Thread: Compression of full-page-writes
Hi, Attached patch adds new GUC parameter 'compress_backup_block'. When this parameter is enabled, the server just compresses FPW (full-page-writes) in WAL by using pglz_compress() before inserting it to the WAL buffers. Then, the compressed FPW is decompressed in recovery. This is very simple patch. The purpose of this patch is the reduction of WAL size. Under heavy write load, the server needs to write a large amount of WAL and this is likely to be a bottleneck. What's the worse is, in replication, a large amount of WAL would have harmful effect on not only WAL writing in the master, but also WAL streaming and WAL writing in the standby. Also we would need to spend more money on the storage to store such a large data. I'd like to alleviate such harmful situations by reducing WAL size. My idea is very simple, just compress FPW because FPW is a big part of WAL. I used pglz_compress() as a compression method, but you might think that other method is better. We can add something like FPW-compression-hook for that later. The patch adds new GUC parameter, but I'm thinking to merge it to full_page_writes parameter to avoid increasing the number of GUC. That is, I'm thinking to change full_page_writes so that it can accept new value 'compress'. I measured how much WAL this patch can reduce, by using pgbench. * Server spec CPU: 8core, Intel(R) Core(TM) i7-3630QM CPU @ 2.40GHz Mem: 16GB Disk: 500GB SSD Samsung 840 * Benchmark pgbench -c 32 -j 4 -T 900 -M prepared scaling factor: 100 checkpoint_segments = 1024 checkpoint_timeout = 5min (every checkpoint during benchmark were triggered by checkpoint_timeout) * Result [tps] 1386.8 (compress_backup_block = off) 1627.7 (compress_backup_block = on) [the amount of WAL generated during running pgbench] 4302 MB (compress_backup_block = off) 1521 MB (compress_backup_block = on) At least in my test, the patch could reduce the WAL size to one-third! The patch is WIP yet. But I'd like to hear the opinions about this idea before completing it, and then add the patch to next CF if okay. Regards, -- Fujii Masao
Attachment
(2013/08/30 11:55), Fujii Masao wrote: > Hi, > > Attached patch adds new GUC parameter 'compress_backup_block'. > When this parameter is enabled, the server just compresses FPW > (full-page-writes) in WAL by using pglz_compress() before inserting it > to the WAL buffers. Then, the compressed FPW is decompressed > in recovery. This is very simple patch. > > The purpose of this patch is the reduction of WAL size. > Under heavy write load, the server needs to write a large amount of > WAL and this is likely to be a bottleneck. What's the worse is, > in replication, a large amount of WAL would have harmful effect on > not only WAL writing in the master, but also WAL streaming and > WAL writing in the standby. Also we would need to spend more > money on the storage to store such a large data. > I'd like to alleviate such harmful situations by reducing WAL size. > > My idea is very simple, just compress FPW because FPW is > a big part of WAL. I used pglz_compress() as a compression method, > but you might think that other method is better. We can add > something like FPW-compression-hook for that later. The patch > adds new GUC parameter, but I'm thinking to merge it to full_page_writes > parameter to avoid increasing the number of GUC. That is, > I'm thinking to change full_page_writes so that it can accept new value > 'compress'. > > I measured how much WAL this patch can reduce, by using pgbench. > > * Server spec > CPU: 8core, Intel(R) Core(TM) i7-3630QM CPU @ 2.40GHz > Mem: 16GB > Disk: 500GB SSD Samsung 840 > > * Benchmark > pgbench -c 32 -j 4 -T 900 -M prepared > scaling factor: 100 > > checkpoint_segments = 1024 > checkpoint_timeout = 5min > (every checkpoint during benchmark were triggered by checkpoint_timeout) I believe that the amount of backup blocks in WAL files is affected by how often the checkpoints are occurring, particularly under such update-intensive workload. Under your configuration, checkpoint should occur so often. So, you need to change checkpoint_timeout larger in order to determine whether the patch is realistic. Regards, > > * Result > [tps] > 1386.8 (compress_backup_block = off) > 1627.7 (compress_backup_block = on) > > [the amount of WAL generated during running pgbench] > 4302 MB (compress_backup_block = off) > 1521 MB (compress_backup_block = on) > > At least in my test, the patch could reduce the WAL size to one-third! > > The patch is WIP yet. But I'd like to hear the opinions about this idea > before completing it, and then add the patch to next CF if okay. > > Regards, > > > > -- Satoshi Nagayasu <snaga@uptime.jp> Uptime Technologies, LLC. http://www.uptime.jp
(2013/08/30 12:07), Satoshi Nagayasu wrote: > > > (2013/08/30 11:55), Fujii Masao wrote: >> Hi, >> >> Attached patch adds new GUC parameter 'compress_backup_block'. >> When this parameter is enabled, the server just compresses FPW >> (full-page-writes) in WAL by using pglz_compress() before inserting it >> to the WAL buffers. Then, the compressed FPW is decompressed >> in recovery. This is very simple patch. >> >> The purpose of this patch is the reduction of WAL size. >> Under heavy write load, the server needs to write a large amount of >> WAL and this is likely to be a bottleneck. What's the worse is, >> in replication, a large amount of WAL would have harmful effect on >> not only WAL writing in the master, but also WAL streaming and >> WAL writing in the standby. Also we would need to spend more >> money on the storage to store such a large data. >> I'd like to alleviate such harmful situations by reducing WAL size. >> >> My idea is very simple, just compress FPW because FPW is >> a big part of WAL. I used pglz_compress() as a compression method, >> but you might think that other method is better. We can add >> something like FPW-compression-hook for that later. The patch >> adds new GUC parameter, but I'm thinking to merge it to full_page_writes >> parameter to avoid increasing the number of GUC. That is, >> I'm thinking to change full_page_writes so that it can accept new value >> 'compress'. >> >> I measured how much WAL this patch can reduce, by using pgbench. >> >> * Server spec >> CPU: 8core, Intel(R) Core(TM) i7-3630QM CPU @ 2.40GHz >> Mem: 16GB >> Disk: 500GB SSD Samsung 840 >> >> * Benchmark >> pgbench -c 32 -j 4 -T 900 -M prepared >> scaling factor: 100 >> >> checkpoint_segments = 1024 >> checkpoint_timeout = 5min >> (every checkpoint during benchmark were triggered by >> checkpoint_timeout) > > I believe that the amount of backup blocks in WAL files is affected > by how often the checkpoints are occurring, particularly under such > update-intensive workload. > > Under your configuration, checkpoint should occur so often. > So, you need to change checkpoint_timeout larger in order to > determine whether the patch is realistic. In fact, the following chart shows that checkpoint_timeout=30min also reduces WAL size to one-third, compared with 5min timeout, in the pgbench experimentation. https://www.oss.ecl.ntt.co.jp/ossc/oss/img/pglesslog_img02.jpg Regards, > > Regards, > >> >> * Result >> [tps] >> 1386.8 (compress_backup_block = off) >> 1627.7 (compress_backup_block = on) >> >> [the amount of WAL generated during running pgbench] >> 4302 MB (compress_backup_block = off) >> 1521 MB (compress_backup_block = on) >> >> At least in my test, the patch could reduce the WAL size to one-third! >> >> The patch is WIP yet. But I'd like to hear the opinions about this idea >> before completing it, and then add the patch to next CF if okay. >> >> Regards, >> >> >> >> > -- Satoshi Nagayasu <snaga@uptime.jp> Uptime Technologies, LLC. http://www.uptime.jp
{kind=link}
On Thu, Aug 29, 2013 at 7:55 PM, Fujii Masao <masao.fujii@gmail.com> wrote: > [the amount of WAL generated during running pgbench] > 4302 MB (compress_backup_block = off) > 1521 MB (compress_backup_block = on) Interesting. I wonder, what is the impact on recovery time under the same conditions? I suppose that the cost of the random I/O involved would probably dominate just as with compress_backup_block = off. That said, you've used an SSD here, so perhaps not. -- Peter Geoghegan
On Fri, Aug 30, 2013 at 8:25 AM, Fujii Masao <masao.fujii@gmail.com> wrote: > Hi, > > Attached patch adds new GUC parameter 'compress_backup_block'. > When this parameter is enabled, the server just compresses FPW > (full-page-writes) in WAL by using pglz_compress() before inserting it > to the WAL buffers. Then, the compressed FPW is decompressed > in recovery. This is very simple patch. > > The purpose of this patch is the reduction of WAL size. > Under heavy write load, the server needs to write a large amount of > WAL and this is likely to be a bottleneck. What's the worse is, > in replication, a large amount of WAL would have harmful effect on > not only WAL writing in the master, but also WAL streaming and > WAL writing in the standby. Also we would need to spend more > money on the storage to store such a large data. > I'd like to alleviate such harmful situations by reducing WAL size. > > My idea is very simple, just compress FPW because FPW is > a big part of WAL. I used pglz_compress() as a compression method, > but you might think that other method is better. We can add > something like FPW-compression-hook for that later. The patch > adds new GUC parameter, but I'm thinking to merge it to full_page_writes > parameter to avoid increasing the number of GUC. That is, > I'm thinking to change full_page_writes so that it can accept new value > 'compress'. > > I measured how much WAL this patch can reduce, by using pgbench. > > * Server spec > CPU: 8core, Intel(R) Core(TM) i7-3630QM CPU @ 2.40GHz > Mem: 16GB > Disk: 500GB SSD Samsung 840 > > * Benchmark > pgbench -c 32 -j 4 -T 900 -M prepared > scaling factor: 100 > > checkpoint_segments = 1024 > checkpoint_timeout = 5min > (every checkpoint during benchmark were triggered by checkpoint_timeout) > > * Result > [tps] > 1386.8 (compress_backup_block = off) > 1627.7 (compress_backup_block = on) > > [the amount of WAL generated during running pgbench] > 4302 MB (compress_backup_block = off) > 1521 MB (compress_backup_block = on) This is really nice data. I think if you want, you can once try with one of the tests Heikki has posted for one of my other patch which is here: http://www.postgresql.org/message-id/51366323.8070606@vmware.com Also if possible, for with lesser clients (1,2,4) and may be with more frequency of checkpoint. This is just to show benefits of this idea with other kind of workload. I think we can do these tests later as well, I had mentioned because sometime back (probably 6 months), one of my colleagues have tried exactly the same idea of using compression method (LZ and few others) for FPW, but it turned out that even though the WAL size is reduced but performance went down which is not the case in the data you have shown even though you have used SSD, might be he has done some mistake as he was not as experienced, but I think still it's good to check on various workloads. With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
(2013/08/30 11:55), Fujii Masao wrote: > * Benchmark > pgbench -c 32 -j 4 -T 900 -M prepared > scaling factor: 100 > > checkpoint_segments = 1024 > checkpoint_timeout = 5min > (every checkpoint during benchmark were triggered by checkpoint_timeout) Did you execute munual checkpoint before starting benchmark? We read only your message, it occuered three times checkpoint during benchmark. But if you did not executed manual checkpoint, it would be different. You had better clear this point for more transparent evaluation. Regards, -- Mitsumasa KONDO NTT Open Software Center
Nikhils
Hi,
Attached patch adds new GUC parameter 'compress_backup_block'.
When this parameter is enabled, the server just compresses FPW
(full-page-writes) in WAL by using pglz_compress() before inserting it
to the WAL buffers. Then, the compressed FPW is decompressed
in recovery. This is very simple patch.
The purpose of this patch is the reduction of WAL size.
Under heavy write load, the server needs to write a large amount of
WAL and this is likely to be a bottleneck. What's the worse is,
in replication, a large amount of WAL would have harmful effect on
not only WAL writing in the master, but also WAL streaming and
WAL writing in the standby. Also we would need to spend more
money on the storage to store such a large data.
I'd like to alleviate such harmful situations by reducing WAL size.
My idea is very simple, just compress FPW because FPW is
a big part of WAL. I used pglz_compress() as a compression method,
but you might think that other method is better. We can add
something like FPW-compression-hook for that later. The patch
adds new GUC parameter, but I'm thinking to merge it to full_page_writes
parameter to avoid increasing the number of GUC. That is,
I'm thinking to change full_page_writes so that it can accept new value
'compress'.
I measured how much WAL this patch can reduce, by using pgbench.
* Server spec
CPU: 8core, Intel(R) Core(TM) i7-3630QM CPU @ 2.40GHz
Mem: 16GB
Disk: 500GB SSD Samsung 840
* Benchmark
pgbench -c 32 -j 4 -T 900 -M prepared
scaling factor: 100
checkpoint_segments = 1024
checkpoint_timeout = 5min
(every checkpoint during benchmark were triggered by checkpoint_timeout)
* Result
[tps]
1386.8 (compress_backup_block = off)
1627.7 (compress_backup_block = on)
[the amount of WAL generated during running pgbench]
4302 MB (compress_backup_block = off)
1521 MB (compress_backup_block = on)
At least in my test, the patch could reduce the WAL size to one-third!
The patch is WIP yet. But I'd like to hear the opinions about this idea
before completing it, and then add the patch to next CF if okay.
Regards,
--
Fujii Masao
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
On Fri, Aug 30, 2013 at 11:55 AM, Fujii Masao <masao.fujii@gmail.com> wrote: > My idea is very simple, just compress FPW because FPW is > a big part of WAL. I used pglz_compress() as a compression method, > but you might think that other method is better. We can add > something like FPW-compression-hook for that later. The patch > adds new GUC parameter, but I'm thinking to merge it to full_page_writes > parameter to avoid increasing the number of GUC. That is, > I'm thinking to change full_page_writes so that it can accept new value > 'compress'. Instead of a generic 'compress', what about using the name of the compression method as parameter value? Just to keep the door open to new types of compression methods. > * Result > [tps] > 1386.8 (compress_backup_block = off) > 1627.7 (compress_backup_block = on) > > [the amount of WAL generated during running pgbench] > 4302 MB (compress_backup_block = off) > 1521 MB (compress_backup_block = on) > > At least in my test, the patch could reduce the WAL size to one-third! Nice numbers! Testing this patch with other benchmarks than pgbench would be interesting as well. -- Michael
On Fri, Aug 30, 2013 at 12:43 PM, Peter Geoghegan <pg@heroku.com> wrote: > On Thu, Aug 29, 2013 at 7:55 PM, Fujii Masao <masao.fujii@gmail.com> wrote: >> [the amount of WAL generated during running pgbench] >> 4302 MB (compress_backup_block = off) >> 1521 MB (compress_backup_block = on) > > Interesting. > > I wonder, what is the impact on recovery time under the same > conditions? Will test! I can imagine that the recovery time would be a bit longer with compress_backup_block=on because compressed FPW needs to be decompressed. > I suppose that the cost of the random I/O involved would > probably dominate just as with compress_backup_block = off. That said, > you've used an SSD here, so perhaps not. Oh, maybe my description was confusing. full_page_writes was enabled while running the benchmark even if compress_backup_block = off. I've not merged those two parameters yet. So even in compress_backup_block = off, random I/O would not be increased in recovery. Regards, -- Fujii Masao
On Fri, Aug 30, 2013 at 1:43 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Fri, Aug 30, 2013 at 8:25 AM, Fujii Masao <masao.fujii@gmail.com> wrote: >> Hi, >> >> Attached patch adds new GUC parameter 'compress_backup_block'. >> When this parameter is enabled, the server just compresses FPW >> (full-page-writes) in WAL by using pglz_compress() before inserting it >> to the WAL buffers. Then, the compressed FPW is decompressed >> in recovery. This is very simple patch. >> >> The purpose of this patch is the reduction of WAL size. >> Under heavy write load, the server needs to write a large amount of >> WAL and this is likely to be a bottleneck. What's the worse is, >> in replication, a large amount of WAL would have harmful effect on >> not only WAL writing in the master, but also WAL streaming and >> WAL writing in the standby. Also we would need to spend more >> money on the storage to store such a large data. >> I'd like to alleviate such harmful situations by reducing WAL size. >> >> My idea is very simple, just compress FPW because FPW is >> a big part of WAL. I used pglz_compress() as a compression method, >> but you might think that other method is better. We can add >> something like FPW-compression-hook for that later. The patch >> adds new GUC parameter, but I'm thinking to merge it to full_page_writes >> parameter to avoid increasing the number of GUC. That is, >> I'm thinking to change full_page_writes so that it can accept new value >> 'compress'. >> >> I measured how much WAL this patch can reduce, by using pgbench. >> >> * Server spec >> CPU: 8core, Intel(R) Core(TM) i7-3630QM CPU @ 2.40GHz >> Mem: 16GB >> Disk: 500GB SSD Samsung 840 >> >> * Benchmark >> pgbench -c 32 -j 4 -T 900 -M prepared >> scaling factor: 100 >> >> checkpoint_segments = 1024 >> checkpoint_timeout = 5min >> (every checkpoint during benchmark were triggered by checkpoint_timeout) >> >> * Result >> [tps] >> 1386.8 (compress_backup_block = off) >> 1627.7 (compress_backup_block = on) >> >> [the amount of WAL generated during running pgbench] >> 4302 MB (compress_backup_block = off) >> 1521 MB (compress_backup_block = on) > > This is really nice data. > > I think if you want, you can once try with one of the tests Heikki has > posted for one of my other patch which is here: > http://www.postgresql.org/message-id/51366323.8070606@vmware.com > > Also if possible, for with lesser clients (1,2,4) and may be with more > frequency of checkpoint. > > This is just to show benefits of this idea with other kind of workload. Yep, I will do more tests. > I think we can do these tests later as well, I had mentioned because > sometime back (probably 6 months), one of my colleagues have tried > exactly the same idea of using compression method (LZ and few others) > for FPW, but it turned out that even though the WAL size is reduced > but performance went down which is not the case in the data you have > shown even though you have used SSD, might be he has done some mistake > as he was not as experienced, but I think still it's good to check on > various workloads. I'd appreciate if you test the patch with HDD. Now I have no machine with HDD. Regards, -- Fujii Masao
On Fri, Aug 30, 2013 at 2:32 PM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > (2013/08/30 11:55), Fujii Masao wrote: >> >> * Benchmark >> pgbench -c 32 -j 4 -T 900 -M prepared >> scaling factor: 100 >> >> checkpoint_segments = 1024 >> checkpoint_timeout = 5min >> (every checkpoint during benchmark were triggered by >> checkpoint_timeout) > > Did you execute munual checkpoint before starting benchmark? Yes. > We read only your message, it occuered three times checkpoint during > benchmark. > But if you did not executed manual checkpoint, it would be different. > > You had better clear this point for more transparent evaluation. What I executed was: ------------------------------------- CHECKPOINT SELECT pg_current_xlog_location() pgbench -c 32 -j 4 -T 900 -M prepared -r -P 10 SELECT pg_current_xlog_location() SELECT pg_xlog_location_diff() -- calculate the diff of the above locations ------------------------------------- I repeated this several times to eliminate the noise. Regards, -- Fujii Masao
On Thu, Aug 29, 2013 at 10:55 PM, Fujii Masao <masao.fujii@gmail.com> wrote: >> I suppose that the cost of the random I/O involved would >> probably dominate just as with compress_backup_block = off. That said, >> you've used an SSD here, so perhaps not. > > Oh, maybe my description was confusing. full_page_writes was enabled > while running the benchmark even if compress_backup_block = off. > I've not merged those two parameters yet. So even in > compress_backup_block = off, random I/O would not be increased in recovery. I understood it that way. I just meant that it could be that the random I/O was so expensive that the additional cost of decompressing the FPIs looked insignificant in comparison. If that was the case, the increase in recovery time would be modest. -- Peter Geoghegan
On Fri, Aug 30, 2013 at 2:37 PM, Nikhil Sontakke <nikkhils@gmail.com> wrote: > Hi Fujii-san, > > I must be missing something really trivial, but why not try to compress all > types of WAL blocks and not just FPW? The size of non-FPW WAL is small, compared to that of FPW. I thought that compression of such a small WAL would not have big effect on the reduction of WAL size. Rather, compression of every WAL records might cause large performance overhead. Also, focusing on FPW makes the patch very simple. We can add the compression of other WAL later if we want. Regards, -- Fujii Masao
On 30.08.2013 05:55, Fujii Masao wrote: > * Result > [tps] > 1386.8 (compress_backup_block = off) > 1627.7 (compress_backup_block = on) It would be good to check how much of this effect comes from reducing the amount of data that needs to be CRC'd, because there has been some talk of replacing the current CRC-32 algorithm with something faster. See http://www.postgresql.org/message-id/20130829223004.GD4283@awork2.anarazel.de. It might even be beneficial to use one routine for full-page-writes, which are generally much larger than other WAL records, and another routine for smaller records. As long as they both produce the same CRC, of course. Speeding up the CRC calculation obviously won't help with the WAL volume per se, ie. you still generate the same amount of WAL that needs to be shipped in replication. But then again, if all you want to do is to reduce the volume, you could just compress the whole WAL stream. - Heikki
On Thu, Aug 29, 2013 at 10:55 PM, Fujii Masao <masao.fujii@gmail.com> wrote: > Attached patch adds new GUC parameter 'compress_backup_block'. I think this is a great idea. (This is not to disagree with any of the suggestions made on this thread for further investigation, all of which I think I basically agree with. But I just wanted to voice general support for the general idea, regardless of what specifically we end up with.) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Aug 30, 2013 at 11:55 AM, Fujii Masao <masao.fujii@gmail.com> wrote:
> Hi,
>
> Attached patch adds new GUC parameter 'compress_backup_block'.
> When this parameter is enabled, the server just compresses FPW
> (full-page-writes) in WAL by using pglz_compress() before inserting it
> to the WAL buffers. Then, the compressed FPW is decompressed
> in recovery. This is very simple patch.
>
> The purpose of this patch is the reduction of WAL size.
> Under heavy write load, the server needs to write a large amount of
> WAL and this is likely to be a bottleneck. What's the worse is,
> in replication, a large amount of WAL would have harmful effect on
> not only WAL writing in the master, but also WAL streaming and
> WAL writing in the standby. Also we would need to spend more
> money on the storage to store such a large data.
> I'd like to alleviate such harmful situations by reducing WAL size.
>
> My idea is very simple, just compress FPW because FPW is
> a big part of WAL. I used pglz_compress() as a compression method,
> but you might think that other method is better. We can add
> something like FPW-compression-hook for that later. The patch
> adds new GUC parameter, but I'm thinking to merge it to full_page_writes
> parameter to avoid increasing the number of GUC. That is,
> I'm thinking to change full_page_writes so that it can accept new value
> 'compress'.
Done. Attached is the updated version of the patch.
In this patch, full_page_writes accepts three values: on, compress, and off.
When it's set to compress, the full page image is compressed before it's
inserted into the WAL buffers.
I measured how much this patch affects the performance and the WAL
volume again, and I also measured how much this patch affects the
recovery time.
* Server spec
CPU: 8core, Intel(R) Core(TM) i7-3630QM CPU @ 2.40GHz
Mem: 16GB
Disk: 500GB SSD Samsung 840
* Benchmark
pgbench -c 32 -j 4 -T 900 -M prepared
scaling factor: 100
checkpoint_segments = 1024
checkpoint_timeout = 5min
(every checkpoint during benchmark were triggered by checkpoint_timeout)
* Result
[tps]
1344.2 (full_page_writes = on)
1605.9 (compress)
1810.1 (off)
[the amount of WAL generated during running pgbench]
4422 MB (on)
1517 MB (compress)
885 MB (off)
[time required to replay WAL generated during running pgbench]
61s (on) .... 1209911 transactions were replayed,
recovery speed: 19834.6 transactions/sec
39s (compress) .... 1445446 transactions were replayed,
recovery speed: 37062.7 transactions/sec
37s (off) .... 1629235 transactions were replayed,
recovery speed: 44033.3 transactions/sec
When full_page_writes is disabled, the recovery speed is basically very low
because of random I/O. But, ISTM that, since I was using SSD in my box,
the recovery with full_page_writse=off was fastest.
Regards,
--
Fujii Masao
Attachment
On 2013-09-11 19:39:14 +0900, Fujii Masao wrote: > * Benchmark > pgbench -c 32 -j 4 -T 900 -M prepared > scaling factor: 100 > > checkpoint_segments = 1024 > checkpoint_timeout = 5min > (every checkpoint during benchmark were triggered by checkpoint_timeout) > > * Result > [tps] > 1344.2 (full_page_writes = on) > 1605.9 (compress) > 1810.1 (off) > > [the amount of WAL generated during running pgbench] > 4422 MB (on) > 1517 MB (compress) > 885 MB (off) > > [time required to replay WAL generated during running pgbench] > 61s (on) .... 1209911 transactions were replayed, > recovery speed: 19834.6 transactions/sec > 39s (compress) .... 1445446 transactions were replayed, > recovery speed: 37062.7 transactions/sec > 37s (off) .... 1629235 transactions were replayed, > recovery speed: 44033.3 transactions/sec ISTM for those benchmarks you should use an absolute number of transactions, not one based on elapsed time. Otherwise the comparison isn't really meaningful. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Sep 11, 2013 at 7:39 PM, Fujii Masao <masao.fujii@gmail.com> wrote: > On Fri, Aug 30, 2013 at 11:55 AM, Fujii Masao <masao.fujii@gmail.com> wrote: >> Hi, >> >> Attached patch adds new GUC parameter 'compress_backup_block'. >> When this parameter is enabled, the server just compresses FPW >> (full-page-writes) in WAL by using pglz_compress() before inserting it >> to the WAL buffers. Then, the compressed FPW is decompressed >> in recovery. This is very simple patch. >> >> The purpose of this patch is the reduction of WAL size. >> Under heavy write load, the server needs to write a large amount of >> WAL and this is likely to be a bottleneck. What's the worse is, >> in replication, a large amount of WAL would have harmful effect on >> not only WAL writing in the master, but also WAL streaming and >> WAL writing in the standby. Also we would need to spend more >> money on the storage to store such a large data. >> I'd like to alleviate such harmful situations by reducing WAL size. >> >> My idea is very simple, just compress FPW because FPW is >> a big part of WAL. I used pglz_compress() as a compression method, >> but you might think that other method is better. We can add >> something like FPW-compression-hook for that later. The patch >> adds new GUC parameter, but I'm thinking to merge it to full_page_writes >> parameter to avoid increasing the number of GUC. That is, >> I'm thinking to change full_page_writes so that it can accept new value >> 'compress'. > > Done. Attached is the updated version of the patch. > > In this patch, full_page_writes accepts three values: on, compress, and off. > When it's set to compress, the full page image is compressed before it's > inserted into the WAL buffers. > > I measured how much this patch affects the performance and the WAL > volume again, and I also measured how much this patch affects the > recovery time. > > * Server spec > CPU: 8core, Intel(R) Core(TM) i7-3630QM CPU @ 2.40GHz > Mem: 16GB > Disk: 500GB SSD Samsung 840 > > * Benchmark > pgbench -c 32 -j 4 -T 900 -M prepared > scaling factor: 100 > > checkpoint_segments = 1024 > checkpoint_timeout = 5min > (every checkpoint during benchmark were triggered by checkpoint_timeout) > > * Result > [tps] > 1344.2 (full_page_writes = on) > 1605.9 (compress) > 1810.1 (off) > > [the amount of WAL generated during running pgbench] > 4422 MB (on) > 1517 MB (compress) > 885 MB (off) On second thought, the patch could compress WAL very much because I used pgbench. Most of data in pgbench are pgbench_accounts table's "filler" columns, i.e., blank-padded empty strings. So, the compression ratio of WAL was very high. I will do the same measurement by using another benchmark. Regards, -- Fujii Masao
Hi Fujii-san, (2013/09/30 12:49), Fujii Masao wrote:> On second thought, the patch could compress WAL very much because I used pgbench. > I will do the same measurement by using another benchmark. If you hope, I can test this patch in DBT-2 benchmark in end of this week. I will use under following test server. * Test server Server: HP Proliant DL360 G7 CPU: Xeon E5640 2.66GHz (1P/4C) Memory: 18GB(PC3-10600R-9) Disk: 146GB(15k)*4RAID1+0 RAID controller: P410i/256MB This is PG-REX test server as you know. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On Mon, Sep 30, 2013 at 1:27 PM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > Hi Fujii-san, > > > (2013/09/30 12:49), Fujii Masao wrote: >> On second thought, the patch could compress WAL very much because I used >> pgbench. >> >> I will do the same measurement by using another benchmark. > > If you hope, I can test this patch in DBT-2 benchmark in end of this week. > I will use under following test server. > > * Test server > Server: HP Proliant DL360 G7 > CPU: Xeon E5640 2.66GHz (1P/4C) > Memory: 18GB(PC3-10600R-9) > Disk: 146GB(15k)*4 RAID1+0 > RAID controller: P410i/256MB Yep, please! It's really helpful! Regards, -- Fujii Masao
On Mon, Sep 30, 2013 at 10:04 AM, Fujii Masao <masao.fujii@gmail.com> wrote: > On Mon, Sep 30, 2013 at 1:27 PM, KONDO Mitsumasa > <kondo.mitsumasa@lab.ntt.co.jp> wrote: >> Hi Fujii-san, >> >> >> (2013/09/30 12:49), Fujii Masao wrote: >>> On second thought, the patch could compress WAL very much because I used >>> pgbench. >>> >>> I will do the same measurement by using another benchmark. >> >> If you hope, I can test this patch in DBT-2 benchmark in end of this week. >> I will use under following test server. >> >> * Test server >> Server: HP Proliant DL360 G7 >> CPU: Xeon E5640 2.66GHz (1P/4C) >> Memory: 18GB(PC3-10600R-9) >> Disk: 146GB(15k)*4 RAID1+0 >> RAID controller: P410i/256MB > > Yep, please! It's really helpful! I think it will be useful if you can get the data for 1 and 2 threads (may be with pgbench itself) as well, because the WAL reduction is almost sure, but the only thing is that it should not dip tps in some of the scenarios. With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
(2013/09/30 13:55), Amit Kapila wrote: > On Mon, Sep 30, 2013 at 10:04 AM, Fujii Masao <masao.fujii@gmail.com> wrote: >> Yep, please! It's really helpful! OK! I test with single instance and synchronous replication constitution. By the way, you posted patch which is sync_file_range() WAL writing method in 3 years ago. I think it is also good for performance. As the reason, I read sync_file_range() and fdatasync() in latest linux kernel code(3.9.11), fdatasync() writes in dirty buffers of the whole file, on the other hand, sync_file_range() writes in partial dirty buffers. In more detail, these functions use the same function in kernel source code, fdatasync() is vfs_fsync_range(file, 0, LLONG_MAX, 1), and sync_file_range() is vfs_fsync_range(file, offset, amount, 1). It is obvious that which is more efficiently in WAL writing. You had better confirm it in linux kernel's git. I think your conviction will be more deeply. https://git.kernel.org/cgit/linux/kernel/git/stable/linux-stable.git/tree/fs/sync.c?id=refs/tags/v3.11.2 > I think it will be useful if you can get the data for 1 and 2 threads > (may be with pgbench itself) as well, because the WAL reduction is > almost sure, but the only thing is that it should not dip tps in some > of the scenarios. That's right. I also want to know about this patch in MD environment, because MD has strong point in sequential write which like WAL writing. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On Mon, Sep 30, 2013 at 1:55 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Mon, Sep 30, 2013 at 10:04 AM, Fujii Masao <masao.fujii@gmail.com> wrote: >> On Mon, Sep 30, 2013 at 1:27 PM, KONDO Mitsumasa >> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>> Hi Fujii-san, >>> >>> >>> (2013/09/30 12:49), Fujii Masao wrote: >>>> On second thought, the patch could compress WAL very much because I used >>>> pgbench. >>>> >>>> I will do the same measurement by using another benchmark. >>> >>> If you hope, I can test this patch in DBT-2 benchmark in end of this week. >>> I will use under following test server. >>> >>> * Test server >>> Server: HP Proliant DL360 G7 >>> CPU: Xeon E5640 2.66GHz (1P/4C) >>> Memory: 18GB(PC3-10600R-9) >>> Disk: 146GB(15k)*4 RAID1+0 >>> RAID controller: P410i/256MB >> >> Yep, please! It's really helpful! > > I think it will be useful if you can get the data for 1 and 2 threads > (may be with pgbench itself) as well, because the WAL reduction is > almost sure, but the only thing is that it should not dip tps in some > of the scenarios. Here is the measurement result of pgbench with 1 thread. scaling factor: 100 query mode: prepared number of clients: 1 number of threads: 1 duration: 900 s WAL Volume - 1344 MB (full_page_writes = on) - 349 MB (compress) - 78 MB (off) TPS 117.369221 (on) 143.908024 (compress) 163.722063 (off) Regards, -- Fujii Masao
On Fri, Oct 4, 2013 at 10:49 AM, Fujii Masao <masao.fujii@gmail.com> wrote: > On Mon, Sep 30, 2013 at 1:55 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> On Mon, Sep 30, 2013 at 10:04 AM, Fujii Masao <masao.fujii@gmail.com> wrote: >>> On Mon, Sep 30, 2013 at 1:27 PM, KONDO Mitsumasa >>> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>>> Hi Fujii-san, >>>> >>>> >>>> (2013/09/30 12:49), Fujii Masao wrote: >>>>> On second thought, the patch could compress WAL very much because I used >>>>> pgbench. >>>>> >>>>> I will do the same measurement by using another benchmark. >>>> >>>> If you hope, I can test this patch in DBT-2 benchmark in end of this week. >>>> I will use under following test server. >>>> >>>> * Test server >>>> Server: HP Proliant DL360 G7 >>>> CPU: Xeon E5640 2.66GHz (1P/4C) >>>> Memory: 18GB(PC3-10600R-9) >>>> Disk: 146GB(15k)*4 RAID1+0 >>>> RAID controller: P410i/256MB >>> >>> Yep, please! It's really helpful! >> >> I think it will be useful if you can get the data for 1 and 2 threads >> (may be with pgbench itself) as well, because the WAL reduction is >> almost sure, but the only thing is that it should not dip tps in some >> of the scenarios. > > Here is the measurement result of pgbench with 1 thread. > > scaling factor: 100 > query mode: prepared > number of clients: 1 > number of threads: 1 > duration: 900 s > > WAL Volume > - 1344 MB (full_page_writes = on) > - 349 MB (compress) > - 78 MB (off) > > TPS > 117.369221 (on) > 143.908024 (compress) > 163.722063 (off) This data is good. I will check if with the help of my old colleagues, I can get the performance data on m/c where we have tried similar idea. With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 05 October 2013 17:12 Amit Kapila wrote:
>On Fri, Oct 4, 2013 at 10:49 AM, Fujii Masao <masao.fujii@gmail.com> wrote:
>> On Mon, Sep 30, 2013 at 1:55 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>> On Mon, Sep 30, 2013 at 10:04 AM, Fujii Masao <masao.fujii@gmail.com> wrote:
>>>> On Mon, Sep 30, 2013 at 1:27 PM, KONDO Mitsumasa
>>>> <kondo.mitsumasa@lab.ntt.co.jp> wrote:
>>>>> Hi Fujii-san,
>>>>>
>>>>>
>>>>> (2013/09/30 12:49), Fujii Masao wrote:
>>>>>> On second thought, the patch could compress WAL very much because
>>>>>> I used pgbench.
>>>>>>
>>>>>> I will do the same measurement by using another benchmark.
>>>>>
>>>>> If you hope, I can test this patch in DBT-2 benchmark in end of this week.
>>>>> I will use under following test server.
>>>>>
>>>>> * Test server
>>>>> Server: HP Proliant DL360 G7
>>>>> CPU: Xeon E5640 2.66GHz (1P/4C)
>>>>> Memory: 18GB(PC3-10600R-9)
>>>>> Disk: 146GB(15k)*4 RAID1+0
>>>>> RAID controller: P410i/256MB
>>>>
>>>> Yep, please! It's really helpful!
>>>
>>> I think it will be useful if you can get the data for 1 and 2 threads
>>> (may be with pgbench itself) as well, because the WAL reduction is
>>> almost sure, but the only thing is that it should not dip tps in some
>>> of the scenarios.
>>
>> Here is the measurement result of pgbench with 1 thread.
>>
>> scaling factor: 100
>> query mode: prepared
>> number of clients: 1
>> number of threads: 1
>> duration: 900 s
>>
>> WAL Volume
>> - 1344 MB (full_page_writes = on)
>> - 349 MB (compress)
>> - 78 MB (off)
>>
>> TPS
>> 117.369221 (on)
>> 143.908024 (compress)
>> 163.722063 (off)
>This data is good.
>I will check if with the help of my old colleagues, I can get the performance data on m/c where we have tried similar
idea.
Thread-1 Threads-2
Head code FPW compress Head code FPW compress
Pgbench-org 5min 1011(0.96GB) 815(0.20GB) 2083(1.24GB) 1843(0.40GB)
Pgbench-1000 5min 958(1.16GB) 778(0.24GB) 1937(2.80GB) 1659(0.73GB)
Pgbench-org 15min 1065(1.43GB) 983(0.56GB) 2094(1.93GB) 2025(1.09GB)
Pgbench-1000 15min 1020(3.70GB) 898(1.05GB) 1383(5.31GB) 1908(2.49GB)
Pgbench-org - original pgbench
Pgbench-1000 - changed pgbench with a record size of 1000.
5 min - pgbench test carried out for 5 min.
15 min - pgbench test carried out for 15 min.
The checkpoint_timeout and checkpoint_segments are increased to make sure no checkpoint happens during the test run.
>From the above readings it is observed that,
1. There a performance dip in one or two threads test, the amount of dip reduces with the test run time.
2. For two threads pgbench-1000 record size test, the fpw compress performance is good in 15min run.
3. More than 50% WAL reduction in all scenarios.
All these readings are measured with pgbench query mode as simple.
Please find the attached sheet for more details regarding machine and test configuration.
Regards,
Hari babu.
Attachment
(2013/10/08 17:33), Haribabu kommi wrote: > The checkpoint_timeout and checkpoint_segments are increased to make sure no checkpoint happens during the test run. Your setting is easy occurred checkpoint in checkpoint_segments = 256. I don't know number of disks in your test server, in my test server which has 4 magnetic disk(1.5k rpm), postgres generates 50 - 100 WALs per minutes. And I cannot understand your setting which is sync_commit = off. This setting tend to cause cpu bottle-neck and data-loss. It is not general in database usage. Therefore, your test is not fair comparison for Fujii's patch. Going back to my DBT-2 benchmark, I have not got good performance (almost same performance). So I am checking hunk, my setting, or something wrong in Fujii's patch now. I am going to try to send test result tonight. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On 2013-09-11 12:43:21 +0200, Andres Freund wrote: > On 2013-09-11 19:39:14 +0900, Fujii Masao wrote: > > * Benchmark > > pgbench -c 32 -j 4 -T 900 -M prepared > > scaling factor: 100 > > > > checkpoint_segments = 1024 > > checkpoint_timeout = 5min > > (every checkpoint during benchmark were triggered by checkpoint_timeout) > > > > * Result > > [tps] > > 1344.2 (full_page_writes = on) > > 1605.9 (compress) > > 1810.1 (off) > > > > [the amount of WAL generated during running pgbench] > > 4422 MB (on) > > 1517 MB (compress) > > 885 MB (off) > > > > [time required to replay WAL generated during running pgbench] > > 61s (on) .... 1209911 transactions were replayed, > > recovery speed: 19834.6 transactions/sec > > 39s (compress) .... 1445446 transactions were replayed, > > recovery speed: 37062.7 transactions/sec > > 37s (off) .... 1629235 transactions were replayed, > > recovery speed: 44033.3 transactions/sec > > ISTM for those benchmarks you should use an absolute number of > transactions, not one based on elapsed time. Otherwise the comparison > isn't really meaningful. I really think we need to see recovery time benchmarks with a constant amount of transactions to judge this properly. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 08 October 2013 15:22 KONDO Mitsumasa wrote: > (2013/10/08 17:33), Haribabu kommi wrote: >> The checkpoint_timeout and checkpoint_segments are increased to make sure no checkpoint happens during the test run. >Your setting is easy occurred checkpoint in checkpoint_segments = 256. I don't know number of disks in your test server,in my test server which has 4 magnetic disk(1.5k rpm), postgres generates 50 - 100 WALs per minutes. A manual checkpoint is executed before starting of the test and verified as no checkpoint happened during the run by increasingthe "checkpoint_warning". >And I cannot understand your setting which is sync_commit = off. This setting tend to cause cpu bottle-neck and data-loss.It is not general in database usage. Therefore, your test is not fair comparison for Fujii's patch. I chosen the sync_commit=off mode because it generates more tps, thus it increases the volume of WAL. I will test with sync_commit=on mode and provide the test results. Regards, Hari babu.
Hi,
I tested dbt-2 benchmark in single instance and synchronous replication.
Unfortunately, my benchmark results were not seen many differences...
* Test server
Server: HP Proliant DL360 G7
CPU: Xeon E5640 2.66GHz (1P/4C)
Memory: 18GB(PC3-10600R-9)
Disk: 146GB(15k)*4 RAID1+0
RAID controller: P410i/256MB
* Result
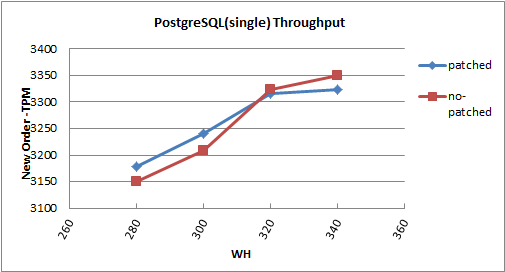
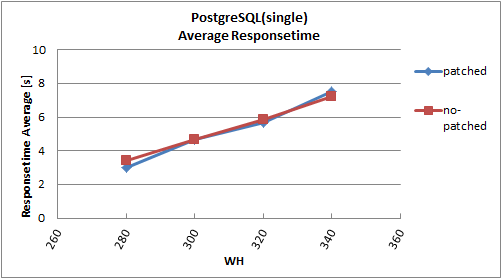
** Single instance**
| NOTPM | 90%tile | Average | S.Deviation
------------+-----------+-------------+---------+-------------
no-patched | 3322.93 | 20.469071 | 5.882 | 10.478
patched | 3315.42 | 19.086105 | 5.669 | 9.108
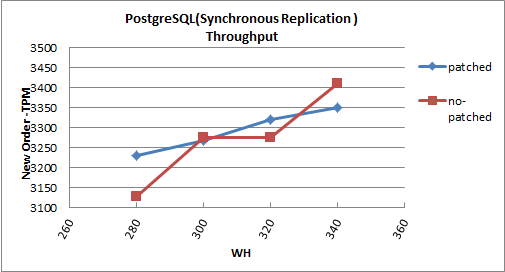
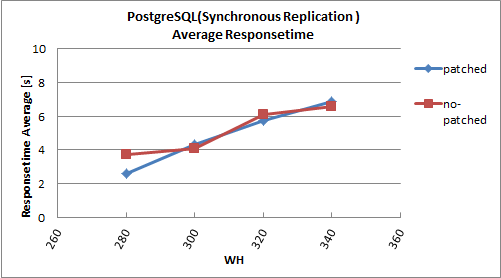
** Synchronous Replication **
| NOTPM | 90%tile | Average | S.Deviation
------------+-----------+-------------+---------+-------------
no-patched | 3275.55 | 21.332866 | 6.072 | 9.882
patched | 3318.82 | 18.141807 | 5.757 | 9.829
** Detail of result
http://pgstatsinfo.projects.pgfoundry.org/DBT-2_Fujii_patch/
I set full_page_write = compress with Fujii's patch in DBT-2. But it does not
seems to effect for eleminating WAL files. I will try to DBT-2 benchmark more
once, and try to normal pgbench in my test server.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
(2013/10/08 20:13), Haribabu kommi wrote: > I chosen the sync_commit=off mode because it generates more tps, thus it increases the volume of WAL. I did not think to there. Sorry... > I will test with sync_commit=on mode and provide the test results. OK. Thanks! -- Mitsumasa KONDO NTT Open Source Software Center
On 08 October 2013 18:42 KONDO Mitsumasa wrote:
>(2013/10/08 20:13), Haribabu kommi wrote:
>> I will test with sync_commit=on mode and provide the test results.
>OK. Thanks!
Pgbench test results with synchronous_commit mode as on.
Thread-1 Threads-2
Head code FPW compress Head code FPW compress
Pgbench-org 5min 138(0.24GB) 131(0.04GB) 160(0.28GB) 163(0.05GB)
Pgbench-1000 5min 140(0.29GB) 128(0.03GB) 160(0.33GB) 162(0.02GB)
Pgbench-org 15min 141(0.59GB) 136(0.12GB) 160(0.65GB) 162(0.14GB)
Pgbench-1000 15min 138(0.81GB) 134(0.11GB) 159(0.92GB) 162(0.18GB)
Pgbench-org - original pgbench
Pgbench-1000 - changed pgbench with a record size of 1000.
5 min - pgbench test carried out for 5 min.
15 min - pgbench test carried out for 15 min.
From the above readings it is observed that,
1. There a performance dip in one thread test, the amount of dip reduces with the test run time.
2. More than 75% WAL reduction in all scenarios.
Please find the attached sheet for more details regarding machine and test configuration
Regards,
Hari babu.
Attachment
Hi,
I did a partial review of this patch, wherein I focused on the patch and
the code itself, as I saw other contributors already did some testing on
it, so that we know it applies cleanly and work to some good extend.
Fujii Masao <masao.fujii@gmail.com> writes:
> In this patch, full_page_writes accepts three values: on, compress, and off.
> When it's set to compress, the full page image is compressed before it's
> inserted into the WAL buffers.
Code review :
In full_page_writes_str() why are you returning "unrecognized" rather
than doing an ELOG(ERROR, …) for this unexpected situation?
The code switches to compression (or trying to) when the following
condition is met:
+ if (fpw <= FULL_PAGE_WRITES_COMPRESS)
+ {
+ rdt->data = CompressBackupBlock(page, BLCKSZ - bkpb->hole_length, &(rdt->len));
We have
+ typedef enum FullPageWritesLevel
+ {
+ FULL_PAGE_WRITES_OFF = 0,
+ FULL_PAGE_WRITES_COMPRESS,
+ FULL_PAGE_WRITES_ON
+ } FullPageWritesLevel;
+ #define FullPageWritesIsNeeded(fpw) (fpw >= FULL_PAGE_WRITES_COMPRESS)
I don't much like using the <= test against and ENUM and I'm not sure I
understand the intention you have here. It somehow looks like a typo and
disagrees with the macro. What about using the FullPageWritesIsNeeded
macro, and maybe rewriting the macro as
#define FullPageWritesIsNeeded(fpw) \ (fpw == FULL_PAGE_WRITES_COMPRESS || fpw == FULL_PAGE_WRITES_ON)
Also, having "on" imply "compress" is a little funny to me. Maybe we
should just finish our testing and be happy to always compress the full
page writes. What would the downside be exactly (on buzy IO system
writing less data even if needing more CPU will be the right trade-off).
I like that you're checking the savings of the compressed data with
respect to the uncompressed data and cancel the compression if there's
no gain. I wonder if your test accounts for enough padding and headers
though given the results we saw in other tests made in this thread.
Why do we have both the static function full_page_writes_str() and the
macro FullPageWritesStr, with two different implementations issuing
either "true" and "false" or "on" and "off"?
! unsigned hole_offset:15, /* number of bytes before "hole" */
! flags:2, /* state of a backup block, see below */
! hole_length:15; /* number of bytes in "hole" */
I don't understand that. I wanted to use that patch as a leverage to
smoothly discover the internals of our WAL system but won't have the
time to do that here. That said, I don't even know that C syntax.
+ #define BKPBLOCK_UNCOMPRESSED 0 /* uncompressed */
+ #define BKPBLOCK_COMPRESSED 1 /* comperssed */
There's a typo in the comment above.
> [time required to replay WAL generated during running pgbench]
> 61s (on) .... 1209911 transactions were replayed,
> recovery speed: 19834.6 transactions/sec
> 39s (compress) .... 1445446 transactions were replayed,
> recovery speed: 37062.7 transactions/sec
> 37s (off) .... 1629235 transactions were replayed,
> recovery speed: 44033.3 transactions/sec
How did you get those numbers ? pg_basebackup before the test and
archiving, then a PITR maybe? Is it possible to do the same test with
the same number of transactions to replay, I guess using the -t
parameter rather than the -T one for this testing.
Regards,
--
Dimitri Fontaine
http://2ndQuadrant.fr PostgreSQL : Expertise, Formation et Support
On Tue, Oct 8, 2013 at 10:07 PM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > Hi, > > I tested dbt-2 benchmark in single instance and synchronous replication. Thanks! > Unfortunately, my benchmark results were not seen many differences... > > > * Test server > Server: HP Proliant DL360 G7 > CPU: Xeon E5640 2.66GHz (1P/4C) > Memory: 18GB(PC3-10600R-9) > Disk: 146GB(15k)*4 RAID1+0 > RAID controller: P410i/256MB > > * Result > ** Single instance** > | NOTPM | 90%tile | Average | S.Deviation > ------------+-----------+-------------+---------+------------- > no-patched | 3322.93 | 20.469071 | 5.882 | 10.478 > patched | 3315.42 | 19.086105 | 5.669 | 9.108 > > > ** Synchronous Replication ** > | NOTPM | 90%tile | Average | S.Deviation > ------------+-----------+-------------+---------+------------- > no-patched | 3275.55 | 21.332866 | 6.072 | 9.882 > patched | 3318.82 | 18.141807 | 5.757 | 9.829 > > ** Detail of result > http://pgstatsinfo.projects.pgfoundry.org/DBT-2_Fujii_patch/ > > > I set full_page_write = compress with Fujii's patch in DBT-2. But it does > not > seems to effect for eleminating WAL files. Could you let me know how much WAL records were generated during each benchmark? I think that this benchmark result clearly means that the patch has only limited effects in the reduction of WAL volume and the performance improvement unless the database contains highly-compressible data like pgbench_accounts.filler. But if we can use other compression algorithm, maybe we can reduce WAL volume very much. I'm not sure what algorithm is good for WAL compression, though. It might be better to introduce the hook for compression of FPW so that users can freely use their compression module, rather than just using pglz_compress(). Thought? Regards, -- Fujii Masao
On Wed, Oct 9, 2013 at 1:35 PM, Haribabu kommi <haribabu.kommi@huawei.com> wrote: > On 08 October 2013 18:42 KONDO Mitsumasa wrote: >>(2013/10/08 20:13), Haribabu kommi wrote: >>> I will test with sync_commit=on mode and provide the test results. >>OK. Thanks! > > Pgbench test results with synchronous_commit mode as on. Thanks! > Thread-1 Threads-2 > Head code FPW compress Head code FPW compress > Pgbench-org 5min 138(0.24GB) 131(0.04GB) 160(0.28GB) 163(0.05GB) > Pgbench-1000 5min 140(0.29GB) 128(0.03GB) 160(0.33GB) 162(0.02GB) > Pgbench-org 15min 141(0.59GB) 136(0.12GB) 160(0.65GB) 162(0.14GB) > Pgbench-1000 15min 138(0.81GB) 134(0.11GB) 159(0.92GB) 162(0.18GB) > > Pgbench-org - original pgbench > Pgbench-1000 - changed pgbench with a record size of 1000. This means that you changed the data type of pgbench_accounts.filler to char(1000)? Regards, -- Fujii Masao
On Fri, Oct 11, 2013 at 1:20 AM, Dimitri Fontaine
<dimitri@2ndquadrant.fr> wrote:
> Hi,
>
> I did a partial review of this patch, wherein I focused on the patch and
> the code itself, as I saw other contributors already did some testing on
> it, so that we know it applies cleanly and work to some good extend.
Thanks a lot!
> In full_page_writes_str() why are you returning "unrecognized" rather
> than doing an ELOG(ERROR, …) for this unexpected situation?
It's because the similar functions 'wal_level_str' and 'dbState' also return
'unrecognized' in the unexpected situation. I just implemented
full_page_writes_str()
in the same manner.
If we do an elog(ERROR) in that case, pg_xlogdump would fail to dump
the 'broken' (i.e., unrecognized fpw is set) WAL file. I think that some
users want to use pg_xlogdump to investigate the broken WAL file, so
doing an elog(ERROR) seems not good to me.
> The code switches to compression (or trying to) when the following
> condition is met:
>
> + if (fpw <= FULL_PAGE_WRITES_COMPRESS)
> + {
> + rdt->data = CompressBackupBlock(page, BLCKSZ - bkpb->hole_length, &(rdt->len));
>
> We have
>
> + typedef enum FullPageWritesLevel
> + {
> + FULL_PAGE_WRITES_OFF = 0,
> + FULL_PAGE_WRITES_COMPRESS,
> + FULL_PAGE_WRITES_ON
> + } FullPageWritesLevel;
>
> + #define FullPageWritesIsNeeded(fpw) (fpw >= FULL_PAGE_WRITES_COMPRESS)
>
> I don't much like using the <= test against and ENUM and I'm not sure I
> understand the intention you have here. It somehow looks like a typo and
> disagrees with the macro.
I thought that FPW should be compressed only when full_page_writes is
set to 'compress' or 'off'. That is, 'off' implies a compression. When it's set
to 'off', FPW is basically not generated, so there is no need to call
CompressBackupBlock() in that case. But only during online base backup,
FPW is forcibly generated even when it's set to 'off'. So I used the check
"fpw <= FULL_PAGE_WRITES_COMPRESS" there.
> What about using the FullPageWritesIsNeeded
> macro, and maybe rewriting the macro as
>
> #define FullPageWritesIsNeeded(fpw) \
> (fpw == FULL_PAGE_WRITES_COMPRESS || fpw == FULL_PAGE_WRITES_ON)
I'm OK to change the macro so that the <= test is not used.
> Also, having "on" imply "compress" is a little funny to me. Maybe we
> should just finish our testing and be happy to always compress the full
> page writes. What would the downside be exactly (on buzy IO system
> writing less data even if needing more CPU will be the right trade-off).
"on" doesn't imply "compress". When full_page_writes is set to "on",
FPW is not compressed at all.
> I like that you're checking the savings of the compressed data with
> respect to the uncompressed data and cancel the compression if there's
> no gain. I wonder if your test accounts for enough padding and headers
> though given the results we saw in other tests made in this thread.
I'm afraid that the patch has only limited effects in WAL reduction and
performance improvement unless the database contains highly-compressible
data like large blank characters column. It really depends on the contents
of the database. So, obviously FPW compression should not be the default.
Maybe we can treat it as just tuning knob.
> Why do we have both the static function full_page_writes_str() and the
> macro FullPageWritesStr, with two different implementations issuing
> either "true" and "false" or "on" and "off"?
First I was thinking to use "on" and "off" because they are often used
as the setting value of boolean GUC. But unfortunately the existing
pg_xlogdump uses "true" and "false" to show the value of full_page_writes
in WAL. To avoid breaking the backward compatibility, I implmented
the "true/false" version of function. I'm really not sure how many people
want such a compatibility of pg_xlogdump, though.
> ! unsigned hole_offset:15, /* number of bytes before "hole" */
> ! flags:2, /* state of a backup block, see below */
> ! hole_length:15; /* number of bytes in "hole" */
>
> I don't understand that. I wanted to use that patch as a leverage to
> smoothly discover the internals of our WAL system but won't have the
> time to do that here.
We need the flag indicating whether each FPW is compressed or not.
If no such a flag exists in WAL, the standby cannot determine whether
it should decompress each FPW or not, and then cannot replay
the WAL containing FPW properly. That is, I just used a 'space' in
the header of FPW to have such a flag.
> That said, I don't even know that C syntax.
The struct 'ItemIdData' uses the same C syntax.
> + #define BKPBLOCK_UNCOMPRESSED 0 /* uncompressed */
> + #define BKPBLOCK_COMPRESSED 1 /* comperssed */
>
> There's a typo in the comment above.
Yep.
>> [time required to replay WAL generated during running pgbench]
>> 61s (on) .... 1209911 transactions were replayed,
>> recovery speed: 19834.6 transactions/sec
>> 39s (compress) .... 1445446 transactions were replayed,
>> recovery speed: 37062.7 transactions/sec
>> 37s (off) .... 1629235 transactions were replayed,
>> recovery speed: 44033.3 transactions/sec
>
> How did you get those numbers ? pg_basebackup before the test and
> archiving, then a PITR maybe? Is it possible to do the same test with
> the same number of transactions to replay, I guess using the -t
> parameter rather than the -T one for this testing.
Sure. To be honest, when I received the same request from Andres,
I did that benchmark. But unfortunately because of machine trouble,
I could not report it, yet. Will do that again.
Regards,
--
Fujii Masao
Hi, On 2013-10-11 03:44:01 +0900, Fujii Masao wrote: > I'm afraid that the patch has only limited effects in WAL reduction and > performance improvement unless the database contains highly-compressible > data like large blank characters column. It really depends on the contents > of the database. So, obviously FPW compression should not be the default. > Maybe we can treat it as just tuning knob. Have you tried using lz4 (or snappy) instead of pglz? There's a patch adding it to pg in http://archives.postgresql.org/message-id/20130621000900.GA12425%40alap2.anarazel.de If this really is only a benefit in scenarios with lots of such data, I have to say I have my doubts about the benefits of the patch. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Oct 11, 2013 at 3:44 AM, Fujii Masao <masao.fujii@gmail.com> wrote:
> On Fri, Oct 11, 2013 at 1:20 AM, Dimitri Fontaine
> <dimitri@2ndquadrant.fr> wrote:
>> Hi,
>>
>> I did a partial review of this patch, wherein I focused on the patch and
>> the code itself, as I saw other contributors already did some testing on
>> it, so that we know it applies cleanly and work to some good extend.
>
> Thanks a lot!
>
>> In full_page_writes_str() why are you returning "unrecognized" rather
>> than doing an ELOG(ERROR, …) for this unexpected situation?
>
> It's because the similar functions 'wal_level_str' and 'dbState' also return
> 'unrecognized' in the unexpected situation. I just implemented
> full_page_writes_str()
> in the same manner.
>
> If we do an elog(ERROR) in that case, pg_xlogdump would fail to dump
> the 'broken' (i.e., unrecognized fpw is set) WAL file. I think that some
> users want to use pg_xlogdump to investigate the broken WAL file, so
> doing an elog(ERROR) seems not good to me.
>
>> The code switches to compression (or trying to) when the following
>> condition is met:
>>
>> + if (fpw <= FULL_PAGE_WRITES_COMPRESS)
>> + {
>> + rdt->data = CompressBackupBlock(page, BLCKSZ - bkpb->hole_length, &(rdt->len));
>>
>> We have
>>
>> + typedef enum FullPageWritesLevel
>> + {
>> + FULL_PAGE_WRITES_OFF = 0,
>> + FULL_PAGE_WRITES_COMPRESS,
>> + FULL_PAGE_WRITES_ON
>> + } FullPageWritesLevel;
>>
>> + #define FullPageWritesIsNeeded(fpw) (fpw >= FULL_PAGE_WRITES_COMPRESS)
>>
>> I don't much like using the <= test against and ENUM and I'm not sure I
>> understand the intention you have here. It somehow looks like a typo and
>> disagrees with the macro.
>
> I thought that FPW should be compressed only when full_page_writes is
> set to 'compress' or 'off'. That is, 'off' implies a compression. When it's set
> to 'off', FPW is basically not generated, so there is no need to call
> CompressBackupBlock() in that case. But only during online base backup,
> FPW is forcibly generated even when it's set to 'off'. So I used the check
> "fpw <= FULL_PAGE_WRITES_COMPRESS" there.
>
>> What about using the FullPageWritesIsNeeded
>> macro, and maybe rewriting the macro as
>>
>> #define FullPageWritesIsNeeded(fpw) \
>> (fpw == FULL_PAGE_WRITES_COMPRESS || fpw == FULL_PAGE_WRITES_ON)
>
> I'm OK to change the macro so that the <= test is not used.
>
>> Also, having "on" imply "compress" is a little funny to me. Maybe we
>> should just finish our testing and be happy to always compress the full
>> page writes. What would the downside be exactly (on buzy IO system
>> writing less data even if needing more CPU will be the right trade-off).
>
> "on" doesn't imply "compress". When full_page_writes is set to "on",
> FPW is not compressed at all.
>
>> I like that you're checking the savings of the compressed data with
>> respect to the uncompressed data and cancel the compression if there's
>> no gain. I wonder if your test accounts for enough padding and headers
>> though given the results we saw in other tests made in this thread.
>
> I'm afraid that the patch has only limited effects in WAL reduction and
> performance improvement unless the database contains highly-compressible
> data like large blank characters column. It really depends on the contents
> of the database. So, obviously FPW compression should not be the default.
> Maybe we can treat it as just tuning knob.
>
>> Why do we have both the static function full_page_writes_str() and the
>> macro FullPageWritesStr, with two different implementations issuing
>> either "true" and "false" or "on" and "off"?
>
> First I was thinking to use "on" and "off" because they are often used
> as the setting value of boolean GUC. But unfortunately the existing
> pg_xlogdump uses "true" and "false" to show the value of full_page_writes
> in WAL. To avoid breaking the backward compatibility, I implmented
> the "true/false" version of function. I'm really not sure how many people
> want such a compatibility of pg_xlogdump, though.
>
>> ! unsigned hole_offset:15, /* number of bytes before "hole" */
>> ! flags:2, /* state of a backup block, see below */
>> ! hole_length:15; /* number of bytes in "hole" */
>>
>> I don't understand that. I wanted to use that patch as a leverage to
>> smoothly discover the internals of our WAL system but won't have the
>> time to do that here.
>
> We need the flag indicating whether each FPW is compressed or not.
> If no such a flag exists in WAL, the standby cannot determine whether
> it should decompress each FPW or not, and then cannot replay
> the WAL containing FPW properly. That is, I just used a 'space' in
> the header of FPW to have such a flag.
>
>> That said, I don't even know that C syntax.
>
> The struct 'ItemIdData' uses the same C syntax.
>
>> + #define BKPBLOCK_UNCOMPRESSED 0 /* uncompressed */
>> + #define BKPBLOCK_COMPRESSED 1 /* comperssed */
>>
>> There's a typo in the comment above.
>
> Yep.
>
>>> [time required to replay WAL generated during running pgbench]
>>> 61s (on) .... 1209911 transactions were replayed,
>>> recovery speed: 19834.6 transactions/sec
>>> 39s (compress) .... 1445446 transactions were replayed,
>>> recovery speed: 37062.7 transactions/sec
>>> 37s (off) .... 1629235 transactions were replayed,
>>> recovery speed: 44033.3 transactions/sec
>>
>> How did you get those numbers ? pg_basebackup before the test and
>> archiving, then a PITR maybe? Is it possible to do the same test with
>> the same number of transactions to replay, I guess using the -t
>> parameter rather than the -T one for this testing.
>
> Sure. To be honest, when I received the same request from Andres,
> I did that benchmark. But unfortunately because of machine trouble,
> I could not report it, yet. Will do that again.
Here is the benchmark result:
* Result
[tps]
1317.306391 (full_page_writes = on)
1628.407752 (compress)
[the amount of WAL generated during running pgbench]
1319 MB (on)326 MB (compress)
[time required to replay WAL generated during running pgbench]
19s (on)
2013-10-11 12:05:09 JST LOG: redo starts at F/F1000028
2013-10-11 12:05:28 JST LOG: redo done at 10/446B7BF0
12s (on)
2013-10-11 12:06:22 JST LOG: redo starts at F/F1000028
2013-10-11 12:06:34 JST LOG: redo done at 10/446B7BF0
12s (on)
2013-10-11 12:07:19 JST LOG: redo starts at F/F1000028
2013-10-11 12:07:31 JST LOG: redo done at 10/446B7BF0
8s (compress)
2013-10-11 12:17:36 JST LOG: redo starts at 10/50000028
2013-10-11 12:17:44 JST LOG: redo done at 10/655AE478
8s (compress)
2013-10-11 12:18:26 JST LOG: redo starts at 10/50000028
2013-10-11 12:18:34 JST LOG: redo done at 10/655AE478
8s (compress)
2013-10-11 12:19:07 JST LOG: redo starts at 10/50000028
2013-10-11 12:19:15 JST LOG: redo done at 10/655AE478
[benchmark]
transaction type: TPC-B (sort of)
scaling factor: 100
query mode: prepared
number of clients: 32
number of threads: 4
number of transactions per client: 10000
number of transactions actually processed: 320000/320000
Regards,
--
Fujii Masao
On Fri, Oct 11, 2013 at 8:35 AM, Andres Freund <andres@2ndquadrant.com> wrote: > Hi, > On 2013-10-11 03:44:01 +0900, Fujii Masao wrote: >> I'm afraid that the patch has only limited effects in WAL reduction and >> performance improvement unless the database contains highly-compressible >> data like large blank characters column. It really depends on the contents >> of the database. So, obviously FPW compression should not be the default. >> Maybe we can treat it as just tuning knob. > > > Have you tried using lz4 (or snappy) instead of pglz? There's a patch > adding it to pg in > http://archives.postgresql.org/message-id/20130621000900.GA12425%40alap2.anarazel.de Yeah, it's worth checking them! Will do that. > If this really is only a benefit in scenarios with lots of such data, I > have to say I have my doubts about the benefits of the patch. Yep, maybe the patch needs to be redesigned. Currently in the patch compression is performed per FPW, i.e., the size of data to compress is just 8KB. If we can increase the size of data to compress, we might be able to improve the compression ratio. For example, by storing all outstanding WAL data temporarily in local buffer, compressing them, and then storing the compressed WAL data to WAL buffers. Regards, -- Fujii Masao
On Fri, Oct 11, 2013 at 5:05 AM, Andres Freund <andres@2ndquadrant.com> wrote: > Hi, > On 2013-10-11 03:44:01 +0900, Fujii Masao wrote: >> I'm afraid that the patch has only limited effects in WAL reduction and >> performance improvement unless the database contains highly-compressible >> data like large blank characters column. It really depends on the contents >> of the database. So, obviously FPW compression should not be the default. >> Maybe we can treat it as just tuning knob. > > > Have you tried using lz4 (or snappy) instead of pglz? There's a patch > adding it to pg in > http://archives.postgresql.org/message-id/20130621000900.GA12425%40alap2.anarazel.de > > If this really is only a benefit in scenarios with lots of such data, I > have to say I have my doubts about the benefits of the patch. I think it will be difficult to prove by using any compression algorithm, that it compresses in most of the scenario's. In many cases it can so happen that the WAL will also not be reduced and tps can also come down if the data is non-compressible, because any compression algorithm will have to try to compress the data and it will burn some cpu for that, which inturn will reduce tps. As this patch is giving a knob to user to turn compression on/off, so users can decide if they want such benefit. Now some users can say that they have no idea, how or what kind of data will be there in their databases, so such kind of users should not use this option, but on the other side some users know that they have similar pattern of data, so they can get benefit out of such optimisations. For example in telecom industry, i have seen that they have lot of data as CDR's (call data records) in their HLR databases for which the data records will be different but of same pattern. Being said above, I think both this patch and my patch "WAL reduction for Update" (https://commitfest.postgresql.org/action/patch_view?id=1209) are using same technique for WAL compression and can lead to similar consequences in different ways. So I suggest to have unified method to enable WAL Compression for both the patches. With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 10 October 2013 23:06 Fujii Masao wrote: >On Wed, Oct 9, 2013 at 1:35 PM, Haribabu kommi <haribabu.kommi@huawei.com> wrote: >> Thread-1 Threads-2 >> Head code FPW compress Head code FPW compress >> Pgbench-org 5min 138(0.24GB) 131(0.04GB) 160(0.28GB) 163(0.05GB) >> Pgbench-1000 5min 140(0.29GB) 128(0.03GB) 160(0.33GB) 162(0.02GB) >> Pgbench-org 15min 141(0.59GB) 136(0.12GB) 160(0.65GB) 162(0.14GB) >> Pgbench-1000 15min 138(0.81GB) 134(0.11GB) 159(0.92GB) 162(0.18GB) >> >> Pgbench-org - original pgbench >> Pgbench-1000 - changed pgbench with a record size of 1000. >This means that you changed the data type of pgbench_accounts.filler to char(1000)? Yes, I changed the filler column as char(1000). Regards, Hari babu.
On 2013-10-11 09:22:50 +0530, Amit Kapila wrote: > I think it will be difficult to prove by using any compression > algorithm, that it compresses in most of the scenario's. > In many cases it can so happen that the WAL will also not be reduced > and tps can also come down if the data is non-compressible, because > any compression algorithm will have to try to compress the data and it > will burn some cpu for that, which inturn will reduce tps. Then those concepts maybe aren't such a good idea after all. Storing lots of compressible data in an uncompressed fashion isn't an all that common usecase. I most certainly don't want postgres to optimize for blank padded data, especially if it can hurt other scenarios. Just not enough benefit. That said, I actually have relatively high hopes for compressing full page writes. There often enough is lot of repetitiveness between rows on the same page that it should be useful outside of such strange scenarios. But maybe pglz is just not a good fit for this, it really isn't a very good algorithm in this day and aage. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Oct 11, 2013 at 10:36 PM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2013-10-11 09:22:50 +0530, Amit Kapila wrote: >> I think it will be difficult to prove by using any compression >> algorithm, that it compresses in most of the scenario's. >> In many cases it can so happen that the WAL will also not be reduced >> and tps can also come down if the data is non-compressible, because >> any compression algorithm will have to try to compress the data and it >> will burn some cpu for that, which inturn will reduce tps. > > Then those concepts maybe aren't such a good idea after all. Storing > lots of compressible data in an uncompressed fashion isn't an all that > common usecase. I most certainly don't want postgres to optimize for > blank padded data, especially if it can hurt other scenarios. Just not > enough benefit. > That said, I actually have relatively high hopes for compressing full > page writes. There often enough is lot of repetitiveness between rows on > the same page that it should be useful outside of such strange > scenarios. But maybe pglz is just not a good fit for this, it really > isn't a very good algorithm in this day and aage. Do you think that if WAL reduction or performance with other compression algorithm (for ex. snappy) is better, then chances of getting the new compression algorithm in postresql will be more? Wouldn't it be okay, if we have GUC to enable it and have pluggable api for calling compression method, with this we can even include other compression algorithm's if they proved to be good and reduce the dependency of this patch on inclusion of new compression methods in postgresql? With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 11/10/13 19:06, Andres Freund wrote: > On 2013-10-11 09:22:50 +0530, Amit Kapila wrote: >> I think it will be difficult to prove by using any compression >> algorithm, that it compresses in most of the scenario's. >> In many cases it can so happen that the WAL will also not be reduced >> and tps can also come down if the data is non-compressible, because >> any compression algorithm will have to try to compress the data and it >> will burn some cpu for that, which inturn will reduce tps. > Then those concepts maybe aren't such a good idea after all. Storing > lots of compressible data in an uncompressed fashion isn't an all that > common usecase. I most certainly don't want postgres to optimize for > blank padded data, especially if it can hurt other scenarios. Just not > enough benefit. > That said, I actually have relatively high hopes for compressing full > page writes. There often enough is lot of repetitiveness between rows on > the same page that it should be useful outside of such strange > scenarios. But maybe pglz is just not a good fit for this, it really > isn't a very good algorithm in this day and aage. > Hm,. There is a clear benefit for compressible data and clearly no benefit from incompressible data.. how about letting autovacuum "taste" the compressibillity of pages on per relation/index basis and set a flag that triggers this functionality where it provides a benefit? not hugely more magical than figuring out wether the data ends up in the heap or in a toast table as it is now. -- Jesper
(2013/10/13 0:14), Amit Kapila wrote: > On Fri, Oct 11, 2013 at 10:36 PM, Andres Freund <andres@2ndquadrant.com> wrote: >> But maybe pglz is just not a good fit for this, it really >> isn't a very good algorithm in this day and aage. +1. This compression algorithm is needed more faster than pglz which is like general compression algorithm, to avoid the CPU bottle-neck. I think pglz doesn't have good performance, and it is like fossil compression algorithm. So we need to change latest compression algorithm for more better future. > Do you think that if WAL reduction or performance with other > compression algorithm (for ex. snappy) is better, then chances of > getting the new compression algorithm in postresql will be more? Latest compression algorithms papers(also snappy) have indecated. I think it is enough to select algorithm. It may be also good work in postgres. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On Tue, Oct 15, 2013 at 6:30 AM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > (2013/10/13 0:14), Amit Kapila wrote: >> >> On Fri, Oct 11, 2013 at 10:36 PM, Andres Freund <andres@2ndquadrant.com> >> wrote: >>> >>> But maybe pglz is just not a good fit for this, it really >>> isn't a very good algorithm in this day and aage. > > +1. This compression algorithm is needed more faster than pglz which is like > general compression algorithm, to avoid the CPU bottle-neck. I think pglz > doesn't have good performance, and it is like fossil compression algorithm. > So we need to change latest compression algorithm for more better future. > > >> Do you think that if WAL reduction or performance with other >> compression algorithm (for ex. snappy) is better, then chances of >> getting the new compression algorithm in postresql will be more? > > Latest compression algorithms papers(also snappy) have indecated. I think it > is enough to select algorithm. It may be also good work in postgres. Snappy is good mainly for un-compressible data, see the link below: http://www.postgresql.org/message-id/CAAZKuFZCOCHsswQM60ioDO_hk12tA7OG3YcJA8v=4YebMOA-wA@mail.gmail.com I think it is bit difficult to prove that any one algorithm is best for all kind of loads. With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
(2013/10/15 13:33), Amit Kapila wrote: > Snappy is good mainly for un-compressible data, see the link below: > http://www.postgresql.org/message-id/CAAZKuFZCOCHsswQM60ioDO_hk12tA7OG3YcJA8v=4YebMOA-wA@mail.gmail.com This result was gotten in ARM architecture, it is not general CPU. Please see detail document. http://www.reddit.com/r/programming/comments/1aim6s/lz4_extremely_fast_compression_algorithm/c8y0ew9 I found compression algorithm test in HBase. I don't read detail, but it indicates snnapy algorithm gets best performance. http://blog.erdemagaoglu.com/post/4605524309/lzo-vs-snappy-vs-lzf-vs-zlib-a-comparison-of In fact, most of modern NoSQL storages use snappy. Because it has good performance and good licence(BSD license). > I think it is bit difficult to prove that any one algorithm is best > for all kind of loads. I think it is necessary to make best efforts in community than I do the best choice with strict test. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On Tue, Oct 15, 2013 at 03:11:22PM +0900, KONDO Mitsumasa wrote: > (2013/10/15 13:33), Amit Kapila wrote: > >Snappy is good mainly for un-compressible data, see the link below: > >http://www.postgresql.org/message-id/CAAZKuFZCOCHsswQM60ioDO_hk12tA7OG3YcJA8v=4YebMOA-wA@mail.gmail.com > This result was gotten in ARM architecture, it is not general CPU. > Please see detail document. > http://www.reddit.com/r/programming/comments/1aim6s/lz4_extremely_fast_compression_algorithm/c8y0ew9 > > I found compression algorithm test in HBase. I don't read detail, > but it indicates snnapy algorithm gets best performance. > http://blog.erdemagaoglu.com/post/4605524309/lzo-vs-snappy-vs-lzf-vs-zlib-a-comparison-of > > In fact, most of modern NoSQL storages use snappy. Because it has > good performance and good licence(BSD license). > > >I think it is bit difficult to prove that any one algorithm is best > >for all kind of loads. > I think it is necessary to make best efforts in community than I do > the best choice with strict test. > > Regards, > -- > Mitsumasa KONDO > NTT Open Source Software Center > Google's lz4 is also a very nice algorithm with 33% better compression performance than snappy and 2X the decompression performance in some benchmarks also with a bsd license: https://code.google.com/p/lz4/ Regards, Ken
(2013/10/15 22:01), ktm@rice.edu wrote: > Google's lz4 is also a very nice algorithm with 33% better compression > performance than snappy and 2X the decompression performance in some > benchmarks also with a bsd license: > > https://code.google.com/p/lz4/ If we judge only performance, we will select lz4. However, we should think another important factor which is software robustness,achievement, bug fix history, and etc... If we see unknown bugs, can we fix it or improve algorithm? It seems very difficult, because we only use it and don't understand algorihtms. Therefore, I think that we had better to select robust and having more user software. Regards, -- Mitsumasa KONDO NTT Open Source Software
On Wed, Oct 16, 2013 at 01:42:34PM +0900, KONDO Mitsumasa wrote: > (2013/10/15 22:01), ktm@rice.edu wrote: > >Google's lz4 is also a very nice algorithm with 33% better compression > >performance than snappy and 2X the decompression performance in some > >benchmarks also with a bsd license: > > > >https://code.google.com/p/lz4/ > If we judge only performance, we will select lz4. However, we should think > another important factor which is software robustness, achievement, bug > fix history, and etc... If we see unknown bugs, can we fix it or improve > algorithm? It seems very difficult, because we only use it and don't > understand algorihtms. Therefore, I think that we had better to select > robust and having more user software. > > Regards, > -- > Mitsumasa KONDO > NTT Open Source Software > Hi, Those are all very good points. lz4 however is being used by Hadoop. It is implemented natively in the Linux 3.11 kernel and the BSD version of the ZFS filesystem supports the lz4 algorithm for on-the-fly compression. With more and more CPU cores available in modern system, using an algorithm with very fast decompression speeds can make storing data, even in memory, in a compressed form can reduce space requirements in exchange for a higher CPU cycle cost. The ability to make those sorts of trade-offs can really benefit from a plug-able compression algorithm interface. Regards, Ken
Hi,
Sorry for my reply late...
(2013/10/11 2:32), Fujii Masao wrote:
> Could you let me know how much WAL records were generated
> during each benchmark?
It was not seen difference hardly about WAL in DBT-2 benchmark. It was because
largest tuples are filled in random character which is difficult to compress, I
survey it.
So I test two pattern data. One is original data which is hard to compress data.
Second is little bit changing data which are easy to compress data. Specifically,
I substitute zero padding tuple for random character tuple.
Record size is same in original test data, I changed only character fo record.
Sample changed record is here.
* Original record (item table)
> 1 9830 W+ùMî/aGhÞVJ;t+Pöþm5v2î. 82.62 Tî%N#ROò|?ö;[_îë~!YäHPÜï[S!JV58Ü#;+$cPì=dãNò;=Þô5
> 2 1492 VIKëyC..UCçWSèQð2?&s÷Jf 95.78 >ýoCj'nîHR`i]cøuDH&-wì4èè}{39ámLß2mC712Tao÷
> 3 4485 oJ)kLvP^_:91BOïé 32.00 ð<èüJ÷RÝ_Jze+?é4Ü7ä-r=DÝK\\$;Fsà8ál5
* Changed sample record (item table)
> 1 9830 000000000000000000000000 95.77 00000000000000000000000000000000000000000
> 2 764 00000000000000 47.92 00000000000000000000000000000000000000000000000000
> 3 4893 000000000000000000000 15.90 00000000000000000000000000000000000
* DBT-2 Result
@Werehouse = 340
| NOTPM | 90%tile | Average | S.Deviation
------------------------+-----------+-------------+---------+-------------
no-patched | 3319.02 | 13.606648 | 7.589 | 8.428
patched | 3341.25 | 20.132364 | 7.471 | 10.458
patched-testdata_changed| 3738.07 | 20.493533 | 3.795 | 10.003
Compression patch gets higher performance than no-patch in easy to compress test
data. It is because compression patch make archive WAL more small size, in
result, waste file cache is less than no-patch. Therefore, it was inflected
file-cache more effectively.
However, test in hard to compress test data have little bit lessor performance
than no-patch. I think it is compression overhead in pglz.
> I think that this benchmark result clearly means that the patch
> has only limited effects in the reduction of WAL volume and
> the performance improvement unless the database contains
> highly-compressible data like pgbench_accounts.
Your expectation is right. I think that low CPU cost and high compression
algorithm make your patch more better and better performance, too.
> filler. But if
> we can use other compression algorithm, maybe we can reduce
> WAL volume very much.
Yes, Please!
> I'm not sure what algorithm is good for WAL compression, though.
Community member think Snappy or lz4 is better. You'd better to select one,
or test two algorithms.
> It might be better to introduce the hook for compression of FPW
> so that users can freely use their compression module, rather
> than just using pglz_compress(). Thought?
In my memory, Andres Freund developed like this patch. Did it commit or
developing now? I have thought this idea is very good.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
Attachment
{kind=link}
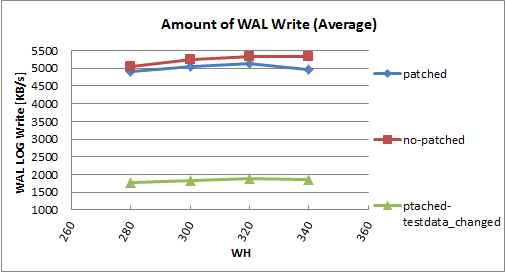{kind=link}
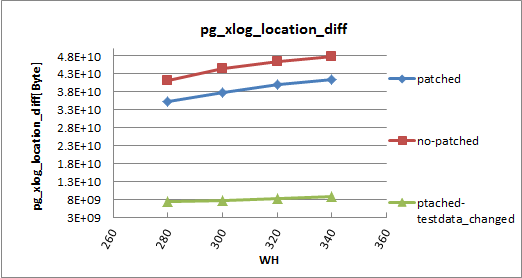{kind=link}
{kind=link}
On Tue, Oct 15, 2013 at 11:41 AM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > (2013/10/15 13:33), Amit Kapila wrote: >> >> Snappy is good mainly for un-compressible data, see the link below: >> >> http://www.postgresql.org/message-id/CAAZKuFZCOCHsswQM60ioDO_hk12tA7OG3YcJA8v=4YebMOA-wA@mail.gmail.com > > This result was gotten in ARM architecture, it is not general CPU. > Please see detail document. > http://www.reddit.com/r/programming/comments/1aim6s/lz4_extremely_fast_compression_algorithm/c8y0ew9 I think in general also snappy is mostly preferred for it's low CPU usage not for compression, but overall my vote is also for snappy. > I found compression algorithm test in HBase. I don't read detail, but it > indicates snnapy algorithm gets best performance. > http://blog.erdemagaoglu.com/post/4605524309/lzo-vs-snappy-vs-lzf-vs-zlib-a-comparison-of The dataset used for performance is quite different from the data which we are talking about here (WAL). "These are the scores for a data which consist of 700kB rows, each containing a binary image data. They probably won’t apply to things like numeric or text data." > In fact, most of modern NoSQL storages use snappy. Because it has good > performance and good licence(BSD license). > > >> I think it is bit difficult to prove that any one algorithm is best >> for all kind of loads. > > I think it is necessary to make best efforts in community than I do the best > choice with strict test. Sure, it is good to make effort to select the best algorithm, but if you are combining this patch with inclusion of new compression algorithm in PG, it can only make the patch to take much longer time. In general, my thinking is that we should prefer compression to reduce IO (WAL volume), because reducing WAL volume has other benefits as well like sending it to subscriber nodes. I think it will help cases where due to less n/w bandwidth, the disk allocated for WAL becomes full due to high traffic on master and then users need some alternative methods to handle such situations. I think many users would like to use a method which can reduce WAL volume and the users which don't find it enough useful in their environments due to decrease in TPS or not significant reduction in WAL have the option to disable it. With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
(2013/10/19 14:58), Amit Kapila wrote:> On Tue, Oct 15, 2013 at 11:41 AM, KONDO Mitsumasa> <kondo.mitsumasa@lab.ntt.co.jp>wrote:> I think in general also snappy is mostly preferred for it's low CPU> usage not forcompression, but overall my vote is also for snappy. I think low CPU usage is the best important factor in WAL compression. It is because WAL write is sequencial write, so few compression ratio improvement cannot change PostgreSQL's performance, and furthermore raid card with writeback feature. Furthermore PG executes programs by single proccess, high CPU usage compression algorithm will cause lessor performance. >> I found compression algorithm test in HBase. I don't read detail, but it>> indicates snnapy algorithm gets best performance.>> http://blog.erdemagaoglu.com/post/4605524309/lzo-vs-snappy-vs-lzf-vs-zlib-a-comparison-of>> The dataset used for performanceis quite different from the data> which we are talking about here (WAL).> "These are the scores for a data whichconsist of 700kB rows, each> containing a binary image data. They probably won’t apply to things> like numeric or textdata." Yes, you are right. We need testing about compression algorithm in WAL write. >> I think it is necessary to make best efforts in community than I do the best>> choice with strict test.>> Sure, it isgood to make effort to select the best algorithm, but if> you are combining this patch with inclusion of new compression>algorithm in PG, it can only make the patch to take much longer time. I think if our direction is specifically decided, it is easy to make the patch. Complession patch's direction isn't still become clear, it will be a troublesome patch which is like sync-rep patch. > In general, my thinking is that we should prefer compression to reduce> IO (WAL volume), because reducing WAL volume hasother benefits as> well like sending it to subscriber nodes. I think it will help cases> where due to less n/w bandwidth,the disk allocated for WAL becomes> full due to high traffic on master and then users need some> alternative methodsto handle such situations. Do you talk about archiving WAL file? It can easy to reduce volume that we set and add compression command with copy command at archive_command. > I think many users would like to use a method which can reduce WAL> volume and the users which don't find it enough usefulin their> environments due to decrease in TPS or not significant reduction in> WAL have the option to disable it. I favor to select compression algorithm for higher performance. If we need to compress WAL file more, in spite of lessor performance, we can change archive copy command with high compression algorithm and add documents that how to compress archive WAL files at archive_command. Does it wrong? In actual, many of NoSQLs use snappy for purpose of higher performance. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On Mon, Oct 21, 2013 at 4:40 PM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > (2013/10/19 14:58), Amit Kapila wrote: >> On Tue, Oct 15, 2013 at 11:41 AM, KONDO Mitsumasa >> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >> In general, my thinking is that we should prefer compression to reduce >> IO (WAL volume), because reducing WAL volume has other benefits as >> well like sending it to subscriber nodes. I think it will help cases >> where due to less n/w bandwidth, the disk allocated for WAL becomes >> full due to high traffic on master and then users need some >> alternative methods to handle such situations. > Do you talk about archiving WAL file? One of the points what I am talking about is sending data over network to subscriber nodes for streaming replication and another is WAL in pg_xlog. Both scenario's get benefited if there is is WAL volume. > It can easy to reduce volume that we > set and add compression command with copy command at archive_command. Okay. >> I think many users would like to use a method which can reduce WAL >> volume and the users which don't find it enough useful in their >> environments due to decrease in TPS or not significant reduction in >> WAL have the option to disable it. > I favor to select compression algorithm for higher performance. If we need > to compress WAL file more, in spite of lessor performance, we can change > archive copy command with high compression algorithm and add documents that > how to compress archive WAL files at archive_command. Does it wrong? No, it is not wrong, but there are scenario's as mentioned above where less WAL volume can be beneficial. > In > actual, many of NoSQLs use snappy for purpose of higher performance. Okay, you can also check the results with snappy algorithm, but don't just rely completely on snappy for this patch, you might want to think of another alternative for this patch. With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Oct 22, 2013 at 12:47 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Mon, Oct 21, 2013 at 4:40 PM, KONDO Mitsumasa > <kondo.mitsumasa@lab.ntt.co.jp> wrote: >> (2013/10/19 14:58), Amit Kapila wrote: >>> On Tue, Oct 15, 2013 at 11:41 AM, KONDO Mitsumasa >>> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>> In general, my thinking is that we should prefer compression to reduce >>> IO (WAL volume), because reducing WAL volume has other benefits as >>> well like sending it to subscriber nodes. I think it will help cases >>> where due to less n/w bandwidth, the disk allocated for WAL becomes >>> full due to high traffic on master and then users need some >>> alternative methods to handle such situations. >> Do you talk about archiving WAL file? > > One of the points what I am talking about is sending data over > network to subscriber nodes for streaming replication and another is > WAL in pg_xlog. Both scenario's get benefited if there is is WAL > volume. > >> It can easy to reduce volume that we >> set and add compression command with copy command at archive_command. > > Okay. > >>> I think many users would like to use a method which can reduce WAL >>> volume and the users which don't find it enough useful in their >>> environments due to decrease in TPS or not significant reduction in >>> WAL have the option to disable it. >> I favor to select compression algorithm for higher performance. If we need >> to compress WAL file more, in spite of lessor performance, we can change >> archive copy command with high compression algorithm and add documents that >> how to compress archive WAL files at archive_command. Does it wrong? > > No, it is not wrong, but there are scenario's as mentioned above > where less WAL volume can be beneficial. > >> In >> actual, many of NoSQLs use snappy for purpose of higher performance. > > Okay, you can also check the results with snappy algorithm, but don't > just rely completely on snappy for this patch, you might want to think > of another alternative for this patch. So, our consensus is to introduce the hooks for FPW compression so that users can freely select their own best compression algorithm? Also, probably we need to implement at least one compression contrib module using that hook, maybe it's based on pglz or snappy. Regards, -- Fujii Masao
On Tue, Oct 22, 2013 at 9:22 AM, Fujii Masao <masao.fujii@gmail.com> wrote: > On Tue, Oct 22, 2013 at 12:47 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> On Mon, Oct 21, 2013 at 4:40 PM, KONDO Mitsumasa >> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>> (2013/10/19 14:58), Amit Kapila wrote: >>>> On Tue, Oct 15, 2013 at 11:41 AM, KONDO Mitsumasa >>>> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >> >>> In >>> actual, many of NoSQLs use snappy for purpose of higher performance. >> >> Okay, you can also check the results with snappy algorithm, but don't >> just rely completely on snappy for this patch, you might want to think >> of another alternative for this patch. > > So, our consensus is to introduce the hooks for FPW compression so that > users can freely select their own best compression algorithm? We can also provide GUC for whether to enable WAL compression, which I think you are also planing to include based on some previous e-mails in this thread. You can consider my vote for this idea. However I think we should wait to see if anyone else have objection to this idea. > Also, probably we need to implement at least one compression contrib module > using that hook, maybe it's based on pglz or snappy. With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 2013-10-22 12:52:09 +0900, Fujii Masao wrote: > So, our consensus is to introduce the hooks for FPW compression so that > users can freely select their own best compression algorithm? No, I don't think that's concensus yet. If you want to make it configurable on that level you need to have: 1) compression format signature on fpws 2) mapping between identifiers for compression formats and the libraries implementing them. Otherwise you can only change the configuration at initdb time... > Also, probably we need to implement at least one compression contrib module > using that hook, maybe it's based on pglz or snappy. From my tests for toast compression I'd suggest starting with lz4. I'd suggest starting by publishing test results with a more modern compression formats, but without hacks like increasing padding. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
(2013/10/22 12:52), Fujii Masao wrote: > On Tue, Oct 22, 2013 at 12:47 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> On Mon, Oct 21, 2013 at 4:40 PM, KONDO Mitsumasa >> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>> (2013/10/19 14:58), Amit Kapila wrote: >>>> On Tue, Oct 15, 2013 at 11:41 AM, KONDO Mitsumasa >>>> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>>> In general, my thinking is that we should prefer compression to reduce >>>> IO (WAL volume), because reducing WAL volume has other benefits as >>>> well like sending it to subscriber nodes. I think it will help cases >>>> where due to less n/w bandwidth, the disk allocated for WAL becomes >>>> full due to high traffic on master and then users need some >>>> alternative methods to handle such situations. >>> Do you talk about archiving WAL file? >> >> One of the points what I am talking about is sending data over >> network to subscriber nodes for streaming replication and another is >> WAL in pg_xlog. Both scenario's get benefited if there is is WAL >> volume. >> >>> It can easy to reduce volume that we >>> set and add compression command with copy command at archive_command. >> >> Okay. >> >>>> I think many users would like to use a method which can reduce WAL >>>> volume and the users which don't find it enough useful in their >>>> environments due to decrease in TPS or not significant reduction in >>>> WAL have the option to disable it. >>> I favor to select compression algorithm for higher performance. If we need >>> to compress WAL file more, in spite of lessor performance, we can change >>> archive copy command with high compression algorithm and add documents that >>> how to compress archive WAL files at archive_command. Does it wrong? >> >> No, it is not wrong, but there are scenario's as mentioned above >> where less WAL volume can be beneficial. >> >>> In >>> actual, many of NoSQLs use snappy for purpose of higher performance. >> >> Okay, you can also check the results with snappy algorithm, but don't >> just rely completely on snappy for this patch, you might want to think >> of another alternative for this patch. > > So, our consensus is to introduce the hooks for FPW compression so that > users can freely select their own best compression algorithm? Yes, it will be also good for future improvement. But I think WAL compression for disaster recovery system should be need in walsender and walreceiver proccess, and it is propety architecture for DR system. Higher compression ratio with high CPU usage algorithm in FPW might affect bad for perfomance in master server. If we can set compression algorithm in walsender and walreciever, performance is same as before or better, and WAL send performance will be better. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On Wed, Oct 23, 2013 at 7:05 AM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > (2013/10/22 12:52), Fujii Masao wrote: >> >> On Tue, Oct 22, 2013 at 12:47 PM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: >>> >>> On Mon, Oct 21, 2013 at 4:40 PM, KONDO Mitsumasa >>> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>>> >>>> (2013/10/19 14:58), Amit Kapila wrote: >>>>> >>>>> On Tue, Oct 15, 2013 at 11:41 AM, KONDO Mitsumasa >>>>> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>>> In >>>> actual, many of NoSQLs use snappy for purpose of higher performance. >>> >>> >>> Okay, you can also check the results with snappy algorithm, but don't >>> just rely completely on snappy for this patch, you might want to think >>> of another alternative for this patch. >> >> >> So, our consensus is to introduce the hooks for FPW compression so that >> users can freely select their own best compression algorithm? > > Yes, it will be also good for future improvement. But I think WAL > compression for disaster recovery system should be need in walsender and > walreceiver proccess, and it is propety architecture for DR system. Higher > compression ratio with high CPU usage algorithm in FPW might affect bad for > perfomance in master server. This is true, thats why there is a discussion for pluggable API for compression of WAL, we should try to choose best algorithm from the available choices. Even after that I am not sure it works same for all kind of loads, so user will have option to completely disable it as well. > If we can set compression algorithm in > walsender and walreciever, performance is same as before or better, and WAL > send performance will be better. Do you mean to say that walsender should compress the data before sending and then walreceiver will decompress it, if yes then won't it add extra overhead on standby, or do you think as walreceiver has to read less data from socket, so it will compensate for it. I think may be we should consider this if the test results are good, but lets not try to do this until the current patch proves that such mechanism is good for WAL compression. With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Mon, Oct 21, 2013 at 11:52 PM, Fujii Masao <masao.fujii@gmail.com> wrote: > So, our consensus is to introduce the hooks for FPW compression so that > users can freely select their own best compression algorithm? > Also, probably we need to implement at least one compression contrib module > using that hook, maybe it's based on pglz or snappy. I don't favor making this pluggable. I think we should pick snappy or lz4 (or something else), put it in the tree, and use it. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Mon, Oct 21, 2013 at 11:52 PM, Fujii Masao <masao.fujii@gmail.com> wrote:
>> So, our consensus is to introduce the hooks for FPW compression so that
>> users can freely select their own best compression algorithm?
>> Also, probably we need to implement at least one compression contrib module
>> using that hook, maybe it's based on pglz or snappy.
> I don't favor making this pluggable. I think we should pick snappy or
> lz4 (or something else), put it in the tree, and use it.
I agree. Hooks in this area are going to be a constant source of
headaches, vastly outweighing any possible benefit.
regards, tom lane
On Thu, Oct 24, 2013 at 11:07:38AM -0400, Robert Haas wrote: > On Mon, Oct 21, 2013 at 11:52 PM, Fujii Masao <masao.fujii@gmail.com> wrote: > > So, our consensus is to introduce the hooks for FPW compression so that > > users can freely select their own best compression algorithm? > > Also, probably we need to implement at least one compression contrib module > > using that hook, maybe it's based on pglz or snappy. > > I don't favor making this pluggable. I think we should pick snappy or > lz4 (or something else), put it in the tree, and use it. > Hi, My vote would be for lz4 since it has faster single thread compression and decompression speeds with the decompression speed being almost 2X snappy's decompression speed. The both are BSD licensed so that is not an issue. The base code for lz4 is c and it is c++ for snappy. There is also a HC (high-compression) varient for lz4 that pushes its compression rate to about the same as zlib (-1) which uses the same decompressor which can provide data even faster due to better compression. Some more real world tests would be useful, which is really where being pluggable would help. Regards, Ken
On Thu, Oct 24, 2013 at 11:40 AM, ktm@rice.edu <ktm@rice.edu> wrote: > On Thu, Oct 24, 2013 at 11:07:38AM -0400, Robert Haas wrote: >> On Mon, Oct 21, 2013 at 11:52 PM, Fujii Masao <masao.fujii@gmail.com> wrote: >> > So, our consensus is to introduce the hooks for FPW compression so that >> > users can freely select their own best compression algorithm? >> > Also, probably we need to implement at least one compression contrib module >> > using that hook, maybe it's based on pglz or snappy. >> >> I don't favor making this pluggable. I think we should pick snappy or >> lz4 (or something else), put it in the tree, and use it. >> > Hi, > > My vote would be for lz4 since it has faster single thread compression > and decompression speeds with the decompression speed being almost 2X > snappy's decompression speed. The both are BSD licensed so that is not > an issue. The base code for lz4 is c and it is c++ for snappy. There > is also a HC (high-compression) varient for lz4 that pushes its compression > rate to about the same as zlib (-1) which uses the same decompressor which > can provide data even faster due to better compression. Some more real > world tests would be useful, which is really where being pluggable would > help. Well, it's probably a good idea for us to test, during the development cycle, which algorithm works better for WAL compression, and then use that one. Once we make that decision, I don't see that there are many circumstances in which a user would care to override it. Now if we find that there ARE reasons for users to prefer different algorithms in different situations, that would be a good reason to make it configurable (or even pluggable). But if we find that no such reasons exist, then we're better off avoiding burdening users with the need to configure a setting that has only one sensible value. It seems fairly clear from previous discussions on this mailing list that snappy and lz4 are the top contenders for the position of "compression algorithm favored by PostgreSQL". I am wondering, though, whether it wouldn't be better to add support for both - say we added both to libpgcommon, and perhaps we could consider moving pglz there as well. That would allow easy access to all of those algorithms from both front-end and backend-code. If we can make the APIs parallel, it should very simple to modify any code we add now to use a different algorithm than the one initially chosen if in the future we add algorithms to or remove algorithms from the list, or if one algorithm is shown to outperform another in some particular context. I think we'll do well to isolate the question of adding support for these algorithms form the current patch or any other particular patch that may be on the table, and FWIW, I think having two leading contenders and adding support for both may have a variety of advantages over crowning a single victor. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Oct 24, 2013 at 12:22:59PM -0400, Robert Haas wrote: > On Thu, Oct 24, 2013 at 11:40 AM, ktm@rice.edu <ktm@rice.edu> wrote: > > On Thu, Oct 24, 2013 at 11:07:38AM -0400, Robert Haas wrote: > >> On Mon, Oct 21, 2013 at 11:52 PM, Fujii Masao <masao.fujii@gmail.com> wrote: > >> > So, our consensus is to introduce the hooks for FPW compression so that > >> > users can freely select their own best compression algorithm? > >> > Also, probably we need to implement at least one compression contrib module > >> > using that hook, maybe it's based on pglz or snappy. > >> > >> I don't favor making this pluggable. I think we should pick snappy or > >> lz4 (or something else), put it in the tree, and use it. > >> > > Hi, > > > > My vote would be for lz4 since it has faster single thread compression > > and decompression speeds with the decompression speed being almost 2X > > snappy's decompression speed. The both are BSD licensed so that is not > > an issue. The base code for lz4 is c and it is c++ for snappy. There > > is also a HC (high-compression) varient for lz4 that pushes its compression > > rate to about the same as zlib (-1) which uses the same decompressor which > > can provide data even faster due to better compression. Some more real > > world tests would be useful, which is really where being pluggable would > > help. > > Well, it's probably a good idea for us to test, during the development > cycle, which algorithm works better for WAL compression, and then use > that one. Once we make that decision, I don't see that there are many > circumstances in which a user would care to override it. Now if we > find that there ARE reasons for users to prefer different algorithms > in different situations, that would be a good reason to make it > configurable (or even pluggable). But if we find that no such reasons > exist, then we're better off avoiding burdening users with the need to > configure a setting that has only one sensible value. > > It seems fairly clear from previous discussions on this mailing list > that snappy and lz4 are the top contenders for the position of > "compression algorithm favored by PostgreSQL". I am wondering, > though, whether it wouldn't be better to add support for both - say we > added both to libpgcommon, and perhaps we could consider moving pglz > there as well. That would allow easy access to all of those > algorithms from both front-end and backend-code. If we can make the > APIs parallel, it should very simple to modify any code we add now to > use a different algorithm than the one initially chosen if in the > future we add algorithms to or remove algorithms from the list, or if > one algorithm is shown to outperform another in some particular > context. I think we'll do well to isolate the question of adding > support for these algorithms form the current patch or any other > particular patch that may be on the table, and FWIW, I think having > two leading contenders and adding support for both may have a variety > of advantages over crowning a single victor. > +++1 Ken
On Thu, Oct 24, 2013 at 8:37 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Mon, Oct 21, 2013 at 11:52 PM, Fujii Masao <masao.fujii@gmail.com> wrote: >> So, our consensus is to introduce the hooks for FPW compression so that >> users can freely select their own best compression algorithm? >> Also, probably we need to implement at least one compression contrib module >> using that hook, maybe it's based on pglz or snappy. > > I don't favor making this pluggable. I think we should pick snappy or > lz4 (or something else), put it in the tree, and use it. The reason why the discussion went towards making it pluggable (or at least what made me to think like that) was because of below reasons: a. what somebody needs to do to make snappy or lz4 in the tree, is it only performance/compression data for some of the scenario's or some other legal stuff as well, if it is only performance/compression then what will be the scenario's (is pgbench sufficient?). b. there can be cases where one or the other algorithm can be better or not doing compression is better. For example in one of the other patches where we were trying to achieve WAL reduction in Update operation (http://www.postgresql.org/message-id/8977CB36860C5843884E0A18D8747B036B9A4B04@szxeml558-mbs.china.huawei.com), Heikki hascame up with a test (where data is not much compressible), in such a case, the observation was that LZ was better than native compression method used in that patch and Snappy was better than LZ and not doing compression could be considered preferable in such a scenario because all the algorithm's were reducingTPS for that case. Now I think it is certainly better if we could choose one of the algorithms (snappy or lz4) and test them for most used scenario's for compression and performance and call it done, but I think giving at least an option to user to make compression altogether off should be still considered. With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Fri, Oct 11, 2013 at 12:30:41PM +0900, Fujii Masao wrote: > > Sure. To be honest, when I received the same request from Andres, > > I did that benchmark. But unfortunately because of machine trouble, > > I could not report it, yet. Will do that again. > > Here is the benchmark result: > > * Result > [tps] > 1317.306391 (full_page_writes = on) > 1628.407752 (compress) > > [the amount of WAL generated during running pgbench] > 1319 MB (on) > 326 MB (compress) > > [time required to replay WAL generated during running pgbench] > 19s (on) > 2013-10-11 12:05:09 JST LOG: redo starts at F/F1000028 > 2013-10-11 12:05:28 JST LOG: redo done at 10/446B7BF0 > > 12s (on) > 2013-10-11 12:06:22 JST LOG: redo starts at F/F1000028 > 2013-10-11 12:06:34 JST LOG: redo done at 10/446B7BF0 > > 12s (on) > 2013-10-11 12:07:19 JST LOG: redo starts at F/F1000028 > 2013-10-11 12:07:31 JST LOG: redo done at 10/446B7BF0 > > 8s (compress) > 2013-10-11 12:17:36 JST LOG: redo starts at 10/50000028 > 2013-10-11 12:17:44 JST LOG: redo done at 10/655AE478 > > 8s (compress) > 2013-10-11 12:18:26 JST LOG: redo starts at 10/50000028 > 2013-10-11 12:18:34 JST LOG: redo done at 10/655AE478 > > 8s (compress) > 2013-10-11 12:19:07 JST LOG: redo starts at 10/50000028 > 2013-10-11 12:19:15 JST LOG: redo done at 10/655AE478 Fujii, are you still working on this? I sure hope so. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On Sat, Feb 1, 2014 at 10:22 AM, Bruce Momjian <bruce@momjian.us> wrote: > On Fri, Oct 11, 2013 at 12:30:41PM +0900, Fujii Masao wrote: >> > Sure. To be honest, when I received the same request from Andres, >> > I did that benchmark. But unfortunately because of machine trouble, >> > I could not report it, yet. Will do that again. >> >> Here is the benchmark result: >> >> * Result >> [tps] >> 1317.306391 (full_page_writes = on) >> 1628.407752 (compress) >> >> [the amount of WAL generated during running pgbench] >> 1319 MB (on) >> 326 MB (compress) >> >> [time required to replay WAL generated during running pgbench] >> 19s (on) >> 2013-10-11 12:05:09 JST LOG: redo starts at F/F1000028 >> 2013-10-11 12:05:28 JST LOG: redo done at 10/446B7BF0 >> >> 12s (on) >> 2013-10-11 12:06:22 JST LOG: redo starts at F/F1000028 >> 2013-10-11 12:06:34 JST LOG: redo done at 10/446B7BF0 >> >> 12s (on) >> 2013-10-11 12:07:19 JST LOG: redo starts at F/F1000028 >> 2013-10-11 12:07:31 JST LOG: redo done at 10/446B7BF0 >> >> 8s (compress) >> 2013-10-11 12:17:36 JST LOG: redo starts at 10/50000028 >> 2013-10-11 12:17:44 JST LOG: redo done at 10/655AE478 >> >> 8s (compress) >> 2013-10-11 12:18:26 JST LOG: redo starts at 10/50000028 >> 2013-10-11 12:18:34 JST LOG: redo done at 10/655AE478 >> >> 8s (compress) >> 2013-10-11 12:19:07 JST LOG: redo starts at 10/50000028 >> 2013-10-11 12:19:15 JST LOG: redo done at 10/655AE478 > > Fujii, are you still working on this? I sure hope so. Yes, but it's too late to implement and post new patch in this development cycle of 9.4dev. I will propose that in next CF. Regards, -- Fujii Masao
Hello, >Done. Attached is the updated version of the patch. I was trying to check WAL reduction using this patch on latest available git version of Postgres using JDBC runner with tpcc benchmark. patching_problems.txt <http://postgresql.1045698.n5.nabble.com/file/n5803482/patching_problems.txt> I did resolve the patching conflicts and then compiled the source, removing couple of compiler errors in process. But the server crashes in the compress mode i.e. the moment any WAL is generated. Works fine in 'on' and 'off' mode. Clearly i must be resolving patch conflicts incorrectly as this patch applied cleanly earlier. Is there a version of the source where i could apply it the patch cleanly? Thank you, Sameer -- View this message in context: http://postgresql.1045698.n5.nabble.com/Compression-of-full-page-writes-tp5769039p5803482.html Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
Sameer Thakur <samthakur74@gmail.com> writes: > I was trying to check WAL reduction using this patch on latest available git > version of Postgres using JDBC runner with tpcc benchmark. > patching_problems.txt > <http://postgresql.1045698.n5.nabble.com/file/n5803482/patching_problems.txt> > I did resolve the patching conflicts and then compiled the source, removing > couple of compiler errors in process. But the server crashes in the compress > mode i.e. the moment any WAL is generated. Works fine in 'on' and 'off' > mode. > Clearly i must be resolving patch conflicts incorrectly as this patch > applied cleanly earlier. Is there a version of the source where i could > apply it the patch cleanly? If the patch used to work, it's a good bet that what broke it is the recent pgindent run: http://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=0a7832005792fa6dad171f9cadb8d587fe0dd800 It's going to need to be rebased past that, but doing so by hand would be tedious, and evidently was error-prone too. If you've got pgindent installed, you could consider applying the patch to the parent of that commit, pgindent'ing the whole tree, and then diffing against that commit to generate an updated patch. See src/tools/pgindent/README for some build/usage notes about pgindent. regards, tom lane
On Sat, May 10, 2014 at 8:33 PM, Sameer Thakur <samthakur74@gmail.com> wrote: > Hello, >>Done. Attached is the updated version of the patch. > I was trying to check WAL reduction using this patch on latest available git > version of Postgres using JDBC runner with tpcc benchmark. > > patching_problems.txt > <http://postgresql.1045698.n5.nabble.com/file/n5803482/patching_problems.txt> > > I did resolve the patching conflicts and then compiled the source, removing > couple of compiler errors in process. But the server crashes in the compress > mode i.e. the moment any WAL is generated. Works fine in 'on' and 'off' > mode. What kind of error did you get at the server crash? Assertion error? If yes, it might be because of the conflict with 4a170ee9e0ebd7021cb1190fabd5b0cbe2effb8e. This commit forbids palloc from being called within a critical section, but the patch does that and then the assertion error happens. That's a bug of the patch. Regards, -- Fujii Masao
Hello,
> What kind of error did you get at the server crash? Assertion error? If yes,
> it might be because of the conflict with
> 4a170ee9e0ebd7021cb1190fabd5b0cbe2effb8e.
> This commit forbids palloc from being called within a critical section, but
> the patch does that and then the assertion error happens. That's a bug of
> the patch.
seems to be that
STATEMENT: create table test (id integer);
TRAP: FailedAssertion("!(CritSectionCount == 0 ||
(CurrentMemoryContext) == ErrorContext || (MyAuxProcType ==
CheckpointerProcess))", File: "mcxt.c", Line: 670)
LOG: server process (PID 29721) was terminated by signal 6: Aborted
DETAIL: Failed process was running: drop table test;
LOG: terminating any other active server processes
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back
the current transaction and exit, because another server process
exited abnormally and possibly corrupted shared memory.
How do i resolve this?
Thank you,
Sameer
On 30 August 2013 04:55, Fujii Masao <masao.fujii@gmail.com> wrote: > My idea is very simple, just compress FPW because FPW is > a big part of WAL. I used pglz_compress() as a compression method, > but you might think that other method is better. We can add > something like FPW-compression-hook for that later. The patch > adds new GUC parameter, but I'm thinking to merge it to full_page_writes > parameter to avoid increasing the number of GUC. That is, > I'm thinking to change full_page_writes so that it can accept new value > 'compress'. > * Result > [tps] > 1386.8 (compress_backup_block = off) > 1627.7 (compress_backup_block = on) > > [the amount of WAL generated during running pgbench] > 4302 MB (compress_backup_block = off) > 1521 MB (compress_backup_block = on) Compressing FPWs definitely makes sense for bulk actions. I'm worried that the loss of performance occurs by greatly elongating transaction response times immediately after a checkpoint, which were already a problem. I'd be interested to look at the response time curves there. Maybe it makes sense to compress FPWs if we do, say, > N FPW writes in a transaction. Just ideas. I was thinking about this and about our previous thoughts about double buffering. FPWs are made in foreground, so will always slow down transaction rates. If we could move to double buffering we could avoid FPWs altogether. Thoughts? -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Sun, May 11, 2014 at 7:30 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > On 30 August 2013 04:55, Fujii Masao <masao.fujii@gmail.com> wrote: > >> My idea is very simple, just compress FPW because FPW is >> a big part of WAL. I used pglz_compress() as a compression method, >> but you might think that other method is better. We can add >> something like FPW-compression-hook for that later. The patch >> adds new GUC parameter, but I'm thinking to merge it to full_page_writes >> parameter to avoid increasing the number of GUC. That is, >> I'm thinking to change full_page_writes so that it can accept new value >> 'compress'. > >> * Result >> [tps] >> 1386.8 (compress_backup_block = off) >> 1627.7 (compress_backup_block = on) >> >> [the amount of WAL generated during running pgbench] >> 4302 MB (compress_backup_block = off) >> 1521 MB (compress_backup_block = on) > > Compressing FPWs definitely makes sense for bulk actions. > > I'm worried that the loss of performance occurs by greatly elongating > transaction response times immediately after a checkpoint, which were > already a problem. I'd be interested to look at the response time > curves there. Yep, I agree that we should check how the compression of FPW affects the response time, especially just after checkpoint starts. > I was thinking about this and about our previous thoughts about double > buffering. FPWs are made in foreground, so will always slow down > transaction rates. If we could move to double buffering we could avoid > FPWs altogether. Thoughts? If I understand the double buffering correctly, it would eliminate the need for FPW. But I'm not sure how easy we can implement the double buffering. Regards, -- Fujii Masao
On Tue, May 13, 2014 at 3:33 AM, Fujii Masao <masao.fujii@gmail.com> wrote: > On Sun, May 11, 2014 at 7:30 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >> On 30 August 2013 04:55, Fujii Masao <masao.fujii@gmail.com> wrote: >> >>> My idea is very simple, just compress FPW because FPW is >>> a big part of WAL. I used pglz_compress() as a compression method, >>> but you might think that other method is better. We can add >>> something like FPW-compression-hook for that later. The patch >>> adds new GUC parameter, but I'm thinking to merge it to full_page_writes >>> parameter to avoid increasing the number of GUC. That is, >>> I'm thinking to change full_page_writes so that it can accept new value >>> 'compress'. >> >>> * Result >>> [tps] >>> 1386.8 (compress_backup_block = off) >>> 1627.7 (compress_backup_block = on) >>> >>> [the amount of WAL generated during running pgbench] >>> 4302 MB (compress_backup_block = off) >>> 1521 MB (compress_backup_block = on) >> >> Compressing FPWs definitely makes sense for bulk actions. >> >> I'm worried that the loss of performance occurs by greatly elongating >> transaction response times immediately after a checkpoint, which were >> already a problem. I'd be interested to look at the response time >> curves there. > > Yep, I agree that we should check how the compression of FPW affects > the response time, especially just after checkpoint starts. > >> I was thinking about this and about our previous thoughts about double >> buffering. FPWs are made in foreground, so will always slow down >> transaction rates. If we could move to double buffering we could avoid >> FPWs altogether. Thoughts? > > If I understand the double buffering correctly, it would eliminate the need for > FPW. But I'm not sure how easy we can implement the double buffering. There is already a patch on the double buffer write to eliminate the FPW. But It has some performance problem because of CRC calculation for the entire page. http://www.postgresql.org/message-id/1962493974.656458.1327703514780.JavaMail.root@zimbra-prod-mbox-4.vmware.com I think this patch can be further modified with a latest multi core CRC calculation and can be used for testing. Regards, Hari Babu Fujitsu Australia
Hello All, 0001-CompressBackupBlock_snappy_lz4_pglz extends patch on compression of full page writes to include LZ4 and Snappy . Changes include making "compress_backup_block" GUC from boolean to enum. Value of the GUC can be OFF, pglz, snappy or lz4 which can be used to turn off compression or set the desired compression algorithm. 0002-Support_snappy_lz4 adds support for LZ4 and Snappy in PostgreSQL. It uses Andres’s patch for getting Makefiles working and has a few wrappers to make the function calls to LZ4 and Snappy compression functions and handle varlena datatypes. Patch Courtesy: Pavan Deolasee These patches serve as a way to test various compression algorithms. These are WIP yet. They don’t support changing compression algorithms on standby . Also, compress_backup_block GUC needs to be merged with full_page_writes. The patch uses LZ4 high compression(HC) variant. I have conducted initial tests which I would like to share and solicit feedback Tests use JDBC runner TPC-C benchmark to measure the amount of WAL compression ,tps and response time in each of the scenarios viz . Compression = OFF , pglz, LZ4 , snappy ,FPW=off Server specifications: Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos RAM: 32GB Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos 1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm Benchmark: Scale : 100 Command :java JR /home/postgres/jdbcrunner-1.2/scripts/tpcc.js -sleepTime 600,350,300,250,250 Warmup time : 1 sec Measurement time : 900 sec Number of tx types : 5 Number of agents : 16 Connection pool size : 16 Statement cache size : 40 Auto commit : false Sleep time : 600,350,300,250,250 msec Checkpoint segments:1024 Checkpoint timeout:5 mins Scenario WAL generated(bytes) Compression (bytes) TPS (tx1,tx2,tx3,tx4,tx5) No_compress 2220787088 (~2221MB) NULL 13.3,13.3,1.3,1.3,1.3 tps Pglz 1796213760 (~1796MB) 424573328 (19.11%) 13.1,13.1,1.3,1.3,1.3 tps Snappy 1724171112 (~1724MB) 496615976( 22.36%) 13.2,13.2,1.3,1.3,1.3 tps LZ4(HC) 1658941328 (~1659MB) 561845760(25.29%) 13.2,13.2,1.3,1.3,1.3 tps FPW(off) 139384320(~139 MB) NULL 13.3,13.3,1.3,1.3,1.3 tps As per measurement results, WAL reduction using LZ4 is close to 25% which shows 6 percent increase in WAL reduction when compared to pglz . WAL reduction in snappy is close to 22 % . The numbers for compression using LZ4 and Snappy doesn’t seem to be very high as compared to pglz for given workload. This can be due to in-compressible nature of the TPC-C data which contains random strings Compression does not have bad impact on the response time. In fact, response times for Snappy, LZ4 are much better than no compression with almost ½ to 1/3 of the response times of no-compression(FPW=on) and FPW = off. The response time order for each type of compression is Pglz>Snappy>LZ4 Scenario Response time (tx1,tx2,tx3,tx4,tx5) no_compress 5555,1848,4221,6791,5747 msec pglz 4275,2659,1828,4025,3326 msec Snappy 3790,2828,2186,1284,1120 msec LZ4(hC) 2519,2449,1158,2066,2065 msec FPW(off) 6234,2430,3017,5417,5885 msec LZ4 and Snappy are almost at par with each other in terms of response time as average response times of five types of transactions remains almost same for both. 0001-CompressBackupBlock_snappy_lz4_pglz.patch <http://postgresql.1045698.n5.nabble.com/file/n5805044/0001-CompressBackupBlock_snappy_lz4_pglz.patch> 0002-Support_snappy_lz4.patch <http://postgresql.1045698.n5.nabble.com/file/n5805044/0002-Support_snappy_lz4.patch> -- View this message in context: http://postgresql.1045698.n5.nabble.com/Compression-of-full-page-writes-tp5769039p5805044.html Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
On Tue, May 27, 2014 at 12:57 PM, Rahila Syed <rahilasyed.90@gmail.com> wrote: > Hello All, > > 0001-CompressBackupBlock_snappy_lz4_pglz extends patch on compression of > full page writes to include LZ4 and Snappy . Changes include making > "compress_backup_block" GUC from boolean to enum. Value of the GUC can be > OFF, pglz, snappy or lz4 which can be used to turn off compression or set > the desired compression algorithm. > > 0002-Support_snappy_lz4 adds support for LZ4 and Snappy in PostgreSQL. It > uses Andres’s patch for getting Makefiles working and has a few wrappers to > make the function calls to LZ4 and Snappy compression functions and handle > varlena datatypes. > Patch Courtesy: Pavan Deolasee Thanks for extending and revising the FPW-compress patch! Could you add your patch into next CF? > Also, compress_backup_block GUC needs to be merged with full_page_writes. Basically I agree with you because I don't want to add new GUC very similar to the existing one. But could you imagine the case where full_page_writes = off. Even in this case, FPW is forcibly written only during base backup. Such FPW also should be compressed? Which compression algorithm should be used? If we want to choose the algorithm for such FPW, we would not be able to merge those two GUCs. IMO it's OK to always use the best compression algorithm for such FPW and merge them, though. > Tests use JDBC runner TPC-C benchmark to measure the amount of WAL > compression ,tps and response time in each of the scenarios viz . > Compression = OFF , pglz, LZ4 , snappy ,FPW=off Isn't it worth measuring the recovery performance for each compression algorithm? Regards, -- Fujii Masao
On 28 May 2014 15:34, Fujii Masao <masao.fujii@gmail.com> wrote: >> Also, compress_backup_block GUC needs to be merged with full_page_writes. > > Basically I agree with you because I don't want to add new GUC very similar to > the existing one. > > But could you imagine the case where full_page_writes = off. Even in this case, > FPW is forcibly written only during base backup. Such FPW also should be > compressed? Which compression algorithm should be used? If we want to > choose the algorithm for such FPW, we would not be able to merge those two > GUCs. IMO it's OK to always use the best compression algorithm for such FPW > and merge them, though. I'd prefer a new name altogether torn_page_protection = 'full_page_writes' torn_page_protection = 'compressed_full_page_writes' torn_page_protection = 'none' this allows us to add new techniques later like torn_page_protection = 'background_FPWs' or torn_page_protection = 'double_buffering' when/if we add those new techniques -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Wed, May 28, 2014 at 04:04:13PM +0100, Simon Riggs wrote: > On 28 May 2014 15:34, Fujii Masao <masao.fujii@gmail.com> wrote: > > >> Also, compress_backup_block GUC needs to be merged with full_page_writes. > > > > Basically I agree with you because I don't want to add new GUC very similar to > > the existing one. > > > > But could you imagine the case where full_page_writes = off. Even in this case, > > FPW is forcibly written only during base backup. Such FPW also should be > > compressed? Which compression algorithm should be used? If we want to > > choose the algorithm for such FPW, we would not be able to merge those two > > GUCs. IMO it's OK to always use the best compression algorithm for such FPW > > and merge them, though. > > I'd prefer a new name altogether > > torn_page_protection = 'full_page_writes' > torn_page_protection = 'compressed_full_page_writes' > torn_page_protection = 'none' > > this allows us to add new techniques later like > > torn_page_protection = 'background_FPWs' > > or > > torn_page_protection = 'double_buffering' > > when/if we add those new techniques Uh, how would that work if you want to compress the background_FPWs? Use compressed_background_FPWs? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On 29 May 2014 01:07, Bruce Momjian <bruce@momjian.us> wrote: > On Wed, May 28, 2014 at 04:04:13PM +0100, Simon Riggs wrote: >> On 28 May 2014 15:34, Fujii Masao <masao.fujii@gmail.com> wrote: >> >> >> Also, compress_backup_block GUC needs to be merged with full_page_writes. >> > >> > Basically I agree with you because I don't want to add new GUC very similar to >> > the existing one. >> > >> > But could you imagine the case where full_page_writes = off. Even in this case, >> > FPW is forcibly written only during base backup. Such FPW also should be >> > compressed? Which compression algorithm should be used? If we want to >> > choose the algorithm for such FPW, we would not be able to merge those two >> > GUCs. IMO it's OK to always use the best compression algorithm for such FPW >> > and merge them, though. >> >> I'd prefer a new name altogether >> >> torn_page_protection = 'full_page_writes' >> torn_page_protection = 'compressed_full_page_writes' >> torn_page_protection = 'none' >> >> this allows us to add new techniques later like >> >> torn_page_protection = 'background_FPWs' >> >> or >> >> torn_page_protection = 'double_buffering' >> >> when/if we add those new techniques > > Uh, how would that work if you want to compress the background_FPWs? > Use compressed_background_FPWs? We've currently got 1 technique for torn page protection, soon to have 2 and with a 3rd on the horizon and likely to receive effort in next release. It seems sensible to have just one parameter to describe the various techniques, as suggested. I'm suggesting that we plan for how things will look when we have the 3rd one as well. Alternate suggestions welcome. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
>your patch into next CF?
>algorithm?
On Tue, May 27, 2014 at 12:57 PM, Rahila Syed <rahilasyed.90@gmail.com> wrote:Thanks for extending and revising the FPW-compress patch! Could you add
> Hello All,
>
> 0001-CompressBackupBlock_snappy_lz4_pglz extends patch on compression of
> full page writes to include LZ4 and Snappy . Changes include making
> "compress_backup_block" GUC from boolean to enum. Value of the GUC can be
> OFF, pglz, snappy or lz4 which can be used to turn off compression or set
> the desired compression algorithm.
>
> 0002-Support_snappy_lz4 adds support for LZ4 and Snappy in PostgreSQL. It
> uses Andres’s patch for getting Makefiles working and has a few wrappers to
> make the function calls to LZ4 and Snappy compression functions and handle
> varlena datatypes.
> Patch Courtesy: Pavan Deolasee
your patch into next CF?Basically I agree with you because I don't want to add new GUC very similar to
> Also, compress_backup_block GUC needs to be merged with full_page_writes.
the existing one.
But could you imagine the case where full_page_writes = off. Even in this case,
FPW is forcibly written only during base backup. Such FPW also should be
compressed? Which compression algorithm should be used? If we want to
choose the algorithm for such FPW, we would not be able to merge those two
GUCs. IMO it's OK to always use the best compression algorithm for such FPW
and merge them, though.Isn't it worth measuring the recovery performance for each compression
> Tests use JDBC runner TPC-C benchmark to measure the amount of WAL
> compression ,tps and response time in each of the scenarios viz .
> Compression = OFF , pglz, LZ4 , snappy ,FPW=off
algorithm?
Regards,
--
Fujii Masao
On Thu, May 29, 2014 at 11:21:44AM +0100, Simon Riggs wrote: > > Uh, how would that work if you want to compress the background_FPWs? > > Use compressed_background_FPWs? > > We've currently got 1 technique for torn page protection, soon to have > 2 and with a 3rd on the horizon and likely to receive effort in next > release. > > It seems sensible to have just one parameter to describe the various > techniques, as suggested. I'm suggesting that we plan for how things > will look when we have the 3rd one as well. > > Alternate suggestions welcome. I was just pointing out that we might need compression to be a separate boolean variable from the type of page tear protection. I know I am usually anti-adding-variables, but in this case it seems trying to have one variable control several things will lead to confusion. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On Thu, May 29, 2014 at 7:21 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > On 29 May 2014 01:07, Bruce Momjian <bruce@momjian.us> wrote: >> On Wed, May 28, 2014 at 04:04:13PM +0100, Simon Riggs wrote: >>> On 28 May 2014 15:34, Fujii Masao <masao.fujii@gmail.com> wrote: >>> >>> >> Also, compress_backup_block GUC needs to be merged with full_page_writes. >>> > >>> > Basically I agree with you because I don't want to add new GUC very similar to >>> > the existing one. >>> > >>> > But could you imagine the case where full_page_writes = off. Even in this case, >>> > FPW is forcibly written only during base backup. Such FPW also should be >>> > compressed? Which compression algorithm should be used? If we want to >>> > choose the algorithm for such FPW, we would not be able to merge those two >>> > GUCs. IMO it's OK to always use the best compression algorithm for such FPW >>> > and merge them, though. >>> >>> I'd prefer a new name altogether >>> >>> torn_page_protection = 'full_page_writes' >>> torn_page_protection = 'compressed_full_page_writes' >>> torn_page_protection = 'none' >>> >>> this allows us to add new techniques later like >>> >>> torn_page_protection = 'background_FPWs' >>> >>> or >>> >>> torn_page_protection = 'double_buffering' >>> >>> when/if we add those new techniques >> >> Uh, how would that work if you want to compress the background_FPWs? >> Use compressed_background_FPWs? > > We've currently got 1 technique for torn page protection, soon to have > 2 and with a 3rd on the horizon and likely to receive effort in next > release. > > It seems sensible to have just one parameter to describe the various > techniques, as suggested. I'm suggesting that we plan for how things > will look when we have the 3rd one as well. > > Alternate suggestions welcome. Is even compression of double buffer worthwhile? If yes, what about separating the GUC parameter into torn_page_protection and something like full_page_compression? ISTM that any combination of settings of those parameters can work. torn_page_protection = 'FPW', 'background FPW', 'none', 'double buffer' full_page_compression = 'no', 'pglz', 'lz4', 'snappy' Regards, -- Fujii Masao
<div dir="ltr"><p class="MsoNormal">Hello ,<p class="MsoNormal"><br /><p class="MsoNormal">In order to facilitate changingof compression algorithms and to be able to recover using WAL records compressed with different compression algorithms,information about compression algorithm can be stored in WAL record.<p class="MsoNormal">XLOG record header has2 to 4 padding bytes in order to align the WAL record. This space can be used for a new flag in order to store informationabout the compression algorithm used. Like the xl_info field of XlogRecord struct, 8 bits flag can be constructedwith the lower 4 bits of the flag used to indicate which backup block is compressed out of 0,1,2,3. Higher fourbits can be used to indicate state of compression i.e off,lz4,snappy,pglz.<p class="MsoNormal">The flag can be extendedto incorporate more compression algorithms added in future if any.<p class="MsoNormal">What is your opinion on this?<pclass="MsoNormal"><br /><p class="MsoNormal">Thank you,<p class="MsoNormal">Rahila Syed</div><div class="gmail_extra"><br/><br /><div class="gmail_quote">On Tue, May 27, 2014 at 9:27 AM, Rahila Syed <span dir="ltr"><<ahref="mailto:rahilasyed.90@gmail.com" target="_blank">rahilasyed.90@gmail.com</a>></span> wrote:<br /><blockquoteclass="gmail_quote" style="margin:0 0 0 .8ex;border-left:1px #ccc solid;padding-left:1ex">Hello All,<br /><br/> 0001-CompressBackupBlock_snappy_lz4_pglz extends patch on compression of<br /> full page writes to include LZ4 andSnappy . Changes include making<br /> "compress_backup_block" GUC from boolean to enum. Value of the GUC can be<br />OFF, pglz, snappy or lz4 which can be used to turn off compression or set<br /> the desired compression algorithm.<br /><br/> 0002-Support_snappy_lz4 adds support for LZ4 and Snappy in PostgreSQL. It<br /> uses Andres’s patch for getting Makefilesworking and has a few wrappers to<br /> make the function calls to LZ4 and Snappy compression functions and handle<br/> varlena datatypes.<br /> Patch Courtesy: Pavan Deolasee<br /><br /> These patches serve as a way to test variouscompression algorithms. These<br /> are WIP yet. They don’t support changing compression algorithms on standby .<br/> Also, compress_backup_block GUC needs to be merged with full_page_writes.<br /> The patch uses LZ4 high compression(HC)variant.<br /> I have conducted initial tests which I would like to share and solicit<br /> feedback<br /><br/> Tests use JDBC runner TPC-C benchmark to measure the amount of WAL<br /> compression ,tps and response time in eachof the scenarios viz .<br /> Compression = OFF , pglz, LZ4 , snappy ,FPW=off<br /><br /> Server specifications:<br />Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos<br /> RAM: 32GB<br /> Disk : HDD 450GB 10KHot Plug 2.5-inch SAS HDD * 8 nos<br /> 1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm<br /><br /><br /> Benchmark:<br/> Scale : 100<br /> Command :java JR /home/postgres/jdbcrunner-1.2/scripts/tpcc.js -sleepTime<br /> 600,350,300,250,250<br/> Warmup time : 1 sec<br /> Measurement time : 900 sec<br /> Number of tx types : 5<br/> Number of agents : 16<br /> Connection pool size : 16<br /> Statement cache size : 40<br /> Auto commit : false<br /> Sleep time : 600,350,300,250,250 msec<br /><br /> Checkpoint segments:1024<br /> Checkpoint timeout:5mins<br /><br /><br /> Scenario WAL generated(bytes) Compression<br /> (bytes) TPS (tx1,tx2,tx3,tx4,tx5)<br /> No_compress 2220787088 (~2221MB) NULL<br /> 13.3,13.3,1.3,1.3,1.3 tps<br/> Pglz 1796213760 (~1796MB) 424573328<br /> (19.11%) 13.1,13.1,1.3,1.3,1.3 tps<br/> Snappy 1724171112 (~1724MB) 496615976( 22.36%)<br /> 13.2,13.2,1.3,1.3,1.3 tps<br />LZ4(HC) 1658941328 (~1659MB) 561845760(25.29%)<br /> 13.2,13.2,1.3,1.3,1.3 tps<br /> FPW(off) 139384320(~139 MB) NULL<br /> 13.3,13.3,1.3,1.3,1.3 tps<br /><br /> As per measurementresults, WAL reduction using LZ4 is close to 25% which<br /> shows 6 percent increase in WAL reduction when comparedto pglz . WAL<br /> reduction in snappy is close to 22 % .<br /> The numbers for compression using LZ4 and Snappydoesn’t seem to be very<br /> high as compared to pglz for given workload. This can be due to<br /> in-compressiblenature of the TPC-C data which contains random strings<br /><br /> Compression does not have bad impact onthe response time. In fact, response<br /> times for Snappy, LZ4 are much better than no compression with almost ½ to<br/> 1/3 of the response times of no-compression(FPW=on) and FPW = off.<br /> The response time order for each type ofcompression is<br /> Pglz>Snappy>LZ4<br /><br /> Scenario Response time (tx1,tx2,tx3,tx4,tx5)<br />no_compress 5555,1848,4221,6791,5747 msec<br /> pglz 4275,2659,1828,4025,3326 msec<br /> Snappy 3790,2828,2186,1284,1120 msec<br /> LZ4(hC) 2519,2449,1158,2066,2065 msec<br /> FPW(off) 6234,2430,3017,5417,5885 msec<br /><br /> LZ4 and Snappy are almost at par with each other in terms ofresponse time<br /> as average response times of five types of transactions remains almost same<br /> for both.<br /> 0001-CompressBackupBlock_snappy_lz4_pglz.patch<br/> <<a href="http://postgresql.1045698.n5.nabble.com/file/n5805044/0001-CompressBackupBlock_snappy_lz4_pglz.patch" target="_blank">http://postgresql.1045698.n5.nabble.com/file/n5805044/0001-CompressBackupBlock_snappy_lz4_pglz.patch</a>><br />0002-Support_snappy_lz4.patch<br /> <<a href="http://postgresql.1045698.n5.nabble.com/file/n5805044/0002-Support_snappy_lz4.patch" target="_blank">http://postgresql.1045698.n5.nabble.com/file/n5805044/0002-Support_snappy_lz4.patch</a>><br/><br /><br/><br /><br /> --<br /> View this message in context: <a href="http://postgresql.1045698.n5.nabble.com/Compression-of-full-page-writes-tp5769039p5805044.html" target="_blank">http://postgresql.1045698.n5.nabble.com/Compression-of-full-page-writes-tp5769039p5805044.html</a><br/> Sentfrom the PostgreSQL - hackers mailing list archive at Nabble.com.<br /><span class="HOEnZb"><font color="#888888"><br/><br /> --<br /> Sent via pgsql-hackers mailing list (<a href="mailto:pgsql-hackers@postgresql.org">pgsql-hackers@postgresql.org</a>)<br/> To make changes to your subscription:<br/><a href="http://www.postgresql.org/mailpref/pgsql-hackers" target="_blank">http://www.postgresql.org/mailpref/pgsql-hackers</a><br/></font></span></blockquote></div><br /></div>
On Tue, Jun 10, 2014 at 11:49 PM, Rahila Syed <rahilasyed90@gmail.com> wrote: > Hello , > > > In order to facilitate changing of compression algorithms and to be able to > recover using WAL records compressed with different compression algorithms, > information about compression algorithm can be stored in WAL record. > > XLOG record header has 2 to 4 padding bytes in order to align the WAL > record. This space can be used for a new flag in order to store information > about the compression algorithm used. Like the xl_info field of XlogRecord > struct, 8 bits flag can be constructed with the lower 4 bits of the flag > used to indicate which backup block is compressed out of 0,1,2,3. Higher > four bits can be used to indicate state of compression i.e > off,lz4,snappy,pglz. > > The flag can be extended to incorporate more compression algorithms added in > future if any. > > What is your opinion on this? -1 for any additional bytes in WAL record to control such things, having one single compression that we know performs well and relying on it makes the life of user and developer easier. -- Michael
On Wed, Jun 11, 2014 at 10:05 AM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Tue, Jun 10, 2014 at 11:49 PM, Rahila Syed <rahilasyed90@gmail.com> wrote: >> Hello , >> >> >> In order to facilitate changing of compression algorithms and to be able to >> recover using WAL records compressed with different compression algorithms, >> information about compression algorithm can be stored in WAL record. >> >> XLOG record header has 2 to 4 padding bytes in order to align the WAL >> record. This space can be used for a new flag in order to store information >> about the compression algorithm used. Like the xl_info field of XlogRecord >> struct, 8 bits flag can be constructed with the lower 4 bits of the flag >> used to indicate which backup block is compressed out of 0,1,2,3. Higher >> four bits can be used to indicate state of compression i.e >> off,lz4,snappy,pglz. >> >> The flag can be extended to incorporate more compression algorithms added in >> future if any. >> >> What is your opinion on this? > -1 for any additional bytes in WAL record to control such things, > having one single compression that we know performs well and relying > on it makes the life of user and developer easier. IIUC even when we adopt only one algorithm, additional at least one bit is necessary to see whether this backup block is compressed or not. This flag is necessary only for backup block, so there is no need to use the header of each WAL record. What about just using the backup block header? Regards, -- Fujii Masao
IIUC even when we adopt only one algorithm, additional at least one bit is
necessary to see whether this backup block is compressed or not.
This flag is necessary only for backup block, so there is no need to use
the header of each WAL record. What about just using the backup block
header?
Pavan Deolasee
http://www.linkedin.com/in/pavandeolasee
Scenario Amount of WAL(bytes) Compression (bytes) WALRecovery time(secs) TPS
FPW(on)Compression(Off) 1393681216 (~1394MB) NA 17 s 15.8,15.8,1.6,1.6,1.6 tps
Pglz 1192524560 (~1193 MB) 14% 17 s 15.6,15.6,1.6,1.6,1.6 tps
LZ4 1124745880 (~1125MB) 19.2% 16 s 15.7,15.7,1.6,1.6,1.6 tps
Snappy 1123117704 (~1123MB) 19.4% 17 s 15.6,15.6,1.6,1.6,1.6 tps
FPW (off) 171287384 ( ~171MB) NA 12 s 16.0,16.0,1.6,1.6,1.6 tps
Compression ratios of LZ4 and Snappy are almost at par for given workload. The nature of TPC-C type of data used is highly incompressible which explains the low compression ratios.
Turning compression on reduces tps overall. TPS numbers for LZ4 is slightly better than pglz and snappy.
Recovery(decompression) speed of LZ4 is slightly faster than Snappy.
Overall LZ4 scores over Snappy and pglz in terms of recovery (decompression) speed ,TPS and response times. Also, compression of LZ4 is at par with Snappy.
Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos
RAM: 32GB
Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos
1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm
Benchmark:
Scale : 16
Command :java JR /home/postgres/jdbcrunner-1.2/scripts/tpcc.js -sleepTime 550,250,250,200,200
Warmup time : 1 sec
Measurement time : 900 sec
Number of tx types : 5
Number of agents : 16
Connection pool size : 16
Statement cache size : 40
Auto commit : false
Checkpoint segments:1024
Checkpoint timeout:5 mins
Hello All,
0001-CompressBackupBlock_snappy_lz4_pglz extends patch on compression of
full page writes to include LZ4 and Snappy . Changes include making
"compress_backup_block" GUC from boolean to enum. Value of the GUC can be
OFF, pglz, snappy or lz4 which can be used to turn off compression or set
the desired compression algorithm.
0002-Support_snappy_lz4 adds support for LZ4 and Snappy in PostgreSQL. It
uses Andres’s patch for getting Makefiles working and has a few wrappers to
make the function calls to LZ4 and Snappy compression functions and handle
varlena datatypes.
Patch Courtesy: Pavan Deolasee
These patches serve as a way to test various compression algorithms. These
are WIP yet. They don’t support changing compression algorithms on standby .
Also, compress_backup_block GUC needs to be merged with full_page_writes.
The patch uses LZ4 high compression(HC) variant.
I have conducted initial tests which I would like to share and solicit
feedback
Tests use JDBC runner TPC-C benchmark to measure the amount of WAL
compression ,tps and response time in each of the scenarios viz .
Compression = OFF , pglz, LZ4 , snappy ,FPW=off
Server specifications:
Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos
RAM: 32GB
Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos
1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm
Benchmark:
Scale : 100
Command :java JR /home/postgres/jdbcrunner-1.2/scripts/tpcc.js -sleepTime
600,350,300,250,250
Warmup time : 1 sec
Measurement time : 900 sec
Number of tx types : 5
Number of agents : 16
Connection pool size : 16
Statement cache size : 40
Auto commit : false
Sleep time : 600,350,300,250,250 msec
Checkpoint segments:1024
Checkpoint timeout:5 mins
Scenario WAL generated(bytes) Compression
(bytes) TPS (tx1,tx2,tx3,tx4,tx5)
No_compress 2220787088 (~2221MB) NULL
13.3,13.3,1.3,1.3,1.3 tps
Pglz 1796213760 (~1796MB) 424573328
(19.11%) 13.1,13.1,1.3,1.3,1.3 tps
Snappy 1724171112 (~1724MB) 496615976( 22.36%)
13.2,13.2,1.3,1.3,1.3 tps
LZ4(HC) 1658941328 (~1659MB) 561845760(25.29%)
13.2,13.2,1.3,1.3,1.3 tps
FPW(off) 139384320(~139 MB) NULL
13.3,13.3,1.3,1.3,1.3 tps
As per measurement results, WAL reduction using LZ4 is close to 25% which
shows 6 percent increase in WAL reduction when compared to pglz . WAL
reduction in snappy is close to 22 % .
The numbers for compression using LZ4 and Snappy doesn’t seem to be very
high as compared to pglz for given workload. This can be due to
in-compressible nature of the TPC-C data which contains random strings
Compression does not have bad impact on the response time. In fact, response
times for Snappy, LZ4 are much better than no compression with almost ½ to
1/3 of the response times of no-compression(FPW=on) and FPW = off.
The response time order for each type of compression is
Pglz>Snappy>LZ4
Scenario Response time (tx1,tx2,tx3,tx4,tx5)
no_compress 5555,1848,4221,6791,5747 msec
pglz 4275,2659,1828,4025,3326 msec
Snappy 3790,2828,2186,1284,1120 msec
LZ4(hC) 2519,2449,1158,2066,2065 msec
FPW(off) 6234,2430,3017,5417,5885 msec
LZ4 and Snappy are almost at par with each other in terms of response time
as average response times of five types of transactions remains almost same
for both.
0001-CompressBackupBlock_snappy_lz4_pglz.patch
<http://postgresql.1045698.n5.nabble.com/file/n5805044/0001-CompressBackupBlock_snappy_lz4_pglz.patch>
0002-Support_snappy_lz4.patch
<http://postgresql.1045698.n5.nabble.com/file/n5805044/0002-Support_snappy_lz4.patch>
--
View this message in context: http://postgresql.1045698.n5.nabble.com/Compression-of-full-page-writes-tp5769039p5805044.html
Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
At 2014-06-13 20:07:29 +0530, rahilasyed90@gmail.com wrote:
>
> Patch named Support-for-lz4-and-snappy adds support for LZ4 and Snappy
> in PostgreSQL.
I haven't looked at this in any detail yet, but I note that the patch
creates src/common/lz4/.travis.yml, which it shouldn't.
I have a few preliminary comments about your patch.
> @@ -84,6 +87,7 @@ bool XLogArchiveMode = false;
> char *XLogArchiveCommand = NULL;
> bool EnableHotStandby = false;
> bool fullPageWrites = true;
> +int compress_backup_block = false;
I think compress_backup_block should be initialised to
BACKUP_BLOCK_COMPRESSION_OFF. (But see below.)
> + for (j = 0; j < XLR_MAX_BKP_BLOCKS; j++)
> + compressed_pages[j] = (char *) malloc(buffer_size);
Shouldn't this use palloc?
> + * Create a compressed version of a backup block
> + *
> + * If successful, return a compressed result and set 'len' to its length.
> + * Otherwise (ie, compressed result is actually bigger than original),
> + * return NULL.
> + */
> +static char *
> +CompressBackupBlock(char *page, uint32 orig_len, char *dest, uint32 *len)
> +{
First, the calling convention is a bit strange. I understand that you're
pre-allocating compressed_pages[] so as to avoid repeated allocations;
and that you're doing it outside CompressBackupBlock so as to avoid
passing in the index i. But the result is a little weird.
At the very minimum, I would move the "if (!compressed_pages_allocated)"
block outside the "for (i = 0; i < XLR_MAX_BKP_BLOCKS; i++)" loop, and
add some comments. I think we could live with that.
But I'm not at all fond of the code in this function either. I'd write
it like this:
struct varlena *buf = (struct varlena *) dest;
if (compress_backup_block = BACKUP_BLOCK_COMPRESSION_SNAPPY) { if (pg_snappy_compress(page, BLCKSZ, buf) ==
EIO) return NULL; } else if (compress_backup_block = BACKUP_BLOCK_COMPRESSION_LZ4) { if
(pg_LZ4_compress(page,BLCKSZ, buf) == 0) return NULL; } else if (compress_backup_block =
BACKUP_BLOCK_COMPRESSION_PGLZ) { if (pglz_compress(page, BLCKSZ, (PGLZ_Header *) buf,
PGLZ_strategy_default)!= 0) return NULL; } else elog(ERROR, "Wrong value for compress_backup_block
GUC");
/* * …comment about insisting on saving at least two bytes… */
if (VARSIZE(buf) >= orig_len - 2) return NULL;
*len = VARHDRSIZE + VARSIZE(buf);
return buf;
I guess it doesn't matter *too* much if the intention is to have all
these compression algorithms only during development/testing and pick
just one in the end. But the above is considerably easier to read in
the meanwhile.
If we were going to keep multiple compression algorithms around, I'd be
inclined to create a "pg_compress(…, compression_algorithm)" function to
hide these return-value differences from the callers.
> + else if (VARATT_IS_COMPRESSED((struct varlena *) blk) && compress_backup_block!=BACKUP_BLOCK_COMPRESSION_OFF)
> + {
> + if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_SNAPPY)
> + {
> + int ret;
> + size_t compressed_length = VARSIZE((struct varlena *) blk) - VARHDRSZ;
> + char *compressed_data = (char *)VARDATA((struct varlena *) blk);
> + size_t s_uncompressed_length;
> +
> + ret = snappy_uncompressed_length(compressed_data,
> + compressed_length,
> + &s_uncompressed_length);
> + if (!ret)
> + elog(ERROR, "snappy: failed to determine compression length");
> + if (BLCKSZ != s_uncompressed_length)
> + elog(ERROR, "snappy: compression size mismatch %d != %zu",
> + BLCKSZ, s_uncompressed_length);
> +
> + ret = snappy_uncompress(compressed_data,
> + compressed_length,
> + page);
> + if (ret != 0)
> + elog(ERROR, "snappy: decompression failed: %d", ret);
> + }
…and a "pg_decompress()" function that does error checking.
> +static const struct config_enum_entry backup_block_compression_options[] = {
> + {"off", BACKUP_BLOCK_COMPRESSION_OFF, false},
> + {"false", BACKUP_BLOCK_COMPRESSION_OFF, true},
> + {"no", BACKUP_BLOCK_COMPRESSION_OFF, true},
> + {"0", BACKUP_BLOCK_COMPRESSION_OFF, true},
> + {"pglz", BACKUP_BLOCK_COMPRESSION_PGLZ, true},
> + {"snappy", BACKUP_BLOCK_COMPRESSION_SNAPPY, true},
> + {"lz4", BACKUP_BLOCK_COMPRESSION_LZ4, true},
> + {NULL, 0, false}
> +};
Finally, I don't like the name "compress_backup_block".
1. It should have been plural (compress_backup_blockS).
2. Looking at the enum values, "backup_block_compression = x" would be a better name anyway…
3. But we don't use the term "backup block" anywhere in the documentation, and it's very likely to confuse people.
I don't mind the suggestion elsewhere in this thread to use
"full_page_compression = y" (as a setting alongside
"torn_page_protection = x").
I haven't tried the patch (other than applying and building it) yet. I
will do so after I hear what you and others think of the above points.
-- Abhijit
On Tue, Jun 17, 2014 at 8:47 AM, Abhijit Menon-Sen <ams@2ndquadrant.com> wrote: > if (compress_backup_block = BACKUP_BLOCK_COMPRESSION_SNAPPY) You mean == right?
At 2014-06-17 15:31:33 -0300, klaussfreire@gmail.com wrote: > > On Tue, Jun 17, 2014 at 8:47 AM, Abhijit Menon-Sen <ams@2ndquadrant.com> wrote: > > if (compress_backup_block = BACKUP_BLOCK_COMPRESSION_SNAPPY) > > You mean == right? Of course. Thanks. -- Abhijit
>add some comments. I think we could live with that
>inclined to create a "pg_compress(…, compression_algorithm)" function to
>hide these return-value differences from the callers. and a "pg_decompress()" function that does error checking
> {
if (pg_snappy_compress(page, BLCKSZ, buf) == EIO)
return NULL;
> }
> else if (compress_backup_block = BACKUP_BLOCK_COMPRESSION_LZ4)
> {
> if (pg_LZ4_compress(page, BLCKSZ, buf) == 0)
> return NULL;
> }
> else if (compress_backup_block = BACKUP_BLOCK_COMPRESSION_PGLZ)
> {
> if (pglz_compress(page, BLCKSZ, (PGLZ_Header *) buf,
> PGLZ_strategy_default) != 0)
> return NULL;
> }
> else
> elog(ERROR, "Wrong value for compress_backup_block GUC");
> /*
> * …comment about insisting on saving at least two bytes…
> */
> if (VARSIZE(buf) >= orig_len - 2)
> return NULL;
> *len = VARHDRSIZE + VARSIZE(buf);
> return buf;
>these compression algorithms only during development/testing and pick
>just one in the end. But the above is considerably easier to read in
>the meanwhile.
>"torn_page_protection = x").
This change of GUC is in the ToDo for this patch.
Thank you,
Rahila
At 2014-06-13 20:07:29 +0530, rahilasyed90@gmail.com wrote:I haven't looked at this in any detail yet, but I note that the patch
>
> Patch named Support-for-lz4-and-snappy adds support for LZ4 and Snappy
> in PostgreSQL.
creates src/common/lz4/.travis.yml, which it shouldn't.
I have a few preliminary comments about your patch.
> @@ -84,6 +87,7 @@ bool XLogArchiveMode = false;
> char *XLogArchiveCommand = NULL;
> bool EnableHotStandby = false;
> bool fullPageWrites = true;
> +int compress_backup_block = false;
I think compress_backup_block should be initialised to
BACKUP_BLOCK_COMPRESSION_OFF. (But see below.)
> + for (j = 0; j < XLR_MAX_BKP_BLOCKS; j++)
> + compressed_pages[j] = (char *) malloc(buffer_size);
Shouldn't this use palloc?
> + * Create a compressed version of a backup block
> + *
> + * If successful, return a compressed result and set 'len' to its length.
> + * Otherwise (ie, compressed result is actually bigger than original),
> + * return NULL.
> + */
> +static char *
> +CompressBackupBlock(char *page, uint32 orig_len, char *dest, uint32 *len)
> +{
First, the calling convention is a bit strange. I understand that you're
pre-allocating compressed_pages[] so as to avoid repeated allocations;
and that you're doing it outside CompressBackupBlock so as to avoid
passing in the index i. But the result is a little weird.
At the very minimum, I would move the "if (!compressed_pages_allocated)"
block outside the "for (i = 0; i < XLR_MAX_BKP_BLOCKS; i++)" loop, and
add some comments. I think we could live with that.
But I'm not at all fond of the code in this function either. I'd write
it like this:
struct varlena *buf = (struct varlena *) dest;
if (compress_backup_block = BACKUP_BLOCK_COMPRESSION_SNAPPY)
{
if (pg_snappy_compress(page, BLCKSZ, buf) == EIO)
return NULL;
}
else if (compress_backup_block = BACKUP_BLOCK_COMPRESSION_LZ4)
{
if (pg_LZ4_compress(page, BLCKSZ, buf) == 0)
return NULL;
}
else if (compress_backup_block = BACKUP_BLOCK_COMPRESSION_PGLZ)
{
if (pglz_compress(page, BLCKSZ, (PGLZ_Header *) buf,
PGLZ_strategy_default) != 0)
return NULL;
}
else
elog(ERROR, "Wrong value for compress_backup_block GUC");
/*
* …comment about insisting on saving at least two bytes…
*/
if (VARSIZE(buf) >= orig_len - 2)
return NULL;
*len = VARHDRSIZE + VARSIZE(buf);
return buf;
I guess it doesn't matter *too* much if the intention is to have all
these compression algorithms only during development/testing and pick
just one in the end. But the above is considerably easier to read in
the meanwhile.
If we were going to keep multiple compression algorithms around, I'd be
inclined to create a "pg_compress(…, compression_algorithm)" function to
hide these return-value differences from the callers.
> + else if (VARATT_IS_COMPRESSED((struct varlena *) blk) && compress_backup_block!=BACKUP_BLOCK_COMPRESSION_OFF)
> + {
> + if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_SNAPPY)
> + {
> + int ret;
> + size_t compressed_length = VARSIZE((struct varlena *) blk) - VARHDRSZ;
> + char *compressed_data = (char *)VARDATA((struct varlena *) blk);
> + size_t s_uncompressed_length;
> +
> + ret = snappy_uncompressed_length(compressed_data,
> + compressed_length,
> + &s_uncompressed_length);
> + if (!ret)
> + elog(ERROR, "snappy: failed to determine compression length");
> + if (BLCKSZ != s_uncompressed_length)
> + elog(ERROR, "snappy: compression size mismatch %d != %zu",
> + BLCKSZ, s_uncompressed_length);
> +
> + ret = snappy_uncompress(compressed_data,
> + compressed_length,
> + page);
> + if (ret != 0)
> + elog(ERROR, "snappy: decompression failed: %d", ret);
> + }
…and a "pg_decompress()" function that does error checking.
> +static const struct config_enum_entry backup_block_compression_options[] = {
> + {"off", BACKUP_BLOCK_COMPRESSION_OFF, false},
> + {"false", BACKUP_BLOCK_COMPRESSION_OFF, true},
> + {"no", BACKUP_BLOCK_COMPRESSION_OFF, true},
> + {"0", BACKUP_BLOCK_COMPRESSION_OFF, true},
> + {"pglz", BACKUP_BLOCK_COMPRESSION_PGLZ, true},
> + {"snappy", BACKUP_BLOCK_COMPRESSION_SNAPPY, true},
> + {"lz4", BACKUP_BLOCK_COMPRESSION_LZ4, true},
> + {NULL, 0, false}
> +};
Finally, I don't like the name "compress_backup_block".
1. It should have been plural (compress_backup_blockS).
2. Looking at the enum values, "backup_block_compression = x" would be a
better name anyway…
3. But we don't use the term "backup block" anywhere in the
documentation, and it's very likely to confuse people.
I don't mind the suggestion elsewhere in this thread to use
"full_page_compression = y" (as a setting alongside
"torn_page_protection = x").
I haven't tried the patch (other than applying and building it) yet. I
will do so after I hear what you and others think of the above points.
-- Abhijit
On 2014-06-18 18:10:34 +0530, Rahila Syed wrote: > Hello , > > >I have a few preliminary comments about your patch > Thank you for review comments. > > >the patch creates src/common/lz4/.travis.yml, which it shouldn't. > Agree. I will remove it. > > >Shouldn't this use palloc? > palloc() is disallowed in critical sections and we are already in CS while > executing this code. So we use malloc(). It's OK since the memory is > allocated just once per session and it stays till the end. malloc() isn't allowed either. You'll need to make sure all memory is allocated beforehand Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
At 2014-06-18 18:10:34 +0530, rahilasyed90@gmail.com wrote: > > palloc() is disallowed in critical sections and we are already in CS > while executing this code. So we use malloc(). Are these allocations actually inside a critical section? It seems to me that the critical section starts further down, but perhaps I am missing something. Second, as Andres says, you shouldn't malloc() inside a critical section either; and anyway, certainly not without checking the return value. > I am not sure if the change will be a significant improvement from > performance point of view except it will save few condition checks. Moving that allocation out of the outer for loop it's currently in is *nothing* to do with performance, but about making the code easier to read. -- Abhijit
At 2014-06-18 18:25:34 +0530, ams@2ndQuadrant.com wrote: > > Are these allocations actually inside a critical section? It seems to me > that the critical section starts further down, but perhaps I am missing > something. OK, I was missing that XLogInsert() itself can be called from inside a critical section. So the allocation has to be moved somewhere else altogether. -- Abhijit
At 2014-06-18 18:10:34 +0530, rahilasyed90@gmail.com wrote:Are these allocations actually inside a critical section? It seems to me
>
> palloc() is disallowed in critical sections and we are already in CS
> while executing this code. So we use malloc().
that the critical section starts further down, but perhaps I am missing
something.
Second, as Andres says, you shouldn't malloc() inside a critical section
either; and anyway, certainly not without checking the return value.
> I am not sure if the change will be a significant improvement fromMoving that allocation out of the outer for loop it's currently in is
> performance point of view except it will save few condition checks.
*nothing* to do with performance, but about making the code easier to
read.
Pavan Deolasee
http://www.linkedin.com/in/pavandeolasee
At 2014-06-13 20:07:29 +0530, rahilasyed90@gmail.com wrote:I haven't looked at this in any detail yet, but I note that the patch
>
> Patch named Support-for-lz4-and-snappy adds support for LZ4 and Snappy
> in PostgreSQL.
creates src/common/lz4/.travis.yml, which it shouldn't.
I have a few preliminary comments about your patch.
> @@ -84,6 +87,7 @@ bool XLogArchiveMode = false;
> char *XLogArchiveCommand = NULL;
> bool EnableHotStandby = false;
> bool fullPageWrites = true;
> +int compress_backup_block = false;
I think compress_backup_block should be initialised to
BACKUP_BLOCK_COMPRESSION_OFF. (But see below.)
> + for (j = 0; j < XLR_MAX_BKP_BLOCKS; j++)
> + compressed_pages[j] = (char *) malloc(buffer_size);
Shouldn't this use palloc?
> + * Create a compressed version of a backup block
> + *
> + * If successful, return a compressed result and set 'len' to its length.
> + * Otherwise (ie, compressed result is actually bigger than original),
> + * return NULL.
> + */
> +static char *
> +CompressBackupBlock(char *page, uint32 orig_len, char *dest, uint32 *len)
> +{
First, the calling convention is a bit strange. I understand that you're
pre-allocating compressed_pages[] so as to avoid repeated allocations;
and that you're doing it outside CompressBackupBlock so as to avoid
passing in the index i. But the result is a little weird.
At the very minimum, I would move the "if (!compressed_pages_allocated)"
block outside the "for (i = 0; i < XLR_MAX_BKP_BLOCKS; i++)" loop, and
add some comments. I think we could live with that.
But I'm not at all fond of the code in this function either. I'd write
it like this:
struct varlena *buf = (struct varlena *) dest;
if (compress_backup_block = BACKUP_BLOCK_COMPRESSION_SNAPPY)
{
if (pg_snappy_compress(page, BLCKSZ, buf) == EIO)
return NULL;
}
else if (compress_backup_block = BACKUP_BLOCK_COMPRESSION_LZ4)
{
if (pg_LZ4_compress(page, BLCKSZ, buf) == 0)
return NULL;
}
else if (compress_backup_block = BACKUP_BLOCK_COMPRESSION_PGLZ)
{
if (pglz_compress(page, BLCKSZ, (PGLZ_Header *) buf,
PGLZ_strategy_default) != 0)
return NULL;
}
else
elog(ERROR, "Wrong value for compress_backup_block GUC");
/*
* …comment about insisting on saving at least two bytes…
*/
if (VARSIZE(buf) >= orig_len - 2)
return NULL;
*len = VARHDRSIZE + VARSIZE(buf);
return buf;
I guess it doesn't matter *too* much if the intention is to have all
these compression algorithms only during development/testing and pick
just one in the end. But the above is considerably easier to read in
the meanwhile.
If we were going to keep multiple compression algorithms around, I'd be
inclined to create a "pg_compress(…, compression_algorithm)" function to
hide these return-value differences from the callers.
> + else if (VARATT_IS_COMPRESSED((struct varlena *) blk) && compress_backup_block!=BACKUP_BLOCK_COMPRESSION_OFF)
> + {
> + if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_SNAPPY)
> + {
> + int ret;
> + size_t compressed_length = VARSIZE((struct varlena *) blk) - VARHDRSZ;
> + char *compressed_data = (char *)VARDATA((struct varlena *) blk);
> + size_t s_uncompressed_length;
> +
> + ret = snappy_uncompressed_length(compressed_data,
> + compressed_length,
> + &s_uncompressed_length);
> + if (!ret)
> + elog(ERROR, "snappy: failed to determine compression length");
> + if (BLCKSZ != s_uncompressed_length)
> + elog(ERROR, "snappy: compression size mismatch %d != %zu",
> + BLCKSZ, s_uncompressed_length);
> +
> + ret = snappy_uncompress(compressed_data,
> + compressed_length,
> + page);
> + if (ret != 0)
> + elog(ERROR, "snappy: decompression failed: %d", ret);
> + }
…and a "pg_decompress()" function that does error checking.
> +static const struct config_enum_entry backup_block_compression_options[] = {
> + {"off", BACKUP_BLOCK_COMPRESSION_OFF, false},
> + {"false", BACKUP_BLOCK_COMPRESSION_OFF, true},
> + {"no", BACKUP_BLOCK_COMPRESSION_OFF, true},
> + {"0", BACKUP_BLOCK_COMPRESSION_OFF, true},
> + {"pglz", BACKUP_BLOCK_COMPRESSION_PGLZ, true},
> + {"snappy", BACKUP_BLOCK_COMPRESSION_SNAPPY, true},
> + {"lz4", BACKUP_BLOCK_COMPRESSION_LZ4, true},
> + {NULL, 0, false}
> +};
Finally, I don't like the name "compress_backup_block".
1. It should have been plural (compress_backup_blockS).
2. Looking at the enum values, "backup_block_compression = x" would be a
better name anyway…
3. But we don't use the term "backup block" anywhere in the
documentation, and it's very likely to confuse people.
I don't mind the suggestion elsewhere in this thread to use
"full_page_compression = y" (as a setting alongside
"torn_page_protection = x").
I haven't tried the patch (other than applying and building it) yet. I
will do so after I hear what you and others think of the above points.
-- Abhijit
Attachment
On Fri, Jul 4, 2014 at 4:58 AM, Rahila Syed <rahilasyed90@gmail.com> wrote:
> Hello,
>
> Updated version of patches are attached.
> Changes are as follows
> 1. Improved readability of the code as per the review comments.
> 2. Addition of block_compression field in BkpBlock structure to store
> information about compression of block. This provides for switching
> compression on/off and changing compression algorithm as required.
> 3.Handling of OOM in critical section by checking for return value of malloc
> and proceeding without compression of FPW if return value is NULL.
Thanks for updating the patches!
But 0002-CompressBackupBlock_snappy_lz4_pglz-2.patch doesn't seem to
be able to apply to HEAD cleanly.
-----------------------------------------------
$ git am ~/Desktop/0001-Support-for-LZ4-and-Snappy-2.patch
Applying: Support for LZ4 and Snappy-2
$ git am ~/Desktop/0002-CompressBackupBlock_snappy_lz4_pglz-2.patch
Applying: CompressBackupBlock_snappy_lz4_pglz-2
/home/postgres/pgsql/git/.git/rebase-apply/patch:42: indent with spaces. /*Allocates memory for compressed backup
blocksaccording to
the compression algorithm used.Once per session at the time of
insertion of first XLOG record.
/home/postgres/pgsql/git/.git/rebase-apply/patch:43: indent with spaces. This memory stays till the end of
session.OOM is handled by
making the code proceed without FPW compression*/
/home/postgres/pgsql/git/.git/rebase-apply/patch:58: indent with spaces. if(compressed_pages[j]
==NULL)
/home/postgres/pgsql/git/.git/rebase-apply/patch:59: space before tab in indent. {
/home/postgres/pgsql/git/.git/rebase-apply/patch:60: space before tab in indent.
compress_backup_block=BACKUP_BLOCK_COMPRESSION_OFF;
error: patch failed: src/backend/access/transam/xlog.c:60
error: src/backend/access/transam/xlog.c: patch does not apply
Patch failed at 0001 CompressBackupBlock_snappy_lz4_pglz-2
When you have resolved this problem run "git am --resolved".
If you would prefer to skip this patch, instead run "git am --skip".
To restore the original branch and stop patching run "git am --abort".
-----------------------------------------------
Regards,
--
Fujii Masao
At 2014-07-04 14:38:27 +0900, masao.fujii@gmail.com wrote: > > But 0002-CompressBackupBlock_snappy_lz4_pglz-2.patch doesn't seem to > be able to apply to HEAD cleanly. Yes, and it needs quite some reformatting beyond fixing whitespace damage too (long lines, comment formatting, consistent spacing etc.). -- Abhijit
> But 0002-CompressBackupBlock_snappy_lz4_pglz-2.patch doesn't seem to
> be able to apply to HEAD cleanly.
>damage too (long lines, comment formatting, consistent spacing etc.).
At 2014-07-04 14:38:27 +0900, masao.fujii@gmail.com wrote:Yes, and it needs quite some reformatting beyond fixing whitespace
>
> But 0002-CompressBackupBlock_snappy_lz4_pglz-2.patch doesn't seem to
> be able to apply to HEAD cleanly.
damage too (long lines, comment formatting, consistent spacing etc.).
-- Abhijit
Attachment
At 2014-07-04 19:27:10 +0530, rahilasyed90@gmail.com wrote:
>
> Please find attached patches with no whitespace error and improved
> formatting.
Thanks.
There are still numerous formatting changes required, e.g. spaces around
"=" and correct formatting of comments. And "git diff --check" still has
a few whitespace problems. I won't point these out one by one, but maybe
you should run pgindent.
> diff --git a/src/backend/access/transam/xlog.c b/src/backend/access/transam/xlog.c
> index 3f92482..39635de 100644
> --- a/src/backend/access/transam/xlog.c
> +++ b/src/backend/access/transam/xlog.c
> @@ -60,6 +60,9 @@
> #include "storage/spin.h"
> #include "utils/builtins.h"
> #include "utils/guc.h"
> +#include "utils/pg_lzcompress.h"
> +#include "utils/pg_snappy.h"
> +#include "utils/pg_lz4.h"
> #include "utils/ps_status.h"
> #include "utils/relmapper.h"
> #include "utils/snapmgr.h"
This hunk still fails to apply to master (due to the subsequent
inclusion of memutils.h), but I just added it in by hand.
> +int compress_backup_block = false;
Should be initialised to BACKUP_BLOCK_COMPRESSION_OFF as noted earlier.
> + /* Allocates memory for compressed backup blocks according to the compression
> + * algorithm used.Once per session at the time of insertion of first XLOG
> + * record.
> + * This memory stays till the end of session. OOM is handled by making the
> + * code proceed without FPW compression*/
I suggest something like this:
/* * Allocates pages to store compressed backup blocks, with the page * size depending on the compression
algorithmselected. These pages * persist throughout the life of the backend. If the allocation * fails, we
disablebackup block compression entirely. */
But though the code looks better locally than before, the larger problem
is that this is still unsafe. As Pavan pointed out, XLogInsert is called
from inside critical sections, so we can't allocate memory here.
Could you look into his suggestions of other places to do the
allocation, please?
> + static char *compressed_pages[XLR_MAX_BKP_BLOCKS];
> + static bool compressed_pages_allocated = false;
These declarations can't just be in the middle of the function, they'll
have to move up to near the top of the closest enclosing scope (wherever
you end up doing the allocation).
> + if (compress_backup_block != BACKUP_BLOCK_COMPRESSION_OFF &&
> + compressed_pages_allocated!= true)
No need for "!= true" with a boolean.
> + if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_SNAPPY)
> + buffer_size += snappy_max_compressed_length(BLCKSZ);
> + else if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_LZ4)
> + buffer_size += LZ4_compressBound(BLCKSZ);
> + else if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_PGLZ)
> + buffer_size += PGLZ_MAX_OUTPUT(BLCKSZ);
There's nothing wrong with this, but given that XLR_MAX_BKP_BLOCKS is 4,
I would just allocate pages of size BLCKSZ. But maybe that's just me.
> + bkpb->block_compression=BACKUP_BLOCK_COMPRESSION_OFF;
Wouldn't it be better to set
bkpb->block_compression = compress_backup_block;
once earlier instead of setting it that way once and setting it to
BACKUP_BLOCK_COMPRESSION_OFF in two other places?
> + if(VARSIZE(buf) < orig_len-2)
> + /* successful compression */
> + {
> + *len = VARSIZE(buf);
> + return (char *) buf;
> + }
> + else
> + return NULL;
> +}
That comment after the "if" just has to go. It's redundant given the
detailed explanation above anyway. Also, I'd strongly prefer checking
for failure rather than success here, i.e.
if (VARSIZE(buf) >= orig_len - 2) return NULL;
*len = VARSIZE(buf); /* Doesn't this need + VARHDRSIZE? */
return (char *) buf;
I don't quite remember what I suggested last time, but if it was what's
in the patch now, I apologise.
> + /* Decompress if backup block is compressed*/
> + else if (VARATT_IS_COMPRESSED((struct varlena *) blk)
> + && bkpb.block_compression!=BACKUP_BLOCK_COMPRESSION_OFF)
If you're using VARATT_IS_COMPRESSED() to detect compression, don't you
need SET_VARSIZE_COMPRESSED() in CompressBackupBlock? pglz_compress()
does it for you, but the other two algorithms don't.
But now that you've added bkpb.block_compression, you should be able to
avoid VARATT_IS_COMPRESSED() altogether, unless I'm missing something.
What do you think?
> +/*
> + */
> +static const struct config_enum_entry backup_block_compression_options[] = {
> + {"off", BACKUP_BLOCK_COMPRESSION_OFF, false},
> + {"false", BACKUP_BLOCK_COMPRESSION_OFF, true},
> + {"no", BACKUP_BLOCK_COMPRESSION_OFF, true},
> + {"0", BACKUP_BLOCK_COMPRESSION_OFF, true},
> + {"pglz", BACKUP_BLOCK_COMPRESSION_PGLZ, true},
> + {"snappy", BACKUP_BLOCK_COMPRESSION_SNAPPY, true},
> + {"lz4", BACKUP_BLOCK_COMPRESSION_LZ4, true},
> + {NULL, 0, false}
> +};
An empty comment probably isn't the best idea. ;-)
Thanks for all your work on this patch. I'll set it back to waiting on
author for now, but let me know if you need more time to resubmit, and
I'll move it to the next CF.
-- Abhijit
At 2014-07-04 21:02:33 +0530, ams@2ndQuadrant.com wrote:
>
> > +/*
> > + */
> > +static const struct config_enum_entry backup_block_compression_options[] = {
Oh, I forgot to mention that the configuration setting changes are also
pending. I think we had a working consensus to use full_page_compression
as the name of the GUC. As I understand it, that'll accept an algorithm
name as an argument while we're still experimenting, but eventually once
we select an algorithm, it'll become just a boolean (and then we don't
need to put algorithm information into BkpBlock any more either).
-- Abhijit
>"=" and correct formatting of comments. And "git diff --check" still has
>a few whitespace problems. I won't point these out one by one, but maybe
>you should run pgindent
> bkpb->block_compression = compress_backup_block;
>once earlier instead of setting it that way once and setting it to
>BACKUP_BLOCK_COMPRESSION_OFF in two other places
does it for you, but the other two algorithms don't.
>avoid VARATT_IS_COMPRESSED() altogether, unless I'm missing something.
>What do you think?
At 2014-07-04 21:02:33 +0530, ams@2ndQuadrant.com wrote:Oh, I forgot to mention that the configuration setting changes are also
>
> > +/*
> > + */
> > +static const struct config_enum_entry backup_block_compression_options[] = {
pending. I think we had a working consensus to use full_page_compression
as the name of the GUC. As I understand it, that'll accept an algorithm
name as an argument while we're still experimenting, but eventually once
we select an algorithm, it'll become just a boolean (and then we don't
need to put algorithm information into BkpBlock any more either).
-- Abhijit
>is that this is still unsafe. As Pavan pointed out, XLogInsert is called
>from inside critical sections, so we can't allocate memory here.
Thank you for review comments.>There are still numerous formatting changes required, e.g. spaces around
>"=" and correct formatting of comments. And "git diff --check" still has
>a few whitespace problems. I won't point these out one by one, but maybe
>you should run pgindentI will do this.>Could you look into his suggestions of other places to do the>allocation, please?I will get back to you on this>Wouldn't it be better to set
> bkpb->block_compression = compress_backup_block;
>once earlier instead of setting it that way once and setting it to
>BACKUP_BLOCK_COMPRESSION_OFF in two other placesYes.If you're using VARATT_IS_COMPRESSED() to detect compression, don't youneed SET_VARSIZE_COMPRESSED() in CompressBackupBlock? pglz_compress()
does it for you, but the other two algorithms don't.Yes we need SET_VARSIZE_COMPRESSED. It is present in wrappers around snappy and LZ4 namely pg_snappy_compress and pg_LZ4_compress.>But now that you've added bkpb.block_compression, you should be able to
>avoid VARATT_IS_COMPRESSED() altogether, unless I'm missing something.
>What do you think?You are right. It can be removed.Thank you,On Fri, Jul 4, 2014 at 9:35 PM, Abhijit Menon-Sen <ams@2ndquadrant.com> wrote:At 2014-07-04 21:02:33 +0530, ams@2ndQuadrant.com wrote:Oh, I forgot to mention that the configuration setting changes are also
>
> > +/*
> > + */
> > +static const struct config_enum_entry backup_block_compression_options[] = {
pending. I think we had a working consensus to use full_page_compression
as the name of the GUC. As I understand it, that'll accept an algorithm
name as an argument while we're still experimenting, but eventually once
we select an algorithm, it'll become just a boolean (and then we don't
need to put algorithm information into BkpBlock any more either).
-- Abhijit
On 2014-07-04 19:27:10 +0530, Rahila Syed wrote:
> + /* Allocates memory for compressed backup blocks according to the compression
> + * algorithm used.Once per session at the time of insertion of first XLOG
> + * record.
> + * This memory stays till the end of session. OOM is handled by making the
> + * code proceed without FPW compression*/
> + static char *compressed_pages[XLR_MAX_BKP_BLOCKS];
> + static bool compressed_pages_allocated = false;
> + if (compress_backup_block != BACKUP_BLOCK_COMPRESSION_OFF &&
> + compressed_pages_allocated!= true)
> + {
> + size_t buffer_size = VARHDRSZ;
> + int j;
> + if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_SNAPPY)
> + buffer_size += snappy_max_compressed_length(BLCKSZ);
> + else if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_LZ4)
> + buffer_size += LZ4_compressBound(BLCKSZ);
> + else if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_PGLZ)
> + buffer_size += PGLZ_MAX_OUTPUT(BLCKSZ);
> + for (j = 0; j < XLR_MAX_BKP_BLOCKS; j++)
> + { compressed_pages[j] = (char *) malloc(buffer_size);
> + if(compressed_pages[j] == NULL)
> + {
> + compress_backup_block=BACKUP_BLOCK_COMPRESSION_OFF;
> + break;
> + }
> + }
> + compressed_pages_allocated = true;
> + }
Why not do this in InitXLOGAccess() or similar?
> /*
> * Make additional rdata chain entries for the backup blocks, so that we
> * don't need to special-case them in the write loop. This modifies the
> @@ -1015,11 +1048,32 @@ begin:;
> rdt->next = &(dtbuf_rdt2[i]);
> rdt = rdt->next;
>
> + if (compress_backup_block != BACKUP_BLOCK_COMPRESSION_OFF)
> + {
> + /* Compress the backup block before including it in rdata chain */
> + rdt->data = CompressBackupBlock(page, BLCKSZ - bkpb->hole_length,
> + compressed_pages[i], &(rdt->len));
> + if (rdt->data != NULL)
> + {
> + /*
> + * write_len is the length of compressed block and its varlena
> + * header
> + */
> + write_len += rdt->len;
> + bkpb->hole_length = BLCKSZ - rdt->len;
> + /*Adding information about compression in the backup block header*/
> + bkpb->block_compression=compress_backup_block;
> + rdt->next = NULL;
> + continue;
> + }
> + }
> +
So, you're compressing backup blocks one by one. I wonder if that's the
right idea and if we shouldn't instead compress all of them in one run to
increase the compression ratio.
> +/*
> * Get a pointer to the right location in the WAL buffer containing the
> * given XLogRecPtr.
> *
> @@ -4061,6 +4174,50 @@ RestoreBackupBlockContents(XLogRecPtr lsn, BkpBlock bkpb, char *blk,
> {
> memcpy((char *) page, blk, BLCKSZ);
> }
> + /* Decompress if backup block is compressed*/
> + else if (VARATT_IS_COMPRESSED((struct varlena *) blk)
> + && bkpb.block_compression!=BACKUP_BLOCK_COMPRESSION_OFF)
> + {
> + if (bkpb.block_compression == BACKUP_BLOCK_COMPRESSION_SNAPPY)
> + {
> + int ret;
> + size_t compressed_length = VARSIZE((struct varlena *) blk) - VARHDRSZ;
> + char *compressed_data = (char *)VARDATA((struct varlena *) blk);
> + size_t s_uncompressed_length;
> +
> + ret = snappy_uncompressed_length(compressed_data,
> + compressed_length,
> + &s_uncompressed_length);
> + if (!ret)
> + elog(ERROR, "snappy: failed to determine compression length");
> + if (BLCKSZ != s_uncompressed_length)
> + elog(ERROR, "snappy: compression size mismatch %d != %zu",
> + BLCKSZ, s_uncompressed_length);
> +
> + ret = snappy_uncompress(compressed_data,
> + compressed_length,
> + page);
> + if (ret != 0)
> + elog(ERROR, "snappy: decompression failed: %d", ret);
> + }
> + else if (bkpb.block_compression == BACKUP_BLOCK_COMPRESSION_LZ4)
> + {
> + int ret;
> + size_t compressed_length = VARSIZE((struct varlena *) blk) - VARHDRSZ;
> + char *compressed_data = (char *)VARDATA((struct varlena *) blk);
> + ret = LZ4_decompress_fast(compressed_data, page,
> + BLCKSZ);
> + if (ret != compressed_length)
> + elog(ERROR, "lz4: decompression size mismatch: %d vs %zu", ret,
> + compressed_length);
> + }
> + else if (bkpb.block_compression == BACKUP_BLOCK_COMPRESSION_PGLZ)
> + {
> + pglz_decompress((PGLZ_Header *) blk, (char *) page);
> + }
> + else
> + elog(ERROR, "Wrong value for compress_backup_block GUC");
> + }
> else
> {
> memcpy((char *) page, blk, bkpb.hole_offset);
So why aren't we compressing the hole here instead of compressing the
parts that the current logic deems to be filled with important information?
> /*
> * Options for enum values stored in other modules
> */
> @@ -3498,6 +3512,16 @@ static struct config_enum ConfigureNamesEnum[] =
> NULL, NULL, NULL
> },
>
> + {
> + {"compress_backup_block", PGC_SIGHUP, WAL_SETTINGS,
> + gettext_noop("Compress backup block in WAL using specified compression algorithm."),
> + NULL
> + },
> + &compress_backup_block,
> + BACKUP_BLOCK_COMPRESSION_OFF, backup_block_compression_options,
> + NULL, NULL, NULL
> + },
> +
This should be named 'compress_full_page_writes' or so, even if a
temporary guc. There's the 'full_page_writes' guc and I see little
reaason to deviate from its name.
Greetings,
Andres Freund
>right idea and if we shouldn't instead compress all of them in one run to
>increase the compression ratio.
>parts that the current logic deems to be filled with important information?
>temporary guc. There's the 'full_page_writes' guc and I see little
>reaason to deviate from its name.
On 2014-07-04 19:27:10 +0530, Rahila Syed wrote:> + * This memory stays till the end of session. OOM is handled by making the
> + /* Allocates memory for compressed backup blocks according to the compression
> + * algorithm used.Once per session at the time of insertion of first XLOG
> + * record.
> + * code proceed without FPW compression*/> + static char *compressed_pages[XLR_MAX_BKP_BLOCKS];
> + static bool compressed_pages_allocated = false;> + if (compress_backup_block != BACKUP_BLOCK_COMPRESSION_OFF &&> + {
> + compressed_pages_allocated!= true)
> + size_t buffer_size = VARHDRSZ;
> + int j;> + if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_SNAPPY)> + buffer_size += snappy_max_compressed_length(BLCKSZ);
> + else if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_LZ4)
> + buffer_size += LZ4_compressBound(BLCKSZ);
> + else if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_PGLZ)
> + buffer_size += PGLZ_MAX_OUTPUT(BLCKSZ);> + for (j = 0; j < XLR_MAX_BKP_BLOCKS; j++)> + if(compressed_pages[j] == NULL)
> + { compressed_pages[j] = (char *) malloc(buffer_size);
> + {
> + compress_backup_block=BACKUP_BLOCK_COMPRESSION_OFF;
> + break;
> + }
> + }
> + compressed_pages_allocated = true;
> + }
Why not do this in InitXLOGAccess() or similar?
> /*
> * Make additional rdata chain entries for the backup blocks, so that we
> * don't need to special-case them in the write loop. This modifies the
> @@ -1015,11 +1048,32 @@ begin:;
> rdt->next = &(dtbuf_rdt2[i]);
> rdt = rdt->next;
>
> + if (compress_backup_block != BACKUP_BLOCK_COMPRESSION_OFF)
> + {
> + /* Compress the backup block before including it in rdata chain */
> + rdt->data = CompressBackupBlock(page, BLCKSZ - bkpb->hole_length,
> + compressed_pages[i], &(rdt->len));
> + if (rdt->data != NULL)
> + {
> + /*
> + * write_len is the length of compressed block and its varlena
> + * header
> + */
> + write_len += rdt->len;
> + bkpb->hole_length = BLCKSZ - rdt->len;
> + /*Adding information about compression in the backup block header*/
> + bkpb->block_compression=compress_backup_block;
> + rdt->next = NULL;
> + continue;
> + }
> + }
> +
So, you're compressing backup blocks one by one. I wonder if that's the
right idea and if we shouldn't instead compress all of them in one run to
increase the compression ratio.
> +/*
> * Get a pointer to the right location in the WAL buffer containing the
> * given XLogRecPtr.
> *
> @@ -4061,6 +4174,50 @@ RestoreBackupBlockContents(XLogRecPtr lsn, BkpBlock bkpb, char *blk,
> {
> memcpy((char *) page, blk, BLCKSZ);> }
> + /* Decompress if backup block is compressed*/> + else if (VARATT_IS_COMPRESSED((struct varlena *) blk)> + && bkpb.block_compression!=BACKUP_BLOCK_COMPRESSION_OFF)
> + {
> + if (bkpb.block_compression == BACKUP_BLOCK_COMPRESSION_SNAPPY)> + {> + else if (bkpb.block_compression == BACKUP_BLOCK_COMPRESSION_LZ4)
> + int ret;
> + size_t compressed_length = VARSIZE((struct varlena *) blk) - VARHDRSZ;
> + char *compressed_data = (char *)VARDATA((struct varlena *) blk);
> + size_t s_uncompressed_length;
> +
> + ret = snappy_uncompressed_length(compressed_data,
> + compressed_length,
> + &s_uncompressed_length);
> + if (!ret)
> + elog(ERROR, "snappy: failed to determine compression length");
> + if (BLCKSZ != s_uncompressed_length)
> + elog(ERROR, "snappy: compression size mismatch %d != %zu",
> + BLCKSZ, s_uncompressed_length);
> +
> + ret = snappy_uncompress(compressed_data,
> + compressed_length,
> + page);
> + if (ret != 0)
> + elog(ERROR, "snappy: decompression failed: %d", ret);
> + }> + {> + ret = LZ4_decompress_fast(compressed_data, page,
> + int ret;
> + size_t compressed_length = VARSIZE((struct varlena *) blk) - VARHDRSZ;
> + char *compressed_data = (char *)VARDATA((struct varlena *) blk);
> + BLCKSZ);
> + if (ret != compressed_length)
> + elog(ERROR, "lz4: decompression size mismatch: %d vs %zu", ret,
> + compressed_length);
> + }
> + else if (bkpb.block_compression == BACKUP_BLOCK_COMPRESSION_PGLZ)
> + {
> + pglz_decompress((PGLZ_Header *) blk, (char *) page);
> + }
> + else
> + elog(ERROR, "Wrong value for compress_backup_block GUC");
> + }
> else
> {
> memcpy((char *) page, blk, bkpb.hole_offset);
So why aren't we compressing the hole here instead of compressing the
parts that the current logic deems to be filled with important information?
> /*
> * Options for enum values stored in other modules
> */
> @@ -3498,6 +3512,16 @@ static struct config_enum ConfigureNamesEnum[] =
> NULL, NULL, NULL
> },
>
> + {
> + {"compress_backup_block", PGC_SIGHUP, WAL_SETTINGS,
> + gettext_noop("Compress backup block in WAL using specified compression algorithm."),
> + NULL
> + },
> + &compress_backup_block,
> + BACKUP_BLOCK_COMPRESSION_OFF, backup_block_compression_options,
> + NULL, NULL, NULL
> + },
> +
This should be named 'compress_full_page_writes' or so, even if a
temporary guc. There's the 'full_page_writes' guc and I see little
reaason to deviate from its name.
Greetings,
Andres Freund
On Wed, Jul 23, 2014 at 5:21 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > 1. Need for compressing full page backups: > There are good number of benchmarks done by various people on this list > which clearly shows the need of the feature. Many people have already voiced > their agreement on having this in core, even as a configurable parameter. Yes! > Having said that, IMHO we should go one step at a time. We are using pglz > for compressing toast data for long, so we can continue to use the same for > compressing full page images. We can simultaneously work on adding more > algorithms to core and choose the right candidate for different scenarios > such as toast or FPW based on test evidences. But that work can happen > independent of this patch. This gradual approach looks good to me. And, if the additional compression algorithm like lz4 is always better than pglz for every scenarios, we can just change the code so that the additional algorithm is always used. Which would make the code simpler. > 3. Compressing one block vs all blocks: > Andres suggested that compressing all backup blocks in one go may give us > better compression ratio. This is worth trying. I'm wondering what would the > best way to do so without minimal changes to the xlog insertion code. Today, > we add more rdata items for backup block header(s) and backup blocks > themselves (if there is a "hole" then 2 per backup block) beyond what the > caller has supplied. If we have to compress all the backup blocks together, > then one approach is to copy the backup block headers and the blocks to a > temp buffer, compress that and replace the rdata entries added previously > with a single rdata. Basically sounds reasonable. But, how does this logic work if there are multiple rdata and only some of them are backup blocks? If a "hole" is not copied to that temp buffer, ISTM that we should change backup block header so that it contains the info for a "hole", e.g., location that a "hole" starts. No? Regards, -- Fujii Masao
This gradual approach looks good to me. And, if the additional compression
algorithm like lz4 is always better than pglz for every scenarios, we can just
change the code so that the additional algorithm is always used. Which would
make the code simpler.
> 3. Compressing one block vs all blocks:Basically sounds reasonable. But, how does this logic work if there are
> Andres suggested that compressing all backup blocks in one go may give us
> better compression ratio. This is worth trying. I'm wondering what would the
> best way to do so without minimal changes to the xlog insertion code. Today,
> we add more rdata items for backup block header(s) and backup blocks
> themselves (if there is a "hole" then 2 per backup block) beyond what the
> caller has supplied. If we have to compress all the backup blocks together,
> then one approach is to copy the backup block headers and the blocks to a
> temp buffer, compress that and replace the rdata entries added previously
> with a single rdata.
multiple rdata and only some of them are backup blocks?
If a "hole" is not copied to that temp buffer, ISTM that we should
change backup block header so that it contains the info for a
"hole", e.g., location that a "hole" starts. No?
Pavan Deolasee
http://www.linkedin.com/in/pavandeolasee
>right idea and if we shouldn't instead compress all of them in one run to
>increase the compression ratio
Benchmark:
Scale : 16
Command :java JR /home/postgres/jdbcrunner-1.2/scripts/tpcc.js -sleepTime 550,250,250,200,200
Warmup time : 1 sec
Measurement time : 900 sec
Number of tx types : 5
Number of agents : 16
Connection pool size : 16
Statement cache size : 40
Auto commit : false
Checkpoint segments:1024
Checkpoint timeout:5 mins
Compression Multiple Blocks in one run Single Block in one run
Bytes saved 0 0
OFF WAL generated 1265150984(~1265MB) 1264771760(~1265MB)
% Compression NA NA
Bytes saved 215215079 (~215MB) 285675622 (~286MB)
LZ4 WAL generated 125118783(~1251MB) 1329031918(~1329MB)
% Compression 17.2 % 21.49 %
Bytes saved 203705959 (~204MB) 271009408 (~271MB)
Snappy WAL generated 1254505415(~1254MB) 1329628352(~1330MB)
% Compression 16.23 % 20.38%
Bytes saved 155910177(~156MB) 182804997(~182MB)
pglz WAL generated 1259773129(~1260MB) 1286670317(~1287MB)
% Compression 12.37% 14.21%
As per measurement results of this benchmark, compression of multiple blocks didn't improve compression ratio over compression of single block.
LZ4 outperforms Snappy and pglz in terms of compression ratio.
Thank you,
On 2014-07-04 19:27:10 +0530, Rahila Syed wrote:> + * This memory stays till the end of session. OOM is handled by making the
> + /* Allocates memory for compressed backup blocks according to the compression
> + * algorithm used.Once per session at the time of insertion of first XLOG
> + * record.
> + * code proceed without FPW compression*/> + static char *compressed_pages[XLR_MAX_BKP_BLOCKS];
> + static bool compressed_pages_allocated = false;> + if (compress_backup_block != BACKUP_BLOCK_COMPRESSION_OFF &&> + {
> + compressed_pages_allocated!= true)
> + size_t buffer_size = VARHDRSZ;
> + int j;> + if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_SNAPPY)> + buffer_size += snappy_max_compressed_length(BLCKSZ);
> + else if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_LZ4)
> + buffer_size += LZ4_compressBound(BLCKSZ);
> + else if (compress_backup_block == BACKUP_BLOCK_COMPRESSION_PGLZ)
> + buffer_size += PGLZ_MAX_OUTPUT(BLCKSZ);> + for (j = 0; j < XLR_MAX_BKP_BLOCKS; j++)> + if(compressed_pages[j] == NULL)
> + { compressed_pages[j] = (char *) malloc(buffer_size);
> + {
> + compress_backup_block=BACKUP_BLOCK_COMPRESSION_OFF;
> + break;
> + }
> + }
> + compressed_pages_allocated = true;
> + }
Why not do this in InitXLOGAccess() or similar?
> /*
> * Make additional rdata chain entries for the backup blocks, so that we
> * don't need to special-case them in the write loop. This modifies the
> @@ -1015,11 +1048,32 @@ begin:;
> rdt->next = &(dtbuf_rdt2[i]);
> rdt = rdt->next;
>
> + if (compress_backup_block != BACKUP_BLOCK_COMPRESSION_OFF)
> + {
> + /* Compress the backup block before including it in rdata chain */
> + rdt->data = CompressBackupBlock(page, BLCKSZ - bkpb->hole_length,
> + compressed_pages[i], &(rdt->len));
> + if (rdt->data != NULL)
> + {
> + /*
> + * write_len is the length of compressed block and its varlena
> + * header
> + */
> + write_len += rdt->len;
> + bkpb->hole_length = BLCKSZ - rdt->len;
> + /*Adding information about compression in the backup block header*/
> + bkpb->block_compression=compress_backup_block;
> + rdt->next = NULL;
> + continue;
> + }
> + }
> +
So, you're compressing backup blocks one by one. I wonder if that's the
right idea and if we shouldn't instead compress all of them in one run to
increase the compression ratio.
> +/*
> * Get a pointer to the right location in the WAL buffer containing the
> * given XLogRecPtr.
> *
> @@ -4061,6 +4174,50 @@ RestoreBackupBlockContents(XLogRecPtr lsn, BkpBlock bkpb, char *blk,
> {
> memcpy((char *) page, blk, BLCKSZ);> }
> + /* Decompress if backup block is compressed*/> + else if (VARATT_IS_COMPRESSED((struct varlena *) blk)> + && bkpb.block_compression!=BACKUP_BLOCK_COMPRESSION_OFF)
> + {
> + if (bkpb.block_compression == BACKUP_BLOCK_COMPRESSION_SNAPPY)> + {> + else if (bkpb.block_compression == BACKUP_BLOCK_COMPRESSION_LZ4)
> + int ret;
> + size_t compressed_length = VARSIZE((struct varlena *) blk) - VARHDRSZ;
> + char *compressed_data = (char *)VARDATA((struct varlena *) blk);
> + size_t s_uncompressed_length;
> +
> + ret = snappy_uncompressed_length(compressed_data,
> + compressed_length,
> + &s_uncompressed_length);
> + if (!ret)
> + elog(ERROR, "snappy: failed to determine compression length");
> + if (BLCKSZ != s_uncompressed_length)
> + elog(ERROR, "snappy: compression size mismatch %d != %zu",
> + BLCKSZ, s_uncompressed_length);
> +
> + ret = snappy_uncompress(compressed_data,
> + compressed_length,
> + page);
> + if (ret != 0)
> + elog(ERROR, "snappy: decompression failed: %d", ret);
> + }> + {> + ret = LZ4_decompress_fast(compressed_data, page,
> + int ret;
> + size_t compressed_length = VARSIZE((struct varlena *) blk) - VARHDRSZ;
> + char *compressed_data = (char *)VARDATA((struct varlena *) blk);
> + BLCKSZ);
> + if (ret != compressed_length)
> + elog(ERROR, "lz4: decompression size mismatch: %d vs %zu", ret,
> + compressed_length);
> + }
> + else if (bkpb.block_compression == BACKUP_BLOCK_COMPRESSION_PGLZ)
> + {
> + pglz_decompress((PGLZ_Header *) blk, (char *) page);
> + }
> + else
> + elog(ERROR, "Wrong value for compress_backup_block GUC");
> + }
> else
> {
> memcpy((char *) page, blk, bkpb.hole_offset);
So why aren't we compressing the hole here instead of compressing the
parts that the current logic deems to be filled with important information?
> /*
> * Options for enum values stored in other modules
> */
> @@ -3498,6 +3512,16 @@ static struct config_enum ConfigureNamesEnum[] =
> NULL, NULL, NULL
> },
>
> + {
> + {"compress_backup_block", PGC_SIGHUP, WAL_SETTINGS,
> + gettext_noop("Compress backup block in WAL using specified compression algorithm."),
> + NULL
> + },
> + &compress_backup_block,
> + BACKUP_BLOCK_COMPRESSION_OFF, backup_block_compression_options,
> + NULL, NULL, NULL
> + },
> +
This should be named 'compress_full_page_writes' or so, even if a
temporary guc. There's the 'full_page_writes' guc and I see little
reaason to deviate from its name.
Greetings,
Andres Freund
Attachment
On Sat, Aug 16, 2014 at 6:51 PM, Rahila Syed <rahilasyed90@gmail.com> wrote: >>So, you're compressing backup blocks one by one. I wonder if that's the >>right idea and if we shouldn't instead compress all of them in one run to >>increase the compression ratio > > Please find attached patch for compression of all blocks of a record > together . > > Following are the measurement results: > > > Benchmark: > > Scale : 16 > Command :java JR /home/postgres/jdbcrunner-1.2/scripts/tpcc.js -sleepTime > 550,250,250,200,200 > > Warmup time : 1 sec > Measurement time : 900 sec > Number of tx types : 5 > Number of agents : 16 > Connection pool size : 16 > Statement cache size : 40 > Auto commit : false > > > Checkpoint segments:1024 > Checkpoint timeout:5 mins > > > > > Compression Multiple > Blocks in one run Single Block in one run > > Bytes saved > 0 0 > > > > OFF WAL generated > 1265150984(~1265MB) 1264771760(~1265MB) > > > > % Compression > NA NA > > > > > Bytes saved > 215215079 (~215MB) 285675622 (~286MB) > > > > LZ4 WAL generated > 125118783(~1251MB) 1329031918(~1329MB) > > > > % Compression 17.2 > % 21.49 % > > > > > Bytes saved > 203705959 (~204MB) 271009408 (~271MB) > > > > Snappy WAL generated > 1254505415(~1254MB) 1329628352(~1330MB) > > > > % Compression 16.23 > % 20.38% > > > > > Bytes saved > 155910177(~156MB) 182804997(~182MB) > > > > pglz WAL generated > 1259773129(~1260MB) 1286670317(~1287MB) > > > > % Compression 12.37% > 14.21% > > > > > > As per measurement results of this benchmark, compression of multiple blocks > didn't improve compression ratio over compression of single block. According to the measurement result, the amount of WAL generated in "Multiple Blocks in one run" than that in "Single Block in one run". So ISTM that compression of multiple blocks at one run can improve the compression ratio. Am I missing something? Regards, -- Fujii Masao
On Mon, Aug 18, 2014 at 7:19 AM, Rahila Syed <rahilasyed90@gmail.com> wrote: >>According to the measurement result, the amount of WAL generated in >>"Multiple Blocks in one run" than that in "Single Block in one run". >>So ISTM that compression of multiple blocks at one run can improve >>the compression ratio. Am I missing something? > > Sorry for using unclear terminology. WAL generated here means WAL that gets > generated in each run without compression. > So, the value WAL generated in the above measurement is uncompressed WAL > generated to be specific. > uncompressed WAL = compressed WAL + Bytes saved. > > Here, the measurements are done for a constant amount of time rather than > fixed number of transactions. Hence amount of WAL generated does not > correspond to compression ratios of each algo. Hence have calculated bytes > saved in order to get accurate idea of the amount of compression in each > scenario and for various algorithms. > > Compression ratio i.e Uncompressed WAL/compressed WAL in each of the above > scenarios are as follows: > > Compression algo Multiple Blocks in one run Single Block in one run > > LZ4 1.21 1.27 > > Snappy 1.19 1.25 > > pglz 1.14 1.16 > > This shows compression ratios of both the scenarios Multiple blocks and > single block are nearly same for this benchmark. I don't agree with that conclusion. The difference between 1.21 and 1.27, or between 1.19 and 1.25, is quite significant. Even the difference beyond 1.14 and 1.16 is not trivial. We should try to get the larger benefit, if it is possible to do so without an unreasonable effort. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2014-08-18 13:06:15 -0400, Robert Haas wrote: > On Mon, Aug 18, 2014 at 7:19 AM, Rahila Syed <rahilasyed90@gmail.com> wrote: > >>According to the measurement result, the amount of WAL generated in > >>"Multiple Blocks in one run" than that in "Single Block in one run". > >>So ISTM that compression of multiple blocks at one run can improve > >>the compression ratio. Am I missing something? > > > > Sorry for using unclear terminology. WAL generated here means WAL that gets > > generated in each run without compression. > > So, the value WAL generated in the above measurement is uncompressed WAL > > generated to be specific. > > uncompressed WAL = compressed WAL + Bytes saved. > > > > Here, the measurements are done for a constant amount of time rather than > > fixed number of transactions. Hence amount of WAL generated does not > > correspond to compression ratios of each algo. Hence have calculated bytes > > saved in order to get accurate idea of the amount of compression in each > > scenario and for various algorithms. > > > > Compression ratio i.e Uncompressed WAL/compressed WAL in each of the above > > scenarios are as follows: > > > > Compression algo Multiple Blocks in one run Single Block in one run > > > > LZ4 1.21 1.27 > > > > Snappy 1.19 1.25 > > > > pglz 1.14 1.16 > > > > This shows compression ratios of both the scenarios Multiple blocks and > > single block are nearly same for this benchmark. > > I don't agree with that conclusion. The difference between 1.21 and > 1.27, or between 1.19 and 1.25, is quite significant. Even the > difference beyond 1.14 and 1.16 is not trivial. We should try to get > the larger benefit, if it is possible to do so without an unreasonable > effort. Agreed. One more question: Do I see it right that multiple blocks compressed together compress *worse* than compressing individual blocks? If so, I have a rather hard time believing that the patch is sane. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Jul 3, 2014 at 3:58 PM, Rahila Syed <rahilasyed90@gmail.com> wrote: > Updated version of patches are attached. > Changes are as follows > 1. Improved readability of the code as per the review comments. > 2. Addition of block_compression field in BkpBlock structure to store > information about compression of block. This provides for switching > compression on/off and changing compression algorithm as required. > 3.Handling of OOM in critical section by checking for return value of malloc > and proceeding without compression of FPW if return value is NULL. So, it seems like you're basically using malloc to work around the fact that a palloc failure is an error, and we can't throw an error in a critical section. I don't think that's good; we want all of our allocations, as far as possible, to be tracked via palloc. It might be a good idea to add a new variant of palloc or MemoryContextAlloc that returns NULL on failure instead of throwing an error; I've wanted that once or twice. But in this particular case, I'm not quite seeing why it should be necessary - the number of backup blocks per record is limited to some pretty small number, so it ought to be possible to preallocate enough memory to compress them all, perhaps just by declaring a global variable like char wal_compression_space[8192]; or whatever. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Aug 19, 2014 at 2:08 AM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2014-08-18 13:06:15 -0400, Robert Haas wrote: >> On Mon, Aug 18, 2014 at 7:19 AM, Rahila Syed <rahilasyed90@gmail.com> wrote: >> >>According to the measurement result, the amount of WAL generated in >> >>"Multiple Blocks in one run" than that in "Single Block in one run". >> >>So ISTM that compression of multiple blocks at one run can improve >> >>the compression ratio. Am I missing something? >> > >> > Sorry for using unclear terminology. WAL generated here means WAL that gets >> > generated in each run without compression. >> > So, the value WAL generated in the above measurement is uncompressed WAL >> > generated to be specific. >> > uncompressed WAL = compressed WAL + Bytes saved. >> > >> > Here, the measurements are done for a constant amount of time rather than >> > fixed number of transactions. Hence amount of WAL generated does not >> > correspond to compression ratios of each algo. Hence have calculated bytes >> > saved in order to get accurate idea of the amount of compression in each >> > scenario and for various algorithms. >> > >> > Compression ratio i.e Uncompressed WAL/compressed WAL in each of the above >> > scenarios are as follows: >> > >> > Compression algo Multiple Blocks in one run Single Block in one run >> > >> > LZ4 1.21 1.27 >> > >> > Snappy 1.19 1.25 >> > >> > pglz 1.14 1.16 >> > >> > This shows compression ratios of both the scenarios Multiple blocks and >> > single block are nearly same for this benchmark. >> >> I don't agree with that conclusion. The difference between 1.21 and >> 1.27, or between 1.19 and 1.25, is quite significant. Even the >> difference beyond 1.14 and 1.16 is not trivial. We should try to get >> the larger benefit, if it is possible to do so without an unreasonable >> effort. > > Agreed. > > One more question: Do I see it right that multiple blocks compressed > together compress *worse* than compressing individual blocks? If so, I > have a rather hard time believing that the patch is sane. Or the way of benchmark might have some problems. Rahila, I'd like to measure the compression ratio in both multiple blocks and single block cases. Could you tell me where the patch for "single block in one run" is? Regards, -- Fujii Masao
Or the way of benchmark might have some problems.On Tue, Aug 19, 2014 at 2:08 AM, Andres Freund <andres@2ndquadrant.com> wrote:
> On 2014-08-18 13:06:15 -0400, Robert Haas wrote:
>> On Mon, Aug 18, 2014 at 7:19 AM, Rahila Syed <rahilasyed90@gmail.com> wrote:
>> >>According to the measurement result, the amount of WAL generated in
>> >>"Multiple Blocks in one run" than that in "Single Block in one run".
>> >>So ISTM that compression of multiple blocks at one run can improve
>> >>the compression ratio. Am I missing something?
>> >
>> > Sorry for using unclear terminology. WAL generated here means WAL that gets
>> > generated in each run without compression.
>> > So, the value WAL generated in the above measurement is uncompressed WAL
>> > generated to be specific.
>> > uncompressed WAL = compressed WAL + Bytes saved.
>> >
>> > Here, the measurements are done for a constant amount of time rather than
>> > fixed number of transactions. Hence amount of WAL generated does not
>> > correspond to compression ratios of each algo. Hence have calculated bytes
>> > saved in order to get accurate idea of the amount of compression in each
>> > scenario and for various algorithms.
>> >
>> > Compression ratio i.e Uncompressed WAL/compressed WAL in each of the above
>> > scenarios are as follows:
>> >
>> > Compression algo Multiple Blocks in one run Single Block in one run
>> >
>> > LZ4 1.21 1.27
>> >
>> > Snappy 1.19 1.25
>> >
>> > pglz 1.14 1.16
>> >
>> > This shows compression ratios of both the scenarios Multiple blocks and
>> > single block are nearly same for this benchmark.
>>
>> I don't agree with that conclusion. The difference between 1.21 and
>> 1.27, or between 1.19 and 1.25, is quite significant. Even the
>> difference beyond 1.14 and 1.16 is not trivial. We should try to get
>> the larger benefit, if it is possible to do so without an unreasonable
>> effort.
>
> Agreed.
>
> One more question: Do I see it right that multiple blocks compressed
> together compress *worse* than compressing individual blocks? If so, I
> have a rather hard time believing that the patch is sane.
Rahila,
I'd like to measure the compression ratio in both multiple blocks and
single block cases.
Could you tell me where the patch for "single block in one run" is?
Regards,
--
Fujii Masao
Attachment
>fact that a palloc failure is an error, and we can't throw an error in
>a critical section. I don't think that's good; we want all of our
>allocations, as far as possible, to be tracked via palloc. It might
>be a good idea to add a new variant of palloc or MemoryContextAlloc
>that returns NULL on failure instead of throwing an error; I've wanted
>that once or twice. But in this particular case, I'm not quite seeing
>why it should be necessary
>preallocate enough memory to compress them all, perhaps just by
>declaring a global variable like char wal_compression_space[8192]; or
>whatever.
On Thu, Jul 3, 2014 at 3:58 PM, Rahila Syed <rahilasyed90@gmail.com> wrote:So, it seems like you're basically using malloc to work around the
> Updated version of patches are attached.
> Changes are as follows
> 1. Improved readability of the code as per the review comments.
> 2. Addition of block_compression field in BkpBlock structure to store
> information about compression of block. This provides for switching
> compression on/off and changing compression algorithm as required.
> 3.Handling of OOM in critical section by checking for return value of malloc
> and proceeding without compression of FPW if return value is NULL.
fact that a palloc failure is an error, and we can't throw an error in
a critical section. I don't think that's good; we want all of our
allocations, as far as possible, to be tracked via palloc. It might
be a good idea to add a new variant of palloc or MemoryContextAlloc
that returns NULL on failure instead of throwing an error; I've wanted
that once or twice. But in this particular case, I'm not quite seeing
why it should be necessary - the number of backup blocks per record is
limited to some pretty small number, so it ought to be possible to
preallocate enough memory to compress them all, perhaps just by
declaring a global variable like char wal_compression_space[8192]; or
whatever.
On Tue, Aug 19, 2014 at 6:37 PM, Rahila Syed <rahilasyed90@gmail.com> wrote:
> Hello,
> Thank you for comments.
>
>>Could you tell me where the patch for "single block in one run" is?
> Please find attached patch for single block compression in one run.
Thanks! I ran the benchmark using pgbench and compared the results.
I'd like to share the results.
[RESULT]
Amount of WAL generated during the benchmark. Unit is MB.
Multiple Single off 202.0 201.5 on 6051.0
6053.0 pglz 3543.0 3567.0 lz4 3344.0 3485.0 snappy
3354.0 3449.5
Latency average during the benchmark. Unit is ms.
Multiple Single off 19.1 19.0 on 55.3
57.3 pglz 45.0 45.9 lz4 44.2 44.7 snappy 43.4
43.3
These results show that FPW compression is really helpful for decreasing
the WAL volume and improving the performance.
The compression ratio by lz4 or snappy is better than that by pglz. But
it's difficult to conclude which lz4 or snappy is best, according to these
results.
ISTM that compression-of-multiple-pages-at-a-time approach can compress
WAL more than compression-of-single-... does.
[HOW TO BENCHMARK]
Create pgbench database with scall factor 1000.
Change the data type of the column "filler" on each pgbench table
from CHAR(n) to TEXT, and fill the data with the result of pgcrypto's
gen_random_uuid() in order to avoid empty column, e.g.,
alter table pgbench_accounts alter column filler type text using
gen_random_uuid()::text
After creating the test database, run the pgbench as follows. The
number of transactions executed during benchmark is almost same
between each benchmark because -R option is used.
pgbench -c 64 -j 64 -r -R 400 -T 900 -M prepared
checkpoint_timeout is 5min, so it's expected that checkpoint was
executed at least two times during the benchmark.
Regards,
--
Fujii Masao
On Tue, Aug 26, 2014 at 8:14 AM, Fujii Masao <masao.fujii@gmail.com> wrote: > On Tue, Aug 19, 2014 at 6:37 PM, Rahila Syed <rahilasyed90@gmail.com> wrote: >> Hello, >> Thank you for comments. >> >>>Could you tell me where the patch for "single block in one run" is? >> Please find attached patch for single block compression in one run. > > Thanks! I ran the benchmark using pgbench and compared the results. > I'd like to share the results. > > [RESULT] > Amount of WAL generated during the benchmark. Unit is MB. > > Multiple Single > off 202.0 201.5 > on 6051.0 6053.0 > pglz 3543.0 3567.0 > lz4 3344.0 3485.0 > snappy 3354.0 3449.5 > > Latency average during the benchmark. Unit is ms. > > Multiple Single > off 19.1 19.0 > on 55.3 57.3 > pglz 45.0 45.9 > lz4 44.2 44.7 > snappy 43.4 43.3 > > These results show that FPW compression is really helpful for decreasing > the WAL volume and improving the performance. Yeah, those look like good numbers. What happens if you run it at full speed, without -R? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
<p dir="ltr"><br /> Em 26/08/2014 09:16, "Fujii Masao" <<a href="mailto:masao.fujii@gmail.com">masao.fujii@gmail.com</a>>escreveu:<br /> ><br /> > On Tue, Aug 19, 2014 at6:37 PM, Rahila Syed <<a href="mailto:rahilasyed90@gmail.com">rahilasyed90@gmail.com</a>> wrote:<br /> > >Hello,<br /> > > Thank you for comments.<br /> > ><br /> > >>Could you tell me where the patch for"single block in one run" is?<br /> > > Please find attached patch for single block compression in one run.<br />><br /> > Thanks! I ran the benchmark using pgbench and compared the results.<br /> > I'd like to share the results.<br/> ><br /> > [RESULT]<br /> > Amount of WAL generated during the benchmark. Unit is MB.<br /> ><br/> > Multiple Single<br /> > off 202.0 201.5<br/> > on 6051.0 6053.0<br /> > pglz 3543.0 3567.0<br/> > lz4 3344.0 3485.0<br /> > snappy 3354.0 3449.5<br/> ><br /> > Latency average during the benchmark. Unit is ms.<br /> ><br /> > Multiple Single<br /> > off 19.1 19.0<br /> > on 55.3 57.3<br /> > pglz 45.0 45.9<br /> > lz4 44.2 44.7<br /> > snappy 43.4 43.3<br /> ><br /> > These results show that FPW compressionis really helpful for decreasing<br /> > the WAL volume and improving the performance.<br /> ><br /> >The compression ratio by lz4 or snappy is better than that by pglz. But<br /> > it's difficult to conclude which lz4or snappy is best, according to these<br /> > results.<br /> ><br /> > ISTM that compression-of-multiple-pages-at-a-timeapproach can compress<br /> > WAL more than compression-of-single-... does.<br/> ><br /> > [HOW TO BENCHMARK]<br /> > Create pgbench database with scall factor 1000.<br /> ><br />> Change the data type of the column "filler" on each pgbench table<br /> > from CHAR(n) to TEXT, and fill the datawith the result of pgcrypto's<br /> > gen_random_uuid() in order to avoid empty column, e.g.,<br /> ><br /> > alter table pgbench_accounts alter column filler type text using<br /> > gen_random_uuid()::text<br /> ><br />> After creating the test database, run the pgbench as follows. The<br /> > number of transactions executed duringbenchmark is almost same<br /> > between each benchmark because -R option is used.<br /> ><br /> > pgbench-c 64 -j 64 -r -R 400 -T 900 -M prepared<br /> ><br /> > checkpoint_timeout is 5min, so it's expected that checkpointwas<br /> > executed at least two times during the benchmark.<br /> ><br /> > Regards,<br /> ><br />> --<br /> > Fujii Masao<br /> ><br /> ><br /> > --<br /> > Sent via pgsql-hackers mailing list (<a href="mailto:pgsql-hackers@postgresql.org">pgsql-hackers@postgresql.org</a>)<br/> > To make changes to your subscription:<br/> > <a href="http://www.postgresql.org/mailpref/pgsql-hackers">http://www.postgresql.org/mailpref/pgsql-hackers</a><p dir="ltr">It'dbe interesting to check avg cpu usage as well.
On Wed, Aug 27, 2014 at 11:52 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> On Tue, Aug 26, 2014 at 8:14 AM, Fujii Masao <masao.fujii@gmail.com> wrote:
>> On Tue, Aug 19, 2014 at 6:37 PM, Rahila Syed <rahilasyed90@gmail.com> wrote:
>>> Hello,
>>> Thank you for comments.
>>>
>>>>Could you tell me where the patch for "single block in one run" is?
>>> Please find attached patch for single block compression in one run.
>>
>> Thanks! I ran the benchmark using pgbench and compared the results.
>> I'd like to share the results.
>>
>> [RESULT]
>> Amount of WAL generated during the benchmark. Unit is MB.
>>
>> Multiple Single
>> off 202.0 201.5
>> on 6051.0 6053.0
>> pglz 3543.0 3567.0
>> lz4 3344.0 3485.0
>> snappy 3354.0 3449.5
>>
>> Latency average during the benchmark. Unit is ms.
>>
>> Multiple Single
>> off 19.1 19.0
>> on 55.3 57.3
>> pglz 45.0 45.9
>> lz4 44.2 44.7
>> snappy 43.4 43.3
>>
>> These results show that FPW compression is really helpful for decreasing
>> the WAL volume and improving the performance.
>
> Yeah, those look like good numbers. What happens if you run it at
> full speed, without -R?
OK, I ran the same benchmark except -R option. Here are the results:
[RESULT]
Throughput in the benchmark.
Multiple Single off 2162.6
2164.5 on 891.8 895.6 pglz 1037.2
1042.3 lz4 1084.7 1091.8 snappy 1058.4
1073.3
Latency average during the benchmark. Unit is ms.
Multiple Single off 29.6 29.6
on 71.7 71.5 pglz 61.7 61.4
lz4 59.0 58.6 snappy 60.5 59.6
Amount of WAL generated during the benchmark. Unit is MB.
Multiple Single off 948.0
948.0 on 7675.5 7702.0 pglz 5492.0
5528.5 lz4 5494.5 5596.0 snappy 5667.0
5804.0
pglz vs. lz4 vs. snappy In this benchmark, lz4 seems to have been the best compression
algorithm. It caused best performance and highest WAL compression ratio.
Multiple vs. Single WAL volume with "Multiple" was smaller than that with "Single". But the throughput was
betterin "Single". So the "Multiple" is more useful for WAL compression, but it may cause higher performance
overhead at least in current implementation.
Regards,
--
Fujii Masao
On Thu, Aug 28, 2014 at 12:46 AM, Arthur Silva <arthurprs@gmail.com> wrote: > > Em 26/08/2014 09:16, "Fujii Masao" <masao.fujii@gmail.com> escreveu: > > >> >> On Tue, Aug 19, 2014 at 6:37 PM, Rahila Syed <rahilasyed90@gmail.com> >> wrote: >> > Hello, >> > Thank you for comments. >> > >> >>Could you tell me where the patch for "single block in one run" is? >> > Please find attached patch for single block compression in one run. >> >> Thanks! I ran the benchmark using pgbench and compared the results. >> I'd like to share the results. >> >> [RESULT] >> Amount of WAL generated during the benchmark. Unit is MB. >> >> Multiple Single >> off 202.0 201.5 >> on 6051.0 6053.0 >> pglz 3543.0 3567.0 >> lz4 3344.0 3485.0 >> snappy 3354.0 3449.5 >> >> Latency average during the benchmark. Unit is ms. >> >> Multiple Single >> off 19.1 19.0 >> on 55.3 57.3 >> pglz 45.0 45.9 >> lz4 44.2 44.7 >> snappy 43.4 43.3 >> >> These results show that FPW compression is really helpful for decreasing >> the WAL volume and improving the performance. >> >> The compression ratio by lz4 or snappy is better than that by pglz. But >> it's difficult to conclude which lz4 or snappy is best, according to these >> results. >> >> ISTM that compression-of-multiple-pages-at-a-time approach can compress >> WAL more than compression-of-single-... does. >> >> [HOW TO BENCHMARK] >> Create pgbench database with scall factor 1000. >> >> Change the data type of the column "filler" on each pgbench table >> from CHAR(n) to TEXT, and fill the data with the result of pgcrypto's >> gen_random_uuid() in order to avoid empty column, e.g., >> >> alter table pgbench_accounts alter column filler type text using >> gen_random_uuid()::text >> >> After creating the test database, run the pgbench as follows. The >> number of transactions executed during benchmark is almost same >> between each benchmark because -R option is used. >> >> pgbench -c 64 -j 64 -r -R 400 -T 900 -M prepared >> >> checkpoint_timeout is 5min, so it's expected that checkpoint was >> executed at least two times during the benchmark. >> >> Regards, >> >> -- >> Fujii Masao >> >> >> -- >> Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) >> To make changes to your subscription: >> http://www.postgresql.org/mailpref/pgsql-hackers > > It'd be interesting to check avg cpu usage as well. Yep, but I forgot to collect those info... Regards, -- Fujii Masao
Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos
RAM: 32GB
Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos
1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm
Benchmark:
Scale : 16
Command :java JR /home/postgres/jdbcrunner-1.2/scripts/tpcc.js -sleepTime 550,250,250,200,200
Warmup time : 1 sec
Measurement time : 900 sec
Number of tx types : 5
Number of agents : 16
Connection pool size : 16
Statement cache size : 40
Auto commit : false
Checkpoint segments:1024
Checkpoint timeout:5 mins
Compression Off = 3.34133
Snappy = 3.41044
LZ4 = 3.59556
Pglz = 3.66422
Em 26/08/2014 09:16, "Fujii Masao" <masao.fujii@gmail.com> escreveu:
>
> On Tue, Aug 19, 2014 at 6:37 PM, Rahila Syed <rahilasyed90@gmail.com> wrote:
> > Hello,
> > Thank you for comments.
> >
> >>Could you tell me where the patch for "single block in one run" is?
> > Please find attached patch for single block compression in one run.
>
> Thanks! I ran the benchmark using pgbench and compared the results.
> I'd like to share the results.
>
> [RESULT]
> Amount of WAL generated during the benchmark. Unit is MB.
>
> Multiple Single
> off 202.0 201.5
> on 6051.0 6053.0
> pglz 3543.0 3567.0
> lz4 3344.0 3485.0
> snappy 3354.0 3449.5
>
> Latency average during the benchmark. Unit is ms.
>
> Multiple Single
> off 19.1 19.0
> on 55.3 57.3
> pglz 45.0 45.9
> lz4 44.2 44.7
> snappy 43.4 43.3
>
> These results show that FPW compression is really helpful for decreasing
> the WAL volume and improving the performance.
>
> The compression ratio by lz4 or snappy is better than that by pglz. But
> it's difficult to conclude which lz4 or snappy is best, according to these
> results.
>
> ISTM that compression-of-multiple-pages-at-a-time approach can compress
> WAL more than compression-of-single-... does.
>
> [HOW TO BENCHMARK]
> Create pgbench database with scall factor 1000.
>
> Change the data type of the column "filler" on each pgbench table
> from CHAR(n) to TEXT, and fill the data with the result of pgcrypto's
> gen_random_uuid() in order to avoid empty column, e.g.,
>
> alter table pgbench_accounts alter column filler type text using
> gen_random_uuid()::text
>
> After creating the test database, run the pgbench as follows. The
> number of transactions executed during benchmark is almost same
> between each benchmark because -R option is used.
>
> pgbench -c 64 -j 64 -r -R 400 -T 900 -M prepared
>
> checkpoint_timeout is 5min, so it's expected that checkpoint was
> executed at least two times during the benchmark.
>
> Regards,
>
> --
> Fujii Masao
>
>> --
> Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackersIt'd be interesting to check avg cpu usage as well.
Attachment
{kind=link}
Hello,>It'd be interesting to check avg cpu usage as wellI have collected average CPU utilization numbers by collecting sar output at interval of 10 seconds for following benchmark:Server specifications:
Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos
RAM: 32GB
Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos
1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpmBenchmark:
Scale : 16
Command :java JR /home/postgres/jdbcrunner-1.2/scripts/tpcc.js -sleepTime 550,250,250,200,200Warmup time : 1 sec
Measurement time : 900 sec
Number of tx types : 5
Number of agents : 16
Connection pool size : 16
Statement cache size : 40
Auto commit : false
Checkpoint segments:1024
Checkpoint timeout:5 minsAverage % of CPU utilization at user level for multiple blocks compression:Compression Off = 3.34133
Snappy = 3.41044
LZ4 = 3.59556
Pglz = 3.66422
The numbers show the average CPU utilization is in the following order pglz > LZ4 > Snappy > No compressionAttached is the graph which gives plot of % CPU utilization versus time elapsed for each of the compression algorithms.Also, the overall CPU utilization during tests is very low i.e below 10% . CPU remained idle for large(~90) percentage of time. I will repeat the above tests with high load on CPU and using the benchmark given by Fujii-san and post the results.Thank you,On Wed, Aug 27, 2014 at 9:16 PM, Arthur Silva <arthurprs@gmail.com> wrote:
Em 26/08/2014 09:16, "Fujii Masao" <masao.fujii@gmail.com> escreveu:
>
> On Tue, Aug 19, 2014 at 6:37 PM, Rahila Syed <rahilasyed90@gmail.com> wrote:
> > Hello,
> > Thank you for comments.
> >
> >>Could you tell me where the patch for "single block in one run" is?
> > Please find attached patch for single block compression in one run.
>
> Thanks! I ran the benchmark using pgbench and compared the results.
> I'd like to share the results.
>
> [RESULT]
> Amount of WAL generated during the benchmark. Unit is MB.
>
> Multiple Single
> off 202.0 201.5
> on 6051.0 6053.0
> pglz 3543.0 3567.0
> lz4 3344.0 3485.0
> snappy 3354.0 3449.5
>
> Latency average during the benchmark. Unit is ms.
>
> Multiple Single
> off 19.1 19.0
> on 55.3 57.3
> pglz 45.0 45.9
> lz4 44.2 44.7
> snappy 43.4 43.3
>
> These results show that FPW compression is really helpful for decreasing
> the WAL volume and improving the performance.
>
> The compression ratio by lz4 or snappy is better than that by pglz. But
> it's difficult to conclude which lz4 or snappy is best, according to these
> results.
>
> ISTM that compression-of-multiple-pages-at-a-time approach can compress
> WAL more than compression-of-single-... does.
>
> [HOW TO BENCHMARK]
> Create pgbench database with scall factor 1000.
>
> Change the data type of the column "filler" on each pgbench table
> from CHAR(n) to TEXT, and fill the data with the result of pgcrypto's
> gen_random_uuid() in order to avoid empty column, e.g.,
>
> alter table pgbench_accounts alter column filler type text using
> gen_random_uuid()::text
>
> After creating the test database, run the pgbench as follows. The
> number of transactions executed during benchmark is almost same
> between each benchmark because -R option is used.
>
> pgbench -c 64 -j 64 -r -R 400 -T 900 -M prepared
>
> checkpoint_timeout is 5min, so it's expected that checkpoint was
> executed at least two times during the benchmark.
>
> Regards,
>
> --
> Fujii Masao
>
>> --
> Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackersIt'd be interesting to check avg cpu usage as well.
Is there any reason to default to LZ4-HC? Shouldn't we try the default as well? LZ4-default is known for its near realtime speeds in exchange for a few % of compression, which sounds optimal for this use case.
Also, we might want to compile these libraries with -O3 instead of the default -O2. They're finely tuned to work with all possible compiler optimizations w/ hints and other tricks, this is specially true for LZ4, not sure for snappy.
In my virtual machine LZ4 w/ -O3 compression runs at twice the speed (950MB/s) of -O2 (450MB/s) @ (61.79%), LZ4-HC seems unaffected though (58MB/s) @ (60.27%).
On Tue, Sep 02, 2014 at 10:30:11AM -0300, Arthur Silva wrote: > On Tue, Sep 2, 2014 at 9:11 AM, Rahila Syed <rahilasyed90@gmail.com> wrote: > > > Hello, > > > > >It'd be interesting to check avg cpu usage as well > > > > I have collected average CPU utilization numbers by collecting sar output > > at interval of 10 seconds for following benchmark: > > > > Server specifications: > > Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos > > RAM: 32GB > > Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos > > 1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm > > > > Benchmark: > > > > Scale : 16 > > Command :java JR /home/postgres/jdbcrunner-1.2/scripts/tpcc.js > > -sleepTime 550,250,250,200,200 > > > > Warmup time : 1 sec > > Measurement time : 900 sec > > Number of tx types : 5 > > Number of agents : 16 > > Connection pool size : 16 > > Statement cache size : 40 > > Auto commit : false > > > > > > Checkpoint segments:1024 > > Checkpoint timeout:5 mins > > > > > > Average % of CPU utilization at user level for multiple blocks compression: > > > > Compression Off = 3.34133 > > > > Snappy = 3.41044 > > > > LZ4 = 3.59556 > > > > Pglz = 3.66422 > > > > > > The numbers show the average CPU utilization is in the following order > > pglz > LZ4 > Snappy > No compression > > Attached is the graph which gives plot of % CPU utilization versus time > > elapsed for each of the compression algorithms. > > Also, the overall CPU utilization during tests is very low i.e below 10% . > > CPU remained idle for large(~90) percentage of time. I will repeat the > > above tests with high load on CPU and using the benchmark given by > > Fujii-san and post the results. > > > > > > Thank you, > > > > > > > > On Wed, Aug 27, 2014 at 9:16 PM, Arthur Silva <arthurprs@gmail.com> wrote: > > > >> > >> Em 26/08/2014 09:16, "Fujii Masao" <masao.fujii@gmail.com> escreveu: > >> > >> > > >> > On Tue, Aug 19, 2014 at 6:37 PM, Rahila Syed <rahilasyed90@gmail.com> > >> wrote: > >> > > Hello, > >> > > Thank you for comments. > >> > > > >> > >>Could you tell me where the patch for "single block in one run" is? > >> > > Please find attached patch for single block compression in one run. > >> > > >> > Thanks! I ran the benchmark using pgbench and compared the results. > >> > I'd like to share the results. > >> > > >> > [RESULT] > >> > Amount of WAL generated during the benchmark. Unit is MB. > >> > > >> > Multiple Single > >> > off 202.0 201.5 > >> > on 6051.0 6053.0 > >> > pglz 3543.0 3567.0 > >> > lz4 3344.0 3485.0 > >> > snappy 3354.0 3449.5 > >> > > >> > Latency average during the benchmark. Unit is ms. > >> > > >> > Multiple Single > >> > off 19.1 19.0 > >> > on 55.3 57.3 > >> > pglz 45.0 45.9 > >> > lz4 44.2 44.7 > >> > snappy 43.4 43.3 > >> > > >> > These results show that FPW compression is really helpful for decreasing > >> > the WAL volume and improving the performance. > >> > > >> > The compression ratio by lz4 or snappy is better than that by pglz. But > >> > it's difficult to conclude which lz4 or snappy is best, according to > >> these > >> > results. > >> > > >> > ISTM that compression-of-multiple-pages-at-a-time approach can compress > >> > WAL more than compression-of-single-... does. > >> > > >> > [HOW TO BENCHMARK] > >> > Create pgbench database with scall factor 1000. > >> > > >> > Change the data type of the column "filler" on each pgbench table > >> > from CHAR(n) to TEXT, and fill the data with the result of pgcrypto's > >> > gen_random_uuid() in order to avoid empty column, e.g., > >> > > >> > alter table pgbench_accounts alter column filler type text using > >> > gen_random_uuid()::text > >> > > >> > After creating the test database, run the pgbench as follows. The > >> > number of transactions executed during benchmark is almost same > >> > between each benchmark because -R option is used. > >> > > >> > pgbench -c 64 -j 64 -r -R 400 -T 900 -M prepared > >> > > >> > checkpoint_timeout is 5min, so it's expected that checkpoint was > >> > executed at least two times during the benchmark. > >> > > >> > Regards, > >> > > >> > -- > >> > Fujii Masao > >> > > >> > > >> > -- > >> > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) > >> > To make changes to your subscription: > >> > http://www.postgresql.org/mailpref/pgsql-hackers > >> > >> It'd be interesting to check avg cpu usage as well. > >> > > > > > Is there any reason to default to LZ4-HC? Shouldn't we try the default as > well? LZ4-default is known for its near realtime speeds in exchange for a > few % of compression, which sounds optimal for this use case. > > Also, we might want to compile these libraries with -O3 instead of the > default -O2. They're finely tuned to work with all possible compiler > optimizations w/ hints and other tricks, this is specially true for LZ4, > not sure for snappy. > > In my virtual machine LZ4 w/ -O3 compression runs at twice the speed > (950MB/s) of -O2 (450MB/s) @ (61.79%), LZ4-HC seems unaffected though > (58MB/s) @ (60.27%). > > Yes, that's right, almost 1GB/s! And the compression ratio is only 1,5% > short compared to LZ4-HC. Hi, I agree completely. For day-to-day use we should use LZ4-default. For read-only tables, it might be nice to "archive" them with LZ4-HC for the higher compression would increase read speed and reduce storage space needs. I believe that LZ4-HC is only slower to compress and the decompression is unaffected. Regards, Ken
On 2014-09-02 08:37:42 -0500, ktm@rice.edu wrote: > I agree completely. For day-to-day use we should use LZ4-default. For read-only > tables, it might be nice to "archive" them with LZ4-HC for the higher compression > would increase read speed and reduce storage space needs. I believe that LZ4-HC > is only slower to compress and the decompression is unaffected. This is about the write ahead log, not relations Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
>I will repeat the above tests with high load on CPU and using the benchmark given by Fujii-san and post the results. Average % of CPU usage at user level for each of the compression algorithm are as follows. Compression Multiple Single Off 81.1338 81.1267 LZ4 81.0998 81.1695 Snappy: 80.9741 80.9703 Pglz : 81.2353 81.2753 <http://postgresql.1045698.n5.nabble.com/file/n5818552/CPU_utilization_user_single.png> <http://postgresql.1045698.n5.nabble.com/file/n5818552/CPU_utilization_user.png> The numbers show CPU utilization of Snappy is the least. The CPU utilization in increasing order is pglz > No compression > LZ4 > Snappy The variance of average CPU utilization numbers is very low. However , snappy seems to be best when it comes to lesser utilization of CPU. As per the measurement results posted till date LZ4 outperforms snappy and pglz in terms of compression ratio and performance. However , CPU utilization numbers show snappy utilizes least amount of CPU . Difference is not much though. As there has been no consensus yet about which compression algorithm to adopt, is it better to make this decision independent of the FPW compression patch as suggested earlier in this thread?. FPW compression can be done using built in compression pglz as it shows considerable performance over uncompressed WAL and good compression ratio Also, the patch to compress multiple blocks at once gives better compression as compared to single block. ISTM that performance overhead introduced by multiple blocks compression is slightly higher than single block compression which can be tested again after modifying the patch to use pglz . Hence, this patch can be built using multiple blocks compression. Thoughts? -- View this message in context: http://postgresql.1045698.n5.nabble.com/Compression-of-full-page-writes-tp5769039p5818552.html Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
{kind=link}
{kind=link}
Arthur Silva
>I will repeat the above tests with high load on CPU and using the benchmark
given by Fujii-san and post the results.
