Thread: Reducing the chunk header sizes on all memory context types
Over on [1], I highlighted that 40af10b57 (Use Generation memory contexts to store tuples in sorts) could cause some performance regressions for sorts when the size of the tuple is exactly a power of 2. The reason for this is that the chunk header for generation.c contexts is 8 bytes larger (on 64-bit machines) than the aset.c chunk header. This means that we can store fewer tuples per work_mem during the sort and that results in more batches being required. As I write this, this regression is still marked as an open item for PG15 in [2]. So I've been working on this to try to assist the discussion about if we need to do anything about that for PG15. Over on [3], I mentioned that Andres came up with an idea and a prototype patch to reduce the chunk header size across the board by storing the context type in the 3 least significant bits in a uint64 header. I've taken Andres' patch and made some quite significant changes to it. In the patch's current state, the sort performance regression in PG15 vs PG14 is fixed. The generation.c context chunk header has been reduced to 8 bytes from the previous 24 bytes as it is in master. aset.c context chunk header is now 8 bytes instead of 16 bytes. We can use this 8-byte chunk header by using the remaining 61-bits of the uint64 header to encode 2 30-bit values to store the chunk size and also the number of bytes we must subtract from the given pointer to find the block that the chunk is stored on. Once we have the block, we can find the owning context by having a pointer back to the context from the block. For memory allocations that are larger than what can be stored in 30 bits, the chunk header gets an additional two Size fields to store the chunk_size and the block offset. We can tell the difference between the 2 chunk sizes by looking at the spare 1-bit the uint64 portion of the header. Aside from speeding up the sort case, this also seems to have a good positive performance impact on pgbench read-only workload with -M simple. I'm seeing about a 17% performance increase on my AMD Threadripper machine. master + Reduced Memory Context Chunk Overhead drowley@amd3990x:~$ pgbench -S -T 60 -j 156 -c 156 -M simple postgres tps = 1876841.953096 (without initial connection time) tps = 1919605.408254 (without initial connection time) tps = 1891734.480141 (without initial connection time) Master drowley@amd3990x:~$ pgbench -S -T 60 -j 156 -c 156 -M simple postgres tps = 1632248.236962 (without initial connection time) tps = 1615663.151604 (without initial connection time) tps = 1602004.146259 (without initial connection time) The attached .png file shows the same results for PG14 and PG15 as I showed in the blog [4] where I discovered the regression and adds the results from current master + the attached patch. See bars in orange. You can see that the regression at 64MB work_mem is fixed. Adding some tracing to the sort shows that we're now doing 671745 tuples per batch instead of 576845 tuples. This reduces the number of batches from 245 down to 210. Drawbacks: There is at least one. It might be major; to reduce the AllocSet chunk header from 16 bytes down to 8 bytes I had to get rid of the freelist pointer that was reusing the "aset" field in the chunk header struct. This works now by storing that pointer in the actual palloc'd memory. This could lead to pretty hard-to-trace bugs if we have any code that accidentally writes to memory after pfree. The slab.c context already does this, but that's far less commonly used. If we decided this was unacceptable then it does not change anything for the generation.c context. The chunk header will still be 8 bytes instead of 24 there. So the sort performance regression will still be fixed. To improve this situation, we might be able code it up so that MEMORY_CONTEXT_CHECKING builds add an additional freelist pointer to the header and also write it to the palloc'd memory then verify they're set to the same thing when we reuse a chunk from the freelist. If they're not the same then MEMORY_CONTEXT_CHECKING builds could either spit out a WARNING or ERROR for this case. That would make it pretty easy for developers to find their write after pfree bugs. This might actually be better than the Valgrind detection method that we have for this today. Patch: I've attached the WIP patch. At this stage, I'm more looking for a design review. I'm not aware of any bugs, but I am aware that I've not tested with Valgrind. I've not paid a great deal of attention to updating the Valgrind macros at all. I'll add this to the September CF. I'm submitting now due to the fact that we still have an open item in PG15 for the sort regression and the existence of this patch might cause us to decide whether we can defer fixing that to PG16 by way of the method in this patch, or revert 40af10b57. Benchmark code in [5]. David [1] https://www.postgresql.org/message-id/CAApHDvqXpLzav6dUeR5vO_RBh_feHrHMLhigVQXw9jHCyKP9PA%40mail.gmail.com [2] https://wiki.postgresql.org/wiki/PostgreSQL_15_Open_Items [3] https://www.postgresql.org/message-id/CAApHDvowHNSVLhMc0cnovg8PfnYQZxit-gP_bn3xkT4rZX3G0w%40mail.gmail.com [4] https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/speeding-up-sort-performance-in-postgres-15/ba-p/3396953 [5] https://www.postgresql.org/message-id/attachment/134161/sortbench_varcols.sh
Attachment
{kind=link}
Good day, David. В Вт, 12/07/2022 в 17:01 +1200, David Rowley пишет: > Over on [1], I highlighted that 40af10b57 (Use Generation memory > contexts to store tuples in sorts) could cause some performance > regressions for sorts when the size of the tuple is exactly a power of > 2. The reason for this is that the chunk header for generation.c > contexts is 8 bytes larger (on 64-bit machines) than the aset.c chunk > header. This means that we can store fewer tuples per work_mem during > the sort and that results in more batches being required. > > As I write this, this regression is still marked as an open item for > PG15 in [2]. So I've been working on this to try to assist the > discussion about if we need to do anything about that for PG15. > > Over on [3], I mentioned that Andres came up with an idea and a > prototype patch to reduce the chunk header size across the board by > storing the context type in the 3 least significant bits in a uint64 > header. > > I've taken Andres' patch and made some quite significant changes to > it. In the patch's current state, the sort performance regression in > PG15 vs PG14 is fixed. The generation.c context chunk header has been > reduced to 8 bytes from the previous 24 bytes as it is in master. > aset.c context chunk header is now 8 bytes instead of 16 bytes. > > We can use this 8-byte chunk header by using the remaining 61-bits of > the uint64 header to encode 2 30-bit values to store the chunk size > and also the number of bytes we must subtract from the given pointer > to find the block that the chunk is stored on. Once we have the > block, we can find the owning context by having a pointer back to the > context from the block. For memory allocations that are larger than > what can be stored in 30 bits, the chunk header gets an additional two > Size fields to store the chunk_size and the block offset. We can tell > the difference between the 2 chunk sizes by looking at the spare 1-bit > the uint64 portion of the header. I don't get, why "large chunk" needs additional fields for size and offset. Large allocation sizes are certainly rounded to page size. And allocations which doesn't fit 1GB we could easily round to 1MB. Then we could simply store `size>>20`. It will limit MaxAllocHugeSize to `(1<<(30+20))-1` - 1PB. Doubdfully we will deal with such huge allocations in near future. And to limit block offset, we just have to limit maxBlockSize to 1GB, which is quite reasonable limitation. Chunks that are larger than maxBlockSize goes to separate blocks anyway, therefore they have small block offset. > Aside from speeding up the sort case, this also seems to have a good > positive performance impact on pgbench read-only workload with -M > simple. I'm seeing about a 17% performance increase on my AMD > Threadripper machine. > > master + Reduced Memory Context Chunk Overhead > drowley@amd3990x:~$ pgbench -S -T 60 -j 156 -c 156 -M simple postgres > tps = 1876841.953096 (without initial connection time) > tps = 1919605.408254 (without initial connection time) > tps = 1891734.480141 (without initial connection time) > > Master > drowley@amd3990x:~$ pgbench -S -T 60 -j 156 -c 156 -M simple postgres > tps = 1632248.236962 (without initial connection time) > tps = 1615663.151604 (without initial connection time) > tps = 1602004.146259 (without initial connection time) Trick with 3bit context type is great. > The attached .png file shows the same results for PG14 and PG15 as I > showed in the blog [4] where I discovered the regression and adds the > results from current master + the attached patch. See bars in orange. > You can see that the regression at 64MB work_mem is fixed. Adding some > tracing to the sort shows that we're now doing 671745 tuples per batch > instead of 576845 tuples. This reduces the number of batches from 245 > down to 210. > > Drawbacks: > > There is at least one. It might be major; to reduce the AllocSet chunk > header from 16 bytes down to 8 bytes I had to get rid of the freelist > pointer that was reusing the "aset" field in the chunk header struct. > This works now by storing that pointer in the actual palloc'd memory. > This could lead to pretty hard-to-trace bugs if we have any code that > accidentally writes to memory after pfree. The slab.c context already > does this, but that's far less commonly used. If we decided this was > unacceptable then it does not change anything for the generation.c > context. The chunk header will still be 8 bytes instead of 24 there. > So the sort performance regression will still be fixed. At least we can still mark free list pointer as VALGRIND_MAKE_MEM_NOACCESS and do VALGRIND_MAKE_MEM_DEFINED on fetching from free list, can we? > To improve this situation, we might be able code it up so that > MEMORY_CONTEXT_CHECKING builds add an additional freelist pointer to > the header and also write it to the palloc'd memory then verify > they're set to the same thing when we reuse a chunk from the freelist. > If they're not the same then MEMORY_CONTEXT_CHECKING builds could > either spit out a WARNING or ERROR for this case. That would make it > pretty easy for developers to find their write after pfree bugs. This > might actually be better than the Valgrind detection method that we > have for this today. > > Patch: > > I've attached the WIP patch. At this stage, I'm more looking for a > design review. I'm not aware of any bugs, but I am aware that I've not > tested with Valgrind. I've not paid a great deal of attention to > updating the Valgrind macros at all. > > I'll add this to the September CF. I'm submitting now due to the fact > that we still have an open item in PG15 for the sort regression and > the existence of this patch might cause us to decide whether we can > defer fixing that to PG16 by way of the method in this patch, or > revert 40af10b57. > > Benchmark code in [5]. > > David > > [1] https://www.postgresql.org/message-id/CAApHDvqXpLzav6dUeR5vO_RBh_feHrHMLhigVQXw9jHCyKP9PA%40mail.gmail.com > [2] https://wiki.postgresql.org/wiki/PostgreSQL_15_Open_Items > [3] https://www.postgresql.org/message-id/CAApHDvowHNSVLhMc0cnovg8PfnYQZxit-gP_bn3xkT4rZX3G0w%40mail.gmail.com > [4] https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/speeding-up-sort-performance-in-postgres-15/ba-p/3396953 > [5] https://www.postgresql.org/message-id/attachment/134161/sortbench_varcols.sh
Hi, On 2022-07-12 17:01:18 +1200, David Rowley wrote: > I've taken Andres' patch and made some quite significant changes to > it. In the patch's current state, the sort performance regression in > PG15 vs PG14 is fixed. The generation.c context chunk header has been > reduced to 8 bytes from the previous 24 bytes as it is in master. > aset.c context chunk header is now 8 bytes instead of 16 bytes. I think this is *very* cool. But I might be biased :) > There is at least one. It might be major; to reduce the AllocSet chunk > header from 16 bytes down to 8 bytes I had to get rid of the freelist > pointer that was reusing the "aset" field in the chunk header struct. > This works now by storing that pointer in the actual palloc'd memory. > This could lead to pretty hard-to-trace bugs if we have any code that > accidentally writes to memory after pfree. Can't we use the same trick for allcations in the freelist as we do for the header in a live allocation? I.e. split the 8 byte header into two and use part of it to point to the next element in the list using the offset from the start of the block, and part of it to indicate the size? Greetings, Andres Freund
Hi, On 2022-07-12 20:22:57 +0300, Yura Sokolov wrote: > I don't get, why "large chunk" needs additional fields for size and > offset. > Large allocation sizes are certainly rounded to page size. > And allocations which doesn't fit 1GB we could easily round to 1MB. > Then we could simply store `size>>20`. > It will limit MaxAllocHugeSize to `(1<<(30+20))-1` - 1PB. Doubdfully we > will deal with such huge allocations in near future. What would gain by doing something like this? The storage density loss of storing an exact size is smaller than what you propose here. Greetings, Andres Freund
On Wed, 13 Jul 2022 at 05:44, Andres Freund <andres@anarazel.de> wrote: > On 2022-07-12 20:22:57 +0300, Yura Sokolov wrote: > > I don't get, why "large chunk" needs additional fields for size and > > offset. > > Large allocation sizes are certainly rounded to page size. > > And allocations which doesn't fit 1GB we could easily round to 1MB. > > Then we could simply store `size>>20`. > > It will limit MaxAllocHugeSize to `(1<<(30+20))-1` - 1PB. Doubdfully we > > will deal with such huge allocations in near future. > > What would gain by doing something like this? The storage density loss of > storing an exact size is smaller than what you propose here. I do agree that the 16-byte additional header size overhead for allocations >= 1GB are not really worth troubling too much over. However, if there was some way to make it so we always had an 8-byte header, it would simplify some of the code in places such as AllocSetFree(). For example, (ALLOC_BLOCKHDRSZ + hdrsize + chunksize) could be simplified at compile time if hdrsize was a known constant. I did consider that in all cases where the allocations are above allocChunkLimit that the chunk is put on a dedicated block and in fact, the blockoffset is always the same for those. I wondered if we could use the full 60 bits for the chunksize for those cases. The reason I didn't pursue that is because: #define MaxAllocHugeSize (SIZE_MAX / 2) That's 63-bits, so 60 isn't enough. Yeah, we likely could reduce that without upsetting anyone. It feels like it'll be a while before not being able to allocate a chunk of memory more than 1024 petabytes will be an issue, although, I do hope to grow old enough to one day come back here at laugh at that. David
On Wed, 13 Jul 2022 at 05:42, Andres Freund <andres@anarazel.de> wrote: > > There is at least one. It might be major; to reduce the AllocSet chunk > > header from 16 bytes down to 8 bytes I had to get rid of the freelist > > pointer that was reusing the "aset" field in the chunk header struct. > > This works now by storing that pointer in the actual palloc'd memory. > > This could lead to pretty hard-to-trace bugs if we have any code that > > accidentally writes to memory after pfree. > > Can't we use the same trick for allcations in the freelist as we do for the > header in a live allocation? I.e. split the 8 byte header into two and use > part of it to point to the next element in the list using the offset from the > start of the block, and part of it to indicate the size? That can't work as the next freelist item might be on some other block. David
Hi, On 2022-07-12 10:42:07 -0700, Andres Freund wrote: > On 2022-07-12 17:01:18 +1200, David Rowley wrote: > > There is at least one. It might be major; to reduce the AllocSet chunk > > header from 16 bytes down to 8 bytes I had to get rid of the freelist > > pointer that was reusing the "aset" field in the chunk header struct. > > This works now by storing that pointer in the actual palloc'd memory. > > This could lead to pretty hard-to-trace bugs if we have any code that > > accidentally writes to memory after pfree. > > Can't we use the same trick for allcations in the freelist as we do for the > header in a live allocation? I.e. split the 8 byte header into two and use > part of it to point to the next element in the list using the offset from the > start of the block, and part of it to indicate the size? So that doesn't work because the members in the freelist can be in different blocks and those can be further away from each other. Perhaps that could still made work somehow: To point to a block we don't actually need 64bit pointers, they're always at least of some certain size - assuming we can allocate them suitably aligned. And chunks are always 8 byte aligned. Unfortunately that doesn't quite get us far enough - assuming a 4kB minimum block size (larger than now, but potentially sensible as a common OS page size), we still only get to 2^12*8 = 32kB. It'd easily work if we made each context have an array of allocated non-huge blocks, so that the blocks can be addressed with a small index. The overhead of that could be reduced in the common case by embedding a small constant sized array in the Aset. That might actually be worth trying out. Greetings, Andres Freund
В Вт, 12/07/2022 в 22:41 -0700, Andres Freund пишет: > Hi, > > On 2022-07-12 10:42:07 -0700, Andres Freund wrote: > > On 2022-07-12 17:01:18 +1200, David Rowley wrote: > > > There is at least one. It might be major; to reduce the AllocSet chunk > > > header from 16 bytes down to 8 bytes I had to get rid of the freelist > > > pointer that was reusing the "aset" field in the chunk header struct. > > > This works now by storing that pointer in the actual palloc'd memory. > > > This could lead to pretty hard-to-trace bugs if we have any code that > > > accidentally writes to memory after pfree. > > > > Can't we use the same trick for allcations in the freelist as we do for the > > header in a live allocation? I.e. split the 8 byte header into two and use > > part of it to point to the next element in the list using the offset from the > > start of the block, and part of it to indicate the size? > > So that doesn't work because the members in the freelist can be in different > blocks and those can be further away from each other. > > > Perhaps that could still made work somehow: To point to a block we don't > actually need 64bit pointers, they're always at least of some certain size - > assuming we can allocate them suitably aligned. And chunks are always 8 byte > aligned. Unfortunately that doesn't quite get us far enough - assuming a 4kB > minimum block size (larger than now, but potentially sensible as a common OS > page size), we still only get to 2^12*8 = 32kB. Well, we actually have freelists for 11 size classes. It is just 11 pointers. We could embed this 88 bytes in every ASet block and then link blocks. And then in every block have 44 bytes for in-block free lists. Total overhead is 132 bytes per-block. Or 110 if we limit block size to 65k*8b=512kb. With double-linked block lists (176bytes per block + 44bytes for in-block lists = 220bytes), we could track block fullness and deallocate it if it doesn't contain any alive alocation. Therefore "generational" and "slab" allocators will be less useful. But CPU overhead will be noticeable. > It'd easily work if we made each context have an array of allocated non-huge > blocks, so that the blocks can be addressed with a small index. The overhead > of that could be reduced in the common case by embedding a small constant > sized array in the Aset. That might actually be worth trying out. > > Greetings, > > Andres Freund > >
On Wed, 13 Jul 2022 at 17:20, David Rowley <dgrowleyml@gmail.com> wrote:
> I did consider that in all cases where the allocations are above
> allocChunkLimit that the chunk is put on a dedicated block and in
> fact, the blockoffset is always the same for those. I wondered if we
> could use the full 60 bits for the chunksize for those cases. The
> reason I didn't pursue that is because:
As it turns out, we don't really need to explicitly store the chunk
size for chunks which are on dedicated blocks. We can just calculate
this by subtracting the pointer to the memory from the block's endptr.
The block offset is always fixed too, like I mentioned above.
I've now revised the patch to completely get rid of the concept of
"large" chunks and instead memory chunks are always 8 bytes in size.
I've created a struct to this effect and named it MemoryChunk. All
memory contexts make use of this new struct. The header bit which I
was previously using to denote a "large" chunk now marks if the chunk
is "external", meaning that the MemoryChunk does not have knowledge of
the chunk size and/or block offset. The MemoryContext itself is
expected to manage this when the chunk is external. I've coded up
aset.c and generation.c to always use these external chunks when size
> set->allocChunkLimit. There is now a coding pattern like the
following (taken from AllocSetRealloc:
if (MemoryChunkIsExternal(chunk))
{
block = ExternalChunkGetBlock(chunk);
oldsize = block->endptr - (char *) pointer;
}
else
{
block = MemoryChunkGetBlock(chunk);
oldsize = MemoryChunkGetSize(chunk);
}
Here the ExternalChunkGetBlock() macro is just subtracting the
ALLOC_BLOCKHDRSZ from the chunk pointer to obtain the block pointer,
whereas MemoryChunkGetBlock() is subtracting the blockoffset as is
stored in the 30-bits of the chunk header.
Andres and I had a conversation off-list about the storage of freelist
pointers. Currently I have these stored in the actual allocated
memory. The minimum allocation size is 8-bytes, which is big enough
for storing sizeof(void *). Andres suggested that it might be safer to
store this link at the end of the chunk rather than at the start.
I've not quite done that in the attached, but doing this should just
be a matter of adjusting the GetFreeListLink() macro to add the
chunksize - sizeof(AllocFreelistLink).
I did a little bit of benchmarking of the attached with a scale 1 pgbench.
master = 0b039e3a8
master
drowley@amd3990x:~$ pgbench -c 156 -j 156 -T 60 -S postgres
tps = 1638436.367793 (without initial connection time)
tps = 1652688.009579 (without initial connection time)
tps = 1671281.281856 (without initial connection time)
master + v2 patch
drowley@amd3990x:~$ pgbench -c 156 -j 156 -T 60 -S postgres
tps = 1825346.734486 (without initial connection time)
tps = 1824539.294142 (without initial connection time)
tps = 1807359.758822 (without initial connection time)
~10% faster.
There are a couple of things to note that might require discussion:
1. I've added a new restriction that block sizes cannot be above 1GB.
This is because the 30-bits in the MemoryChunk used for storing the
offset between the chunk and the block wouldn't be able to store the
offset if the chunk was offset more than 1GB from the block. I used
debian code search to see if I could find any user code that used
blocks this big. I found nothing.
2. slab.c has a new restriction that the chunk size cannot be >= 1GB.
I'm not at all concerned about this. I think if someone needed chunks
that big there'd be no benefits from slab context over an aset
context.
3. As mentioned above, aset.c now stores freelist pointers in the
allocated chunk's memory. This allows us to get the header down to 8
bytes instead of today's 16 bytes. There's an increased danger that
buggy code that writes to memory after a pfree could stomp on this.
I think the patch is now starting to take shape. I've added it to the
September commitfest [1].
David
[1] https://commitfest.postgresql.org/39/3810/
Attachment
On Tue, Aug 9, 2022 at 8:53 AM David Rowley <dgrowleyml@gmail.com> wrote: > I think the patch is now starting to take shape. I've added it to the > September commitfest [1]. This is extremely cool. The memory savings are really nice. And I also like this: # Additionally, this commit completely changes the rule that pointers must # be directly prefixed by the owning memory context and instead, we now # insist that they're directly prefixed by an 8-byte value where the least # significant 3-bits are set to a value to indicate which type of memory # context the pointer belongs to. Using those 3 bits as an index to a new # array which stores the methods for each memory context type, we're now # able to pass the pointer given to functions such as pfree and repalloc to # the function specific to that context implementation to allow them to # devise their own methods of finding the memory context which owns the # given allocated chunk of memory. That seems like a good system. This part of the commit message might need to be clarified: # We also add a restriction that block sizes for all 3 of the memory # allocators cannot be 1GB or larger. We would be unable to store the # number of bytes that the block is offset from the chunk stored beyond this #1GB boundary on any block that was larger than 1GB. Earlier in the commit message, you say that allocations of 1GB or more are stored in dedicated blocks. But here you say that blocks can't be more than 1GB. Those statements seem to contradict each other. I guess you mean block sizes for blocks that contain chunks, or something like that? -- Robert Haas EDB: http://www.enterprisedb.com
Hi,
On 2022-08-09 10:36:57 -0400, Robert Haas wrote:
> On Tue, Aug 9, 2022 at 8:53 AM David Rowley <dgrowleyml@gmail.com> wrote:
> > I think the patch is now starting to take shape. I've added it to the
> > September commitfest [1].
>
> This is extremely cool. The memory savings are really nice.
+1
> And I also like this:
>
> # Additionally, this commit completely changes the rule that pointers must
> # be directly prefixed by the owning memory context and instead, we now
> # insist that they're directly prefixed by an 8-byte value where the least
> # significant 3-bits are set to a value to indicate which type of memory
> # context the pointer belongs to. Using those 3 bits as an index to a new
> # array which stores the methods for each memory context type, we're now
> # able to pass the pointer given to functions such as pfree and repalloc to
> # the function specific to that context implementation to allow them to
> # devise their own methods of finding the memory context which owns the
> # given allocated chunk of memory.
>
> That seems like a good system.
I'm obviously biased, but I agree.
I think it's fine, given that we can change this at any time, but it's
probably worth to explicitly agree that this will for now restrict us to 8
context methods?
> This part of the commit message might need to be clarified:
>
> # We also add a restriction that block sizes for all 3 of the memory
> # allocators cannot be 1GB or larger. We would be unable to store the
> # number of bytes that the block is offset from the chunk stored beyond this
> #1GB boundary on any block that was larger than 1GB.
>
> Earlier in the commit message, you say that allocations of 1GB or more
> are stored in dedicated blocks. But here you say that blocks can't be
> more than 1GB. Those statements seem to contradict each other. I guess
> you mean block sizes for blocks that contain chunks, or something like
> that?
I would guess so as well.
> diff --git a/src/include/utils/memutils_internal.h b/src/include/utils/memutils_internal.h
> new file mode 100644
> index 0000000000..2dcfdd7ec3
> --- /dev/null
> +++ b/src/include/utils/memutils_internal.h
> @@ -0,0 +1,117 @@
> +/*-------------------------------------------------------------------------
> + *
> + * memutils_internal.h
> + * This file contains declarations for memory allocation utility
> + * functions for internal use.
> + *
> + *
> + * Portions Copyright (c) 2022, PostgreSQL Global Development Group
> + * Portions Copyright (c) 1994, Regents of the University of California
> + *
> + * src/include/utils/memutils_internal.h
> + *
> + *-------------------------------------------------------------------------
> + */
> +
> +#ifndef MEMUTILS_INTERNAL_H
> +#define MEMUTILS_INTERNAL_H
> +
> +#include "utils/memutils.h"
> +
> +extern void *AllocSetAlloc(MemoryContext context, Size size);
> +extern void AllocSetFree(void *pointer);
> [much more]
I really wish I knew of a technique to avoid this kind of thing, allowing to
fill a constant array from different translation units... On the linker level
that should be trivial, but I don't think there's a C way to reach that.
> +/*
> + * MemoryContextMethodID
> + * A unique identifier for each MemoryContext implementation which
> + * indicates the index into the mcxt_methods[] array. See mcxt.c.
> + */
> +typedef enum MemoryContextMethodID
> +{
> + MCTX_ASET_ID = 0,
Is there a reason to reserve 0 here? Practically speaking the 8-byte header
will always contain not just zeroes, but I don't think the patch currently
enforces that. It's probably not worth wasting a "valuable" entry here...
> diff --git a/src/include/utils/memutils_memorychunk.h b/src/include/utils/memutils_memorychunk.h
> new file mode 100644
> index 0000000000..6239cf9008
> --- /dev/null
> +++ b/src/include/utils/memutils_memorychunk.h
> @@ -0,0 +1,185 @@
> +/*-------------------------------------------------------------------------
> + *
> + * memutils_memorychunk.h
> + * Here we define a struct named MemoryChunk which implementations of
> + * MemoryContexts may use as a header for chunks of memory they allocate.
> + *
> + * A MemoryChunk provides a lightweight header which a MemoryContext can use
> + * to store the size of an allocation and a reference back to the block which
> + * the given chunk is allocated on.
> + *
> + * Although MemoryChunks are used by each of our MemoryContexts, other
> + * implementations may choose to implement their own method for storing chunk
> + * headers. The only requirement is that the header end with an 8-byte value
> + * which the least significant 3-bits of are set to the MemoryContextMethodID
> + * of the given context.
Well, there can't be other implementations other than ours. So maybe phrase it
as "future implementations"?
> + * By default, a MemoryChunk is 8 bytes in size, however when
> + * MEMORY_CONTEXT_CHECKING is defined the header becomes 16 bytes in size due
> + * to the additional requested_size field. The MemoryContext may use this
> + * field for whatever they wish, but it is intended to be used for additional
> + * checks which are only done in MEMORY_CONTEXT_CHECKING builds.
> + *
> + * The MemoryChunk contains a uint64 field named 'hdrmask'. This field is
> + * used to encode 4 separate pieces of information. Starting with the least
> + * significant bits of 'hdrmask', the bits of this field as used as follows:
> + *
> + * 1. 3-bits to indicate the MemoryContextMethodID
> + * 2. 1-bit to indicate if the chunk is externally managed (see below)
> + * 3. 30-bits for the amount of memory which was reserved for the chunk
> + * 4. 30-bits for the number of bytes that must be subtracted from the chunk
> + * to obtain the address of the block that the chunk is stored on.
> + *
> + * Because we're limited to a block offset and chunk size of 1GB (30-bits),
> + * any allocation which exceeds this amount must call MemoryChunkSetExternal()
> + * and the MemoryContext must devise its own method for storing the offset for
> + * the block and size of the chunk.
Hm. So really only the first four bits have eactly that layout, correct?
Perhaps that could be clarified somehow?
> + /*
> + * The maximum size for a memory chunk before it must be externally managed.
> + */
> +#define MEMORYCHUNK_MAX_SIZE 0x3FFFFFFF
> +
> + /*
> + * The value to AND onto the hdrmask to determine if it's an externally
> + * managed memory chunk.
> + */
> +#define MEMORYCHUNK_EXTERNAL_BIT (1 << 3)
We should probably have a define for the three bits reserved for the context
id, likely in _internal.h
> @@ -109,6 +112,25 @@ typedef struct AllocChunkData *AllocChunk;
> */
> typedef void *AllocPointer;
>
> +/*
> + * AllocFreelistLink
> + * When pfreeing memory, if we maintain a freelist for the given chunk's
> + * size then we use a AllocFreelistLink to point to the current item in
> + * the AllocSetContext's freelist and then set the given freelist element
> + * to point to the chunk being freed.
> + */
> +typedef struct AllocFreelistLink
> +{
> + MemoryChunk *next;
> +} AllocFreelistLink;
I know we have no agreement on that, but I personally would add
AllocFreelistLink to typedefs.list and then re-pgindent ;)
> /*
> * AllocSetGetChunkSpace
> * Given a currently-allocated chunk, determine the total space
> * it occupies (including all memory-allocation overhead).
> */
> -static Size
> -AllocSetGetChunkSpace(MemoryContext context, void *pointer)
> +Size
> +AllocSetGetChunkSpace(void *pointer)
> {
> - AllocChunk chunk = AllocPointerGetChunk(pointer);
> - Size result;
> + MemoryChunk *chunk = PointerGetMemoryChunk(pointer);
>
> - VALGRIND_MAKE_MEM_DEFINED(chunk, ALLOCCHUNK_PRIVATE_LEN);
> - result = chunk->size + ALLOC_CHUNKHDRSZ;
> - VALGRIND_MAKE_MEM_NOACCESS(chunk, ALLOCCHUNK_PRIVATE_LEN);
> - return result;
> + if (MemoryChunkIsExternal(chunk))
> + {
Hm. We don't mark the chunk header as noaccess anymore? If so, why? I realize
it'd be a bit annoying because there's plenty places that look at it, but I
think it's also a good way to catch errors.
> +static const MemoryContextMethods mcxt_methods[] = {
> + [MCTX_ASET_ID] = {
> + AllocSetAlloc,
> + AllocSetFree,
> + AllocSetRealloc,
> + AllocSetReset,
> + AllocSetDelete,
> + AllocSetGetChunkContext,
> + AllocSetGetChunkSpace,
> + AllocSetIsEmpty,
> + AllocSetStats
> +#ifdef MEMORY_CONTEXT_CHECKING
> + ,AllocSetCheck
> +#endif
> + },
> +
> + [MCTX_GENERATION_ID] = {
> + GenerationAlloc,
> + GenerationFree,
> + GenerationRealloc,
> + GenerationReset,
> + GenerationDelete,
> + GenerationGetChunkContext,
> + GenerationGetChunkSpace,
> + GenerationIsEmpty,
> + GenerationStats
> +#ifdef MEMORY_CONTEXT_CHECKING
> + ,GenerationCheck
> +#endif
> + },
> +
> + [MCTX_SLAB_ID] = {
> + SlabAlloc,
> + SlabFree,
> + SlabRealloc,
> + SlabReset,
> + SlabDelete,
> + SlabGetChunkContext,
> + SlabGetChunkSpace,
> + SlabIsEmpty,
> + SlabStats
> +#ifdef MEMORY_CONTEXT_CHECKING
> + ,SlabCheck
> +#endif
> + },
> +};
Mildly wondering whether we ought to use designated initializers instead,
given we're whacking it around already. Too easy to get the order wrong when
adding new members, and we might want to have optional callbacks too.
Greetings,
Andres Freund
Andres Freund <andres@anarazel.de> writes:
> I think it's fine, given that we can change this at any time, but it's
> probably worth to explicitly agree that this will for now restrict us to 8
> context methods?
Do we really need it to be that tight? I know we only have 3 methods today,
but 8 doesn't seem that far away. If there were six bits reserved for
this I'd be happier.
>> # We also add a restriction that block sizes for all 3 of the memory
>> # allocators cannot be 1GB or larger. We would be unable to store the
>> # number of bytes that the block is offset from the chunk stored beyond this
>> #1GB boundary on any block that was larger than 1GB.
Losing MemoryContextAllocHuge would be very bad, so I assume this comment
is not telling the full truth.
regards, tom lane
On 2022-Aug-09, Andres Freund wrote: > Mildly wondering whether we ought to use designated initializers instead, > given we're whacking it around already. Too easy to get the order wrong when > adding new members, and we might want to have optional callbacks too. Strong +1. It makes code much easier to navigate (see XmlTableRoutine and compare with heapam_methods, for example). -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/ Subversion to GIT: the shortest path to happiness I've ever heard of (Alexey Klyukin)
Hi, On 2022-08-09 15:21:57 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > I think it's fine, given that we can change this at any time, but it's > > probably worth to explicitly agree that this will for now restrict us to 8 > > context methods? > > Do we really need it to be that tight? I know we only have 3 methods today, > but 8 doesn't seem that far away. If there were six bits reserved for > this I'd be happier. We only have so many bits available, so that'd have to come from some other resource. The current division is: + * 1. 3-bits to indicate the MemoryContextMethodID + * 2. 1-bit to indicate if the chunk is externally managed (see below) + * 3. 30-bits for the amount of memory which was reserved for the chunk + * 4. 30-bits for the number of bytes that must be subtracted from the chunk + * to obtain the address of the block that the chunk is stored on. I suspect we could reduce 3) here a bit, which I think would end up with slab context's max chunkSize shrinking further. Which should still be fine. But also, we could defer that to later, this is a limit that we can easily change. > >> # We also add a restriction that block sizes for all 3 of the memory > >> # allocators cannot be 1GB or larger. We would be unable to store the > >> # number of bytes that the block is offset from the chunk stored beyond this > >> #1GB boundary on any block that was larger than 1GB. > > Losing MemoryContextAllocHuge would be very bad, so I assume this comment > is not telling the full truth. It's just talking about chunked allocation (except for slab, which doesn't have anything else, but as David pointed out, it makes no sense to use slab for that large allocations). I.e. it's the max you can pass to AllocSetContextCreate()'s and GenerationContextCreate()'s maxBlockSize, and to SlabContextCreate()'s chunkSize. I don't think we have any code that currently sets a bigger limit than 8MB. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2022-08-09 15:21:57 -0400, Tom Lane wrote:
>> Do we really need it to be that tight? I know we only have 3 methods today,
>> but 8 doesn't seem that far away. If there were six bits reserved for
>> this I'd be happier.
> We only have so many bits available, so that'd have to come from some other
> resource. The current division is:
> + * 1. 3-bits to indicate the MemoryContextMethodID
> + * 2. 1-bit to indicate if the chunk is externally managed (see below)
> + * 3. 30-bits for the amount of memory which was reserved for the chunk
> + * 4. 30-bits for the number of bytes that must be subtracted from the chunk
> + * to obtain the address of the block that the chunk is stored on.
