Thread: checkpointer continuous flushing
Hello pg-devs, This patch is a simplified and generalized version of Andres Freund's August 2014 patch for flushing while writing during checkpoints, with some documentation and configuration warnings added. For the initial patch, see: http://www.postgresql.org/message-id/20140827091922.GD21544@awork2.anarazel.de For the whole thread: http://www.postgresql.org/message-id/alpine.DEB.2.10.1408251900211.11151@sto The objective is to help avoid PG stalling when fsyncing on checkpoints, and in general to get better latency-bound performance. Flushes are managed with pg throttled writes instead of waiting for the checkpointer final "fsync" which induces occasional stalls. From "pgbench -P 1 ...", such stalls look like this: progress: 35.0 s, 615.9 tps, lat 1.344 ms stddev 4.043 # ok progress: 36.0 s, 3.0 tps, lat 346.111 ms stddev 123.828# stalled progress: 37.0 s, 4.0 tps, lat 252.462 ms stddev 29.346 # ... progress: 38.0 s, 161.0 tps, lat 6.968ms stddev 32.964 # restart progress: 39.0 s, 701.0 tps, lat 1.421 ms stddev 3.326 # ok I've seen similar behavior on FreeBSD with its native FS, so it is not a Linux-specific or ext4-specific issue, even if both factor may contribute. There are two implementations, first one based on "sync_file_range" is Linux specific, while the other relies on "posix_fadvise". Tests below ran on Linux. If someone could test the posix_fadvise version on relevant platforms, that would be great... The Linux specific "sync_file_range" approach was suggested among other ideas by Theodore Ts'o on Robert Haas blog in March 2014: http://rhaas.blogspot.fr/2014/03/linuxs-fsync-woes-are-getting-some.html Two guc variables control whether the feature is activated for writes of dirty pages issued by checkpointer and bgwriter. Given that the settings may improve or degrade performance, having GUC seems justified. In particular the stalling issue disappears with SSD. The effect is significant on a series of tests shown below with scale 10 pgbench on an (old) dedicated host (8 GB memory, 8 cores, ext4 over hw RAID), with shared_buffers=1GB checkpoint_completion_target=0.8 completion_timeout=30s, unless stated otherwise. Note: I know that this completion_timeout is too small for a normal config, but the point is to test how checkpoints behave, so the test triggers as many checkpoints as possible, hence the minimum timeout setting. I have also done some tests with larger timeout. (1) THROTTLED PGBENCH The objective of the patch is to be able to reduce the latency of transactions under a moderate load. These first serie of tests focuses on this point with the help of pgbench -R (rate) and -L (skip/count late transactions). The measure counts transactions which were skipped or beyond the expected latency limit while targetting a transaction rate. * "pgbench -M prepared -N -T 100 -P 1 -R 100 -L 100" (100 tps targeted during 100 seconds, and latency limit is 100 ms),over 256 runs, 7 hours per case: flush | percent of skipped cp | bgw | & out of latency limit transactions off | off | 6.5 % off | on | 6.1 % on | off | 0.4 % on | on | 0.4 % * Same as above (100 tps target) over one run of 4000 seconds with shared_buffers=256MB and checkpoint_timeout=10mn: flush | percent of skipped cp | bgw | & out of latency limit transactions off | off | 1.3 % off | on | 1.5 % on | off | 0.6 % on | on | 0.6 % * Same as first one but with "-R 150", i.e. targetting 150 tps, 256 runs: flush | percent of skipped cp | bgw | & out of latency limit transactions off | off | 8.0 % off | on | 8.0 % on | off | 0.4 % on | on | 0.4 % * Same as above (150 tps target) over one run of 4000 seconds with shared_buffers=256MB and checkpoint_timeout=10mn: flush | percent of skipped cp | bgw | & out of latency limit transactions off | off | 1.7 % off | on | 1.9 % on | off | 0.7 % on | on | 0.6 % Turning "checkpoint_flush_to_disk = on" reduces significantly the number of late transactions. These late transactions are not uniformly distributed, but are rather clustered around times when pg is stalled, i.e. more or less unresponsive. bgwriter_flush_to_disk does not seem to have a significant impact on these tests, maybe because pg shared_buffers size is much larger than the database, so the bgwriter is seldom active. (2) FULL SPEED PGBENCH This is not the target use case, but it seems necessary to assess the impact of these options of tps figures and their variability. * "pgbench -M prepared -N -T 100 -P 1" over 512 runs, 14 hours per case. flush | performance on ... cp | bgw | 512 100-seconds runs | 1s intervals (over 51200 seconds) off | off |691 +- 36 tps | 691 +- 236 tps off | on | 677 +- 29 tps | 677 +- 230 tps on | off | 655 +- 23 tps | 655 +- 130 tps on | on | 657 +- 22 tps | 657 +- 130 tps On this first test, setting checkpoint_flush_to_disk reduces the performance by 5%, but the per second standard deviation is nearly halved, that is the performance is more stable over the runs, although lower. Option bgwriter_flush_to_disk effect is inconclusive. * "pgbench -M prepared -N -T 4000 -P 1" on only 1 (long) run, with checkpoint_timeout=10mn and shared_buffers=256MB (atleast 6 checkpoints during the run, probably more because segments are filled more often than every 10mn): flush | performance ... (stddev over per second tps) off | off | 877 +- 179 tps off | on | 880 +- 183 tps on | off | 896 +- 131 tps on | on | 888 +- 132 tps On this second short test, setting checkpoint_flush_to_disk seems to maybe slightly improve performance (maybe 2% ?) and significantly reduces variability, so it looks like a good move. * "pgbench -M prepared -N -T 100 -j 2 -c 4 -P 1" over 32 runs (4 clients) flush | performance on ... cp | bgw | 32 100-seconds runs | 1s intervals (over 3200 seconds) off | off | 1970+- 60 tps | 1970 +- 783 tps off | on | 1928 +- 61 tps | 1928 +- 813 tps on | off | 1578 +- 45 tps | 1578 +- 631 tps on | on | 1594 +- 47 tps | 1594 +- 618 tps On this test both average and standard deviation are both reduced by 20%. This does not look like a win. CONCLUSION This approach is simple and significantly improves pg fsync behavior under moderate load, where the database stays mostly responsive. Under full load, the situation may be improved or degraded, it depends. OTHER OPTIONS Another idea suggested by Theodore Ts'o seems impractical: playing with Linux io-scheduler priority (ioprio_set) looks only relevant with the "sfq" scheduler on actual hard disk, but does not work with other schedulers, especially "deadline" which seems more advisable for Pg, nor for hardware RAID, which is a common setting. Also, Theodore Ts'o suggested to use "sync_file_range" to check whether the writes have reached the disk, and possibly to delay the actual fsync/checkpoint conclusion if not... I have not tried that, the implementation is not as trivial, and I'm not sure what to do when the completion target is coming, but possibly that could be an interesting option to investigate. Preliminary tests by adding a sleep between the writes and the final fsync did not yield very good results. I've also played with numerous other options (changing checkpointer throttling parameters, reducing checkpoint timeout to 1 second, playing around with various kernel settings), but that did not seem to be very effective for the problem at hand. I also attached a test script I used, that can be adapted if someone wants to collect some performance data. I also have some basic scripts to extract and compute stats, ask if needed. -- Fabien.
Hi Fabien, On 2015-06-01 PM 08:40, Fabien COELHO wrote: > > Turning "checkpoint_flush_to_disk = on" reduces significantly the number > of late transactions. These late transactions are not uniformly distributed, > but are rather clustered around times when pg is stalled, i.e. more or less > unresponsive. > > bgwriter_flush_to_disk does not seem to have a significant impact on these > tests, maybe because pg shared_buffers size is much larger than the database, > so the bgwriter is seldom active. > Not that the GUC naming is the most pressing issue here, but do you think "*_flush_on_write" describes what the patch does? Thanks, Amit
Hello Amit, > Not that the GUC naming is the most pressing issue here, but do you think > "*_flush_on_write" describes what the patch does? It is currently "*_flush_to_disk". In Andres Freund version the name is "sync_on_checkpoint_flush", but I did not found it very clear. Using "*_flush_on_write" instead as your suggest, would be fine as well, it emphasizes the "when/how" it occurs instead of the final "destination", why not... About words: checkpoint "write"s pages, but this really mean passing the pages to the memory manager, which will think about it... "flush" seems to suggest a more effective write, but really it may mean the same, the page is just passed to the OS. So "write/flush" is really "to OS" and not "to disk". I like the data to be on "disk" in the end, and as soon as possible, hence the choice to emphasize that point. Now I would really be okay with anything that people find simple to understand, so any opinion is welcome! -- Fabien.
Hi, It's nice to see the topic being picked up. If I see correctly you picked up the version without sorting durch checkpoints. I think that's not going to work - there'll be too many situations where the new behaviour will be detrimental. Did you consider combining both approaches? Greetings, Andres Freund
Hello pg-devs,
This patch is a simplified and generalized version of Andres Freund's August 2014 patch for flushing while writing during checkpoints, with some documentation and configuration warnings added.
For the initial patch, see:
http://www.postgresql.org/message-id/20140827091922.GD21544@awork2.anarazel.de
For the whole thread:
http://www.postgresql.org/message-id/alpine.DEB.2.10.1408251900211.11151@sto
The objective is to help avoid PG stalling when fsyncing on checkpoints, and in general to get better latency-bound performance.
Hello Andres, > If I see correctly you picked up the version without sorting durch > checkpoints. I think that's not going to work - there'll be too many > situations where the new behaviour will be detrimental. Did you > consider combining both approaches? Ja, I thought that it was a more complex patch with uncertain/less clear benefits, and as this simpler version was already effective enough as it was, so I decided to start with that and try to have reasonable proof of benefits so that it could get through. -- Fabien.
Hello Amit, > [...] >> The objective is to help avoid PG stalling when fsyncing on checkpoints, >> and in general to get better latency-bound performance. > > Won't this lead to more-unsorted writes (random I/O) as the > FlushBuffer requests (by checkpointer or bgwriter) are not sorted as > per files or order of blocks on disk? Yep, probably. Under "moderate load" this is not an issue. The io-scheduler and other hd firmware will probably reorder writes anyway. Also, if several data are updated together, probably they are likely to be already neighbours in memory as well as on disk. > I remember sometime back there was some discusion regarding > sorting writes during checkpoint, one idea could be try to > check this idea along with that patch. I just saw that Andres has > also given same suggestion which indicates that it is important > to see both the things together. I would rather separate them, unless this is a blocker. This version seems already quite effective and very light. ISTM that adding a sort phase would mean reworking significantly how the checkpointer processes pages. > Also here another related point is that I think currently even fsync > requests are not in order of the files as they are stored on disk so > that also might cause random I/O? I think that currently the fsync is on the file handler, so what happens depends on how fsync is implemented by the system. > Yet another idea could be to allow BGWriter to also fsync the dirty > buffers, ISTM That it is done with this patch with "bgwriter_flush_to_disk=on". > that may have side impact of not able to clear the dirty pages at speed > required by system, but I think if that happens one can think of having > multiple BGwriter tasks. -- Fabien.
On 2015-06-02 15:15:39 +0200, Fabien COELHO wrote: > >Won't this lead to more-unsorted writes (random I/O) as the > >FlushBuffer requests (by checkpointer or bgwriter) are not sorted as > >per files or order of blocks on disk? > > Yep, probably. Under "moderate load" this is not an issue. The io-scheduler > and other hd firmware will probably reorder writes anyway. They pretty much can't if you flush things frequently. That's why I think this won't be acceptable without the sorting in the checkpointer. > Also, if several > data are updated together, probably they are likely to be already neighbours > in memory as well as on disk. No, that's not how it'll happen outside of simplistic cases where you start with an empty shared_buffers. Shared buffers are maintained by a simplified LRU, so how often individual blocks are touched will define the buffer replacement. > >I remember sometime back there was some discusion regarding > >sorting writes during checkpoint, one idea could be try to > >check this idea along with that patch. I just saw that Andres has > >also given same suggestion which indicates that it is important > >to see both the things together. > > I would rather separate them, unless this is a blocker. I think it is a blocker. > This version seems > already quite effective and very light. ISTM that adding a sort phase would > mean reworking significantly how the checkpointer processes pages. Meh. The patch for that wasn't that big. The problem with doing this separately is that without the sorting this will be slower for throughput in a good number of cases. So we'll have yet another GUC that's very hard to tune. Greetings, Andres Freund
Hello Andres, >> I would rather separate them, unless this is a blocker. > > I think it is a blocker. Hmmm. This is an argument... >> This version seems already quite effective and very light. ISTM that >> adding a sort phase would mean reworking significantly how the >> checkpointer processes pages. > > Meh. The patch for that wasn't that big. Hmmm. I think it should be implemented as Tom suggested, that is per chunks of shared buffers, in order to avoid allocating a "large" memory. > The problem with doing this separately is that without the sorting this > will be slower for throughput in a good number of cases. So we'll have > yet another GUC that's very hard to tune. ISTM that the two aspects are orthogonal, which would suggests two gucs anyway. -- Fabien.
On 2015-06-02 15:42:14 +0200, Fabien COELHO wrote: > >>This version seems already quite effective and very light. ISTM that > >>adding a sort phase would mean reworking significantly how the > >>checkpointer processes pages. > > > >Meh. The patch for that wasn't that big. > > Hmmm. I think it should be implemented as Tom suggested, that is per chunks > of shared buffers, in order to avoid allocating a "large" memory. I don't necessarily agree. But that's really just a minor implementation detail. The actual problem is sorting & fsyncing in a way that deals efficiently with tablespaces, i.e. doesn't write to tablespaces one-by-one. Not impossible, but it requires some thought. > >The problem with doing this separately is that without the sorting this > >will be slower for throughput in a good number of cases. So we'll have > >yet another GUC that's very hard to tune. > > ISTM that the two aspects are orthogonal, which would suggests two gucs > anyway. They're pretty closely linked from their performance impact. IMO this feature, if done correctly, should result in better performance in 95+% of the workloads and be enabled by default. And that'll not be possible without actually writing mostly sequentially. It's also not just the sequential writes making this important, it's also that it allows to do the final fsync() of the individual segments as soon as their last buffer has been written out. That's important because it means the file will get fewer writes done independently (i.e. backends writing out dirty buffers) which will make the final fsync more expensive. It might be that we want to different gucs, but I don't think we can release without both features. Greetings, Andres Freund
>> Hmmm. I think it should be implemented as Tom suggested, that is per chunks >> of shared buffers, in order to avoid allocating a "large" memory. > > I don't necessarily agree. But that's really just a minor implementation > detail. Probably. > The actual problem is sorting & fsyncing in a way that deals efficiently > with tablespaces, i.e. doesn't write to tablespaces one-by-one. > Not impossible, but it requires some thought. Hmmm... I would have neglected this point in a first approximation, but I agree that not interleaving tablespaces could indeed loose some performance. >> ISTM that the two aspects are orthogonal, which would suggests two gucs >> anyway. > > They're pretty closely linked from their performance impact. Sure. > IMO this feature, if done correctly, should result in better performance > in 95+% of the workloads To demonstrate that would require time... > and be enabled by default. I did not had such an ambition with the submitted patch:-) > And that'll not be possible without actually writing mostly > sequentially. > It's also not just the sequential writes making this important, it's > also that it allows to do the final fsync() of the individual segments > as soon as their last buffer has been written out. Hmmm... I'm not sure this would have a large impact. The writes are throttled as much as possible, so fsync will catch plenty other writes anyway, if there are some. -- Fabien.
On 2015-06-02 17:01:50 +0200, Fabien COELHO wrote: > >The actual problem is sorting & fsyncing in a way that deals efficiently > >with tablespaces, i.e. doesn't write to tablespaces one-by-one. > >Not impossible, but it requires some thought. > > Hmmm... I would have neglected this point in a first approximation, > but I agree that not interleaving tablespaces could indeed loose some > performance. I think it'll be a hard to diagnose performance regression. So we'll have to fix it. That argument actually was the blocker in previous attempts... > >IMO this feature, if done correctly, should result in better performance > >in 95+% of the workloads > > To demonstrate that would require time... Well, that's part of the contribution process. Obviously you can't test 100% of the problems, but you can work hard with coming up with very adversarial scenarios and evaluate performance for those. > >and be enabled by default. > > I did not had such an ambition with the submitted patch:-) I don't think we want yet another tuning knob that's hard to tune because it's critical for one factor (latency) but bad for another (throughput); especially when completely unnecessarily. > >And that'll not be possible without actually writing mostly sequentially. > > >It's also not just the sequential writes making this important, it's also > >that it allows to do the final fsync() of the individual segments as soon > >as their last buffer has been written out. > > Hmmm... I'm not sure this would have a large impact. The writes are > throttled as much as possible, so fsync will catch plenty other writes > anyway, if there are some. That might be the case in a database with a single small table; i.e. where all the writes go to a single file. But as soon as you have large tables (i.e. many segments) or multiple tables, a significant part of the writes issued independently from checkpointing will be outside the processing of the individual segment. Greetings, Andres Freund
>>> IMO this feature, if done correctly, should result in better performance >>> in 95+% of the workloads >> >> To demonstrate that would require time... > > Well, that's part of the contribution process. Obviously you can't test > 100% of the problems, but you can work hard with coming up with very > adversarial scenarios and evaluate performance for those. I did spent time (well, a machine spent time, really) to collect some convincing data for the simple version without sorting to demonstrate that it brings a clear value, which seems not to be enough... > I don't think we want yet another tuning knob that's hard to tune > because it's critical for one factor (latency) but bad for another > (throughput); especially when completely unnecessarily. Hmmm. My opinion is that throughput is given too much attention in general, but if both can be kept/improved, this would be easier to sell, obviously. >>> It's also not just the sequential writes making this important, it's also >>> that it allows to do the final fsync() of the individual segments as soon >>> as their last buffer has been written out. >> >> Hmmm... I'm not sure this would have a large impact. The writes are >> throttled as much as possible, so fsync will catch plenty other writes >> anyway, if there are some. > > That might be the case in a database with a single small table; > i.e. where all the writes go to a single file. But as soon as you have > large tables (i.e. many segments) or multiple tables, a significant part > of the writes issued independently from checkpointing will be outside > the processing of the individual segment. Statistically, I think that it would reduce the number of unrelated writes taken in a fsync by about half: the last table to be written on a tablespace, at the end of the checkpoint, will have accumulated checkpoint-unrelated writes (bgwriter, whatever) from the whole checkpoint time, while the first table will have avoided most of them. -- Fabien.
On 2015-06-02 18:59:05 +0200, Fabien COELHO wrote: > > >>>IMO this feature, if done correctly, should result in better performance > >>>in 95+% of the workloads > >> > >>To demonstrate that would require time... > > > >Well, that's part of the contribution process. Obviously you can't test > >100% of the problems, but you can work hard with coming up with very > >adversarial scenarios and evaluate performance for those. > > I did spent time (well, a machine spent time, really) to collect some > convincing data for the simple version without sorting to demonstrate that > it brings a clear value, which seems not to be enough... "which seems not to be enough" - man. It's trivial to make things faster/better/whatever if you don't care about regressions in other parts. And if we'd add a guc for each of these cases we'd end up with thousands of them. > My opinion is that throughput is given too much attention in general, but if > both can be kept/improved, this would be easier to sell, obviously. Your priorities are not everyone's. That's life. > >That might be the case in a database with a single small table; > >i.e. where all the writes go to a single file. But as soon as you have > >large tables (i.e. many segments) or multiple tables, a significant part > >of the writes issued independently from checkpointing will be outside > >the processing of the individual segment. > > Statistically, I think that it would reduce the number of unrelated writes > taken in a fsync by about half: the last table to be written on a > tablespace, at the end of the checkpoint, will have accumulated > checkpoint-unrelated writes (bgwriter, whatever) from the whole checkpoint > time, while the first table will have avoided most of them. That's disregarding that a buffer written out by a backend starts to get written out by the kernel after ~5-30s, even without a fsync triggering it.
Hi, On 2015-06-02 PM 07:19, Fabien COELHO wrote: > >> Not that the GUC naming is the most pressing issue here, but do you think >> "*_flush_on_write" describes what the patch does? > > It is currently "*_flush_to_disk". In Andres Freund version the name is > "sync_on_checkpoint_flush", but I did not found it very clear. Using > "*_flush_on_write" instead as your suggest, would be fine as well, it > emphasizes the "when/how" it occurs instead of the final "destination", why > not... > > About words: checkpoint "write"s pages, but this really mean passing the pages > to the memory manager, which will think about it... "flush" seems to suggest a > more effective write, but really it may mean the same, the page is just passed > to the OS. So "write/flush" is really "to OS" and not "to disk". I like the > data to be on "disk" in the end, and as soon as possible, hence the choice to > emphasize that point. > > Now I would really be okay with anything that people find simple to > understand, so any opinion is welcome! > It seems 'sync' gets closer to what I really wanted 'flush' to mean. If I understand this and the previous discussion(s) correctly, the patch tries to alleviate the problems caused by one-big-sync-at-the end-of-writes by doing the sync in step with writes (which do abide by the checkpoint_completion_target). Given that impression, it seems *_sync_on_write may even do the job. Again, this is a minor issue. By the way, I tend to agree with others here that there needs to be found a good balance such that this sync-blocks-one-at-time-in-random-order approach does not hurt generalized workload too much although it seems to help with solving the latency problem that you seem set out to solve. Thanks, Amit
>
>
> Hello Amit,
>
>> [...]
>>>
>>> The objective is to help avoid PG stalling when fsyncing on checkpoints,
>>> and in general to get better latency-bound performance.
>>
>>
>> Won't this lead to more-unsorted writes (random I/O) as the
>> FlushBuffer requests (by checkpointer or bgwriter) are not sorted as
>> per files or order of blocks on disk?
>
>
> Yep, probably. Under "moderate load" this is not an issue. The io-scheduler and other hd firmware will probably reorder writes anyway. Also, if several data are updated together, probably they are likely to be already neighbours in memory as well as on disk.
>
>> I remember sometime back there was some discusion regarding
>> sorting writes during checkpoint, one idea could be try to
>> check this idea along with that patch. I just saw that Andres has
>> also given same suggestion which indicates that it is important
>> to see both the things together.
>
>
> I would rather separate them, unless this is a blocker. This version seems already quite effective and very light. ISTM that adding a sort phase would mean reworking significantly how the checkpointer processes pages.
>
>> Also here another related point is that I think currently even fsync
>> requests are not in order of the files as they are stored on disk so
>> that also might cause random I/O?
>
>
> I think that currently the fsync is on the file handler, so what happens depends on how fsync is implemented by the system.
>
>> Yet another idea could be to allow BGWriter to also fsync the dirty
>> buffers,
>
>
> ISTM That it is done with this patch with "bgwriter_flush_to_disk=on".
>
>>> That might be the case in a database with a single small table; i.e. >>> where all the writes go to a single file. But as soon as you have >>> large tables (i.e. many segments) or multiple tables, a significant >>> part of the writes issued independently from checkpointing will be >>> outside the processing of the individual segment. >> >> Statistically, I think that it would reduce the number of unrelated writes >> taken in a fsync by about half: the last table to be written on a >> tablespace, at the end of the checkpoint, will have accumulated >> checkpoint-unrelated writes (bgwriter, whatever) from the whole checkpoint >> time, while the first table will have avoided most of them. > > That's disregarding that a buffer written out by a backend starts to get > written out by the kernel after ~5-30s, even without a fsync triggering > it. I meant my argument with "continuous flushing" activated, so there is no up to 30 seconds delay induced my the memory manager. Hmmm, maybe I do not understood your argument. -- Fabien.
Hello Amit, >> It is currently "*_flush_to_disk". In Andres Freund version the name is >> "sync_on_checkpoint_flush", but I did not found it very clear. Using >> "*_flush_on_write" instead as your suggest, would be fine as well, it >> emphasizes the "when/how" it occurs instead of the final "destination", why >> not... > [...] > > It seems 'sync' gets closer to what I really wanted 'flush' to mean. If > I understand this and the previous discussion(s) correctly, the patch > tries to alleviate the problems caused by one-big-sync-at-the > end-of-writes by doing the sync in step with writes (which do abide by > the checkpoint_completion_target). Given that impression, it seems > *_sync_on_write may even do the job. I desagree with this one, because the sync is only *initiated*, not done. For this reason I think that "flush" seems a better word. I understand "sync" as "committed to disk". For the data to be synced, it should call with the "wait after" option, which is a partial "fsync", but that would be terrible for performance as all checkpointed pages would be written one by one, without any opportunity for reordering them. For what it's worth and for the record, Linux sync_file_range documentation says "This is an asynchronous flush-to-disk operation" to describe the corresponding option. This is probably where I took it. So two contenders: *_flush_to_disk *_flush_on_write -- Fabien.
> I agree with you that if we have to add a sort phase, there is additional
> work and that work could be significant depending on the design we
> choose, however without that, this patch can have impact on many kind
> of workloads, even in your mail in one of the tests
> ("pgbench -M prepared -N -T 100 -j 2 -c 4 -P 1" over 32 runs (4 clients))
> it has shown 20% degradation which is quite significant and test also
> seems to be representative of the workload which many users in real-world
> will use.
Yes, I do agree with the 4 clients, but I doubt that many user run their
application at maximum available throughput all the time (like always
driving foot to the floor). So for me throttled runs are more
representative of real life.
> Now one can say that for such workloads turn the new knob to off, but
> in reality it could be difficult to predict if the load is always moderate.
Hmmm. The switch says "I prefer stable (say latency bounded) performance",
if you run a web site probably you should want that.
Anyway, I'll look at sorting when I have some time.
--
Fabien.
Fabien, On 2015-06-03 PM 02:53, Fabien COELHO wrote: > >> >> It seems 'sync' gets closer to what I really wanted 'flush' to mean. If I >> understand this and the previous discussion(s) correctly, the patch tries to >> alleviate the problems caused by one-big-sync-at-the end-of-writes by doing >> the sync in step with writes (which do abide by the >> checkpoint_completion_target). Given that impression, it seems >> *_sync_on_write may even do the job. > > I desagree with this one, because the sync is only *initiated*, not done. For > this reason I think that "flush" seems a better word. I understand "sync" as > "committed to disk". For the data to be synced, it should call with the "wait > after" option, which is a partial "fsync", but that would be terrible for > performance as all checkpointed pages would be written one by one, without any > opportunity for reordering them. > > For what it's worth and for the record, Linux sync_file_range documentation > says "This is an asynchronous flush-to-disk operation" to describe the > corresponding option. This is probably where I took it. > Ah, okay! I didn't quite think about the async aspect here. But, I sure do hope that the added mechanism turns out to be *less* async than kernel's own dirty cache handling to achieve the hoped for gain. > So two contenders: > > *_flush_to_disk > *_flush_on_write > Yep! Regards, Amit
Hello Andres, > They pretty much can't if you flush things frequently. That's why I > think this won't be acceptable without the sorting in the checkpointer. * VERSION 2 "WORK IN PROGRESS". The implementation is more a proof-of-concept for having feedback than clean code. What it does: - as version 1 : simplified asynchronous flush based on Andres Freund patch, with sync_file_range/posix_fadvise used tohint the OS that the buffer must be sent to disk "now". - added: checkpoint buffer sorting based on a 2007 patch by Takahiro Itagaki but with a smaller and static buffer allocatedonce. Also, sorting is done by chunks in the current version. - also added: sync/advise calls are now merged if possible, so less calls are used, especially when buffers are sorted, but also if there are few files. * PERFORMANCE TESTS Impacts on "pgbench -M prepared -N -P 1" scale 10 (simple update pgbench with a mostly-write activity), with checkpoint_completion_target=0.8 and shared_buffers=1GB. Contrary to v1, I have not tested bgwriter flushing as the impact on the first round was close to nought. This does not mean that particular loads may benefit or be harmed but flushing from bgwriter. - 100 tps throttled max 100 ms latency over 6400 seconds with checkpoint_timeout=30s flush | sort | late transactions off | off | 6.0 % off | on | 6.1 % on | off | 0.4 % on | on | 0.4% (93% improvement) - 100 tps throttled max 100 ms latency over 4000 seconds with checkpoint_timeout=10mn flush | sort | late transactions off | off | 1.5 % off | on | 0.6 % (?!) on | off | 0.8 % on | on |0.6 % (60% improvement) - 150 tps throttled max 100 ms latency over 19600 seconds (5.5 hours) with checkpoint_timeout=30s flush | sort | late transactions off | off | 8.5 % off | on | 8.1 % on | off | 0.5 % on | on | 0.4% (95% improvement) - full speed bgbench over 6400 seconds with checkpoint_timeout=30s flush | sort | tps performance over per second data off | off | 676 +- 230 off | on | 683 +- 213 on | off| 712 +- 130 on | on | 725 +- 116 (7.2% avg/50% stddev improvements) - full speed bgbench over 4000 seconds with checkpoint_timeout=10mn flush | sort | tps performance over per second data off | off | 885 +- 188 off | on | 940 +- 120 (6%/36%!) on | off | 778 +- 245 (hmmm... not very consistent?) on | on | 927 +- 108 (4.5% avg/43% sttdev improvements) - full speed bgbench "-j2 -c4" over 6400 seconds with checkpoint_timeout=30s flush | sort | tps performance over per second data off | off | 2012 +- 747 off | on | 2086 +- 708 on | off| 2099 +- 459 on | on | 2114 +- 422 (5% avg/44% stddev improvements) * CONCLUSION : For all these HDD tests, when both options are activated the tps performance is improved, the latency is reduced and the performance is more stable (smaller standard deviation). Overall the option effects, not surprisingly, are quite (with exceptions) orthogonal: - latency is essentially improved (60 to 95% reduction) by flushing - throughput is improved (4 to 7% better)thanks to sorting In detail, some loads may benefit more from only one option activated. Also on SSD probably both options would have limited benefit. Usual caveat: these are only benches on one host at a particular time and location, which may or may not be reproducible nor be representative as such of any other load. The good news is that all these tests tell the same thing. * LOOK FOR THOUGHTS - The bgwriter flushing option seems ineffective, it could be removed from the patch? - Move fsync as early as possible, suggested by Andres Freund? In these tests, when the flush option is activated, the fsync duration at the end of the checkpoint is small: on more than 5525 checkpoint fsyncs, 0.5% are above 1 second when flush is on, but the figure raises to 24% when it is off.... This suggest that doing the fsync as soon as possible would probably have no significant effect on these tests. My opinion is that this should be left out for the nonce. - Take into account tablespaces, as pointed out by Andres Freund? The issue is that if writes are sorted, they are not be distributed randomly over tablespaces, inducing lower performance on such systems. How to do it: while scanning shared_buffers, count dirty buffers for each tablespace. Then start as many threads as table spaces, each one doing its own independent throttling for a tablespace? For some obscure reason there are 2 tablespaces by default (pg_global and pg_default), that would mean at least 2 threads. Alternatively, maybe it can be done from one thread, but it would probably involve some strange hocus-pocus to switch frequently between tablespaces. -- Fabien.
Le 07/06/2015 16:53, Fabien COELHO a écrit : > +» » /*·Others:·say·that·data·should·not·be·kept·in·memory... > +» » ·*·This·is·not·exactly·what·we·want·to·say,·because·we·want·to·write > +» » ·*·the·data·for·durability·but·we·may·need·it·later·nevertheless. > +» » ·*·It·seems·that·Linux·would·free·the·memory·*if*·the·data·has > +» » ·*·already·been·written·do·disk,·else·it·is·ignored. > +» » ·*·For·FreeBSD·this·may·have·the·desired·effect·of·moving·the > +» » ·*·data·to·the·io·layer. > +» » ·*/ > +» » rc·=·posix_fadvise(context->fd,·context->offset,·context->nbytes, > +» » » » » » ···POSIX_FADV_DONTNEED); > + It looks a bit hazardous, do you have a benchmark for freeBSD ? Sources says:case POSIX_FADV_DONTNEED: /* * Flush any open FS buffers and then remove pages * from the backingVM object. Using vinvalbuf() here * is a bit heavy-handed as it flushes all buffers for * the given vnode,not just the buffers covering the * requested range. -- Cédric Villemain +33 (0)6 20 30 22 52 http://2ndQuadrant.fr/ PostgreSQL: Support 24x7 - Développement, Expertise et Formation
Hello Cédric, > It looks a bit hazardous, do you have a benchmark for freeBSD ? No, I just consulted the FreeBSD man page for posix_fadvise. I someone can run tests on something which HDDs is not linux, that would be nice. > Sources says: > case POSIX_FADV_DONTNEED: > /* > * Flush any open FS buffers and then remove pages > * from the backing VM object. Using vinvalbuf() here > * is a bit heavy-handed as it flushes all buffers for > * the given vnode, not just the buffers covering the > * requested range. It is indeed heavy-handed, but that would probably trigger the expected behavior which is to start writing to disk, so I would expect to see benefits similar to those of "sync_file_range" on Linux. Buffer writes from bgwriter & checkpointer are throttled, which reduces the potential impact of a "heavy-handed" approach in the kernel. Now if on some platforms the behavior is absurd, obviously it would be better to turn the feature off on those. Note that this is already used by pg in "initdb", but the impact would probably be very small anyway. -- Fabien.
Hello,
Here is version 3, including many performance tests with various settings,
representing about 100 hours of pgbench run. This patch aims at improving
checkpoint I/O behavior so that tps throughput is improved, late
transactions are less frequent, and overall performances are more stable.
* SOLILOQUIZING
> - The bgwriter flushing option seems ineffective, it could be removed
> from the patch?
I did that.
> - Move fsync as early as possible, suggested by Andres Freund?
>
> My opinion is that this should be left out for the nonce.
I did that.
> - Take into account tablespaces, as pointed out by Andres Freund?
>
> Alternatively, maybe it can be done from one thread, but it would probably
> involve some strange hocus-pocus to switch frequently between tablespaces.
I did the hocus-pocus approach, including a quasi-proof (not sure what is
this mathematical object:-) in comments to show how/why it works.
* PATCH CONTENTS
- as version 1: simplified asynchronous flush based on Andres Freund patch, with sync_file_range/posix_fadvise used
tohint the OS that the buffer must be sent to disk "now".
- as version 2: checkpoint buffer sorting based on a 2007 patch by Takahiro Itagaki but with a smaller and static
bufferallocated once. Also, sorting is done by chunks of 131072 pages in the current version, with a guc to change
thisvalue.
- as version 2: sync/advise calls are now merged if possible, so less calls will be used, especially when buffers
aresorted, but also if there are few files written.
- new: the checkpointer balance its page writes per tablespace. this is done by choosing to write pages for a
tablespacefor which the progress ratio (written/to_write) is beyond the overall progress ratio for all tablespace,
andby doing that in a round robin manner so that all tablespaces regularly get some attention. No threads.
- new: some more documentation is added.
- removed: "bgwriter_flush_to_write" is removed, as there was no clear benefit on the (simple) tests. It could be
consideredfor another patch.
- question: I'm not sure I understand the checkpointer memory management. There is some exception handling in the
checkpointermain. I wonder whether the allocated memory would be lost in such event and should be reallocated. The
patchcurrently assumes that the memory is kept.
* PERFORMANCE TESTS
Impacts on "pgbench -M prepared -N -P 1 ..." (simple update test, mostly
random write activity on one table), checkpoint_completion_target=0.8, with
different settings on a 16GB 8-core host:
. tiny: scale=10 shared_buffers=1GB checkpoint_timeout=30s time=6400s . small: scale=120 shared_buffers=2GB
checkpoint_timeout=300stime=4000s . medium: scale=250 shared_buffers=4GB checkpoint_timeout=15min time=4000s . large:
scale=1000shared_buffers=4GB checkpoint_timeout=40min time=7500s
Note: figures noted with a star (*) had various issues during their run, so
pgbench progress figures were more or less incorrect, thus the standard
deviation computation is not to be trusted beyond "pretty bad".
Caveat: these are only benches on one host at a particular time and
location, which may or may not be reproducible nor be representative
as such of any other load. The good news is that all these tests tell
the same thing.
- full-speed 1-client
options | tps performance over per second data flush | sort | tiny | small | medium |
large off | off | 687 +- 231 | 163 +- 280 * | 191 +- 626 * | 37.7 +- 25.6 off | on | 699 +- 223 | 457 +- 315
|479 +- 319 | 48.4 +- 28.8 on | off | 740 +- 125 | 143 +- 387 * | 179 +- 501 * | 37.3 +- 13.3 on | on |
722+- 119 | 550 +- 140 | 549 +- 180 | 47.2 +- 16.8
- full speed 4-clients
options | tps performance over per second data flush | sort | tiny | small | medium off |
off| 2006 +- 748 | 193 +- 1898 * | 205 +- 2465 * off | on | 2086 +- 673 | 819 +- 905 * | 807 +- 1029 * on |
off| 2212 +- 451 | 169 +- 1269 * | 160 +- 502 * on | on | 2073 +- 437 | 743 +- 413 | 822 +- 467
- 100-tps 1-client max 100-ms latency
options | percent of late transactions flush | sort | tiny | small | medium off | off | 6.31 | 29.44 |
30.74 off | on | 6.23 | 8.93 | 7.12 on | off | 0.44 | 7.01 | 8.14 on | on | 0.59 | 0.83 | 1.84
- 200-tps 1-client max 100-ms latency
options | percent of late transactions flush | sort | tiny | small | medium off | off | 10.00 | 50.61 |
45.51 off | on | 8.82 | 12.75 | 12.89 on | off | 0.59 | 40.48 | 42.64 on | on | 0.53 | 1.76 | 2.59
- 400-tps 1-client (or 4 for medium) max 100-ms latency
options | percent of late transactions flush | sort | tiny | small | medium off | off | 12.0 | 64.28 | 68.6
off | on | 11.3 | 22.05 | 22.6 on | off | 1.1 | 67.93 | 67.9 on | on | 0.6 | 3.24 | 3.1
* CONCLUSION :
For most of these HDD tests, when both options are activated the tps
throughput is improved (+3 to +300%), late transactions are reduced (by
91% to 97%) and overall the performance is more stable (tps standard
deviation is typically halved).
The option effects are somehow orthogonal:
- latency is essentially limited by flushing, although sorting also contributes.
- throughput is mostly improved thanks to sorting, with some occasional small positive or negative effect from
flushing.
In detail, some loads may benefit more from only one option activated. In
particular, flushing may have a small adverse effect on throughput in some
conditions, although not always. With SSD probably both options would
probably have limited benefit.
--
Fabien.
Hi, On 2015-06-17 08:24:38 +0200, Fabien COELHO wrote: > Here is version 3, including many performance tests with various settings, > representing about 100 hours of pgbench run. This patch aims at improving > checkpoint I/O behavior so that tps throughput is improved, late > transactions are less frequent, and overall performances are more stable. First off: This is pretty impressive stuff. Being at pgcon, I don't have time to look into this in detail, but I do plan to comment more extensively. > >- Move fsync as early as possible, suggested by Andres Freund? > > > >My opinion is that this should be left out for the nonce. "for the nonce" - what does that mean? > I did that. I'm doubtful that it's a good idea to separate this out, if you did. > - as version 2: checkpoint buffer sorting based on a 2007 patch by > Takahiro Itagaki but with a smaller and static buffer allocated once. > Also, sorting is done by chunks of 131072 pages in the current version, > with a guc to change this value. I think it's a really bad idea to do this in chunks. That'll mean we'll frequently uselessly cause repetitive random IO, often interleaved. That pattern is horrible for SSDs too. We should always try to do this at once, and only fail back to using less memory if we couldn't allocate everything. > * PERFORMANCE TESTS > > Impacts on "pgbench -M prepared -N -P 1 ..." (simple update test, mostly > random write activity on one table), checkpoint_completion_target=0.8, with > different settings on a 16GB 8-core host: > > . tiny: scale=10 shared_buffers=1GB checkpoint_timeout=30s time=6400s > . small: scale=120 shared_buffers=2GB checkpoint_timeout=300s time=4000s > . medium: scale=250 shared_buffers=4GB checkpoint_timeout=15min time=4000s > . large: scale=1000 shared_buffers=4GB checkpoint_timeout=40min time=7500s It'd be interesting to see numbers for tiny, without the overly small checkpoint timeout value. 30s is below the OS's writeback time. > Note: figures noted with a star (*) had various issues during their run, so > pgbench progress figures were more or less incorrect, thus the standard > deviation computation is not to be trusted beyond "pretty bad". > > Caveat: these are only benches on one host at a particular time and > location, which may or may not be reproducible nor be representative > as such of any other load. The good news is that all these tests tell > the same thing. > > - full-speed 1-client > > options | tps performance over per second data > flush | sort | tiny | small | medium | large > off | off | 687 +- 231 | 163 +- 280 * | 191 +- 626 * | 37.7 +- 25.6 > off | on | 699 +- 223 | 457 +- 315 | 479 +- 319 | 48.4 +- 28.8 > on | off | 740 +- 125 | 143 +- 387 * | 179 +- 501 * | 37.3 +- 13.3 > on | on | 722 +- 119 | 550 +- 140 | 549 +- 180 | 47.2 +- 16.8 > > - full speed 4-clients > > options | tps performance over per second data > flush | sort | tiny | small | medium > off | off | 2006 +- 748 | 193 +- 1898 * | 205 +- 2465 * > off | on | 2086 +- 673 | 819 +- 905 * | 807 +- 1029 * > on | off | 2212 +- 451 | 169 +- 1269 * | 160 +- 502 * > on | on | 2073 +- 437 | 743 +- 413 | 822 +- 467 > > - 100-tps 1-client max 100-ms latency > > options | percent of late transactions > flush | sort | tiny | small | medium > off | off | 6.31 | 29.44 | 30.74 > off | on | 6.23 | 8.93 | 7.12 > on | off | 0.44 | 7.01 | 8.14 > on | on | 0.59 | 0.83 | 1.84 > > - 200-tps 1-client max 100-ms latency > > options | percent of late transactions > flush | sort | tiny | small | medium > off | off | 10.00 | 50.61 | 45.51 > off | on | 8.82 | 12.75 | 12.89 > on | off | 0.59 | 40.48 | 42.64 > on | on | 0.53 | 1.76 | 2.59 > > - 400-tps 1-client (or 4 for medium) max 100-ms latency > > options | percent of late transactions > flush | sort | tiny | small | medium > off | off | 12.0 | 64.28 | 68.6 > off | on | 11.3 | 22.05 | 22.6 > on | off | 1.1 | 67.93 | 67.9 > on | on | 0.6 | 3.24 | 3.1 > So you've not run things at more serious concurrency, that'd be interesting to see. I'd also like to see concurrent workloads with synchronous_commit=off - I've seen absolutely horrible latency behaviour for that, and I'm hoping this will help. It's also a good way to simulate faster hardware than you have. It's also curious that sorting is detrimental for full speed 'tiny'. > * CONCLUSION : > > For most of these HDD tests, when both options are activated the tps > throughput is improved (+3 to +300%), late transactions are reduced (by 91% > to 97%) and overall the performance is more stable (tps standard deviation > is typically halved). > > The option effects are somehow orthogonal: > > - latency is essentially limited by flushing, although sorting also > contributes. > > - throughput is mostly improved thanks to sorting, with some occasional > small positive or negative effect from flushing. > > In detail, some loads may benefit more from only one option activated. In > particular, flushing may have a small adverse effect on throughput in some > conditions, although not always. > With SSD probably both options would probably have limited benefit. I doubt that. Small random writes have bad consequences for wear leveling. You might not notice that with a short tests - again, I doubt it - but it'll definitely become visible over time. Greetings, Andres Freund
Hello Andres,
>>> - Move fsync as early as possible, suggested by Andres Freund?
>>>
>>> My opinion is that this should be left out for the nonce.
>
> "for the nonce" - what does that mean?
Nonce \Nonce\ (n[o^]ns), n. [For the nonce, OE. for the nones, ... {for the nonce}, i. e. for the present time.
> I'm doubtful that it's a good idea to separate this out, if you did.
Actually I did, because as explained in another mail the fsync time when
the other options are activated as reported in the logs is essentially
null, so it would not bring significant improvements on these runs,
and also the patch changes enough things as it is.
So this is an evidence-based decision.
I also agree that it seems interesting on principle and should be
beneficial in some case, but I would rather keep that on a TODO list
together with trying to do better things in the bgwriter and try to focus
on the current proposal which already changes significantly the
checkpointer throttling logic.
>> - as version 2: checkpoint buffer sorting based on a 2007 patch by
>> Takahiro Itagaki but with a smaller and static buffer allocated once.
>> Also, sorting is done by chunks of 131072 pages in the current version,
>> with a guc to change this value.
>
> I think it's a really bad idea to do this in chunks.
The small problem I see is that for a very large setting there could be
several seconds or even minutes of sorting, which may or may not be
desirable, so having some control on that seems a good idea.
Another argument is that Tom said he wanted that:-)
In practice the value can be set at a high value so that it is nearly
always sorted in one go. Maybe value "0" could be made special and used to
trigger this behavior systematically, and be the default.
> That'll mean we'll frequently uselessly cause repetitive random IO,
This is not an issue if the chunks are large enough, and anyway the guc
allows to change the behavior as desired. As I said, keeping some control
seems a good idea, and the "full sorting" can be made the default
behavior.
> often interleaved. That pattern is horrible for SSDs too. We should
> always try to do this at once, and only fail back to using less memory
> if we couldn't allocate everything.
The memory is needed anyway in order to avoid a double or significantly
more heavy implementation for the throttling loop. It is allocated once on
the first checkpoint. The allocation could be moved to the checkpointer
initialization if this is a concern. The memory needed is one int per
buffer, which is smaller than the 2007 patch.
>> . tiny: scale=10 shared_buffers=1GB checkpoint_timeout=30s time=6400s
>
> It'd be interesting to see numbers for tiny, without the overly small
> checkpoint timeout value. 30s is below the OS's writeback time.
The point of tiny was to trigger a lot of checkpoints. The size is pretty
ridiculous anyway, as "tiny" implies. I think I did some tests on other
versions of the patch and longer checkpoint_timeout on pretty small
database that showed smaller benefit from the options, as one would
expect. I'll try to re-run some.
> So you've not run things at more serious concurrency, that'd be
> interesting to see.
I do not have a box available for "serious concurrency".
> I'd also like to see concurrent workloads with synchronous_commit=off -
> I've seen absolutely horrible latency behaviour for that, and I'm hoping
> this will help. It's also a good way to simulate faster hardware than
> you have.
> It's also curious that sorting is detrimental for full speed 'tiny'.
Yep.
>> With SSD probably both options would probably have limited benefit.
>
> I doubt that. Small random writes have bad consequences for wear
> leveling. You might not notice that with a short tests - again, I doubt
> it - but it'll definitely become visible over time.
Possibly. Testing such effects does not seem easy, though. At least I have
not seen "write stalls" on SSD, which is my primary concern.
--
Fabien.
Hi, On 2015-06-20 08:57:57 +0200, Fabien COELHO wrote: > Actually I did, because as explained in another mail the fsync time when the > other options are activated as reported in the logs is essentially null, so > it would not bring significant improvements on these runs, > and also the patch changes enough things as it is. > > So this is an evidence-based decision. Meh. You're testing on low concurrency. > >> - as version 2: checkpoint buffer sorting based on a 2007 patch by > >> Takahiro Itagaki but with a smaller and static buffer allocated once. > >> Also, sorting is done by chunks of 131072 pages in the current version, > >> with a guc to change this value. > > > >I think it's a really bad idea to do this in chunks. > > The small problem I see is that for a very large setting there could be > several seconds or even minutes of sorting, which may or may not be > desirable, so having some control on that seems a good idea. If the sorting of the dirty blocks alone takes minutes, it'll never finish writing that many buffers out. That's a utterly bogus argument. > Another argument is that Tom said he wanted that:-) I don't think he said that when we discussed this last. > In practice the value can be set at a high value so that it is nearly always > sorted in one go. Maybe value "0" could be made special and used to trigger > this behavior systematically, and be the default. You're just making things too complicated. > >That'll mean we'll frequently uselessly cause repetitive random IO, > > This is not an issue if the chunks are large enough, and anyway the guc > allows to change the behavior as desired. I don't think this is true. If two consecutive blocks are dirty, but you sync them in two different chunks, you *always* will cause additional random IO. Either the drive will have to skip the write for that block, or the os will prefetch the data. More importantly with SSDs it voids the wear leveling advantages. > >often interleaved. That pattern is horrible for SSDs too. We should always > >try to do this at once, and only fail back to using less memory if we > >couldn't allocate everything. > > The memory is needed anyway in order to avoid a double or significantly more > heavy implementation for the throttling loop. It is allocated once on the > first checkpoint. The allocation could be moved to the checkpointer > initialization if this is a concern. The memory needed is one int per > buffer, which is smaller than the 2007 patch. There's a reason the 2007 patch (and my revision of it last year) did what it did. You can't just access buffer descriptors without locking. Besides, causing additional cacheline bouncing during the sorting process is a bad idea. Greetings, Andres Freund
On 6/20/15 2:57 AM, Fabien COELHO wrote: >>> - as version 2: checkpoint buffer sorting based on a 2007 patch by >>> Takahiro Itagaki but with a smaller and static buffer allocated once. >>> Also, sorting is done by chunks of 131072 pages in the current >>> version, >>> with a guc to change this value. >> >> I think it's a really bad idea to do this in chunks. > > The small problem I see is that for a very large setting there could be > several seconds or even minutes of sorting, which may or may not be > desirable, so having some control on that seems a good idea. ISTM a more elegant way to handle that would be to start off with a very small number of buffers and sort larger and larger lists while the OS is busy writing/syncing. > Another argument is that Tom said he wanted that:-) Did he elaborate why? I don't see him on this thread (though I don't have all of it). > In practice the value can be set at a high value so that it is nearly > always sorted in one go. Maybe value "0" could be made special and used > to trigger this behavior systematically, and be the default. It'd be nice if it was just self-tuning, with no GUC. It looks like it'd be much better to get this committed without more than we have now than to do without it though... -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Data in Trouble? Get it in Treble! http://BlueTreble.com
Hello Andres, >> So this is an evidence-based decision. > > Meh. You're testing on low concurrency. Well, I'm just testing on the available box. I do not see the link between high concurrency and whether moving fsync as early as possible would have a large performance impact. I think it might be interesting if bgwriter is doing a lot of writes, but I'm not sure under which configuration & load that would be. >>> I think it's a really bad idea to do this in chunks. >> >> The small problem I see is that for a very large setting there could be >> several seconds or even minutes of sorting, which may or may not be >> desirable, so having some control on that seems a good idea. > > If the sorting of the dirty blocks alone takes minutes, it'll never > finish writing that many buffers out. That's a utterly bogus argument. Well, if in the future you have 8 TB of memory (I've seen a 512GB memory server a few weeks ago), set shared_buffers=2TB, then if I'm not mistaken in the worst case you may have 256 millions 8k-buffers to checkpoint. Then it really depends on the I/O backend stuff used by the box, but if you bought 8 TB of RAM probably you would have a nice I/O stuff attached. >> Another argument is that Tom said he wanted that:-) > > I don't think he said that when we discussed this last. That is what I was recalling when I wrote this sentence: http://www.postgresql.org/message-id/6599.1409421040@sss.pgh.pa.us But it had more to do with memory-allocation management. >> In practice the value can be set at a high value so that it is nearly always >> sorted in one go. Maybe value "0" could be made special and used to trigger >> this behavior systematically, and be the default. > > You're just making things too complicated. ISTM that it is not really complicated, but anyway it is easy to change the checkpoint_sort stuff to a boolean. In the reported performance tests, the is usually just one chunk anyway, sometimes two, so this gives an idea of the overall performance effect. >> This is not an issue if the chunks are large enough, and anyway the guc >> allows to change the behavior as desired. > > I don't think this is true. If two consecutive blocks are dirty, but you > sync them in two different chunks, you *always* will cause additional > random IO. I think that it could be a small number if the chunks are large, i.e. the performance benefit of sorting larger and larger chunks is decreasing. > Either the drive will have to skip the write for that block, > or the os will prefetch the data. More importantly with SSDs it voids > the wear leveling advantages. Possibly. I do not understand wear leveling done by SSD firmware. >>> often interleaved. That pattern is horrible for SSDs too. We should always >>> try to do this at once, and only fail back to using less memory if we >>> couldn't allocate everything. >> >> The memory is needed anyway in order to avoid a double or significantly more >> heavy implementation for the throttling loop. It is allocated once on the >> first checkpoint. The allocation could be moved to the checkpointer >> initialization if this is a concern. The memory needed is one int per >> buffer, which is smaller than the 2007 patch. > > There's a reason the 2007 patch (and my revision of it last year) did > what it did. You can't just access buffer descriptors without > locking. I really think that you can because the sorting is really "advisory", i.e. the checkpointer will work fine if the sorting is wrong or not done at all, as it is now, when the checkpointer writes buffers. The only condition is that the buffers must not be moved with their "to write in this checkpoint" flag, but this is also necessary for the current checkpointer stuff to work. Moreover, this trick is alreay pre-existing from the patch I submitted: some tests are done without locking, but the actual "buffer write" does the locking and would skip it if the previous test was wrong, as described in comments in the code. > Besides, causing additional cacheline bouncing during the > sorting process is a bad idea. Hmmm. The impact would be to multiply the memory required by 3 or 4 (buf_id, relation, forknum, offset), instead of just buf_id, and I understood that memory was a concern. Moreover, once the sort process get the lines which contain the sorting data from the buffer descriptor in its cache, I think that it should be pretty much okay. Incidentally, they would probably have been brought to cache by the scan to collect them. Also, I do not think that the sorting time for 128000 buffers, and possible cache misses, was a big issue, but I do not have a measure to defend that. I could try to collect some data about that. -- Fabien.
Hello Jim, >> The small problem I see is that for a very large setting there could be >> several seconds or even minutes of sorting, which may or may not be >> desirable, so having some control on that seems a good idea. > > ISTM a more elegant way to handle that would be to start off with a very > small number of buffers and sort larger and larger lists while the OS is busy > writing/syncing. You really have to have done a significant part/most/all of sorting before starting to write. >> Another argument is that Tom said he wanted that:-) > > Did he elaborate why? I don't see him on this thread (though I don't have all > of it). http://www.postgresql.org/message-id/6599.1409421040@sss.pgh.pa.us But it has more to do with memory management. >> In practice the value can be set at a high value so that it is nearly >> always sorted in one go. Maybe value "0" could be made special and used >> to trigger this behavior systematically, and be the default. > > It'd be nice if it was just self-tuning, with no GUC. Hmmm. It can easilly be turned into a boolean, but otherwise I have no clue about how to decide whether to sort and/or flush. > It looks like it'd be much better to get this committed without more than we > have now than to do without it though... Yep, I think the figures are definitely encouraging. -- Fabien.
<sorry, resent stalled post, wrong from> > It'd be interesting to see numbers for tiny, without the overly small > checkpoint timeout value. 30s is below the OS's writeback time. Here are some tests with longer timeout: tiny2: scale=10 shared_buffers=1GB checkpoint_timeout=5min max_wal_size=1GB warmup=600 time=4000 flsh | full speed tps | percent of late tx, 4 clients, for tps: /srt | 1 client | 4 clients | 100 | 200| 400 | 800 | 1200 | 1600 N/N | 930 +- 124 | 2560 +- 394 | 0.70 | 1.03 | 1.27 | 1.56 | 2.02 | 2.38 N/Y | 924 +-122 | 2612 +- 326 | 0.63 | 0.79 | 0.94 | 1.15 | 1.45 | 1.67 Y/N | 907 +- 112 | 2590 +- 315 | 0.58 | 0.83 | 0.68 | 0.71| 0.81 | 1.26 Y/Y | 915 +- 114 | 2590 +- 317 | 0.60 | 0.68 | 0.70 | 0.78 | 0.88 | 1.13 There seems to be a small 1-2% performance benefit with 4 clients, this is reversed for 1 client, there are significantly and consistently less late transactions when options are activated, the performance is more stable (standard deviation reduced by 10-18%). The db is about 200 MB ~ 25000 pages, at 2500+ tps it is written 40 times over in 5 minutes, so the checkpoint basically writes everything in 220 seconds, 0.9 MB/s. Given the preload phase the buffers may be more or less in order in memory, so may be written out in order anyway. medium2: scale=300 shared_buffers=5GB checkpoint_timeout=30min max_wal_size=4GB warmup=1200 time=7500 flsh | full speed tps | percent of late tx, 4 clients /srt | 1 client | 4 clients | 100 | 200 | 400 | N/N | 173 +- 289* | 198 +- 531* | 27.61 | 43.92 | 61.16 | N/Y | 458 +- 327* | 743 +- 920* | 7.05 | 14.24 | 24.07| Y/N | 169 +- 166* | 187 +- 302* | 4.01 | 39.84 | 65.70 | Y/Y | 546 +- 143 | 681 +- 459 | 1.55 | 3.51 | 2.84| The effect of sorting is very positive (+150% to 270% tps). On this run, flushing has a positive (+20% with 1 client) or negative (-8 % with 4 clients) on throughput, and late transactions are reduced by 92-95% when both options are activated. At 550 tps checkpoints are xlog-triggered and write about 1/3 of the database, (170000 buffers to write very 220-260 seconds, 4 MB/s). -- Fabien.
>
>
> <sorry, resent stalled post, wrong from>
>
>> It'd be interesting to see numbers for tiny, without the overly small
>> checkpoint timeout value. 30s is below the OS's writeback time.
>
>
> Here are some tests with longer timeout:
>
> tiny2: scale=10 shared_buffers=1GB checkpoint_timeout=5min
> max_wal_size=1GB warmup=600 time=4000
>
> flsh | full speed tps | percent of late tx, 4 clients, for tps:
> /srt | 1 client | 4 clients | 100 | 200 | 400 | 800 | 1200 | 1600
> N/N | 930 +- 124 | 2560 +- 394 | 0.70 | 1.03 | 1.27 | 1.56 | 2.02 | 2.38
> N/Y | 924 +- 122 | 2612 +- 326 | 0.63 | 0.79 | 0.94 | 1.15 | 1.45 | 1.67
> Y/N | 907 +- 112 | 2590 +- 315 | 0.58 | 0.83 | 0.68 | 0.71 | 0.81 | 1.26
> Y/Y | 915 +- 114 | 2590 +- 317 | 0.60 | 0.68 | 0.70 | 0.78 | 0.88 | 1.13
>
> There seems to be a small 1-2% performance benefit with 4 clients, this is reversed for 1 client, there are significantly and consistently less late transactions when options are activated, the performance is more stable
> (standard deviation reduced by 10-18%).
>
> The db is about 200 MB ~ 25000 pages, at 2500+ tps it is written 40 times over in 5 minutes, so the checkpoint basically writes everything in 220 seconds, 0.9 MB/s. Given the preload phase the buffers may be more or less in order in memory, so may be written out in order anyway.
>
>
> medium2: scale=300 shared_buffers=5GB checkpoint_timeout=30min
> max_wal_size=4GB warmup=1200 time=7500
>
> flsh | full speed tps | percent of late tx, 4 clients
> /srt | 1 client | 4 clients | 100 | 200 | 400 |
> N/N | 173 +- 289* | 198 +- 531* | 27.61 | 43.92 | 61.16 |
> N/Y | 458 +- 327* | 743 +- 920* | 7.05 | 14.24 | 24.07 |
> Y/N | 169 +- 166* | 187 +- 302* | 4.01 | 39.84 | 65.70 |
> Y/Y | 546 +- 143 | 681 +- 459 | 1.55 | 3.51 | 2.84 |
>
> The effect of sorting is very positive (+150% to 270% tps). On this run, flushing has a positive (+20% with 1 client) or negative (-8 % with 4 clients) on throughput, and late transactions are reduced by 92-95% when both options are activated.
>
Hello Amit,
>> medium2: scale=300 shared_buffers=5GB checkpoint_timeout=30min
>> max_wal_size=4GB warmup=1200 time=7500
>>
>> flsh | full speed tps | percent of late tx, 4 clients
>> /srt | 1 client | 4 clients | 100 | 200 | 400 |
>> N/N | 173 +- 289* | 198 +- 531* | 27.61 | 43.92 | 61.16 |
>> N/Y | 458 +- 327* | 743 +- 920* | 7.05 | 14.24 | 24.07 |
>> Y/N | 169 +- 166* | 187 +- 302* | 4.01 | 39.84 | 65.70 |
>> Y/Y | 546 +- 143 | 681 +- 459 | 1.55 | 3.51 | 2.84 |
>>
>> The effect of sorting is very positive (+150% to 270% tps). On this run,
> flushing has a positive (+20% with 1 client) or negative (-8 % with 4
> clients) on throughput, and late transactions are reduced by 92-95% when
> both options are activated.
>
> Why there is dip in performance with multiple clients,
I'm not sure to see the "dip". The performances are better with 4 clients
compared to 1 client?
> can it be due to reason that we started doing more stuff after holding
> bufhdr lock in below code?
I think it is very unlikely that the buffer being locked would be
simultaneously requested by one of the 4 clients for an UPDATE, so I do
not think it should have a significant impact.
> BufferSync() [...]
> BufferSync()
> {
> ..
> - buf_id = StrategySyncStart(NULL, NULL);
> - num_to_scan = NBuffers;
> + active_spaces = nb_spaces;
> + space = 0;
> num_written = 0;
> - while (num_to_scan-- > 0)
> +
> + while (active_spaces != 0)
> ..
