is bad. I think Pavan had the "crash durin the index entry removal" fixed via: > During the second heap scan, we fix WARM chain by clearing HEAP_WARM_TUPLE flag > and also reset Red flag to Blue. so the marking from WARM to HOT only happens after the index has been cleaned. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Thu, Sep 1, 2016 at 1:33 AM, Bruce Momjian <bruce@momjian.us> wrote:
-- On Wed, Aug 31, 2016 at 10:15:33PM +0530, Pavan Deolasee wrote:
> Instead, what I would like to propose and the patch currently implements is to
> restrict WARM update to once per chain. So the first non-HOT update to a tuple
> or a HOT chain can be a WARM update. The chain can further be HOT updated any
> number of times. But it can no further be WARM updated. This might look too
> restrictive, but it can still bring down the number of regular updates by
> almost 50%. Further, if we devise a strategy to convert a WARM chain back to
> HOT chain, it can again be WARM updated. (This part is currently not
> implemented). A good side effect of this simple strategy is that we know there
> can maximum two index entries pointing to any given WARM chain.
I like the simplified approach, as long as it doesn't block further
improvements.
Yes, the proposed approach is simple yet does not stop us from improving things further. Moreover it has shown good performance characteristics and I believe it's a good first step.
> Master:
> tps = 1138.072117 (including connections establishing)
>
> WARM:
> tps = 2016.812924 (including connections establishing)
These are very impressive results.
Thanks. What's also interesting and something that headline numbers don't show is that WARM TPS is as much as 3 times of master TPS when the percentage of WARM updates is very high. Notice the spike in TPS in the comparison graph.
Results with non-default heap fill factor are even better. In both cases, the improvement in TPS stays constant over long periods.
>
> During first heap scan of VACUUM, we look for tuples with HEAP_WARM_TUPLE set.
> If all live tuples in the chain are either marked with Blue flag or Red flag
> (but no mix of Red and Blue), then the chain is a candidate for HOT conversion.
Uh, if the chain is all blue, then there is are WARM entries so it
already a HOT chain, so there is nothing to do, right?
For aborted WARM updates, the heap chain may be all blue, but there may still be a red index pointer which must be cleared before we allow further WARM updates to the chain.
> We remember the root line pointer and Red-Blue flag of the WARM chain in a
> separate array.
>
> If we have a Red WARM chain, then our goal is to remove Blue pointers and vice
> versa. But there is a catch. For Index2 above, there is only Blue pointer
> and that must not be removed. IOW we should remove Blue pointer iff a Red
> pointer exists. Since index vacuum may visit Red and Blue pointers in any
> order, I think we will need another index pass to remove dead
> index pointers. So in the first index pass we check which WARM candidates have
> 2 index pointers. In the second pass, we remove the dead pointer and reset Red
> flag is the surviving index pointer is Red.
Why not just remember the tid of chains converted from WARM to HOT, then
use "amrecheck" on an index entry matching that tid to see if the index
matches one of the entries in the chain.
That will require random access to heap during index vacuum phase, something I would like to avoid. But we can have that as a fall back solution for handling aborted vacuums.
(It will match all of them or
none of them, because they are all red.) I don't see a point in
coloring the index entries as reds as later you would have to convert to
blue in the WARM-to-HOT conversion, and a vacuum crash could lead to
inconsistencies.
Yes, that's a concern since the conversion of red to blue will also need to WAL logged to ensure that a crash doesn't leave us in inconsistent state. I still think that this will be an overall improvement as compared to allowing one WARM update per chain.
Consider that you can just call "amrecheck" on the few
chains that have converted from WARM to HOT. I believe this is more
crash-safe too. However, if you have converted WARM to HOT in the heap,
but crash durin the index entry removal, you could potentially have
duplicates in the index later, which is bad.
As you probably already noted, we clear heap flags only after all indexes are cleared of duplicate entries and hence a crash in between should not cause any correctness issue. As long as heap tuples are marked as warm, amrecheck will ensure that only valid tuples are returned to the caller.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Sep 1, 2016 at 02:37:40PM +0530, Pavan Deolasee wrote: > I like the simplified approach, as long as it doesn't block further > improvements. > > > > Yes, the proposed approach is simple yet does not stop us from improving things > further. Moreover it has shown good performance characteristics and I believe > it's a good first step. Agreed. This is BIG. Do you think it can be done for PG 10? > Thanks. What's also interesting and something that headline numbers don't show > is that WARM TPS is as much as 3 times of master TPS when the percentage of > WARM updates is very high. Notice the spike in TPS in the comparison graph. > > Results with non-default heap fill factor are even better. In both cases, the > improvement in TPS stays constant over long periods. Yes, I expect the benefits of this to show up in better long-term performance. > > During first heap scan of VACUUM, we look for tuples with HEAP_WARM_TUPLE > set. > > If all live tuples in the chain are either marked with Blue flag or Red > flag > > (but no mix of Red and Blue), then the chain is a candidate for HOT > conversion. > > Uh, if the chain is all blue, then there is are WARM entries so it > already a HOT chain, so there is nothing to do, right? > > > For aborted WARM updates, the heap chain may be all blue, but there may still > be a red index pointer which must be cleared before we allow further WARM > updates to the chain. Ah, understood now. Thanks. > Why not just remember the tid of chains converted from WARM to HOT, then > use "amrecheck" on an index entry matching that tid to see if the index > matches one of the entries in the chain. > > > That will require random access to heap during index vacuum phase, something I > would like to avoid. But we can have that as a fall back solution for handling > aborted vacuums. Yes, that is true. So the challenge is figuring how which of the index entries pointing to the same tid is valid, and coloring helps with that? > (It will match all of them or > none of them, because they are all red.) I don't see a point in > coloring the index entries as reds as later you would have to convert to > blue in the WARM-to-HOT conversion, and a vacuum crash could lead to > inconsistencies. > > > Yes, that's a concern since the conversion of red to blue will also need to WAL > logged to ensure that a crash doesn't leave us in inconsistent state. I still > think that this will be an overall improvement as compared to allowing one WARM > update per chain. OK. I will think some more on this to see if I can come with another approach. > > > Consider that you can just call "amrecheck" on the few > chains that have converted from WARM to HOT. I believe this is more > crash-safe too. However, if you have converted WARM to HOT in the heap, > but crash durin the index entry removal, you could potentially have > duplicates in the index later, which is bad. > > As you probably already noted, we clear heap flags only after all indexes are > cleared of duplicate entries and hence a crash in between should not cause any > correctness issue. As long as heap tuples are marked as warm, amrecheck will > ensure that only valid tuples are returned to the caller. OK, got it. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Thu, Sep 1, 2016 at 9:44 PM, Bruce Momjian <bruce@momjian.us> wrote:
On Thu, Sep 1, 2016 at 02:37:40PM +0530, Pavan Deolasee wrote:
> I like the simplified approach, as long as it doesn't block further
> improvements.
>
>
>
> Yes, the proposed approach is simple yet does not stop us from improving things
> further. Moreover it has shown good performance characteristics and I believe
> it's a good first step.
Agreed. This is BIG. Do you think it can be done for PG 10?
I definitely think so. The patches as submitted are fully functional and sufficient. Of course, there are XXX and TODOs that I hope to sort out during the review process. There are also further tests needed to ensure that the feature does not cause significant regression in the worst cases. Again something I'm willing to do once I get some feedback on the broader design and test cases. What I am looking at this stage is to know if I've missed something important in terms of design or if there is some show stopper that I overlooked.
Latest patches rebased with current master are attached. I also added a few more comments to the code. I forgot to give a brief about the patches, so including that as well.
0001_track_root_lp_v4.patch: This patch uses a free t_infomask2 bit to track latest tuple in an update chain. The t_ctid.ip_posid is used to track the root line pointer of the update chain. We do this only in the latest tuple in the chain because most often that tuple will be updated and we need to quickly find the root only during update.
0002_warm_updates_v4.patch: This patch implements the core of WARM logic. During WARM update, we only insert new entries in the indexes whose key has changed. But instead of indexing the real TID of the new tuple, we index the root line pointer and then use additional recheck logic to ensure only correct tuples are returned from such potentially broken HOT chains. Each index AM must implement a amrecheck method to support WARM. The patch currently implements this for hash and btree indexes.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Mon, Sep 5, 2016 at 1:53 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > 0001_track_root_lp_v4.patch: This patch uses a free t_infomask2 bit to track > latest tuple in an update chain. The t_ctid.ip_posid is used to track the > root line pointer of the update chain. We do this only in the latest tuple > in the chain because most often that tuple will be updated and we need to > quickly find the root only during update. > > 0002_warm_updates_v4.patch: This patch implements the core of WARM logic. > During WARM update, we only insert new entries in the indexes whose key has > changed. But instead of indexing the real TID of the new tuple, we index the > root line pointer and then use additional recheck logic to ensure only > correct tuples are returned from such potentially broken HOT chains. Each > index AM must implement a amrecheck method to support WARM. The patch > currently implements this for hash and btree indexes. Moved to next CF, I was surprised to see that it is not *that* large:43 files changed, 1539 insertions(+), 199 deletions(-) -- Michael
On 09/05/2016 06:53 AM, Pavan Deolasee wrote:
>
>
> On Thu, Sep 1, 2016 at 9:44 PM, Bruce Momjian <bruce@momjian.us
> <mailto:bruce@momjian.us>> wrote:
>
> On Thu, Sep 1, 2016 at 02:37:40PM +0530, Pavan Deolasee wrote:
> > I like the simplified approach, as long as it doesn't block further
> > improvements.
> >
> >
> >
> > Yes, the proposed approach is simple yet does not stop us from improving things
> > further. Moreover it has shown good performance characteristics and I believe
> > it's a good first step.
>
> Agreed. This is BIG. Do you think it can be done for PG 10?
>
>
> I definitely think so. The patches as submitted are fully functional and
> sufficient. Of course, there are XXX and TODOs that I hope to sort out
> during the review process. There are also further tests needed to ensure
> that the feature does not cause significant regression in the worst
> cases. Again something I'm willing to do once I get some feedback on the
> broader design and test cases. What I am looking at this stage is to
> know if I've missed something important in terms of design or if there
> is some show stopper that I overlooked.
>
> Latest patches rebased with current master are attached. I also added a
> few more comments to the code. I forgot to give a brief about the
> patches, so including that as well.
>
> 0001_track_root_lp_v4.patch: This patch uses a free t_infomask2 bit to
> track latest tuple in an update chain. The t_ctid.ip_posid is used to
> track the root line pointer of the update chain. We do this only in the
> latest tuple in the chain because most often that tuple will be updated
> and we need to quickly find the root only during update.
>
> 0002_warm_updates_v4.patch: This patch implements the core of WARM
> logic. During WARM update, we only insert new entries in the indexes
> whose key has changed. But instead of indexing the real TID of the new
> tuple, we index the root line pointer and then use additional recheck
> logic to ensure only correct tuples are returned from such potentially
> broken HOT chains. Each index AM must implement a amrecheck method to
> support WARM. The patch currently implements this for hash and btree
> indexes.
>
Hi,
I've been looking at the patch over the past few days, running a bunch
of benchmarks etc. I can confirm the significant speedup, often by more
than 75% (depending on number of indexes, whether the data set fits into
RAM, etc.). Similarly for the amount of WAL generated, although that's a
bit more difficult to evaluate due to full_page_writes.
I'm not going to send detailed results, as that probably does not make
much sense at this stage of the development - I can repeat the tests
once the open questions get resolved.
There's a lot of useful and important feedback in the thread(s) so far,
particularly the descriptions of various failure cases. I think it'd be
very useful to collect those examples and turn them into regression
tests - that's something the patch should include anyway.
I don't really have much comments regarding the code, but during the
testing I noticed a bit strange behavior when updating statistics.
Consider a table like this:
create table t (a int, b int, c int) with (fillfactor = 10); insert into t select i, i from
generate_series(1,1000)s(i); create index on t(a); create index on t(b);
and update:
update t set a = a+1, b=b+1;
which has to update all indexes on the table, but:
select n_tup_upd, n_tup_hot_upd from pg_stat_user_tables
n_tup_upd | n_tup_hot_upd -----------+--------------- 1000 | 1000
So it's still counted as "WARM" - does it make sense? I mean, we're
creating a WARM chain on the page, yet we have to add pointers into all
indexes (so not really saving anything). Doesn't this waste the one WARM
update per HOT chain without actually getting anything in return?
The way this is piggy-backed on the current HOT statistics seems a bit
strange for another reason, although WARM is a relaxed version of HOT.
Until now, HOT was "all or nothing" - we've either added index entries
to all indexes or none of them. So the n_tup_hot_upd was fine.
But WARM changes that - it allows adding index entries only to a subset
of indexes, which means the "per row" n_tup_hot_upd counter is not
sufficient. When you have a table with 10 indexes, and the counter
increases by 1, does that mean the update added index tuple to 1 index
or 9 of them?
So I think we'll need two counters to track WARM - number of index
tuples we've added, and number of index tuples we've skipped. So
something like blks_hit and blks_read. I'm not sure whether we should
replace the n_tup_hot_upd entirely, or keep it for backwards
compatibility (and to track perfectly HOT updates).
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Oct 5, 2016 at 1:43 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
I've been looking at the patch over the past few days, running a bunch of benchmarks etc.
Thanks for doing that.
I can confirm the significant speedup, often by more than 75% (depending on number of indexes, whether the data set fits into RAM, etc.). Similarly for the amount of WAL generated, although that's a bit more difficult to evaluate due to full_page_writes.
I'm not going to send detailed results, as that probably does not make much sense at this stage of the development - I can repeat the tests once the open questions get resolved.
Sure. Anything that stands out? Any regression that you see? I'm not sure if your benchmarks exercise the paths which might show overheads without any tangible benefits. For example, I wonder if a test with many indexes where most of them get updated and then querying the table via those updated indexes could be one such test case.
There's a lot of useful and important feedback in the thread(s) so far, particularly the descriptions of various failure cases. I think it'd be very useful to collect those examples and turn them into regression tests - that's something the patch should include anyway.
Sure. I added only a handful test cases which I knew regression isn't covering. But I'll write more of them. One good thing is that the code gets heavily exercised even during regression. I caught and fixed multiple bugs running regression. I'm not saying that's enough, but it certainly gives some confidence.
and update:
update t set a = a+1, b=b+1;
which has to update all indexes on the table, but:
select n_tup_upd, n_tup_hot_upd from pg_stat_user_tables
n_tup_upd | n_tup_hot_upd
-----------+---------------
1000 | 1000
So it's still counted as "WARM" - does it make sense?
No, it does not. The code currently just marks any update as a WARM update if the table supports it and there is enough free space in the page. And yes, you're right. It's worth fixing that because of one-WARM update per chain limitation. Will fix.
The way this is piggy-backed on the current HOT statistics seems a bit strange for another reason,
Agree. We could add a similar n_tup_warm_upd counter.
But WARM changes that - it allows adding index entries only to a subset of indexes, which means the "per row" n_tup_hot_upd counter is not sufficient. When you have a table with 10 indexes, and the counter increases by 1, does that mean the update added index tuple to 1 index or 9 of them?
How about having counters similar to n_tup_ins/n_tup_del for indexes as well? Today it does not make sense because every index gets the same number of inserts, but WARM will change that.
For example, we could have idx_tup_insert and idx_tup_delete that shows up in pg_stat_user_indexes. I don't know if idx_tup_delete adds any value, but one can then look at idx_tup_insert for various indexes to get a sense which indexes receives more inserts than others. The indexes which receive more inserts are the ones being frequently updated as compared to other indexes.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On 10/06/2016 07:36 AM, Pavan Deolasee wrote:
>
>
> On Wed, Oct 5, 2016 at 1:43 PM, Tomas Vondra
> <tomas.vondra@2ndquadrant.com <mailto:tomas.vondra@2ndquadrant.com>> wrote:
>
...
> I can confirm the significant speedup, often by more than 75%
> (depending on number of indexes, whether the data set fits into RAM,
> etc.). Similarly for the amount of WAL generated, although that's a
> bit more difficult to evaluate due to full_page_writes.
>
> I'm not going to send detailed results, as that probably does not
> make much sense at this stage of the development - I can repeat the
> tests once the open questions get resolved.
>
>
> Sure. Anything that stands out? Any regression that you see? I'm not
> sure if your benchmarks exercise the paths which might show overheads
> without any tangible benefits. For example, I wonder if a test with many
> indexes where most of them get updated and then querying the table via
> those updated indexes could be one such test case.
>
No, nothing that would stand out. Let me explain what benchmark(s) I've
done. I've made some minor mistakes when running the benchmarks, so I
plan to rerun them and post the results after that. So let's take the
data with a grain of salt.
My goal was to compare current non-HOT behavior (updating all indexes)
with the WARM (updating only indexes on modified columns), and I've
taken two approaches:
1) fixed number of indexes, update variable number of columns
Create a table with 8 secondary indexes and then run a bunch of
benchmarks updating increasing number of columns. So the first run did
UPDATE t SET c1 = c1+1 WHERE id = :id;
while the second did
UPDATE t SET c1 = c1+1, c2 = c2+1 WHERE id = :id;
and so on, up to updating all the columns in the last run. I've used
multiple scripts to update all the columns / indexes uniformly
(essentially using multiple "-f" flags with pgbench). The runs were
fairly long (2h, enough to get stable behavior).
For a small data set (fits into RAM), the results look like this:
master patched diff 1 5994 8490 +42% 2 4347 7903 +81% 3 4340
7400 +70% 4 4324 6929 +60% 5 4256 6495 +52% 6 4253 5059 +19% 7
4235 4534 +7% 8 4194 4237 +1%
and the amount of WAL generated (after correction for tps difference)
looks like this (numbers are MBs)
master patched diff 1 27257 18508 -32% 2 21753 14599 -33% 3 21912
15864 -28% 4 22021 17135 -22% 5 21819 18258 -16% 6 21929 20659 -6% 7
21994 22234 +1% 8 21851 23267 +6%
So this is quite significant difference. I'm pretty sure the minor WAL
increase for the last two runs is due to full page writes (which also
affects the preceding runs, making the WAL reduction smaller than the
tps increase).
I do have results for larger data sets (>RAM), the results are very
similar although the speedup seems a bit smaller. But I need to rerun those.
2) single-row update, adding indexes between runs
This is kinda the opposite of the previous approach, i.e. transactions
always update a single column (multiple scripts to update the columns
uniformly), but there are new indexes added between runs. The results
(for a large data set, exceeding RAM) look like this:
master patched diff 0 954 1404 +47% 1 701 1045 +49% 2 484
816 +70% 3 346 683 +97% 4 248 608 +145% 5 190 525 +176% 6
152 397 +161% 7 123 315 +156% 8 123 270 +119%
So this looks really interesting.
>
> There's a lot of useful and important feedback in the thread(s) so
> far, particularly the descriptions of various failure cases. I think
> it'd be very useful to collect those examples and turn them into
> regression tests - that's something the patch should include anyway.
>
>
> Sure. I added only a handful test cases which I knew regression isn't
> covering. But I'll write more of them. One good thing is that the code
> gets heavily exercised even during regression. I caught and fixed
> multiple bugs running regression. I'm not saying that's enough, but it
> certainly gives some confidence.
>
I don't see any changes to src/test in the patch, so I'm not sure what
you mean when you say you added a handful of test cases?
>
>
> and update:
>
> update t set a = a+1, b=b+1;
>
> which has to update all indexes on the table, but:
>
> select n_tup_upd, n_tup_hot_upd from pg_stat_user_tables
>
> n_tup_upd | n_tup_hot_upd
> -----------+---------------
> 1000 | 1000
>
> So it's still counted as "WARM" - does it make sense?
>
>
> No, it does not. The code currently just marks any update as a WARM
> update if the table supports it and there is enough free space in the
> page. And yes, you're right. It's worth fixing that because of one-WARM
> update per chain limitation. Will fix.
>
Hmmm, so this makes monitoring of %WARM during benchmarks less reliable
than I hoped for :-(
>
> The way this is piggy-backed on the current HOT statistics seems a
> bit strange for another reason,
>
>
> Agree. We could add a similar n_tup_warm_upd counter.
>
Yes, although HOT is a special case of WARM. But it probably makes sense
to differentiate them, I guess.
>
> But WARM changes that - it allows adding index entries only to a
> subset of indexes, which means the "per row" n_tup_hot_upd counter
> is not sufficient. When you have a table with 10 indexes, and the
> counter increases by 1, does that mean the update added index tuple
> to 1 index or 9 of them?
>
>
> How about having counters similar to n_tup_ins/n_tup_del for indexes
> as well? Today it does not make sense because every index gets the
> same number of inserts, but WARM will change that.
>
> For example, we could have idx_tup_insert and idx_tup_delete that shows
> up in pg_stat_user_indexes. I don't know if idx_tup_delete adds any
> value, but one can then look at idx_tup_insert for various indexes to
> get a sense which indexes receives more inserts than others. The indexes
> which receive more inserts are the ones being frequently updated as
> compared to other indexes.
>
Hmmm, I'm not sure that'll work. I mean, those metrics would be useful
(although I can't think of a use case for idx_tup_delete), but I'm not
sure it's a enough to measure WARM. We need to compute
index_tuples_inserted / index_tuples_total
where (index_tuples_total - index_tuples_inserted) is the number of
index tuples we've been able to skip thanks to WARM. So we'd also need
to track the number of index tuples that we skipped for the index, and
I'm not sure that's a good idea.
Also, we really don't care about inserted tuples - what matters for WARM
are updates, so idx_tup_insert is either useless (because it also
includes non-UPDATE entries) or the naming is misleading.
> This also relates to vacuuming strategies. Today HOT updates do not
> count for triggering vacuum (or to be more precise, HOT pruned tuples
> are discounted while counting dead tuples). WARM tuples get the same
> treatment as far as pruning is concerned, but since they cause fresh
> index inserts, I wonder if we need some mechanism to cleanup the dead
> line pointers and dead index entries. This will become more important if
> we do something to convert WARM chains into HOT chains, something that
> only VACUUM can do in the design I've proposed so far.
>
True.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Thanks for the patch. This shows a very good performance improvement.
I started reviewing the patch, during this process and I ran the regression
test on the WARM patch. I observed a failure in create_index test.
This may be a bug in code or expected that needs to be corrected.
Regards,
Hari Babu
Fujitsu Australia
On Tue, Nov 8, 2016 at 9:13 AM, Haribabu Kommi <kommi.haribabu@gmail.com> wrote:
Thanks for the patch. This shows a very good performance improvement.
Thank you. Can you please share the benchmark you ran, results and observations?
I started reviewing the patch, during this process and I ran the regressiontest on the WARM patch. I observed a failure in create_index test.This may be a bug in code or expected that needs to be corrected.
Can you please share the diff? I ran regression after applying patch on the current master and did not find any change? Does it happen consistently?
I'm also attaching fresh set of patches. The first patch hasn't changed at all (though I changed the name to v5 to keep it consistent with the other patch). The second patch has the following changes:
1. WARM updates are now tracked separately. We still don't count number of index inserts separately as suggested by Tomas.
2. We don't do a WARM update if all columns referenced by all indexes have changed. Ideally, we should check if all indexes will require an update and avoid WARM. So there is still some room for improvement here
3. I added a very minimal regression test case. But really, it just contains one test case which I specifically wanted to test.
So not a whole lot of changes since the last version. I'm still waiting for some serious review of the design/code before I spend a lot more time on the patch. I hope the patch receives some attention in this CF.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Sat, Nov 12, 2016 at 10:12 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
On Tue, Nov 8, 2016 at 9:13 AM, Haribabu Kommi <kommi.haribabu@gmail.com> wrote:Thanks for the patch. This shows a very good performance improvement.Thank you. Can you please share the benchmark you ran, results and observations?
I just ran a performance test on my laptop with minimal configuration, it didn't show much
improvement, currently I don't have access to a big machine to test the performance.
I started reviewing the patch, during this process and I ran the regressiontest on the WARM patch. I observed a failure in create_index test.This may be a bug in code or expected that needs to be corrected.Can you please share the diff? I ran regression after applying patch on the current master and did not find any change? Does it happen consistently?
Yes, it is happening consistently. I ran the make installcheck. Attached the regression.diffs file with the failed test.
I applied the previous warm patch on this commit -
Regards,
Hari Babu
Fujitsu Australia
Attachment
On Tue, Nov 15, 2016 at 5:58 PM, Haribabu Kommi <kommi.haribabu@gmail.com> wrote:
On Sat, Nov 12, 2016 at 10:12 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:On Tue, Nov 8, 2016 at 9:13 AM, Haribabu Kommi <kommi.haribabu@gmail.com> wrote:Thanks for the patch. This shows a very good performance improvement.Thank you. Can you please share the benchmark you ran, results and observations?I just ran a performance test on my laptop with minimal configuration, it didn't show muchimprovement, currently I don't have access to a big machine to test the performance.I started reviewing the patch, during this process and I ran the regressiontest on the WARM patch. I observed a failure in create_index test.This may be a bug in code or expected that needs to be corrected.Can you please share the diff? I ran regression after applying patch on the current master and did not find any change? Does it happen consistently?Yes, it is happening consistently. I ran the make installcheck. Attached the regression.diffs file with the failed test.I applied the previous warm patch on this commit - e3e66d8a9813d22c2aa027d8f373a96d4d4c1b15
Currently the patch is moved to next CF with "needs review" state.
Regards,
Hari Babu
Fujitsu Australia
On Fri, Dec 2, 2016 at 8:34 AM, Haribabu Kommi <kommi.haribabu@gmail.com> wrote:
On Tue, Nov 15, 2016 at 5:58 PM, Haribabu Kommi <kommi.haribabu@gmail.com> wrote:Yes, it is happening consistently. I ran the make installcheck. Attached the regression.diffs file with the failed test.I applied the previous warm patch on this commit - e3e66d8a9813d22c2aa027d8f373a96d4d4c1b15 Are you able to reproduce the issue?
Apologies for the delay. I could reproduce this on a different environment. It was a case of uninitialised variable and hence the inconsistent results.
I've updated the patches after fixing the issue. Multiple rounds of regression passes for me without any issue. Please let me know if it works for you.
Currently the patch is moved to next CF with "needs review" state.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
I noticed that this patch changes HeapSatisfiesHOTAndKeyUpdate() by adding one more set of attributes to check, and one more output boolean flag. My patch to add indirect indexes also modifies that routine to add the same set of things. I think after committing both these patches, the API is going to be fairly ridiculous. I propose to use a different approach. With your WARM and my indirect indexes, plus the additions for for-key locks, plus identity columns, there is no longer a real expectation that we can exit early from the function. In your patch, as well as mine, there is a semblance of optimization that tries to avoid computing the updated_attrs output bitmapset if the pointer is not passed in, but it's effectively pointless because the only interesting use case is from ExecUpdate() which always activates the feature. Can we just agree to drop that? If we do drop that, then the function can become much simpler: compare all columns in new vs. old, return output bitmapset of changed columns. Then "satisfies_hot" and all the other boolean output flags can be computed simply in the caller by doing bms_overlap(). Thoughts? -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera wrote: > With your WARM and my indirect indexes, plus the additions for for-key > locks, plus identity columns, there is no longer a real expectation that > we can exit early from the function. In your patch, as well as mine, > there is a semblance of optimization that tries to avoid computing the > updated_attrs output bitmapset if the pointer is not passed in, but it's > effectively pointless because the only interesting use case is from > ExecUpdate() which always activates the feature. Can we just agree to > drop that? I think the only case that gets worse is the path that does simple_heap_update, which is used for DDL. I would be very surprised if a change there is noticeable, when compared to the rest of the stuff that goes on for DDL commands. Now, after saying that, I think that a table with a very large number of columns is going to be affected by this. But we don't really need to compute the output bits for every single column -- we only care about those that are covered by some index. So we should pass an input bitmapset comprising all such columns, and the output bitmapset only considers those columns, and ignores columns not indexed. My patch for indirect indexes already does something similar (though it passes a bitmapset of columns indexed by indirect indexes only, so it needs a tweak there.) -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2 December 2016 at 07:36, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
>
> I've updated the patches after fixing the issue. Multiple rounds of
> regression passes for me without any issue. Please let me know if it works
> for you.
>
Hi Pavan,
Today i was playing with your patch and running some tests and found
some problems i wanted to report before i forget them ;)
* You need to add a prototype in src/backend/utils/adt/pgstatfuncs.c:
extern Datum pg_stat_get_tuples_warm_updated(PG_FUNCTION_ARGS);
* The isolation test for partial_index fails (attached the regression.diffs)
* running a home-made test i have at hand i got this assertion:
"""
TRAP: FailedAssertion("!(buf_state & (1U << 24))", File: "bufmgr.c", Line: 837)
LOG: server process (PID 18986) was terminated by signal 6: Aborted
"""
To reproduce:
1) run prepare_test.sql
2) then run the following pgbench command (sql scripts attached):
pgbench -c 24 -j 24 -T 600 -n -f inserts.sql@15 -f updates_1.sql@20 -f
updates_2.sql@20 -f deletes.sql@45 db_test
* sometimes when i have made the server crash the attempt to recovery
fails with this assertion:
"""
LOG: database system was not properly shut down; automatic recovery in progress
LOG: redo starts at 0/157F970
TRAP: FailedAssertion("!(!warm_update)", File: "heapam.c", Line: 8924)
LOG: startup process (PID 14031) was terminated by signal 6: Aborted
LOG: aborting startup due to startup process failure
"""
still cannot reproduce this one consistently but happens often enough
will continue playing with it...
--
Jaime Casanova www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
Jaime Casanova wrote: > * The isolation test for partial_index fails (attached the regression.diffs) Hmm, I had a very similar (if not identical) failure with indirect indexes; in my case it was a bug in RelationGetIndexAttrBitmap() -- I was missing to have HOT considerate the columns in index predicate, that is, the second pull_varattnos() call. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera wrote: > Jaime Casanova wrote: > > > * The isolation test for partial_index fails (attached the regression.diffs) > > Hmm, I had a very similar (if not identical) failure with indirect > indexes; in my case it was a bug in RelationGetIndexAttrBitmap() -- I > was missing to have HOT considerate the columns in index predicate, that > is, the second pull_varattnos() call. Sorry, I meant: Hmm, I had a very similar (if not identical) failure with indirect indexes; in my case it was a bug in RelationGetIndexAttrBitmap()-- I was missing to have HOT [take into account] the columns in index predicate, that is, thesecond pull_varattnos() call. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Dec 26, 2016 at 11:49 AM, Jaime Casanova <jaime.casanova@2ndquadrant.com> wrote:
-- On 2 December 2016 at 07:36, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
>
> I've updated the patches after fixing the issue. Multiple rounds of
> regression passes for me without any issue. Please let me know if it works
> for you.
>
Hi Pavan,
Today i was playing with your patch and running some tests and found
some problems i wanted to report before i forget them ;)
Thanks Jaime for the tests and bug reports. I'm attaching an add-on patch which fixes these issues for me. I'm deliberately not sending a fresh revision because the changes are still minor.
* You need to add a prototype in src/backend/utils/adt/pgstatfuncs.c:
extern Datum pg_stat_get_tuples_warm_updated(PG_FUNCTION_ARGS);
Added.
* The isolation test for partial_index fails (attached the regression.diffs)
Fixed. Looks like I forgot to include attributes from predicates and expressions in the list of index attributes (as pointed by Alvaro)
* running a home-made test i have at hand i got this assertion:
"""
TRAP: FailedAssertion("!(buf_state & (1U << 24))", File: "bufmgr.c", Line: 837)
LOG: server process (PID 18986) was terminated by signal 6: Aborted
"""
To reproduce:
1) run prepare_test.sql
2) then run the following pgbench command (sql scripts attached):
pgbench -c 24 -j 24 -T 600 -n -f inserts.sql@15 -f updates_1.sql@20 -f
updates_2.sql@20 -f deletes.sql@45 db_test
Looks like the patch was failing to set the block number correctly in the t_ctid field, leading to these strange failures. There was also couple of instances where the t_ctid field was being accessed directly, instead of the newly added macro. I think we need some better mechanism to ensure that we don't miss out on such things. But I don't have a very good idea about doing that right now.
* sometimes when i have made the server crash the attempt to recovery
fails with this assertion:
"""
LOG: database system was not properly shut down; automatic recovery in progress
LOG: redo starts at 0/157F970
TRAP: FailedAssertion("!(!warm_update)", File: "heapam.c", Line: 8924)
LOG: startup process (PID 14031) was terminated by signal 6: Aborted
LOG: aborting startup due to startup process failure
"""
still cannot reproduce this one consistently but happens often enough
This could be a case of uninitialised variable in log_heap_update(). What surprises me though that none of the compilers I tried so far could catch that. In the following code snippet, if the condition evaluates to false then "warm_update" may remain uninitialised, leading to wrong xlog entry, which may later result in assertion failure during redo recovery.
7845
7846 if (HeapTupleIsHeapWarmTuple(newtup))
7847 warm_update = true;
7848
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Tue, Dec 27, 2016 at 6:51 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
Thanks Jaime for the tests and bug reports. I'm attaching an add-on patch which fixes these issues for me. I'm deliberately not sending a fresh revision because the changes are still minor.
Per Alvaro's request in another thread, I've rebased these patches on his patch to refactor HeapSatisfiesHOTandKeyUpdate(). I've also attached that patch here for easy reference.
The fixes based on bug reports by Jaime are also included in this patch set. Other than that there are not any significant changes. The patch still disables WARM on system tables, something I would like to fix. But I've been delaying that because it will require changes at several places since indexes on system tables are managed separately. In addition to that, the patch only works with btree and hash indexes. We must implement the recheck method for other index types so as to support them.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Tue, Jan 3, 2017 at 9:43 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
The patch still disables WARM on system tables, something I would like to fix. But I've been delaying that because it will require changes at several places since indexes on system tables are managed separately.
Here is another version which fixes a bug that I discovered while adding support for system tables. The patch set now also includes a patch to enable WARM on system tables. I'm attaching that as a separate patch because while the changes to support WARM on system tables are many, almost all of them are purely mechanical. We need to pass additional information to CatalogUpdateIndexes()/CatalogIndexInsert(). We need to tell these routines whether the update leading to them was a WARM update and which columns were modified so that it can correctly avoid adding new index tuples for indexes for which index keys haven't changed.
I wish I could find another way of passing this information instead of making changes at so many places, but the only other way I could think of was tracking that information as part of the HeapTuple itself, which doesn't seem nice and may also require changes at many call sites where tuples are constructed. One minor improvement could be that instead of two, we could just pass "modified_attrs" and a NULL value may imply non-WARM update. Other suggestions are welcome though.
I'm quite happy that all tests pass even after adding support for system tables. One reason for testing support for system tables was to ensure some more code paths get exercised. As before, I've included Alvaro's refactoring patch too.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
Reading through the track_root_lp patch now.
> + /*
> + * For HOT (or WARM) updated tuples, we store the offset of the root
> + * line pointer of this chain in the ip_posid field of the new tuple.
> + * Usually this information will be available in the corresponding
> + * field of the old tuple. But for aborted updates or pg_upgraded
> + * databases, we might be seeing the old-style CTID chains and hence
> + * the information must be obtained by hard way
> + */
> + if (HeapTupleHeaderHasRootOffset(oldtup.t_data))
> + root_offnum = HeapTupleHeaderGetRootOffset(oldtup.t_data);
> + else
> + heap_get_root_tuple_one(page,
> + ItemPointerGetOffsetNumber(&(oldtup.t_self)),
> + &root_offnum);
Hmm. So the HasRootOffset tests the HEAP_LATEST_TUPLE bit, which is
reset temporarily during an update. So that case shouldn't occur often.
Oh, I just noticed that HeapTupleHeaderSetNextCtid also clears the flag.
> @@ -4166,10 +4189,29 @@ l2:
> HeapTupleClearHotUpdated(&oldtup);
> HeapTupleClearHeapOnly(heaptup);
> HeapTupleClearHeapOnly(newtup);
> + root_offnum = InvalidOffsetNumber;
> }
>
> - RelationPutHeapTuple(relation, newbuf, heaptup, false); /* insert new tuple */
> + /* insert new tuple */
> + RelationPutHeapTuple(relation, newbuf, heaptup, false, root_offnum);
> + HeapTupleHeaderSetHeapLatest(heaptup->t_data);
> + HeapTupleHeaderSetHeapLatest(newtup->t_data);
>
> + /*
> + * Also update the in-memory copy with the root line pointer information
> + */
> + if (OffsetNumberIsValid(root_offnum))
> + {
> + HeapTupleHeaderSetRootOffset(heaptup->t_data, root_offnum);
> + HeapTupleHeaderSetRootOffset(newtup->t_data, root_offnum);
> + }
> + else
> + {
> + HeapTupleHeaderSetRootOffset(heaptup->t_data,
> + ItemPointerGetOffsetNumber(&heaptup->t_self));
> + HeapTupleHeaderSetRootOffset(newtup->t_data,
> + ItemPointerGetOffsetNumber(&heaptup->t_self));
> + }
This is repetitive. I think after RelationPutHeapTuple it'd be better
to assign root_offnum = &heaptup->t_self, so that we can just call
SetRootOffset() on each tuple without the if().
> + HeapTupleHeaderSetHeapLatest((HeapTupleHeader) item);
> + if (OffsetNumberIsValid(root_offnum))
> + HeapTupleHeaderSetRootOffset((HeapTupleHeader) item,
> + root_offnum);
> + else
> + HeapTupleHeaderSetRootOffset((HeapTupleHeader) item,
> + offnum);
Just a matter of style, but this reads nicer IMO:
HeapTupleHeaderSetRootOffset((HeapTupleHeader) item, OffsetNumberIsValid(root_offnum) ? root_offnum : offnum);
> @@ -740,8 +742,9 @@ heap_page_prune_execute(Buffer buffer,
> * holds a pin on the buffer. Once pin is released, a tuple might be pruned
> * and reused by a completely unrelated tuple.
> */
> -void
> -heap_get_root_tuples(Page page, OffsetNumber *root_offsets)
> +static void
> +heap_get_root_tuples_internal(Page page, OffsetNumber target_offnum,
> + OffsetNumber *root_offsets)
> {
> OffsetNumber offnum,
I think this function deserves more/better/updated commentary.
> @@ -439,7 +439,9 @@ rewrite_heap_tuple(RewriteState state,
> * set the ctid of this tuple to point to the new location, and
> * insert it right away.
> */
> - new_tuple->t_data->t_ctid = mapping->new_tid;
> + HeapTupleHeaderSetNextCtid(new_tuple->t_data,
> + ItemPointerGetBlockNumber(&mapping->new_tid),
> + ItemPointerGetOffsetNumber(&mapping->new_tid));
I think this would be nicer:HeapTupleHeaderSetNextTid(new_tuple->t_data, &mapping->new_tid);
AFAICS all the callers are doing ItemPointerGetFoo for a TID, so this is
overly verbose for no reason. Also, the "c" in Ctid stands for
"current"; I think we can omit that.
> @@ -525,7 +527,9 @@ rewrite_heap_tuple(RewriteState state,
> new_tuple = unresolved->tuple;
> free_new = true;
> old_tid = unresolved->old_tid;
> - new_tuple->t_data->t_ctid = new_tid;
> + HeapTupleHeaderSetNextCtid(new_tuple->t_data,
> + ItemPointerGetBlockNumber(&new_tid),
> + ItemPointerGetOffsetNumber(&new_tid));
Did you forget to SetHeapLatest here, or ..? (If not, a comment is
warranted).
> diff --git a/src/backend/executor/execMain.c b/src/backend/executor/execMain.c
> index 32bb3f9..466609c 100644
> --- a/src/backend/executor/execMain.c
> +++ b/src/backend/executor/execMain.c
> @@ -2443,7 +2443,7 @@ EvalPlanQualFetch(EState *estate, Relation relation, int lockmode,
> * As above, it should be safe to examine xmax and t_ctid without the
> * buffer content lock, because they can't be changing.
> */
> - if (ItemPointerEquals(&tuple.t_self, &tuple.t_data->t_ctid))
> + if (HeapTupleHeaderIsHeapLatest(tuple.t_data, tuple.t_self))
> {
> /* deleted, so forget about it */
> ReleaseBuffer(buffer);
This is the place where this patch would have an effect. To test this
bit I think we're going to need an ad-hoc stress-test harness.
> +/*
> + * If HEAP_LATEST_TUPLE is set in the last tuple in the update chain. But for
> + * clusters which are upgraded from pre-10.0 release, we still check if c_tid
> + * is pointing to itself and declare such tuple as the latest tuple in the
> + * chain
> + */
> +#define HeapTupleHeaderIsHeapLatest(tup, tid) \
> +( \
> + ((tup)->t_infomask2 & HEAP_LATEST_TUPLE) || \
> + ((ItemPointerGetBlockNumber(&(tup)->t_ctid) == ItemPointerGetBlockNumber(&tid)) && \
> + (ItemPointerGetOffsetNumber(&(tup)->t_ctid) == ItemPointerGetOffsetNumber(&tid))) \
> +)
Please add a "!= 0" to the first arm of the ||, so that we return a boolean.
> +/*
> + * Get TID of next tuple in the update chain. Traditionally, we have stored
> + * self TID in the t_ctid field if the tuple is the last tuple in the chain. We
> + * try to preserve that behaviour by returning self-TID if HEAP_LATEST_TUPLE
> + * flag is set.
> + */
> +#define HeapTupleHeaderGetNextCtid(tup, next_ctid, offnum) \
> +do { \
> + if ((tup)->t_infomask2 & HEAP_LATEST_TUPLE) \
> + { \
> + ItemPointerSet((next_ctid), ItemPointerGetBlockNumber(&(tup)->t_ctid), \
> + (offnum)); \
> + } \
> + else \
> + { \
> + ItemPointerSet((next_ctid), ItemPointerGetBlockNumber(&(tup)->t_ctid), \
> + ItemPointerGetOffsetNumber(&(tup)->t_ctid)); \
> + } \
> +} while (0)
This is a really odd macro, I think. Is any of the callers really
depending on the traditional behavior? If so, can we change them to
avoid that? (I think the "else" can be more easily written with
ItemPointerCopy). In any case, I think the documentation of the macro
leaves a bit to be desired -- I don't think we really care all that much
what we used to do, except perhaps as a secondary comment, but we do
care very much about what it actually does, which the current comment
doesn't really explain.
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi Alvaro,
--
On Tue, Jan 17, 2017 at 8:41 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Reading through the track_root_lp patch now.
Thanks for the review.
> + /*
> + * For HOT (or WARM) updated tuples, we store the offset of the root
> + * line pointer of this chain in the ip_posid field of the new tuple.
> + * Usually this information will be available in the corresponding
> + * field of the old tuple. But for aborted updates or pg_upgraded
> + * databases, we might be seeing the old-style CTID chains and hence
> + * the information must be obtained by hard way
> + */
> + if (HeapTupleHeaderHasRootOffset(oldtup.t_data))
> + root_offnum = HeapTupleHeaderGetRootOffset(oldtup.t_data);
> + else
> + heap_get_root_tuple_one(page,
> + ItemPointerGetOffsetNumber(&(oldtup.t_self)),
> + &root_offnum);
Hmm. So the HasRootOffset tests the HEAP_LATEST_TUPLE bit, which is
reset temporarily during an update. So that case shouldn't occur often.
Right. The root offset is stored only in those tuples where HEAP_LATEST_TUPLE is set. This flag should generally be set on the tuples that are being updated, except for the case when the last update failed and the flag was cleared. In other common case is going to be pg-upgraded cluster where none of the existing tuples will have this flag set. So in those cases, we must find the root line pointer hard way.
Oh, I just noticed that HeapTupleHeaderSetNextCtid also clears the flag.
Yes, but this should happen only during updates and unless the update fails, the next-to-be-updated tuple should have the flag set.
> @@ -4166,10 +4189,29 @@ l2:
> HeapTupleClearHotUpdated(&oldtup);
> HeapTupleClearHeapOnly(heaptup);
> HeapTupleClearHeapOnly(newtup);
> + root_offnum = InvalidOffsetNumber;
> }
>
> - RelationPutHeapTuple(relation, newbuf, heaptup, false); /* insert new tuple */
> + /* insert new tuple */
> + RelationPutHeapTuple(relation, newbuf, heaptup, false, root_offnum);
> + HeapTupleHeaderSetHeapLatest(heaptup->t_data);
> + HeapTupleHeaderSetHeapLatest(newtup->t_data);
>
> + /*
> + * Also update the in-memory copy with the root line pointer information
> + */
> + if (OffsetNumberIsValid(root_offnum))
> + {
> + HeapTupleHeaderSetRootOffset(heaptup->t_data, root_offnum);
> + HeapTupleHeaderSetRootOffset(newtup->t_data, root_offnum);
> + }
> + else
> + {
> + HeapTupleHeaderSetRootOffset(heaptup->t_data,
> + ItemPointerGetOffsetNumber(&heaptup->t_self));
> + HeapTupleHeaderSetRootOffset(newtup->t_data,
> + ItemPointerGetOffsetNumber(&heaptup->t_self));
> + }
This is repetitive. I think after RelationPutHeapTuple it'd be better
to assign root_offnum = &heaptup->t_self, so that we can just call
SetRootOffset() on each tuple without the if().
Fixed. I actually ripped off HeapTupleHeaderSetRootOffset() completely and pushed setting of root line pointer into the
> + HeapTupleHeaderSetHeapLatest((HeapTupleHeader) item);
> + if (OffsetNumberIsValid(root_offnum))
> + HeapTupleHeaderSetRootOffset((HeapTupleHeader) item,
> + root_offnum);
> + else
> + HeapTupleHeaderSetRootOffset((HeapTupleHeader) item,
> + offnum);
Just a matter of style, but this reads nicer IMO:
HeapTupleHeaderSetRootOffset((HeapTupleHeader) item,
OffsetNumberIsValid(root_offnum) ? root_offnum : offnum);
Understood. This code no longer exists in the new patch since HeapTupleHeaderSetRootOffset is merged with HeapTupleHeaderSetHeapLatest.
> @@ -740,8 +742,9 @@ heap_page_prune_execute(Buffer buffer,
> * holds a pin on the buffer. Once pin is released, a tuple might be pruned
> * and reused by a completely unrelated tuple.
> */
> -void
> -heap_get_root_tuples(Page page, OffsetNumber *root_offsets)
> +static void
> +heap_get_root_tuples_internal(Page page, OffsetNumber target_offnum,
> + OffsetNumber *root_offsets)
> {
> OffsetNumber offnum,
I think this function deserves more/better/updated commentary.
Sure. I added more commentary. I also reworked the function so that the caller can pass just one item array when it's interested in finding root line pointer for just one item. Hopefully that will save a few bytes on the stack.
> @@ -439,7 +439,9 @@ rewrite_heap_tuple(RewriteState state,
> * set the ctid of this tuple to point to the new location, and
> * insert it right away.
> */
> - new_tuple->t_data->t_ctid = mapping->new_tid;
> + HeapTupleHeaderSetNextCtid(new_tuple->t_data,
> + ItemPointerGetBlockNumber(&mapping->new_tid),
> + ItemPointerGetOffsetNumber(&mapping->new_tid));
I think this would be nicer:
HeapTupleHeaderSetNextTid(new_tuple->t_data, &mapping->new_tid);
AFAICS all the callers are doing ItemPointerGetFoo for a TID, so this is
overly verbose for no reason. Also, the "c" in Ctid stands for
"current"; I think we can omit that.
Yes, fixed. I realised that all callers where anyways calling the macro with the block/offset of the same TID. So it makes sense to just pass TID to the macro.