> I suspect we could reduce 3) here a bit, which I think would end up with slab
> context's max chunkSize shrinking further. Which should still be fine.
Hmm, I suppose you mean we could reduce 4) if we needed to. Yeah, that
seems like a reasonable place to buy more bits later if we run out of
MemoryContextMethodIDs. Should be fine then.
regards, tom lane
On Wed, 10 Aug 2022 at 09:23, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Andres Freund <andres@anarazel.de> writes: > > On 2022-08-09 15:21:57 -0400, Tom Lane wrote: > >> Do we really need it to be that tight? I know we only have 3 methods today, > >> but 8 doesn't seem that far away. If there were six bits reserved for > >> this I'd be happier. > > > We only have so many bits available, so that'd have to come from some other > > resource. The current division is: > > > + * 1. 3-bits to indicate the MemoryContextMethodID > > + * 2. 1-bit to indicate if the chunk is externally managed (see below) > > + * 3. 30-bits for the amount of memory which was reserved for the chunk > > + * 4. 30-bits for the number of bytes that must be subtracted from the chunk > > + * to obtain the address of the block that the chunk is stored on. > > > I suspect we could reduce 3) here a bit, which I think would end up with slab > > context's max chunkSize shrinking further. Which should still be fine. > > Hmm, I suppose you mean we could reduce 4) if we needed to. Yeah, that > seems like a reasonable place to buy more bits later if we run out of > MemoryContextMethodIDs. Should be fine then. I think he means 3). If 4) was reduced then that would further reduce the maxBlockSize we could pass when creating a context. At least for aset.c and generation.c, we don't really need 3) to be 30-bits wide as the set->allocChunkLimit is almost certainly much smaller than that. Allocations bigger than allocChunkLimit use a dedicated block with an external chunk. External chunks don't use 3) or 4). David
David Rowley <dgrowleyml@gmail.com> writes:
> On Wed, 10 Aug 2022 at 09:23, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Hmm, I suppose you mean we could reduce 4) if we needed to. Yeah, that
>> seems like a reasonable place to buy more bits later if we run out of
>> MemoryContextMethodIDs. Should be fine then.
> I think he means 3). If 4) was reduced then that would further reduce
> the maxBlockSize we could pass when creating a context. At least for
> aset.c and generation.c, we don't really need 3) to be 30-bits wide as
> the set->allocChunkLimit is almost certainly much smaller than that.
Oh, I see: we'd just be further constraining the size of chunk that
has to be pushed out as an "external" chunk. Got it.
regards, tom lane
Thanks for giving this a look. On Wed, 10 Aug 2022 at 02:37, Robert Haas <robertmhaas@gmail.com> wrote: > # We also add a restriction that block sizes for all 3 of the memory > # allocators cannot be 1GB or larger. We would be unable to store the > # number of bytes that the block is offset from the chunk stored beyond this > #1GB boundary on any block that was larger than 1GB. > > Earlier in the commit message, you say that allocations of 1GB or more > are stored in dedicated blocks. But here you say that blocks can't be > more than 1GB. Those statements seem to contradict each other. I guess > you mean block sizes for blocks that contain chunks, or something like > that? I'll update that so it's more clear. But, just to clarify here first, the 1GB restriction is just in regards to the maxBlockSize parameter when creating a context. Anything over set->allocChunkLimit goes on a dedicated block and there is no 1GB size restriction on those dedicated blocks. David
On Wed, 10 Aug 2022 at 06:44, Andres Freund <andres@anarazel.de> wrote:
> I think it's fine, given that we can change this at any time, but it's
> probably worth to explicitly agree that this will for now restrict us to 8
> context methods?
I know there was some discussion about this elsewhere in this thread
about 8 possibly not being enough, but that seems to have concluded
with we'll just make more space if we ever need to.
To make that easier, I've adapted the code in memutils_memorychunk.h
to separate out the max values for the block offset from the max value
for the chunk size. The chunk size is the one we'd likely want to
lower if we ever needed more bits. I think this also helps document
the maxBlockSize limitations in aset.c and generation.c.
> > +/*
> > + * MemoryContextMethodID
> > + * A unique identifier for each MemoryContext implementation which
> > + * indicates the index into the mcxt_methods[] array. See mcxt.c.
> > + */
> > +typedef enum MemoryContextMethodID
> > +{
> > + MCTX_ASET_ID = 0,
>
> Is there a reason to reserve 0 here? Practically speaking the 8-byte header
> will always contain not just zeroes, but I don't think the patch currently
> enforces that. It's probably not worth wasting a "valuable" entry here...
The code was just being explicit about that being set to 0. I'm not
really sure I see this as reserving 0. I've removed the = 0 anyway
since it wasn't really doing anything useful.
> > + * Although MemoryChunks are used by each of our MemoryContexts, other
> > + * implementations may choose to implement their own method for storing chunk
> Well, there can't be other implementations other than ours. So maybe phrase it
> as "future implementations"?
Yeah, that seems better.
> > + * 1. 3-bits to indicate the MemoryContextMethodID
> > + * 2. 1-bit to indicate if the chunk is externally managed (see below)
> > + * 3. 30-bits for the amount of memory which was reserved for the chunk
> > + * 4. 30-bits for the number of bytes that must be subtracted from the chunk
> > + * to obtain the address of the block that the chunk is stored on.
> Hm. So really only the first four bits have eactly that layout, correct?
> Perhaps that could be clarified somehow?
I've clarified that #3 and #4 are unused in external chunks.
> > +#define MEMORYCHUNK_EXTERNAL_BIT (1 << 3)
>
> We should probably have a define for the three bits reserved for the context
> id, likely in _internal.h
I've added both MEMORY_CONTEXT_METHODID_BITS and
MEMORY_CONTEXT_METHODID_MASK and tidied up the defines in
memutils_memorychunk.h so that they'll follow on from whatever
MEMORY_CONTEXT_METHODID_BITS is set to.
> > +typedef struct AllocFreelistLink
> > +{
> > + MemoryChunk *next;
> > +} AllocFreelistLink;
>
> I know we have no agreement on that, but I personally would add
> AllocFreelistLink to typedefs.list and then re-pgindent ;)
I tend to leave that up to the build farm to generate. I really wasn't
sure which should sort first out of the following:
MemoryContextMethods
MemoryContextMethodID
The correct answer depends on if the sort is case-sensitive or not. I
imagine it is since it is in C, but don't really know if the buildfarm
will generate the same.
I've added them in the above order now.
> Hm. We don't mark the chunk header as noaccess anymore? If so, why? I realize
> it'd be a bit annoying because there's plenty places that look at it, but I
> think it's also a good way to catch errors.
I don't think I've really changed anything here. If I understand
correctly the pointer to the MemoryContext was not marked as NOACCESS
before. I guessed that's because it's accessed outside of aset.c. I've
kept that due to how the 3 lower bits are still accessed outside of
aset.c. It's just that we're stuffing more information into that
8-byte variable now.
> > +static const MemoryContextMethods mcxt_methods[] = {
...
> Mildly wondering whether we ought to use designated initializers instead,
> given we're whacking it around already. Too easy to get the order wrong when
> adding new members, and we might want to have optional callbacks too.
I've adjusted how this array is initialized now.
I've attached version 3 of the patch.
Thanks for having a look at this.
David
Attachment
I've spent a bit more time hacking on this patch. Changes: 1. Changed GetFreeListLink() so that it stores the AllocFreelistLink at the end of the chunk rather than at the start. 2. Made it so MemoryChunk stores a magic number in the spare 60 bits of the hdrmask when the chunk is "external". This is always set but only verified in assert builds. 3. In aset.c, I'm no longer storing the chunk_size in the hdrmask. I'm now instead storing the freelist index. I'll explain this below. 4. Various other cleanups. For #3, I was doing some benchmarking of the patch with a function I wrote to heavily exercise palloc() and pfree(). When this function is called to only allocate a small amount of memory at once, I saw a small regression in the palloc() / pfree() performance for aset.c. On looking at profiles, I saw that the code in AllocSetFreeIndex() was standing out AllocSetFree(). That function uses the __builtin_clz() intrinsic function which I see on x86-64 uses the "bsr" instruction. Going by page 104 of [1], it tells me the latency of that instruction is 4 for my Zen 2 CPU. I'm not yet sure why the v3 patch appeared slower than master for this workload. To make AllocSetFree() faster, I've now changed things so that instead of storing the chunk size in the hdrmask of the MemoryChunk, I'm now just storing the freelist index. The chunk size is always a power of 2 for non-external chunks. It's very cheap to obtain the chunk size from the freelist index when we need to. That's just a "sal" or "shl" instruction, effectively 8 << freelist_idx, both of which have a latency of 1. This means that AllocSetFreeIndex() is only called in AllocSetAlloc now. This changes the performance as follows: Master: postgres=# select pg_allocate_memory_test(64, 1024, 20::bigint*1024*1024*1024, 'aset'); Time: 2524.438 ms (00:02.524) Old patch (v3): postgres=# select pg_allocate_memory_test(64, 1024, 20::bigint*1024*1024*1024, 'aset'); Time: 2646.438 ms (00:02.646) New patch (v4): postgres=# select pg_allocate_memory_test(64, 1024, 20::bigint*1024*1024*1024, 'aset'); Time: 2296.228 ms (00:02.296) (about ~10% faster than master) This function is allocating 64-byte chunks and keeping 1k of them around at once, but allocating a total of 20GBs of them. I've attached another patch with that function in it for anyone who wants to check the performance. I also tried another round of the pgbench -S workload that I ran upthread [2] on the v2 patch. Confusingly, even when testing on 0b039e3a8 as I was last week, I'm unable to see that same 10% performance increase. Does anyone else want to have a go at taking v4 for a spin to see how it performs? David [1] https://www.agner.org/optimize/instruction_tables.pdf [2] https://www.postgresql.org/message-id/CAApHDvrrYfcCXfuc_bZ0xsqBP8U62Y0i27agr9Qt-2geE_rv0Q@mail.gmail.com
Attachment
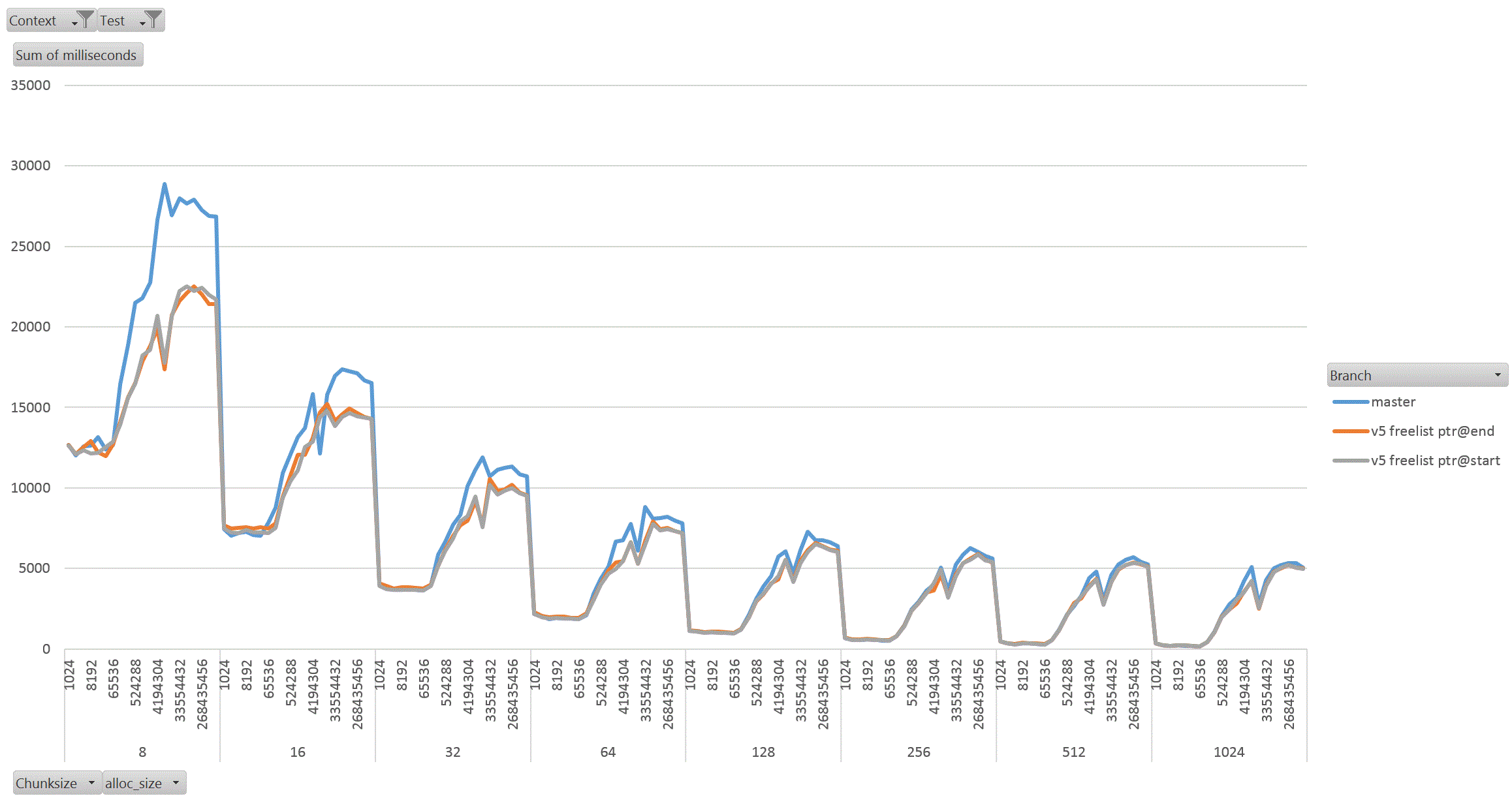
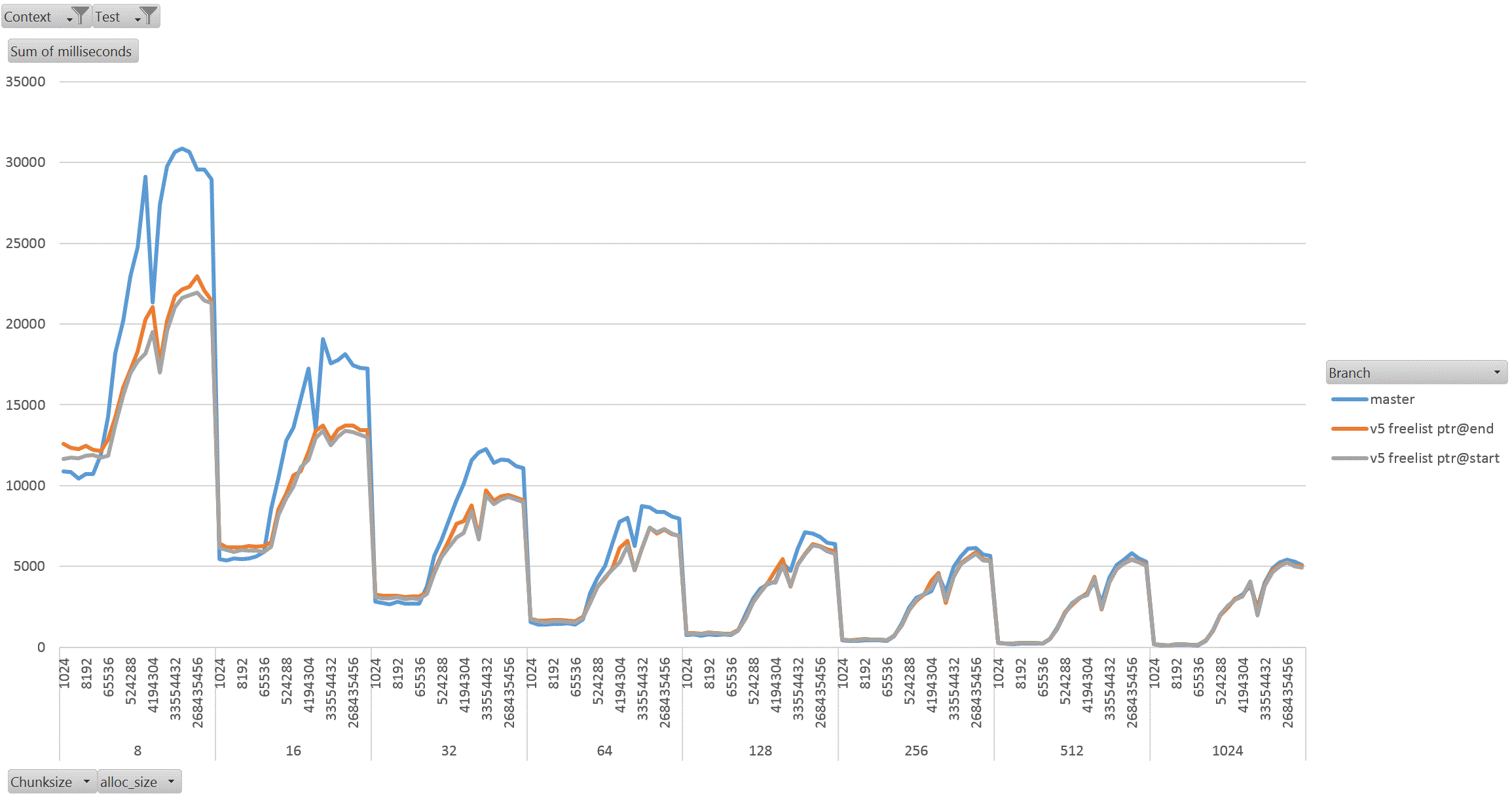
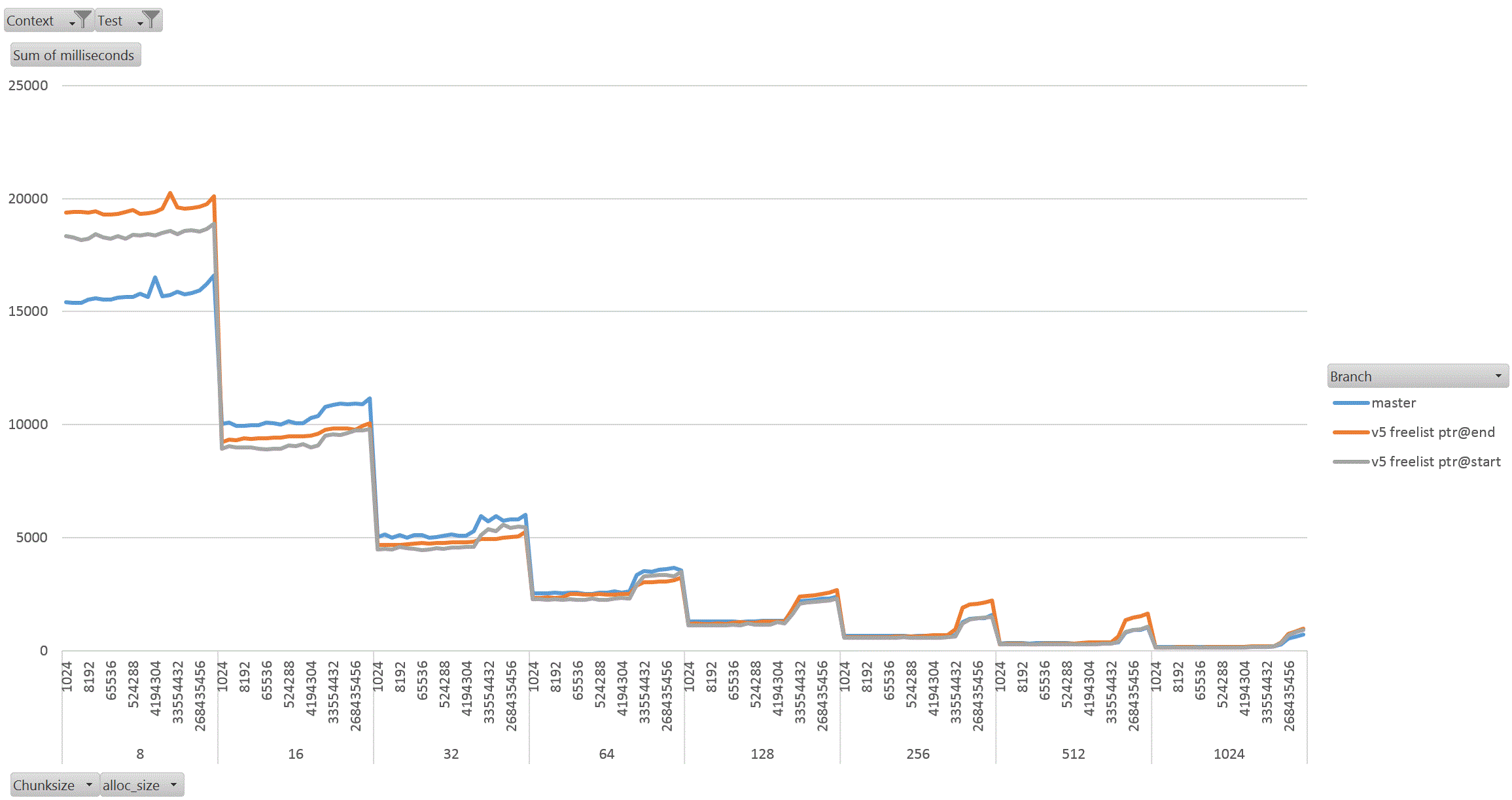
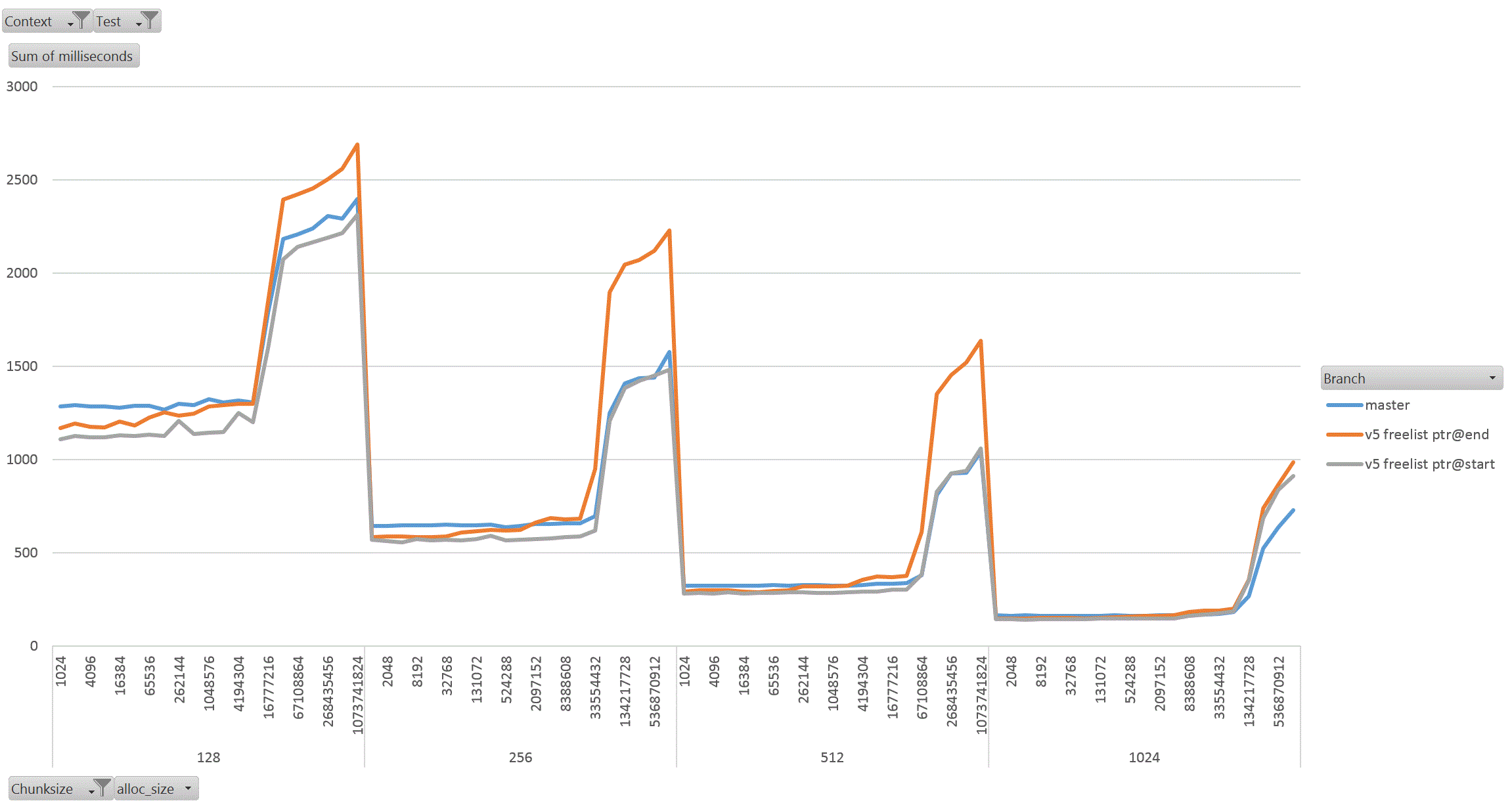
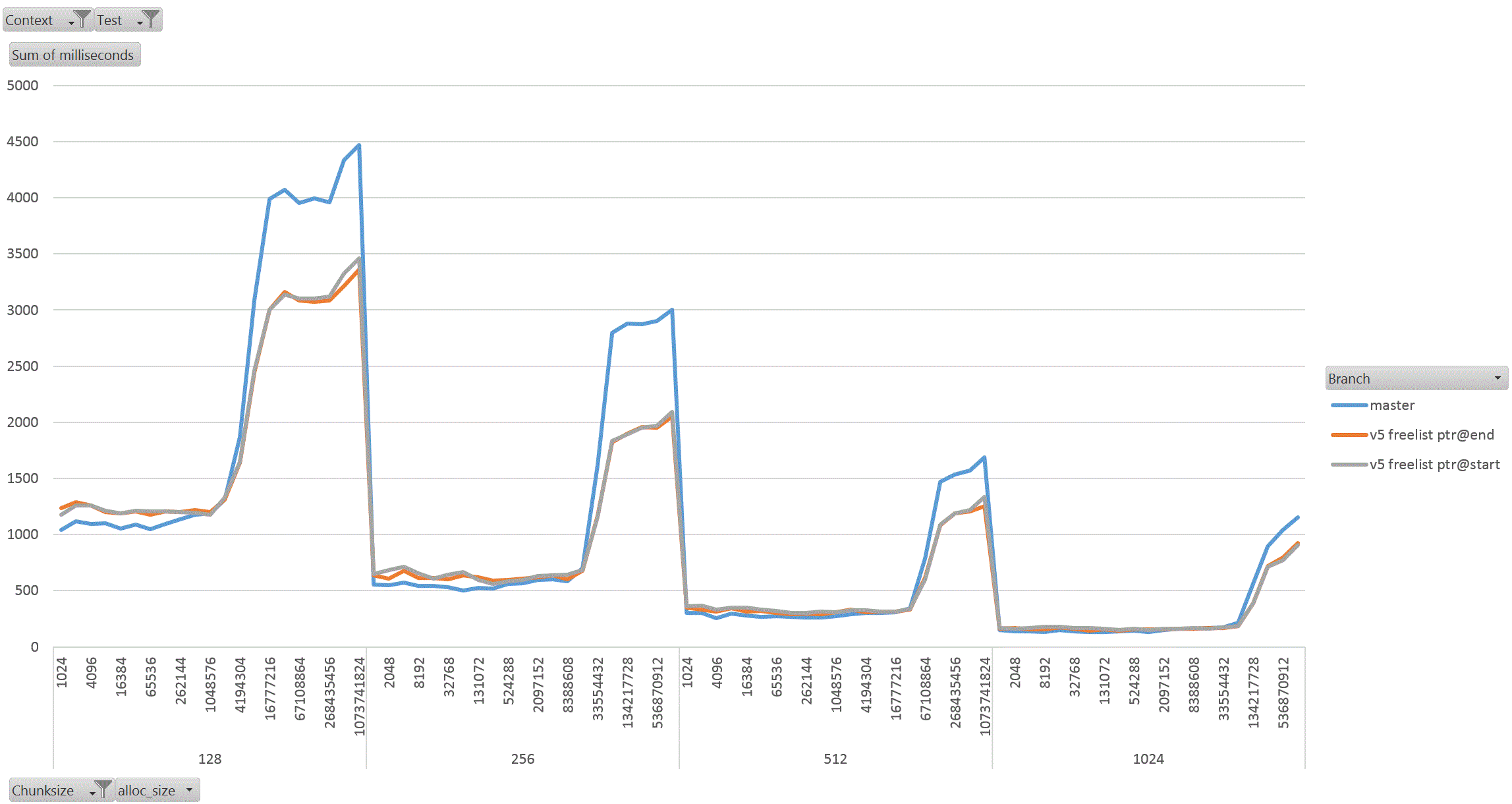
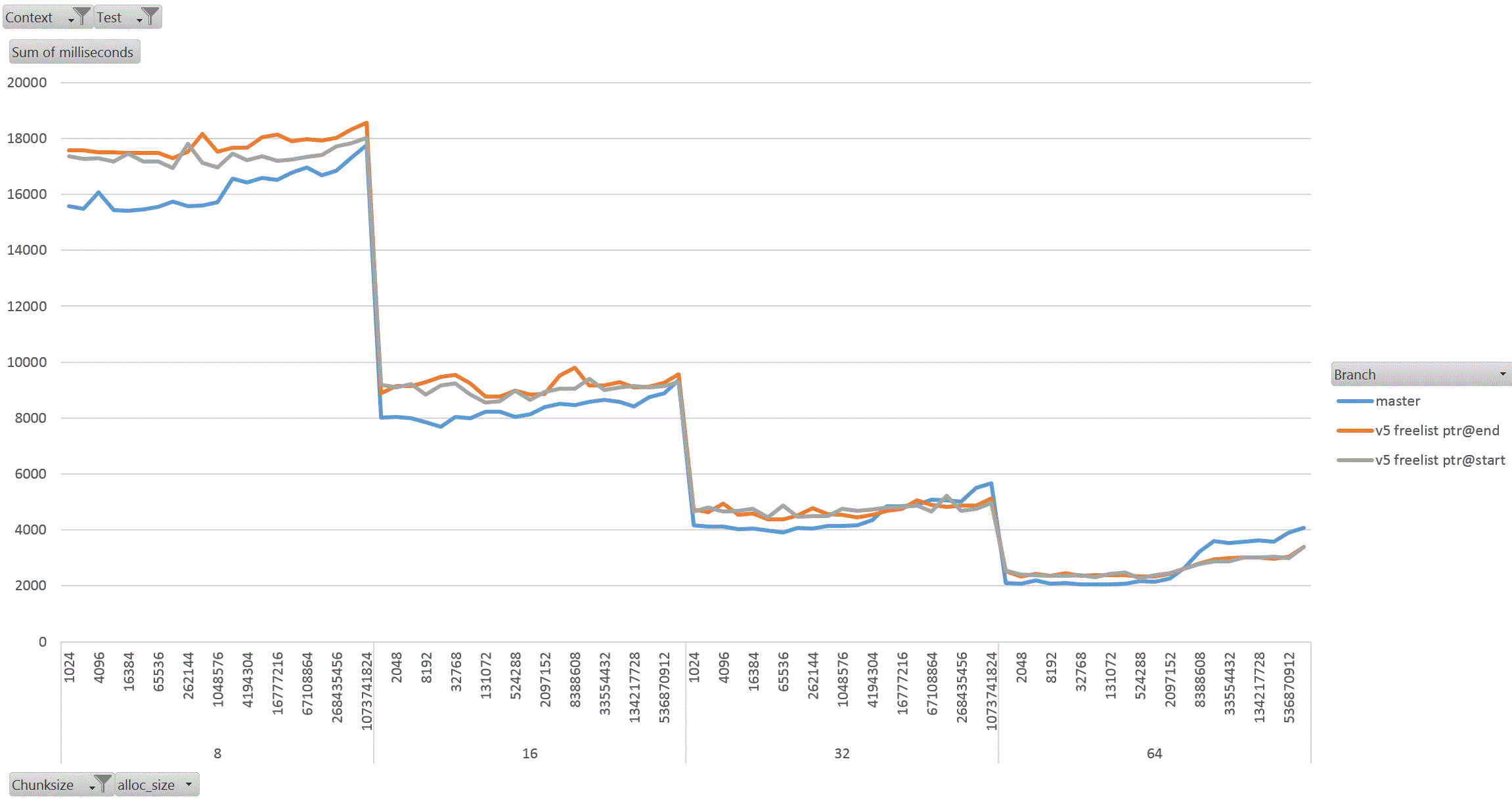
On Thu, 18 Aug 2022 at 01:58, David Rowley <dgrowleyml@gmail.com> wrote: > Does anyone else want to have a go at taking v4 for a spin to see how > it performs? I've been working on this patch again. The v4 patch didn't quite get the palloc(0) behaviour correct. There were no actual bugs in non-MEMORY_CONTEXT_CHECKING builds. It was just my detection method for free'd chunks in AllocSetCheck and GenerationCheck that was broken. In the free function, I'd been setting the requested_size back to 0 to indicate a free'd chunk. Unfortunately that was getting confused with palloc(0) chunks during the checks. The solution to that was to add: #define InvalidAllocSize SIZE_MAX to memutils.h and set free'd chunk's requested_size to that value. That seems fine, because: #define MaxAllocHugeSize (SIZE_MAX / 2) After fixing that I moved on and did some quite extensive benchmarking of the patch. I've learned quite a few things from this, namely: a) putting the freelist pointer at the end of the chunk costs us in performance. b) the patch makes GenerationFree() slower than it is in master. I believe a) is due to the chunk header and the freelist pointer being on different cache lines when the chunk becomes larger. This means having to load more cache lines resulting in slower performance. For b), I'm not sure the reason for this. I wondered if it is due to how the pointer to the MemoryContext is obtained in GenerationFree(). We first look at the MemoryChunk to find the block offset, then get the address of the block from that, we then must dereference the block->context pointer to get the owning MemoryContext. Previously we just looked at the GenerationChunk's context field. Due to a), I decided to benchmark the patch twice, once with the freelist pointer at the end of the chunk (as it was in v4 patch), and again with the pointer at the start of the chunk. For b), I looked again at GenerationFree() and saw that I really only need to look at the owning context when the block is to be freed. The vast majority of calls won't need to do that. Unfortunately moving the "set = block->context;" to just after we've checked if the block needs to be freed did not improve things. I've not run the complete benchmark again to make sure though, only a single data point of it. Benchmarking: I did this benchmarking on an AMD 3990x machine which has 64GB of RAM installed. The tests I performed entirely used two SQL functions that I've written especially for exercising palloc() and pfree(). To allow me to run the tests I wanted to, I wrote the following functions: 1. pg_allocate_memory_test(): Accepts an allocation size parameter (chunk_size), an amount of memory to keep palloc'd at once. Once this amount is reached we'll start pfreeing 1 chunk for every newly allocated chunk. Another parameter controls the total amount of allocations. We'll do this number / chunk_size allocations in total. The final parameter specifies the memory context type to use; aset, generation, etc. The intention of this function is to see if palloc/pfree has become faster or slower and also see how the reduction in the chunk header size affects performance when the amount of memory being allocated at once starts to get big. I'm expecting better CPU cache hit ratios due to the memory reductions. 2. pg_allocate_memory_test_reset(). Since we mostly don't do pfree(), function #1 might not be that accurate a test. Mostly we palloc() then MemoryContextReset(). Tests: I ran both of the above functions starting with a chunk size of 8 and doubled that each time up to 1024. I tested both aset.c and generation.c context types. In order to check how performance is affected by allocating more memory at once, I started the total concurrent memory allocation at 1k and doubled each time to 1GB. 3 branches tested; master, patch (with freelist at end of chunk) and patch (with freelist at start of chunk). So, 2 memory context types, 8 chunk sizes, 21 concurrent allocation sizes, 2 functions, 3 * 2 * 8 * 21 * 2 = 2016 data points. I ran each test for 30 seconds in pgbench. I used 20GBs as the total amount of memory to allocate. The results: The patch with freelist pointers at the start of the chunk seems a clear winner in the pg_allocate_memory_test_reset() test for both aset (graph1.gif) and generation (graph2.gif). There are a few data points where the times come out slower than master, but not by much. I suspect this might be noise, but didn't investigate. For function #1, pg_allocate_memory_test(), the performance is pretty complex. For aset, the performance is mostly better with the freelist start version of the patch. There is an exception to this with the 8 byte chunk size where performance comes out worse than master. That flips around with the 16 byte chunk test and becomes better overall. Ignoring the 8 byte chunk, the remaining performance is faster than master. This shows that having the freelist pointer at the start of the free'd chunk is best (graph3.gif) (graph4.gif better shows this for the larger chunks). With the generation context, it's complex. The more memory we allocate at once, the better performance generally gets (especially for larger chunks). I wondered if this might be due to the reduction in the chunk header size, but I'm really not sure as I'd have expected the most gains to appear in small chunks if that was the case as the header is a larger proportion of the total allocation size for those. Weirdly the opposite is true, larger chunks are showing better gains in the patched version when compared to the same data point in the unpatched master branch. graph5.gif shows this for the smaller chunks and graph6.gif for the larger ones In summary, I'm not too concerned that GenerationFree() is a small amount slower. I think the other gains are significant enough to make up for this. We could probably modify dumptuples() so that WRITETUP() does not call pfree() just before we do MemoryContextReset(state->base.tuplecontext). Those pfree calls are a complete waste of effort, although we *can't* unconditionally remove that pfree() call in WRITETUP(). I've attached the full results in bench_results.sql. If anyone else wants to repeat these tests then I've attached pg_allocate_memory_test.sh.txt and allocate_performance_functions.patch.txt with the 2 new SQL functions I used to test with. Finally, the v5 patch with the fixes mentioned above. Also, I'm leaning towards wanting to put the freelist pointer at the start of the chunk's memory rather than at the end. I understand that code which actually does something with the allocated memory is more likely to have loaded the useful cache lines already and that's not something my benchmark would have done, but for larger chunks the power of 2 wastage is likely to mean that many of those cache lines nearing the end of the chunk would never have to be loaded at all. I'm pretty keen to get this patch committed early next week. This is quite core infrastructure, so it would be good if the patch gets a few extra eyeballs on it before then. David
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
On Tue, 23 Aug 2022 at 21:03, David Rowley <dgrowleyml@gmail.com> wrote: > Finally, the v5 patch with the fixes mentioned above. The CFbot just alerted me to the cplusplus check was failing with the v5 patch, so here's v6. > I'm pretty keen to get this patch committed early next week. This is > quite core infrastructure, so it would be good if the patch gets a few > extra eyeballs on it before then. That'll probably be New Zealand Monday, unless objects before then. David
Attachment
On Fri, 26 Aug 2022 at 17:16, David Rowley <dgrowleyml@gmail.com> wrote: > The CFbot just alerted me to the cplusplus check was failing with the > v5 patch, so here's v6. I'll try that one again... David
Attachment
On Sun, 28 Aug 2022 at 23:04, David Rowley <dgrowleyml@gmail.com> wrote: > I'll try that one again... One more try to make CFbot happy. David
Attachment
On Mon, 29 Aug 2022 at 10:39, David Rowley <dgrowleyml@gmail.com> wrote: > One more try to make CFbot happy. After a bit more revision, mostly updating outdated comments and naming adjustments, I've pushed this. Per the benchmark results I showed in [1], due to the performance of having the AllocSet free list pointers stored at the end of the allocated chunk being quite a bit slower than having them at the start of the chunk, I adjusted the patch to have them at the start. Time for me to go and watch the buildfarm results come in. David [1] https://postgr.es/m/CAApHDvpuhcPWCzkXZuQQgB8YjPNQSvnncbzZ6pwpHFr2QMMD2w@mail.gmail.com
On Mon, Aug 29, 2022 at 10:57 AM David Rowley <dgrowleyml@gmail.com> wrote:
>
> After a bit more revision, mostly updating outdated comments and
> naming adjustments, I've pushed this.