> }
>
> The changed code doesn't seems to give any consideration to
> clock-sweep point
Indeed.
> which might not be helpful for cases when checkpoint could have flushed
> soon-to-be-recycled buffers. I think flushing the sorted buffers w.r.t
> tablespaces is a good idea, but not giving any preference to clock-sweep
> point seems to me that we would loose in some cases by this new change.
I do not see how to do both, as these two orders seem more or less
unrelated? The traditionnal assumption is that the I/O are very slow and
they are to be optimized first, so going for buffer ordering to be nice to
the disk looks like the priority.
--
Fabien.
> I'd also like to see concurrent workloads with synchronous_commit=off - > I've seen absolutely horrible latency behaviour for that, and I'm hoping > this will help. It's also a good way to simulate faster hardware than > you have. It helps. I've done a few runs, where the very-very-bad situation is improved to... I would say very-bad: medium3: scale=200 shared_buffers=4GB checkpoint_timeout=15min max_wal_size=4GB warmup=1200 time=6000 clients=4 synchronous_commit=off flush sort | tps | percent of seconds offline off off | 296 | 83% offline off on | 1496 | 33% offline off on | 1641 | 59% offline on on | 1515 | 31% offline The offline figure is the percentage of seconds in the 6000 seconds run where 0.0 tps are reported, or where nothing is reported because pgbench is stuck. It is somehow better... on an abysmal scale: sorting and flushing reduced the offline time by a factor of 2.6. Too bad it is so high to begin with. The tps is improved by a factor of 5 with either options. -- Fabien.
> It'd be interesting to see numbers for tiny, without the overly small > checkpoint timeout value. 30s is below the OS's writeback time. Here are some tests with longer timeout: tiny2: scale=10 shared_buffers=1GB checkpoint_timeout=5min max_wal_size=1GB warmup=600 time=4000 flsh | full speed tps | percent of late tx, 4 clients, for tps: /srt | 1 client | 4 clients | 100 | 200| 400 | 800 | 1200 | 1600 N/N | 930 +- 124 | 2560 +- 394 | 0.70 | 1.03 | 1.27 | 1.56 | 2.02 | 2.38 N/Y | 924 +- 122| 2612 +- 326 | 0.63 | 0.79 | 0.94 | 1.15 | 1.45 | 1.67 Y/N | 907 +- 112 | 2590 +- 315 | 0.58 | 0.83 | 0.68 | 0.71 |0.81 | 1.26 Y/Y | 915 +- 114 | 2590 +- 317 | 0.60 | 0.68 | 0.70 | 0.78 | 0.88 | 1.13 There seems to be a small 1-2% performance benefit with 4 clients, this is reversed for 1 client, there are significantly and consistently less late transactions when options are activated, the performance is more stable (standard deviation reduced by 10-18%). The db is about 200 MB ~ 25000 pages, at 2500+ tps it is written 40 times over in 5 minutes, so the checkpoint basically writes everything over 220 seconds, 0.9 MB/s. Given the preload phase the buffers may be more or less in order in memory, so would be written out in order. medium2: scale=300 shared_buffers=5GB checkpoint_timeout=30min max_wal_size=4GB warmup=1200 time=7500 flsh | full speed tps | percent of late tx, 4 clients /srt | 1 client | 4 clients | 100 | 200 | 400| N/N | 173 +- 289* | 198 +- 531* | 27.61 | 43.92 | 61.16 | N/Y | 458 +- 327* | 743 +- 920* | 7.05 | 14.24 | 24.07| Y/N | 169 +- 166* | 187 +- 302* | 4.01 | 39.84 | 65.70 | Y/Y | 546 +- 143 | 681 +- 459 | 1.55 | 3.51 | 2.84| The effect of sorting is very positive (+150% to 270% tps). On this run, flushing has a positive (+20% with 1 client) or negative (-8 % with 4 clients) on throughput, and late transactions are reduced by 92-95% when both options are activated. At 550 tps checkpoints are xlog-triggered and write about 1/3 of the database, (170000 buffers to write very 220-260 seconds, 4 MB/s). -- Fabien.
On 6/22/15 11:59 PM, Fabien COELHO wrote: >> which might not be helpful for cases when checkpoint could have >> flushed soon-to-be-recycled buffers. I think flushing the sorted >> buffers w.r.t tablespaces is a good idea, but not giving any >> preference to clock-sweep point seems to me that we would loose in >> some cases by this new change. > > I do not see how to do both, as these two orders seem more or less > unrelated? The traditionnal assumption is that the I/O are very slow > and they are to be optimized first, so going for buffer ordering to be > nice to the disk looks like the priority. The point is that it's already expensive for backends to advance the clock; if they then have to wait on IO as well it gets REALLY expensive. So we want to avoid that. Other than that though, it is pretty orthogonal, so perhaps another indication that the clock should be handled separately from both backends and bgwriter... -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Data in Trouble? Get it in Treble! http://BlueTreble.com
Hello Amit,medium2: scale=300 shared_buffers=5GB checkpoint_timeout=30minflushing has a positive (+20% with 1 client) or negative (-8 % with 4
max_wal_size=4GB warmup=1200 time=7500
flsh | full speed tps | percent of late tx, 4 clients
/srt | 1 client | 4 clients | 100 | 200 | 400 |
N/N | 173 +- 289* | 198 +- 531* | 27.61 | 43.92 | 61.16 |
N/Y | 458 +- 327* | 743 +- 920* | 7.05 | 14.24 | 24.07 |
Y/N | 169 +- 166* | 187 +- 302* | 4.01 | 39.84 | 65.70 |
Y/Y | 546 +- 143 | 681 +- 459 | 1.55 | 3.51 | 2.84 |
The effect of sorting is very positive (+150% to 270% tps). On this run,
clients) on throughput, and late transactions are reduced by 92-95% when
both options are activated.
Why there is dip in performance with multiple clients,
I'm not sure to see the "dip". The performances are better with 4 clients compared to 1 client?
can it be due to reason that we started doing more stuff after holding bufhdr lock in below code?
I think it is very unlikely that the buffer being locked would be simultaneously requested by one of the 4 clients for an UPDATE, so I do not think it should have a significant impact.
BufferSync() [...]BufferSync()
{
..
- buf_id = StrategySyncStart(NULL, NULL);
- num_to_scan = NBuffers;
+ active_spaces = nb_spaces;
+ space = 0;
num_written = 0;
- while (num_to_scan-- > 0)
+
+ while (active_spaces != 0)
..
}
The changed code doesn't seems to give any consideration to
clock-sweep point
Indeed.which might not be helpful for cases when checkpoint could have flushed soon-to-be-recycled buffers. I think flushing the sorted buffers w.r.t tablespaces is a good idea, but not giving any preference to clock-sweep point seems to me that we would loose in some cases by this new change.
I do not see how to do both, as these two orders seem more or less unrelated?
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
>>>> flsh | full speed tps | percent of late tx, 4 clients >>>> /srt | 1 client | 4 clients | 100 | 200 | 400 | >>>> N/N | 173 +- 289* | 198 +- 531* | 27.61 | 43.92 | 61.16 | >>>> N/Y | 458 +- 327* | 743 +- 920* | 7.05 | 14.24 | 24.07 | >>>> Y/N | 169 +- 166* | 187 +- 302* | 4.01 | 39.84 | 65.70 | >>>> Y/Y | 546 +- 143 | 681 +- 459 | 1.55 | 3.51 | 2.84 | >>>> >>>> The effect of sorting is very positive (+150% to 270% tps). On this run, >>>> >>> flushing has a positive (+20% with 1 client) or negative (-8 % with 4 >>> clients) on throughput, and late transactions are reduced by 92-95% when >>> both options are activated. >>> >>> Why there is dip in performance with multiple clients, >> >> I'm not sure to see the "dip". The performances are better with 4 clients >> compared to 1 client? > > What do you mean by "negative (-8 % with 4 clients) on throughput" in > above sentence? I thought by that you mean that there is dip in TPS with > patch as compare to HEAD at 4 clients. Ok, I misunderstood your question. I thought you meant a dip between 1 client and 4 clients. I meant that when flush is turned on tps goes down by 8% (743 to 681 tps) on this particular run. Basically tps improvements mostly come from "sort", and "flush" has uncertain effects on tps (throuput), but much more on latency and performance stability (lower late rate, lower standard deviation). Note that I'm not comparing to HEAD in the above tests, but with the new options desactivated, which should be more or less comparable to current HEAD, i.e. there is no sorting nor flushing done, but this is not strictly speaking HEAD behavior. Probably I should get some figures with HEAD as well to check the "more or less" assumption. > Also I am not completely sure what's +- means in your data above? The first figure before "+-" is the tps, the second after is its standard deviation computed in per-second traces. Some runs are very bad, with pgbench stuck at times, and result on stddev larger than the average, they ere noted with "*". > I understand your point and I also don't have any specific answer > for it at this moment, the point of worry is that it should not lead > to degradation of certain cases as compare to current algorithm. > The workload where it could effect is when your data doesn't fit > in shared buffers, but can fit in RAM. Hmmm. My point of view is still that the logical priority is to optimize for disk IO first, then look for compatible RAM optimisations later. I can run tests with a small shared_buffers, but probably it would just trigger a lot of checkpoints, or worse rely on the bgwriter to find space, which would generate random IOs. -- Fabien.
>> I do not see how to do both, as these two orders seem more or less >> unrelated? The traditionnal assumption is that the I/O are very slow >> and they are to be optimized first, so going for buffer ordering to be >> nice to the disk looks like the priority. > > The point is that it's already expensive for backends to advance the clock; > if they then have to wait on IO as well it gets REALLY expensive. So we want > to avoid that. I do not know what this clock stuff does. Note that the checkpoint buffer scan is done once at the beginning of the checkpoint and its time is relatively small compared to everything else in the checkpoint. If this scan is an issue, it can be done in reverse order, or in some other order, but I think it is better to do it in order for better cache behavior, although the effect should be marginal. -- Fabien.
>> Besides, causing additional cacheline bouncing during the >> sorting process is a bad idea. > > Hmmm. The impact would be to multiply the memory required by 3 or 4 (buf_id, > relation, forknum, offset), instead of just buf_id, and I understood that > memory was a concern. > > Moreover, once the sort process get the lines which contain the sorting data > from the buffer descriptor in its cache, I think that it should be pretty > much okay. Incidentally, they would probably have been brought to cache by > the scan to collect them. Also, I do not think that the sorting time for > 128000 buffers, and possible cache misses, was a big issue, but I do not have > a measure to defend that. I could try to collect some data about that. I've collected some data by adding a "sort time" measure, with checkpoint_sort_size=10000000 so that sorting is in one chunk, and done some large checkpoints: LOG: checkpoint complete: wrote 41091 buffers (6.3%); 0 transaction log file(s) added, 0 removed, 0 recycled; sort=0.024s, write=0.488 s, sync=8.790 s, total=9.837 s; sync files=41, longest=8.717 s, average=0.214 s; distance=404972kB, estimate=404972 kB LOG: checkpoint complete: wrote 212124 buffers (32.4%); 0 transaction log file(s) added, 0 removed, 0 recycled; sort=0.078s, write=128.885 s, sync=1.269 s, total=131.646 s; sync files=43, longest=1.155 s, average=0.029 s; distance=2102950kB, estimate=2102950 kB LOG: checkpoint complete: wrote 384427 buffers (36.7%); 0 transaction log file(s) added, 0 removed, 1 recycled; sort=0.120s, write=83.995 s, sync=13.944 s, total=98.035 s; sync files=9, longest=13.724 s, average=1.549 s; distance=3783305kB, estimate=3783305 kB LOG: checkpoint complete: wrote 809211 buffers (77.2%); 0 transaction log file(s) added, 0 removed, 1 recycled; sort=0.358s, write=138.146 s, sync=14.943 s, total=153.124 s; sync files=13, longest=14.871 s, average=1.149 s; distance=8075338kB, estimate=8075338 kB Summary of these checkpoints: #buffers size sort 41091 328MB 0.024 212124 1.7GB 0.078 384427 2.9GB 0.120 809211 6.2GB 0.358 Sort times are pretty negligeable compared to the whole checkpoint time, and under 0.1 s/GB of buffers sorted. On a 512 GB server with shared_buffers=128GB (25%), this suggest a worst case checkpoint sorting in a few seconds, and then you have a hundred GB to write anyway. If we project on next decade 1 TB checkpoint that would make sorting in under a minute... But then you have 1 TB of data to dump. As a comparison point, I've done the large checkpoint with the default sort size of 131072: LOG: checkpoint complete: wrote 809211 buffers (77.2%); 0 transaction log file(s) added, 0 removed, 1 recycled; sort=0.251s, write=152.377 s, sync=15.062 s, total=167.453 s; sync files=13, longest=14.974 s, average=1.158 s; distance=8075338kB, estimate=8075338 kB The 0.251 sort time is to be compared to 0.358. Well, n.log(n) is not too bad, as expected. These figures suggest that sorting time and associated cache misses are not a significant issue and thus are not worth bothering much about, and also that probably a simple boolean option would be quite acceptable instead of the chunk approach. Attached is an updated version of the patch which turns the sort option into a boolean, and also include the sort time in the checkpoint log. There is still an open question about whether the sorting buffer allocation is lost on some signals and should be reallocated in such event. -- Fabien.
flsh | full speed tps | percent of late tx, 4 clientsflushing has a positive (+20% with 1 client) or negative (-8 % with 4
/srt | 1 client | 4 clients | 100 | 200 | 400 |
N/N | 173 +- 289* | 198 +- 531* | 27.61 | 43.92 | 61.16 |
N/Y | 458 +- 327* | 743 +- 920* | 7.05 | 14.24 | 24.07 |
Y/N | 169 +- 166* | 187 +- 302* | 4.01 | 39.84 | 65.70 |
Y/Y | 546 +- 143 | 681 +- 459 | 1.55 | 3.51 | 2.84 |
The effect of sorting is very positive (+150% to 270% tps). On this run,
clients) on throughput, and late transactions are reduced by 92-95% when
both options are activated.
Why there is dip in performance with multiple clients,
I'm not sure to see the "dip". The performances are better with 4 clients
compared to 1 client?
What do you mean by "negative (-8 % with 4 clients) on throughput" in above sentence? I thought by that you mean that there is dip in TPS with patch as compare to HEAD at 4 clients.
Ok, I misunderstood your question. I thought you meant a dip between 1 client and 4 clients. I meant that when flush is turned on tps goes down by 8% (743 to 681 tps) on this particular run.
Basically tps improvements mostly come from "sort", and "flush" has uncertain effects on tps (throuput), but much more on latency and performance stability (lower late rate, lower standard deviation).
Note that I'm not comparing to HEAD in the above tests, but with the new options desactivated, which should be more or less comparable to current HEAD, i.e. there is no sorting nor flushing done, but this is not strictly speaking HEAD behavior. Probably I should get some figures with HEAD as well to check the "more or less" assumption.Also I am not completely sure what's +- means in your data above?
The first figure before "+-" is the tps, the second after is its standard deviation computed in per-second traces. Some runs are very bad, with pgbench stuck at times, and result on stddev larger than the average, they ere noted with "*".I understand your point and I also don't have any specific answer
for it at this moment, the point of worry is that it should not lead
to degradation of certain cases as compare to current algorithm.
The workload where it could effect is when your data doesn't fit
in shared buffers, but can fit in RAM.
Hmmm. My point of view is still that the logical priority is to optimize for disk IO first, then look for compatible RAM optimisations later.
With Regards,
Amit Kapila.
Hello Amit, >> [...] >> Ok, I misunderstood your question. I thought you meant a dip between 1 >> client and 4 clients. I meant that when flush is turned on tps goes down by >> 8% (743 to 681 tps) on this particular run. > > This 8% might matter if the dip is bigger with more clients and > more aggressive workload. Do you know what could lead to this > dip, because if we know what is the reason than it will be more > predictable to know if this is the max dip that could happen or it > could lead to bigger dip in other cases. I do not know the cause of the dip, and whether it would increase with more clients. I do not have a box for such tests. If someone can provided the box, I can provide test scripts:-) The first, although higher, measure is really very unstable, with pg totaly unresponsive (offline, really) at time. I think that the flush option may always have a risk of (small) detrimental effects on tps, because there are two steady states: one with pg only doing wal-logged transactions with great tps, and one with pg doing the checkpoint at nought tps. If this is on the same disk, even at best the combination means that probably each operation will amper the other one a little bit, so the combined tps performance would/could be lower than doing one after the other and having pg offline 50% of the time... Please also note that this 8% "dip" is on a 681 (with the dip) vs 198 (no options at all) a X 3.4 improvement compared to pg current behavior. >> Basically tps improvements mostly come from "sort", and "flush" has >> uncertain effects on tps (throuput), but much more on latency and >> performance stability (lower late rate, lower standard deviation). > > I agree that performance stability is important, but not sure if it > is good idea to sacrifice the throuput for it. See discussion above. I think better stability may imply slightly lower throughput on some load. That is why there are options and DBA to choose them:-) > If sort + flush always gives better results, then isn't it better to > perform these actions together under one option. Sure, but that is not currently the case. Also what is done is very orthogonal, so I would tend to keep these separate. If one is always beneficial and it is wished that it should be always activated, then the option could be removed. >> Hmmm. My point of view is still that the logical priority is to optimize >> for disk IO first, then look for compatible RAM optimisations later. > > It is not only about RAM optimisation which we can do later, but also > about avoiding regression in existing use-cases. Hmmm. Currently I have not seen really significant regressions. I have seen some less good impact of some options on some loads. -- Fabien.
> Note that I'm not comparing to HEAD in the above tests, but with the new
> options desactivated, which should be more or less comparable to current
> HEAD, i.e. there is no sorting nor flushing done, but this is not strictly
> speaking HEAD behavior. Probably I should get some figures with HEAD as well
> to check the "more or less" assumption.
Just for answering myself on this point, I tried current HEAD vs patch v4
with sort OFF + flush OFF: the figures are indeed quite comparable (see
below), so although the internal implementation is different, the
performance when both options are off is still a reasonable approximation
of the performance without the patch, as I was expecting. What patch v4
still does with OFF/OFF which is not done by HEAD is balancing writes
among tablespaces, but there is only one disk on these tests so it does
not matter.
tps & stddev full speed:
HEAD OFF/OFF
tiny 1 client 727 +- 227 221 +- 246 small 1 client 158 +- 316 158 +- 325 medium 1 client
148 +- 285 157 +- 326 tiny 4 clients 2088 +- 786 2074 +- 699 small 4 clients 192 +- 648 188
+-560 medium 4 clients 220 +- 654 220 +- 648
percent of late transactions:
HEAD OFF/OFF
tiny 4 clients 100 tps 6.31 6.67 small 4c 100 tps 35.68 35.23 medium 4c 100 tps
37.38 38.00 tiny 4c 200 tps 9.06 9.10 small 4c 200 tps 51.65 51.16 medium 4c
200tps 51.35 50.20 tiny 4 clients 400 tps 11.4 10.5 small 4 clients 400 tps 66.4
67.6
--
Fabien.
On 2015-06-26 21:47:30 +0200, Fabien COELHO wrote: > tps & stddev full speed: > HEAD OFF/OFF > > tiny 1 client 727 +- 227 221 +- 246 Huh?
Hello Andres, >> HEAD OFF/OFF >> >> tiny 1 client 727 +- 227 221 +- 246 > > Huh? Indeed, just to check that someone was reading this magnificent mail:-) Just a typo because I reformated the figures for simpler comparison. 221 is really 721, quite close to 727. -- Fabien.
> Attached is an updated version of the patch which turns the sort option into > a boolean, and also include the sort time in the checkpoint log. > > There is still an open question about whether the sorting buffer allocation > is lost on some signals and should be reallocated in such event. In such case, probably the allocation should be managed from CheckpointerMain, and the lazy allocation could remain for other callers (I guess just "initdb"). More open questions: - best name for the flush option (checkpoint_flush_to_disk, checkpoint_flush_on_write, checkpoint_flush, ...) - best name for the sort option (checkpoint_sort, checkpoint_sort_buffers, checkpoint_sort_ios, ...) Other nice-to-have inputs: - tests on a non-linux system with posix_fadvise (FreeBSD? others?) - tests on a large dedicated box Attached are some scripts to help with testing, if someone's feels like that: - cp_test.sh: run some tests, to adapt to one's setup... - cp_test_count.pl: show percent of late transactions - avg.py: show stats about stuff sh> grep 'progress: ' OUTPUT_FILE | cut -d' ' -f4 | avg.py *BEWARE* that if pgbench got stuck some "0" data are missing, look for the actual tps in the output file and for theline count to check whether it is the case... some currently submitted patch on pgbench helps, see https://commitfest.postgresql.org/5/199/ -- Fabien.
Hello, Attached is very minor v5 update which does a rebase & completes the cleanup of doing a full sort instead of a chuncked sort. >> Attached is an updated version of the patch which turns the sort option >> into a boolean, and also include the sort time in the checkpoint log. >> >> There is still an open question about whether the sorting buffer allocation >> is lost on some signals and should be reallocated in such event. > > In such case, probably the allocation should be managed from > CheckpointerMain, and the lazy allocation could remain for other callers (I > guess just "initdb"). > > > More open questions: > > - best name for the flush option (checkpoint_flush_to_disk, > checkpoint_flush_on_write, checkpoint_flush, ...) > > - best name for the sort option (checkpoint_sort, > checkpoint_sort_buffers, checkpoint_sort_ios, ...) > > > Other nice-to-have inputs: > > - tests on a non-linux system with posix_fadvise > (FreeBSD? others?) > > - tests on a large dedicated box > > > Attached are some scripts to help with testing, if someone's feels like that: > > - cp_test.sh: run some tests, to adapt to one's setup... > > - cp_test_count.pl: show percent of late transactions > > - avg.py: show stats about stuff > > sh> grep 'progress: ' OUTPUT_FILE | cut -d' ' -f4 | avg.py > > *BEWARE* that if pgbench got stuck some "0" data are missing, > look for the actual tps in the output file and for the line > count to check whether it is the case... some currently submitted > patch on pgbench helps, see https://commitfest.postgresql.org/5/199/ As this pgbench patch is now in master, pgbench is less likely to get stuck, but check nevertheless that the number of progress line matches the expected number. -- Fabien.
On 07/26/2015 06:01 PM, Fabien COELHO wrote: > Attached is very minor v5 update which does a rebase & completes the > cleanup of doing a full sort instead of a chuncked sort. Some thoughts on this: * I think we should drop the "flush" part of this for now. It's not as clearly beneficial as the sorting part, and adds a great deal more code complexity. And it's orthogonal to the sorting patch, so we can deal with it separately. * Is it really necessary to parallelize the I/O among tablespaces? I can see the point, but I wonder if it makes any difference in practice. * Is there ever any harm in sorting the buffers? The GUC is useful for benchmarking, but could we leave it out of the final patch? * Do we need to worry about exceeding the 1 GB allocation limit in AllocateCheckpointBufferIds? It's enough got 2 TB of shared_buffers. That's a lot, but it's not totally crazy these days that someone might do that. At the very least, we need to lower the maximum of shared_buffers so that you can't hit that limit. I ripped out the "flushing" part, keeping only the sorting. I refactored the logic in BufferSync() a bit. There's now a separate function, nextCheckpointBuffer(), that returns the next buffer ID from the sorted list. The tablespace-parallelization behaviour in encapsulated there, keeping the code in BufferSync() much simpler. See attached. Needs some minor cleanup and commenting still before committing, and I haven't done any testing besides a simple "make check". - Heikki
Attachment
Hello Heikki,
Thanks for having a look at the patch.
> * I think we should drop the "flush" part of this for now. It's not as
> clearly beneficial as the sorting part, and adds a great deal more code
> complexity. And it's orthogonal to the sorting patch, so we can deal with it
> separately.
I agree that it is orthogonal and that the two features could be in
distinct patches. The flush part is the first patch I really submitted
because it has significant effect on latency, and I was told to mix it
with sorting...
The flushing part really helps to keep "write stalls" under control in
many cases, for instance:
- 400-tps 1-client (or 4 for medium) max 100-ms latency
options | percent of late transactions flush | sort | tiny | small | medium off | off | 12.0 | 64.28 | 68.6
off | on | 11.3 | 22.05 | 22.6 on | off | 1.1 | 67.93 | 67.9 on | on | 0.6 | 3.24 | 3.1
The "percent of late transactions" is really the fraction of time the
database is unreachable because of write stalls... So sort without flush
is cleary not enough.
Another thing suggested by Andres is to fsync as early as possible, but
this is not a simple patch because is intermix things which are currently
in distinct parts of checkpoint processing, so I already decided that this
would be for another submission.
> * Is it really necessary to parallelize the I/O among tablespaces? I can see
> the point, but I wonder if it makes any difference in practice.
I think that if someone bothers with tablespace there is no reason to kill
them behind her. Without sorting you may hope that tablespaces will be
touched randomly enough, but once buffers are sorted you can probably find
cases where it would write on one table space and then on the other.
So I think that it really should be kept.
> * Is there ever any harm in sorting the buffers? The GUC is useful for
> benchmarking, but could we leave it out of the final patch?
I think that the performance show that it is basically always beneficial,
so the guc may be left out. However on SSD it is unclear to me whether it
is just a loss of time or whether it helps, say with wear-leveling. Maybe
best to keep it? Anyway it is definitely needed for testing.
> * Do we need to worry about exceeding the 1 GB allocation limit in
> AllocateCheckpointBufferIds? It's enough got 2 TB of shared_buffers. That's a
> lot, but it's not totally crazy these days that someone might do that. At the
> very least, we need to lower the maximum of shared_buffers so that you can't
> hit that limit.
Yep.
> I ripped out the "flushing" part, keeping only the sorting. I refactored
> the logic in BufferSync() a bit. There's now a separate function,
> nextCheckpointBuffer(), that returns the next buffer ID from the sorted
> list. The tablespace-parallelization behaviour in encapsulated there,
I do not understand the new tablespace-parallelization logic: there is no
test about the tablespace of the buffer in the selection process... Note
that I did wrote a proof for the one I put, and also did some detailed
testing on the side because I'm always wary of proofs, especially mines:-)
I notice that you assume that table space numbers are always small and
contiguous. Is that a fact? I was feeling more at ease with relying on a
hash table to avoid such an assumption.
> keeping the code in BufferSync() much simpler. See attached. Needs some
> minor cleanup and commenting still before committing, and I haven't done
> any testing besides a simple "make check".
Hmmm..., just another detail, the patch does not sort:
+ if (checkpoint_sort && num_to_write > 1 && false)
I'll resubmit a patch with only the sorting part, and do the kind of
restructuring you suggest which is a good thing.
--
Fabien.
On 2015-08-08 20:49:03 +0300, Heikki Linnakangas wrote: > * I think we should drop the "flush" part of this for now. It's not as > clearly beneficial as the sorting part, and adds a great deal more code > complexity. And it's orthogonal to the sorting patch, so we can deal with it > separately. I don't agree. For one I've seen it cause rather big latency improvements, and we're horrible at that. But more importantly I think the requirements of the flush logic influences how exactly the sorting is done. Splitting them will just make it harder to do the flushing in a not too big patch. > * Is it really necessary to parallelize the I/O among tablespaces? I can see > the point, but I wonder if it makes any difference in practice. Today it's somewhat common to have databases that are bottlenecked on write IO and all those writes being done by the checkpointer. If we suddenly do the writes to individual tablespaces separately and sequentially we'll be bottlenecked on the peak IO of a single tablespace. > * Is there ever any harm in sorting the buffers? The GUC is useful for > benchmarking, but could we leave it out of the final patch? Agreed. > * Do we need to worry about exceeding the 1 GB allocation limit in > AllocateCheckpointBufferIds? It's enough got 2 TB of shared_buffers. That's > a lot, but it's not totally crazy these days that someone might do that. At > the very least, we need to lower the maximum of shared_buffers so that you > can't hit that limit. We can just use the _huge variant? Greetings, Andres Freund
Hi,
On 2015-08-08 20:49:03 +0300, Heikki Linnakangas wrote:
> I ripped out the "flushing" part, keeping only the sorting. I refactored the
> logic in BufferSync() a bit. There's now a separate function,
> nextCheckpointBuffer(), that returns the next buffer ID from the sorted
> list. The tablespace-parallelization behaviour in encapsulated there,
> keeping the code in BufferSync() much simpler. See attached. Needs some
> minor cleanup and commenting still before committing, and I haven't done any
> testing besides a simple "make check".
Thought it'd be useful to review the current version as well. Some of
what I'm commenting on you'll probably already have though of under the
label of "minor cleanup".
> /*
> + * Array of buffer ids of all buffers to checkpoint.
> + */
> +static int *CheckpointBufferIds = NULL;
> +
> +/* Compare checkpoint buffers
> + */
Should be at the beginning of the file. There's a bunch more cases of that.
> +/* Compare checkpoint buffers
> + */
> +static int bufcmp(const int * pa, const int * pb)
> +{
> + BufferDesc
> + *a = GetBufferDescriptor(*pa),
> + *b = GetBufferDescriptor(*pb);
> +
> + /* tag: rnode, forkNum (different files), blockNum
> + * rnode: { spcNode (ignore: not really needed),
> + * dbNode (ignore: this is a directory), relNode }
> + * spcNode: table space oid, not that there are at least two
> + * (pg_global and pg_default).
> + */
> + /* compare relation */
> + if (a->tag.rnode.spcNode < b->tag.rnode.spcNode)
> + return -1;
> + else if (a->tag.rnode.spcNode > b->tag.rnode.spcNode)
> + return 1;
> + if (a->tag.rnode.relNode < b->tag.rnode.relNode)
> + return -1;
> + else if (a->tag.rnode.relNode > b->tag.rnode.relNode)
> + return 1;
> + /* same relation, compare fork */
> + else if (a->tag.forkNum < b->tag.forkNum)
> + return -1;
> + else if (a->tag.forkNum > b->tag.forkNum)
> + return 1;
> + /* same relation/fork, so same segmented "file", compare block number
> + * which are mapped on different segments depending on the number.
> + */
> + else if (a->tag.blockNum < b->tag.blockNum)
> + return -1;
> + else /* should not be the same block anyway... */
> + return 1;
> +}
This definitely needs comments about ignoring the normal buffer header
locking.
Why are we ignoring the database directory? I doubt it'll make a huge
difference, but grouping metadata affecting operations by directory
helps.
> +
> +static void
> +AllocateCheckpointBufferIds(void)
> +{
> + /* Safe worst case allocation, all buffers belong to the checkpoint...
> + * that is pretty unlikely.
> + */
> + CheckpointBufferIds = (int *) palloc(sizeof(int) * NBuffers);
> +}
(wrong comment style...)
Heikki, you were concerned about the size of the allocation of this,
right? I don't think it's relevant - we used to allocate an array of
that size for the backend's private buffer pin array until 9.5, so in
theory we should be safe agains that. NBuffers is limited to INT_MAX/2
in guc.ċ, which ought to be sufficient?
> + /*
> + * Lazy allocation: this function is called through the checkpointer,
> + * but also by initdb. Maybe the allocation could be moved to the callers.
> + */
> + if (CheckpointBufferIds == NULL)
> + AllocateCheckpointBufferIds();
> +
>
I don't think it's a good idea to allocate this on every round. That
just means a lot of page table entries have to be built and torn down
regularly. It's not like checkpoints only run for 1% of the time or
such.
FWIW, I still think it's a much better idea to allocate the memory once
in shared buffers. It's not like that makes us need more memory overall,
and it'll be huge page allocations if configured. I also think that
sooner rather than later we're going to need more than one process
flushing buffers, and then it'll need to be moved there.
> + /*
> + * Sort buffer ids to help find sequential writes.
> + *
> + * Note: buffers are not locked in anyway, but that does not matter,
> + * this sorting is really advisory, if some buffer changes status during
> + * this pass it will be filtered out later. The only necessary property
> + * is that marked buffers do not move elsewhere.
> + */
That reasoning makes it impossible to move the fsyncing of files into
the loop (whenever we move to a new file). That's not nice. The
formulation with "necessary property" doesn't seem very clear to me?
How about:
/** Note: Buffers are not locked in any way during sorting, but that's ok:* A change in the buffer header is only
relevantwhen it changes the* buffer's identity. If the identity has changed it'll have been* written out by
BufferAlloc(),so there's no need for checkpointer to* write it out anymore. The buffer might also get written out by a*
backendor bgwriter, but that's equally harmless.*/
> Also, qsort implementation
> + * should be resilient to occasional contradictions (cmp(a,b) != -cmp(b,a))
> + * because of these possible concurrent changes.
Hm. Is that actually the case for our qsort implementation? If the pivot
element changes its identity won't the result be pretty much random?
> +
> + if (checkpoint_sort && num_to_write > 1 && false)
> + {
&& false - Huh?
> + qsort(CheckpointBufferIds, num_to_write, sizeof(int),
> + (int(*)(const void *, const void *)) bufcmp);
> +
Ick, I'd rather move the typecasts to the comparator.
> + for (i = 1; i < num_to_write; i++)
> + {
> + bufHdr = GetBufferDescriptor(CheckpointBufferIds[i]);
> +
> + spc = bufHdr->tag.rnode.spcNode;
> + if (spc != lastspc && (bufHdr->flags & BM_CHECKPOINT_NEEDED) != 0)
> + {
> + if (allocatedSpc <= j)
> + {
> + allocatedSpc = j + 5;
> + spcStatus = (TableSpaceCheckpointStatus *)
> + repalloc(spcStatus, sizeof(TableSpaceCheckpointStatus) * allocatedSpc);
> + }
> +
> + spcStatus[j].index_end = spcStatus[j + 1].index = i;
> + j++;
> + lastspc = spc;
> + }
> + }
> + spcStatus[j].index_end = num_to_write;
This really deserves some explanation.
Regards,
Andres Freund
Hello Andres,
Thanks for your comments. Some answers and new patches included.
>> + /*
>> + * Array of buffer ids of all buffers to checkpoint.
>> + */
>> +static int *CheckpointBufferIds = NULL;
>
> Should be at the beginning of the file. There's a bunch more cases of that.
done.
>> +/* Compare checkpoint buffers
>> + */
>> +static int bufcmp(const int * pa, const int * pb)
>> +{
>> + BufferDesc
>> + *a = GetBufferDescriptor(*pa),
>> + *b = GetBufferDescriptor(*pb);
>
> This definitely needs comments about ignoring the normal buffer header
> locking.
Added.
> Why are we ignoring the database directory? I doubt it'll make a huge
> difference, but grouping metadata affecting operations by directory
> helps.
I wanted to do the minimal comparisons to order buffers per file, so I
skipped everything else. My idea of a checkpoint is a lot of data in a few
files (at least compared to the data...), so I do not think that it is
worth it. I may be proven wrong!
>> +static void
>> +AllocateCheckpointBufferIds(void)
>> +{
>> + /* Safe worst case allocation, all buffers belong to the checkpoint...
>> + * that is pretty unlikely.
>> + */
>> + CheckpointBufferIds = (int *) palloc(sizeof(int) * NBuffers);
>> +}
>
> (wrong comment style...)
Fixed.
> Heikki, you were concerned about the size of the allocation of this,
> right? I don't think it's relevant - we used to allocate an array of
> that size for the backend's private buffer pin array until 9.5, so in
> theory we should be safe agains that. NBuffers is limited to INT_MAX/2
> in guc.ċ, which ought to be sufficient?
I think that there is no issue with the current shared_buffers limit. I
could allocate and use 4 GB on my laptop without problem. I added a cast
to ensure that unsigned int are used for the size computation.
>> + /* + * Lazy allocation: this function is called through the
>> checkpointer, + * but also by initdb. Maybe the allocation could be
>> moved to the callers. + */ + if (CheckpointBufferIds == NULL) +
>> AllocateCheckpointBufferIds(); +
>>
>
> I don't think it's a good idea to allocate this on every round.
> That just means a lot of page table entries have to be built and torn
> down regularly. It's not like checkpoints only run for 1% of the time or
> such.
Sure. It is not allocated on every round, it is allocated once on the
first checkpoint, the variable tested is static. There is no free. Maybe
the allocation could be moved to the callers, though.
> FWIW, I still think it's a much better idea to allocate the memory once
> in shared buffers.
Hmmm. The memory does not need to be shared with other processes?
> It's not like that makes us need more memory overall, and it'll be huge
> page allocations if configured. I also think that sooner rather than
> later we're going to need more than one process flushing buffers, and
> then it'll need to be moved there.
That is an argument. I think that it could wait for the need to actually
arise.
>> + /*
>> + * Sort buffer ids to help find sequential writes.
>> + *
>> + * Note: buffers are not locked in anyway, but that does not matter,
>> + * this sorting is really advisory, if some buffer changes status during
>> + * this pass it will be filtered out later. The only necessary property
>> + * is that marked buffers do not move elsewhere.
>> + */
>
> That reasoning makes it impossible to move the fsyncing of files into
> the loop (whenever we move to a new file). That's not nice.
I do not see why. Moving rsync ahead is definitely an idea that you
already pointed out, I have given it some thoughts, and it would require
a carefull implementation and some restructuring. For instance, you do not
want to issue fsync right after having done writes, you want to wait a
little bit so that the system had time to write the buffers to disk.
> The formulation with "necessary property" doesn't seem very clear to me?
Removed.
> How about: /* * Note: Buffers are not locked in any way during sorting,
> but that's ok: * A change in the buffer header is only relevant when it
> changes the * buffer's identity. If the identity has changed it'll have
> been * written out by BufferAlloc(), so there's no need for checkpointer
> to * write it out anymore. The buffer might also get written out by a *
> backend or bgwriter, but that's equally harmless. */
This new version included.
>> Also, qsort implementation
>> + * should be resilient to occasional contradictions (cmp(a,b) != -cmp(b,a))
>> + * because of these possible concurrent changes.
>
> Hm. Is that actually the case for our qsort implementation?
I think that it is hard to write a qsort which would fail that. That would
mean that it would compare the same items twice, which would be
inefficient.
> If the pivot element changes its identity won't the result be pretty
> much random?
That would be a very unlikely event, given the short time spent in qsort.
Anyway, this is not a problem, and is the beauty of the "advisory" sort:
if the sort is wrong because of any such rare event, it just mean that the
buffers would not be strictly in file order, which is currently the
case.... Well, too bad, but the correctness of the checkpoint does not
depend on it, that just mean that the checkpointer would come back twice
on one file, no big deal.
>> + if (checkpoint_sort && num_to_write > 1 && false)
>> + {
>
> && false - Huh?
Probably Heikki tests.
>> + qsort(CheckpointBufferIds, num_to_write, sizeof(int),
>> + (int(*)(const void *, const void *)) bufcmp);
>> +
>
> Ick, I'd rather move the typecasts to the comparator.
Done.
>> + for (i = 1; i < num_to_write; i++)
>> + { [...]
>
> This really deserves some explanation.
I think that this version does not work. I've reinstated my version and a
lot of comments in the attached patches.
Please find attached two combined patches which provide both features one
after the other.
(a) shared buffer sorting
- I took Heikki hint about restructuring the buffer selection in a separate function, which makes the code much more
readable.
- I also followed Heikki intention (I think) that only active table spaces are considered in the switching loop.
(b) add asynchronous flushes on top of the previous sort patch
I think that the many performance results I reported show that the
improvements need both features, and one feature without the other is much
less effective at improving responsiveness, which is my primary concern.
The TPS improvements are just a side effect.
I did not remove the gucs: I think it could be kept so that people can
test around with it, and they may be removed in the future? I would be
also fine if they are removed.
There are a lot of comments in some places. I think that they should be
kept because the code is subtle.
--
Fabien.
On 2015-08-10 19:07:12 +0200, Fabien COELHO wrote: > I think that there is no issue with the current shared_buffers limit. I > could allocate and use 4 GB on my laptop without problem. I added a cast to > ensure that unsigned int are used for the size computation. You can't allocate 4GB with palloc(), it has a builtin limit against allocating more than 1GB. > >>+ /* + * Lazy allocation: this function is called through the > >>checkpointer, + * but also by initdb. Maybe the allocation could be > >>moved to the callers. + */ + if (CheckpointBufferIds == NULL) + > >>AllocateCheckpointBufferIds(); + > >> > > > >I don't think it's a good idea to allocate this on every round. > >That just means a lot of page table entries have to be built and torn down > >regularly. It's not like checkpoints only run for 1% of the time or such. > > Sure. It is not allocated on every round, it is allocated once on the first > checkpoint, the variable tested is static. There is no free. Maybe > the allocation could be moved to the callers, though. Well, then everytime the checkpointer is restarted. > >FWIW, I still think it's a much better idea to allocate the memory once > >in shared buffers. > > Hmmm. The memory does not need to be shared with other processes? The point is that it's done at postmaster startup, and we're pretty much guaranteed that the memory will availabl.e. > >It's not like that makes us need more memory overall, and it'll be huge > >page allocations if configured. I also think that sooner rather than later > >we're going to need more than one process flushing buffers, and then it'll > >need to be moved there. > > That is an argument. I think that it could wait for the need to actually > arise. Huge pages are used today. > >>+ /* > >>+ * Sort buffer ids to help find sequential writes. > >>+ * > >>+ * Note: buffers are not locked in anyway, but that does not matter, > >>+ * this sorting is really advisory, if some buffer changes status during > >>+ * this pass it will be filtered out later. The only necessary property > >>+ * is that marked buffers do not move elsewhere. > >>+ */ > > > >That reasoning makes it impossible to move the fsyncing of files into the > >loop (whenever we move to a new file). That's not nice. > > I do not see why. Because it means that the sorting isn't necessarily correct. I.e. we can't rely on it to determine whether a file has already been fsynced. > >> Also, qsort implementation > >>+ * should be resilient to occasional contradictions (cmp(a,b) != -cmp(b,a)) > >>+ * because of these possible concurrent changes. > > > >Hm. Is that actually the case for our qsort implementation? > > I think that it is hard to write a qsort which would fail that. That would > mean that it would compare the same items twice, which would be inefficient. What? The same two elements aren't frequently compared pairwise with each other, but of course an individual element is frequently compared with other elements. Consider what happens when the chosen pivot element changes its identity after already dividing half. The two partitions will not be divided in any meaning full way anymore. I don't see how this will results in a meaningful sort. > >If the pivot element changes its identity won't the result be pretty much > >random? > > That would be a very unlikely event, given the short time spent in > qsort. Meh, we don't want to rely on "likeliness" on such things. Greetings, Andres Freund
Hello Andres, > You can't allocate 4GB with palloc(), it has a builtin limit against > allocating more than 1GB. Argh, too bad, I assumed very naively that palloc was malloc in disguise. >> [...] > Well, then everytime the checkpointer is restarted. Hm... > The point is that it's done at postmaster startup, and we're pretty much > guaranteed that the memory will availabl.e. Ok ok, I stop resisting... I'll have a look. Would it also fix the 1 GB palloc limit on the same go? I guess so... >>> That reasoning makes it impossible to move the fsyncing of files into the >>> loop (whenever we move to a new file). That's not nice. >> >> I do not see why. > > Because it means that the sorting isn't necessarily correct. I.e. we > can't rely on it to determine whether a file has already been fsynced. Ok, I understand your point. Then the file would be fsynced twice: if the fsync is done properly (data have already been flushed to disk) then it would not cost much, and doing it sometimes twice on some file would not be a big issue. The code could also detect such event and log a warning, which would give a hint about how often it occurs in practice. >>> Hm. Is that actually the case for our qsort implementation? >> >> I think that it is hard to write a qsort which would fail that. That would >> mean that it would compare the same items twice, which would be inefficient. > > What? The same two elements aren't frequently compared pairwise with > each other, but of course an individual element is frequently compared > with other elements. Sure. > Consider what happens when the chosen pivot element changes its identity > after already dividing half. The two partitions will not be divided in > any meaning full way anymore. I don't see how this will results in a > meaningful sort. It would be partly meaningful, which is enough for performance, and does not matter for correctness: currently buffers are not sorted at all and it works, even if it does not work well. >>> If the pivot element changes its identity won't the result be pretty much >>> random? >> >> That would be a very unlikely event, given the short time spent in >> qsort. > > Meh, we don't want to rely on "likeliness" on such things. My main argument is that even if it occurs, and the qsort result is partly wrong, it does not change correctness, it just mean that the actual writes will be less in order than wished. If it occurs, one pivot separation would be quite strange, but then others would be right, so the buffers would be "partly sorted". Another issue I see is that even if buffers are locked within cmp, the status may change between two cmp... I do not think that locking all buffers for sorting them is an option. So on the whole, I think that locking buffers for sorting is probably not possible with the simple (and efficient) lightweight approach used in the patch. The good news, as I argued before, is that the order is only advisory to help with performance, but the correctness is really that all checkpoint buffers are written and fsync is called in the end, and does not depend on the buffer order. That is how it currently works anyway. If you block on this then I'll put a heavy weight approach, but that would be a waste of memory in my opinion, hence my argumentation for the lightweight approach. -- Fabien.
> Ok ok, I stop resisting... I'll have a look. Here is a v7 a&b version which uses shared memory instead of palloc. -- Fabien.
On August 10, 2015 8:24:21 PM GMT+02:00, Fabien COELHO <coelho@cri.ensmp.fr> wrote: > >Hello Andres, > >> You can't allocate 4GB with palloc(), it has a builtin limit against >> allocating more than 1GB. > >Argh, too bad, I assumed very naively that palloc was malloc in >disguise. It is, but there's some layering (memory pools/contexts) on top. You can get huge allocations with polloc_huge. >Then the file would be fsynced twice: if the fsync is done properly >(data >have already been flushed to disk) then it would not cost much, and >doing >it sometimes twice on some file would not be a big issue. The code >could >also detect such event and log a warning, which would give a hint about > >how often it occurs in practice. Right. At the cost of keeping track of all files... >>>> If the pivot element changes its identity won't the result be >pretty much >>>> random? >>> >>> That would be a very unlikely event, given the short time spent in >>> qsort. >> >> Meh, we don't want to rely on "likeliness" on such things. > >My main argument is that even if it occurs, and the qsort result is >partly >wrong, it does not change correctness, it just mean that the actual >writes >will be less in order than wished. If it occurs, one pivot separation >would be quite strange, but then others would be right, so the buffers >would be "partly sorted". It doesn't matter for correctness today, correct. But it makes out impossible to rely on or too. >Another issue I see is that even if buffers are locked within cmp, the >status may change between two cmp... Sure. That's not what in suggesting. Earlier versions of the patch kept an array of buffer headers exactly because of that. I do not think that locking all >buffers for sorting them is an option. So on the whole, I think that >locking buffers for sorting is probably not possible with the simple >(and >efficient) lightweight approach used in the patch. Yes, the other version has a higher space overhead. I'm not convinced that's meaningful in comparison to shared buffets inspace. And rather doubtful it a loss performance wise in a loaded server. All the buffer headers are touched on other cores anddoing the sort with indirection will greatly increase bus traffic. >The good news, as I argued before, is that the order is only advisory >to >help with performance, but the correctness is really that all >checkpoint >buffers are written and fsync is called in the end, and does not depend >on >the buffer order. That is how it currently works anyway It's not particularly desirable to have a performance feature that works less well if the server is heavily and concurrentlyloaded. The likelihood of bogus sort results will increase with the churn rate in shared buffers. Andres --- Please excuse brevity and formatting - I am writing this on my mobile phone.
On Tue, Aug 11, 2015 at 4:28 AM, Andres Freund wrote: > On August 10, 2015 8:24:21 PM GMT+02:00, Fabien COELHO wrote: >>> You can't allocate 4GB with palloc(), it has a builtin limit against >>> allocating more than 1GB. >> >>Argh, too bad, I assumed very naively that palloc was malloc in >>disguise. > > It is, but there's some layering (memory pools/contexts) on top. You can get huge allocations with polloc_huge. palloc_huge does not exist yet ;) There is either repalloc_huge or palloc_extended now, though implementing one would be trivial. -- Michael
Hello Andres, > [...] Right. At the cost of keeping track of all files... Sure. Pg already tracks all files, and probably some more tracking would be necessary for an early fsync feature to know what are those already fsync'ed and what are those not yet fsync'ed. > Yes, the other version has a higher space overhead. Yep, this is my concern. > I'm not convinced that's meaningful in comparison to shared buffers in > space. And rather doubtful it a loss performance wise in a loaded > server. All the buffer headers are touched on other cores and doing the > sort with indirection will greatly increase bus traffic. The measures I collected and reported showed that the sorting time is basically insignificant, so bus traffic induced by sorting does not seem to be an issue. > [...] It's not particularly desirable to have a performance feature that > works less well if the server is heavily and concurrently loaded. The > likelihood of bogus sort results will increase with the churn rate in > shared buffers. Hm. In conclusion I'm not convinced that it is worth the memory, but I'm also tired of arguing, and hopefully nobody else cares about a few more bytes per shared_buffers, so why should I care? Here is a v8, I reduced the memory overhead of the "heavy weight" approach from 24 to 16 bytes per buffer, so it is medium weight:-). It might be compacted further down to 12 bytes by combining the 2 bits of forkNum either with relNode or blockNum, and use a uint64_t comparison field with all data so that the comparison code would be simpler and faster. I also fixed the computation of the shmem size which I had not updated when switching to shmem. The patches still include the two guc, but it is easy to remove one or the other. They are useful is someone wants to test. The default is on for sort, and off for flush. Maybe it should be on for both. -- Fabien.
> Here is a v8,
I collected a few performance figures with this patch on an old box with 8
cores, 16 GB, RAID 1 HDD, under Ubuntu precise.
postgresql.conf: shared_buffers = 4GB checkpoint_timeout = 15min checkpoint_completion_target = 0.8
max_wal_size= 4GB
init> pgbench -i -s 250 warmup> pgbench -T 1200 -M prepared -S -j 2 -c 4
# 400 tps throttled "simple update" test sh> pgbench -M prepared -N -P 1 -T 4000 -R 400 -L 100 -j 2 -c 4
sort/flush : percent of skipped/late transactions on on : 2.7 on off : 16.2 off on : 68.4
off off : 68.7
# 200 tps sh> pgbench -M prepared -N -P 1 -T 4000 -R 200 -L 100 -j 2 -c 4
sort/flush : percent of skipped/late transactions on on : 2.7 on off : 9.5 off on : 47.4
off off : 48.8
The large "percent of skipped/late transactions" is to be understood as
"fraction of time with postgresql offline because of a write stall".
# full speed 1 client sh> pgbench -M prepared -N -P 1 -T 4000
sort/flush : tps avg & stddev (percent of time beyond 10.0 tps) on on : 631 +- 131 (0.1%) on off :
564+- 303 (12.0%) off on : 167 +- 315 (76.8%) # stuck... off off : 177 +- 305 (71.2%) # ~ current pg
# full speed 2 threads 4 clients sh> pgbench -M prepared -N -P 1 -T 4000 -j 2 -c 4
sort/flush : tps avg & stddev (percent of time below 10.0 tps) on on : 1058 +- 455 (0.1%) on off :
1056+- 942 (32.8%) off on : 170 +- 500 (88.3%) # stuck... off off : 209 +- 506 (82.0%) # ~ current pg
The combined features provide a tps speedup of 3-5 on these runs, and
allow to have some control on write stalls. Flushing is not effective on
unsorted buffers, at least on these example.
--
Fabien.
Hi Fabien, On 2015-08-12 22:34:59 +0200, Fabien COELHO wrote: > sort/flush : tps avg & stddev (percent of time beyond 10.0 tps) > on on : 631 +- 131 (0.1%) > on off : 564 +- 303 (12.0%) > off on : 167 +- 315 (76.8%) # stuck... > off off : 177 +- 305 (71.2%) # ~ current pg What exactly do you mean with 'stuck'? - Andres
On 2015-08-11 17:15:22 +0200, Fabien COELHO wrote:
> +void
> +PerformFileFlush(FileFlushContext * context)
> +{
> + if (context->ncalls != 0)
> + {
> + int rc;
> +
> +#if defined(HAVE_SYNC_FILE_RANGE)
> +
> + /* Linux: tell the memory manager to move these blocks to io so
> + * that they are considered for being actually written to disk.
> + */
> + rc = sync_file_range(context->fd, context->offset, context->nbytes,
> + SYNC_FILE_RANGE_WRITE);
> +
> +#elif defined(HAVE_POSIX_FADVISE)
> +
> + /* Others: say that data should not be kept in memory...
> + * This is not exactly what we want to say, because we want to write
> + * the data for durability but we may need it later nevertheless.
> + * It seems that Linux would free the memory *if* the data has
> + * already been written do disk, else the "dontneed" call is ignored.
> + * For FreeBSD this may have the desired effect of moving the
> + * data to the io layer, although the system does not seem to
> + * take into account the provided offset & size, so it is rather
> + * rough...
> + */
> + rc = posix_fadvise(context->fd, context->offset, context->nbytes,
> + POSIX_FADV_DONTNEED);
> +
> +#endif
> +
> + if (rc < 0)
> + ereport(ERROR,
> + (errcode_for_file_access(),
> + errmsg("could not flush block " INT64_FORMAT
> + " on " INT64_FORMAT " blocks in file \"%s\": %m",
> + context->offset / BLCKSZ,
> + context->nbytes / BLCKSZ,
> + context->filename)));
> + }
I'm a bit wary that this might cause significant regressions on
platforms not supporting sync_file_range, but support posix_fadvise()
for workloads that are bigger than shared_buffers. Consider what happens
if the workload does *not* fit into shared_buffers but *does* fit into
the OS's buffer cache. Suddenly reads will go to disk again, no?
Greetings,
Andres Freund
Hello Andres,
> On 2015-08-12 22:34:59 +0200, Fabien COELHO wrote:
>> sort/flush : tps avg & stddev (percent of time beyond 10.0 tps)
>> on on : 631 +- 131 (0.1%)
>> on off : 564 +- 303 (12.0%)
>> off on : 167 +- 315 (76.8%) # stuck...
>> off off : 177 +- 305 (71.2%) # ~ current pg
>
> What exactly do you mean with 'stuck'?
I mean that the during the I/O storms induced by the checkpoint pgbench
sometimes get stuck, i.e. does not report its progression every second (I
run with "-P 1"). This occurs when sort is off, either with or without
flush, for instance an extract from the off/off medium run:
progress: 573.0 s, 5.0 tps, lat 933.022 ms stddev 83.977 progress: 574.0 s, 777.1 tps, lat 7.161 ms stddev 37.059
progress:575.0 s, 148.9 tps, lat 4.597 ms stddev 10.708 progress: 814.4 s, 0.0 tps, lat -nan ms stddev -nan progress:
815.0s, 0.0 tps, lat -nan ms stddev -nan progress: 816.0 s, 0.0 tps, lat -nan ms stddev -nan progress: 817.0 s, 0.0
tps,lat -nan ms stddev -nan progress: 818.0 s, 0.0 tps, lat -nan ms stddev -nan progress: 819.0 s, 0.0 tps, lat -nan ms
stddev-nan progress: 820.0 s, 0.0 tps, lat -nan ms stddev -nan progress: 821.0 s, 0.0 tps, lat -nan ms stddev -nan
progress:822.0 s, 0.0 tps, lat -nan ms stddev -nan progress: 823.0 s, 0.0 tps, lat -nan ms stddev -nan progress: 824.0
s,0.0 tps, lat -nan ms stddev -nan progress: 825.0 s, 0.0 tps, lat -nan ms stddev -nan progress: 826.0 s, 0.0 tps, lat
-nanms stddev -nan
There is a 239.4 seconds gap in pgbench output. This occurs from time to
time and may represent a significant part of the run, and I count these
"stuck" times as 0 tps. Sometimes pgbench is stuck performance wise but
manages nevetheless to report a "0.0 tps" every second, as above after it
unstuck.
The actual origin of the issue with a stuck client (pgbench, libpq, OS,
postgres...) is unclear to me, but the whole system does not behave well
under an I/O storm anyway, and I have not succeeded in understanding where
pgbench is stuck when it does not report its progress. I tried some runs
with gdb but it did not get stuck and reported a lot of "0.0 tps" during
the storms.
Here are a few more figures with the v8 version of the patch, on a host
with 8 cores, 16 GB, RAID 1 HDD, under Ubuntu precise. I already reported
the medium case, and the small case turned afterwards.
small postgresql.conf: shared_buffers = 2GB checkpoint_timeout = 300s # this is the default
checkpoint_completion_target= 0.8 # initialization: pgbench -i -s 120
medium postgresql.conf: ## ALREADY REPORTED shared_buffers = 4GB checkpoint_timeout = 15min
checkpoint_completion_target= 0.8 max_wal_size = 4GB # initialization: pgbench -i -s 250
warmup> pgbench -T 1200 -M prepared -S -j 2 -c 4
# 400 tps throttled test sh> pgbench -M prepared -N -P 1 -T 4000 -R 400 -L 100 -j 2 -c 4
options / percent of skipped/late transactions sort/flush / small medium on on : 3.5 2.7
on off : 24.6 16.2 off on : 66.1 68.4 off off : 63.2 68.7
# 200 tps throttled test sh> pgbench -M prepared -N -P 1 -T 4000 -R 200 -L 100 -j 2 -c 4
options / percent of skipped/late transactions sort/flush / small medium on on : 1.9 2.7
on off : 14.3 9.5 off on : 45.6 47.4 off off : 47.4 48.8
# 100 tps throttled test sh> pgbench -M prepared -N -P 1 -T 4000 -R 100 -L 100 -j 2 -c 4
options / percent of skipped/late transactions sort/flush / small medium on on : 0.9 1.8
on off : 9.3 7.9 off on : 5.0 13.0 off off : 31.2 31.9
# full speed 1 client sh> pgbench -M prepared -N -P 1 -T 4000
options / tps avg & stddev (percent of time below 10.0 tps) sort/flush / small medium on
on : 564 +- 148 ( 0.1%) 631 +- 131 ( 0.1%) on off : 470 +- 340 (21.7%) 564 +- 303 (12.0%) off on :
157+- 296 (66.2%) 167 +- 315 (76.8%) off off : 154 +- 251 (61.5%) 177 +- 305 (71.2%)
# full speed 2 threads 4 clients sh> pgbench -M prepared -N -P 1 -T 4000 -j 2 -c 4
options / tps avg & stddev (percent of time below 10.0 tps) sort/flush / small medium on
on : 757 +- 417 ( 0.1%) 1058 +- 455 ( 0.1%) on off : 752 +- 893 (48.4%) 1056 +- 942 (32.8%) off on :
173+- 521 (83.0%) 170 +- 500 (88.3%) off off : 199 +- 512 (82.5%) 209 +- 506 (82.0%)
In all cases, the "sort on & flush on" provides the best results, with tps
speedup from 3-5, and overall high responsiveness (& lower latency).
--
Fabien.
<Oops, stalled post, sorry wrong "From", resent..> Hello Andres, >> + rc = posix_fadvise(context->fd, context->offset, [...] > > I'm a bit wary that this might cause significant regressions on > platforms not supporting sync_file_range, but support posix_fadvise() > for workloads that are bigger than shared_buffers. Consider what happens > if the workload does *not* fit into shared_buffers but *does* fit into > the OS's buffer cache. Suddenly reads will go to disk again, no? That is an interesting question! My current thinking is "maybe yes, maybe no":-), as it may depend on the OS implementation of posix_fadvise, so it may differ between OS. This is a reason why I think that flushing should be kept a guc, even if the sort guc is removed and always on. The sync_file_range implementation is clearly always very beneficial for Linux, and the posix_fadvise may or may not induce a good behavior depending on the underlying system. This is also a reason why the default value for the flush guc is currently set to false in the patch. The documentation should advise to turn it on for Linux and to test otherwise. Or if Linux is assumed to be often a host, then maybe to set the default to on and to suggest that on some systems it may be better to have it off. (Another reason to keep it "off" is that I'm not sure about what happens with such HD flushing features on virtual servers). Overall, I'm not pessimistic, because I've seen I/O storms on a FreeBSD host and it was as bad as Linux (namely the database and even the box was offline for long minutes...), and if you can avoid that having to read back some data may be not that bad a down payment. The issue is largely mitigated if the data is not removed from shared_buffers, because the OS buffer is just a copy of already hold data. What I would do on such systems is to increase shared_buffers and keep flushing on, that is to count less on the system cache and more on postgres own cache. Overall, I'm not convince that the practice of relying on the OS cache is a good one, given what it does with it, at least on Linux. Now, if someone could provide a dedicated box with posix_fadvise (say FreeBSD, maybe others...) for testing that would allow to provide data instead of speculating... and then maybe to decide to change its default value. -- Fabien.
On 2015-08-17 15:21:22 +0200, Fabien COELHO wrote: > My current thinking is "maybe yes, maybe no":-), as it may depend on the OS > implementation of posix_fadvise, so it may differ between OS. As long as fadvise has no 'undirty' option, I don't see how that problem goes away. You're telling the OS to throw the buffer away, so unless it ignores it that'll have consequences when you read the page back in. > This is a reason why I think that flushing should be kept a guc, even if the > sort guc is removed and always on. The sync_file_range implementation is > clearly always very beneficial for Linux, and the posix_fadvise may or may > not induce a good behavior depending on the underlying system. That's certainly an argument. > This is also a reason why the default value for the flush guc is currently > set to false in the patch. The documentation should advise to turn it on for > Linux and to test otherwise. Or if Linux is assumed to be often a host, then > maybe to set the default to on and to suggest that on some systems it may be > better to have it off. I'd say it should then be an os-specific default. No point in making people work for it needlessly on linux and/or elsewhere. > (Another reason to keep it "off" is that I'm not sure about what > happens with such HD flushing features on virtual servers). I don't see how that matters? Either the host will entirely ignore flushing, and thus the sync_file_range and the fsync won't cost much, or fsync will be honored, in which case the pre-flushing is helpful. > Overall, I'm not pessimistic, because I've seen I/O storms on a FreeBSD host > and it was as bad as Linux (namely the database and even the box was offline > for long minutes...), and if you can avoid that having to read back some > data may be not that bad a down payment. I don't see how that'd alleviate my fear. Sure, the latency for many workloads will be better, but I don't how that argument says anything about the reads? And we'll not just use this in cases it'd be beneficial... > The issue is largely mitigated if the data is not removed from > shared_buffers, because the OS buffer is just a copy of already hold data. > What I would do on such systems is to increase shared_buffers and keep > flushing on, that is to count less on the system cache and more on postgres > own cache. That doesn't work that well for a bunch of reasons. For one it's completely non-adaptive. With the OS's page cache you can rely on free memory being used for caching *and* it be available should a query or another program need lots of memory. > Overall, I'm not convince that the practice of relying on the OS cache is a > good one, given what it does with it, at least on Linux. The alternatives aren't super realistic near-term though. Using direct IO efficiently on the set of operating systems we support is *hard*. It's more or less trivial to hack pg up to use direct IO for relations/shared_buffers, but it'll perform utterly horribly in many many cases. To pick one thing out: Without the OS buffering writes any write will have to wait for the disks, instead being asynchronous. That'll make writes performed by backends a massive bottleneck. > Now, if someone could provide a dedicated box with posix_fadvise (say > FreeBSD, maybe others...) for testing that would allow to provide data > instead of speculating... and then maybe to decide to change its default > value. Testing, as an approximation, how it turns out to work on linux would be a good step. Greetings, Andres Freund
Hello Andres, >>> [...] posix_fadvise(). >> >> My current thinking is "maybe yes, maybe no":-), as it may depend on the OS >> implementation of posix_fadvise, so it may differ between OS. > > As long as fadvise has no 'undirty' option, I don't see how that > problem goes away. You're telling the OS to throw the buffer away, so > unless it ignores it that'll have consequences when you read the page > back in. Yep, probably. Note that we are talking about checkpoints, which "write" buffers out *but* keep them nevertheless. As the buffer is kept, the OS page is a duplicate, and freeing it should not harm, at least immediatly. The situation is different if the memory is reused in between, which is the work of the bgwriter I think, based on LRU/LFU heuristics, but such writes are not flushed by the current patch. Now, if a buffer was recently updated it should not be selected by the bgwriter, if the LRU/LFU heuristics works as expected, which mitigate the issue somehow... To sum up, I agree that it is indeed possible that flushing with posix_fadvise could reduce read OS-memory hits on some systems for some workloads, although not on Linux, see below. So the option is best kept as "off" for now, without further data, I'm fine with that. > [...] I'd say it should then be an os-specific default. No point in > making people work for it needlessly on linux and/or elsewhere. Ok. Version 9 attached does that, "on" for Linux, "off" for others because of the potential issues you mentioned. >> (Another reason to keep it "off" is that I'm not sure about what >> happens with such HD flushing features on virtual servers). > > I don't see how that matters? Either the host will entirely ignore > flushing, and thus the sync_file_range and the fsync won't cost much, or > fsync will be honored, in which case the pre-flushing is helpful. Possibly. I know that I do not know:-) The distance between the database and real hardware is so great in VM, that I think that it may have any effect, including good, bad or none:-) >> Overall, I'm not pessimistic, because I've seen I/O storms on a FreeBSD host >> and it was as bad as Linux (namely the database and even the box was offline >> for long minutes...), and if you can avoid that having to read back some >> data may be not that bad a down payment. > > I don't see how that'd alleviate my fear. I'm trying to mitigate your fears, not to alleviate them:-) > Sure, the latency for many workloads will be better, but I don't how > that argument says anything about the reads? It just says that there may be a compromise, better in some case, possibly not so in others, because posix_fadvise does not really say what the database would like to say to the OS, this is why I wrote such a large comment about it in the source file in the first place. > And we'll not just use this in cases it'd be beneficial... I'm fine if it is off by default for some systems. If people want to avoid write stalls they can use the option, but it may have adverse effect on the tps in some cases, that's life? Not using the option also has adverse effects in some cases, because you have write stalls... and currently you do not have the choice, so it would be a progress. >> The issue is largely mitigated if the data is not removed from >> shared_buffers, because the OS buffer is just a copy of already hold data. >> What I would do on such systems is to increase shared_buffers and keep >> flushing on, that is to count less on the system cache and more on postgres >> own cache. > > That doesn't work that well for a bunch of reasons. For one it's > completely non-adaptive. With the OS's page cache you can rely on free > memory being used for caching *and* it be available should a query or > another program need lots of memory. Yep. I was thinking about a dedicated database server, not a shared one. >> Overall, I'm not convince that the practice of relying on the OS cache is a >> good one, given what it does with it, at least on Linux. > > The alternatives aren't super realistic near-term though. Using direct > IO efficiently on the set of operating systems we support is > *hard*. [...] Sure. This is not necessarily what I had in mind. Currently pg "write"s stuff to the OS, and then suddenly calls "fsync" out of the blue, hoping that in between the OS will actually have done a good job with the underlying hardware. This is pretty naive, the fsync generates write storms, and the database is offline: trying to improve these things is the motivation for this patch. Now if you think of the bgwriter, it does pretty much the same, and probably may generate plenty of random I/Os, because the underlying LRU/LFU heuristics used to select buffers does not care about the file structures. So I think that to get good performance the database must take some control over the OS. That does not mean that direct I/O needs to be involved, although maybe it could, but this patch shows that it is not needed to improve things. >> Now, if someone could provide a dedicated box with posix_fadvise (say >> FreeBSD, maybe others...) for testing that would allow to provide data >> instead of speculating... and then maybe to decide to change its default >> value. > > Testing, as an approximation, how it turns out to work on linux would be > a good step. Do you mean testing with posix_fadvise on Linux? I did think about it, but the documented behavior of this call on Linux is disappointing: if the buffer has been written to disk, it is freed by the OS. If not, nothing is done. Given that the flush is called pretty close after writes, mostly the buffer will not have been written to disk yet, and the call would just be a no-op... So I concluded that there is no point in trying that on Linux because it will have no effect other than loosing some time, IMO. Really, a useful test would be FreeBSD, when posix_fadvise does move things to disk, although the actual offsets & length are ignored, but I do not think that it would be a problem. I do not know about other systems and what they do with posix_fadvise. -- Fabien.
Hello Andres,[...] posix_fadvise().
My current thinking is "maybe yes, maybe no":-), as it may depend on the OS
implementation of posix_fadvise, so it may differ between OS.
As long as fadvise has no 'undirty' option, I don't see how that
problem goes away. You're telling the OS to throw the buffer away, so
unless it ignores it that'll have consequences when you read the page
back in.
Yep, probably.
Note that we are talking about checkpoints, which "write" buffers out *but* keep them nevertheless. As the buffer is kept, the OS page is a duplicate, and freeing it should not harm, at least immediatly.
To sum up, I agree that it is indeed possible that flushing with posix_fadvise could reduce read OS-memory hits on some systems for some workloads, although not on Linux, see below.
So the option is best kept as "off" for now, without further data, I'm fine with that.
+/* Status of buffers to checkpoint for a particular tablespace,
+ * used internally in BufferSync.
+ * - space: oid of the tablespace
+ * - num_to_write: number of checkpoint pages counted for this tablespace
+ * - num_written: number of pages actually written out
+/* entry structure for table space to count hashtable,
+ * used internally in BufferSync.
+ */
Hello Amit, >> So the option is best kept as "off" for now, without further data, I'm >> fine with that. > > One point to think here is on what basis user can decide make > this option on, is it predictable in any way? > I think one case could be when the data set fits in shared_buffers. Yep. > In general, providing an option is a good idea if user can decide with > ease when to use that option or we can give some clear recommendation > for the same otherwise one has to recommend that test your workload with > this option and if it works then great else don't use it which might > also be okay in some cases, but it is better to be clear. My opinion, which is not backed by any data (anyone can feel free to provide a FreeBSD box for testing...) is that it would mostly be an improvement if you have a significant write load to have the flush option on when running on non-Linux systems which provide posix_fadvise. If you have a lot of reads and few writes, then postgresql currently works reasonably enough, which is why people do not complain too much about write stalls, and I expect that the situation would not be significantly degraded. Now there are competing positive and negative effects induced by using posix_fadvise, and moreover its implementation varries from OS to OS, so without running some experiments it is hard to be definite. > One minor point, while glancing through the patch, I noticed that couple > of multiline comments are not written in the way which is usually used > in code (Keep the first line as empty). Indeed. Please find attached a v10, where I have reviewed comments for style & contents, and also slightly extended the documentation about the flush option to hint that it is essentially useful for high write loads. Without further data, I think it is not obvious to give more definite advices. -- Fabien.
Hello Amit,So the option is best kept as "off" for now, without further data, I'm
fine with that.
One point to think here is on what basis user can decide make
this option on, is it predictable in any way?
I think one case could be when the data set fits in shared_buffers.
Yep.In general, providing an option is a good idea if user can decide with ease when to use that option or we can give some clear recommendation for the same otherwise one has to recommend that test your workload with this option and if it works then great else don't use it which might also be okay in some cases, but it is better to be clear.
My opinion, which is not backed by any data (anyone can feel free to provide a FreeBSD box for testing...) is that it would mostly be an improvement if you have a significant write load to have the flush option on when running on non-Linux systems which provide posix_fadvise.
If you have a lot of reads and few writes, then postgresql currently works reasonably enough, which is why people do not complain too much about write stalls, and I expect that the situation would not be significantly degraded.
Now there are competing positive and negative effects induced by using posix_fadvise, and moreover its implementation varries from OS to OS, so without running some experiments it is hard to be definite.
> Sure, I think what can help here is a testcase/'s (in form of script file > or some other form, to test this behaviour of patch) which you can write > and post here, so that others can use that to get the data and share it. Sure... note that I already did that on this thread, without any echo... but I can do it again... Tests should be run on a dedicated host. If it has n cores, I suggest to share them between postgres checkpointer & workers and pgbench threads so as to avoid thread competition to use cores. With 8 cores I used up to 2 threads & 4 clients, so that there is 2 core left for the checkpointer and other stuff (i.e. I also run iotop & htop in parallel...). Although it may seem conservative to do so, I think that the point of the test is to exercise checkpoints and not to test the process scheduler of the OS. Here are the latest version of my test scripts: (1) cp_test.sh <name> <test> Run "test" with setup "name". Currently it runs 4000 seconds pgbench with the 4 possible on/off combinations for sorting & flushing, after some warmup. The 4000 second is chosen so that there are a few checkpoint cycles. For larger checkpoint times, I suggest to extend the run time to see at least 3 checkpoints during the run. More test settings can be added to the 2 "case"s. Postgres settings, especially shared_buffers, should be set to a pertinent value wrt the memory of the test host. The test run with postgres version found in the PATH, so ensure that the right version is found! (2) cp_test_count.py one-test-output.log For rate limited runs, look at the final figures and compute the number of late & skipped transactions. This can also be done by hand. (3) avg.py For full speed runs, compute stats about per second tps: sh> grep 'progress:' one-test-output.log | cut -d' ' -f4 | \ ./avg.py --limit=10 --length=4000 warning: 633 missingdata, extending with zeros avg over 4000: 199.290575 ± 512.114070 [0.000000, 0.000000, 4.000000, 5.000000, 2280.900000] percent of values below 10.0: 82.5% The figures I reported are the 199 (average tps), 512 (standard deviation on per second figures), 82.5% (percent of time below 10 tps, aka postgres is basically unresponsive). In brakets, the min q1 median q3 and max tps seen in the run. > Ofcourse, that is not mandatory to proceed with this patch, but still can > help you to prove your point as you might not have access to different > kind of systems to run the tests. I agree that more tests would be useful to decide which default value for the flushing option is the better. For Linux, all tests so far suggest "on" is the best choice, but for other systems that use posix_fadvise, it is really an open question. Another option would be to give me a temporary access for some available host, I'm used to running these tests... -- Fabien.
Sure, I think what can help here is a testcase/'s (in form of script file
or some other form, to test this behaviour of patch) which you can write
and post here, so that others can use that to get the data and share it.
Sure... note that I already did that on this thread, without any echo... but I can do it again...
+NextBufferToWrite(
+ TableSpaceCheckpointStatus *spcStatus, int nb_spaces,
+ int *pspace, int num_to_write, int num_written)
+{
+ int space = *pspace, buf_id = -1, index;
+
+ /*
+ * Select a tablespace depending on the current overall progress.
+ *
+ * The progress ratio of each unfinished tablespace is compared to
+ * the overall progress ratio to find one with is not in advance
+ * (i.e. overall ratio > tablespace ratio,
+ * i.e. tablespace written/to_write > overall written/to_write
Hello Amit, > I have tried your scripts and found some problem while using avg.py > script. > grep 'progress:' test_medium4_FW_off.out | cut -d' ' -f4 | ./avg.py > --limit=10 --length=300 > : No such file or directory > I didn't get chance to poke into avg.py script (the command without > avg.py works fine). Python version on the m/c, I planned to test is > Python 2.7.5. Strange... What does "/usr/bin/env python" say? Can the script be started on its own at all? I think that the script should work both with python2 and python3, at least it does on my laptop... > Today while reading the first patch (checkpoint-continuous-flush-10-a), > I have given some thought to below part of patch which I would like > to share with you. > > + * Select a tablespace depending on the current overall progress. > + * > + * The progress ratio of each unfinished tablespace is compared to > + * the overall progress ratio to find one with is not in advance > + * (i.e. overall ratio > tablespace ratio, > + * i.e. tablespace written/to_write > overall written/to_write > Here, I think above calculation can go for toss if backend or bgwriter > starts writing buffers when checkpoint is in progress. The tablespace > written parameter won't be able to consider the one's written by backends > or bgwriter. Sure... This is *already* the case with the current checkpointer, the schedule is performed with respect to the initial number of buffers it think it will have to write, and if someone else writes these buffers then the schedule is skewed a little bit, or more... I have not changed this logic, but I extended it to handle several tablespaces. If this (the checkpointer progress evaluation used for its schedule is sometimes wrong because of other writes) is proven to be a major performance issue, then the processes which writes the checkpointed buffers behind its back should tell the checkpointer about it, probably with some shared data structure, so that the checkpointer can adapt its schedule. This is an independent issue, that may be worth to address some day. My opinion is that when the bgwriter or backends quick in to write buffers, they are basically generating random I/Os on HDD and killing tps and latency, so it is a very bad time anyway, thus I'm not sure that this is the next problem to address to improve pg performance and responsiveness. > Now it may not big thing to worry but I find Heikki's version worth > considering, he has not changed the overall idea of this patch, but the > calculations are somewhat simpler and hence less chance of going wrong. I do not think that Heikki version worked wrt to balancing writes over tablespaces, and I'm not sure it worked at all. However I reused some of his ideas to simplify and improve the code. -- Fabien.
Hello Amit,I have tried your scripts and found some problem while using avg.py
script.
grep 'progress:' test_medium4_FW_off.out | cut -d' ' -f4 | ./avg.py
--limit=10 --length=300
: No such file or directoryI didn't get chance to poke into avg.py script (the command without
avg.py works fine). Python version on the m/c, I planned to test is
Python 2.7.5.
Strange... What does "/usr/bin/env python" say?
Can the script be started on its own at all?
Here, I think above calculation can go for toss if backend or bgwriter
starts writing buffers when checkpoint is in progress. The tablespace
written parameter won't be able to consider the one's written by backends
or bgwriter.
Sure... This is *already* the case with the current checkpointer, the schedule is performed with respect to the initial number of buffers it think it will have to write, and if someone else writes these buffers then the schedule is skewed a little bit, or more... I have not changed this logic, but I extended it to handle several tablespaces.
I do not think that Heikki version worked wrt to balancing writes over tablespaces,
and I'm not sure it worked at all.
Hello Amit, >> Can the script be started on its own at all? > > I have tried like below which results in same error, also I tried few > other variations but could not succeed. > ./avg.py Hmmm... Ensure that the script is readable and executable: sh> chmod a+rx ./avg.py Also check the file: sh> file ./avg.py ./avg.py: Python script, UTF-8 Unicode text executable >> Sure... This is *already* the case with the current checkpointer, the >> schedule is performed with respect to the initial number of buffers it >> think it will have to write, and if someone else writes these buffers then >> the schedule is skewed a little bit, or more... I have not changed this > > I don't know how good or bad it is to build further on somewhat skewed > logic, The logic is no more skewed that it is with the current version: your remark about the estimation which may be wrong in some cases is clearly valid, but it is orthogonal (independent, unrelated, different) to what is addressed by this patch. I currently have no reason to believe that the issue you raise is a major performance issue, but if so it may be addressed by another patch by whoever want to do so. What I have done is to demonstrate that generating a lot of random I/Os is a major performance issue (well, sure), and this patch addresses this point and provide major speedup (*3-5) and latency reductions (from +60% unavailability to nearly full availability) for high OLTP write load, by reordering and flushing checkpoint buffers in a sensible way. > but the point is that unless it is required why to use it. This is really required to avoid predictable performance regressions, see below. >> I do not think that Heikki version worked wrt to balancing writes over >> tablespaces, > > I also think that it doesn't balances over tablespaces, but the question > is why do we need to balance over tablespaces, can we reliably predict > in someway which indicates that performing balancing over tablespace can > help the workload. The reason for the tablespace balancing is that in the current postgres buffers are written more or less randomly, so it is (probably) implicitely and statistically balanced over tablespaces because of this randomness, and indeed, AFAIK, people with multi tablespace setup have not complained that postgres was using the disks sequentially. However, once the buffers are sorted per file, the order becomes deterministic and there is no more implicit balancing, which means that if someone has a pg setup with several disks it will write sequentially on these instead of in parallel. This regression was pointed out by Andres Freund, I agree that such a regression for high end systems must be avoided, hence the tablespace balancing. > I think here we are doing more engineering than required for this patch. I do not think so, I think that Andres remark is justified to avoid a performance regression on high end systems which use tablespaces, which is really undesirable. About the balancing code, it is not that difficult, even if it is not trivial: the point is to select the tablespace for which the progress ratio (written/to_write) is below the overall progress ratio, so that it catches up, and do so in a round robin maner, so that all tablespaces get to write things. I also have both written a proof and tested the logic (in a separate script). -- Fabien.
On Mon, Aug 24, 2015 at 4:15 PM, Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > [stuff] Moved to next CF 2015-09. -- Michael
On 2015-08-18 09:08:43 +0200, Fabien COELHO wrote: > Please find attached a v10, where I have reviewed comments for style & > contents, and also slightly extended the documentation about the flush > option to hint that it is essentially useful for high write loads. Without > further data, I think it is not obvious to give more definite advices. v10b misses the checkpoint_sort part of the patch, and thus cannot be applied. Andres
Hello Andres, >> Please find attached a v10, where I have reviewed comments for style & >> contents, and also slightly extended the documentation about the flush >> option to hint that it is essentially useful for high write loads. >> Without further data, I think it is not obvious to give more definite >> advices. > > v10b misses the checkpoint_sort part of the patch, and thus cannot be > applied. Yes, indeed, the second part is expected to be applied on top of v10a. Please find attached the cumulated version (v10a + v10b). -- Fabien.
On 2015-08-27 14:32:39 +0200, Fabien COELHO wrote: > >v10b misses the checkpoint_sort part of the patch, and thus cannot be > >applied. > > Yes, indeed, the second part is expected to be applied on top of v10a. Oh, sorry. I'd somehow assumed they were two variants of the same patch (one with "slim" sorting and the other without).
>>> v10b misses the checkpoint_sort part of the patch, and thus cannot be >>> applied. >> >> Yes, indeed, the second part is expected to be applied on top of v10a. > > Oh, sorry. I'd somehow assumed they were two variants of the same patch > (one with "slim" sorting and the other without). The idea is that as these two features could be committed separately. However, experiments show that flushing is really efficient when sorting is done first, and moreover the two features conflict, so I've made two dependent patches. -- Fabien.
>
>
> Also check the file:
>
> sh> file ./avg.py
> ./avg.py: Python script, UTF-8 Unicode text executable
>
There were some CRLF line terminators, after removing those, it worked
--------------------IBM POWER-8 24 cores, 192 hardware threads
RAM = 492GB
> The reason for the tablespace balancing is that in the current postgres buffers are written more or less randomly, so it is (probably) implicitely and statistically balanced over tablespaces because of this randomness, and indeed, AFAIK, people with multi tablespace setup have not complained that postgres was using the disks sequentially.
>
> However, once the buffers are sorted per file, the order becomes deterministic and there is no more implicit balancing, which means that if someone has a pg setup with several disks it will write sequentially on these instead of in parallel.
>
Hello Amit, > IBM POWER-8 24 cores, 192 hardware threads > RAM = 492GB Wow! Thanks for trying the patch on such high-end hardware! About the disks: what kind of HDD (RAID? speed?)? HDD write cache? What is the OS? The FS? > warmup=60 Quite short, but probably ok. > scale=300 Means about 4-4.5 GB base. > time=7200 > synchronous_commit=on > shared_buffers=8GB This is small wrt hardware, but given the scale setup I think that it should not matter much. > max_wal_size=5GB Hmmm... Maybe quite small given the average performance? > checkpoint_timeout=2min This seems rather small. Are the checkpoints xlog or time triggered? You did not update checkpoint_completion_target, which means 0.5 so that the checkpoint is scheduled to run in at most 1 minute, which suggest at least 130 MB/s write performance for the checkpoint. > parallelism - 128 clients, 128 threads Given 192 hw threads, I would have tried used 128 clients & 64 threads, so that each pgbench client has its own dedicated postgres in a thread, and that postgres processes are not competing with pgbench. Now as pgbench is mostly sleeping, probably that does not matter much... I may also be totally wrong:-) > Sort - off > avg over 7200: 8256.382528 ± 6218.769282 [0.000000, 76.050000, > 10975.500000, 13105.950000, 21729.000000] > percent of values below 10.0: 19.5% The max performance is consistent with 128 threads * 200 (random) writes per second. > Sort - on > avg over 7200: 8375.930639 ± 6148.747366 [0.000000, 84.000000, > 10946.000000, 13084.000000, 20289.900000] > percent of values below 10.0: 18.6% This is really a small improvement, probably in the error interval of the measure. I would not trust much 1.5% tps or 0.9% availability improvements. I think that we could conclude that on your (great) setup, with these configuration parameter, this patch does not harm performance. This is a good thing, even if I would have hoped to see better performance. > Before going to conclusion, let me try to explain above data (I am > explaining again even though Fabien has explained, to make it clear > if someone has not read his mail) > > Let's try to understand with data for sorting - off option > > avg over 7200: 8256.382528 ± 6218.769282 > > 8256.382528 - average tps for 7200s pgbench run > 6218.769282 - standard deviation on per second figures > > [0.000000, 84.000000, 10946.000000, 13084.000000, 20289.900000] > > These 5 values can be read as minimum TPS, q1, median TPS, q3, > maximum TPS over 7200s pgbench run. As far as I understand q1 > and q3 median of subset of values which I didn't focussed much. q1 = 84 means that 25% of the time the performance was below 84 tps, about 1% of the average performance, which I would translate as "pg is pretty unresponsive 25% of the time". This is the kind of issue I really want to address, the eventual tps improvements are just a side effect. > percent of values below 10.0: 19.5% > > Above means percent of time the result is below 10 tps. Which means "postgres is really unresponsive 19.5% of the time". If you count zeros, you will get "postgres was totally unresponsive X% of the time". > Now about test results, these tests are done for pgbench full speed runs > and the above results indicate that there is approximately 1.5% > improvement in avg. TPS and ~1% improvement in tps values which are > below 10 with sorting on and there is almost no improvement in median or > maximum TPS values, instead they or slightly less when sorting is > on which could be due to run-to-run variation. Yes, I agree. > I have done more tests as well by varying time and number of clients > keeping other configuration same as above, but the results are quite > similar. Given the hardware, I would suggest to raise checkpoint_timeout, shared_buffers and max_wal_size, and use checkpoint_completion_target=0.8. I would expect that it should improve performance both with and without sorting. It would be interesting to have informations from checkpoint logs (especially how many buffers written in how long, whether checkpoints are time or xlog triggered, ...). > The results of sorting patch for the tests done indicate that the win is > not big enough with just doing sorting during checkpoints, ISTM that you do too much generalization: The win is not big "under this configuration and harware". I think that the patch may have very small influence under some conditions, but should not degrade performance significantly, and on the other hand it should provide great improvements under some (other) conditions. So having no performance degradation is a good result, even if I would hope to get better results. It would be interesting to understand why random disk writes do not perform too poorly on this box: size of I/O queue, kind of (expensive:-) disks, write caches, file system, raid level... > we should consider flush patch along with sorting. I also think that it would be interesting. > I would like to perform some tests with both the patches together (sort > + flush) unless somebody else thinks that sorting patch alone is > beneficial and we should test some other kind of scenarios to see it's > benefit. Yep. Is it a Linux box? If not, does it support posix_fadvise()? >> The reason for the tablespace balancing is [...] > > What if tablespaces are not on separate disks I would expect that it might very slightly degrade performance, but only marginally. > or not enough hardware support to make Writes parallel? I'm not sure that balancing or not writes over tablespaces would change anything to an I/O bottleneck which is not the disk write performance, so I would say "no impact" in that case. > I think for such cases it might be better to do it sequentially. Writing sequentially to different disks would be a bug, and degrade performance significantly on a setup with several disks, up to dividing the performance by the number of disks... so I do think that a patch which predictability and significantly degrades performance on high-end harware is a reasonable option. If you want to be able to disactivate balancing, it could be done with a guc, but I cannot see good reasons to want to do that: it would complicate the code and it does not make much sense to use many tablespaces on one disk, while anyone who uses several tablespaces on several disks is probably expecting to see her expensive disks actually used in parallel. -- Fabien.
>
>
> Hello Amit,
>
>> IBM POWER-8 24 cores, 192 hardware threads
>> RAM = 492GB
>
>
> Wow! Thanks for trying the patch on such high-end hardware!
>
> About the disks: what kind of HDD (RAID? speed?)? HDD write cache?
>
> What is the OS? The FS?
>
>> shared_buffers=8GB
>
>
> This is small wrt hardware, but given the scale setup I think that it should not matter much.
>
>> max_wal_size=5GB
>
>
> Hmmm... Maybe quite small given the average performance?
>
>> checkpoint_timeout=2min
>
>
> This seems rather small. Are the checkpoints xlog or time triggered?
>
> You did not update checkpoint_completion_target, which means 0.5 so that the checkpoint is scheduled to run in at most 1 minute, which suggest at least 130 MB/s write performance for the checkpoint.
>
>> parallelism - 128 clients, 128 threads
>
>
> Given 192 hw threads, I would have tried used 128 clients & 64 threads, so that each pgbench client has its own dedicated postgres in a thread, and that postgres processes are not competing with pgbench. Now as pgbench is mostly sleeping, probably that does not matter much... I may also be totally wrong:-)
>
>
> Given the hardware, I would suggest to raise checkpoint_timeout, shared_buffers and max_wal_size, and use checkpoint_completion_target=0.8. I would expect that it should improve performance both with and without sorting.
>
> It would be interesting to have informations from checkpoint logs (especially how many buffers written in how long, whether checkpoints are time or xlog triggered, ...).
>
>> The results of sorting patch for the tests done indicate that the win is not big enough with just doing sorting during checkpoints,
>
>
> ISTM that you do too much generalization: The win is not big "under this configuration and harware".
>
> I think that the patch may have very small influence under some conditions, but should not degrade performance significantly, and on the other hand it should provide great improvements under some (other) conditions.
>
>>
>> What if tablespaces are not on separate disks
>
>
> I would expect that it might very slightly degrade performance, but only marginally.
>
> If you want to be able to disactivate balancing, it could be done with a guc, but I cannot see good reasons to want to do that: it would complicate the code and it does not make much sense to use many tablespaces on one disk, while anyone who uses several tablespaces on several disks is probably expecting to see her expensive disks actually used in parallel.
>
Hello Amit, >> About the disks: what kind of HDD (RAID? speed?)? HDD write cache? > > Speed of Reads - > Timing cached reads: 27790 MB in 1.98 seconds = 14001.86 MB/sec > Timing buffered disk reads: 3830 MB in 3.00 seconds = 1276.55 MB/sec Woops.... 14 GB/s and 1.2 GB/s?! Is this a *hard* disk?? > Copy speed - > > dd if=/dev/zero of=/tmp/output.img bs=8k count=256k > 262144+0 records in > 262144+0 records out > 2147483648 bytes (2.1 GB) copied, 1.30993 s, 1.6 GB/s Woops, 1.6 GB/s write... same questions, "rotating plates"?? Looks more like several SSD... Or the file is kept in memory and not committed to disk yet? Try a "sync" afterwards?? If these are SSD, or if there is some SSD cache on top of the HDD, I would not expect the patch to do much, because the SSD random I/O writes are pretty comparable to sequential I/O writes. I would be curious whether flushing helps, though. >>> max_wal_size=5GB >> >> Hmmm... Maybe quite small given the average performance? > > We can check with larger value, but do you expect some different > results and why? Because checkpoints are xlog triggered (which depends on max_wal_size) or time triggered (which depends on checkpoint_timeout). Given the large tps, I expect that the WAL is filled very quickly hence may trigger checkpoints every ... that is the question. >>> checkpoint_timeout=2min >> >> This seems rather small. Are the checkpoints xlog or time triggered? > > I wanted to test by triggering more checkpoints, but I can test with > larger checkpoint interval as wel like 5 or 10 mins. Any suggestions? For a +2 hours test, I would suggest 10 or 15 minutes. It would be useful to know about checkpoint stats before suggesting values for max_wal_size and checkpoint_timeout. > [...] The value used in your script was 0.8 for > checkpoint_completion_target which I have not changed during tests. Ok. >>> parallelism - 128 clients, 128 threads [...] > In next run, I can use it with 64 threads, lets settle on other parameters > first for which you expect there could be a clear win with the first patch. Ok. >> Given the hardware, I would suggest to raise checkpoint_timeout, >> shared_buffers and max_wal_size, [...]. I would expect that it should >> improve performance both with and without sorting. > > I don't think increasing shared_buffers would have any impact, because > 8GB is sufficient for 300 scale factor data, It fits at the beginning, but when updates and inserts are performed postgres adds new pages (update = delete + insert), and the deleted space is eventually reclaimed by vacuum later on. Now if space is available in the page it is reused, so what really happens is not that simple... At 8500 tps the disk space extension for tables may be up to 3 MB/s at the beginning, and would evolve but should be at least about 0.6 MB/s (insert in history, assuming updates are performed in page), on average. So whether the database fits in 8 GB shared buffer during the 2 hours of the pgbench run is an open question. > checkpoint_completion_target is already 0.8 in my previous tests. Lets > try with checkpoint_timeout = 10 min and max_wal_size = 15GB, do you > have any other suggestion? Maybe shared_buffers = 32GB to ensure that it is a "in buffer" run ? >> It would be interesting to have informations from checkpoint logs >> (especially how many buffers written in how long, whether checkpoints >> are time or xlog triggered, ...). Information still welcome. > Hmm.. nothing like that, this was based on couple of tests done by > me and I am open to do some more if you or anybody feels that the > first patch (checkpoint-continuous-flush-10-a) can alone gives benefit, > in-fact I have started these tests with the intention to see if first > patch gives benefit, then that could be evaluated and eventually > committed separately. Ok. My initial question remains: is the setup using HDDs? For SSD there should be probably no significant benefit with sorting, although it should not harm, and I'm not sure about flushing. > True, let us try to find conditions/scenarios where you think it can give > big boost, suggestions are welcome. HDDs? > I think we can leave this for committer to take a call or if anybody > else has any opinion, because there is nothing wrong in what you > have done, but I am not clear if there is a clear need for the same. I may have an old box available with two disks, so that I can run some tests with table spaces, but with very few cores. -- Fabien.
Hello Amit,About the disks: what kind of HDD (RAID? speed?)? HDD write cache?
Speed of Reads -
Timing cached reads: 27790 MB in 1.98 seconds = 14001.86 MB/sec
Timing buffered disk reads: 3830 MB in 3.00 seconds = 1276.55 MB/sec
Woops.... 14 GB/s and 1.2 GB/s?! Is this a *hard* disk??
Copy speed -
dd if=/dev/zero of=/tmp/output.img bs=8k count=256k
262144+0 records in
262144+0 records out
2147483648 bytes (2.1 GB) copied, 1.30993 s, 1.6 GB/s
Woops, 1.6 GB/s write... same questions, "rotating plates"??
Looks more like several SSD... Or the file is kept in memory and not committed to disk yet? Try a "sync" afterwards??
If these are SSD, or if there is some SSD cache on top of the HDD, I would not expect the patch to do much, because the SSD random I/O writes are pretty comparable to sequential I/O writes.
I would be curious whether flushing helps, though.
max_wal_size=5GB
Hmmm... Maybe quite small given the average performance?
We can check with larger value, but do you expect some different
results and why?
Because checkpoints are xlog triggered (which depends on max_wal_size) or time triggered (which depends on checkpoint_timeout). Given the large tps, I expect that the WAL is filled very quickly hence may trigger checkpoints every ... that is the question.checkpoint_timeout=2min
This seems rather small. Are the checkpoints xlog or time triggered?
I wanted to test by triggering more checkpoints, but I can test with
larger checkpoint interval as wel like 5 or 10 mins. Any suggestions?
For a +2 hours test, I would suggest 10 or 15 minutes.
I don't think increasing shared_buffers would have any impact, because
8GB is sufficient for 300 scale factor data,
It fits at the beginning, but when updates and inserts are performed postgres adds new pages (update = delete + insert), and the deleted space is eventually reclaimed by vacuum later on.
Now if space is available in the page it is reused, so what really happens is not that simple...
At 8500 tps the disk space extension for tables may be up to 3 MB/s at the beginning, and would evolve but should be at least about 0.6 MB/s (insert in history, assuming updates are performed in page), on average.
So whether the database fits in 8 GB shared buffer during the 2 hours of the pgbench run is an open question.
Hello Amit,
>> Woops.... 14 GB/s and 1.2 GB/s?! Is this a *hard* disk??
>
> Yes, there is no SSD in system. I have confirmed the same. There are RAID
> spinning drives.
Ok...
I guess that there is some kind of cache to explain these great tps
figures, probably on the RAID controller. What does "lspci" says? Does
"hdparm" suggests that the write cache is enabled? It would be fine if the
I/O system has a BBU, but that could also hide some of the patch
benefits...
A tentative explanation for the similar figures with and without sorting
could be that depending on the controller cache size (may be 1GB or more)
and firmware, the I/O system reorders disk writes so that they are
basically sequential and the fact that pg sorts them beforehand has little
or no impact. This may also be help by the fact that buffers are not
really in random order to begin with as the warmup phase does an initial
"select stuff from table".
There could be other possible factors such as the file system details,
"WAFL" hacks... the tricks are endless:-)
Checking for the right explanation would involve removing the
unconditional select warmup to use only a long and random warmup, and
probably trying a much larger than cache database, and/or disabling the
write cache, reading the hardware documentation in detail... But this is
also a lot of bother and time.
Maybe the simplest approach would be to disable the write cache for the
test. Is that possible?
>> Woops, 1.6 GB/s write... same questions, "rotating plates"??
>
> One thing to notice is that if I don't remove the output file
> (output.img) the speed is much slower, see the below output. I think
> this means in our case we will get ~320 MB/s
I would say that the OS was doing something here, and 320 MB/s looks more
like an actual HDD RAID system sequential write performance.
>> If these are SSD, or if there is some SSD cache on top of the HDD, I would
>> not expect the patch to do much, because the SSD random I/O writes are
>> pretty comparable to sequential I/O writes.
>>
>> I would be curious whether flushing helps, though.
>
> Yes, me too. I think we should try to reach on consensus for exact
> scenarios and configuration where this patch('es) can give benefit or we
> want to verify if there is any regression as I have access to this m/c
> for a very-very limited time. This m/c might get formatted soon for
> some other purpose.
Yep, it would be great if you have time for a flush test before it
disappears... I think it is advisable to disable the write cache as it may
also hide the impact of flushing.
>> So whether the database fits in 8 GB shared buffer during the 2 hours of
>> the pgbench run is an open question.
>
> With this kind of configuration, I have noticed that more than 80%
> of updates are HOT updates, not much bloat, so I think it won't
> cross 8GB limit, but still I can keep it to 32GB if you have any doubts.
The problem with performance tests is that you want to test one thing, but
there are many factors that intervene and you may end up testing something
else, such as lock contention or process scheduler or whatever, rather
than what you were trying to put in evidence. So I would suggest to be on
the safe side and use the larger value.
--
Fabien.
>>> I would be curious whether flushing helps, though.
>>
>> Yes, me too. I think we should try to reach on consensus for exact
>> scenarios and configuration where this patch('es) can give benefit or we
>> want to verify if there is any regression as I have access to this m/c for
>> a very-very limited time. This m/c might get formatted soon for some other
>> purpose.
>
> Yep, it would be great if you have time for a flush test before it
> disappears... I think it is advisable to disable the write cache as it may
> also hide the impact of flushing.
Still thinking... Depending on the results, it might be interesting to
have these tests run with the write cache enabled as well, to check how
much it interferes positively with performance.
I would guess "quite a lot".
--
Fabien.
Hi, Here's a bunch of comments on this (hopefully the latest?) version of the patch: * I'm not sure I like the FileWrite & FlushBuffer API changes. Do you forsee other callsites needing similar logic? Wouldn'tit be just as easy to put this logic into the checkpointing code? * We don't do one-line ifs; function parameters are always in the same line as the function name * Wouldn't a binary heap over the tablespaces + progress be nicer? If you make the sorting criterion include the tablespaceid you wouldn't need the lookahead loop in NextBufferToWrite(). Isn't the current approach O(NBuffers^2) in theworst case? Greetings, Andres Freund
Hello Andres, > Here's a bunch of comments on this (hopefully the latest?) Who knows?! :-) > version of the patch: > > * I'm not sure I like the FileWrite & FlushBuffer API changes. Do you > forsee other callsites needing similar logic? I foresee that the bgwriter should also do something more sensible than generating random I/Os over HDDs, and this is also true for workers... But this is for another time, maybe. > Wouldn't it be just as easy to put this logic into the checkpointing > code? Not sure it would simplify anything, because the checkpointer currently knows about buffers but flushing is about files, which are hidden from view. Doing it with this API change means that the code does not have to compute twice in which file is a buffer: The buffer/file boundary has to be broken somewhere anyway so that flushing can be done when needed, and the solution I took seems the simplest way to do it, without having to make the checkpointer too much file concious. > * We don't do one-line ifs; Ok, I'll return them. > function parameters are always in the same line as the function name Ok, I'll try to improve. > * Wouldn't a binary heap over the tablespaces + progress be nicer? I'm not sure where it would fit exactly. Anyway, I think it would complicate the code significantly (compared to the straightforward array), so I would not do anything like that without a strong intensive, such as an actual failing case. Moreover such a data structure would probably require some kind of pointer (probably 8 bytes added per node, maybe more), and the amount of memory is already a concern, at least to me, and moreover it has to reside in shared memory which does not simplify allocation of tree data structures. > If you make the sorting criterion include the tablespace id you wouldn't > need the lookahead loop in NextBufferToWrite(). Yep, I thought of it. It would mean 4 more bytes per buffer, and bsearch to find the boundaries, so significantly less simple code. I think that the current approach is ok as the number of tablespace should be small. It may be improved upon later if there is a motivation to do so. > Isn't the current approach O(NBuffers^2) in the worst case? ISTM that the overall lookahead complexity is Nbuffers * Ntablespace: buffers are scanned once for each tablespace. I assume that the number of tablespace is kept low, and having a simpler code which use less memory seems a good idea. ISTM that using a tablespace in the sorting would reduce the complexity to ln(NBuffers) * Ntablespace for finding the boundaries, and then Nbuffers * (Ntablespace/Ntablespace) = NBuffers for scanning, at the expense of more memory and code complexity. So this is a voluntary design decision. -- Fabien.
Here is a rebased two-part v11. > * We don't do one-line ifs; I've found one instance. > function parameters are always in the same line as the function name ISTM that I did that, or maybe I did not understand what I've done wrong. -- Fabien.
On 2015-09-06 19:05, Fabien COELHO wrote:
>
> Here is a rebased two-part v11.
>
>> function parameters are always in the same line as the function name
>
> ISTM that I did that, or maybe I did not understand what I've done wrong.
>
I see one instance of this issue
+static int
+NextBufferToWrite(
+ TableSpaceCheckpointStatus *spcStatus, int nb_spaces,
+ int *pspace, int num_to_write, int num_written)
Also
+static int bufcmp(const void * pa, const void * pb)
+{
should IMHO be formatted as
+static int
+bufcmp(const void * pa, const void * pb)
+{
And I think we generally put the struct typedefs at the top of the C
file and don't mix them with function definitions (I am talking about
the TableSpaceCheckpointStatus and TableSpaceCountEntry).
-- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training &
Services
Hello Petr,
>>> function parameters are always in the same line as the function name
>>
>> ISTM that I did that, or maybe I did not understand what I've done wrong.
>
> I see one instance of this issue
> +static int
> +NextBufferToWrite(
> + TableSpaceCheckpointStatus *spcStatus, int nb_spaces,
> + int *pspace, int num_to_write, int num_written)
Ok, I was looking for function calls.
> should IMHO be formatted as
> +static int
> +bufcmp(const void * pa, const void * pb)
> +{
Indeed.
> And I think we generally put the struct typedefs at the top of the C file and
> don't mix them with function definitions (I am talking about the
> TableSpaceCheckpointStatus and TableSpaceCountEntry).
Ok, moved up.
Thanks for the hints! Two-part v12 attached fixes these.
--
Fabien.
On 2015-09-06 16:05:01 +0200, Fabien COELHO wrote: > >Wouldn't it be just as easy to put this logic into the checkpointing code? > > Not sure it would simplify anything, because the checkpointer currently > knows about buffers but flushing is about files, which are hidden from > view. It'd not really simplify things, but it'd keep it local. > >* Wouldn't a binary heap over the tablespaces + progress be nicer? > > I'm not sure where it would fit exactly. Imagine a binaryheap.h style heap over a structure like (tablespaceid, progress, progress_inc, nextbuf) where the comparator compares the progress. > Anyway, I think it would complicate the code significantly (compared to the > straightforward array) I doubt it. I mean instead of your GetNext you'd just do: next_tblspc = DatumGetPointer(binaryheap_first(heap)); if (next_tblspc== 0) return 0; next_tblspc.progress += next_tblspc.progress_slice; binaryheap_replace_first(PointerGetDatum(next_tblspc)); return next_tblspc.nextbuf++; progress_slice is the number of buffers in the tablespace divided by the number of total buffers, to avoid doing any sort of expensive math in the more frequently executed path. > Moreover such a data structure would probably require some kind of pointer > (probably 8 bytes added per node, maybe more), and the amount of memory is > already a concern, at least to me, and moreover it has to reside in shared > memory which does not simplify allocation of tree data structures. I'm not seing where you'd need an extra pointer? Maybe the misunderstanding is that I'm proposing to do a heap over the *tablespaces* not the actual buffers. > >If you make the sorting criterion include the tablespace id you wouldn't > >need the lookahead loop in NextBufferToWrite(). > > Yep, I thought of it. It would mean 4 more bytes per buffer, and bsearch to > find the boundaries, so significantly less simple code. What for would you need to bsearch? > I think that the current approach is ok as the number of tablespace > should be small. Right that's often the case. > >Isn't the current approach O(NBuffers^2) in the worst case? > > ISTM that the overall lookahead complexity is Nbuffers * Ntablespace: > buffers are scanned once for each tablespace. Which in the worst case is NBuffers * 2... > ISTM that using a tablespace in the sorting would reduce the complexity to > ln(NBuffers) * Ntablespace for finding the boundaries, and then Nbuffers * > (Ntablespace/Ntablespace) = NBuffers for scanning, at the expense of more > memory and code complexity. Afaics finding the boundaries can be done as part of the enumeration of tablespaces in BufferSync(). That code needs to be moved, but that's not too bad. I don't see the code be that much more complicated? Greetings, Andres Freund
>
> On 2015-09-06 16:05:01 +0200, Fabien COELHO wrote:
> > >Wouldn't it be just as easy to put this logic into the checkpointing code?
> >
> > Not sure it would simplify anything, because the checkpointer currently
> > knows about buffers but flushing is about files, which are hidden from
> > view.
>
> It'd not really simplify things, but it'd keep it local.
>
How about using the value of guc (checkpoint_flush_to_disk) and
AmCheckpointerProcess to identify whether to do async flush in FileWrite?
Hello Amit, >> It'd not really simplify things, but it'd keep it local. > > How about using the value of guc (checkpoint_flush_to_disk) and > AmCheckpointerProcess to identify whether to do async flush in > FileWrite? ISTM that what you suggest would just replace the added function arguments with global variables to communicate and keep the necessary data for managing the asynchronous flushing, which is called per tablespace (1) on file changes (2) when the checkpointer is going to sleep. Although it can be done obviously, I prefer to have functions arguments rather than global variables, on principle. Also, because of (2) and of the dependency on the number of tablespaces being flushed, the flushing stuff cannot be fully hidden from the checkpointer anyway. Also I think that probably the bgwriter should do something similar, so function parameters would be useful to drive flushing from it, rather than adding yet another set of global variables, or share the same variables for somehow different purposes. So having these added parameters look reasonable to me. -- Fabien.
I would be curious whether flushing helps, though.
Yes, me too. I think we should try to reach on consensus for exact scenarios and configuration where this patch('es) can give benefit or we want to verify if there is any regression as I have access to this m/c for a very-very limited time. This m/c might get formatted soon for some other purpose.
Yep, it would be great if you have time for a flush test before it disappears... I think it is advisable to disable the write cache as it may also hide the impact of flushing.
Still thinking... Depending on the results, it might be interesting to have these tests run with the write cache enabled as well, to check how much it interferes positively with performance.
--------------------IBM POWER-8 24 cores, 192 hardware threads
RAM = 492GB
Hello Amit, > I have done some tests with both the patches(sort+flush) and below > are results: Thanks a lot for these runs on this great harware! > Test - 1 (Data Fits in shared_buffers) Rounded for easier comparison: flush/sort off off: 27480.4 ± 12791.1 [ 0, 16009, 32109, 37629, 51671] (2.8%) off on : 27482.5 ± 12552.0 [ 0, 16587,31226, 37516, 51297] (2.8%) The two above case are pretty indistinguishable, sorting has no impact. The 2.8% means more than 1 minute offline per hour (not necessarily a whole minute, it may be distributed over the whole hour). on off: 25214.8 ± 11059.7 [5268, 14188, 26472, 35626, 51479] (0.0%) on on : 26819.6 ± 10589.7 [5192, 16825, 29430, 35708,51475] (0.0%) > For this test run, the best results are when both the sort and flush > options are enabled, the value of lowest TPS is increased substantially > without sacrificing much on average or median TPS values (though there > is ~9% dip in median TPS value). When only sorting is enabled, there is > neither significant gain nor any loss. When only flush is enabled, > there is significant degradation in both average and median value of TPS > ~8% and ~21% respectively. I interpret the five numbers in bracket as an indicator of performance stability: they should be equal for perfect stability. Once they show some stability, the next point for me is to focus at the average performance. I do not see a median decrease as a big issue if the average is reasonably good. Thus I essentially note the -2.5% dip on average of on-on vs off-on. I would say that it is probably significant, although it might be in the error margin of the measure. Not sure whether the little stddev reduction is really significant. Anyway the benefit is clear: 100% availability. Flushing without sorting is a bad idea (tm), not a surprise. > Test - 2 (Data doesn't fit in shared_buffers, but fits in RAM) flush/sort off off: 5050.1 ± 4884.5 [ 0, 98, 4699, 10126, 13631] ( 7.7%) off on : 6194.2 ± 4913.5 [ 0, 98, 8982,10558, 14035] (11.0%) on off: 2771.3 ± 1861.0 [ 288, 2039, 2375, 2679, 12862] ( 0.0%) on on : 6110.6 ± 1939.3 [1652,5215, 5724, 6196, 13828] ( 0.0%) I'm not sure that the off-on vs on-on -1.3% avg tps dip is significant, but it may be. With both flushing and sorting pg becomes fully available, and the standard deviation is devided by more than 2, so the benefit is clear. > For this test run, again the best results are when both the sort and flush > options are enabled, the value of lowest TPS is increased substantially > and the average and median value of TPS has also increased to > ~21% and ~22% respectively. When only sorting is enabled, there is a > significant gain in average and median TPS values, but then there is also > an increase in number of times when TPS is below 10 which is bad. > When only flush is enabled, there is significant degradation in both average > and median value of TPS to ~82% and ~97% respectively, now I am not > sure if such a big degradation could be expected for this case or it's just > a problem in this run, I have not repeated this test. Yes, I agree that it is strange that sorting without flushing on its own both improves performance (+20% tps) but seems to degrade availability at the same time. A rerun would have helped to check whether it is a fluke or it is reproducible. > Test - 3 (Data doesn't fit in shared_buffers, but fits in RAM) > ---------------------------------------------------------------------------------------- > Same configuration and settings as above, but this time, I have enforced > Flush to use posix_fadvise() rather than sync_file_range() (basically > changed code to comment out sync_file_range() and enable posix_fadvise()). > > On using posix_fadvise(), the results for best case (both flush and sort as > on) shows significant degradation in average and median TPS values > by ~48% and ~43% which indicates that probably using posix_fadvise() > with the current options might not be the best way to achieve Flush. Yes, indeed. The way posix_fadvise is implemented on Linux is between no effect and bad effect (the buffer is erased). You hit the later quite strongly... As you are doing a "not fit in shared buffer" test, it is essential that buffers are kept in ram, but posix_fadvise on Linux just instructs to erase the buffer from memory if it was already passed to the I/O subsystem, which given the probably large I/O device cache on your host should be done pretty quickly, so that later read must be fetch back from the device (either cache or disk), which means a drop in performance. Note that FreeBSD implementation seems more convincing, although less good than Linux sync_file_range function. I've no idea about other systems. > Overall, I think this patch (sort+flush) brings a lot of value on table > in terms of stablizing the TPS during checkpoint, however some of the > cases like use of posix_fadvise() and the case (all data fits in > shared_buffers) where the value of median TPS is regressed could be > investigated to see what can be done to improve them. I think more > tests can be done to ensure the benefit or regression of this patch, but > for now this is what best I can do. Thanks a lot, again, for these tests! I think that we may conclude, on these run: (1) sorting seems not to harm performance, and may help a lot. (2) Linux flushing with sync_file_range may degrade a little raw tps average in some case, but definitely improves performancestability (always 100% availability when on !). (3) posix_fadvise on Linux is a bad idea... the good news is that it is not needed there:-) How good or bad an idea itis on other system is an open question... These results are consistent with the current default values in the patch: sorting is on by default, flushing is on with Linux and off otherwise (posix_fadvise). Also, as the effect on other systems is unclear, I think it is best to keep both settings as GUCs for now. -- Fabien.
>
>
>
> I think that we may conclude, on these run:
>
> (1) sorting seems not to harm performance, and may help a lot.
>
> (2) Linux flushing with sync_file_range may degrade a little raw tps
> average in some case, but definitely improves performance stability
> (always 100% availability when on !).
>
> is not needed there:-) How good or bad an idea it is on other system
> is an open question...
>
Hello Amit, >> I think that we may conclude, on these run: >> >> (1) sorting seems not to harm performance, and may help a lot. > > I agree with first part, but about helping a lot, I am not sure I'm focussing on the "sort" dimension alone, that is I'm comparing the average tps performance with sorting with the same test without sorting, : There are 4 cases from your tests, if I'm not mistaken: - T1 flush=off 27480 -> 27482 : +0.0% - T1 flush=on 25214 -> 26819 : +6.3% - T2 flush=off 5050 -> 6194 : +22.6%- T2 flush=on 2771 -> 6110 : +120.4% The average improvement induced by sort=on is +50%, if you do not agree on "a lot", maybe we can agree on "significantly":-) > based on the tests conducted by me, among all the runs, it has shown > improvement in average TPS is one case and that too with a dip in number > of times the TPS is below 10. >> (2) Linux flushing with sync_file_range may degrade a little raw tps >> average in some case, but definitely improves performance stability >> (always 100% availability when on !). > > Agreed, I think the benefit is quite clear, but it would be better if we try > to do some more test for the cases (data fits in shared_buffers) where > we saw small regression just to make sure that regression is small. I've already reported a lot of tests (several hundred of hours on two different hosts), and I did not have such a dip, but the hardware was more "usual" or "casual", really different from your runs. If you can run more tests, great! I think that the main safeguard to handle the (small) uncertainty is to keep gucs to control these features. >> (3) posix_fadvise on Linux is a bad idea... the good news is that it >> is not needed there:-) How good or bad an idea it is on other system >> is an open question... > > I don't know what is the best way to verify that, if some body else has > access to such a m/c, please help to get that verified. Yep. There has been such calls on this thread which were not very effective, up to now. -- Fabien.
On Tue, Sep 8, 2015 at 11:31 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> (3) posix_fadvise on Linux is a bad idea... the good news is that it >> is not needed there:-) How good or bad an idea it is on other system >> is an open question... > > I don't know what is the best way to verify that, if some body else has > access to such a m/c, please help to get that verified. Why wouldn't we just leave it out then? Putting it in when the one platform we've tried it on shows a regression makes no sense. We shouldn't include it and then remove it if someone can prove it's bad; we should only include it in the first place if we have good benchmarks showing that it is good. Does anyone have a big Windows box they can try this on? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
>>> (3) posix_fadvise on Linux is a bad idea... the good news is that it >>> is not needed there:-) How good or bad an idea it is on other system >>> is an open question... >> >> I don't know what is the best way to verify that, if some body else has >> access to such a m/c, please help to get that verified. > > Why wouldn't we just leave it out then? Putting it in when the one > platform we've tried it on shows a regression makes no sense. We > shouldn't include it and then remove it if someone can prove it's bad; > we should only include it in the first place if we have good benchmarks > showing that it is good. > > Does anyone have a big Windows box they can try this on? Just a box with a disk would be enough, it does not need to be big! As I wrote before, FreeBSD would be a good candidate because the posix_fadvise seems much more reasonable than on Linux, and should be profitable, so it would be a pity to remove it. -- Fabien.
On 2015-09-09 20:56:15 +0200, Fabien COELHO wrote: > As I wrote before, FreeBSD would be a good candidate because the > posix_fadvise seems much more reasonable than on Linux, and should be > profitable, so it would be a pity to remove it. Why do you think it's different on fbsd? Also, why is it unreasonable that DONNEED removes stuff from the cache? Greetings, Andres Freund
Hello Andres, >>> Wouldn't it be just as easy to put this logic into the checkpointing >>> code? >> >> Not sure it would simplify anything, because the checkpointer currently >> knows about buffers but flushing is about files, which are hidden from >> view. > > It'd not really simplify things, but it'd keep it local. Ok, it would be local, but it would also mean that the checkpointer would have to deal explicitely with files, whereas it currently does not have to. I think that the current buffer/file boundary is on engineering principle a good one, so I tried to break it as little as possible to enable the feature, and I wanted to avoid to have to do a buffer to file translation twice, once in the checkpointer and once when writing the buffer. >>> * Wouldn't a binary heap over the tablespaces + progress be nicer? >> >> I'm not sure where it would fit exactly. > > Imagine a binaryheap.h style heap over a structure like (tablespaceid, > progress, progress_inc, nextbuf) where the comparator compares the progress. It would replace what is currently an array. The balancing code needs to enumerate all tablespaces in a round-robin way so as to ensure that all tablespaces are given some attention, otherwise you could have a balance on two tablespaces but others could be left out. The array makes this property straightforward. >> Anyway, I think it would complicate the code significantly (compared to the >> straightforward array) > > I doubt it. I mean instead of your GetNext you'd just do: > next_tblspc = DatumGetPointer(binaryheap_first(heap)); > if (next_tblspc == 0) > return 0; > next_tblspc.progress += next_tblspc.progress_slice; > binaryheap_replace_first(PointerGetDatum(next_tblspc)); > > return next_tblspc.nextbuf++; Compare to the array, this tree approach would required ln(Ntablespace) work to extract and reinsert the tablespace under progress, so there is no complexity advantage. Moreover, given that in most cases there are 1 or 2 tablespaces, a tree structure is really on the heavy side. > progress_slice is the number of buffers in the tablespace divided by the > number of total buffers, to avoid doing any sort of expensive math in > the more frequently executed path. If there are many buffers, I'm not too sure about rounding issues and the like, so the current approach with a rational seems more secure. > [...] I'm not seing where you'd need an extra pointer? Indeed, I misunderstood. > [...] What for would you need to bsearch? To find the tablespace boundaries in the sorted buffer array in log(NBuffers) * Ntablespace, instead of NBuffers. >> I think that the current approach is ok as the number of tablespace >> should be small. > > Right that's often the case. Yep. >> ISTM that using a tablespace in the sorting would reduce the complexity to >> ln(NBuffers) * Ntablespace for finding the boundaries, and then Nbuffers * >> (Ntablespace/Ntablespace) = NBuffers for scanning, at the expense of more >> memory and code complexity. > > Afaics finding the boundaries can be done as part of the enumeration of > tablespaces in BufferSync(). That code needs to be moved, but that's not > too bad. I don't see the code be that much more complicated? Hmmm. you are proposing to replace prooved and heavilly tested code by a more complex tree data structures distributed quite differently around the source, and no very clear benefit. So I would prefer to keep the code as is, that is pretty straightforward, and wait for a strong incentive before doing anything fancier. ISTM that there are other places in pg need attention more that further tweaking this patch. -- Fabien.
On 2015-09-09 21:29:12 +0200, Fabien COELHO wrote: > >Imagine a binaryheap.h style heap over a structure like (tablespaceid, > >progress, progress_inc, nextbuf) where the comparator compares the progress. > > It would replace what is currently an array. It'd still be one afterwards. > The balancing code needs to enumerate all tablespaces in a round-robin > way so as to ensure that all tablespaces are given some attention, > otherwise you could have a balance on two tablespaces but others could > be left out. The array makes this property straightforward. Why would a heap as I've described it require that? > >>Anyway, I think it would complicate the code significantly (compared to the > >>straightforward array) > > > >I doubt it. I mean instead of your GetNext you'd just do: > > next_tblspc = DatumGetPointer(binaryheap_first(heap)); > > if (next_tblspc == 0) > > return 0; > > next_tblspc.progress += next_tblspc.progress_slice; > > binaryheap_replace_first(PointerGetDatum(next_tblspc)); > > > > return next_tblspc.nextbuf++; > > Compare to the array, this tree approach would required ln(Ntablespace) work > to extract and reinsert the tablespace under progress, so there is no > complexity advantage. extract/reinsert is actually O(1). > >progress_slice is the number of buffers in the tablespace divided by the > >number of total buffers, to avoid doing any sort of expensive math in > >the more frequently executed path. > > If there are many buffers, I'm not too sure about rounding issues and the > like, so the current approach with a rational seems more secure. Meh. The amount of imbalance introduced by rounding won't matter. > >>ISTM that using a tablespace in the sorting would reduce the complexity to > >>ln(NBuffers) * Ntablespace for finding the boundaries, and then Nbuffers * > >>(Ntablespace/Ntablespace) = NBuffers for scanning, at the expense of more > >>memory and code complexity. > > > >Afaics finding the boundaries can be done as part of the enumeration of > >tablespaces in BufferSync(). That code needs to be moved, but that's not > >too bad. I don't see the code be that much more complicated? > > Hmmm. you are proposing to replace prooved and heavilly tested code by a > more complex tree data structures distributed quite differently around the > source, and no very clear benefit. There's no "proved and heavily tested code" touched here. > So I would prefer to keep the code as is, that is pretty straightforward, > and wait for a strong incentive before doing anything fancier. I find the proposed code not particularly pretty, so I don't really buy the straightforwardness argument. Greetings, Andres Freund
>> As I wrote before, FreeBSD would be a good candidate because the >> posix_fadvise seems much more reasonable than on Linux, and should be >> profitable, so it would be a pity to remove it. > > Why do you think it's different on fbsd? Also, why is it unreasonable > that DONNEED removes stuff from the cache? Yep, I agree that this part is a bad point, obviously, but at least there is also some advantage: I understood that buffers are actually pushed towards the disk when calling posix_fadvise with DONTNEED on FreeBSD, so in-buffer tests shoud see better performance, and out-of-buffer in-memory tests would probably be degraded as Amit test shown on Linux. As an admin I can choose if I know whether I run in buffer or not. On Linux either the call is ignored (if the page is not written yet) or the page is coldly removed, so it has either no effect or a bad effect, basically. So I think that the current off default when running with posix_fadvise is reasonable, and in some case turning it on can probably provide a better performance stability, esp for in-buffer runs. Now, franckly I do not care much about FreeBSD or Windows, so I'm fine with dropping posix_fadvise if this is a blocker. -- Fabien.
