Thread: Speedup twophase transactions
Hello. While working with cluster stuff (DTM, tsDTM) we noted that postgres 2pc transactions is approximately two times slower thanan ordinary commit on workload with fast transactions — few single-row updates and COMMIT or PREPARE/COMMIT. Perf topshowed that a lot of time is spent in kernel on fopen/fclose, so it worth a try to reduce file operations with 2pc tx. Now 2PC in postgres does following: * on prepare 2pc data (subxacts, commitrels, abortrels, invalmsgs) saved to xlog and to file, but file not is not fsynced * on commit backend reads data from file * if checkpoint occurs before commit, then files are fsynced during checkpoint * if case of crash replay will move data from xlog to files In this patch I’ve changed this procedures to following: * on prepare backend writes data only to xlog and store pointer to the start of the xlog record * if commit occurs before checkpoint then backend reads data from xlog by this pointer * on checkpoint 2pc data copied to files and fsynced * if commit happens after checkpoint then backend reads files * in case of crash replay will move data from xlog to files (as it was before patch) Most of that ideas was already mentioned in 2009 thread by Michael Paquier http://www.postgresql.org/message-id/c64c5f8b0908062031k3ff48428j824a9a46f28180ac@mail.gmail.comwhere he suggested to store2pc data in shared memory. At that time patch was declined because no significant speedup were observed. Now I see performance improvements by my patchat about 60%. Probably old benchmark overall tps was lower and it was harder to hit filesystem fopen/fclose limits. Now results of benchmark are following (dual 6-core xeon server): Current master without 2PC: ~42 ktps Current master with 2PC: ~22 ktps Current master with 2PC: ~36 ktps Benchmark done with following script: \set naccounts 100000 * :scale \setrandom from_aid 1 :naccounts \setrandom to_aid 1 :naccounts \setrandom delta 1 100 \set scale :scale+1 BEGIN; UPDATE pgbench_accounts SET abalance = abalance - :delta WHERE aid = :from_aid; UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :to_aid; PREPARE TRANSACTION ':client_id.:scale'; COMMIT PREPARED ':client_id.:scale'; --- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On Wed, Dec 9, 2015 at 12:44 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > Now 2PC in postgres does following: > * on prepare 2pc data (subxacts, commitrels, abortrels, invalmsgs) saved to xlog and to file, but file not is not fsynced > * on commit backend reads data from file > * if checkpoint occurs before commit, then files are fsynced during checkpoint > * if case of crash replay will move data from xlog to files > > In this patch I’ve changed this procedures to following: > * on prepare backend writes data only to xlog and store pointer to the start of the xlog record > * if commit occurs before checkpoint then backend reads data from xlog by this pointer > * on checkpoint 2pc data copied to files and fsynced > * if commit happens after checkpoint then backend reads files > * in case of crash replay will move data from xlog to files (as it was before patch) That sounds like a very good plan to me. > Now results of benchmark are following (dual 6-core xeon server): > > Current master without 2PC: ~42 ktps > Current master with 2PC: ~22 ktps > Current master with 2PC: ~36 ktps I assume that last one should have been *Patched master with 2PC"? Please add this to the January CommitFest. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Thanks, Kevin. > I assume that last one should have been *Patched master with 2PC”? Yes, this list should look like this: Current master without 2PC: ~42 ktps Current master with 2PC: ~22 ktps Patched master with 2PC: ~36 ktps And created CommitFest entry for this patch. -- Stas Kelvich Postgres Professional: http://www.postgrespro.com The Russian Postgres Company > On 10 Dec 2015, at 00:37, Kevin Grittner <kgrittn@gmail.com> wrote: > > On Wed, Dec 9, 2015 at 12:44 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > >> Now 2PC in postgres does following: >> * on prepare 2pc data (subxacts, commitrels, abortrels, invalmsgs) saved to xlog and to file, but file not is not fsynced >> * on commit backend reads data from file >> * if checkpoint occurs before commit, then files are fsynced during checkpoint >> * if case of crash replay will move data from xlog to files >> >> In this patch I’ve changed this procedures to following: >> * on prepare backend writes data only to xlog and store pointer to the start of the xlog record >> * if commit occurs before checkpoint then backend reads data from xlog by this pointer >> * on checkpoint 2pc data copied to files and fsynced >> * if commit happens after checkpoint then backend reads files >> * in case of crash replay will move data from xlog to files (as it was before patch) > > That sounds like a very good plan to me. > >> Now results of benchmark are following (dual 6-core xeon server): >> >> Current master without 2PC: ~42 ktps >> Current master with 2PC: ~22 ktps >> Current master with 2PC: ~36 ktps > > I assume that last one should have been *Patched master with 2PC"? > > Please add this to the January CommitFest. > > -- > Kevin Grittner > EDB: http://www.enterprisedb.com > The Enterprise PostgreSQL Company
On Thu, Dec 10, 2015 at 3:44 AM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > Most of that ideas was already mentioned in 2009 thread by Michael Paquier http://www.postgresql.org/message-id/c64c5f8b0908062031k3ff48428j824a9a46f28180ac@mail.gmail.comwhere he suggested to store2pc data in shared memory. > At that time patch was declined because no significant speedup were observed. Now I see performance improvements by mypatch at about 60%. Probably old benchmark overall tps was lower and it was harder to hit filesystem fopen/fclose limits. Glad to see this patch is given a second life 6 years later. > Now results of benchmark are following (dual 6-core xeon server): > > Current master without 2PC: ~42 ktps > Current master with 2PC: ~22 ktps > Current master with 2PC: ~36 ktps That's nice. + XLogRecPtr prepare_xlogptr; /* XLOG offset of prepare record start + * or NULL if twophase data moved to file + * after checkpoint. + */ This has better be InvalidXLogRecPtr if unused. + if (gxact->prepare_lsn) + { + XlogReadTwoPhaseData(gxact->prepare_xlogptr, &buf, NULL); + } Perhaps you mean prepare_xlogptr here? -- Michael
On Wed, Dec 9, 2015 at 10:44 AM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > Hello. > > While working with cluster stuff (DTM, tsDTM) we noted that postgres 2pc transactions is approximately two times slowerthan an ordinary commit on workload with fast transactions — few single-row updates and COMMIT or PREPARE/COMMIT. Perftop showed that a lot of time is spent in kernel on fopen/fclose, so it worth a try to reduce file operations with 2pctx. > I've tested this through my testing harness which forces the database to go through endless runs of crash recovery and checks for consistency, and so far it has survived perfectly. ... > > Now results of benchmark are following (dual 6-core xeon server): > > Current master without 2PC: ~42 ktps > Current master with 2PC: ~22 ktps > Current master with 2PC: ~36 ktps Can you give the full command line? -j, -c, etc. > > Benchmark done with following script: > > \set naccounts 100000 * :scale > \setrandom from_aid 1 :naccounts > \setrandom to_aid 1 :naccounts > \setrandom delta 1 100 > \set scale :scale+1 Why are you incrementing :scale ? I very rapidly reach a point where most of the updates are against tuples that don't exist, and then get integer overflow problems. > BEGIN; > UPDATE pgbench_accounts SET abalance = abalance - :delta WHERE aid = :from_aid; > UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :to_aid; > PREPARE TRANSACTION ':client_id.:scale'; > COMMIT PREPARED ':client_id.:scale'; > Cheers, Jeff
Michael, Jeff thanks for reviewing and testing.
> On 10 Dec 2015, at 02:16, Michael Paquier <michael.paquier@gmail.com> wrote:
>
> This has better be InvalidXLogRecPtr if unused.
Yes, that’s better. Changed.
> On 10 Dec 2015, at 02:16, Michael Paquier <michael.paquier@gmail.com> wrote:
> + if (gxact->prepare_lsn)
> + {
> + XlogReadTwoPhaseData(gxact->prepare_xlogptr, &buf, NULL);
> + }
> Perhaps you mean prepare_xlogptr here?
Yes, my bad. But funnily I have this error even number of times: code in CheckPointTwoPhase also uses prepare_lsn
insteadof xlogptr, so overall this was working well, that’s why it survived my own tests and probably Jeff’s tests.
I think that’s a bad variable naming, for example because lsn in pg_xlogdump points to start of the record, but here
startused as xloptr and end as lsn.
So changed both variables to prepare_start_lsn and prepare_end_lsn.
> On 10 Dec 2015, at 09:48, Jeff Janes <jeff.janes@gmail.com> wrote:
> I've tested this through my testing harness which forces the database
> to go through endless runs of crash recovery and checks for
> consistency, and so far it has survived perfectly.
Cool! I think that patch is most vulnerable to following type of workload: prepare transaction, do a lot of stuff with
databaseto force checkpoints (or even recovery cycles), and commit it.
> On 10 Dec 2015, at 09:48, Jeff Janes <jeff.janes@gmail.com> wrote:
> Can you give the full command line? -j, -c, etc.
pgbench -h testhost -i && pgbench -h testhost -f 2pc.pgb -T 300 -P 1 -c 64 -j 16 -r
where 2pc.pgb as in previous message.
Also all this applies to hosts with uniform memory. I tried to run patched postgres on NUMA with 60 physical cores and
patchdidn’t change anything. Perf top shows that main bottleneck is access to gxact, but on ordinary host with 1/2
cpu’sthat access even not in top ten heaviest routines.
> On 10 Dec 2015, at 09:48, Jeff Janes <jeff.janes@gmail.com> wrote:
> Why are you incrementing :scale ?
That’s a funny part, overall 2pc speed depends on how you will name your prepared transaction. Concretely I tried to
userandom numbers for gid’s and it was slower than having constantly incrementing gid. Probably that happens due to
linearsearch by gid in gxact array on commit. So I used :scale just as a counter, bacause it is initialised on pgbench
startand line like “\set scale :scale+1” works well. (may be there is a different way to do it in pgbench).
> I very rapidly reach a point where most of the updates are against
> tuples that don't exist, and then get integer overflow problems.
Hmm, that’s strange. Probably you set scale to big value, so that 100000*:scale is bigger that int4? But i thought that
pgbenchwill change aid columns to bigint if scale is more than 20000.
---
Stas Kelvich
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Attachment
On 9 December 2015 at 18:44, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
--
In this patch I’ve changed this procedures to following:
* on prepare backend writes data only to xlog and store pointer to the start of the xlog record
* if commit occurs before checkpoint then backend reads data from xlog by this pointer
* on checkpoint 2pc data copied to files and fsynced
* if commit happens after checkpoint then backend reads files
* in case of crash replay will move data from xlog to files (as it was before patch)
This looks sound to me.
I think we could do better still, but this looks like the easiest 80% and actually removes code.
The lack of substantial comments on the patch is a problem though - the details above should go in the patch. I'll have a go at reworking this for you, this time.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Simon Riggs wrote: > I think we could do better still, but this looks like the easiest 80% and > actually removes code. > > The lack of substantial comments on the patch is a problem though - the > details above should go in the patch. I'll have a go at reworking this for > you, this time. Is someone submitting an updated patch here? -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi. I’ve updated patch and wrote description of thighs that happens with 2PC state data in the beginning of the file. I think now this patch is well documented, but if somebody points me to places that probably requires more detailed description I’m ready to extend that. Stas Kelvich Postgres Professional: http://www.postgrespro.com The Russian Postgres Company > On 08 Jan 2016, at 19:29, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > > Simon Riggs wrote: > >> I think we could do better still, but this looks like the easiest 80% and >> actually removes code. >> >> The lack of substantial comments on the patch is a problem though - the >> details above should go in the patch. I'll have a go at reworking this for >> you, this time. > > Is someone submitting an updated patch here? > > -- > Álvaro Herrera http://www.2ndQuadrant.com/ > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services > > > -- > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On 9 January 2016 at 12:26, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
--
I’ve updated patch and wrote description of thighs that happens
with 2PC state data in the beginning of the file. I think now this patch is well documented,
but if somebody points me to places that probably requires more detailed description I’m ready
to extend that.
Hmm, I was just preparing this for commit.
Please have a look at my mild edits and extended comments.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On 9 January 2016 at 12:26, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
--
I’ve updated patch and wrote description of thighs that happens
with 2PC state data in the beginning of the file. I think now this patch is well documented,
but if somebody points me to places that probably requires more detailed description I’m ready
to extend that.
Your comments say
"In case of crash replay will move data from xlog to files, if that hasn't happened before."
but I don't see that in code. Can you show me where that happens?
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Thanks a lot for your edits, now that patch is much more cleaner. > Your comments say > > "In case of crash replay will move data from xlog to files, if that hasn't happened before." > > but I don't see that in code. Can you show me where that happens? xact.c calls RecreateTwoPhaseFile in xact_redo() function (xact.c:5596) > On 09 Jan 2016, at 18:29, Simon Riggs <simon@2ndquadrant.com> wrote: > > Hmm, I was just preparing this for commit. > > Please have a look at my mild edits and extended comments. One concern that come into my mind while reading updated patch is about creating extra bool field in GlobalTransactionData structure. While this improves readability, it also increases size of that structure and that size have impact on performance on systems with many cores (say like 60-80). Probably one byte will not make measurable difference, but I think it is good idea to keep GXact as small as possible. As far as I understand the same logic was behind split of PGPROC to PGPROC+PGXACT in 9.2 (comment in proc.h:166) Stas Kelvich Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 9 January 2016 at 20:28, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
--
Thanks a lot for your edits, now that patch is much more cleaner.
> Your comments say
>
> "In case of crash replay will move data from xlog to files, if that hasn't happened before."
>
> but I don't see that in code. Can you show me where that happens?
xact.c calls RecreateTwoPhaseFile in xact_redo() function (xact.c:5596)
So we've only optimized half the usage? We're still going to cause replication delays.
Sounds like we should be fixing both.
We can either
1) Skip fsyncing the RecreateTwoPhaseFile and then fsync during restartpoints
2) Copy the contents to shmem and then write them at restartpoint as we do for checkpoint
(preferred)
> On 09 Jan 2016, at 18:29, Simon Riggs <simon@2ndquadrant.com> wrote:
>
> Hmm, I was just preparing this for commit.
>
> Please have a look at my mild edits and extended comments.
One concern that come into my mind while reading updated
patch is about creating extra bool field in GlobalTransactionData structure. While this improves readability, it
also increases size of that structure and that size have impact on performance on systems with many cores
(say like 60-80). Probably one byte will not make measurable difference, but I think it is good idea to keep
GXact as small as possible. As far as I understand the same logic was behind split of
PGPROC to PGPROC+PGXACT in 9.2 (comment in proc.h:166)
I think padding will negate the effects of the additional bool.
If we want to reduce the size of the array GIDSIZE is currently 200, but XA says maximum 128 bytes.
Anybody know why that is set to 200?
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
> On 10 Jan 2016, at 12:15, Simon Riggs <simon@2ndquadrant.com> wrote: > > So we've only optimized half the usage? We're still going to cause replication delays. Yes, replica will go through old procedures of moving data to and from file. > We can either > > 1) Skip fsyncing the RecreateTwoPhaseFile and then fsync during restartpoints From what i’ve seen with old 2pc code main performance bottleneck was caused by frequent creating of files. So better toavoid files if possible. > > 2) Copy the contents to shmem and then write them at restartpoint as we do for checkpoint > (preferred) Problem with shared memory is that we can’t really predict size of state data, and anyway it isn’t faster then reading datafrom WAL (I have tested that while preparing original patch). We can just apply the same logic on replica that on master: do not do anything special on prepare, and just read that datafrom WAL. If checkpoint occurs during recovery/replay probably existing code will handle moving data to files. I will update patch to address this issue. > I think padding will negate the effects of the additional bool. > > If we want to reduce the size of the array GIDSIZE is currently 200, but XA says maximum 128 bytes. > > Anybody know why that is set to 200? Good catch about GID size. If we talk about further optimisations i see two ways: 1) Optimising access to GXACT. Here we can try to shrink it; introduce more granular locks, e.g. move GIDs out of GXACT and lock GIDs array only once while checking new GID uniqueness; try to lock only part of GXACTby hash; etc. 2) Be optimistic about consequent COMMIT PREPARED. In normal workload next command after PREPARE will be COMMIT/ROLLBACK,so we can save transaction context and release it only if next command isn’t our designated COMMIT/ROLLBACK. But that is a big amount ofwork and requires changes to whole transaction pipeline in postgres. Anyway I suggest that we should consider that as a separate task. --- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company
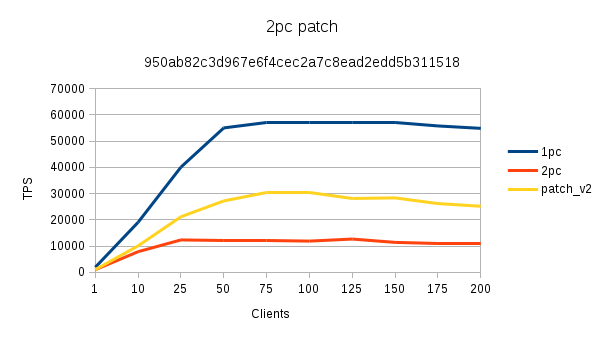
On 01/09/2016 10:29 AM, Simon Riggs wrote: > On 9 January 2016 at 12:26, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > > >> I’ve updated patch and wrote description of thighs that happens >> with 2PC state data in the beginning of the file. I think now this patch >> is well documented, >> but if somebody points me to places that probably requires more detailed >> description I’m ready >> to extend that. >> > > Hmm, I was just preparing this for commit. > > Please have a look at my mild edits and extended comments. > I have done a run with the patch and it looks really great. Attached is the TPS graph - with a 1pc run too - and the perf profile as a flame graph (28C/56T w/ 256Gb mem, 2 x RAID10 SSD). Maybe +static void +XlogReadTwoPhaseData(XLogRecPtr lsn, char **buf, int *len) to +static void +ReadTwoPhaseDataFromXlog(XLogRecPtr lsn, char **buf, int *len) Best regards, Jesper
Attachment
{kind=link}
{kind=link}
On 11 January 2016 at 12:58, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
--
> On 10 Jan 2016, at 12:15, Simon Riggs <simon@2ndquadrant.com> wrote:
>
> So we've only optimized half the usage? We're still going to cause replication delays.
Yes, replica will go through old procedures of moving data to and from file.
> We can either
>
> 1) Skip fsyncing the RecreateTwoPhaseFile and then fsync during restartpoints
From what i’ve seen with old 2pc code main performance bottleneck was caused by frequent creating of files. So better to avoid files if possible.
>
> 2) Copy the contents to shmem and then write them at restartpoint as we do for checkpoint
> (preferred)
Problem with shared memory is that we can’t really predict size of state data, and anyway it isn’t faster then reading data from WAL
(I have tested that while preparing original patch).
We can just apply the same logic on replica that on master: do not do anything special on prepare, and just read that data from WAL.
If checkpoint occurs during recovery/replay probably existing code will handle moving data to files.
I will update patch to address this issue.
I'm looking to commit what we have now, so lets do that as a separate but necessary patch please.
> I think padding will negate the effects of the additional bool.
>
> If we want to reduce the size of the array GIDSIZE is currently 200, but XA says maximum 128 bytes.
>
> Anybody know why that is set to 200?
Good catch about GID size.
I'll apply that as a separate patch also.
If we talk about further optimisations i see two ways:
1) Optimising access to GXACT. Here we can try to shrink it; introduce more granular locks,
e.g. move GIDs out of GXACT and lock GIDs array only once while checking new GID uniqueness; try to lock only part of GXACT by hash; etc.
Have you measured lwlocking as a problem?
2) Be optimistic about consequent COMMIT PREPARED. In normal workload next command after PREPARE will be COMMIT/ROLLBACK, so we can save
transaction context and release it only if next command isn’t our designated COMMIT/ROLLBACK. But that is a big amount of work and requires
changes to whole transaction pipeline in postgres.
We'd need some way to force session pools to use that correctly, but yes, agreed.
Anyway I suggest that we should consider that as a separate task.
Definitely. From the numbers, I can see there is still considerable performance gain to be had.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 01/10/2016 04:15 AM, Simon Riggs wrote: >> One concern that come into my mind while reading updated >> patch is about creating extra bool field in GlobalTransactionData >> structure. While this improves readability, it >> also increases size of that structure and that size have impact on >> performance on systems with many cores >> (say like 60-80). Probably one byte will not make measurable difference, >> but I think it is good idea to keep >> GXact as small as possible. As far as I understand the same logic was >> behind split of >> PGPROC to PGPROC+PGXACT in 9.2 (comment in proc.h:166) > > > I think padding will negate the effects of the additional bool. > > If we want to reduce the size of the array GIDSIZE is currently 200, but XA > says maximum 128 bytes. > > Anybody know why that is set to 200? > Even though GlobalTransactionId and BranchQualifer have a maximum of 64 each, external clients may choose to encode the information, and thereby need more space, https://github.com/pgjdbc/pgjdbc/blob/master/pgjdbc/src/main/java/org/postgresql/xa/RecoveredXid.java#L66-L70 http://docs.oracle.com/javaee/7/api/javax/transaction/xa/Xid.html which in this case adds up to a maximum of 189 characters. Best regards, Jesper
Hi,
On 2016-01-09 15:29:11 +0000, Simon Riggs wrote:
> Hmm, I was just preparing this for commit.
Just read downthread that you want to commit this soon. Please hold of
for a while, this doesn't really look ready to me. I don't have time for
a real review right now, but I'll try to get to it asap.
> +
> +/*
> + * Reads 2PC data from xlog. During checkpoint this data will be moved to
> + * twophase files and ReadTwoPhaseFile should be used instead.
> + */
> +static void
> +XlogReadTwoPhaseData(XLogRecPtr lsn, char **buf, int *len)
> +{
> + XLogRecord *record;
> + XLogReaderState *xlogreader;
> + char *errormsg;
> +
> + xlogreader = XLogReaderAllocate(&logical_read_local_xlog_page,
> NULL);
logical_read_local_xlog_page isn't really suitable for the use
here. Besides the naming issue, at the very least it'll be wrong during
WAL replay in the presence of promotions on an upstream node - it
doesn't dealwith timelines.
More generally, I'm doubtful that the approach of reading data from WAL
as proposed here is a very good idea. It seems better to "just" dump the
entire 2pc state into *one* file at checkpoint time.
Greetings,
Andres Freund
On 2016-01-11 20:03:18 +0100, Andres Freund wrote: > More generally, I'm doubtful that the approach of reading data from WAL > as proposed here is a very good idea. It seems better to "just" dump the > entire 2pc state into *one* file at checkpoint time. Or better: After determining the checkpoint redo location, insert a WAL record representing the entire 2PC state as of that moment. That way it can easily restored during WAL replay and nothing special has to be done on a standby. This way we'll need no extra wal flushes and fsyncs.
On 11 January 2016 at 19:03, Andres Freund <andres@anarazel.de> wrote:
--
Hi,
On 2016-01-09 15:29:11 +0000, Simon Riggs wrote:
> Hmm, I was just preparing this for commit.
Just read downthread that you want to commit this soon. Please hold of
for a while, this doesn't really look ready to me. I don't have time for
a real review right now, but I'll try to get to it asap.
"A real review"? Huh.
> +
> +/*
> + * Reads 2PC data from xlog. During checkpoint this data will be moved to
> + * twophase files and ReadTwoPhaseFile should be used instead.
> + */
> +static void
> +XlogReadTwoPhaseData(XLogRecPtr lsn, char **buf, int *len)
> +{
> + XLogRecord *record;
> + XLogReaderState *xlogreader;
> + char *errormsg;
> +
> + xlogreader = XLogReaderAllocate(&logical_read_local_xlog_page,
> NULL);
logical_read_local_xlog_page isn't really suitable for the use
here. Besides the naming issue, at the very least it'll be wrong during
WAL replay in the presence of promotions on an upstream node - it
doesn't dealwith timelines.
I'm aware of that, though note that it isn't being used in that way here.
More generally, I'm doubtful that the approach of reading data from WAL
as proposed here is a very good idea. It seems better to "just" dump the
entire 2pc state into *one* file at checkpoint time.
I think you misunderstand the proposed approach. This isn't just to do with reading things back at checkpoint.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 11 January 2016 at 19:07, Andres Freund <andres@anarazel.de> wrote:
Feel free to submit a patch that does that.
--
On 2016-01-11 20:03:18 +0100, Andres Freund wrote:
> More generally, I'm doubtful that the approach of reading data from WAL
> as proposed here is a very good idea. It seems better to "just" dump the
> entire 2pc state into *one* file at checkpoint time.
Or better: After determining the checkpoint redo location, insert a WAL
record representing the entire 2PC state as of that moment. That way it
can easily restored during WAL replay and nothing special has to be done
on a standby. This way we'll need no extra wal flushes and fsyncs.
Feel free to submit a patch that does that.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2016-01-11 19:15:23 +0000, Simon Riggs wrote: > On 11 January 2016 at 19:03, Andres Freund <andres@anarazel.de> wrote: > > > Hi, > > > > On 2016-01-09 15:29:11 +0000, Simon Riggs wrote: > > > Hmm, I was just preparing this for commit. > > > > Just read downthread that you want to commit this soon. Please hold of > > for a while, this doesn't really look ready to me. I don't have time for > > a real review right now, but I'll try to get to it asap. > > > > "A real review"? Huh. All I meant was that my email didn't consist out of a real review, but just was a quick scan > > More generally, I'm doubtful that the approach of reading data from WAL > > as proposed here is a very good idea. It seems better to "just" dump the > > entire 2pc state into *one* file at checkpoint time. > > > > I think you misunderstand the proposed approach. This isn't just to do > with reading things back at checkpoint. Sure, the main purpose is not to write 2pc state files in the common path - or is that not the main purpose? Greetings, Andres Freund
On 11 January 2016 at 18:51, Jesper Pedersen <jesper.pedersen@redhat.com> wrote:
--
On 01/10/2016 04:15 AM, Simon Riggs wrote:One concern that come into my mind while reading updated
patch is about creating extra bool field in GlobalTransactionData
structure. While this improves readability, it
also increases size of that structure and that size have impact on
performance on systems with many cores
(say like 60-80). Probably one byte will not make measurable difference,
but I think it is good idea to keep
GXact as small as possible. As far as I understand the same logic was
behind split of
PGPROC to PGPROC+PGXACT in 9.2 (comment in proc.h:166)
I think padding will negate the effects of the additional bool.
If we want to reduce the size of the array GIDSIZE is currently 200, but XA
says maximum 128 bytes.
Anybody know why that is set to 200?
Even though GlobalTransactionId and BranchQualifer have a maximum of 64 each, external clients may choose to encode the information, and thereby need more space,
https://github.com/pgjdbc/pgjdbc/blob/master/pgjdbc/src/main/java/org/postgresql/xa/RecoveredXid.java#L66-L70
http://docs.oracle.com/javaee/7/api/javax/transaction/xa/Xid.html
which in this case adds up to a maximum of 189 characters.
OK, thanks for those references.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 11 January 2016 at 19:18, Andres Freund <andres@anarazel.de> wrote:
--
> > More generally, I'm doubtful that the approach of reading data from WAL
> > as proposed here is a very good idea. It seems better to "just" dump the
> > entire 2pc state into *one* file at checkpoint time.
> >
>
> I think you misunderstand the proposed approach. This isn't just to do
> with reading things back at checkpoint.
Sure, the main purpose is not to write 2pc state files in the common
path - or is that not the main purpose?
Yes, that is the main purpose, but that's not what you were talking about.
Currently, the patch reuses all of the code related to reading/write state files, so it is the minimal patch that can implement the important things for performance. The current patch succeeds in its goal to improve performance, so I personally see no further need for code churn.
As you suggest, we could also completely redesign the state file mechanism and/or put it in WAL at checkpoint. That's all very nice but is much more code and doesn't anything more for performance, since the current mainline path writes ZERO files at checkpoint. If you want that for some other reason or refactoring, I won't stop you, but its a separate patch for a separate purpose.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 11 January 2016 at 18:43, Simon Riggs <simon@2ndquadrant.com> wrote:
--
I'm looking to commit what we have now.
Here is the patch in its "final" state after my minor additions, edits and review.
Performance tests for me show that the patch is effective; my results match Jesper's roughly in relative numbers.
My robustness review is that the approach and implementation are safe.
It's clear there are various additional tuning opportunities, but the objective of the current patch to improve performance is very, very clearly met, so I'm aiming to commit *this* patch soon.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On January 11, 2016 8:57:58 PM GMT+01:00, Simon Riggs <simon@2ndQuadrant.com> wrote: >On 11 January 2016 at 18:43, Simon Riggs <simon@2ndquadrant.com> wrote: >It's clear there are various additional tuning opportunities, but the >objective of the current patch to improve performance is very, very >clearly >met, so I'm aiming to commit *this* patch soon. Again, the WAL read routine used doesn't deal with timeline changes. So no, it's bit ready to be committed. --- Please excuse brevity and formatting - I am writing this on my mobile phone.
On 11 January 2016 at 20:10, Andres Freund <andres@anarazel.de> wrote:
--
On January 11, 2016 8:57:58 PM GMT+01:00, Simon Riggs <simon@2ndQuadrant.com> wrote:
>On 11 January 2016 at 18:43, Simon Riggs <simon@2ndquadrant.com> wrote:
>It's clear there are various additional tuning opportunities, but the
>objective of the current patch to improve performance is very, very
>clearly
>met, so I'm aiming to commit *this* patch soon.
Again, the WAL read routine used doesn't deal with timeline changes.
Not relevant: The direct WAL read routine is never used during replay, so your comment is not relevant since we don't change timelines on the master.
So no, it's bit ready to be committed.
I will update the comment on that function to explain its usage and its limitations for future usage, to make that clearer.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On January 11, 2016 10:46:01 PM GMT+01:00, Simon Riggs <simon@2ndQuadrant.com> wrote: >On 11 January 2016 at 20:10, Andres Freund <andres@anarazel.de> wrote: > >> On January 11, 2016 8:57:58 PM GMT+01:00, Simon Riggs >> <simon@2ndQuadrant.com> wrote: >> >On 11 January 2016 at 18:43, Simon Riggs <simon@2ndquadrant.com> >wrote: >> >> >It's clear there are various additional tuning opportunities, but >the >> >objective of the current patch to improve performance is very, very >> >clearly >> >met, so I'm aiming to commit *this* patch soon. >> >> Again, the WAL read routine used doesn't deal with timeline changes. > > >Not relevant: The direct WAL read routine is never used during replay, >so >your comment is not relevant since we don't change timelines on the >master. Hm, OK. But, isn't this actually a bad sign? Currently recovery of 2pc often already is a bigger bottleneck than the workloadon the master, because replay has to execute the fsyncs implied by statefile re-creation serially, whereas on themaster they'll usually be executed in parallel. So, if I understand correctly this patch would widen that gap? Anyway, as evidenced here, review on a phone isn't efficient, and that's all i have access to right now. Please wait tillat least tomorrow evening, so I can have a meaningful look. Andres --- Please excuse brevity and formatting - I am writing this on my mobile phone.
> > On 11 Jan 2016, at 21:40, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > > I have done a run with the patch and it looks really great. > > Attached is the TPS graph - with a 1pc run too - and the perf profile as a flame graph (28C/56T w/ 256Gb mem, 2 x RAID10SSD). > Thanks for testing and especially for the flame graph. That is somewhat in between the cases that I have tested. On commodityserver with dual Xeon (6C each) 2pc speed is about 80% of 1pc speed, but on 60C/120T system that patch didn’t makesignificant difference because main bottleneck changes from file access to locks on array of running global transactions. How did you generated names for your PREPARE’s? One funny thing that I’ve spotted that tx rate increased when i was usingincrementing counter as GID instead of random string. And can you also share flame graph for 1pc workload? > > On 11 Jan 2016, at 21:43, Simon Riggs <simon@2ndquadrant.com> wrote: > > Have you measured lwlocking as a problem? > Yes. GXACT locks that wasn’t even in perf top 10 on dual Xeon moves to the first places when running on 60 core system. ButJesper’s flame graph on 24 core system shows different picture. > On 12 Jan 2016, at 01:24, Andres Freund <andres@anarazel.de> wrote: > > Currently recovery of 2pc often already is a bigger bottleneck than the workload on the master, because replay has to executethe fsyncs implied by statefile re-creation serially, whereas on the master they'll usually be executed in parallel. That’s interesting observation. Simon already pointed me to this problem in 2pc replay, but I didn’t thought that it is soslow. I’m now working on that. Stas Kelvich Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 11 January 2016 at 22:24, Andres Freund <andres@anarazel.de> wrote:
--
Please wait till at least tomorrow evening, so I can have a meaningful look.