>
> Per the benchmark results I showed in [1], due to the performance of
> having the AllocSet free list pointers stored at the end of the
> allocated chunk being quite a bit slower than having them at the start
> of the chunk, I adjusted the patch to have them at the start.
>
> Time for me to go and watch the buildfarm results come in.
>
There is a BF failure with a callstack:
2022-08-29 03:29:56.911 EDT [1056:67] pg_regress/ddl STATEMENT:
SELECT data FROM pg_logical_slot_get_changes('regression_slot', NULL,
NULL, 'include-xids', '0', 'skip-empty-xacts', '1');
TRAP: FailedAssertion("pointer == (void *) MAXALIGN(pointer)", File:
"../../../../src/include/utils/memutils_internal.h", Line: 120, PID:
1056)
0x1e6f71c <ExceptionalCondition+0x9c> at postgres
0x1ea8494 <MemoryContextAllowInCriticalSection.part.0> at postgres
0x1ea9ee8 <repalloc> at postgres
0x1c56dc4 <ReorderBufferCleanupTXN+0xbc> at postgres
0x1c58a1c <ReorderBufferProcessTXN+0x1980> at postgres
0x1c44c5c <xact_decode+0x46c> at postgres
0x1c445f0 <LogicalDecodingProcessRecord+0x98> at postgres
0x1c4b578 <pg_logical_slot_get_changes_guts+0x318> at postgres
0x1ad69ec <ExecMakeTableFunctionResult+0x268> at postgres
0x1aedc88 <FunctionNext+0x3a0> at postgres
0x1ad7808 <ExecScan+0x100> at postgres
0x1acaaa0 <standard_ExecutorRun+0x158> at postgres
0x1ceac3c <PortalRunSelect+0x2d0> at postgres
0x1cec8ec <PortalRun+0x16c> at postgres
0x1ce7b30 <exec_simple_query+0x3a4> at postgres
0x1ce96ec <PostgresMain+0x1720> at postgres
0x1c2c784 <PostmasterMain+0x1a3c> at postgres
0x1ee6a1c <main+0x248> at postgres
I am not completely sure if the failure is due to your commit but it
was showing the line added by this commit. Note that I had also
committed (commit id: d2169c9985) one patch today but couldn't
correlate the failure with that so thought of checking with you. There
are other similar failures[2][3] as well but [1] shows the stack
trace. Any idea?
[1] - https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=mamba&dt=2022-08-29%2005%3A53%3A57
[2] - https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=grison&dt=2022-08-29%2008%3A13%3A09
[3] - https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=skate&dt=2022-08-29%2006%3A13%3A24
--
With Regards,
Amit Kapila.
On Mon, 29 Aug 2022 at 21:37, Amit Kapila <amit.kapila16@gmail.com> wrote: > I am not completely sure if the failure is due to your commit but it > was showing the line added by this commit. Note that I had also > committed (commit id: d2169c9985) one patch today but couldn't > correlate the failure with that so thought of checking with you. There > are other similar failures[2][3] as well but [1] shows the stack > trace. Any idea? I'm currently suspecting that I broke it. I'm thinking it was just an unfortunate coincidence that you made some changes to test_decoding shortly before. I'm currently seeing it I can recreate this on a Raspberry PI. David > [1] - https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=mamba&dt=2022-08-29%2005%3A53%3A57 > [2] - https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=grison&dt=2022-08-29%2008%3A13%3A09 > [3] - https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=skate&dt=2022-08-29%2006%3A13%3A24
On Mon, 29 Aug 2022 at 21:37, Amit Kapila <amit.kapila16@gmail.com> wrote:
> 2022-08-29 03:29:56.911 EDT [1056:67] pg_regress/ddl STATEMENT:
> SELECT data FROM pg_logical_slot_get_changes('regression_slot', NULL,
> NULL, 'include-xids', '0', 'skip-empty-xacts', '1');
> TRAP: FailedAssertion("pointer == (void *) MAXALIGN(pointer)", File:
> "../../../../src/include/utils/memutils_internal.h", Line: 120, PID:
> 1056)
I suspect, going by all 3 failing animals being 32-bit which have a
MAXIMUM_ALIGNOF 8 and SIZEOF_SIZE_T of 4 that this is due to the lack
of padding in the MemoryChunk struct.
AllocChunkData and GenerationChunk had padding to account for
sizeof(Size) being 4 and sizeof(void *) being 8, I didn't add that to
MemoryChunk, so I'll do that now.
David
David Rowley <dgrowleyml@gmail.com> writes:
> I suspect, going by all 3 failing animals being 32-bit which have a
> MAXIMUM_ALIGNOF 8 and SIZEOF_SIZE_T of 4 that this is due to the lack
> of padding in the MemoryChunk struct.
> AllocChunkData and GenerationChunk had padding to account for
> sizeof(Size) being 4 and sizeof(void *) being 8, I didn't add that to
> MemoryChunk, so I'll do that now.
Doesn't seem to have fixed it. IMO, the fact that we can get through
core regression tests and pg_upgrade is a strong indicator that
there's not anything fundamentally wrong with memory context
management. I'm inclined to think the problem is in d2169c9985,
instead ... though I can't see anything wrong with it.
Another possibility is that there's a pre-existing bug in the
logical decoding stuff that your changes accidentally exposed.
I wonder if valgrind would show anything interesting.
regards, tom lane
On Mon, Aug 29, 2022 at 7:17 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > I suspect, going by all 3 failing animals being 32-bit which have a > > MAXIMUM_ALIGNOF 8 and SIZEOF_SIZE_T of 4 that this is due to the lack > > of padding in the MemoryChunk struct. > > AllocChunkData and GenerationChunk had padding to account for > > sizeof(Size) being 4 and sizeof(void *) being 8, I didn't add that to > > MemoryChunk, so I'll do that now. > > Doesn't seem to have fixed it. IMO, the fact that we can get through > core regression tests and pg_upgrade is a strong indicator that > there's not anything fundamentally wrong with memory context > management. I'm inclined to think the problem is in d2169c9985, > instead ... though I can't see anything wrong with it. > Yeah, I also thought that way but couldn't find a reason. I think if David is able to reproduce it on one of his systems then he can try locally reverting both the commits one by one. > Another possibility is that there's a pre-existing bug in the > logical decoding stuff that your changes accidentally exposed. > Yeah, this is another possibility. -- With Regards, Amit Kapila.
On 8/29/22 16:02, Amit Kapila wrote:
> On Mon, Aug 29, 2022 at 7:17 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>>
>> David Rowley <dgrowleyml@gmail.com> writes:
>>> I suspect, going by all 3 failing animals being 32-bit which have a
>>> MAXIMUM_ALIGNOF 8 and SIZEOF_SIZE_T of 4 that this is due to the lack
>>> of padding in the MemoryChunk struct.
>>> AllocChunkData and GenerationChunk had padding to account for
>>> sizeof(Size) being 4 and sizeof(void *) being 8, I didn't add that to
>>> MemoryChunk, so I'll do that now.
>>
>> Doesn't seem to have fixed it. IMO, the fact that we can get through
>> core regression tests and pg_upgrade is a strong indicator that
>> there's not anything fundamentally wrong with memory context
>> management. I'm inclined to think the problem is in d2169c9985,
>> instead ... though I can't see anything wrong with it.
>>
>
> Yeah, I also thought that way but couldn't find a reason. I think if
> David is able to reproduce it on one of his systems then he can try
> locally reverting both the commits one by one.
>
I can reproduce it on my system (rpi4 running 32-bit raspbian). I can't
grant access very easily at the moment, so I'll continue investigating
do more debugging on perhaps I can grant access to the system.
So far all I know is that it doesn't happen on d2169c9985 (so ~5 commits
back), and then it starts failing on c6e0fe1f2a. The extra padding added
by df0f4feef8 makes no difference, because the struct looked like this:
struct MemoryChunk {
Size requested_size; /* 0 4 */
/* XXX 4 bytes hole, try to pack */
uint64 hdrmask; /* 8 8 */
/* size: 16, cachelines: 1, members: 2 */
/* sum members: 12, holes: 1, sum holes: 4 */
/* last cacheline: 16 bytes */
};
and the padding makes it look like this:
struct MemoryChunk {
Size requested_size; /* 0 4 */
char padding[4]; /* 4 8 */
uint64 hdrmask; /* 8 8 */
/* size: 16, cachelines: 1, members: 2 */
/* sum members: 12, holes: 1, sum holes: 4 */
/* last cacheline: 16 bytes */
};
so it makes no difference.
I did look at the pointers in GetMemoryChunkMethodID, and it looks like
this (p1 is result of MAXALIGN(pointer):
(gdb) p pointer
$1 = (void *) 0x1ca1d2c
(gdb) p p1
$2 = 0x1ca1d30 ""
(gdb) p p1 - pointer
$3 = 4
(gdb) p (long int) pointer
$4 = 30022956
(gdb) p (long int) p1
$5 = 30022960
(gdb) p 30022956 % 8
$6 = 4
So the input pointer is not actually aligned to MAXIMUM_ALIGNOF (8B),
but only to 4B. That seems a bit strange.
>> Another possibility is that there's a pre-existing bug in the
>> logical decoding stuff that your changes accidentally exposed.
>>
>
> Yeah, this is another possibility.
No idea.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Amit Kapila <amit.kapila16@gmail.com> writes:
> Yeah, I also thought that way but couldn't find a reason. I think if
> David is able to reproduce it on one of his systems then he can try
> locally reverting both the commits one by one.
It seems to repro easily on any 32-bit platform. Aside from the
buildfarm results, I've now duplicated it on 32-bit ARM (which
eliminates the possibility that it's big-endian specific).
"bt full" from the first crash gives
#0 0xb6d7126c in raise () from /lib/libc.so.6
No symbol table info available.
#1 0xb6d5c360 in abort () from /lib/libc.so.6
No symbol table info available.
#2 0x00572430 in ExceptionalCondition (
conditionName=conditionName@entry=0x745110 "pointer == (void *) MAXALIGN(pointer)",
errorType=errorType@entry=0x5d18d0"FailedAssertion",
fileName=fileName@entry=0x7450dc "../../../../src/include/utils/memutils_internal.h",
lineNumber=lineNumber@entry=120)at assert.c:69
No locals.
#3 0x005a0d90 in GetMemoryChunkMethodID (pointer=<optimized out>)
at ../../../../src/include/utils/memutils_internal.h:120
header = <optimized out>
#4 0x005a231c in GetMemoryChunkMethodID (pointer=<optimized out>)
at ../../../../src/include/utils/memutils_internal.h:119
header = <optimized out>
header = <optimized out>
#5 pfree (pointer=<optimized out>) at mcxt.c:1242
No locals.
#6 0x003c8fdc in ReorderBufferCleanupTXN (rb=0x7450dc, rb@entry=0x1f,
txn=0x745110, txn@entry=0xe1f800) at reorderbuffer.c:1493
change = <optimized out>
found = false
iter = {cur = <optimized out>, next = 0xddcb18, end = 0xde4e64}
#7 0x003ca968 in ReorderBufferProcessTXN (rb=0x1f, rb@entry=0xe1f800,
txn=0xe1f800, commit_lsn=<optimized out>, snapshot_now=<optimized out>,
command_id=<optimized out>, streaming=false) at reorderbuffer.c:2514
change = 0x0
_save_exception_stack = 0x0
_save_context_stack = 0x1
_local_sigjmp_buf = {{__jmpbuf = {-552117431, 1640676937, -1092521468,
14569068, 14569068, 14568932, 729, 0, 228514434, 166497, 0,
8195960, 8196088, 7, 0 <repeats 13 times>, 13847224, 0, 196628,
0, 1844909312, 5178548, -1092520644, 13979392, 13979388,
14801472, 0, 8195960, 8196088, 7, 0, 8108342, 8108468, 1,
715827883, -1030792151, 0, 8195960, 729, 7, 0, 14809088,
14809088, 14542436, 0, 26303888, 0, 14568932, 3978796, 156, 0,
1, 0}, __mask_was_saved = 0, __saved_mask = {__val = {64,
7242472, 14740696, 7244624, 14809088, 14741512, 5, 14740696,
7244624, 7245864, 3982844, 14542436, 0, 14809092, 0, 26303888,
729, 14569112, 14809092, 7242472, 729, 14741512, 32, 14809088,
0, 228514434, 166497, 0, 0, 26303888, 3980968, 0}}}}
_do_rethrow = <optimized out>
using_subtxn = 228
ccxt = 0x7aae68 <my_wait_event_info>
iterstate = 0x0
prev_lsn = 26303888
specinsert = 0x0
stream_started = false
curtxn = 0x0
__func__ = "ReorderBufferProcessTXN"
#8 0x003cb460 in ReorderBufferReplay (txn=<optimized out>,
rb=rb@entry=0xe1f800, commit_lsn=<optimized out>, end_lsn=<optimized out>,
commit_time=715099169882112, origin_id=0, origin_lsn=0, xid=729)
at reorderbuffer.c:2641
snapshot_now = <optimized out>
#9 0x003cbedc in ReorderBufferCommit (rb=rb@entry=0xe1f800,
xid=xid@entry=729, commit_lsn=<optimized out>, end_lsn=<optimized out>,
commit_time=<optimized out>, commit_time@entry=715099398396546,
origin_id=<optimized out>, origin_id@entry=0, origin_lsn=0,
origin_lsn@entry=5906902891454464) at reorderbuffer.c:2665
txn = <optimized out>
#10 0x003bb19c in DecodeCommit (two_phase=false, xid=729, parsed=0xbee17478,
buf=<optimized out>, ctx=0xe1d7f8) at decode.c:682
origin_lsn = <optimized out>
commit_time = <optimized out>
origin_id = 0
i = <optimized out>
origin_lsn = <optimized out>
commit_time = <optimized out>
origin_id = <optimized out>
i = <optimized out>
#11 xact_decode (ctx=0xe1d7f8, buf=<optimized out>) at decode.c:216
xlrec = <optimized out>
parsed = {xact_time = 715099398396546, xinfo = 73, dbId = 16384,
tsId = 1663, nsubxacts = 0, subxacts = 0x0, nrels = 0,
xlocators = 0x0, nstats = 0, stats = 0x0, nmsgs = 70,
msgs = 0xe2b828, twophase_xid = 0,
twophase_gid = '\000' <repeats 199 times>, nabortrels = 0,
abortlocators = 0x0, nabortstats = 0, abortstats = 0x0,
origin_lsn = 0, origin_timestamp = 0}
xid = <optimized out>
two_phase = false
builder = <optimized out>
reorder = <optimized out>
r = <optimized out>
info = <optimized out>
__func__ = "xact_decode"
#12 0x003babf0 in LogicalDecodingProcessRecord (ctx=ctx@entry=0xe1d7f8,
record=0xe1dad0) at decode.c:119
buf = {origptr = 26303888, endptr = 26305088, record = 0xe1dad0}
txid = <optimized out>
rmgr = <optimized out>
#13 0x003c0390 in pg_logical_slot_get_changes_guts (fcinfo=0x0,
confirm=<optimized out>, binary=<optimized out>) at logicalfuncs.c:271
record = <optimized out>
errm = 0x0
_save_exception_stack = 0xd60380
_save_context_stack = 0x1
_local_sigjmp_buf = {{__jmpbuf = {-552117223, 1640638557, 4, 14770368,
-1092519792, -1, 14770320, 8, 1, 14691520, 0, 8195960, 8196088,
7, 0 <repeats 12 times>, 3398864, 0, 13849464, 13848680,
14650600, 3399100, 4, 3125412, 0, 144, 0, 0, 8192, 7616300, 0,
1576, 7616452, 14585296, 8192, 7616300, 14651128, 0, 0,
14651128, -1092519880, 3398864, 0, 13849464, 13848680, 3399100,
0, 5904972, 8112272, -1, 14591624, -1375937000, -1375937248,
14591376}, __mask_was_saved = 0, __saved_mask = {__val = {
14530312, 14528852, 2348328335, 14527224, 5699140, 3202447388,
4, 14527080, 5699156, 14530312, 5769228, 2918792552, 0, 0, 0,
14767888, 3067834868, 14591600, 13824008, 1023, 3068719720, 1,
184, 14589688, 14586024, 14587400, 14691504, 14586024,
14585752, 14586200, 2615480, 8112268}}}}
_do_rethrow = <optimized out>
name = 0xe16090
upto_lsn = 3933972
upto_nchanges = 14707744
rsinfo = <optimized out>
per_query_ctx = <optimized out>
oldcontext = 0xe06cc0
end_of_wal = 0
ctx = 0xe1d7f8
old_resowner = 0xd35568
arr = <optimized out>
ndim = <optimized out>
options = 0x0
p = 0xe02cb0
__func__ = "pg_logical_slot_get_changes_guts"
#14 0x00292864 in ExecMakeTableFunctionResult (setexpr=0xdea9b0,
econtext=0xde90a8, argContext=<optimized out>, expectedDesc=0x1,
randomAccess=false) at execSRF.c:234
result = 2590380
tupstore = 0x0
tupdesc = 0x0
funcrettype = 8040208
returnsTuple = <optimized out>
returnsSet = 32
fcinfo = 0xe02cb0
fcusage = {fs = 0x0, save_f_total_time = {tv_sec = 14592432,
tv_nsec = 7093408}, save_total = {tv_sec = 0, tv_nsec = 0},
f_start = {tv_sec = 14767936, tv_nsec = 14767940}}
rsinfo = {type = T_ReturnSetInfo, econtext = 0xde90a8,
expectedDesc = 0xdea7a0, allowedModes = 11,
returnMode = SFRM_Materialize, isDone = ExprSingleResult,
setResult = 0xe16548, setDesc = 0xe16338}
tmptup = {t_len = 3, t_self = {ip_blkid = {bi_hi = 0, bi_lo = 0},
ip_posid = 0}, t_tableOid = 0, t_data = 0x3}
callerContext = 0xdea7a0
first_time = true
__func__ = "ExecMakeTableFunctionResult"
... etc ...
Anything ring a bell?
regards, tom lane
Hi,
I've got another problem with this patch here on macOS:
ccache clang -Wall -Wmissing-prototypes -Wpointer-arith
-Wdeclaration-after-statement -Werror=vla
-Werror=unguarded-availability-new -Wendif-labels
-Wmissing-format-attribute -Wformat-security -fno-strict-aliasing
-fwrapv -Wno-unused-command-line-argument -g -O2 -Wall -Werror
-Wno-unknown-warning-option -fno-omit-frame-pointer
-I../../../../src/include -isysroot
/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk
-I/opt/local/include/libxml2 -I/opt/local/include -I/opt/local/include
-I/opt/local/include -c -o aset.o aset.c -MMD -MP -MF .deps/aset.Po
In file included from aset.c:52:
../../../../src/include/utils/memutils_memorychunk.h:170:18: error:
comparison of constant 7 with expression of type
'MemoryContextMethodID' (aka 'enum MemoryContextMethodID') is always
true [-Werror,-Wtautological-constant-out-of-range-compare]
Assert(methodid <= MEMORY_CONTEXT_METHODID_MASK);
~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
../../../../src/include/c.h:827:9: note: expanded from macro 'Assert'
if (!(condition)) \
^~~~~~~~~
In file included from aset.c:52:
../../../../src/include/utils/memutils_memorychunk.h:186:18: error:
comparison of constant 7 with expression of type
'MemoryContextMethodID' (aka 'enum MemoryContextMethodID') is always
true [-Werror,-Wtautological-constant-out-of-range-compare]
Assert(methodid <= MEMORY_CONTEXT_METHODID_MASK);
~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
../../../../src/include/c.h:827:9: note: expanded from macro 'Assert'
if (!(condition)) \
^~~~~~~~~
I'm not sure what to do about that, but every file that includes
memutils_memorychunk.h produces those warnings (which become errors
due to -Werror).
...Robert
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> I can reproduce it on my system (rpi4 running 32-bit raspbian).
Yeah, more or less same as what I'm testing on.
Seeing that the complaint is about pfree'ing a non-maxaligned
ReorderBufferChange pointer, I tried adding
diff --git a/src/backend/replication/logical/reorderbuffer.c b/src/backend/replication/logical/reorderbuffer.c
index 89cf9f9389..dfa9b6c9ee 100644
--- a/src/backend/replication/logical/reorderbuffer.c
+++ b/src/backend/replication/logical/reorderbuffer.c
@@ -472,6 +472,8 @@ ReorderBufferGetChange(ReorderBuffer *rb)
change = (ReorderBufferChange *)
MemoryContextAlloc(rb->change_context, sizeof(ReorderBufferChange));
+ Assert(change == (void *) MAXALIGN(change));
+
memset(change, 0, sizeof(ReorderBufferChange));
return change;
}
and this failed!
(gdb) f 3
#3 0x003cb888 in ReorderBufferGetChange (rb=0x24ed820) at reorderbuffer.c:475
475 Assert(change == (void *) MAXALIGN(change));
(gdb) p change
$1 = (ReorderBufferChange *) 0x24aaa14
So the bug is in fact in David's changes, and it consists in palloc
sometimes handing back non-maxaligned pointers. I find it mildly
astonishing that we managed to get through core regression tests
without such a fault surfacing, but there you have it.
This machine has MAXALIGN 8 but 4-byte pointers, so there's something
wrong with that situation.
regards, tom lane
I wrote:
> So the bug is in fact in David's changes, and it consists in palloc
> sometimes handing back non-maxaligned pointers. I find it mildly
> astonishing that we managed to get through core regression tests
> without such a fault surfacing, but there you have it.
Oh! I just noticed that the troublesome context (rb->change_context)
is a SlabContext, so it may be that this only happens in non-aset
contexts. It's a lot easier to believe that the core tests never
exercise the case of pfree'ing a slab chunk.
regards, tom lane
On 8/29/22 17:20, Tom Lane wrote:
> Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
>> I can reproduce it on my system (rpi4 running 32-bit raspbian).
>
> Yeah, more or less same as what I'm testing on.
>
> Seeing that the complaint is about pfree'ing a non-maxaligned
> ReorderBufferChange pointer, I tried adding
>
> diff --git a/src/backend/replication/logical/reorderbuffer.c b/src/backend/replication/logical/reorderbuffer.c
> index 89cf9f9389..dfa9b6c9ee 100644
> --- a/src/backend/replication/logical/reorderbuffer.c
> +++ b/src/backend/replication/logical/reorderbuffer.c
> @@ -472,6 +472,8 @@ ReorderBufferGetChange(ReorderBuffer *rb)
> change = (ReorderBufferChange *)
> MemoryContextAlloc(rb->change_context, sizeof(ReorderBufferChange));
>
> + Assert(change == (void *) MAXALIGN(change));
> +
> memset(change, 0, sizeof(ReorderBufferChange));
> return change;
> }
>
> and this failed!
>
> (gdb) f 3
> #3 0x003cb888 in ReorderBufferGetChange (rb=0x24ed820) at reorderbuffer.c:475
> 475 Assert(change == (void *) MAXALIGN(change));
> (gdb) p change
> $1 = (ReorderBufferChange *) 0x24aaa14
>
> So the bug is in fact in David's changes, and it consists in palloc
> sometimes handing back non-maxaligned pointers. I find it mildly
> astonishing that we managed to get through core regression tests
> without such a fault surfacing, but there you have it.
>
> This machine has MAXALIGN 8 but 4-byte pointers, so there's something
> wrong with that situation.
>
I suspect it's a pre-existing bug in Slab allocator, because it does this:
#define SlabBlockGetChunk(slab, block, idx) \
((MemoryChunk *) ((char *) (block) + sizeof(SlabBlock) \
+ (idx * slab->fullChunkSize)))
and SlabBlock is only 20B, i.e. not a multiple of 8B. Which would mean
that even if we allocate block and size the chunks carefully (with all
the MAXALIGN things), we ultimately slice the block incorrectly.
This would explain the 4B difference I reported before, I think. But I'm
just as astonished we got this far in the tests - regular regression
tests don't do much logical decoding, and we only use slab for changes,
but I see the failure in 006 test in src/test/recovery, so the first
five completed fine.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> I've got another problem with this patch here on macOS:
> In file included from aset.c:52:
> ../../../../src/include/utils/memutils_memorychunk.h:170:18: error:
> comparison of constant 7 with expression of type
> 'MemoryContextMethodID' (aka 'enum MemoryContextMethodID') is always
> true [-Werror,-Wtautological-constant-out-of-range-compare]
> Assert(methodid <= MEMORY_CONTEXT_METHODID_MASK);
> ~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
> ../../../../src/include/c.h:827:9: note: expanded from macro 'Assert'
> if (!(condition)) \
> ^~~~~~~~~
Huh. My macOS buildfarm animals aren't showing that, nor can I
repro it on my laptop. Which compiler version are you using exactly?
regards, tom lane
Got it: sizeof(SlabBlock) isn't a multiple of MAXALIGN,
(gdb) p sizeof(SlabBlock)
$4 = 20
but this coding requires it to be:
#define SlabBlockGetChunk(slab, block, idx) \
((MemoryChunk *) ((char *) (block) + sizeof(SlabBlock) \
+ (idx * slab->fullChunkSize)))
So what you actually need to do is add some alignment padding to
SlabBlock. I'd suggest reverting df0f4feef as it seems to be
a red herring.
regards, tom lane
On 8/29/22 17:27, Tomas Vondra wrote: > ... > > I suspect it's a pre-existing bug in Slab allocator, because it does this: > > #define SlabBlockGetChunk(slab, block, idx) \ > ((MemoryChunk *) ((char *) (block) + sizeof(SlabBlock) \ > + (idx * slab->fullChunkSize))) > > and SlabBlock is only 20B, i.e. not a multiple of 8B. Which would mean > that even if we allocate block and size the chunks carefully (with all > the MAXALIGN things), we ultimately slice the block incorrectly. > The attached patch seems to fix the issue for me - at least it seems like that. This probably will need to get backpatched, I guess. Maybe we should add an assert to MemoryChunkGetPointer to check alignment? > This would explain the 4B difference I reported before, I think. But I'm > just as astonished we got this far in the tests - regular regression > tests don't do much logical decoding, and we only use slab for changes, > but I see the failure in 006 test in src/test/recovery, so the first > five completed fine. > I got confused - the first 5 tests in src/test/recovery don't do any logical decoding, so it's not surprising it's the 006 that fails. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> I suspect it's a pre-existing bug in Slab allocator, because it does this:
> #define SlabBlockGetChunk(slab, block, idx) \
> ((MemoryChunk *) ((char *) (block) + sizeof(SlabBlock) \
> + (idx * slab->fullChunkSize)))
> and SlabBlock is only 20B, i.e. not a multiple of 8B. Which would mean
> that even if we allocate block and size the chunks carefully (with all
> the MAXALIGN things), we ultimately slice the block incorrectly.
Right, same conclusion I just came to. But it's not a "pre-existing"
bug, because sizeof(SlabBlock) *was* maxaligned until David added
another field to it.
I think adding a padding field to SlabBlock would be a less messy
solution than your patch.
regards, tom lane
Hi, On 2022-08-29 11:43:14 -0400, Tom Lane wrote: > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: > > I suspect it's a pre-existing bug in Slab allocator, because it does this: > > > #define SlabBlockGetChunk(slab, block, idx) \ > > ((MemoryChunk *) ((char *) (block) + sizeof(SlabBlock) \ > > + (idx * slab->fullChunkSize))) > > > and SlabBlock is only 20B, i.e. not a multiple of 8B. Which would mean > > that even if we allocate block and size the chunks carefully (with all > > the MAXALIGN things), we ultimately slice the block incorrectly. > > Right, same conclusion I just came to. But it's not a "pre-existing" > bug, because sizeof(SlabBlock) *was* maxaligned until David added > another field to it. > > I think adding a padding field to SlabBlock would be a less messy > solution than your patch. That just seems to invite the same problem happening again later and it's harder to ensure that the padding is correct across platforms. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2022-08-29 11:43:14 -0400, Tom Lane wrote:
>> I think adding a padding field to SlabBlock would be a less messy
>> solution than your patch.
> That just seems to invite the same problem happening again later and it's
> harder to ensure that the padding is correct across platforms.
Yeah, I just tried and failed to write a general padding computation
--- you can't use sizeof() in the #if, which makes it a lot more
fragile than I was expecting. Tomas' way is probably the best.
regards, tom lane
On 8/29/22 17:43, Tom Lane wrote: > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: >> I suspect it's a pre-existing bug in Slab allocator, because it does this: > >> #define SlabBlockGetChunk(slab, block, idx) \ >> ((MemoryChunk *) ((char *) (block) + sizeof(SlabBlock) \ >> + (idx * slab->fullChunkSize))) > >> and SlabBlock is only 20B, i.e. not a multiple of 8B. Which would mean >> that even if we allocate block and size the chunks carefully (with all >> the MAXALIGN things), we ultimately slice the block incorrectly. > > Right, same conclusion I just came to. But it's not a "pre-existing" > bug, because sizeof(SlabBlock) *was* maxaligned until David added > another field to it. > Yeah, that's true. Still, there was an implicit expectation the size is maxaligned, but it wasn't mentioned anywhere. I don't even recall if I was aware of it when I wrote that code, or if I was just lucky. > I think adding a padding field to SlabBlock would be a less messy > solution than your patch. Maybe, although I find it a bit annoying that we do MAXALIGN() for a bunch of structs, and then in other places we add padding. Maybe not for Slab, but e.g. for Generation. Maybe we should try doing the same thing in all those places. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, 30 Aug 2022 at 03:43, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I think adding a padding field to SlabBlock would be a less messy > solution than your patch. Thank you both of you for looking at this while I was sleeping. I've read over the emails and glanced at Tomas' patch. I think that seems good. I think I'd rather see us do that than pad the struct out further as Tomas' method is more aligned to what we do in aset.c (ALLOC_BLOCKHDRSZ) and generation.c (Generation_BLOCKHDRSZ). I can adjust Tomas' patch to #define Slab_BLOCKHDRSZ David
David Rowley <dgrowleyml@gmail.com> writes:
> I've read over the emails and glanced at Tomas' patch. I think that
> seems good. I think I'd rather see us do that than pad the struct out
> further as Tomas' method is more aligned to what we do in aset.c
> (ALLOC_BLOCKHDRSZ) and generation.c (Generation_BLOCKHDRSZ).
