Thread: [HACKERS] GSoC 2017: Foreign Key Arrays
The Problem
Foreign Key Arrays were introduced by Marco Nenciarini[1], however, the proposed patch had some performance issues. Let's assume we have two tables, table B has a foreign key array that references table A, any change in table A (INSERT, UPDATE, DELETE) would trigger a referential integrity check on table B. The current implementation uses sequential scans to accomplish this. This limits the size of tables using Foreign Key Arrays to ~100 records which is not practical in real life applications.
The Proposed Solution
To achieve this, introducing a number of new operators is required. However, for the scope of the project, we will focus on the most basic case where the Primary Keys are of pseudo-type anyelement and the Foreign Keys are of pseudo-type anyarray, thus the main operator of concern will be @>(anyarray,anyelement).
Progress So Far
- Collected resources about GIN indexing
- http://www.sigaev.ru/gin/READM
E.txt - https://wiki.postgresql.org/wi
ki/GIN_generalization - src\backend\access\gin\README in the repo
- http://www.sigaev.ru/gin/READM
- Cloned the git repo found @ https://github.com/postgres/
postgres and identified the main two files I will be concerned with. (I know I may need to edit other files but these seem to where I will spend most of my summer) - src/backend/commands/
tablecmds.c - src/backend/utils/ri_triggers.
c
- src/backend/commands/
I am yet to identify the files concerned with the GIN opclass. <-- if anyone can help with this
- read a little about op classes
- explored the existing op classes in Postgres
I have attached the original proposal here.
Attachment
On Mon, May 22, 2017 at 7:51 PM, Mark Rofail <markm.rofail@gmail.com> wrote: > Cloned the git repo found @ https://github.com/postgres/postgres and > identified the main two files I will be concerned with. (I know I may need > to edit other files but these seem to where I will spend most of my summer) > > src/backend/commands/tablecmds.c > src/backend/utils/ri_triggers.c > > I am yet to identify the files concerned with the GIN opclass. <-- if anyone > can help with this There's not only one GIN opclass. You can get a list like this: select oid, * from pg_opclass where opcmethod = 2742; Actually, you probably want to look for GIN opfamilies: rhaas=# select oid, * from pg_opfamily where opfmethod = 2742;oid | opfmethod | opfname | opfnamespace | opfowner ------+-----------+----------------+--------------+----------2745 | 2742 | array_ops | 11 | 103659| 2742 | tsvector_ops | 11 | 104036 | 2742 | jsonb_ops | 11 | 104037| 2742 | jsonb_path_ops | 11 | 10 (4 rows) To see which SQL functions are used to implement a particular opfamily, use the OID from the previous step in a query like this: rhaas=# select prosrc from pg_amop, pg_operator, pg_proc where amopfamily = 2745 and amopopr = pg_operator.oid and oprcode = pg_proc.oid; prosrc ----------------array_eqarrayoverlaparraycontainsarraycontained (4 rows) Then, you can look for those in the source tree. You can also search for the associated support functions, e.g.: rhaas=# select distinct amprocnum, prosrc from pg_amproc, pg_proc where amprocfamily = 2745 and amproc = pg_proc.oid order by 1, 2;amprocnum | prosrc -----------+----------------------- 1 | bitcmp 1 | bpcharcmp 1 | btabstimecmp 1 | btboolcmp 1 | btcharcmp 1 | btfloat4cmp 1 | btfloat8cmp 1 | btint2cmp 1 | btint4cmp 1 | btint8cmp 1 | btnamecmp 1 | btoidcmp 1 | btoidvectorcmp 1 | btreltimecmp 1 | bttextcmp 1 | bttintervalcmp 1 | byteacmp 1 | cash_cmp 1 | date_cmp 1 | interval_cmp 1 | macaddr_cmp 1 | network_cmp 1 | numeric_cmp 1 | time_cmp 1 | timestamp_cmp 1| timetz_cmp 2 | ginarrayextract 3 | ginqueryarrayextract 4 | ginarrayconsistent 6 | ginarraytriconsistent (30 rows) You might want to read https://www.postgresql.org/docs/devel/static/xindex.html -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
rhaas=# select oid, * from pg_opfamily where opfmethod = 2742;
oid | opfmethod | opfname | opfnamespace | opfowner
------+-----------+----------------+--------------+--------- -
2745 | 2742 | array_ops | 11 | 10
3659 | 2742 | tsvector_ops | 11 | 10
4036 | 2742 | jsonb_ops | 11 | 10
4037 | 2742 | jsonb_path_ops | 11 | 10
(4 rows)
Best Regards,
Mark Rofail
rhaas=# select oid, * from pg_opfamily where opfmethod = 2742;
oid | opfmethod | opfname | opfnamespace | opfowner
------+-----------+----------------+--------------+--------- -
2745 | 2742 | array_ops | 11 | 10
3659 | 2742 | tsvector_ops | 11 | 10
4036 | 2742 | jsonb_ops | 11 | 10
4037 | 2742 | jsonb_path_ops | 11 | 10
(4 rows)I am particulary intrested in array_ops but I have failed in locating the code behind it. Where is it reflected in the source code
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
src/include/catalog/pg_amop.hsrc/include/catalog/pg_amproc.h src/include/catalog/pg_opclass.h src/include/catalog/pg_opfamily.h
I am going to post the steps I took to locate the procedure, the following is the trail of tables I followed.
pg_opfamily | pg_opfamily defines operator families. { opfmethod; /* index access method opfamily is for */ opfname; /* name of this opfamily */ opfnamespace; /* namespace of this opfamily */ opfowner; /* opfamily owner */ }
gin=# select oid, * from pg_opfamily where opfmethod = 2742; oid | opfmethod | opfname | opfnamespace | opfowner ------+-----------+----------- 2745 | 2742 | array_ops | 11 | 10 3659 | 2742 | tsvector_ops | 11 | 10 4036 | 2742 | jsonb_ops | 11 | 10 4037 | 2742 | jsonb_path_ops | 11 | 10 (4 rows)
|
pg_opclass | pg_opclass defines index access method operator classes. { gin=# select * from pg_opclass where opcfamily = 2745; opcmethod | opcname | opcnamespace | opcowner | opcfamily | opcintype | opcdefault | opckeytype -----------+-----------+------ 2742 | array_ops | 11 | 10 | 2745 | 2277 | t | 2283 (1 row)
|
pg_amproc | pg_amproc stores information about support procedures associated with access method operator families. { amprocfamily; /* the index opfamily this entry is for */ amproclefttype; /* procedure's left input data type */ amprocrighttype; /* procedure's right input data type */ amprocnum[1]; /* support procedure index */ amproc; /* OID of the proc */ } gin=# select * from pg_amproc where amprocfamily = 2745; amprocfamily | amproclefttype | amprocrighttype | amprocnum | amproc ------------------+----------- 2745 | 2277 | 2277 | 2 | pg_catalog.ginarrayextract 2745 | 2277 | 2277 | 3 | ginqueryarrayextract 2745 | 2277 | 2277 | 4 | ginarrayconsistent 2745 | 2277 | 2277 | 6 | ginarraytriconsistent (4 rows)
[1]amprocnum refers to this table |
pg_amop | pg_amop stores information about operators associated with access method operator families. { amopfamily; /* the index opfamily this entry is for */ amoplefttype; /* operator's left input data type */ amoprighttype; /* operator's right input data type */ amopstrategy; /* operator strategy number */ amoppurpose; /* is operator for 's'earch or 'o'rdering? */ amopopr; /* the operator's pg_operator OID */ amopmethod; /* the index access method this entry is for amopsortfamily; /* ordering opfamily OID, or 0 if search op }
=# select * from pg_amop where amopfamily = 2745; amopfamily | amoplefttype | amoprighttype | amopstrategy | amoppurpose | amopopr | amopmethod | amopsortfamily ------------+--------------+-- 2745 | 2277 | 2277 | 1 | s | 2750 | 2742 | 0 2745 | 2277 | 2277 | 2 | s | 2751 | 2742 | 0 2745 | 2277 | 2277 | 3 | s | 2752 | 2742 | 0 2745 | 2277 | 2277 | 4 | s | 1070 | 2742 | 0 (4 rows) |
I will need to add a record of my new operator to this table by appending this line to src/include/catalog/pg_amop.h
DATA(insert (2745 2277 2277 1 s 2750 2742 0 ));
This will result in the following entry
=# select * from pg_amop where amopfamily = 2745;
amopfamily | amoplefttype | amoprighttype | amopstrategy | amoppurpose | amopopr | amopmethod | amopsortfamily
------------+--------------+--
2745 | 2277 | 2283 | 1 | s | 2750 | 2742 | 0
this led me to pg_operator
pg_operator | pg_operator stores information about operators. {
postgres=# select * from pg_operator where oid = 2751; oprname | oprnamespace | oprowner | oprkind | oprcanmerge | oprcanhash | oprleft | oprright | oprresult | oprcom | oprnegate | oprcode | oprrest | oprjoin ---------+--------------+----- @> | 11 | 10 | b | f | f | 2277 | 2277 | 16 | 2752 | 0 | arraycontains | arraycontsel | arraycontjoinsel (1 row)
|
I will need to add a record of my new operator to this table by appending this line to src/include/catalog/pg_
However, as this is dependent on the procedure I have yet to create there are still uknown values
DATA(insert OID = <uniqueProcId> ( "@>" PGNSP PGUID b f f 2277 2283 16 2752 0 arraycontainselem ???? ???? ));
DESCR("contains");
#define OID_ARRAY_CONTAINS_OP <uniqueProcId>
This will lead to this entry
oprname | oprnamespace | oprowner | oprkind | oprcanmerge | oprcanhash | oprleft | oprright | oprresult | oprcom | oprnegate | oprcode | oprrest | oprjoin
---------+--------------+-----
@> | 11 | 10 | b | f | f | 2277 | 2283 | 16 | 2752 | 0 | arraycontainselem | ???? | ????
(1 row)
this led me to pg_proc
pg_proc | pg_proc stores information about functions (or procedures) { proname; /* procedure name */ pronamespace; /* OID of namespace containing this proc */ proowner; /* procedure owner */ prolang; /* OID of pg_language entry */ procost; /* estimated execution cost */ prorows; /* estimated # of rows out (if proretset) */ provariadic; /* element type of variadic array, or 0 */ protransform; /* transforms calls to it during planning */ proisagg; /* is it an aggregate? */ proiswindow; /* is it a window function? */ prosecdef; /* security definer */ proleakproof; /* is it a leak-proof function? */ proisstrict; /* strict with respect to NULLs? */ proretset; /* returns a set? */ provolatile; /* see PROVOLATILE_ categories below */ proparallel; /* see PROPARALLEL_ categories below */ pronargs; /* number of arguments */ pronargdefaults; /* number of arguments with defaults */ prorettype; /* OID of result type */ proargtypes; /* parameter types (excludes OUT params) */ proallargtypes[1]; /* all param types (NULL if IN only) */ proargmodes[1]; /* parameter modes (NULL if IN only) */ proargnames[1]; /* parameter names (NULL if no names) */ proargdefaults; /* list of expression trees for argument protrftypes[1]; /* types for which to apply transforms */ prosrc; /* procedure source text */ probin; /* secondary procedure info (can be NULL) */ proconfig[1]; /* procedure-local GUC settings */ proacl[1]; /* access permissions */ }
postgres=# select * from pg_proc where oid = 2748; proname | pronamespace | proowner | prolang | procost | prorows | provariadic | protransform | proisagg | proiswindow | prosecdef | proleakproof | proisstrict | proretset | provolatile | proparallel | pron args | pronargdefaults | prorettype | proargtypes | proallargtypes | proargmodes | proargnames | proargdefaults | protrftypes | prosrc | probin | proconfig | proacl ---------------+-------------- -----+-----------------+------ arraycontains | 11 | 10 | 12 | 1 | 0 | 0 | - | f | f | f | f | t | f | i | s | 2 | 0 | 16 | 2277 2277 | | | | | | arraycontains | | | (1 row) |
Datum
arraycontains(PG_FUNCTION_
{
AnyArrayType *array1 = PG_GETARG_ANY_ARRAY(0);
AnyArrayType *array2 = PG_GETARG_ANY_ARRAY(1);
Oid collation = PG_GET_COLLATION();
bool result;
result = array_contain_compare(array2, array1, collation, true,
&fcinfo->flinfo->fn_extra);
/* Avoid leaking memory when handed toasted input. */
AARR_FREE_IF_COPY(array1, 0);
AARR_FREE_IF_COPY(array2, 1);
PG_RETURN_BOOL(result);
}
Studying the syntax will help me produce a function that follows the postgres style rules.
• After finding the arraycontains function, I implemented
arraycontainselem that corresponds to the operator @<(anyarray,
anyelem)
◦ Please read the attached patch file to view my progress.
• In addition to src/backend/utils/adt/arrayfuncs.c where I
implemented arraycontainselem.
◦ I also edited pg_amop (src/include/catalog/pg_amop.h) since
it stores information about operators associated with access method
operator families.
+DATA(insert ( 2745 2277 2283 2 s 2753 2742 0 ));
{
2745: Oid amopfamily; (denotes gin array_ops)
277: Oid amoplefttype; (denotes anyaray)
2283: Oid amoprighttype; (denotes anyelem)
5: int16 amopstrategy; /* operator strategy number */ (denotes the new
startegy that is yet to be created)
's': char amoppurpose; (denotes 's' for search)
2753: Oid amopopr; (denotes the new operator Oid)
2742: Oid amopmethod;(denotes gin)
0: Oid amopsortfamily; (0 since search operator)
}
◦ And pg_operator (src/include/catalog/pg_operator.h) since it
stores information about operators.
+DATA(insert OID = 2753 ( "@>" PGNSP PGUID b f f 2277 2283 16 0 0
arraycontainselem 0 0 ));
{
"@>": NameData oprname; /* name of operator */
Oid oprnamespace; /* OID of namespace containing this oper */
Oid oprowner; /* operator owner */
'b': char oprkind; /* 'l', 'r', or 'b' */ (denotes infix)
'f': bool oprcanmerge; /* can be used in merge join? */
'f': bool oprcanhash; /* can be used in hash join? */
277: Oid oprleft; (denotes anyaray)
2283: Oid oprright; (denotes anyelem)
16: Oid oprresult; (denotes boolean)
0: Oid oprcom; /* OID of commutator oper, or 0 if none */ (needs to be
revisited)
0: Oid oprnegate; /* OID of negator oper, or 0 if none */ (needs to be
revisited)
arraycontainselem: regproc oprcode; /* OID of underlying function */
0: regproc oprrest; /* OID of restriction estimator, or 0 */
0: regproc oprjoin; /* OID of join estimator, or 0 */
}
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
I was idly following along in GSoC 2017: Foreign Key Arrays when I noticed this: =# select * from pg_amproc where amprocfamily = 2745;amprocfamily | amproclefttype | amprocrighttype | amprocnum | amproc --------------+----------------+-----------------+-----------+ 2745 | 2277 | 2277 | 2| pg_catalog.ginarrayextract 2745 | 2277 | 2277 | 3 | ginqueryarrayextract ... where only ginarrayextract is schema-qualified. It seems to be regproc's output procedure doing it: =# select 2743::regproc, 2774::regproc; regproc | regproc ----------------------------+----------------------pg_catalog.ginarrayextract | ginqueryarrayextract The manual says regproc "will display schema-qualified names on output if the object would not be found in the current search path without being qualified." Is regproc displaying the schema in this case because there are two overloaded flavors of ginarrayextract, though both are in pg_catalog? Could it be searching for the object by name, ignoring the argument signature, and just detecting that it hit one with a different OID first? -Chap
Chapman Flack <chap@anastigmatix.net> writes:
> The manual says regproc "will display schema-qualified names on output
> if the object would not be found in the current search path without
> being qualified."
That's less than the full truth :-(
> Is regproc displaying the schema in this case because there are two
> overloaded flavors of ginarrayextract, though both are in pg_catalog?
Yes, see the test in regprocout:
* Would this proc be found (uniquely!) by regprocin? If not, * qualify it.
Of course, in a situation like this, schema-qualification is not enough to
save the day; regprocin will still fail because the name is ambiguous.
You really need to use regprocedure not regproc if you want any guarantees
about the results.
(The fact that we have regproc at all is a bit of a historical accident,
caused by some limitations of the bootstrap mode.)
regards, tom lane
- added a record to pg_proc (src/include/catalog/pg_proc.h)
- modified opr_sanity regression check expected results
- implemented a low-level function called `array_contains_elem` as an equivalent to `array_contain_compare` but accepts anyelement instead of anyarray as the right operand. This is more efficient than constructing an array and then immediately deconstructing it.
- I'd like to check that anyelem and anyarray have the same element type. but anyelem is obtained from PG_FUNCTION_ARGS as a Datum. How can I make such a check?
Mark Rofail
Attachment
Questions:
- I'd like to check that anyelem and anyarray have the same element type. but anyelem is obtained from PG_FUNCTION_ARGS as a Datum. How can I make such a check?
Updates:
- The operator @>(anyarray, anyelement) is now functional
- The segmentation fault was due to applying PG_FREE_IF_COPY on a datum when it should only be applied on TOASTed inputs
- The only problem now is if for example you apply the operator as follows '{AAAAAAAAAA646'}' @> 'AAAAAAAAAA646' it maps to @>(anyarray, anyarray) since 'AAAAAAAAAA646' is interpreted as char[] instead of Text
- Added some regression tests (src/test/regress/sql/arrays.sql) and their results(src/test/regress/expected/arrays.out)
- wokred on the new GIN strategy, I don't think it would vary much from GinContainsStrategy.
- I need to start working on the Referential Integrity code but I don't where to start
Mark Rofail
Attachment
Mark Rofail wrote:
> Okay, so major breakthrough.
>
> *Updates:*
>
> - The operator @>(anyarray, anyelement) is now functional
> - The segmentation fault was due to applying PG_FREE_IF_COPY on a
> datum when it should only be applied on TOASTed inputs
> - The only problem now is if for example you apply the operator as
> follows '{AAAAAAAAAA646'}' @> 'AAAAAAAAAA646' it maps to @>(anyarray,
> anyarray) since 'AAAAAAAAAA646' is interpreted as char[] instead of Text
> - Added some regression tests (src/test/regress/sql/arrays.sql) and
> their results(src/test/regress/expected/arrays.out)
> - wokred on the new GIN strategy, I don't think it would vary much from
> GinContainsStrategy.
OK, that's great.
> *What I plan to do:*
>
> - I need to start working on the Referential Integrity code but I don't
> where to start
You need to study the old patch posted by Marco Nenciarini.
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
- read into the old patch but couldn't apply it since it's quite old. It needs to be rebased and that's what I am working on. It's a lot of work.
- incomplete patch can be found attached here
- problem with the @>(anyarray, anyelement) opertator: if for example, you apply the operator as follows '{AAAAAAAAAA646'}' @> 'AAAAAAAAAA646' it maps to @>(anyarray, anyarray) since 'AAAAAAAAAA646' is interpreted as char[] instead of Text
- since I needed to check if the Datum was null and its type, I had to do it in the arraycontainselem and pass it as a parameter to the underlying function array_contains_elem. I'm proposing to introduce a new struct like ArrayType, but ElementType along all with brand new MACROs to make dealing with anyelement easier in any polymorphic context.
Best Regards,
Mark Rofail
Mark Rofail wrote:
> Okay, so major breakthrough.
>
> *Updates:*
>
> - The operator @>(anyarray, anyelement) is now functional
> - The segmentation fault was due to applying PG_FREE_IF_COPY on a
> datum when it should only be applied on TOASTed inputs
> - The only problem now is if for example you apply the operator as
> follows '{AAAAAAAAAA646'}' @> 'AAAAAAAAAA646' it maps to @>(anyarray,
> anyarray) since 'AAAAAAAAAA646' is interpreted as char[] instead of Text
> - Added some regression tests (src/test/regress/sql/arrays.sql) and
> their results(src/test/regress/expected/arrays.out)
> - wokred on the new GIN strategy, I don't think it would vary much from
> GinContainsStrategy.
OK, that's great.
> *What I plan to do:*
>
> - I need to start working on the Referential Integrity code but I don't
> where to start
You need to study the old patch posted by Marco Nenciarini.
