Re: Reducing the chunk header sizes on all memory context types - Mailing list pgsql-hackers
| From | David Rowley |
|---|---|
| Subject | Re: Reducing the chunk header sizes on all memory context types |
| Date | |
| Msg-id | CAApHDvpuhcPWCzkXZuQQgB8YjPNQSvnncbzZ6pwpHFr2QMMD2w@mail.gmail.com Whole thread Raw |
| In response to | Re: Reducing the chunk header sizes on all memory context types (David Rowley <dgrowleyml@gmail.com>) |
| Responses |
Re: Reducing the chunk header sizes on all memory context types
|
| List | pgsql-hackers |
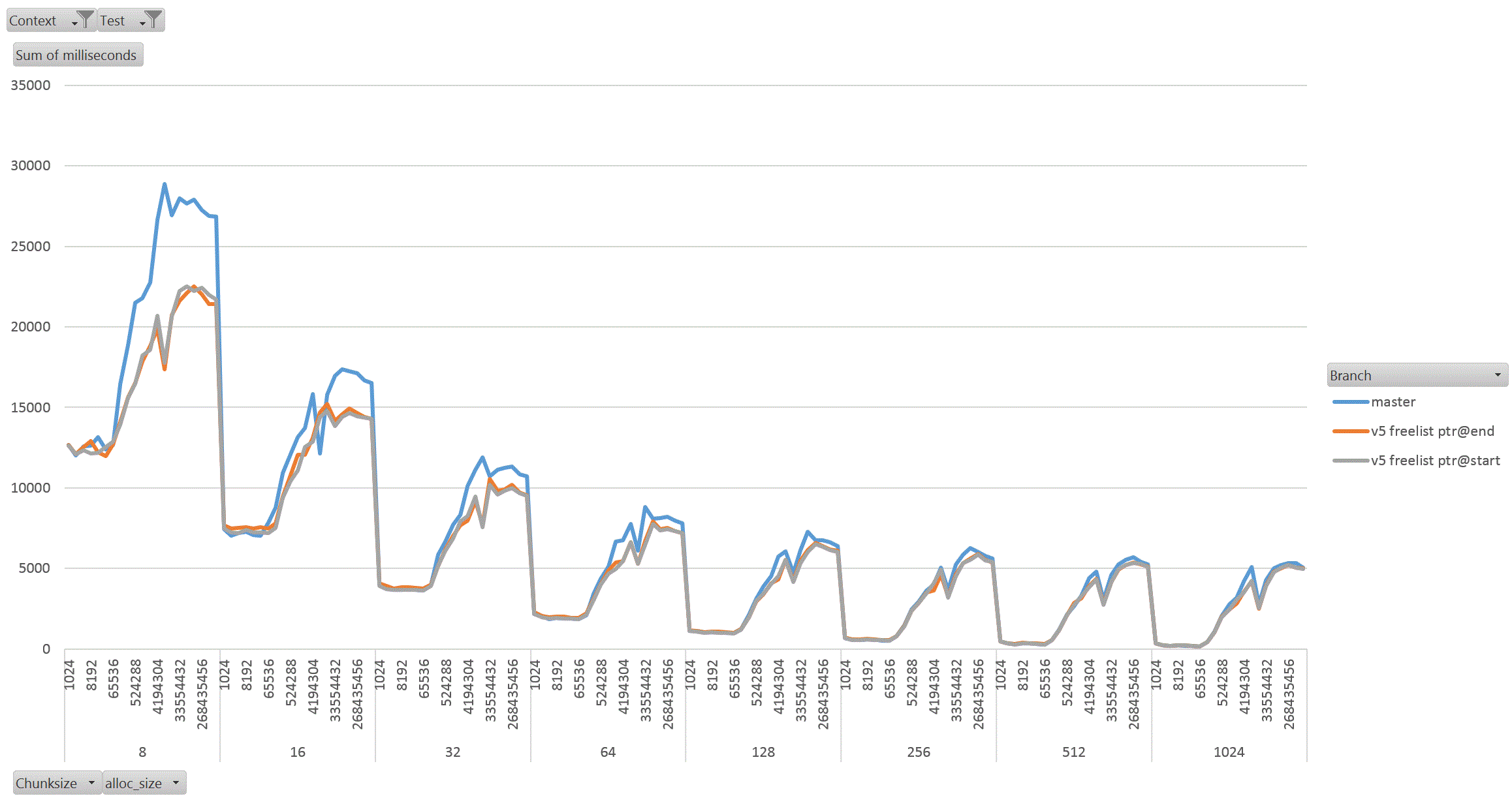
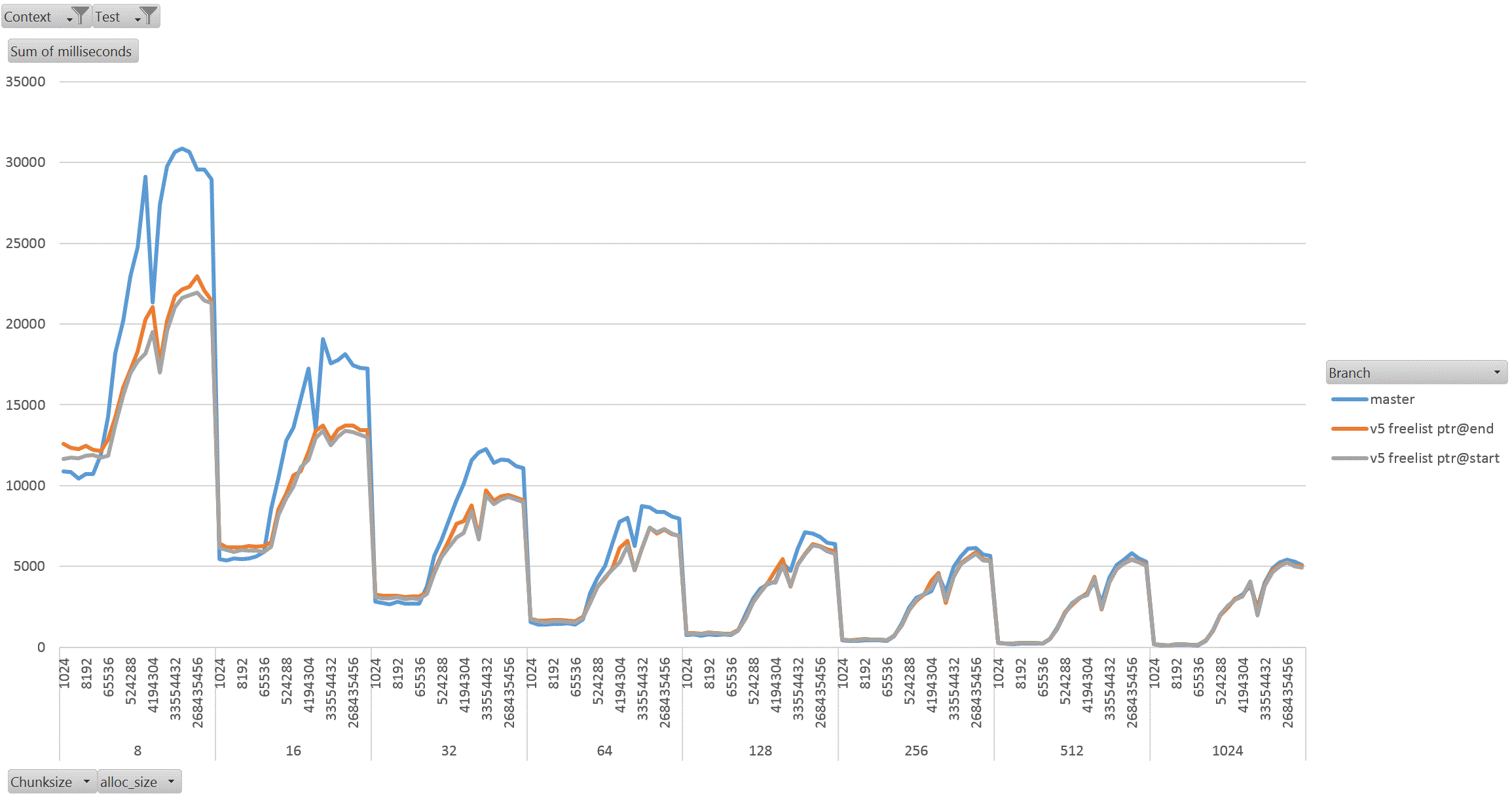
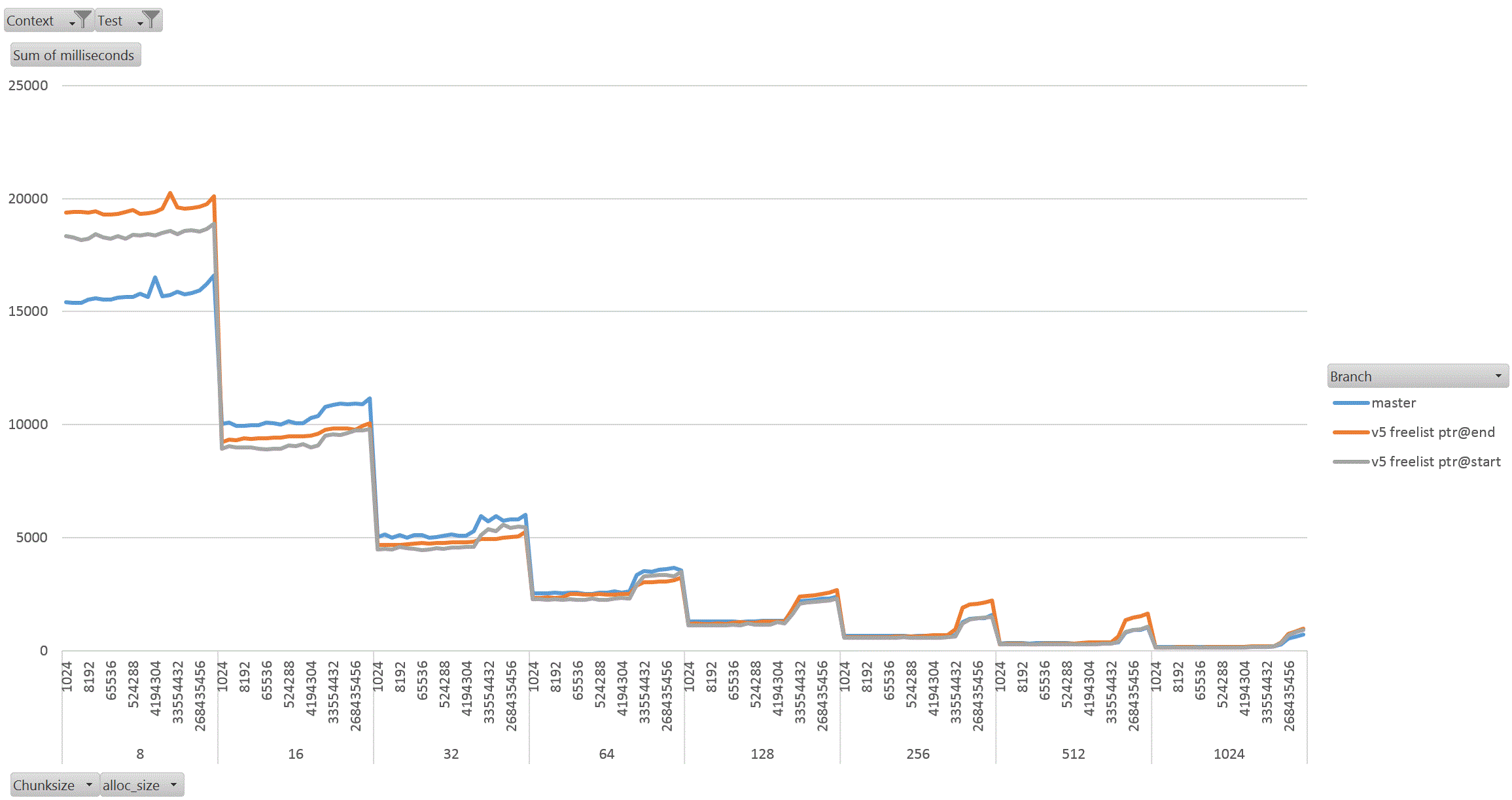
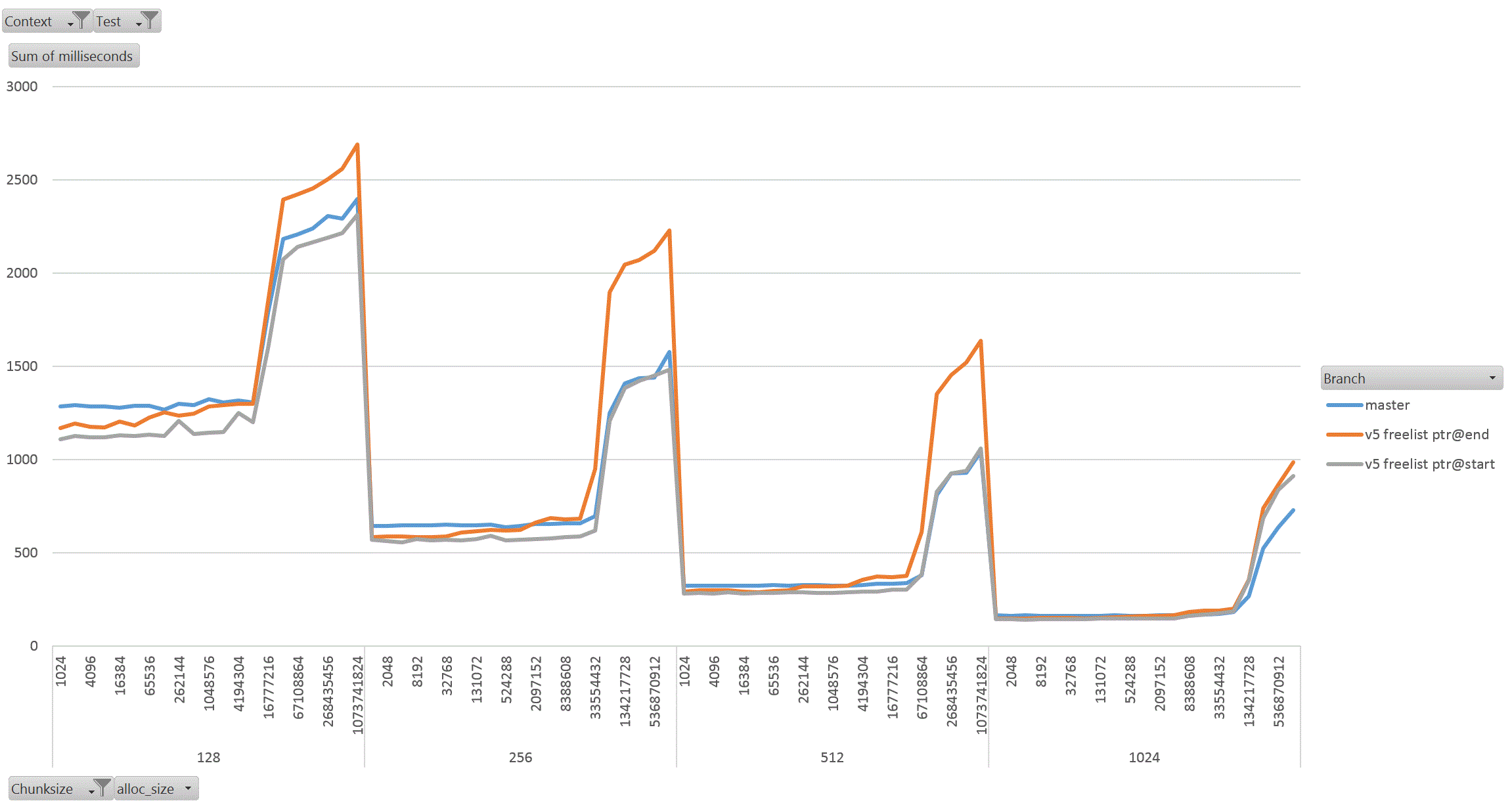
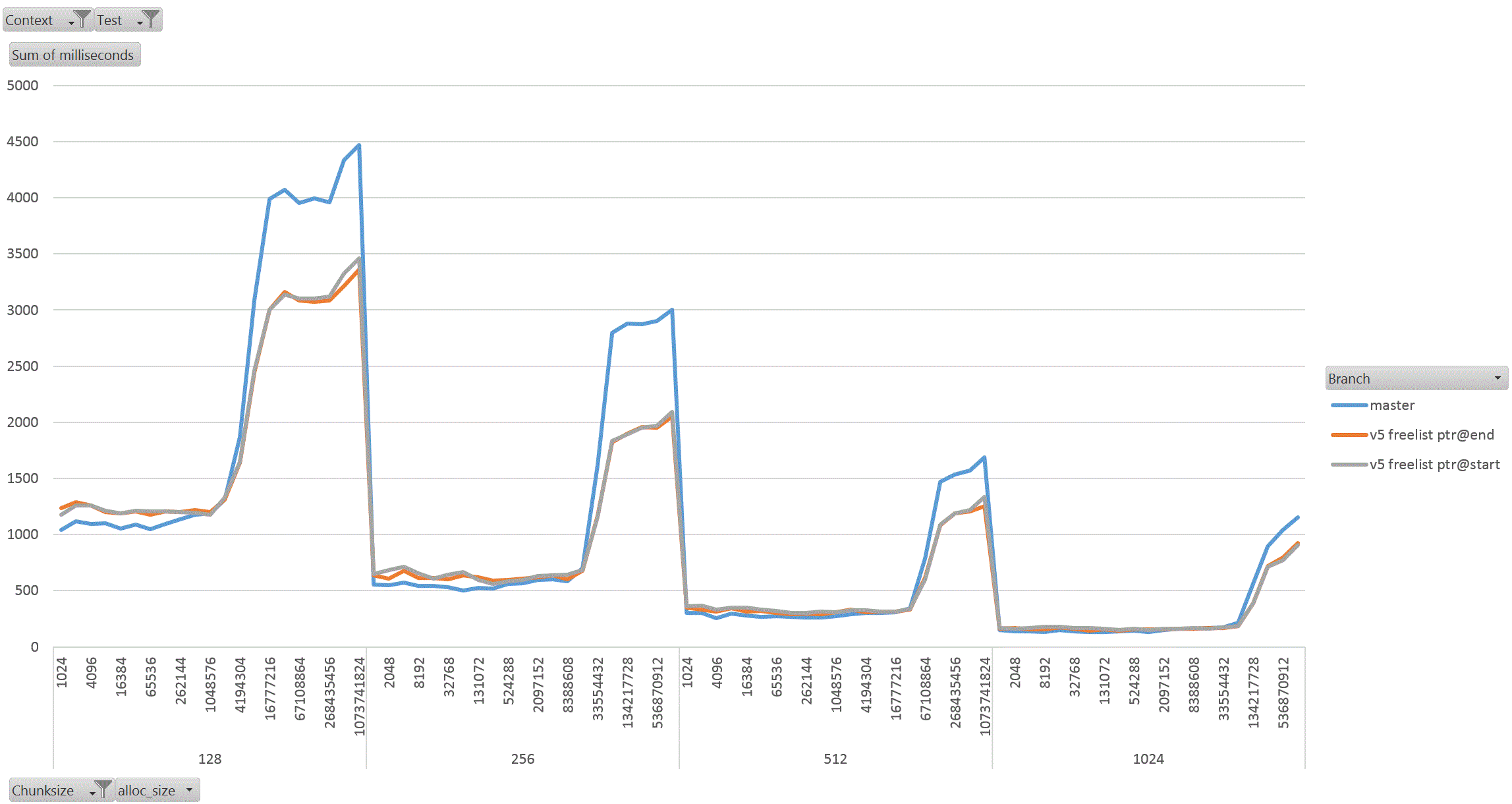
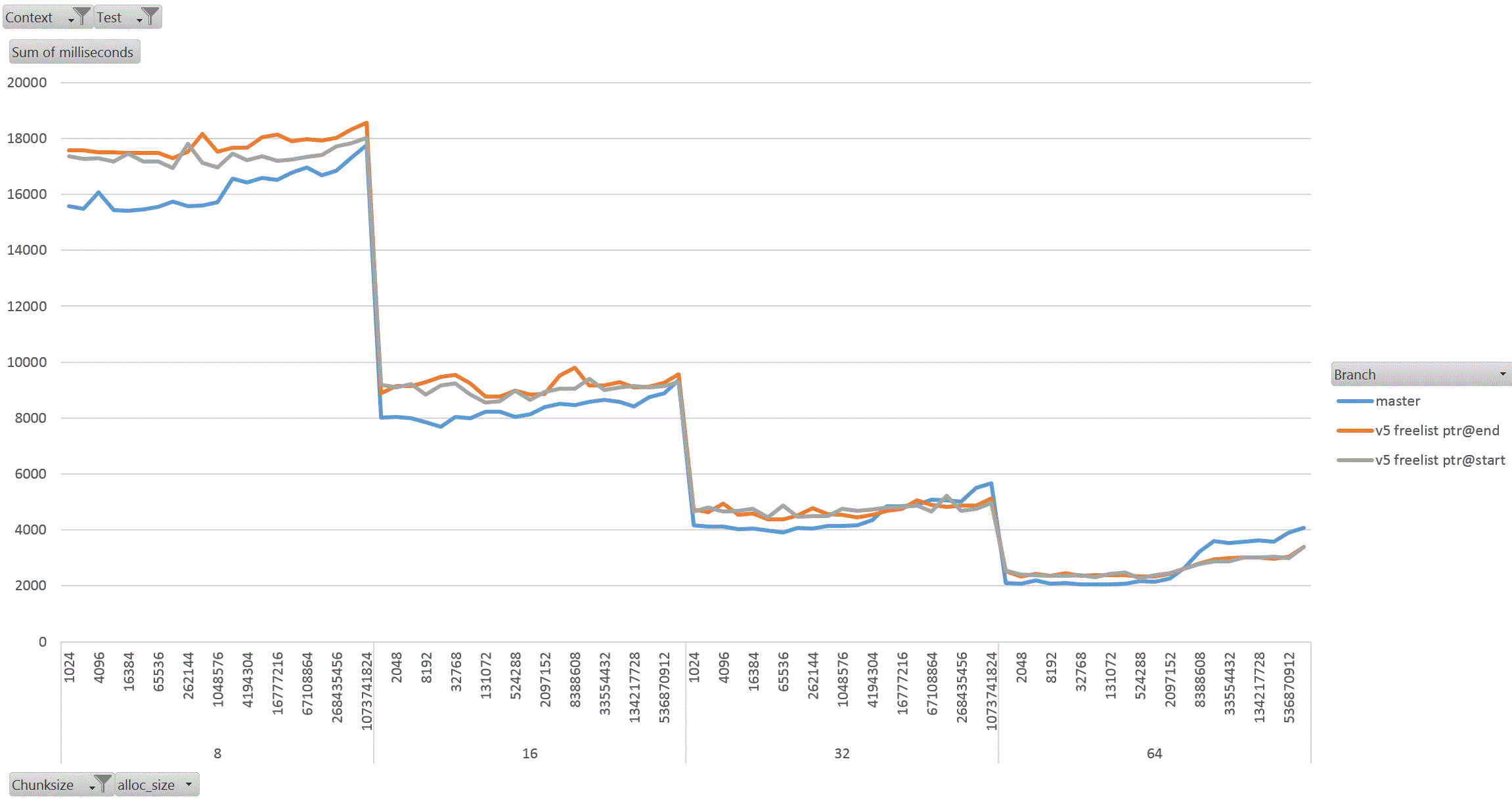
On Thu, 18 Aug 2022 at 01:58, David Rowley <dgrowleyml@gmail.com> wrote: > Does anyone else want to have a go at taking v4 for a spin to see how > it performs? I've been working on this patch again. The v4 patch didn't quite get the palloc(0) behaviour correct. There were no actual bugs in non-MEMORY_CONTEXT_CHECKING builds. It was just my