> @@ -525,7 +527,9 @@ rewrite_heap_tuple(RewriteState state,
> new_tuple = unresolved->tuple;
> free_new = true;
> old_tid = unresolved->old_tid;
> - new_tuple->t_data->t_ctid = new_tid;
> + HeapTupleHeaderSetNextCtid(new_tuple->t_data,
> + ItemPointerGetBlockNumber(&new_tid),
> + ItemPointerGetOffsetNumber(&new_tid));
Did you forget to SetHeapLatest here, or ..? (If not, a comment is
warranted).
Umm probably not. The way I see it, new_tuple is not actually the new tuple when this is called, but it's changed to the unresolved tuple (see the start of the hunk). So what we're doing is setting next CTID in the previous tuple in the chain. SetHeapLatest is called on the new tuple inside raw_heap_insert(). I did not add any more comments, but please let me know if you think it's still confusing or if I'm missing something.
> diff --git a/src/backend/executor/execMain.c b/src/backend/executor/execMai n.c
> index 32bb3f9..466609c 100644
> --- a/src/backend/executor/execMain.c
> +++ b/src/backend/executor/execMain.c
> @@ -2443,7 +2443,7 @@ EvalPlanQualFetch(EState *estate, Relation relation, int lockmode,
> * As above, it should be safe to examine xmax and t_ctid without the
> * buffer content lock, because they can't be changing.
> */
> - if (ItemPointerEquals(&tuple.t_self, &tuple.t_data->t_ctid))
> + if (HeapTupleHeaderIsHeapLatest(tuple.t_data, tuple.t_self))
> {
> /* deleted, so forget about it */
> ReleaseBuffer(buffer);
This is the place where this patch would have an effect. To test this
bit I think we're going to need an ad-hoc stress-test harness.
Sure. I did some pgbench tests and ran consistency checks during and at the end of tests. I chose a small scale factor and many clients so that same tuple is often concurrently updated. That should exercise the new chain-following code reguorsly. But I'll do more of those on a bigger box. Do you have other suggestions for ad-hoc tests?
> +/*
> + * If HEAP_LATEST_TUPLE is set in the last tuple in the update chain. But for
> + * clusters which are upgraded from pre-10.0 release, we still check if c_tid
> + * is pointing to itself and declare such tuple as the latest tuple in the
> + * chain
> + */
> +#define HeapTupleHeaderIsHeapLatest(tup, tid) \
> +( \
> + ((tup)->t_infomask2 & HEAP_LATEST_TUPLE) || \
> + ((ItemPointerGetBlockNumber(&(tup)->t_ctid) == ItemPointerGetBlockNumber(&tid )) && \
> + (ItemPointerGetOffsetNumber(&(tup)->t_ctid) == ItemPointerGetOffsetNumber(&ti d))) \
> +)
Please add a "!= 0" to the first arm of the ||, so that we return a boolean.
Done. Also rebased with new master where similar changes have been done.
> +/*
> + * Get TID of next tuple in the update chain. Traditionally, we have stored
> + * self TID in the t_ctid field if the tuple is the last tuple in the chain. We
> + * try to preserve that behaviour by returning self-TID if HEAP_LATEST_TUPLE
> + * flag is set.
> + */
> +#define HeapTupleHeaderGetNextCtid(tup, next_ctid, offnum) \
> +do { \
> + if ((tup)->t_infomask2 & HEAP_LATEST_TUPLE) \
> + { \
> + ItemPointerSet((next_ctid), ItemPointerGetBlockNumber(&(tup)->t_ctid), \
> + (offnum)); \
> + } \
> + else \
> + { \
> + ItemPointerSet((next_ctid), ItemPointerGetBlockNumber(&(tup)->t_ctid), \
> + ItemPointerGetOffsetNumber(&(tup)->t_ctid)); \
> + } \
> +} while (0)
This is a really odd macro, I think. Is any of the callers really
depending on the traditional behavior? If so, can we change them to
avoid that? (I think the "else" can be more easily written with
ItemPointerCopy). In any case, I think the documentation of the macro
leaves a bit to be desired -- I don't think we really care all that much
what we used to do, except perhaps as a secondary comment, but we do
care very much about what it actually does, which the current comment
doesn't really explain.
I reworked this quite a bit and I believe the new code does what you suggested. The HeapTupleHeaderGetNextTid macro is now much simpler (it just copies the TID) and we leave it to the caller to ensure they don't call this on a tuple which is already at the end of the chain (i.e has HEAP_LATEST_TUPLE set, but we don't look for old-style end-of-the-chain markers). The callers can choose to return the same TID back if their callers rely on that behaviour. But inside this macro, we now assert that HEAP_LATEST_TUPLE is not set.
One thing that worried me is if there exists a path which sets the t_infomask (and hence HEAP_LATEST_TUPLE) during redo recovery and if we will fail to set the root line pointer correctly along with that. But AFAICS the interesting cases of insert, multi-insert and update are being handled ok. The only other places where I saw t_infomask being copied as-is from the WAL record is DecodeXLogTuple() and DecodeMultiInsert(), but those should not cause any problem AFAICS.
Revised patch is attached. All regression tests, isolation tests and pgbench test with -c40 -j10 pass on my laptop.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Thu, Jan 19, 2017 at 6:35 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
Revised patch is attached.
I've now also rebased the main WARM patch against the current master (3eaf03b5d331b7a06d79 to be precise). I'm attaching Alvaro's patch to get interesting attributes (prefixed with 0000 since the other two patches are based on that). The changes to support system tables are now merged with the main patch. I could separate them if it helps in review.
I am also including a stress test workload that I am currently running to test WARM's correctness since Robert raised a valid concern about that. The idea is to include a few more columns in the pgbench_accounts table and have a few more indexes. The additional columns with indexes kind of share a relationship with the "aid" column. But instead of a fixed value, values for these columns can vary within a fixed, non-overlapping range. For example, for aid = 1, aid1's original value will be 10 and it can vary between 8 to 12. Similarly, aid2's original value will be 20 and it can vary between 16 to 24. This setup allows us to update these additional columns (thus force WARM), but still ensure that we can do some sanity checks on the results.
The test contains a bunch of UPDATE, FOR UPDATE, FOR SHARE transactions. Some of these transactions commit and some rollback. The checks are in-place to ensure that we always find exactly one tuple irrespective of which column we use to fetch the row. Of course, when the aid[1-4] columns are used to fetch tuples, we need to scan with a range instead of an equality. Then we do a bunch of operations like CREATE INDEX, DROP INDEX, CIC, run long transactions, VACUUM FULL etc while the tests are running and ensure that the sanity checks always pass. We could do a few other things like, may be marking these indexes as UNIQUE or keeping a long transaction open while doing updates and other operations. I'll add some of those to the test, but suggestions are welcome.
I do see a problem with CREATE INDEX CONCURRENTLY with these tests, though everything else has run ok so far (I am yet to do very long running tests. Probably just a few hours tests today).
I'm trying to understand why CIC fails to build a consistent index. I think I've some clue now why it could be happening. With HOT, we don't need to worry about broken chains since at the very beginning we add the index tuple and all subsequent updates will honour the new index while deciding on HOT updates i.e. we won't create any new broken HOT chains once we start building the index. Later during validation phase, we only need to insert tuples that are not already in the index. But with WARM, I think the check needs to be more elaborate. So even if the TID (we always look at its root line pointer etc) exists in the index, we will need to ensure that the index key matches the heap tuple we are dealing with. That looks a bit tricky. May be we can lookup the index using key from the current heap tuple and then see if we get a tuple with the same TID back. Of course, we need to do this only if the tuple is a WARM tuple. The other option is that we collect not only TIDs but also keys while scanning the index. That might increase the size of the state information for wildly wide indexes. Or may be just turn WARM off if there exists a build-in-progress index.
Suggestions/reviews/tests welcome.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
Reading 0001_track_root_lp_v9.patch again:
> +/*
> + * We use the same HEAP_LATEST_TUPLE flag to check if the tuple's t_ctid field
> + * contains the root line pointer. We can't use the same
> + * HeapTupleHeaderIsHeapLatest macro because that also checks for TID-equality
> + * to decide whether a tuple is at the of the chain
> + */
> +#define HeapTupleHeaderHasRootOffset(tup) \
> +( \
> + ((tup)->t_infomask2 & HEAP_LATEST_TUPLE) != 0 \
> +)
>
> +#define HeapTupleHeaderGetRootOffset(tup) \
> +( \
> + AssertMacro(((tup)->t_infomask2 & HEAP_LATEST_TUPLE) != 0), \
> + ItemPointerGetOffsetNumber(&(tup)->t_ctid) \
> +)
Interesting stuff; it took me a bit to see why these macros are this
way. I propose the following wording which I think is clearer:
Return whether the tuple has a cached root offset. We don't use HeapTupleHeaderIsHeapLatest because that one also
considersthe slow case of scanning the whole block.
Please flag the macros that have multiple evaluation hazards -- there
are a few of them.
> +/*
> + * If HEAP_LATEST_TUPLE is set in the last tuple in the update chain. But for
> + * clusters which are upgraded from pre-10.0 release, we still check if c_tid
> + * is pointing to itself and declare such tuple as the latest tuple in the
> + * chain
> + */
> +#define HeapTupleHeaderIsHeapLatest(tup, tid) \
> +( \
> + (((tup)->t_infomask2 & HEAP_LATEST_TUPLE) != 0) || \
> + ((ItemPointerGetBlockNumber(&(tup)->t_ctid) == ItemPointerGetBlockNumber(tid)) && \
> + (ItemPointerGetOffsetNumber(&(tup)->t_ctid) == ItemPointerGetOffsetNumber(tid))) \
> +)
I suggest rewording this comment as: Starting from PostgreSQL 10, the latest tuple in an update chain has
HEAP_LATEST_TUPLEset; but tuples upgraded from earlier versions do not. For those, we determine whether a tuple is
latestby testing that its t_ctid points to itself.
(as discussed, there is no "10.0 release"; it's called the "10 release"
only, no ".0". Feel free to use "v10" or "pg10").
> +/*
> + * Get TID of next tuple in the update chain. Caller should have checked that
> + * we are not already at the end of the chain because in that case t_ctid may
> + * actually store the root line pointer of the HOT chain whose member this
> + * tuple is.
> + */
> +#define HeapTupleHeaderGetNextTid(tup, next_ctid) \
> +do { \
> + AssertMacro(!((tup)->t_infomask2 & HEAP_LATEST_TUPLE)); \
> + ItemPointerCopy(&(tup)->t_ctid, (next_ctid)); \
> +} while (0)
Actually, I think this macro could just return the TID so that it can be
used as struct assignment, just like ItemPointerCopy does internally --
callers can doctid = HeapTupleHeaderGetNextTid(tup);
or more precisely, this pattern
> + if (!HeapTupleHeaderIsHeapLatest(tp.t_data, &tp.t_self))
> + HeapTupleHeaderGetNextTid(tp.t_data, &hufd->ctid);
> + else
> + ItemPointerCopy(&tp.t_self, &hufd->ctid);
becomes hufd->ctid = HeapTupleHeaderIsHeapLatest(foo) ? HeapTupleHeaderGetNextTid(foo) : &tp->t_self;
or something like that. I further wonder if it'd make sense to hide
this into yet another macro.
The API of RelationPutHeapTuple appears a bit contorted, where
root_offnum is both input and output. I think it's cleaner to have the
argument be the input, and have the output offset be the return value --
please check whether that simplifies things; for example I think this:
> + root_offnum = InvalidOffsetNumber;
> + RelationPutHeapTuple(relation, buffer, heaptup, false,
> + &root_offnum);
becomes
root_offnum = RelationPutHeapTuple(relation, buffer, heaptup, false, InvalidOffsetNumber);
Please remove the words "must have" in this comment:
> + /*
> + * Also mark both copies as latest and set the root offset information. If
> + * we're doing a HOT/WARM update, then we just copy the information from
> + * old tuple, if available or computed above. For regular updates,
> + * RelationPutHeapTuple must have returned us the actual offset number
> + * where the new version was inserted and we store the same value since the
> + * update resulted in a new HOT-chain
> + */
Many comments lack finishing periods in complete sentences, which looks
odd. Please fix.
I have not looked at the other patch yet.
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Looking at your 0002 patch now. It no longer applies, but the conflicts
are trivial to fix. Please rebase and resubmit.
I think the way WARM works has been pretty well hammered by now, other
than the CREATE INDEX CONCURRENTLY issues, so I'm looking at the code
from a maintainability point of view only.
I think we should have some test harness for WARM as part of the source
repository. A test that runs for an hour hammering the machine to
highest possible load cannot be run in "make check", of course, but we
could have some specific Make target to run it manually. We don't have
this for any other feature, but this looks like a decent place to start.
Maybe we should even do it before going any further. The test code you
submitted looks OK to test the feature, but I'm not in love with it
enough to add it to the repo. Maybe I will spend some time trying to
convert it to Perl using PostgresNode.
I think having the "recheck" index methods create an ExecutorState looks
out of place. How difficult is it to pass the estate from the calling
code?
IMO heap_get_root_tuple_one should be called just heap_get_root_tuple().
That function and its plural sibling heap_get_root_tuples() should
indicate in their own comments what the expectations are regarding the
root_offsets output argument, rather than deferring to the comments in
the "internal" function, since they differ on that point; for the rest
of the invariants I think it makes sense to say "Also see the comment
for heap_get_root_tuples_internal". I wonder if heap_get_root_tuple
should just return the ctid instead of assigning the value to a
passed-in pointer, i.e.
OffsetNumber
heap_get_root_tuple(Page page, OffsetNumber target_offnum)
{OffsetNumber off;heap_get_root_tuples_internal(page, target_offnum, &off);return off;
}
The simple_heap_update + CatalogUpdateIndexes pattern is getting
obnoxious. How about creating something like catalog_heap_update which
does both things at once, and stop bothering each callsite with the WARM
stuff? In fact, given that CatalogUpdateIndexes is used in other
places, maybe we should leave its API alone and create another function,
so that we don't have to change the many places that only do
simple_heap_insert. (Places like OperatorCreate which do either insert
or update could just move the index update call into each branch.)
I'm not real sure about the interface between index AM and executor,
namely IndexScanDesc->xs_tuple_recheck. For example, this pattern: if (!scan->xs_recheck)
scan->xs_tuple_recheck= false; else scan->xs_tuple_recheck = true;
can become simplyscan->xs_tuple_recheck = scan->xs_recheck;
which looks odd. I can't pinpoint exactly what's the problem, though.
I'll continue looking at this one.
I wonder if heap_hot_search_buffer() and heap_hot_search() should return
a tri-valued enum instead of boolean; that idea looks reasonable in
theory but callers have to do more work afterwards, so maybe not.
I think heap_hot_search() sometimes leaving the buffer pinned is
confusing. Really, the whole idea of having heap_hot_search have a
buffer output argument is an important API change that should be better
thought. Maybe it'd be better to return the buffer pinned always, and
the caller is always in charge of unpinning if not InvalidBuffer. Or
perhaps we need a completely new function, given how different it is to
the original? If you tried to document in the comment above
heap_hot_search how it works, you'd find that it's difficult to
describe, which'd be an indicator that it's not well considered.
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera wrote: > I wonder if heap_hot_search_buffer() and heap_hot_search() should return > a tri-valued enum instead of boolean; that idea looks reasonable in > theory but callers have to do more work afterwards, so maybe not. > > I think heap_hot_search() sometimes leaving the buffer pinned is > confusing. Really, the whole idea of having heap_hot_search have a > buffer output argument is an important API change that should be better > thought. Maybe it'd be better to return the buffer pinned always, and > the caller is always in charge of unpinning if not InvalidBuffer. Or > perhaps we need a completely new function, given how different it is to > the original? If you tried to document in the comment above > heap_hot_search how it works, you'd find that it's difficult to > describe, which'd be an indicator that it's not well considered. Even before your patch, heap_hot_search claims to have the same API as heap_hot_search_buffer "except that caller does not provide the buffer." But this is a lie and has been since 9.2 (more precisely, since commit 4da99ea4231e). I think WARM makes things even worse and we should fix that. Not yet sure which direction to fix it ... -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Jan 25, 2017 at 4:08 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > I think the way WARM works has been pretty well hammered by now, other > than the CREATE INDEX CONCURRENTLY issues, so I'm looking at the code > from a maintainability point of view only. Which senior hackers have previously reviewed it in detail? Where would I go to get a good overview of the overall theory of operation? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas wrote: > On Wed, Jan 25, 2017 at 4:08 PM, Alvaro Herrera > <alvherre@2ndquadrant.com> wrote: > > I think the way WARM works has been pretty well hammered by now, other > > than the CREATE INDEX CONCURRENTLY issues, so I'm looking at the code > > from a maintainability point of view only. > > Which senior hackers have previously reviewed it in detail? The previous thread, https://postgr.es/m/CABOikdMop5Rb_RnS2xFdAXMZGSqcJ-P-BY2ruMd+buUkJ4iDPw@mail.gmail.com contains some discussion of it, which uncovered bugs in the initial idea and gave rise to the current design. > Where would I go to get a good overview of the overall theory of operation? The added README file does a pretty good job, I thought. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Jan 25, 2017 at 10:06 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Reading 0001_track_root_lp_v9.patch again:
Thanks for the review.
> +/*
> + * We use the same HEAP_LATEST_TUPLE flag to check if the tuple's t_ctid field
> + * contains the root line pointer. We can't use the same
> + * HeapTupleHeaderIsHeapLatest macro because that also checks for TID-equality
> + * to decide whether a tuple is at the of the chain
> + */
> +#define HeapTupleHeaderHasRootOffset(tup) \
> +( \
> + ((tup)->t_infomask2 & HEAP_LATEST_TUPLE) != 0 \
> +)
>
> +#define HeapTupleHeaderGetRootOffset(tup) \
> +( \
> + AssertMacro(((tup)->t_infomask2 & HEAP_LATEST_TUPLE) != 0), \
> + ItemPointerGetOffsetNumber(&(tup)->t_ctid) \
> +)
Interesting stuff; it took me a bit to see why these macros are this
way. I propose the following wording which I think is clearer:
Return whether the tuple has a cached root offset. We don't use
HeapTupleHeaderIsHeapLatest because that one also considers the slow
case of scanning the whole block.
Umm, not scanning the whole block, but HeapTupleHeaderIsHeapLatest compares t_ctid with the passed in TID and returns true if those matches. To know if root lp is cached, we only rely on the HEAP_LATEST_TUPLE flag. Though if the flag is set, then it implies latest tuple too.
Please flag the macros that have multiple evaluation hazards -- there
are a few of them.
Can you please tell me an example? I must be missing something.
> +/*
> + * Get TID of next tuple in the update chain. Caller should have checked that
> + * we are not already at the end of the chain because in that case t_ctid may
> + * actually store the root line pointer of the HOT chain whose member this
> + * tuple is.
> + */
> +#define HeapTupleHeaderGetNextTid(tup, next_ctid) \
> +do { \
> + AssertMacro(!((tup)->t_infomask2 & HEAP_LATEST_TUPLE)); \
> + ItemPointerCopy(&(tup)->t_ctid, (next_ctid)); \
> +} while (0)
Actually, I think this macro could just return the TID so that it can be
used as struct assignment, just like ItemPointerCopy does internally --
callers can do
ctid = HeapTupleHeaderGetNextTid(tup);
Yes, makes sense. Will fix.
The API of RelationPutHeapTuple appears a bit contorted, where
root_offnum is both input and output. I think it's cleaner to have the
argument be the input, and have the output offset be the return value --
please check whether that simplifies things; for example I think this:
> + root_offnum = InvalidOffsetNumber;
> + RelationPutHeapTuple(relation, buffer, heaptup, false,
> + &root_offnum);
becomes
root_offnum = RelationPutHeapTuple(relation, buffer, heaptup, false,
InvalidOffsetNumber);
Make sense. Will fix.
Many comments lack finishing periods in complete sentences, which looks
odd. Please fix.
Sorry, not sure where I picked that style from. I see that the existing code has both styles, though I will add finishing periods because I like that way too.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Jan 26, 2017 at 2:38 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Looking at your 0002 patch now. It no longer applies, but the conflicts
are trivial to fix. Please rebase and resubmit.
Thanks.
Maybe I will spend some time trying to
convert it to Perl using PostgresNode.
Agree. I put together a test harness to hammer the WARM code as much as we can. This harness has already discovered some bugs, especially around index creation part. It also discovered one outstanding bug in master, so it's been useful. But I agree to rewrite it using perl.
I think having the "recheck" index methods create an ExecutorState looks
out of place. How difficult is it to pass the estate from the calling
code?
I couldn't find an easy way given the place where recheck is required. Can you suggest something?
IMO heap_get_root_tuple_one should be called just heap_get_root_tuple().
That function and its plural sibling heap_get_root_tuples() should
indicate in their own comments what the expectations are regarding the
root_offsets output argument, rather than deferring to the comments in
the "internal" function, since they differ on that point; for the rest
of the invariants I think it makes sense to say "Also see the comment
for heap_get_root_tuples_internal". I wonder if heap_get_root_tuple
should just return the ctid instead of assigning the value to a
passed-in pointer, i.e.
OffsetNumber
heap_get_root_tuple(Page page, OffsetNumber target_offnum)
{
OffsetNumber off;
heap_get_root_tuples_internal(page, target_offnum, &off);
return off;
}
Yes, all of that makes sense. Will fix.
The simple_heap_update + CatalogUpdateIndexes pattern is getting
obnoxious. How about creating something like catalog_heap_update which
does both things at once, and stop bothering each callsite with the WARM
stuff? In fact, given that CatalogUpdateIndexes is used in other
places, maybe we should leave its API alone and create another function,
so that we don't have to change the many places that only do
simple_heap_insert. (Places like OperatorCreate which do either insert
or update could just move the index update call into each branch.)
What I ended up doing is I added two new APIs.
- CatalogUpdateHeapAndIndex
- CatalogInsertHeapAndIndex
I could replace almost all occurrences of simple_heap_update + CatalogUpdateIndexes with the first API and simple_heap_insert + CatalogUpdateIndexes with the second API. This looks like a good improvement to me anyways since there are about 180 places where these functions are called almost in the same pattern. May be it will also avoid a bug when someone forgets to update the index after inserting/updating heap.
.
I wonder if heap_hot_search_buffer() and heap_hot_search() should return
a tri-valued enum instead of boolean; that idea looks reasonable in
theory but callers have to do more work afterwards, so maybe not.
Ok. I'll try to rearrange it a bit. May be we just have one API after all? There are only a very few callers of these APIs.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Pavan Deolasee wrote: > On Wed, Jan 25, 2017 at 10:06 PM, Alvaro Herrera <alvherre@2ndquadrant.com> > wrote: > > > +( \ > > > + ((tup)->t_infomask2 & HEAP_LATEST_TUPLE) != 0 \ > > > +) > > > > > > +#define HeapTupleHeaderGetRootOffset(tup) \ > > > +( \ > > > + AssertMacro(((tup)->t_infomask2 & HEAP_LATEST_TUPLE) != 0), \ > > > + ItemPointerGetOffsetNumber(&(tup)->t_ctid) \ > > > +) > > > > Interesting stuff; it took me a bit to see why these macros are this > > way. I propose the following wording which I think is clearer: > > > > Return whether the tuple has a cached root offset. We don't use > > HeapTupleHeaderIsHeapLatest because that one also considers the slow > > case of scanning the whole block. > > Umm, not scanning the whole block, but HeapTupleHeaderIsHeapLatest compares > t_ctid with the passed in TID and returns true if those matches. To know if > root lp is cached, we only rely on the HEAP_LATEST_TUPLE flag. Though if > the flag is set, then it implies latest tuple too. Well, I'm just trying to fix the problem that when I saw that macro, I thought "why is this checking the bitmask directly instead of using the existing IsHeapLatest macro?" when I saw the code. It turned out that IsHeapLatest is not just simply comparing the bitmask, but it also does more expensive processing which is unwanted in this case. I think the comment to this macro should explain why the other macro cannot be used. > > Please flag the macros that have multiple evaluation hazards -- there > > are a few of them. > > Can you please tell me an example? I must be missing something. Any macro that uses an argument more than once is subject to multiple evaluations of that argument; for example, if you pass a function call to the macro as one of the parameters, the function is called multiple times. In many cases this is not a problem because the argument is always a constant, but sometimes it does become a problem. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Jan 26, 2017 at 2:38 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Looking at your 0002 patch now. It no longer applies, but the conflicts
are trivial to fix. Please rebase and resubmit.
Please see rebased and updated patches attached.
I think having the "recheck" index methods create an ExecutorState looks
out of place. How difficult is it to pass the estate from the calling
code?
I couldn't find a good way to pass estate from the calling code. It would require changes to many other APIs. I saw all other callers who need to form index keys do that too. But please suggest if there are better ways.
OffsetNumber
heap_get_root_tuple(Page page, OffsetNumber target_offnum)
{
OffsetNumber off;
heap_get_root_tuples_internal(page, target_offnum, &off);
return off;
}
Ok. Changed this way. Definitely looks better.
The simple_heap_update + CatalogUpdateIndexes pattern is getting
obnoxious. How about creating something like catalog_heap_update which
does both things at once, and stop bothering each callsite with the WARM
stuff?
What I realised that there are really 2 patterns:
1. simple_heap_insert, CatalogUpdateIndexes
2. simple_heap_update, CatalogUpdateIndexes
There are only couple of places where we already have indexes open or have more than one tuple to update, so we call CatalogIndexInsert directly. What I ended up doing in the attached patch is add two new APIs which combines the two steps of each of these patterns. It seems much cleaner to me and also less buggy for future users. I hope I am not missing a reason not to do combine these steps.
I'm not real sure about the interface between index AM and executor,
namely IndexScanDesc->xs_tuple_recheck. For example, this pattern:
if (!scan->xs_recheck)
scan->xs_tuple_recheck = false;
else
scan->xs_tuple_recheck = true;
can become simply
scan->xs_tuple_recheck = scan->xs_recheck;
Fixed.
which looks odd. I can't pinpoint exactly what's the problem, though.
I'll continue looking at this one.
What we do is if the index scan is marked to do recheck, we do it for each tuple anyways. Otherwise recheck is required only if a tuple comes from a WARM chain.
I wonder if heap_hot_search_buffer() and heap_hot_search() should return
a tri-valued enum instead of boolean; that idea looks reasonable in
theory but callers have to do more work afterwards, so maybe not.
I did not do anything with this yet. But I agree with you that we need to make it better/simpler. Will continue to work on that.
I've addressed other review comments on the 0001 patch, except this one.
> +/*
> + * Get TID of next tuple in the update chain. Caller should have checked that
> + * we are not already at the end of the chain because in that case t_ctid may
> + * actually store the root line pointer of the HOT chain whose member this
> + * tuple is.
> + */
> +#define HeapTupleHeaderGetNextTid(tup, next_ctid) \
> +do { \
> + AssertMacro(!((tup)->t_infoma
> + ItemPointerCopy(&(tup)->t_cti
> +} while (0)
> Actually, I think this macro could just return the TID so that it can be
> used as struct assignment, just like ItemPointerCopy does internally --
> callers can do
> ctid = HeapTupleHeaderGetNextTid(tup)
> +/*
> + * Get TID of next tuple in the update chain. Caller should have checked that
> + * we are not already at the end of the chain because in that case t_ctid may
> + * actually store the root line pointer of the HOT chain whose member this
> + * tuple is.
> + */
> +#define HeapTupleHeaderGetNextTid(tup, next_ctid) \
> +do { \
> + AssertMacro(!((tup)->t_infoma
> + ItemPointerCopy(&(tup)->t_cti
> +} while (0)
> Actually, I think this macro could just return the TID so that it can be
> used as struct assignment, just like ItemPointerCopy does internally --
> callers can do
> ctid = HeapTupleHeaderGetNextTid(tup)
While I agree with your proposal, I wonder why we have ItemPointerCopy() in the first place because we freely copy TIDs as struct assignment. Is there a reason for that? And if there is, does it impact this specific case?
Other than the review comments, there were couple of bugs that I discovered while running the stress test notably around visibility map handling. The patch has those fixes. I also ripped out the kludge to record WARM-ness in the line pointer because that is no longer needed after I reworked the code a few versions back.
The other critical bug I found, which unfortunately exists in the master too, is the index corruption during CIC. The patch includes the same fix that I've proposed on the other thread. With these changes, WARM stress is running fine for last 24 hours on a decently powerful box. Multiple CREATE/DROP INDEX cycles and updates via different indexed columns, with a mix of FOR SHARE/UPDATE and rollbacks did not produce any consistency issues. A side note: while performance measurement wasn't a goal of stress tests, WARM has done about 67% more transaction than master in 24 hour period (95M in master vs 156M in WARM to be precise on a 30GB table including indexes). I believe the numbers would be far better had the test not dropping and recreating the indexes, thus effectively cleaning up all index bloats. Also the table is small enough to fit in the shared buffers. I'll rerun these tests with much larger scale factor and without dropping indexes.
Of course, make check-world, including all TAP tests, passes too.
The CREATE INDEX CONCURRENTLY now works. The way we handle this is by ensuring that no broken WARM chains are created while the initial index build is happening. We check the list of attributes of indexes currently in-progress (i.e. not ready for inserts) and if any of these attributes are being modified, we don't do a WARM update. This is enough to address CIC issue and all other mechanisms remain same as HOT. I've updated README to include CIC algorithm.
There is one issue that bothers me. The current implementation lacks ability to convert WARM chains into HOT chains. The README.WARM has some proposal to do that. But it requires additional free bit in tuple header (which we don't have) and of course, it needs to be vetted and implemented. If the heap ends up with many WARM tuples, then index-only-scans will become ineffective because index-only-scan can not skip a heap page, if it contains a WARM tuple. Alternate ideas/suggestions and review of the design are welcome!
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
Pavan Deolasee wrote:
> On Thu, Jan 26, 2017 at 2:38 AM, Alvaro Herrera <alvherre@2ndquadrant.com>
> wrote:
> > The simple_heap_update + CatalogUpdateIndexes pattern is getting
> > obnoxious. How about creating something like catalog_heap_update which
> > does both things at once, and stop bothering each callsite with the WARM
> > stuff?
>
> What I realised that there are really 2 patterns:
> 1. simple_heap_insert, CatalogUpdateIndexes
> 2. simple_heap_update, CatalogUpdateIndexes
>
> There are only couple of places where we already have indexes open or have
> more than one tuple to update, so we call CatalogIndexInsert directly. What
> I ended up doing in the attached patch is add two new APIs which combines
> the two steps of each of these patterns. It seems much cleaner to me and
> also less buggy for future users. I hope I am not missing a reason not to
> do combine these steps.
CatalogUpdateIndexes was just added as a convenience function on top of
a very common pattern. If we now have a reason to create a second one
because there are now two very common patterns, it seems reasonable to
have two functions. I think I would commit the refactoring to create
these functions ahead of the larger WARM patch, since I think it'd be
bulky and largely mechanical. (I'm going from this description; didn't
read your actual code.)
> > +#define HeapTupleHeaderGetNextTid(tup, next_ctid) \
> > +do { \
> > + AssertMacro(!((tup)->t_infomask2 & HEAP_LATEST_TUPLE)); \
> > + ItemPointerCopy(&(tup)->t_ctid, (next_ctid)); \
> > +} while (0)
>
> > Actually, I think this macro could just return the TID so that it can be
> > used as struct assignment, just like ItemPointerCopy does internally --
> > callers can do
> > ctid = HeapTupleHeaderGetNextTid(tup);
>
> While I agree with your proposal, I wonder why we have ItemPointerCopy() in
> the first place because we freely copy TIDs as struct assignment. Is there
> a reason for that? And if there is, does it impact this specific case?
I dunno. This macro is present in our very first commit d31084e9d1118b.
Maybe it's an artifact from the Lisp to C conversion. Even then, we had
some cases of iptrs being copied by struct assignment, so it's not like
it didn't work. Perhaps somebody envisioned that the internal details
could change, but that hasn't happened in two decades so why should we
worry about it now? If somebody needs it later, it can be changed then.
> There is one issue that bothers me. The current implementation lacks
> ability to convert WARM chains into HOT chains. The README.WARM has some
> proposal to do that. But it requires additional free bit in tuple header
> (which we don't have) and of course, it needs to be vetted and implemented.
> If the heap ends up with many WARM tuples, then index-only-scans will
> become ineffective because index-only-scan can not skip a heap page, if it
> contains a WARM tuple. Alternate ideas/suggestions and review of the design
> are welcome!
t_infomask2 contains one last unused bit, and we could reuse vacuum
full's bits (HEAP_MOVED_OUT, HEAP_MOVED_IN), but that will need some
thinking ahead. Maybe now's the time to start versioning relations so
that we can ensure clusters upgraded to pg10 do not contain any of those
bits in any tuple headers.
I don't have any ideas regarding the estate passed to recheck yet --
haven't looked at the callsites in detail. I'll give this another look
later.
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Jan 31, 2017 at 7:21 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Pavan Deolasee wrote:
> On Thu, Jan 26, 2017 at 2:38 AM, Alvaro Herrera <alvherre@2ndquadrant.com>
> wrote:
> > The simple_heap_update + CatalogUpdateIndexes pattern is getting
> > obnoxious. How about creating something like catalog_heap_update which
> > does both things at once, and stop bothering each callsite with the WARM
> > stuff?
>
> What I realised that there are really 2 patterns:
> 1. simple_heap_insert, CatalogUpdateIndexes
> 2. simple_heap_update, CatalogUpdateIndexes
>
> There are only couple of places where we already have indexes open or have
> more than one tuple to update, so we call CatalogIndexInsert directly. What
> I ended up doing in the attached patch is add two new APIs which combines
> the two steps of each of these patterns. It seems much cleaner to me and
> also less buggy for future users. I hope I am not missing a reason not to
> do combine these steps.
CatalogUpdateIndexes was just added as a convenience function on top of
a very common pattern. If we now have a reason to create a second one
because there are now two very common patterns, it seems reasonable to
have two functions. I think I would commit the refactoring to create
these functions ahead of the larger WARM patch, since I think it'd be
bulky and largely mechanical. (I'm going from this description; didn't
read your actual code.)
Sounds good. Should I submit that as a separate patch on current master?
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Pavan Deolasee wrote: > On Tue, Jan 31, 2017 at 7:21 PM, Alvaro Herrera <alvherre@2ndquadrant.com> > wrote: > > CatalogUpdateIndexes was just added as a convenience function on top of > > a very common pattern. If we now have a reason to create a second one > > because there are now two very common patterns, it seems reasonable to > > have two functions. I think I would commit the refactoring to create > > these functions ahead of the larger WARM patch, since I think it'd be > > bulky and largely mechanical. (I'm going from this description; didn't > > read your actual code.) > > Sounds good. Should I submit that as a separate patch on current master? Yes, please. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Jan 31, 2017 at 7:37 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Pavan Deolasee wrote:
>
> Sounds good. Should I submit that as a separate patch on current master?
Yes, please.
Attached.
Two new APIs added.
- CatalogInsertHeapAndIndex which does a simple_heap_insert followed by catalog updates
- CatalogUpdateHeapAndIndex which does a simple_heap_update followed by catalog updates
There are only a handful callers remain for simple_heap_insert/update after this patch. They are typically working with already opened indexes and hence I left them unchanged.
make check-world passes with the patch.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
Pavan Deolasee wrote: > Two new APIs added. > > - CatalogInsertHeapAndIndex which does a simple_heap_insert followed by > catalog updates > - CatalogUpdateHeapAndIndex which does a simple_heap_update followed by > catalog updates > > There are only a handful callers remain for simple_heap_insert/update after > this patch. They are typically working with already opened indexes and > hence I left them unchanged. Hmm, I was thinking we would get rid of CatalogUpdateIndexes altogether. Two of the callers are in the new routines (which I propose to rename to CatalogTupleInsert and CatalogTupleUpdate); the only remaining one is in InsertPgAttributeTuple. I propose that we inline the three lines into all those places and just remove CatalogUpdateIndexes. Half the out-of- core places that are using this function will be broken as soon as WARM lands anyway. I see no reason to keep it. (I have already modified the patch this way -- no need to resend). Unless there are objections I will push this later this afternoon. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera wrote: > Unless there are objections I will push this later this afternoon. Done. Let's get on with the show -- please post a rebased WARM. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2017-01-31 14:10:01 -0300, Alvaro Herrera wrote: > Pavan Deolasee wrote: > > > Two new APIs added. > > > > - CatalogInsertHeapAndIndex which does a simple_heap_insert followed by > > catalog updates > > - CatalogUpdateHeapAndIndex which does a simple_heap_update followed by > > catalog updates > > > > There are only a handful callers remain for simple_heap_insert/update after > > this patch. They are typically working with already opened indexes and > > hence I left them unchanged. > > Hmm, I was thinking we would get rid of CatalogUpdateIndexes altogether. > Two of the callers are in the new routines (which I propose to rename to > CatalogTupleInsert and CatalogTupleUpdate); the only remaining one is in > InsertPgAttributeTuple. I propose that we inline the three lines into > all those places and just remove CatalogUpdateIndexes. Half the out-of- > core places that are using this function will be broken as soon as WARM > lands anyway. I see no reason to keep it. (I have already modified the > patch this way -- no need to resend). > > Unless there are objections I will push this later this afternoon. Hm, sorry for missing this earlier. I think CatalogUpdateIndexes() is fairly widely used in extensions - it seems like a pretty harsh change to not leave some backward compatibility layer in place. Andres
Andres Freund wrote: > On 2017-01-31 14:10:01 -0300, Alvaro Herrera wrote: > > Hmm, I was thinking we would get rid of CatalogUpdateIndexes altogether. > > Two of the callers are in the new routines (which I propose to rename to > > CatalogTupleInsert and CatalogTupleUpdate); the only remaining one is in > > InsertPgAttributeTuple. I propose that we inline the three lines into > > all those places and just remove CatalogUpdateIndexes. Half the out-of- > > core places that are using this function will be broken as soon as WARM > > lands anyway. I see no reason to keep it. (I have already modified the > > patch this way -- no need to resend). > > > > Unless there are objections I will push this later this afternoon. > > Hm, sorry for missing this earlier. I think CatalogUpdateIndexes() is > fairly widely used in extensions - it seems like a pretty harsh change > to not leave some backward compatibility layer in place. Yeah, I can put it back if there's pushback about the removal, but I think it's going to break due to WARM anyway. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2017-01-31 19:10:05 -0300, Alvaro Herrera wrote: > Andres Freund wrote: > > On 2017-01-31 14:10:01 -0300, Alvaro Herrera wrote: > > > > Hmm, I was thinking we would get rid of CatalogUpdateIndexes altogether. > > > Two of the callers are in the new routines (which I propose to rename to > > > CatalogTupleInsert and CatalogTupleUpdate); the only remaining one is in > > > InsertPgAttributeTuple. I propose that we inline the three lines into > > > all those places and just remove CatalogUpdateIndexes. Half the out-of- > > > core places that are using this function will be broken as soon as WARM > > > lands anyway. I see no reason to keep it. (I have already modified the > > > patch this way -- no need to resend). > > > > > > Unless there are objections I will push this later this afternoon. > > > > Hm, sorry for missing this earlier. I think CatalogUpdateIndexes() is > > fairly widely used in extensions - it seems like a pretty harsh change > > to not leave some backward compatibility layer in place. > > Yeah, I can put it back if there's pushback about the removal, but I > think it's going to break due to WARM anyway. I'm a bit doubtful (but not extremely so) that that's ok.
Andres Freund <andres@anarazel.de> writes:
> Hm, sorry for missing this earlier. I think CatalogUpdateIndexes() is
> fairly widely used in extensions - it seems like a pretty harsh change
> to not leave some backward compatibility layer in place.
If an extension is doing that, it is probably constructing tuples to put
into the catalog, which means it'd be equally (and much more quietly)
broken by any change to the catalog's schema. We've never considered
such an argument as a reason not to change catalog schemas, though.
In short, I've got mighty little sympathy for that argument.
(I'm a little more concerned by Alvaro's apparent position that WARM
is a done deal; I didn't think so. This particular change seems like
good cleanup anyhow, however.)
regards, tom lane
* Tom Lane (tgl@sss.pgh.pa.us) wrote: > Andres Freund <andres@anarazel.de> writes: > > Hm, sorry for missing this earlier. I think CatalogUpdateIndexes() is > > fairly widely used in extensions - it seems like a pretty harsh change > > to not leave some backward compatibility layer in place. > > If an extension is doing that, it is probably constructing tuples to put > into the catalog, which means it'd be equally (and much more quietly) > broken by any change to the catalog's schema. We've never considered > such an argument as a reason not to change catalog schemas, though. > > In short, I've got mighty little sympathy for that argument. +1 > (I'm a little more concerned by Alvaro's apparent position that WARM > is a done deal; I didn't think so. This particular change seems like > good cleanup anyhow, however.) Agreed. Thanks! Stephen
Stephen Frost <sfrost@snowman.net> writes:
> * Tom Lane (tgl@sss.pgh.pa.us) wrote:
>> (I'm a little more concerned by Alvaro's apparent position that WARM
>> is a done deal; I didn't think so. This particular change seems like
>> good cleanup anyhow, however.)
> Agreed.
BTW, the reason I think it's good cleanup is that it's something that my
colleagues at Salesforce also had to do as part of putting PG on top of a
different storage engine that had different ideas about index handling.
Essentially it's providing a bit of abstraction as to whether catalog
storage is exactly heaps or not (a topic I've noticed Robert is starting
to take some interest in, as well). However, the patch misses an
important part of such an abstraction layer by not also converting
catalog-related simple_heap_delete() calls into some sort of
CatalogTupleDelete() operation. It is certainly a peculiarity of
PG heaps that deletions don't require any immediate index work --- most
other storage engines would need that.
I propose that we should finish the job by inventing CatalogTupleDelete(),
which for the moment would be a trivial wrapper around
simple_heap_delete(), maybe just a macro for it.
If there's no objections I'll go make that happen in a day or two.
regards, tom lane
On 2017-01-31 17:21:28 -0500, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > Hm, sorry for missing this earlier. I think CatalogUpdateIndexes() is > > fairly widely used in extensions - it seems like a pretty harsh change > > to not leave some backward compatibility layer in place. > > If an extension is doing that, it is probably constructing tuples to put > into the catalog, which means it'd be equally (and much more quietly) > broken by any change to the catalog's schema. We've never considered > such an argument as a reason not to change catalog schemas, though. I know of several extensions that use CatalogUpdateIndexes() to update their own tables. Citus included (It's trivial to change on our side, so that's not a reason to do or not do something). There really is no convenient API to do so without it. > (I'm a little more concerned by Alvaro's apparent position that WARM > is a done deal; I didn't think so. This particular change seems like > good cleanup anyhow, however.) Yea, I don't think we're even close to that either. Andres
Tom Lane wrote: > BTW, the reason I think it's good cleanup is that it's something that my > colleagues at Salesforce also had to do as part of putting PG on top of a > different storage engine that had different ideas about index handling. > Essentially it's providing a bit of abstraction as to whether catalog > storage is exactly heaps or not (a topic I've noticed Robert is starting > to take some interest in, as well). Yeah, I remembered that too. Of course, we'd need to change the whole idea of mapping tuples to C structs too, but this seemed a nice step forward. (I renamed Pavan's proposed routine precisely to avoid the word "Heap" in it.) > However, the patch misses an > important part of such an abstraction layer by not also converting > catalog-related simple_heap_delete() calls into some sort of > CatalogTupleDelete() operation. It is certainly a peculiarity of > PG heaps that deletions don't require any immediate index work --- most > other storage engines would need that. > I propose that we should finish the job by inventing CatalogTupleDelete(), > which for the moment would be a trivial wrapper around > simple_heap_delete(), maybe just a macro for it. > > If there's no objections I'll go make that happen in a day or two. Sounds good. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Feb 1, 2017 at 9:36 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: >> I propose that we should finish the job by inventing CatalogTupleDelete(), >> which for the moment would be a trivial wrapper around >> simple_heap_delete(), maybe just a macro for it. >> >> If there's no objections I'll go make that happen in a day or two. > > Sounds good. As you are on it, I have moved the patch to CF 2017-03. -- Michael
On Tue, Jan 31, 2017 at 7:21 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
> > +#define HeapTupleHeaderGetNextTid(tup, next_ctid) \
> > +do { \
> > + AssertMacro(!((tup)->t_infomask2 & HEAP_LATEST_TUPLE)); \
> > + ItemPointerCopy(&(tup)->t_ctid, (next_ctid)); \
> > +} while (0)
>
> > Actually, I think this macro could just return the TID so that it can be
> > used as struct assignment, just like ItemPointerCopy does internally --
> > callers can do
> > ctid = HeapTupleHeaderGetNextTid(tup);
>
> While I agree with your proposal, I wonder why we have ItemPointerCopy() in
> the first place because we freely copy TIDs as struct assignment. Is there
> a reason for that? And if there is, does it impact this specific case?
I dunno. This macro is present in our very first commit d31084e9d1118b.
Maybe it's an artifact from the Lisp to C conversion. Even then, we had
some cases of iptrs being copied by struct assignment, so it's not like
it didn't work. Perhaps somebody envisioned that the internal details
could change, but that hasn't happened in two decades so why should we
worry about it now? If somebody needs it later, it can be changed then.
May I suggest in that case that we apply the attached patch which removes all references to ItemPointerCopy and its definition as well? This will avoid confusion in future too. No issues noticed in regression tests.
> There is one issue that bothers me. The current implementation lacks
> ability to convert WARM chains into HOT chains. The README.WARM has some
> proposal to do that. But it requires additional free bit in tuple header
> (which we don't have) and of course, it needs to be vetted and implemented.
> If the heap ends up with many WARM tuples, then index-only-scans will
> become ineffective because index-only-scan can not skip a heap page, if it
> contains a WARM tuple. Alternate ideas/suggestions and review of the design
> are welcome!
t_infomask2 contains one last unused bit,
Umm, WARM is using 2 unused bits from t_infomask2. You mean there is another free bit after that too?
and we could reuse vacuum
full's bits (HEAP_MOVED_OUT, HEAP_MOVED_IN), but that will need some
thinking ahead. Maybe now's the time to start versioning relations so
that we can ensure clusters upgraded to pg10 do not contain any of those
bits in any tuple headers.
Yeah, IIRC old VACUUM FULL was removed in 9.0, which is good 6 year old. Obviously, there still a chance that a pre-9.0 binary upgraded cluster exists and upgrades to 10. So we still need to do something about them if we reuse these bits. I'm surprised to see that we don't have any mechanism in place to clear those bits. So may be we add something to do that.
I'd some other ideas (and a patch too) to reuse bits from t_ctid.ip_pos given that offset numbers can be represented in just 13 bits, even with the maximum block size. Can look at that if it comes to finding more bits.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> Tom Lane wrote:
>> However, the patch misses an
>> important part of such an abstraction layer by not also converting
>> catalog-related simple_heap_delete() calls into some sort of
>> CatalogTupleDelete() operation. It is certainly a peculiarity of
>> PG heaps that deletions don't require any immediate index work --- most
>> other storage engines would need that.
>> I propose that we should finish the job by inventing CatalogTupleDelete(),
>> which for the moment would be a trivial wrapper around
>> simple_heap_delete(), maybe just a macro for it.
>>
>> If there's no objections I'll go make that happen in a day or two.
> Sounds good.
So while I was working on this I got quite unhappy with the
already-committed patch: it's a leaky abstraction in more ways than
this, and it's created a possibly-serious performance regression
for large objects (and maybe other places).