> I can adjust Tomas' patch to #define Slab_BLOCKHDRSZ
WFM
regards, tom lane
On 8/29/22 23:57, Tom Lane wrote: > David Rowley <dgrowleyml@gmail.com> writes: >> I've read over the emails and glanced at Tomas' patch. I think that >> seems good. I think I'd rather see us do that than pad the struct out >> further as Tomas' method is more aligned to what we do in aset.c >> (ALLOC_BLOCKHDRSZ) and generation.c (Generation_BLOCKHDRSZ). > >> I can adjust Tomas' patch to #define Slab_BLOCKHDRSZ > > WFM > Same here. I also suggested doing a similar check in MemoryChunkGetPointer, so that we catch the issue earlier - right after we allocate the chunk. Any opinion on that? With an assert only in GetMemoryChunkMethodID() we'd notice the issue much later, when it may not be obvious if it's a memory corruption or what. But maybe it's overkill. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, 30 Aug 2022 at 03:39, Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
> The attached patch seems to fix the issue for me - at least it seems
> like that. This probably will need to get backpatched, I guess. Maybe we
> should add an assert to MemoryChunkGetPointer to check alignment?
Hi Tomas,
I just wanted to check with you if you ran the full make check-world
with this patch?
I don't yet have a working ARM 32-bit environment to test, but on
trying it with x86 32-bit and adjusting MAXIMUM_ALIGNOF to 8, I'm
getting failures in test_decoding. Namely:
test twophase ... FAILED 51 ms
test twophase_stream ... FAILED 25 ms
INSERT INTO test_prepared2 VALUES (5);
SELECT data FROM pg_logical_slot_get_changes('regression_slot', NULL,
NULL, 'include-xids', '0', 'skip-empty-xacts', '1');
+WARNING: problem in slab Change: detected write past chunk end in
block 0x58b8ecf0, chunk 0x58b8ed08
+WARNING: problem in slab Change: detected write past chunk end in
block 0x58b8ecf0, chunk 0x58b8ed58
+WARNING: problem in slab Change: detected write past chunk end in
block 0x58b8ecf0, chunk 0x58b8eda8
+WARNING: problem in slab Change: detected write past chunk end in
block 0x58b8ecf0, chunk 0x58b8edf8
+WARNING: problem in slab Change: detected write past chunk end in
block 0x58b8ecf0, chunk 0x58b8ee48
I think the existing sentinel check looks wrong:
if (!sentinel_ok(chunk, slab->chunkSize))
shouldn't that be passing the pointer rather than the chunk?
David
On Tue, 30 Aug 2022 at 12:22, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > I also suggested doing a similar check in MemoryChunkGetPointer, so that > we catch the issue earlier - right after we allocate the chunk. Any > opinion on that? I think it's probably a good idea. However, I'm not yet sure if we can keep it as a macro or if it would need to become a static inline function to do that. What I'd really have wished for is a macro like AssertPointersEqual() that spat out the two pointer values. That would probably have saved more time on this issue. David
On Tue, 30 Aug 2022 at 12:45, David Rowley <dgrowleyml@gmail.com> wrote: > I think the existing sentinel check looks wrong: > > if (!sentinel_ok(chunk, slab->chunkSize)) > > shouldn't that be passing the pointer rather than the chunk? Here's v2 of the slab-fix patch. I've included the sentinel check fix. This passes make check-world for me when do a 32-bit build on my x86_64 machine and adjust pg_config.h to set MAXIMUM_ALIGNOF to 8. Any chance you could run make check-world on your 32-bit Raspberry PI? I'm also wondering if this should also be backpatched back to v10, providing the build farm likes it well enough on master.
Attachment
On 8/30/22 02:45, David Rowley wrote:
> On Tue, 30 Aug 2022 at 03:39, Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>> The attached patch seems to fix the issue for me - at least it seems
>> like that. This probably will need to get backpatched, I guess. Maybe we
>> should add an assert to MemoryChunkGetPointer to check alignment?
>
> Hi Tomas,
>
> I just wanted to check with you if you ran the full make check-world
> with this patch?
>
> I don't yet have a working ARM 32-bit environment to test, but on
> trying it with x86 32-bit and adjusting MAXIMUM_ALIGNOF to 8, I'm
> getting failures in test_decoding. Namely:
>
> test twophase ... FAILED 51 ms
> test twophase_stream ... FAILED 25 ms
>
> INSERT INTO test_prepared2 VALUES (5);
> SELECT data FROM pg_logical_slot_get_changes('regression_slot', NULL,
> NULL, 'include-xids', '0', 'skip-empty-xacts', '1');
> +WARNING: problem in slab Change: detected write past chunk end in
> block 0x58b8ecf0, chunk 0x58b8ed08
> +WARNING: problem in slab Change: detected write past chunk end in
> block 0x58b8ecf0, chunk 0x58b8ed58
> +WARNING: problem in slab Change: detected write past chunk end in
> block 0x58b8ecf0, chunk 0x58b8eda8
> +WARNING: problem in slab Change: detected write past chunk end in
> block 0x58b8ecf0, chunk 0x58b8edf8
> +WARNING: problem in slab Change: detected write past chunk end in
> block 0x58b8ecf0, chunk 0x58b8ee48
>
> I think the existing sentinel check looks wrong:
>
> if (!sentinel_ok(chunk, slab->chunkSize))
>
> shouldn't that be passing the pointer rather than the chunk?
>
I agree the check in SlabCheck() looks wrong, as it's ignoring the chunk
header (unlike the other contexts).
But yeah, I ran "make check-world" and it passed just fine, so my only
explanation is that the check never actually executes because there's no
space for the sentinel thanks to alignment, and the tweak you did breaks
that. Strange ...
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
David Rowley <dgrowleyml@gmail.com> writes:
> Here's v2 of the slab-fix patch.
> I've included the sentinel check fix. This passes make check-world
> for me when do a 32-bit build on my x86_64 machine and adjust
> pg_config.h to set MAXIMUM_ALIGNOF to 8.
> Any chance you could run make check-world on your 32-bit Raspberry PI?
I have clean core and test_decoding passes on both 32-bit ARM and
32-bit PPC. It'll take awhile (couple hours) to finish a full
check-world, but I'd say that's good enough evidence to commit.
regards, tom lane
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> On 8/30/22 02:45, David Rowley wrote:
>> I think the existing sentinel check looks wrong:
>> if (!sentinel_ok(chunk, slab->chunkSize))
>> shouldn't that be passing the pointer rather than the chunk?
> I agree the check in SlabCheck() looks wrong, as it's ignoring the chunk
> header (unlike the other contexts).
> But yeah, I ran "make check-world" and it passed just fine, so my only
> explanation is that the check never actually executes because there's no
> space for the sentinel thanks to alignment, and the tweak you did breaks
> that. Strange ...
A quick code-coverage check confirms that the sentinel_ok() line
is not reached in core or test_decoding tests as of HEAD
(on a 64-bit machine anyway). So we just happen to be using
only allocation requests that are already maxaligned.
I wonder if slab ought to artificially bump up such requests when
MEMORY_CONTEXT_CHECKING is enabled, so there's room for a sentinel.
I think it's okay for aset.c to not do that, because its power-of-2
behavior means there usually is room for a sentinel; but slab's
policy makes it much more likely that there won't be.
regards, tom lane
On 8/30/22 03:16, David Rowley wrote: > On Tue, 30 Aug 2022 at 12:45, David Rowley <dgrowleyml@gmail.com> wrote: >> I think the existing sentinel check looks wrong: >> >> if (!sentinel_ok(chunk, slab->chunkSize)) >> >> shouldn't that be passing the pointer rather than the chunk? > > Here's v2 of the slab-fix patch. > > I've included the sentinel check fix. This passes make check-world > for me when do a 32-bit build on my x86_64 machine and adjust > pg_config.h to set MAXIMUM_ALIGNOF to 8. > > Any chance you could run make check-world on your 32-bit Raspberry PI? > Will do, but I think the sentinel fix should be if (!sentinel_ok(chunk, Slab_CHUNKHDRSZ + slab->chunkSize)) which is what the other contexts do. However, considering check-world passed even before the sentinel_ok fix, I'm a bit skeptical about that proving anything. FWIW I added a WARNING to SlabCheck before the condition guarding the sentinel check, printing the (full) chunk size and header size, and this is what I got in test_decoding (deduplicated): armv7l (32-bit rpi4) +WARNING: chunkSize 216 fullChunkSize 232 header 16 +WARNING: chunkSize 64 fullChunkSize 80 header 16 aarch64 (64-bit rpi4) +WARNING: chunkSize 304 fullChunkSize 320 header 16 +WARNING: chunkSize 80 fullChunkSize 96 header 16 So indeed, those are *perfect* matches and thus the sentinel_ok() never executed. So no failures until now. On x86-64 I get the same thing as on aarch64. I guess that explains why it never failed. Seems like a pretty amazing coincidence ... > I'm also wondering if this should also be backpatched back to v10, > providing the build farm likes it well enough on master. I'd say the sentinel fix may need to be backpatched. regard -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 8/30/22 03:55, Tom Lane wrote: > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: >> On 8/30/22 02:45, David Rowley wrote: >>> I think the existing sentinel check looks wrong: >>> if (!sentinel_ok(chunk, slab->chunkSize)) >>> shouldn't that be passing the pointer rather than the chunk? > >> I agree the check in SlabCheck() looks wrong, as it's ignoring the chunk >> header (unlike the other contexts). > >> But yeah, I ran "make check-world" and it passed just fine, so my only >> explanation is that the check never actually executes because there's no >> space for the sentinel thanks to alignment, and the tweak you did breaks >> that. Strange ... > > A quick code-coverage check confirms that the sentinel_ok() line > is not reached in core or test_decoding tests as of HEAD > (on a 64-bit machine anyway). So we just happen to be using > only allocation requests that are already maxaligned. > > I wonder if slab ought to artificially bump up such requests when > MEMORY_CONTEXT_CHECKING is enabled, so there's room for a sentinel. > I think it's okay for aset.c to not do that, because its power-of-2 > behavior means there usually is room for a sentinel; but slab's > policy makes it much more likely that there won't be. > +1 to that For aset that's fine not just because of power-of-2 behavior, but because we use it for chunks of many different sizes - so at least some of those will have sentinel. But Slab in used only for changes and txns in reorderbuffer, and it just so happens both structs are maxaligned on 32-bit and 64-bit machines (rpi and x86-64). We're unlikely to use slab in many other places, and the structs don't change very often, and it'd probably grow to another maxaligned size anyway. So it may be pretty rare to have a sentinel. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, 30 Aug 2022 at 13:58, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > armv7l (32-bit rpi4) > > +WARNING: chunkSize 216 fullChunkSize 232 header 16 > +WARNING: chunkSize 64 fullChunkSize 80 header 16 > > aarch64 (64-bit rpi4) > > +WARNING: chunkSize 304 fullChunkSize 320 header 16 > +WARNING: chunkSize 80 fullChunkSize 96 header 16 > > So indeed, those are *perfect* matches and thus the sentinel_ok() never > executed. So no failures until now. On x86-64 I get the same thing as on > aarch64. I guess that explains why it never failed. Seems like a pretty > amazing coincidence ... hmm, I'm not so sure I agree that it's an amazing coincidence. Isn't it quite likely that the chunksize being given to SlabContextCreate() is the same as MAXALIGN(chunksize)? Isn't that all it would take? David
On Tue, 30 Aug 2022 at 13:55, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I wonder if slab ought to artificially bump up such requests when > MEMORY_CONTEXT_CHECKING is enabled, so there's room for a sentinel. > I think it's okay for aset.c to not do that, because its power-of-2 > behavior means there usually is room for a sentinel; but slab's > policy makes it much more likely that there won't be. I think it's fairly likely that small allocations are a power of 2, and I think most of our allocates are small, so I imagine that if we didn't do that for aset.c, we'd miss out on most of the benefits. David
On Tue, 30 Aug 2022 at 13:58, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 8/30/22 03:16, David Rowley wrote: > > Any chance you could run make check-world on your 32-bit Raspberry PI? > > > > Will do, but I think the sentinel fix should be Thank you. I think Tom is also running make check-world. I now have an old RPI3 setup with a 32-bit OS, which is currently busy compiling Postgres. I'll kick off a make check-world run once that's done. > if (!sentinel_ok(chunk, Slab_CHUNKHDRSZ + slab->chunkSize)) Agreed. I've changed the patch to do it that way. Since the 32-bit ARM animals are already broken and per what Tom mentioned in [1], I've pushed the patch. Thanks again for taking the time to look at this. David [1] https://www.postgresql.org/message-id/3455754.1661823905@sss.pgh.pa.us
On Tue, 30 Aug 2022 at 03:39, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> I'd suggest reverting df0f4feef as it seems to be
> a red herring.
I think it's useless providing that a 64-bit variable will always be
aligned to 8 bytes on all of our supported 32-bit platforms as,
without the padding, the uint64 hdrmask in MemoryChunk will always be
aligned to 8 bytes meaning the memory following that will be aligned
too. If we have a platform where a uint64 isn't aligned to 8 bytes
then we might need the padding.
long long seems to align to 8 bytes on my 32-bit Rasberry PI going the
struct being 16 bytes rather than 12.
drowley@raspberrypi:~ $ cat struct.c
#include <stdio.h>
typedef struct test
{
int a;
long long b;
} test;
int main(void)
{
printf("%d\n", sizeof(test));
return 0;
}
drowley@raspberrypi:~ $ gcc struct.c -o struct
drowley@raspberrypi:~ $ ./struct
16
drowley@raspberrypi:~ $ uname -m
armv7l
Is that the case for your 32-bit PPC too?
David
David Rowley <dgrowleyml@gmail.com> writes:
> On Tue, 30 Aug 2022 at 03:39, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> I'd suggest reverting df0f4feef as it seems to be
>> a red herring.
> I think it's useless providing that a 64-bit variable will always be
> aligned to 8 bytes on all of our supported 32-bit platforms as,
> without the padding, the uint64 hdrmask in MemoryChunk will always be
> aligned to 8 bytes meaning the memory following that will be aligned
> too. If we have a platform where a uint64 isn't aligned to 8 bytes
> then we might need the padding.
It's not so much "8 bytes". The question is this: is there any
platform on which uint64 has less than MAXALIGN alignment
requirement? If it is maxaligned then the compiler will insert any
required padding automatically, so the patch accomplishes little.
AFAICS that could only happen if "double" has 8-byte alignment
requirement but int64 does not. I recall some discussion about
that possibility a month or two back, but I think we concluded
that we weren't going to support it.
I guess what I mostly don't like about df0f4feef is the hardwired "8"
constants. Yeah, it's hard to see how sizeof(uint64) isn't 8, but
it's not very readable like this IMO.
regards, tom lane
On Tue, 30 Aug 2022 at 15:15, Tom Lane <tgl@sss.pgh.pa.us> wrote: > AFAICS that could only happen if "double" has 8-byte alignment > requirement but int64 does not. I recall some discussion about > that possibility a month or two back, but I think we concluded > that we weren't going to support it. ok > I guess what I mostly don't like about df0f4feef is the hardwired "8" > constants. Yeah, it's hard to see how sizeof(uint64) isn't 8, but > it's not very readable like this IMO. Yeah, that was just down to lack of any SIZEOF_* macro to tell me uint64 was 8 bytes. I can revert df0f4feef, but would prefer just to get the green light for d5ee4db0e from those 32-bit arm animals before doing so. David
David Rowley <dgrowleyml@gmail.com> writes:
> I can revert df0f4feef, but would prefer just to get the green light
> for d5ee4db0e from those 32-bit arm animals before doing so.
I have a check-world pass on my RPI3 (Fedora 30 armv7l image).
PPC test still running, but I don't doubt it will pass; it's
finished contrib/test_decoding.
regards, tom lane
On Tue, 30 Aug 2022 at 03:16, Robert Haas <robertmhaas@gmail.com> wrote: > ../../../../src/include/utils/memutils_memorychunk.h:186:18: error: > comparison of constant 7 with expression of type > 'MemoryContextMethodID' (aka 'enum MemoryContextMethodID') is always > true [-Werror,-Wtautological-constant-out-of-range-compare] > Assert(methodid <= MEMORY_CONTEXT_METHODID_MASK); > ~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ > ../../../../src/include/c.h:827:9: note: expanded from macro 'Assert' > if (!(condition)) \ > ^~~~~~~~~ > > I'm not sure what to do about that, but every file that includes > memutils_memorychunk.h produces those warnings (which become errors > due to -Werror). I'm not really sure either. I tried compiling with clang 12.0.1 with -Wtautological-constant-out-of-range-compare and don't get this warning. I think the Assert is useful as if we were ever to add an enum member with the value of 8 and forgot to adjust MEMORY_CONTEXT_METHODID_BITS then bad things would happen inside MemoryChunkSetHdrMask() and MemoryChunkSetHdrMaskExternal(). I think it's unlikely we'll ever get that many MemoryContext types, but I don't know for sure and would rather the person who adds the 9th one get alerted to the lack of bit space in MemoryChunk as soon as possible. As much as I'm not a fan of adding new warnings for compiler options that are not part of our standard set, I feel like if there are warning flags out there that are as giving us false warnings such as this one, then we shouldn't trouble ourselves trying to get rid of them, especially so when they force us to remove something which might catch a future bug. David
On 8/30/22 03:04, David Rowley wrote: > On Tue, 30 Aug 2022 at 12:22, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> I also suggested doing a similar check in MemoryChunkGetPointer, so that >> we catch the issue earlier - right after we allocate the chunk. Any >> opinion on that? > > I think it's probably a good idea. However, I'm not yet sure if we can > keep it as a macro or if it would need to become a static inline > function to do that. > I'd bet it can be done in the macro. See VARATT_EXTERNAL_GET_POINTER for example of a "do" block with an Assert. > What I'd really have wished for is a macro like AssertPointersEqual() > that spat out the two pointer values. That would probably have saved > more time on this issue. > Hmm, maybe. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 8/30/22 04:31, David Rowley wrote: > On Tue, 30 Aug 2022 at 13:55, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> I wonder if slab ought to artificially bump up such requests when >> MEMORY_CONTEXT_CHECKING is enabled, so there's room for a sentinel. >> I think it's okay for aset.c to not do that, because its power-of-2 >> behavior means there usually is room for a sentinel; but slab's >> policy makes it much more likely that there won't be. > > I think it's fairly likely that small allocations are a power of 2, > and I think most of our allocates are small, so I imagine that if we > didn't do that for aset.c, we'd miss out on most of the benefits. > Yeah. I think we have a fair number of "larger" allocations (once you get to ~100B it probably won't be a 2^N), but we may easily miss whole sections of allocations. I guess the idea was to add a sentinel only when there already is space for it, but perhaps that's a bad tradeoff limiting the benefits. Either we add the sentinel fairly often (and then why not just add it all the time - it'll need a bit more space), or we do it only very rarely (and then it's a matter of luck if it catches an issue). Considering we only do this with asserts, I doubt the extra bytes / CPU is a major issue, and a (more) reliable detection of issues seems worth it. But maybe I underestimate the costs. The only alternative seems to be valgrind, and that's way costlier, though. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> I guess the idea was to add a sentinel only when there already is space
> for it, but perhaps that's a bad tradeoff limiting the benefits. Either
> we add the sentinel fairly often (and then why not just add it all the
> time - it'll need a bit more space), or we do it only very rarely (and
> then it's a matter of luck if it catches an issue).
I'm fairly sure that when we made that decision originally, a top-of-mind
case was ListCells, which are plentiful, small, power-of-2-sized, and
not used in a way likely to have buffer overruns. But since the List
rewrite a couple years back we no longer palloc individual ListCells.
So maybe we should revisit the question. It'd be worth collecting some
stats about how much extra space would be needed if we force there
to be room for a sentinel.
regards, tom lane
David Rowley <dgrowleyml@gmail.com> writes:
> On Tue, 30 Aug 2022 at 03:16, Robert Haas <robertmhaas@gmail.com> wrote:
>> ../../../../src/include/utils/memutils_memorychunk.h:186:18: error:
>> comparison of constant 7 with expression of type
>> 'MemoryContextMethodID' (aka 'enum MemoryContextMethodID') is always
>> true [-Werror,-Wtautological-constant-out-of-range-compare]
>> Assert(methodid <= MEMORY_CONTEXT_METHODID_MASK);
>> ~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
> I think the Assert is useful as if we were ever to add an enum member
> with the value of 8 and forgot to adjust MEMORY_CONTEXT_METHODID_BITS
> then bad things would happen inside MemoryChunkSetHdrMask() and
> MemoryChunkSetHdrMaskExternal(). I think it's unlikely we'll ever get
> that many MemoryContext types, but I don't know for sure and would
> rather the person who adds the 9th one get alerted to the lack of bit
> space in MemoryChunk as soon as possible.
I think that's a weak argument, so I don't mind dropping this Assert.
What would be far more useful is a comment inside the
MemoryContextMethodID enum pointing out that we can support at most
8 values because XYZ.
However, I'm still wondering why Robert sees this when the rest of us
don't.
regards, tom lane
I wrote:
> So maybe we should revisit the question. It'd be worth collecting some
> stats about how much extra space would be needed if we force there
> to be room for a sentinel.
Actually, after ingesting more caffeine, the problem with this for aset.c
is that the only way to add space for a sentinel that didn't fit already
is to double the space allocation. That's a little daunting, especially
remembering how many places deliberately allocate power-of-2-sized
arrays.
You could imagine deciding that the space classifications are not
power-of-2 but power-of-2-plus-one, or something like that. But that
would be very invasive to the logic, and I doubt it's a good idea.
regards, tom lane
On Tue, Aug 30, 2022 at 3:14 AM David Rowley <dgrowleyml@gmail.com> wrote: > I'm not really sure either. I tried compiling with clang 12.0.1 with > -Wtautological-constant-out-of-range-compare and don't get this > warning. I have a much older clang version, it seems. clang -v reports 5.0.2. I use -Wall and -Werror as a matter of habit. It looks like 5.0.2 was released in May 2018, installed by me in November of 2019, and I just haven't had a reason to upgrade. > I think the Assert is useful as if we were ever to add an enum member > with the value of 8 and forgot to adjust MEMORY_CONTEXT_METHODID_BITS > then bad things would happen inside MemoryChunkSetHdrMask() and > MemoryChunkSetHdrMaskExternal(). I think it's unlikely we'll ever get > that many MemoryContext types, but I don't know for sure and would > rather the person who adds the 9th one get alerted to the lack of bit > space in MemoryChunk as soon as possible. Well I don't have a problem with that, but I think we should try to do it without causing compiler warnings. The attached patch fixes it for me. > As much as I'm not a fan of adding new warnings for compiler options > that are not part of our standard set, I feel like if there are > warning flags out there that are as giving us false warnings such as > this one, then we shouldn't trouble ourselves trying to get rid of > them, especially so when they force us to remove something which might > catch a future bug. For me the point is that, at least on the compiler that I'm using, the warning suggests that the compiler will optimize the test away completely, and therefore it wouldn't catch a future bug. Could there be compilers where no warning is generated but the assertion is still optimized away? I don't know, but I don't think a 4-year-old compiler is such a fossil that we shouldn't care whether it produces warnings. We worry about operating systems and PostgreSQL versions that are almost extinct in the wild, so saying we're not going to worry about failing to update the compiler regularly enough within the lifetime of one off-the-shelf MacBook does not really make sense to me. -- Robert Haas EDB: http://www.enterprisedb.com
Attachment
On Wed, 31 Aug 2022 at 03:00, Robert Haas <robertmhaas@gmail.com> wrote: > > On Tue, Aug 30, 2022 at 3:14 AM David Rowley <dgrowleyml@gmail.com> wrote: > > I think the Assert is useful as if we were ever to add an enum member > > with the value of 8 and forgot to adjust MEMORY_CONTEXT_METHODID_BITS > > then bad things would happen inside MemoryChunkSetHdrMask() and > > MemoryChunkSetHdrMaskExternal(). I think it's unlikely we'll ever get > > that many MemoryContext types, but I don't know for sure and would > > rather the person who adds the 9th one get alerted to the lack of bit > > space in MemoryChunk as soon as possible. > > Well I don't have a problem with that, but I think we should try to do > it without causing compiler warnings. The attached patch fixes it for > me. I'm fine with adding the int cast. Seems like a good idea. > > As much as I'm not a fan of adding new warnings for compiler options > > that are not part of our standard set, I feel like if there are > > warning flags out there that are as giving us false warnings such as > > this one, then we shouldn't trouble ourselves trying to get rid of > > them, especially so when they force us to remove something which might > > catch a future bug. > > For me the point is that, at least on the compiler that I'm using, the > warning suggests that the compiler will optimize the test away > completely, and therefore it wouldn't catch a future bug. Could there > be compilers where no warning is generated but the assertion is still > optimized away? I'd not considered that the compiler might optimise it away. My suspicions had been more along the lines of that clang removed the enum out of range warnings because they were annoying and wrong as it's pretty easy to set an enum variable to something out of range of the defined enum values. Looking at [1], it seems like 5.0.2 is producing the correct code and it's just producing a warning. The 2nd compiler window has -Werror and shows that it does fail to compile. If I change that to use clang 6.0.0 then it works. It seems to fail all the way back to clang 3.1. clang 3.0.0 works. David [1] https://godbolt.org/z/Gx388z5Ej
On Wed, 31 Aug 2022 at 01:36, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > I think the Assert is useful as if we were ever to add an enum member > > with the value of 8 and forgot to adjust MEMORY_CONTEXT_METHODID_BITS > > then bad things would happen inside MemoryChunkSetHdrMask() and > > MemoryChunkSetHdrMaskExternal(). I think it's unlikely we'll ever get > > that many MemoryContext types, but I don't know for sure and would > > rather the person who adds the 9th one get alerted to the lack of bit > > space in MemoryChunk as soon as possible. > > I think that's a weak argument, so I don't mind dropping this Assert. > What would be far more useful is a comment inside the > MemoryContextMethodID enum pointing out that we can support at most > 8 values because XYZ. I'd just sleep better knowing that we have some test coverage to ensure that MemoryChunkSetHdrMask() and MemoryChunkSetHdrMaskExternal() have some verification that we don't end up with future code that will cause the hdrmask to be invalid. I tried to make those functions as lightweight as possible. Without the Assert, I just feel that there's a bit too much trust that none of the bits overlap. I've no objections to adding a comment to the enum to explain to future devs. My vote would be for that and add the (int) cast as proposed by Robert. David
On Wed, 31 Aug 2022 at 03:31, David Rowley <dgrowleyml@gmail.com> wrote: > I've no objections to adding a comment to the enum to > explain to future devs. My vote would be for that and add the (int) > cast as proposed by Robert. Here's a patch which adds a comment to MemoryContextMethodID to Robert's patch. David
Attachment
On Tue, Aug 30, 2022 at 11:39 AM David Rowley <dgrowleyml@gmail.com> wrote: > On Wed, 31 Aug 2022 at 03:31, David Rowley <dgrowleyml@gmail.com> wrote: > > I've no objections to adding a comment to the enum to > > explain to future devs. My vote would be for that and add the (int) > > cast as proposed by Robert. > > Here's a patch which adds a comment to MemoryContextMethodID to Robert's patch. LGTM. -- Robert Haas EDB: http://www.enterprisedb.com
David Rowley <dgrowleyml@gmail.com> writes:
> Here's a patch which adds a comment to MemoryContextMethodID to Robert's patch.
OK, but while looking at that I noticed the adjacent
#define MEMORY_CONTEXT_METHODID_MASK \
UINT64CONST((1 << MEMORY_CONTEXT_METHODID_BITS) - 1)
I'm rather astonished that that compiles; UINT64CONST was only ever
meant to be applied to *literals*. I think what it's expanding to
is
((1 << MEMORY_CONTEXT_METHODID_BITS) - 1UL)
(or on some machines 1ULL) which only accidentally does approximately
what you want. It'd be all right perhaps to write
((UINT64CONST(1) << MEMORY_CONTEXT_METHODID_BITS) - 1)
but you might as well avoid the Postgres-ism and just write
((uint64) ((1 << MEMORY_CONTEXT_METHODID_BITS) - 1))
Nobody's ever going to make MEMORY_CONTEXT_METHODID_BITS large
enough for the shift to overflow in int arithmetic.
regards, tom lane
On Wed, 31 Aug 2022 at 02:17, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> I wrote:
> > So maybe we should revisit the question. It'd be worth collecting some
> > stats about how much extra space would be needed if we force there
> > to be room for a sentinel.
>
> Actually, after ingesting more caffeine, the problem with this for aset.c
> is that the only way to add space for a sentinel that didn't fit already
> is to double the space allocation. That's a little daunting, especially
> remembering how many places deliberately allocate power-of-2-sized
> arrays.
I decided to try and quantify that by logging the size, MAXALIGN(size)
and the power of 2 size during AllocSetAlloc and GenerationAlloc. I
made the pow2_size 0 in GenerationAlloc and in AlloocSetAlloc when
size > allocChunkLimit.
After running make installcheck, grabbing the records out the log and
loading them into Postgres, I see that if we did double the pow2_size
when there's no space for the sentinel byte then we'd go from
allocating a total of 10.2GB all the way to 16.4GB (!) of
non-dedicated block aset.c allocations.
select
round(sum(pow2_Size)::numeric/1024/1024/1024,3) as pow2_size,
round(sum(case when maxalign_size=pow2_size then pow2_size*2 else
pow2_size end)::numeric/1024/1024/1024,3) as method1,
round(sum(case when maxalign_size=pow2_size then pow2_size+8 else
pow2_size end)::numeric/1024/1024/1024,3) as method2
from memstats
where pow2_size > 0;
pow2_size | method1 | method2
-----------+---------+---------
10.194 | 16.382 | 10.463
if we did just add on an extra 8 bytes (or or MAXALIGN(size+1) at
least), then that would take the size up to 10.5GB.
David
On 8/31/22 00:40, David Rowley wrote:
> On Wed, 31 Aug 2022 at 02:17, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>>
>> I wrote:
>>> So maybe we should revisit the question. It'd be worth collecting some
>>> stats about how much extra space would be needed if we force there
>>> to be room for a sentinel.
>>
>> Actually, after ingesting more caffeine, the problem with this for aset.c
>> is that the only way to add space for a sentinel that didn't fit already
>> is to double the space allocation. That's a little daunting, especially
>> remembering how many places deliberately allocate power-of-2-sized
>> arrays.
>
> I decided to try and quantify that by logging the size, MAXALIGN(size)
> and the power of 2 size during AllocSetAlloc and GenerationAlloc. I
> made the pow2_size 0 in GenerationAlloc and in AlloocSetAlloc when
> size > allocChunkLimit.
>
> After running make installcheck, grabbing the records out the log and
> loading them into Postgres, I see that if we did double the pow2_size
> when there's no space for the sentinel byte then we'd go from
> allocating a total of 10.2GB all the way to 16.4GB (!) of
> non-dedicated block aset.c allocations.
>
> select
> round(sum(pow2_Size)::numeric/1024/1024/1024,3) as pow2_size,
> round(sum(case when maxalign_size=pow2_size then pow2_size*2 else
> pow2_size end)::numeric/1024/1024/1024,3) as method1,
> round(sum(case when maxalign_size=pow2_size then pow2_size+8 else
> pow2_size end)::numeric/1024/1024/1024,3) as method2
> from memstats
> where pow2_size > 0;
> pow2_size | method1 | method2
> -----------+---------+---------
> 10.194 | 16.382 | 10.463
>
> if we did just add on an extra 8 bytes (or or MAXALIGN(size+1) at
> least), then that would take the size up to 10.5GB.
>
I've been experimenting with this a bit too, and my results are similar,
but not exactly the same. I've logged all Alloc/Realloc calls for the
two memory contexts, and when I aggregated the results I get this:
f | size | pow2(size) | pow2(size+1)
-----------------+----------+------------+--------------
AllocSetAlloc | 23528 | 28778 | 31504
AllocSetRelloc | 761 | 824 | 1421
GenerationAlloc | 68 | 90 | 102
So the raw size (what we asked for) is ~23.5GB, but in practice we
allocate ~28.8GB because of the pow-of-2 logic. And by adding the extra
1B we end up allocating 31.5GB. That doesn't seem like a huge increase,
and it's far from the +60% you got.
I wonder where does the difference come - I did make installcheck too,
so how come you get 10/16GB, and I get 28/31GB? My patch is attached,
maybe I did something silly.
I also did a quick hack to see if always having the sentinel detects any
pre-existing issues, but that didn't happen. I guess valgrind would find
those, but not sure?
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
On Thu, 1 Sept 2022 at 08:53, Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
> So the raw size (what we asked for) is ~23.5GB, but in practice we
> allocate ~28.8GB because of the pow-of-2 logic. And by adding the extra
> 1B we end up allocating 31.5GB. That doesn't seem like a huge increase,
> and it's far from the +60% you got.
>
> I wonder where does the difference come - I did make installcheck too,
> so how come you get 10/16GB, and I get 28/31GB? My patch is attached,
> maybe I did something silly.
The reason my reported results were lower is because I ignored size >
allocChunkLimit allocations. These are not raised to the next power of
2, so I didn't think they should be included.
I'm not sure why you're seeing only a 3GB additional overhead. I
noticed a logic error in my query where I was checking
maxaligned_size=pow2_size and doubling that to give sentinel space.
That really should have been "case size=pow2_size then pow2_size * 2
else pow2_size end", However, after adjusting the query, it does not
seem to change the results much:
postgres=# select
postgres-# round(sum(pow2_Size)::numeric/1024/1024/1024,3) as pow2_size,
postgres-# round(sum(case when size=pow2_size then pow2_size*2 else
pow2_size end)::numeric/1024/1024/1024,3) as method1,
postgres-# round(sum(case when size=pow2_size then pow2_size+8 else
pow2_size end)::numeric/1024/1024/1024,3) as method2
postgres-# from memstats
postgres-# where pow2_size > 0;
pow2_size | method1 | method2
-----------+---------+---------
10.269 | 16.322 | 10.476
I've attached the crude patch I came up with for this. For some
reason it was crashing on Linux, but it ran ok on Windows, so I used
the results from that instead. Maybe that accounts for some
differences as e.g sizeof(long) == 4 on 64-bit windows. I'd be
surprised if that accounted for so many GBs though.
I also forgot to add code to GenerationRealloc and AllocSetRealloc
David
Attachment
On 8/31/22 23:46, David Rowley wrote:
> On Thu, 1 Sept 2022 at 08:53, Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>> So the raw size (what we asked for) is ~23.5GB, but in practice we
>> allocate ~28.8GB because of the pow-of-2 logic. And by adding the extra
>> 1B we end up allocating 31.5GB. That doesn't seem like a huge increase,
>> and it's far from the +60% you got.
>>
>> I wonder where does the difference come - I did make installcheck too,
>> so how come you get 10/16GB, and I get 28/31GB? My patch is attached,
>> maybe I did something silly.
>
> The reason my reported results were lower is because I ignored size >
> allocChunkLimit allocations. These are not raised to the next power of
> 2, so I didn't think they should be included.
If I differentiate the large chunks allocated separately (v2 patch
attached), I get this:
f | t | count | s1 | s2 | s3
-----------------+----------+----------+----------+----------+----------
AllocSetAlloc | normal | 60714914 | 4982 | 6288 | 8185
AllocSetAlloc | separate | 824390 | 18245 | 18245 | 18251
AllocSetRelloc | normal | 182070 | 763 | 826 | 1423
GenerationAlloc | normal | 2118115 | 68 | 90 | 102
GenerationAlloc | separate | 28 | 0 | 0 | 0
(5 rows)
Where s1 is the sum of requested sizes, s2 is the sum of allocated
chunks, and s3 is chunks allocated with 1B sentinel.
Focusing on the aset, vast majority of allocations (60M out of 64M) is
small enough to use power-of-2 logic, and we go from 6.3GB to 8.2GB, so
~30%. Not great, not terrible.
For the large allocations, there's almost no increase - in the last
query I used the power-of-2 logic in the calculations, but that was
incorrect, of course.
>
> I'm not sure why you're seeing only a 3GB additional overhead. I
> noticed a logic error in my query where I was checking
> maxaligned_size=pow2_size and doubling that to give sentinel space.
> That really should have been "case size=pow2_size then pow2_size * 2
> else pow2_size end", However, after adjusting the query, it does not
> seem to change the results much:
>
> postgres=# select
> postgres-# round(sum(pow2_Size)::numeric/1024/1024/1024,3) as pow2_size,
> postgres-# round(sum(case when size=pow2_size then pow2_size*2 else
> pow2_size end)::numeric/1024/1024/1024,3) as method1,
> postgres-# round(sum(case when size=pow2_size then pow2_size+8 else
> pow2_size end)::numeric/1024/1024/1024,3) as method2
> postgres-# from memstats
> postgres-# where pow2_size > 0;
> pow2_size | method1 | method2
> -----------+---------+---------
> 10.269 | 16.322 | 10.476
>
> I've attached the crude patch I came up with for this. For some
> reason it was crashing on Linux, but it ran ok on Windows, so I used
> the results from that instead. Maybe that accounts for some
> differences as e.g sizeof(long) == 4 on 64-bit windows. I'd be
> surprised if that accounted for so many GBs though.
>
I tried to use that patch, but "make installcheck" never completes for
me, for some reason. It seems to get stuck in infinite_recurse.sql, but
I haven't looked into the details.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> Focusing on the aset, vast majority of allocations (60M out of 64M) is
> small enough to use power-of-2 logic, and we go from 6.3GB to 8.2GB, so
> ~30%. Not great, not terrible.
Not sure why this escaped me before, but I remembered another argument
for not forcibly adding space for a sentinel: if you don't have room,
that means the chunk end is up against the header for the next chunk,
which means that any buffer overrun will clobber that header. So we'll
detect the problem anyway if we validate the headers to a reasonable
extent.
The hole in this argument is that the very last chunk allocated in a
block might have no following chunk to validate. But we could probably
special-case that somehow, maybe by laying down a sentinel in the free
space, where it will get overwritten by the next chunk when that does
get allocated.
30% memory bloat seems like a high price to pay if it's adding negligible
detection ability, which it seems is true if this argument is valid.
Is there reason to think we can't validate headers enough to catch
clobbers?
regards, tom lane
On Thu, 1 Sept 2022 at 12:23, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Is there reason to think we can't validate headers enough to catch > clobbers? For non-sentinel chunks, the next byte after the end of the chunk will be storing the block offset for the following chunk. I think: if (block != MemoryChunkGetBlock(chunk)) elog(WARNING, "problem in alloc set %s: bad block offset for chunk %p in block %p", name, chunk, block); should catch those. Maybe we should just consider always making room for a sentinel for chunks that are on dedicated blocks. At most that's an extra 8 bytes in some allocation that's either over 1024 or 8192 (depending on maxBlockSize). David
David Rowley <dgrowleyml@gmail.com> writes:
> Maybe we should just consider always making room for a sentinel for
> chunks that are on dedicated blocks. At most that's an extra 8 bytes
> in some allocation that's either over 1024 or 8192 (depending on
> maxBlockSize).
Agreed, if we're not doing that already then we should.
regards, tom lane
On 9/1/22 02:23, Tom Lane wrote: > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: >> Focusing on the aset, vast majority of allocations (60M out of 64M) is >> small enough to use power-of-2 logic, and we go from 6.3GB to 8.2GB, so >> ~30%. Not great, not terrible. > > Not sure why this escaped me before, but I remembered another argument > for not forcibly adding space for a sentinel: if you don't have room, > that means the chunk end is up against the header for the next chunk, > which means that any buffer overrun will clobber that header. So we'll > detect the problem anyway if we validate the headers to a reasonable > extent. > > The hole in this argument is that the very last chunk allocated in a > block might have no following chunk to validate. But we could probably > special-case that somehow, maybe by laying down a sentinel in the free > space, where it will get overwritten by the next chunk when that does > get allocated. > > 30% memory bloat seems like a high price to pay if it's adding negligible > detection ability, which it seems is true if this argument is valid. > Is there reason to think we can't validate headers enough to catch > clobbers? > I'm not quite convinced the 30% figure is correct - it might be if you ignore cases exceeding allocChunkLimit, but that also makes it pretty bogus (because large allocations represent ~2x as much space). You're probably right we'll notice the clobber cases due to corruption of the next chunk header. The annoying thing is having a corrupted header only tells you there's a corruption somewhere, but it may be hard to know which part of the code caused it. I was hoping the sentinel would make it easier, because we mark it as NOACCESS for valgrind. But now I see we mark the first part of a MemoryChunk too, so maybe that's enough. OTOH we have platforms where valgrind is either not supported or no one runs tests with (e.g. on rpi4 it'd take insane amounts of code). In that case the sentinel might be helpful, especially considering alignment on those platforms can cause funny memory issues, as evidenced by this thread. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes: > You're probably right we'll notice the clobber cases due to corruption > of the next chunk header. The annoying thing is having a corrupted > header only tells you there's a corruption somewhere, but it may be hard > to know which part of the code caused it. Same's true of a sentinel, though. > OTOH we have platforms where valgrind is either not supported or no one > runs tests with (e.g. on rpi4 it'd take insane amounts of code). According to https://valgrind.org/info/platforms.html valgrind supports a pretty respectable set of platforms. It might be too slow to be useful on ancient hardware, of course. I've had some success in identifying clobber perpetrators by putting a hardware watchpoint on the clobbered word, which IIRC does work on recent ARM hardware. It's tedious and far more manual than valgrind, but it's possible. regards, tom lane
On Tue, 30 Aug 2022 at 13:16, David Rowley <dgrowleyml@gmail.com> wrote: > I'm also wondering if this should also be backpatched back to v10, > providing the build farm likes it well enough on master. Does anyone have any objections to d5ee4db0e in its entirety being backpatched? David
David Rowley <dgrowleyml@gmail.com> writes:
> Does anyone have any objections to d5ee4db0e in its entirety being backpatched?
It doesn't seem to be fixing any live bug in the back branches,
but by the same token it's harmless.
regards, tom lane
On Thu, 1 Sept 2022 at 16:06, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > Does anyone have any objections to d5ee4db0e in its entirety being backpatched? > > It doesn't seem to be fixing any live bug in the back branches, > but by the same token it's harmless. I considered that an extension might use the Slab allocator with a non-MAXALIGNED chunksize and might run into some troubles during SlabCheck(). David
David Rowley <dgrowleyml@gmail.com> writes:
> On Thu, 1 Sept 2022 at 16:06, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> It doesn't seem to be fixing any live bug in the back branches,
>> but by the same token it's harmless.
> I considered that an extension might use the Slab allocator with a
> non-MAXALIGNED chunksize and might run into some troubles during
> SlabCheck().
Oh, yeah, the sentinel_ok() change is a live bug. Extensions
have no control over sizeof(SlabBlock) though.
regards, tom lane
Hi,
Excuse me for posting on this thread.
Coverity has a complaints about aset.c
CID 1497225 (#1 of 2): Out-of-bounds write (OVERRUN)3. overrun-local: Overrunning array set->freelist of 11 8-byte elements at element index 1073741823 (byte offset 8589934591) using index fidx (which evaluates to 1073741823).
CID 1497225 (#2 of 2): Out-of-bounds write (OVERRUN)3. overrun-local: Overrunning array set->freelist of 11 8-byte elements at element index 1073741823 (byte offset 8589934591) using index fidx (which evaluates to 1073741823).
I think that this is an oversight.
diff --git a/src/backend/utils/mmgr/aset.c b/src/backend/utils/mmgr/aset.c
index b6eeb8abab..8f709514b2 100644
--- a/src/backend/utils/mmgr/aset.c
+++ b/src/backend/utils/mmgr/aset.c
@@ -1024,7 +1024,7 @@ AllocSetFree(void *pointer)
}
else
{
- int fidx = MemoryChunkGetValue(chunk);
+ Size fidx = MemoryChunkGetValue(chunk);
AllocBlock block = MemoryChunkGetBlock(chunk);
AllocFreeListLink *link = GetFreeListLink(chunk);
index b6eeb8abab..8f709514b2 100644
--- a/src/backend/utils/mmgr/aset.c
+++ b/src/backend/utils/mmgr/aset.c
@@ -1024,7 +1024,7 @@ AllocSetFree(void *pointer)
}
else
{
- int fidx = MemoryChunkGetValue(chunk);
+ Size fidx = MemoryChunkGetValue(chunk);
AllocBlock block = MemoryChunkGetBlock(chunk);
AllocFreeListLink *link = GetFreeListLink(chunk);
MemoryChunkGetValue return Size not int.
Not sure if this fix is enough.
regards,
Ranier Vilela
On Thu, 1 Sept 2022 at 12:46, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > Maybe we should just consider always making room for a sentinel for > > chunks that are on dedicated blocks. At most that's an extra 8 bytes > > in some allocation that's either over 1024 or 8192 (depending on > > maxBlockSize). > > Agreed, if we're not doing that already then we should. Here's a patch to that effect. I've made it so that there's always space for the sentinel for all generation.c and slab.c allocations. There is no power of 2 rounding with those, so no concern about doubling the memory for power-of-2 sized allocations. With aset.c, I'm only adding sentinel space when size > allocChunkLimit, aka external chunks. David
Attachment
On Fri, 2 Sept 2022 at 20:11, David Rowley <dgrowleyml@gmail.com> wrote: > > On Thu, 1 Sept 2022 at 12:46, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > > > David Rowley <dgrowleyml@gmail.com> writes: > > > Maybe we should just consider always making room for a sentinel for > > > chunks that are on dedicated blocks. At most that's an extra 8 bytes > > > in some allocation that's either over 1024 or 8192 (depending on > > > maxBlockSize). > > > > Agreed, if we're not doing that already then we should. > > Here's a patch to that effect. If there are no objections, then I plan to push that patch soon. David
Hi, On 2022-08-29 17:26:29 +1200, David Rowley wrote: > On Mon, 29 Aug 2022 at 10:39, David Rowley <dgrowleyml@gmail.com> wrote: > > One more try to make CFbot happy. > > After a bit more revision, mostly updating outdated comments and > naming adjustments, I've pushed this. Responding to Tom's email about guc.c changes [1], I was looking at MemoryContextContains(). Unless I am missing something, the patch omitted adjusting that? We'll probably always return false right now. Probably should have something that tests that MemoryContextContains() works at least to some degree. Perhaps a test in regress.c? Greetings, Andres Freund [1] https://postgr.es/m/2982579.1662416866%40sss.pgh.pa.us
On Tue, 6 Sept 2022 at 11:09, Andres Freund <andres@anarazel.de> wrote: > I was looking at > MemoryContextContains(). Unless I am missing something, the patch omitted > adjusting that? We'll probably always return false right now. Oops. Yes. I'll push a fix a bit later. David
David Rowley <dgrowleyml@gmail.com> writes:
> On Tue, 6 Sept 2022 at 11:09, Andres Freund <andres@anarazel.de> wrote:
>> I was looking at
>> MemoryContextContains(). Unless I am missing something, the patch omitted
>> adjusting that? We'll probably always return false right now.
> Oops. Yes. I'll push a fix a bit later.
The existing uses in nodeAgg and nodeWindowAgg failed to expose this
because an incorrect false result just causes them to do extra work
(ie, a useless datumCopy). I think there might be a memory leak
too, but the regression tests wouldn't run an aggregation long
enough to make that obvious either.
+1 for adding something to regress.c that verifies that this
works properly for all three allocators. I suggest making
three contexts and cross-checking the correct results for
all combinations of chunk A vs context B.
regards, tom lane
On Tue, 6 Sept 2022 at 12:27, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > On Tue, 6 Sept 2022 at 11:09, Andres Freund <andres@anarazel.de> wrote: > >> I was looking at > >> MemoryContextContains(). Unless I am missing something, the patch omitted > >> adjusting that? We'll probably always return false right now. > > > Oops. Yes. I'll push a fix a bit later. I think the fix is harder than I thought, or perhaps impossible to do given how we now determine the owning MemoryContext of a pointer. There's a comment in MemoryContextContains which says: * NB: Can't use GetMemoryChunkContext() here - that performs assertions * that aren't acceptable here since we might be passed memory not * allocated by any memory context. That seems to indicate that we should be able to handle any random pointer given to us (!). That comment seems more confident that'll work than the function's header comment does: * Caution: this test is reliable as long as 'pointer' does point to * a chunk of memory allocated from *some* context. If 'pointer' points * at memory obtained in some other way, there is a small chance of a * false-positive result, since the bits right before it might look like * a valid chunk header by chance. Here that's just claiming the test might not be reliable and could return false-positive results. I find this entire function pretty scary as even before the context changes that function seems to think it's fine to subtract sizeof(void *) from the given pointer and dereference that memory. That could very well segfault. I wonder if there are many usages of MemoryContextContains in extensions. If there's not, I'd be much happier if we got rid of this function and used GetMemoryChunkContext() in nodeAgg.c and nodeWindowAgg.c. > +1 for adding something to regress.c that verifies that this > works properly for all three allocators. I suggest making > three contexts and cross-checking the correct results for > all combinations of chunk A vs context B. I went as far as adding an Assert to palloc(). I'm not quite sure what you have in mind in regress.c Attached is a draft patch. I just don't like this function one bit. David
Attachment
On Tue, 6 Sept 2022 at 14:32, David Rowley <dgrowleyml@gmail.com> wrote: > I wonder if there are many usages of MemoryContextContains in > extensions. If there's not, I'd be much happier if we got rid of this > function and used GetMemoryChunkContext() in nodeAgg.c and > nodeWindowAgg.c. I see postgis is one user of it, per [1]. The other extensions mentioned there just seem to be copying code and not using it. David [1] https://codesearch.debian.net/search?q=MemoryContextContains&literal=1
David Rowley <dgrowleyml@gmail.com> writes:
> I think the fix is harder than I thought, or perhaps impossible to do
> given how we now determine the owning MemoryContext of a pointer.
> There's a comment in MemoryContextContains which says:
> * NB: Can't use GetMemoryChunkContext() here - that performs assertions
> * that aren't acceptable here since we might be passed memory not
> * allocated by any memory context.
I think MemoryContextContains' charter is to return
GetMemoryChunkContext(pointer) == context
*except* that instead of asserting what GetMemoryChunkContext asserts,
it should treat those cases as reasons to return false. So if you
can still do GetMemoryChunkContext then you can still do
MemoryContextContains. The point of having the separate function
is to be as forgiving as we can of bogus pointers.
regards, tom lane
On Tue, 6 Sept 2022 at 14:43, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I think MemoryContextContains' charter is to return > > GetMemoryChunkContext(pointer) == context > > *except* that instead of asserting what GetMemoryChunkContext asserts, > it should treat those cases as reasons to return false. So if you > can still do GetMemoryChunkContext then you can still do > MemoryContextContains. The point of having the separate function > is to be as forgiving as we can of bogus pointers. Ok. I've readded the Asserts that c6e0fe1f2 mistakenly removed from GetMemoryChunkContext() and changed MemoryContextContains() to do those same pre-checks before calling GetMemoryChunkContext(). I've also boosted the Assert in mcxt.c to Assert(MemoryContextContains(context, ret)) in each place we call the context's callback function to obtain a newly allocated pointer. I think this should cover the testing. I felt the need to keep the adjustments I made to the header comment in MemoryContextContains() to ward off anyone who thinks it's ok to pass this any random pointer and have it do something sane. It's much more prone to misbehaving/segfaulting now given the extra dereferences that c6e0fe1f2 added to obtain a pointer to the owning context. David
Attachment
On Tue, 6 Sept 2022 at 01:41, David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Fri, 2 Sept 2022 at 20:11, David Rowley <dgrowleyml@gmail.com> wrote:
> >
> > On Thu, 1 Sept 2022 at 12:46, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> > >
> > > David Rowley <dgrowleyml@gmail.com> writes:
> > > > Maybe we should just consider always making room for a sentinel for
> > > > chunks that are on dedicated blocks. At most that's an extra 8 bytes
> > > > in some allocation that's either over 1024 or 8192 (depending on
> > > > maxBlockSize).
> > >
> > > Agreed, if we're not doing that already then we should.
> >
> > Here's a patch to that effect.
>
> If there are no objections, then I plan to push that patch soon.
I've now pushed the patch which adds the sentinel space in more cases.
The final analysis I did on the stats gathered during make
installcheck show that we'll now allocate about 19MBs more over the
entire installcheck run out of about 26GBs total allocations.
That analysis looks something like:
Before:
SELECT CASE
WHEN pow2_size > 0
AND pow2_size = size THEN 'No'
WHEN pow2_size = 0
AND size = maxalign_size THEN 'No'
ELSE 'Yes'
END AS has_sentinel,
Count(*) AS n_allocations,
Sum(CASE
WHEN pow2_size > 0 THEN pow2_size
ELSE maxalign_size
END) / 1024 / 1024 mega_bytes_alloc
FROM memstats
GROUP BY 1;
has_sentinel | n_allocations | mega_bytes_alloc
--------------+---------------+------------------
No | 26445855 | 21556
Yes | 37602052 | 5044
After:
SELECT CASE
WHEN pow2_size > 0
AND pow2_size = size THEN 'No'
WHEN pow2_size = 0
AND size = maxalign_size THEN 'Yes' -- this part changed
ELSE 'Yes'
END AS has_sentinel,
Count(*) AS n_allocations,
Sum(CASE
WHEN pow2_size > 0 THEN pow2_size
WHEN size = maxalign_size THEN maxalign_size + 8
ELSE maxalign_size
END) / 1024 / 1024 mega_bytes_alloc
FROM memstats
GROUP BY 1;
has_sentinel | n_allocations | mega_bytes_alloc
--------------+---------------+------------------
No | 23980527 | 2177
Yes | 40067380 | 24442
That amounts to previously having about 58.7% of allocations having a
sentinel up to 62.6% currently, during the installcheck run.
It seems a pretty large portion of allocation request sizes are
power-of-2 sized and use AllocSet.
David
David Rowley <dgrowleyml@gmail.com> writes:
> It seems a pretty large portion of allocation request sizes are
> power-of-2 sized and use AllocSet.
No surprise there, we've been programming with aset.c's behavior
in mind for ~20 years ...
regards, tom lane
В Ср, 07/09/2022 в 16:13 +1200, David Rowley пишет: > On Tue, 6 Sept 2022 at 01:41, David Rowley <dgrowleyml@gmail.com> wrote: > > > > On Fri, 2 Sept 2022 at 20:11, David Rowley <dgrowleyml@gmail.com> wrote: > > > > > > On Thu, 1 Sept 2022 at 12:46, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > > > > > > > David Rowley <dgrowleyml@gmail.com> writes: > > > > > Maybe we should just consider always making room for a sentinel for > > > > > chunks that are on dedicated blocks. At most that's an extra 8 bytes > > > > > in some allocation that's either over 1024 or 8192 (depending on > > > > > maxBlockSize). > > > > > > > > Agreed, if we're not doing that already then we should. > > > > > > Here's a patch to that effect. > > > > If there are no objections, then I plan to push that patch soon. > > I've now pushed the patch which adds the sentinel space in more cases. > > The final analysis I did on the stats gathered during make > installcheck show that we'll now allocate about 19MBs more over the > entire installcheck run out of about 26GBs total allocations. > > That analysis looks something like: > > Before: > > SELECT CASE > WHEN pow2_size > 0 > AND pow2_size = size THEN 'No' > WHEN pow2_size = 0 > AND size = maxalign_size THEN 'No' > ELSE 'Yes' > END AS has_sentinel, > Count(*) AS n_allocations, > Sum(CASE > WHEN pow2_size > 0 THEN pow2_size > ELSE maxalign_size > END) / 1024 / 1024 mega_bytes_alloc > FROM memstats > GROUP BY 1; > has_sentinel | n_allocations | mega_bytes_alloc > --------------+---------------+------------------ > No | 26445855 | 21556 > Yes | 37602052 | 5044 > > After: > > SELECT CASE > WHEN pow2_size > 0 > AND pow2_size = size THEN 'No' > WHEN pow2_size = 0 > AND size = maxalign_size THEN 'Yes' -- this part changed > ELSE 'Yes' > END AS has_sentinel, > Count(*) AS n_allocations, > Sum(CASE > WHEN pow2_size > 0 THEN pow2_size > WHEN size = maxalign_size THEN maxalign_size + 8 > ELSE maxalign_size > END) / 1024 / 1024 mega_bytes_alloc > FROM memstats > GROUP BY 1; > has_sentinel | n_allocations | mega_bytes_alloc > --------------+---------------+------------------ > No | 23980527 | 2177 > Yes | 40067380 | 24442 > > That amounts to previously having about 58.7% of allocations having a > sentinel up to 62.6% currently, during the installcheck run. > > It seems a pretty large portion of allocation request sizes are > power-of-2 sized and use AllocSet. 19MB over 26GB is almost nothing. If it is only for enable-casserts builds, then it is perfectly acceptable. regards Yura
On Tue, 6 Sept 2022 at 15:17, David Rowley <dgrowleyml@gmail.com> wrote: > > On Tue, 6 Sept 2022 at 14:43, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > I think MemoryContextContains' charter is to return > > > > GetMemoryChunkContext(pointer) == context > > > > *except* that instead of asserting what GetMemoryChunkContext asserts, > > it should treat those cases as reasons to return false. So if you > > can still do GetMemoryChunkContext then you can still do > > MemoryContextContains. The point of having the separate function > > is to be as forgiving as we can of bogus pointers. > > Ok. I've readded the Asserts that c6e0fe1f2 mistakenly removed from > GetMemoryChunkContext() and changed MemoryContextContains() to do > those same pre-checks before calling GetMemoryChunkContext(). > > I've also boosted the Assert in mcxt.c to > Assert(MemoryContextContains(context, ret)) in each place we call the > context's callback function to obtain a newly allocated pointer. I > think this should cover the testing. > > I felt the need to keep the adjustments I made to the header comment > in MemoryContextContains() to ward off anyone who thinks it's ok to > pass this any random pointer and have it do something sane. It's much > more prone to misbehaving/segfaulting now given the extra dereferences > that c6e0fe1f2 added to obtain a pointer to the owning context. I spent some time looking at our existing usages of MemoryContextContains() to satisfy myself that we'll only ever pass in a pointer to memory allocated by a MemoryContext and pushed this patch. I put some notes in the commit message about it being unsafe now to pass in arbitrary pointers to MemoryContextContains(). Just a note to the archives that I'd personally feel much better if we just removed this function in favour of using GetMemoryChunkContext() instead. That would force extension authors using MemoryContextContains() to rewrite and revalidate their code. I feel that it's unlikely anyone will notice until something crashes otherwise. Hopefully that'll happen before their extension is released. David
Hi, On Thu, Sep 08, 2022 at 12:29:22AM +1200, David Rowley wrote: > > I spent some time looking at our existing usages of > MemoryContextContains() to satisfy myself that we'll only ever pass in > a pointer to memory allocated by a MemoryContext and pushed this > patch. FYI lapwing isn't happy with this patch: https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=lapwing&dt=2022-09-07%2012%3A40%3A16.
On Thu, 8 Sept 2022 at 01:05, Julien Rouhaud <rjuju123@gmail.com> wrote: > FYI lapwing isn't happy with this patch: > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=lapwing&dt=2022-09-07%2012%3A40%3A16. Thanks. It does seem to be because of the nodeWindowAgg.c usage of MemoryContextContains. I'll look into it further. David
On Thu, 8 Sept 2022 at 01:22, David Rowley <dgrowleyml@gmail.com> wrote: > > On Thu, 8 Sept 2022 at 01:05, Julien Rouhaud <rjuju123@gmail.com> wrote: > > FYI lapwing isn't happy with this patch: > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=lapwing&dt=2022-09-07%2012%3A40%3A16. > > I'll look into it further. Looks like my analysis wasn't that good in nodeWindowAgg.c. The reason it's crashing is due to int2int4_sum() returning Int64GetDatumFast(transdata->sum). For 64-bit machines, Int64GetDatumFast() translates to Int64GetDatum() and and that's byval, so the MemoryContextContains() call is not triggered, but on 32-bit machines that's PointerGetDatum() and a byref type, and we're returning a pointer to transdata->sum, which is part way into an allocation. Funnily, the struct looks like: typedef struct Int8TransTypeData { int64 count; int64 sum; } Int8TransTypeData; so the previous version of MemoryContextContains() would have subtracted sizeof(void *) from &transdata->sum which, on this 32-bit machine would have pointed halfway up the "count" field. That count field seems like it would be a good candidate for the "false positive" that the previous comment in MemoryContextContains mentioned about. So it looks like it had about a 1 in 2^32 odds of doing the wrong thing before. Had the fields in that struct happened to be in the opposite order, then I don't think it would have crashed, but that's certainly no fix. I'll need to think about how best to fix this. In the meantime, I think the other 32-bit animals are probably not going to like this either :-( David
David Rowley <dgrowleyml@gmail.com> writes:
> Looks like my analysis wasn't that good in nodeWindowAgg.c. The
> reason it's crashing is due to int2int4_sum() returning
> Int64GetDatumFast(transdata->sum).
Ugh. I thought for a bit about whether we could define that as wrong,
but it's returning a portion of its input, which seems kosher enough
(not much different from array subscripting, for instance).
> I'll need to think about how best to fix this. In the meantime, I
> think the other 32-bit animals are probably not going to like this
> either :-(
Yeah. The basic problem here is that we've greatly reduced the amount
of redundancy in chunk headers.
Perhaps we need to proceed about like this:
1. Check the provided pointer is non-null and maxaligned
(if not, return false).
2. Pull out the mcxt type bits and check that they match the
type of the provided context.
3. If 1 and 2 pass, it's safe enough to call a context-specific
check routine.
4. For aset.c, I'd be inclined to have it compute the AllocBlock
address implied by the putative chunk header, and then run through
the context's alloc blocks and see if any of them match. If we
do find a match, and the chunk address is within the allocated
length of the block, call it good. Probably the same could be done
for the other two methods.
Step 4 is annoyingly expensive, but perhaps not too awful given
the way we step up alloc block sizes. We should make sure that
any context we want to use MemoryContextContains with is allowed
to let its blocks grow large, so that there can't be too many
of them.
I don't see a way to do better if we're afraid to dereference
the computed AllocBlock address.
BTW, if we do it this way, what we'd actually be guaranteeing
is that the address is within some alloc block belonging to
the context; it wouldn't quite prove that the address corresponds
to a currently-allocated chunk. That'd be good enough probably
for the important use-cases. In particular it'd be 100% correct
at rejecting chunks of other contexts and chunks gotten from
raw malloc().
regards, tom lane
On Thu, 8 Sept 2022 at 03:08, Tom Lane <tgl@sss.pgh.pa.us> wrote: > 4. For aset.c, I'd be inclined to have it compute the AllocBlock > address implied by the putative chunk header, and then run through > the context's alloc blocks and see if any of them match. If we > do find a match, and the chunk address is within the allocated > length of the block, call it good. Probably the same could be done > for the other two methods. > > Step 4 is annoyingly expensive, but perhaps not too awful given > the way we step up alloc block sizes. We should make sure that > any context we want to use MemoryContextContains with is allowed > to let its blocks grow large, so that there can't be too many > of them. Thanks for the idea. I've not come up with anything better other than remove the calls to MemoryContextContains and just copy the Datum each time. That doesn't fix the problems with function, however. I'll go code up your idea and see if doing that triggers any other ideas. David
On Thu, 8 Sept 2022 at 09:32, David Rowley <dgrowleyml@gmail.com> wrote: > > On Thu, 8 Sept 2022 at 03:08, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Step 4 is annoyingly expensive, but perhaps not too awful given > > the way we step up alloc block sizes. We should make sure that > > any context we want to use MemoryContextContains with is allowed > > to let its blocks grow large, so that there can't be too many > > of them. > > I'll go code up your idea and see if doing that triggers any other ideas. I've attached a very much draft grade patch for this. I have a couple of thoughts: 1. I should remove all the Assert(MemoryContextContains(context, ret)); I littered around mcxt.c. This function is not as cheap as it once was and I'm expecting that Assert to be a bit too expensive now. 2. I changed the header comment in MemoryContextContains again, but I removed the part about false positives since I don't believe that is possible now. What I do think is just as possible as it was before is a segfault. We're still accessing the 8 bytes prior to the given pointer and there's a decent chance that would segfault when working with a pointer which was returned by malloc. I imagine I'm not the only C programmer around that dislikes writing comments along the lines of "this might segfault, but..." 3. For external chunks, I'd coded MemoryChunk to put a magic number in the 60 free bits of the hdrmask. Since we still need to call MemoryChunkIsExternal on the given pointer, that function will Assert that the magic number matches if the external chunk bit is set. We can't expect that magic number check to pass when the external bit just happens to be on because it's not a MemoryChunk we're looking at. For now I commented out those Asserts to make the tests pass. Not sure what's best there, maybe another version of MemoryChunkIsExternal or export the underlying macro. I'm currently more focused on what I wrote in #2. David
Attachment
Hi, On 2022-09-07 11:08:27 -0400, Tom Lane wrote: > > I'll need to think about how best to fix this. In the meantime, I > > think the other 32-bit animals are probably not going to like this > > either :-( > > Yeah. The basic problem here is that we've greatly reduced the amount > of redundancy in chunk headers. Even with the prior amount of redundancy it's quite scary. It's one thing if the only consequence is a bit of added overhead - but if we *don't* copy the tuple due to a false positive we're in trouble. Afaict the user would have some control over the memory contents and so an attacker could work on triggering this issue. MemoryContextContains() may be ok for an assertion or such, but relying on it for correctness seems a bad idea. I wonder if we can get away from needing these checks, without unnecessarily copying datums every time: If there is no finalfunc, we know that the tuple ought to be in curaggcontext or such, and we need to copy. If there is a finalfunc, they're typically going to return data from within the current memory context, but could legitimately also return part of the data from curaggcontext. Perhaps we could forbid that? Our docs already say the following for serialization funcs: The result of the deserialization function should simply be allocated in the current memory context, as unlike the combine function's result, it is not long-lived. Perhaps we could institute a similar rule for finalfuncs? The argument against that is that we can use arbitrary functions as finalfuncs currently. Perhaps we could treat taking an internal argument as opting into the requirement and default to copying otherwise? Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> If there is a finalfunc, they're typically going to return data from within
> the current memory context, but could legitimately also return part of the
> data from curaggcontext. Perhaps we could forbid that?
No, I don't think we can get away with that. See int8inc() for a
counterexample.
regards, tom lane
Hi, On 2022-09-08 14:10:36 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > If there is a finalfunc, they're typically going to return data from within > > the current memory context, but could legitimately also return part of the > > data from curaggcontext. Perhaps we could forbid that? > > No, I don't think we can get away with that. See int8inc() for a > counterexample. What I was suggesting a bit below the bit quoted above, was that we'd copy whenever there's no finalfunc or if the finalfunc doesn't take an internal parameter. And that finalfuncs returning byref with an internal parameter can be expected to return memory allocated in the right context (which we of course could check with an assert). It's not super satisfying - but I don't think it'd have the problem you describe above. Alternatively we could add a column to pg_aggregate denoting this. That'd only be permissible to set for a superuser presumably. This business with interpreting random memory as a palloc'd chunk seems like a fundamentally wrong approach worth incurring some pain to fix. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2022-09-08 14:10:36 -0400, Tom Lane wrote:
>> No, I don't think we can get away with that. See int8inc() for a
>> counterexample.
> What I was suggesting a bit below the bit quoted above, was that we'd copy
> whenever there's no finalfunc or if the finalfunc doesn't take an internal
> parameter.
Hmm, OK, I was confusing this with the optimization for transition
functions; but that one is looking for pointer equality rather than
checking MemoryContextContains. So maybe this'd work.
> This business with interpreting random memory as a palloc'd chunk seems like a
> fundamentally wrong approach worth incurring some pain to fix.
I hate to give up MemoryContextContains altogether. The assertions
that David nuked in b76fb6c2a had some value I think, and I was hoping
to address your concerns in [1] by adding Assert(MemoryContextContains())
to guc_free. But I'm not sure how much that'll help to diagnose you-
malloced-instead-of-pallocing if the result is not an assertion failure
but a segfault in a not-obviously-related place. The failure at guc_free
is already going to be some distance from the scene of the crime.