Average % of CPU usage at user level for each of the compression algorithm
are as follows.
Compression Multiple Single
Off 81.1338 81.1267
LZ4 81.0998 81.1695
Snappy: 80.9741 80.9703
Pglz : 81.2353 81.2753
<http://postgresql.1045698.n5.nabble.com/file/n5818552/CPU_utilization_user_single.png>
<http://postgresql.1045698.n5.nabble.com/file/n5818552/CPU_utilization_user.png>
The numbers show CPU utilization of Snappy is the least. The CPU utilization
in increasing order is
pglz > No compression > LZ4 > Snappy
The variance of average CPU utilization numbers is very low. However ,
snappy seems to be best when it comes to lesser utilization of CPU.
As per the measurement results posted till date
LZ4 outperforms snappy and pglz in terms of compression ratio and
performance. However , CPU utilization numbers show snappy utilizes least
amount of CPU . Difference is not much though.
As there has been no consensus yet about which compression algorithm to
adopt, is it better to make this decision independent of the FPW compression
patch as suggested earlier in this thread?. FPW compression can be done
using built in compression pglz as it shows considerable performance over
uncompressed WAL and good compression ratio
Also, the patch to compress multiple blocks at once gives better compression
as compared to single block. ISTM that performance overhead introduced by
multiple blocks compression is slightly higher than single block compression
which can be tested again after modifying the patch to use pglz . Hence,
this patch can be built using multiple blocks compression.
Thoughts?
--
View this message in context: http://postgresql.1045698.n5.nabble.com/Compression-of-full-page-writes-tp5769039p5818552.html
Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
On Thu, Sep 11, 2014 at 09:37:07AM -0300, Arthur Silva wrote: > I agree that there's no reason to fix an algorithm to it, unless maybe it's > pglz. There's some initial talk about implementing pluggable compression > algorithms for TOAST and I guess the same must be taken into consideration > for the WAL. > > -- > Arthur Silva > > > On Thu, Sep 11, 2014 at 2:46 AM, Rahila Syed <rahilasyed.90@gmail.com> > wrote: > > > >I will repeat the above tests with high load on CPU and using the > > benchmark > > given by Fujii-san and post the results. > > > > Average % of CPU usage at user level for each of the compression algorithm > > are as follows. > > > > Compression Multiple Single > > > > Off 81.1338 81.1267 > > LZ4 81.0998 81.1695 > > Snappy: 80.9741 80.9703 > > Pglz : 81.2353 81.2753 > > > > < > > http://postgresql.1045698.n5.nabble.com/file/n5818552/CPU_utilization_user_single.png > > > > > < > > http://postgresql.1045698.n5.nabble.com/file/n5818552/CPU_utilization_user.png > > > > > > > The numbers show CPU utilization of Snappy is the least. The CPU > > utilization > > in increasing order is > > pglz > No compression > LZ4 > Snappy > > > > The variance of average CPU utilization numbers is very low. However , > > snappy seems to be best when it comes to lesser utilization of CPU. > > > > As per the measurement results posted till date > > > > LZ4 outperforms snappy and pglz in terms of compression ratio and > > performance. However , CPU utilization numbers show snappy utilizes least > > amount of CPU . Difference is not much though. > > > > As there has been no consensus yet about which compression algorithm to > > adopt, is it better to make this decision independent of the FPW > > compression > > patch as suggested earlier in this thread?. FPW compression can be done > > using built in compression pglz as it shows considerable performance over > > uncompressed WAL and good compression ratio > > Also, the patch to compress multiple blocks at once gives better > > compression > > as compared to single block. ISTM that performance overhead introduced by > > multiple blocks compression is slightly higher than single block > > compression > > which can be tested again after modifying the patch to use pglz . Hence, > > this patch can be built using multiple blocks compression. > > > > Thoughts? > > Hi, The big (huge) win for lz4 (not the HC variant) is the enormous compression and decompression speed. It compresses quite a bit faster (33%) than snappy and decompresses twice as fast as snappy. Regards, Ken
{kind=link}
{kind=link}
On Thu, Sep 11, 2014 at 09:37:07AM -0300, Arthur Silva wrote:
> I agree that there's no reason to fix an algorithm to it, unless maybe it's
> pglz.
The big (huge) win for lz4 (not the HC variant) is the enormous compression
and decompression speed. It compresses quite a bit faster (33%) than snappy
and decompresses twice as fast as snappy.
On Thu, Sep 11, 2014 at 1:46 AM, Rahila Syed <rahilasyed.90@gmail.com> wrote: >>I will repeat the above tests with high load on CPU and using the benchmark > given by Fujii-san and post the results. > > Average % of CPU usage at user level for each of the compression algorithm > are as follows. > > Compression Multiple Single > > Off 81.1338 81.1267 > LZ4 81.0998 81.1695 > Snappy: 80.9741 80.9703 > Pglz : 81.2353 81.2753 > > <http://postgresql.1045698.n5.nabble.com/file/n5818552/CPU_utilization_user_single.png> > <http://postgresql.1045698.n5.nabble.com/file/n5818552/CPU_utilization_user.png> > > The numbers show CPU utilization of Snappy is the least. The CPU utilization > in increasing order is > pglz > No compression > LZ4 > Snappy > > The variance of average CPU utilization numbers is very low. However , > snappy seems to be best when it comes to lesser utilization of CPU. > > As per the measurement results posted till date > > LZ4 outperforms snappy and pglz in terms of compression ratio and > performance. However , CPU utilization numbers show snappy utilizes least > amount of CPU . Difference is not much though. > > As there has been no consensus yet about which compression algorithm to > adopt, is it better to make this decision independent of the FPW compression > patch as suggested earlier in this thread?. FPW compression can be done > using built in compression pglz as it shows considerable performance over > uncompressed WAL and good compression ratio > Also, the patch to compress multiple blocks at once gives better compression > as compared to single block. ISTM that performance overhead introduced by > multiple blocks compression is slightly higher than single block compression > which can be tested again after modifying the patch to use pglz . Hence, > this patch can be built using multiple blocks compression. I advise supporting pglz only for the initial patch, and adding support for the others later if it seems worthwhile. The approach seems to work well enough with pglz that it's worth doing even if we never add the other algorithms. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2014-09-11 12:55:21 -0400, Robert Haas wrote: > I advise supporting pglz only for the initial patch, and adding > support for the others later if it seems worthwhile. The approach > seems to work well enough with pglz that it's worth doing even if we > never add the other algorithms. That approach is fine with me. Note though that I am pretty strongly against adding support for more than one algorithm at the same time. So, if we gain lz4 support - which I think is definitely where we should go - we should drop pglz support for the WAL. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Sep 11, 2014 at 12:55:21PM -0400, Robert Haas wrote: > I advise supporting pglz only for the initial patch, and adding > support for the others later if it seems worthwhile. The approach > seems to work well enough with pglz that it's worth doing even if we > never add the other algorithms. +1 -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On Thu, Sep 11, 2014 at 12:58 PM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2014-09-11 12:55:21 -0400, Robert Haas wrote: >> I advise supporting pglz only for the initial patch, and adding >> support for the others later if it seems worthwhile. The approach >> seems to work well enough with pglz that it's worth doing even if we >> never add the other algorithms. > > That approach is fine with me. Note though that I am pretty strongly > against adding support for more than one algorithm at the same time. What if one algorithm compresses better and the other algorithm uses less CPU time? I don't see a compelling need for an option if we get a new algorithm that strictly dominates what we've already got in all parameters, and it may well be that, as respects pglz, that's achievable. But ISTM that it need not be true in general. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2014-09-11 13:04:43 -0400, Robert Haas wrote: > On Thu, Sep 11, 2014 at 12:58 PM, Andres Freund <andres@2ndquadrant.com> wrote: > > On 2014-09-11 12:55:21 -0400, Robert Haas wrote: > >> I advise supporting pglz only for the initial patch, and adding > >> support for the others later if it seems worthwhile. The approach > >> seems to work well enough with pglz that it's worth doing even if we > >> never add the other algorithms. > > > > That approach is fine with me. Note though that I am pretty strongly > > against adding support for more than one algorithm at the same time. > > What if one algorithm compresses better and the other algorithm uses > less CPU time? Then we make a choice for our users. A configuration option about an aspect of postgres that darned view people will understand with for the marginal differences between snappy and lz4 doesn't make sense. > I don't see a compelling need for an option if we get a new algorithm > that strictly dominates what we've already got in all parameters, and > it may well be that, as respects pglz, that's achievable. But ISTM > that it need not be true in general. If you look at the results lz4 is pretty much there. Sure, there's algorithms which have a much better compression - but the time overhead is so large it just doesn't make sense for full page compression. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Sep 11, 2014 at 1:17 PM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2014-09-11 13:04:43 -0400, Robert Haas wrote: >> On Thu, Sep 11, 2014 at 12:58 PM, Andres Freund <andres@2ndquadrant.com> wrote: >> > On 2014-09-11 12:55:21 -0400, Robert Haas wrote: >> >> I advise supporting pglz only for the initial patch, and adding >> >> support for the others later if it seems worthwhile. The approach >> >> seems to work well enough with pglz that it's worth doing even if we >> >> never add the other algorithms. >> > >> > That approach is fine with me. Note though that I am pretty strongly >> > against adding support for more than one algorithm at the same time. >> >> What if one algorithm compresses better and the other algorithm uses >> less CPU time? > > Then we make a choice for our users. A configuration option about an > aspect of postgres that darned view people will understand with for the > marginal differences between snappy and lz4 doesn't make sense. Maybe. Let's get the basic patch done first; then we can argue about that. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Sep 11, 2014 at 06:58:06PM +0200, Andres Freund wrote: > On 2014-09-11 12:55:21 -0400, Robert Haas wrote: > > I advise supporting pglz only for the initial patch, and adding > > support for the others later if it seems worthwhile. The approach > > seems to work well enough with pglz that it's worth doing even if we > > never add the other algorithms. > > That approach is fine with me. Note though that I am pretty strongly > against adding support for more than one algorithm at the same time. So, > if we gain lz4 support - which I think is definitely where we should go > - we should drop pglz support for the WAL. > > Greetings, > > Andres Freund > +1 Regards, Ken
On Thu, Sep 11, 2014 at 07:17:42PM +0200, Andres Freund wrote: > On 2014-09-11 13:04:43 -0400, Robert Haas wrote: > > On Thu, Sep 11, 2014 at 12:58 PM, Andres Freund <andres@2ndquadrant.com> wrote: > > > On 2014-09-11 12:55:21 -0400, Robert Haas wrote: > > >> I advise supporting pglz only for the initial patch, and adding > > >> support for the others later if it seems worthwhile. The approach > > >> seems to work well enough with pglz that it's worth doing even if we > > >> never add the other algorithms. > > > > > > That approach is fine with me. Note though that I am pretty strongly > > > against adding support for more than one algorithm at the same time. > > > > What if one algorithm compresses better and the other algorithm uses > > less CPU time? > > Then we make a choice for our users. A configuration option about an > aspect of postgres that darned view people will understand with for the > marginal differences between snappy and lz4 doesn't make sense. > > > I don't see a compelling need for an option if we get a new algorithm > > that strictly dominates what we've already got in all parameters, and > > it may well be that, as respects pglz, that's achievable. But ISTM > > that it need not be true in general. > > If you look at the results lz4 is pretty much there. Sure, there's > algorithms which have a much better compression - but the time overhead > is so large it just doesn't make sense for full page compression. > > Greetings, > > Andres Freund > In addition, you can leverage the the presence of a higher-compression version of lz4 (lz4hc) that can utilize the same decompression engine that could possibly be applied to static tables as a REINDEX option or even slowly growing tables that would benefit from the better compression as well as the increased decompression speed available. Regards, Ken
On 09/02/2014 09:52 AM, Fujii Masao wrote: > [RESULT] > Throughput in the benchmark. > > Multiple Single > off 2162.6 2164.5 > on 891.8 895.6 > pglz 1037.2 1042.3 > lz4 1084.7 1091.8 > snappy 1058.4 1073.3 Most of the CPU overhead of writing full pages is because of CRC calculation. Compression helps because then you have less data to CRC. It's worth noting that there are faster CRC implementations out there than what we use. The Slicing-by-4 algorithm was discussed years ago, but was not deemed worth it back then IIRC because we typically calculate CRC over very small chunks of data, and the benefit of Slicing-by-4 and many other algorithms only show up when you work on larger chunks. But a full-page image is probably large enough to benefit. What I'm trying to say is that this should be compared with the idea of just switching the CRC implementation. That would make the 'on' case faster, and and the benefit of compression smaller. I wouldn't be surprised if it made the 'on' case faster than compressed cases. I don't mean that we should abandon this patch - compression makes the WAL smaller which has all kinds of other benefits, even if it makes the raw TPS throughput of the system worse. But I'm just saying that these TPS comparisons should be taken with a grain of salt. We probably should consider switching to a faster CRC algorithm again, regardless of what we do with compression. - Heikki
At 2014-09-12 22:38:01 +0300, hlinnakangas@vmware.com wrote: > > We probably should consider switching to a faster CRC algorithm again, > regardless of what we do with compression. As it happens, I'm already working on resurrecting a patch that Andres posted in 2010 to switch to zlib's faster CRC implementation. -- Abhijit
On 09/12/2014 10:54 PM, Abhijit Menon-Sen wrote: > At 2014-09-12 22:38:01 +0300, hlinnakangas@vmware.com wrote: >> >> We probably should consider switching to a faster CRC algorithm again, >> regardless of what we do with compression. > > As it happens, I'm already working on resurrecting a patch that Andres > posted in 2010 to switch to zlib's faster CRC implementation. As it happens, I also wrote an implementation of Slice-by-4 the other day :-). Haven't gotten around to post it, but here it is. What algorithm does zlib use for CRC calculation? - Heikki
Attachment
On Fri, Sep 12, 2014 at 10:38 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > I don't mean that we should abandon this patch - compression makes the WAL > smaller which has all kinds of other benefits, even if it makes the raw TPS > throughput of the system worse. But I'm just saying that these TPS > comparisons should be taken with a grain of salt. We probably should > consider switching to a faster CRC algorithm again, regardless of what we do > with compression. CRC is a pretty awfully slow algorithm for checksums. We should consider switching it out for something more modern. CityHash, MurmurHash3 and xxhash look like pretty good candidates, being around an order of magnitude faster than CRC. I'm hoping to investigate substituting the WAL checksum algorithm 9.5. Given the room for improvement in this area I think it would make sense to just short-circuit the CRC calculations for testing this patch to see if the performance improvement is due to less data being checksummed. Regards, Ants Aasma -- Cybertec Schönig & Schönig GmbH Gröhrmühlgasse 26 A-2700 Wiener Neustadt Web: http://www.postgresql-support.de
On 2014-09-12 23:03:00 +0300, Heikki Linnakangas wrote: > On 09/12/2014 10:54 PM, Abhijit Menon-Sen wrote: > >At 2014-09-12 22:38:01 +0300, hlinnakangas@vmware.com wrote: > >> > >>We probably should consider switching to a faster CRC algorithm again, > >>regardless of what we do with compression. > > > >As it happens, I'm already working on resurrecting a patch that Andres > >posted in 2010 to switch to zlib's faster CRC implementation. > > As it happens, I also wrote an implementation of Slice-by-4 the other day > :-). Haven't gotten around to post it, but here it is. > > What algorithm does zlib use for CRC calculation? Also slice-by-4, with a manually unrolled loop doing 32bytes at once, using individual slice-by-4's. IIRC I tried and removing that slowed things down overall. What it also did was move crc to a function. I'm not sure why I did it that way, but it really might be beneficial - if you look at profiles today there's sometimes icache/decoding stalls... Hm. Let me look: http://archives.postgresql.org/message-id/201005202227.49990.andres%40anarazel.de Ick, there's quite some debugging leftovers ;) I think it might be a good idea to also switch the polynom at the same time. I really really think we should, when the hardware supports, use the polynom that's available in SSE4.2. It has similar properties, can implemented in software just the same... Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 2014-09-12 23:17:12 +0300, Ants Aasma wrote: > On Fri, Sep 12, 2014 at 10:38 PM, Heikki Linnakangas > <hlinnakangas@vmware.com> wrote: > > I don't mean that we should abandon this patch - compression makes the WAL > > smaller which has all kinds of other benefits, even if it makes the raw TPS > > throughput of the system worse. But I'm just saying that these TPS > > comparisons should be taken with a grain of salt. We probably should > > consider switching to a faster CRC algorithm again, regardless of what we do > > with compression. > > CRC is a pretty awfully slow algorithm for checksums. We should > consider switching it out for something more modern. CityHash, > MurmurHash3 and xxhash look like pretty good candidates, being around > an order of magnitude faster than CRC. I'm hoping to investigate > substituting the WAL checksum algorithm 9.5. I think that might not be a bad plan. But it'll involve *far* more effort and arguing to change to fundamentally different algorithms. So personally I'd just go with slice-by-4. that's relatively uncontroversial I think. Then maybe switch the polynom so we can use the CRC32 instruction. > Given the room for improvement in this area I think it would make > sense to just short-circuit the CRC calculations for testing this > patch to see if the performance improvement is due to less data being > checksummed. FWIW, I don't think it's 'bad' that less data provides speedups. I don't really see a need to see that get that out of the benchmarks. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 2014-09-12 22:38:01 +0300, Heikki Linnakangas wrote: > It's worth noting that there are faster CRC implementations out there than > what we use. The Slicing-by-4 algorithm was discussed years ago, but was not > deemed worth it back then IIRC because we typically calculate CRC over very > small chunks of data, and the benefit of Slicing-by-4 and many other > algorithms only show up when you work on larger chunks. But a full-page > image is probably large enough to benefit. I've recently pondered moving things around so the CRC sum can be computed over the whole data instead of the individual chain elements. I think, regardless of the checksum algorithm and implementation we end up with, that might end up as a noticeable benefit. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Sep 12, 2014 at 11:17:12PM +0300, Ants Aasma wrote: > On Fri, Sep 12, 2014 at 10:38 PM, Heikki Linnakangas > <hlinnakangas@vmware.com> wrote: > > I don't mean that we should abandon this patch - compression makes the WAL > > smaller which has all kinds of other benefits, even if it makes the raw TPS > > throughput of the system worse. But I'm just saying that these TPS > > comparisons should be taken with a grain of salt. We probably should > > consider switching to a faster CRC algorithm again, regardless of what we do > > with compression. > > CRC is a pretty awfully slow algorithm for checksums. We should > consider switching it out for something more modern. CityHash, > MurmurHash3 and xxhash look like pretty good candidates, being around > an order of magnitude faster than CRC. I'm hoping to investigate > substituting the WAL checksum algorithm 9.5. > > Given the room for improvement in this area I think it would make > sense to just short-circuit the CRC calculations for testing this > patch to see if the performance improvement is due to less data being > checksummed. > > Regards, > Ants Aasma +1 for xxhash - version speed on 64-bits speed on 32-bits ------- ---------------- ---------------- XXH64 13.8 GB/s 1.9 GB/s XXH32 6.8 GB/s 6.0 GB/s Here is a blog about its performance as a hash function: http://fastcompression.blogspot.com/2014/07/xxhash-wider-64-bits.html Regards, Ken
<p dir="ltr">That's not entirely true. CRC-32C beats pretty much everything with the same length quality-wise and has bothhardware implementations and highly optimized software versions.<div class="gmail_quote">Em 12/09/2014 17:18, "Ants Aasma"<<a href="mailto:ants@cybertec.at">ants@cybertec.at</a>> escreveu:<br type="attribution" /><blockquote class="gmail_quote"style="margin:0 0 0 .8ex;border-left:1px #ccc solid;padding-left:1ex">On Fri, Sep 12, 2014 at 10:38 PM,Heikki Linnakangas<br /> <<a href="mailto:hlinnakangas@vmware.com">hlinnakangas@vmware.com</a>> wrote:<br /> >I don't mean that we should abandon this patch - compression makes the WAL<br /> > smaller which has all kinds ofother benefits, even if it makes the raw TPS<br /> > throughput of the system worse. But I'm just saying that theseTPS<br /> > comparisons should be taken with a grain of salt. We probably should<br /> > consider switching toa faster CRC algorithm again, regardless of what we do<br /> > with compression.<br /><br /> CRC is a pretty awfullyslow algorithm for checksums. We should<br /> consider switching it out for something more modern. CityHash,<br />MurmurHash3 and xxhash look like pretty good candidates, being around<br /> an order of magnitude faster than CRC. I'mhoping to investigate<br /> substituting the WAL checksum algorithm 9.5.<br /><br /> Given the room for improvement inthis area I think it would make<br /> sense to just short-circuit the CRC calculations for testing this<br /> patch tosee if the performance improvement is due to less data being<br /> checksummed.<br /><br /> Regards,<br /> Ants Aasma<br/> --<br /> Cybertec Schönig & Schönig GmbH<br /> Gröhrmühlgasse 26<br /> A-2700 Wiener Neustadt<br /> Web: <ahref="http://www.postgresql-support.de" target="_blank">http://www.postgresql-support.de</a><br /><br /><br /> --<br />Sent via pgsql-hackers mailing list (<a href="mailto:pgsql-hackers@postgresql.org">pgsql-hackers@postgresql.org</a>)<br/> To make changes to your subscription:<br/><a href="http://www.postgresql.org/mailpref/pgsql-hackers" target="_blank">http://www.postgresql.org/mailpref/pgsql-hackers</a><br/></blockquote></div>
<p dir="ltr"><br /> Em 12/09/2014 17:23, "Andres Freund" <<a href="mailto:andres@2ndquadrant.com">andres@2ndquadrant.com</a>>escreveu:<br /> ><br /> > On 2014-09-12 23:03:00+0300, Heikki Linnakangas wrote:<br /> > > On 09/12/2014 10:54 PM, Abhijit Menon-Sen wrote:<br /> > >>At 2014-09-12 22:38:01 +0300, <a href="mailto:hlinnakangas@vmware.com">hlinnakangas@vmware.com</a> wrote:<br /> >> >><br /> > > >>We probably should consider switching to a faster CRC algorithm again,<br /> >> >>regardless of what we do with compression.<br /> > > ><br /> > > >As it happens, I'm alreadyworking on resurrecting a patch that Andres<br /> > > >posted in 2010 to switch to zlib's faster CRC implementation.<br/> > ><br /> > > As it happens, I also wrote an implementation of Slice-by-4 the other day<br/> > > :-). Haven't gotten around to post it, but here it is.<br /> > ><br /> > > What algorithmdoes zlib use for CRC calculation?<br /> ><br /> > Also slice-by-4, with a manually unrolled loop doing 32bytesat once, using<br /> > individual slice-by-4's. IIRC I tried and removing that slowed things<br /> > down overall.What it also did was move crc to a function. I'm not sure<br /> > why I did it that way, but it really might bebeneficial - if you look<br /> > at profiles today there's sometimes icache/decoding stalls...<br /> ><br /> >Hm. Let me look:<br /> > <a href="http://archives.postgresql.org/message-id/201005202227.49990.andres%40anarazel.de">http://archives.postgresql.org/message-id/201005202227.49990.andres%40anarazel.de</a><br />><br /> > Ick, there's quite some debugging leftovers ;)<br /> ><br /> > I think it might be a good idea toalso switch the polynom at the same<br /> > time. I really really think we should, when the hardware supports, use<br/> > the polynom that's available in SSE4.2. It has similar properties, can<br /> > implemented in software justthe same...<br /> ><br /> > Greetings,<br /> ><br /> > Andres Freund<br /> ><br /> > --<br /> > Andres Freund <a href="http://www.2ndQuadrant.com/">http://www.2ndQuadrant.com/</a><br /> > PostgreSQLDevelopment, 24x7 Support, Training & Services<br /> ><br /> ><br /> > --<br /> > Sent via pgsql-hackersmailing list (<a href="mailto:pgsql-hackers@postgresql.org">pgsql-hackers@postgresql.org</a>)<br /> > Tomake changes to your subscription:<br /> > <a href="http://www.postgresql.org/mailpref/pgsql-hackers">http://www.postgresql.org/mailpref/pgsql-hackers</a><p dir="ltr">ThisGoogle library is worth a look <a href="https://code.google.com/p/crcutil/">https://code.google.com/p/crcutil/</a>as it has some extremely optimized versions.
On Sat, Sep 13, 2014 at 6:59 AM, Arthur Silva <arthurprs@gmail.com> wrote: > That's not entirely true. CRC-32C beats pretty much everything with the same > length quality-wise and has both hardware implementations and highly > optimized software versions. For better or for worse CRC is biased by detecting all single bit errors, the detection capability of larger errors is slightly diminished. The quality of the other algorithms I mentioned is also very good, while producing uniformly varying output. CRC has exactly one hardware implementation in general purpose CPU's and Intel has a patent on the techniques they used to implement it. The fact that AMD hasn't yet implemented this instruction shows that this patent is non-trivial to work around. The hardware CRC is about as fast as xxhash. The highly optimized software CRCs are an order of magnitude slower and require large cache trashing lookup tables. If we choose to stay with CRC we must accept that we can only solve the performance issues for Intel CPUs and provide slight alleviation for others. Regards, Ants Aasma -- Cybertec Schönig & Schönig GmbH Gröhrmühlgasse 26 A-2700 Wiener Neustadt Web: http://www.postgresql-support.de
On 2014-09-13 08:52:33 +0300, Ants Aasma wrote: > On Sat, Sep 13, 2014 at 6:59 AM, Arthur Silva <arthurprs@gmail.com> wrote: > > That's not entirely true. CRC-32C beats pretty much everything with the same > > length quality-wise and has both hardware implementations and highly > > optimized software versions. > > For better or for worse CRC is biased by detecting all single bit > errors, the detection capability of larger errors is slightly > diminished. The quality of the other algorithms I mentioned is also > very good, while producing uniformly varying output. There's also much more literature about the various CRCs in comparison to some of these hash allgorithms. Pretty much everything tests how well they're suited for hashtables, but that's not really what we need (although it might not hurt *at all* to have something faster there...). I do think we need to think about the types of errors we really have to detect. It's not all that clear that either the typical guarantees/tests for CRCs nor for checksums (smhasher, whatever) are very representative... > CRC has exactly > one hardware implementation in general purpose CPU's and Intel has a > patent on the techniques they used to implement it. The fact that AMD > hasn't yet implemented this instruction shows that this patent is > non-trivial to work around. I think AMD has implemeded SSE4.2 with bulldozer. It's still only recent x86 though. So I think there's good reasons for moving away from it. How one could get patents on exposing hardware CRC implementations - hard to find a computing device without one - as a instruction is beyond me... I think it's pretty clear by now that we should move to lz4 for a couple things - which bundles xxhash with it. So that has one argument for it. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Andres Freund <andres@2ndquadrant.com> writes:
> On 2014-09-13 08:52:33 +0300, Ants Aasma wrote:
>> On Sat, Sep 13, 2014 at 6:59 AM, Arthur Silva <arthurprs@gmail.com> wrote:
>>> That's not entirely true. CRC-32C beats pretty much everything with the same
>>> length quality-wise and has both hardware implementations and highly
>>> optimized software versions.
>> For better or for worse CRC is biased by detecting all single bit
>> errors, the detection capability of larger errors is slightly
>> diminished. The quality of the other algorithms I mentioned is also
>> very good, while producing uniformly varying output.
> There's also much more literature about the various CRCs in comparison
> to some of these hash allgorithms.
Indeed. CRCs have well-understood properties for error detection.
Have any of these new algorithms been analyzed even a hundredth as
thoroughly? No. I'm unimpressed by evidence-free claims that
something else is "also very good".
Now, CRCs are designed for detecting the sorts of short burst errors
that are (or were, back in the day) common on phone lines. You could
certainly make an argument that that's not the type of threat we face
for PG data. However, I've not seen anyone actually make such an
argument, let alone demonstrate that some other algorithm would be better.
To start with, you'd need to explain precisely what other error pattern
is more important to defend against, and why.
regards, tom lane
On Sat, Sep 13, 2014 at 12:55:33PM -0400, Tom Lane wrote: > Andres Freund <andres@2ndquadrant.com> writes: > > On 2014-09-13 08:52:33 +0300, Ants Aasma wrote: > >> On Sat, Sep 13, 2014 at 6:59 AM, Arthur Silva <arthurprs@gmail.com> wrote: > >>> That's not entirely true. CRC-32C beats pretty much everything with the same > >>> length quality-wise and has both hardware implementations and highly > >>> optimized software versions. > > >> For better or for worse CRC is biased by detecting all single bit > >> errors, the detection capability of larger errors is slightly > >> diminished. The quality of the other algorithms I mentioned is also > >> very good, while producing uniformly varying output. > > > There's also much more literature about the various CRCs in comparison > > to some of these hash allgorithms. > > Indeed. CRCs have well-understood properties for error detection. > Have any of these new algorithms been analyzed even a hundredth as > thoroughly? No. I'm unimpressed by evidence-free claims that > something else is "also very good". > > Now, CRCs are designed for detecting the sorts of short burst errors > that are (or were, back in the day) common on phone lines. You could > certainly make an argument that that's not the type of threat we face > for PG data. However, I've not seen anyone actually make such an > argument, let alone demonstrate that some other algorithm would be better. > To start with, you'd need to explain precisely what other error pattern > is more important to defend against, and why. > > regards, tom lane > Here is a blog on the development of xxhash: http://fastcompression.blogspot.com/2012/04/selecting-checksum-algorithm.html Regards, Ken
Andres Freund <andres@2ndquadrant.com> writes:
> On 2014-09-13 08:52:33 +0300, Ants Aasma wrote:
>> On Sat, Sep 13, 2014 at 6:59 AM, Arthur Silva <arthurprs@gmail.com> wrote:
>>> That's not entirely true. CRC-32C beats pretty much everything with the same
>>> length quality-wise and has both hardware implementations and highly
>>> optimized software versions.
>> For better or for worse CRC is biased by detecting all single bit
>> errors, the detection capability of larger errors is slightly
>> diminished. The quality of the other algorithms I mentioned is also
>> very good, while producing uniformly varying output.
> There's also much more literature about the various CRCs in comparison
> to some of these hash allgorithms.
Indeed. CRCs have well-understood properties for error detection.
Have any of these new algorithms been analyzed even a hundredth as
thoroughly? No. I'm unimpressed by evidence-free claims that
something else is "also very good".
Now, CRCs are designed for detecting the sorts of short burst errors
that are (or were, back in the day) common on phone lines. You could
certainly make an argument that that's not the type of threat we face
for PG data. However, I've not seen anyone actually make such an
argument, let alone demonstrate that some other algorithm would be better.
To start with, you'd need to explain precisely what other error pattern
is more important to defend against, and why.
regards, tom lane
Mysql went this way as well, changing the CRC polynomial in 5.6.
crc sb8: 90444623
elapsed: 0.513688s
speed: 1.485220 GB/s
crc hw: 90444623
elapsed: 0.048327s
speed: 15.786877 GB/s
xxhash: 7f4a8d5
elapsed: 0.182100s
speed: 4.189663 GB/s
Attachment
On Sat, Sep 13, 2014 at 09:50:55PM -0300, Arthur Silva wrote: > On Sat, Sep 13, 2014 at 1:55 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > > Andres Freund <andres@2ndquadrant.com> writes: > > > On 2014-09-13 08:52:33 +0300, Ants Aasma wrote: > > >> On Sat, Sep 13, 2014 at 6:59 AM, Arthur Silva <arthurprs@gmail.com> > > wrote: > > >>> That's not entirely true. CRC-32C beats pretty much everything with > > the same > > >>> length quality-wise and has both hardware implementations and highly > > >>> optimized software versions. > > > > >> For better or for worse CRC is biased by detecting all single bit > > >> errors, the detection capability of larger errors is slightly > > >> diminished. The quality of the other algorithms I mentioned is also > > >> very good, while producing uniformly varying output. > > > > > There's also much more literature about the various CRCs in comparison > > > to some of these hash allgorithms. > > > > Indeed. CRCs have well-understood properties for error detection. > > Have any of these new algorithms been analyzed even a hundredth as > > thoroughly? No. I'm unimpressed by evidence-free claims that > > something else is "also very good". > > > > Now, CRCs are designed for detecting the sorts of short burst errors > > that are (or were, back in the day) common on phone lines. You could > > certainly make an argument that that's not the type of threat we face > > for PG data. However, I've not seen anyone actually make such an > > argument, let alone demonstrate that some other algorithm would be better. > > To start with, you'd need to explain precisely what other error pattern > > is more important to defend against, and why. > > > > regards, tom lane > > > > Mysql went this way as well, changing the CRC polynomial in 5.6. > > What we are looking for here is uniqueness thus better error detection. Not > avalanche effect, nor cryptographically secure, nor bit distribution. > As far as I'm aware CRC32C is unbeaten collision wise and time proven. > > I couldn't find tests with xxhash and crc32 on the same hardware so I spent > some time putting together a benchmark (see attachment, to run it just > start run.sh) > > I included a crc32 implementation using ssr4.2 instructions (which works on > pretty much any Intel processor built after 2008 and AMD built after 2012), > a portable Slice-By-8 software implementation and xxhash since it's the > fastest software 32bit hash I know of. > > Here're the results running the test program on my i5-4200M > > crc sb8: 90444623 > elapsed: 0.513688s > speed: 1.485220 GB/s > > crc hw: 90444623 > elapsed: 0.048327s > speed: 15.786877 GB/s > > xxhash: 7f4a8d5 > elapsed: 0.182100s > speed: 4.189663 GB/s > > The hardware version is insanely and works on the majority of Postgres > setups and the fallback software implementations is 2.8x slower than the > fastest 32bit hash around. > > Hopefully it'll be useful in the discussion. Thank you for running this sample benchmark. It definitely shows that the hardware version of the CRC is very fast, unfortunately it is really only available on x64 Intel/AMD processors which leaves all the rest lacking. For current 64-bit hardware, it might be instructive to also try using the XXH64 version and just take one half of the hash. It should come in at around 8.5 GB/s, or very nearly the speed of the hardware accelerated CRC. Also, while I understand that CRC has a very venerable history and is well studied for transmission type errors, I have been unable to find any research on its applicability to validating file/block writes to a disk drive. While it is to quote you "unbeaten collision wise", xxhash, both the 32-bit and 64-bit version are its equal. Since there seems to be a lack of research on disk based error detection versus CRC polynomials, it seems likely that any of the proposed hash functions are on an equal footing in this regard. As Andres commented up-thread, xxhash comes along for "free" with lz4. Regards, Ken
Thank you for running this sample benchmark. It definitely shows that theOn Sat, Sep 13, 2014 at 09:50:55PM -0300, Arthur Silva wrote:
> On Sat, Sep 13, 2014 at 1:55 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> > Andres Freund <andres@2ndquadrant.com> writes:
> > > On 2014-09-13 08:52:33 +0300, Ants Aasma wrote:
> > >> On Sat, Sep 13, 2014 at 6:59 AM, Arthur Silva <arthurprs@gmail.com>
> > wrote:
> > >>> That's not entirely true. CRC-32C beats pretty much everything with
> > the same
> > >>> length quality-wise and has both hardware implementations and highly
> > >>> optimized software versions.
> >
> > >> For better or for worse CRC is biased by detecting all single bit
> > >> errors, the detection capability of larger errors is slightly
> > >> diminished. The quality of the other algorithms I mentioned is also
> > >> very good, while producing uniformly varying output.
> >
> > > There's also much more literature about the various CRCs in comparison
> > > to some of these hash allgorithms.
> >
> > Indeed. CRCs have well-understood properties for error detection.
> > Have any of these new algorithms been analyzed even a hundredth as
> > thoroughly? No. I'm unimpressed by evidence-free claims that
> > something else is "also very good".
> >
> > Now, CRCs are designed for detecting the sorts of short burst errors
> > that are (or were, back in the day) common on phone lines. You could
> > certainly make an argument that that's not the type of threat we face
> > for PG data. However, I've not seen anyone actually make such an
> > argument, let alone demonstrate that some other algorithm would be better.
> > To start with, you'd need to explain precisely what other error pattern
> > is more important to defend against, and why.
> >
> > regards, tom lane
> >
>
> Mysql went this way as well, changing the CRC polynomial in 5.6.
>
> What we are looking for here is uniqueness thus better error detection. Not
> avalanche effect, nor cryptographically secure, nor bit distribution.
> As far as I'm aware CRC32C is unbeaten collision wise and time proven.
>
> I couldn't find tests with xxhash and crc32 on the same hardware so I spent
> some time putting together a benchmark (see attachment, to run it just
> start run.sh)
>
> I included a crc32 implementation using ssr4.2 instructions (which works on
> pretty much any Intel processor built after 2008 and AMD built after 2012),
> a portable Slice-By-8 software implementation and xxhash since it's the
> fastest software 32bit hash I know of.
>
> Here're the results running the test program on my i5-4200M
>
> crc sb8: 90444623
> elapsed: 0.513688s
> speed: 1.485220 GB/s
>
> crc hw: 90444623
> elapsed: 0.048327s
> speed: 15.786877 GB/s
>
> xxhash: 7f4a8d5
> elapsed: 0.182100s
> speed: 4.189663 GB/s
>
> The hardware version is insanely and works on the majority of Postgres
> setups and the fallback software implementations is 2.8x slower than the
> fastest 32bit hash around.
>
> Hopefully it'll be useful in the discussion.
hardware version of the CRC is very fast, unfortunately it is really only
available on x64 Intel/AMD processors which leaves all the rest lacking.
For current 64-bit hardware, it might be instructive to also try using
the XXH64 version and just take one half of the hash. It should come in
at around 8.5 GB/s, or very nearly the speed of the hardware accelerated
CRC. Also, while I understand that CRC has a very venerable history and
is well studied for transmission type errors, I have been unable to find
any research on its applicability to validating file/block writes to a
disk drive. While it is to quote you "unbeaten collision wise", xxhash,
both the 32-bit and 64-bit version are its equal. Since there seems to
be a lack of research on disk based error detection versus CRC polynomials,
it seems likely that any of the proposed hash functions are on an equal
footing in this regard. As Andres commented up-thread, xxhash comes along
for "free" with lz4.
Regards,
Ken
xxhash64
speed: 7.365398 GB/s
On Sat, Sep 13, 2014 at 10:27 PM, ktm@rice.edu <ktm@rice.edu> wrote: >> Here're the results running the test program on my i5-4200M >> >> crc sb8: 90444623 >> elapsed: 0.513688s >> speed: 1.485220 GB/s >> >> crc hw: 90444623 >> elapsed: 0.048327s >> speed: 15.786877 GB/s >> >> xxhash: 7f4a8d5 >> elapsed: 0.182100s >> speed: 4.189663 GB/s >> >> The hardware version is insanely and works on the majority of Postgres >> setups and the fallback software implementations is 2.8x slower than the >> fastest 32bit hash around. >> >> Hopefully it'll be useful in the discussion. > > Thank you for running this sample benchmark. It definitely shows that the > hardware version of the CRC is very fast, unfortunately it is really only > available on x64 Intel/AMD processors which leaves all the rest lacking. > For current 64-bit hardware, it might be instructive to also try using > the XXH64 version and just take one half of the hash. It should come in > at around 8.5 GB/s, or very nearly the speed of the hardware accelerated > CRC. Also, while I understand that CRC has a very venerable history and > is well studied for transmission type errors, I have been unable to find > any research on its applicability to validating file/block writes to a > disk drive. While it is to quote you "unbeaten collision wise", xxhash, > both the 32-bit and 64-bit version are its equal. Since there seems to > be a lack of research on disk based error detection versus CRC polynomials, > it seems likely that any of the proposed hash functions are on an equal > footing in this regard. As Andres commented up-thread, xxhash comes along > for "free" with lz4. Bear in mind that a) taking half of the CRC will invalidate all error detection capability research, and it may also invalidate its properties, depending on the CRC itself. b) bit corruption as is the target kind of error for CRC are resurging in SSDs, as can be seen in table 4 of a link that I think appeared on this same list: https://www.usenix.org/system/files/conference/fast13/fast13-final80.pdf I would totally forget of taking half of whatever CRC. That's looking for pain, in that it will invalidate all existing and future research on that hash/CRC type.
On 2014-09-13 20:27:51 -0500, ktm@rice.edu wrote: > > > > What we are looking for here is uniqueness thus better error detection. Not > > avalanche effect, nor cryptographically secure, nor bit distribution. > > As far as I'm aware CRC32C is unbeaten collision wise and time proven. > > > > I couldn't find tests with xxhash and crc32 on the same hardware so I spent > > some time putting together a benchmark (see attachment, to run it just > > start run.sh) > > > > I included a crc32 implementation using ssr4.2 instructions (which works on > > pretty much any Intel processor built after 2008 and AMD built after 2012), > > a portable Slice-By-8 software implementation and xxhash since it's the > > fastest software 32bit hash I know of. > > > > Here're the results running the test program on my i5-4200M > > > > crc sb8: 90444623 > > elapsed: 0.513688s > > speed: 1.485220 GB/s > > > > crc hw: 90444623 > > elapsed: 0.048327s > > speed: 15.786877 GB/s > > > > xxhash: 7f4a8d5 > > elapsed: 0.182100s > > speed: 4.189663 GB/s > > > > The hardware version is insanely and works on the majority of Postgres > > setups and the fallback software implementations is 2.8x slower than the > > fastest 32bit hash around. > > > > Hopefully it'll be useful in the discussion. Note that all these numbers aren't fully relevant to the use case here. For the WAL - which is what we're talking about and the only place where CRC32 is used with high throughput - the individual parts of a record are pretty darn small on average. So performance of checksumming small amounts of data is more relevant. Mind, that's not likely to go for CRC32, especially not slice-by-8. The cache fooprint of the large tables is likely going to be noticeable in non micro benchmarks. > Also, while I understand that CRC has a very venerable history and > is well studied for transmission type errors, I have been unable to find > any research on its applicability to validating file/block writes to a > disk drive. Which incidentally doesn't really match what the CRC is used for here. It's used for individual WAL records. Usually these are pretty small, far smaller than disk/postgres' blocks on average. There's a couple scenarios where they can get large, true, but most of them are small. The primary reason they're important is to correctly detect the end of the WAL. To ensure we're interpreting half written records, or records from before the WAL file was overwritten. > While it is to quote you "unbeaten collision wise", xxhash, > both the 32-bit and 64-bit version are its equal. Aha? You take that from the smhasher results? > Since there seems to be a lack of research on disk based error > detection versus CRC polynomials, it seems likely that any of the > proposed hash functions are on an equal footing in this regard. As > Andres commented up-thread, xxhash comes along for "free" with lz4. This is pure handwaving. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Sun, Sep 14, 2014 at 05:21:10PM +0200, Andres Freund wrote: > On 2014-09-13 20:27:51 -0500, ktm@rice.edu wrote: > > > Also, while I understand that CRC has a very venerable history and > > is well studied for transmission type errors, I have been unable to find > > any research on its applicability to validating file/block writes to a > > disk drive. > > Which incidentally doesn't really match what the CRC is used for > here. It's used for individual WAL records. Usually these are pretty > small, far smaller than disk/postgres' blocks on average. There's a > couple scenarios where they can get large, true, but most of them are > small. > The primary reason they're important is to correctly detect the end of > the WAL. To ensure we're interpreting half written records, or records > from before the WAL file was overwritten. > > > > While it is to quote you "unbeaten collision wise", xxhash, > > both the 32-bit and 64-bit version are its equal. > > Aha? You take that from the smhasher results? Yes. > > > Since there seems to be a lack of research on disk based error > > detection versus CRC polynomials, it seems likely that any of the > > proposed hash functions are on an equal footing in this regard. As > > Andres commented up-thread, xxhash comes along for "free" with lz4. > > This is pure handwaving. Yes. But without research to support the use of CRC32 in this same environment, it is handwaving in the other direction. :) Regards, Ken
<div dir="ltr"><p dir="ltr"><br /> Em 14/09/2014 12:21, "Andres Freund" <<a href="mailto:andres@2ndquadrant.com" target="_blank">andres@2ndquadrant.com</a>>escreveu:<br /> ><br /> > On 2014-09-13 20:27:51 -0500, <a href="mailto:ktm@rice.edu"target="_blank">ktm@rice.edu</a> wrote:<br /> > > ><br /> > > > What we are lookingfor here is uniqueness thus better error detection. Not<br /> > > > avalanche effect, nor cryptographicallysecure, nor bit distribution.<br /> > > > As far as I'm aware CRC32C is unbeaten collision wiseand time proven.<br /> > > ><br /> > > > I couldn't find tests with xxhash and crc32 on the same hardwareso I spent<br /> > > > some time putting together a benchmark (see attachment, to run it just<br /> >> > start run.sh)<br /> > > ><br /> > > > I included a crc32 implementation using ssr4.2 instructions(which works on<br /> > > > pretty much any Intel processor built after 2008 and AMD built after 2012),<br/> > > > a portable Slice-By-8 software implementation and xxhash since it's the<br /> > > > fastestsoftware 32bit hash I know of.<br /> > > ><br /> > > > Here're the results running the test programon my i5-4200M<br /> > > ><br /> > > > crc sb8: 90444623<br /> > > > elapsed: 0.513688s<br/> > > > speed: 1.485220 GB/s<br /> > > ><br /> > > > crc hw: 90444623<br /> >> > elapsed: 0.048327s<br /> > > > speed: 15.786877 GB/s<br /> > > ><br /> > > > xxhash:7f4a8d5<br /> > > > elapsed: 0.182100s<br /> > > > speed: 4.189663 GB/s<br /> > > ><br/> > > > The hardware version is insanely and works on the majority of Postgres<br /> > > > setupsand the fallback software implementations is 2.8x slower than the<br /> > > > fastest 32bit hash around.<br/> > > ><br /> > > > Hopefully it'll be useful in the discussion.<br /> ><br /> > Notethat all these numbers aren't fully relevant to the use case<br /> > here. For the WAL - which is what we're talkingabout and the only place<br /> > where CRC32 is used with high throughput - the individual parts of a<br /> >record are pretty darn small on average. So performance of checksumming<br /> > small amounts of data is more relevant.Mind, that's not likely to go<br /> > for CRC32, especially not slice-by-8. The cache fooprint of the large<br/> > tables is likely going to be noticeable in non micro benchmarks.<br /> ><p dir="ltr">Indeed, the smallinput sizes is something I was missing. Something more cache friendly would be better, it's just a matter of findinga better candidate.<p dir="ltr"> Although I find it highly unlikely that the 4kb extra table of sb8 brings its performancedown to sb4 level, even considering the small inputs and cache misses.<p>For what's worth mysql, cassandra, kafka,ext4, xfx all use crc32c checksums in their WAL/Journals.<br /><p dir="ltr">> > Also, while I understand thatCRC has a very venerable history and<br /> > > is well studied for transmission type errors, I have been unableto find<br /> > > any research on its applicability to validating file/block writes to a<br /> > > diskdrive.<br /> ><br /> > Which incidentally doesn't really match what the CRC is used for<br /> > here. It's usedfor individual WAL records. Usually these are pretty<br /> > small, far smaller than disk/postgres' blocks on average.There's a<br /> > couple scenarios where they can get large, true, but most of them are<br /> > small.<br />> The primary reason they're important is to correctly detect the end of<br /> > the WAL. To ensure we're interpretinghalf written records, or records<br /> > from before the WAL file was overwritten.<br /> ><br /> ><br/> > > While it is to quote you "unbeaten collision wise", xxhash,<br /> > > both the 32-bit and 64-bitversion are its equal.<br /> ><br /> > Aha? You take that from the smhasher results?<br /> ><br /> > >Since there seems to be a lack of research on disk based error<br /> > > detection versus CRC polynomials, it seemslikely that any of the<br /> > > proposed hash functions are on an equal footing in this regard. As<br /> >> Andres commented up-thread, xxhash comes along for "free" with lz4.<br /> ><br /> > This is pure handwaving.<br/> ><br /> > Greetings,<br /> ><br /> > Andres Freund<br /> ><br /> > --<br /> > AndresFreund <a href="http://www.2ndQuadrant.com/" target="_blank">http://www.2ndQuadrant.com/</a><br/> > PostgreSQL Development, 24x7 Support, Training & Services<br/></div>
On 09/14/2014 09:27 AM, ktm@rice.edu wrote: > Thank you for running this sample benchmark. It definitely shows that the > hardware version of the CRC is very fast, unfortunately it is really only > available on x64 Intel/AMD processors which leaves all the rest lacking. We're talking about something that'd land in 9.5 at best, and going by the adoption rates I see, get picked up slowly over the next couple of years by users. Given that hardware support is already widespread now, I'm not at all convinced that this is a problem. In mid-2015 we'd be talking about 4+ year old AMD CPUs and Intel CPUs that're 6+ years old. In a quick search around I did find one class of machine I have access to that doesn't have SSE 4.2 support. Well, two if you count the POWER7 boxes. It is a type of pre-OpenStack slated-for-retirement RackSpace server with an Opteron 2374. People on older, slower hardware won't get a big performance boost when adopting a new PostgreSQL major release on their old gear. This doesn't greatly upset me. It'd be another thing if we were talking about something where people without the required support would be unable to run the Pg release or take a massive performance hit, but that doesn't appear to be the case here. So I'm all for taking advantage of the hardware support. -- Craig Ringer http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 09/15/2014 02:42 AM, Arthur Silva wrote: > Em 14/09/2014 12:21, "Andres Freund" <andres@2ndquadrant.com> escreveu: >> >> On 2014-09-13 20:27:51 -0500, ktm@rice.edu wrote: >>>> >>>> What we are looking for here is uniqueness thus better error > detection. Not >>>> avalanche effect, nor cryptographically secure, nor bit distribution. >>>> As far as I'm aware CRC32C is unbeaten collision wise and time proven. >>>> >>>> I couldn't find tests with xxhash and crc32 on the same hardware so I > spent >>>> some time putting together a benchmark (see attachment, to run it just >>>> start run.sh) >>>> >>>> I included a crc32 implementation using ssr4.2 instructions (which > works on >>>> pretty much any Intel processor built after 2008 and AMD built after > 2012), >>>> a portable Slice-By-8 software implementation and xxhash since it's > the >>>> fastest software 32bit hash I know of. >>>> >>>> Here're the results running the test program on my i5-4200M >>>> >>>> crc sb8: 90444623 >>>> elapsed: 0.513688s >>>> speed: 1.485220 GB/s >>>> >>>> crc hw: 90444623 >>>> elapsed: 0.048327s >>>> speed: 15.786877 GB/s >>>> >>>> xxhash: 7f4a8d5 >>>> elapsed: 0.182100s >>>> speed: 4.189663 GB/s >>>> >>>> The hardware version is insanely and works on the majority of Postgres >>>> setups and the fallback software implementations is 2.8x slower than > the >>>> fastest 32bit hash around. >>>> >>>> Hopefully it'll be useful in the discussion. >> >> Note that all these numbers aren't fully relevant to the use case >> here. For the WAL - which is what we're talking about and the only place >> where CRC32 is used with high throughput - the individual parts of a >> record are pretty darn small on average. So performance of checksumming >> small amounts of data is more relevant. Mind, that's not likely to go >> for CRC32, especially not slice-by-8. The cache fooprint of the large >> tables is likely going to be noticeable in non micro benchmarks. > > Indeed, the small input sizes is something I was missing. Something more > cache friendly would be better, it's just a matter of finding a better > candidate. It's worth noting that the extra tables that slicing-by-4 requires are and *in addition to* the lookup table we already have. And slicing-by-8 builds on the slicing-by-4 lookup tables. Our current algorithm uses a 1kB lookup table, slicing-by-4 a 4kB, and slicing-by-8 8kB. But the first 1kB of the slicing-by-4 lookup table is identical to the current 1kB lookup table, and the first 4kB of the slicing-by-8 are identical to the slicing-by-4 tables. It would be pretty straightforward to use the current algorithm when the WAL record is very small, and slicing-by-4 or slicing-by-8 for larger records (like FPWs), where the larger table is more likely to pay off. I have no idea where the break-even point is with the current algorithm vs. slicing-by-4 and a cold cache, but maybe we can get a handle on that with some micro-benchmarking. Although this is complicated by the fact that slicing-by-4 or -8 might well be a win even with very small records, if you generate a lot of them. - Heikki
> On 09/12/2014 10:54 PM, Abhijit Menon-Sen wrote:
>> At 2014-09-12 22:38:01 +0300, hlinnakangas@vmware.com wrote:
>>> We probably should consider switching to a faster CRC algorithm again,
>>> regardless of what we do with compression.
>>
>> As it happens, I'm already working on resurrecting a patch that Andres
>> posted in 2010 to switch to zlib's faster CRC implementation.
>
> As it happens, I also wrote an implementation of Slice-by-4 the other day :-).
Attachment
On 2014-09-16 15:43:06 +0530, Amit Kapila wrote: > On Sat, Sep 13, 2014 at 1:33 AM, Heikki Linnakangas <hlinnakangas@vmware.com> > wrote: > > On 09/12/2014 10:54 PM, Abhijit Menon-Sen wrote: > >> At 2014-09-12 22:38:01 +0300, hlinnakangas@vmware.com wrote: > >>> We probably should consider switching to a faster CRC algorithm again, > >>> regardless of what we do with compression. > >> > >> As it happens, I'm already working on resurrecting a patch that Andres > >> posted in 2010 to switch to zlib's faster CRC implementation. > > > > As it happens, I also wrote an implementation of Slice-by-4 the other day > :-). > > Haven't gotten around to post it, but here it is. > > Incase we are using the implementation for everything that uses > COMP_CRC32() macro, won't it give problem for older version > databases. I have created a database with Head code and then > tried to start server after applying this patch it gives below error: > FATAL: incorrect checksum in control file That's indicative of a bug. This really shouldn't cause such problems - at least my version was compatible with the current definition, and IIRC Heikki's should be the same in theory. If I read it right. > In general, the idea sounds quite promising. To see how it performs > on small to medium size data, I have used attached test which is > written be you (with some additional tests) during performance test > of WAL reduction patch in 9.4. Yes, we should really do this. > The patched version gives better results in all cases > (in range of 10~15%), though this is not the perfect test, however > it gives fair idea that the patch is quite promising. I think to test > the benefit from crc calculation for full page, we can have some > checkpoint during each test (may be after insert). Let me know > what other kind of tests do you think are required to see the > gain/loss from this patch. I actually think we don't really need this. It's pretty evident that slice-by-4 is a clear improvement. > I think the main difference in this patch and what Andres has > developed sometime back was code for manually unrolled loop > doing 32bytes at once, so once Andres or Abhijit will post an > updated version, we can do some performance tests to see > if there is any additional gain. If Heikki's version works I see little need to use my/Abhijit's patch. That version has part of it under the zlib license. If Heikki's version is a 'clean room', then I'd say we go with it. It looks really quite similar though... We can make minor changes like additional unrolling without problems lateron. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Re: CRC algorithm (was Re: [REVIEW] Re: Compression of full-page-writes)
On 09/16/2014 01:28 PM, Andres Freund wrote: > On 2014-09-16 15:43:06 +0530, Amit Kapila wrote: >> On Sat, Sep 13, 2014 at 1:33 AM, Heikki Linnakangas <hlinnakangas@vmware.com> >> wrote: >>> On 09/12/2014 10:54 PM, Abhijit Menon-Sen wrote: >>>> At 2014-09-12 22:38:01 +0300, hlinnakangas@vmware.com wrote: >>>>> We probably should consider switching to a faster CRC algorithm again, >>>>> regardless of what we do with compression. >>>> >>>> As it happens, I'm already working on resurrecting a patch that Andres >>>> posted in 2010 to switch to zlib's faster CRC implementation. >>> >>> As it happens, I also wrote an implementation of Slice-by-4 the other day >> :-). >>> Haven't gotten around to post it, but here it is. >> >> Incase we are using the implementation for everything that uses >> COMP_CRC32() macro, won't it give problem for older version >> databases. I have created a database with Head code and then >> tried to start server after applying this patch it gives below error: >> FATAL: incorrect checksum in control file > > That's indicative of a bug. This really shouldn't cause such problems - > at least my version was compatible with the current definition, and IIRC > Heikki's should be the same in theory. If I read it right. > >> In general, the idea sounds quite promising. To see how it performs >> on small to medium size data, I have used attached test which is >> written be you (with some additional tests) during performance test >> of WAL reduction patch in 9.4. > > Yes, we should really do this. > >> The patched version gives better results in all cases >> (in range of 10~15%), though this is not the perfect test, however >> it gives fair idea that the patch is quite promising. I think to test >> the benefit from crc calculation for full page, we can have some >> checkpoint during each test (may be after insert). Let me know >> what other kind of tests do you think are required to see the >> gain/loss from this patch. > > I actually think we don't really need this. It's pretty evident that > slice-by-4 is a clear improvement. > >> I think the main difference in this patch and what Andres has >> developed sometime back was code for manually unrolled loop >> doing 32bytes at once, so once Andres or Abhijit will post an >> updated version, we can do some performance tests to see >> if there is any additional gain. > > If Heikki's version works I see little need to use my/Abhijit's > patch. That version has part of it under the zlib license. If Heikki's > version is a 'clean room', then I'd say we go with it. It looks really > quite similar though... We can make minor changes like additional > unrolling without problems lateron. I used http://create.stephan-brumme.com/crc32/#slicing-by-8-overview as reference - you can probably see the similarity. Any implementation is going to look more or less the same, though; there aren't that many ways to write the implementation. - Heikki
On 2014-09-16 13:49:20 +0300, Heikki Linnakangas wrote: > I used http://create.stephan-brumme.com/crc32/#slicing-by-8-overview as > reference - you can probably see the similarity. Any implementation is going > to look more or less the same, though; there aren't that many ways to write > the implementation. True. I think I see what's the problem causing Amit's test to fail. Amit, did you use the powerpc machine? Heikki, you swap bytes unconditionally - afaics that's wrong on big endian systems. My patch had: + static inline uint32 swab32(const uint32 x); + static inline uint32 swab32(const uint32 x){ + return ((x & (uint32)0x000000ffUL) << 24) | + ((x & (uint32)0x0000ff00UL) << 8) | + ((x & (uint32)0x00ff0000UL) >> 8) | + ((x & (uint32)0xff000000UL) >> 24); + } + + #if defined __BIG_ENDIAN__ + #define cpu_to_be32(x) + #else + #define cpu_to_be32(x) swab32(x) + #endif I guess yours needs something similar. I personally like the cpu_to_be* naming - it imo makes it pretty clear what happens. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
> On 2014-09-16 13:49:20 +0300, Heikki Linnakangas wrote:
> > I used http://create.stephan-brumme.com/crc32/#slicing-by-8-overview as
> > reference - you can probably see the similarity. Any implementation is going
> > to look more or less the same, though; there aren't that many ways to write
> > the implementation.
>
> True.
>
> I think I see what's the problem causing Amit's test to fail. Amit, did
> you use the powerpc machine?
Yes.
Hello,
>Maybe. Let's get the basic patch done first; then we can argue about that
Please find attached patch to compress FPW using pglz compression.
All backup blocks in WAL record are compressed at once before inserting it
into WAL buffers . Full_page_writes GUC has been modified to accept three
values
1. On
2. Compress
3. Off
FPW are compressed when full_page_writes is set to compress. FPW generated
forcibly during online backup even when full_page_writes is off are also
compressed. When full_page_writes is set on FPW are not compressed.
Benckmark:
Server Specification:
Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos
RAM: 32GB
Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos
1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm
Checkpoint segments: 1024
Checkpoint timeout: 5 mins
pgbench -c 64 -j 64 -r -T 900 -M prepared
Scale factor: 1000
WAL generated (MB) Throughput
(tps) Latency(ms)
On 9235.43
979.03 65.36
Compress(pglz) 6518.68
1072.34 59.66
Off 501.04 1135.17
56.34
The results show around 30 percent decrease in WAL volume due to
compression of FPW.
compress_fpw_v1.patch
<http://postgresql.1045698.n5.nabble.com/file/n5819645/compress_fpw_v1.patch>
--
View this message in context:
http://postgresql.1045698.n5.nabble.com/Compression-of-full-page-writes-tp5769039p5819645.html
Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
>Please find attached patch to compress FPW using pglz compression. Please refer the updated patch attached. The earlier patch added few duplicate lines of code in guc.c file. compress_fpw_v1.patch <http://postgresql.1045698.n5.nabble.com/file/n5819659/compress_fpw_v1.patch> Thank you, Rahila Syed -- View this message in context: http://postgresql.1045698.n5.nabble.com/Compression-of-full-page-writes-tp5769039p5819659.html Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
Rahila Syed <rahilasyed.90@gmail.com> writes:
> Please find attached patch to compress FPW using pglz compression.
Patch not actually attached AFAICS (no, a link is not good enough).
regards, tom lane
On Fri, Sep 19, 2014 at 11:05 PM, Rahila Syed <rahilasyed.90@gmail.com> wrote: > >>Please find attached patch to compress FPW using pglz compression. > Please refer the updated patch attached. The earlier patch added few > duplicate lines of code in guc.c file. > > compress_fpw_v1.patch > <http://postgresql.1045698.n5.nabble.com/file/n5819659/compress_fpw_v1.patch> > > I got patching failed to HEAD. Detail is following. Hunk #3 FAILED at 142. 1 out of 3 hunks FAILED -- saving rejects to file src/backend/access/rmgrdesc/xlogdesc.c.rej Regards, ------- Sawada Masahiko
Tom Lane wrote: > Rahila Syed <rahilasyed.90@gmail.com> writes: > > Please find attached patch to compress FPW using pglz compression. > > Patch not actually attached AFAICS (no, a link is not good enough). Well, from Rahila's point of view the patch is actually attached, but she's posting from the Nabble interface, which mangles it and turns into a link instead. Not her fault, really -- but the end result is the same: to properly submit a patch, you need to send an email to the pgsql-hackers@postgresql.org mailing list, not join a group/forum from some intermediary newsgroup site that mirrors the list. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
<p dir="ltr"><br /> Hello All,<p dir="ltr"> <br /> >Well, from Rahila's point of view the patch is actually attached,but <br /> >she's posting from the Nabble interface, which mangles it and turns into <br /> >a link instead.<pdir="ltr">Yes.<p dir="ltr"> <p dir="ltr">>but the end result is the <br /> >same: to properly submit a patch,you need to send an email to the <br /> > mailing list, not join a group/forum from <br /> >some intermediarynewsgroup site that mirrors the list.<br /> <p dir="ltr">Thank you. I will take care of it henceforth. <p dir="ltr">Pleasefind attached the patch to compress FPW. Patch submitted by Fujii-san earlier in the thread is used to mergecompression GUC with full_page_writes.<p dir="ltr"> <p dir="ltr">I am reposting the measurement numbers.<p dir="ltr">ServerSpecification: <br /> Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos <br /> RAM:32GB <br /> Disk : HDWD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos <br /> 1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000rpm <p dir="ltr">Checkpoint segments: 1024 <br /> Checkpoint timeout: 5 mins <p dir="ltr">pgbench -c 64 -j 64 -r -T900 -M prepared <br /> Scale factor: 1000 <p dir="ltr"> WAL generated (MB) Throughput(tps) Latency(ms) <br /> On 9235.43 979.03 65.36 <br /> Compress(pglz) 6518.68 1072.34 59.66 <br /> Off 501.04 1135.17 56.34 <p dir="ltr">The results show around 30 percentdecrease in WAL volume due to compression of FPW.<p dir="ltr">Thank you ,<p dir="ltr">Rahila Syed<p dir="ltr">TomLane wrote:<br /> > Rahila Syed <<a href="mailto:rahilasyed.90@gmail.com">rahilasyed</a><a href="mailto:rahilasyed.90@gmail.com">.90@</a><ahref="mailto:rahilasyed.90@gmail.com">gmail.com</a>> writes:<br /> >> Please find attached patch to compress FPW using pglz compression.<br /> ><br /> > Patch not actually attachedAFAICS (no, a link is not good enough).<p dir="ltr">Well, from Rahila's point of view the patch is actually attached,but<br /> she's posting from the Nabble interface, which mangles it and turns into<br /> a link instead. Not herfault, really -- but the end result is the<br /> same: to properly submit a patch, you need to send an email to the<br/><a href="mailto:pgsql-hackers@postgresql.org">pgsql</a><a href="mailto:pgsql-hackers@postgresql.org">-</a><a href="mailto:pgsql-hackers@postgresql.org">hackers</a><ahref="mailto:pgsql-hackers@postgresql.org">@</a><a href="mailto:pgsql-hackers@postgresql.org">postgresql.org</a>mailinglist, not join a group/forum from<br /> some intermediarynewsgroup site that mirrors the list.<p dir="ltr">--<br /> Álvaro Herrera <a href="http://www.2ndQuadrant.com/">http://www.2ndQuadrant.com/</a><br/> PostgreSQL Development, 24x7 Support, Training &Services<br /><br />
Hello,
>Please find attached the patch to compress FPW.
Sorry I had forgotten to attach. Please find the patch attached.
Thank you,
Rahila Syed
From: pgsql-hackers-owner@postgresql.org [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Rahila Syed
Sent: Monday, September 22, 2014 3:16 PM
To: Alvaro Herrera
Cc: Rahila Syed; PostgreSQL-development; Tom Lane
Subject: Re: [HACKERS] [REVIEW] Re: Compression of full-page-writes
Hello All,
>Well, from Rahila's point of view the patch is actually attached, but
>she's posting from the Nabble interface, which mangles it and turns into
>a link instead.
Yes.
>but the end result is the
>same: to properly submit a patch, you need to send an email to the
> mailing list, not join a group/forum from
>some intermediary newsgroup site that mirrors the list.
Thank you. I will take care of it henceforth.
Please find attached the patch to compress FPW. Patch submitted by Fujii-san earlier in the thread is used to merge compression GUC with full_page_writes.
I am reposting the measurement numbers.
Server Specification:
Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos
RAM: 32GB
Disk : HDWD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos
1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm
Checkpoint segments: 1024
Checkpoint timeout: 5 mins
pgbench -c 64 -j 64 -r -T 900 -M prepared
Scale factor: 1000
WAL generated (MB) Throughput (tps) Latency(ms)
On 9235.43 979.03 65.36
Compress(pglz) 6518.68 1072.34 59.66
Off 501.04 1135.17 56.34
The results show around 30 percent decrease in WAL volume due to compression of FPW.
Thank you ,
Rahila Syed
Tom Lane wrote:
> Rahila Syed <rahilasyed.90@gmail.com> writes:
> > Please find attached patch to compress FPW using pglz compression.
>
> Patch not actually attached AFAICS (no, a link is not good enough).
Well, from Rahila's point of view the patch is actually attached, but
she's posting from the Nabble interface, which mangles it and turns into
a link instead. Not her fault, really -- but the end result is the
same: to properly submit a patch, you need to send an email to the
pgsql-hackers@postgresql.orgmailing list, not join a group/forum from
some intermediary newsgroup site that mirrors the list.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
______________________________________________________________________
Disclaimer:This email and any attachments are sent in strictest confidence for the sole use of the addressee and may contain legally privileged, confidential, and proprietary data. If you are not the intended recipient, please advise the sender by replying promptly to this email and then delete and destroy this email and any attachments without any further use, copying or forwarding
Attachment
* Ants Aasma: > CRC has exactly one hardware implementation in general purpose CPU's I'm pretty sure that's not true. Many general purpose CPUs have CRC circuity, and there must be some which also expose them as instructions. > and Intel has a patent on the techniques they used to implement > it. The fact that AMD hasn't yet implemented this instruction shows > that this patent is non-trivial to work around. I think you're jumping to conclusions. Intel and AMD have various cross-licensing deals. AMD faces other constraints which can make implementing the instruction difficult.
On Tue, Sep 23, 2014 at 8:15 PM, Florian Weimer <fw@deneb.enyo.de> wrote: > * Ants Aasma: > >> CRC has exactly one hardware implementation in general purpose CPU's > > I'm pretty sure that's not true. Many general purpose CPUs have CRC > circuity, and there must be some which also expose them as > instructions. I must eat my words here, indeed AMD processors starting from Bulldozer do implement the CRC32 instruction. However, according to Agner Fog, AMD's implementation has a 6 cycle latency and more importantly a throughput of 1/6 per cycle. While Intel's implementation on all CPUs except the new Atom has 3 cycle latency and 1 instruction/cycle throughput. This means that there still is a significant handicap for AMD platforms, not to mention Power or Sparc with no hardware support. Some ARM's implement CRC32, but I haven't researched what their performance is. Regards, Ants Aasma -- Cybertec Schönig & Schönig GmbH Gröhrmühlgasse 26 A-2700 Wiener Neustadt Web: http://www.postgresql-support.de
Hi, On 2014-09-22 10:39:32 +0000, Syed, Rahila wrote: > >Please find attached the patch to compress FPW. I've given this a quick look and noticed some things: 1) I don't think it's a good idea to put the full page write compression into struct XLogRecord. 2) You've essentially removed a lot of checks about the validity of bkp blocks in xlogreader. I don't think that's acceptable. 3) You have both FullPageWritesStr() and full_page_writes_str(). 4) I don't like FullPageWritesIsNeeded(). For one it, at least to me, sounds grammatically wrong. More importantly whenreading it I'm thinking of it being about the LSN check. How about instead directly checking whatever != FULL_PAGE_WRITES_OFF? 5) CompressBackupBlockPagesAlloc is declared static but not defined as such. 6) You call CompressBackupBlockPagesAlloc() from two places. Neither is IIRC within a critical section. So you imo shouldremove the outOfMem handling and revert to palloc() instead of using malloc directly. One thing worthy of note isthat I don't think you currently can "legally" check fullPageWrites == FULL_PAGE_WRITES_ON when calling it only duringstartup as fullPageWrites can be changed at runtime. 7) Unless I miss something CompressBackupBlock should be plural, right? ATM it compresses all the blocks? 8) I don't tests like "if (fpw <= FULL_PAGE_WRITES_COMPRESS)". That relies on the, less than intuitive, ordering of FULL_PAGE_WRITES_COMPRESS(=1) before FULL_PAGE_WRITES_ON (=2). 9) I think you've broken the case where we first think 1 block needs to be backed up, and another doesn't. If we then detect,after the START_CRIT_SECTION(), that we need to "goto begin;" orig_len will still have it's old content. I think that's it for now. Imo it'd be ok to mark this patch as returned with feedback and deal with it during the next fest. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Mon, Sep 29, 2014 at 8:36 AM, Andres Freund <andres@anarazel.de> wrote: > 1) I don't think it's a good idea to put the full page write compression > into struct XLogRecord. Why not, and where should that be put? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2014-09-29 11:02:49 -0400, Robert Haas wrote: > On Mon, Sep 29, 2014 at 8:36 AM, Andres Freund <andres@anarazel.de> wrote: > > 1) I don't think it's a good idea to put the full page write compression > > into struct XLogRecord. > > Why not, and where should that be put? Hah. I knew that somebody would pick that comment up ;) I think it shouldn't be there because it looks trivial to avoid putting it there. There's no runtime and nearly no code complexity reduction gained by adding a field to struct XLogRecord. The best way to do that depends a bit on how my complaint about the removed error checking during reading the backup block data is resolved. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 09/29/2014 06:02 PM, Robert Haas wrote: > On Mon, Sep 29, 2014 at 8:36 AM, Andres Freund <andres@anarazel.de> wrote: >> 1) I don't think it's a good idea to put the full page write compression >> into struct XLogRecord. > > Why not, and where should that be put? It should be a flag in BkpBlock. - Heikki
On 2014-09-29 18:27:01 +0300, Heikki Linnakangas wrote: > On 09/29/2014 06:02 PM, Robert Haas wrote: > >On Mon, Sep 29, 2014 at 8:36 AM, Andres Freund <andres@anarazel.de> wrote: > >>1) I don't think it's a good idea to put the full page write compression > >> into struct XLogRecord. > > > >Why not, and where should that be put? > > It should be a flag in BkpBlock. Doesn't work with the current approach (which I don't really like much). The backup blocks are all compressed together. *Including* all the struct BkpBlocks. Then the field in struct XLogRecord is used to decide whether to decompress the whole thing or to take it verbatim. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Sep 16, 2014 at 6:49 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: >>>> As it happens, I also wrote an implementation of Slice-by-4 the other >>>> day >>> >> If Heikki's version works I see little need to use my/Abhijit's >> patch. That version has part of it under the zlib license. If Heikki's >> version is a 'clean room', then I'd say we go with it. It looks really >> quite similar though... We can make minor changes like additional >> unrolling without problems lateron. > > > I used http://create.stephan-brumme.com/crc32/#slicing-by-8-overview as > reference - you can probably see the similarity. Any implementation is going > to look more or less the same, though; there aren't that many ways to write > the implementation. So, it seems like the status of this patch is: 1. It probably has a bug, since Amit's testing seemed to show that it wasn't returning the same results as unpatched master. 2. The performance tests showed a significant win on an important workload. 3. It's not in any CommitFest anywhere. Given point #2, it's seems like we ought to find a way to keep this from sliding into oblivion. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hello, Thank you for review. >1) I don't think it's a good idea to put the full page write compression into struct XLogRecord. Full page write compression information can be stored in varlena struct of compressed blocks as done for toast data in pluggable compression support patch. If I understand correctly, it can be done similar to the manner in which compressed Datum is modified to contain information about compression algorithm in pluggable compression support patch. >2) You've essentially removed a lot of checks about the validity of bkp blocks in xlogreader. I don't think that's acceptable To ensure this, the raw size stored in first four byte of compressed datum can be used to perform error checking for backup blocks Currently, the error checking for size of backup blocks happens individually for each block. If backup blocks are compressed together , it can happen once for the entire set of backup blocks in a WAL record. The total raw size of compressed blocks can be checked against the total size stored in WAL record header. >3) You have both FullPageWritesStr() and full_page_writes_str(). full_page_writes_str() is true/false version of FullPageWritesStr macro. It is implemented for backward compatibility with pg_xlogdump >4)I don't like FullPageWritesIsNeeded(). For one it, at least to me, sounds grammatically wrong. More importantly whenreading it I'm thinking of it being about the LSN check. How about instead directly checking whatever != FULL_PAGE_WRITES_OFF? I will modify this. >5) CompressBackupBlockPagesAlloc is declared static but not defined as such. >7) Unless I miss something CompressBackupBlock should be plural, right? ATM it compresses all the blocks? I will correct these. >6)You call CompressBackupBlockPagesAlloc() from two places. Neither is > IIRC within a critical section. So you imo shouldremove the outOfMem > handling and revert to palloc() instead of using malloc directly. Yes neither is in critical section. outOfMem handling is done in order to proceed without compression of FPW in case sufficient memory is not available for compression. Thank you, Rahila Syed -- View this message in context: http://postgresql.1045698.n5.nabble.com/Compression-of-full-page-writes-tp5769039p5822391.html Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
into struct XLogRecord.
blocks in xlogreader. I don't think that's acceptable
This has not changed for now reason being full_page_writes_str() is true/false version of FullPageWritesStr macro. It
is implemented for backward compatibility with pg_xlogdump.
ATM it compresses all the blocks?
>8) I don't tests like "if (fpw <= FULL_PAGE_WRITES_COMPRESS)". That
relies on the, less than intuitive, ordering of
FULL_PAGE_WRITES_COMPRESS (=1) before FULL_PAGE_WRITES_ON (=2).
>9) I think you've broken the case where we first think 1 block needs to
be backed up, and another doesn't. If we then detect, after the
START_CRIT_SECTION(), that we need to "goto begin;" orig_len will
still have it's old content.
such.
>6) You call CompressBackupBlockPagesAlloc() from two places. Neither is
IIRC within a critical section. So you imo should remove the outOfMem
handling and revert to palloc() instead of using malloc directly.
available for compression.
> thing worthy of note is that I don't think you currently can
> "legally" check fullPageWrites == FULL_PAGE_WRITES_ON when calling it
> only during startup as fullPageWrites can be changed at runtime
Hi,
On 2014-09-22 10:39:32 +0000, Syed, Rahila wrote:
> >Please find attached the patch to compress FPW.
I've given this a quick look and noticed some things:
1) I don't think it's a good idea to put the full page write compression
into struct XLogRecord.
2) You've essentially removed a lot of checks about the validity of bkp
blocks in xlogreader. I don't think that's acceptable.
3) You have both FullPageWritesStr() and full_page_writes_str().
4) I don't like FullPageWritesIsNeeded(). For one it, at least to me,
sounds grammatically wrong. More importantly when reading it I'm
thinking of it being about the LSN check. How about instead directly
checking whatever != FULL_PAGE_WRITES_OFF?
5) CompressBackupBlockPagesAlloc is declared static but not defined as
such.
6) You call CompressBackupBlockPagesAlloc() from two places. Neither is
IIRC within a critical section. So you imo should remove the outOfMem
handling and revert to palloc() instead of using malloc directly. One
thing worthy of note is that I don't think you currently can
"legally" check fullPageWrites == FULL_PAGE_WRITES_ON when calling it
only during startup as fullPageWrites can be changed at runtime.
7) Unless I miss something CompressBackupBlock should be plural, right?
ATM it compresses all the blocks?
8) I don't tests like "if (fpw <= FULL_PAGE_WRITES_COMPRESS)". That
relies on the, less than intuitive, ordering of
FULL_PAGE_WRITES_COMPRESS (=1) before FULL_PAGE_WRITES_ON (=2).
9) I think you've broken the case where we first think 1 block needs to
be backed up, and another doesn't. If we then detect, after the
START_CRIT_SECTION(), that we need to "goto begin;" orig_len will
still have it's old content.
I think that's it for now. Imo it'd be ok to mark this patch as returned
with feedback and deal with it during the next fest.
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Fri, Oct 17, 2014 at 1:52 PM, Rahila Syed <rahilasyed90@gmail.com> wrote:
> Hello,
>
> Please find the updated patch attached.
Thanks for updating the patch! Here are the comments.
The patch isn't applied to the master cleanly.
I got the following compiler warnings.
xlog.c:930: warning: ISO C90 forbids mixed declarations and code
xlogreader.c:744: warning: ISO C90 forbids mixed declarations and code
xlogreader.c:744: warning: ISO C90 forbids mixed declarations and code
The compilation of the document failed with the following error message.
openjade:config.sgml:2188:12:E: end tag for element "TERM" which is not open
make[3]: *** [HTML.index] Error 1
Only backend calls CompressBackupBlocksPagesAlloc when SIGHUP is sent.
Why does only backend need to do that? What about other processes which
can write FPW, e.g., autovacuum?
Do we release the buffers for compressed data when fpw is changed from
"compress" to "on"?
+ if (uncompressedPages == NULL)
+ {
+ uncompressedPages = (char *)malloc(XLR_TOTAL_BLCKSZ);
+ if (uncompressedPages == NULL)
+ outOfMem = 1;
+ }
The memory is always (i.e., even when fpw=on) allocated to uncompressedPages,
but not to compressedPages. Why? I guess that the test of fpw needs to be there.
Regards,
--
Fujii Masao
Hello Fujii-san,
Thank you for your comments.
>The patch isn't applied to the master cleanly.
>The compilation of the document failed with the following error message.
>openjade:config.sgml:2188:12:E: end tag for element "TERM" which is not open
>make[3]: *** [HTML.index] Error 1
>xlog.c:930: warning: ISO C90 forbids mixed declarations and code
>xlogreader.c:744: warning: ISO C90 forbids mixed declarations and code
>xlogreader.c:744: warning: ISO C90 forbids mixed declarations and code
Please find attached patch with these rectified.
>Only backend calls CompressBackupBlocksPagesAlloc when SIGHUP is sent.
>Why does only backend need to do that? What about other processes which can write FPW, e.g., autovacuum?
I had overlooked this. I will correct it.
>Do we release the buffers for compressed data when fpw is changed from "compress" to "on"?
The current code does not do this.
>The memory is always (i.e., even when fpw=on) allocated to uncompressedPages, but not to compressedPages. Why? I guess
thatthe test of fpw needs to be there
uncompressedPages is also used to store the decompression output at the time of recovery. Hence, memory for
uncompressedPagesneeds to be allocated even if fpw=on which is not the case for compressedPages.
Thank you,
Rahila Syed
-----Original Message-----
From: Fujii Masao [mailto:masao.fujii@gmail.com]
Sent: Monday, October 27, 2014 6:50 PM
To: Rahila Syed
Cc: Andres Freund; Syed, Rahila; Alvaro Herrera; Rahila Syed; PostgreSQL-development; Tom Lane
Subject: Re: [HACKERS] [REVIEW] Re: Compression of full-page-writes
On Fri, Oct 17, 2014 at 1:52 PM, Rahila Syed <rahilasyed90@gmail.com> wrote:
> Hello,
>
> Please find the updated patch attached.
Thanks for updating the patch! Here are the comments.
The patch isn't applied to the master cleanly.
I got the following compiler warnings.
xlog.c:930: warning: ISO C90 forbids mixed declarations and code
xlogreader.c:744: warning: ISO C90 forbids mixed declarations and code
xlogreader.c:744: warning: ISO C90 forbids mixed declarations and code
The compilation of the document failed with the following error message.
openjade:config.sgml:2188:12:E: end tag for element "TERM" which is not open
make[3]: *** [HTML.index] Error 1
Only backend calls CompressBackupBlocksPagesAlloc when SIGHUP is sent.
Why does only backend need to do that? What about other processes which can write FPW, e.g., autovacuum?
Do we release the buffers for compressed data when fpw is changed from "compress" to "on"?
+ if (uncompressedPages == NULL)
+ {
+ uncompressedPages = (char *)malloc(XLR_TOTAL_BLCKSZ);
+ if (uncompressedPages == NULL)
+ outOfMem = 1;
+ }
The memory is always (i.e., even when fpw=on) allocated to uncompressedPages, but not to compressedPages. Why? I guess
thatthe test of fpw needs to be there.
Regards,
--
Fujii Masao
______________________________________________________________________
Disclaimer: This email and any attachments are sent in strictest confidence
for the sole use of the addressee and may contain legally privileged,
confidential, and proprietary data. If you are not the intended recipient,
please advise the sender by replying promptly to this email and then delete
and destroy this email and any attachments without any further use, copying
or forwarding.
Attachment
On Tue, Oct 28, 2014 at 4:54 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote: > Hello Fujii-san, > > Thank you for your comments. > >>The patch isn't applied to the master cleanly. >>The compilation of the document failed with the following error message. >>openjade:config.sgml:2188:12:E: end tag for element "TERM" which is not open >>make[3]: *** [HTML.index] Error 1 >>xlog.c:930: warning: ISO C90 forbids mixed declarations and code >>xlogreader.c:744: warning: ISO C90 forbids mixed declarations and code >>xlogreader.c:744: warning: ISO C90 forbids mixed declarations and code > > Please find attached patch with these rectified. > >>Only backend calls CompressBackupBlocksPagesAlloc when SIGHUP is sent. >>Why does only backend need to do that? What about other processes which can write FPW, e.g., autovacuum? > I had overlooked this. I will correct it. > >>Do we release the buffers for compressed data when fpw is changed from "compress" to "on"? > The current code does not do this. Don't we need to do that? >>The memory is always (i.e., even when fpw=on) allocated to uncompressedPages, but not to compressedPages. Why? I guessthat the test of fpw needs to be there > uncompressedPages is also used to store the decompression output at the time of recovery. Hence, memory for uncompressedPagesneeds to be allocated even if fpw=on which is not the case for compressedPages. You don't need to make the processes except the startup process allocate the memory for uncompressedPages when fpw=on. Only the startup process uses it for the WAL decompression. BTW, what happens if the memory allocation for uncompressedPages for the recovery fails? Which would prevent the recovery at all, so PANIC should happen in that case? Regards, -- Fujii Masao
>>>Do we release the buffers for compressed data when fpw is changed from "compress" to "on"? >> The current code does not do this. >Don't we need to do that? Yes this needs to be done in order to avoid memory leak when compression is turned off at runtime while the backend session is running. >You don't need to make the processes except the startup process allocate >the memory for uncompressedPages when fpw=on. Only the startup process >uses it for the WAL decompression I see. fpw != on check can be put at the time of memory allocation of uncompressedPages in the backend code . And at the time of recovery uncompressedPages can be allocated separately if not already allocated. >BTW, what happens if the memory allocation for uncompressedPages for >the recovery fails? The current code does not handle this. This will be rectified. >Which would prevent the recovery at all, so PANIC should >happen in that case? IIUC, instead of reporting PANIC , palloc can be used to allocate memory for uncompressedPages at the time of recovery which will throw ERROR and abort startup process in case of failure. Thank you, Rahila Syed -- View this message in context: http://postgresql.1045698.n5.nabble.com/Compression-of-full-page-writes-tp5769039p5824613.html Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
>>>Do we release the buffers for compressed data when fpw is changed from
"compress" to "on"?
>> The current code does not do this.
>Don't we need to do that?
Yes this needs to be done in order to avoid memory leak when compression is
turned off at runtime while the backend session is running.
>You don't need to make the processes except the startup process allocate
>the memory for uncompressedPages when fpw=on. Only the startup process
>uses it for the WAL decompression
I see. fpw != on check can be put at the time of memory allocation of
uncompressedPages in the backend code . And at the time of recovery
uncompressedPages can be allocated separately if not already allocated.
>BTW, what happens if the memory allocation for uncompressedPages for
>the recovery fails?
The current code does not handle this. This will be rectified.
>Which would prevent the recovery at all, so PANIC should
>happen in that case?
IIUC, instead of reporting PANIC , palloc can be used to allocate memory
for uncompressedPages at the time of recovery which will throw ERROR and
abort startup process in case of failure.
Thank you,
Rahila Syed
--
View this message in context: http://postgresql.1045698.n5.nabble.com/Compression-of-full-page-writes-tp5769039p5824613.htmlSent from the PostgreSQL - hackers mailing list archive at Nabble.com.
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Tue, Nov 4, 2014 at 2:03 PM, Rahila Syed <rahilasyed90@gmail.com> wrote: > Hello , > > Please find updated patch with the review comments given above implemented Hunk #3 FAILED at 692. 1 out of 3 hunks FAILED -- saving rejects to file src/backend/access/transam/xlogreader.c.rej The patch was not applied to the master cleanly. Could you update the patch? Regards, -- Fujii Masao
>The patch was not applied to the master cleanly. Could you update the patch?
On Tue, Nov 4, 2014 at 2:03 PM, Rahila Syed <rahilasyed90@gmail.com> wrote:
> Hello ,
>
> Please find updated patch with the review comments given above implemented
Hunk #3 FAILED at 692.
1 out of 3 hunks FAILED -- saving rejects to file
src/backend/access/transam/xlogreader.c.rej
The patch was not applied to the master cleanly. Could you update the patch?
Regards,
--
Fujii Masao
Attachment
On Sun, Nov 9, 2014 at 6:41 AM, Rahila Syed <rahilasyed90@gmail.com> wrote: > Hello, > >>The patch was not applied to the master cleanly. Could you update the >> patch? > Please find attached updated and rebased patch to compress FPW. Review > comments given above have been implemented. Thanks for updating the patch! Will review it. BTW, I got the following compiler warnings. xlogreader.c:755: warning: assignment from incompatible pointer type autovacuum.c:1412: warning: implicit declaration of function 'CompressBackupBlocksPagesAlloc' xlogreader.c:755: warning: assignment from incompatible pointer type Regards, -- Fujii Masao
On Sun, Nov 9, 2014 at 10:32 PM, Fujii Masao <masao.fujii@gmail.com> wrote:
> On Sun, Nov 9, 2014 at 6:41 AM, Rahila Syed <rahilasyed90@gmail.com> wrote:
>> Hello,
>>
>>>The patch was not applied to the master cleanly. Could you update the
>>> patch?
>> Please find attached updated and rebased patch to compress FPW. Review
>> comments given above have been implemented.
>
> Thanks for updating the patch! Will review it.
>
> BTW, I got the following compiler warnings.
>
> xlogreader.c:755: warning: assignment from incompatible pointer type
> autovacuum.c:1412: warning: implicit declaration of function
> 'CompressBackupBlocksPagesAlloc'
> xlogreader.c:755: warning: assignment from incompatible pointer type
I have been looking at this patch, here are some comments:
1) This documentation change is incorrect:
- <term><varname>full_page_writes</varname> (<type>boolean</type>)
+ <term><varname>full_page_writes</varname> (<type>enum</type>)</term>
<indexterm>
<primary><varname>full_page_writes</> configuration parameter</primary>
</indexterm>
- </term>
The termination of block term was correctly places before.
2) This patch defines FullPageWritesStr and full_page_writes_str, but both do more or less the same thing.
3) This patch is touching worker_spi.c and calling CompressBackupBlocksPagesAlloc directly. Why is that necessary? Doesn't a bgworker call InitXLOGAccess once it connects to a database?
4) Be careful as well of whitespaces (code lines should have as well a maximum of 80 characters):
+ * If compression is set on replace the rdata nodes of backup blocks added in the loop
+ * above by single rdata node that contains compressed backup blocks and their headers
+ * except the header of first block which is used to store the information about compression.
+ */
5) GetFullPageWriteGUC or something similar is necessary, but I think that for consistency with doPageWrites its value should be fetched in XLogInsert and then passed as an extra argument in XLogRecordAssemble. Thinking more about this, I think that it would be cleaner to simply have a bool flag tracking if compression is active or not, something like doPageCompression, that could be fetched using GetFullPageWriteInfo. Thinking more about it, we could directly track forcePageWrites and fullPageWrites, but that would make back-patching more difficult with not that much gain.
6) Not really a complaint, but note that this patch is using two bits that were unused up to now to store the compression status of a backup block. This is actually safe as long as the maximum page is not higher than 32k, which is the limit authorized by --with-blocksize btw. I think that this deserves a comment at the top of the declaration of BkpBlock.
! unsigned hole_offset:15, /* number of bytes before "hole" */
! flags:2, /* state of a backup block, see below */
! hole_length:15; /* number of bytes in "hole" */
+
+ uncompressedPages = (char *)palloc(XLR_TOTAL_BLCKSZ);
[...]
+ /* Check if blocks in WAL record are compressed */
+ if (bkpb.flag_compress == BKPBLOCKS_COMPRESSED)
+ {
+ /* Checks to see if decompression is successful is made inside the function */
+ pglz_decompress((PGLZ_Header *) blk, uncompressedPages);
+ blk = uncompressedPages;
+ }
uncompressedPages is pallocd'd all the time but you actually just need to do that when the block is compressed.
9) Is avw_sighup_handler really necessary, what's wrong in allocating it all the time by default? This avoids some potential caveats in error handling as well as in value updates for full_page_writes.
So, note that I am not only complaining about the patch, I actually rewrote it as attached while reviewing, with additional minor cleanups and enhancements. I did as well a couple of tests like the script attached, compression numbers being more or less the same as your previous patch, some noise creating differences. I have done also some regression test runs with a standby replaying behind.
Michael
Attachment
On Mon, Nov 10, 2014 at 5:26 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > I'll go through the patch once again a bit later, but feel free to comment. Reading again the patch with a fresher mind, I am not sure if the current approach taken is really the best one. What the patch does now is looking at the header of the first backup block, and then compresses the rest, aka the other blocks, up to 4, and their headers, up to 3. I think that we should instead define an extra bool flag in XLogRecord to determine if the record is compressed, and then use this information. Attaching the compression status to XLogRecord is more in-line with the fact that all the blocks are compressed, and not each one individually, so we basically now duplicate an identical flag value in all the backup block headers, which is a waste IMO. Thoughts? -- Michael
On Tue, Nov 11, 2014 at 5:10 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Mon, Nov 10, 2014 at 5:26 PM, Michael Paquier > <michael.paquier@gmail.com> wrote: >> I'll go through the patch once again a bit later, but feel free to comment. > Reading again the patch with a fresher mind, I am not sure if the > current approach taken is really the best one. What the patch does now > is looking at the header of the first backup block, and then > compresses the rest, aka the other blocks, up to 4, and their headers, > up to 3. I think that we should instead define an extra bool flag in > XLogRecord to determine if the record is compressed, and then use this > information. Attaching the compression status to XLogRecord is more > in-line with the fact that all the blocks are compressed, and not each > one individually, so we basically now duplicate an identical flag > value in all the backup block headers, which is a waste IMO. > Thoughts? I think this was changed based on following, if I am not wrong. http://www.postgresql.org/message-id/54297A45.8080904@vmware.com Regards, Amit
>I think this was changed based on following, if I am not wrong. >http://www.postgresql.org/message-id/54297A45.8080904@... Yes this change is the result of the above complaint. >Attaching the compression status to XLogRecord is more >in-line with the fact that all the blocks are compressed, and not each >one individually, so we basically now duplicate an identical flag >value in all the backup block headers, which is a waste IMO. >Thoughts? If I understand your point correctly, as all blocks are compressed, adding compression attribute to XLogRecord surely makes more sense if the record contains backup blocks . But in case of XLOG records without backup blocks the compression attribute in record header might not make much sense. Attaching the status of compression to XLogRecord will mean that the status is duplicated across all records. It will mean that it is an attribute of all the records when it is only an attribute of records with backup blocks or the attribute of backup blocks. The current approach is adopted with this thought. Regards, Rahila Syed -- View this message in context: http://postgresql.nabble.com/Compression-of-full-page-writes-tp5769039p5826487.html Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
On 2014-11-11 17:10:01 +0900, Michael Paquier wrote: > On Mon, Nov 10, 2014 at 5:26 PM, Michael Paquier > <michael.paquier@gmail.com> wrote: > > I'll go through the patch once again a bit later, but feel free to comment. > Reading again the patch with a fresher mind, I am not sure if the > current approach taken is really the best one. What the patch does now > is looking at the header of the first backup block, and then > compresses the rest, aka the other blocks, up to 4, and their headers, > up to 3. I think that we should instead define an extra bool flag in > XLogRecord to determine if the record is compressed, and then use this > information. Attaching the compression status to XLogRecord is more > in-line with the fact that all the blocks are compressed, and not each > one individually, so we basically now duplicate an identical flag > value in all the backup block headers, which is a waste IMO. I don't buy the 'waste' argument. If there's a backup block those up bytes won't make a noticeable difference. But for the majority of record where there's no backup blocks it will. The more important thing here is that I see little chance of this getting in before Heikki's larger rework of the wal format gets in. Since that'll change everything around anyay I'm unsure how much point there is to iterate till that's done. I know that sucks, but I don't see much of an alternative. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Nov 11, 2014 at 6:27 PM, Andres Freund <andres@2ndquadrant.com> wrote: > The more important thing here is that I see little chance of this > getting in before Heikki's larger rework of the wal format gets > in. Since that'll change everything around anyay I'm unsure how much > point there is to iterate till that's done. I know that sucks, but I > don't see much of an alternative. True enough. Hopefully the next patch changing WAL format will put in all the infrastructure around backup blocks, so we won't have any need to worry about major conflicts for this release cycle after it. -- Michael
On Tue, Nov 11, 2014 at 4:27 AM, Andres Freund <andres@2ndquadrant.com> wrote: > The more important thing here is that I see little chance of this > getting in before Heikki's larger rework of the wal format gets > in. Since that'll change everything around anyay I'm unsure how much > point there is to iterate till that's done. I know that sucks, but I > don't see much of an alternative. Why not do this first? Heikki's patch seems quite far from being ready to commit at this point - it significantly increases WAL volume and reduces performance. Heikki may well be able to fix that, but I don't know that it's a good idea to make everyone else wait while he does. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2014-11-12 10:13:18 -0500, Robert Haas wrote: > On Tue, Nov 11, 2014 at 4:27 AM, Andres Freund <andres@2ndquadrant.com> wrote: > > The more important thing here is that I see little chance of this > > getting in before Heikki's larger rework of the wal format gets > > in. Since that'll change everything around anyay I'm unsure how much > > point there is to iterate till that's done. I know that sucks, but I > > don't see much of an alternative. > > Why not do this first? Heikki's patch seems quite far from being > ready to commit at this point - it significantly increases WAL volume > and reduces performance. Heikki may well be able to fix that, but I > don't know that it's a good idea to make everyone else wait while he > does. Because it imo builds the infrastructure to do the compression more sanely. I.e. provide proper space to store information about the compressedness of the blocks and such. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Nov 13, 2014 at 12:15 AM, Andres Freund <andres@2ndquadrant.com> wrote: > > On 2014-11-12 10:13:18 -0500, Robert Haas wrote: > > On Tue, Nov 11, 2014 at 4:27 AM, Andres Freund <andres@2ndquadrant.com> wrote: > > > The more important thing here is that I see little chance of this > > > getting in before Heikki's larger rework of the wal format gets > > > in. Since that'll change everything around anyay I'm unsure how much > > > point there is to iterate till that's done. I know that sucks, but I > > > don't see much of an alternative. > > > > Why not do this first? Heikki's patch seems quite far from being > > ready to commit at this point - it significantly increases WAL volume > > and reduces performance. Heikki may well be able to fix that, but I > > don't know that it's a good idea to make everyone else wait while he > > does. > > Because it imo builds the infrastructure to do the compression more > sanely. I.e. provide proper space to store information about the > compressedness of the blocks and such. Now that the new WAL format has been committed, here are some comments about this patch and what we can do. First, in xlogrecord.h there is a short description of how a record looks like. The portion of a block data looks like that for a given block ID: 1) block image if BKPBLOCK_HAS_IMAGE, whose size of BLCKSZ - hole 2) data related to the block if BKPBLOCK_HAS_DATA, with a size determined by what the caller inserts with XLogRegisterBufData for a given block. The data associated with a block has a length that cannot be determined before XLogRegisterBufData is used. We could add a 3rd parameter to XLogEnsureRecordSpace to allocate enough space for a buffer wide enough to allocate data for a single buffer before compression (BLCKSZ * number of blocks + total size of block data) but this seems really error-prone for new features as well as existing features. So for those reasons I think that it would be wise to not include the block data in what is compressed. This brings me to the second point: we would need to reorder the entries in the record chain if we are going to do the compression of all the blocks inside a single buffer, it has the following advantages: - More compression, as proved with measurements on this thread And the following disadvantages: - Need to change the entries in record chain once again for this release to something like that for the block data (note that current record chain format is quite elegant btw): compressed block images block data of ID = M block data of ID = N etc. - Slightly longer replay time, because we would need to loop two times through the block data to fill in DecodedBkpBlock: once to decompress all the blocks, and once for the data of each block. It is not much because there are not that many blocks replayed per record, but still. So, all those things gathered, with a couple of hours hacking this code, make me think that it would be more elegant to do the compression per block and not per group of blocks in a single record. I actually found a couple of extra things: - pg_lzcompress and pg_lzdecompress should be in src/port to make pg_xlogdump work. Note that pg_lzdecompress has one call to elog, hence it would be better to have it return a boolean state and let the caller return an error of decompression failed. - In the previous patch versions, a WAL record was doing unnecessary processing: first it built uncompressed image block entries, then compressed them, and replaced in the record chain the existing uncompressed records by the compressed ones. - CompressBackupBlocks enforced compression to BLCKSZ, which was incorrect for groups of blocks, it should have been BLCKSZ * num_blocks. - it looks to be better to add a simple uint16 in XLogRecordBlockImageHeader to store the compressed length of a block, if 0 the block is not compressed. This helps the new decoder facility to track the length of data received. If a block has a hole, it is compressed without it. Now here are two patches: - Move pg_lzcompress.c to src/port to make pg_xlogdump work with the 2nd patch. I imagine that this would be useful as well for client utilities, similarly to what has been done for pg_crc some time ago. - The patch itself doing the FPW compression, note that it passes regression tests but at replay there is still one bug, triggered roughly before numeric.sql when replaying changes on a standby. I am still looking at it, but it does not prevent basic testing as well as a continuation of the discussion. For now here are the patches either way, so feel free to comment. Regards, -- Michael
Attachment
On Tue, Nov 25, 2014 at 3:33 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > For now here are the patches either way, so feel free to comment. And of course the patches are incorrect... -- Michael
Attachment
Michael Paquier wrote: > Exposing compression and decompression APIs of pglz makes possible its > use by extensions and contrib modules. pglz_decompress contained a call > to elog to emit an error message in case of corrupted data. This function > is changed to return a boolean status to let its callers return an error > instead. I think pglz_compress belongs into src/common instead. It seems way too high-level for src/port. Isn't a simple boolean return value too simple-minded? Maybe an enum would be more future-proof, as later you might want to add more values, say distinguish between different forms of corruption, or fail due to out of memory, whatever. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Nov 25, 2014 at 10:48 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Michael Paquier wrote: > >> Exposing compression and decompression APIs of pglz makes possible its >> use by extensions and contrib modules. pglz_decompress contained a call >> to elog to emit an error message in case of corrupted data. This function >> is changed to return a boolean status to let its callers return an error >> instead. > > I think pglz_compress belongs into src/common instead. It > seems way too high-level for src/port. OK. Sounds fine to me. > Isn't a simple boolean return value too simple-minded? Maybe an enum > would be more future-proof, as later you might want to add more values, > say distinguish between different forms of corruption, or fail due to > out of memory, whatever. Hm. I am less sure about that. If we take this road we should do something similar for the compression portion as well. -- Michael
So, Here are reworked patches for the whole set, with the following changes: - Found why replay was failing, xlogreader.c took into account BLCKSZ - hole while it should have taken into account the compressed data length when fetching a compressed block image. - Reworked pglz portion to have it return status errors instead of simple booleans. pglz stuff is as well moved to src/common as Alvaro suggested. I am planning to run some tests to check how much compression can reduce WAL size with this new set of patches. I have been however able to check that those patches pass installcheck-world with a standby replaying the changes behind. Feel free to play with those patches... Regards, -- Michael
Attachment
Hello, I would like to contribute few points. >XLogInsertRecord(XLogRecData *rdata, XLogRecPtr fpw_lsn) > RedoRecPtr = Insert->RedoRecPtr; > } > doPageWrites = (Insert->fullPageWrites || Insert->forcePageWrites); > doPageCompression = (Insert->fullPageWrites == FULL_PAGE_WRITES_COMPRESS); Don't we need to initialize doPageCompression similar to doPageWrites in InitXLOGAccess? Also , in the earlier patches compression was set 'on' even when fpw GUC is 'off'. This was to facilitate compression ofFPW which are forcibly written even when fpw GUC is turned off.doPageCompression in this patch is set to true only if valueof fpw GUC is 'compress'. I think its better to compress forcibly written full page writes. Regards, Rahila Syed -----Original Message----- From: pgsql-hackers-owner@postgresql.org [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Michael Paquier Sent: Wednesday, November 26, 2014 1:55 PM To: Alvaro Herrera Cc: Andres Freund; Robert Haas; Fujii Masao; Rahila Syed; Rahila Syed; PostgreSQL-development Subject: Re: [HACKERS] [REVIEW] Re: Compression of full-page-writes So, Here are reworked patches for the whole set, with the following changes: - Found why replay was failing, xlogreader.c took into account BLCKSZ - hole while it should have taken into account the compressed data length when fetching a compressed block image. - Reworked pglz portion to have it return status errors instead of simple booleans. pglz stuff is as well moved to src/commonas Alvaro suggested. I am planning to run some tests to check how much compression can reduce WAL size with this new set of patches. I have beenhowever able to check that those patches pass installcheck-world with a standby replaying the changes behind. Feel freeto play with those patches... Regards, -- Michael ______________________________________________________________________ Disclaimer: This email and any attachments are sent in strictest confidence for the sole use of the addressee and may contain legally privileged, confidential, and proprietary data. If you are not the intended recipient, please advise the sender by replying promptly to this email and then delete and destroy this email and any attachments without any further use, copying or forwarding.
On Wed, Nov 26, 2014 at 8:27 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote: > Don't we need to initialize doPageCompression similar to doPageWrites in InitXLOGAccess? Yep, you're right. I missed this code path. > Also , in the earlier patches compression was set 'on' even when fpw GUC is 'off'. This was to facilitate compression ofFPW which are forcibly written even when fpw GUC is turned off. > doPageCompression in this patch is set to true only if value of fpw GUC is 'compress'. I think its better to compressforcibly written full page writes. Meh? (stealing a famous quote). This is backward-incompatible in the fact that forcibly-written FPWs would be compressed all the time, even if FPW is set to off. The documentation of the previous patches also mentioned that images are compressed only if this parameter value is switched to compress. -- Michael
On 2014-11-27 13:00:57 +0900, Michael Paquier wrote: > On Wed, Nov 26, 2014 at 8:27 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote: > > Don't we need to initialize doPageCompression similar to doPageWrites in InitXLOGAccess? > Yep, you're right. I missed this code path. > > > Also , in the earlier patches compression was set 'on' even when fpw GUC is 'off'. This was to facilitate compressionof FPW which are forcibly written even when fpw GUC is turned off. > > doPageCompression in this patch is set to true only if value of fpw GUC is 'compress'. I think its better to compressforcibly written full page writes. > Meh? (stealing a famous quote). > This is backward-incompatible in the fact that forcibly-written FPWs > would be compressed all the time, even if FPW is set to off. The > documentation of the previous patches also mentioned that images are > compressed only if this parameter value is switched to compress. err, "backward incompatible"? I think it's quite useful to allow compressing newpage et. al records even if FPWs aren't required for the hardware. One thing Heikki brought up somewhere, which I thought to be a good point, was that it might be worthwile to forget about compressing FDWs themselves, and instead compress entire records when they're large. I think that might just end up being rather beneficial, both from a code simplicity and from the achievable compression ratio. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Nov 27, 2014 at 11:42 PM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2014-11-27 13:00:57 +0900, Michael Paquier wrote: >> This is backward-incompatible in the fact that forcibly-written FPWs >> would be compressed all the time, even if FPW is set to off. The >> documentation of the previous patches also mentioned that images are >> compressed only if this parameter value is switched to compress. > > err, "backward incompatible"? I think it's quite useful to allow > compressing newpage et. al records even if FPWs aren't required for the > hardware. Incorrect words. This would enforce a new behavior on something that's been like that for ages even if we have a switch to activate it. > One thing Heikki brought up somewhere, which I thought to be a good > point, was that it might be worthwile to forget about compressing FDWs > themselves, and instead compress entire records when they're large. I > think that might just end up being rather beneficial, both from a code > simplicity and from the achievable compression ratio. Indeed, that would be quite simple to do. Now determining an ideal cap value is tricky. We could always use a GUC switch to control that but that seems sensitive to set, still we could have a recommended value in the docs found after looking at some average record size using the regression tests. -- Michael
On Thu, Nov 27, 2014 at 11:59 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Thu, Nov 27, 2014 at 11:42 PM, Andres Freund <andres@2ndquadrant.com> wrote: >> One thing Heikki brought up somewhere, which I thought to be a good >> point, was that it might be worthwile to forget about compressing FDWs >> themselves, and instead compress entire records when they're large. I >> think that might just end up being rather beneficial, both from a code >> simplicity and from the achievable compression ratio. > Indeed, that would be quite simple to do. Now determining an ideal cap > value is tricky. We could always use a GUC switch to control that but > that seems sensitive to set, still we could have a recommended value > in the docs found after looking at some average record size using the > regression tests. Thinking more about that, it would be difficult to apply the compression for all records because of the buffer that needs to be pre-allocated for compression, or we would need to have each code path creating a WAL record able to forecast the size of this record, and then adapt the size of the buffer before entering a critical section. Of course we could still apply this idea for records within a given windows size. Still, the FPW compression does not have those concerns. A buffer used for compression is capped by BLCKSZ for a single block, and nblk * BLCKSZ if blocks are grouped for compression. Feel free to comment if I am missing smth obvious. Regards, -- Michael
> if (!fullPageWrites)
> {
> WALInsertLockAcquireExclusive();
> Insert->fullPageWrites = fullPageWrites;
> WALInsertLockRelease();
> }
>
>doPageWrites = (Insert->fullPageWrites || Insert->forcePageWrites);
Considering Insert -> fullPageWrites is an int now, I think its better to explicitly write the above as ,
Rahila Syed
Attachment
So, I have been doing some more tests with this patch. I think the compression numbers are in line with the previous tests. Configuration ========== 3 sets are tested: - HEAD (a5eb85e) + fpw = on - patch + fpw = on - patch + fpw = compress With the following configuration: shared_buffers=512MB checkpoint_segments=1024 checkpoint_timeout = 5min fsync=off WAL quantity =========== pgbench -s 30 -i (455MB of data) pgbench -c 32 -j 32 -t 45000 -M prepared (roughly 11 min of run on laptop, two checkpoints kick in) 1) patch + fdw = compress tps = 2086.893948 (including connections establishing) tps = 2087.031543 (excluding connections establishing) start LSN: 0/19000090 stop LSN: 0/49F73D78 difference: 783MB 2) patch + fdw = on start LSN: 0/1B000090 stop LSN: 0/8F4E1BD0 difference: 1861 MB tps = 2106.812454 (including connections establishing) tps = 2106.953329 (excluding connections establishing) 3) HEAD + fdw = on start LSN: 0/1B0000C8 stop LSN: difference: WAL replay performance =================== Then tested replay time of a standby after replaying WAL files generated by previous pgbench runs and by tracking "redo start" and "redo stop". Goal here is to check for the same amount of activity how much block decompression plays on replay. The replay includes the pgbench initialization phase. 1) patch + fdw = compress 1-1) Try 1. 2014-11-28 14:09:27.287 JST: LOG: redo starts at 0/3000380 2014-11-28 14:10:19.836 JST: LOG: redo done at 0/49F73E18 Result: 52.549 1-2) Try 2. 2014-11-28 14:15:04.196 JST: LOG: redo starts at 0/3000380 2014-11-28 14:15:56.238 JST: LOG: redo done at 0/49F73E18 Result: 52.042 1-3) Try 3 2014-11-28 14:20:27.186 JST: LOG: redo starts at 0/3000380 2014-11-28 14:21:19.350 JST: LOG: redo done at 0/49F73E18 Result: 52.164 2) patch + fdw = on 2-1) Try 1 2014-11-28 14:42:54.670 JST: LOG: redo starts at 0/3000750 2014-11-28 14:43:56.221 JST: LOG: redo done at 0/8F4E1BD0 Result: 61.5s 2-2) Try 2 2014-11-28 14:46:03.198 JST: LOG: redo starts at 0/3000750 2014-11-28 14:47:03.545 JST: LOG: redo done at 0/8F4E1BD0 Result: 60.3s 2-3) Try 3 2014-11-28 14:50:26.896 JST: LOG: redo starts at 0/3000750 2014-11-28 14:51:30.950 JST: LOG: redo done at 0/8F4E1BD0 Result: 64.0s 3) HEAD + fdw = on 3-1) Try 1 2014-11-28 15:21:48.153 JST: LOG: redo starts at 0/3000750 2014-11-28 15:22:53.864 JST: LOG: redo done at 0/8FFFFFA8 Result: 65.7s 3-2) Try 2 2014-11-28 15:27:16.271 JST: LOG: redo starts at 0/3000750 2014-11-28 15:28:20.677 JST: LOG: redo done at 0/8FFFFFA8 Result: 64.4s 3-3) Try 3 2014-11-28 15:36:30.434 JST: LOG: redo starts at 0/3000750 2014-11-28 15:37:33.208 JST: LOG: redo done at 0/8FFFFFA8 Result: 62.7s So we are getting an equivalent amount of WAL when compression is not enabled with both HEAD and the patch, aka a reduction of 55% at constant number of transactions with pgbench. The difference seems to be some noise. Note that basically as the patch adds a uint16 in XLogRecordBlockImageHeader to store the length of the block compressed and achieve a double level of compression (1st level being the removal of the page hole), the records are 2 bytes longer per block image, it does not seem to be much a problem in those tests. Regarding the WAL replay, compressed blocks need extra CPU for decompression in exchange of having less WAL to replay in quantity, this is actually reducing by ~15% the replay time, so the replay plays in favor of putting the load on the CPU. Also, I haven't seen any difference with or without the patch when compression is disabled. Updated patches attached, I found a couple of issues with the code this morning (issues more or less pointed out as well by Rahila earlier) before running those tests. Regards, Regards, -- Michael
Attachment
On Fri, Nov 28, 2014 at 3:48 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > Configuration > ========== > 3) HEAD + fdw = on > start LSN: 0/1B0000C8 > stop LSN: > difference: Wrong copy/paste: stop LSN = 0/8FFFFFA8 difference = 1872MB tps = 2057.344827 (including connections establishing) tps = 2057.468800 (excluding connections establishing) -- Michael
On Fri, Nov 28, 2014 at 1:30 PM, Rahila Syed <rahilasyed90@gmail.com> wrote: > I have attached the changes separately as changes.patch. Yes thanks. FWIW, I noticed those things as well when going through the code again this morning for my tests. Note as well that the declaration of doPageCompression at the top of xlog.c was an integer while it should have been a boolean. Regards, -- Michael
On Wed, Nov 26, 2014 at 11:00 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Wed, Nov 26, 2014 at 8:27 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote: >> Don't we need to initialize doPageCompression similar to doPageWrites in InitXLOGAccess? > Yep, you're right. I missed this code path. > >> Also , in the earlier patches compression was set 'on' even when fpw GUC is 'off'. This was to facilitate compressionof FPW which are forcibly written even when fpw GUC is turned off. >> doPageCompression in this patch is set to true only if value of fpw GUC is 'compress'. I think its better to compressforcibly written full page writes. > Meh? (stealing a famous quote). > This is backward-incompatible in the fact that forcibly-written FPWs > would be compressed all the time, even if FPW is set to off. The > documentation of the previous patches also mentioned that images are > compressed only if this parameter value is switched to compress. If we have a separate GUC to determine whether to do compression of full page writes, then it seems like that parameter ought to apply regardless of WHY we are doing full page writes, which might be either that full_pages_writes=on in general, or that we've temporarily turned them on for the duration of a full backup. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Dec 3, 2014 at 2:17 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Nov 26, 2014 at 11:00 PM, Michael Paquier > <michael.paquier@gmail.com> wrote: >> On Wed, Nov 26, 2014 at 8:27 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote: >>> Don't we need to initialize doPageCompression similar to doPageWrites in InitXLOGAccess? >> Yep, you're right. I missed this code path. >> >>> Also , in the earlier patches compression was set 'on' even when fpw GUC is 'off'. This was to facilitate compressionof FPW which are forcibly written even when fpw GUC is turned off. >>> doPageCompression in this patch is set to true only if value of fpw GUC is 'compress'. I think its better to compressforcibly written full page writes. >> Meh? (stealing a famous quote). >> This is backward-incompatible in the fact that forcibly-written FPWs >> would be compressed all the time, even if FPW is set to off. The >> documentation of the previous patches also mentioned that images are >> compressed only if this parameter value is switched to compress. > > If we have a separate GUC to determine whether to do compression of > full page writes, then it seems like that parameter ought to apply > regardless of WHY we are doing full page writes, which might be either > that full_pages_writes=on in general, or that we've temporarily turned > them on for the duration of a full backup. In the latest versions of the patch, control of compression is done within full_page_writes by assigning a new value 'compress'. Something that I am scared of is that if we enforce compression when full_page_writes is off for forcibly-written pages and if a bug shows up in the compression/decompression algorithm at some point (that's unlikely to happen as this has been used for years with toast but let's say "if"), we may corrupt a lot of backups. Hence why not simply having a new GUC parameter to fully control it. First versions of the patch did that but ISTM that it is better than enforcing the use of a new feature for our user base. Now, something that has not been mentioned on this thread is to make compression the default behavior in all cases so as we won't even have to use a GUC parameter. We are usually conservative about changing default behaviors so I don't really think that's the way to go. Just mentioning the possibility. Regards, -- Michael
On Tue, Dec 2, 2014 at 7:16 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > In the latest versions of the patch, control of compression is done > within full_page_writes by assigning a new value 'compress'. Something > that I am scared of is that if we enforce compression when > full_page_writes is off for forcibly-written pages and if a bug shows > up in the compression/decompression algorithm at some point (that's > unlikely to happen as this has been used for years with toast but > let's say "if"), we may corrupt a lot of backups. Hence why not simply > having a new GUC parameter to fully control it. First versions of the > patch did that but ISTM that it is better than enforcing the use of a > new feature for our user base. That's a very valid concern. But maybe it shows that full_page_writes=compress is not the Right Way To Do It, because then there's no way for the user to choose the behavior they want when full_page_writes=off but yet a backup is in progress. If we had a separate GUC, we could know the user's actual intention, instead of guessing. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Dec 3, 2014 at 12:35 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Dec 2, 2014 at 7:16 PM, Michael Paquier > <michael.paquier@gmail.com> wrote: >> In the latest versions of the patch, control of compression is done >> within full_page_writes by assigning a new value 'compress'. Something >> that I am scared of is that if we enforce compression when >> full_page_writes is off for forcibly-written pages and if a bug shows >> up in the compression/decompression algorithm at some point (that's >> unlikely to happen as this has been used for years with toast but >> let's say "if"), we may corrupt a lot of backups. Hence why not simply >> having a new GUC parameter to fully control it. First versions of the >> patch did that but ISTM that it is better than enforcing the use of a >> new feature for our user base. > > That's a very valid concern. But maybe it shows that > full_page_writes=compress is not the Right Way To Do It, because then > there's no way for the user to choose the behavior they want when > full_page_writes=off but yet a backup is in progress. If we had a > separate GUC, we could know the user's actual intention, instead of > guessing. Note that implementing a separate parameter for this patch would not be much complicated if the core portion does not change much. What about the long name full_page_compression or the longer name full_page_writes_compression? -- Michael
IIUC, forcibly written fpws are not exposed to user , so is it worthwhile to add a GUC similar to full_page_writes in order to control a feature which is unexposed to user in first place? If full page writes is set ‘off’ by user, user probably cannot afford the overhead involved in writing large pages to disk . So , if a full page write is forcibly written in such a situation it is better to compress it before writing to alleviate the drawbacks of writing full_page_writes in servers with heavy write load. The only scenario in which a user would not want to compress forcibly written pages is when CPU utilization is high. But according to measurements done earlier the CPU utilization of compress=’on’ and ‘off’ are not significantly different. -- View this message in context: http://postgresql.nabble.com/Compression-of-full-page-writes-tp5769039p5829204.html Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
On Thu, Dec 4, 2014 at 7:36 PM, Rahila Syed <rahilasyed.90@gmail.com> wrote: > IIUC, forcibly written fpws are not exposed to user , so is it worthwhile to > add a GUC similar to full_page_writes in order to control a feature which is > unexposed to user in first place? > > If full page writes is set 'off' by user, user probably cannot afford the > overhead involved in writing large pages to disk . So , if a full page write > is forcibly written in such a situation it is better to compress it before > writing to alleviate the drawbacks of writing full_page_writes in servers > with heavy write load. > > The only scenario in which a user would not want to compress forcibly > written pages is when CPU utilization is high. But according to measurements > done earlier the CPU utilization of compress='on' and 'off' are not > significantly different. Yes they are not visible to the user still they exist. I'd prefer that we have a safety net though to prevent any problems that may occur if compression algorithm has a bug as if we enforce compression for forcibly-written blocks all the backups of our users would be impacted. I pondered something that Andres mentioned upthread: we may not do the compression in WAL record only for blocks, but also at record level. Hence joining the two ideas together I think that we should definitely have a different GUC to control the feature, consistently for all the images. Let's call it wal_compression, with the following possible values: - on, meaning that a maximum of compression is done, for this feature basically full_page_writes = on. - full_page_writes, meaning that full page writes are compressed - off, default value, to disable completely the feature. This would let room for another mode: 'record', to completely compress a record. For now though, I think that a simple on/off switch would be fine for this patch. Let's keep things simple. Regards, -- Michael
On Thu, Dec 4, 2014 at 5:36 AM, Rahila Syed <rahilasyed.90@gmail.com> wrote: > The only scenario in which a user would not want to compress forcibly > written pages is when CPU utilization is high. Or if they think the code to compress full pages is buggy. > But according to measurements > done earlier the CPU utilization of compress=’on’ and ‘off’ are not > significantly different. If that's really true, we could consider having no configuration any time, and just compressing always. But I'm skeptical that it's actually true. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
>If that's really true, we could consider having no configuration any >time, and just compressing always. But I'm skeptical that it's >actually true. I was referring to this for CPU utilization: http://www.postgresql.org/message-id/1410414381339-5818552.post@n5.nabble.com <http://> The above tests were performed on machine with configuration as follows Server specifications: Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos RAM: 32GB Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos 1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm Thank you, Rahila Syed -- View this message in context: http://postgresql.nabble.com/Compression-of-full-page-writes-tp5769039p5829339.html Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
On Thu, Dec 4, 2014 at 8:37 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Thu, Dec 4, 2014 at 7:36 PM, Rahila Syed <rahilasyed.90@gmail.com> wrote: >> IIUC, forcibly written fpws are not exposed to user , so is it worthwhile to >> add a GUC similar to full_page_writes in order to control a feature which is >> unexposed to user in first place? >> >> If full page writes is set 'off' by user, user probably cannot afford the >> overhead involved in writing large pages to disk . So , if a full page write >> is forcibly written in such a situation it is better to compress it before >> writing to alleviate the drawbacks of writing full_page_writes in servers >> with heavy write load. >> >> The only scenario in which a user would not want to compress forcibly >> written pages is when CPU utilization is high. But according to measurements >> done earlier the CPU utilization of compress='on' and 'off' are not >> significantly different. > > Yes they are not visible to the user still they exist. I'd prefer that we have > a safety net though to prevent any problems that may occur if compression > algorithm has a bug as if we enforce compression for forcibly-written blocks > all the backups of our users would be impacted. > > I pondered something that Andres mentioned upthread: we may not do the > compression in WAL record only for blocks, but also at record level. Hence > joining the two ideas together I think that we should definitely have > a different > GUC to control the feature, consistently for all the images. Let's call it > wal_compression, with the following possible values: > - on, meaning that a maximum of compression is done, for this feature > basically full_page_writes = on. > - full_page_writes, meaning that full page writes are compressed > - off, default value, to disable completely the feature. > This would let room for another mode: 'record', to completely compress > a record. For now though, I think that a simple on/off switch would be > fine for this patch. Let's keep things simple. +1 Regards, -- Fujii Masao
On Thu, Dec 4, 2014 at 5:36 AM, Rahila Syed <rahilasyed.90@gmail.com> wrote:
> The only scenario in which a user would not want to compress forcibly
> written pages is when CPU utilization is high.
Or if they think the code to compress full pages is buggy.
> But according to measurements
> done earlier the CPU utilization of compress=’on’ and ‘off’ are not
> significantly different.
If that's really true, we could consider having no configuration any
time, and just compressing always. But I'm skeptical that it's
actually true.
Attachment
I attempted quick review and could not come up with much except this
+ /*
+ * Calculate the amount of FPI data in the record. Each backup block
+ * takes up BLCKSZ bytes, minus the "hole" length.
+ *
+ * XXX: We peek into xlogreader's private decoded backup blocks for the
+ * hole_length. It doesn't seem worth it to add an accessor macro for
+ * this.
+ */
+ fpi_len = 0;
+ for (block_id = 0; block_id <= record->max_block_id; block_id++)
+ {
+ if (XLogRecHasCompressedBlockImage(record, block_id))
+ fpi_len += BLCKSZ - record->blocks[block_id].compress_len;
IIUC, fpi_len in case of compressed block image should be
fpi_len = record->blocks[block_id].compress_len;
Thank you,
Rahila Syed
--
View this message in context: http://postgresql.nabble.com/Compression-of-full-page-writes-tp5769039p5829403.html
Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
I attempted quick review and could not come up with much except this
+ /*
+ * Calculate the amount of FPI data in the record. Each backup block
+ * takes up BLCKSZ bytes, minus the "hole" length.
+ *
+ * XXX: We peek into xlogreader's private decoded backup blocks for the
+ * hole_length. It doesn't seem worth it to add an accessor macro for
+ * this.
+ */
+ fpi_len = 0;
+ for (block_id = 0; block_id <= record->max_block_id; block_id++)
+ {
+ if (XLogRecHasCompressedBlockImage(record, block_id))
+ fpi_len += BLCKSZ - record->blocks[block_id].compress_len;
IIUC, fpi_len in case of compressed block image should be
fpi_len = record->blocks[block_id].compress_len;
On Fri, Dec 5, 2014 at 11:10 PM, Rahila Syed <rahilasyed.90@gmail.com> wrote:I attempted quick review and could not come up with much except this
+ /*
+ * Calculate the amount of FPI data in the record. Each backup block
+ * takes up BLCKSZ bytes, minus the "hole" length.
+ *
+ * XXX: We peek into xlogreader's private decoded backup blocks for the
+ * hole_length. It doesn't seem worth it to add an accessor macro for
+ * this.
+ */
+ fpi_len = 0;
+ for (block_id = 0; block_id <= record->max_block_id; block_id++)
+ {
+ if (XLogRecHasCompressedBlockImage(record, block_id))
+ fpi_len += BLCKSZ - record->blocks[block_id].compress_len;
IIUC, fpi_len in case of compressed block image should be
fpi_len = record->blocks[block_id].compress_len;Yep, true. Patches need a rebase btw as Heikki fixed a commit related to the stats of pg_xlogdump.
--
On 2014-12-06 00:10:11 +0900, Michael Paquier wrote:
> On Sat, Dec 6, 2014 at 12:06 AM, Michael Paquier <michael.paquier@gmail.com>
> wrote:
>
> >
> >
> >
> > On Fri, Dec 5, 2014 at 11:10 PM, Rahila Syed <rahilasyed.90@gmail.com>
> > wrote:
> >
> >> I attempted quick review and could not come up with much except this
> >>
> >> + /*
> >> + * Calculate the amount of FPI data in the record. Each backup block
> >> + * takes up BLCKSZ bytes, minus the "hole" length.
> >> + *
> >> + * XXX: We peek into xlogreader's private decoded backup blocks for
> >> the
> >> + * hole_length. It doesn't seem worth it to add an accessor macro for
> >> + * this.
> >> + */
> >> + fpi_len = 0;
> >> + for (block_id = 0; block_id <= record->max_block_id; block_id++)
> >> + {
> >> + if (XLogRecHasCompressedBlockImage(record, block_id))
> >> + fpi_len += BLCKSZ - record->blocks[block_id].compress_len;
> >>
> >>
> >> IIUC, fpi_len in case of compressed block image should be
> >>
> >> fpi_len = record->blocks[block_id].compress_len;
> >>
> > Yep, true. Patches need a rebase btw as Heikki fixed a commit related to
> > the stats of pg_xlogdump.
> >
>
> In any case, any opinions to switch this patch as "Ready for committer"?
Needing a rebase is a obvious conflict to that... But I guess some wider
looks afterwards won't hurt.
Greetings,
Andres Freund
-- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training &
Services
On Fri, Dec 5, 2014 at 1:49 AM, Rahila Syed <rahilasyed.90@gmail.com> wrote: >>If that's really true, we could consider having no configuration any >>time, and just compressing always. But I'm skeptical that it's >>actually true. > > I was referring to this for CPU utilization: > http://www.postgresql.org/message-id/1410414381339-5818552.post@n5.nabble.com > <http://> > > The above tests were performed on machine with configuration as follows > Server specifications: > Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos > RAM: 32GB > Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos > 1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm I think that measurement methodology is not very good for assessing the CPU overhead, because you are only measuring the percentage CPU utilization, not the absolute amount of CPU utilization. It's not clear whether the duration of the tests was the same for all the configurations you tried - in which case the number of transactions might have been different - or whether the number of operations was exactly the same - in which case the runtime might have been different. Either way, it could obscure an actual difference in absolute CPU usage per transaction. It's unlikely that both the runtime and the number of transactions were identical for all of your tests, because that would imply that the patch makes no difference to performance; if that were true, you wouldn't have bothered writing it.... What I would suggest is instrument the backend with getrusage() at startup and shutdown and have it print the difference in user time and system time. Then, run tests for a fixed number of transactions and see how the total CPU usage for the run differs. Last cycle, Amit Kapila did a bunch of work trying to compress the WAL footprint for updates, and we found that compression was pretty darn expensive there in terms of CPU time. So I am suspicious of the finding that it is free here. It's not impossible that there's some effect which causes us to recoup more CPU time than we spend compressing in this case that did not apply in that case, but the projects are awfully similar, so I tend to doubt it. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Dec 6, 2014 at 12:17 AM, Andres Freund <andres@2ndquadrant.com> wrote:
Needing a rebase is a obvious conflict to that... But I guess some widerOn 2014-12-06 00:10:11 +0900, Michael Paquier wrote:
> On Sat, Dec 6, 2014 at 12:06 AM, Michael Paquier <michael.paquier@gmail.com>
> wrote:
>
> >
> >
> >
> > On Fri, Dec 5, 2014 at 11:10 PM, Rahila Syed <rahilasyed.90@gmail.com>
> > wrote:
> >
> >> I attempted quick review and could not come up with much except this
> >>
> >> + /*
> >> + * Calculate the amount of FPI data in the record. Each backup block
> >> + * takes up BLCKSZ bytes, minus the "hole" length.
> >> + *
> >> + * XXX: We peek into xlogreader's private decoded backup blocks for
> >> the
> >> + * hole_length. It doesn't seem worth it to add an accessor macro for
> >> + * this.
> >> + */
> >> + fpi_len = 0;
> >> + for (block_id = 0; block_id <= record->max_block_id; block_id++)
> >> + {
> >> + if (XLogRecHasCompressedBlockImage(record, block_id))
> >> + fpi_len += BLCKSZ - record->blocks[block_id].compress_len;
> >>
> >>
> >> IIUC, fpi_len in case of compressed block image should be
> >>
> >> fpi_len = record->blocks[block_id].compress_len;
> >>
> > Yep, true. Patches need a rebase btw as Heikki fixed a commit related to
> > the stats of pg_xlogdump.
> >
>
> In any case, any opinions to switch this patch as "Ready for committer"?
looks afterwards won't hurt.
Robert wrote:
> What I would suggest is instrument the backend with getrusage() at
> startup and shutdown and have it print the difference in user time and
> system time. Then, run tests for a fixed number of transactions and
> see how the total CPU usage for the run differs.
1) Compression = on:
Stop LSN: 0/487E49B8
getrusage: proc 11163: LOG: user diff: 63.071127, system diff: 10.898386
pg_xlogdump: FPI size: 122296653 [90.52%]
Result: proc 11648: LOG: user diff: 43.855212, system diff: 7.857965
pg_xlogdump: FPI size: 204359192 [94.10%]
Attachment
> On Thu, Dec 4, 2014 at 8:37 PM, Michael Paquier wrote > I pondered something that Andres mentioned upthread: we may not do the >compression in WAL record only for blocks, but also at record level. Hence >joining the two ideas together I think that we should definitely have >a different >GUC to control the feature, consistently for all the images. Let's call it >wal_compression, with the following possible values: >- on, meaning that a maximum of compression is done, for this feature >basically full_page_writes = on. >- full_page_writes, meaning that full page writes are compressed >- off, default value, to disable completely the feature. >This would let room for another mode: 'record', to completely compress >a record. For now though, I think that a simple on/off switch would be >fine for this patch. Let's keep things simple. +1 for a separate parameter for compression Some changed thoughts to the above * parameter should be SUSET - it doesn't *need* to be set only at server start since all records are independent of each other * ideally we'd like to be able to differentiate the types of usage. which then allows the user to control the level of compression depending upon the type of action. My first cut at what those settings should be are ALL > LOGICAL > PHYSICAL > VACUUM. VACUUM - only compress while running vacuum commands PHYSICAL - only compress while running physical DDL commands (ALTER TABLE set tablespace, CREATE INDEX), i.e. those that wouldn't typically be used for logical decoding LOGICAL - compress FPIs for record types that change tables ALL - all user commands (each level includes all prior levels) * name should not be wal_compression - we're not compressing all wal records, just fpis. There is no evidence that we even want to compress other record types, nor that our compression mechanism is effective at doing so. Simple => keep name as compress_full_page_writes Though perhaps we should have it called wal_compression_level -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Mon, Dec 8, 2014 at 11:30 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > * parameter should be SUSET - it doesn't *need* to be set only at > server start since all records are independent of each other Check. > * ideally we'd like to be able to differentiate the types of usage. > which then allows the user to control the level of compression > depending upon the type of action. My first cut at what those settings > should be are ALL > LOGICAL > PHYSICAL > VACUUM. > VACUUM - only compress while running vacuum commands > PHYSICAL - only compress while running physical DDL commands (ALTER > TABLE set tablespace, CREATE INDEX), i.e. those that wouldn't > typically be used for logical decoding > LOGICAL - compress FPIs for record types that change tables > ALL - all user commands > (each level includes all prior levels) Well, that's clearly an optimization so I don't think this should be done for a first shot but those are interesting fresh ideas. Technically speaking, note that we would need to support such things with a new API to switch a new context flag in registered_buffers of xloginsert.c for each block, and decide if the block is compressed based on this context flag, and the compression level wanted. > * name should not be wal_compression - we're not compressing all wal > records, just fpis. There is no evidence that we even want to compress > other record types, nor that our compression mechanism is effective at > doing so. Simple => keep name as compress_full_page_writes > Though perhaps we should have it called wal_compression_level I don't really like those new names, but I'd prefer wal_compression_level if we go down that road with 'none' as default value. We may still decide in the future to support compression at the record level instead of context level, particularly if we have an API able to do palloc_return_null_at_oom, so the idea of WAL compression is not related only to FPIs IMHO. Regards, -- Michael
unsigned hole_offset:15,
compress_flag:2,
hole_length:15;
Here compress_flag can be 0 or 1 depending on status of compression. We can reduce the compress_flag to just 1 bit flag.
IIUC, the purpose of adding compress_len field in the latest patch is to store length of compressed blocks which is used at the time of decoding the blocks.
With this approach, length of compressed block can be stored in hole_length as,
hole_length = BLCKSZ - compress_len.
Thus, hole_length can serve the purpose of storing length of a compressed block without the need of additional 2-bytes. In DecodeXLogRecord, hole_length can be used for tracking the length of data received in cases of both compressed as well as uncompressed blocks.
As you already mentioned, this will need compressing images with hole but we can MemSet hole to 0 in order to make compression of hole less expensive and effective.
Thank you,
Rahila Syed
--Needing a rebase is a obvious conflict to that... But I guess some widerOn 2014-12-06 00:10:11 +0900, Michael Paquier wrote:
> On Sat, Dec 6, 2014 at 12:06 AM, Michael Paquier <michael.paquier@gmail.com>
> wrote:
>
> >
> >
> >
> > On Fri, Dec 5, 2014 at 11:10 PM, Rahila Syed <rahilasyed.90@gmail.com>
> > wrote:
> >
> >> I attempted quick review and could not come up with much except this
> >>
> >> + /*
> >> + * Calculate the amount of FPI data in the record. Each backup block
> >> + * takes up BLCKSZ bytes, minus the "hole" length.
> >> + *
> >> + * XXX: We peek into xlogreader's private decoded backup blocks for
> >> the
> >> + * hole_length. It doesn't seem worth it to add an accessor macro for
> >> + * this.
> >> + */
> >> + fpi_len = 0;
> >> + for (block_id = 0; block_id <= record->max_block_id; block_id++)
> >> + {
> >> + if (XLogRecHasCompressedBlockImage(record, block_id))
> >> + fpi_len += BLCKSZ - record->blocks[block_id].compress_len;
> >>
> >>
> >> IIUC, fpi_len in case of compressed block image should be
> >>
> >> fpi_len = record->blocks[block_id].compress_len;
> >>
> > Yep, true. Patches need a rebase btw as Heikki fixed a commit related to
> > the stats of pg_xlogdump.
> >
>
> In any case, any opinions to switch this patch as "Ready for committer"?
looks afterwards won't hurt.Here are rebased versions, which are patches 1 and 2. And I am switching as well the patch to "Ready for Committer". The important point to consider for this patch is the use of the additional 2-bytes as uint16 in the block information structure to save the length of a compressed block, which may be compressed without its hole to achieve a double level of compression (image compressed without its hole). We may use a simple flag on one or two bits using for example a bit from hole_length, but in this case we would need to always compress images with their hole included, something more expensive as the compression would take more time.
Robert wrote:
> What I would suggest is instrument the backend with getrusage() at
> startup and shutdown and have it print the difference in user time and
> system time. Then, run tests for a fixed number of transactions and
> see how the total CPU usage for the run differs.That's a nice idea, which is done with patch 3 as a simple hack calling twice getrusage at the beginning of PostgresMain and before proc_exit, calculating the difference time and logging it for each process (used as well log_line_prefix with %p).Then I just did a small test with a load of a pgbench-scale-100 database on fresh instances:
1) Compression = on:
Stop LSN: 0/487E49B8
getrusage: proc 11163: LOG: user diff: 63.071127, system diff: 10.898386
pg_xlogdump: FPI size: 122296653 [90.52%]2) Compression = offStop LSN: 0/4E54EB88
Result: proc 11648: LOG: user diff: 43.855212, system diff: 7.857965
pg_xlogdump: FPI size: 204359192 [94.10%]And the CPU consumption is showing quite some difference... I'd expect as well pglz_compress to show up high in a perf profile for this case (don't have the time to do that now, but a perf record -a -g would be fine I guess).Regards,Michael
On Mon, Dec 8, 2014 at 3:42 PM, Rahila Syed <rahilasyed90@gmail.com> wrote: > >>The important point to consider for this patch is the use of the additional >> 2-bytes as uint16 in the block information structure to save the length of a >> compressed >>block, which may be compressed without its hole to achieve a double level >> of compression (image compressed without its hole). We may use a simple flag >> on >>one or two bits using for example a bit from hole_length, but in this case >> we would need to always compress images with their hole included, something >> more > >expensive as the compression would take more time. > As you have mentioned here the idea to use bits from existing fields rather > than adding additional 2 bytes in header, > FWIW elaborating slightly on the way it was done in the initial patches, > We can use the following struct > > unsigned hole_offset:15, > compress_flag:2, > hole_length:15; > > Here compress_flag can be 0 or 1 depending on status of compression. We can > reduce the compress_flag to just 1 bit flag. Just adding that this is fine as the largest page size that can be set is 32k. > IIUC, the purpose of adding compress_len field in the latest patch is to > store length of compressed blocks which is used at the time of decoding the > blocks. > > With this approach, length of compressed block can be stored in hole_length > as, > > hole_length = BLCKSZ - compress_len. > > Thus, hole_length can serve the purpose of storing length of a compressed > block without the need of additional 2-bytes. In DecodeXLogRecord, > hole_length can be used for tracking the length of data received in cases of > both compressed as well as uncompressed blocks. > > As you already mentioned, this will need compressing images with hole but > we can MemSet hole to 0 in order to make compression of hole less expensive > and effective. Thanks for coming back to this point in more details, this is very important. The additional 2 bytes used make compression less expensive by ignoring the hole, for a bit more data in each record. Using uint16 is as well a cleaner code style, more in-line wit hte other fields, but that's a personal opinion ;) Doing a switch from one approach to the other is easy enough though, so let's see what others think. Regards, -- Michael
On 8 December 2014 at 11:46, Michael Paquier <michael.paquier@gmail.com> wrote: >> * ideally we'd like to be able to differentiate the types of usage. >> which then allows the user to control the level of compression >> depending upon the type of action. My first cut at what those settings >> should be are ALL > LOGICAL > PHYSICAL > VACUUM. >> VACUUM - only compress while running vacuum commands >> PHYSICAL - only compress while running physical DDL commands (ALTER >> TABLE set tablespace, CREATE INDEX), i.e. those that wouldn't >> typically be used for logical decoding >> LOGICAL - compress FPIs for record types that change tables >> ALL - all user commands >> (each level includes all prior levels) > > Well, that's clearly an optimization so I don't think this should be > done for a first shot but those are interesting fresh ideas. It is important that we offer an option that retains user performance. I don't see that as an optimisation, but as an essential item. The current feature will reduce WAL volume, at the expense of foreground user performance. Worse, that will all happen around time of new checkpoint, so I expect this will have a large impact. Presumably testing has been done to show the impact on user response times? If not, we need that. The most important distinction is between foreground and background tasks. If you think the above is too complex, then we should make the parameter into a USET, but set it to on in VACUUM, CLUSTER and autovacuum. > Technically speaking, note that we would need to support such things > with a new API to switch a new context flag in registered_buffers of > xloginsert.c for each block, and decide if the block is compressed > based on this context flag, and the compression level wanted. > >> * name should not be wal_compression - we're not compressing all wal >> records, just fpis. There is no evidence that we even want to compress >> other record types, nor that our compression mechanism is effective at >> doing so. Simple => keep name as compress_full_page_writes >> Though perhaps we should have it called wal_compression_level > > I don't really like those new names, but I'd prefer > wal_compression_level if we go down that road with 'none' as default > value. We may still decide in the future to support compression at the > record level instead of context level, particularly if we have an API > able to do palloc_return_null_at_oom, so the idea of WAL compression > is not related only to FPIs IMHO. We may yet decide, but the pglz implementation is not effective on smaller record lengths. Nor has any testing been done to show that is even desirable. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Sun, Dec 7, 2014 at 9:30 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > * parameter should be SUSET - it doesn't *need* to be set only at > server start since all records are independent of each other Why not USERSET? There's no point in trying to prohibit users from doing things that will cause bad performance because they can do that anyway. > * ideally we'd like to be able to differentiate the types of usage. > which then allows the user to control the level of compression > depending upon the type of action. My first cut at what those settings > should be are ALL > LOGICAL > PHYSICAL > VACUUM. > > VACUUM - only compress while running vacuum commands > PHYSICAL - only compress while running physical DDL commands (ALTER > TABLE set tablespace, CREATE INDEX), i.e. those that wouldn't > typically be used for logical decoding > LOGICAL - compress FPIs for record types that change tables > ALL - all user commands > (each level includes all prior levels) Interesting idea, but what evidence do we have that a simple on/off switch isn't good enough? > * name should not be wal_compression - we're not compressing all wal > records, just fpis. There is no evidence that we even want to compress > other record types, nor that our compression mechanism is effective at > doing so. Simple => keep name as compress_full_page_writes Quite right. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2014-12-08 14:09:19 -0500, Robert Haas wrote: > > records, just fpis. There is no evidence that we even want to compress > > other record types, nor that our compression mechanism is effective at > > doing so. Simple => keep name as compress_full_page_writes > > Quite right. I don't really agree with this. There's lots of records which can be quite big where compression could help a fair bit. Most prominently HEAP2_MULTI_INSERT + INIT_PAGE. During initial COPY that's the biggest chunk of WAL. And these are big and repetitive enough that compression is very likely to be beneficial. I still think that just compressing the whole record if it's above a certain size is going to be better than compressing individual parts. Michael argued thta that'd be complicated because of the varying size of the required 'scratch space'. I don't buy that argument though. It's easy enough to simply compress all the data in some fixed chunk size. I.e. always compress 64kb in one go. If there's more compress that independently. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Mon, Dec 8, 2014 at 2:21 PM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2014-12-08 14:09:19 -0500, Robert Haas wrote: >> > records, just fpis. There is no evidence that we even want to compress >> > other record types, nor that our compression mechanism is effective at >> > doing so. Simple => keep name as compress_full_page_writes >> >> Quite right. > > I don't really agree with this. There's lots of records which can be > quite big where compression could help a fair bit. Most prominently > HEAP2_MULTI_INSERT + INIT_PAGE. During initial COPY that's the biggest > chunk of WAL. And these are big and repetitive enough that compression > is very likely to be beneficial. > > I still think that just compressing the whole record if it's above a > certain size is going to be better than compressing individual > parts. Michael argued thta that'd be complicated because of the varying > size of the required 'scratch space'. I don't buy that argument > though. It's easy enough to simply compress all the data in some fixed > chunk size. I.e. always compress 64kb in one go. If there's more > compress that independently. I agree that idea is worth considering. But I think we should decide which way is better and then do just one or the other. I can't see the point in adding wal_compress=full_pages now and then offering an alternative wal_compress=big_records in 9.5. I think it's also quite likely that there may be cases where context-aware compression strategies can be employed. For example, the prefix/suffix compression of updates that Amit did last cycle exploit the likely commonality between the old and new tuple. We might have cases like that where there are meaningful trade-offs to be made between CPU and I/O, or other reasons to have user-exposed knobs. I think we'll be much happier if those are completely separate GUCs, so we can say things like compress_gin_wal=true and compress_brin_effort=3.14 rather than trying to have a single wal_compress GUC and assuming that we can shoehorn all future needs into it. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 12/08/2014 09:21 PM, Andres Freund wrote: > I still think that just compressing the whole record if it's above a > certain size is going to be better than compressing individual > parts. Michael argued thta that'd be complicated because of the varying > size of the required 'scratch space'. I don't buy that argument > though. It's easy enough to simply compress all the data in some fixed > chunk size. I.e. always compress 64kb in one go. If there's more > compress that independently. Doing it in fixed-size chunks doesn't help - you have to hold onto the compressed data until it's written to the WAL buffers. But you could just allocate a "large enough" scratch buffer, and give up if it doesn't fit. If the compressed data doesn't fit in e.g. 3 * 8kb, it didn't compress very well, so there's probably no point in compressing it anyway. Now, an exception to that might be a record that contains something else than page data, like a commit record with millions of subxids, but I think we could live with not compressing those, even though it would be beneficial to do so. - Heikki
On Tue, Dec 9, 2014 at 5:33 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > On 12/08/2014 09:21 PM, Andres Freund wrote: >> >> I still think that just compressing the whole record if it's above a >> certain size is going to be better than compressing individual >> parts. Michael argued thta that'd be complicated because of the varying >> size of the required 'scratch space'. I don't buy that argument >> though. It's easy enough to simply compress all the data in some fixed >> chunk size. I.e. always compress 64kb in one go. If there's more >> compress that independently. > > > Doing it in fixed-size chunks doesn't help - you have to hold onto the > compressed data until it's written to the WAL buffers. > > But you could just allocate a "large enough" scratch buffer, and give up if > it doesn't fit. If the compressed data doesn't fit in e.g. 3 * 8kb, it > didn't compress very well, so there's probably no point in compressing it > anyway. Now, an exception to that might be a record that contains something > else than page data, like a commit record with millions of subxids, but I > think we could live with not compressing those, even though it would be > beneficial to do so. Another thing to consider is the possibility to control at GUC level what is the maximum size of a record we allow to compress. -- Michael
On 9 December 2014 at 04:09, Robert Haas <robertmhaas@gmail.com> wrote: > On Sun, Dec 7, 2014 at 9:30 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >> * parameter should be SUSET - it doesn't *need* to be set only at >> server start since all records are independent of each other > > Why not USERSET? There's no point in trying to prohibit users from > doing things that will cause bad performance because they can do that > anyway. Yes, I think USERSET would work fine for this. >> * ideally we'd like to be able to differentiate the types of usage. >> which then allows the user to control the level of compression >> depending upon the type of action. My first cut at what those settings >> should be are ALL > LOGICAL > PHYSICAL > VACUUM. >> >> VACUUM - only compress while running vacuum commands >> PHYSICAL - only compress while running physical DDL commands (ALTER >> TABLE set tablespace, CREATE INDEX), i.e. those that wouldn't >> typically be used for logical decoding >> LOGICAL - compress FPIs for record types that change tables >> ALL - all user commands >> (each level includes all prior levels) > > Interesting idea, but what evidence do we have that a simple on/off > switch isn't good enough? Yes, I think that was overcooked. What I'm thinking is that in the long run we might have groups of parameters attached to different types of action, so we wouldn't need, for example, two parameters for work_mem and maintenance_work_mem. We'd just have work_mem and then a scheme that has different values of work_mem for different action types. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 9 December 2014 at 04:21, Andres Freund <andres@2ndquadrant.com> wrote: > On 2014-12-08 14:09:19 -0500, Robert Haas wrote: >> > records, just fpis. There is no evidence that we even want to compress >> > other record types, nor that our compression mechanism is effective at >> > doing so. Simple => keep name as compress_full_page_writes >> >> Quite right. > > I don't really agree with this. There's lots of records which can be > quite big where compression could help a fair bit. Most prominently > HEAP2_MULTI_INSERT + INIT_PAGE. During initial COPY that's the biggest > chunk of WAL. And these are big and repetitive enough that compression > is very likely to be beneficial. Yes, you're right there. I was forgetting those aren't FPIs. However they are close enough that it wouldn't necessarily effect the naming of a parameter that controls such compression. > I still think that just compressing the whole record if it's above a > certain size is going to be better than compressing individual > parts. I think its OK to think it, but we should measure it. For now then, I remove my objection to a commit of this patch based upon parameter naming/rethinking. We have a fine tradition of changing the names after the release is mostly wrapped, so lets pick a name in a few months time when the dust has settled on what's in. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
>
> On 8 December 2014 at 11:46, Michael Paquier <michael.paquier@gmail.com> wrote:
> > I don't really like those new names, but I'd prefer
> > wal_compression_level if we go down that road with 'none' as default
> > value. We may still decide in the future to support compression at the
> > record level instead of context level, particularly if we have an API
> > able to do palloc_return_null_at_oom, so the idea of WAL compression
> > is not related only to FPIs IMHO.
>
> We may yet decide, but the pglz implementation is not effective on
> smaller record lengths. Nor has any testing been done to show that is
> even desirable.
>
On Mon, Dec 8, 2014 at 3:17 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
>
> On 8 December 2014 at 11:46, Michael Paquier <michael.paquier@gmail.com> wrote:
> > I don't really like those new names, but I'd prefer
> > wal_compression_level if we go down that road with 'none' as default
> > value. We may still decide in the future to support compression at the
> > record level instead of context level, particularly if we have an API
> > able to do palloc_return_null_at_oom, so the idea of WAL compression
> > is not related only to FPIs IMHO.
>
> We may yet decide, but the pglz implementation is not effective on
> smaller record lengths. Nor has any testing been done to show that is
> even desirable.
>It's even much worse for non-compressible (or less-compressible)WAL data. I am not clear here that how a simple on/off switchcould address such cases because the data could be sometimesdependent on which table user is doing operations (means schema ordata in some tables are more prone for compression in which caseit can give us benefits). I think may be we should think something onlines what Robert has touched in one of his e-mails (context-awarecompression strategy).
shared_buffers=512MB
checkpoint_segments=1024
checkpoint_timeout = 5min
fsync=off
pgbench -i -s 100
psql -c 'checkpoint;'
date > ~/report.txt
pgbench -P 1 -c 16 -j 16 -T 1200 2>> ~/report.txt &
latency average: 9.007 ms
latency stddev: 25.527 ms
tps = 1775.614812 (including connections establishing)
Here is the latency when a checkpoint that wrote 28% of the buffers begun (570s):
progress: 568.0 s, 2000.9 tps, lat 8.098 ms stddev 23.799
progress: 569.0 s, 1873.9 tps, lat 8.442 ms stddev 22.837
progress: 570.2 s, 1622.4 tps, lat 9.533 ms stddev 24.027
progress: 571.0 s, 1633.4 tps, lat 10.302 ms stddev 27.331
progress: 572.1 s, 1588.4 tps, lat 9.908 ms stddev 25.728
progress: 573.1 s, 1579.3 tps, lat 10.186 ms stddev 25.782
latency average: 8.507 ms
latency stddev: 25.052 ms
tps = 1870.368880 (including connections establishing)
Here is the latency for a checkpoint that wrote 28% of buffers:
progress: 297.1 s, 1997.9 tps, lat 8.112 ms stddev 24.288
progress: 298.1 s, 1990.4 tps, lat 7.806 ms stddev 21.849
progress: 299.0 s, 1986.9 tps, lat 8.366 ms stddev 22.896
progress: 300.0 s, 1648.1 tps, lat 9.728 ms stddev 25.811
progress: 301.0 s, 1806.5 tps, lat 8.646 ms stddev 24.187
progress: 302.1 s, 1810.9 tps, lat 8.960 ms stddev 24.201
progress: 303.0 s, 1831.9 tps, lat 8.623 ms stddev 23.199
progress: 304.0 s, 1951.2 tps, lat 8.149 ms stddev 22.871
Here is another one that began around 600s (20% of buffers):
progress: 594.0 s, 1738.8 tps, lat 9.135 ms stddev 25.140
progress: 595.0 s, 893.2 tps, lat 18.153 ms stddev 67.186
progress: 596.1 s, 1671.0 tps, lat 9.470 ms stddev 25.691
progress: 597.1 s, 1580.3 tps, lat 10.189 ms stddev 26.430
progress: 598.0 s, 1570.9 tps, lat 10.089 ms stddev 23.684
progress: 599.2 s, 1657.0 tps, lat 9.385 ms stddev 23.794
progress: 600.0 s, 1665.5 tps, lat 10.280 ms stddev 25.857
progress: 601.1 s, 1571.7 tps, lat 9.851 ms stddev 25.341
progress: 602.1 s, 1577.7 tps, lat 10.056 ms stddev 25.331
progress: 603.0 s, 1600.1 tps, lat 10.329 ms stddev 25.429
progress: 604.0 s, 1593.8 tps, lat 10.004 ms stddev 26.816
Not sure what happened here, the burst has been a bit higher.
However roughly the latency was never higher than 10.5ms for the non-compression case. With those measurements I am getting more or less 1ms of latency difference between the compression and non-compression cases when checkpoint show up. Note that fsync is disabled.
Also, I am still planning to hack a patch able to compress directly records with a scratch buffer up 32k and see the difference with what I got here. For now, the results are attached.
Attachment
>startup and shutdown and have it print the difference in user time and
>system time. Then, run tests for a fixed number of transactions and
>see how the total CPU usage for the run differs.
RAM: 32GB
Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos
1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm
On Fri, Dec 5, 2014 at 1:49 AM, Rahila Syed <rahilasyed.90@gmail.com> wrote:
>>If that's really true, we could consider having no configuration any
>>time, and just compressing always. But I'm skeptical that it's
>>actually true.
>
> I was referring to this for CPU utilization:
> http://www.postgresql.org/message-id/1410414381339-5818552.post@n5.nabble.com
> <http://>
>
> The above tests were performed on machine with configuration as follows
> Server specifications:
> Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos
> RAM: 32GB
> Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos
> 1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm
I think that measurement methodology is not very good for assessing
the CPU overhead, because you are only measuring the percentage CPU
utilization, not the absolute amount of CPU utilization. It's not
clear whether the duration of the tests was the same for all the
configurations you tried - in which case the number of transactions
might have been different - or whether the number of operations was
exactly the same - in which case the runtime might have been
different. Either way, it could obscure an actual difference in
absolute CPU usage per transaction. It's unlikely that both the
runtime and the number of transactions were identical for all of your
tests, because that would imply that the patch makes no difference to
performance; if that were true, you wouldn't have bothered writing
it....
What I would suggest is instrument the backend with getrusage() at
startup and shutdown and have it print the difference in user time and
system time. Then, run tests for a fixed number of transactions and
see how the total CPU usage for the run differs.
Last cycle, Amit Kapila did a bunch of work trying to compress the WAL
footprint for updates, and we found that compression was pretty darn
expensive there in terms of CPU time. So I am suspicious of the
finding that it is free here. It's not impossible that there's some
effect which causes us to recoup more CPU time than we spend
compressing in this case that did not apply in that case, but the
projects are awfully similar, so I tend to doubt it.
On Wed, Dec 10, 2014 at 07:40:46PM +0530, Rahila Syed wrote: > The tests ran for around 30 mins.Manual checkpoint was run before each test. > > Compression WAL generated %compression Latency-avg CPU usage > (seconds) TPS Latency > stddev > > > on 1531.4 MB ~35 % 7.351 ms > user diff: 562.67s system diff: 41.40s 135.96 > 13.759 ms > > > off 2373.1 MB 6.781 ms > user diff: 354.20s system diff: 39.67s 147.40 > 14.152 ms > > The compression obtained is quite high close to 35 %. > CPU usage at user level when compression is on is quite noticeably high as > compared to that when compression is off. But gain in terms of reduction of WAL > is also high. I am sorry but I can't understand the above results due to wrapping. Are you saying compression was twice as slow? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
>What I would suggest is instrument the backend with getrusage() at
>startup and shutdown and have it print the difference in user time and
>system time. Then, run tests for a fixed number of transactions and
>see how the total CPU usage for the run differs.Folllowing are the numbers obtained on tests with absolute CPU usage, fixed number of transactions and longer duration with latest fpw compression patchpgbench command : pgbench -r -t 250000 -M preparedTo ensure that data is not highly compressible, empty filler columns were altered usingalter table pgbench_accounts alter column filler type text usinggen_random_uuid()::textcheckpoint_segments = 1024checkpoint_timeout = 5minfsync = onThe tests ran for around 30 mins.Manual checkpoint was run before each test.Compression WAL generated %compression Latency-avg CPU usage (seconds) TPS Latency stddevon 1531.4 MB ~35 % 7.351 ms user diff: 562.67s system diff: 41.40s 135.96 13.759 msoff 2373.1 MB 6.781 ms user diff: 354.20s system diff: 39.67s 147.40 14.152 msThe compression obtained is quite high close to 35 %.CPU usage at user level when compression is on is quite noticeably high as compared to that when compression is off. But gain in terms of reduction of WAL is also high.Server specifications:Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos
RAM: 32GB
Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos
1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpmThank you,Rahila SyedOn Fri, Dec 5, 2014 at 10:38 PM, Robert Haas <robertmhaas@gmail.com> wrote:On Fri, Dec 5, 2014 at 1:49 AM, Rahila Syed <rahilasyed.90@gmail.com> wrote:
>>If that's really true, we could consider having no configuration any
>>time, and just compressing always. But I'm skeptical that it's
>>actually true.
>
> I was referring to this for CPU utilization:
> http://www.postgresql.org/message-id/1410414381339-5818552.post@n5.nabble.com
> <http://>
>
> The above tests were performed on machine with configuration as follows
> Server specifications:
> Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos
> RAM: 32GB
> Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos
> 1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm
I think that measurement methodology is not very good for assessing
the CPU overhead, because you are only measuring the percentage CPU
utilization, not the absolute amount of CPU utilization. It's not
clear whether the duration of the tests was the same for all the
configurations you tried - in which case the number of transactions
might have been different - or whether the number of operations was
exactly the same - in which case the runtime might have been
different. Either way, it could obscure an actual difference in
absolute CPU usage per transaction. It's unlikely that both the
runtime and the number of transactions were identical for all of your
tests, because that would imply that the patch makes no difference to
performance; if that were true, you wouldn't have bothered writing
it....
What I would suggest is instrument the backend with getrusage() at
startup and shutdown and have it print the difference in user time and
system time. Then, run tests for a fixed number of transactions and
see how the total CPU usage for the run differs.
Last cycle, Amit Kapila did a bunch of work trying to compress the WAL
footprint for updates, and we found that compression was pretty darn
expensive there in terms of CPU time. So I am suspicious of the
finding that it is free here. It's not impossible that there's some
effect which causes us to recoup more CPU time than we spend
compressing in this case that did not apply in that case, but the
projects are awfully similar, so I tend to doubt it.
>Are you saying compression was twice as slow?
On Wed, Dec 10, 2014 at 07:40:46PM +0530, Rahila Syed wrote:
> The tests ran for around 30 mins.Manual checkpoint was run before each test.
>
> Compression WAL generated %compression Latency-avg CPU usage
> (seconds) TPS Latency
> stddev
>
>
> on 1531.4 MB ~35 % 7.351 ms
> user diff: 562.67s system diff: 41.40s 135.96
> 13.759 ms
>
>
> off 2373.1 MB 6.781 ms
> user diff: 354.20s system diff: 39.67s 147.40
> 14.152 ms
>
> The compression obtained is quite high close to 35 %.
> CPU usage at user level when compression is on is quite noticeably high as
> compared to that when compression is off. But gain in terms of reduction of WAL
> is also high.
I am sorry but I can't understand the above results due to wrapping.
Are you saying compression was twice as slow?
--
Bruce Momjian <bruce@momjian.us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ Everyone has their own god. +
On Thu, Dec 11, 2014 at 01:26:38PM +0530, Rahila Syed wrote: > >I am sorry but I can't understand the above results due to wrapping. > >Are you saying compression was twice as slow? > > CPU usage at user level (in seconds) for compression set 'on' is 562 secs > while that for compression set 'off' is 354 secs. As per the readings, it > takes little less than double CPU time to compress. > However , the total time taken to run 250000 transactions for each of the > scenario is as follows, > > compression = 'on' : 1838 secs > = 'off' : 1701 secs > > > Different is around 140 secs. OK, so the compression took 2x the cpu and was 8% slower. The only benefit is WAL files are 35% smaller? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On Thu, Dec 11, 2014 at 01:26:38PM +0530, Rahila Syed wrote:
> >I am sorry but I can't understand the above results due to wrapping.
> >Are you saying compression was twice as slow?
>
> CPU usage at user level (in seconds) for compression set 'on' is 562 secs
> while that for compression set 'off' is 354 secs. As per the readings, it
> takes little less than double CPU time to compress.
> However , the total time taken to run 250000 transactions for each of the
> scenario is as follows,
>
> compression = 'on' : 1838 secs
> = 'off' : 1701 secs
>
>
> Different is around 140 secs.
OK, so the compression took 2x the cpu and was 8% slower. The only
benefit is WAL files are 35% smaller?
On Tue, Dec 9, 2014 at 4:09 AM, Robert Haas <robertmhaas@gmail.com> wrote: > > On Sun, Dec 7, 2014 at 9:30 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > > * parameter should be SUSET - it doesn't *need* to be set only at > > server start since all records are independent of each other > > Why not USERSET? There's no point in trying to prohibit users from > doing things that will cause bad performance because they can do that > anyway. Using SUSET or USERSET has a small memory cost: we should unconditionally palloc the buffers containing the compressed data until WAL is written out. We could always call an equivalent of InitXLogInsert when this parameter is updated but that would be bug-prone IMO and it does not plead in favor of code simplicity. Regards, -- Michael
On Thu, Dec 11, 2014 at 10:33 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Tue, Dec 9, 2014 at 4:09 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Sun, Dec 7, 2014 at 9:30 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >> > * parameter should be SUSET - it doesn't *need* to be set only at >> > server start since all records are independent of each other >> >> Why not USERSET? There's no point in trying to prohibit users from >> doing things that will cause bad performance because they can do that >> anyway. > > Using SUSET or USERSET has a small memory cost: we should > unconditionally palloc the buffers containing the compressed data > until WAL is written out. We could always call an equivalent of > InitXLogInsert when this parameter is updated but that would be > bug-prone IMO and it does not plead in favor of code simplicity. I don't understand what you're saying here. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Dec 11, 2014 at 11:34 AM, Bruce Momjian <bruce@momjian.us> wrote: >> compression = 'on' : 1838 secs >> = 'off' : 1701 secs >> >> Different is around 140 secs. > > OK, so the compression took 2x the cpu and was 8% slower. The only > benefit is WAL files are 35% smaller? Compression didn't take 2x the CPU. It increased user CPU from 354.20 s to 562.67 s over the course of the run, so it took about 60% more CPU. But I wouldn't be too discouraged by that. At least AIUI, there are quite a number of users for whom WAL volume is a serious challenge, and they might be willing to pay that price to have less of it. Also, we have talked a number of times before about incorporating Snappy or LZ4, which I'm guessing would save a fair amount of CPU -- but the decision was made to leave that out of the first version, and just use pg_lz, to keep the initial patch simple. I think that was a good decision. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2014-12-12 08:27:59 -0500, Robert Haas wrote: > On Thu, Dec 11, 2014 at 11:34 AM, Bruce Momjian <bruce@momjian.us> wrote: > >> compression = 'on' : 1838 secs > >> = 'off' : 1701 secs > >> > >> Different is around 140 secs. > > > > OK, so the compression took 2x the cpu and was 8% slower. The only > > benefit is WAL files are 35% smaller? > > Compression didn't take 2x the CPU. It increased user CPU from 354.20 > s to 562.67 s over the course of the run, so it took about 60% more > CPU. > > But I wouldn't be too discouraged by that. At least AIUI, there are > quite a number of users for whom WAL volume is a serious challenge, > and they might be willing to pay that price to have less of it. And it might actually result in *higher* performance in a good number of cases if the the WAL flushes are a significant part of the cost. IIRC he test used a single process - that's probably not too representative... > Also, > we have talked a number of times before about incorporating Snappy or > LZ4, which I'm guessing would save a fair amount of CPU -- but the > decision was made to leave that out of the first version, and just use > pg_lz, to keep the initial patch simple. I think that was a good > decision. Agreed. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Dec 12, 2014 at 10:23 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Dec 11, 2014 at 10:33 PM, Michael Paquier > <michael.paquier@gmail.com> wrote: >> On Tue, Dec 9, 2014 at 4:09 AM, Robert Haas <robertmhaas@gmail.com> wrote: >>> On Sun, Dec 7, 2014 at 9:30 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >>> > * parameter should be SUSET - it doesn't *need* to be set only at >>> > server start since all records are independent of each other >>> >>> Why not USERSET? There's no point in trying to prohibit users from >>> doing things that will cause bad performance because they can do that >>> anyway. >> >> Using SUSET or USERSET has a small memory cost: we should >> unconditionally palloc the buffers containing the compressed data >> until WAL is written out. We could always call an equivalent of >> InitXLogInsert when this parameter is updated but that would be >> bug-prone IMO and it does not plead in favor of code simplicity. > > I don't understand what you're saying here. I just meant that the scratch buffers used to store temporarily the compressed and uncompressed data should be palloc'd all the time, even if the switch is off. -- Michael
On Fri, Dec 12, 2014 at 08:27:59AM -0500, Robert Haas wrote: > On Thu, Dec 11, 2014 at 11:34 AM, Bruce Momjian <bruce@momjian.us> wrote: > >> compression = 'on' : 1838 secs > >> = 'off' : 1701 secs > >> > >> Different is around 140 secs. > > > > OK, so the compression took 2x the cpu and was 8% slower. The only > > benefit is WAL files are 35% smaller? > > Compression didn't take 2x the CPU. It increased user CPU from 354.20 > s to 562.67 s over the course of the run, so it took about 60% more > CPU. > > But I wouldn't be too discouraged by that. At least AIUI, there are > quite a number of users for whom WAL volume is a serious challenge, > and they might be willing to pay that price to have less of it. Also, > we have talked a number of times before about incorporating Snappy or > LZ4, which I'm guessing would save a fair amount of CPU -- but the > decision was made to leave that out of the first version, and just use > pg_lz, to keep the initial patch simple. I think that was a good > decision. Well, the larger question is why wouldn't we just have the user compress the entire WAL file before archiving --- why have each backend do it? Is it the write volume we are saving? I though this WAL compression gave better performance in some cases. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On 2014-12-12 09:18:01 -0500, Bruce Momjian wrote: > On Fri, Dec 12, 2014 at 08:27:59AM -0500, Robert Haas wrote: > > On Thu, Dec 11, 2014 at 11:34 AM, Bruce Momjian <bruce@momjian.us> wrote: > > >> compression = 'on' : 1838 secs > > >> = 'off' : 1701 secs > > >> > > >> Different is around 140 secs. > > > > > > OK, so the compression took 2x the cpu and was 8% slower. The only > > > benefit is WAL files are 35% smaller? > > > > Compression didn't take 2x the CPU. It increased user CPU from 354.20 > > s to 562.67 s over the course of the run, so it took about 60% more > > CPU. > > > > But I wouldn't be too discouraged by that. At least AIUI, there are > > quite a number of users for whom WAL volume is a serious challenge, > > and they might be willing to pay that price to have less of it. Also, > > we have talked a number of times before about incorporating Snappy or > > LZ4, which I'm guessing would save a fair amount of CPU -- but the > > decision was made to leave that out of the first version, and just use > > pg_lz, to keep the initial patch simple. I think that was a good > > decision. > > Well, the larger question is why wouldn't we just have the user compress > the entire WAL file before archiving --- why have each backend do it? > Is it the write volume we are saving? I though this WAL compression > gave better performance in some cases. Err. Streaming? Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Dec 12, 2014 at 03:22:24PM +0100, Andres Freund wrote: > On 2014-12-12 09:18:01 -0500, Bruce Momjian wrote: > > On Fri, Dec 12, 2014 at 08:27:59AM -0500, Robert Haas wrote: > > > On Thu, Dec 11, 2014 at 11:34 AM, Bruce Momjian <bruce@momjian.us> wrote: > > > >> compression = 'on' : 1838 secs > > > >> = 'off' : 1701 secs > > > >> > > > >> Different is around 140 secs. > > > > > > > > OK, so the compression took 2x the cpu and was 8% slower. The only > > > > benefit is WAL files are 35% smaller? > > > > > > Compression didn't take 2x the CPU. It increased user CPU from 354.20 > > > s to 562.67 s over the course of the run, so it took about 60% more > > > CPU. > > > > > > But I wouldn't be too discouraged by that. At least AIUI, there are > > > quite a number of users for whom WAL volume is a serious challenge, > > > and they might be willing to pay that price to have less of it. Also, > > > we have talked a number of times before about incorporating Snappy or > > > LZ4, which I'm guessing would save a fair amount of CPU -- but the > > > decision was made to leave that out of the first version, and just use > > > pg_lz, to keep the initial patch simple. I think that was a good > > > decision. > > > > Well, the larger question is why wouldn't we just have the user compress > > the entire WAL file before archiving --- why have each backend do it? > > Is it the write volume we are saving? I though this WAL compression > > gave better performance in some cases. > > Err. Streaming? Well, you can already set up SSL for compression while streaming. In fact, I assume many are already using SSL for streaming as the majority of SSL overhead is from connection start. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On 2014-12-12 09:24:27 -0500, Bruce Momjian wrote: > On Fri, Dec 12, 2014 at 03:22:24PM +0100, Andres Freund wrote: > > > Well, the larger question is why wouldn't we just have the user compress > > > the entire WAL file before archiving --- why have each backend do it? > > > Is it the write volume we are saving? I though this WAL compression > > > gave better performance in some cases. > > > > Err. Streaming? > > Well, you can already set up SSL for compression while streaming. In > fact, I assume many are already using SSL for streaming as the majority > of SSL overhead is from connection start. That's not really true. The overhead of SSL during streaming is *significant*. Both the kind of compression it does (which is far more expensive than pglz or lz4) and the encyrption itself. In many cases it's prohibitively expensive - there's even a fair number on-list reports about this. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Dec 12, 2014 at 11:32 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Fri, Dec 12, 2014 at 9:15 AM, Michael Paquier > <michael.paquier@gmail.com> wrote: >> I just meant that the scratch buffers used to store temporarily the >> compressed and uncompressed data should be palloc'd all the time, even >> if the switch is off. > > If they're fixed size, you can just put them on the heap as static globals. > static char space_for_stuff[65536]; Well sure :) > Or whatever you need. > I don't think that's a cost worth caring about. OK, I thought it was. -- Michael
On Fri, Dec 12, 2014 at 9:15 AM, Michael Paquier <michael.paquier@gmail.com> wrote: > I just meant that the scratch buffers used to store temporarily the > compressed and uncompressed data should be palloc'd all the time, even > if the switch is off. If they're fixed size, you can just put them on the heap as static globals. static char space_for_stuff[65536]; Or whatever you need. I don't think that's a cost worth caring about. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Dec 12, 2014 at 9:34 AM, Michael Paquier <michael.paquier@gmail.com> wrote: >> I don't think that's a cost worth caring about. > OK, I thought it was. Space on the heap that never gets used is basically free. The OS won't actually allocate physical memory unless the pages are actually accessed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
>the entire WAL file before archiving --- why have each backend do it?
>Is it the write volume we are saving?
Well, the larger question is why wouldn't we just have the user compressOn Fri, Dec 12, 2014 at 08:27:59AM -0500, Robert Haas wrote:
> On Thu, Dec 11, 2014 at 11:34 AM, Bruce Momjian <bruce@momjian.us> wrote:
> >> compression = 'on' : 1838 secs
> >> = 'off' : 1701 secs
> >>
> >> Different is around 140 secs.
> >
> > OK, so the compression took 2x the cpu and was 8% slower. The only
> > benefit is WAL files are 35% smaller?
>
> Compression didn't take 2x the CPU. It increased user CPU from 354.20
> s to 562.67 s over the course of the run, so it took about 60% more
> CPU.
>
> But I wouldn't be too discouraged by that. At least AIUI, there are
> quite a number of users for whom WAL volume is a serious challenge,
> and they might be willing to pay that price to have less of it. Also,
> we have talked a number of times before about incorporating Snappy or
> LZ4, which I'm guessing would save a fair amount of CPU -- but the
> decision was made to leave that out of the first version, and just use
> pg_lz, to keep the initial patch simple. I think that was a good
> decision.
the entire WAL file before archiving --- why have each backend do it?
Is it the write volume we are saving? I though this WAL compression
gave better performance in some cases.
--
Bruce Momjian <bruce@momjian.us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ Everyone has their own god. +
On Fri, Dec 12, 2014 at 03:27:33PM +0100, Andres Freund wrote: > On 2014-12-12 09:24:27 -0500, Bruce Momjian wrote: > > On Fri, Dec 12, 2014 at 03:22:24PM +0100, Andres Freund wrote: > > > > Well, the larger question is why wouldn't we just have the user compress > > > > the entire WAL file before archiving --- why have each backend do it? > > > > Is it the write volume we are saving? I though this WAL compression > > > > gave better performance in some cases. > > > > > > Err. Streaming? > > > > Well, you can already set up SSL for compression while streaming. In > > fact, I assume many are already using SSL for streaming as the majority > > of SSL overhead is from connection start. > > That's not really true. The overhead of SSL during streaming is > *significant*. Both the kind of compression it does (which is far more > expensive than pglz or lz4) and the encyrption itself. In many cases > it's prohibitively expensive - there's even a fair number on-list > reports about this. Well, I am just trying to understand when someone would benefit from WAL compression. Are we saying it is only useful for non-SSL streaming? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On Wed, Dec 10, 2014 at 07:40:46PM +0530, Rahila Syed wrote:
> The tests ran for around 30 mins.Manual checkpoint was run before each test.
>
> Compression WAL generated %compression Latency-avg CPU usage
> (seconds) TPS Latency
> stddev
>
>
> on 1531.4 MB ~35 % 7.351 ms
> user diff: 562.67s system diff: 41.40s 135.96
> 13.759 ms
>
>
> off 2373.1 MB 6.781 ms
> user diff: 354.20s system diff: 39.67s 147.40
> 14.152 ms
>
> The compression obtained is quite high close to 35 %.
> CPU usage at user level when compression is on is quite noticeably high as
> compared to that when compression is off. But gain in terms of reduction of WAL
> is also high.
I am sorry but I can't understand the above results due to wrapping.
Are you saying compression was twice as slow?
psql <<EOF
SELECT pg_backend_pid();
CREATE TABLE aa (a int);
CREATE TABLE results (phase text, position pg_lsn);
CREATE EXTENSION IF NOT EXISTS pg_prewarm;
ALTER TABLE aa SET (FILLFACTOR = 50);
INSERT INTO results VALUES ('pre-insert', pg_current_xlog_location());
INSERT INTO aa VALUES (generate_series(1,7000000)); -- 484MB
SELECT pg_size_pretty(pg_relation_size('aa'::regclass));
SELECT pg_prewarm('aa'::regclass);
CHECKPOINT;
INSERT INTO results VALUES ('pre-update', pg_current_xlog_location());
UPDATE aa SET a = 7000000 + a;
CHECKPOINT;
INSERT INTO results VALUES ('post-update', pg_current_xlog_location());
SELECT * FROM results;
EOF
pg_size_pretty(pre_update - pre_insert),
pg_size_pretty(post_update - pre_update) from results;
phase | user_diff | system_diff | pg_size_pretty | pg_size_pretty
--------------------+-----------+-------------+----------------+----------------
Compression FPW | 42.990799 | 0.868179 | 429 MB | 567 MB
No compression | 25.688731 | 1.236551 | 429 MB | 727 MB
Compression record | 56.376750 | 0.769603 | 429 MB | 566 MB
(3 rows)
Attachment
On 2014-12-12 09:46:13 -0500, Bruce Momjian wrote: > On Fri, Dec 12, 2014 at 03:27:33PM +0100, Andres Freund wrote: > > On 2014-12-12 09:24:27 -0500, Bruce Momjian wrote: > > > On Fri, Dec 12, 2014 at 03:22:24PM +0100, Andres Freund wrote: > > > > > Well, the larger question is why wouldn't we just have the user compress > > > > > the entire WAL file before archiving --- why have each backend do it? > > > > > Is it the write volume we are saving? I though this WAL compression > > > > > gave better performance in some cases. > > > > > > > > Err. Streaming? > > > > > > Well, you can already set up SSL for compression while streaming. In > > > fact, I assume many are already using SSL for streaming as the majority > > > of SSL overhead is from connection start. > > > > That's not really true. The overhead of SSL during streaming is > > *significant*. Both the kind of compression it does (which is far more > > expensive than pglz or lz4) and the encyrption itself. In many cases > > it's prohibitively expensive - there's even a fair number on-list > > reports about this. > > Well, I am just trying to understand when someone would benefit from WAL > compression. Are we saying it is only useful for non-SSL streaming? No, not at all. It's useful in a lot more situations: * The amount of WAL in pg_xlog can make up a significant portion of a database's size. Especially in large OLTP databases.Compressing archives doesn't help with that. * The original WAL volume itself can be quite problematic because at some point its exhausting the underlying IO subsystem.Both due to the pure write rate and to the fsync()s regularly required. * ssl compression can often not be used for WAL streaming because it's too slow as it's uses a much more expensive algorithm.Which is why we even have a GUC to disable it. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 2014-12-12 23:50:43 +0900, Michael Paquier wrote:
> I got curious to see how the compression of an entire record would perform
> and how it compares for small WAL records, and here are some numbers based
> on the patch attached, this patch compresses the whole record including the
> block headers, letting only XLogRecord out of it with a flag indicating
> that the record is compressed (note that this patch contains a portion for
> replay untested, still this patch gives an idea on how much compression of
> the whole record affects user CPU in this test case). It uses a buffer of 4
> * BLCKSZ, if the record is longer than that compression is simply given up.
> Those tests are using the hack upthread calculating user and system CPU
> using getrusage() when a backend.
>
> Here is the simple test case I used with 512MB of shared_buffers and small
> records, filling up a bunch of buffers, dirtying them and them compressing
> FPWs with a checkpoint.
> #!/bin/bash
> psql <<EOF
> SELECT pg_backend_pid();
> CREATE TABLE aa (a int);
> CREATE TABLE results (phase text, position pg_lsn);
> CREATE EXTENSION IF NOT EXISTS pg_prewarm;
> ALTER TABLE aa SET (FILLFACTOR = 50);
> INSERT INTO results VALUES ('pre-insert', pg_current_xlog_location());
> INSERT INTO aa VALUES (generate_series(1,7000000)); -- 484MB
> SELECT pg_size_pretty(pg_relation_size('aa'::regclass));
> SELECT pg_prewarm('aa'::regclass);
> CHECKPOINT;
> INSERT INTO results VALUES ('pre-update', pg_current_xlog_location());
> UPDATE aa SET a = 7000000 + a;
> CHECKPOINT;
> INSERT INTO results VALUES ('post-update', pg_current_xlog_location());
> SELECT * FROM results;
> EOF
>
> Note that autovacuum and fsync are off.
> =# select phase, user_diff, system_diff,
> pg_size_pretty(pre_update - pre_insert),
> pg_size_pretty(post_update - pre_update) from results;
> phase | user_diff | system_diff | pg_size_pretty |
> pg_size_pretty
> --------------------+-----------+-------------+----------------+----------------
> Compression FPW | 42.990799 | 0.868179 | 429 MB | 567 MB
> No compression | 25.688731 | 1.236551 | 429 MB | 727 MB
> Compression record | 56.376750 | 0.769603 | 429 MB | 566 MB
> (3 rows)
> If we do record-level compression, we'll need to be very careful in
> defining a lower-bound to not eat unnecessary CPU resources, perhaps
> something that should be controlled with a GUC. I presume that this stands
> true as well for the upper bound.
Record level compression pretty obviously would need a lower boundary
for when to use compression. It won't be useful for small heapam/btree
records, but it'll be rather useful for large multi_insert, clean or
similar records...
Greetings,
Andres Freund
On Fri, Dec 12, 2014 at 10:04 AM, Andres Freund <andres@anarazel.de> wrote: >> Note that autovacuum and fsync are off. >> =# select phase, user_diff, system_diff, >> pg_size_pretty(pre_update - pre_insert), >> pg_size_pretty(post_update - pre_update) from results; >> phase | user_diff | system_diff | pg_size_pretty | >> pg_size_pretty >> --------------------+-----------+-------------+----------------+---------------- >> Compression FPW | 42.990799 | 0.868179 | 429 MB | 567 MB >> No compression | 25.688731 | 1.236551 | 429 MB | 727 MB >> Compression record | 56.376750 | 0.769603 | 429 MB | 566 MB >> (3 rows) >> If we do record-level compression, we'll need to be very careful in >> defining a lower-bound to not eat unnecessary CPU resources, perhaps >> something that should be controlled with a GUC. I presume that this stands >> true as well for the upper bound. > > Record level compression pretty obviously would need a lower boundary > for when to use compression. It won't be useful for small heapam/btree > records, but it'll be rather useful for large multi_insert, clean or > similar records... Unless I'm missing something, this test is showing that FPW compression saves 298MB of WAL for 17.3 seconds of CPU time, as against master. And compressing the whole record saves a further 1MB of WAL for a further 13.39 seconds of CPU time. That makes compressing the whole record sound like a pretty terrible idea - even if you get more benefit by reducing the lower boundary, you're still burning a ton of extra CPU time for almost no gain on the larger records. Ouch! (Of course, I'm assuming that Michael's patch is reasonably efficient, which might not be true.) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2014-12-12 11:08:52 -0500, Robert Haas wrote: > Unless I'm missing something, this test is showing that FPW > compression saves 298MB of WAL for 17.3 seconds of CPU time, as > against master. And compressing the whole record saves a further 1MB > of WAL for a further 13.39 seconds of CPU time. That makes > compressing the whole record sound like a pretty terrible idea - even > if you get more benefit by reducing the lower boundary, you're still > burning a ton of extra CPU time for almost no gain on the larger > records. Ouch! Well, that test pretty much doesn't have any large records besides FPWs afaics. So it's unsurprising that it's not beneficial. Greetings, Andres Freund
On Fri, Dec 12, 2014 at 11:12 AM, Andres Freund <andres@anarazel.de> wrote: > On 2014-12-12 11:08:52 -0500, Robert Haas wrote: >> Unless I'm missing something, this test is showing that FPW >> compression saves 298MB of WAL for 17.3 seconds of CPU time, as >> against master. And compressing the whole record saves a further 1MB >> of WAL for a further 13.39 seconds of CPU time. That makes >> compressing the whole record sound like a pretty terrible idea - even >> if you get more benefit by reducing the lower boundary, you're still >> burning a ton of extra CPU time for almost no gain on the larger >> records. Ouch! > > Well, that test pretty much doesn't have any large records besides FPWs > afaics. So it's unsurprising that it's not beneficial. "Not beneficial" is rather an understatement. It's actively harmful, and not by a small margin. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2014-12-12 11:15:46 -0500, Robert Haas wrote: > On Fri, Dec 12, 2014 at 11:12 AM, Andres Freund <andres@anarazel.de> wrote: > > On 2014-12-12 11:08:52 -0500, Robert Haas wrote: > >> Unless I'm missing something, this test is showing that FPW > >> compression saves 298MB of WAL for 17.3 seconds of CPU time, as > >> against master. And compressing the whole record saves a further 1MB > >> of WAL for a further 13.39 seconds of CPU time. That makes > >> compressing the whole record sound like a pretty terrible idea - even > >> if you get more benefit by reducing the lower boundary, you're still > >> burning a ton of extra CPU time for almost no gain on the larger > >> records. Ouch! > > > > Well, that test pretty much doesn't have any large records besides FPWs > > afaics. So it's unsurprising that it's not beneficial. > > "Not beneficial" is rather an understatement. It's actively harmful, > and not by a small margin. Sure, but that's just because it's too simplistic. I don't think it makes sense to make any inference about the worthyness of the general approach from the, nearly obvious, fact that compressing every tiny record is a bad idea. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Dec 12, 2014 at 05:19:42PM +0100, Andres Freund wrote: > On 2014-12-12 11:15:46 -0500, Robert Haas wrote: > > On Fri, Dec 12, 2014 at 11:12 AM, Andres Freund <andres@anarazel.de> wrote: > > > On 2014-12-12 11:08:52 -0500, Robert Haas wrote: > > >> Unless I'm missing something, this test is showing that FPW > > >> compression saves 298MB of WAL for 17.3 seconds of CPU time, as > > >> against master. And compressing the whole record saves a further 1MB > > >> of WAL for a further 13.39 seconds of CPU time. That makes > > >> compressing the whole record sound like a pretty terrible idea - even > > >> if you get more benefit by reducing the lower boundary, you're still > > >> burning a ton of extra CPU time for almost no gain on the larger > > >> records. Ouch! > > > > > > Well, that test pretty much doesn't have any large records besides FPWs > > > afaics. So it's unsurprising that it's not beneficial. > > > > "Not beneficial" is rather an understatement. It's actively harmful, > > and not by a small margin. > > Sure, but that's just because it's too simplistic. I don't think it > makes sense to make any inference about the worthyness of the general > approach from the, nearly obvious, fact that compressing every tiny > record is a bad idea. Well, it seems we need to see some actual cases where compression does help before moving forward. I thought Amit had some amazing numbers for WAL compression --- has that changed? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On 12 December 2014 at 18:04, Bruce Momjian <bruce@momjian.us> wrote: > Well, it seems we need to see some actual cases where compression does > help before moving forward. I thought Amit had some amazing numbers for > WAL compression --- has that changed? For background processes, like VACUUM, then WAL compression will be helpful. The numbers show that only applies to FPWs. I remain concerned about the cost in foreground processes, especially since the cost will be paid immediately after checkpoint, making our spikes worse. What I don't understand is why we aren't working on double buffering, since that cost would be paid in a background process and would be evenly spread out across a checkpoint. Plus we'd be able to remove FPWs altogether, which is like 100% compression. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Dec 12, 2014 at 1:51 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > What I don't understand is why we aren't working on double buffering, > since that cost would be paid in a background process and would be > evenly spread out across a checkpoint. Plus we'd be able to remove > FPWs altogether, which is like 100% compression. The previous patch to implement that - by somebody at vmware - was an epic fail. I'm not opposed to seeing somebody try again, but it's a tricky problem. When the double buffer fills up, then you've got to finish flushing the pages whose images are stored in the buffer to disk before you can overwrite it, which acts like a kind of mini-checkpoint. That problem might be solvable, but let's use this thread to discuss this patch, not some other patch that someone might have chosen to write but didn't. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Dec 13, 2014 at 1:08 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Fri, Dec 12, 2014 at 10:04 AM, Andres Freund <andres@anarazel.de> wrote: >>> Note that autovacuum and fsync are off. >>> =# select phase, user_diff, system_diff, >>> pg_size_pretty(pre_update - pre_insert), >>> pg_size_pretty(post_update - pre_update) from results; >>> phase | user_diff | system_diff | pg_size_pretty | >>> pg_size_pretty >>> --------------------+-----------+-------------+----------------+---------------- >>> Compression FPW | 42.990799 | 0.868179 | 429 MB | 567 MB >>> No compression | 25.688731 | 1.236551 | 429 MB | 727 MB >>> Compression record | 56.376750 | 0.769603 | 429 MB | 566 MB >>> (3 rows) >>> If we do record-level compression, we'll need to be very careful in >>> defining a lower-bound to not eat unnecessary CPU resources, perhaps >>> something that should be controlled with a GUC. I presume that this stands >>> true as well for the upper bound. >> >> Record level compression pretty obviously would need a lower boundary >> for when to use compression. It won't be useful for small heapam/btree >> records, but it'll be rather useful for large multi_insert, clean or >> similar records... > > Unless I'm missing something, this test is showing that FPW > compression saves 298MB of WAL for 17.3 seconds of CPU time, as > against master. And compressing the whole record saves a further 1MB > of WAL for a further 13.39 seconds of CPU time. That makes > compressing the whole record sound like a pretty terrible idea - even > if you get more benefit by reducing the lower boundary, you're still > burning a ton of extra CPU time for almost no gain on the larger > records. Ouch! > > (Of course, I'm assuming that Michael's patch is reasonably efficient, > which might not be true.) Note that I was curious about the worst-case ever, aka how much CPU pg_lzcompress would use if everything is compressed, even the smallest records. So we'll surely need a lower-bound. I think that doing some tests with a lower bound set as a multiple of SizeOfXLogRecord would be fine, but in this case what we'll see is a result similar to what FPW compression does. -- Michael
On Fri, Dec 12, 2014 at 7:25 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Sat, Dec 13, 2014 at 1:08 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Fri, Dec 12, 2014 at 10:04 AM, Andres Freund <andres@anarazel.de> wrote: >>>> Note that autovacuum and fsync are off. >>>> =# select phase, user_diff, system_diff, >>>> pg_size_pretty(pre_update - pre_insert), >>>> pg_size_pretty(post_update - pre_update) from results; >>>> phase | user_diff | system_diff | pg_size_pretty | >>>> pg_size_pretty >>>> --------------------+-----------+-------------+----------------+---------------- >>>> Compression FPW | 42.990799 | 0.868179 | 429 MB | 567 MB >>>> No compression | 25.688731 | 1.236551 | 429 MB | 727 MB >>>> Compression record | 56.376750 | 0.769603 | 429 MB | 566 MB >>>> (3 rows) >>>> If we do record-level compression, we'll need to be very careful in >>>> defining a lower-bound to not eat unnecessary CPU resources, perhaps >>>> something that should be controlled with a GUC. I presume that this stands >>>> true as well for the upper bound. >>> >>> Record level compression pretty obviously would need a lower boundary >>> for when to use compression. It won't be useful for small heapam/btree >>> records, but it'll be rather useful for large multi_insert, clean or >>> similar records... >> >> Unless I'm missing something, this test is showing that FPW >> compression saves 298MB of WAL for 17.3 seconds of CPU time, as >> against master. And compressing the whole record saves a further 1MB >> of WAL for a further 13.39 seconds of CPU time. That makes >> compressing the whole record sound like a pretty terrible idea - even >> if you get more benefit by reducing the lower boundary, you're still >> burning a ton of extra CPU time for almost no gain on the larger >> records. Ouch! >> >> (Of course, I'm assuming that Michael's patch is reasonably efficient, >> which might not be true.) > Note that I was curious about the worst-case ever, aka how much CPU > pg_lzcompress would use if everything is compressed, even the smallest > records. So we'll surely need a lower-bound. I think that doing some > tests with a lower bound set as a multiple of SizeOfXLogRecord would > be fine, but in this case what we'll see is a result similar to what > FPW compression does. In general, lz4 (and pg_lz is similar to lz4) compresses very poorly anything below about 128b in length. Of course there are outliers, with some very compressible stuff, but with regular text or JSON data, it's quite unlikely to compress at all with smaller input. Compression is modest up to about 1k when it starts to really pay off. That's at least my experience with lots JSON-ish, text-ish and CSV data sets, compressible but not so much in small bits.
> On Mon, Dec 8, 2014 at 3:17 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
> >
> > On 8 December 2014 at 11:46, Michael Paquier <michael.paquier@gmail.com> wrote:
> > > I don't really like those new names, but I'd prefer
> > > wal_compression_level if we go down that road with 'none' as default
> > > value. We may still decide in the future to support compression at the
> > > record level instead of context level, particularly if we have an API
> > > able to do palloc_return_null_at_oom, so the idea of WAL compression
> > > is not related only to FPIs IMHO.
> >
> > We may yet decide, but the pglz implementation is not effective on
> > smaller record lengths. Nor has any testing been done to show that is
> > even desirable.
> >
>
> It's even much worse for non-compressible (or less-compressible)
> WAL data.
RAM = 492GB
Attachment
On 12 December 2014 at 21:40, Robert Haas <robertmhaas@gmail.com> wrote: > On Fri, Dec 12, 2014 at 1:51 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >> What I don't understand is why we aren't working on double buffering, >> since that cost would be paid in a background process and would be >> evenly spread out across a checkpoint. Plus we'd be able to remove >> FPWs altogether, which is like 100% compression. > > The previous patch to implement that - by somebody at vmware - was an > epic fail. I'm not opposed to seeing somebody try again, but it's a > tricky problem. When the double buffer fills up, then you've got to > finish flushing the pages whose images are stored in the buffer to > disk before you can overwrite it, which acts like a kind of > mini-checkpoint. That problem might be solvable, but let's use this > thread to discuss this patch, not some other patch that someone might > have chosen to write but didn't. No, I think its relevant. WAL compression looks to me like a short term tweak, not the end game. On that basis, we should go for simple and effective, user-settable compression of FPWs and not spend too much Valuable Committer Time on it. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Dec 12, 2014 at 11:50 PM, Michael Paquier
<michael.paquier@gmail.com> wrote:
>
>
> On Wed, Dec 10, 2014 at 11:25 PM, Bruce Momjian <bruce@momjian.us> wrote:
>>
>> On Wed, Dec 10, 2014 at 07:40:46PM +0530, Rahila Syed wrote:
>> > The tests ran for around 30 mins.Manual checkpoint was run before each
>> > test.
>> >
>> > Compression WAL generated %compression Latency-avg CPU usage
>> > (seconds) TPS
>> > Latency
>> > stddev
>> >
>> >
>> > on 1531.4 MB ~35 % 7.351 ms
>> > user diff: 562.67s system diff: 41.40s 135.96
>> > 13.759 ms
>> >
>> >
>> > off 2373.1 MB 6.781
>> > ms
>> > user diff: 354.20s system diff: 39.67s 147.40
>> > 14.152 ms
>> >
>> > The compression obtained is quite high close to 35 %.
>> > CPU usage at user level when compression is on is quite noticeably high
>> > as
>> > compared to that when compression is off. But gain in terms of reduction
>> > of WAL
>> > is also high.
>>
>> I am sorry but I can't understand the above results due to wrapping.
>> Are you saying compression was twice as slow?
>
>
> I got curious to see how the compression of an entire record would perform
> and how it compares for small WAL records, and here are some numbers based
> on the patch attached, this patch compresses the whole record including the
> block headers, letting only XLogRecord out of it with a flag indicating that
> the record is compressed (note that this patch contains a portion for replay
> untested, still this patch gives an idea on how much compression of the
> whole record affects user CPU in this test case). It uses a buffer of 4 *
> BLCKSZ, if the record is longer than that compression is simply given up.
> Those tests are using the hack upthread calculating user and system CPU
> using getrusage() when a backend.
>
> Here is the simple test case I used with 512MB of shared_buffers and small
> records, filling up a bunch of buffers, dirtying them and them compressing
> FPWs with a checkpoint.
> #!/bin/bash
> psql <<EOF
> SELECT pg_backend_pid();
> CREATE TABLE aa (a int);
> CREATE TABLE results (phase text, position pg_lsn);
> CREATE EXTENSION IF NOT EXISTS pg_prewarm;
> ALTER TABLE aa SET (FILLFACTOR = 50);
> INSERT INTO results VALUES ('pre-insert', pg_current_xlog_location());
> INSERT INTO aa VALUES (generate_series(1,7000000)); -- 484MB
> SELECT pg_size_pretty(pg_relation_size('aa'::regclass));
> SELECT pg_prewarm('aa'::regclass);
> CHECKPOINT;
> INSERT INTO results VALUES ('pre-update', pg_current_xlog_location());
> UPDATE aa SET a = 7000000 + a;
> CHECKPOINT;
> INSERT INTO results VALUES ('post-update', pg_current_xlog_location());
> SELECT * FROM results;
> EOF
Re-using this test case, I have produced more results by changing the
fillfactor of the table:
=# select test || ', ffactor ' || ffactor, pg_size_pretty(post_update
- pre_update), user_diff, system_diff from results;
?column? | pg_size_pretty | user_diff | system_diff
-------------------------------+----------------+-----------+-------------
FPW on + 2 bytes, ffactor 50 | 582 MB | 42.391894 | 0.807444
FPW on + 2 bytes, ffactor 20 | 229 MB | 14.330304 | 0.729626
FPW on + 2 bytes, ffactor 10 | 117 MB | 7.335442 | 0.570996
FPW off + 2 bytes, ffactor 50 | 746 MB | 25.330391 | 1.248503
FPW off + 2 bytes, ffactor 20 | 293 MB | 10.537475 | 0.755448
FPW off + 2 bytes, ffactor 10 | 148 MB | 5.762775 | 0.763761
HEAD, ffactor 50 | 746 MB | 25.181729 | 1.133433
HEAD, ffactor 20 | 293 MB | 9.962242 | 0.765970
HEAD, ffactor 10 | 148 MB | 5.693426 | 0.775371
Record, ffactor 50 | 582 MB | 54.904374 | 0.678204
Record, ffactor 20 | 229 MB | 19.798268 | 0.807220
Record, ffactor 10 | 116 MB | 9.401877 | 0.668454
(12 rows)
The following tests are run:
- "Record" means the record-level compression
- "HEAD" is postgres at 1c5c70df
- "FPW off" is HEAD + patch with switch set to off
- "FPW on" is HEAD + patch with switch set to on
The gain in compression has a linear profile with the length of page
hole. There was visibly some noise in the tests: you can see that the
CPU of "FPW off" is a bit higher than HEAD.
Something to be aware of btw is that this patch introduces an
additional 8 bytes per block image in WAL as it contains additional
information to control the compression. In this case this is the
uint16 compress_len present in XLogRecordBlockImageHeader. In the case
of the measurements done, knowing that 63638 FPWs have been written,
there is a difference of a bit less than 500k in WAL between HEAD and
"FPW off" in favor of HEAD. The gain with compression is welcome,
still for the default there is a small price to track down if a block
is compressed or not. This patch still takes advantage of it by not
compressing the hole present in page and reducing CPU work a bit.
Attached are as well updated patches, switching wal_compression to
USERSET and cleaning up things related to this switch from
PGC_POSTMASTER. I am attaching as well the results I got, feel free to
have a look.
Regards,
--
Michael
Attachment
On 13 December 2014 at 14:36, Michael Paquier <michael.paquier@gmail.com> wrote: > Something to be aware of btw is that this patch introduces an > additional 8 bytes per block image in WAL as it contains additional > information to control the compression. In this case this is the > uint16 compress_len present in XLogRecordBlockImageHeader. So we add 8 bytes to all FPWs, or only for compressed FPWs? -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Sun, Dec 14, 2014 at 5:45 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > On 13 December 2014 at 14:36, Michael Paquier <michael.paquier@gmail.com> wrote: > >> Something to be aware of btw is that this patch introduces an >> additional 8 bytes per block image in WAL as it contains additional >> information to control the compression. In this case this is the >> uint16 compress_len present in XLogRecordBlockImageHeader. > > So we add 8 bytes to all FPWs, or only for compressed FPWs? In this case that was all. We could still use xl_info to put a flag telling that blocks are compressed, but it feels more consistent to have a way to identify if a block is compressed inside its own header. -- Michael
On 2014-12-14 09:56:59 +0900, Michael Paquier wrote: > On Sun, Dec 14, 2014 at 5:45 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > > On 13 December 2014 at 14:36, Michael Paquier <michael.paquier@gmail.com> wrote: > > > >> Something to be aware of btw is that this patch introduces an > >> additional 8 bytes per block image in WAL as it contains additional > >> information to control the compression. In this case this is the > >> uint16 compress_len present in XLogRecordBlockImageHeader. > > > > So we add 8 bytes to all FPWs, or only for compressed FPWs? > In this case that was all. We could still use xl_info to put a flag > telling that blocks are compressed, but it feels more consistent to > have a way to identify if a block is compressed inside its own header. Your 'consistency' argument doesn't convince me. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Sun, Dec 14, 2014 at 1:16 PM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2014-12-14 09:56:59 +0900, Michael Paquier wrote: >> On Sun, Dec 14, 2014 at 5:45 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >> > On 13 December 2014 at 14:36, Michael Paquier <michael.paquier@gmail.com> wrote: >> > >> >> Something to be aware of btw is that this patch introduces an >> >> additional 8 bytes per block image in WAL as it contains additional >> >> information to control the compression. In this case this is the >> >> uint16 compress_len present in XLogRecordBlockImageHeader. >> > >> > So we add 8 bytes to all FPWs, or only for compressed FPWs? >> In this case that was all. We could still use xl_info to put a flag >> telling that blocks are compressed, but it feels more consistent to >> have a way to identify if a block is compressed inside its own header. > > Your 'consistency' argument doesn't convince me. Could you be more precise (perhaps my use of the word "consistent" was incorrect here)? Isn't it the most natural way of doing to have the compression information of each block in their own headers? There may be blocks that are marked as incompressible in a whole set, so we need to track for each block individually if they are compressed. Now, instead of an additional uint16 to store the compressed length of the block, we can take 1 bit from hole_length and 1 bit from hole_offset to store a status flag deciding if a block is compressed. If we do so, the tradeoff is to fill in the block hole with zeros and compress BLCKSZ worth of data all the time, costing more CPU. But doing so we would still use only 4 bytes for the block information, making default case, aka compression switch off, behave like HEAD in term of pure record quantity. This second method has been as well mentioned upthread a couple of times. -- Michael
Note: this patch has been moved to CF 2014-12 and I marked myself as an author if that's fine... I've finished by being really involved in that. -- Michael
On Sat, Dec 13, 2014 at 9:36 AM, Michael Paquier <michael.paquier@gmail.com> wrote: > Something to be aware of btw is that this patch introduces an > additional 8 bytes per block image in WAL as it contains additional > information to control the compression. In this case this is the > uint16 compress_len present in XLogRecordBlockImageHeader. In the case > of the measurements done, knowing that 63638 FPWs have been written, > there is a difference of a bit less than 500k in WAL between HEAD and > "FPW off" in favor of HEAD. The gain with compression is welcome, > still for the default there is a small price to track down if a block > is compressed or not. This patch still takes advantage of it by not > compressing the hole present in page and reducing CPU work a bit. That sounds like a pretty serious problem to me. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Dec 12, 2014 at 8:27 AM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2014-12-12 09:24:27 -0500, Bruce Momjian wrote: >> On Fri, Dec 12, 2014 at 03:22:24PM +0100, Andres Freund wrote: >> > > Well, the larger question is why wouldn't we just have the user compress >> > > the entire WAL file before archiving --- why have each backend do it? >> > > Is it the write volume we are saving? I though this WAL compression >> > > gave better performance in some cases. >> > >> > Err. Streaming? >> >> Well, you can already set up SSL for compression while streaming. In >> fact, I assume many are already using SSL for streaming as the majority >> of SSL overhead is from connection start. > > That's not really true. The overhead of SSL during streaming is > *significant*. Both the kind of compression it does (which is far more > expensive than pglz or lz4) and the encyrption itself. In many cases > it's prohibitively expensive - there's even a fair number on-list > reports about this. (late to the party) That may be true, but there are a number of ways to work around SSL performance issues such as hardware acceleration (perhaps deferring encryption to another point in the network), weakening the protocol, or not using it at all. OTOH, Our built in compressor as we all know is a complete dog in terms of cpu when stacked up against some more modern implementations. All that said, as long as there is a clean path to migrating to another compression alg should one materialize, that problem can be nicely decoupled from this patch as Robert pointed out. merlin
On Tue, Dec 16, 2014 at 3:46 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Sat, Dec 13, 2014 at 9:36 AM, Michael Paquier > <michael.paquier@gmail.com> wrote: >> Something to be aware of btw is that this patch introduces an >> additional 8 bytes per block image in WAL as it contains additional >> information to control the compression. In this case this is the >> uint16 compress_len present in XLogRecordBlockImageHeader. In the case >> of the measurements done, knowing that 63638 FPWs have been written, >> there is a difference of a bit less than 500k in WAL between HEAD and >> "FPW off" in favor of HEAD. The gain with compression is welcome, >> still for the default there is a small price to track down if a block >> is compressed or not. This patch still takes advantage of it by not >> compressing the hole present in page and reducing CPU work a bit. > > That sounds like a pretty serious problem to me. OK. If that's so much a problem, I'll switch back to the version using 1 bit in the block header to identify if a block is compressed or not. This way, when switch will be off the record length will be the same as HEAD. -- Michael
On Tue, Dec 16, 2014 at 5:14 AM, Merlin Moncure <mmoncure@gmail.com> wrote: > OTOH, Our built in compressor as we all know is a complete dog in > terms of cpu when stacked up against some more modern implementations. > All that said, as long as there is a clean path to migrating to > another compression alg should one materialize, that problem can be > nicely decoupled from this patch as Robert pointed out. I am curious to see some numbers about that. Has anyone done such comparison measurements? -- Michael
On Tue, Dec 16, 2014 at 8:35 AM, Michael Paquier <michael.paquier@gmail.com> wrote:
> On Tue, Dec 16, 2014 at 3:46 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>> On Sat, Dec 13, 2014 at 9:36 AM, Michael Paquier
>> <michael.paquier@gmail.com> wrote:
>>> Something to be aware of btw is that this patch introduces an
>>> additional 8 bytes per block image in WAL as it contains additional
>>> information to control the compression. In this case this is the
>>> uint16 compress_len present in XLogRecordBlockImageHeader. In the case
>>> of the measurements done, knowing that 63638 FPWs have been written,
>>> there is a difference of a bit less than 500k in WAL between HEAD and
>>> "FPW off" in favor of HEAD. The gain with compression is welcome,
>>> still for the default there is a small price to track down if a block
>>> is compressed or not. This patch still takes advantage of it by not
>>> compressing the hole present in page and reducing CPU work a bit.
>>
>> That sounds like a pretty serious problem to me.
> OK. If that's so much a problem, I'll switch back to the version using
> 1 bit in the block header to identify if a block is compressed or not.
> This way, when switch will be off the record length will be the same
> as HEAD.
And here are attached fresh patches reducing the WAL record size to what it is in head when the compression switch is off. Looking at the logic in xlogrecord.h, the block header stores the hole length and hole offset. I changed that a bit to store the length of raw block, with hole or compressed as the 1st uint16. The second uint16 is used to store the hole offset, same as HEAD when compression switch is off. When compression is on, a special value 0xFFFF is saved (actually only filling 1 in the 16th bit is fine...). Note that this forces to fill in the hole with zeros and to compress always BLCKSZ worth of data.
Those patches pass make check-world, even WAL replay on standbys.
I have done as well measurements using this patch set, with the following things that can be noticed:
- When compression switch is off, the same quantity of WAL as HEAD is produced
- pglz is very bad at compressing page hole. I mean, really bad. Have a look at the user CPU particularly when pages are empty and you'll understand... Other compression algorithms would be better here. Tests are done with various values of fillfactor, 10 means that after the update 80% of the page is empty, at 50% the page is more or less completely full.
Here are the results, with 5 test cases:
- FPW on + 2 bytes, compression switch is on, using 2 additional bytes in block header, resulting in WAL records longer as 8 more bytes are used per block with lower CPU usage as page holes are not compressed by pglz.
- FPW off + 2 bytes, same as previous, with compression switch to on.
- FPW on + 0 bytes, compression switch to on, the same block header size as HEAD is used, at the cost of compressing page holes filled with zeros
- FPW on + 0 bytes, compression switch to off, same as previous
- HEAD, unpatched master (except with hack to calculate user and system CPU)
- Record, the record-level compression, with compression lower-bound set at 0.
=# select test || ', ffactor ' || ffactor, pg_size_pretty(post_update - pre_update), user_diff, system_diff from results;
?column? | pg_size_pretty | user_diff | system_diff
-------------------------------+----------------+-----------+-------------
FPW on + 2 bytes, ffactor 50 | 582 MB | 42.391894 | 0.807444
FPW on + 2 bytes, ffactor 20 | 229 MB | 14.330304 | 0.729626
FPW on + 2 bytes, ffactor 10 | 117 MB | 7.335442 | 0.570996
FPW off + 2 bytes, ffactor 50 | 746 MB | 25.330391 | 1.248503
FPW off + 2 bytes, ffactor 20 | 293 MB | 10.537475 | 0.755448
FPW off + 2 bytes, ffactor 10 | 148 MB | 5.762775 | 0.763761
FPW on + 0 bytes, ffactor 50 | 585 MB | 54.115496 | 0.924891
FPW on + 0 bytes, ffactor 20 | 234 MB | 26.270404 | 0.755862
FPW on + 0 bytes, ffactor 10 | 122 MB | 19.540131 | 0.800981
FPW off + 0 bytes, ffactor 50 | 746 MB | 25.102241 | 1.110677
FPW off + 0 bytes, ffactor 20 | 293 MB | 9.889374 | 0.749884
FPW off + 0 bytes, ffactor 10 | 148 MB | 5.286767 | 0.682746
HEAD, ffactor 50 | 746 MB | 25.181729 | 1.133433
HEAD, ffactor 20 | 293 MB | 9.962242 | 0.765970
HEAD, ffactor 10 | 148 MB | 5.693426 | 0.775371
Record, ffactor 50 | 582 MB | 54.904374 | 0.678204
Record, ffactor 20 | 229 MB | 19.798268 | 0.807220
Record, ffactor 10 | 116 MB | 9.401877 | 0.668454
(18 rows)
Attached are as well the results of the measurements, and the test case used.
Regards,
--
Michael
Attachment
Michael Paquier wrote: > And here are attached fresh patches reducing the WAL record size to what it > is in head when the compression switch is off. Looking at the logic in > xlogrecord.h, the block header stores the hole length and hole offset. I > changed that a bit to store the length of raw block, with hole or > compressed as the 1st uint16. The second uint16 is used to store the hole > offset, same as HEAD when compression switch is off. When compression is > on, a special value 0xFFFF is saved (actually only filling 1 in the 16th > bit is fine...). Note that this forces to fill in the hole with zeros and > to compress always BLCKSZ worth of data. Why do we compress the hole? This seems pointless, considering that we know it's all zeroes. Is it possible to compress the head and tail of page separately? -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Michael Paquier wrote:
> And here are attached fresh patches reducing the WAL record size to what it
> is in head when the compression switch is off. Looking at the logic in
> xlogrecord.h, the block header stores the hole length and hole offset. I
> changed that a bit to store the length of raw block, with hole or
> compressed as the 1st uint16. The second uint16 is used to store the hole
> offset, same as HEAD when compression switch is off. When compression is
> on, a special value 0xFFFF is saved (actually only filling 1 in the 16th
> bit is fine...). Note that this forces to fill in the hole with zeros and
> to compress always BLCKSZ worth of data.
Why do we compress the hole? This seems pointless, considering that we
know it's all zeroes. Is it possible to compress the head and tail of
page separately?
On Tue, Dec 16, 2014 at 11:24 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:Michael Paquier wrote:
> And here are attached fresh patches reducing the WAL record size to what it
> is in head when the compression switch is off. Looking at the logic in
> xlogrecord.h, the block header stores the hole length and hole offset. I
> changed that a bit to store the length of raw block, with hole or
> compressed as the 1st uint16. The second uint16 is used to store the hole
> offset, same as HEAD when compression switch is off. When compression is
> on, a special value 0xFFFF is saved (actually only filling 1 in the 16th
> bit is fine...). Note that this forces to fill in the hole with zeros and
> to compress always BLCKSZ worth of data.
Why do we compress the hole? This seems pointless, considering that we
know it's all zeroes. Is it possible to compress the head and tail of
page separately?This would take 2 additional bytes at minimum in the block header, resulting in 8 additional bytes in record each time a FPW shows up. IMO it is important to check the length of things obtained when replaying WAL, that's something the current code of HEAD does quite well.
--
On Mon, Dec 15, 2014 at 5:37 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Tue, Dec 16, 2014 at 5:14 AM, Merlin Moncure <mmoncure@gmail.com> wrote: >> OTOH, Our built in compressor as we all know is a complete dog in >> terms of cpu when stacked up against some more modern implementations. >> All that said, as long as there is a clean path to migrating to >> another compression alg should one materialize, that problem can be >> nicely decoupled from this patch as Robert pointed out. > I am curious to see some numbers about that. Has anyone done such > comparison measurements? I don't, but I can make some. There are some numbers on the web but it's better to make some new ones because IIRC some light optimization had gone into plgz of late. Compressing *one* file with lz4 and a quick/n/dirty plgz i hacked out of the source (borrowing heavily from https://github.com/maropu/pglz_bench/blob/master/pglz_bench.cpp), I tested the results: lz4 real time: 0m0.032s pglz real time: 0m0.281s mmoncure@mernix2 ~/src/lz4/lz4-r125 $ ls -lh test.* -rw-r--r-- 1 mmoncure mmoncure 2.7M Dec 16 09:04 test.lz4 -rw-r--r-- 1 mmoncure mmoncure 2.5M Dec 16 09:01 test.pglz A better test would examine all manner of different xlog files in a fashion closer to how your patch would need to compress them but the numbers here tell a fairly compelling story: similar compression results for around 9x the cpu usage. Be advised that compression alg selection is one of those types of discussions that tends to spin off into outer space; that's not something you have to solve today. Just try and make things so that they can be switched out if things change.... merlin
Actually, the original length of the compressed block in saved in PGLZ_Header, so if we are fine to not check the size of the block decompressed when decoding WAL we can do without the hole filled with zeros, and use only 1 bit to see if the block is compressed or not.
test_name | pg_size_pretty | user_diff | system_diff
-------------------------------+----------------+-----------+-------------
FPW on + 2 bytes, ffactor 50 | 582 MB | 42.391894 | 0.807444
FPW on + 2 bytes, ffactor 20 | 229 MB | 14.330304 | 0.729626
FPW on + 2 bytes, ffactor 10 | 117 MB | 7.335442 | 0.570996
FPW off + 2 bytes, ffactor 50 | 746 MB | 25.330391 | 1.248503
FPW off + 2 bytes, ffactor 20 | 293 MB | 10.537475 | 0.755448
FPW off + 2 bytes, ffactor 10 | 148 MB | 5.762775 | 0.763761
FPW on + 0 bytes, ffactor 50 | 582 MB | 42.174297 | 0.790596
FPW on + 0 bytes, ffactor 20 | 229 MB | 14.424233 | 0.770459
FPW on + 0 bytes, ffactor 10 | 117 MB | 7.057195 | 0.584806
FPW off + 0 bytes, ffactor 50 | 746 MB | 25.261998 | 1.054516
FPW off + 0 bytes, ffactor 20 | 293 MB | 10.589888 | 0.860207
FPW off + 0 bytes, ffactor 10 | 148 MB | 5.827191 | 0.874285
HEAD, ffactor 50 | 746 MB | 25.181729 | 1.133433
HEAD, ffactor 20 | 293 MB | 9.962242 | 0.765970
HEAD, ffactor 10 | 148 MB | 5.693426 | 0.775371
Record, ffactor 50 | 582 MB | 54.904374 | 0.678204
Record, ffactor 20 | 229 MB | 19.798268 | 0.807220
Record, ffactor 10 | 116 MB | 9.401877 | 0.668454
(18 rows)
Attachment
Compressing *one* file with lz4 and a quick/n/dirty plgz i hacked out
of the source (borrowing heavily from
https://github.com/maropu/pglz_bench/blob/master/pglz_bench.cpp), I
tested the results:
lz4 real time: 0m0.032s
pglz real time: 0m0.281s
mmoncure@mernix2 ~/src/lz4/lz4-r125 $ ls -lh test.*
-rw-r--r-- 1 mmoncure mmoncure 2.7M Dec 16 09:04 test.lz4
-rw-r--r-- 1 mmoncure mmoncure 2.5M Dec 16 09:01 test.pglz
A better test would examine all manner of different xlog files in a
fashion closer to how your patch would need to compress them but the
numbers here tell a fairly compelling story: similar compression
results for around 9x the cpu usage.
Be advised that compression algOne way to get around that would be a set of hooks to allow people to set up the compression algorithm they want:
selection is one of those types of discussions that tends to spin off
into outer space; that's not something you have to solve today. Just
try and make things so that they can be switched out if things
change....
On Wed, Dec 17, 2014 at 12:00 AM, Michael Paquier <michael.paquier@gmail.com> wrote:And.. After some more hacking, I have been able to come up with a patch that is able to compress blocks without the page hole, and that keeps the WAL record length the same as HEAD when compression switch is off. The numbers are pretty good, CPU is saved in the same proportions as previous patches when compression is enabled, and there is zero delta with HEAD when compression switch is off.Actually, the original length of the compressed block in saved in PGLZ_Header, so if we are fine to not check the size of the block decompressed when decoding WAL we can do without the hole filled with zeros, and use only 1 bit to see if the block is compressed or not.Here are the actual numbers:
test_name | pg_size_pretty | user_diff | system_diff
-------------------------------+----------------+-----------+-------------
FPW on + 2 bytes, ffactor 50 | 582 MB | 42.391894 | 0.807444
FPW on + 2 bytes, ffactor 20 | 229 MB | 14.330304 | 0.729626
FPW on + 2 bytes, ffactor 10 | 117 MB | 7.335442 | 0.570996
FPW off + 2 bytes, ffactor 50 | 746 MB | 25.330391 | 1.248503
FPW off + 2 bytes, ffactor 20 | 293 MB | 10.537475 | 0.755448
FPW off + 2 bytes, ffactor 10 | 148 MB | 5.762775 | 0.763761
FPW on + 0 bytes, ffactor 50 | 582 MB | 42.174297 | 0.790596
FPW on + 0 bytes, ffactor 20 | 229 MB | 14.424233 | 0.770459
FPW on + 0 bytes, ffactor 10 | 117 MB | 7.057195 | 0.584806
FPW off + 0 bytes, ffactor 50 | 746 MB | 25.261998 | 1.054516
FPW off + 0 bytes, ffactor 20 | 293 MB | 10.589888 | 0.860207
FPW off + 0 bytes, ffactor 10 | 148 MB | 5.827191 | 0.874285
HEAD, ffactor 50 | 746 MB | 25.181729 | 1.133433
HEAD, ffactor 20 | 293 MB | 9.962242 | 0.765970
HEAD, ffactor 10 | 148 MB | 5.693426 | 0.775371
Record, ffactor 50 | 582 MB | 54.904374 | 0.678204
Record, ffactor 20 | 229 MB | 19.798268 | 0.807220
Record, ffactor 10 | 116 MB | 9.401877 | 0.668454
(18 rows)The new tests of this patch are "FPW off + 0 bytes". Patches as well as results are attached.Regards,--Michael
On Wed, Dec 17, 2014 at 1:34 AM, Michael Paquier <michael.paquier@gmail.com> wrote: > > > On Wed, Dec 17, 2014 at 12:00 AM, Michael Paquier > <michael.paquier@gmail.com> wrote: >> >> Actually, the original length of the compressed block in saved in >> PGLZ_Header, so if we are fine to not check the size of the block >> decompressed when decoding WAL we can do without the hole filled with zeros, >> and use only 1 bit to see if the block is compressed or not. > > And.. After some more hacking, I have been able to come up with a patch that > is able to compress blocks without the page hole, and that keeps the WAL > record length the same as HEAD when compression switch is off. The numbers > are pretty good, CPU is saved in the same proportions as previous patches > when compression is enabled, and there is zero delta with HEAD when > compression switch is off. > > Here are the actual numbers: > test_name | pg_size_pretty | user_diff | system_diff > -------------------------------+----------------+-----------+------------- > FPW on + 2 bytes, ffactor 50 | 582 MB | 42.391894 | 0.807444 > FPW on + 2 bytes, ffactor 20 | 229 MB | 14.330304 | 0.729626 > FPW on + 2 bytes, ffactor 10 | 117 MB | 7.335442 | 0.570996 > FPW off + 2 bytes, ffactor 50 | 746 MB | 25.330391 | 1.248503 > FPW off + 2 bytes, ffactor 20 | 293 MB | 10.537475 | 0.755448 > FPW off + 2 bytes, ffactor 10 | 148 MB | 5.762775 | 0.763761 > FPW on + 0 bytes, ffactor 50 | 582 MB | 42.174297 | 0.790596 > FPW on + 0 bytes, ffactor 20 | 229 MB | 14.424233 | 0.770459 > FPW on + 0 bytes, ffactor 10 | 117 MB | 7.057195 | 0.584806 > FPW off + 0 bytes, ffactor 50 | 746 MB | 25.261998 | 1.054516 > FPW off + 0 bytes, ffactor 20 | 293 MB | 10.589888 | 0.860207 > FPW off + 0 bytes, ffactor 10 | 148 MB | 5.827191 | 0.874285 > HEAD, ffactor 50 | 746 MB | 25.181729 | 1.133433 > HEAD, ffactor 20 | 293 MB | 9.962242 | 0.765970 > HEAD, ffactor 10 | 148 MB | 5.693426 | 0.775371 > Record, ffactor 50 | 582 MB | 54.904374 | 0.678204 > Record, ffactor 20 | 229 MB | 19.798268 | 0.807220 > Record, ffactor 10 | 116 MB | 9.401877 | 0.668454 > (18 rows) > > The new tests of this patch are "FPW off + 0 bytes". Patches as well as > results are attached. I think that neither pg_control nor xl_parameter_change need to have the info about WAL compression because each backup block has that entry. Will review the remaining part later. Regards, -- Fujii Masao
On Thu, Dec 18, 2014 at 1:05 PM, Fujii Masao <masao.fujii@gmail.com> wrote: > On Wed, Dec 17, 2014 at 1:34 AM, Michael Paquier > <michael.paquier@gmail.com> wrote: > I think that neither pg_control nor xl_parameter_change need to have the info > about WAL compression because each backup block has that entry. > > Will review the remaining part later. I got into wondering the utility of this part earlier this morning as that's some remnant of when wal_compression was set as PGC_POSTMASTER. Will remove. -- Michael
I had a look at code. I have few minor points,
+ bkpb.fork_flags |= BKPBLOCK_HAS_IMAGE;++ if (is_compressed){- rdt_datas_last->data = page;- rdt_datas_last->len = BLCKSZ;+ /* compressed block information */+ bimg.length = compress_len;+ bimg.extra_data = hole_offset;+ bimg.extra_data |= XLR_BLCK_COMPRESSED_MASK;For consistency with the existing code , how about renaming the macro XLR_BLCK_COMPRESSED_MASK as BKPBLOCK_HAS_COMPRESSED_IMAGE on the lines of BKPBLOCK_HAS_IMAGE.
+ blk->hole_offset = extra_data & ~XLR_BLCK_COMPRESSED_MASK;Here , I think that having the mask as BKPBLOCK_HOLE_OFFSET_MASK will be more indicative of the fact that lower 15 bits of extra_data field comprises of hole_offset value. This suggestion is also just to achieve consistency with the existing BKPBLOCK_FORK_MASK for fork_flags field.
And comment typo+ * First try to compress block, filling in the page hole with zeros+ * to improve the compression of the whole. If the block is considered+ * as incompressible, complete the block header information as if+ * nothing happened.As hole is no longer being compressed, this needs to be changed.
Attachment
On Thu, Dec 18, 2014 at 2:21 PM, Michael Paquier
<michael.paquier@gmail.com> wrote:
>
>
> On Wed, Dec 17, 2014 at 11:33 PM, Rahila Syed <rahilasyed90@gmail.com>
> wrote:
>>
>> I had a look at code. I have few minor points,
>
> Thanks!
>
>> + bkpb.fork_flags |= BKPBLOCK_HAS_IMAGE;
>> +
>> + if (is_compressed)
>> {
>> - rdt_datas_last->data = page;
>> - rdt_datas_last->len = BLCKSZ;
>> + /* compressed block information */
>> + bimg.length = compress_len;
>> + bimg.extra_data = hole_offset;
>> + bimg.extra_data |= XLR_BLCK_COMPRESSED_MASK;
>>
>> For consistency with the existing code , how about renaming the macro
>> XLR_BLCK_COMPRESSED_MASK as BKPBLOCK_HAS_COMPRESSED_IMAGE on the lines of
>> BKPBLOCK_HAS_IMAGE.
>
> OK, why not...
>
>>
>> + blk->hole_offset = extra_data & ~XLR_BLCK_COMPRESSED_MASK;
>> Here , I think that having the mask as BKPBLOCK_HOLE_OFFSET_MASK will be
>> more indicative of the fact that lower 15 bits of extra_data field comprises
>> of hole_offset value. This suggestion is also just to achieve consistency
>> with the existing BKPBLOCK_FORK_MASK for fork_flags field.
>
> Yeah that seems clearer, let's define it as ~XLR_BLCK_COMPRESSED_MASK
> though.
>
>> And comment typo
>> + * First try to compress block, filling in the page hole with
>> zeros
>> + * to improve the compression of the whole. If the block is
>> considered
>> + * as incompressible, complete the block header information as
>> if
>> + * nothing happened.
>>
>> As hole is no longer being compressed, this needs to be changed.
>
> Fixed. As well as an additional comment block down.
>
> A couple of things noticed on the fly:
> - Fixed pg_xlogdump being not completely correct to report the FPW
> information
> - A couple of typos and malformed sentences fixed
> - Added an assertion to check that the hole offset value does not the bit
> used for compression status
> - Reworked docs, mentioning as well that wal_compression is off by default.
> - Removed stuff in pg_controldata and XLOG_PARAMETER_CHANGE (mentioned by
> Fujii-san)
Thanks!
+ else
+ memcpy(compression_scratch, page, page_len);
I don't think the block image needs to be copied to scratch buffer here.
We can try to compress the "page" directly.
+#include "utils/pg_lzcompress.h"#include "utils/memutils.h"
pg_lzcompress.h should be after meutils.h.
+/* Scratch buffer used to store block image to-be-compressed */
+static char compression_scratch[PGLZ_MAX_BLCKSZ];
Isn't it better to allocate the memory for compression_scratch in
InitXLogInsert()
like hdr_scratch?
+ uncompressed_page = (char *) palloc(PGLZ_RAW_SIZE(header));
Why don't we allocate the buffer for uncompressed page only once and
keep reusing it like XLogReaderState->readBuf? The size of uncompressed
page is at most BLCKSZ, so we can allocate the memory for it even before
knowing the real size of each block image.
- printf(" (FPW); hole: offset: %u, length: %u\n",
- record->blocks[block_id].hole_offset,
- record->blocks[block_id].hole_length);
+ if (record->blocks[block_id].is_compressed)
+ printf(" (FPW); hole offset: %u, compressed length %u\n",
+ record->blocks[block_id].hole_offset,
+ record->blocks[block_id].bkp_len);
+ else
+ printf(" (FPW); hole offset: %u, length: %u\n",
+ record->blocks[block_id].hole_offset,
+ record->blocks[block_id].bkp_len);
We need to consider what info about FPW we want pg_xlogdump to report.
I'd like to calculate how much bytes FPW was compressed, from the report
of pg_xlogdump. So I'd like to see also the both length of uncompressed FPW
and that of compressed one in the report.
In pg_config.h, the comment of BLCKSZ needs to be updated? Because
the maximum size of BLCKSZ can be affected by not only itemid but also
XLogRecordBlockImageHeader.
bool has_image;
+ bool is_compressed;
Doesn't ResetDecoder need to reset is_compressed?
+#wal_compression = off # enable compression of full-page writes
Currently wal_compression compresses only FPW, so isn't it better to place
it after full_page_writes in postgresql.conf.sample?
+ uint16 extra_data; /* used to store offset of bytes in
"hole", with
+ * last free bit used to check if block is
+ * compressed */
At least to me, defining something like the following seems more easy to
read.
uint16 hole_offset:15, is_compressed:1
Regards,
--
Fujii Masao
>InitXLogInsert()
>like hdr_scratch?
Thanks!On Thu, Dec 18, 2014 at 2:21 PM, Michael Paquier
<michael.paquier@gmail.com> wrote:
>
>
> On Wed, Dec 17, 2014 at 11:33 PM, Rahila Syed <rahilasyed90@gmail.com>
> wrote:
>>
>> I had a look at code. I have few minor points,
>
> Thanks!
>
>> + bkpb.fork_flags |= BKPBLOCK_HAS_IMAGE;
>> +
>> + if (is_compressed)
>> {
>> - rdt_datas_last->data = page;
>> - rdt_datas_last->len = BLCKSZ;
>> + /* compressed block information */
>> + bimg.length = compress_len;
>> + bimg.extra_data = hole_offset;
>> + bimg.extra_data |= XLR_BLCK_COMPRESSED_MASK;
>>
>> For consistency with the existing code , how about renaming the macro
>> XLR_BLCK_COMPRESSED_MASK as BKPBLOCK_HAS_COMPRESSED_IMAGE on the lines of
>> BKPBLOCK_HAS_IMAGE.
>
> OK, why not...
>
>>
>> + blk->hole_offset = extra_data & ~XLR_BLCK_COMPRESSED_MASK;
>> Here , I think that having the mask as BKPBLOCK_HOLE_OFFSET_MASK will be
>> more indicative of the fact that lower 15 bits of extra_data field comprises
>> of hole_offset value. This suggestion is also just to achieve consistency
>> with the existing BKPBLOCK_FORK_MASK for fork_flags field.
>
> Yeah that seems clearer, let's define it as ~XLR_BLCK_COMPRESSED_MASK
> though.
>
>> And comment typo
>> + * First try to compress block, filling in the page hole with
>> zeros
>> + * to improve the compression of the whole. If the block is
>> considered
>> + * as incompressible, complete the block header information as
>> if
>> + * nothing happened.
>>
>> As hole is no longer being compressed, this needs to be changed.
>
> Fixed. As well as an additional comment block down.
>
> A couple of things noticed on the fly:
> - Fixed pg_xlogdump being not completely correct to report the FPW
> information
> - A couple of typos and malformed sentences fixed
> - Added an assertion to check that the hole offset value does not the bit
> used for compression status
> - Reworked docs, mentioning as well that wal_compression is off by default.
> - Removed stuff in pg_controldata and XLOG_PARAMETER_CHANGE (mentioned by
> Fujii-san)
+ else
+ memcpy(compression_scratch, page, page_len);
I don't think the block image needs to be copied to scratch buffer here.
We can try to compress the "page" directly.
+#include "utils/pg_lzcompress.h"
#include "utils/memutils.h"
pg_lzcompress.h should be after meutils.h.
+/* Scratch buffer used to store block image to-be-compressed */
+static char compression_scratch[PGLZ_MAX_BLCKSZ];
Isn't it better to allocate the memory for compression_scratch in
InitXLogInsert()
like hdr_scratch?
+ uncompressed_page = (char *) palloc(PGLZ_RAW_SIZE(header));
Why don't we allocate the buffer for uncompressed page only once and
keep reusing it like XLogReaderState->readBuf? The size of uncompressed
page is at most BLCKSZ, so we can allocate the memory for it even before
knowing the real size of each block image.
- printf(" (FPW); hole: offset: %u, length: %u\n",
- record->blocks[block_id].hole_offset,
- record->blocks[block_id].hole_length);
+ if (record->blocks[block_id].is_compressed)
+ printf(" (FPW); hole offset: %u, compressed length %u\n",
+ record->blocks[block_id].hole_offset,
+ record->blocks[block_id].bkp_len);
+ else
+ printf(" (FPW); hole offset: %u, length: %u\n",
+ record->blocks[block_id].hole_offset,
+ record->blocks[block_id].bkp_len);
We need to consider what info about FPW we want pg_xlogdump to report.
I'd like to calculate how much bytes FPW was compressed, from the report
of pg_xlogdump. So I'd like to see also the both length of uncompressed FPW
and that of compressed one in the report.
In pg_config.h, the comment of BLCKSZ needs to be updated? Because
the maximum size of BLCKSZ can be affected by not only itemid but also
XLogRecordBlockImageHeader.
bool has_image;
+ bool is_compressed;
Doesn't ResetDecoder need to reset is_compressed?
+#wal_compression = off # enable compression of full-page writes
Currently wal_compression compresses only FPW, so isn't it better to place
it after full_page_writes in postgresql.conf.sample?
+ uint16 extra_data; /* used to store offset of bytes in
"hole", with
+ * last free bit used to check if block is
+ * compressed */
At least to me, defining something like the following seems more easy to
read.
uint16 hole_offset:15,
is_compressed:1
Regards,
--
Fujii Masao
On Thu, Dec 18, 2014 at 7:31 PM, Rahila Syed <rahilasyed90@gmail.com> wrote: >>Isn't it better to allocate the memory for compression_scratch in >>InitXLogInsert() >>like hdr_scratch? > > I think making compression_scratch a statically allocated global variable > is the result of following discussion earlier, > > http://www.postgresql.org/message-id/CA+TgmoazNBuwnLS4bpwyqgqteEznOAvy7KWdBm0A2-tBARn_aQ@mail.gmail.com /* * Permanently allocate readBuf. We do it this way, rather than just * making a static array, for two reasons:(1) no need to waste the * storage in most instantiations of the backend; (2) a static char array * isn't guaranteedto have any particular alignment, whereas palloc() * will provide MAXALIGN'd storage. */ The above source code comment in XLogReaderAllocate() makes me think that it's better to avoid using a static array. The point (1) seems less important in this case because most processes need the buffer for WAL compression, though. Regards, -- Fujii Masao
On Thu, Dec 18, 2014 at 7:31 PM, Rahila Syed <rahilasyed90@gmail.com> wrote: >>Isn't it better to allocate the memory for compression_scratch in >>InitXLogInsert() >>like hdr_scratch? > > I think making compression_scratch a statically allocated global variable > is the result of following discussion earlier, > http://www.postgresql.org/message-id/CA+TgmoazNBuwnLS4bpwyqgqteEznOAvy7KWdBm0A2-tBARn_aQ@mail.gmail.com Yep, in this case the OS does not request this memory as long as it is not touched, like when wal_compression is off all the time in the backend. Robert mentioned that upthread. -- Michael
On Thu, Dec 18, 2014 at 5:27 PM, Fujii Masao <masao.fujii@gmail.com> wrote:
> Thanks!
Thanks for your input.
> + else
> + memcpy(compression_scratch, page, page_len);
>
> I don't think the block image needs to be copied to scratch buffer here.
> We can try to compress the "page" directly.
Check.
> +#include "utils/pg_lzcompress.h"
> #include "utils/memutils.h"
>
> pg_lzcompress.h should be after meutils.h.
Oops.
> +/* Scratch buffer used to store block image to-be-compressed */
> +static char compression_scratch[PGLZ_MAX_BLCKSZ];
>
> Isn't it better to allocate the memory for compression_scratch in
> InitXLogInsert()
> like hdr_scratch?
Because the OS would not touch it if wal_compression is never used,
but now that you mention it, it may be better to get that in the
context of xlog_insert..
> + uncompressed_page = (char *) palloc(PGLZ_RAW_SIZE(header));
>
> Why don't we allocate the buffer for uncompressed page only once and
> keep reusing it like XLogReaderState->readBuf? The size of uncompressed
> page is at most BLCKSZ, so we can allocate the memory for it even before
> knowing the real size of each block image.
OK, this would save some cycles. I was trying to make process allocate
a minimum of memory only when necessary.
> - printf(" (FPW); hole: offset: %u, length: %u\n",
> - record->blocks[block_id].hole_offset,
> - record->blocks[block_id].hole_length);
> + if (record->blocks[block_id].is_compressed)
> + printf(" (FPW); hole offset: %u, compressed length %u\n",
> + record->blocks[block_id].hole_offset,
> + record->blocks[block_id].bkp_len);
> + else
> + printf(" (FPW); hole offset: %u, length: %u\n",
> + record->blocks[block_id].hole_offset,
> + record->blocks[block_id].bkp_len);
>
> We need to consider what info about FPW we want pg_xlogdump to report.
> I'd like to calculate how much bytes FPW was compressed, from the report
> of pg_xlogdump. So I'd like to see also the both length of uncompressed FPW
> and that of compressed one in the report.
OK, so let's add a parameter in the decoder for the uncompressed
length. Sounds fine?
> In pg_config.h, the comment of BLCKSZ needs to be updated? Because
> the maximum size of BLCKSZ can be affected by not only itemid but also
> XLogRecordBlockImageHeader.
Check.
> bool has_image;
> + bool is_compressed;
>
> Doesn't ResetDecoder need to reset is_compressed?
Check.
> +#wal_compression = off # enable compression of full-page writes
> Currently wal_compression compresses only FPW, so isn't it better to place
> it after full_page_writes in postgresql.conf.sample?
Check.
> + uint16 extra_data; /* used to store offset of bytes in
> "hole", with
> + * last free bit used to check if block is
> + * compressed */
> At least to me, defining something like the following seems more easy to
> read.
> uint16 hole_offset:15,
> is_compressed:1
Check++.
Updated patches addressing all those things are attached.
Regards,
--
Michael
Attachment
RAM: 32GB
Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos
1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm
On Fri, Dec 19, 2014 at 12:19 AM, Michael Paquier
<michael.paquier@gmail.com> wrote:
> On Thu, Dec 18, 2014 at 5:27 PM, Fujii Masao <masao.fujii@gmail.com> wrote:
>> Thanks!
> Thanks for your input.
>
>> + else
>> + memcpy(compression_scratch, page, page_len);
>>
>> I don't think the block image needs to be copied to scratch buffer here.
>> We can try to compress the "page" directly.
> Check.
>
>> +#include "utils/pg_lzcompress.h"
>> #include "utils/memutils.h"
>>
>> pg_lzcompress.h should be after meutils.h.
> Oops.
>
>> +/* Scratch buffer used to store block image to-be-compressed */
>> +static char compression_scratch[PGLZ_MAX_BLCKSZ];
>>
>> Isn't it better to allocate the memory for compression_scratch in
>> InitXLogInsert()
>> like hdr_scratch?
> Because the OS would not touch it if wal_compression is never used,
> but now that you mention it, it may be better to get that in the
> context of xlog_insert..
>
>> + uncompressed_page = (char *) palloc(PGLZ_RAW_SIZE(header));
>>
>> Why don't we allocate the buffer for uncompressed page only once and
>> keep reusing it like XLogReaderState->readBuf? The size of uncompressed
>> page is at most BLCKSZ, so we can allocate the memory for it even before
>> knowing the real size of each block image.
> OK, this would save some cycles. I was trying to make process allocate
> a minimum of memory only when necessary.
>
>> - printf(" (FPW); hole: offset: %u, length: %u\n",
>> - record->blocks[block_id].hole_offset,
>> - record->blocks[block_id].hole_length);
>> + if (record->blocks[block_id].is_compressed)
>> + printf(" (FPW); hole offset: %u, compressed length %u\n",
>> + record->blocks[block_id].hole_offset,
>> + record->blocks[block_id].bkp_len);
>> + else
>> + printf(" (FPW); hole offset: %u, length: %u\n",
>> + record->blocks[block_id].hole_offset,
>> + record->blocks[block_id].bkp_len);
>>
>> We need to consider what info about FPW we want pg_xlogdump to report.
>> I'd like to calculate how much bytes FPW was compressed, from the report
>> of pg_xlogdump. So I'd like to see also the both length of uncompressed FPW
>> and that of compressed one in the report.
> OK, so let's add a parameter in the decoder for the uncompressed
> length. Sounds fine?
>
>> In pg_config.h, the comment of BLCKSZ needs to be updated? Because
>> the maximum size of BLCKSZ can be affected by not only itemid but also
>> XLogRecordBlockImageHeader.
> Check.
>
>> bool has_image;
>> + bool is_compressed;
>>
>> Doesn't ResetDecoder need to reset is_compressed?
> Check.
>
>> +#wal_compression = off # enable compression of full-page writes
>> Currently wal_compression compresses only FPW, so isn't it better to place
>> it after full_page_writes in postgresql.conf.sample?
> Check.
>
>> + uint16 extra_data; /* used to store offset of bytes in
>> "hole", with
>> + * last free bit used to check if block is
>> + * compressed */
>> At least to me, defining something like the following seems more easy to
>> read.
>> uint16 hole_offset:15,
>> is_compressed:1
> Check++.
>
> Updated patches addressing all those things are attached.
Thanks for updating the patch!
Firstly I'm thinking to commit the
0001-Move-pg_lzcompress.c-to-src-common.patch.
pg_lzcompress.h still exists in include/utils, but it should be moved to
include/common?
Do we really need PGLZ_Status? I'm not sure whether your categorization of
the result status of compress/decompress functions is right or not. For example,
pglz_decompress() can return PGLZ_INCOMPRESSIBLE status, but which seems
invalid logically... Maybe this needs to be revisited when we introduce other
compression algorithms and create the wrapper function for those compression
and decompression functions. Anyway making pg_lzdecompress return
the boolean value seems enough.
I updated 0001-Move-pg_lzcompress.c-to-src-common.patch accordingly.
Barring objections, I will push the attached patch firstly.
Regards,
--
Fujii Masao
Attachment
On Wed, Dec 24, 2014 at 8:44 PM, Fujii Masao <masao.fujii@gmail.com> wrote: > On Fri, Dec 19, 2014 at 12:19 AM, Michael Paquier > <michael.paquier@gmail.com> wrote: > Firstly I'm thinking to commit the > 0001-Move-pg_lzcompress.c-to-src-common.patch. > > pg_lzcompress.h still exists in include/utils, but it should be moved to > include/common? You are right. This is a remnant of first version of this patch where pglz was added in port/ and not common/. > Do we really need PGLZ_Status? I'm not sure whether your categorization of > the result status of compress/decompress functions is right or not. For example, > pglz_decompress() can return PGLZ_INCOMPRESSIBLE status, but which seems > invalid logically... Maybe this needs to be revisited when we introduce other > compression algorithms and create the wrapper function for those compression > and decompression functions. Anyway making pg_lzdecompress return > the boolean value seems enough. Returning only a boolean is fine for me (that's what my first patch did), especially if we add at some point hooks for compression and decompression calls. Regards, -- Michael
On Wed, Dec 24, 2014 at 9:03 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > Returning only a boolean is fine for me (that's what my first patch > did), especially if we add at some point hooks for compression and > decompression calls. Here is a patch rebased on current HEAD (60838df) for the core feature with the APIs of pglz using booleans as return values. -- Michael
Attachment
On Thu, Dec 25, 2014 at 10:10 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Wed, Dec 24, 2014 at 9:03 PM, Michael Paquier > <michael.paquier@gmail.com> wrote: >> Returning only a boolean is fine for me (that's what my first patch >> did), especially if we add at some point hooks for compression and >> decompression calls. > Here is a patch rebased on current HEAD (60838df) for the core feature > with the APIs of pglz using booleans as return values. After the revert of 1st patch moving pglz to src/common, I have reworked both patches, resulting in the attached. For pglz, the dependency to varlena has been removed to make the code able to run independently on both frontend and backend sides. In order to do that the APIs of pglz_compress and pglz_decompress have been changed a bit: - pglz_compress returns the number of bytes compressed. - pglz_decompress takes as additional argument the compressed length of the buffer, and returns the number of bytes decompressed instead of a simple boolean for consistency with the compression API. PGLZ_Header is not modified to keep the on-disk format intact. The WAL compression patch is realigned based on those changes. Regards, -- Michael
Attachment
On Fri, Dec 26, 2014 at 12:31 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Thu, Dec 25, 2014 at 10:10 PM, Michael Paquier > <michael.paquier@gmail.com> wrote: >> On Wed, Dec 24, 2014 at 9:03 PM, Michael Paquier >> <michael.paquier@gmail.com> wrote: >>> Returning only a boolean is fine for me (that's what my first patch >>> did), especially if we add at some point hooks for compression and >>> decompression calls. >> Here is a patch rebased on current HEAD (60838df) for the core feature >> with the APIs of pglz using booleans as return values. > After the revert of 1st patch moving pglz to src/common, I have > reworked both patches, resulting in the attached. > > For pglz, the dependency to varlena has been removed to make the code > able to run independently on both frontend and backend sides. In order > to do that the APIs of pglz_compress and pglz_decompress have been > changed a bit: > - pglz_compress returns the number of bytes compressed. > - pglz_decompress takes as additional argument the compressed length > of the buffer, and returns the number of bytes decompressed instead of > a simple boolean for consistency with the compression API. > PGLZ_Header is not modified to keep the on-disk format intact. pglz_compress() and pglz_decompress() still use PGLZ_Header, so the frontend which uses those functions needs to handle PGLZ_Header. But it basically should be handled via the varlena macros. That is, the frontend still seems to need to understand the varlena datatype. I think we should avoid that. Thought? Regards, -- Fujii Masao
On Fri, Dec 26, 2014 at 3:24 PM, Fujii Masao <masao.fujii@gmail.com> wrote: > pglz_compress() and pglz_decompress() still use PGLZ_Header, so the frontend > which uses those functions needs to handle PGLZ_Header. But it basically should > be handled via the varlena macros. That is, the frontend still seems to need to > understand the varlena datatype. I think we should avoid that. Thought? Hm, yes it may be wiser to remove it and make the data passed to pglz for varlena 8 bytes shorter.. -- Michael
On Fri, Dec 26, 2014 at 4:16 PM, Michael Paquier <michael.paquier@gmail.com> wrote:
> On Fri, Dec 26, 2014 at 3:24 PM, Fujii Masao <masao.fujii@gmail.com> wrote:
>> pglz_compress() and pglz_decompress() still use PGLZ_Header, so the frontend
>> which uses those functions needs to handle PGLZ_Header. But it basically should
>> be handled via the varlena macros. That is, the frontend still seems to need to
>> understand the varlena datatype. I think we should avoid that. Thought?
> Hm, yes it may be wiser to remove it and make the data passed to pglz
> for varlena 8 bytes shorter..
OK, here is the result of this work, made of 3 patches.
The first two patches move pglz stuff to src/common and make it a frontend utility entirely independent on varlena and its related metadata.
- Patch 1 is a simple move of pglz to src/common, with PGLZ_Header still present. There is nothing amazing here, and that's the broken version that has been reverted in 966115c.
- The real stuff comes with patch 2, that implements the removal of PGLZ_Header, changing the APIs of compression and decompression to pglz to not have anymore toast metadata, this metadata being now localized in tuptoaster.c. Note that this patch protects the on-disk format (tested with pg_upgrade from 9.4 to a patched HEAD server). Here is how the APIs of compression and decompression look like with this patch, simply performing operations from a source to a destination:
extern int32 pglz_compress(const char *source, int32 slen, char *dest,
const PGLZ_Strategy *strategy);
extern int32 pglz_decompress(const char *source, char *dest,
int32 compressed_size, int32 raw_size);
The return value of those functions is the number of bytes written in the destination buffer, and 0 if operation failed. This is aimed to make backend as well more pluggable. The reason why patch 2 exists (it could be merged with patch 1), is to facilitate the review and the changes made to pglz to make it an entirely independent facility.
Patch 3 is the FPW compression, changed to fit with those changes. Note that as PGLZ_Header contains the raw size of the compressed data, and that it does not exist, it is necessary to store the raw length of the block image directly in the block image header with 2 additional bytes. Those 2 bytes are used only if wal_compression is set to true thanks to a boolean flag, so if wal_compression is disabled, the WAL record length is exactly the same as HEAD, and there is no penalty in the default case. Similarly to previous patches, the block image is compressed without its hole.
http://www.postgresql.org/message-id/CAB7nPqSc97o-UE5paxfMUKWcxE_JioyxO1M4A0pMnmYqAnec2g@mail.gmail.com
test | ffactor | user_diff | system_diff | pg_size_pretty
---------+---------+-----------+-------------+----------------
FPW on | 50 | 48.823907 | 0.737649 | 582 MB
FPW on | 20 | 16.135000 | 0.764682 | 229 MB
FPW on | 10 | 8.521099 | 0.751947 | 116 MB
FPW off | 50 | 29.722793 | 1.045577 | 746 MB
FPW off | 20 | 12.673375 | 0.905422 | 293 MB
FPW off | 10 | 6.723120 | 0.779936 | 148 MB
HEAD | 50 | 30.763136 | 1.129822 | 746 MB
HEAD | 20 | 13.340823 | 0.893365 | 293 MB
HEAD | 10 | 7.267311 | 0.909057 | 148 MB
(9 rows)
Patches, as well as the test script and the results are attached.
Regards,
--
Michael
Attachment
On Fri, 2013-08-30 at 09:57 +0300, Heikki Linnakangas wrote: > Speeding up the CRC calculation obviously won't help with the WAL volume > per se, ie. you still generate the same amount of WAL that needs to be > shipped in replication. But then again, if all you want to do is to > reduce the volume, you could just compress the whole WAL stream. Was this point addressed? How much benefit is there to compressing the data before it goes into the WAL stream versus after? Regards,Jeff Davis
On Tue, Dec 30, 2014 at 6:21 PM, Jeff Davis <pgsql@j-davis.com> wrote: > On Fri, 2013-08-30 at 09:57 +0300, Heikki Linnakangas wrote: >> Speeding up the CRC calculation obviously won't help with the WAL volume >> per se, ie. you still generate the same amount of WAL that needs to be >> shipped in replication. But then again, if all you want to do is to >> reduce the volume, you could just compress the whole WAL stream. > > Was this point addressed? Compressing the whole record is interesting for multi-insert records, but as we need to keep the compressed data in a pre-allocated buffer until WAL is written, we can only compress things within a given size range. The point is, even if we define a lower bound, compression is going to perform badly with an application that generates for example many small records that are just higher than the lower bound... Unsurprisingly for small records this was bad: http://www.postgresql.org/message-id/CAB7nPqSc97o-UE5paxfMUKWcxE_JioyxO1M4A0pMnmYqAnec2g@mail.gmail.com Now are there still people interested in seeing the amount of time spent in the CRC calculation depending on the record length? Isn't that worth speaking on the CRC thread btw? I'd imagine that it would be simple to evaluate the effect of the CRC calculation within a single process using a bit getrusage. > How much benefit is there to compressing the data before it goes into the WAL stream versus after? Here is a good list: http://www.postgresql.org/message-id/20141212145330.GK31413@awork2.anarazel.de Regards, -- Michael
On 2014-12-30 21:23:38 +0900, Michael Paquier wrote: > On Tue, Dec 30, 2014 at 6:21 PM, Jeff Davis <pgsql@j-davis.com> wrote: > > On Fri, 2013-08-30 at 09:57 +0300, Heikki Linnakangas wrote: > >> Speeding up the CRC calculation obviously won't help with the WAL volume > >> per se, ie. you still generate the same amount of WAL that needs to be > >> shipped in replication. But then again, if all you want to do is to > >> reduce the volume, you could just compress the whole WAL stream. > > > > Was this point addressed? > Compressing the whole record is interesting for multi-insert records, > but as we need to keep the compressed data in a pre-allocated buffer > until WAL is written, we can only compress things within a given size > range. The point is, even if we define a lower bound, compression is > going to perform badly with an application that generates for example > many small records that are just higher than the lower bound... > Unsurprisingly for small records this was bad: So why are you bringing it up? That's not an argument for anything, except not doing it in such a simplistic way. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Dec 30, 2014 at 01:27:44PM +0100, Andres Freund wrote: > On 2014-12-30 21:23:38 +0900, Michael Paquier wrote: > > On Tue, Dec 30, 2014 at 6:21 PM, Jeff Davis <pgsql@j-davis.com> wrote: > > > On Fri, 2013-08-30 at 09:57 +0300, Heikki Linnakangas wrote: > > >> Speeding up the CRC calculation obviously won't help with the WAL volume > > >> per se, ie. you still generate the same amount of WAL that needs to be > > >> shipped in replication. But then again, if all you want to do is to > > >> reduce the volume, you could just compress the whole WAL stream. > > > > > > Was this point addressed? > > Compressing the whole record is interesting for multi-insert records, > > but as we need to keep the compressed data in a pre-allocated buffer > > until WAL is written, we can only compress things within a given size > > range. The point is, even if we define a lower bound, compression is > > going to perform badly with an application that generates for example > > many small records that are just higher than the lower bound... > > Unsurprisingly for small records this was bad: > > So why are you bringing it up? That's not an argument for anything, > except not doing it in such a simplistic way. I still don't understand the value of adding WAL compression, given the high CPU usage and minimal performance improvement. The only big advantage is WAL storage, but again, why not just compress the WAL file when archiving. I thought we used to see huge performance benefits from WAL compression, but not any more? Has the UPDATE WAL compression removed that benefit? Am I missing something? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
>
> On Tue, Dec 30, 2014 at 01:27:44PM +0100, Andres Freund wrote:
> > On 2014-12-30 21:23:38 +0900, Michael Paquier wrote:
> > > On Tue, Dec 30, 2014 at 6:21 PM, Jeff Davis <pgsql@j-davis.com> wrote:
> > > > On Fri, 2013-08-30 at 09:57 +0300, Heikki Linnakangas wrote:
> > > >> Speeding up the CRC calculation obviously won't help with the WAL volume
> > > >> per se, ie. you still generate the same amount of WAL that needs to be
> > > >> shipped in replication. But then again, if all you want to do is to
> > > >> reduce the volume, you could just compress the whole WAL stream.
> > > >
> > > > Was this point addressed?
> > > Compressing the whole record is interesting for multi-insert records,
> > > but as we need to keep the compressed data in a pre-allocated buffer
> > > until WAL is written, we can only compress things within a given size
> > > range. The point is, even if we define a lower bound, compression is
> > > going to perform badly with an application that generates for example
> > > many small records that are just higher than the lower bound...
> > > Unsurprisingly for small records this was bad:
> >
> > So why are you bringing it up? That's not an argument for anything,
> > except not doing it in such a simplistic way.
>
> I still don't understand the value of adding WAL compression, given the
> high CPU usage and minimal performance improvement. The only big
> advantage is WAL storage, but again, why not just compress the WAL file
> when archiving.
>
> I thought we used to see huge performance benefits from WAL compression,
> but not any more?
In general, I think this idea has merit with respect to compressible data,
On Thu, Jan 1, 2015 at 2:10 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Thu, Jan 1, 2015 at 2:39 AM, Bruce Momjian <bruce@momjian.us> wrote: >> > So why are you bringing it up? That's not an argument for anything, >> > except not doing it in such a simplistic way. >> >> I still don't understand the value of adding WAL compression, given the >> high CPU usage and minimal performance improvement. The only big >> advantage is WAL storage, but again, why not just compress the WAL file >> when archiving. When doing some tests with pgbench for a fixed number of transactions, I also noticed a reduction in replay time as well, see here for example some results here: http://www.postgresql.org/message-id/CAB7nPqRv6RaSx7hTnp=g3dYqOu++FeL0UioYqPLLBdbhAyB_jQ@mail.gmail.com >> I thought we used to see huge performance benefits from WAL compression, >> but not any more? > > I think there can be performance benefit for the cases when the data > is compressible, but it would be loss otherwise. The main thing is > that the current compression algorithm (pg_lz) used is not so > favorable for non-compresible data. Yes definitely. Switching to a different algorithm would be the next step forward. We have been discussing mainly about lz4 that has a friendly license, I think that it would be worth studying other things as well once we have all the infrastructure in place. >>Has the UPDATE WAL compression removed that benefit? > > Good question, I think there might be some impact due to that, but in > general for page level compression still there will be much more to > compress. That may be a good thing to put a number on. We could try to patch a build with a revert of a3115f0d and measure a bit that the difference in WAL size that it creates. Thoughts? > In general, I think this idea has merit with respect to compressible data, > and to save for the cases where it will not perform well, there is a on/off > switch for this feature and in future if PostgreSQL has some better > compression method, we can consider the same as well. One thing > that we need to think is whether user's can decide with ease when to > enable this global switch. The opposite is true as well, we shouldn't force the user to have data compressed even if the switch is disabled. -- Michael
On Thu, Jan 1, 2015 at 10:40:53AM +0530, Amit Kapila wrote: > Good question, I think there might be some impact due to that, but in > general for page level compression still there will be much more to > compress. > > In general, I think this idea has merit with respect to compressible data, > and to save for the cases where it will not perform well, there is a on/off > switch for this feature and in future if PostgreSQL has some better > compression method, we can consider the same as well. One thing > that we need to think is whether user's can decide with ease when to > enable this global switch. Yes, that is the crux of my concern. I am worried about someone who assumes compressions == good, and then enables it. If we can't clearly know when it is good, it is even harder for users to know. If we think it isn't generally useful until a new compression algorithm is used, perhaps we need to wait until the we implement this. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
> On Thu, Jan 1, 2015 at 2:10 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > On Thu, Jan 1, 2015 at 2:39 AM, Bruce Momjian <bruce@momjian.us> wrote:
> >> > So why are you bringing it up? That's not an argument for anything,
> >> > except not doing it in such a simplistic way.
> >>
> >> I still don't understand the value of adding WAL compression, given the
> >> high CPU usage and minimal performance improvement. The only big
> >> advantage is WAL storage, but again, why not just compress the WAL file
> >> when archiving.
> When doing some tests with pgbench for a fixed number of transactions,
> I also noticed a reduction in replay time as well, see here for
> example some results here:
> http://www.postgresql.org/message-id/CAB7nPqRv6RaSx7hTnp=g3dYqOu++FeL0UioYqPLLBdbhAyB_jQ@mail.gmail.com
>
> >> I thought we used to see huge performance benefits from WAL compression,
> >> but not any more?
> >
> > I think there can be performance benefit for the cases when the data
> > is compressible, but it would be loss otherwise. The main thing is
> > that the current compression algorithm (pg_lz) used is not so
> > favorable for non-compresible data.
> Yes definitely. Switching to a different algorithm would be the next
> step forward. We have been discussing mainly about lz4 that has a
> friendly license, I think that it would be worth studying other things
> as well once we have all the infrastructure in place.
>
> >>Has the UPDATE WAL compression removed that benefit?
> >
> > Good question, I think there might be some impact due to that, but in
> > general for page level compression still there will be much more to
> > compress.
> That may be a good thing to put a number on. We could try to patch a
> build with a revert of a3115f0d and measure a bit that the difference
> in WAL size that it creates. Thoughts?
>
You can do that, but what inference you want to deduce from it?
>
> On Thu, Jan 1, 2015 at 10:40:53AM +0530, Amit Kapila wrote:
> > Good question, I think there might be some impact due to that, but in
> > general for page level compression still there will be much more to
> > compress.
> >
> > In general, I think this idea has merit with respect to compressible data,
> > and to save for the cases where it will not perform well, there is a on/off
> > switch for this feature and in future if PostgreSQL has some better
> > compression method, we can consider the same as well. One thing
> > that we need to think is whether user's can decide with ease when to
> > enable this global switch.
>
> Yes, that is the crux of my concern. I am worried about someone who
> assumes compressions == good, and then enables it. If we can't clearly
> know when it is good, it is even harder for users to know.
On 2014-12-31 16:09:31 -0500, Bruce Momjian wrote: > I still don't understand the value of adding WAL compression, given the > high CPU usage and minimal performance improvement. The only big > advantage is WAL storage, but again, why not just compress the WAL file > when archiving. before: pg_xlog is 800GB after: pg_xlog is 600GB. I'm damned sure that many people would be happy with that, even if the *per backend* overhead is a bit higher. And no, compression of archives when archiving helps *zap* with that (streaming, wal_keep_segments, checkpoint_timeout). As discussed before. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Jan 02, 2015 at 01:01:06PM +0100, Andres Freund wrote: > On 2014-12-31 16:09:31 -0500, Bruce Momjian wrote: > > I still don't understand the value of adding WAL compression, given the > > high CPU usage and minimal performance improvement. The only big > > advantage is WAL storage, but again, why not just compress the WAL file > > when archiving. > > before: pg_xlog is 800GB > after: pg_xlog is 600GB. > > I'm damned sure that many people would be happy with that, even if the > *per backend* overhead is a bit higher. And no, compression of archives > when archiving helps *zap* with that (streaming, wal_keep_segments, > checkpoint_timeout). As discussed before. > > Greetings, > > Andres Freund > +1 On an I/O constrained system assuming 50:50 table:WAL I/O, in the case above you can process 100GB of transaction data at the cost of a bit more CPU. Regards, Ken
On Fri, Jan 2, 2015 at 10:15:57AM -0600, ktm@rice.edu wrote: > On Fri, Jan 02, 2015 at 01:01:06PM +0100, Andres Freund wrote: > > On 2014-12-31 16:09:31 -0500, Bruce Momjian wrote: > > > I still don't understand the value of adding WAL compression, given the > > > high CPU usage and minimal performance improvement. The only big > > > advantage is WAL storage, but again, why not just compress the WAL file > > > when archiving. > > > > before: pg_xlog is 800GB > > after: pg_xlog is 600GB. > > > > I'm damned sure that many people would be happy with that, even if the > > *per backend* overhead is a bit higher. And no, compression of archives > > when archiving helps *zap* with that (streaming, wal_keep_segments, > > checkpoint_timeout). As discussed before. > > > > Greetings, > > > > Andres Freund > > > > +1 > > On an I/O constrained system assuming 50:50 table:WAL I/O, in the case > above you can process 100GB of transaction data at the cost of a bit > more CPU. OK, so given your stats, the feature give a 12.5% reduction in I/O. If that is significant, shouldn't we see a performance improvement? If we don't see a performance improvement, is I/O reduction worthwhile? Is it valuable in that it gives non-database applications more I/O to use? Is that all? I suggest we at least document that this feature as mostly useful for I/O reduction, and maybe say CPU usage and performance might be negatively impacted. OK, here is the email I remember from Fujii Masao this same thread that showed a performance improvement for WAL compression: http://www.postgresql.org/message-id/CAHGQGwGqG8e9YN0fNCUZqTTT=hNr7Ly516kfT5ffqf4pp1qnHg@mail.gmail.com Why are we not seeing the 33% compression and 15% performance improvement he saw? What am I missing here? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On 2015-01-02 11:52:42 -0500, Bruce Momjian wrote: > Why are we not seeing the 33% compression and 15% performance > improvement he saw? What am I missing here? To see performance improvements something needs to be the bottleneck. If WAL writes/flushes aren't that in the tested scenario, you won't see a performance benefit. Amdahl's law and all that. I don't understand your negativity about the topic. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Jan 2, 2015 at 05:55:52PM +0100, Andres Freund wrote: > On 2015-01-02 11:52:42 -0500, Bruce Momjian wrote: > > Why are we not seeing the 33% compression and 15% performance > > improvement he saw? What am I missing here? > > To see performance improvements something needs to be the bottleneck. If > WAL writes/flushes aren't that in the tested scenario, you won't see a > performance benefit. Amdahl's law and all that. > > I don't understand your negativity about the topic. I remember the initial post from Masao in August 2013 showing a performance boost, so I assumed, while we had the concurrent WAL insert performance improvement in 9.4, this was going to be our 9.5 WAL improvement. While the WAL insert performance improvement required no tuning and was never a negative, I now see the compression patch as something that has negatives, so has to be set by the user, and only wins in certain cases. I am disappointed, and am trying to figure out how this became such a marginal win for 9.5. :-( My negativity is not that I don't want it, but I want to understand why it isn't better than I remembered. You are basically telling me it was always a marginal win. :-( Boohoo! -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On 2015-01-02 12:06:33 -0500, Bruce Momjian wrote: > On Fri, Jan 2, 2015 at 05:55:52PM +0100, Andres Freund wrote: > > On 2015-01-02 11:52:42 -0500, Bruce Momjian wrote: > > > Why are we not seeing the 33% compression and 15% performance > > > improvement he saw? What am I missing here? > > > > To see performance improvements something needs to be the bottleneck. If > > WAL writes/flushes aren't that in the tested scenario, you won't see a > > performance benefit. Amdahl's law and all that. > > > > I don't understand your negativity about the topic. > > I remember the initial post from Masao in August 2013 showing a > performance boost, so I assumed, while we had the concurrent WAL insert > performance improvement in 9.4, this was going to be our 9.5 WAL > improvement. I don't think it makes sense to compare features/improvements that way. > While the WAL insert performance improvement required no tuning and > was never a negative It's actually a negative in some cases. > , I now see the compression patch as something that has negatives, so > has to be set by the user, and only wins in certain cases. I am > disappointed, and am trying to figure out how this became such a > marginal win for 9.5. :-( I find the notion that a multi digit space reduction is a "marginal win" pretty ridiculous and way too narrow focused. Our WAL volume is a *significant* problem in the field. And it mostly consists out of FPWs spacewise. > My negativity is not that I don't want it, but I want to understand why > it isn't better than I remembered. You are basically telling me it was > always a marginal win. :-( Boohoo! No, I didn't. I told you that *IN ONE BENCHMARK* wal writes apparently are not the bottleneck. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Jan 2, 2015 at 06:11:29PM +0100, Andres Freund wrote: > > My negativity is not that I don't want it, but I want to understand why > > it isn't better than I remembered. You are basically telling me it was > > always a marginal win. :-( Boohoo! > > No, I didn't. I told you that *IN ONE BENCHMARK* wal writes apparently > are not the bottleneck. What I have not seen is any recent benchmarks that show it as a win, while the original email did, so I was confused. I tried to explain exactly how I viewed things --- you can not like it, but that is how I look for upcoming features, and where we should focus our time. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On Fri, Jan 2, 2015 at 2:11 PM, Andres Freund <andres@2ndquadrant.com> wrote: >> , I now see the compression patch as something that has negatives, so >> has to be set by the user, and only wins in certain cases. I am >> disappointed, and am trying to figure out how this became such a >> marginal win for 9.5. :-( > > I find the notion that a multi digit space reduction is a "marginal win" > pretty ridiculous and way too narrow focused. Our WAL volume is a > *significant* problem in the field. And it mostly consists out of FPWs > spacewise. One thing I'd like to point out, is that in cases where WAL I/O is an issue (ie: WAL archiving), usually people already compress the segments during archiving. I know I do, and I know it's recommended on the web, and by some consultants. So, I wouldn't want this FPW compression, which is desirable in replication scenarios if you can spare the CPU cycles (because of streaming), adversely affecting WAL compression during archiving. Has anyone tested the compressability of WAL segments with FPW compression on? AFAIK, both pglz and lz4 output should still be compressible with deflate, but I've never tried.
On Fri, Jan 2, 2015 at 02:18:12PM -0300, Claudio Freire wrote: > On Fri, Jan 2, 2015 at 2:11 PM, Andres Freund <andres@2ndquadrant.com> wrote: > >> , I now see the compression patch as something that has negatives, so > >> has to be set by the user, and only wins in certain cases. I am > >> disappointed, and am trying to figure out how this became such a > >> marginal win for 9.5. :-( > > > > I find the notion that a multi digit space reduction is a "marginal win" > > pretty ridiculous and way too narrow focused. Our WAL volume is a > > *significant* problem in the field. And it mostly consists out of FPWs > > spacewise. > > One thing I'd like to point out, is that in cases where WAL I/O is an > issue (ie: WAL archiving), usually people already compress the > segments during archiving. I know I do, and I know it's recommended on > the web, and by some consultants. > > So, I wouldn't want this FPW compression, which is desirable in > replication scenarios if you can spare the CPU cycles (because of > streaming), adversely affecting WAL compression during archiving. To be specific, desirable in streaming replication scenarios that don't use SSL compression. (What percentage is that?) It is something we should mention in the docs for this feature? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
* Bruce Momjian (bruce@momjian.us) wrote:
> To be specific, desirable in streaming replication scenarios that don't
> use SSL compression. (What percentage is that?) It is something we
> should mention in the docs for this feature?
Considering how painful the SSL rengeotiation problems were and the CPU
overhead, I'd be surprised if many high-write-volume replication
environments use SSL at all.
There's a lot of win to be had from compression of FPWs, but it's like
most compression in that there are trade-offs to be had and environments
where it won't be a win, but I believe those cases to be the minority.
Thanks,
Stephen
On Sat, Jan 3, 2015 at 1:52 AM, Bruce Momjian <bruce@momjian.us> wrote: > I suggest we at least document that this feature as mostly useful for > I/O reduction, and maybe say CPU usage and performance might be > negatively impacted. FWIW, that's mentioned in the documentation included in the patch.. -- Michael
On Sat, Jan 3, 2015 at 1:52 AM, Bruce Momjian <bruce@momjian.us> wrote: > On Fri, Jan 2, 2015 at 10:15:57AM -0600, ktm@rice.edu wrote: >> On Fri, Jan 02, 2015 at 01:01:06PM +0100, Andres Freund wrote: >> > On 2014-12-31 16:09:31 -0500, Bruce Momjian wrote: >> > > I still don't understand the value of adding WAL compression, given the >> > > high CPU usage and minimal performance improvement. The only big >> > > advantage is WAL storage, but again, why not just compress the WAL file >> > > when archiving. >> > >> > before: pg_xlog is 800GB >> > after: pg_xlog is 600GB. >> > >> > I'm damned sure that many people would be happy with that, even if the >> > *per backend* overhead is a bit higher. And no, compression of archives >> > when archiving helps *zap* with that (streaming, wal_keep_segments, >> > checkpoint_timeout). As discussed before. >> > >> > Greetings, >> > >> > Andres Freund >> > >> >> +1 >> >> On an I/O constrained system assuming 50:50 table:WAL I/O, in the case >> above you can process 100GB of transaction data at the cost of a bit >> more CPU. > > OK, so given your stats, the feature give a 12.5% reduction in I/O. If > that is significant, shouldn't we see a performance improvement? If we > don't see a performance improvement, is I/O reduction worthwhile? Is it > valuable in that it gives non-database applications more I/O to use? Is > that all? > > I suggest we at least document that this feature as mostly useful for > I/O reduction, and maybe say CPU usage and performance might be > negatively impacted. > > OK, here is the email I remember from Fujii Masao this same thread that > showed a performance improvement for WAL compression: > > http://www.postgresql.org/message-id/CAHGQGwGqG8e9YN0fNCUZqTTT=hNr7Ly516kfT5ffqf4pp1qnHg@mail.gmail.com > > Why are we not seeing the 33% compression and 15% performance > improvement he saw? Because the benchmarks I and Michael used are very difffernet. I just used pgbench, but he used his simple test SQLs (see http://www.postgresql.org/message-id/CAB7nPqSc97o-UE5paxfMUKWcxE_JioyxO1M4A0pMnmYqAnec2g@mail.gmail.com). Furthermore, the data type of pgbench_accounts.filler column is character(84) and its content is empty, so pgbench_accounts is very compressible. This is one of the reasons I could see good performance improvement and high compression ratio. Regards, -- Fujii Masao
On Sat, Jan 3, 2015 at 2:24 AM, Bruce Momjian <bruce@momjian.us> wrote: > On Fri, Jan 2, 2015 at 02:18:12PM -0300, Claudio Freire wrote: >> On Fri, Jan 2, 2015 at 2:11 PM, Andres Freund <andres@2ndquadrant.com> wrote: >> >> , I now see the compression patch as something that has negatives, so >> >> has to be set by the user, and only wins in certain cases. I am >> >> disappointed, and am trying to figure out how this became such a >> >> marginal win for 9.5. :-( >> > >> > I find the notion that a multi digit space reduction is a "marginal win" >> > pretty ridiculous and way too narrow focused. Our WAL volume is a >> > *significant* problem in the field. And it mostly consists out of FPWs >> > spacewise. >> >> One thing I'd like to point out, is that in cases where WAL I/O is an >> issue (ie: WAL archiving), usually people already compress the >> segments during archiving. I know I do, and I know it's recommended on >> the web, and by some consultants. >> >> So, I wouldn't want this FPW compression, which is desirable in >> replication scenarios if you can spare the CPU cycles (because of >> streaming), adversely affecting WAL compression during archiving. > > To be specific, desirable in streaming replication scenarios that don't > use SSL compression. (What percentage is that?) It is something we > should mention in the docs for this feature? Even if SSL is used in replication, FPW compression is useful. It can reduce the amount of I/O in the standby side. Sometimes I've seen walreceiver's I/O had become a performance bottleneck especially in synchronous replication cases. FPW compression can be useful for those cases, for example. Regards, -- Fujii Masao
On Sun, Dec 28, 2014 at 10:57 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > > > On Fri, Dec 26, 2014 at 4:16 PM, Michael Paquier <michael.paquier@gmail.com> > wrote: >> On Fri, Dec 26, 2014 at 3:24 PM, Fujii Masao <masao.fujii@gmail.com> >> wrote: >>> pglz_compress() and pglz_decompress() still use PGLZ_Header, so the >>> frontend >>> which uses those functions needs to handle PGLZ_Header. But it basically >>> should >>> be handled via the varlena macros. That is, the frontend still seems to >>> need to >>> understand the varlena datatype. I think we should avoid that. Thought? >> Hm, yes it may be wiser to remove it and make the data passed to pglz >> for varlena 8 bytes shorter.. > > OK, here is the result of this work, made of 3 patches. Thanks for updating the patches! > The first two patches move pglz stuff to src/common and make it a frontend > utility entirely independent on varlena and its related metadata. > - Patch 1 is a simple move of pglz to src/common, with PGLZ_Header still > present. There is nothing amazing here, and that's the broken version that > has been reverted in 966115c. The patch 1 cannot be applied to the master successfully because of recent change. > - The real stuff comes with patch 2, that implements the removal of > PGLZ_Header, changing the APIs of compression and decompression to pglz to > not have anymore toast metadata, this metadata being now localized in > tuptoaster.c. Note that this patch protects the on-disk format (tested with > pg_upgrade from 9.4 to a patched HEAD server). Here is how the APIs of > compression and decompression look like with this patch, simply performing > operations from a source to a destination: > extern int32 pglz_compress(const char *source, int32 slen, char *dest, > const PGLZ_Strategy *strategy); > extern int32 pglz_decompress(const char *source, char *dest, > int32 compressed_size, int32 raw_size); > The return value of those functions is the number of bytes written in the > destination buffer, and 0 if operation failed. So it's guaranteed that 0 is never returned in success case? I'm not sure if that case can really happen, though. Regards, -- Fujii Masao
On Mon, Jan 5, 2015 at 10:29 PM, Fujii Masao <masao.fujii@gmail.com> wrote: > On Sun, Dec 28, 2014 at 10:57 PM, Michael Paquier wrote: > The patch 1 cannot be applied to the master successfully because of > recent change. Yes, that's caused by ccb161b. Attached are rebased versions. >> - The real stuff comes with patch 2, that implements the removal of >> PGLZ_Header, changing the APIs of compression and decompression to pglz to >> not have anymore toast metadata, this metadata being now localized in >> tuptoaster.c. Note that this patch protects the on-disk format (tested with >> pg_upgrade from 9.4 to a patched HEAD server). Here is how the APIs of >> compression and decompression look like with this patch, simply performing >> operations from a source to a destination: >> extern int32 pglz_compress(const char *source, int32 slen, char *dest, >> const PGLZ_Strategy *strategy); >> extern int32 pglz_decompress(const char *source, char *dest, >> int32 compressed_size, int32 raw_size); >> The return value of those functions is the number of bytes written in the >> destination buffer, and 0 if operation failed. > > So it's guaranteed that 0 is never returned in success case? I'm not sure > if that case can really happen, though. This is an inspiration from lz4 APIs. Wouldn't it be buggy for a compression algorithm to return a size of 0 bytes as compressed or decompressed length btw? We could as well make it return a negative value when a failure occurs if you feel more comfortable with it. -- Michael
Attachment
Hello,
>Yes, that's caused by ccb161b. Attached are rebased versions.
Following are some comments,
>uint16 hole_offset:15, /* number of bytes in "hole" */
Typo in description of hole_offset
> for (block_id = 0; block_id <= record->max_block_id; block_id++)
>- {
>- if (XLogRecHasBlockImage(record, block_id))
>- fpi_len += BLCKSZ -
record->blocks[block_id].hole_length;
>- }
>+ fpi_len += record->blocks[block_id].bkp_len;
IIUC, if condition, /if(XLogRecHasBlockImage(record, block_id))/ is
incorrectly removed from the above for loop.
>typedef struct XLogRecordCompressedBlockImageHeader
I am trying to understand the purpose behind declaration of the above
struct. IIUC, it is defined in order to introduce new field uint16
raw_length and it has been declared as a separate struct from
XLogRecordBlockImageHeader to not affect the size of WAL record when
compression is off.
I wonder if it is ok to simply memcpy the uint16 raw_length in the
hdr_scratch when compression is on
and not have a separate header struct for it neither declare it in existing
header. raw_length can be a locally defined variable is XLogRecordAssemble
or it can be a field in registered_buffer struct like compressed_page.
I think this can simplify the code.
Am I missing something obvious?
> /*
> * Fill in the remaining fields in the XLogRecordBlockImageHeader
> * struct and add new entries in the record chain.
> */
> bkpb.fork_flags |= BKPBLOCK_HAS_IMAGE;
This code line seems to be misplaced with respect to the above comment.
Comment indicates filling of XLogRecordBlockImageHeader fields while
fork_flags is a field of XLogRecordBlockHeader.
Is it better to place the code close to following condition? if (needs_backup) {
>+ *the original length of the
>+ * block without its page hole being deducible from the compressed data
>+ * itself.
IIUC, this comment before XLogRecordBlockImageHeader seems to be no longer
valid as original length is not deducible from compressed data and rather
stored in header.
Thank you,
Rahila Syed
--
View this message in context: http://postgresql.nabble.com/Compression-of-full-page-writes-tp5769039p5833025.html
Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
On Wed, Jan 7, 2015 at 12:51 AM, Rahila Syed <rahilasyed.90@gmail.com> wrote:
> Following are some comments,
Thanks for the feedback.
>>uint16 hole_offset:15, /* number of bytes in "hole" */
> Typo in description of hole_offset
Fixed. That's "before hole".
>> for (block_id = 0; block_id <= record->max_block_id; block_id++)
>>- {
>>- if (XLogRecHasBlockImage(record, block_id))
>>- fpi_len += BLCKSZ -
> record->blocks[block_id].hole_length;
>>- }
>>+ fpi_len += record->blocks[block_id].bkp_len;
>
> IIUC, if condition, /if(XLogRecHasBlockImage(record, block_id))/ is
> incorrectly removed from the above for loop.
Fixed.
>>typedef struct XLogRecordCompressedBlockImageHeader
> I am trying to understand the purpose behind declaration of the above
> struct. IIUC, it is defined in order to introduce new field uint16
> raw_length and it has been declared as a separate struct from
> XLogRecordBlockImageHeader to not affect the size of WAL record when
> compression is off.
> I wonder if it is ok to simply memcpy the uint16 raw_length in the
> hdr_scratch when compression is on
> and not have a separate header struct for it neither declare it in existing
> header. raw_length can be a locally defined variable is XLogRecordAssemble
> or it can be a field in registered_buffer struct like compressed_page.
> I think this can simplify the code.
> Am I missing something obvious?
You are missing nothing. I just introduced this structure for a matter
of readability to show the two-byte difference between non-compressed
and compressed header information. It is true that doing it my way
makes the structures duplicated, so let's simply add the
compression-related information as an extra structure added after
XLogRecordBlockImageHeader if the block is compressed. I hope this
addresses your concerns.
>> /*
>> * Fill in the remaining fields in the XLogRecordBlockImageHeader
>> * struct and add new entries in the record chain.
>> */
>
>> bkpb.fork_flags |= BKPBLOCK_HAS_IMAGE;
>
> This code line seems to be misplaced with respect to the above comment.
> Comment indicates filling of XLogRecordBlockImageHeader fields while
> fork_flags is a field of XLogRecordBlockHeader.
> Is it better to place the code close to following condition?
> if (needs_backup)
> {
Yes, this comment should not be here. I replaced it with the comment in HEAD.
>>+ *the original length of the
>>+ * block without its page hole being deducible from the compressed data
>>+ * itself.
> IIUC, this comment before XLogRecordBlockImageHeader seems to be no longer
> valid as original length is not deducible from compressed data and rather
> stored in header.
Aah, true. This was originally present in the header of PGLZ that has
been removed to make it available for frontends.
Updated patches are attached.
Regards,
--
Michael
Attachment
Hello, Below are performance numbers in case of synchronous replication with and without fpw compression using latest version of patch(version 14). The patch helps improve performance considerably. Both master and standby are on the same machine in order to get numbers independent of network overhead. The compression patch helps to increase tps by 10% . It also helps reduce I/O to disk , latency and total runtime for a fixed number of transactions as shown below. The compression of WAL is quite high around 40%. pgbench scale :1000 pgbench command : pgbench -c 16 -j 16 -r -t 250000 -M prepared To ensure that data is not highly compressible, empty filler columns were altered using alter table pgbench_accounts alter column filler type text using gen_random_uuid()::text checkpoint_segments = 1024 checkpoint_timeout = 5min fsync = on Compression on off WAL generated 23037180520(~23.04MB) 38196743704(~38.20MB) TPS 264.18 239.34 Latency average 60.541 ms 66.822 ms Latency stddev 126.567 ms 130.434 ms Total writes to disk 145045.310 MB 192357.250 MB Runtime 15141.0 s 16712.0 s Server specifications: Processors:Intel® Xeon ® Processor E5-2650 (2 GHz, 8C/16T, 20 MB) * 2 nos RAM: 32GB Disk : HDD 450GB 10K Hot Plug 2.5-inch SAS HDD * 8 nos 1 x 450 GB SAS HDD, 2.5-inch, 6Gb/s, 10,000 rpm Thank you, Rahila Syed -- View this message in context: http://postgresql.nabble.com/Compression-of-full-page-writes-tp5769039p5833315.html Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
On Thu, Jan 8, 2015 at 11:59 PM, Rahila Syed <rahilasyed.90@gmail.com> wrote: > Below are performance numbers in case of synchronous replication with and > without fpw compression using latest version of patch(version 14). The patch > helps improve performance considerably. > Both master and standby are on the same machine in order to get numbers > independent of network overhead. So this test can be used to evaluate how shorter records influence performance since the master waits for flush confirmation from the standby, right? > The compression patch helps to increase tps by 10% . It also helps reduce > I/O to disk , latency and total runtime for a fixed number of transactions > as shown below. > The compression of WAL is quite high around 40%. > > Compression on > off > > WAL generated 23037180520(~23.04MB) > 38196743704(~38.20MB) Isn't that GB and not MB? > TPS 264.18 239.34 > > Latency average 60.541 ms 66.822 > ms > > Latency stddev 126.567 ms 130.434 > ms > > Total writes to disk 145045.310 MB 192357.250MB > Runtime 15141.0 s 16712.0 s How many FPWs have been generated and how many dirty buffers have been flushed for the 3 checkpoints of each test? Any data about the CPU activity? -- Michael
>So this test can be used to evaluate how shorter records influence >performance since the master waits for flush confirmation from the >standby, right? Yes. This test can help measure performance improvement due to reduced I/O on standby as master waits for WAL records flush on standby. >Isn't that GB and not MB? Yes. That is a typo. It should be GB. >How many FPWs have been generated and how many dirty buffers have been >flushed for the 3 checkpoints of each test? >Any data about the CPU activity? Above data is not available for this run . I will rerun the tests to gather above data. Thank you, Rahila Syed -- View this message in context: http://postgresql.nabble.com/Compression-of-full-page-writes-tp5769039p5833389.html Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
On Fri, Jan 9, 2015 at 9:49 PM, Rahila Syed <rahilasyed.90@gmail.com> wrote: >>So this test can be used to evaluate how shorter records influence >>performance since the master waits for flush confirmation from the >>standby, right? > > Yes. This test can help measure performance improvement due to reduced I/O > on standby as master waits for WAL records flush on standby. It may be interesting to run such tests with more concurrent connections at the same time, like 32 or 64. -- Michael
On Fri, Jan 2, 2015 at 11:52 AM, Bruce Momjian <bruce@momjian.us> wrote: > OK, so given your stats, the feature give a 12.5% reduction in I/O. If > that is significant, shouldn't we see a performance improvement? If we > don't see a performance improvement, is I/O reduction worthwhile? Is it > valuable in that it gives non-database applications more I/O to use? Is > that all? > > I suggest we at least document that this feature as mostly useful for > I/O reduction, and maybe say CPU usage and performance might be > negatively impacted. > > OK, here is the email I remember from Fujii Masao this same thread that > showed a performance improvement for WAL compression: > > http://www.postgresql.org/message-id/CAHGQGwGqG8e9YN0fNCUZqTTT=hNr7Ly516kfT5ffqf4pp1qnHg@mail.gmail.com > > Why are we not seeing the 33% compression and 15% performance > improvement he saw? What am I missing here? Bruce, some database workloads are I/O bound and others are CPU bound. Any patch that reduces I/O by using CPU is going to be a win when the system is I/O bound and a loss when it is CPU bound. I'm not really sure what else to say about that; it seems pretty obvious. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Marking this patch as returned with feedback for this CF, moving it to the next one. I doubt that there will be much progress here for the next couple of days, so let's try at least to get something for this release cycle. -- Michael
On Tue, Jan 6, 2015 at 11:09 AM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Mon, Jan 5, 2015 at 10:29 PM, Fujii Masao <masao.fujii@gmail.com> wrote: >> On Sun, Dec 28, 2014 at 10:57 PM, Michael Paquier wrote: >> The patch 1 cannot be applied to the master successfully because of >> recent change. > Yes, that's caused by ccb161b. Attached are rebased versions. > >>> - The real stuff comes with patch 2, that implements the removal of >>> PGLZ_Header, changing the APIs of compression and decompression to pglz to >>> not have anymore toast metadata, this metadata being now localized in >>> tuptoaster.c. Note that this patch protects the on-disk format (tested with >>> pg_upgrade from 9.4 to a patched HEAD server). Here is how the APIs of >>> compression and decompression look like with this patch, simply performing >>> operations from a source to a destination: >>> extern int32 pglz_compress(const char *source, int32 slen, char *dest, >>> const PGLZ_Strategy *strategy); >>> extern int32 pglz_decompress(const char *source, char *dest, >>> int32 compressed_size, int32 raw_size); >>> The return value of those functions is the number of bytes written in the >>> destination buffer, and 0 if operation failed. >> >> So it's guaranteed that 0 is never returned in success case? I'm not sure >> if that case can really happen, though. > This is an inspiration from lz4 APIs. Wouldn't it be buggy for a > compression algorithm to return a size of 0 bytes as compressed or > decompressed length btw? We could as well make it return a negative > value when a failure occurs if you feel more comfortable with it. I feel that's better. Attached is the updated version of the patch. I changed the pg_lzcompress and pg_lzdecompress so that they return -1 when failure happens. Also I applied some cosmetic changes to the patch (e.g., shorten the long name of the newly-added macros). Barring any objection, I will commit this. Regards, -- Fujii Masao
Attachment
Hello,
>/*
>+ * We recheck the actual size even if pglz_compress() report success,
>+ * because it might be satisfied with having saved as little as one byte
>+ * in the compressed data.
>+ */
>+ *len = (uint16) compressed_len;
>+ if (*len >= orig_len - 1)
>+ return false;
>+ return true;
>+}
As per latest code ,when compression is 'on' we introduce additional 2 bytes in the header of each block image for
storingraw_length of the compressed block.
In order to achieve compression while accounting for these two additional bytes, we must ensure that compressed length
isless than original length - 2.
So , IIUC the above condition should rather be
If (*len >= orig_len -2 )
return false;
return true;
The attached patch contains this. It also has a cosmetic change- renaming compressBuf to uncompressBuf as it is used
tostore uncompressed page.
Thank you,
Rahila Syed
-----Original Message-----
From: pgsql-hackers-owner@postgresql.org [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Michael Paquier
Sent: Wednesday, January 07, 2015 9:32 AM
To: Rahila Syed
Cc: PostgreSQL mailing lists
Subject: Re: [HACKERS] [REVIEW] Re: Compression of full-page-writes
On Wed, Jan 7, 2015 at 12:51 AM, Rahila Syed <rahilasyed.90@gmail.com> wrote:
> Following are some comments,
Thanks for the feedback.
>>uint16 hole_offset:15, /* number of bytes in "hole" */
> Typo in description of hole_offset
Fixed. That's "before hole".
>> for (block_id = 0; block_id <= record->max_block_id; block_id++)
>>- {
>>- if (XLogRecHasBlockImage(record, block_id))
>>- fpi_len += BLCKSZ -
> record->blocks[block_id].hole_length;
>>- }
>>+ fpi_len += record->blocks[block_id].bkp_len;
>
> IIUC, if condition, /if(XLogRecHasBlockImage(record, block_id))/ is
> incorrectly removed from the above for loop.
Fixed.
>>typedef struct XLogRecordCompressedBlockImageHeader
> I am trying to understand the purpose behind declaration of the above
> struct. IIUC, it is defined in order to introduce new field uint16
> raw_length and it has been declared as a separate struct from
> XLogRecordBlockImageHeader to not affect the size of WAL record when
> compression is off.
> I wonder if it is ok to simply memcpy the uint16 raw_length in the
> hdr_scratch when compression is on and not have a separate header
> struct for it neither declare it in existing header. raw_length can be
> a locally defined variable is XLogRecordAssemble or it can be a field
> in registered_buffer struct like compressed_page.
> I think this can simplify the code.
> Am I missing something obvious?
You are missing nothing. I just introduced this structure for a matter of readability to show the two-byte difference
betweennon-compressed and compressed header information. It is true that doing it my way makes the structures
duplicated,so let's simply add the compression-related information as an extra structure added after
XLogRecordBlockImageHeaderif the block is compressed. I hope this addresses your concerns.
>> /*
>> * Fill in the remaining fields in the XLogRecordBlockImageHeader
>> * struct and add new entries in the record chain.
>> */
>
>> bkpb.fork_flags |= BKPBLOCK_HAS_IMAGE;
>
> This code line seems to be misplaced with respect to the above comment.
> Comment indicates filling of XLogRecordBlockImageHeader fields while
> fork_flags is a field of XLogRecordBlockHeader.
> Is it better to place the code close to following condition?
> if (needs_backup)
> {
Yes, this comment should not be here. I replaced it with the comment in HEAD.
>>+ *the original length of the
>>+ * block without its page hole being deducible from the compressed
>>+ data
>>+ * itself.
> IIUC, this comment before XLogRecordBlockImageHeader seems to be no
> longer valid as original length is not deducible from compressed data
> and rather stored in header.
Aah, true. This was originally present in the header of PGLZ that has been removed to make it available for frontends.
Updated patches are attached.
Regards,
--
Michael
______________________________________________________________________
Disclaimer: This email and any attachments are sent in strictest confidence
for the sole use of the addressee and may contain legally privileged,
confidential, and proprietary data. If you are not the intended recipient,
please advise the sender by replying promptly to this email and then delete
and destroy this email and any attachments without any further use, copying
or forwarding.
Attachment
Fujii Masao wrote: > I wrote >> This is an inspiration from lz4 APIs. Wouldn't it be buggy for a >> compression algorithm to return a size of 0 bytes as compressed or >> decompressed length btw? We could as well make it return a negative >> value when a failure occurs if you feel more comfortable with it. > > I feel that's better. Attached is the updated version of the patch. > I changed the pg_lzcompress and pg_lzdecompress so that they return -1 > when failure happens. Also I applied some cosmetic changes to the patch > (e.g., shorten the long name of the newly-added macros). > Barring any objection, I will commit this. I just had a look at your updated version, ran some sanity tests, and things look good from me. The new names of the macros at the top of tuptoaster.c are clearer as well. -- Michael
On Thu, Feb 5, 2015 at 11:06 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote:
>>/*
>>+ * We recheck the actual size even if pglz_compress() report success,
>>+ * because it might be satisfied with having saved as little as one byte
>>+ * in the compressed data.
>>+ */
>>+ *len = (uint16) compressed_len;
>>+ if (*len >= orig_len - 1)
>>+ return false;
>>+ return true;
>>+}
>
> As per latest code ,when compression is 'on' we introduce additional 2 bytes in the header of each block image for
storingraw_length of the compressed block.
> In order to achieve compression while accounting for these two additional bytes, we must ensure that compressed
lengthis less than original length - 2.
> So , IIUC the above condition should rather be
>
> If (*len >= orig_len -2 )
> return false;
> return true;
> The attached patch contains this. It also has a cosmetic change- renaming compressBuf to uncompressBuf as it is used
tostore uncompressed page.
Agreed on both things.
Just looking at your latest patch after some time to let it cool down,
I noticed a couple of things.
#define MaxSizeOfXLogRecordBlockHeader \
(SizeOfXLogRecordBlockHeader + \
- SizeOfXLogRecordBlockImageHeader + \
+ SizeOfXLogRecordBlockImageHeader, \
+ SizeOfXLogRecordBlockImageCompressionInfo + \
There is a comma here instead of a sum sign. We should really sum up
all those sizes to evaluate the maximum size of a block header.
+ * Permanently allocate readBuf uncompressBuf. We do it this way,
+ * rather than just making a static array, for two reasons:
This comment is just but weird, "readBuf AND uncompressBuf" is more appropriate.
+ * We recheck the actual size even if pglz_compress() report success,
+ * because it might be satisfied with having saved as little as one byte
+ * in the compressed data. We add two bytes to store raw_length with the
+ * compressed image. So for compression to be effective
compressed_len should
+ * be atleast < orig_len - 2
This comment block should be reworked, and misses a dot at its end. I
rewrote it like that, hopefully that's clearer:
+ /*
+ * We recheck the actual size even if pglz_compress() reports
success and see
+ * if at least 2 bytes of length have been saved, as this
corresponds to the
+ * additional amount of data stored in WAL record for a compressed block
+ * via raw_length.
+ */
In any case, those things have been introduced by what I did in
previous versions... And attached is a new patch.
--
Michael
Attachment
On Fri, Feb 6, 2015 at 4:15 AM, Michael Paquier
<michael.paquier@gmail.com> wrote:
> On Thu, Feb 5, 2015 at 11:06 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote:
>>>/*
>>>+ * We recheck the actual size even if pglz_compress() report success,
>>>+ * because it might be satisfied with having saved as little as one byte
>>>+ * in the compressed data.
>>>+ */
>>>+ *len = (uint16) compressed_len;
>>>+ if (*len >= orig_len - 1)
>>>+ return false;
>>>+ return true;
>>>+}
>>
>> As per latest code ,when compression is 'on' we introduce additional 2 bytes in the header of each block image for
storingraw_length of the compressed block.
>> In order to achieve compression while accounting for these two additional bytes, we must ensure that compressed
lengthis less than original length - 2.
>> So , IIUC the above condition should rather be
>>
>> If (*len >= orig_len -2 )
>> return false;
"2" should be replaced with the macro variable indicating the size of
extra header for compressed backup block.
Do we always need extra two bytes for compressed backup block?
ISTM that extra bytes are not necessary when the hole length is zero.
In this case the length of the original backup block (i.e., uncompressed)
must be BLCKSZ, so we don't need to save the original size in
the extra bytes.
Furthermore, when fpw compression is disabled and the hole length
is zero, we seem to be able to save one byte from the header of
backup block. Currently we use 4 bytes for the header, 2 bytes for
the length of backup block, 15 bits for the hole offset and 1 bit for
the flag indicating whether block is compressed or not. But in that case,
the length of backup block doesn't need to be stored because it must
be BLCKSZ. Shouldn't we optimize the header in this way? Thought?
+ int page_len = BLCKSZ - hole_length;
+ char *scratch_buf;
+ if (hole_length != 0)
+ {
+ scratch_buf = compression_scratch;
+ memcpy(scratch_buf, page, hole_offset);
+ memcpy(scratch_buf + hole_offset,
+ page + (hole_offset + hole_length),
+ BLCKSZ - (hole_length + hole_offset));
+ }
+ else
+ scratch_buf = page;
+
+ /* Perform compression of block */
+ if (XLogCompressBackupBlock(scratch_buf,
+ page_len,
+ regbuf->compressed_page,
+ &compress_len))
+ {
+ /* compression is done, add record */
+ is_compressed = true;
+ }
You can refactor XLogCompressBackupBlock() and move all the
above code to it for more simplicity.
Regards,
--
Fujii Masao
On Fri, Feb 6, 2015 at 3:03 PM, Fujii Masao wrote:
> Do we always need extra two bytes for compressed backup block?
> ISTM that extra bytes are not necessary when the hole length is zero.
> In this case the length of the original backup block (i.e., uncompressed)
> must be BLCKSZ, so we don't need to save the original size in
> the extra bytes.
Yes, we would need a additional bit to identify that. We could steal
it from length in XLogRecordBlockImageHeader.
> Furthermore, when fpw compression is disabled and the hole length
> is zero, we seem to be able to save one byte from the header of
> backup block. Currently we use 4 bytes for the header, 2 bytes for
> the length of backup block, 15 bits for the hole offset and 1 bit for
> the flag indicating whether block is compressed or not. But in that case,
> the length of backup block doesn't need to be stored because it must
> be BLCKSZ. Shouldn't we optimize the header in this way? Thought?
If we do it, that's something to tackle even before this patch on
HEAD, because you could use the 16th bit of the first 2 bytes of
XLogRecordBlockImageHeader to do necessary sanity checks, to actually
not reduce record by 1 byte, but 2 bytes as hole-related data is not
necessary. I imagine that a patch optimizing that wouldn't be that
hard to write as well.
> + int page_len = BLCKSZ - hole_length;
> + char *scratch_buf;
> + if (hole_length != 0)
> + {
> + scratch_buf = compression_scratch;
> + memcpy(scratch_buf, page, hole_offset);
> + memcpy(scratch_buf + hole_offset,
> + page + (hole_offset + hole_length),
> + BLCKSZ - (hole_length + hole_offset));
> + }
> + else
> + scratch_buf = page;
> +
> + /* Perform compression of block */
> + if (XLogCompressBackupBlock(scratch_buf,
> + page_len,
> + regbuf->compressed_page,
> + &compress_len))
> + {
> + /* compression is done, add record */
> + is_compressed = true;
> + }
>
> You can refactor XLogCompressBackupBlock() and move all the
> above code to it for more simplicity.
Sure.
--
Michael
On Fri, Feb 6, 2015 at 4:30 PM, Michael Paquier wrote: > On Fri, Feb 6, 2015 at 3:03 PM, Fujii Masao wrote: >> Do we always need extra two bytes for compressed backup block? >> ISTM that extra bytes are not necessary when the hole length is zero. >> In this case the length of the original backup block (i.e., uncompressed) >> must be BLCKSZ, so we don't need to save the original size in >> the extra bytes. > > Yes, we would need a additional bit to identify that. We could steal > it from length in XLogRecordBlockImageHeader. > >> Furthermore, when fpw compression is disabled and the hole length >> is zero, we seem to be able to save one byte from the header of >> backup block. Currently we use 4 bytes for the header, 2 bytes for >> the length of backup block, 15 bits for the hole offset and 1 bit for >> the flag indicating whether block is compressed or not. But in that case, >> the length of backup block doesn't need to be stored because it must >> be BLCKSZ. Shouldn't we optimize the header in this way? Thought? > > If we do it, that's something to tackle even before this patch on > HEAD, because you could use the 16th bit of the first 2 bytes of > XLogRecordBlockImageHeader to do necessary sanity checks, to actually > not reduce record by 1 byte, but 2 bytes as hole-related data is not > necessary. I imagine that a patch optimizing that wouldn't be that > hard to write as well. Actually, as Heikki pointed me out... A block image is 8k and pages without holes are rare, so it may be not worth sacrificing code simplicity for record reduction at the order of 0.1% or smth like that, and the current patch is light because it keeps things simple. -- Michael
>In any case, those things have been introduced by what I did in previous versions... And attached is a new patch.
Thank you for feedback.
> /* allocate scratch buffer used for compression of block images */
>+ if (compression_scratch == NULL)
>+ compression_scratch = MemoryContextAllocZero(xloginsert_cxt,
>+ BLCKSZ);
>}
The compression patch can use the latest interface MemoryContextAllocExtended to proceed without compression when
sufficientmemory is not available for
scratch buffer.
The attached patch introduces OutOfMem flag which is set on when MemoryContextAllocExtended returns NULL .
Thank you,
Rahila Syed
-----Original Message-----
From: Michael Paquier [mailto:michael.paquier@gmail.com]
Sent: Friday, February 06, 2015 12:46 AM
To: Syed, Rahila
Cc: PostgreSQL mailing lists
Subject: Re: [HACKERS] [REVIEW] Re: Compression of full-page-writes
On Thu, Feb 5, 2015 at 11:06 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote:
>>/*
>>+ * We recheck the actual size even if pglz_compress() report success,
>>+ * because it might be satisfied with having saved as little as one byte
>>+ * in the compressed data.
>>+ */
>>+ *len = (uint16) compressed_len;
>>+ if (*len >= orig_len - 1)
>>+ return false;
>>+ return true;
>>+}
>
> As per latest code ,when compression is 'on' we introduce additional 2 bytes in the header of each block image for
storingraw_length of the compressed block.
> In order to achieve compression while accounting for these two additional bytes, we must ensure that compressed
lengthis less than original length - 2.
> So , IIUC the above condition should rather be
>
> If (*len >= orig_len -2 )
> return false;
> return true;
> The attached patch contains this. It also has a cosmetic change- renaming compressBuf to uncompressBuf as it is used
tostore uncompressed page.
Agreed on both things.
Just looking at your latest patch after some time to let it cool down, I noticed a couple of things.
#define MaxSizeOfXLogRecordBlockHeader \
(SizeOfXLogRecordBlockHeader + \
- SizeOfXLogRecordBlockImageHeader + \
+ SizeOfXLogRecordBlockImageHeader, \
+ SizeOfXLogRecordBlockImageCompressionInfo + \
There is a comma here instead of a sum sign. We should really sum up all those sizes to evaluate the maximum size of a
blockheader.
+ * Permanently allocate readBuf uncompressBuf. We do it this way,
+ * rather than just making a static array, for two reasons:
This comment is just but weird, "readBuf AND uncompressBuf" is more appropriate.
+ * We recheck the actual size even if pglz_compress() report success,
+ * because it might be satisfied with having saved as little as one byte
+ * in the compressed data. We add two bytes to store raw_length with the
+ * compressed image. So for compression to be effective
compressed_len should
+ * be atleast < orig_len - 2
This comment block should be reworked, and misses a dot at its end. I rewrote it like that, hopefully that's clearer:
+ /*
+ * We recheck the actual size even if pglz_compress() reports
success and see
+ * if at least 2 bytes of length have been saved, as this
corresponds to the
+ * additional amount of data stored in WAL record for a compressed block
+ * via raw_length.
+ */
In any case, those things have been introduced by what I did in previous versions... And attached is a new patch.
--
Michael
______________________________________________________________________
Disclaimer: This email and any attachments are sent in strictest confidence
for the sole use of the addressee and may contain legally privileged,
confidential, and proprietary data. If you are not the intended recipient,
please advise the sender by replying promptly to this email and then delete
and destroy this email and any attachments without any further use, copying
or forwarding.
Attachment
On Fri, Feb 6, 2015 at 6:35 PM, Syed, Rahila wrote: > The compression patch can use the latest interface MemoryContextAllocExtended to proceed without compression when sufficientmemory is not available for > scratch buffer. > The attached patch introduces OutOfMem flag which is set on when MemoryContextAllocExtended returns NULL . TBH, I don't think that brings much as this allocation is done once and process would surely fail before reaching the first code path doing a WAL record insertion. In any case, OutOfMem is useless, you could simply check if compression_scratch is NULL when assembling a record. -- Michael
On Fri, Feb 6, 2015 at 3:42 AM, Michael Paquier <michael.paquier@gmail.com> wrote: > Fujii Masao wrote: >> I wrote >>> This is an inspiration from lz4 APIs. Wouldn't it be buggy for a >>> compression algorithm to return a size of 0 bytes as compressed or >>> decompressed length btw? We could as well make it return a negative >>> value when a failure occurs if you feel more comfortable with it. >> >> I feel that's better. Attached is the updated version of the patch. >> I changed the pg_lzcompress and pg_lzdecompress so that they return -1 >> when failure happens. Also I applied some cosmetic changes to the patch >> (e.g., shorten the long name of the newly-added macros). >> Barring any objection, I will commit this. > > I just had a look at your updated version, ran some sanity tests, and > things look good from me. The new names of the macros at the top of > tuptoaster.c are clearer as well. Thanks for the review! Pushed! Regards, -- Fujii Masao
Hello,
>> Do we always need extra two bytes for compressed backup block?
>> ISTM that extra bytes are not necessary when the hole length is zero.
>> In this case the length of the original backup block (i.e.,
>> uncompressed) must be BLCKSZ, so we don't need to save the original
>> size in the extra bytes.
>Yes, we would need a additional bit to identify that. We could steal it from length in XLogRecordBlockImageHeader.
This is implemented in the attached patch by dividing length field as follows,
uint16 length:15,
with_hole:1;
>"2" should be replaced with the macro variable indicating the size of
>extra header for compressed backup block.
Macro SizeOfXLogRecordBlockImageCompressionInfo is used instead of 2
>You can refactor XLogCompressBackupBlock() and move all the
>above code to it for more simplicity
This is also implemented in the patch attached.
Thank you,
Rahila Syed
-----Original Message-----
From: Michael Paquier [mailto:michael.paquier@gmail.com]
Sent: Friday, February 06, 2015 6:00 PM
To: Fujii Masao
Cc: Syed, Rahila; PostgreSQL mailing lists
Subject: Re: [HACKERS] [REVIEW] Re: Compression of full-page-writes
On Fri, Feb 6, 2015 at 3:03 PM, Fujii Masao wrote:
> Do we always need extra two bytes for compressed backup block?
> ISTM that extra bytes are not necessary when the hole length is zero.
> In this case the length of the original backup block (i.e.,
> uncompressed) must be BLCKSZ, so we don't need to save the original
> size in the extra bytes.
Yes, we would need a additional bit to identify that. We could steal it from length in XLogRecordBlockImageHeader.
> Furthermore, when fpw compression is disabled and the hole length is
> zero, we seem to be able to save one byte from the header of backup
> block. Currently we use 4 bytes for the header, 2 bytes for the length
> of backup block, 15 bits for the hole offset and 1 bit for the flag
> indicating whether block is compressed or not. But in that case, the
> length of backup block doesn't need to be stored because it must be
> BLCKSZ. Shouldn't we optimize the header in this way? Thought?
If we do it, that's something to tackle even before this patch on HEAD, because you could use the 16th bit of the first
2bytes of XLogRecordBlockImageHeader to do necessary sanity checks, to actually not reduce record by 1 byte, but 2
bytesas hole-related data is not necessary. I imagine that a patch optimizing that wouldn't be that hard to write as
well.
> + int page_len = BLCKSZ - hole_length;
> + char *scratch_buf;
> + if (hole_length != 0)
> + {
> + scratch_buf = compression_scratch;
> + memcpy(scratch_buf, page, hole_offset);
> + memcpy(scratch_buf + hole_offset,
> + page + (hole_offset + hole_length),
> + BLCKSZ - (hole_length + hole_offset));
> + }
> + else
> + scratch_buf = page;
> +
> + /* Perform compression of block */
> + if (XLogCompressBackupBlock(scratch_buf,
> + page_len,
> + regbuf->compressed_page,
> + &compress_len))
> + {
> + /* compression is done, add record */
> + is_compressed = true;
> + }
>
> You can refactor XLogCompressBackupBlock() and move all the above code
> to it for more simplicity.
Sure.
--
Michael
______________________________________________________________________
Disclaimer: This email and any attachments are sent in strictest confidence
for the sole use of the addressee and may contain legally privileged,
confidential, and proprietary data. If you are not the intended recipient,
please advise the sender by replying promptly to this email and then delete
and destroy this email and any attachments without any further use, copying
or forwarding.
Attachment
On Mon, Feb 9, 2015 at 10:27 PM, Syed, Rahila wrote:
> (snip)
Thanks for showing up here! I have not tested the test the patch,
those comments are based on what I read from v17.
>>> Do we always need extra two bytes for compressed backup block?
>>> ISTM that extra bytes are not necessary when the hole length is zero.
>>> In this case the length of the original backup block (i.e.,
>>> uncompressed) must be BLCKSZ, so we don't need to save the original
>>> size in the extra bytes.
>
>>Yes, we would need a additional bit to identify that. We could steal it from length in XLogRecordBlockImageHeader.
>
> This is implemented in the attached patch by dividing length field as follows,
> uint16 length:15,
> with_hole:1;
IMO, we should add details about how this new field is used in the
comments on top of XLogRecordBlockImageHeader, meaning that when a
page hole is present we use the compression info structure and when
there is no hole, we are sure that the FPW raw length is BLCKSZ
meaning that the two bytes of the CompressionInfo stuff is
unnecessary.
>
>>"2" should be replaced with the macro variable indicating the size of
>>extra header for compressed backup block.
> Macro SizeOfXLogRecordBlockImageCompressionInfo is used instead of 2
>
>>You can refactor XLogCompressBackupBlock() and move all the
>>above code to it for more simplicity
> This is also implemented in the patch attached.
This portion looks correct to me.
A couple of other comments:
1) Nitpicky but, code format is sometimes strange.
For example here you should not have a space between the function
definition and the variable declarations:
+{
+
+ int orig_len = BLCKSZ - hole_length;
This is as well incorrect in two places:
if(hole_length != 0)
There should be a space between the if and its condition in parenthesis.
2) For correctness with_hole should be set even for uncompressed
pages. I think that we should as well use it for sanity checks in
xlogreader.c when decoding records.
Regards,
--
Michael
Hello,
A bug had been introduced in the latest versions of the patch. The order of parameters passed to pglz_decompress was
wrong.
Please find attached patch with following correction,
Original code,
+ if (pglz_decompress(block_image, record->uncompressBuf,
+ bkpb->bkp_len, bkpb->bkp_uncompress_len) == 0)
Correction
+ if (pglz_decompress(block_image, bkpb->bkp_len,
+ record->uncompressBuf, bkpb->bkp_uncompress_len) == 0)
>For example here you should not have a space between the function definition and the variable declarations:
>+{
>+
>+ int orig_len = BLCKSZ - hole_length;
>This is as well incorrect in two places:
>if(hole_length != 0)
>There should be a space between the if and its condition in parenthesis.
Also corrected above code format mistakes.
Thank you,
Rahila Syed
-----Original Message-----
From: pgsql-hackers-owner@postgresql.org [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Syed, Rahila
Sent: Monday, February 09, 2015 6:58 PM
To: Michael Paquier; Fujii Masao
Cc: PostgreSQL mailing lists
Subject: Re: [HACKERS] [REVIEW] Re: Compression of full-page-writes
Hello,
>> Do we always need extra two bytes for compressed backup block?
>> ISTM that extra bytes are not necessary when the hole length is zero.
>> In this case the length of the original backup block (i.e.,
>> uncompressed) must be BLCKSZ, so we don't need to save the original
>> size in the extra bytes.
>Yes, we would need a additional bit to identify that. We could steal it from length in XLogRecordBlockImageHeader.
This is implemented in the attached patch by dividing length field as follows,
uint16 length:15,
with_hole:1;
>"2" should be replaced with the macro variable indicating the size of
>extra header for compressed backup block.
Macro SizeOfXLogRecordBlockImageCompressionInfo is used instead of 2
>You can refactor XLogCompressBackupBlock() and move all the above code
>to it for more simplicity
This is also implemented in the patch attached.
Thank you,
Rahila Syed
-----Original Message-----
From: Michael Paquier [mailto:michael.paquier@gmail.com]
Sent: Friday, February 06, 2015 6:00 PM
To: Fujii Masao
Cc: Syed, Rahila; PostgreSQL mailing lists
Subject: Re: [HACKERS] [REVIEW] Re: Compression of full-page-writes
On Fri, Feb 6, 2015 at 3:03 PM, Fujii Masao wrote:
> Do we always need extra two bytes for compressed backup block?
> ISTM that extra bytes are not necessary when the hole length is zero.
> In this case the length of the original backup block (i.e.,
> uncompressed) must be BLCKSZ, so we don't need to save the original
> size in the extra bytes.
Yes, we would need a additional bit to identify that. We could steal it from length in XLogRecordBlockImageHeader.
> Furthermore, when fpw compression is disabled and the hole length is
> zero, we seem to be able to save one byte from the header of backup
> block. Currently we use 4 bytes for the header, 2 bytes for the length
> of backup block, 15 bits for the hole offset and 1 bit for the flag
> indicating whether block is compressed or not. But in that case, the
> length of backup block doesn't need to be stored because it must be
> BLCKSZ. Shouldn't we optimize the header in this way? Thought?
If we do it, that's something to tackle even before this patch on HEAD, because you could use the 16th bit of the first
2bytes of XLogRecordBlockImageHeader to do necessary sanity checks, to actually not reduce record by 1 byte, but 2
bytesas hole-related data is not necessary. I imagine that a patch optimizing that wouldn't be that hard to write as
well.
> + int page_len = BLCKSZ - hole_length;
> + char *scratch_buf;
> + if (hole_length != 0)
> + {
> + scratch_buf = compression_scratch;
> + memcpy(scratch_buf, page, hole_offset);
> + memcpy(scratch_buf + hole_offset,
> + page + (hole_offset + hole_length),
> + BLCKSZ - (hole_length + hole_offset));
> + }
> + else
> + scratch_buf = page;
> +
> + /* Perform compression of block */
> + if (XLogCompressBackupBlock(scratch_buf,
> + page_len,
> + regbuf->compressed_page,
> + &compress_len))
> + {
> + /* compression is done, add record */
> + is_compressed = true;
> + }
>
> You can refactor XLogCompressBackupBlock() and move all the above code
> to it for more simplicity.
Sure.
--
Michael
______________________________________________________________________
Disclaimer: This email and any attachments are sent in strictest confidence for the sole use of the addressee and may
containlegally privileged, confidential, and proprietary data. If you are not the intended recipient, please advise the
senderby replying promptly to this email and then delete and destroy this email and any attachments without any further
use,copying or forwarding.
______________________________________________________________________
Disclaimer: This email and any attachments are sent in strictest confidence
for the sole use of the addressee and may contain legally privileged,
confidential, and proprietary data. If you are not the intended recipient,
please advise the sender by replying promptly to this email and then delete
and destroy this email and any attachments without any further use, copying
or forwarding.
Attachment
>IMO, we should add details about how this new field is used in the comments on top of XLogRecordBlockImageHeader, meaningthat when a page hole is present we use the compression info structure and when there is no hole, we are sure thatthe FPW raw length is BLCKSZ meaning that the two bytes of the CompressionInfo stuff is unnecessary. This comment is included in the patch attached. > For correctness with_hole should be set even for uncompressed pages. I think that we should as well use it for sanity checksin xlogreader.c when decoding records. This change is made in the attached patch. Following sanity checks have been added in xlogreader.c if (!(blk->with_hole) && blk->hole_offset != 0 || blk->with_hole && blk->hole_offset <= 0)) if (blk->with_hole && blk->bkp_len >= BLCKSZ) if (!(blk->with_hole) && blk->bkp_len != BLCKSZ) Thank you, Rahila Syed ______________________________________________________________________ Disclaimer: This email and any attachments are sent in strictest confidence for the sole use of the addressee and may contain legally privileged, confidential, and proprietary data. If you are not the intended recipient, please advise the sender by replying promptly to this email and then delete and destroy this email and any attachments without any further use, copying or forwarding.
Attachment
>IMO, we should add details about how this new field is used in the comments on top of XLogRecordBlockImageHeader, meaning that when a page hole is present we use the compression info structure and when there is no hole, we are sure that the FPW raw length is BLCKSZ meaning that the two bytes of the CompressionInfo stuff is unnecessary.
This comment is included in the patch attached.
> For correctness with_hole should be set even for uncompressed pages. I think that we should as well use it for sanity checks in xlogreader.c when decoding records.
This change is made in the attached patch. Following sanity checks have been added in xlogreader.c
if (!(blk->with_hole) && blk->hole_offset != 0 || blk->with_hole && blk->hole_offset <= 0))
if (blk->with_hole && blk->bkp_len >= BLCKSZ)
if (!(blk->with_hole) && blk->bkp_len != BLCKSZ)
xlogreader.c:1049:46: error: extraneous ')' after condition, expected a statement
blk->with_hole && blk->hole_offset <= 0))
+ * "with_hole" is used to identify the presence of hole in a block.
+ * As mentioned above, length of block cannnot be more than 15-bit long.
+ * So, the free bit in the length field is used by "with_hole" to identify presence of
+ * XLogRecordBlockImageCompressionInfo. If hole is not present ,the raw size of
+ * a compressed block is equal to BLCKSZ therefore XLogRecordBlockImageCompressionInfo
+ * for the corresponding compressed block need not be stored in header.
+ * If hole is present raw size is stored.
+ /* Followed by the data related to compression if block is compressed */
+ lp_off and lp_len fields in ItemIdData (see include/storage/itemid.h) and
+ XLogRecordBlockImageHeader where page hole offset and length is limited to 15-bit
+ length (see src/include/access/xlogrecord.h).
Thank you for comments. Please find attached the updated patch.
>This patch fails to compile:
>xlogreader.c:1049:46: error: extraneous ')' after condition, expected a statement
> blk->with_hole && blk->hole_offset <= 0))
This has been rectified.
>Note as well that at least clang does not like much how the sanity check with with_hole are done. You should place parentheses around the '&&' expressions. Also, I would rather define with_hole == 0 or with_hole == 1 explicitly int those checks
The expressions are modified accordingly.
>There is a typo:
>s/true,see/true, see/
>[nitpicky]Be as well aware of the 80-character limit per line that is usually normally by comment blocks.[/]
Have corrected the typos and changed the comments as mentioned. Also , realigned certain lines to meet the 80-char limit.
Thank you,
Rahila Syed
______________________________________________________________________
Disclaimer: This email and any attachments are sent in strictest confidence
for the sole use of the addressee and may contain legally privileged,
confidential, and proprietary data. If you are not the intended recipient,
please advise the sender by replying promptly to this email and then delete
and destroy this email and any attachments without any further use, copying
or forwarding.
Attachment
On Thu, Feb 12, 2015 at 8:08 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote:
>
>
>
> Thank you for comments. Please find attached the updated patch.
>
>
>
> >This patch fails to compile:
> >xlogreader.c:1049:46: error: extraneous ')' after condition, expected a statement
> > blk->with_hole && blk->hole_offset <= 0))
>
> This has been rectified.
>
>
>
> >Note as well that at least clang does not like much how the sanity check with with_hole are done. You should place parentheses around the '&&' expressions. Also, I would rather define with_hole == 0 or with_hole == 1 explicitly int those checks
>
> The expressions are modified accordingly.
>
>
>
> >There is a typo:
>
> >s/true,see/true, see/
>
> >[nitpicky]Be as well aware of the 80-character limit per line that is usually normally by comment blocks.[/]
>
>
>
> Have corrected the typos and changed the comments as mentioned. Also , realigned certain lines to meet the 80-char limit.
Thanks for the updated patch.
+ /* leave if data cannot be compressed */
+ if (compressed_len == 0)
+ return false;
This should be < 0, pglz_compress returns -1 when compression fails.
+ if (pglz_decompress(block_image, bkpb->bkp_len, record->uncompressBuf,
+ bkpb->bkp_uncompress_len) == 0)
Similarly, this should be < 0.
Regarding the sanity checks that have been added recently. I think that they are useful but I am suspecting as well that only a check on the record CRC is done because that's reliable enough and not doing those checks accelerates a bit replay. So I am thinking that we should simply replace them by assertions.
I have as well re-run my small test case, with the following results (scripts and results attached)
=# select test, user_diff,system_diff, pg_size_pretty(pre_update - pre_insert),
pg_size_pretty(post_update - pre_update) from results;
test | user_diff | system_diff | pg_size_pretty | pg_size_pretty
---------+-----------+-------------+----------------+----------------
FPW on | 46.134564 | 0.823306 | 429 MB | 566 MB
FPW on | 16.307575 | 0.798591 | 171 MB | 229 MB
FPW on | 8.325136 | 0.848390 | 86 MB | 116 MB
FPW off | 29.992383 | 1.100458 | 440 MB | 746 MB
FPW off | 12.237578 | 1.027076 | 171 MB | 293 MB
FPW off | 6.814926 | 0.931624 | 86 MB | 148 MB
HEAD | 26.590816 | 1.159255 | 440 MB | 746 MB
HEAD | 11.620359 | 0.990851 | 171 MB | 293 MB
HEAD | 6.300401 | 0.904311 | 86 MB | 148 MB
(9 rows)
The level of compression reached is the same as previous mark, 566MB for the case of fillfactor=50 (CAB7nPqSc97o-UE5paxfMUKWcxE_JioyxO1M4A0pMnmYqAnec2g@mail.gmail.com) with a similar CPU usage.
Once we get those small issues fixes, I think that it is with having a committer look at this patch, presumably Fujii-san.
Regards,
--
Michael
Attachment
Hello,
Thank you for reviewing and testing the patch.
>+ /* leave if data cannot be compressed */
>+ if (compressed_len == 0)
>+ return false;
>This should be < 0, pglz_compress returns -1 when compression fails.
>
>+ if (pglz_decompress(block_image, bkpb->bkp_len, record->uncompressBuf,
>+ bkpb->bkp_uncompress_len) == 0)
>Similarly, this should be < 0.
These have been corrected in the attached.
>Regarding the sanity checks that have been added recently. I think that they are useful but I am suspecting as well that only a check on the record CRC is done because that's reliable enough and not doing those checks accelerates a bit replay. So I am thinking that we should simply replace >them by assertions.
Removing the checks makes sense as CRC ensures correctness . Moreover ,as error message for invalid length of record is present in the code , messages for invalid block length can be redundant.
Checks have been replaced by assertions in the attached patch.
Following if condition in XLogCompressBackupBlock has been modified as follows
Previous
/*
+ * We recheck the actual size even if pglz_compress() reports success and
+ * see if at least 2 bytes of length have been saved, as this corresponds
+ * to the additional amount of data stored in WAL record for a compressed
+ * block via raw_length when block contains hole..
+ */
+ *len = (uint16) compressed_len;
+ if (*len >= orig_len - SizeOfXLogRecordBlockImageCompressionInfo)
+ return false;
+ return true;
Current
if ((hole_length != 0) &&
+ (*len >= orig_len - SizeOfXLogRecordBlockImageCompressionInfo))
+ return false;
+return true
This is because the extra information raw_length is included only if compressed block has hole in it.
>Once we get those small issues fixes, I think that it is with having a committer look at this patch, presumably Fujii-san
Agree. I will mark this patch as ready for committer
Thank you,
Rahila Syed
______________________________________________________________________
Disclaimer: This email and any attachments are sent in strictest confidence
for the sole use of the addressee and may contain legally privileged,
confidential, and proprietary data. If you are not the intended recipient,
please advise the sender by replying promptly to this email and then delete
and destroy this email and any attachments without any further use, copying
or forwarding.
Attachment
Regarding the sanity checks that have been added recently. I think that they are useful but I am suspecting as well that only a check on the record CRC is done because that's reliable enough and not doing those checks accelerates a bit replay. So I am thinking that we should simply replace >them by assertions.Removing the checks makes sense as CRC ensures correctness . Moreover ,as error message for invalid length of record is present in the code , messages for invalid block length can be redundant.
Checks have been replaced by assertions in the attached patch.
Current
if ((hole_length != 0) &&
+ (*len >= orig_len - SizeOfXLogRecordBlockImageCompressionInfo))
+ return false;
+return true
+ Assert(!(blk->with_hole == 1 && blk->hole_offset <= 0));
char * page
--
On 2015-02-16 11:30:20 +0000, Syed, Rahila wrote:
> - * As a trivial form of data compression, the XLOG code is aware that
> - * PG data pages usually contain an unused "hole" in the middle, which
> - * contains only zero bytes. If hole_length > 0 then we have removed
> - * such a "hole" from the stored data (and it's not counted in the
> - * XLOG record's CRC, either). Hence, the amount of block data actually
> - * present is BLCKSZ - hole_length bytes.
> + * Block images are able to do several types of compression:
> + * - When wal_compression is off, as a trivial form of compression, the
> + * XLOG code is aware that PG data pages usually contain an unused "hole"
> + * in the middle, which contains only zero bytes. If length < BLCKSZ
> + * then we have removed such a "hole" from the stored data (and it is
> + * not counted in the XLOG record's CRC, either). Hence, the amount
> + * of block data actually present is "length" bytes. The hole "offset"
> + * on page is defined using "hole_offset".
> + * - When wal_compression is on, block images are compressed using a
> + * compression algorithm without their hole to improve compression
> + * process of the page. "length" corresponds in this case to the length
> + * of the compressed block. "hole_offset" is the hole offset of the page,
> + * and the length of the uncompressed block is defined by "raw_length",
> + * whose data is included in the record only when compression is enabled
> + * and "with_hole" is set to true, see below.
> + *
> + * "is_compressed" is used to identify if a given block image is compressed
> + * or not. Maximum page size allowed on the system being 32k, the hole
> + * offset cannot be more than 15-bit long so the last free bit is used to
> + * store the compression state of block image. If the maximum page size
> + * allowed is increased to a value higher than that, we should consider
> + * increasing this structure size as well, but this would increase the
> + * length of block header in WAL records with alignment.
> + *
> + * "with_hole" is used to identify the presence of a hole in a block image.
> + * As the length of a block cannot be more than 15-bit long, the extra bit in
> + * the length field is used for this identification purpose. If the block image
> + * has no hole, it is ensured that the raw size of a compressed block image is
> + * equal to BLCKSZ, hence the contents of XLogRecordBlockImageCompressionInfo
> + * are not necessary.
> */
> typedef struct XLogRecordBlockImageHeader
> {
> - uint16 hole_offset; /* number of bytes before "hole" */
> - uint16 hole_length; /* number of bytes in "hole" */
> + uint16 length:15, /* length of block data in record */
> + with_hole:1; /* status of hole in the block */
> +
> + uint16 hole_offset:15, /* number of bytes before "hole" */
> + is_compressed:1; /* compression status of image */
> +
> + /* Followed by the data related to compression if block is compressed */
> } XLogRecordBlockImageHeader;
Yikes, this is ugly.
I think we should change the xlog format so that the block_id (which
currently is XLR_BLOCK_ID_DATA_SHORT/LONG or a actual block id) isn't
the block id but something like XLR_CHUNK_ID. Which is used as is for
XLR_CHUNK_ID_DATA_SHORT/LONG, but for backup blocks can be set to to
XLR_CHUNK_BKP_WITH_HOLE, XLR_CHUNK_BKP_COMPRESSED,
XLR_CHUNK_BKP_REFERENCE... The BKP blocks will then follow, storing the
block id following the chunk id.
Yes, that'll increase the amount of data for a backup block by 1 byte,
but I think that's worth it. I'm pretty sure we will be happy about the
added extensibility pretty soon.
Greetings,
Andres Freund
-- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training &
Services
On 2015-02-16 20:55:20 +0900, Michael Paquier wrote:
> On Mon, Feb 16, 2015 at 8:30 PM, Syed, Rahila <Rahila.Syed@nttdata.com>
> wrote:
>
> >
> > Regarding the sanity checks that have been added recently. I think that
> > they are useful but I am suspecting as well that only a check on the record
> > CRC is done because that's reliable enough and not doing those checks
> > accelerates a bit replay. So I am thinking that we should simply replace
> > >them by assertions.
> >
> > Removing the checks makes sense as CRC ensures correctness . Moreover ,as
> > error message for invalid length of record is present in the code ,
> > messages for invalid block length can be redundant.
> >
> > Checks have been replaced by assertions in the attached patch.
> >
>
> After more thinking, we may as well simply remove them, an error with CRC
> having high chances to complain before reaching this point...
Surely not. The existing code explicitly does it like if (blk->has_data && blk->data_len == 0)
report_invalid_record(state, "BKPBLOCK_HAS_DATA set, but no data included at %X/%X",
(uint32) (state->ReadRecPtr >> 32), (uint32) state->ReadRecPtr);
these cross checks are important. And I see no reason to deviate from
that. The CRC sum isn't foolproof - we intentionally do checks at
several layers. And, as you can see from some other locations, we
actually try to *not* fatally error out when hitting them at times - so
an Assert also is wrong.
Heikki: /* cross-check that the HAS_DATA flag is set iff data_length > 0 */ if (blk->has_data &&
blk->data_len== 0) report_invalid_record(state, "BKPBLOCK_HAS_DATA set, but no
dataincluded at %X/%X", (uint32) (state->ReadRecPtr >> 32),
(uint32)state->ReadRecPtr); if (!blk->has_data && blk->data_len != 0) report_invalid_record(state,
"BKPBLOCK_HAS_DATA not set, but data length is %u at %X/%X",
(unsigned int) blk->data_len, (uint32) (state->ReadRecPtr >> 32), (uint32)
state->ReadRecPtr);
those look like they're missing a goto err; to me.
Greetings,
Andres Freund
-- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training &
Services
Hello,
>I think we should change the xlog format so that the block_id (which currently is XLR_BLOCK_ID_DATA_SHORT/LONG or a
actualblock id) isn't the block id but something like XLR_CHUNK_ID. Which is used as is for
XLR_CHUNK_ID_DATA_SHORT/LONG,but for backup blocks can be set to to >XLR_CHUNK_BKP_WITH_HOLE, XLR_CHUNK_BKP_COMPRESSED,
XLR_CHUNK_BKP_REFERENCE...The BKP blocks will then follow, storing the block id following the chunk id.
>Yes, that'll increase the amount of data for a backup block by 1 byte, but I think that's worth it. I'm pretty sure we
willbe happy about the added extensibility pretty soon.
To clarify my understanding of the above change,
Instead of a block id to reference different fragments of an xlog record , a single byte field "chunk_id" should be
used. chunk_id will be same as XLR_BLOCK_ID_DATA_SHORT/LONG for main data fragments.
But for block references, it will take store following values in order to store information about the backup blocks.
#define XLR_CHUNK_BKP_COMPRESSED 0x01
#define XLR_CHUNK_BKP_WITH_HOLE 0x02
...
The new xlog format should look like follows,
Fixed-size header (XLogRecord struct)
Chunk_id(add a field before id field in XLogRecordBlockHeader struct)
XLogRecordBlockHeader
Chunk_idXLogRecordBlockHeader ... ...
Chunk_id ( rename id field of the XLogRecordDataHeader struct)
XLogRecordDataHeader[Short|Long] block datablock data...main data
I will post a patch based on this.
Thank you,
Rahila Syed
-----Original Message-----
From: Andres Freund [mailto:andres@2ndquadrant.com]
Sent: Monday, February 16, 2015 5:26 PM
To: Syed, Rahila
Cc: Michael Paquier; Fujii Masao; PostgreSQL mailing lists
Subject: Re: [HACKERS] [REVIEW] Re: Compression of full-page-writes
On 2015-02-16 11:30:20 +0000, Syed, Rahila wrote:
> - * As a trivial form of data compression, the XLOG code is aware that
> - * PG data pages usually contain an unused "hole" in the middle,
> which
> - * contains only zero bytes. If hole_length > 0 then we have removed
> - * such a "hole" from the stored data (and it's not counted in the
> - * XLOG record's CRC, either). Hence, the amount of block data
> actually
> - * present is BLCKSZ - hole_length bytes.
> + * Block images are able to do several types of compression:
> + * - When wal_compression is off, as a trivial form of compression,
> + the
> + * XLOG code is aware that PG data pages usually contain an unused "hole"
> + * in the middle, which contains only zero bytes. If length < BLCKSZ
> + * then we have removed such a "hole" from the stored data (and it is
> + * not counted in the XLOG record's CRC, either). Hence, the amount
> + * of block data actually present is "length" bytes. The hole "offset"
> + * on page is defined using "hole_offset".
> + * - When wal_compression is on, block images are compressed using a
> + * compression algorithm without their hole to improve compression
> + * process of the page. "length" corresponds in this case to the
> + length
> + * of the compressed block. "hole_offset" is the hole offset of the
> + page,
> + * and the length of the uncompressed block is defined by
> + "raw_length",
> + * whose data is included in the record only when compression is
> + enabled
> + * and "with_hole" is set to true, see below.
> + *
> + * "is_compressed" is used to identify if a given block image is
> + compressed
> + * or not. Maximum page size allowed on the system being 32k, the
> + hole
> + * offset cannot be more than 15-bit long so the last free bit is
> + used to
> + * store the compression state of block image. If the maximum page
> + size
> + * allowed is increased to a value higher than that, we should
> + consider
> + * increasing this structure size as well, but this would increase
> + the
> + * length of block header in WAL records with alignment.
> + *
> + * "with_hole" is used to identify the presence of a hole in a block image.
> + * As the length of a block cannot be more than 15-bit long, the
> + extra bit in
> + * the length field is used for this identification purpose. If the
> + block image
> + * has no hole, it is ensured that the raw size of a compressed block
> + image is
> + * equal to BLCKSZ, hence the contents of
> + XLogRecordBlockImageCompressionInfo
> + * are not necessary.
> */
> typedef struct XLogRecordBlockImageHeader {
> - uint16 hole_offset; /* number of bytes before "hole" */
> - uint16 hole_length; /* number of bytes in "hole" */
> + uint16 length:15, /* length of block data in record */
> + with_hole:1; /* status of hole in the block */
> +
> + uint16 hole_offset:15, /* number of bytes before "hole" */
> + is_compressed:1; /* compression status of image */
> +
> + /* Followed by the data related to compression if block is
> +compressed */
> } XLogRecordBlockImageHeader;
Yikes, this is ugly.
I think we should change the xlog format so that the block_id (which currently is XLR_BLOCK_ID_DATA_SHORT/LONG or a
actualblock id) isn't the block id but something like XLR_CHUNK_ID. Which is used as is for
XLR_CHUNK_ID_DATA_SHORT/LONG,but for backup blocks can be set to to XLR_CHUNK_BKP_WITH_HOLE, XLR_CHUNK_BKP_COMPRESSED,
XLR_CHUNK_BKP_REFERENCE...The BKP blocks will then follow, storing the block id following the chunk id.
Yes, that'll increase the amount of data for a backup block by 1 byte, but I think that's worth it. I'm pretty sure we
willbe happy about the added extensibility pretty soon.
Greetings,
Andres Freund
-- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training &
Services
______________________________________________________________________
Disclaimer: This email and any attachments are sent in strictest confidence
for the sole use of the addressee and may contain legally privileged,
confidential, and proprietary data. If you are not the intended recipient,
please advise the sender by replying promptly to this email and then delete
and destroy this email and any attachments without any further use, copying
or forwarding.
On Mon, Feb 16, 2015 at 8:55 PM, Andres Freund <andres@2ndquadrant.com> wrote:
> On 2015-02-16 11:30:20 +0000, Syed, Rahila wrote:
>> - * As a trivial form of data compression, the XLOG code is aware that
>> - * PG data pages usually contain an unused "hole" in the middle, which
>> - * contains only zero bytes. If hole_length > 0 then we have removed
>> - * such a "hole" from the stored data (and it's not counted in the
>> - * XLOG record's CRC, either). Hence, the amount of block data actually
>> - * present is BLCKSZ - hole_length bytes.
>> + * Block images are able to do several types of compression:
>> + * - When wal_compression is off, as a trivial form of compression, the
>> + * XLOG code is aware that PG data pages usually contain an unused "hole"
>> + * in the middle, which contains only zero bytes. If length < BLCKSZ
>> + * then we have removed such a "hole" from the stored data (and it is
>> + * not counted in the XLOG record's CRC, either). Hence, the amount
>> + * of block data actually present is "length" bytes. The hole "offset"
>> + * on page is defined using "hole_offset".
>> + * - When wal_compression is on, block images are compressed using a
>> + * compression algorithm without their hole to improve compression
>> + * process of the page. "length" corresponds in this case to the length
>> + * of the compressed block. "hole_offset" is the hole offset of the page,
>> + * and the length of the uncompressed block is defined by "raw_length",
>> + * whose data is included in the record only when compression is enabled
>> + * and "with_hole" is set to true, see below.
>> + *
>> + * "is_compressed" is used to identify if a given block image is compressed
>> + * or not. Maximum page size allowed on the system being 32k, the hole
>> + * offset cannot be more than 15-bit long so the last free bit is used to
>> + * store the compression state of block image. If the maximum page size
>> + * allowed is increased to a value higher than that, we should consider
>> + * increasing this structure size as well, but this would increase the
>> + * length of block header in WAL records with alignment.
>> + *
>> + * "with_hole" is used to identify the presence of a hole in a block image.
>> + * As the length of a block cannot be more than 15-bit long, the extra bit in
>> + * the length field is used for this identification purpose. If the block image
>> + * has no hole, it is ensured that the raw size of a compressed block image is
>> + * equal to BLCKSZ, hence the contents of XLogRecordBlockImageCompressionInfo
>> + * are not necessary.
>> */
>> typedef struct XLogRecordBlockImageHeader
>> {
>> - uint16 hole_offset; /* number of bytes before "hole" */
>> - uint16 hole_length; /* number of bytes in "hole" */
>> + uint16 length:15, /* length of block data in record */
>> + with_hole:1; /* status of hole in the block */
>> +
>> + uint16 hole_offset:15, /* number of bytes before "hole" */
>> + is_compressed:1; /* compression status of image */
>> +
>> + /* Followed by the data related to compression if block is compressed */
>> } XLogRecordBlockImageHeader;
>
> Yikes, this is ugly.
>
> I think we should change the xlog format so that the block_id (which
> currently is XLR_BLOCK_ID_DATA_SHORT/LONG or a actual block id) isn't
> the block id but something like XLR_CHUNK_ID. Which is used as is for
> XLR_CHUNK_ID_DATA_SHORT/LONG, but for backup blocks can be set to to
> XLR_CHUNK_BKP_WITH_HOLE, XLR_CHUNK_BKP_COMPRESSED,
> XLR_CHUNK_BKP_REFERENCE... The BKP blocks will then follow, storing the
> block id following the chunk id.
> Yes, that'll increase the amount of data for a backup block by 1 byte,
> but I think that's worth it. I'm pretty sure we will be happy about the
> added extensibility pretty soon.
Yeah, that would help for readability and does not cost much compared
to BLCKSZ. Still could you explain what kind of extensibility you have
in mind except code readability? It is hard to make a nice picture
with only the paper and the pencils, and the current patch approach
has been taken to minimize the record length, particularly for users
who do not care about WAL compression.
--
Michael
XLR_CHUNK_ID_DATA_SHORT
XLR_CHUNK_ID_DATA_LONG
XLR_CHUNK_BKP_COMPRESSED
XLR_CHUNK_BKP_WITH_HOLE
WAL
Hello,
>I think we should change the xlog format so that the block_id (which currently is XLR_BLOCK_ID_DATA_SHORT/LONG or a actual block id) isn't the block id but something like XLR_CHUNK_ID. Which is used as is for XLR_CHUNK_ID_DATA_SHORT/LONG, but for backup blocks can be set to to >XLR_CHUNK_BKP_WITH_HOLE, XLR_CHUNK_BKP_COMPRESSED, XLR_CHUNK_BKP_REFERENCE... The BKP blocks will then follow, storing the block id following the chunk id.
>Yes, that'll increase the amount of data for a backup block by 1 byte, but I think that's worth it. I'm pretty sure we will be happy about the added extensibility pretty soon.To clarify my understanding of the above change,
Instead of a block id to reference different fragments of an xlog record , a single byte field "chunk_id" should be used. chunk_id will be same as XLR_BLOCK_ID_DATA_SHORT/LONG for main data fragments.
But for block references, it will take store following values in order to store information about the backup blocks.
#define XLR_CHUNK_BKP_COMPRESSED 0x01
#define XLR_CHUNK_BKP_WITH_HOLE 0x02
...
The new xlog format should look like follows,
Fixed-size header (XLogRecord struct)
Chunk_id(add a field before id field in XLogRecordBlockHeader struct)
XLogRecordBlockHeader
Chunk_id
XLogRecordBlockHeader
...
...
Chunk_id ( rename id field of the XLogRecordDataHeader struct)
XLogRecordDataHeader[Short|Long]
block data
block data
...
main data
I will post a patch based on this.
Thank you,
Rahila Syed
-----Original Message-----
From: Andres Freund [mailto:andres@2ndquadrant.com]
Sent: Monday, February 16, 2015 5:26 PM
To: Syed, Rahila
Cc: Michael Paquier; Fujii Masao; PostgreSQL mailing lists
Subject: Re: [HACKERS] [REVIEW] Re: Compression of full-page-writes> +compressed */On 2015-02-16 11:30:20 +0000, Syed, Rahila wrote:
> - * As a trivial form of data compression, the XLOG code is aware that
> - * PG data pages usually contain an unused "hole" in the middle,
> which
> - * contains only zero bytes. If hole_length > 0 then we have removed
> - * such a "hole" from the stored data (and it's not counted in the
> - * XLOG record's CRC, either). Hence, the amount of block data
> actually
> - * present is BLCKSZ - hole_length bytes.
> + * Block images are able to do several types of compression:
> + * - When wal_compression is off, as a trivial form of compression,
> + the
> + * XLOG code is aware that PG data pages usually contain an unused "hole"
> + * in the middle, which contains only zero bytes. If length < BLCKSZ
> + * then we have removed such a "hole" from the stored data (and it is
> + * not counted in the XLOG record's CRC, either). Hence, the amount
> + * of block data actually present is "length" bytes. The hole "offset"
> + * on page is defined using "hole_offset".
> + * - When wal_compression is on, block images are compressed using a
> + * compression algorithm without their hole to improve compression
> + * process of the page. "length" corresponds in this case to the
> + length
> + * of the compressed block. "hole_offset" is the hole offset of the
> + page,
> + * and the length of the uncompressed block is defined by
> + "raw_length",
> + * whose data is included in the record only when compression is
> + enabled
> + * and "with_hole" is set to true, see below.
> + *
> + * "is_compressed" is used to identify if a given block image is
> + compressed
> + * or not. Maximum page size allowed on the system being 32k, the
> + hole
> + * offset cannot be more than 15-bit long so the last free bit is
> + used to
> + * store the compression state of block image. If the maximum page
> + size
> + * allowed is increased to a value higher than that, we should
> + consider
> + * increasing this structure size as well, but this would increase
> + the
> + * length of block header in WAL records with alignment.
> + *
> + * "with_hole" is used to identify the presence of a hole in a block image.
> + * As the length of a block cannot be more than 15-bit long, the
> + extra bit in
> + * the length field is used for this identification purpose. If the
> + block image
> + * has no hole, it is ensured that the raw size of a compressed block
> + image is
> + * equal to BLCKSZ, hence the contents of
> + XLogRecordBlockImageCompressionInfo
> + * are not necessary.
> */
> typedef struct XLogRecordBlockImageHeader {
> - uint16 hole_offset; /* number of bytes before "hole" */
> - uint16 hole_length; /* number of bytes in "hole" */
> + uint16 length:15, /* length of block data in record */
> + with_hole:1; /* status of hole in the block */
> +
> + uint16 hole_offset:15, /* number of bytes before "hole" */
> + is_compressed:1; /* compression status of image */
> +
> + /* Followed by the data related to compression if block is
> } XLogRecordBlockImageHeader;
Yikes, this is ugly.
I think we should change the xlog format so that the block_id (which currently is XLR_BLOCK_ID_DATA_SHORT/LONG or a actual block id) isn't the block id but something like XLR_CHUNK_ID. Which is used as is for XLR_CHUNK_ID_DATA_SHORT/LONG, but for backup blocks can be set to to XLR_CHUNK_BKP_WITH_HOLE, XLR_CHUNK_BKP_COMPRESSED, XLR_CHUNK_BKP_REFERENCE... The BKP blocks will then follow, storing the block id following the chunk id.
Yes, that'll increase the amount of data for a backup block by 1 byte, but I think that's worth it. I'm pretty sure we will be happy about the added extensibility pretty soon.
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
______________________________________________________________________
Disclaimer: This email and any attachments are sent in strictest confidence
for the sole use of the addressee and may contain legally privileged,
confidential, and proprietary data. If you are not the intended recipient,
please advise the sender by replying promptly to this email and then delete
and destroy this email and any attachments without any further use, copying
or forwarding.--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Mon, Feb 23, 2015 at 5:28 PM, Rahila Syed <rahilasyed90@gmail.com> wrote: > Hello, > > Attached is a patch which has following changes, > > As suggested above block ID in xlog structs has been replaced by chunk ID. > Chunk ID is used to distinguish between different types of xlog record > fragments. > Like, > XLR_CHUNK_ID_DATA_SHORT > XLR_CHUNK_ID_DATA_LONG > XLR_CHUNK_BKP_COMPRESSED > XLR_CHUNK_BKP_WITH_HOLE > > In block references, block ID follows the chunk ID. Here block ID retains > its functionality. > This approach increases data by 1 byte for each block reference in an xlog > record. This approach separates ID referring different fragments of xlog > record from the actual block ID which is used to refer block references in > xlog record. I've not read this logic yet, but ISTM there is a bug in that new WAL format because I got the following error and the startup process could not replay any WAL records when I set up replication and enabled wal_compression. LOG: record with invalid length at 0/30000B0 LOG: record with invalid length at 0/3000518 LOG: Invalid block length in record 0/30005A0 LOG: Invalid block length in record 0/3000D60 ... Regards, -- Fujii Masao
On Mon, Feb 23, 2015 at 5:28 PM, Rahila Syed <rahilasyed90@gmail.com> wrote:
> Hello,
>
> Attached is a patch which has following changes,
>
> As suggested above block ID in xlog structs has been replaced by chunk ID.
> Chunk ID is used to distinguish between different types of xlog record
> fragments.
> Like,
> XLR_CHUNK_ID_DATA_SHORT
> XLR_CHUNK_ID_DATA_LONG
> XLR_CHUNK_BKP_COMPRESSED
> XLR_CHUNK_BKP_WITH_HOLE
>
> In block references, block ID follows the chunk ID. Here block ID retains
> its functionality.
> This approach increases data by 1 byte for each block reference in an xlog
> record. This approach separates ID referring different fragments of xlog
> record from the actual block ID which is used to refer block references in
> xlog record.
I've not read this logic yet, but ISTM there is a bug in that new WAL format
because I got the following error and the startup process could not replay
any WAL records when I set up replication and enabled wal_compression.
LOG: record with invalid length at 0/30000B0
LOG: record with invalid length at 0/3000518
LOG: Invalid block length in record 0/30005A0
LOG: Invalid block length in record 0/3000D60
uint32 length:15,
+#define XLR_CHUNK_ID_DATA_SHORT 255
+#define XLR_CHUNK_ID_DATA_LONG 254
+#define XLR_CHUNK_BKP_COMPRESSED 0x01
+#define XLR_CHUNK_BKP_WITH_HOLE 0x02
- lp_off and lp_len fields in ItemIdData (see include/storage/itemid.h).
+ lp_off and lp_len fields in ItemIdData (see include/storage/itemid.h)
Hello , >I've not read this logic yet, but ISTM there is a bug in that new WAL format because I got the following error and the startupprocess could not replay any WAL records when I set up replication and enabled wal_compression. >LOG: record with invalid length at 0/30000B0 >LOG: record with invalid length at 0/3000518 >LOG: Invalid block length in record 0/30005A0 >LOG: Invalid block length in record 0/3000D60 ... Please fine attached patch which replays WAL records. Thank you, Rahila Syed -----Original Message----- From: pgsql-hackers-owner@postgresql.org [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Fujii Masao Sent: Monday, February 23, 2015 5:52 PM To: Rahila Syed Cc: PostgreSQL-development; Andres Freund; Michael Paquier Subject: Re: [HACKERS] [REVIEW] Re: Compression of full-page-writes On Mon, Feb 23, 2015 at 5:28 PM, Rahila Syed <rahilasyed90@gmail.com> wrote: > Hello, > > Attached is a patch which has following changes, > > As suggested above block ID in xlog structs has been replaced by chunk ID. > Chunk ID is used to distinguish between different types of xlog record > fragments. > Like, > XLR_CHUNK_ID_DATA_SHORT > XLR_CHUNK_ID_DATA_LONG > XLR_CHUNK_BKP_COMPRESSED > XLR_CHUNK_BKP_WITH_HOLE > > In block references, block ID follows the chunk ID. Here block ID > retains its functionality. > This approach increases data by 1 byte for each block reference in an > xlog record. This approach separates ID referring different fragments > of xlog record from the actual block ID which is used to refer block > references in xlog record. I've not read this logic yet, but ISTM there is a bug in that new WAL format because I got the following error and the startupprocess could not replay any WAL records when I set up replication and enabled wal_compression. LOG: record with invalid length at 0/30000B0 LOG: record with invalid length at 0/3000518 LOG: Invalid block length in record 0/30005A0 LOG: Invalid block length in record 0/3000D60 ... Regards, -- Fujii Masao -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers ______________________________________________________________________ Disclaimer: This email and any attachments are sent in strictest confidence for the sole use of the addressee and may contain legally privileged, confidential, and proprietary data. If you are not the intended recipient, please advise the sender by replying promptly to this email and then delete and destroy this email and any attachments without any further use, copying or forwarding.
Attachment
On 2015-02-24 16:03:41 +0900, Michael Paquier wrote:
> Looking at this code, I think that it is really confusing to move the data
> related to the status of the backup block out of XLogRecordBlockImageHeader
> to the chunk ID itself that may *not* include a backup block at all as it
> is conditioned by the presence of BKPBLOCK_HAS_IMAGE.
What's the problem here? We could actually now easily remove
BKPBLOCK_HAS_IMAGE and replace it by a chunk id.
> the idea of having the backup block data in its dedicated header with bits
> stolen from the existing fields, perhaps by rewriting it to something like
> that:
> typedef struct XLogRecordBlockImageHeader {
> uint32 length:15,
> hole_length:15,
> is_compressed:1,
> is_hole:1;
> } XLogRecordBlockImageHeader;
> Now perhaps I am missing something and this is really "ugly" ;)
I think it's fantastically ugly. We'll also likely want different
compression formats and stuff in the not too far away future. This will
just end up being a pain.
Greetings,
Andres Freund
-- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training &
Services
On Tue, Feb 24, 2015 at 6:46 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote: > Hello , > >>I've not read this logic yet, but ISTM there is a bug in that new WAL format because I got the following error and thestartup process could not replay any WAL records when I set up replication and enabled wal_compression. > >>LOG: record with invalid length at 0/30000B0 >>LOG: record with invalid length at 0/3000518 >>LOG: Invalid block length in record 0/30005A0 >>LOG: Invalid block length in record 0/3000D60 ... > > Please fine attached patch which replays WAL records. Even this patch doesn't work fine. The standby emit the following error messages. LOG: invalid block_id 255 at 0/30000B0 LOG: record with invalid length at 0/30017F0 LOG: invalid block_id 255 at 0/3001878 LOG: record with invalid length at 0/30027D0 LOG: record with invalid length at 0/3002E58 ... Regards, -- Fujii Masao
>Even this patch doesn't work fine. The standby emit the following
>error messages.
Following chunk IDs have been added in the attached patch as suggested upthread.
+#define XLR_CHUNK_BLOCK_REFERENCE 0x10
+#define XLR_CHUNK_BLOCK_HAS_IMAGE 0x04
+#define XLR_CHUNK_BLOCK_HAS_DATA 0x08
Attachment
On Fri, Feb 27, 2015 at 6:54 AM, Rahila Syed <rahilasyed90@gmail.com> wrote: > Hello, > >>Even this patch doesn't work fine. The standby emit the following >>error messages. > > Yes this bug remains unsolved. I am still working on resolving this. > > Following chunk IDs have been added in the attached patch as suggested > upthread. > +#define XLR_CHUNK_BLOCK_REFERENCE 0x10 > +#define XLR_CHUNK_BLOCK_HAS_IMAGE 0x04 > +#define XLR_CHUNK_BLOCK_HAS_DATA 0x08 > > XLR_CHUNK_BLOCK_REFERENCE denotes chunk ID of block references. > XLR_CHUNK_BLOCK_HAS_IMAGE is a replacement of BKPBLOCK_HAS_IMAGE > and XLR_CHUNK_BLOCK_HAS DATA a replacement of BKPBLOCK_HAS_DATA. Before sending a new version, be sure that this get fixed by for example building up a master with a standby replaying WAL, and running make installcheck-world or similar. If the standby does not complain at all, you have good chances to not have bugs. You could also build with WAL_DEBUG to check record consistency. -- Michael
On Fri, Feb 27, 2015 at 8:01 AM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Fri, Feb 27, 2015 at 6:54 AM, Rahila Syed <rahilasyed90@gmail.com> wrote: >>>Even this patch doesn't work fine. The standby emit the following >>>error messages. >> >> Yes this bug remains unsolved. I am still working on resolving this. >> >> Following chunk IDs have been added in the attached patch as suggested >> upthread. >> +#define XLR_CHUNK_BLOCK_REFERENCE 0x10 >> +#define XLR_CHUNK_BLOCK_HAS_IMAGE 0x04 >> +#define XLR_CHUNK_BLOCK_HAS_DATA 0x08 >> >> XLR_CHUNK_BLOCK_REFERENCE denotes chunk ID of block references. >> XLR_CHUNK_BLOCK_HAS_IMAGE is a replacement of BKPBLOCK_HAS_IMAGE >> and XLR_CHUNK_BLOCK_HAS DATA a replacement of BKPBLOCK_HAS_DATA. > > Before sending a new version, be sure that this get fixed by for > example building up a master with a standby replaying WAL, and running > make installcheck-world or similar. If the standby does not complain > at all, you have good chances to not have bugs. You could also build > with WAL_DEBUG to check record consistency. It would be good to get those problems fixed first. Could you send an updated patch? I'll look into it in more details. For the time being I am switching this patch to "Waiting on Author". -- Michael
On Fri, Feb 27, 2015 at 12:44 PM, Michael Paquier
<michael.paquier@gmail.com> wrote:
> On Fri, Feb 27, 2015 at 8:01 AM, Michael Paquier
> <michael.paquier@gmail.com> wrote:
>> On Fri, Feb 27, 2015 at 6:54 AM, Rahila Syed <rahilasyed90@gmail.com> wrote:
>>>>Even this patch doesn't work fine. The standby emit the following
>>>>error messages.
>>>
>>> Yes this bug remains unsolved. I am still working on resolving this.
>>>
>>> Following chunk IDs have been added in the attached patch as suggested
>>> upthread.
>>> +#define XLR_CHUNK_BLOCK_REFERENCE 0x10
>>> +#define XLR_CHUNK_BLOCK_HAS_IMAGE 0x04
>>> +#define XLR_CHUNK_BLOCK_HAS_DATA 0x08
>>>
>>> XLR_CHUNK_BLOCK_REFERENCE denotes chunk ID of block references.
>>> XLR_CHUNK_BLOCK_HAS_IMAGE is a replacement of BKPBLOCK_HAS_IMAGE
>>> and XLR_CHUNK_BLOCK_HAS DATA a replacement of BKPBLOCK_HAS_DATA.
>>
>> Before sending a new version, be sure that this get fixed by for
>> example building up a master with a standby replaying WAL, and running
>> make installcheck-world or similar. If the standby does not complain
>> at all, you have good chances to not have bugs. You could also build
>> with WAL_DEBUG to check record consistency.
+1
When I test the WAL or replication related features, I usually run
"make installcheck" and pgbench against the master at the same time
after setting up the replication environment.
typedef struct XLogRecordBlockHeader{
+ uint8 chunk_id; /* xlog fragment id */ uint8 id; /* block reference ID */
Seems this increases the header size of WAL record even if no backup block
image is included. Right? Isn't it better to add the flag info about backup
block image into XLogRecordBlockImageHeader rather than XLogRecordBlockHeader?
Originally we borrowed one or two bits from its existing fields to minimize
the header size, but we can just add new flag field if we prefer
the extensibility and readability of the code.
Regards,
--
Fujii Masao
>"make installcheck" and pgbench against the master at the same time
>after setting up the replication environment.
>Seems this increases the header size of WAL record even if no backup block image is included. Right?
Yes, this increases the header size of WAL record by 1 byte for every block reference even if it has no backup block image.
>Isn't it better to add the flag info about backup block image into XLogRecordBlockImageHeader rather than XLogRecordBlockHeader
Yes , this will make the code extensible,readable and will save couple of bytes per record.
On Fri, Feb 27, 2015 at 12:44 PM, Michael Paquier
<michael.paquier@gmail.com> wrote:
> On Fri, Feb 27, 2015 at 8:01 AM, Michael Paquier
> <michael.paquier@gmail.com> wrote:
>> On Fri, Feb 27, 2015 at 6:54 AM, Rahila Syed <rahilasyed90@gmail.com> wrote:
>>>>Even this patch doesn't work fine. The standby emit the following
>>>>error messages.
>>>
>>> Yes this bug remains unsolved. I am still working on resolving this.
>>>
>>> Following chunk IDs have been added in the attached patch as suggested
>>> upthread.
>>> +#define XLR_CHUNK_BLOCK_REFERENCE 0x10
>>> +#define XLR_CHUNK_BLOCK_HAS_IMAGE 0x04
>>> +#define XLR_CHUNK_BLOCK_HAS_DATA 0x08
>>>
>>> XLR_CHUNK_BLOCK_REFERENCE denotes chunk ID of block references.
>>> XLR_CHUNK_BLOCK_HAS_IMAGE is a replacement of BKPBLOCK_HAS_IMAGE
>>> and XLR_CHUNK_BLOCK_HAS DATA a replacement of BKPBLOCK_HAS_DATA.
>>
>> Before sending a new version, be sure that this get fixed by for
>> example building up a master with a standby replaying WAL, and running
>> make installcheck-world or similar. If the standby does not complain
>> at all, you have good chances to not have bugs. You could also build
>> with WAL_DEBUG to check record consistency.
+1
When I test the WAL or replication related features, I usually run
"make installcheck" and pgbench against the master at the same time
after setting up the replication environment.
typedef struct XLogRecordBlockHeader
{
+ uint8 chunk_id; /* xlog fragment id */
uint8 id; /* block reference ID */
Seems this increases the header size of WAL record even if no backup block
image is included. Right? Isn't it better to add the flag info about backup
block image into XLogRecordBlockImageHeader rather than XLogRecordBlockHeader?
Originally we borrowed one or two bits from its existing fields to minimize
the header size, but we can just add new flag field if we prefer
the extensibility and readability of the code.
Regards,
--
Fujii Masao
On Tue, Mar 3, 2015 at 5:17 AM, Rahila Syed <rahilasyed90@gmail.com> wrote: > Hello, > >>When I test the WAL or replication related features, I usually run >>"make installcheck" and pgbench against the master at the same time >>after setting up the replication environment. > I will conduct these tests before sending updated version. > >>Seems this increases the header size of WAL record even if no backup block >> image is included. Right? > Yes, this increases the header size of WAL record by 1 byte for every block > reference even if it has no backup block image. > >>Isn't it better to add the flag info about backup block image into >> XLogRecordBlockImageHeader rather than XLogRecordBlockHeader > Yes , this will make the code extensible,readable and will save couple of > bytes per record. > But the current approach is to provide a chunk ID identifying different > xlog record fragments like main data , block references etc. > Currently , block ID is used to identify record fragments which can be > either XLR_BLOCK_ID_DATA_SHORT , XLR_BLOCK_ID_DATA_LONG or actual block ID. > This can be replaced by chunk ID to separate it from block ID. Block ID can > be used to number the block fragments whereas chunk ID can be used to > distinguish between main data fragments and block references. Chunk ID of > block references can contain information about presence of data, image , > hole and compression. > Chunk ID for main data fragments remains as it is . This approach provides > for readability and extensibility. Already mentioned upthread, but I agree with Fujii-san here: adding information related to the state of a block image in XLogRecordBlockHeader makes little sense because we are not sure to have a block image, perhaps there is only data associated to it, and that we should control that exclusively in XLogRecordBlockImageHeader and let the block ID alone for now. Hence we'd better have 1 extra int8 in XLogRecordBlockImageHeader with now 2 flags: - Is block compressed or not? - Does block have a hole? Perhaps this will not be considered as ugly, and this leaves plenty of room for storing a version number for compression. -- Michael
On 2015-03-03 08:59:30 +0900, Michael Paquier wrote: > Already mentioned upthread, but I agree with Fujii-san here: adding > information related to the state of a block image in > XLogRecordBlockHeader makes little sense because we are not sure to > have a block image, perhaps there is only data associated to it, and > that we should control that exclusively in XLogRecordBlockImageHeader > and let the block ID alone for now. This argument doesn't make much sense to me. The flag byte could very well indicate 'block reference without image following' vs 'block reference with data + hole following' vs 'block reference with compressed data following'. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Mar 3, 2015 at 9:24 AM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2015-03-03 08:59:30 +0900, Michael Paquier wrote: >> Already mentioned upthread, but I agree with Fujii-san here: adding >> information related to the state of a block image in >> XLogRecordBlockHeader makes little sense because we are not sure to >> have a block image, perhaps there is only data associated to it, and >> that we should control that exclusively in XLogRecordBlockImageHeader >> and let the block ID alone for now. > > This argument doesn't make much sense to me. The flag byte could very > well indicate 'block reference without image following' vs 'block > reference with data + hole following' vs 'block reference with > compressed data following'. Information about the state of a block is decoupled with its existence, aka in the block header, we should control if: - record has data - record has a block And in the block image header, we control if the block is: - compressed or not - has a hole or not. Are you willing to sacrifice bytes in the block header to control if a block is compressed or has a hole even if the block has only data but no image? -- Michael
Hello,
>It would be good to get those problems fixed first. Could you send an updated patch?
Please find attached updated patch with WAL replay error fixed. The patch follows chunk ID approach of xlog format.
Following are brief measurement numbers.
WAL
FPW compression on 122.032 MB
FPW compression off 155.239 MB
HEAD 155.236 MB
Thank you,
Rahila Syed
______________________________________________________________________
Disclaimer: This email and any attachments are sent in strictest confidence
for the sole use of the addressee and may contain legally privileged,
confidential, and proprietary data. If you are not the intended recipient,
please advise the sender by replying promptly to this email and then delete
and destroy this email and any attachments without any further use, copying
or forwarding.
Attachment
On Tue, Mar 3, 2015 at 9:34 AM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Tue, Mar 3, 2015 at 9:24 AM, Andres Freund <andres@2ndquadrant.com> wrote: >> On 2015-03-03 08:59:30 +0900, Michael Paquier wrote: >>> Already mentioned upthread, but I agree with Fujii-san here: adding >>> information related to the state of a block image in >>> XLogRecordBlockHeader makes little sense because we are not sure to >>> have a block image, perhaps there is only data associated to it, and >>> that we should control that exclusively in XLogRecordBlockImageHeader >>> and let the block ID alone for now. >> >> This argument doesn't make much sense to me. The flag byte could very >> well indicate 'block reference without image following' vs 'block >> reference with data + hole following' vs 'block reference with >> compressed data following'. > > Information about the state of a block is decoupled with its > existence, aka in the block header, we should control if: > - record has data > - record has a block > And in the block image header, we control if the block is: > - compressed or not > - has a hole or not. Are there any other flag bits that we should or are planning to add into WAL header newly, except the above two? If yes and they are required by even a block which doesn't have an image, I will change my mind and agree to add something like chunk ID to a block header. But I guess the answer of the question is No. Since the flag bits now we are thinking to add are required only by a block having an image, adding them into a block header (instead of block image header) seems a waste of bytes in WAL. So I concur with Michael. Regards, -- Fujii Masao
On Wed, Mar 4, 2015 at 12:41 AM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote:
> Please find attached updated patch with WAL replay error fixed. The patch follows chunk ID approach of xlog format.
(Review done independently of the chunk_id stuff being good or not,
already gave my opinion on the matter).
* readRecordBufSize is set to the new buffer size.
- *
+
The patch has some noise diffs.
You may want to change the values of BKPBLOCK_WILL_INIT and
BKPBLOCK_SAME_REL to respectively 0x01 and 0x02.
+ uint8 chunk_id = 0;
+ chunk_id |= XLR_CHUNK_BLOCK_REFERENCE;
Why not simply that:
chunk_id = XLR_CHUNK_BLOCK_REFERENCE;
+#define XLR_CHUNK_ID_DATA_SHORT 255
+#define XLR_CHUNK_ID_DATA_LONG 254
Why aren't those just using one bit as well? This seems inconsistent
with the rest.
+ if ((blk->with_hole == 0 && blk->hole_offset != 0) ||
+ (blk->with_hole == 1 && blk->hole_offset <= 0))
In xlogreader.c blk->with_hole is defined as a boolean but compared
with an integer, could you remove the ==0 and ==1 portions for
clarity?
- goto err;
+ goto err; } }
- if (remaining != datatotal)
This gathers incorrect code alignment and unnecessary diffs.
typedef struct XLogRecordBlockHeader{
+ /* Chunk ID precedes */
+ uint8 id;
What prevents the declaration of chunk_id as an int8 here instead of
this comment? This is confusing.
> Following are brief measurement numbers.
> WAL
> FPW compression on 122.032 MB
> FPW compression off 155.239 MB
> HEAD 155.236 MB
What is the test run in this case? How many block images have been
generated in WAL for each case? You could gather some of those numbers
with pg_xlogdump --stat for example.
--
Michael
Hello, >Are there any other flag bits that we should or are planning to add into WAL header newly, except the above two? If yesand they are required by even a block which doesn't have an image, I will change my mind and agree to add something likechunk ID to a block header. >But I guess the answer of the question is No. Since the flag bits now we are thinking to add are required only by a blockhaving an image, adding them into a block header (instead of block image header) seems a waste of bytes in WAL. So Iconcur with Michael. I agree. As per my understanding, this change of xlog format was to provide for future enhancement which would need flags relevantto entire block. But as mentioned, currently the flags being added are related to block image only. Hence for this patch it makes sense toadd a field to XLogRecordImageHeader rather than block header. This will also save bytes per WAL record. Thank you, Rahila Syed ______________________________________________________________________ Disclaimer: This email and any attachments are sent in strictest confidence for the sole use of the addressee and may contain legally privileged, confidential, and proprietary data. If you are not the intended recipient, please advise the sender by replying promptly to this email and then delete and destroy this email and any attachments without any further use, copying or forwarding.
Hello,
Please find attached a patch. As discussed, flag to denote compression and presence of hole in block image has been
addedin XLogRecordImageHeader rather than block header.
Following are WAL numbers based on attached test script posted by Michael earlier in the thread.
WAL generated
FPW compression on 122.032 MB
FPW compression off 155.223 MB
HEAD 155.236 MB
Compression : 21 %
Number of block images generated in WAL : 63637
Thank you,
Rahila Syed
______________________________________________________________________
Disclaimer: This email and any attachments are sent in strictest confidence
for the sole use of the addressee and may contain legally privileged,
confidential, and proprietary data. If you are not the intended recipient,
please advise the sender by replying promptly to this email and then delete
and destroy this email and any attachments without any further use, copying
or forwarding.
Attachment
On Thu, Mar 5, 2015 at 9:14 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote: > Please find attached a patch. As discussed, flag to denote compression and presence of hole in block image has been addedin XLogRecordImageHeader rather than block header. > > Following are WAL numbers based on attached test script posted by Michael earlier in the thread. > > WAL generated > FPW compression on 122.032 MB > > FPW compression off 155.223 MB > > HEAD 155.236 MB > > Compression : 21 % > Number of block images generated in WAL : 63637 ISTM that we are getting a nice thing here. I tested the patch and WAL replay is working correctly. Some nitpicky comments... + * bkp_info stores flags for information about the backup block image + * BKPIMAGE_IS_COMPRESSED is used to identify if a given block image is compressed. + * BKPIMAGE_WITH_HOLE is used to identify the presence of a hole in a block image. + * If the block image has no hole, it is ensured that the raw size of a compressed + * block image is equal to BLCKSZ, hence the contents of + * XLogRecordBlockImageCompressionInfo are not necessary. Take care of the limit of 80 characters per line. (Perhaps you could run pgindent on your code before sending a patch?). The first line of this paragraph is a sentence in itself, no? In xlogreader.c, blk->with_hole is a boolean, you could remove the ==0 and ==1 it is compared with. + /* + * Length of a block image must be less than BLCKSZ + * if the block has hole + */ "if the block has a hole." (End of the sentence needs a dot.) + /* + * Length of a block image must be equal to BLCKSZ + * if the block does not have hole + */ "if the block does not have a hole." Regards, -- Michael
On 2015-03-05 12:14:04 +0000, Syed, Rahila wrote: > Please find attached a patch. As discussed, flag to denote > compression and presence of hole in block image has been added in > XLogRecordImageHeader rather than block header. FWIW, I personally won't commit it with things done that way. I think it's going the wrong way, leading to a harder to interpret and less flexible format. I'm not going to further protest if Fujii or Heikki commit it this way though. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Mar 5, 2015 at 10:28 PM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2015-03-05 12:14:04 +0000, Syed, Rahila wrote: >> Please find attached a patch. As discussed, flag to denote >> compression and presence of hole in block image has been added in >> XLogRecordImageHeader rather than block header. > > FWIW, I personally won't commit it with things done that way. I think > it's going the wrong way, leading to a harder to interpret and less > flexible format. I'm not going to further protest if Fujii or Heikki > commit it this way though. I'm pretty sure that we can discuss the *better* WAL format even after committing this patch. Regards, -- Fujii Masao
On Mon, Feb 16, 2015 at 9:08 PM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2015-02-16 20:55:20 +0900, Michael Paquier wrote: >> On Mon, Feb 16, 2015 at 8:30 PM, Syed, Rahila <Rahila.Syed@nttdata.com> >> wrote: >> >> > >> > Regarding the sanity checks that have been added recently. I think that >> > they are useful but I am suspecting as well that only a check on the record >> > CRC is done because that's reliable enough and not doing those checks >> > accelerates a bit replay. So I am thinking that we should simply replace >> > >them by assertions. >> > >> > Removing the checks makes sense as CRC ensures correctness . Moreover ,as >> > error message for invalid length of record is present in the code , >> > messages for invalid block length can be redundant. >> > >> > Checks have been replaced by assertions in the attached patch. >> > >> >> After more thinking, we may as well simply remove them, an error with CRC >> having high chances to complain before reaching this point... > > Surely not. The existing code explicitly does it like > if (blk->has_data && blk->data_len == 0) > report_invalid_record(state, > "BKPBLOCK_HAS_DATA set, but no data included at %X/%X", > (uint32) (state->ReadRecPtr >> 32), (uint32) state->ReadRecPtr); > these cross checks are important. And I see no reason to deviate from > that. The CRC sum isn't foolproof - we intentionally do checks at > several layers. And, as you can see from some other locations, we > actually try to *not* fatally error out when hitting them at times - so > an Assert also is wrong. > > Heikki: > /* cross-check that the HAS_DATA flag is set iff data_length > 0 */ > if (blk->has_data && blk->data_len == 0) > report_invalid_record(state, > "BKPBLOCK_HAS_DATA set, but no data included at %X/%X", > (uint32) (state->ReadRecPtr >> 32), (uint32) state->ReadRecPtr); > if (!blk->has_data && blk->data_len != 0) > report_invalid_record(state, > "BKPBLOCK_HAS_DATA not set, but data length is %u at %X/%X", > (unsigned int) blk->data_len, > (uint32) (state->ReadRecPtr >> 32), (uint32)state->ReadRecPtr); > those look like they're missing a goto err; to me. Yes. I pushed the fix. Thanks! Regards, -- Fujii Masao
On Thu, Mar 5, 2015 at 10:08 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Thu, Mar 5, 2015 at 9:14 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote: >> Please find attached a patch. As discussed, flag to denote compression and presence of hole in block image has been addedin XLogRecordImageHeader rather than block header. Thanks for updating the patch! Attached is the refactored version of the patch. Regards, -- Fujii Masao
Attachment
On Mon, Mar 9, 2015 at 4:29 PM, Fujii Masao <masao.fujii@gmail.com> wrote:
> On Thu, Mar 5, 2015 at 10:08 PM, Michael Paquier
> <michael.paquier@gmail.com> wrote:
>> On Thu, Mar 5, 2015 at 9:14 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote:
>>> Please find attached a patch. As discussed, flag to denote compression and presence of hole in block image has
beenadded in XLogRecordImageHeader rather than block header.
>
> Thanks for updating the patch! Attached is the refactored version of the patch.
Cool. Thanks!
I have some minor comments:
+ The default value is <literal>off</>
Dot at the end of this sentence.
+ Turning this parameter on can reduce the WAL volume without
"Turning <value>on</> this parameter
+ but at the cost of some extra CPU time by the compression during
+ WAL logging and the decompression during WAL replay."
Isn't a verb missing here, for something like that:
"but at the cost of some extra CPU spent on the compression during WAL
logging and on the decompression during WAL replay."
+ * This can reduce the WAL volume, but at some extra cost of CPU time
+ * by the compression during WAL logging.
Er, similarly "some extra cost of CPU spent on the compression...".
+ if (blk->bimg_info & BKPIMAGE_HAS_HOLE &&
+ (blk->hole_offset == 0 ||
+ blk->hole_length == 0 ||
I think that extra parenthesis should be used for the first expression
with BKPIMAGE_HAS_HOLE.
+ if (blk->bimg_info & BKPIMAGE_IS_COMPRESSED &&
+ blk->bimg_len == BLCKSZ)
+ {
Same here.
+ /*
+ * cross-check that hole_offset == 0
and hole_length == 0
+ * if the HAS_HOLE flag is set.
+ */
I think that you mean here that this happens when the flag is *not* set.
+ /*
+ * If BKPIMAGE_HAS_HOLE and BKPIMAGE_IS_COMPRESSED,
+ * an XLogRecordBlockCompressHeader follows
+ */
Maybe a "struct" should be added for "an XLogRecordBlockCompressHeader
struct". And a dot at the end of the sentence should be added?
Regards,
--
Michael
On Mon, Mar 9, 2015 at 9:08 PM, Michael Paquier wrote:
> On Mon, Mar 9, 2015 at 4:29 PM, Fujii Masao wrote:
>> Thanks for updating the patch! Attached is the refactored version of the patch.
Fujii-san and I had a short chat about tuning a bit the PGLZ strategy
which is now PGLZ_strategy_default in the patch (at least 25% of
compression, etc.). In particular min_input_size which is not set at
32B is too low, and knowing that the minimum fillfactor of a relation
page is 10% this looks really too low.
For example, using the extension attached to this email able to
compress and decompress bytea strings that I have developed after pglz
has been moved to libpqcommon (contains as well a function able to get
a relation page without its hole, feel free to use it), I am seeing
that we can gain quite a lot of space even with some incompressible
data like UUID or some random float data (pages are compressed without
their hole):
1) Float table:
=# create table float_tab (id float);
CREATE TABLE
=# insert into float_tab select random() from generate_series(1, 20);
INSERT 0 20
=# SELECT bytea_size(compress_data(page)) AS compress_size,
bytea_size(page) AS raw_size_no_hole FROM
get_raw_page('float_tab'::regclass, 0, false);
-[ RECORD 1 ]----+----
compress_size | 329
raw_size_no_hole | 744
=# SELECT bytea_size(compress_data(page)) AS compress_size,
bytea_size(page) AS raw_size_no_hole FROM
get_raw_page('float_tab'::regclass, 0, false);
-[ RECORD 1 ]----+-----
compress_size | 1753
raw_size_no_hole | 4344
So that's more or less 60% saved...
2) UUID table
=# SELECT bytea_size(compress_data(page)) AS compress_size,
bytea_size(page) AS raw_size_no_hole FROM
get_raw_page('uuid_tab'::regclass, 0, false);
-[ RECORD 1 ]----+----
compress_size | 590
raw_size_no_hole | 904
=# insert into uuid_tab select gen_random_uuid() from generate_series(1, 100);
INSERT 0 100
=# SELECT bytea_size(compress_data(page)) AS compress_size,
bytea_size(page) AS raw_size_no_hole FROM
get_raw_page('uuid_tab'::regclass, 0, false);
-[ RECORD 1 ]----+-----
compress_size | 3338
raw_size_no_hole | 5304
And in this case we are close to 40% saved...
At least, knowing that with the header there are at least 24B used on
a page, what about increasing min_input_size to something like 128B or
256B? I don't think that this is a blocker for this patch as most of
the relation pages are going to have far more data than that so they
will be unconditionally compressed, but there is definitely something
we could do in this area later on, perhaps even we could do
improvement with the other parameters like the compression rate. So
that's something to keep in mind...
--
Michael
Attachment
>I have some minor comments
>I think that extra parenthesis should be used for the first expression
>with BKPIMAGE_HAS_HOLE.
Cool. Thanks!On Mon, Mar 9, 2015 at 4:29 PM, Fujii Masao <masao.fujii@gmail.com> wrote:
> On Thu, Mar 5, 2015 at 10:08 PM, Michael Paquier
> <michael.paquier@gmail.com> wrote:
>> On Thu, Mar 5, 2015 at 9:14 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote:
>>> Please find attached a patch. As discussed, flag to denote compression and presence of hole in block image has been added in XLogRecordImageHeader rather than block header.
>
> Thanks for updating the patch! Attached is the refactored version of the patch.
I have some minor comments:
+ The default value is <literal>off</>
Dot at the end of this sentence.
+ Turning this parameter on can reduce the WAL volume without
"Turning <value>on</> this parameter
+ but at the cost of some extra CPU time by the compression during
+ WAL logging and the decompression during WAL replay."
Isn't a verb missing here, for something like that:
"but at the cost of some extra CPU spent on the compression during WAL
logging and on the decompression during WAL replay."
+ * This can reduce the WAL volume, but at some extra cost of CPU time
+ * by the compression during WAL logging.
Er, similarly "some extra cost of CPU spent on the compression...".
+ if (blk->bimg_info & BKPIMAGE_HAS_HOLE &&
+ (blk->hole_offset == 0 ||
+ blk->hole_length == 0 ||
I think that extra parenthesis should be used for the first expression
with BKPIMAGE_HAS_HOLE.
+ if (blk->bimg_info & BKPIMAGE_IS_COMPRESSED &&
+ blk->bimg_len == BLCKSZ)
+ {
Same here.
+ /*
+ * cross-check that hole_offset == 0
and hole_length == 0
+ * if the HAS_HOLE flag is set.
+ */
I think that you mean here that this happens when the flag is *not* set.
+ /*
+ * If BKPIMAGE_HAS_HOLE and BKPIMAGE_IS_COMPRESSED,
+ * an XLogRecordBlockCompressHeader follows
+ */
Maybe a "struct" should be added for "an XLogRecordBlockCompressHeader
struct". And a dot at the end of the sentence should be added?
Regards,
--
Michael
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Mon, Mar 9, 2015 at 9:08 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Mon, Mar 9, 2015 at 4:29 PM, Fujii Masao <masao.fujii@gmail.com> wrote: >> On Thu, Mar 5, 2015 at 10:08 PM, Michael Paquier >> <michael.paquier@gmail.com> wrote: >>> On Thu, Mar 5, 2015 at 9:14 PM, Syed, Rahila <Rahila.Syed@nttdata.com> wrote: >>>> Please find attached a patch. As discussed, flag to denote compression and presence of hole in block image has beenadded in XLogRecordImageHeader rather than block header. >> >> Thanks for updating the patch! Attached is the refactored version of the patch. > > Cool. Thanks! > > I have some minor comments: Thanks for the comments! > + Turning this parameter on can reduce the WAL volume without > "Turning <value>on</> this parameter That tag is not used in other place in config.sgml, so I'm not sure if that's really necessary. Regards, -- Fujii Masao
On Wed, Mar 11, 2015 at 7:08 AM, Rahila Syed <rahilasyed90@gmail.com> wrote: > Hello, > >>I have some minor comments > > The comments have been implemented in the attached patch. Thanks for updating the patch! I just changed a bit and finally pushed it. Thanks everyone involved in this patch! Regards, -- Fujii Masao
On Wed, Mar 11, 2015 at 3:57 PM, Fujii Masao <masao.fujii@gmail.com> wrote: > On Wed, Mar 11, 2015 at 7:08 AM, Rahila Syed <rahilasyed90@gmail.com> wrote: >> Hello, >> >>>I have some minor comments >> >> The comments have been implemented in the attached patch. > > Thanks for updating the patch! I just changed a bit and finally pushed it. > Thanks everyone involved in this patch! Woohoo! Thanks! -- Michael