The source of both of those problems is that in some places, we
did CatalogOpenIndexes and then used the CatalogIndexState for
multiple tuple inserts/updates before doing CatalogCloseIndexes.
The patch dealt with these either by not touching them, just
leaving the simple_heap_insert/update calls in place (thus failing
to create any abstraction), or by blithely ignoring the optimization
and doing s/simple_heap_insert/CatalogTupleInsert/ anyway. For example,
in inv_api.c we are now doing a CatalogOpenIndexes/CatalogCloseIndexes
cycle for each chunk of the large object ... and just to add insult to
injury, the now-useless open/close calls outside the loop are still there.
I think what we ought to do about this is invent additional API
functions, say
Oid CatalogTupleInsertWithInfo(Relation heapRel, HeapTuple tup, CatalogIndexState
indstate);
void CatalogTupleUpdateWithInfo(Relation heapRel, ItemPointer otid, HeapTuple tup,
CatalogIndexStateindstate);
and use these in place of simple_heap_foo plus CatalogIndexInsert
in the places where this optimization had been applied.
An alternative but much more complicated fix would be to get rid of
the necessity for callers to worry about this at all, by caching
a CatalogIndexState in the catalog's relcache entry. That might be
worth doing eventually (because it would allow sharing index info
collection across unrelated operations) but I don't want to do it today.
Objections, better naming ideas?
regards, tom lane
Tom Lane wrote: > The source of both of those problems is that in some places, we > did CatalogOpenIndexes and then used the CatalogIndexState for > multiple tuple inserts/updates before doing CatalogCloseIndexes. > The patch dealt with these either by not touching them, just > leaving the simple_heap_insert/update calls in place (thus failing > to create any abstraction), or by blithely ignoring the optimization > and doing s/simple_heap_insert/CatalogTupleInsert/ anyway. For example, > in inv_api.c we are now doing a CatalogOpenIndexes/CatalogCloseIndexes > cycle for each chunk of the large object ... and just to add insult to > injury, the now-useless open/close calls outside the loop are still there. Ouch. You're right, I missed that. > I think what we ought to do about this is invent additional API > functions, say > > Oid CatalogTupleInsertWithInfo(Relation heapRel, HeapTuple tup, > CatalogIndexState indstate); > void CatalogTupleUpdateWithInfo(Relation heapRel, ItemPointer otid, > HeapTuple tup, CatalogIndexState indstate); > > and use these in place of simple_heap_foo plus CatalogIndexInsert > in the places where this optimization had been applied. This looks reasonable enough to me. > An alternative but much more complicated fix would be to get rid of > the necessity for callers to worry about this at all, by caching > a CatalogIndexState in the catalog's relcache entry. That might be > worth doing eventually (because it would allow sharing index info > collection across unrelated operations) but I don't want to do it today. Hmm, interesting idea. No disagreement on postponing. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> Tom Lane wrote:
>> I think what we ought to do about this is invent additional API
>> functions, say
>>
>> Oid CatalogTupleInsertWithInfo(Relation heapRel, HeapTuple tup,
>> CatalogIndexState indstate);
>> void CatalogTupleUpdateWithInfo(Relation heapRel, ItemPointer otid,
>> HeapTuple tup, CatalogIndexState indstate);
>>
>> and use these in place of simple_heap_foo plus CatalogIndexInsert
>> in the places where this optimization had been applied.
> This looks reasonable enough to me.
Done.
regards, tom lane
On Thu, Feb 2, 2017 at 3:49 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> Tom Lane wrote:
>> I think what we ought to do about this is invent additional API
>> functions, say
>>
>> Oid CatalogTupleInsertWithInfo(Relation heapRel, HeapTuple tup,
>> CatalogIndexState indstate);
>> void CatalogTupleUpdateWithInfo(Relation heapRel, ItemPointer otid,
>> HeapTuple tup, CatalogIndexState indstate);
>>
>> and use these in place of simple_heap_foo plus CatalogIndexInsert
>> in the places where this optimization had been applied.
> This looks reasonable enough to me.
Done.
Thanks for taking care of this. Shame that I missed this because I'd specifically noted the special casing for large objects etc. But looks like while changing 180+ call sites, I forgot my notes.
Pavan
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Feb 1, 2017 at 3:21 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Alvaro Herrera wrote:
> Unless there are objections I will push this later this afternoon.
Done. Let's get on with the show -- please post a rebased WARM.
Please see rebased patches attached. There is not much change other than the fact the patch now uses new catalog maintenance API.
Do you think we should apply the patch to remove ItemPointerCopy()? I will rework the HeapTupleHeaderGetNextTid() after that. Not that it depends on removing ItemPointerCopy(), but decided to postpone it until we make a call on that patch.
BTW I've run now long stress tests with the patch applied and see no new issues, even when indexes are dropped and recreated concurrently (includes my patch to fix CIC bug in the master though). In another 24 hour test, WARM could do 274M transactions where as master did 164M transactions. I did not drop and recreate indexes during this run.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
Pavan Deolasee wrote: > Do you think we should apply the patch to remove ItemPointerCopy()? I will > rework the HeapTupleHeaderGetNextTid() after that. Not that it depends on > removing ItemPointerCopy(), but decided to postpone it until we make a call > on that patch. My inclination is not to. We don't really know where we are going with storage layer reworks in the near future, and we might end up changing this in other ways. We might find ourselves needing this kind of abstraction again. I don't think this means we need to follow it completely in new code, since it's already broken in other places, but let's not destroy it completely just yet. > BTW I've run now long stress tests with the patch applied and see no new > issues, even when indexes are dropped and recreated concurrently (includes > my patch to fix CIC bug in the master though). In another 24 hour test, > WARM could do 274M transactions where as master did 164M transactions. I > did not drop and recreate indexes during this run. Eh, that's a 67% performance improvement. Nice. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Feb 2, 2017 at 6:17 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
Please see rebased patches attached. There is not much change other than the fact the patch now uses new catalog maintenance API.
Another rebase on current master.
This time I am also attaching a proof-of-concept patch to demonstrate chain conversion. The proposed algorithm is mentioned in the README.WARM, but I'll briefly explain here.
The chain conversion works in two phases and requires another index pass during vacuum. During first heap scan, we collect candidate chains for conversion. A chain qualifies for conversion if it has all tuples with matching index keys with respect to all current indexes (i.e. chain becomes HOT). WARM chains become HOT as and when old versions retire (or new versions retire in case of aborts). But before we can mark them HOT again, we must first remove duplicate (and potentially wrong) index pointers. This algorithm deals with that.
When a WARM update occurs and we insert a new index entry in one or more indexes, we mark the new index pointer with a special RED flag. The heap tuple created by this UPDATE is also marked as RED. If the tuple is then HOT-updated, subsequent versions will be marked RED as well. IOW each WARM chain has two HOT chains inside it and these chains are identified as BLUE and RED chains. The index pointer which satisfies key in RED chain is marked RED too.
When we collect candidate WARM chains in the first heap scan, we also remember the color of the chain.
During first index scan we delete all known dead index pointers (same as lazy_tid_reaped). Also we also count number of RED and BLUE pointers to each candidate chain.
The next index scan will either 1. remove an index pointer which is known to be useless or 2. color a RED pointer BLUE.
- A BLUE pointer to a RED chain is removed when there exists a RED pointer to the chain. If there is no RED pointer, we can't remove the BLUE pointer because that is the only path to the heap tuple (case when WARM does not cause new index entry). But we instead color the heap tuples BLUE
- A BLUE pointer to a BLUE chain is always retained
- A RED pointer to a BLUE chain is always removed (aborted updates)
- A RED pointer to a RED chain is colored BLUE (we will color the heap tuples BLUE in the second heap scan)
Once the index pointers are taken care of such that there exists exactly one pointer to a chain, the chain can be converted into HOT chains by clearing WARM and RED flags.
There is one case of aborted vacuums. If a crash happens after coloring RED pointer BLUE, but before we can clear the heap tuples, we might end up with two BLUE pointers to a RED chain. This case will require recheck logic and is not yet implemented.
The POC only works with BTREEs because the unused bit in IndexTuple's t_info is already used by HASH indexes. For heap tuples, we can reuse one of HEAP_MOVED_IN/OFF bits for marking tuples RED since this is only required for WARM tuples. So the bit can be checked along with WARM bit.
Unless there is an objection to the design or someone thinks it cannot work, I'll look at some alternate mechanism to free up more bits in tuple header or at least in the index tuples. One idea is to free up 3 bits from ip_posid knowing that OffsetNumber can never really need more than 13 bits with the other constraints in place. We could use some bit-field magic to do that with minimal changes. The thing that concerns me is whether there will be a guaranteed way to make that work on all hardwares without breaking the on-disk layout.
Comments/suggestions?
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
Hi Tom,
On Wed, Feb 1, 2017 at 3:51 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
--
(I'm a little more concerned by Alvaro's apparent position that WARM
is a done deal; I didn't think so.
Are there any specific aspects of the design that you're not comfortable with? I'm sure there could be some rough edges in the implementation that I'm hoping will get handled during the further review process. But if there are some obvious things I'm overlooking please let me know.
Probably the same question to Andres/Robert who has flagged concerns. On my side, I've run some very long tests with data validation and haven't found any new issues with the most recent patches.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Jan 31, 2017 at 04:52:39PM +0530, Pavan Deolasee wrote: > The other critical bug I found, which unfortunately exists in the master too, > is the index corruption during CIC. The patch includes the same fix that I've > proposed on the other thread. With these changes, WARM stress is running fine > for last 24 hours on a decently powerful box. Multiple CREATE/DROP INDEX cycles > and updates via different indexed columns, with a mix of FOR SHARE/UPDATE and > rollbacks did not produce any consistency issues. A side note: while > performance measurement wasn't a goal of stress tests, WARM has done about 67% > more transaction than master in 24 hour period (95M in master vs 156M in WARM > to be precise on a 30GB table including indexes). I believe the numbers would > be far better had the test not dropping and recreating the indexes, thus > effectively cleaning up all index bloats. Also the table is small enough to fit > in the shared buffers. I'll rerun these tests with much larger scale factor and > without dropping indexes. Thanks for setting up the test harness. I know it is hard but in this case it has found an existing bug and given good performance numbers. :-) I have what might be a supid question. As I remember, WARM only allows a single index-column change in the chain. Why are you seeing such a large performance improvement? I would have thought it would be that high if we allowed an unlimited number of index changes in the chain. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Wed, Feb 1, 2017 at 10:46:45AM +0530, Pavan Deolasee wrote: > > contains a WARM tuple. Alternate ideas/suggestions and review of the > design > > are welcome! > > t_infomask2 contains one last unused bit, > > > Umm, WARM is using 2 unused bits from t_infomask2. You mean there is another > free bit after that too? We are obviously going to use several heap or item pointer bits for WARM, and once we do that it is going to be hard to undo that. Pavan, are you saying you could do more with WARM if you had more bits? Are we sure we have given you all the bits we can? Do we want to commit to a lesser feature because the bits are not available? > and we could reuse vacuum > full's bits (HEAP_MOVED_OUT, HEAP_MOVED_IN), but that will need some > thinking ahead. Maybe now's the time to start versioning relations so > that we can ensure clusters upgraded to pg10 do not contain any of those > bits in any tuple headers. > > > Yeah, IIRC old VACUUM FULL was removed in 9.0, which is good 6 year old. > Obviously, there still a chance that a pre-9.0 binary upgraded cluster exists > and upgrades to 10. So we still need to do something about them if we reuse > these bits. I'm surprised to see that we don't have any mechanism in place to > clear those bits. So may be we add something to do that. Yeah, good question. :-( We have talked about adding some page, table, or cluster-level version number so we could identify if a given tuple _could_ be using those bits, but never did it. > I'd some other ideas (and a patch too) to reuse bits from t_ctid.ip_pos given > that offset numbers can be represented in just 13 bits, even with the maximum > block size. Can look at that if it comes to finding more bits. OK, so it seems more bits is not a blocker to enhancements, yet. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
Bruce Momjian wrote: > As I remember, WARM only allows > a single index-column change in the chain. Why are you seeing such a > large performance improvement? I would have thought it would be that > high if we allowed an unlimited number of index changes in the chain. The second update in a chain creates another non-warm-updated tuple, so the third update can be a warm update again, and so on. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Feb 23, 2017 at 03:03:39PM -0300, Alvaro Herrera wrote: > Bruce Momjian wrote: > > > As I remember, WARM only allows > > a single index-column change in the chain. Why are you seeing such a > > large performance improvement? I would have thought it would be that > > high if we allowed an unlimited number of index changes in the chain. > > The second update in a chain creates another non-warm-updated tuple, so > the third update can be a warm update again, and so on. Right, before this patch they would be two independent HOT chains. It still seems like an unexpectedly-high performance win. Are two independent HOT chains that much more expensive than joining them via WARM? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
Bruce Momjian wrote: > On Thu, Feb 23, 2017 at 03:03:39PM -0300, Alvaro Herrera wrote: > > Bruce Momjian wrote: > > > > > As I remember, WARM only allows > > > a single index-column change in the chain. Why are you seeing such a > > > large performance improvement? I would have thought it would be that > > > high if we allowed an unlimited number of index changes in the chain. > > > > The second update in a chain creates another non-warm-updated tuple, so > > the third update can be a warm update again, and so on. > > Right, before this patch they would be two independent HOT chains. No, they would be a regular update chain, not HOT updates. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Feb 23, 2017 at 03:26:09PM -0300, Alvaro Herrera wrote: > Bruce Momjian wrote: > > On Thu, Feb 23, 2017 at 03:03:39PM -0300, Alvaro Herrera wrote: > > > Bruce Momjian wrote: > > > > > > > As I remember, WARM only allows > > > > a single index-column change in the chain. Why are you seeing such a > > > > large performance improvement? I would have thought it would be that > > > > high if we allowed an unlimited number of index changes in the chain. > > > > > > The second update in a chain creates another non-warm-updated tuple, so > > > the third update can be a warm update again, and so on. > > > > Right, before this patch they would be two independent HOT chains. > > No, they would be a regular update chain, not HOT updates. Well, let's walk through this. Let's suppose you have three updates that stay on the same page and don't update any indexed columns --- that would produce a HOT chain of four tuples. If you then do an update that changes an indexed column, prior to this patch, you get a normal update, and more HOT updates can be added to this. With WARM, we can join those chains and potentially trim the first HOT chain as those tuples become invisible. Am I missing something? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
Bruce Momjian wrote: > Well, let's walk through this. Let's suppose you have three updates > that stay on the same page and don't update any indexed columns --- that > would produce a HOT chain of four tuples. If you then do an update that > changes an indexed column, prior to this patch, you get a normal update, > and more HOT updates can be added to this. With WARM, we can join those > chains With WARM, what happens is that the first three updates are HOT updates just like currently, and the fourth one is a WARM update. > and potentially trim the first HOT chain as those tuples become > invisible. That can already happen even without WARM, no? -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Feb 23, 2017 at 03:45:24PM -0300, Alvaro Herrera wrote: > Bruce Momjian wrote: > > > Well, let's walk through this. Let's suppose you have three updates > > that stay on the same page and don't update any indexed columns --- that > > would produce a HOT chain of four tuples. If you then do an update that > > changes an indexed column, prior to this patch, you get a normal update, > > and more HOT updates can be added to this. With WARM, we can join those > > chains > > With WARM, what happens is that the first three updates are HOT updates > just like currently, and the fourth one is a WARM update. Right. > > and potentially trim the first HOT chain as those tuples become > > invisible. > > That can already happen even without WARM, no? Uh, the point is that with WARM those four early tuples can be removed via a prune, rather than requiring a VACUUM. Without WARM, the fourth tuple can't be removed until the index is cleared by VACUUM. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
Bruce Momjian wrote: > On Thu, Feb 23, 2017 at 03:45:24PM -0300, Alvaro Herrera wrote: > > > and potentially trim the first HOT chain as those tuples become > > > invisible. > > > > That can already happen even without WARM, no? > > Uh, the point is that with WARM those four early tuples can be removed > via a prune, rather than requiring a VACUUM. Without WARM, the fourth > tuple can't be removed until the index is cleared by VACUUM. I *think* that the WARM-updated one cannot be pruned either, because it's pointed to by at least one index (otherwise it'd have been a HOT update). The ones prior to that can be removed either way. I think the part you want (be able to prune the WARM updated tuple) is part of what Pavan calls "turning the WARM chain into a HOT chain", so not part of the initial patch. Pavan can explain this part better, and also set me straight in case I'm wrong in the above :-) -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Feb 23, 2017 at 03:58:59PM -0300, Alvaro Herrera wrote: > Bruce Momjian wrote: > > On Thu, Feb 23, 2017 at 03:45:24PM -0300, Alvaro Herrera wrote: > > > > > and potentially trim the first HOT chain as those tuples become > > > > invisible. > > > > > > That can already happen even without WARM, no? > > > > Uh, the point is that with WARM those four early tuples can be removed > > via a prune, rather than requiring a VACUUM. Without WARM, the fourth > > tuple can't be removed until the index is cleared by VACUUM. > > I *think* that the WARM-updated one cannot be pruned either, because > it's pointed to by at least one index (otherwise it'd have been a HOT > update). The ones prior to that can be removed either way. Well, if you can't prune across index-column changes, how is a WARM update different than just two HOT chains with no WARM linkage? > I think the part you want (be able to prune the WARM updated tuple) is > part of what Pavan calls "turning the WARM chain into a HOT chain", so > not part of the initial patch. Pavan can explain this part better, and > also set me straight in case I'm wrong in the above :-) VACUUM can already remove entire HOT chains that have expired. What his VACUUM patch does, I think, is to remove the index entries that no longer point to values in the HOT/WARM chain, turning the chain into fully HOT, so another WARM addition to the chain can happen. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Thu, Feb 23, 2017 at 11:30 PM, Bruce Momjian <bruce@momjian.us> wrote:
On Wed, Feb 1, 2017 at 10:46:45AM +0530, Pavan Deolasee wrote:
> > contains a WARM tuple. Alternate ideas/suggestions and review of the
> design
> > are welcome!
>
> t_infomask2 contains one last unused bit,
>
>
> Umm, WARM is using 2 unused bits from t_infomask2. You mean there is another
> free bit after that too?
We are obviously going to use several heap or item pointer bits for
WARM, and once we do that it is going to be hard to undo that. Pavan,
are you saying you could do more with WARM if you had more bits? Are we
sure we have given you all the bits we can? Do we want to commit to a
lesser feature because the bits are not available?
btree implementation is complete as much as I would like (there are a few TODOs, but no show stoppers), at least for the first release. There is a free bit in btree index tuple header that I could use for chain conversion. In the heap tuples, I can reuse HEAP_MOVED_OFF because that bit will only be set along with HEAP_WARM_TUPLE bit. Since none of the upgraded clusters can have HEAP_WARM_TUPLE bit set, I think we are safe.
WARM currently also supports hash indexes, but there is no free bit left in hash index tuple header. I think I can work around that by using a bit from ip_posid (not yet implemented/tested, but seems doable).
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Feb 23, 2017 at 9:21 PM, Bruce Momjian <bruce@momjian.us> wrote: > On Tue, Jan 31, 2017 at 04:52:39PM +0530, Pavan Deolasee wrote: >> The other critical bug I found, which unfortunately exists in the master too, >> is the index corruption during CIC. The patch includes the same fix that I've >> proposed on the other thread. With these changes, WARM stress is running fine >> for last 24 hours on a decently powerful box. Multiple CREATE/DROP INDEX cycles >> and updates via different indexed columns, with a mix of FOR SHARE/UPDATE and >> rollbacks did not produce any consistency issues. A side note: while >> performance measurement wasn't a goal of stress tests, WARM has done about 67% >> more transaction than master in 24 hour period (95M in master vs 156M in WARM >> to be precise on a 30GB table including indexes). I believe the numbers would >> be far better had the test not dropping and recreating the indexes, thus >> effectively cleaning up all index bloats. Also the table is small enough to fit >> in the shared buffers. I'll rerun these tests with much larger scale factor and >> without dropping indexes. > > Thanks for setting up the test harness. I know it is hard but > in this case it has found an existing bug and given good performance > numbers. :-) > > I have what might be a supid question. As I remember, WARM only allows > a single index-column change in the chain. Why are you seeing such a > large performance improvement? I would have thought it would be that > high if we allowed an unlimited number of index changes in the chain. I'm not sure how the test case is set up. If the table has multiple indexes, each on a different column, and only one of the indexes is updated, then you figure to win because now the other indexes need less maintenance (and get less bloated). If you have only a single index, then I don't see how WARM can be any better than HOT, but maybe I just don't understand the situation. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Feb 23, 2017 at 11:53 PM, Bruce Momjian <bruce@momjian.us> wrote:
On Thu, Feb 23, 2017 at 03:03:39PM -0300, Alvaro Herrera wrote:
> Bruce Momjian wrote:
>
> > As I remember, WARM only allows
> > a single index-column change in the chain. Why are you seeing such a
> > large performance improvement? I would have thought it would be that
> > high if we allowed an unlimited number of index changes in the chain.
>
> The second update in a chain creates another non-warm-updated tuple, so
> the third update can be a warm update again, and so on.
Right, before this patch they would be two independent HOT chains. It
still seems like an unexpectedly-high performance win. Are two
independent HOT chains that much more expensive than joining them via
WARM?
insert new index entry *only* in affected index. That itself does a good bit for performance.
So to answer your question: yes, joining two HOT chains via WARM is much cheaper because it results in creating new index entries just for affected indexes.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Feb 24, 2017 at 2:13 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Thu, Feb 23, 2017 at 9:21 PM, Bruce Momjian <bruce@momjian.us> wrote:
>
> I have what might be a supid question. As I remember, WARM only allows
> a single index-column change in the chain. Why are you seeing such a
> large performance improvement? I would have thought it would be that
> high if we allowed an unlimited number of index changes in the chain.
I'm not sure how the test case is set up. If the table has multiple
indexes, each on a different column, and only one of the indexes is
updated, then you figure to win because now the other indexes need
less maintenance (and get less bloated). If you have only a single
index, then I don't see how WARM can be any better than HOT, but maybe
I just don't understand the situation.
That's correct. If you have just one index and if the UPDATE modifies indexed indexed, the UPDATE won't be a WARM update and the patch gives you no benefit. OTOH if the UPDATE doesn't modify any indexed columns, then it will be a HOT update and again the patch gives you no benefit. It might be worthwhile to see if patch causes any regression in these scenarios, though I think it will be minimal or zero.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Feb 24, 2017 at 12:28 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Bruce Momjian wrote:
> On Thu, Feb 23, 2017 at 03:45:24PM -0300, Alvaro Herrera wrote:
> > > and potentially trim the first HOT chain as those tuples become
> > > invisible.
> >
> > That can already happen even without WARM, no?
>
> Uh, the point is that with WARM those four early tuples can be removed
> via a prune, rather than requiring a VACUUM. Without WARM, the fourth
> tuple can't be removed until the index is cleared by VACUUM.
I *think* that the WARM-updated one cannot be pruned either, because
it's pointed to by at least one index (otherwise it'd have been a HOT
update). The ones prior to that can be removed either way.
No, even the WARM-updated can be pruned and if there are further HOT updates, those can be pruned too. All indexes and even multiple pointers from the same index are always pointing to the root of the WARM chain and that line pointer does not go away unless the entire chain become dead. The only material difference between HOT and WARM is that since there are two index pointers from the same index to the same root line pointer, we must do recheck. But HOT-pruning and all such things remain the same.
Let's take an example. Say, we have a table (a int, b int, c text) and two indexes on first two columns.
H W H
(1, 100, 'foo') -----> (1, 100, 'bar') ------> (1, 200, 'bar') -----> (1, 200, 'foo')
The first update will be a HOT update, the second update will be a WARM update and the third update will again be a HOT update. The first and third update do not create any new index entry, though the second update will create a new index entry in the second index. Any further WARM updates to this chain is not allowed, but further HOT updates are ok.
If all but the last version become DEAD, HOT-prune will remove all of them and turn the first line pointer into REDIRECT line pointer. At this point, the first index has one index pointer and the second index has two index pointers, but all pointing to the same root line pointer, which has not become REDIRECT line pointer.
Redirect
o-----------------------> (1, 200, 'foo')
I think the part you want (be able to prune the WARM updated tuple) is
part of what Pavan calls "turning the WARM chain into a HOT chain", so
not part of the initial patch. Pavan can explain this part better, and
also set me straight in case I'm wrong in the above :-)
The latest patch that I proposed will handle this case and convert such chains into regular HOT-pruned chains. To do that, we must remove the duplicate (and now wrong) index pointer to the chain. Once we do that and change the state on the heap tuple, we can once again do WARM update to this tuple. Note that in this example the chain has just one tuple, which will be the case typically, but the algorithm can deal with the case where there are multiple tuples but with matching index keys.
Hope this helps.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Feb 24, 2017 at 2:42 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > Let's take an example. Say, we have a table (a int, b int, c text) and two > indexes on first two columns. > > H W > H > (1, 100, 'foo') -----> (1, 100, 'bar') ------> (1, 200, 'bar') -----> (1, > 200, 'foo') > > The first update will be a HOT update, the second update will be a WARM > update and the third update will again be a HOT update. The first and third > update do not create any new index entry, though the second update will > create a new index entry in the second index. Any further WARM updates to > this chain is not allowed, but further HOT updates are ok. > > If all but the last version become DEAD, HOT-prune will remove all of them > and turn the first line pointer into REDIRECT line pointer. So, when you do the WARM update, the new index entries still point at the original root, which they don't match, not the version where that new value first appeared? I don't immediately see how this will work with index-only scans. If the tuple is HOT updated several times, HOT-pruned back to a single version, and then the page is all-visible, the index entries are guaranteed to agree with the remaining tuple, so it's fine to believe the data in the index tuple. But with WARM, that would no longer be true, unless you have some trick for that... -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Feb 24, 2017 at 3:23 PM, Robert Haas <robertmhaas@gmail.com> wrote:
I don't immediately see how this will work with index-only scans. If
the tuple is HOT updated several times, HOT-pruned back to a single
version, and then the page is all-visible, the index entries are
guaranteed to agree with the remaining tuple, so it's fine to believe
the data in the index tuple. But with WARM, that would no longer be
true, unless you have some trick for that...
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Feb 24, 2017 at 3:31 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > On Fri, Feb 24, 2017 at 3:23 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> I don't immediately see how this will work with index-only scans. If >> the tuple is HOT updated several times, HOT-pruned back to a single >> version, and then the page is all-visible, the index entries are >> guaranteed to agree with the remaining tuple, so it's fine to believe >> the data in the index tuple. But with WARM, that would no longer be >> true, unless you have some trick for that... > > Well the trick is to not allow index-only scans on such pages by not marking > them all-visible. That's why when a tuple is WARM updated, we carry that > information in the subsequent versions even when later updates are HOT > updates. The chain conversion algorithm will handle this by clearing those > bits and thus allowing index-only scans again. Wow, OK. In my view, that makes the chain conversion code pretty much essential, because if you had WARM without chain conversion then the visibility map gets more or less irrevocably less effective over time, which sounds terrible. But it sounds to me like even with the chain conversion, it might take multiple vacuum passes before all visibility map bits are set, which isn't such a great property (thus e.g. fdf9e21196a6f58c6021c967dc5776a16190f295). -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Feb 24, 2017 at 3:42 PM, Robert Haas <robertmhaas@gmail.com> wrote:
Wow, OK. In my view, that makes the chain conversion code pretty much
essential, because if you had WARM without chain conversion then the
visibility map gets more or less irrevocably less effective over time,
which sounds terrible.
Yes. I decided to complete chain conversion patch when I realised that IOS will otherwise become completely useful if large percentage of rows are updated just once. So I agree. It's not an optional patch and should get in with the main WARM patch.
But it sounds to me like even with the chain
conversion, it might take multiple vacuum passes before all visibility
map bits are set, which isn't such a great property (thus e.g.
fdf9e21196a6f58c6021c967dc5776a16190f295).
The chain conversion algorithm first converts the chains during vacuum and then checks if the page can be set all-visible. So I'm not sure why it would take multiple vacuums before a page is set all-visible. The commit you quote was written to ensure that we make another attempt to set the page all-visible after al dead tuples are removed from the page. Similarly, we will convert all WARM chains to HOT chains and then check for all-visibility of the page.
Pavan
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Feb 24, 2017 at 4:06 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: >> Wow, OK. In my view, that makes the chain conversion code pretty much >> essential, because if you had WARM without chain conversion then the >> visibility map gets more or less irrevocably less effective over time, >> which sounds terrible. > > Yes. I decided to complete chain conversion patch when I realised that IOS > will otherwise become completely useful if large percentage of rows are > updated just once. So I agree. It's not an optional patch and should get in > with the main WARM patch. Right, and it's not just index-only scans. VACUUM gets permanently more expensive, too, which is probably a much worse problem. >> But it sounds to me like even with the chain >> conversion, it might take multiple vacuum passes before all visibility >> map bits are set, which isn't such a great property (thus e.g. >> fdf9e21196a6f58c6021c967dc5776a16190f295). > > The chain conversion algorithm first converts the chains during vacuum and > then checks if the page can be set all-visible. So I'm not sure why it would > take multiple vacuums before a page is set all-visible. The commit you quote > was written to ensure that we make another attempt to set the page > all-visible after al dead tuples are removed from the page. Similarly, we > will convert all WARM chains to HOT chains and then check for all-visibility > of the page. OK, that sounds good. And there are no bugs, right? :-) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Feb 24, 2017 at 02:14:23PM +0530, Pavan Deolasee wrote: > > > On Thu, Feb 23, 2017 at 11:53 PM, Bruce Momjian <bruce@momjian.us> wrote: > > On Thu, Feb 23, 2017 at 03:03:39PM -0300, Alvaro Herrera wrote: > > Bruce Momjian wrote: > > > > > As I remember, WARM only allows > > > a single index-column change in the chain. Why are you seeing such a > > > large performance improvement? I would have thought it would be that > > > high if we allowed an unlimited number of index changes in the chain. > > > > The second update in a chain creates another non-warm-updated tuple, so > > the third update can be a warm update again, and so on. > > Right, before this patch they would be two independent HOT chains. It > still seems like an unexpectedly-high performance win. Are two > independent HOT chains that much more expensive than joining them via > WARM? > > > In these tests, there are zero HOT updates, since every update modifies some > index column. With WARM, we could reduce regular updates to half, even when we > allow only one WARM update per chain (chain really has a single tuple for this > discussion). IOW approximately half updates insert new index entry in *every* > index and half updates > insert new index entry *only* in affected index. That itself does a good bit > for performance. > > So to answer your question: yes, joining two HOT chains via WARM is much > cheaper because it results in creating new index entries just for affected > indexes. OK, all my questions have been answered, including the use of flag bits. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Fri, Feb 24, 2017 at 9:47 PM, Robert Haas <robertmhaas@gmail.com> wrote:
And there are no bugs, right? :-)
I need to polish the chain conversion patch a bit and also add missing support for redo, hash indexes etc. Support for hash indexes will need overloading of ip_posid bits in the index tuple (since there are no free bits left in hash tuples). I plan to work on that next and submit a fully functional patch, hopefully before the commit-fest starts.
(I have mentioned the idea of overloading ip_posid bits a few times now and haven't heard any objection so far. Well, that could either mean that nobody has read those emails seriously or there is general acceptance to that idea.. I am assuming latter :-))
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Sat, Feb 25, 2017 at 10:50:57AM +0530, Pavan Deolasee wrote: > > On Fri, Feb 24, 2017 at 9:47 PM, Robert Haas <robertmhaas@gmail.com> wrote: > And there are no bugs, right? :-) > > Yeah yeah absolutely nothing. Just like any other feature committed to Postgres > so far ;-) > > I need to polish the chain conversion patch a bit and also add missing support > for redo, hash indexes etc. Support for hash indexes will need overloading of > ip_posid bits in the index tuple (since there are no free bits left in hash > tuples). I plan to work on that next and submit a fully functional patch, > hopefully before the commit-fest starts. > > (I have mentioned the idea of overloading ip_posid bits a few times now and > haven't heard any objection so far. Well, that could either mean that nobody > has read those emails seriously or there is general acceptance to that idea.. I > am assuming latter :-)) Yes, I think it is the latter. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Sat, Feb 25, 2017 at 10:50 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > On Fri, Feb 24, 2017 at 9:47 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> And there are no bugs, right? :-) > > Yeah yeah absolutely nothing. Just like any other feature committed to > Postgres so far ;-) Fair point, but I've already said why I think the stakes for this particular feature are pretty high. > I need to polish the chain conversion patch a bit and also add missing > support for redo, hash indexes etc. Support for hash indexes will need > overloading of ip_posid bits in the index tuple (since there are no free > bits left in hash tuples). I plan to work on that next and submit a fully > functional patch, hopefully before the commit-fest starts. > > (I have mentioned the idea of overloading ip_posid bits a few times now and > haven't heard any objection so far. Well, that could either mean that nobody > has read those emails seriously or there is general acceptance to that > idea.. I am assuming latter :-)) I'm not sure about that. I'm not really sure I have an opinion on that yet, without seeing the patch. The discussion upthread was a bit vague: "One idea is to free up 3 bits from ip_posid knowing that OffsetNumber can never really need more than 13 bits with the other constraints in place." Not sure exactly what "the other constraints" are, exactly. /me goes off, tries to figure it out. If I'm reading the definition of MaxIndexTuplesPerPage correctly, it thinks that the minimum number of bytes per index tuple is at least 16: I think sizeof(IndexTupleData) will be 8, so when you add 1 and MAXALIGN, you get to 12, and then ItemIdData is another 4. So an 8k page (2^13 bits) could have, on a platform with MAXIMUM_ALIGNOF == 4, as many as 2^9 tuples. To store more than 2^13 tuples, we'd need a block size > 128k, but it seems 32k is the most we support. So that seems OK, if I haven't gotten confused about the logic. I suppose the only other point of concern about stealing some bits there is that it might make some operations a little more expensive, because they've got to start masking out the high bits. But that's *probably* negligible. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Feb 26, 2017 at 2:14 PM, Robert Haas <robertmhaas@gmail.com> wrote:
--
Fair point, but I've already said why I think the stakes for this
particular feature are pretty high.
I understand your concerns and not trying to downplay them. I'm doing my best to test the patch in different ways to ensure we can catch most of the bugs before the patch is committed. Hopefully with additional reviews and tests we can plug remaining holes, if any, and be in a comfortable state.
>
> (I have mentioned the idea of overloading ip_posid bits a few times now and
> haven't heard any objection so far. Well, that could either mean that nobody
> has read those emails seriously or there is general acceptance to that
> idea.. I am assuming latter :-))
I'm not sure about that. I'm not really sure I have an opinion on
that yet, without seeing the patch. The discussion upthread was a bit
vague:
Attached is a complete set of rebased and finished patches. Patches 0002 and 0003 does what I've in mind as far as OffsetNumber bits.
AFAICS this version is a fully functional implementation of WARM, ready for serious review/test. The chain conversion is now fully functional and tested with btrees. I've also added support for chain conversion in hash indexes by overloading ip_posid high order bits. Even though there is a free bit available in btree index tuple, the patch now uses the same ip_posid bit even for btree indexes.
A short summary of all attached patches.
0000_interesting_attrs_v15.patch:
This is Alvaro's patch to refactor HeapSatisfiesHOTandKeyUpdate. We now return a set of modified attributes and let the caller consume that information in a way it wants. The main WARM patch uses this refactored API.
0001_track_root_lp_v15.patch:
This implements the logic to store the root offset of the HOT chain in the t_ctid.ip_posid field. We use a free bit in heap tuple header to mark that a particular tuple is at the end of the chain and store the root offset in the ip_posid. For pg_upgraded clusters, this information could be missing and we do the hard-work of going through the page tuples to find the root offset.
0002_clear_ip_posid_blkid_refs_v15.patch:
This is mostly a cleanup patch which removes direct references to ip_posid and ip_blkid from various places and replace them with appropriate ItemPointer[Get|Set][Offset|Block]Number macros.
0003_freeup_3bits_ip_posid_v15.patch:
This patch frees up the high order 3 bits from ip_posid and makes them available for other uses. As noted, we only need 13 bits to represent OffsetNumber and hence the high order bits are unused. This patch should only be applied along with 0002_clear_ip_posid_blkid_refs_v15.patch
0004_warm_updates_v15.patch:
This implements the main WARM logic, except for chain conversion (which is implemented in the last patch of the series). It uses another free bit in the heap tuple header to identify the WARM tuples. When the first WARM update happens, the old and new versions of the tuple are marked with this flag. All subsequent HOT tuples in the chain are also marked with this flag so we never lose information about WARM updates, irrespective of whether it commits or aborts. We then implement recheck logic to decide which index pointer should return a tuple from the HOT chain.
WARM is currently supported for hash and btree indexes. If a table has an index of any other type, WARM is disabled.
0005_warm_chain_conversion_v15.patch:
This patch implements the WARM chain conversion as discussed upthread and also noted in the README.WARM. This patch requires yet another bit in the heap tuple header. But since the bit is only set along with the HEAP_WARM_TUPLE bit, we can safely reuse HEAP_MOVED_OFF bit for this purpose. We also need a bit to distinguish two copies of index pointers to know which pointer points to the pre-WARM-update HOT chain (Blue chain) and which pointer points to post-WARM-update HOT chain (Red chain). We steal this bit from t_tid.ip_posid field in the index tuple headers. As part of this patch, I moved XLOG_HEAP2_MULTI_INSERT to RM_HEAP_ID (and renamed it to XLOG_HEAP_MULTI_INSERT). While it's not necessary, I thought it will allow us to restrict XLOG_HEAP_INIT_PAGE to RM_HEAP_ID and make that bit available to define additional opcodes in RM_HEAD2_ID.
I've done some elaborate tests with these patches applied. I've primarily used make-world, pgbench with additional indexes and the WARM stress test (which was useful in catching CIC bug) to test the feature. While it does not mean there are no additional bugs, all bugs that were known to me are fixed in this version. I'll continue to run more tests, especially around crash recovery, when indexes are dropped and recreated and also do more performance tests.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
Here's a rebased set of patches. This is the same Pavan posted; I only fixed some whitespace and a trivial conflict in indexam.c, per 9b88f27cb42f. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Mar 8, 2017 at 12:00 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Here's a rebased set of patches. This is the same Pavan posted; I only > fixed some whitespace and a trivial conflict in indexam.c, per 9b88f27cb42f. No attachments. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Alvaro Herrera wrote: > Here's a rebased set of patches. This is the same Pavan posted; I only > fixed some whitespace and a trivial conflict in indexam.c, per 9b88f27cb42f. Jaime noted that I forgot the attachments. Here they are -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Wed, Mar 8, 2017 at 12:14 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Alvaro Herrera wrote: >> Here's a rebased set of patches. This is the same Pavan posted; I only >> fixed some whitespace and a trivial conflict in indexam.c, per 9b88f27cb42f. > > Jaime noted that I forgot the attachments. Here they are If I recall correctly, the main concern about 0001 was whether it might negatively affect performance, and testing showed that, if anything, it was a little better. Does that sound right? Regarding 0002, I think this could use some documentation someplace explaining the overall theory of operation. README.HOT, maybe? + * Most often and unless we are dealing with a pg-upgraded cluster, the + * root offset information should be cached. So there should not be too + * much overhead of fetching this information. Also, once a tuple is + * updated, the information will be copied to the new version. So it's not + * as if we're going to pay this price forever. What if a tuple is updated -- presumably clearing the HEAP_LATEST_TUPLE on the tuple at the end of the chain -- and then the update aborts? Then we must be back to not having this information. One overall question about this patch series is how we feel about using up this many bits. 0002 uses a bit from infomask, and 0005 uses a bit from infomask2. I'm not sure if that's everything, and then I think we're steeling some bits from the item pointers, too. While the performance benefits of the patch sound pretty good based on the test results so far, this is definitely the very last time we'll be able to implement a feature that requires this many bits. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas wrote: > On Wed, Mar 8, 2017 at 12:14 PM, Alvaro Herrera > <alvherre@2ndquadrant.com> wrote: > > Alvaro Herrera wrote: > >> Here's a rebased set of patches. This is the same Pavan posted; I only > >> fixed some whitespace and a trivial conflict in indexam.c, per 9b88f27cb42f. > > > > Jaime noted that I forgot the attachments. Here they are > > If I recall correctly, the main concern about 0001 was whether it > might negatively affect performance, and testing showed that, if > anything, it was a little better. Does that sound right? Not really -- it's a bit slower actually in a synthetic case measuring exactly the slowed-down case. See https://www.postgresql.org/message-id/CAD__OugK12ZqMWWjZiM-YyuD1y8JmMy6x9YEctNiF3rPp6hy0g@mail.gmail.com I bet in normal cases it's unnoticeable. If WARM flies, then it's going to provide a larger improvement than is lost to this. > Regarding 0002, I think this could use some documentation someplace > explaining the overall theory of operation. README.HOT, maybe? Hmm. Yeah, we should have something to that effect. 0005 includes README.WARM, but I think there should be some place unified that explains the whole thing. > + * Most often and unless we are dealing with a pg-upgraded cluster, the > + * root offset information should be cached. So there should not be too > + * much overhead of fetching this information. Also, once a tuple is > + * updated, the information will be copied to the new version. So it's not > + * as if we're going to pay this price forever. > > What if a tuple is updated -- presumably clearing the > HEAP_LATEST_TUPLE on the tuple at the end of the chain -- and then the > update aborts? Then we must be back to not having this information. I will leave this question until I have grokked how this actually works. > One overall question about this patch series is how we feel about > using up this many bits. 0002 uses a bit from infomask, and 0005 uses > a bit from infomask2. I'm not sure if that's everything, and then I > think we're steeling some bits from the item pointers, too. While the > performance benefits of the patch sound pretty good based on the test > results so far, this is definitely the very last time we'll be able to > implement a feature that requires this many bits. Yeah, this patch series uses a lot of bits. At some point we should really add the "last full-scanned by version X" we discussed a long time ago, and free the MOVED_IN / MOVED_OFF bits that have been unused for so long. Sadly, once we add that, we need to wait one more release before we can use the bits anyway. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Mar 8, 2017 at 2:30 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Not really -- it's a bit slower actually in a synthetic case measuring > exactly the slowed-down case. See > https://www.postgresql.org/message-id/CAD__OugK12ZqMWWjZiM-YyuD1y8JmMy6x9YEctNiF3rPp6hy0g@mail.gmail.com > I bet in normal cases it's unnoticeable. If WARM flies, then it's going > to provide a larger improvement than is lost to this. Hmm, that test case isn't all that synthetic. It's just a single column bulk update, which isn't anything all that crazy, and 5-10% isn't nothing. I'm kinda surprised it made that much difference, though. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas wrote: > On Wed, Mar 8, 2017 at 2:30 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > > Not really -- it's a bit slower actually in a synthetic case measuring > > exactly the slowed-down case. See > > https://www.postgresql.org/message-id/CAD__OugK12ZqMWWjZiM-YyuD1y8JmMy6x9YEctNiF3rPp6hy0g@mail.gmail.com > > I bet in normal cases it's unnoticeable. If WARM flies, then it's going > > to provide a larger improvement than is lost to this. > > Hmm, that test case isn't all that synthetic. It's just a single > column bulk update, which isn't anything all that crazy, The problem is that the update touches the second indexed column. With the original code we would have stopped checking at that point, but with the patched code we continue to verify all the other indexed columns for changes. Maybe we need more than one bitmapset to be given -- multiple ones for for "any of these" checks (such as HOT, KEY and Identity) which can be stopped as soon as one is found, and one for "all of these" (for WARM, indirect indexes) which needs to be checked to completion. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
> @@ -234,6 +236,21 @@ index_beginscan(Relation heapRelation, > scan->heapRelation = heapRelation; > scan->xs_snapshot = snapshot; > > + /* > + * If the index supports recheck, make sure that index tuple is saved > + * during index scans. > + * > + * XXX Ideally, we should look at all indexes on the table and check if > + * WARM is at all supported on the base table. If WARM is not supported > + * then we don't need to do any recheck. RelationGetIndexAttrBitmap() does > + * do that and sets rd_supportswarm after looking at all indexes. But we > + * don't know if the function was called earlier in the session when we're > + * here. We can't call it now because there exists a risk of causing > + * deadlock. > + */ > + if (indexRelation->rd_amroutine->amrecheck) > + scan->xs_want_itup = true; > + > return scan; > } I didn't like this comment very much. But it's not necessary: you have already given relcache responsibility for setting rd_supportswarm. The only problem seems to be that you set it in RelationGetIndexAttrBitmap instead of RelationGetIndexList, but it's not clear to me why. I think if the latter function is in charge, then we can trust the flag more than the current situation. Let's set the value to false on relcache entry build, for safety's sake. I noticed that nbtinsert.c and nbtree.c have a bunch of new includes that they don't actually need. Let's remove those. nbtutils.c does need them because of btrecheck(). Speaking of which: I have already commented about the executor involvement in btrecheck(); that doesn't seem good. I previously suggested to pass the EState down from caller, but that's not a great idea either since you still need to do the actual FormIndexDatum. I now think that a workable option would be to compute the values/isnulls arrays so that btrecheck gets them already computed. With that, this function would be no more of a modularity violation that HeapSatisfiesHOTAndKey() itself. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
After looking at how index_fetch_heap and heap_hot_search_buffer interact, I can't say I'm in love with the idea. I started thinking that we should not have index_fetch_heap release the buffer lock only to re-acquire it five lines later, so it should keep the buffer lock, do the recheck and only release it afterwards (I realize that this means there'd be need for two additional "else release buffer lock" branches); but then this got me thinking that perhaps it would be better to have another routine that does both call heap_hot_search_buffer and then call recheck -- it occurs to me that what we're doing here is essentially heap_warm_search_buffer. Does that make sense? Another thing is BuildIndexInfo being called over and over for each recheck(). Surely we need to cache the indexinfo for each indexscan. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Mar 14, 2017 at 7:17 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
> @@ -234,6 +236,21 @@ index_beginscan(Relation heapRelation,
> scan->heapRelation = heapRelation;
> scan->xs_snapshot = snapshot;
>
> + /*
> + * If the index supports recheck, make sure that index tuple is saved
> + * during index scans.
> + *
> + * XXX Ideally, we should look at all indexes on the table and check if
> + * WARM is at all supported on the base table. If WARM is not supported
> + * then we don't need to do any recheck. RelationGetIndexAttrBitmap() does
> + * do that and sets rd_supportswarm after looking at all indexes. But we
> + * don't know if the function was called earlier in the session when we're
> + * here. We can't call it now because there exists a risk of causing
> + * deadlock.
> + */
> + if (indexRelation->rd_amroutine->amrecheck)
> + scan->xs_want_itup = true;
> +
> return scan;
> }
I didn't like this comment very much. But it's not necessary: you have
already given relcache responsibility for setting rd_supportswarm. The
only problem seems to be that you set it in RelationGetIndexAttrBitmap
instead of RelationGetIndexList, but it's not clear to me why.
Hmm. I think you're right. Will fix that way and test.
I noticed that nbtinsert.c and nbtree.c have a bunch of new includes
that they don't actually need. Let's remove those. nbtutils.c does
need them because of btrecheck().
Right. It's probably a left over from the way I wrote the first version. Will fix.
Speaking of which:
I have already commented about the executor involvement in btrecheck();
that doesn't seem good. I previously suggested to pass the EState down
from caller, but that's not a great idea either since you still need to
do the actual FormIndexDatum. I now think that a workable option would
be to compute the values/isnulls arrays so that btrecheck gets them
already computed.