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
What I did:
- read into the old patch but couldn't apply it since it's quite old. It needs to be rebased and that's what I am working on. It's a lot of work.
- incomplete patch can be found attached here
Bugs
- problem with the @>(anyarray, anyelement) opertator: if for example, you apply the operator as follows '{AAAAAAAAAA646'}' @> 'AAAAAAAAAA646' it maps to @>(anyarray, anyarray) since 'AAAAAAAAAA646' is interpreted as char[] instead of Text
Suggestion:
- since I needed to check if the Datum was null and its type, I had to do it in the arraycontainselem and pass it as a parameter to the underlying function array_contains_elem. I'm proposing to introduce a new struct like ArrayType, but ElementType along all with brand new MACROs to make dealing with anyelement easier in any polymorphic context.
Alexander Korotkov
Postgres Professional: http://www.
The Russian Postgres Company
Have you met any particular problem here? Or is it just a lot of mechanical work?
I don't think it is bug.
- study ri_triggers.c (src/backend/utils/adt/ri_triggers.c) since this is where the new RI code will reside
Mark Rofail
Attachment
Mark Rofail wrote: > On Mon, Jun 26, 2017 at 6:44 PM, Alexander Korotkov <aekorotkov@gmail.com> > wrote: > > > Have you met any particular problem here? Or is it just a lot of > > mechanical work? > > > > Just A LOT of mechanictal work, thankfully. The patch is now rebased and > all regress tests have passed (even the element_foreign_key). Please find > the patch below ! Great! > *What I plan to do next * > > - study ri_triggers.c (src/backend/utils/adt/ri_triggers.c) since this > is where the new RI code will reside Any news? -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
I rebased this also (rebased version attached here).
- Only one "ELEMENT" column allowed in a multi-column key
- - e.g. FOREIGN KEY (c1, ELEMENT c2, ELEMENT c3) REFERENCES t1 (u1, u2, u3) will throw an error
- Supported actions:
- - NO ACTION
- - RESTRICT
- The use of count(distinct y) in the SQL statements if the referencing column is an array. Since its equality operator is different from the PK unique index equality operator this leads to a broken statement
- regression=# create table ff (f1 float8 primary key);
CREATE TABLE
regression=# create table cc (f1 numeric references ff);
CREATE TABLE
regression=# create table cc2 (f1 numeric[], foreign key(each element of f1) references ff);
ERROR: foreign key constraint "cc2_f1_fkey" cannot be implemented
DETAIL: Key column "f1" has element type numeric which does not have a default btree operator class that's compatible with class "float8_ops".
- regression=# create table ff (f1 float8 primary key);
- undesirable dependency on default opclass semantics in the patch, which is that it supposes it can use array_eq() to detect whether or not the referencing column has changed. But I think that can be fixed without undue pain by providing a refactored version of array_eq() that can be told which element-comparison function to use
- fatal performance issues. If you issue any UPDATE or DELETE against the PK table, you get a query like this for checking to see if the RI constraint would be violated:
SELECT 1 FROM ONLY fktable x WHERE $1 = ANY (fkcol) FOR SHARE OF x; - cross-type FKs are unsupported
I am pretty sure other limitations will arise.
I am confident that between the time the patch was implemented(2012) and now postgres has grown considerably, the array functions are now more robust and will help in resolving many issues.
I would like to point out that Limitation #5 is the first limitation we should eliminate as it deems the feature unbeneficial.
I would like to thank Marco Nenciarini, Gabriele, Gianni and Tom Lane, for their hard work in the previous patches and anyone else I forgot.
- since anyarray @< anyarray and anyarray @> anyelem have the same symbol when a statemnt like this is executed '{AAAAAAAAAA646'}' @> 'AAAAAAAAAA646' it's mapped to anyarray @< anyarray instead of anyarray @> anyelem
- but as Alexander pointed out
What I plan to do next:When types are not specified explicitly, then optimizer do its best on guessing them. Sometimes results are counterintuitive to user. But that is not bug, it's probably a room for improvement. And I don't think this improvement should be subject of this GSoC. Anyway, array FK code should use explicit type cast, and then you wouldn't meet this problem.
- located the SQL statements triggered at any insert or update and will now "convert" them to use GIN. However, NO ACTION and RESTRICT are the only actions supported right now
Mark Rofail
Attachment
What I plan to do:
- study how to index the fk table upon its creation. I suspect this can be done in tablecmds.c
- how can you programmatically in C index a table?
Mark Rofail
Attachment
- since we want to create an index on the referencing column, I am working on firing a 'CREATE INDEX' query programatically right after the 'CREATE TABLE' query
- The problem I ran into is how to specify my Strategy (GinContainsElemStrategy) within the CREATE INDEX query. For example: CREATE INDEX ON fktable USING gin (fkcolumn array_ops)
Where does the strategy number fit? - The patch is attached here, is the approach I took to creating an index programmatically, correct?
- The problem I ran into is how to specify my Strategy (GinContainsElemStrategy) within the CREATE INDEX query. For example: CREATE INDEX ON fktable USING gin (fkcolumn array_ops)
Mark Rofail
Attachment
What I am working on
- since we want to create an index on the referencing column, I am working on firing a 'CREATE INDEX' query programatically right after the 'CREATE TABLE' query
- The problem I ran into is how to specify my Strategy (GinContainsElemStrategy) within the CREATE INDEX query. For example: CREATE INDEX ON fktable USING gin (fkcolumn array_ops)
Where does the strategy number fit?- The patch is attached here, is the approach I took to creating an index programmatically, correct?
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Could you, please, specify idea of what you're implementing in more detail?
On Sun, Jul 9, 2017 at 2:38 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:Could you, please, specify idea of what you're implementing in more detail?Ultimatley we would like an indexed scan instead of a sequential scan, so I thought we needed to index the FK array columns first.
Alexander Korotkov
Postgres Professional: http://www.postg
The Russian Postgres Company
We may document that GIN index is required to accelerate RI queries for array FKs. And users are encouraged to manually define them.It's also possible to define new option when index on referencing column(s) would be created automatically. But I think this option should work the same way for regular FKs and array FKs.
So we should leave it to the user ? I think tht would be fine too.
What I did
- now the RI checks utilise the @>(anyarray, anyelement)
- however there's a small problem:
operator does not exist: integer[] @> smallint
I assume that external casting would be required here. But how can I downcast smallint to integer or interger to numeric automatically ?
- however there's a small problem:
- work on the above mentioned buy/limitation
- otherwise, I think this concludes limitation #5
fatal performance issues. If you issue any UPDATE or DELETE against the PK table, you get a query like this for checking to see if the RI constraint would be violated:SELECT 1 FROM ONLY fktable x WHERE $1 = ANY (fkcol) FOR SHARE OF x;.
Best Regards,or is there anything remaining ?
Mark Rofail
Best Regards,What I did
- now the RI checks utilise the @>(anyarray, anyelement)
Mark Rofail
Attachment
Mark Rofail wrote: > - now the RI checks utilise the @>(anyarray, anyelement) > - however there's a small problem: > operator does not exist: integer[] @> smallint > I assume that external casting would be required here. But how can I > downcast smallint to integer or interger to numeric automatically ? We have one opclass for each type combination -- int4 to int2, int4 to int4, int4 to int8, etc. You just need to add the new strategy to all the opclasses. BTW now that we've gone through this a little further, it's starting to look like a mistake to me to use the same @> operator for (anyarray, anyelement) than we use for (anyarray, anyarray). I have the feeling we'd do better by having some other operator for this purpose -- dunno, maybe @>> or @>. ... whatever you think is reasonable and not already in use. Unless there is some other reason to pick @> for this purpose. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
We have one opclass for each type combination -- int4 to int2, int4 to
int4, int4 to int8, etc. You just need to add the new strategy to all
the opclasses.
BTW now that we've gone through this a little further, it's starting to
look like a mistake to me to use the same @> operator for (anyarray,
anyelement) than we use for (anyarray, anyarray).
Mark Rofail
On Wed, Jul 12, 2017 at 12:53 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:We have one opclass for each type combination -- int4 to int2, int4 to
int4, int4 to int8, etc. You just need to add the new strategy to all
the opclasses.Can you clarify this solution ? I think another solution would be external casting
Mark Rofail
Mark Rofail wrote: > On Wed, Jul 12, 2017 at 2:30 PM, Mark Rofail <markm.rofail@gmail.com> wrote: > > > On Wed, Jul 12, 2017 at 12:53 AM, Alvaro Herrera <alvherre@2ndquadrant.com > > > wrote: > >> > >> We have one opclass for each type combination -- int4 to int2, int4 to > >> int4, int4 to int8, etc. You just need to add the new strategy to all > >> the opclasses. > >> > > > > Can you clarify this solution ? I think another solution would be external > > casting > > > If external casting is to be used. If for example the two types in > question are smallint and integer. Would a function get_common_type(Oid > leftopr, Oid rightopr) be useful ?, that given the two types return the > "common" type between the two in this case integer. Do you mean adding cast decorators to the query constructed by ri_triggers.c? That looks like an inferior solution. What problem do you see with adding more rows to the opclass? -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
We have one opclass for each type combination -- int4 to int2, int4 to
int4, int4 to int8, etc. You just need to add the new strategy to all
the opclasses.
DATA(insert ( 2745 2277 2283 5 s 6108 2742 0 )); /* anyarray @>> anyelem */
However, make check produced:
could not create unique index "pg_amop_opr_fam_index"
Key (amopopr, amoppurpose, amopfamily)=(6108, s, 2745) is duplicated.
Am I implementing this the wrong way or do we need to look for another approach?
Attachment
On Wed, Jul 12, 2017 at 12:53 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:We have one opclass for each type combination -- int4 to int2, int4 to
int4, int4 to int8, etc. You just need to add the new strategy to all
the opclasses.I tried this approach by manually declaring the operator multiple of times in pg_amop.h (src/include/catalog/pg_amop.h)so instead of the polymorphic declaration
DATA(insert ( 2745 2277 2283 5 s 6108 2742 0 )); /* anyarray @>> anyelem */multiple declarations were used, for example for int4[] :DATA(insert ( 2745 1007 20 5 s 6108 2742 0 )); /* int4[] @>> int8 */DATA(insert ( 2745 1007 23 5 s 6108 2742 0 )); /* int4[] @>> int4 */DATA(insert ( 2745 1007 21 5 s 6108 2742 0 )); /* int4[] @>> int2 */DATA(insert ( 2745 1007 1700 5 s 6108 2742 0 ));/* int4[] @>> numeric */
However, make check produced:
could not create unique index "pg_amop_opr_fam_index"
Key (amopopr, amoppurpose, amopfamily)=(6108, s, 2745) is duplicated.
Am I implementing this the wrong way or do we need to look for another approach?
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
On Wed, Jul 12, 2017 at 12:53 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: We have one opclass for each type combination -- int4 to int2, int4 to
int4, int4 to int8, etc. You just need to add the new strategy to all
the opclasses.I tried this approach by manually declaring the operator multiple of times in pg_amop.h (src/include/catalog/pg_amop.h) so instead of the polymorphic declaration
DATA(insert ( 2745 2277 2283 5 s 6108 2742 0 )); /* anyarray @>> anyelem */multiple declarations were used, for example for int4[] :DATA(insert ( 2745 1007 20 5 s 6108 2742 0 )); /* int4[] @>> int8 */DATA(insert ( 2745 1007 23 5 s 6108 2742 0 )); /* int4[] @>> int4 */DATA(insert ( 2745 1007 21 5 s 6108 2742 0 )); /* int4[] @>> int2 */DATA(insert ( 2745 1007 1700 5 s 6108 2742 0 ));/* int4[] @>> numeric */
However, make check produced:
could not create unique index "pg_amop_opr_fam_index"
Key (amopopr, amoppurpose, amopfamily)=(6108, s, 2745) is duplicated.
Am I implementing this the wrong way or do we need to look for another approach?
The problem is that you need to have not only opclass entries for the operators, but also operators themselves. I.e. separate operators for int4[] @>> int8, int4[] @>> int4, int4[] @>> int2, int4[] @>> numeric. You tried to add multiple pg_amop rows for single operator and consequently get unique index violation.
On T upue, Jul 18, 2017 at 2:24 AM, Mark Rofail <markm.rofail@gmail.com> wrote:On Wed, Jul 12, 2017 at 12:53 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:We have one opclass for each type combination -- int4 to int2, int4 to
int4, int4 to int8, etc. You just need to add the new strategy to all
the opclasses.I tried this approach by manually declaring the operator multiple of times in pg_amop.h (src/include/catalog/pg_amop.h)so instead of the polymorphic declaration
DATA(insert ( 2745 2277 2283 5 s 6108 2742 0 )); /* anyarray @>> anyelem */multiple declarations were used, for example for int4[] :DATA(insert ( 2745 1007 20 5 s 6108 2742 0 )); /* int4[] @>> int8 */DATA(insert ( 2745 1007 23 5 s 6108 2742 0 )); /* int4[] @>> int4 */DATA(insert ( 2745 1007 21 5 s 6108 2742 0 )); /* int4[] @>> int2 */DATA(insert ( 2745 1007 1700 5 s 6108 2742 0 ));/* int4[] @>> numeric */
However, make check produced:
could not create unique index "pg_amop_opr_fam_index"
Key (amopopr, amoppurpose, amopfamily)=(6108, s, 2745) is duplicated.
Am I implementing this the wrong way or do we need to look for another approach?The problem is that you need to have not only opclass entries for the operators, but also operators themselves. I.e. separate operators for int4[] @>> int8, int4[] @>> int4, int4[] @>> int2, int4[] @>> numeric. You tried to add multiple pg_amop rows for single operator and consequently get unique index violation.Alvaro, do you think we need to define all these operators? I'm not sure. If even we need it, I thinkThe Russian Postgres Company
separate operators for int4[] @>> int8, int4[] @>> int4, int4[] @>> int2, int4[] @>> numeric.
Mark Rofail wrote: > On Tue, 18 Jul 2017 at 7:43 pm, Alexander Korotkov <aekorotkov@gmail.com> > wrote: > > > separate operators for int4[] @>> int8, int4[] @>> int4, int4[] @>> int2, > > int4[] @>> numeric. > > > > My only comment on the separate operators is its high maintenance. Any new > datatype introduced a corresponding operator should be created. Yes. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alexander Korotkov wrote: > The problem is that you need to have not only opclass entries for the > operators, but also operators themselves. I.e. separate operators for > int4[] @>> int8, int4[] @>> int4, int4[] @>> int2, int4[] @>> numeric. You > tried to add multiple pg_amop rows for single operator and consequently get > unique index violation. > > Alvaro, do you think we need to define all these operators? I'm not sure. > If even we need it, I think we shouldn't do this during this GSoC. What > particular shortcomings do you see in explicit cast in RI triggers queries? I'm probably confused. Why did we add an operator and not a support procedure? I think we should have added rows in pg_amproc, not pg_amproc. I'm very tired right now so I may be speaking nonsense. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Why did we add an operator and not a support
procedure?
Mark Rofail.
Option 1: Multiple Operators
Drawback: High maintenance.
Option 2: Explicit casting
Drawback: figuring out the appropriate cast may require considerable computation
Drawback: a lot of defensive programming has to be implemented to guard against any exception.
Another thing
Mark Rofail
On Wed, Jul 19, 2017 at 8:08 AM, Mark Rofail <markm.rofail@gmail.com> wrote: > To summarise, the options we have to solve the limitation of the @>(anyarray > , anyelement) where it produces the following error: operator does not > exist: integer[] @> smallint Why do we have to solve that limitation? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Why do we have to solve that limitation?
On Wed, Jul 19, 2017 at 2:29 PM, Mark Rofail <markm.rofail@gmail.com> wrote: > On Wed, Jul 19, 2017 at 7:28 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> >> Why do we have to solve that limitation? > > Since the regress test labled element_foreing_key fails now that I made the > RI queries utilise @(anyarray, anyelement), that means it's not functioning > as it is meant to be. Well, if this is a new test introduced by the patch, you could also just change the test. Off-hand, I'm not sure that it's very important to make the case work where the types don't match between the referenced table and the referencing table, which is what you seem to be talking about here. But maybe I'm misunderstanding the situation. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Mark Rofail wrote: > On Tue, Jul 18, 2017 at 11:14 PM, Alvaro Herrera <alvherre@2ndquadrant.com> > wrote: > > > > Why did we add an operator and not a support > > procedure? > > I thought the support procedures were constant within an opclass. Uhh ... I apologize but I think I was barking at the wrong tree. I was thinking that it mattered that the opclass mechanism was able to determine whether some array @>> some element, but that's not true: it's the queries in ri_triggers.c, which have no idea about opclasses. (I tihnk we would have wanted to use to opclasses in order to find out what operator to use in the first place, if ri_triggers.c was already using that general idea; but in reality it's already using hardcoded operator names, so it doesn't matter.) I'm not entirely sure what's the best way to deal with the polymorphic problem, but on the other hand as Robert says downthread maybe we shouldn't be solving it at this stage anyway. So let's step back a bit, get a patch that works for the case where the types match on both sides of the FK, then we review that patch; if all is well, we can discuss the other problem as a stretch goal. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
So let's step back a bit,
get a patch that works for the case where the types match on both sides
of the FK, then we review that patch; if all is well, we can discuss the
other problem as a stretch goal.
I think the next step should be testing the performnce before/after the modifiactions.
I'm not entirely sure what's the best way to deal with the polymorphic
problem, but on the other hand as Robert says downthread maybe we
shouldn't be solving it at this stage anyway. So let's step back a bit,
get a patch that works for the case where the types match on both sides
of the FK, then we review that patch; if all is well, we can discuss the
other problem as a stretch goal.
But if it comes to it, should I introduce a new opclass specifically for anyelement or add new supporting procedures to the old opclass ? .
Attachment
On Sat, Jul 22, 2017 at 5:50 PM, Mark Rofail <markm.rofail@gmail.com> wrote: > so personally I don't think we should leave creating a GIN index up to the > user, it should be automatically generated instead. I can certainly understand why you feel that way, but trying to do that in your patch is just going to get your patch rejected. We don't want array foreign keys to have different behavior than regular foreign keys, and regular foreign keys don't do this automatically. We could change that, but I suspect it would cause us some pretty serious problems with upgrades from older versions with the existing behavior to newer versions with the revised behavior. There are other problems, too. Suppose the user creates the foreign key and then drops the associated index; then, they run pg_dump. Will restoring the dump recreate the index? If so, then you've broken dump/restore, because now it doesn't actually recreate the original state of the database. You might think of fixing this by not letting the index be dropped, but that's problematic too, because a fairly-standard way of removing index bloat is to create a new index with the "concurrently" flag and then drop the old one. Another problem entirely is that the auto-generated index will need to have an auto-generated name, and that name might happen to conflict with the name of some other object that already exists in the database, which doesn't initially seem like a problem because you can just generate a different name instead; indeed, we already do such things. But the thorny point is that you have to preserve whatever name you choose -- and the linkage to the array foreign key that caused it to be created -- across a dump/restore cycle; otherwise you'll have cases where conflicting names cause failures. I doubt this is a comprehensive list of things that might go wrong; it's intended as an illustrative list, not an exhaustive one. This is a jumbo king-sized can of worms, and even a very experienced contributor would likely find it extremely difficult to sort all of the problems that would result from a change in this area. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
This is a jumbo king-sized can of worms, and even a very experienced
contributor would likely find it extremely difficult to sort all of
the problems that would result from a change in this area.
Best Regards,
Mark Rofail
However, there is a bug that prevented me from testing the third scenario, I assume there's an issue of incompatible types problem since the right operand type is anyelement and the supporting procedures expect anyarray.I am working on debugging it right now.