No problem, make sure to look at 2pc_optimize.v4.patch
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 11 January 2016 at 23:11, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
--
>
> On 11 Jan 2016, at 21:43, Simon Riggs <simon@2ndquadrant.com> wrote:
>
> Have you measured lwlocking as a problem?
>
Yes. GXACT locks that wasn’t even in perf top 10 on dual Xeon moves to the first places when running on 60 core system. But Jesper’s flame graph on 24 core system shows different picture.
I think we can use a shmem hash table to identify the GID by name during LockGxact and avoid duplicates during prepare. Hashing on the first 16 bytes of the GID should be sufficient in most cases; the worst case would be the same as it is now, all depending on how people use the GID name field. The hash value can be calculated outside of the lock. We can also partition the lock without risk, just adds a little extra code.
We can also optimize final removal (sketch of how to do that attached).
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On Tue, Jan 12, 2016 at 4:57 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
> Performance tests for me show that the patch is effective; my results match
> Jesper's roughly in relative numbers.
>
> My robustness review is that the approach and implementation are safe.
>
> It's clear there are various additional tuning opportunities, but the
> objective of the current patch to improve performance is very, very clearly
> met, so I'm aiming to commit *this* patch soon.
- /* initialize LSN to 0 (start of WAL) */
- gxact->prepare_lsn = 0;
+ /* initialize LSN to InvalidXLogRecPtr */
+ gxact->prepare_start_lsn = InvalidXLogRecPtr;
+ gxact->prepare_end_lsn = InvalidXLogRecPtr;
I think that it would be better to explicitly initialize gxact->ondisk
to false here.
+ xlogreader = XLogReaderAllocate(&logical_read_local_xlog_page, NULL);
+ if (!xlogreader)
+ ereport(ERROR,
+ (errcode(ERRCODE_OUT_OF_MEMORY),
+ errmsg("out of memory"),
+ errdetail("Failed while allocating an
XLog reading processor.")));
Depending on something that is part of logical decoding to decode WAL
is not a good idea. If you want to move on with this approach, you
should have a dedicated function. Even better, it would be nice to
come up with a generic function used by both 2PC and logical decoding.
--
Michael
On Tue, Jan 12, 2016 at 3:35 PM, Michael Paquier
<michael.paquier@gmail.com> wrote:
> On Tue, Jan 12, 2016 at 4:57 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
>> Performance tests for me show that the patch is effective; my results match
>> Jesper's roughly in relative numbers.
>>
>> My robustness review is that the approach and implementation are safe.
>>
>> It's clear there are various additional tuning opportunities, but the
>> objective of the current patch to improve performance is very, very clearly
>> met, so I'm aiming to commit *this* patch soon.
>
> - /* initialize LSN to 0 (start of WAL) */
> - gxact->prepare_lsn = 0;
> + /* initialize LSN to InvalidXLogRecPtr */
> + gxact->prepare_start_lsn = InvalidXLogRecPtr;
> + gxact->prepare_end_lsn = InvalidXLogRecPtr;
>
> I think that it would be better to explicitly initialize gxact->ondisk
> to false here.
>
> + xlogreader = XLogReaderAllocate(&logical_read_local_xlog_page, NULL);
> + if (!xlogreader)
> + ereport(ERROR,
> + (errcode(ERRCODE_OUT_OF_MEMORY),
> + errmsg("out of memory"),
> + errdetail("Failed while allocating an
> XLog reading processor.")));
> Depending on something that is part of logical decoding to decode WAL
> is not a good idea. If you want to move on with this approach, you
> should have a dedicated function. Even better, it would be nice to
> come up with a generic function used by both 2PC and logical decoding.
+ if (log_checkpoints && n > 0)
+ ereport(LOG,
+ (errmsg("%u two-phase state files were written "
+ "for long-running
prepared transactions",
+ n)));
This would be better as an independent change. That looks useful for
debugging, and I guess that's why you added it.
--
Michael
On 12 January 2016 at 06:35, Michael Paquier <michael.paquier@gmail.com> wrote:
--
On Tue, Jan 12, 2016 at 4:57 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
> Performance tests for me show that the patch is effective; my results match
> Jesper's roughly in relative numbers.
>
> My robustness review is that the approach and implementation are safe.
>
> It's clear there are various additional tuning opportunities, but the
> objective of the current patch to improve performance is very, very clearly
> met, so I'm aiming to commit *this* patch soon.
- /* initialize LSN to 0 (start of WAL) */
- gxact->prepare_lsn = 0;
+ /* initialize LSN to InvalidXLogRecPtr */
+ gxact->prepare_start_lsn = InvalidXLogRecPtr;
+ gxact->prepare_end_lsn = InvalidXLogRecPtr;
OK
I think that it would be better to explicitly initialize gxact->ondisk
to false here.
+ xlogreader = XLogReaderAllocate(&logical_read_local_xlog_page, NULL);
+ if (!xlogreader)
+ ereport(ERROR,
+ (errcode(ERRCODE_OUT_OF_MEMORY),
+ errmsg("out of memory"),
+ errdetail("Failed while allocating an
XLog reading processor.")));
Depending on something that is part of logical decoding to decode WAL
is not a good idea.
Well, if you put it like that, it sounds wrong, clearly; that's not how I saw it, when reviewed.
I think any fuss can be avoided simply by renaming logical_read_local_xlog_page() to read_local_xlog_page()
If you want to move on with this approach, you
should have a dedicated function.
The code is exactly what we need, apart from the point that the LSN is always known flushed by the time we execute it, for 2PC.
Even better, it would be nice to
come up with a generic function used by both 2PC and logical decoding.
Surely that is exactly what has been done?
A specific function could have been written, which would simply have duplicated about 160 lines of code. Reusing the existing code makes the code generic. So lets just rename the function, as mentioned above.
Should we just move the code somewhere just to imply it is generic? Seems pointless refactoring to me.
The code is clearly due for refactoring once we can share elog with client programs, as described in comments on the functions.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 12 January 2016 at 06:41, Michael Paquier <michael.paquier@gmail.com> wrote:
--
+ if (log_checkpoints && n > 0)
+ ereport(LOG,
+ (errmsg("%u two-phase state files were written "
+ "for long-running
prepared transactions",
+ n)));
This would be better as an independent change. That looks useful for
debugging, and I guess that's why you added it.
The typical case is that no LOG message would be written at all, since that only happens minutes after a prepared transaction is created and then not terminated. Restarting a transaction manager likely won't take that long, so it implies a crash or emergency shutdown of the transaction manager.
I think it is sensible and useful to be notified of this as a condition the operator would wish to know about. The message doesn't recur every checkpoint, it occurs only once at the point the files are created, so its not log spam either.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Jan 12, 2016 at 5:26 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
> On 12 January 2016 at 06:41, Michael Paquier <michael.paquier@gmail.com>
> wrote:
>>
>>
>> + if (log_checkpoints && n > 0)
>> + ereport(LOG,
>> + (errmsg("%u two-phase state files were
>> written "
>> + "for long-running
>> prepared transactions",
>> + n)));
>> This would be better as an independent change. That looks useful for
>> debugging, and I guess that's why you added it.
>
>
> The typical case is that no LOG message would be written at all, since that
> only happens minutes after a prepared transaction is created and then not
> terminated. Restarting a transaction manager likely won't take that long, so
> it implies a crash or emergency shutdown of the transaction manager.
Thanks for the detailed explanation.
> I think it is sensible and useful to be notified of this as a condition the
> operator would wish to know about. The message doesn't recur every
> checkpoint, it occurs only once at the point the files are created, so its
> not log spam either.
Well, I am not saying that this is bad, quite the contrary actually.
It is just that this seems unrelated to this patch and would still be
useful even now with CheckPointTwoPhase.
--
Michael
On Tue, Jan 12, 2016 at 5:21 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > Should we just move the code somewhere just to imply it is generic? Seems > pointless refactoring to me. Er, why not xlogutils.c? Having the 2PC code depending directly on something that is within logicalfuncs.c is weird. -- Michael
On 01/11/2016 06:11 PM, Stas Kelvich wrote: >> On 11 Jan 2016, at 21:40, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: >> I have done a run with the patch and it looks really great. >> >> Attached is the TPS graph - with a 1pc run too - and the perf profile as a flame graph (28C/56T w/ 256Gb mem, 2 x RAID10SSD). >> > > Thanks for testing and especially for the flame graph. That is somewhat in between the cases that I have tested. On commodityserver with dual Xeon (6C each) 2pc speed is about 80% of 1pc speed, but on 60C/120T system that patch didn’t makesignificant difference because main bottleneck changes from file access to locks on array of running global transactions. > > How did you generated names for your PREPARE’s? One funny thing that I’ve spotted that tx rate increased when i was usingincrementing counter as GID instead of random string. > I'm using https://github.com/jesperpedersen/postgres/tree/pgbench_xa - so just the client_id. The strcmp() in MarkAsPreparing() is under the exclusive lock, so maybe that is what you are seeing, as shorter gid's are faster. > And can you also share flame graph for 1pc workload? > Attached with a new 2pc, as the server runs Linux 4.4.0 now, both using -F 497 over a 6 min run. Best regards, Jesper
Attachment
{kind=link}
{kind=link}
Hi,
On 2016-01-11 19:39:14 +0000, Simon Riggs wrote:
> Currently, the patch reuses all of the code related to reading/write state
> files, so it is the minimal patch that can implement the important things
> for performance. The current patch succeeds in its goal to improve
> performance, so I personally see no further need for code churn.
Sorry, I don't buy that argument. This approach leaves us with a bunch
of code related to statefiles that's barely ever going to be exercised,
and leaves the performance bottleneck on WAL replay in place.
> As you suggest, we could also completely redesign the state file mechanism
> and/or put it in WAL at checkpoint. That's all very nice but is much more
> code and doesn't anything more for performance, since the current mainline
> path writes ZERO files at checkpoint.
Well, on the primary, yes.
> If you want that for some other reason or refactoring, I won't stop
> you, but its a separate patch for a separate purpose.
Maintainability/complexity very much has to be considered during review
and can't just be argued away with "but this is what we implemented".
> - * In order to survive crashes and shutdowns, all prepared
> - * transactions must be stored in permanent storage. This includes
> - * locking information, pending notifications etc. All that state
> - * information is written to the per-transaction state file in
> - * the pg_twophase directory.
> + * Information to recover prepared transactions in case of crash is
> + * now stored in WAL for the common case. In some cases there will be
> + * an extended period between preparing a GXACT and commit/abort, in
Absolutely minor: The previous lines were differently indented (two tabs
before, one space + two tabs now), which will probably mean pgindent
will yank all of it around, besides looking confusing with different tab
settings.
> * * In case of crash replay will move data from xlog to files, if that
> * hasn't happened before. XXX TODO - move to shmem in replay also
This is a bit confusing - causing my earlier confusion about using
XlogReadTwoPhaseData in recovery - because what this actually means is
that we get the data from normal WAL replay, not our new way of getting
things from the WAL.
> @@ -772,7 +769,7 @@ TwoPhaseGetGXact(TransactionId xid)
> * During a recovery, COMMIT PREPARED, or ABORT PREPARED, we'll be called
> * repeatedly for the same XID. We can save work with a simple cache.
> */
> - if (xid == cached_xid)
> + if (xid == cached_xid && cached_gxact)
> return cached_gxact;
What's that about? When can cached_xid be be equal xid and cached_gxact
not set? And why did that change with this patch?
> /*
> * Finish preparing state file.
> *
> * Calculates CRC and writes state file to WAL and in pg_twophase directory.
> */
> void
> EndPrepare(GlobalTransaction gxact)
In contrast to that comment we're not writing to pg_twophase anymore.
> /*
> * If the file size exceeds MaxAllocSize, we won't be able to read it in
> * ReadTwoPhaseFile. Check for that now, rather than fail at commit time.
> */
> if (hdr->total_len > MaxAllocSize)
> ereport(ERROR,
> (errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED),
> errmsg("two-phase state file maximum length exceeded")));
>
Outdated comment.
> +/*
> + * Reads 2PC data from xlog. During checkpoint this data will be moved to
> + * twophase files and ReadTwoPhaseFile should be used instead.
> + */
> +static void
> +XlogReadTwoPhaseData(XLogRecPtr lsn, char **buf, int *len)
> +{
> + XLogRecord *record;
> + XLogReaderState *xlogreader;
> + char *errormsg;
> +
> + xlogreader = XLogReaderAllocate(&logical_read_local_xlog_page, NULL);
> + if (!xlogreader)
> + ereport(ERROR,
> + (errcode(ERRCODE_OUT_OF_MEMORY),
> + errmsg("out of memory"),
> + errdetail("Failed while allocating an XLog reading processor.")));
Creating and deleting an xlogreader for every 2pc transaction isn't
particularly efficient. Reading the 2pc state from WAL will often also
mean hitting disk if there's significant WAL volume (we even hint that
we want the cache to be throw away for low wal_level!).
If we really go this way, we really need a) a comment here explaining
why timelines are never an issue b) an assert, preventing to be called
during recovery.
> + record = XLogReadRecord(xlogreader, lsn, &errormsg);
> + if (record == NULL ||
> + XLogRecGetRmid(xlogreader) != RM_XACT_ID ||
> + (XLogRecGetInfo(xlogreader) & XLOG_XACT_OPMASK) != XLOG_XACT_PREPARE)
> + ereport(ERROR,
> + (errcode_for_file_access(),
> + errmsg("could not read two-phase state from xlog at %X/%X",
> + (uint32) (lsn >> 32),
> + (uint32) lsn)));
I think the record == NULL case should be handled separately (printing
->errormsg), and XLogRecGetRmid(xlogreader) != RM_XACT_ID &
(XLogRecGetInfo(xlogreader) & XLOG_XACT_OPMASK) != XLOG_XACT_PREPARE)
should get a more descriptive error message.
>
> /*
> * Scan a 2PC state file (already read into memory by ReadTwoPhaseFile)
> * and call the indicated callbacks for each 2PC record.
> */
> static void
> ProcessRecords(char *bufptr, TransactionId xid,
> const TwoPhaseCallback callbacks[])
>
The data isn't neccesarily coming from a statefile anymore.
> void
> CheckPointTwoPhase(XLogRecPtr redo_horizon)
> {
> - TransactionId *xids;
> - int nxids;
> - char path[MAXPGPATH];
> int i;
> + int n = 0;
s/n/serialized_xacts/?
Maybe also add a quick exit for when this is called during recovery?
> + /*
> + * We are expecting there to be zero GXACTs that need to be
> + * copied to disk, so we perform all I/O while holding
> + * TwoPhaseStateLock for simplicity. This prevents any new xacts
> + * from preparing while this occurs, which shouldn't be a problem
> + * since the presence of long-lived prepared xacts indicates the
> + * transaction manager isn't active.
It's not *that* unlikely. Depending on settings the time between the
computation of the redo pointer and CheckPointTwoPhase() isn't
necessarily that large.
I wonder if we can address the replay performance issue significantly
enough by simply not fsyncing in RecreateTwoPhaseFile() during WAL
replay. If we make CheckPointTwoPhase() do that for the relevant 2pc
state files, we ought to be good, no? Now that'd still not get close to
the performance on the primary (we do many more file creations!), but
it'd remove the most expensive part, the fsync.
Greetings,
Andres Freund
Michael Paquier wrote: > On Tue, Jan 12, 2016 at 5:21 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > > Should we just move the code somewhere just to imply it is generic? Seems > > pointless refactoring to me. > > Er, why not xlogutils.c? Having the 2PC code depending directly on > something that is within logicalfuncs.c is weird. Yes, I agree with Michael -- it's better to place code in its logical location than keep it somewhere else just because historically it was there. That way, future coders can find the function more easily. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
My +1 for moving function to xlogutils.c too. Now call to this function goes through series of callbacks so it is hard to find it. Personally I found it only after I have implemented same function by myself (based on code in pg_xlogdump). Stas Kelvich Postgres Professional: http://www.postgrespro.com The Russian Postgres Company > On 12 Jan 2016, at 18:56, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > > Michael Paquier wrote: >> On Tue, Jan 12, 2016 at 5:21 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >>> Should we just move the code somewhere just to imply it is generic? Seems >>> pointless refactoring to me. >> >> Er, why not xlogutils.c? Having the 2PC code depending directly on >> something that is within logicalfuncs.c is weird. > > Yes, I agree with Michael -- it's better to place code in its logical > location than keep it somewhere else just because historically it was > there. That way, future coders can find the function more easily. > > -- > Álvaro Herrera http://www.2ndQuadrant.com/ > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services > > > -- > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-hackers
On 12 January 2016 at 18:14, Andres Freund <andres@anarazel.de> wrote:
CheckPointTwoPhase() deliberately happens after CheckPointBuffers()
--
Hi,
Thank you for the additional review.
On 2016-01-11 19:39:14 +0000, Simon Riggs wrote:
> Currently, the patch reuses all of the code related to reading/write state
> files, so it is the minimal patch that can implement the important things
> for performance. The current patch succeeds in its goal to improve
> performance, so I personally see no further need for code churn.
Sorry, I don't buy that argument. This approach leaves us with a bunch
of code related to statefiles that's barely ever going to be exercised,
and leaves the performance bottleneck on WAL replay in place.
I raised the issue of WAL replay performance before you were involved, as has been mentioned already. I don't see it as a blocker for this patch. I have already requested it from Stas and he has already agreed to write that.
Anyway, we know the statefile code works, so I'd prefer to keep it, rather than write a whole load of new code that would almost certainly fail. Whatever the code looks like, the frequency of usage is the same. As I already said, you can submit a patch for the new way if you wish; the reality is that this code works and there's no additional performance gain from doing it a different way.
> As you suggest, we could also completely redesign the state file mechanism
> and/or put it in WAL at checkpoint. That's all very nice but is much more
> code and doesn't anything more for performance, since the current mainline
> path writes ZERO files at checkpoint.
Well, on the primary, yes.
Your changes proposed earlier wouldn't change performance on the standby.
> If you want that for some other reason or refactoring, I won't stop
> you, but its a separate patch for a separate purpose.
Maintainability/complexity very much has to be considered during review
and can't just be argued away with "but this is what we implemented".
;-) ehem, please don't make the mistake of thinking that because your judgement differs to mine that you can claim that you are the only one that has thought about maintainability and complexity.
I'm happy to do some refactoring if you and Michael think it necessary.
> - * In order to survive crashes and shutdowns, all prepared
> - * transactions must be stored in permanent storage. This includes
> - * locking information, pending notifications etc. All that state
> - * information is written to the per-transaction state file in
> - * the pg_twophase directory.
> + * Information to recover prepared transactions in case of crash is
> + * now stored in WAL for the common case. In some cases there will be
> + * an extended period between preparing a GXACT and commit/abort, in
Absolutely minor: The previous lines were differently indented (two tabs
before, one space + two tabs now), which will probably mean pgindent
will yank all of it around, besides looking confusing with different tab
settings.
> * * In case of crash replay will move data from xlog to files, if that
> * hasn't happened before. XXX TODO - move to shmem in replay also
This is a bit confusing - causing my earlier confusion about using
XlogReadTwoPhaseData in recovery - because what this actually means is
that we get the data from normal WAL replay, not our new way of getting
things from the WAL.
> @@ -772,7 +769,7 @@ TwoPhaseGetGXact(TransactionId xid)
> * During a recovery, COMMIT PREPARED, or ABORT PREPARED, we'll be called
> * repeatedly for the same XID. We can save work with a simple cache.
> */
> - if (xid == cached_xid)
> + if (xid == cached_xid && cached_gxact)
> return cached_gxact;
What's that about? When can cached_xid be be equal xid and cached_gxact
not set? And why did that change with this patch?
> /*
> * Finish preparing state file.
> *
> * Calculates CRC and writes state file to WAL and in pg_twophase directory.
> */
> void
> EndPrepare(GlobalTransaction gxact)
In contrast to that comment we're not writing to pg_twophase anymore.
> /*
> * If the file size exceeds MaxAllocSize, we won't be able to read it in
> * ReadTwoPhaseFile. Check for that now, rather than fail at commit time.
> */
> if (hdr->total_len > MaxAllocSize)
> ereport(ERROR,
> (errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED),
> errmsg("two-phase state file maximum length exceeded")));
>
Outdated comment.
Ack all above.
> +/*
> + * Reads 2PC data from xlog. During checkpoint this data will be moved to
> + * twophase files and ReadTwoPhaseFile should be used instead.
> + */
> +static void
> +XlogReadTwoPhaseData(XLogRecPtr lsn, char **buf, int *len)
> +{
> + XLogRecord *record;
> + XLogReaderState *xlogreader;
> + char *errormsg;
> +
> + xlogreader = XLogReaderAllocate(&logical_read_local_xlog_page, NULL);
> + if (!xlogreader)
> + ereport(ERROR,
> + (errcode(ERRCODE_OUT_OF_MEMORY),
> + errmsg("out of memory"),
> + errdetail("Failed while allocating an XLog reading processor.")));
Creating and deleting an xlogreader for every 2pc transaction isn't
particularly efficient.
Is keeping an xlogreader around in a backend for potentially long periods a better solution? I'd be happy to hear that a statically allocated one would be better.
Reading the 2pc state from WAL will often also
mean hitting disk if there's significant WAL volume (we even hint that
we want the cache to be throw away for low wal_level!).
Nobody has yet proposed an alternative to this design (reading the WAL at commit prepared).
It's better than the last one and I haven't thought of anything better.
If we really go this way, we really need a) a comment here explaining
why timelines are never an issue b) an assert, preventing to be called
during recovery.
Sure
> + record = XLogReadRecord(xlogreader, lsn, &errormsg);
> + if (record == NULL ||
> + XLogRecGetRmid(xlogreader) != RM_XACT_ID ||
> + (XLogRecGetInfo(xlogreader) & XLOG_XACT_OPMASK) != XLOG_XACT_PREPARE)
> + ereport(ERROR,
> + (errcode_for_file_access(),
> + errmsg("could not read two-phase state from xlog at %X/%X",
> + (uint32) (lsn >> 32),
> + (uint32) lsn)));
I think the record == NULL case should be handled separately (printing
->errormsg), and XLogRecGetRmid(xlogreader) != RM_XACT_ID &
(XLogRecGetInfo(xlogreader) & XLOG_XACT_OPMASK) != XLOG_XACT_PREPARE)
should get a more descriptive error message.
OK
> /*
> * Scan a 2PC state file (already read into memory by ReadTwoPhaseFile)
> * and call the indicated callbacks for each 2PC record.
> */
> static void
> ProcessRecords(char *bufptr, TransactionId xid,
> const TwoPhaseCallback callbacks[])
>
The data isn't neccesarily coming from a statefile anymore.
> void
> CheckPointTwoPhase(XLogRecPtr redo_horizon)
> {
> - TransactionId *xids;
> - int nxids;
> - char path[MAXPGPATH];
> int i;
> + int n = 0;
s/n/serialized_xacts/?
Maybe also add a quick exit for when this is called during recovery?
OK
> + /*
> + * We are expecting there to be zero GXACTs that need to be
> + * copied to disk, so we perform all I/O while holding
> + * TwoPhaseStateLock for simplicity. This prevents any new xacts
> + * from preparing while this occurs, which shouldn't be a problem
> + * since the presence of long-lived prepared xacts indicates the
> + * transaction manager isn't active.
It's not *that* unlikely. Depending on settings the time between the
computation of the redo pointer and CheckPointTwoPhase() isn't
necessarily that large.
Default settings would make that gap 2.5 minutes. Common tuning parameters would take that to >9 minutes.
That is much, much longer than acceptable transaction response times. So in normal circumstances there will be zero transactions and I concur with the decision not to bother with complex locking to avoid longer lock times, robustness being a consideration for seldom executed code.
I wonder if we can address the replay performance issue significantly
enough by simply not fsyncing in RecreateTwoPhaseFile() during WAL
replay. If we make CheckPointTwoPhase() do that for the relevant 2pc
state files, we ought to be good, no?
That was the design I was thinking for simplicity, but we could do better.
Now that'd still not get close to
the performance on the primary (we do many more file creations!), but
it'd remove the most expensive part, the fsync.
Which is why I asked Stas to consider it. As soon as I realised the potential timeline issues was the point where I say "separate patch".
This is a good performance patch with some subtle code that after much thought I agree with. I'd like to see more from Stas and I trust that he will progress to the next performance patch after this.
So, I will make some refactoring changes, fix your code suggestions above and commit.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 12 January 2016 at 12:53, Michael Paquier <michael.paquier@gmail.com> wrote:
--
On Tue, Jan 12, 2016 at 5:21 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
> Should we just move the code somewhere just to imply it is generic? Seems
> pointless refactoring to me.
Er, why not xlogutils.c? Having the 2PC code depending directly on
something that is within logicalfuncs.c is weird.