I agree with your complaint about modularity violation. What I am unclear is how passing values/isnulls array will fix that. The way code is structured currently, recheck routines are called by index_fetch_heap(). So if we try to compute values/isnulls in that function, we'll still need access EState, which AFAIU will lead to similar violation. Or am I mis-reading your idea?
I wonder if we should instead invent something similar to IndexRecheck(), but instead of running ExecQual(), this new routine will compare the index values by the given HeapTuple against given IndexTuple. ISTM that for this to work we'll need to modify all callers of index_getnext() and teach them to invoke the AM specific recheck method if xs_tuple_recheck flag is set to true by index_getnext().
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 14, 2017 at 5:17 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
-- After looking at how index_fetch_heap and heap_hot_search_buffer
interact, I can't say I'm in love with the idea. I started thinking
that we should not have index_fetch_heap release the buffer lock only to
re-acquire it five lines later, so it should keep the buffer lock, do
the recheck and only release it afterwards (I realize that this means
there'd be need for two additional "else release buffer lock" branches);
Yes, it makes sense.
but then this got me thinking that perhaps it would be better to have
another routine that does both call heap_hot_search_buffer and then call
recheck -- it occurs to me that what we're doing here is essentially
heap_warm_search_buffer.
Does that make sense?
We can do that, but it's not clear to me if that would be a huge improvement. Also, I think we need to first decide on how to model the recheck logic since that might affect this function significantly. For example, if we decide to do recheck at a higher level then we will most likely end up releasing and reacquiring the lock anyways.
Another thing is BuildIndexInfo being called over and over for each
recheck(). Surely we need to cache the indexinfo for each indexscan.
Good point. What should that place be though? Can we just cache them in the relcache and maintain them along with the list of indexes? Looking at the current callers, ExecOpenIndices() usually cache them in the ResultRelInfo, which is sufficient because INSERT/UPDATE/DELETE code paths are the most relevant paths where caching definitely helps. The only other place where it may get called once per tuple is unique_key_recheck(), which is used for deferred unique key tests and hence probably not very common.
BTW I wanted to share some more numbers from a recent performance test. I thought it's important because the latest patch has fully functional chain conversion code as well as all WAL-logging related pieces are in place too. I ran these tests on a box borrowed from Tomas (thanks!). This has 64GB RAM and 350GB SSD with 1GB on-board RAM. I used the same test setup that I used for the first test results reported on this thread i.e. a modified pgbench_accounts table with additional columns and additional indexes (one index on abalance so that every UPDATE is a potential WARM update).
In a test where table + indexes exceeds RAM, running for 8hrs and auto-vacuum parameters set such that we get 2-3 autovacuums on the table during the test, we see WARM delivering more than 100% TPS as compared to master. In this graph, I've plotted a moving average of TPS and the spikes that we see coincides with the checkpoints (checkpoint_timeout is set to 20mins and max_wal_size large enough to avoid any xlog-based checkpoints). The spikes are more prominent on WARM but I guess that's purely because it delivers much higher TPS. I haven't shown here but I see WARM updates close to 65-70% of the total updates. Also there is significant reduction in WAL generated per txn.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
Pavan Deolasee wrote: > On Tue, Mar 14, 2017 at 7:17 AM, Alvaro Herrera <alvherre@2ndquadrant.com> > wrote: > > I have already commented about the executor involvement in btrecheck(); > > that doesn't seem good. I previously suggested to pass the EState down > > from caller, but that's not a great idea either since you still need to > > do the actual FormIndexDatum. I now think that a workable option would > > be to compute the values/isnulls arrays so that btrecheck gets them > > already computed. > > I agree with your complaint about modularity violation. What I am unclear > is how passing values/isnulls array will fix that. The way code is > structured currently, recheck routines are called by index_fetch_heap(). So > if we try to compute values/isnulls in that function, we'll still need > access EState, which AFAIU will lead to similar violation. Or am I > mis-reading your idea? You're right, it's still a problem. (Honestly, I think the whole idea of trying to compute a fake index tuple starting from a just-read heap tuple is a problem in itself; I just wonder if there's a way to do the recheck that doesn't involve such a thing.) > I wonder if we should instead invent something similar to IndexRecheck(), > but instead of running ExecQual(), this new routine will compare the index > values by the given HeapTuple against given IndexTuple. ISTM that for this > to work we'll need to modify all callers of index_getnext() and teach them > to invoke the AM specific recheck method if xs_tuple_recheck flag is set to > true by index_getnext(). Yeah, grumble, that idea does sound intrusive, but perhaps it's workable. What about bitmap indexscans? AFAICS we already have a recheck there natively, so we only need to mark the page as lossy, which we're already doing anyway. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Pavan Deolasee wrote: > BTW I wanted to share some more numbers from a recent performance test. I > thought it's important because the latest patch has fully functional chain > conversion code as well as all WAL-logging related pieces are in place > too. I ran these tests on a box borrowed from Tomas (thanks!). This has > 64GB RAM and 350GB SSD with 1GB on-board RAM. I used the same test setup > that I used for the first test results reported on this thread i.e. a > modified pgbench_accounts table with additional columns and additional > indexes (one index on abalance so that every UPDATE is a potential WARM > update). > > In a test where table + indexes exceeds RAM, running for 8hrs and > auto-vacuum parameters set such that we get 2-3 autovacuums on the table > during the test, we see WARM delivering more than 100% TPS as compared to > master. In this graph, I've plotted a moving average of TPS and the spikes > that we see coincides with the checkpoints (checkpoint_timeout is set to > 20mins and max_wal_size large enough to avoid any xlog-based checkpoints). > The spikes are more prominent on WARM but I guess that's purely because it > delivers much higher TPS. I haven't shown here but I see WARM updates close > to 65-70% of the total updates. Also there is significant reduction in WAL > generated per txn. Impressive results. Labels on axes would improve readability of the chart :-) -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Mar 14, 2017 at 7:19 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Pavan Deolasee wrote:
> BTW I wanted to share some more numbers from a recent performance test. I
> thought it's important because the latest patch has fully functional chain
> conversion code as well as all WAL-logging related pieces are in place
> too. I ran these tests on a box borrowed from Tomas (thanks!). This has
> 64GB RAM and 350GB SSD with 1GB on-board RAM. I used the same test setup
> that I used for the first test results reported on this thread i.e. a
> modified pgbench_accounts table with additional columns and additional
> indexes (one index on abalance so that every UPDATE is a potential WARM
> update).
>
> In a test where table + indexes exceeds RAM, running for 8hrs and
> auto-vacuum parameters set such that we get 2-3 autovacuums on the table
> during the test, we see WARM delivering more than 100% TPS as compared to
> master. In this graph, I've plotted a moving average of TPS and the spikes
> that we see coincides with the checkpoints (checkpoint_timeout is set to
> 20mins and max_wal_size large enough to avoid any xlog-based checkpoints).
> The spikes are more prominent on WARM but I guess that's purely because it
> delivers much higher TPS. I haven't shown here but I see WARM updates close
> to 65-70% of the total updates. Also there is significant reduction in WAL
> generated per txn.
Impressive results. Labels on axes would improve readability of the chart :-)
Just to make it clear, the X-axis is duration of tests in seconds and Y-axis is 450s moving average of TPS. BTW 450 is no magic figure. I collected stats every 15s and took a moving average of last 30 samples.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 14, 2017 at 12:19 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Impressive results. Agreed. It seems like an important invariant for WARM is that any duplicate index values ought to have different TIDs (actually, it's a bit stricter than that, since btrecheck() cares about simple binary equality). ISTM that it would be fairly easy to modify amcheck such that the "items in logical order" check, as well as the similar "cross-page order" check (the one that detects transposed pages) also check that this new WARM invariant holds. Obviously this would only make sense on the leaf level of the index. You wouldn't have to teach amcheck about the heap, because a TID that points to the heap can only be duplicated within a B-Tree index because of WARM. So, if we find that two adjacent tuples are equal, check if the TIDs are equal. If they are also equal, check for strict binary equality. If strict binary equality is indicated, throw an error due to invariant failing. IIUC, the design of WARM makes this simple enough to implement, and cheap enough that the additional runtime overhead is well worthwhile. You could just add this check to the existing checks without changing the user-visible interface. It seems pretty complementary to what is already there. -- Peter Geoghegan
On Tue, Mar 14, 2017 at 7:16 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Pavan Deolasee wrote:
> On Tue, Mar 14, 2017 at 7:17 AM, Alvaro Herrera <alvherre@2ndquadrant.com>
> wrote:
> > I have already commented about the executor involvement in btrecheck();
> > that doesn't seem good. I previously suggested to pass the EState down
> > from caller, but that's not a great idea either since you still need to
> > do the actual FormIndexDatum. I now think that a workable option would
> > be to compute the values/isnulls arrays so that btrecheck gets them
> > already computed.
>
> I agree with your complaint about modularity violation. What I am unclear
> is how passing values/isnulls array will fix that. The way code is
> structured currently, recheck routines are called by index_fetch_heap(). So
> if we try to compute values/isnulls in that function, we'll still need
> access EState, which AFAIU will lead to similar violation. Or am I
> mis-reading your idea?
You're right, it's still a problem. (Honestly, I think the whole idea
of trying to compute a fake index tuple starting from a just-read heap
tuple is a problem in itself;
Why do you think so?
I just wonder if there's a way to do the
recheck that doesn't involve such a thing.)
I couldn't find a better way without a lot of complex infrastructure. Even though we now have ability to mark index pointers and we know that a given pointer either points to the pre-WARM chain or post-WARM chain, this does not solve the case when an index does not receive a new entry. In that case, both pre-WARM and post-WARM tuples are reachable via the same old index pointer. The only way we could deal with this is to mark index pointers as "common", "pre-warm" and "post-warm". But that would require us to update the old pointer's state from "common" to "pre-warm" for the index whose keys are being updated. May be it's doable, but might be more complex than the current approach.
> I wonder if we should instead invent something similar to IndexRecheck(),
> but instead of running ExecQual(), this new routine will compare the index
> values by the given HeapTuple against given IndexTuple. ISTM that for this
> to work we'll need to modify all callers of index_getnext() and teach them
> to invoke the AM specific recheck method if xs_tuple_recheck flag is set to
> true by index_getnext().
Yeah, grumble, that idea does sound intrusive, but perhaps it's
workable. What about bitmap indexscans? AFAICS we already have a
recheck there natively, so we only need to mark the page as lossy, which
we're already doing anyway.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Mar 15, 2017 at 3:44 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > I couldn't find a better way without a lot of complex infrastructure. Even > though we now have ability to mark index pointers and we know that a given > pointer either points to the pre-WARM chain or post-WARM chain, this does > not solve the case when an index does not receive a new entry. In that case, > both pre-WARM and post-WARM tuples are reachable via the same old index > pointer. The only way we could deal with this is to mark index pointers as > "common", "pre-warm" and "post-warm". But that would require us to update > the old pointer's state from "common" to "pre-warm" for the index whose keys > are being updated. May be it's doable, but might be more complex than the > current approach. /me scratches head. Aren't pre-warm and post-warm just (better) names for blue and red? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Mar 16, 2017 at 12:53 PM, Robert Haas <robertmhaas@gmail.com> wrote:
Does that sound ok? I can change the patch accordingly.On Wed, Mar 15, 2017 at 3:44 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> I couldn't find a better way without a lot of complex infrastructure. Even
> though we now have ability to mark index pointers and we know that a given
> pointer either points to the pre-WARM chain or post-WARM chain, this does
> not solve the case when an index does not receive a new entry. In that case,
> both pre-WARM and post-WARM tuples are reachable via the same old index
> pointer. The only way we could deal with this is to mark index pointers as
> "common", "pre-warm" and "post-warm". But that would require us to update
> the old pointer's state from "common" to "pre-warm" for the index whose keys
> are being updated. May be it's doable, but might be more complex than the
> current approach.
/me scratches head.
Aren't pre-warm and post-warm just (better) names for blue and red?
Yeah, sounds better. Just to make it clear, the current design sets the following information:
HEAP_WARM_TUPLE - When a row gets WARM updated, both old and new versions of the row are marked with HEAP_WARM_TUPLE flag. This allows us to remember that a certain row was WARM-updated, even if the update later aborts and we cleanup the new version and truncate the chain. All subsequent tuple versions will carry this flag until a non-HOT updates happens, which breaks the HOT chain.
HEAP_WARM_RED - After first WARM update, the new version of the tuple is marked with this flag. This flag is also carried forward to all future HOT updated tuples. So the only tuple that has HEAP_WARM_TUPLE but not HEAP_WARM_RED is the old version before the WARM update. Also, all tuples marked with HEAP_WARM_RED flag satisfies HOT property (i.e. all index key columns share the same value). Similarly, all tuples NOT marked with HEAP_WARM_RED also satisfy HOT property. I've so far called them Red and Blue chains respectively.
In addition, in the current patch, the new index pointers resulted from WARM updates are marked BTREE_INDEX_RED_POINTER/HASH_INDEX_RED_POINTER
I think per your suggestion we can change HEAP_WARM_RED to HEAP_WARM_TUPLE and similarly rename the index pointers to BTREE/HASH_INDEX_WARM_POINTER and replace HEAP_WARM_TUPLE with something like HEAP_WARM_UPDATED_TUPLE to signify that this or some previous version of this chain was once WARM-updated.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 14, 2017 at 8:14 PM, Peter Geoghegan <pg@bowt.ie> wrote:
-- On Tue, Mar 14, 2017 at 12:19 PM, Alvaro Herrera
<alvherre@2ndquadrant.com> wrote:
> Impressive results.
Agreed.
Thanks. I repeated the same tests with slightly lower scale factor so that most (but not all) data fits in memory. The results are kinda similar (attached here). The spikes are still there and they correspond to the checkpoint_timeout set for these tests.
It seems like an important invariant for WARM is that any duplicate
index values ought to have different TIDs (actually, it's a bit
stricter than that, since btrecheck() cares about simple binary
equality).
Yes. I think in the current code, indexes can never duplicate TIDs (at least for btrees and hash). With WARM, indexes can have duplicate TIDs, but iff index values differ. In addition there can only be one more duplicate and one of them must be a Blue pointer (or a non-WARM pointer if we accept the new nomenclature proposed a few mins back).
You wouldn't have to teach amcheck about the heap, because a TID that
points to the heap can only be duplicated within a B-Tree index
because of WARM. So, if we find that two adjacent tuples are equal,
check if the TIDs are equal. If they are also equal, check for strict
binary equality. If strict binary equality is indicated, throw an
error due to invariant failing.
Wouldn't this be much more expensive for non-unique indexes?
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Sun, Mar 19, 2017 at 3:05 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > On Thu, Mar 16, 2017 at 12:53 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Wed, Mar 15, 2017 at 3:44 PM, Pavan Deolasee >> <pavan.deolasee@gmail.com> wrote: >> > I couldn't find a better way without a lot of complex infrastructure. >> > Even >> > though we now have ability to mark index pointers and we know that a >> > given >> > pointer either points to the pre-WARM chain or post-WARM chain, this >> > does >> > not solve the case when an index does not receive a new entry. In that >> > case, >> > both pre-WARM and post-WARM tuples are reachable via the same old index >> > pointer. The only way we could deal with this is to mark index pointers >> > as >> > "common", "pre-warm" and "post-warm". But that would require us to >> > update >> > the old pointer's state from "common" to "pre-warm" for the index whose >> > keys >> > are being updated. May be it's doable, but might be more complex than >> > the >> > current approach. >> >> /me scratches head. >> >> Aren't pre-warm and post-warm just (better) names for blue and red? >> > > Yeah, sounds better. My point here wasn't really about renaming, although I do think renaming is something that should get done. My point was that you were saying we need to mark index pointers as common, pre-warm, and post-warm. But you're pretty much already doing that, I think. I guess you don't have "common", but you do have "pre-warm" and "post-warm". -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Mar 20, 2017 at 8:11 PM, Robert Haas <robertmhaas@gmail.com> wrote:
-- My point here wasn't really about renaming, although I do thinkOn Sun, Mar 19, 2017 at 3:05 AM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> On Thu, Mar 16, 2017 at 12:53 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>>
>> /me scratches head.
>>
>> Aren't pre-warm and post-warm just (better) names for blue and red?
>>
>
> Yeah, sounds better.
renaming is something that should get done. My point was that you
were saying we need to mark index pointers as common, pre-warm, and
post-warm. But you're pretty much already doing that, I think. I
guess you don't have "common", but you do have "pre-warm" and
"post-warm".
Ah, I mis-read that. Strictly speaking, we already have common (blue) and post-warm (red), and I just finished renaming them to CLEAR (of WARM bit) and WARM. May be it's still not the best name, but I think it looks better than before.
But the larger point is that we don't have an easy to know if an index pointer which was inserted with the original heap tuple (i.e. pre-WARM update) should only return pre-WARM tuples or should it also return post-WARM tuples. Right now we make that decision by looking at the index-keys and discard the pointer whose index-key does not match the ones created from heap-keys. If we need to change that then at every WARM update, we will have to go back to the original pointer and change it's state to pre-warm. That looks more invasive and requires additional index management.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Mar 15, 2017 at 12:46 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Pavan Deolasee wrote:
> On Tue, Mar 14, 2017 at 7:17 AM, Alvaro Herrera <alvherre@2ndquadrant.com>
> wrote:
> > I have already commented about the executor involvement in btrecheck();
> > that doesn't seem good. I previously suggested to pass the EState down
> > from caller, but that's not a great idea either since you still need to
> > do the actual FormIndexDatum. I now think that a workable option would
> > be to compute the values/isnulls arrays so that btrecheck gets them
> > already computed.
>
> I agree with your complaint about modularity violation. What I am unclear
> is how passing values/isnulls array will fix that. The way code is
> structured currently, recheck routines are called by index_fetch_heap(). So
> if we try to compute values/isnulls in that function, we'll still need
> access EState, which AFAIU will lead to similar violation. Or am I
> mis-reading your idea?
You're right, it's still a problem.
BTW I realised that we don't really need those executor bits in recheck routines. We don't support WARM when attributes in index expressions are modified. So we really don't need to do any comparison for those attributes. I've written a separate form of FormIndexDatum() which will only return basic index attributes and comparing them should be enough. Will share rebased and updated patch soon.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 14, 2017 at 7:17 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
> @@ -234,6 +236,21 @@ index_beginscan(Relation heapRelation,
> scan->heapRelation = heapRelation;
> scan->xs_snapshot = snapshot;
>
> + /*
> + * If the index supports recheck, make sure that index tuple is saved
> + * during index scans.
> + *
> + * XXX Ideally, we should look at all indexes on the table and check if
> + * WARM is at all supported on the base table. If WARM is not supported
> + * then we don't need to do any recheck. RelationGetIndexAttrBitmap() does
> + * do that and sets rd_supportswarm after looking at all indexes. But we
> + * don't know if the function was called earlier in the session when we're
> + * here. We can't call it now because there exists a risk of causing
> + * deadlock.
> + */
> + if (indexRelation->rd_amroutine->amrecheck)
> + scan->xs_want_itup = true;
> +
> return scan;
> }
I didn't like this comment very much. But it's not necessary: you have
already given relcache responsibility for setting rd_supportswarm. The
only problem seems to be that you set it in RelationGetIndexAttrBitmap
instead of RelationGetIndexList, but it's not clear to me why. I think
if the latter function is in charge, then we can trust the flag more
than the current situation.
I looked at this today. AFAICS we don't have access to rd_amroutine in RelationGetIndexList since we don't actually call index_open() in that function. Would it be safe to do that? I'll give it a shot, but thought of asking here first.
Thanks,
Pavan
Pavan Deolasee wrote: > On Tue, Mar 14, 2017 at 7:17 AM, Alvaro Herrera <alvherre@2ndquadrant.com> > wrote: > > I didn't like this comment very much. But it's not necessary: you have > > already given relcache responsibility for setting rd_supportswarm. The > > only problem seems to be that you set it in RelationGetIndexAttrBitmap > > instead of RelationGetIndexList, but it's not clear to me why. I think > > if the latter function is in charge, then we can trust the flag more > > than the current situation. > > I looked at this today. AFAICS we don't have access to rd_amroutine in > RelationGetIndexList since we don't actually call index_open() in that > function. Would it be safe to do that? I'll give it a shot, but thought of > asking here first. Ah, you're right, we only have the pg_index tuple for the index, not the pg_am one. I think one pg_am cache lookup isn't really all that terrible (though we should ensure that there's no circularity problem in doing that), but I doubt that going to the trouble of invoking the amhandler just to figure out if it supports WARM is acceptable. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sun, Mar 19, 2017 at 12:15 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: >> It seems like an important invariant for WARM is that any duplicate >> index values ought to have different TIDs (actually, it's a bit >> stricter than that, since btrecheck() cares about simple binary >> equality). > > Yes. I think in the current code, indexes can never duplicate TIDs (at least > for btrees and hash). With WARM, indexes can have duplicate TIDs, but iff > index values differ. In addition there can only be one more duplicate and > one of them must be a Blue pointer (or a non-WARM pointer if we accept the > new nomenclature proposed a few mins back). It looks like those additional Red/Blue details are available right from the IndexTuple, which makes the check a good fit for amcheck (no need to bring the heap into it). >> You wouldn't have to teach amcheck about the heap, because a TID that >> points to the heap can only be duplicated within a B-Tree index >> because of WARM. So, if we find that two adjacent tuples are equal, >> check if the TIDs are equal. If they are also equal, check for strict >> binary equality. If strict binary equality is indicated, throw an >> error due to invariant failing. >> > > Wouldn't this be much more expensive for non-unique indexes? Only in the worst case, where there are many many duplicates, and only if you insisted on being completely comprehensive, rather than merely very comprehensive. That is, you can store the duplicate TIDs in local memory up to a quasi-arbitrary budget, since you do have to make sure that any local buffer cannot grow in an unbounded fashion. Certainly, if you stored 10,000 TIDs, there is always going to be a theoretical case where that wasn't enough. But you can always say something like that. We are defending against Murphy here, not Machiavelli. You're going to have to qsort() a particular value's duplicate TIDs once you encounter a distinct value, and therefore need to evaluate the invariant. That's not a big deal, because sorting less than 1,000 items is generally very fast. It's well worth it. I'd probably choose a generic budget for storing TIDs in local memory, and throw out half of the TIDs when that budget is exceeded. I see no difficulty with race conditions when you have only an AccessShareLock on target. Concurrent page splits won't hurt, because you reliably skip over those by always moving right. I'm pretty sure that VACUUM killing IndexTuples that you've already stored with the intention of sorting later is also not a complicating factor, since you know that the heap TIDs that are WARM root pointers are not going to be recycled in the lifetime of the amcheck query such that you get a false positive. A WARM check seems like a neat adjunct to what amcheck does already. It seems like a really good idea for WARM to buy into this kind of verification. It is, at worst, cheap insurance. -- Peter Geoghegan
On Fri, Mar 10, 2017 at 11:37 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Robert Haas wrote: >> On Wed, Mar 8, 2017 at 2:30 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: >> > Not really -- it's a bit slower actually in a synthetic case measuring >> > exactly the slowed-down case. See >> > https://www.postgresql.org/message-id/CAD__OugK12ZqMWWjZiM-YyuD1y8JmMy6x9YEctNiF3rPp6hy0g@mail.gmail.com >> > I bet in normal cases it's unnoticeable. If WARM flies, then it's going >> > to provide a larger improvement than is lost to this. >> >> Hmm, that test case isn't all that synthetic. It's just a single >> column bulk update, which isn't anything all that crazy, > > The problem is that the update touches the second indexed column. With > the original code we would have stopped checking at that point, but with > the patched code we continue to verify all the other indexed columns for > changes. > > Maybe we need more than one bitmapset to be given -- multiple ones for > for "any of these" checks (such as HOT, KEY and Identity) which can be > stopped as soon as one is found, and one for "all of these" (for WARM, > indirect indexes) which needs to be checked to completion. > How will that help to mitigate the regression? I think what might help here is if we fetch the required columns for WARM only when we know hot_update is false. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Mar 9, 2017 at 8:43 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Mar 8, 2017 at 2:30 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: >> Not really -- it's a bit slower actually in a synthetic case measuring >> exactly the slowed-down case. See >> https://www.postgresql.org/message-id/CAD__OugK12ZqMWWjZiM-YyuD1y8JmMy6x9YEctNiF3rPp6hy0g@mail.gmail.com >> I bet in normal cases it's unnoticeable. If WARM flies, then it's going >> to provide a larger improvement than is lost to this. > > Hmm, that test case isn't all that synthetic. It's just a single > column bulk update, which isn't anything all that crazy, and 5-10% > isn't nothing. > > I'm kinda surprised it made that much difference, though. > I think it is because heap_getattr() is not that cheap. We have noticed the similar problem during development of scan key push down work [1]. [1] - https://commitfest.postgresql.org/12/850/ -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Mar 21, 2017 at 6:56 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> Hmm, that test case isn't all that synthetic. It's just a single >> column bulk update, which isn't anything all that crazy, and 5-10% >> isn't nothing. >> >> I'm kinda surprised it made that much difference, though. >> > > I think it is because heap_getattr() is not that cheap. We have > noticed the similar problem during development of scan key push down > work [1]. Yeah. So what's the deal with this? Is somebody working on figuring out a different approach that would reduce this overhead? Are we going to defer WARM to v11? Or is the intent to just ignore the 5-10% slowdown on a single column update and commit everything anyway? (A strong -1 on that course of action from me.) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Mar 21, 2017 at 5:34 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Tue, Mar 21, 2017 at 6:56 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> Hmm, that test case isn't all that synthetic. It's just a single
>> column bulk update, which isn't anything all that crazy, and 5-10%
>> isn't nothing.
>>
>> I'm kinda surprised it made that much difference, though.
>>
>
> I think it is because heap_getattr() is not that cheap. We have
> noticed the similar problem during development of scan key push down
> work [1].
Yeah. So what's the deal with this? Is somebody working on figuring
out a different approach that would reduce this overhead? Are we
going to defer WARM to v11? Or is the intent to just ignore the 5-10%
slowdown on a single column update and commit everything anyway?
I think I should clarify something. The test case does a single column update, but it also has columns which are very wide, has an index on many columns (and it updates a column early in the list). In addition, in the test Mithun updated all 10million rows of the table in a single transaction, used UNLOGGED table and fsync was turned off.
Having said that, may be if we can do a few things to reduce the overhead.
- Check if the page has enough free space to perform a HOT/WARM update. If not, don't look for all index keys.
- Pass bitmaps separately for each index and bail out early if we conclude neither HOT nor WARM is possible. In this case since there is just one index and as soon as we check the second column we know neither HOT nor WARM is possible, we will return early. It might complicate the API a lot, but I can give it a shot if that's what is needed to make progress.
Any other ideas?
Thanks,
Pavan
-- Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 14, 2017 at 10:47 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
-- After looking at how index_fetch_heap and heap_hot_search_buffer
interact, I can't say I'm in love with the idea. I started thinking
that we should not have index_fetch_heap release the buffer lock only to
re-acquire it five lines later, so it should keep the buffer lock, do
the recheck and only release it afterwards (I realize that this means
there'd be need for two additional "else release buffer lock" branches);
but then this got me thinking that perhaps it would be better to have
another routine that does both call heap_hot_search_buffer and then call
recheck -- it occurs to me that what we're doing here is essentially
heap_warm_search_buffer.
Does that make sense?
Another thing is BuildIndexInfo being called over and over for each
recheck(). Surely we need to cache the indexinfo for each indexscan.
Please find attached rebased patches. There are a few changes in this version, so let me mention them here instead of trying to reply in-line to various points on various emails:
1. The patch now has support for hash redo recovery since that was added to the master (it might be broken since a bug was reported in the original code itself)
2. Based on Robert's comments and my discussion with him in person, I removed the Blue/Red naming and instead now using CLEAR and WARM to identify the parts of the chain and the index pointers. This also resulted in changes to the way heap tuple header bits are named. So HEAP_WARM_UPDATED is now used to mark the old tuple which gets WARM updated and the same flag is copied to all subsequent versions of the tuple, until a non-HOT updates happens. The new version and all subsequent versions are marked with HEAP_WARM_TUPLE flag (in the earlier versions this was used for marking old and the new versions. This might cause confusion, but looks a more accurate naming to me.
3. IndexInfo is now cached inside IndexScanDescData, which should address your comment above.
4. I realised that we don't really need to ever compare expression attributes in the index since WARM is never used when one of those columns is updated. Hence I've now created a new version of FormIndexDatum which only returns plain attributes and hence recheck routine does not need access to any executor stuff.
5. We don't release the lock of the buffer if we are going to apply recheck. This should address part of the your comment. I haven't though put them inside a single wrapper function because there is just one caller to amrecheck function and after this change, it looked ok. But if you don't still like, I'll make that change.
6. Unnecessary header files included at various places have been removed.
7. Some comments have been updated and rewritten. Hopefully they look better than before now.
8. I merged the main WARM patch and the chain conversion code in a single patch since I don't think we will apply them separately. But if it helps with review, let me know and I can split that again.
9. I realised that we don't really need xs_tuple_recheck in the scan descriptor and hence removed that and used a stack variable to get that info.
10. Accidentally WARM was disabled on the system relations during one of the earlier rebases. So restored that back and made a slight change to regression expected output.
All tests pass with the patch set. I am now writing TAP tests for WARM and will submit that separately. Per your suggestion, I am first turning the stress tests I'd used earlier to use TAP tests and then add more tests, especially around recovery and index addition/deletion.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Tue, Mar 21, 2017 at 8:41 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: >> Yeah. So what's the deal with this? Is somebody working on figuring >> out a different approach that would reduce this overhead? Are we >> going to defer WARM to v11? Or is the intent to just ignore the 5-10% >> slowdown on a single column update and commit everything anyway? > > I think I should clarify something. The test case does a single column > update, but it also has columns which are very wide, has an index on many > columns (and it updates a column early in the list). In addition, in the > test Mithun updated all 10million rows of the table in a single transaction, > used UNLOGGED table and fsync was turned off. > > TBH I see many artificial scenarios here. It will be very useful if he can > rerun the query with some of these restrictions lifted. I'm all for > addressing whatever we can, but I am not sure if this test demonstrates a > real world usage. That's a very fair point, but if these patches - or some of them - are going to get committed then these things need to get discussed. Let's not just have nothing-nothing-nothing giant unagreed code drop. I think that very wide columns and highly indexed tables are not particularly unrealistic, nor do I think updating all the rows is particularly unrealistic. Sure, it's not everything, but it's something. Now, I would agree that all of that PLUS unlogged tables with fsync=off is not too realistic. What kind of regression would we observe if we eliminated those last two variables? > Having said that, may be if we can do a few things to reduce the overhead. > > - Check if the page has enough free space to perform a HOT/WARM update. If > not, don't look for all index keys. > - Pass bitmaps separately for each index and bail out early if we conclude > neither HOT nor WARM is possible. In this case since there is just one index > and as soon as we check the second column we know neither HOT nor WARM is > possible, we will return early. It might complicate the API a lot, but I can > give it a shot if that's what is needed to make progress. I think that whether the code ends up getting contorted is an important consideration here. For example, if the first of the things you mention can be done without making the code ugly, then I think that would be worth doing; it's likely to help fairly often in real-world cases. The problem with making the code contorted and ugly, as you say that the second idea would require, is that it can easily mask bugs. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Amit Kapila wrote: > I think it is because heap_getattr() is not that cheap. We have > noticed the similar problem during development of scan key push down > work [1]. One possibility to reduce the cost of that is to use whole tuple deform instead of repeated individual heap_getattr() calls. Since we don't actually need *all* attrs, we can create a version of heap_deform_tuple that takes an attribute number as argument and decodes up to that point. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Mar 21, 2017 at 6:55 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Mar 21, 2017 at 8:41 AM, Pavan Deolasee > <pavan.deolasee@gmail.com> wrote: >>> Yeah. So what's the deal with this? Is somebody working on figuring >>> out a different approach that would reduce this overhead? Are we >>> going to defer WARM to v11? Or is the intent to just ignore the 5-10% >>> slowdown on a single column update and commit everything anyway? >> >> I think I should clarify something. The test case does a single column >> update, but it also has columns which are very wide, has an index on many >> columns (and it updates a column early in the list). In addition, in the >> test Mithun updated all 10million rows of the table in a single transaction, >> used UNLOGGED table and fsync was turned off. >> >> TBH I see many artificial scenarios here. It will be very useful if he can >> rerun the query with some of these restrictions lifted. I'm all for >> addressing whatever we can, but I am not sure if this test demonstrates a >> real world usage. > > That's a very fair point, but if these patches - or some of them - are > going to get committed then these things need to get discussed. Let's > not just have nothing-nothing-nothing giant unagreed code drop. > > I think that very wide columns and highly indexed tables are not > particularly unrealistic, nor do I think updating all the rows is > particularly unrealistic. Sure, it's not everything, but it's > something. Now, I would agree that all of that PLUS unlogged tables > with fsync=off is not too realistic. What kind of regression would we > observe if we eliminated those last two variables? > Sure, we can try that. I think we need to try it with synchronous_commit = off, otherwise, WAL writes completely overshadows everything. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Mar 21, 2017 at 10:01 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> I think that very wide columns and highly indexed tables are not >> particularly unrealistic, nor do I think updating all the rows is >> particularly unrealistic. Sure, it's not everything, but it's >> something. Now, I would agree that all of that PLUS unlogged tables >> with fsync=off is not too realistic. What kind of regression would we >> observe if we eliminated those last two variables? > > Sure, we can try that. I think we need to try it with > synchronous_commit = off, otherwise, WAL writes completely overshadows > everything. synchronous_commit = off is a much more realistic scenario than fsync = off. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Mar 21, 2017 at 6:55 PM, Robert Haas <robertmhaas@gmail.com> wrote:
I think that very wide columns and highly indexed tables are not
particularly unrealistic, nor do I think updating all the rows is
particularly unrealistic.
Ok. But those who update 10M rows in a single transaction, would they really notice 5-10% variation? I think it probably makes sense to run those updates in smaller transactions and see if the regression is still visible (otherwise tweaking synchronous_commit is mute anyways).
Sure, it's not everything, but it's
something. Now, I would agree that all of that PLUS unlogged tables
with fsync=off is not too realistic. What kind of regression would we
observe if we eliminated those last two variables?
Hard to say. I didn't find any regression on the machines available to me even with the original test case that I used, which was pretty bad case to start with (sure, Mithun tweaked it further to create even worse scenario). May be the kind of machines he has access to, it might show up even with those changes.
I think that whether the code ends up getting contorted is an
important consideration here. For example, if the first of the things
you mention can be done without making the code ugly, then I think
that would be worth doing; it's likely to help fairly often in
real-world cases. The problem with making the code contorted and
ugly, as you say that the second idea would require, is that it can
easily mask bugs.
Thanks,
Pavan
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Robert Haas wrote: > On Tue, Mar 21, 2017 at 10:01 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > > Sure, we can try that. I think we need to try it with > > synchronous_commit = off, otherwise, WAL writes completely overshadows > > everything. > > synchronous_commit = off is a much more realistic scenario than fsync = off. Sure, synchronous_commit=off is a reasonable case. But I say if we lose a few % on the case where you update only the first indexed of a large number of very wide columns all indexed, and this is only noticeable if you don't write WAL and only if you update all the rows in the table, then I don't see much reason for concern. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Mar 21, 2017 at 10:21 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Robert Haas wrote: >> On Tue, Mar 21, 2017 at 10:01 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > >> > Sure, we can try that. I think we need to try it with >> > synchronous_commit = off, otherwise, WAL writes completely overshadows >> > everything. >> >> synchronous_commit = off is a much more realistic scenario than fsync = off. > > Sure, synchronous_commit=off is a reasonable case. But I say if we lose > a few % on the case where you update only the first indexed of a large > number of very wide columns all indexed, and this is only noticeable if > you don't write WAL and only if you update all the rows in the table, > then I don't see much reason for concern. If the WAL writing hides the loss, then I agree that's not a big concern. But if the loss is still visible even when WAL is written, then I'm not so sure. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2017-03-21 08:04:11 -0400, Robert Haas wrote: > On Tue, Mar 21, 2017 at 6:56 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > >> Hmm, that test case isn't all that synthetic. It's just a single > >> column bulk update, which isn't anything all that crazy, and 5-10% > >> isn't nothing. > >> > >> I'm kinda surprised it made that much difference, though. > >> > > > > I think it is because heap_getattr() is not that cheap. We have > > noticed the similar problem during development of scan key push down > > work [1]. > > Yeah. So what's the deal with this? Is somebody working on figuring > out a different approach that would reduce this overhead? I think one reasonable thing would be to use slots here, and use slot_getsomeattrs(), with a pre-computed offset, for doing the deforming. Given that more than one place run into the issue with deforming cost via heap_*, that seems like something we're going to have to do. Additionally the patches I had for JITed deforming all integrated at the slot layer, so it'd be a good thing from that angle as well. Deforming all columns at once would also a boon for the accompanying index_getattr calls. Greetings, Andres Freund
On 2017-03-21 19:49:07 +0530, Pavan Deolasee wrote: > On Tue, Mar 21, 2017 at 6:55 PM, Robert Haas <robertmhaas@gmail.com> wrote: > > > > > I think that very wide columns and highly indexed tables are not > > particularly unrealistic, nor do I think updating all the rows is > > particularly unrealistic. > > > Ok. But those who update 10M rows in a single transaction, would they > really notice 5-10% variation? Yes. It's very common in ETL, and that's quite performance sensitive. Greetings, Andres Freund
On Tue, Mar 21, 2017 at 09:25:49AM -0400, Robert Haas wrote: > On Tue, Mar 21, 2017 at 8:41 AM, Pavan Deolasee > > TBH I see many artificial scenarios here. It will be very useful if he can > > rerun the query with some of these restrictions lifted. I'm all for > > addressing whatever we can, but I am not sure if this test demonstrates a > > real world usage. > > That's a very fair point, but if these patches - or some of them - are > going to get committed then these things need to get discussed. Let's > not just have nothing-nothing-nothing giant unagreed code drop. First, let me say I love this feature for PG 10, along with multi-variate statistics. However, not to be a bummer on this, but the persistent question I have is whether we are locking ourselves into a feature that can only do _one_ index-change per WARM chain before a lazy vacuum is required. Are we ever going to figure out how to do more changes per WARM chain in the future, and is our use of so many bits for this feature going to restrict our ability to do that in the future. I know we have talked about it, but not recently, and if everyone else is fine with it, I am too, but I have to ask these questions. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Tue, Mar 21, 2017 at 12:49 PM, Bruce Momjian <bruce@momjian.us> wrote: > On Tue, Mar 21, 2017 at 09:25:49AM -0400, Robert Haas wrote: >> On Tue, Mar 21, 2017 at 8:41 AM, Pavan Deolasee >> > TBH I see many artificial scenarios here. It will be very useful if he can >> > rerun the query with some of these restrictions lifted. I'm all for >> > addressing whatever we can, but I am not sure if this test demonstrates a >> > real world usage. >> >> That's a very fair point, but if these patches - or some of them - are >> going to get committed then these things need to get discussed. Let's >> not just have nothing-nothing-nothing giant unagreed code drop. > > First, let me say I love this feature for PG 10, along with > multi-variate statistics. > > However, not to be a bummer on this, but the persistent question I have > is whether we are locking ourselves into a feature that can only do > _one_ index-change per WARM chain before a lazy vacuum is required. Are > we ever going to figure out how to do more changes per WARM chain in the > future, and is our use of so many bits for this feature going to > restrict our ability to do that in the future. > > I know we have talked about it, but not recently, and if everyone else > is fine with it, I am too, but I have to ask these questions. I think that's a good question. I previously expressed similar concerns. On the one hand, it's hard to ignore the fact that, in the cases where this wins, it already buys us a lot of performance improvement. On the other hand, as you say (and as I said), it eats up a lot of bits, and that limits what we can do in the future. On the one hand, there is a saying that a bird in the hand is worth two in the bush. On the other hand, there is also a saying that one should not paint oneself into the corner. I'm not sure we've had any really substantive discussion of these issues. Pavan's response to my previous comments was basically "well, I think it's worth it", which is entirely reasonable, because he presumably wouldn't have written the patch that way if he thought it sucked. But it might not be the only opinion. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Mar 21, 2017 at 10:04 AM, Robert Haas <robertmhaas@gmail.com> wrote: > I think that's a good question. I previously expressed similar > concerns. On the one hand, it's hard to ignore the fact that, in the > cases where this wins, it already buys us a lot of performance > improvement. On the other hand, as you say (and as I said), it eats > up a lot of bits, and that limits what we can do in the future. On > the one hand, there is a saying that a bird in the hand is worth two > in the bush. On the other hand, there is also a saying that one > should not paint oneself into the corner. Are we really saying that there can be no incompatible change to the on-disk representation for the rest of eternity? I can see why that's something to avoid indefinitely, but I wouldn't like to rule it out. -- Peter Geoghegan
On Tue, Mar 21, 2017 at 1:08 PM, Peter Geoghegan <pg@bowt.ie> wrote: > On Tue, Mar 21, 2017 at 10:04 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> I think that's a good question. I previously expressed similar >> concerns. On the one hand, it's hard to ignore the fact that, in the >> cases where this wins, it already buys us a lot of performance >> improvement. On the other hand, as you say (and as I said), it eats >> up a lot of bits, and that limits what we can do in the future. On >> the one hand, there is a saying that a bird in the hand is worth two >> in the bush. On the other hand, there is also a saying that one >> should not paint oneself into the corner. > > Are we really saying that there can be no incompatible change to the > on-disk representation for the rest of eternity? I can see why that's > something to avoid indefinitely, but I wouldn't like to rule it out. Well, I don't want to rule it out either, but if we do a release to which you can't pg_upgrade, it's going to be really painful for a lot of users. Many users can't realistically upgrade using pg_dump, ever. So they'll be stuck on the release before the one that breaks compatibility for a very long time. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Mar 21, 2017 at 01:04:14PM -0400, Robert Haas wrote: > > I know we have talked about it, but not recently, and if everyone else > > is fine with it, I am too, but I have to ask these questions. > > I think that's a good question. I previously expressed similar > concerns. On the one hand, it's hard to ignore the fact that, in the > cases where this wins, it already buys us a lot of performance > improvement. On the other hand, as you say (and as I said), it eats > up a lot of bits, and that limits what we can do in the future. On > the one hand, there is a saying that a bird in the hand is worth two > in the bush. On the other hand, there is also a saying that one > should not paint oneself into the corner. > > I'm not sure we've had any really substantive discussion of these > issues. Pavan's response to my previous comments was basically "well, > I think it's worth it", which is entirely reasonable, because he > presumably wouldn't have written the patch that way if he thought it > sucked. But it might not be the only opinion. Early in the discussion we talked about allowing multiple changes per WARM chain if they all changed the same index and were in the same direction so there were no duplicates, but it was complicated. There was also discussion about checking the index during INSERT/UPDATE to see if there was a duplicate. However, those ideas never led to further discussion. I know the current patch yields good results, but only on a narrow test case, so I am not ready to just stop asking questions based the opinion of the author or test results alone. If someone came to me and said, "We have thought about allowing more than one index change per WARM chain, and if we can ever do it, it will probably be done this way, and we have the bits for it," I would be more comfortable. One interesting side-issue is that indirect indexes have a similar problem with duplicate index entries, and there is no plan on how to fix that either. I guess I just don't feel we have explored the duplicate-index-entry problem enough for me to be comfortable. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Tue, Mar 21, 2017 at 01:14:00PM -0400, Robert Haas wrote: > On Tue, Mar 21, 2017 at 1:08 PM, Peter Geoghegan <pg@bowt.ie> wrote: > > On Tue, Mar 21, 2017 at 10:04 AM, Robert Haas <robertmhaas@gmail.com> wrote: > >> I think that's a good question. I previously expressed similar > >> concerns. On the one hand, it's hard to ignore the fact that, in the > >> cases where this wins, it already buys us a lot of performance > >> improvement. On the other hand, as you say (and as I said), it eats > >> up a lot of bits, and that limits what we can do in the future. On > >> the one hand, there is a saying that a bird in the hand is worth two > >> in the bush. On the other hand, there is also a saying that one > >> should not paint oneself into the corner. > > > > Are we really saying that there can be no incompatible change to the > > on-disk representation for the rest of eternity? I can see why that's > > something to avoid indefinitely, but I wouldn't like to rule it out. > > Well, I don't want to rule it out either, but if we do a release to > which you can't pg_upgrade, it's going to be really painful for a lot > of users. Many users can't realistically upgrade using pg_dump, ever. > So they'll be stuck on the release before the one that breaks > compatibility for a very long time. Right. If we weren't setting tuple and tid bits we could imrpove it easily in PG 11, but if we use them for a single-change WARM chain for PG 10, we might need bits that are not available to improve it later. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On 21/03/17 18:14, Robert Haas wrote: > On Tue, Mar 21, 2017 at 1:08 PM, Peter Geoghegan <pg@bowt.ie> wrote: >> On Tue, Mar 21, 2017 at 10:04 AM, Robert Haas <robertmhaas@gmail.com> wrote: >>> I think that's a good question. I previously expressed similar >>> concerns. On the one hand, it's hard to ignore the fact that, in the >>> cases where this wins, it already buys us a lot of performance >>> improvement. On the other hand, as you say (and as I said), it eats >>> up a lot of bits, and that limits what we can do in the future. On >>> the one hand, there is a saying that a bird in the hand is worth two >>> in the bush. On the other hand, there is also a saying that one >>> should not paint oneself into the corner. >> >> Are we really saying that there can be no incompatible change to the >> on-disk representation for the rest of eternity? I can see why that's >> something to avoid indefinitely, but I wouldn't like to rule it out. > > Well, I don't want to rule it out either, but if we do a release to > which you can't pg_upgrade, it's going to be really painful for a lot > of users. Many users can't realistically upgrade using pg_dump, ever. > So they'll be stuck on the release before the one that breaks > compatibility for a very long time. > This is why I like the idea of pluggable storage, if we ever get that it would buy us ability to implement completely different heap format without breaking pg_upgrade. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On 21/03/17 18:19, Bruce Momjian wrote: > On Tue, Mar 21, 2017 at 01:14:00PM -0400, Robert Haas wrote: >> On Tue, Mar 21, 2017 at 1:08 PM, Peter Geoghegan <pg@bowt.ie> wrote: >>> On Tue, Mar 21, 2017 at 10:04 AM, Robert Haas <robertmhaas@gmail.com> wrote: >>>> I think that's a good question. I previously expressed similar >>>> concerns. On the one hand, it's hard to ignore the fact that, in the >>>> cases where this wins, it already buys us a lot of performance >>>> improvement. On the other hand, as you say (and as I said), it eats >>>> up a lot of bits, and that limits what we can do in the future. On >>>> the one hand, there is a saying that a bird in the hand is worth two >>>> in the bush. On the other hand, there is also a saying that one >>>> should not paint oneself into the corner. >>> >>> Are we really saying that there can be no incompatible change to the >>> on-disk representation for the rest of eternity? I can see why that's >>> something to avoid indefinitely, but I wouldn't like to rule it out. >> >> Well, I don't want to rule it out either, but if we do a release to >> which you can't pg_upgrade, it's going to be really painful for a lot >> of users. Many users can't realistically upgrade using pg_dump, ever. >> So they'll be stuck on the release before the one that breaks >> compatibility for a very long time. > > Right. If we weren't setting tuple and tid bits we could imrpove it > easily in PG 11, but if we use them for a single-change WARM chain for > PG 10, we might need bits that are not available to improve it later. > I thought there is still couple of bits available. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 21, 2017 at 10:47 PM, Bruce Momjian <bruce@momjian.us> wrote:
On Tue, Mar 21, 2017 at 01:04:14PM -0400, Robert Haas wrote:
> > I know we have talked about it, but not recently, and if everyone else
> > is fine with it, I am too, but I have to ask these questions.