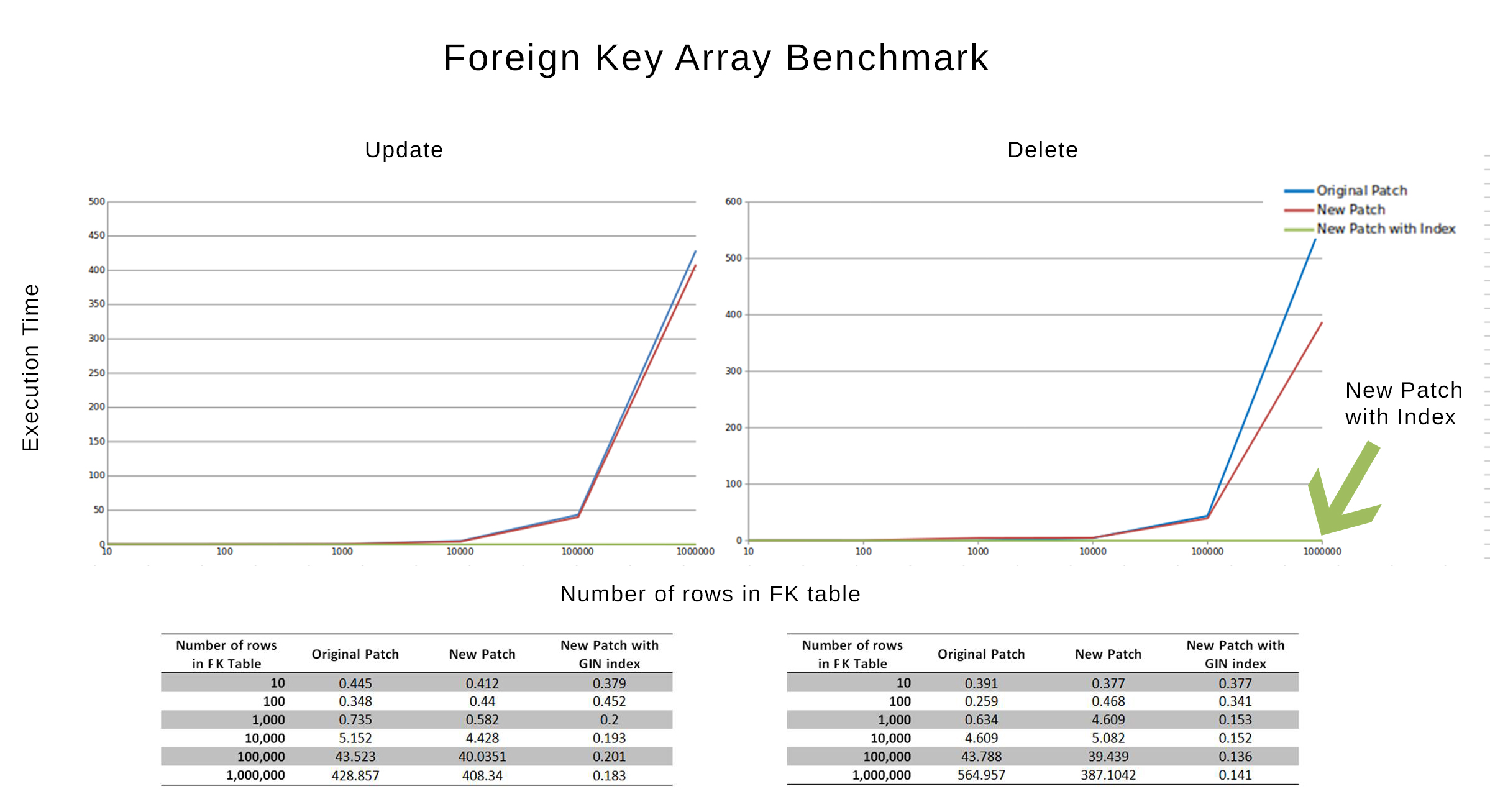
Here is a summary of the results:
I just want to point this out because I still can't believe the numbers. In reference to the old patch:
The new patch without the index suffers a 41.68% slow down, while the new patch with the index has a 95.18% speed up!
Best Regards,
Mark Rofail
Attachment
On 2017-07-24 23:08, Mark Rofail wrote: > Here is the new Patch with the bug fixes and the New Patch with the > Index > in place performance results. > > I just want to point this out because I still can't believe the > numbers. In > reference to the old patch: > The new patch without the index suffers a 41.68% slow down, while the > new > patch with the index has a 95.18% speed up! > [elemOperatorV4.patch] This patch doesn't apply to HEAD at the moment ( e2c8100e6072936 ). Can you have a look? thanks, Erik Rijkers patching file doc/src/sgml/ref/create_table.sgml Hunk #1 succeeded at 816 with fuzz 3. patching file src/backend/access/gin/ginarrayproc.c patching file src/backend/utils/adt/arrayfuncs.c patching file src/backend/utils/adt/ri_triggers.c Hunk #1 FAILED at 2650. Hunk #2 FAILED at 2694. 2 out of 2 hunks FAILED -- saving rejects to file src/backend/utils/adt/ri_triggers.c.rej patching file src/include/catalog/pg_amop.h patching file src/include/catalog/pg_operator.h patching file src/include/catalog/pg_proc.h patching file src/test/regress/expected/arrays.out patching file src/test/regress/expected/opr_sanity.out patching file src/test/regress/sql/arrays.sql
This patch doesn't apply to HEAD at the moment ( e2c8100e6072936 ).
Here is a unified patch that I just tested.
I would appreciate it if you could review it.
Best Regards,
Mark Rofail
Attachment
On 2017-07-24 23:31, Mark Rofail wrote: > On Mon, Jul 24, 2017 at 11:25 PM, Erik Rijkers <er@xs4all.nl> wrote: >> >> This patch doesn't apply to HEAD at the moment ( e2c8100e6072936 ). >> > > My bad, I should have mentioned that the patch is dependant on the > original > patch. > Here is a *unified* patch that I just tested. Thanks. Apply is now good, but I get this error when compiling: ELEMENT' not present in UNRESERVED_KEYWORD section of gram.y make[4]: *** [gram.c] Error 1 make[3]: *** [parser/gram.h] Error 2 make[2]: *** [../../src/include/parser/gram.h] Error 2 make[1]: *** [all-common-recurse] Error 2 make: *** [all-src-recurse] Error 2
Thanks. Apply is now good, but I get this error when compiling:
Thanks for your patience.
Attachment
With two tables a PK table with 5 rows and an FK table with growing row count.
Once triggering an RI check
at 10 rows,
100 rows,
1,000 rows,
10,000 rows,
100,000 rows and
1,000,000 rows
Please find the graph with the findings attached below
Attachment
{kind=link}
I have written some benchmark test.
With two tables a PK table with 5 rows and an FK table with growing row count.
Once triggering an RI check
at 10 rows,
100 rows,
1,000 rows,
10,000 rows,
100,000 rows and
1,000,000 rows
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
How many rows of FK table were referencing the PK table row you're updating/deleting.I wonder how may RI trigger work so fast if it has to do some job besides index search with no results?
So we have two options. Either implement CASCADE or if there's a configration for EXPLAIN to show costs even if it violates the FK constraints.
I think we should also vary the number of referencing rows.
On 2017-07-27 02:31, Mark Rofail wrote: > I have written some benchmark test. > It would help (me at least) if you could be more explicit about what exactly each instance is. Apparently there is an 'original patch': is this the original patch by Marco Nenciarini? Or is it something you posted earlier? I guess it could be distilled from the earlier posts but when I looked those over yesterday evening I still didn't get it. A link to the post where the 'original patch' is would be ideal... thanks! Erik Rijkers > With two tables a PK table with 5 rows and an FK table with growing row > count. > > Once triggering an RI check > at 10 rows, > 100 rows, > 1,000 rows, > 10,000 rows, > 100,000 rows and > 1,000,000 rows > > Please find the graph with the findings attached below > > > -- > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-hackers
On Thu, Jul 27, 2017 at 12:54 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:How many rows of FK table were referencing the PK table row you're updating/deleting.I wonder how may RI trigger work so fast if it has to do some job besides index search with no results?The problem here is that the only to option for the foreign key arrays are NO ACTION and RESTRICT which don't allow me to update/delete a refrenced row in the PK Table. the EXPLAIN ANALYZE only tells me that this violates the FK constraint.
So we have two options. Either implement CASCADE or if there's a configration for EXPLAIN to show costs even if it violates the FK constraints.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
It would help (me at least) if you could be more explicit about what exactly each instance is.
The new patch is the latest one submitted by me[3].
And the new patch with index is the same[3], but with a GIN index built over it. CREATE INDEX ON fktableforarray USING gin (fktest array_ops);
[1] https://www.postgresql.org/message-id/28617.1351095467@sss.pgh.pa.us
Best Regards,
Mark Rofail
Oh, ok. I missed that.Could you remind me why don't we have DELETE CASCADE? I understand that UPDATE CASCADE is problematic because it's unclear which way should we delete elements from array. But what about DELETE CASCADE?
Honestly, I didn't touch that part of the patch. It's very interesting though, I think it would be great to spend the rest of GSoC in it.
Off the top of my head though, there's many ways to go about DELETE CASCADE. You could only delete the member of the referencing array or the whole array. I think there's a lot of options the user might want to consider and it's hard to generalize to DELETE CASCADE. Maybe new grammar would be introduced here ?|
Best Regards,
Mark Rofail
On 2017-07-27 21:08, Mark Rofail wrote: > On Thu, Jul 27, 2017 at 7:15 PM, Erik Rijkers <er@xs4all.nl> wrote: > >> It would help (me at least) if you could be more explicit about what >> exactly each instance is. >> > > I apologize, I thought it was clear through the context. Thanks a lot. It's just really easy for testers like me that aren't following a thread too closely and just snatch a half hour here and there to look into a feature/patch. One small thing while building docs: $ cd doc/src/sgml && make html osx -wall -wno-unused-param -wno-empty -wfully-tagged -D . -D . -x lower postgres.sgml >postgres.xml.tmp osx:ref/create_table.sgml:960:100:E: document type does not allow element "VARLISTENTRY" here Makefile:147: recipe for target 'postgres.xml' failed make: *** [postgres.xml] Error 1 (Debian 8/jessie) thanks, Erik Rijkers
One small thing while building docs:
$ cd doc/src/sgml && make html
osx -wall -wno-unused-param -wno-empty -wfully-tagged -D . -D . -x lower postgres.sgml >postgres.xml.tmp
osx:ref/create_table.sgml:960:100:E: document type does not allow element "VARLISTENTRY" here
Makefile:147: recipe for target 'postgres.xml' failed
make: *** [postgres.xml] Error 1
How's the rest of the patch ?
One small thing while building docs:
$ cd doc/src/sgml && make html
osx -wall -wno-unused-param -wno-empty -wfully-tagged -D . -D . -x lower postgres.sgml >postgres.xml.tmp
osx:ref/create_table.sgml:960:100:E: document type does not allow element "VARLISTENTRY" here
Makefile:147: recipe for target 'postgres.xml' failed
make: *** [postgres.xml] Error 1
Best Regards,
Mark Rofail
Attachment
Can someone help me understand the first limitation?
Mark Rofail wrote: > These are limitations of the patch ordered by importance: > > ✗ presupposes that count(distinct y) has exactly the same notion of > equality that the PK unique index has. In reality, count(distinct) will > fall back to the default btree opclass for the array element type. Operators are classified in operator classes; each data type may have more than one operator class for a particular access method. Exactly one operator class for some access method can be designated as the default one for a type. However, when you create an index, you can indicate which operator class to use, and it may not be the default one. If a different one is chosen at index creation time, then a query using COUNT(distinct) will do the wrong thing, because DISTINCT will select an equality type using the type's default operator class, not the equality that belongs to the operator class used to create the index. That's wrong: DISTINCT should use the equality operator that corresponds to the index' operator class instead, not the default one. I hope that made sense. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> ... However, when you create an index, you can
> indicate which operator class to use, and it may not be the default one.
> If a different one is chosen at index creation time, then a query using
> COUNT(distinct) will do the wrong thing, because DISTINCT will select
> an equality type using the type's default operator class, not the
> equality that belongs to the operator class used to create the index.
> That's wrong: DISTINCT should use the equality operator that corresponds
> to the index' operator class instead, not the default one.
Uh, what? Surely the semantics of count(distinct x) *must not* vary
depending on what indexes happen to be available.
I think what you meant to say is that the planner may only choose an
optimization of this sort when the index's opclass matches the one
DISTINCT will use, ie the default for the data type.
regards, tom lane
Tom Lane wrote: > Alvaro Herrera <alvherre@2ndquadrant.com> writes: > > ... However, when you create an index, you can > > indicate which operator class to use, and it may not be the default one. > > If a different one is chosen at index creation time, then a query using > > COUNT(distinct) will do the wrong thing, because DISTINCT will select > > an equality type using the type's default operator class, not the > > equality that belongs to the operator class used to create the index. > > > That's wrong: DISTINCT should use the equality operator that corresponds > > to the index' operator class instead, not the default one. > > Uh, what? Surely the semantics of count(distinct x) *must not* vary > depending on what indexes happen to be available. Err ... > I think what you meant to say is that the planner may only choose an > optimization of this sort when the index's opclass matches the one > DISTINCT will use, ie the default for the data type. Um, yeah, absolutely. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Tom Lane wrote:
> Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> > ... However, when you create an index, you can
> > indicate which operator class to use, and it may not be the default one.
> > If a different one is chosen at index creation time, then a query using
> > COUNT(distinct) will do the wrong thing, because DISTINCT will select
> > an equality type using the type's default operator class, not the
> > equality that belongs to the operator class used to create the index.
>
> > That's wrong: DISTINCT should use the equality operator that corresponds
> > to the index' operator class instead, not the default one.
>
> Uh, what? Surely the semantics of count(distinct x) *must not* vary
> depending on what indexes happen to be available.
Err ...
> I think what you meant to say is that the planner may only choose an
> optimization of this sort when the index's opclass matches the one
> DISTINCT will use, ie the default for the data type.
Best Regards,
Mark Rofail
Through some reading:
Mark Rofail
SELECT 1 FROM ONLY <pktable> x WHERE pkatt1 = $1 [AND ...] FOR KEY SHARE OF x
This is what I came up with:
I understand there might be some syntax errors but this is just a proof of concept.
Is this the right way to go?
It's been a week and I don't think I made significant progress. Any pointers?
MarkRofail
SELECT 1 WHERE(SELECT COUNT(*)FROM(SELECT yFROM unnest($1) yGROUP BY y))= (SELECT count(*) (<QUERY>) z)
This passes all the regress tests and elimnates the DISTINCT keyword that created the limitation.
However a look on the performance change is a must and that's what I plan to do next.
There is another problem though. When I remove the part of the code setting the default opclass in tablecmd.c I get this error message afterwards:
CREATE TABLE FKTABLEFORARRAY ( ftest1 int[], FOREIGN KEY (EACH ELEMENT OF ftest1) REFERENCES PKTABLEFORARRAY, ftest2 int );
Best Regards,
Mark Rofail
Attachment
This is the query fired upon any UPDATE/DELETE for RI checks:
SELECT 1 FROM ONLY <pktable> x WHERE pkatt1 = $1 [AND ...] FOR KEY SHARE OF xin the case of foreign key arrays, it's wrapped in this query:SELECT 1 WHERE(SELECT count(DISTINCT y) FROM unnest($1) y)= (SELECT count(*) FROM (<QUERY>) z)This is where the limitation appears, the DISTINCT keyword. Since in reality, count(DISTINCT) will fall back to the default btree opclass for the array element type regardless of the opclass indicated in the access method. Thus I believe going around DISTINCT is the way to go.
This is what I came up with:SELECT 1 WHERE(SELECT COUNT(*)FROM(SELECT yFROM unnest($1) yGROUP BY y))= (SELECT count(*) (<QUERY>) z)
I understand there might be some syntax errors but this is just a proof of concept.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Do we already assume that default btree opclass for array element type matches PK opclass when using @>> operator on UPDATE/DELETE of referenced table?
If so, we don't introduce additional restriction here...
GROUP BY would also use default btree/hash opclass for element type. It doesn't differ from DISTINCT from that point.
Best Regard,
Mark Rofail
On Tue, Aug 8, 2017 at 2:25 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:Do we already assume that default btree opclass for array element type matches PK opclass when using @>> operator on UPDATE/DELETE of referenced table?I believe so, since it's a polymorphic function.
If so, we don't introduce additional restriction here...You mean to remove the wrapper query ?
GROUP BY would also use default btree/hash opclass for element type. It doesn't differ from DISTINCT from that point.Then there's no going around this limitation,
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On Tue, Aug 8, 2017 at 4:12 PM, Mark Rofail <markm.rofail@gmail.com> wrote:On Tue, Aug 8, 2017 at 2:25 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:GROUP BY would also use default btree/hash opclass for element type. It doesn't differ from DISTINCT from that point.Then there's no going around this limitation,That seems like this.
Since for now, the limitation
✗ presupposes that count(distinct y) has exactly the same notion of equality that the PK unique index has. In reality, count(distinct) will fall back to the default btree opclass for the array element type.
I started to look at the next one on the list.
✗ coercion is unsopported. i.e. a numeric can't refrence int8
The limitation in short.
should be accepted but this produces the following error
The algorithm I propose:
I don't think it's easy to modify the @>> operator as we discussed here.
I think we should cast the operands in the RI queries fired as follows
1. we get the array type from the right operand
For example:
The left operand here is int2[] and the right int4
1.get int4[] oid and store it
2. compare int4[] and int2[] oid numerically
3. since int4[] is larger the cast is applied to int2[] to make the left operant int4[]
If the example was reversed:
The left operand here is int4[] and the right int2
1.get int2[] oid and store it
2. compare int4[] and int2[] oid numerically
3. since int4[] is larger the cast is applied to int2 to make the right operant int 4
However, if there's a cleaner way to go about this or a more "postgres" way. let me know.
The changes are int ri_trigger.c and the patch is attached here.
Best Regards,
Mark Rofail
Attachment
On Tue, Aug 8, 2017 at 3:24 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:On Tue, Aug 8, 2017 at 4:12 PM, Mark Rofail <markm.rofail@gmail.com> wrote:On Tue, Aug 8, 2017 at 2:25 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:GROUP BY would also use default btree/hash opclass for element type. It doesn't differ from DISTINCT from that point.Then there's no going around this limitation,That seems like this.
Since for now, the limitation✗ presupposes that count(distinct y) has exactly the same notion of equality that the PK unique index has. In reality, count(distinct) will fall back to the default btree opclass for the array element type.is unavoidable.
I started to look at the next one on the list.✗ coercion is unsopported. i.e. a numeric can't refrence int8
The limitation in short.#= CREATE TABLE PKTABLEFORARRAY ( ptest1 int4 PRIMARY KEY, ptest2 text );#= CREATE TABLE FKTABLEFORARRAY ( ftest1 int2[], FOREIGN KEY (EACH ELEMENT OF ftest1) REFERENCES PKTABLEFORARRAY, ftest2 int );operator does not exist: integer[] @> smallint
should be accepted but this produces the following error
The algorithm I propose:
I don't think it's easy to modify the @>> operator as we discussed here.
I think we should cast the operands in the RI queries fired as follows
1. we get the array type from the right operand2. compare the two array type and see which type is more "general" (as to which should be cast to which, int2 should be cast to int4, since casting int4 to int2 could lead to data loss). This can be done by seeing which Oid is larger numerically since, coincidentally, they are declared in this way in pg_type.h.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov <aekorotkov@gmail.com> writes: > On Mon, Aug 14, 2017 at 2:09 PM, Mark Rofail <markm.rofail@gmail.com> wrote: >> I think we should cast the operands in the RI queries fired as follows >> 1. we get the array type from the right operand >> 2. compare the two array type and see which type is more "general" (as to >> which should be cast to which, int2 should be cast to int4, since casting >> int4 to int2 could lead to data loss). This can be done by seeing which Oid >> is larger numerically since, coincidentally, they are declared in this way >> in pg_type.h. > I'm not sure numerical comparison of Oids is a good idea. I absolutely, positively guarantee that a patch written that way will be rejected. > Should we instead use logic similar to select_common_type() and underlying > functions? Right. What we typically do in cases like this is check to see if there is an implicit coercion available in one direction but not the other. I don't know if you can use select_common_type() directly, but it would be worth looking at. Also, given that the context here is RI constraints, what you're really worried about is whether the referenced column's uniqueness constraint is associated with compatible operators, so looking into its operator class for relevant operators might be the right way to think about it. I wrote something just very recently that touches on that ... ah, here it is: https://www.postgresql.org/message-id/13220.1502376894@sss.pgh.pa.us regards, tom lane
Should we instead use logic similar to select_common_type() and underlying functions?
The new function passes all the old coercion regress tests included in the original patch written by Marco.
Attachment
On Thu, Jul 27, 2017 at 12:54 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
I wonder how may RI trigger work so fast if it has to do some job besides index search with no results?
Best Regards,
Mark Rofail
1) Whenever there was an index on the Foreign Key Array column and I issue the following query "SELECT * FROM FKTABLEFORARRAY WHERE ftest1 @>> 5;" I wouldn't get any results, even though it works without an index.
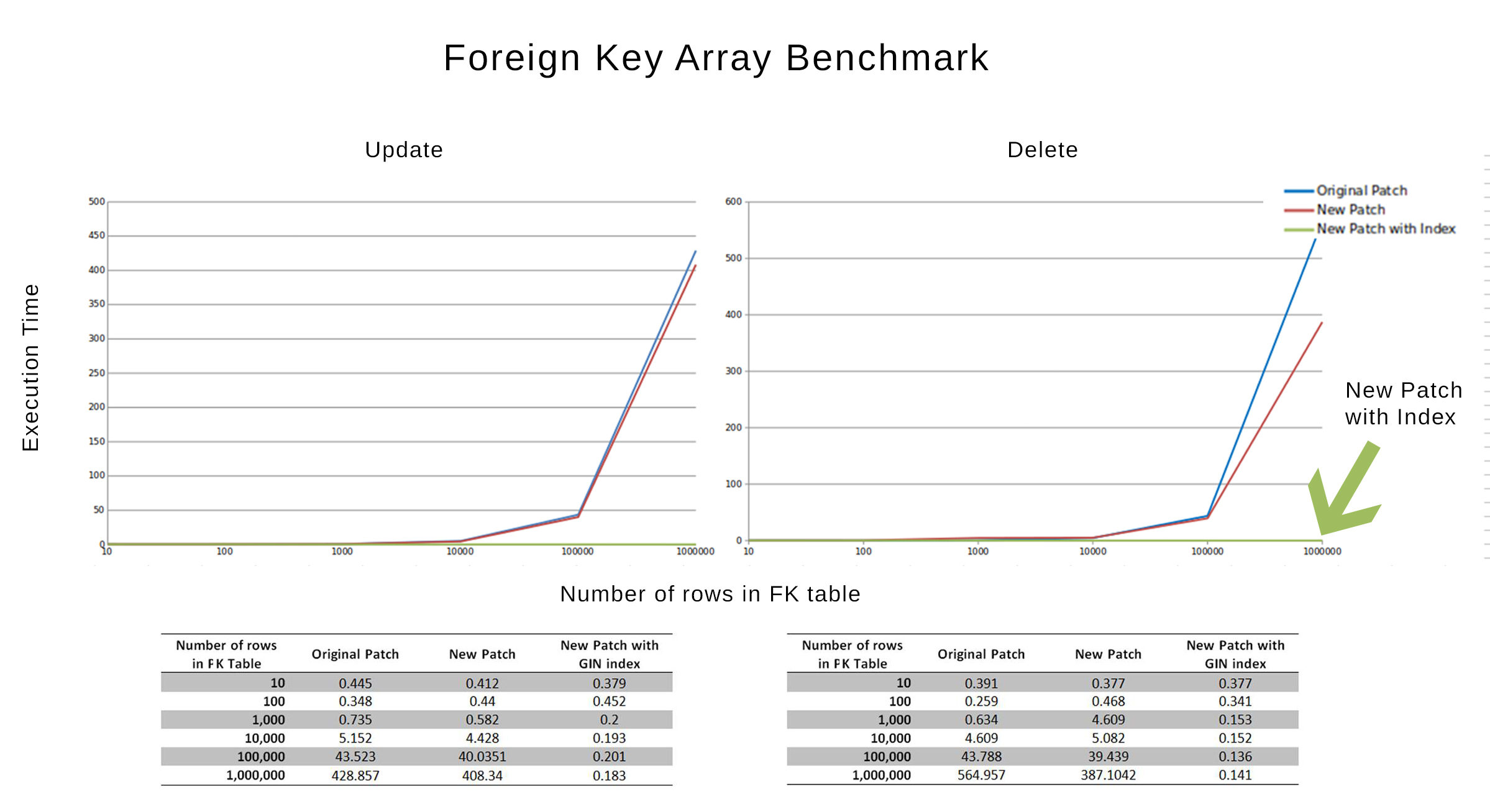
This confirmed my suspicion that there was something wrong with the GIN index, the results were too good to be true in the comparison here. It's almost O(1);
Turns out the index search wasn't performed at all. When I fixed this bug, the performance changed. And the new benchmark graph is attached below.
3) As of patch v4.4 DELETE CASCADE is now supported. The rest of the actions, however, will require array manipulation.
Once the updates are confirmed, I'll update the limitation checklist.
Best Regards,
Mark Rofail
Attachment
{kind=link}
In short, this patch allows each element in an array to act as a foreign key, with the following syntax:
The initial patch was written by Marco Nenciarini, Gabriele Bartolini and Gianni Ciolli, and modified by Tom Lan.[2]
The GSoC proposal was to overcome the performance issues that appear whenever an UPDATE/DELETE was performed on the PK table; this fires a Referential Integrity check on the FK table using sequential scan, which is responsible for the performance issues.
We planned on replacing the sequential scan with an indexed scan under GIN and to do that we introduced a new operator anyarray @>> anyelem that returns true if the element is present in the array.
The benchmarking test showed exactly how much rewarding the use of the GIN index has proven to be.[3]
Having accomplished the initial goals, I compiled a comprehensive limitation check list and started to work on each limitation.
Here's a summary of Foreign Key Arrays limitations:
-- ------------------------------------------------------------------------------------------------------------------------
The final patch v5 is attached here.
I also attached a diff file to highlight my changes to the old rebased patch v3
Thank you, everyone, the Postgres community for your support.
Best Regards,
Mark Rofail
-- ------------------------------------------------------------------------------------------------------------------------
[1] https://www.postgresql.org/message-id/CAJvoCuv=EeXMs7My-8AKFf1WmvXO+M_ngUEP9B=7Xaxr4EqFeg@mail.gmail.com
Attachment
https://travis-ci.org/
The full backtrace can be found here: https://pastebin.com/
The error originates from src/backend/access/gin/
The if condition is necessary since it decides whether "the queryKey" variable is a single element or the first cell of an array. The logic behind the if condition is as follows: since we defined GinContainsElemStrategy to be strategy number 5. are sure the strategy is GinContainsElemStrategy.
The if condition needs to be more precise but can't find a common attribute to check within the ginFillScanKey() function.
If someone can take a look. I can use some help with this.
I also worked in another direction. Since there was a lot of modifications in the code to support taking an element instead of an array and this is the source of many conflicts. I tried going back to the old RI query:
We were worried about the decrease in performance caused by creating a new array with every check So I put it to the test and here are the results: https://pastebin.com/carj9Bur
As expected it led to a decrease in performance, but I think it is forgivable.
Now all the contrib regression tests pass.
To summarise, we can fix the old if condition or neglect the decrease in performance encountered when going back to the old RI query.
Best Regards,
Mark Rofail
Attachment
I have not looked at the issue with the btree_gin tests yet, but here is
the first part of my review.
= Review
This is my first quick review where I just read the documentation and
quickly tested the feature. I will review it more in-depth later.
This is a very useful feature, one which I have a long time wished for.
The patch applies, compiles and passes the test suite with just one warning.
parse_coerce.c: In function ‘select_common_type_2args’:
parse_coerce.c:1379:7: warning: statement with no effect [-Wunused-value] rightOid; ^~~~~~~~
= Functional
The documentation does not agree with the code on the syntax. The
documentation claims it is "FOREIGN KEY (ELEMENT xs) REFERENCES t1 (x)"
when it actually is "FOREIGN KEY (EACH ELEMENT OF xs) REFERENCES t1 (x)".
Likewise I can't get the "final_positions integer[] ELEMENT REFERENCES
drivers" syntax to work, but here I cannot see any change in the syntax
to support it.
Related to the above: I am not sure if it is a good idea to make ELEMENT
a reserved word in column definitions. What if the SQL standard wants to
use it for something?
The documentation claims ON CASCADE DELETE is not supported by array
element foreign keys, but I do not think that is actually the case.
I think I prefer (EACH ELEMENT OF xs) over (ELEMENT xs) given how the
former is more in what I feel is the spirit of SQL. And if so we should
match it as "xs integer[] EACH ELEMENT REFERENCES t1 (x)", assuming we
want that syntax.
Once I have created an array element foreign key the basic features seem
to work as expected.
The error message below fails to mention that it is an array element
foreign key, but I do not think that is not a blocker for getting this
feature merged. Right now I cannot think of how to improve it either.
$ INSERT INTO t3 VALUES ('{1,3}');
ERROR: insert or update on table "t3" violates foreign key constraint
"t3_xs_fkey"
DETAIL: Key (xs)=({1,3}) is not present in table "t1".
= Nitpicking/style comments
In doc/src/sgml/catalogs.sgml the
"<entry><structfield>conpfeqop</structfield></entry>" line is
incorrectly indented.
I am not fan of calling it "array-vs-scalar". What about array to scalar?
In ddl.sgml date should be lower case like the other types in "race_day
DATE,".
In ddl.sgml I suggest removing the "..." from the examples to make it
possible to copy paste them easily.
Your text wrapping in ddl.sqml and create_table.sgqml is quite
arbitrary. I suggest wrapping all paragraphs at 80 characters (except
for code which should not be wrapped). Your text editor probably has
tools for wrapping paragraphs.
Please be consistent about how you write table names and SQL in general.
I think almost all places use lower case for table names, while your
examples in create_table.sgml are FKTABLEFORARRAY.
Andreas
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Please find the new patch here, with your comments taken into consideration.
However, the following comment "Related to the above: I am not sure if it is a good idea to make ELEMENT a reserved word in column definitions. What if the SQL standard wants to use it for something?
Best Regards,
Mark Rofail
Attachment
Sorry for the very late review.
I like this feature and have needed it myself in the past, and the
current syntax seems pretty good. One could argue for if the syntax
could be generalized to support other things like json and hstore, but I
do not think it would be fair to block this patch due to that.
== Limitations of the current design
1) Array element foreign keys can only be specified at the table level
(not at columns): I think this limitation is fine. Other PostgreSQL
specific features like exclusion contraints can also only be specified
at the table level.
2) Lack of support for SET NULL and SET DEFAULT: these do not seem very
useful for arrays.
3) Lack of support for specifiying multiple arrays in the foreign key:
seems like a good thing to me since it is not obvious what such a thing
even would do.
4) That you need to add a cast to the index if you have different types:
due to there not being a int4[] <@ int2[] operator you need to add an
index on (col::int4[]) to speed up deletes and updates. This one i
annoying since EXPLAIN wont give you the query plans for the foreign key
queries, but I do not think fixing this should be within the scope of
the patch and that having a smaller interger in the referring table is rare.
5) The use of count(DISTINCT) requiring types to support btree equality:
this has been discussed a lot up-thread and I think the current state is
good enough.
== Functional review
I have played around some with it and things seem to work and the test
suite passes, but I noticed a couple of strange behaviors.
1) MATCH FULL does not seem to care about NULLS in arrays. In the
example below I expected both inserts into the referring table to fail.
CREATE TABLE t (x int, y int, PRIMARY KEY (x, y));
CREATE TABLE fk (x int, ys int[], FOREIGN KEY (x, EACH ELEMENT OF ys)
REFERENCES t MATCH FULL);
INSERT INTO t VALUES (10, 1);
INSERT INTO fk VALUES (10, '{1,NULL}');
INSERT INTO fk VALUES (NULL, '{1}');
CREATE TABLE
CREATE TABLE
INSERT 0 1
INSERT 0 1
ERROR: insert or update on table "fk" violates foreign key constraint
"fk_x_fkey"
DETAIL: MATCH FULL does not allow mixing of null and nonnull key values.
2) To me it was not obvious that ON DELETE CASCADE would delete the
whole rows rather than delete the members from the array, and this kind
of misunderstanding can lead to pretty bad surprises in production. I am
leaning towards not supporting CASCADE.
== The @>> operator
A previous version of your patch added the "anyelement <<@ anyarray"
operator to avoid having to build arrays, but that part was reverted due
to a bug.
I am not expert on the gin code, but as far as I can tell it would be
relatively simple to fix that bug. Just allocate an array of Datums of
length one where you put the element you are searching for (or maybe a
copy of it).
Potential issues with adding the operators:
1) Do we really want to add an operator just for array element foreign
keys? I think this is not an issue since it seems like it should be
useful in general. I know I have wanted it myself.
2) I am not sure, but the committers might prefer if adding the
operators is done in a separate patch.
3) Bikeshedding about operator names. I personally think @>> is clear
enough and as far as I know it is not used for anything else.
== Code review
The patch no longer applies to HEAD, but the conflicts are small.
I think we should be more consistent in the naming, both in code and in
the documentation. Right now we have "array foreign keys", "element
foreign keys", "ELEMENT foreign keys", etc.
+ /*
+ * If this is an array foreign key, we must look up the
operators for
+ * the array element type, not the array type itself.
+ */
+ if (fkreftypes[i] != FKCONSTR_REF_PLAIN)
+ if (fkreftypes[i] != FKCONSTR_REF_PLAIN)
+ {
+ old_fktype = get_base_element_type(old_fktype);
+ /* this shouldn't happen ... */
+ if (!OidIsValid(old_fktype))
+ elog(ERROR, "old foreign key column is not an array");
+ }
+ if (riinfo->fk_reftypes[i] != FKCONSTR_REF_PLAIN)
+ {
+ riinfo->has_array = true;
+ riinfo->ff_eq_oprs[i] = ARRAY_EQ_OP;
+ }
In the three diffs above it would be much cleaner to check for "==
FKCONSTR_REF_EACH_ELEMENT" since that better conveys the intent and is
safer for adding new types in the future.
+ /* We look through any domain here */
+ fktype = get_base_element_type(fktype);
What does the comment above mean?
if (!(OidIsValid(pfeqop) && OidIsValid(ffeqop))) ereport(ERROR,
(errcode(ERRCODE_DATATYPE_MISMATCH),
- errmsg("foreign key constraint \"%s\" "
- "cannot be implemented",
- fkconstraint->conname),
- errdetail("Key columns \"%s\" and \"%s\" "
- "are of incompatible types: %s and %s.",
+ errmsg("foreign key constraint \"%s\" cannot be
implemented",
+ fkconstraint->conname),
+ errdetail("Key columns \"%s\" and \"%s\" are of
incompatible types: %s and %s.", strVal(list_nth(fkconstraint->fk_attrs, i)),
strVal(list_nth(fkconstraint->pk_attrs, i)),
- format_type_be(fktype),
+ format_type_be(fktypoid[i]), format_type_be(pktype))));
The above diff looks like pointless code churn which possibly introduces
a bug in how it changed fktype to fktypoid[i].
I think the code in RI_Initial_Check() would be cleaner if you used
"CROSS JOIN LATERAL unnest(col)" rather than having unnest() in the
target list. This way you would not need to rename all columns and the
code paths for the array case could look more like the code path for the
normal case.
== Minor things in the code
+ {
+ pk_attrs = lappend(pk_attrs, arg);
+ fk_reftypes = lappend_int(fk_reftypes, FKCONSTR_REF_PLAIN);
+ }
This is incorrectly indented.
I suggest that you should only allocate countbuf in RI_FKey_check() if
has_array is set.
I think the code would be more readable if both branches of
ri_GenerateQual() used the same pattern for whitespace so the
differences are easier to spot.
You can use DROP TABLE IF EXISTS to silence the "ERROR: table
"fktableforarray" does not exist" errors.
I am not sure that you need to test all combinations of ON UPDATE and ON
DELETE. I think it should be enough to test one of each ON UPDATE and
one of each ON DELETE should be enough.
+-- Create the foreign table
It is probably a bad idea to call the referencing table the foreign table.
+-- Repeat a similar test using INT4 keys coerced from INT2
This comment is repeated twice in the test suite.
== Documentation
Remove the ELEMENT REFERENCES form from
doc/src/sgml/ref/create_table.sgml since we no longer support it.
- FOREIGN KEY ( <replaceable
class="parameter">column_name</replaceable> [, ... ] ) REFERENCES
<replaceable class="parameter">reftable</replaceable> [ ( <replaceable
class="parameter">refcolumn</replaceable> [, ... ] ) ]
+ FOREIGN KEY ( [ELEMENT] <replaceable
class="parameter">column_name</replaceable> [, ... ] ) REFERENCES
<replaceable class="parameter">reftable</replaceable> [ ( <replaceable
class="parameter">refcolumn</replaceable> [, ... ] ) ]
Change this to "FOREIGN KEY ( [EACH ELEMENT OF] ...".
- <term><literal>FOREIGN KEY ( <replaceable
class="parameter">column_name</replaceable> [, ... ] )
+ <term><literal>FOREIGN KEY ( [ELEMENT] <replaceable
class="parameter">column_name</replaceable> [, ... ] )
Change this to "... FOREIGN KEY ( [EACH ELEMENT OF] ...".
+ <literal>ELEMENT</literal> keyword and <replaceable
Change this to "... <literal>EACH ELEMENT OF</literal> ...". Maybe you
should also fix other instances of ELEMENT in the same paragraph but
these are less obvious.
You should remove the "ELEMENT REFERENCES" section of
doc/src/sgml/ref/create_table.sgml, and move any still relevant bits
elsewhere since we do not support this syntax.
The sql-createtable-foreign-key-arrays section need to be updated to
remove references to "ELEMENT REFERENCES".
Your indentation in doc/src/sgml/catalogs.sgml is two spaces but the
rest of the file looks like it uses 1 space indentation. Additionally
you seem to have accidentally reindented something which was correctly
indented.
Same with the idnentation in doc/src/sgml/ddl.sgml and
doc/src/sgml/ref/create_table.sgml.
- <varlistentry>
+ <varlistentry id="sql-createtable-foreign-key" xreflabel="FOREIGN KEY">
You have accidentally reindented this in doc/src/sgml/ref/create_table.sgml.
The paragraph in doc/src/sgml/ref/create_table.sgml which starts with
"In case the column name" seems to actually be multiple paragraphs. Is
that intentional or a mistake?
The documentation in doc/src/sgml/ddl.sgml mentions that "it must be
written in table constraint form" for when you have multiple columns,
but I feel this is just redundant and confusing since this is always
true, both for array foreign keys and for when you have multiple columns.
The documentation in doc/src/sgml/ddl.sgml should mention that we only
support one array reference per foreign key.
Maybe the documentation in doc/src/sgml/ddl.sgml should mention that we
only support the table constraint form.
Andreas
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
>1) MATCH FULL does not seem to care about NULLS in arrays. In the example below I expected both inserts into the referring table to fail.
>2) To me it was not obvious that ON DELETE CASCADE would delete the whole rows rather than delete the members from the array, and this kind of misunderstanding can lead to pretty bad surprises in production. I am leaning towards not supporting CASCADE.
>I think the code in RI_Initial_Check() would be cleaner if you used "CROSS JOIN LATERAL unnest(col)" rather than having unnest() in the target list. This way you would not need to rename all columns and the code paths for the array case could look more like the code path for the normal case.
Mark Rofail
Attachment
On 11/10/2017 01:47 AM, Mark Rofail wrote:
> I am sorry for the late reply
There is no reason for you to be. It did not take you 6 weeks to do a
review. :) Thanks for this new version.
> == Functional review
>
> >1) MATCH FULL does not seem to care about NULLS in arrays. In the
> example below I expected both inserts into the referring table to fail.
>
>
> It seems in your example the only failed case was: INSERT INTO fk VALUES
> (NULL, '{1}');
> which shouldn't work, can you clarify this?
I think that if you use MATH FULL the query should fail if you have a
NULL in the array.
> >2) To me it was not obvious that ON DELETE CASCADE would delete
> the whole rows rather than delete the members from the array, and
> this kind of misunderstanding can lead to pretty bad surprises in
> production. I am leaning towards not supporting CASCADE.
>
>
> I would say so too, maybe we should remove ON DELETE CASCADE until we
> have supported all remaining actions.
I am leaning towards this too. I would personally be fine with a first
version without support for CASCADE since it is not obvious to me what
CASCADE should do.
> == The @>> operator
> I would argue that allocating an array of datums and building an array
> would have the same complexity
I am not sure what you mean here. Just because something has the same
complexity does not mean there can't be major performance differences.
> == Code review
>
> >I think the code in RI_Initial_Check() would be cleaner if you
> used "CROSS JOIN LATERAL unnest(col)" rather than having unnest() in
> the target list. This way you would not need to rename all columns
> and the code paths for the array case could look more like the code
> path for the normal case.
>
> Can you clarify what you mean a bit more?
I think the code would look cleaner if you generate the following query:
SELECT fk.x, fk.ys FROM ONLY t2 fk CROSS JOIN LATERAL
pg_catalog.unnest(ys) a2 (v) LEFT OUTER JOIN ONLY t1 pk ON pk.x = fk.x
AND pk.y = a2.v WHERE [...]
rather than:
SELECT fk.k1, fk.ak2 FROM (SELECT x k1, pg_catalog.unnest(ys) k2, ys ak2
FROM ONLY t2) fk LEFT OUTER JOIN ONLY t1 pk ON pk.x = fk.k1 AND pk.y =
fk.k2 WHERE [...]
= New stuff
When applying the patch I got some white space warnings:
Array-ELEMENT-foreign-key-v5.3.patch:1343: space before tab in indent,
indent with spaces. format_type_be(oprleft), format_type_be(oprright))));
Array-ELEMENT-foreign-key-v5.3.patch:1345: trailing whitespace.
When compiling I got an error:
ri_triggers.c: In function ‘ri_GenerateQual’:
ri_triggers.c:2693:19: error: unknown type name ‘d’ Oid oprcommon;d ^
ri_triggers.c:2700:3: error: conflicting types for ‘oprright’ oprright = get_array_type(operform->oprleft);
^~~~~~~~
ri_triggers.c:2691:9: note: previous declaration of ‘oprright’ was here Oid oprright; ^~~~~~~~
<builtin>: recipe for target 'ri_triggers.o' failed
When building the documentation I got two warnings:
/usr/bin/osx:catalogs.sgml:2349:17:W: empty end-tag
/usr/bin/osx:catalogs.sgml:2350:17:W: empty end-tag
When running the tests I got a failure in element_foreign_key.
Andreas
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
>2) To me it was not obvious that ON DELETE CASCADE would deletethe whole rows rather than delete the members from the array, and
this kind of misunderstanding can lead to pretty bad surprises in
production. I am leaning towards not supporting CASCADE.
I would say so too, maybe we should remove ON DELETE CASCADE until we have supported all remaining actions.
== The @>> operator
I would argue that allocating an array of datums and building an array would have the same complexity
I am not sure what you mean here. Just because something has the same complexity does not mean there can't be major performance differences.
= New stuff
== Functional review
>1) MATCH FULL does not seem to care about NULLS in arrays. In the
example below I expected both inserts into the referring table to fail.
It seems in your example the only failed case was: INSERT INTO fk VALUES (NULL, '{1}');
which shouldn't work, can you clarify this?
I think that if you use MATH FULL the query should fail if you have a NULL in the array.
== Code review
>I think the code in RI_Initial_Check() would be cleaner if you
used "CROSS JOIN LATERAL unnest(col)" rather than having unnest() in
the target list. This way you would not need to rename all columns
and the code paths for the array case could look more like the code
path for the normal case.
Can you clarify what you mean a bit more?
I think the code would look cleaner if you generate the following query:
SELECT fk.x, fk.ys FROM ONLY t2 fk CROSS JOIN LATERAL pg_catalog.unnest(ys) a2 (v) LEFT OUTER JOIN ONLY t1 pk ON pk.x = fk.x AND pk.y = a2.v WHERE [...]
rather than:
SELECT fk.k1, fk.ak2 FROM (SELECT x k1, pg_catalog.unnest(ys) k2, ys ak2 FROM ONLY t2) fk LEFT OUTER JOIN ONLY t1 pk ON pk.x = fk.k1 AND pk.y = fk.k2 WHERE [...]
Best Regards,
Mark Rofail
Attachment
On 11/13/2017 12:32 PM, Mark Rofail wrote: > == The @>> operator > I would argue that allocating an array of datums and building an > array would have the same complexity > > > I am not sure what you mean here. Just because something has the > same complexity does not mean there can't be major performance > differences. > > I have spend a lot of time working on this operator and would like to > benefit from it. How should I go about this ? Start a new patch ? I am still not sure what you mean here. Feel free to add @>> to this patch if you like. You may want to submit it as two patch files (but please keep them as the same commitfest entry) but I leave that decision all up to you. > So the two main issues we remain to resolve are MATCH FULL and the > RI_Initial_Check() query refactoring. The problem is that I am not one > of the original authors and have not touched this part of the code. > I understand the problem but it will take some time for me to understand > how to resolve everything. Cool, feel free to ask if you need some assistance. I want this patch. Andreas
On Mon, Nov 27, 2017 at 10:47 AM, Andreas Karlsson <andreas@proxel.se> wrote: > Cool, feel free to ask if you need some assistance. I want this patch. The last patch submitted did not get a review, and it does not apply as well. So I am moving it to next CF with waiting on author as status. Please rebase the patch. -- Michael
Here's a rebased version of this patch. I have done nothing other than fix the conflicts and verify that it passes existing regression tests. I intend to go over the reviews sometime later and hopefully get it all fixed for inclusion in pg11. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
1) MATCH FULL does not seem to care about NULLS in arrays. In the example below I expected both inserts into the referring table to fail.
CREATE TABLE t (x int, y int, PRIMARY KEY (x, y));
CREATE TABLE fk (x int, ys int[], FOREIGN KEY (x, EACH ELEMENT OF ys) REFERENCES t MATCH FULL);
INSERT INTO t VALUES (10, 1);
INSERT INTO fk VALUES (10, '{1,NULL}');
INSERT INTO fk VALUES (NULL, '{1}');
CREATE TABLE
CREATE TABLE
INSERT 0 1
INSERT 0 1
ERROR: insert or update on table "fk" violates foreign key constraint "fk_x_fkey"
DETAIL: MATCH FULL does not allow mixing of null and nonnull key values.
2) I think the code in RI_Initial_Check() would be cleaner if you used "CROSS JOIN LATERAL unnest(col)" rather than having unnest() in the target list. This way you would not need to rename all columns and the code paths for the array case could look more like the code path for the normal case.
Mark Rofail wrote:
> > 1) MATCH FULL does not seem to care about NULLS in arrays. In the example
> > below I expected both inserts into the referring table to fail.
> >
> > CREATE TABLE t (x int, y int, PRIMARY KEY (x, y));
> > CREATE TABLE fk (x int, ys int[], FOREIGN KEY (x, EACH ELEMENT OF ys) REFERENCES t MATCH FULL);
> > INSERT INTO t VALUES (10, 1);
> > INSERT INTO fk VALUES (10, '{1,NULL}');
> > INSERT INTO fk VALUES (NULL, '{1}');
> >
> I understand that Match full should contain nulls in the results. However,
> I don't think that it's semantically correct, so I suggest we don't use
> Match full. What would be the consequences of that ?
Well, I think you could get away with not supporting MATCH FULL with
array FK references (meaning you ought to raise an error if you see it) ...
clearly EACH ELEMENT OF is an extension of the spec so we're not forced
to comply with all the clauses. On the other hand, it would be better if it
can be made to work.
If I understand correctly, you would need a new operator similar to @>
but which rejects NULLs in order to implement MATCH FULL, right?
> > 2) I think the code in RI_Initial_Check() would be cleaner if you used
> > "CROSS JOIN LATERAL unnest(col)" rather than having unnest() in the target
> > list. This way you would not need to rename all columns and the code paths
> > for the array case could look more like the code path for the normal case.
> >
> I have repeatedly tried to generate the suggested query using C code and I
> failed. I would like some help with it
Well, the way to go about it would be to first figure out what is the
correct SQL query, and only later try to implement it in C. Is SQL the
problem, or is it C? I'm sure we can get in touch with somebody that
knows a little bit of SQL. Can you do a write-up of the query requirements?
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
I think the code would look cleaner if you generate the following query:
SELECT fk.x, fk.ys FROM ONLY t2 fk CROSS JOIN LATERAL pg_catalog.unnest(ys) a2 (v) LEFT OUTER JOIN ONLY t1 pk ON pk.x = fk.x AND pk.y = a2.v WHERE [...]
rather than:
SELECT fk.k1, fk.ak2 FROM (SELECT x k1, pg_catalog.unnest(ys) k2, ys ak2 FROM ONLY t2) fk LEFT OUTER JOIN ONLY t1 pk ON pk.x = fk.k1 AND pk.y = fk.k2 WHERE [...]
> > 2) I think the code in RI_Initial_Check() would be cleaner if you used
> > "CROSS JOIN LATERAL unnest(col)" rather than having unnest() in the target
> > list. This way you would not need to rename all columns and the code paths
> > for the array case could look more like the code path for the normal case.
== The @>> operator
A previous version of your patch added the "anyelement <<@ anyarray" operator to avoid having to build arrays, but that part was reverted due to a bug.
I am not expert on the gin code, but as far as I can tell it would be relatively simple to fix that bug. Just allocate an array of Datums of length one where you put the element you are searching for (or maybe a copy of it).
> > 1) MATCH FULL does not seem to care about NULLS in arrays. In the example
> > below I expected both inserts into the referring table to fail.
> >
> > CREATE TABLE t (x int, y int, PRIMARY KEY (x, y));
> > CREATE TABLE fk (x int, ys int[], FOREIGN KEY (x, EACH ELEMENT OF ys) REFERENCES t MATCH FULL);
> > INSERT INTO t VALUES (10, 1);
> > INSERT INTO fk VALUES (10, '{1,NULL}');
> > INSERT INTO fk VALUES (NULL, '{1}');
Attachment
On 01/21/2018 10:36 PM, Mark Rofail wrote: > == The @>> operator > > A previous version of your patch added the "anyelement <<@ anyarray" > operator to avoid having to build arrays, but that part was reverted > due to a bug. > > I am not expert on the gin code, but as far as I can tell it would > be relatively simple to fix that bug. Just allocate an array of > Datums of length one where you put the element you are searching for > (or maybe a copy of it). > > The @>> is now restored and functioning correctly, all issues with > contrib libraries has been resolved Hi, I looked some at your anyarray @>> anyelement code and sadly it does not look like the index code could work. The issue I see is that ginqueryarrayextract() needs to make a copy of the search key but to do so it needs to know the type of anyelement (to know if it needs to detoast, etc). But there is as far as I can tell no way to check the type of anyelement in this context. Am I missing something? Andreas
I looked some at your anyarray @>> anyelement code and sadly it does not look like the index code could work. The issue I see is that ginqueryarrayextract() needs to make a copy of the search key but to do so it needs to know the type of anyelement (to know if it needs to detoast, etc). But there is as far as I can tell no way to check the type of anyelement in this context.
On 02/01/2018 04:17 PM, Mark Rofail wrote: > since its a polymorphic function it only passes if the `anyarray` is the > same type of the `anyelement` so we are sure they are the same type. > Can't we get the type from the anyarray ? the type is already stored in > ` arr_type`. In theory, yes, but I saw no obvious way to get it without major changes to the code. Unless I am missing something, of course. If I am right my recommendation for getting this patch in is to initially skip the new operators and go back to the version of the patch which uses @>. Andreas
If I am right my recommendation for getting this patch in is to
initially skip the new operators and go back to the version of the patch
which uses @>.
So yes, I move towards delaying the introduction of @>> to the patch.
Attachment
The patch looks good to me now other than some smaller issues, mostly in
the documentation. If you fix these I will set it as ready for
committer, and let a committer chime in on the casting logic which we
both find a bit ugly.
== Comments
The only a bit bigger issue I see is the error messages. Can they be
improved?
For example:
CREATE TABLE t1 (a int, b int, PrIMARY KEY (a, b));
CREATE TABLE t2 (a int, bs int8[], FOREIGN KEY (a, EACH ELEMENT OF bs)
REFERENCES t1 (a, b));
INSERT INTO t2 VALUES (0, ARRAY[1, 2]);
Results in:
ERROR: insert or update on table "t2" violates foreign key constraint
"t2_a_fkey"
DETAIL: Key (a, bs)=(0, {1,2}) is not present in table "t1".
Would it be possible to make the DETAIL something like the below
instead? Do you think my suggested error message is clear?
I am imaging something like the below as a patch. Does it look sane? The
test cases need to be updated at least.
diff --git a/src/backend/utils/adt/ri_triggers.c
b/src/backend/utils/adt/ri_triggers.c
index 402bde19d4..9dc7c9812c 100644
--- a/src/backend/utils/adt/ri_triggers.c
+++ b/src/backend/utils/adt/ri_triggers.c
@@ -3041,6 +3041,10 @@ ri_ReportViolation(const RI_ConstraintInfo *riinfo,
appendStringInfoString(&key_names, ", ");
appendStringInfoString(&key_values, ", ");
}
+
+ if (riinfo->fk_reftypes[idx] == FKCONSTR_REF_EACH_ELEMENT)
+ appendStringInfoString(&key_names, "EACH ELEMENT OF ");
+
appendStringInfoString(&key_names, name);
appendStringInfoString(&key_values, val);
}
DETAIL: Key (a, EACH ELEMENT OF bs)=(0, {1,2}) is not present in table
"t1".
- REFERENCES <replaceable class="parameter">reftable</replaceable> [ (
<replaceable class="parameter">refcolumn</replaceable> ) ] [ MATCH FULL
| MATCH PARTIAL | MATCH SIMPLE ]
+ [EACH ELEMENT OF] REFERENCES <replaceable
class="parameter">reftable</replaceable> [ ( <replaceable
class="parameter">refcolumn</replaceable> ) ] [ MATCH FULL | MATCH
PARTIAL | MATCH SIMPLE ]
I think this documentation in doc/src/sgml/ref/create_table.sgml should
be removed since it is no longer correct.
+ <para>
+ Foreign Key Arrays are an extension
+ of PostgreSQL and are not included in the SQL standard.
+ </para>
This pargraph and some of the others you added to
doc/src/sgml/ref/create_table.sgml are strangely line wrapped.
+ <varlistentry>
+ <term><literal>ON DELETE CASCADE</literal></term>
+ <listitem>
+ <para>
+ Same as standard foreign key constraints. Deletes the entire
array.
+ </para>
+ </listitem>
+ </varlistentry>
+ </variablelist>
I thought this was no longer supported.
+ however, this syntax will cast ftest1 to int4 upon RI checks,
thus defeating the
+ purpose of the index.
There is a minor indentation error on these lines.
+
+ <para>
+ Array <literal>ELEMENT</literal> foreign keys and the <literal>ELEMENT
+ REFERENCES</literal> clause are a
<productname>PostgreSQL</productname>
+ extension.
+ </para>
We do not have any ELEMENT REFERENCES clause.
- ereport(ERROR,
- (errcode(ERRCODE_DATATYPE_MISMATCH),
- errmsg("foreign key constraint \"%s\" "
- "cannot be implemented",
- fkconstraint->conname),
- errdetail("Key columns \"%s\" and \"%s\" "
- "are of incompatible types: %s and %s.",
- strVal(list_nth(fkconstraint->fk_attrs, i)),
- strVal(list_nth(fkconstraint->pk_attrs, i)),
- format_type_be(fktype),
- format_type_be(pktype))));
+ ereport(ERROR,
+ (errcode(ERRCODE_DATATYPE_MISMATCH),
+ errmsg("foreign key constraint \"%s\" "
+ "cannot be implemented",
+ fkconstraint->conname),
+ errdetail("Key columns \"%s\" and \"%s\" "
+ "are of incompatible types: %s and %s.",
+ strVal(list_nth(fkconstraint->fk_attrs, i)),
+ strVal(list_nth(fkconstraint->pk_attrs, i)),
+ format_type_be(fktype),
+ format_type_be(pktype))));
It seems like you accidentally change the indentation here,
Andreas
The patch looks good to me now other than some smaller issues, mostly in the documentation. If you fix these I will set it as ready for committer, and let a committer chime in on the casting logic which we both find a bit ugly
Can you give the docs another look. I re-wrapped, re-indented and changed all `Foreign Key Arrays` to `Array Element Foreign Keys` for consistency.
Attachment
On 02/06/2018 11:15 AM, Mark Rofail wrote: > A new patch including all the fixes is ready. > > Can you give the docs another look. I re-wrapped, re-indented and > changed all `Foreign Key Arrays` to `Array Element Foreign Keys` for > consistency. Looks good to me so set it to ready for committer. I still feel the type casting logic is a bit ugly but I am not sure if it can be improved much. Andreas
Andreas Karlsson wrote: > On 02/06/2018 11:15 AM, Mark Rofail wrote: > > A new patch including all the fixes is ready. > > > > Can you give the docs another look. I re-wrapped, re-indented and > > changed all `Foreign Key Arrays` to `Array Element Foreign Keys` for > > consistency. > > Looks good to me so set it to ready for committer. I still feel the type > casting logic is a bit ugly but I am not sure if it can be improved much. I gave this a quick look. I searched for the new GIN operator so that I could brush it up for commit ahead of the rest -- only to find out that it was eviscerated from the patch between v5 and v5.1. The explanation for doing so is that the GIN code had some sort of bug that made it crash; so the performance was measured to see if the GIN operator was worth it, and the numbers are pretty confusing (the test don't seem terribly exhaustive; some numbers go up, some go down, it doesn't appear that the tests were run more than once for each case therefore the numbers are pretty noisy) so the decision was to ditch all the GIN support code anyway ..?? I didn't go any further since ISTM the GIN operator prerequisite was there for good reasons, so we'll need to see much more evidence that it's really unneeded before deciding to omit it. At this point I'm not sure what to do with this patch. It needs a lot of further work, for which I don't have time now, and given the pressure we're under I think we should punt it to the next dev cycle. Here's a rebased pgindented version. I renamed the regression test. I didn't touch anything otherwise. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On 3/7/18 5:43 AM, Alvaro Herrera wrote: > > At this point I'm not sure what to do with this patch. It needs a lot > of further work, for which I don't have time now, and given the pressure > we're under I think we should punt it to the next dev cycle. > > Here's a rebased pgindented version. I renamed the regression test. I > didn't touch anything otherwise. I have changed this entry to Waiting on Author in case Mark wants to comment. At the end of the CF it will be Returned with Feedback. Regards, -- -David david@pgmasters.net
On 3/7/18 5:43 AM, Alvaro Herrera wrote:
I searched for the new GIN operator so that I could brush it up for commit ahead of the rest -- only to find out that it was eviscerated from the patch between v5 and v5.1.
On Wed, Jan 31, 2018 at 1:52 AM, Andreas Karlsson <andreas(at)proxel(dot)se> wrote:
The issue I see is that ginqueryarrayextract() needs to make a copy of the search key but to do so it needs to know the type of anyelement (to know if it needs to detoast, etc). But there is as far as I can tell no way to check the type of anyelement in this context.
Hi Mark, On 3/26/18 4:50 PM, Mark Rofail wrote: > On 3/7/18 5:43 AM, Alvaro Herrera wrote: > > I searched for the new GIN operator so that I > could brush it up for commit ahead of the rest -- only to find out that > it was eviscerated from the patch between v5 and v5.1. > > The latest version of the patch which contained the new GIN operator is > version `*Array-ELEMENT-foreign-key-v6.patch > <https://www.postgresql.org/message-id/attachment/58007/Array-ELEMENT-foreign-key-v6.patch>*` > which works fine and passed all the regression tests at the time > (2018-01-21). We abandoned the GIN operator since it couldn't follow the > same logic as the rest of GIN operators use since it operates on a Datum > not an array. Not because of any error. > > just as Andreas said > > On Wed, Jan 31, 2018 at 1:52 AM, Andreas Karlsson <andreas(at)proxel(dot)se> wrote: > > The issue I see is that > ginqueryarrayextract() needs to make a copy of the search key but to do > so it needs to know the type of anyelement (to know if it needs to > detoast, etc). But there is as far as I can tell no way to check the > type of anyelement in this context. > > > If there is any way to obtain a copy of the datum I would be more than > happy to integrate the GIN operator to the patch. Since you have expressed a willingness to continue work on this patch I have moved it to the next CF in Waiting on Author state. You should produce a new version by then that addresses Alvaro's concerns and I imagine that will require quite a bit of discussion and work. Everyone is a bit fatigued at the moment so it would best to hold off on that for a while. Regards, -- -David david@pgmasters.net
You should produce a new version by then that addresses Alvaro's
concerns and I imagine that will require quite a bit of discussion and
work.
I'll produce a patch with two alternate versions, one with and one without the GIN operators.
so the performance was measured to see if the GIN operator was
worth it, and the numbers are pretty confusing (the test don't seem
terribly exhaustive; some numbers go up, some go down, it doesn't appear
that the tests were run more than once for each case therefore the
numbers are pretty noisy
> On Wed, Jan 31, 2018 at 1:52 AM, Andreas Karlsson <andreas(at)proxel(dot)se> wrote:
>
> The issue I see is that
> ginqueryarrayextract() needs to make a copy of the search key but to do
> so it needs to know the type of anyelement (to know if it needs to
> detoast, etc). But there is as far as I can tell no way to check the
> type of anyelement in this context.
>
> If there is any way to obtain a copy of the datum I would be more than
> happy to integrate the GIN operator to the patch.
Mark Rofail wrote: > Hello David, > > On Tue, Apr 10, 2018 at 3:47 PM, David Steele <david@pgmasters.net> wrote: > > > You should produce a new version by then that addresses Alvaro's > > concerns and I imagine that will require quite a bit of discussion and > > work. > > I'll get working. > I'll produce a patch with two alternate versions, one with and one without > the GIN operators. I'd rather see one patch with just the GIN operator (you may think it's a very small patch, but that's only because you forget to add documentation to it and a few extensive tests to ensure it works well); then the array-fk stuff as a follow-on patch. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
documentation to it and a few extensive tests to ensure it works well);
We need more *exhaustive* tests to test performance, not functionality.
Mark Rofail wrote: > On Tue, Apr 10, 2018 at 3:59 PM, Alvaro Herrera <alvherre@alvh.no-ip.org> > wrote: > > > > documentation to it and a few extensive tests to ensure it works well); > > I think the existing regression tests verify that the patch works as > expectations, correct? I meant for the GIN operator. (Remember, these are two patches, and each of them needs its own tests.) > We need more *exhaustive* tests to test performance, not functionality. True. So my impression from the numbers you posted last time is that you need to run each measurement case several times, and provide averages/ stddevs/etc for the resulting numbers, and see about outliers (maybe throw them away, or maybe they indicate some problem in the test or in the code); then we can make an informed decision about whether the variations between the several different scenarios are real improvements (or pessimizations) or just measurement noise. In particular: it seemed to me that you decided to throw away the idea of the new GIN operator without sufficient evidence that it was unnecessary. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Mark Rofail wrote:
I meant for the GIN operator. (Remember, these are two patches, and each
of them needs its own tests.)
True. So my impression from the numbers you posted last time is that
you need to run each measurement case several times, and provide
averages/ stddevs/etc for the resulting numbers, and see about outliers
(maybe throw them away, or maybe they indicate some problem in the test
or in the code); then we can make an informed decision about whether the
variations between the several different scenarios are real improvements
(or pessimizations) or just measurement noise.
In particular: it seemed to me that you decided to throw away the idea
of the new GIN operator without sufficient evidence that it was
unnecessary.
Mark Rofail wrote:
> On Tue, Apr 10, 2018 at 3:59 PM, Alvaro Herrera <alvherre@alvh.no-ip.org>
> wrote:
> >
> > documentation to it and a few extensive tests to ensure it works well);
>
> I think the existing regression tests verify that the patch works as
> expectations, correct?
I meant for the GIN operator. (Remember, these are two patches, and each
of them needs its own tests.)
> We need more *exhaustive* tests to test performance, not functionality.
True. So my impression from the numbers you posted last time is that
you need to run each measurement case several times, and provide
averages/ stddevs/etc for the resulting numbers, and see about outliers
(maybe throw them away, or maybe they indicate some problem in the test
or in the code); then we can make an informed decision about whether the
variations between the several different scenarios are real improvements
(or pessimizations) or just measurement noise.
In particular: it seemed to me that you decided to throw away the idea
of the new GIN operator without sufficient evidence that it was
unnecessary.
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Mark Rofail wrote: > > In particular: it seemed to me that you decided to throw away the idea > > of the new GIN operator without sufficient evidence that it was > > unnecessary. > > I have to admit to that. But in my defence @> is also GIN indexable so the > only difference in performance between 'anyarray @>> anyelement' and > 'anyarray @> ARRAY [anyelement]' is the delay caused by the ARRAY[] > operation theoretically. I think I need to review Tom's bounce-for-rework email https://postgr.es/m/28389.1351094795@sss.pgh.pa.us to respond to this intelligently. Tom mentioned @> there but there was a comment about the comparison semantics used by that operator, so I'm unclear on whether or not that issue has been fixed. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
1. Generate Table A with 5 rows
2. Generate Table B with n rows such as:
every row of Table B is an array of IDs referencing rows in Table A.
The tests we ran previously had Table B up to 1 million rows and the results can be seen here :
https://www.postgresql.org/message-id/CAJvoCusMuLnYZUbwTBKt%2Bp6bB9GwiTqF95OsQFHXixJj3LkxVQ%40mail.gmail.com
How would we change this so it would be more exhaustive and accurate?
Regards,
Mark Rofail
issue 1: `pg_constraint.c:564`
I need to check that `conppeqop` is not null and copy it but I don't know how to check its type since its a char*
issue 2: `matview.c:768`
I need to pass `fkreftype` but I don't have it in the rest of the function
In other news, I am currently working on exhaustive tests for the GIN operator, but some pointers on how to do so would be appreciated.
Regards,
Mark Rofail
I was wondering if anyone knows the proper way to write a benchmarking test for the @>> operator. I used the below script in my previous attempt https://gist.github.com/markrofail/174ed370a2f2ac248 00fde2fc27e2d38 The script does the following steps:
1. Generate Table A with 5 rows
2. Generate Table B with n rows such as:
every row of Table B is an array of IDs referencing rows in Table A.
The tests we ran previously had Table B up to 1 million rows and the results can be seen here :
https://www.postgresql.org/message-id/ CAJvoCusMuLnYZUbwTBKt% 2Bp6bB9GwiTqF95OsQFHXixJj3LkxV Q%40mail.gmail.com
How would we change this so it would be more exhaustive and accurate?
Regards,
Mark Rofail
Attachment
issue 1: `pg_constraint.c:564`
I need to check that `conppeqop` is not null and copy it but I don't know how to check its type since its a char*
issue 2: `matview.c:768`
I need to pass `fkreftype` but I don't have it in the rest of the functIonOn Wed, May 16, 2018 at 10:31 AM, Mark Rofail <markm.rofail@gmail.com> wrote:I was wondering if anyone knows the proper way to write a benchmarking test for the @>> operator. I used the below script in my previous attempt https://gist.github.com/markrofail/174ed370a2f2ac24800fde2fc27e2d38The script does the following steps:
1. Generate Table A with 5 rows
2. Generate Table B with n rows such as:
every row of Table B is an array of IDs referencing rows in Table A.
The tests we ran previously had Table B up to 1 million rows and the results can be seen here :
https://www.postgresql.org/message-id/CAJvoCusMuLnYZUbwTBKt%2Bp6bB9GwiTqF95OsQFHXixJj3LkxVQ%40mail.gmail.com
How would we change this so it would be more exhaustive and accurate?
Regards,
Mark Rofail
On Sat, Aug 11, 2018 at 05:20:57AM +0200, Mark Rofail wrote: > I am still having problems rebasing this patch. I can not figure it out on > my own. Okay, it's been a couple of months since this last email, and nothing has happened, so I am marking it as returned with feedback. -- Michael
Attachment
I am trying to revive this patch, Foreign Key Arrays. The original proposal from my GSoC 2017 days can be found here:
https://www.postgresql.org/message-id/flat/1343842863.5162.4.camel%40greygoo.devise-it.lan#1343842863.5162.4.camel@greygoo.devise-it.lan
ALTER TABLE B ADD CONSTRAINT FKARRAY FOREIGN KEY (EACH ELEMENT OF btest1) REFERENCES A;
On Sat, Aug 11, 2018 at 05:20:57AM +0200, Mark Rofail wrote:
> I am still having problems rebasing this patch. I can not figure it out on
> my own.
Okay, it's been a couple of months since this last email, and nothing
has happened, so I am marking it as returned with feedback.
--
Michael
Greetings,
I am trying to revive this patch, Foreign Key Arrays. The original proposal from my GSoC 2017 days can be found here:Disclaimer, I am not the original author of this patch, I picked up this patch in 2017 to migrate the original patch from 2012 and add a GIN index to make it usable as the performance without a GIN index is not usable after 100 rows.The original authors, Tom Lane and Marco Nenciarini, are the ones who did most of the heavy lifting. The original discussion can be found here:
https://www.postgresql.org/message-id/flat/1343842863.5162.4.camel%40greygoo.devise-it.lan#1343842863.5162.4.camel@greygoo.devise-it.lanIn brief, it would be used as follows:```sqlCREATE TABLE A ( atest1 int PRIMARY KEY, atest2 text );CREATE TABLE B ( btest1 int[], btest2 int );
ALTER TABLE B ADD CONSTRAINT FKARRAY FOREIGN KEY (EACH ELEMENT OF btest1) REFERENCES A;```and now table B references table A as follows:```sqlINSERT INTO B VALUES ('{10,1}', 2);```where this row references rows 1 and 10 from A without the need of a many-to-many tableChangelog (since the last version, v8):- v9 (made compatible with Postgresql 11)support `DeconstructFkConstraintRow`support `CloneFkReferencing`support `generate_operator_clause`- v10 (made compatible with Postgresql v12)support `addFkRecurseReferenced` and `addFkRecurseReferencing`support `CloneFkReferenced` and `CloneFkReferencing`migrate tests- v11(make compatible with Postgresql v13)drop `ConvertTriggerToFK`drop `select_common_type_2args` in favor of `select_common_type_from_oids`migrate tests- v12(made compatible with current master, 2021-01-23, commit a8ed6bb8f4cf259b95c1bff5da09a8f4c79dca46)add ELEMENT to `bare_label_keyword`migrate docsTodo:- re-add @>> operator which allows comparison of between array and element and returns true iff the element is within the arrayto allow easier select statements and lower overhead of explicitly creating an array within the SELECT statement.```diff- SELECT * FROM B WHERE btest1 @> ARRAY[5];+ SELECT * FROM B WHERE btest1 @>> 5;```I apologize it took so long to get a new version here (years). However, this is not the first time I tried to migrate the patch, every time a different issue blocked me from doing so.Reviews and suggestions are most welcome, @Joel Jacobson please review and test as previously agreed./MarkOn Tue, Oct 2, 2018 at 7:13 AM Michael Paquier <michael@paquier.xyz> wrote:On Sat, Aug 11, 2018 at 05:20:57AM +0200, Mark Rofail wrote:
> I am still having problems rebasing this patch. I can not figure it out on
> my own.
Okay, it's been a couple of months since this last email, and nothing
has happened, so I am marking it as returned with feedback.
--
Michael
Attachment
+ ARR_DIMS(arr)[0] != numkeys ||
+ ARR_HASNULL(arr) ||
+ ARR_ELEMTYPE(arr) != CHAROID)
+ elog(ERROR, "confreftype is not a 1-D char array");
+ * that's been put into the rest of the RI mechanisms to make them
+ */
+ char confreftype[1];
> Changelog (since the last version, v8):Below are the versions mentioned in the changelog. v12 is the latest version./MarkOn Sat, Jan 23, 2021 at 2:34 PM Mark Rofail <markm.rofail@gmail.com> wrote:Greetings,
I am trying to revive this patch, Foreign Key Arrays. The original proposal from my GSoC 2017 days can be found here:Disclaimer, I am not the original author of this patch, I picked up this patch in 2017 to migrate the original patch from 2012 and add a GIN index to make it usable as the performance without a GIN index is not usable after 100 rows.The original authors, Tom Lane and Marco Nenciarini, are the ones who did most of the heavy lifting. The original discussion can be found here:
https://www.postgresql.org/message-id/flat/1343842863.5162.4.camel%40greygoo.devise-it.lan#1343842863.5162.4.camel@greygoo.devise-it.lanIn brief, it would be used as follows:```sqlCREATE TABLE A ( atest1 int PRIMARY KEY, atest2 text );CREATE TABLE B ( btest1 int[], btest2 int );
ALTER TABLE B ADD CONSTRAINT FKARRAY FOREIGN KEY (EACH ELEMENT OF btest1) REFERENCES A;```and now table B references table A as follows:```sqlINSERT INTO B VALUES ('{10,1}', 2);```where this row references rows 1 and 10 from A without the need of a many-to-many tableChangelog (since the last version, v8):- v9 (made compatible with Postgresql 11)support `DeconstructFkConstraintRow`support `CloneFkReferencing`support `generate_operator_clause`- v10 (made compatible with Postgresql v12)support `addFkRecurseReferenced` and `addFkRecurseReferencing`support `CloneFkReferenced` and `CloneFkReferencing`migrate tests- v11(make compatible with Postgresql v13)drop `ConvertTriggerToFK`drop `select_common_type_2args` in favor of `select_common_type_from_oids`migrate tests- v12(made compatible with current master, 2021-01-23, commit a8ed6bb8f4cf259b95c1bff5da09a8f4c79dca46)add ELEMENT to `bare_label_keyword`migrate docsTodo:- re-add @>> operator which allows comparison of between array and element and returns true iff the element is within the arrayto allow easier select statements and lower overhead of explicitly creating an array within the SELECT statement.```diff- SELECT * FROM B WHERE btest1 @> ARRAY[5];+ SELECT * FROM B WHERE btest1 @>> 5;```I apologize it took so long to get a new version here (years). However, this is not the first time I tried to migrate the patch, every time a different issue blocked me from doing so.Reviews and suggestions are most welcome, @Joel Jacobson please review and test as previously agreed./MarkOn Tue, Oct 2, 2018 at 7:13 AM Michael Paquier <michael@paquier.xyz> wrote:On Sat, Aug 11, 2018 at 05:20:57AM +0200, Mark Rofail wrote:
> I am still having problems rebasing this patch. I can not figure it out on
> my own.
Okay, it's been a couple of months since this last email, and nothing
has happened, so I am marking it as returned with feedback.
--
Michael
Thank you for your prompt review.
Is the above going to be addressed in subsequent patches
Changelog:
* add not null assertions to"SplitFKColElems"
I encourage everyone to take review this patch. After considerable reviews and performance testing, it will be ready for a commitfest.
Attachment
HINT: No operator matches the given name and argument types. You might need to add explicit type casts.QUERY: SELECT 1 WHERE (SELECT pg_catalog.count(DISTINCT y) FROM pg_catalog.unnest($1) y) OPERATOR(pg_catalog.=) (SELECT pg_catalog.count(*) FROM (SELECT 1 FROM ONLY "catalog_clone"."pg_type" x WHERE $1 OPERATOR(pg_catalog. @>) ARRAY["oid"] FOR KEY SHARE OF x) z)It seems to me there is some type conversion between oidvector and oid[] that isn't working properly?
I am aware of the problem and will try to fix it, but I assume this is because of "Array-containselem-gin-v1.patch" can you give the v13 patch a try alone?
UPDATE catalog_clone.pg_index SET indkey = '1 2 12345'::int2vector WHERE indexrelid = 2837;ERROR: operator does not exist: int2vector pg_catalog.@> smallint[]LINE 1: ...WHERE "attrelid" OPERATOR(pg_catalog.=) $1 AND $2 OPERATOR(p...
UPDATE catalog_clone.pg_index SET indkey = '1 2 12345'::int2vector WHERE indexrelid = 2837;ERROR: operator does not exist: int2vector pg_catalog.@> smallint[]LINE 1: ...WHERE "attrelid" OPERATOR(pg_catalog.=) $1 AND $2 OPERATOR(p...In your example, you are using the notation '1 2 12345'::int2vector which signifies a vector as you have mentioned, however in this patch we use the array operator @> to help with the indexing, the incompatibility stems from here.I do not think that postgres contains vector operators, correct me if I am wrong. I feel that supporting vectors is our of the scope of this patch, if you have an idea how to support it please let me know.
Attachment
On 2021-Jan-24, Mark Rofail wrote: > I do not think that postgres contains vector operators, correct me if I am > wrong. I feel that supporting vectors is our of the scope of this patch, if > you have an idea how to support it please let me know. I do not think that this patch needs to support oidvector and int2vector types as if they were oid[] and int2[] respectively. If you really want an element FK there, you can alter the column types to the real array types in your catalog clone. oidvector and int2vector are internal implementation artifacts. -- Álvaro Herrera 39°49'30"S 73°17'W "Someone said that it is at least an order of magnitude more work to do production software than a prototype. I think he is wrong by at least an order of magnitude." (Brian Kernighan)
I'll continue testing over the next couple of days and report if I find any more oddities.
Thank you for your kind words and happy that you benefited from this patch.
Hi Mark,On Mon, Jan 25, 2021, at 09:14, Joel Jacobson wrote:I'll continue testing over the next couple of days and report if I find any more oddities.I've continued testing by trying to make full use of this feature in the catalog-diff-tool I'm working on.Today I became aware of a SQL feature that I must confess I've never used before,that turned out to be useful in my tool, as I then wouldn't need to follow FKsto do updates manually, but let the database do them automatically.I'm talking about "ON CASCADE UPDATE", which I see is not supported in the patch.In my tool, I could simplify the code for normal FKs by using ON CASCADE UPDATE,but will continue to need my hand-written traverse-FKs-recursively code for Foreign Key Arrays.I lived a long SQL life without ever needing ON CASCADE UPDATE,so I would definitively vote for Foreign Key Arrays to be added even without support for this.Would you say the patch is written in a way which would allow adding support for ON CASCADE UPDATElater on mostly by adding code, or would it require a major rewrite?I hesitated if I should share this with you, since I'm really grateful for this feature even without ON CASCADE UPDATE,but since this was discovered when testing real-life scenario and not some hypothetical example,I felt it should be noted that I stumbled upon this during testing.Again, thank you so much for working on this./Joel
As always, great catch!
On Tue, Jan 26, 2021, at 12:59, Mark Rofail wrote:> Please don't hesitate to give your feedback.The error message for insert or update violations looks fine:UPDATE catalog_clone.pg_extension SET extconfig = ARRAY[12345] WHERE oid = 10;ERROR: insert or update on table "pg_extension" violates foreign key constraint "pg_extension_extconfig_fkey"DETAIL: Key (EACH ELEMENT OF extconfig)=(12345) is not present in table "pg_class".But when trying to delete a still referenced row,the column mentioned in the "EACH ELEMENT OF" sentenceis not the array column, but the column in the referenced table:DELETE FROM catalog_clone.pg_class WHERE oid = 10;ERROR: update or delete on table "pg_class" violates foreign key constraint "pg_extension_extconfig_fkey" on table "pg_extension"DETAIL: Key (EACH ELEMENT OF oid)=(10) is still referenced from table "pg_extension".I think either the "EACH ELEMENT OF" part of the latter error message should be dropped,or the column name for the array column should be used./Joel
I think you forgot to attach the patch.
Attachment
I apologize for my rash response, I did not quite understand your example at first, it appears the UPDATE statement is neither over the referencing nor the referenced columns
+ ARR_HASNULL(arr) ||
+ ARR_ELEMTYPE(arr) != CHAROID)
+ elog(ERROR, "confreftype is not a 1-D char array");
+ * RESTRICT amd DELETE CASCADE actions
Hello Joel,I think you forgot to attach the patch.Appears so, sorry about that.Here it is./Mark
I think the ARR_HASNULL(arr) condition is not reflected in the error message.
I don't see CASCADE in the if condition that follows the above comment.
The code would be FKCONSTR_REF_EACH_ELEMENT and FKCONSTR_REF_PLAIN. I think you can mention them in the comment.
Attachment
This means, as a user, I might not be aware of the vector restriction when adding the foreign keysfor my existing schema, and think everything is fine, and not realize there is a problem untilnew data arrives.
/Mark
I have performed the performance comparison.
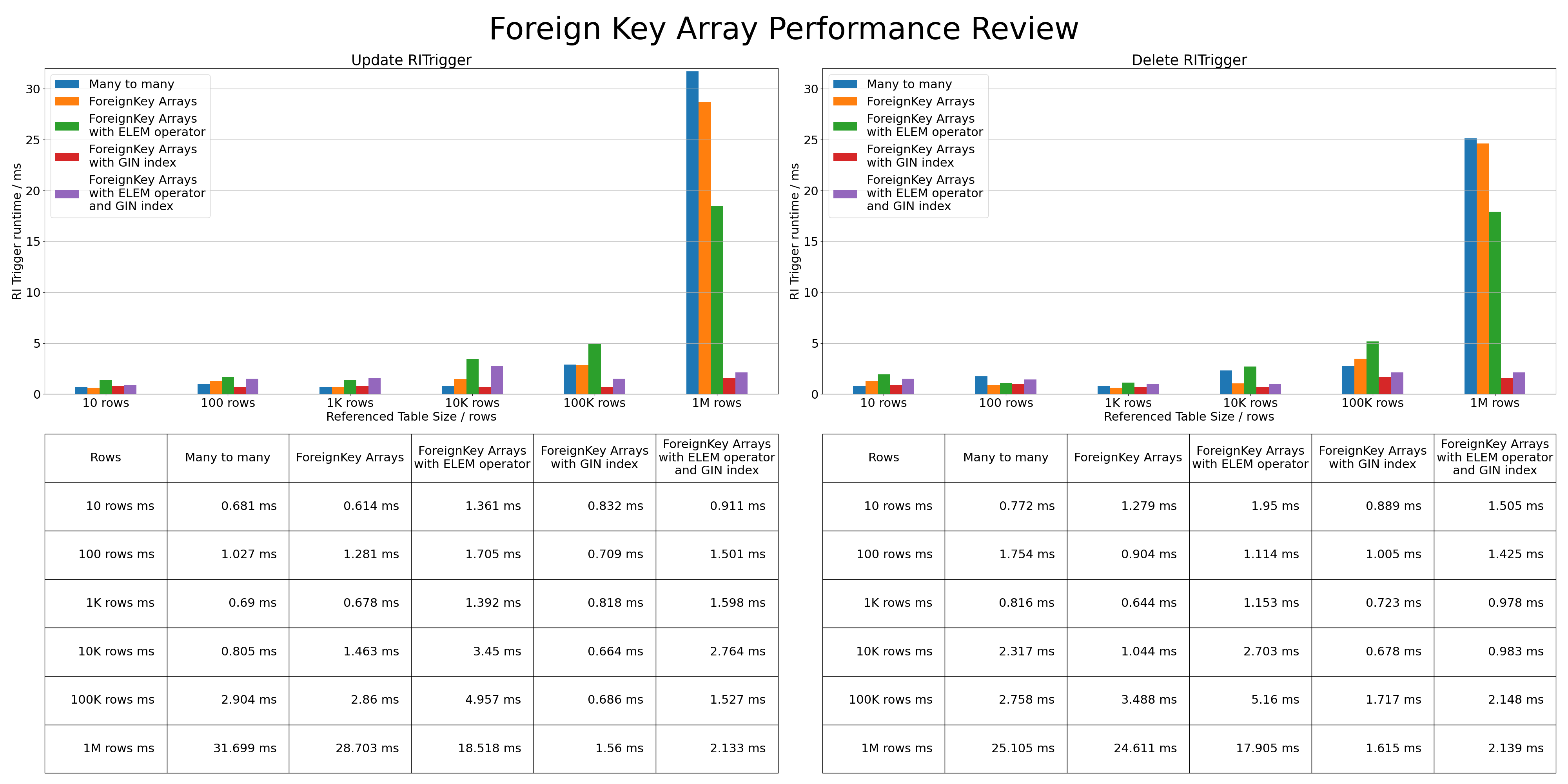
- create a referenced table of 1k rows
- create an SQL file for each case
- referencing table with array FKs
- referencing table with array FKs with ELEMENT operator <<@
- referencing table with array FKs and GIN index
- referencing table with array FKs with ELEMENT operator <<@ and GIN index
- referencing table with standard FKs through many2many table
- each case contains INSERT statements referencing the referenced table
- after which I trigger an UPDATE and DELETE statements on the referenced table
- UPDATE: "UPDATE pktableforarray SET ptest1 = 1001 WHERE pktableforarray.ptest1 = 1000;"
- DELETE: "DELETE FROM PKTABLEFORARRAY WHERE pktableforarray.ptest1 = 999;"
- UPDATE: "UPDATE pktableforarray SET ptest1 = 1001 WHERE pktableforarray.ptest1 = 1000;"
- I repeat this for 10^1, 10^2, 10^3, 10^4, 10^5, and 10^6 rows.
- v17 (compatible with current master 2021-02-02, commit 1d71f3c83c113849fe3aa60cb2d2c12729485e97)
* refactor "generate_operator_clause"
Changelog (FK arrays Elem addon)
* fix bug in "ginqueryarrayextract"
Attachment
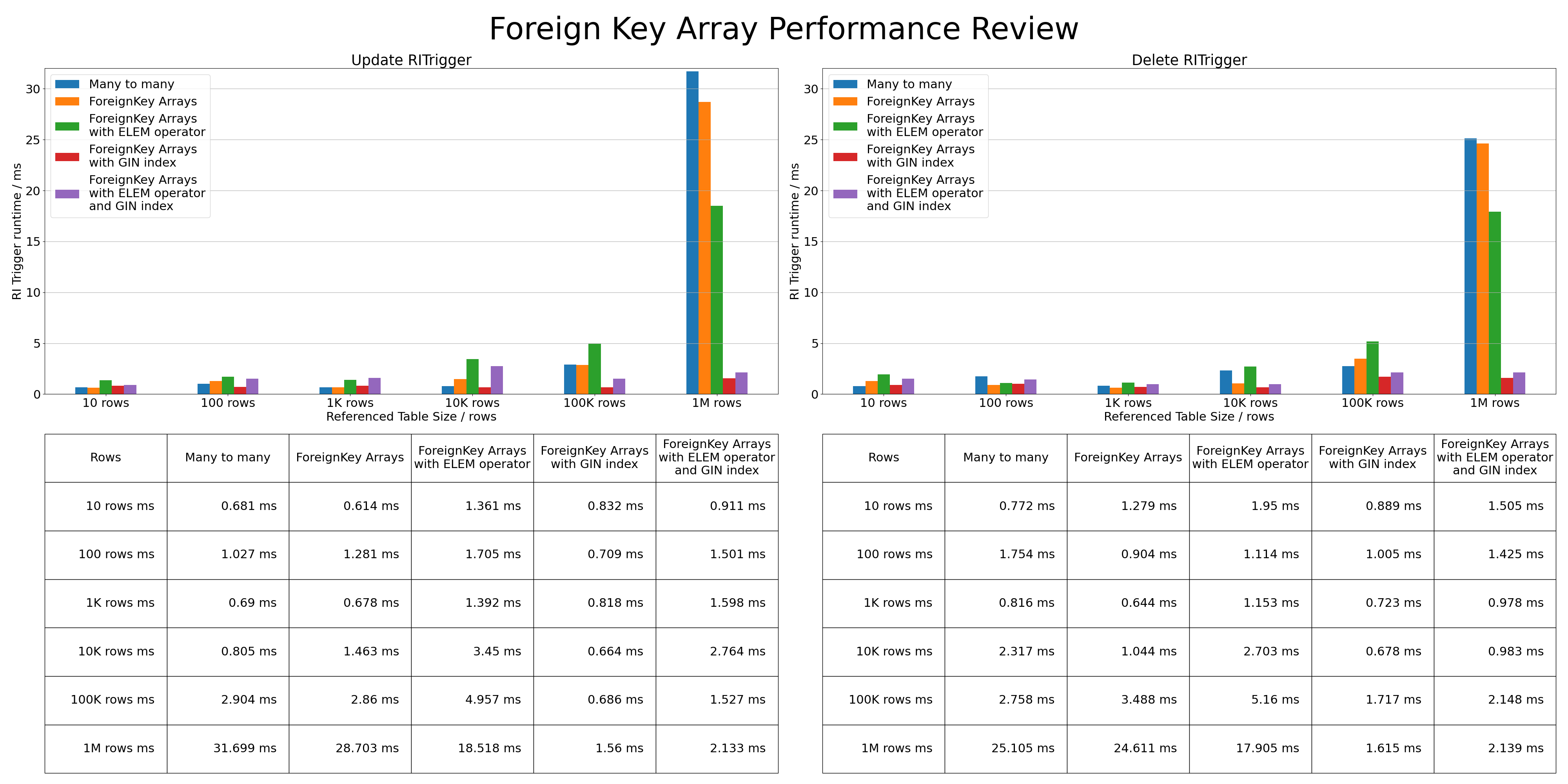{kind=link}
No error, even though bigint[] isn't compatible with smallint.
Please try v18 attached below, you should get the following message
```
ERROR: foreign key constraint "fktableviolating_ftest1_fkey" cannot be implemented
DETAIL: Specified columns have element types smallint and bigint which are not homogenous.
```
- v18 (compatible with current master 2021-02-54, commit c34787f910585f82320f78b0afd53a6a170aa229)
* add check for operand compatibility at constraint creation
Changelog (FK arrays Elem addon)
* re-add Composite Type support
I believe we should start merging these two patches as one, due to the Elem addon's benefits. such as adding Composite Type support.
/Mark
On Tue, Feb 2, 2021, at 13:51, Mark Rofail wrote:>Array-ELEMENT-foreign-key-v17.patchWhen working on my pit tool, I found another implicit type casts problem.First an example to show a desired error message:CREATE TABLE a (a_id smallint,PRIMARY KEY (a_id));CREATE TABLE b (b_id bigint,a_ids text[],PRIMARY KEY (b_id));ALTER TABLE b ADD FOREIGN KEY (EACH ELEMENT OF a_ids) REFERENCES a;The below error message is good:ERROR: foreign key constraint "b_a_ids_fkey" cannot be implementedDETAIL: Key column "a_ids" has element type text which does not have a default btree operator class that's compatible with class "int2_ops".But if we instead make a_ids a bigint[], we don't get any error:DROP TABLE b;CREATE TABLE b (b_id bigint,a_ids bigint[],PRIMARY KEY (b_id));ALTER TABLE b ADD FOREIGN KEY (EACH ELEMENT OF a_ids) REFERENCES a;No error, even though bigint[] isn't compatible with smallint.We do get an error when trying to insert into the table:INSERT INTO a (a_id) VALUES (1);INSERT INTO b (b_id, a_ids) VALUES (2, ARRAY[1]);ERROR: operator does not exist: smallint[] pg_catalog.<@ bigint[]LINE 1: ..."."a" x WHERE ARRAY ["a_id"]::pg_catalog.anyarray OPERATOR(p...^HINT: No operator matches the given name and argument types. You might need to add explicit type casts.QUERY: SELECT 1 WHERE (SELECT pg_catalog.count(DISTINCT y) FROM pg_catalog.unnest($1) y) OPERATOR(pg_catalog.=) (SELECT pg_catalog.count(*) FROM (SELECT 1 FROM ONLY "public"."a" x WHERE ARRAY ["a_id"]::pg_catalog.anyarray OPERATOR(pg_catalog.<@) $1::pg_catalog.anyarray FOR KEY SHARE OF x) z)I wonder if we can come up with some general way to detect theseproblems already at constraint creation time,instead of having to wait for data to get the error,similar to why compile time error are preferred over run time errors./Joel
Attachment
Hello Joel,No error, even though bigint[] isn't compatible with smallint.I added a check to compart the element type of the fkoperand and the type of the pkoperand should be the same
Please try v18 attached below, you should get the following message
```
ERROR: foreign key constraint "fktableviolating_ftest1_fkey" cannot be implemented
DETAIL: Specified columns have element types smallint and bigint which are not homogenous.
```Changelog (FK arrays):
- v18 (compatible with current master 2021-02-54, commit c34787f910585f82320f78b0afd53a6a170aa229)
* add check for operand compatibility at constraint creation
Changelog (FK arrays Elem addon)- v4 (compatible with FK arrays v18)
* re-add Composite Type support
I believe we should start merging these two patches as one, due to the Elem addon's benefits. such as adding Composite Type support.
/MarkOn Thu, Feb 4, 2021 at 9:00 AM Joel Jacobson <joel@compiler.org> wrote:On Tue, Feb 2, 2021, at 13:51, Mark Rofail wrote:>Array-ELEMENT-foreign-key-v17.patchWhen working on my pit tool, I found another implicit type casts problem.First an example to show a desired error message:CREATE TABLE a (a_id smallint,PRIMARY KEY (a_id));CREATE TABLE b (b_id bigint,a_ids text[],PRIMARY KEY (b_id));ALTER TABLE b ADD FOREIGN KEY (EACH ELEMENT OF a_ids) REFERENCES a;The below error message is good:ERROR: foreign key constraint "b_a_ids_fkey" cannot be implementedDETAIL: Key column "a_ids" has element type text which does not have a default btree operator class that's compatible with class "int2_ops".But if we instead make a_ids a bigint[], we don't get any error:DROP TABLE b;CREATE TABLE b (b_id bigint,a_ids bigint[],PRIMARY KEY (b_id));ALTER TABLE b ADD FOREIGN KEY (EACH ELEMENT OF a_ids) REFERENCES a;No error, even though bigint[] isn't compatible with smallint.We do get an error when trying to insert into the table:INSERT INTO a (a_id) VALUES (1);INSERT INTO b (b_id, a_ids) VALUES (2, ARRAY[1]);ERROR: operator does not exist: smallint[] pg_catalog.<@ bigint[]LINE 1: ..."."a" x WHERE ARRAY ["a_id"]::pg_catalog.anyarray OPERATOR(p...^HINT: No operator matches the given name and argument types. You might need to add explicit type casts.QUERY: SELECT 1 WHERE (SELECT pg_catalog.count(DISTINCT y) FROM pg_catalog.unnest($1) y) OPERATOR(pg_catalog.=) (SELECT pg_catalog.count(*) FROM (SELECT 1 FROM ONLY "public"."a" x WHERE ARRAY ["a_id"]::pg_catalog.anyarray OPERATOR(pg_catalog.<@) $1::pg_catalog.anyarray FOR KEY SHARE OF x) z)I wonder if we can come up with some general way to detect theseproblems already at constraint creation time,instead of having to wait for data to get the error,similar to why compile time error are preferred over run time errors./Joel
On 2021-Feb-05, Mark Rofail wrote: > I believe we should start merging these two patches as one, due to the Elem > addon's benefits. such as adding Composite Type support. I disagree -- I think we should get the second patch in, and consider it a requisite for the other one. Let's iron it out fully and get it pushed soon, then we can rebase the array FK patch on top. I think it's missing docs, though. I wonder if it can usefully get cross-type operators, i.e., @>>(bigint[],smallint) in some way? Maybe the "anycompatiblearray" thing can be used for that purpose? -- Álvaro Herrera 39°49'30"S 73°17'W "Pido que me den el Nobel por razones humanitarias" (Nicanor Parra)
I disagree -- I think we should get the second patch in, and consider it
a requisite for the other one.
Hello Mark On 2021-Feb-05, Mark Rofail wrote: > I disagree -- I think we should get the second patch in, and consider it > > a requisite for the other one. > > I just want to make sure I got your last message right. We should work on > adding the <<@ and @>> operators and their GIN logic as a separate patch > then submit the FKARRAY as a future patch? Well, *I* think it makes sense to do it that way. I said so three years ago :-) https://postgr.es/m/20180410135917.odjh5coa4cjatz5v@alvherre.pgsql > So basically reverse the order of the patches. Yeah. Thanks a lot for your persistence, by the way. -- Álvaro Herrera 39°49'30"S 73°17'W "We're here to devour each other alive" (Hobbes)
Greetings, * Alvaro Herrera (alvherre@alvh.no-ip.org) wrote: > On 2021-Feb-05, Mark Rofail wrote: > > I disagree -- I think we should get the second patch in, and consider it > > > a requisite for the other one. > > > > I just want to make sure I got your last message right. We should work on > > adding the <<@ and @>> operators and their GIN logic as a separate patch > > then submit the FKARRAY as a future patch? > > Well, *I* think it makes sense to do it that way. I said so three years > ago :-) > https://postgr.es/m/20180410135917.odjh5coa4cjatz5v@alvherre.pgsql > > > So basically reverse the order of the patches. > > Yeah. I tend to agree with Alvaro on this, that getting the operators in first makes more sense. > Thanks a lot for your persistence, by the way. +100 Hopefully we'll get this in during this cycle and perhaps then you'll work on something else? :D Great to see a GSoC student continue to work with the community years after the GSoC they participated in. If you'd be interested in being a mentor for this upcoming GSoC season, please let me know! Thanks! Stephen
Attachment
Well, *I* think it makes sense to do it that way. I said so three years
ago :-)
https://postgr.es/m/20180410135917.odjh5coa4cjatz5v@alvherre.pgsql
I wonder if it can usefully get cross-type
operators, i.e., @>>(bigint[],smallint) in some way? Maybe the
"anycompatiblearray" thing can be used for that purpose?
@>>(anyarray, anycompatiblenonearray) and <<@(anycompatiblenonearray, anyarray)
Thanks a lot for your persistence, by the way.
https://commitfest.postgresql.org/32/2966/
Changelog (operator patch):
* add tests and documentation to array operators and gin index
/Mark
Attachment
> Thanks a lot for your persistence, by the way.
+100
Hopefully we'll get this in during this cycle and perhaps then you'll work on something else? :D
Great to see a GSoC student continue to work
with the community years after the GSoC they participated in. If you'd
be interested in being a mentor for this upcoming GSoC season, please
let me know!
Changelog (operator patch):- v1 (compatible with current master 2021-02-05, commit c444472af5c202067a9ecb0ff8df7370fb1ea8f4)
* add tests and documentation to array operators and gin index
ftest2 int PRIMARY KEY,
FOREIGN KEY (EACH ELEMENT OF ftest1) REFERENCES PKTABLEFORARRAY
ON DELETE NO ACTION ON UPDATE NO ACTION);
CREATE INDEX ON FKTABLEFORARRAY USING gin (ftest1 array_ops);
-- Populate Table
INSERT INTO FKTABLEFORARRAY VALUES ('5', 1);
INSERT INTO FKTABLEFORARRAY VALUES ('3 2', 2);
INSERT INTO FKTABLEFORARRAY VALUES ('3 5 2 5', 3);
Attachment
On 2021-Feb-07, Mark Rofail wrote: > Changelog (operator patch): > > - v1 (compatible with current master 2021-02-05, > > commit c444472af5c202067a9ecb0ff8df7370fb1ea8f4) > > * add tests and documentation to array operators and gin index > > > Since we agreed to separate @>> and <<@ operators to prerequisite patch to > the FK Arrays, I have rebased the patch to be applied on > "anyarray_anyelement_operators-vX.patch" Um, where is that other patch? -- Álvaro Herrera 39°49'30"S 73°17'W
[Found it :-)] On 2021-Feb-05, Mark Rofail wrote: > We will focus on getting the operator patch through first. Should I create > a separate commitfest ticket? or the current one suffices? > https://commitfest.postgresql.org/32/2966/ I think the current one is fine. In fact I would encourage you to post both patches together as two attachment in the same email; that way, the CF bot would pick them up correctly. When you post them in separate emails, it doesn't know what to do with them. See here: http://cfbot.cputube.org/mark-rofail.html -- Álvaro Herrera 39°49'30"S 73°17'W
In fact I would encourage you to post
both patches together as two attachment in the same email;
Changelog (operator patch):- v1 (compatible with current master 2021-02-05, commit c444472af5c202067a9ecb0ff8df7370fb1ea8f4)
* add tests and documentation to array operators and gin index
Changelog (FK Arrays)
- v1 (compatible with anyarray_anyelement_operators-v1.patch)
* rebase on anyarray_anyelement_operators-v1.patch
* support coercion
* support vectors instead of arrays
Attachment
anyarray_anyelement_operators-v1.patch
Thanks again for your thorough review!