The implementation I suggested upthread would reliably distinguish
malloc from palloc, and while it is potentially a tad expensive
I don't think it's too much so for Assert checks. I don't have an
objection to trying to get to a place where we only use it in
Assert, though.
regards, tom lane
[1] https://www.postgresql.org/message-id/20220905233233.jhcu5jqsrtosmgh5%40awork3.anarazel.de
On Fri, 9 Sept 2022 at 10:53, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I hate to give up MemoryContextContains altogether. The assertions > that David nuked in b76fb6c2a had some value I think, Those can be put back if we decide to keep MemoryContextContains. Those newly added Asserts just temporarily had to go due to b76fb6c2a making MemoryContextContains temporarily always return false. > The implementation I suggested upthread would reliably distinguish > malloc from palloc, and while it is potentially a tad expensive > I don't think it's too much so for Assert checks. I don't have an > objection to trying to get to a place where we only use it in > Assert, though. I really think the Assert only form of MemoryContextContains() is the best move, and if it's doing Assert only, then we can do the loop-over-the-blocks idea as you described and I drafted in [1]. If the need comes up that we're certain we always have a pointer to some allocated chunk, but need to know if it's in some memory context, then the proper form of expressing that, I think, should be: if (GetMemoryChunkContext(pointer) == somecontext) If we're worried about getting that wrong, we can beef up the MemoryChunk struct with a magic_number field in MEMORY_CONTEXT_CHECKING builds to ensure we catch any code which passes invalid pointers. David [1] https://www.postgresql.org/message-id/CAApHDvoKjOmPQeokicwDuO-_Edh=tKp23-=jskYcyKfw5QuDhA@mail.gmail.com
On Fri, 9 Sept 2022 at 11:33, David Rowley <dgrowleyml@gmail.com> wrote: > I really think the Assert only form of MemoryContextContains() is the > best move, and if it's doing Assert only, then we can do the > loop-over-the-blocks idea as you described and I drafted in [1]. > > If the need comes up that we're certain we always have a pointer to > some allocated chunk, but need to know if it's in some memory context, > then the proper form of expressing that, I think, should be: > > if (GetMemoryChunkContext(pointer) == somecontext) > > If we're worried about getting that wrong, we can beef up the > MemoryChunk struct with a magic_number field in > MEMORY_CONTEXT_CHECKING builds to ensure we catch any code which > passes invalid pointers. I've attached a patch series which is my proposal on what we should do about MemoryContextContains. In summary, this basically changes MemoryContextContains() so it's only available in MEMORY_CONTEXT_CHECKING builds and removes 4 current usages of the function. 0001: Makes MemoryContextContains work again with the loop-over-the-blocks method mentioned by Tom. 0002: Adds a new "chunk_magic" field to MemoryChunk. My thoughts are that it might be a good idea to do this so that we get Assert failures if we use functions like GetMemoryChunkContext() on a pointer that's not a MemoryChunk. 0003: This adjusts aggregate final functions and window functions so that any byref Datum they return is allocated in CurrentMemoryContext 0004: Makes MemoryContextContains only available in MEMORY_CONTEXT_CHECKING builds and adjusts our usages of the function to use GetMemoryChunkContext() instead. An alternative to 0004, would be more along the lines of what was mentioned by Andres and just Assert that the returned value is in the memory context that we expect. I don't think we need to do anything special with aggregates that take an internal state. I think the rule is just as simple as; all final functions and window functions must return any byref values in CurrentMemoryContext. For aggregates without a finalfn, we can just datumCopy() the returned byref value. There's no chance for those to be in CurrentMemoryContext anyway. The return value must be in the aggregate state's context. The attached assert.patch shows that this holds true in make check after applying each of the other patches. I see that one of the drawbacks from not using MemoryContextContains() is that window functions such as lead(), lag(), first_value(), last_value() and nth_value() may now do the datumCopy() when it's not needed. For example, with a window function call such as lead(byref_col ), the expression evaluation code in WinGetFuncArgInPartition() will just return the address in the tuplestore tuple for "byref_col". The datumCopy() is needed for that. However, if the function call was lead(byref_col || 'something') then we'd have ended up with a new allocation in CurrentMemoryContext to concatenate the two values. We'll now do a datumCopy() where we previously wouldn't have. I don't really see any way around that without doing some highly invasive surgery to the expression evaluation code. None of the attached patches are polished. I can do that once we agree on the best way to fix the issue. David
Attachment
On Tue, 13 Sept 2022 at 20:27, David Rowley <dgrowleyml@gmail.com> wrote: > I see that one of the drawbacks from not using MemoryContextContains() > is that window functions such as lead(), lag(), first_value(), > last_value() and nth_value() may now do the datumCopy() when it's not > needed. For example, with a window function call such as > lead(byref_col ), the expression evaluation code in > WinGetFuncArgInPartition() will just return the address in the > tuplestore tuple for "byref_col". The datumCopy() is needed for that. > However, if the function call was lead(byref_col || 'something') then > we'd have ended up with a new allocation in CurrentMemoryContext to > concatenate the two values. We'll now do a datumCopy() where we > previously wouldn't have. I don't really see any way around that > without doing some highly invasive surgery to the expression > evaluation code. It feels like a terrible idea, but I wondered if we could look at the WindowFunc->args and make a decision if we should do the datumCopy() based on the type of the argument. Vars would need to be copied as they will point into the tuple's memory, but an OpExpr likely would not need to be copied. Aside from that, I don't have any ideas on how to get rid of the possible additional datumCopy() from non-Var arguments to these window functions. Should we just suffer it? It's quite likely that most arguments to these functions are plain Vars anyway. David
David Rowley <dgrowleyml@gmail.com> writes:
> Aside from that, I don't have any ideas on how to get rid of the
> possible additional datumCopy() from non-Var arguments to these window
> functions. Should we just suffer it? It's quite likely that most
> arguments to these functions are plain Vars anyway.
No, we shouldn't. I'm pretty sure that we have various window
functions that are deliberately designed to take advantage of the
no-copy behavior, and that they have taken a significant speed
hit from your having disabled that optimization. I don't say
that this is enough to justify reverting the chunk header changes
altogether ... but I'm completely not satisfied with the current
situation in HEAD.
regards, tom lane
On Tue, 20 Sept 2022 at 13:23, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > Aside from that, I don't have any ideas on how to get rid of the > > possible additional datumCopy() from non-Var arguments to these window > > functions. Should we just suffer it? It's quite likely that most > > arguments to these functions are plain Vars anyway. > > No, we shouldn't. I'm pretty sure that we have various window > functions that are deliberately designed to take advantage of the > no-copy behavior, and that they have taken a significant speed > hit from your having disabled that optimization. I don't say > that this is enough to justify reverting the chunk header changes > altogether ... but I'm completely not satisfied with the current > situation in HEAD. Maybe you've forgotten that MemoryContextContains() is broken in the back branches or just don't think it is broken? David
David Rowley <dgrowleyml@gmail.com> writes:
> On Tue, 20 Sept 2022 at 13:23, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> ... but I'm completely not satisfied with the current
>> situation in HEAD.
> Maybe you've forgotten that MemoryContextContains() is broken in the
> back branches or just don't think it is broken?
"Broken" is a strong claim. There's reason to think it could fail
in the back branches, but little evidence that it actually has failed
in the field. So yeah, we have work to do --- which is the exact
opposite of your apparent stand that we can walk away from the
problem.
regards, tom lane
On Tue, 20 Sept 2022 at 17:23, Tom Lane <tgl@sss.pgh.pa.us> wrote: > "Broken" is a strong claim. There's reason to think it could fail > in the back branches, but little evidence that it actually has failed > in the field. I've posted some code to the security list that shows that I can get MemoryContextContains() to return true when it should return false. This results in the datumCopy() in eval_windowfunction() being skipped and the result of the window function being left in the incorrect memory context. I was unable to get this to produce a crash, but if there's some way to have the result point into a shared buffer page and that page is evicted and replaced with something else before the value is used then we'd have issues. > So yeah, we have work to do --- which is the exact > opposite of your apparent stand that we can walk away from the > problem. My problem is that I'm unable to think of a way to fix something I see as an existing bug. I've given it a week and nobody else has come forward with any proposals on how to fix this. I'm very open to finding some way to allow us to keep this optimisation, but so far I've been unable to. We have reverted broken optimisations before. Also, reverting c6e0fe1f2a does not seem that appealing to me as it just returns MemoryContextContains() back into a state where it can return false positives again. David
On Tue, 20 Sept 2022 at 13:23, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > Aside from that, I don't have any ideas on how to get rid of the > > possible additional datumCopy() from non-Var arguments to these window > > functions. Should we just suffer it? It's quite likely that most > > arguments to these functions are plain Vars anyway. > > No, we shouldn't. I'm pretty sure that we have various window > functions that are deliberately designed to take advantage of the > no-copy behavior, and that they have taken a significant speed > hit from your having disabled that optimization. I don't say > that this is enough to justify reverting the chunk header changes > altogether ... but I'm completely not satisfied with the current > situation in HEAD. Looking more closely at window_gettupleslot(), it always allocates the tuple in ecxt_per_query_memory, so any column we fetch out of that tuple will be in that memory context. window_gettupleslot() is used in lead(), lag(), first_value(), last_value() and nth_value() to fetch the Nth tuple out of the partition window. The other window functions all return BIGINT, FLOAT8 or INT which are byval on 64-bit, and on 32-bit these functions return a freshly palloc'd Datum in the CurrentMemoryContext. Maybe we could remove the datumCopy() from eval_windowfunction() and also document that a window function when returning a non-byval type, must allocate the Datum in either ps_ExprContext's ecxt_per_tuple_memory or ecxt_per_query_memory. We could ensure any extension which has its own window functions get the memo about the API change by adding an Assert to ensure that the return value (for byref types) is in the current context by calling the loop-over-the-blocks version of MemoryContextContains(). This would mean that wfuncs like lead(column_name) would no longer do that extra datumCopy and the likes of lead(col || 'some OpExpr') would save a little as we'd no longer call MemoryContextContains on non-Assert builds. David
On Tue, 27 Sept 2022 at 11:28, David Rowley <dgrowleyml@gmail.com> wrote: > Maybe we could remove the datumCopy() from eval_windowfunction() and > also document that a window function when returning a non-byval type, > must allocate the Datum in either ps_ExprContext's > ecxt_per_tuple_memory or ecxt_per_query_memory. We could ensure any > extension which has its own window functions get the memo about the > API change by adding an Assert to ensure that the return value (for > byref types) is in the current context by calling the > loop-over-the-blocks version of MemoryContextContains(). I did some work on this and it turned out that the value returned by any of lead(), lag(), first_value(), last_value() and nth_value() could also be in MessageContext or some child context to CacheMemoryContext. The reason for the latter two is that cases like LAG(col, 1, 'default value') will return the Const in the 3rd arg when the offset value is outside of the window frame. That means MessageContext for normal queries and it means it'll be cached in a child context of CacheMemoryContext for PREPAREd queries. This means the Assert that I wanted to add to eval_windowfunction became quite complex. Namely: Assert(perfuncstate->resulttypeByVal || fcinfo->isnull || MemoryContextContains(winstate->ss.ps.ps_ExprContext->ecxt_per_tuple_memory, (void *) *result) || MemoryContextContains(winstate->ss.ps.ps_ExprContext->ecxt_per_query_memory, (void *) *result) || MemoryContextContains(MessageContext, (void *) *result) || MemoryContextOrChildOfContains(CacheMemoryContext, (void *) *result)); Notice the invention of MemoryContextOrChildOfContains() to recursively search the CacheMemoryContext children. It does not seem so great as CacheMemoryContext tends to have many children and searching through them all could make that Assert a bit slow. I think I am fairly happy that all the 4 message contexts I mentioned in the Assert will be around long enough for the result value to not be freed. It's just that the whole thing feels a bit wrong and that the context the return value is in should be a bit more predictable. Does anyone have any opinions on this? David
Attachment
On Thu, 29 Sept 2022 at 18:30, David Rowley <dgrowleyml@gmail.com> wrote: > Does anyone have any opinions on this? I by no means think I've nailed the fix in other_ideas_to_fix_MemoryContextContains.patch, so it would be good to see if anyone else has any new ideas on how to solve this issue. Andres did mention to me off-list about perhaps adding a boolean field to FunctionCallInfoBaseData to indicate if the return value can be assumed to be in CurrentMemoryContext. I feel like that might be quite a bit of work to go and change all functions to ensure that that's properly populated. For example, look at split_part() in varlena.c, it's going to be a little tedious to ensure we set that field correctly there as that function sometimes returns it's input, sometimes returns a string constant and sometimes allocates new memory. I feel fixing it this way will be error-prone and cause lots of future bugs. I'm also aware that the change made in b76fb6c2a becomes less temporary with each day that passes, so I really would like to find a solution to the MemoryContextContains issue. I'll reiterate that I don't think reverting c6e0fe1f2 fixes MemoryContextContains. That would just put back the behaviour of it returning true based on the owning MemoryContext and/or the direction that the wind is coming from on the particular day the function is called. Although I do think other_ideas_to_fix_MemoryContextContains.patch does fix the problem. I also fear a few people would be reaching for their pitchforks if I was to go and commit it. However, as of now, I'm starting to look more favourably at it as more time passes. David
David Rowley <dgrowleyml@gmail.com> writes:
> Andres did mention to me off-list about perhaps adding a boolean field
> to FunctionCallInfoBaseData to indicate if the return value can be
> assumed to be in CurrentMemoryContext. I feel like that might be
> quite a bit of work to go and change all functions to ensure that
> that's properly populated.
That seems like the right basic answer, but wrong in detail. We have only
a tiny number of places that care about this --- aggregates and window
functions basically --- and those already have a bunch of special calling
conventions. So changing the generic fmgr APIs has side-effects far
beyond what's justified.
I think what we should look at is extending the aggregate/window
function APIs so that such functions can report where they put their
output, and then we can nuke MemoryContextContains(), with the
code code set up to assume that it has to copy if the called function
didn't report anything. The existing FunctionCallInfo.resultinfo
mechanism (cf. ReturnSetInfo for SRFs) is probably the right thing
to pass the flag through.
I can take a look at this once the release dust settles a little.
regards, tom lane
On Thu, 29 Sept 2022 at 18:30, David Rowley <dgrowleyml(at)gmail(dot)com> wrote:
> Does anyone have any opinions on this?
Hi,
Revisiting my work on reducing memory consumption, I found this patch left out.
I'm not sure I can help.
But basically I was able to write and read the block size, in the chunk.
Could it be the case of writing and reading the context pointer in the same way?
Sure this leads to some performance loss, but would it make it possible to get the context pointer from the chunk?
In other words, would it be possible to save the context pointer and compare it later in MemoryContextContains?
I'm not sure I can help.
But basically I was able to write and read the block size, in the chunk.
Could it be the case of writing and reading the context pointer in the same way?
Sure this leads to some performance loss, but would it make it possible to get the context pointer from the chunk?
In other words, would it be possible to save the context pointer and compare it later in MemoryContextContains?
regards,
Ranier Vilela
Attachment
On Tue, 4 Oct 2022 at 13:35, Ranier Vilela <ranier.vf@gmail.com> wrote: > Revisiting my work on reducing memory consumption, I found this patch left out. > I'm not sure I can help. > But basically I was able to write and read the block size, in the chunk. > Could it be the case of writing and reading the context pointer in the same way? > Sure this leads to some performance loss, but would it make it possible to get the context pointer from the chunk? > In other words, would it be possible to save the context pointer and compare it later in MemoryContextContains? I'm not really sure I understand the intention of the patch. The header size for all our memory contexts was already reduced in c6e0fe1f2. The patch you sent seems to pre-date that commit. David
Em ter., 4 de out. de 2022 às 05:36, David Rowley <dgrowleyml@gmail.com> escreveu:
On Tue, 4 Oct 2022 at 13:35, Ranier Vilela <ranier.vf@gmail.com> wrote:
> Revisiting my work on reducing memory consumption, I found this patch left out.
> I'm not sure I can help.
> But basically I was able to write and read the block size, in the chunk.
> Could it be the case of writing and reading the context pointer in the same way?
> Sure this leads to some performance loss, but would it make it possible to get the context pointer from the chunk?
> In other words, would it be possible to save the context pointer and compare it later in MemoryContextContains?
I'm not really sure I understand the intention of the patch. The
header size for all our memory contexts was already reduced in
c6e0fe1f2. The patch you sent seems to pre-date that commit.
There is zero intention to commit this. It's just an experiment I did.
As it is in the patch, it is possible to save the context pointer outside the header chunk.
Making it possible to retrieve it in MemoryContextContains.
It's just an idea.
regards,
Ranier Vilela
Em ter., 4 de out. de 2022 às 08:29, Ranier Vilela <ranier.vf@gmail.com> escreveu:
Em ter., 4 de out. de 2022 às 05:36, David Rowley <dgrowleyml@gmail.com> escreveu:On Tue, 4 Oct 2022 at 13:35, Ranier Vilela <ranier.vf@gmail.com> wrote:
> Revisiting my work on reducing memory consumption, I found this patch left out.
> I'm not sure I can help.
> But basically I was able to write and read the block size, in the chunk.
> Could it be the case of writing and reading the context pointer in the same way?
> Sure this leads to some performance loss, but would it make it possible to get the context pointer from the chunk?
> In other words, would it be possible to save the context pointer and compare it later in MemoryContextContains?
I'm not really sure I understand the intention of the patch. The
header size for all our memory contexts was already reduced in
c6e0fe1f2. The patch you sent seems to pre-date that commit.There is zero intention to commit this. It's just an experiment I did.As it is in the patch, it is possible to save the context pointer outside the header chunk.Making it possible to retrieve it in MemoryContextContains.
Never mind, it's a waste of time.
regards,
Ranier Vilela
I wrote:
> I think what we should look at is extending the aggregate/window
> function APIs so that such functions can report where they put their
> output, and then we can nuke MemoryContextContains(), with the
> code code set up to assume that it has to copy if the called function
> didn't report anything. The existing FunctionCallInfo.resultinfo
> mechanism (cf. ReturnSetInfo for SRFs) is probably the right thing
> to pass the flag through.
After studying the existing usages of MemoryContextContains, I think
there is a better answer, which is to just nuke them.
As far as I can tell, the datumCopy steps associated with aggregate
finalfns are basically useless. They only serve to prevent
returning a pointer directly to the aggregate's transition value
(or, perhaps, to a portion thereof). But what's wrong with that?
It'll last as long as we need it to. Maybe there was a reason
back before we required finalfns to not scribble on the transition
values, but those days are gone.
The same goes for aggregate serialfns --- although there, I can't
avoid the feeling that the datumCopy step was just cargo-culted in.
I don't think there can exist a serialfn that doesn't return a
freshly-palloced bytea.
The one place where we actually need the conditional datumCopy is
with window functions, and even there I don't think we need it
in simple cases with only one window function. The case that is
hazardous is where multiple window functions are sharing a
WindowObject. So I'm content to optimize the single-window-function
case and just always copy if there's more than one. (Sadly, there
is no existing regression test that catches this, so I added one.)
See attached.
regards, tom lane
diff --git a/src/backend/executor/nodeAgg.c b/src/backend/executor/nodeAgg.c
index fe74e49814..45fcd37253 100644
--- a/src/backend/executor/nodeAgg.c
+++ b/src/backend/executor/nodeAgg.c
@@ -1028,6 +1028,8 @@ process_ordered_aggregate_multi(AggState *aggstate,
*
* The finalfn will be run, and the result delivered, in the
* output-tuple context; caller's CurrentMemoryContext does not matter.
+ * (But note that in some cases, such as when there is no finalfn, the
+ * result might be a pointer to or into the agg's transition value.)
*
* The finalfn uses the state as set in the transno. This also might be
* being used by another aggregate function, so it's important that we do
@@ -1112,21 +1114,13 @@ finalize_aggregate(AggState *aggstate,
}
else
{
- /* Don't need MakeExpandedObjectReadOnly; datumCopy will copy it */
- *resultVal = pergroupstate->transValue;
+ *resultVal =
+ MakeExpandedObjectReadOnly(pergroupstate->transValue,
+ pergroupstate->transValueIsNull,
+ pertrans->transtypeLen);
*resultIsNull = pergroupstate->transValueIsNull;
}
- /*
- * If result is pass-by-ref, make sure it is in the right context.
- */
- if (!peragg->resulttypeByVal && !*resultIsNull &&
- !MemoryContextContains(CurrentMemoryContext,
- DatumGetPointer(*resultVal)))
- *resultVal = datumCopy(*resultVal,
- peragg->resulttypeByVal,
- peragg->resulttypeLen);
-
MemoryContextSwitchTo(oldContext);
}
@@ -1176,19 +1170,13 @@ finalize_partialaggregate(AggState *aggstate,
}
else
{
- /* Don't need MakeExpandedObjectReadOnly; datumCopy will copy it */
- *resultVal = pergroupstate->transValue;
+ *resultVal =
+ MakeExpandedObjectReadOnly(pergroupstate->transValue,
+ pergroupstate->transValueIsNull,
+ pertrans->transtypeLen);
*resultIsNull = pergroupstate->transValueIsNull;
}
- /* If result is pass-by-ref, make sure it is in the right context. */
- if (!peragg->resulttypeByVal && !*resultIsNull &&
- !MemoryContextContains(CurrentMemoryContext,
- DatumGetPointer(*resultVal)))
- *resultVal = datumCopy(*resultVal,
- peragg->resulttypeByVal,
- peragg->resulttypeLen);
-
MemoryContextSwitchTo(oldContext);
}
diff --git a/src/backend/executor/nodeWindowAgg.c b/src/backend/executor/nodeWindowAgg.c
index 8b0858e9f5..ce860bceeb 100644
--- a/src/backend/executor/nodeWindowAgg.c
+++ b/src/backend/executor/nodeWindowAgg.c
@@ -630,20 +630,13 @@ finalize_windowaggregate(WindowAggState *winstate,
}
else
{
- /* Don't need MakeExpandedObjectReadOnly; datumCopy will copy it */
- *result = peraggstate->transValue;
+ *result =
+ MakeExpandedObjectReadOnly(peraggstate->transValue,
+ peraggstate->transValueIsNull,
+ peraggstate->transtypeLen);
*isnull = peraggstate->transValueIsNull;
}
- /*
- * If result is pass-by-ref, make sure it is in the right context.
- */
- if (!peraggstate->resulttypeByVal && !*isnull &&
- !MemoryContextContains(CurrentMemoryContext,
- DatumGetPointer(*result)))
- *result = datumCopy(*result,
- peraggstate->resulttypeByVal,
- peraggstate->resulttypeLen);
MemoryContextSwitchTo(oldContext);
}
@@ -1057,13 +1050,14 @@ eval_windowfunction(WindowAggState *winstate, WindowStatePerFunc perfuncstate,
*isnull = fcinfo->isnull;
/*
- * Make sure pass-by-ref data is allocated in the appropriate context. (We
- * need this in case the function returns a pointer into some short-lived
- * tuple, as is entirely possible.)
+ * The window function might have returned a pass-by-ref result that's
+ * just a pointer into one of the WindowObject's temporary slots. That's
+ * not a problem if it's the only window function using the WindowObject;
+ * but if there's more than one function, we'd better copy the result to
+ * ensure it's not clobbered by later window functions.
*/
if (!perfuncstate->resulttypeByVal && !fcinfo->isnull &&
- !MemoryContextContains(CurrentMemoryContext,
- DatumGetPointer(*result)))
+ winstate->numfuncs > 1)
*result = datumCopy(*result,
perfuncstate->resulttypeByVal,
perfuncstate->resulttypeLen);
diff --git a/src/test/regress/expected/window.out b/src/test/regress/expected/window.out
index 55dcd668c9..170bea23c2 100644
--- a/src/test/regress/expected/window.out
+++ b/src/test/regress/expected/window.out
@@ -657,6 +657,23 @@ select first_value(max(x)) over (), y
-> Seq Scan on tenk1
(4 rows)
+-- window functions returning pass-by-ref values from different rows
+select x, lag(x, 1) over (order by x), lead(x, 3) over (order by x)
+from (select x::numeric as x from generate_series(1,10) x);
+ x | lag | lead
+----+-----+------
+ 1 | | 4
+ 2 | 1 | 5
+ 3 | 2 | 6
+ 4 | 3 | 7
+ 5 | 4 | 8
+ 6 | 5 | 9
+ 7 | 6 | 10
+ 8 | 7 |
+ 9 | 8 |
+ 10 | 9 |
+(10 rows)
+
-- test non-default frame specifications
SELECT four, ten,
sum(ten) over (partition by four order by ten),
diff --git a/src/test/regress/sql/window.sql b/src/test/regress/sql/window.sql
index 57c39e796c..1138453131 100644
--- a/src/test/regress/sql/window.sql
+++ b/src/test/regress/sql/window.sql
@@ -153,6 +153,10 @@ select first_value(max(x)) over (), y
from (select unique1 as x, ten+four as y from tenk1) ss
group by y;
+-- window functions returning pass-by-ref values from different rows
+select x, lag(x, 1) over (order by x), lead(x, 3) over (order by x)
+from (select x::numeric as x from generate_series(1,10) x);
+
-- test non-default frame specifications
SELECT four, ten,
sum(ten) over (partition by four order by ten),
diff --git a/src/backend/utils/mmgr/mcxt.c b/src/backend/utils/mmgr/mcxt.c
index 115a64cfe4..c80236d285 100644
--- a/src/backend/utils/mmgr/mcxt.c
+++ b/src/backend/utils/mmgr/mcxt.c
@@ -224,10 +224,8 @@ MemoryContextResetOnly(MemoryContext context)
* If context->ident points into the context's memory, it will become
* a dangling pointer. We could prevent that by setting it to NULL
* here, but that would break valid coding patterns that keep the
- * ident elsewhere, e.g. in a parent context. Another idea is to use
- * MemoryContextContains(), but we don't require ident strings to be
- * in separately-palloc'd chunks, so that risks false positives. So
- * for now we assume the programmer got it right.
+ * ident elsewhere, e.g. in a parent context. So for now we assume
+ * the programmer got it right.
*/
context->methods->reset(context);
@@ -482,15 +480,6 @@ MemoryContextAllowInCriticalSection(MemoryContext context, bool allow)
MemoryContext
GetMemoryChunkContext(void *pointer)
{
- /*
- * Try to detect bogus pointers handed to us, poorly though we can.
- * Presumably, a pointer that isn't MAXALIGNED isn't pointing at an
- * allocated chunk.
- */
- Assert(pointer != NULL);
- Assert(pointer == (void *) MAXALIGN(pointer));
- /* adding further Asserts here? See pre-checks in MemoryContextContains */
-
return MCXT_METHOD(pointer, get_chunk_context) (pointer);
}
@@ -813,49 +802,6 @@ MemoryContextCheck(MemoryContext context)
}
#endif
-/*
- * MemoryContextContains
- * Detect whether an allocated chunk of memory belongs to a given
- * context or not.
- *
- * Caution: 'pointer' must point to a pointer which was allocated by a
- * MemoryContext. It's not safe or valid to use this function on arbitrary
- * pointers as obtaining the MemoryContext which 'pointer' belongs to requires
- * possibly several pointer dereferences.
- */
-bool
-MemoryContextContains(MemoryContext context, void *pointer)
-{
- /*
- * Temporarily make this always return false as we don't yet have a fully
- * baked idea on how to make it work correctly with the new MemoryChunk
- * code.
- */
- return false;
-
-#ifdef NOT_USED
- MemoryContext ptr_context;
-
- /*
- * NB: We must perform run-time checks here which GetMemoryChunkContext()
- * does as assertions before calling GetMemoryChunkContext().
- *
- * Try to detect bogus pointers handed to us, poorly though we can.
- * Presumably, a pointer that isn't MAXALIGNED isn't pointing at an
- * allocated chunk.
- */
- if (pointer == NULL || pointer != (void *) MAXALIGN(pointer))
- return false;
-
- /*
- * OK, it's probably safe to look at the context.
- */
- ptr_context = GetMemoryChunkContext(pointer);
-
- return ptr_context == context;
-#endif
-}
-
/*
* MemoryContextCreate
* Context-type-independent part of context creation.
diff --git a/src/include/utils/memutils.h b/src/include/utils/memutils.h
index 52bc41ec53..4f6c5435ca 100644
--- a/src/include/utils/memutils.h
+++ b/src/include/utils/memutils.h
@@ -96,7 +96,6 @@ extern void MemoryContextAllowInCriticalSection(MemoryContext context,
#ifdef MEMORY_CONTEXT_CHECKING
extern void MemoryContextCheck(MemoryContext context);
#endif
-extern bool MemoryContextContains(MemoryContext context, void *pointer);
/* Handy macro for copying and assigning context ID ... but note double eval */
#define MemoryContextCopyAndSetIdentifier(cxt, id) \
On Wed, 5 Oct 2022 at 04:55, Tom Lane <tgl@sss.pgh.pa.us> wrote: > After studying the existing usages of MemoryContextContains, I think > there is a better answer, which is to just nuke them. I was under the impression you wanted to keep that function around in cassert builds for some of the guc.c changes you were making. > As far as I can tell, the datumCopy steps associated with aggregate > finalfns are basically useless. They only serve to prevent > returning a pointer directly to the aggregate's transition value > (or, perhaps, to a portion thereof). But what's wrong with that? > It'll last as long as we need it to. Maybe there was a reason > back before we required finalfns to not scribble on the transition > values, but those days are gone. Yeah, I wondered the same thing. I couldn't see a situation where the aggregate context would disappear. > The same goes for aggregate serialfns --- although there, I can't > avoid the feeling that the datumCopy step was just cargo-culted in. > I don't think there can exist a serialfn that doesn't return a > freshly-palloced bytea. Most likely. I probably copied that as I wouldn't have understood why we did any copying when calling the finalfn. I still don't understand why. Seems there's no good reason if we're both in favour of removing it. > The one place where we actually need the conditional datumCopy is > with window functions, and even there I don't think we need it > in simple cases with only one window function. The case that is > hazardous is where multiple window functions are sharing a > WindowObject. So I'm content to optimize the single-window-function > case and just always copy if there's more than one. (Sadly, there > is no existing regression test that catches this, so I added one.) I was unsure what window functions might exist out in the wild, so I'd added some code to pass along the return type information so that any extensions which need to make a copy can do so. However, maybe it's better just to wait to see if anyone complains about that before we go to the trouble. I've looked at your patches and don't see any problems. Our findings seem to be roughly the same. i.e the datumCopy is mostly useless. However, you've noticed the requirement to datumCopy when there are multiple window functions using the same window along with yours containing the call to MakeExpandedObjectReadOnly() where I missed that. This should also slightly improve the performance of LEAD and LAG with byref types, which seems like a good side-effect. I guess the commit message for 0002 should mention that for pointers to allocated chunks that GetMemoryChunkContext() can be used in place of MemoryContextContains(). I did see that PostGIS does use MemoryContextContains(), though I didn't look at their code to figure out if they're always passing it a pointer to an allocated chunk. Maybe it's worth doing; #define MemoryContextContains(c, p) (GetMemoryChunkContext(p) == (c)) in memutils.h? or are we better to force extension authors to re-evaluate their code in case anyone is passing memory that's not pointing directly to a palloc'd chunk? David
David Rowley <dgrowleyml@gmail.com> writes:
> On Wed, 5 Oct 2022 at 04:55, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> After studying the existing usages of MemoryContextContains, I think
>> there is a better answer, which is to just nuke them.
> I was under the impression you wanted to keep that function around in
> cassert builds for some of the guc.c changes you were making.
I would've liked to have it, but for that purpose an unreliable version
of MemoryContextContains is probably little help. In any case, as you
mention, I can do something with GetMemoryChunkContext() instead.
>> As far as I can tell, the datumCopy steps associated with aggregate
>> finalfns are basically useless. They only serve to prevent
>> returning a pointer directly to the aggregate's transition value
>> (or, perhaps, to a portion thereof). But what's wrong with that?
>> It'll last as long as we need it to. Maybe there was a reason
>> back before we required finalfns to not scribble on the transition
>> values, but those days are gone.
> Yeah, I wondered the same thing. I couldn't see a situation where the
> aggregate context would disappear.
I have a feeling that we might once have aggressively reset the
aggregate context ... but we don't anymore.
>> The one place where we actually need the conditional datumCopy is
>> with window functions, and even there I don't think we need it
>> in simple cases with only one window function. The case that is
>> hazardous is where multiple window functions are sharing a
>> WindowObject. So I'm content to optimize the single-window-function
>> case and just always copy if there's more than one. (Sadly, there
>> is no existing regression test that catches this, so I added one.)
> I was unsure what window functions might exist out in the wild, so I'd
> added some code to pass along the return type information so that any
> extensions which need to make a copy can do so. However, maybe it's
> better just to wait to see if anyone complains about that before we go
> to the trouble.
I'd originally feared that a window function might return a pointer
into the WindowObject's tuplestore, which we manipulate immediately
after the window function returns. However, AFAICS the APIs we
provide don't have any such hazard. The actual hazard is that we
might get a pointer into one of the temp slots, which are independent
storage because we tell them to copy the source tuple. (Maybe a comment
about that would be appropriate.)
> I've looked at your patches and don't see any problems. Our findings
> seem to be roughly the same. i.e the datumCopy is mostly useless.
Cool, I'll push in a little bit.
> Maybe it's worth doing;
> #define MemoryContextContains(c, p) (GetMemoryChunkContext(p) == (c))
> in memutils.h? or are we better to force extension authors to
> re-evaluate their code in case anyone is passing memory that's not
> pointing directly to a palloc'd chunk?
I think the latter. The fact that MemoryContextContains was (mostly)
safe on arbitrary pointers was an important part of its API IMO.
I'm okay with giving up that property to reduce chunk overhead,
but we'll do nobody any service by pretending we still have it.
regards, tom lane
David Rowley <dgrowleyml@gmail.com> writes:
> I did see that PostGIS does use
> MemoryContextContains(), though I didn't look at their code to figure
> out if they're always passing it a pointer to an allocated chunk.
As far as I can tell from a cursory look, they should be able to use
the GetMemoryChunkContext workaround, because they are just doing this
with SHARED_GSERIALIZED objects, which seem to always be palloc'd.
regards, tom lane
One more thing: based on what I saw in working with my pending guc.c
changes, the assertions in GetMemoryChunkMethodID are largely useless
for detecting bogus pointers. I think we should do something more
like the attached, which will result in a clean failure if the method
ID bits are invalid.
I'm a little tempted also to rearrange the MemoryContextMethodID enum
so that likely bit patterns like 000 are not valid IDs.
While I didn't change it here, I wonder why GetMemoryChunkMethodID is
publicly exposed at all. AFAICS it could be static inside mcxt.c.
regards, tom lane
diff --git a/src/backend/utils/mmgr/mcxt.c b/src/backend/utils/mmgr/mcxt.c
index c80236d285..e82d9b21ba 100644
--- a/src/backend/utils/mmgr/mcxt.c
+++ b/src/backend/utils/mmgr/mcxt.c
@@ -32,6 +32,11 @@
#include "utils/memutils_internal.h"
+static void BogusFree(void *pointer);
+static void *BogusRealloc(void *pointer, Size size);
+static MemoryContext BogusGetChunkContext(void *pointer);
+static Size BogusGetChunkSpace(void *pointer);
+
/*****************************************************************************
* GLOBAL MEMORY *
*****************************************************************************/
@@ -74,10 +79,42 @@ static const MemoryContextMethods mcxt_methods[] = {
[MCTX_SLAB_ID].get_chunk_context = SlabGetChunkContext,
[MCTX_SLAB_ID].get_chunk_space = SlabGetChunkSpace,
[MCTX_SLAB_ID].is_empty = SlabIsEmpty,
- [MCTX_SLAB_ID].stats = SlabStats
+ [MCTX_SLAB_ID].stats = SlabStats,
#ifdef MEMORY_CONTEXT_CHECKING
- ,[MCTX_SLAB_ID].check = SlabCheck
+ [MCTX_SLAB_ID].check = SlabCheck,
#endif
+
+ /*
+ * Unused (as yet) IDs should have dummy entries here. This allows us to
+ * fail cleanly if a bogus pointer is passed to pfree or the like. It
+ * seems sufficient to provide routines for the methods that might get
+ * invoked from inspection of a chunk (see MCXT_METHOD calls below).
+ */
+
+ [MCTX_UNUSED3_ID].free_p = BogusFree,
+ [MCTX_UNUSED3_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED3_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED3_ID].get_chunk_space = BogusGetChunkSpace,
+
+ [MCTX_UNUSED4_ID].free_p = BogusFree,
+ [MCTX_UNUSED4_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED4_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED4_ID].get_chunk_space = BogusGetChunkSpace,
+
+ [MCTX_UNUSED5_ID].free_p = BogusFree,
+ [MCTX_UNUSED5_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED5_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED5_ID].get_chunk_space = BogusGetChunkSpace,
+
+ [MCTX_UNUSED6_ID].free_p = BogusFree,
+ [MCTX_UNUSED6_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED6_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED6_ID].get_chunk_space = BogusGetChunkSpace,
+
+ [MCTX_UNUSED7_ID].free_p = BogusFree,
+ [MCTX_UNUSED7_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED7_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED7_ID].get_chunk_space = BogusGetChunkSpace,
};
/*
@@ -125,6 +162,34 @@ static void MemoryContextStatsPrint(MemoryContext context, void *passthru,
#define MCXT_METHOD(pointer, method) \
mcxt_methods[GetMemoryChunkMethodID(pointer)].method
+/*
+ * Support routines to trap use of invalid memory context method IDs
+ * (from calling pfree or the like on a bogus pointer).
+ */
+static void
+BogusFree(void *pointer)
+{
+ elog(ERROR, "pfree called with invalid pointer %p", pointer);
+}
+
+static void *
+BogusRealloc(void *pointer, Size size)
+{
+ elog(ERROR, "repalloc called with invalid pointer %p", pointer);
+}
+
+static MemoryContext
+BogusGetChunkContext(void *pointer)
+{
+ elog(ERROR, "GetMemoryChunkContext called with invalid pointer %p", pointer);
+}
+
+static Size
+BogusGetChunkSpace(void *pointer)
+{
+ elog(ERROR, "GetMemoryChunkSpace called with invalid pointer %p", pointer);
+}
+
/*****************************************************************************
* EXPORTED ROUTINES *
diff --git a/src/include/utils/memutils_internal.h b/src/include/utils/memutils_internal.h
index 377cee7a84..797409ee94 100644
--- a/src/include/utils/memutils_internal.h
+++ b/src/include/utils/memutils_internal.h
@@ -77,12 +77,20 @@ extern void SlabCheck(MemoryContext context);
* The maximum value for this enum is constrained by
* MEMORY_CONTEXT_METHODID_MASK. If an enum value higher than that is
* required then MEMORY_CONTEXT_METHODID_BITS will need to be increased.
+ * For robustness, ensure that MemoryContextMethodID has a value for
+ * each possible bit-pattern of MEMORY_CONTEXT_METHODID_MASK, and make
+ * dummy entries for unused IDs in the mcxt_methods[] array.
*/
typedef enum MemoryContextMethodID
{
MCTX_ASET_ID,
MCTX_GENERATION_ID,
MCTX_SLAB_ID,
+ MCTX_UNUSED3_ID,
+ MCTX_UNUSED4_ID,
+ MCTX_UNUSED5_ID,
+ MCTX_UNUSED6_ID,
+ MCTX_UNUSED7_ID
} MemoryContextMethodID;
/*
@@ -110,20 +118,11 @@ extern void MemoryContextCreate(MemoryContext node,
* directly precedes 'pointer'.
*/
static inline MemoryContextMethodID
-GetMemoryChunkMethodID(void *pointer)
+GetMemoryChunkMethodID(const void *pointer)
{
uint64 header;
- /*
- * Try to detect bogus pointers handed to us, poorly though we can.
- * Presumably, a pointer that isn't MAXALIGNED isn't pointing at an
- * allocated chunk.
- */
- Assert(pointer != NULL);
- Assert(pointer == (void *) MAXALIGN(pointer));
-
- header = *((uint64 *) ((char *) pointer - sizeof(uint64)));
-
+ header = *((const uint64 *) ((const char *) pointer - sizeof(uint64)));
return (MemoryContextMethodID) (header & MEMORY_CONTEXT_METHODID_MASK);
}
Hi,
On 2022-10-06 14:19:21 -0400, Tom Lane wrote:
> One more thing: based on what I saw in working with my pending guc.c
> changes, the assertions in GetMemoryChunkMethodID are largely useless
> for detecting bogus pointers. I think we should do something more
> like the attached, which will result in a clean failure if the method
> ID bits are invalid.
Yea, that makes sense. I wouldn't get rid of the MAXALIGN Assert though - it's
not replaced by the the unused mcxt stuff afaics.
> I'm a little tempted also to rearrange the MemoryContextMethodID enum
> so that likely bit patterns like 000 are not valid IDs.
Yea, I was suggesting that during a review as well. We can still relax it
later if we run out of bits.
> +/*
> + * Support routines to trap use of invalid memory context method IDs
> + * (from calling pfree or the like on a bogus pointer).
> + */
> +static void
> +BogusFree(void *pointer)
> +{
> + elog(ERROR, "pfree called with invalid pointer %p", pointer);
> +}
Maybe worth printing the method ID as well?
Greetings,
Andres Freund
Andres Freund <andres@anarazel.de> writes:
> Yea, that makes sense. I wouldn't get rid of the MAXALIGN Assert though - it's
> not replaced by the the unused mcxt stuff afaics.
OK.
>> + elog(ERROR, "pfree called with invalid pointer %p", pointer);
> Maybe worth printing the method ID as well?
I doubt it'd be useful.
regards, tom lane
Hi, On 2022-10-06 15:10:44 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > >> + elog(ERROR, "pfree called with invalid pointer %p", pointer); > > > Maybe worth printing the method ID as well? > > I doubt it'd be useful. I was thinking it could be useful to see whether the bits are likely to be the result of wipe_mem(). But I guess for that we should print the whole byte, rather than just the method. Perhaps not worth it. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2022-10-06 15:10:44 -0400, Tom Lane wrote:
>> Andres Freund <andres@anarazel.de> writes:
>>> Maybe worth printing the method ID as well?
>> I doubt it'd be useful.
> I was thinking it could be useful to see whether the bits are likely to be the
> result of wipe_mem(). But I guess for that we should print the whole byte,
> rather than just the method. Perhaps not worth it.
I think printing the whole int64 header word would be appropriate if
we were hoping for something like that. Still not sure if it's useful.
On the other hand, if control gets there then you are probably in need
of debugging help ...
regards, tom lane
Here's a v2 incorporating discussed changes.
In reordering enum MemoryContextMethodID, I arranged to avoid using
000 and 111 as valid IDs, since those bit patterns will appear in
zeroed and wipe_mem'd memory respectively. Those should probably be
more-or-less-permanent exclusions, so I added comments about it.
I also avoided using 001: based on my work with converting guc.c to use
palloc [1], it seems that pfree'ing a malloc-provided pointer is likely
to see 001 a lot, at least on 64-bit glibc platforms. I've not stuck
my nose into the glibc sources to see how consistent that might be,
but it definitely recurred several times while I was chasing down
places needing adjustment in that patch.
I'm not sure if there are any platform-dependent reasons to avoid
other bit-patterns, but we do still have a little bit of flexibility
left here if anyone has candidates.
regards, tom lane
[1] https://www.postgresql.org/message-id/2982579.1662416866%40sss.pgh.pa.us
diff --git a/src/backend/utils/mmgr/mcxt.c b/src/backend/utils/mmgr/mcxt.c
index c80236d285..b1a3c74830 100644
--- a/src/backend/utils/mmgr/mcxt.c
+++ b/src/backend/utils/mmgr/mcxt.c
@@ -32,6 +32,11 @@
#include "utils/memutils_internal.h"
+static void BogusFree(void *pointer);
+static void *BogusRealloc(void *pointer, Size size);
+static MemoryContext BogusGetChunkContext(void *pointer);
+static Size BogusGetChunkSpace(void *pointer);
+
/*****************************************************************************
* GLOBAL MEMORY *
*****************************************************************************/
@@ -74,10 +79,42 @@ static const MemoryContextMethods mcxt_methods[] = {
[MCTX_SLAB_ID].get_chunk_context = SlabGetChunkContext,
[MCTX_SLAB_ID].get_chunk_space = SlabGetChunkSpace,
[MCTX_SLAB_ID].is_empty = SlabIsEmpty,
- [MCTX_SLAB_ID].stats = SlabStats
+ [MCTX_SLAB_ID].stats = SlabStats,
#ifdef MEMORY_CONTEXT_CHECKING
- ,[MCTX_SLAB_ID].check = SlabCheck
+ [MCTX_SLAB_ID].check = SlabCheck,
#endif
+
+ /*
+ * Unused (as yet) IDs should have dummy entries here. This allows us to
+ * fail cleanly if a bogus pointer is passed to pfree or the like. It
+ * seems sufficient to provide routines for the methods that might get
+ * invoked from inspection of a chunk (see MCXT_METHOD calls below).
+ */
+
+ [MCTX_UNUSED1_ID].free_p = BogusFree,
+ [MCTX_UNUSED1_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED1_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED1_ID].get_chunk_space = BogusGetChunkSpace,
+
+ [MCTX_UNUSED2_ID].free_p = BogusFree,
+ [MCTX_UNUSED2_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED2_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED2_ID].get_chunk_space = BogusGetChunkSpace,
+
+ [MCTX_UNUSED3_ID].free_p = BogusFree,
+ [MCTX_UNUSED3_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED3_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED3_ID].get_chunk_space = BogusGetChunkSpace,
+
+ [MCTX_UNUSED4_ID].free_p = BogusFree,
+ [MCTX_UNUSED4_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED4_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED4_ID].get_chunk_space = BogusGetChunkSpace,
+
+ [MCTX_UNUSED5_ID].free_p = BogusFree,
+ [MCTX_UNUSED5_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED5_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED5_ID].get_chunk_space = BogusGetChunkSpace,
};
/*
@@ -125,6 +162,77 @@ static void MemoryContextStatsPrint(MemoryContext context, void *passthru,
#define MCXT_METHOD(pointer, method) \
mcxt_methods[GetMemoryChunkMethodID(pointer)].method
+/*
+ * GetMemoryChunkMethodID
+ * Return the MemoryContextMethodID from the uint64 chunk header which
+ * directly precedes 'pointer'.
+ */
+static inline MemoryContextMethodID
+GetMemoryChunkMethodID(const void *pointer)
+{
+ uint64 header;
+
+ /*
+ * Try to detect bogus pointers handed to us, poorly though we can.
+ * Presumably, a pointer that isn't MAXALIGNED isn't pointing at an
+ * allocated chunk.
+ */
+ Assert(pointer == (const void *) MAXALIGN(pointer));
+
+ header = *((const uint64 *) ((const char *) pointer - sizeof(uint64)));
+
+ return (MemoryContextMethodID) (header & MEMORY_CONTEXT_METHODID_MASK);
+}
+
+/*
+ * GetMemoryChunkHeader
+ * Return the uint64 chunk header which directly precedes 'pointer'.
+ *
+ * This is only used after GetMemoryChunkMethodID, so no need for error checks.
+ */
+static inline uint64
+GetMemoryChunkHeader(const void *pointer)
+{
+ return *((const uint64 *) ((const char *) pointer - sizeof(uint64)));
+}
+
+/*
+ * Support routines to trap use of invalid memory context method IDs
+ * (from calling pfree or the like on a bogus pointer). As a possible
+ * aid in debugging, we report the header word along with the pointer
+ * address (if we got here, there must be an accessible header word).
+ */
+static void
+BogusFree(void *pointer)
+{
+ elog(ERROR, "pfree called with invalid pointer %p (header 0x%016llx)",
+ pointer, (long long) GetMemoryChunkHeader(pointer));
+}
+
+static void *
+BogusRealloc(void *pointer, Size size)
+{
+ elog(ERROR, "repalloc called with invalid pointer %p (header 0x%016llx)",
+ pointer, (long long) GetMemoryChunkHeader(pointer));
+ return NULL; /* keep compiler quiet */
+}
+
+static MemoryContext
+BogusGetChunkContext(void *pointer)
+{
+ elog(ERROR, "GetMemoryChunkContext called with invalid pointer %p (header 0x%016llx)",
+ pointer, (long long) GetMemoryChunkHeader(pointer));
+ return NULL; /* keep compiler quiet */
+}
+
+static Size
+BogusGetChunkSpace(void *pointer)
+{
+ elog(ERROR, "GetMemoryChunkSpace called with invalid pointer %p (header 0x%016llx)",
+ pointer, (long long) GetMemoryChunkHeader(pointer));
+ return 0; /* keep compiler quiet */
+}
+
/*****************************************************************************
* EXPORTED ROUTINES *
diff --git a/src/include/utils/memutils_internal.h b/src/include/utils/memutils_internal.h
index 377cee7a84..e90808dbea 100644
--- a/src/include/utils/memutils_internal.h
+++ b/src/include/utils/memutils_internal.h
@@ -74,15 +74,23 @@ extern void SlabCheck(MemoryContext context);
* MemoryContextMethodID
* A unique identifier for each MemoryContext implementation which
* indicates the index into the mcxt_methods[] array. See mcxt.c.
- * The maximum value for this enum is constrained by
- * MEMORY_CONTEXT_METHODID_MASK. If an enum value higher than that is
- * required then MEMORY_CONTEXT_METHODID_BITS will need to be increased.
+ *
+ * For robust error detection, ensure that MemoryContextMethodID has a value
+ * for each possible bit-pattern of MEMORY_CONTEXT_METHODID_MASK, and make
+ * dummy entries for unused IDs in the mcxt_methods[] array. We also try
+ * to avoid using bit-patterns as valid IDs if they are likely to occur in
+ * garbage data.
*/
typedef enum MemoryContextMethodID
{
+ MCTX_UNUSED1_ID, /* avoid: 000 occurs in never-used memory */
+ MCTX_UNUSED2_ID,
MCTX_ASET_ID,
MCTX_GENERATION_ID,
MCTX_SLAB_ID,
+ MCTX_UNUSED3_ID,
+ MCTX_UNUSED4_ID,
+ MCTX_UNUSED5_ID /* avoid: 111 occurs in wipe_mem'd memory */
} MemoryContextMethodID;
/*
@@ -104,27 +112,4 @@ extern void MemoryContextCreate(MemoryContext node,
MemoryContext parent,
const char *name);
-/*
- * GetMemoryChunkMethodID
- * Return the MemoryContextMethodID from the uint64 chunk header which
- * directly precedes 'pointer'.
- */
-static inline MemoryContextMethodID
-GetMemoryChunkMethodID(void *pointer)
-{
- uint64 header;
-
- /*
- * Try to detect bogus pointers handed to us, poorly though we can.
- * Presumably, a pointer that isn't MAXALIGNED isn't pointing at an
- * allocated chunk.
- */
- Assert(pointer != NULL);
- Assert(pointer == (void *) MAXALIGN(pointer));
-
- header = *((uint64 *) ((char *) pointer - sizeof(uint64)));
-
- return (MemoryContextMethodID) (header & MEMORY_CONTEXT_METHODID_MASK);
-}
-
#endif /* MEMUTILS_INTERNAL_H */
On Fri, 7 Oct 2022 at 09:05, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Here's a v2 incorporating discussed changes. > > In reordering enum MemoryContextMethodID, I arranged to avoid using > 000 and 111 as valid IDs, since those bit patterns will appear in > zeroed and wipe_mem'd memory respectively. Those should probably be > more-or-less-permanent exclusions, so I added comments about it. I'm just considering some future developer here that is writing a new MemoryContext type and there's no more space left and she or he needs to either use 000 or 111. I think if that was me, I might be unsure if I should be looking to expand the bit-space to make room. I might think that based on the word "avoid" in: > + MCTX_UNUSED1_ID, /* avoid: 000 occurs in never-used memory */ > + MCTX_UNUSED5_ID /* avoid: 111 occurs in wipe_mem'd memory */ but the final sentence in: > + * dummy entries for unused IDs in the mcxt_methods[] array. We also try > + * to avoid using bit-patterns as valid IDs if they are likely to occur in > + * garbage data. leads me to believe we're just *trying* to avoid using these bit-patterns. Also, the comment in mcxt_methods[] might make me believe that it's ok for me to use them if I really need to. > + * Unused (as yet) IDs should have dummy entries here. This allows us to Based on these comments, I'm not quite sure if I should be completely avoiding using 000 and 111 or I should just use those last when there are no other free slots in the array. It might be quite a long time before someone is in this situation, so should we be more clear? However, maybe you've left it this way as you feel it's a decision that must be made in the future, perhaps based on how difficult it would be to free up another bit? David
David Rowley <dgrowleyml@gmail.com> writes:
> However, maybe you've left it this way as you feel it's a decision
> that must be made in the future, perhaps based on how difficult it
> would be to free up another bit?
Yeah, pretty much. I think it'll be a long time before we run out
of memory context IDs, and it's hard to anticipate the tradeoffs
that will matter at that time.
regards, tom lane
I wrote:
> I also avoided using 001: based on my work with converting guc.c to use
> palloc [1], it seems that pfree'ing a malloc-provided pointer is likely
> to see 001 a lot, at least on 64-bit glibc platforms.
I poked at this some more by creating a function that intentionally
does pfree(malloc(N)) for various values of N.
RHEL8, x86_64: the low-order nibble of the header is consistently 0001.
macOS 12.6, arm64: the low-order nibble is consistently 0000.
FreeBSD 13.0, arm64: Usually the low-order nibble is 0000 or 1111,
but for some smaller values of N it sometimes comes up as 0010.
NetBSD 9.2, amd64: results similar to FreeBSD.
I still haven't looked into anybody's source code, but based on these
results I'm inclined to leave both 001 and 010 IDs unused for now.
That'll help the GUC malloc -> palloc transition tremendously, because
people will get fairly clear errors rather than weird assertions
and/or memory corruption. That'll leave us in a situation where only
one more context ID can be assigned without risk of reducing our error
detection ability, but I'm content with that for now.
regards, tom lane
On Fri, 7 Oct 2022 at 10:57, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I poked at this some more by creating a function that intentionally > does pfree(malloc(N)) for various values of N. > > RHEL8, x86_64: the low-order nibble of the header is consistently 0001. > > macOS 12.6, arm64: the low-order nibble is consistently 0000. > > FreeBSD 13.0, arm64: Usually the low-order nibble is 0000 or 1111, > but for some smaller values of N it sometimes comes up as 0010. > > NetBSD 9.2, amd64: results similar to FreeBSD. Out of curiosity I tried using the attached on a Windows machine and got: 0: 130951 1: 131061 2: 133110 3: 129053 4: 131061 5: 131067 6: 131070 7: 131203 So it seems pretty much entirely inconsistent on that platform. Also, on an Ubuntu machine I didn't get the consistent 0001 as you got on your RHEL machine. There were a very small number of 010's there too: 0: 0 1: 1048569 2: 7 3: 0 4: 0 5: 0 6: 0 7: 0 Despite Windows not being very consistent here, I think it's a useful change as if our most common platform (Linux/glibc) is fairly consistent, then that'll give us wide coverage to track down any buggy code. In anycase, even on Windows (assuming it's completely random) we'll have a 5 out of 8 chance of getting a nice error message if there are any bad pointers being passed. David
Attachment
I wrote:
> FreeBSD 13.0, arm64: Usually the low-order nibble is 0000 or 1111,
> but for some smaller values of N it sometimes comes up as 0010.
> NetBSD 9.2, amd64: results similar to FreeBSD.
I looked into NetBSD's malloc.c, and what I discovered is that
their implementation doesn't have any chunk headers: chunks of
the same size are allocated consecutively within pages, and all
the bookkeeping data is somewhere else. Presumably FreeBSD is
the same. So the apparent special case with 0010 is an illusion,
even though I saw it on two different machines (maybe it's a
specific value that we're allocating??) The most likely case
is 0000 due to the immediately previous word having never been
used (note that like palloc, they round chunk sizes up to powers
of two, so unused space at the end of a chunk is common). I'm
not sure whether the cases I saw with 1111 are chance artifacts
or reflect some real mechanism, but probably the former. I
thought for a bit that that might be the effects of wipe_mem
on the previous chunk, but palloc'd storage would never share
the same page as malloc'd storage under this allocator, because
we grab it from malloc in larger-than-page chunks.
However ... after looking into glib's malloc.c, I find that
it does use a chunk header, and very conveniently the three bits
that we care about are flag bits (at least on 64-bit machines):
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
The A bit is only used when threading, and hence should always
be zero in our usage. The M bit only gets set in chunks large
enough to be separately mmap'd, so when it is set P must be 0.
If M is not set then P seems to usually be 1, although it could
be 0. So the three possibilities for what we can see under
glibc are 000, 001, 010 (the last only occuring for chunks
larger than 128K). This squares with experimental results on
my machine --- I'd not thought to try sizes above 100K before.
So I'm still inclined to leave 001 and 010 both unused, but the
reason why is different than I thought before.
Going forward, we could commandeer 010 if we need to without losing
very much debuggability, since malloc'ing more than 128K in a chunk
won't happen often.
regards, tom lane
I wrote:
> So I'm still inclined to leave 001 and 010 both unused, but the
> reason why is different than I thought before.
Which leaves me with the attached proposed wording.
regards, tom lane
diff --git a/src/backend/utils/mmgr/mcxt.c b/src/backend/utils/mmgr/mcxt.c
index c80236d285..b1a3c74830 100644
--- a/src/backend/utils/mmgr/mcxt.c
+++ b/src/backend/utils/mmgr/mcxt.c
@@ -32,6 +32,11 @@
#include "utils/memutils_internal.h"
+static void BogusFree(void *pointer);
+static void *BogusRealloc(void *pointer, Size size);
+static MemoryContext BogusGetChunkContext(void *pointer);
+static Size BogusGetChunkSpace(void *pointer);
+
/*****************************************************************************
* GLOBAL MEMORY *
*****************************************************************************/
@@ -74,10 +79,42 @@ static const MemoryContextMethods mcxt_methods[] = {
[MCTX_SLAB_ID].get_chunk_context = SlabGetChunkContext,
[MCTX_SLAB_ID].get_chunk_space = SlabGetChunkSpace,
[MCTX_SLAB_ID].is_empty = SlabIsEmpty,
- [MCTX_SLAB_ID].stats = SlabStats
+ [MCTX_SLAB_ID].stats = SlabStats,
#ifdef MEMORY_CONTEXT_CHECKING
- ,[MCTX_SLAB_ID].check = SlabCheck
+ [MCTX_SLAB_ID].check = SlabCheck,
#endif
+
+ /*
+ * Unused (as yet) IDs should have dummy entries here. This allows us to
+ * fail cleanly if a bogus pointer is passed to pfree or the like. It
+ * seems sufficient to provide routines for the methods that might get
+ * invoked from inspection of a chunk (see MCXT_METHOD calls below).
+ */
+
+ [MCTX_UNUSED1_ID].free_p = BogusFree,
+ [MCTX_UNUSED1_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED1_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED1_ID].get_chunk_space = BogusGetChunkSpace,
+
+ [MCTX_UNUSED2_ID].free_p = BogusFree,
+ [MCTX_UNUSED2_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED2_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED2_ID].get_chunk_space = BogusGetChunkSpace,
+
+ [MCTX_UNUSED3_ID].free_p = BogusFree,
+ [MCTX_UNUSED3_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED3_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED3_ID].get_chunk_space = BogusGetChunkSpace,
+
+ [MCTX_UNUSED4_ID].free_p = BogusFree,
+ [MCTX_UNUSED4_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED4_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED4_ID].get_chunk_space = BogusGetChunkSpace,
+
+ [MCTX_UNUSED5_ID].free_p = BogusFree,
+ [MCTX_UNUSED5_ID].realloc = BogusRealloc,
+ [MCTX_UNUSED5_ID].get_chunk_context = BogusGetChunkContext,
+ [MCTX_UNUSED5_ID].get_chunk_space = BogusGetChunkSpace,
};
/*
@@ -125,6 +162,77 @@ static void MemoryContextStatsPrint(MemoryContext context, void *passthru,
#define MCXT_METHOD(pointer, method) \
mcxt_methods[GetMemoryChunkMethodID(pointer)].method
+/*
+ * GetMemoryChunkMethodID
+ * Return the MemoryContextMethodID from the uint64 chunk header which
+ * directly precedes 'pointer'.
+ */
+static inline MemoryContextMethodID
+GetMemoryChunkMethodID(const void *pointer)
+{
+ uint64 header;
+
+ /*
+ * Try to detect bogus pointers handed to us, poorly though we can.
+ * Presumably, a pointer that isn't MAXALIGNED isn't pointing at an
+ * allocated chunk.
+ */
+ Assert(pointer == (const void *) MAXALIGN(pointer));
+
+ header = *((const uint64 *) ((const char *) pointer - sizeof(uint64)));
+
+ return (MemoryContextMethodID) (header & MEMORY_CONTEXT_METHODID_MASK);
+}
+
+/*
+ * GetMemoryChunkHeader
+ * Return the uint64 chunk header which directly precedes 'pointer'.
+ *
+ * This is only used after GetMemoryChunkMethodID, so no need for error checks.
+ */
+static inline uint64
+GetMemoryChunkHeader(const void *pointer)
+{
+ return *((const uint64 *) ((const char *) pointer - sizeof(uint64)));
+}
+
+/*
+ * Support routines to trap use of invalid memory context method IDs
+ * (from calling pfree or the like on a bogus pointer). As a possible
+ * aid in debugging, we report the header word along with the pointer
+ * address (if we got here, there must be an accessible header word).
+ */
+static void
+BogusFree(void *pointer)
+{
+ elog(ERROR, "pfree called with invalid pointer %p (header 0x%016llx)",
+ pointer, (long long) GetMemoryChunkHeader(pointer));
+}
+
+static void *
+BogusRealloc(void *pointer, Size size)
+{
+ elog(ERROR, "repalloc called with invalid pointer %p (header 0x%016llx)",
+ pointer, (long long) GetMemoryChunkHeader(pointer));
+ return NULL; /* keep compiler quiet */
+}
+
+static MemoryContext
+BogusGetChunkContext(void *pointer)
+{
+ elog(ERROR, "GetMemoryChunkContext called with invalid pointer %p (header 0x%016llx)",
+ pointer, (long long) GetMemoryChunkHeader(pointer));
+ return NULL; /* keep compiler quiet */
+}
+
+static Size
+BogusGetChunkSpace(void *pointer)
+{
+ elog(ERROR, "GetMemoryChunkSpace called with invalid pointer %p (header 0x%016llx)",
+ pointer, (long long) GetMemoryChunkHeader(pointer));
+ return 0; /* keep compiler quiet */
+}
+
/*****************************************************************************
* EXPORTED ROUTINES *
diff --git a/src/include/utils/memutils_internal.h b/src/include/utils/memutils_internal.h
index 377cee7a84..bc2cbdd506 100644
--- a/src/include/utils/memutils_internal.h
+++ b/src/include/utils/memutils_internal.h
@@ -74,15 +74,26 @@ extern void SlabCheck(MemoryContext context);
* MemoryContextMethodID
* A unique identifier for each MemoryContext implementation which
* indicates the index into the mcxt_methods[] array. See mcxt.c.
- * The maximum value for this enum is constrained by
- * MEMORY_CONTEXT_METHODID_MASK. If an enum value higher than that is
- * required then MEMORY_CONTEXT_METHODID_BITS will need to be increased.
+ *
+ * For robust error detection, ensure that MemoryContextMethodID has a value
+ * for each possible bit-pattern of MEMORY_CONTEXT_METHODID_MASK, and make
+ * dummy entries for unused IDs in the mcxt_methods[] array. We also try
+ * to avoid using bit-patterns as valid IDs if they are likely to occur in
+ * garbage data, or if they could falsely match on chunks that are really from
+ * malloc not palloc. (We can't tell that for most malloc implementations,
+ * but it happens that glibc stores flag bits in the same place where we put
+ * the MemoryContextMethodID, so the possible values are predictable for it.)
*/
typedef enum MemoryContextMethodID
{
+ MCTX_UNUSED1_ID, /* 000 occurs in never-used memory */
+ MCTX_UNUSED2_ID, /* glibc malloc'd chunks usually match 001 */
+ MCTX_UNUSED3_ID, /* glibc malloc'd chunks > 128kB match 010 */
MCTX_ASET_ID,
MCTX_GENERATION_ID,
MCTX_SLAB_ID,
+ MCTX_UNUSED4_ID, /* available */
+ MCTX_UNUSED5_ID /* 111 occurs in wipe_mem'd memory */
} MemoryContextMethodID;
/*
@@ -104,27 +115,4 @@ extern void MemoryContextCreate(MemoryContext node,
MemoryContext parent,
const char *name);
-/*
- * GetMemoryChunkMethodID
- * Return the MemoryContextMethodID from the uint64 chunk header which
- * directly precedes 'pointer'.
- */
-static inline MemoryContextMethodID
-GetMemoryChunkMethodID(void *pointer)
-{
- uint64 header;
-
- /*
- * Try to detect bogus pointers handed to us, poorly though we can.
- * Presumably, a pointer that isn't MAXALIGNED isn't pointing at an
- * allocated chunk.
- */
- Assert(pointer != NULL);
- Assert(pointer == (void *) MAXALIGN(pointer));
-
- header = *((uint64 *) ((char *) pointer - sizeof(uint64)));
-
- return (MemoryContextMethodID) (header & MEMORY_CONTEXT_METHODID_MASK);
-}
-
#endif /* MEMUTILS_INTERNAL_H */
On Fri, 7 Oct 2022 at 12:35, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Which leaves me with the attached proposed wording. No objections here. With these comments I'd be using slot MCTX_UNUSED4_ID first, then I'd probably be looking at MCTX_UNUSED5_ID after adjusting wipe_mem to do something other than setting bytes to 0x7F. I'd then use MCTX_UNUSED3_ID since that pattern is only used for larger chunks with glibc (per your findings). After that, I'd probably start looking into making more than 3 bits available. If that wasn't possible, I'd be using MCTX_UNUSED2_ID and at last resort MCTX_UNUSED1_ID. David
David Rowley <dgrowleyml@gmail.com> writes:
> On Fri, 7 Oct 2022 at 12:35, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Which leaves me with the attached proposed wording.
> No objections here.
Cool, I'll push in a little bit.
> With these comments I'd be using slot MCTX_UNUSED4_ID first, then I'd
> probably be looking at MCTX_UNUSED5_ID after adjusting wipe_mem to do
> something other than setting bytes to 0x7F.
Well, the only way that you could free up a bitpattern that way is
to make wipe_mem use something ending in 000 or 001. I'd be against
using 000 because then wiped memory might appear to contain valid
(aligned) pointers. But perhaps 001 would be ok.
> I'd then use
> MCTX_UNUSED3_ID since that pattern is only used for larger chunks with
> glibc (per your findings). After that, I'd probably start looking
> into making more than 3 bits available. If that wasn't possible, I'd
> be using MCTX_UNUSED2_ID and at last resort MCTX_UNUSED1_ID.
If we get to having three-quarters or seven-eighths of the bitpatterns
being valid IDs, we'll have precious little ability to detect garbage.
So personally I'd put "find a fourth bit" higher on the priority list.
In any case, we needn't invest more effort here until someone comes
with a fifth context method ... and I don't recall hearing discussions
of even a fourth one yet.
regards, tom lane
So I pushed that, but I don't feel that we're out of the woods yet.
As I mentioned at [1], while testing this stuff I hit a case where
aset.c will try to wipe_mem practically the entire address space after
being asked to pfree() an invalid pointer. The specific reproducer
isn't too interesting because it depends on the pre-80ef92675 state of
the code, but what I take away from this is that aset.c is still far
too fragile as it stands.
One problem is that aset.c generally isn't too careful about whether
a putative chunk is actually one of its chunks. That was okay before
c6e0fe1f2 because we would never get to AllocSetFree etc unless the
word before the chunk data pointed at a moderately-sane AllocSet.
Now, we can arrive at that code on the strength of three random bits,
so it's got to be more careful. In the attached patch, I make
AllocSetIsValid do an IsA() test, and make sure to apply it to the
aset we think we have found from the chunk header. This is not in
any way a new check: what it is doing is replacing the IsA check done
by the "AssertArg(MemoryContextIsValid(context))" that was performed
by GetMemoryChunkContext in the old code, and that we've completely
lost in the code as it stands.
The other problem, which is what is leading to wipe_mem-the-universe,
is that aset.c figures the size of a non-external chunk essentially
as "1 << MemoryChunkGetValue(chunk)", where the "value" field is 30
bits wide and has undergone exactly zero validation before
AllocSetFree uses the size in memset. That's far, far too trusting.
In the attached I put in some asserts to verify that the value field
is in the valid range for a freelist index, which should usually
trigger if we have a garbage value, or at the very least constrain
the damage.
What I am mainly wondering about at this point is whether Asserts
are good enough or we should use actual test-and-elog checks for
these things. The precedent of the old GetMemoryChunkContext
implementation suggests that assertions are good enough for the
AllocSetIsValid tests. On the other hand, there are existing
cross-checks like
if (block->freeptr != block->endptr)
elog(ERROR, "could not find block containing chunk %p", chunk);
so at least in some code paths we've thought it is worth expending
such tests in production builds. Any opinions?
I imagine generation.c and slab.c need similar bulletproofing
measures, but I didn't look at them yet.
regards, tom lane
[1] https://www.postgresql.org/message-id/3436789.1665187055%40sss.pgh.pa.us
diff --git a/src/backend/utils/mmgr/aset.c b/src/backend/utils/mmgr/aset.c
index ec423375ae..76a9f02bd8 100644
--- a/src/backend/utils/mmgr/aset.c
+++ b/src/backend/utils/mmgr/aset.c
@@ -132,6 +132,10 @@ typedef struct AllocFreeListLink
#define GetFreeListLink(chkptr) \
(AllocFreeListLink *) ((char *) (chkptr) + ALLOC_CHUNKHDRSZ)
+/* Validate a freelist index retrieved from a chunk header */
+#define FreeListIdxIsValid(fidx) \
+ ((fidx) >= 0 && (fidx) < ALLOCSET_NUM_FREELISTS)
+
/* Determine the size of the chunk based on the freelist index */
#define GetChunkSizeFromFreeListIdx(fidx) \
((((Size) 1) << ALLOC_MINBITS) << (fidx))
@@ -202,7 +206,15 @@ typedef struct AllocBlockData
* AllocSetIsValid
* True iff set is valid allocation set.
*/
-#define AllocSetIsValid(set) PointerIsValid(set)
+#define AllocSetIsValid(set) \
+ (PointerIsValid(set) && IsA(set, AllocSetContext))
+
+/*
+ * AllocBlockIsValid
+ * True iff block is valid block of allocation set.
+ */
+#define AllocBlockIsValid(block) \
+ (PointerIsValid(block) && AllocSetIsValid((block)->aset))
/*
* We always store external chunks on a dedicated block. This makes fetching
@@ -530,8 +542,7 @@ AllocSetReset(MemoryContext context)
{
AllocSet set = (AllocSet) context;
AllocBlock block;
- Size keepersize PG_USED_FOR_ASSERTS_ONLY
- = set->keeper->endptr - ((char *) set);
+ Size keepersize PG_USED_FOR_ASSERTS_ONLY;
AssertArg(AllocSetIsValid(set));
@@ -540,6 +551,9 @@ AllocSetReset(MemoryContext context)
AllocSetCheck(context);
#endif
+ /* Remember keeper block size for Assert below */
+ keepersize = set->keeper->endptr - ((char *) set);
+
/* Clear chunk freelists */
MemSetAligned(set->freelist, 0, sizeof(set->freelist));
@@ -598,8 +612,7 @@ AllocSetDelete(MemoryContext context)
{
AllocSet set = (AllocSet) context;
AllocBlock block = set->blocks;
- Size keepersize PG_USED_FOR_ASSERTS_ONLY
- = set->keeper->endptr - ((char *) set);
+ Size keepersize PG_USED_FOR_ASSERTS_ONLY;
AssertArg(AllocSetIsValid(set));
@@ -608,6 +621,9 @@ AllocSetDelete(MemoryContext context)
AllocSetCheck(context);
#endif
+ /* Remember keeper block size for Assert below */
+ keepersize = set->keeper->endptr - ((char *) set);
+
/*
* If the context is a candidate for a freelist, put it into that freelist
* instead of destroying it.
@@ -994,9 +1010,10 @@ AllocSetFree(void *pointer)
if (MemoryChunkIsExternal(chunk))
{
-
+ /* Release single-chunk block. */
AllocBlock block = ExternalChunkGetBlock(chunk);
+ AssertArg(AllocBlockIsValid(block));
set = block->aset;
#ifdef MEMORY_CONTEXT_CHECKING
@@ -1011,7 +1028,6 @@ AllocSetFree(void *pointer)
}
#endif
-
/*
* Try to verify that we have a sane block pointer, the freeptr should
* match the endptr.
@@ -1036,12 +1052,17 @@ AllocSetFree(void *pointer)
}
else
{
- int fidx = MemoryChunkGetValue(chunk);
AllocBlock block = MemoryChunkGetBlock(chunk);
- AllocFreeListLink *link = GetFreeListLink(chunk);
+ int fidx;
+ AllocFreeListLink *link;
+ AssertArg(AllocBlockIsValid(block));
set = block->aset;
+ fidx = MemoryChunkGetValue(chunk);
+ Assert(FreeListIdxIsValid(fidx));
+ link = GetFreeListLink(chunk);
+
#ifdef MEMORY_CONTEXT_CHECKING
/* Test for someone scribbling on unused space in chunk */
if (chunk->requested_size < GetChunkSizeFromFreeListIdx(fidx))
@@ -1089,6 +1110,7 @@ AllocSetRealloc(void *pointer, Size size)
AllocSet set;
MemoryChunk *chunk = PointerGetMemoryChunk(pointer);
Size oldsize;
+ int fidx;
/* Allow access to private part of chunk header. */
VALGRIND_MAKE_MEM_DEFINED(chunk, ALLOCCHUNK_PRIVATE_LEN);
@@ -1105,9 +1127,11 @@ AllocSetRealloc(void *pointer, Size size)
Size oldblksize;
block = ExternalChunkGetBlock(chunk);
- oldsize = block->endptr - (char *) pointer;
+ AssertArg(AllocBlockIsValid(block));
set = block->aset;
+ oldsize = block->endptr - (char *) pointer;
+
#ifdef MEMORY_CONTEXT_CHECKING
/* Test for someone scribbling on unused space in chunk */
Assert(chunk->requested_size < oldsize);
@@ -1201,9 +1225,13 @@ AllocSetRealloc(void *pointer, Size size)
}
block = MemoryChunkGetBlock(chunk);
- oldsize = GetChunkSizeFromFreeListIdx(MemoryChunkGetValue(chunk));
+ AssertArg(AllocBlockIsValid(block));
set = block->aset;
+ fidx = MemoryChunkGetValue(chunk);
+ Assert(FreeListIdxIsValid(fidx));
+ oldsize = GetChunkSizeFromFreeListIdx(fidx);
+
#ifdef MEMORY_CONTEXT_CHECKING
/* Test for someone scribbling on unused space in chunk */
if (chunk->requested_size < oldsize)
@@ -1328,6 +1356,7 @@ AllocSetGetChunkContext(void *pointer)
else
block = (AllocBlock) MemoryChunkGetBlock(chunk);
+ AssertArg(AllocBlockIsValid(block));
set = block->aset;
return &set->header;
@@ -1342,16 +1371,19 @@ Size
AllocSetGetChunkSpace(void *pointer)
{
MemoryChunk *chunk = PointerGetMemoryChunk(pointer);
+ int fidx;
if (MemoryChunkIsExternal(chunk))
{
AllocBlock block = ExternalChunkGetBlock(chunk);
+ AssertArg(AllocBlockIsValid(block));
return block->endptr - (char *) chunk;
}
- return GetChunkSizeFromFreeListIdx(MemoryChunkGetValue(chunk)) +
- ALLOC_CHUNKHDRSZ;
+ fidx = MemoryChunkGetValue(chunk);
+ Assert(FreeListIdxIsValid(fidx));
+ return GetChunkSizeFromFreeListIdx(fidx) + ALLOC_CHUNKHDRSZ;
}
/*
@@ -1361,6 +1393,8 @@ AllocSetGetChunkSpace(void *pointer)
bool
AllocSetIsEmpty(MemoryContext context)
{
+ AssertArg(AllocSetIsValid(context));
+
/*
* For now, we say "empty" only if the context is new or just reset. We
* could examine the freelists to determine if all space has been freed,
@@ -1394,6 +1428,8 @@ AllocSetStats(MemoryContext context,
AllocBlock block;
int fidx;
+ AssertArg(AllocSetIsValid(set));
+
/* Include context header in totalspace */
totalspace = MAXALIGN(sizeof(AllocSetContext));
@@ -1405,14 +1441,14 @@ AllocSetStats(MemoryContext context,
}
for (fidx = 0; fidx < ALLOCSET_NUM_FREELISTS; fidx++)
{
+ Size chksz = GetChunkSizeFromFreeListIdx(fidx);
MemoryChunk *chunk = set->freelist[fidx];
while (chunk != NULL)
{
- Size chksz = GetChunkSizeFromFreeListIdx(MemoryChunkGetValue(chunk));
AllocFreeListLink *link = GetFreeListLink(chunk);
- Assert(GetChunkSizeFromFreeListIdx(fidx) == chksz);
+ Assert(MemoryChunkGetValue(chunk) == fidx);
freechunks++;
freespace += chksz + ALLOC_CHUNKHDRSZ;
@@ -1522,7 +1558,13 @@ AllocSetCheck(MemoryContext context)
}
else
{
- chsize = GetChunkSizeFromFreeListIdx(MemoryChunkGetValue(chunk)); /* aligned chunk size */
+ int fidx = MemoryChunkGetValue(chunk);
+
+ if (!FreeListIdxIsValid(fidx))
+ elog(WARNING, "problem in alloc set %s: bad chunk size for chunk %p in block %p",
+ name, chunk, block);
+
+ chsize = GetChunkSizeFromFreeListIdx(fidx); /* aligned chunk size */
/*
* Check the stored block offset correctly references this
I wrote:
> What I am mainly wondering about at this point is whether Asserts
> are good enough or we should use actual test-and-elog checks for
> these things.
Hearing no comments on that, I decided that a good policy would be
to use Asserts in the paths dealing with small chunks but test-and-elog
in the paths dealing with large chunks. We already had test-and-elog
sanity checks in the latter paths, at least in aset.c, which the new
checks can reasonably be combined with. It's unlikely that the
large-chunk case is at all performance-critical, too. But adding
runtime checks in the small-chunk paths would probably risk losing
some performance in production builds, and I'm not currently prepared
to argue that the problem is big enough to justify that.
Hence v2 attached, which cleans things up a tad in aset.c and then
extends similar policy to generation.c and slab.c. Of note is
that slab.c was doing things like this:
SlabContext *slab = castNode(SlabContext, context);
Assert(slab);
which has about the same effect as what I'm proposing with
AllocSetIsValid, but (a) it's randomly different from the
other allocators, and (b) it's probably a hair less efficient,
because I doubt the compiler can optimize away castNode's
special handling of NULL. So I made these bits follow the
style of aset.c.
regards, tom lane
diff --git a/src/backend/utils/mmgr/aset.c b/src/backend/utils/mmgr/aset.c
index ec423375ae..db402e3a41 100644
--- a/src/backend/utils/mmgr/aset.c
+++ b/src/backend/utils/mmgr/aset.c
@@ -132,6 +132,10 @@ typedef struct AllocFreeListLink
#define GetFreeListLink(chkptr) \
(AllocFreeListLink *) ((char *) (chkptr) + ALLOC_CHUNKHDRSZ)
+/* Validate a freelist index retrieved from a chunk header */
+#define FreeListIdxIsValid(fidx) \
+ ((fidx) >= 0 && (fidx) < ALLOCSET_NUM_FREELISTS)
+
/* Determine the size of the chunk based on the freelist index */
#define GetChunkSizeFromFreeListIdx(fidx) \
((((Size) 1) << ALLOC_MINBITS) << (fidx))
@@ -202,7 +206,15 @@ typedef struct AllocBlockData
* AllocSetIsValid
* True iff set is valid allocation set.
*/
-#define AllocSetIsValid(set) PointerIsValid(set)
+#define AllocSetIsValid(set) \
+ (PointerIsValid(set) && IsA(set, AllocSetContext))
+
+/*
+ * AllocBlockIsValid
+ * True iff block is valid block of allocation set.
+ */
+#define AllocBlockIsValid(block) \
+ (PointerIsValid(block) && AllocSetIsValid((block)->aset))
/*
* We always store external chunks on a dedicated block. This makes fetching
@@ -530,8 +542,7 @@ AllocSetReset(MemoryContext context)
{
AllocSet set = (AllocSet) context;
AllocBlock block;
- Size keepersize PG_USED_FOR_ASSERTS_ONLY
- = set->keeper->endptr - ((char *) set);
+ Size keepersize PG_USED_FOR_ASSERTS_ONLY;
AssertArg(AllocSetIsValid(set));
@@ -540,6 +551,9 @@ AllocSetReset(MemoryContext context)
AllocSetCheck(context);
#endif
+ /* Remember keeper block size for Assert below */
+ keepersize = set->keeper->endptr - ((char *) set);
+
/* Clear chunk freelists */
MemSetAligned(set->freelist, 0, sizeof(set->freelist));
@@ -598,8 +612,7 @@ AllocSetDelete(MemoryContext context)
{
AllocSet set = (AllocSet) context;
AllocBlock block = set->blocks;
- Size keepersize PG_USED_FOR_ASSERTS_ONLY
- = set->keeper->endptr - ((char *) set);
+ Size keepersize PG_USED_FOR_ASSERTS_ONLY;
AssertArg(AllocSetIsValid(set));
@@ -608,6 +621,9 @@ AllocSetDelete(MemoryContext context)
AllocSetCheck(context);
#endif
+ /* Remember keeper block size for Assert below */
+ keepersize = set->keeper->endptr - ((char *) set);
+
/*
* If the context is a candidate for a freelist, put it into that freelist
* instead of destroying it.
@@ -994,9 +1010,16 @@ AllocSetFree(void *pointer)
if (MemoryChunkIsExternal(chunk))
{
-
+ /* Release single-chunk block. */
AllocBlock block = ExternalChunkGetBlock(chunk);
+ /*
+ * Try to verify that we have a sane block pointer: the block header
+ * should reference an aset and the freeptr should match the endptr.
+ */
+ if (!AllocBlockIsValid(block) || block->freeptr != block->endptr)
+ elog(ERROR, "could not find block containing chunk %p", chunk);
+
set = block->aset;
#ifdef MEMORY_CONTEXT_CHECKING
@@ -1011,14 +1034,6 @@ AllocSetFree(void *pointer)
}
#endif
-
- /*
- * Try to verify that we have a sane block pointer, the freeptr should
- * match the endptr.
- */
- if (block->freeptr != block->endptr)
- elog(ERROR, "could not find block containing chunk %p", chunk);
-
/* OK, remove block from aset's list and free it */
if (block->prev)
block->prev->next = block->next;
@@ -1036,12 +1051,23 @@ AllocSetFree(void *pointer)
}
else
{
- int fidx = MemoryChunkGetValue(chunk);
AllocBlock block = MemoryChunkGetBlock(chunk);
- AllocFreeListLink *link = GetFreeListLink(chunk);
+ int fidx;
+ AllocFreeListLink *link;
+ /*
+ * In this path, for speed reasons we just Assert that the referenced
+ * block is good. We can also Assert that the value field is sane.
+ * Future field experience may show that these Asserts had better
+ * become regular runtime test-and-elog checks.
+ */
+ AssertArg(AllocBlockIsValid(block));
set = block->aset;
+ fidx = MemoryChunkGetValue(chunk);
+ Assert(FreeListIdxIsValid(fidx));
+ link = GetFreeListLink(chunk);
+
#ifdef MEMORY_CONTEXT_CHECKING
/* Test for someone scribbling on unused space in chunk */
if (chunk->requested_size < GetChunkSizeFromFreeListIdx(fidx))
@@ -1089,6 +1115,7 @@ AllocSetRealloc(void *pointer, Size size)
AllocSet set;
MemoryChunk *chunk = PointerGetMemoryChunk(pointer);
Size oldsize;
+ int fidx;
/* Allow access to private part of chunk header. */
VALGRIND_MAKE_MEM_DEFINED(chunk, ALLOCCHUNK_PRIVATE_LEN);
@@ -1105,9 +1132,18 @@ AllocSetRealloc(void *pointer, Size size)
Size oldblksize;
block = ExternalChunkGetBlock(chunk);
- oldsize = block->endptr - (char *) pointer;
+
+ /*
+ * Try to verify that we have a sane block pointer: the block header
+ * should reference an aset and the freeptr should match the endptr.
+ */
+ if (!AllocBlockIsValid(block) || block->freeptr != block->endptr)
+ elog(ERROR, "could not find block containing chunk %p", chunk);
+
set = block->aset;
+ oldsize = block->endptr - (char *) pointer;
+
#ifdef MEMORY_CONTEXT_CHECKING
/* Test for someone scribbling on unused space in chunk */
Assert(chunk->requested_size < oldsize);
@@ -1116,13 +1152,6 @@ AllocSetRealloc(void *pointer, Size size)
set->header.name, chunk);
#endif
- /*
- * Try to verify that we have a sane block pointer, the freeptr should
- * match the endptr.
- */
- if (block->freeptr != block->endptr)
- elog(ERROR, "could not find block containing chunk %p", chunk);
-
#ifdef MEMORY_CONTEXT_CHECKING
/* ensure there's always space for the sentinel byte */
chksize = MAXALIGN(size + 1);
@@ -1201,9 +1230,20 @@ AllocSetRealloc(void *pointer, Size size)
}
block = MemoryChunkGetBlock(chunk);
- oldsize = GetChunkSizeFromFreeListIdx(MemoryChunkGetValue(chunk));
+
+ /*
+ * In this path, for speed reasons we just Assert that the referenced
+ * block is good. We can also Assert that the value field is sane. Future
+ * field experience may show that these Asserts had better become regular
+ * runtime test-and-elog checks.
+ */
+ AssertArg(AllocBlockIsValid(block));
set = block->aset;
+ fidx = MemoryChunkGetValue(chunk);
+ Assert(FreeListIdxIsValid(fidx));
+ oldsize = GetChunkSizeFromFreeListIdx(fidx);
+
#ifdef MEMORY_CONTEXT_CHECKING
/* Test for someone scribbling on unused space in chunk */
if (chunk->requested_size < oldsize)
@@ -1328,6 +1368,7 @@ AllocSetGetChunkContext(void *pointer)
else
block = (AllocBlock) MemoryChunkGetBlock(chunk);
+ AssertArg(AllocBlockIsValid(block));
set = block->aset;
return &set->header;
@@ -1342,16 +1383,19 @@ Size
AllocSetGetChunkSpace(void *pointer)
{
MemoryChunk *chunk = PointerGetMemoryChunk(pointer);
+ int fidx;
if (MemoryChunkIsExternal(chunk))
{
AllocBlock block = ExternalChunkGetBlock(chunk);
+ AssertArg(AllocBlockIsValid(block));
return block->endptr - (char *) chunk;
}
- return GetChunkSizeFromFreeListIdx(MemoryChunkGetValue(chunk)) +
- ALLOC_CHUNKHDRSZ;
+ fidx = MemoryChunkGetValue(chunk);
+ Assert(FreeListIdxIsValid(fidx));
+ return GetChunkSizeFromFreeListIdx(fidx) + ALLOC_CHUNKHDRSZ;
}
/*
@@ -1361,6 +1405,8 @@ AllocSetGetChunkSpace(void *pointer)
bool
AllocSetIsEmpty(MemoryContext context)
{
+ AssertArg(AllocSetIsValid(context));
+
/*
* For now, we say "empty" only if the context is new or just reset. We
* could examine the freelists to determine if all space has been freed,
@@ -1394,6 +1440,8 @@ AllocSetStats(MemoryContext context,
AllocBlock block;
int fidx;
+ AssertArg(AllocSetIsValid(set));
+
/* Include context header in totalspace */
totalspace = MAXALIGN(sizeof(AllocSetContext));
@@ -1405,14 +1453,14 @@ AllocSetStats(MemoryContext context,
}
for (fidx = 0; fidx < ALLOCSET_NUM_FREELISTS; fidx++)
{
+ Size chksz = GetChunkSizeFromFreeListIdx(fidx);
MemoryChunk *chunk = set->freelist[fidx];
while (chunk != NULL)
{
- Size chksz = GetChunkSizeFromFreeListIdx(MemoryChunkGetValue(chunk));
AllocFreeListLink *link = GetFreeListLink(chunk);
- Assert(GetChunkSizeFromFreeListIdx(fidx) == chksz);
+ Assert(MemoryChunkGetValue(chunk) == fidx);
freechunks++;
freespace += chksz + ALLOC_CHUNKHDRSZ;
@@ -1522,7 +1570,13 @@ AllocSetCheck(MemoryContext context)
}
else
{
- chsize = GetChunkSizeFromFreeListIdx(MemoryChunkGetValue(chunk)); /* aligned chunk size */
+ int fidx = MemoryChunkGetValue(chunk);
+
+ if (!FreeListIdxIsValid(fidx))
+ elog(WARNING, "problem in alloc set %s: bad chunk size for chunk %p in block %p",
+ name, chunk, block);
+
+ chsize = GetChunkSizeFromFreeListIdx(fidx); /* aligned chunk size */
/*
* Check the stored block offset correctly references this
diff --git a/src/backend/utils/mmgr/generation.c b/src/backend/utils/mmgr/generation.c
index c743b24fa7..4cb75f493f 100644
--- a/src/backend/utils/mmgr/generation.c
+++ b/src/backend/utils/mmgr/generation.c
@@ -105,11 +105,20 @@ struct GenerationBlock
* simplicity.
*/
#define GENERATIONCHUNK_PRIVATE_LEN offsetof(MemoryChunk, hdrmask)
+
/*
* GenerationIsValid
- * True iff set is valid allocation set.
+ * True iff set is valid generation set.
+ */
+#define GenerationIsValid(set) \
+ (PointerIsValid(set) && IsA(set, GenerationContext))
+
+/*
+ * GenerationBlockIsValid
+ * True iff block is valid block of generation set.
*/
-#define GenerationIsValid(set) PointerIsValid(set)
+#define GenerationBlockIsValid(block) \
+ (PointerIsValid(block) && GenerationIsValid((block)->context))
/*
* We always store external chunks on a dedicated block. This makes fetching
@@ -345,6 +354,8 @@ GenerationAlloc(MemoryContext context, Size size)
Size chunk_size;
Size required_size;
+ AssertArg(GenerationIsValid(set));
+
#ifdef MEMORY_CONTEXT_CHECKING
/* ensure there's always space for the sentinel byte */
chunk_size = MAXALIGN(size + 1);
@@ -625,6 +636,14 @@ GenerationFree(void *pointer)
if (MemoryChunkIsExternal(chunk))
{
block = ExternalChunkGetBlock(chunk);
+
+ /*
+ * Try to verify that we have a sane block pointer: the block header
+ * should reference a generation context.
+ */
+ if (!GenerationBlockIsValid(block))
+ elog(ERROR, "could not find block containing chunk %p", chunk);
+
#if defined(MEMORY_CONTEXT_CHECKING) || defined(CLOBBER_FREED_MEMORY)
chunksize = block->endptr - (char *) pointer;
#endif
@@ -632,6 +651,14 @@ GenerationFree(void *pointer)
else
{
block = MemoryChunkGetBlock(chunk);
+
+ /*
+ * In this path, for speed reasons we just Assert that the referenced
+ * block is good. Future field experience may show that this Assert
+ * had better become a regular runtime test-and-elog check.
+ */
+ AssertArg(GenerationBlockIsValid(block));
+
#if defined(MEMORY_CONTEXT_CHECKING) || defined(CLOBBER_FREED_MEMORY)
chunksize = MemoryChunkGetValue(chunk);
#endif
@@ -723,11 +750,27 @@ GenerationRealloc(void *pointer, Size size)
if (MemoryChunkIsExternal(chunk))
{
block = ExternalChunkGetBlock(chunk);
+
+ /*
+ * Try to verify that we have a sane block pointer: the block header
+ * should reference a generation context.
+ */
+ if (!GenerationBlockIsValid(block))
+ elog(ERROR, "could not find block containing chunk %p", chunk);
+
oldsize = block->endptr - (char *) pointer;
}
else
{
block = MemoryChunkGetBlock(chunk);
+
+ /*
+ * In this path, for speed reasons we just Assert that the referenced
+ * block is good. Future field experience may show that this Assert
+ * had better become a regular runtime test-and-elog check.
+ */
+ AssertArg(GenerationBlockIsValid(block));
+
oldsize = MemoryChunkGetValue(chunk);
}
@@ -845,6 +888,7 @@ GenerationGetChunkContext(void *pointer)
else
block = (GenerationBlock *) MemoryChunkGetBlock(chunk);
+ AssertArg(GenerationBlockIsValid(block));
return &block->context->header;
}
@@ -863,6 +907,7 @@ GenerationGetChunkSpace(void *pointer)
{
GenerationBlock *block = ExternalChunkGetBlock(chunk);
+ AssertArg(GenerationBlockIsValid(block));
chunksize = block->endptr - (char *) pointer;
}
else
@@ -881,6 +926,8 @@ GenerationIsEmpty(MemoryContext context)
GenerationContext *set = (GenerationContext *) context;
dlist_iter iter;
+ AssertArg(GenerationIsValid(set));
+
dlist_foreach(iter, &set->blocks)
{
GenerationBlock *block = dlist_container(GenerationBlock, node, iter.cur);
@@ -917,6 +964,8 @@ GenerationStats(MemoryContext context,
Size freespace = 0;
dlist_iter iter;
+ AssertArg(GenerationIsValid(set));
+
/* Include context header in totalspace */
totalspace = MAXALIGN(sizeof(GenerationContext));
diff --git a/src/backend/utils/mmgr/slab.c b/src/backend/utils/mmgr/slab.c
index 9149aaafcb..f4f40007a4 100644
--- a/src/backend/utils/mmgr/slab.c
+++ b/src/backend/utils/mmgr/slab.c
@@ -111,6 +111,21 @@ typedef struct SlabBlock
#define SlabChunkIndex(slab, block, chunk) \
(((char *) chunk - SlabBlockStart(block)) / slab->fullChunkSize)
+/*
+ * SlabIsValid
+ * True iff set is valid slab allocation set.
+ */
+#define SlabIsValid(set) \
+ (PointerIsValid(set) && IsA(set, SlabContext))
+
+/*
+ * SlabBlockIsValid
+ * True iff block is valid block of slab allocation set.
+ */
+#define SlabBlockIsValid(block) \
+ (PointerIsValid(block) && SlabIsValid((block)->slab))
+
+
/*
* SlabContextCreate
* Create a new Slab context.
@@ -236,10 +251,10 @@ SlabContextCreate(MemoryContext parent,
void
SlabReset(MemoryContext context)
{
+ SlabContext *slab = (SlabContext *) context;
int i;
- SlabContext *slab = castNode(SlabContext, context);
- Assert(slab);
+ AssertArg(SlabIsValid(slab));
#ifdef MEMORY_CONTEXT_CHECKING
/* Check for corruption and leaks before freeing */
@@ -293,12 +308,12 @@ SlabDelete(MemoryContext context)
void *
SlabAlloc(MemoryContext context, Size size)
{
- SlabContext *slab = castNode(SlabContext, context);
+ SlabContext *slab = (SlabContext *) context;
SlabBlock *block;
MemoryChunk *chunk;
int idx;
- Assert(slab);
+ AssertArg(SlabIsValid(slab));
Assert((slab->minFreeChunks >= 0) &&
(slab->minFreeChunks < slab->chunksPerBlock));
@@ -450,10 +465,18 @@ SlabAlloc(MemoryContext context, Size size)
void
SlabFree(void *pointer)
{
- int idx;
MemoryChunk *chunk = PointerGetMemoryChunk(pointer);
SlabBlock *block = MemoryChunkGetBlock(chunk);
- SlabContext *slab = block->slab;
+ SlabContext *slab;
+ int idx;
+
+ /*
+ * Try to verify that we have a sane block pointer: the block header
+ * should reference a slab context.
+ */
+ if (!SlabBlockIsValid(block))
+ elog(ERROR, "could not find block containing chunk %p", chunk);
+ slab = block->slab;
#ifdef MEMORY_CONTEXT_CHECKING
/* Test for someone scribbling on unused space in chunk */
@@ -540,9 +563,16 @@ SlabRealloc(void *pointer, Size size)
{
MemoryChunk *chunk = PointerGetMemoryChunk(pointer);
SlabBlock *block = MemoryChunkGetBlock(chunk);
- SlabContext *slab = block->slab;
+ SlabContext *slab;
+
+ /*
+ * Try to verify that we have a sane block pointer: the block header
+ * should reference a slab context.
+ */
+ if (!SlabBlockIsValid(block))
+ elog(ERROR, "could not find block containing chunk %p", chunk);
+ slab = block->slab;
- Assert(slab);
/* can't do actual realloc with slab, but let's try to be gentle */
if (size == slab->chunkSize)
return pointer;
@@ -560,11 +590,9 @@ SlabGetChunkContext(void *pointer)
{
MemoryChunk *chunk = PointerGetMemoryChunk(pointer);
SlabBlock *block = MemoryChunkGetBlock(chunk);
- SlabContext *slab = block->slab;
-
- Assert(slab != NULL);
- return &slab->header;
+ AssertArg(SlabBlockIsValid(block));
+ return &block->slab->header;
}
/*
@@ -577,9 +605,10 @@ SlabGetChunkSpace(void *pointer)
{
MemoryChunk *chunk = PointerGetMemoryChunk(pointer);
SlabBlock *block = MemoryChunkGetBlock(chunk);
- SlabContext *slab = block->slab;
+ SlabContext *slab;
- Assert(slab);
+ AssertArg(SlabBlockIsValid(block));
+ slab = block->slab;
return slab->fullChunkSize;
}
@@ -591,9 +620,9 @@ SlabGetChunkSpace(void *pointer)
bool
SlabIsEmpty(MemoryContext context)
{
- SlabContext *slab = castNode(SlabContext, context);
+ SlabContext *slab = (SlabContext *) context;
- Assert(slab);
+ AssertArg(SlabIsValid(slab));
return (slab->nblocks == 0);
}
@@ -613,13 +642,15 @@ SlabStats(MemoryContext context,
MemoryContextCounters *totals,
bool print_to_stderr)
{
- SlabContext *slab = castNode(SlabContext, context);
+ SlabContext *slab = (SlabContext *) context;
Size nblocks = 0;
Size freechunks = 0;
Size totalspace;
Size freespace = 0;
int i;
+ AssertArg(SlabIsValid(slab));
+
/* Include context header in totalspace */
totalspace = slab->headerSize;
@@ -672,11 +703,11 @@ SlabStats(MemoryContext context,
void
SlabCheck(MemoryContext context)
{
+ SlabContext *slab = (SlabContext *) context;
int i;
- SlabContext *slab = castNode(SlabContext, context);
const char *name = slab->header.name;
- Assert(slab);
+ AssertArg(SlabIsValid(slab));
Assert(slab->chunksPerBlock > 0);
/* walk all the freelists */
On Tue, 11 Oct 2022 at 08:35, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Hearing no comments on that, I decided that a good policy would be > to use Asserts in the paths dealing with small chunks but test-and-elog > in the paths dealing with large chunks. This seems like a good policy. I think it's good to get at least the Asserts in there. If we have any troubles in the future then we can revisit this and reconsider if we need to elog them instead. > Hence v2 attached, which cleans things up a tad in aset.c and then > extends similar policy to generation.c and slab.c. Looking at your changes to SlabFree(), I don't really think that change is well aligned to the newly proposed policy. My understanding of the rationale behind this policy is that large chunks get malloced and will be slower anyway, so the elog(ERROR) is less overhead for those. In SlabFree(), we're most likely not doing any free()s, so I don't quite understand why you've added the elog rather than the Assert for this case. The slab allocator *should* be very fast. I don't have any issue with any of the other changes. David
David Rowley <dgrowleyml@gmail.com> writes:
> Looking at your changes to SlabFree(), I don't really think that
> change is well aligned to the newly proposed policy. My understanding
> of the rationale behind this policy is that large chunks get malloced
> and will be slower anyway, so the elog(ERROR) is less overhead for
> those. In SlabFree(), we're most likely not doing any free()s, so I
> don't quite understand why you've added the elog rather than the
> Assert for this case. The slab allocator *should* be very fast.
Yeah, slab.c hasn't any distinction between large and small chunks,
so we have to just pick one policy or the other. I'd hoped to get
away with the more robust runtime test on the basis that slab allocation
is not used so much that this'd result in any noticeable performance
change. SlabRealloc, at least, is not used *at all* per the code
coverage tests, and if we're there at all we should be highly suspicious
that something is wrong. However, I could be wrong about SlabFree,
and if you're going to hold my feet to the fire then I'll change it
rather than try to produce some performance evidence.
regards, tom lane
On Tue, 11 Oct 2022 at 10:07, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Yeah, slab.c hasn't any distinction between large and small chunks, > so we have to just pick one policy or the other. I'd hoped to get > away with the more robust runtime test on the basis that slab allocation > is not used so much that this'd result in any noticeable performance > change. SlabRealloc, at least, is not used *at all* per the code > coverage tests, and if we're there at all we should be highly suspicious > that something is wrong. However, I could be wrong about SlabFree, > and if you're going to hold my feet to the fire then I'll change it > rather than try to produce some performance evidence. The main reason I brought it up was that only yesterday I was looking into fixing the slowness of the Slab allocator. It's currently quite far behind the performance of both generation.c and aset.c and it would be very nice to bring it up to at least be on-par with those. Ideally there would be some performance advantages of the fixed-sized chunks. I'd just rather not have any additional things go in to make that goal harder to reach. The proposed patches in [1] do aim to make additional usages of the slab allocator, and I have a feeling that we'll want to fix the performance of slab.c before those. Perhaps the Asserts are a better option if we're to get the proposed radix tree implementation. David [1] https://postgr.es/m/CAD21AoD3w76wERs_Lq7_uA6+gTaoOERPji+Yz8Ac6aui4JwvTg@mail.gmail.com
David Rowley <dgrowleyml@gmail.com> writes:
> The main reason I brought it up was that only yesterday I was looking
> into fixing the slowness of the Slab allocator. It's currently quite
> far behind the performance of both generation.c and aset.c and it
> would be very nice to bring it up to at least be on-par with those.
Really!? That's pretty sad, because surely it should be handling a
simpler case.
Anyway, I'm about to push this with an Assert in SlabFree and
run-time test in SlabRealloc. That should be enough to assuage
my safety concerns, and then we can think about better performance.
regards, tom lane
On Tue, Oct 11, 2022 at 5:31 AM David Rowley <dgrowleyml@gmail.com> wrote:
>
> The proposed patches in [1] do aim to make additional usages of the
> slab allocator, and I have a feeling that we'll want to fix the
> performance of slab.c before those. Perhaps the Asserts are a better
> option if we're to get the proposed radix tree implementation.
Going by [1], that use case is not actually a natural fit for slab because of memory fragmentation. The motivation to use slab there was that the allocation sizes are just over a power of two, leading to a lot of wasted space for aset. FWIW, I have proposed in that thread a scheme to squeeze things into power-of-two sizes without wasting quite as much space. That's not a done deal, of course, but it could work today without adding memory management code.
[1] https://www.postgresql.org/message-id/20220704220038.at2ane5xkymzzssb%40awork3.anarazel.de
--
John Naylor
EDB: http://www.enterprisedb.com
Hi, On 2022-10-11 10:21:17 +0700, John Naylor wrote: > On Tue, Oct 11, 2022 at 5:31 AM David Rowley <dgrowleyml@gmail.com> wrote: > > > > The proposed patches in [1] do aim to make additional usages of the > > slab allocator, and I have a feeling that we'll want to fix the > > performance of slab.c before those. Perhaps the Asserts are a better > > option if we're to get the proposed radix tree implementation. > > Going by [1], that use case is not actually a natural fit for slab because > of memory fragmentation. > > [1] > https://www.postgresql.org/message-id/20220704220038.at2ane5xkymzzssb%40awork3.anarazel.de Not so sure about that - IIRC I made one slab for each different size class, which seemed to work well and suit slab well? Greetings, Andres Freund
On Thu, Oct 20, 2022 at 1:55 AM Andres Freund <andres@anarazel.de> wrote:
>
> Hi,
>
> On 2022-10-11 10:21:17 +0700, John Naylor wrote:
> > On Tue, Oct 11, 2022 at 5:31 AM David Rowley <dgrowleyml@gmail.com> wrote:
> > >
> > > The proposed patches in [1] do aim to make additional usages of the
> > > slab allocator, and I have a feeling that we'll want to fix the
> > > performance of slab.c before those. Perhaps the Asserts are a better
> > > option if we're to get the proposed radix tree implementation.
> >
> > Going by [1], that use case is not actually a natural fit for slab because
> > of memory fragmentation.
> >
> > [1]
> > https://www.postgresql.org/message-id/20220704220038.at2ane5xkymzzssb%40awork3.anarazel.de
>
> Not so sure about that - IIRC I made one slab for each different size class,
> which seemed to work well and suit slab well?
If that's the case, then great! The linked message didn't give me that impression, but I won't worry about it.
--
John Naylor
EDB: http://www.enterprisedb.com