If that sounds better, I'm happy to move the code there.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, Thanks for reviews and commit! As Simon and Andres already mentioned in this thread replay of twophase transaction is significantly slower then the sameoperations in normal mode. Major reason is that each state file is fsynced during replay and while it is not a problemfor recovery, it is a problem for replication. Under high 2pc update load lag between master and async replica isconstantly increasing (see graph below). One way to improve things is to move fsyncs to restartpoints, but as we saw previously it is a half-measure and just frequentcalls to fopen can cause bottleneck. Other option is to use the same scenario for replay that was used already for non-recovery mode: read state files to memoryduring replay of prepare, and if checkpoint/restartpoint occurs between prepare and commit move data to files. On commitwe can read xlog or files. So here is the patch that implements this scenario for replay. Patch is quite straightforward. During replay of prepare records RecoverPreparedFromXLOG() is called to create memory statein GXACT, PROC, PGPROC; on commit XlogRedoFinishPrepared() is called to clean up that state. Also there are severalfunctions (PrescanPreparedTransactions, StandbyTransactionIdIsPrepared) that were assuming that during replay allprepared xacts have files in pg_twophase, so I have extended them to check GXACT too. Side effect of that behaviour is that we can see prepared xacts in pg_prepared_xacts view on slave. While this patch touches quite sensible part of postgres replay and there is some rarely used code paths, I wrote shell scriptto setup master/slave replication and test different failure scenarios that can happened with instances. Attachingthis file to show test scenarios that I have tested and more importantly to show what I didn’t tested. ParticularlyI failed to reproduce situation where StandbyTransactionIdIsPrepared() is called, may be somebody can suggestway how to force it’s usage. Also I’m not too sure about necessity of calling cache invalidation callbacks duringXlogRedoFinishPrepared(), I’ve marked this place in patch with 2REVIEWER comment. Tests shows that this patch increases speed of 2pc replay to the level when replica can keep pace with master. Graph: replica lag under a pgbench run for a 200 seconds with 2pc update transactions (80 connections, one update per 2pctx, two servers with 12 cores each, 10GbE interconnect) on current master and with suggested patch. Replica lag measuredwith "select sent_location-replay_location as delay from pg_stat_replication;" each second. --- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company > On 12 Jan 2016, at 22:57, Simon Riggs <simon@2ndquadrant.com> wrote: > > On 12 January 2016 at 18:14, Andres Freund <andres@anarazel.de> wrote: > Hi, > > Thank you for the additional review. > > On 2016-01-11 19:39:14 +0000, Simon Riggs wrote: > > Currently, the patch reuses all of the code related to reading/write state > > files, so it is the minimal patch that can implement the important things > > for performance. The current patch succeeds in its goal to improve > > performance, so I personally see no further need for code churn. > > Sorry, I don't buy that argument. This approach leaves us with a bunch > of code related to statefiles that's barely ever going to be exercised, > and leaves the performance bottleneck on WAL replay in place. > > I raised the issue of WAL replay performance before you were involved, as has been mentioned already. I don't see it asa blocker for this patch. I have already requested it from Stas and he has already agreed to write that. > > Anyway, we know the statefile code works, so I'd prefer to keep it, rather than write a whole load of new code that wouldalmost certainly fail. Whatever the code looks like, the frequency of usage is the same. As I already said, you cansubmit a patch for the new way if you wish; the reality is that this code works and there's no additional performancegain from doing it a different way. > > > As you suggest, we could also completely redesign the state file mechanism > > and/or put it in WAL at checkpoint. That's all very nice but is much more > > code and doesn't anything more for performance, since the current mainline > > path writes ZERO files at checkpoint. > > Well, on the primary, yes. > > Your changes proposed earlier wouldn't change performance on the standby. > > > If you want that for some other reason or refactoring, I won't stop > > you, but its a separate patch for a separate purpose. > > Maintainability/complexity very much has to be considered during review > and can't just be argued away with "but this is what we implemented". > > ;-) ehem, please don't make the mistake of thinking that because your judgement differs to mine that you can claim thatyou are the only one that has thought about maintainability and complexity. > > I'm happy to do some refactoring if you and Michael think it necessary. > > > - * In order to survive crashes and shutdowns, all prepared > > - * transactions must be stored in permanent storage. This includes > > - * locking information, pending notifications etc. All that state > > - * information is written to the per-transaction state file in > > - * the pg_twophase directory. > > + * Information to recover prepared transactions in case of crash is > > + * now stored in WAL for the common case. In some cases there will be > > + * an extended period between preparing a GXACT and commit/abort, in > > Absolutely minor: The previous lines were differently indented (two tabs > before, one space + two tabs now), which will probably mean pgindent > will yank all of it around, besides looking confusing with different tab > settings. > > > > * * In case of crash replay will move data from xlog to files, if that > > * hasn't happened before. XXX TODO - move to shmem in replay also > > This is a bit confusing - causing my earlier confusion about using > XlogReadTwoPhaseData in recovery - because what this actually means is > that we get the data from normal WAL replay, not our new way of getting > things from the WAL. > > > > @@ -772,7 +769,7 @@ TwoPhaseGetGXact(TransactionId xid) > > * During a recovery, COMMIT PREPARED, or ABORT PREPARED, we'll be called > > * repeatedly for the same XID. We can save work with a simple cache. > > */ > > - if (xid == cached_xid) > > + if (xid == cached_xid && cached_gxact) > > return cached_gxact; > > What's that about? When can cached_xid be be equal xid and cached_gxact > not set? And why did that change with this patch? > > > > /* > > * Finish preparing state file. > > * > > * Calculates CRC and writes state file to WAL and in pg_twophase directory. > > */ > > void > > EndPrepare(GlobalTransaction gxact) > > In contrast to that comment we're not writing to pg_twophase anymore. > > > > /* > > * If the file size exceeds MaxAllocSize, we won't be able to read it in > > * ReadTwoPhaseFile. Check for that now, rather than fail at commit time. > > */ > > if (hdr->total_len > MaxAllocSize) > > ereport(ERROR, > > (errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED), > > errmsg("two-phase state file maximum length exceeded"))); > > > > Outdated comment. > > Ack all above. > > > +/* > > + * Reads 2PC data from xlog. During checkpoint this data will be moved to > > + * twophase files and ReadTwoPhaseFile should be used instead. > > + */ > > +static void > > +XlogReadTwoPhaseData(XLogRecPtr lsn, char **buf, int *len) > > +{ > > + XLogRecord *record; > > + XLogReaderState *xlogreader; > > + char *errormsg; > > + > > + xlogreader = XLogReaderAllocate(&logical_read_local_xlog_page, NULL); > > + if (!xlogreader) > > + ereport(ERROR, > > + (errcode(ERRCODE_OUT_OF_MEMORY), > > + errmsg("out of memory"), > > + errdetail("Failed while allocating an XLog reading processor."))); > > Creating and deleting an xlogreader for every 2pc transaction isn't > particularly efficient. > > Is keeping an xlogreader around in a backend for potentially long periods a better solution? I'd be happy to hear thata statically allocated one would be better. > > Reading the 2pc state from WAL will often also > mean hitting disk if there's significant WAL volume (we even hint that > we want the cache to be throw away for low wal_level!). > > Nobody has yet proposed an alternative to this design (reading the WAL at commit prepared). > > It's better than the last one and I haven't thought of anything better. > > If we really go this way, we really need a) a comment here explaining > why timelines are never an issue b) an assert, preventing to be called > during recovery. > > Sure > > > + record = XLogReadRecord(xlogreader, lsn, &errormsg); > > + if (record == NULL || > > + XLogRecGetRmid(xlogreader) != RM_XACT_ID || > > + (XLogRecGetInfo(xlogreader) & XLOG_XACT_OPMASK) != XLOG_XACT_PREPARE) > > + ereport(ERROR, > > + (errcode_for_file_access(), > > + errmsg("could not read two-phase state from xlog at %X/%X", > > + (uint32) (lsn >> 32), > > + (uint32) lsn))); > > I think the record == NULL case should be handled separately (printing > ->errormsg), and XLogRecGetRmid(xlogreader) != RM_XACT_ID & > (XLogRecGetInfo(xlogreader) & XLOG_XACT_OPMASK) != XLOG_XACT_PREPARE) > should get a more descriptive error message. > > OK > > > /* > > * Scan a 2PC state file (already read into memory by ReadTwoPhaseFile) > > * and call the indicated callbacks for each 2PC record. > > */ > > static void > > ProcessRecords(char *bufptr, TransactionId xid, > > const TwoPhaseCallback callbacks[]) > > > > The data isn't neccesarily coming from a statefile anymore. > > > > void > > CheckPointTwoPhase(XLogRecPtr redo_horizon) > > { > > - TransactionId *xids; > > - int nxids; > > - char path[MAXPGPATH]; > > int i; > > + int n = 0; > > s/n/serialized_xacts/? > > > Maybe also add a quick exit for when this is called during recovery? > > OK > > > + /* > > + * We are expecting there to be zero GXACTs that need to be > > + * copied to disk, so we perform all I/O while holding > > + * TwoPhaseStateLock for simplicity. This prevents any new xacts > > + * from preparing while this occurs, which shouldn't be a problem > > + * since the presence of long-lived prepared xacts indicates the > > + * transaction manager isn't active. > > It's not *that* unlikely. Depending on settings the time between the > computation of the redo pointer and CheckPointTwoPhase() isn't > necessarily that large. > > CheckPointTwoPhase() deliberately happens after CheckPointBuffers() > > Default settings would make that gap 2.5 minutes. Common tuning parameters would take that to >9 minutes. > > That is much, much longer than acceptable transaction response times. So in normal circumstances there will be zero transactionsand I concur with the decision not to bother with complex locking to avoid longer lock times, robustness beinga consideration for seldom executed code. > > I wonder if we can address the replay performance issue significantly > enough by simply not fsyncing in RecreateTwoPhaseFile() during WAL > replay. If we make CheckPointTwoPhase() do that for the relevant 2pc > state files, we ought to be good, no? > > That was the design I was thinking for simplicity, but we could do better. > > Now that'd still not get close to > the performance on the primary (we do many more file creations!), but > it'd remove the most expensive part, the fsync. > > Which is why I asked Stas to consider it. As soon as I realised the potential timeline issues was the point where I say"separate patch". > > This is a good performance patch with some subtle code that after much thought I agree with. I'd like to see more fromStas and I trust that he will progress to the next performance patch after this. > > So, I will make some refactoring changes, fix your code suggestions above and commit. > > -- > Simon Riggs http://www.2ndQuadrant.com/ > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
{kind=link}
Stas Kelvich wrote: > While this patch touches quite sensible part of postgres replay and there is some rarely used code paths, I wrote shellscript to setup master/slave replication and test different failure scenarios that can happened with instances. Attachingthis file to show test scenarios that I have tested and more importantly to show what I didn’t tested. ParticularlyI failed to reproduce situation where StandbyTransactionIdIsPrepared() is called, may be somebody can suggestway how to force it’s usage. Also I’m not too sure about necessity of calling cache invalidation callbacks duringXlogRedoFinishPrepared(), I’ve marked this place in patch with 2REVIEWER comment. I think this is the third thread in which I say this: We need to push Michael Paquier's recovery test framework, then convert your test script to that. That way we can put your tests in core. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Agree, I had the same idea in my mind when was writing that script. I will migrate it to TAP suite and write a review for Michael Paquier's patch. Stas Kelvich Postgres Professional: http://www.postgrespro.com The Russian Postgres Company > On 26 Jan 2016, at 20:20, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > > Stas Kelvich wrote: > >> While this patch touches quite sensible part of postgres replay and there is some rarely used code paths, I wrote shellscript to setup master/slave replication and test different failure scenarios that can happened with instances. Attachingthis file to show test scenarios that I have tested and more importantly to show what I didn’t tested. ParticularlyI failed to reproduce situation where StandbyTransactionIdIsPrepared() is called, may be somebody can suggestway how to force it’s usage. Also I’m not too sure about necessity of calling cache invalidation callbacks duringXlogRedoFinishPrepared(), I’ve marked this place in patch with 2REVIEWER comment. > > I think this is the third thread in which I say this: We need to push > Michael Paquier's recovery test framework, then convert your test script > to that. That way we can put your tests in core. > > -- > Álvaro Herrera http://www.2ndQuadrant.com/ > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Jan 27, 2016 at 5:39 AM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > Agree, I had the same idea in my mind when was writing that script. > I will migrate it to TAP suite and write a review for Michael Paquier's patch. Yeah, please! And you have won a free-hug coupon that I can give in person next week. -- Michael
On 01/26/2016 07:43 AM, Stas Kelvich wrote: > Thanks for reviews and commit! > > As Simon and Andres already mentioned in this thread replay of twophase transaction is significantly slower then thesame operations in normal mode. Major reason is that each state file is fsynced during replay and while it is not a problemfor recovery, it is a problem for replication. Under high 2pc update load lag between master and async replica isconstantly increasing (see graph below). > > One way to improve things is to move fsyncs to restartpoints, but as we saw previously it is a half-measure and justfrequent calls to fopen can cause bottleneck. > > Other option is to use the same scenario for replay that was used already for non-recovery mode: read state files tomemory during replay of prepare, and if checkpoint/restartpoint occurs between prepare and commit move data to files. Oncommit we can read xlog or files. So here is the patch that implements this scenario for replay. > > Patch is quite straightforward. During replay of prepare records RecoverPreparedFromXLOG() is called to create memorystate in GXACT, PROC, PGPROC; on commit XlogRedoFinishPrepared() is called to clean up that state. Also there are severalfunctions (PrescanPreparedTransactions, StandbyTransactionIdIsPrepared) that were assuming that during replay allprepared xacts have files in pg_twophase, so I have extended them to check GXACT too. > Side effect of that behaviour is that we can see prepared xacts in pg_prepared_xacts view on slave. > > While this patch touches quite sensible part of postgres replay and there is some rarely used code paths, I wrote shellscript to setup master/slave replication and test different failure scenarios that can happened with instances. Attachingthis file to show test scenarios that I have tested and more importantly to show what I didn’t tested. ParticularlyI failed to reproduce situation where StandbyTransactionIdIsPrepared() is called, may be somebody can suggestway how to force it’s usage. Also I’m not too sure about necessity of calling cache invalidation callbacks duringXlogRedoFinishPrepared(), I’ve marked this place in patch with 2REVIEWER comment. > > Tests shows that this patch increases speed of 2pc replay to the level when replica can keep pace with master. > > Graph: replica lag under a pgbench run for a 200 seconds with 2pc update transactions (80 connections, one update per 2pctx, two servers with 12 cores each, 10GbE interconnect) on current master and with suggested patch. Replica lag measuredwith "select sent_location-replay_location as delay from pg_stat_replication;" each second. > Some comments: * The patch needs a rebase against the latest TwoPhaseFileHeader change * Rework the check.sh script into a TAP test case (src/test/recovery), as suggested by Alvaro and Michael down thread * Add documentation for RecoverPreparedFromXLOG + * that xlog record. We need just to clen up memmory state. 'clean' + 'memory' + * This is usually called after end-of-recovery checkpoint, so all 2pc + * files moved xlog to files. But if we restart slave when master is + * switched off this function will be called before checkpoint ans we need + * to check PGXACT array as it can contain prepared transactions that + * didn't created any state files yet. => "We need to check the PGXACT array for prepared transactions that doesn't have any state file in case of a slave restart with the master being off." + * prepare xlog resords in shared memory in the same way as it happens 'records' + * We need such behaviour because speed of 2PC replay on replica should + * be at least not slower than 2PC tx speed on master. => "We need this behaviour because the speed of the 2PC replay on the replica should be at least the same as the 2PC transaction speed of the master." I'll leave the 2REVIEWER section to Simon. Best regards, Jesper
On 1/26/16 3:39 PM, Stas Kelvich wrote: > Agree, I had the same idea in my mind when was writing that script. > > I will migrate it to TAP suite and write a review for Michael Paquier's patch. > > Stas Kelvich > Postgres Professional: http://www.postgrespro.com > The Russian Postgres Company > > >> On 26 Jan 2016, at 20:20, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: >> >> Stas Kelvich wrote: >> >>> While this patch touches quite sensible part of postgres replay and there is some rarely used code paths, I wrote shellscript to setup master/slave replication and test different failure scenarios that can happened with instances. Attachingthis file to show test scenarios that I have tested and more importantly to show what I didn’t tested. ParticularlyI failed to reproduce situation where StandbyTransactionIdIsPrepared() is called, may be somebody can suggestway how to force it’s usage. Also I’m not too sure about necessity of calling cache invalidation callbacks duringXlogRedoFinishPrepared(), I’ve marked this place in patch with 2REVIEWER comment. >> >> I think this is the third thread in which I say this: We need to push >> Michael Paquier's recovery test framework, then convert your test script >> to that. That way we can put your tests in core. It seems this thread has been waiting quite a while on a new patch. If one doesn't appear by Monday I will mark this "returned with feedback". -- -David david@pgmasters.net
> On 11 Mar 2016, at 19:41, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > Thanks for review, Jesper. > Some comments: > > * The patch needs a rebase against the latest TwoPhaseFileHeader change Done. > * Rework the check.sh script into a TAP test case (src/test/recovery), as suggested by Alvaro and Michael down thread Done. Originally I thought about reducing number of tests (11 right now), but now, after some debugging, I’m more convincedthat it is better to include them all, as they are really testing different code paths. > * Add documentation for RecoverPreparedFromXLOG Done. --- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On 03/18/2016 12:50 PM, Stas Kelvich wrote: >> On 11 Mar 2016, at 19:41, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: >> > > Thanks for review, Jesper. > >> Some comments: >> >> * The patch needs a rebase against the latest TwoPhaseFileHeader change > > Done. > >> * Rework the check.sh script into a TAP test case (src/test/recovery), as suggested by Alvaro and Michael down thread > > Done. Originally I thought about reducing number of tests (11 right now), but now, after some debugging, I’m more convincedthat it is better to include them all, as they are really testing different code paths. > >> * Add documentation for RecoverPreparedFromXLOG > > Done. Thanks, Stas. I have gone over this version, and tested with --enable-tap-tests + make check in src/test/recovery, which passes. Simon, do you want to move this entry to "Ready for Committer" and take the 2REVIEWER section as part of that, or leave it in "Needs Review" and update the thread ? Best regards, Jesper
On Tue, Mar 22, 2016 at 1:53 AM, Jesper Pedersen
<jesper.pedersen@redhat.com> wrote:
> On 03/18/2016 12:50 PM, Stas Kelvich wrote:
>>>
>>> On 11 Mar 2016, at 19:41, Jesper Pedersen <jesper.pedersen@redhat.com>
>>> wrote:
>>>
>>
>> Thanks for review, Jesper.
>>
>>> Some comments:
>>>
>>> * The patch needs a rebase against the latest TwoPhaseFileHeader change
>>
>>
>> Done.
>>
>>> * Rework the check.sh script into a TAP test case (src/test/recovery), as
>>> suggested by Alvaro and Michael down thread
>>
>>
>> Done. Originally I thought about reducing number of tests (11 right now),
>> but now, after some debugging, I’m more convinced that it is better to
>> include them all, as they are really testing different code paths.
>>
>>> * Add documentation for RecoverPreparedFromXLOG
>>
>>
>> Done.
>
>
> Thanks, Stas.
>
> I have gone over this version, and tested with --enable-tap-tests + make
> check in src/test/recovery, which passes.
>
> Simon, do you want to move this entry to "Ready for Committer" and take the
> 2REVIEWER section as part of that, or leave it in "Needs Review" and update
> the thread ?
Looking at this patch....
+++ b/src/test/recovery/t/006_twophase.pl
@@ -0,0 +1,226 @@
+# Checks for recovery_min_apply_delay
+use strict;
This description is wrong, this file has been copied from 005.
+my $node_master = get_new_node("Candie");
+my $node_slave = get_new_node('Django');
Please let's use a node names that are more descriptive.
+# Switch to synchronous replication
+$node_master->append_conf('postgresql.conf', qq(
+synchronous_standby_names = '*'
+));
+$node_master->restart;
Reloading would be fine.
+ /* During replay that lock isn't really necessary, but let's take
it anyway */
+ LWLockAcquire(TwoPhaseStateLock, LW_EXCLUSIVE);
+ for (i = 0; i < TwoPhaseState->numPrepXacts; i++)
+ {
+ gxact = TwoPhaseState->prepXacts[i];
+ proc = &ProcGlobal->allProcs[gxact->pgprocno];
+ pgxact = &ProcGlobal->allPgXact[gxact->pgprocno];
+
+ if (TransactionIdEquals(xid, pgxact->xid))
+ {
+ gxact->locking_backend = MyBackendId;
+ MyLockedGxact = gxact;
+ break;
+ }
+ }
+ LWLockRelease(TwoPhaseStateLock);
Not taking ProcArrayLock here?
The comment at the top of XlogReadTwoPhaseData is incorrect.
RecoverPreparedFromXLOG and RecoverPreparedFromFiles have a lot of
code in common, having this duplication is not good, and you could
simplify your patch.
--
Michael
Hi Stas, On 3/22/16 9:20 AM, Michael Paquier wrote: > Not taking ProcArrayLock here? > > The comment at the top of XlogReadTwoPhaseData is incorrect. > > RecoverPreparedFromXLOG and RecoverPreparedFromFiles have a lot of > code in common, having this duplication is not good, and you could > simplify your patch. It looks like you should post a new patch or respond to Michael's comments. Marked as "waiting on author". Thanks, -- -David david@pgmasters.net
On Mar 29, 2016, at 6:04 PM, David Steele <david@pgmasters.net> wrote:
It looks like you should post a new patch or respond to Michael's comments. Marked as "waiting on author".
Yep, here it is.
On Mar 22, 2016, at 4:20 PM, Michael Paquier <michael.paquier@gmail.com> wrote:
Looking at this patch….
+++ b/src/test/recovery/t/006_twophase.pl
@@ -0,0 +1,226 @@
+# Checks for recovery_min_apply_delay
+use strict;
This description is wrong, this file has been copied from 005.
Yep, done.
+my $node_master = get_new_node("Candie");
+my $node_slave = get_new_node('Django');
Please let's use a node names that are more descriptive.
Hm, it’s hard to create descriptive names because test changes master/slave roles for that nodes several times during test. It’s possible to call them “node1” and “node2” but I’m not sure that improves something. But anyway I’m not insisting on that particular names and will agree with any reasonable suggestion.
+# Switch to synchronous replication
+$node_master->append_conf('postgresql.conf', qq(
+synchronous_standby_names = '*'
+));
+$node_master->restart;
Reloading would be fine.
Good catch, done.
+ /* During replay that lock isn't really necessary, but let's take
it anyway */
+ LWLockAcquire(TwoPhaseStateLock, LW_EXCLUSIVE);
+ for (i = 0; i < TwoPhaseState->numPrepXacts; i++)
+ {
+ gxact = TwoPhaseState->prepXacts[i];
+ proc = &ProcGlobal->allProcs[gxact->pgprocno];
+ pgxact = &ProcGlobal->allPgXact[gxact->pgprocno];
+
+ if (TransactionIdEquals(xid, pgxact->xid))
+ {
+ gxact->locking_backend = MyBackendId;
+ MyLockedGxact = gxact;
+ break;
+ }
+ }
+ LWLockRelease(TwoPhaseStateLock);
Not taking ProcArrayLock here?
All accesses to 2pc dummies in ProcArray are covered with TwoPhaseStateLock, so I thick that’s safe. Also I’ve deleted comment above that block, probably it’s more confusing than descriptive.
The comment at the top of XlogReadTwoPhaseData is incorrect.
Yep, fixed.
RecoverPreparedFromXLOG and RecoverPreparedFromFiles have a lot of
code in common, having this duplication is not good, and you could
simplify your patch.
I reworked patch to avoid duplicated code between RecoverPreparedFromXLOG/RecoverPreparedFromFiles and also between FinishPreparedTransaction/XlogRedoFinishPrepared.
--
Attachment
On 03/30/2016 09:19 AM, Stas Kelvich wrote:
>> > +++ b/src/test/recovery/t/006_twophase.pl
>> > @@ -0,0 +1,226 @@
>> > +# Checks for recovery_min_apply_delay
>> > +use strict;
>> > This description is wrong, this file has been copied from 005.
>>
>> Yep, done.
>>
>> >
>> > +my $node_master = get_new_node("Candie");
>> > +my $node_slave = get_new_node('Django');
>> > Please let's use a node names that are more descriptive.
>>
>> Hm, it’s hard to create descriptive names because test changes master/slave
>> roles for that nodes several times during test. It’s possible to call them
>> “node1” and “node2” but I’m not sure that improves something. But anyway I’m not
>> insisting on that particular names and will agree with any reasonable suggestion.
>>
>> >
>> > +# Switch to synchronous replication
>> > +$node_master->append_conf('postgresql.conf', qq(
>> > +synchronous_standby_names = '*'
>> > +));
>> > +$node_master->restart;
>> > Reloading would be fine.
>>
>> Good catch, done.
>>
>> >
>> > + /* During replay that lock isn't really necessary, but let's take
>> > it anyway */
>> > + LWLockAcquire(TwoPhaseStateLock, LW_EXCLUSIVE);
>> > + for (i = 0; i < TwoPhaseState->numPrepXacts; i++)
>> > + {
>> > + gxact = TwoPhaseState->prepXacts[i];
>> > + proc = &ProcGlobal->allProcs[gxact->pgprocno];
>> > + pgxact = &ProcGlobal->allPgXact[gxact->pgprocno];
>> > +
>> > + if (TransactionIdEquals(xid, pgxact->xid))
>> > + {
>> > + gxact->locking_backend = MyBackendId;
>> > + MyLockedGxact = gxact;
>> > + break;
>> > + }
>> > + }
>> > + LWLockRelease(TwoPhaseStateLock);
>> > Not taking ProcArrayLock here?
>>
>> All accesses to 2pc dummies in ProcArray are covered with TwoPhaseStateLock, so
>> I thick that’s safe. Also I’ve deleted comment above that block, probably it’s
>> more confusing than descriptive.
>>
>> >
>> > The comment at the top of XlogReadTwoPhaseData is incorrect.
>>
>> Yep, fixed.
>>
>> >
>> > RecoverPreparedFromXLOG and RecoverPreparedFromFiles have a lot of
>> > code in common, having this duplication is not good, and you could
>> > simplify your patch.
>>
>> I reworked patch to avoid duplicated code between
>> RecoverPreparedFromXLOG/RecoverPreparedFromFiles and also
>> between FinishPreparedTransaction/XlogRedoFinishPrepared.
>>
>>
Patch applies with hunks, and test cases are passing.
Best regards, Jesper
On Wed, Mar 30, 2016 at 10:19 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
> Hm, it’s hard to create descriptive names because test changes master/slave
> roles for that nodes several times during test.
Really? the names used in the patch help less then.
> It’s possible to call them
> “node1” and “node2” but I’m not sure that improves something. But anyway I’m
> not insisting on that particular names and will agree with any reasonable
> suggestion.
I would suggest the following name modifications, node names have been
introduced to help tracking of each node's log:
- Candie => master
- Django => slave or just standby
There is no need for complication! And each node's log file is
prefixed by the test number. Note that in other tests there are no
promotions, or fallbacks done, but we stick with a node name that
represents the initial state of the cluster.
> +# Switch to synchronous replication
> +$node_master->append_conf('postgresql.conf', qq(
> +synchronous_standby_names = '*'
> +));
> +$node_master->restart;
> Reloading would be fine.
>
> Good catch, done.
+$node_master->psql('postgres', "select pg_reload_conf()");
It would be cleaner to introduce a new routine in PostgresNode that
calls pg_ctl reload (mentioned in the N-sync patch as well, that would
be useful for many purposes).
> All accesses to 2pc dummies in ProcArray are covered with TwoPhaseStateLock,
> so I thick that’s safe. Also I’ve deleted comment above that block, probably
> it’s more confusing than descriptive.
OK, you removed the use to allProcs. Though by reading again the code
just holding TwoPhaseStateLock that's actually fine.
The patch needs a small cleanup:
$ git diff master --check
src/test/recovery/t/006_twophase.pl:224: new blank line at EOF.
006_twophase.pl should be renamed to 007. It keeps its license to
kill, and gains in being famous.
- * Scan the pg_twophase directory and setup all the required information to
- * allow standby queries to treat prepared transactions as still active.
- * This is never called at the end of recovery - we use
- * RecoverPreparedTransactions() at that point.
+ * It's a caller responsibility to call MarkAsPrepared() on returned gxact. *
Wouldn't it be more simple to just call MarkAsPrepared at the end of
RecoverPreparedFromBuffer?
While testing the patch, I found a bug in the recovery conflict code
path. You can do the following to reproduce it:
1) Start a master with a standby
2) prepare a transaction on master
3) Stop immediate on standby to force replay
4) commit prepare transaction on master
5) When starting the standby, it remains stuck here:
* thread #1: tid = 0x229b4, 0x00007fff8e2d4f96
libsystem_kernel.dylib`poll + 10, queue = 'com.apple.main-thread',
stop reason = signal SIGSTOP * frame #0: 0x00007fff8e2d4f96 libsystem_kernel.dylib`poll + 10 frame #1:
0x0000000107e5e043
postgres`WaitEventSetWaitBlock(set=0x00007f90c20596a8, cur_timeout=-1,
occurred_events=0x00007fff581efd28, nevents=1) + 51 at latch.c:1102 frame #2: 0x0000000107e5da26
postgres`WaitEventSetWait(set=0x00007f90c20596a8, timeout=-1,
occurred_events=0x00007fff581efd28, nevents=1) + 390 at latch.c:935 frame #3: 0x0000000107e5d4c7
postgres`WaitLatchOrSocket(latch=0x0000000111432464, wakeEvents=1,
sock=-1, timeout=-1) + 343 at latch.c:347 frame #4: 0x0000000107e5d36a
postgres`WaitLatch(latch=0x0000000111432464, wakeEvents=1, timeout=0)
+ 42 at latch.c:302 frame #5: 0x0000000107e7b5a6 postgres`ProcWaitForSignal + 38 at proc.c:1731 frame #6:
0x0000000107e6a4eb
postgres`ResolveRecoveryConflictWithLock(locktag=LOCKTAG at
0x00007fff581efde8) + 187 at standby.c:391 frame #7: 0x0000000107e7a6a8
postgres`ProcSleep(locallock=0x00007f90c203dac8,
lockMethodTable=0x00000001082f6218) + 1128 at proc.c:1215 frame #8: 0x0000000107e72886
postgres`WaitOnLock(locallock=0x00007f90c203dac8,
owner=0x0000000000000000) + 358 at lock.c:1703 frame #9: 0x0000000107e70f93
postgres`LockAcquireExtended(locktag=0x00007fff581f0238, lockmode=8,
sessionLock='\x01', dontWait='\0', reportMemoryError='\0') + 2819 at
lock.c:998 frame #10: 0x0000000107e6a9a6
postgres`StandbyAcquireAccessExclusiveLock(xid=863, dbOid=16384,
relOid=16385) + 358 at standby.c:627 frame #11: 0x0000000107e6af0b
postgres`standby_redo(record=0x00007f90c2041e38) + 251 at
standby.c:809 frame #12: 0x0000000107b0e227 postgres`StartupXLOG + 9351 at xlog.c:6871
It seems that the replay on on-memory state of the PREPARE transaction
is conflicting directly with replay.
--
Michael
> On Apr 1, 2016, at 10:04 AM, Michael Paquier <michael.paquier@gmail.com> wrote:
>
> I would suggest the following name modifications, node names have been
> introduced to help tracking of each node's log:
> - Candie => master
> - Django => slave or just standby
> There is no need for complication! And each node's log file is
> prefixed by the test number. Note that in other tests there are no
> promotions, or fallbacks done, but we stick with a node name that
> represents the initial state of the cluster.
Ok, let’s reflect initial state in node names. So master and standby then.
>
>> +# Switch to synchronous replication
>> +$node_master->append_conf('postgresql.conf', qq(
>> +synchronous_standby_names = '*'
>> +));
>> +$node_master->restart;
>> Reloading would be fine.
>>
>> Good catch, done.
>
> +$node_master->psql('postgres', "select pg_reload_conf()");
>
> It would be cleaner to introduce a new routine in PostgresNode that
> calls pg_ctl reload (mentioned in the N-sync patch as well, that would
> be useful for many purposes).
Okay.
>
>> All accesses to 2pc dummies in ProcArray are covered with TwoPhaseStateLock,
>> so I thick that’s safe. Also I’ve deleted comment above that block, probably
>> it’s more confusing than descriptive.
>
> OK, you removed the use to allProcs. Though by reading again the code
> just holding TwoPhaseStateLock that's actually fine.
>
> The patch needs a small cleanup:
> $ git diff master --check
> src/test/recovery/t/006_twophase.pl:224: new blank line at EOF.
>
> 006_twophase.pl should be renamed to 007. It keeps its license to
> kill, and gains in being famous.
Huh, eventually there will be Fleming reference, instead of Tarantino one in node names.
>
> - * Scan the pg_twophase directory and setup all the required information to
> - * allow standby queries to treat prepared transactions as still active.
> - * This is never called at the end of recovery - we use
> - * RecoverPreparedTransactions() at that point.
> + * It's a caller responsibility to call MarkAsPrepared() on returned gxact.
> *
> Wouldn't it be more simple to just call MarkAsPrepared at the end of
> RecoverPreparedFromBuffer?
I did that intentionally to allow modification of gxact before unlock.
RecoverPreparedFromXLOG:gxact = RecoverPreparedFromBuffer((char *) XLogRecGetData(record),
false);gxact->prepare_start_lsn= record->ReadRecPtr;gxact->prepare_end_lsn = record->EndRecPtr;MarkAsPrepared(gxact);
RecoverPreparedFromFiles:gxact = RecoverPreparedFromBuffer(buf, forceOverwriteOK);gxact->ondisk =
true;MarkAsPrepared(gxact);
While both function are only called during recovery, I think that it is better to write that
in a way when it possible to use it in multiprocess environment.
>
> While testing the patch, I found a bug in the recovery conflict code
> path. You can do the following to reproduce it:
> 1) Start a master with a standby
> 2) prepare a transaction on master
> 3) Stop immediate on standby to force replay
> 4) commit prepare transaction on master
> 5) When starting the standby, it remains stuck here:
Hm, I wasn’t able to reproduce that. Do you mean following scenario or am I missing something?
(async replication)
$node_master->psql('postgres', "begin;insert into t values (1);prepare transaction 'x';
");
$node_slave->teardown_node;
$node_master->psql('postgres',"commit prepared 'x'");
$node_slave->start;
$node_slave->psql('postgres',"select count(*) from pg_prepared_xacts", stdout => \$psql_out);
is($psql_out, '0', "Commit prepared on master while slave is down.");
> * thread #1: tid = 0x229b4, 0x00007fff8e2d4f96
> libsystem_kernel.dylib`poll + 10, queue = 'com.apple.main-thread',
> stop reason = signal SIGSTOP
> * frame #0: 0x00007fff8e2d4f96 libsystem_kernel.dylib`poll + 10
> frame #1: 0x0000000107e5e043
> postgres`WaitEventSetWaitBlock(set=0x00007f90c20596a8, cur_timeout=-1,
> occurred_events=0x00007fff581efd28, nevents=1) + 51 at latch.c:1102
> frame #2: 0x0000000107e5da26
> postgres`WaitEventSetWait(set=0x00007f90c20596a8, timeout=-1,
> occurred_events=0x00007fff581efd28, nevents=1) + 390 at latch.c:935
> frame #3: 0x0000000107e5d4c7
> postgres`WaitLatchOrSocket(latch=0x0000000111432464, wakeEvents=1,
> sock=-1, timeout=-1) + 343 at latch.c:347
> frame #4: 0x0000000107e5d36a
> postgres`WaitLatch(latch=0x0000000111432464, wakeEvents=1, timeout=0)
> + 42 at latch.c:302
> frame #5: 0x0000000107e7b5a6 postgres`ProcWaitForSignal + 38 at proc.c:1731
> frame #6: 0x0000000107e6a4eb
> postgres`ResolveRecoveryConflictWithLock(locktag=LOCKTAG at
> 0x00007fff581efde8) + 187 at standby.c:391
> frame #7: 0x0000000107e7a6a8
> postgres`ProcSleep(locallock=0x00007f90c203dac8,
> lockMethodTable=0x00000001082f6218) + 1128 at proc.c:1215
> frame #8: 0x0000000107e72886
> postgres`WaitOnLock(locallock=0x00007f90c203dac8,
> owner=0x0000000000000000) + 358 at lock.c:1703
> frame #9: 0x0000000107e70f93
> postgres`LockAcquireExtended(locktag=0x00007fff581f0238, lockmode=8,
> sessionLock='\x01', dontWait='\0', reportMemoryError='\0') + 2819 at
> lock.c:998
> frame #10: 0x0000000107e6a9a6
> postgres`StandbyAcquireAccessExclusiveLock(xid=863, dbOid=16384,
> relOid=16385) + 358 at standby.c:627
> frame #11: 0x0000000107e6af0b
> postgres`standby_redo(record=0x00007f90c2041e38) + 251 at
> standby.c:809
> frame #12: 0x0000000107b0e227 postgres`StartupXLOG + 9351 at xlog.c:6871
> It seems that the replay on on-memory state of the PREPARE transaction
> is conflicting directly with replay.
--
Stas Kelvich
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
On Fri, Apr 1, 2016 at 10:53 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
> I wrote:
>> While testing the patch, I found a bug in the recovery conflict code
>> path. You can do the following to reproduce it:
>> 1) Start a master with a standby
>> 2) prepare a transaction on master
>> 3) Stop immediate on standby to force replay
>> 4) commit prepare transaction on master
>> 5) When starting the standby, it remains stuck here:
>
> Hm, I wasn’t able to reproduce that. Do you mean following scenario or am I missing something?
>
> (async replication)
>
> $node_master->psql('postgres', "
> begin;
> insert into t values (1);
> prepare transaction 'x';
> ");
> $node_slave->teardown_node;
> $node_master->psql('postgres',"commit prepared 'x'");
> $node_slave->start;
> $node_slave->psql('postgres',"select count(*) from pg_prepared_xacts", stdout => \$psql_out);
> is($psql_out, '0', "Commit prepared on master while slave is down.");
Actually, not exactly, the transaction prepared on master created a
table. Sorry for the lack of precisions in my review.
--
Michael
> On Apr 2, 2016, at 3:14 AM, Michael Paquier <michael.paquier@gmail.com> wrote:
>
> On Fri, Apr 1, 2016 at 10:53 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
>> I wrote:
>>> While testing the patch, I found a bug in the recovery conflict code
>>> path. You can do the following to reproduce it:
>>> 1) Start a master with a standby
>>> 2) prepare a transaction on master
>>> 3) Stop immediate on standby to force replay
>>> 4) commit prepare transaction on master
>>> 5) When starting the standby, it remains stuck here:
>>
>> Hm, I wasn’t able to reproduce that. Do you mean following scenario or am I missing something?
>>
>> (async replication)
>>
>> $node_master->psql('postgres', "
>> begin;
>> insert into t values (1);
>> prepare transaction 'x';
>> ");
>> $node_slave->teardown_node;
>> $node_master->psql('postgres',"commit prepared 'x'");
>> $node_slave->start;
>> $node_slave->psql('postgres',"select count(*) from pg_prepared_xacts", stdout => \$psql_out);
>> is($psql_out, '0', "Commit prepared on master while slave is down.");
>
> Actually, not exactly, the transaction prepared on master created a
> table. Sorry for the lack of precisions in my review.
Sorry for delay.
Actually I can’t reproduce that again, tried with following tx:
begin;
insert into t values(0);
create table t1(id int);
insert into t1 values(1);
create table t2(id int);
insert into t2 values(2);
savepoint s1;
drop table t1;
select * from t for update;
select * from t2 for share;
prepare transaction 'x’;
--
Stas Kelvich
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Attachment
On Wed, Apr 6, 2016 at 6:47 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
>> On Apr 2, 2016, at 3:14 AM, Michael Paquier <michael.paquier@gmail.com> wrote:
>>
>> On Fri, Apr 1, 2016 at 10:53 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
>>> I wrote:
>>>> While testing the patch, I found a bug in the recovery conflict code
>>>> path. You can do the following to reproduce it:
>>>> 1) Start a master with a standby
>>>> 2) prepare a transaction on master
>>>> 3) Stop immediate on standby to force replay
>>>> 4) commit prepare transaction on master
>>>> 5) When starting the standby, it remains stuck here:
>>>
>>> Hm, I wasn’t able to reproduce that. Do you mean following scenario or am I missing something?
>>>
>>> (async replication)
>>>
>>> $node_master->psql('postgres', "
>>> begin;
>>> insert into t values (1);
>>> prepare transaction 'x';
>>> ");
>>> $node_slave->teardown_node;
>>> $node_master->psql('postgres',"commit prepared 'x'");
>>> $node_slave->start;
>>> $node_slave->psql('postgres',"select count(*) from pg_prepared_xacts", stdout => \$psql_out);
>>> is($psql_out, '0', "Commit prepared on master while slave is down.");
>>
>> Actually, not exactly, the transaction prepared on master created a
>> table. Sorry for the lack of precisions in my review.
>
> Sorry for delay.
>
> Actually I can’t reproduce that again, tried with following tx:
Well not for me, here are more details, with a test case attached:
* thread #1: tid = 0x50c5b, 0x00007fff93822f96
libsystem_kernel.dylib`poll + 10, queue = 'com.apple.main-thread',
stop reason = signal SIGSTOP
* frame #0: 0x00007fff93822f96 libsystem_kernel.dylib`poll + 10
frame #1: 0x00000001023cdda3
postgres`WaitEventSetWaitBlock(set=0x00007fde50858f28, cur_timeout=-1,
occurred_events=0x00007fff5dc87cf8, nevents=1) + 51 at latch.c:1102
frame #2: 0x00000001023cd786
postgres`WaitEventSetWait(set=0x00007fde50858f28, timeout=-1,
occurred_events=0x00007fff5dc87cf8, nevents=1) + 390 at latch.c:935
frame #3: 0x00000001023cd227
postgres`WaitLatchOrSocket(latch=0x000000010b9b12e4, wakeEvents=1,
sock=-1, timeout=-1) + 343 at latch.c:347
frame #4: 0x00000001023cd0ca
postgres`WaitLatch(latch=0x000000010b9b12e4, wakeEvents=1, timeout=0)
+ 42 at latch.c:302
frame #5: 0x00000001023eb306 postgres`ProcWaitForSignal + 38 at proc.c:1731
frame #6: 0x00000001023da24b
postgres`ResolveRecoveryConflictWithLock(locktag=LOCKTAG at
0x00007fff5dc87db8) + 187 at standby.c:391
frame #7: 0x00000001023ea408
postgres`ProcSleep(locallock=0x00007fde5083dac8,
lockMethodTable=0x000000010286e278) + 1128 at proc.c:1215
frame #8: 0x00000001023e25e6
postgres`WaitOnLock(locallock=0x00007fde5083dac8,
owner=0x0000000000000000) + 358 at lock.c:1703
frame #9: 0x00000001023e0cf3
postgres`LockAcquireExtended(locktag=0x00007fff5dc88208, lockmode=8,
sessionLock='\x01', dontWait='\0', reportMemoryError='\0') + 2819 at
lock.c:998
frame #10: 0x00000001023da706
postgres`StandbyAcquireAccessExclusiveLock(xid=867, dbOid=16384,
relOid=16385) + 358 at standby.c:627
frame #11: 0x00000001023dac6b
postgres`standby_redo(record=0x00007fde50841e38) + 251 at
standby.c:809
(LOCALLOCK) $1 = {
tag = {
lock = {
locktag_field1 = 16384
locktag_field2 = 16385
locktag_field3 = 0
locktag_field4 = 0
locktag_type = '\0'
locktag_lockmethodid = '\x01'
}
mode = 8
}
=# select relname, oid from pg_class where oid > 16000;
relname | oid
---------+-------
aa | 16385
(1 row)
So recovery is conflicting here. My guess is that this patch is
missing some lock cleanup.
With the test case attached in my case the COMMIT PREPARED record does
not even get replayed.
--
Michael
Attachment
On 04/07/2016 02:29 AM, Michael Paquier wrote: > So recovery is conflicting here. My guess is that this patch is > missing some lock cleanup. > > With the test case attached in my case the COMMIT PREPARED record does > not even get replayed. > Should we create an entry for the open item list [0] for this, due to the replication lag [1] ? CommitFest entry [2] Original commit [3] Cc'ed RMT. [0] https://wiki.postgresql.org/wiki/PostgreSQL_9.6_Open_Items [1] http://www.postgresql.org/message-id/E7497864-DE11-4099-83F5-89FB97AF5073@postgrespro.ru [2] https://commitfest.postgresql.org/9/523/ [3] http://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=978b2f65aa1262eb4ecbf8b3785cb1b9cf4db78e Best regards, Jesper
> On 07 Apr 2016, at 09:29, Michael Paquier <michael.paquier@gmail.com> wrote:
>
> relOid=16385) + 358 at standby.c:627
> frame #11: 0x00000001023dac6b
> postgres`standby_redo(record=0x00007fde50841e38) + 251 at
> standby.c:809
>
> (LOCALLOCK) $1 = {
> tag = {
> lock = {
> locktag_field1 = 16384
> locktag_field2 = 16385
> locktag_field3 = 0
> locktag_field4 = 0
> locktag_type = '\0'
> locktag_lockmethodid = '\x01'
> }
> mode = 8
> }
>
> =# select relname, oid from pg_class where oid > 16000;
> relname | oid
Tried on linux and os x 10.11 and 10.4.
Still can’t reproduce, but have played around with your backtrace.
I see in xlodump on slave following sequence of records:
rmgr: Storage len (rec/tot): 16/ 42, tx: 0, lsn: 0/03015AF0, prev 0/03015958, desc: CREATE
base/12669/16387
rmgr: Heap len (rec/tot): 3/ 1518, tx: 867, lsn: 0/03015B20, prev 0/03015AF0, desc: INSERT off 8,
blkref#0: rel 1663/12669/1247 blk 8 FPW
<...>
rmgr: Btree len (rec/tot): 2/ 72, tx: 867, lsn: 0/03019CD0, prev 0/03019C88, desc: INSERT_LEAF off
114,blkref #0: rel 1663/12669/2674 blk 22
rmgr: Standby len (rec/tot): 16/ 42, tx: 867, lsn: 0/03019D18, prev 0/03019CD0, desc: LOCK xid 867 db
12669rel 16387
rmgr: Transaction len (rec/tot): 784/ 813, tx: 867, lsn: 0/03019D48, prev 0/03019D18, desc: PREPARE
rmgr: Transaction len (rec/tot): 380/ 409, tx: 0, lsn: 0/0301A090, prev 0/03019D48, desc: COMMIT_PREPARED
867:2016-04-08 14:38:33.347851 MSK;
It looks like that you had stuck in LOCK xid 867 even before replaying PREPARE record, so I have not that much ideas on
whythat can be caused by changing procedures of PREPARE replay.
Just to keep things sane, here is my current diff:
--
Stas Kelvich
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Attachment
On 7 April 2016 at 07:29, Michael Paquier <michael.paquier@gmail.com> wrote:
--
With the test case attached in my case the COMMIT PREPARED record does
not even get replayed.
I was surprised to see this in the test...
sleep 2; # wait for changes to arrive on slave
I think the test framework needs a WaitForLSN function to allow us to know for certain that something has been delivered.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
> On 08 Apr 2016, at 16:36, Simon Riggs <simon@2ndQuadrant.com> wrote: > > On 7 April 2016 at 07:29, Michael Paquier <michael.paquier@gmail.com> wrote: > > With the test case attached in my case the COMMIT PREPARED record does > not even get replayed. > > I was surprised to see this in the test... > > sleep 2; # wait for changes to arrive on slave > > I think the test framework needs a WaitForLSN function to allow us to know for certain that something has been delivered. Yes, test framework already has that function. That was just quick script to reproduce bug, that Michael faced. If there will be deterministic way to reproduce that bug, i'll rework it and move to 00X_twophase.pl -- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Fri, Apr 8, 2016 at 8:49 AM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > On 04/07/2016 02:29 AM, Michael Paquier wrote: >> So recovery is conflicting here. My guess is that this patch is >> missing some lock cleanup. >> >> With the test case attached in my case the COMMIT PREPARED record does >> not even get replayed. >> > > Should we create an entry for the open item list [0] for this, due to the > replication lag [1] ? > > CommitFest entry [2] > Original commit [3] > > Cc'ed RMT. If there is something you think needs to be fixed that is a new issue in 9.6, then yes you should. I don't quite understand what thing is from reading this, so please make sure to describe it clearly. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jan 26, 2016 at 7:43 AM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > Hi, > > Thanks for reviews and commit! I apologize for being clueless here, but was this patch committed? It's still marked as "Needs Review" in the CommitFest application. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 04/08/2016 02:42 PM, Robert Haas wrote: > On Tue, Jan 26, 2016 at 7:43 AM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >> Hi, >> >> Thanks for reviews and commit! > > I apologize for being clueless here, but was this patch committed? > It's still marked as "Needs Review" in the CommitFest application. > There are 2 parts to this - both in the same email thread. Part 1 [0] dealt with 2-phase commits on the master node. Part 2 [1] deals with replaying on slaves, which currently shows lag. There is still an open item found by Michael, so part 2 isn't ready to be moved to "Ready for Committer" yet. [0] http://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=978b2f65aa1262eb4ecbf8b3785cb1b9cf4db78e [1] https://commitfest.postgresql.org/9/523/ Best regards, Jesper
On 04/08/2016 02:37 PM, Robert Haas wrote: > On Fri, Apr 8, 2016 at 8:49 AM, Jesper Pedersen > <jesper.pedersen@redhat.com> wrote: >> On 04/07/2016 02:29 AM, Michael Paquier wrote: >>> So recovery is conflicting here. My guess is that this patch is >>> missing some lock cleanup. >>> >>> With the test case attached in my case the COMMIT PREPARED record does >>> not even get replayed. >>> >> >> Should we create an entry for the open item list [0] for this, due to the >> replication lag [1] ? >> >> CommitFest entry [2] >> Original commit [3] >> >> Cc'ed RMT. > > If there is something you think needs to be fixed that is a new issue > in 9.6, then yes you should. I don't quite understand what thing is > from reading this, so please make sure to describe it clearly. > Michael, you seem to have the necessary permission for this. Could you add an entry ? Best regards, Jesper
> On 08 Apr 2016, at 21:42, Robert Haas <robertmhaas@gmail.com> wrote: > > On Tue, Jan 26, 2016 at 7:43 AM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >> Hi, >> >> Thanks for reviews and commit! > > I apologize for being clueless here, but was this patch committed? > It's still marked as "Needs Review" in the CommitFest application. There was a patch to skip two phase file creation when there were no checkpoint between PREPARE and COMMIT, and that patch was commited. But that patch didn’t touch anything in replay, so replay speed of 2pc is significantly slower than 2pc in normal mode. And that can cause constantly increasing replication lag for async replication. After that i’ve wrote new patch introducing same behaviour in replay and used the same mail thread. Now Michael found a (heisen)bug in second patch, that i can’t reproduce. Stas Kelvich Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Fri, Apr 08, 2016 at 02:57:00PM -0400, Jesper Pedersen wrote: > On 04/08/2016 02:37 PM, Robert Haas wrote: > >On Fri, Apr 8, 2016 at 8:49 AM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > >>Should we create an entry for the open item list [0] for this, due to the > >>replication lag [1] ? > >> > >>CommitFest entry [2] > >>Original commit [3] > >> > >>Cc'ed RMT. > > > >If there is something you think needs to be fixed that is a new issue > >in 9.6, then yes you should. I don't quite understand what thing is > >from reading this, so please make sure to describe it clearly. > > > > Michael, you seem to have the necessary permission for this. Could you add > an entry ? Everyone may edit the list; follow https://wiki.postgresql.org/wiki/WikiEditing to setup access.
> On 08 Apr 2016, at 16:09, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > > Tried on linux and os x 10.11 and 10.4. > > Still can’t reproduce, but have played around with your backtrace. > > I see in xlodump on slave following sequence of records: > > rmgr: Storage len (rec/tot): 16/ 42, tx: 0, lsn: 0/03015AF0, prev 0/03015958, desc: CREATE base/12669/16387 > rmgr: Heap len (rec/tot): 3/ 1518, tx: 867, lsn: 0/03015B20, prev 0/03015AF0, desc: INSERT off 8, blkref#0: rel 1663/12669/1247 blk 8 FPW > <...> > rmgr: Btree len (rec/tot): 2/ 72, tx: 867, lsn: 0/03019CD0, prev 0/03019C88, desc: INSERT_LEAF off114, blkref #0: rel 1663/12669/2674 blk 22 > rmgr: Standby len (rec/tot): 16/ 42, tx: 867, lsn: 0/03019D18, prev 0/03019CD0, desc: LOCK xid 867 db12669 rel 16387 > rmgr: Transaction len (rec/tot): 784/ 813, tx: 867, lsn: 0/03019D48, prev 0/03019D18, desc: PREPARE > rmgr: Transaction len (rec/tot): 380/ 409, tx: 0, lsn: 0/0301A090, prev 0/03019D48, desc: COMMIT_PREPARED867: 2016-04-08 14:38:33.347851 MSK; > > It looks like that you had stuck in LOCK xid 867 even before replaying PREPARE record, so I have not that much ideas onwhy that can be caused by changing procedures of PREPARE replay. > > Just to keep things sane, here is my current diff: > > <twophase_replay.v4.patch> Michael, it looks like that you are the only one person who can reproduce that bug. I’ve tried on bunch of OS’s and didn’tobserve that behaviour, also looking at your backtraces I can’t get who is holding this lock (and all of that happensbefore first prepare record is replayed). Can you investigate it more? Particularly find out who holds the lock? There is last version of the patch: -- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On Mon, Apr 11, 2016 at 7:16 PM, Stas Kelvich wrote:
> Michael, it looks like that you are the only one person who can reproduce that bug. I’ve tried on bunch of OS’s and
didn’tobserve that behaviour, also looking at your backtraces I can’t get who is holding this lock (and all of that
happensbefore first prepare record is replayed).
Where did you try it. FWIW, I can reproduce that on Linux and OSX, and
only manually though:
1) Create a master and a streaming standby.
2) Run the following on master:
BEGIN;
CREATE TABLE foo (a int);
PREPARE TRANSACTION 'tx';
3) stop -m immediate the standby
4) COMMIT PREPARED 'tx' on master
5) Restart standby, and the node will wait for a lock
> Can you investigate it more? Particularly find out who holds the lock?
OK, so if I look at this backtrace that's a standby LOCK record, but
we already know that:
frame #9: 0x0000000107600383
postgres`LockAcquireExtended(locktag=0x00007fff58a4b228, lockmode=8,
sessionLock='\x01', dontWait='\0', reportMemoryError='\0') + 2819 at
lock.c:998
frame #10: 0x00000001075f9cd6
postgres`StandbyAcquireAccessExclusiveLock(xid=867, dbOid=16384,
relOid=16385) + 358 at standby.c:627
* frame #11: 0x00000001075fa23b
postgres`standby_redo(record=0x00007f90a9841e38) + 251 at
standby.c:809
frame #12: 0x0000000107298d37 postgres`StartupXLOG + 9351 at xlog.c:6871
Here is the record pointer:
(lldb) p *record
(XLogReaderState) $4 = {
read_page = 0x000000010729b3c0 (postgres`XLogPageRead at xlog.c:10973)
system_identifier = 6272572355656465658
private_data = 0x00007fff58a4bf40
ReadRecPtr = 50424128
EndRecPtr = 50424176
decoded_record = 0x00007f90a9843178
main_data = 0x00007f90a9804b78 "\x01"
main_data_len = 16
main_data_bufsz = 784
record_origin = 0
blocks = {
[0] = {
in_use = '\0'
rnode = (spcNode = 1663, dbNode = 16384, relNode = 2674)
forknum = MAIN_FORKNUM
blkno = 22
flags = '\x10'
has_image = '\0'
bkp_image = 0x00007f90a984826b "\x01"
hole_offset = 892
hole_length = 2076
bimg_len = 6116
bimg_info = '\x01'
has_data = '\0'
data = 0x00007f90a98595d8 "\a"
data_len = 0
data_bufsz = 154
}
And in our case this corresponds to the record with LSN 0/03016940
that cannot take an exclusive LOCK:
rmgr: Transaction len (rec/tot): 784/ 813, tx: 867, lsn:
0/03016610, prev 0/030165D8, desc: PREPARE
rmgr: Standby len (rec/tot): 16/ 42, tx: 0, lsn:
0/03016940, prev 0/03016610, desc: LOCK xid 867 db 16384 rel 16385
rmgr: Standby len (rec/tot): 28/ 54, tx: 0, lsn:
0/03016970, prev 0/03016940, desc: RUNNING_XACTS nextXid 868
latestCompletedXid 866 oldestRunningXid 867; 1 xacts: 867
There are two XID locks taken before that:
rmgr: Standby len (rec/tot): 16/ 42, tx: 867, lsn:
0/03016578, prev 0/03014D40, desc: LOCK xid 867 db 16384 rel 16385
rmgr: Standby len (rec/tot): 16/ 42, tx: 0, lsn:
0/030165A8, prev 0/03016578, desc: LOCK xid 867 db 16384 rel 16385
And pg_locks on the standby is reporting that another lock has been
taken but not released:
=# select locktype, pid, mode, granted, fastpath from pg_locks where
relation = 16385;
locktype | pid | mode | granted | fastpath
----------+-------+---------------------+---------+----------
relation | 68955 | AccessExclusiveLock | f | f
relation | null | AccessExclusiveLock | t | f
(2 rows)
In this case 68955 is the startup process trying to take the lock for
the LOCK record and it is not granted yet:
ioltas 68955 0.0 0.0 2593064 3228 ?? TXs 4:44PM 0:00.05
postgres: startup process recovering 000000010000000000000003
waiting
Now there is already a lock that has been taken and granted,
conflicting here... As the relation is only PREPARE'd yet and not
COMMIT PREPARED at this stage of the replay, isn't this lock taken
during the PREPARE phase, then it is not released by your new code
paths, no?
[One LOCK_DEBUG build later...]
It looks to be the case... The PREPARE phase replayed after the
standby is restarted in recovery creates a series of exclusive locks
on the table created and those are not taken on HEAD. Once those are
replayed the LOCK_STANDBY record is conflicting with it. In the case
of the failure, the COMMIT PREPARED record cannot be fetched from
master via the WAL stream so the relation never becomes visible.
Attached as two log files that are the result of a couple of runs,
those are the logs of the standby after being restarted in crash
recovery
- 2pc_master_logs.log, for HEAD.
- 2pc_patch_logs.log, with your last patch applied.
Feel free to have a look at them.
Regards,
--
Michael
Attachment
> On 12 Apr 2016, at 15:47, Michael Paquier <michael.paquier@gmail.com> wrote: > > On Mon, Apr 11, 2016 at 7:16 PM, Stas Kelvich wrote: >> Michael, it looks like that you are the only one person who can reproduce that bug. I’ve tried on bunch of OS’s and didn’tobserve that behaviour, also looking at your backtraces I can’t get who is holding this lock (and all of that happensbefore first prepare record is replayed). > > Where did you try it. FWIW, I can reproduce that on Linux and OSX, and > only manually though: Thanks a lot, Michael! Now I was able to reproduce that. Seems that when you was performing manual setup, master instance issued checkpoint, but in my script that didn’t happened because of shorter timing. There are tests with checkpoint between prepare/commit in proposed test suite, but none of them was issuing ddl. > It looks to be the case... The PREPARE phase replayed after the > standby is restarted in recovery creates a series of exclusive locks > on the table created and those are not taken on HEAD. Once those are > replayed the LOCK_STANDBY record is conflicting with it. In the case > of the failure, the COMMIT PREPARED record cannot be fetched from > master via the WAL stream so the relation never becomes visible. Yep, it is. It is okay for prepared xact hold a locks for created/changed tables, but code in standby_redo() was written in assumption that there are no prepared xacts at the time of recovery. I’ll look closer at checkpointer code and will send updated patch. And thanks again. -- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Wed, Apr 13, 2016 at 1:53 AM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >> On 12 Apr 2016, at 15:47, Michael Paquier <michael.paquier@gmail.com> wrote: >> >> It looks to be the case... The PREPARE phase replayed after the >> standby is restarted in recovery creates a series of exclusive locks >> on the table created and those are not taken on HEAD. Once those are >> replayed the LOCK_STANDBY record is conflicting with it. In the case >> of the failure, the COMMIT PREPARED record cannot be fetched from >> master via the WAL stream so the relation never becomes visible. > > Yep, it is. It is okay for prepared xact hold a locks for created/changed tables, > but code in standby_redo() was written in assumption that there are no prepared > xacts at the time of recovery. I’ll look closer at checkpointer code and will send > updated patch. > > And thanks again. That's too late for 9.6 unfortunately, don't forget to add that in the next CF! -- Michael
> On 13 Apr 2016, at 01:04, Michael Paquier <michael.paquier@gmail.com> wrote: > > On Wed, Apr 13, 2016 at 1:53 AM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >>> On 12 Apr 2016, at 15:47, Michael Paquier <michael.paquier@gmail.com> wrote: >>> >>> It looks to be the case... The PREPARE phase replayed after the >>> standby is restarted in recovery creates a series of exclusive locks >>> on the table created and those are not taken on HEAD. Once those are >>> replayed the LOCK_STANDBY record is conflicting with it. In the case >>> of the failure, the COMMIT PREPARED record cannot be fetched from >>> master via the WAL stream so the relation never becomes visible. >> >> Yep, it is. It is okay for prepared xact hold a locks for created/changed tables, >> but code in standby_redo() was written in assumption that there are no prepared >> xacts at the time of recovery. I’ll look closer at checkpointer code and will send >> updated patch. >> >> And thanks again. > > That's too late for 9.6 unfortunately, don't forget to add that in the next CF! Fixed patch attached. There already was infrastructure to skip currently held locks during replay of standby_redo() and I’ve extended that with check for prepared xids. The reason why I’m still active on this thread is because I see real problems in deploying 9.6 in current state. Let me stress my concern: current state of things _WILL_BREAK_ async replication in case of substantial load of two phase transactions on master. And a lot of J2EE apps falls into that category, as they wrap most of their transactions in prepare/commit. Slave server just will always increase it lag and will never catch up. It is possible to deal with that by switching to synchronous replication or inserting triggers with pg_sleep on master, but it doesn’t looks like normal behaviour of system. -- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
Hi, On 04/13/2016 10:31 AM, Stas Kelvich wrote: >> On 13 Apr 2016, at 01:04, Michael Paquier <michael.paquier@gmail.com> wrote: >> That's too late for 9.6 unfortunately, don't forget to add that in the next CF! > > Fixed patch attached. There already was infrastructure to skip currently > held locks during replay of standby_redo() and I’ve extended that with check for > prepared xids. > > The reason why I’m still active on this thread is because I see real problems > in deploying 9.6 in current state. Let me stress my concern: current state of things > _WILL_BREAK_ async replication in case of substantial load of two phase > transactions on master. And a lot of J2EE apps falls into that category, as they > wrap most of their transactions in prepare/commit. Slave server just will always > increase it lag and will never catch up. It is possible to deal with that by switching > to synchronous replication or inserting triggers with pg_sleep on master, but it > doesn’t looks like normal behaviour of system. > Discussed with Noah off-list I think we should revisit this for 9.6 due to the async replica lag as shown in [1]. The performance improvement for the master node is shown in [2]. As I see it there are 3 options to resolve this (in one way or another) * Leave as is, document the behaviour in release notes/documentation * Apply the patch for slaves * Revert the changes done to the twophase.c during the 9.6 cycle. All have pros/cons for the release. Latest slave patch by Stas is on [3]. Thoughts from others on the matter would be appreciated. [1] http://www.postgresql.org/message-id/E7497864-DE11-4099-83F5-89FB97AF5073@postgrespro.ru [2] http://www.postgresql.org/message-id/5693F703.3000009@redhat.com [3] https://commitfest.postgresql.org/10/523/ Best regards, Jesper
Jesper Pedersen wrote: > Discussed with Noah off-list I think we should revisit this for 9.6 due to > the async replica lag as shown in [1]. The performance improvement for the > master node is shown in [2]. I gave a very quick look and it seems to me far more invasive than we would normally consider in the beta period. I would just put it to sleep till release 10 opens up. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, May 20, 2016 at 12:46 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Jesper Pedersen wrote: >> Discussed with Noah off-list I think we should revisit this for 9.6 due to >> the async replica lag as shown in [1]. The performance improvement for the >> master node is shown in [2]. > > I gave a very quick look and it seems to me far more invasive than we > would normally consider in the beta period. I would just put it to > sleep till release 10 opens up. I share the same opinion. Improving 2PC is definitely a huge win thanks to the first patch that got committed when WAL is generated, but considering how the second patch is invasive really concerns me, and I looked at the patch in an extended way a couple of weeks back. As we care about stability now regarding 9.6, let's bump the second portion to 10.0 as well as keep the improvement for WAL generation in 9.6. -- Michael
On 13 April 2016 at 15:31, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > Fixed patch attached. There already was infrastructure to skip currently > held locks during replay of standby_redo() and I’ve extended that with check for > prepared xids. Please confirm that everything still works on current HEAD for the new CF, so review can start. Thanks -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Sep 2, 2016 at 5:06 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > On 13 April 2016 at 15:31, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > >> Fixed patch attached. There already was infrastructure to skip currently >> held locks during replay of standby_redo() and I’ve extended that with check for >> prepared xids. > > Please confirm that everything still works on current HEAD for the new > CF, so review can start. The patch does not apply cleanly. Stas, could you rebase? I am switching the patch to "waiting on author" for now. -- Michael
On Sat, Sep 3, 2016 at 10:26 PM, Michael Paquier
<michael.paquier@gmail.com> wrote:
> On Fri, Sep 2, 2016 at 5:06 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
>> On 13 April 2016 at 15:31, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
>>
>>> Fixed patch attached. There already was infrastructure to skip currently
>>> held locks during replay of standby_redo() and I’ve extended that with check for
>>> prepared xids.
>>
>> Please confirm that everything still works on current HEAD for the new
>> CF, so review can start.
>
> The patch does not apply cleanly. Stas, could you rebase? I am
> switching the patch to "waiting on author" for now.
So, I have just done the rebase myself and did an extra round of
reviews of the patch. Here are couple of comments after this extra
lookup.
LockGXactByXid() is aimed to be used only in recovery, so it seems
adapted to be to add an assertion with RecoveryInProgress(). Using
this routine in non-recovery code paths is risky because it assumes
that a PGXACT could be missing, which is fine in recovery as prepared
transactions could be moved to twophase files because of a checkpoint,
but not in normal cases. We could also add an assertion of the kind
gxact->locking_backend == InvalidBackendId before locking the PGXACT
but as this routine is just normally used by the startup process (in
non-standalone mode!) that's fine without.
The handling of invalidation messages and removal of relfilenodes done
in FinishGXact can be grouped together, checking only once for
!RecoveryInProgress().
+ *
+ * The same procedure happens during replication and crash recovery.
*
"during WAL replay" is more generic and applies here.
+
+next_file:
+ continue;
+
That can be removed and replaced by a "continue;".
+ /*
+ * At first check prepared tx that wasn't yet moved to disk.
+ */
+ LWLockAcquire(TwoPhaseStateLock, LW_SHARED);
+ for (i = 0; i < TwoPhaseState->numPrepXacts; i++)
+ {
+ GlobalTransaction gxact = TwoPhaseState->prepXacts[i];
+ PGXACT *pgxact = &ProcGlobal->allPgXact[gxact->pgprocno];
+
+ if (TransactionIdEquals(pgxact->xid, xid))
+ {
+ LWLockRelease(TwoPhaseStateLock);
+ return true;
+ }
+ }
+ LWLockRelease(TwoPhaseStateLock);
This overlaps with TwoPhaseGetGXact but I'd rather keep both things
separated: it does not seem worth complicating the existing interface,
and putting that in cache during recovery has no meaning.
I have also reworked the test format, and fixed many typos and grammar
problems in the patch as well as in the tests.
After review the result is attached. Perhaps a committer could get a look at it?
--
Michael
Attachment
On 6 September 2016 at 02:41, Michael Paquier <michael.paquier@gmail.com> wrote: > After review the result is attached. Perhaps a committer could get a look at it? Yes, will do, but it will be a few more days yet. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
> On 06 Sep 2016, at 04:41, Michael Paquier <michael.paquier@gmail.com> wrote:
>
> On Sat, Sep 3, 2016 at 10:26 PM, Michael Paquier
> <michael.paquier@gmail.com> wrote:
>> On Fri, Sep 2, 2016 at 5:06 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
>>> On 13 April 2016 at 15:31, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
>>>
>>>> Fixed patch attached. There already was infrastructure to skip currently
>>>> held locks during replay of standby_redo() and I’ve extended that with check for
>>>> prepared xids.
>>>
>>> Please confirm that everything still works on current HEAD for the new
>>> CF, so review can start.
>>
>> The patch does not apply cleanly. Stas, could you rebase? I am
>> switching the patch to "waiting on author" for now.
>
> So, I have just done the rebase myself and did an extra round of
> reviews of the patch. Here are couple of comments after this extra
> lookup.
>
> LockGXactByXid() is aimed to be used only in recovery, so it seems
> adapted to be to add an assertion with RecoveryInProgress(). Using
> this routine in non-recovery code paths is risky because it assumes
> that a PGXACT could be missing, which is fine in recovery as prepared
> transactions could be moved to twophase files because of a checkpoint,
> but not in normal cases. We could also add an assertion of the kind
> gxact->locking_backend == InvalidBackendId before locking the PGXACT
> but as this routine is just normally used by the startup process (in
> non-standalone mode!) that's fine without.
>
> The handling of invalidation messages and removal of relfilenodes done
> in FinishGXact can be grouped together, checking only once for
> !RecoveryInProgress().
>
> + *
> + * The same procedure happens during replication and crash recovery.
> *
> "during WAL replay" is more generic and applies here.
>
> +
> +next_file:
> + continue;
> +
> That can be removed and replaced by a "continue;".
>
> + /*
> + * At first check prepared tx that wasn't yet moved to disk.
> + */
> + LWLockAcquire(TwoPhaseStateLock, LW_SHARED);
> + for (i = 0; i < TwoPhaseState->numPrepXacts; i++)
> + {
> + GlobalTransaction gxact = TwoPhaseState->prepXacts[i];
> + PGXACT *pgxact = &ProcGlobal->allPgXact[gxact->pgprocno];
> +
> + if (TransactionIdEquals(pgxact->xid, xid))
> + {
> + LWLockRelease(TwoPhaseStateLock);
> + return true;
> + }
> + }
> + LWLockRelease(TwoPhaseStateLock);
> This overlaps with TwoPhaseGetGXact but I'd rather keep both things
> separated: it does not seem worth complicating the existing interface,
> and putting that in cache during recovery has no meaning.