I was surprised to see <<@ and @>> don't complain when trying to compare incompatible types:Indeed you are right, to support the correct behaviour we have to use @>>(anycompatiblearray, anycompatiblenonarry) and this throws a sanity error in opr_santiy since the left operand doesn't equal the gin opclass which is anyarray. I am thinking to solve this we need to add a new opclass under gin "compatible_array_ops" beside the already existing "array_ops", what do you think?
Maybe it's the combination of "anyarray" and "anycompatiblenonarray" that is the problem here?
@Alvaro your input here would be valuable.
I included the @>>(anycompatiblearray, anycompatiblenonarry) for now as a fix to the segmentation fault and incompatible data types in v2, the error messages should be listed correctly as follows:
```sql
select '1'::text <<@ ARRAY[1::integer,2::integer];ERROR: operator does not exist: text <<@ integer[]LINE 1: select '1'::text <<@ ARRAY[1::integer,2::integer];HINT: No operator matches the given name and argument types. You might need to add explicit type casts.select 1::integer <<@ ARRAY['1'::text,'2'::text];ERROR: operator does not exist: integer <<@ text[]LINE 1: select 1::integer <<@ ARRAY['1'::text,'2'::text];HINT: No operator matches the given name and argument types. You might need to add explicit type casts.
doc/src/sgml/func.sgml
+ Does the array contain specified element ?
* Maybe remove the extra blank space before question mark?
doc/src/sgml/indices.sgmlAddressed in v2.
-<@ @> = &&
+<@ @> <<@ @>> = &&
* To me it looks like the pattern is to insert between each operator
src/backend/access/gin/ginarrayproc.cAddressed in v2.
/* Make copy of array input to ensure it doesn't disappear while in use */
- ArrayType *array = PG_GETARG_ARRAYTYPE_P_COPY(0);
+ ArrayType *array;
I think the comment above should be changed/moved
src/backend/utils/adt/arrayfuncs.cAddressed in v2.
+ /*
+ * We assume that the comparison operator is strict, so a NULL can't
+ * match anything. XXX this diverges from the "NULL=NULL" behavior of
+ * array_eq, should we act like that?
+ */
It seems unnecessary to have this open question.
array_contains_elem(AnyArrayType *array, Datum elem,Addressed in v2.
+ /*
+ * Apply the comparison operator to each pair of array elements.
+ */
This comment has been copy/pasted from array_contain_compare().
Maybe the wording should clarify there is only one array in this function,
the word "pair" seems to imply working with two arrays.
+ for (i = 0; i < nelems; i++)Addressed in v2.
+ {
+ Datum elt1;
The name `elt1` originates from the array_contain_compare() function.
But since this function, array_contains_elem(), doesn't have a `elt2`,
it would be better to use `elt` as a name here. The same goes for `it1`.
- anyarray_anyelement_operators-v2.patch (compatible with current master 2021-02-12, commit 993bdb9f935a751935a03c80d30857150ba2b645):
* all issues discussed above
Attachment
+ oprresult = DatumGetBool(FunctionCallInvoke(locfcinfo));-+ if (oprresult)++ if (!locfcinfo->isnull && oprresult)+ return true;+ }Is checking !locfcinfo->isnull due to something new in v2,or what is just a correction for a problem also in v1?
test opr_sanity ... FAILEDAND binary_coercible(p2.opcintype, p1.amoplefttype));amopfamily | amopstrategy | amopopr------------+--------------+----------(0 rows)+ 2745 | 5 | 6105+(1 row)-- Operators that are primary members of opclasses must be immutable (else-- it suggests that the index ordering isn't fixed). Operators that are
Attachment
I know that avoiding trivial coercion problems is convenient but at the end of the day, it's the DB Architect's job to use the proper tables to be able to use FK Arrays.
For instance, if we have two tables, TABLE A (atest1 int2) and TABLE B (btest1 int, btest2 int4[]) and an FK constraint between A(atest1) and B(btest2), it simply shouldn't work. btest2 should be of type int2[].
Thus, I have reverted back the signature @>>(anyarray,anyelement) and <<@(anyelement,anyarray). I am open to discuss this if anyone has any input, would be appreciated.
Changelog:
* refactor ginqueryarrayextract in ginarrayproc.c
* revert back the signature @>>(anyarray,anyelement) and <<@(anyelement,anyarray)
Hi all,I've reviewed Mark's anyarray_anyelement_operators-v2.patchand the only remaining issue I've identified is the opr_sanity problem.Mark seems to be in need of some input here from more experienced hackers, see below.Hopefully someone can guide him in the right direction./JoelOn Sat, Feb 13, 2021, at 11:49, Mark Rofail wrote:>Hey Joel,>>test opr_sanity ... FAILED>> AND binary_coercible(p2.opcintype, p1.amoplefttype));> amopfamily | amopstrategy | amopopr>------------+--------------+--------->-(0 rows)>+ 2745 | 5 | 6105>+(1 row)>-- Operators that are primary members of opclasses must be immutable (else>-- it suggests that the index ordering isn't fixed). Operators that are>This is due using anycompatiblearray for the left operand in @>>.>To solve this problem we need to use @>>(anyarray,anyelement) or introduce a new opclass for gin indices.>These are the two approaches that come to mind to solve this. Which one is the right way or is there another solution I am not aware of?>That’s why I’m asking this on the mailing list, to get the community’s input.
Attachment
Attachment
Hmm, I think it looks like you forgot to update the documentation? It still says anycompatiblenonarray.
Anyway, I've tested the patch, not only using your tests, but also the attached test.No problems were found. Good.
Attachment
The following review has been posted through the commitfest application: make installcheck-world: tested, passed Implements feature: tested, passed Spec compliant: tested, passed Documentation: tested, passed I've tested and reviewed anyarray_anyelement_operators-v4.patch. The added code is based on array_contain_compare() and the changes are mostly mechanical. The new status of this patch is: Ready for Committer
I will now proceed with the review of fk_arrays_elem_v2 as well.
On 3/15/21 4:29 PM, Mark Rofail wrote: > Actually, your fix led me in the right way, the issue was how windows > handle pointers. Hi, I have started working on a partially new strategy for the second patch. The ideas are: 1. I have removed the dependency on count(DISTINCT ...) by using an anti-join instead (this was implemented by Joel Jacobson with cleanup and finishing touches by me). The code is much clearer now IMHO. 2. That instead of selecting operators at execution time we save which operators to use in pg_constraint. This is heavily a work in progress in my attached patches. I am not 100% convinced this is the right way to go but I plan to work some on this this weekend to see how ti will work out. Another thing I will look into is you gin patch. While you fixed it for simple scalar types which fit into the Datum type I wonder if we do not also need to copy types which are too large to fit into a Datum but I have not investigated yet which memory context the datum passed to ginqueryarrayextract() is allocated in. Andreas
Attachment
Thank you so much for your hard work!
1. I have removed the dependency on count(DISTINCT ...) by using an
anti-join instead. The code is much clearer now IMHO.
2. That instead of selecting operators at execution time we save whichThis is a clever approach. If you have any updates on this please let me know.
operators to use in pg_constraint.
I am still reviewing your changes. I have split your changes from my work to be able to isolate the changes and review them carefully. And to help others review the changes.
Changelist:
* rebase
On 3/15/21 4:29 PM, Mark Rofail wrote:
> Actually, your fix led me in the right way, the issue was how windows
> handle pointers.
Hi,
I have started working on a partially new strategy for the second patch.
The ideas are:
1. I have removed the dependency on count(DISTINCT ...) by using an
anti-join instead (this was implemented by Joel Jacobson with cleanup
and finishing touches by me). The code is much clearer now IMHO.
2. That instead of selecting operators at execution time we save which
operators to use in pg_constraint. This is heavily a work in progress in
my attached patches. I am not 100% convinced this is the right way to go
but I plan to work some on this this weekend to see how ti will work out.
Another thing I will look into is you gin patch. While you fixed it for
simple scalar types which fit into the Datum type I wonder if we do not
also need to copy types which are too large to fit into a Datum but I
have not investigated yet which memory context the datum passed to
ginqueryarrayextract() is allocated in.
Andreas
Attachment
Hey Andreas and Joel!
Thank you so much for your hard work!1. I have removed the dependency on count(DISTINCT ...) by using an
anti-join instead. The code is much clearer now IMHO.It is much cleaner! I2. That instead of selecting operators at execution time we save whichThis is a clever approach. If you have any updates on this please let me know.
operators to use in pg_constraint.
I am still reviewing your changes. I have split your changes from my work to be able to isolate the changes and review them carefully. And to help others review the changes.
Changelist:- v11 (compatible with current master 2021, 03, 20, commit e835e89a0fd267871e7fbddc39ad00ee3d0cb55c)
* rebase* split andreas and joel's workOn Tue, Mar 16, 2021 at 1:27 AM Andreas Karlsson <andreas@proxel.se> wrote:On 3/15/21 4:29 PM, Mark Rofail wrote:
> Actually, your fix led me in the right way, the issue was how windows
> handle pointers.
Hi,
I have started working on a partially new strategy for the second patch.
The ideas are:
1. I have removed the dependency on count(DISTINCT ...) by using an
anti-join instead (this was implemented by Joel Jacobson with cleanup
and finishing touches by me). The code is much clearer now IMHO.
2. That instead of selecting operators at execution time we save which
operators to use in pg_constraint. This is heavily a work in progress in
my attached patches. I am not 100% convinced this is the right way to go
but I plan to work some on this this weekend to see how ti will work out.
Another thing I will look into is you gin patch. While you fixed it for
simple scalar types which fit into the Datum type I wonder if we do not
also need to copy types which are too large to fit into a Datum but I
have not investigated yet which memory context the datum passed to
ginqueryarrayextract() is allocated in.
Andreas
Hi,In v11-0004-fk_arrays_elems_edits.patch :+ riinfo->fk_reftypes[i] == FKCONSTR_REF_EACH_ELEMENT ? OID_ARRAY_ELEMCONTAINED_OP : riinfo->pf_eq_oprs[i], // XXXIs XXX placeholder for some comment you will fill in later ?CheersOn Sat, Mar 20, 2021 at 11:42 AM Mark Rofail <markm.rofail@gmail.com> wrote:Hey Andreas and Joel!
Thank you so much for your hard work!1. I have removed the dependency on count(DISTINCT ...) by using an
anti-join instead. The code is much clearer now IMHO.It is much cleaner! I2. That instead of selecting operators at execution time we save whichThis is a clever approach. If you have any updates on this please let me know.
operators to use in pg_constraint.
I am still reviewing your changes. I have split your changes from my work to be able to isolate the changes and review them carefully. And to help others review the changes.
Changelist:- v11 (compatible with current master 2021, 03, 20, commit e835e89a0fd267871e7fbddc39ad00ee3d0cb55c)
* rebase* split andreas and joel's workOn Tue, Mar 16, 2021 at 1:27 AM Andreas Karlsson <andreas@proxel.se> wrote:On 3/15/21 4:29 PM, Mark Rofail wrote:
> Actually, your fix led me in the right way, the issue was how windows
> handle pointers.
Hi,
I have started working on a partially new strategy for the second patch.
The ideas are:
1. I have removed the dependency on count(DISTINCT ...) by using an
anti-join instead (this was implemented by Joel Jacobson with cleanup
and finishing touches by me). The code is much clearer now IMHO.
2. That instead of selecting operators at execution time we save which
operators to use in pg_constraint. This is heavily a work in progress in
my attached patches. I am not 100% convinced this is the right way to go
but I plan to work some on this this weekend to see how ti will work out.
Another thing I will look into is you gin patch. While you fixed it for
simple scalar types which fit into the Datum type I wonder if we do not
also need to copy types which are too large to fit into a Datum but I
have not investigated yet which memory context the datum passed to
ginqueryarrayextract() is allocated in.
Andreas
Looking at 0001+0003, I see it claims GIN support for <<@ and @>>, but actually only the former is implemented fully; the latter is missing a strategy number in ginarrayproc.c and pg_amop.dat, and also src/test/regress/sql/gin.sql does not test it. I suspect ginqueryarrayextract needs to be told about this too. -- Álvaro Herrera 39°49'30"S 73°17'W "This is what I like so much about PostgreSQL. Most of the surprises are of the "oh wow! That's cool" Not the "oh shit!" kind. :)" Scott Marlowe, http://archives.postgresql.org/pgsql-admin/2008-10/msg00152.php
Looking at 0001+0003, I see it claims GIN support for <<@ and @>>, but
actually only the former is implemented fully; the latter is missing a
strategy number in ginarrayproc.c and pg_amop.dat, and also
src/test/regress/sql/gin.sql does not test it. I suspect
ginqueryarrayextract needs to be told about this too.
On 2021-Mar-27, Mark Rofail wrote: > Hello Alvaro, > > Looking at 0001+0003, I see it claims GIN support for <<@ and @>>, but > > actually only the former is implemented fully; the latter is missing a > > strategy number in ginarrayproc.c and pg_amop.dat, and also > > src/test/regress/sql/gin.sql does not test it. I suspect > > ginqueryarrayextract needs to be told about this too. > > GIN/array_ops requires the left operand to be an array, so only @>> can be > used in GIN. > > However, <<@ is defined as @>> commutative counterpart, so > when for example “5 <<@ index” it will be translated to “index @>> index” > thus indirectly using the GIN index. Ah, that makes sense. Looking at the docs again, I don't see anything that's wrong. I was confused about the lack of a new strategy number, but that's explained by what you say above. > We can definitely add tests to “ src/test/regress/sql/gin.sql” to test > this. Do you agree? Yes, we should do that. > Also what do you mean by “ ginqueryarrayextract needs to be told about this > too”? Well, if it's true that it's translated to the commutator, then I don't think any other code changes are needed. -- Álvaro Herrera 39°49'30"S 73°17'W "En las profundidades de nuestro inconsciente hay una obsesiva necesidad de un universo lógico y coherente. Pero el universo real se halla siempre un paso más allá de la lógica" (Irulan)
Well, if it's true that it's translated to the commutator, then I don't
think any other code changes are needed.
Yes, we should do that.
* add more tests to “ src/test/regress/sql/gin.sql”
Attachment
On Tue, Mar 30, 2021 at 2:14 AM Mark Rofail <markm.rofail@gmail.com> wrote: > > Hey Alvaro > >> Yes, we should do that. > > I have attached v12 with more tests in “ src/test/regress/sql/gin.sql” > > Changelog: > - v12 (compatible with current master 2021/03/29, commit 6d7a6feac48b1970c4cd127ee65d4c487acbb5e9) > * add more tests to “ src/test/regress/sql/gin.sql” > * merge Andreas' edits to the GIN patch > > Also, @Andreas Karlsson, waiting for your edits to "pg_constraint" The patch does not apply on Head anymore, could you rebase and post a patch. I'm changing the status to "Waiting for Author". Regards, Vignesh
On 2021-Jul-14, vignesh C wrote: > The patch does not apply on Head anymore, could you rebase and post a > patch. I'm changing the status to "Waiting for Author". BTW I gave a look at this patch in the March commitfest and concluded it still requires some major surgery that I didn't have time for. I did so by re-reading early in the thread to understand what the actual requirements were for this feature to work, and it seemed to me that the patch started to derail at some point. I suggest that somebody needs to write up exactly what we need, lest the patches end up implementing something else. I don't have time for this patch during the current commitfest, and I'm not sure that I will during the next one. If somebody else wants to spend time with it, ... be my guest. -- Álvaro Herrera Valdivia, Chile — https://www.EnterpriseDB.com/ "Sallah, I said NO camels! That's FIVE camels; can't you count?" (Indiana Jones)
> On 14 Jul 2021, at 18:07, Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2021-Jul-14, vignesh C wrote: > >> The patch does not apply on Head anymore, could you rebase and post a >> patch. I'm changing the status to "Waiting for Author". > > BTW I gave a look at this patch in the March commitfest and concluded it > still requires some major surgery that I didn't have time for. I did so > by re-reading early in the thread to understand what the actual > requirements were for this feature to work, and it seemed to me that the > patch started to derail at some point. I suggest that somebody needs to > write up exactly what we need, lest the patches end up implementing > something else. > > I don't have time for this patch during the current commitfest, and I'm > not sure that I will during the next one. If somebody else wants to > spend time with it, ... be my guest. Given the above, and that nothing has happened on this thread since this note, I think we should mark this Returned with Feedback and await a new submission. Does that seem reasonable Alvaro? -- Daniel Gustafsson https://vmware.com/
On 2021-Sep-14, Daniel Gustafsson wrote: > Given the above, and that nothing has happened on this thread since this note, > I think we should mark this Returned with Feedback and await a new submission. > Does that seem reasonable Alvaro? It seems reasonable to me. -- Álvaro Herrera Valdivia, Chile — https://www.EnterpriseDB.com/
> On 14 Sep 2021, at 20:54, Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2021-Sep-14, Daniel Gustafsson wrote: > >> Given the above, and that nothing has happened on this thread since this note, >> I think we should mark this Returned with Feedback and await a new submission. >> Does that seem reasonable Alvaro? > > It seems reasonable to me. Thanks, done that way now. -- Daniel Gustafsson https://vmware.com/
On 2021-Sep-14, Daniel Gustafsson wrote:
> Given the above, and that nothing has happened on this thread since this note,
> I think we should mark this Returned with Feedback and await a new submission.
> Does that seem reasonable Alvaro?
It seems reasonable to me.
--
Álvaro Herrera Valdivia, Chile — https://www.EnterpriseDB.com/
Dear all Just for my understanding - and perhaps as input for the documentation of this: Are Foreign Key Arrays a means to implement "Generic Foreign Keys" as in Oracle [1] and Django [2], and of "Polymorphic Associations" as they call this in Ruby on Rails? Yours, Stefan [1] Steven Feuerstein and Debby Russell (1995): Oracle Extension "PLVfk - Generic Foreign Key Lookups" in: "Advanced Oracle Pl/Sql: Programming With Packages" (Nutshell Handbook), Oreilly, ISBN B00006AVR6. Webaccess: https://flylib.com/books/en/2.408.1.159/1/ [2] Stackoverflow: https://stackoverflow.com/questions/14333460/django-generic-foreign-keys-good-or-bad-considering-the-sql-performance Am Di., 14. Sept. 2021 um 21:00 Uhr schrieb Mark Rofail <markm.rofail@gmail.com>: > > Dear Alvaro, > > We just need to rewrite the scope of the patch so I work on the next generation. I do not know what was "out of scope"in the current version > > /Mark > > On Tue, 14 Sep 2021, 8:55 pm Alvaro Herrera, <alvherre@alvh.no-ip.org> wrote: >> >> On 2021-Sep-14, Daniel Gustafsson wrote: >> >> > Given the above, and that nothing has happened on this thread since this note, >> > I think we should mark this Returned with Feedback and await a new submission. >> > Does that seem reasonable Alvaro? >> >> It seems reasonable to me. >> >> -- >> Álvaro Herrera Valdivia, Chile — https://www.EnterpriseDB.com/
Hi Stefan, On 2021-Oct-03, Stefan Keller wrote: > Just for my understanding - and perhaps as input for the documentation of this: > Are Foreign Key Arrays a means to implement "Generic Foreign Keys" as > in Oracle [1] and Django [2], and of "Polymorphic Associations" as > they call this in Ruby on Rails? No -- at least as far as I was able to understand the pages you linked to. It's intended for array elements of one column to reference values in a scalar column. These are always specific columns, not "generic" or "polymorphic" (which I understand to mean one of several possible columns). Thanks, -- Álvaro Herrera 39°49'30"S 73°17'W — https://www.EnterpriseDB.com/