>> It would replace what is currently an array. > > It'd still be one afterwards. > [...] > extract/reinsert is actually O(1). Hm, strange. I probably did not understood at all the heap structure you're suggesting. No big deal. > [...] Why would a heap as I've described it require that? Hmmm... The heap does *not* require anything, the *balancing* requires this property. > [...] There's no "proved and heavily tested code" touched here. I've prooved and tested heavily the submitted patch based on an array, that you want to replace with some heap, so I think that my point stands. Moreover, I do not see a clear benefit in changing the data structure. >> So I would prefer to keep the code as is, that is pretty straightforward, >> and wait for a strong incentive before doing anything fancier. > > I find the proposed code not particularly pretty, so I don't really buy > the straightforwardness argument. No big deal. From my point of view, the data structure change you're suggesting does not bring significant value, so there is no good reason to do it. If you want to submit another patch, this is free software, please proceed. -- Fabien.
>
>
> Hello Amit,
>
>>> I think that we may conclude, on these run:
>>>
>>> (1) sorting seems not to harm performance, and may help a lot.
>>
>>
>> I agree with first part, but about helping a lot, I am not sure
>
>
> I'm focussing on the "sort" dimension alone, that is I'm comparing the average tps performance with sorting with the same test without sorting, : There are 4 cases from your tests, if I'm not mistaken:
>
> - T1 flush=off 27480 -> 27482 : +0.0%
> - T1 flush=on 25214 -> 26819 : +6.3%
> - T2 flush=off 5050 -> 6194 : +22.6%
> - T2 flush=on 2771 -> 6110 : +120.4%
>
There is a clear win only in cases when sort is used with flush, apart
On 2015-09-09 20:56:15 +0200, Fabien COELHO wrote:
> As I wrote before, FreeBSD would be a good candidate because the
> posix_fadvise seems much more reasonable than on Linux, and should be
> profitable, so it would be a pity to remove it.
Why do you think it's different on fbsd? Also, why is it unreasonable
that DONNEED removes stuff from the cache?
Hello Amit, >> - T1 flush=off 27480 -> 27482 : +0.0% >> - T1 flush=on 25214 -> 26819 : +6.3% >> - T2 flush=off 5050 -> 6194 : +22.6% >> - T2 flush=on 2771 -> 6110 : +120.4% > > There is a clear win only in cases when sort is used with flush, apart > from that using sort alone doesn't have any clear advantage. Indeed, I agree that the improvement is much smaller without flushing, although it is there somehow (+0.0 & +22.6 => +11.3% on average). Well, at least we may agree that it is "somehow significantly better" ?:-) -- Fabien.
> Thanks for the hints! Two-part v12 attached fixes these. Here is a v13, which is just a rebase after 1aba62ec. -- Fabien.
Hello, > [...] If you make the sorting criterion include the tablespace id you > wouldn't need the lookahead loop in NextBufferToWrite(). I'm considering this precise point, i.e. including the tablespace as a sorting criterion. Currently the array used for sorting is 16 bytes per buffer (although I wrote 12 in another mail, I was wrong...). The data include the bufid (4 bytes) the relation & fork num (8 bytes, but really 4 bytes + 2 bits are used), and the block number (4 bytes) which is the offset within the relation. These 3 combined data allow to find the file and the offset within that file, for the given buffer id. I'm concerned that these 16 bytes are already significant and I do not want to extend them any more. I was already pretty happy with the previous version with 4 bytes per buffer. Now as the number of tablespace is expected to be very small (1, 2, maybe 3), there is no problem to pack it within the unused 30 bits in forknum. That would mean some masking and casts here and there, so it would not be very beautiful, but it would make it easy to find the buffers for a given tablespace, and indeed remove the lookahead stuff in the next buffer function, as you suggest. My question is: would that be acceptable, or would someone object to the use of masks and things like that? The benefit would be a simpler/more direct next buffer function, but some more tinkering around the sorting criterion to use a packed representation. Note that I do not think that it would have any actual impact on performance... it would only make a difference if there were really many tablespaces (the scanning complexity would be Nbuffer instead of Nbuffer*Ntablespace, but as Ntablespace is small...). My motivation is rather to help the patch get through, so I'm fine if this is not needed. -- Fabien.
Hi, On 2015-09-10 17:15:26 +0200, Fabien COELHO wrote: > > >Thanks for the hints! Two-part v12 attached fixes these. > > Here is a v13, which is just a rebase after 1aba62ec. I'm working on this patch, to get it into a state I think it'd be commitable. In my performance testing it showed that calling PerformFileFlush() only at segment boundaries and in CheckpointWriteDelay() can lead to rather spikey IO - not that surprisingly. The sync in CheckpointWriteDelay() is problematic because it only is triggered while on schedule, and not when behind. My testing seems to show that just adding a limit of 32 buffers to FileAsynchronousFlush() leads to markedly better results. I wonder if mmap() && msync(MS_ASYNC) isn't a better replacement for sync_file_range(SYNC_FILE_RANGE_WRITE) than posix_fadvise(DONTNEED). It might even be possible to later approximate that on windows using FlushViewOfFile(). As far as I can see the while (nb_spaces != 0)/NextBufferToWrite() logic doesn't work correctly if tablespaces aren't actually sorted. I'm actually inclined to fix this by simply removing the flag to enable/disable sorting. Having defined(HAVE_SYNC_FILE_RANGE) || defined(HAVE_POSIX_FADVISE) in so many places looks ugly, I want to push that to the underlying functions. If we add a different flushing approach we shouldn't have to touch several places that don't actually really care. I've replaced the NextBufferToWrite() logic with a binaryheap.h heap - seems to work well, with a bit less code actually. I'll post this after some more cleanup & testing. I've also noticed that sleeping logic in CheckpointWriteDelay() isn't particularly good. In high throughput workloads the 100ms sleep is too long, leading to bursty IO behaviour. If 1k+ buffers a written out a second 100ms is a rather long sleep. For another that we only sleep 100ms when the write rate is low makes the checkpoint finish rather quickly - on a slow disk (say microsd) that can cause unneccesary slowdowns for concurrent activity. ISTM we should calculate the sleep time in a better way. The SIGHUP behaviour is also weird. Anyway, this probably belongs on a new thread. Greetings, Andres Freund
Hello Andres, >> Here is a v13, which is just a rebase after 1aba62ec. > > I'm working on this patch, to get it into a state I think it'd be > commitable. I'll review it carefully. Also, if you can include some performance feature it would help, even if I'll do some more runs. > In my performance testing it showed that calling PerformFileFlush() only > at segment boundaries and in CheckpointWriteDelay() can lead to rather > spikey IO - not that surprisingly. The sync in CheckpointWriteDelay() is > problematic because it only is triggered while on schedule, and not when > behind. When behind, the PerformFileFlush should be called on segment boundaries. The idea was not to go to sleep without flushing, and to do it as little as possible. > My testing seems to show that just adding a limit of 32 buffers to > FileAsynchronousFlush() leads to markedly better results. Hmmm. 32 buffers means 256 KB, which is quite small. Not sure what a good "limit" would be. It could depend whether pages are close or not. > I wonder if mmap() && msync(MS_ASYNC) isn't a better replacement for > sync_file_range(SYNC_FILE_RANGE_WRITE) than posix_fadvise(DONTNEED). It > might even be possible to later approximate that on windows using > FlushViewOfFile(). I'm not sure that mmap/msync can be used for this purpose, because there is no real control it seems about where the file is mmapped. > As far as I can see the while (nb_spaces != 0)/NextBufferToWrite() logic > doesn't work correctly if tablespaces aren't actually sorted. I'm > actually inclined to fix this by simply removing the flag to > enable/disable sorting. I do no think that there is a significant downside to having sort always on, but showing it requires to be able to test, so to have a guc. The point of the guc is to demonstrate that the feature is harmless:-) > Having defined(HAVE_SYNC_FILE_RANGE) || defined(HAVE_POSIX_FADVISE) in > so many places looks ugly, I want to push that to the underlying > functions. If we add a different flushing approach we shouldn't have to > touch several places that don't actually really care. I agree that it is pretty ugly, but I do not think that you can remove them all. You need at least one for checking the guc and one for enabling the feature. Maybe their number could be reduced if the functions are switched to do-nothing stubs which are called nevertheless, but I was not keen on letting unused code when there is no sync_file_range nor posix_fadvise. > I've replaced the NextBufferToWrite() logic with a binaryheap.h heap - > seems to work well, with a bit less code actually. Hmmm. I'll check. I'm still unconvinced that using a tree for a 2-3 element set in most case is an improvement. > I'll post this after some more cleanup & testing. I'll have a look when it is ready. > I've also noticed that sleeping logic in CheckpointWriteDelay() isn't > particularly good. In high throughput workloads the 100ms sleep is too > long, leading to bursty IO behaviour. If 1k+ buffers a written out a > second 100ms is a rather long sleep. For another that we only sleep > 100ms when the write rate is low makes the checkpoint finish rather > quickly - on a slow disk (say microsd) that can cause unneccesary > slowdowns for concurrent activity. ISTM we should calculate the sleep > time in a better way. I also noted this point, but I'm not sure how to have a better approach, so I let it as it is. I tried 50 ms & 200 ms on some runs, without significant effect on performance for the test I ran then. The point of having not too small a value is that it provide some significant work to the IO subsystem without overflowing it. On average it does not matter. I'm unsure how it would interact with flushing. So I decided not to do anything about it. Maybe it should be a guc, but I would not know how to choose it. > The SIGHUP behaviour is also weird. Anyway, this probably belongs on a > new thread. Probably. I did not try to look at that. -- Fabien.
>
>
> I wonder if mmap() && msync(MS_ASYNC) isn't a better replacement for
> sync_file_range(SYNC_FILE_RANGE_WRITE) than posix_fadvise(DONTNEED). It
> might even be possible to later approximate that on windows using
> FlushViewOfFile().
>
With Regards,
Amit Kapila.
On 2015-10-19 21:14:55 +0200, Fabien COELHO wrote: > >In my performance testing it showed that calling PerformFileFlush() only > >at segment boundaries and in CheckpointWriteDelay() can lead to rather > >spikey IO - not that surprisingly. The sync in CheckpointWriteDelay() is > >problematic because it only is triggered while on schedule, and not when > >behind. > > When behind, the PerformFileFlush should be called on segment > boundaries. That means it's flushing up to a gigabyte of data at once. Far too much. The implementation pretty always will go behind schedule for some time. Since sync_file_range() doesn't flush in the foreground I don't think it's important to do the flushing in concert with sleeping. > >My testing seems to show that just adding a limit of 32 buffers to > >FileAsynchronousFlush() leads to markedly better results. > > Hmmm. 32 buffers means 256 KB, which is quite small. Why? The aim is to not overwhelm the request queue - which is where the coalescing is done. And usually that's rather small. If you flush much more sync_file_range starts to do work in the foreground. > >I wonder if mmap() && msync(MS_ASYNC) isn't a better replacement for > >sync_file_range(SYNC_FILE_RANGE_WRITE) than posix_fadvise(DONTNEED). It > >might even be possible to later approximate that on windows using > >FlushViewOfFile(). > > I'm not sure that mmap/msync can be used for this purpose, because there is > no real control it seems about where the file is mmapped. I'm not following? Why does it matter where a file is mapped? I have had a friend (Christian Kruse, thanks!) confirm that at least on OSX msync(MS_ASYNC) triggers writeback. A freebsd dev confirmed that that should be the case on freebsd too. > >Having defined(HAVE_SYNC_FILE_RANGE) || defined(HAVE_POSIX_FADVISE) in > >so many places looks ugly, I want to push that to the underlying > >functions. If we add a different flushing approach we shouldn't have to > >touch several places that don't actually really care. > > I agree that it is pretty ugly, but I do not think that you can remove them > all. Sure, never said all. But most. > >I've replaced the NextBufferToWrite() logic with a binaryheap.h heap - > >seems to work well, with a bit less code actually. > > Hmmm. I'll check. I'm still unconvinced that using a tree for a 2-3 element > set in most case is an improvement. Yes, it'll not matter that much in many cases. But I rather disliked the NextBufferToWrite() implementation, especially that it walkes the array multiple times. And I did see setups with ~15 tablespaces. > >I've also noticed that sleeping logic in CheckpointWriteDelay() isn't > >particularly good. In high throughput workloads the 100ms sleep is too > >long, leading to bursty IO behaviour. If 1k+ buffers a written out a > >second 100ms is a rather long sleep. For another that we only sleep > >100ms when the write rate is low makes the checkpoint finish rather > >quickly - on a slow disk (say microsd) that can cause unneccesary > >slowdowns for concurrent activity. ISTM we should calculate the sleep > >time in a better way. > > I also noted this point, but I'm not sure how to have a better approach, so > I let it as it is. I tried 50 ms & 200 ms on some runs, without significant > effect on performance for the test I ran then. The point of having not too > small a value is that it provide some significant work to the IO subsystem > without overflowing it. I don't think that makes much sense. All a longer sleep achieves is creating a larger burst of writes afterwards. We should really sleep adaptively. Greetings, Andres Freund
Hello Andres, >>> In my performance testing it showed that calling PerformFileFlush() only >>> at segment boundaries and in CheckpointWriteDelay() can lead to rather >>> spikey IO - not that surprisingly. The sync in CheckpointWriteDelay() is >>> problematic because it only is triggered while on schedule, and not when >>> behind. >> >> When behind, the PerformFileFlush should be called on segment >> boundaries. > > That means it's flushing up to a gigabyte of data at once. Far too > much. Hmmm. I do not get it. There would not be gigabytes, there would be as much as was written since the last sleep, about 100 ms ago, which is not likely to be gigabytes? > The implementation pretty always will go behind schedule for some > time. Since sync_file_range() doesn't flush in the foreground I don't > think it's important to do the flushing in concert with sleeping. For me it is important to avoid accumulating too large flushes, and that is the point of the call before sleeping. >>> My testing seems to show that just adding a limit of 32 buffers to >>> FileAsynchronousFlush() leads to markedly better results. >> >> Hmmm. 32 buffers means 256 KB, which is quite small. > > Why? Because the point of sorting is to generate sequential writes so that the HDD has a lot of aligned stuff to write without moving the head, and 32 is rather small for that. > The aim is to not overwhelm the request queue - which is where the > coalescing is done. And usually that's rather small. That is an argument. How small, though? It seems to be 128 by default, so I'd rather have 128? Also, it can be changed, so maybe it should really be a guc? > If you flush much more sync_file_range starts to do work in the > foreground. Argh, too bad. I would have hoped that the would just deal with in an asynchronous way, this is not a "fsync" call, just a flush advise. >>> I wonder if mmap() && msync(MS_ASYNC) isn't a better replacement for >>> sync_file_range(SYNC_FILE_RANGE_WRITE) than posix_fadvise(DONTNEED). It >>> might even be possible to later approximate that on windows using >>> FlushViewOfFile(). >> >> I'm not sure that mmap/msync can be used for this purpose, because there is >> no real control it seems about where the file is mmapped. > > I'm not following? Why does it matter where a file is mapped? Because it should be in shared buffers where pg needs it? You probably should not want to mmap all pg data files in user space for a large database? Or if so, currently the OS keeps the data in memory if it has enough space, but if you got to mmap this cache management would be pg responsability, if I understand correctly mmap and your intentions. > I have had a friend (Christian Kruse, thanks!) confirm that at least on > OSX msync(MS_ASYNC) triggers writeback. A freebsd dev confirmed that > that should be the case on freebsd too. Good. My concern is how mmap could be used, though, not the flushing part. >> Hmmm. I'll check. I'm still unconvinced that using a tree for a 2-3 element >> set in most case is an improvement. > > Yes, it'll not matter that much in many cases. But I rather disliked the > NextBufferToWrite() implementation, especially that it walkes the array > multiple times. And I did see setups with ~15 tablespaces. ISTM that it is rather an argument for taking the tablespace into the sorting, not necessarily for a binary heap. >> I also noted this point, but I'm not sure how to have a better approach, so >> I let it as it is. I tried 50 ms & 200 ms on some runs, without significant >> effect on performance for the test I ran then. The point of having not too >> small a value is that it provide some significant work to the IO subsystem >> without overflowing it. > > I don't think that makes much sense. All a longer sleep achieves is > creating a larger burst of writes afterwards. We should really sleep > adaptively. It sounds reasonable, but what would be the criterion? -- Fabien.
On 2015-10-21 07:49:23 +0200, Fabien COELHO wrote:
>
> Hello Andres,
>
> >>>In my performance testing it showed that calling PerformFileFlush() only
> >>>at segment boundaries and in CheckpointWriteDelay() can lead to rather
> >>>spikey IO - not that surprisingly. The sync in CheckpointWriteDelay() is
> >>>problematic because it only is triggered while on schedule, and not when
> >>>behind.
> >>
> >>When behind, the PerformFileFlush should be called on segment
> >>boundaries.
> >
> >That means it's flushing up to a gigabyte of data at once. Far too
> >much.
>
> Hmmm. I do not get it. There would not be gigabytes,
I said 'up to a gigabyte' not gigabytes. But it actually can be more
than one if you're unluckly.
> there would be as much as was written since the last sleep, about 100
> ms ago, which is not likely to be gigabytes?
In many cases we don't sleep all that frequently - after one 100ms sleep
we're already behind a lot. And even so, it's pretty easy to get into
checkpoint scenarios with ~500 mbyte/s as a writeout rate. Only issuing
a sync_file_range() 10 times for that is obviously problematic.
> >The implementation pretty always will go behind schedule for some
> >time. Since sync_file_range() doesn't flush in the foreground I don't
> >think it's important to do the flushing in concert with sleeping.
>
> For me it is important to avoid accumulating too large flushes, and that is
> the point of the call before sleeping.
I don't follow this argument. It's important to avoid large flushes,
therefore we potentially allow large flushes to accumulate?
> >>>My testing seems to show that just adding a limit of 32 buffers to
> >>>FileAsynchronousFlush() leads to markedly better results.
> >>
> >>Hmmm. 32 buffers means 256 KB, which is quite small.
> >
> >Why?
>
> Because the point of sorting is to generate sequential writes so that the
> HDD has a lot of aligned stuff to write without moving the head, and 32 is
> rather small for that.
A sync_file_range(SYNC_FILE_RANGE_WRITE) doesn't synchronously write
data back. It just puts it into the write queue. You can have merging
between IOs from either side. But more importantly you can't merge that
many requests together anyway.
> >The aim is to not overwhelm the request queue - which is where the
> >coalescing is done. And usually that's rather small.
>
> That is an argument. How small, though? It seems to be 128 by default, so
> I'd rather have 128? Also, it can be changed, so maybe it should really be a
> guc?
I couldn't see any benefits above (and below) 32 on a 20 drive system,
so I doubt it's worthwhile. It's actually good for interactivity to
allow other requests into the queue concurrently - otherwise other
reads/writes will obviously have a higher latency...
> >If you flush much more sync_file_range starts to do work in the
> >foreground.
>
> Argh, too bad. I would have hoped that the would just deal with in an
> asynchronous way,
It's even in the man page:
"Note that even this may block if you attempt to write more than
request queue size."
> this is not a "fsync" call, just a flush advise.
sync_file_range isn't fadvise().
> Because it should be in shared buffers where pg needs it?
Huh? I'm just suggesting p = mmap(fd, offset, bytes);msync(p, bytes);munmap(p);
instead of sync_file_range().
> >>Hmmm. I'll check. I'm still unconvinced that using a tree for a 2-3 element
> >>set in most case is an improvement.
> >
> >Yes, it'll not matter that much in many cases. But I rather disliked the
> >NextBufferToWrite() implementation, especially that it walkes the array
> >multiple times. And I did see setups with ~15 tablespaces.
>
> ISTM that it is rather an argument for taking the tablespace into the
> sorting, not necessarily for a binary heap.
I don't understand your problem with that. The heap specific code is
small, smaller than your NextBufferToWrite() implementation?
ts_heap = binaryheap_allocate(nb_spaces, ts_progress_cmp,
NULL);
spcContext = (FileFlushContext *) palloc(sizeof(FileFlushContext) * nb_spaces);
for (i = 0; i < nb_spaces; i++) { TableSpaceCheckpointStatus *spc = &spcStatus[i];
spc->progress_slice = ((float8) num_to_write) / (float8) spc->num_to_write;
ResetFileFlushContext(&spcContext[i]); spc->flushContext = &spcContext[i];
binaryheap_add_unordered(ts_heap, PointerGetDatum(&spcStatus[i])); }
binaryheap_build(ts_heap);
and then
while (!binaryheap_empty(ts_heap)) { TableSpaceCheckpointStatus *ts = (TableSpaceCheckpointStatus *)
DatumGetPointer(binaryheap_first(ts_heap));
... ts->progress += ts->progress_slice; ts->num_written++;
... if (ts->num_written == ts->num_to_write) {
... binaryheap_remove_first(ts_heap); } else { /* update heap with the new
progress*/ binaryheap_replace_first(ts_heap, PointerGetDatum(ts)); }
> >>I also noted this point, but I'm not sure how to have a better approach, so
> >>I let it as it is. I tried 50 ms & 200 ms on some runs, without significant
> >>effect on performance for the test I ran then. The point of having not too
> >>small a value is that it provide some significant work to the IO subsystem
> >>without overflowing it.
> >
> >I don't think that makes much sense. All a longer sleep achieves is
> >creating a larger burst of writes afterwards. We should really sleep
> >adaptively.
>
> It sounds reasonable, but what would be the criterion?
What IsCheckpointOnSchedule() does is essentially to calculate progress
for two things:
1) Are we on schedule based on WAL segments until CheckPointSegments (computed via max_wal_size these days). I.e. is
thepercentage of used up WAL bigger than the percentage of written out buffers.
2) Are we on schedule based on checkpoint_timeout. I.e. is the percentage of checkpoint_timeout already passed bigger
thanthe percentage of buffers written out.
So the trick is just to compute the number of work items (e.g. buffers
to write out) and divide the remaining time by it. That's how long you
can sleep.
It's slightly trickier for WAL and I'm not sure it's equally
important. But even there it shouldn't be too hard to calculate the
amount of time till we're behind on schedule and only sleep that long.
I'm running benchmarks right now, they'll take a bit to run to
completion.
Greetings,
Andres Freund
Hello Andres, >> there would be as much as was written since the last sleep, about 100 >> ms ago, which is not likely to be gigabytes? > > In many cases we don't sleep all that frequently - after one 100ms sleep > we're already behind a lot. I think that "being behind" is not a problem as such, it is really the way the scheduler has been designed and works, by keeping pace with time & wall progress by little bursts of writes. If you reduce the sleep time a lot then it would end up having writes interleaved with small sleeps, but then this would be bad for performance has the OS would loose the ability to write much data sequentially on the disk. It does not mean that the default 100 ms is a good figure, but the "being behind" is a feature, not an issue as such. > And even so, it's pretty easy to get into checkpoint scenarios with ~500 > mbyte/s as a writeout rate. Hmmmm. Not with my hardware:-) > Only issuing a sync_file_range() 10 times for that is obviously > problematic. Hmmm. Then it should depend on the expected write capacity of the underlying disks... >>> The implementation pretty always will go behind schedule for some >>> time. Since sync_file_range() doesn't flush in the foreground I don't >>> think it's important to do the flushing in concert with sleeping. >> >> For me it is important to avoid accumulating too large flushes, and that is >> the point of the call before sleeping. > > I don't follow this argument. It's important to avoid large flushes, > therefore we potentially allow large flushes to accumulate? On my simple test hardware the flushes are not large, I think, so the problem does not arise. Maybe I should check. >>>>> My testing seems to show that just adding a limit of 32 buffers to >>>>> FileAsynchronousFlush() leads to markedly better results. >>>> >>>> Hmmm. 32 buffers means 256 KB, which is quite small. >>> >>> Why? >> >> Because the point of sorting is to generate sequential writes so that the >> HDD has a lot of aligned stuff to write without moving the head, and 32 is >> rather small for that. > > A sync_file_range(SYNC_FILE_RANGE_WRITE) doesn't synchronously write > data back. It just puts it into the write queue. Yes. > You can have merging between IOs from either side. But more importantly > you can't merge that many requests together anyway. Probably. >>> The aim is to not overwhelm the request queue - which is where the >>> coalescing is done. And usually that's rather small. >> >> That is an argument. How small, though? It seems to be 128 by default, so >> I'd rather have 128? Also, it can be changed, so maybe it should really be a >> guc? > > I couldn't see any benefits above (and below) 32 on a 20 drive system, So it is one kind of (big) hardware. Assuming that pages are contiguous, how much is written on each disk depends on the RAID type, the stripe size, and when it is really written depends on the various cache (in the RAID HW card if any, on the disk, ...), so whether 32 at the OS level is the right size is pretty unclear to me. I would have said the larger the better, but indeed you should avoid blocking. > so I doubt it's worthwhile. It's actually good for interactivity to > allow other requests into the queue concurrently - otherwise other > reads/writes will obviously have a higher latency... Sure. Now on my tests, with my (old & little) hardware it seemed quite smooth. What I'm driving at is that what is good may be relative and depend on the underlying hardware, which makes it not obvious to choose the right parameter. >>> If you flush much more sync_file_range starts to do work in the >>> foreground. >> >> Argh, too bad. I would have hoped that the would just deal with in an >> asynchronous way, > > It's even in the man page: > "Note that even this may block if you attempt to write more than > request queue size." Hmmm. What about choosing "request queue size * 0.5", then ? >> Because it should be in shared buffers where pg needs it? > > Huh? I'm just suggesting p = mmap(fd, offset, bytes);msync(p, bytes);munmap(p); > instead of sync_file_range(). I think that I do not really understand how it may work, but possible it could. >> ISTM that it is rather an argument for taking the tablespace into the >> sorting, not necessarily for a binary heap. > > I don't understand your problem with that. The heap specific code is > small, smaller than your NextBufferToWrite() implementation? You have not yet posted the updated version of the patch. Thee complexity of the round robin scan on the array is O(1) and very few instructions, plus some stop condition which is mostly true I think if the writes are balanced between table spaces, there is no dynamic allocation in the data structure (it is an array). The binary heap is O(log(n)), probably there are dynamic allocations and frees when extracting/inserting something, there are functions calls to rebalance the tree, and so on. Ok, "n" is expected to be small. So basically, for me it is not obviously superior to the previous version. Now I'm also tired, so if it works reasonably I'll be fine with it. > [... code extract ...] >>> I don't think that makes much sense. All a longer sleep achieves is >>> creating a larger burst of writes afterwards. We should really sleep >>> adaptively. >> >> It sounds reasonable, but what would be the criterion? > > What IsCheckpointOnSchedule() does is essentially to calculate progress > for two things: > 1) Are we on schedule based on WAL segments until CheckPointSegments > (computed via max_wal_size these days). I.e. is the percentage of > used up WAL bigger than the percentage of written out buffers. > > 2) Are we on schedule based on checkpoint_timeout. I.e. is the > percentage of checkpoint_timeout already passed bigger than the > percentage of buffers written out. > So the trick is just to compute the number of work items (e.g. buffers > to write out) and divide the remaining time by it. That's how long you > can sleep. See discussion above. ISTM that the "bursts" is a useful feature of the checkpoint scheduler, especially with sorted buffers & flushes. You want to provide grouped writes that will be easilly written to disk together. You do not want to have page writes issued one by one and interleaved with small sleeps. > It's slightly trickier for WAL and I'm not sure it's equally > important. But even there it shouldn't be too hard to calculate the > amount of time till we're behind on schedule and only sleep that long. The scheduler stops writing as soon as it has overtaken the progress, so it should be a very small time, but if you do that you would end up writing pages one by one, which is not desirable at all. > I'm running benchmarks right now, they'll take a bit to run to > completion. Good. I'm looking forward to have a look at the updated version of the patch. -- Fabien.
On 2015-09-10 17:15:26 +0200, Fabien COELHO wrote: > Here is a v13, which is just a rebase after 1aba62ec. And here's v14. It's not something entirely ready. A lot of details have changed, I unfortunately don't remember them all. But there are more important things than the details of the patch. I've played *a lot* with this patch. I found a bunch of issues: 1) The FileFlushContext context infrastructure isn't actually correct. There's two problems: First, using the actual 'fd' number to reference a to-be-flushed file isn't meaningful. If there are lots of files open, fds get reused within fd.c. That part is enough fixed by referencing File instead the fd. The bigger problem is that the infrastructure doesn't deal with files being closed. There can, which isn't that hard to trigger, be smgr invalidations causing smgr handle and thus the file to be closed. I think this means that the entire flushing infrastructure actually needs to be hoisted up, onto the smgr/md level. 2) I noticed that sync_file_range() blocked far more often than I'd expected. Reading the kernel code that turned out to be caused by a pessimization in the kernel introduced years ago - in many situation SFR_WRITE waited for the writes. A fix for this will be in the 4.4 kernel. 3) I found that latency wasn't improved much for workloads that are significantly bigger than shared buffers. The problem here is that neither bgwriter nor the backends have, so far, done sync_file_range() calls. That meant that the old problem of having gigabytes of dirty data that periodically get flushed out, still exists. Having these do flushes mostly attacks that problem. Benchmarking revealed that for workloads where the hot data set mostly fits into shared buffers flushing and sorting is anywhere from a small to a massive improvement, both in throughput and latency. Even without the patch from 2), although fixing that improves things furhter. What I did not expect, and what confounded me for a long while, is that for workloads where the hot data set does *NOT* fit into shared buffers, sorting often led to be a noticeable reduction in throughput. Up to 30%. The performance was still much more regular than before, i.e. no more multi-second periods without any transactions happening. By now I think I know what's going on: Before the sorting portion of the patch the write-loop in BufferSync() starts at the current clock hand, by using StrategySyncStart(). But after the sorting that obviously doesn't happen anymore - buffers are accessed in their sort order. By starting at the current clock hand and moving on from there the checkpointer basically makes it more less likely that victim buffers need to be written either by the backends themselves or by bgwriter. That means that the sorted checkpoint writes can, indirectly, increase the number of unsorted writes by other processes :( My benchmarking suggest that that effect is the larger, the shorter the checkpoint timeout is. That seems to intuitively make sense, give the above explanation attempt. If the checkpoint takes longer the clock hand will almost certainly soon overtake checkpoints 'implicit' hand. I'm not sure if we can really do anything about this problem. While I'm pretty jet lagged, I still spent a fair amount of time thinking about it. Seems to suggest that we need to bring back the setting to enable/disable sorting :( What I think needs to happen next with the patch is: 1) Hoist up the FileFlushContext stuff into the smgr layer. Carefully handling the issue of smgr invalidations. 2) Replace the boolean checkpoint_flush_to_disk GUC with a list guc that later can contain multiple elements like checkpoint, bgwriter, backends, ddl, bulk-writes. That seems better than adding GUCs for these separately. Then make the flush locations in the patch configurable using that. 3) I think we should remove the sort timing from the checkpoint logging before commit. It'll always be pretty short. Greetings, Andres Freund
Attachment
Hello Andres, > And here's v14. It's not something entirely ready. I'm going to have a careful look at it. > A lot of details have changed, I unfortunately don't remember them all. > But there are more important things than the details of the patch. > > I've played *a lot* with this patch. I found a bunch of issues: > > 1) The FileFlushContext context infrastructure isn't actually > correct. There's two problems: First, using the actual 'fd' number to > reference a to-be-flushed file isn't meaningful. If there are lots > of files open, fds get reused within fd.c. Hmm. My assumption is that a file being used (i.e. with modifie pages, being used for writes...) would not be closed before everything is cleared... After some poking in the code, I think that this issue may indeed be there, although the probability of hitting it is close to 0, but alas not 0:-) To fix it, ITSM that it is enough to hold a "do not close lock" on the file while a flush is in progress (a short time) that would prevent mdclose to do its stuff. > That part is enough fixed by referencing File instead the fd. The bigger > problem is that the infrastructure doesn't deal with files being closed. > There can, which isn't that hard to trigger, be smgr invalidations > causing smgr handle and thus the file to be closed. > > I think this means that the entire flushing infrastructure actually > needs to be hoisted up, onto the smgr/md level. Hmmm. I'm not sure that it is necessary, see above my suggestion. > 2) I noticed that sync_file_range() blocked far more often than I'd > expected. Reading the kernel code that turned out to be caused by a > pessimization in the kernel introduced years ago - in many situation > SFR_WRITE waited for the writes. A fix for this will be in the 4.4 > kernel. Alas, Pg cannot help issues in the kernel. > 3) I found that latency wasn't improved much for workloads that are > significantly bigger than shared buffers. The problem here is that > neither bgwriter nor the backends have, so far, done > sync_file_range() calls. That meant that the old problem of having > gigabytes of dirty data that periodically get flushed out, still > exists. Having these do flushes mostly attacks that problem. I'm concious that the patch only addresses *checkpointer* writes, not those from bgwrither or backends writes. I agree that these should need to be addressed at some point as well, but given the time to get a patch through, the more complex the slower (sort propositions are 10 years old), I think this should be postponed for later. > Benchmarking revealed that for workloads where the hot data set mostly > fits into shared buffers flushing and sorting is anywhere from a small > to a massive improvement, both in throughput and latency. Even without > the patch from 2), although fixing that improves things furhter. This is consistent with my experiments: sorting improves things, and flushing on top of sorting improves things further. > What I did not expect, and what confounded me for a long while, is that > for workloads where the hot data set does *NOT* fit into shared buffers, > sorting often led to be a noticeable reduction in throughput. Up to > 30%. I did not see such behavior in the many tests I ran. Could you share more precise details so that I can try to reproduce this performance regression? (available memory, shared buffers, db size, ...). > The performance was still much more regular than before, i.e. no > more multi-second periods without any transactions happening. > > By now I think I know what's going on: Before the sorting portion of the > patch the write-loop in BufferSync() starts at the current clock hand, > by using StrategySyncStart(). But after the sorting that obviously > doesn't happen anymore - buffers are accessed in their sort order. By > starting at the current clock hand and moving on from there the > checkpointer basically makes it more less likely that victim buffers > need to be written either by the backends themselves or by > bgwriter. That means that the sorted checkpoint writes can, indirectly, > increase the number of unsorted writes by other processes :( I'm quite surprised at such a large effect on throughput, though. This explanation seems to suggest that if bgwriter/workders write are sorted and/or coordinated with the checkpointer somehow then all would be well? ISTM that this explanation could be checked by looking whether bgwriter/workers writes are especially large compared to checkpointer writes in those cases with reduced throughput? The data is in the log. > My benchmarking suggest that that effect is the larger, the shorter the > checkpoint timeout is. Hmmm. The shorter the timeout, the more likely the sorting NOT to be effective, and the more likely to go back to random I/Os, and maybe to seem some effect of the sync strategy stuff. > That seems to intuitively make sense, give the above explanation > attempt. If the checkpoint takes longer the clock hand will almost > certainly soon overtake checkpoints 'implicit' hand. > > I'm not sure if we can really do anything about this problem. While I'm > pretty jet lagged, I still spent a fair amount of time thinking about > it. Seems to suggest that we need to bring back the setting to > enable/disable sorting :( > > > What I think needs to happen next with the patch is: > 1) Hoist up the FileFlushContext stuff into the smgr layer. Carefully > handling the issue of smgr invalidations. Not sure that much is necessary, see above. > 2) Replace the boolean checkpoint_flush_to_disk GUC with a list guc that > later can contain multiple elements like checkpoint, bgwriter, > backends, ddl, bulk-writes. That seems better than adding GUCs for > these separately. Then make the flush locations in the patch > configurable using that. My 0,02€ on this point: I have not seen much of this style of guc elsewhere. The only one I found while scanning the postgres file are *_path and *_libraries. It seems to me that this would depart significantly from the usual style, so one guc per case, or one shared guc but with only on/off, would blend in more cleanly with the usual style. > 3) I think we should remove the sort timing from the checkpoint logging > before commit. It'll always be pretty short. I added it to show that it was really short, in response to concerns that my approach of just sorting through indexes to reduce the memory needed instead of copying the data to be sorted did not induce significant performance issues. I prooved my point, but peer pressure made me switch to larger memory anyway. I think it should be kept while the features are under testing. I do not think that it harms in anyway. -- Fabien.
Hi, On 2015-11-12 15:31:41 +0100, Fabien COELHO wrote: > >A lot of details have changed, I unfortunately don't remember them all. > >But there are more important things than the details of the patch. > > > >I've played *a lot* with this patch. I found a bunch of issues: > > > >1) The FileFlushContext context infrastructure isn't actually > > correct. There's two problems: First, using the actual 'fd' number to > > reference a to-be-flushed file isn't meaningful. If there are lots > > of files open, fds get reused within fd.c. > > Hmm. > > My assumption is that a file being used (i.e. with modifie pages, being used > for writes...) would not be closed before everything is cleared... That's likely, but far from guaranteed. > After some poking in the code, I think that this issue may indeed be there, > although the probability of hitting it is close to 0, but alas not 0:-) I did hit it... > To fix it, ITSM that it is enough to hold a "do not close lock" on the file > while a flush is in progress (a short time) that would prevent mdclose to do > its stuff. Could you expand a bit more on this? You're suggesting something like a boolean in the vfd struct? If that, how would you deal with FileClose() being called? > >3) I found that latency wasn't improved much for workloads that are > > significantly bigger than shared buffers. The problem here is that > > neither bgwriter nor the backends have, so far, done > > sync_file_range() calls. That meant that the old problem of having > > gigabytes of dirty data that periodically get flushed out, still > > exists. Having these do flushes mostly attacks that problem. > > I'm concious that the patch only addresses *checkpointer* writes, not those > from bgwrither or backends writes. I agree that these should need to be > addressed at some point as well, but given the time to get a patch through, > the more complex the slower (sort propositions are 10 years old), I think > this should be postponed for later. I think we need to have at least a PoC of all of the relevant changes. We're doing these to fix significant latency and throughput issues, and if the approach turns out not to be suitable for e.g. bgwriter or backends, that might have influence over checkpointer's design as well. > >What I did not expect, and what confounded me for a long while, is that > >for workloads where the hot data set does *NOT* fit into shared buffers, > >sorting often led to be a noticeable reduction in throughput. Up to > >30%. > > I did not see such behavior in the many tests I ran. Could you share more > precise details so that I can try to reproduce this performance regression? > (available memory, shared buffers, db size, ...). I generally found that I needed to disable autovacuum's analyze to get anything even close to stable numbers. The issue in described in http://archives.postgresql.org/message-id/20151031145303.GC6064%40alap3.anarazel.de otherwise badly kicks in. I basically just set autovacuum_analyze_threshold to INT_MAX/2147483647 to prevent that from occuring. I'll show actual numbers at some point yes. I tried three different systems: * my laptop, 16 GB Ram, 840 EVO 1TB as storage. With 2GB shared_buffers. Tried checkpoint timeouts from 60 to 300s. I couldsee issues in workloads ranging from scale 300 to 5000. Throughput regressions are visible for both sync_commit on/offworkloads. Here the largest regressions were visible. * my workstation: 24GB Ram, 2x E5520, a) Raid 10 of of 4 4TB, 7.2krpm devices b) Raid 1 of 2 m4 512GB SSDs. One of the latterwas killed during the test. Both showed regressions, but smaller. * EC2 d2.8xlarge, 244 GB RAM, 24 x 2000 HDD, 64GB shared_buffers. I tried scale 3000,8000,15000. Here sorting, without flushing,didn't lead much to regressions. I think generally the regressions were visible with a) noticeable shared buffers, b) workload not fitting into shared buffers, c) significant throughput, leading to high cache replacement ratios. Another thing that's worthwhile to mention, while not surprising, is that the benefits of this patch are massively smaller when WAL and data are separated onto different disks. For workloads fitting into shared_buffers I saw no performance difference - not particularly surprising. I guess if you'd construct a case where the data, not WAL, is the bottleneck that'd be different. Also worthwhile to mention that the separate disks setups was noticeably faster. > >The performance was still much more regular than before, i.e. no > >more multi-second periods without any transactions happening. > > > >By now I think I know what's going on: Before the sorting portion of the > >patch the write-loop in BufferSync() starts at the current clock hand, > >by using StrategySyncStart(). But after the sorting that obviously > >doesn't happen anymore - buffers are accessed in their sort order. By > >starting at the current clock hand and moving on from there the > >checkpointer basically makes it more less likely that victim buffers > >need to be written either by the backends themselves or by > >bgwriter. That means that the sorted checkpoint writes can, indirectly, > >increase the number of unsorted writes by other processes :( > > I'm quite surprised at such a large effect on throughput, though. Me too. > This explanation seems to suggest that if bgwriter/workders write are sorted > and/or coordinated with the checkpointer somehow then all would be well? Well, you can't easily sort bgwriter/backend writes stemming from cache replacement. Unless your access patterns are entirely sequential the data in shared buffers will be laid out in a nearly entirely random order. We could try sorting the data, but with any reasonable window, for many workloads the likelihood of actually achieving much with that seems low. > ISTM that this explanation could be checked by looking whether > bgwriter/workers writes are especially large compared to checkpointer writes > in those cases with reduced throughput? The data is in the log. What do you mean with "large"? Numerous? > >My benchmarking suggest that that effect is the larger, the shorter the > >checkpoint timeout is. > > Hmmm. The shorter the timeout, the more likely the sorting NOT to be > effective You mean, as evidenced by the results, or is that what you'd actually expect? > >2) Replace the boolean checkpoint_flush_to_disk GUC with a list guc that > > later can contain multiple elements like checkpoint, bgwriter, > > backends, ddl, bulk-writes. That seems better than adding GUCs for > > these separately. Then make the flush locations in the patch > > configurable using that. > > My 0,02€ on this point: I have not seen much of this style of guc elsewhere. > The only one I found while scanning the postgres file are *_path and > *_libraries. It seems to me that this would depart significantly from the > usual style, so one guc per case, or one shared guc but with only on/off, > would blend in more cleanly with the usual style. Such a guc would allow one 'on' and 'off' setting, and either would hopefully be the norm. That seems advantageous to me. > >3) I think we should remove the sort timing from the checkpoint logging > > before commit. It'll always be pretty short. > > I added it to show that it was really short, in response to concerns that my > approach of just sorting through indexes to reduce the memory needed instead > of copying the data to be sorted did not induce significant performance > issues. I prooved my point, but peer pressure made me switch to larger > memory anyway. Grumble. I'm getting a bit tired about this topic. This wasn't even remotely primarily about sorting speed, and you damn well know it. > I think it should be kept while the features are under testing. I do not > think that it harms in anyway. That's why I said we should remove it *before commit*. Greetings, Andres Freund
>> To fix it, ITSM that it is enough to hold a "do not close lock" on the file >> while a flush is in progress (a short time) that would prevent mdclose to do >> its stuff. > > Could you expand a bit more on this? You're suggesting something like a > boolean in the vfd struct? Basically yes, I'm suggesting a mutex in the vdf struct. > If that, how would you deal with FileClose() being called? Just wait for the mutex, which would be held while flushes are accumulated into the flush context and released after the flush is performed and the fd is not necessary anymore for this purpose, which is expected to be short (at worst between the wake & sleep of the checkpointer, and just one file at a time). >> I'm concious that the patch only addresses *checkpointer* writes, not those >> from bgwrither or backends writes. I agree that these should need to be >> addressed at some point as well, but given the time to get a patch through, >> the more complex the slower (sort propositions are 10 years old), I think >> this should be postponed for later. > > I think we need to have at least a PoC of all of the relevant > changes. We're doing these to fix significant latency and throughput > issues, and if the approach turns out not to be suitable for > e.g. bgwriter or backends, that might have influence over checkpointer's > design as well. Hmmm. See below. >>> What I did not expect, and what confounded me for a long while, is that >>> for workloads where the hot data set does *NOT* fit into shared buffers, >>> sorting often led to be a noticeable reduction in throughput. Up to >>> 30%. >> >> I did not see such behavior in the many tests I ran. Could you share more >> precise details so that I can try to reproduce this performance regression? >> (available memory, shared buffers, db size, ...). > > > I generally found that I needed to disable autovacuum's analyze to get > anything even close to stable numbers. The issue in described in > http://archives.postgresql.org/message-id/20151031145303.GC6064%40alap3.anarazel.de > otherwise badly kicks in. I basically just set > autovacuum_analyze_threshold to INT_MAX/2147483647 to prevent that from occuring. > > I'll show actual numbers at some point yes. I tried three different systems: > > * my laptop, 16 GB Ram, 840 EVO 1TB as storage. With 2GB > shared_buffers. Tried checkpoint timeouts from 60 to 300s. Hmmm. This is quite short. I tend to do tests with much larger timeouts. I would advise against a short timeout esp. in a high throughput system, the whole point of the checkpointer is to accumulate as much changes as possible. I'll look into that. >> This explanation seems to suggest that if bgwriter/workders write are sorted >> and/or coordinated with the checkpointer somehow then all would be well? > > Well, you can't easily sort bgwriter/backend writes stemming from cache > replacement. Unless your access patterns are entirely sequential the > data in shared buffers will be laid out in a nearly entirely random > order. We could try sorting the data, but with any reasonable window, > for many workloads the likelihood of actually achieving much with that > seems low. Maybe the sorting could be shared with others so that everybody uses the same order? That would suggest to have one global sorting of buffers, maybe maintained by the checkpointer, which could be used by all processes that need to scan the buffers (in file order), instead of scanning them in memory order. For this purpose, I think that the initial index-based sorting would suffice. Could be resorted periodically with some delay maintained in a guc, or when significant buffer changes have occured (read & writes). >> ISTM that this explanation could be checked by looking whether >> bgwriter/workers writes are especially large compared to checkpointer writes >> in those cases with reduced throughput? The data is in the log. > > What do you mean with "large"? Numerous? I mean the amount of buffers written by bgwriter/worker is greater than what is written by the checkpointer. If all fits in shared buffers, bgwriter/worker mostly do not need to write anything and the checkpointer does all the writes. The larger the memory needed, the more likely workers/bgwriter will have to quick in and generate random I/Os because nothing sensible is currently done, so this is consistent with your findings, although I'm surprised that it would have a large effect on throughput, as already said. >> Hmmm. The shorter the timeout, the more likely the sorting NOT to be >> effective > > You mean, as evidenced by the results, or is that what you'd actually > expect? What I would expect... -- Fabien.
On 2015-11-12 17:44:40 +0100, Fabien COELHO wrote: > > >>To fix it, ITSM that it is enough to hold a "do not close lock" on the file > >>while a flush is in progress (a short time) that would prevent mdclose to do > >>its stuff. > > > >Could you expand a bit more on this? You're suggesting something like a > >boolean in the vfd struct? > > Basically yes, I'm suggesting a mutex in the vdf struct. I can't see that being ok. I mean what would that thing even do? VFD isn't shared between processes, and if we get a smgr flush we have to apply it, or risk breaking other things. > >* my laptop, 16 GB Ram, 840 EVO 1TB as storage. With 2GB > > shared_buffers. Tried checkpoint timeouts from 60 to 300s. > > Hmmm. This is quite short. Indeed. I'd never do that in a production scenario myself. But nonetheless it showcases a problem. > >Well, you can't easily sort bgwriter/backend writes stemming from cache > >replacement. Unless your access patterns are entirely sequential the > >data in shared buffers will be laid out in a nearly entirely random > >order. We could try sorting the data, but with any reasonable window, > >for many workloads the likelihood of actually achieving much with that > >seems low. > > Maybe the sorting could be shared with others so that everybody uses the > same order? > > That would suggest to have one global sorting of buffers, maybe maintained > by the checkpointer, which could be used by all processes that need to scan > the buffers (in file order), instead of scanning them in memory order. Uh. Cache replacement is based on an approximated LRU, you can't just remove that without serious regressions. > >>Hmmm. The shorter the timeout, the more likely the sorting NOT to be > >>effective > > > >You mean, as evidenced by the results, or is that what you'd actually > >expect? > > What I would expect... I don't see why then? If you very quickly writes lots of data the OS will continously flush dirty data to the disk, in which case sorting is rather important? Greetings, Andres Freund
Hello, >> Basically yes, I'm suggesting a mutex in the vdf struct. > > I can't see that being ok. I mean what would that thing even do? VFD > isn't shared between processes, and if we get a smgr flush we have to > apply it, or risk breaking other things. Probably something is eluding my comprehension:-) My basic assumption is that the fopen & fd is per process, so we just have to deal with the one in the checkpointer process, so it is enough that the checkpointer does not close the file while it is flushing things to it? >>> * my laptop, 16 GB Ram, 840 EVO 1TB as storage. With 2GB >>> shared_buffers. Tried checkpoint timeouts from 60 to 300s. >> >> Hmmm. This is quite short. > > Indeed. I'd never do that in a production scenario myself. But > nonetheless it showcases a problem. I would say that it would render sorting ineffective because all the rewriting is done by bgwriter or workers, which does not totally explain why the throughput would be worst than before, I would expect it to be as bad as before... >>> Well, you can't easily sort bgwriter/backend writes stemming from cache >>> replacement. Unless your access patterns are entirely sequential the >>> data in shared buffers will be laid out in a nearly entirely random >>> order. We could try sorting the data, but with any reasonable window, >>> for many workloads the likelihood of actually achieving much with that >>> seems low. >> >> Maybe the sorting could be shared with others so that everybody uses the >> same order? >> >> That would suggest to have one global sorting of buffers, maybe maintained >> by the checkpointer, which could be used by all processes that need to scan >> the buffers (in file order), instead of scanning them in memory order. > > Uh. Cache replacement is based on an approximated LRU, you can't just > remove that without serious regressions. I understand that, but there is a balance to find. Generating random I/Os is very bad for performance, so the decision process must combine LRU/LFU heuristics with considering things in some order as well. >>>> Hmmm. The shorter the timeout, the more likely the sorting NOT to be >>>> effective >>> >>> You mean, as evidenced by the results, or is that what you'd actually >>> expect? >> >> What I would expect... > > I don't see why then? If you very quickly writes lots of data the OS > will continously flush dirty data to the disk, in which case sorting is > rather important? What I have in mind is: the shorter the timeout the less neighboring buffers will be touched, so the less nice sequential writes will be found by sorting them, so the worst the positive impact on performance... -- Fabien.
>>> Basically yes, I'm suggesting a mutex in the vdf struct. >> >> I can't see that being ok. I mean what would that thing even do? VFD >> isn't shared between processes, and if we get a smgr flush we have to >> apply it, or risk breaking other things. > > Probably something is eluding my comprehension:-) > > My basic assumption is that the fopen & fd is per process, so we just have to > deal with the one in the checkpointer process, so it is enough that the > checkpointer does not close the file while it is flushing things to it? Hmmm... Maybe I'm a little bit too optimistic here, because it seems that I'm suggesting to create a dead lock if the checkpointer has both buffers to flush in waiting and wishes to close the very same file that holds them. So on wanting to close the file the checkpointer should rather flushes the outstanding flushes in wait and then close the fd, which suggest some global variable to hold flush context so that this can be done. Hmmm. -- Fabien.
>
> On 2015-09-10 17:15:26 +0200, Fabien COELHO wrote:
> > Here is a v13, which is just a rebase after 1aba62ec.
>
>
> 3) I found that latency wasn't improved much for workloads that are
> significantly bigger than shared buffers. The problem here is that
> neither bgwriter nor the backends have, so far, done
> sync_file_range() calls. That meant that the old problem of having
> gigabytes of dirty data that periodically get flushed out, still
> exists. Having these do flushes mostly attacks that problem.
>
>
> Benchmarking revealed that for workloads where the hot data set mostly
> fits into shared buffers flushing and sorting is anywhere from a small
> to a massive improvement, both in throughput and latency. Even without
> the patch from 2), although fixing that improves things furhter.
>
>
>
> What I did not expect, and what confounded me for a long while, is that
> for workloads where the hot data set does *NOT* fit into shared buffers,
> sorting often led to be a noticeable reduction in throughput. Up to
> 30%. The performance was still much more regular than before, i.e. no
> more multi-second periods without any transactions happening.
>
> By now I think I know what's going on: Before the sorting portion of the
> patch the write-loop in BufferSync() starts at the current clock hand,
> by using StrategySyncStart(). But after the sorting that obviously
> doesn't happen anymore - buffers are accessed in their sort order. By
> starting at the current clock hand and moving on from there the
> checkpointer basically makes it more less likely that victim buffers
> need to be written either by the backends themselves or by
> bgwriter. That means that the sorted checkpoint writes can, indirectly,
> increase the number of unsorted writes by other processes :(
>
That sounds to be a tricky problem. I think the way to improve the current
>
> My benchmarking suggest that that effect is the larger, the shorter the
> checkpoint timeout is. That seems to intuitively make sense, give the
> above explanation attempt. If the checkpoint takes longer the clock hand
> will almost certainly soon overtake checkpoints 'implicit' hand.
>
> I'm not sure if we can really do anything about this problem. While I'm
> pretty jet lagged, I still spent a fair amount of time thinking about
> it. Seems to suggest that we need to bring back the setting to
> enable/disable sorting :(
>
>
> What I think needs to happen next with the patch is:
> 1) Hoist up the FileFlushContext stuff into the smgr layer. Carefully
> handling the issue of smgr invalidations.
> 2) Replace the boolean checkpoint_flush_to_disk GUC with a list guc that
> later can contain multiple elements like checkpoint, bgwriter,
> backends, ddl, bulk-writes. That seems better than adding GUCs for
> these separately. Then make the flush locations in the patch
> configurable using that.
> 3) I think we should remove the sort timing from the checkpoint logging
> before commit. It'll always be pretty short.
>
> Hmmm... > > Maybe I'm a little bit too optimistic here, because it seems that I'm > suggesting to create a dead lock if the checkpointer has both buffers to > flush in waiting and wishes to close the very same file that holds them. > > So on wanting to close the file the checkpointer should rather flushes the > outstanding flushes in wait and then close the fd, which suggest some global > variable to hold flush context so that this can be done. > > Hmmm. On third (fourth, fifth:-) thoughts: The vfd (virtual file descriptor?) structure in the checkpointer could keep a pointer to the current flush if it concerns this fd, so that if it decides to close if while there is a write in progress (I'm still baffled at why and when the checkpointer process would take such a decision, maybe while responding to some signals, because it seems that there is no such event in the checkpointer loop itself...) then on close the process could flush before close, or just close which probably would induce flushing, but at least cleanup the structure so that the the closed fd would not be flushed after being closed and result in an error. -- Fabien.
Hi, I'm planning to do some thorough benchmarking of the patches proposed in this thread, on various types of hardware (10k SAS drives and SSDs). But is that actually needed? I see Andres did some testing, as he posted summary of the results on 11/12, but I don't see any actual results or even info about what benchmarks were done (pgbench?). If yes, do we only want to compare 0001-ckpt-14-andres.patch against master, or do we need to test one of the previous Fabien's patches? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hello Tomas, > I'm planning to do some thorough benchmarking of the patches proposed in this > thread, on various types of hardware (10k SAS drives and SSDs). But is that > actually needed? I see Andres did some testing, as he posted summary of the > results on 11/12, but I don't see any actual results or even info about what > benchmarks were done (pgbench?). > > If yes, do we only want to compare 0001-ckpt-14-andres.patch against master, > or do we need to test one of the previous Fabien's patches? My 0.02€, Although I disagree with some aspects of Andres patch, I'm not a committer and I'm tired of arguing. I'm just planing to do minor changes to Andres version to fix a potential issue if the file is closed which flushing is in progress, but that will not change the overall shape of it. So testing on Andres version seems relevant to me. For SSD the performance impact should be limited. For disk it should be significant if there is no big cache in front of it. There were some concerns raised for some loads in the thread (shared memory smaller than needed I think?), if you can include such cases that would be great. My guess is that it should be not very beneficial in this case because the writing is mostly done by bgwriter & worker in this case, and these are still random. -- Fabien.
On Thu, Dec 17, 2015 at 4:27 AM, Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > Hello Tomas, > >> I'm planning to do some thorough benchmarking of the patches proposed in >> this thread, on various types of hardware (10k SAS drives and SSDs). But is >> that actually needed? I see Andres did some testing, as he posted summary of >> the results on 11/12, but I don't see any actual results or even info about >> what benchmarks were done (pgbench?). >> >> If yes, do we only want to compare 0001-ckpt-14-andres.patch against >> master, or do we need to test one of the previous Fabien's patches? > > > My 0.02€, > > Although I disagree with some aspects of Andres patch, I'm not a committer > and I'm tired of arguing. I'm just planing to do minor changes to Andres > version to fix a potential issue if the file is closed which flushing is in > progress, but that will not change the overall shape of it. > > So testing on Andres version seems relevant to me. > > For SSD the performance impact should be limited. For disk it should be > significant if there is no big cache in front of it. There were some > concerns raised for some loads in the thread (shared memory smaller than > needed I think?), if you can include such cases that would be great. My > guess is that it should be not very beneficial in this case because the > writing is mostly done by bgwriter & worker in this case, and these are > still random. As there are still plans to move on regarding tests (and because this patch makes a difference), this is moved to next CF. -- Michael
Hi, On 12/16/2015 08:27 PM, Fabien COELHO wrote: > > Hello Tomas, > >> I'm planning to do some thorough benchmarking of the patches proposed >> in this thread, on various types of hardware (10k SAS drives and >> SSDs). But is that actually needed? I see Andres did some testing, as >> he posted summary of the results on 11/12, but I don't see any actual >> results or even info about what benchmarks were done (pgbench?). >> >> If yes, do we only want to compare 0001-ckpt-14-andres.patch against >> master, or do we need to test one of the previous Fabien's patches? > > My 0.02€, > > Although I disagree with some aspects of Andres patch, I'm not a > committer and I'm tired of arguing. I'm just planing to do minor changes > to Andres version to fix a potential issue if the file is closed which > flushing is in progress, but that will not change the overall shape of it. > > So testing on Andres version seems relevant to me. The patch no longer applies to master. Can someone rebase it? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2016-01-06 21:01:47 +0100, Tomas Vondra wrote: > >Although I disagree with some aspects of Andres patch, I'm not a > >committer and I'm tired of arguing. I'm just planing to do minor changes > >to Andres version to fix a potential issue if the file is closed which > >flushing is in progress, but that will not change the overall shape of it. Are you working on that aspect? > >So testing on Andres version seems relevant to me. > > The patch no longer applies to master. Can someone rebase it? I'm working on an updated version, trying to mitigate the performance regressions I observed. Andres
<Ooops, wrong from address, resent, sorry for the noise> Hello Andres, >>> Although I disagree with some aspects of Andres patch, I'm not a >>> committer and I'm tired of arguing. I'm just planing to do minor changes >>> to Andres version to fix a potential issue if the file is closed which >>> flushing is in progress, but that will not change the overall shape of >>> it. > > Are you working on that aspect? I read your patch and I know what I want to try to have a small and simple fix. I must admit that I have not really understood in which condition the checkpointer would decide to close a file, but that does not mean that the potential issue should not be addressed. Also, I gave some thoughts about what should be done for bgwriter random IOs. The idea is to implement some per-file sorting there and then do some LRU/LFU combing. It would not interact much with the checkpointer, so for me the two issues should be kept separate and this should not preclude changing the checkpointer, esp. given the significant performance benefit of the patch. However, all this is still in my stack of things to do, and I had not much time in the Fall for that. I may have more time in the coming weeks. I'm fine if things are updated and performance figures are collected in between, I'll take it from where it is when I have time, if something remains to be done. -- Fabien.
On 2016-01-07 11:27:13 +0100, Fabien COELHO wrote: > I read your patch and I know what I want to try to have a small and simple > fix. I must admit that I have not really understood in which condition the > checkpointer would decide to close a file, but that does not mean that the > potential issue should not be addressed. There's a trivial example: Consider three tablespaces and max_files_per_process = 2. The balancing can easily cause three files being flushed at the same time. But more importantly: You designed the API to be generic because you wanted it to be usable for other purposes as well. And for that it certainly needs to deal with that. > Also, I gave some thoughts about what should be done for bgwriter random > IOs. The idea is to implement some per-file sorting there and then do some > LRU/LFU combing. It would not interact much with the checkpointer, so for me > the two issues should be kept separate and this should not preclude changing > the checkpointer, esp. given the significant performance benefit of the > patch. Well, the problem is that the patch significantly regresses some cases right now. So keeping them separate isn't particularly feasible. Greetings, Andres Freund
Hello, >> I read your patch and I know what I want to try to have a small and simple >> fix. I must admit that I have not really understood in which condition the >> checkpointer would decide to close a file, but that does not mean that the >> potential issue should not be addressed. > > There's a trivial example: Consider three tablespaces and > max_files_per_process = 2. The balancing can easily cause three files > being flushed at the same time. Indeed. Thanks for this explanation! > But more importantly: You designed the API to be generic because you > wanted it to be usable for other purposes as well. And for that it > certainly needs to deal with that. Yes, I'm planning to try to do the minimum possible damage to the current API to fix the issue. >> Also, I gave some thoughts about what should be done for bgwriter random >> IOs. The idea is to implement some per-file sorting there and then do some >> LRU/LFU combing. It would not interact much with the checkpointer, so for me >> the two issues should be kept separate and this should not preclude changing >> the checkpointer, esp. given the significant performance benefit of the >> patch. > > Well, the problem is that the patch significantly regresses some cases > right now. So keeping them separate isn't particularly feasible. I have not seen significant regressions on my many test runs. In particular, I would not consider that having a tps deep in cases where postgresql is doing 0 tps most of the time anyway (ie pg is offline) because of random IO issues should be blocker. As I understood it, the regressions occur when the checkpointer is less used, i.e. bgwriter is doing most of the writes, but this does not change much whether the checkpointer sorts buffers or not, and the overall behavior of pg is very bad anyway in these cases. Also I think that coupling the two issues is a recipee for never having anything done in the end and keep the current awful behavior:-( The solution on the bgwriter front is somehow similar to the checkpointer, but from a code point of view there is minimum interaction, so I would really separate them, esp. as the bgwriter part will require extensive testing and discussions as well. -- Fabien.