Oh, I was preparing new version of patch, after fresh look on it. Probably, I should
said that in this topic. I’ve found a bug in sub transaction handling and now working
on fix.
>
> I have also reworked the test format, and fixed many typos and grammar
> problems in the patch as well as in the tests.
Thanks!
>
> After review the result is attached. Perhaps a committer could get a look at it?
I'll check it against my failure scenario with subtransactions and post results or updated patch here.
--
Stas Kelvich
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
On Tue, Sep 6, 2016 at 5:58 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >> On 06 Sep 2016, at 04:41, Michael Paquier <michael.paquier@gmail.com> wrote: >> This overlaps with TwoPhaseGetGXact but I'd rather keep both things >> separated: it does not seem worth complicating the existing interface, >> and putting that in cache during recovery has no meaning. > > Oh, I was preparing new version of patch, after fresh look on it. Probably, I should > said that in this topic. I’ve found a bug in sub transaction handling and now working > on fix. What's the problem actually? -- Michael
On 6 September 2016 at 09:58, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >> On 06 Sep 2016, at 04:41, Michael Paquier <michael.paquier@gmail.com> wrote: >> >> On Sat, Sep 3, 2016 at 10:26 PM, Michael Paquier >> <michael.paquier@gmail.com> wrote: >>> On Fri, Sep 2, 2016 at 5:06 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >>>> On 13 April 2016 at 15:31, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >>>> >>>>> Fixed patch attached. There already was infrastructure to skip currently >>>>> held locks during replay of standby_redo() and I’ve extended that with check for >>>>> prepared xids. >>>> >>>> Please confirm that everything still works on current HEAD for the new >>>> CF, so review can start. >>> >>> The patch does not apply cleanly. Stas, could you rebase? I am >>> switching the patch to "waiting on author" for now. >> >> So, I have just done the rebase myself and did an extra round of >> reviews of the patch. Here are couple of comments after this extra >> lookup. > Oh, I was preparing new version of patch, after fresh look on it. Probably, I should > said that in this topic. I’ve found a bug in sub transaction handling and now working > on fix. Not replying has wasted time and effort. >> After review the result is attached. Perhaps a committer could get a look at it? > > I'll check it against my failure scenario with subtransactions and post results or updated patch here. Make sure tests are added for that. It would have been better to say you knew there were bugs in it earlier. This has been buggy so far, so I am hesitant about this now. I suggest we add significant docs to explain how it works, so everybody can double-check the concepts. Please also do what you can to reduce the patch complexity. I'll look at this again in two weeks time. Help me to make sure it gets committed that time by doing a full and complete patch. Thanks. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
> On 06 Sep 2016, at 12:09, Simon Riggs <simon@2ndquadrant.com> wrote: > > On 6 September 2016 at 09:58, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >> >> I'll check it against my failure scenario with subtransactions and post results or updated patch here. > > Make sure tests are added for that. It would have been better to say > you knew there were bugs in it earlier. I’ve spotted that yesterday during rebase. Sorry. Next time in same situation i’ll write right away to save everyone’s time. > On 06 Sep 2016, at 12:03, Michael Paquier <michael.paquier@gmail.com> wrote: > > On Tue, Sep 6, 2016 at 5:58 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >> Oh, I was preparing new version of patch, after fresh look on it. Probably, I should >> said that in this topic. I’ve found a bug in sub transaction handling and now working >> on fix. > > What's the problem actually? Handling of xids_p array in PrescanPreparedTransactions() is wrong for prepared tx's in memory. Also I want to double-check and add comments to RecoveryInProgress() checks in FinishGXact. I’ll post reworked patch in several days. -- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company
>> On 06 Sep 2016, at 12:03, Michael Paquier <michael.paquier@gmail.com> wrote: >> >> On Tue, Sep 6, 2016 at 5:58 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >>> Oh, I was preparing new version of patch, after fresh look on it. Probably, I should >>> said that in this topic. I’ve found a bug in sub transaction handling and now working >>> on fix. >> >> What's the problem actually? > > Handling of xids_p array in PrescanPreparedTransactions() is wrong for prepared tx's in memory. > Also I want to double-check and add comments to RecoveryInProgress() checks in FinishGXact. > > I’ll post reworked patch in several days. Could you use as a base the version I just sent yesterday then? I noticed many mistakes in the comments, for example many s/it's/its/ and did a couple of adjustments around the code, the goto next_file was particularly ugly. That will be that much work not do to again later. -- Michael
> On 07 Sep 2016, at 03:09, Michael Paquier <michael.paquier@gmail.com> wrote: > >>> On 06 Sep 2016, at 12:03, Michael Paquier <michael.paquier@gmail.com> wrote: >>> >>> On Tue, Sep 6, 2016 at 5:58 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >>>> Oh, I was preparing new version of patch, after fresh look on it. Probably, I should >>>> said that in this topic. I’ve found a bug in sub transaction handling and now working >>>> on fix. >>> >>> What's the problem actually? >> >> Handling of xids_p array in PrescanPreparedTransactions() is wrong for prepared tx's in memory. >> Also I want to double-check and add comments to RecoveryInProgress() checks in FinishGXact. >> >> I’ll post reworked patch in several days. > > Could you use as a base the version I just sent yesterday then? I > noticed many mistakes in the comments, for example many s/it's/its/ > and did a couple of adjustments around the code, the goto next_file > was particularly ugly. That will be that much work not do to again > later. Yes. Already merged branch with your version. -- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company
> On 07 Sep 2016, at 11:07, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > >> On 07 Sep 2016, at 03:09, Michael Paquier <michael.paquier@gmail.com> wrote: >> >>>> On 06 Sep 2016, at 12:03, Michael Paquier <michael.paquier@gmail.com> wrote: >>>> >>>> On Tue, Sep 6, 2016 at 5:58 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >>>>> Oh, I was preparing new version of patch, after fresh look on it. Probably, I should >>>>> said that in this topic. I’ve found a bug in sub transaction handling and now working >>>>> on fix. >>>> >>>> What's the problem actually? >>> >>> Handling of xids_p array in PrescanPreparedTransactions() is wrong for prepared tx's in memory. >>> Also I want to double-check and add comments to RecoveryInProgress() checks in FinishGXact. >>> >>> I’ll post reworked patch in several days. >> >> Could you use as a base the version I just sent yesterday then? I >> noticed many mistakes in the comments, for example many s/it's/its/ >> and did a couple of adjustments around the code, the goto next_file >> was particularly ugly. That will be that much work not do to again >> later. > > Yes. Already merged branch with your version. Here is updated version of patch. Looking through old version i’ve noted few things that were bothering me: * In case of crash replay PREPARE redo accesses SUBTRANS, but StartupSUBTRANS() isn’t called yet in StartupXLOG(). * Several functions in twophase.c have to walk through both PGPROC and pg_twophase directory. Now I slightly changed order of things in StartupXLOG() so twophase state loaded from from file and StartupSUBTRANS called before actual recovery starts. So in all other functions we can be sure that file were already loaded in memory. Also since 2pc transactions now are dumped to files only on checkpoint, we can get rid of PrescanPreparedTransactions() — all necessary info can reside in checkpoint itself. I’ve changed behaviour of oldestActiveXid write in checkpoint and that’s probably discussable topic, but ISTM that simplifies a lot recovery logic in both twophase.c and xlog.c. More comments on that in patch itself. -- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On Sat, Sep 17, 2016 at 2:45 AM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > Looking through old version i’ve noted few things that were bothering me: > > * In case of crash replay PREPARE redo accesses SUBTRANS, but StartupSUBTRANS() isn’t called yet > in StartupXLOG(). > * Several functions in twophase.c have to walk through both PGPROC and pg_twophase directory. > > Now I slightly changed order of things in StartupXLOG() so twophase state loaded from from file and > StartupSUBTRANS called before actual recovery starts. So in all other functions we can be sure that > file were already loaded in memory. > > Also since 2pc transactions now are dumped to files only on checkpoint, we can get rid of > PrescanPreparedTransactions() — all necessary info can reside in checkpoint itself. I’ve changed > behaviour of oldestActiveXid write in checkpoint and that’s probably discussable topic, but ISTM > that simplifies a lot recovery logic in both twophase.c and xlog.c. More comments on that in patch itself. Finally I am back on this one.. First be more careful about typos in the comments of your code. Just reading through the patch I found quite a couple of places that needed to be fixed. cosequent, unavalable, SUBTRANCE are some examples among many other things.. + StartupCLOG(); + StartupSUBTRANS(checkPoint.oldestActiveXid); + RecoverPreparedFromFiles(); [...] /* - * Startup commit log and subtrans only. MultiXact and commit - * timestamp have already been started up and other SLRUs are not - * maintained during recovery and need not be started yet. - */ - StartupCLOG(); - StartupSUBTRANS(oldestActiveXID); Something is definitely wrong in this patch if we begin to do that. There is no need to move those two calls normally, and I think that we had better continue to do that only for hot standbys just to improve 2PC handling... CleanupPreparedTransactionsOnPITR() cleans up pg_twophase, but isn't it necessary to do something as well for what is in memory? I have been thinking about this patch quite a bit, and the approach taken looks really over-complicated to me. Basically what we are trying to do here is to reuse as much as possible code paths that are being used by non-recovery code paths during recovery, and then try to adapt a bunch of things like SUBTRANS structures, CLOG, XID handling and PGXACT things in sync to handle the 2PC information in memory correctly. I am getting to think that this is *really* bug-prone in the future and really going to make maintenance hard. Taking one step back, and I know that I am a noisy one, but looking at this patch is making me aware of the fact that it is trying more and more to patch things around the more we dig into issues, and I'd suspect that trying to adapt for example sub-transaction and clog handling is just the tip of the iceberg and that there are more things that need to be taken care of if we continue to move on with this approach. Coming to the point: why don't we simplify things? In short: - Just use a static list and allocate a chunk of shared memory as needed. DSM could come into play here to adapt to the size of a 2PC status file, this way there is no need to allocate a chunk of memory with an upper bound. Still we could use an hardcoded upper-bound of say 2k with max_prepared_transactions, and just write the 2PC status file to disk if its size is higher than what can stick into memory. - save 2PC information in memory instead of writing it to a 2PC file when XLOG_XACT_PREPARE shows up. - flush information to disk when there is a valid restart point in RecoveryRestartPoint(). We would need as well to tweak PrescanPreparedTransactions accordingly than everything we are trying to do here. That would be way more simple than what's proposed here, and we'd still keep all the performance benefits. -- Michael
> > On 20 Sep 2016, at 09:40, Michael Paquier <michael.paquier@gmail.com> wrote: > Thanks for digging into this. > + StartupCLOG(); > + StartupSUBTRANS(checkPoint.oldestActiveXid); > + RecoverPreparedFromFiles(); > [...] > /* > - * Startup commit log and subtrans only. MultiXact and commit > - * timestamp have already been started up and other SLRUs are not > - * maintained during recovery and need not be started yet. > - */ > - StartupCLOG(); > - StartupSUBTRANS(oldestActiveXID); > Something is definitely wrong in this patch if we begin to do that. Putting that before actual WAL replay is just following historical order of events. Prepared files are pieces of WAL that happened before checkpoint, so ISTM there is no conceptual problem in restoring their state before replay. Moreover I think that this approach is better then oldest one. There is kind of circular dependency between StartupSUBTRANS() and restoring old prepared transaction: StartupSUBTRANS requires oldestActiveXID, but you can get it only after recovering 2pc files, but that recovery requires working SUBTRANS. In old code that was resolved by two passes through 2pc files: first one finds oldestActiveXmin but doesn’t restore their state, then subtrans was started, and only after that RecoverPreparedTransactions() is called. And that logic was repeated three times in xlog.c with help of following functions: PrescanPreparedTransactions() — 3 calls StandbyRecoverPreparedTransactions() — 2 calls RecoverPreparedTransactions() — 1 call Now, since we know that 2pc files are written only on checkpoint we can boil all that cases down to one: get oldestActiveXID from checkpoint and restore it before WAL replay. So only one call of RecoverPreparedFromFiles() and one call of CleanupPreparedTransactionsOnPITR() in case of PITR. And each of them does only what stated on function name without side-effects like advancing nextXid in previous versions. So, to summarise, i think keeping old interfaces here is bigger evil because in each of mentioned functions we will need to deal with both memory and file 2pc states. > There is no need to move those two calls normally, and I think that we > had better continue to do that only for hot standbys just to improve > 2PC handling… We can simulate old interface, it’s not a big problem. But that will complicate 2pc code and keep useless code in xlog.c because it was written in assumption that 2pc file can be created before checkpoint and now it isn’t true. > CleanupPreparedTransactionsOnPITR() cleans up pg_twophase, but isn't > it necessary to do something as well for what is in memory? Yes, that is necessary. Thanks, will fix. And probably add prepared tx to PITR test. > I have been thinking about this patch quite a bit, and the approach > taken looks really over-complicated to me. Basically what we are > trying to do here is to reuse as much as possible code paths that are > being used by non-recovery code paths during recovery, and then try to > adapt a bunch of things like SUBTRANS structures, CLOG, XID handling > and PGXACT things in sync to handle the 2PC information in memory > correctly. I am getting to think that this is *really* bug-prone in > the future and really going to make maintenance hard. With this patch we are reusing one infrastructure for normal work, recovery and replay. I don’t think that we will win a lot reliability if we split that to a different code paths. > Taking one step back, and I know that I am a noisy one, but looking at > this patch is making me aware of the fact that it is trying more and > more to patch things around the more we dig into issues, and I'd > suspect that trying to adapt for example sub-transaction and clog > handling is just the tip of the iceberg and that there are more things > that need to be taken care of if we continue to move on with this > approach. Again, it isn’t patching around to fix issues, it’s totally possible to keep old interface. However it’s possible that current approach is wrong because of some aspect that i didn’t think of, but now I don’t see good counterarguments. > Coming to the point: why don't we simplify things? In short: > - Just use a static list and allocate a chunk of shared memory as > needed. DSM could come into play here to adapt to the size of a 2PC > status file, this way there is no need to allocate a chunk of memory > with an upper bound. Still we could use an hardcoded upper-bound of > say 2k with max_prepared_transactions, and just write the 2PC status > file to disk if its size is higher than what can stick into memory. > - save 2PC information in memory instead of writing it to a 2PC file > when XLOG_XACT_PREPARE shows up. > - flush information to disk when there is a valid restart point in > RecoveryRestartPoint(). We would need as well to tweak > PrescanPreparedTransactions accordingly than everything we are trying > to do here. > That would be way more simple than what's proposed here, and we'd > still keep all the performance benefits. So file arrives to replica through WAL and instead of directly reading it you suggest to copy it do DSM if it is small enough, and to filesystem if not. Probably that will allow us to stay only around reading/writing files, but: * That will be measurably slower than proposed approach because of unnecessary copying between WAL and DSM. Not to mention prepare records of arbitrary length. * Different behaviour on replica and master — less tested code for replica. * Almost the same behaviour can be achieved by delaying fsync on 2pc files till checkpoint. But if reword you comment in a way that it is better to avoid replaying prepare record at all, like it happens now in master, then I see the point. And that is possible even without DSM, it possible to allocate static sized array storing some info about tx, whether it is in the WAL or in file, xid, gid. Some sort of PGXACT doppelganger only for replay purposes instead of using normal one. So taking into account my comments what do you think? Should we keep current approach or try to avoid replaying prepare records at all? -- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Tue, Sep 20, 2016 at 11:13 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >> On 20 Sep 2016, at 09:40, Michael Paquier <michael.paquier@gmail.com> wrote: >> + StartupCLOG(); >> + StartupSUBTRANS(checkPoint.oldestActiveXid); >> + RecoverPreparedFromFiles(); >> [...] >> /* >> - * Startup commit log and subtrans only. MultiXact and commit >> - * timestamp have already been started up and other SLRUs are not >> - * maintained during recovery and need not be started yet. >> - */ >> - StartupCLOG(); >> - StartupSUBTRANS(oldestActiveXID); >> Something is definitely wrong in this patch if we begin to do that. > > Putting that before actual WAL replay is just following historical order of events. > Prepared files are pieces of WAL that happened before checkpoint, so ISTM > there is no conceptual problem in restoring their state before replay. For wal_level = minimal there is no need to call that to begin with.. And I'd think that it is better to continue with things the same way. >> I have been thinking about this patch quite a bit, and the approach >> taken looks really over-complicated to me. Basically what we are >> trying to do here is to reuse as much as possible code paths that are >> being used by non-recovery code paths during recovery, and then try to >> adapt a bunch of things like SUBTRANS structures, CLOG, XID handling >> and PGXACT things in sync to handle the 2PC information in memory >> correctly. I am getting to think that this is *really* bug-prone in >> the future and really going to make maintenance hard. > > With this patch we are reusing one infrastructure for normal work, recovery and replay. The mix between normal work and recovery is the scary part. Normal work and recovery are entirely two different things. >> Taking one step back, and I know that I am a noisy one, but looking at >> this patch is making me aware of the fact that it is trying more and >> more to patch things around the more we dig into issues, and I'd >> suspect that trying to adapt for example sub-transaction and clog >> handling is just the tip of the iceberg and that there are more things >> that need to be taken care of if we continue to move on with this >> approach. > > Again, it isn’t patching around to fix issues, it’s totally possible to keep old interface. > However it’s possible that current approach is wrong because of some aspect > that i didn’t think of, but now I don’t see good counterarguments. Any missing points could be costly here. If we have a way to make things with the same performance >> Coming to the point: why don't we simplify things? In short: > >> - Just use a static list and allocate a chunk of shared memory as >> needed. DSM could come into play here to adapt to the size of a 2PC >> status file, this way there is no need to allocate a chunk of memory >> with an upper bound. Still we could use an hardcoded upper-bound of >> say 2k with max_prepared_transactions, and just write the 2PC status >> file to disk if its size is higher than what can stick into memory. >> - save 2PC information in memory instead of writing it to a 2PC file >> when XLOG_XACT_PREPARE shows up. >> - flush information to disk when there is a valid restart point in >> RecoveryRestartPoint(). We would need as well to tweak >> PrescanPreparedTransactions accordingly than everything we are trying >> to do here. >> That would be way more simple than what's proposed here, and we'd >> still keep all the performance benefits. > > So file arrives to replica through WAL and instead of directly reading it you suggest > to copy it do DSM if it is small enough, and to filesystem if not. Probably that will > allow us to stay only around reading/writing files, but: > > * That will be measurably slower than proposed approach because of unnecessary > copying between WAL and DSM. Not to mention prepare records of arbitrary length. > * Different behaviour on replica and master — less tested code for replica. Well, the existing code on HEAD is battery-tested as well. This reduces the likeliness of bugs at replay with new features. > * Almost the same behaviour can be achieved by delaying fsync on 2pc files till > checkpoint. Oh, that's an idea here. It may be interesting to see if this meets your performance goals... And that could result in a far smaller patch. > But if reword you comment in a way that it is better to avoid replaying prepare record at all, > like it happens now in master, then I see the point. And that is possible even without DSM, it possible > to allocate static sized array storing some info about tx, whether it is in the WAL or in file, xid, gid. > Some sort of PGXACT doppelganger only for replay purposes instead of using normal one. That's exactly what I meant. The easiest approach is just to allocate a bunk of shared memory made of 2PC_STATUS_SIZE * max_prepared_xacts with 2PC_STATUS_SIZE set up at an arbitrary size that we find appropriate to store the information of the file. DSM may be useful to take care of the case where the status file is bigger than one slot, but with a sufficiently wise upper bound, we can get away without it. > So taking into account my comments what do you think? Should we keep current approach > or try to avoid replaying prepare records at all? I'd really like to give a try to the idea you just mentioned, aka delay the fsync of the 2PC files from RecreateTwoPhaseFile to CreateRestartPoint, or get things into memory.. I could write one, or both of those patches. I don't mind. -- Michael
> On 21 Sep 2016, at 10:32, Michael Paquier <michael.paquier@gmail.com> wrote: > > On Tue, Sep 20, 2016 at 11:13 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >> >> Putting that before actual WAL replay is just following historical order of events. >> Prepared files are pieces of WAL that happened before checkpoint, so ISTM >> there is no conceptual problem in restoring their state before replay. > > For wal_level = minimal there is no need to call that to begin with.. > And I'd think that it is better to continue with things the same way. > Hm, why? >> >> With this patch we are reusing one infrastructure for normal work, recovery and replay. > > The mix between normal work and recovery is the scary part. Normal > work and recovery are entirely two different things. > Okay, agreed. Commit procedure that checks whether recovery is active or not is quite hacky solution. >> So taking into account my comments what do you think? Should we keep current approach >> or try to avoid replaying prepare records at all? > > I'd really like to give a try to the idea you just mentioned, aka > delay the fsync of the 2PC files from RecreateTwoPhaseFile to > CreateRestartPoint, or get things into memory.. I could write one, or > both of those patches. I don't mind. I’m not giving up yet, i’ll write them) I still have in mind several other patches to 2pc handling in postgres during this release cycle — logical decoding and partitioned hash instead of TwoPhaseState list. My bet that relative speed of that patches will depend on used filesystem. Like it was with the first patch in that mail thread it is totally possible sometimes to hit filesystem limits on file creation speed. Otherwise both approaches should be more or less equal, i suppose. -- Stas Kelvich Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Thu, Sep 22, 2016 at 12:30 AM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > I’m not giving up yet, i’ll write them) I still have in mind several other patches to 2pc handling in > postgres during this release cycle — logical decoding and partitioned hash instead of > TwoPhaseState list. > > My bet that relative speed of that patches will depend on used filesystem. Like it was with the > first patch in that mail thread it is totally possible sometimes to hit filesystem limits on file > creation speed. Otherwise both approaches should be more or less equal, i suppose. OK. I am marking this patch as returned with feedback then. Looking forward to seeing the next investigations.. At least this review has taught us one thing or two. -- Michael
On 27 Sep 2016, at 03:30, Michael Paquier <michael.paquier@gmail.com> wrote:OK. I am marking this patch as returned with feedback then. Looking
forward to seeing the next investigations.. At least this review has
taught us one thing or two.
So, here is brand new implementation of the same thing.
Now instead of creating pgproc entry for prepared transaction during recovery,
I just store recptr/xid correspondence in separate 2L-list and deleting entries in that
list if redo process faced commit/abort. In case of checkpoint or end of recovery
transactions remaining in that list are dumped to files in pg_twophase.
Seems that current approach is way more simpler and patch has two times less
LOCs then previous one.
--
Attachment
On Fri, Dec 16, 2016 at 02:00:46PM +0300, Stas Kelvich wrote: > > > On 27 Sep 2016, at 03:30, Michael Paquier <michael.paquier@gmail.com> wrote: > > > > OK. I am marking this patch as returned with feedback then. Looking > > forward to seeing the next investigations.. At least this review has > > taught us one thing or two. > > So, here is brand new implementation of the same thing. > > Now instead of creating pgproc entry for prepared transaction during recovery, > I just store recptr/xid correspondence in separate 2L-list and deleting entries in that > list if redo process faced commit/abort. In case of checkpoint or end of recovery > transactions remaining in that list are dumped to files in pg_twophase. > > Seems that current approach is way more simpler and patch has two times less > LOCs then previous one. Uh, did you mean to attached patch here? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Sun, Dec 18, 2016 at 6:42 AM, Bruce Momjian <bruce@momjian.us> wrote: > Uh, did you mean to attached patch here? Strange. I can confirm that I have received the patch as attached, but it is not on the archives. -- Michael -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Sun, Dec 18, 2016 at 07:41:50AM +0900, Michael Paquier wrote: > On Sun, Dec 18, 2016 at 6:42 AM, Bruce Momjian <bruce@momjian.us> wrote: > > Uh, did you mean to attached patch here? > > Strange. I can confirm that I have received the patch as attached, but > it is not on the archives. It must have been stripped by our email system. You were a direct CC so you received it. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
> On 18 Dec 2016, at 01:54, Bruce Momjian <bruce@momjian.us> wrote: > > On Sun, Dec 18, 2016 at 07:41:50AM +0900, Michael Paquier wrote: >> >> >> Strange. I can confirm that I have received the patch as attached, but >> it is not on the archives. > > It must have been stripped by our email system. You were a direct CC so > you received it. > Then, probably, my mail client did something strange. I’ll check. -- Stas Kelvich Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Sat, Dec 17, 2016 at 05:54:04PM -0500, Bruce Momjian wrote: > On Sun, Dec 18, 2016 at 07:41:50AM +0900, Michael Paquier wrote: > > On Sun, Dec 18, 2016 at 6:42 AM, Bruce Momjian <bruce@momjian.us> wrote: > > > Uh, did you mean to attached patch here? > > > > Strange. I can confirm that I have received the patch as attached, but > > it is not on the archives. > > It must have been stripped by our email system. You were a direct > CC so you received it. I was neither, and I received it, so I don't thing PostgreSQL's email system stripped it. It's pretty mystifying, though. Best, David. -- David Fetter <david(at)fetter(dot)org> http://fetter.org/ Phone: +1 415 235 3778 AIM: dfetter666 Yahoo!: dfetter Skype: davidfetter XMPP: david(dot)fetter(at)gmail(dot)com Remember to vote! Consider donating to Postgres: http://www.postgresql.org/about/donate
On 2016-12-17 15:30:08 -0800, David Fetter wrote: > On Sat, Dec 17, 2016 at 05:54:04PM -0500, Bruce Momjian wrote: > > On Sun, Dec 18, 2016 at 07:41:50AM +0900, Michael Paquier wrote: > > > On Sun, Dec 18, 2016 at 6:42 AM, Bruce Momjian <bruce@momjian.us> wrote: > > > > Uh, did you mean to attached patch here? > > > > > > Strange. I can confirm that I have received the patch as attached, but > > > it is not on the archives. > > > > It must have been stripped by our email system. You were a direct > > CC so you received it. > > I was neither, and I received it, so I don't thing PostgreSQL's email > system stripped it. It's pretty mystifying, though. The mime construction in the email is weird. The attachement is below a multipart/alternative and multipart/mixed, besides the text/html version of the plain text email. Because the attachement is below the multipart/alternative (i.e. the switch between plain text / html), it'll not be considered a proper attachement by many mail readers. It seems quite borked to put an attachement there - weird that apple mail does so. Andres -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Sat, Dec 17, 2016 at 03:47:34PM -0800, Andres Freund wrote: > On 2016-12-17 15:30:08 -0800, David Fetter wrote: > > On Sat, Dec 17, 2016 at 05:54:04PM -0500, Bruce Momjian wrote: > > > On Sun, Dec 18, 2016 at 07:41:50AM +0900, Michael Paquier wrote: > > > > On Sun, Dec 18, 2016 at 6:42 AM, Bruce Momjian <bruce@momjian.us> wrote: > > > > > Uh, did you mean to attached patch here? > > > > > > > > Strange. I can confirm that I have received the patch as attached, but > > > > it is not on the archives. > > > > > > It must have been stripped by our email system. You were a direct > > > CC so you received it. > > > > I was neither, and I received it, so I don't thing PostgreSQL's email > > system stripped it. It's pretty mystifying, though. > > The mime construction in the email is weird. The attachement is below a > multipart/alternative and multipart/mixed, besides the text/html version > of the plain text email. Because the attachement is below the > multipart/alternative (i.e. the switch between plain text / html), it'll > not be considered a proper attachement by many mail readers. > > It seems quite borked to put an attachement there - weird that apple > mail does so. Oh, I now see the attachment _is_ in the original email, it is just that mutt doesn't show it. Here is the heirarchy of the email as shown by mutt: I 1 <no description> [multipa/alternativ,7bit, 27K] I 2 ├─><no description> [text/plain,quoted, us-ascii, 0.8K] I 3 └─><no description> [multipa/mixed,7bit, 26K] I 4 ├─><no description> [text/html,quoted, us-ascii, 5.4K] A 5 ├─>twophase_recovery_list.diff [applica/octet-stre,7bit, 20K] I 6 └─><no description> [text/html,7bit, us-ascii, 0.4K] As Andres already stated, the problem is that there is a text/plain and text/html of the same email, and the diff is _inside_ the multipa/mixed HTML block. I think it needs to be outside on its own. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription + -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Sat, Dec 17, 2016 at 07:38:46PM -0500, Bruce Momjian wrote: > As Andres already stated, the problem is that there is a text/plain and > text/html of the same email, and the diff is _inside_ the multipa/mixed > HTML block. I think it needs to be outside on its own. Mutt shows text/plain by default. I bet email readers that prefer to display HTML see the patch. Mystery solved by Andres! :-) -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Fri, Dec 16, 2016 at 8:00 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > So, here is brand new implementation of the same thing. > > Now instead of creating pgproc entry for prepared transaction during > recovery, > I just store recptr/xid correspondence in separate 2L-list and deleting > entries in that > list if redo process faced commit/abort. In case of checkpoint or end of > recovery > transactions remaining in that list are dumped to files in pg_twophase. > > Seems that current approach is way more simpler and patch has two times less > LOCs then previous one. That's indeed way simpler than before. Have you as well looked at the most simple approach discussed? That would be just roughly replacing the pg_fsync() calls currently in RecreateTwoPhaseFile() by a save into a list as you are doing, then issue them all checkpoint. Even for 2PC files that are created and then removed before the next checkpoint, those will likely be in system cache. This removes as well the need to have XlogReadTwoPhaseData() work in crash recovery, which makes me a bit nervous. And this saves lookups at the WAL segments still present in pg_xlog, making the operation at checkpoint much faster with many 2PC files to process. -- Michael
On 21 Dec 2016, at 19:56, Michael Paquier <michael.paquier@gmail.com> wrote:
That's indeed way simpler than before. Have you as well looked at the
most simple approach discussed? That would be just roughly replacing
the pg_fsync() calls currently in RecreateTwoPhaseFile() by a save
into a list as you are doing, then issue them all checkpoint.Even for
2PC files that are created and then removed before the next
checkpoint, those will likely be in system cache.
Yes, I tried that as well. But in such approach another bottleneck arises —
new file creation isn’t very cheap operation itself. Dual xeon with 100 backends
quickly hit that, and OS routines about file creation occupies first places in
perf top. Probably that depends on filesystem (I used ext4), but avoiding
file creation when it isn’t necessary seems like cleaner approach.
On the other hand it is possible to skip file creation by reusing files, for example
naming them by dummy PGPROC offset, but that would require some changes
to places that right now looks only at filenames.
This removes as well
the need to have XlogReadTwoPhaseData() work in crash recovery, which
makes me a bit nervous.
Hm, do you have any particular bad scenario for that case in you mind?
And this saves lookups at the WAL segments
still present in pg_xlog, making the operation at checkpoint much
faster with many 2PC files to process.
spending time on file creation.
--
On Wed, Dec 21, 2016 at 10:37 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > On 21 Dec 2016, at 19:56, Michael Paquier <michael.paquier@gmail.com> wrote: >> That's indeed way simpler than before. Have you as well looked at the >> most simple approach discussed? That would be just roughly replacing >> the pg_fsync() calls currently in RecreateTwoPhaseFile() by a save >> into a list as you are doing, then issue them all checkpoint.Even for > >> 2PC files that are created and then removed before the next >> checkpoint, those will likely be in system cache. > > Yes, I tried that as well. But in such approach another bottleneck arises > — > new file creation isn’t very cheap operation itself. Dual xeon with 100 > backends > quickly hit that, and OS routines about file creation occupies first places > in perf top. Probably that depends on filesystem (I used ext4), but avoiding > file creation when it isn’t necessary seems like cleaner approach. > On the other hand it is possible to skip file creation by reusing files, > for example > naming them by dummy PGPROC offset, but that would require some changes > to places that right now looks only at filenames. Interesting. Thanks for looking at it. Your latest approach looks more promising based on that then. >> And this saves lookups at the WAL segments >> still present in pg_xlog, making the operation at checkpoint much >> faster with many 2PC files to process. > > ISTM your reasoning about filesystem cache applies here as well, but just > without spending time on file creation. True. The more spread the checkpoints and 2PC files, the more risk to require access to disk. Memory's cheap anyway. What was the system memory? How many checkpoints did you trigger for how many 2PC files created? Perhaps it would be a good idea to look for the 2PC files from WAL records in a specific order. Did you try to use dlist_push_head instead of dlist_push_tail? This may make a difference on systems where WAL segments don't fit in system cache as the latest files generated would be looked at first for 2PC data. -- Michael
On Thu, Dec 22, 2016 at 7:35 AM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Wed, Dec 21, 2016 at 10:37 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >> ISTM your reasoning about filesystem cache applies here as well, but just >> without spending time on file creation. > > True. The more spread the checkpoints and 2PC files, the more risk to > require access to disk. Memory's cheap anyway. What was the system > memory? How many checkpoints did you trigger for how many 2PC files > created? Perhaps it would be a good idea to look for the 2PC files > from WAL records in a specific order. Did you try to use > dlist_push_head instead of dlist_push_tail? This may make a difference > on systems where WAL segments don't fit in system cache as the latest > files generated would be looked at first for 2PC data. Stas, have you tested as well tested the impact on recovery time when WAL segments are very likely evicted from the OS cache? This could be a plausible scenario if a standby instance is heavily used for read-only transactions (say pgbench -S), and that the data quantity is higher than the amount of RAM available. It would not be complicated to test that: just drop_caches before beginning recovery. The maximum amount of 2PC transactions that need to have access to the past WAL segments is linearly related to the volume of WAL between two checkpoints, so max_wal_size does not really matter. What matters is the time it takes to recover the same amount of WAL. Increasing max_wal_size would give more room to reduce the overall noise between two measurements though. -- Michael
On 22 Dec 2016, at 05:35, Michael Paquier <michael.paquier@gmail.com> wrote:True. The more spread the checkpoints and 2PC files, the more risk to
require access to disk. Memory's cheap anyway. What was the system
memory? How many checkpoints did you trigger for how many 2PC files
created?
Standard config with increased shared_buffers. I think the most significant
impact on the recovery speed here is on the client side, namely time between
prepare and commit. Right now I’m using pgbench script that issues commit
right after prepare. It’s also possible to put sleep between prepare and commit
and increase number of connections to thousands. That will be probably the
worst case — majority of prepared tx will be moved to files.
Perhaps it would be a good idea to look for the 2PC files
from WAL records in a specific order. Did you try to use
dlist_push_head instead of dlist_push_tail? This may make a difference
on systems where WAL segments don't fit in system cache as the latest
files generated would be looked at first for 2PC data.
Ouch! Good catch. I didn’t actually noticed that list populated in opposite order
with respect to traversal. I’ll fix that.
On 27 Dec 2016, at 08:33, Michael Paquier <michael.paquier@gmail.com> wrote:
Stas, have you tested as well tested the impact on recovery time when
WAL segments are very likely evicted from the OS cache? This could be
a plausible scenario if a standby instance is heavily used for
read-only transactions (say pgbench -S), and that the data quantity is
higher than the amount of RAM available. It would not be complicated
to test that: just drop_caches before beginning recovery. The maximum
amount of 2PC transactions that need to have access to the past WAL
segments is linearly related to the volume of WAL between two
checkpoints, so max_wal_size does not really matter. What matters is
the time it takes to recover the same amount of WAL. Increasing
max_wal_size would give more room to reduce the overall noise between
two measurements though.
Okay, i’ll perform such testing.
--
On Tue, Dec 27, 2016 at 12:59 PM, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: > Standard config with increased shared_buffers. I think the most significant > impact on the recovery speed here is on the client side, namely time between > prepare and commit. Right now I’m using pgbench script that issues commit > right after prepare. It’s also possible to put sleep between prepare and > commit > and increase number of connections to thousands. That will be probably the > worst case — majority of prepared tx will be moved to files. I think that it would be a good idea to actually test that in pure recovery time, aka no client, and just use a base backup and make it recover X prepared transactions that have created Y checkpoints after dropping cache (or restarting server). -- Michael
> On 27 Dec 2016, at 07:31, Michael Paquier <michael.paquier@gmail.com> wrote:
>
> I think that it would be a good idea to actually test that in pure
> recovery time, aka no client, and just use a base backup and make it
> recover X prepared transactions that have created Y checkpoints after
> dropping cache (or restarting server).
I did tests with following setup:
* Start postgres initialised with pgbench
* Start pg_receivexlog
* Take basebackup
* Perform 1.5 M transactions
* Stop everything and apply wal files stored by pg_receivexlog to base backup.
All tests performed on a laptop with nvme ssd
number of transactions: 1.5M
start segment: 0x4
-master non-2pc:
last segment: 0x1b
average recovery time per 16 wal files: 11.8s
average total recovery time: 17.0s
-master 2pc:
last segment: 0x44
average recovery time per 16 wal files: 142s
average total recovery time: 568s
-patched 2pc (previous patch):
last segment: 0x44
average recovery time per 16 wal files: 5.3s
average total recovery time: 21.2s
-patched2 2pc (dlist_push_tail changed to dlist_push_head):
last segment: 0x44
average recovery time per 16 wal files: 5.2s
average total recovery time: 20.8s
So skipping unnecessary fsyncs gave us x25 speed increase even on ssd (on hdd difference should be bigger).
Pushing to list's head didn’t yield measurable results, but anyway seems to be conceptually better.
PS:
I’ve faced situation when pg_basebackup freezes until checkpoint happens (automatic or user-issued).
Is that expected behaviour?
--
Stas Kelvich
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hi Stas,
>
> So, here is brand new implementation of the same thing.
>
> Now instead of creating pgproc entry for prepared transaction during recovery,
> I just store recptr/xid correspondence in separate 2L-list and
> deleting entries in that
> list if redo process faced commit/abort. In case of checkpoint or end
> of recovery
> transactions remaining in that list are dumped to files in pg_twophase.
>
> Seems that current approach is way more simpler and patch has two times less
> LOCs then previous one.
>
The proposed approach and patch does appear to be much simpler than
the previous one.
I have some comments/questions on the patch (twophase_recovery_list_2.diff):
1)
+ /*
+ * Move prepared transactions from KnownPreparedList to files, if any.
+ * It is possible to skip that step and teach subsequent code about
+ * KnownPreparedList, but whole PrescanPreparedTransactions() happens
+ * once during end of recovery or promote, so probably it isn't worth
+ * complications.
+ */
+ KnownPreparedRecreateFiles(InvalidXLogRecPtr);
+
Speeding up recovery or failover activity via a faster promote is a
desirable thing. So, maybe, we should look at teaching the relevant
code about using "KnownPreparedList"? I know that would increase the
size of this patch and would mean more testing, but this seems to be
last remaining optimization in this code path.
2)
+ /*
+ * Here we know that file should be moved to disk. But
aborting recovery because
+ * of absence of unnecessary file doesn't seems to be a good
idea, so call remove
+ * with giveWarning=false.
+ */
+ RemoveTwoPhaseFile(xid, false);
We are going to call the above in case of COMMIT/ABORT. If so, we
should always find the "xid" entry either in the KnownPreparedList or
as a file. Does it make sense to call the above function with "false"
then?
3) We are pushing the fsyncing of 2PC files to the checkpoint replay
activity with this patch. Now, typically, we would assume that PREPARE
followed by COMMIT/ABORT would happen within a checkpoint replay
cycle, if not, this would make checkpoint replays slower since the
earlier spread out fsyncs are now getting bunched up. I had concerns
about this but clearly your latest performance measurements don't show
any negatives around this directly.
4) Minor nit-pick on existing code.
(errmsg_plural("%u two-phase state file was written "
"for
long-running prepared transactions",
"%u
two-phase state files were written "
"for
long-running prepared transactions",
serialized_xacts,
serialized_xacts)
Shouldn’t the singular part of the message above be:
"%u two-phase state file was written for a long-running prepared transaction"
But, then, English is not my native language, so I might be off here :-)
5) Why isn't KnownPreparedRecreateFiles() tracking which entries from
KnownPreparedList have been written to disk in an earlier iteration
like in the normal code path? Why is it removing the entry from
KnownPreparedList and not just marking it as saved on disk?
6) Do we need to hold TwoPhaseStateLock lock in shared mode while
calling KnownPreparedRecreateFiles()? I think, it does not matter in
the recovery/replay code path.
7) I fixed some typos and comments. PFA, patch attached.
Other than this, I ran TAP tests and they succeed as needed.
Regards,
Nikhils
On 23 January 2017 at 16:56, Stas Kelvich <s.kelvich@postgrespro.ru> wrote:
>
>> On 27 Dec 2016, at 07:31, Michael Paquier <michael.paquier@gmail.com> wrote:
>>
>> I think that it would be a good idea to actually test that in pure
>> recovery time, aka no client, and just use a base backup and make it
>> recover X prepared transactions that have created Y checkpoints after
>> dropping cache (or restarting server).
>
> I did tests with following setup:
>
> * Start postgres initialised with pgbench
> * Start pg_receivexlog
> * Take basebackup
> * Perform 1.5 M transactions
> * Stop everything and apply wal files stored by pg_receivexlog to base backup.
>
> All tests performed on a laptop with nvme ssd
> number of transactions: 1.5M
> start segment: 0x4
>
> -master non-2pc:
> last segment: 0x1b
> average recovery time per 16 wal files: 11.8s
> average total recovery time: 17.0s
>
> -master 2pc:
> last segment: 0x44
> average recovery time per 16 wal files: 142s
> average total recovery time: 568s
>
> -patched 2pc (previous patch):
> last segment: 0x44
> average recovery time per 16 wal files: 5.3s
> average total recovery time: 21.2s
>
> -patched2 2pc (dlist_push_tail changed to dlist_push_head):
> last segment: 0x44
> average recovery time per 16 wal files: 5.2s
> average total recovery time: 20.8s
>
> So skipping unnecessary fsyncs gave us x25 speed increase even on ssd (on hdd difference should be bigger).
> Pushing to list's head didn’t yield measurable results, but anyway seems to be conceptually better.
>
> PS:
> I’ve faced situation when pg_basebackup freezes until checkpoint happens (automatic or user-issued).
> Is that expected behaviour?
>
> --
> Stas Kelvich
> Postgres Professional: http://www.postgrespro.com
> The Russian Postgres Company
>
>
>
> --
> Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackers
>
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Mon, Jan 23, 2017 at 9:00 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: > Hi Stas, > >> >> So, here is brand new implementation of the same thing. >> >> Now instead of creating pgproc entry for prepared transaction during recovery, >> I just store recptr/xid correspondence in separate 2L-list and >> deleting entries in that >> list if redo process faced commit/abort. In case of checkpoint or end >> of recovery >> transactions remaining in that list are dumped to files in pg_twophase. >> >> Seems that current approach is way more simpler and patch has two times less >> LOCs then previous one. >> > > The proposed approach and patch does appear to be much simpler than > the previous one. > > I have some comments/questions on the patch (twophase_recovery_list_2.diff): > > 1) > + /* > + * Move prepared transactions from KnownPreparedList to files, if any. > + * It is possible to skip that step and teach subsequent code about > + * KnownPreparedList, but whole PrescanPreparedTransactions() happens > + * once during end of recovery or promote, so probably it isn't worth > + * complications. > + */ > + KnownPreparedRecreateFiles(InvalidXLogRecPtr); > + > > Speeding up recovery or failover activity via a faster promote is a > desirable thing. So, maybe, we should look at teaching the relevant > code about using "KnownPreparedList"? I know that would increase the > size of this patch and would mean more testing, but this seems to be > last remaining optimization in this code path. That's a good idea, worth having in this patch. Actually we may not want to call KnownPreparedRecreateFiles() here as promotion is not synonym of end-of-recovery checkpoint for a couple of releases now. > 3) We are pushing the fsyncing of 2PC files to the checkpoint replay > activity with this patch. Now, typically, we would assume that PREPARE > followed by COMMIT/ABORT would happen within a checkpoint replay > cycle, if not, this would make checkpoint replays slower since the > earlier spread out fsyncs are now getting bunched up. I had concerns > about this but clearly your latest performance measurements don't show > any negatives around this directly. Most of the 2PC syncs just won't happen, such transactions normally don't last long, and the number you would get during a checkpoint is largely lower than what would happen between two checkpoints. When working on Postgres-XC, the number of 2PC was really more funky. > 6) Do we need to hold TwoPhaseStateLock lock in shared mode while > calling KnownPreparedRecreateFiles()? I think, it does not matter in > the recovery/replay code path. It does not matter as the only code path tracking that would be the checkpointer in TwoPhaseCheckpoint(), and this 2PC recovery patch does not touch anymore TwoPhaseStateData. Actually the patch makes no use of it. > 7) I fixed some typos and comments. PFA, patch attached. > > Other than this, I ran TAP tests and they succeed as needed. > > On 23 January 2017 at 16:56, Stas Kelvich <s.kelvich@postgrespro.ru> wrote: >> I did tests with following setup: >> >> * Start postgres initialised with pgbench >> * Start pg_receivexlog >> * Take basebackup >> * Perform 1.5 M transactions >> * Stop everything and apply wal files stored by pg_receivexlog to base backup. >> >> All tests performed on a laptop with nvme ssd >> number of transactions: 1.5M >> start segment: 0x4 >> >> -master non-2pc: >> last segment: 0x1b >> average recovery time per 16 wal files: 11.8s >> average total recovery time: 17.0s >> >> -master 2pc: >> last segment: 0x44 >> average recovery time per 16 wal files: 142s >> average total recovery time: 568s >> >> -patched 2pc (previous patch): >> last segment: 0x44 >> average recovery time per 16 wal files: 5.3s >> average total recovery time: 21.2s >> >> -patched2 2pc (dlist_push_tail changed to dlist_push_head): >> last segment: 0x44 >> average recovery time per 16 wal files: 5.2s >> average total recovery time: 20.8s The difference between those two is likely noise. By the way, in those measurements, the OS cache is still filled with the past WAL segments, which is a rather best case, no? What happens if you do the same kind of tests on a box where memory is busy doing something else and replayed WAL segments get evicted from the OS cache more aggressively once the startup process switches to a new segment? This could be tested for example on a VM with few memory (say 386MB or less) so as the startup process needs to access again the past WAL segments to recover the 2PC information it needs to get them back directly from disk... One trick that you could use here would be to tweak the startup process so as it drops the OS cache once a segment is finished replaying, and see the effects of an aggressive OS cache eviction. This patch is showing really nice improvements with the OS cache backing up the data, still it would make sense to test things with a worse test case and see if things could be done better. The startup process now only reads records sequentially, not randomly which is a concept that this patch introduces. Anyway, perhaps this does not matter much, the non-recovery code path does the same thing as this patch, and the improvement is too much to be ignored. So for consistency's sake we could go with the approach proposed which has the advantage to not put any restriction on the size of the 2PC file contrary to what an implementation saving the contents of the 2PC files into memory would need to do. >> So skipping unnecessary fsyncs gave us x25 speed increase even on ssd (on hdd difference should be bigger). >> Pushing to list's head didn’t yield measurable results, but anyway seems to be conceptually better. That's in the logic of more recent segments getting priority as startup process reads the records sequentially, so it is definitely better. -- Michael
>> Speeding up recovery or failover activity via a faster promote is a >> desirable thing. So, maybe, we should look at teaching the relevant >> code about using "KnownPreparedList"? I know that would increase the >> size of this patch and would mean more testing, but this seems to be >> last remaining optimization in this code path. > > That's a good idea, worth having in this patch. Actually we may not > want to call KnownPreparedRecreateFiles() here as promotion is not > synonym of end-of-recovery checkpoint for a couple of releases now. > Once implemented, a good way to performance test this could be to set checkpoint_timeout to a a large value like an hour. Then, generate enough 2PC WAL while ensuring that a checkpoint does not happen automatically or otherwise. We could then measure the time taken to recover on startup to see the efficacy. > Most of the 2PC syncs just won't happen, such transactions normally > don't last long, and the number you would get during a checkpoint is > largely lower than what would happen between two checkpoints. When > working on Postgres-XC, the number of 2PC was really more funky. > Yes, postgres-xl is full of 2PC, so hopefully this optimization should help a lot in that case as well. Regards, Nikhils -- Nikhil Sontakke http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
> On 24 Jan 2017, at 09:42, Michael Paquier <michael.paquier@gmail.com> wrote: > > On Mon, Jan 23, 2017 at 9:00 PM, Nikhil Sontakke > <nikhils@2ndquadrant.com> wrote: >> Speeding up recovery or failover activity via a faster promote is a >> desirable thing. So, maybe, we should look at teaching the relevant >> code about using "KnownPreparedList"? I know that would increase the >> size of this patch and would mean more testing, but this seems to be >> last remaining optimization in this code path. > > That's a good idea, worth having in this patch. Actually we may not > want to call KnownPreparedRecreateFiles() here as promotion is not > synonym of end-of-recovery checkpoint for a couple of releases now. Thanks for review, Nikhil and Michael. I don’t follow here. We are moving data away from WAL to files on checkpoint because after checkpoint there is no guaranty that WAL segment with our prepared tx will be still available. > The difference between those two is likely noise. > > By the way, in those measurements, the OS cache is still filled with > the past WAL segments, which is a rather best case, no? What happens > if you do the same kind of tests on a box where memory is busy doing > something else and replayed WAL segments get evicted from the OS cache > more aggressively once the startup process switches to a new segment? > This could be tested for example on a VM with few memory (say 386MB or > less) so as the startup process needs to access again the past WAL > segments to recover the 2PC information it needs to get them back > directly from disk... One trick that you could use here would be to > tweak the startup process so as it drops the OS cache once a segment > is finished replaying, and see the effects of an aggressive OS cache > eviction. This patch is showing really nice improvements with the OS > cache backing up the data, still it would make sense to test things > with a worse test case and see if things could be done better. The > startup process now only reads records sequentially, not randomly > which is a concept that this patch introduces. > > Anyway, perhaps this does not matter much, the non-recovery code path > does the same thing as this patch, and the improvement is too much to > be ignored. So for consistency's sake we could go with the approach > proposed which has the advantage to not put any restriction on the > size of the 2PC file contrary to what an implementation saving the > contents of the 2PC files into memory would need to do. Maybe i’m missing something, but I don’t see how OS cache can affect something here. Total WAL size was 0x44 * 16 = 1088 MB, recovery time is about 20s. Sequential reading 1GB of data is order of magnitude faster even on the old hdd, not speaking of ssd. Also you can take a look on flame graphs attached to previous message — majority of time during recovery spent in pg_qsort while replaying PageRepairFragmentation, while whole xact_redo_commit() takes about 1% of time. That amount can grow in case of uncached disk read but taking into account total recovery time this should not affect much. If you are talking about uncached access only during checkpoint than here we are restricted with max_prepared_transaction, so at max we will read about hundred of small files (usually fitting into one filesystem page)which will also be barely noticeable comparing to recovery time between checkpoints. Also wal segments cache eviction during replay doesn’t seems to me as standard scenario. Anyway i took the machine with hdd to slow down read speed and run tests again. During one of the runs i launched in parallel bash loop that was dropping os cache each second (while wal fragment replay takesalso about one second). 1.5M transactionsstart segment: 0x06last segment: 0x47 patched, with constant cache_drop: total recovery time: 86s patched, without constant cache_drop: total recovery time: 68s (while difference is significant, i bet that happens mostly because of database file segments should be re-read after cachedrop) master, without constant cache_drop: time to recover 35 segments: 2h 25m (after that i tired to wait) expected total recoverytime: 4.5 hours -- Stas Kelvich Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
> Thanks for review, Nikhil and Michael. > > I don’t follow here. We are moving data away from WAL to files on checkpoint because after checkpoint > there is no guaranty that WAL segment with our prepared tx will be still available. > We are talking about the recovery/promote code path. Specifically this call to KnownPreparedRecreateFiles() in PrescanPreparedTransactions(). We write the files to disk and they get immediately read up in the following code. We could not write the files to disk and read KnownPreparedList in the code path that follows as well as elsewhere. Regards, Nikhils >> The difference between those two is likely noise. >> >> By the way, in those measurements, the OS cache is still filled with >> the past WAL segments, which is a rather best case, no? What happens >> if you do the same kind of tests on a box where memory is busy doing >> something else and replayed WAL segments get evicted from the OS cache >> more aggressively once the startup process switches to a new segment? >> This could be tested for example on a VM with few memory (say 386MB or >> less) so as the startup process needs to access again the past WAL >> segments to recover the 2PC information it needs to get them back >> directly from disk... One trick that you could use here would be to >> tweak the startup process so as it drops the OS cache once a segment >> is finished replaying, and see the effects of an aggressive OS cache >> eviction. This patch is showing really nice improvements with the OS >> cache backing up the data, still it would make sense to test things >> with a worse test case and see if things could be done better. The >> startup process now only reads records sequentially, not randomly >> which is a concept that this patch introduces. >> >> Anyway, perhaps this does not matter much, the non-recovery code path >> does the same thing as this patch, and the improvement is too much to >> be ignored. So for consistency's sake we could go with the approach >> proposed which has the advantage to not put any restriction on the >> size of the 2PC file contrary to what an implementation saving the >> contents of the 2PC files into memory would need to do. > > Maybe i’m missing something, but I don’t see how OS cache can affect something here. > > Total WAL size was 0x44 * 16 = 1088 MB, recovery time is about 20s. Sequential reading 1GB of data > is order of magnitude faster even on the old hdd, not speaking of ssd. Also you can take a look on flame graphs > attached to previous message — majority of time during recovery spent in pg_qsort while replaying > PageRepairFragmentation, while whole xact_redo_commit() takes about 1% of time. That amount can > grow in case of uncached disk read but taking into account total recovery time this should not affect much. > > If you are talking about uncached access only during checkpoint than here we are restricted with > max_prepared_transaction, so at max we will read about hundred of small files (usually fitting into one filesystem page)which will also > be barely noticeable comparing to recovery time between checkpoints. Also wal segments cache eviction during > replay doesn’t seems to me as standard scenario. > > Anyway i took the machine with hdd to slow down read speed and run tests again. During one of the runs i > launched in parallel bash loop that was dropping os cache each second (while wal fragment replay takes > also about one second). > > 1.5M transactions > start segment: 0x06 > last segment: 0x47 > > patched, with constant cache_drop: > total recovery time: 86s > > patched, without constant cache_drop: > total recovery time: 68s > > (while difference is significant, i bet that happens mostly because of database file segments should be re-read after cachedrop) > > master, without constant cache_drop: > time to recover 35 segments: 2h 25m (after that i tired to wait) > expected total recovery time: 4.5 hours > > -- > Stas Kelvich > Postgres Professional: http://www.postgrespro.com > The Russian Postgres Company > > -- Nikhil Sontakke http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
> We are talking about the recovery/promote code path. Specifically this > call to KnownPreparedRecreateFiles() in PrescanPreparedTransactions(). > > We write the files to disk and they get immediately read up in the > following code. We could not write the files to disk and read > KnownPreparedList in the code path that follows as well as elsewhere. Thinking more on this. The only optimization that's really remaining is handling of prepared transactions that have not been committed or will linger around for long. The short lived 2PC transactions have been optimized already via this patch. The question remains whether saving off a few fsyncs/reads for these long-lived prepared transactions is worth the additional code churn. Even if we add code to go through the KnownPreparedList, we still will have to go through the other on-disk 2PC transactions anyways. So, maybe not. Regards, Nikhils > > Regards, > Nikhils > > >>> The difference between those two is likely noise. >>> >>> By the way, in those measurements, the OS cache is still filled with >>> the past WAL segments, which is a rather best case, no? What happens >>> if you do the same kind of tests on a box where memory is busy doing >>> something else and replayed WAL segments get evicted from the OS cache >>> more aggressively once the startup process switches to a new segment? >>> This could be tested for example on a VM with few memory (say 386MB or >>> less) so as the startup process needs to access again the past WAL >>> segments to recover the 2PC information it needs to get them back >>> directly from disk... One trick that you could use here would be to >>> tweak the startup process so as it drops the OS cache once a segment >>> is finished replaying, and see the effects of an aggressive OS cache >>> eviction. This patch is showing really nice improvements with the OS >>> cache backing up the data, still it would make sense to test things >>> with a worse test case and see if things could be done better. The >>> startup process now only reads records sequentially, not randomly >>> which is a concept that this patch introduces. >>> >>> Anyway, perhaps this does not matter much, the non-recovery code path >>> does the same thing as this patch, and the improvement is too much to >>> be ignored. So for consistency's sake we could go with the approach >>> proposed which has the advantage to not put any restriction on the >>> size of the 2PC file contrary to what an implementation saving the >>> contents of the 2PC files into memory would need to do. >> >> Maybe i’m missing something, but I don’t see how OS cache can affect something here. >> >> Total WAL size was 0x44 * 16 = 1088 MB, recovery time is about 20s. Sequential reading 1GB of data >> is order of magnitude faster even on the old hdd, not speaking of ssd. Also you can take a look on flame graphs >> attached to previous message — majority of time during recovery spent in pg_qsort while replaying >> PageRepairFragmentation, while whole xact_redo_commit() takes about 1% of time. That amount can >> grow in case of uncached disk read but taking into account total recovery time this should not affect much. >> >> If you are talking about uncached access only during checkpoint than here we are restricted with >> max_prepared_transaction, so at max we will read about hundred of small files (usually fitting into one filesystem page)which will also >> be barely noticeable comparing to recovery time between checkpoints. Also wal segments cache eviction during >> replay doesn’t seems to me as standard scenario. >> >> Anyway i took the machine with hdd to slow down read speed and run tests again. During one of the runs i >> launched in parallel bash loop that was dropping os cache each second (while wal fragment replay takes >> also about one second). >> >> 1.5M transactions >> start segment: 0x06 >> last segment: 0x47 >> >> patched, with constant cache_drop: >> total recovery time: 86s >> >> patched, without constant cache_drop: >> total recovery time: 68s >> >> (while difference is significant, i bet that happens mostly because of database file segments should be re-read aftercache drop) >> >> master, without constant cache_drop: >> time to recover 35 segments: 2h 25m (after that i tired to wait) >> expected total recovery time: 4.5 hours >> >> -- >> Stas Kelvich >> Postgres Professional: http://www.postgrespro.com >> The Russian Postgres Company >> >> > > > > -- > Nikhil Sontakke http://www.2ndQuadrant.com/ > PostgreSQL Development, 24x7 Support, Training & Services -- Nikhil Sontakke http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Jan 25, 2017 at 11:55 PM, Nikhil Sontakke
<nikhils@2ndquadrant.com> wrote:
>> We are talking about the recovery/promote code path. Specifically this
>> call to KnownPreparedRecreateFiles() in PrescanPreparedTransactions().
>>
>> We write the files to disk and they get immediately read up in the
>> following code. We could not write the files to disk and read
>> KnownPreparedList in the code path that follows as well as elsewhere.
>
> Thinking more on this.
>
> The only optimization that's really remaining is handling of prepared
> transactions that have not been committed or will linger around for
> long. The short lived 2PC transactions have been optimized already via
> this patch.
>
> The question remains whether saving off a few fsyncs/reads for these
> long-lived prepared transactions is worth the additional code churn.
> Even if we add code to go through the KnownPreparedList, we still will
> have to go through the other on-disk 2PC transactions anyways. So,
> maybe not.
We should really try to do things right now, or we'll never come back
to it. 9.3 (if my memory does not fail me?) has reduced the time to do
promotion by removing the need of the end-of-recovery checkpoint,
while I agree that there should not be that many 2PC transactions at
this point, if there are for a reason or another, the time it takes to
complete promotion would be impacted. So let's refactor
PrescanPreparedTransactions() so as it is able to handle 2PC data from
a buffer extracted by XlogReadTwoPhaseData(), and we are good to go.
--- a/src/backend/access/transam/xlog.c
+++ b/src/backend/access/transam/xlog.c
@@ -9573,6 +9573,15 @@ xlog_redo(XLogReaderState *record) (errmsg("unexpected timeline ID %u (should
be%u)
in checkpoint record", checkPoint.ThisTimeLineID, ThisTimeLineID)));
+
+ /*
+ * Move prepared transactions, if any, from KnownPreparedList to files.
+ * It is possible to skip this step and teach subsequent code about
+ * KnownPreparedList, but PrescanPreparedTransactions() happens once
+ * during end of recovery or on promote, so probably it isn't worth
+ * the additional code.
+ */
+ KnownPreparedRecreateFiles(checkPoint.redo); RecoveryRestartPoint(&checkPoint);
Looking again at this code, I think that this is incorrect. The
checkpointer should be in charge of doing this work and not the
startup process, so this should go into CheckpointTwoPhase() instead.
At the end, we should be able to just live without
KnownPreparedRecreateFiles() and just rip it off from the patch.
--
Michael
>> The question remains whether saving off a few fsyncs/reads for these >> long-lived prepared transactions is worth the additional code churn. >> Even if we add code to go through the KnownPreparedList, we still will >> have to go through the other on-disk 2PC transactions anyways. So, >> maybe not. > > We should really try to do things right now, or we'll never come back > to it. 9.3 (if my memory does not fail me?) has reduced the time to do > promotion by removing the need of the end-of-recovery checkpoint, > while I agree that there should not be that many 2PC transactions at > this point, if there are for a reason or another, the time it takes to > complete promotion would be impacted. So let's refactor > PrescanPreparedTransactions() so as it is able to handle 2PC data from > a buffer extracted by XlogReadTwoPhaseData(), and we are good to go. > Not quite. If we modify PrescanPreparedTransactions(), we also need to make RecoverPreparedTransactions() and StandbyRecoverPreparedTransactions() handle 2PC data via XlogReadTwoPhaseData(). > + /* > + * Move prepared transactions, if any, from KnownPreparedList to files. > + * It is possible to skip this step and teach subsequent code about > + * KnownPreparedList, but PrescanPreparedTransactions() happens once > + * during end of recovery or on promote, so probably it isn't worth > + * the additional code. > + */ This comment is misplaced. Does not make sense before this specific call. > + KnownPreparedRecreateFiles(checkPoint.redo); > RecoveryRestartPoint(&checkPoint); > Looking again at this code, I think that this is incorrect. The > checkpointer should be in charge of doing this work and not the > startup process, so this should go into CheckpointTwoPhase() instead. I don't see a function by the above name in the code? Regards, Nikhils -- Nikhil Sontakke http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Jan 26, 2017 at 1:38 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >> We should really try to do things right now, or we'll never come back >> to it. 9.3 (if my memory does not fail me?) has reduced the time to do >> promotion by removing the need of the end-of-recovery checkpoint, >> while I agree that there should not be that many 2PC transactions at >> this point, if there are for a reason or another, the time it takes to >> complete promotion would be impacted. So let's refactor >> PrescanPreparedTransactions() so as it is able to handle 2PC data from >> a buffer extracted by XlogReadTwoPhaseData(), and we are good to go. > > Not quite. If we modify PrescanPreparedTransactions(), we also need to > make RecoverPreparedTransactions() and > StandbyRecoverPreparedTransactions() handle 2PC data via > XlogReadTwoPhaseData(). Ah, right for both, even for RecoverPreparedTransactions() that happens at the end of recovery. Thanks for noticing. The patch mentions that as well: + * * At the end of recovery we move all known prepared transactions to disk. + * This allows RecoverPreparedTransactions() and + * StandbyRecoverPreparedTransactions() to do their work. I need some strong coffee.. >> + KnownPreparedRecreateFiles(checkPoint.redo); >> RecoveryRestartPoint(&checkPoint); >> Looking again at this code, I think that this is incorrect. The >> checkpointer should be in charge of doing this work and not the >> startup process, so this should go into CheckpointTwoPhase() instead. > > I don't see a function by the above name in the code? I look at this patch from you and that's present for me: https://www.postgresql.org/message-id/CAMGcDxf8Bn9ZPBBJZba9wiyQq-Qk5uqq=VjoMnRnW5s+fKST3w@mail.gmail.com If I look as well at the last version of Stas it is here: https://www.postgresql.org/message-id/BECC988A-DB74-48D5-B5D5-A54551A6242A@postgrespro.ru As this change: --- a/src/backend/access/transam/xlog.c +++ b/src/backend/access/transam/xlog.c @@ -9573,6 +9573,7 @@ xlog_redo(XLogReaderState *record) (errmsg("unexpected timeline ID %u (should be%u) in checkpoint record", checkPoint.ThisTimeLineID, ThisTimeLineID))); + KnownPreparedRecreateFiles(checkPoint.redo); RecoveryRestartPoint(&checkPoint); } And actually, when a XLOG_CHECKPOINT_SHUTDOWN record is taken, 2PC files are not flushed to disk with this patch. This is a problem as a new restart point is created... Having the flush in CheckpointTwoPhase really makes the most sense. -- Michael
>I look at this patch from you and that's present for me: >https://www.postgresql.org/message-id/CAMGcDxf8Bn9ZPBBJZba9wiyQq->Qk5uqq=VjoMnRnW5s+fKST3w@mail.gmail.com > --- a/src/backend/access/transam/xlog.c > +++ b/src/backend/access/transam/xlog.c > @@ -9573,6 +9573,7 @@ xlog_redo(XLogReaderState *record) > (errmsg("unexpected timeline ID %u (should be %u) > in checkpoint record", > checkPoint.ThisTimeLineID, ThisTimeLineID))); > > + KnownPreparedRecreateFiles(checkPoint.redo); > RecoveryRestartPoint(&checkPoint); > } Oh, sorry. I was asking about CheckpointTwoPhase(). I don't see a function by this name. And now I see, the name is CheckPointTwoPhase() :-) > And actually, when a XLOG_CHECKPOINT_SHUTDOWN record is taken, 2PC > files are not flushed to disk with this patch. This is a problem as a > new restart point is created... Having the flush in CheckpointTwoPhase > really makes the most sense. Umm, AFAICS, CheckPointTwoPhase() does not get called in the "standby promote" code path. Regards, Nikhils -- Nikhil Sontakke http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Jan 26, 2017 at 4:09 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >>I look at this patch from you and that's present for me: >>https://www.postgresql.org/message-id/CAMGcDxf8Bn9ZPBBJZba9wiyQq->Qk5uqq=VjoMnRnW5s+fKST3w@mail.gmail.com > >> --- a/src/backend/access/transam/xlog.c >> +++ b/src/backend/access/transam/xlog.c >> @@ -9573,6 +9573,7 @@ xlog_redo(XLogReaderState *record) >> (errmsg("unexpected timeline ID %u (should be %u) >> in checkpoint record", >> checkPoint.ThisTimeLineID, ThisTimeLineID))); >> >> + KnownPreparedRecreateFiles(checkPoint.redo); >> RecoveryRestartPoint(&checkPoint); >> } > > Oh, sorry. I was asking about CheckpointTwoPhase(). I don't see a > function by this name. And now I see, the name is CheckPointTwoPhase() > :-) My mistake then :D >> And actually, when a XLOG_CHECKPOINT_SHUTDOWN record is taken, 2PC >> files are not flushed to disk with this patch. This is a problem as a >> new restart point is created... Having the flush in CheckpointTwoPhase >> really makes the most sense. > > Umm, AFAICS, CheckPointTwoPhase() does not get called in the "standby > promote" code path. CreateRestartPoint() calls it via CheckPointGuts() while in recovery. -- Michael
> On 26 Jan 2017, at 10:34, Michael Paquier <michael.paquier@gmail.com> wrote: > > On Thu, Jan 26, 2017 at 4:09 PM, Nikhil Sontakke > <nikhils@2ndquadrant.com> wrote: >>> I look at this patch from you and that's present for me: >>> https://www.postgresql.org/message-id/CAMGcDxf8Bn9ZPBBJZba9wiyQq->Qk5uqq=VjoMnRnW5s+fKST3w@mail.gmail.com >> >>> --- a/src/backend/access/transam/xlog.c >>> +++ b/src/backend/access/transam/xlog.c >>> @@ -9573,6 +9573,7 @@ xlog_redo(XLogReaderState *record) >>> (errmsg("unexpected timeline ID %u (should be %u) >>> in checkpoint record", >>> checkPoint.ThisTimeLineID, ThisTimeLineID))); >>> >>> + KnownPreparedRecreateFiles(checkPoint.redo); >>> RecoveryRestartPoint(&checkPoint); >>> } >> >> Oh, sorry. I was asking about CheckpointTwoPhase(). I don't see a >> function by this name. And now I see, the name is CheckPointTwoPhase() >> :-) > > My mistake then :D > >>> And actually, when a XLOG_CHECKPOINT_SHUTDOWN record is taken, 2PC >>> files are not flushed to disk with this patch. This is a problem as a >>> new restart point is created... Having the flush in CheckpointTwoPhase >>> really makes the most sense. >> >> Umm, AFAICS, CheckPointTwoPhase() does not get called in the "standby >> promote" code path. > > CreateRestartPoint() calls it via CheckPointGuts() while in recovery. > Huh, glad that this tread received a lot of attention. > On 24 Jan 2017, at 17:26, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: > > We are talking about the recovery/promote code path. Specifically this > call to KnownPreparedRecreateFiles() in PrescanPreparedTransactions(). > > We write the files to disk and they get immediately read up in the > following code. We could not write the files to disk and read > KnownPreparedList in the code path that follows as well as elsewhere. Thanks Nikhil, now I got that. Since we are talking about promotion we are on different timescale and 1-10 second lag matters a lot. I think I have in my mind realistic scenario when proposed recovery code path will hit the worst case: Google cloud. They have quite fast storage, but fsync time is really big and can go up to 10-100ms (i suppose it is network-attacheble). Having say 300 prepared tx, we can delay promotion up to half minute. So i think it worth of examination. -- Stas Kelvich Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
>> Umm, AFAICS, CheckPointTwoPhase() does not get called in the "standby >> promote" code path. > > CreateRestartPoint() calls it via CheckPointGuts() while in recovery. May be that I am missing something. But, I put the recovery process and the checkpointer process of the standby under gdb with breakpoints on these functions, but both did not hit CreateRestartPoint() as well as CheckPointGuts() when I issued a promote :-| Regards, Nikhils -- Nikhil Sontakke http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Jan 26, 2017 at 5:02 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >>> Umm, AFAICS, CheckPointTwoPhase() does not get called in the "standby >>> promote" code path. >> >> CreateRestartPoint() calls it via CheckPointGuts() while in recovery. > > May be that I am missing something. > > But, I put the recovery process and the checkpointer process of the > standby under gdb with breakpoints on these functions, but both did > not hit CreateRestartPoint() as well as CheckPointGuts() when I issued > a promote :-| No end-of-recovery checkpoints happen at promotion since 9.3. You can still use fallback_promote as promote file to trigger the pre-9.2 (9.2 included) behavior. -- Michael
>> But, I put the recovery process and the checkpointer process of the >> standby under gdb with breakpoints on these functions, but both did >> not hit CreateRestartPoint() as well as CheckPointGuts() when I issued >> a promote :-| > > No end-of-recovery checkpoints happen at promotion since 9.3. You can > still use fallback_promote as promote file to trigger the pre-9.2 (9.2 > included) behavior. Ok, so that means, we also need to fsync out these 2PC XIDs at promote time as well for their durability. Regards, Nikhils -- Nikhil Sontakke http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 27 January 2017 at 09:59, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >>> But, I put the recovery process and the checkpointer process of the >>> standby under gdb with breakpoints on these functions, but both did >>> not hit CreateRestartPoint() as well as CheckPointGuts() when I issued >>> a promote :-| >> >> No end-of-recovery checkpoints happen at promotion since 9.3. You can >> still use fallback_promote as promote file to trigger the pre-9.2 (9.2 >> included) behavior. > > Ok, so that means, we also need to fsync out these 2PC XIDs at promote > time as well for their durability. Why? The data files haven't been fsynced either at that point. If there is a bug there it doesn't just affect 2PC. What sequence of actions would cause data loss? -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 27 January 2017 at 15:37, Simon Riggs <simon@2ndquadrant.com> wrote: > On 27 January 2017 at 09:59, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >>>> But, I put the recovery process and the checkpointer process of the >>>> standby under gdb with breakpoints on these functions, but both did >>>> not hit CreateRestartPoint() as well as CheckPointGuts() when I issued >>>> a promote :-| >>> >>> No end-of-recovery checkpoints happen at promotion since 9.3. You can >>> still use fallback_promote as promote file to trigger the pre-9.2 (9.2 >>> included) behavior. >> >> Ok, so that means, we also need to fsync out these 2PC XIDs at promote >> time as well for their durability. > > Why? The xact_redo code will add prepared transactions to the KnownPreparedList in memory. Earlier it used to create the on-disk 2PC file. At standby promote, the surviving (yet uncommitted) prepared transactions from KnownPreparedList need to be persisted, right? Regards, Nikhils
On 27 January 2017 at 11:01, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: > On 27 January 2017 at 15:37, Simon Riggs <simon@2ndquadrant.com> wrote: >> On 27 January 2017 at 09:59, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >>>>> But, I put the recovery process and the checkpointer process of the >>>>> standby under gdb with breakpoints on these functions, but both did >>>>> not hit CreateRestartPoint() as well as CheckPointGuts() when I issued >>>>> a promote :-| >>>> >>>> No end-of-recovery checkpoints happen at promotion since 9.3. You can >>>> still use fallback_promote as promote file to trigger the pre-9.2 (9.2 >>>> included) behavior. >>> >>> Ok, so that means, we also need to fsync out these 2PC XIDs at promote >>> time as well for their durability. >> >> Why? > > The xact_redo code will add prepared transactions to the > KnownPreparedList in memory. Earlier it used to create the on-disk 2PC > file. > > At standby promote, the surviving (yet uncommitted) prepared > transactions from KnownPreparedList need to be persisted, right? I don't see why, so please explain or show the error that can be caused if we don't. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jan 27, 2017 at 8:23 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > On 27 January 2017 at 11:01, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >> The xact_redo code will add prepared transactions to the >> KnownPreparedList in memory. Earlier it used to create the on-disk 2PC >> file. >> >> At standby promote, the surviving (yet uncommitted) prepared >> transactions from KnownPreparedList need to be persisted, right? > > I don't see why, so please explain or show the error that can be > caused if we don't. I agree with Simon here. There is no point to fsync the 2PC files are in case of an immediate crash after promotion replay will happen from the last checkpoint, aka the one before the promotion has been triggered. So there is no point to flush them at promotion, they would be replayed anyway. -- Michael
>>> The xact_redo code will add prepared transactions to the >>> KnownPreparedList in memory. Earlier it used to create the on-disk 2PC >>> file. >>> >>> At standby promote, the surviving (yet uncommitted) prepared >>> transactions from KnownPreparedList need to be persisted, right? >> >> I don't see why, so please explain or show the error that can be >> caused if we don't. > > I agree with Simon here. There is no point to fsync the 2PC files are > in case of an immediate crash after promotion replay will happen from > the last checkpoint, aka the one before the promotion has been > triggered. So there is no point to flush them at promotion, they would > be replayed anyway. 1) start master 2) start streaming replica 3) on master begin; create table test1(g int); prepare transaction 'test'; 4) Promote standby via trigger file or via "pg_ctl promote" I thought if we don't fsync the KnownPreparedList then we might not create the 2PC state properly on the standby. However, I do realize that we will be calling RecoverPreparedTransactions() eventually on promote. This function will be modified to go through the KnownPreparedList to reload shmem appropriately for 2PC. So, all good in that case. Apologies for the digression. Regards, Nikhils -- Nikhil Sontakke http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
> --- a/src/backend/access/transam/xlog.c
> +++ b/src/backend/access/transam/xlog.c
> @@ -9573,6 +9573,7 @@ xlog_redo(XLogReaderState *record)
> (errmsg("unexpected timeline ID %u (should be %u)
> in checkpoint record",
> checkPoint.ThisTimeLineID, ThisTimeLineID)));
>
> + KnownPreparedRecreateFiles(checkPoint.redo);
> RecoveryRestartPoint(&checkPoint);
> }
> And actually, when a XLOG_CHECKPOINT_SHUTDOWN record is taken, 2PC
> files are not flushed to disk with this patch. This is a problem as a
> new restart point is created... Having the flush in CheckpointTwoPhase
> really makes the most sense.
Having CheckPointTwoPhase() do the flush would mean shifting the data
from KnownPreparedList into TwoPhaseState shmem.
I wonder what's the best location for this in the common case when we
do shutdown of standby. We could add code in XLOG_CHECKPOINT_SHUTDOWN
and XLOG_CHECKPOINT_ONLINE xlog_redo code path.
Regards,
Nikhils
-- Nikhil Sontakke http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training &
Services
On Tue, Jan 31, 2017 at 3:45 AM, Nikhil Sontakke
<nikhils@2ndquadrant.com> wrote:
>> --- a/src/backend/access/transam/xlog.c
>> +++ b/src/backend/access/transam/xlog.c
>> @@ -9573,6 +9573,7 @@ xlog_redo(XLogReaderState *record)
>> (errmsg("unexpected timeline ID %u (should be %u)
>> in checkpoint record",
>> checkPoint.ThisTimeLineID, ThisTimeLineID)));
>>
>> + KnownPreparedRecreateFiles(checkPoint.redo);
>> RecoveryRestartPoint(&checkPoint);
>> }
>> And actually, when a XLOG_CHECKPOINT_SHUTDOWN record is taken, 2PC
>> files are not flushed to disk with this patch. This is a problem as a
>> new restart point is created... Having the flush in CheckpointTwoPhase
>> really makes the most sense.
>
> Having CheckPointTwoPhase() do the flush would mean shifting the data
> from KnownPreparedList into TwoPhaseState shmem.
Er, no. For CheckPointTwoPhase(), at recovery what needs to be done is
to have all the entries in KnownPreparedList() flushed to disk and
have those entries removed while holding a shared memory lock. And for
the rest we need to be careful to have PrescanPreparedTransactions,
RecoverPreparedTransactions and StandbyRecoverPreparedTransactions
aware of entries that are in KnownPreparedList(). Let's leave the
business of putting the information from KnownPreparedList to
TwoPhaseState in RecoverPreparedTransactions, which need to be aware
of entries in KnownPreparedList() anyway. The only thing that differs
is how the 2PC information is fetched: from the segments or from the
files in pg_twophase.
> I wonder what's the best location for this in the common case when we
> do shutdown of standby. We could add code in XLOG_CHECKPOINT_SHUTDOWN
> and XLOG_CHECKPOINT_ONLINE xlog_redo code path.
ShutdownXLOG() calls CreateRestartPoint() when a standby shuts down,
so doing all the durability work in CheckPointTwoPhase() would take
care of any problems.
(moving patch to CF 2017-03)
--
Michael
>> Having CheckPointTwoPhase() do the flush would mean shifting the data >> from KnownPreparedList into TwoPhaseState shmem. > > Er, no. For CheckPointTwoPhase(), at recovery what needs to be done is > to have all the entries in KnownPreparedList() flushed to disk and > have those entries removed while holding a shared memory lock. The KnownPreparedList is constructed by the recovery process. CheckPointTwoPhase() gets called by the checkpointer process. The checkpointer does not have access to this valid KnownPreparedList. >And for > the rest we need to be careful to have PrescanPreparedTransactions, > RecoverPreparedTransactions and StandbyRecoverPreparedTransactions > aware of entries that are in KnownPreparedList(). Yeah, that part is straightforward. It does involve duplication of the earlier while loops to work against KnownPreparedList. A smart single while loop which loops over the 2PC files followed by the list would help here :-) > Let's leave the > business of putting the information from KnownPreparedList to > TwoPhaseState in RecoverPreparedTransactions, which need to be aware > of entries in KnownPreparedList() anyway. The only thing that differs > is how the 2PC information is fetched: from the segments or from the > files in pg_twophase. > Yeah. This part is also ok. We also got to be careful to mark the shmem gxact entry with "ondisk = false" and need to set prepare_start_lsn/prepare_end_lsn properly as well. >> I wonder what's the best location for this in the common case when we >> do shutdown of standby. We could add code in XLOG_CHECKPOINT_SHUTDOWN >> and XLOG_CHECKPOINT_ONLINE xlog_redo code path. > > ShutdownXLOG() calls CreateRestartPoint() when a standby shuts down, > so doing all the durability work in CheckPointTwoPhase() would take > care of any problems. > ShutdownXLOG() gets called from the checkpointer process. See comments above about the checkpointer not having access to the proper KnownPreparedList. The following test sequence will trigger the issue: 1) start master 2) start replica 3) prepare a transaction on master 4) shutdown master 5) shutdown replica CheckPointTwoPhase() in (5) does not sync this prepared transaction because the checkpointer's KnownPreparedList is empty. Regards, Nikhils -- Nikhil Sontakke http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Jan 31, 2017 at 2:34 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >>> I wonder what's the best location for this in the common case when we >>> do shutdown of standby. We could add code in XLOG_CHECKPOINT_SHUTDOWN >>> and XLOG_CHECKPOINT_ONLINE xlog_redo code path. >> >> ShutdownXLOG() calls CreateRestartPoint() when a standby shuts down, >> so doing all the durability work in CheckPointTwoPhase() would take >> care of any problems. >> > > ShutdownXLOG() gets called from the checkpointer process. See comments > above about the checkpointer not having access to the proper > KnownPreparedList. > > The following test sequence will trigger the issue: > > 1) start master > 2) start replica > 3) prepare a transaction on master > 4) shutdown master > 5) shutdown replica > > CheckPointTwoPhase() in (5) does not sync this prepared transaction > because the checkpointer's KnownPreparedList is empty. And that's why this needs to be stored in shared memory with a number of elements made of max_prepared_xacts... -- Michael
>> CheckPointTwoPhase() in (5) does not sync this prepared transaction >> because the checkpointer's KnownPreparedList is empty. > > And that's why this needs to be stored in shared memory with a number > of elements made of max_prepared_xacts... Yeah. Was thinking about this yesterday. How about adding entries in TwoPhaseState itself (which become valid later)? Only if it does not cause a lot of code churn. The current non-shmem list patch only needs to handle standby shutdowns correctly. Other aspects like standby promotion/recovery are handled ok AFAICS. Regards, Nikhils -- Nikhil Sontakke http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Jan 31, 2017 at 2:58 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >>> CheckPointTwoPhase() in (5) does not sync this prepared transaction >>> because the checkpointer's KnownPreparedList is empty. >> >> And that's why this needs to be stored in shared memory with a number >> of elements made of max_prepared_xacts... > > Yeah. Was thinking about this yesterday. How about adding entries in > TwoPhaseState itself (which become valid later)? Only if it does not > cause a lot of code churn. That's possible as well, yes. -- Michael
On Mon, Jan 23, 2017 at 7:00 AM, Nikhil Sontakke
<nikhils@2ndquadrant.com> wrote:
> 4) Minor nit-pick on existing code.
>
> (errmsg_plural("%u two-phase state file was written "
> "for
> long-running prepared transactions",
> "%u
> two-phase state files were written "
> "for
> long-running prepared transactions",
> serialized_xacts,
> serialized_xacts)
>
> Shouldn’t the singular part of the message above be:
> "%u two-phase state file was written for a long-running prepared transaction"
>
> But, then, English is not my native language, so I might be off here :-)
If there's one file per long-running prepared transaction, which I
think is true, then I agree with you.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
>> Shouldn’t the singular part of the message above be: >> "%u two-phase state file was written for a long-running prepared transaction" >> >> But, then, English is not my native language, so I might be off here :-) > > If there's one file per long-running prepared transaction, which I > think is true, then I agree with you. PFA, small patch to fix this, then. Regards, Nikhils -- Nikhil Sontakke http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
>> Yeah. Was thinking about this yesterday. How about adding entries in >> TwoPhaseState itself (which become valid later)? Only if it does not >> cause a lot of code churn. > > That's possible as well, yes. PFA a patch which does the above. It re-uses the TwoPhaseState gxact entries to track 2PC PREPARE/COMMIT in shared memory. The advantage being that CheckPointTwoPhase() becomes the only place where the fsync of 2PC files happens. A minor annoyance in the patch is the duplication of the code to add the 2nd while loop to go through these shared memory entries in PrescanPreparedTransactions, RecoverPreparedTransactions and StandbyRecoverPreparedTransactions. Other than this, I ran TAP tests and they succeed as needed. Regards, Nikhils -- Nikhil Sontakke http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Wed, Feb 1, 2017 at 3:29 AM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >>> Shouldn’t the singular part of the message above be: >>> "%u two-phase state file was written for a long-running prepared transaction" >>> >>> But, then, English is not my native language, so I might be off here :-) >> >> If there's one file per long-running prepared transaction, which I >> think is true, then I agree with you. > > PFA, small patch to fix this, then. Committed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
I have pushed the TAP test file, which is already passing, at least for me. Let's see what the buildfarm says. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Feb 22, 2017 at 7:03 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > I have pushed the TAP test file, which is already passing, at least for > me. Let's see what the buildfarm says. Thanks. I still have on my sheet to look at the latest 2PC patch. -- Michael
On Thu, Feb 2, 2017 at 3:07 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote:
>>> Yeah. Was thinking about this yesterday. How about adding entries in
>>> TwoPhaseState itself (which become valid later)? Only if it does not
>>> cause a lot of code churn.
>>
>> That's possible as well, yes.
>
> PFA a patch which does the above. It re-uses the TwoPhaseState gxact
> entries to track 2PC PREPARE/COMMIT in shared memory. The advantage
> being that CheckPointTwoPhase() becomes the only place where the fsync
> of 2PC files happens.
>
> A minor annoyance in the patch is the duplication of the code to add
> the 2nd while loop to go through these shared memory entries in
> PrescanPreparedTransactions, RecoverPreparedTransactions and
> StandbyRecoverPreparedTransactions.
>
> Other than this, I ran TAP tests and they succeed as needed.
Thanks for the new patch. Finally I am looking at it... The regression
tests already committed are all able to pass.
twophase.c: In function ‘PrepareRedoAdd’:
twophase.c:2539:20: warning: variable ‘gxact’ set but not used
[-Wunused-but-set-variable] GlobalTransaction gxact;
There is a warning at compilation.
The comment at the top of PrescanPreparedTransactions() needs to be
updated. Not only does this routine look for the contents of
pg_twophase, but it does also look at the shared memory contents, at
least those ones marked with inredo and not on_disk.
+ ereport(WARNING,
+ (errmsg("removing future two-phase state data from
memory \"%u\"",
+ xid)));
+ PrepareRedoRemove(xid);
+ continue
Those are not normal (partially because unlink is atomic, but not
durable)... But they match the correct coding pattern regarding
incorrect 2PC entries... I'd really like to see those switched to a
FATAL with unlink() made durable for those calls.
+ /* Deconstruct header */
+ hdr = (TwoPhaseFileHeader *) buf;
+ Assert(TransactionIdEquals(hdr->xid, xid));
+
+ if (TransactionIdPrecedes(xid, result))
+ result = xid;
This portion is repeated three times and could be easily refactored.
You could just have a routine that returns the oldes transaction ID
used, and ignore the result for StandbyRecoverPreparedTransactions()
by casting a (void) to let any kind of static analyzer understand that
we don't care about the result for example. Handling for subxids is
necessary as well depending on the code path. Spliting things into a
could of sub-routines may be more readable as well. There are really a
couple of small parts that can be gathered and strengthened.
+ /*
+ * Recreate its GXACT and dummy PGPROC
+ */
+ gxactnew = MarkAsPreparing(xid, gid,
+ hdr->prepared_at,
+ hdr->owner, hdr->database,
+ gxact->prepare_start_lsn,
+ gxact->prepare_end_lsn);
MarkAsPreparing() does not need to be extended with two new arguments.
RecoverPreparedTransactions() is used only at the end of recovery,
where it is not necessary to look at the 2PC state files from the
records. In this code path inredo is also set to false :)
+ {
+ /*
+ * Entry could be on disk. Call with giveWarning=false
+ * since it can be expected during replay.
+ */
+ RemoveTwoPhaseFile(xid, false);
+ }
This would be removed at the end of recovery anyway as a stale entry,
so that's not necessary.
+ /* Delete TwoPhaseState gxact entry and/or 2PC file. */
+ PrepareRedoRemove(parsed.twophase_xid);
Both things should not be present, no? If the file is pushed to disk
it means that the checkpoint horizon has already moved.
- ereport(ERROR,
+ /* It's ok to find an entry in the redo/recovery case */
+ if (!gxact->inredo)
+ ereport(ERROR, (errcode(ERRCODE_DUPLICATE_OBJECT),
errmsg("transactionidentifier \"%s\" is already in use", gid)));
+ else
+ {
+ found = true;
+ break;
+ }
I would not have thought so.
MarkAsPreparing and MarkAsPreparingInRedo really share the same code.
What if the setup of the dummy PGPROC entry is made conditional?
--
Michael
Hi Michael,
Thanks for taking a look at the patch.
twophase.c: In function ‘PrepareRedoAdd’:
twophase.c:2539:20: warning: variable ‘gxact’ set but not used
[-Wunused-but-set-variable]
GlobalTransaction gxact;
There is a warning at compilation.
Will fix.
The comment at the top of PrescanPreparedTransactions() needs to be
updated. Not only does this routine look for the contents of
pg_twophase, but it does also look at the shared memory contents, at
least those ones marked with inredo and not on_disk.
Oh yes. Will change comments at top of StandbyRecoverPreparedTransactions(), RecoverPreparedTransactions() as well.
+ ereport(WARNING,
+ (errmsg("removing future two-phase state data from
memory \"%u\"",
+ xid)));
+ PrepareRedoRemove(xid);
+ continue
Those are not normal (partially because unlink is atomic, but not
durable)... But they match the correct coding pattern regarding
incorrect 2PC entries... I'd really like to see those switched to a
FATAL with unlink() made durable for those calls.
Hmm, not sure what exactly we need to do here. If you look at the prior checks, there we already skip on-disk entries. So, typically, the entries that we encounter here will be in shmem only.
+ /* Deconstruct header */
+ hdr = (TwoPhaseFileHeader *) buf;
+ Assert(TransactionIdEquals(hdr->xid, xid));
+
+ if (TransactionIdPrecedes(xid, result))
+ result = xid;
This portion is repeated three times and could be easily refactored.
You could just have a routine that returns the oldes transaction ID
used, and ignore the result for StandbyRecoverPreparedTransactions()
by casting a (void) to let any kind of static analyzer understand that
we don't care about the result for example. Handling for subxids is
necessary as well depending on the code path. Spliting things into a
could of sub-routines may be more readable as well. There are really a
couple of small parts that can be gathered and strengthened.
I will see if we can reduce this to a couple of function calls.
+ /*
+ * Recreate its GXACT and dummy PGPROC
+ */
+ gxactnew = MarkAsPreparing(xid, gid,
+ hdr->prepared_at,
+ hdr->owner, hdr->database,
+ gxact->prepare_start_lsn,
+ gxact->prepare_end_lsn);
MarkAsPreparing() does not need to be extended with two new arguments.
RecoverPreparedTransactions() is used only at the end of recovery,
where it is not necessary to look at the 2PC state files from the
records. In this code path inredo is also set to false :)
That's not true. We will have entries with inredo set at the end of recovery as well. Infact the MarkAsPreparing() call from RecoverPreparedTransactions() is the one which will remove these inredo entries and convert them into regular entries. We have optimized the recovery code path as well.
+ {
+ /*
+ * Entry could be on disk. Call with giveWarning=false
+ * since it can be expected during replay.
+ */
+ RemoveTwoPhaseFile(xid, false);
+ }
This would be removed at the end of recovery anyway as a stale entry,
so that's not necessary.
Ok, will remove this.
+ /* Delete TwoPhaseState gxact entry and/or 2PC file. */
+ PrepareRedoRemove(parsed.twophase_xid);
Both things should not be present, no? If the file is pushed to disk
it means that the checkpoint horizon has already moved.
PREPARE in redo, followed by a checkpoint, followed by a COMMIT/ROLLBACK. We can have both the bits set in this case.
- ereport(ERROR,
+ /* It's ok to find an entry in the redo/recovery case */
+ if (!gxact->inredo)
+ ereport(ERROR,
(errcode(ERRCODE_DUPLICATE_OBJECT),
errmsg("transaction identifier \"%s\" is already in use",
gid)));
+ else
+ {
+ found = true;
+ break;
+ }
I would not have thought so.
Since we are using the TwoPhaseState structure to track redo entries, at end of recovery, we will find existing entries. Please see my comments above for RecoverPreparedTransactions()
MarkAsPreparing and MarkAsPreparingInRedo really share the same code.
What if the setup of the dummy PGPROC entry is made conditional?
I thought it was cleaner this ways. We can definitely add a bunch of if-else in MarkAsPreparing() but it won't look pretty.
Regards,
Nikhils
-- Nikhil Sontakke http://www.2ndQuadrant.com/
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
Nikhil, On 2/27/17 12:19 AM, Nikhil Sontakke wrote: > Hi Michael, > > Thanks for taking a look at the patch. > > twophase.c: In function ‘PrepareRedoAdd’: > twophase.c:2539:20: warning: variable ‘gxact’ set but not used > [-Wunused-but-set-variable] > GlobalTransaction gxact; > There is a warning at compilation. > > Will fix. <...> Do you know when you will have a new patch ready? It would be great to get this thread closed out after 14 months and many commits. Thanks, -- -David david@pgmasters.net
Hi David and Michael,
It would be great to get this thread closed out after 14 months and many
commits.
PFA, latest patch which addresses Michael's comments.
twophase.c: In function ‘PrepareRedoAdd’:
twophase.c:2539:20: warning: variable ‘gxact’ set but not used
[-Wunused-but-set-variable]
GlobalTransaction gxact;
There is a warning at compilation.
Fixed.
The comment at the top of PrescanPreparedTransactions() needs to be
updated. Not only does this routine look for the contents of
pg_twophase, but it does also look at the shared memory contents, at
least those ones marked with inredo and not on_disk.
Changed comments at top of PrescanPreparedTransactions
+ ereport(WARNING,
+ (errmsg("removing future two-phase state data from
memory \"%u\"",
+ xid)));
+ PrepareRedoRemove(xid);
+ continue
Those are not normal (partially because unlink is atomic, but not
durable)... But they match the correct coding pattern regarding
incorrect 2PC entries... I'd really like to see those switched to a
FATAL with unlink() made durable for those calls.
Hmm, not sure what exactly we need to do here. If you look at the prior checks, there we already skip on-disk entries. So, typically, the entries that we encounter here will be in shmem only.
+ /* Deconstruct header */
+ hdr = (TwoPhaseFileHeader *) buf;
+ Assert(TransactionIdEquals(hdr->xid, xid));
+
+ if (TransactionIdPrecedes(xid, result))
+ result = xid;
This portion is repeated three times and could be easily refactored.
You could just have a routine that returns the oldes transaction ID
used, and ignore the result for StandbyRecoverPreparedTransactions()
by casting a (void) to let any kind of static analyzer understand that
we don't care about the result for example. Handling for subxids is
necessary as well depending on the code path. Spliting things into a
could of sub-routines may be more readable as well. There are really a
couple of small parts that can be gathered and strengthened.
Have added a new function to do this now. It reads either from disk or shared memory and produces error/log messages accordingly as well now.
+ /*
+ * Recreate its GXACT and dummy PGPROC
+ */
+ gxactnew = MarkAsPreparing(xid, gid,
+ hdr->prepared_at,
+ hdr->owner, hdr->database,
+ gxact->prepare_start_lsn,
+ gxact->prepare_end_lsn);
MarkAsPreparing() does not need to be extended with two new arguments.
RecoverPreparedTransactions() is used only at the end of recovery,
where it is not necessary to look at the 2PC state files from the
records. In this code path inredo is also set to false :)
That's not true. We will have entries with inredo set at the end of recovery as well. Infact the MarkAsPreparing() call from RecoverPreparedTransactio
+ /* Delete TwoPhaseState gxact entry and/or 2PC file. */
+ PrepareRedoRemove(parsed.twophase_xid);
Both things should not be present, no? If the file is pushed to disk
it means that the checkpoint horizon has already moved.
PREPARE in redo, followed by a checkpoint, followed by a COMMIT/ROLLBACK. We can have both the bits set in this case.
- ereport(ERROR,
+ /* It's ok to find an entry in the redo/recovery case */
+ if (!gxact->inredo)
+ ereport(ERROR,
(errcode(ERRCODE_DUPLICATE_OBJECT),
errmsg("transaction identifier \"%s\" is already in use",
gid)));
+ else
+ {
+ found = true;
+ break;
+ }
I would not have thought so.
Since we are using the TwoPhaseState structure to track redo entries, at end of recovery, we will find existing entries. Please see my comments above for RecoverPreparedTransactions()
MarkAsPreparing and MarkAsPreparingInRedo really share the same code.
What if the setup of the dummy PGPROC entry is made conditional?
I realized that MarkAsPreparingInRedo() does not need to do all the sanity checking since it's going to be invoked during redo and everything that comes in is kosher already. So its contents are much simplified in this latest patch.
Tests pass with this latest patch.
Regards,
Nikhils
Attachment
On Sat, Mar 11, 2017 at 7:26 PM, Nikhil Sontakke
<nikhils@2ndquadrant.com> wrote:
> Hi David and Michael,
>> It would be great to get this thread closed out after 14 months and many
>> commits.
>
> PFA, latest patch which addresses Michael's comments.
Thanks for the new version. Let's head toward a final patch.
>> + ereport(WARNING,
>> + (errmsg("removing future two-phase state data from
>> memory \"%u\"",
>> + xid)));
>> + PrepareRedoRemove(xid);
>> + continue
>> Those are not normal (partially because unlink is atomic, but not
>> durable)... But they match the correct coding pattern regarding
>> incorrect 2PC entries... I'd really like to see those switched to a
>> FATAL with unlink() made durable for those calls.
>
> Hmm, not sure what exactly we need to do here. If you look at the prior
> checks, there we already skip on-disk entries. So, typically, the entries
> that we encounter here will be in shmem only.
As long as we don't have an alternative to offer a durable unlink,
let's do nothing then. This is as well consistent with the other code
paths handling corrupted or incorrect 2PC entries.
>> + /* Deconstruct header */
>> + hdr = (TwoPhaseFileHeader *) buf;
>> + Assert(TransactionIdEquals(hdr->xid, xid));
>> +
>> + if (TransactionIdPrecedes(xid, result))
>> + result = xid;
>> This portion is repeated three times and could be easily refactored.
>> You could just have a routine that returns the oldes transaction ID
>> used, and ignore the result for StandbyRecoverPreparedTransactions()
>> by casting a (void) to let any kind of static analyzer understand that
>> we don't care about the result for example. Handling for subxids is
>> necessary as well depending on the code path. Spliting things into a
>> could of sub-routines may be more readable as well. There are really a
>> couple of small parts that can be gathered and strengthened.
>
> Have added a new function to do this now. It reads either from disk or
> shared memory and produces error/log messages accordingly as well now.
And that's ProcessTwoPhaseBufferAndReturn in the patch.
ProcessTwoPhaseBuffer may be a better name.
>> + /*
>> + * Recreate its GXACT and dummy PGPROC
>> + */
>> + gxactnew = MarkAsPreparing(xid, gid,
>> + hdr->prepared_at,
>> + hdr->owner, hdr->database,
>> + gxact->prepare_start_lsn,
>> + gxact->prepare_end_lsn);
>> MarkAsPreparing() does not need to be extended with two new arguments.
>> RecoverPreparedTransactions() is used only at the end of recovery,
>> where it is not necessary to look at the 2PC state files from the
>> records. In this code path inredo is also set to false :)
>
> That's not true. We will have entries with inredo set at the end of recovery
> as well. Infact the MarkAsPreparing() call from
> RecoverPreparedTransactions() is the one which will remove these inredo
> entries and convert them into regular entries. We have optimized the
> recovery code path as well.
>
>> + /* Delete TwoPhaseState gxact entry and/or 2PC file. */
>> + PrepareRedoRemove(parsed.twophase_xid);
>> Both things should not be present, no? If the file is pushed to disk
>> it means that the checkpoint horizon has already moved.
>>
> PREPARE in redo, followed by a checkpoint, followed by a COMMIT/ROLLBACK. We
> can have both the bits set in this case.
Oh, I see where our thoughts don't overlap. I actually thought that
the shared memory entry and the on-disk file cannot co-exist (or if
you want a file flushed at checkpoint should have its shmem entry
removed). But you are right and I am wrong. In order to have the error
handling done properly if the maximum amount of 2PC transactions is
reached. Still....
>> - ereport(ERROR,
>> + /* It's ok to find an entry in the redo/recovery case */
>> + if (!gxact->inredo)
>> + ereport(ERROR,
>> (errcode(ERRCODE_DUPLICATE_OBJECT),
>> errmsg("transaction identifier \"%s\" is already in
>> use",
>> gid)));
>> + else
>> + {
>> + found = true;
>> + break;
>> + }
>> I would not have thought so.
>
> Since we are using the TwoPhaseState structure to track redo entries, at end
> of recovery, we will find existing entries. Please see my comments above for
> RecoverPreparedTransactions()
This is absolutely not good, because it is a direct result of the
interactions of the first loop of RecoverPreparedTransaction() with
its second loop, and because MarkAsPreparing() can finished by being
called *twice* from the same transaction. I really think that this
portion should be removed and that RecoverPreparedTransactions()
should be more careful when scanning the entries in pg_twophase by
looking up at what exists as well in shared memory, instead of doing
that in MarkAsPreparing().
Here are some more comments:
+ /*
+ * Recreate its GXACT and dummy PGPROC
+ */
+ gxactnew = MarkAsPreparing(xid, gid,
+ hdr->prepared_at,
+ hdr->owner, hdr->database,
+ gxact->prepare_start_lsn,
+ gxact->prepare_end_lsn);
+
+ Assert(gxactnew == gxact);
Here it would be better to set ondisk to false. This makes the code
more consistent with the previous loop, and the intention clear.
The first loop of RecoverPreparedTransactions() has a lot in common
with its second loop. You may want to refactor a little bit more here.
+/*
+ * PrepareRedoRemove
+ *
+ * Remove the corresponding gxact entry from TwoPhaseState. Also
+ * remove the 2PC file.
+ */
This could be a bit more expanded. The removal of the 2PC does not
happen after removing the in-memory data, it would happen if the
in-memory data is not found.
+MarkAsPreparingInRedo(TransactionId xid, const char *gid,
+ TimestampTz prepared_at, Oid owner, Oid databaseid,
+ XLogRecPtr prepare_start_lsn, XLogRecPtr prepare_end_lsn)
+{
+ GlobalTransaction gxact;
+
+ LWLockAcquire(TwoPhaseStateLock, LW_EXCLUSIVE);
MarkAsPreparingInRedo is internal to twophase.c. There is no need to
expose it externally and it is just used in PrepareRedoAdd so you
could just group both.
bool valid; /* TRUE if PGPROC entry is in proc array */ bool ondisk; /* TRUE if
preparestate file is on disk */
+ bool inredo; /* TRUE if entry was added via xlog_redo */
We could have a set of flags here, that's the 3rd boolean of the
structure used for a status.
--
Michael
Thanks for the new version. Let's head toward a final patch.
:-)
> Have added a new function to do this now. It reads either from disk or
> shared memory and produces error/log messages accordingly as well now.
And that's ProcessTwoPhaseBufferAndReturn in the patch.
ProcessTwoPhaseBuffer may be a better name.
Renamed to ProcessTwoPhaseBuffer()
> Since we are using the TwoPhaseState structure to track redo entries, at end
> of recovery, we will find existing entries. Please see my comments above for
> RecoverPreparedTransactions()
This is absolutely not good, because it is a direct result of the
interactions of the first loop of RecoverPreparedTransaction() with
its second loop, and because MarkAsPreparing() can finished by being
called *twice* from the same transaction. I really think that this
portion should be removed and that RecoverPreparedTransactions()
should be more careful when scanning the entries in pg_twophase by
looking up at what exists as well in shared memory, instead of doing
that in MarkAsPreparing().
Ok. Modified MarkAsPreparing() to call a new MarkAsPreparingGuts() function. This function takes in a "gxact' and works on it.
RecoverPreparedTransaction() now calls a newly added RecoverFromTwoPhaseBuffer() function which checks if an entry already exists via redo and calls the MarkAsPreparingGuts() function by passing in that gxact. Otherwise the existing MarkAsPreparing() gets called.
Here are some more comments:
+ /*
+ * Recreate its GXACT and dummy PGPROC
+ */
+ gxactnew = MarkAsPreparing(xid, gid,
+ hdr->prepared_at,
+ hdr->owner, hdr->database,
+ gxact->prepare_start_lsn,
+ gxact->prepare_end_lsn);
+
+ Assert(gxactnew == gxact);
Here it would be better to set ondisk to false. This makes the code
more consistent with the previous loop, and the intention clear.
Done.
The first loop of RecoverPreparedTransactions() has a lot in common
with its second loop. You may want to refactor a little bit more here.
Done. Added the new function RecoverFromTwoPhaseBuffer() as mentioned above.
+/*
+ * PrepareRedoRemove
+ *
+ * Remove the corresponding gxact entry from TwoPhaseState. Also
+ * remove the 2PC file.
+ */
This could be a bit more expanded. The removal of the 2PC does not
happen after removing the in-memory data, it would happen if the
in-memory data is not found.
Done
+MarkAsPreparingInRedo(TransactionId xid, const char *gid,
+ TimestampTz prepared_at, Oid owner, Oid databaseid,
+ XLogRecPtr prepare_start_lsn, XLogRecPtr prepare_end_lsn)
+{
+ GlobalTransaction gxact;
+
+ LWLockAcquire(TwoPhaseStateLock, LW_EXCLUSIVE);
MarkAsPreparingInRedo is internal to twophase.c. There is no need to
expose it externally and it is just used in PrepareRedoAdd so you
could just group both.
Removed this MarkAsPreparingInRedo() function and inlined the code in PrepareRedoAdd().
bool valid; /* TRUE if PGPROC entry is in proc array */
bool ondisk; /* TRUE if prepare state file is on disk */
+ bool inredo; /* TRUE if entry was added via xlog_redo */
We could have a set of flags here, that's the 3rd boolean of the
structure used for a status.
This is more of a cleanup and does not need to be part of this patch. This can be a follow-on cleanup patch.
I also managed to do some perf testing.
Modified Stas' earlier scripts slightly:
\set naccounts 100000 * :scale
\set from_aid random(1, :naccounts)
\set to_aid random(1, :naccounts)
\set delta random(1, 100)
\set scale :scale+1
BEGIN;
UPDATE pgbench_accounts SET abalance = abalance - :delta WHERE aid = :from_aid;
UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :to_aid;
PREPARE TRANSACTION ':client_id.:scale';
COMMIT PREPARED ':client_id.:scale';
Created a base backup with scale factor 125 on an AWS t2.large instance. Set up archiving and did a 20 minute run with the above script saving the WALs in the archive.
Then used recovery.conf to point to this WAL location and used the base backup to recover.
With this patch applied: 20s
Without patch: Stopped measuring after 5 minutes ;-)
Regards,
Nikhils
--
Nikhil Sontakke http://www.2ndQuadrant.com/
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
Attachment
On Wed, Mar 15, 2017 at 4:48 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >> bool valid; /* TRUE if PGPROC entry is in proc array >> */ >> bool ondisk; /* TRUE if prepare state file is on disk >> */ >> + bool inredo; /* TRUE if entry was added via xlog_redo >> */ >> We could have a set of flags here, that's the 3rd boolean of the >> structure used for a status. > > This is more of a cleanup and does not need to be part of this patch. This > can be a follow-on cleanup patch. OK, that's fine for me. This patch is complicated enough anyway. After some time thinking about it, I have finally put my finger on what was itching me about this patch, and the answer is here: + * Replay of twophase records happens by the following rules: + * + * * On PREPARE redo we add the transaction to TwoPhaseState->prepXacts. + * We set gxact->inredo to true for such entries. + * + * * On Checkpoint we iterate through TwoPhaseState->prepXacts entries + * that have gxact->inredo set and are behind the redo_horizon. We + * save them to disk and also set gxact->ondisk to true. + * + * * On COMMIT/ABORT we delete the entry from TwoPhaseState->prepXacts. + * If gxact->ondisk is true, we delete the corresponding entry from + * the disk as well. + * + * * RecoverPreparedTransactions(), StandbyRecoverPreparedTransactions() + * and PrescanPreparedTransactions() have been modified to go through + * gxact->inredo entries that have not made to disk yet. It seems to me that there should be an initial scan of pg_twophase at the beginning of recovery, discarding on the way with a WARNING entries that are older than the checkpoint redo horizon. This should fill in shmem entries using something close to PrepareRedoAdd(), and mark those entries as inredo. Then, at the end of recovery, PrescanPreparedTransactions does not need to look at the entries in pg_twophase. And that's the case as well of RecoverPreparedTransaction(). I think that you could get the patch much simplified this way, as any 2PC data can be fetched directly from WAL segments and there is no need to rely on scans of pg_twophase, this is replaced by scans of entries in TwoPhaseState. > I also managed to do some perf testing. > > Modified Stas' earlier scripts slightly: > > \set naccounts 100000 * :scale > \set from_aid random(1, :naccounts) > \set to_aid random(1, :naccounts) > \set delta random(1, 100) > \set scale :scale+1 > BEGIN; > UPDATE pgbench_accounts SET abalance = abalance - :delta WHERE aid = > :from_aid; > UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = > :to_aid; > PREPARE TRANSACTION ':client_id.:scale'; > COMMIT PREPARED ':client_id.:scale'; > > Created a base backup with scale factor 125 on an AWS t2.large instance. Set > up archiving and did a 20 minute run with the above script saving the WALs > in the archive. > > Then used recovery.conf to point to this WAL location and used the base > backup to recover. > > With this patch applied: 20s > Without patch: Stopped measuring after 5 minutes ;-) And that's really nice. -- Michael
+ * * RecoverPreparedTransactions(), StandbyRecoverPreparedTransactions()
+ * and PrescanPreparedTransactions() have been modified to go throug
+ * gxact->inredo entries that have not made to disk yet.
It seems to me that there should be an initial scan of pg_twophase at
the beginning of recovery, discarding on the way with a WARNING
entries that are older than the checkpoint redo horizon. This should
fill in shmem entries using something close to PrepareRedoAdd(), and
mark those entries as inredo. Then, at the end of recovery,
PrescanPreparedTransactions does not need to look at the entries in
pg_twophase. And that's the case as well of
RecoverPreparedTransaction(). I think that you could get the patch
much simplified this way, as any 2PC data can be fetched directly from
WAL segments and there is no need to rely on scans of pg_twophase,
this is replaced by scans of entries in TwoPhaseState.
I don't think this will work. We cannot replace pg_twophase with shmem entries + WAL pointers. This is because we cannot expect to have WAL entries around for long running prepared queries which survive across checkpoints.
Regards,
Nikhils
On Thu, Mar 16, 2017 at 7:18 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >> + * * RecoverPreparedTransactions(), >> StandbyRecoverPreparedTransactions() >> + * and PrescanPreparedTransactions() have been modified to go >> throug >> + * gxact->inredo entries that have not made to disk yet. >> >> It seems to me that there should be an initial scan of pg_twophase at >> the beginning of recovery, discarding on the way with a WARNING >> entries that are older than the checkpoint redo horizon. This should >> fill in shmem entries using something close to PrepareRedoAdd(), and >> mark those entries as inredo. Then, at the end of recovery, >> PrescanPreparedTransactions does not need to look at the entries in >> pg_twophase. And that's the case as well of >> RecoverPreparedTransaction(). I think that you could get the patch >> much simplified this way, as any 2PC data can be fetched directly from >> WAL segments and there is no need to rely on scans of pg_twophase, >> this is replaced by scans of entries in TwoPhaseState. >> > > I don't think this will work. We cannot replace pg_twophase with shmem > entries + WAL pointers. This is because we cannot expect to have WAL entries > around for long running prepared queries which survive across checkpoints. But at the beginning of recovery, we can mark such entries with ondisk and inredo, in which case the WAL pointers stored in the shmem entries do not matter because the data is already on disk. -- Michael
On Thu, Mar 16, 2017 at 9:25 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Thu, Mar 16, 2017 at 7:18 PM, Nikhil Sontakke > <nikhils@2ndquadrant.com> wrote: >>> + * * RecoverPreparedTransactions(), >>> StandbyRecoverPreparedTransactions() >>> + * and PrescanPreparedTransactions() have been modified to go >>> throug >>> + * gxact->inredo entries that have not made to disk yet. >>> >>> It seems to me that there should be an initial scan of pg_twophase at >>> the beginning of recovery, discarding on the way with a WARNING >>> entries that are older than the checkpoint redo horizon. This should >>> fill in shmem entries using something close to PrepareRedoAdd(), and >>> mark those entries as inredo. Then, at the end of recovery, >>> PrescanPreparedTransactions does not need to look at the entries in >>> pg_twophase. And that's the case as well of >>> RecoverPreparedTransaction(). I think that you could get the patch >>> much simplified this way, as any 2PC data can be fetched directly from >>> WAL segments and there is no need to rely on scans of pg_twophase, >>> this is replaced by scans of entries in TwoPhaseState. >>> >> >> I don't think this will work. We cannot replace pg_twophase with shmem >> entries + WAL pointers. This is because we cannot expect to have WAL entries >> around for long running prepared queries which survive across checkpoints. > > But at the beginning of recovery, we can mark such entries with ondisk > and inredo, in which case the WAL pointers stored in the shmem entries > do not matter because the data is already on disk. Nikhil, do you mind if I try something like that? As we already know what is the first XID when beginning redo via ShmemVariableCache->nextXid it is possible to discard 2PC files that should not be here. What makes me worry is the control of the maximum number of entries in shared memory. If there are legit 2PC files that are flushed on disk at checkpoint, you would finish with potentially more 2PC transactions than what should be possible (even if updates of max_prepared_xacts are WAL-logged). -- Michael
Nikhil, do you mind if I try something like that? As we already know
what is the first XID when beginning redo via
ShmemVariableCache->nextXid it is possible to discard 2PC files that
should not be here.
Yeah, that is ok.
What makes me worry is the control of the maximum
number of entries in shared memory. If there are legit 2PC files that
are flushed on disk at checkpoint, you would finish with potentially
more 2PC transactions than what should be possible (even if updates of
max_prepared_xacts are WAL-logged).
The max_prepared_xacts number restricts the number of pending PREPARED transactions *across* the 2PC files and shmem inredo entries. We can never have more entries than this value.
Regards,
Nikhils
--
Nikhil Sontakke http://www.2ndQuadrant.com/
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
>
> I don't think this will work. We cannot replace pg_twophase with shmem
> entries + WAL pointers. This is because we cannot expect to have WAL entries
> around for long running prepared queries which survive across checkpoints.
But at the beginning of recovery, we can mark such entries with ondisk
and inredo, in which case the WAL pointers stored in the shmem entries
do not matter because the data is already on disk.
Ok, we can do that and then yes, RecoverPreparedTransaction() can just have one loop going through the shmem entries. BUT, we cannot ignore "inredo"+"ondisk" entries. For such entries, we will have to read and recover from the corresponding 2PC files.
Regards,
Nikhils
-- Nikhil Sontakke http://www.2ndQuadrant.com/
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
On Fri, Mar 17, 2017 at 4:42 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >> > >> > I don't think this will work. We cannot replace pg_twophase with shmem >> > entries + WAL pointers. This is because we cannot expect to have WAL >> > entries >> > around for long running prepared queries which survive across >> > checkpoints. >> >> But at the beginning of recovery, we can mark such entries with ondisk >> and inredo, in which case the WAL pointers stored in the shmem entries >> do not matter because the data is already on disk. > > Ok, we can do that and then yes, RecoverPreparedTransaction() can just have > one loop going through the shmem entries. BUT, we cannot ignore > "inredo"+"ondisk" entries. For such entries, we will have to read and > recover from the corresponding 2PC files. Yes. About other things I found... In CheckPointTwoPhase(), I am actually surprised that prepare_start_lsn and prepare_end_lsn are not reset to InvalidXLogRecPtr when a shmem entry is flushed to disk after ondisk is set to true, there is no need for them as the data does not need to be fetched from WAL segments so we had better be consistent (regression tests fail if I do that). And the two extra arguments in MarkAsPreparing() are really unnecessary, they get set all the time to InvalidXLogRecPtr. -- Michael
>
> Ok, we can do that and then yes, RecoverPreparedTransaction() can just have
> one loop going through the shmem entries. BUT, we cannot ignore
> "inredo"+"ondisk" entries. For such entries, we will have to read and
> recover from the corresponding 2PC files.
Yes. About other things I found... In CheckPointTwoPhase(), I am
actually surprised that prepare_start_lsn and prepare_end_lsn are not
reset to InvalidXLogRecPtr when a shmem entry is flushed to disk after
ondisk is set to true, there is no need for them as the data does not
need to be fetched from WAL segments so we had better be consistent
(regression tests fail if I do that). And the two extra arguments in
MarkAsPreparing() are really unnecessary, they get set all the time to
InvalidXLogRecPtr.
Micheal, it looks like you are working on a final version of this patch? I will wait to review it from my end, then.
Regards,
Nikhils
-- Nikhil Sontakke http://www.2ndQuadrant.com/
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
On Fri, Mar 17, 2017 at 5:00 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >> > >> > Ok, we can do that and then yes, RecoverPreparedTransaction() can just >> > have >> > one loop going through the shmem entries. BUT, we cannot ignore >> > "inredo"+"ondisk" entries. For such entries, we will have to read and >> > recover from the corresponding 2PC files. >> >> Yes. About other things I found... In CheckPointTwoPhase(), I am >> actually surprised that prepare_start_lsn and prepare_end_lsn are not >> reset to InvalidXLogRecPtr when a shmem entry is flushed to disk after >> ondisk is set to true, there is no need for them as the data does not >> need to be fetched from WAL segments so we had better be consistent >> (regression tests fail if I do that). And the two extra arguments in >> MarkAsPreparing() are really unnecessary, they get set all the time to >> InvalidXLogRecPtr. > > > Micheal, it looks like you are working on a final version of this patch? I > will wait to review it from my end, then. I have to admit that I am beginning to get drawn into it... -- Michael
On Fri, Mar 17, 2017 at 5:15 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Fri, Mar 17, 2017 at 5:00 PM, Nikhil Sontakke > <nikhils@2ndquadrant.com> wrote: >> Micheal, it looks like you are working on a final version of this patch? I >> will wait to review it from my end, then. > > I have to admit that I am beginning to get drawn into it... And here is what I got. I have found a couple of inconsistencies in the patch, roughly: - During recovery entries marked with ondisk = true should have their start and end LSN reset to InvalidXLogRecPtr. This was actually leading to some inconsistencies in MarkAsPreparing() for 2PC transactions staying around for more than 2 checkpoints. - RecoverPreparedTransactions(), StandbyRecoverPreparedTransactions() and PrescanPreparedTransactions() doing both a scan of pg_twophase and the shared memory entries was way too complicated. I have changed things so as only memory entries are scanned by those routines, but an initial scan of pg_twophase is done before recovery. - Some inconsistencies in the comments and some typos found on the way. - Simplification of some routines used in redo, as well as simplified the set of routines made available to users. Tests are passing for me, an extra lookup would be nice. -- Michael -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
Thanks Michael,
I was away for a bit. I will take a look at this patch and get back to you soon.
Regards,
Nikhils
On 22 March 2017 at 07:40, Michael Paquier <michael.paquier@gmail.com> wrote:
On Fri, Mar 17, 2017 at 5:15 PM, Michael Paquier
<michael.paquier@gmail.com> wrote:
> On Fri, Mar 17, 2017 at 5:00 PM, Nikhil Sontakke
> <nikhils@2ndquadrant.com> wrote:
>> Micheal, it looks like you are working on a final version of this patch? I
>> will wait to review it from my end, then.
>
> I have to admit that I am beginning to get drawn into it...
And here is what I got. I have found a couple of inconsistencies in
the patch, roughly:
- During recovery entries marked with ondisk = true should have their
start and end LSN reset to InvalidXLogRecPtr. This was actually
leading to some inconsistencies in MarkAsPreparing() for 2PC
transactions staying around for more than 2 checkpoints.
- RecoverPreparedTransactions(), StandbyRecoverPreparedTransactions()
and PrescanPreparedTransactions() doing both a scan of pg_twophase and
the shared memory entries was way too complicated. I have changed
things so as only memory entries are scanned by those routines, but an
initial scan of pg_twophase is done before recovery.
- Some inconsistencies in the comments and some typos found on the way.
- Simplification of some routines used in redo, as well as simplified
the set of routines made available to users.
Tests are passing for me, an extra lookup would be nice.
--
Michael
Nikhil Sontakke http://www.2ndQuadrant.com/
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
On Sun, Mar 26, 2017 at 4:50 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: > I was away for a bit. I will take a look at this patch and get back to you > soon. No problem. Thanks for your time! -- Michael
Hi Micheal,
"# testing connection parameter "target_session_attrs"
not ok 5 - connect to node master if mode "read-write" and master,standby_1 listed
# Failed test 'connect to node master if mode "read-write" and master,standby_1 listed'
# at t/001_stream_rep.pl line 93.
# got: ''
# expected: '1'
not ok 6 - connect to node master if mode "read-write" and standby_1,master listed
# Failed test 'connect to node master if mode "read-write" and standby_1,master listed'
# at t/001_stream_rep.pl line 93.
# got: ''
# expected: '1'
not ok 7 - connect to node master if mode "any" and master,standby_1 listed
# Failed test 'connect to node master if mode "any" and master,standby_1 listed'
# at t/001_stream_rep.pl line 93.
# got: ''
# expected: '1'
not ok 8 - connect to node standby_1 if mode "any" and standby_1,master listed"
The latest patch looks good. By now doing a single scan of shmem two phase data, we have removed the double loops in all the affected functions which is good.
My only question is if the added call to restoreTwoPhaseData() is good enough to handle all the 3 functions PrescanPreparedTransactions(), StandbyRecoverPreparedTransactions() and RecoverPreparedTransactions() appropriately? It looks as if it does, but we need to be doubly sure..
PFA, revised patch with a very minor typo fix and rebase against latest master. The test cases pass as needed.
Oh, btw, while running TAP tests, I got a few errors in unrelated tests.
"# testing connection parameter "target_session_attrs"
not ok 5 - connect to node master if mode "read-write" and master,standby_1 listed
# Failed test 'connect to node master if mode "read-write" and master,standby_1 listed'
# at t/001_stream_rep.pl line 93.
# got: ''
# expected: '1'
not ok 6 - connect to node master if mode "read-write" and standby_1,master listed
# Failed test 'connect to node master if mode "read-write" and standby_1,master listed'
# at t/001_stream_rep.pl line 93.
# got: ''
# expected: '1'
not ok 7 - connect to node master if mode "any" and master,standby_1 listed
# Failed test 'connect to node master if mode "any" and master,standby_1 listed'
# at t/001_stream_rep.pl line 93.
# got: ''
# expected: '1'
not ok 8 - connect to node standby_1 if mode "any" and standby_1,master listed"
Again, not related to this recovery code path, but not sure if others see this as well.
Regards,
Nikhils
On 27 March 2017 at 05:35, Michael Paquier <michael.paquier@gmail.com> wrote:
On Sun, Mar 26, 2017 at 4:50 PM, Nikhil Sontakke
<nikhils@2ndquadrant.com> wrote:
> I was away for a bit. I will take a look at this patch and get back to you
> soon.
No problem. Thanks for your time!
--
Michael
Nikhil Sontakke http://www.2ndQuadrant.com/
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
Attachment
Please ignore reports about errors in other tests. Seem spurious..
Regards,
Nikhils
On 28 March 2017 at 10:40, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote:
Hi Micheal,The latest patch looks good. By now doing a single scan of shmem two phase data, we have removed the double loops in all the affected functions which is good.My only question is if the added call to restoreTwoPhaseData() is good enough to handle all the 3 functionsPrescanPreparedTransactions(), StandbyRecoverPreparedTransact ions() and RecoverPreparedTransactions() appropriately? It looks as if it does, but we need to be doubly sure.. PFA, revised patch with a very minor typo fix and rebase against latest master. The test cases pass as needed.Oh, btw, while running TAP tests, I got a few errors in unrelated tests.
"# testing connection parameter "target_session_attrs"
not ok 5 - connect to node master if mode "read-write" and master,standby_1 listed
# Failed test 'connect to node master if mode "read-write" and master,standby_1 listed'
# at t/001_stream_rep.pl line 93.
# got: ''
# expected: '1'
not ok 6 - connect to node master if mode "read-write" and standby_1,master listed
# Failed test 'connect to node master if mode "read-write" and standby_1,master listed'
# at t/001_stream_rep.pl line 93.
# got: ''
# expected: '1'
not ok 7 - connect to node master if mode "any" and master,standby_1 listed
# Failed test 'connect to node master if mode "any" and master,standby_1 listed'
# at t/001_stream_rep.pl line 93.
# got: ''
# expected: '1'
not ok 8 - connect to node standby_1 if mode "any" and standby_1,master listed"Again, not related to this recovery code path, but not sure if others see this as well.Regards,Nikhils--On 27 March 2017 at 05:35, Michael Paquier <michael.paquier@gmail.com> wrote:On Sun, Mar 26, 2017 at 4:50 PM, Nikhil Sontakke
<nikhils@2ndquadrant.com> wrote:
> I was away for a bit. I will take a look at this patch and get back to you
> soon.
No problem. Thanks for your time!
--
MichaelNikhil Sontakke http://www.2ndQuadrant.com/
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
Nikhil Sontakke http://www.2ndQuadrant.com/
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
On Tue, Mar 28, 2017 at 2:10 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: > The latest patch looks good. By now doing a single scan of shmem two phase > data, we have removed the double loops in all the affected functions which > is good. Yup. > My only question is if the added call to restoreTwoPhaseData() is good > enough to handle all the 3 functions PrescanPreparedTransactions(), > StandbyRecoverPreparedTransactions() and RecoverPreparedTransactions() > appropriately? It looks as if it does, but we need to be doubly sure.. Yeah, I have spent a bit of time thinking about that. But as restoreTwoPhaseData() is basically what those other three routines do but at an earlier stage I cannot see a problem with it. I don't discard being in shortage of imagination of course. > PFA, revised patch with a very minor typo fix and rebase against latest > master. The test cases pass as needed. Thanks! > Oh, btw, while running TAP tests, I got a few errors in unrelated tests. > [...] > Again, not related to this recovery code path, but not sure if others see > this as well. Definitely not related to this patch, and I am unable to see anything like that. Even spurious errors merit attention, but even by running those tests multiple times daily I have not seen anything like that. That's mainly on OSX 10.11 though. I don't have anything else to say about this patch, so should we mark that as ready for committer? There are still a couple of days left until the end of the CF, and quite a lot has happened, so this could get on time into PG10. -- Michael
I don't have anything else to say about this patch, so should we mark
that as ready for committer? There are still a couple of days left
until the end of the CF, and quite a lot has happened, so this could
get on time into PG10.
Yes, let's mark it "ready for committer". This patch/feature has been a long journey! :)
Regards,
Nikhils
-- Nikhil Sontakke http://www.2ndQuadrant.com/
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
PostgreSQL/Postgres-XL Development, 24x7 Support, Training & Services
On Tue, Mar 28, 2017 at 3:08 PM, Nikhil Sontakke <nikhils@2ndquadrant.com> wrote: >> >> I don't have anything else to say about this patch, so should we mark >> that as ready for committer? There are still a couple of days left >> until the end of the CF, and quite a lot has happened, so this could >> get on time into PG10. > > > Yes, let's mark it "ready for committer". This patch/feature has been a long > journey! :) OK, done. I have just noticed that Simon has marked himself as a committer of this patch 24 hours ago. -- Michael
On Tue, Mar 28, 2017 at 3:10 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > OK, done. I have just noticed that Simon has marked himself as a > committer of this patch 24 hours ago. For the archive's sake, this has been committed as 728bd991. Thanks Simon! -- Michael