>
> I think that's a good question. I previously expressed similar
> concerns. On the one hand, it's hard to ignore the fact that, in the
> cases where this wins, it already buys us a lot of performance
> improvement. On the other hand, as you say (and as I said), it eats
> up a lot of bits, and that limits what we can do in the future. On
> the one hand, there is a saying that a bird in the hand is worth two
> in the bush. On the other hand, there is also a saying that one
> should not paint oneself into the corner.
>
> I'm not sure we've had any really substantive discussion of these
> issues. Pavan's response to my previous comments was basically "well,
> I think it's worth it", which is entirely reasonable, because he
> presumably wouldn't have written the patch that way if he thought it
> sucked. But it might not be the only opinion.
Early in the discussion we talked about allowing multiple changes per
WARM chain if they all changed the same index and were in the same
direction so there were no duplicates, but it was complicated. There
was also discussion about checking the index during INSERT/UPDATE to see
if there was a duplicate. However, those ideas never led to further
discussion.
Well, once I started thinking about how to do vacuum etc, I realised that any mechanism which allows unlimited (even handful) updates per chain is going to be very complex and error prone. But if someone has ideas to do that, I am open. I must say though, it will make an already complex problem even more complex.
I know the current patch yields good results, but only on a narrow test
case,
Hmm. I am kinda surprised you say that because I never thought it was a narrow test case that we are targeting here. But may be I'm wrong.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 21, 2017 at 2:03 PM, Petr Jelinek <petr.jelinek@2ndquadrant.com> wrote: > This is why I like the idea of pluggable storage, if we ever get that it > would buy us ability to implement completely different heap format > without breaking pg_upgrade. You probably won't be surprised to hear that I agree. :-) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Mar 21, 2017 at 10:34 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Tue, Mar 21, 2017 at 12:49 PM, Bruce Momjian <bruce@momjian.us> wrote:
> On Tue, Mar 21, 2017 at 09:25:49AM -0400, Robert Haas wrote:
>> On Tue, Mar 21, 2017 at 8:41 AM, Pavan Deolasee
>> > TBH I see many artificial scenarios here. It will be very useful if he can
>> > rerun the query with some of these restrictions lifted. I'm all for
>> > addressing whatever we can, but I am not sure if this test demonstrates a
>> > real world usage.
>>
>> That's a very fair point, but if these patches - or some of them - are
>> going to get committed then these things need to get discussed. Let's
>> not just have nothing-nothing-nothing giant unagreed code drop.
>
> First, let me say I love this feature for PG 10, along with
> multi-variate statistics.
>
> However, not to be a bummer on this, but the persistent question I have
> is whether we are locking ourselves into a feature that can only do
> _one_ index-change per WARM chain before a lazy vacuum is required. Are
> we ever going to figure out how to do more changes per WARM chain in the
> future, and is our use of so many bits for this feature going to
> restrict our ability to do that in the future.
>
> I know we have talked about it, but not recently, and if everyone else
> is fine with it, I am too, but I have to ask these questions.
I think that's a good question. I previously expressed similar
concerns. On the one hand, it's hard to ignore the fact that, in the
cases where this wins, it already buys us a lot of performance
improvement. On the other hand, as you say (and as I said), it eats
up a lot of bits, and that limits what we can do in the future.
We can also save HEAP_WARM_UPDATED flag since this is required only for abort-handling case. We can find a way to push that information down to the old tuple if UPDATE aborts and we detect the broken chain. Again, not fully thought through, but doable. Of course, we will have to carefully evaluate all code paths and make sure that we don't lose that information ever.
If the consumption of bits become a deal breaker then I would first trade the HEAP_LATEST_TUPLE bit and then HEAP_WARM_UPDATED just from correctness perspective.
Thanks,
Pavan
-- Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 21, 2017 at 07:05:15PM +0100, Petr Jelinek wrote: > >> Well, I don't want to rule it out either, but if we do a release to > >> which you can't pg_upgrade, it's going to be really painful for a lot > >> of users. Many users can't realistically upgrade using pg_dump, ever. > >> So they'll be stuck on the release before the one that breaks > >> compatibility for a very long time. > > > > Right. If we weren't setting tuple and tid bits we could improve it > > easily in PG 11, but if we use them for a single-change WARM chain for > > PG 10, we might need bits that are not available to improve it later. > > > > I thought there is still couple of bits available. Yes, there are. The issue is that we don't know how we would improve it so we don't know how many bits we need, and my concern is that we haven't discussed the improvement ideas enough to know we have done the best we can for PG 10. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Tue, Mar 21, 2017 at 11:45:09PM +0530, Pavan Deolasee wrote: > Early in the discussion we talked about allowing multiple changes per > WARM chain if they all changed the same index and were in the same > direction so there were no duplicates, but it was complicated. There > was also discussion about checking the index during INSERT/UPDATE to see > if there was a duplicate. However, those ideas never led to further > discussion. > > > Well, once I started thinking about how to do vacuum etc, I realised that any > mechanism which allows unlimited (even handful) updates per chain is going to > be very complex and error prone. But if someone has ideas to do that, I am > open. I must say though, it will make an already complex problem even more > complex. Yes, that is where we got stuck. Have enough people studied the issue to know that there are no simple answers? > I know the current patch yields good results, but only on a narrow test > case, > > > Hmm. I am kinda surprised you say that because I never thought it was a narrow > test case that we are targeting here. But may be I'm wrong. Well, it is really a question of how often you want to do a second WARM update (not possible) vs. the frequency of lazy vacuum. I assumed that would be a 100X or 10kX difference, but I am not sure myself either. My initial guess was that only allowing a single WARM update between lazy vacuums would show no improvementin in real-world workloads, but maybe I am wrong. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Tue, Mar 21, 2017 at 11:54:25PM +0530, Pavan Deolasee wrote: > We can also save HEAP_WARM_UPDATED flag since this is required only for > abort-handling case. We can find a way to push that information down to the old > tuple if UPDATE aborts and we detect the broken chain. Again, not fully thought > through, but doable. Of course, we will have to carefully evaluate all code > paths and make sure that we don't lose that information ever. > > If the consumption of bits become a deal breaker then I would first trade the > HEAP_LATEST_TUPLE bit and then HEAP_WARM_UPDATED just from correctness > perspective. I don't think it makes sense to try and save bits and add complexity when we have no idea if we will ever use them, but again, I am back to my original question of whether we have done sufficient research, and if everyone says "yes", I am find with that. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
Bruce Momjian wrote: > I don't think it makes sense to try and save bits and add complexity > when we have no idea if we will ever use them, If we find ourselves in dire need of additional bits, there is a known mechanism to get back 2 bits from old-style VACUUM FULL. I assume that the reason nobody has bothered to write the code for that is that there's no *that* much interest. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Mar 21, 2017 at 04:43:58PM -0300, Alvaro Herrera wrote: > Bruce Momjian wrote: > > > I don't think it makes sense to try and save bits and add complexity > > when we have no idea if we will ever use them, > > If we find ourselves in dire need of additional bits, there is a known > mechanism to get back 2 bits from old-style VACUUM FULL. I assume that > the reason nobody has bothered to write the code for that is that > there's no *that* much interest. We have no way of tracking if users still have pages that used the bits via pg_upgrade before they were removed. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
Bruce Momjian wrote: > On Tue, Mar 21, 2017 at 04:43:58PM -0300, Alvaro Herrera wrote: > > Bruce Momjian wrote: > > > > > I don't think it makes sense to try and save bits and add complexity > > > when we have no idea if we will ever use them, > > > > If we find ourselves in dire need of additional bits, there is a known > > mechanism to get back 2 bits from old-style VACUUM FULL. I assume that > > the reason nobody has bothered to write the code for that is that > > there's no *that* much interest. > > We have no way of tracking if users still have pages that used the bits > via pg_upgrade before they were removed. Yes, that's exactly the code that needs to be written. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Mar 21, 2017 at 04:56:16PM -0300, Alvaro Herrera wrote: > Bruce Momjian wrote: > > On Tue, Mar 21, 2017 at 04:43:58PM -0300, Alvaro Herrera wrote: > > > Bruce Momjian wrote: > > > > > > > I don't think it makes sense to try and save bits and add complexity > > > > when we have no idea if we will ever use them, > > > > > > If we find ourselves in dire need of additional bits, there is a known > > > mechanism to get back 2 bits from old-style VACUUM FULL. I assume that > > > the reason nobody has bothered to write the code for that is that > > > there's no *that* much interest. > > > > We have no way of tracking if users still have pages that used the bits > > via pg_upgrade before they were removed. > > Yes, that's exactly the code that needs to be written. Yes, but once it is written it will take years before those bits can be used on most installations. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Tue, Mar 21, 2017 at 8:10 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> If the WAL writing hides the loss, then I agree that's not a big
> concern. But if the loss is still visible even when WAL is written,
> then I'm not so sure.
The tests table schema was taken from earlier tests what Pavan has posted [1], hence it is UNLOGGED all I tried to stress the tests. Instead of updating 1 row at a time through pgbench (For which I and Pavan both did not see any regression), I tried to update all the rows in the single statement. I have changed the settings as recommended and did a quick test as above in our machine by removing UNLOGGED world in create table statement.
[1] Re: rewrite HeapSatisfiesHOTAndKey
[2] Re: Patch: Write Amplification Reduction Method (WARM)
--
Thanks and Regards
Mithun C Y
EnterpriseDB: http://www.enterprisedb.com
> If the WAL writing hides the loss, then I agree that's not a big
> concern. But if the loss is still visible even when WAL is written,
> then I'm not so sure.
The tests table schema was taken from earlier tests what Pavan has posted [1], hence it is UNLOGGED all I tried to stress the tests. Instead of updating 1 row at a time through pgbench (For which I and Pavan both did not see any regression), I tried to update all the rows in the single statement. I have changed the settings as recommended and did a quick test as above in our machine by removing UNLOGGED world in create table statement.
Patch Tested : Only 0001_interesting_attrs_v18.patch in [2]
Machine: Scylla [ Last time I did same tests on IBM power2 but It is not immediately available. So trying on another intel based performance machine.]
============
[mithun.cy@scylla bin]$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 56
On-line CPU(s) list: 0-55
Thread(s) per core: 2
Core(s) per socket: 14
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2695 v3 @ 2.30GHz
Stepping: 2
CPU MHz: 1235.800
BogoMIPS: 4594.35
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 35840K
NUMA node0 CPU(s): 0-13,28-41
NUMA node1 CPU(s): 14-27,42-55
[mithun.cy@scylla bin]$ cat /proc/meminfo
MemTotal: 65687464 kB
Postgresql.conf non default settings
===========================
shared_buffers = 24 GB
max_wal_size = 10GB
min_wal_size = 5GB
synchronous_commit=off
autovacuum = off /*manually doing vacumm full before every update. */
This system has 2 storage I have kept datadir on spinning disc and pg_wal on ssd.
Tests :
DROP TABLE IF EXISTS testtab;
CREATE TABLE testtab (
col1 integer,
col2 text,
col3 float,
col4 text,
col5 text,
col6 char(30),
col7 text,
col8 date,
col9 text,
col10 text
);
INSERT INTO testtab
SELECT generate_series(1,10000000),
md5(random()::text),
random(),
md5(random()::text),
md5(random()::text),
md5(random()::text)::char(30),
md5(random()::text),
now(),
md5(random()::text),
md5(random()::text);
CREATE INDEX testindx ON testtab (col1, col2, col3, col4, col5, col6, col7, col8, col9);
Performance measurement tests: Ran12 times to eliminate run to run latencies.
==========================
VACUUM FULL;
BEGIN;
UPDATE testtab SET col2 = md5(random()::text);
ROLLBACK;
Response time recorded shows there is a much higher increase in response time from 10% to 25% after the patch.
[1] Re: rewrite HeapSatisfiesHOTAndKey
[2] Re: Patch: Write Amplification Reduction Method (WARM)
--
Thanks and Regards
Mithun C Y
EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Mar 22, 2017 at 3:51 AM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:
On Tue, Mar 21, 2017 at 8:10 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> If the WAL writing hides the loss, then I agree that's not a big
> concern. But if the loss is still visible even when WAL is written,
> then I'm not so sure.
The tests table schema was taken from earlier tests what Pavan has posted [1], hence it is UNLOGGED all I tried to stress the tests. Instead of updating 1 row at a time through pgbench (For which I and Pavan both did not see any regression), I tried to update all the rows in the single statement.
Sorry, I did not mean to suggest that you set it up wrongly, I was just trying to point out that the test case itself may not be very practical. But given your recent numbers, the regression is clearly non-trivial and something we must address.
I have changed the settings as recommended and did a quick test as above in our machine by removing UNLOGGED world in create table statement.Patch Tested : Only 0001_interesting_attrs_v18.patch in [2] Response time recorded shows there is a much higher increase in response time from 10% to 25% after the patch.
BTW may I request another test with the attached patch? In this patch, we check if the PageIsFull() even before deciding which attributes to check for modification. If the page is already full, there is hardly any chance of doing a HOT update (there could be a corner case where the new tuple is smaller than the tuple used in previous UPDATE and we have just enough space to do HOT update this time, but I can think that's too narrow).
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Wed, Mar 22, 2017 at 8:43 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
BTW may I request another test with the attached patch? In this patch, we check if the PageIsFull() even before deciding which attributes to check for modification. If the page is already full, there is hardly any chance of doing a HOT update (there could be a corner case where the new tuple is smaller than the tuple used in previous UPDATE and we have just enough space to do HOT update this time, but I can think that's too narrow).
I would also request you to do a slightly different test where instead of updating the second column, we update the last column of the index i.e. col9. Would really appreciate if you share results with both master and v19 patch.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Mar 22, 2017 at 3:51 AM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:
CREATE INDEX testindx ON testtab (col1, col2, col3, col4, col5, col6, col7, col8, col9);
Performance measurement tests: Ran12 times to eliminate run to run latencies.==========================VACUUM FULL;BEGIN;UPDATE testtab SET col2 = md5(random()::text);ROLLBACK;Response time recorded shows there is a much higher increase in response time from 10% to 25% after the patch.
After doing some tests on my side, I now think that there is something else going on, unrelated to the patch. I ran the same benchmark on AWS i2.xlarge machine with 32GB RAM. shared_buffers set to 16GB, max_wal_size to 256GB, checkpoint_timeout to 60min and autovacuum off.
I compared master and v19, every time running 6 runs of the test. The database was restarted whenever changing binaries, tables dropped/recreated and checkpoint taken after each restart (but not between 2 runs, which I believe what you did too.. but correct me if that's a wrong assumption).
Instead of col2, I am updating col9, but that's probably not too much relevant.
VACUUM FULL;
BEGIN;
UPDATE testtab SET col9 = md5(random()::text);
ROLLBACK;
First set of 6 runs with master:
163629.8
181183.8
194788.1
194606.1
194589.9
196002.6
(database restart, table drop/create, checkpoint)
First set of 6 runs with v19:
190566.55
228274.489
238110.202
239304.681
258748.189
284882.4
(database restart, table drop/create, checkpoint)
Second set of 6 runs with master:
232267.5
298259.6
312315.1
341817.3
360729.2
385210.7
May be we can blame it on AWS instance completely, but the pattern in your tests looks very similar where the number slowly and steadily keeps going up. If you do complete retest but run v18/v19 first and then run master, may be we'll see a complete opposite picture?
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 21, 2017 at 6:47 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
>
>>
>
> Please find attached rebased patches.
>
Few comments on 0005_warm_updates_v18.patch:
1.
@@ -806,20 +835,35 @@ hashbucketcleanup(Relation rel, Bucket
cur_bucket, Buffer bucket_buf,
{
..
- if (callback && callback(htup, callback_state))
+ if(callback) {
- kill_tuple = true;
-
if (tuples_removed)
- *tuples_removed += 1;
+result = callback(htup, is_warm, callback_state);
+ if (result== IBDCR_DELETE)
+ {
+ kill_tuple = true;
+ if (tuples_removed)
+*tuples_removed += 1;
+ }
+ else if (result ==IBDCR_CLEAR_WARM)
+ {
+ clear_tuple= true;
+ } } else if
(split_cleanup)
..
}
I think this will break the existing mechanism of split cleanup. We
need to check for split cleanup if the tuple is tuple is not deletable
by the callback. This is not merely an optimization but a must
condition because we will clear the split cleanup flag after this
bucket is scanned completely.
2.
- PageIndexMultiDelete(page, deletable, ndeletable);
+ /*
+
* Clear the WARM pointers.
+ *
+ * We mustdo this before dealing with the dead items because
+ * PageIndexMultiDelete may move items around to compactify the
+ * array and hence offnums recorded earlierwon't make any sense
+ * after PageIndexMultiDelete is called.
+*/
+ if (nclearwarm > 0)
+ _hash_clear_items(page,clearwarm, nclearwarm);
+
+ /*
+ * And delete the deletableitems
+ */
+ if (ndeletable > 0)
+
PageIndexMultiDelete(page, deletable, ndeletable);
I think this assumes that the items where we need to clear warm flag
are not deletable, otherwise what is the need to clear the flag if we
are going to delete the tuple. The deletable tuple can have a warm
flag if it is deletable due to split cleanup.
3.
+ /*
+ * HASH indexes compute a hash value of the key and store that in the
+ * index. So
we must first obtain the hash of the value obtained from the
+ * heap and then do a comparison
+*/
+ _hash_convert_tuple(indexRel, values, isnull, values2, isnull2);
I think here, you need to handle the case where heap has a NULL value
as the hash index doesn't contain NULL values, otherwise, the code in
below function can return true which is not right.
4.
+bool
+hashrecheck(Relation indexRel, IndexInfo *indexInfo, IndexTuple indexTuple,
+ Relation heapRel, HeapTuple heapTuple)
{
..
+ att = indexRel->rd_att->attrs[i - 1];
+ if (!datumIsEqual(values2[i - 1], indxvalue, att->attbyval,
+ att->attlen))
+ {
+ equal = false;
+ break;
+ }
..
}
Hash values are always uint32 and attlen can be different for
different datatypes, so I think above doesn't seem to be the right way
to do the comparison.
5.
@@ -274,6 +301,8 @@ hashgettuple(IndexScanDesc scan, ScanDirection dir) OffsetNumber offnum;
ItemPointer current; bool res;
+ IndexTuple itup;
+
/* Hash
indexes are always lossy since we store only the hash code */ scan->xs_recheck = true;
@@ -316,8
+345,6 @@ hashgettuple(IndexScanDesc scan, ScanDirection dir) offnum <=
maxoffnum; offnum = OffsetNumberNext(offnum)) {
-IndexTuple itup;
-
Why above change?
6.
+ *stats = index_bulk_delete(&ivinfo, *stats,
+lazy_indexvac_phase1, (void *) vacrelstats);
+ ereport(elevel,
+(errmsg("scanned index \"%s\" to remove %d row version, found "
+"%0.f warm pointers, %0.f clear pointers, removed "
+"%0.f warm pointers, removed %0.f clear pointers",
+RelationGetRelationName(indrel),
+ vacrelstats->num_dead_tuples,
+ (*stats)->num_warm_pointers,
+(*stats)->num_clear_pointers,
+(*stats)->warm_pointers_removed,
+ (*stats)->clear_pointers_removed)));
+
+ (*stats)->num_warm_pointers = 0;
+ (*stats)->num_clear_pointers = 0;
+ (*stats)->warm_pointers_removed = 0;
+ (*stats)->clear_pointers_removed = 0;
+ (*stats)->pointers_cleared = 0;
+
+ *stats =index_bulk_delete(&ivinfo, *stats,
+ lazy_indexvac_phase2, (void *)vacrelstats);
To convert WARM chains, we need to do two index passes for all the
indexes. I think it can substantially increase the random I/O. I
think this can help us in doing more WARM updates, but I don't see how
the downside of that (increased random I/O) will be acceptable for all
kind of cases.
+exists. Since index vacuum may visit these pointers in any order, we will need
+another index pass to remove dead index pointers. So in the first index pass we
+check which WARM candidates have 2 index pointers. In the second pass, we
+remove the dead pointer and clear the INDEX_WARM_POINTER flag if that's the
+surviving index pointer.
I think there is some mismatch between README and code. In README, it
is mentioned that dead pointers will be removed in the second phase,
but I think the first phase code lazy_indexvac_phase1() will also
allow to delete the dead pointers (it can return IBDCR_DELETE which
will allow index am to remove dead items.). Am I missing something
here?
7.
+ * For CLEAR chains, we just kill the WARM pointer, if it exist,s and keep
+ * the CLEAR pointer.
typo (exist,s)
8.
+/*
+ * lazy_indexvac_phase2() -- run first pass of index vacuum
Shouldn't this be -- run the second pass
9.
- indexInfo); /* index AM may need this */
+indexInfo, /* index AM may need this */
+(modified_attrs != NULL)); /* type of uniqueness check to do */
comment for the last parameter seems to be wrong.
10.
+follow the update chain everytime to the end to see check if this is a WARM
+chain.
"see check" - seems one of those words is sufficient to explain the meaning.
11.
+chain. This simplifies the design and addresses certain issues around
+duplicate scans.
"duplicate scans" - shouldn't be duplicate key scans.
12.
+index on the table, irrespective of whether the key pertaining to the
+index changed or not.
typo.
/index changed/index is changed
13.
+For example, if we have a table with two columns and two indexes on each
+of the column. When a tuple is first inserted the table, we have exactly
typo.
/inserted the table/inserted in the table
14.
+ lp [1] [2]
+ [1111, aaaa]->[111, bbbb]
Here, after the update, the first column should be 1111.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Wed, Mar 22, 2017 at 3:44 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > This looks quite weird to me. Obviously these numbers are completely > non-comparable. Even the time for VACUUM FULL goes up with every run. > > May be we can blame it on AWS instance completely, but the pattern in your > tests looks very similar where the number slowly and steadily keeps going > up. If you do complete retest but run v18/v19 first and then run master, may > be we'll see a complete opposite picture? > For those tests I have done tests in the order --- <Master, patch18, patch18, Master> both the time numbers were same. One different thing I did was I was deleting the data directory between tests and creating the database from scratch. Unfortunately the machine I tested this is not available. I will test same with v19 once I get the machine and report you back. -- Thanks and Regards Mithun C Y EnterpriseDB: http://www.enterprisedb.com
On 21 March 2017 at 20:04, Bruce Momjian <bruce@momjian.us> wrote: > Yes, but once it is written it will take years before those bits can be > used on most installations. Well the problem isn't most installations. On most installations it should be pretty straightforward to check the oldest database xid and compare that to when the database was migrated to post-9.0. (Actually there may be some additional code to write but it's just ensuring that the bits are actually cleared and not just ignored but even so databases do generally need to be vacuumed more often than on the order of years though.) The problem is that somebody tomorrow could upgrade an 8.4 database to 10.0. In general it seems even versions we don't support get extra support for migrating away from. I assume it's better to help support upgrading than to continue to have users using unsupported versions... And even if you're not concerned about 8.4 someone could still upgrade 9.4 for years to come. It probably does make sense pick a version, say, 10.0, and have it go out of its way to ensure it cleans up the MOVED_IN/MOVED_OFF so that we can be sure that any database was pg_upgraded from 10.0+ doesn't have any left. Then at least we'll know when the bits are available again. -- greg
On Wed, Mar 22, 2017 at 8:43 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > Sorry, I did not mean to suggest that you set it up wrongly, I was just > trying to point out that the test case itself may not be very practical. That is cool np!, I was just trying to explain why those tests were made if others wondered about it. -- Thanks and Regards Mithun C Y EnterpriseDB: http://www.enterprisedb.com
On Wed, Mar 22, 2017 at 4:53 PM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:
On Wed, Mar 22, 2017 at 3:44 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
>
> This looks quite weird to me. Obviously these numbers are completely
> non-comparable. Even the time for VACUUM FULL goes up with every run.
>
> May be we can blame it on AWS instance completely, but the pattern in your
> tests looks very similar where the number slowly and steadily keeps going
> up. If you do complete retest but run v18/v19 first and then run master, may
> be we'll see a complete opposite picture?
>
For those tests I have done tests in the order --- <Master, patch18,
patch18, Master> both the time numbers were same.
Hmm, interesting.
One different thing
I did was I was deleting the data directory between tests and creating
the database from scratch. Unfortunately the machine I tested this is
not available. I will test same with v19 once I get the machine and
report you back.
I reverted back to UNLOGGED table because with WAL the results looked very weird (as posted earlier) even when I was taking a CHECKPOINT before each set and had set max_wal_size and checkpoint_timeout high enough to avoid any checkpoint during the run. Anyways, that's a matter of separate investigation and not related to this patch.
I did two kinds of tests.
a) update last column of the index
b) update second column of the index
v19 does considerably better than even master for the last column update case and pretty much inline for the second column update test. The reason is very clear because v19 determines early in the cycle that the buffer is already full and there is very little chance of doing a HOT update on the page. In that case, it does not check any columns for modification. The master on the other hand will scan through all 9 columns (for last column update case) and incur the same kind of overhead of doing wasteful work.
The first/second/fourth column shows response time in ms and third and fifth column shows percentage difference over master. (I hope the table looks fine, trying some text-table generator tool :-). Apologies if it looks messed up)
+-------------------------------------------------------+
| Second column update |
+-------------------------------------------------------+
| Master | v18 | v19 |
+-----------+---------------------+---------------------+
| 96657.681 | 108122.868 | 11.86% | 96873.642 | 0.22% |
+-----------+------------+--------+------------+--------+
| 98546.35 | 110021.27 | 11.64% | 97569.187 | -0.99% |
+-----------+------------+--------+------------+--------+
| 99297.231 | 110550.054 | 11.33% | 100241.261 | 0.95% |
+-----------+------------+--------+------------+--------+
| 97196.556 | 110235.808 | 13.42% | 97216.207 | 0.02% |
+-----------+------------+--------+------------+--------+
| 99072.432 | 110477.327 | 11.51% | 97950.687 | -1.13% |
+-----------+------------+--------+------------+--------+
| 96730.056 | 109217.939 | 12.91% | 96929.617 | 0.21% |
+-----------+------------+--------+------------+--------+
+-------------------------------------------------------+
| Last column update |
+-------------------------------------------------------+
| Master | v18 | v19 |
+------------+--------------------+---------------------+
| 112545.537 | 116563.608 | 3.57% | 103067.276 | -8.42% |
+------------+------------+-------+------------+--------+
| 110169.224 | 115753.991 | 5.07% | 104411.44 | -5.23% |
+------------+------------+-------+------------+--------+
| 112280.874 | 116437.11 | 3.70% | 104868.98 | -6.60% |
+------------+------------+-------+------------+--------+
| 113171.556 | 116813.262 | 3.22% | 103907.012 | -8.19% |
+------------+------------+-------+------------+--------+
| 110721.881 | 117442.709 | 6.07% | 104124.131 | -5.96% |
+------------+------------+-------+------------+--------+
| 112138.601 | 115834.549 | 3.30% | 104858.624 | -6.49% |
+------------+------------+-------+------------+--------+
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Thu, Mar 23, 2017 at 12:19 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > > On Wed, Mar 22, 2017 at 4:53 PM, Mithun Cy <mithun.cy@enterprisedb.com> > wrote: > Ok, no problem. I did some tests on AWS i2.xlarge instance (4 vCPU, 30GB > RAM, attached SSD) and results are shown below. But I think it is important > to get independent validation from your side too, just to ensure I am not > making any mistake in measurement. I've attached naively put together > scripts which I used to run the benchmark. If you find them useful, please > adjust the paths and run on your machine. Looking at your postgresql.conf JFYI, I have synchronous_commit = off but same is on with your run (for logged tables) and rest remains same. Once I get the machine probably next morning, I will run same tests on v19. -- Thanks and Regards Mithun C Y EnterpriseDB: http://www.enterprisedb.com
On Wed, Mar 22, 2017 at 4:06 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Tue, Mar 21, 2017 at 6:47 PM, Pavan Deolasee
> <pavan.deolasee@gmail.com> wrote:
>>
>>>
>>
>> Please find attached rebased patches.
>>
>
> Few comments on 0005_warm_updates_v18.patch:
>
Few more comments on 0005_warm_updates_v18.patch:
1.
@@ -234,6 +241,25 @@ index_beginscan(Relation heapRelation, scan->heapRelation = heapRelation; scan->xs_snapshot =
snapshot;
+ /*
+ * If the index supports recheck,
make sure that index tuple is saved
+ * during index scans. Also build and cache IndexInfo which is used by
+ * amrecheck routine.
+ *
+ * XXX Ideally, we should look at
all indexes on the table and check if
+ * WARM is at all supported on the base table. If WARM is not supported
+ * then we don't need to do any recheck.
RelationGetIndexAttrBitmap() does
+ * do that and sets rd_supportswarm after looking at all indexes. But we
+ * don't know if the function was called earlier in the
session when we're
+ * here. We can't call it now because there exists a risk of causing
+ * deadlock.
+ */
+ if (indexRelation->rd_amroutine->amrecheck)
+ {
+scan->xs_want_itup = true;
+ scan->indexInfo = BuildIndexInfo(indexRelation);
+ }
+
Don't we need to do this rechecking during parallel scans? Also what
about bitmap heap scans?
2.
+++ b/src/backend/access/nbtree/nbtinsert.c
-typedef struct
Above change is not require.
3.
+_bt_clear_items(Page page, OffsetNumber *clearitemnos, uint16 nclearitems)
+void _hash_clear_items(Page page, OffsetNumber *clearitemnos,
+ uint16 nclearitems)
Both the above functions look exactly same, isn't it better to have a
single function like page_clear_items? If you want separation for
different index types, then we can have one common function which can
be called from different index types.
4.
- if (callback(htup, callback_state))
+ flags = ItemPointerGetFlags(&itup->t_tid);
+ is_warm = ((flags & BTREE_INDEX_WARM_POINTER) != 0);
+
+ if (is_warm)
+ stats->num_warm_pointers++;
+ else
+ stats->num_clear_pointers++;
+
+ result = callback(htup, is_warm, callback_state);
+ if (result == IBDCR_DELETE)
+ {
+ if (is_warm)
+ stats->warm_pointers_removed++;
+ else
+ stats->clear_pointers_removed++;
The patch looks to be inconsistent in collecting stats for btree and
hash. I don't see above stats are getting updated in hash index code.
5.
+btrecheck(Relation indexRel, IndexInfo *indexInfo, IndexTuple indexTuple,
+ Relation heapRel, HeapTuple heapTuple)
{
..
+ if (!datumIsEqual(values[i - 1], indxvalue, att->attbyval,
+ att->attlen))
..
}
Will this work if the index is using non-default collation?
6.
+++ b/src/backend/access/nbtree/nbtxlog.c
@@ -390,83 +390,9 @@ btree_xlog_vacuum(XLogReaderState *record)
-#ifdef UNUSED xl_btree_vacuum *xlrec = (xl_btree_vacuum *) XLogRecGetData(record);
/*
- * This section of code is thought to be no longer needed, after analysis
- * of the calling paths. It is retained to allow the code to be reinstated
- * if a flaw is revealed in that thinking.
- *
..
Why does this patch need to remove the above code under #ifdef UNUSED
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Thu, Mar 23, 2017 at 12:19 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > Ok, no problem. I did some tests on AWS i2.xlarge instance (4 vCPU, 30GB > RAM, attached SSD) and results are shown below. But I think it is important > to get independent validation from your side too, just to ensure I am not > making any mistake in measurement. I've attached naively put together > scripts which I used to run the benchmark. If you find them useful, please > adjust the paths and run on your machine. > > I reverted back to UNLOGGED table because with WAL the results looked very > weird (as posted earlier) even when I was taking a CHECKPOINT before each > set and had set max_wal_size and checkpoint_timeout high enough to avoid any > checkpoint during the run. Anyways, that's a matter of separate > investigation and not related to this patch. > > I did two kinds of tests. > a) update last column of the index > b) update second column of the index > > v19 does considerably better than even master for the last column update > case and pretty much inline for the second column update test. The reason is > very clear because v19 determines early in the cycle that the buffer is > already full and there is very little chance of doing a HOT update on the > page. In that case, it does not check any columns for modification. > That sounds like you are dodging the actual problem. I mean you can put that same PageIsFull() check in master code as well and then you will most probably again see the same regression. Also, I think if we test at fillfactor 80 or 75 (which is not unrealistic considering an update-intensive workload), then we might again see regression. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Mar 22, 2017 at 4:06 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
Thanks,On Tue, Mar 21, 2017 at 6:47 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
>
>>
>
> Please find attached rebased patches.
>
Few comments on 0005_warm_updates_v18.patch:
Thanks a lot Amit for review comments.
1.
@@ -806,20 +835,35 @@ hashbucketcleanup(Relation rel, Bucket
cur_bucket, Buffer bucket_buf,
{
..
- if (callback && callback(htup, callback_state))
+ if(callback)
{
- kill_tuple = true;
-
if (tuples_removed)
- *tuples_removed += 1;
+result = callback(htup, is_warm, callback_state);
+ if (result== IBDCR_DELETE)
+ {
+ kill_tuple = true;
+ if (tuples_removed)
+*tuples_removed += 1;
+ }
+ else if (result ==IBDCR_CLEAR_WARM)
+ {
+ clear_tuple= true;
+ }
}
else if
(split_cleanup)
..
}
I think this will break the existing mechanism of split cleanup. We
need to check for split cleanup if the tuple is tuple is not deletable
by the callback. This is not merely an optimization but a must
condition because we will clear the split cleanup flag after this
bucket is scanned completely.
Ok, I see. Fixed, but please check if this looks good.
2.
- PageIndexMultiDelete(page, deletable, ndeletable);
+ /*
+
* Clear the WARM pointers.
+ *
+ * We mustdo this before dealing with the dead items because
+ * PageIndexMultiDelete may move items around to compactify the
+ * array and hence offnums recorded earlierwon't make any sense
+ * after PageIndexMultiDelete is called.
+
*/
+ if (nclearwarm > 0)
+ _hash_clear_items(page,clearwarm, nclearwarm);
+
+ /*
+ * And delete the deletableitems
+ */
+ if (ndeletable > 0)
+
PageIndexMultiDelete(page, deletable, ndeletable);
I think this assumes that the items where we need to clear warm flag
are not deletable, otherwise what is the need to clear the flag if we
are going to delete the tuple. The deletable tuple can have a warm
flag if it is deletable due to split cleanup.
Yes. Since the callback will either say IBDCR_DELETE or IBDCR_CLEAR_WARM, I don't think we will ever has a situation where a tuple is deleted as well as cleared. I also checked that the bucket split code should carry the WARM flag correctly to the new bucket.
Based on your first comment, I believe the rearranged code with take care of deleting a tuple even if WARM flag is set, if the deletion is because of bucket split.
3.
+ /*
+ * HASH indexes compute a hash value of the key and store that in the
+ * index. So
we must first obtain the hash of the value obtained from the
+ * heap and then do a comparison
+
*/
+ _hash_convert_tuple(indexRel, values, isnull, values2, isnull2);
I think here, you need to handle the case where heap has a NULL value
as the hash index doesn't contain NULL values, otherwise, the code in
below function can return true which is not right.
I think we can simply conclude hashrecheck has failed the equality if the heap has NULL value because such a tuple should not have been reached via hash index unless a non-NULL hash key was later updated to a NULL key, right?
4.
+bool
+hashrecheck(Relation indexRel, IndexInfo *indexInfo, IndexTuple indexTuple,
+ Relation heapRel, HeapTuple heapTuple)
{
..
+ att = indexRel->rd_att->attrs[i - 1];
+ if (!datumIsEqual(values2[i - 1], indxvalue, att->attbyval,
+ att->attlen))
+ {
+ equal = false;
+ break;
+ }
..
}
Hash values are always uint32 and attlen can be different for
different datatypes, so I think above doesn't seem to be the right way
to do the comparison.
Since we're referring to the attr from the index relation, wouldn't it tell us the attribute specs of what gets stored in the index and not what's there in the heap? I could be wrong but some quick tests show me that pg_attribute->attlen for the index relation always returns 4 irrespective of the underlying data type in heap.
5.
@@ -274,6 +301,8 @@ hashgettuple(IndexScanDesc scan, ScanDirection dir)
OffsetNumber offnum;
ItemPointer current;
bool res;
+ IndexTuple itup;
+
/* Hash
indexes are always lossy since we store only the hash code */
scan->xs_recheck = true;
@@ -316,8
+345,6 @@ hashgettuple(IndexScanDesc scan, ScanDirection dir)
offnum <=
maxoffnum;
offnum = OffsetNumberNext(offnum))
{
-IndexTuple itup;
-
Why above change?
Seems spurious. Fixed.
6.
+ *stats = index_bulk_delete(&ivinfo, *stats,
+lazy_indexvac_phase1, (void *) vacrelstats);
+ ereport(elevel,
+(errmsg("scanned index \"%s\" to remove %d row version, found "
+"%0.f warm pointers, %0.f clear pointers, removed "
+"%0.f warm pointers, removed %0.f clear pointers",
+RelationGetRelationName(indrel),
+ vacrelstats->num_dead_tuples,
+ (*stats)->num_warm_pointers,
+(*stats)->num_clear_pointers,
+(*stats)->warm_pointers_removed,
+ (*stats)->clear_pointers_removed)));
+
+ (*stats)->num_warm_pointers = 0;
+ (*stats)->num_clear_pointers = 0;
+ (*stats)->warm_pointers_removed = 0;
+ (*stats)->clear_pointers_removed = 0;
+ (*stats)->pointers_cleared = 0;
+
+ *stats =index_bulk_delete(&ivinfo, *stats,
+ lazy_indexvac_phase2, (void *)vacrelstats);
To convert WARM chains, we need to do two index passes for all the
indexes. I think it can substantially increase the random I/O. I
think this can help us in doing more WARM updates, but I don't see how
the downside of that (increased random I/O) will be acceptable for all
kind of cases.
Yes, this is a very fair point. The way I proposed to address this upthread is by introducing a set of threshold/scale GUCs specific to WARM. So users can control when to invoke WARM cleanup. Only if the WARM cleanup is required, we do 2 index scans. Otherwise vacuum will work the way it works today without any additional overhead.
We already have some intelligence to skip the second index scan if we did not find any WARM candidate chains during the first heap scan. This should take care of majority of the users who never update their indexed columns. For others, we need either a knob or some built-in way to deduce whether to do WARM cleanup or not.
Does that seem worthwhile?
+exists. Since index vacuum may visit these pointers in any order, we will need
+another index pass to remove dead index pointers. So in the first index pass we
+check which WARM candidates have 2 index pointers. In the second pass, we
+remove the dead pointer and clear the INDEX_WARM_POINTER flag if that's the
+surviving index pointer.
I think there is some mismatch between README and code. In README, it
is mentioned that dead pointers will be removed in the second phase,
but I think the first phase code lazy_indexvac_phase1() will also
allow to delete the dead pointers (it can return IBDCR_DELETE which
will allow index am to remove dead items.). Am I missing something
here?
Hmm.. fixed the README. Clearly we do allow removal of dead pointers which are known to be certainly dead in the first index pass itself. Some other pointers can be removed during the second scan once we know about the existence or non existence of WARM index pointers.
7.
+ * For CLEAR chains, we just kill the WARM pointer, if it exist,s and keep
+ * the CLEAR pointer.
typo (exist,s)
Fixed.
8.
+/*
+ * lazy_indexvac_phase2() -- run first pass of index vacuum
Shouldn't this be -- run the second pass
Yes, fixed.
9.
- indexInfo); /* index AM may need this */
+indexInfo, /* index AM may need this */
+(modified_attrs != NULL)); /* type of uniqueness check to do */
comment for the last parameter seems to be wrong.
Fixed.
10.
+follow the update chain everytime to the end to see check if this is a WARM
+chain.
"see check" - seems one of those words is sufficient to explain the meaning.
Fixed.
11.
+chain. This simplifies the design and addresses certain issues around
+duplicate scans.
"duplicate scans" - shouldn't be duplicate key scans.
Ok, seems better. Fixed.
12.
+index on the table, irrespective of whether the key pertaining to the
+index changed or not.
typo.
/index changed/index is changed
Fixed.
13.
+For example, if we have a table with two columns and two indexes on each
+of the column. When a tuple is first inserted the table, we have exactly
typo.
/inserted the table/inserted in the table
Fixed.
14.
+ lp [1] [2]
+ [1111, aaaa]->[111, bbbb]
Here, after the update, the first column should be 1111.
Fixed.
Pavan
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
Thanks Amit. v19 addresses some of the comments below.
On Thu, Mar 23, 2017 at 10:28 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Wed, Mar 22, 2017 at 4:06 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Tue, Mar 21, 2017 at 6:47 PM, Pavan Deolasee
> <pavan.deolasee@gmail.com> wrote:
>>
>>>
>>
>> Please find attached rebased patches.
>>
>
> Few comments on 0005_warm_updates_v18.patch:
>
Few more comments on 0005_warm_updates_v18.patch:
1.
@@ -234,6 +241,25 @@ index_beginscan(Relation heapRelation,
scan->heapRelation = heapRelation;
scan->xs_snapshot = snapshot;
+ /*
+ * If the index supports recheck,
make sure that index tuple is saved
+ * during index scans. Also build and cache IndexInfo which is used by
+ * amrecheck routine.
+ *
+ * XXX Ideally, we should look at
all indexes on the table and check if
+ * WARM is at all supported on the base table. If WARM is not supported
+ * then we don't need to do any recheck.
RelationGetIndexAttrBitmap() does
+ * do that and sets rd_supportswarm after looking at all indexes. But we
+ * don't know if the function was called earlier in the
session when we're
+ * here. We can't call it now because there exists a risk of causing
+ * deadlock.
+ */
+ if (indexRelation->rd_amroutine->amrecheck)
+ {
+scan->xs_want_itup = true;
+ scan->indexInfo = BuildIndexInfo(indexRelation);
+ }
+
Don't we need to do this rechecking during parallel scans? Also what
about bitmap heap scans?
Yes, we need to handle parallel scans. Bitmap scans are not a problem because it can never return the same TID twice. I fixed this though by moving this inside index_beginscan_internal.
2.
+++ b/src/backend/access/nbtree/nbtinsert.c
-
typedef struct
Above change is not require.
Sure. Fixed.
3.
+_bt_clear_items(Page page, OffsetNumber *clearitemnos, uint16 nclearitems)
+void _hash_clear_items(Page page, OffsetNumber *clearitemnos,
+ uint16 nclearitems)
Both the above functions look exactly same, isn't it better to have a
single function like page_clear_items? If you want separation for
different index types, then we can have one common function which can
be called from different index types.
Yes, makes sense. Moved that to bufpage.c. The reason why I originally had index-specific versions because I started by putting WARM flag in IndexTuple header. But since hash index does not have the bit free, moved everything to TID bit-flag. I still left index-specific wrappers, but they just call PageIndexClearWarmTuples.
4.
- if (callback(htup, callback_state))
+ flags = ItemPointerGetFlags(&itup->t_tid);
+ is_warm = ((flags & BTREE_INDEX_WARM_POINTER) != 0);
+
+ if (is_warm)
+ stats->num_warm_pointers++;
+ else
+ stats->num_clear_pointers++;
+
+ result = callback(htup, is_warm, callback_state);
+ if (result == IBDCR_DELETE)
+ {
+ if (is_warm)
+ stats->warm_pointers_removed++;
+ else
+ stats->clear_pointers_removed++;
The patch looks to be inconsistent in collecting stats for btree and
hash. I don't see above stats are getting updated in hash index code.
Fixed. The hashbucketcleanup signature is just getting a bit too long. May be we should move some of these counters in a structure and pass that around. Not done here though.
5.
+btrecheck(Relation indexRel, IndexInfo *indexInfo, IndexTuple indexTuple,
+ Relation heapRel, HeapTuple heapTuple)
{
..
+ if (!datumIsEqual(values[i - 1], indxvalue, att->attbyval,
+ att->attlen))
..
}
Will this work if the index is using non-default collation?
Not sure I understand that. Can you please elaborate?
6.
+++ b/src/backend/access/nbtree/nbtxlog.c
@@ -390,83 +390,9 @@ btree_xlog_vacuum(XLogReaderState *record)
-#ifdef UNUSED
xl_btree_vacuum *xlrec = (xl_btree_vacuum *) XLogRecGetData(record);
/*
- * This section of code is thought to be no longer needed, after analysis
- * of the calling paths. It is retained to allow the code to be reinstated
- * if a flaw is revealed in that thinking.
- *
..
Why does this patch need to remove the above code under #ifdef UNUSED
Yeah, it isn't strictly necessary. But that dead code was coming in the way and hence I decided to strip it out. I can put it back if it's an issue or remove that as a separate commit first.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Mar 23, 2017 at 3:02 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
--
That sounds like you are dodging the actual problem. I mean you can
put that same PageIsFull() check in master code as well and then you
will most probably again see the same regression.
Well I don't see it that way. There was a specific concern about a specific workload that WARM might regress. I think this change addresses that. Sure if you pick that one piece, put it in master first and then compare against rest of the WARM code, you will see a regression. But I thought what we were worried is WARM causing regression to some existing user, who might see her workload running 10% slower, which this change mitigates.
Also, I think if we
test at fillfactor 80 or 75 (which is not unrealistic considering an
update-intensive workload), then we might again see regression.
Yeah, we might, but it will be lesser than before, may be 2% instead of 10%. And by doing this we are further narrowing an already narrow test case. I think we need to see things in totality and weigh in costs-benefits trade offs. There are numbers for very common workloads, where WARM may provide 20, 30 or even more than 100% improvements.
Andres and Alvaro already have other ideas to address this problem even further. And as I said, we can pass-in index specific information and make that routine bail-out even earlier. We need to accept that WARM will need to do more attr checks than master, especially when there are more than 1 indexes on the table, and sometimes those checks will go waste. I am ok if we want to provide table-specific knob to disable WARM, but not sure if others would like that idea.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Mar 23, 2017 at 4:08 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
On Thu, Mar 23, 2017 at 3:02 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
That sounds like you are dodging the actual problem. I mean you can
put that same PageIsFull() check in master code as well and then you
will most probably again see the same regression.Well I don't see it that way. There was a specific concern about a specific workload that WARM might regress. I think this change addresses that. Sure if you pick that one piece, put it in master first and then compare against rest of the WARM code, you will see a regression.
BTW the PageIsFull() check may not help as much in master as it does with WARM. In master we anyways bail out early after couple of column checks. In master it may help to reduce the 10% drop that we see while updating last index column, but if we compare master and WARM with the patch applied, regression should be quite nominal.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Mar 23, 2017 at 3:44 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> On Wed, Mar 22, 2017 at 4:06 PM, Amit Kapila <amit.kapila16@gmail.com>
> wrote:
>>
>
>> 3.
>> + /*
>> + * HASH indexes compute a hash value of the key and store that in the
>> + * index. So
>> we must first obtain the hash of the value obtained from the
>> + * heap and then do a comparison
>> +
>> */
>> + _hash_convert_tuple(indexRel, values, isnull, values2, isnull2);
>>
>> I think here, you need to handle the case where heap has a NULL value
>> as the hash index doesn't contain NULL values, otherwise, the code in
>> below function can return true which is not right.
>>
>
> I think we can simply conclude hashrecheck has failed the equality if the
> heap has NULL value because such a tuple should not have been reached via
> hash index unless a non-NULL hash key was later updated to a NULL key,
> right?
>
Right.
>>
>>
>> 6.
>> + *stats = index_bulk_delete(&ivinfo, *stats,
>> +lazy_indexvac_phase1, (void *) vacrelstats);
>> + ereport(elevel,
>> +(errmsg("scanned index \"%s\" to remove %d row version, found "
>> +"%0.f warm pointers, %0.f clear pointers, removed "
>> +"%0.f warm pointers, removed %0.f clear pointers",
>> +RelationGetRelationName(indrel),
>> + vacrelstats->num_dead_tuples,
>> + (*stats)->num_warm_pointers,
>> +(*stats)->num_clear_pointers,
>> +(*stats)->warm_pointers_removed,
>> + (*stats)->clear_pointers_removed)));
>> +
>> + (*stats)->num_warm_pointers = 0;
>> + (*stats)->num_clear_pointers = 0;
>> + (*stats)->warm_pointers_removed = 0;
>> + (*stats)->clear_pointers_removed = 0;
>> + (*stats)->pointers_cleared = 0;
>> +
>> + *stats =index_bulk_delete(&ivinfo, *stats,
>> + lazy_indexvac_phase2, (void *)vacrelstats);
>>
>> To convert WARM chains, we need to do two index passes for all the
>> indexes. I think it can substantially increase the random I/O. I
>> think this can help us in doing more WARM updates, but I don't see how
>> the downside of that (increased random I/O) will be acceptable for all
>> kind of cases.
>>
>
> Yes, this is a very fair point. The way I proposed to address this upthread
> is by introducing a set of threshold/scale GUCs specific to WARM. So users
> can control when to invoke WARM cleanup. Only if the WARM cleanup is
> required, we do 2 index scans. Otherwise vacuum will work the way it works
> today without any additional overhead.
>
I am not sure on what basis user can set such parameters, it will be
quite difficult to tune those parameters. I think the point is
whatever threshold we keep, once that is crossed, it will perform two
scans for all the indexes. IIUC, this conversion of WARM chains is
required so that future updates can be WARM or is there any other
reason? I see this as a big penalty for future updates.
> We already have some intelligence to skip the second index scan if we did
> not find any WARM candidate chains during the first heap scan. This should
> take care of majority of the users who never update their indexed columns.
> For others, we need either a knob or some built-in way to deduce whether to
> do WARM cleanup or not.
>
> Does that seem worthwhile?
>
Is there any consensus on your proposal, because I feel this needs
somewhat broader discussion, me and you can't take a call on this
point. I request others also to share their opinion on this point.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Hi Pavan, On Thu, Mar 23, 2017 at 12:19 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > Ok, no problem. I did some tests on AWS i2.xlarge instance (4 vCPU, 30GB > RAM, attached SSD) and results are shown below. But I think it is important > to get independent validation from your side too, just to ensure I am not > making any mistake in measurement. I've attached naively put together > scripts which I used to run the benchmark. If you find them useful, please > adjust the paths and run on your machine. I did a similar test appears. Your v19 looks fine to me, it does not cause any regression, On the other hand, I also ran tests reducing table fillfactor to 80 there I can see a small regression 2-3% in average when updating col2 and on updating col9 again I do not see any regression. -- Thanks and Regards Mithun C Y EnterpriseDB: http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Thu, Mar 23, 2017 at 11:44 PM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:
Thanks Mithun for repeating the tests and confirming that the v19 patch looks ok.Hi Pavan,
On Thu, Mar 23, 2017 at 12:19 AM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> Ok, no problem. I did some tests on AWS i2.xlarge instance (4 vCPU, 30GB
> RAM, attached SSD) and results are shown below. But I think it is important
> to get independent validation from your side too, just to ensure I am not
> making any mistake in measurement. I've attached naively put together
> scripts which I used to run the benchmark. If you find them useful, please
> adjust the paths and run on your machine.
I did a similar test appears. Your v19 looks fine to me, it does not
cause any regression, On the other hand, I also ran tests reducing
table fillfactor to 80 there I can see a small regression 2-3% in
average when updating col2 and on updating col9 again I do not see any
regression.
Thanks,
Pavan
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Mar 22, 2017 at 12:30 AM, Bruce Momjian <bruce@momjian.us> wrote:
Well, it is really a question of how often you want to do a second WARM
update (not possible) vs. the frequency of lazy vacuum. I assumed that
would be a 100X or 10kX difference, but I am not sure myself either. My
initial guess was that only allowing a single WARM update between lazy
vacuums would show no improvementin in real-world workloads, but maybe I
am wrong.
It's quite hard to say that until we see many more benchmarks. As author of the patch, I might have got repetitive with my benchmarks. But I've seen over 50% improvement in TPS even without chain conversion (6 indexes on a 12 column table test).
With chain conversion, in my latest tests, I saw over 100% improvement. The benchmark probably received between 6-8 autovac cycles in an 8hr test. This was with a large table which doesn't fit in memory or barely fit in memory. Graphs attached again just in case you missed (x-axis test duration in seconds, y-axis moving average of TPS)
May be we should run another set with just 2 or 3 indexes on a 12 column table and see how much that helps, if at all. Or may be do a mix of HOT and WARM updates. Or even just do HOT updates on small and large tables and look for any regression. Will try to schedule some of those tests.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Thu, Mar 23, 2017 at 7:53 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Thu, Mar 23, 2017 at 3:44 PM, Pavan DeolaseeI am not sure on what basis user can set such parameters, it will be
>
> Yes, this is a very fair point. The way I proposed to address this upthread
> is by introducing a set of threshold/scale GUCs specific to WARM. So users
> can control when to invoke WARM cleanup. Only if the WARM cleanup is
> required, we do 2 index scans. Otherwise vacuum will work the way it works
> today without any additional overhead.
>
quite difficult to tune those parameters. I think the point is
whatever threshold we keep, once that is crossed, it will perform two
scans for all the indexes.
Well, that applies to even vacuum parameters, no? The general sense I've got here is that we're ok to push some work in background if it helps the real-time queries, and I kinda agree with that. If WARM improves things in a significant manner even with these additional maintenance work, it's still worth doing.
Having said that, I see many ways we can improve on this later. Like we can track somewhere else information about tuples which may have received WARM updates (I think it will need to be a per-index bitmap or so) and use that to do WARM chain conversion in a single index pass. But this is clearly not PG 10 material.
IIUC, this conversion of WARM chains is
required so that future updates can be WARM or is there any other
reason? I see this as a big penalty for future updates.
It's also necessary for index-only-scans. But I don't see this as a big penalty for future updates, because if there are indeed significant WARM updates then not preparing for future updates will result in write-amplification, something we are trying to solve here and something which seems to be showing good gains.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Mar 24, 2017 at 12:25 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > > On Thu, Mar 23, 2017 at 7:53 PM, Amit Kapila <amit.kapila16@gmail.com> > wrote: >> >> > >> >> I am not sure on what basis user can set such parameters, it will be >> quite difficult to tune those parameters. I think the point is >> whatever threshold we keep, once that is crossed, it will perform two >> scans for all the indexes. > > > Well, that applies to even vacuum parameters, no? > I don't know how much we can directly compare the usability of the new parameters you are proposing here to existing parameters. > The general sense I've got > here is that we're ok to push some work in background if it helps the > real-time queries, and I kinda agree with that. > I don't think we can define this work as "some" work, it can be a lot of work depending on the number of indexes. Also, I think for some cases it will generate maintenance work without generating benefit. For example, when there is one index on a table and there are updates for that index column. > Having said that, I see many ways we can improve on this later. Like we can > track somewhere else information about tuples which may have received WARM > updates (I think it will need to be a per-index bitmap or so) and use that > to do WARM chain conversion in a single index pass. > Sure, if we have some way to do it in a single pass or does most of the time in foreground process (like we have some dead marking idea for indexes), then it would have been better. > But this is clearly not > PG 10 material. > I don't see much discussion about this aspect of the patch, so not sure if it is acceptable to increase the cost of vacuum. Now, I don't know if your idea of GUC's make it such that the additional cost will occur seldom and this additional pass has a minimal impact which will make it acceptable. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Fri, Mar 24, 2017 at 4:04 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Fri, Mar 24, 2017 at 12:25 AM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
>
>
> On Thu, Mar 23, 2017 at 7:53 PM, Amit Kapila <amit.kapila16@gmail.com>
>
> The general sense I've got
> here is that we're ok to push some work in background if it helps the
> real-time queries, and I kinda agree with that.
>
I don't think we can define this work as "some" work, it can be a lot
of work depending on the number of indexes. Also, I think for some
cases it will generate maintenance work without generating benefit.
For example, when there is one index on a table and there are updates
for that index column.
That's a fair point. I think we can address this though. At the end of first index scan we would know how many warm pointers the index has and whether it's worth doing a second scan. For the case you mentioned, we will do a second scan just on that one index and skip on all other indexes and still achieve the same result. On the other hand, if one index receives many updates and other indexes are rarely updated then we might leave behind a few WARM chains behind and won't be able to do IOS on those pages. But given the premise that other indexes are receiving rare updates, it may not be a problem. Note: the code is not currently written that way, but it should be a fairly small change.
The other thing that we didn't talk about is that vacuum will need to track dead tuples and warm candidate chains separately which increases memory overhead. So for very large tables, and for the same amount of maintenance_work_mem, one round of vacuum will be able to clean lesser pages. We can work out more compact representation, but something not done currently.
> But this is clearly not
> PG 10 material.
>
I don't see much discussion about this aspect of the patch, so not
sure if it is acceptable to increase the cost of vacuum. Now, I don't
know if your idea of GUC's make it such that the additional cost will
occur seldom and this additional pass has a minimal impact which will
make it acceptable.
Yeah, I agree. I'm trying to schedule some more benchmarks, but any help is appreciated.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Mar 23, 2017 at 3:54 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> Thanks Amit. v19 addresses some of the comments below.
>
> On Thu, Mar 23, 2017 at 10:28 AM, Amit Kapila <amit.kapila16@gmail.com>
> wrote:
>>
>> On Wed, Mar 22, 2017 at 4:06 PM, Amit Kapila <amit.kapila16@gmail.com>
>> wrote:
>> > On Tue, Mar 21, 2017 at 6:47 PM, Pavan Deolasee
>> > <pavan.deolasee@gmail.com> wrote:
>
>>
>> 5.
>> +btrecheck(Relation indexRel, IndexInfo *indexInfo, IndexTuple indexTuple,
>> + Relation heapRel, HeapTuple heapTuple)
>> {
>> ..
>> + if (!datumIsEqual(values[i - 1], indxvalue, att->attbyval,
>> + att->attlen))
>> ..
>> }
>>
>> Will this work if the index is using non-default collation?
>>
>
> Not sure I understand that. Can you please elaborate?
>
I was worried for the case if the index is created non-default
collation, will the datumIsEqual() suffice the need. Now again
thinking about it, I think it will because in the index tuple we are
storing the value as in heap tuple. However today it occurred to me
how will this work for toasted index values (index value >
TOAST_INDEX_TARGET). It is mentioned on top of datumIsEqual() that it
probably won't work for toasted values. Have you considered that
point?
>>
>> 6.
>> +++ b/src/backend/access/nbtree/nbtxlog.c
>> @@ -390,83 +390,9 @@ btree_xlog_vacuum(XLogReaderState *record)
>> -#ifdef UNUSED
>> xl_btree_vacuum *xlrec = (xl_btree_vacuum *) XLogRecGetData(record);
>>
>> /*
>> - * This section of code is thought to be no longer needed, after analysis
>> - * of the calling paths. It is retained to allow the code to be
>> reinstated
>> - * if a flaw is revealed in that thinking.
>> - *
>> ..
>>
>> Why does this patch need to remove the above code under #ifdef UNUSED
>>
>
> Yeah, it isn't strictly necessary. But that dead code was coming in the way
> and hence I decided to strip it out. I can put it back if it's an issue or
> remove that as a separate commit first.
>
I think it is better to keep unrelated changes out of patch.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Fri, Mar 24, 2017 at 6:46 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
I was worried for the case if the index is created non-default
collation, will the datumIsEqual() suffice the need. Now again
thinking about it, I think it will because in the index tuple we are
storing the value as in heap tuple. However today it occurred to me
how will this work for toasted index values (index value >
TOAST_INDEX_TARGET). It is mentioned on top of datumIsEqual() that it
probably won't work for toasted values. Have you considered that
point?
While looking at this problem, it occurred to me that the assumptions made for hash indexes are also wrong :-( Hash index has the same problem as expression indexes have. A change in heap value may not necessarily cause a change in the hash key. If we don't detect that, we will end up having two hash identical hash keys with the same TID pointer. This will cause the duplicate key scans problem since hashrecheck will return true for both the hash entries. That's a bummer as far as supporting WARM for hash indexes is concerned, unless we find a way to avoid duplicate index entries.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Mar 24, 2017 at 11:49 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > > On Fri, Mar 24, 2017 at 6:46 PM, Amit Kapila <amit.kapila16@gmail.com> > wrote: >> >> >> >> I was worried for the case if the index is created non-default >> collation, will the datumIsEqual() suffice the need. Now again >> thinking about it, I think it will because in the index tuple we are >> storing the value as in heap tuple. However today it occurred to me >> how will this work for toasted index values (index value > >> TOAST_INDEX_TARGET). It is mentioned on top of datumIsEqual() that it >> probably won't work for toasted values. Have you considered that >> point? >> > > No, I haven't and thanks for bringing that up. And now that I think more > about it and see the code, I think the naive way of just comparing index > attribute value against heap values is probably wrong. The example of > TOAST_INDEX_TARGET is one such case, but I wonder if there are other varlena > attributes that we might store differently in heap and index. Like > index_form_tuple() ->heap_fill_tuple seem to some churning for varlena. It's > not clear to me if index_get_attr will return the values which are binary > comparable to heap values.. I wonder if calling index_form_tuple on the heap > values, fetching attributes via index_get_attr on both index tuples and then > doing a binary compare is a more robust idea. > I am not sure how do you want to binary compare two datums, if you are thinking datumIsEqual(), that won't work. I think you need to use datatype specific compare function something like what we do in _bt_compare(). > Or may be that's just > duplicating efforts. > I think if we do something on the lines as mentioned by me above we might not need to duplicate the efforts. > While looking at this problem, it occurred to me that the assumptions made > for hash indexes are also wrong :-( Hash index has the same problem as > expression indexes have. A change in heap value may not necessarily cause a > change in the hash key. If we don't detect that, we will end up having two > hash identical hash keys with the same TID pointer. This will cause the > duplicate key scans problem since hashrecheck will return true for both the > hash entries. That's a bummer as far as supporting WARM for hash indexes is > concerned, > Yeah, I also think so. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Sat, Mar 25, 2017 at 12:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > I am not sure how do you want to binary compare two datums, if you are > thinking datumIsEqual(), that won't work. I think you need to use > datatype specific compare function something like what we do in > _bt_compare(). How will that interact with types like numeric, that have display scale or similar? -- Peter Geoghegan
On Sat, 25 Mar 2017 at 11:03 PM, Peter Geoghegan <pg@bowt.ie> wrote:
On Sat, Mar 25, 2017 at 12:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> I am not sure how do you want to binary compare two datums, if you are
> thinking datumIsEqual(), that won't work. I think you need to use
> datatype specific compare function something like what we do in
> _bt_compare().
How will that interact with types like numeric, that have display
scale or similar?
I wonder why Amit thinks that datumIsEqual won't work once we convert the heap values to index tuple and then fetch using index_get_attr. After all that's how the current index tuple was constructed when it was inserted. In fact, we must not rely on _bt_compare because that might return "false positive" even for two different heap binary values (I think). To decide whether to do WARM update or not in heap_update we only rely on binary comparison. Could it happen that for two different binary heap values, we still compute the same index attribute? Even when expression indexes are not supported?
Thanks,
Pavan
--
Peter Geoghegan
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Sat, Mar 25, 2017 at 11:24 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > On Sat, 25 Mar 2017 at 11:03 PM, Peter Geoghegan <pg@bowt.ie> wrote: >> >> On Sat, Mar 25, 2017 at 12:54 AM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: >> > I am not sure how do you want to binary compare two datums, if you are >> > thinking datumIsEqual(), that won't work. I think you need to use >> > datatype specific compare function something like what we do in >> > _bt_compare(). >> >> How will that interact with types like numeric, that have display >> scale or similar? >> > I wonder why Amit thinks that datumIsEqual won't work once we convert the > heap values to index tuple and then fetch using index_get_attr. After all > that's how the current index tuple was constructed when it was inserted. I think for toasted values you need to detoast before comparison and it seems datamIsEqual won't do that job. Am I missing something which makes you think that datumIsEqual will work in this context. > In > fact, we must not rely on _bt_compare because that might return "false > positive" even for two different heap binary values (I think). I am not telling to rely on _bt_compare, what I was trying to hint at it was that I think we might need to use some column type specific information for comparison. I am not sure at this stage what is the best way to deal with this problem without incurring non trivial cost. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Fri, Mar 24, 2017 at 11:49 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
On Fri, Mar 24, 2017 at 6:46 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
I was worried for the case if the index is created non-default
collation, will the datumIsEqual() suffice the need. Now again
thinking about it, I think it will because in the index tuple we are
storing the value as in heap tuple. However today it occurred to me
how will this work for toasted index values (index value >
TOAST_INDEX_TARGET). It is mentioned on top of datumIsEqual() that it
probably won't work for toasted values. Have you considered that
point?No, I haven't and thanks for bringing that up. And now that I think more about it and see the code, I think the naive way of just comparing index attribute value against heap values is probably wrong. The example of TOAST_INDEX_TARGET is one such case, but I wonder if there are other varlena attributes that we might store differently in heap and index. Like index_form_tuple() ->heap_fill_tuple seem to some churning for varlena. It's not clear to me if index_get_attr will return the values which are binary comparable to heap values.. I wonder if calling index_form_tuple on the heap values, fetching attributes via index_get_attr on both index tuples and then doing a binary compare is a more robust idea. Or may be that's just duplicating efforts.While looking at this problem, it occurred to me that the assumptions made for hash indexes are also wrong :-( Hash index has the same problem as expression indexes have. A change in heap value may not necessarily cause a change in the hash key. If we don't detect that, we will end up having two hash identical hash keys with the same TID pointer. This will cause the duplicate key scans problem since hashrecheck will return true for both the hash entries. That's a bummer as far as supporting WARM for hash indexes is concerned, unless we find a way to avoid duplicate index entries.
Revised patches are attached. I've added a few more regression tests which demonstrates the problems with compressed and toasted attributes. I've now implemented the idea of creating index tuple from heap values before doing binary comparison using datumIsEqual. This seems to work ok and I see no reason this should not be robust. But if there are things which could still be problematic, please let me know.
Other than that, I've now converted the stress test framework used earlier to test WARM into TAP tests and those tests are attached too.
Finally, I've implemented complete pg_stat support for tracking amount of WARM chains in the table. AV can use that to trigger clean-up only when the fraction of warm chains goes beyond configured scale. Similarly, the patch also adds an index-level scale factor and cleanup is triggered on an index only if the number of WARM pointers in the index are beyond the set fraction. This should greatly help us to avoid second index scans on indexes which are either not updated at all or updated rarely. The best case scenario where out of N indexes only one index receives update, WARM will avoid updates to N-1 indexes and these N-1 indexes need not be scanned twice during WARM cleanup. OTOH if most indexes on a table receive updates, then probably neither WARM nor cleanup will be efficient for such workloads. I wonder if we should provide a table-level knob to turn WARM completely off on such workloads, however rare they might be. I think this patch requires some more work and documentation changes are completely missing.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Mon, Mar 27, 2017 at 2:19 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
-- Revised patches are attached.
Hmm.. for some reason check_keywords.pl wasn't failing in my development environment. Or to be precise, it failed once and then almost magically got fixed.. still a mystery to me. Anyways, I think a change in gram.y will be necessary to make 0007 compile. Attaching the entire set again, with just 0007 fixed.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Sat, Mar 25, 2017 at 1:24 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Fri, Mar 24, 2017 at 11:49 PM, Pavan Deolasee > <pavan.deolasee@gmail.com> wrote: >> >> On Fri, Mar 24, 2017 at 6:46 PM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: >>> > >> While looking at this problem, it occurred to me that the assumptions made >> for hash indexes are also wrong :-( Hash index has the same problem as >> expression indexes have. A change in heap value may not necessarily cause a >> change in the hash key. If we don't detect that, we will end up having two >> hash identical hash keys with the same TID pointer. This will cause the >> duplicate key scans problem since hashrecheck will return true for both the >> hash entries. Isn't it possible to detect duplicate keys in hashrecheck if we compare both hashkey and tid stored in index tuple with the corresponding values from heap tuple? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Is the WARM tap test suite supposed to work when applied without all the other patches? I just tried applied that one and running "make check -C src/test/modules", and it seems to hang after giving "ok 5" for t/002_warm_stress.pl. (I had to add a Makefile too, attached.) -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On Thu, Mar 23, 2017 at 2:47 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > It's quite hard to say that until we see many more benchmarks. As author of > the patch, I might have got repetitive with my benchmarks. But I've seen > over 50% improvement in TPS even without chain conversion (6 indexes on a 12 > column table test). This seems quite mystifying. What can account for such a large performance difference in such a pessimal scenario? It seems to me that without chain conversion, WARM can only apply to each row once and therefore no sustained performance improvement should be possible -- unless rows are regularly being moved to new blocks, in which case those updates would "reset" the ability to again perform an update. However, one would hope that most updates get done within a single block, so that the row-moves-to-new-block case wouldn't happen very often. I'm perplexed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Mar 28, 2017 at 1:32 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Is the WARM tap test suite supposed to work when applied without all the
other patches? I just tried applied that one and running "make check -C
src/test/modules", and it seems to hang after giving "ok 5" for
t/002_warm_stress.pl. (I had to add a Makefile too, attached.)
These tests should run without WARM. I wonder though if IPC::Run's start/pump/finish facility is fully portable. Andrew on off-list conversation reminded me that there are no (or may be one) tests currently using that in Postgres. I've run these tests on OSX, will try on some linux platform too.
Thanks,
Pavan
-- Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Mon, Mar 27, 2017 at 04:29:56PM -0400, Robert Haas wrote: > On Thu, Mar 23, 2017 at 2:47 PM, Pavan Deolasee > <pavan.deolasee@gmail.com> wrote: > > It's quite hard to say that until we see many more benchmarks. As author of > > the patch, I might have got repetitive with my benchmarks. But I've seen > > over 50% improvement in TPS even without chain conversion (6 indexes on a 12 > > column table test). > > This seems quite mystifying. What can account for such a large > performance difference in such a pessimal scenario? It seems to me > that without chain conversion, WARM can only apply to each row once > and therefore no sustained performance improvement should be possible > -- unless rows are regularly being moved to new blocks, in which case > those updates would "reset" the ability to again perform an update. > However, one would hope that most updates get done within a single > block, so that the row-moves-to-new-block case wouldn't happen very > often. > > I'm perplexed. Yes, I asked the same question in this email: https://www.postgresql.org/message-id/20170321190000.GE16918@momjian.us -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Tue, Mar 28, 2017 at 1:59 AM, Robert Haas <robertmhaas@gmail.com> wrote:
On Thu, Mar 23, 2017 at 2:47 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> It's quite hard to say that until we see many more benchmarks. As author of
> the patch, I might have got repetitive with my benchmarks. But I've seen
> over 50% improvement in TPS even without chain conversion (6 indexes on a 12
> column table test).
This seems quite mystifying. What can account for such a large
performance difference in such a pessimal scenario? It seems to me
that without chain conversion, WARM can only apply to each row once
and therefore no sustained performance improvement should be possible
-- unless rows are regularly being moved to new blocks, in which case
those updates would "reset" the ability to again perform an update.
However, one would hope that most updates get done within a single
block, so that the row-moves-to-new-block case wouldn't happen very
often.
I think you're confusing between update chains that stay within a block vs HOT/WARM chains. Even when the entire update chain stays within a block, it can be made up of multiple HOT/WARM chains and each of these chains offer ability to do one WARM update. So even without chain conversion, every alternate update will be a WARM update. So the gains are perpetual.
1. WARM update, new entry in just one index
2. Regular update, new entries in all indexes
3. WARM update, new entry in just one index
4. Regular update, new entries in all indexes
At the end of N updates (assuming all fit in the same block), one index will have N entries and rest will have N/2 entries.
Compare that against master:
1. Regular update, new entries in all indexes
2. Regular update, new entries in all indexes
3. Regular update, new entries in all indexes
4. Regular update, new entries in all indexes
At the end of N updates (assuming all fit in the same block), all indexes will have N entries. So with WARM we reduce bloats in 3 indexes. And WARM works almost in a perpetual way even without chain conversion. If you see the graph I earlier shared (attach again), without WARM chain conversion the rate of WARM updates settle down to 50%, which is not surprising given what I explained above.
Thanks,
Pavan
-- Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
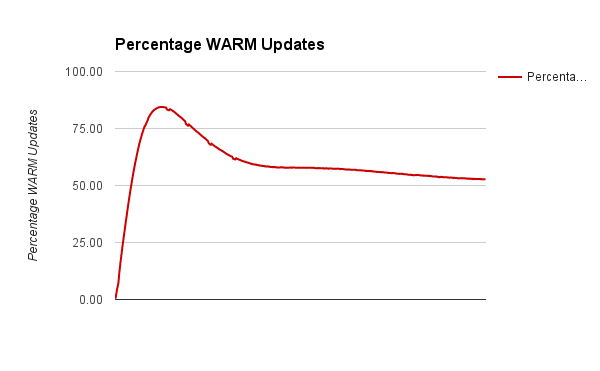{kind=link}
On Tue, Mar 28, 2017 at 7:49 AM, Bruce Momjian <bruce@momjian.us> wrote:
On Mon, Mar 27, 2017 at 04:29:56PM -0400, Robert Haas wrote:
> On Thu, Mar 23, 2017 at 2:47 PM, Pavan Deolasee
> <pavan.deolasee@gmail.com> wrote:
> > It's quite hard to say that until we see many more benchmarks. As author of
> > the patch, I might have got repetitive with my benchmarks. But I've seen
> > over 50% improvement in TPS even without chain conversion (6 indexes on a 12
> > column table test).
>
> This seems quite mystifying. What can account for such a large
> performance difference in such a pessimal scenario? It seems to me
> that without chain conversion, WARM can only apply to each row once
> and therefore no sustained performance improvement should be possible
> -- unless rows are regularly being moved to new blocks, in which case
> those updates would "reset" the ability to again perform an update.
> However, one would hope that most updates get done within a single
> block, so that the row-moves-to-new-block case wouldn't happen very
> often.
>
> I'm perplexed.
Yes, I asked the same question in this email:
https://www.postgresql.org/message-id/20170321190000. GE16918@momjian.us
And I've answered it so many times by now :-)
Just to add more to what I just said in another email, note that HOT/WARM chains are created when a new root line pointer is created in the heap (a line pointer that has an index pointing to it). And a new root line pointer is created when a non-HOT/non-WARM update is performed. As soon as you do a non-HOT/non-WARM update, the next update can again be a WARM update even when everything fits in a single block.
That's why for a workload which doesn't do HOT updates and where not all index keys are updated, you'll find every alternate update to a row to be a WARM update, even when there is no chain conversion. That itself can save lots of index bloat, reduce IO on the index and WAL.
Let me know if its still not clear and I can draw some diagrams to explain it.
Thanks,
Pavan
-- Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 28, 2017 at 08:04:34AM +0530, Pavan Deolasee wrote: > And I've answered it so many times by now :-) LOL > Just to add more to what I just said in another email, note that HOT/WARM > chains are created when a new root line pointer is created in the heap (a line > pointer that has an index pointing to it). And a new root line pointer is > created when a non-HOT/non-WARM update is performed. As soon as you do a > non-HOT/non-WARM update, the next update can again be a WARM update even when > everything fits in a single block. > > That's why for a workload which doesn't do HOT updates and where not all index > keys are updated, you'll find every alternate update to a row to be a WARM > update, even when there is no chain conversion. That itself can save lots of > index bloat, reduce IO on the index and WAL. > > Let me know if its still not clear and I can draw some diagrams to explain it. Ah, yes, that does help to explain the 50% because 50% of updates are now HOT/WARM. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Mon, Mar 27, 2017 at 4:45 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Sat, Mar 25, 2017 at 1:24 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Fri, Mar 24, 2017 at 11:49 PM, Pavan Deolasee
> <pavan.deolasee@gmail.com> wrote:
>>
>> On Fri, Mar 24, 2017 at 6:46 PM, Amit Kapila <amit.kapila16@gmail.com>
>> wrote:
>>>
>
>> While looking at this problem, it occurred to me that the assumptions made
>> for hash indexes are also wrong :-( Hash index has the same problem as
>> expression indexes have. A change in heap value may not necessarily cause a
>> change in the hash key. If we don't detect that, we will end up having two
>> hash identical hash keys with the same TID pointer. This will cause the
>> duplicate key scans problem since hashrecheck will return true for both the
>> hash entries.
Isn't it possible to detect duplicate keys in hashrecheck if we
compare both hashkey and tid stored in index tuple with the
corresponding values from heap tuple?
Hmm.. I thought that won't work. For example, say we have a tuple (X, Y, Z) in the heap with a btree index on X and a hash index on Y. If that is updated to (X, Y', Z) and say we do a WARM update and insert a new entry in the hash index. Now if Y and Y' both generate the same hashkey, we will have exactly similar looking <hashkey, TID> tuples in the hash index leading to duplicate key scans.
Thanks,
Pavan
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 28, 2017 at 1:32 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Is the WARM tap test suite supposed to work when applied without all the
other patches? I just tried applied that one and running "make check -C
src/test/modules", and it seems to hang after giving "ok 5" for
t/002_warm_stress.pl. (I had to add a Makefile too, attached.)
Yeah, sorry. Looks like I forgot to git add the Makefile.
BTW just tested on Ubuntu, and it works fine on that too. FWIW I'm using perl v5.22.1 and IPC::Run 0.94 (assuming I got the versions correctly).
$ make -C src/test/modules/warm/ prove-check
make: Entering directory '/home/ubuntu/postgresql/src/test/modules/warm'
rm -rf /home/ubuntu/postgresql/src/test/modules/warm/tmp_check/log
cd . && TESTDIR='/home/ubuntu/postgresql/src/test/modules/warm' PATH="/home/ubuntu/postgresql/tmp_install/home/ubuntu/pg-master-install/bin:$PATH" LD_LIBRARY_PATH="/home/ubuntu/postgresql/tmp_install/home/ubuntu/pg-master-install/lib" PGPORT='65432' PG_REGRESS='/home/ubuntu/postgresql/src/test/modules/warm/../../../../src/test/regress/pg_regress' prove -I ../../../../src/test/perl/ -I . --verbose t/*.pl
t/001_recovery.pl .....
1..2
ok 1 - balanace matches after recovery
ok 2 - sum(delta) matches after recovery
ok
t/002_warm_stress.pl ..
1..10
ok 1 - dummy test passed
ok 2 - Fine match
ok 3 - psql exited normally
ok 4 - psql exited normally
ok 5 - psql exited normally
ok 6 - psql exited normally
ok 7 - psql exited normally
ok 8 - psql exited normally
ok 9 - psql exited normally
ok 10 - Fine match
ok
All tests successful.
Files=2, Tests=12, 22 wallclock secs ( 0.03 usr 0.00 sys + 7.94 cusr 2.41 csys = 10.38 CPU)
Result: PASS
make: Leaving directory '/home/ubuntu/postgresql/src/test/modules/warm'
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Mon, Mar 27, 2017 at 2:19 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > On Fri, Mar 24, 2017 at 11:49 PM, Pavan Deolasee <pavan.deolasee@gmail.com> > wrote: >> >> >> >> On Fri, Mar 24, 2017 at 6:46 PM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: >>> >>> >>> >>> I was worried for the case if the index is created non-default >>> collation, will the datumIsEqual() suffice the need. Now again >>> thinking about it, I think it will because in the index tuple we are >>> storing the value as in heap tuple. However today it occurred to me >>> how will this work for toasted index values (index value > >>> TOAST_INDEX_TARGET). It is mentioned on top of datumIsEqual() that it >>> probably won't work for toasted values. Have you considered that >>> point? >>> >> >> No, I haven't and thanks for bringing that up. And now that I think more >> about it and see the code, I think the naive way of just comparing index >> attribute value against heap values is probably wrong. The example of >> TOAST_INDEX_TARGET is one such case, but I wonder if there are other varlena >> attributes that we might store differently in heap and index. Like >> index_form_tuple() ->heap_fill_tuple seem to some churning for varlena. It's >> not clear to me if index_get_attr will return the values which are binary >> comparable to heap values.. I wonder if calling index_form_tuple on the heap >> values, fetching attributes via index_get_attr on both index tuples and then >> doing a binary compare is a more robust idea. Or may be that's just >> duplicating efforts. >> >> While looking at this problem, it occurred to me that the assumptions made >> for hash indexes are also wrong :-( Hash index has the same problem as >> expression indexes have. A change in heap value may not necessarily cause a >> change in the hash key. If we don't detect that, we will end up having two >> hash identical hash keys with the same TID pointer. This will cause the >> duplicate key scans problem since hashrecheck will return true for both the >> hash entries. That's a bummer as far as supporting WARM for hash indexes is >> concerned, unless we find a way to avoid duplicate index entries. >> > > Revised patches are attached. I've added a few more regression tests which > demonstrates the problems with compressed and toasted attributes. I've now > implemented the idea of creating index tuple from heap values before doing > binary comparison using datumIsEqual. This seems to work ok and I see no > reason this should not be robust. > As asked previously, can you explain me on what basis are you considering it robust? The comments on top of datumIsEqual() clearly indicates the danger of using it for toasted values (Also, it will probably not give the answer you want if either datum has been "toasted".). If you think that because we are using it during heap_update to find modified columns, then I think that is not right comparison, because there we are comparing compressed value (of old tuple) with uncompressed value (of new tuple) which should always give result as false. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Mon, Mar 27, 2017 at 2:19 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > > On Fri, Mar 24, 2017 at 11:49 PM, Pavan Deolasee <pavan.deolasee@gmail.com> > wrote: >> >> >> >> On Fri, Mar 24, 2017 at 6:46 PM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: >>> >>> >>> >>> I was worried for the case if the index is created non-default >>> collation, will the datumIsEqual() suffice the need. Now again >>> thinking about it, I think it will because in the index tuple we are >>> storing the value as in heap tuple. However today it occurred to me >>> how will this work for toasted index values (index value > >>> TOAST_INDEX_TARGET). It is mentioned on top of datumIsEqual() that it >>> probably won't work for toasted values. Have you considered that >>> point? >>> >> >> No, I haven't and thanks for bringing that up. And now that I think more >> about it and see the code, I think the naive way of just comparing index >> attribute value against heap values is probably wrong. The example of >> TOAST_INDEX_TARGET is one such case, but I wonder if there are other varlena >> attributes that we might store differently in heap and index. Like >> index_form_tuple() ->heap_fill_tuple seem to some churning for varlena. It's >> not clear to me if index_get_attr will return the values which are binary >> comparable to heap values.. I wonder if calling index_form_tuple on the heap >> values, fetching attributes via index_get_attr on both index tuples and then >> doing a binary compare is a more robust idea. Or may be that's just >> duplicating efforts. >> >> While looking at this problem, it occurred to me that the assumptions made >> for hash indexes are also wrong :-( Hash index has the same problem as >> expression indexes have. A change in heap value may not necessarily cause a >> change in the hash key. If we don't detect that, we will end up having two >> hash identical hash keys with the same TID pointer. This will cause the >> duplicate key scans problem since hashrecheck will return true for both the >> hash entries. That's a bummer as far as supporting WARM for hash indexes is >> concerned, unless we find a way to avoid duplicate index entries. >> > > Revised patches are attached. > Noted few cosmetic issues in 0005_warm_updates_v21: 1. pruneheap.c(939): warning C4098: 'heap_get_root_tuples' : 'void' function returning a value 2. + * HCWC_WARM_UPDATED_TUPLE - a tuple with HEAP_WARM_UPDATED is found somewhere + * in the chain. Note that when a tuple is WARM + * updated, both old and new versions are marked + * with this flag/ + * + * HCWC_WARM_TUPLE - a tuple with HEAP_WARM_TUPLE is found somewhere in + * the chain. + * + * HCWC_CLEAR_TUPLE - a tuple without HEAP_WARM_TUPLE is found somewhere in + * the chain. Description of all three flags is same. 3. + * HCWC_WARM_UPDATED_TUPLE - a tuple with HEAP_WARM_UPDATED is found somewhere + * in the chain. Note that when a tuple is WARM + * updated, both old and new versions are marked + * with this flag/ Spurious '/' at end of line. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Mar 28, 2017 at 4:05 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Mon, Mar 27, 2017 at 2:19 PM, Pavan Deolasee > <pavan.deolasee@gmail.com> wrote: >> On Fri, Mar 24, 2017 at 11:49 PM, Pavan Deolasee <pavan.deolasee@gmail.com> >> wrote: >>> >>> >>> >>> On Fri, Mar 24, 2017 at 6:46 PM, Amit Kapila <amit.kapila16@gmail.com> >>> wrote: >>>> >>>> >>>> >>>> I was worried for the case if the index is created non-default >>>> collation, will the datumIsEqual() suffice the need. Now again >>>> thinking about it, I think it will because in the index tuple we are >>>> storing the value as in heap tuple. However today it occurred to me >>>> how will this work for toasted index values (index value > >>>> TOAST_INDEX_TARGET). It is mentioned on top of datumIsEqual() that it >>>> probably won't work for toasted values. Have you considered that >>>> point? >>>> >>> >>> No, I haven't and thanks for bringing that up. And now that I think more >>> about it and see the code, I think the naive way of just comparing index >>> attribute value against heap values is probably wrong. The example of >>> TOAST_INDEX_TARGET is one such case, but I wonder if there are other varlena >>> attributes that we might store differently in heap and index. Like >>> index_form_tuple() ->heap_fill_tuple seem to some churning for varlena. It's >>> not clear to me if index_get_attr will return the values which are binary >>> comparable to heap values.. I wonder if calling index_form_tuple on the heap >>> values, fetching attributes via index_get_attr on both index tuples and then >>> doing a binary compare is a more robust idea. Or may be that's just >>> duplicating efforts. >>> >>> While looking at this problem, it occurred to me that the assumptions made >>> for hash indexes are also wrong :-( Hash index has the same problem as >>> expression indexes have. A change in heap value may not necessarily cause a >>> change in the hash key. If we don't detect that, we will end up having two >>> hash identical hash keys with the same TID pointer. This will cause the >>> duplicate key scans problem since hashrecheck will return true for both the >>> hash entries. That's a bummer as far as supporting WARM for hash indexes is >>> concerned, unless we find a way to avoid duplicate index entries. >>> >> >> Revised patches are attached. I've added a few more regression tests which >> demonstrates the problems with compressed and toasted attributes. I've now >> implemented the idea of creating index tuple from heap values before doing >> binary comparison using datumIsEqual. This seems to work ok and I see no >> reason this should not be robust. >> > > As asked previously, can you explain me on what basis are you > considering it robust? The comments on top of datumIsEqual() clearly > indicates the danger of using it for toasted values (Also, it will > probably not give the answer you want if either datum has been > "toasted".). If you think that because we are using it during > heap_update to find modified columns, then I think that is not right > comparison, because there we are comparing compressed value (of old > tuple) with uncompressed value (of new tuple) which should always give > result as false. > Yet another point to think about the recheck implementation is will it work correctly when heap tuple itself is toasted. Consider a case where table has integer and text column (t1 (c1 int, c2 text)) and we have indexes on c1 and c2 columns. Now, insert a tuple such that the text column has value more than 2 or 3K which will make it stored in compressed form in heap (and the size of compressed value is still more than TOAST_INDEX_TARGET). For such an heap insert, we will pass the actual value of column to index_form_tuple during index insert. However during recheck when we fetch the value of c2 from heap tuple and pass it index tuple, the value is already in compressed form and index_form_tuple might again try to compress it because the size will still be greater than TOAST_INDEX_TARGET and if it does so, it might make recheck fail. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Mon, Mar 27, 2017 at 10:25 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > On Tue, Mar 28, 2017 at 1:59 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Thu, Mar 23, 2017 at 2:47 PM, Pavan Deolasee >> <pavan.deolasee@gmail.com> wrote: >> > It's quite hard to say that until we see many more benchmarks. As author >> > of >> > the patch, I might have got repetitive with my benchmarks. But I've seen >> > over 50% improvement in TPS even without chain conversion (6 indexes on >> > a 12 >> > column table test). >> >> This seems quite mystifying. What can account for such a large >> performance difference in such a pessimal scenario? It seems to me >> that without chain conversion, WARM can only apply to each row once >> and therefore no sustained performance improvement should be possible >> -- unless rows are regularly being moved to new blocks, in which case >> those updates would "reset" the ability to again perform an update. >> However, one would hope that most updates get done within a single >> block, so that the row-moves-to-new-block case wouldn't happen very >> often. > > I think you're confusing between update chains that stay within a block vs > HOT/WARM chains. Even when the entire update chain stays within a block, it > can be made up of multiple HOT/WARM chains and each of these chains offer > ability to do one WARM update. So even without chain conversion, every > alternate update will be a WARM update. So the gains are perpetual. You're right, I had overlooked that. But then I'm confused: how does the chain conversion stuff help as much as it does? You said that you got a 50% improvement from WARM, because we got to skip half the index updates. But then you said with chain conversion you got an improvement of more like 100%. However, I would think that on this workload, chain conversion shouldn't save much. If you're sweeping through the database constantly performing updates, the updates ought to be a lot more frequent than the vacuums. No? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi Pavan, On 3/28/17 11:04 AM, Robert Haas wrote: > On Mon, Mar 27, 2017 at 10:25 PM, Pavan Deolasee > <pavan.deolasee@gmail.com> wrote: >> On Tue, Mar 28, 2017 at 1:59 AM, Robert Haas <robertmhaas@gmail.com> wrote: >>> On Thu, Mar 23, 2017 at 2:47 PM, Pavan Deolasee >>> <pavan.deolasee@gmail.com> wrote: >>>> It's quite hard to say that until we see many more benchmarks. As author >>>> of >>>> the patch, I might have got repetitive with my benchmarks. But I've seen >>>> over 50% improvement in TPS even without chain conversion (6 indexes on >>>> a 12 >>>> column table test). >>> >>> This seems quite mystifying. What can account for such a large >>> performance difference in such a pessimal scenario? It seems to me >>> that without chain conversion, WARM can only apply to each row once >>> and therefore no sustained performance improvement should be possible >>> -- unless rows are regularly being moved to new blocks, in which case >>> those updates would "reset" the ability to again perform an update. >>> However, one would hope that most updates get done within a single >>> block, so that the row-moves-to-new-block case wouldn't happen very >>> often. >> >> I think you're confusing between update chains that stay within a block vs >> HOT/WARM chains. Even when the entire update chain stays within a block, it >> can be made up of multiple HOT/WARM chains and each of these chains offer >> ability to do one WARM update. So even without chain conversion, every >> alternate update will be a WARM update. So the gains are perpetual. > > You're right, I had overlooked that. But then I'm confused: how does > the chain conversion stuff help as much as it does? You said that you > got a 50% improvement from WARM, because we got to skip half the index > updates. But then you said with chain conversion you got an > improvement of more like 100%. However, I would think that on this > workload, chain conversion shouldn't save much. If you're sweeping > through the database constantly performing updates, the updates ought > to be a lot more frequent than the vacuums. > > No? It appears that a patch is required to address Amit's review. I have marked this as "Waiting for Author". Thanks, -- -David david@pgmasters.net
On Tue, Mar 28, 2017 at 4:05 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
As asked previously, can you explain me on what basis are you
considering it robust? The comments on top of datumIsEqual() clearly
indicates the danger of using it for toasted values (Also, it will
probably not give the answer you want if either datum has been
"toasted".).
Hmm. I don' see why the new code in recheck is unsafe. The index values themselves can't be toasted (IIUC), but they can be compressed. index_form_tuple() already untoasts any toasted heap attributes and compresses them if needed. So once we pass heap values via index_form_tuple() we should have exactly the same index values as they were inserted. Or am I missing something obvious here?
If you think that because we are using it during
heap_update to find modified columns, then I think that is not right
comparison, because there we are comparing compressed value (of old
tuple) with uncompressed value (of new tuple) which should always give
result as false.
Hmm, this seems like a problem. While HOT could tolerate occasional false results (i.e. reporting a heap column as modified even though it it not), WARM assumes that if the heap has reported different values, then they better be different and should better result in different index values. Because that's how recheck later works. Since index expressions are not supported, I wonder if toasted heap values are the only remaining problem in this area. So heap_tuple_attr_equals() should first detoast the heap values and then do the comparison. I already have a test case that fails for this reason, so let me try this approach.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 28, 2017 at 4:07 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
-- Noted few cosmetic issues in 0005_warm_updates_v21:
1.
pruneheap.c(939): warning C4098: 'heap_get_root_tuples' : 'void'
function returning a value
Thanks. Will fix.
2.
+ * HCWC_WARM_UPDATED_TUPLE - a tuple with HEAP_WARM_UPDATED is found somewhere
+ * in the chain. Note that when a tuple is WARM
+ * updated, both old and new versions are marked
+ * with this flag/
+ *
+ * HCWC_WARM_TUPLE - a tuple with HEAP_WARM_TUPLE is found somewhere in
+ * the chain.
+ *
+ * HCWC_CLEAR_TUPLE - a tuple without HEAP_WARM_TUPLE is found somewhere in
+ * the chain.
Description of all three flags is same.
Well the description is different (and correct), but given that it confused you, I think I should rewrite those comments. Will do.
3.
+ * HCWC_WARM_UPDATED_TUPLE - a tuple with HEAP_WARM_UPDATED is found somewhere
+ * in the chain. Note that when a tuple is WARM
+ * updated, both old and new versions are marked
+ * with this flag/
Spurious '/' at end of line.
Thanks. Will fix.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 28, 2017 at 7:04 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
For such an heap insert, we will pass
the actual value of column to index_form_tuple during index insert.
However during recheck when we fetch the value of c2 from heap tuple
and pass it index tuple, the value is already in compressed form and
index_form_tuple might again try to compress it because the size will
still be greater than TOAST_INDEX_TARGET and if it does so, it might
make recheck fail.
Would it? I thought "if (!VARATT_IS_EXTENDED(DatumGetPointer(untoasted_values[i]))" check should prevent that. But I could be reading those macros wrong. They are probably heavily uncommented and it's not clear what each of those VARATT_* macro do.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 28, 2017 at 8:34 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Mon, Mar 27, 2017 at 10:25 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> On Tue, Mar 28, 2017 at 1:59 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>> On Thu, Mar 23, 2017 at 2:47 PM, Pavan Deolasee
>> <pavan.deolasee@gmail.com> wrote:
>> > It's quite hard to say that until we see many more benchmarks. As author
>> > of
>> > the patch, I might have got repetitive with my benchmarks. But I've seen
>> > over 50% improvement in TPS even without chain conversion (6 indexes on
>> > a 12
>> > column table test).