On 2016-01-07 12:50:07 +0100, Fabien COELHO wrote: > >But more importantly: You designed the API to be generic because you > >wanted it to be usable for other purposes as well. And for that it > >certainly needs to deal with that. > > Yes, I'm planning to try to do the minimum possible damage to the current > API to fix the issue. What's your thought there? Afaics it's infeasible to do the flushing tat the fd.c level. Andres
>> Yes, I'm planning to try to do the minimum possible damage to the current >> API to fix the issue. > > What's your thought there? Afaics it's infeasible to do the flushing tat > the fd.c level. I thought of adding a pointer to the current flush structure at the vfd level, so that on closing a file with a flush in progress the flush can be done and the structure properly cleaned up, hence later the checkpointer would see a clean thing and be able to skip it instead of generating flushes on a closed file or on a different file... Maybe I'm missing something, but that is the plan I had in mind. -- Fabien.
On 2016-01-07 13:07:33 +0100, Fabien COELHO wrote: > > >>Yes, I'm planning to try to do the minimum possible damage to the current > >>API to fix the issue. > > > >What's your thought there? Afaics it's infeasible to do the flushing tat > >the fd.c level. > > I thought of adding a pointer to the current flush structure at the vfd > level, so that on closing a file with a flush in progress the flush can be > done and the structure properly cleaned up, hence later the checkpointer > would see a clean thing and be able to skip it instead of generating flushes > on a closed file or on a different file... > > Maybe I'm missing something, but that is the plan I had in mind. That might work, although it'd not be pretty (not fatally so though). But I'm inclined to go a different way: I think it's a mistake to do flusing based on a single file. It seems better to track a fixed number of outstanding 'block flushes', independent of the file. Whenever the number of outstanding blocks is exceeded, sort that list, and flush all outstanding flush requests after merging neighbouring flushes. Imo that means that we'd better track writes on a relfilenode + block number level. Andres
Hello Andres, >> I thought of adding a pointer to the current flush structure at the vfd >> level, so that on closing a file with a flush in progress the flush can be >> done and the structure properly cleaned up, hence later the checkpointer >> would see a clean thing and be able to skip it instead of generating flushes >> on a closed file or on a different file... >> >> Maybe I'm missing something, but that is the plan I had in mind. > > That might work, although it'd not be pretty (not fatally so > though). Alas, any solution has to communicate somehow between the API levels, so it cannot be "pretty", although we should avoid the worse. > But I'm inclined to go a different way: I think it's a mistake to do > flusing based on a single file. It seems better to track a fixed number > of outstanding 'block flushes', independent of the file. Whenever the > number of outstanding blocks is exceeded, sort that list, and flush all > outstanding flush requests after merging neighbouring flushes. Hmmm. I'm not sure I understand your strategy. I do not think that flushing without a prior sorting would be effective, because there is no clear reason why buffers written together would then be next to the other and thus give sequential write benefits, we would just get flushed random IO, I tested that and it worked badly. One of the point of aggregating flushes is that the range flush call cost is significant, as shown by preliminary tests I did, probably up in the thread, so it makes sense to limit this cost, hence the aggregation. These removed some performation regression I had in some cases. Also, the granularity of the buffer flush call is a file + offset + size, so necessarily it should be done this way (i.e. per file). Once buffers are sorted per file and offset within file, then written buffers are as close as possible one after the other, the merging is very easy to compute (it is done on the fly, no need to keep the list of buffers for instance), it is optimally effective, and when the checkpointed file changes then we will never go back to it before the next checkpoint, so there is no reason not to flush right then. So basically I do not see a clear positive advantage to your suggestion, especially when taking into consideration the scheduling process of the scheduler: In effect the checkpointer already works with little bursts of activity between sleep phases, so that it writes buffers a few at a time, so it may already work more or less as you expect, but not for the same reason. The closest stategy that I experimented which is maybe close to your suggestion was to manage a minimum number of buffers to write when awaken and to change the sleep delay in between, but I had no clear way to choose values and the experiments I did did not show significant performance impact by varying these parameters, so I kept that out. If you find a magic number of buffer which results in consistant better performance, fine with me, but this is independent with aggregating before or after. > Imo that means that we'd better track writes on a relfilenode + block > number level. I do not think that it is a better option. Moreover, the current approach has been proven to be very effective on hundreds of runs, so redoing it differently for the sake of it does not look like good resource allocation. -- Fabien.
On 2016-01-07 16:05:32 +0100, Fabien COELHO wrote: > >But I'm inclined to go a different way: I think it's a mistake to do > >flusing based on a single file. It seems better to track a fixed number of > >outstanding 'block flushes', independent of the file. Whenever the number > >of outstanding blocks is exceeded, sort that list, and flush all > >outstanding flush requests after merging neighbouring flushes. > > Hmmm. I'm not sure I understand your strategy. > > I do not think that flushing without a prior sorting would be effective, > because there is no clear reason why buffers written together would then be > next to the other and thus give sequential write benefits, we would just get > flushed random IO, I tested that and it worked badly. Oh, I was thinking of sorting & merging these outstanding flushes. Sorry for not making that clear. > One of the point of aggregating flushes is that the range flush call cost > is significant, as shown by preliminary tests I did, probably up in the > thread, so it makes sense to limit this cost, hence the aggregation. These > removed some performation regression I had in some cases. FWIW, my tests show that flushing for clean ranges is pretty cheap. > Also, the granularity of the buffer flush call is a file + offset + size, so > necessarily it should be done this way (i.e. per file). What syscalls we issue, and at what level we track outstanding flushes, doesn't have to be the same. > Once buffers are sorted per file and offset within file, then written > buffers are as close as possible one after the other, the merging is very > easy to compute (it is done on the fly, no need to keep the list of buffers > for instance), it is optimally effective, and when the checkpointed file > changes then we will never go back to it before the next checkpoint, so > there is no reason not to flush right then. Well, that's true if there's only one tablespace, but e.g. not the case with two tablespaces of about the same number of dirty buffers. > So basically I do not see a clear positive advantage to your suggestion, > especially when taking into consideration the scheduling process of the > scheduler: I don't think it makes a big difference for the checkpointer alone, but it makes the interface much more suitable for other processes, e.g. the bgwriter, and normal backends. > >Imo that means that we'd better track writes on a relfilenode + block > >number level. > > I do not think that it is a better option. Moreover, the current approach > has been proven to be very effective on hundreds of runs, so redoing it > differently for the sake of it does not look like good resource allocation. For a subset of workloads, yes. Greetings, Andres Freund
Hello Andres, >> One of the point of aggregating flushes is that the range flush call cost >> is significant, as shown by preliminary tests I did, probably up in the >> thread, so it makes sense to limit this cost, hence the aggregation. These >> removed some performation regression I had in some cases. > > FWIW, my tests show that flushing for clean ranges is pretty cheap. Yes, I agree that it is quite cheap, but I had a few % tps regressions in some cases without aggregating, and aggregating was enough to avoid these small regressions. >> Also, the granularity of the buffer flush call is a file + offset + size, so >> necessarily it should be done this way (i.e. per file). > > What syscalls we issue, and at what level we track outstanding flushes, > doesn't have to be the same. Sure. But the current version is simple, efficient and proven by many runs, so there should be a very strong argument to justify a significant benefit to change the approach, and I see no such thing in your arguments. For me the current approach is optimal for the checkpointer, because it takes advantage of all available information to perform a better job. >> Once buffers are sorted per file and offset within file, then written >> buffers are as close as possible one after the other, the merging is very >> easy to compute (it is done on the fly, no need to keep the list of buffers >> for instance), it is optimally effective, and when the checkpointed file >> changes then we will never go back to it before the next checkpoint, so >> there is no reason not to flush right then. > > Well, that's true if there's only one tablespace, but e.g. not the case > with two tablespaces of about the same number of dirty buffers. ISTM that in the version of the patch I sent there was one flushing structure per tablespace each doing its own flushing on its files, so it should work the same, only the writing intensity is devided by the number of tablespace? Or am I missing something? >> So basically I do not see a clear positive advantage to your suggestion, >> especially when taking into consideration the scheduling process of the >> scheduler: > > I don't think it makes a big difference for the checkpointer alone, but > it makes the interface much more suitable for other processes, e.g. the > bgwriter, and normal backends. Hmmm. ISTM that the requirement are not exactly the same for the bgwriter and backends vs the checkpointer. The checkpointer has the advantage of being able to plan its IOs on the long term (volume & time is known...) and the implementation takes the full benefit of this planing by sorting and scheduling and flushing buffers so as to generate as much sequential writes as possible. The bgwriter and backends have a much shorter vision (a few seconds, or juste one query being process), so the solution will be less efficient and probably more messy on the coding side. This is life. I do not see why not to take the benefit of a full planing in the checkpointer just because other processes cannot do the same, especially as under plenty of loads the checkpointer does most of the writing so is the limiting factor. So I do not buy your suggestion for the checkpointer. Maybe it will be the way to go for bgwriter and backends, then fine for them. >>> Imo that means that we'd better track writes on a relfilenode + block >>> number level. >> >> I do not think that it is a better option. Moreover, the current approach >> has been proven to be very effective on hundreds of runs, so redoing it >> differently for the sake of it does not look like good resource allocation. > > For a subset of workloads, yes. Hmmm. What I understood is that the workloads that have some performance regressions (regressions that I have *not* seen in the many tests I ran) are not due to checkpointer IOs, but rather in settings where most of the writes is done by backends or bgwriter. I do not see the point of rewriting the checkpointer for them, although obviously I agree that something has to be done also for the other processes. Maybe if all the writes (bgwriter and checkpointer) where performed by the same process then some dynamic mixing and sorting and aggregating would make sense, but this is currently not the case, and would probably have quite limited effect. Basically I do not understand how changing the flushing organisation as you suggest would improve the checkpointer performance significantly, for me it should only degrade the performance compared to the current version, as far as the checkpointer is concerned. -- Fabien.
On 2016-01-07 21:08:10 +0100, Fabien COELHO wrote: > Hmmm. What I understood is that the workloads that have some performance > regressions (regressions that I have *not* seen in the many tests I ran) are > not due to checkpointer IOs, but rather in settings where most of the writes > is done by backends or bgwriter. As far as I can see you've not run many tests where the hot/warm data set is larger than memory (the full machine's memory, not shared_buffers). That quite drastically alters the performance characteristics here, because you suddenly have lots of synchronous read IO thrown into the mix. Whether it's bgwriter or not I've not fully been able to establish, but it's a working theory. > I do not see the point of rewriting the checkpointer for them, although > obviously I agree that something has to be done also for the other > processes. Rewriting the checkpointer and fixing the flush interface in a more generic way aren't the same thing at all. Greetings, Andres Freund
Hello Andres, >> Hmmm. What I understood is that the workloads that have some performance >> regressions (regressions that I have *not* seen in the many tests I ran) are >> not due to checkpointer IOs, but rather in settings where most of the writes >> is done by backends or bgwriter. > > As far as I can see you've not run many tests where the hot/warm data > set is larger than memory (the full machine's memory, not > shared_buffers). Indeed, I think I ran some, but not many with such characteristics. > That quite drastically alters the performance characteristics here, > because you suddenly have lots of synchronous read IO thrown into the > mix. If I understand this point correctly... I would expect the overall performance to be abysmal in such a situation because you get only intermixed *random* read and writes: As you point out, synchroneous *random* reads (very slow), but on the write side the IOs are mostly random as well on the checkpointer side because there is not much to aggregate to get sequential writes. Now why would that degrade performance significantly? For me it should render the sorting/flushing less and less effective, and it would go back to the previous performance levels... Or maybe it only the flushing itself which degrades performance, as you point out, because then you have some synchronous (synced) writes as well as read, as opposed to just the reads before without the patch. If this is indeed the issue, then the solution to avoid the regression is *not* to flush so that the OS IO scheduler is less constrained in its job, and can be slightly more effective (well, we talking of abysmal random IO disk performance here, so effective would be between slightly more or less very very very bad). Maybe a trick could be not to aggregate and flush when buffers in the same file are too much apart anyway, for instance, based on some threshold? This can be implemented locally when deciding to merge buffer flushes or not, and whether to flush or not, so it would fit the current code quite simply. Now my understanding of the sync_file_range call is that it is an advice to flush the stuff, but it is still asynchronous in nature, so whether it would impact performance that badly depends on the OS IO scheduler. Also, I would like to check whether, under the "regressed performance" (in tps term that you observed), pg is more or less responsive. It could be that the average performance is better but pg is offline longer on fsync. In which case, I would consider it better to have lower tps in such cases *if* pg responsiveness is significantly improved. Would you have these measures for the regression runs you observed? > Whether it's bgwriter or not I've not fully been able to establish, but > it's a working theory. Ok, that is something to check for confirmation or infirmation. Given the above discussion, I think my suggestion may be wrong: as the tps is low because of random read/write accesses then not many buffers are modified (so the bgwriter/backends won't need to make space), the checkpointer does not have much to write (good), *but* all of it is random (bad). >> I do not see the point of rewriting the checkpointer for them, although >> obviously I agree that something has to be done also for the other >> processes. > > Rewriting the checkpointer and fixing the flush interface in a more > generic way aren't the same thing at all. Hmmm, probably I misunderstood something in the discussion. It started with an implementation strategy, but it derived to discussing a performance regression. I aggree that these are two different subjects. -- Fabien.
>
> On 2016-01-07 11:27:13 +0100, Fabien COELHO wrote:
> > I read your patch and I know what I want to try to have a small and simple
> > fix. I must admit that I have not really understood in which condition the
> > checkpointer would decide to close a file, but that does not mean that the
> > potential issue should not be addressed.
>
> There's a trivial example: Consider three tablespaces and
> max_files_per_process = 2. The balancing can easily cause three files
> being flushed at the same time.
>
mdsync()
{
..
/*
* It is possible that the relation has been dropped or
* truncated since the fsync request was entered.
* Therefore, allow ENOENT, but only if we didn't fail
* already on this file. This applies both for
* _mdfd_getseg() and for FileSync, since fd.c might have
* closed the file behind our back.
*
* XXX is there any point in allowing more than one retry?
* Don't see one at the moment, but easy to change the
* test here if so.
*/
if (!FILE_POSSIBLY_DELETED(errno) ||
failures > 0)
ereport(ERROR,
(errcode_for_file_access(),
errmsg("could not fsync file \"%s\": %m",
path)));
else
ereport(DEBUG1,
(errcode_for_file_access(),
errmsg("could not fsync file \"%s\" but retrying: %m",
path)));
On 2016-01-09 18:04:39 +0530, Amit Kapila wrote: > On Thu, Jan 7, 2016 at 4:21 PM, Andres Freund <andres@anarazel.de> wrote: > > > > On 2016-01-07 11:27:13 +0100, Fabien COELHO wrote: > > > I read your patch and I know what I want to try to have a small and > simple > > > fix. I must admit that I have not really understood in which condition > the > > > checkpointer would decide to close a file, but that does not mean that > the > > > potential issue should not be addressed. > > > > There's a trivial example: Consider three tablespaces and > > max_files_per_process = 2. The balancing can easily cause three files > > being flushed at the same time. > > > > Won't the same thing can occur without patch in mdsync() and can't > we handle it in same way? In particular, I am referring to below code: I don't see how that's corresponding - the problem is that current proposed infrastructure keeps a kernel level (or fd.c in my versio) fd open in it's 'pending flushes' struct. But since that isn't associated with fd.c opening/closing files that fd isn't very meaningful. > mdsync() That seems to address different issues. Greetings, Andres Freund
>
> On 2016-01-09 18:04:39 +0530, Amit Kapila wrote:
> > On Thu, Jan 7, 2016 at 4:21 PM, Andres Freund <andres@anarazel.de> wrote:
> > >
> > > On 2016-01-07 11:27:13 +0100, Fabien COELHO wrote:
> > > > I read your patch and I know what I want to try to have a small and
> > simple
> > > > fix. I must admit that I have not really understood in which condition
> > the
> > > > checkpointer would decide to close a file, but that does not mean that
> > the
> > > > potential issue should not be addressed.
> > >
> > > There's a trivial example: Consider three tablespaces and
> > > max_files_per_process = 2. The balancing can easily cause three files
> > > being flushed at the same time.
> > >
> >
> > Won't the same thing can occur without patch in mdsync() and can't
> > we handle it in same way? In particular, I am referring to below code:
>
> I don't see how that's corresponding - the problem is that current
> proposed infrastructure keeps a kernel level (or fd.c in my versio) fd
> open in it's 'pending flushes' struct. But since that isn't associated
> with fd.c opening/closing files that fd isn't very meaningful.
>
On 2016-01-09 18:24:01 +0530, Amit Kapila wrote: > Okay, but I think that is the reason why you are worried that it is possible > to issue sync_file_range() on a closed file, is that right or am I missing > something? That's one potential issue. You can also fsync a different file, try to print an error message containing an unallocated filename (that's how I noticed the issue in the first place)... I don't think it's going to be acceptable to issue operations on more or less random fds, even if that operation is hopefully harmless. Greetings, Andres Freund
>
> On 2016-01-09 18:24:01 +0530, Amit Kapila wrote:
> > Okay, but I think that is the reason why you are worried that it is possible
> > to issue sync_file_range() on a closed file, is that right or am I missing
> > something?
>
> That's one potential issue. You can also fsync a different file, try to
> print an error message containing an unallocated filename (that's how I
> noticed the issue in the first place)...
>
> I don't think it's going to be acceptable to issue operations on more or
> less random fds, even if that operation is hopefully harmless.
>
On 2016-01-09 19:05:54 +0530, Amit Kapila wrote: > Right that won't be acceptable, however I think with your latest > proposal [1] Sure, that'd address that problem. > [...] think that idea will help to mitigate the problem of backend and > bgwriter writes as well. In that, can't we do it with the help of > existing infrastructure of *pendingOpsTable* and > *CheckpointerShmem->requests[]*, as already the flush requests are > remembered in those structures, we can use those to apply your idea to > issue flush requests. Hm, that might be possible. But that might have some bigger implications - we currently can issue thousands of flush requests a second, without much chance of merging. I'm not sure it's a good idea to overlay that into the lower frequency pendingOpsTable. Backends having to issue fsyncs because the pending fsync queue is full is darn expensive. In contrast to that a 'flush hint' request getting lost doesn't cost that much. Greetings, Andres Freund
On 2016-01-07 21:17:32 +0100, Andres Freund wrote: > On 2016-01-07 21:08:10 +0100, Fabien COELHO wrote: > > Hmmm. What I understood is that the workloads that have some performance > > regressions (regressions that I have *not* seen in the many tests I ran) are > > not due to checkpointer IOs, but rather in settings where most of the writes > > is done by backends or bgwriter. > > As far as I can see you've not run many tests where the hot/warm data > set is larger than memory (the full machine's memory, not > shared_buffers). That quite drastically alters the performance > characteristics here, because you suddenly have lots of synchronous read > IO thrown into the mix. > > Whether it's bgwriter or not I've not fully been able to establish, but > it's a working theory. Hm. New theory: The current flush interface does the flushing inside FlushBuffer()->smgrwrite()->mdwrite()->FileWrite()->FlushContextSchedule(). The problem with that is that at that point we (need to) hold a content lock on the buffer! Especially on a system that's bottlenecked on IO that means we'll frequently hold content locks for a noticeable amount of time, while flushing blocks, without any need to. Even if that's not the reason for the slowdowns I observed, I think this fact gives further credence to the current "pending flushes" tracking residing on the wrong level. Andres
Hello Andres, > Hm. New theory: The current flush interface does the flushing inside > FlushBuffer()->smgrwrite()->mdwrite()->FileWrite()->FlushContextSchedule(). The > problem with that is that at that point we (need to) hold a content lock > on the buffer! You are worrying that FlushBuffer is holding a lock on a buffer and the "sync_file_range" call occurs is issued at that moment. Although I agree that it is not that good, I would be surprise if that was the explanation for a performance regression, because the sync_file_range with the chosen parameters is an async call, it "advises" the OS to send the file, but it does not wait for it to be completed. Moreover, for this issue to have a significant impact, it would require that another backend just happen to need this very buffer, but ISTM that the performance regression you are arguing about is on random IO bound performance, that is a few 100 tps in the best case, for very large bases, so a lot of buffers, so the probability of such a collision is very small, so it would not explain a significant regression. > Especially on a system that's bottlenecked on IO that means we'll > frequently hold content locks for a noticeable amount of time, while > flushing blocks, without any need to. I'm not that sure it is really noticeable, because sync_file_range does not wait for completion. > Even if that's not the reason for the slowdowns I observed, I think this > fact gives further credence to the current "pending flushes" tracking > residing on the wrong level. ISTM that I put the tracking at the level where is the information is available without having to recompute it several times, as the flush needs to know the fd and offset. Doing it differently would mean more code and translating buffer to file/offset several times, I think. Also, maybe you could answer a question I had about the performance regression you observed, I could not find the post where you gave the detailed information about it, so that I could try reproducing it: what are the exact settings and conditions (shared_buffers, pgbench scaling, host memory, ...), what is the observed regression (tps? other?), and what is the responsiveness of the database under the regression (eg % of seconds with 0 tps for instance, or something like that). -- Fabien.
>
> On 2016-01-09 19:05:54 +0530, Amit Kapila wrote:
> > Right that won't be acceptable, however I think with your latest
> > proposal [1]
>
> Sure, that'd address that problem.
>
>
> > [...] think that idea will help to mitigate the problem of backend and
> > bgwriter writes as well. In that, can't we do it with the help of
> > existing infrastructure of *pendingOpsTable* and
> > *CheckpointerShmem->requests[]*, as already the flush requests are
> > remembered in those structures, we can use those to apply your idea to
> > issue flush requests.
>
> Hm, that might be possible. But that might have some bigger implications
> - we currently can issue thousands of flush requests a second, without
> much chance of merging. I'm not sure it's a good idea to overlay that
> into the lower frequency pendingOpsTable.
> fsyncs because the pending fsync queue is full is darn expensive. In
> contrast to that a 'flush hint' request getting lost doesn't cost that
> much.
>
On 2016-01-09 16:49:56 +0100, Fabien COELHO wrote: > > Hello Andres, > > >Hm. New theory: The current flush interface does the flushing inside > >FlushBuffer()->smgrwrite()->mdwrite()->FileWrite()->FlushContextSchedule(). The > >problem with that is that at that point we (need to) hold a content lock > >on the buffer! > > You are worrying that FlushBuffer is holding a lock on a buffer and the > "sync_file_range" call occurs is issued at that moment. > > Although I agree that it is not that good, I would be surprise if that was > the explanation for a performance regression, because the sync_file_range > with the chosen parameters is an async call, it "advises" the OS to send the > file, but it does not wait for it to be completed. I frequently see sync_file_range blocking - it waits till it could submit the writes into the io queues. On a system bottlenecked on IO that's not always possible immediately. > Also, maybe you could answer a question I had about the performance > regression you observed, I could not find the post where you gave the > detailed information about it, so that I could try reproducing it: what are > the exact settings and conditions (shared_buffers, pgbench scaling, host > memory, ...), what is the observed regression (tps? other?), and what is the > responsiveness of the database under the regression (eg % of seconds with 0 > tps for instance, or something like that). I measured it in a different number of cases, both on SSDs and spinning rust. I just reproduced it with: postgres-ckpt14 \ -D /srv/temp/pgdev-dev-800/ \ -c maintenance_work_mem=2GB \ -c fsync=on \ -c synchronous_commit=off\ -c shared_buffers=2GB \ -c wal_level=hot_standby \ -c max_wal_senders=10 \ -c max_wal_size=100GB \ -c checkpoint_timeout=30s Using a fresh cluster each time (copied from a "template" to save time) and using pgbench -M prepared -c 16 -j16 -T 300 -P 1 I get My laptop 1 EVO 840, 1 i7-4800MQ, 16GB ram: master: scaling factor: 800 query mode: prepared number of clients: 16 number of threads: 16 duration: 300 s number of transactions actually processed: 1155733 latency average: 4.151 ms latency stddev: 8.712 ms tps = 3851.242965 (including connections establishing) tps = 3851.725856 (excluding connections establishing) ckpt-14 (flushing by backends disabled): scaling factor: 800 query mode: prepared number of clients: 16 number of threads: 16 duration: 300 s number of transactions actually processed: 855156 latency average: 5.612 ms latency stddev: 7.896 ms tps = 2849.876327 (including connections establishing) tps = 2849.912015 (excluding connections establishing) My laptop 1 850 PRO, 1 i7-4800MQ, 16GB ram: master: transaction type: TPC-B (sort of) scaling factor: 800 query mode: prepared number of clients: 16 number of threads: 16 duration: 300 s number of transactions actually processed: 2104781 latency average: 2.280 ms latency stddev: 9.868 ms tps = 7010.397938 (including connections establishing) tps = 7010.475848 (excluding connections establishing) ckpt-14 (flushing by backends disabled): scaling factor: 800 query mode: prepared number of clients: 16 number of threads: 16 duration: 300 s number of transactions actually processed: 1930716 latency average: 2.484 ms latency stddev: 7.303 ms tps = 6434.785605 (including connections establishing) tps = 6435.177773 (excluding connections establishing) In neither case there are periods of 0 tps, but both have times of < 1000 tps with noticeably increased latency. The endresults are similar with a sane checkpoint timeout - the tests just take much longer to give meaningful results. Constantly running long tests on prosumer level SSDs isn't nice - I've now killed 5 SSDs with postgres testing... As you can see there's roughly a 30% performance regression on the slower SSD and a ~9% on the faster one. HDD results are similar (but I can't repeat on the laptop right now since the 2nd hdd is now an SSD). My working copy of checkpoint sorting & flushing currently results in: My laptop 1 EVO 840, 1 i7-4800MQ, 16GB ram: transaction type: TPC-B (sort of) scaling factor: 800 query mode: prepared number of clients: 16 number of threads: 16 duration: 300 s number of transactions actually processed: 1136260 latency average: 4.223 ms latency stddev: 8.298 ms tps = 3786.696499 (including connections establishing) tps = 3786.778875 (excluding connections establishing) My laptop 1 850 PRO, 1 i7-4800MQ, 16GB ram: transaction type: TPC-B (sort of) scaling factor: 800 query mode: prepared number of clients: 16 number of threads: 16 duration: 300 s number of transactions actually processed: 2050661 latency average: 2.339 ms latency stddev: 7.708 ms tps = 6833.593170 (including connections establishing) tps = 6833.680391 (excluding connections establishing) My version of the patch currently addresses various points, which need to be separated and benchmarked separate: * Different approach to background writer, trying to make backends write less. While that proves to be beneficial in isolation,on its own that doesn't address the performance regression. * Different flushing API, done outside the lock So this partially addresses the performance problems, but not yet completely. Greetings, Andres Freund
On 2016-01-11 14:45:16 +0100, Andres Freund wrote: > On 2016-01-09 16:49:56 +0100, Fabien COELHO wrote: > > >Hm. New theory: The current flush interface does the flushing inside > > >FlushBuffer()->smgrwrite()->mdwrite()->FileWrite()->FlushContextSchedule(). The > > >problem with that is that at that point we (need to) hold a content lock > > >on the buffer! > > > > You are worrying that FlushBuffer is holding a lock on a buffer and the > > "sync_file_range" call occurs is issued at that moment. > > > > Although I agree that it is not that good, I would be surprise if that was > > the explanation for a performance regression, because the sync_file_range > > with the chosen parameters is an async call, it "advises" the OS to send the > > file, but it does not wait for it to be completed. > > I frequently see sync_file_range blocking - it waits till it could > submit the writes into the io queues. On a system bottlenecked on IO > that's not always possible immediately. > > > Also, maybe you could answer a question I had about the performance > > regression you observed, I could not find the post where you gave the > > detailed information about it, so that I could try reproducing it: what are > > the exact settings and conditions (shared_buffers, pgbench scaling, host > > memory, ...), what is the observed regression (tps? other?), and what is the > > responsiveness of the database under the regression (eg % of seconds with 0 > > tps for instance, or something like that). > > I measured it in a different number of cases, both on SSDs and spinning > rust. I just reproduced it with: > > postgres-ckpt14 \ > -D /srv/temp/pgdev-dev-800/ \ > -c maintenance_work_mem=2GB \ > -c fsync=on \ > -c synchronous_commit=off \ > -c shared_buffers=2GB \ > -c wal_level=hot_standby \ > -c max_wal_senders=10 \ > -c max_wal_size=100GB \ > -c checkpoint_timeout=30s > > Using a fresh cluster each time (copied from a "template" to save time) > and using > pgbench -M prepared -c 16 -j16 -T 300 -P 1 > I get > > My laptop 1 EVO 840, 1 i7-4800MQ, 16GB ram: > master: > scaling factor: 800 > query mode: prepared > number of clients: 16 > number of threads: 16 > duration: 300 s > number of transactions actually processed: 1155733 > latency average: 4.151 ms > latency stddev: 8.712 ms > tps = 3851.242965 (including connections establishing) > tps = 3851.725856 (excluding connections establishing) > > ckpt-14 (flushing by backends disabled): > scaling factor: 800 > query mode: prepared > number of clients: 16 > number of threads: 16 > duration: 300 s > number of transactions actually processed: 855156 > latency average: 5.612 ms > latency stddev: 7.896 ms > tps = 2849.876327 (including connections establishing) > tps = 2849.912015 (excluding connections establishing) Hm. I think I have an entirely different theory that might explain some of this theory. I instrumented lwlocks to check for additional blocking and found some. Admittedly not exactly where I thought it might be. Check out what you can observe when adding/enabling an elog in FlushBuffer() (and the progress printing from BufferSync()): (sorry, a bit long, but it's necessary to understand) [2016-01-11 20:15:02 CET][14957] CONTEXT: writing block 0 of relation base/13000/16387 to_scan: 131141, scanned: 6, %processed: 0.00, %writeouts: 100.00 [2016-01-11 20:15:02 CET][14957] LOG: xlog flush request 1F/D2FD7E0; write 1F/D296000; flush 1F/D296000; insert: 1F/D33B418 [2016-01-11 20:15:02 CET][14957] CONTEXT: writing block 2 of relation base/13000/16387 to_scan: 131141, scanned: 7, %processed: 0.01, %writeouts: 100.00 [2016-01-11 20:15:02 CET][14957] LOG: xlog flush request 1F/D3B2E30; write 1F/D33C000; flush 1F/D33C000; insert: 1F/D403198 [2016-01-11 20:15:02 CET][14957] CONTEXT: writing block 3 of relation base/13000/16387 to_scan: 131141, scanned: 9, %processed: 0.01, %writeouts: 100.00 [2016-01-11 20:15:02 CET][14957] LOG: xlog flush request 1F/D469990; write 1F/D402000; flush 1F/D402000; insert: 1F/D4FDD00 [2016-01-11 20:15:02 CET][14957] CONTEXT: writing block 5 of relation base/13000/16387 to_scan: 131141, scanned: 11, %processed: 0.01, %writeouts: 100.00 [2016-01-11 20:15:02 CET][14957] LOG: xlog flush request 1F/D5663E8; write 1F/D4FC000; flush 1F/D4FC000; insert: 1F/D5D1390 [2016-01-11 20:15:02 CET][14957] CONTEXT: writing block 7 of relation base/13000/16387 to_scan: 131141, scanned: 14, %processed: 0.01, %writeouts: 100.00 [2016-01-11 20:15:02 CET][14957] LOG: xlog flush request 1F/D673700; write 1F/D5D0000; flush 1F/D5D0000; insert: 1F/D687E58 [2016-01-11 20:15:02 CET][14957] CONTEXT: writing block 10 of relation base/13000/16387 to_scan: 131141, scanned: 15, %processed: 0.01, %writeouts: 100.00 [2016-01-11 20:15:02 CET][14957] LOG: xlog flush request 1F/D76BEC8; write 1F/D686000; flush 1F/D686000; insert: 1F/D7A83A0 [2016-01-11 20:15:02 CET][14957] CONTEXT: writing block 11 of relation base/13000/16387 to_scan: 131141, scanned: 16, %processed: 0.01, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/D7AE5C0; write 1F/D7A83E8; flush 1F/D7A83E8; insert: 1F/D8B9A88 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 12 of relation base/13000/16387 to_scan: 131141, scanned: 17, %processed: 0.01, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/DA08370; write 1F/D963A38; flush 1F/D963A38; insert: 1F/DA0A7D0 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 13 of relation base/13000/16387 to_scan: 131141, scanned: 18, %processed: 0.01, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/DAC09A0; write 1F/DA92250; flush 1F/DA92250; insert: 1F/DB9AAC8 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 14 of relation base/13000/16387 to_scan: 131141, scanned: 21, %processed: 0.02, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/DCEFF18; write 1F/DC2AD30; flush 1F/DC2AD30; insert: 1F/DCF25B0 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 17 of relation base/13000/16387 to_scan: 131141, scanned: 23, %processed: 0.02, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/DD0E9E0; write 1F/DCF25F8; flush 1F/DCF25F8; insert: 1F/DDD6198 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 19 of relation base/13000/16387 to_scan: 131141, scanned: 24, %processed: 0.02, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/DED6A20; write 1F/DEC0358; flush 1F/DEC0358; insert: 1F/DFB64C8 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 20 of relation base/13000/16387 to_scan: 131141, scanned: 25, %processed: 0.02, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/DFDEE90; write 1F/DFB6560; flush 1F/DFB6560; insert: 1F/E073468 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 21 of relation base/13000/16387 to_scan: 131141, scanned: 26, %processed: 0.02, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/E295638; write 1F/E10B9F8; flush 1F/E10B9F8; insert: 1F/E2B40E0 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 22 of relation base/13000/16387 to_scan: 131141, scanned: 27, %processed: 0.02, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/E381688; write 1F/E354BC0; flush 1F/E354BC0; insert: 1F/E459598 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 23 of relation base/13000/16387 to_scan: 131141, scanned: 28, %processed: 0.02, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/E56EF70; write 1F/E4C0C98; flush 1F/E4C0C98; insert: 1F/E56F200 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 24 of relation base/13000/16387 to_scan: 131141, scanned: 29, %processed: 0.02, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/E67E538; write 1F/E5DC440; flush 1F/E5DC440; insert: 1F/E6F7FF8 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 25 of relation base/13000/16387 to_scan: 131141, scanned: 31, %processed: 0.02, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/E873DD8; write 1F/E7D81F0; flush 1F/E7D81F0; insert: 1F/E8A1710 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 27 of relation base/13000/16387 to_scan: 131141, scanned: 33, %processed: 0.03, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/E9E3948; write 1F/E979610; flush 1F/E979610; insert: 1F/EA27AC0 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 29 of relation base/13000/16387 to_scan: 131141, scanned: 35, %processed: 0.03, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/EABDDC8; write 1F/EA6DFE0; flush 1F/EA6DFE0; insert: 1F/EB10728 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 31 of relation base/13000/16387 to_scan: 131141, scanned: 37, %processed: 0.03, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/EC07328; write 1F/EBAABE0; flush 1F/EBAABE0; insert: 1F/EC9B8A8 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 33 of relation base/13000/16387 to_scan: 131141, scanned: 40, %processed: 0.03, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/ED18FF8; write 1F/EC9B8A8; flush 1F/EC9B8A8; insert: 1F/ED8C2F8 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 36 of relation base/13000/16387 to_scan: 131141, scanned: 41, %processed: 0.03, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/EEED640; write 1F/EE0BAD8; flush 1F/EE0BAD8; insert: 1F/EF35EA8 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 37 of relation base/13000/16387 to_scan: 131141, scanned: 42, %processed: 0.03, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/EFF20B8; write 1F/EFAAE20; flush 1F/EFAAE20; insert: 1F/F06FAC0 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 38 of relation base/13000/16387 to_scan: 131141, scanned: 43, %processed: 0.03, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/F1430B0; write 1F/F0DEAB8; flush 1F/F0DEAB8; insert: 1F/F265020 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 39 of relation base/13000/16387 to_scan: 131141, scanned: 45, %processed: 0.03, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/F3556C0; write 1F/F268F68; flush 1F/F268F68; insert: 1F/F3682B8 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 41 of relation base/13000/16387 to_scan: 131141, scanned: 46, %processed: 0.04, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/F5005F8; write 1F/F4376F8; flush 1F/F4376F8; insert: 1F/F523838 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 42 of relation base/13000/16387 to_scan: 131141, scanned: 47, %processed: 0.04, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/F6261C0; write 1F/F5A07A0; flush 1F/F5A07A0; insert: 1F/F691288 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 43 of relation base/13000/16387 to_scan: 131141, scanned: 48, %processed: 0.04, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/F7CBCD0; write 1F/F719020; flush 1F/F719020; insert: 1F/F80DBB0 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 44 of relation base/13000/16387 to_scan: 131141, scanned: 49, %processed: 0.04, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/F9359C8; write 1F/F874CB8; flush 1F/F874CB8; insert: 1F/F95AD58 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 45 of relation base/13000/16387 to_scan: 131141, scanned: 50, %processed: 0.04, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/FA33F38; write 1F/FA03490; flush 1F/FA03490; insert: 1F/FAD4DF8 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 46 of relation base/13000/16387 to_scan: 131141, scanned: 51, %processed: 0.04, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/FBDBCD8; write 1F/FB52238; flush 1F/FB52238; insert: 1F/FC54E68 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 47 of relation base/13000/16387 to_scan: 131141, scanned: 52, %processed: 0.04, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/FD74B60; write 1F/FD10360; flush 1F/FD10360; insert: 1F/FDB6A88 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 48 of relation base/13000/16387 to_scan: 131141, scanned: 53, %processed: 0.04, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/FE4FF60; write 1F/FDB6AD0; flush 1F/FDB6AD0; insert: 1F/FE90028 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 49 of relation base/13000/16387 to_scan: 131141, scanned: 54, %processed: 0.04, %writeouts: 100.00 [2016-01-11 20:15:03 CET][14957] LOG: xlog flush request 1F/FFD6A78; write 1F/FF223F0; flush 1F/FF223F0; insert: 1F/10022F70 [2016-01-11 20:15:03 CET][14957] CONTEXT: writing block 50 of relation base/13000/16387 to_scan: 131141, scanned: 55, %processed: 0.04, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/10144C98; write 1F/10023000; flush 1F/10023000; insert: 1F/10157730 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 51 of relation base/13000/16387 to_scan: 131141, scanned: 58, %processed: 0.04, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/102AA468; write 1F/1020C600; flush 1F/1020C600; insert: 1F/102C73F0 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 54 of relation base/13000/16387 to_scan: 131141, scanned: 60, %processed: 0.05, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/10313470; write 1F/102C7460; flush 1F/102C7460; insert: 1F/103D4F38 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 56 of relation base/13000/16387 to_scan: 131141, scanned: 61, %processed: 0.05, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/10510CE8; write 1F/104562F0; flush 1F/104562F0; insert: 1F/105171E8 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 57 of relation base/13000/16387 to_scan: 131141, scanned: 62, %processed: 0.05, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/10596B18; write 1F/105191B0; flush 1F/105191B0; insert: 1F/106076F8 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 58 of relation base/13000/16387 to_scan: 131141, scanned: 63, %processed: 0.05, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/1073FB28; write 1F/10693638; flush 1F/10693638; insert: 1F/10787D40 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 59 of relation base/13000/16387 to_scan: 131141, scanned: 64, %processed: 0.05, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/1088D058; write 1F/107F7068; flush 1F/107F7068; insert: 1F/10920EA0 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 60 of relation base/13000/16387 to_scan: 131141, scanned: 67, %processed: 0.05, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/109D9158; write 1F/109A8458; flush 1F/109A8458; insert: 1F/10A8A240 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 63 of relation base/13000/16387 to_scan: 131141, scanned: 68, %processed: 0.05, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/10BDAA38; write 1F/10B2AD48; flush 1F/10B2AD48; insert: 1F/10C16768 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 64 of relation base/13000/16387 to_scan: 131141, scanned: 69, %processed: 0.05, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/10D824D0; write 1F/10C859A0; flush 1F/10C859A0; insert: 1F/10DCC860 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 65 of relation base/13000/16387 to_scan: 131141, scanned: 70, %processed: 0.05, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/10E24CD8; write 1F/10DCC8A8; flush 1F/10DCC8A8; insert: 1F/10EA8588 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 66 of relation base/13000/16387 to_scan: 131141, scanned: 71, %processed: 0.05, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/10FD3E90; write 1F/10F57530; flush 1F/10F57530; insert: 1F/11043A58 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 67 of relation base/13000/16387 to_scan: 131141, scanned: 72, %processed: 0.05, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/111CE4A0; write 1F/11043AC8; flush 1F/11043AC8; insert: 1F/111ED470 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 68 of relation base/13000/16387 to_scan: 131141, scanned: 73, %processed: 0.06, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/11338080; write 1F/112917C8; flush 1F/112917C8; insert: 1F/1135CF80 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 69 of relation base/13000/16387 to_scan: 131141, scanned: 76, %processed: 0.06, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/11369068; write 1F/1135CF80; flush 1F/1135CF80; insert: 1F/1140BE88 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 72 of relation base/13000/16387 to_scan: 131141, scanned: 77, %processed: 0.06, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/1146A420; write 1F/1136E000; flush 1F/1136E000; insert: 1F/11483530 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 73 of relation base/13000/16387 to_scan: 131141, scanned: 78, %processed: 0.06, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/1157B800; write 1F/11483530; flush 1F/11483530; insert: 1F/11583E20 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 74 of relation base/13000/16387 to_scan: 131141, scanned: 79, %processed: 0.06, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/116368C0; write 1F/11583E20; flush 1F/11583E20; insert: 1F/116661A8 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 75 of relation base/13000/16387 to_scan: 131141, scanned: 81, %processed: 0.06, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/116FC598; write 1F/11668178; flush 1F/11668178; insert: 1F/11716758 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 0 of relation base/13000/16393 to_scan: 131141, scanned: 82, %processed: 0.06, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/117DA658; write 1F/117631F0; flush 1F/117631F0; insert: 1F/118206F0 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 1 of relation base/13000/16393 to_scan: 131141, scanned: 83, %processed: 0.06, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/11956320; write 1F/118E96B8; flush 1F/118E96B8; insert: 1F/1196F000 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 2 of relation base/13000/16393 to_scan: 131141, scanned: 84, %processed: 0.06, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/11A09B00; write 1F/1196F090; flush 1F/1196F090; insert: 1F/11A23D38 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 3 of relation base/13000/16393 to_scan: 131141, scanned: 85, %processed: 0.06, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/11B43C80; write 1F/11AB2148; flush 1F/11AB2148; insert: 1F/11B502D8 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 4 of relation base/13000/16393 to_scan: 131141, scanned: 86, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/11BE2610; write 1F/11B503B8; flush 1F/11B503B8; insert: 1F/11BF9068 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 5 of relation base/13000/16393 to_scan: 131141, scanned: 87, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/11CB9FD8; write 1F/11BF9168; flush 1F/11BF9168; insert: 1F/11CBE1F8 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 6 of relation base/13000/16393 to_scan: 131141, scanned: 88, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/11D24E10; write 1F/11CBE268; flush 1F/11CBE268; insert: 1F/11D8BC18 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 7 of relation base/13000/16393 to_scan: 131141, scanned: 89, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/11E9B070; write 1F/11DEC840; flush 1F/11DEC840; insert: 1F/11EB7EC0 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 8 of relation base/13000/16393 to_scan: 131141, scanned: 90, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/11F5C3F0; write 1F/11F3FBD0; flush 1F/11F3FBD0; insert: 1F/11FE1A08 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 9 of relation base/13000/16393 to_scan: 131141, scanned: 91, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/121EDC00; write 1F/1208E838; flush 1F/1208E838; insert: 1F/121F1EF8 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 10 of relation base/13000/16393 to_scan: 131141, scanned: 92, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/122E0A70; write 1F/121F1F90; flush 1F/121F1F90; insert: 1F/122E9198 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 11 of relation base/13000/16393 to_scan: 131141, scanned: 93, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/1243B698; write 1F/123A7EC8; flush 1F/123A7EC8; insert: 1F/1245E620 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 12 of relation base/13000/16393 to_scan: 131141, scanned: 94, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/1258E7B0; write 1F/124BF6B8; flush 1F/124BF6B8; insert: 1F/1259F198 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 13 of relation base/13000/16393 to_scan: 131141, scanned: 95, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/126C8E38; write 1F/12662BA0; flush 1F/12662BA0; insert: 1F/126FE690 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 14 of relation base/13000/16393 to_scan: 131141, scanned: 96, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/127DE810; write 1F/126FE6D8; flush 1F/126FE6D8; insert: 1F/128081B0 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 15 of relation base/13000/16393 to_scan: 131141, scanned: 97, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:04 CET][14957] LOG: xlog flush request 1F/12980108; write 1F/128A6000; flush 1F/128A6000; insert: 1F/129A8E00 [2016-01-11 20:15:04 CET][14957] CONTEXT: writing block 16 of relation base/13000/16393 to_scan: 131141, scanned: 98, %processed: 0.07, %writeouts: 100.00 [2016-01-11 20:15:05 CET][14957] LOG: xlog flush request 1F/12A55978; write 1F/129ACDB8; flush 1F/129ACDB8; insert: 1F/12A6A408 [2016-01-11 20:15:05 CET][14957] CONTEXT: writing block 17 of relation base/13000/16393 to_scan: 131141, scanned: 99, %processed: 0.08, %writeouts: 100.00 [2016-01-11 20:15:05 CET][14957] LOG: xlog flush request 1F/12BC1148; write 1F/12B12F40; flush 1F/12B12F40; insert: 1F/12BC15F8 [2016-01-11 20:15:05 CET][14957] CONTEXT: writing block 18 of relation base/13000/16393 to_scan: 131141, scanned: 100, %processed: 0.08, %writeouts: 100.00 [2016-01-11 20:15:05 CET][14957] LOG: xlog flush request 1F/12D36E20; write 1F/12C70120; flush 1F/12C70120; insert: 1F/12D4DC08 [2016-01-11 20:15:05 CET][14957] CONTEXT: writing block 19 of relation base/13000/16393 to_scan: 131141, scanned: 9892, %processed: 7.54, %writeouts: 100.00 [2016-01-11 20:15:05 CET][14957] LOG: xlog flush request 1F/13128AF8; write 1F/12DEE670; flush 1F/12DEE670; insert: 1F/1313B7D0 [2016-01-11 20:15:05 CET][14957] CONTEXT: writing block 101960 of relation base/13000/16396 to_scan: 131141, scanned: 18221, %processed: 13.89, %writeouts: 100.00 [2016-01-11 20:15:05 CET][14957] LOG: xlog flush request 1F/13276328; write 1F/1313A000; flush 1F/1313A000; insert: 1F/134E93A8 [2016-01-11 20:15:05 CET][14957] CONTEXT: writing block 188242 of relation base/13000/16396 to_scan: 131141, scanned: 25857, %processed: 19.72, %writeouts: 100.00 [2016-01-11 20:15:06 CET][14957] LOG: xlog flush request 1F/13497370; write 1F/1346E000; flush 1F/1346E000; insert: 1F/136C00F8 [2016-01-11 20:15:06 CET][14957] CONTEXT: writing block 267003 of relation base/13000/16396 to_scan: 131141, scanned: 26859, %processed: 20.48, %writeouts: 100.00 [2016-01-11 20:15:06 CET][14957] LOG: xlog flush request 1F/136B5BB0; write 1F/135D6000; flush 1F/135D6000; insert: 1F/136C00F8 [2016-01-11 20:15:06 CET][14957] CONTEXT: writing block 277621 of relation base/13000/16396 to_scan: 131141, scanned: 27582, %processed: 21.03, %writeouts: 100.00 [2016-01-11 20:15:06 CET][14957] LOG: xlog flush request 1F/138C6C38; write 1F/1375E900; flush 1F/1375E900; insert: 1F/138D5518 [2016-01-11 20:15:06 CET][14957] CONTEXT: writing block 285176 of relation base/13000/16396 to_scan: 131141, scanned: 28943, %processed: 22.07, %writeouts: 100.00 [2016-01-11 20:15:06 CET][14957] LOG: xlog flush request 1F/13A5B768; write 1F/138C8000; flush 1F/138C8000; insert: 1F/13AB61D0 [2016-01-11 20:15:06 CET][14957] CONTEXT: writing block 300007 of relation base/13000/16396 to_scan: 131141, scanned: 36181, %processed: 27.59, %writeouts: 100.00 [2016-01-11 20:15:06 CET][14957] LOG: xlog flush request 1F/13C320C8; write 1F/13A8A000; flush 1F/13A8A000; insert: 1F/13DAAB40 [2016-01-11 20:15:06 CET][14957] CONTEXT: writing block 375983 of relation base/13000/16396 to_scan: 131141, scanned: 40044, %processed: 30.54, %writeouts: 100.00 [2016-01-11 20:15:07 CET][14957] LOG: xlog flush request 1F/13E196C8; write 1F/13CBA000; flush 1F/13CBA000; insert: 1F/13F9E6D8 [2016-01-11 20:15:07 CET][14957] CONTEXT: writing block 416439 of relation base/13000/16396 to_scan: 131141, scanned: 48250, %processed: 36.79, %writeouts: 100.00 [2016-01-11 20:15:07 CET][14957] LOG: xlog flush request 1F/143F6160; write 1F/13EE8000; flush 1F/13EE8000; insert: 1F/1461BB08 You can see that initially every buffer triggers a WAL flush. That causes a slowdown because a) we're doing significantly more WAL flushes in that time period, both causing slowdown of concurrent IO and concurrent WAL insertions b) due to the many slow flushes we get behind on the checkpoint schedule, triggering a rapid fire period of writes afterwards. My theory is that this happens due to the sorting: pgbench is an update heavy workload, the first few pages are always going to be used if there's free space as freespacemap.c essentially prefers those. Due to the sorting all a relation's early pages are going to be in "in a row". Indeed, the behaviour is not visible in a significant manner when using pgbench -N, where there are far fewer updated pages. I'm not entirely sure how we can deal with that. Greetings, Andres Freund
> My theory is that this happens due to the sorting: pgbench is an update
> heavy workload, the first few pages are always going to be used if
> there's free space as freespacemap.c essentially prefers those. Due to
> the sorting all a relation's early pages are going to be in "in a row".
>
On 2016-01-12 17:50:36 +0530, Amit Kapila wrote: > On Tue, Jan 12, 2016 at 12:57 AM, Andres Freund <andres@anarazel.de> wrote:> > > > > My theory is that this happens due to the sorting: pgbench is an update > > heavy workload, the first few pages are always going to be used if > > there's free space as freespacemap.c essentially prefers those. Due to > > the sorting all a relation's early pages are going to be in "in a row". > > > > Not sure, what is best way to tackle this problem, but I think one way could > be to perform sorting at flush requests level rather than before writing > to OS buffers. I'm not following. If you just sort a couple hundred more or less random buffers - which is what you get if you look in buf_id order through shared_buffers - the likelihood of actually finding neighbouring writes is pretty low.
Hello Andres, Thanks for the details. Many comments and some questions below. >> Also, maybe you could answer a question I had about the performance >> regression you observed, I could not find the post where you gave the >> detailed information about it, so that I could try reproducing it: what are >> the exact settings and conditions (shared_buffers, pgbench scaling, host >> memory, ...), what is the observed regression (tps? other?), and what is the >> responsiveness of the database under the regression (eg % of seconds with 0 >> tps for instance, or something like that). > > I measured it in a different number of cases, both on SSDs > and spinning rust. Argh! This is a key point: the sort/flush is designed to help HDDs, and would have limited effect on SSDs, and it seems that you are showing that the effect is in fact negative on SSDs, too bad:-( The bad news is that I do not have a host with a SSD available for reproducing such results. On SSDs, the linux IO scheduler works quite well, so this is a place where I would consider simply disactivating flushing and/or sorting. ISTM that I would rather update the documentation to "do not activate on SSD" than try to find a miraculous solution which may or may not exist. Basically I would use your results to give better advises in the documentation, not as a motivation to rewrite the patch from scratch. > postgres-ckpt14 \ > -D /srv/temp/pgdev-dev-800/ \ > -c maintenance_work_mem=2GB \ > -c fsync=on \ > -c synchronous_commit=off \ I'm not sure I like this one. I guess the intention is to focus on checkpointer writes and reduce the impact of WAL writes. Why not. > -c shared_buffers=2GB \ > -c wal_level=hot_standby \ > -c max_wal_senders=10 \ > -c max_wal_size=100GB \ > -c checkpoint_timeout=30s That is a very short one, but the point is to exercise the checkpoint, so why not. > My laptop 1 EVO 840, 1 i7-4800MQ, 16GB ram: > master: > scaling factor: 800 The DB is probably about 12GB, so it fits in memory in the end, meaning that there should be only write activity after some time? So this is not really the case where it does not fit in memory, but it is large enough to get mostly random IOs both in read & write, so why not. > query mode: prepared > number of clients: 16 > number of threads: 16 > duration: 300 s > number of transactions actually processed: 1155733 Assuming one buffer accessed per transaction on average, and considering a uniform random distribution, this means about 50% of pages actually loaded in memory at the end of the run (1 - e(-1155766/800*2048)) (with 2048 pages per scale unit). > latency average: 4.151 ms > latency stddev: 8.712 ms > tps = 3851.242965 (including connections establishing) > tps = 3851.725856 (excluding connections establishing) > ckpt-14 (flushing by backends disabled): Is this comment refering to "synchronous_commit = off"? I guess this is the same on master above, even if not written? > [...] In neither case there are periods of 0 tps, but both have times of > 1000 tps with noticeably increased latency. Ok, but we are talking SSDs, things are not too bad, even if there are ups and downs. > The endresults are similar with a sane checkpoint timeout - the tests > just take much longer to give meaningful results. Constantly running > long tests on prosumer level SSDs isn't nice - I've now killed 5 SSDs > with postgres testing... Indeed. It wears out and costs, too bad:-( > As you can see there's roughly a 30% performance regression on the > slower SSD and a ~9% on the faster one. HDD results are similar (but I > can't repeat on the laptop right now since the 2nd hdd is now an SSD). Ok, that is what I would have expected, the larger the database, the smaller the impact of sorting & flushin on SSDs. Now I would have hoped that flushing would help get a more constant load even in this case, at least this is what I measured in my tests. The closest to your setting test I ran is scale=660, and the sort/flush got 400 tps vs 100 tps without, with 30 minutes checkpoints, but HDDs do not compare to SSDs... My overall comments about this SSD regression is that the patch is really designed to make a difference for HDDs, so to advise not activate on SSDs if there is a regression in such a case. Now this is a little disappointing as on paper sorted writes should also be slightly better on SSDs, but if the bench says the contrary, I have to believe the bench:-) -- Fabien.
>
> On 2016-01-12 17:50:36 +0530, Amit Kapila wrote:
> > On Tue, Jan 12, 2016 at 12:57 AM, Andres Freund <andres@anarazel.de> wrote:>
> > >
> > > My theory is that this happens due to the sorting: pgbench is an update
> > > heavy workload, the first few pages are always going to be used if
> > > there's free space as freespacemap.c essentially prefers those. Due to
> > > the sorting all a relation's early pages are going to be in "in a row".
> > >
> >
> > Not sure, what is best way to tackle this problem, but I think one way could
> > be to perform sorting at flush requests level rather than before writing
> > to OS buffers.
>
> I'm not following. If you just sort a couple hundred more or less random
> buffers - which is what you get if you look in buf_id order through
> shared_buffers - the likelihood of actually finding neighbouring writes
> is pretty low.
On 2016-01-12 13:54:21 +0100, Fabien COELHO wrote: > >I measured it in a different number of cases, both on SSDs > >and spinning rust. > > Argh! This is a key point: the sort/flush is designed to help HDDs, and > would have limited effect on SSDs, and it seems that you are showing that > the effect is in fact negative on SSDs, too bad:-( As you quoted, I could reproduce the slowdown both with SSDs *and* with rotating disks. > On SSDs, the linux IO scheduler works quite well, so this is a place where I > would consider simply disactivating flushing and/or sorting. Not my experience. In different scenarios, primarily with a large shared_buffers fitting the whole hot working set, the patch significantly improves performance. > >postgres-ckpt14 \ > > -D /srv/temp/pgdev-dev-800/ \ > > -c maintenance_work_mem=2GB \ > > -c fsync=on \ > > -c synchronous_commit=off \ > > I'm not sure I like this one. I guess the intention is to focus on > checkpointer writes and reduce the impact of WAL writes. Why not. Now sure what you mean? s_c = off is *very* frequent in the field. > >My laptop 1 EVO 840, 1 i7-4800MQ, 16GB ram: > >master: > >scaling factor: 800 > > The DB is probably about 12GB, so it fits in memory in the end, meaning that > there should be only write activity after some time? So this is not really > the case where it does not fit in memory, but it is large enough to get > mostly random IOs both in read & write, so why not. Doesn't really fit into ram - shared buffers uses some space (which will be double buffered) and the xlog will use some more. > >ckpt-14 (flushing by backends disabled): > > Is this comment refering to "synchronous_commit = off"? > I guess this is the same on master above, even if not written? No, what I mean by that is that I didn't active flushing writes in backends - something I found hugely effective in reducing jitter in a number of workloads, but doesn't help throughput. > >As you can see there's roughly a 30% performance regression on the > >slower SSD and a ~9% on the faster one. HDD results are similar (but I > >can't repeat on the laptop right now since the 2nd hdd is now an SSD). > > Ok, that is what I would have expected, the larger the database, the smaller > the impact of sorting & flushin on SSDs. Again: "HDD results are similar". I primarily tested on a 4 disk raid10 of 4 disks, and a raid0 of 20 disks. Greetings, Andres Freund
On 2016-01-12 19:17:49 +0530, Amit Kapila wrote: > Why can't we do it at larger intervals (relative to total amount of writes)? > To explain, what I have in mind, let us assume that checkpoint interval > is longer (10 mins) and in the mean time all the writes are being done > by bgwriter But that's not the scenario with the regression here, so I'm not sure why you're bringing it up? And if we're flushing significant portion of the writes, how does that avoid the performance problem pointed out two messages upthread? Where sorting leads to flushing highly contended buffers together, leading to excessive wal flushing? But more importantly, unless you also want to delay the writes themselves, leaving that many dirty buffers in the kernel page cache will bring back exactly the type of stalls (where the kernel flushes all the pending dirty data in a short amount of time) we're trying to avoid with the forced flushing. So doing flushes in a large patches is something we really fundamentally do *not* want! > which it registers in shared memory so that later checkpoint > can perform corresponding fsync's, now when the request queue > becomes threshhold size (let us say 1/3rd) full, then we can perform > sorting and merging and issue flush hints. Which means that a significant portion of the writes won't be able to be collapsed, since only a random 1/3 of the buffers is sorted together. > Basically, I think this can lead to lesser merging of neighbouring > writes, but might not hurt if sync_file_range() API is cheap. The cost of writing out data doess correspond heavily with the number of random writes - which is what you get if you reduce the number of neighbouring writes. Greetings, Andres Freund
> On 2016-01-12 19:17:49 +0530, Amit Kapila wrote:
> > Why can't we do it at larger intervals (relative to total amount of writes)?
> > To explain, what I have in mind, let us assume that checkpoint interval
> > is longer (10 mins) and in the mean time all the writes are being done
> > by bgwriter
>
> But that's not the scenario with the regression here, so I'm not sure
> why you're bringing it up?
>
> And if we're flushing significant portion of the writes, how does that
> avoid the performance problem pointed out two messages upthread? Where
> sorting leads to flushing highly contended buffers together, leading to
> excessive wal flushing?
>
>
> But more importantly, unless you also want to delay the writes
> themselves, leaving that many dirty buffers in the kernel page cache
> will bring back exactly the type of stalls (where the kernel flushes all
> the pending dirty data in a short amount of time) we're trying to avoid
> with the forced flushing. So doing flushes in a large patches is
> something we really fundamentally do *not* want!
>
> > which it registers in shared memory so that later checkpoint
> > can perform corresponding fsync's, now when the request queue
> > becomes threshhold size (let us say 1/3rd) full, then we can perform
> > sorting and merging and issue flush hints.
>
> Which means that a significant portion of the writes won't be able to be
> collapsed, since only a random 1/3 of the buffers is sorted together.
>
>
> > Basically, I think this can lead to lesser merging of neighbouring
> > writes, but might not hurt if sync_file_range() API is cheap.
>
> The cost of writing out data doess correspond heavily with the number of
> random writes - which is what you get if you reduce the number of
> neighbouring writes.
>
Hello Andres, >> Argh! This is a key point: the sort/flush is designed to help HDDs, and >> would have limited effect on SSDs, and it seems that you are showing that >> the effect is in fact negative on SSDs, too bad:-( > > As you quoted, I could reproduce the slowdown both with SSDs *and* with > rotating disks. Ok, once again I misunderstood. So you have a regression on HDD with the settings you pointed out, I can try that. >> On SSDs, the linux IO scheduler works quite well, so this is a place where I >> would consider simply disactivating flushing and/or sorting. > > Not my experience. In different scenarios, primarily with a large > shared_buffers fitting the whole hot working set, the patch > significantly improves performance. Good! That would be what I expected, but I have no way to test that. >>> postgres-ckpt14 \ >>> -D /srv/temp/pgdev-dev-800/ \ >>> -c maintenance_work_mem=2GB \ >>> -c fsync=on \ >>> -c synchronous_commit=off \ >> >> I'm not sure I like this one. I guess the intention is to focus on >> checkpointer writes and reduce the impact of WAL writes. Why not. > > Now sure what you mean? s_c = off is *very* frequent in the field. Too bad, because for me it is really disactivating the D of ACID... I think that this setting would not issue the "sync" calls on the WAL file, which means that the impact of WAL writing is somehow reduced and random writes (more or less for each transaction) is switched to sequential writes by the IO scheduler. >>> My laptop 1 EVO 840, 1 i7-4800MQ, 16GB ram: >>> master: >>> scaling factor: 800 >> >> The DB is probably about 12GB, so it fits in memory in the end, meaning that >> there should be only write activity after some time? So this is not really >> the case where it does not fit in memory, but it is large enough to get >> mostly random IOs both in read & write, so why not. > > Doesn't really fit into ram - shared buffers uses some space (which will > be double buffered) and the xlog will use some more. Hmmm. My understanding is that you are really using about 6GB of shared buffer data in a run, plus some write only stuff... xlog is flush/synced constantly and never read again, I would be surprise that it has a significant memory impact. >>> ckpt-14 (flushing by backends disabled): >> >> Is this comment refering to "synchronous_commit = off"? >> I guess this is the same on master above, even if not written? > > No, what I mean by that is that I didn't active flushing writes in > backends - I'm not sure that I understand. What is the actual corresponding directive in the configuration file? >>> As you can see there's roughly a 30% performance regression on the >>> slower SSD and a ~9% on the faster one. HDD results are similar (but I >>> can't repeat on the laptop right now since the 2nd hdd is now an SSD). >> >> Ok, that is what I would have expected, the larger the database, the smaller >> the impact of sorting & flushin on SSDs. > > Again: "HDD results are similar". I primarily tested on a 4 disk raid10 > of 4 disks, and a raid0 of 20 disks. I guess similar but with a much lower tps. Anyway I can try that. -- Fabien.
Hi Fabien, On 2016-01-11 14:45:16 +0100, Andres Freund wrote: > I measured it in a different number of cases, both on SSDs and spinning > rust. I just reproduced it with: > > postgres-ckpt14 \ > -D /srv/temp/pgdev-dev-800/ \ > -c maintenance_work_mem=2GB \ > -c fsync=on \ > -c synchronous_commit=off \ > -c shared_buffers=2GB \ > -c wal_level=hot_standby \ > -c max_wal_senders=10 \ > -c max_wal_size=100GB \ > -c checkpoint_timeout=30s What kernel, filesystem and filesystem option did you measure with? I was/am using ext4, and it turns out that, when abling flushing, the results are hugely dependant on barriers=on/off, with the latter making flushing rather advantageous. Additionally data=ordered/writeback makes measureable difference too. Reading kernel sources trying to understand some more of the performance impact. Greetings, Andres Freund
> Hi Fabien, Hello Tomas. > On 2016-01-11 14:45:16 +0100, Andres Freund wrote: >> I measured it in a different number of cases, both on SSDs and spinning >> rust. I just reproduced it with: >> >> postgres-ckpt14 \ >> -D /srv/temp/pgdev-dev-800/ \ >> -c maintenance_work_mem=2GB \ >> -c fsync=on \ >> -c synchronous_commit=off \ >> -c shared_buffers=2GB \ >> -c wal_level=hot_standby \ >> -c max_wal_senders=10 \ >> -c max_wal_size=100GB \ >> -c checkpoint_timeout=30s > > What kernel, filesystem and filesystem option did you measure with? Andres did these measures, not me, so I do not know. > I was/am using ext4, and it turns out that, when abling flushing, the > results are hugely dependant on barriers=on/off, with the latter making > flushing rather advantageous. Additionally data=ordered/writeback makes > measureable difference too. These are very interesting tests, I'm looking forward to have a look at the results. The fact that these options change performance is expected. Personnaly the test I submitted on the thread used ext4 with default mount options plus "relatime". If I had a choice, I would tend to take the safest options, because the point of a database is to keep data safe. That's why I'm not found of the "synchronous_commit=off" chosen above. > Reading kernel sources trying to understand some more of the performance > impact. Wow! -- Fabien.
Hello Andres, > Hello Tomas. Ooops, sorry Andres, I mixed up the thread in my head so was not clear who was asking the questions to whom. >> I was/am using ext4, and it turns out that, when abling flushing, the >> results are hugely dependant on barriers=on/off, with the latter making >> flushing rather advantageous. Additionally data=ordered/writeback makes >> measureable difference too. > > These are very interesting tests, I'm looking forward to have a look at the > results. > > The fact that these options change performance is expected. Personnaly the > test I submitted on the thread used ext4 with default mount options plus > "relatime". I confirm that: nothing special but "relatime" on ext4 on my test host. > If I had a choice, I would tend to take the safest options, because the point > of a database is to keep data safe. That's why I'm not found of the > "synchronous_commit=off" chosen above. "found" -> "fond". I confirm this opinion. If you have BBU on you disk/raid system probably playing with some of these options is safe, though. Not the case with my basic hardware. -- Fabien.
Hello Andres, > I measured it in a different number of cases, both on SSDs and spinning > rust. I just reproduced it with: > > postgres-ckpt14 \ > -D /srv/temp/pgdev-dev-800/ \ > -c maintenance_work_mem=2GB \ > -c fsync=on \ > -c synchronous_commit=off \ > -c shared_buffers=2GB \ > -c wal_level=hot_standby \ > -c max_wal_senders=10 \ > -c max_wal_size=100GB \ > -c checkpoint_timeout=30s > > Using a fresh cluster each time (copied from a "template" to save time) > and using > pgbench -M prepared -c 16 -j 16 -T 300 -P 1 I'm running some tests similar to those above... Do you do some warmup when testing? I guess the answer is "no". I understand that you have 8 cores/16 threads on your host? Loading scale 800 data for 300 seconds tests takes much more than 300 seconds (init takes ~360 seconds, vacuum & index are slow). With 30 seconds checkpoint cycles and without any warmup, I feel that these tests are really on the very short (too short) side, so I'm not sure how much I can trust such results as significant. The data I reported were with more real life like parameters. Anyway, I'll have some results to show with a setting more or less similar to yours. -- Fabien.
On 2016-01-16 10:01:25 +0100, Fabien COELHO wrote:
>
> Hello Andres,
>
> >I measured it in a different number of cases, both on SSDs and spinning
> >rust. I just reproduced it with:
> >
> >postgres-ckpt14 \
> > -D /srv/temp/pgdev-dev-800/ \
> > -c maintenance_work_mem=2GB \
> > -c fsync=on \
> > -c synchronous_commit=off \
> > -c shared_buffers=2GB \
> > -c wal_level=hot_standby \
> > -c max_wal_senders=10 \
> > -c max_wal_size=100GB \
> > -c checkpoint_timeout=30s
> >
> >Using a fresh cluster each time (copied from a "template" to save time)
> >and using
> >pgbench -M prepared -c 16 -j 16 -T 300 -P 1
So, I've analyzed the problem further, and I think I found something
rater interesting. I'd profiled the kernel looking where it blocks in
the IO request queues, and found that the wal writer was involved
surprisingly often.
So, in a workload where everything (checkpoint, bgwriter, backend
writes) is flushed: 2995 tps
After I kill the wal writer with -STOP: 10887 tps
Stracing the wal writer shows:
17:29:02.001517 --- SIGUSR1 {si_signo=SIGUSR1, si_code=SI_USER, si_pid=17857, si_uid=1000} ---
17:29:02.001538 rt_sigreturn({mask=[]}) = 0
17:29:02.001582 read(8, 0x7ffea6b6b200, 16) = -1 EAGAIN (Resource temporarily unavailable)
17:29:02.001615 write(3, "\210\320\5\0\1\0\0\0\0@\330_/\0\0\0w\f\0\0\0\0\0\0\0\4\0\2\t\30\0\372"..., 49152) = 49152
17:29:02.001671 fdatasync(3) = 0
17:29:02.005022 --- SIGUSR1 {si_signo=SIGUSR1, si_code=SI_USER, si_pid=17825, si_uid=1000} ---
17:29:02.005043 rt_sigreturn({mask=[]}) = 0
17:29:02.005081 read(8, 0x7ffea6b6b200, 16) = -1 EAGAIN (Resource temporarily unavailable)
17:29:02.005111 write(3, "\210\320\5\0\1\0\0\0\0\0\331_/\0\0\0\7\26\0\0\0\0\0\0T\251\0\0\0\0\0\0"..., 8192) = 8192
17:29:02.005147 fdatasync(3) = 0
17:29:02.008688 --- SIGUSR1 {si_signo=SIGUSR1, si_code=SI_USER, si_pid=17866, si_uid=1000} ---
17:29:02.008705 rt_sigreturn({mask=[]}) = 0
17:29:02.008730 read(8, 0x7ffea6b6b200, 16) = -1 EAGAIN (Resource temporarily unavailable)
17:29:02.008757 write(3, "\210\320\5\0\1\0\0\0\0 \331_/\0\0\0\267\30\0\0\0\0\0\0 "..., 98304) = 98304
17:29:02.008822 fdatasync(3) = 0
17:29:02.016125 --- SIGUSR1 {si_signo=SIGUSR1, si_code=SI_USER, si_pid=17865, si_uid=1000} ---
17:29:02.016141 rt_sigreturn({mask=[]}) = 0
17:29:02.016174 read(8, 0x7ffea6b6b200, 16) = -1 EAGAIN (Resource temporarily unavailable)
17:29:02.016204 write(3, "\210\320\5\0\1\0\0\0\0\240\332_/\0\0\0s\5\0\0\0\0\0\0\t\30\0\2|8\2u"..., 57344) = 57344
17:29:02.016281 fdatasync(3) = 0
17:29:02.019181 --- SIGUSR1 {si_signo=SIGUSR1, si_code=SI_USER, si_pid=17865, si_uid=1000} ---
17:29:02.019199 rt_sigreturn({mask=[]}) = 0
17:29:02.019226 read(8, 0x7ffea6b6b200, 16) = -1 EAGAIN (Resource temporarily unavailable)
17:29:02.019249 write(3, "\210\320\5\0\1\0\0\0\0\200\333_/\0\0\0\307\f\0\0\0\0\0\0 "..., 73728) = 73728
17:29:02.019355 fdatasync(3) = 0
17:29:02.022680 --- SIGUSR1 {si_signo=SIGUSR1, si_code=SI_USER, si_pid=17865, si_uid=1000} ---
17:29:02.022696 rt_sigreturn({mask=[]}) = 0
I.e. we're fdatasync()ing small amount of pages. Roughly 500 times a
second. As soon as the wal writer is stopped, it's much bigger chunks,
on the order of 50-130 pages. And, not that surprisingly, that improves
performance, because there's far fewer cache flushes submitted to the
hardware.
> I'm running some tests similar to those above...
> Do you do some warmup when testing? I guess the answer is "no".
Doesn't make a difference here, I tried both. As long as before/after
benchmarks start from the same state...
> I understand that you have 8 cores/16 threads on your host?
On one of them, 4 cores/8 threads on the laptop.
> Loading scale 800 data for 300 seconds tests takes much more than 300
> seconds (init takes ~360 seconds, vacuum & index are slow). With 30 seconds
> checkpoint cycles and without any warmup, I feel that these tests are really
> on the very short (too short) side, so I'm not sure how much I can trust
> such results as significant. The data I reported were with more real life
> like parameters.
I see exactly the same with 300s or 1000s checkpoint cycles, it just
takes a lot longer to repeat. They're also similar (although obviously
both before/after patch are higher) if I disable full_page_writes,
thereby eliminating a lot of other IO.
Andres
<Oops, wrong "From" again, resent> >>> I measured it in a different number of cases, both on SSDs and spinning >>> rust. I just reproduced it with: >>> >>> postgres-ckpt14 \ >>> -D /srv/temp/pgdev-dev-800/ \ >>> -c maintenance_work_mem=2GB \ >>> -c fsync=on \ >>> -c synchronous_commit=off \ >>> -c shared_buffers=2GB \ >>> -c wal_level=hot_standby \ >>> -c max_wal_senders=10 \ >>> -c max_wal_size=100GB \ >>> -c checkpoint_timeout=30s >>> >>> Using a fresh cluster each time (copied from a "template" to save time) >>> and using >>> pgbench -M prepared -c 16 -j 16 -T 300 -P 1 I must say that I have not succeeded in reproducing any significant regression up to now on an HDD. I'm running some more tests again because I had left out some options above that I thought were non essential. I have deep problems with the 30-second checkpoint tests: basically the checkpoints take much more than 30 seconds to complete, the system is not stable, the 300 seconds runs last more than 900 seconds because the clients are stuck a long time. The overall behavior is appaling as most of the time is spent in IO panic at 0 tps. Also, the performance level is around 160 tps on HDDs, which make sense to me for a 7200 rpm HDD capable of about x00 random writes per second. It seems to me that you reported much better performance on HDD, but I cannot really see how this would be possible if data are indeed writen to disk. Any idea? Also, what is the very precise postgres version & patch used in your tests on HDDs? > both before/after patch are higher) if I disable full_page_writes, > thereby eliminating a lot of other IO. Maybe this is an explanation.... -- Fabien.
On 2016-01-19 10:27:31 +0100, Fabien COELHO wrote: > Also, the performance level is around 160 tps on HDDs, which make sense to > me for a 7200 rpm HDD capable of about x00 random writes per second. It > seems to me that you reported much better performance on HDD, but I cannot > really see how this would be possible if data are indeed writen to disk. Any > idea? synchronous_commit = off does make a significant difference.
> synchronous_commit = off does make a significant difference. Sure, but I had thought about that and kept this one... I think I found one possible culprit: I automatically wrote 300 seconds for checkpoint_timeout, instead of 30 seconds in your settings. I'll have to rerun the tests with this (unreasonnable) figure to check whether I really get a regression. Other tests I ran with "reasonnable" settings on a large (scale=800) db did not show any significant performance regression, up to know. -- Fabien.
On 2016-01-19 13:34:14 +0100, Fabien COELHO wrote: > > >synchronous_commit = off does make a significant difference. > > Sure, but I had thought about that and kept this one... But why are you then saying this is fundamentally limited to 160 xacts/sec? > I think I found one possible culprit: I automatically wrote 300 seconds for > checkpoint_timeout, instead of 30 seconds in your settings. I'll have to > rerun the tests with this (unreasonnable) figure to check whether I really > get a regression. I've not seen meaningful changes in the size of the regression between 30/300s. > Other tests I ran with "reasonnable" settings on a large (scale=800) db did > not show any significant performance regression, up to know. Try running it so that the data set nearly, but not entirely fit into the OS page cache, while definitely not fitting into shared_buffers. The scale=800 just worked for that on my hardware, no idea how it's for yours. That seems to be the point where the effect is the worst.
On Mon, Jan 18, 2016 at 11:39 AM, Andres Freund <andres@anarazel.de> wrote:
> On 2016-01-16 10:01:25 +0100, Fabien COELHO wrote:
>> Hello Andres,
>>
>> >I measured it in a different number of cases, both on SSDs and spinning
>> >rust. I just reproduced it with:
>> >
>> >postgres-ckpt14 \
>> > -D /srv/temp/pgdev-dev-800/ \
>> > -c maintenance_work_mem=2GB \
>> > -c fsync=on \
>> > -c synchronous_commit=off \
>> > -c shared_buffers=2GB \
>> > -c wal_level=hot_standby \
>> > -c max_wal_senders=10 \
>> > -c max_wal_size=100GB \
>> > -c checkpoint_timeout=30s
>> >
>> >Using a fresh cluster each time (copied from a "template" to save time)
>> >and using
>> >pgbench -M prepared -c 16 -j 16 -T 300 -P 1
>
> So, I've analyzed the problem further, and I think I found something
> rater interesting. I'd profiled the kernel looking where it blocks in
> the IO request queues, and found that the wal writer was involved
> surprisingly often.
>
> So, in a workload where everything (checkpoint, bgwriter, backend
> writes) is flushed: 2995 tps
> After I kill the wal writer with -STOP: 10887 tps
>
> Stracing the wal writer shows:
>
> 17:29:02.001517 --- SIGUSR1 {si_signo=SIGUSR1, si_code=SI_USER, si_pid=17857, si_uid=1000} ---
> 17:29:02.001538 rt_sigreturn({mask=[]}) = 0
> 17:29:02.001582 read(8, 0x7ffea6b6b200, 16) = -1 EAGAIN (Resource temporarily unavailable)
> 17:29:02.001615 write(3, "\210\320\5\0\1\0\0\0\0@\330_/\0\0\0w\f\0\0\0\0\0\0\0\4\0\2\t\30\0\372"..., 49152) = 49152
> 17:29:02.001671 fdatasync(3) = 0
> 17:29:02.005022 --- SIGUSR1 {si_signo=SIGUSR1, si_code=SI_USER, si_pid=17825, si_uid=1000} ---
> 17:29:02.005043 rt_sigreturn({mask=[]}) = 0
> 17:29:02.005081 read(8, 0x7ffea6b6b200, 16) = -1 EAGAIN (Resource temporarily unavailable)
> 17:29:02.005111 write(3, "\210\320\5\0\1\0\0\0\0\0\331_/\0\0\0\7\26\0\0\0\0\0\0T\251\0\0\0\0\0\0"..., 8192) = 8192
> 17:29:02.005147 fdatasync(3) = 0
> 17:29:02.008688 --- SIGUSR1 {si_signo=SIGUSR1, si_code=SI_USER, si_pid=17866, si_uid=1000} ---
> 17:29:02.008705 rt_sigreturn({mask=[]}) = 0
> 17:29:02.008730 read(8, 0x7ffea6b6b200, 16) = -1 EAGAIN (Resource temporarily unavailable)
> 17:29:02.008757 write(3, "\210\320\5\0\1\0\0\0\0 \331_/\0\0\0\267\30\0\0\0\0\0\0 "..., 98304) = 98304
> 17:29:02.008822 fdatasync(3) = 0
> 17:29:02.016125 --- SIGUSR1 {si_signo=SIGUSR1, si_code=SI_USER, si_pid=17865, si_uid=1000} ---
> 17:29:02.016141 rt_sigreturn({mask=[]}) = 0
> 17:29:02.016174 read(8, 0x7ffea6b6b200, 16) = -1 EAGAIN (Resource temporarily unavailable)
> 17:29:02.016204 write(3, "\210\320\5\0\1\0\0\0\0\240\332_/\0\0\0s\5\0\0\0\0\0\0\t\30\0\2|8\2u"..., 57344) = 57344
> 17:29:02.016281 fdatasync(3) = 0
> 17:29:02.019181 --- SIGUSR1 {si_signo=SIGUSR1, si_code=SI_USER, si_pid=17865, si_uid=1000} ---
> 17:29:02.019199 rt_sigreturn({mask=[]}) = 0
> 17:29:02.019226 read(8, 0x7ffea6b6b200, 16) = -1 EAGAIN (Resource temporarily unavailable)
> 17:29:02.019249 write(3, "\210\320\5\0\1\0\0\0\0\200\333_/\0\0\0\307\f\0\0\0\0\0\0 "..., 73728) = 73728
> 17:29:02.019355 fdatasync(3) = 0
> 17:29:02.022680 --- SIGUSR1 {si_signo=SIGUSR1, si_code=SI_USER, si_pid=17865, si_uid=1000} ---
> 17:29:02.022696 rt_sigreturn({mask=[]}) = 0
>
> I.e. we're fdatasync()ing small amount of pages. Roughly 500 times a
> second. As soon as the wal writer is stopped, it's much bigger chunks,
> on the order of 50-130 pages. And, not that surprisingly, that improves
> performance, because there's far fewer cache flushes submitted to the
> hardware.
This seems like a problem with the WAL writer quite independent of
anything else. It seems likely to be inadvertent fallout from this
patch:
Author: Simon Riggs <simon@2ndQuadrant.com>
Branch: master Release: REL9_2_BR [4de82f7d7] 2011-11-13 09:00:57 +0000
Wakeup WALWriter as needed for asynchronous commit performance. Previously we waited for wal_writer_delay before
flushingWAL. Now we also wake WALWriter as soon as a WAL buffer page has filled. Significant effect observed on
performanceof asynchronous commits by Robert Haas, attributed to the ability to set hint bits on tuples earlier and
soreducing contention caused by clog lookups.
If I understand correctly, prior to that commit, WAL writer woke up 5
times per second and flushed just that often (unless you changed the
default settings). But as the commit message explained, that turned
out to suck - you could make performance go up very significantly by
radically decreasing wal_writer_delay. This commit basically lets it
flush at maximum velocity - as fast as we finish one flush, we can
start the next. That must have seemed like a win at the time from the
way the commit message was written, but you seem to now be seeing the
opposite effect, where performance is suffering because flushes are
too frequent rather than too infrequent. I wonder if there's an ideal
flush rate and what it is, and how much it depends on what hardware
you have got.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
>>> synchronous_commit = off does make a significant difference. >> >> Sure, but I had thought about that and kept this one... > > But why are you then saying this is fundamentally limited to 160 > xacts/sec? I'm just saying that the tested load generates mostly random IOs (probably on average over 1 page per transaction), random IOs are very slow on a HDD, so I do not expect great tps. >> I think I found one possible culprit: I automatically wrote 300 seconds for >> checkpoint_timeout, instead of 30 seconds in your settings. I'll have to >> rerun the tests with this (unreasonnable) figure to check whether I really >> get a regression. > > I've not seen meaningful changes in the size of the regression between 30/300s. At 300 seconds (5 minutes) the checkpoints of the accumulated takes 15-25 minutes, during which the database is mostly offline, and there is no clear difference with/without sort+flush. >> Other tests I ran with "reasonnable" settings on a large (scale=800) db did >> not show any significant performance regression, up to now. > > Try running it so that the data set nearly, but not entirely fit into > the OS page cache, while definitely not fitting into shared_buffers. The > scale=800 just worked for that on my hardware, no idea how it's for yours. > That seems to be the point where the effect is the worst. I have 16GB memory on the tested host, same as your hardware I think, so I use scale 800 => 12GB at the beginning of the run. Not sure it fits the bill as I think it fits in memory, so the load is mostly write and no/very few reads. I'll also try with scale 1000. -- Fabien.
On 2016-01-19 12:58:38 -0500, Robert Haas wrote: > This seems like a problem with the WAL writer quite independent of > anything else. It seems likely to be inadvertent fallout from this > patch: > > Author: Simon Riggs <simon@2ndQuadrant.com> > Branch: master Release: REL9_2_BR [4de82f7d7] 2011-11-13 09:00:57 +0000 > > Wakeup WALWriter as needed for asynchronous commit performance. > Previously we waited for wal_writer_delay before flushing WAL. Now > we also wake WALWriter as soon as a WAL buffer page has filled. > Significant effect observed on performance of asynchronous commits > by Robert Haas, attributed to the ability to set hint bits on tuples > earlier and so reducing contention caused by clog lookups. In addition to that the "powersaving" effort also plays a role - without the latch we'd not wake up at any meaningful rate at all atm. > If I understand correctly, prior to that commit, WAL writer woke up 5 > times per second and flushed just that often (unless you changed the > default settings). But as the commit message explained, that turned > out to suck - you could make performance go up very significantly by > radically decreasing wal_writer_delay. This commit basically lets it > flush at maximum velocity - as fast as we finish one flush, we can > start the next. That must have seemed like a win at the time from the > way the commit message was written, but you seem to now be seeing the > opposite effect, where performance is suffering because flushes are > too frequent rather than too infrequent. I wonder if there's an ideal > flush rate and what it is, and how much it depends on what hardware > you have got. I think the problem isn't really that it's flushing too much WAL in total, it's that it's flushing WAL in a too granular fashion. I suspect we want something where we attempt a minimum number of flushes per second (presumably tied to wal_writer_delay) and, once exceeded, a minimum number of pages per flush. I think we even could continue to write() the data at the same rate as today, we just would need to reduce the number of fdatasync()s we issue. And possibly could make the eventual fdatasync()s cheaper by hinting the kernel to write them out earlier. Now the question what the minimum number of pages we want to flush for (setting wal_writer_delay triggered ones aside) isn't easy to answer. A simple model would be to statically tie it to the size of wal_buffers; say, don't flush unless at least 10% of XLogBuffers have been written since the last flush. More complex approaches would be to measure the continuous WAL writeout rate. By tying it to both a minimum rate under activity (ensuring things go to disk fast) and a minimum number of pages to sync (ensuring a reasonable number of cache flush operations) we should be able to mostly accomodate the different types of workloads. I think. Andres
On 2016-01-19 22:43:21 +0100, Andres Freund wrote: > On 2016-01-19 12:58:38 -0500, Robert Haas wrote: > > This seems like a problem with the WAL writer quite independent of > > anything else. It seems likely to be inadvertent fallout from this > > patch: > > > > Author: Simon Riggs <simon@2ndQuadrant.com> > > Branch: master Release: REL9_2_BR [4de82f7d7] 2011-11-13 09:00:57 +0000 > > > > Wakeup WALWriter as needed for asynchronous commit performance. > > Previously we waited for wal_writer_delay before flushing WAL. Now > > we also wake WALWriter as soon as a WAL buffer page has filled. > > Significant effect observed on performance of asynchronous commits > > by Robert Haas, attributed to the ability to set hint bits on tuples > > earlier and so reducing contention caused by clog lookups. > > In addition to that the "powersaving" effort also plays a role - without > the latch we'd not wake up at any meaningful rate at all atm. The relevant thread is at http://archives.postgresql.org/message-id/CA%2BTgmoaCr3kDPafK5ygYDA9mF9zhObGp_13q0XwkEWsScw6h%3Dw%40mail.gmail.com what I didn't remember is that I voiced concern back then about exactly this: http://archives.postgresql.org/message-id/201112011518.29964.andres%40anarazel.de ;) Simon: CCed you, as the author of the above commit. Quick summary: The frequent wakeups of wal writer can lead to significant performance regressions in workloads that are bigger than shared_buffers, because the super-frequent fdatasync()s by the wal writer slow down concurrent writes (bgwriter, checkpointer, individual backend writes) dramatically. To the point that SIGSTOPing the wal writer gets a pgbench workload from 2995 to 10887 tps. The reasons fdatasyncs cause a slow down is that it prevents real use of queuing to the storage devices. On 2016-01-19 22:43:21 +0100, Andres Freund wrote: > On 2016-01-19 12:58:38 -0500, Robert Haas wrote: > > If I understand correctly, prior to that commit, WAL writer woke up 5 > > times per second and flushed just that often (unless you changed the > > default settings). But as the commit message explained, that turned > > out to suck - you could make performance go up very significantly by > > radically decreasing wal_writer_delay. This commit basically lets it > > flush at maximum velocity - as fast as we finish one flush, we can > > start the next. That must have seemed like a win at the time from the > > way the commit message was written, but you seem to now be seeing the > > opposite effect, where performance is suffering because flushes are > > too frequent rather than too infrequent. I wonder if there's an ideal > > flush rate and what it is, and how much it depends on what hardware > > you have got. > > I think the problem isn't really that it's flushing too much WAL in > total, it's that it's flushing WAL in a too granular fashion. I suspect > we want something where we attempt a minimum number of flushes per > second (presumably tied to wal_writer_delay) and, once exceeded, a > minimum number of pages per flush. I think we even could continue to > write() the data at the same rate as today, we just would need to reduce > the number of fdatasync()s we issue. And possibly could make the > eventual fdatasync()s cheaper by hinting the kernel to write them out > earlier. > > Now the question what the minimum number of pages we want to flush for > (setting wal_writer_delay triggered ones aside) isn't easy to answer. A > simple model would be to statically tie it to the size of wal_buffers; > say, don't flush unless at least 10% of XLogBuffers have been written > since the last flush. More complex approaches would be to measure the > continuous WAL writeout rate. > > By tying it to both a minimum rate under activity (ensuring things go to > disk fast) and a minimum number of pages to sync (ensuring a reasonable > number of cache flush operations) we should be able to mostly accomodate > the different types of workloads. I think. This unfortunately leaves out part of the reasoning for the above commit: We want WAL to be flushed fast, so we immediately can set hint bits. One, relatively extreme, approach would be to continue *writing* WAL in the background writer as today, but use rules like suggested above guiding the actual flushing. Additionally using operations like sync_file_range() (and equivalents on other OSs). Then, to address the regression of SetHintBits() having to bail out more often, actually trigger a WAL flush whenever WAL is already written, but not flushed. has the potential to be bad in a number of other cases tho :( Andres
On 2016-01-20 11:13:26 +0100, Andres Freund wrote:
> On 2016-01-19 22:43:21 +0100, Andres Freund wrote:
> > On 2016-01-19 12:58:38 -0500, Robert Haas wrote:
> > I think the problem isn't really that it's flushing too much WAL in
> > total, it's that it's flushing WAL in a too granular fashion. I suspect
> > we want something where we attempt a minimum number of flushes per
> > second (presumably tied to wal_writer_delay) and, once exceeded, a
> > minimum number of pages per flush. I think we even could continue to
> > write() the data at the same rate as today, we just would need to reduce
> > the number of fdatasync()s we issue. And possibly could make the
> > eventual fdatasync()s cheaper by hinting the kernel to write them out
> > earlier.
> >
> > Now the question what the minimum number of pages we want to flush for
> > (setting wal_writer_delay triggered ones aside) isn't easy to answer. A
> > simple model would be to statically tie it to the size of wal_buffers;
> > say, don't flush unless at least 10% of XLogBuffers have been written
> > since the last flush. More complex approaches would be to measure the
> > continuous WAL writeout rate.
> >
> > By tying it to both a minimum rate under activity (ensuring things go to
> > disk fast) and a minimum number of pages to sync (ensuring a reasonable
> > number of cache flush operations) we should be able to mostly accomodate
> > the different types of workloads. I think.
>
> This unfortunately leaves out part of the reasoning for the above
> commit: We want WAL to be flushed fast, so we immediately can set hint
> bits.
>
> One, relatively extreme, approach would be to continue *writing* WAL in
> the background writer as today, but use rules like suggested above
> guiding the actual flushing. Additionally using operations like
> sync_file_range() (and equivalents on other OSs). Then, to address the
> regression of SetHintBits() having to bail out more often, actually
> trigger a WAL flush whenever WAL is already written, but not flushed.
> has the potential to be bad in a number of other cases tho :(
Chatting on IM with Heikki, I noticed that we're pretty pessimistic in
SetHintBits(). Namely we don't set the bit if XLogNeedsFlush(commitLSN),
because we can't easily set the LSN. But, it's actually fairly common
that the pages LSN is already newer than the commitLSN - in which case
we, afaics, just can go ahead and set the hint bit, no?
So, instead of if (XLogNeedsFlush(commitLSN) && BufferIsPermanent(buffer) return; /* not
flushedyet, so don't set hint */
we do if (BufferIsPermanent(buffer) && XLogNeedsFlush(commitLSN) && BufferGetLSNAtomic(buffer) < commitLSN)
return; /* not flushed yet, so don't set hint */
In my tests with pgbench -s 100, 2GB of shared buffers, that's recovers
a large portion of the hint writes that we currently skip.
Right now, on my laptop, I get (-M prepared -c 32 -j 32):
current wal-writer 12827 tps, 95 % IO util, 93 % CPU
no flushing in wal writer * 13185 tps, 46 % IO util, 93 % CPU
no flushing in wal writer & above change 16366 tps, 41 % IO util, 95 % CPU
flushing in wal writer & above change: 14812 tps, 94 % IO util, 95 % CPU
* sometimes the results initially were much lower, with lots of lock contention. Can't figure out why that's only
sometimesthe case. In those cases the results were more like 8967 tps.
these aren't meant as thorough benchmarks, just to provide some
orientation.
Now that solution won't improve every situation, e.g. for a workload
that inserts a lot of rows in one transaction, and only does inserts, it
probably won't do all that much. But it still seems like a pretty good
mitigation strategy. I hope that with a smarter write strategy (getting
that 50% reduction in IO util) and the above we should be ok.
Andres
Andres Freund wrote: > The relevant thread is at > http://archives.postgresql.org/message-id/CA%2BTgmoaCr3kDPafK5ygYDA9mF9zhObGp_13q0XwkEWsScw6h%3Dw%40mail.gmail.com > what I didn't remember is that I voiced concern back then about exactly this: > http://archives.postgresql.org/message-id/201112011518.29964.andres%40anarazel.de > ;) Interesting. If we consider for a minute that part of the cause for the slowdown is slowness in pg_clog, maybe we should reconsider the initial decision to flush as quickly as possible (i.e. adopt a strategy where walwriter sleeps a bit between two flushes) in light of the group-update feature for CLOG being proposed by Amit Kapila in another thread -- it seems that these things might go hand-in-hand. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2016-01-20 12:16:24 -0300, Alvaro Herrera wrote: > Andres Freund wrote: > > > The relevant thread is at > > http://archives.postgresql.org/message-id/CA%2BTgmoaCr3kDPafK5ygYDA9mF9zhObGp_13q0XwkEWsScw6h%3Dw%40mail.gmail.com > > what I didn't remember is that I voiced concern back then about exactly this: > > http://archives.postgresql.org/message-id/201112011518.29964.andres%40anarazel.de > > ;) > > Interesting. If we consider for a minute that part of the cause for the > slowdown is slowness in pg_clog, maybe we should reconsider the initial > decision to flush as quickly as possible (i.e. adopt a strategy where > walwriter sleeps a bit between two flushes) in light of the group-update > feature for CLOG being proposed by Amit Kapila in another thread -- it > seems that these things might go hand-in-hand. I don't think it's strongly related - the contention here is on read access to the clog, not on write access. While Amit's patch will reduce the impact of that a bit, I don't see it making a fundamental difference. Andres
>
> On 2016-01-20 12:16:24 -0300, Alvaro Herrera wrote:
> > Andres Freund wrote:
> >
> > > The relevant thread is at
> > > http://archives.postgresql.org/message-id/CA%2BTgmoaCr3kDPafK5ygYDA9mF9zhObGp_13q0XwkEWsScw6h%3Dw%40mail.gmail.com
> > > what I didn't remember is that I voiced concern back then about exactly this:
> > > http://archives.postgresql.org/message-id/201112011518.29964.andres%40anarazel.de
> > > ;)
> >
> > Interesting. If we consider for a minute that part of the cause for the
> > slowdown is slowness in pg_clog, maybe we should reconsider the initial
> > decision to flush as quickly as possible (i.e. adopt a strategy where
> > walwriter sleeps a bit between two flushes) in light of the group-update
> > feature for CLOG being proposed by Amit Kapila in another thread -- it
> > seems that these things might go hand-in-hand.
>
> I don't think it's strongly related - the contention here is on read
> access to the clog, not on write access.
On 2016-01-21 11:33:15 +0530, Amit Kapila wrote: > On Wed, Jan 20, 2016 at 9:07 PM, Andres Freund <andres@anarazel.de> wrote: > > I don't think it's strongly related - the contention here is on read > > access to the clog, not on write access. > > Aren't reads on clog contended with parallel writes to clog? Sure. But you're not going to beat "no access to the clog" due to hint bits, by making parallel writes a bit better citizens.
On Wed, Jan 20, 2016 at 9:02 AM, Andres Freund <andres@anarazel.de> wrote: > Chatting on IM with Heikki, I noticed that we're pretty pessimistic in > SetHintBits(). Namely we don't set the bit if XLogNeedsFlush(commitLSN), > because we can't easily set the LSN. But, it's actually fairly common > that the pages LSN is already newer than the commitLSN - in which case > we, afaics, just can go ahead and set the hint bit, no? > > So, instead of > if (XLogNeedsFlush(commitLSN) && BufferIsPermanent(buffer) > return; /* not flushed yet, so don't set hint */ > we do > if (BufferIsPermanent(buffer) && XLogNeedsFlush(commitLSN) > && BufferGetLSNAtomic(buffer) < commitLSN) > return; /* not flushed yet, so don't set hint */ > > In my tests with pgbench -s 100, 2GB of shared buffers, that's recovers > a large portion of the hint writes that we currently skip. Dang. That's a really good idea. Although I think you'd probably better revise the comment, since it will otherwise be false. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
This patch got its fair share of reviewer attention this commitfest. Moving to the next one. Andres, if you want to commit ahead of time you're of course encouraged to do so. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, Fabien asked me to post a new version of the checkpoint flushing patch series. While this isn't entirely ready for commit, I think we're getting closer. I don't want to post a full series right now, but my working state is available on http://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/checkpoint-flush git://git.postgresql.org/git/users/andresfreund/postgres.git checkpoint-flush The main changes are that: 1) the significant performance regressions I saw are addressed by changing the wal writer flushing logic 2) The flushing API moved up a couple layers, and now deals with buffer tags, rather than the physical files 3) Writes from checkpoints, bgwriter and files are flushed, configurable by individual GUCs. Without that I still saw thespiked in a lot of circumstances. There's also a more experimental reimplementation of bgwriter, but I'm not sure it's realistic to polish that up within the constraints of 9.6. Regards, Andres
Hi Fabien, On 2016-02-04 16:54:58 +0100, Andres Freund wrote: > I don't want to post a full series right now, but my working state is > available on > http://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/checkpoint-flush > git://git.postgresql.org/git/users/andresfreund/postgres.git checkpoint-flush > > The main changes are that: > 1) the significant performance regressions I saw are addressed by > changing the wal writer flushing logic > 2) The flushing API moved up a couple layers, and now deals with buffer > tags, rather than the physical files > 3) Writes from checkpoints, bgwriter and files are flushed, configurable > by individual GUCs. Without that I still saw the spiked in a lot of circumstances. > > There's also a more experimental reimplementation of bgwriter, but I'm > not sure it's realistic to polish that up within the constraints of 9.6. Any comments before I spend more time polishing this? I'm currently updating docs and comments to actually describe the current state... Andres
Hello Andres, > Any comments before I spend more time polishing this? I'm running tests on various settings, I'll send a report when it is done. Up to now the performance seems as good as with the previous version. > I'm currently updating docs and comments to actually describe the > current state... I did notice the mismatched documentation. I think I would appreciate comments to understand why/how the ringbuffer is used, and more comments in general, so it is fine if you improve this part. Minor details: "typedefs.list" should be updated to WritebackContext. "WritebackContext" is a typedef, "struct" is not needed. I'll look at the code more deeply probably over next weekend. -- Fabien.
On 2016-02-08 19:52:30 +0100, Fabien COELHO wrote: > I think I would appreciate comments to understand why/how the ringbuffer is > used, and more comments in general, so it is fine if you improve this part. I'd suggest to leave out the ringbuffer/new bgwriter parts. I think they'd be committed separately, and probably not in 9.6. Thanks, Andres
>> I think I would appreciate comments to understand why/how the >> ringbuffer is used, and more comments in general, so it is fine if you >> improve this part. > > I'd suggest to leave out the ringbuffer/new bgwriter parts. Ok, so the patch would only onclude the checkpointer stuff. I'll look at this part in detail. -- Fabien.
On February 9, 2016 10:46:34 AM GMT+01:00, Fabien COELHO <coelho@cri.ensmp.fr> wrote: > >>> I think I would appreciate comments to understand why/how the >>> ringbuffer is used, and more comments in general, so it is fine if >you >>> improve this part. >> >> I'd suggest to leave out the ringbuffer/new bgwriter parts. > >Ok, so the patch would only onclude the checkpointer stuff. > >I'll look at this part in detail. Yes, that's the more pressing part. I've seen pretty good results with the new bgwriter, but it's not really worthwhile untilsorting and flushing is in... Andres --- Please excuse brevity and formatting - I am writing this on my mobile phone.
On 2016-02-04 16:54:58 +0100, Andres Freund wrote: > Fabien asked me to post a new version of the checkpoint flushing patch > series. While this isn't entirely ready for commit, I think we're > getting closer. > > I don't want to post a full series right now, but my working state is > available on > http://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/checkpoint-flush > git://git.postgresql.org/git/users/andresfreund/postgres.git checkpoint-flush The first two commits of the series are pretty close to being ready. I'd welcome review of those, and I plan to commit them independently of the rest as they're beneficial independently. The most important bits are the comments and docs of 0002 - they weren't particularly good beforehand, so I had to rewrite a fair bit. 0001: Make SetHintBit() a bit more aggressive, afaics that fixes all the potential regressions of 0002 0002: Fix the overaggressive flushing by the wal writer, by only flushing every wal_writer_delay ms or wal_writer_flush_after bytes. Greetings, Andres Freund
Attachment
On Thu, Feb 11, 2016 at 1:44 PM, Andres Freund <andres@anarazel.de> wrote: > On 2016-02-04 16:54:58 +0100, Andres Freund wrote: >> Fabien asked me to post a new version of the checkpoint flushing patch >> series. While this isn't entirely ready for commit, I think we're >> getting closer. >> >> I don't want to post a full series right now, but my working state is >> available on >> http://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/checkpoint-flush >> git://git.postgresql.org/git/users/andresfreund/postgres.git checkpoint-flush > > The first two commits of the series are pretty close to being ready. I'd > welcome review of those, and I plan to commit them independently of the > rest as they're beneficial independently. The most important bits are > the comments and docs of 0002 - they weren't particularly good > beforehand, so I had to rewrite a fair bit. > > 0001: Make SetHintBit() a bit more aggressive, afaics that fixes all the > potential regressions of 0002 > 0002: Fix the overaggressive flushing by the wal writer, by only > flushing every wal_writer_delay ms or wal_writer_flush_after > bytes. I previously reviewed 0001 and I think it's fine. I haven't reviewed 0002 in detail, but I like the concept. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hello Andres, > 0001: Make SetHintBit() a bit more aggressive, afaics that fixes all the > potential regressions of 0002 > 0002: Fix the overaggressive flushing by the wal writer, by only > flushing every wal_writer_delay ms or wal_writer_flush_after > bytes. I've looked at these patches, especially the whole bench of explanations and comments which is a good source for understanding what is going on in the WAL writer, a part of pg I'm not familiar with. When reading the patch 0002 explanations, I had the following comments: AFAICS, there are several levels of actions when writing things in pg: 0: the thing is written in some internal buffer 1: the buffer is advised to be passed to the OS (hint bits?) 2: the buffer is actually passed to the OS (write, flush) 3: the OS is advised to send the written data to the io subsystem (sync_file_range with SYNC_FILE_RANGE_WRITE) 4: the OS is required to send the written data to the disk (fsync, sync_file_range with SYNC_FILE_RANGE_WAIT_AFTER) It is not clear when reading the text which level is discussed. In particular, I'm not sure that "flush" refers to level 2, which is misleading. When reading the description, I'm rather under the impression that it is about level 4, but then if actual fsync are performed every 200 ms then the tps would be very low... After more considerations, my final understanding is that this behavior only occurs with "asynchronous commit", aka a situation when COMMIT does not wait for data to be really fsynced, but the fsync is to occur within some delay so it will not be too far away, some kind of compromise for performance where commits can be lost. Now all this is somehow alien to me because the whole point of committing is having the data to disk, and I would not consider a database to be safe if commit does not imply fsync, but I understand that people may have to compromise for performance. Is my understanding right? -- Fabien.
On 2016-02-11 19:44:25 +0100, Andres Freund wrote: > The first two commits of the series are pretty close to being ready. I'd > welcome review of those, and I plan to commit them independently of the > rest as they're beneficial independently. The most important bits are > the comments and docs of 0002 - they weren't particularly good > beforehand, so I had to rewrite a fair bit. > > 0001: Make SetHintBit() a bit more aggressive, afaics that fixes all the > potential regressions of 0002 > 0002: Fix the overaggressive flushing by the wal writer, by only > flushing every wal_writer_delay ms or wal_writer_flush_after > bytes. I've pushed these after some more polishing, now working on the next two. Greetings, Andres Freund
On 2016-02-18 09:51:20 +0100, Fabien COELHO wrote: > I've looked at these patches, especially the whole bench of explanations and > comments which is a good source for understanding what is going on in the > WAL writer, a part of pg I'm not familiar with. > > When reading the patch 0002 explanations, I had the following comments: > > AFAICS, there are several levels of actions when writing things in pg: > > 0: the thing is written in some internal buffer > > 1: the buffer is advised to be passed to the OS (hint bits?) Hint bits aren't related to OS writes. They're about information like 'this transaction committed' or 'all tuples on this page are visible'. > 2: the buffer is actually passed to the OS (write, flush) > > 3: the OS is advised to send the written data to the io subsystem > (sync_file_range with SYNC_FILE_RANGE_WRITE) > > 4: the OS is required to send the written data to the disk > (fsync, sync_file_range with SYNC_FILE_RANGE_WAIT_AFTER) We can't easily rely on sync_file_range(SYNC_FILE_RANGE_WAIT_AFTER) - the guarantees it gives aren't well defined, and actually changed across releases. 0002 is about something different, it's about the WAL writer. Which writes WAL to disk, so individual backends don't have to. It does so in the background every wal_writer_delay or whenever a tranasaction asynchronously commits. The reason this interacts with checkpoint flushing is that, when we flush writes on a regular pace, the writes by the checkpointer happen inbetween the very frequent writes/fdatasync() by the WAL writer. That means the disk's caches are flushed every fdatasync() - which causes considerable slowdowns. On a decent SSD the WAL writer, before this patch, often did 500-1000 fdatasync()s a second; the regular sync_file_range calls slowed down things too much. That's what caused the large regression when using checkpoint sorting/flushing with synchronous_commit=off. With that fixed - often a performance improvement on its own - I don't see that regression anymore. > After more considerations, my final understanding is that this behavior only > occurs with "asynchronous commit", aka a situation when COMMIT does not wait > for data to be really fsynced, but the fsync is to occur within some delay > so it will not be too far away, some kind of compromise for performance > where commits can be lost. Right. > Now all this is somehow alien to me because the whole point of committing is > having the data to disk, and I would not consider a database to be safe if > commit does not imply fsync, but I understand that people may have to > compromise for performance. It's obviously not applicable for every scenario, but in a *lot* of real-world scenario a sub-second loss window doesn't have any actual negative implications. Andres
Hello Andres, > I don't want to post a full series right now, but my working state is > available on > http://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/checkpoint-flush > git://git.postgresql.org/git/users/andresfreund/postgres.git checkpoint-flush Below the results of a lot of tests with pgbench to exercise checkpoints on the above version when fetched. Overall comments: - sorting & flushing is basically always a winner - benchmarking with short runs on large databases isa bad idea the results are very different if a longer run is used (see andres00b vs andres00c) # HOST/SOFT 16 GB 2 cpu 8 cores 200 GB RAID1 HDD, ext4 FS Ubuntu 12.04 LTS (precise) # ABOUT THE REPORTED STATISTICS tps: is the "excluding connection" time tps, the higher the better 1-sec tps: average of measured per-second tps note- it should be the same as the previous one, but due to various hazards in the trace, especially when thingsgo badly and pg get stuck, it may be different. Such hazard also explain why there may be some non-integertps reported for some seconds. stddev: standard deviation, the lower the better the five figures in bracket givea feel of the distribution: - min: minimal per-second tps seen in the trace - q1: first quarter per-second tps seen inthe trace - med: median per-second tps seen in the trace - q3: third quarter per-second tps seen in the trace - max: maximalper-second tps seen in the trace the last percentage dubbed "<=10.0" is percent of seconds where performance isbelow 10 tps: this measures of how unresponsive pg was during the run ###### TINY2 pgbench -M prepared -N -P 1 -T 4000 -j 2 -c 4 with scale = 10 (~ 200 MB) postgresql.conf: shared_buffers = 1GB max_wal_size = 1GB checkpoint_timeout = 300s checkpoint_completion_target= 0.8 checkpoint_flush_after = { none, 0, 32, 64 } opts # | tps / 1-sec tps ± stddev [ min q1 med q2 max ] <=10.0 head 0 | 2574.1 / 2574.3 ± 367.4 [229.0, 2570.1, 2721.9, 2746.1, 2857.2] 0.0% 1 | 2575.0 / 2575.1 ± 359.3 [ 1.0, 2595.9,2712.0, 2732.0, 2847.0] 0.1% 2 | 2602.6 / 2602.7 ± 359.5 [ 54.0, 2607.1, 2735.1, 2768.1, 2908.0] 0.0% 0 0 | 2583.2 / 2583.7 ± 296.4 [164.0, 2580.0, 2690.0, 2717.1, 2833.8] 0.0% 1 | 2596.6 / 2596.9 ± 307.4 [296.0, 2590.5,2707.9, 2738.0, 2847.8] 0.0% 2 | 2604.8 / 2605.0 ± 300.5 [110.9, 2619.1, 2712.4, 2738.1, 2849.1] 0.0% 32 0 | 2625.5 / 2625.5 ± 250.5 [ 1.0, 2645.9, 2692.0, 2719.9, 2839.0] 0.1% 1 | 2630.2 / 2630.2 ± 243.1 [301.8, 2654.9,2697.2, 2726.0, 2837.4] 0.0% 2 | 2648.3 / 2648.4 ± 236.7 [570.1, 2664.4, 2708.9, 2739.0, 2844.9] 0.0% 64 0 | 2587.8 / 2587.9 ± 306.1 [ 83.0, 2610.1, 2680.0, 2731.0, 2857.1] 0.0% 1 | 2591.1 / 2591.1 ± 305.2 [455.9, 2608.9,2680.2, 2734.1, 2859.0] 0.0% 2 | 2047.8 / 2046.4 ± 925.8 [ 0.0, 1486.2, 2592.6, 2691.1, 3001.0] 0.2% ? Pretty small setup, all data fit in buffers. Good tps performance all around (best for 32 flushes), and flushing shows a noticable (360 -> 240) reduction in tps stddev. ###### SMALL pgbench -M prepared -N -P 1 -T 4000 -j 2 -c 4 with scale = 120 (~ 2 GB) postgresql.conf: shared_buffers = 2GB checkpoint_timeout = 300s checkpoint_completion_target = 0.8 checkpoint_flush_after= { none, 0, 32, 64 } opts # | tps / 1-sec tps ± stddev [ min q1 med q2 max ] <=10.0 head 0 | 209.2 / 204.2 ± 516.5 [0.0, 0.0, 4.0, 5.0, 2251.0] 82.3% 1 | 207.4 / 204.2 ± 518.7 [0.0, 0.0, 4.0, 5.0, 2245.1] 82.3% 2 | 217.5 / 211.0 ± 530.3 [0.0, 0.0, 3.0, 5.0, 2255.0] 82.0% 3 | 217.8 / 213.2± 531.7 [0.0, 0.0, 4.0, 6.0, 2261.9] 81.7% 4 | 230.7 / 223.9 ± 542.7 [0.0, 0.0, 4.0, 7.0, 2282.0]80.7% 0 0 | 734.8 / 735.5 ± 879.9 [0.0, 1.0, 16.5, 1748.3, 2281.1] 47.0% 1 | 694.9 / 693.0 ± 849.0 [0.0, 1.0, 29.5,1545.7, 2428.0] 46.4% 2 | 735.3 / 735.5 ± 888.4 [0.0, 0.0, 12.0, 1781.2, 2312.1] 47.9% 3 | 736.0 / 737.5± 887.1 [0.0, 1.0, 16.0, 1794.3, 2317.0] 47.5% 4 | 734.9 / 735.1 ± 885.1 [0.0, 1.0, 15.5, 1781.0, 2297.1]47.2% 32 0 | 738.1 / 737.9 ± 415.8 [0.0, 553.0, 679.0, 753.0, 2312.1] 0.2% 1 | 730.5 / 730.7 ± 413.2 [0.0, 546.5, 671.0, 744.0, 2319.0] 0.1% 2 | 741.9 / 741.9 ± 416.5 [0.0, 556.0, 682.0, 756.0, 2331.0] 0.2% 3 | 744.1 / 744.1± 414.4 [0.0, 555.5, 685.2, 758.0, 2285.1] 0.1% 4 | 746.9 / 746.9 ± 416.6 [0.0, 566.6, 685.0, 759.0, 2308.1] 0.1% 64 0 | 743.0 / 743.1 ± 416.5 [1.0, 555.0, 683.0, 759.0, 2353.0] 0.1% 1 | 742.5 / 742.5 ± 415.6 [0.0, 558.2, 680.0, 758.2, 2296.0] 0.1% 2 | 742.5 / 742.5 ± 415.9 [0.0, 559.0, 681.1, 757.0, 2310.0] 0.1% 3 | 529.0 / 526.6± 410.9 [0.0, 245.0, 444.0, 701.0, 2380.9] 1.5% ?? 4 | 734.8 / 735.0 ± 414.1 [0.0, 550.0, 673.0, 754.0, 2298.0] 0.1% Sorting brings * 3.3 tps, flushing significantly reduces tps stddev. Pg comes from 80% unresponsive to nearly always responsive. ###### MEDIUM pgbench: -M prepared -N -P 1 -T 4000 -j 2 -c 4 with scale = 250 (~ 3.8 GB) postgresql.conf: shared_buffers = 4GB max_wal_size = 4GB checkpoint_timeout = 15min checkpoint_completion_target= 0.8 checkpoint_flush_after = { none, 0, 32, 64 } opts # | tps / 1-sec tps ± stddev [ min q1 med q2 max ] <=10.0 head 0 | 214.8 / 211.8 ± 513.7 [0.0, 1.0, 4.0, 5.0, 2344.0] 82.4% 1 | 219.2 / 215.0 ± 524.1 [0.0, 0.0, 4.0, 5.0, 2316.0] 82.2% 2 | 240.9 / 234.6 ± 550.8 [0.0, 0.0, 4.0, 6.0, 2320.2] 81.0% 0 0 | 1064.7 / 1065.3 ± 888.2 [0.0, 11.0, 1089.0, 2017.7, 2461.9] 24.7% 1 | 1060.2 / 1061.2 ± 889.9 [0.0, 10.0,1056.7, 2022.0, 2444.9] 25.1% 2 | 1060.2 / 1061.4 ± 889.1 [0.0, 9.0, 1085.8, 2002.8, 2473.0] 25.6% 32 0 | 1059.4 / 1059.4 ± 476.3 [3.0, 804.9, 980.0, 1123.0, 2448.1] 0.1% 1 | 1062.5 / 1062.6 ± 475.6 [0.0, 807.0, 988.0, 1132.0, 2441.0] 0.1% 2 | 1063.7 / 1063.7 ± 475.4 [0.0, 814.0, 987.0, 1131.2, 2432.1] 0.1% 64 0 | 1052.6 / 1052.6 ± 475.3 [0.0, 793.0, 974.0, 1118.1, 2445.1] 0.1% 1 | 1059.8 / 1059.8 ± 475.1 [0.0, 799.0, 987.5, 1131.0, 2457.1] 0.1% 2 | 1058.5 / 1058.5 ± 472.8 [0.0, 807.0, 985.0, 1127.7, 2442.0] 0.1% Sorting brings * 4.8 tps, flushing significantly reduces tps stddev. Pg comes from +80% unresponsive to nearly always responsive. Performance is significantly better than "small" above, probably thanks to the longer checkpoint timeout. ###### LARGE pgbench -M prepared -N -P 1 -T 7500 -j 2 -c 4 with scale = 1000 (~ 15 GB) postgresql.conf: shared_buffers = 4GB max_wal_size = 2GB checkpoint_timeout = 40min checkpoint_completion_target= 0.8 checkpoint_flush_after = { none, 0, 32, 64} opts # | tps / 1-sec tps ± stddev [ min q1 med q2 max ] <=10.0 head 0 | 68.7 / 65.3 ± 78.6 [0.0, 3.0, 6.0, 136.0, 291.0] 53.1% 1 | 70.6 / 70.3 ± 80.1 [0.0, 4.0, 10.0, 151.0,282.0] 50.1% 2 | 74.3 / 75.8 ± 84.9 [0.0, 4.0, 9.0, 162.0, 311.2] 50.3% 0 0 | 117.2 / 116.9 ± 83.8 [0.0, 14.0, 139.0, 193.0, 372.4] 24.0% 1 | 117.3 / 117.8 ± 83.8 [0.0, 16.0, 140.0, 193.0,279.0] 23.9% 2 | 117.6 / 118.2 ± 84.1 [0.0, 16.0, 141.0, 194.0, 297.8] 23.7% 32 0 | 114.2 / 114.2 ± 45.7 [0.0, 84.0, 100.0, 131.0, 613.6] 0.4% 1 | 112.5 / 112.6 ± 44.0 [0.0, 83.0, 98.0, 130.0,293.0] 0.2% 2 | 108.0 / 108.0 ± 44.7 [0.0, 79.0, 94.0, 124.0, 303.6] 0.3% 64 0 | 113.0 / 113.0 ± 45.5 [0.0, 83.0, 99.0, 131.0, 289.0] 0.4% 1 | 80.0 / 80.3 ± 39.1 [0.0, 56.0, 72.0, 95.0,281.0] 0.8% ?? 2 | 112.2 / 112.3 ± 44.5 [0.0, 82.0, 99.0, 129.0, 282.0] 0.3% Data do not fit in the available memory, so plenty of read accesses. Sorting still has some impact on tps performance (* 1.6), flushing greatly improves responsiveness. ###### ANDRES00 pgbench -M prepared -N -P 1 -T 300 -c 16 -j 16 with scale = 800 (~ 13 GB) postgresql.conf: shared_buffers = 2GB max_wal_size = 100GB wal_level = hot_standby maintenance_work_mem = 2GB checkpoint_timeout = 30s checkpoint_completion_target = 0.8 synchronous_commit = off checkpoint_flush_after = { none,0, 32, 64 } opts # | tps / 1-sec tps ± stddev [ min q1 med q2 max ] <=10.0 head 0 | 328.7 / 329.9 ± 716.9 [0.0, 0.0, 0.0, 0.0, 3221.2] 77.7% 1 | 338.2 / 338.7 ± 728.6 [0.0, 0.0, 0.0, 17.0, 3296.3] 75.0% 2 | 304.5 / 304.3 ± 705.5 [0.0, 0.0, 0.0, 0.0, 3463.4] 79.3% 0 0 | 425.6 / 464.0 ± 724.0 [0.0, 0.0, 0.0, 1000.6, 3363.7] 61.0% 1 | 461.5 / 463.1 ± 735.8 [0.0, 0.0, 0.0,1011.2, 3490.9] 58.7% 2 | 452.4 / 452.6 ± 744.3 [0.0, 0.0, 0.0, 1078.9, 3631.9] 63.3% 32 0 | 514.4 / 515.8 ± 651.8 [0.0, 0.0, 337.4, 808.3, 2876.0] 40.7% 1 | 512.0 / 514.6 ± 661.6 [0.0, 0.0, 317.6, 690.8, 3315.8] 35.0% 2 | 529.5 / 530.3 ± 673.0 [0.0, 0.0, 321.1, 906.4, 3360.8] 40.3% 64 0 | 529.6 / 530.9 ± 668.2 [0.0, 0.0, 322.1, 786.1, 3538.0] 33.3% 1 | 496.4 / 498.0 ± 606.6 [0.0, 0.0, 321.4, 746.0, 2629.6] 36.3% 2 | 521.0 / 521.7 ± 657.0 [0.0, 0.0, 328.4, 737.9, 3262.9] 34.3% Data just hold in memory, maybe. Run is very short, settings are low, this is not representative of an sane installation, this is for testing a lot of checkpoints in a difficult situation. Sorting and flushing do bring significant benefits. ###### ANDRES00b (same as ANDRES00 but scale 800->1000) pgbench -M prepared -N -P 1 -T 300 -c 16 -j 16 with scale = 1000 (~ 15 GB) postgresql.conf: shared_buffers = 2GB max_wal_size = 100GB wal_level = hot_standby maintenance_work_mem = 2GB checkpoint_timeout= 30s checkpoint_completion_target = 0.8 synchronous_commit = off checkpoint_flush_after = { none, 0,32, 64 } opts # | tps / 1-sec tps ± stddev [ min q1 med q2 max ] <=10.0 head 0 | 150.2 / 150.3 ± 401.6 [0.0, 0.0, 0.0, 0.0, 2199.4] 75.1% 1 | 139.2 / 139.2 ± 372.2 [0.0, 0.0, 0.0, 0.0, 2111.4] 78.3% *** 2 | 127.3 / 127.1 ± 341.2 [0.0, 0.0, 0.0, 53.0, 2144.3] 74.7% *** 0 0 | 199.0 / 209.2 ± 400.4 [0.0, 0.0, 0.0, 243.6, 1846.0] 65.7% 1 | 220.4 / 226.7 ± 423.2 [0.0, 0.0, 0.0,264.0, 1777.0] 63.5% * 2 | 195.5 / 205.3 ± 337.9 [0.0, 0.0, 123.0, 212.0, 1721.9] 43.2% 32 0 | 362.3 / 359.0 ± 308.4 [0.0, 200.0, 265.0, 416.4, 1816.6] 5.0% 1 | 323.6 / 321.2 ± 327.1 [0.0, 142.9, 210.0,353.4, 1907.0] 4.0% 2 | 309.0 / 310.7 ± 381.3 [0.0, 122.0, 175.5, 298.0, 2090.4] 5.0% 64 0 | 342.7 / 343.6 ± 331.1 [0.0, 143.0, 239.5, 409.9, 1623.6] 5.3% 1 | 333.8 / 328.2 ± 356.3 [0.0, 132.9, 211.5,358.1, 1629.1] 10.7% ?? 2 | 352.0 / 352.0 ± 332.3 [0.0, 163.5, 239.9, 400.1, 1643.4] 5.3% A little bit larger than previous so that it does not really fit in memory. The performance inpact is significant compared to previous. Sorting and flushing brings * 2 tps, unresponsiveness comes from 75% to reach a better 5%. ###### ANDRES00c (same as ANDRES00b but time 300 -> 4000) opts # | tps / 1-sec tps ± stddev [ min q1 med q2 max ] <=10.0 head 0 | 115.2 / 114.3 ± 256.4 [0.0, 0.0, 75.0, 131.1, 3389.0] 46.5% 1 | 118.4 / 117.9 ± 248.3 [0.0, 0.0, 87.0,151.0, 3603.6] 46.7% 2 | 120.1 / 119.2 ± 254.4 [0.0, 0.0, 91.0, 143.0, 3307.8] 43.8% 0 0 | 217.4 / 211.0 ± 237.1 [0.0, 139.0, 193.0, 239.0, 3115.4] 16.8% 1 | 216.2 / 209.6 ± 244.9 [0.0, 138.9, 188.0,231.0, 3331.3] 16.3% 2 | 218.6 / 213.8 ± 246.7 [0.0, 137.0, 187.0, 232.0, 3229.6] 16.2% 32 0 | 146.6 / 142.5 ± 234.5 [0.0, 59.0, 93.0, 151.1, 3294.7] 17.5% 1 | 148.0 / 142.6 ± 239.2 [0.0, 64.0, 95.9,144.0, 3361.8] 16.0% 2 | 147.6 / 140.4 ± 233.2 [0.0, 59.4, 94.0, 148.0, 3108.4] 18.0% 64 0 | 145.3 / 140.5 ± 233.6 [0.0, 61.0, 93.0, 147.7, 3212.6] 16.5% 1 | 145.6 / 140.3 ± 233.3 [0.0, 58.0, 93.0,146.0, 3351.8] 17.3% 2 | 147.7 / 142.2 ± 233.2 [0.0, 61.0, 97.0, 148.4, 3616.3] 17.0% The only difference between ANDRES00B and ANDRES00C is the duration, from 5 minutes to 66 minutes. This show that short runs can be widelely misleading: In particular the longer runs shows less that half tps for some settings, and the relative comparison of head vs sort vs sort+flush is different. ###### ANDRES00d (same as ANDRES00b but wal_level hot_standby->minimal) opts # | tps / 1-sec tps ± stddev [ min q1 med q2 max ] <=10.0 head 0 | 191.6 / 195.1 ± 439.3 [0.0, 0.0, 0.0, 0.0, 2540.2] 76.3% 1 | 211.3 / 213.6 ± 461.9 [0.0, 0.0, 0.0, 13.0, 3203.7] 75.0% 2 | 152.4 / 154.9 ± 217.6 [0.0, 0.0, 58.0, 235.6, 995.9] 39.3% ??? 0 0 | 247.2 / 251.7 ± 454.0 [0.0, 0.0, 0.0, 375.3, 2592.4] 67.7% 1 | 215.4 / 232.7 ± 446.5 [0.0, 0.0, 0.0,103.0, 3046.7] 72.3% 2 | 160.6 / 160.8 ± 222.1 [0.0, 0.0, 80.0, 209.6, 885.3] 42.0% ??? 32 0 | 399.9 / 397.0 ± 356.6 [0.0, 67.0, 348.0, 572.8, 2604.2] 21.0% 1 | 391.8 / 392.5 ± 371.7 [0.0, 85.5, 314.4,549.3, 2590.3] 20.7% 2 | 406.1 / 404.8 ± 380.6 [0.0, 95.0, 348.5, 569.0, 3383.7] 21.3% 64 0 | 395.9 / 396.1 ± 352.4 [0.0, 89.5, 342.5, 556.0, 2366.9] 17.7% 1 | 355.1 / 351.9 ± 296.7 [0.0, 172.5, 306.1,468.1, 1663.5] 16.0% 2 | 403.6 / 401.8 ± 390.5 [0.0, 0.0, 337.0, 636.1, 2591.3] 26.7% ??? ###### ANDRES00e (same as ANDRES00b but maintenance_work_mem=2GB->64MB) opts # | tps / 1-sec tps ± stddev [ min q1 med q2 max ] <=10.0 head 0 | 153.5 / 161.3 ± 401.3 [0.0, 0.0, 0.0, 0.0, 2546.0] 82.0% 1 | 170.7 / 175.9 ± 399.9 [0.0, 0.0, 0.0, 14.0, 2537.4] 74.7% 2 | 184.7 / 190.4 ± 389.2 [0.0, 0.0, 0.0, 158.5, 2544.6] 69.3% 0 0 | 211.2 / 227.8 ± 418.8 [0.0, 0.0, 0.0, 334.6, 2589.3] 65.7% 1 | 221.7 / 226.0 ± 415.7 [0.0, 0.0, 0.0,276.8, 2588.2] 68.4% 2 | 232.5 / 233.2 ± 403.5 [0.0, 0.0, 0.0, 377.0, 2260.2] 62.0% 32 0 | 373.2 / 374.4 ± 309.2 [0.0, 180.6, 321.8, 475.2, 2596.5] 11.3% 1 | 348.7 / 348.1 ± 328.4 [0.0, 127.0, 284.1,451.9, 2595.1] 17.3% 2 | 376.3 / 375.3 ± 315.5 [0.0, 186.5, 329.6, 487.1, 2365.4] 15.3% 64 0 | 388.9 / 387.8 ± 348.7 [0.0, 164.0, 305.9, 546.5, 2587.2] 15.0% 1 | 380.3 / 378.7 ± 338.8 [0.0, 171.1, 317.4,524.8, 2592.4] 16.7% 2 | 369.8 / 367.4 ± 340.5 [0.0, 77.4, 320.6, 525.5, 2484.7] 20.7% Hmmm, interesting: maintenance_work_mem seems to have some influence on performance, although it is not too consistent between settings, probably because as the memory is used to its limit the performance is quite sensitive to the available memory. -- Fabien.
Hi,
On 2016-02-19 10:16:41 +0100, Fabien COELHO wrote:
> Below the results of a lot of tests with pgbench to exercise checkpoints on
> the above version when fetched.
Wow, that's a great test series.
> Overall comments:
> - sorting & flushing is basically always a winner
> - benchmarking with short runs on large databases is a bad idea
> the results are very different if a longer run is used
> (see andres00b vs andres00c)
Based on these results I think 32 will be a good default for
checkpoint_flush_after? There's a few cases where 64 showed to be
beneficial, and some where 32 is better. I've seen 64 perform a bit
better in some cases here, but the differences were not too big.
I gather that you didn't play with
backend_flush_after/bgwriter_flush_after, i.e. you left them at their
default values? Especially backend_flush_after can have a significant
positive and negative performance impact.
> 16 GB 2 cpu 8 cores
> 200 GB RAID1 HDD, ext4 FS
> Ubuntu 12.04 LTS (precise)
That's with 12.04's standard kernel?
> postgresql.conf:
> shared_buffers = 1GB
> max_wal_size = 1GB
> checkpoint_timeout = 300s
> checkpoint_completion_target = 0.8
> checkpoint_flush_after = { none, 0, 32, 64 }
Did you re-initdb between the runs?
I've seen massively varying performance differences due to autovacuum
triggered analyzes. It's not completely deterministic when those run,
and on bigger scale clusters analyze can take ages, while holding a
snapshot.
> Hmmm, interesting: maintenance_work_mem seems to have some influence on
> performance, although it is not too consistent between settings, probably
> because as the memory is used to its limit the performance is quite
> sensitive to the available memory.
That's probably because of differing behaviour of autovacuum/vacuum,
which sometime will have to do several scans of the tables if there are
too many dead tuples.
Regards,
Andres
Hello.
> Based on these results I think 32 will be a good default for
> checkpoint_flush_after? There's a few cases where 64 showed to be
> beneficial, and some where 32 is better. I've seen 64 perform a bit
> better in some cases here, but the differences were not too big.
Yes, these many runs show that 32 is basically as good or better than 64.
I'll do some runs with 16/48 to have some more data.
> I gather that you didn't play with
> backend_flush_after/bgwriter_flush_after, i.e. you left them at their
> default values? Especially backend_flush_after can have a significant
> positive and negative performance impact.
Indeed, non reported configuration options have their default values.
There were also minor changes in the default options for logging (prefix,
checkpoint, ...), but nothing significant, and always the same for all
runs.
>> [...] Ubuntu 12.04 LTS (precise)
>
> That's with 12.04's standard kernel?
Yes.
>> checkpoint_flush_after = { none, 0, 32, 64 }
>
> Did you re-initdb between the runs?
Yes, all runs are from scratch (initdb, pgbench -i, some warmup...).
> I've seen massively varying performance differences due to autovacuum
> triggered analyzes. It's not completely deterministic when those run,
> and on bigger scale clusters analyze can take ages, while holding a
> snapshot.
Yes, I agree that probably the performance changes on long vs short runs
(andres00c vs andres00b) is due to autovacuum.
--
Fabien.
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 Hi Fabien, Fabien COELHO schrieb am 19.02.2016 um 16:04: > >>> [...] Ubuntu 12.04 LTS (precise) >> >> That's with 12.04's standard kernel? > > Yes. Kernel 3.2 is extremely bad for Postgresql, as the vm seems to amplify IO somehow. The difference to 3.13 (the latest LTS kernel for 12.04) is huge. https://medium.com/postgresql-talk/benchmarking-postgresql-with-different-linux-kernel-versions-on-ubuntu-lts-e61d57b70dd4#.6dx44vipu You might consider upgrading your kernel to 3.13 LTS. It's quite easy normally: https://wiki.ubuntu.com/Kernel/LTSEnablementStack /Patric -----BEGIN PGP SIGNATURE----- Version: GnuPG v2.0.22 (GNU/Linux) Comment: GnuPT 2.5.2 iEYEARECAAYFAlbHW4AACgkQfGgGu8y7ypC1EACgy8mW6AoaWjKycbuAnCZ3CEPW Al8AmwfF0smqmDvNsaPkq0dAtop7jP5M =TxT+ -----END PGP SIGNATURE-----
Hallo Patric, > Kernel 3.2 is extremely bad for Postgresql, as the vm seems to amplify > IO somehow. The difference to 3.13 (the latest LTS kernel for 12.04) is > huge. > > https://medium.com/postgresql-talk/benchmarking-postgresql-with-different-linux-kernel-versions-on-ubuntu-lts-e61d57b70dd4#.6dx44vipu Interesting! To summarize it, 25% performance degradation from best kernel (2.6.32) to worst (3.2.0), that is indeed significant. > You might consider upgrading your kernel to 3.13 LTS. It's quite easy > [...] There are other stuff running on the hardware that I do not wish to touch, so upgrading the particular host is currently not an option, otherwise I would have switched to trusty. Thanks for the pointer. -- Fabien.
On 2016-02-04 16:54:58 +0100, Andres Freund wrote: > Hi, > > Fabien asked me to post a new version of the checkpoint flushing patch > series. While this isn't entirely ready for commit, I think we're > getting closer. > > I don't want to post a full series right now, but my working state is > available on > http://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/checkpoint-flush > git://git.postgresql.org/git/users/andresfreund/postgres.git checkpoint-flush I've updated the git tree. Here's the next two (the most important) patches of the series: 0001: Allow to trigger kernel writeback after a configurable number of writes. 0002: Checkpoint sorting and balancing. For 0001 I've recently changed: * Don't schedule writeback after smgrextend() - that defeats linux delayed allocation mechanism, increasing fragmentation noticeably. * Add docs for the new GUC variables * comment polishing * BackendWritebackContext now isn't dynamically allocated anymore I think this patch primarily needs: * review of the docs, not sure if they're easy enough to understand. Some language polishing might also be needed. * review of the writeback API, combined with the smgr/md.c changes. * Currently *_flush_after can be set to a nonzero value, even if there's no support for flushing on that platform. Imo that's ok, but perhaps other people's opinion differ. For 0002 I've recently changed: * Removed the sort timing information, we've proven sufficiently that it doesn't take a lot of time. * Minor comment polishing. I think this patch primarily needs: * Benchmarking on FreeBSD/OSX to see whether we should enable the mmap()/msync(MS_ASYNC) method by default. Unless somebody does so, I'm inclined to leave it off till then. Regards, Andres
Attachment
Hello Andres, > Here's the next two (the most important) patches of the series: > 0001: Allow to trigger kernel writeback after a configurable number of writes. > 0002: Checkpoint sorting and balancing. I will look into these two in depth. Note that I would have ordered them in reverse because sorting is nearly always very beneficial, and "writeback" (formely called flushing) is then nearly always very beneficial on sorted buffers. -- Fabien.
On 2016-02-19 22:46:44 +0100, Fabien COELHO wrote: > > Hello Andres, > > >Here's the next two (the most important) patches of the series: > >0001: Allow to trigger kernel writeback after a configurable number of writes. > >0002: Checkpoint sorting and balancing. > > I will look into these two in depth. > > Note that I would have ordered them in reverse because sorting is nearly > always very beneficial, and "writeback" (formely called flushing) is then > nearly always very beneficial on sorted buffers. I had it that way earlier. I actually saw pretty large regressions from sorting alone in some cases as well, apparently because the kernel submits much larger IOs to disk; although that probably only shows on SSDs. This way the modifications imo look a trifle better ;). I'm intending to commit both at the same time, keep them separate only because they're easier to ynderstand separately. Andres
On Sat, Feb 20, 2016 at 5:08 AM, Fabien COELHO <coelho@cri.ensmp.fr> wrote: >> Kernel 3.2 is extremely bad for Postgresql, as the vm seems to amplify IO >> somehow. The difference to 3.13 (the latest LTS kernel for 12.04) is huge. >> >> >> https://medium.com/postgresql-talk/benchmarking-postgresql-with-different-linux-kernel-versions-on-ubuntu-lts-e61d57b70dd4#.6dx44vipu > > > Interesting! To summarize it, 25% performance degradation from best kernel > (2.6.32) to worst (3.2.0), that is indeed significant. As far as I recall, the OS cache eviction is very aggressive in 3.2, so it would be possible that data from the FS cache that was just read could be evicted even if it was not used yet. Thie represents a large difference when the database does not fit in RAM. -- Michael
Hello Andres, > For 0001 I've recently changed: > * Don't schedule writeback after smgrextend() - that defeats linux > delayed allocation mechanism, increasing fragmentation noticeably. > * Add docs for the new GUC variables > * comment polishing > * BackendWritebackContext now isn't dynamically allocated anymore > > > I think this patch primarily needs: > * review of the docs, not sure if they're easy enough to > understand. Some language polishing might also be needed. Yep, see below. > * review of the writeback API, combined with the smgr/md.c changes. See various comments below. > * Currently *_flush_after can be set to a nonzero value, even if there's > no support for flushing on that platform. Imo that's ok, but perhaps > other people's opinion differ. In some previous version I think a warning was shown of the feature was requested but not available. Here are some quick comments on the patch: Patch applies cleanly on head. Compiled and checked on Linux. Compilation issues on other systems, see below. When pages are written by a process (checkpointer, bgwriter, backend worker), the list of recently written pages is kept and every so often an advisory fsync (sync_file_range, other options for other systems) is issued so that the data is sent to the io system without relying on more or less (un)controllable os policy. The documentation seems to use "flush" but the code talks about "writeback" or "flush", depending. I think one vocabulary, whichever it is, should be chosen and everything should stick to it, otherwise everything look kind of fuzzy and raises doubt for the reader (is it the same thing? is it something else?). I initially used "flush", but it seems a bad idea because it has nothing to do with the flush function, so I'm fine with writeback or anything else, I just think that *one* word should be chosen and used everywhere. The sgml documentation about "*_flush_after" configuration parameter talks about bytes, but the actual unit should be buffers. I think that keeping a number of buffers should be fine, because that is what the internal stuff will manage, not bytes. Also, the maximum value (128 ?) should appear in the text. In the discussion in the wal section, I'm not sure about the effect of setting writebacks on SSD, but I think that you have made some tests so maybe you have an answer and the corresponding section could be written with some more definitive text than "probably brings no benefit on SSD". A good point of the whole approach is that it is available to all kind of pg processes. However it does not address the point that bgwriter and backends basically issue random writes, so I would not expect much positive effect before these writes are somehow sorted, which means doing some compromise in the LRU/LFU logic... well, all this is best kept for later, and I'm fine to have the logic flushing logic there. I'm wondering why you choose 16 & 64 as default for backends & bgwriter, though. IssuePendingWritebacks: you merge only strictly neightboring writes. Maybe the merging strategy could be more aggressive than just strict neighbors? mdwriteback: all variables could be declared within the while, I do not understand why some are in and some are out. ISTM that putting writeback management at the relation level does not help a lot, because you have to translate again from relation to files. The good news is that it should work as well, and that it does avoid the issue that the file may have been closed in between, so why not. The PendingWriteback struct looks useless. I think it should be removed, and maybe put back if one day if it is needed, which I rather doubt it. struct WritebackContext: keeping a pointer to guc variables is a kind of trick, I think it deserves a comment. ScheduleBufferTagForWriteback: the "pending" variable is not very useful. Maybe consider shortening the "pending_writebacks" field name to "writebacks"? IssuePendingWritebacks: I understand that qsort is needed "again" because when balancing writes over tablespaces they may be intermixed. AFAICR I used a "flush context" for each table space in some version I submitted, because I do think that this whole writeback logic really does make sense *per table space*, which suggest that there should be as many write backs contexts as table spaces, otherwise the positive effect may going to be totally lost of tables spaces are used. Any thoughts? Assert(*context->max_pending <= WRITEBACK_MAX_PENDING_FLUSHES); is always true, I think, it is already checked in the initialization and when setting gucs. SyncOneBuffer: I'm wonder why you copy the tag after releasing the lock. I guess it is okay because it is still pinned. pg_flush_data: in the first #elif, "context" is undeclared line 446. Label "out" is not defined line 455. In the second #elif, "context" is undeclared line 490 and label "out" line 500 is not defined either. For the checkpointer, a key aspect is that the scheduling process goes to sleep from time to time, and this sleep time looked like a great opportunity to do this kind of flushing. You choose not to take advantage of the behavior, why? -- Fabien.
Hi, On 2016-02-20 20:56:31 +0100, Fabien COELHO wrote: > >* Currently *_flush_after can be set to a nonzero value, even if there's > > no support for flushing on that platform. Imo that's ok, but perhaps > > other people's opinion differ. > > In some previous version I think a warning was shown of the feature was > requested but not available. I think we should either silently ignore it, or error out. Warnings somewhere in the background aren't particularly meaningful. > Here are some quick comments on the patch: > > Patch applies cleanly on head. Compiled and checked on Linux. Compilation > issues on other systems, see below. For those I've already pushed a small fixup commit to git... Stupid mistake. > The documentation seems to use "flush" but the code talks about "writeback" > or "flush", depending. I think one vocabulary, whichever it is, should be > chosen and everything should stick to it, otherwise everything look kind of > fuzzy and raises doubt for the reader (is it the same thing? is it something > else?). I initially used "flush", but it seems a bad idea because it has > nothing to do with the flush function, so I'm fine with writeback or anything > else, I just think that *one* word should be chosen and used everywhere. Hm. > The sgml documentation about "*_flush_after" configuration parameter talks > about bytes, but the actual unit should be buffers. The unit actually is buffers, but you can configure it using bytes. We've done the same for other GUCs (shared_buffers, wal_buffers, ...). Refering to bytes is easier because you don't have to explain that it depends on compilation settings how many data it actually is and such. > Also, the maximum value (128 ?) should appear in the text. \ Right. > In the discussion in the wal section, I'm not sure about the effect of > setting writebacks on SSD, but I think that you have made some tests > so maybe you have an answer and the corresponding section could be > written with some more definitive text than "probably brings no > benefit on SSD". Yea, that paragraph needs some editing. I think we should basically remove that last sentence. > A good point of the whole approach is that it is available to all kind > of pg processes. Exactly. > However it does not address the point that bgwriter and > backends basically issue random writes, so I would not expect much positive > effect before these writes are somehow sorted, which means doing some > compromise in the LRU/LFU logic... The benefit is primarily that you don't collect large amounts of dirty buffers in the kernel page cache. In most cases the kernel will not be able to coalesce these writes either... I've measured *massive* performance latency differences for workloads that are bigger than shared buffers - because suddenly bgwriter / backends do the majority of the writes. Flushing in the checkpoint quite possibly makes nearly no difference in such cases. > well, all this is best kept for later, and I'm fine to have the logic > flushing logic there. I'm wondering why you choose 16 & 64 as default > for backends & bgwriter, though. I chose a small value for backends because there often are a large number of backends, and thus the amount of dirty data of each adds up. I used a larger value for bgwriter because I saw that ending up using bigger IOs. > IssuePendingWritebacks: you merge only strictly neightboring writes. > Maybe the merging strategy could be more aggressive than just strict > neighbors? I don't think so. If you flush more than neighbouring writes you'll often end up flushing buffers dirtied by another backend, causing additional stalls. And if the writes aren't actually neighbouring there's not much gained from issuing them in one sync_file_range call. > mdwriteback: all variables could be declared within the while, I do not > understand why some are in and some are out. Right. > ISTM that putting writeback management at the relation level does not > help a lot, because you have to translate again from relation to > files. Sure, but what's the problem with that? That's how normal read/write IO works as well? > struct WritebackContext: keeping a pointer to guc variables is a kind of > trick, I think it deserves a comment. It has, it's just in WritebackContextInit(). Can duplicateit. > ScheduleBufferTagForWriteback: the "pending" variable is not very > useful. Shortens line length a good bit, at no cost. > IssuePendingWritebacks: I understand that qsort is needed "again" > because when balancing writes over tablespaces they may be intermixed. Also because the infrastructure is used for more than checkpoint writes. There's absolutely no ordering guarantees there. > AFAICR I used a "flush context" for each table space in some version > I submitted, because I do think that this whole writeback logic really > does make sense *per table space*, which suggest that there should be as > many write backs contexts as table spaces, otherwise the positive effect > may going to be totally lost of tables spaces are used. Any thoughts? Leads to less regular IO, because if your tablespaces are evenly sized (somewhat common) you'll sometimes end up issuing sync_file_range's shortly after each other. For latency outside checkpoints it's important to control the total amount of dirty buffers, and that's obviously independent of tablespaces. > SyncOneBuffer: I'm wonder why you copy the tag after releasing the lock. > I guess it is okay because it is still pinned. Don't do things while holding a lock that don't require said lock. A pin prevents a buffer changing its identity. > For the checkpointer, a key aspect is that the scheduling process goes > to sleep from time to time, and this sleep time looked like a great > opportunity to do this kind of flushing. You choose not to take advantage > of the behavior, why? Several reasons: Most importantly there's absolutely no guarantee that you'll ever end up sleeping, it's quite common to happen only seldomly. If you're bottlenecked on IO, you can end up being behind all the time. But even then you don't want to cause massive latency spikes due to gigabytes of dirty data - a slower checkpoint is a much better choice. It'd make the writeback infrastructure less generic. I also don't really believe it helps that much, although that's a complex argument to make. Thanks for the review! Andres
On Sun, Feb 21, 2016 at 3:37 AM, Andres Freund <andres@anarazel.de> wrote: >> The documentation seems to use "flush" but the code talks about "writeback" >> or "flush", depending. I think one vocabulary, whichever it is, should be >> chosen and everything should stick to it, otherwise everything look kind of >> fuzzy and raises doubt for the reader (is it the same thing? is it something >> else?). I initially used "flush", but it seems a bad idea because it has >> nothing to do with the flush function, so I'm fine with writeback or anything >> else, I just think that *one* word should be chosen and used everywhere. > > Hm. I think there might be a semantic distinction between these two terms. Doesn't writeback mean writing pages to disk, and flushing mean making sure that they are durably on disk? So for example when the Linux kernel thinks there is too much dirty data, it initiates writeback, not a flush; on the other hand, at transaction commit, we initiate a flush, not writeback. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hallo Andres, >> In some previous version I think a warning was shown if the feature was >> requested but not available. > > I think we should either silently ignore it, or error out. Warnings > somewhere in the background aren't particularly meaningful. I like "ignoring with a warning" in the log file, because when things do not behave as expected that is where I'll be looking. I do not think that it should error out. >> The sgml documentation about "*_flush_after" configuration parameter >> talks about bytes, but the actual unit should be buffers. > > The unit actually is buffers, but you can configure it using > bytes. We've done the same for other GUCs (shared_buffers, wal_buffers, > ...). Refering to bytes is easier because you don't have to explain that > it depends on compilation settings how many data it actually is and > such. So I understand that it works with kb as well. Now I do not think that it would need a lot if explanations if you say that it is a number of pages, and I think that a number of pages is significant because it is a number of IO requests to be coalesced, eventually. >> In the discussion in the wal section, I'm not sure about the effect of >> setting writebacks on SSD, [...] > > Yea, that paragraph needs some editing. I think we should basically > remove that last sentence. Ok, fine with me. Does that mean that flushing as a significant positive impact on SSD in your tests? >> However it does not address the point that bgwriter and backends >> basically issue random writes, [...] > > The benefit is primarily that you don't collect large amounts of dirty > buffers in the kernel page cache. In most cases the kernel will not be > able to coalesce these writes either... I've measured *massive* > performance latency differences for workloads that are bigger than > shared buffers - because suddenly bgwriter / backends do the majority of > the writes. Flushing in the checkpoint quite possibly makes nearly no > difference in such cases. So I understand that there is a positive impact under some load. Good! >> Maybe the merging strategy could be more aggressive than just strict >> neighbors? > > I don't think so. If you flush more than neighbouring writes you'll > often end up flushing buffers dirtied by another backend, causing > additional stalls. Ok. Maybe the neightbor definition could be relaxed just a little bit so that small holes are overtake, but not large holes? If there is only a few pages in between, even if written by another process, then writing them together should be better? Well, this can wait for a clear case, because hopefully the OS will recoalesce them behind anyway. >> struct WritebackContext: keeping a pointer to guc variables is a kind of >> trick, I think it deserves a comment. > > It has, it's just in WritebackContextInit(). Can duplicateit. I missed it, I expected something in the struct definition. Do not duplicate, but cross reference it? >> IssuePendingWritebacks: I understand that qsort is needed "again" >> because when balancing writes over tablespaces they may be intermixed. > > Also because the infrastructure is used for more than checkpoint > writes. There's absolutely no ordering guarantees there. Yep, but not much benefit to expect from a few dozens random pages either. >> [...] I do think that this whole writeback logic really does make sense >> *per table space*, > > Leads to less regular IO, because if your tablespaces are evenly sized > (somewhat common) you'll sometimes end up issuing sync_file_range's > shortly after each other. For latency outside checkpoints it's > important to control the total amount of dirty buffers, and that's > obviously independent of tablespaces. I do not understand/buy this argument. The underlying IO queue is per device, and table spaces should be per device as well (otherwise what the point?), so you should want to coalesce and "writeback" pages per device as wel. Calling sync_file_range on distinct devices should probably be issued more or less randomly, and should not interfere one with the other. If you use just one context, the more table spaces the less performance gains, because there is less and less aggregation thus sequential writes per device. So for me there should really be one context per tablespace. That would suggest a hashtable or some other structure to keep and retrieve them, which would not be that bad, and I think that it is what is needed. >> For the checkpointer, a key aspect is that the scheduling process goes >> to sleep from time to time, and this sleep time looked like a great >> opportunity to do this kind of flushing. You choose not to take advantage >> of the behavior, why? > > Several reasons: Most importantly there's absolutely no guarantee that > you'll ever end up sleeping, it's quite common to happen only seldomly. Well, that would be under a situation when pg is completely unresponsive. More so, this behavior *makes* pg unresponsive. > If you're bottlenecked on IO, you can end up being behind all the time. Hopefully sorting & flushing should improve this situation a lot. > But even then you don't want to cause massive latency spikes > due to gigabytes of dirty data - a slower checkpoint is a much better > choice. It'd make the writeback infrastructure less generic. Sure. It would be sufficient to have a call to ask for writebacks independently of the number of writebacks accumulated in the queue, it does not need to change the infrastructure. Also, I think that such a call would make sense at the end of the checkpoint. > I also don't really believe it helps that much, although that's a > complex argument to make. Yep. My thinking is that doing things in the sleeping interval does not interfere with the checkpointer scheduling, so it is less likely to go wrong and falling behind. -- Fabien.
Hallo Andres, >>> [...] I do think that this whole writeback logic really does make sense >>> *per table space*, >> >> Leads to less regular IO, because if your tablespaces are evenly sized >> (somewhat common) you'll sometimes end up issuing sync_file_range's >> shortly after each other. For latency outside checkpoints it's >> important to control the total amount of dirty buffers, and that's >> obviously independent of tablespaces. > > I do not understand/buy this argument. > > The underlying IO queue is per device, and table spaces should be per device > as well (otherwise what the point?), so you should want to coalesce and > "writeback" pages per device as wel. Calling sync_file_range on distinct > devices should probably be issued more or less randomly, and should not > interfere one with the other. > > If you use just one context, the more table spaces the less performance > gains, because there is less and less aggregation thus sequential writes per > device. > > So for me there should really be one context per tablespace. That would > suggest a hashtable or some other structure to keep and retrieve them, which > would not be that bad, and I think that it is what is needed. Note: I think that an easy way to do that in the "checkpoint sort" patch is simply to keep a WritebackContext in CkptTsStatus structure which is per table space in the checkpointer. For bgwriter & backends it can wait, there is few "writeback" coalescing because IO should be pretty random, so it does not matter much. -- Fabien.
Hallo Andres, Here is a review for the second patch. > For 0002 I've recently changed: > * Removed the sort timing information, we've proven sufficiently that > it doesn't take a lot of time. I put it there initialy to demonstrate that there was no cache performance issue when sorting on just buffer indexes. As it is always small, I agree that it is not needed. Well, it could be still be in seconds on a very large shared buffers setting with a very large checkpoint, but then the checkpoint would be tremendously huge... > * Minor comment polishing. Patch applies and checks on Linux. * CpktSortItem: I think that allocating 20 bytes per buffer in shared memory is a little on the heavy side. Some compression can be achieved: sizeof(ForlNum) is 4 bytes to hold 4 values, could be one byte or even 2 bits somewhere. Also, there are very few tablespaces, they could be given a small number and this number could be used instead of the Oid, so the space requirement could be reduced to say 16 bytes per buffer by combining space & fork in 2 shorts and keeping 4 bytes alignement and also getting 8 byte alignement... If this is too much, I have shown that it can work with only 4 bytes per buffer, as the sorting is really just a performance optimisation and is not broken if some stuff changes between sorting & writeback, but you did not like the idea. If the amount of shared memory required is a significant concern, it could be resurrected, though. * CkptTsStatus: As I suggested in the other mail, I think that this structure should also keep a per tablespace WritebackContext so that coalescing is done per tablespace. ISTM that "progress" and "progress_slice" only depend on num_scanned and per-tablespace num_to_scan and total num_to_scan, so they are somehow redundant and the progress could be recomputed from the initial figures when needed. If these fields are kept, I think that a comment should justify why float8 precision is okay for the purpose. I think it is quite certainly fine in the worst case with 32 bits buffer_ids, but it would not be if this size is changed someday. * BufferSync After a first sweep to collect buffers to write, they are sorted, and then there those buffers are swept again to compute some per tablespace data and organise a heap. ISTM that nearly all of the collected data on the second sweep could be collected on the first sweep, so that this second sweep could be avoided altogether. The only missing data is the index of the first buffer in the array, which can be computed by considering tablespaces only, sweeping over buffers is not needed. That would suggest creating the heap or using a hash in the initial buffer sweep to keep this information. This would also provide a point where to number tablespaces for compressing the CkptSortItem struct. I'm wondering about calling CheckpointWriteDelay on each round, maybe a minimum amount of write would make sense. This remark is independent of this patch. Probably it works fine because after a sleep the checkpointer is behind enough so that it will write a bunch of buffers before sleeping again. I see a binary_heap_allocate but no corresponding deallocation, this looks like a memory leak... or is there some magic involved? There are some debug stuff to remove in #ifdefs. I think that the buffer/README should be updated with explanations about sorting in the checkpointer. > I think this patch primarily needs: > * Benchmarking on FreeBSD/OSX to see whether we should enable the > mmap()/msync(MS_ASYNC) method by default. Unless somebody does so, I'm > inclined to leave it off till then. I do not have that. As "msync" seems available on Linux, it is possible to force using it with a "ifdef 0" to skip sync_file_range and check whether it does some good there. Idem for the "posix_fadvise" stuff. I can try to do that, but it takes time to do so, if someone can test on other OS it would be much better. I think that if it works it should be kept in, so it is just a matter of testing it. -- Fabien.
On 2016-02-21 08:26:28 +0100, Fabien COELHO wrote: > >>In the discussion in the wal section, I'm not sure about the effect of > >>setting writebacks on SSD, [...] > > > >Yea, that paragraph needs some editing. I think we should basically > >remove that last sentence. > > Ok, fine with me. Does that mean that flushing as a significant positive > impact on SSD in your tests? Yes. The reason we need flushing is that the kernel amasses dirty pages, and then flushes them at once. That hurts for both SSDs and rotational media. Sorting is the the bigger question, but I've seen it have clearly beneficial performance impacts. I guess if you look at devices with a internal block size bigger than 8k, you'd even see larger differences. > >>Maybe the merging strategy could be more aggressive than just strict > >>neighbors? > > > >I don't think so. If you flush more than neighbouring writes you'll > >often end up flushing buffers dirtied by another backend, causing > >additional stalls. > > Ok. Maybe the neightbor definition could be relaxed just a little bit so > that small holes are overtake, but not large holes? If there is only a few > pages in between, even if written by another process, then writing them > together should be better? Well, this can wait for a clear case, because > hopefully the OS will recoalesce them behind anyway. I'm against doing so without clear measurements of a benefit. > >Also because the infrastructure is used for more than checkpoint > >writes. There's absolutely no ordering guarantees there. > > Yep, but not much benefit to expect from a few dozens random pages either. Actually, there's kinda frequently a benefit observable. Even if few requests can be merged, doing IO requests in an order more likely doable within a few rotations is beneficial. Also, the cost is marginal, so why worry? > >>[...] I do think that this whole writeback logic really does make > >>sense *per table space*, > > > >Leads to less regular IO, because if your tablespaces are evenly sized > >(somewhat common) you'll sometimes end up issuing sync_file_range's > >shortly after each other. For latency outside checkpoints it's > >important to control the total amount of dirty buffers, and that's > >obviously independent of tablespaces. > > I do not understand/buy this argument. > > The underlying IO queue is per device, and table spaces should be per device > as well (otherwise what the point?), so you should want to coalesce and > "writeback" pages per device as wel. Calling sync_file_range on distinct > devices should probably be issued more or less randomly, and should not > interfere one with the other. The kernel's dirty buffer accounting is global, not per block device. It's also actually rather common to have multiple tablespaces on a single block device. Especially if SANs and such are involved; where you don't even know which partitions are on which disks. > If you use just one context, the more table spaces the less performance > gains, because there is less and less aggregation thus sequential writes per > device. > > So for me there should really be one context per tablespace. That would > suggest a hashtable or some other structure to keep and retrieve them, which > would not be that bad, and I think that it is what is needed. That'd be much easier to do by just keeping the context in the per-tablespace struct. But anyway, I'm really doubtful about going for that; I had it that way earlier, and observing IO showed it not being beneficial. > >>For the checkpointer, a key aspect is that the scheduling process goes > >>to sleep from time to time, and this sleep time looked like a great > >>opportunity to do this kind of flushing. You choose not to take advantage > >>of the behavior, why? > > > >Several reasons: Most importantly there's absolutely no guarantee that > >you'll ever end up sleeping, it's quite common to happen only seldomly. > > Well, that would be under a situation when pg is completely unresponsive. > More so, this behavior *makes* pg unresponsive. No. The checkpointer being bottlenecked on actual IO performance doesn't impact production that badly. It'll just sometimes block in sync_file_range(), but the IO queues will have enough space to frequently give way to other backends, particularly to synchronous reads (most pg reads) and synchronous writes (fdatasync()). So a single checkpoint will take a bit longer, but otherwise the system will mostly keep up the work in a regular manner. Without the sync_file_range() calls the kernel will amass dirty buffers until global dirty limits are reached, which then will bring the whole system to a standstill. It's pretty common that checkpoint_timeout is too short to be able to write all shared_buffers out, in that case it's much better to slow down the whole checkpoint, instead of being incredibly slow at the end. > >I also don't really believe it helps that much, although that's a complex > >argument to make. > > Yep. My thinking is that doing things in the sleeping interval does not > interfere with the checkpointer scheduling, so it is less likely to go wrong > and falling behind. I don't really see why that's the case. Triggering writeback every N writes doesn't really influence the scheduling in a bad way - the flushing is done *before* computing the sleep time. Triggering the writeback *after* computing the sleep time, and then sleep for that long, in addition of the time for sync_file_range, skews things more. Greetings, Andres Freund
Hi, On 2016-02-21 10:52:45 +0100, Fabien COELHO wrote: > * CpktSortItem: > > I think that allocating 20 bytes per buffer in shared memory is a little on > the heavy side. Some compression can be achieved: sizeof(ForlNum) is 4 bytes > to hold 4 values, could be one byte or even 2 bits somewhere. Also, there > are very few tablespaces, they could be given a small number and this number > could be used instead of the Oid, so the space requirement could be reduced > to say 16 bytes per buffer by combining space & fork in 2 shorts and keeping > 4 bytes alignement and also getting 8 byte alignement... If this is too > much, I have shown that it can work with only 4 bytes per buffer, as the > sorting is really just a performance optimisation and is not broken if some > stuff changes between sorting & writeback, but you did not like the idea. If > the amount of shared memory required is a significant concern, it could be > resurrected, though. This is less than 0.2 % of memory related to shared buffers. We have the same amount of memory allocated in CheckpointerShmemSize(), and nobody has complained so far. And sorry, going back to the previous approach isn't going to fly, and I've no desire to discuss that *again*. > ISTM that "progress" and "progress_slice" only depend on num_scanned and > per-tablespace num_to_scan and total num_to_scan, so they are somehow > redundant and the progress could be recomputed from the initial figures > when needed. They don't cause much space usage, and we access the values frequently. So why not store them? > If these fields are kept, I think that a comment should justify why float8 > precision is okay for the purpose. I think it is quite certainly fine in the > worst case with 32 bits buffer_ids, but it would not be if this size is > changed someday. That seems pretty much unrelated to having the fields - the question of accuracy plays a role regardless, no? Given realistic amounts of memory the max potential "skew" seems fairly small with float8. If we ever flush one buffer "too much" for a tablespace it's pretty much harmless. > ISTM that nearly all of the collected data on the second sweep could be > collected on the first sweep, so that this second sweep could be avoided > altogether. The only missing data is the index of the first buffer in the > array, which can be computed by considering tablespaces only, sweeping over > buffers is not needed. That would suggest creating the heap or using a hash > in the initial buffer sweep to keep this information. This would also > provide a point where to number tablespaces for compressing the CkptSortItem > struct. Doesn't seem worth the complexity to me. > I'm wondering about calling CheckpointWriteDelay on each round, maybe > a minimum amount of write would make sense. Why? There's not really much benefit of doing more work than needed. I think we should sleep far shorter in many cases, but that's indeed a separate issue. > I see a binary_heap_allocate but no corresponding deallocation, this > looks like a memory leak... or is there some magic involved? Hm. I think we really should use a memory context for all of this - we could after all error out somewhere in the middle... > >I think this patch primarily needs: > >* Benchmarking on FreeBSD/OSX to see whether we should enable the > > mmap()/msync(MS_ASYNC) method by default. Unless somebody does so, I'm > > inclined to leave it off till then. > > I do not have that. As "msync" seems available on Linux, it is possible to > force using it with a "ifdef 0" to skip sync_file_range and check whether it > does some good there. Unfortunately it doesn't work well on linux: * On many OSs msync() on a mmap'ed file triggers writeback. On linux * it only does so when MS_SYNC is specified, but then it does the * writeback synchronously. Luckily all common linuxsystems have * sync_file_range(). This is preferrable over FADV_DONTNEED because * it doesn't flush out cleandata. I've verified beforehand, with a simple demo program, that msync(MS_ASYNC) does something reasonable of freebsd... > Idem for the "posix_fadvise" stuff. I can try to do > that, but it takes time to do so, if someone can test on other OS it would > be much better. I think that if it works it should be kept in, so it is just > a matter of testing it. I'm not arguing for ripping it out, what I mean is that we don't set a nondefault value for the GUCs on platforms with just posix_fadivise available... Greetings, Andres Freund
>>>> [...] I do think that this whole writeback logic really does make >>>> sense *per table space*, >>> >>> Leads to less regular IO, because if your tablespaces are evenly sized >>> (somewhat common) you'll sometimes end up issuing sync_file_range's >>> shortly after each other. For latency outside checkpoints it's >>> important to control the total amount of dirty buffers, and that's >>> obviously independent of tablespaces. >> >> I do not understand/buy this argument. >> >> The underlying IO queue is per device, and table spaces should be per device >> as well (otherwise what the point?), so you should want to coalesce and >> "writeback" pages per device as wel. Calling sync_file_range on distinct >> devices should probably be issued more or less randomly, and should not >> interfere one with the other. > > The kernel's dirty buffer accounting is global, not per block device. Sure, but this is not my point. My point is that "sync_file_range" moves buffers to the device io queues, which are per device. If there is one queue in pg and many queues on many devices, the whole point of coalescing to get sequential writes is somehow lost. > It's also actually rather common to have multiple tablespaces on a > single block device. Especially if SANs and such are involved; where you > don't even know which partitions are on which disks. Ok, some people would not benefit if the use many tablespaces on one device, too bad but that does not look like a useful very setting anyway, and I do not think it would harm much in this case. >> If you use just one context, the more table spaces the less performance >> gains, because there is less and less aggregation thus sequential writes per >> device. >> >> So for me there should really be one context per tablespace. That would >> suggest a hashtable or some other structure to keep and retrieve them, which >> would not be that bad, and I think that it is what is needed. > > That'd be much easier to do by just keeping the context in the > per-tablespace struct. But anyway, I'm really doubtful about going for > that; I had it that way earlier, and observing IO showed it not being > beneficial. ISTM that you would need a significant number of tablespaces to see the benefit. If you do not do that, the more table spaces the more random the IOs, which is disappointing. Also, "the cost is marginal", so I do not see any good argument not to do it. -- Fabien.
>> ISTM that "progress" and "progress_slice" only depend on num_scanned and >> per-tablespace num_to_scan and total num_to_scan, so they are somehow >> redundant and the progress could be recomputed from the initial figures >> when needed. > > They don't cause much space usage, and we access the values frequently. > So why not store them? The same question would work the other way around: these values are one division away, why not compute them when needed? No big deal. > [...] Given realistic amounts of memory the max potential "skew" seems > fairly small with float8. If we ever flush one buffer "too much" for a > tablespace it's pretty much harmless. I do agree. I'm suggesting that a comment should be added to justify why float8 accuracy is okay. >> I see a binary_heap_allocate but no corresponding deallocation, this >> looks like a memory leak... or is there some magic involved? > > Hm. I think we really should use a memory context for all of this - we > could after all error out somewhere in the middle... I'm not sure that a memory context is justified here, there are only two mallocs and the checkpointer works for very long times. I think that it is simpler to just get the malloc/free right. > [...] I'm not arguing for ripping it out, what I mean is that we don't > set a nondefault value for the GUCs on platforms with just > posix_fadivise available... Ok with that. -- Fabien.
Hallo Andres, >> AFAICR I used a "flush context" for each table space in some version >> I submitted, because I do think that this whole writeback logic really >> does make sense *per table space*, which suggest that there should be as >> many write backs contexts as table spaces, otherwise the positive effect >> may going to be totally lost of tables spaces are used. Any thoughts? > > Leads to less regular IO, because if your tablespaces are evenly sized > (somewhat common) you'll sometimes end up issuing sync_file_range's > shortly after each other. For latency outside checkpoints it's > important to control the total amount of dirty buffers, and that's > obviously independent of tablespaces. I did a quick & small test with random updates on 16 tables with checkpoint_flush_after=16 checkpoint_timeout=30 (1) with 16 tablespaces (1 per table, but same disk) : tps = 1100, 27% time under 100 tps (2) with 1 tablespace : tps = 1200, 3% time under 100 tps This result is logical: with one writeback context shared between tablespaces the sync_file_range is issued on a few buffers per file at a time on the 16 files, no coalescing occurs there, so this result in random IOs, while with one table space all writes are aggregated per file. ISTM that this quick test shows that a writeback context are relevant per tablespace, as I expected. -- Fabien.
> I did a quick & small test with random updates on 16 tables with > checkpoint_flush_after=16 checkpoint_timeout=30 Another run with more "normal" settings and over 1000 seconds, so less "quick & small" that the previous one. checkpoint_flush_after = 16 checkpoint_timeout = 5min # default shared_buffers = 2GB # 1/8 of available memory Random updates on 16 tables which total to 1.1GB of data, so this is in buffer, no significant "read" traffic. (1) with 16 tablespaces (1 per table) on 1 disk : 680.0 tps per second avg, stddev [ min q1 median d3 max ] <=300tps 679.6 ± 750.4 [0.0, 317.0, 371.0, 438.5, 2724.0] 19.5% (2) with 1 tablespace on 1 disk : 956.0 tps per second avg, stddev [ min q1 median d3 max ] <=300tps 956.2 ± 796.5[3.0, 488.0, 583.0, 742.0, 2774.0] 2.1% -- Fabien.
On 2016-02-22 14:11:05 +0100, Fabien COELHO wrote: > > >I did a quick & small test with random updates on 16 tables with > >checkpoint_flush_after=16 checkpoint_timeout=30 > > Another run with more "normal" settings and over 1000 seconds, so less > "quick & small" that the previous one. > > checkpoint_flush_after = 16 > checkpoint_timeout = 5min # default > shared_buffers = 2GB # 1/8 of available memory > > Random updates on 16 tables which total to 1.1GB of data, so this is in > buffer, no significant "read" traffic. > > (1) with 16 tablespaces (1 per table) on 1 disk : 680.0 tps > per second avg, stddev [ min q1 median d3 max ] <=300tps > 679.6 ± 750.4 [0.0, 317.0, 371.0, 438.5, 2724.0] 19.5% > > (2) with 1 tablespace on 1 disk : 956.0 tps > per second avg, stddev [ min q1 median d3 max ] <=300tps > 956.2 ± 796.5 [3.0, 488.0, 583.0, 742.0, 2774.0] 2.1% Interesting. That doesn't reflect my own tests, even on rotating media, at all. I wonder if it's related to: https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=23d0127096cb91cb6d354bdc71bd88a7bae3a1d5 If you use your 12.04 kernel, that'd not be fixed. Which might be a reason to do it as you suggest. Could you share the exact details of that workload? Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes: > Interesting. That doesn't reflect my own tests, even on rotating media, > at all. I wonder if it's related to: > https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=23d0127096cb91cb6d354bdc71bd88a7bae3a1d5 > If you use your 12.04 kernel, that'd not be fixed. Which might be a > reason to do it as you suggest. Hmm ... that kernel commit is less than 4 months old. Would it be reflected in *any* production kernels yet? regards, tom lane
On 2016-02-22 11:05:20 -0500, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > Interesting. That doesn't reflect my own tests, even on rotating media, > > at all. I wonder if it's related to: > > https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=23d0127096cb91cb6d354bdc71bd88a7bae3a1d5 > > > If you use your 12.04 kernel, that'd not be fixed. Which might be a > > reason to do it as you suggest. > > Hmm ... that kernel commit is less than 4 months old. Would it be > reflected in *any* production kernels yet? Probably not - so far I though it mainly has some performance benefits on relatively extreme workloads; where without the patch, flushing still is better performancewise than not flushing. But in the scenario Fabien has brought up it seems quite possible that sync_file_range emitting "storage cache flush" instructions, could explain the rather large performance difference between his and my experiments. Regards, Andres
>> Random updates on 16 tables which total to 1.1GB of data, so this is in >> buffer, no significant "read" traffic. >> >> (1) with 16 tablespaces (1 per table) on 1 disk : 680.0 tps >> per second avg, stddev [ min q1 median d3 max ] <=300tps >> 679.6 ± 750.4 [0.0, 317.0, 371.0, 438.5, 2724.0] 19.5% >> >> (2) with 1 tablespace on 1 disk : 956.0 tps >> per second avg, stddev [ min q1 median d3 max ] <=300tps >> 956.2 ± 796.5 [3.0, 488.0, 583.0, 742.0, 2774.0] 2.1% > > Interesting. That doesn't reflect my own tests, even on rotating media, > at all. I wonder if it's related to: > https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=23d0127096cb91cb6d354bdc71bd88a7bae3a1d5 > > If you use your 12.04 kernel, that'd not be fixed. Which might be a > reason to do it as you suggest. > > Could you share the exact details of that workload? See attached scripts (sh to create the 16 tables in the default or 16 table spaces, small sql bench script, stat computation script). The per-second stats were computed with: grep progress: pgbench.out | cut -d' ' -f4 | avg.py --length=1000 --limit=300 Host is 8 cpu 16 GB, 2 HDD in RAID 1. -- Fabien.
Hi,
On 02/18/2016 11:31 AM, Andres Freund wrote:
> On 2016-02-11 19:44:25 +0100, Andres Freund wrote:
>> The first two commits of the series are pretty close to being ready. I'd
>> welcome review of those, and I plan to commit them independently of the
>> rest as they're beneficial independently. The most important bits are
>> the comments and docs of 0002 - they weren't particularly good
>> beforehand, so I had to rewrite a fair bit.
>>
>> 0001: Make SetHintBit() a bit more aggressive, afaics that fixes all the
>> potential regressions of 0002
>> 0002: Fix the overaggressive flushing by the wal writer, by only
>> flushing every wal_writer_delay ms or wal_writer_flush_after
>> bytes.
>
> I've pushed these after some more polishing, now working on the next
> two.
I've finally had time to do some benchmarks on those two (already
committed) pieces. I've promised to do more testing while discussing the
patches with Andres some time ago, so here we go.
I do have two machines I use for this kind of benchmarks
1) HP DL380 G5 (old rack server)
- 2x Xeon E5450, 16GB RAM (8 cores)
- 4x 10k SAS drives in RAID-10 on H400 controller (with BBWC)
- RedHat 6
- shared_buffers = 4GB
- min_wal_size = 2GB
- max_wal_size = 6GB
2) workstation with i5 CPU
- 1x i5-2500k, 8GB RAM
- 6x Intel S3700 100GB (in RAID0 for this benchmark)
- Gentoo
- shared_buffers = 2GB
- min_wal_size = 1GB
- max_wal_size = 8GB
Both machines were using the same kernel version 4.4.2 and default io
scheduler (cfq). The
The test procedure was quite simple - pgbench with three different
scales, for each scale three runs, 1h per run (and 30 minutes of warmup
before each run).
Due to the difference in amount of RAM, each machine used different
scales - the goal is to have small, ~50% RAM, >200% RAM sizes:
1) Xeon: 100, 400, 6000
2) i5: 50, 200, 3000
The commits actually tested are
cfafd8be (right before the first patch)
7975c5e0 Allow the WAL writer to flush WAL at a reduced rate.
db76b1ef Allow SetHintBits() to succeed if the buffer's LSN ...
For the Xeon, the total tps for each run looks like this:
scale commit 1 2 3
----------------------------------------------------
100 cfafd8be 5136 5132 5144
7975c5e0 5172 5148 5164
db76b1ef 5131 5139 5131
400 cfafd8be 3049 3042 2880
7975c5e0 3038 3026 3027
db76b1ef 2946 2940 2933
6000 cfafd8be 394 389 391
7975c5e0 391 479 467
db76b1ef 443 416 481
So I'd say not much difference, except for the largest data set where
the improvement is visible (although it's a bit too noisy and additional
runs would be useful).
On the i5 workstation with SSDs, the results look like this:
scale commit 1 2 3
------------------------------------------------
50 cfafd8be 5478 5486 5485
7975c5e0 5473 5468 5436
db76b1ef 5484 5453 5452
200 cfafd8be 5169 5176 5167
7975c5e0 5144 5151 5148
db76b1ef 5162 5131 5131
3000 cfafd8be 2392 2367 2359
7975c5e0 2301 2340 2347
db76b1ef 2277 2348 2342
So pretty much no difference, or perhaps maybe a slight slowdown.
One of the goals of this thread (as I understand it) was to make the
overall behavior smoother - eliminate sudden drops in transaction rate
due to bursts of random I/O etc.
One way to look at this is in terms of how much the tps fluctuates, so
let's see some charts. I've collected per-second tps measurements (using
the aggregation built into pgbench) but looking at that directly is
pretty pointless because it's very difficult to compare two noisy lines
jumping up and down.
So instead let's see CDF of the per-second tps measurements. I.e. we
have 3600 tps measurements, and given a tps value the question is what
percentage of the measurements is below this value.
y = Probability(tps <= x)
We prefer higher values, and the ideal behavior would be that we get
exactly the same tps every second. Thus an ideal CDF line would be a
step line. Of course, that's rarely the case in practice. But comparing
two CDF curves is easy - the line more to the right is better, at least
for tps measurements, where we prefer higher values.
1) tps-xeon.png
The original behavior (red lines) is quite consistent. The two patches
generally seem to improve the performance, although sadly it seems that
the variability of the performance actually increased quite a bit, as
the CDFs are much wider (but generally to the right of the old ones).
I'm not sure what exactly causes the volatility.
2) maxlat-xeon.png
Another view at the per-second data, this time using "max latency" from
the pgbench aggregated log. Of course, this time "lower is better" so
we'd like to move the CDF to the left (to get lower max latencies).
Sadly, it changes is mostly the other direction, i.e. the max latency
slightly increases (but the differences are not as significant as for
the tps rate, discussed in the previous paragraph). But apparently the
average latency actually improves (which gives us better tps).
Note: In this chart, x-axis is logarithmic.
3) tps-i5.png
Same chart with CDF of tps, but for the i5 workstation. This actually
shows the consistent slowdown due to the two patches, the tps
consistently shifts to the lower end (~2000tps).
I do have some more data, but those are the most interesting charts. The
rest usually shows about the same thing (or nothing).
Overall, I'm not quite sure the patches actually achieve the intended
goals. On the 10k SAS drives I got better performance, but apparently
much more variable behavior. On SSDs, I get a bit worse results.
Also, I really wonder what will happen with non-default io schedulers. I
believe all the testing so far was done with cfq, so what happens on
machines that use e.g. "deadline" (as many DB machines actually do)?
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
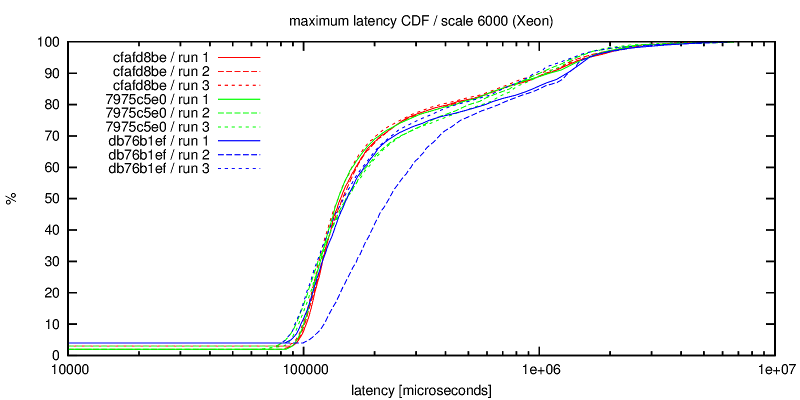{kind=link}
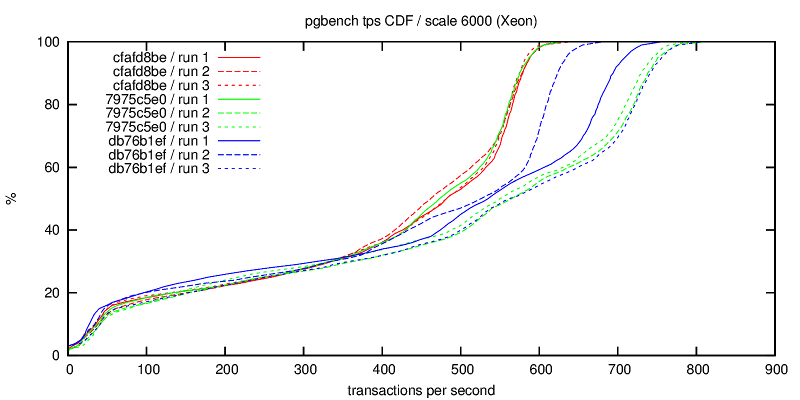{kind=link}
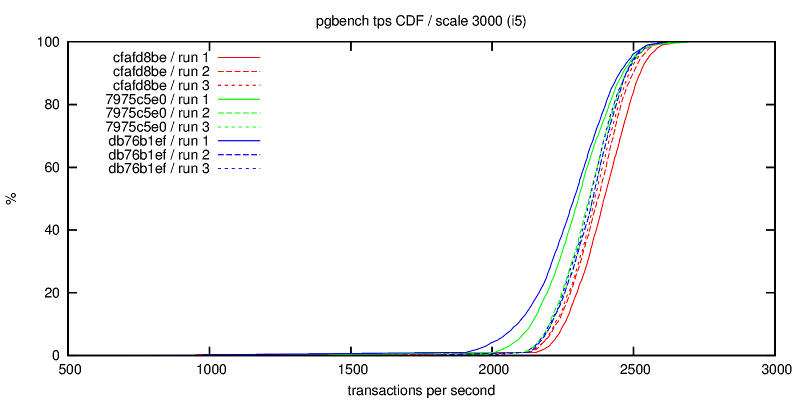{kind=link}
Hello Tomas, > One of the goals of this thread (as I understand it) was to make the overall > behavior smoother - eliminate sudden drops in transaction rate due to bursts > of random I/O etc. > > One way to look at this is in terms of how much the tps fluctuates, so let's > see some charts. I've collected per-second tps measurements (using the > aggregation built into pgbench) but looking at that directly is pretty > pointless because it's very difficult to compare two noisy lines jumping up > and down. > > So instead let's see CDF of the per-second tps measurements. I.e. we have > 3600 tps measurements, and given a tps value the question is what percentage > of the measurements is below this value. > > y = Probability(tps <= x) > > We prefer higher values, and the ideal behavior would be that we get exactly > the same tps every second. Thus an ideal CDF line would be a step line. Of > course, that's rarely the case in practice. But comparing two CDF curves is > easy - the line more to the right is better, at least for tps measurements, > where we prefer higher values. Very nice and interesting graphs! Alas not easy to interpret for the HDD, as there are better/worse variation all along the distribution, the lines cross one another, so how it fares overall is unclear. Maybe a simple indication would be to compute the standard deviation on the per second tps? The median maybe interesting as well. > I do have some more data, but those are the most interesting charts. The rest > usually shows about the same thing (or nothing). > > Overall, I'm not quite sure the patches actually achieve the intended goals. > On the 10k SAS drives I got better performance, but apparently much more > variable behavior. On SSDs, I get a bit worse results. Indeed. -- Fabien.
On 2016-03-01 16:06:47 +0100, Tomas Vondra wrote: > 1) HP DL380 G5 (old rack server) > - 2x Xeon E5450, 16GB RAM (8 cores) > - 4x 10k SAS drives in RAID-10 on H400 controller (with BBWC) > - RedHat 6 > - shared_buffers = 4GB > - min_wal_size = 2GB > - max_wal_size = 6GB > > 2) workstation with i5 CPU > - 1x i5-2500k, 8GB RAM > - 6x Intel S3700 100GB (in RAID0 for this benchmark) > - Gentoo > - shared_buffers = 2GB > - min_wal_size = 1GB > - max_wal_size = 8GB Thinking about with that hardware I'm not suprised if you're only seing small benefits. The amount of ram limits the amount of dirty data; and you have plenty have on-storage buffering in comparison to that. > Both machines were using the same kernel version 4.4.2 and default io > scheduler (cfq). The > > The test procedure was quite simple - pgbench with three different scales, > for each scale three runs, 1h per run (and 30 minutes of warmup before each > run). > > Due to the difference in amount of RAM, each machine used different scales - > the goal is to have small, ~50% RAM, >200% RAM sizes: > > 1) Xeon: 100, 400, 6000 > 2) i5: 50, 200, 3000 > > The commits actually tested are > > cfafd8be (right before the first patch) > 7975c5e0 Allow the WAL writer to flush WAL at a reduced rate. > db76b1ef Allow SetHintBits() to succeed if the buffer's LSN ... Huh, now I'm a bit confused. These are the commits you tested? Those aren't the ones doing sorting and flushing? > Also, I really wonder what will happen with non-default io schedulers. I > believe all the testing so far was done with cfq, so what happens on > machines that use e.g. "deadline" (as many DB machines actually do)? deadline and noop showed slightly bigger benefits in my testing. Greetings, Andres Freund
On 2016-03-07 09:41:51 -0800, Andres Freund wrote: > > Due to the difference in amount of RAM, each machine used different scales - > > the goal is to have small, ~50% RAM, >200% RAM sizes: > > > > 1) Xeon: 100, 400, 6000 > > 2) i5: 50, 200, 3000 > > > > The commits actually tested are > > > > cfafd8be (right before the first patch) > > 7975c5e0 Allow the WAL writer to flush WAL at a reduced rate. > > db76b1ef Allow SetHintBits() to succeed if the buffer's LSN ... > > Huh, now I'm a bit confused. These are the commits you tested? Those > aren't the ones doing sorting and flushing? To clarify: The reason we'd not expect to see much difference here is that the above commits really only have any affect above noise if you use synchronous_commit=off. Without async commit it's just one additional gettimeofday() call and a few additional branches in the wal writer every wal_writer_delay. Andres
On 2016-02-22 20:44:35 +0100, Fabien COELHO wrote: > > >>Random updates on 16 tables which total to 1.1GB of data, so this is in > >>buffer, no significant "read" traffic. > >> > >>(1) with 16 tablespaces (1 per table) on 1 disk : 680.0 tps > >> per second avg, stddev [ min q1 median d3 max ] <=300tps > >> 679.6 ± 750.4 [0.0, 317.0, 371.0, 438.5, 2724.0] 19.5% > >> > >>(2) with 1 tablespace on 1 disk : 956.0 tps > >> per second avg, stddev [ min q1 median d3 max ] <=300tps > >> 956.2 ± 796.5 [3.0, 488.0, 583.0, 742.0, 2774.0] 2.1% > > > >Interesting. That doesn't reflect my own tests, even on rotating media, > >at all. I wonder if it's related to: > >https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=23d0127096cb91cb6d354bdc71bd88a7bae3a1d5 > > > >If you use your 12.04 kernel, that'd not be fixed. Which might be a > >reason to do it as you suggest. > > > >Could you share the exact details of that workload? > > See attached scripts (sh to create the 16 tables in the default or 16 table > spaces, small sql bench script, stat computation script). > > The per-second stats were computed with: > > grep progress: pgbench.out | cut -d' ' -f4 | avg.py --length=1000 --limit=300 > > Host is 8 cpu 16 GB, 2 HDD in RAID 1. Well, that's not a particularly meaningful workload. You increased the number of flushed to the same number of disks considerably. For a meaningful comparison you'd have to compare using one writeback context for N tablespaces on N separate disks/raids, and using N writeback contexts for the same. Andres
Hello Andres, >>>> (1) with 16 tablespaces (1 per table) on 1 disk : 680.0 tps >>>> per second avg, stddev [ min q1 median d3 max ] <=300tps >>>> 679.6 ± 750.4 [0.0, 317.0, 371.0, 438.5, 2724.0] 19.5% >>>> >>>> (2) with 1 tablespace on 1 disk : 956.0 tps >>>> per second avg, stddev [ min q1 median d3 max ] <=300tps >>>> 956.2 ± 796.5 [3.0, 488.0, 583.0, 742.0, 2774.0] 2.1% > > Well, that's not a particularly meaningful workload. You increased the > number of flushed to the same number of disks considerably. It is just a simple workload designed to emphasize the effect of having one context shared for all table space instead of on per tablespace, without rewriting the patch and without a large host with multiple disks. > For a meaningful comparison you'd have to compare using one writeback > context for N tablespaces on N separate disks/raids, and using N > writeback contexts for the same. Sure, it would be better to do that, but that would require (1) rewriting the patch, which is a small work, and also (2) having access to a machine with a number of disks/raids, that I do NOT have available. What happens in the 16 tb workload is that much smaller flushes are performed on the 16 files writen in parallel, so the tps performance is significantly degraded, despite the writes being sorted in each file. On one tb, all buffers flushed are in the same file, so flushes are much more effective. When the context is shared and checkpointer buffer writes are balanced against table spaces, then when the limit is reached the flushing gets few buffers per tablespace, so this limits sequential writes to few buffers, hence the performance degradation. So I can explain the performance degradation *because* the flush context is shared between the table spaces, which is a logical argument backed with experimental data, so it is better than handwaving. Given the available hardware, this is the best proof I can have that context should be per table space. Now I cannot see how having one context per table space would have a significant negative performance impact. So the logical conclusion for me is that without further experimental data it is better to have one context per table space. If you have a hardware with plenty disks available for testing, that would provide better data, obviously. -- Fabien.
On 2016-03-07 21:10:19 +0100, Fabien COELHO wrote: > Now I cannot see how having one context per table space would have a > significant negative performance impact. The 'dirty data' etc. limits are global, not per block device. By having several contexts with unflushed dirty data the total amount of dirty data in the kernel increases. Thus you're more likely to see stalls by the kernel moving pages into writeback. Andres
Hello Andres, >> Now I cannot see how having one context per table space would have a >> significant negative performance impact. > > The 'dirty data' etc. limits are global, not per block device. By having > several contexts with unflushed dirty data the total amount of dirty > data in the kernel increases. Possibly, but how much? Do you have experimental data to back up that this is really an issue? We are talking about 32 (context size) * #table spaces * 8KB buffers = 4MB of dirty buffers to manage for 16 table spaces, I do not see that as a major issue for the kernel. > Thus you're more likely to see stalls by the kernel moving pages into > writeback. I do not see the above data having a 30% negative impact on tps, given the quite small amount of data under discussion, and switching to random IOs cost so much that it must really be avoided. Without further experimental data, I still think that the one context per table space is the reasonnable choice. -- Fabien.
>>> Now I cannot see how having one context per table space would have a >>> significant negative performance impact. >> >> The 'dirty data' etc. limits are global, not per block device. By having >> several contexts with unflushed dirty data the total amount of dirty >> data in the kernel increases. > > Possibly, but how much? Do you have experimental data to back up that this > is really an issue? > > We are talking about 32 (context size) * #table spaces * 8KB buffers = 4MB of > dirty buffers to manage for 16 table spaces, I do not see that as a major > issue for the kernel. More thoughts about your theoretical argument: To complete the argument, the 4MB is just a worst case scenario, in reality flushing the different context would be randomized over time, so the frequency of flushing a context would be exactly the same in both cases (shared or per table space context) if the checkpoints are the same size, just that with shared table space each flushing potentially targets all tablespace with a few pages, while with the other version each flushing targets one table space only. So my handwaving analysis is that the flow of dirty buffers is the same with both approaches, but for the shared version buffers are more equaly distributed on table spaces, hence reducing sequential write effectiveness, and for the other the dirty buffers are grouped more clearly per table space, so it should get better sequential write performance. -- Fabien.
On 2016-03-08 09:28:15 +0100, Fabien COELHO wrote: > > >>>Now I cannot see how having one context per table space would have a > >>>significant negative performance impact. > >> > >>The 'dirty data' etc. limits are global, not per block device. By having > >>several contexts with unflushed dirty data the total amount of dirty > >>data in the kernel increases. > > > >Possibly, but how much? Do you have experimental data to back up that > >this is really an issue? > > > >We are talking about 32 (context size) * #table spaces * 8KB buffers = 4MB > >of dirty buffers to manage for 16 table spaces, I do not see that as a > >major issue for the kernel. We flush in those increments, that doesn't mean there's only that much dirty data. I regularly see one order of magnitude more being dirty. I had originally kept it with one context per tablespace after refactoring this, but found that it gave worse results in rate limited loads even over only two tablespaces. That's on SSDs though. > To complete the argument, the 4MB is just a worst case scenario, in reality > flushing the different context would be randomized over time, so the > frequency of flushing a context would be exactly the same in both cases > (shared or per table space context) if the checkpoints are the same size, > just that with shared table space each flushing potentially targets all > tablespace with a few pages, while with the other version each flushing > targets one table space only. The number of pages still in writeback (i.e. for which sync_file_range has been issued, but which haven't finished running yet) at the end of the checkpoint matters for the latency hit incurred by the fsync()s from smgrsync(); at least by my measurement. My current plan is to commit this with the current behaviour (as in this week[end]), and then do some actual benchmarking on this specific part. It's imo a relatively minor detail. Greetings, Andres Freund
On 2016-02-21 09:49:53 +0530, Robert Haas wrote: > I think there might be a semantic distinction between these two terms. > Doesn't writeback mean writing pages to disk, and flushing mean making > sure that they are durably on disk? So for example when the Linux > kernel thinks there is too much dirty data, it initiates writeback, > not a flush; on the other hand, at transaction commit, we initiate a > flush, not writeback. I don't think terminology is sufficiently clear to make such a distinction. Take e.g. our FlushBuffer()...
On Thu, Mar 10, 2016 at 5:24 PM, Andres Freund <andres@anarazel.de> wrote: > On 2016-02-21 09:49:53 +0530, Robert Haas wrote: >> I think there might be a semantic distinction between these two terms. >> Doesn't writeback mean writing pages to disk, and flushing mean making >> sure that they are durably on disk? So for example when the Linux >> kernel thinks there is too much dirty data, it initiates writeback, >> not a flush; on the other hand, at transaction commit, we initiate a >> flush, not writeback. > > I don't think terminology is sufficiently clear to make such a > distinction. Take e.g. our FlushBuffer()... Well then we should clarify it! :-) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2016-03-10 17:33:33 -0500, Robert Haas wrote: > On Thu, Mar 10, 2016 at 5:24 PM, Andres Freund <andres@anarazel.de> wrote: > > On 2016-02-21 09:49:53 +0530, Robert Haas wrote: > >> I think there might be a semantic distinction between these two terms. > >> Doesn't writeback mean writing pages to disk, and flushing mean making > >> sure that they are durably on disk? So for example when the Linux > >> kernel thinks there is too much dirty data, it initiates writeback, > >> not a flush; on the other hand, at transaction commit, we initiate a > >> flush, not writeback. > > > > I don't think terminology is sufficiently clear to make such a > > distinction. Take e.g. our FlushBuffer()... > > Well then we should clarify it! Trying that as we speak, err, write. How about: <para> Whenever more than <varname>bgwriter_flush_after</varname>bytes have been written by the bgwriter, attempt to force the OS to issue these writes to the underlying storage. Doing so will limit the amount of dirty data in the kernel's page cache,reducing the likelihood of stalls when an fsync is issued at the end of a checkpoint, or when the OSwrites data back in larger batches in the background. Often that will result in greatly reduced transaction latency,but there also are some cases, especially with workloads that are bigger than <xref linkend="guc-shared-buffers">,but smaller than the OS's page cache, where performance might degrade. This settingmay have no effect on some platforms. <literal>0</literal> disables controlled writeback. The defaultis <literal>256Kb</> on Linux, <literal>0</> otherwise. This parameter can only be set in the <filename>postgresql.conf</>file or on the server command line. </para> (plus adjustments for the other gucs)
[...] > I had originally kept it with one context per tablespace after > refactoring this, but found that it gave worse results in rate limited > loads even over only two tablespaces. That's on SSDs though. Might just mean that a smaller context size is better on SSD, and it could still be better per table space. > The number of pages still in writeback (i.e. for which sync_file_range > has been issued, but which haven't finished running yet) at the end of > the checkpoint matters for the latency hit incurred by the fsync()s from > smgrsync(); at least by my measurement. I'm not sure I've seen these performance... If you have hard evidence, please feel free to share it. -- Fabien.
On 2016-03-10 23:38:38 +0100, Fabien COELHO wrote: > I'm not sure I've seen these performance... If you have hard evidence, > please feel free to share it. Man, are you intentionally trying to be hard to work with? To quote the email you responded to: > My current plan is to commit this with the current behaviour (as in this > week[end]), and then do some actual benchmarking on this specific > part. It's imo a relatively minor detail.
> <para> > Whenever more than <varname>bgwriter_flush_after</varname> bytes have > been written by the bgwriter, attempt to force the OS to issue these > writes to the underlying storage. Doing so will limit the amount of > dirty data in the kernel's page cache, reducing the likelihood of > stalls when an fsync is issued at the end of a checkpoint, or when > the OS writes data back in larger batches in the background. Often > that will result in greatly reduced transaction latency, but there > also are some cases, especially with workloads that are bigger than > <xref linkend="guc-shared-buffers">, but smaller than the OS's page > cache, where performance might degrade. This setting may have no > effect on some platforms. <literal>0</literal> disables controlled > writeback. The default is <literal>256Kb</> on Linux, <literal>0</> > otherwise. This parameter can only be set in the > <filename>postgresql.conf</> file or on the server command line. > </para> > > (plus adjustments for the other gucs) Some suggestions: What about the maximum value? If the default is in pages, maybe you could state it and afterwards translate it in size. "The default is 64 pages on Linux (usually 256Kb)..." The text could say something about sequential writes performance because pages are sorted.., but that it is lost for large bases and/or short checkpoints ? -- Fabien.
On 2016-03-10 23:43:46 +0100, Fabien COELHO wrote:
>
> > <para>
> > Whenever more than <varname>bgwriter_flush_after</varname> bytes have
> > been written by the bgwriter, attempt to force the OS to issue these
> > writes to the underlying storage. Doing so will limit the amount of
> > dirty data in the kernel's page cache, reducing the likelihood of
> > stalls when an fsync is issued at the end of a checkpoint, or when
> > the OS writes data back in larger batches in the background. Often
> > that will result in greatly reduced transaction latency, but there
> > also are some cases, especially with workloads that are bigger than
> > <xref linkend="guc-shared-buffers">, but smaller than the OS's page
> > cache, where performance might degrade. This setting may have no
> > effect on some platforms. <literal>0</literal> disables controlled
> > writeback. The default is <literal>256Kb</> on Linux, <literal>0</>
> > otherwise. This parameter can only be set in the
> > <filename>postgresql.conf</> file or on the server command line.
> > </para>
> >
> >(plus adjustments for the other gucs)
> What about the maximum value?
Added.
<varlistentry id="guc-bgwriter-flush-after" xreflabel="bgwriter_flush_after">
<term><varname>bgwriter_flush_after</varname>(<type>int</type>) <indexterm>
<primary><varname>bgwriter_flush_after</>configuration parameter</primary> </indexterm> </term>
<listitem> <para> Whenever more than <varname>bgwriter_flush_after</varname> bytes have been written
bythe bgwriter, attempt to force the OS to issue these writes to the underlying storage. Doing so will limit
theamount of dirty data in the kernel's page cache, reducing the likelihood of stalls when an fsync is
issuedat the end of a checkpoint, or when the OS writes data back in larger batches in the background. Often
that will result in greatly reduced transaction latency, but there also are some cases, especially with
workloadsthat are bigger than <xref linkend="guc-shared-buffers">, but smaller than the OS's page cache,
whereperformance might degrade. This setting may have no effect on some platforms. The valid range is between
<literal>0</literal>, which disables controlled writeback, and <literal>2MB</literal>. The default is
<literal>256Kb</>on Linux, <literal>0</> elsewhere. (Non-default values of <symbol>BLCKSZ</symbol>
changethe default and maximum.) This parameter can only be set in the <filename>postgresql.conf</> file
oron the server command line. </para> </listitem> </varlistentry> </variablelist>
> If the default is in pages, maybe you could state it and afterwards
> translate it in size.
Hm, I think that's more complicated for users than it's worth.
> The text could say something about sequential writes performance because
> pages are sorted.., but that it is lost for large bases and/or short
> checkpoints ?
I think that's an implementation detail.
- Andres
Hello Andres, >> I'm not sure I've seen these performance... If you have hard evidence, >> please feel free to share it. > > Man, are you intentionally trying to be hard to work with? Sorry, I do not understand this remark. You were refering to some latency measures in your answer, and I was just stating that I was interested in seeing these figures which were used to justify your choice to keep a shared writeback context. I did not intend this wish to be an issue, I was expressing an interest. > To quote the email you responded to: > >> My current plan is to commit this with the current behaviour (as in >> this week[end]), and then do some actual benchmarking on this specific >> part. It's imo a relatively minor detail. Good. From the evidence in the thread, I would have given the per tablespace context the preference, but this is just a personal opinion and I agree that it can work the other way around. I look forward to see these benchmarks later on, when you have them. So all is well, and hopefully will be even better later on. -- Fabien.
[...] >> If the default is in pages, maybe you could state it and afterwards >> translate it in size. > > Hm, I think that's more complicated for users than it's worth. As you wish. I liked the number of pages you used initially because it really gives a hint of how much random IOs are avoided when they are contiguous, and I do not have the same just intuition with sizes. Also it is related to the io queue length manage by the OS. >> The text could say something about sequential writes performance because >> pages are sorted.., but that it is lost for large bases and/or short >> checkpoints ? > > I think that's an implementation detail. As you wish. I thought that understanding the underlying performance model with sequential writes written in chunks is important for the admin, and as this guc would have an impact on performance it should be hinted about, including the limits of its effect where large bases will converge to random io performance. But maybe that is not the right place. -- Fabien
On 2016-03-11 00:23:56 +0100, Fabien COELHO wrote: > As you wish. I thought that understanding the underlying performance model > with sequential writes written in chunks is important for the admin, and as > this guc would have an impact on performance it should be hinted about, > including the limits of its effect where large bases will converge to random > io performance. But maybe that is not the right place. I do agree that that's something interesting to document somewhere. But I don't think any of the current places in the documentation are a good fit, and it's a topic much more general than the feature we're debating here. I'm not volunteering, but a good discussion of storage and the interactions with postgres surely would be a significant improvement to the postgres docs. - Andres
Hi, I just pushed the two major remaining patches in this thread. Let's see what the buildfarm has to say; I'd not be surprised if there's some lingering portability problem in the flushing code. There's one remaining issue we definitely want to resolve before the next release: Right now we always use one writeback context across all tablespaces in a checkpoint, but Fabien's testing shows that that's likely to hurt in a number of cases. I've some data suggesting the contrary in others. Things that'd be good: * Some benchmarking. Right now controlled flushing is enabled by default on linux, but disabled by default on other operatingsystems. Somebody running benchmarks on e.g. freebsd or OSX might be good. * If somebody has the energy to provide a windows implemenation for flush control, that might be worthwhile. There's severalplaces that could benefit from that. * The default values are basically based on benchmarking by me and Fabien. Regards, Andres
>> As you wish. I thought that understanding the underlying performance model >> with sequential writes written in chunks is important for the admin, and as >> this guc would have an impact on performance it should be hinted about, >> including the limits of its effect where large bases will converge to random >> io performance. But maybe that is not the right place. > > I do agree that that's something interesting to document somewhere. But > I don't think any of the current places in the documentation are a good > fit, and it's a topic much more general than the feature we're debating > here. I'm not volunteering, but a good discussion of storage and the > interactions with postgres surely would be a significant improvement to > the postgres docs. I can only concur! The "Performance Tips" chapter (II.14) is more user/query oriented. The "Server Administration" bool (III) does not discuss this much. There is a wiki about performance tuning, but it is not integrated into the documentation. It could be a first documentation source. Also the README in some development directories are very interesting, although they contains too much details about the implementation. There has been a lot of presentations over the years, and blog posts. -- Fabien.
> I just pushed the two major remaining patches in this thread. Hurray! Nine months the this baby out:-) -- Fabien.
On Thu, Mar 10, 2016 at 11:18 PM, Fabien COELHO <coelho@cri.ensmp.fr> wrote: > I can only concur! > > The "Performance Tips" chapter (II.14) is more user/query oriented. The > "Server Administration" bool (III) does not discuss this much. That's definitely one area in which the docs are lacking -- I've heard several complaints about this myself. I think we've been hesitant to do more in part because the docs must always be categorically correct, and must not use weasel words. I think it's hard to talk about performance while maintaining the general tone of the documentation. I don't know what can be done about that. -- Peter Geoghegan
On Thu, Mar 10, 2016 at 11:25 PM, Peter Geoghegan <pg@heroku.com> wrote: > On Thu, Mar 10, 2016 at 11:18 PM, Fabien COELHO <coelho@cri.ensmp.fr> wrote: >> I can only concur! >> >> The "Performance Tips" chapter (II.14) is more user/query oriented. The >> "Server Administration" bool (III) does not discuss this much. > > That's definitely one area in which the docs are lacking -- I've heard > several complaints about this myself. I think we've been hesitant to > do more in part because the docs must always be categorically correct, > and must not use weasel words. I think it's hard to talk about > performance while maintaining the general tone of the documentation. I > don't know what can be done about that. Would the wiki be a good place for such tips? Not as formal as the documentation, and more centralized (and editable) than a collection of blog posts. Cheers, Jeff
On Sat, Mar 12, 2016 at 5:21 PM, Jeff Janes <jeff.janes@gmail.com> wrote: > Would the wiki be a good place for such tips? Not as formal as the > documentation, and more centralized (and editable) than a collection > of blog posts. That general direction makes sense, but I'm not sure if the Wiki is something that this will work for. I fear that it could become something like the TODO list page: a page that contains theoretically accurate information, but isn't very helpful. The TODO list needs to be heavily pruned, but that seems like something that will never happen. A centralized location for performance tips will probably only work well if there are still high standards that are actively enforced. There still needs to be tight editorial control. -- Peter Geoghegan
On 3/13/16 6:30 PM, Peter Geoghegan wrote: > On Sat, Mar 12, 2016 at 5:21 PM, Jeff Janes <jeff.janes@gmail.com> wrote: >> Would the wiki be a good place for such tips? Not as formal as the >> documentation, and more centralized (and editable) than a collection >> of blog posts. > > That general direction makes sense, but I'm not sure if the Wiki is > something that this will work for. I fear that it could become > something like the TODO list page: a page that contains theoretically > accurate information, but isn't very helpful. The TODO list needs to > be heavily pruned, but that seems like something that will never > happen. > > A centralized location for performance tips will probably only work > well if there are still high standards that are actively enforced. > There still needs to be tight editorial control. I think there's ways to significantly restrict who can edit a page, so this could probably still be done via the wiki. IMO we should also be encouraging users to test various tips and provide feedback, so maybe a wiki page with a big fat request at the top asking users to submit any feedback about the page to -performance. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com
Hi,
On 03/11/2016 02:34 AM, Andres Freund wrote:
> Hi,
>
> I just pushed the two major remaining patches in this thread. Let's see
> what the buildfarm has to say; I'd not be surprised if there's some
> lingering portability problem in the flushing code.
>
> There's one remaining issue we definitely want to resolve before the
> next release: Right now we always use one writeback context across all
> tablespaces in a checkpoint, but Fabien's testing shows that that's
> likely to hurt in a number of cases. I've some data suggesting the
> contrary in others.
>
> Things that'd be good:
> * Some benchmarking. Right now controlled flushing is enabled by default
> on linux, but disabled by default on other operating systems. Somebody
> running benchmarks on e.g. freebsd or OSX might be good.
So I've done some benchmarks of this, and I think the results are very
good. I've compared a298a1e06 and 23a27b039d (so the two patches
mentioned here are in-between those two), and I've done a few long
pgbench runs - 24h each:
1) master (a298a1e06), regular pgbench
2) master (a298a1e06), throttled to 5000 tps
3) patched (23a27b039), regular pgbench
3) patched (23a27b039), throttled to 5000 tps
All of this was done on a quite large machine:
* 4 x CPU E5-4620 (2.2GHz)
* 256GB of RAM
* 24x SSD on LSI 2208 controller (with 1GB BBWC)
The page cache was using the default config, although in production
setups we'd probably lower the limits (particularly the background
threshold):
* vm.dirty_background_ratio = 10
* vm.dirty_ratio = 20
The main PostgreSQL configuration changes are these:
* shared_buffers=64GB
* bgwriter_delay = 10ms
* bgwriter_lru_maxpages = 1000
* checkpoint_timeout = 30min
* max_wal_size = 64GB
* min_wal_size = 32GB
I haven't touched the flush_after values, so those are at default. Full
config in the github repo, along with all the results and scripts used
to generate the charts etc:
https://github.com/tvondra/flushing-benchmark
I'd like to see some benchmarks on machines with regular rotational
storage, but I don't have a suitable system at hand.
The pgbench was scale 60000, so ~750GB of data on disk, and was executed
either like this (the "default"):
pgbench -c 32 -j 8 -T 86400 -l --aggregate-interval=1 pgbench
or like this ("throttled"):
pgbench -c 32 -j 8 -T 86400 -R 5000 -l --aggregate-interval=1 pgbench
The reason for the throttling is that people generally don't run
production databases 100% saturated, so it'd be sad to improve the 100%
saturated case and hurt the common case by increasing latency. The
machine does ~8000 tps, so 5000 tps is ~60% of that.
It's difficult to judge based on a single run (although a long one), but
it seems the throughput increased a tiny bit from 7725 to 8000. That's
~4% difference, but I guess more runs would be needed to see if this is
noise or actual improvement.
Now, let's see at the per-second results, i.e. how much the performance
fluctuates over time (due to checkpoints etc.). That's where the
aggregated log (per-second) gets useful, as it's used for generating the
various charts for tps, max latency, stddev of latency etc.
All those charts are CDF, i.e. cumulative distribution function, i.e.
they plot a metric on x-axis, and probability P(X <= x) on y-axis.
In general the steeper the curve the better (more consistent behavior
over time). It also allows comparing two curves - e.g. for tps metric
the "lower" curve is better, as it means higher values are more likely.
default (non-throttled) pgbench runs
------------------------------------
Let's see the regular (non-throttled) pgbench runs first:
* regular-tps.png (per-second TPS)
Clearly, the patched version is much more consistent - firstly it's much
less "wobbly" and it's considerably steeper, which means the per-second
throughput fluctuates much less. That's good.
We already know the total throughput is almost exactly the same (just 4%
difference), this also shows that the medians are almost exactly the
same (the curves intersect at pretty much exactly 50%).
* regular-max-lat.png (per-second maximum latency)
* regular-stddev-lat.png (per-second latency stddev)
Apparently the additional processing slightly increases both the maximum
latency and standard deviation, as the green line (patched) is
consistently below the pink one (unpatched).
Notice however that x-axis is using log scale, so the differences are
actually very small, and we also know that the total throughput slightly
increased. So while those two metrics slightly increased, the overall
impact on latency has to be positive.
throttled pgbench runs
----------------------
* throttled-tps.png (per-second TPS)
OK, this is great - the chart shows that the performance is way more
consistent. Originally there was ~10% of samples with ~2000 tps, but
with the flushing you'd have to go to ~4600 tps. It's actually pretty
difficult to determine this from the chart, because the curve got so
steep and I had to check the data used to generate the charts.
Similarly for the upper end, but I assume that's a consequence of the
throttling not having to compensate for the "slow" seconds anymore.
* throttled-max-lat.png (per-second maximum latency)
* throttled-stddev-lat.png (per-second latency stddev)
This time the stddev/max latency charts are actually in favor of the
patched code. It's actually a bit worse for the low latencies (the green
line is below the pink one, so there are fewer low values), but then it
starts winning for higher values. And that's what counts when it comes
to consistency.
Again, notice that the x-axis is log scale, so the differences for large
values are actually way more significant than it might look.
So, good work I guess!
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
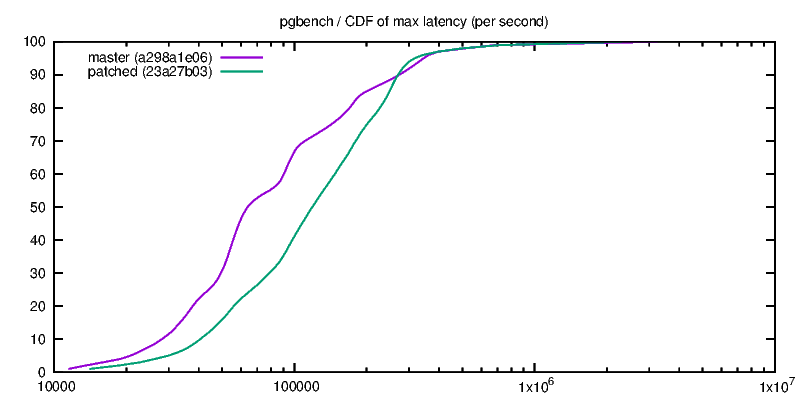{kind=link}
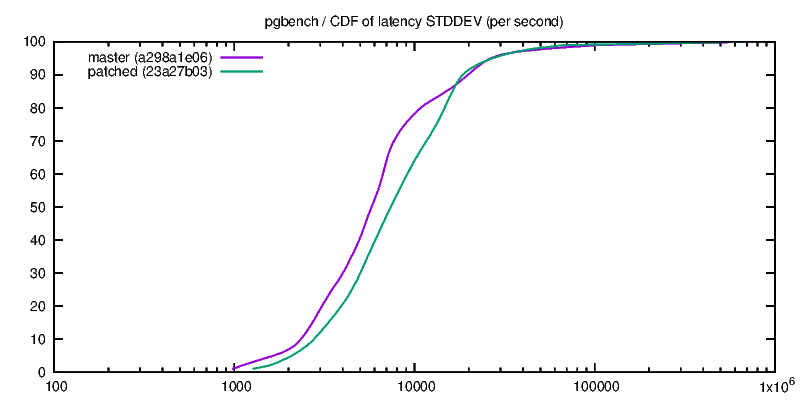{kind=link}
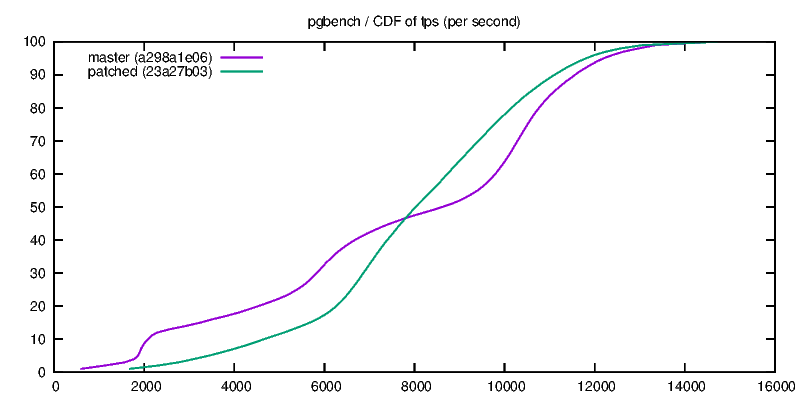{kind=link}
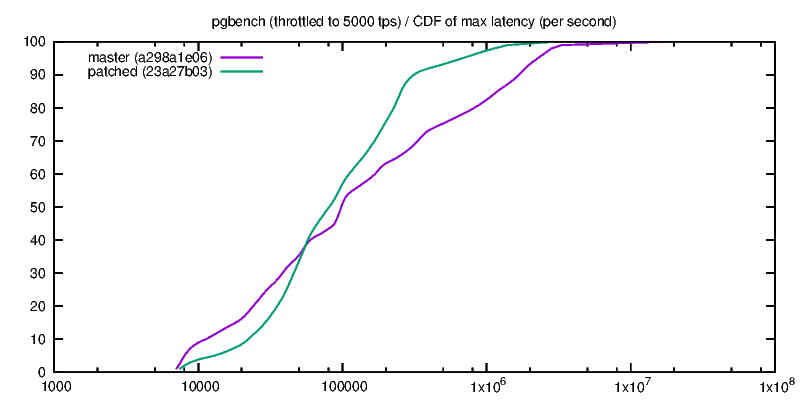{kind=link}
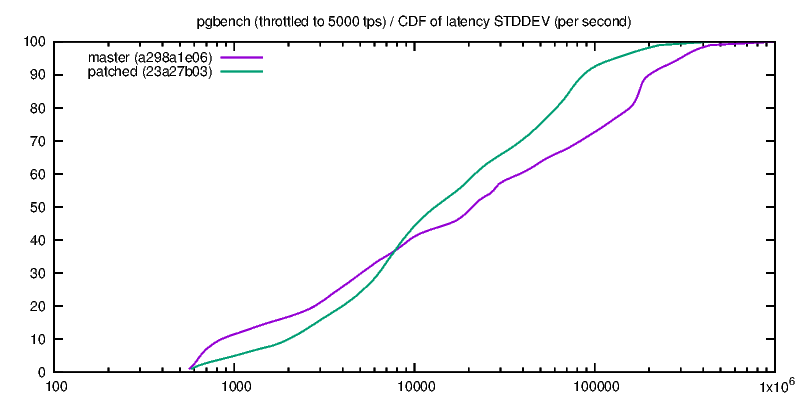{kind=link}
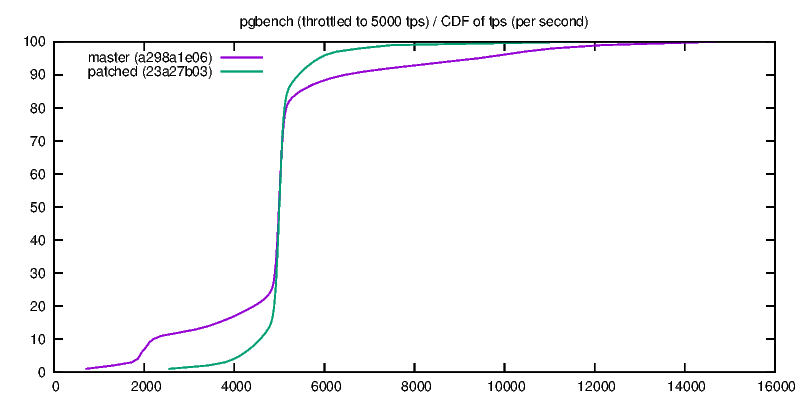{kind=link}
Hello Tomas,
Thanks for these great measures.
> * 4 x CPU E5-4620 (2.2GHz)
4*8 = 32 cores / 64 threads.
> * 256GB of RAM
Wow!
> * 24x SSD on LSI 2208 controller (with 1GB BBWC)
Wow! RAID configuration ? The patch is designed to fix very big issues on
HDD, but it is good to see that the impact is good on SSD as well.
Is it possible to run tests with distinct table spaces on those many
disks?
> * shared_buffers=64GB
1/4 of the available memory.
> The pgbench was scale 60000, so ~750GB of data on disk,
*3 available memory, mostly on disk.
> or like this ("throttled"):
>
> pgbench -c 32 -j 8 -T 86400 -R 5000 -l --aggregate-interval=1 pgbench
>
> The reason for the throttling is that people generally don't run production
> databases 100% saturated, so it'd be sad to improve the 100% saturated case
> and hurt the common case by increasing latency.
Sure.
> The machine does ~8000 tps, so 5000 tps is ~60% of that.
Ok.
I would have suggested using the --latency-limit option to filter out very
slow queries, otherwise if the system is stuck it may catch up later, but
then this is not representative of "sustainable" performance.
When pgbench is running under a target rate, in both runs the transaction
distribution is expected to be the same, around 5000 tps, and the green
run looks pretty ok with respect to that. The magenta one shows that about
25% of the time, things are not good at all, and the higher figures just
show the catching up, which is not really interesting if you asked for a
web page and it is finally delivered 1 minutes later.
> * regular-tps.png (per-second TPS) [...]
Great curves!
> consistent. Originally there was ~10% of samples with ~2000 tps, but with the
> flushing you'd have to go to ~4600 tps. It's actually pretty difficult to
> determine this from the chart, because the curve got so steep and I had to
> check the data used to generate the charts.
>
> Similarly for the upper end, but I assume that's a consequence of the
> throttling not having to compensate for the "slow" seconds anymore.
Yep, but they should be filtered out, "sorry, too late", so that would
count as unresponsisveness, at least for a large class of applications.
Thanks a lot for there interesting tests!
--
Fabien.
Hi,
On 03/17/2016 06:36 PM, Fabien COELHO wrote:
>
> Hello Tomas,
>
> Thanks for these great measures.
>
>> * 4 x CPU E5-4620 (2.2GHz)
>
> 4*8 = 32 cores / 64 threads.
Yep. I only used 32 clients though, to keep some of the CPU available
for the rest of the system (also, HT does not really double the number
of cores).
>
>> * 256GB of RAM
>
> Wow!
>
>> * 24x SSD on LSI 2208 controller (with 1GB BBWC)
>
> Wow! RAID configuration ? The patch is designed to fix very big issues
> on HDD, but it is good to see that the impact is good on SSD as well.
Yep, RAID-10. I agree that doing the test on a HDD-based system would be
useful, however (a) I don't have a comparable system at hand at the
moment, and (b) I was a bit worried that it'll hurt performance on SSDs,
but thankfully that's not the case.
I will do the test on a much smaller system with HDDs in a few days.
>
> Is it possible to run tests with distinct table spaces on those many disks?
Nope, that'd require reconfiguring the system (and then back), and I
don't have access to that system (just SSH). Also, I don't quite see
what would that tell us?
>> * shared_buffers=64GB
>
> 1/4 of the available memory.
>
>> The pgbench was scale 60000, so ~750GB of data on disk,
>
> *3 available memory, mostly on disk.
>
>> or like this ("throttled"):
>>
>> pgbench -c 32 -j 8 -T 86400 -R 5000 -l --aggregate-interval=1 pgbench
>>
>> The reason for the throttling is that people generally don't run
>> production databases 100% saturated, so it'd be sad to improve the
>> 100% saturated case and hurt the common case by increasing latency.
>
> Sure.
>
>> The machine does ~8000 tps, so 5000 tps is ~60% of that.
>
> Ok.
>
> I would have suggested using the --latency-limit option to filter out
> very slow queries, otherwise if the system is stuck it may catch up
> later, but then this is not representative of "sustainable" performance.
>
> When pgbench is running under a target rate, in both runs the
> transaction distribution is expected to be the same, around 5000 tps,
> and the green run looks pretty ok with respect to that. The magenta one
> shows that about 25% of the time, things are not good at all, and the
> higher figures just show the catching up, which is not really
> interesting if you asked for a web page and it is finally delivered 1
> minutes later.
Maybe. But that'd only increase the stress on the system, possibly
causing more issues, no? And the magenta line is the old code, thus it
would only increase the improvement of the new code.
Notice the max latency is in microseconds (as logged by pgbench), so
according to the "max latency" charts the latencies are below 10 seconds
(old) and 1 second (new) about 99% of the time. So I don't think this
would make any measurable difference in practice.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
>> Is it possible to run tests with distinct table spaces on those many disks? > > Nope, that'd require reconfiguring the system (and then back), and I don't > have access to that system (just SSH). Ok. > Also, I don't quite see what would that tell us? Currently the flushing context is shared between table space, but I think that it should be per table space. My tests did not manage to convince Andres, so getting some more figures would be great. That will be another time! >> I would have suggested using the --latency-limit option to filter out >> very slow queries, otherwise if the system is stuck it may catch up >> later, but then this is not representative of "sustainable" performance. >> >> When pgbench is running under a target rate, in both runs the >> transaction distribution is expected to be the same, around 5000 tps, >> and the green run looks pretty ok with respect to that. The magenta one >> shows that about 25% of the time, things are not good at all, and the >> higher figures just show the catching up, which is not really >> interesting if you asked for a web page and it is finally delivered 1 >> minutes later. > > Maybe. But that'd only increase the stress on the system, possibly causing > more issues, no? And the magenta line is the old code, thus it would only > increase the improvement of the new code. Yes and no. I agree that it stresses the system a little more, but the fact that you have 5000 tps in the end does not show that you can really sustain 5000 tps with reasonnable latency. I find this later information more interesting than knowing that you can get 5000 tps on average, thanks to some catching up. Moreover the non throttled runs already shown that the system could do 8000 tps, so the bandwidth is already there. > Notice the max latency is in microseconds (as logged by pgbench), so > according to the "max latency" charts the latencies are below 10 seconds > (old) and 1 second (new) about 99% of the time. AFAICS, the max latency is aggregated by second, but then it does not say much about the distribution of individuals latencies in the interval, that is whether they were all close to the max or not, Having the same chart with median or average might help. Also, with the stddev chart, the percent do not correspond with the latency one, so it may be that the latency is high but the stddev is low, i.e. all transactions are equally bad on the interval, or not. So I must admit that I'm not clear at all how to interpret the max latency & stddev charts you provided. > So I don't think this would make any measurable difference in practice. I think that it may show that 25% of the time the system could not match the target tps, even if it can handle much more on average, so the tps achieved when discarding late transactions would be under 4000 tps. -- Fabien.
Hi, On 03/17/2016 10:14 PM, Fabien COELHO wrote: > ... >>> I would have suggested using the --latency-limit option to filter out >>> very slow queries, otherwise if the system is stuck it may catch up >>> later, but then this is not representative of "sustainable" performance. >>> >>> When pgbench is running under a target rate, in both runs the >>> transaction distribution is expected to be the same, around 5000 tps, >>> and the green run looks pretty ok with respect to that. The magenta one >>> shows that about 25% of the time, things are not good at all, and the >>> higher figures just show the catching up, which is not really >>> interesting if you asked for a web page and it is finally delivered 1 >>> minutes later. >> >> Maybe. But that'd only increase the stress on the system, possibly >> causing more issues, no? And the magenta line is the old code, thus it >> would only increase the improvement of the new code. > > Yes and no. I agree that it stresses the system a little more, but > the fact that you have 5000 tps in the end does not show that you can > really sustain 5000 tps with reasonnable latency. I find this later > information more interesting than knowing that you can get 5000 tps > on average, thanks to some catching up. Moreover the non throttled > runs already shown that the system could do 8000 tps, so the > bandwidth is already there. Sure, but thanks to the tps charts we *do know* that for vast majority of the intervals (each second) the number of completed transactions is very close to 5000. And that wouldn't be possible if large part of the latencies were close to the maximums. With 5000 tps and 32 clients, that means the average latency should be less than 6ms, otherwise the clients couldn't make ~160 tps each. But we do see that the maximum latency for most intervals is way higher. Only ~10% of the intervals have max latency below 10ms, for example. > >> Notice the max latency is in microseconds (as logged by pgbench), >> so according to the "max latency" charts the latencies are below >> 10 seconds (old) and 1 second (new) about 99% of the time. > > AFAICS, the max latency is aggregated by second, but then it does > not say much about the distribution of individuals latencies in the > interval, that is whether they were all close to the max or not, > Having the same chart with median or average might help. Also, with > the stddev chart, the percent do not correspond with the latency one, > so it may be that the latency is high but the stddev is low, i.e. all > transactions are equally bad on the interval, or not.> > So I must admit that I'm not clear at all how to interpret the max > latency & stddev charts you provided. You're right those charts are not describing distributions of the latencies but those aggregated metrics. And it's not particularly simple to deduce information about the source statistics, for example because all the intervals have the same "weight" although the number of transactions that completed in each interval may be different. But I do think it's a very useful tool when it comes to measuring the consistency of behavior over time, assuming you're asking questions about the intervals and not the original transactions. For example, had there been intervals with vastly different transaction rates, we'd see that on the tps charts (i.e. the chart would be much more gradual or wobbly, just like the "unpatched" one). Or if there were intervals with much higher variance of latencies, we'd see that on the STDDEV chart. I'll consider repeating the benchmark and logging some reasonable sample of transactions - for the 24h run the unthrottled benchmark did ~670M transactions. Assuming ~30B per line, that's ~20GB, so 5% sample should be ~1GB of data, which I think is enough. But of course, that's useful for answering questions about distribution of the individual latencies in global, not about consistency over time. > >> So I don't think this would make any measurable difference in practice. > > I think that it may show that 25% of the time the system could not > match the target tps, even if it can handle much more on average, so > the tps achieved when discarding late transactions would be under > 4000 tps. You mean the 'throttled-tps' chart? Yes, that one shows that without the patches, there's a lot of intervals where the tps was much lower - presumably due to a lot of slow transactions. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hello Tomas, > But I do think it's a very useful tool when it comes to measuring the > consistency of behavior over time, assuming you're asking questions > about the intervals and not the original transactions. For a throttled run, I think it is better to check whether or not the system could handle the load "as expected", i.e. with reasonnable latency, so somehow I'm interested in the "original transactions" as scheduled by the client, and whether they were processed efficiently, but then it must be aggregated by interval to get some statistics. > For example, had there been intervals with vastly different transaction > rates, we'd see that on the tps charts (i.e. the chart would be much more > gradual or wobbly, just like the "unpatched" one). Or if there were intervals > with much higher variance of latencies, we'd see that on the STDDEV chart. On HDDs what happens is that transactions are "blocked/freezed", the tps is very low, the latency very high, but then with few tx (even 1 or 0 at time) and all latencies very bad but nevertheless close one to the other, in a bad way, the resulting stddev may be quite small anyway. > I'll consider repeating the benchmark and logging some reasonable sample of > transactions Beware that this measure is skewed, because on HDDs when the system is stuck, it is stuck on very few transactions which are waiting, but they would seldom show on statistics are there are very few of them. That is why I'm interested in those that could not make it, hence my interest in --latency-limit option which just say that. >>> So I don't think this would make any measurable difference in practice. >> >> I think that it may show that 25% of the time the system could not >> match the target tps, even if it can handle much more on average, so >> the tps achieved when discarding late transactions would be under >> 4000 tps. > > You mean the 'throttled-tps' chart? Yes. > Yes, that one shows that without the patches, there's a lot of intervals > where the tps was much lower - presumably due to a lot of slow > transactions. Yep. That is what is measured with the latency limit option, by counting the dropped transactions that where not processed in a timely maner. -- Fabien.
Hi,
I've repeated the tests, but this time logged details for 5% of the
transaction (instead of aggregating the data for each second). I've also
made the tests shorter - just 12 hours instead of 24, to reduce the time
needed to complete the benchmark.
Overall, this means ~300M transactions in total for the un-throttled
case, so sample with ~15M transactions available when computing the
following charts.
I've used the same commits as during the previous testing, i.e. a298a1e0
(before patches) and 23a27b03 (with patches).
One interesting difference is that while the "patched" version resulted
in slightly better performance (8122 vs. 8000 tps), the "unpatched"
version got considerably slower (6790 vs. 7725 tps) - that's ~13%
difference, so not negligible. Not sure what's the cause - the
configuration was exactly the same, there's nothing in the log and the
machine was dedicated to the testing. The only explanation I have is
that the unpatched code is a bit more unstable when it comes to this
type of stress testing.
There results (including scripts for generating the charts) are here:
https://github.com/tvondra/flushing-benchmark-2
Attached are three charts - again, those are using CDF to illustrate the
distributions and compare them easily:
1) regular-latency.png
The two curves intersect at ~4ms, where both CDF reach ~85%. For the
shorter transactions, the old code is slightly faster (i.e. apparently
there's some per-transaction overhead). For higher latencies though, the
patched code is clearly winning - there are far fewer transactions over
6ms, which makes a huge difference. (Notice the x-axis is actually
log-scale, so the tail on the old code is actually much longer than it
might appear.)
2) throttled-latency.png
In the throttled case (i.e. when the system is not 100% utilized, so
it's more representative of actual production use), the difference is
quite clearly in favor of the new code.
3) throttled-schedule-lag.png
Mostly just an alternative view on the previous chart, showing how much
later the transactions were scheduled. Again, the new code is winning.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
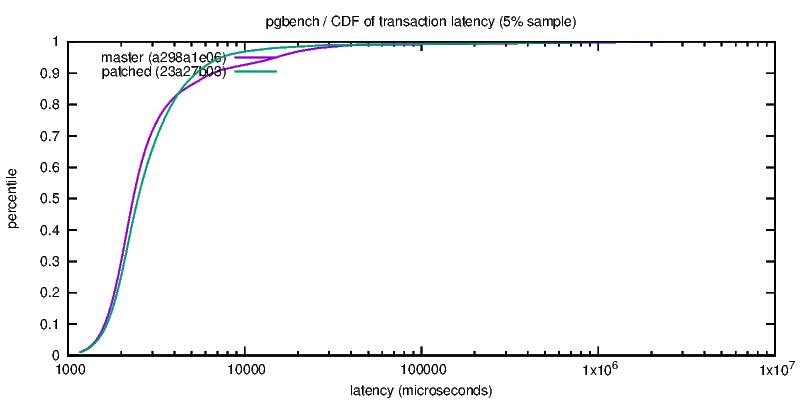{kind=link}
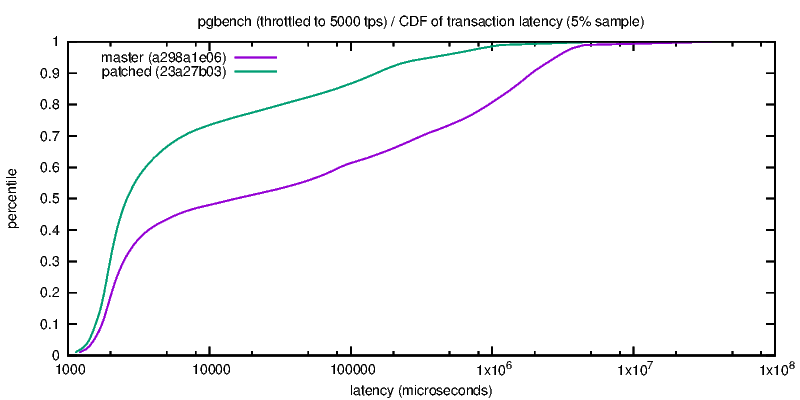{kind=link}
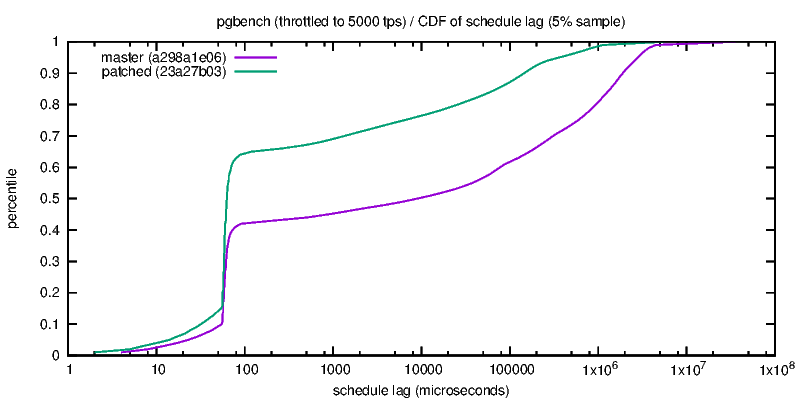{kind=link}
Hello Tomas, Thanks again for these interesting benches. > Overall, this means ~300M transactions in total for the un-throttled case, so > sample with ~15M transactions available when computing the following charts. Still a very sizable run! > There results (including scripts for generating the charts) are here: > > https://github.com/tvondra/flushing-benchmark-2 This repository seems empty. > 1) regular-latency.png I'm wondering whether it would be clearer if the percentiles where relative to the largest sample, not to itself, so that the figures from the largest one would still be between 0 and 1, but the other (unpatched) one would go between 0 and 0.85, that is would be cut short proportionnaly to the actual performance. > The two curves intersect at ~4ms, where both CDF reach ~85%. For the > shorter transactions, the old code is slightly faster (i.e. apparently > there's some per-transaction overhead). I'm not sure how meaningfull is the crossing, because both curves do not reflect the same performance. I think that they may not cross at all if the normalization is with the same reference, i.e. the better run. > 2) throttled-latency.png > > In the throttled case (i.e. when the system is not 100% utilized, so it's > more representative of actual production use), the difference is quite > clearly in favor of the new code. Indeed, it is a no brainer. > 3) throttled-schedule-lag.png > > Mostly just an alternative view on the previous chart, showing how much later > the transactions were scheduled. Again, the new code is winning. No brainer again. I infer from this figure that with the initial version 60% of transactions have trouble being processed on time, while this is maybe about 35% with the new version. -- Fabien.
Hi, On 03/22/2016 07:35 AM, Fabien COELHO wrote: > > Hello Tomas, > > Thanks again for these interesting benches. > >> Overall, this means ~300M transactions in total for the un-throttled >> case, so sample with ~15M transactions available when computing the >> following charts. > > Still a very sizable run! > >> There results (including scripts for generating the charts) are here: >> >> https://github.com/tvondra/flushing-benchmark-2 > > This repository seems empty. Strange. Apparently I forgot to push, or maybe it did not complete before I closed the terminal. Anyway, pushing now (it'll take a bit more time to complete). > >> 1) regular-latency.png > > I'm wondering whether it would be clearer if the percentiles where > relative to the largest sample, not to itself, so that the figures > from the largest one would still be between 0 and 1, but the other > (unpatched) one would go between 0 and 0.85, that is would be cut > short proportionnaly to the actual performance. > I'm not sure what you mean by 'relative to largest sample'? >> The two curves intersect at ~4ms, where both CDF reach ~85%. For >> the shorter transactions, the old code is slightly faster (i.e. >> apparently there's some per-transaction overhead). > > I'm not sure how meaningfull is the crossing, because both curves do > not reflect the same performance. I think that they may not cross at > all if the normalization is with the same reference, i.e. the better > run. Well, I think the curves illustrate exactly the performance difference, because with the old code the percentiles after p=0.85 get much higher. Which is the point of the crossing, although I agree the exact point does not have a particular meaning. >> 2) throttled-latency.png >> >> In the throttled case (i.e. when the system is not 100% utilized, >> so it's more representative of actual production use), the >> difference is quite clearly in favor of the new code. > > Indeed, it is a no brainer. Yep. > >> 3) throttled-schedule-lag.png >> >> Mostly just an alternative view on the previous chart, showing how >> much later the transactions were scheduled. Again, the new code is >> winning. > > No brainer again. I infer from this figure that with the initial > version 60% of transactions have trouble being processed on time, > while this is maybe about 35% with the new version. Yep. -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On 2016-03-21 18:46:58 +0100, Tomas Vondra wrote: > I've repeated the tests, but this time logged details for 5% of the > transaction (instead of aggregating the data for each second). I've also > made the tests shorter - just 12 hours instead of 24, to reduce the time > needed to complete the benchmark. > > Overall, this means ~300M transactions in total for the un-throttled case, > so sample with ~15M transactions available when computing the following > charts. > > I've used the same commits as during the previous testing, i.e. a298a1e0 > (before patches) and 23a27b03 (with patches). > > One interesting difference is that while the "patched" version resulted in > slightly better performance (8122 vs. 8000 tps), the "unpatched" version got > considerably slower (6790 vs. 7725 tps) - that's ~13% difference, so not > negligible. Not sure what's the cause - the configuration was exactly the > same, there's nothing in the log and the machine was dedicated to the > testing. The only explanation I have is that the unpatched code is a bit > more unstable when it comes to this type of stress testing. > > There results (including scripts for generating the charts) are here: > > https://github.com/tvondra/flushing-benchmark-2 > > Attached are three charts - again, those are using CDF to illustrate the > distributions and compare them easily: > > 1) regular-latency.png > > The two curves intersect at ~4ms, where both CDF reach ~85%. For the shorter > transactions, the old code is slightly faster (i.e. apparently there's some > per-transaction overhead). For higher latencies though, the patched code is > clearly winning - there are far fewer transactions over 6ms, which makes a > huge difference. (Notice the x-axis is actually log-scale, so the tail on > the old code is actually much longer than it might appear.) > > 2) throttled-latency.png > > In the throttled case (i.e. when the system is not 100% utilized, so it's > more representative of actual production use), the difference is quite > clearly in favor of the new code. > > 3) throttled-schedule-lag.png > > Mostly just an alternative view on the previous chart, showing how much > later the transactions were scheduled. Again, the new code is winning. Thanks for running these tests! I think this shows that we're in a good shape, and that the commits succeeded in what they were attempting. Very glad to hear that. WRT tablespaces: What I'm planning to do, unless somebody has a better proposal, is to basically rent two big amazon instances, and run pgbench in parallel over N tablespaces. Once with local SSD and once with local HDD storage. Greetings, Andres Freund
>>> 1) regular-latency.png >> >> I'm wondering whether it would be clearer if the percentiles where >> relative to the largest sample, not to itself, so that the figures >> from the largest one would still be between 0 and 1, but the other >> (unpatched) one would go between 0 and 0.85, that is would be cut >> short proportionnaly to the actual performance. > > I'm not sure what you mean by 'relative to largest sample'? You took 5% of the tx on two 12 hours runs, totaling say 85M tx on one and 100M tx on the other, so you get 4.25M tx from the first and 5M from the second. I'm saying that the percentile should be computed on the largest one (5M), so that you get a curve like the following, with both curve having the same transaction density on the y axis, so the second one does not go up to the top, reflecting that in this case less transactions where processed. A + ____----- # up to 100% | / ___---- # cut short | | / | | | | _/ / |/__/ +-------------> -- Fabien.
Hi, On 03/22/2016 10:44 AM, Fabien COELHO wrote: > > >>>> 1) regular-latency.png >>> >>> I'm wondering whether it would be clearer if the percentiles >>> where relative to the largest sample, not to itself, so that the >>> figures from the largest one would still be between 0 and 1, but >>> the other (unpatched) one would go between 0 and 0.85, that is >>> would be cut short proportionnaly to the actual performance. >> >> I'm not sure what you mean by 'relative to largest sample'? > > You took 5% of the tx on two 12 hours runs, totaling say 85M tx on > one and 100M tx on the other, so you get 4.25M tx from the first and > 5M from the second. OK > I'm saying that the percentile should be computed on the largest one > (5M), so that you get a curve like the following, with both curve > having the same transaction density on the y axis, so the second one > does not go up to the top, reflecting that in this case less > transactions where processed. Huh, that seems weird. That's not how percentiles or CDFs work, and I don't quite understand what would that tell us. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
> WRT tablespaces: What I'm planning to do, unless somebody has a better > proposal, is to basically rent two big amazon instances, and run pgbench > in parallel over N tablespaces. Once with local SSD and once with local > HDD storage. Ok. Not sure how to control that table spaces are actually on distinct dedicated disks with VMs, but this is the idea. To emphasize potential bad effects without having to build too large a host and involve too many table spaces, I would suggest to reduce significantly the "checkpoint_flush_after" setting while running these tests. -- Fabien.
On 2016-03-22 10:48:20 +0100, Tomas Vondra wrote: > Hi, > > On 03/22/2016 10:44 AM, Fabien COELHO wrote: > > > > > >>>>1) regular-latency.png > >>> > >>>I'm wondering whether it would be clearer if the percentiles > >>>where relative to the largest sample, not to itself, so that the > >>>figures from the largest one would still be between 0 and 1, but > >>>the other (unpatched) one would go between 0 and 0.85, that is > >>>would be cut short proportionnaly to the actual performance. > >> > >>I'm not sure what you mean by 'relative to largest sample'? > > > >You took 5% of the tx on two 12 hours runs, totaling say 85M tx on > >one and 100M tx on the other, so you get 4.25M tx from the first and > >5M from the second. > > OK > > >I'm saying that the percentile should be computed on the largest one > >(5M), so that you get a curve like the following, with both curve > >having the same transaction density on the y axis, so the second one > >does not go up to the top, reflecting that in this case less > >transactions where processed. > > Huh, that seems weird. That's not how percentiles or CDFs work, and I don't > quite understand what would that tell us. My impression is that we actually know what we need to know anyway?
On 2016-03-22 10:52:55 +0100, Fabien COELHO wrote: > To emphasize potential bad effects without having to build too large a host > and involve too many table spaces, I would suggest to reduce significantly > the "checkpoint_flush_after" setting while running these tests. Meh, that completely distorts the test.
>> You took 5% of the tx on two 12 hours runs, totaling say 85M tx on >> one and 100M tx on the other, so you get 4.25M tx from the first and >> 5M from the second. > > OK > >> I'm saying that the percentile should be computed on the largest one >> (5M), so that you get a curve like the following, with both curve >> having the same transaction density on the y axis, so the second one >> does not go up to the top, reflecting that in this case less >> transactions where processed. > > Huh, that seems weird. That's not how percentiles or CDFs work, and I don't > quite understand what would that tell us. It would tell us that for a given transaction number (in the latency-ordered list) whether its latency is above or below the other run. I think it would probably show that the latency is always better for the patched version by getting rid of the crossing which has no meaning and seems to suggest, wrongly, that in some case the other is better than the first, but as the y axis of both curves are not in the same unit (not same transaction density) this is just an illusion implied by a misplaced normalization. So I'm basically saying that the y axis should be just the transaction number, not a percent. Anyway, these are just details, your figures show that the patch is a very significant win on SSDs, all is well! -- Fabien.
> My impression is that we actually know what we need to know anyway? Sure, the overall summary is "it is much better with the patch" on this large SSD test, which is good news because the patch was really designed to help with HDDs. -- Fabien.
>> To emphasize potential bad effects without having to build too large a host >> and involve too many table spaces, I would suggest to reduce significantly >> the "checkpoint_flush_after" setting while running these tests. > > Meh, that completely distorts the test. Yep, I agree. The point would be to show whether there is a significant impact, or not, with less hardware & cost involved in the test. Now if you can put 16 disks with 16 table spaces with 16 buffers per bucket, that is good, fine with me! I'm just trying to point out that you could probably get comparable relative results with 4 disks, 4 tables spaces and 4 buffers per bucket, so it is an alternative and less expensive testing strategy. This just shows that I usually work on a tight (negligeable?) budget:-) -- Fabien.