detection method for free'd chunks in AllocSetCheck and GenerationCheck that was broken. In the free function, I'd been setting the requested_size back to 0 to indicate a free'd chunk. Unfortunately that was getting confused with palloc(0) chunks during the checks. The solution to that was to add: #define InvalidAllocSize SIZE_MAX to memutils.h and set free'd chunk's requested_size to that value. That seems fine, because: #define MaxAllocHugeSize (SIZE_MAX / 2) After fixing that I moved on and did some quite extensive benchmarking of the patch. I've learned quite a few things from this, namely: a) putting the freelist pointer at the end of the chunk costs us in performance. b) the patch makes GenerationFree() slower than it is in master. I believe a) is due to the chunk header and the freelist pointer being on different cache lines when the chunk becomes larger. This means having to load more cache lines resulting in slower performance. For b), I'm not sure the reason for this. I wondered if it is due to how the pointer to the MemoryContext is obtained in GenerationFree(). We first look at the MemoryChunk to find the block offset, then get the address of the block from that, we then must dereference the block->context pointer to get the owning MemoryContext. Previously we just looked at the GenerationChunk's context field. Due to a), I decided to benchmark the patch twice, once with the freelist pointer at the end of the chunk (as it was in v4 patch), and again with the pointer at the start of the chunk. For b), I looked again at GenerationFree() and saw that I really only need to look at the owning context when the block is to be freed. The vast majority of calls won't need to do that. Unfortunately moving the "set = block->context;" to just after we've checked if the block needs to be freed did not improve things. I've not run the complete benchmark again to make sure though, only a single data point of it. Benchmarking: I did this benchmarking on an AMD 3990x machine which has 64GB of RAM installed. The tests I performed entirely used two SQL functions that I've written especially for exercising palloc() and pfree(). To allow me to run the tests I wanted to, I wrote the following functions: 1. pg_allocate_memory_test(): Accepts an allocation size parameter (chunk_size), an amount of memory to keep palloc'd at once. Once this amount is reached we'll start pfreeing 1 chunk for every newly allocated chunk. Another parameter controls the total amount of allocations. We'll do this number / chunk_size allocations in total. The final parameter specifies the memory context type to use; aset, generation, etc. The intention of this function is to see if palloc/pfree has become faster or slower and also see how the reduction in the chunk header size affects performance when the amount of memory being allocated at once starts to get big. I'm expecting better CPU cache hit ratios due to the memory reductions. 2. pg_allocate_memory_test_reset(). Since we mostly don't do pfree(), function #1 might not be that accurate a test. Mostly we palloc() then MemoryContextReset(). Tests: I ran both of the above functions starting with a chunk size of 8 and doubled that each time up to 1024. I tested both aset.c and generation.c context types. In order to check how performance is affected by allocating more memory at once, I started the total concurrent memory allocation at 1k and doubled each time to 1GB. 3 branches tested; master, patch (with freelist at end of chunk) and patch (with freelist at start of chunk). So, 2 memory context types, 8 chunk sizes, 21 concurrent allocation sizes, 2 functions, 3 * 2 * 8 * 21 * 2 = 2016 data points. I ran each test for 30 seconds in pgbench. I used 20GBs as the total amount of memory to allocate. The results: The patch with freelist pointers at the start of the chunk seems a clear winner in the pg_allocate_memory_test_reset() test for both aset (graph1.gif) and generation (graph2.gif). There are a few data points where the times come out slower than master, but not by much. I suspect this might be noise, but didn't investigate. For function #1, pg_allocate_memory_test(), the performance is pretty complex. For aset, the performance is mostly better with the freelist start version of the patch. There is an exception to this with the 8 byte chunk size where performance comes out worse than master. That flips around with the 16 byte chunk test and becomes better overall. Ignoring the 8 byte chunk, the remaining performance is faster than master. This shows that having the freelist pointer at the start of the free'd chunk is best (graph3.gif) (graph4.gif better shows this for the larger chunks). With the generation context, it's complex. The more memory we allocate at once, the better performance generally gets (especially for larger chunks). I wondered if this might be due to the reduction in the chunk header size, but I'm really not sure as I'd have expected the most gains to appear in small chunks if that was the case as the header is a larger proportion of the total allocation size for those. Weirdly the opposite is true, larger chunks are showing better gains in the patched version when compared to the same data point in the unpatched master branch. graph5.gif shows this for the smaller chunks and graph6.gif for the larger ones In summary, I'm not too concerned that GenerationFree() is a small amount slower. I think the other gains are significant enough to make up for this. We could probably modify dumptuples() so that WRITETUP() does not call pfree() just before we do MemoryContextReset(state->base.tuplecontext). Those pfree calls are a complete waste of effort, although we *can't* unconditionally remove that pfree() call in WRITETUP(). I've attached the full results in bench_results.sql. If anyone else wants to repeat these tests then I've attached pg_allocate_memory_test.sh.txt and allocate_performance_functions.patch.txt with the 2 new SQL functions I used to test with. Finally, the v5 patch with the fixes mentioned above. Also, I'm leaning towards wanting to put the freelist pointer at the start of the chunk's memory rather than at the end. I understand that code which actually does something with the allocated memory is more likely to have loaded the useful cache lines already and that's not something my benchmark would have done, but for larger chunks the power of 2 wastage is likely to mean that many of those cache lines nearing the end of the chunk would never have to be loaded at all. I'm pretty keen to get this patch committed early next week. This is quite core infrastructure, so it would be good if the patch gets a few extra eyeballs on it before then. David
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: