Thread: [HACKERS] JIT compiling expressions/deform + inlining prototype v2.0
Hi, I previously had an early prototype of JITing [1] expression evaluation and tuple deforming. I've since then worked a lot on this. Here's an initial, not really pretty but functional, submission. This supports all types of expressions, and tuples, and allows, albeit with some drawbacks, inlining of builtin functions. Between the version at [1] and this I'd done some work in c++, because that allowed to experiment more with llvm, but I've now translated everything back. Some features I'd to re-implement due to limitations of C API. As a teaser: tpch_5[9586][1]=# set jit_expressions=0;set jit_tuple_deforming=0; tpch_5[9586][1]=# \i ~/tmp/tpch/pg-tpch/queries/q01.sql ┌──────────────┬──────────────┬───────────┬──────────────────┬──────────────────┬──────────────────┬──────────────────┬──────────────────┬────────────────────┬─────────────┐ │ l_returnflag │ l_linestatus │ sum_qty │ sum_base_price │ sum_disc_price │ sum_charge │ avg_qty │ avg_price │ avg_disc │ count_order │ ├──────────────┼──────────────┼───────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼────────────────────┼─────────────┤ │ A │ F │ 188818373 │ 283107483036.109 │ 268952035589.054 │ 279714361804.23 │ 25.5025937044707 │ 38237.6725307617│ 0.0499976863510723 │ 7403889 │ │ N │ F │ 4913382 │ 7364213967.94998 │ 6995782725.6633 │ 7275821143.98952 │ 25.5321530459003 │ 38267.7833908406│ 0.0500308669240696 │ 192439 │ │ N │ O │ 375088356 │ 562442339707.852 │ 534321895537.884 │ 555701690243.972 │ 25.4978961033505 │ 38233.9150565265│ 0.0499956453049625 │ 14710561 │ │ R │ F │ 188960009 │ 283310887148.206 │ 269147687267.211 │ 279912972474.866 │ 25.5132328961366 │ 38252.4148049933│ 0.0499958481590264 │ 7406353 │ └──────────────┴──────────────┴───────────┴──────────────────┴──────────────────┴──────────────────┴──────────────────┴──────────────────┴────────────────────┴─────────────┘ (4 rows) Time: 4367.486 ms (00:04.367) tpch_5[9586][1]=# set jit_expressions=1;set jit_tuple_deforming=1; tpch_5[9586][1]=# \i ~/tmp/tpch/pg-tpch/queries/q01.sql <repeat> (4 rows) Time: 3158.575 ms (00:03.159) tpch_5[9586][1]=# set jit_expressions=0;set jit_tuple_deforming=0; tpch_5[9586][1]=# \i ~/tmp/tpch/pg-tpch/queries/q01.sql <repeat> (4 rows) Time: 4383.562 ms (00:04.384) The potential wins of the JITing itself are considerably larger than the already significant gains demonstrated above - this version here doesn't exactly generate the nicest native code around. After these patches the bottlencks for TCP-H's Q01 are largely inside the float* functions and the non-expressionified execGrouping.c code. The latter needs to be expressified to gain benefits due to JIT - that shouldn't be very hard. The code generation can be improved by moving more of the variable data into llvm allocated stack data, that also has other benefits. The patch series currently consists out of the following: 0001-Rely-on-executor-utils-to-build-targetlist-for-DML-R.patch - boring prep work 0002-WIP-Allow-tupleslots-to-have-a-fixed-tupledesc-use-i.patch - for JITed deforming we need to know whether a slot's tupledesc will change 0003-WIP-Add-configure-infrastructure-to-enable-LLVM.patch - boring 0004-WIP-Beginning-of-a-LLVM-JIT-infrastructure.patch - infrastructure for llvm, including memory lifetime management, and bulk emission of functions. 0005-Perform-slot-validity-checks-in-a-separate-pass-over.patch - boring, prep work for expression jiting 0006-WIP-deduplicate-int-float-overflow-handling-code.patch - boring 0007-Pass-through-PlanState-parent-to-expression-instanti.patch - boring 0008-WIP-JIT-compile-expression.patch - that's the biggest patch, actually adding JITing - code needs to be better documented, tested, and deduplicated 0009-Simplify-aggregate-code-a-bit.patch 0010-More-efficient-AggState-pertrans-iteration.patch 0011-Avoid-dereferencing-tts_values-nulls-repeatedly.patch 0012-Centralize-slot-deforming-logic-a-bit.patch - boring, mostly to make comparison between JITed and non-jitted a bit fairer and to remove unnecessary other bottlenecks. 0013-WIP-Make-scan-desc-available-for-all-PlanStates.patch - this isn't clean enough. 0014-WIP-JITed-tuple-deforming.patch - do JITing of deforming, but only when called from within expression, there we know which columns we want to be deformed etc. - Not clear what'd be a good way to also JIT other deforming without additional infrastructure - doing a separate function emission for every slot_deform_tuple() is unattractive performancewise and memory-lifetime wise, I did have that at first. 0015-WIP-Expression-based-agg-transition.patch - allows to JIT aggregate transition invocation, but also speeds up aggregates without JIT. 0016-Hacky-Preliminary-inlining-implementation.patch - allows to inline functions, by using bitcode. That bitcode can be loaded from a list of directories - as long as compatibly configured the bitcode doesn't have to be generated by the same compiler as the postgres binary. i.e. gcc postgres + clang bitcode works. I've whacked this around quite heavily today, this likely has some new bugs, sorry for that :( I plan to spend some considerable time over the next weeks to clean this up and address some of the areas where the performance isn't yet as good as desirable. Greetings, Andres Freund [1] http://archives.postgresql.org/message-id/20161206034955.bh33paeralxbtluv%40alap3.anarazel.de -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
- 0001-Rely-on-executor-utils-to-build-targetlist-for-DML-R.patch
- 0002-WIP-Allow-tupleslots-to-have-a-fixed-tupledesc-use-i.patch
- 0003-WIP-Add-configure-infrastructure-to-enable-LLVM.patch
- 0004-WIP-Beginning-of-a-LLVM-JIT-infrastructure.patch
- 0005-Perform-slot-validity-checks-in-a-separate-pass-over.patch
- 0006-WIP-deduplicate-int-float-overflow-handling-code.patch
- 0007-Pass-through-PlanState-parent-to-expression-instanti.patch
- 0008-WIP-JIT-compile-expression.patch
- 0009-Simplify-aggregate-code-a-bit.patch
- 0010-More-efficient-AggState-pertrans-iteration.patch
- 0011-Avoid-dereferencing-tts_values-nulls-repeatedly.patch
- 0012-Centralize-slot-deforming-logic-a-bit.patch
- 0013-WIP-Make-scan-desc-available-for-all-PlanStates.patch
- 0014-WIP-JITed-tuple-deforming.patch
- 0015-WIP-Expression-based-agg-transition.patch
- 0016-Hacky-Preliminary-inlining-implementation.patch
Hi, On 2017-08-31 23:41:31 -0700, Andres Freund wrote: > I previously had an early prototype of JITing [1] expression evaluation > and tuple deforming. I've since then worked a lot on this. > > Here's an initial, not really pretty but functional, submission. One of the things I'm not really happy about yet is the naming of the generated functions. Those primarily matter when doing profiling, where the function name will show up when the profiler supports JIT stuff (e.g. with a patch I proposed to LLVM that emits perf compatible output, there's also existing LLVM support for a profiler by intel and oprofile). Currently there's essentially a per EState counter and the generated functions get named deform$n and evalexpr$n. That allows for profiling of a single query, because different compiled expressions are disambiguated. It even allows to run the same query over and over, still giving meaningful results. But it breaks down when running multiple queries while profiling - evalexpr0 can mean something entirely different for different queries. The best idea I have so far would be to name queries like evalexpr_$fingerprint_$n, but for that we'd need fingerprinting support outside of pg_stat_statement, which seems painful-ish. Perhaps somebody has a better idea? Regards, Andres
On 09/03/2017 02:59 AM, Andres Freund wrote: > Hi, > > On 2017-08-31 23:41:31 -0700, Andres Freund wrote: >> I previously had an early prototype of JITing [1] expression evaluation >> and tuple deforming. I've since then worked a lot on this. >> >> Here's an initial, not really pretty but functional, submission. > One of the things I'm not really happy about yet is the naming of the > generated functions. Those primarily matter when doing profiling, where > the function name will show up when the profiler supports JIT stuff > (e.g. with a patch I proposed to LLVM that emits perf compatible output, > there's also existing LLVM support for a profiler by intel and > oprofile). > > Currently there's essentially a per EState counter and the generated > functions get named deform$n and evalexpr$n. That allows for profiling > of a single query, because different compiled expressions are > disambiguated. It even allows to run the same query over and over, still > giving meaningful results. But it breaks down when running multiple > queries while profiling - evalexpr0 can mean something entirely > different for different queries. > > The best idea I have so far would be to name queries like > evalexpr_$fingerprint_$n, but for that we'd need fingerprinting support > outside of pg_stat_statement, which seems painful-ish. > > Perhaps somebody has a better idea? As far as I understand we do not need precise fingerprint. So may be just calculate some lightweight fingerprint? For example take query text (es_sourceText from EText), replace all non-alphanumeric characters spaces with '_' and takefirst N (16?) characters of the result? It seems to me that in most cases it will help to identify the query... -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Andres Freund <andres@anarazel.de> writes:
> Currently there's essentially a per EState counter and the generated
> functions get named deform$n and evalexpr$n. That allows for profiling
> of a single query, because different compiled expressions are
> disambiguated. It even allows to run the same query over and over, still
> giving meaningful results. But it breaks down when running multiple
> queries while profiling - evalexpr0 can mean something entirely
> different for different queries.
> The best idea I have so far would be to name queries like
> evalexpr_$fingerprint_$n, but for that we'd need fingerprinting support
> outside of pg_stat_statement, which seems painful-ish.
Yeah. Why not just use a static counter to give successive unique IDs
to each query that gets JIT-compiled? Then the function names would
be like deform_$querynumber_$subexprnumber.
regards, tom lane
On 2017-09-03 10:11:37 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > Currently there's essentially a per EState counter and the generated > > functions get named deform$n and evalexpr$n. That allows for profiling > > of a single query, because different compiled expressions are > > disambiguated. It even allows to run the same query over and over, still > > giving meaningful results. But it breaks down when running multiple > > queries while profiling - evalexpr0 can mean something entirely > > different for different queries. > > > The best idea I have so far would be to name queries like > > evalexpr_$fingerprint_$n, but for that we'd need fingerprinting support > > outside of pg_stat_statement, which seems painful-ish. > > Yeah. Why not just use a static counter to give successive unique IDs > to each query that gets JIT-compiled? Then the function names would > be like deform_$querynumber_$subexprnumber. That works, but unfortunately it doesn't keep the names the same over reruns. So if you rerun the query inside the same session - a quite reasonable thing to get more accurate profiles - the names in the profile will change. That makes it quite hard to compare profiles, especially when a single execution of the query is too quick to see something meaningful. Greetings, Andres Freund
Re: [HACKERS] JIT compiling expressions/deform + inlining prototypev2.0
From
Konstantin Knizhnik
Date:
On 01.09.2017 09:41, Andres Freund wrote:
> Hi,
>
> I previously had an early prototype of JITing [1] expression evaluation
> and tuple deforming. I've since then worked a lot on this.
>
> Here's an initial, not really pretty but functional, submission. This
> supports all types of expressions, and tuples, and allows, albeit with
> some drawbacks, inlining of builtin functions. Between the version at
> [1] and this I'd done some work in c++, because that allowed to
> experiment more with llvm, but I've now translated everything back.
> Some features I'd to re-implement due to limitations of C API.
>
>
> I've whacked this around quite heavily today, this likely has some new
> bugs, sorry for that :(
Can you please clarify the following fragment calculating attributes
alignment:
/* compute what following columns are aligned to */
+ if (att->attlen < 0)
+ {
+ /* can't guarantee any alignment after varlen field */
+ attcuralign = -1;
+ }
+ else if (att->attnotnull && attcuralign >= 0)
+ {
+ Assert(att->attlen > 0);
+ attcuralign += att->attlen;
+ }
+ else if (att->attnotnull)
+ {
+ /*
+ * After a NOT NULL fixed-width column, alignment is
+ * guaranteed to be the minimum of the forced alignment and
+ * length. XXX
+ */
+ attcuralign = alignto + att->attlen;
+ Assert(attcuralign > 0);
+ }
+ else
+ {
+ //elog(LOG, "attnotnullreset: %d", attnum);
+ attcuralign = -1;
+ }
I wonder why in this branch (att->attnotnull && attcuralign >= 0)
we are not adding "alignto" and comment in the following branch else if
(att->attnotnull)
seems to be not related to this branch, because in this case attcuralign
is expected to be less then zero wjhich means that previous attribute is
varlen field.
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Hi,
On 2017-09-04 20:01:03 +0300, Konstantin Knizhnik wrote:
> > I previously had an early prototype of JITing [1] expression evaluation
> > and tuple deforming. I've since then worked a lot on this.
> >
> > Here's an initial, not really pretty but functional, submission. This
> > supports all types of expressions, and tuples, and allows, albeit with
> > some drawbacks, inlining of builtin functions. Between the version at
> > [1] and this I'd done some work in c++, because that allowed to
> > experiment more with llvm, but I've now translated everything back.
> > Some features I'd to re-implement due to limitations of C API.
> >
> >
> > I've whacked this around quite heavily today, this likely has some new
> > bugs, sorry for that :(
>
> Can you please clarify the following fragment calculating attributes
> alignment:
Hi. That piece of code isn't particularly clear (and has a bug in the
submitted version), I'm revising it.
>
> /* compute what following columns are aligned to */
> + if (att->attlen < 0)
> + {
> + /* can't guarantee any alignment after varlen field */
> + attcuralign = -1;
> + }
> + else if (att->attnotnull && attcuralign >= 0)
> + {
> + Assert(att->attlen > 0);
> + attcuralign += att->attlen;
> + }
> + else if (att->attnotnull)
> + {
> + /*
> + * After a NOT NULL fixed-width column, alignment is
> + * guaranteed to be the minimum of the forced alignment and
> + * length. XXX
> + */
> + attcuralign = alignto + att->attlen;
> + Assert(attcuralign > 0);
> + }
> + else
> + {
> + //elog(LOG, "attnotnullreset: %d", attnum);
> + attcuralign = -1;
> + }
>
>
> I wonder why in this branch (att->attnotnull && attcuralign >= 0)
> we are not adding "alignto" and comment in the following branch else if
> (att->attnotnull)
> seems to be not related to this branch, because in this case attcuralign is
> expected to be less then zero wjhich means that previous attribute is varlen
> field.
Yea, I've changed that already, although it's currently added earlier,
because the alignment is needed before, to access the column correctly.
I've also made number of efficiency improvements, primarily to access
columns with an absolute offset if all preceding ones are fixed width
not null columns - that is quite noticeable performancewise.
Greetings,
Andres Freund
Re: [HACKERS] JIT compiling expressions/deform + inlining prototypev2.0
From
Konstantin Knizhnik
Date:
On 04.09.2017 23:52, Andres Freund wrote: > > Yea, I've changed that already, although it's currently added earlier, > because the alignment is needed before, to access the column correctly. > I've also made number of efficiency improvements, primarily to access > columns with an absolute offset if all preceding ones are fixed width > not null columns - that is quite noticeable performancewise. Unfortunately, in most of real table columns are nullable. I wonder if we can perform some optimization in this case (assuming that in typical cases column either contains mostly non-null values, either mostly null values). -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Re: [HACKERS] JIT compiling expressions/deform + inlining prototypev2.0
From
andres@anarazel.de (Andres Freund)
Date:
On 2017-09-05 13:58:56 +0300, Konstantin Knizhnik wrote:
>
>
> On 04.09.2017 23:52, Andres Freund wrote:
> >
> > Yea, I've changed that already, although it's currently added earlier,
> > because the alignment is needed before, to access the column correctly.
> > I've also made number of efficiency improvements, primarily to access
> > columns with an absolute offset if all preceding ones are fixed width
> > not null columns - that is quite noticeable performancewise.
>
> Unfortunately, in most of real table columns are nullable.
I'm not sure I agree with that assertion, but:
> I wonder if we can perform some optimization in this case (assuming that in
> typical cases column either contains mostly non-null values, either mostly
> null values).
Even if all columns are NULLABLE, the JITed code is still a good chunk
faster (a significant part of that is the slot->tts_{nulls,values}
accesses). Alignment is still cheaper with constants, and often enough
the alignment can be avoided (consider e.g. a table full of nullable
ints - everything is guaranteed to be aligned, or columns after an
individual NOT NULL column is also guaranteed to be aligned). What
largely changes is that the 'offset' from the start of the tuple has to
be tracked.
Greetings,
Andres Freund
On 5 September 2017 at 11:58, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > I wonder if we can perform some optimization in this case (assuming that in > typical cases column either contains mostly non-null values, either mostly > null values). If you really wanted to go crazy here you could do lookup tables of bits of null bitmaps. Ie, you look at the first byte of the null bitmap, index into an array and it points to 8 offsets for the 8 fields covered by that much of the bitmap. The lookup table might be kind of large since offsets are 16-bits so you're talking 256 * 16 bytes or 2kB for every 8 columns up until the first variable size column (or I suppose you could even continue in the case where the variable size column is null). -- greg
On 2017-09-05 19:43:33 +0100, Greg Stark wrote: > On 5 September 2017 at 11:58, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: > > > > I wonder if we can perform some optimization in this case (assuming that in > > typical cases column either contains mostly non-null values, either mostly > > null values). > > If you really wanted to go crazy here you could do lookup tables of > bits of null bitmaps. Ie, you look at the first byte of the null > bitmap, index into an array and it points to 8 offsets for the 8 > fields covered by that much of the bitmap. The lookup table might be > kind of large since offsets are 16-bits so you're talking 256 * 16 > bytes or 2kB for every 8 columns up until the first variable size > column (or I suppose you could even continue in the case where the > variable size column is null). I'm missing something here. What's this saving? The code for lookups with NULLs after jitting effectively is a) one load for every 8 columns (could be optimized to one load every sizeof(void*) cols) b) one bitmask for every column + one branch for null c) load for the datum, indexed by register d) saving the column value, that's independent of NULLness e) one addi adding the length to the offset Greetings, Andres Freund
Re: [HACKERS] JIT compiling expressions/deform + inlining prototypev2.0
From
Konstantin Knizhnik
Date:
On 04.09.2017 23:52, Andres Freund wrote: > > Hi. That piece of code isn't particularly clear (and has a bug in the > submitted version), I'm revising it. ... > Yea, I've changed that already, although it's currently added earlier, > because the alignment is needed before, to access the column correctly. > I've also made number of efficiency improvements, primarily to access > columns with an absolute offset if all preceding ones are fixed width > not null columns - that is quite noticeable performancewise. > > Should I wait for new version of your patch or continue review of this code? -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 2017-09-19 12:57:33 +0300, Konstantin Knizhnik wrote: > > > On 04.09.2017 23:52, Andres Freund wrote: > > > > Hi. That piece of code isn't particularly clear (and has a bug in the > > submitted version), I'm revising it. > > ... > > Yea, I've changed that already, although it's currently added earlier, > > because the alignment is needed before, to access the column correctly. > > I've also made number of efficiency improvements, primarily to access > > columns with an absolute offset if all preceding ones are fixed width > > not null columns - that is quite noticeable performancewise. > > > > > Should I wait for new version of your patch or continue review of this code? I'll update the posted version later this week, sorry for the delay. Regards, Andres -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Hi, Here's an updated version of the patchset. There's some substantial changes here, but it's still very obviously very far from committable as a whole. There's some helper commmits that are simple and independent enough to be committable earlier on. The git tree of this work, which is *frequently* rebased, is at: https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/jit The biggest changes are: - The JIT "infrastructure" is less bad than before, and starting to shape up. - The tuple deforming logic is considerably faster than before due to various optimizations. The optimizations are: - build deforming exactly to the required natts for the specific caller - avoid checking the tuple's natts for attributes that have "following" NOT NULL columns. - a bunch of minor codegen improvements. - The tuple deforming codegen also got simpler by relying on LLVM to promote a stack variable to a register, instead of working with a register manually - the need to keep IR in SSA form makes doing so manually rather painful. - WIP patch to do execGrouping.c TupleHashTableMatch() via JIT. That makes the column comparison faster, but more importantly it JITs the deforming (one side at least always is a MinimalTuple). - All tests pass with JITed expression, tuple deforming, agg transition value computation and execGrouping logic. There were a number of bugs, who would have imagined that. - some more experimental changes later in the series to address some bottlenecks. Functionally this covers all of what I think a sensible goal for v11 is. There's a lot of details to figure out, and the inlining *implementation* isn't what I think we should do. I'll follow up, not tonight though, with an email outlining the first few design decisions we're going to have to finalize, which'll be around the memory/lifetime management of functions, and other infrastructure pieces (currently patch 0006). As the patchset is pretty large already, and not going to get any smaller, I'll make smaller adjustments solely via the git tree, rather than full reposts. Greetings, Andres Freund -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
- 0001-Rely-on-executor-utils-to-build-targetlist-for-DM.v4.patch.gz
- 0002-WIP-Allow-tupleslots-to-have-a-fixed-tupledesc-us.v4.patch.gz
- 0003-Perform-slot-validity-checks-in-a-separate-pass-o.v4.patch.gz
- 0004-Pass-through-PlanState-parent-to-expression-insta.v4.patch.gz
- 0005-Add-configure-infrastructure-to-enable-LLVM.v4.patch.gz
- 0006-Beginning-of-a-LLVM-JIT-infrastructure.v4.patch.gz
- 0007-JIT-compile-expressions.v4.patch.gz
- 0008-Centralize-slot-deforming-logic-a-bit.v4.patch.gz
- 0009-WIP-Make-scan-desc-available-for-all-PlanStates.v4.patch.gz
- 0010-JITed-tuple-deforming.v4.patch.gz
- 0011-Simplify-aggregate-code-a-bit.v4.patch.gz
- 0012-More-efficient-AggState-pertrans-iteration.v4.patch.gz
- 0013-Avoid-dereferencing-tts_values-nulls-repeatedly-i.v4.patch.gz
- 0014-WIP-Expression-based-agg-transition.v4.patch.gz
- 0015-Hacky-Preliminary-inlining-implementation.v4.patch.gz
- 0016-WIP-Inline-ExecScan-mostly-to-make-profiles-easie.v4.patch.gz
- 0017-WIP-Do-execGrouping.c-via-expression-eval-machine.v4.patch.gz
- 0018-WIP-deduplicate-int-float-overflow-handling-code.v4.patch.gz
- 0019-Make-timestamp_cmp_internal-an-inline-function.v4.patch.gz
- 0020-Make-hot-path-of-pg_detoast_datum-an-inline-funct.v4.patch.gz
- 0021-WIP-Inline-additional-function.v4.patch.gz
- 0022-WIP-Faster-order.v4.patch.gz
On Wed, Oct 4, 2017 at 9:48 AM, Andres Freund <andres@anarazel.de> wrote: > Here's an updated version of the patchset. There's some substantial > changes here, but it's still very obviously very far from committable as > a whole. There's some helper commmits that are simple and independent > enough to be committable earlier on. Looks pretty impressive already. I wanted to take it for a spin, but got errors about the following symbols being missing: LLVMOrcUnregisterPerf LLVMOrcRegisterGDB LLVMOrcRegisterPerf LLVMOrcGetSymbolAddressIn LLVMLinkModules2Needed As far as I can tell these are not in mainline LLVM. Is there a branch or patchset of LLVM available somewhere that I need to use this? Regards, Ants Aasma -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 2017-10-04 11:56:47 +0300, Ants Aasma wrote: > On Wed, Oct 4, 2017 at 9:48 AM, Andres Freund <andres@anarazel.de> wrote: > > Here's an updated version of the patchset. There's some substantial > > changes here, but it's still very obviously very far from committable as > > a whole. There's some helper commmits that are simple and independent > > enough to be committable earlier on. > > Looks pretty impressive already. Thanks! > I wanted to take it for a spin, but got errors about the following > symbols being missing: > > LLVMOrcUnregisterPerf > LLVMOrcRegisterGDB > LLVMOrcRegisterPerf > LLVMOrcGetSymbolAddressIn > LLVMLinkModules2Needed > > As far as I can tell these are not in mainline LLVM. Is there a branch > or patchset of LLVM available somewhere that I need to use this? Oops, I'd forgotten about the modifications. Sorry. I've attached them here. The GDB and Perf stuff should now be an optional dependency, too. The required changes are fairly small, so they hopefully shouldn't be too hard to upstream. Please check the git tree for a rebased version of the pg patches, with a bunch bugfixes (oops, some last minute "cleanups") and performance fixes. Here's some numbers for a a TPC-H scale 5 run. Obviously the Q01 numbers are pretty nice in partcular. But it's also visible that the shorter query can loose, which is largely due to the JIT overhead - that can be ameliorated to some degree, but JITing obviously isn't always going to be a win. It's pretty impressive that in q01, even after all of this, expression evaluation *still* is 35% of the total time (25% in the aggregate transition function). That's partially just because the query does primarily aggregation, but also because the generated code can stand a good chunk of improvements. master q01 min: 14146.498 dev min: 11479.05 [diff -23.24] dev-jit min: 8659.961 [diff -63.36] dev-jit-deformmin: 7279.395 [diff -94.34] dev-jit-deform-inline min: 6997.956 [diff -102.15] master q02 min: 1234.229 dev min: 1208.102 [diff -2.16] dev-jit min: 1292.983 [diff +4.54] dev-jit-deform min:1580.505 [diff +21.91] dev-jit-deform-inline min: 1809.046 [diff +31.77] master q03 min: 6220.814 dev min: 5424.107 [diff -14.69] dev-jit min: 5175.125 [diff -20.21] dev-jit-deform min:4257.368 [diff -46.12] dev-jit-deform-inline min: 4218.115 [diff -47.48] master q04 min: 947.476 dev min: 970.608 [diff +2.38] dev-jit min: 969.944 [diff +2.32] dev-jit-deform min: 999.006[diff +5.16] dev-jit-deform-inline min: 1033.78 [diff +8.35] master q05 min: 4729.9 dev min: 4059.665 [diff -16.51] dev-jit min: 4182.941 [diff -13.08] dev-jit-deform min:4147.493 [diff -14.04] dev-jit-deform-inline min: 4284.473 [diff -10.40] master q06 min: 1603.708 dev min: 1592.107 [diff -0.73] dev-jit min: 1556.216 [diff -3.05] dev-jit-deform min:1516.078 [diff -5.78] dev-jit-deform-inline min: 1579.839 [diff -1.51] master q07 min: 4549.738 dev min: 4331.565 [diff -5.04] dev-jit min: 4475.654 [diff -1.66] dev-jit-deform min:4645.773 [diff +2.07] dev-jit-deform-inline min: 4885.781 [diff +6.88] master q08 min: 1394.428 dev min: 1350.363 [diff -3.26] dev-jit min: 1434.366 [diff +2.78] dev-jit-deform min:1716.65 [diff +18.77] dev-jit-deform-inline min: 1938.152 [diff +28.05] master q09 min: 5958.198 dev min: 5700.329 [diff -4.52] dev-jit min: 5491.683 [diff -8.49] dev-jit-deform min:5582.431 [diff -6.73] dev-jit-deform-inline min: 5797.475 [diff -2.77] master q10 min: 5228.69 dev min: 4475.154 [diff -16.84] dev-jit min: 4269.365 [diff -22.47] dev-jit-deform min:3767.888 [diff -38.77] dev-jit-deform-inline min: 3962.084 [diff -31.97] master q11 min: 281.201 dev min: 280.132 [diff -0.38] dev-jit min: 351.85 [diff +20.08] dev-jit-deform min: 455.885[diff +38.32] dev-jit-deform-inline min: 532.093 [diff +47.15] master q12 min: 4289.268 dev min: 4082.359 [diff -5.07] dev-jit min: 4007.199 [diff -7.04] dev-jit-deform min:3752.396 [diff -14.31] dev-jit-deform-inline min: 3916.653 [diff -9.51] master q13 min: 7110.545 dev min: 6898.576 [diff -3.07] dev-jit min: 6579.554 [diff -8.07] dev-jit-deform min:6304.15 [diff -12.79] dev-jit-deform-inline min: 6135.952 [diff -15.88] master q14 min: 678.024 dev min: 650.943 [diff -4.16] dev-jit min: 682.387 [diff +0.64] dev-jit-deform min: 746.354[diff +9.16] dev-jit-deform-inline min: 878.437 [diff +22.81] master q15 min: 1641.897 dev min: 1650.57 [diff +0.53] dev-jit min: 1661.591 [diff +1.19] dev-jit-deform min:1821.02 [diff +9.84] dev-jit-deform-inline min: 1863.304 [diff +11.88] master q16 min: 1890.246 dev min: 1819.423 [diff -3.89] dev-jit min: 1838.079 [diff -2.84] dev-jit-deform min:1962.274 [diff +3.67] dev-jit-deform-inline min: 2096.154 [diff +9.82] master q17 min: 502.605 dev min: 462.881 [diff -8.58] dev-jit min: 495.648 [diff -1.40] dev-jit-deform min: 537.666[diff +6.52] dev-jit-deform-inline min: 613.144 [diff +18.03] master q18 min: 12863.972 dev min: 11257.57 [diff -14.27] dev-jit min: 10847.61 [diff -18.59] dev-jit-deformmin: 10119.769 [diff -27.12] dev-jit-deform-inline min: 10103.051 [diff -27.33] master q19 min: 281.991 dev min: 264.191 [diff -6.74] dev-jit min: 331.102 [diff +14.83] dev-jit-deform min:373.759 [diff +24.55] dev-jit-deform-inline min: 531.07 [diff +46.90] master q20 min: 541.154 dev min: 511.372 [diff -5.82] dev-jit min: 565.378 [diff +4.28] dev-jit-deform min: 662.926[diff +18.37] dev-jit-deform-inline min: 805.835 [diff +32.85] master q22 min: 678.266 dev min: 656.643 [diff -3.29] dev-jit min: 676.886 [diff -0.20] dev-jit-deform min: 735.058[diff +7.73] dev-jit-deform-inline min: 943.013 [diff +28.07] master total min: 76772.848 dev min: 69125.71 [diff -11.06] dev-jit min: 65545.522 [diff -17.13] dev-jit-deformmin: 62963.844 [diff -21.93] dev-jit-deform-inline min: 64925.407 [diff -18.25] Greetings, Andres Freund -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
- 0001-ORC-Add-findSymbolIn-wrapper-to-C-bindings.patch
- 0002-C-API-WIP-Add-LLVMGetHostCPUName.patch
- 0003-C-API-Add-LLVMLinkModules2Needed.patch
- 0004-MCJIT-Call-JIT-notifiers-only-after-code-sections-ar.patch
- 0005-Add-PerfJITEventListener-for-perf-profiling-support.patch
- 0006-ORC-JIT-event-listener-support.patch
On 5 October 2017 at 19:57, Andres Freund <andres@anarazel.de> wrote: > Here's some numbers for a a TPC-H scale 5 run. Obviously the Q01 numbers > are pretty nice in partcular. But it's also visible that the shorter > query can loose, which is largely due to the JIT overhead - that can be > ameliorated to some degree, but JITing obviously isn't always going to > be a win. It's pretty exciting to see thing being worked on. I've not looked at the code, but I'm thinking, could you not just JIT if the total cost of the plan is estimated to be > X ? Where X is some JIT threshold GUC. -- David Rowley http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 2017-10-05 23:43:37 +1300, David Rowley wrote: > On 5 October 2017 at 19:57, Andres Freund <andres@anarazel.de> wrote: > > Here's some numbers for a a TPC-H scale 5 run. Obviously the Q01 numbers > > are pretty nice in partcular. But it's also visible that the shorter > > query can loose, which is largely due to the JIT overhead - that can be > > ameliorated to some degree, but JITing obviously isn't always going to > > be a win. > > It's pretty exciting to see thing being worked on. > > I've not looked at the code, but I'm thinking, could you not just JIT > if the total cost of the plan is estimated to be > X ? Where X is some > JIT threshold GUC. Right, that's the plan. But it seems fairly important to make the envelope in which it is beneficial as broad as possible. Also, test coverage is more interesting for me right now ;) Greetings, Andres Freund -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Thu, Oct 5, 2017 at 2:57 AM, Andres Freund <andres@anarazel.de> wrote: > master q01 min: 14146.498 dev min: 11479.05 [diff -23.24] dev-jit min: 8659.961 [diff -63.36] dev-jit-deformmin: 7279.395 [diff -94.34] dev-jit-deform-inline min: 6997.956 [diff -102.15] I think this is a really strange way to display this information. Instead of computing the percentage of time that you saved, you've computed the negative of the percentage that you would have lost if the patch were already committed and you reverted it. That's just confusing. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Thu, Sep 21, 2017 at 2:52 AM, Andres Freund <andres@anarazel.de> wrote: > On 2017-09-19 12:57:33 +0300, Konstantin Knizhnik wrote: >> >> >> On 04.09.2017 23:52, Andres Freund wrote: >> > >> > Hi. That piece of code isn't particularly clear (and has a bug in the >> > submitted version), I'm revising it. >> >> ... >> > Yea, I've changed that already, although it's currently added earlier, >> > because the alignment is needed before, to access the column correctly. >> > I've also made number of efficiency improvements, primarily to access >> > columns with an absolute offset if all preceding ones are fixed width >> > not null columns - that is quite noticeable performancewise. >> > >> > >> Should I wait for new version of your patch or continue review of this code? > > I'll update the posted version later this week, sorry for the delay. I know that you are working on this actively per the set of patches you have sent lately, but this thread has stalled, so I am marking it as returned with feedback. There is now only one CF entry to track this work: https://commitfest.postgresql.org/15/1285/. Depending on the work you are doing you may want to spawn a CF entry for each sub-item. Just an idea. -- Michael
Hi,
One part of the work to make JITing worth it's while is JITing tuple
deforming. That's currently often the biggest consumer of time, and if not
most often in the top entries.
My experimentation shows that tuple deforming is primarily beneficial
when it happens as *part* of jit compiling expressions. I'd originally
tried to jit compile deforming inside heaptuple.c, and cache the
deforming program inside the tuple slot. That turns out to not work very
well, because a lot of tuple descriptors are very short lived, computed
during ExecInitNode(). Even if that were not the case, compiling for
each deforming on demand has significant downsides:
- it requires emitting code in smaller increments (whenever something
new is deformed)
- because the generated code has to be generic for all potential
deformers, the number of branches to check for that are
significant. If instead the the deforming code is generated for a
specific callsite, no branches for the number of to-be-deformed
columns has to be generated. The primary remaining branches then are
the ones checking for NULLs and the number of attributes in the
column, and those can often be optimized away if there's NOT NULL
columns present.
- the call overhead is still noticeable
- the memory / function lifetime management is awkward.
If the JITing of expressions is instead done as part of expression
evaluation we can emit all the necessary code for the whole plantree
during executor startup, in one go. And, more importantly, LLVMs
optimizer is free to inline the deforming code into the expression code,
often yielding noticeable improvements (although that still could use
some improvements).
To allow doing JITing at ExecReadyExpr() time, we need to know the tuple
descriptor a EEOP_{INNER,OUTER,SCAN}_FETCHSOME step refers to. There's
currently two major impediments to that.
1) At a lot of ExecInitExpr() callsites the tupledescs for inner, outer,
scan aren't yet known. Therefore that code needs to be reordered so
we (if applicable):
a) initialize subsidiary nodes, thereby determining the left/right
(inner/outer) tupledescs
b) initialize the scan tuple desc, often that refers to a)
c) determine the result tuple desc, required to build the projection
d) build projections
e) build expressions
Attached is a patch doing so. Currently it only applies with a few
preliminary patches applied, but that could be easily reordered.
The patch is relatively large, as I decided to try to get the
different ExecInitNode functions to look a bit more similar. There's
some judgement calls involved, but I think the result looks a good
bit better, regardless of the later need.
I'm not really happy with the, preexisting, split of functions
between execScan.c, execTuples.c, execUtils.c. I wonder if the
majority, except the low level slot ones, shouldn't be moved to
execUtils.c, I think that'd be clearer. There seems to be no
justification for execScan.c to contain
ExecAssignScanProjectionInfo[WithVarno].
2) TupleSlots need to describe whether they'll contain a fixed tupledesc
for all their lifetime, or whether they can change their nature. Most
places don't need to ever change a slot's identity, but in a few
places it's quite convenient.
I've introduced the notion that a tupledesc can be marked as "fixed",
by passing a tupledesc at its creation. That also gains a bit of
efficiency (memory management overhead, higher cache hit ratio)
because the slot, tts_values, tts_isnull can be allocated in one
chunk.
3) At expression initialization time we need to figure out what slots
(or just descs INNER/OUTER/SCAN refer to. I've solved that by looking
up inner/outer/scan via the provided parent node, which required
adding a new field to store the scan slot.
Currently no expressions initialized with a parent node have a
INNER/OUTER/SCAN slot + desc that doesn't refer to the relevant node,
but I'm not sure I like that as a requirement.
Attached is a patch that implements 1 + 2. I'd welcome a quick look
through it. It currently only applies ontop a few other recently
submitted patches, but it'd just be an hour's work or so to reorder
that.
Comments about either the outline above or the patch?
Regards,
Andres
Attachment
Hi, I've spent the last weeks working on my LLVM compilation patchset. In the course of that I *heavily* revised it. While still a good bit away from committable, it's IMO definitely not a prototype anymore. There's too many small changes, so I'm only going to list the major things. A good bit of that is new. The actual LLVM IR emissions itself hasn't changed that drastically. Since I've not described them in detail before I'll describe from scratch in a few cases, even if things haven't fully changed. == JIT Interface == To avoid emitting code in very small increments (increases mmap/mremap rw vs exec remapping, compile/optimization time), code generation doesn't happen for every single expression individually, but in batches. The basic object to emit code via is a jit context created with: extern LLVMJitContext *llvm_create_context(bool optimize); which in case of expression is stored on-demand in the EState. For other usecases that might not be the right location. To emit LLVM IR (ie. the portabe code that LLVM then optimizes and generates native code for), one gets a module from that with: extern LLVMModuleRef llvm_mutable_module(LLVMJitContext *context); to which "arbitrary" numbers of functions can be added. In case of expression evaluation, we get the module once for every expression, and emit one function for the expression itself, and one for every applicable/referenced deform function. As explained above, we do not want to emit code immediately from within ExecInitExpr()/ExecReadyExpr(). To facilitate that readying a JITed expression sets the function to callback, which gets the actual native function on the first actual call. That allows to batch together the generation of all native functions that are defined before the first expression is evaluated - in a lot of queries that'll be all. Said callback then calls extern void *llvm_get_function(LLVMJitContext *context, const char *funcname); which'll emit code for the "in progress" mutable module if necessary, and then searches all generated functions for the name. The names are created via extern void *llvm_get_function(LLVMJitContext *context, const char *funcname); currently "evalexpr" and deform" with a generation and counter suffix. Currently expression which do not have access to an EState, basically all "parent" less expressions, aren't JIT compiled. That could be changed, but I so far do not see a huge need. == Error handling == There's two aspects to error handling. Firstly, generated (LLVM IR) and emitted functions (mmap()ed segments) need to be cleaned up both after a successful query execution and after an error. I've settled on a fairly boring resowner based mechanism. On errors all expressions owned by a resowner are released, upon success expressions are reassigned to the parent / released on commit (unless executor shutdown has cleaned them up of course). A second, less pretty and newly developed, aspect of error handling is OOM handling inside LLVM itself. The above resowner based mechanism takes care of cleaning up emitted code upon ERROR, but there's also the chance that LLVM itself runs out of memory. LLVM by default does *not* use any C++ exceptions. It's allocations are primarily funneled through the standard "new" handlers, and some direct use of malloc() and mmap(). For the former a 'new handler' exists http://en.cppreference.com/w/cpp/memory/new/set_new_handler for the latter LLVM provides callback that get called upon failure (unfortunately mmap() failures are treated as fatal rather than OOM errors). What I've chosen to do, and I'd be interested to get some input about that, is to have two functions that LLVM using code must use: extern void llvm_enter_fatal_on_oom(void); extern void llvm_leave_fatal_on_oom(void); before interacting with LLVM code (ie. emitting IR, or using the above functions) llvm_enter_fatal_on_oom() needs to be called. When a libstdc++ new or LLVM error occurs, the handlers set up by the above functions trigger a FATAL error. We have to use FATAL rather than ERROR, as we *cannot* reliably throw ERROR inside a foreign library without risking corrupting its internal state. Users of the above sections do *not* have to use PG_TRY/CATCH blocks, the handlers instead are reset on toplevel sigsetjmp() level. Using a relatively small enter/leave protected section of code, rather than setting up these handlers globally, avoids negative interactions with extensions that might use C++ like e.g. postgis. As LLVM code generation should never execute arbitrary code, just setting these handlers temporarily ought to suffice. == LLVM Interface / patches == Unfortunately a bit of required LLVM functionality, particularly around error handling but also initialization, aren't currently fully exposed via LLVM's C-API. A bit more *optional* API isn't exposed either. Instead of requiring a brand-new version of LLVM that has exposed this functionality I decided it's better to have a small C++ wrapper that can provide this functionality. Due to that new wrapper significantly older LLVM versions can now be used (for now I've only runtime tested 5.0 and master, 4.0 would be possible with a few ifdefs, a bit older probably doable as well). Given that LLVM is written in C++ itself, and optional dependency to a C++ compiler for one file doesn't seem to be too bad. == Inlining == One big advantage of JITing expressions is that it can significantly reduce the overhead of postgres' extensible function/operator mechanism, by inlining the body of called operators. This is the part of code that I've worked on most significantly. While I think JITing is an entirely viable project without committed inlining, I felt that we definitely need to know how exactly we want to do inlining before merging other parts. 3 different implementations later, I'm fairly confident that I have a good concept, even though a few corners still need to be smoothed. As a quick background, LLVM works on the basis of a high-level "abstract" assembly representation (llvm.org/docs/LangRef.html). This can be generated in memory, stored in binary form (bitcode files ending in .bc) or text representation (.ll files). The clang compiler always generates the in-memory representation and the -emit-llvm flag tells it to write that out to disk, rather than .o files/binaries. This facility allows us to get the bitcode for all operators (e.g. int8eq, float8pl etc), without maintaining two copies. The way I've currently set it up is that, if --with-llvm is passed to configure, all backend files are also compiled to bitcode files. These bitcode files get installed into the server's $pkglibdir/bitcode/postgres/ under their original subfolder, eg. ~/build/postgres/dev-assert/install/lib/bitcode/postgres/utils/adt/float.bc Using existing LLVM functionality (for parallel LTO compilation), additionally an index is over these is stored to $pkglibdir/bitcode/postgres.index.bc When deciding to JIT for the first time, $pkglibdir/bitcode/ is scanned for all .index.bc files and a *combined* index over all these files is built in memory. The reason for doing so is that that allows "easy" access to inlining access for extensions - they can install code into $pkglibdir/bitcode/[extension]/ accompanied by $pkglibdir/bitcode/[extension].index.bc just alongside the actual library. The inlining implementation, I had to write my own LLVM's isn't suitable for a number of reasons, can then use the combined in-memory index to look up all 'extern' function references, judge their size, and then open just the file containing its implementation (ie. the above float.bc). Currently there's a limit of 150 instructions for functions to be inlined, functions used by inlined functions have a budget of 0.5 * limit, and so on. This gets rid of most operators I in queries I tested, although there's a few that resist inlining due to references to file-local static variables - but those largely don't seem to be performance relevant. == Type Synchronization == For my current two main avenues of performance optimizations due to JITing, expression eval and tuple deforming, it's obviously required that code generation knows about at least a few postgres types (tuple slots, heap tuples, expr context/state, etc). Initially I'd provided LLVM by emitting types manually like: { LLVMTypeRef members[15]; members[ 0] = LLVMInt32Type(); /* type */ members[ 1] = LLVMInt8Type(); /* isempty */ members[ 2] = LLVMInt8Type(); /* shouldFree */ members[ 3] = LLVMInt8Type(); /* shouldFreeMin */ members[ 4] = LLVMInt8Type(); /* slow */ members[ 5] = LLVMPointerType(StructHeapTupleData, 0); /* tuple */ members[ 6] = LLVMPointerType(StructtupleDesc, 0); /* tupleDescriptor */ members[ 7] = TypeMemoryContext; /* mcxt */ members[ 8] = LLVMInt32Type(); /* buffer */ members[ 9] = LLVMInt32Type(); /* nvalid */ members[10] = LLVMPointerType(TypeSizeT, 0); /* values */ members[11] = LLVMPointerType(LLVMInt8Type(), 0); /* nulls */ members[12] = LLVMPointerType(StructMinimalTupleData, 0); /* mintuple */ members[13] = StructHeapTupleData; /* minhdr */ members[14] = LLVMInt64Type(); /* off */ StructTupleTableSlot = LLVMStructCreateNamed(LLVMGetGlobalContext(), "struct.TupleTableSlot"); LLVMStructSetBody(StructTupleTableSlot, members, lengthof(members), false); } and then using numeric offset when emitting code like: LLVMBuildStructGEP(builder, v_slot, 9, "") to compute the address of nvalid field of a slot at runtime. but that obviously duplicates a lot of information and is incredibly failure prone. Doesn't seem acceptable. What I've now instead done is have one small file (llvmjit_types.c) which references each of the types required for JITing. That file is translated to bitcode at compile time, and loaded when LLVM is initialized in a backend. That works very well to synchronize the type definition, unfortunately it does *not* synchronize offsets as the IR level representation doesn't know field names. Instead I've added defines to the original struct definition that provide access to the relevant offsets. Eg. #define FIELDNO_TUPLETABLESLOT_NVALID 9 int tts_nvalid; /* # of valid values in tts_values */ while that still needs to be defined, it's only required for a relatively small number of fields, and it's bunched together with the struct definition, so it's easily kept synchronized. A significant downside for this is that clang needs to be around to create that bitcode file, but that doesn't seem that bad as an optional *build*-time, *not* runtime, dependency. Not a perfect solution, but I don't quite see a better approach. == Minimal cost based planning & config == Currently there's a number of GUCs that influence JITing: - jit_above_cost = -1, 0-DBL_MAX - all queries with a higher total cost get JITed, *without* optimization (expensive part), corresponding to -O0. This commonly already results in significant speedups if expression/deforming is a bottleneck (removing dynamic branches mostly). - jit_optimize_above_cost = -1, 0-DBL_MAX - all queries with a higher total cost get JITed, *with* optimization (expensive part). - jit_inline_above_cost = -1, 0-DBL_MAX - inlining is tried if query has higher cost. For all of these -1 is a hard disable. There currently also exist: - jit_expressions = 0/1 - jit_deform = 0/1 - jit_perform_inlining = 0/1 but I think they could just be removed in favor of the above. Additionally there's a few debugging/other GUCs: - jit_debugging_support = 0/1 - register generated functions with the debugger. Unfortunately GDBs JIT integration scales O(#functions^2), albeit with a very small constant, so it cannot always be enabled :( - jit_profiling_support = 0/1 - emit information so perf gets notified about JITed functions. As this logs data to disk that is not automatically cleaned up (otherwise it'd be useless), this definitely cannot be enabled by default. - jit_dump_bitcode = 0/1 - log generated pre/post optimization bitcode to disk. This is quite useful for development, so I'd want to keep it. - jit_log_ir = 0/1 - dump generated IR to the logfile. I found this to be too verbose, and I think it should be yanked. Do people feel these should be hidden behind #ifdefs, always present but prevent from being set to a meaningful, or unrestricted? === Remaining work == These I'm planning to tackle in the near future and need to be tackled before mergin. - Add a big readme - Add docs - Add / check LLVM 4.0 support - reconsider location of JITing code (lib/ and heaptuple.c specifically) - Split llvmjit_wrap.cpp into three files (error handling, inlining, temporary LLVM C API extensions) - Split the bigger commit, improve commit messages - Significant amounts of local code cleanup and comments - duplicated code in expression emission for very related step types - more consistent LLVM variable naming - pgindent - timing information about JITing needs to be fewer messages, and hidden behind a GUC. - improve logging (mostly remove) == Future Todo (some already in-progress) == - JITed hash computation for nodeAgg & nodeHash. That's currently a major bottleneck. - Increase quality of generated code. There's a *lot* left still on the table. The generated code currently spills far too much into memory, and LLVM only can optimize that away to a limited degree. I've experimented some and for TPCH Q01 it's possible to get at least another x1.8 due to that, with expression eval *still* being the bottleneck afterwards... - Caching of the generated code, drastically reducing overhead and allowing JITing to be beneficial in OLTP cases. Currently the biggest obstacle to that is the number of specific memory locations referenced in the expression representation, but that definitely can be improved (a lot of it by the above point alone). - More elaborate planning model - The cloning of modules could e reduced to only cloning required parts. As that's the most expensive part of inlining and most of the time only a few functions are used, this should probably be done soon. == Code == As the patchset is large (500kb) and I'm still quickly evolving it, I do not yet want to attach it. The git tree is at https://git.postgresql.org/git/users/andresfreund/postgres.git in the jit branch https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/jit to build --with-llvm has to be passed to configure, llvm-config either needs to be in PATH or provided with LLVM_CONFIG to make. A c++ compiler and clang need to be available under common names or provided via CXX / CLANG respectively. Regards, Andres Freund
On Wednesday, January 24, 2018 8:20:38 AM CET Andres Freund wrote: > As the patchset is large (500kb) and I'm still quickly evolving it, I do > not yet want to attach it. The git tree is at > https://git.postgresql.org/git/users/andresfreund/postgres.git > in the jit branch > > https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shor > tlog;h=refs/heads/jit > > to build --with-llvm has to be passed to configure, llvm-config either > needs to be in PATH or provided with LLVM_CONFIG to make. A c++ compiler > and clang need to be available under common names or provided via CXX / > CLANG respectively. > > Regards, > > Andres Freund Hi I tried to build on Debian sid, using GCC 7 and LLVM 5. I used the following to compile, using your branch @3195c2821d : $ export LLVM_CONFIG=/usr/bin/llvm-config-5.0 $ ./configure --with-llvm $ make And I had the following build error : llvmjit_wrap.cpp:32:10: fatal error: llvm-c/DebugInfo.h: No such file or directory #include "llvm-c/DebugInfo.h" ^~~~~~~~~~~~~~~~~~~~ compilation terminated. In LLVM 5.0, it looks like DebugInfo.h is not available in llvm-c, only as a C ++ API in llvm/IR/DebugInfo.h. For 'sport' (I have not played with LLVM API since more than one year), I tried to fix it, changing it to the C++ include. The DebugInfo related one was easy, only one function was used. But I still could not build because the LLVM API changed between 5.0 and 6.0 regarding value info SummaryList. llvmjit_wrap.cpp: In function ‘std::unique_ptr<llvm::StringMap<llvm::StringSet<> > > llvm_build_inline_plan(llvm::Module*)’: llvmjit_wrap.cpp:285:48: error: ‘class llvm::GlobalValueSummary’ has no member named ‘getBaseObject’ fs = llvm::cast<llvm::FunctionSummary>(gvs->getBaseObject()); ^~~~~~~~~~~~~ That one was a bit uglier. I'm not sure how to test everything properly, so the patch is attached for both these issues, do as you wish with it… :) Regards Pierre Ducroquet
Attachment
Hi, On 2018-01-24 22:35:08 +0100, Pierre Ducroquet wrote: > I tried to build on Debian sid, using GCC 7 and LLVM 5. I used the following > to compile, using your branch @3195c2821d : Thanks! > $ export LLVM_CONFIG=/usr/bin/llvm-config-5.0 > $ ./configure --with-llvm > $ make > > And I had the following build error : > llvmjit_wrap.cpp:32:10: fatal error: llvm-c/DebugInfo.h: No such file or > directory > #include "llvm-c/DebugInfo.h" > ^~~~~~~~~~~~~~~~~~~~ > compilation terminated. > > In LLVM 5.0, it looks like DebugInfo.h is not available in llvm-c, only as a C > ++ API in llvm/IR/DebugInfo.h. Hm, I compiled against 5.0 quite recently, but added the stripping of debuginfo lateron. I'll add a fallback method, thanks for pointing that out! > But I still could not build because the LLVM API changed between 5.0 and 6.0 > regarding value info SummaryList. Hm, thought these changes were from before my 5.0 test. But the code evolved heavily, so I might misremember. Let me see. Thanks, I'll try to push fixes into the tree soon-ish.. > I'm not sure how to test everything properly, so the patch is attached for > both these issues, do as you wish with it… :) What I do for testing is running postgres' tests against a started server that has all cost based behaviour turned off (which makes no sense from a runtime optimization perspective, but increases coverage...). The flags I pass to the server are: -c jit_expressions=1 -c jit_tuple_deforming=1 -c jit_perform_inlining=1 -c jit_above_cost=0 -c jit_optimize_above_cost=0 then I run make -s installcheck-parallel to see whether things pass. The flags makes the tests slow-ish, but tests everything under jit. In particular errors.sql's recursion check takes a while... Obviously none of the standard tests are interesting from a performance perspective... FWIW, here's an shortened excerpt of the debugging output of TPCH query: DEBUG: checking inlinability of ExecAggInitGroup DEBUG: considering extern function datumCopy at 75 for inlining DEBUG: inline top function ExecAggInitGroup total_instcount: 24, partial: 21 so the inliner found a reference to ExecAggInitGroup, inlined it, and scheduled to checkout datumCopy, externally referenced from ExecAggInitGroup, later. DEBUG: uneligible to import errstart due to early threshold: 150 vs 37 elog stuff wasn't inlined because errstart has 150 insn, but at this point the limit was 37 (aka 150 / 2 / 2). Early means this was decided based on the summary. There's also 'late' checks preventing inlining if dependencies of the inlined variable (local static functions, constant static global variables) make it bigger than the summary knows about. Then we get to execute the importing: DEBUG: performing import of postgres/utils/fmgr/fmgr.bc pg_detoast_datum, pg_detoast_datum_packed DEBUG: performing import of postgres/utils/adt/arrayfuncs.bc construct_array DEBUG: performing import of postgres/utils/error/assert.bc ExceptionalCondition, .str.1, .str DEBUG: performing import of postgres/utils/adt/expandeddatum.bc EOH_flatten_into, DeleteExpandedObject, .str.1, .str.2,.str.4, EOH_get_flat_size DEBUG: performing import of postgres/utils/adt/int8.bc __func__.overflowerr, .str, .str.12, int8inc, overflowerr, pg_add_s64_overflow ... DEBUG: performing import of postgres/utils/adt/date.bc date_le_timestamp, date2timestamp, .str, __func__.date2timestamp, .str.26 And there's a timing summary (debugging build) DEBUG: time to inline: 0.145s DEBUG: time to opt: 0.156s DEBUG: time to emit: 0.078s Same debugging build: tpch_10[6930][1]=# set jit_expressions = 1; tpch_10[6930][1]=# \i ~/tmp/tpch/pg-tpch/queries/q01.sql ... Time: 28442.870 ms (00:28.443) tpch_10[6930][1]=# set jit_expressions = 0; tpch_10[6930][1]=# \i ~/tmp/tpch/pg-tpch/queries/q01.sql ... Time: 70357.830 ms (01:10.358) tpch_10[6930][1]=# show max_parallel_workers_per_gather; ┌─────────────────────────────────┐ │ max_parallel_workers_per_gather │ ├─────────────────────────────────┤ │ 0 │ └─────────────────────────────────┘ Now admittedly a debugging/assertion enabled build isn't quite a fair fight, but it's not that much smaller a win without that. - Andres
Hi, On 2018-01-24 14:06:30 -0800, Andres Freund wrote: > > In LLVM 5.0, it looks like DebugInfo.h is not available in llvm-c, only as a C > > ++ API in llvm/IR/DebugInfo.h. > > Hm, I compiled against 5.0 quite recently, but added the stripping of > debuginfo lateron. I'll add a fallback method, thanks for pointing that > out! Went more with your fix, there's not much point in using the C API here. Should probably remove the use of it nearly entirely from the .cpp file (save for wrap/unwrap() use). But man, the 'class Error' usage is one major ugly pain. > > But I still could not build because the LLVM API changed between 5.0 and 6.0 > > regarding value info SummaryList. > > Hm, thought these changes were from before my 5.0 test. But the code > evolved heavily, so I might misremember. Let me see. Ah, that one was actually easier to fix. There's no need to get the base object at all, so it's just a one-line change. > Thanks, I'll try to push fixes into the tree soon-ish.. Pushed. Thanks again for looking! - Andres
On Wed, Jan 24, 2018 at 1:35 PM, Pierre Ducroquet <p.psql@pinaraf.info> wrote:
> In LLVM 5.0, it looks like DebugInfo.h is not available in llvm-c, only as a C
> ++ API in llvm/IR/DebugInfo.h.
The LLVM APIs don't seem to be very stable; won't there just be a
continuous stream of similar issues?
Pinning major postgresql versions to specific LLVM versions doesn't
seem very appealing. Even if you aren't interested in the latest
changes in LLVM, trying to get the right version on your machine will
be annoying.
Regards,
Jeff Davis
Hi, On 2018-01-24 22:33:30 -0800, Jeff Davis wrote: > On Wed, Jan 24, 2018 at 1:35 PM, Pierre Ducroquet <p.psql@pinaraf.info> wrote: > > In LLVM 5.0, it looks like DebugInfo.h is not available in llvm-c, only as a C > > ++ API in llvm/IR/DebugInfo.h. > > The LLVM APIs don't seem to be very stable; won't there just be a > continuous stream of similar issues? There'll be some of that yes. But the entire difference between 5 and what will be 6 was not including one header, and not calling one unneded function. That doesn't seem like a crazy amount of adaption that needs to be done. From a quick look about porting to 4, it'll be a bit, but not much more effort. The reason I'm using the C-API where possible is that it's largely forward compatible (i.e. new features added, but seldomly things are removed). The C++ code changes a bit more, but it's not that much code we're interfacing with either. I think we'll have to make do with a number of ifdefs - I don't really see an alternative. Unless you've a better idea? Greetings, Andres Freund
On Tue, Jan 23, 2018 at 11:20 PM, Andres Freund <andres@anarazel.de> wrote:
> Hi,
>
> I've spent the last weeks working on my LLVM compilation patchset. In
> the course of that I *heavily* revised it. While still a good bit away
> from committable, it's IMO definitely not a prototype anymore.
Great!
A couple high-level questions:
1. I notice a lot of use of the LLVM builder, for example, in
slot_compile_deform(). Why can't you do the same thing you did with
function code, where you create the ".bc" at build time from plain C
code, and then load it at runtime?
2. I'm glad you considered extensions. How far can we go with this in
the future? Can we have bitcode-only extensions that don't need a .so
file? Can we store the bitcode in pg_proc, simplifying deployment and
allowing extensions to travel over replication? I am not asking for
this now, of course, but I'd like to get the idea out there so we
leave room.
Regards,
Jeff Davis
Hi! On 2018-01-24 22:51:36 -0800, Jeff Davis wrote: > A couple high-level questions: > > 1. I notice a lot of use of the LLVM builder, for example, in > slot_compile_deform(). Why can't you do the same thing you did with > function code, where you create the ".bc" at build time from plain C > code, and then load it at runtime? Not entirely sure what you mean. You mean why I don't inline slot_getsomeattrs() etc and instead generate code manually? The reason is that the generated code is a *lot* smarter due to knowing the specific tupledesc. > 2. I'm glad you considered extensions. How far can we go with this in > the future? > Can we have bitcode-only extensions that don't need a .so > file? Hm. I don't see a big problem introducing this. There'd be some complexity in how to manage the lifetime of JITed functions generated that way, but that should be solvable. > Can we store the bitcode in pg_proc, simplifying deployment and > allowing extensions to travel over replication? Yes, we could. You'd need to be a bit careful that all the machines have similar-ish cpu generations or compile with defensive settings, but that seems okay. Greetings, Andres Freund
On Thursday, January 25, 2018 7:38:16 AM CET Andres Freund wrote: > Hi, > > On 2018-01-24 22:33:30 -0800, Jeff Davis wrote: > > On Wed, Jan 24, 2018 at 1:35 PM, Pierre Ducroquet <p.psql@pinaraf.info> wrote: > > > In LLVM 5.0, it looks like DebugInfo.h is not available in llvm-c, only > > > as a C ++ API in llvm/IR/DebugInfo.h. > > > > The LLVM APIs don't seem to be very stable; won't there just be a > > continuous stream of similar issues? > > There'll be some of that yes. But the entire difference between 5 and > what will be 6 was not including one header, and not calling one unneded > function. That doesn't seem like a crazy amount of adaption that needs > to be done. From a quick look about porting to 4, it'll be a bit, but > not much more effort. I don't know when this would be released, but the minimal supported LLVM version will have a strong influence on the availability of that feature. If today this JIT compiling was released with only LLVM 5/6 support, it would be unusable for most Debian users (llvm-5 is only available in sid). Even llvm 4 is not available in latest stable. I'm already trying to build with llvm-4 and I'm going to try further with llvm 3.9 (Debian Stretch doesn't have a more recent than this one, and I won't have something better to play with my data), I'll keep you informed. For sport, I may also try llvm 3.5 (for Debian Jessie). Pierre
On 24.01.2018 10:20, Andres Freund wrote: > Hi, > > I've spent the last weeks working on my LLVM compilation patchset. In > the course of that I *heavily* revised it. While still a good bit away > from committable, it's IMO definitely not a prototype anymore. > > There's too many small changes, so I'm only going to list the major > things. A good bit of that is new. The actual LLVM IR emissions itself > hasn't changed that drastically. Since I've not described them in > detail before I'll describe from scratch in a few cases, even if things > haven't fully changed. > > > == JIT Interface == > > To avoid emitting code in very small increments (increases mmap/mremap > rw vs exec remapping, compile/optimization time), code generation > doesn't happen for every single expression individually, but in batches. > > The basic object to emit code via is a jit context created with: > extern LLVMJitContext *llvm_create_context(bool optimize); > which in case of expression is stored on-demand in the EState. For other > usecases that might not be the right location. > > To emit LLVM IR (ie. the portabe code that LLVM then optimizes and > generates native code for), one gets a module from that with: > extern LLVMModuleRef llvm_mutable_module(LLVMJitContext *context); > > to which "arbitrary" numbers of functions can be added. In case of > expression evaluation, we get the module once for every expression, and > emit one function for the expression itself, and one for every > applicable/referenced deform function. > > As explained above, we do not want to emit code immediately from within > ExecInitExpr()/ExecReadyExpr(). To facilitate that readying a JITed > expression sets the function to callback, which gets the actual native > function on the first actual call. That allows to batch together the > generation of all native functions that are defined before the first > expression is evaluated - in a lot of queries that'll be all. > > Said callback then calls > extern void *llvm_get_function(LLVMJitContext *context, const char *funcname); > which'll emit code for the "in progress" mutable module if necessary, > and then searches all generated functions for the name. The names are > created via > extern void *llvm_get_function(LLVMJitContext *context, const char *funcname); > currently "evalexpr" and deform" with a generation and counter suffix. > > Currently expression which do not have access to an EState, basically > all "parent" less expressions, aren't JIT compiled. That could be > changed, but I so far do not see a huge need. Hi, As far as I understand generation of native code is now always done for all supported expressions and individually by each backend. I wonder it will be useful to do more efforts to understand when compilation to native code should be done and when interpretation is better. For example many JIT-able languages like Lua are using traces, i.e. query is first interpreted and trace is generated. If the same trace is followed more than N times, then native code is generated for it. In context of DBMS executor it is obvious that only frequently executed or expensive queries have to be compiled. So we can use estimated plan cost and number of query executions as simple criteria for JIT-ing the query. May be compilation of simple queries (with small cost) should be done only for prepared statements... Another question is whether it is sensible to redundantly do expensive work (llvm compilation) in all backends. This question refers to shared prepared statement cache. But even without such cache, it seems to be possible to use for library name some signature of the compiled expression and allow to share this libraries between backends. So before starting code generation, ExecReadyCompiledExpr can first build signature and check if correspondent library is already present. Also it will be easier to control space used by compiled libraries in this case. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi, On 2018-01-25 10:00:14 +0100, Pierre Ducroquet wrote: > I don't know when this would be released, August-October range. > but the minimal supported LLVM > version will have a strong influence on the availability of that feature. If > today this JIT compiling was released with only LLVM 5/6 support, it would be > unusable for most Debian users (llvm-5 is only available in sid). Even llvm 4 > is not available in latest stable. > I'm already trying to build with llvm-4 and I'm going to try further with llvm > 3.9 (Debian Stretch doesn't have a more recent than this one, and I won't have > something better to play with my data), I'll keep you informed. For sport, I > may also try llvm 3.5 (for Debian Jessie). I don't think it's unreasonable to not support super old llvm versions. This is a complex feature, and will take some time to mature. Supporting too many LLVM versions at the outset will have some cost. Versions before 3.8 would require supporting mcjit rather than orc, and I don't think that'd be worth doing. I think 3.9 might be a reasonable baseline... Greetings, Andres Freund
Hi, On 2018-01-25 18:40:53 +0300, Konstantin Knizhnik wrote: > As far as I understand generation of native code is now always done for all > supported expressions and individually by each backend. Mostly, yes. It's done "always" done, because there's cost based checks whether to do so or not. > I wonder it will be useful to do more efforts to understand when compilation > to native code should be done and when interpretation is better. > For example many JIT-able languages like Lua are using traces, i.e. query is > first interpreted and trace is generated. If the same trace is followed > more than N times, then native code is generated for it. Right. That's where I actually had started out, but my experimentation showed that that's not that interesting a path to pursue. Emitting code in much smaller increments (as you'd do so for individual expressions) has considerable overhead. We also have a planner that allows us reasonable guesses when to JIT and when not - something not available in many other languages. That said, nothing in the infrastructure would preent you from pursuing that, it'd just be a wrapper function for the generated exprs that tracks infocations. > Another question is whether it is sensible to redundantly do expensive work > (llvm compilation) in all backends. Right now we kinda have to, but I really want to get rid of that. There's some pointers included as constants in the generated code. I plan to work on getting rid of that requirement, but after getting the basics in (i.e. realistically not this release). Even after that I'm personally much more interested in caching the generated code inside a backend, rather than across backends. Function addresses et al being different between backends would add some complications, can be overcome, but I'm doubtful it's immediately worth it. > So before starting code generation, ExecReadyCompiledExpr can first > build signature and check if correspondent library is already present. > Also it will be easier to control space used by compiled libraries in > this Right, I definitely think we want to do that at some point not too far away in the future. That makes the applicability of JITing much broader. More advanced forms of this are that you JIT in the background for frequently executed code (so not to incur latency the first time somebody executes). Aand/or that you emit unoptimized code the first time through, which is quite quick, and run the optimizer after the query has been executed a number of times. Greetings, Andres Freund
Hi, I've spent the last weeks working on my LLVM compilation patchset. In the course of that I *heavily* revised it. While still a good bit away from committable, it's IMO definitely not a prototype anymore.
Below are results on my system for Q1 TPC-H scale 10 (~13Gb database)
| Options | Time |
| Default | 20075 |
| jit_expressions=on | 16105 |
| jit_tuple_deforming=on | 14734 |
| jit_perform_inlining=on | 13441 |
Also I noticed that parallel execution didsables JIT.
At my computer with 4 cores time of Q1 with parallel execution is 6549.
Are there any principle problems with combining JIT and parallel execution?
-- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi, Thanks for testing things out! On 2018-01-26 10:44:24 +0300, Konstantin Knizhnik wrote: > Also I noticed that parallel execution didsables JIT. Oh, oops, I broke that recently by moving where the decisition about whether to jit or not is. There actually is JITing, but only in the leader. > Are there any principle problems with combining JIT and parallel execution? No, there's not, I just need to send down the flag to JIT down to the workers. Will look at it tomorrow. If you want to measure / play around till then you can manually hack the PGJIT_* checks in execExprCompile.c with that done, on my laptop, tpch-Q01, scale 10: SET max_parallel_workers_per_gather=0; SET jit_expressions = 1; 15145.508 ms SET max_parallel_workers_per_gather=0; SET jit_expressions = 0; 23808.809 ms SET max_parallel_workers_per_gather=4; SET jit_expressions = 1; 4775.170 ms SET max_parallel_workers_per_gather=4; SET jit_expressions = 0; 7173.483 ms (that's with inlining and deforming enabled too) Greetings, Andres Freund
On 26.01.2018 11:23, Andres Freund wrote:
> Hi,
>
> Thanks for testing things out!
>
Thank you for this work.
One more question: do you have any idea how to profile JITed code?
There is no LLVMOrcRegisterPerf in LLVM 5, so jit_profiling_support
option does nothing.
And without it perf is not able to unwind stack trace for generated code.
A attached the produced profile, looks like "unknown" bar corresponds to
JIT code.
There is NoFramePointerElim option in LLVMMCJITCompilerOptions
structure, but it requires use of ExecutionEngine.
Something like this:
mod = llvm_mutable_module(context);
{
struct LLVMMCJITCompilerOptions options;
LLVMExecutionEngineRef jit;
char* error;
LLVMCreateExecutionEngineForModule(&jit, mod, &error);
LLVMInitializeMCJITCompilerOptions(&options, sizeof(options));
options.NoFramePointerElim = 1;
LLVMCreateMCJITCompilerForModule(&jit, mod, &options,
sizeof(options),
&error);
}
...
But you are compiling code using LLVMOrcAddEagerlyCompiledIR
and I find no way to pass no-omit-frame pointer option here.
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
{kind=link}
On Thu, Jan 25, 2018 at 11:20:28AM -0800, Andres Freund wrote: > On 2018-01-25 18:40:53 +0300, Konstantin Knizhnik wrote: > > Another question is whether it is sensible to redundantly do > > expensive work (llvm compilation) in all backends. > > Right now we kinda have to, but I really want to get rid of that. > There's some pointers included as constants in the generated code. I > plan to work on getting rid of that requirement, but after getting > the basics in (i.e. realistically not this release). Even after > that I'm personally much more interested in caching the generated > code inside a backend, rather than across backends. Function > addresses et al being different between backends would add some > complications, can be overcome, but I'm doubtful it's immediately > worth it. If we go with threading for this part, sharing that state may be simpler. It seems a lot of work is going into things that threading does at a much lower developer cost, but that's a different conversation. > > So before starting code generation, ExecReadyCompiledExpr can first > > build signature and check if correspondent library is already present. > > Also it will be easier to control space used by compiled libraries in > > this > > Right, I definitely think we want to do that at some point not too far > away in the future. That makes the applicability of JITing much broader. > > More advanced forms of this are that you JIT in the background for > frequently executed code (so not to incur latency the first time > somebody executes). Aand/or that you emit unoptimized code the first > time through, which is quite quick, and run the optimizer after the > query has been executed a number of times. Both sound pretty neat. Best, David. -- David Fetter <david(at)fetter(dot)org> http://fetter.org/ Phone: +1 415 235 3778 Remember to vote! Consider donating to Postgres: http://www.postgresql.org/about/donate
Hi,
On 2018-01-26 13:06:27 +0300, Konstantin Knizhnik wrote:
> One more question: do you have any idea how to profile JITed code?
Yes ;). It depends a bit on what exactly you want to do. Is it
sufficient to get time associated with the parent caller, or do you need
instruction-level access.
> There is no LLVMOrcRegisterPerf in LLVM 5, so jit_profiling_support option
> does nothing.
Right, it's a patch I'm trying to get into the next version of
llvm. With that you get access to the shared object and everything.
> And without it perf is not able to unwind stack trace for generated
> code.
You can work around that by using --call-graph lbr with a sufficiently
new perf. That'll not know function names et al, but at least the parent
will be associated correctly.
> But you are compiling code using LLVMOrcAddEagerlyCompiledIR
> and I find no way to pass no-omit-frame pointer option here.
It shouldn't be too hard to open code support for it, encapsulated in a
function:
// Set function attribute "no-frame-pointer-elim" based on
// NoFramePointerElim.
for (auto &F : *Mod) {
auto Attrs = F.getAttributes();
StringRef Value(options.NoFramePointerElim ? "true" : "false");
Attrs = Attrs.addAttribute(F.getContext(), AttributeList::FunctionIndex,
"no-frame-pointer-elim", Value);
F.setAttributes(Attrs);
}
that's all that option did for mcjit.
Greetings,
Andres Freund
On Wed, Jan 24, 2018 at 11:02 PM, Andres Freund <andres@anarazel.de> wrote:
> Not entirely sure what you mean. You mean why I don't inline
> slot_getsomeattrs() etc and instead generate code manually? The reason
> is that the generated code is a *lot* smarter due to knowing the
> specific tupledesc.
I would like to see if we can get a combination of JIT and LTO to work
together to specialize generic code at runtime.
Let's say you have a function f(int x, int y, int z). You want to be
able to specialize it on y at runtime, so that a loop gets unrolled in
the common case where y is small.
1. At build time, create bitcode for the generic implementation of f().
2. At run time, load the generic bitcode into a module (let's call it
the "generic module")
3. At run time, create a new module (let's call it the "bind module")
that only does the following things:
a. declares a global variable bind_y, and initialize it to the value 3
b. declares a wrapper function f_wrapper(int x, int z), and all the
function does is call f(x, bind_y, z)
4. Link the generic module and the bind module together (let's call
the result the "linked module")
5. Optimize the linked module
After sorting out a few details about symbols and inlining, what will
happen is that the generic f() will be inlined into f_wrapper, and it
will see that bind_y is a constant, and then unroll a "for" loop over
y.
I experimented a bit before and it works for basic cases, but I'm not
sure if it's as good as your hand-generated LLVM.
If we can make this work, it would be a big win for
readability/maintainability. The hand-generated LLVM is limited to the
bind module, which is very simple, and doesn't need to be changed when
the implementation of f() changes.
Regards,
Jeff Davis
Hi, On 2018-01-26 18:26:03 -0800, Jeff Davis wrote: > On Wed, Jan 24, 2018 at 11:02 PM, Andres Freund <andres@anarazel.de> wrote: > > Not entirely sure what you mean. You mean why I don't inline > > slot_getsomeattrs() etc and instead generate code manually? The reason > > is that the generated code is a *lot* smarter due to knowing the > > specific tupledesc. > > I would like to see if we can get a combination of JIT and LTO to work > together to specialize generic code at runtime. Well, LTO can't quite work. It relies on being able to mark code in modules linked together as externally visible - and cleary we can't do that for a running postgres binary. At least in all incarnations I'm aware of. But that's why the tree I posted supports inlining of code. > Let's say you have a function f(int x, int y, int z). You want to be > able to specialize it on y at runtime, so that a loop gets unrolled in > the common case where y is small. > > 1. At build time, create bitcode for the generic implementation of f(). > 2. At run time, load the generic bitcode into a module (let's call it > the "generic module") > 3. At run time, create a new module (let's call it the "bind module") > that only does the following things: > a. declares a global variable bind_y, and initialize it to the value 3 > b. declares a wrapper function f_wrapper(int x, int z), and all the > function does is call f(x, bind_y, z) > 4. Link the generic module and the bind module together (let's call > the result the "linked module") > 5. Optimize the linked module Afaict that's effectively what I've already implemented. We could export more input as constants to the generated program, but other than that... Whenever any extern functions are referenced, and jit_inlining=1, then the code will see whether the called external code is available as jit bitcode. Based on a simple instruction based cost limit that function will get inlined (unless it references file local non-constant static variables and such). Now the JITed expressions tree currently makes it hard for LLVM to recognize some constant input as constant, but what's largely needed for that to be better is some improvements in where temporary values are stored (should be in alloca's rather than local memory, so mem2reg can do its thing). It's a TODO... Right now LLVM will figure out constant inputs to non-strict functions, but not strict ones, but after fixing some of what I've mentioned previously it works pretty universally. Have I misunderstood adn there's some significant functional difference? > I experimented a bit before and it works for basic cases, but I'm not > sure if it's as good as your hand-generated LLVM. For deforming it doesn't even remotely get as good in my experiments. > If we can make this work, it would be a big win for > readability/maintainability. The hand-generated LLVM is limited to the > bind module, which is very simple, and doesn't need to be changed when > the implementation of f() changes. Right. Thats why I think we definitely want that for the large majority of referenced functionality. Greetings, Andres Freund
Hi,
On Fri, Jan 26, 2018 at 6:40 PM, Andres Freund <andres@anarazel.de> wrote:
>> I would like to see if we can get a combination of JIT and LTO to work
>> together to specialize generic code at runtime.
>
> Well, LTO can't quite work. It relies on being able to mark code in
> modules linked together as externally visible - and cleary we can't do
> that for a running postgres binary. At least in all incarnations I'm
> aware of. But that's why the tree I posted supports inlining of code.
I meant a more narrow use of LTO: since we are doing linking in step
#4 and optimization in step #5, it's optimizing the code after
linking, which is a kind of LTO (though perhaps I'm misusing the
term?).
The version of LLVM that I tried this against had a linker option
called "InternalizeLinkedSymbols" that would prevent the visibility
problem you mention (assuming I understand you correctly). That option
is no longer there so I will have to figure out how to do it with the
current LLVM API.
> Afaict that's effectively what I've already implemented. We could export
> more input as constants to the generated program, but other than that...
I brought this up in the context of slot_compile_deform(). In your
patch, you have code like:
+ if (!att->attnotnull)
+ {
...
+ v_nullbyte = LLVMBuildLoad(
+ builder,
+ LLVMBuildGEP(builder, v_bits,
+ &v_nullbyteno, 1, ""),
+ "attnullbyte");
+
+ v_nullbit = LLVMBuildICmp(
+ builder,
+ LLVMIntEQ,
+ LLVMBuildAnd(builder, v_nullbyte,
v_nullbytemask, ""),
+ LLVMConstInt(LLVMInt8Type(), 0, false),
+ "attisnull");
...
So it looks like you are reimplementing the generic code, but with
conditional code gen. If the generic code changes, someone will need
to read, understand, and change this code, too, right?
With my approach, then it would initially do *un*conditional code gen,
and be less efficient and less specialized than the code generated by
your current patch. But then it would link in the constant tupledesc,
and optimize, and the optimizer will realize that they are constants
(hopefully) and then cut out a lot of the dead code and specialize it
to the given tupledesc.
This places a lot of faith in the optimizer and I realize it may not
happen as nicely with real code as it did with my earlier experiments.
Maybe you already tried and you are saying that's a dead end? I'll
give it a shot, though.
> Now the JITed expressions tree currently makes it hard for LLVM to
> recognize some constant input as constant, but what's largely needed for
> that to be better is some improvements in where temporary values are
> stored (should be in alloca's rather than local memory, so mem2reg can
> do its thing). It's a TODO... Right now LLVM will figure out constant
> inputs to non-strict functions, but not strict ones, but after fixing
> some of what I've mentioned previously it works pretty universally.
>
>
> Have I misunderstood adn there's some significant functional difference?
I'll try to explain with code, and then we can know for sure ;-)
Sorry for the ambiguity, I'm probably misusing a few terms.
>> I experimented a bit before and it works for basic cases, but I'm not
>> sure if it's as good as your hand-generated LLVM.
>
> For deforming it doesn't even remotely get as good in my experiments.
I'd like some more information here -- what didn't work? It didn't
recognize constants? Or did recognize them, but didn't optimize as
well as you did by hand?
Regards,
Jeff Davis
Hi,
On 2018-01-26 22:52:35 -0800, Jeff Davis wrote:
> The version of LLVM that I tried this against had a linker option
> called "InternalizeLinkedSymbols" that would prevent the visibility
> problem you mention (assuming I understand you correctly).
I don't think they're fully solvable - you can't really internalize a
reference to a mutable static variable in another translation
unit. Unless you modify that translation unit, which doesn't work when
postgres running.
> That option is no longer there so I will have to figure out how to do
> it with the current LLVM API.
Look at the llvmjit_wrap.c code invoking FunctionImporter - that pretty
much does that. I'll push a cleaned up version of that code sometime
this weekend (it'll then live in llvmjit_inline.cpp).
> > Afaict that's effectively what I've already implemented. We could export
> > more input as constants to the generated program, but other than that...
>
> I brought this up in the context of slot_compile_deform(). In your
> patch, you have code like:
>
> + if (!att->attnotnull)
> + {
> ...
> + v_nullbyte = LLVMBuildLoad(
> + builder,
> + LLVMBuildGEP(builder, v_bits,
> + &v_nullbyteno, 1, ""),
> + "attnullbyte");
> +
> + v_nullbit = LLVMBuildICmp(
> + builder,
> + LLVMIntEQ,
> + LLVMBuildAnd(builder, v_nullbyte,
> v_nullbytemask, ""),
> + LLVMConstInt(LLVMInt8Type(), 0, false),
> + "attisnull");
> ...
>
> So it looks like you are reimplementing the generic code, but with
> conditional code gen. If the generic code changes, someone will need
> to read, understand, and change this code, too, right?
Right. Not that that's code that has changed that much...
> With my approach, then it would initially do *un*conditional code gen,
> and be less efficient and less specialized than the code generated by
> your current patch. But then it would link in the constant tupledesc,
> and optimize, and the optimizer will realize that they are constants
> (hopefully) and then cut out a lot of the dead code and specialize it
> to the given tupledesc.
Right.
> This places a lot of faith in the optimizer and I realize it may not
> happen as nicely with real code as it did with my earlier experiments.
> Maybe you already tried and you are saying that's a dead end? I'll
> give it a shot, though.
I did that, yes. There's two major downsides:
a) The code isn't as efficient as the handrolled code. The handrolled
code e.g. can take into account that it doesn't need to access the
NULL bitmap for a NOT NULL column and we don't need to check the
tuple's number of attributes if there's a following NOT NULL
attribute. Those safe a good number of cycles.
b) The optimizations to take advantage of the constants and make the
code faster with the constant tupledesc is fairly slow (you pretty
much need at least an -O2 equivalent), whereas the handrolled tuple
deforming is faster than the slot_getsomeattrs with just a single,
pretty cheap, mem2reg pass. We're talking about ~1ms vs 70-100ms in
a lot of cases. The optimizer often will not actually unroll the
loop with many attributes despite that being beneficial.
I think in most cases using the approach you advocate makes sense, to
avoid duplication, but tuple deforming is such a major bottleneck that I
think it's clearly worth doing it manually. Being able to use llvm with
just a always-inline and a mem2reg pass makes it so much more widely
applicable than doing the full inlining and optimization work.
> >> I experimented a bit before and it works for basic cases, but I'm not
> >> sure if it's as good as your hand-generated LLVM.
> >
> > For deforming it doesn't even remotely get as good in my experiments.
>
> I'd like some more information here -- what didn't work? It didn't
> recognize constants? Or did recognize them, but didn't optimize as
> well as you did by hand?
It didn't optimize as well as I did by hand, without significantly
complicating (and slowing) the originating the code. It sometimes
decided not to unroll the loop, and it takes a *lot* longer than the
direct emission of the code.
I'm hoping to work on making more of the executor JITed, and there I do
think it's largely going to be what you're proposing, due to the sheer
mass of code.
Greetings,
Andres Freund
On Sat, Jan 27, 2018 at 1:20 PM, Andres Freund <andres@anarazel.de> wrote:
> b) The optimizations to take advantage of the constants and make the
> code faster with the constant tupledesc is fairly slow (you pretty
> much need at least an -O2 equivalent), whereas the handrolled tuple
> deforming is faster than the slot_getsomeattrs with just a single,
> pretty cheap, mem2reg pass. We're talking about ~1ms vs 70-100ms in
> a lot of cases. The optimizer often will not actually unroll the
> loop with many attributes despite that being beneficial.
This seems like the major point. We would have to customize the
optimization passes a lot and/or choose carefully which ones we apply.
> I think in most cases using the approach you advocate makes sense, to
> avoid duplication, but tuple deforming is such a major bottleneck that I
> think it's clearly worth doing it manually. Being able to use llvm with
> just a always-inline and a mem2reg pass makes it so much more widely
> applicable than doing the full inlining and optimization work.
OK.
On another topic, I'm trying to find a way we could break this patch
into smaller pieces. For instance, if we concentrate on tuple
deforming, maybe it would be committable in time for v11?
I see that you added some optimizations to the existing generic code.
Do those offer a measurable improvement, and if so, can you commit
those first to make the JIT stuff more readable?
Also, I'm sure you considered this, but I'd like to ask if we can try
harder make the JIT itself happen in an extension. It has some pretty
huge benefits:
* The JIT code is likely to go through a lot of changes, and it
would be nice if it wasn't tied to a yearly release cycle.
* Would mean postgres itself isn't dependent on a huge library like
llvm, which just seems like a good idea from a packaging standpoint.
* May give GCC or something else a chance to compete with it's own JIT.
* It may make it easier to get something in v11.
It appears reasonable to make the slot deforming and expression
evaluator parts an extension. execExpr.h only exports a couple new
functions; heaptuple.c has a lot of changes but they seem like they
could be separated (unless I'm missing something).
The biggest problem is that the inlining would be much harder to
separate out, because you are building the .bc files at build time. I
really like the idea of inlining, but it doesn't necessarily need to
be in the first commit.
Regards,
Jeff Davis
Hi, On 2018-01-27 16:56:17 -0800, Jeff Davis wrote: > On another topic, I'm trying to find a way we could break this patch > into smaller pieces. For instance, if we concentrate on tuple > deforming, maybe it would be committable in time for v11? Yea, I'd planned and started to do so. I actually hope we can get more committed than just the tuple deforming code - for one it currently integrates directly with the expression evaluation code, and my experience with trying to do so outside of it have not gone well. > I see that you added some optimizations to the existing generic code. > Do those offer a measurable improvement, and if so, can you commit > those first to make the JIT stuff more readable? I think basically the later a patch currently is in the series the less important it is. I've already committed a lot of preparatory patches (like that aggs now use the expression engine), and I plan to continue doing so. > Also, I'm sure you considered this, but I'd like to ask if we can try > harder make the JIT itself happen in an extension. It has some pretty > huge benefits: I'm very strongly against this. To the point that I'll not pursue JITing further if that becomes a requirement. I could be persuaded to put it into a shared library instead of the main binary itself, but I think developing it outside of core is entirely infeasible because quite freuquently both non-JITed code and JITed code need adjustments. That'd solve your concern about > * Would mean postgres itself isn't dependent on a huge library like > llvm, which just seems like a good idea from a packaging standpoint. to some degree. I think it's a fools errand to try to keep in sync with core changes on the expression evaluation and struct definition side of things. There's planner integration, error handling integration and similar related things too, all of which require core changes. Therefore I don't think there's a reasonable chance of success of doing this outside of core postgres. > It appears reasonable to make the slot deforming and expression > evaluator parts an extension. execExpr.h only exports a couple new > functions; heaptuple.c has a lot of changes but they seem like they > could be separated (unless I'm missing something). The heaptuple.c stuff could largely be dropped, that was more an effort to level the plainfield a bit to make the comparison fairer. I kinda wondered about putting the JIT code in a heaptuple_jit.c file instead of heaptuple.c. > The biggest problem is that the inlining would be much harder to > separate out, because you are building the .bc files at build time. I > really like the idea of inlining, but it doesn't necessarily need to > be in the first commit. Well, but doing this outside of core would pretty much prohibit doing so forever, no? Getting the inlining design right has influenced several other parts of the code. I think it's right that the inlining doesn't necessarily have to be part of the initial set of commits (and I plan to separate it out in the next revision), but I do think it has to be written in a reasonably ready form at the time of commit. Greetings, Andres Freund
On Sat, Jan 27, 2018 at 5:15 PM, Andres Freund <andres@anarazel.de> wrote:
>> Also, I'm sure you considered this, but I'd like to ask if we can try
>> harder make the JIT itself happen in an extension. It has some pretty
>> huge benefits:
>
> I'm very strongly against this. To the point that I'll not pursue JITing
> further if that becomes a requirement.
I would like to see this feature succeed and I'm not making any
specific demands.
> infeasible because quite freuquently both non-JITed code and JITed code
> need adjustments. That'd solve your concern about
Can you explain further?
> I think it's a fools errand to try to keep in sync with core changes on
> the expression evaluation and struct definition side of things. There's
> planner integration, error handling integration and similar related
> things too, all of which require core changes. Therefore I don't think
> there's a reasonable chance of success of doing this outside of core
> postgres.
I wasn't suggesting the entire patch be done outside of core. Core
will certainly need to know about JIT compilation, but I am not
convinced that it needs to know about the details of LLVM. All the
references to the LLVM library itself are contained in a few files, so
you've already got it well organized. What's stopping us from putting
that code into a "jit provider" extension that implements the proper
interfaces?
> Well, but doing this outside of core would pretty much prohibit doing so
> forever, no?
First of all, building .bc files at build time is much less invasive
than linking to the LLVM library. Any version of clang will produce
bitcode that can be read by any LLVM library or tool later (more or
less).
Second, we could change our minds later. Mark any extension APIs as
experimental, and decide we want to move LLVM into postgres whenever
it is needed.
Third, there's lots of cool stuff we can do here:
* put the source in the catalog
* an extension could have its own catalog and build the source into
bitcode and cache it there
* the source for functions would flow to replicas, etc.
* security-conscious environments might even choose to run some of
the C code in a safe C interpreter rather than machine code
So I really don't see this as permanently closing off our options.
Regards,
Jeff Davis
On Thursday, January 25, 2018 8:12:42 PM CET Andres Freund wrote:
> Hi,
>
> On 2018-01-25 10:00:14 +0100, Pierre Ducroquet wrote:
> > I don't know when this would be released,
>
> August-October range.
>
> > but the minimal supported LLVM
> > version will have a strong influence on the availability of that feature.
> > If today this JIT compiling was released with only LLVM 5/6 support, it
> > would be unusable for most Debian users (llvm-5 is only available in
> > sid). Even llvm 4 is not available in latest stable.
> > I'm already trying to build with llvm-4 and I'm going to try further with
> > llvm 3.9 (Debian Stretch doesn't have a more recent than this one, and I
> > won't have something better to play with my data), I'll keep you
> > informed. For sport, I may also try llvm 3.5 (for Debian Jessie).
>
> I don't think it's unreasonable to not support super old llvm
> versions. This is a complex feature, and will take some time to
> mature. Supporting too many LLVM versions at the outset will have some
> cost. Versions before 3.8 would require supporting mcjit rather than
> orc, and I don't think that'd be worth doing. I think 3.9 might be a
> reasonable baseline...
>
> Greetings,
>
> Andres Freund
Hi
I have fixed the build issues with LLVM 3.9 and 4.0. The LLVM documentation is
really lacking when it comes to porting from version x to x+1.
The only really missing part I found is that in 3.9, GlobalValueSummary has no
flag showing if it's not EligibleToImport. I am not sure about the
consequences.
I'm still fixing some runtime issues so I will not bother you with the patch
right now.
BTW, the makefile for src/backend/lib does not remove the llvmjit_types.bc
file when cleaning, and doesn't seem to install in the right folder.
Regards
Pierre
On Thursday, January 25, 2018 8:02:54 AM CET Andres Freund wrote: > Hi! > > On 2018-01-24 22:51:36 -0800, Jeff Davis wrote: > > Can we store the bitcode in pg_proc, simplifying deployment and > > allowing extensions to travel over replication? > > Yes, we could. You'd need to be a bit careful that all the machines have > similar-ish cpu generations or compile with defensive settings, but that > seems okay. Hi Doing this would 'bind' the database to the LLVM release used. LLVM can, as far as I know, generate bitcode only for the current version, and will only be able to read bitcode from previous versions. So you can't have, for instance a master server with LLVM 5 and a standby server with LLVM 4. So maybe PostgreSQL would have to expose what LLVM version is currently used ? Or a major PostgreSQL release could accept only one major LLVM release, as was suggested in another thread ? Pierre
Hi, On 2018-01-27 22:06:59 -0800, Jeff Davis wrote: > > infeasible because quite freuquently both non-JITed code and JITed code > > need adjustments. That'd solve your concern about > > Can you explain further? There's already a *lot* of integration points in the patchseries. Error handling needs to happen in parts of code we do not want to make extensible, the defintion of expression steps has to exactly match, the core code needs to emit the right types for syncing, the core code needs to define the right FIELDNO accessors, there needs to be planner integrations. Many of those aren't doable with even remotely the same effort, both initial and continual, from non-core code.... I think those alone make it bad, but there'll be more. Short-Medium term expression evaluation needs to evolve further to make JITing cachable: http://archives.postgresql.org/message-id/20180124203616.3gx4vm45hpoijpw3%40alap3.anarazel.de which again definitely has to be happen in core and will require corresponding changes on the JIT side very step. Then we'll need to introduce something like plancache (or something similar?) support for JITing to reuse JITed functions. Then there's also a significant difference in how large the adoption's going to be, and how all the core code that'd need to be added is supposed to be testable without the JIT emitting side in core. > > I think it's a fools errand to try to keep in sync with core changes on > > the expression evaluation and struct definition side of things. There's > > planner integration, error handling integration and similar related > > things too, all of which require core changes. Therefore I don't think > > there's a reasonable chance of success of doing this outside of core > > postgres. > > I wasn't suggesting the entire patch be done outside of core. Core > will certainly need to know about JIT compilation, but I am not > convinced that it needs to know about the details of LLVM. All the > references to the LLVM library itself are contained in a few files, so > you've already got it well organized. What's stopping us from putting > that code into a "jit provider" extension that implements the proper > interfaces? The above hopefully answers that? What we could do, imo somewhat realistically, is to put most of the provider into a dynamically loaded shared library that lives in core (similar to how we build the pgoutput output plugin shared library as part of core). But that still would end up hard coding things like LLVM specific error handling etc, which we currently do *NOT* want to be extensible. > > Well, but doing this outside of core would pretty much prohibit doing so > > forever, no? > > First of all, building .bc files at build time is much less invasive > than linking to the LLVM library. Could you expand on that, I don't understand why that'd be the case? > Any version of clang will produce bitcode that can be read by any LLVM > library or tool later (more or less). Well, forward portable, not backward portable. > Second, we could change our minds later. Mark any extension APIs as > experimental, and decide we want to move LLVM into postgres whenever > it is needed. > > Third, there's lots of cool stuff we can do here: > * put the source in the catalog > * an extension could have its own catalog and build the source into > bitcode and cache it there > * the source for functions would flow to replicas, etc. > * security-conscious environments might even choose to run some of > the C code in a safe C interpreter rather than machine code I agree, but what does that have to do with the llvmjit stuff being an extension or not? Greetings, Andres Freund
Hi, On 2018-01-28 23:02:56 +0100, Pierre Ducroquet wrote: > I have fixed the build issues with LLVM 3.9 and 4.0. The LLVM documentation is > really lacking when it comes to porting from version x to x+1. > The only really missing part I found is that in 3.9, GlobalValueSummary has no > flag showing if it's not EligibleToImport. I am not sure about the > consequences. I think that'd not be too bad, it'd just lead to some small increase in overhead as more modules would be loaded. > BTW, the makefile for src/backend/lib does not remove the llvmjit_types.bc > file when cleaning, and doesn't seem to install in the right folder. Hm, both seems to be right here? Note that the llvmjit_types.bc file should *not* go into the bitcode/ directory, as it's about syncing types not inlining. I've added a comment to that effect. Greetings, Andres Freund
Hi, On 2018-01-23 23:20:38 -0800, Andres Freund wrote: > == Code == > > As the patchset is large (500kb) and I'm still quickly evolving it, I do > not yet want to attach it. The git tree is at > https://git.postgresql.org/git/users/andresfreund/postgres.git > in the jit branch > https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/jit I've just pushed an updated and rebased version of the tree: - Split the large "jit infrastructure" commits into a number of smaller commits - Split the C++ file - Dropped some of the performance stuff done to heaptuple.c - that was mostly to make performance comparisons a bit more interesting, but doesn't seem important enough to deal with. - Added a commit renaming datetime.h symbols so they don't conflict with LLVM variables anymore, removing ugly #undef PM/#define PM dance around includes. Will post separately. - Reduced the number of pointer constants in the generated LLVM IR, by doing more getelementptr accesses (stem from before the time types were automatically synced) - Increased number of comments a bit There's a jit-before-rebase-2018-01-29 tag, for the state of the tree before the rebase. Regards, Andres
On Monday, January 29, 2018 10:46:13 AM CET Andres Freund wrote: > Hi, > > On 2018-01-28 23:02:56 +0100, Pierre Ducroquet wrote: > > I have fixed the build issues with LLVM 3.9 and 4.0. The LLVM > > documentation is really lacking when it comes to porting from version x > > to x+1. > > The only really missing part I found is that in 3.9, GlobalValueSummary > > has no flag showing if it's not EligibleToImport. I am not sure about the > > consequences. > > I think that'd not be too bad, it'd just lead to some small increase in > overhead as more modules would be loaded. > > > BTW, the makefile for src/backend/lib does not remove the llvmjit_types.bc > > file when cleaning, and doesn't seem to install in the right folder. > > Hm, both seems to be right here? Note that the llvmjit_types.bc file > should *not* go into the bitcode/ directory, as it's about syncing types > not inlining. I've added a comment to that effect. The file was installed in lib/ while the code expected it in lib/postgresql. So there was something wrong here. And deleting the file when cleaning is needed if at configure another llvm version is used. The file must be generated with a clang release that is not more recent than the llvm version linked to postgresql. Otherwise, the bitcode generated is not accepted by llvm. Regards Pierre
On 26.01.2018 22:38, Andres Freund wrote:
> And without it perf is not able to unwind stack trace for generated
>> code.
> You can work around that by using --call-graph lbr with a sufficiently
> new perf. That'll not know function names et al, but at least the parent
> will be associated correctly.
With --call-graph lbr result is ... slightly different (see attached
profile) but still there is "unknown" bar.
>> But you are compiling code using LLVMOrcAddEagerlyCompiledIR
>> and I find no way to pass no-omit-frame pointer option here.
> It shouldn't be too hard to open code support for it, encapsulated in a
> function:
> // Set function attribute "no-frame-pointer-elim" based on
> // NoFramePointerElim.
> for (auto &F : *Mod) {
> auto Attrs = F.getAttributes();
> StringRef Value(options.NoFramePointerElim ? "true" : "false");
> Attrs = Attrs.addAttribute(F.getContext(), AttributeList::FunctionIndex,
> "no-frame-pointer-elim", Value);
> F.setAttributes(Attrs);
> }
> that's all that option did for mcjit.
I have implemented the following function:
void
llvm_no_frame_pointer_elimination(LLVMModuleRef mod)
{
llvm::Module *module = llvm::unwrap(mod);
for (auto &F : *module) {
auto Attrs = F.getAttributes();
Attrs = Attrs.addAttribute(F.getContext(),
llvm::AttributeList::FunctionIndex,
"no-frame-pointer-elim", "true");
F.setAttributes(Attrs);
}
}
and call it before LLVMOrcAddEagerlyCompiledIR in llvm_compile_module:
llvm_no_frame_pointer_elimination(context->module);
smod = LLVMOrcMakeSharedModule(context->module);
if (LLVMOrcAddEagerlyCompiledIR(compile_orc, &orc_handle, smod,
llvm_resolve_symbol, NULL))
{
elog(ERROR, "failed to jit module");
}
... but it has no effect: produced profile is the same (with
--call-graph dwarf).
May be you can point me on my mistake...
Actually I am trying to find answer for the question why your version of
JIT provides ~2 times speedup at Q1, while ISPRAS version
(https://www.pgcon.org/2017/schedule/attachments/467_PGCon%202017-05-26%2015-00%20ISPRAS%20Dynamic%20Compilation%20of%20SQL%20Queries%20in%20PostgreSQL%20Using%20LLVM%20JIT.pdf)
speedup Q1 is 5.5x times.
May be it is because them are using double type to calculate aggregates
while as far as I understand you are using standard Postgres aggregate
functions?
Or may be because ISPRAS version is not checking for NULL values...
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
{kind=link}
Hi, On 2018-01-29 15:45:56 +0300, Konstantin Knizhnik wrote: > On 26.01.2018 22:38, Andres Freund wrote: > > And without it perf is not able to unwind stack trace for generated > > > code. > > You can work around that by using --call-graph lbr with a sufficiently > > new perf. That'll not know function names et al, but at least the parent > > will be associated correctly. > > With --call-graph lbr result is ... slightly different (see attached > profile) but still there is "unknown" bar. Right. All that allows is to attribute the cost below the parent in the perf report --children case. For it to be attributed to proper symbols you need my llvm patch to support pef. > Actually I am trying to find answer for the question why your version of JIT > provides ~2 times speedup at Q1, while ISPRAS version (https://www.pgcon.org/2017/schedule/attachments/467_PGCon%202017-05-26%2015-00%20ISPRAS%20Dynamic%20Compilation%20of%20SQL%20Queries%20in%20PostgreSQL%20Using%20LLVM%20JIT.pdf) > speedup Q1 is 5.5x times. > May be it is because them are using double type to calculate aggregates > while as far as I understand you are using standard Postgres aggregate > functions? > Or may be because ISPRAS version is not checking for NULL values... All of those together, yes. And added that I'm aiming to work incrementally towards core inclusions, rather than getting the best results. There's a *lot* that can be done to improve the generated code - after e.g. hacking together an improvement to the argument passing (by allocating isnull / nargs / arg[], argnull[] as a separate on-stack from FunctionCallInfoData), I get another 1.8x. Eliminating redundant float overflow checks gives another 1.2x. And so on. Greetings, Andres Freund
On Mon, Jan 29, 2018 at 1:36 AM, Andres Freund <andres@anarazel.de> wrote:
> There's already a *lot* of integration points in the patchseries. Error
> handling needs to happen in parts of code we do not want to make
> extensible, the defintion of expression steps has to exactly match, the
> core code needs to emit the right types for syncing, the core code needs
> to define the right FIELDNO accessors, there needs to be planner
> integrations. Many of those aren't doable with even remotely the same
> effort, both initial and continual, from non-core code....
OK. How about this: are you open to changes that move us in the
direction of extensibility later? (By this I do *not* mean imposing a
bunch of requirements on you... either small changes to your patches
or something part of another commit.) Or are you determined that this
always should be a part of core?
I don't want to stand in your way, but I am also hesitant to dive head
first into LLVM and not look back. Postgres has always been lean, fast
building, and with few dependencies. Who knows what LLVM will do in
the future and how that will affect postgres? Especially when, on day
one, we already know that it causes a few annoyances?
In other words, are you "strongly against [extensbility being a
requirement for the first commit]" or "strongly against [extensible
JIT]"?
>> > Well, but doing this outside of core would pretty much prohibit doing so
>> > forever, no?
>>
>> First of all, building .bc files at build time is much less invasive
>> than linking to the LLVM library.
>
> Could you expand on that, I don't understand why that'd be the case?
Building the .bc files at build time depends on LLVM, but is not very
version-dependent and has no impact on the resulting binary. That's
less invasive than a dependency on a library with an unstable API that
doesn't entirely work with our error reporting facility.
>> Third, there's lots of cool stuff we can do here:
>> * put the source in the catalog
>> * an extension could have its own catalog and build the source into
>> bitcode and cache it there
>> * the source for functions would flow to replicas, etc.
>> * security-conscious environments might even choose to run some of
>> the C code in a safe C interpreter rather than machine code
>
> I agree, but what does that have to do with the llvmjit stuff being an
> extension or not?
If the source for functions is in the catalog, we could build the
bitcode at runtime and still do the inlining. We wouldn't need to do
anything at build time. (Again, this would be "cool stuff for the
future", I am not asking you for it now.)
Regards,
Jeff Davis
Hi, On 2018-01-29 10:28:18 -0800, Jeff Davis wrote: > OK. How about this: are you open to changes that move us in the > direction of extensibility later? (By this I do *not* mean imposing a > bunch of requirements on you... either small changes to your patches > or something part of another commit.) I'm good with that. > Or are you determined that this always should be a part of core? I do think JIT compilation should be in core, yes. And after quite some looking around that currently means either using LLVM or building our own from scratch, and the latter doesn't seem attractive. But that doesn't mean there *also* can be extensibility. If somebody wants to experiment with a more advanced version of JIT compilation, develop a gcc backed version (which can't be in core due to licensing), ... - I'm happy to provide hooks that only require a reasonable effort and don't affect the overall stability of the system (i.e. no callback from PostgresMain()'s sigsetjmp() block). > I don't want to stand in your way, but I am also hesitant to dive head > first into LLVM and not look back. Postgres has always been lean, fast > building, and with few dependencies. It's an optional dependency, and it doesn't increase build time that much... If we were to move the llvm interfacing code to a .so, there'd not even be a packaging issue, you can just package that .so separately and get errors if somebody tries to enable LLVM without that .so being installed. > In other words, are you "strongly against [extensbility being a > requirement for the first commit]" or "strongly against [extensible > JIT]"? I'm strongly against there not being an in-core JIT. I'm not at all against adding APIs that allow to do different JIT implementations out of core. > If the source for functions is in the catalog, we could build the > bitcode at runtime and still do the inlining. We wouldn't need to do > anything at build time. (Again, this would be "cool stuff for the > future", I am not asking you for it now.) Well, the source would require an actual compiler around. And the inlining *just* for the function code itself isn't actually that interesting, you e.g. want to also be able to Greetings, Andres Freund
On 01/24/2018 08:20 AM, Andres Freund wrote: > Hi, > > I've spent the last weeks working on my LLVM compilation patchset. In > the course of that I *heavily* revised it. While still a good bit away > from committable, it's IMO definitely not a prototype anymore. > > There's too many small changes, so I'm only going to list the major > things. A good bit of that is new. The actual LLVM IR emissions itself > hasn't changed that drastically. Since I've not described them in > detail before I'll describe from scratch in a few cases, even if things > haven't fully changed. > Hi, I wanted to look at this, but my attempts to build the jit branch fail with some compile-time warnings (uninitialized variables) and errors (unknown types, incorrect number of arguments). See the file attached. I wonder if I'm doing something wrong, or if there's something wrong with my environment. I do have this: $ clang -v clang version 5.0.0 (trunk 299717) Target: x86_64-unknown-linux-gnu Thread model: posix InstalledDir: /usr/local/bin Selected GCC installation: /usr/lib/gcc/x86_64-pc-linux-gnu/6.4.0 Candidate multilib: .;@m64 Candidate multilib: 32;@m32 Selected multilib: .;@m64 regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
Hi, On 2018-01-29 22:51:38 +0100, Tomas Vondra wrote: > Hi, I wanted to look at this, but my attempts to build the jit branch > fail with some compile-time warnings (uninitialized variables) and > errors (unknown types, incorrect number of arguments). See the file > attached. Which git hash are you building? What llvm version is this building against? If you didn't specify LLVM_CONFIG=... what does llvm-config --version return? Greetings, Andres Freund
On 01/29/2018 10:57 PM, Andres Freund wrote:
> Hi,
>
> On 2018-01-29 22:51:38 +0100, Tomas Vondra wrote:
>> Hi, I wanted to look at this, but my attempts to build the jit branch
>> fail with some compile-time warnings (uninitialized variables) and
>> errors (unknown types, incorrect number of arguments). See the file
>> attached.
>
> Which git hash are you building? What llvm version is this building
> against? If you didn't specify LLVM_CONFIG=... what does llvm-config
> --version return?
>
I'm building against fdc6c7a6dddbd6df63717f2375637660bcd00fc6 (current
HEAD in the jit branch, AFAICS).
I'm building like this:
$ ./configure --enable-debug CFLAGS="-fno-omit-frame-pointer -O2" \
--with-llvm --prefix=/home/postgres/pg-llvm
$ make -s -j4 install
and llvm-config --version says this:
$ llvm-config --version
5.0.0svn
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2018-01-29 23:01:14 +0100, Tomas Vondra wrote:
> On 01/29/2018 10:57 PM, Andres Freund wrote:
> > Hi,
> >
> > On 2018-01-29 22:51:38 +0100, Tomas Vondra wrote:
> >> Hi, I wanted to look at this, but my attempts to build the jit branch
> >> fail with some compile-time warnings (uninitialized variables) and
> >> errors (unknown types, incorrect number of arguments). See the file
> >> attached.
> >
> > Which git hash are you building? What llvm version is this building
> > against? If you didn't specify LLVM_CONFIG=... what does llvm-config
> > --version return?
> >
>
> I'm building against fdc6c7a6dddbd6df63717f2375637660bcd00fc6 (current
> HEAD in the jit branch, AFAICS).
The warnings come from an incomplete patch I probably shouldn't have
pushed (Heavily-WIP: JIT hashing.). They should largely be irrelevant
(although will cause a handful of "ERROR: hm" regression failures),
but I'll definitely pop that commit on the next rebase. If you want you
can just reset --hard to its parent.
That errors are weird however:
> llvmjit.c: In function ‘llvm_get_function’:
> llvmjit.c:239:45: warning: passing argument 2 of ‘LLVMOrcGetSymbolAddress’ from incompatible pointer type
[-Wincompatible-pointer-types]
> if (LLVMOrcGetSymbolAddress(llvm_opt0_orc, &addr, mangled))
> ^
> In file included from llvmjit.c:45:0:
> /usr/local/include/llvm-c/OrcBindings.h:129:22: note: expected ‘const char *’ but argument is of type
‘LLVMOrcTargetAddress* {aka long unsigned int *}’
> LLVMOrcTargetAddress LLVMOrcGetSymbolAddress(LLVMOrcJITStackRef JITStack,
> ^~~~~~~~~~~~~~~~~~~~~~~
> llvmjit.c:239:6: error: too many arguments to function ‘LLVMOrcGetSymbolAddress’
> if (LLVMOrcGetSymbolAddress(llvm_opt0_orc, &addr, mangled))
> ^~~~~~~~~~~~~~~~~~~~~~~
> In file included from llvmjit.c:45:0:
> /usr/local/include/llvm-c/OrcBindings.h:129:22: note: declared here
> LLVMOrcTargetAddress LLVMOrcGetSymbolAddress(LLVMOrcJITStackRef JITStack,
> ^~~~~~~~~~~~~~~~~~~~~~~
> llvmjit.c:243:45: warning: passing argument 2 of ‘LLVMOrcGetSymbolAddress’ from incompatible pointer type
[-Wincompatible-pointer-types]
> if (LLVMOrcGetSymbolAddress(llvm_opt3_orc, &addr, mangled))
> ^
> I'm building like this:
>
> $ ./configure --enable-debug CFLAGS="-fno-omit-frame-pointer -O2" \
> --with-llvm --prefix=/home/postgres/pg-llvm
>
> $ make -s -j4 install
>
> and llvm-config --version says this:
>
> $ llvm-config --version
> 5.0.0svn
Is thta llvm-config the one in /usr/local/include/ referenced by the
error message above? Or is it possible that llvm-config is from a
different version than the one the compiler picks the headers up from?
could you go to src/backend/lib, rm llvmjit.o, and show the full output
of make llvmjit.o?
I wonder whether the issue is that my configure patch does
-I*|-D*) CPPFLAGS="$CPPFLAGS $pgac_option";;
rather than
-I*|-D*) CPPFLAGS="$pgac_option $CPPFLAGS";;
and that it thus picks up the wrong header first?
Greetings,
Andres Freund
On 01/29/2018 11:17 PM, Andres Freund wrote:
> On 2018-01-29 23:01:14 +0100, Tomas Vondra wrote:
>> On 01/29/2018 10:57 PM, Andres Freund wrote:
>>> Hi,
>>>
>>> On 2018-01-29 22:51:38 +0100, Tomas Vondra wrote:
>>>> Hi, I wanted to look at this, but my attempts to build the jit branch
>>>> fail with some compile-time warnings (uninitialized variables) and
>>>> errors (unknown types, incorrect number of arguments). See the file
>>>> attached.
>>>
>>> Which git hash are you building? What llvm version is this building
>>> against? If you didn't specify LLVM_CONFIG=... what does llvm-config
>>> --version return?
>>>
>>
>> I'm building against fdc6c7a6dddbd6df63717f2375637660bcd00fc6 (current
>> HEAD in the jit branch, AFAICS).
>
> The warnings come from an incomplete patch I probably shouldn't have
> pushed (Heavily-WIP: JIT hashing.). They should largely be irrelevant
> (although will cause a handful of "ERROR: hm" regression failures),
> but I'll definitely pop that commit on the next rebase. If you want you
> can just reset --hard to its parent.
>
OK
>
> That errors are weird however:
>
>> ... ^
>
>> I'm building like this:
>>
>> $ ./configure --enable-debug CFLAGS="-fno-omit-frame-pointer -O2" \
>> --with-llvm --prefix=/home/postgres/pg-llvm
>>
>> $ make -s -j4 install
>>
>> and llvm-config --version says this:
>>
>> $ llvm-config --version
>> 5.0.0svn
>
> Is thta llvm-config the one in /usr/local/include/ referenced by the
> error message above?
I don't see it referenced anywhere, but it comes from here:
$ which llvm-config
/usr/local/bin/llvm-config
> Or is it possible that llvm-config is from a different version than
> the one the compiler picks the headers up from?
>
I don't think so. I don't have any other llvm versions installed, AFAICS.
> could you go to src/backend/lib, rm llvmjit.o, and show the full output
> of make llvmjit.o?
>
Attached.
> I wonder whether the issue is that my configure patch does
> -I*|-D*) CPPFLAGS="$CPPFLAGS $pgac_option";;
> rather than
> -I*|-D*) CPPFLAGS="$pgac_option $CPPFLAGS";;
> and that it thus picks up the wrong header first?
>
I've tried this configure tweak:
if test -n "$LLVM_CONFIG"; then
for pgac_option in `$LLVM_CONFIG --cflags`; do
case $pgac_option in
- -I*|-D*) CPPFLAGS="$CPPFLAGS $pgac_option";;
+ -I*|-D*) CPPFLAGS="$pgac_option $CPPFLAGS";;
esac
done
and that indeed changes the failure to this:
Writing postgres.bki
Writing schemapg.h
Writing postgres.description
Writing postgres.shdescription
llvmjit_error.cpp: In function ‘void llvm_enter_fatal_on_oom()’:
llvmjit_error.cpp:61:3: error: ‘install_bad_alloc_error_handler’ is not
a member of ‘llvm’
llvm::install_bad_alloc_error_handler(fatal_llvm_new_handler);
^~~~
llvmjit_error.cpp: In function ‘void llvm_leave_fatal_on_oom()’:
llvmjit_error.cpp:77:3: error: ‘remove_bad_alloc_error_handler’ is not a
member of ‘llvm’
llvm::remove_bad_alloc_error_handler();
^~~~
llvmjit_error.cpp: In function ‘void llvm_reset_fatal_on_oom()’:
llvmjit_error.cpp:92:3: error: ‘remove_bad_alloc_error_handler’ is not a
member of ‘llvm’
llvm::remove_bad_alloc_error_handler();
^~~~
make[3]: *** [<builtin>: llvmjit_error.o] Error 1
make[2]: *** [common.mk:45: lib-recursive] Error 2
make[2]: *** Waiting for unfinished jobs....
make[1]: *** [Makefile:38: all-backend-recurse] Error 2
make: *** [GNUmakefile:11: all-src-recurse] Error 2
I'm not sure what that means, though ... maybe I really have system
broken in some strange way.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
Hi,
On 2018-01-29 23:49:14 +0100, Tomas Vondra wrote:
> On 01/29/2018 11:17 PM, Andres Freund wrote:
> > On 2018-01-29 23:01:14 +0100, Tomas Vondra wrote:
> >> $ llvm-config --version
> >> 5.0.0svn
> >
> > Is thta llvm-config the one in /usr/local/include/ referenced by the
> > error message above?
>
> I don't see it referenced anywhere, but it comes from here:
>
> $ which llvm-config
> /usr/local/bin/llvm-config
>
> > Or is it possible that llvm-config is from a different version than
> > the one the compiler picks the headers up from?
> >
>
> I don't think so. I don't have any other llvm versions installed, AFAICS.
Hm.
> > could you go to src/backend/lib, rm llvmjit.o, and show the full output
> > of make llvmjit.o?
> >
>
> Attached.
>
> > I wonder whether the issue is that my configure patch does
> > -I*|-D*) CPPFLAGS="$CPPFLAGS $pgac_option";;
> > rather than
> > -I*|-D*) CPPFLAGS="$pgac_option $CPPFLAGS";;
> > and that it thus picks up the wrong header first?
> >
>
> I've tried this configure tweak:
>
> if test -n "$LLVM_CONFIG"; then
> for pgac_option in `$LLVM_CONFIG --cflags`; do
> case $pgac_option in
> - -I*|-D*) CPPFLAGS="$CPPFLAGS $pgac_option";;
> + -I*|-D*) CPPFLAGS="$pgac_option $CPPFLAGS";;
> esac
> done
>
> and that indeed changes the failure to this:
Err, huh? I don't understand how that can change anything if you
actually only have only one version of LLVM installed. Perhaps the
effect was just an ordering related artifact of [parallel] make?
I.e. just a question what failed first?
> Writing postgres.bki
> Writing schemapg.h
> Writing postgres.description
> Writing postgres.shdescription
> llvmjit_error.cpp: In function ‘void llvm_enter_fatal_on_oom()’:
> llvmjit_error.cpp:61:3: error: ‘install_bad_alloc_error_handler’ is not
> a member of ‘llvm’
> llvm::install_bad_alloc_error_handler(fatal_llvm_new_handler);
> ^~~~
> llvmjit_error.cpp: In function ‘void llvm_leave_fatal_on_oom()’:
> llvmjit_error.cpp:77:3: error: ‘remove_bad_alloc_error_handler’ is not a
> member of ‘llvm’
> llvm::remove_bad_alloc_error_handler();
> ^~~~
> llvmjit_error.cpp: In function ‘void llvm_reset_fatal_on_oom()’:
> llvmjit_error.cpp:92:3: error: ‘remove_bad_alloc_error_handler’ is not a
> member of ‘llvm’
> llvm::remove_bad_alloc_error_handler();
> ^~~~
It's a bit hard to interpret this without the actual compiler
invocation. But I've just checked both manually by inspecting 5.0 source
and by compiling against 5.0 that that function definition definitely
exists:
andres@alap4:~/src/llvm-5$ git branch
master
* release_50
andres@alap4:~/src/llvm-5$ ack remove_bad_alloc_error_handler
lib/Support/ErrorHandling.cpp
139:void llvm::remove_bad_alloc_error_handler() {
include/llvm/Support/ErrorHandling.h
101:void remove_bad_alloc_error_handler();
So does my system llvm 5:
$ ack remove_bad_alloc_error_handler /usr/include/llvm-5.0/
/usr/include/llvm-5.0/llvm/Support/ErrorHandling.h
101:void remove_bad_alloc_error_handler();
But not in 4.0:
$ ack remove_bad_alloc_error_handler /usr/include/llvm-4.0/
> gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels
-Wmissing-format-attribute-Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -g
-fno-omit-frame-pointer-O2 -I../../../src/include -D_GNU_SOURCE -I/usr/local/include -DNDEBUG -DLLVM_BUILD_GLOBAL_ISEL
-D_GNU_SOURCE-D__STDC_CONSTANT_MACROS -D__STDC_FORMAT_MACROS -D__STDC_LIMIT_MACROS -c -o llvmjit.o llvmjit.c
> llvmjit.c: In function ‘llvm_get_function’:
> llvmjit.c:239:45: warning: passing argument 2 of ‘LLVMOrcGetSymbolAddress’ from incompatible pointer type
[-Wincompatible-pointer-types]
> if (LLVMOrcGetSymbolAddress(llvm_opt0_orc, &addr, mangled))
> ^
> In file included from llvmjit.c:45:0:
> /usr/local/include/llvm-c/OrcBindings.h:129:22: note: expected ‘const char *’ but argument is of type
‘LLVMOrcTargetAddress* {aka long unsigned int *}’
> LLVMOrcTargetAddress LLVMOrcGetSymbolAddress(LLVMOrcJITStackRef JITStack,
> ^~~~~~~~~~~~~~~~~~~~~~~
To me this looks like those headers are from llvm 4, rather than 5:
$ grep -A2 -B3 LLVMOrcGetSymbolAddress ~/src/llvm-4/include/llvm-c/OrcBindings.h
/**
* Get symbol address from JIT instance.
*/
LLVMOrcTargetAddress LLVMOrcGetSymbolAddress(LLVMOrcJITStackRef JITStack,
const char *SymbolName);
$ grep -A3 -B3 LLVMOrcGetSymbolAddress ~/src/llvm-5/include/llvm-c/OrcBindings.h
/**
* Get symbol address from JIT instance.
*/
LLVMOrcErrorCode LLVMOrcGetSymbolAddress(LLVMOrcJITStackRef JITStack,
LLVMOrcTargetAddress *RetAddr,
const char *SymbolName);
So it does appear that your llvm-config and the actually installed llvm
don't quite agree. How did you install llvm?
Greetings,
Andres Freund
On 01/29/2018 11:49 PM, Tomas Vondra wrote: > > ... > > and that indeed changes the failure to this: > > Writing postgres.bki > Writing schemapg.h > Writing postgres.description > Writing postgres.shdescription > llvmjit_error.cpp: In function ‘void llvm_enter_fatal_on_oom()’: > llvmjit_error.cpp:61:3: error: ‘install_bad_alloc_error_handler’ is not > a member of ‘llvm’ > llvm::install_bad_alloc_error_handler(fatal_llvm_new_handler); > ^~~~ > llvmjit_error.cpp: In function ‘void llvm_leave_fatal_on_oom()’: > llvmjit_error.cpp:77:3: error: ‘remove_bad_alloc_error_handler’ is not a > member of ‘llvm’ > llvm::remove_bad_alloc_error_handler(); > ^~~~ > llvmjit_error.cpp: In function ‘void llvm_reset_fatal_on_oom()’: > llvmjit_error.cpp:92:3: error: ‘remove_bad_alloc_error_handler’ is not a > member of ‘llvm’ > llvm::remove_bad_alloc_error_handler(); > ^~~~ > make[3]: *** [<builtin>: llvmjit_error.o] Error 1 > make[2]: *** [common.mk:45: lib-recursive] Error 2 > make[2]: *** Waiting for unfinished jobs.... > make[1]: *** [Makefile:38: all-backend-recurse] Error 2 > make: *** [GNUmakefile:11: all-src-recurse] Error 2 > > > I'm not sure what that means, though ... maybe I really have system > broken in some strange way. > FWIW I've installed llvm 5.0.1 from distribution package, and now everything builds fine (I don't even need the configure tweak). I think I had to build the other binaries because there was no 5.x llvm back then, but it's too far back so I don't remember. Anyway, seems I'm fine for now. Sorry for the noise. -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On 2018-01-30 00:16:46 +0100, Tomas Vondra wrote: > FWIW I've installed llvm 5.0.1 from distribution package, and now > everything builds fine (I don't even need the configure tweak). > > I think I had to build the other binaries because there was no 5.x llvm > back then, but it's too far back so I don't remember. > > Anyway, seems I'm fine for now. Phew, I'm relieved. I'd guess you buily a 5.0 version while 5.0 was still in development, so not all 5.0 functionality was available. Hence the inconsistent looking result. While I think we can support 4.0 without too much problem, there's obviously no point in trying to support old between releases versions... > Sorry for the noise. No worries. - Andres
On 29 January 2018 at 22:53, Andres Freund <andres@anarazel.de> wrote:
Hi,
On 2018-01-23 23:20:38 -0800, Andres Freund wrote:
> == Code ==
>
> As the patchset is large (500kb) and I'm still quickly evolving it, I do
> not yet want to attach it. The git tree is at
> https://git.postgresql.org/git/users/andresfreund/ postgres.git
> in the jit branch
> https://git.postgresql.org/gitweb/?p=users/andresfreund/ postgres.git;a=shortlog;h= refs/heads/jit
I've just pushed an updated and rebased version of the tree:
- Split the large "jit infrastructure" commits into a number of smaller
commits
- Split the C++ file
- Dropped some of the performance stuff done to heaptuple.c - that was
mostly to make performance comparisons a bit more interesting, but
doesn't seem important enough to deal with.
- Added a commit renaming datetime.h symbols so they don't conflict with
LLVM variables anymore, removing ugly #undef PM/#define PM dance
around includes. Will post separately.
- Reduced the number of pointer constants in the generated LLVM IR, by
doing more getelementptr accesses (stem from before the time types
were automatically synced)
- Increased number of comments a bit
There's a jit-before-rebase-2018-01-29 tag, for the state of the tree
before the rebase.
If you submit the C++ support separately I'd like to sign up as reviewer and get that in. It's non-intrusive and just makes our existing c++ compilation support actually work properly. Your patch is a more complete version of the C++ support I hacked up during linux.conf.au - I should've thought to look in your tree.
The only part I had to add that I don't see in yours is a workaround for mismatched throw() annotations on our redefinition of inet_net_ntop :
src/include/port.h:
@@ -421,7 +425,7 @@ extern int pg_codepage_to_encoding(UINT cp);
/* port/inet_net_ntop.c */
extern char *inet_net_ntop(int af, const void *src, int bits,
- char *dst, size_t size);
+ char *dst, size_t size) __THROW;
src/include/c.h:
@@ -1131,6 +1131,16 @@ extern int fdatasync(int fildes);
#define NON_EXEC_STATIC static
#endif
+/*
+ * glibc uses __THROW when compiling with the c++ compiler, but port.h reclares
+ * inet_net_ntop. If we don't annotate it the same way as the prototype in
+ * <inet/arpa.h> we'll upset g++, so we must use __THROW from <sys/cdefs.h>. If
+ * we're not on glibc, we need to define it away.
+ */
+#ifndef __GNU_LIBRARY__
+#define __THROW
+#endif
+
/* /port compatibility functions */
#include "port.h"
This might be better solved by renaming it to pg_inet_net_ntop so we don't conflict with a standard name.
Hi,
On Mon, Jan 29, 2018 at 10:40 AM, Andres Freund <andres@anarazel.de> wrote:
> Hi,
>
> On 2018-01-29 10:28:18 -0800, Jeff Davis wrote:
>> OK. How about this: are you open to changes that move us in the
>> direction of extensibility later? (By this I do *not* mean imposing a
>> bunch of requirements on you... either small changes to your patches
>> or something part of another commit.)
>
> I'm good with that.
>
>
>> Or are you determined that this always should be a part of core?
> I'm strongly against there not being an in-core JIT. I'm not at all
> against adding APIs that allow to do different JIT implementations out
> of core.
I can live with that.
I recommend that you discuss with packagers and a few others, to
reduce the chance of disagreement later.
> Well, the source would require an actual compiler around. And the
> inlining *just* for the function code itself isn't actually that
> interesting, you e.g. want to also be able to
I think you hit enter too quicly... what's the rest of that sentence?
Regards,
Jeff Davis
On Mon, Jan 29, 2018 at 1:40 PM, Andres Freund <andres@anarazel.de> wrote: > It's an optional dependency, and it doesn't increase build time that > much... If we were to move the llvm interfacing code to a .so, there'd > not even be a packaging issue, you can just package that .so separately > and get errors if somebody tries to enable LLVM without that .so being > installed. I suspect that would be really valuable. If 'yum install postgresql-server' (or your favorite equivalent) sucks down all of LLVM, some people are going to complain, either because they are trying to build little tiny machine images or because they are subject to policies which preclude the presence of a compiler on a production server. If you can do 'yum install postgresql-server' without additional dependencies and 'yum install postgresql-server-jit' to make it go faster, that issue is solved. Unfortunately, that has the pretty significant downside that a lot of people who actually want the postgresql-server-jit package will not realize that they need to install it, which sucks. But I think it might still be the better way to go. Anyway, it's for individual packagers to cope with that problem; as far as the patch goes, +1 for structuring things in a way which gives packagers the option to divide it up that way. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Jan 24, 2018 at 2:20 AM, Andres Freund <andres@anarazel.de> wrote: > == Error handling == > > There's two aspects to error handling. > > Firstly, generated (LLVM IR) and emitted functions (mmap()ed segments) > need to be cleaned up both after a successful query execution and after > an error. I've settled on a fairly boring resowner based mechanism. On > errors all expressions owned by a resowner are released, upon success > expressions are reassigned to the parent / released on commit (unless > executor shutdown has cleaned them up of course). Cool. > A second, less pretty and newly developed, aspect of error handling is > OOM handling inside LLVM itself. The above resowner based mechanism > takes care of cleaning up emitted code upon ERROR, but there's also the > chance that LLVM itself runs out of memory. LLVM by default does *not* > use any C++ exceptions. It's allocations are primarily funneled through > the standard "new" handlers, and some direct use of malloc() and > mmap(). For the former a 'new handler' exists > http://en.cppreference.com/w/cpp/memory/new/set_new_handler for the > latter LLVM provides callback that get called upon failure > (unfortunately mmap() failures are treated as fatal rather than OOM > errors). > What I've chosen to do, and I'd be interested to get some input about > that, is to have two functions that LLVM using code must use: > extern void llvm_enter_fatal_on_oom(void); > extern void llvm_leave_fatal_on_oom(void); > before interacting with LLVM code (ie. emitting IR, or using the above > functions) llvm_enter_fatal_on_oom() needs to be called. > > When a libstdc++ new or LLVM error occurs, the handlers set up by the > above functions trigger a FATAL error. We have to use FATAL rather than > ERROR, as we *cannot* reliably throw ERROR inside a foreign library > without risking corrupting its internal state. That bites, although it's probably tolerable if we expect such errors only in exceptional situations such as a needed shared library failing to load or something. Killing the session when we run out of memory during JIT compilation is not very nice at all. Does the LLVM library have any useful hooks that we can leverage here, like a hypothetical function LLVMProvokeFailureAsSoonAsConvenient()? The equivalent function for PostgreSQL would do { InterruptPending = true; QueryCancelPending = true; }. And maybe LLVMSetProgressCallback() that would get called periodically and let us set a handler that could check for interrupts on the PostgreSQL side and then call LLVMProvokeFailureAsSoonAsConvenient() as applicable? This problem can't be completely unique to PostgreSQL; anybody who is using LLVM for JIT from a long-running process needs a solution, so you might think that the library would provide one. > This facility allows us to get the bitcode for all operators > (e.g. int8eq, float8pl etc), without maintaining two copies. The way > I've currently set it up is that, if --with-llvm is passed to configure, > all backend files are also compiled to bitcode files. These bitcode > files get installed into the server's > $pkglibdir/bitcode/postgres/ > under their original subfolder, eg. > ~/build/postgres/dev-assert/install/lib/bitcode/postgres/utils/adt/float.bc > Using existing LLVM functionality (for parallel LTO compilation), > additionally an index is over these is stored to > $pkglibdir/bitcode/postgres.index.bc That sounds pretty sweet. > When deciding to JIT for the first time, $pkglibdir/bitcode/ is scanned > for all .index.bc files and a *combined* index over all these files is > built in memory. The reason for doing so is that that allows "easy" > access to inlining access for extensions - they can install code into > $pkglibdir/bitcode/[extension]/ > accompanied by > $pkglibdir/bitcode/[extension].index.bc > just alongside the actual library. But that means that if an extension is installed after the initial scan has been done, concurrent sessions won't notice the new files. Maybe that's OK, but I wonder if we can do better. > Do people feel these should be hidden behind #ifdefs, always present but > prevent from being set to a meaningful, or unrestricted? We shouldn't allow non-superusers to set any GUC that dumps files to the data directory or provides an easy to way to crash the server, run the machine out of memory, or similar. GUCs that just print stuff, or make queries faster/slower, can be set by anyone, I think. I favor having the debugging stuff available in the default build. This feature has a chance of containing bugs, and those bugs will be hard to troubleshoot if the first step in getting information on what went wrong is "recompile". -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi,
On 2018-01-30 13:57:50 -0500, Robert Haas wrote:
> > When a libstdc++ new or LLVM error occurs, the handlers set up by the
> > above functions trigger a FATAL error. We have to use FATAL rather than
> > ERROR, as we *cannot* reliably throw ERROR inside a foreign library
> > without risking corrupting its internal state.
>
> That bites, although it's probably tolerable if we expect such errors
> only in exceptional situations such as a needed shared library failing
> to load or something. Killing the session when we run out of memory
> during JIT compilation is not very nice at all. Does the LLVM library
> have any useful hooks that we can leverage here, like a hypothetical
> function LLVMProvokeFailureAsSoonAsConvenient()?
I don't see how that'd help if a memory allocation fails? We can't just
continue in that case? You could arguably have reserve memory pool that
you release in that case and then try to continue, but that seems
awfully fragile.
> The equivalent function for PostgreSQL would do { InterruptPending =
> true; QueryCancelPending = true; }. And maybe
> LLVMSetProgressCallback() that would get called periodically and let
> us set a handler that could check for interrupts on the PostgreSQL
> side and then call LLVMProvokeFailureAsSoonAsConvenient() as
> applicable? This problem can't be completely unique to PostgreSQL;
> anybody who is using LLVM for JIT from a long-running process needs a
> solution, so you might think that the library would provide one.
The ones I looked at just error out. Needing to handle OOM in soft fail
manner isn't actually that common a demand, I guess :/.
> > for all .index.bc files and a *combined* index over all these files is
> > built in memory. The reason for doing so is that that allows "easy"
> > access to inlining access for extensions - they can install code into
> > $pkglibdir/bitcode/[extension]/
> > accompanied by
> > $pkglibdir/bitcode/[extension].index.bc
> > just alongside the actual library.
>
> But that means that if an extension is installed after the initial
> scan has been done, concurrent sessions won't notice the new files.
> Maybe that's OK, but I wonder if we can do better.
I mean we could periodically rescan, rescan after sighup, or such? But
that seems like something for later to me. It's not going to be super
common to install new extensions while a lot of sessions are
running. And things will work in that case, the functions just won't get inlined...
> > Do people feel these should be hidden behind #ifdefs, always present but
> > prevent from being set to a meaningful, or unrestricted?
>
> We shouldn't allow non-superusers to set any GUC that dumps files to
> the data directory or provides an easy to way to crash the server, run
> the machine out of memory, or similar.
I don't buy the OOM one - there's so so so many of those already...
The profiling one does dump to ~/.debug/jit/ - it seems a bit annoying
if profiling can only be done by a superuser? Hm :/
Greetings,
Andres Freund
On Tue, Jan 30, 2018 at 2:08 PM, Andres Freund <andres@anarazel.de> wrote: >> That bites, although it's probably tolerable if we expect such errors >> only in exceptional situations such as a needed shared library failing >> to load or something. Killing the session when we run out of memory >> during JIT compilation is not very nice at all. Does the LLVM library >> have any useful hooks that we can leverage here, like a hypothetical >> function LLVMProvokeFailureAsSoonAsConvenient()? > > I don't see how that'd help if a memory allocation fails? We can't just > continue in that case? You could arguably have reserve memory pool that > you release in that case and then try to continue, but that seems > awfully fragile. Well, I'm just asking what the library supports. For example: https://curl.haxx.se/libcurl/c/CURLOPT_PROGRESSFUNCTION.html If you had something like that, you could arrange to safely interrupt the library the next time the progress-function was called. > The ones I looked at just error out. Needing to handle OOM in soft fail > manner isn't actually that common a demand, I guess :/. Bummer. > I mean we could periodically rescan, rescan after sighup, or such? But > that seems like something for later to me. It's not going to be super > common to install new extensions while a lot of sessions are > running. And things will work in that case, the functions just won't get inlined... Fair enough. >> > Do people feel these should be hidden behind #ifdefs, always present but >> > prevent from being set to a meaningful, or unrestricted? >> >> We shouldn't allow non-superusers to set any GUC that dumps files to >> the data directory or provides an easy to way to crash the server, run >> the machine out of memory, or similar. > > I don't buy the OOM one - there's so so so many of those already... > > The profiling one does dump to ~/.debug/jit/ - it seems a bit annoying > if profiling can only be done by a superuser? Hm :/ The server's ~/.debug/jit? Or are you somehow getting the output to the client? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes: > Unfortunately, that has the pretty significant downside that a lot of > people who actually want the postgresql-server-jit package will not > realize that they need to install it, which sucks. But I think it > might still be the better way to go. Anyway, it's for individual > packagers to cope with that problem; as far as the patch goes, +1 for > structuring things in a way which gives packagers the option to divide > it up that way. I don't know about rpm/yum/dnf, but in dpkg/apt one could declare that postgresql-server recommends postgresql-server-jit, which installs the package by default, but can be overridden by config or on the command line. - ilmari -- "The surreality of the universe tends towards a maximum" -- Skud's Law "Never formulate a law or axiom that you're not prepared to live with the consequences of." -- Skud's Meta-Law
Hi, On 2018-01-30 15:06:02 -0500, Robert Haas wrote: > On Tue, Jan 30, 2018 at 2:08 PM, Andres Freund <andres@anarazel.de> wrote: > >> That bites, although it's probably tolerable if we expect such errors > >> only in exceptional situations such as a needed shared library failing > >> to load or something. Killing the session when we run out of memory > >> during JIT compilation is not very nice at all. Does the LLVM library > >> have any useful hooks that we can leverage here, like a hypothetical > >> function LLVMProvokeFailureAsSoonAsConvenient()? > > > > I don't see how that'd help if a memory allocation fails? We can't just > > continue in that case? You could arguably have reserve memory pool that > > you release in that case and then try to continue, but that seems > > awfully fragile. > > Well, I'm just asking what the library supports. For example: > > https://curl.haxx.se/libcurl/c/CURLOPT_PROGRESSFUNCTION.html I get that type of function, what I don't understand how that applies to OOM: > If you had something like that, you could arrange to safely interrupt > the library the next time the progress-function was called. Yea, but how are you going to *get* to the next time, given that an allocator just couldn't allocate memory? You can't just return a NULL pointer because the caller will use that memory? > > The profiling one does dump to ~/.debug/jit/ - it seems a bit annoying > > if profiling can only be done by a superuser? Hm :/ > > The server's ~/.debug/jit? Or are you somehow getting the output to the client? Yes, the servers - I'm not sure I understand the "client" bit? It's about perf profiling, which isn't available to the client either? Greetings, Andres Freund
On 01/30/2018 12:24 AM, Andres Freund wrote: > Hi, > > On 2018-01-30 00:16:46 +0100, Tomas Vondra wrote: >> FWIW I've installed llvm 5.0.1 from distribution package, and now >> everything builds fine (I don't even need the configure tweak). >> >> I think I had to build the other binaries because there was no 5.x llvm >> back then, but it's too far back so I don't remember. >> >> Anyway, seems I'm fine for now. > > Phew, I'm relieved. I'd guess you buily a 5.0 version while 5.0 was > still in development, so not all 5.0 functionality was available. Hence > the inconsistent looking result. While I think we can support 4.0 > without too much problem, there's obviously no point in trying to > support old between releases versions... > That's quite possible, but I don't really remember :-/ But I ran into another issue today, where everything builds fine (llvm 5.0.1, gcc 6.4.0), but at runtime I get errors like this: ERROR: LLVMCreateMemoryBufferWithContentsOfFile(/home/tomas/pg-llvm/lib/postgresql/llvmjit_types.bc) failed: No such file or directory It seems the llvmjit_types.bc file ended up in the parent directory (/home/tomas/pg-llvm/lib/) for some reason. After simply copying it to the expected place everything started working. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Jan 30, 2018 at 01:46:37PM -0500, Robert Haas wrote: > On Mon, Jan 29, 2018 at 1:40 PM, Andres Freund <andres@anarazel.de> wrote: > > It's an optional dependency, and it doesn't increase build time > > that much... If we were to move the llvm interfacing code to a > > .so, there'd not even be a packaging issue, you can just package > > that .so separately and get errors if somebody tries to enable > > LLVM without that .so being installed. > > I suspect that would be really valuable. If 'yum install > postgresql-server' (or your favorite equivalent) sucks down all of > LLVM, As I understand it, LLVM is organized in such a way as not to require this. Andres, am I understanding correctly that what you're using doesn't require much of LLVM at runtime? > some people are going to complain, either because they are > trying to build little tiny machine images or because they are > subject to policies which preclude the presence of a compiler on a > production server. If you can do 'yum install postgresql-server' > without additional dependencies and 'yum install > postgresql-server-jit' to make it go faster, that issue is solved. Would you consider it solved if there were some very small part of the LLVM (or similar JIT-capable) toolchain added as a dependency, or does it need to be optional into a long future? > Unfortunately, that has the pretty significant downside that a lot of > people who actually want the postgresql-server-jit package will not > realize that they need to install it, which sucks. It does indeed. Best, David. -- David Fetter <david(at)fetter(dot)org> http://fetter.org/ Phone: +1 415 235 3778 Remember to vote! Consider donating to Postgres: http://www.postgresql.org/about/donate
Hi, On 2018-01-30 22:57:06 +0100, David Fetter wrote: > On Tue, Jan 30, 2018 at 01:46:37PM -0500, Robert Haas wrote: > > On Mon, Jan 29, 2018 at 1:40 PM, Andres Freund <andres@anarazel.de> wrote: > > > It's an optional dependency, and it doesn't increase build time > > > that much... If we were to move the llvm interfacing code to a > > > .so, there'd not even be a packaging issue, you can just package > > > that .so separately and get errors if somebody tries to enable > > > LLVM without that .so being installed. > > > > I suspect that would be really valuable. If 'yum install > > postgresql-server' (or your favorite equivalent) sucks down all of > > LLVM, > > As I understand it, LLVM is organized in such a way as not to require > this. Andres, am I understanding correctly that what you're using > doesn't require much of LLVM at runtime? I'm not sure what you exactly mean. Yes, you need the llvm library at runtime. Perhaps you're thinking of clang or llvm binarieries? The latter we *not* need. What's required is something like: $ apt show libllvm5.0 Package: libllvm5.0 Version: 1:5.0.1-2 Priority: optional Section: libs Source: llvm-toolchain-5.0 Maintainer: LLVM Packaging Team <pkg-llvm-team@lists.alioth.debian.org> Installed-Size: 56.9 MB Depends: libc6 (>= 2.15), libedit2 (>= 2.11-20080614), libffi6 (>= 3.0.4), libgcc1 (>= 1:3.4), libstdc++6 (>= 6), libtinfo5(>= 6), zlib1g (>= 1:1.2.0) Breaks: libllvm3.9v4 Replaces: libllvm3.9v4 Homepage: http://www.llvm.org/ Tag: role::shared-lib Download-Size: 13.7 MB APT-Manual-Installed: no APT-Sources: http://debian.osuosl.org/debian unstable/main amd64 Packages Description: Modular compiler and toolchain technologies, runtime library LLVM is a collection of libraries and tools that make it easy to build compilers, optimizers, just-in-time code generators, and many other compiler-related programs. . This package contains the LLVM runtime library. So ~14MB to download, ~57MB on disk. We only need a subset of libllvm5.0, and LLVM allows to build such a subset. But obviously distributions aren't going to target their LLVM just for postgres. > > Unfortunately, that has the pretty significant downside that a lot of > > people who actually want the postgresql-server-jit package will not > > realize that they need to install it, which sucks. > > It does indeed. With things like apt recommends and such I don't think this is a huge problem. It'll be installed by default unless somebody is on a space constrained system and doesn't want that... Greetings, Andres Freund
Hi,
On 2018-01-30 13:46:37 -0500, Robert Haas wrote:
> On Mon, Jan 29, 2018 at 1:40 PM, Andres Freund <andres@anarazel.de> wrote:
> > It's an optional dependency, and it doesn't increase build time that
> > much... If we were to move the llvm interfacing code to a .so, there'd
> > not even be a packaging issue, you can just package that .so separately
> > and get errors if somebody tries to enable LLVM without that .so being
> > installed.
>
> I suspect that would be really valuable. If 'yum install
> postgresql-server' (or your favorite equivalent) sucks down all of
> LLVM, some people are going to complain, either because they are
> trying to build little tiny machine images or because they are subject
> to policies which preclude the presence of a compiler on a production
> server. If you can do 'yum install postgresql-server' without
> additional dependencies and 'yum install postgresql-server-jit' to
> make it go faster, that issue is solved.
So, I'm working on that now. In the course of this I'll be
painfully rebase and rename a lot of code, which I'd like not to repeat
unnecessarily.
Right now there primarily is:
src/backend/lib/llvmjit.c - infrastructure, optimization, error handling
src/backend/lib/llvmjit_{error,wrap,inline}.cpp - expose more stuff to C
src/backend/executor/execExprCompile.c - emit LLVM IR for expressions
src/backend/access/common/heaptuple.c - emit LLVM IR for deforming
Given that we need a shared library it'll be best buildsystem wise if
all of this is in a directory, and there's a separate file containing
the stubs that call into it.
I'm not quite sure where to put the code. I'm a bit inclined to add a
new
src/backend/jit/
because we're dealing with code from across different categories? There
we could have a pgjit.c with the stubs, and llvmjit/ with the llvm
specific code?
Alternatively I'd say we put the stub into src/backend/executor/pgjit.c,
and the actual llvm using code into src/backend/executor/llvmjit/?
Comments?
Andres Freund
On Tue, Jan 30, 2018 at 02:08:30PM -0800, Andres Freund wrote: > Hi, > > On 2018-01-30 22:57:06 +0100, David Fetter wrote: > > On Tue, Jan 30, 2018 at 01:46:37PM -0500, Robert Haas wrote: > > > On Mon, Jan 29, 2018 at 1:40 PM, Andres Freund <andres@anarazel.de> wrote: > > > > It's an optional dependency, and it doesn't increase build > > > > time that much... If we were to move the llvm interfacing code > > > > to a .so, there'd not even be a packaging issue, you can just > > > > package that .so separately and get errors if somebody tries > > > > to enable LLVM without that .so being installed. > > > > > > I suspect that would be really valuable. If 'yum install > > > postgresql-server' (or your favorite equivalent) sucks down all > > > of LLVM, > > > > As I understand it, LLVM is organized in such a way as not to > > require this. Andres, am I understanding correctly that what > > you're using doesn't require much of LLVM at runtime? > > I'm not sure what you exactly mean. Yes, you need the llvm library > at runtime. Perhaps you're thinking of clang or llvm binarieries? > The latter we *not* need. I was, and glad I understood correctly. > What's required is something like: > $ apt show libllvm5.0 > Package: libllvm5.0 > Version: 1:5.0.1-2 > Priority: optional > Section: libs > Source: llvm-toolchain-5.0 > Maintainer: LLVM Packaging Team <pkg-llvm-team@lists.alioth.debian.org> > Installed-Size: 56.9 MB > Depends: libc6 (>= 2.15), libedit2 (>= 2.11-20080614), libffi6 (>= 3.0.4), libgcc1 (>= 1:3.4), libstdc++6 (>= 6), libtinfo5(>= 6), zlib1g (>= 1:1.2.0) > Breaks: libllvm3.9v4 > Replaces: libllvm3.9v4 > Homepage: http://www.llvm.org/ > Tag: role::shared-lib > Download-Size: 13.7 MB > APT-Manual-Installed: no > APT-Sources: http://debian.osuosl.org/debian unstable/main amd64 Packages > Description: Modular compiler and toolchain technologies, runtime library > LLVM is a collection of libraries and tools that make it easy to build > compilers, optimizers, just-in-time code generators, and many other > compiler-related programs. > . > This package contains the LLVM runtime library. > > So ~14MB to download, ~57MB on disk. We only need a subset of > libllvm5.0, and LLVM allows to build such a subset. But obviously > distributions aren't going to target their LLVM just for postgres. True, although if they're using an LLVM only for PostgreSQL and care about 57MB of disk, they're probably also ready to do that work. > > > Unfortunately, that has the pretty significant downside that a > > > lot of people who actually want the postgresql-server-jit > > > package will not realize that they need to install it, which > > > sucks. > > > > It does indeed. > > With things like apt recommends and such I don't think this is a > huge problem. It'll be installed by default unless somebody is on a > space constrained system and doesn't want that... Don't most of the wins for JITing come in the OLAP space anyway? I'm having trouble picturing a severely space-constrained OLAP system, but of course it's a possible scenario. Best, David. -- David Fetter <david(at)fetter(dot)org> http://fetter.org/ Phone: +1 415 235 3778 Remember to vote! Consider donating to Postgres: http://www.postgresql.org/about/donate
On Jan 30, 2018, at 2:08 PM, Andres Freund <andres@anarazel.de> wrote:With things like apt recommends and such I don't think this is a huge problem.
Which means in the rpm packages we’ll have to decide whether this is required or must be opt-in by end users (which as discussed would hurt adoption).
On Wed, Jan 31, 2018 at 11:57 AM, Andres Freund <andres@anarazel.de> wrote:
> On 2018-01-30 13:46:37 -0500, Robert Haas wrote:
>> On Mon, Jan 29, 2018 at 1:40 PM, Andres Freund <andres@anarazel.de> wrote:
>> > It's an optional dependency, and it doesn't increase build time that
>> > much... If we were to move the llvm interfacing code to a .so, there'd
>> > not even be a packaging issue, you can just package that .so separately
>> > and get errors if somebody tries to enable LLVM without that .so being
>> > installed.
>>
>> I suspect that would be really valuable. If 'yum install
>> postgresql-server' (or your favorite equivalent) sucks down all of
>> LLVM, some people are going to complain, either because they are
>> trying to build little tiny machine images or because they are subject
>> to policies which preclude the presence of a compiler on a production
>> server. If you can do 'yum install postgresql-server' without
>> additional dependencies and 'yum install postgresql-server-jit' to
>> make it go faster, that issue is solved.
>
> So, I'm working on that now. In the course of this I'll be
> painfully rebase and rename a lot of code, which I'd like not to repeat
> unnecessarily.
>
> Right now there primarily is:
>
> src/backend/lib/llvmjit.c - infrastructure, optimization, error handling
> src/backend/lib/llvmjit_{error,wrap,inline}.cpp - expose more stuff to C
> src/backend/executor/execExprCompile.c - emit LLVM IR for expressions
> src/backend/access/common/heaptuple.c - emit LLVM IR for deforming
>
> Given that we need a shared library it'll be best buildsystem wise if
> all of this is in a directory, and there's a separate file containing
> the stubs that call into it.
>
> I'm not quite sure where to put the code. I'm a bit inclined to add a
> new
> src/backend/jit/
> because we're dealing with code from across different categories? There
> we could have a pgjit.c with the stubs, and llvmjit/ with the llvm
> specific code?
>
> Alternatively I'd say we put the stub into src/backend/executor/pgjit.c,
> and the actual llvm using code into src/backend/executor/llvmjit/?
>
> Comments?
I'm just starting to look at this (amazing) work, and I don't have a
strong opinion yet. But certainly, making it easy for packagers to
put the -jit stuff into a separate package for the reasons already
given sounds sensible to me. Some systems package LLVM as one
gigantic package that'll get you 1GB of compiler/debugger/other stuff
and perhaps violate local rules by installing a compiler when you
really just wanted libLLVM{whatever}.so. I guess it should be made
very clear to users (explain plans, maybe startup message, ...?)
whether JIT support is active/installed so that people are at least
very aware when they encounter a system that is interpreting stuff it
could be compiling. Putting all the JIT into a separate directory
under src/backend/jit certainly looks sensible at first glance, but
I'm not sure.
Incidentally, from commit fdc6c7a6dddbd6df63717f2375637660bcd00fc6
(HEAD -> jit, andresfreund/jit) on your branch I get:
ccache c++ -Wall -Wpointer-arith -fno-strict-aliasing -fwrapv -g -g
-O2 -fno-exceptions -I../../../src/include
-I/usr/local/llvm50/include -DLLVM_BUILD_GLOBAL_ISEL
-D__STDC_CONSTANT_MACROS -D__STDC_FORMAT_MACROS -D__STDC_LIMIT_MACROS
-I/usr/local/include -c -o llvmjit_error.o llvmjit_error.cpp -MMD -MP
-MF .deps/llvmjit_error.Po
In file included from llvmjit_error.cpp:26:
In file included from ../../../src/include/lib/llvmjit.h:48:
In file included from /usr/local/llvm50/include/llvm-c/Types.h:17:
In file included from /usr/local/llvm50/include/llvm/Support/DataTypes.h:33:
/usr/include/c++/v1/cmath:555:1: error: templates must have C++ linkage
template <class _A1>
^~~~~~~~~~~~~~~~~~~~
llvmjit_error.cpp:24:1: note: extern "C" language linkage
specification begins here
extern "C"
^
$ c++ -v
FreeBSD clang version 4.0.0 (tags/RELEASE_400/final 297347) (based on
LLVM 4.0.0)
This seems to be a valid complaint. I don't think you should be
(indirectly) wrapping Types.h in extern "C". At a guess, your
llvmjit.h should be doing its own #ifdef __cplusplus'd linkage
specifiers, so you can use it from C or C++, but making sure that you
don't #include LLVM's headers from a bizarro context where __cplusplus
is defined but the linkage is unexpectedly already "C"?
--
Thomas Munro
http://www.enterprisedb.com
On 2018-01-31 14:42:26 +1300, Thomas Munro wrote:
> I'm just starting to look at this (amazing) work, and I don't have a
> strong opinion yet. But certainly, making it easy for packagers to
> put the -jit stuff into a separate package for the reasons already
> given sounds sensible to me. Some systems package LLVM as one
> gigantic package that'll get you 1GB of compiler/debugger/other stuff
> and perhaps violate local rules by installing a compiler when you
> really just wanted libLLVM{whatever}.so. I guess it should be made
> very clear to users (explain plans, maybe startup message, ...?)
I'm not quite sure I understand. You mean have it display whether
available? I think my plan is to "just" set jit_expressions=on (or
whatever we're going to name it) fail if the prerequisites aren't
available. I personally don't think this should be enabled by default,
definitely not in the first release.
> $ c++ -v
> FreeBSD clang version 4.0.0 (tags/RELEASE_400/final 297347) (based on
> LLVM 4.0.0)
>
> This seems to be a valid complaint. I don't think you should be
> (indirectly) wrapping Types.h in extern "C". At a guess, your
> llvmjit.h should be doing its own #ifdef __cplusplus'd linkage
> specifiers, so you can use it from C or C++, but making sure that you
> don't #include LLVM's headers from a bizarro context where __cplusplus
> is defined but the linkage is unexpectedly already "C"?
Hm, this seems like a bit of pointless nitpickery by the compiler to me,
but I guess...
Greetings,
Andres Freund
On Wed, Jan 31, 2018 at 3:05 PM, Andres Freund <andres@anarazel.de> wrote:
> On 2018-01-31 14:42:26 +1300, Thomas Munro wrote:
>> I'm just starting to look at this (amazing) work, and I don't have a
>> strong opinion yet. But certainly, making it easy for packagers to
>> put the -jit stuff into a separate package for the reasons already
>> given sounds sensible to me. Some systems package LLVM as one
>> gigantic package that'll get you 1GB of compiler/debugger/other stuff
>> and perhaps violate local rules by installing a compiler when you
>> really just wanted libLLVM{whatever}.so. I guess it should be made
>> very clear to users (explain plans, maybe startup message, ...?)
>
> I'm not quite sure I understand. You mean have it display whether
> available? I think my plan is to "just" set jit_expressions=on (or
> whatever we're going to name it) fail if the prerequisites aren't
> available. I personally don't think this should be enabled by default,
> definitely not in the first release.
I assumed (incorrectly) that you wanted it to default to on if
available, so I was suggesting making it obvious to end users if
they've accidentally forgotten to install -jit. If it's not enabled
until you actually ask for it and trying to enable it when it's not
installed barfs, then that seems sensible.
>> This seems to be a valid complaint. I don't think you should be
>> (indirectly) wrapping Types.h in extern "C". At a guess, your
>> llvmjit.h should be doing its own #ifdef __cplusplus'd linkage
>> specifiers, so you can use it from C or C++, but making sure that you
>> don't #include LLVM's headers from a bizarro context where __cplusplus
>> is defined but the linkage is unexpectedly already "C"?
>
> Hm, this seems like a bit of pointless nitpickery by the compiler to me,
> but I guess...
Well that got me curious about how GCC could possibly be accepting
that (it certainly doesn't like extern "C" template ... any more than
the next compiler). I dug a bit and realised that it's the stdlib
that's different: libstdc++ has its own extern "C++" in <cmath>,
while libc++ doesn't.
--
Thomas Munro
http://www.enterprisedb.com
Hi, On 2018-01-31 15:48:09 +1300, Thomas Munro wrote: > On Wed, Jan 31, 2018 at 3:05 PM, Andres Freund <andres@anarazel.de> wrote: > > I'm not quite sure I understand. You mean have it display whether > > available? I think my plan is to "just" set jit_expressions=on (or > > whatever we're going to name it) fail if the prerequisites aren't > > available. I personally don't think this should be enabled by default, > > definitely not in the first release. > > I assumed (incorrectly) that you wanted it to default to on if > available, so I was suggesting making it obvious to end users if > they've accidentally forgotten to install -jit. If it's not enabled > until you actually ask for it and trying to enable it when it's not > installed barfs, then that seems sensible. I'm open to changing my mind on it, but it seems a bit weird that a feature that relies on a shlib being installed magically turns itself on if avaible. And leaving that angle aside, ISTM, that it's a complex enough feature that it should be opt-in the first release... Think we roughly did that right for e.g. parallellism. Greetings, Andres Freund
On 31.01.2018 05:48, Thomas Munro wrote: > >>> This seems to be a valid complaint. I don't think you should be >>> (indirectly) wrapping Types.h in extern "C". At a guess, your >>> llvmjit.h should be doing its own #ifdef __cplusplus'd linkage >>> specifiers, so you can use it from C or C++, but making sure that you >>> don't #include LLVM's headers from a bizarro context where __cplusplus >>> is defined but the linkage is unexpectedly already "C"? >> Hm, this seems like a bit of pointless nitpickery by the compiler to me, >> but I guess... > Well that got me curious about how GCC could possibly be accepting > that (it certainly doesn't like extern "C" template ... any more than > the next compiler). I dug a bit and realised that it's the stdlib > that's different: libstdc++ has its own extern "C++" in <cmath>, > while libc++ doesn't. > The same problem takes place with old versions of GCC: I have to upgrade GCC to 7.2 to make it possible to compile this code. The problem in not in compiler itself, but in libc++ headers. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 1/30/18 21:55, Andres Freund wrote: > I'm open to changing my mind on it, but it seems a bit weird that a > feature that relies on a shlib being installed magically turns itself on > if avaible. And leaving that angle aside, ISTM, that it's a complex > enough feature that it should be opt-in the first release... Think we > roughly did that right for e.g. parallellism. That sounds reasonable, for both of those reasons. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Jan 31, 2018 at 10:22 AM, Peter Eisentraut <peter.eisentraut@2ndquadrant.com> wrote: > On 1/30/18 21:55, Andres Freund wrote: >> I'm open to changing my mind on it, but it seems a bit weird that a >> feature that relies on a shlib being installed magically turns itself on >> if avaible. And leaving that angle aside, ISTM, that it's a complex >> enough feature that it should be opt-in the first release... Think we >> roughly did that right for e.g. parallellism. > > That sounds reasonable, for both of those reasons. The first one is a problem that's not going to go away. If the problem of JIT being enabled "magically" is something we're concerned about, we need to figure out a good solution, not just disable the feature by default. As far as the second one, looking back at what happened with parallel query, I found (on a quick read) 13 back-patched commits in REL9_6_STABLE prior to the release of 10.0, 3 of which I would qualify as low-importance (improving documentation, fixing something that's not really a bug, improving a test case). A couple of those were really stupid mistakes on my part. On the other hand, would it have been overall worse for our users if that feature had been turned on in 9.6? I don't know. They would have had those bugs (at least until we fixed them) but they would have had parallel query, too. It's hard for me to judge whether that was a win or a loss, and so here. Like parallel query, this is a feature which seems to have a low risk of data corruption, but a fairly high risk of wrong answers to queries and/or strange errors. Users don't like that. On the other hand, also like parallel query, if you've got the right kind of queries, it can make them go a lot faster. Users DO like that. So I could go either way on whether to enable this in the first release. I definitely would not like to see it stay disabled by default for a second release unless we find a lot of problems with it. There's no point in developing new features unless users are going to get the benefit of them, and while SOME users will enable features that aren't turned on by default, many will not. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jan 30, 2018 at 5:57 PM, Andres Freund <andres@anarazel.de> wrote: > Given that we need a shared library it'll be best buildsystem wise if > all of this is in a directory, and there's a separate file containing > the stubs that call into it. > > I'm not quite sure where to put the code. I'm a bit inclined to add a > new > src/backend/jit/ > because we're dealing with code from across different categories? There > we could have a pgjit.c with the stubs, and llvmjit/ with the llvm > specific code? That's kind of ugly, in that if we eventually end up with many different parts of the system using JIT, they're all going to have to all put their code in that directory rather than putting it with the subsystem to which it pertains. On the other hand, I don't really have a better idea. I'd definitely at least try to keep executor-specific considerations in a separate FILE from general JIT infrastructure, and make, as far as possible, a clean separation at the API level. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2018-01-31 11:53:25 -0500, Robert Haas wrote: > On Wed, Jan 31, 2018 at 10:22 AM, Peter Eisentraut > <peter.eisentraut@2ndquadrant.com> wrote: > > On 1/30/18 21:55, Andres Freund wrote: > >> I'm open to changing my mind on it, but it seems a bit weird that a > >> feature that relies on a shlib being installed magically turns itself on > >> if avaible. And leaving that angle aside, ISTM, that it's a complex > >> enough feature that it should be opt-in the first release... Think we > >> roughly did that right for e.g. parallellism. > > > > That sounds reasonable, for both of those reasons. > > The first one is a problem that's not going to go away. If the > problem of JIT being enabled "magically" is something we're concerned > about, we need to figure out a good solution, not just disable the > feature by default. That's a fair argument, and I don't really have a good answer to it. We could have a jit = off/try/on, and use that to signal things? I.e. it can be set to try (possibly default in version + 1), and things will work if it's not installed, but if set to on it'll refuse to work if not enabled. Similar to how huge pages work now. Greetings, Andres Freund
Hi, On 2018-01-31 11:56:59 -0500, Robert Haas wrote: > On Tue, Jan 30, 2018 at 5:57 PM, Andres Freund <andres@anarazel.de> wrote: > > Given that we need a shared library it'll be best buildsystem wise if > > all of this is in a directory, and there's a separate file containing > > the stubs that call into it. > > > > I'm not quite sure where to put the code. I'm a bit inclined to add a > > new > > src/backend/jit/ > > because we're dealing with code from across different categories? There > > we could have a pgjit.c with the stubs, and llvmjit/ with the llvm > > specific code? > > That's kind of ugly, in that if we eventually end up with many > different parts of the system using JIT, they're all going to have to > all put their code in that directory rather than putting it with the > subsystem to which it pertains. Yea, that's what I really dislike about the idea too. > On the other hand, I don't really have a better idea. I guess one alternative would be to leave the individual files in their subsystem directories, but not in the corresponding OBJS lists, and instead pick them up from the makefile in the jit shlib? That might better... It's a bit weird because the files would be compiled when make-ing that directory and rather when the jit shlib one made, but that's not too bad. > I'd definitely at least try to keep executor-specific considerations > in a separate FILE from general JIT infrastructure, and make, as far > as possible, a clean separation at the API level. Absolutely. Right now there's general infrastructure files (error handling, optimization, inlining), expression compilation, tuple deform compilation, and I thought to continue keeping the files separately just like that. Greetings, Andres Freund
On Wed, Jan 31, 2018 at 1:34 PM, Andres Freund <andres@anarazel.de> wrote: >> The first one is a problem that's not going to go away. If the >> problem of JIT being enabled "magically" is something we're concerned >> about, we need to figure out a good solution, not just disable the >> feature by default. > > That's a fair argument, and I don't really have a good answer to it. We > could have a jit = off/try/on, and use that to signal things? I.e. it > can be set to try (possibly default in version + 1), and things will > work if it's not installed, but if set to on it'll refuse to work if not > enabled. Similar to how huge pages work now. We could do that, but I'd be more inclined just to let JIT be magically enabled. In general, if a user could do 'yum install ip4r' (for example) and have that Just Work without any further database configuration, I think a lot of people would consider that to be a huge improvement. Unfortunately we can't really do that for various reasons, the biggest of which is that there's no way for installing an OS package to modify the internal state of a database that may not even be running at the time. But as a general principle, I think having to configure both the OS and the DB is an anti-feature, and that if installing an extra package is sufficient to get the new-and-improved behavior, users will like it. Bonus points if it doesn't require a server restart. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2018-01-31 14:45:46 -0500, Robert Haas wrote: > On Wed, Jan 31, 2018 at 1:34 PM, Andres Freund <andres@anarazel.de> wrote: > >> The first one is a problem that's not going to go away. If the > >> problem of JIT being enabled "magically" is something we're concerned > >> about, we need to figure out a good solution, not just disable the > >> feature by default. > > > > That's a fair argument, and I don't really have a good answer to it. We > > could have a jit = off/try/on, and use that to signal things? I.e. it > > can be set to try (possibly default in version + 1), and things will > > work if it's not installed, but if set to on it'll refuse to work if not > > enabled. Similar to how huge pages work now. > > We could do that, but I'd be more inclined just to let JIT be > magically enabled. In general, if a user could do 'yum install ip4r' > (for example) and have that Just Work without any further database > configuration, I think a lot of people would consider that to be a > huge improvement. Unfortunately we can't really do that for various > reasons, the biggest of which is that there's no way for installing an > OS package to modify the internal state of a database that may not > even be running at the time. But as a general principle, I think > having to configure both the OS and the DB is an anti-feature, and > that if installing an extra package is sufficient to get the > new-and-improved behavior, users will like it. I'm not seing a contradiction between what you describe as desired, and what I describe? If it defaulted to try, that'd just do what you want, no? I do think it's important to configure the system so it'll error if JITing is not available. > Bonus points if it doesn't require a server restart. I think server restart might be doable (although it'll increase memory usage because the shlib needs to be loaded in each backend rather than postmaster), but once a session is running I'm fairly sure we do not want to retry. Re-checking whether a shlib is available on the filesystem every query does not sound like a good idea... Greetings, Andres Freund
On Wed, Jan 31, 2018 at 2:49 PM, Andres Freund <andres@anarazel.de> wrote: >> We could do that, but I'd be more inclined just to let JIT be >> magically enabled. In general, if a user could do 'yum install ip4r' >> (for example) and have that Just Work without any further database >> configuration, I think a lot of people would consider that to be a >> huge improvement. Unfortunately we can't really do that for various >> reasons, the biggest of which is that there's no way for installing an >> OS package to modify the internal state of a database that may not >> even be running at the time. But as a general principle, I think >> having to configure both the OS and the DB is an anti-feature, and >> that if installing an extra package is sufficient to get the >> new-and-improved behavior, users will like it. > > I'm not seing a contradiction between what you describe as desired, and > what I describe? If it defaulted to try, that'd just do what you want, > no? I do think it's important to configure the system so it'll error if > JITing is not available. Hmm, I guess that's true. I'm not sure that we really need a way to error out if JIT is not available, but maybe we do. >> Bonus points if it doesn't require a server restart. > > I think server restart might be doable (although it'll increase memory > usage because the shlib needs to be loaded in each backend rather than > postmaster), but once a session is running I'm fairly sure we do not > want to retry. Re-checking whether a shlib is available on the > filesystem every query does not sound like a good idea... Agreed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 1/31/18 13:34, Andres Freund wrote: > That's a fair argument, and I don't really have a good answer to it. We > could have a jit = off/try/on, and use that to signal things? I.e. it > can be set to try (possibly default in version + 1), and things will > work if it's not installed, but if set to on it'll refuse to work if not > enabled. Similar to how huge pages work now. But that setup also has the problem that you can't query the setting to know whether it's actually on. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 1/31/18 14:45, Robert Haas wrote: > We could do that, but I'd be more inclined just to let JIT be > magically enabled. In general, if a user could do 'yum install ip4r' > (for example) and have that Just Work without any further database > configuration, One way to do that would be to have a system-wide configuration file like /usr/local/pgsql/etc/postgresql/postgresql.conf, which in turn includes /usr/local/pgsql/etc/postgresql/postgreql.conf.d/*, and have the add-on package install its configuration file with the setting jit = on there. Then again, if we want to make it simpler, just link the whole thing in and turn it on by default and be done with it. Presumably, there will be planner-level knobs to model the jit startup time, and if you don't like it, you can set that very high to disable it. So we don't necessarily need a separate turn-it-off-it's-broken setting. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2018-02-01 08:46:08 -0500, Peter Eisentraut wrote: > On 1/31/18 14:45, Robert Haas wrote: > > We could do that, but I'd be more inclined just to let JIT be > > magically enabled. In general, if a user could do 'yum install ip4r' > > (for example) and have that Just Work without any further database > > configuration, > > One way to do that would be to have a system-wide configuration file > like /usr/local/pgsql/etc/postgresql/postgresql.conf, which in turn > includes /usr/local/pgsql/etc/postgresql/postgreql.conf.d/*, and have > the add-on package install its configuration file with the setting jit = > on there. I think Robert's comment about extensions wasn't about extensions and jit, just about needing CREATE EXTENSION. I don't see any need for per-extension/shlib configurability of JITing. > Then again, if we want to make it simpler, just link the whole thing in > and turn it on by default and be done with it. I'd personally be ok with that too... Greetings, Andres Freund
On Wed, Jan 31, 2018 at 1:45 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Jan 31, 2018 at 1:34 PM, Andres Freund <andres@anarazel.de> wrote: >>> The first one is a problem that's not going to go away. If the >>> problem of JIT being enabled "magically" is something we're concerned >>> about, we need to figure out a good solution, not just disable the >>> feature by default. >> >> That's a fair argument, and I don't really have a good answer to it. We >> could have a jit = off/try/on, and use that to signal things? I.e. it >> can be set to try (possibly default in version + 1), and things will >> work if it's not installed, but if set to on it'll refuse to work if not >> enabled. Similar to how huge pages work now. > > We could do that, but I'd be more inclined just to let JIT be > magically enabled. In general, if a user could do 'yum install ip4r' > (for example) and have that Just Work without any further database > configuration, I think a lot of people would consider that to be a > huge improvement. Unfortunately we can't really do that for various > reasons, the biggest of which is that there's no way for installing an > OS package to modify the internal state of a database that may not > even be running at the time. But as a general principle, I think > having to configure both the OS and the DB is an anti-feature, and > that if installing an extra package is sufficient to get the > new-and-improved behavior, users will like it. Bonus points if it > doesn't require a server restart. You bet. It'd be helpful to have some obvious, well advertised ways to determine when it's enabled and when it isn't, and to have a straightforward process to determine what to fix when it's not enabled and the user thinks it ought to be though. merlin
On Wed, Jan 31, 2018 at 12:03 AM, Konstantin Knizhnik
<k.knizhnik@postgrespro.ru> wrote:
> The same problem takes place with old versions of GCC: I have to upgrade GCC
> to 7.2 to make it possible to compile this code.
> The problem in not in compiler itself, but in libc++ headers.
How can I get this branch to compile on ubuntu 16.04? I have llvm-5.0
and gcc-5.4 installed. Do I need to compile with clang or gcc? Any
CXXFLAGS required?
Regards,
Jeff Davis
On 2018-02-01 09:32:17 -0800, Jeff Davis wrote:
> On Wed, Jan 31, 2018 at 12:03 AM, Konstantin Knizhnik
> <k.knizhnik@postgrespro.ru> wrote:
> > The same problem takes place with old versions of GCC: I have to upgrade GCC
> > to 7.2 to make it possible to compile this code.
> > The problem in not in compiler itself, but in libc++ headers.
>
> How can I get this branch to compile on ubuntu 16.04? I have llvm-5.0
> and gcc-5.4 installed. Do I need to compile with clang or gcc? Any
> CXXFLAGS required?
Just to understand: You're running in the issue with the header being
included from within the extern "C" {}? Hm, I've pushed a quick fix for
that.
Other than that, you can compile with both gcc or clang, but clang needs
to be available. Will be guessed from PATH if clang clang-5.0 clang-4.0
(in that order) exist, similar with llvm-config llvm-config-5.0 being
guessed. LLVM_CONFIG/CLANG/CXX= as an argument to configure overrides
both of that. E.g.
./configure --with-llvm LLVM_CONFIG=~/build/llvm/5/opt/install/bin/llvm-config
is what I use, although I also add:
LDFLAGS='-Wl,-rpath,/home/andres/build/llvm/5/opt/install/lib'
so I don't have to install llvm anywhere the system knows about.
Greetings,
Andres Freund
On Fri, Feb 2, 2018 at 2:05 PM, Andres Freund <andres@anarazel.de> wrote:
> On 2018-02-01 09:32:17 -0800, Jeff Davis wrote:
>> On Wed, Jan 31, 2018 at 12:03 AM, Konstantin Knizhnik
>> <k.knizhnik@postgrespro.ru> wrote:
>> > The same problem takes place with old versions of GCC: I have to upgrade GCC
>> > to 7.2 to make it possible to compile this code.
>> > The problem in not in compiler itself, but in libc++ headers.
>>
>> How can I get this branch to compile on ubuntu 16.04? I have llvm-5.0
>> and gcc-5.4 installed. Do I need to compile with clang or gcc? Any
>> CXXFLAGS required?
>
> Just to understand: You're running in the issue with the header being
> included from within the extern "C" {}? Hm, I've pushed a quick fix for
> that.
That change wasn't quite enough: to get this building against libc++
(Clang's native stdlb) I also needed this change to llvmjit.h so that
<llvm-c/Types.h> wouldn't be included with the wrong linkage (perhaps
you can find a less ugly way):
+#ifdef __cplusplus
+}
+#endif
#include <llvm-c/Types.h>
+#ifdef __cplusplus
+extern "C"
+{
+#endif
> Other than that, you can compile with both gcc or clang, but clang needs
> to be available. Will be guessed from PATH if clang clang-5.0 clang-4.0
> (in that order) exist, similar with llvm-config llvm-config-5.0 being
> guessed. LLVM_CONFIG/CLANG/CXX= as an argument to configure overrides
> both of that. E.g.
> ./configure --with-llvm LLVM_CONFIG=~/build/llvm/5/opt/install/bin/llvm-config
> is what I use, although I also add:
> LDFLAGS='-Wl,-rpath,/home/andres/build/llvm/5/opt/install/lib'
> so I don't have to install llvm anywhere the system knows about.
BTW if you're building with clang (vendor compiler on at least macOS
and FreeBSD) you'll probably need CXXFLAGS=-std=c++11 (or later
standard) because it's still defaulting to '98.
--
Thomas Munro
http://www.enterprisedb.com
Another small thing which might be environmental... llvmjit_types.bc
is getting installed into ${prefix}/lib here, but you're looking for
it in ${prefix}/lib/postgresql:
gmake[3]: Entering directory '/usr/home/munro/projects/postgres/src/backend/lib'
/usr/bin/install -c -m 644 llvmjit_types.bc '/home/munro/install/lib'
postgres=# set jit_above_cost = 0;
SET
postgres=# set jit_expressions = on;
SET
postgres=# select 4 + 4;
ERROR: LLVMCreateMemoryBufferWithContentsOfFile(/usr/home/munro/install/lib/postgresql/llvmjit_types.bc)
failed: No such file or directory
$ mv ~/install/lib/llvmjit_types.bc ~/install/lib/postgresql/
postgres=# select 4 + 4;
?column?
----------
8
(1 row)
--
Thomas Munro
http://www.enterprisedb.com
On Fri, Feb 2, 2018 at 5:11 PM, Thomas Munro
<thomas.munro@enterprisedb.com> wrote:
> Another small thing which might be environmental... llvmjit_types.bc
> is getting installed into ${prefix}/lib here, but you're looking for
> it in ${prefix}/lib/postgresql:
Is there something broken about my installation? I see simple
arithmetic expressions apparently compiling and working but I can
easily find stuff that breaks... so far I think it's anything
involving string literals:
postgres=# set jit_above_cost = 0;
SET
postgres=# select quote_ident('x');
ERROR: failed to resolve name MakeExpandedObjectReadOnlyInternal
Well actually just select 'hello world' does it. I've attached a backtrace.
Tab completion is broken for me with jit_above_cost = 0 due to
tab-complete.c queries failing with various other errors including:
set <tab>:
ERROR: failed to resolve name ExecEvalScalarArrayOp
update <tab>:
ERROR: failed to resolve name quote_ident
show <tab>:
ERROR: failed to resolve name slot_getsomeattrs
I wasn't sure from your status message how much of this is expected at
this stage...
This is built from:
commit 302b7a284d30fb0e00eb5f0163aa933d4d9bea10 (HEAD -> jit, andresfreund/jit)
... plus the extern "C" tweak I posted earlier to make my clang 4.0
compiler happy, built on a FreeBSD 11.1 box with:
./configure --prefix=/home/munro/install/ --enable-tap-tests
--enable-cassert --enable-debug --enable-depend --with-llvm CC="ccache
cc" CXX="ccache c++" CXXFLAGS="-std=c++11"
LLVM_CONFIG=/usr/local/llvm50/bin/llvm-config
--with-libraries="/usr/local/lib" --with-includes="/usr/local/include"
The clang that was used for bitcode was the system /usr/bin/clang,
version 4.0. Is it a problem that I used that for compiling the
bitcode, but LLVM5 for JIT? I actually tried
CLANG=/usr/local/llvm50/bin/clang but ran into weird failures I
haven't got to the bottom of at ThinLink time so I couldn't get as far
as a running system.
I installed llvm50 from a package. I did need to make a tiny tweak by
hand: in src/Makefile.global, llvm-config --system-libs had said
-l/usr/lib/libexecinfo.so which wasn't linking and looks wrong to me
so I changed it to -lexecinfo, noted that it worked and reported a bug
upstream: https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=225621
--
Thomas Munro
http://www.enterprisedb.com
Attachment
On Thu, Feb 1, 2018 at 5:05 PM, Andres Freund <andres@anarazel.de> wrote:
> Just to understand: You're running in the issue with the header being
> included from within the extern "C" {}? Hm, I've pushed a quick fix for
> that.
>
> Other than that, you can compile with both gcc or clang, but clang needs
> to be available. Will be guessed from PATH if clang clang-5.0 clang-4.0
> (in that order) exist, similar with llvm-config llvm-config-5.0 being
> guessed. LLVM_CONFIG/CLANG/CXX= as an argument to configure overrides
> both of that. E.g.
> ./configure --with-llvm LLVM_CONFIG=~/build/llvm/5/opt/install/bin/llvm-config
> is what I use, although I also add:
> LDFLAGS='-Wl,-rpath,/home/andres/build/llvm/5/opt/install/lib'
> so I don't have to install llvm anywhere the system knows about.
On Ubuntu 16.04
SHA1: 302b7a284
gcc (Ubuntu 5.4.0-6ubuntu1~16.04.6) 5.4.0 20160609
packages: llvm-5.0 llvm-5.0-dev llvm-5.0-runtime libllvm-5.0
clang-5.0 libclang-common-5.0-dev libclang1-5.0
./configure --with-llvm --prefix=/home/jdavis/install/pgsql-dev
...
checking for llvm-config... no
checking for llvm-config-5.0... llvm-config-5.0
checking for clang... no
checking for clang-5.0... clang-5.0
checking for LLVMOrcGetSymbolAddressIn... no
checking for LLVMGetHostCPUName... no
checking for LLVMOrcRegisterGDB... no
checking for LLVMOrcRegisterPerf... no
checking for LLVMOrcUnregisterPerf... no
...
That encounters errors like:
/usr/include/c++/5/bits/c++0x_warning.h:32:2: error: #error This file
requires compiler an
d library support for the ISO C++ 2011 standard. This support must be
enabled with the -st
d=c++11 or -std=gnu++11 compiler options.
...
/usr/include/c++/5/cmath:505:22: error: conflicting declaration of C
function ‘long double
...
/usr/include/c++/5/cmath:926:3: error: template with C linkage
...
So I reconfigure with:
CXXFLAGS="-std=c++11" ./configure --with-llvm
--prefix=/home/jdavis/install/pgsql-dev
I think that got rid of the first error, but the other errors remain.
I also tried installing libc++-dev and using CC=clang-5.0
CXX=clang++-5.0 and with CXXFLAGS="-std=c++11 -stdlib=libc++" but I am
not making much progress, I'm still getting:
/usr/include/c++/v1/cmath:316:1: error: templates must have C++ linkage
I suggest that you share your exact configuration so we can get past
this for now, and you can work on the build issues in the background.
We can't be the first ones with this problem; maybe you can just ask
on an LLVM channel what the right thing to do is that will work on a
variety of machines (or at least reliably detect the problem at
configure time)?
Regards,
Jeff Davis
On Fri, Feb 2, 2018 at 7:06 PM, Jeff Davis <pgsql@j-davis.com> wrote:
> /usr/include/c++/5/cmath:505:22: error: conflicting declaration of C
> function ‘long double
> ...
> /usr/include/c++/5/cmath:926:3: error: template with C linkage
I suspect you can fix these with this change:
+#ifdef __cplusplus
+}
+#endif
#include <llvm-c/Types.h>
+#ifdef __cplusplus
+extern "C"
+{
+#endif
... in llvmjit.h.
--
Thomas Munro
http://www.enterprisedb.com
On Thu, Feb 1, 2018 at 10:09 PM, Thomas Munro
<thomas.munro@enterprisedb.com> wrote:
> On Fri, Feb 2, 2018 at 7:06 PM, Jeff Davis <pgsql@j-davis.com> wrote:
>> /usr/include/c++/5/cmath:505:22: error: conflicting declaration of C
>> function ‘long double
>> ...
>> /usr/include/c++/5/cmath:926:3: error: template with C linkage
>
> I suspect you can fix these with this change:
>
> +#ifdef __cplusplus
> +}
> +#endif
> #include <llvm-c/Types.h>
> +#ifdef __cplusplus
> +extern "C"
> +{
> +#endif
>
> ... in llvmjit.h.
Thanks! That worked, but I had to remove the "-stdlib=libc++" also,
which was causing me problems.
Regards,
Jeff Davis
Hi,
On 2018-02-02 18:22:34 +1300, Thomas Munro wrote:
> Is there something broken about my installation? I see simple
> arithmetic expressions apparently compiling and working but I can
> easily find stuff that breaks... so far I think it's anything
> involving string literals:
That definitely should all work. Did you compile with lto and forced it
to internalize all symbols or such?
> postgres=# set jit_above_cost = 0;
> SET
> postgres=# select quote_ident('x');
> ERROR: failed to resolve name MakeExpandedObjectReadOnlyInternal
...
> The clang that was used for bitcode was the system /usr/bin/clang,
> version 4.0. Is it a problem that I used that for compiling the
> bitcode, but LLVM5 for JIT?
No, I did that locally without problems.
> I actually tried CLANG=/usr/local/llvm50/bin/clang but ran into weird
> failures I haven't got to the bottom of at ThinLink time so I couldn't
> get as far as a running system.
So you'd clang 5 level issues rather than with this patchset, do I
understand correctly?
> I installed llvm50 from a package. I did need to make a tiny tweak by
> hand: in src/Makefile.global, llvm-config --system-libs had said
> -l/usr/lib/libexecinfo.so which wasn't linking and looks wrong to me
> so I changed it to -lexecinfo, noted that it worked and reported a bug
> upstream: https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=225621
Yea, that seems outside of my / our hands.
- Andres
On 2018-02-01 22:20:01 -0800, Jeff Davis wrote: > Thanks! That worked, but I had to remove the "-stdlib=libc++" also, > which was causing me problems. That'll be gone as soon as I finish the shlib thing. Will hope to have something over the weekend. Right now I'm at FOSDEM and need to prepare a talk for tomorrow. Greetings, Andres Freund
On Monday, January 29, 2018 10:53:50 AM CET Andres Freund wrote: > Hi, > > On 2018-01-23 23:20:38 -0800, Andres Freund wrote: > > == Code == > > > > As the patchset is large (500kb) and I'm still quickly evolving it, I do > > not yet want to attach it. The git tree is at > > > > https://git.postgresql.org/git/users/andresfreund/postgres.git > > > > in the jit branch > > > > https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=s > > hortlog;h=refs/heads/jit > I've just pushed an updated and rebased version of the tree: > - Split the large "jit infrastructure" commits into a number of smaller > commits > - Split the C++ file > - Dropped some of the performance stuff done to heaptuple.c - that was > mostly to make performance comparisons a bit more interesting, but > doesn't seem important enough to deal with. > - Added a commit renaming datetime.h symbols so they don't conflict with > LLVM variables anymore, removing ugly #undef PM/#define PM dance > around includes. Will post separately. > - Reduced the number of pointer constants in the generated LLVM IR, by > doing more getelementptr accesses (stem from before the time types > were automatically synced) > - Increased number of comments a bit > > There's a jit-before-rebase-2018-01-29 tag, for the state of the tree > before the rebase. > > Regards, > > Andres Hi I have successfully built the JIT branch against LLVM 4.0.1 on Debian testing. This is not enough for Debian stable (LLVM 3.9 is the latest available there), but it's a first step. I've split the patch in four files. The first three fix the build issues, the last one fixes a runtime issue. I think they are small enough to not be a burden for you in your developments. But if you don't want to carry these ifdefs right now, I maintain them in a branch on a personal git and rebase as frequently as I can. LLVM 3.9 support isn't going to be hard, but I prefer splitting. I also hope this will help more people test this wonderful toy… :) Regards Pierre
Attachment
Hi, On 2018-02-02 18:22:34 +1300, Thomas Munro wrote: > The clang that was used for bitcode was the system /usr/bin/clang, > version 4.0. Is it a problem that I used that for compiling the > bitcode, but LLVM5 for JIT? I actually tried > CLANG=/usr/local/llvm50/bin/clang but ran into weird failures I > haven't got to the bottom of at ThinLink time so I couldn't get as far > as a running system. You're using thinlto to compile pg? Could you provide what you pass to configure for that? IIRC I tried that a while ago and ran into some issues with us creating archives (libpgport, libpgcommon). Greetings, Andres Freund
On Friday, February 2, 2018 10:48:16 AM CET Pierre Ducroquet wrote: > On Monday, January 29, 2018 10:53:50 AM CET Andres Freund wrote: > > Hi, > > > > On 2018-01-23 23:20:38 -0800, Andres Freund wrote: > > > == Code == > > > > > > As the patchset is large (500kb) and I'm still quickly evolving it, I do > > > not yet want to attach it. The git tree is at > > > > > > https://git.postgresql.org/git/users/andresfreund/postgres.git > > > > > > in the jit branch > > > > > > https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a > > > =s > > > hortlog;h=refs/heads/jit > > > > I've just pushed an updated and rebased version of the tree: > > - Split the large "jit infrastructure" commits into a number of smaller > > > > commits > > > > - Split the C++ file > > - Dropped some of the performance stuff done to heaptuple.c - that was > > > > mostly to make performance comparisons a bit more interesting, but > > doesn't seem important enough to deal with. > > > > - Added a commit renaming datetime.h symbols so they don't conflict with > > > > LLVM variables anymore, removing ugly #undef PM/#define PM dance > > around includes. Will post separately. > > > > - Reduced the number of pointer constants in the generated LLVM IR, by > > > > doing more getelementptr accesses (stem from before the time types > > were automatically synced) > > > > - Increased number of comments a bit > > > > There's a jit-before-rebase-2018-01-29 tag, for the state of the tree > > before the rebase. > > > > Regards, > > > > Andres > > Hi > > I have successfully built the JIT branch against LLVM 4.0.1 on Debian > testing. This is not enough for Debian stable (LLVM 3.9 is the latest > available there), but it's a first step. > I've split the patch in four files. The first three fix the build issues, > the last one fixes a runtime issue. > I think they are small enough to not be a burden for you in your > developments. But if you don't want to carry these ifdefs right now, I > maintain them in a branch on a personal git and rebase as frequently as I > can. > > LLVM 3.9 support isn't going to be hard, but I prefer splitting. I also hope > this will help more people test this wonderful toy… :) > > Regards > > Pierre For LLVM 3.9, only small changes were needed. I've attached the patches to this email. I only did very basic, primitive testing, but it seems to work. I'll do more testing in the next days. Pierre
Attachment
On Mon, Jan 29, 2018 at 1:53 AM, Andres Freund <andres@anarazel.de> wrote: >> https://git.postgresql.org/git/users/andresfreund/postgres.git There's a patch in there to change the scan order. I suggest that you rename the GUC "synchronize_seqscans" to something more generic like "optimize_scan_order", and use it to control your feature as well (after all, it's the same trade-off: weird scan order vs. performance). Then, go ahead and commit it. FWIW I see about a 7% boost on my laptop[1] from that patch on master, without JIT or anything else. I also see you dropped "7ae518bf Centralize slot deforming logic a bit.". Was that intentional? Do we want it? I think I saw about a 2% gain here over master, but when I applied it on top of the fast scans it did not seem to add anything on top of fast scans. Seems reproducible, but I don't have an explanation. And you are probably already working on this, but it would be helpful to get the following two patches in also: * 3c22065f Do execGrouping via expression eval * a9dde4aa Allow tupleslots to have a fixed tupledesc I took a brief look at those two, but will review them in more detail. Regards, Jeff Davis [1] Simple scan with simple predicate on 50M tuples, after pg_prewarm.
Hi, On 2018-02-02 18:21:12 -0800, Jeff Davis wrote: > On Mon, Jan 29, 2018 at 1:53 AM, Andres Freund <andres@anarazel.de> wrote: > >> https://git.postgresql.org/git/users/andresfreund/postgres.git > > There's a patch in there to change the scan order. Yes - note it's "deactivated" at the moment in the series. I primarily have it in there because I found profiles to be a lot more useful if it's enabled, as otherwise the number of cache misses and related stalls from heap accesses completely swamp everything else. FWIW, there's http://archives.postgresql.org/message-id/20161030073655.rfa6nvbyk4w2kkpk%40alap3.anarazel.de > I suggest that you rename the GUC "synchronize_seqscans" to something > more generic like "optimize_scan_order", and use it to control your > feature as well (after all, it's the same trade-off: weird scan order > vs. performance). Then, go ahead and commit it. FWIW I see about a 7% > boost on my laptop[1] from that patch on master, without JIT or > anything else. Yea, that's roughly the same magnitude of what I'm seeing, some queries even bigger. I'm not sure I want to commit this right now - ISTM we couldn't default this to on without annoying a lot of people, and letting the performance wins on the table by default seems like a shame. I think we should probably either change the order we store things on the page by default or only use the faster order if the scan above doesn't care about order - the planner could figure that out easily. I personally don't think it is necessary to get this committed at the same time as the JIT stuff, so I'm not planning to push very hard on that front. Should you be interested in taking it up, please feel entirely free. > I also see you dropped "7ae518bf Centralize slot deforming logic a > bit.". Was that intentional? Do we want it? The problem is that there's probably some controversial things in there. I think the checks I dropped largely make no sense, but I don't really want to push for that hard. I suspect we probably still want it, but I do not want to put into the critical path right now. > I think I saw about a 2% gain here over master, but when I applied it > on top of the fast scans it did not seem to add anything on top of > fast scans. Seems reproducible, but I don't have an explanation. Yea, that makes sense. The primary reason the patch is beneficial is that it centralizes the place where the HeapTupleHeader is accessed to a single piece of code (slot_deform_tuple()). In a lot of cases that first access will result in a cache miss in all layers, requiring a memory access. In slot_getsomeattrs() there's very little that can be done in an out-of-order manner, whereas slot_deform_tuple() can continue execution a bit further. Also, the latter will then go and sequentially access the rest (or a significant part of) the tuple, so a centralized access is more prefetchable. > And you are probably already working on this, but it would be helpful > to get the following two patches in also: > * 3c22065f Do execGrouping via expression eval > * a9dde4aa Allow tupleslots to have a fixed tupledesc Yes, I plan to resume working in whipping them up into shape as soon as I've finished the move to a shared library. This weekend I'm at fosdem, so that's going to be after... Thanks for looking! Andres Freund
Hi, On 2018-02-03 01:13:21 -0800, Andres Freund wrote: > On 2018-02-02 18:21:12 -0800, Jeff Davis wrote: > > I think I saw about a 2% gain here over master, but when I applied it > > on top of the fast scans it did not seem to add anything on top of > > fast scans. Seems reproducible, but I don't have an explanation. > > Yea, that makes sense. The primary reason the patch is beneficial is > that it centralizes the place where the HeapTupleHeader is accessed to a > single piece of code (slot_deform_tuple()). In a lot of cases that first > access will result in a cache miss in all layers, requiring a memory > access. In slot_getsomeattrs() there's very little that can be done in > an out-of-order manner, whereas slot_deform_tuple() can continue > execution a bit further. Also, the latter will then go and sequentially > access the rest (or a significant part of) the tuple, so a centralized > access is more prefetchable. Oops missed part of the argument here: The reason that isn't that large an effect anymore with the scan order patch applied is that suddenly the accesses are, due to the better scan order, more likely to be cacheable and prefetchable. So in that case the few additional instructions and branches in slot_getsomeattrs/slot_getattr don't hurt as much anymore. IIRC I could still show it up, but it's a much smaller win. Greetings, Andres Freund
Hi, I've done some initial benchmarking on the branch over the last couple of days, focusing on analytics workloads using the DBT-3 benchmark. Attached are two spreadsheets with results from two machines (the same two I use for all benchmarks), and a couple of charts illustrating the impact of enabling different JIT options. I did the tests with 10GB and 50GB data sets (load into database generally increases the size by a factor of 2-3x). So at least on the larger machine the 10GB dataset should be fully in memory. The numbers are medians for 10 consecutive runs of each query, so the data tends to be well cached. In this round of tests I've disabled parallelism. Based on discussion with Andres I've decided to repeat the tests with parallel queries enabled - that's running now, and will take some time to complete. According to the results, most of the DBT-3 queries see slight improvement in the 5-10% range, but the JIT options vary depending on the query. What surprised me quite a bit is that the improvement is way more significant on the 50GB dataset (on both machines). I have expected the opposite behavior, i.e. that the JIT impact will be more obvious on the small dataset and then will diminish as I/O becomes more prominent. Yet that's not the case, apparently. One possible explanation is that on the 50GB data set the queries switch to plans that are more sensitive to the JIT optimizations. A couple of queries saw much more significant improvements - Q1 and Q20 got about 30%-40% faster, and I have no problem believing that other queries may see even more significant benefits. Other queries (Q19 and Q21) saw regressions - for Q19 it's relatively harmless, I think. It's a short query and so the relative slowdown seems somewhat worse that in absolute terms. Not sure what's going on for Q21, though. But I think we'll need to look at the costing model, and try tweaking it to make the right decision in those cases. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
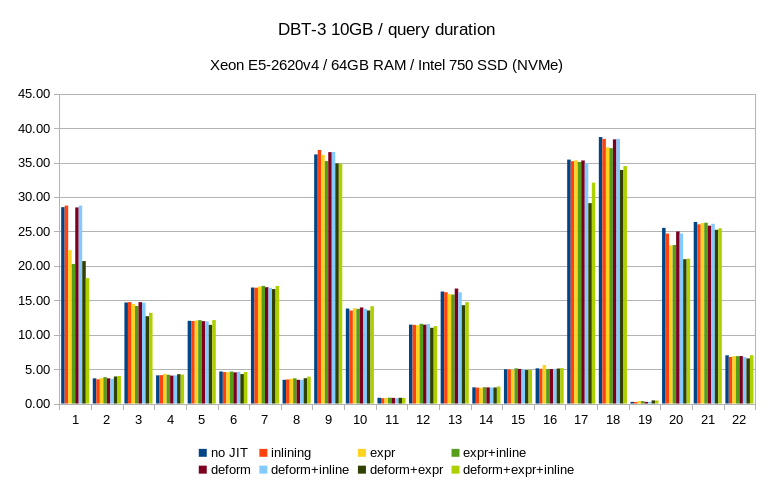{kind=link}
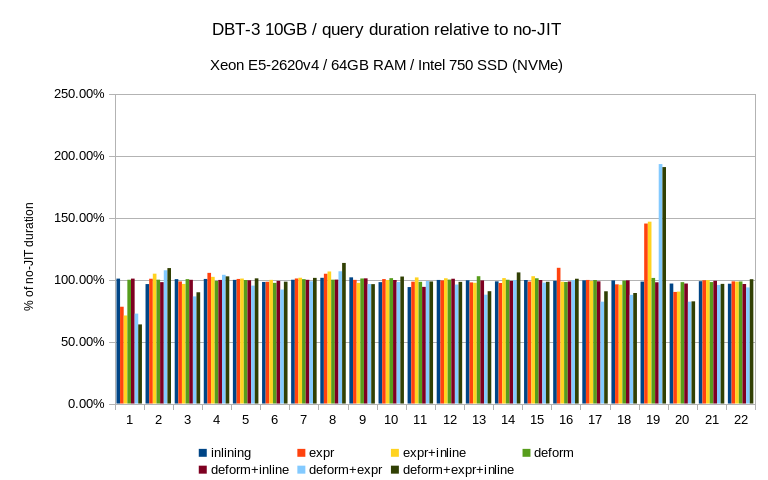{kind=link}
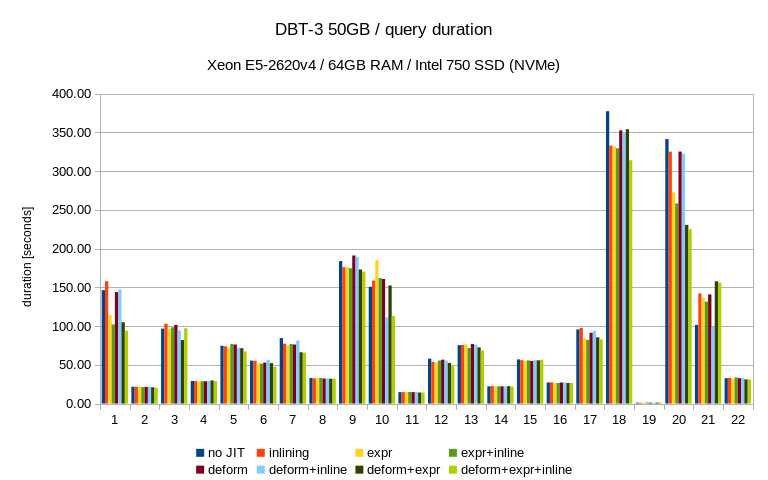{kind=link}
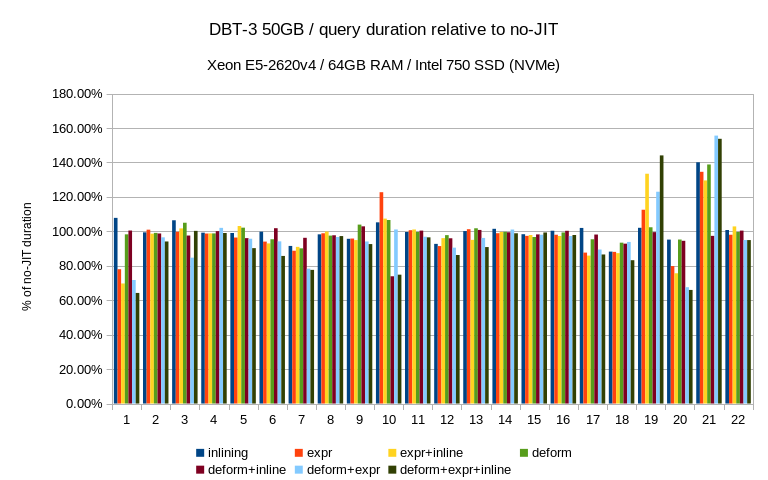{kind=link}
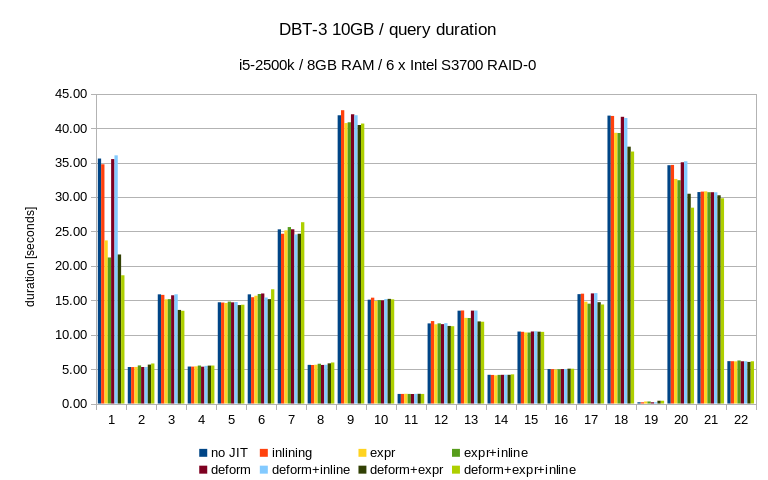{kind=link}
{kind=link}
{kind=link}
{kind=link}
On 02/02/2018 10:48 AM, Pierre Ducroquet wrote:
> I have successfully built the JIT branch against LLVM 4.0.1 on Debian testing.
> This is not enough for Debian stable (LLVM 3.9 is the latest available there),
> but it's a first step.
> I've split the patch in four files. The first three fix the build issues, the
> last one fixes a runtime issue.
> I think they are small enough to not be a burden for you in your developments.
> But if you don't want to carry these ifdefs right now, I maintain them in a
> branch on a personal git and rebase as frequently as I can.
I tested these patches and while the code built for me and passed the
test suite on Debian testing I have a weird bug where the very first
query fails to JIT while the rest work as they should. I think I need to
dig into LLVM's codebase to see what it is, but can you reproduce this
bug at your machine?
Code to reproduce:
SET jit_expressions = true;
SET jit_above_cost = 0;
SELECT 1;
SELECT 1;
Output:
postgres=# SELECT 1;
ERROR: failed to jit module
postgres=# SELECT 1;
?column?
----------
1
(1 row)
Config:
Version: You patches applied on top of
302b7a284d30fb0e00eb5f0163aa933d4d9bea10
OS: Debian testing
llvm/clang: 4.0.1-8
Andreas
On Sunday, February 4, 2018 12:45:50 AM CET Andreas Karlsson wrote: > On 02/02/2018 10:48 AM, Pierre Ducroquet wrote: > > I have successfully built the JIT branch against LLVM 4.0.1 on Debian > > testing. This is not enough for Debian stable (LLVM 3.9 is the latest > > available there), but it's a first step. > > I've split the patch in four files. The first three fix the build issues, > > the last one fixes a runtime issue. > > I think they are small enough to not be a burden for you in your > > developments. But if you don't want to carry these ifdefs right now, I > > maintain them in a branch on a personal git and rebase as frequently as I > > can. > > I tested these patches and while the code built for me and passed the > test suite on Debian testing I have a weird bug where the very first > query fails to JIT while the rest work as they should. I think I need to > dig into LLVM's codebase to see what it is, but can you reproduce this > bug at your machine? > > Code to reproduce: > > SET jit_expressions = true; > SET jit_above_cost = 0; > SELECT 1; > SELECT 1; > > Output: > > postgres=# SELECT 1; > ERROR: failed to jit module > postgres=# SELECT 1; > ?column? > ---------- > 1 > (1 row) > > Config: > > Version: You patches applied on top of > 302b7a284d30fb0e00eb5f0163aa933d4d9bea10 > OS: Debian testing > llvm/clang: 4.0.1-8 > > Andreas Hi Indeed, thanks for reporting this. I scripted the testing but failed to see it, I forgot to set on_error_stop. I will look into this and fix it. Thanks Pierre
On Sunday, February 4, 2018 12:45:50 AM CET Andreas Karlsson wrote: > On 02/02/2018 10:48 AM, Pierre Ducroquet wrote: > > I have successfully built the JIT branch against LLVM 4.0.1 on Debian > > testing. This is not enough for Debian stable (LLVM 3.9 is the latest > > available there), but it's a first step. > > I've split the patch in four files. The first three fix the build issues, > > the last one fixes a runtime issue. > > I think they are small enough to not be a burden for you in your > > developments. But if you don't want to carry these ifdefs right now, I > > maintain them in a branch on a personal git and rebase as frequently as I > > can. > > I tested these patches and while the code built for me and passed the > test suite on Debian testing I have a weird bug where the very first > query fails to JIT while the rest work as they should. I think I need to > dig into LLVM's codebase to see what it is, but can you reproduce this > bug at your machine? > > Code to reproduce: > > SET jit_expressions = true; > SET jit_above_cost = 0; > SELECT 1; > SELECT 1; > > Output: > > postgres=# SELECT 1; > ERROR: failed to jit module > postgres=# SELECT 1; > ?column? > ---------- > 1 > (1 row) > > Config: > > Version: You patches applied on top of > 302b7a284d30fb0e00eb5f0163aa933d4d9bea10 > OS: Debian testing > llvm/clang: 4.0.1-8 > > Andreas I have fixed the patches, I was wrong on 'guessing' the migration of the API for one function. I have rebuilt the whole patch set. It is still based on 302b7a284d and has been tested with both LLVM 3.9 and 4.0 on Debian testing. Thanks for your feedback !
Attachment
OK that fixed the issue, but you have a typo in your patch set.
diff --git a/src/backend/lib/llvmjit_inline.cpp
b/src/backend/lib/llvmjit_inline.cpp
index a785261bea..51f38e10d2 100644
--- a/src/backend/lib/llvmjit_inline.cpp
+++ b/src/backend/lib/llvmjit_inline.cpp
@@ -37,7 +37,7 @@ extern "C"
#include <llvm/ADT/StringSet.h>
#include <llvm/ADT/StringMap.h>
#include <llvm/Analysis/ModuleSummaryAnalysis.h>
-#if LLVM_MAJOR_VERSION > 3
+#if LLVM_VERSION_MAJOR > 3
#include <llvm/Bitcode/BitcodeReader.h>
#else
#include "llvm/Bitcode/ReaderWriter.h"
Also I get some warning. Not sure if they are from your patches or from
Andres's.
llvmjit_error.cpp:118:1: warning: unused function
'fatal_llvm_new_handler' [-Wunused-function]
fatal_llvm_new_handler(void *user_data,
^
1 warning generated.
llvmjit_inline.cpp:114:6: warning: no previous prototype for function
'operator!' [-Wmissing-prototypes]
bool operator!(const llvm::ValueInfo &vi) {
^
1 warning generated.
psqlscanslash.l: In function ‘psql_scan_slash_option’:
psqlscanslash.l:550:8: warning: variable ‘lexresult’ set but not used
[-Wunused-but-set-variable]
int final_state;
^~~~~~~~~
Andreas
On 02/05/2018 11:39 AM, Pierre Ducroquet wrote:
> On Sunday, February 4, 2018 12:45:50 AM CET Andreas Karlsson wrote:
>> On 02/02/2018 10:48 AM, Pierre Ducroquet wrote:
>>> I have successfully built the JIT branch against LLVM 4.0.1 on Debian
>>> testing. This is not enough for Debian stable (LLVM 3.9 is the latest
>>> available there), but it's a first step.
>>> I've split the patch in four files. The first three fix the build issues,
>>> the last one fixes a runtime issue.
>>> I think they are small enough to not be a burden for you in your
>>> developments. But if you don't want to carry these ifdefs right now, I
>>> maintain them in a branch on a personal git and rebase as frequently as I
>>> can.
>>
>> I tested these patches and while the code built for me and passed the
>> test suite on Debian testing I have a weird bug where the very first
>> query fails to JIT while the rest work as they should. I think I need to
>> dig into LLVM's codebase to see what it is, but can you reproduce this
>> bug at your machine?
>>
>> Code to reproduce:
>>
>> SET jit_expressions = true;
>> SET jit_above_cost = 0;
>> SELECT 1;
>> SELECT 1;
>>
>> Output:
>>
>> postgres=# SELECT 1;
>> ERROR: failed to jit module
>> postgres=# SELECT 1;
>> ?column?
>> ----------
>> 1
>> (1 row)
>>
>> Config:
>>
>> Version: You patches applied on top of
>> 302b7a284d30fb0e00eb5f0163aa933d4d9bea10
>> OS: Debian testing
>> llvm/clang: 4.0.1-8
>>
>> Andreas
>
>
> I have fixed the patches, I was wrong on 'guessing' the migration of the API
> for one function.
> I have rebuilt the whole patch set. It is still based on 302b7a284d and has
> been tested with both LLVM 3.9 and 4.0 on Debian testing.
>
> Thanks for your feedback !
>
On Monday, February 5, 2018 10:20:27 PM CET Andreas Karlsson wrote:
> OK that fixed the issue, but you have a typo in your patch set.
>
> diff --git a/src/backend/lib/llvmjit_inline.cpp
> b/src/backend/lib/llvmjit_inline.cpp
> index a785261bea..51f38e10d2 100644
> --- a/src/backend/lib/llvmjit_inline.cpp
> +++ b/src/backend/lib/llvmjit_inline.cpp
> @@ -37,7 +37,7 @@ extern "C"
> #include <llvm/ADT/StringSet.h>
> #include <llvm/ADT/StringMap.h>
> #include <llvm/Analysis/ModuleSummaryAnalysis.h>
> -#if LLVM_MAJOR_VERSION > 3
> +#if LLVM_VERSION_MAJOR > 3
> #include <llvm/Bitcode/BitcodeReader.h>
> #else
> #include "llvm/Bitcode/ReaderWriter.h"
Thanks, it's weird I had no issue with it. I will fix in the next patch set.
> Also I get some warning. Not sure if they are from your patches or from
> Andres's.
>
> llvmjit_error.cpp:118:1: warning: unused function
> 'fatal_llvm_new_handler' [-Wunused-function]
> fatal_llvm_new_handler(void *user_data,
> ^
> 1 warning generated.
> llvmjit_inline.cpp:114:6: warning: no previous prototype for function
> 'operator!' [-Wmissing-prototypes]
> bool operator!(const llvm::ValueInfo &vi) {
> ^
> 1 warning generated.
Both are mine, I knew about the first one, but I did not see the second one. I
will fix them too, thanks for the review!
> psqlscanslash.l: In function ‘psql_scan_slash_option’:
> psqlscanslash.l:550:8: warning: variable ‘lexresult’ set but not used
> [-Wunused-but-set-variable]
> int final_state;
> ^~~~~~~~~
I'm not sure Andres's patches have anything to do with psql, it's surprising.
Hi, On 02/03/2018 01:05 PM, Tomas Vondra wrote: > Hi, > > ... > > In this round of tests I've disabled parallelism. Based on > discussion with Andres I've decided to repeat the tests with parallel > queries enabled - that's running now, and will take some time to > complete. > And here are the results with parallelism enabled - same machines, but with max_parallel_workers_per_gather > 0. Based on discussions and Andres' FOSDEM talk I somehow expected more significant JIT benefits in the parallel case, but the results are pretty much exactly the same (modulo speedup thanks to parallelism, of course). In fact, the JIT impact is much noisier with parallelism enabled, for some reason, with regressions where there were no measurable regressions before (particularly for the 10GB case). That is not to say we shouldn't be doing JIT, or that Andres did not observe the speedups/benefits he mentioned during the talk - I have no trouble believing it depends on queries, and DBT-3 may not match that. I don't plan doing any further benchmarks on this patch series unless someone requests that (possibly with ideas what to focus on). I'll keep looking at the patch, of course. I've seen some build issues, so I'll try finding more details. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
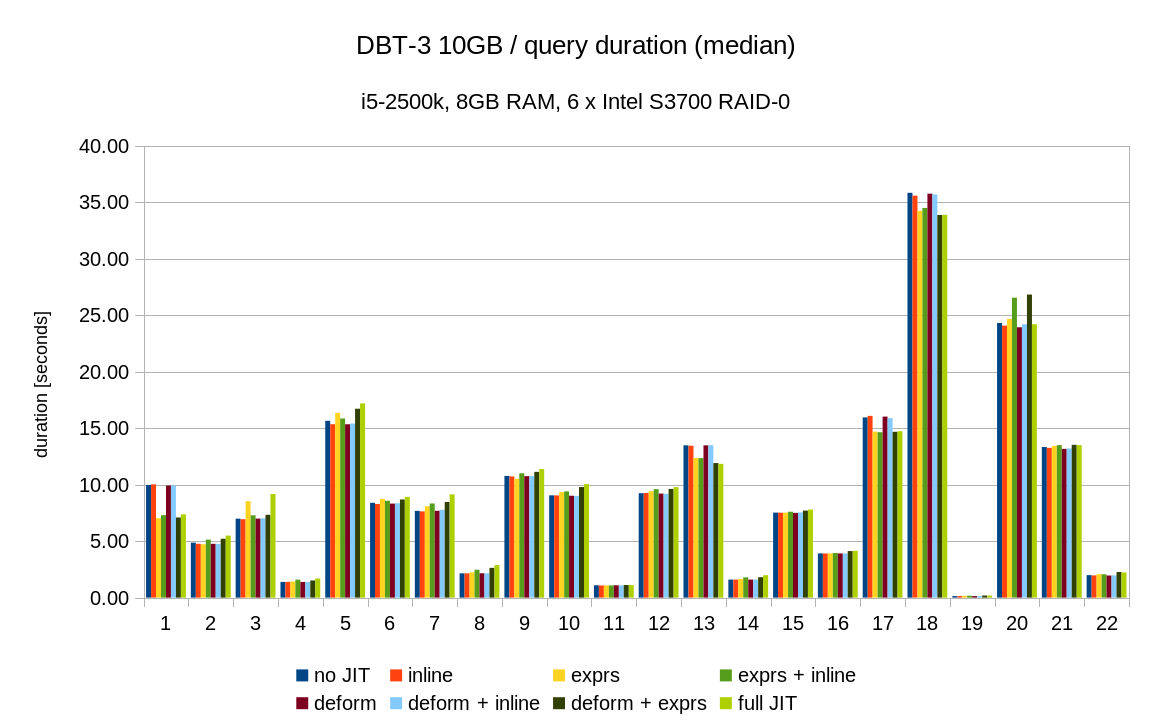{kind=link}
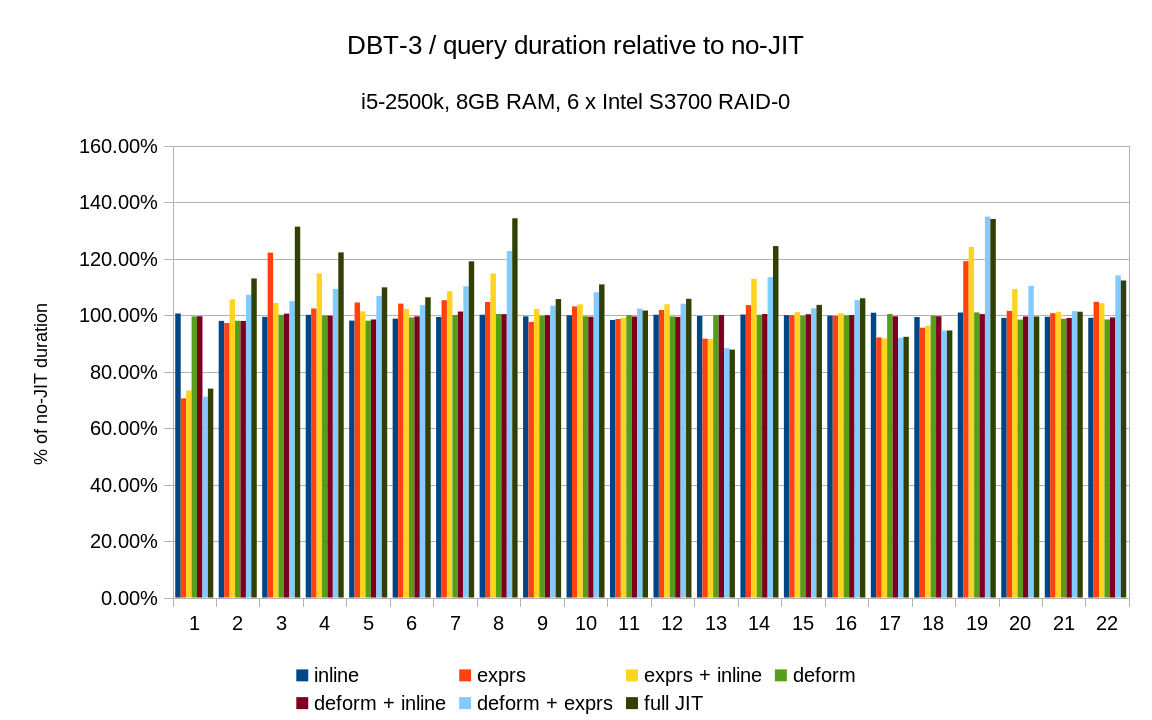{kind=link}
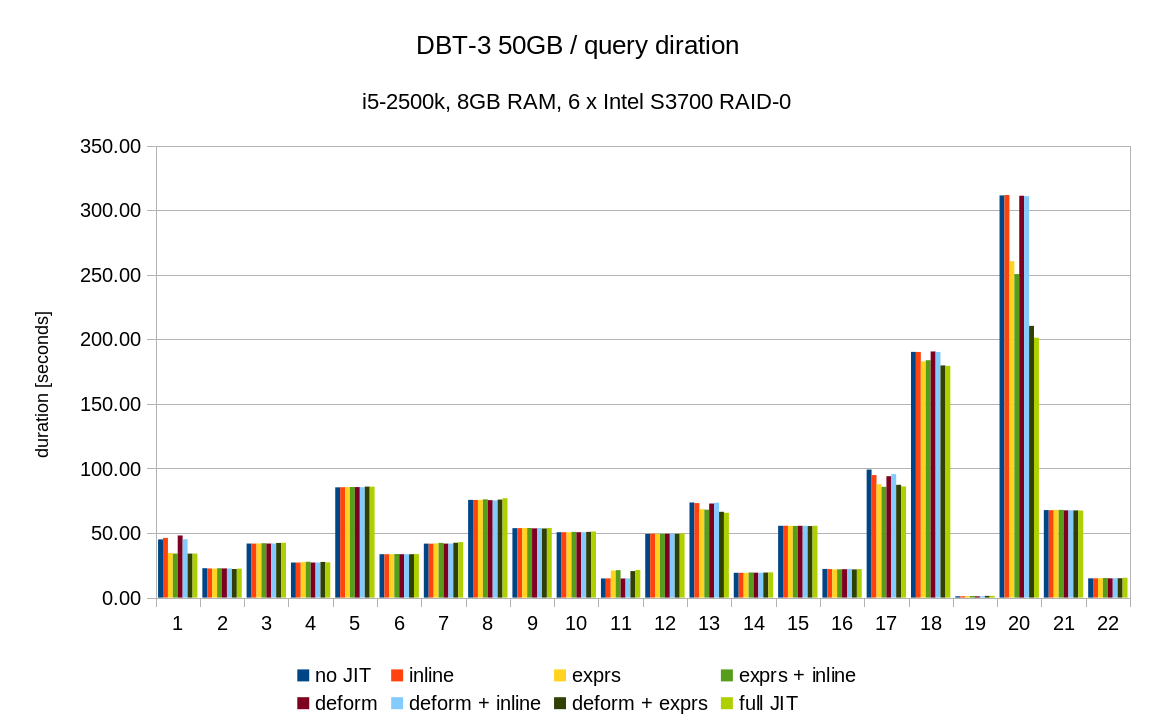{kind=link}
{kind=link}
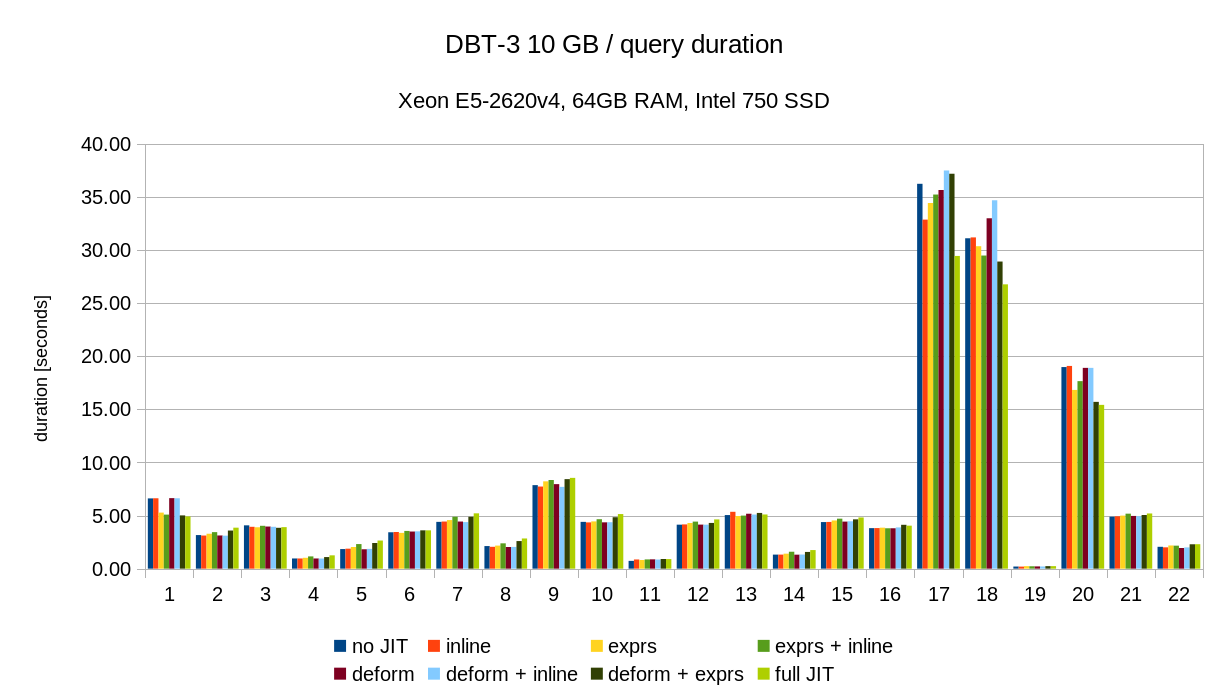{kind=link}
{kind=link}
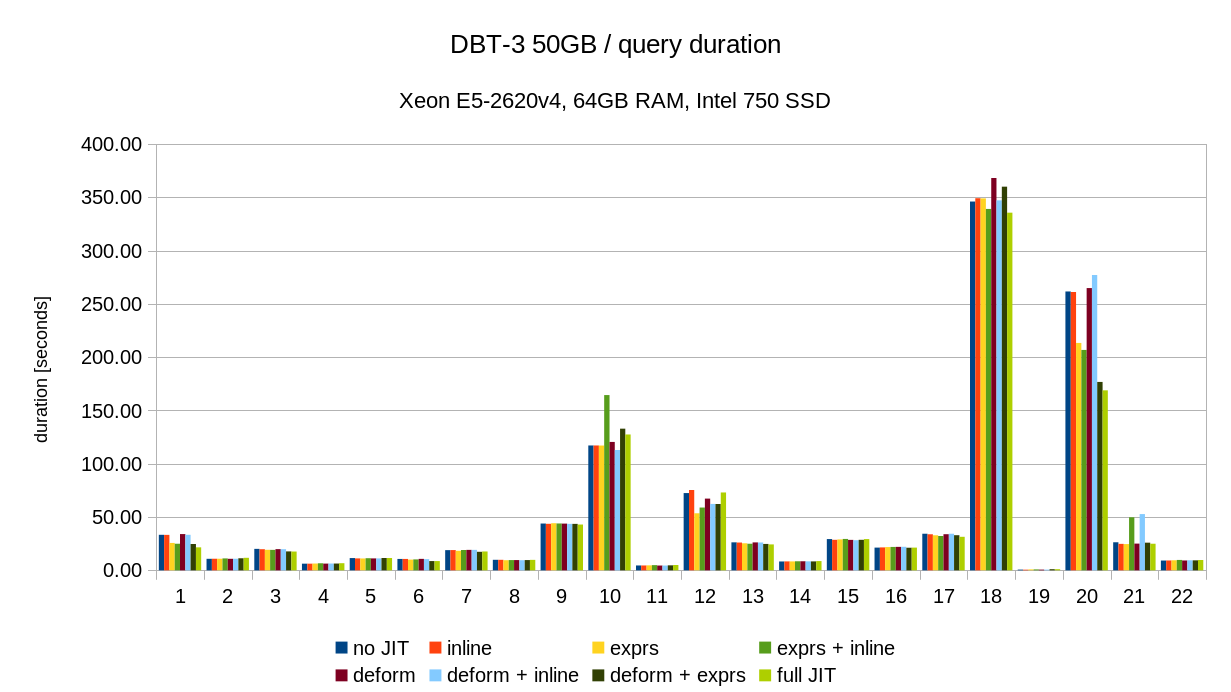{kind=link}
{kind=link}
Hi,
I've pushed v10.0. The big (and pretty painful to make) change is that
now all the LLVM specific code lives in src/backend/jit/llvm, which is
built as a shared library which is loaded on demand.
The layout is now as follows:
src/backend/jit/jit.c:
Part of JITing always linked into the server. Supports loading the
LLVM using JIT library.
src/backend/jit/llvm/
Infrastructure:
llvmjit.c:
General code generation and optimization infrastructure
llvmjit_error.cpp, llvmjit_wrap.cpp:
Error / backward compat wrappers
llvmjit_inline.cpp:
Cross module inlining support
Code-Gen:
llvmjit_expr.c
Expression compilation
llvmjit_deform.c
Deform compilation
I generally like how this shaped out. There's a good amount of followup
cleanup needed, but I'd appreciate some early feedback.
I've also rebased onto a recent master version.
postgres[21915][1]=# SELECT pg_llvmjit_available();
┌──────────────────────┐
│ pg_llvmjit_available │
├──────────────────────┤
│ t │
└──────────────────────┘
(1 row)
make -C src/backend/jit/llvm/ uninstall
postgres[21915][1]=# \c
You are now connected to database "postgres" as user "andres".
postgres[21922][1]=# SELECT pg_llvmjit_available();
┌──────────────────────┐
│ pg_llvmjit_available │
├──────────────────────┤
│ f │
└──────────────────────┘
(1 row)
Yeha ;)
Greetings,
Andres Freund
On Wednesday, February 7, 2018 3:54:05 PM CET Andres Freund wrote: > Hi, > > I've pushed v10.0. The big (and pretty painful to make) change is that > now all the LLVM specific code lives in src/backend/jit/llvm, which is > built as a shared library which is loaded on demand. > > The layout is now as follows: > > src/backend/jit/jit.c: > Part of JITing always linked into the server. Supports loading the > LLVM using JIT library. > > src/backend/jit/llvm/ > Infrastructure: > llvmjit.c: > General code generation and optimization infrastructure > llvmjit_error.cpp, llvmjit_wrap.cpp: > Error / backward compat wrappers > llvmjit_inline.cpp: > Cross module inlining support > Code-Gen: > llvmjit_expr.c > Expression compilation > llvmjit_deform.c > Deform compilation > > I generally like how this shaped out. There's a good amount of followup > cleanup needed, but I'd appreciate some early feedback. Hi I also find it more readable and it looks cleaner, insane guys could be able to write their own JIT engines for PostgreSQL by patching a single file :) Since it's now in its own .so file, does it still make as much sense using mostly the LLVM C API ? I'll really look in the jit code itself later, right now I've just rebased my previous patches and did a quick check that everything worked for LLVM4 and 3.9. I included a small addition to the gitignore file, I'm surprised you were not bothered by the various .bc files generated. Anyway, great work, and I look forward exploring the code :) Pierre
Attachment
- 0001-Add-support-for-LLVM4-in-llvmjit.c.patch
- 0002-Add-LLVM4-support-in-llvmjit_error.cpp.patch
- 0003-Add-LLVM4-support-in-llvmjit_inline.cpp.patch
- 0004-Don-t-emit-bitcode-depending-on-an-LLVM-5-function.patch
- 0005-Fix-warning.patch
- 0006-Ignore-LLVM-.bc-files.patch
- 0007-Fix-building-with-LLVM-3.9.patch
- 0008-Fix-segfault-with-LLVM-3.9.patch
Hi, On 2018-02-07 20:35:12 +0100, Pierre Ducroquet wrote: > I also find it more readable and it looks cleaner, insane guys could be able > to write their own JIT engines for PostgreSQL by patching a single > file :) Right - we could easily make the libname configurable if requested. > Since it's now in its own .so file, does it still make as much sense using > mostly the LLVM C API ? Yes, I definitely want to continue that. For one the C API is a *lot* more stable, for another postgres is C. > I included a small addition to the gitignore file, I'm surprised you were not > bothered by the various .bc files generated. I use a VPATH build (i.e. source code is in a different directory than the build products), so I do not really see that. But yes, it makes sense to add ignores.... Thanks for looking, Andres Freund
On Thu, Feb 8, 2018 at 3:54 AM, Andres Freund <andres@anarazel.de> wrote:
> I've pushed v10.0. The big (and pretty painful to make) change is that
> now all the LLVM specific code lives in src/backend/jit/llvm, which is
> built as a shared library which is loaded on demand.
>
> The layout is now as follows:
>
> src/backend/jit/jit.c:
> Part of JITing always linked into the server. Supports loading the
> LLVM using JIT library.
>
> src/backend/jit/llvm/
> Infrastructure:
> llvmjit.c:
> General code generation and optimization infrastructure
> llvmjit_error.cpp, llvmjit_wrap.cpp:
> Error / backward compat wrappers
> llvmjit_inline.cpp:
> Cross module inlining support
> Code-Gen:
> llvmjit_expr.c
> Expression compilation
> llvmjit_deform.c
> Deform compilation
You are asking LLVM to dlopen(""), which doesn't work on my not-Linux,
explaining the errors I reported in the older thread. The portable
way to dlopen the main binary is dlopen(NULL), so I think you need to
pass NULL in to LLVMLoadLibraryPermanently(), even though that isn't
really clear from any LLVM documentation I've looked at.
diff --git a/src/backend/jit/llvm/llvmjit.c b/src/backend/jit/llvm/llvmjit.c
index a1bc6449f7..874bddf81e 100644
--- a/src/backend/jit/llvm/llvmjit.c
+++ b/src/backend/jit/llvm/llvmjit.c
@@ -443,7 +443,7 @@ llvm_session_initialize(void)
cpu = NULL;
/* force symbols in main binary to be loaded */
- LLVMLoadLibraryPermanently("");
+ LLVMLoadLibraryPermanently(NULL);
llvm_opt0_orc = LLVMOrcCreateInstance(llvm_opt0_targetmachine);
llvm_opt3_orc = LLVMOrcCreateInstance(llvm_opt3_targetmachine);
--
Thomas Munro
http://www.enterprisedb.com
On 2018-02-08 11:50:17 +1300, Thomas Munro wrote:
> You are asking LLVM to dlopen(""), which doesn't work on my not-Linux,
> explaining the errors I reported in the older thread. The portable
> way to dlopen the main binary is dlopen(NULL), so I think you need to
> pass NULL in to LLVMLoadLibraryPermanently(), even though that isn't
> really clear from any LLVM documentation I've looked at.
Ugh. Thanks for figuring that out, will incorporate!
Greetings,
Andres Freund
On 02/07/2018 03:54 PM, Andres Freund wrote:
> I've pushed v10.0. The big (and pretty painful to make) change is that
> now all the LLVM specific code lives in src/backend/jit/llvm, which is
> built as a shared library which is loaded on demand.
It does not seem to be possible build without LLVM anymore.
Error:
In file included from planner.c:32:0:
../../../../src/include/jit/llvmjit.h:13:10: fatal error:
llvm-c/Types.h: No such file or directory
#include <llvm-c/Types.h>
^~~~~~~~~~~~~~~~
Options:
./configure --prefix=/home/andreas/dev/postgresql-inst
--enable-tap-tests --enable-cassert --enable-debug
I also noticed the following typo:
diff --git a/configure.in b/configure.in
index b035966c0a..b89c4a138a 100644
--- a/configure.in
+++ b/configure.in
@@ -499,7 +499,7 @@ fi
if test "$enable_coverage" = yes; then
if test "$GCC" = yes; then
CFLAGS="$CFLAGS -fprofile-arcs -ftest-coverage"
- CFLAGS="$CXXFLAGS -fprofile-arcs -ftest-coverage"
+ CXXFLAGS="$CXXFLAGS -fprofile-arcs -ftest-coverage"
else
AC_MSG_ERROR([--enable-coverage is supported only when using GCC])
fi
Andreas
> On 8 February 2018 at 10:29, Andreas Karlsson <andreas@proxel.se> wrote:
>> On 02/07/2018 03:54 PM, Andres Freund wrote:
>>
>> I've pushed v10.0. The big (and pretty painful to make) change is that
>> now all the LLVM specific code lives in src/backend/jit/llvm, which is
>> built as a shared library which is loaded on demand.
>
>
> It does not seem to be possible build without LLVM anymore.
Maybe I'm doing something wrong, but I also see some issues during compilation
even with llvm included (with gcc 5.4.0 and 7.1.0). Is it expected, do I need
to use another version to check it out?
$ git rev-parse HEAD
e24cac5951575cf86f138080acec663a0a05983e
$ ./configure --prefix=/build/postgres-jit/ --with-llvm
--enable-debug --enable-depend --enable-cassert
In file included from llvmjit_error.cpp:22:0:
/usr/lib/llvm-5.0/include/llvm/Support/ErrorHandling.h:47:36:
warning: identifier 'nullptr' is a keyword in C++11 [-Wc++0x-compat]
void *user_data = nullptr);
^
In file included from /usr/include/c++/5/cinttypes:35:0,
from /usr/lib/llvm-5.0/include/llvm/Support/DataTypes.h:39,
from /usr/lib/llvm-5.0/include/llvm-c/Types.h:17,
from ../../../../src/include/jit/llvmjit.h:13,
from llvmjit_error.cpp:24:
/usr/include/c++/5/bits/c++0x_warning.h:32:2: error: #error This
file requires compiler and library support for the ISO C++ 2011
standard. This support must be enabled with the -std=c++11 or
-std=gnu++11 compiler options.
#error This file requires compiler and library support \
^
In file included from llvmjit_error.cpp:22:0:
/usr/lib/llvm-5.0/include/llvm/Support/ErrorHandling.h:47:54:
error: 'nullptr' was not declared in this scope
void *user_data = nullptr);
^
/usr/lib/llvm-5.0/include/llvm/Support/ErrorHandling.h:57:56:
error: 'nullptr' was not declared in this scope
void *user_data = nullptr) {
^
/usr/lib/llvm-5.0/include/llvm/Support/ErrorHandling.h:98:56:
error: 'nullptr' was not declared in this scope
void *user_data = nullptr);
^
/usr/lib/llvm-5.0/include/llvm/Support/ErrorHandling.h:121:45:
error: 'nullptr' was not declared in this scope
llvm_unreachable_internal(const char *msg = nullptr, const char
*file = nullptr,
^
/usr/lib/llvm-5.0/include/llvm/Support/ErrorHandling.h:121:73:
error: 'nullptr' was not declared in this scope
llvm_unreachable_internal(const char *msg = nullptr, const char
*file = nullptr,
^
../../../../src/Makefile.global:838: recipe for target
'llvmjit_error.o' failed
make[2]: *** [llvmjit_error.o] Error 1
make[2]: Leaving directory '/postgres/src/backend/jit/llvm'
Makefile:42: recipe for target 'all-backend/jit/llvm-recurse' failed
make[1]: *** [all-backend/jit/llvm-recurse] Error 2
make[1]: Leaving directory '/postgres/src'
GNUmakefile:11: recipe for target 'all-src-recurse' failed
make: *** [all-src-recurse] Error 2
On 2018-02-08 15:14:42 +0100, Dmitry Dolgov wrote: > > On 8 February 2018 at 10:29, Andreas Karlsson <andreas@proxel.se> wrote: > >> On 02/07/2018 03:54 PM, Andres Freund wrote: > >> > >> I've pushed v10.0. The big (and pretty painful to make) change is that > >> now all the LLVM specific code lives in src/backend/jit/llvm, which is > >> built as a shared library which is loaded on demand. > > > > > > It does not seem to be possible build without LLVM anymore. Yea, wrong header included. Will fix. > Maybe I'm doing something wrong, but I also see some issues during compilation > even with llvm included (with gcc 5.4.0 and 7.1.0). Is it expected, do I need > to use another version to check it out? > > $ git rev-parse HEAD > e24cac5951575cf86f138080acec663a0a05983e > > $ ./configure --prefix=/build/postgres-jit/ --with-llvm > --enable-debug --enable-depend --enable-cassert Seems you need to provide a decent C++ compiler (via CXX=... to configure). Will test that it actually works with a recent clang. Greetings, Andres Freund
On Fri, Feb 9, 2018 at 3:14 AM, Dmitry Dolgov <9erthalion6@gmail.com> wrote: > $ ./configure --prefix=/build/postgres-jit/ --with-llvm > --enable-debug --enable-depend --enable-cassert > /usr/include/c++/5/bits/c++0x_warning.h:32:2: error: #error This > file requires compiler and library support for the ISO C++ 2011 > standard. This support must be enabled with the -std=c++11 or > -std=gnu++11 compiler options. Did you try passing CXXFLAGS="-std=c++11" to configure? -- Thomas Munro http://www.enterprisedb.com
On Thu, Feb 1, 2018 at 8:16 PM, Thomas Munro
<thomas.munro@enterprisedb.com> wrote:
> On Fri, Feb 2, 2018 at 2:05 PM, Andres Freund <andres@anarazel.de> wrote:
>> On 2018-02-01 09:32:17 -0800, Jeff Davis wrote:
>>> On Wed, Jan 31, 2018 at 12:03 AM, Konstantin Knizhnik
>>> <k.knizhnik@postgrespro.ru> wrote:
>>> > The same problem takes place with old versions of GCC: I have to upgrade GCC
>>> > to 7.2 to make it possible to compile this code.
>>> > The problem in not in compiler itself, but in libc++ headers.
>>>
>>> How can I get this branch to compile on ubuntu 16.04? I have llvm-5.0
>>> and gcc-5.4 installed. Do I need to compile with clang or gcc? Any
>>> CXXFLAGS required?
>>
>> Just to understand: You're running in the issue with the header being
>> included from within the extern "C" {}? Hm, I've pushed a quick fix for
>> that.
>
> That change wasn't quite enough: to get this building against libc++
> (Clang's native stdlb) I also needed this change to llvmjit.h so that
> <llvm-c/Types.h> wouldn't be included with the wrong linkage (perhaps
> you can find a less ugly way):
>
> +#ifdef __cplusplus
> +}
> +#endif
> #include <llvm-c/Types.h>
> +#ifdef __cplusplus
> +extern "C"
> +{
> +#endif
This did the trick -- thanks. Sitting through 20 minute computer
crashing link times really brings back C++ nightmares -- if anyone
else needs to compile llvm/clang as I did (I'm stuck on 3.2 with my
aging mint box), I strongly encourage you to use the gold linker.
Question: when watching the compilation log, I see quite a few files
being compiled with both O2 and O1, for example:
clang -Wall -Wmissing-prototypes -Wpointer-arith
-Wdeclaration-after-statement -Wendif-labels
-Wmissing-format-attribute -Wformat-security -fno-strict-aliasing
-fwrapv -Wno-unused-command-line-argument -O2 -O1
-Wno-ignored-attributes -Wno-unknown-warning-option
-Wno-ignored-optimization-argument -I../../../../src/include
-D_GNU_SOURCE -I/home/mmoncure/llvm/include -DLLVM_BUILD_GLOBAL_ISEL
-D_GNU_SOURCE -D_DEBUG -D__STDC_CONSTANT_MACROS -D__STDC_FORMAT_MACROS
-D__STDC_LIMIT_MACROS -flto=thin -emit-llvm -c -o nbtsort.bc
nbtsort.c
Is this intentional? (didn't check standard compilation, it just jumped out).
merlin
On 2018-02-09 09:10:25 -0600, Merlin Moncure wrote:
> Question: when watching the compilation log, I see quite a few files
> being compiled with both O2 and O1, for example:
>
> clang -Wall -Wmissing-prototypes -Wpointer-arith
> -Wdeclaration-after-statement -Wendif-labels
> -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing
> -fwrapv -Wno-unused-command-line-argument -O2 -O1
> -Wno-ignored-attributes -Wno-unknown-warning-option
> -Wno-ignored-optimization-argument -I../../../../src/include
> -D_GNU_SOURCE -I/home/mmoncure/llvm/include -DLLVM_BUILD_GLOBAL_ISEL
> -D_GNU_SOURCE -D_DEBUG -D__STDC_CONSTANT_MACROS -D__STDC_FORMAT_MACROS
> -D__STDC_LIMIT_MACROS -flto=thin -emit-llvm -c -o nbtsort.bc
> nbtsort.c
>
> Is this intentional? (didn't check standard compilation, it just jumped out).
It stemms from the following hunk in Makefile.global.in about emitting
bitcode:
# Add -O1 to the options as clang otherwise will emit 'noinline'
# attributes everywhere, making JIT inlining impossible to test in a
# debugging build.
#
# FIXME: While LLVM will re-optimize when emitting code (after
# inlining), it'd be better to only do this if -O0 is specified.
%.bc : CFLAGS +=-O1
%.bc : %.c
$(COMPILE.c.bc) -o $@ $<
Inspecting the clang source code it's impossible to stop clang from
emitting noinline attributes for every function on -O0.
I think it makes sense to change this to filtering out -O0 and only
adding -O1 if that's not present. :/
Greetings,
Andres Freund
> On 8 February 2018 at 21:26, Thomas Munro <thomas.munro@enterprisedb.com> wrote: > On Fri, Feb 9, 2018 at 3:14 AM, Dmitry Dolgov <9erthalion6@gmail.com> wrote: >> $ ./configure --prefix=/build/postgres-jit/ --with-llvm >> --enable-debug --enable-depend --enable-cassert > >> /usr/include/c++/5/bits/c++0x_warning.h:32:2: error: #error This >> file requires compiler and library support for the ISO C++ 2011 >> standard. This support must be enabled with the -std=c++11 or >> -std=gnu++11 compiler options. > > Did you try passing CXXFLAGS="-std=c++11" to configure? Yes, it solved the issue, thanks.
On Wed, Jan 31, 2018 at 8:53 AM, Robert Haas <robertmhaas@gmail.com> wrote: > As far as the second one, looking back at what happened with parallel > query, I found (on a quick read) 13 back-patched commits in > REL9_6_STABLE prior to the release of 10.0, 3 of which I would qualify > as low-importance (improving documentation, fixing something that's > not really a bug, improving a test case). A couple of those were > really stupid mistakes on my part. On the other hand, would it have > been overall worse for our users if that feature had been turned on in > 9.6? I don't know. They would have had those bugs (at least until we > fixed them) but they would have had parallel query, too. It's hard > for me to judge whether that was a win or a loss, and so here. Like > parallel query, this is a feature which seems to have a low risk of > data corruption, but a fairly high risk of wrong answers to queries > and/or strange errors. Users don't like that. On the other hand, > also like parallel query, if you've got the right kind of queries, it > can make them go a lot faster. Users DO like that. As a data point, I can tell you that Heroku enabled parallel query for 9.6 immediately, and it turned out fine. The first version available as stable was probably 9.6.3 -- there or thereabouts. There were some bugs, of course, but not to the extent that 9.6 was looked upon as being more buggy than the average Postgres release. -- Peter Geoghegan
On Thu, Jan 25, 2018 at 9:40 AM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > As far as I understand generation of native code is now always done for all > supported expressions and individually by each backend. > I wonder it will be useful to do more efforts to understand when compilation > to native code should be done and when interpretation is better. > For example many JIT-able languages like Lua are using traces, i.e. query is > first interpreted and trace is generated. If the same trace is followed > more than N times, then native code is generated for it. > > In context of DBMS executor it is obvious that only frequently executed or > expensive queries have to be compiled. > So we can use estimated plan cost and number of query executions as simple > criteria for JIT-ing the query. > May be compilation of simple queries (with small cost) should be done only > for prepared statements... > > Another question is whether it is sensible to redundantly do expensive work > (llvm compilation) in all backends. > This question refers to shared prepared statement cache. But even without > such cache, it seems to be possible to use for library name some signature > of the compiled expression and allow > to share this libraries between backends. So before starting code > generation, ExecReadyCompiledExpr can first build signature and check if > correspondent library is already present. > Also it will be easier to control space used by compiled libraries in this > case. Totally agree; these considerations are very important. I tested several queries in my application that had >30 second compile times against a one second run time,. Not being able to manage when compilation happens is making it difficult to get a sense of llvm performance in the general case. Having explain analyze print compile time and being able to prepare llvm compiled queries ought to help measurement and tuning. There may be utility here beyond large analytical queries as the ability to optimize spreads through the executor with the right trade off management. This work is very exciting...thank you. merlin
On Sun, Feb 11, 2018 at 10:00 AM, Merlin Moncure <mmoncure@gmail.com> wrote: > I tested several queries in my application that had >30 second compile > times against a one second run time,. Not being able to manage when > compilation happens is making it difficult to get a sense of llvm > performance in the general case. In theory, the GUCs Andres has added to only compile if the estimated total cost is above some threshold is supposed to help with this. But if the compile time and the cost don't correlate, then we've got trouble. How did you manage to create an expression that took 30 seconds to compile? It doesn't take that long to compile a 5000-line C file. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2018-02-13 13:43:40 -0500, Robert Haas wrote: > On Sun, Feb 11, 2018 at 10:00 AM, Merlin Moncure <mmoncure@gmail.com> wrote: > > I tested several queries in my application that had >30 second compile > > times against a one second run time,. Not being able to manage when > > compilation happens is making it difficult to get a sense of llvm > > performance in the general case. > > In theory, the GUCs Andres has added to only compile if the estimated > total cost is above some threshold is supposed to help with this. Note that the GUCs as posted are set *way* too low, they're currently toy thresholds. That's easier for testing, but I guess I should set them to something better. It's not unrealistic to expect them to be insufficient however - the overhead roughly linearly grows with the number of expressions, which might not reflect the gain equally. > How did you manage to create an expression that took 30 seconds to > compile? It doesn't take that long to compile a 5000-line C file. Any chance a debug build of LLVM was used? The overhead of that are easily an order of magnitude or more. Greetings, Andres Freund
Hi, On 2018-02-07 06:54:05 -0800, Andres Freund wrote: > I've pushed v10.0. The big (and pretty painful to make) change is that > now all the LLVM specific code lives in src/backend/jit/llvm, which is > built as a shared library which is loaded on demand. > > The layout is now as follows: > > src/backend/jit/jit.c: > Part of JITing always linked into the server. Supports loading the > LLVM using JIT library. > > src/backend/jit/llvm/ > Infrastructure: > llvmjit.c: > General code generation and optimization infrastructure > llvmjit_error.cpp, llvmjit_wrap.cpp: > Error / backward compat wrappers > llvmjit_inline.cpp: > Cross module inlining support > Code-Gen: > llvmjit_expr.c > Expression compilation > llvmjit_deform.c > Deform compilation I've pushed a revised version that hopefully should address Jeff's wish/need of being able to experiment with this out of core. There's now a "jit_provider" PGC_POSTMASTER GUC that's by default set to "llvmjit". llvmjit.so is the .so implementing JIT using LLVM. It fills a set of callbacks via extern void _PG_jit_provider_init(JitProviderCallbacks *cb); which can also be implemented by any other potential provider. The other two biggest changes are that I've added a README https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=blob;f=src/backend/jit/README;hb=jit and that I've revised the configure support so it does more error checks, and moved it into config/llvm.m4. There's a larger smattering of small changes too. I'm pretty happy with how the separation of core / shlib looks now. I'm planning to work on cleaning and then pushing some of the preliminary patches (fixed tupledesc, grouping) over the next few days. Greetings, Andres Freund
On Wednesday, February 14, 2018 7:17:10 PM CET Andres Freund wrote: > Hi, > > On 2018-02-07 06:54:05 -0800, Andres Freund wrote: > > I've pushed v10.0. The big (and pretty painful to make) change is that > > now all the LLVM specific code lives in src/backend/jit/llvm, which is > > built as a shared library which is loaded on demand. > > > > The layout is now as follows: > > > > src/backend/jit/jit.c: > > Part of JITing always linked into the server. Supports loading the > > LLVM using JIT library. > > > > src/backend/jit/llvm/ > > > > Infrastructure: > > llvmjit.c: > > General code generation and optimization infrastructure > > > > llvmjit_error.cpp, llvmjit_wrap.cpp: > > Error / backward compat wrappers > > > > llvmjit_inline.cpp: > > Cross module inlining support > > > > Code-Gen: > > llvmjit_expr.c > > > > Expression compilation > > > > llvmjit_deform.c > > > > Deform compilation > > I've pushed a revised version that hopefully should address Jeff's > wish/need of being able to experiment with this out of core. There's now > a "jit_provider" PGC_POSTMASTER GUC that's by default set to > "llvmjit". llvmjit.so is the .so implementing JIT using LLVM. It fills a > set of callbacks via > extern void _PG_jit_provider_init(JitProviderCallbacks *cb); > which can also be implemented by any other potential provider. > > The other two biggest changes are that I've added a README > https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=blob; > f=src/backend/jit/README;hb=jit and that I've revised the configure support > so it does more error > checks, and moved it into config/llvm.m4. > > There's a larger smattering of small changes too. > > I'm pretty happy with how the separation of core / shlib looks now. I'm > planning to work on cleaning and then pushing some of the preliminary > patches (fixed tupledesc, grouping) over the next few days. > > Greetings, > > Andres Freund Hi Here are the LLVM4 and LLVM3.9 compatibility patches. Successfully built, and executed some silly queries with JIT forced to make sure it worked. Pierre
Attachment
- 0001-Add-support-for-LLVM4-in-llvmjit.c.patch
- 0002-Add-LLVM4-support-in-llvmjit_error.cpp.patch
- 0003-Add-LLVM4-support-in-llvmjit_inline.cpp.patch
- 0004-Don-t-emit-bitcode-depending-on-an-LLVM-5-function.patch
- 0006-Ignore-LLVM-.bc-files.patch
- 0005-Fix-warning.patch
- 0007-Fix-building-with-LLVM-3.9.patch
- 0008-Fix-segfault-with-LLVM-3.9.patch
Hi, On 2018-02-14 23:32:17 +0100, Pierre Ducroquet wrote: > Here are the LLVM4 and LLVM3.9 compatibility patches. > Successfully built, and executed some silly queries with JIT forced to make > sure it worked. Thanks! I'm going to integrate them into my series in the next few days. Regards, Andres
On 14.02.2018 21:17, Andres Freund wrote:
Hi, On 2018-02-07 06:54:05 -0800, Andres Freund wrote:I've pushed v10.0. The big (and pretty painful to make) change is that now all the LLVM specific code lives in src/backend/jit/llvm, which is built as a shared library which is loaded on demand. The layout is now as follows: src/backend/jit/jit.c: Part of JITing always linked into the server. Supports loading the LLVM using JIT library. src/backend/jit/llvm/ Infrastructure:llvmjit.c: General code generation and optimization infrastructurellvmjit_error.cpp, llvmjit_wrap.cpp: Error / backward compat wrappersllvmjit_inline.cpp: Cross module inlining support Code-Gen: llvmjit_expr.c Expression compilation llvmjit_deform.c Deform compilationI've pushed a revised version that hopefully should address Jeff's wish/need of being able to experiment with this out of core. There's now a "jit_provider" PGC_POSTMASTER GUC that's by default set to "llvmjit". llvmjit.so is the .so implementing JIT using LLVM. It fills a set of callbacks via extern void _PG_jit_provider_init(JitProviderCallbacks *cb); which can also be implemented by any other potential provider. The other two biggest changes are that I've added a README https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=blob;f=src/backend/jit/README;hb=jit and that I've revised the configure support so it does more error checks, and moved it into config/llvm.m4. There's a larger smattering of small changes too. I'm pretty happy with how the separation of core / shlib looks now. I'm planning to work on cleaning and then pushing some of the preliminary patches (fixed tupledesc, grouping) over the next few days. Greetings, Andres Freund
I have made some more experiments with efficiency of JIT-ing of deform tuple and I want to share this results (I hope that them will be interesting).
It is well known fact that Postgres spends most of the time in sequence scan queries for warm data in deforming tuples (17% in case of TPC-H Q1).
Postgres tries to optimize access to the tuple by caching fixed size offsets to the fields whenever possible and loading attributes on demand.
It is also well know recommendation to put fixed size, non-null, frequently used attributes at the beginning of table's attribute list to make this optimization work more efficiently.
You can see in the code of heap_deform_tuple shows that first NULL value will switch it to "slow" mode:
for (attnum = 0; attnum < natts; attnum++)
{
Form_pg_attribute thisatt = TupleDescAttr(tupleDesc, attnum);
if (hasnulls && att_isnull(attnum, bp))
{
values[attnum] = (Datum) 0;
isnull[attnum] = true;
slow = true; /* can't use attcacheoff anymore */
continue;
}
I tried to investigate importance of this optimization and what is actual penalty of "slow" mode.
At the same time I want to understand how JIT help to speed-up tuple deforming.
I have populated with data three tables:
create table t1(id integer primary key,c1 integer,c2 integer,c3 integer,c4 integer,c5 integer,c6 integer,c7 integer,c8 integer,c9 integer);
create table t2(id integer primary key,c1 integer,c2 integer,c3 integer,c4 integer,c5 integer,c6 integer,c7 integer,c8 integer,c9 integer);
create table t3(id integer primary key,c1 integer not null,c2 integer not null,c3 integer not null,c4 integer not null,c5 integer not null,c6 integer not null,c7 integer not null,c8 integer not null,c9 integer not null);
insert into t1 (id,c1,c2,c3,c4,c5,c6,c7,c8) values (generate_series(1,10000000),0,0,0,0,0,0,0,0);
insert into t2 (id,c2,c3,c4,c5,c6,c7,c8,c9) values (generate_series(1,10000000),0,0,0,0,0,0,0,0);
insert into t3 (id,c1,c2,c3,c4,c5,c6,c7,c8,c9) values (generate_series(1,10000000),0,0,0,0,0,0,0,0,0);
vacuum analyze t1;
vacuum analyze t2;
vacuum analyze t3;
t1 contains null in last c9 column, t2 - in first c1 columns and t3 has all attributes declared as not-null (and JIT can use this knowledge to generate more efficient deforming code).
All data set is hold in memory (shared buffer size is greater than database size) and I intentionally switch off parallel execution to make results more deterministic.
I run two queries calculating aggregates on one/all not-null fields:
select sum(c8) from t*;
select sum(c2), sum(c3), sum(c4), sum(c5), sum(c6), sum(c7), sum(c8) from t*;
As expected 35% time was spent in heap_deform_tuple.
But results (msec) were slightly confusing and unexected:
select sum(c8) from t*;
| w/o JIT | with JIT | |
| t1 | 763 | 563 |
| t2 | 772 | 570 |
| t3 | 776 | 592 |
select sum(c2), sum(c3), sum(c4), sum(c5), sum(c6), sum(c7), sum(c8) from t*;
| w/o JIT | with JIT | |
| t1 | 1239 | 742 |
| t2 | 1233 | 747 |
| t3 | 1255 | 803 |
I repeat each query 10 times and take the minimal time ( I think that it is more meaningful than average time which depends on some other activity on the system).
So there is no big difference between "slow" and "fast" ways of deforming tuple.
Moreover, for sometimes "slow" case is faster. Although I have to say that variance of results is quite large: about 10%.
But in any case, I can made two conclusions from this results:
1. Modern platforms are mostly limited by memory access time, number of performed instructions is less critical.
This is why extra processing needed for nullable attributes can not significantly affect performance.
2. For large number of attributes JIT-ing of deform tuple can improve speed up to two time. Which is quite good result from my point of view.
--
Moreover, for sometimes "slow" case is faster. Although I have to say that variance of results is quite large: about 10%.
But in any case, I can made two conclusions from this results:
1. Modern platforms are mostly limited by memory access time, number of performed instructions is less critical.
This is why extra processing needed for nullable attributes can not significantly affect performance.
2. For large number of attributes JIT-ing of deform tuple can improve speed up to two time. Which is quite good result from my point of view.
--
Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 02/05/2018 10:44 PM, Pierre Ducroquet wrote: >> psqlscanslash.l: In function ‘psql_scan_slash_option’: >> psqlscanslash.l:550:8: warning: variable ‘lexresult’ set but not used >> [-Wunused-but-set-variable] >> int final_state; >> ^~~~~~~~~ > > I'm not sure Andres's patches have anything to do with psql, it's surprising. I managed to track down the bug and apparently when building with --with-llvm the -DNDEBUG option is added to CPPFLAGS, but I am not entirely sure what the code in config/llvm.m4 is trying to do in the first place. The two issues I see with what the code does are: 1) Why does config/llvm.m4 modify CPPFLAGS? That affects the building of the binaries too which may be done with gcc like in my case. Shouldn't it use a LLVM_CPPFLAGS or something? 2) When I build with --with-cassert I expect the assertions to be there, both in the binaries and the bitcode. Is that just a bug or is there any thought behind this? Below is the diff in src/Makefile.global between when I run configure with --with-llvm or not. diff src/Makefile.global-nollvm src/Makefile.global-llvm 78c78 < configure_args = '--prefix=/home/andreas/dev/postgresql-inst' '--enable-tap-tests' '--enable-cassert' '--enable-debug' --- > configure_args = '--prefix=/home/andreas/dev/postgresql-inst' '--enable-tap-tests' '--enable-cassert' '--enable-debug' '--with-llvm' 190c190 < with_llvm = no --- > with_llvm = yes 227,229c227,229 < LLVM_CONFIG = < LLVM_BINPATH = < CLANG = --- > LLVM_CONFIG = /usr/bin/llvm-config > LLVM_BINPATH = /usr/lib/llvm-4.0/bin > CLANG = /usr/bin/clang 238c238 < CPPFLAGS = -D_GNU_SOURCE --- > CPPFLAGS = -D__STDC_LIMIT_MACROS -D__STDC_FORMAT_MACROS -D__STDC_CONSTANT_MACROS -D_GNU_SOURCE -DNDEBUG -I/usr/lib/llvm-4.0/include -D_GNU_SOURCE 261c261 < LLVM_CXXFLAGS = --- > LLVM_CXXFLAGS = -std=c++0x -std=c++11 -fno-exceptions 283c283 < LLVM_LIBS= --- > LLVM_LIBS= -lLLVM-4.0 297c297 < LDFLAGS += -Wl,--as-needed --- > LDFLAGS += -L/usr/lib/llvm-4.0/lib -Wl,--as-needed
Hi, On 2018-02-15 12:54:34 +0100, Andreas Karlsson wrote: > 1) Why does config/llvm.m4 modify CPPFLAGS? That affects the building of the > binaries too which may be done with gcc like in my case. Shouldn't it use a > LLVM_CPPFLAGS or something? Well, most of the time cppflags just are things like additional include directories. And the established precedent is to just add those to the global cppflags (c.f. libxml stuff in configure in). I've no problem changing this, I just followed established practice. > 2) When I build with --with-cassert I expect the assertions to be there, > both in the binaries and the bitcode. Is that just a bug or is there any > thought behind this? Not sure what you mean by that. NDEBUG and cassert are independent mechanisms, no? Greetings, Andres Freund
Hi, On 2018-02-15 11:59:46 +0300, Konstantin Knizhnik wrote: > It is well known fact that Postgres spends most of the time in sequence scan > queries for warm data in deforming tuples (17% in case of TPC-H Q1). I think that the majority of the time therein is not actually bottlenecked by CPU, but by cache misses. It might be worthwhile to repeat your analysis with the last patch of my series applied, and the #define FASTORDER uncommented. > Postgres tries to optimize access to the tuple by caching fixed size > offsets to the fields whenever possible and loading attributes on demand. > It is also well know recommendation to put fixed size, non-null, frequently > used attributes at the beginning of table's attribute list to make this > optimization work more efficiently. FWIW, I think this optimization causes vastly more trouble than it's worth. > You can see in the code of heap_deform_tuple shows that first NULL value > will switch it to "slow" mode: Note that in most workloads the relevant codepath isn't heap_deform_tuple but slot_deform_tuple. > 1. Modern platforms are mostly limited by memory access time, number of > performed instructions is less critical. I don't think this is quite the correct result. Especially because a lot of time is spent accessing memory, having code that the CPU can execute out-of-order (by speculatively executing forward) is hugely beneficial. Some of the benefit of JITing comes from being able to start deforming the next field while memory fetches for the previous one are still ongoing (iff dealing with fixed width cols). > 2. For large number of attributes JIT-ing of deform tuple can improve speed > up to two time. Which is quite good result from my point of view. +1 Note the last version has a small deficiency in decoding varlena datums that I need to fix (varsize_any isn't inlined anymore). Greetings, Andres Freund
On 02/15/2018 06:23 PM, Andres Freund wrote: >> 2) When I build with --with-cassert I expect the assertions to be there, >> both in the binaries and the bitcode. Is that just a bug or is there any >> thought behind this? > > Not sure what you mean by that. NDEBUG and cassert are independent > mechanisms, no? Yeah, I think I just managed to confuse myself there. The actual issue is that --with-llvm changes if NDEBUG is set or not, which is quite surprising. I would not expect assertions to be disabled in the fronted code just because I compiled PostgreSQL with llvm. Andreas
Hi, On 02/14/2018 01:17 PM, Andres Freund wrote: > On 2018-02-07 06:54:05 -0800, Andres Freund wrote: >> I've pushed v10.0. The big (and pretty painful to make) change is that >> now all the LLVM specific code lives in src/backend/jit/llvm, which is >> built as a shared library which is loaded on demand. >> I thought https://db.in.tum.de/~leis/papers/adaptiveexecution.pdf?lang=en was relevant for this thread. Best regards, Jesper
Hi, I've pushed a revised version of my JIT patchset. The git tree is at https://git.postgresql.org/git/users/andresfreund/postgres.git in the jit branch https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/jit Biggest changes: - LLVM 3.9 - master are now supported. This includes a good chunk of work by Pierre Ducroquet. Doing so I found that the patches Pierre provided didn't work when a query was expensive enough to warrant inlining. Turns out LLVM < 5 can't combine the summaries of multiple thin module summaries. But that actually turned out to be a good thing, because it made me think about symbol resolution preferences. Previously it was basically arbitrary whether a function with conflicting names would be choosen from core postgres or one of the extension libs providing it. This is now rewritten so we don't build a combined module summary for core postgres and extensions at backend start. Instead summaries for core pg and extensions are loaded separately, and the correct one for a symbol is used. - Functions in extension libraries are now not referred to with their C symbol in LLVM IR, instead we generate a fictious symbol that includes the library path. E.g. hstore's hstore_from_record is now referenced as @"pgextern.$libdir/hstore.hstore_from_record". Both symbol resolution and inlining knows how to properly resolve those. - As hinted to above, the inlining support has evolved considerably. Instead of a combined index built at backend start we now have individual indexes for each extension / shlib. Symbols are searched with a search path (internal functions just in the 'postgres' index, for extensions it's main 'postgres', 'extension'), and symbols that explicitly reference a function are just looked up within that extension. This has the nice advantage that we don't have to process indexes for extensions that aren't used, which in turn means that extensions can be installed on the system level while a backend is running, and JITing will work even for old backends once the extension is created (or rather functions in it). Additionally the inline costing logic has improved, the super verbose logging is #ifdef'ed out ('ilog' wrapper that's just (void) 0). - The installation of bitcode is now a nice separate make function. pgxs (including contrib's kinda use of pgxs) now automatically generate & install bitcode when the server was compiled --with-llvm. I learned some about make I didn't know ;). - bunch of compilation issues (older clang, -D_NDEBUG from llvm-config being used for all of postgres, ...) have been fixed. - Two bigger prerequisite patches have been merged. - lotsa smaller stuff. Regards, Andres
On 3/1/18 03:02, Andres Freund wrote: > I've pushed a revised version of my JIT patchset. > The git tree is at > https://git.postgresql.org/git/users/andresfreund/postgres.git > in the jit branch > https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/jit (testing 2e15e8b8100a61ec092a1e5b2db4a93f07a64cbd) I'm having an interesting time getting this to build on macOS. First, you need to use a CXX that is reasonably similar to the CC. Otherwise, the CXX will complain about things like attributes not being supported etc. That's not surprising, but it's a support issue that we'll have to prepare ourselves for. Using my standard set of CC=gcc-7 and CXX=g++-7, the build fails with g++-7: error: unrecognized command line option '-stdlib=libc++' That comes from llvm-config --cxxflags, which was apparently made for /usr/bin/cc (which is clang). I see here the same problems as we had in the olden days with Perl, where it gave us a bunch of compiler flags that applied to the system compiler but not the compiler currently in use. We should just take the flags that we really need, like -I and -L. Maybe we don't need it at all. Trying it again then with CC=/usr/bin/cc and CXX=/usr/bin/c++, it fails with In file included from llvmjit_inline.cpp:25: In file included from ../../../../src/include/jit/llvmjit.h:16: In file included from /usr/local/Cellar/llvm/5.0.1/include/llvm-c/Types.h:17: In file included from /usr/local/Cellar/llvm/5.0.1/include/llvm/Support/DataTypes.h:33: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/include/c++/v1/cmath:555:1: error: templates must have C++ linkage Using this patch gets it past that: diff --git a/src/backend/jit/llvm/llvmjit_inline.cpp b/src/backend/jit/llvm/llvmjit_inline.cpp index d4204d2cd2..ad87cfd2d9 100644 --- a/src/backend/jit/llvm/llvmjit_inline.cpp +++ b/src/backend/jit/llvm/llvmjit_inline.cpp @@ -22,7 +22,6 @@ extern "C" { #include "postgres.h" -#include "jit/llvmjit.h" #include <fcntl.h> #include <sys/mman.h> @@ -35,6 +34,8 @@ extern "C" #include "storage/fd.h" } +#include "jit/llvmjit.h" + #include <llvm-c/Core.h> #include <llvm-c/BitReader.h> It seems that it was intended that way anyway, since llvmjit.h contains its own provisions for extern C. Then, I'm getting this error: /usr/bin/cc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -Wno-unused-command-line-argument -g -O2 -Wno-deprecated-declarations -Werror -bundle -multiply_defined suppress -o llvmjit.so llvmjit.o llvmjit_error.o llvmjit_inline.o llvmjit_wrap.o llvmjit_expr.o llvmjit_deform.o -L../../../../src/port -L../../../../src/common -L/usr/local/lib -L/usr/local/opt/openssl/lib -L/usr/local/opt/readline/lib -L/usr/local/Cellar/libxml2/2.9.7/lib -L/usr/local/Cellar/llvm/5.0.1/lib -L/usr/local/lib -L/usr/local/opt/openssl/lib -L/usr/local/opt/readline/lib -Wl,-dead_strip_dylibs -Werror -lLLVMPasses -lLLVMipo -lLLVMInstrumentation -lLLVMVectorize -lLLVMLinker -lLLVMIRReader -lLLVMAsmParser -lLLVMOrcJIT -lLLVMX86Disassembler -lLLVMX86AsmParser -lLLVMX86CodeGen -lLLVMGlobalISel -lLLVMSelectionDAG -lLLVMAsmPrinter -lLLVMDebugInfoCodeView -lLLVMDebugInfoMSF -lLLVMCodeGen -lLLVMScalarOpts -lLLVMInstCombine -lLLVMTransformUtils -lLLVMBitWriter -lLLVMX86Desc -lLLVMMCDisassembler -lLLVMX86Info -lLLVMX86AsmPrinter -lLLVMX86Utils -lLLVMMCJIT -lLLVMExecutionEngine -lLLVMTarget -lLLVMAnalysis -lLLVMProfileData -lLLVMRuntimeDyld -lLLVMDebugInfoDWARF -lLLVMObject -lLLVMMCParser -lLLVMMC -lLLVMBitReader -lLLVMCore -lLLVMBinaryFormat -lLLVMSupport -lLLVMDemangle -lcurses -lz -lm -bundle_loader ../../../../src/backend/postgres Undefined symbols for architecture x86_64: "std::__1::error_code::message() const", referenced from: _LLVMPrintModuleToFile in libLLVMCore.a(Core.cpp.o) _LLVMCreateMemoryBufferWithContentsOfFile in libLLVMCore.a(Core.cpp.o) _LLVMCreateMemoryBufferWithSTDIN in libLLVMCore.a(Core.cpp.o) _LLVMTargetMachineEmitToFile in libLLVMTarget.a(TargetMachineC.cpp.o) llvm::errorToErrorCode(llvm::Error) in libLLVMSupport.a(Error.cpp.o) llvm::ECError::log(llvm::raw_ostream&) const in libLLVMSupport.a(Error.cpp.o) llvm::SectionMemoryManager::finalizeMemory(std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> >*) in libLLVMExecutionEngine.a(SectionMemoryManager.cpp.o) [snipped about 900 lines] It seems the problem here is linking C++ with the C compiler. If I hack in to use c++ in the above command, it continues, and the build completes. configure didn't find any of the LLVMOrc* symbols it was looking for. Is that a problem? They seem to be for some debugging support. So, how do I turn this on then? I see a bunch of new GUC settings that are all off by default. Which ones turn the feature(s) on? -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On 2018-03-02 19:13:01 -0500, Peter Eisentraut wrote: > On 3/1/18 03:02, Andres Freund wrote: > > I've pushed a revised version of my JIT patchset. > > The git tree is at > > https://git.postgresql.org/git/users/andresfreund/postgres.git > > in the jit branch > > https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/jit > > (testing 2e15e8b8100a61ec092a1e5b2db4a93f07a64cbd) > > I'm having an interesting time getting this to build on macOS. Sorry for that... > First, you need to use a CXX that is reasonably similar to the CC. > Otherwise, the CXX will complain about things like attributes not > being supported etc. That's not surprising, but it's a support issue > that we'll have to prepare ourselves for. Right. > Using my standard set of CC=gcc-7 and CXX=g++-7, the build fails with > > g++-7: error: unrecognized command line option '-stdlib=libc++' > > That comes from llvm-config --cxxflags, which was apparently made for > /usr/bin/cc (which is clang). > I see here the same problems as we had in the olden days with Perl, > where it gave us a bunch of compiler flags that applied to the system > compiler but not the compiler currently in use. We should just take the > flags that we really need, like -I and -L. Maybe we don't need it at all. It's actually already filtered, I just added -std*, because of selecting the c++ standard, I guess I need to filter more aggressively. This is fairly fairly annoying. > Using this patch gets it past that: > > diff --git a/src/backend/jit/llvm/llvmjit_inline.cpp > b/src/backend/jit/llvm/llvmjit_inline.cpp > index d4204d2cd2..ad87cfd2d9 100644 > --- a/src/backend/jit/llvm/llvmjit_inline.cpp > +++ b/src/backend/jit/llvm/llvmjit_inline.cpp > @@ -22,7 +22,6 @@ > extern "C" > { > #include "postgres.h" > -#include "jit/llvmjit.h" > > #include <fcntl.h> > #include <sys/mman.h> > @@ -35,6 +34,8 @@ extern "C" > #include "storage/fd.h" > } > > +#include "jit/llvmjit.h" > + > #include <llvm-c/Core.h> > #include <llvm-c/BitReader.h> > > It seems that it was intended that way anyway, since llvmjit.h contains > its own provisions for extern C. Hrmpf, yea, I broke that the third time now. I'm actually inclined to add an appropriate #ifdef ... #error so it's not repeated, what do you think? > Then, I'm getting this error: > It seems the problem here is linking C++ with the C compiler. If I > hack in to use c++ in the above command, it continues, and the build > completes. Yea, I was afraid of that, even if I didn't see it locally. Unfortunately Makefile.shlib has a bunch of references both to $(COMPILER) and $(CC). Most of the relevant platforms (using llvmjit on hpux seems like and edge case somebody desiring it can fix) use $(COMPILER). Does putting an override COMPILER = $(CXX) $(CFLAGS) into src/backend/jit/llvm/Makefile work? It does force the use of CXX for all important platforms if I see it correctly. Verified that it works on linux. > configure didn't find any of the LLVMOrc* symbols it was looking for. > Is that a problem? They seem to be for some debugging support. That's not a problem, except that the symbols won't be registered with the debugger, which is a bit annoying for backtraces. I tried to have configure throw errors in cases llvm is too old or such. > So, how do I turn this on then? I see a bunch of new GUC settings > that are all off by default. Which ones turn the feature(s) on? Hm, I'll switch them on in the development branch. Independent of the final decision that's definitely the right thing for now. The "full capability" of the patchset is used if you turn on these three GUCs: -c jit_expressions=1 -c jit_tuple_deforming=1 -c jit_perform_inlining=1 If you set -c log_min_messages=debug one and run a query you'd see something like: 2018-03-02 16:27:19.717 PST [11077][3/8] DEBUG: time to inline: 0.087s 2018-03-02 16:27:19.724 PST [11077][3/8] DEBUG: time to opt: 0.007s 2018-03-02 16:27:19.750 PST [11077][3/8] DEBUG: time to emit: 0.027s I think I should just remove jit_tuple_deforming=1, jit_perform_inlining=1, they're better done via the cost settings (-1 disables). I think having -c jit_expressions is helpful leaving the cost settings aside, because it allows to enable/disable jitting wholesale without changing cost settings, which seems good. Greetings, Andres Freund
On 2018-03-02 16:29:54 -0800, Andres Freund wrote: > > #include <llvm-c/Core.h> > > #include <llvm-c/BitReader.h> > > > > It seems that it was intended that way anyway, since llvmjit.h contains > > its own provisions for extern C. > > Hrmpf, yea, I broke that the third time now. I'm actually inclined to > add an appropriate #ifdef ... #error so it's not repeated, what do you > think? Hm, don't think that's easily possible :( - Andres
On 3/2/18 19:29, Andres Freund wrote: >> Using my standard set of CC=gcc-7 and CXX=g++-7, the build fails with >> >> g++-7: error: unrecognized command line option '-stdlib=libc++' > It's actually already filtered, I just added -std*, because of selecting > the c++ standard, I guess I need to filter more aggressively. This is > fairly fairly annoying. I see you already filter llvm-config --cflags by picking only -I and -D. Why not do the same for --cxxflags? Any other options that we need like -f* should be discovered using the normal does-the-compiler-support-this-option tests. >> It seems that it was intended that way anyway, since llvmjit.h contains >> its own provisions for extern C. > > Hrmpf, yea, I broke that the third time now. I'm actually inclined to > add an appropriate #ifdef ... #error so it's not repeated, what do you > think? Not sure. Why not just move the line and not move it again? ;-) > Does putting an > override COMPILER = $(CXX) $(CFLAGS) > > into src/backend/jit/llvm/Makefile work? It does force the use of CXX > for all important platforms if I see it correctly. Verified that it > works on linux. Your latest HEAD builds out of the box for me now using the system compiler. >> configure didn't find any of the LLVMOrc* symbols it was looking for. >> Is that a problem? They seem to be for some debugging support. > > That's not a problem, except that the symbols won't be registered with > the debugger, which is a bit annoying for backtraces. I tried to have > configure throw errors in cases llvm is too old or such. Where does one get those then? I have LLVM 5.0.1. Is there something even newer? > Hm, I'll switch them on in the development branch. Independent of the > final decision that's definitely the right thing for now. The "full > capability" of the patchset is used if you turn on these three GUCs: > > -c jit_expressions=1 > -c jit_tuple_deforming=1 > -c jit_perform_inlining=1 The last one doesn't seem to exist anymore. If I turn on either of the first two, then make installcheck fails. See attached diff. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
Hi, On 2018-03-03 09:37:35 -0500, Peter Eisentraut wrote: > On 3/2/18 19:29, Andres Freund wrote: > >> Using my standard set of CC=gcc-7 and CXX=g++-7, the build fails with > >> > >> g++-7: error: unrecognized command line option '-stdlib=libc++' > > > It's actually already filtered, I just added -std*, because of selecting > > the c++ standard, I guess I need to filter more aggressively. This is > > fairly fairly annoying. > > I see you already filter llvm-config --cflags by picking only -I and -D. > Why not do the same for --cxxflags? Any other options that we need > like -f* should be discovered using the normal > does-the-compiler-support-this-option tests. Well, some -f obtions are ABI / behaviour influencing. You can't, to my knowledge, mix/match code build with -fno-rtti with code built with it (influences symbol names). LLVM builds without rtti by default, but a lot of distros enable it... I narrowed the filter to -std= (from -std), which should take care of the -stdlib bit. I also dropped -fno-exceptions being copied since that should not conflict. > >> It seems that it was intended that way anyway, since llvmjit.h contains > >> its own provisions for extern C. > > > > Hrmpf, yea, I broke that the third time now. I'm actually inclined to > > add an appropriate #ifdef ... #error so it's not repeated, what do you > > think? > > Not sure. Why not just move the line and not move it again? ;-) Heh, done ;). Let's see how long it takes... > > Does putting an > > override COMPILER = $(CXX) $(CFLAGS) > > > > into src/backend/jit/llvm/Makefile work? It does force the use of CXX > > for all important platforms if I see it correctly. Verified that it > > works on linux. > > Your latest HEAD builds out of the box for me now using the system compiler. Cool. > >> configure didn't find any of the LLVMOrc* symbols it was looking for. > >> Is that a problem? They seem to be for some debugging support. > > > > That's not a problem, except that the symbols won't be registered with > > the debugger, which is a bit annoying for backtraces. I tried to have > > configure throw errors in cases llvm is too old or such. > > Where does one get those then? I have LLVM 5.0.1. Is there something > even newer? I've submitted them upstream, but they're not yet released. > > Hm, I'll switch them on in the development branch. Independent of the > > final decision that's definitely the right thing for now. The "full > > capability" of the patchset is used if you turn on these three GUCs: > > > > -c jit_expressions=1 > > -c jit_tuple_deforming=1 > > -c jit_perform_inlining=1 > > The last one doesn't seem to exist anymore. Yup, as discussed in the earlier reply to you, I decided it's not particularly useful to have. As also threatened in that reply, I've switched the defaults so you shouldn't have to change them anymore. > If I turn on either of the first two, then make installcheck fails. See > attached diff. Hm, so there's definitely something going on here that I don't yet understand. I've pushed something that I've a slight hunch about (dropping the dots from the symbol names, some tooling doesn't seem to like that). I'd to rebase to fix a few issues, but I've left the changes made since the last push as separate commits. Could you run something like: regression[18425][1]=# set jit_above_cost = 0; SET regression[18425][1]=# set client_min_messages=debug2; SET regression[18425][1]=# SELECT pg_jit_available(); DEBUG: 00000: probing availability of llvm for JIT at /home/andres/build/postgres/dev-assert/install/lib/llvmjit.so LOCATION: provider_init, jit.c:83 DEBUG: 00000: successfully loaded LLVM in current session LOCATION: provider_init, jit.c:107 DEBUG: 00000: time to opt: 0.001s LOCATION: llvm_compile_module, llvmjit.c:435 DEBUG: 00000: time to emit: 0.014s LOCATION: llvm_compile_module, llvmjit.c:481 ┌──────────────────┐ │ pg_jit_available │ ├──────────────────┤ │ t │ └──────────────────┘ (1 row) regression[18425][1]=# select now(); DEBUG: 00000: time to opt: 0.001s LOCATION: llvm_compile_module, llvmjit.c:435 DEBUG: 00000: time to emit: 0.008s LOCATION: llvm_compile_module, llvmjit.c:481 ┌───────────────────────────────┐ │ now │ ├───────────────────────────────┤ │ 2018-03-03 11:33:13.776947-08 │ └───────────────────────────────┘ (1 row) regression[18425][1]=# SET jit_dump_bitcode = 1; SET regression[18425][1]=# select now(); DEBUG: 00000: time to opt: 0.002s LOCATION: llvm_compile_module, llvmjit.c:435 DEBUG: 00000: time to emit: 0.018s LOCATION: llvm_compile_module, llvmjit.c:481 ┌───────────────────────────────┐ │ now │ ├───────────────────────────────┤ │ 2018-03-03 11:33:23.508875-08 │ └───────────────────────────────┘ (1 row) The last command should have dumped something into your data directory, even if it failed like your regression test output showed. Could attach the two files something like ls -lstr /srv/dev/pgdev-dev/*.b would show if /srv/dev/pgdev-dev/ is your test directory? If my random hunch or this doesn't bear fruit, I'm going to have to get access to an OSX machine somehow :( Independent of this, I'm working to make the code pgindent compliant. Given the typical coding patterns when emitting IR (nested function calls) that's painful because pgindent insists on indenting everything a lot. I've started adding a few small wrapper functions to make that bearable... Greetings, Andres Freund
On Sun, Mar 4, 2018 at 8:39 AM, Andres Freund <andres@anarazel.de> wrote: > On 2018-03-03 09:37:35 -0500, Peter Eisentraut wrote: >> [discussion of making this work on a Mac] I tried out your "jit" branch on my macOS 10.13.3 system. Vendor "cc" and "c++" are version "Apple LLVM version 9.0.0 (clang-900.0.39.2)". I used MacPorts (whereas Peter E is using HomeBrew) to install LLVM with "sudo port install llvm-5.0". First, I built it like this: ./configure --prefix=$HOME/install/postgres \ --enable-debug --enable-cassert --enable-depend --with-llvm --with-openssl \ --enable-tap-tests \ --with-includes="/opt/local/include" --with-libraries="/opt/local/lib" \ CC="ccache cc" CXX="ccache c++" LLVM_CONFIG=/opt/local/bin/llvm-config-mp-5.0 The build succeeded, initdb ran, the server started up, and then I tried the sequence Andres showed: set jit_above_cost = 0; set client_min_messages=debug2; SELECT pg_jit_available(); On that last command I got: DEBUG: probing availability of llvm for JIT at /Users/munro/install/postgres/lib/llvmjit.so DEBUG: successfully loaded LLVM in current session DEBUG: time to opt: 0.001s DEBUG: time to emit: 0.034s ERROR: failed to JIT: evalexpr_0_0 Looking at the server output I saw: warning: ignoring debug info with an invalid version (700000003) in /Users/munro/install/postgres/lib/llvmjit_types.bc 2018-03-05 16:50:05.888 NZDT [14797] ERROR: failed to JIT: evalexpr_0_0 2018-03-05 16:50:05.888 NZDT [14797] STATEMENT: SELECT pg_jit_available(); I could see that llvmjit_types.bc had been produced by this command: /usr/bin/clang -Wno-ignored-attributes -Wno-unknown-warning-option -Wno-ignored-optimization-argument -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -Wno-unused-command-line-argument -g -O0 -Wall -Werror -O1 -I../../../../src/include -I/opt/local/include -flto=thin -emit-llvm -c -o pseudotypes.bc pseudotypes.c So I tried installing a later clang with "sudo port install clang-5.0" and setting CLANG=/pt/local/bin/clang-mp-5.0. It builds and uses that clang to generate the .bc files, but gives the same error, this time without the "warning" message. Looking at llvm_get_function(), the function that raises that error, I see that there are a few different paths here. I don't have HAVE_DECL_LLVMORCGETSYMBOLADDRESSIN defined, and I don't have LLVM < 5, so I should be getting the symbol address with LLVMOrcGetSymbolAddress(llvm_opt0_orc, &addr, mangled) or LLVMOrcGetSymbolAddress(llvm_opt3_orc, &addr, mangled), but clearly those are returning NULL. Not sure what's happening yet... -- Thomas Munro http://www.enterprisedb.com
Hi, On 2018-03-05 17:32:09 +1300, Thomas Munro wrote: > I tried out your "jit" branch on my macOS 10.13.3 system. Vendor "cc" > and "c++" are version "Apple LLVM version 9.0.0 (clang-900.0.39.2)". > I used MacPorts (whereas Peter E is using HomeBrew) to install LLVM > with "sudo port install llvm-5.0". Thanks for checking! > warning: ignoring debug info with an invalid version (700000003) in > /Users/munro/install/postgres/lib/llvmjit_types.bc That's harmless, log output aside. Should strip the debug info there, to remove the potential for that issue. > Looking at llvm_get_function(), the function that raises that error, I > see that there are a few different paths here. I don't have > HAVE_DECL_LLVMORCGETSYMBOLADDRESSIN defined, and I don't have LLVM < > 5, so I should be getting the symbol address with > LLVMOrcGetSymbolAddress(llvm_opt0_orc, &addr, mangled) or > LLVMOrcGetSymbolAddress(llvm_opt3_orc, &addr, mangled), but clearly > those are returning NULL. Yep. I wonder if this is some symbol naming issue or such, because emitting and relocating the object worked without an error. > Not sure what's happening yet... Hm. :/ Greetings, Andres Freund
Hi, On 2018-03-04 21:00:06 -0800, Andres Freund wrote: > > Looking at llvm_get_function(), the function that raises that error, I > > see that there are a few different paths here. I don't have > > HAVE_DECL_LLVMORCGETSYMBOLADDRESSIN defined, and I don't have LLVM < > > 5, so I should be getting the symbol address with > > LLVMOrcGetSymbolAddress(llvm_opt0_orc, &addr, mangled) or > > LLVMOrcGetSymbolAddress(llvm_opt3_orc, &addr, mangled), but clearly > > those are returning NULL. > > Yep. I wonder if this is some symbol naming issue or such, because > emitting and relocating the object worked without an error. Thanks to Thomas helping get access to an OSX machine I was able to discover what the issue is. OSX prepends, for reason unbeknownst to me, a leading underscore to all function names. That lead to two issues: First JITed functions do not have that underscore (making us look up a non-existing symbol, because llvm_get_function applied mangling). Secondly, llvm_resolve_symbol failed looking up symbol names, because for $reason dlsym() etc do *not* have the names prefixed by the underscore. Easily enough fixed. After that I discovered another problem, the bitcode files for core pg / contrib modules weren't installed. That turned out to be a make version issue, I'd used define install_llvm_module = # body but older make only like define install_llvm_module # body Writing up a patch that I can actually push. Thanks both to Thomas and Peter for pointing me towards this issue! Greetings, Andres Freund
Testing 0732ee73cf3ffd18d0f651376d69d4798d351ccc on Debian testing ...
The build works out of the box with whatever the default system packages
are.
Regression tests crash many times. One backtrace looks like this:
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51
#1 0x00007fd5b1730231 in __GI_abort () at abort.c:79
#2 0x000055c10a1555e3 in ExceptionalCondition
(conditionName=conditionName@entry=0x7fd5a245c2d8
"!(LLVMGetIntrinsicID(fn))",
errorType=errorType@entry=0x7fd5a245bb1d "FailedAssertion",
fileName=fileName@entry=0x7fd5a245c294 "llvmjit_expr.c",
lineNumber=lineNumber@entry=193) at assert.c:54
#3 0x00007fd5a245510f in get_LifetimeEnd (mod=mod@entry=0x55c10b1db670)
at llvmjit_expr.c:193
#4 0x00007fd5a24553c8 in get_LifetimeEnd (mod=0x55c10b1db670) at
llvmjit_expr.c:233
#5 BuildFunctionCall (context=context@entry=0x55c10b0ca340,
builder=builder@entry=0x55c10b225160,
mod=mod@entry=0x55c10b1db670, fcinfo=0x55c10b1a08b0,
v_fcinfo_isnull=v_fcinfo_isnull@entry=0x7ffc701f5c60)
at llvmjit_expr.c:244
...
#16 0x000055c10a0433ad in exec_simple_query (
query_string=0x55c10b096358 "SELECT COUNT(*) FROM test_tsquery WHERE
keyword < 'new & york';") at postgres.c:1082
--
Peter Eisentraut http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2018-03-05 16:19:52 -0500, Peter Eisentraut wrote: > Testing 0732ee73cf3ffd18d0f651376d69d4798d351ccc on Debian testing ... > > The build works out of the box with whatever the default system packages > are. > > Regression tests crash many times. One backtrace looks like this: > > #0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51 > #1 0x00007fd5b1730231 in __GI_abort () at abort.c:79 > #2 0x000055c10a1555e3 in ExceptionalCondition > (conditionName=conditionName@entry=0x7fd5a245c2d8 > "!(LLVMGetIntrinsicID(fn))", > errorType=errorType@entry=0x7fd5a245bb1d "FailedAssertion", > fileName=fileName@entry=0x7fd5a245c294 "llvmjit_expr.c", > lineNumber=lineNumber@entry=193) at assert.c:54 > #3 0x00007fd5a245510f in get_LifetimeEnd (mod=mod@entry=0x55c10b1db670) > at llvmjit_expr.c:193 > #4 0x00007fd5a24553c8 in get_LifetimeEnd (mod=0x55c10b1db670) at > llvmjit_expr.c:233 > #5 BuildFunctionCall (context=context@entry=0x55c10b0ca340, > builder=builder@entry=0x55c10b225160, > mod=mod@entry=0x55c10b1db670, fcinfo=0x55c10b1a08b0, > v_fcinfo_isnull=v_fcinfo_isnull@entry=0x7ffc701f5c60) > at llvmjit_expr.c:244 Hm, that should be trivial to fix. Which version of llvm are you building against? There appear to be a lot of them in testing: https://packages.debian.org/search?keywords=llvm+dev&searchon=names&suite=testing§ion=all Greetings, Andres Freund
Hi, On 2018-03-05 12:17:30 -0800, Andres Freund wrote: > Writing up a patch that I can actually push. Thanks both to Thomas and > Peter for pointing me towards this issue! After screwing the first attempt at a fix, the second one seems to work nicely. With optimizations, inlining, etc all core tests pass on Thomas' machine. Greetings, Andres Freund
On 2018-03-05 13:36:04 -0800, Andres Freund wrote: > On 2018-03-05 16:19:52 -0500, Peter Eisentraut wrote: > > Testing 0732ee73cf3ffd18d0f651376d69d4798d351ccc on Debian testing ... > > > > The build works out of the box with whatever the default system packages > > are. > > > > Regression tests crash many times. One backtrace looks like this: > > > > #0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51 > > #1 0x00007fd5b1730231 in __GI_abort () at abort.c:79 > > #2 0x000055c10a1555e3 in ExceptionalCondition > > (conditionName=conditionName@entry=0x7fd5a245c2d8 > > "!(LLVMGetIntrinsicID(fn))", > > errorType=errorType@entry=0x7fd5a245bb1d "FailedAssertion", > > fileName=fileName@entry=0x7fd5a245c294 "llvmjit_expr.c", > > lineNumber=lineNumber@entry=193) at assert.c:54 > > #3 0x00007fd5a245510f in get_LifetimeEnd (mod=mod@entry=0x55c10b1db670) > > at llvmjit_expr.c:193 > > #4 0x00007fd5a24553c8 in get_LifetimeEnd (mod=0x55c10b1db670) at > > llvmjit_expr.c:233 > > #5 BuildFunctionCall (context=context@entry=0x55c10b0ca340, > > builder=builder@entry=0x55c10b225160, > > mod=mod@entry=0x55c10b1db670, fcinfo=0x55c10b1a08b0, > > v_fcinfo_isnull=v_fcinfo_isnull@entry=0x7ffc701f5c60) > > at llvmjit_expr.c:244 > > Hm, that should be trivial to fix. Which version of llvm are you > building against? There appear to be a lot of them in testing: > https://packages.debian.org/search?keywords=llvm+dev&searchon=names&suite=testing§ion=all On Debian unstable, I built against a wide variety of branches: for v in 3.9 4.0 5.0 6.0;do rm -f ../config.cache;CLANG="ccache clang-$v" LLVM_CONFIG=/usr/lib/llvm-$v/bin/llvm-config ../config.sh--with-llvm && make -j16 -s install && make -s check;done All of those pass. I'll create a testing chroot. Regards, Andres
On 2018-03-05 14:01:05 -0800, Andres Freund wrote: > On 2018-03-05 13:36:04 -0800, Andres Freund wrote: > > On 2018-03-05 16:19:52 -0500, Peter Eisentraut wrote: > > > Testing 0732ee73cf3ffd18d0f651376d69d4798d351ccc on Debian testing ... > > > > > > The build works out of the box with whatever the default system packages > > > are. > > > > > > Regression tests crash many times. One backtrace looks like this: > > > > > > #0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51 > > > #1 0x00007fd5b1730231 in __GI_abort () at abort.c:79 > > > #2 0x000055c10a1555e3 in ExceptionalCondition > > > (conditionName=conditionName@entry=0x7fd5a245c2d8 > > > "!(LLVMGetIntrinsicID(fn))", > > > errorType=errorType@entry=0x7fd5a245bb1d "FailedAssertion", > > > fileName=fileName@entry=0x7fd5a245c294 "llvmjit_expr.c", > > > lineNumber=lineNumber@entry=193) at assert.c:54 > > > #3 0x00007fd5a245510f in get_LifetimeEnd (mod=mod@entry=0x55c10b1db670) > > > at llvmjit_expr.c:193 > > > #4 0x00007fd5a24553c8 in get_LifetimeEnd (mod=0x55c10b1db670) at > > > llvmjit_expr.c:233 > > > #5 BuildFunctionCall (context=context@entry=0x55c10b0ca340, > > > builder=builder@entry=0x55c10b225160, > > > mod=mod@entry=0x55c10b1db670, fcinfo=0x55c10b1a08b0, > > > v_fcinfo_isnull=v_fcinfo_isnull@entry=0x7ffc701f5c60) > > > at llvmjit_expr.c:244 > > > > Hm, that should be trivial to fix. Which version of llvm are you > > building against? There appear to be a lot of them in testing: > > https://packages.debian.org/search?keywords=llvm+dev&searchon=names&suite=testing§ion=all > > On Debian unstable, I built against a wide variety of branches: > > for v in 3.9 4.0 5.0 6.0;do rm -f ../config.cache;CLANG="ccache clang-$v" LLVM_CONFIG=/usr/lib/llvm-$v/bin/llvm-config../config.sh --with-llvm && make -j16 -s install && make -s check;done > > All of those pass. I'll create a testing chroot. I did, and reproduced. Turned out I just missed the error in the above test. The bug was caused by one ifdef in get_LifetimeEnd() being wrong (function is is overloaded starting in 5 rather than 4). The comment above it even had it right... Greetings, Andres Freund
On 3/6/18 04:39, Andres Freund wrote: > I did, and reproduced. Turned out I just missed the error in the above > test. > > The bug was caused by one ifdef in get_LifetimeEnd() being wrong > (function is is overloaded starting in 5 rather than 4). The comment > above it even had it right... OK, it's fixed for me now. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
With the build issues in check, I'm looking at the configuration settings. I think taking the total cost as the triggering threshold is probably good enough for a start. The cost modeling can be refined over time. We should document that both jit_optimize_above_cost and jit_inline_above_cost require jit_above_cost to be set, or otherwise nothing happens. One problem I see is that if someone sets things like enable_seqscan=off, the artificial cost increase created by those settings would quite likely bump the query over the jit threshold, which would alter the query performance characteristics in a way that the user would not have intended. I don't have an idea how to address this right now. I ran some performance assessments: merge base (0b1d1a038babff4aadf0862c28e7b667f1b12a30) make installcheck 3.14s user 3.34s system 17% cpu 37.954 total jit branch default settings make installcheck 3.17s user 3.30s system 13% cpu 46.596 total jit_above_cost=0 make installcheck 3.30s user 3.53s system 5% cpu 1:59.89 total jit_optimize_above_cost=0 (and jit_above_cost=0) make installcheck 3.44s user 3.76s system 1% cpu 8:12.42 total jit_inline_above_cost=0 (and jit_above_cost=0) make installcheck 3.32s user 3.62s system 2% cpu 5:35.58 total One can see the CPU savings quite nicely. One obvious problem is that with the default settings, the test suite run gets about 15% slower. (These figures are reproducible over several runs.) Is there some debugging stuff turned on that would explain this? Or would just loading the jit module in each session cause this? From the other results, we can see that one clearly needs quite a big database to see a solid benefit from this. Do you have any information gathered about this so far? Any scripts to create test databases and test queries? -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On 2018-03-06 10:29:47 -0500, Peter Eisentraut wrote: > I think taking the total cost as the triggering threshold is probably > good enough for a start. The cost modeling can be refined over time. Cool. > We should document that both jit_optimize_above_cost and > jit_inline_above_cost require jit_above_cost to be set, or otherwise > nothing happens. Yea, that's a good plan. We could also change it so it would, but I don't think there's much point? > One problem I see is that if someone sets things like > enable_seqscan=off, the artificial cost increase created by those > settings would quite likely bump the query over the jit threshold, which > would alter the query performance characteristics in a way that the user > would not have intended. I don't have an idea how to address this right > now. I'm not too worried about that scenario. If, for a cheap plan, the planner ends up with a seqscan despite it being disabled, you're pretty close to randomly choosing plans already, as the pruning doesn't work well anymore (as the %1 percent fuzz factor in compare_path_costs_fuzzily() swamps the actual plan costs). > I ran some performance assessments: > > merge base (0b1d1a038babff4aadf0862c28e7b667f1b12a30) > > make installcheck 3.14s user 3.34s system 17% cpu 37.954 total > > jit branch default settings > > make installcheck 3.17s user 3.30s system 13% cpu 46.596 total > > jit_above_cost=0 > > make installcheck 3.30s user 3.53s system 5% cpu 1:59.89 total > > jit_optimize_above_cost=0 (and jit_above_cost=0) > > make installcheck 3.44s user 3.76s system 1% cpu 8:12.42 total > > jit_inline_above_cost=0 (and jit_above_cost=0) > > make installcheck 3.32s user 3.62s system 2% cpu 5:35.58 total > > One can see the CPU savings quite nicely. I'm not quite sure what you mean by that. > One obvious problem is that with the default settings, the test suite > run gets about 15% slower. (These figures are reproducible over several > runs.) Is there some debugging stuff turned on that would explain this? > Or would just loading the jit module in each session cause this? I suspect it's loading the module. There's two pretty easy avenues to improve this: 1) Attempt to load the JIT provider in postmaster, thereby avoiding a lot of redundant dynamic linker work if already installed. That's ~5-10 lines or such. I basically refrained from that because it's convenient to not have to restart the server during development (one can just reconnect and get a newer jit plugin). 2) Don't load the JIT provider until fully needed. Right now jit_compile_expr() will load the jit provider even if not really needed. We should probably move the first two return blocks in llvm_compile_expr() into jit_compile_expr(), to avoid that. > From the other results, we can see that one clearly needs quite a big > database to see a solid benefit from this. Right, until we've got caching this'll only be beneficial for ~1s+ analytics queries. Unfortunately caching requires some larger planner & executor surgery, so I don't want to go there at the same time (I'm already insane enough). > Do you have any information gathered about this so far? Any scripts > to create test databases and test queries? Yes. I've used tpc-h. Not because it's the greatest, but because it's semi conveniently available and a lot of others have experience with it already. Do you mean whether I've run a couple benchmarks? If so, yes. I'll schedule some more later - am on battery power rn. Greetings, Andres Freund
On 2018-03-06 12:16:01 -0800, Andres Freund wrote: > > I ran some performance assessments: > > > > merge base (0b1d1a038babff4aadf0862c28e7b667f1b12a30) > > > > make installcheck 3.14s user 3.34s system 17% cpu 37.954 total > > > > jit branch default settings > > > > make installcheck 3.17s user 3.30s system 13% cpu 46.596 total > > > > jit_above_cost=0 > > > > make installcheck 3.30s user 3.53s system 5% cpu 1:59.89 total > > > > jit_optimize_above_cost=0 (and jit_above_cost=0) > > > > make installcheck 3.44s user 3.76s system 1% cpu 8:12.42 total > > > > jit_inline_above_cost=0 (and jit_above_cost=0) > > > > make installcheck 3.32s user 3.62s system 2% cpu 5:35.58 total > > > > One can see the CPU savings quite nicely. > > I'm not quite sure what you mean by that. > > > > One obvious problem is that with the default settings, the test suite > > run gets about 15% slower. (These figures are reproducible over several > > runs.) Is there some debugging stuff turned on that would explain this? > > Or would just loading the jit module in each session cause this? > > I suspect it's loading the module. There's also another issue: For a lot queries in the tests the stats are way way way off because the relevant tables have never been analyzed. There's a few cases where costs are off by like 5-7 orders of magnitude... Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> I'm not too worried about that scenario. If, for a cheap plan, the
> planner ends up with a seqscan despite it being disabled, you're pretty
> close to randomly choosing plans already, as the pruning doesn't work
> well anymore (as the %1 percent fuzz factor in
> compare_path_costs_fuzzily() swamps the actual plan costs).
Something I've wanted to do for awhile is to get rid of disable_cost
in favor of pruning disabled plans through logic rather than costing.
I've looked at this once or twice, and it seems doable but not entirely
trivial --- the sticky bits are places where you do need to allow a
disabled plan type because there's no other alternative. But if we
could get that done, it'd help with this sort of problem.
regards, tom lane
On Tue, Mar 6, 2018 at 10:39 PM, Andres Freund <andres@anarazel.de> wrote:
> [more commits]
+ * OSX prefixes all object level symbols with an underscore. But neither
"macOS" (see commit da6c4f6c and all mentions since).
make check at today's HEAD of your jit branch crashes on my FreeBSD
box. The first thing to crash is this query from point.sql:
LOG: server process (PID 87060) was terminated by signal 4: Illegal instruction
DETAIL: Failed process was running: SELECT '' AS thirtysix, p1.f1 AS
point1, p2.f1 AS point2, p1.f1 <-> p2.f1 AS dist
FROM POINT_TBL p1, POINT_TBL p2
ORDER BY dist, p1.f1[0], p2.f1[0];
Unfortunately when I tried to load the core file into lldb, the stack
is like this:
* thread #1, name = 'postgres', stop reason = signal SIGILL
* frame #0: 0x0000000800e7c1ea
Apparently the generated code is nuking the stack and executing
garbage? I don't have time to investigate right now, and this may
indicate something busted in my environment, but I thought this might
tell you something.
These variants of that query don't crash (even though I set
jit_above_cost = 0 and checked that it's actually JIT-ing), which
might be clues:
-- no p1.f1 <-> p2.f1
SELECT p1.f1 AS point1, p2.f1 AS point2
FROM POINT_TBL p1, POINT_TBL p2
ORDER BY p1.f1[0], p2.f1[0];
-- no join
SELECT p1.f1 <-> p1.f1 AS dist
FROM POINT_TBL p1
ORDER BY 1;
These variants do crash:
-- p1.f1 <-> p2.f1 in order by, but not select list
SELECT p1.f1 AS point1, p2.f1 AS point2
FROM POINT_TBL p1, POINT_TBL p2
ORDER BY p1.f1 <-> p2.f1, p1.f1[0], p2.f1[0];
-- p1.f1 <-> p2.f1 in select list, but not in order by
SELECT p1.f1 AS point1, p2.f1 AS point2, p1.f1 <-> p2.f1 AS dist
FROM POINT_TBL p1, POINT_TBL p2
ORDER BY p1.f1[0], p2.f1[0];
-- simple, with a join
SELECT p1.f1 <-> p1.f1 AS dist
FROM POINT_TBL p1, POINT_TBL p2
ORDER BY 1;
I build it like this:
./configure \
--prefix=$HOME/install/ \
--enable-tap-tests \
--enable-cassert \
--enable-debug \
--enable-depend \
--with-llvm \
CC="ccache cc" CFLAGS="-O0" CXX="ccache c++" CXXFLAGS="-std=c++11" \
CLANG=/usr/local/llvm50/bin/clang \
LLVM_CONFIG=/usr/local/llvm50/bin/llvm-config \
--with-libraries="/usr/local/lib" \
--with-includes="/usr/local/include"
--
Thomas Munro
http://www.enterprisedb.com
On Wed, Mar 7, 2018 at 3:49 PM, Thomas Munro
<thomas.munro@enterprisedb.com> wrote:
> make check at today's HEAD of your jit branch crashes on my FreeBSD
> box. The first thing to crash is this query from point.sql:
>
> LOG: server process (PID 87060) was terminated by signal 4: Illegal instruction
> DETAIL: Failed process was running: SELECT '' AS thirtysix, p1.f1 AS
> point1, p2.f1 AS point2, p1.f1 <-> p2.f1 AS dist
> FROM POINT_TBL p1, POINT_TBL p2
> ORDER BY dist, p1.f1[0], p2.f1[0];
Hmm. It's trying to execute an AVX instruction.
* thread #1, stop reason = breakpoint 1.1
frame #0: llvmjit.so`ExecRunCompiledExpr(state=0x0000000801de4880,
econtext=0x0000000801de3560, isNull="") at llvmjit_expr.c:432
429
430 state->evalfunc = func;
431
-> 432 return func(state, econtext, isNull);
433 }
434
435 static void emit_lifetime_end(ExprState *state, LLVMModuleRef
mod, LLVMBuilderRef b);
(lldb) s
Process 44513 stopped
* thread #1, stop reason = signal SIGILL: privileged instruction
frame #0: 0x0000000801157193
-> 0x801157193: vmovsd (%rax), %xmm0 ; xmm0 = mem[0],zero
0x801157197: vmovsd 0x8(%rax), %xmm1 ; xmm1 = mem[0],zero
0x80115719c: vsubsd (%rcx), %xmm0, %xmm2
0x8011571a0: vsubsd 0x8(%rcx), %xmm1, %xmm0
(lldb) bt
* thread #1, stop reason = signal SIGILL: privileged instruction
* frame #0: 0x0000000801157193
This is running on a "Intel(R) Celeron(R) CPU G1610T @ 2.30GHz" with no AVX.
I am not sure if that is real though, because the stack is immediately
corrupted. So either func is not really a function, or it is but was
compiled for the wrong target. I see that you call
LLVMCreateTargetMachine() with the result of LLVMGetHostCPUName() as
cpu. For me that's "ivybridge", so I tried hard coding "generic"
instead and it didn't help. I see that you say "" for features, where
is where one would normally put "avx" to turn on AVX instructions, so
I think perhaps that theory is entirely bogus.
--
Thomas Munro
http://www.enterprisedb.com
Hi,
On 2018-03-09 00:33:03 +1300, Thomas Munro wrote:
> On Wed, Mar 7, 2018 at 3:49 PM, Thomas Munro
> <thomas.munro@enterprisedb.com> wrote:
> > make check at today's HEAD of your jit branch crashes on my FreeBSD
> > box. The first thing to crash is this query from point.sql:
> >
> > LOG: server process (PID 87060) was terminated by signal 4: Illegal instruction
> > DETAIL: Failed process was running: SELECT '' AS thirtysix, p1.f1 AS
> > point1, p2.f1 AS point2, p1.f1 <-> p2.f1 AS dist
> > FROM POINT_TBL p1, POINT_TBL p2
> > ORDER BY dist, p1.f1[0], p2.f1[0];
>
> Hmm. It's trying to execute an AVX instruction.
Ah, that's interesting.
> I am not sure if that is real though, because the stack is immediately
> corrupted.
I don't think the stack is corrupted at all, it's just that lldb can't
unwind with functions it doesn't know. To add that capability I've a
pending LLVM patch.
> So either func is not really a function, or it is but was
> compiled for the wrong target. I see that you call
> LLVMCreateTargetMachine() with the result of LLVMGetHostCPUName() as
> cpu. For me that's "ivybridge", so I tried hard coding "generic"
> instead and it didn't help.
Hm.
> I see that you say "" for features, where
> is where one would normally put "avx" to turn on AVX instructions, so
> I think perhaps that theory is entirely bogus.
Could you try a -avx in features and see whether it fixes things?
This kinda suggests an LLVM bug or at least an oddity, but I'll try to
drill down more into this. Is this a native machine or a VM?
I think we can easily fix this by behaving like clang, which uses
llvm::sys::getHostCPUFeatures(HostFeatures) to built the feature list:
// If -march=native, autodetect the feature list.
if (const Arg *A = Args.getLastArg(clang::driver::options::OPT_march_EQ)) {
if (StringRef(A->getValue()) == "native") {
llvm::StringMap<bool> HostFeatures;
if (llvm::sys::getHostCPUFeatures(HostFeatures))
for (auto &F : HostFeatures)
Features.push_back(
Args.MakeArgString((F.second ? "+" : "-") + F.first()));
}
}
which seems easy enough.
Greetings,
Andres Freund
On 2018-03-08 11:58:41 -0800, Andres Freund wrote:
> I think we can easily fix this by behaving like clang, which uses
> llvm::sys::getHostCPUFeatures(HostFeatures) to built the feature list:
>
> // If -march=native, autodetect the feature list.
> if (const Arg *A = Args.getLastArg(clang::driver::options::OPT_march_EQ)) {
> if (StringRef(A->getValue()) == "native") {
> llvm::StringMap<bool> HostFeatures;
> if (llvm::sys::getHostCPUFeatures(HostFeatures))
> for (auto &F : HostFeatures)
> Features.push_back(
> Args.MakeArgString((F.second ? "+" : "-") + F.first()));
> }
> }
>
> which seems easy enough.
Or even in core LLVM, which has this nice comment:
// If user asked for the 'native' CPU, we need to autodetect features.
// This is necessary for x86 where the CPU might not support all the
// features the autodetected CPU name lists in the target. For example,
// not all Sandybridge processors support AVX.
if (MCPU == "native") {
which pretty much describes the issue you're apparently hitting.
I've pushed an attempted fix (needs a comment, but works here).
Greetings,
Andres Freund
On Fri, Mar 9, 2018 at 9:12 AM, Andres Freund <andres@anarazel.de> wrote:
> Or even in core LLVM, which has this nice comment:
>
> // If user asked for the 'native' CPU, we need to autodetect features.
> // This is necessary for x86 where the CPU might not support all the
> // features the autodetected CPU name lists in the target. For example,
> // not all Sandybridge processors support AVX.
> if (MCPU == "native") {
>
> which pretty much describes the issue you're apparently hitting.
>
> I've pushed an attempted fix (needs a comment, but works here).
=======================
All 186 tests passed.
=======================
That did the trick. Thanks!
--
Thomas Munro
http://www.enterprisedb.com
On 3/6/18 15:16, Andres Freund wrote: > 2) Don't load the JIT provider until fully needed. Right now > jit_compile_expr() will load the jit provider even if not really > needed. We should probably move the first two return blocks in > llvm_compile_expr() into jit_compile_expr(), to avoid that. I see that you have implemented that, but it doesn't seem to have helped with my make installcheck times. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 3/6/18 10:29, Peter Eisentraut wrote: > I think taking the total cost as the triggering threshold is probably > good enough for a start. The cost modeling can be refined over time. I looked into this a bit more. The default of jit_above_cost = 500000 seems pretty good. I constructed a query that cost about 450000 where the run time with and without JIT were about even. This is obviously very limited testing, but it's a good start. For jit_optimize_above_cost, in my testing, any query where JIT payed off was even faster with optimizing. So right now I don't see a need to make this a separate setting. Maybe just make it an on/off setting for experimenting. For inlining, I haven't been able to get a clear picture. It's a bit faster perhaps, but the optimizing dominates it. I don't have a clear mental model for what kind of returns to expect from this. What I'd quite like is if EXPLAIN or EXPLAIN ANALYZE showed something about what kind of JIT processing was done, if any, to help with this kind of testing. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2018-03-09 15:28:19 -0500, Peter Eisentraut wrote: > On 3/6/18 15:16, Andres Freund wrote: > > 2) Don't load the JIT provider until fully needed. Right now > > jit_compile_expr() will load the jit provider even if not really > > needed. We should probably move the first two return blocks in > > llvm_compile_expr() into jit_compile_expr(), to avoid that. > > I see that you have implemented that, but it doesn't seem to have helped > with my make installcheck times. What's the exact comparison you're looking at? I think that's largely that unnecessary trivial queries get JITed and optimized, because the stats are entirely completely off. Greetings, Andres Freund
On 2018-03-09 15:42:24 -0500, Peter Eisentraut wrote: > For jit_optimize_above_cost, in my testing, any query where JIT payed > off was even faster with optimizing. So right now I don't see a need to > make this a separate setting. Maybe just make it an on/off setting for > experimenting. I'd prefer to be more defensive here. The time needed for JITing without optimization is roughly linear, whereas optimization is definitely not linear with input size. > For inlining, I haven't been able to get a clear picture. It's a bit > faster perhaps, but the optimizing dominates it. I don't have a clear > mental model for what kind of returns to expect from this. Yea, you need longrunning queries to benefit significantly. There's a *lot* more potential once some structural issues with the expression format (both with and without JIT) are fixed. > What I'd quite like is if EXPLAIN or EXPLAIN ANALYZE showed something > about what kind of JIT processing was done, if any, to help with this > kind of testing. Yea, I like that. I think we can only show that when timing is on, because otherwise the tests will not be stable depending on --with-jit being specified or not. So I'm thinking of displaying it similar to the "Planning time" piece, i.e. depending on es->summary being enabled. It'd be good to display the inline/optimize/emit times too. I think we can just store it in the JitContext. But the inline/optimize/emission times will only be meaningful when the query is actually executed, I don't see a way around that... Greetings, Andres Freund
On 3/9/18 15:56, Andres Freund wrote: > On 2018-03-09 15:28:19 -0500, Peter Eisentraut wrote: >> On 3/6/18 15:16, Andres Freund wrote: >>> 2) Don't load the JIT provider until fully needed. Right now >>> jit_compile_expr() will load the jit provider even if not really >>> needed. We should probably move the first two return blocks in >>> llvm_compile_expr() into jit_compile_expr(), to avoid that. >> >> I see that you have implemented that, but it doesn't seem to have helped >> with my make installcheck times. > > What's the exact comparison you're looking at? I'm just running `time make installcheck` with default settings, as described in my message from March 6. > I think that's largely that unnecessary trivial queries get JITed and > optimized, because the stats are entirely completely off. Right. I instrumented this a bit, and there are indeed two handfuls of queries that exceed the default JIT thresholds, as well as a few that trigger JIT because they disable some enable_* planner setting, as previously discussed. Should we throw in some ANALYZEs to avoid this? If I set jit_expressions = off, then the timings match again. It's perhaps a bit confusing that some of the jit_* settings take effect at plan time and some at execution time. At the moment, this mainly affects me reading the code ;-), but it would also have some effect on prepared statements and such. Also, jit_tuple_deforming is apparently used only when jit_expressions is on. So, we should work toward more clarity on all these different settings, what they are useful for, when to set them, how they interact. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 3/9/18 15:42, Peter Eisentraut wrote: > The default of jit_above_cost = 500000 seems pretty good. I constructed > a query that cost about 450000 where the run time with and without JIT > were about even. This is obviously very limited testing, but it's a > good start. Actually, the default in your latest code is 100000, which per my analysis would be too low. Did you arrive at that setting based on testing? -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2018-03-11 13:19:57 -0400, Peter Eisentraut wrote: > On 3/9/18 15:56, Andres Freund wrote: > > I think that's largely that unnecessary trivial queries get JITed and > > optimized, because the stats are entirely completely off. > > Right. I instrumented this a bit, and there are indeed two handfuls of > queries that exceed the default JIT thresholds, as well as a few that > trigger JIT because they disable some enable_* planner setting, as > previously discussed. > > Should we throw in some ANALYZEs to avoid this? Hm, I'd actually lean to just leave it as is for now. JITing halfway random queries isn't actually that bad... If we get fed up with the additional time after a while, we can do something then? > It's perhaps a bit confusing that some of the jit_* settings take effect > at plan time and some at execution time. At the moment, this mainly > affects me reading the code ;-), but it would also have some effect on > prepared statements and such. Not quite sure what you mean? > Also, jit_tuple_deforming is apparently used only when jit_expressions > is on. Right. I've not found a good place to hook into that has enough context to do JITed deforming otherwise. I'm inclined to just relegate jit_tuple_deforming to debugging status (i.e. exclude from show all, docs etc) for now. > So, we should work toward more clarity on all these different settings, > what they are useful for, when to set them, how they interact. Yep. Greetings, Andres Freund
On 3/11/18 14:25, Andres Freund wrote: >> It's perhaps a bit confusing that some of the jit_* settings take effect >> at plan time and some at execution time. At the moment, this mainly >> affects me reading the code ;-), but it would also have some effect on >> prepared statements and such. > Not quite sure what you mean? I haven't tested this, but what appears to be the case is that SET jit_above_cost = 0; PREPARE foo AS SELECT ....; SET jit_above_cost = infinity; EXECUTE foo; will use JIT, because jit_above_cost applies at plan time, whereas SET jit_expressions = on; PREPARE foo AS SELECT ....; SET jit_expressions = off; EXECUTE foo; will *not* use JIT, becaue jit_expressions applies at execution time. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2018-03-12 11:21:36 -0400, Peter Eisentraut wrote: > On 3/11/18 14:25, Andres Freund wrote: > >> It's perhaps a bit confusing that some of the jit_* settings take effect > >> at plan time and some at execution time. At the moment, this mainly > >> affects me reading the code ;-), but it would also have some effect on > >> prepared statements and such. > > Not quite sure what you mean? > > I haven't tested this, but what appears to be the case is that > > SET jit_above_cost = 0; > PREPARE foo AS SELECT ....; > SET jit_above_cost = infinity; > EXECUTE foo; > > will use JIT, because jit_above_cost applies at plan time, whereas > > SET jit_expressions = on; > PREPARE foo AS SELECT ....; > SET jit_expressions = off; > EXECUTE foo; > > will *not* use JIT, becaue jit_expressions applies at execution time. Right. It'd be easy to change that so jit_expressions=off wouldn't have an effect there anymore. But I'm not sure we want that? I don't have a strong feeling about this, except that I think jit_above_cost etc should apply at plan, not execution time. Greetings, Andres Freund
On 3/12/18 13:05, Andres Freund wrote: >> will *not* use JIT, becaue jit_expressions applies at execution time. > Right. It'd be easy to change that so jit_expressions=off wouldn't have > an effect there anymore. But I'm not sure we want that? I don't have a > strong feeling about this, except that I think jit_above_cost etc should > apply at plan, not execution time. I lean toward making everything apply at plan time. Not only is that easier in the current code structure, but over time we'll probably want to add more detailed planner knobs, e.g., perhaps an alternative cpu_tuple_cost, and all of that would be a planner setting. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2018-03-09 13:08:36 -0800, Andres Freund wrote:
> On 2018-03-09 15:42:24 -0500, Peter Eisentraut wrote:
> > What I'd quite like is if EXPLAIN or EXPLAIN ANALYZE showed something
> > about what kind of JIT processing was done, if any, to help with this
> > kind of testing.
>
> Yea, I like that. I think we can only show that when timing is on,
> because otherwise the tests will not be stable depending on --with-jit
> being specified or not.
>
> So I'm thinking of displaying it similar to the "Planning time" piece,
> i.e. depending on es->summary being enabled. It'd be good to display the
> inline/optimize/emit times too. I think we can just store it in the
> JitContext. But the inline/optimize/emission times will only be
> meaningful when the query is actually executed, I don't see a way around
> that...
Not yet really happy with how it exactly looks, but here's my current
state:
tpch_10[20923][1]=# ;explain (format text, analyze, timing off) SELECT relkind, relname FROM pg_class pgc WHERE relkind
='r';
┌────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├────────────────────────────────────────────────────────────────────────────────────────┤
│ Seq Scan on pg_class pgc (cost=0.00..15.70 rows=77 width=65) (actual rows=77 loops=1) │
│ Filter: (relkind = 'r'::"char") │
│ Rows Removed by Filter: 299 │
│ Planning time: 0.187 ms │
│ JIT: │
│ Functions: 4 │
│ Inlining: false │
│ Optimization: false │
│ Execution time: 72.229 ms │
└────────────────────────────────────────────────────────────────────────────────────────┘
(9 rows)
tpch_10[20923][1]=# ;explain (format text, analyze, timing on) SELECT relkind, relname FROM pg_class pgc WHERE relkind
='r';
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Seq Scan on pg_class pgc (cost=0.00..15.70 rows=77 width=65) (actual time=40.570..40.651 rows=77 loops=1) │
│ Filter: (relkind = 'r'::"char") │
│ Rows Removed by Filter: 299 │
│ Planning time: 0.138 ms │
│ JIT: │
│ Functions: 4 │
│ Inlining: false │
│ Inlining Time: 0.000 │
│ Optimization: false │
│ Optimization Time: 5.023 │
│ Emission Time: 34.987 │
│ Execution time: 46.277 ms │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
(12 rows)
json (excerpt):
│ "Triggers": [ ↵│
│ ], ↵│
│ "JIT": { ↵│
│ "Functions": 4, ↵│
│ "Inlining": false, ↵│
│ "Inlining Time": 0.000, ↵│
│ "Optimization": false, ↵│
│ "Optimization Time": 9.701, ↵│
│ "Emission Time": 52.951 ↵│
│ }, ↵│
│ "Execution Time": 70.292 ↵│
I'm not at all wedded to the current format, but I feel like that's the
basic functionality needed?
Right now the JIT bit will only be displayed if at least one JITed
function has been emitted. Otherwise we'll just create noise for
everyone.
Currently a handful of explain outputs in the regression tests change
output when compiled with JITing. Therefore I'm thinking of adding
JITINFO or such option, which can be set to false for those tests?
Maintaining duplicate output for them seems painful. Better ideas?
Greetings,
Andres Freund
Andres Freund <andres@anarazel.de> writes:
> Currently a handful of explain outputs in the regression tests change
> output when compiled with JITing. Therefore I'm thinking of adding
> JITINFO or such option, which can be set to false for those tests?
> Maintaining duplicate output for them seems painful. Better ideas?
Why not just suppress that info when COSTS OFF is specified?
regards, tom lane
Hi, On 2018-03-12 17:14:00 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > Currently a handful of explain outputs in the regression tests change > > output when compiled with JITing. Therefore I'm thinking of adding > > JITINFO or such option, which can be set to false for those tests? > > Maintaining duplicate output for them seems painful. Better ideas? > > Why not just suppress that info when COSTS OFF is specified? I wondered about that too. But that'd mean it'd be harder to write a test that tests the planning bits of JITing (i.e. decision whether to use optimization & inlining or not) . Not sure if it's worth adding complexity to be able to do so. Greetings, Andres Freund
On 3/12/18 17:04, Andres Freund wrote: > │ JIT: │ > │ Functions: 4 │ > │ Inlining: false │ > │ Inlining Time: 0.000 │ > │ Optimization: false │ > │ Optimization Time: 5.023 │ > │ Emission Time: 34.987 │ The time quantities need some units. > │ Execution time: 46.277 ms │ like this :) -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2018-03-13 10:25:49 -0400, Peter Eisentraut wrote:
> On 3/12/18 17:04, Andres Freund wrote:
> > │ JIT: │
> > │ Functions: 4 │
> > │ Inlining: false │
> > │ Inlining Time: 0.000 │
> > │ Optimization: false │
> > │ Optimization Time: 5.023 │
> > │ Emission Time: 34.987 │
>
> The time quantities need some units.
>
> > │ Execution time: 46.277 ms │
>
> like this :)
Yea, I know. I was planning to start a thread about that. explain.c is
littered with code like
if (es->format == EXPLAIN_FORMAT_TEXT)
appendStringInfo(es->str, "Planning time: %.3f ms\n",
1000.0 * plantime);
else
ExplainPropertyFloat("Planning Time", 1000.0 * plantime, 3, es);
which, to me, is bonkers. I think we should add add 'const char *unit'
parameter to at least ExplainProperty{Float,Integer,Long}? Or a *Unit
version of them doing so, allowing a bit more gradual change?
Greetings,
Andres Freund
On Mon, Mar 12, 2018 at 5:04 PM, Andres Freund <andres@anarazel.de> wrote: > Currently a handful of explain outputs in the regression tests change > output when compiled with JITing. Therefore I'm thinking of adding > JITINFO or such option, which can be set to false for those tests? Can we spell that JIT or at least JIT_INFO? I realize that EXPLAIN (JIT OFF) may sound like it's intended to disable JIT itself, but I think it's pretty clear that EXPLAIN (BUFFERS OFF) does not disable the use of actual buffers, only the display of buffer-related information. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2018-03-13 14:36:44 -0400, Robert Haas wrote: > On Mon, Mar 12, 2018 at 5:04 PM, Andres Freund <andres@anarazel.de> wrote: > > Currently a handful of explain outputs in the regression tests change > > output when compiled with JITing. Therefore I'm thinking of adding > > JITINFO or such option, which can be set to false for those tests? > > Can we spell that JIT or at least JIT_INFO? The latter works, I don't have a strong opinion on that. For now I've just tied it to COSTS off. > I realize that EXPLAIN (JIT OFF) may sound like it's intended to > disable JIT itself Yea, that's what I'm concerned about. > , but I think it's pretty clear that EXPLAIN (BUFFERS OFF) does not > disable the use of actual buffers, only the display of buffer-related > information. Hm. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2018-03-13 14:36:44 -0400, Robert Haas wrote:
>> I realize that EXPLAIN (JIT OFF) may sound like it's intended to
>> disable JIT itself
> Yea, that's what I'm concerned about.
>> , but I think it's pretty clear that EXPLAIN (BUFFERS OFF) does not
>> disable the use of actual buffers, only the display of buffer-related
>> information.
> Hm.
FWIW, I agree with Robert's preference for just JIT here. The "info"
bit isn't conveying anything. And we've never had any EXPLAIN options
that actually change the behavior of the explained command, only ones
that change the amount of info displayed. I don't see why we'd
consider JIT an exception to that.
regards, tom lane
On Thu, Mar 1, 2018 at 9:02 PM, Andres Freund <andres@anarazel.de> wrote:
> Biggest changes:
> - LLVM 3.9 - master are now supported. This includes a good chunk of
> work by Pierre Ducroquet.
I decided to try this on a CentOS 7.2 box. It has LLVM 3.9 in the
'epel' package repo, but unfortunately it only has clang 3.4. I
suppose it's important to make this work for RHEL7 using only
dependencies that can be met by the vendor package repos? Maybe
someone who knows more about CentOS/RHE could tell me if I'm mistaken
and there is a way to get a more modern clang from a reputable repo
that our packages could depend on, though I release that clang is only a
build dependency, not a runtime one. I'm unsure how that constrains
things.
clang: "clang version 3.4.2 (tags/RELEASE_34/dot2-final)"
gcc and g++: "gcc version 4.8.5 20150623 (Red Hat 4.8.5-16) (GCC)"
llvm: "3.9.1"
First problem:
clang: error: unknown argument: '-fexcess-precision=standard'
clang: error: unknown argument: '-flto=thin'
Ok, so I hacked src/Makefile.global.in to remove -flto=thin. It looks
like -fexcess-precision-standard is coming from a configure test that
was run against ${CC}, not against ${CLANG}, so I hacked the generated
src/Makefile.global to remove that too, just to see if I could get
past that.
I don't know if there was another way to control floating point
precision in ancient clang before they adopted the GCC-compatible
flag, but it would seem slightly fishy to have .o files and .bc files
compiled with different floating point settings because then you could
get different answers depending on whether your expression is JITted.
Then I could build successfully and make check passed. I did see one warning:
In file included from execExpr.c:39:
../../../src/include/jit/jit.h:36:3: warning: redefinition of typedef
'JitProviderCallbacks' is a C11 feature [-Wtypedef-redefinition]
} JitProviderCallbacks;
^
../../../src/include/jit/jit.h:22:37: note: previous definition is here
typedef struct JitProviderCallbacks JitProviderCallbacks;
^
That's a legit complaint.
--
Thomas Munro
http://www.enterprisedb.com
Hi,
On 2018-03-14 10:32:40 +1300, Thomas Munro wrote:
> I decided to try this on a CentOS 7.2 box. It has LLVM 3.9 in the
> 'epel' package repo, but unfortunately it only has clang 3.4.
That's a bit odd, given llvm and clang really live in the same repo...
> clang: error: unknown argument: '-fexcess-precision=standard'
> clang: error: unknown argument: '-flto=thin'
>
> Ok, so I hacked src/Makefile.global.in to remove -flto=thin.
I think I can get actually rid of that entirely.
> It looks
> like -fexcess-precision-standard is coming from a configure test that
> was run against ${CC}, not against ${CLANG}, so I hacked the generated
> src/Makefile.global to remove that too, just to see if I could get
> past that.
Yea, I'd hoped we could avoid duplicating all the configure tests, but
maybe not :(.
> Then I could build successfully and make check passed. I did see one warning:
>
> In file included from execExpr.c:39:
> ../../../src/include/jit/jit.h:36:3: warning: redefinition of typedef
> 'JitProviderCallbacks' is a C11 feature [-Wtypedef-redefinition]
> } JitProviderCallbacks;
> ^
> ../../../src/include/jit/jit.h:22:37: note: previous definition is here
> typedef struct JitProviderCallbacks JitProviderCallbacks;
> ^
Yep. Removed the second superflous / redundant typedef. Will push a
heavily rebased version in a bit, will include fix for this.
Greetings,
Andres Freund
Hi, I've pushed a revised and rebased version of my JIT patchset. The git tree is at https://git.postgresql.org/git/users/andresfreund/postgres.git in the jit branch https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/jit There's nothing hugely exciting, mostly lots of cleanups. - added some basic EXPLAIN output, displaying JIT options and time spent jitting (see todo below) JIT: Functions: 9 Generation Time: 4.604 Inlining: false Inlining Time: 0.000 Optimization: false Optimization Time: 0.585 Emission Time: 12.858 - Fixed bugs around alignment computations in tuple deforming. Wasn't able to trigger any bad consequences, but it was clearly wrong. - Worked a lot on making code more pgindent safe. There's still some minor layout damage, but it's mostly ok now. For that I had to add a bunch of helpers that make the code shorter - Freshly emitted functions now have proper attributes indicating architecture, floating point behaviour etc. That's what previously prevented the inliner of doing its job without forcing its hand. That yields a bit of a speedup. - reduced size of code a bit by deduplicating code, in particular don't "manually" create signatures for function declarations anymore. Besides deduplicating, this also ensures code generation time errors when function signatures change. - fixed a number of FIXMEs etc - added a lot of comments - portability fixes (OSX, freebsd) Todo: - some build issues with old clang versions pointed out by Thomas Munro - when to take jit_expressions into account (both exec and plan or just latter) - EXPLAIN for queries that are JITed should display units. Starting thread about effort to not duplicate code for that - more explanations of type & function signature syncing - GUC docs (including postgresql.conf.sample) Thanks everyone, particularly Peter in this update, for helping me along! Regards, Andres
Hi, On 2018-03-13 15:29:33 -0700, Andres Freund wrote: > On 2018-03-14 10:32:40 +1300, Thomas Munro wrote: > > I decided to try this on a CentOS 7.2 box. It has LLVM 3.9 in the > > 'epel' package repo, but unfortunately it only has clang 3.4. > > That's a bit odd, given llvm and clang really live in the same repo... I don't really live in the RHEL world, but I wonder if https://developers.redhat.com/blog/2017/10/04/red-hat-adds-go-clangllvm-rust-compiler-toolsets-updates-gcc/ is relevant? Appears to be available on centos too https://www.softwarecollections.org/en/scls/rhscl/devtoolset-7/ I checked it out and supporting 3.4 would be a bit painful due to not being able to directly emit module summaries. We could support that by building the summaries separately using LLVM, but that'd be either slower for everyone, or we'd need somewhat finnicky conditionals. > > clang: error: unknown argument: '-fexcess-precision=standard' > > clang: error: unknown argument: '-flto=thin' > > > > Ok, so I hacked src/Makefile.global.in to remove -flto=thin. > > I think I can get actually rid of that entirely. Err, no, not really. Would increase overhead due to separate module summary generation, so I'd rather not do it. > > It looks > > like -fexcess-precision-standard is coming from a configure test that > > was run against ${CC}, not against ${CLANG}, so I hacked the generated > > src/Makefile.global to remove that too, just to see if I could get > > past that. > > Yea, I'd hoped we could avoid duplicating all the configure tests, but > maybe not :(. I've mostly done that now (not pushed). I've created new PGAC_PROG_VARCC_VARFLAGS_OPT(compiler variable, flag variable, testflag) function, which now is used to implement PGAC_PROG_CC_CFLAGS_OPT and PGAC_PROG_CC_VAR_OPT (similar for CXX). That makes it reasonable to test the variables clang recognizes separately. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2018-03-13 15:29:33 -0700, Andres Freund wrote:
>> On 2018-03-14 10:32:40 +1300, Thomas Munro wrote:
>>> It looks
>>> like -fexcess-precision-standard is coming from a configure test that
>>> was run against ${CC}, not against ${CLANG}, so I hacked the generated
>>> src/Makefile.global to remove that too, just to see if I could get
>>> past that.
>> Yea, I'd hoped we could avoid duplicating all the configure tests, but
>> maybe not :(.
> I've mostly done that now (not pushed). I've created new
> PGAC_PROG_VARCC_VARFLAGS_OPT(compiler variable, flag variable, testflag)
> function, which now is used to implement PGAC_PROG_CC_CFLAGS_OPT and
> PGAC_PROG_CC_VAR_OPT (similar for CXX). That makes it reasonable to
> test the variables clang recognizes separately.
Meh. I agree with Thomas' concern that it's not clear we can or should
just ignore discrepancies between the -f options supported by the C
and CLANG compilers.
Is it really so necessary to bring a second compiler into the mix for
this? Why not just insist that JIT is only supported if the main build
is done with clang, too? My experience with mixing results from different
compilers is, eh, not positive.
regards, tom lane
Hi,
On 2018-03-14 22:36:52 -0400, Tom Lane wrote:
> Andres Freund <andres@anarazel.de> writes:
> > On 2018-03-13 15:29:33 -0700, Andres Freund wrote:
> >> On 2018-03-14 10:32:40 +1300, Thomas Munro wrote:
> >>> It looks
> >>> like -fexcess-precision-standard is coming from a configure test that
> >>> was run against ${CC}, not against ${CLANG}, so I hacked the generated
> >>> src/Makefile.global to remove that too, just to see if I could get
> >>> past that.
>
> >> Yea, I'd hoped we could avoid duplicating all the configure tests, but
> >> maybe not :(.
>
> > I've mostly done that now (not pushed). I've created new
> > PGAC_PROG_VARCC_VARFLAGS_OPT(compiler variable, flag variable, testflag)
> > function, which now is used to implement PGAC_PROG_CC_CFLAGS_OPT and
> > PGAC_PROG_CC_VAR_OPT (similar for CXX). That makes it reasonable to
> > test the variables clang recognizes separately.
>
> Meh.
Why? The necessary configure code isn't that large:
# Test for behaviour changing compiler flags, to keep compatibility
# with compiler used for normal postgres code. XXX expand
if test "$with_llvm" = yes ; then
PGAC_PROG_VARCC_VARFLAGS_OPT(CLANG, BITCODE_CFLAGS, [-fno-strict-aliasing])
PGAC_PROG_VARCC_VARFLAGS_OPT(CLANG, BITCODE_CFLAGS, [-fwrapv])
PGAC_PROG_VARCC_VARFLAGS_OPT(CLANG, BITCODE_CFLAGS, [-fexcess-precision=standard])
AC_SUBST(BITCODE_CFLAGS, $BITCODE_CFLAGS)
fi
If the relevant clang version doesn't understand, say
-fno-strict-aliasing, then we'd in trouble already if it's
required. After all we do support compiling postgres with clang.
> I agree with Thomas' concern that it's not clear we can or should
> just ignore discrepancies between the -f options supported by the C
> and CLANG compilers.
What's the precise concern here? We pass these flags to work around
compiler issues / "defining our standard". As I said above, if we do not
know the right flags to make clang behave sensibly, we're in trouble
already.
For a good part of the code we already want to be compatible with
compiling postgres with one compiler, and linking to libraries compiled
with something else.
> Is it really so necessary to bring a second compiler into the mix for
> this? Why not just insist that JIT is only supported if the main build
> is done with clang, too? My experience with mixing results from different
> compilers is, eh, not positive.
I don't like that option. It doesn't really buy us much, a few lines of
config code, and one additional configure option that should normally be
autodected from the environment. Requiring a specific compiler will be
terrible on windows, seems out of line how we do development, requires
using clang which is still generates a bit slower code, prevent getting
gcc warnings etc.
Greetings,
Andres Freund
On Thu, Mar 15, 2018 at 1:20 AM, Andres Freund <andres@anarazel.de> wrote: > I don't really live in the RHEL world, but I wonder if > https://developers.redhat.com/blog/2017/10/04/red-hat-adds-go-clangllvm-rust-compiler-toolsets-updates-gcc/ > is relevant? Indeed. It might be a bit awkward for packagers to depend on something from Software Collections, for example because they come as separate trees in /opt that are by default not in your path or dynamic loader path - one needs to run everything via a scl wrapper or source the /opt/rh/llvm-toolset-7/enable file to get the appropriate PATH and LD_LIBRARY_PATH settings, But it seems doable. I just installed llvm-toolset-7 (the LLVM version is 4.0.1) on RHEL 7.4 and did a build of your tree at 475b4da439ae397345ab3df509e0e8eb26a8ff39. make installcheck passes for both the default config and a server forced to jit everything (I think) via: jit_above_cost = '0' jit_inline_above_cost = '0' jit_optimize_above_cost = '0' As a side note, this increases the runtime from approx 4 min to 18 min. Disabling jit completely with -1 in all of the above yields 3 min 48s, close to the default question raising maybe the question of how much coverage does jit get with the default config. The build was with the newer gcc 7.2.1 from the aforementioned collections, I'll try the system gcc as well. I run a buildfarm animal (katydid) on this RHEL. When JIT gets committed I'll make it use --with-llvm against this Software Collections LLVM. > Appears to be available on centos too > https://www.softwarecollections.org/en/scls/rhscl/devtoolset-7/ Indeed they are available for CentOS as well.
Hi, On 2018-03-15 17:19:23 +0100, Catalin Iacob wrote: > On Thu, Mar 15, 2018 at 1:20 AM, Andres Freund <andres@anarazel.de> wrote: > > I don't really live in the RHEL world, but I wonder if > > https://developers.redhat.com/blog/2017/10/04/red-hat-adds-go-clangllvm-rust-compiler-toolsets-updates-gcc/ > > is relevant? > > Indeed. It might be a bit awkward for packagers to depend on something > from Software Collections, for example because they come as separate > trees in /opt that are by default not in your path or dynamic loader > path - one needs to run everything via a scl wrapper or source the > /opt/rh/llvm-toolset-7/enable file to get the appropriate PATH and > LD_LIBRARY_PATH settings, But it seems doable. It'd be just for clang, and they're not *forced* to do it, it's an optional dependency. So I think I'm ok with that. > I just installed llvm-toolset-7 (the LLVM version is 4.0.1) on RHEL > 7.4 and did a build of your tree at > 475b4da439ae397345ab3df509e0e8eb26a8ff39. make installcheck passes for > both the default config and a server forced to jit everything (I > think) via: > jit_above_cost = '0' > jit_inline_above_cost = '0' > jit_optimize_above_cost = '0' > > As a side note, this increases the runtime from approx 4 min to 18 > min. Sure, that jits everything, which is obviously pointless to do for performancereasons. Especially SQL functions play very badly, because they're replanned every execution. But it's good for testing ;) > Disabling jit completely with -1 in all of the above yields 3 min > 48s, close to the default question raising maybe the question of how > much coverage does jit get with the default config. A bit, but not hugely so. I'm not too concerned about that. I plan to stand up a few buildfarm animals testing JITing with everything on w/ various LLVM versions. > The build was with the newer gcc 7.2.1 from the aforementioned > collections, I'll try the system gcc as well. I run a buildfarm animal > (katydid) on this RHEL. When JIT gets committed I'll make it use > --with-llvm against this Software Collections LLVM. Cool! Thanks for testing! Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2018-03-15 17:19:23 +0100, Catalin Iacob wrote:
>> Indeed. It might be a bit awkward for packagers to depend on something
>> from Software Collections, for example because they come as separate
>> trees in /opt that are by default not in your path or dynamic loader
>> path - one needs to run everything via a scl wrapper or source the
>> /opt/rh/llvm-toolset-7/enable file to get the appropriate PATH and
>> LD_LIBRARY_PATH settings, But it seems doable.
> It'd be just for clang, and they're not *forced* to do it, it's an
> optional dependency. So I think I'm ok with that.
The "software collections" stuff was still in its infancy when I left
Red Hat, so things might've changed, but I'm pretty sure at the time
it was verboten for any mainstream package to depend on an SCL one.
But they very probably wouldn't want postgresql depending on a
compiler package even if the dependency was mainstream, so I rather
doubt that you'll ever see an --enable-jit PG build out of there,
making this most likely moot as far as the official RH package goes.
I don't know what Devrim's opinion might be about PGDG.
regards, tom lane
On 2018-03-15 12:33:08 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > On 2018-03-15 17:19:23 +0100, Catalin Iacob wrote: > >> Indeed. It might be a bit awkward for packagers to depend on something > >> from Software Collections, for example because they come as separate > >> trees in /opt that are by default not in your path or dynamic loader > >> path - one needs to run everything via a scl wrapper or source the > >> /opt/rh/llvm-toolset-7/enable file to get the appropriate PATH and > >> LD_LIBRARY_PATH settings, But it seems doable. > > > It'd be just for clang, and they're not *forced* to do it, it's an > > optional dependency. So I think I'm ok with that. > > The "software collections" stuff was still in its infancy when I left > Red Hat, so things might've changed, but I'm pretty sure at the time > it was verboten for any mainstream package to depend on an SCL one. But we won't get PG 11 into RHEL7.x either way, no? > But they very probably wouldn't want postgresql depending on a > compiler package even if the dependency was mainstream, so I rather > doubt that you'll ever see an --enable-jit PG build out of there, > making this most likely moot as far as the official RH package goes. > I don't know what Devrim's opinion might be about PGDG. It'd be a build not runtime dependency, doesn't that change things? Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2018-03-15 12:33:08 -0400, Tom Lane wrote:
>> The "software collections" stuff was still in its infancy when I left
>> Red Hat, so things might've changed, but I'm pretty sure at the time
>> it was verboten for any mainstream package to depend on an SCL one.
> But we won't get PG 11 into RHEL7.x either way, no?
Well, they've been known to back-port newer releases of PG into older
RHEL; I wouldn't necessarily assume it'd happen for 11, but maybe 12
or beyond could be made available for RHEL7 at some point.
>> But they very probably wouldn't want postgresql depending on a
>> compiler package even if the dependency was mainstream, so I rather
>> doubt that you'll ever see an --enable-jit PG build out of there,
>> making this most likely moot as far as the official RH package goes.
>> I don't know what Devrim's opinion might be about PGDG.
> It'd be a build not runtime dependency, doesn't that change things?
How could it not be a runtime dependency? You're not proposing that
we'd embed all of LLVM into a Postgres package are you? If you are, be
assured that Red Hat will *never* ship that. Static linking/embedding of
one package in another is forbidden for obvious maintainability reasons.
I would think that other distros have similar policies.
regards, tom lane
On 2018-03-15 12:42:54 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > It'd be a build not runtime dependency, doesn't that change things? > > How could it not be a runtime dependency? What we were talking about in this subthread was about a depency on clang, not LLVM. And that's just needed at buildtime, to generate the bitcode files (including synchronizing types / function signatures). For the yum.pg.o, which already depends on EPEL, there's a new enough LLVM version. There's a new enough version in RHEL proper, but it appears to only be there for mesa (llvm-private). > You're not proposing that we'd embed all of LLVM into a Postgres > package are you? No. Greetings, Andres Freund
On Thu, Mar 15, 2018 at 6:19 PM, Andres Freund <andres@anarazel.de> wrote: > What we were talking about in this subthread was about a depency on > clang, not LLVM. And that's just needed at buildtime, to generate the > bitcode files (including synchronizing types / function signatures). I was actually thinking of both the buildtime and runtime dependency because I did not realize the PGDG packages already depend on EPEL. > For the yum.pg.o, which already depends on EPEL, there's a new enough > LLVM version. There's a new enough version in RHEL proper, but it > appears to only be there for mesa (llvm-private). Indeed RHEL 7 comes with llvm-private for mesa but that doesn't seem kosher to use for other things. When I said packagers I was only thinking of PGDG. I was thinking the software collections would be the likely solution for the PGDG packages for both buildtime and runtime. But it seems using clang from software collections and LLVM from EPEL is also a possibility, assuming that the newer clang generates IR that the older libraries are guaranteed to be able to load. For RHEL proper, I would guess that PG11 is too late for RHEL8 which, according to history, should be coming soon. For RHEL9 I would really expect RedHat to add llvm and clang to proper RHEL and build/run against those, even if they add it only for Postgres (like they did for mesa). I really don't see them shipping without a major speedup for a major DB, also because in the meantime the JIT in PG will have matured. That's also why I find it important to support gcc and not restrict JIT to clang builds as I expect that RedHat and all other Linux distros want to build everything with gcc and asking them to switch to clang or give up JIT will put them in a hard spot. As far as I know clang does promise gcc compatibility in the sense that one can link together .o files compiled with both so I expect the combination not to cause issues (assuming the other compiler flags affecting binary compatibility are aligned).
Hi, On 2018-03-15 19:14:09 +0100, Catalin Iacob wrote: > For RHEL proper, I would guess that PG11 is too late for RHEL8 which, > according to history, should be coming soon. Yea. > For RHEL9 I would really expect RedHat to add llvm and clang to proper > RHEL and build/run against those, even if they add it only for > Postgres (like they did for mesa). By the looks of what's going to come for RHEL8 I think it already contains a suitable LLVM and clang (i.e. >= 3.9)? > As far as I know clang does promise gcc compatibility in > the sense that one can link together .o files compiled with both so I > expect the combination not to cause issues (assuming the other > compiler flags affecting binary compatibility are aligned). Right. But that's not even needed, as we just use plain old C ABI via dlsym(). Nothing needs to be linked together outside of dlsym(), so I'm not too concerned about that aspect. Greetings, Andres Freund
Hi, On 2018-03-13 16:40:32 -0700, Andres Freund wrote: > I've pushed a revised and rebased version of my JIT patchset. > The git tree is at > https://git.postgresql.org/git/users/andresfreund/postgres.git > in the jit branch > https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/jit The biggest change is that this contains docbook docs. Please check it out, I'm not entirely sure the structure is perfect. I'll make a language prettying pass tomorrow, to tired for that now. > Todo: > - some build issues with old clang versions pointed out by Thomas Munro I've added the configure magic to properly detect capabilities of different clang versions. This doesn't resolve the 3.4 issues Thomas had reported however, because we still rely on -flto=thin. If necessary we could support it by adding a 'opt -module-summary $@ -o $@' to the %.bc rules, but that'd require some version specific handling. Given that it doesn't yet look necessary I'm loath to go there. > - when to take jit_expressions into account (both exec and plan or just > latter) It's just plan time now. There's a new 'jit' GUC that works *both* at execution time and plan time, and is documented as such. > - EXPLAIN for queries that are JITed should display units. Starting > thread about effort to not duplicate code for that done. > - GUC docs (including postgresql.conf.sample) done. > - more explanations of type & function signature syncing Still WIP. Greetings, Andres Freund
Hi, I've pushed a revised and rebased version of my JIT patchset. The git tree is at https://git.postgresql.org/git/users/andresfreund/postgres.git in the jit branch https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/jit There's a lot of tiny changes in here: - doc proofreading, addition of --with-llvm docs - comments - pgindent (jit files, not whole tree) - syncing of order between compiled and interpreted expressions in case statement - line-by-line review of expression compliation - fix of a small memory leak (missing pfree of the JIT context struct itself) - slight simplification of JIT resowner integration (no need to re-associate with parent) My current plan is to push the first few commits relatively soon, give the BF a few cycles to shake out. Set up a few BF animals with each supported LLVM version. Then continue mergin. Greetings, Andres Freund
On Tue, Mar 20, 2018 at 11:14 PM, Andres Freund <andres@anarazel.de> wrote: > - doc proofreading, addition of --with-llvm docs The documentation builds and the resulting HTML looks good, and I like what you've written for users and also for developers in the README file. Perhaps it could use something about how to know it's working with EXPLAIN (or any other introspection there might be), but maybe you're still working on that? I did a proof-reading pass and have some minor language and typesetting suggestions. See comments below and attached patch (against current HEAD of your jit branch) which implements all of these changes, which of course you can feel free to take individual hunks from or ignore if you disagree! + <varlistentry> + <term><acronym>JIT</acronym></term> + <listitem> + <para> + <ulink url="https://en.wikipedia.org/wiki/Just-in-time_compilation">Just in Time + Compilation</ulink> + </para> + </listitem> + </varlistentry> The usual typesetting seems to be "just-in-time" (with hyphens), including on Wikipedia, various literature and in dictionaries. Here "compilation" doesn't seem to need a capital letter (it's not part of the acronym, it's not otherwise in a title context where capitalisation is called for). Similar comments apply to all other mentions, also changed (though I won't repeat them here; see patch). + <title>JIT accelerated operations</title> Although the existing documentation is not entirely consistent on this point, it almost always follows the US convention for titles: initial capitals except for a handful of small words ("is", "of", "to", ...), like the New York Times and unlike the (London) Times. So here "JIT Accelerated Operations". Same change elsewhere. + <title>What is <acronym>JIT</acronym></title> Needs a question mark. + As explained in <xref linkend="jit-decision"/> the configuration variables + xref <xref linkend="guc-jit-above-cost"/>, <xref Extra "xref" in the text. + <varlistentry id="guc-jit-above-cost" xreflabel="guc-jit-above-cost"> xreflabel should use underscores not hyphens, and shouldn't have the leading "guc" (this breaks the resulting HTML). + Sets the planner's cutoff after which JIT compilation is used as part ... + Sets the planner's cutoff after which JIT compiled programs (see <xref s/after which/above which/. I see there was some nearby text that used "after which", but that was talking about time. I think writers might do s/JIT compiled/JIT-compiled/ here and some similar places (JIT-generated, JIT-accelerated etc), though I'm not sure about that and I doubt anyone cares so I didn't change it. + available, but no error will be raised. This allows to install JIT + support separately from the main <productname>PostgreSQL</productname> + package. "allows to ..." isn't correct English. You can say things like "allows <object> to <infinitive>", and "allows installation ...", and maybe "to allow installing ..." (though the last sounds a bit clumsy). I rewrote it as "This allows JIT support to be installed separately from ...". Same sort of thing in several places. + Writes the generated <productname>LLVM</productname> IR out to the + filesystem, inside <xref linkend="guc-data-directory"/>. This is only + useful for development of JIT. Seems a little vague... maybe "... for working on the internals of the JIT implementation"? Just to make clear it's not for end users unless curious. + E.g. instead of using a facility that can evaluate arbitrary arbitrary SQL + expressions to evaluate an SQL predicate like <literal>WHERE a.col = I'd write "For example" here. "E.g." seems more appropriate for fitting into examples into tight spaces, like a remark in parentheses. YMMV. "arbitrary" is repeated. + Expression evaluation is used to evaluate <literal>WHERE</literal> + clauses, target lists, aggregates and projections. It can be accelerated + by generating code specific to the used expression. How about "... by generating code specific to each case." + Tuple deforming is the process of transforming an on-disk tuple (see <xref + linkend="heaptuple"/>) into its in-memory representation. It can be + accelerated by creating a function specific to the table layout and the + number of to be extracted columns. "... number of columns to be extracted." + <productname>LLVM</productname> has support for optimizing generated + code. Some of the optimizations are cheap enough to be performed whenever + <acronym>JIT</acronym> is used, others are only beneficial for more longer + running queries. ", while others are only beneficial for longer running queries." + <productname>PostgreSQL</productname> is very extensible and allows to + extend the set of datatypes, functions, operators, etc.; see <xref + linkend="extend"/>. In fact the builtin ones are implemented using nearly + the same mechanisms. This extensibility implies some overhead, e.g. due + to function calls (see <xref linkend="xfunc"/>). To reduce that overhead + <acronym>JIT</acronym> compilation can inline the body for small functions + into the expression using them. That allows to optimize away a significant + percentage of the overhead. "... and allows new datatypes, functions, operators and other database objects to be defined; ..." "... can inline the body *of* small functions ..." "... That allows a significant percentage of the overhead to be optimized away." + <acronym>JIT</acronym> is beneficial primarily for long-running, CPU bound, + queries. Frequently these will be analytical queries. For short queries I'd lose those commas. + made. Firstly, if the query is more costly than the <xref + linkend="guc-jit-optimize-above-cost"/> GUC expensive optimizations are I'd add a comma (and maybe "then") before "GUC". + For development and debugging purposes a few additional GUCs exist. <xref + linkend="guc-jit-dump-bitcode"/> allows to inspect the generated + bitcode. <xref linkend="guc-jit-debugging-support"/> allows GDB to see + generated functions. <xref linkend="guc-jit-profiling-support"/> emits + information so the <productname>perf</productname> profiler can interpret + JIT generated functions sensibly. "... allows the generated bitcode to be inspected." + <programlisting> +struct JitProviderCallbacks +{ + JitProviderResetAfterErrorCB reset_after_error; + JitProviderReleaseContextCB release_context; + JitProviderCompileExprCB compile_expr; +}; +extern void _PG_jit_provider_init(JitProviderCallbacks *cb); + </programlisting> Some weird tabs in here. Changed to spaces. About the README, some of this text is similar to the user-facing docs and the same comments apply, and there are also some nitpicks about apostrophes etc that I won't bother to repeat here. -- Thomas Munro http://www.enterprisedb.com
Attachment
Hi, On 2018-03-21 12:07:59 +1300, Thomas Munro wrote: > The documentation builds and the resulting HTML looks good, and I like > what you've written for users and also for developers in the README > file. Cool. > Perhaps it could use something about how to know it's working > with EXPLAIN (or any other introspection there might be), but maybe > you're still working on that? I'd not yet seen that as a priority, but I think it'd make sense to show an example of that. Perhaps showing a select query from a function, once with that function's cost set to the default, and once with it set to something high? > I did a proof-reading pass and have some minor language and > typesetting suggestions. See comments below and attached patch > (against current HEAD of your jit branch) which implements all of > these changes, which of course you can feel free to take individual > hunks from or ignore if you disagree! Yeha! > + <varlistentry> > + <term><acronym>JIT</acronym></term> > + <listitem> > + <para> > + <ulink url="https://en.wikipedia.org/wiki/Just-in-time_compilation">Just > in Time > + Compilation</ulink> > + </para> > + </listitem> > + </varlistentry> > > The usual typesetting seems to be "just-in-time" (with hyphens), > including on Wikipedia, various literature and in dictionaries. Here > "compilation" doesn't seem to need a capital letter (it's not part of > the acronym, it's not otherwise in a title context where > capitalisation is called for). I wasn't sure about that one, thanks. > + <varlistentry id="guc-jit-above-cost" xreflabel="guc-jit-above-cost"> > > xreflabel should use underscores not hyphens, and shouldn't have the > leading "guc" (this breaks the resulting HTML). Oops, yea, that's definitely a mistake. > + Sets the planner's cutoff after which JIT compilation is used as part > ... > + Sets the planner's cutoff after which JIT compiled programs (see <xref > > s/after which/above which/. I see there was some nearby text that > used "after which", but that was talking about time. > > I think writers might do s/JIT compiled/JIT-compiled/ here and some > similar places (JIT-generated, JIT-accelerated etc), though I'm not > sure about that and I doubt anyone cares so I didn't change it. I was wondering about that... Thanks a lot for going through this! Greetings, Andres Freund
Hi, On 2018-03-20 03:14:55 -0700, Andres Freund wrote: > My current plan is to push the first few commits relatively soon, give > the BF a few cycles to shake out. Set up a few BF animals with each > supported LLVM version. Then continue mergin. I've done that. I'll set up a number of BF animals as soon as I've got the buildfarm secrets for them. - Andres
On Wed, Mar 21, 2018 at 1:50 PM, Andres Freund <andres@anarazel.de> wrote: > On 2018-03-20 03:14:55 -0700, Andres Freund wrote: >> My current plan is to push the first few commits relatively soon, give >> the BF a few cycles to shake out. Set up a few BF animals with each >> supported LLVM version. Then continue mergin. > > I've done that. I'll set up a number of BF animals as soon as I've got > the buildfarm secrets for them. Somehow your configure test correctly concludes that my $CC (clang 4.0) doesn't support -fexcess-precision=standard but that my $CXX (clang++ 4.0) does, despite producing a nearly identical warning: configure:5489: checking whether ccache cc supports -fexcess-precision=standard, for CFLAGS configure:5511: ccache cc -c -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard conftest.c >&5 cc: warning: optimization flag '-fexcess-precision=standard' is not supported [-Wignored-optimization-argument] configure:5511: $? = 0 configure: failed program was: ... configure:5521: result: no configure:5528: checking whether ccache c++ supports -fexcess-precision=standard, for CXXFLAGS configure:5556: ccache c++ -c -Wall -Wpointer-arith -fno-strict-aliasing -fwrapv -fexcess-precision=standard conftest.cpp >&5 c++: warning: optimization flag '-fexcess-precision=standard' is not supported [-Wignored-optimization-argument] configure:5556: $? = 0 configure:5572: result: yes So it goes into my $CXXFLAGS and then I get the same warning when compiling the three .cpp files in the tree. GCC also doesn't like that in C++ mode, but it seems to report an error (rather than a warning) so with g++ as your $CXX configure sees $? = 1 and draws the correct conclusion. $ gcc -fexcess-precision=standard -c test.c $ g++ -fexcess-precision=standard -c test.cpp cc1plus: sorry, unimplemented: -fexcess-precision=standard for C++ -- Thomas Munro http://www.enterprisedb.com
Hi, On 2018-03-21 15:22:08 +1300, Thomas Munro wrote: > Somehow your configure test correctly concludes that my $CC (clang > 4.0) doesn't support -fexcess-precision=standard but that my $CXX > (clang++ 4.0) does, despite producing a nearly identical warning: Yea, there was a copy & pasto (s/ac_c_werror_flag/ac_cxx_werror_flag/), sorry. If you rebase onto the committed version, it should work? I'll push a version rebased of the jit tree soon. Greetings, Andres Freund
On 2018-03-20 19:29:55 -0700, Andres Freund wrote: > Hi, > > On 2018-03-21 15:22:08 +1300, Thomas Munro wrote: > > Somehow your configure test correctly concludes that my $CC (clang > > 4.0) doesn't support -fexcess-precision=standard but that my $CXX > > (clang++ 4.0) does, despite producing a nearly identical warning: > > Yea, there was a copy & pasto (s/ac_c_werror_flag/ac_cxx_werror_flag/), > sorry. If you rebase onto the committed version, it should work? I'll > push a version rebased of the jit tree soon. Well, or not. Seems git.pg.o is down atm: debug1: Next authentication method: publickey debug1: Offering public key: RSA SHA256:cMbSa8YBm8AgaIeMtCSFvvPDrrrdadCxzQaFiWFe+7c /home/andres/.ssh/id_rsa debug1: Server accepts key: pkalg ssh-rsa blen 277 <hang> Will try tomorrow. Greetings, Andres Freund
Greetings, * Andres Freund (andres@anarazel.de) wrote: > On 2018-03-20 19:29:55 -0700, Andres Freund wrote: > > On 2018-03-21 15:22:08 +1300, Thomas Munro wrote: > > > Somehow your configure test correctly concludes that my $CC (clang > > > 4.0) doesn't support -fexcess-precision=standard but that my $CXX > > > (clang++ 4.0) does, despite producing a nearly identical warning: > > > > Yea, there was a copy & pasto (s/ac_c_werror_flag/ac_cxx_werror_flag/), > > sorry. If you rebase onto the committed version, it should work? I'll > > push a version rebased of the jit tree soon. > > Well, or not. Seems git.pg.o is down atm: > > debug1: Next authentication method: publickey > debug1: Offering public key: RSA SHA256:cMbSa8YBm8AgaIeMtCSFvvPDrrrdadCxzQaFiWFe+7c /home/andres/.ssh/id_rsa > debug1: Server accepts key: pkalg ssh-rsa blen 277 > <hang> > > Will try tomorrow. Andres contacted pginfra over IRC about this, but it seems that it resolved itself shortly following (per a comment from Andres to that effect), so, afaik, things are working properly. If anyone has issues with git.p.o, please let us know, but hopefully all is good now. Thanks! Stephen
Attachment
Hi, On 2018-03-20 23:03:13 -0400, Stephen Frost wrote: > Greetings, > > * Andres Freund (andres@anarazel.de) wrote: > > On 2018-03-20 19:29:55 -0700, Andres Freund wrote: > > > On 2018-03-21 15:22:08 +1300, Thomas Munro wrote: > > > > Somehow your configure test correctly concludes that my $CC (clang > > > > 4.0) doesn't support -fexcess-precision=standard but that my $CXX > > > > (clang++ 4.0) does, despite producing a nearly identical warning: > > > > > > Yea, there was a copy & pasto (s/ac_c_werror_flag/ac_cxx_werror_flag/), > > > sorry. If you rebase onto the committed version, it should work? I'll > > > push a version rebased of the jit tree soon. > > > > Well, or not. Seems git.pg.o is down atm: > > > > debug1: Next authentication method: publickey > > debug1: Offering public key: RSA SHA256:cMbSa8YBm8AgaIeMtCSFvvPDrrrdadCxzQaFiWFe+7c /home/andres/.ssh/id_rsa > > debug1: Server accepts key: pkalg ssh-rsa blen 277 > > <hang> > > > > Will try tomorrow. > > Andres contacted pginfra over IRC about this, but it seems that it > resolved itself shortly following (per a comment from Andres to that > effect), so, afaik, things are working properly. Indeed. I've pushed a rebased version now, that basically just fixes the issue Thomas observed. Thanks, Andres Freund
On Wed, Mar 21, 2018 at 4:07 PM, Andres Freund <andres@anarazel.de> wrote:
> Indeed. I've pushed a rebased version now, that basically just fixes the
> issue Thomas observed.
I set up a 32 bit i386 virtual machine and installed Debian 9.4.
Compiler warnings:
gcc -Wall -Wmissing-prototypes -Wpointer-arith
-Wdeclaration-after-statement -Wendif-labels
-Wmissing-format-attribute -Wformat-security -fno-strict-aliasing
-fwrapv -fexcess-precision=standard -g -O2 -fPIC
-D__STDC_LIMIT_MACROS -D__STDC_FORMAT_MACROS -D__STDC_CONSTANT_MACROS
-D_GNU_SOURCE -I/usr/lib/llvm-3.9/include -I../../../../src/include
-D_GNU_SOURCE -c -o llvmjit.o llvmjit.c
llvmjit.c: In function ‘llvm_get_function’:
llvmjit.c:268:10: warning: cast to pointer from integer of different
size [-Wint-to-pointer-cast]
return (void *) addr;
^
llvmjit.c:270:10: warning: cast to pointer from integer of different
size [-Wint-to-pointer-cast]
return (void *) addr;
^
llvmjit.c: In function ‘llvm_resolve_symbol’:
llvmjit.c:842:10: warning: cast from pointer to integer of different
size [-Wpointer-to-int-cast]
addr = (uint64_t) load_external_function(modname, funcname,
^
llvmjit.c:845:10: warning: cast from pointer to integer of different
size [-Wpointer-to-int-cast]
addr = (uint64_t) LLVMSearchForAddressOfSymbol(symname);
^
Then "make check" bombs:
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0xac233453 in llvm::SelectionDAG::getNode(unsigned int,
llvm::SDLoc const&, llvm::EVT, llvm::SDValue) () from
/usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
(gdb) bt
#0 0xac233453 in llvm::SelectionDAG::getNode(unsigned int,
llvm::SDLoc const&, llvm::EVT, llvm::SDValue) () from
/usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#1 0xac270c29 in llvm::TargetLowering::SimplifySetCC(llvm::EVT,
llvm::SDValue, llvm::SDValue, llvm::ISD::CondCode, bool,
llvm::TargetLowering::DAGCombinerInfo&, llvm::SDLoc const&) const ()
from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#2 0xac11d3a8 in ?? () from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#3 0xac11ef0b in ?? () from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#4 0xac12030e in llvm::SelectionDAG::Combine(llvm::CombineLevel,
llvm::AAResults&, llvm::CodeGenOpt::Level) () from
/usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#5 0xac24ccec in llvm::SelectionDAGISel::CodeGenAndEmitDAG() () from
/usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#6 0xac24d239 in
llvm::SelectionDAGISel::SelectBasicBlock(llvm::ilist_iterator<llvm::Instruction
const>, llvm::ilist_iterator<llvm::Instruction const>, bool&) () from
/usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#7 0xac25466f in
llvm::SelectionDAGISel::SelectAllBasicBlocks(llvm::Function const&) ()
from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#8 0xac25773c in
llvm::SelectionDAGISel::runOnMachineFunction(llvm::MachineFunction&)
() from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#9 0xad356414 in ?? () from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#10 0xabf5a019 in
llvm::MachineFunctionPass::runOnFunction(llvm::Function&) () from
/usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#11 0xabdefaeb in llvm::FPPassManager::runOnFunction(llvm::Function&)
() from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#12 0xabdefe35 in llvm::FPPassManager::runOnModule(llvm::Module&) ()
from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#13 0xabdf019a in llvm::legacy::PassManagerImpl::run(llvm::Module&) ()
from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#14 0xabdf037f in llvm::legacy::PassManager::run(llvm::Module&) ()
from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#15 0xacb3c3de in
std::_Function_handler<llvm::object::OwningBinary<llvm::object::ObjectFile>
(llvm::Module&), llvm::orc::SimpleCompiler>::_M_invoke(std::_Any_data
const&, llvm::Module&) () from
/usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#16 0xacb37d00 in ?? () from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#17 0xacb384f8 in ?? () from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#18 0xacb388d5 in LLVMOrcAddEagerlyCompiledIR () from
/usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
#19 0xae7bb3e4 in llvm_compile_module (context=0x20858a0) at llvmjit.c:539
#20 llvm_get_function (context=0x20858a0, funcname=0x21da818
"evalexpr_2_3") at llvmjit.c:244
#21 0xae7c333e in ExecRunCompiledExpr (state=0x2119634,
econtext=0x211810c, isNull=0xbfdd138e "\207") at llvmjit_expr.c:2563
#22 0x00745e10 in ExecEvalExprSwitchContext (isNull=0xbfdd138e "\207",
econtext=<optimized out>, state=0x2119634) at
../../../src/include/executor/executor.h:305
#23 ExecQual (econtext=<optimized out>, state=0x2119634) at
../../../src/include/executor/executor.h:374
#24 ExecNestLoop (pstate=<optimized out>) at nodeNestloop.c:214
#25 0x00748ddd in ExecProcNode (node=0x2118080) at
../../../src/include/executor/executor.h:239
#26 ExecSort (pstate=0x2117ff4) at nodeSort.c:107
#27 0x0071e9d2 in ExecProcNode (node=0x2117ff4) at
../../../src/include/executor/executor.h:239
#28 ExecutePlan (execute_once=<optimized out>, dest=0x0,
direction=NoMovementScanDirection, numberTuples=<optimized out>,
sendTuples=<optimized out>, operation=CMD_SELECT,
use_parallel_mode=<optimized out>, planstate=0x2117ff4,
estate=0x2117ee8) at execMain.c:1729
#29 standard_ExecutorRun (queryDesc=0x207da50,
direction=ForwardScanDirection, count=0, execute_once=1 '\001') at
execMain.c:365
#30 0x00883e8d in PortalRunSelect (portal=portal@entry=0x20a7f58,
forward=forward@entry=1 '\001', count=0, count@entry=2147483647,
dest=0x21a8888) at pquery.c:932
#31 0x008856a0 in PortalRun (portal=0x20a7f58, count=2147483647,
isTopLevel=1 '\001', run_once=1 '\001', dest=0x21a8888,
altdest=0x21a8888, completionTag=0xbfdd1620 "") at pquery.c:773
#32 0x008808a7 in exec_simple_query
(query_string=query_string@entry=0x205a628 "SELECT '' AS tf_12_ff_4,
BOOLTBL1.*, BOOLTBL2.*\n FROM BOOLTBL1, BOOLTBL2\n WHERE
BOOLTBL2.f1 = BOOLTBL1.f1 or BOOLTBL1.f1 = bool 'true'\n ORDER BY
BOOLTBL1.f1, BOOLTBL2.f1;")
at postgres.c:1121
#33 0x0088270e in PostgresMain (argc=1, argv=0x2083c44,
dbname=<optimized out>, username=0x2083aa0 "munro") at postgres.c:4147
#34 0x00552cff in BackendRun (port=0x207d518) at postmaster.c:4409
#35 BackendStartup (port=0x207d518) at postmaster.c:4081
#36 ServerLoop () at postmaster.c:1754
#37 0x007fc68f in PostmasterMain (argc=<optimized out>,
argv=<optimized out>) at postmaster.c:1362
#38 0x0055475a in main (argc=<optimized out>, argv=<optimized out>) at
main.c:228
(gdb)
That's with clang-3.9 and llvm-3.9-dev installed, which configure
automagically found.
"make -C src/interfaces/ecpg/test check" consistently fails on my macOS machine:
test compat_oracle/char_array ... stderr source FAILED
*** /Users/munro/projects/postgresql/src/interfaces/ecpg/test/expected/compat_oracle-char_array.stdout
2018-03-21 09:46:33.000000000 +1300
--- /Users/munro/projects/postgresql/src/interfaces/ecpg/test/results/compat_oracle-char_array.stdout
2018-03-21 19:13:43.000000000 +1300
***************
*** 1,10 ****
Full Str. : Short Ind.
! " ": " " -1
! "AB ": "AB " 0
! "ABCD ": "ABCD" 0
! "ABCDE ": "ABCD" 5
! "ABCDEF ": "ABCD" 6
! "ABCDEFGHIJ": "ABCD" 10
GOOD-BYE!!
--- 1,10 ----
Full Str. : Short Ind.
! "": "" 0
! "AB": "AB" 0
! "ABCD": "ABCD" 0
! "ABCDE": "ABCDE" 0
! "ABCDEF": "ABCDE" 6
! "ABCDEFGHIJ": "ABCDE" 10
GOOD-BYE!!
======================================================================
*** /Users/munro/projects/postgresql/src/interfaces/ecpg/test/expected/compat_oracle-char_array.stderr
2018-03-21 16:27:05.000000000 +1300
--- /Users/munro/projects/postgresql/src/interfaces/ecpg/test/results/compat_oracle-char_array.stderr
2018-03-21 19:13:43.000000000 +1300
***************
*** 90,96 ****
[NO_PID]: sqlca: code: 0, state: 00000
[NO_PID]: ecpg_get_data on line 50: RESULT: ABCDE offset: -1; array: no
[NO_PID]: sqlca: code: 0, state: 00000
- Warning: At least one column was truncated
[NO_PID]: ecpg_execute on line 50: query: fetch C; with 0
parameter(s) on connection ecpg1_regression
[NO_PID]: sqlca: code: 0, state: 00000
[NO_PID]: ecpg_execute on line 50: using PQexec
--- 90,95 ----
======================================================================
I couldn't immediately see what was going wrong there since I'm not
too familiar with ecpg... That's with vendor cc/c++ and LLVM 5.0 and
6.0, using a couple of different clang versions.
While trying out many combinations of versions of stuff on different
OSes, I found another way to screw up that I wanted to report here.
It's obvious that this is doomed if you know what's going on, but I
thought the failure mode was interesting enough to report here. There
is a hazard for people running systems where the vendor ships some
version (possibly a mystery version) of clang in the PATH but you have
to get LLVM separately (eg from ports/brew/whatever):
1. If you use macOS High Sierra's current /usr/bin/clang ("9.0.0"),
ie the default if you didn't set CLANG to something else when you ran
./configure, and you build against LLVM 3.9, then llvm-lto gives this
message during "make install":
Invalid summary version 3, 1 expected
error: can't create ModuleSummaryIndexObjectFile for buffer: Corrupted bitcode
Then it segfaults! Presumably clang "9.0.0" derives from a more
recent upstream version (why must they mess with the reported
version?!). Apple's clang 9.0.0 bitcode works fine with LLVM 5.0. I
don't have 4.0 to hand to test.
2. If you use FreeBSD 11's current /usr/bin/clang (4.0) and you build
against LLVM 3.9 then it's the same:
Invalid summary version 3, 1 expected
error: can't create ModuleSummaryIndexObjectFile for buffer: Corrupted bitcode
gmake[3]: *** [Makefile:252: install-postgres-bitcode] Segmentation
fault (core dumped)
It works fine with 4.0 or 5.0, as expected.
Neither of these cases should be too surprising, and users of those
operating systems can easily get a newer LLVM or an older -- it was
just interesting to see exactly what goes wrong and exactly when. I
suppose there could be a configure test to see if your $CLANG can play
nicely with your $LLVM_CONFIG.
--
Thomas Munro
http://www.enterprisedb.com
On Wed, Mar 21, 2018 at 4:07 AM, Andres Freund <andres@anarazel.de> wrote: > Indeed. I've pushed a rebased version now, that basically just fixes the > issue Thomas observed. Testing 2d6f2fba from your repository configured --with-llvm I noticed some weird things in the configure output. Without --enable-debug: configure: using compiler=gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-16) configure: using CFLAGS=-Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -O2 configure: using CPPFLAGS= -D_GNU_SOURCE configure: using LDFLAGS= -L/opt/rh/llvm-toolset-7/root/usr/lib64 -Wl,--as-needed configure: using CXX=g++ configure: using CXXFLAGS=-Wall -Wpointer-arith -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -g -O2 configure: using CLANG=/opt/rh/llvm-toolset-7/root/usr/bin/clang configure: using BITCODE_CFLAGS= -fno-strict-aliasing -fwrapv -O2 configure: using BITCODE_CXXFLAGS= -fno-strict-aliasing -fwrapv -O2 BITCODE_CXXFLAGS With --enable-debug: configure: using compiler=gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-16) configure: using CFLAGS=-Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -g -O2 configure: using CPPFLAGS= -D_GNU_SOURCE configure: using LDFLAGS= -L/opt/rh/llvm-toolset-7/root/usr/lib64 -Wl,--as-needed configure: using CXX=g++ configure: using CXXFLAGS=-Wall -Wpointer-arith -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -g -g -O2 configure: using CLANG=/opt/rh/llvm-toolset-7/root/usr/bin/clang configure: using BITCODE_CFLAGS= -fno-strict-aliasing -fwrapv -O2 configure: using BITCODE_CXXFLAGS= -fno-strict-aliasing -fwrapv -O2 BITCODE_CXXFLAGS So I unconditionally get one -g added to CXXFLAGS regardless of whether I specify --enable-debug or not. And --enable-debug results in -g -g in CXXFLAGS. Didn't get to look at the code yet, maybe that comes from: $ llvm-config --cxxflags -I/opt/rh/llvm-toolset-7/root/usr/include -O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic -fPIC -fvisibility-inlines-hidden -Wall -W -Wno-unused-parameter -Wwrite-strings -Wcast-qual -Wno-missing-field-initializers -pedantic -Wno-long-long -Wno-maybe-uninitialized -Wdelete-non-virtual-dtor -Wno-comment -std=c++11 -ffunction-sections -fdata-sections -O2 -g -DNDEBUG -fno-exceptions -D_GNU_SOURCE -D__STDC_CONSTANT_MACROS -D__STDC_FORMAT_MACROS -D__STDC_LIMIT_MACROS But on the other hand there are lots of other flags in there that don't end up in CXXFLAGS. BTW, you should probably specify -std=c++11 (or whatever you need) as various g++ and clang++ versions default to various things. Will the required C++ standard be based on the requirements of the C++ code in the PG tree or will you take it from LLVM's CXXFLAGS? Can --std=c++11 and --std=c++14 compiled .o files be linked together? Or in other words, in case in the future LLVM starts requiring C++14 but the code in the PG tree you wrote still builds with C++11, will PG upgrade it's requirement with LLVM or will it stay with the older standard? Also, my CXXFLAGS did not get -fexcess-precision=standard neither did BITCODE_CFLAGS nor BITCODE_CXXFLAGS. In case it's interesting: $ llvm-config --cflags -I/opt/rh/llvm-toolset-7/root/usr/include -O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic -fPIC -Wall -W -Wno-unused-parameter -Wwrite-strings -Wno-missing-field-initializers -pedantic -Wno-long-long -Wno-comment -ffunction-sections -fdata-sections -O2 -g -DNDEBUG -D_GNU_SOURCE -D__STDC_CONSTANT_MACROS -D__STDC_FORMAT_MACROS -D__STDC_LIMIT_MACROS 2. Unlike all the other *FLAGS, BITCODE_CXXFLAGS includes itself on the right hand side of the equal configure: using BITCODE_CXXFLAGS= -fno-strict-aliasing -fwrapv -O2 BITCODE_CXXFLAGS
On Wed, Mar 21, 2018 at 8:06 PM, Thomas Munro
<thomas.munro@enterprisedb.com> wrote:
> On Wed, Mar 21, 2018 at 4:07 PM, Andres Freund <andres@anarazel.de> wrote:
>> Indeed. I've pushed a rebased version now, that basically just fixes the
>> issue Thomas observed.
>
> I set up a 32 bit i386 virtual machine and installed Debian 9.4.
Next up, I have an arm64 system running Debian 9.4. It bombs in
"make check" and in simple tests:
postgres=# set jit_above_cost = 0;
SET
postgres=# select 42;
<boom>
The stack looks like this:
Program received signal SIGABRT, Aborted.
__GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51
51 ../sysdeps/unix/sysv/linux/raise.c: No such file or directory.
(gdb) bt
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51
#1 0x0000ffff8f65adf4 in __GI_abort () at abort.c:89
#2 0x0000ffff83e2de40 in __gnu_cxx::__verbose_terminate_handler() ()
from /usr/lib/aarch64-linux-gnu/libstdc++.so.6
#3 0x0000ffff83e2bd4c in ?? () from /usr/lib/aarch64-linux-gnu/libstdc++.so.6
#4 0x0000ffff83e2bd98 in std::terminate() () from
/usr/lib/aarch64-linux-gnu/libstdc++.so.6
#5 0x0000ffff83e2c01c in __cxa_throw () from
/usr/lib/aarch64-linux-gnu/libstdc++.so.6
#6 0x0000ffff83e544bc in std::__throw_bad_function_call() () from
/usr/lib/aarch64-linux-gnu/libstdc++.so.6
#7 0x0000ffff85176a2c in LLVMOrcCreateInstance () from
/usr/lib/aarch64-linux-gnu/libLLVM-3.9.so.1
#8 0x0000ffff865c4db0 in llvm_session_initialize () at llvmjit.c:643
#9 llvm_create_context (jitFlags=9) at llvmjit.c:136
#10 0x0000ffff865cf8c8 in llvm_compile_expr (state=0xaaaaf2300208) at
llvmjit_expr.c:132
#11 0x0000aaaab64ca71c in ExecReadyExpr
(state=state@entry=0xaaaaf2300208) at execExpr.c:627
#12 0x0000aaaab64cd7b8 in ExecBuildProjectionInfo
(targetList=<optimized out>, econtext=<optimized out>, slot=<optimized
out>, parent=parent@entry=0xaaaaf22ffde0,
inputDesc=inputDesc@entry=0x0)
at execExpr.c:471
#13 0x0000aaaab64e0028 in ExecAssignProjectionInfo
(planstate=planstate@entry=0xaaaaf22ffde0,
inputDesc=inputDesc@entry=0x0) at execUtils.c:460
#14 0x0000aaaab64fca28 in ExecInitResult
(node=node@entry=0xaaaaf224e1a0, estate=estate@entry=0xaaaaf22ffbc8,
eflags=eflags@entry=16) at nodeResult.c:221
#15 0x0000aaaab64db828 in ExecInitNode (node=0xaaaaf224e1a0,
node@entry=0xaaaaf227a610, estate=estate@entry=0xaaaaf22ffbc8,
eflags=eflags@entry=16) at execProcnode.c:164
#16 0x0000aaaab64d6a70 in InitPlan (eflags=16,
queryDesc=0xaaaaf226d808) at execMain.c:1051
#17 standard_ExecutorStart (queryDesc=0xaaaaf226d808, eflags=16) at
execMain.c:266
#18 0x0000aaaab662dbec in PortalStart (portal=0x400,
portal@entry=0xaaaaf22b04d8, params=0x59004077f060bc65,
params@entry=0x0, eflags=43690, eflags@entry=0,
snapshot=0xaaaab689df58, snapshot@entry=0x0)
at pquery.c:520
#19 0x0000aaaab6628b18 in exec_simple_query
(query_string=query_string@entry=0xaaaaf224c3d8 "select 42;") at
postgres.c:1082
#20 0x0000aaaab662a6a8 in PostgresMain (argc=<optimized out>,
argv=argv@entry=0xaaaaf2278b70, dbname=<optimized out>,
username=<optimized out>) at postgres.c:4147
#21 0x0000aaaab631cdd0 in BackendRun (port=0xaaaaf226d410) at postmaster.c:4409
#22 BackendStartup (port=0xaaaaf226d410) at postmaster.c:4081
#23 ServerLoop () at postmaster.c:1754
#24 0x0000aaaab65ab048 in PostmasterMain (argc=<optimized out>,
argv=<optimized out>) at postmaster.c:1362
#25 0x0000aaaab631e7cc in main (argc=3, argv=0xaaaaf2246f70) at main.c:228
Taking frame 6 at face value, it appears to be trying to call an empty
std::function (that's what the exception std::bad_function_call
means). No clue how or why though.
With LLVM 5.0 (from backports) it seemed to get further (?):
Program terminated with signal SIGABRT, Aborted.
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51
51 ../sysdeps/unix/sysv/linux/raise.c: No such file or directory.
(gdb) bt
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51
#1 0x0000ffffa9642df4 in __GI_abort () at abort.c:89
#2 0x0000ffff9d306e40 in __gnu_cxx::__verbose_terminate_handler() ()
from /usr/lib/aarch64-linux-gnu/libstdc++.so.6
#3 0x0000ffff9d304d4c in ?? () from /usr/lib/aarch64-linux-gnu/libstdc++.so.6
#4 0x0000ffff9d304d98 in std::terminate() () from
/usr/lib/aarch64-linux-gnu/libstdc++.so.6
#5 0x0000ffff9d30501c in __cxa_throw () from
/usr/lib/aarch64-linux-gnu/libstdc++.so.6
#6 0x0000ffff9d32d4bc in std::__throw_bad_function_call() () from
/usr/lib/aarch64-linux-gnu/libstdc++.so.6
#7 0x0000ffff9eac7dc4 in ?? () from /usr/lib/aarch64-linux-gnu/libLLVM-5.0.so.1
#8 0x0000aaaadd2dced0 in ?? ()
#9 0x0000000040100401 in ?? ()
Backtrace stopped: previous frame identical to this frame (corrupt stack?)
(gdb)
Configure was run like this:
./configure \
--prefix=$HOME/install \
--enable-cassert \
--enable-debug \
--with-llvm \
CC="ccache gcc" \
CXX="ccache g++" \
CLANG="ccache /usr/lib/llvm-3.9/bin/clang" \
LLVM_CONFIG="/usr/lib/llvm-3.9/bin/llvm-config"
I can provide access to this thing if you think that'd be useful.
--
Thomas Munro
http://www.enterprisedb.com
Hi,
On 2018-03-21 20:06:49 +1300, Thomas Munro wrote:
> On Wed, Mar 21, 2018 at 4:07 PM, Andres Freund <andres@anarazel.de> wrote:
> > Indeed. I've pushed a rebased version now, that basically just fixes the
> > issue Thomas observed.
>
> I set up a 32 bit i386 virtual machine and installed Debian 9.4.
> Compiler warnings:
Was that with a 64bit CPU and 32bit OS, or actually a 32bit CPU?
> gcc -Wall -Wmissing-prototypes -Wpointer-arith
> -Wdeclaration-after-statement -Wendif-labels
> -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing
> -fwrapv -fexcess-precision=standard -g -O2 -fPIC
> -D__STDC_LIMIT_MACROS -D__STDC_FORMAT_MACROS -D__STDC_CONSTANT_MACROS
> -D_GNU_SOURCE -I/usr/lib/llvm-3.9/include -I../../../../src/include
> -D_GNU_SOURCE -c -o llvmjit.o llvmjit.c
> llvmjit.c: In function ‘llvm_get_function’:
> llvmjit.c:268:10: warning: cast to pointer from integer of different
> size [-Wint-to-pointer-cast]
> return (void *) addr;
> ^
> llvmjit.c:270:10: warning: cast to pointer from integer of different
> size [-Wint-to-pointer-cast]
> return (void *) addr;
> ^
> llvmjit.c: In function ‘llvm_resolve_symbol’:
> llvmjit.c:842:10: warning: cast from pointer to integer of different
> size [-Wpointer-to-int-cast]
> addr = (uint64_t) load_external_function(modname, funcname,
> ^
> llvmjit.c:845:10: warning: cast from pointer to integer of different
> size [-Wpointer-to-int-cast]
> addr = (uint64_t) LLVMSearchForAddressOfSymbol(symname);
> ^
Hrmpf, those need to be fixed.
> While trying out many combinations of versions of stuff on different
> OSes, I found another way to screw up that I wanted to report here.
> It's obvious that this is doomed if you know what's going on, but I
> thought the failure mode was interesting enough to report here. There
> is a hazard for people running systems where the vendor ships some
> version (possibly a mystery version) of clang in the PATH but you have
> to get LLVM separately (eg from ports/brew/whatever):
> 1. If you use macOS High Sierra's current /usr/bin/clang ("9.0.0"),
> ie the default if you didn't set CLANG to something else when you ran
> ./configure, and you build against LLVM 3.9, then llvm-lto gives this
> message during "make install":
>
> Invalid summary version 3, 1 expected
> error: can't create ModuleSummaryIndexObjectFile for buffer: Corrupted bitcode
>
> Then it segfaults!
Gah, that's not desirable :/. It's fine that it doesn't work, but it'd
be better if it didn't segfault. I guess I could just try by corrupting
the file explicitly...
> Neither of these cases should be too surprising, and users of those
> operating systems can easily get a newer LLVM or an older -- it was
> just interesting to see exactly what goes wrong and exactly when. I
> suppose there could be a configure test to see if your $CLANG can play
> nicely with your $LLVM_CONFIG.
Not precisely sure how. I think suggesting to use compatible clang is
going to be sufficient for most cases...
Greetings,
Andres Freund
On Thu, Mar 22, 2018 at 8:47 AM, Andres Freund <andres@anarazel.de> wrote: > On 2018-03-21 20:06:49 +1300, Thomas Munro wrote: >> On Wed, Mar 21, 2018 at 4:07 PM, Andres Freund <andres@anarazel.de> wrote: >> > Indeed. I've pushed a rebased version now, that basically just fixes the >> > issue Thomas observed. >> >> I set up a 32 bit i386 virtual machine and installed Debian 9.4. >> Compiler warnings: > > Was that with a 64bit CPU and 32bit OS, or actually a 32bit CPU? 64 bit CPU, 32 bit OS. I didn't try Debian multi-arch i386 support on an amd64 system, but that's probably an easier way to do this if you already have one of those... -- Thomas Munro http://www.enterprisedb.com
Hi, On 2018-03-21 08:26:28 +0100, Catalin Iacob wrote: > On Wed, Mar 21, 2018 at 4:07 AM, Andres Freund <andres@anarazel.de> wrote: > > Indeed. I've pushed a rebased version now, that basically just fixes the > > issue Thomas observed. > > Testing 2d6f2fba from your repository configured --with-llvm I noticed > some weird things in the configure output. Thanks! > Without --enable-debug: > configure: using compiler=gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-16) > configure: using CFLAGS=-Wall -Wmissing-prototypes -Wpointer-arith > -Wdeclaration-after-statement -Wendif-labels > -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing > -fwrapv -fexcess-precision=standard -O2 > configure: using CPPFLAGS= -D_GNU_SOURCE > configure: using LDFLAGS= -L/opt/rh/llvm-toolset-7/root/usr/lib64 > -Wl,--as-needed > configure: using CXX=g++ > configure: using CXXFLAGS=-Wall -Wpointer-arith -Wendif-labels > -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing > -fwrapv -g -O2 > configure: using CLANG=/opt/rh/llvm-toolset-7/root/usr/bin/clang > configure: using BITCODE_CFLAGS= -fno-strict-aliasing -fwrapv -O2 > configure: using BITCODE_CXXFLAGS= -fno-strict-aliasing -fwrapv -O2 > BITCODE_CXXFLAGS > > With --enable-debug: > configure: using compiler=gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-16) > configure: using CFLAGS=-Wall -Wmissing-prototypes -Wpointer-arith > -Wdeclaration-after-statement -Wendif-labels > -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing > -fwrapv -fexcess-precision=standard -g -O2 > configure: using CPPFLAGS= -D_GNU_SOURCE > configure: using LDFLAGS= -L/opt/rh/llvm-toolset-7/root/usr/lib64 > -Wl,--as-needed > configure: using CXX=g++ > configure: using CXXFLAGS=-Wall -Wpointer-arith -Wendif-labels > -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing > -fwrapv -g -g -O2 > configure: using CLANG=/opt/rh/llvm-toolset-7/root/usr/bin/clang > configure: using BITCODE_CFLAGS= -fno-strict-aliasing -fwrapv -O2 > configure: using BITCODE_CXXFLAGS= -fno-strict-aliasing -fwrapv -O2 > BITCODE_CXXFLAGS > > So I unconditionally get one -g added to CXXFLAGS regardless of > whether I specify --enable-debug or not. And --enable-debug results in > -g -g in CXXFLAGS. Aaah, nice catch. I was missing an unset CXXFLAGS. > BTW, you should probably specify -std=c++11 (or whatever you need) as > various g++ and clang++ versions default to various things. Will the > required C++ standard be based on the requirements of the C++ code in > the PG tree or will you take it from LLVM's CXXFLAGS? It's currently already taken from LLVM's CXXFLAGS if present there, but just specified for LLVM wrapping files. Relevant code is in src/backend/jit/llvm/Makefile: # All files in this directy link to LLVM. CFLAGS += $(LLVM_CFLAGS) CXXFLAGS += $(LLVM_CXXFLAGS) override CPPFLAGS := $(LLVM_CPPFLAGS) $(CPPFLAGS) SHLIB_LINK += $(LLVM_LIBS) Since there's no other C++ code, and I don't forsee anything else, I'm not planning to set the global CXXFLAGS differently atm. Would just make it more complicated to use the right flag from llvm's CXXFLAGSS. > Can --std=c++11 and --std=c++14 compiled .o files be linked together? Yes, with some limitations. In the PG case all the intra-file calls are C ABI, there wouldn't be a problem. > Also, my CXXFLAGS did not get -fexcess-precision=standard neither did > BITCODE_CFLAGS nor BITCODE_CXXFLAGS. Yea, that's to be expected, gcc doesn't know that for C++ on most versions. Some vendors have it patched into. > 2. Unlike all the other *FLAGS, BITCODE_CXXFLAGS includes itself on > the right hand side of the equal > configure: using BITCODE_CXXFLAGS= -fno-strict-aliasing -fwrapv -O2 > BITCODE_CXXFLAGS Hum, that's definitely a typo bug (missing $ when adding to BITCODE_CXXFLAGS). Greetings, Andres Freund
On 2018-03-21 23:10:27 +1300, Thomas Munro wrote: > On Wed, Mar 21, 2018 at 8:06 PM, Thomas Munro > <thomas.munro@enterprisedb.com> wrote: > > On Wed, Mar 21, 2018 at 4:07 PM, Andres Freund <andres@anarazel.de> wrote: > >> Indeed. I've pushed a rebased version now, that basically just fixes the > >> issue Thomas observed. > > > > I set up a 32 bit i386 virtual machine and installed Debian 9.4. > > Next up, I have an arm64 system running Debian 9.4. It bombs in > "make check" and in simple tests: Hum. Is it running a 32bit or 64 bit kernel/os? > Program received signal SIGABRT, Aborted. > __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51 > 51 ../sysdeps/unix/sysv/linux/raise.c: No such file or directory. > (gdb) bt > #0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51 > #1 0x0000ffff8f65adf4 in __GI_abort () at abort.c:89 > #2 0x0000ffff83e2de40 in __gnu_cxx::__verbose_terminate_handler() () > from /usr/lib/aarch64-linux-gnu/libstdc++.so.6 > #3 0x0000ffff83e2bd4c in ?? () from /usr/lib/aarch64-linux-gnu/libstdc++.so.6 > #4 0x0000ffff83e2bd98 in std::terminate() () from > /usr/lib/aarch64-linux-gnu/libstdc++.so.6 > #5 0x0000ffff83e2c01c in __cxa_throw () from > /usr/lib/aarch64-linux-gnu/libstdc++.so.6 > #6 0x0000ffff83e544bc in std::__throw_bad_function_call() () from > /usr/lib/aarch64-linux-gnu/libstdc++.so.6 > #7 0x0000ffff85176a2c in LLVMOrcCreateInstance () from > /usr/lib/aarch64-linux-gnu/libLLVM-3.9.so.1 > #8 0x0000ffff865c4db0 in llvm_session_initialize () at llvmjit.c:643 > #9 llvm_create_context (jitFlags=9) at llvmjit.c:136 > #10 0x0000ffff865cf8c8 in llvm_compile_expr (state=0xaaaaf2300208) at > llvmjit_expr.c:132 Hm. > With LLVM 5.0 (from backports) it seemed to get further (?): > > Program terminated with signal SIGABRT, Aborted. > #0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51 > 51 ../sysdeps/unix/sysv/linux/raise.c: No such file or directory. > (gdb) bt > #0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51 > #1 0x0000ffffa9642df4 in __GI_abort () at abort.c:89 > #2 0x0000ffff9d306e40 in __gnu_cxx::__verbose_terminate_handler() () > from /usr/lib/aarch64-linux-gnu/libstdc++.so.6 > #3 0x0000ffff9d304d4c in ?? () from /usr/lib/aarch64-linux-gnu/libstdc++.so.6 > #4 0x0000ffff9d304d98 in std::terminate() () from > /usr/lib/aarch64-linux-gnu/libstdc++.so.6 > #5 0x0000ffff9d30501c in __cxa_throw () from > /usr/lib/aarch64-linux-gnu/libstdc++.so.6 > #6 0x0000ffff9d32d4bc in std::__throw_bad_function_call() () from > /usr/lib/aarch64-linux-gnu/libstdc++.so.6 > #7 0x0000ffff9eac7dc4 in ?? () from /usr/lib/aarch64-linux-gnu/libLLVM-5.0.so.1 > #8 0x0000aaaadd2dced0 in ?? () > #9 0x0000000040100401 in ?? () > Backtrace stopped: previous frame identical to this frame (corrupt stack?) > (gdb) > > Configure was run like this: > > ./configure \ > --prefix=$HOME/install \ > --enable-cassert \ > --enable-debug \ > --with-llvm \ > CC="ccache gcc" \ > CXX="ccache g++" \ > CLANG="ccache /usr/lib/llvm-3.9/bin/clang" \ > LLVM_CONFIG="/usr/lib/llvm-3.9/bin/llvm-config" I guess you'd swapped out 3.9 for 5.0? > I can provide access to this thing if you think that'd be useful. Perhaps that's necessary. Before that though, could you check how the backtrace looks with LLVM debug symbols installed? Greetings, Andres Freund
Hi, On 2018-03-22 09:00:19 +1300, Thomas Munro wrote: > On Thu, Mar 22, 2018 at 8:47 AM, Andres Freund <andres@anarazel.de> wrote: > > On 2018-03-21 20:06:49 +1300, Thomas Munro wrote: > >> On Wed, Mar 21, 2018 at 4:07 PM, Andres Freund <andres@anarazel.de> wrote: > >> > Indeed. I've pushed a rebased version now, that basically just fixes the > >> > issue Thomas observed. > >> > >> I set up a 32 bit i386 virtual machine and installed Debian 9.4. > >> Compiler warnings: > > > > Was that with a 64bit CPU and 32bit OS, or actually a 32bit CPU? > > 64 bit CPU, 32 bit OS. I didn't try Debian multi-arch i386 support on > an amd64 system, but that's probably an easier way to do this if you > already have one of those... Ah, then I think I might know what happend. Does it start to work if you replace the auto-detected cpu with "x86"? I think what might happen is that it generates 64bit code, because of the detected CPU name. Let me set up a chroot, in this case I should be able to emulate this pretty easily... Greetings, Andres Freund
On Thu, Mar 22, 2018 at 9:06 AM, Andres Freund <andres@anarazel.de> wrote: > On 2018-03-21 23:10:27 +1300, Thomas Munro wrote: >> Next up, I have an arm64 system running Debian 9.4. It bombs in >> "make check" and in simple tests: > > Hum. Is it running a 32bit or 64 bit kernel/os? checking size of void *... 8 >> ./configure \ >> --prefix=$HOME/install \ >> --enable-cassert \ >> --enable-debug \ >> --with-llvm \ >> CC="ccache gcc" \ >> CXX="ccache g++" \ >> CLANG="ccache /usr/lib/llvm-3.9/bin/clang" \ >> LLVM_CONFIG="/usr/lib/llvm-3.9/bin/llvm-config" > > I guess you'd swapped out 3.9 for 5.0? Right, in the second backtrace I showed it was 5.0 (for both clang and llvm-config). >> I can provide access to this thing if you think that'd be useful. > > Perhaps that's necessary. Before that though, could you check how the > backtrace looks with LLVM debug symbols installed? After installing libllvm3.9-dgb: (gdb) bt #0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51 #1 0x0000ffffa1ae1df4 in __GI_abort () at abort.c:89 #2 0x0000ffff9634ee40 in __gnu_cxx::__verbose_terminate_handler() () from /usr/lib/aarch64-linux-gnu/libstdc++.so.6 #3 0x0000ffff9634cd4c in ?? () from /usr/lib/aarch64-linux-gnu/libstdc++.so.6 #4 0x0000ffff9634cd98 in std::terminate() () from /usr/lib/aarch64-linux-gnu/libstdc++.so.6 #5 0x0000ffff9634d01c in __cxa_throw () from /usr/lib/aarch64-linux-gnu/libstdc++.so.6 #6 0x0000ffff963754bc in std::__throw_bad_function_call() () from /usr/lib/aarch64-linux-gnu/libstdc++.so.6 warning: Could not find DWO CU CMakeFiles/LLVMOrcJIT.dir/OrcCBindings.cpp.dwo(0x691f70a1d71f901d) referenced by CU at offset 0x11ffa [in module /usr/lib/debug/.build-id/09/04bb3e707305e175216a59bc3598c2b194775a.debug] #7 0x0000ffff97697a2c in LLVMOrcCreateInstance () at /usr/include/c++/6/functional:2126 #8 0x0000ffff98accdb0 in llvm_session_initialize () at llvmjit.c:643 #9 llvm_create_context (jitFlags=9) at llvmjit.c:136 #10 0x0000ffff98ad78c8 in llvm_compile_expr (state=0xaaaafce73208) at llvmjit_expr.c:132 #11 0x0000aaaac1bd671c in ExecReadyExpr (state=state@entry=0xaaaafce73208) at execExpr.c:627 #12 0x0000aaaac1bd97b8 in ExecBuildProjectionInfo (targetList=<optimized out>, econtext=<optimized out>, slot=<optimized out>, parent=parent@entry=0xaaaafce72de0, inputDesc=inputDesc@entry=0x0) at execExpr.c:471 #13 0x0000aaaac1bec028 in ExecAssignProjectionInfo (planstate=planstate@entry=0xaaaafce72de0, inputDesc=inputDesc@entry=0x0) at execUtils.c:460 #14 0x0000aaaac1c08a28 in ExecInitResult (node=node@entry=0xaaaafcdc11a0, estate=estate@entry=0xaaaafce72bc8, eflags=eflags@entry=16) at nodeResult.c:221 #15 0x0000aaaac1be7828 in ExecInitNode (node=0xaaaafcdc11a0, node@entry=0xaaaafcded630, estate=estate@entry=0xaaaafce72bc8, eflags=eflags@entry=16) at execProcnode.c:164 #16 0x0000aaaac1be2a70 in InitPlan (eflags=16, queryDesc=0xaaaafcde0808) at execMain.c:1051 #17 standard_ExecutorStart (queryDesc=0xaaaafcde0808, eflags=16) at execMain.c:266 #18 0x0000aaaac1d39bec in PortalStart (portal=0x400, portal@entry=0xaaaafce234d8, params=0x274580612ce0a285, params@entry=0x0, eflags=43690, eflags@entry=0, snapshot=0xaaaac1fa9f58, snapshot@entry=0x0) at pquery.c:520 #19 0x0000aaaac1d34b18 in exec_simple_query (query_string=query_string@entry=0xaaaafcdbf3d8 "select 42;") at postgres.c:1082 #20 0x0000aaaac1d366a8 in PostgresMain (argc=<optimized out>, argv=argv@entry=0xaaaafcdebb90, dbname=<optimized out>, username=<optimized out>) at postgres.c:4147 #21 0x0000aaaac1a28dd0 in BackendRun (port=0xaaaafcde0410) at postmaster.c:4409 #22 BackendStartup (port=0xaaaafcde0410) at postmaster.c:4081 #23 ServerLoop () at postmaster.c:1754 #24 0x0000aaaac1cb7048 in PostmasterMain (argc=<optimized out>, argv=<optimized out>) at postmaster.c:1362 #25 0x0000aaaac1a2a7cc in main (argc=3, argv=0xaaaafcdb9f70) at main.c:228 GDB also printed a ton of messages like this for many LLVM .cpp files: warning: Could not find DWO CU CMakeFiles/LLVMLibDriver.dir/LibDriver.cpp.dwo(0x117022032f862080) referenced by CU at offset 0x187da [in module /usr/lib/debug/.build-id/09/04bb3e707305e175216a59bc3598c2b194775a.debug] ... We can see that it's missing some debug info, any clues about that? Here's LLVM 3.9's LLVMOrcCreateInstance function: https://github.com/llvm-mirror/llvm/blob/6531c3164cb9edbfb9f4b43ca383810a94ca5aa0/lib/ExecutionEngine/Orc/OrcCBindings.cpp#L15 Without digging through more source code I'm not sure which line of that is invoking our uninvocable std::function... The server also prints this: terminate called after throwing an instance of 'std::bad_function_call' what(): bad_function_call Aside from whatever problem is causing this, we can see that there is no top-level handling of exceptions. That's probably fine if we are in a no throw scenario (unless there is something seriously corrupted, as is probably the case here), and it seems that we must be because we're accessing this code via its C API. -- Thomas Munro http://www.enterprisedb.com
Andres Freund <andres@anarazel.de> writes: > Hi, > > On 2018-03-21 20:06:49 +1300, Thomas Munro wrote: >> On Wed, Mar 21, 2018 at 4:07 PM, Andres Freund <andres@anarazel.de> wrote: >> > Indeed. I've pushed a rebased version now, that basically just fixes the >> > issue Thomas observed. >> >> I set up a 32 bit i386 virtual machine and installed Debian 9.4. >> Compiler warnings: > > Was that with a 64bit CPU and 32bit OS, or actually a 32bit CPU? > > >> gcc -Wall -Wmissing-prototypes -Wpointer-arith >> -Wdeclaration-after-statement -Wendif-labels >> -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing >> -fwrapv -fexcess-precision=standard -g -O2 -fPIC >> -D__STDC_LIMIT_MACROS -D__STDC_FORMAT_MACROS -D__STDC_CONSTANT_MACROS >> -D_GNU_SOURCE -I/usr/lib/llvm-3.9/include -I../../../../src/include >> -D_GNU_SOURCE -c -o llvmjit.o llvmjit.c >> llvmjit.c: In function ‘llvm_get_function’: >> llvmjit.c:268:10: warning: cast to pointer from integer of different >> size [-Wint-to-pointer-cast] >> return (void *) addr; >> ^ >> llvmjit.c:270:10: warning: cast to pointer from integer of different >> size [-Wint-to-pointer-cast] >> return (void *) addr; >> ^ >> llvmjit.c: In function ‘llvm_resolve_symbol’: >> llvmjit.c:842:10: warning: cast from pointer to integer of different >> size [-Wpointer-to-int-cast] >> addr = (uint64_t) load_external_function(modname, funcname, >> ^ >> llvmjit.c:845:10: warning: cast from pointer to integer of different >> size [-Wpointer-to-int-cast] >> addr = (uint64_t) LLVMSearchForAddressOfSymbol(symname); >> ^ > > Hrmpf, those need to be fixed. How about using uintptr_t is for this? I see configure.in includes AC_TYPE_UINTPTR_T, which probes for an existing uintptr_t or defines it as an alias for the appropriate unsinged (long (long)) int type. - ilmari -- - Twitter seems more influential [than blogs] in the 'gets reported in the mainstream press' sense at least. - Matt McLeod - That'd be because the content of a tweet is easier to condense down to a mainstream media article. - Calle Dybedahl
On Thu, Mar 22, 2018 at 9:09 AM, Andres Freund <andres@anarazel.de> wrote: > Hi, > > On 2018-03-22 09:00:19 +1300, Thomas Munro wrote: >> 64 bit CPU, 32 bit OS. I didn't try Debian multi-arch i386 support on >> an amd64 system, but that's probably an easier way to do this if you >> already have one of those... > > Ah, then I think I might know what happend. Does it start to work if you > replace the auto-detected cpu with "x86"? I think what might happen is > that it generates 64bit code, because of the detected CPU name. Hah, that makes sense. I tried setting cpu to "x86", and now it fails differently: Program terminated with signal SIGSEGV, Segmentation fault. #0 malloc_printerr (action=3, str=0xb7682d00 "free(): invalid pointer", ptr=0xae75f27b, ar_ptr=0xae700220 <llvm::SystemZ::GRX32BitRegClass>) at malloc.c:5036 5036 malloc.c: No such file or directory. (gdb) bt #0 malloc_printerr (action=3, str=0xb7682d00 "free(): invalid pointer", ptr=0xae75f27b, ar_ptr=0xae700220 <llvm::SystemZ::GRX32BitRegClass>) at malloc.c:5036 #1 0xb7593806 in _int_free (av=0xae700220 <llvm::SystemZ::GRX32BitRegClass>, p=0xae75f273, have_lock=0) at malloc.c:3905 #2 0xabd05cd8 in LLVMDisposeMessage () from /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1 #3 0xae75100b in llvm_session_initialize () at llvmjit.c:636 #4 llvm_create_context (jitFlags=15) at llvmjit.c:136 #5 0xae75d3e9 in llvm_compile_expr (state=0x2616e60) at llvmjit_expr.c:132 #6 0x00650118 in ExecReadyExpr (state=state@entry=0x2616e60) at execExpr.c:627 #7 0x00652dd7 in ExecInitExpr (node=0x2666bb4, parent=0x261693c) at execExpr.c:144 ... -- Thomas Munro http://www.enterprisedb.com
On 2018-03-22 09:51:01 +1300, Thomas Munro wrote:
> On Thu, Mar 22, 2018 at 9:09 AM, Andres Freund <andres@anarazel.de> wrote:
> > Hi,
> >
> > On 2018-03-22 09:00:19 +1300, Thomas Munro wrote:
> >> 64 bit CPU, 32 bit OS. I didn't try Debian multi-arch i386 support on
> >> an amd64 system, but that's probably an easier way to do this if you
> >> already have one of those...
> >
> > Ah, then I think I might know what happend. Does it start to work if you
> > replace the auto-detected cpu with "x86"? I think what might happen is
> > that it generates 64bit code, because of the detected CPU name.
>
> Hah, that makes sense. I tried setting cpu to "x86", and now it fails
> differently:
Did you change the variable, or replace the value that's passed to the
LLVMCreateTargetMachine() calls? If you did the former, the error
wouldn't be surprising, because
LLVMDisposeMessage(cpu);
cpu = NULL;
will attempt to free the return value of LLVMGetHostCPUName(), which'll
obviously not work if you just set to a constant.
> #1 0xb7593806 in _int_free (av=0xae700220
> <llvm::SystemZ::GRX32BitRegClass>, p=0xae75f273, have_lock=0) at
> malloc.c:3905
> #2 0xabd05cd8 in LLVMDisposeMessage () from
> /usr/lib/i386-linux-gnu/libLLVM-3.9.so.1
> #3 0xae75100b in llvm_session_initialize () at llvmjit.c:636
> #4 llvm_create_context (jitFlags=15) at llvmjit.c:136
> #5 0xae75d3e9 in llvm_compile_expr (state=0x2616e60) at llvmjit_expr.c:132
> #6 0x00650118 in ExecReadyExpr (state=state@entry=0x2616e60) at execExpr.c:627
> #7 0x00652dd7 in ExecInitExpr (node=0x2666bb4, parent=0x261693c) at
> execExpr.c:144
> ...
FWIW, a 32bit chroot, on a 64bit kernel works:
2018-03-21 20:57:56.576 UTC [3708] DEBUG: successfully loaded LLVM in current session
2018-03-21 20:57:56.577 UTC [3708] DEBUG: JIT detected CPU "skylake", with features
"+sse2,+cx16,-tbm,-avx512ifma,-avx512dq,-fma4,+prfchw,+bmi2,+xsavec,+fsgsbase,+popcnt,+aes,-pcommit,+xsaves,-avx512er,-clwb,-avx512f,-pku,+smap,+mmx,-xop,+rdseed,+hle,-sse4a,-avx512bw,+clflushopt,+xsave,-avx512vl,+invpcid,-avx512cd,+avx,+rtm,+fma,+bmi,-mwaitx,+rdrnd,+sse4.1,+sse4.2,+avx2,+sse,+lzcnt,+pclmul,-prefetchwt1,+f16c,+ssse3,+sgx,+cmov,-avx512vbmi,+movbe,+xsaveopt,-sha,+adx,-avx512pf,+sse3"
2018-03-21 20:57:56.579 UTC [3708] DEBUG: time to inline: 0.000s, opt: 0.000s, emit: 0.002s
that's debian testing though.
Greetings,
Andres Freund
On Thu, Mar 22, 2018 at 9:59 AM, Andres Freund <andres@anarazel.de> wrote:
> On 2018-03-22 09:51:01 +1300, Thomas Munro wrote:
>> Hah, that makes sense. I tried setting cpu to "x86", and now it fails
>> differently:
>
> Did you change the variable, or replace the value that's passed to the
> LLVMCreateTargetMachine() calls? If you did the former, the error
> wouldn't be surprising, because
> LLVMDisposeMessage(cpu);
> cpu = NULL;
> will attempt to free the return value of LLVMGetHostCPUName(), which'll
> obviously not work if you just set to a constant.
Duh. Right.
> FWIW, a 32bit chroot, on a 64bit kernel works:
>
> 2018-03-21 20:57:56.576 UTC [3708] DEBUG: successfully loaded LLVM in current session
> 2018-03-21 20:57:56.577 UTC [3708] DEBUG: JIT detected CPU "skylake", with features
"+sse2,+cx16,-tbm,-avx512ifma,-avx512dq,-fma4,+prfchw,+bmi2,+xsavec,+fsgsbase,+popcnt,+aes,-pcommit,+xsaves,-avx512er,-clwb,-avx512f,-pku,+smap,+mmx,-xop,+rdseed,+hle,-sse4a,-avx512bw,+clflushopt,+xsave,-avx512vl,+invpcid,-avx512cd,+avx,+rtm,+fma,+bmi,-mwaitx,+rdrnd,+sse4.1,+sse4.2,+avx2,+sse,+lzcnt,+pclmul,-prefetchwt1,+f16c,+ssse3,+sgx,+cmov,-avx512vbmi,+movbe,+xsaveopt,-sha,+adx,-avx512pf,+sse3"
> 2018-03-21 20:57:56.579 UTC [3708] DEBUG: time to inline: 0.000s, opt: 0.000s, emit: 0.002s
>
> that's debian testing though.
Hmm. So now I'm doing this:
llvm_opt0_targetmachine =
- LLVMCreateTargetMachine(llvm_targetref, llvm_triple,
cpu, features,
+ LLVMCreateTargetMachine(llvm_targetref, llvm_triple,
"x86" /*cpu*/, "" /*features*/,
LLVMCodeGenLevelNone,
LLVMRelocDefault,
LLVMCodeModelJITDefault);
llvm_opt3_targetmachine =
- LLVMCreateTargetMachine(llvm_targetref, llvm_triple,
cpu, features,
+ LLVMCreateTargetMachine(llvm_targetref, llvm_triple,
"x86" /*cpu*/, "" /*features*/,
LLVMCodeGenLevelAggressive,
LLVMRelocDefault,
LLVMCodeModelJITDefault);
And I'm still getting a segfault:
(gdb)
#0 0xac22c453 in llvm::SelectionDAG::getNode(unsigned int,
llvm::SDLoc const&, llvm::EVT, llvm::SDValue) () at
/build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/CodeGen/SelectionDAG/SelectionDAG.cpp:2898
#1 0xac269c29 in llvm::TargetLowering::SimplifySetCC(llvm::EVT,
llvm::SDValue, llvm::SDValue, llvm::ISD::CondCode, bool,
llvm::TargetLowering::DAGCombinerInfo&, llvm::SDLoc const&) const ()
at /build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/CodeGen/SelectionDAG/TargetLowering.cpp:1480
#2 0xac1163a8 in (anonymous
namespace)::DAGCombiner::visit(llvm::SDNode*) () at
/build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/CodeGen/SelectionDAG/DAGCombiner.cpp:14438
#3 0xac117f0b in (anonymous
namespace)::DAGCombiner::combine(llvm::SDNode*) () at
/build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/CodeGen/SelectionDAG/DAGCombiner.cpp:1449
#4 0xac11930e in llvm::SelectionDAG::Combine(llvm::CombineLevel,
llvm::AAResults&, llvm::CodeGenOpt::Level) () at
/build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/CodeGen/SelectionDAG/DAGCombiner.cpp:1303
#5 0xac245cec in llvm::SelectionDAGISel::CodeGenAndEmitDAG() () at
/build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/CodeGen/SelectionDAG/SelectionDAGISel.cpp:755
#6 0xac246239 in
llvm::SelectionDAGISel::SelectBasicBlock(llvm::ilist_iterator<llvm::Instruction
const>, llvm::ilist_iterator<llvm::Instruction const>, bool&) ()
at /build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/CodeGen/SelectionDAG/SelectionDAGISel.cpp:679
#7 0xac24d66f in
llvm::SelectionDAGISel::SelectAllBasicBlocks(llvm::Function const&) ()
at /build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/CodeGen/SelectionDAG/SelectionDAGISel.cpp:1482
#8 0xac25073c in
llvm::SelectionDAGISel::runOnMachineFunction(llvm::MachineFunction&)
() at /build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/CodeGen/SelectionDAG/SelectionDAGISel.cpp:500
#9 0xad34f414 in (anonymous
namespace)::X86DAGToDAGISel::runOnMachineFunction(llvm::MachineFunction&)
() at /build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/Target/X86/X86ISelDAGToDAG.cpp:175
#10 0xabf53019 in
llvm::MachineFunctionPass::runOnFunction(llvm::Function&) () at
/build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/CodeGen/MachineFunctionPass.cpp:60
#11 0xabde8aeb in llvm::FPPassManager::runOnFunction(llvm::Function&)
() at /build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/IR/LegacyPassManager.cpp:1526
#12 0xabde8e35 in llvm::FPPassManager::runOnModule(llvm::Module&) ()
at /build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/IR/LegacyPassManager.cpp:1547
#13 0xabde919a in llvm::legacy::PassManagerImpl::run(llvm::Module&) ()
at /build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/IR/LegacyPassManager.cpp:1603
#14 0xabde937f in llvm::legacy::PassManager::run(llvm::Module&) () at
/build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/IR/LegacyPassManager.cpp:1737
#15 0xacb353de in
std::_Function_handler<llvm::object::OwningBinary<llvm::object::ObjectFile>
(llvm::Module&), llvm::orc::SimpleCompiler>::_M_invoke(std::_Any_data
const&, llvm::Module&) ()
at /build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/include/llvm/ExecutionEngine/Orc/CompileUtils.h:42
#16 0xacb30d00 in
std::_List_iterator<std::unique_ptr<llvm::orc::ObjectLinkingLayerBase::LinkedObjectSet,
std::default_delete<llvm::orc::ObjectLinkingLayerBase::LinkedObjectSet>
> > llvm::orc::IRCompileLayer<llvm::orc::ObjectLinkingLayer<llvm::orc::DoNothingOnNotifyLoaded>
>::addModuleSet<std::vector<llvm::Module*,
std::allocator<llvm::Module*> >,
std::unique_ptr<llvm::RuntimeDyld::MemoryManager,
std::default_delete<llvm::RuntimeDyld::MemoryManager> >,
std::unique_ptr<llvm::RuntimeDyld::SymbolResolver,
std::default_delete<llvm::RuntimeDyld::SymbolResolver> >
>(std::vector<llvm::Module*, std::allocator<llvm::Module*> >,
std::unique_ptr<llvm::RuntimeDyld::MemoryManager,
std::default_delete<llvm::RuntimeDyld::MemoryManager> >,
std::unique_ptr<llvm::RuntimeDyld::SymbolResolver,
std::default_delete<llvm::RuntimeDyld::SymbolResolver> >) () at
/usr/include/c++/6/functional:2127
#17 0xacb314f8 in unsigned int
llvm::OrcCBindingsStack::addIRModule<llvm::orc::IRCompileLayer<llvm::orc::ObjectLinkingLayer<llvm::orc::DoNothingOnNotifyLoaded>
> >(llvm::orc::IRCompileLayer<llvm::orc::ObjectLinkingLayer<llvm::orc::DoNothingOnNotifyLoaded>
>&, llvm::Module*, std::unique_ptr<llvm::RuntimeDyld::MemoryManager,
std::default_delete<llvm::RuntimeDyld::MemoryManager> >, unsigned long
long (*)(char const*, void*), void*) ()
at /build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/ExecutionEngine/Orc/OrcCBindingsStack.h:190
#18 0xacb318d5 in LLVMOrcAddEagerlyCompiledIR () at
/build/llvm-toolchain-3.9-UOOPrK/llvm-toolchain-3.9-3.9.1/lib/ExecutionEngine/Orc/OrcCBindingsStack.h:208
#19 0xae7b43f4 in llvm_compile_module (context=0x2438444) at llvmjit.c:539
#20 llvm_get_function (context=0x2438444, funcname=0x2542b00
"evalexpr_2_3") at llvmjit.c:244
#21 0xae7bc34e in ExecRunCompiledExpr (state=0x247d634,
econtext=0x247c10c, isNull=0xbfadf6ae "~") at llvmjit_expr.c:2563
#22 0x006b3e10 in ExecEvalExprSwitchContext (isNull=0xbfadf6ae "~",
econtext=<optimized out>, state=0x247d634) at
../../../src/include/executor/executor.h:305
#23 ExecQual (econtext=<optimized out>, state=0x247d634) at
../../../src/include/executor/executor.h:374
#24 ExecNestLoop (pstate=<optimized out>) at nodeNestloop.c:214
#25 0x006b6ddd in ExecProcNode (node=0x247c080) at
../../../src/include/executor/executor.h:239
#26 ExecSort (pstate=0x247bff4) at nodeSort.c:107
#27 0x0068c9d2 in ExecProcNode (node=0x247bff4) at
../../../src/include/executor/executor.h:239
#28 ExecutePlan (execute_once=<optimized out>, dest=0x0,
direction=NoMovementScanDirection, numberTuples=<optimized out>,
sendTuples=<optimized out>, operation=CMD_SELECT,
use_parallel_mode=<optimized out>, planstate=0x247bff4,
estate=0x247bee8) at execMain.c:1729
#29 standard_ExecutorRun (queryDesc=0x23e1a50,
direction=ForwardScanDirection, count=0, execute_once=1 '\001') at
execMain.c:365
#30 0x007f1e8d in PortalRunSelect (portal=portal@entry=0x240bf58,
forward=forward@entry=1 '\001', count=0, count@entry=2147483647,
dest=0x25383c0) at pquery.c:932
#31 0x007f36a0 in PortalRun (portal=0x240bf58, count=2147483647,
isTopLevel=1 '\001', run_once=1 '\001', dest=0x25383c0,
altdest=0x25383c0, completionTag=0xbfadf940 "") at pquery.c:773
#32 0x007ee8a7 in exec_simple_query
(query_string=query_string@entry=0x23be628 "SELECT '' AS tf_12_ff_4,
BOOLTBL1.*, BOOLTBL2.*\n FROM BOOLTBL1, BOOLTBL2\n WHERE
BOOLTBL2.f1 = BOOLTBL1.f1 or BOOLTBL1.f1 = bool 'true'\n ORDER BY
BOOLTBL1.f1, BOOLTBL2.f1;")
at postgres.c:1121
#33 0x007f070e in PostgresMain (argc=1, argv=0x23e7c44,
dbname=<optimized out>, username=0x23e7aa0 "munro") at postgres.c:4147
#34 0x004c0cff in BackendRun (port=0x23e1518) at postmaster.c:4409
#35 BackendStartup (port=0x23e1518) at postmaster.c:4081
#36 ServerLoop () at postmaster.c:1754
#37 0x0076a68f in PostmasterMain (argc=<optimized out>,
argv=<optimized out>) at postmaster.c:1362
#38 0x004c275a in main (argc=<optimized out>, argv=<optimized out>) at
main.c:228
I wonder what I'm doing wrong... what you're doing is very similar,
right? It's a 32 bit user land on a 64 bit kernel whereas mine is a
32 bit user land on a 32 bit kernel (on a 64 bit CPU).
--
Thomas Munro
http://www.enterprisedb.com
Hi, On 2018-03-22 10:09:23 +1300, Thomas Munro wrote: > > FWIW, a 32bit chroot, on a 64bit kernel works: > > > > 2018-03-21 20:57:56.576 UTC [3708] DEBUG: successfully loaded LLVM in current session > > 2018-03-21 20:57:56.577 UTC [3708] DEBUG: JIT detected CPU "skylake", with features "+sse2,+cx16,-tbm,-avx512ifma,-avx512dq,-fma4,+prfchw,+bmi2,+xsavec,+fsgsbase,+popcnt,+aes,-pcommit,+xsaves,-avx512er,-clwb,-avx512f,-pku,+smap,+mmx,-xop,+rdseed,+hle,-sse4a,-avx512bw,+clflushopt,+xsave,-avx512vl,+invpcid,-avx512cd,+avx,+rtm,+fma,+bmi,-mwaitx,+rdrnd,+sse4.1,+sse4.2,+avx2,+sse,+lzcnt,+pclmul,-prefetchwt1,+f16c,+ssse3,+sgx,+cmov,-avx512vbmi,+movbe,+xsaveopt,-sha,+adx,-avx512pf,+sse3" > > 2018-03-21 20:57:56.579 UTC [3708] DEBUG: time to inline: 0.000s, opt: 0.000s, emit: 0.002s > > > > that's debian testing though. > > Hmm. So now I'm doing this: I've now reproduced this. It actually only fails for *some* queries, a good number works. Investigating. As a random aside, our costing is fairly ridiculous here: ┌──────────────────────────────────────────────────────────────────────────────┐ │ QUERY PLAN │ ├──────────────────────────────────────────────────────────────────────────────┤ │ Sort (cost=1088314.21..1103119.40 rows=5922075 width=34) │ │ Sort Key: booltbl1.f1, booltbl2.f1 │ │ -> Nested Loop (cost=0.00..118524.73 rows=5922075 width=34) │ │ Join Filter: ((booltbl2.f1 = booltbl1.f1) OR booltbl1.f1) │ │ -> Seq Scan on booltbl1 (cost=0.00..38.10 rows=2810 width=1) │ │ -> Materialize (cost=0.00..52.15 rows=2810 width=1) │ │ -> Seq Scan on booltbl2 (cost=0.00..38.10 rows=2810 width=1) │ │ JIT: │ │ Functions: 6 │ │ Inlining: true │ │ Optimization: true │ └──────────────────────────────────────────────────────────────────────────────┘ > I wonder what I'm doing wrong... what you're doing is very similar, > right? It's a 32 bit user land on a 64 bit kernel whereas mine is a > 32 bit user land on a 32 bit kernel (on a 64 bit CPU). I think it's I that did something wrong not you. And the architecture thing is a non-issue, because we're taking the target triple from the right place. I think it's a separate issue. Notably the generated code is apparently corrupt, when reading in the generated bitcode: $ opt-6.0 -O3 -S < /tmp/data/6814.1.bc|less opt-6.0: <stdin>: error: Invalid record (Producer: 'LLVM6.0.0' Reader: 'LLVM 6.0.0') I suspect there's a 32bit vs 64bit confusion in the expression code somewhere, might've accidentally used a 64bit type for Datum somewhere or such. Will compile an LLVM with assertions enabled, to figure this out (which verifies this kinda thing). Greetings, Andres Freund
Hi, On 2018-03-21 14:21:01 -0700, Andres Freund wrote: > I think it's I that did something wrong not you. And the architecture > thing is a non-issue, because we're taking the target triple from the > right place. I think it's a separate issue. Notably the generated code > is apparently corrupt, when reading in the generated bitcode: > > $ opt-6.0 -O3 -S < /tmp/data/6814.1.bc|less > opt-6.0: <stdin>: error: Invalid record (Producer: 'LLVM6.0.0' Reader: 'LLVM 6.0.0') > > I suspect there's a 32bit vs 64bit confusion in the expression code > somewhere, might've accidentally used a 64bit type for Datum somewhere > or such. Will compile an LLVM with assertions enabled, to figure this > out (which verifies this kinda thing). Yup, that's it. Found it by searching for 64bit references, while LLVM was compiling. I've pushed quickfixes (for the 32 warnings, as well as for the 32bit x86 issue, as for configure typos). Passes PGOPTIONS='-c jit_above_cost=0' make -s check now. I'll still run 32bit through an LLVM w/ assert run once finished (takes ~30min to compile LLVM). Greetings, Andres Freund
Hi, On 2018-03-21 23:10:27 +1300, Thomas Munro wrote: > Next up, I have an arm64 system running Debian 9.4. It bombs in > "make check" and in simple tests: Any chance you could try w/ LLVM 6? It looks like some parts of ORC only got aarch64 in LLVM 6. I didn't *think* those were necessary, but given the backtrace it looks like that still might be relevant. Greetings, Andres Freund
On Thu, Mar 22, 2018 at 10:36 AM, Andres Freund <andres@anarazel.de> wrote: > On 2018-03-21 14:21:01 -0700, Andres Freund wrote: >> I think it's I that did something wrong not you. And the architecture >> thing is a non-issue, because we're taking the target triple from the >> right place. I think it's a separate issue. Notably the generated code >> is apparently corrupt, when reading in the generated bitcode: >> >> $ opt-6.0 -O3 -S < /tmp/data/6814.1.bc|less >> opt-6.0: <stdin>: error: Invalid record (Producer: 'LLVM6.0.0' Reader: 'LLVM 6.0.0') >> >> I suspect there's a 32bit vs 64bit confusion in the expression code >> somewhere, might've accidentally used a 64bit type for Datum somewhere >> or such. Will compile an LLVM with assertions enabled, to figure this >> out (which verifies this kinda thing). > > Yup, that's it. Found it by searching for 64bit references, while LLVM > was compiling. I've pushed quickfixes (for the 32 warnings, as well as > for the 32bit x86 issue, as for configure typos). Looks good here too. -- Thomas Munro http://www.enterprisedb.com
Hi, On 2018-03-22 09:31:12 +1300, Thomas Munro wrote: > Aside from whatever problem is causing this, we can see that there is > no top-level handling of exceptions. That's probably fine if we are > in a no throw scenario (unless there is something seriously corrupted, > as is probably the case here), and it seems that we must be because > we're accessing this code via its C API. Yea, it should only happen in abort() type situations. Notably LLVM doesn't even default to enabling exceptions... Greetings, Andres Freund
On Thu, Mar 22, 2018 at 10:44 AM, Andres Freund <andres@anarazel.de> wrote: > On 2018-03-21 23:10:27 +1300, Thomas Munro wrote: >> Next up, I have an arm64 system running Debian 9.4. It bombs in >> "make check" and in simple tests: > > Any chance you could try w/ LLVM 6? It looks like some parts of ORC > only got aarch64 in LLVM 6. I didn't *think* those were necessary, but > given the backtrace it looks like that still might be relevant. Hmm. There is no LLVM 6 in backports. I'll have to build it, which I'm happy to do if I can wrap my brain around its cmake build system (or for you to build it if you want), but it may take... who knows, a day? on this little thing. If that turns out to be it I guess we'd need to figure out how to detect an LLVM with bits missing hand handle it more gracefully? -- Thomas Munro http://www.enterprisedb.com
On Thu, Mar 22, 2018 at 10:50 AM, Thomas Munro <thomas.munro@enterprisedb.com> wrote: > On Thu, Mar 22, 2018 at 10:44 AM, Andres Freund <andres@anarazel.de> wrote: >> On 2018-03-21 23:10:27 +1300, Thomas Munro wrote: >>> Next up, I have an arm64 system running Debian 9.4. It bombs in >>> "make check" and in simple tests: >> >> Any chance you could try w/ LLVM 6? It looks like some parts of ORC >> only got aarch64 in LLVM 6. I didn't *think* those were necessary, but >> given the backtrace it looks like that still might be relevant. > > Hmm. There is no LLVM 6 in backports. I'll have to build it, which > I'm happy to do if I can wrap my brain around its cmake build system > (or for you to build it if you want), but it may take... who knows, a > day? on this little thing. Actually scratch that, I'll just install buster. More soon. -- Thomas Munro http://www.enterprisedb.com
On 2018-03-22 10:50:52 +1300, Thomas Munro wrote: > On Thu, Mar 22, 2018 at 10:44 AM, Andres Freund <andres@anarazel.de> wrote: > > On 2018-03-21 23:10:27 +1300, Thomas Munro wrote: > >> Next up, I have an arm64 system running Debian 9.4. It bombs in > >> "make check" and in simple tests: > > > > Any chance you could try w/ LLVM 6? It looks like some parts of ORC > > only got aarch64 in LLVM 6. I didn't *think* those were necessary, but > > given the backtrace it looks like that still might be relevant. > > Hmm. There is no LLVM 6 in backports. I think there now is: https://packages.debian.org/search?keywords=llvm&searchon=names§ion=all&suite=stretch-backports Package llvm-6.0-dev stretch-backports (devel): Modular compiler and toolchain technologies, libraries and headers 1:6.0-1~bpo9+1: amd64 It's a recent addition: llvm-toolchain-6.0 (1:6.0-1~bpo9+1) stretch-backports; urgency=medium * Team upload * Rebuild for stretch-backports. -- Anton Gladky <gladk@debian.org> Mon, 12 Mar 2018 18:58:43 +0100 Otherwise I think LLVM has a repo with the necessary bits: http://apt.llvm.org/ But if it's not this, I think we're going to have to indeed build LLVM. Without proper debugging symbols it's going to be hard to figure this out otherwise. FWIW, I build it with: mkdir -p ~/build/llvm/debug/vpath cd ~/build/llvm/debug/vpath cmake -G Ninja ~/src/llvm/ -DCMAKE_INSTALL_PREFIX=/home/andres/build/llvm/debug/install -DBUILD_SHARED_LIBS=true -DLLVM_TARGETS_TO_BUILD='X86;BPF'-DLLVM_CCACHE_BUILD=true ninja -j8 install I suspect you'd need to replace X86 with AArch64 (BPF isn't needed, that's for stuff unrelated to PG). > If that turns out to be it I guess we'd need to figure out how to > detect an LLVM with bits missing hand handle it more gracefully? Yea :/. Greetings, Andres Freund
On Thu, Mar 22, 2018 at 10:59 AM, Andres Freund <andres@anarazel.de> wrote: > On 2018-03-22 10:50:52 +1300, Thomas Munro wrote: >> Hmm. There is no LLVM 6 in backports. > > I think there now is: > https://packages.debian.org/search?keywords=llvm&searchon=names§ion=all&suite=stretch-backports > > Package llvm-6.0-dev > > stretch-backports (devel): Modular compiler and toolchain technologies, libraries and headers > 1:6.0-1~bpo9+1: amd64 > > It's a recent addition: > > llvm-toolchain-6.0 (1:6.0-1~bpo9+1) stretch-backports; urgency=medium > > * Team upload > * Rebuild for stretch-backports. > > -- Anton Gladky <gladk@debian.org> Mon, 12 Mar 2018 18:58:43 +0100 Huh, it hasn't made it to my mirror yet. Anyway, I upgraded and built with LLVM 6 and make check now passes on my arm64 system. Woohoo! Via an off-list exchange I learned that Andres suspects a bug in LLVM 3.9 on arm64 and will investigate/maybe file a bug report with LLVM. Not sure if we'll want to try to actively identify and avoid known buggy versions or not? -- Thomas Munro http://www.enterprisedb.com
Hi, On 2018-03-22 11:36:47 +1300, Thomas Munro wrote: > On Thu, Mar 22, 2018 at 10:59 AM, Andres Freund <andres@anarazel.de> wrote: > > On 2018-03-22 10:50:52 +1300, Thomas Munro wrote: > >> Hmm. There is no LLVM 6 in backports. > > > > I think there now is: > > https://packages.debian.org/search?keywords=llvm&searchon=names§ion=all&suite=stretch-backports > > > > Package llvm-6.0-dev > > > > stretch-backports (devel): Modular compiler and toolchain technologies, libraries and headers > > 1:6.0-1~bpo9+1: amd64 > > > > It's a recent addition: > > > > llvm-toolchain-6.0 (1:6.0-1~bpo9+1) stretch-backports; urgency=medium > > > > * Team upload > > * Rebuild for stretch-backports. > > > > -- Anton Gladky <gladk@debian.org> Mon, 12 Mar 2018 18:58:43 +0100 > > Huh, it hasn't made it to my mirror yet. Interesting. > Anyway, I upgraded and built with LLVM 6 and make check now passes on > my arm64 system. Woohoo! Yay, thanks for testing! > Via an off-list exchange I learned that Andres suspects a bug in LLVM > 3.9 on arm64 and will investigate/maybe file a bug report with LLVM. > Not sure if we'll want to try to actively identify and avoid known > buggy versions or not? I'm currently not inclined to invest a lot of effort into it, besides trying to get the bug fixed. A possible testcase would be to call createLocalIndirectStubsManagerBuilder() and report an error if it returns nullptr. But that'd fail once the bug is fixed, because we don't actually *need* that functionality, it's just that LLVM instantiates the stub manager unconditionally for some reason. Greetings, Andres Freund
On Thu, Mar 22, 2018 at 11:46 AM, Andres Freund <andres@anarazel.de> wrote: > On 2018-03-22 11:36:47 +1300, Thomas Munro wrote: >> Not sure if we'll want to try to actively identify and avoid known >> buggy versions or not? > > I'm currently not inclined to invest a lot of effort into it, besides > trying to get the bug fixed. > > A possible testcase would be to call > createLocalIndirectStubsManagerBuilder() and report an error if it > returns nullptr. But that'd fail once the bug is fixed, because we don't > actually *need* that functionality, it's just that LLVM instantiates the > stub manager unconditionally for some reason. So how about we test createLocalIndirectStubsManagerBuilder(), and if it's nullptr then we also test the LLVM version number? For each major release (3.9, 4.0, 5.0, ... you can see that they did the same kind of versioning schema change that we did!) there will eventually be a minor/patch release number where this works even when nullptr is returned here. This problem is going to come up on any architecture not covered in the following code, namely anything but x86, x86_64 and (since 6.0) aarch64 (aka arm64), so we definitely don't want to leave JIT disabled once that bug is fixed: https://github.com/llvm-mirror/llvm/blob/release_39/lib/ExecutionEngine/Orc/IndirectionUtils.cpp#L48 https://github.com/llvm-mirror/llvm/blob/release_60/lib/ExecutionEngine/Orc/IndirectionUtils.cpp#L48 -- Thomas Munro http://www.enterprisedb.com
On Wed, Mar 21, 2018 at 8:06 PM, Thomas Munro <thomas.munro@enterprisedb.com> wrote: > "make -C src/interfaces/ecpg/test check" consistently fails on my macOS machine: > > test compat_oracle/char_array ... stderr source FAILED I can't reproduce this anymore on the tip of your jit branch. I don't know what caused it or which change fixed it... I've now run out of things to complain about for now. Nice work! -- Thomas Munro http://www.enterprisedb.com
On Thu, Mar 22, 2018 at 1:36 PM, Thomas Munro
<thomas.munro@enterprisedb.com> wrote:
> I've now run out of things to complain about for now. Nice work!
I jumped on a POWER8 box. As expected, the same breakage occurs. So
I hacked LLVM 6.0 thusly:
diff --git a/lib/ExecutionEngine/Orc/IndirectionUtils.cpp
b/lib/ExecutionEngine/Orc/IndirectionUtils.cpp
index 68397be..08aa3a8 100644
--- a/lib/ExecutionEngine/Orc/IndirectionUtils.cpp
+++ b/lib/ExecutionEngine/Orc/IndirectionUtils.cpp
@@ -54,7 +54,11 @@ createLocalCompileCallbackManager(const Triple &T,
std::function<std::unique_ptr<IndirectStubsManager>()>
createLocalIndirectStubsManagerBuilder(const Triple &T) {
switch (T.getArch()) {
- default: return nullptr;
+ default:
+ return [](){
+ return llvm::make_unique<
+ orc::LocalIndirectStubsManager<orc::OrcGenericABI>>();
+ };
case Triple::aarch64:
return [](){
I am not qualified to have an opinion on whether this is the correct
fix for LLVM, but with this change our make check passes, indicating
that things are otherwise looking good on this architecture.
So I've now tested your branch on various combinations of:
FreeBSD/amd64 (including with a weird CPU that lacks AVX),
Debian/amd64, Debian/i386, Debian/arm64, RHEL/ppc64le, macOS/amd64,
with LLVM 3.9, 4,0, 5.0, 6.0, with GCC and clang as the main compiler,
with libstdc++ and libc++ as the C++ standard library.
If I had access to one I'd try it on a big endian machine, but I
don't. Anyone? The elephant in the room is Windows. I'm not
personally in the same room as that particular elephant, however.
FWIW, your branch doesn't build against LLVM master (future 7.0),
because the shared module stuff is changing:
llvmjit.c: In function ‘llvm_compile_module’:
llvmjit.c:544:4: error: unknown type name ‘LLVMSharedModuleRef’
LLVMSharedModuleRef smod;
^
llvmjit.c:546:4: warning: implicit declaration of function
‘LLVMOrcMakeSharedModule’ [-Wimplicit-function-declaration]
smod = LLVMOrcMakeSharedModule(context->module);
^
llvmjit.c:548:12: warning: passing argument 3 of
‘LLVMOrcAddEagerlyCompiledIR’ makes pointer from integer without a
cast [enabled by default]
llvm_resolve_symbol, NULL))
^
In file included from llvmjit.c:31:0:
/home/thomas.munro/build/llvm/debug/install/include/llvm-c/OrcBindings.h:99:1:
note: expected ‘LLVMModuleRef’ but argument is of type ‘int’
LLVMOrcAddEagerlyCompiledIR(LLVMOrcJITStackRef JITStack,
^
llvmjit.c:552:4: warning: implicit declaration of function
‘LLVMOrcDisposeSharedModuleRef’ [-Wimplicit-function-declaration]
LLVMOrcDisposeSharedModuleRef(smod);
^
--
Thomas Munro
http://www.enterprisedb.com
Hi,
On 2018-03-22 16:09:51 +1300, Thomas Munro wrote:
> On Thu, Mar 22, 2018 at 1:36 PM, Thomas Munro
> <thomas.munro@enterprisedb.com> wrote:
> > I've now run out of things to complain about for now. Nice work!
>
> I jumped on a POWER8 box. As expected, the same breakage occurs. So
> I hacked LLVM 6.0 thusly:
>
> diff --git a/lib/ExecutionEngine/Orc/IndirectionUtils.cpp
> b/lib/ExecutionEngine/Orc/IndirectionUtils.cpp
> index 68397be..08aa3a8 100644
> --- a/lib/ExecutionEngine/Orc/IndirectionUtils.cpp
> +++ b/lib/ExecutionEngine/Orc/IndirectionUtils.cpp
> @@ -54,7 +54,11 @@ createLocalCompileCallbackManager(const Triple &T,
> std::function<std::unique_ptr<IndirectStubsManager>()>
> createLocalIndirectStubsManagerBuilder(const Triple &T) {
> switch (T.getArch()) {
> - default: return nullptr;
> + default:
> + return [](){
> + return llvm::make_unique<
> + orc::LocalIndirectStubsManager<orc::OrcGenericABI>>();
> + };
>
> case Triple::aarch64:
> return [](){
> I am not qualified to have an opinion on whether this is the correct
> fix for LLVM, but with this change our make check passes, indicating
> that things are otherwise looking good on this architecture.
Yea, that should do the trick, as long as one doesn't rely on indirect
stubs, which we don't. Kinda wonder if we could hackfix this by putting
your definition of createLocalIndirectStubsManagerBuilder() into
something earlier on the search path...
> So I've now tested your branch on various combinations of:
> FreeBSD/amd64 (including with a weird CPU that lacks AVX),
> Debian/amd64, Debian/i386, Debian/arm64, RHEL/ppc64le, macOS/amd64,
> with LLVM 3.9, 4,0, 5.0, 6.0, with GCC and clang as the main compiler,
> with libstdc++ and libc++ as the C++ standard library.
Many thanks again.
> If I had access to one I'd try it on a big endian machine, but I
> don't. Anyone? The elephant in the room is Windows. I'm not
> personally in the same room as that particular elephant, however.
Hah. I'm not 100% sure I can MSVC project stuff done for this release,
TBH. Doing it via mingw shouldn't be much trouble. But I'm aiming for
fixing the project generation support too.
> FWIW, your branch doesn't build against LLVM master (future 7.0),
> because the shared module stuff is changing:
>
> llvmjit.c: In function ‘llvm_compile_module’:
> llvmjit.c:544:4: error: unknown type name ‘LLVMSharedModuleRef’
> LLVMSharedModuleRef smod;
> ^
> llvmjit.c:546:4: warning: implicit declaration of function
> ‘LLVMOrcMakeSharedModule’ [-Wimplicit-function-declaration]
> smod = LLVMOrcMakeSharedModule(context->module);
> ^
> llvmjit.c:548:12: warning: passing argument 3 of
> ‘LLVMOrcAddEagerlyCompiledIR’ makes pointer from integer without a
> cast [enabled by default]
> llvm_resolve_symbol, NULL))
> ^
> In file included from llvmjit.c:31:0:
> /home/thomas.munro/build/llvm/debug/install/include/llvm-c/OrcBindings.h:99:1:
> note: expected ‘LLVMModuleRef’ but argument is of type ‘int’
> LLVMOrcAddEagerlyCompiledIR(LLVMOrcJITStackRef JITStack,
> ^
> llvmjit.c:552:4: warning: implicit declaration of function
> ‘LLVMOrcDisposeSharedModuleRef’ [-Wimplicit-function-declaration]
> LLVMOrcDisposeSharedModuleRef(smod);
Yea, I guess we could add branches for that, but 7 just branched and is
a moving target, so I'm inclined to wait a bit.
Greetings,
Andres Freund
Hi Andres, I spotted a couple of typos and some very minor coding details -- see please see attached. -- Thomas Munro http://www.enterprisedb.com
Attachment
Thomas Munro <thomas.munro@enterprisedb.com> wrote: > typos A dead line. -- Thomas Munro http://www.enterprisedb.com
Attachment
Hi, On 2018-03-25 00:07:11 +1300, Thomas Munro wrote: > I spotted a couple of typos and some very minor coding details -- see > please see attached. Thanks, applying 0001 in a bit. > From 648e303072c77e781eca2bb06f488f6be9ccac84 Mon Sep 17 00:00:00 2001 > From: Thomas Munro <thomas.munro@enterprisedb.com> > Date: Sat, 24 Mar 2018 23:12:40 +1300 > Subject: [PATCH 2/2] Minor code cleanup for llvmjit_wrap.cpp. > > llvm::sys::getHostCPUName()'s result is a llvm::StringRef. Its data() member > function doesn't guarantee a null-terminated result, so we'd better jump > through an extra hoop to get a C string. Hm, I checked, and it's fine, I'm not enthusiastic about this... > It seems better to use LLVMCreateMessage() rather than strdup() to allocate > the copy returned by LLVMGetHostCPUFeatures() and LLVMGetHostCPUName(), > since the contract is that the caller should free it with > LLVMDisposeMessage(). While we can see that LLVMCreateMessage() and > LLVMDisposeMessage() are currently just wrappers for strdup() and free(), > using them symmetrically seems like a good idea for future Windows support, > where DLLs can be using different heap allocators (the same reason we provide > PQfreemem in libpq). I just kept it similar to nearby functions in the LLVM code. > Fix brace style. I tried to keep this as it's submitted to LLVM, I hope we can get rid of them for newer version soon... I think I'll update them to be exactly the same as soon as the upstream patch is applied. Greetings, Andres Freund
On 3/13/18 19:40, Andres Freund wrote: > I've pushed a revised and rebased version of my JIT patchset. What is the status of this item as far as the commitfest is concerned? -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2018-03-27 10:05:47 -0400, Peter Eisentraut wrote: > On 3/13/18 19:40, Andres Freund wrote: > > I've pushed a revised and rebased version of my JIT patchset. > > What is the status of this item as far as the commitfest is concerned? 7/10 committed. Inlining, Explain, Docs remain. Greetings, Andres Freund
On 2018-03-27 10:34:26 -0700, Andres Freund wrote: > On 2018-03-27 10:05:47 -0400, Peter Eisentraut wrote: > > On 3/13/18 19:40, Andres Freund wrote: > > > I've pushed a revised and rebased version of my JIT patchset. > > > > What is the status of this item as far as the commitfest is concerned? > > 7/10 committed. Inlining, Explain, Docs remain. I've pushed these three. As explained in the inline commit, I've found an edge case where I could hit an assert in LLVM when using a more efficient interaction with on-disk files. That appears to be a spurious assert, but I don't want to ignore it until that's confirmed from the LLVM side of things. For now LLVM is enabled by default when compiled --with-llvm. I'm mildly inclined to leave it like that until shortly before the release, and then disable it by default (i.e. change the default of jit=off). But I think we can make that decision based on experience during the testing window. I'm opening an open items entry for that. Yay. Also: Tired. Greetings, Andres Freund
Hi, On 2018-03-28 14:27:51 -0700, Andres Freund wrote: > > 7/10 committed. Inlining, Explain, Docs remain. > > I've pushed these three. One tiny pending commit I have is to add a few pg_noinline annotations to slow-path functions, to avoid very common spurious inlines. I'll play a littlebit more with the set that I think make sense there, and will send a separate email about that. Greetings, Andres Freund
On 3/28/18 17:27, Andres Freund wrote: > I've pushed these three. Great, now the only thing remaining is to prepare an unconference session explaining all this to the rest of us. ;-) -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On 2018-03-28 18:06:24 -0400, Peter Eisentraut wrote: > On 3/28/18 17:27, Andres Freund wrote: > > I've pushed these three. > > Great, now the only thing remaining is to prepare an unconference > session explaining all this to the rest of us. ;-) Hah! Happy to, if there's enough people interested. I've a talk about it too (state of jit, 2018 edition), but I wasn't planning to go into too low level details. More about what is good, what is bad, and how we make it better ;) Greetings, Andres Freund
On 3/28/18 6:09 PM, Andres Freund wrote: > > On 2018-03-28 18:06:24 -0400, Peter Eisentraut wrote: >> On 3/28/18 17:27, Andres Freund wrote: >>> I've pushed these three. >> >> Great, now the only thing remaining is to prepare an unconference >> session explaining all this to the rest of us. ;-) > > Hah! Happy to, if there's enough people interested. I've a talk about > it too (state of jit, 2018 edition), but I wasn't planning to go into > too low level details. More about what is good, what is bad, and how we > make it better ;) +1 for an unconference session. This is some seriously cool stuff. -- -David david@pgmasters.net
On Wed, Mar 28, 2018 at 06:24:53PM -0400, David Steele wrote: > On 3/28/18 6:09 PM, Andres Freund wrote: >> Hah! Happy to, if there's enough people interested. I've a talk about >> it too (state of jit, 2018 edition), but I wasn't planning to go into >> too low level details. More about what is good, what is bad, and how we >> make it better ;) > > +1 for an unconference session. This is some seriously cool stuff. Take room for two sessions then, with a break in-between to give enough time to people to recover from the damage of the first session :) Jokes apart, an unconference session at PGcon would be great. -- Michael
Attachment
On 2018/03/29 9:35, Michael Paquier wrote: > On Wed, Mar 28, 2018 at 06:24:53PM -0400, David Steele wrote: >> On 3/28/18 6:09 PM, Andres Freund wrote: >>> Hah! Happy to, if there's enough people interested. I've a talk about >>> it too (state of jit, 2018 edition), but I wasn't planning to go into >>> too low level details. More about what is good, what is bad, and how we >>> make it better ;) >> >> +1 for an unconference session. This is some seriously cool stuff. > > Take room for two sessions then, with a break in-between to give enough > time to people to recover from the damage of the first session :) > > Jokes apart, an unconference session at PGcon would be great. +1 Thanks, Amit
Hi Andres, On 03/28/2018 05:27 PM, Andres Freund wrote: > On 2018-03-27 10:34:26 -0700, Andres Freund wrote: >> On 2018-03-27 10:05:47 -0400, Peter Eisentraut wrote: >>> On 3/13/18 19:40, Andres Freund wrote: >>>> I've pushed a revised and rebased version of my JIT patchset. >>> >>> What is the status of this item as far as the commitfest is concerned? >> >> 7/10 committed. Inlining, Explain, Docs remain. > > I've pushed these three. > It seems that clang is being picked up as the main compiler in certain situations, ala ccache gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -g -O0 -fno-omit-frame-pointer -I../../../src/include -D_GNU_SOURCE -I/usr/include/libxml2 -c -o auth-scram.o auth-scram.c -MMD -MP -MF .deps/auth-scram.Po ccache gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -g -O0 -fno-omit-frame-pointer -I../../../src/include -D_GNU_SOURCE -I/usr/include/libxml2 -c -o be-secure-openssl.o be-secure-openssl.c -MMD -MP -MF .deps/be-secure-openssl.Po /usr/lib64/ccache/clang -Wno-ignored-attributes -fno-strict-aliasing -fwrapv -O2 -I../../../src/include -D_GNU_SOURCE -I/usr/include/libxml2 -flto=thin -emit-llvm -c -o be-fsstubs.bc be-fsstubs.c /usr/lib64/ccache/clang -Wno-ignored-attributes -fno-strict-aliasing -fwrapv -O2 -I../../../src/include -D_GNU_SOURCE -I/usr/include/libxml2 -flto=thin -emit-llvm -c -o namespace.bc namespace.c I would expect LLVM to be isolated to the jit/ hierarchy. Using CC="ccache gcc" and --with-llvm. And congrats on getting the feature in ! Best regards, Jesper
Hi Andres, I spent some time over pouring over the JIT README, and I've attached a patch with some additional corrections as well as some stylistic suggestions. The latter may be debatable, but I'm sure you can take and pick as you see fit. If there are cases where I misunderstood your intent, maybe that's also useful information. :-) -John Naylor
Attachment
On Thursday, March 29, 2018 2:39:17 PM CEST Jesper Pedersen wrote: > Hi Andres, > > On 03/28/2018 05:27 PM, Andres Freund wrote: > > On 2018-03-27 10:34:26 -0700, Andres Freund wrote: > >> On 2018-03-27 10:05:47 -0400, Peter Eisentraut wrote: > >>> On 3/13/18 19:40, Andres Freund wrote: > >>>> I've pushed a revised and rebased version of my JIT patchset. > >>> > >>> What is the status of this item as far as the commitfest is concerned? > >> > >> 7/10 committed. Inlining, Explain, Docs remain. > > > > I've pushed these three. > > It seems that clang is being picked up as the main compiler in certain > situations, ala > > ccache gcc -Wall -Wmissing-prototypes -Wpointer-arith > -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute > -Wformat-security -fno-strict-aliasing -fwrapv > -fexcess-precision=standard -g -O0 -fno-omit-frame-pointer > -I../../../src/include -D_GNU_SOURCE -I/usr/include/libxml2 -c -o > auth-scram.o auth-scram.c -MMD -MP -MF .deps/auth-scram.Po > ccache gcc -Wall -Wmissing-prototypes -Wpointer-arith > -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute > -Wformat-security -fno-strict-aliasing -fwrapv > -fexcess-precision=standard -g -O0 -fno-omit-frame-pointer > -I../../../src/include -D_GNU_SOURCE -I/usr/include/libxml2 -c -o > be-secure-openssl.o be-secure-openssl.c -MMD -MP -MF > .deps/be-secure-openssl.Po > /usr/lib64/ccache/clang -Wno-ignored-attributes -fno-strict-aliasing > -fwrapv -O2 -I../../../src/include -D_GNU_SOURCE > -I/usr/include/libxml2 -flto=thin -emit-llvm -c -o be-fsstubs.bc > be-fsstubs.c > /usr/lib64/ccache/clang -Wno-ignored-attributes -fno-strict-aliasing > -fwrapv -O2 -I../../../src/include -D_GNU_SOURCE > -I/usr/include/libxml2 -flto=thin -emit-llvm -c -o namespace.bc namespace.c > > I would expect LLVM to be isolated to the jit/ hierarchy. Clang is needed to emit the LLVM bitcode required for inlining. The "-emit- llvm" flag is used for that. A dual compilation is required for inlining to work, one compilation with gcc/clang/msvc/… to build the postgresql binary, one with clang to generate the .bc files for inlining. It can be surprising, but there is little way around that (or we accept only clang to build postgresql, but there would be a riot).
Hi, On 03/29/2018 11:03 AM, Pierre Ducroquet wrote: > Clang is needed to emit the LLVM bitcode required for inlining. The "-emit- > llvm" flag is used for that. A dual compilation is required for inlining to > work, one compilation with gcc/clang/msvc/… to build the postgresql binary, > one with clang to generate the .bc files for inlining. > It can be surprising, but there is little way around that (or we accept only > clang to build postgresql, but there would be a riot). > Thanks Pierre. Best regards, Jesper
Attachment
Hi, On 2018-03-29 19:57:42 +0700, John Naylor wrote: > Hi Andres, > I spent some time over pouring over the JIT README, and I've attached > a patch with some additional corrections as well as some stylistic > suggestions. The latter may be debatable, but I'm sure you can take > and pick as you see fit. If there are cases where I misunderstood your > intent, maybe that's also useful information. :-) I've picked most of them, and pushed a change including some additional changes. Thanks! - Andres
On 30.03.2018 02:14, Andres Freund wrote:
I have repeated performance tests at my computer and find out some regression comparing with previous JIT version.Hi, On 2018-03-29 19:57:42 +0700, John Naylor wrote:Hi Andres, I spent some time over pouring over the JIT README, and I've attached a patch with some additional corrections as well as some stylistic suggestions. The latter may be debatable, but I'm sure you can take and pick as you see fit. If there are cases where I misunderstood your intent, maybe that's also useful information. :-)I've picked most of them, and pushed a change including some additional changes. Thanks! - Andres
Previously JIT provides about 2 times improvement at TPC-H Q1. Now the difference is reduced to 1.4 without parallel execution and 1.3 with parallel execution:
| max_parallel_workers_per_gather=0 | max_parallel_workers_per_gather=4 | |
| jit=on | 17500 | 5730 |
| jit=off | 25100 | 7550 |
Previous my result for JIT was 13440 for sequential execution.
I know that performance is not the high priority now, it is more important to commit infrastructure.
Just want to inform that such regression takes place.
It will be nice if you can mark future directions of improving JIT performance...
postgres=# explain (analyze,buffers) select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice*(1-l_discount)) as sum_disc_price,
sum(l_extendedprice*(1-l_discount)*(1+l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
from
lineitem
where
l_shipdate <= '1998-12-01'
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------
------------------------------
Finalize GroupAggregate (cost=2064556.89..2064560.47 rows=6 width=60) (actual time=6573.905..6573.915 rows=4 loops=1)
Group Key: l_returnflag, l_linestatus
Buffers: shared hit=240472
-> Gather Merge (cost=2064556.89..2064559.76 rows=24 width=132) (actual time=6573.888..6573.897 rows=20 loops=1)
Workers Planned: 4
Workers Launched: 4
Buffers: shared hit=240472
-> Sort (cost=2063556.83..2063556.85 rows=6 width=132) (actual time=6562.256..6562.256 rows=4 loops=5)
Sort Key: l_returnflag, l_linestatus
Sort Method: quicksort Memory: 26kB
Worker 0: Sort Method: quicksort Memory: 26kB
Worker 1: Sort Method: quicksort Memory: 26kB
Worker 2: Sort Method: quicksort Memory: 26kB
Worker 3: Sort Method: quicksort Memory: 26kB
Buffers: shared hit=1276327
-> Partial HashAggregate (cost=2063556.69..2063556.75 rows=6 width=132) (actual time=6562.222..6562.224 rows=4
loops=5)
Group Key: l_returnflag, l_linestatus
Buffers: shared hit=1276299
-> Parallel Seq Scan on lineitem (cost=0.00..1463755.41 rows=14995032 width=20) (actual time=312.454..25
20.753 rows=11997210 loops=5)
Filter: (l_shipdate <= '1998-12-01'::date)
Buffers: shared hit=1276299
Planning Time: 0.130 ms
JIT:
Functions: 18
Generation Time: 2.344 ms
Inlining: true
Inlining Time: 15.364 ms
Optimization: true
Optimization Time: 298.833 ms
Emission Time: 155.257 ms
Execution Time: 6807.751 ms
(31 rows)
Time: 6808.216 ms (00:06.808)
-- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 2018-03-30 15:12:05 +0300, Konstantin Knizhnik wrote: > I have repeated performance tests at my computer and find out some > regression comparing with previous JIT version. > Previously JIT provides about 2 times improvement at TPC-H Q1. Now the > difference is reduced to 1.4 without parallel execution and 1.3 with > parallel execution: Huh. That's the same computer you did the tests on? There shouldn't have been any, I'll check it out. - Andres
On 30.03.2018 18:54, Andres Freund wrote: > On 2018-03-30 15:12:05 +0300, Konstantin Knizhnik wrote: >> I have repeated performance tests at my computer and find out some >> regression comparing with previous JIT version. >> Previously JIT provides about 2 times improvement at TPC-H Q1. Now the >> difference is reduced to 1.4 without parallel execution and 1.3 with >> parallel execution: > Huh. That's the same computer you did the tests on? > > There shouldn't have been any, I'll check it out. > > - Andres Yes, it is the same computer. But sorry, may be it is false alarm. I noticed that the time of normal (non-jit) query execution was also faster in the past: for parallel execution 6549 vs. 7550 now, for non-parallel execution 20075 vs. 25100. I do not know whether this difference is caused by some changes in Postgres committed since this time (end of January) or just because of different layout of data in memory. But JIT performance improvement is almost the same in both cases: 1.493 vs 1.434 now. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On March 30, 2018 10:04:25 AM PDT, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > >On 30.03.2018 18:54, Andres Freund wrote: >> On 2018-03-30 15:12:05 +0300, Konstantin Knizhnik wrote: >>> I have repeated performance tests at my computer and find out some >>> regression comparing with previous JIT version. >>> Previously JIT provides about 2 times improvement at TPC-H Q1. Now >the >>> difference is reduced to 1.4 without parallel execution and 1.3 with >>> parallel execution: >> Huh. That's the same computer you did the tests on? >> >> There shouldn't have been any, I'll check it out. >> >> - Andres > >Yes, it is the same computer. >But sorry, may be it is false alarm. >I noticed that the time of normal (non-jit) query execution was also >faster in the past: for parallel execution 6549 vs. 7550 now, for >non-parallel execution 20075 vs. 25100. >I do not know whether this difference is caused by some changes in >Postgres committed since this time (end of January) or just because of >different layout of data in memory. A brief attempt at bisecting would be good. That's quite the regression. Possibly it's OS related though. Meltdown / Spectre? Andres -- Sent from my Android device with K-9 Mail. Please excuse my brevity.
On Wed, Mar 28, 2018 at 02:27:51PM -0700, Andres Freund wrote:
> For now LLVM is enabled by default when compiled --with-llvm. I'm mildly
> inclined to leave it like that until shortly before the release, and
> then disable it by default (i.e. change the default of jit=off). But I
> think we can make that decision based on experience during the testing
> window. I'm opening an open items entry for that.
I'll vote for jit=on and letting any bugs shake out earlier, but it's not a
strong preference.
I see jit slows the regression tests considerably:
# x86_64, non-assert, w/o llvm
$ for n in 1 2 3; do env time make -C src/bin/pg_upgrade check; done 2>&1 | grep elapsed
7.64user 4.24system 0:36.40elapsed 32%CPU (0avgtext+0avgdata 36712maxresident)k
8.09user 4.50system 0:37.71elapsed 33%CPU (0avgtext+0avgdata 36712maxresident)k
7.53user 4.18system 0:36.54elapsed 32%CPU (0avgtext+0avgdata 36712maxresident)k
# x86_64, non-assert, w/ llvm trunk
$ for n in 1 2 3; do env time make -C src/bin/pg_upgrade check; done 2>&1 | grep elapsed
9.58user 5.79system 0:49.61elapsed 30%CPU (0avgtext+0avgdata 36712maxresident)k
9.47user 5.92system 0:47.84elapsed 32%CPU (0avgtext+0avgdata 36712maxresident)k
9.09user 5.51system 0:47.94elapsed 30%CPU (0avgtext+0avgdata 36712maxresident)k
# mips32el, assert, w/o llvm (buildfarm member topminnow) [1]
28min install-check-*
35min check-pg_upgrade
# mips32el, assert, w/ llvm 6.0.1 [1]
63min install-check-*
166min check-pg_upgrade
Regardless of the choice of jit={on|off} default, these numbers tell me that
some or all of jit_*_cost defaults are too low.
[1] The mips32el runs used "nice -+20" and ran on a shared machine. I include
them to show the trend, but exact figures may be non-reproducible.
On 2018-08-22 06:20:21 +0000, Noah Misch wrote:
> On Wed, Mar 28, 2018 at 02:27:51PM -0700, Andres Freund wrote:
> > For now LLVM is enabled by default when compiled --with-llvm. I'm mildly
> > inclined to leave it like that until shortly before the release, and
> > then disable it by default (i.e. change the default of jit=off). But I
> > think we can make that decision based on experience during the testing
> > window. I'm opening an open items entry for that.
>
> I'll vote for jit=on and letting any bugs shake out earlier, but it's not a
> strong preference.
Similar.
> I see jit slows the regression tests considerably:
>
> # x86_64, non-assert, w/o llvm
> $ for n in 1 2 3; do env time make -C src/bin/pg_upgrade check; done 2>&1 | grep elapsed
> 7.64user 4.24system 0:36.40elapsed 32%CPU (0avgtext+0avgdata 36712maxresident)k
> 8.09user 4.50system 0:37.71elapsed 33%CPU (0avgtext+0avgdata 36712maxresident)k
> 7.53user 4.18system 0:36.54elapsed 32%CPU (0avgtext+0avgdata 36712maxresident)k
>
> # x86_64, non-assert, w/ llvm trunk
> $ for n in 1 2 3; do env time make -C src/bin/pg_upgrade check; done 2>&1 | grep elapsed
> 9.58user 5.79system 0:49.61elapsed 30%CPU (0avgtext+0avgdata 36712maxresident)k
> 9.47user 5.92system 0:47.84elapsed 32%CPU (0avgtext+0avgdata 36712maxresident)k
> 9.09user 5.51system 0:47.94elapsed 30%CPU (0avgtext+0avgdata 36712maxresident)k
>
> # mips32el, assert, w/o llvm (buildfarm member topminnow) [1]
> 28min install-check-*
> 35min check-pg_upgrade
>
> # mips32el, assert, w/ llvm 6.0.1 [1]
> 63min install-check-*
> 166min check-pg_upgrade
>
> Regardless of the choice of jit={on|off} default, these numbers tell me that
> some or all of jit_*_cost defaults are too low.
I don't think it really shows that. The reason that JITing gets started
there is that the tables aren't analyzed and we end up with crazy ass
estimates about the cost of the queries. No useful setting of the cost
limits will protect against that... :(
Greetings,
Andres Freund
On 22/08/2018 08:20, Noah Misch wrote:
> Regardless of the choice of jit={on|off} default, these numbers tell me that
> some or all of jit_*_cost defaults are too low.
That was also my earlier analysis.
I'm suspicious that we haven't had much feedback about this. We've
heard of one or two cases where LLVM broke a query outright, and that
was fixed and that was a good result. But we haven't heard anything
about performance regressions. Surely there must be some. There hasn't
been any discussion or further analysis of the default cost settings
either. I feel that we don't have enough information.
Another problem is that LLVM is only enabled in some versions of
packages. For example, in the PGDG RPMs, it's enabled for RHEL 7 but
not RHEL 6. So you could be in for a surprise if you upgrade your
operating system at some point.
I would like, however, that we make a decision one way or the other
before the next beta. I've been handwaving a bit to users not to rely
on the current betas for performance testing because the defaults might
change later. That's bad either way.
--
Peter Eisentraut http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On 2018-08-22 16:36:00 +0200, Peter Eisentraut wrote: > I'm suspicious that we haven't had much feedback about this. We've > heard of one or two cases where LLVM broke a query outright, and that > was fixed and that was a good result. But we haven't heard anything > about performance regressions. Surely there must be some. There hasn't > been any discussion or further analysis of the default cost settings > either. I feel that we don't have enough information. Yea. I don't think we'll get really good feedback before production unfortunately :( > I would like, however, that we make a decision one way or the other > before the next beta. I've been handwaving a bit to users not to rely > on the current betas for performance testing because the defaults might > change later. That's bad either way. I don't see particularly much benefit in deciding before beta, personally. What's making you think it'd be important to decide before? Pretty fundamentally, it'll be a setting you don't know is effectively on, for the forseeable future anyway? Greetings, Andres Freund
På onsdag 22. august 2018 kl. 16:36:00, skrev Peter Eisentraut <peter.eisentraut@2ndquadrant.com>:
On 22/08/2018 08:20, Noah Misch wrote:
> Regardless of the choice of jit={on|off} default, these numbers tell me that
> some or all of jit_*_cost defaults are too low.
That was also my earlier analysis.
I'm suspicious that we haven't had much feedback about this. We've
heard of one or two cases where LLVM broke a query outright, and that
was fixed and that was a good result. But we haven't heard anything
about performance regressions. Surely there must be some. There hasn't
been any discussion or further analysis of the default cost settings
either. I feel that we don't have enough information.
Another problem is that LLVM is only enabled in some versions of
packages. For example, in the PGDG RPMs, it's enabled for RHEL 7 but
not RHEL 6. So you could be in for a surprise if you upgrade your
operating system at some point.
I would like, however, that we make a decision one way or the other
before the next beta. I've been handwaving a bit to users not to rely
on the current betas for performance testing because the defaults might
change later. That's bad either way.
FWIW; Our largest report-queries perform worse (then v10) with jit=on; https://www.postgresql.org/message-id/VisenaEmail.24.e60072a07f006130.162d95c3e17%40tc7-visena
Disabling JIT makes them perform slightly better than v10.
--
Andreas Joseph Krogh
Andreas Joseph Krogh
On 22/08/2018 16:54, Andres Freund wrote: > I don't see particularly much benefit in deciding before beta, > personally. What's making you think it'd be important to decide before? > Pretty fundamentally, it'll be a setting you don't know is effectively > on, for the forseeable future anyway? Users are evaluating PostgreSQL 11 beta in their environments, including its performance. I have to tell them, whatever performance test results you get now might not be what you'll get with the final 11.0. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Andres Freund <andres@anarazel.de> writes:
> On 2018-08-22 06:20:21 +0000, Noah Misch wrote:
>> Regardless of the choice of jit={on|off} default, these numbers tell me that
>> some or all of jit_*_cost defaults are too low.
> I don't think it really shows that. The reason that JITing gets started
> there is that the tables aren't analyzed and we end up with crazy ass
> estimates about the cost of the queries. No useful setting of the cost
> limits will protect against that... :(
I don't buy that line of argument one bit. No, we generally don't
analyze most of the regression test tables, but the planner still
knows that they're not very large. If JIT is kicking in for those
queries, the defaults are set wrong. Additional evidence for the
defaults being wrong is the number of reports we've had of JIT making
things slower.
I was OK with that happening during early beta, on the grounds of getting
more testing for the JIT code; but it's time to fix the numbers.
regards, tom lane
Hi,
On 2018-08-22 18:15:29 -0400, Tom Lane wrote:
> Andres Freund <andres@anarazel.de> writes:
> > On 2018-08-22 06:20:21 +0000, Noah Misch wrote:
> >> Regardless of the choice of jit={on|off} default, these numbers tell me that
> >> some or all of jit_*_cost defaults are too low.
>
> > I don't think it really shows that. The reason that JITing gets started
> > there is that the tables aren't analyzed and we end up with crazy ass
> > estimates about the cost of the queries. No useful setting of the cost
> > limits will protect against that... :(
>
> I don't buy that line of argument one bit. No, we generally don't
> analyze most of the regression test tables, but the planner still
> knows that they're not very large. If JIT is kicking in for those
> queries, the defaults are set wrong.
I looked at the queries that get JITed, I didn't just make that claim up
out of thin air. The first query that's JITed e.g. is:
+explain analyze SELECT '' AS tf_12, BOOLTBL1.*, BOOLTBL2.*
+ FROM BOOLTBL1, BOOLTBL2
+ WHERE BOOLTBL2.f1 <> BOOLTBL1.f1;
+ QUERY PLAN
+------------------------------------------------------------------------------------------------------------------
+ Nested Loop (cost=0.00..118524.73 rows=3948050 width=34) (actual time=8.376..8.390 rows=12 loops=1)
+ Join Filter: (booltbl2.f1 <> booltbl1.f1)
+ Rows Removed by Join Filter: 4
+ -> Seq Scan on booltbl1 (cost=0.00..38.10 rows=2810 width=1) (actual time=0.018..0.019 rows=4 loops=1)
+ -> Materialize (cost=0.00..52.15 rows=2810 width=1) (actual time=0.004..0.005 rows=4 loops=4)
+ -> Seq Scan on booltbl2 (cost=0.00..38.10 rows=2810 width=1) (actual time=0.007..0.009 rows=4 loops=1)
+ Planning Time: 0.074 ms
+ JIT:
+ Functions: 6
+ Generation Time: 0.935 ms
+ Inlining: false
+ Inlining Time: 0.000 ms
+ Optimization: false
+ Optimization Time: 0.451 ms
+ Emission Time: 7.716 ms
+ Execution Time: 43.466 ms
+(16 rows)
Now you can say that'd be solved by bumping the cost up, sure. But
obviously the row / cost model is pretty much out of whack here, I don't
see how we can make reasonable decisions in a trivial query that has a
misestimation by five orders of magnitude.
Another subsequent case is:
set enable_sort = off; -- try to make it pick a hash setop implementation
select '(2,5)'::cashrange except select '(5,6)'::cashrange;
which is expensive because a sort is chosen even though sort is disabled
(yes, this might be a bug in the test):
EXPLAIN select '(2,5)'::cashrange except select '(5,6)'::cashrange;
┌────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├────────────────────────────────────────────────────────────────────────────────────┤
│ SetOp Except (cost=10000000000.06..10000000000.07 rows=1 width=36) │
│ -> Sort (cost=10000000000.06..10000000000.06 rows=2 width=36) │
│ Sort Key: ('($2.00,$5.00)'::cashrange) │
│ -> Append (cost=0.00..0.05 rows=2 width=36) │
│ -> Subquery Scan on "*SELECT* 1" (cost=0.00..0.02 rows=1 width=36) │
│ -> Result (cost=0.00..0.01 rows=1 width=32) │
│ -> Subquery Scan on "*SELECT* 2" (cost=0.00..0.02 rows=1 width=36) │
│ -> Result (cost=0.00..0.01 rows=1 width=32) │
│ JIT: │
│ Functions: 7 │
│ Inlining: true │
│ Optimization: true │
└────────────────────────────────────────────────────────────────────────────────────┘
(12 rows)
Obviously the high costing here distorts things. Many of the other
cases here are along similar lines as the two cases before.
> Additional evidence for the
> defaults being wrong is the number of reports we've had of JIT making
> things slower.
Maybe.
Greetings,
Andres Freund
On Wed, Aug 22, 2018 at 06:20:21AM +0000, Noah Misch wrote: > On Wed, Mar 28, 2018 at 02:27:51PM -0700, Andres Freund wrote: > > For now LLVM is enabled by default when compiled --with-llvm. I'm mildly > > inclined to leave it like that until shortly before the release, and > > then disable it by default (i.e. change the default of jit=off). But I > > think we can make that decision based on experience during the testing > > window. I'm opening an open items entry for that. > > I'll vote for jit=on and letting any bugs shake out earlier, but it's not a > strong preference. In light of later discussion on this thread, my preference bore undue optimism. I maintain that vote philosophically, but that course of action probably entails too much short-term development work. jit=off is reasonable, along with documentation changes to set expectations.
On Wed, Aug 22, 2018 at 6:43 PM, Andres Freund <andres@anarazel.de> wrote: > Now you can say that'd be solved by bumping the cost up, sure. But > obviously the row / cost model is pretty much out of whack here, I don't > see how we can make reasonable decisions in a trivial query that has a > misestimation by five orders of magnitude. Before JIT, it didn't matter whether the costing was wrong, provided that the path with the lowest cost was the cheapest path (or at least close enough to the cheapest path not to bother anyone). Now it does. If the intended path is chosen but the costing is higher than it should be, JIT will erroneously activate. If you had designed this in such a way that we added separate paths for the JIT and non-JIT versions and the JIT version had a bigger startup cost but a reduced runtime cost, then you probably would not have run into this issue, or at least not to the same degree. But as it is, JIT activates when the plan looks expensive, regardless of whether activating JIT will do anything to make it cheaper. As a blindingly obvious example, turning on JIT to mitigate the effects of disable_cost is senseless, but as you point out, that's exactly what happens right now. I'd guess that, as you read this, you're thinking, well, but if I'd added JIT and non-JIT paths for every option, it would have doubled the number of paths, and that would have slowed the planner down way too much. That's certainly true, but my point is just that the problem is probably not as simple as "the defaults are too low". I think the problem is more fundamentally that the model you've chosen is kinda broken. I'm not saying I know how you could have done any better, but I do think we're going to have to try to figure out something to do about it, because saying, "check-pg_upgrade is 4x slower, but that's just because of all those bad estimates" is not going to fly. Those bad estimates were harmlessly bad before, and now they are harmfully bad, and similar bad estimates are going to exist in real-world queries, and those are going to be harmful now too. Blaming the bad costing is a red herring. The problem is that you've made the costing matter in a way that it previously didn't. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
>> Now you can say that'd be solved by bumping the cost up, sure. But >> obviously the row / cost model is pretty much out of whack here, I don't >> see how we can make reasonable decisions in a trivial query that has a >> misestimation by five orders of magnitude. > > Before JIT, it didn't matter whether the costing was wrong, provided > that the path with the lowest cost was the cheapest path (or at least > close enough to the cheapest path not to bother anyone). Now it does. > If the intended path is chosen but the costing is higher than it > should be, JIT will erroneously activate. If you had designed this in > such a way that we added separate paths for the JIT and non-JIT > versions and the JIT version had a bigger startup cost but a reduced > runtime cost, then you probably would not have run into this issue, or > at least not to the same degree. But as it is, JIT activates when the > plan looks expensive, regardless of whether activating JIT will do > anything to make it cheaper. As a blindingly obvious example, turning > on JIT to mitigate the effects of disable_cost is senseless, but as > you point out, that's exactly what happens right now. > > I'd guess that, as you read this, you're thinking, well, but if I'd > added JIT and non-JIT paths for every option, it would have doubled > the number of paths, and that would have slowed the planner down way > too much. That's certainly true, but my point is just that the > problem is probably not as simple as "the defaults are too low". I > think the problem is more fundamentally that the model you've chosen > is kinda broken. I'm not saying I know how you could have done any > better, but I do think we're going to have to try to figure out > something to do about it, because saying, "check-pg_upgrade is 4x > slower, but that's just because of all those bad estimates" is not > going to fly. Those bad estimates were harmlessly bad before, and now > they are harmfully bad, and similar bad estimates are going to exist > in real-world queries, and those are going to be harmful now too. > > Blaming the bad costing is a red herring. The problem is that you've > made the costing matter in a way that it previously didn't. My 0.02€ on this interesting subject. Historically, external IOs, ak rotating disk accesses, have been the main cost (by several order of magnitude) of executing database queries, and cpu costs are relatively very low in most queries. The point of the query planner is mostly to avoid very bad path wrt to IOs. Now, even with significanly faster IOs, eg SSD's, IOs are still a few order of magnitude slower, but less so, so cpu may matter more. Now again, for small database data are often in memory and stay there, in which case CPU is the only cost. This would suggest the following approach to evaluating costs in the planner: (1) are the needed data already in memory? if so use cpu only costs this implies that the planner would know about it... which is probably not the case. (2) if not, then optimise for IOs first, because they are likely to be the main cost driver anyway. (3) once an "IO-optimal" (eg not too bad) plan is selected, consider whether to apply JIT to part of it: if cpu costs are significant and some parts are likely to be executed a lot, with a significant high margin because JIT costs. Basically, I'm suggesting to reevaluate the selected plan, without changing it, with a JIT cost to improve it, as a second stage. -- Fabien.
Moin, On Sat, August 25, 2018 9:34 pm, Robert Haas wrote: > On Wed, Aug 22, 2018 at 6:43 PM, Andres Freund <andres@anarazel.de> wrote: >> Now you can say that'd be solved by bumping the cost up, sure. But >> obviously the row / cost model is pretty much out of whack here, I don't >> see how we can make reasonable decisions in a trivial query that has a >> misestimation by five orders of magnitude. > > Before JIT, it didn't matter whether the costing was wrong, provided > that the path with the lowest cost was the cheapest path (or at least > close enough to the cheapest path not to bother anyone). Now it does. > If the intended path is chosen but the costing is higher than it > should be, JIT will erroneously activate. If you had designed this in > such a way that we added separate paths for the JIT and non-JIT > versions and the JIT version had a bigger startup cost but a reduced > runtime cost, then you probably would not have run into this issue, or > at least not to the same degree. But as it is, JIT activates when the > plan looks expensive, regardless of whether activating JIT will do > anything to make it cheaper. As a blindingly obvious example, turning > on JIT to mitigate the effects of disable_cost is senseless, but as > you point out, that's exactly what happens right now. > > I'd guess that, as you read this, you're thinking, well, but if I'd > added JIT and non-JIT paths for every option, it would have doubled > the number of paths, and that would have slowed the planner down way > too much. That's certainly true, but my point is just that the > problem is probably not as simple as "the defaults are too low". I > think the problem is more fundamentally that the model you've chosen > is kinda broken. I'm not saying I know how you could have done any > better, but I do think we're going to have to try to figure out > something to do about it, because saying, "check-pg_upgrade is 4x > slower, but that's just because of all those bad estimates" is not > going to fly. Those bad estimates were harmlessly bad before, and now > they are harmfully bad, and similar bad estimates are going to exist > in real-world queries, and those are going to be harmful now too. > > Blaming the bad costing is a red herring. The problem is that you've > made the costing matter in a way that it previously didn't. Hm, no, I don't quite follow this argument. Isn't trying to avoid "bad costing having bad consequences" just hiding the symponts instead of curing them? It would have a high development cost, and still bad estimates could ruin your day in other places. Wouldn't it be much smarter to look at why and how the bad costing appears and try to fix this? If a query that returns 12 rows was estimated to return about 4 million, something is wrong on a ridiculous scale. If the costing didn't produce so much "to the moon" values, then it wouldn't matter so much what later decisions do depending on it. I mean, JIT is not the only thing here, even choosing the wrong plan can lead to large runtime differences (think of a sort that spills to disk etc.) So, is there a limit on how many rows can be estimated? Maybe based on things like: * how big the table is? E.g. a table with 2 pages can't have a million rows. * what the column types are? E.g. if you do: SELECT * FROM table WHERE id >= 100 AND id < 200; you cannot have more than 100 rows as a result if "id" is a unique integer column. * Index size: You can't pull out more rows from an index than it contains, maybe this helps limiting "worst estimate"? These things might also be cheaper to implement that rewriting the entire JIT model. Also, why does PG allow the stats to be that outdated - or missing, I'm not sure which case it is in this example. Shouldn't the system aim to have at least some basic stats, even if the user never runs ANALYZE? Or is this on purpose for these tests to see what happens? Best regards, Tels
Hi, On 2018-08-25 21:34:22 -0400, Robert Haas wrote: > On Wed, Aug 22, 2018 at 6:43 PM, Andres Freund <andres@anarazel.de> wrote: > > Now you can say that'd be solved by bumping the cost up, sure. But > > obviously the row / cost model is pretty much out of whack here, I don't > > see how we can make reasonable decisions in a trivial query that has a > > misestimation by five orders of magnitude. > > Before JIT, it didn't matter whether the costing was wrong, provided > that the path with the lowest cost was the cheapest path (or at least > close enough to the cheapest path not to bother anyone). I don't thinkt that's really true. Due to the cost fuzzing absurdly high cost very commonly lead to the actually different planning choices to not have a large enough influence to matter. > I'd guess that, as you read this, you're thinking, well, but if I'd > added JIT and non-JIT paths for every option, it would have doubled > the number of paths, and that would have slowed the planner down way > too much. That's certainly true, but my point is just that the > problem is probably not as simple as "the defaults are too low". I > think the problem is more fundamentally that the model you've chosen > is kinda broken. Right. And that's why I repeatedly brought up this part in discussions... I still think it's a reasonable compromise, but it certainly has costs. I'm also doubtful that just adding a separate path for JIT (with a significantly smaller cpu_*_cost or such) would really have helped in the cases with borked estimations - we'd *still* end up choosing JITing if the loop count is absurd, just because the cost is high. There *are* cases where it helps - if all the cost is incurred, say, due to random page fetches, then JITing isn't going to help that much. > I'm not saying I know how you could have done any better, but I do > think we're going to have to try to figure out something to do about > it, because saying, "check-pg_upgrade is 4x slower, but that's just > because of all those bad estimates" is not going to fly. That I'm unconvinced by however. This was on some quite slow machine and/or with LLVM assertions enabled - the performance difference on a normal machine is smaller: $ PGOPTIONS='-cjit=0' time make -s check ... 5.21user 2.11system 0:24.95elapsed 29%CPU (0avgtext+0avgdata 54212maxresident)k 20976inputs+340848outputs (14major+342228minor)pagefaults 0swaps $ PGOPTIONS='-cjit=1' time make -s check ... 5.33user 2.01system 0:30.49elapsed 24%CPU (0avgtext+0avgdata 54236maxresident)k 0inputs+340856outputs (0major+342616minor)pagefaults 0swaps But also importantly, I think there's actual advantages in triggering JIT in some places in the regression tests. There's buildfarm animals exercising the path that everything is JITed, but that's not really helpful during development. > Those bad estimates were harmlessly bad before, I think that's not true. Greetings, Andres Freund
Hi, On 2018-08-22 06:20:21 +0000, Noah Misch wrote: > I see jit slows the regression tests considerably: Is this with LLVM assertions enabled or not? The differences seem bigger than what I'm observing, especially on the mips animal - which I observe uses a separately installed LLVM build. On my machine, with master, on a postgres assert build w/ non-debug llvm build: PGOPTIONS='-c jit=0' time make -Otarget -j10 -s check-world && echo success || echo f 240.37user 55.55system 2:08.17elapsed 230%CPU (0avgtext+0avgdata 66264maxresident)k PGOPTIONS='-c jit=1' time make -Otarget -j10 -s check-world && echo success || echo f 253.02user 55.77system 2:16.22elapsed 226%CPU (0avgtext+0avgdata 54756maxresident)k Using your command, on a postgres optimized build w/ non-debug llvm build: > # x86_64, non-assert, w/o llvm > $ for n in 1 2 3; do env time make -C src/bin/pg_upgrade check; done 2>&1 | grep elapsed > 7.64user 4.24system 0:36.40elapsed 32%CPU (0avgtext+0avgdata 36712maxresident)k > 8.09user 4.50system 0:37.71elapsed 33%CPU (0avgtext+0avgdata 36712maxresident)k > 7.53user 4.18system 0:36.54elapsed 32%CPU (0avgtext+0avgdata 36712maxresident)k > > # x86_64, non-assert, w/ llvm trunk > $ for n in 1 2 3; do env time make -C src/bin/pg_upgrade check; done 2>&1 | grep elapsed > 9.58user 5.79system 0:49.61elapsed 30%CPU (0avgtext+0avgdata 36712maxresident)k > 9.47user 5.92system 0:47.84elapsed 32%CPU (0avgtext+0avgdata 36712maxresident)k > 9.09user 5.51system 0:47.94elapsed 30%CPU (0avgtext+0avgdata 36712maxresident)k > andres@alap4:~/build/postgres/master-optimize/vpath$ for n in 1 2 3; do PGOPTIONS='-cjit=0' env time make -C src/bin/pg_upgradecheck; done 2>&1 | grep elapsed 8.01user 3.63system 0:39.88elapsed 29%CPU (0avgtext+0avgdata 50196maxresident)k 7.96user 3.86system 0:39.70elapsed 29%CPU (0avgtext+0avgdata 50064maxresident)k 7.96user 3.80system 0:37.17elapsed 31%CPU (0avgtext+0avgdata 50148maxresident)k andres@alap4:~/build/postgres/master-optimize/vpath$ for n in 1 2 3; do PGOPTIONS='-cjit=1' env time make -C src/bin/pg_upgradecheck; done 2>&1 | grep elapsed 7.88user 3.76system 0:44.98elapsed 25%CPU (0avgtext+0avgdata 50092maxresident)k 7.99user 3.72system 0:46.53elapsed 25%CPU (0avgtext+0avgdata 50036maxresident)k 7.88user 3.87system 0:45.26elapsed 25%CPU (0avgtext+0avgdata 50132maxresident)k So here the difference is smaller, but not hugely so. > # mips32el, assert, w/o llvm (buildfarm member topminnow) [1] > 28min install-check-* > 35min check-pg_upgrade > > # mips32el, assert, w/ llvm 6.0.1 [1] > 63min install-check-* > 166min check-pg_upgrade But this seems so absurdly large of a difference that I kinda think LLVM assertions (wich are really expensive and add O(N) operations in a bunch of places) might be to blame. Greetings, Andres Freund
On Wed, Sep 05, 2018 at 11:55:39AM -0700, Andres Freund wrote: > On 2018-08-22 06:20:21 +0000, Noah Misch wrote: > > I see jit slows the regression tests considerably: > > Is this with LLVM assertions enabled or not? Without, I think. I configured them like this: cmake -G Ninja -DCMAKE_INSTALL_PREFIX=$HOME/sw/nopath/llvm -DCMAKE_BUILD_TYPE=MinSizeRel -DLLVM_USE_LINKER=gold -DLLVM_TARGETS_TO_BUILD=X86../llvm cmake -G Ninja -DCMAKE_INSTALL_PREFIX=$HOME/sw/nopath/llvm-el32 -DCMAKE_BUILD_TYPE=MinSizeRel -DLLVM_USE_LINKER=gold -DLLVM_PARALLEL_LINK_JOBS=1../llvm > > # mips32el, assert, w/o llvm (buildfarm member topminnow) [1] > > 28min install-check-* > > 35min check-pg_upgrade > > > > # mips32el, assert, w/ llvm 6.0.1 [1] > > 63min install-check-* > > 166min check-pg_upgrade > > But this seems so absurdly large of a difference that I kinda think LLVM > assertions (wich are really expensive and add O(N) operations in a bunch > of places) might be to blame. The 2018-08-25 and 2018-09-01 published runs were far less bad. Most of the blame goes to the reason given in the footnote (competing load on a shared machine), not to JIT.