>>
>> This seems quite mystifying. What can account for such a large
>> performance difference in such a pessimal scenario? It seems to me
>> that without chain conversion, WARM can only apply to each row once
>> and therefore no sustained performance improvement should be possible
>> -- unless rows are regularly being moved to new blocks, in which case
>> those updates would "reset" the ability to again perform an update.
>> However, one would hope that most updates get done within a single
>> block, so that the row-moves-to-new-block case wouldn't happen very
>> often.
>
> I think you're confusing between update chains that stay within a block vs
> HOT/WARM chains. Even when the entire update chain stays within a block, it
> can be made up of multiple HOT/WARM chains and each of these chains offer
> ability to do one WARM update. So even without chain conversion, every
> alternate update will be a WARM update. So the gains are perpetual.
You're right, I had overlooked that. But then I'm confused: how does
the chain conversion stuff help as much as it does? You said that you
got a 50% improvement from WARM, because we got to skip half the index
updates. But then you said with chain conversion you got an
improvement of more like 100%. However, I would think that on this
workload, chain conversion shouldn't save much. If you're sweeping
through the database constantly performing updates, the updates ought
to be a lot more frequent than the vacuums.
No?
Unfortunately these tests were done on different hardware, with different settings and even slightly different scale factors. So they may not be exactly comparable. But there is no doubt chain conversion will help to some extent. I'll repeat the benchmark with chain conversion turned off and report the exact difference.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
I pushed 0002 after some makeup, since it's just cosmetic and not controversial. Here's 0003 rebased on top of it. (Also, I took out the gin and gist changes: it would be wrong to change that unconditionally, because the 0xFFFF pattern appears in indexes that would be pg_upgraded. We need a different strategy, if we want to enable WARM on GiST/GIN indexes.) -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Mar 29, 2017 at 3:42 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
I pushed 0002 after some makeup, since it's just cosmetic and not
controversial.
Thanks. I think your patch of tracking interesting attributes seems ok too after the performance issue was addressed. Even though we can still improve that further, at least Mithun confirmed that there is no significant regression anymore and in fact for one artificial case, patch does better than even master.
Here's 0003 rebased on top of it.
(Also, I took out the gin and gist changes: it would be wrong to change
that unconditionally, because the 0xFFFF pattern appears in indexes that
would be pg_upgraded. We need a different strategy, if we want to
enable WARM on GiST/GIN indexes.)
BTW we have messed up patch names a bit here. You applied 0003 from v21 and rebased 0004. But the rebased patch was named 0001-Free-3-bits-of-ItemPointerData.ip_posid.patch. I'm reverting back to the earlier used names. So rebased v22 set of patches attached.
0001_interesting_attrs_v22.patch - Alvaro's patch of simplifying attr checks. I think this has settled down
0002_track_root_lp_v22 - We probably need to decide whether its worth saving a bit in tuple header for additional work during WARM update of finding root tuple.
0004_Free-3-bits-of-ItemPointerData.ip_posid_v22 - A slight update to Alvaro's rebased version posted yesterday
0005_warm_updates_v22 - Main WARM patch. Addresses all review comments so far and includes fixes for toasted value handling
0007_vacuum_enhancements_v22 - VACUUM enhancements to control WARM cleanup. This now also includes changes made to memory usage. The dead tuples and warm chains are tracked in a single work area, from two ends. When these ends meet, we do a round of index cleanup. IMO this should give us most optimal utilisation of available memory depending on whether we are doing WARM cleanup or not and percentage of dead tuples and warm chains.
0006_warm_taptests_v22 - Alvaro reported lack of Makefile. It also seemed that he wants to rename it to avoid "warm" reference. So done that, but Alvaro is seeing hangs with the tests in his environment, so probably needs some investigation. It works for me with IPC::Run 0.94
Thanks,
Pavan
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Tue, Mar 28, 2017 at 10:35 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > On Tue, Mar 28, 2017 at 7:04 PM, Amit Kapila <amit.kapila16@gmail.com> > wrote: >> >> >> >> For such an heap insert, we will pass >> the actual value of column to index_form_tuple during index insert. >> However during recheck when we fetch the value of c2 from heap tuple >> and pass it index tuple, the value is already in compressed form and >> index_form_tuple might again try to compress it because the size will >> still be greater than TOAST_INDEX_TARGET and if it does so, it might >> make recheck fail. >> > > Would it? I thought "if > (!VARATT_IS_EXTENDED(DatumGetPointer(untoasted_values[i]))" check should > prevent that. But I could be reading those macros wrong. They are probably > heavily uncommented and it's not clear what each of those VARATT_* macro do. > That won't handle the case where it is simply compressed. You need check like VARATT_IS_COMPRESSED to take care of compressed heap tuples, but then also it won't work because heap_tuple_fetch_attr() doesn't handle compressed tuples. You need to use heap_tuple_untoast_attr() to handle the compressed case. Also, we probably need to handle other type of var attrs. Now, If we want to do all of that index_form_tuple() might not be the right place, we probably want to handle it in caller or provide an alternate API. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Mar 29, 2017 at 11:52 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Tue, Mar 28, 2017 at 10:35 PM, Pavan Deolasee > <pavan.deolasee@gmail.com> wrote: >> >> On Tue, Mar 28, 2017 at 7:04 PM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: >>> >>> For such an heap insert, we will pass >>> the actual value of column to index_form_tuple during index insert. >>> However during recheck when we fetch the value of c2 from heap tuple >>> and pass it index tuple, the value is already in compressed form and >>> index_form_tuple might again try to compress it because the size will >>> still be greater than TOAST_INDEX_TARGET and if it does so, it might >>> make recheck fail. >>> >> >> Would it? I thought "if >> (!VARATT_IS_EXTENDED(DatumGetPointer(untoasted_values[i]))" check should >> prevent that. But I could be reading those macros wrong. They are probably >> heavily uncommented and it's not clear what each of those VARATT_* macro do. >> > > That won't handle the case where it is simply compressed. You need > check like VARATT_IS_COMPRESSED to take care of compressed heap > tuples, but then also it won't work because heap_tuple_fetch_attr() > doesn't handle compressed tuples. You need to use > heap_tuple_untoast_attr() to handle the compressed case. Also, we > probably need to handle other type of var attrs. Now, If we want to > do all of that index_form_tuple() might not be the right place, we > probably want to handle it in caller or provide an alternate API. > Another related, index_form_tuple() has a check for VARATT_IS_EXTERNAL not VARATT_IS_EXTENDED, so may be that is cause of confusion for you, but as I mentioned even if you change the check heap_tuple_fetch_attr won't suffice the need. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Mar 28, 2017 at 10:31 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > On Tue, Mar 28, 2017 at 4:05 PM, Amit Kapila <amit.kapila16@gmail.com> > wrote: >> >> As asked previously, can you explain me on what basis are you >> considering it robust? The comments on top of datumIsEqual() clearly >> indicates the danger of using it for toasted values (Also, it will >> probably not give the answer you want if either datum has been >> "toasted".). > > > Hmm. I don' see why the new code in recheck is unsafe. The index values > themselves can't be toasted (IIUC), but they can be compressed. > index_form_tuple() already untoasts any toasted heap attributes and > compresses them if needed. So once we pass heap values via > index_form_tuple() we should have exactly the same index values as they were > inserted. Or am I missing something obvious here? > I don't think relying on datum comparison for compressed values from heap and index is safe (even after you try to form index tuple from heap value again during recheck) and I have mentioned one of the hazards of doing so upthread. Do you see any place else where we rely on comparison of compressed values? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Mar 29, 2017 at 12:02 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Wed, Mar 29, 2017 at 11:52 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Tue, Mar 28, 2017 at 10:35 PM, Pavan Deolasee
> <pavan.deolasee@gmail.com> wrote:
>>
>> On Tue, Mar 28, 2017 at 7:04 PM, Amit Kapila <amit.kapila16@gmail.com>
>> wrote:
>>>
>>> For such an heap insert, we will pass
>>> the actual value of column to index_form_tuple during index insert.
>>> However during recheck when we fetch the value of c2 from heap tuple
>>> and pass it index tuple, the value is already in compressed form and
>>> index_form_tuple might again try to compress it because the size will
>>> still be greater than TOAST_INDEX_TARGET and if it does so, it might
>>> make recheck fail.
>>>
>>
>> Would it? I thought "if
>> (!VARATT_IS_EXTENDED(DatumGetPointer(untoasted_ values[i]))" check should
>> prevent that. But I could be reading those macros wrong. They are probably
>> heavily uncommented and it's not clear what each of those VARATT_* macro do.
>>
>
> That won't handle the case where it is simply compressed. You need
> check like VARATT_IS_COMPRESSED to take care of compressed heap
> tuples, but then also it won't work because heap_tuple_fetch_attr()
> doesn't handle compressed tuples. You need to use
> heap_tuple_untoast_attr() to handle the compressed case. Also, we
> probably need to handle other type of var attrs. Now, If we want to
> do all of that index_form_tuple() might not be the right place, we
> probably want to handle it in caller or provide an alternate API.
>
Another related, index_form_tuple() has a check for VARATT_IS_EXTERNAL
not VARATT_IS_EXTENDED, so may be that is cause of confusion for you,
but as I mentioned even if you change the check heap_tuple_fetch_attr
won't suffice the need.
I am confused :-(
Assuming big-endian machine:
VARATT_IS_4B_U - !toasted && !compressed
VARATT_IS_4B_C - compressed (may or may not be toasted)
VARATT_IS_4B - !toasted (may or may not be compressed)
VARATT_IS_1B_E - toasted
#define VARATT_IS_EXTERNAL(PTR) VARATT_IS_1B_E(PTR)
#define VARATT_IS_EXTENDED(PTR) (!VARATT_IS_4B_U(PTR))
So VARATT_IS_EXTENDED means that the value is (toasted || compressed). If we are looking at a value from the heap (untoasted) then it implies in-heap compression. If we are looking at untoasted value, then it means compression in the toast.
index_form_tuple() first checks if the value is externally toasted and fetches the untoasted value if so. After that it checks if !VARATT_IS_EXTENDED i.e. if the value is (!toasted && !compressed) and then only try to apply compression on that. It can't be a toasted value because if it was, we just untoasted it. But it can be compressed either in the heap or in the toast, in which case we don't try to compress it again. That makes sense because if the value is already compressed there is not point applying compression again.
Now what you're suggesting (it seems) is that when in-heap compression is used and ExecInsertIndexTuples calls FormIndexDatum to create index tuple values, it always passes uncompressed heap values. So when the index tuple is originally inserted, it index_form_tuple() will try to compress it and see if it fits in the index.
Then during recheck, we pass already compressed values to index_form_tuple(). But my point is, the following code will ensure that we don't compress it again. My reading is that the first check for !VARATT_IS_EXTENDED will return false if the value is already compressed.
/*
* If value is above size target, and is of a compressible datatype,
* try to compress it in-line.
*/
if (!VARATT_IS_EXTENDED(DatumGetPointer(untoasted_values[i])) &&
VARSIZE(DatumGetPointer(untoasted_values[i])) > TOAST_INDEX_TARGET &&
(att->attstorage == 'x' || att->attstorage == 'm'))
{
Datum cvalue = toast_compress_datum(untoasted_values[i]);
if (DatumGetPointer(cvalue) != NULL)
{
/* successful compression */
if (untoasted_free[i])
pfree(DatumGetPointer(untoasted_values[i]));
untoasted_values[i] = cvalue;
untoasted_free[i] = true;
}
}
TBH I couldn't find why the original index insertion code will always supply uncompressed values. But even if does, and even if the recheck gets it in compressed form, I don't see how we will double-compress that.
As far as, comparing two compressed values go, I don't see a problem there. Exact same compressed values should decompress to exact same value. So comparing two compressed values and two uncompressed values should give us the same result.
Would you mind creating a test case to explain the situation? I added a few more test cases to src/test/regress/sql/warm.sql and it also shows how to check for duplicate key scans. If you could come up with a case that shows the problem, it will help immensely.
Thanks,
Pavan
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Mar 29, 2017 at 1:10 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
>
> On Wed, Mar 29, 2017 at 12:02 PM, Amit Kapila <amit.kapila16@gmail.com>
> wrote:
>>
>> On Wed, Mar 29, 2017 at 11:52 AM, Amit Kapila <amit.kapila16@gmail.com>
>> wrote:
>
> Then during recheck, we pass already compressed values to
> index_form_tuple(). But my point is, the following code will ensure that we
> don't compress it again. My reading is that the first check for
> !VARATT_IS_EXTENDED will return false if the value is already compressed.
>
You are right. I was confused with previous check of VARATT_IS_EXTERNAL.
>
> TBH I couldn't find why the original index insertion code will always supply
> uncompressed values.
>
Just try by inserting large value of text column ('aaaaaa.....bbb')
upto 2.5K. Then have a breakpoint in heap_prepare_insert and
index_form_tuple, and debug both the functions, you can find out that
even though we compress during insertion in heap, the index will
compress the original value again.
> But even if does, and even if the recheck gets it in
> compressed form, I don't see how we will double-compress that.
>
No as I agreed above, it won't double-compress, but still looks
slightly risky to rely on different set of values passed to
index_form_tuple and then compare them.
> As far as, comparing two compressed values go, I don't see a problem there.
> Exact same compressed values should decompress to exact same value. So
> comparing two compressed values and two uncompressed values should give us
> the same result.
>
Yeah probably you are right, but I am not sure if it is good idea to
compare compressed values.
I think with this new changes in btrecheck, it would appear to be much
costlier as compare to what you have few versions back. I am afraid
that it can impact performance for cases where there are few WARM
updates in chain and many HOT updates as it will run recheck for all
such updates. Did we any time try to measure the performance of cases
like that?
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Wed, Mar 29, 2017 at 7:12 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > No as I agreed above, it won't double-compress, but still looks > slightly risky to rely on different set of values passed to > index_form_tuple and then compare them. It assumes that the compressor is completely deterministic, which I'm fairly is true today, but might be false in the future. For example: https://groups.google.com/forum/#!topic/snappy-compression/W8v_ydnEPuc We've talked about using snappy as a compression algorithm before, and if the above post is correct, an upgrade to the snappy library version is an example of a change that would break the assumption in question. I think it's generally true for almost any modern compression algorithm (including pglz) that there are multiple compressed texts that would decompress to the same uncompressed text. Any algorithm is required to promise that it will always produce one of the compressed texts that decompress back to the original, but not necessarily that it will always produce the same one. As another example of this, consider that zlib (gzip) has a variety of options to control compression behavior, such as, most obviously, the compression level (1 .. 9). -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Pavan Deolasee wrote: > On Wed, Mar 29, 2017 at 3:42 AM, Alvaro Herrera <alvherre@2ndquadrant.com> > wrote: > > > I pushed 0002 after some makeup, since it's just cosmetic and not > > controversial. > > Thanks. I think your patch of tracking interesting attributes seems ok too > after the performance issue was addressed. Even though we can still improve > that further, at least Mithun confirmed that there is no significant > regression anymore and in fact for one artificial case, patch does better > than even master. Great, thanks. I pushed it, too. One optimization we could try is using slot deform instead of repeated heap_getattr(). Patch is attached. I haven't benchmarked it. On top of that, but perhaps getting in the realm of excessive complication, we could see if the bitmapset is a singleton, and if it is then do heap_getattr without creating the slot. That'd require to have a second copy of heap_tuple_attr_equals() that takes a HeapTuple instead of a TupleTableSlot. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On Wed, Mar 29, 2017 at 11:51 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > Thanks. I think your patch of tracking interesting attributes seems ok too > after the performance issue was addressed. Even though we can still improve > that further, at least Mithun confirmed that there is no significant > regression anymore and in fact for one artificial case, patch does better > than even master. I was trying to compile these patches on latest head(f90d23d0c51895e0d7db7910538e85d3d38691f0) for some testing but I was not able to compile it. make[3]: *** [postgres.bki] Error 1 make[3]: Leaving directory `/home/dilip/work/pg_codes/pbms_final/postgresql/src/backend/catalog' make[2]: *** [submake-schemapg] Error 2 make[2]: Leaving directory `/home/dilip/work/pg_codes/pbms_final/postgresql/src/backend' make[1]: *** [all-backend-recurse] Error 2 make[1]: Leaving directory `/home/dilip/work/pg_codes/pbms_final/postgresql/src' make: *** [all-src-recurse] Error 2 I tried doing maintainer-clean, deleting postgres.bki but still the same error. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Mar 29, 2017 at 4:42 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
(Results with 5 mins tests, txns is total for 5 mins, idx_scan is number of scans on the fat index)
On Wed, Mar 29, 2017 at 1:10 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
>
> On Wed, Mar 29, 2017 at 12:02 PM, Amit Kapila <amit.kapila16@gmail.com>
> wrote:
>>
>> On Wed, Mar 29, 2017 at 11:52 AM, Amit Kapila <amit.kapila16@gmail.com>
>> wrote:
>
> Then during recheck, we pass already compressed values to
> index_form_tuple(). But my point is, the following code will ensure that we
> don't compress it again. My reading is that the first check for
> !VARATT_IS_EXTENDED will return false if the value is already compressed.
>
You are right. I was confused with previous check of VARATT_IS_EXTERNAL.
Ok, thanks.
>
> TBH I couldn't find why the original index insertion code will always supply
> uncompressed values.
>
Just try by inserting large value of text column ('aaaaaa.....bbb')
upto 2.5K. Then have a breakpoint in heap_prepare_insert and
index_form_tuple, and debug both the functions, you can find out that
even though we compress during insertion in heap, the index will
compress the original value again.
Ok, tried that. AFAICS index_form_tuple gets compressed values.
Yeah probably you are right, but I am not sure if it is good idea to
compare compressed values.
Again, I don't see a problem there.
I think with this new changes in btrecheck, it would appear to be much
costlier as compare to what you have few versions back. I am afraid
that it can impact performance for cases where there are few WARM
updates in chain and many HOT updates as it will run recheck for all
such updates.
My feeling is that the recheck could be costly for very fat indexes, but not doing WARM could be costly too for such indexes. We can possibly construct a worst case where
1. set up a table with a fat index.
2. do a WARM update to a tuple
3. then do several HOT updates to the same tuple
4. query the row via the fat index.
Initialisation:
-- Adjust parameters to force index scans
-- enable_seqscan to false
-- seq_page_cost = 10000
DROP TABLE IF EXISTS pgbench_accounts;
CREATE TABLE pgbench_accounts (
aid text,
bid bigint,
abalance bigint,
filler1 text DEFAULT md5(random()::text),
filler2 text DEFAULT md5(random()::text),
filler3 text DEFAULT md5(random()::text),
filler4 text DEFAULT md5(random()::text),
filler5 text DEFAULT md5(random()::text),
filler6 text DEFAULT md5(random()::text),
filler7 text DEFAULT md5(random()::text),
filler8 text DEFAULT md5(random()::text),
filler9 text DEFAULT md5(random()::text),
filler10 text DEFAULT md5(random()::text),
filler11 text DEFAULT md5(random()::text),
filler12 text DEFAULT md5(random()::text)
) WITH (fillfactor=90);
\set end 0
\set start (:end + 1)
\set end (:start + (:scale * 100))
INSERT INTO pgbench_accounts SELECT generate_series(:start, :end )::text || <2300 chars string>, (random()::bigint) % :scale, 0;
CREATE UNIQUE INDEX pgb_a_aid ON pgbench_accounts(aid);
CREATE INDEX pgb_a_filler1 ON pgbench_accounts(filler1);
CREATE INDEX pgb_a_filler2 ON pgbench_accounts(filler2);
CREATE INDEX pgb_a_filler3 ON pgbench_accounts(filler3);
CREATE INDEX pgb_a_filler4 ON pgbench_accounts(filler4);
-- Force a WARM update on one row
UPDATE pgbench_accounts SET filler1 = 'X' WHERE aid = '100' || repeat('abcdefghij', 20000);
Test:
-- Fetch the row using the fat index. Since the row contains a
BEGIN;
SELECT substring(aid, 1, 10) FROM pgbench_accounts WHERE aid = '100' || <2300 chars string> ORDER BY aid;
UPDATE pgbench_accounts SET abalance = abalance + 100 WHERE aid = '100' || <2300 chars string>;
END;
I did 4 5-minutes runs with master and WARM and there is probably a 2-3% regression.
master:
txns idx_scan
414117 828233
411109 822217
411848 823695
408424 816847
WARM:
txns idx_scan
404139 808277
398880 797759
399949 799897
397927 795853
==========
I then also repeated the tests, but this time using compressible values. The regression in this case is much higher, may be 15% or more.
INSERT INTO pgbench_accounts SELECT generate_series(:start, :end )::text || repeat('abcdefghij', 20000), (random()::bigint) % :scale, 0;
-- Fetch the row using the fat index. Since the row contains a
BEGIN;
SELECT substring(aid, 1, 10) FROM pgbench_accounts WHERE aid = '100' || repeat('abcdefghij', 20000) ORDER BY aid;
UPDATE pgbench_accounts SET abalance = abalance + 100 WHERE aid = '100' || repeat('abcdefghij', 20000);
END;
(Results with 5 mins tests, txns is total for 5 mins, idx_scan is number of scans on the fat index)
master:
master:
txns idx_scan
56976 113953
56822 113645
56915 113831
56865 113731
WARM:
txns idx_scan
49044 98087
49020 98039
49007 98013
49006 98011
But TBH I believe this regression is coming from the changes to heap_tuple_attr_equals where we are decompressing both old and new values and then comparing them. For 200K bytes long values, that must be something. Another reason why I think so is because I accidentally did one run which did not use index scans and did not perform any WARM updates, but the regression was kinda similar. So that makes me think that the regression is coming from somewhere else and change in heap_tuple_attr_equals seems like a good candidate.
I think we can fix that by comparing compressed values. I know you had raised concerns, but Robert confirmed that (IIUC) it's not a problem today. We will figure out how to deal with it if we ever add support for different compression algorithms or compression levels. And I also think this is kinda synthetic use case and the fact that there is not much regression with indexes as large as 2K bytes seems quite comforting to me.
===========
Apart from this, I also ran some benchmarks by removing index on the abalance column in my test suite so that all updates are HOT updates. I did not find any regression in that scenario. WARM was a percentage or more better, but I assume that's just noise. These benchmarks were done on scale factor 100, running for 1hr each. Headline numbers are:
WARM: 5802 txns/sec
master: 5719 txns/sec.
===========
Another workload where WARM could cause regression is where there are many indexes on a table and UPDATEs update all but one indexes. We will do WARM update in this case but since N-1 indexes will anyways get a new index entry, benefits of WARM will be marginal. There will be increased cost of AV because we will scan N-1 indexes for cleanup.
While this could be an atypical workload, its probably worth to guard against this. I propose that we stop WARM at the source if we detect that more than certain percentage of indexes will be updated by an UPDATE statement. Of course, we can be more fancy and look at each index structure and arrive at a cost model. But a simple 50% rule seems a good starting point. So if an UPDATE is going to modify more than 50% indexes, do a non-WARM update. Attached patch adds that support.
I ran tests by modifying the benchmark used for previous tests by adding abalance column to all indexes except one on aid. With the patch applied, there are zero WARM updates on the table (as expected). The headline numbers are:
master: 4101 txns/sec
WARM: 4033 txns/sec
So probably within acceptable range.
============
Finally, I tested another workload where we have total 6 indexes and 3 of them are modified by each UPDATE and 3 are not. Ran it with scale factor 100 for 1hr each. The headline numbers:
master: 3679 txns/sec (I don't see a reason why master should worse compared to 5 index update case, so probably needs more runs to check aberration)
WARM: 4050 txns/sec (not much difference from no WARM update case, but since master degenerated, probably worth doing another round.. I am using AWS instance and it's not first time I am seeing aberrations).
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Thu, Mar 30, 2017 at 3:29 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
On Wed, Mar 29, 2017 at 11:51 AM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> Thanks. I think your patch of tracking interesting attributes seems ok too
> after the performance issue was addressed. Even though we can still improve
> that further, at least Mithun confirmed that there is no significant
> regression anymore and in fact for one artificial case, patch does better
> than even master.
I was trying to compile these patches on latest
head(f90d23d0c51895e0d7db7910538e85 d3d38691f0) for some testing but I
was not able to compile it.
make[3]: *** [postgres.bki] Error 1
Looks like OID conflict to me.. Please try rebased set.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Thu, Mar 30, 2017 at 4:07 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
>
> On Wed, Mar 29, 2017 at 4:42 PM, Amit Kapila <amit.kapila16@gmail.com>
> wrote:
>>
>> On Wed, Mar 29, 2017 at 1:10 PM, Pavan Deolasee
>> <pavan.deolasee@gmail.com> wrote:
>> >
>> > On Wed, Mar 29, 2017 at 12:02 PM, Amit Kapila <amit.kapila16@gmail.com>
>> > wrote:
>> >>
>> >> On Wed, Mar 29, 2017 at 11:52 AM, Amit Kapila <amit.kapila16@gmail.com>
>> >> wrote:
>> >
>> > Then during recheck, we pass already compressed values to
>> > index_form_tuple(). But my point is, the following code will ensure that
>> > we
>> > don't compress it again. My reading is that the first check for
>> > !VARATT_IS_EXTENDED will return false if the value is already
>> > compressed.
>> >
>>
>> You are right. I was confused with previous check of VARATT_IS_EXTERNAL.
>>
>
> Ok, thanks.
>
>>
>> >
>> > TBH I couldn't find why the original index insertion code will always
>> > supply
>> > uncompressed values.
>> >
>>
>> Just try by inserting large value of text column ('aaaaaa.....bbb')
>> upto 2.5K. Then have a breakpoint in heap_prepare_insert and
>> index_form_tuple, and debug both the functions, you can find out that
>> even though we compress during insertion in heap, the index will
>> compress the original value again.
>>
>
> Ok, tried that. AFAICS index_form_tuple gets compressed values.
>
How have you verified that? Have you checked that in
heap_prepare_insert it has called toast_insert_or_update() and then
returned a tuple different from what the input tup is? Basically, I
am easily able to see it and even the reason why the heap and index
tuples will be different. Let me try to explain,
toast_insert_or_update returns a new tuple which contains compressed
data and this tuple is inserted in heap where as slot still refers to
original tuple (uncompressed one) which is passed to heap_insert.
Now, ExecInsertIndexTuples and the calls under it like FormIndexDatum
will refer to the tuple in slot which is uncompressed and form the
values[] using uncompressed value. Try with a simple case as below:
Create table t_comp(c1 int, c2 text);
Create index idx_t_comp_c2 on t_comp(c2);
Create index idx_t_comp_c1 on t_comp(c1);
Insert into t_comp(1,'aaaa ...aaa');
Repeat 'a' in above line for 2700 times or so. You should notice what
I am explaining above.
>>
>>
>> Yeah probably you are right, but I am not sure if it is good idea to
>> compare compressed values.
>>
>
> Again, I don't see a problem there.
>
>>
>> I think with this new changes in btrecheck, it would appear to be much
>> costlier as compare to what you have few versions back. I am afraid
>> that it can impact performance for cases where there are few WARM
>> updates in chain and many HOT updates as it will run recheck for all
>> such updates.
>
>
>
> INSERT INTO pgbench_accounts SELECT generate_series(:start, :end )::text ||
> <2300 chars string>, (random()::bigint) % :scale, 0;
>
> CREATE UNIQUE INDEX pgb_a_aid ON pgbench_accounts(aid);
> CREATE INDEX pgb_a_filler1 ON pgbench_accounts(filler1);
> CREATE INDEX pgb_a_filler2 ON pgbench_accounts(filler2);
> CREATE INDEX pgb_a_filler3 ON pgbench_accounts(filler3);
> CREATE INDEX pgb_a_filler4 ON pgbench_accounts(filler4);
>
> -- Force a WARM update on one row
> UPDATE pgbench_accounts SET filler1 = 'X' WHERE aid = '100' ||
> repeat('abcdefghij', 20000);
>
> Test:
> -- Fetch the row using the fat index. Since the row contains a
> BEGIN;
> SELECT substring(aid, 1, 10) FROM pgbench_accounts WHERE aid = '100' ||
> <2300 chars string> ORDER BY aid;
> UPDATE pgbench_accounts SET abalance = abalance + 100 WHERE aid = '100' ||
> <2300 chars string>;
> END;
>
> I did 4 5-minutes runs with master and WARM and there is probably a 2-3%
> regression.
>
So IIUC, in above test during initialization you have one WARM update
and then during actual test all are HOT updates, won't in such a case
the WARM chain will be converted to HOT by vacuum and then all updates
from thereon will be HOT and probably no rechecks?
> (Results with 5 mins tests, txns is total for 5 mins, idx_scan is number of
> scans on the fat index)
> master:
> txns idx_scan
> 414117 828233
> 411109 822217
> 411848 823695
> 408424 816847
>
> WARM:
> txns idx_scan
> 404139 808277
> 398880 797759
> 399949 799897
> 397927 795853
>
> ==========
>
> I then also repeated the tests, but this time using compressible values. The
> regression in this case is much higher, may be 15% or more.
>
Sounds on higher side.
> INSERT INTO pgbench_accounts SELECT generate_series(:start, :end )::text ||
> repeat('abcdefghij', 20000), (random()::bigint) % :scale, 0;
>
> -- Fetch the row using the fat index. Since the row contains a
> BEGIN;
> SELECT substring(aid, 1, 10) FROM pgbench_accounts WHERE aid = '100' ||
> repeat('abcdefghij', 20000) ORDER BY aid;
> UPDATE pgbench_accounts SET abalance = abalance + 100 WHERE aid = '100' ||
> repeat('abcdefghij', 20000);
> END;
>
> (Results with 5 mins tests, txns is total for 5 mins, idx_scan is number of
> scans on the fat index)
> master:
> txns idx_scan
> 56976 113953
> 56822 113645
> 56915 113831
> 56865 113731
>
> WARM:
> txns idx_scan
> 49044 98087
> 49020 98039
> 49007 98013
> 49006 98011
>
> But TBH I believe this regression is coming from the changes to
> heap_tuple_attr_equals where we are decompressing both old and new values
> and then comparing them. For 200K bytes long values, that must be something.
> Another reason why I think so is because I accidentally did one run which
> did not use index scans and did not perform any WARM updates, but the
> regression was kinda similar. So that makes me think that the regression is
> coming from somewhere else and change in heap_tuple_attr_equals seems like a
> good candidate.
>
> I think we can fix that by comparing compressed values.
>
IIUC, by the time you are comparing tuple attrs to check for modified
columns, you don't have the compressed values for new tuple.
> I know you had
> raised concerns, but Robert confirmed that (IIUC) it's not a problem today.
>
Yeah, but I am not sure if we can take Robert's statement as some sort
of endorsement for what the patch does.
> We will figure out how to deal with it if we ever add support for different
> compression algorithms or compression levels. And I also think this is kinda
> synthetic use case and the fact that there is not much regression with
> indexes as large as 2K bytes seems quite comforting to me.
>
I am not sure if we can consider it as completely synthetic because we
might see some similar cases for json datatypes. Can we once try to
see the impact when the same test runs from multiple clients? For
your information, I am also trying to setup some tests along with one
of my colleague and we will report the results once the tests are
complete.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Thu, Mar 30, 2017 at 5:27 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
How have you verified that? Have you checked that in
heap_prepare_insert it has called toast_insert_or_update() and then
returned a tuple different from what the input tup is? Basically, I
am easily able to see it and even the reason why the heap and index
tuples will be different. Let me try to explain,
toast_insert_or_update returns a new tuple which contains compressed
data and this tuple is inserted in heap where as slot still refers to
original tuple (uncompressed one) which is passed to heap_insert.
Now, ExecInsertIndexTuples and the calls under it like FormIndexDatum
will refer to the tuple in slot which is uncompressed and form the
values[] using uncompressed value.
Ah, yes. You're right. Not sure why I saw things differently. That doesn't anything though because during recheck we'll get compressed value and not do anything with it. In the index we already have compressed value and we can compare them. Even if we decide to decompress everything and do the comparison, that should be possible. So I don't see a problem as far as correctness goes.
So IIUC, in above test during initialization you have one WARM update
and then during actual test all are HOT updates, won't in such a case
the WARM chain will be converted to HOT by vacuum and then all updates
from thereon will be HOT and probably no rechecks?
There is no AV.. Just 1 tuple being HOT updated out of 100 tuples. Confirmed by looking at pg_stat_user_tables. Also made sure that the tuple doesn't get non-HOT updated in between, thus breaking the WARM chain.
>
> I then also repeated the tests, but this time using compressible values. The
> regression in this case is much higher, may be 15% or more.
>
Sounds on higher side.
Yes, definitely. If we can't reduce that, we might want to provide table level option to explicitly turn WARM off on such tables.
IIUC, by the time you are comparing tuple attrs to check for modified
columns, you don't have the compressed values for new tuple.
I think it depends. If the value is not being modified, then we will get both values as compressed. At least I confirmed with your example and running an update which only changes c1. Don't know if that holds for all cases.
> I know you had
> raised concerns, but Robert confirmed that (IIUC) it's not a problem today.
>
Yeah, but I am not sure if we can take Robert's statement as some sort
of endorsement for what the patch does.
Sure.
> We will figure out how to deal with it if we ever add support for different
> compression algorithms or compression levels. And I also think this is kinda
> synthetic use case and the fact that there is not much regression with
> indexes as large as 2K bytes seems quite comforting to me.
>
I am not sure if we can consider it as completely synthetic because we
might see some similar cases for json datatypes. Can we once try to
see the impact when the same test runs from multiple clients?
Ok. Might become hard to control HOT behaviour though. Or will need to do mix of WARM/HOT updates. Will see if this is something easily doable by setting high FF etc.
For
your information, I am also trying to setup some tests along with one
of my colleague and we will report the results once the tests are
complete.
That'll be extremely helpful, especially if its a something close to real-world scenario. Thanks for doing that.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Mar 30, 2017 at 6:37 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > I think we can fix that by comparing compressed values. I know you had > raised concerns, but Robert confirmed that (IIUC) it's not a problem today. I'm not sure that's an entirely fair interpretation of what I said. My point was that, while it may not be broken today, it might not be a good idea to rely for correctness on it always being true. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Mar 30, 2017 at 7:27 PM, Robert Haas <robertmhaas@gmail.com> wrote:
-- On Thu, Mar 30, 2017 at 6:37 AM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> I think we can fix that by comparing compressed values. I know you had
> raised concerns, but Robert confirmed that (IIUC) it's not a problem today.
I'm not sure that's an entirely fair interpretation of what I said.
My point was that, while it may not be broken today, it might not be a
good idea to rely for correctness on it always being true.
I take that point. We have a choice of fixing it today or whenever to support multiple compression techniques. We don't even know how that will look like and whether we will be able to look at compressed data and tell whether two values are compressed by exact same way.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Mar 30, 2017 at 5:55 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > On Thu, Mar 30, 2017 at 5:27 PM, Amit Kapila <amit.kapila16@gmail.com> > wrote: >> >> >> >> How have you verified that? Have you checked that in >> heap_prepare_insert it has called toast_insert_or_update() and then >> returned a tuple different from what the input tup is? Basically, I >> am easily able to see it and even the reason why the heap and index >> tuples will be different. Let me try to explain, >> toast_insert_or_update returns a new tuple which contains compressed >> data and this tuple is inserted in heap where as slot still refers to >> original tuple (uncompressed one) which is passed to heap_insert. >> Now, ExecInsertIndexTuples and the calls under it like FormIndexDatum >> will refer to the tuple in slot which is uncompressed and form the >> values[] using uncompressed value. > > > Ah, yes. You're right. Not sure why I saw things differently. That doesn't > anything though because during recheck we'll get compressed value and not do > anything with it. In the index we already have compressed value and we can > compare them. Even if we decide to decompress everything and do the > comparison, that should be possible. > I think we should not consider doing compression and decompression as free at this point in code, because we hold a buffer lock during recheck. Buffer locks are meant for short-term locks (it is even mentioned in storage/buffer/README), doing all the compression/decompression/detoast stuff under these locks doesn't sound advisable to me. It can block many concurrent operations. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Mar 30, 2017 at 10:08 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > I think we should not consider doing compression and decompression as > free at this point in code, because we hold a buffer lock during > recheck. Buffer locks are meant for short-term locks (it is even > mentioned in storage/buffer/README), doing all the > compression/decompression/detoast stuff under these locks doesn't > sound advisable to me. It can block many concurrent operations. Compression and decompression might cause performance problems, but try to access the TOAST table would be fatal; that probably would have deadlock hazards among other problems. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 30/03/17 16:04, Pavan Deolasee wrote: > > > On Thu, Mar 30, 2017 at 7:27 PM, Robert Haas <robertmhaas@gmail.com > <mailto:robertmhaas@gmail.com>> wrote: > > On Thu, Mar 30, 2017 at 6:37 AM, Pavan Deolasee > <pavan.deolasee@gmail.com <mailto:pavan.deolasee@gmail.com>> wrote: > > I think we can fix that by comparing compressed values. I know you had > > raised concerns, but Robert confirmed that (IIUC) it's not a problem today. > > I'm not sure that's an entirely fair interpretation of what I said. > My point was that, while it may not be broken today, it might not be a > good idea to rely for correctness on it always being true. > > > I take that point. We have a choice of fixing it today or whenever to > support multiple compression techniques. We don't even know how that > will look like and whether we will be able to look at compressed data > and tell whether two values are compressed by exact same way. > While reading this thread I am thinking if we could just not do WARM on TOAST and compressed values if we know there might be regressions there. I mean I've seen the problem WARM tries to solve mostly on timestamp or boolean values and sometimes counters so it would still be helpful to quite a lot of people even if we didn't do TOAST and compressed values in v1. It's not like not doing WARM sometimes is somehow terrible, we'll just fall back to current behavior. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Hi, On 2017-03-30 16:43:41 +0530, Pavan Deolasee wrote: > Looks like OID conflict to me.. Please try rebased set. Pavan, Alvaro, everyone: I know you guys are working very hard on this, but I think at this point it's too late to commit this for v10. This is patch that's affecting the on-disk format, in quite subtle ways. Committing this just at the end of the development cyle / shortly before feature freeze, seems too dangerous to me. Let's commit this just at the beginning of the cycle, so we have time to shake out the bugs. - Andres
On Thu, Mar 30, 2017 at 11:41 AM, Andres Freund <andres@anarazel.de> wrote: > On 2017-03-30 16:43:41 +0530, Pavan Deolasee wrote: >> Looks like OID conflict to me.. Please try rebased set. > > Pavan, Alvaro, everyone: I know you guys are working very hard on this, > but I think at this point it's too late to commit this for v10. This is > patch that's affecting the on-disk format, in quite subtle > ways. Committing this just at the end of the development cyle / shortly > before feature freeze, seems too dangerous to me. > > Let's commit this just at the beginning of the cycle, so we have time to > shake out the bugs. +1, although I think it should also have substantially more review first. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Mar 21, 2017 at 04:04:58PM -0400, Bruce Momjian wrote: > On Tue, Mar 21, 2017 at 04:56:16PM -0300, Alvaro Herrera wrote: > > Bruce Momjian wrote: > > > On Tue, Mar 21, 2017 at 04:43:58PM -0300, Alvaro Herrera wrote: > > > > Bruce Momjian wrote: > > > > > > > > > I don't think it makes sense to try and save bits and add complexity > > > > > when we have no idea if we will ever use them, > > > > > > > > If we find ourselves in dire need of additional bits, there is a known > > > > mechanism to get back 2 bits from old-style VACUUM FULL. I assume that > > > > the reason nobody has bothered to write the code for that is that > > > > there's no *that* much interest. > > > > > > We have no way of tracking if users still have pages that used the bits > > > via pg_upgrade before they were removed. > > > > Yes, that's exactly the code that needs to be written. > > Yes, but once it is written it will take years before those bits can be > used on most installations. Actually, the 2 bits from old-style VACUUM FULL bits could be reused if one of the WARM bits would be set when it is checked. The WARM bits will all be zero on pre-9.0. The check would have to be checking the old-style VACUUM FULL bit and checking that a WARM bit is set. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Thu, Mar 30, 2017 at 5:27 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> I am not sure if we can consider it as completely synthetic because we
> might see some similar cases for json datatypes. Can we once try to
> see the impact when the same test runs from multiple clients? For
> your information, I am also trying to setup some tests along with one
> of my colleague and we will report the results once the tests are
> complete.
We have done some testing and below is the test details and results.
Test:
I have derived this test from above test given by pavan[1] except
below difference.
- I have reduced the fill factor to 40 to ensure that multiple there
is scope in the page to store multiple WARM chains.
- WARM updated all the tuples.
- Executed a large select to enforce lot of recheck tuple within single query.
- Smaller tuple size (aid field is around ~100 bytes) just to ensure
tuple have sufficient space on a page to get WARM updated.
Results:
-----------
* I can see more than 15% of regression in this case. This regression
is repeatable.
* If I increase the fill factor to 90 than regression reduced to 7%,
may be only fewer tuples are getting WARM updated and others are not
because of no space left on page after few WARM update.
Test Setup:
----------------
Machine Information:
Intel(R) Xeon(R) CPU E5-2695 v3 @ 2.30GHz
RAM: 64GB
Config Change: synchronous_commit=off
——Setup.sql—
DROP TABLE IF EXISTS pgbench_accounts;
CREATE TABLE pgbench_accounts (
aid text,
bid bigint,
abalance bigint,
filler1 text DEFAULT md5(random()::text),
filler2 text DEFAULT md5(random()::text),
filler3 text DEFAULT md5(random()::text),
filler4 text DEFAULT md5(random()::text),
filler5 text DEFAULT md5(random()::text),
filler6 text DEFAULT md5(random()::text),
filler7 text DEFAULT md5(random()::text),
filler8 text DEFAULT md5(random()::text),
filler9 text DEFAULT md5(random()::text),
filler10 text DEFAULT md5(random()::text),
filler11 text DEFAULT md5(random()::text),
filler12 text DEFAULT md5(random()::text)
) WITH (fillfactor=40);
\set scale 10
\set end 0
\set start (:end + 1)
\set end (:start + (:scale * 100))
INSERT INTO pgbench_accounts SELECT generate_series(:start, :end
)::text || repeat('a', 100), (random()::bigint) % :scale, 0;
CREATE UNIQUE INDEX pgb_a_aid ON pgbench_accounts(aid);
CREATE INDEX pgb_a_filler1 ON pgbench_accounts(filler1);
CREATE INDEX pgb_a_filler2 ON pgbench_accounts(filler2);
CREATE INDEX pgb_a_filler3 ON pgbench_accounts(filler3);
CREATE INDEX pgb_a_filler4 ON pgbench_accounts(filler4);
UPDATE pgbench_accounts SET filler1 = 'X'; --WARM update all the tuples
—Test.sql—
set enable_seqscan=off;
set enable_bitmapscan=off;
explain analyze select * FROM pgbench_accounts WHERE aid < '400' ||
repeat('a', 100) ORDER BY aid
—Script.sh—
./psql -d postgres -f setup.sql
./pgbench -c1 -j1 -T300 -M prepared -f test.sql postgres
Patch:
tps = 3554.345313 (including connections establishing)
tps = 3554.880776 (excluding connections establishing)
Head:
tps = 4208.876829 (including connections establishing)
tps = 4209.440321 (excluding connections establishing)
*** After changing fill factor to 90 —
Patch:
tps = 3794.414770 (including connections establishing)
tps = 3794.919592 (excluding connections establishing)
Head:
tps = 4206.445608 (including connections establishing)
tps = 4207.033559 (excluding connections establishing)
[1]
https://www.postgresql.org/message-id/CABOikdMduu9wOhfvNzqVuNW4YdBgbgwv-A%3DHNFCL7R5Tmbx7JA%40mail.gmail.com
I have done some perfing for the patch and I have noticed that time is
increased in heap_check_warm_chain function.
Top 10 functions in perf results (with patch):
+ 8.98% 1.04% postgres postgres [.] varstr_cmp
+ 7.24% 0.00% postgres [unknown] [.] 0000000000000000
+ 6.34% 0.36% postgres libc-2.17.so [.] clock_gettime
+ 6.34% 0.00% postgres [unknown] [.] 0x0000000000030000
+ 6.18% 6.15% postgres [vdso] [.] __vdso_clock_gettime
+ 5.72% 0.02% postgres [kernel.kallsyms] [k] system_call_fastpath
+ 4.08% 4.06% postgres libc-2.17.so [.] __memcpy_ssse3_back
+ 4.08% 4.06% postgres libc-2.17.so [.] get_next_seq
+ 3.92% 0.00% postgres [unknown] [.] 0x6161616161616161
+ 3.07% 3.05% postgres postgres [.] heap_check_warm_chain
Thanks to Amit for helping in discussing the test ideas.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On 30 March 2017 at 16:50, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Mar 30, 2017 at 11:41 AM, Andres Freund <andres@anarazel.de> wrote: >> On 2017-03-30 16:43:41 +0530, Pavan Deolasee wrote: >>> Looks like OID conflict to me.. Please try rebased set. >> >> Pavan, Alvaro, everyone: I know you guys are working very hard on this, >> but I think at this point it's too late to commit this for v10. This is >> patch that's affecting the on-disk format, in quite subtle >> ways. Committing this just at the end of the development cyle / shortly >> before feature freeze, seems too dangerous to me. >> >> Let's commit this just at the beginning of the cycle, so we have time to >> shake out the bugs. > > +1, although I think it should also have substantially more review first. So Andres says defer this, but Robert says "more review", which is more than just deferral. We have some risky things in this release such as Hash Indexes, function changes. I perfectly understand that perception of risk is affected significantly by whether you wrote something or not. Andres and Robert did not write it and so they see problems. I confess that those two mentioned changes make me very scared and I'm wondering whether we should disable them. Fear is normal. A risk perspective is a good one to take. What I think we should do is strip out the areas of complexity, like TOAST to reduce the footprint and minimize the risk. There is benefit in WARM and PostgreSQL has received public critiscism around our performance in this area. This is more important than just a nice few % points of performance. The bottom line is that this is written by Pavan, the guy we've trusted for a decade to write and support HOT. We all know he can and will fix any problems that emerge because he has shown us many times he can and does. We also observe that people from the same company sometimes support their colleagues when they should not. I see no reason to believe that is influencing my comments here. The question is not whether this is ready today, but will it be trusted and safe to use by Sept. Given the RMT, I would say yes, it can be. So I say we should commit WARM in PG10, with some restrictions. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Mar 31, 2017 at 7:53 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > So Andres says defer this, but Robert says "more review", which is > more than just deferral. > > We have some risky things in this release such as Hash Indexes, > function changes. I perfectly understand that perception of risk is > affected significantly by whether you wrote something or not. Andres > and Robert did not write it and so they see problems. While that's probably true, I don't think that's the only thing going on here: 1. Hash indexes were reviewed and reworked repeatedly until nobody could find any more problems, including people like Jesper Pederson who do not work for EDB and who did extensive testing. Similarly with the expression evaluation stuff, which got some review from Heikki and even more from Tom. Now, several people who do not work for 2ndQuadrant have recently started looking at WARM and many of those reviews have found problems and regressions. If we're to hold things to the same standard, those things should be looked into and fixed before there is any talk of committing anything. My concern is that there seems to be (even with the patches already committed) a desire to minimize the importance of the problems that have been found -- which I think is probably because fixing them would take time, and we don't have much time left in this release cycle. We should regard the time between feature freeze and release as a time to fix the things that good review missed, not as a substitute for fixing things that should have (or actually were) found during review prior to commit. 2. WARM is a non-optional feature which touches the on-disk format. There is nothing more dangerous than that. If hash indexes have bugs, people can avoid those bugs by not using them; there are good reasons to suppose that hash indexes have very few existing users. The expression evaluation changes, IMHO, are much more dangerous because everyone will be exposed to them, but they will not likely corrupt your data because they don't touch the on-disk format. WARM is even a little more dangerous than that; everyone is exposed to those bugs, and in the worst case they could eat your data. I agree that WARM could be a pretty great feature, but I think you're underestimating the negative effects that could result from committing it too soon. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Mar 31, 2017 at 6:47 PM, Robert Haas <robertmhaas@gmail.com> wrote:
2. WARM is a non-optional feature which touches the on-disk format.
There is nothing more dangerous than that. If hash indexes have bugs,
people can avoid those bugs by not using them; there are good reasons
to suppose that hash indexes have very few existing users. The
expression evaluation changes, IMHO, are much more dangerous because
everyone will be exposed to them, but they will not likely corrupt
your data because they don't touch the on-disk format. WARM is even a
little more dangerous than that; everyone is exposed to those bugs,
and in the worst case they could eat your data.
Having worked on it for some time now, I can say that WARM uses pretty much the same infrastructure that HOT uses for cleanup/pruning tuples from the heap. So the risk of having a bug which can eat your data from the heap is very low. Sure, it might mess up with indexes, return duplicate keys, not return a row when it should have. Not saying they are not bad bugs, but probably much less severe than someone removing live rows from the heap.
And we can make it a table level property, keep it off by default, turn it off on system tables in this release and change the defaults only when we get more confidence assuming people use it by explicitly turning it on. Now may be that's not the right approach and keeping it off by default will mean it receives much less testing than we would like. So we can keep it on in the beta cycle and then take a call. I went a good length to make it work on system tables because during HOT development, Tom told me that it better work for everything or it doesn't work at all. But with WARM it works for system tables and I know no known bugs, but if we don't want to risk system tables, we might want to turn it off (just prior to release may be).
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Mar 30, 2017 at 10:49 AM, Petr Jelinek <petr.jelinek@2ndquadrant.com> wrote: > While reading this thread I am thinking if we could just not do WARM on > TOAST and compressed values if we know there might be regressions there. > I mean I've seen the problem WARM tries to solve mostly on timestamp or > boolean values and sometimes counters so it would still be helpful to > quite a lot of people even if we didn't do TOAST and compressed values > in v1. It's not like not doing WARM sometimes is somehow terrible, we'll > just fall back to current behavior. Good point. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Mar 31, 2017 at 10:24 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > Having worked on it for some time now, I can say that WARM uses pretty much > the same infrastructure that HOT uses for cleanup/pruning tuples from the > heap. So the risk of having a bug which can eat your data from the heap is > very low. Sure, it might mess up with indexes, return duplicate keys, not > return a row when it should have. Not saying they are not bad bugs, but > probably much less severe than someone removing live rows from the heap. Yes, that's true. If there's nothing wrong with the way pruning works, then any other problem can be fixed by reindexing, I suppose. > And we can make it a table level property, keep it off by default, turn it > off on system tables in this release and change the defaults only when we > get more confidence assuming people use it by explicitly turning it on. Now > may be that's not the right approach and keeping it off by default will mean > it receives much less testing than we would like. So we can keep it on in > the beta cycle and then take a call. I went a good length to make it work on > system tables because during HOT development, Tom told me that it better > work for everything or it doesn't work at all. But with WARM it works for > system tables and I know no known bugs, but if we don't want to risk system > tables, we might want to turn it off (just prior to release may be). I'm not generally a huge fan of on-off switches for things like this, but I know Simon likes them. I think the question is how much they really insulate us from bugs. For the hash index patch, for example, the only way to really get insulation from bugs added in this release would be to ship both the old and the new code in separate index AMs (hash, hash2). The code has been restructured so much in the process of doing all of this that any other form of on-off switch would be pretty hit-or-miss whether it actually provided any protection. Now, I am less sure about this case, but my guess is that you can't really have this be something that can be flipped on and off for a table. Once a table has any WARM updates in it, the code that knows how to cope with that has to be enabled, and it'll work as well or poorly as it does. Now, I understand you to be suggesting a flag at table-creation time that would, maybe, be immutable after that, but even then - are we going to run completely unmodified 9.6 code for tables where that's not enabled, and only go through any of the WARM logic when it is enabled? Doesn't sound likely. The commits already made from this patch series certainly affect everybody, and I can't see us adding switches that bypass ce96ce60ca2293f75f36c3661e4657a3c79ffd61 for example. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Mar 31, 2017 at 11:16 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Fri, Mar 31, 2017 at 10:24 AM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> Having worked on it for some time now, I can say that WARM uses pretty much
> the same infrastructure that HOT uses for cleanup/pruning tuples from the
> heap. So the risk of having a bug which can eat your data from the heap is
> very low. Sure, it might mess up with indexes, return duplicate keys, not
> return a row when it should have. Not saying they are not bad bugs, but
> probably much less severe than someone removing live rows from the heap.
Yes, that's true. If there's nothing wrong with the way pruning
works, then any other problem can be fixed by reindexing, I suppose.
Yeah, I think so.
I'm not generally a huge fan of on-off switches for things like this,
but I know Simon likes them. I think the question is how much they
really insulate us from bugs. For the hash index patch, for example,
the only way to really get insulation from bugs added in this release
would be to ship both the old and the new code in separate index AMs
(hash, hash2). The code has been restructured so much in the process
of doing all of this that any other form of on-off switch would be
pretty hit-or-miss whether it actually provided any protection.
Now, I am less sure about this case, but my guess is that you can't
really have this be something that can be flipped on and off for a
table. Once a table has any WARM updates in it, the code that knows
how to cope with that has to be enabled, and it'll work as well or
poorly as it does.
That's correct. Once enabled, we will need to handle the case of two index pointers pointing to the same root. The only way to get rid of that is probably do a complete rewrite/reindex, I suppose. But I was mostly talking about immutable flag at table creation time as rightly guessed.
Now, I understand you to be suggesting a flag at
table-creation time that would, maybe, be immutable after that, but
even then - are we going to run completely unmodified 9.6 code for
tables where that's not enabled, and only go through any of the WARM
logic when it is enabled? Doesn't sound likely. The commits already
made from this patch series certainly affect everybody, and I can't
see us adding switches that bypass
ce96ce60ca2293f75f36c3661e4657a3c79ffd61 for example.
I don't think I am going to claim that either. But probably only 5% of the new code would then be involved. Which is a lot less and a lot more manageable. Having said that, I think if we at all do this, we should only do it based on our experiences in the beta cycle, as a last resort. Based on my own experiences during HOT development, long running pgbench tests, with several concurrent clients, subjected to multiple AV cycles and periodic consistency checks, usually brings up issues related to heap corruption. So my confidence level is relatively high on that part of the code. That's not to suggest that there can't be any bugs.
Obviously then there are other things such as regression to some workload or additional work required by vacuum etc. And I think we should address them and I'm fairly certain we can do that. It may not happen immediately, but if we provide right knobs, may be those who are affected can fall back to the old behaviour or not use the new code at all while we improve things for them. Some of these things I could have already implemented, but without a clear understanding of whether the feature will get in or not, it's hard to keep putting infinite efforts into the patch. All non-committers go through that dilemma all the time, I'm sure.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Mar 30, 2017 at 4:13 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
On Thu, Mar 30, 2017 at 3:29 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:On Wed, Mar 29, 2017 at 11:51 AM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> Thanks. I think your patch of tracking interesting attributes seems ok too
> after the performance issue was addressed. Even though we can still improve
> that further, at least Mithun confirmed that there is no significant
> regression anymore and in fact for one artificial case, patch does better
> than even master.
I was trying to compile these patches on latest
head(f90d23d0c51895e0d7db7910538e85d3d38691f0) for some testing but I
was not able to compile it.
make[3]: *** [postgres.bki] Error 1Looks like OID conflict to me.. Please try rebased set.
broken again on oid conflicts for 3373 to 3375 from the monitoring permissions commi 25fff40798fc4.
After bumping those, I get these compiler warnings:
heapam.c: In function 'heap_delete':
heapam.c:3298: warning: 'root_offnum' may be used uninitialized in this function
heapam.c: In function 'heap_update':
heapam.c:4311: warning: 'root_offnum' may be used uninitialized in this function
heapam.c:4311: note: 'root_offnum' was declared here
heapam.c:3784: warning: 'root_offnum' may be used uninitialized in this function
heapam.c: In function 'heap_lock_tuple':
heapam.c:5087: warning: 'root_offnum' may be used uninitialized in this function
And I get a regression test failure, attached.
Cheers,
Jeff
Attachment
On Sat, Apr 1, 2017 at 12:39 AM, Jeff Janes <jeff.janes@gmail.com> wrote:
On Thu, Mar 30, 2017 at 4:13 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:On Thu, Mar 30, 2017 at 3:29 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:On Wed, Mar 29, 2017 at 11:51 AM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> Thanks. I think your patch of tracking interesting attributes seems ok too
> after the performance issue was addressed. Even though we can still improve
> that further, at least Mithun confirmed that there is no significant
> regression anymore and in fact for one artificial case, patch does better
> than even master.
I was trying to compile these patches on latest
head(f90d23d0c51895e0d7db7910538e85d3d38691f0) for some testing but I
was not able to compile it.
make[3]: *** [postgres.bki] Error 1Looks like OID conflict to me.. Please try rebased set.broken again on oid conflicts for 3373 to 3375 from the monitoring permissions commi 25fff40798fc4.
Hi Jeff,
Thanks for trying. Much appreciated,
After bumping those, I get these compiler warnings:heapam.c: In function 'heap_delete':heapam.c:3298: warning: 'root_offnum' may be used uninitialized in this functionheapam.c: In function 'heap_update':heapam.c:4311: warning: 'root_offnum' may be used uninitialized in this functionheapam.c:4311: note: 'root_offnum' was declared hereheapam.c:3784: warning: 'root_offnum' may be used uninitialized in this functionheapam.c: In function 'heap_lock_tuple':heapam.c:5087: warning: 'root_offnum' may be used uninitialized in this function
Thanks. I don't see them on my LLVM compiler even at -O2. Anyways, I inspected. They all looked non-problematic, but fixed in the attached version v24, along with some others I could see on another linux machine.
And I get a regression test failure, attached.
Thanks again. Seems like my last changes to disallow WARM updates if more than 50% indexes are updated caused this regression. Having various features in different branches and merging them right before sending out the patchset was probably not the smartest thing to do. I've fixed the regression simply by adding another index on that table and making changes to the expected output.
BTW I still need 2 regression failures, but I see them on the master too, so not related to the patch. Attached here.
Thanks,
Pavan
Attachment
On Fri, Mar 31, 2017 at 11:54 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > On Fri, Mar 31, 2017 at 11:16 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> >> Now, I understand you to be suggesting a flag at >> table-creation time that would, maybe, be immutable after that, but >> even then - are we going to run completely unmodified 9.6 code for >> tables where that's not enabled, and only go through any of the WARM >> logic when it is enabled? Doesn't sound likely. The commits already >> made from this patch series certainly affect everybody, and I can't >> see us adding switches that bypass >> ce96ce60ca2293f75f36c3661e4657a3c79ffd61 for example. > > > I don't think I am going to claim that either. But probably only 5% of the > new code would then be involved. Which is a lot less and a lot more > manageable. Having said that, I think if we at all do this, we should only > do it based on our experiences in the beta cycle, as a last resort. Based on > my own experiences during HOT development, long running pgbench tests, with > several concurrent clients, subjected to multiple AV cycles and periodic > consistency checks, usually brings up issues related to heap corruption. So > my confidence level is relatively high on that part of the code. That's not > to suggest that there can't be any bugs. > > Obviously then there are other things such as regression to some workload or > additional work required by vacuum etc. And I think we should address them > and I'm fairly certain we can do that. It may not happen immediately, but if > we provide right knobs, may be those who are affected can fall back to the > old behaviour or not use the new code at all while we improve things for > them. > Okay, but even if we want to provide knobs, then there should be some consensus on those. I am sure introducing an additional pass over index has some impact so either we should have some way to reduce the impact or have some additional design to handle it. Do you think it make sense to have a separate thread to discuss and get feedback on same as I am not seeing much input on the knobs you are proposing to handle second pass over index? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Fri, Mar 31, 2017 at 12:31 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
-- On Thu, Mar 30, 2017 at 5:27 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> I am not sure if we can consider it as completely synthetic because we
> might see some similar cases for json datatypes. Can we once try to
> see the impact when the same test runs from multiple clients? For
> your information, I am also trying to setup some tests along with one
> of my colleague and we will report the results once the tests are
> complete.
We have done some testing and below is the test details and results.
Test:
I have derived this test from above test given by pavan[1] except
below difference.
- I have reduced the fill factor to 40 to ensure that multiple there
is scope in the page to store multiple WARM chains.
- WARM updated all the tuples.
- Executed a large select to enforce lot of recheck tuple within single query.
- Smaller tuple size (aid field is around ~100 bytes) just to ensure
tuple have sufficient space on a page to get WARM updated.
Results:
-----------
* I can see more than 15% of regression in this case. This regression
is repeatable.
* If I increase the fill factor to 90 than regression reduced to 7%,
may be only fewer tuples are getting WARM updated and others are not
because of no space left on page after few WARM update.
Thanks for doing the tests. The tests show us that if the table gets filled up with WARM chains, and they are not cleaned up and the table is subjected to read-only workload, we will see regression. Obviously, the test is completely CPU bound, something WARM is not meant to address.I am not yet certain if recheck is causing the problem. Yesterday I ran the test where I was seeing regression with recheck completely turned off and still saw regression. So there is something else that's going on with this kind of workload. Will check.
Having said that, I think there are some other ways to fix some of the common problems with repeated rechecks. One thing that we can do it rely on the index pointer flags to decide whether recheck is necessary or not. For example, a WARM pointer to a WARM tuple does not require recheck. Similarly, a CLEAR pointer to a CLEAR tuple does not require recheck. A WARM pointer to a CLEAR tuple can be discarded immediately because the only situation where it can occur is in the case of aborted WARM updates. The only troublesome situation is a CLEAR pointer to a WARM tuple. That entirely depends on whether the index had received a WARM insert or not. What we can do though, if recheck succeeds for the first time and if the chain has only WARM tuples, we set the WARM bit on the index pointer. We can use the same hint mechanism as used for marking index pointers dead to minimise overhead.
Obviously this will only handle the case when the same tuple is rechecked often. But if a tuple is rechecked only once then may be other overheads will kick-in, thus reducing the regression significantly.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Mar 30, 2017 at 11:17 PM, Bruce Momjian <bruce@momjian.us> wrote:
On Tue, Mar 21, 2017 at 04:04:58PM -0400, Bruce Momjian wrote:
> On Tue, Mar 21, 2017 at 04:56:16PM -0300, Alvaro Herrera wrote:
> > Bruce Momjian wrote:
> > > On Tue, Mar 21, 2017 at 04:43:58PM -0300, Alvaro Herrera wrote:
> > > > Bruce Momjian wrote:
> > > >
> > > > > I don't think it makes sense to try and save bits and add complexity
> > > > > when we have no idea if we will ever use them,
> > > >
> > > > If we find ourselves in dire need of additional bits, there is a known
> > > > mechanism to get back 2 bits from old-style VACUUM FULL. I assume that
> > > > the reason nobody has bothered to write the code for that is that
> > > > there's no *that* much interest.
> > >
> > > We have no way of tracking if users still have pages that used the bits
> > > via pg_upgrade before they were removed.
> >
> > Yes, that's exactly the code that needs to be written.
>
> Yes, but once it is written it will take years before those bits can be
> used on most installations.
Actually, the 2 bits from old-style VACUUM FULL bits could be reused if
one of the WARM bits would be set when it is checked. The WARM bits
will all be zero on pre-9.0. The check would have to be checking the
old-style VACUUM FULL bit and checking that a WARM bit is set.
We're already doing that in the submitted patch.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Mar 31, 2017 at 11:15 PM, Robert Haas <robertmhaas@gmail.com> wrote:
-- On Thu, Mar 30, 2017 at 10:49 AM, Petr Jelinek
<petr.jelinek@2ndquadrant.com> wrote:
> While reading this thread I am thinking if we could just not do WARM on
> TOAST and compressed values if we know there might be regressions there.
> I mean I've seen the problem WARM tries to solve mostly on timestamp or
> boolean values and sometimes counters so it would still be helpful to
> quite a lot of people even if we didn't do TOAST and compressed values
> in v1. It's not like not doing WARM sometimes is somehow terrible, we'll
> just fall back to current behavior.
Good point.
Ok. I've added logic to disable WARM update if either old or the new tuple has compressed/toasted values. The HeapDetermineModifiedColumns() has been materially changed to support this because we not only look for modified_cols, but also toasted and compressed cols and if any of the toasted or compressed cols overlap with the index attributes, we disable WARM. HOT updates which do not modify toasted/compressed attributes should still work.
I am not sure if this will be enough to address the regression that Dilip reported in his last email. AFAICS that test probably does not use toasting/compression. I hope to spend some time on that tomorrow and have a better understanding of why we see the regression.
I've also added a table-level option to turn WARM off on a given table. Right now the option can only be turned ON, but once turned ON, it can't be turned OFF. We can add that support if needed. It might be interesting to get Dilip's test running with enable_warm turned off on the table. That will at least tell us whether turning WARM off fixes the regression. Documentation changes for this reloption are missing.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Thu, Mar 30, 2017 at 7:55 PM, Robert Haas <robertmhaas@gmail.com> wrote:
but
try to access the TOAST table would be fatal; that probably would have
deadlock hazards among other problems.
Hmm. I think you're right. We could make a copy of the heap tuple, drop the lock and then access TOAST to handle that. Would that work?
Pavan
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Apr 4, 2017 at 10:21 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > On Thu, Mar 30, 2017 at 7:55 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> but >> try to access the TOAST table would be fatal; that probably would have >> deadlock hazards among other problems. > > Hmm. I think you're right. We could make a copy of the heap tuple, drop the > lock and then access TOAST to handle that. Would that work? Yeah, but it might suck. :-) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Apr 5, 2017 at 8:42 AM, Robert Haas <robertmhaas@gmail.com> wrote:
On Tue, Apr 4, 2017 at 10:21 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> On Thu, Mar 30, 2017 at 7:55 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>> but
>> try to access the TOAST table would be fatal; that probably would have
>> deadlock hazards among other problems.
>
> Hmm. I think you're right. We could make a copy of the heap tuple, drop the
> lock and then access TOAST to handle that. Would that work?
Yeah, but it might suck. :-)
Well, better than causing a deadlock ;-)
Lets see if we want to go down the path of blocking WARM when tuples have toasted attributes. I submitted a patch yesterday, but having slept over it, I think I made mistakes there. It might not be enough to look at the caller supplied new tuple because that may not have any toasted values, but the final tuple that gets written to the heap may be toasted. We could look at the new tuple's attributes to find if any indexed attributes are toasted, but that might suck as well. Or we can simply block WARM if the old or the new tuple has external attributes i.e. HeapTupleHasExternal() returns true. That could be overly restrictive because irrespective of whether the indexed attributes are toasted or just some other attribute is toasted, we will block WARM on such updates. May be that's not a problem.
We will also need to handle the case where some older tuple in the chain has toasted value and that tuple is presented to recheck (I think we can handle that case fairly easily, but its not done in the code yet) because of a subsequent WARM update and the tuples updated by WARM did not have any toasted values (and hence allowed).
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Apr 4, 2017 at 11:43 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > Well, better than causing a deadlock ;-) Yep. > Lets see if we want to go down the path of blocking WARM when tuples have > toasted attributes. I submitted a patch yesterday, but having slept over it, > I think I made mistakes there. It might not be enough to look at the caller > supplied new tuple because that may not have any toasted values, but the > final tuple that gets written to the heap may be toasted. Yes, you have to make whatever decision you're going to make here after any toast-ing has been done. > We could look at > the new tuple's attributes to find if any indexed attributes are toasted, > but that might suck as well. Or we can simply block WARM if the old or the > new tuple has external attributes i.e. HeapTupleHasExternal() returns true. > That could be overly restrictive because irrespective of whether the indexed > attributes are toasted or just some other attribute is toasted, we will > block WARM on such updates. May be that's not a problem. Well, I think that there's some danger of whittling down this optimization to the point where it still incurs most of the costs -- in bit-space if not in CPU cycles -- but no longer yields much of the benefit. Even though the speed-up might still be substantial in the cases where the optimization kicks in, if a substantial number of users doing things that are basically pretty normal sometimes fail to get the optimization, this isn't going to be very exciting outside of synthetic benchmarks. Backing up a little bit, it seems like the root of the issue here is that, at a certain point in what was once a HOT chain, you make a WARM update, and you make a decision about which indexes to update at that point. Now, later on, when you traverse that chain, you need to be able to figure what decide you made before; otherwise, you might make a bad decision about whether an index pointer applies to a particular tuple. If the index tuple is WARM, then the answer is "yes" if the heap tuple is also WARM, and "no" if the heap tuple is CLEAR (which is an odd antonym to WARM, but leave that aside). If the index tuple is CLEAR, then the answer is "yes" if the heap tuple is also CLEAR, and "maybe" if the heap tuple is WARM. In that "maybe" case, we are trying to reconstruct the decision that we made when we did the update. If, at the time of the update, we decided to insert a new index entry, then the answer is "no"; if not, it's "yes". From an integrity point of view, it doesn't really matter how we make the decision; what matters is that we're consistent. More specifically, if we sometimes insert a new index tuple even when the value has not changed in any user-visible way, I think that would be fine, provided that later chain traversals can tell that we did that. As an extreme example, suppose that the WARM update inserted in some magical way a bitmap of which attributes had changed into the new tuple. Then, when we are walking the chain following a CLEAR index tuple, we test whether the index columns overlap with that bitmap; if they do, then that index got a new entry; if not, then it didn't. It would actually be fine (apart from efficiency) to set extra bits in this bitmap; extra indexes would get updated, but chain traversal would know exactly which ones, so no problem. This is of course just a gedankenexperiment, but the point is that as long as the insert itself and later chain traversals agree on the rule, there's no integrity problem. I think. The first idea I had for an actual solution to this problem was to make the decision as to whether to insert new index entries based on whether the indexed attributes in the final tuple (post-TOAST) are byte-for-byte identical with the original tuple. If somebody injects a new compression algorithm into the system, or just changes the storage parameters on a column, or we re-insert an identical value into the TOAST table when we could have reused the old TOAST pointer, then you might have some potentially-WARM updates that end up being done as regular updates, but that's OK. When you are walking the chain, you will KNOW whether you inserted new index entries or not, because you can do the exact same comparison that was done before and be sure of getting the same answer. But that's actually not really a solution, because it doesn't work if all of the CLEAR tuples are gone -- all you have is the index tuple and the new heap tuple; there's no old heap tuple with which to compare. The only other idea that I have for a really clean solution here is to support this only for index types that are amcanreturn, and actually compare the value stored in the index tuple with the one stored in the heap tuple, ensuring that new index tuples are inserted whenever they don't match and then using the exact same test to determine the applicability of a given index pointer to a given heap tuple. I'm not sure how viable that is either, but hopefully you see my underlying point here: it would be OK for there to be cases where we fall back to a non-WARM update because a logically equal value changed at the physical level, especially if those cases are likely to be rare in practice, but it can never be allowed to happen that chain traversal gets confused about which indexes actually got touched by a particular WARM update. By the way, the "Converting WARM chains back to HOT chains" section of README.WARM seems to be out of date. Any chance you could update that to reflect the current state and thinking of the patch? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2017-04-05 09:36:47 -0400, Robert Haas wrote: > By the way, the "Converting WARM chains back to HOT chains" section of > README.WARM seems to be out of date. Any chance you could update that > to reflect the current state and thinking of the patch? I propose we move this patch to the next CF. That shouldn't prevent you working on it, although focusing on review of patches that still might make it wouldn't hurt either. - Andres
On Wed, Apr 5, 2017 at 7:06 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Tue, Apr 4, 2017 at 11:43 PM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> Well, better than causing a deadlock ;-)
Yep.
> Lets see if we want to go down the path of blocking WARM when tuples have
> toasted attributes. I submitted a patch yesterday, but having slept over it,
> I think I made mistakes there. It might not be enough to look at the caller
> supplied new tuple because that may not have any toasted values, but the
> final tuple that gets written to the heap may be toasted.
Yes, you have to make whatever decision you're going to make here
after any toast-ing has been done.
I am worried that might add more work in that code path since we then have to fetch attributes for the new tuple as well. May be a good compromise would be to still only check on the user supplied new tuple, but be prepared to handle toasted values during recheck. The attached version does that.
Well, I think that there's some danger of whittling down this
optimization to the point where it still incurs most of the costs --
in bit-space if not in CPU cycles -- but no longer yields much of the
benefit. Even though the speed-up might still be substantial in the
cases where the optimization kicks in, if a substantial number of
users doing things that are basically pretty normal sometimes fail to
get the optimization, this isn't going to be very exciting outside of
synthetic benchmarks.
I agree. Blocking WARM off for too many cases won't serve the purpose.
Backing up a little bit, it seems like the root of the issue here is
that, at a certain point in what was once a HOT chain, you make a WARM
update, and you make a decision about which indexes to update at that
point. Now, later on, when you traverse that chain, you need to be
able to figure what decide you made before; otherwise, you might make
a bad decision about whether an index pointer applies to a particular
tuple. If the index tuple is WARM, then the answer is "yes" if the
heap tuple is also WARM, and "no" if the heap tuple is CLEAR (which is
an odd antonym to WARM, but leave that aside). If the index tuple is
CLEAR, then the answer is "yes" if the heap tuple is also CLEAR, and
"maybe" if the heap tuple is WARM.
That's fairly accurate description of the problem.
The first idea I had for an actual solution to this problem was to
make the decision as to whether to insert new index entries based on
whether the indexed attributes in the final tuple (post-TOAST) are
byte-for-byte identical with the original tuple. If somebody injects
a new compression algorithm into the system, or just changes the
storage parameters on a column, or we re-insert an identical value
into the TOAST table when we could have reused the old TOAST pointer,
then you might have some potentially-WARM updates that end up being
done as regular updates, but that's OK. When you are walking the
chain, you will KNOW whether you inserted new index entries or not,
because you can do the exact same comparison that was done before and
be sure of getting the same answer. But that's actually not really a
solution, because it doesn't work if all of the CLEAR tuples are gone
-- all you have is the index tuple and the new heap tuple; there's no
old heap tuple with which to compare.
Right. The old/new tuples may get HOT pruned and hence we cannot rely on any algorithm which assumes that we can compare old and new tuples after the update is committed/aborted.
The only other idea that I have for a really clean solution here is to
support this only for index types that are amcanreturn, and actually
compare the value stored in the index tuple with the one stored in the
heap tuple, ensuring that new index tuples are inserted whenever they
don't match and then using the exact same test to determine the
applicability of a given index pointer to a given heap tuple.
Just so that I understand, are you suggesting that while inserting WARM index pointers, we check if the new index tuple will look exactly the same as the old index tuple and not insert a duplicate pointer at all? I considered that, but it will require us to do an index lookup during WARM index insert and for non-unique keys, that may or may not be exactly cheap. Or we need something like what Claudio wrote to sort all index entries by heap TIDs. If we do that, then the recheck can be done just based on the index and heap flags (because we can then turn the old index pointer into a CLEAR pointer. Index pointer is set to COMMON during initial insert).
The other way is to pass old tuple values along with the new tuple values to amwarminsert, build index tuples and then do a comparison. For duplicate index tuples, skip WARM inserts.
By the way, the "Converting WARM chains back to HOT chains" section of
README.WARM seems to be out of date. Any chance you could update that
to reflect the current state and thinking of the patch?
Ok. I've extensively updated the README to match the current state of affairs. Updated patch set attached. I've also added mechanism to deal with known-dead pointers during regular index scans. We can derive some knowledge from index/heap states and recheck results. One additional thing I did which should help Dilip's test case is that we use the index/heap state to decide whether a recheck is necessary or not. And when we see a CLEAR pointer to all-WARM tuples, we set the pointer WARM and thus avoid repeated recheck for the same tuple. My own tests show that the regression should go away with this version, but I am not suggesting that we can't come up with some other workload where we still see regression.
I also realised that altering table-level enable_warm reloption would require AccessExclusiveLock. So included that change too.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Wed, Apr 5, 2017 at 11:27 AM, Andres Freund <andres@anarazel.de> wrote: > I propose we move this patch to the next CF. I agree. I think it's too late to be working out fine details around TOAST like this. This is a patch that touches the storage format in a fairly fundamental way. The idea of turning WARM on or off reminds me a little bit of the way it was at one time suggested that HOT not be used against catalog tables, a position that Tom pushed against. I'm not saying that it's necessarily a bad idea, but we should exhaust alternatives, and have a clear rationale for it. -- Peter Geoghegan
On Wed, Apr 5, 2017 at 2:32 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: >> The only other idea that I have for a really clean solution here is to >> support this only for index types that are amcanreturn, and actually >> compare the value stored in the index tuple with the one stored in the >> heap tuple, ensuring that new index tuples are inserted whenever they >> don't match and then using the exact same test to determine the >> applicability of a given index pointer to a given heap tuple. > > Just so that I understand, are you suggesting that while inserting WARM > index pointers, we check if the new index tuple will look exactly the same > as the old index tuple and not insert a duplicate pointer at all? Yes. > I considered that, but it will require us to do an index lookup during WARM > index insert and for non-unique keys, that may or may not be exactly cheap. I don't think it requires that. You should be able to figure out based on the tuple being updated and the corresponding new tuple whether this will bet true or not. > Or we need something like what Claudio wrote to sort all index entries by > heap TIDs. If we do that, then the recheck can be done just based on the > index and heap flags (because we can then turn the old index pointer into a > CLEAR pointer. Index pointer is set to COMMON during initial insert). Yeah, I think that patch is going to be needed for some of the storage work I'm interesting in doing, too, so I am tentatively in favor of it, but I wasn't proposing using it here. > The other way is to pass old tuple values along with the new tuple values to > amwarminsert, build index tuples and then do a comparison. For duplicate > index tuples, skip WARM inserts. This is more what I was thinking. But maybe one of the other ideas you wrote here is better; not sure. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Apr 6, 2017 at 1:06 AM, Robert Haas <robertmhaas@gmail.com> wrote:
On Wed, Apr 5, 2017 at 2:32 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
> The other way is to pass old tuple values along with the new tuple values to
> amwarminsert, build index tuples and then do a comparison. For duplicate
> index tuples, skip WARM inserts.
This is more what I was thinking. But maybe one of the other ideas
you wrote here is better; not sure.
Ok. I think I suggested this as one of the ideas upthread, to support hash indexes for example. This might be a good safety-net, but AFAIC what we have today should work since we pretty much construct index tuples in a consistent way before doing a comparison.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On 5 April 2017 at 13:32, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
>
> Ok. I've extensively updated the README to match the current state of
> affairs. Updated patch set attached.
Hi Pavan,
I run a test on current warm patchset, i used pgbench with a scale of
20 and a fillfactor of 90 and then start the pgbench run with 6
clients in parallel i also run sqlsmith on it.
And i got a core dump after sometime of those things running.
The assertion that fails is:
"""
LOG: statement: UPDATE pgbench_tellers SET tbalance = tbalance + 3519
WHERE tid = 34;
TRAP: FailedAssertion("!(((bool) (((const void*)(&tup->t_ctid) !=
((void *)0)) && (((&tup->t_ctid)->ip_posid & ((((uint16) 1) << 13) -
1)) != 0))))", File: "../../../../src/include/access/htup_details.h",
Line: 659)
"""
--
Jaime Casanova www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Fri, Apr 14, 2017 at 9:21 PM, Jaime Casanova <jaime.casanova@2ndquadrant.
Hi Pavan,
I run a test on current warm patchset, i used pgbench with a scale of
20 and a fillfactor of 90 and then start the pgbench run with 6
clients in parallel i also run sqlsmith on it.
And i got a core dump after sometime of those things running.
The assertion that fails is:
"""
LOG: statement: UPDATE pgbench_tellers SET tbalance = tbalance + 3519
WHERE tid = 34;
TRAP: FailedAssertion("!(((bool) (((const void*)(&tup->t_ctid) !=
((void *)0)) && (((&tup->t_ctid)->ip_posid & ((((uint16) 1) << 13) -
1)) != 0))))", File: "../../../../src/include/access/htup_details.h",
Line: 659)
"""
Hi Jaime,
Thanks for doing the tests and reporting the problem. Per our chat, the assertion failure occurs only after a crash recovery. I traced i down to the point where we were failing to set the root line pointer correctly during crash recovery. In fact, we were setting it, but after the local changes are copied to the on-disk image, thus failing to make to the storage.
Can you please test with the attached patch and confirm it works? I was able to reproduce the exact same assertion on my end and the patch seems to fix it. But an additional check won't harm.
I'll include the fix in the next set of patches.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Tue, Apr 18, 2017 at 4:25 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > I'll include the fix in the next set of patches. I haven't see a new set of patches. Are you intending to continue working on this? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Jul 26, 2017 at 6:26 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Tue, Apr 18, 2017 at 4:25 AM, Pavan Deolasee
<pavan.deolasee@gmail.com> wrote:
> I'll include the fix in the next set of patches.
I haven't see a new set of patches. Are you intending to continue
working on this?
Looks like I'll be short on bandwidth to pursue this further, given other work commitments including upcoming Postgres-XL 10 release. While I haven't worked on the patch since April, I think it was in a pretty good shape where I left it. But it's going to be incredibly difficult to estimate the amount of further efforts required, especially with testing and validating all the use cases and finding optimisations to fix regressions in all those cases. Also, many fundamental concerns around the patch touching the core of the database engine can only be addressed if some senior hackers, like you, take serious interest in the patch.
I'll be happy if someone wants to continue hacking the patch further and get it in a committable shape. I can stay actively involved. But TBH the amount of time I can invest is far as compared to what I could during the last cycle.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > I'll be happy if someone wants to continue hacking the patch further and > get it in a committable shape. I can stay actively involved. But TBH the > amount of time I can invest is far as compared to what I could during the > last cycle. That's disappointing. I personally find it very difficult to assess something like this. The problem is that even if you can demonstrate that the patch is strictly better than what we have today, the risk of reaching a local maxima exists. Do we really want to double-down on HOT? If I'm not mistaken, the goal of WARM is, roughly speaking, to make updates that would not be HOT-safe today do a "partial HOT update". My concern with that idea is that it doesn't do much for the worst case. -- Peter Geoghegan
On Fri, Jul 28, 2017 at 5:57 AM, Peter Geoghegan <pg@bowt.ie> wrote:
Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
> I'll be happy if someone wants to continue hacking the patch further and
> get it in a committable shape. I can stay actively involved. But TBH the
> amount of time I can invest is far as compared to what I could during the
> last cycle.
That's disappointing.
Yes, it is even more for me. But I was hard pressed to choose between Postgres-XL 10 and WARM. Given ever increasing interest in XL and my ability to control the outcome, I thought it makes sense to focus on XL for now.
I personally find it very difficult to assess something like this.
One good thing is that the patch is ready and fully functional. So that allows those who are keen to run real performance tests and see the actual impact of the patch.
The
problem is that even if you can demonstrate that the patch is strictly
better than what we have today, the risk of reaching a local maxima
exists. Do we really want to double-down on HOT?
Well HOT has served us well for over a decade now. So I won't hesitate to place my bets on WARM.
If I'm not mistaken, the goal of WARM is, roughly speaking, to make
updates that would not be HOT-safe today do a "partial HOT update". My
concern with that idea is that it doesn't do much for the worst case.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Jul 28, 2017 at 12:39 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > I see your point. But I would like to think this way: does the technology > significantly help many common use cases, that are currently not addressed > by HOT? It probably won't help all workloads, that's given. Also, we don't > have any credible alternative while this patch has progressed quite a lot. > May be Robert will soon present the pluggable storage/UNDO patch and that > will cover everything and more that is currently covered by HOT/WARM. That > will probably make many other things redundant. A lot of work is currently being done on this, by multiple people, mostly not including me, and a lot of good progress is being made. But it's not exactly ready to ship, nor will it be any time soon. I think we can run a 1-client pgbench without crashing the server at this point, if you tweak the configuration a little bit and don't do anything fancy like, say, try to roll back a transaction. :-) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
In-place index updates and HOT (Was: [HACKERS] Patch: WriteAmplification Reduction Method (WARM))
From
Peter Geoghegan
Date:
Pavan Deolasee <pavan.deolasee@gmail.com> wrote: >One good thing is that the patch is ready and fully functional. So that >allows those who are keen to run real performance tests and see the actual >impact of the patch. Very true. >I see your point. But I would like to think this way: does the technology >significantly help many common use cases, that are currently not addressed >by HOT? It probably won't help all workloads, that's given. Also, we don't >have any credible alternative while this patch has progressed quite a lot. >May be Robert will soon present the pluggable storage/UNDO patch and that >will cover everything and more that is currently covered by HOT/WARM. That >will probably make many other things redundant. Well, I don't assume that it will; again, I just don't know. I agree with your general assessment of things, which is that WARM, EDB's Z-Heap/UNDO project, and things like IOTs have significant overlap in terms of the high-level problems that they fix. While it's hard to say just how much overlap exists, it's clearly more than a little. And, you are right that we don't have a credible alternative in this general category right now. The WARM patch is available today. As you may have noticed, in recent weeks I've been very vocal about the role of index bloat in cases where bloat has a big impact on production workloads. I think that it has an under-appreciated role in workloads that deteriorate over time, as bloat accumulates. Perhaps HOT made such a big difference to workloads 10 years ago not just because it prevented creating new index entries. It also reduced fragmentation of the keyspace in indexes, by never inserting duplicates in the first place. I have some rough ideas related to this, and to the general questions you're addressing. I'd like to run these by you. In-place index updates + HOT ============================ Maybe we could improve things markedly in this general area by "chaining together HOT chains", and updating index heap pointers in place, to point to the start of the latest HOT chain in that chain of chains (provided the index tuple was "logically unchanged" -- otherwise, you'd need to have both sets of indexed values at once, of course). Index tuples therefore always point to the latest HOT chain, favoring recent MVCC snapshots over older ones. Pruning ------- HOT pruning is great because you can remove heap bloat without worrying about there being index entries with heap item pointers pointing to what is removed. But isn't that limitation as much about what is in the index as it is about what is in the heap? Under this scheme, you don't even have to keep around the old ItemId stub when pruning, if it's a sufficiently old HOT chain that no index points to the corresponding TID. That may not seem like a lot of bloat to have to keep around, but it accumulates within a page until VACUUM runs, ultimately limiting the effectiveness of pruning for certain workloads. Old snapshots/row versions -------------------------- Superseding HOT chains have their last heap tuple's t_tid point to the start of the preceding/superseded HOT chain (not their own TID, as today, which is redundant), which may or may not be on the same heap page. That's how old snapshots go backwards to get old versions, without needing their own "logically redundant" index entries. So with UPDATE heavy workloads that are essentially HOT-safe today, performance doesn't tank due to a long running transaction that obstructs pruning within a heap page, and thus necessitates the insertion of new index tuples. That's the main justification for this entire design. It's also possible that pruning can be taught that since only one index update was logically necessary when the to-be-pruned HOT chain was created, it's worth doing a "retail index tuple deletion" against the index tuple that was logically necessary, then completely obliterating the HOT chain, stub item pointer and all. Bloat and locality ------------------ README.HOT argues against HOT chains that span pages, which this is a bit like, on the grounds that it's bad news that every recent snapshot has to go through the old heap page. That makes sense, but only because the temporal locality there is horrible, which would not be the case here. README.HOT says that that cost is not worth the benefit of preventing a new index write, but I think that it ought to take into account that not all index writes are equal. There is an appreciable difference between inserting a new tuple, and updating one in-place. We can remove the cost (hurting new snapshots by making them go through old heap pages) while preserving most of the benefits (no logically unnecessary index bloat). The benefit of HOT is clearly more bloat prevention than not having to visit indexes at all. InnoDB secondary index updates update the index twice: The first time, during the update itself, and the second time, by the purge thread, once the xact commits. Clearly they care about doing clean-up of indexes eagerly. Also, a key design goal of UNDO within the original ARIES paper is to make deletion of index tuples make the space reclaimable immediately, even before the transaction commits. While it wouldn't be practical to get that to work for the general case on an MVCC system, I think it can work for logically unchanged index tuples through in-place index tuple updates. If nothing else, the priorities for ARIES tell us something. Obviously what I describe here is totally hand-wavy, and actually undertaking this project would be incredibly difficult. If nothing else it may be useful to you, or to others, to hear me slightly reframe the benefits of HOT in this way. Moreover, a lot of what I'm describing here has overlap with stuff that I presume that EDB will need for Z-Heap/UNDO. For example, since it's clear that you cannot immediately remove an updated secondary index tuple in UNDO, it still has to have its own "out of band" lifetime. How is it ever going to get physically deleted, otherwise? So maybe you end up updating that in-place, to point into UNDO directly, rather than pointing to a heap TID that is necessarily the most recent version, which could introduce ambiguity (what happens when it is changed, then changed back?). That's actually rather similar to what you could do with HOT + the existing heapam, except that there is a clearer demarcation of "current" (heap) and "pending garbage" (UNDO) within Robert's design. -- Peter Geoghegan
Re: In-place index updates and HOT (Was: [HACKERS] Patch: WriteAmplification Reduction Method (WARM))
From
Claudio Freire
Date:
On Fri, Jul 28, 2017 at 8:32 PM, Peter Geoghegan <pg@bowt.ie> wrote: > README.HOT says that that cost is not worth the benefit of > preventing a new index write, but I think that it ought to take into > account that not all index writes are equal. There is an appreciable > difference between inserting a new tuple, and updating one in-place. We > can remove the cost (hurting new snapshots by making them go through old > heap pages) while preserving most of the benefits (no logically > unnecessary index bloat). It's a neat idea. And, well, now that you mention, you don't need to touch indexes at all. You can create the new chain, and "update" the index to point to it, without ever touching the index itself, since you can repoint the old HOT chain's start line pointer to point to the new HOT chain, create a new pointer for the old one and point to it in the new HOT chain's t_tid. Existing index tuples thus now point to the right HOT chain without having to go into the index and make any changes. You do need the new HOT chain to live in the same page for this, however.
Re: In-place index updates and HOT (Was: [HACKERS] Patch: WriteAmplification Reduction Method (WARM))
From
Peter Geoghegan
Date:
Claudio Freire <klaussfreire@gmail.com> wrote: >> README.HOT says that that cost is not worth the benefit of >> preventing a new index write, but I think that it ought to take into >> account that not all index writes are equal. There is an appreciable >> difference between inserting a new tuple, and updating one in-place. We >> can remove the cost (hurting new snapshots by making them go through old >> heap pages) while preserving most of the benefits (no logically >> unnecessary index bloat). > >It's a neat idea. Thanks. I think it's important to both prevent index bloat, and to make sure that only the latest version is pointed to within indexes. There are only so many ways that that can be done. I've tried to come up with a way of doing those two things that breaks as little of heapam.c as possible. As a bonus, some kind of super-pruning of many linked HOT chains may be enabled, which is something that an asynchronous process can do when triggered by a regular prune within a user backend. This is a kind of micro-vacuum that is actually much closer to VACUUM than the kill_prior_tuple stuff, or traditional pruning, in that it potentially kills index entries (just those that were not subsequently updated in place, because the new values for the index differed), and then kills heap tuples, all together, without even keeping around a stub itemId in the heap. And, chaining together HOT chains also lets us chain together pruning. Retail index tuple deletion from pruning needs to be crash safe, unlike LP_DEAD setting. >And, well, now that you mention, you don't need to touch indexes at all. > >You can create the new chain, and "update" the index to point to it, >without ever touching the index itself, since you can repoint the old >HOT chain's start line pointer to point to the new HOT chain, create >a new pointer for the old one and point to it in the new HOT chain's >t_tid. > >Existing index tuples thus now point to the right HOT chain without >having to go into the index and make any changes. > >You do need the new HOT chain to live in the same page for this, >however. That seems complicated. The idea that I'm trying to preserve here is the idea that the beginning of a HOT-chain (a definition that includes a "potential HOT chain" -- a single heap tuple that could later receive a HOT UPDATE) unambiguously signals a need for physical changes to indexes in all cases. The idea that I'm trying to move away from is that those physical changes need to be new index insertions (new insertions should only happen when it is logically necessary, because indexed values changed). Note that this can preserve the kill_prior_tuple stuff, I think, because if everything is dead within a single HOT chain (a HOT chain by our current definition -- not a chain of HOT chains) then nobody can need the index tuple. This does require adding complexity around aborted transactions, whose new (potential) HOT chain t_tid "backpointer" is still needed; we must revise the definition of a HOT chain being all_dead to accommodate that. But for the most part, we preserve HOT chains as a thing that garbage collection can independently reason about, process with single page atomic operations while still being crash safe, etc. As far as microvacuum style garbage collection goes, at a high level, HOT chains seem like a good choke point to do clean-up of both heap tuples (pruning) and index tuples. The complexity of doing that seems manageable. And by chaining together HOT chains, you can really aggressively microvacuum many HOT chains on many pages within an asynchronous process as soon as the long running transaction goes away. We lean on temporal locality for garbage collection. There are numerous complications that I haven't really acknowledged but am at least aware of. For one, when I say "update in place", I don't necessarily mean it literally. It's probably possible to literally update in place with unique indexes. For secondary indexes, which should still have heap TID as part of their keyspace (once you go implement that, Claudio), we probably need an index insertion immediately followed by an index deletion, often within the same leaf page. I hope that this design, such as it is, will be reviewed as a thought experiment. What would be good or bad about a design like this in the real world, particularly as compared to alternatives that we know about? Is *some* "third way" design desirable and achievable, if not this one? By "third way" design, I mean a design that is much less invasive than adopting UNDO for MVCC, that still addresses the issues that we currently have with certain types of UPDATE-heavy workloads, especially when there are long running transactions, etc. I doubt that WARM meets this standard, unfortunately, because it doesn't do anything for cases that suffer only due to a long running xact. I don't accept that there is a rigid dichotomy between Postgres style MVCC, and using UNDO for MVCC, and I most certainly don't accept that garbage collection has been optimized as heavily as the overall heapam.c design allows for. -- Peter Geoghegan
> On 28 Jul 2017, at 16:46, Robert Haas <robertmhaas@gmail.com> wrote: > > On Fri, Jul 28, 2017 at 12:39 AM, Pavan Deolasee > <pavan.deolasee@gmail.com> wrote: >> I see your point. But I would like to think this way: does the technology >> significantly help many common use cases, that are currently not addressed >> by HOT? It probably won't help all workloads, that's given. Also, we don't >> have any credible alternative while this patch has progressed quite a lot. >> May be Robert will soon present the pluggable storage/UNDO patch and that >> will cover everything and more that is currently covered by HOT/WARM. That >> will probably make many other things redundant. > > A lot of work is currently being done on this, by multiple people, > mostly not including me, and a lot of good progress is being made. > But it's not exactly ready to ship, nor will it be any time soon. I > think we can run a 1-client pgbench without crashing the server at > this point, if you tweak the configuration a little bit and don't do > anything fancy like, say, try to roll back a transaction. :-) The discussions in this implies that there is a bit more work on this patch, which also hasn’t moved in the current commitfest, so marking it Returned with Feedback. Please re-submit this work in a future commitfest when ready for a new round of reviews. cheers ./daniel -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers