Thread: Should we cacheline align PGXACT?
Hackers,
originally this idea was proposed by Andres Freund while experimenting with lockfree Pin/UnpinBuffer [1].
The patch is attached as well as results of pgbench -S on 72-cores machine. As before it shows huge benefit in this case.
For sure, we should validate that it doesn't cause performance regression in other cases. At least we should test read-write and smaller machines.
Any other ideas?
------
Attachment
{kind=link}
On Fri, Aug 19, 2016 at 11:42 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Hackers, > > originally this idea was proposed by Andres Freund while experimenting with > lockfree Pin/UnpinBuffer [1]. > The patch is attached as well as results of pgbench -S on 72-cores machine. > As before it shows huge benefit in this case. > For sure, we should validate that it doesn't cause performance regression in > other cases. At least we should test read-write and smaller machines. > Any other ideas? > may be test on Power m/c as well. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> originally this idea was proposed by Andres Freund while experimenting with
> lockfree Pin/UnpinBuffer [1].
> The patch is attached as well as results of pgbench -S on 72-cores
> machine. As before it shows huge benefit in this case.
That's one mighty ugly patch. Can't you do it without needing to
introduce the additional layer of struct nesting?
regards, tom lane
On Fri, Aug 19, 2016 at 4:46 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> originally this idea was proposed by Andres Freund while experimenting with
> lockfree Pin/UnpinBuffer [1].
> The patch is attached as well as results of pgbench -S on 72-cores
> machine. As before it shows huge benefit in this case.
That's one mighty ugly patch. Can't you do it without needing to
introduce the additional layer of struct nesting?
That's worrying me too.
We could use anonymous struct, but it seems to be prohibited in C89 which we stick to.
Another idea, which comes to my mind, is to manually calculate size of padding and insert it directly to PGXACT struct. But that seems rather ugly too. However, it would be ugly definition not ugly usage...
Do you have better ideas?
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Fri, Aug 19, 2016 at 3:19 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
Good idea. I don't have any such machine at hand now. Do you have one?
On Fri, Aug 19, 2016 at 11:42 AM, Alexander Korotkov
<a.korotkov@postgrespro.ru> wrote:
> Hackers,
>
> originally this idea was proposed by Andres Freund while experimenting with
> lockfree Pin/UnpinBuffer [1].
> The patch is attached as well as results of pgbench -S on 72-cores machine.
> As before it shows huge benefit in this case.
> For sure, we should validate that it doesn't cause performance regression in
> other cases. At least we should test read-write and smaller machines.
> Any other ideas?
>
may be test on Power m/c as well.
The Russian Postgres Company
Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> On Fri, Aug 19, 2016 at 4:46 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> That's one mighty ugly patch. Can't you do it without needing to
>> introduce the additional layer of struct nesting?
> That's worrying me too.
> We could use anonymous struct, but it seems to be prohibited in C89 which
> we stick to.
> Another idea, which comes to my mind, is to manually calculate size of
> padding and insert it directly to PGXACT struct. But that seems rather
> ugly too. However, it would be ugly definition not ugly usage...
> Do you have better ideas?
No, that was the best one that had occurred to me, too. You could
probably introduce a StaticAssert that sizeof(PGXACT) is a power of 2
as a means of checking that the manual padding calculation hadn't
gotten broken.
regards, tom lane
On Fri, Aug 19, 2016 at 8:24 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > On Fri, Aug 19, 2016 at 3:19 PM, Amit Kapila <amit.kapila16@gmail.com> > wrote: >> >> On Fri, Aug 19, 2016 at 11:42 AM, Alexander Korotkov >> <a.korotkov@postgrespro.ru> wrote: >> > Hackers, >> > >> > originally this idea was proposed by Andres Freund while experimenting >> > with >> > lockfree Pin/UnpinBuffer [1]. >> > The patch is attached as well as results of pgbench -S on 72-cores >> > machine. >> > As before it shows huge benefit in this case. >> > For sure, we should validate that it doesn't cause performance >> > regression in >> > other cases. At least we should test read-write and smaller machines. >> > Any other ideas? >> > >> >> may be test on Power m/c as well. > > > Good idea. I don't have any such machine at hand now. Do you have one? > Yes, I can help in testing this patch during CF. Feel free to ping, if I missed or forgot to do same. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Aug 19, 2016, at 2:12 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Hackers, > > originally this idea was proposed by Andres Freund while experimenting with lockfree Pin/UnpinBuffer [1]. > The patch is attached as well as results of pgbench -S on 72-cores machine. As before it shows huge benefit in this case. > For sure, we should validate that it doesn't cause performance regression in other cases. At least we should test read-writeand smaller machines. > Any other ideas? Wow, nice results. My intuition on why PGXACT helped in the first place was that it minimized the number of cache linesthat had to be touched to take a snapshot. Padding obviously would somewhat increase that again, so I can't quite understandwhy it seems to be helping... any idea? ...Robert
Robert Haas <robertmhaas@gmail.com> writes:
> Wow, nice results. My intuition on why PGXACT helped in the first place was that it minimized the number of cache
linesthat had to be touched to take a snapshot. Padding obviously would somewhat increase that again, so I can't quite
understandwhy it seems to be helping... any idea?
That's an interesting point. I wonder whether this whole thing will be
useless or even counterproductive after (if) Heikki's CSN-snapshot patch
gets in. I would certainly not mind reverting the PGXACT/PGPROC
separation if it proves no longer helpful after that.
regards, tom lane
On 2016-08-20 14:33:13 -0400, Robert Haas wrote: > On Aug 19, 2016, at 2:12 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > Hackers, > > > > originally this idea was proposed by Andres Freund while experimenting with lockfree Pin/UnpinBuffer [1]. > > The patch is attached as well as results of pgbench -S on 72-cores machine. As before it shows huge benefit in thiscase. > > For sure, we should validate that it doesn't cause performance regression in other cases. At least we should test read-writeand smaller machines. > > Any other ideas? > > Wow, nice results. My intuition on why PGXACT helped in the first > place was that it minimized the number of cache lines that had to be > touched to take a snapshot. Padding obviously would somewhat increase > that again, so I can't quite understand why it seems to be > helping... any idea? I don't think it's that surprising: PGXACT->xid is written to each transaction, and ->xmin is often written to multiple times per transaction. That means that if a PGXACT's cacheline is shared between backends one write will often first have another CPU flush it's store buffer / L1 / L2 cache. If there's several hops between two cores, that can mean quite a bit of added latency. I previously played around with *removing* the optimization of resetting ->xmin when not required anymore - and on a bigger machine it noticeably increased throughput on higher client counts. To me it's pretty clear that rounding up PGXACT's size to a 16 bytes (instead of the current 12, with 4 byte alignment) is going to be a win, the current approach just leeds to pointless sharing. Besides, storing the database oid in there will allow GetOldestXmin() to only use PGXACT, and could, with a bit more work, allow to ignore other databases in GetSnapshotData(). I'm less sure that going up to a full cacheline is always a win. Andres
On 2016-08-19 09:46:12 -0400, Tom Lane wrote: > Alexander Korotkov <a.korotkov@postgrespro.ru> writes: > > originally this idea was proposed by Andres Freund while experimenting with > > lockfree Pin/UnpinBuffer [1]. > > The patch is attached as well as results of pgbench -S on 72-cores > > machine. As before it shows huge benefit in this case. > > That's one mighty ugly patch. My version of it was only intended to nail down some variability on the pgpro machine, it wasn't intended for submission. > Can't you do it without needing to introduce the additional layer of > struct nesting? If we required support for anonymous unions, such things would be a lot easier to do. That aside, the only alternative seems tob e hard-coding padding space - which probably isn't all that un-fragile either.
On 22 August 2016 at 10:40, Andres Freund <andres@anarazel.de> wrote:
On 2016-08-19 09:46:12 -0400, Tom Lane wrote:
> Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> > originally this idea was proposed by Andres Freund while experimenting with
> > lockfree Pin/UnpinBuffer [1].
> > The patch is attached as well as results of pgbench -S on 72-cores
> > machine. As before it shows huge benefit in this case.
>
> That's one mighty ugly patch.
My version of it was only intended to nail down some variability on the
pgpro machine, it wasn't intended for submission.
> Can't you do it without needing to introduce the additional layer of
> struct nesting?
If we required support for anonymous unions, such things would be a lot
easier to do. That aside, the only alternative seems tob e hard-coding
padding space - which probably isn't all that un-fragile either.
Somewhat naïve question from someone with much less clue about low level cache behaviour trying to follow along: given that we determine such padding at compile time, how do we ensure that the cacheline size we're targeting is right at runtime? Or is it safe to assume that using 16 bytes so we don't cross cache line boundaries is always helpful, whether we have 4 PGXACT entries (64 byte line) or some other number per cacheline?
--
On 2016-08-22 11:25:55 +0800, Craig Ringer wrote: > On 22 August 2016 at 10:40, Andres Freund <andres@anarazel.de> wrote: > > > On 2016-08-19 09:46:12 -0400, Tom Lane wrote: > > > Alexander Korotkov <a.korotkov@postgrespro.ru> writes: > > > > originally this idea was proposed by Andres Freund while experimenting > > with > > > > lockfree Pin/UnpinBuffer [1]. > > > > The patch is attached as well as results of pgbench -S on 72-cores > > > > machine. As before it shows huge benefit in this case. > > > > > > That's one mighty ugly patch. > > > > My version of it was only intended to nail down some variability on the > > pgpro machine, it wasn't intended for submission. > > > > > > > Can't you do it without needing to introduce the additional layer of > > > struct nesting? > > > > If we required support for anonymous unions, such things would be a lot > > easier to do. That aside, the only alternative seems tob e hard-coding > > padding space - which probably isn't all that un-fragile either. > > <http://www.postgresql.org/mailpref/pgsql-hackers> > > > > Somewhat naïve question from someone with much less clue about low level > cache behaviour trying to follow along: given that we determine such > padding at compile time, how do we ensure that the cacheline size we're > targeting is right at runtime? There's basically only very few common cacheline sizes. Pretty much only 64 byte and 128 bytes are common these days. By usually padding to the larger of those two, we waste a bit of memory, but not actually cache space on platforms with smaller lines, because the padding is never accessed. > Or is it safe to assume that using 16 bytes so we don't cross cache > line boundaries is always helpful, whether we have 4 PGXACT entries > (64 byte line) or some other number per cacheline? That's generally a good thing to do, yes. It's probably not going to give the full benefits here though. Regards Andres
On Sat, Aug 20, 2016 at 9:38 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Robert Haas <robertmhaas@gmail.com> writes:
> Wow, nice results. My intuition on why PGXACT helped in the first place was that it minimized the number of cache lines that had to be touched to take a snapshot. Padding obviously would somewhat increase that again, so I can't quite understand why it seems to be helping... any idea?
That's an interesting point. I wonder whether this whole thing will be
useless or even counterproductive after (if) Heikki's CSN-snapshot patch
gets in. I would certainly not mind reverting the PGXACT/PGPROC
separation if it proves no longer helpful after that.
Assuming, we wouldn't realistically have CSN-snapshot patch committed to 10, I think we should consider PGXACT cache line alignment patch for 10.
Revision on PGXACT align patch is attached. Now it doesn't introduce new data structure for alignment, but uses manually calculated padding. I added static assertion that PGXACT is exactly PG_CACHE_LINE_SIZE because it still have plenty of room for new fields before PG_CACHE_LINE_SIZE would be exceeded.
Readonly pgbench results on 72 physically cores Intel server are attached. It quite similar to results I posted before, but it's curious that performance degradation of master on high concurrency became larger.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
{kind=link}
Hi, As discussed at the Developer meeting ~ a week ago, I've ran a number of benchmarks on the commit, on a small/medium-size x86 machines. I currently don't have access to a machine as big as used by Alexander (with 72 physical cores), but it seems useful to verify the patch does not have negative impact on smaller machines. In particular I've ran these tests: * r/o pgbench * r/w pgbench * 90% reads, 10% writes * pgbench with skewed distribution * pgbench with skewed distribution and skipping And each of that with a number of clients, depending on the number of cores available. I've used the usual two boxes I use for all benchmarks, i.e. a small i5-2500k machine (8GB RAM, 4 cores), and a medium e5-2620v4 box (32GB RAM, 16/32 cores). Comparing averages of tps, measured on 5 runs (each 5 minutes long), the difference between master and patched master is usually within 2%, which is pretty much within noise. I'm attaching spreadsheets with summary of the results, so that we have it in the archives. As usual, the scripts and much more detailed results are available here: * e5-2620: https://bitbucket.org/tvondra/test-xact-alignment * i5-2500k: https://bitbucket.org/tvondra/test-xact-alignment-i5 I do plan to run these results on the Power8 box I have access to, but that will have to wait for a bit, because it's currently doing something else. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
Hi,
I am currently testing this patch on a large machine and will share the test results in few days of time.
Please excuse any grammatical errors as I am using my mobile device. Thanks.
On Feb 11, 2017 04:59, "Tomas Vondra" <tomas.vondra@2ndquadrant.com> wrote:
Hi,
As discussed at the Developer meeting ~ a week ago, I've ran a number of benchmarks on the commit, on a small/medium-size x86 machines. I currently don't have access to a machine as big as used by Alexander (with 72 physical cores), but it seems useful to verify the patch does not have negative impact on smaller machines.
In particular I've ran these tests:
* r/o pgbench
* r/w pgbench
* 90% reads, 10% writes
* pgbench with skewed distribution
* pgbench with skewed distribution and skipping
And each of that with a number of clients, depending on the number of cores available. I've used the usual two boxes I use for all benchmarks, i.e. a small i5-2500k machine (8GB RAM, 4 cores), and a medium e5-2620v4 box (32GB RAM, 16/32 cores).
Comparing averages of tps, measured on 5 runs (each 5 minutes long), the difference between master and patched master is usually within 2%, which is pretty much within noise.
I'm attaching spreadsheets with summary of the results, so that we have it in the archives. As usual, the scripts and much more detailed results are available here:
* e5-2620: https://bitbucket.org/tvondra/test-xact-alignment
* i5-2500k: https://bitbucket.org/tvondra/test-xact-alignment-i5
I do plan to run these results on the Power8 box I have access to, but that will have to wait for a bit, because it's currently doing something else.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
On 02/11/2017 02:44 AM, Ashutosh Sharma wrote: > Hi, > > I am currently testing this patch on a large machine and will share the > test results in few days of time. > FWIW it might be interesting to have comparable results from the same benchmarks I did. The scripts available in the git repositories should not be that hard to tweak. Let me know if you're interested and need help with that. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, Tomas!
On Sat, Feb 11, 2017 at 2:28 AM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.
As discussed at the Developer meeting ~ a week ago, I've ran a number of benchmarks on the commit, on a small/medium-size x86 machines. I currently don't have access to a machine as big as used by Alexander (with 72 physical cores), but it seems useful to verify the patch does not have negative impact on smaller machines.
In particular I've ran these tests:
* r/o pgbench
* r/w pgbench
* 90% reads, 10% writes
* pgbench with skewed distribution
* pgbench with skewed distribution and skipping
Thank you very much for your efforts!
I took a look at these tests. One thing catch my eyes. You warmup database using pgbench run. Did you consider using pg_prewarm instead?
SELECT sum(x.x) FROM (SELECT pg_prewarm(oid) AS x FROM pg_class WHERE relkind IN ('i', 'r') ORDER BY oid) x;
In my experience pg_prewarm both takes less time and leaves less variation afterwards.
Alexander Korotkov
Postgres Professional: http://www.
The Russian Postgres Company
On 02/11/2017 01:21 PM, Alexander Korotkov wrote:
> Hi, Tomas!
>
> On Sat, Feb 11, 2017 at 2:28 AM, Tomas Vondra
> <tomas.vondra@2ndquadrant.com <mailto:tomas.vondra@2ndquadrant.com>> wrote:
>
> As discussed at the Developer meeting ~ a week ago, I've ran a
> number of benchmarks on the commit, on a small/medium-size x86
> machines. I currently don't have access to a machine as big as used
> by Alexander (with 72 physical cores), but it seems useful to verify
> the patch does not have negative impact on smaller machines.
>
> In particular I've ran these tests:
>
> * r/o pgbench
> * r/w pgbench
> * 90% reads, 10% writes
> * pgbench with skewed distribution
> * pgbench with skewed distribution and skipping
>
>
> Thank you very much for your efforts!
> I took a look at these tests. One thing catch my eyes. You warmup
> database using pgbench run. Did you consider using pg_prewarm instead?
>
> SELECT sum(x.x) FROM (SELECT pg_prewarm(oid) AS x FROM pg_class WHERE
> relkind IN ('i', 'r') ORDER BY oid) x;
>
> In my experience pg_prewarm both takes less time and leaves less
> variation afterwards.
>
I've considered it, but the problem I see in using pg_prewarm for
benchmarking purposes is that it only loads the data into memory, but it
does not modify the tuples (so all tuples have the same xmin/xmax, no
dead tuples, ...), it does not set usage counters on the buffers and
also does not generate any clog records.
I don't think there's a lot of variability in the results I measured. If
you look at (max-min) for each combination of parameters, the delta is
generally within 2% of average, with a very few exceptions, usually
caused by the first run (so perhaps the warmup should be a bit longer).
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
> FWIW it might be interesting to have comparable results from the same > benchmarks I did. The scripts available in the git repositories should not > be that hard to tweak. Let me know if you're interested and need help with > that. > Sure, I will have a look into those scripts once I am done with the simple pgbench testing. Thanks and sorry for the delayed response.
On Sat, Feb 11, 2017 at 4:17 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On 02/11/2017 01:21 PM, Alexander Korotkov wrote:Hi, Tomas!
On Sat, Feb 11, 2017 at 2:28 AM, Tomas Vondra
<tomas.vondra@2ndquadrant.com <mailto:tomas.vondra@2ndquadrant.com>> wrote:
As discussed at the Developer meeting ~ a week ago, I've ran a
number of benchmarks on the commit, on a small/medium-size x86
machines. I currently don't have access to a machine as big as used
by Alexander (with 72 physical cores), but it seems useful to verify
the patch does not have negative impact on smaller machines.
In particular I've ran these tests:
* r/o pgbench
* r/w pgbench
* 90% reads, 10% writes
* pgbench with skewed distribution
* pgbench with skewed distribution and skipping
Thank you very much for your efforts!
I took a look at these tests. One thing catch my eyes. You warmup
database using pgbench run. Did you consider using pg_prewarm instead?
SELECT sum(x.x) FROM (SELECT pg_prewarm(oid) AS x FROM pg_class WHERE
relkind IN ('i', 'r') ORDER BY oid) x;
In my experience pg_prewarm both takes less time and leaves less
variation afterwards.
I've considered it, but the problem I see in using pg_prewarm for benchmarking purposes is that it only loads the data into memory, but it does not modify the tuples (so all tuples have the same xmin/xmax, no dead tuples, ...), it does not set usage counters on the buffers and also does not generate any clog records.
Yes, but please note that pgbench runs VACUUM first, and all the tuples would be hinted. In order to xmin/xmax and clog take effect, you should run subsequent pgbench with --no-vacuum. Also usage counters of buffers make sense only when eviction happens, i.e. data don't fit shared_buffers.
Also, you use pgbench -S to warmup before readonly test. I think pg_prewarm would be much better there unless your data is bigger than shared_buffers.
I don't think there's a lot of variability in the results I measured. If you look at (max-min) for each combination of parameters, the delta is generally within 2% of average, with a very few exceptions, usually caused by the first run (so perhaps the warmup should be a bit longer).
You also could run pg_prewarm before warmup pgbench for readwrite test. In my intuition you should get more stable results with shorter warmup.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 8/22/16 12:24 AM, Andres Freund wrote: >> Somewhat naïve question from someone with much less clue about low level >> cache behaviour trying to follow along: given that we determine such >> padding at compile time, how do we ensure that the cacheline size we're >> targeting is right at runtime? > There's basically only very few common cacheline sizes. Pretty much only > 64 byte and 128 bytes are common these days. By usually padding to the > larger of those two, we waste a bit of memory, but not actually cache > space on platforms with smaller lines, because the padding is never > accessed. Though, with an N-way associative cache 2x more padding than necessary cuts the amount you can fit into the cache by half. That could be meaningful in some cases. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
Am Samstag, den 11.02.2017, 00:28 +0100 schrieb Tomas Vondra: > Comparing averages of tps, measured on 5 runs (each 5 minutes long), > the > difference between master and patched master is usually within 2%, > which > is pretty much within noise. > > I'm attaching spreadsheets with summary of the results, so that we > have > it in the archives. As usual, the scripts and much more detailed > results > are available here: I've done some benchmarking of this patch against the E850/ppc64el Ubuntu LPAR we currently have access to and got the attached results. pg_prewarm as recommended by Alexander was used, the tests run 300s secs, scale 1000, each with a testrun before. The SELECT-only pgbench was run twice each, the write tests only once. Looks like the influence of this patch isn't that big, at least on this machine. We're going to reassign the resources to an AIX LPAR soon, which doesn't give me enough time to test with Tomas' test scripts again. -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
{kind=link}
On Mon, Feb 13, 2017 at 3:34 PM, Bernd Helmle <mailings@oopsware.de> wrote:
Am Samstag, den 11.02.2017, 00:28 +0100 schrieb Tomas Vondra:
> Comparing averages of tps, measured on 5 runs (each 5 minutes long),
> the
> difference between master and patched master is usually within 2%,
> which
> is pretty much within noise.
>
> I'm attaching spreadsheets with summary of the results, so that we
> have
> it in the archives. As usual, the scripts and much more detailed
> results
> are available here:
I've done some benchmarking of this patch against the E850/ppc64el
Ubuntu LPAR we currently have access to and got the attached results.
pg_prewarm as recommended by Alexander was used, the tests run 300s
secs, scale 1000, each with a testrun before. The SELECT-only pgbench
was run twice each, the write tests only once.
Looks like the influence of this patch isn't that big, at least on this
machine.
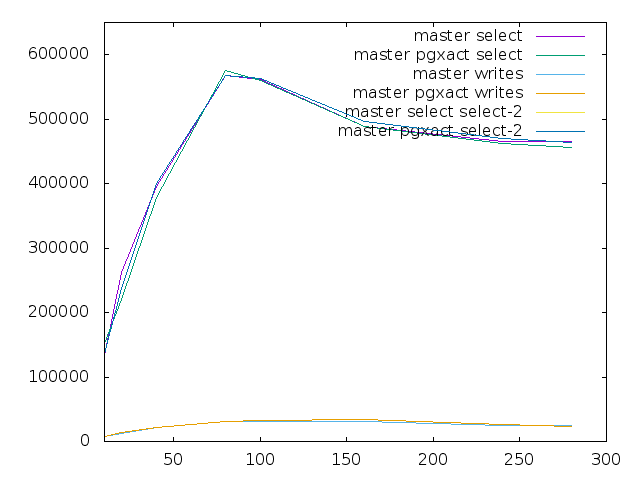
Thank you for testing.
Yes, influence seems to be low. But nevertheless it's important to insure that there is no regression here.
Despite pg_prewarm'ing and running tests 300s, there is still significant variation.
For instance, with clients count = 80:
* pgxact-result-2.txt – 474704
* pgxact-results.txt – 574844
Could some background processes influence the tests? Or could it be another virtual machine?
Also, I wonder why I can't see this variation on the graphs.
Another issue with graphs is that we can't see details of read and write TPS variation on the same scale, because write TPS values are too low. I think you should draw write benchmark on the separate graph.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov wrote: > Yes, influence seems to be low. But nevertheless it's important to insure > that there is no regression here. > Despite pg_prewarm'ing and running tests 300s, there is still significant > variation. > For instance, with clients count = 80: > * pgxact-result-2.txt – 474704 > * pgxact-results.txt – 574844 > Could some background processes influence the tests? Or could it be > another virtual machine? > Also, I wonder why I can't see this variation on the graphs. > Another issue with graphs is that we can't see details of read and write > TPS variation on the same scale, because write TPS values are too low. I > think you should draw write benchmark on the separate graph. So, I'm reading that on PPC64 there is no effect, and on the "lesser" machine Tomas tested on, there is no effect either; this patch only seems to benefit Alexander's 72 core x86_64 machine. It seems to me that Andres comments here were largely ignored: https://www.postgresql.org/message-id/20160822021747.u5bqx2xwwjzac5u5@alap3.anarazel.de He was suggesting to increase the struct size to 16 bytes rather than going all the way up to 128. Did anybody test this? Re the coding of the padding computation, seems it'd be better to use our standard "offsetof(last-struct-member) + sizeof(last-struct-member)" rather than adding each of the members' sizes individually. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Am Montag, den 13.02.2017, 16:55 +0300 schrieb Alexander Korotkov: > > Thank you for testing. > > Yes, influence seems to be low. But nevertheless it's important to > insure > that there is no regression here. > Despite pg_prewarm'ing and running tests 300s, there is still > significant > variation. > For instance, with clients count = 80: > * pgxact-result-2.txt – 474704 > * pgxact-results.txt – 574844 > Could some background processes influence the tests? Or could it be > another virtual machine? > Also, I wonder why I can't see this variation on the graphs. > Another issue with graphs is that we can't see details of read and > write Whoops, good catch. I've mistakenly copied the wrong y-axis for these results in the gnuplot script, shame on me. New plots attached. You're right, the 2nd run with the pgxact alignment patch is notable. I've realized that there was a pgbouncer instance running from a previous test, but not sure if that could explain the difference. > TPS variation on the same scale, because write TPS values are too > low. I > think you should draw write benchmark on the separate graph. > The Linux LPAR is the only one used atm. We got some more time for Linux now and i'm going to prepare Tomas' script to run. Not sure i can get to it today, though. -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
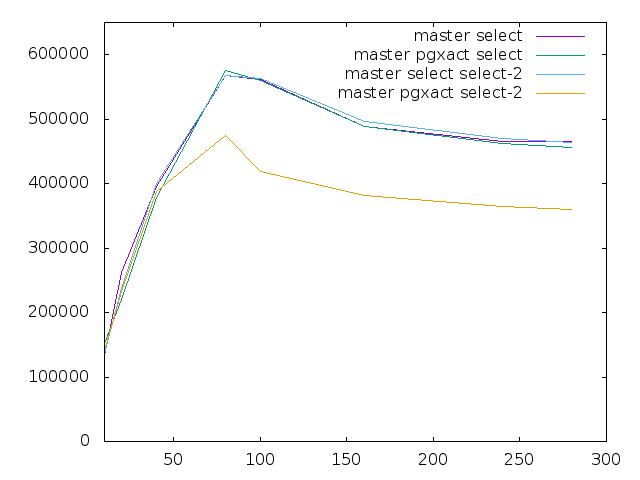{kind=link}
{kind=link}
Hi All, I too have performed benchmarking of this patch on a large machine (with 128 CPU(s), 520GB RAM, intel x86-64 architecture) and would like to share my observations for the same (Please note that, as I had to reverify readings on few client counts, it did take some time for me to share these test-results.) Case1: Data fits in shared buffer, Read Only workload: ------------------------------------------------------------------------------- For data fits in shared buffer, I have taken readings at 300 SF. The result sheet 'results-readonly-300-1000-SF' containing the median of 3 runs is attached with this mail. In this case, I could see very good performance improvement with the patch basically at high client counts (156 - 256). Case2: Data doesn't fit in shared buffer, Read Only workload: -------------------------------------------------------------------------------------- For data doesn't fit in shared buffer, I have taken readings at 1000 SF. The result sheet 'results-readonly-300-1000-SF' is attached with this mail. In this case, the performance improvement is not as in Case1, Infact it just varies in the range of 2-7%. but the good thing is that there is no regression. Case3: Data fits in shared buffer, Read-write workload: ----------------------------------------------------------------------------- In this case, I could see that the tps on head and patch are very close to each other with a small variation of (+-)3-4% which i assume is a run-to-run variation. PFA result sheet 'results-readwrite-300-1000-SF' containing the test-results. Case4: Data doesn't fit in shared buffer, Read-write workload: ---------------------------------------------------------------------------------------- In this case as well, tps on head and patch are very close to each other with small variation of 1-2% which again is a run-to-run variation. PFA result sheet 'results-readwrite-300-1000-SF' containing the test-results. Please note that details on the non-default guc params and pgbench is all provided in the result sheets attached with this mail. Also, I have not used pg_prewarm in my test script. Thank you. On Mon, Feb 13, 2017 at 9:43 PM, Bernd Helmle <mailings@oopsware.de> wrote: > Am Montag, den 13.02.2017, 16:55 +0300 schrieb Alexander Korotkov: >> >> Thank you for testing. >> >> Yes, influence seems to be low. But nevertheless it's important to >> insure >> that there is no regression here. >> Despite pg_prewarm'ing and running tests 300s, there is still >> significant >> variation. >> For instance, with clients count = 80: >> * pgxact-result-2.txt – 474704 >> * pgxact-results.txt – 574844 > >> Could some background processes influence the tests? Or could it be >> another virtual machine? >> Also, I wonder why I can't see this variation on the graphs. >> Another issue with graphs is that we can't see details of read and >> write > > Whoops, good catch. I've mistakenly copied the wrong y-axis for these > results in the gnuplot script, shame on me. New plots attached. > > You're right, the 2nd run with the pgxact alignment patch is notable. > I've realized that there was a pgbouncer instance running from a > previous test, but not sure if that could explain the difference. > >> TPS variation on the same scale, because write TPS values are too >> low. I >> think you should draw write benchmark on the separate graph. >> > > The Linux LPAR is the only one used atm. We got some more time for > Linux now and i'm going to prepare Tomas' script to run. Not sure i can > get to it today, though. > > > > > -- > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-hackers > -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Mon, Feb 13, 2017 at 7:07 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Alexander Korotkov wrote:
> Yes, influence seems to be low. But nevertheless it's important to insure
> that there is no regression here.
> Despite pg_prewarm'ing and running tests 300s, there is still significant
> variation.
> For instance, with clients count = 80:
> * pgxact-result-2.txt – 474704
> * pgxact-results.txt – 574844
> Could some background processes influence the tests? Or could it be
> another virtual machine?
> Also, I wonder why I can't see this variation on the graphs.
> Another issue with graphs is that we can't see details of read and write
> TPS variation on the same scale, because write TPS values are too low. I
> think you should draw write benchmark on the separate graph.
So, I'm reading that on PPC64 there is no effect, and on the "lesser"
machine Tomas tested on, there is no effect either; this patch only
seems to benefit Alexander's 72 core x86_64 machine.
It seems to me that Andres comments here were largely ignored:
https://www.postgresql.org/message-id/20160822021747. u5bqx2xwwjzac5u5@alap3. anarazel.de
He was suggesting to increase the struct size to 16 bytes rather than
going all the way up to 128. Did anybody test this?
Thank you for pointing. I'll provide such version of patch and test it on 72 core x86_64 machine.
Re the coding of the padding computation, seems it'd be better to use
our standard "offsetof(last-struct-member) + sizeof(last-struct-member)"
rather than adding each of the members' sizes individually.
It was done so in order to evade extra level of nesting for PGXACT. See discussion with Tom Lane in [1] and upthread.
Do you think we should introduce extra level of nesting or have better ideas about how to evade it?
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov wrote: > On Mon, Feb 13, 2017 at 7:07 PM, Alvaro Herrera <alvherre@2ndquadrant.com> > wrote: > > Re the coding of the padding computation, seems it'd be better to use > > our standard "offsetof(last-struct-member) + sizeof(last-struct-member)" > > rather than adding each of the members' sizes individually. > > It was done so in order to evade extra level of nesting for PGXACT. See > discussion with Tom Lane in [1] and upthread. Yes, I understand. I just mean that it could be done something like this: #define PGXACTPadSize (PG_CACHE_LINE_SIZE - (offsetof(PGXACT, nxid) + sizeof(uint8))) -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Feb 14, 2017 at 3:57 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Yes, but I can't use such macro in the definition of PGXACT itself.
Alexander Korotkov wrote:
> On Mon, Feb 13, 2017 at 7:07 PM, Alvaro Herrera <alvherre@2ndquadrant.com>
> wrote:
> > Re the coding of the padding computation, seems it'd be better to use
> > our standard "offsetof(last-struct-member) + sizeof(last-struct-member)"
> > rather than adding each of the members' sizes individually.
>
> It was done so in order to evade extra level of nesting for PGXACT. See
> discussion with Tom Lane in [1] and upthread.
Yes, I understand. I just mean that it could be done something like
this:
#define PGXACTPadSize (PG_CACHE_LINE_SIZE - (offsetof(PGXACT, nxid) + sizeof(uint8)))
The Russian Postgres Company
Alexander Korotkov wrote: > On Tue, Feb 14, 2017 at 3:57 PM, Alvaro Herrera <alvherre@2ndquadrant.com> > wrote: > > Yes, I understand. I just mean that it could be done something like > > this: > > > > #define PGXACTPadSize (PG_CACHE_LINE_SIZE - (offsetof(PGXACT, nxid) + > > sizeof(uint8))) > > Yes, but I can't use such macro in the definition of PGXACT itself. /me slaps forehead -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi!
On Mon, Feb 13, 2017 at 8:02 PM, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
I too have performed benchmarking of this patch on a large machine
(with 128 CPU(s), 520GB RAM, intel x86-64 architecture) and would like
to share my observations for the same (Please note that, as I had to
reverify readings on few client counts, it did take some time for me
to share these test-results.)
Great! Thank you very much for testing.
Case3: Data fits in shared buffer, Read-write workload:
------------------------------------------------------------ -----------------
In this case, I could see that the tps on head and patch are very
close to each other with a small variation of (+-)3-4% which i assume
is a run-to-run variation. PFA result sheet
'results-readwrite-300-1000-SF' containing the test-results.
I wouldn't say it's just a variation. It looks like relatively small but noticeable regression in the patch.
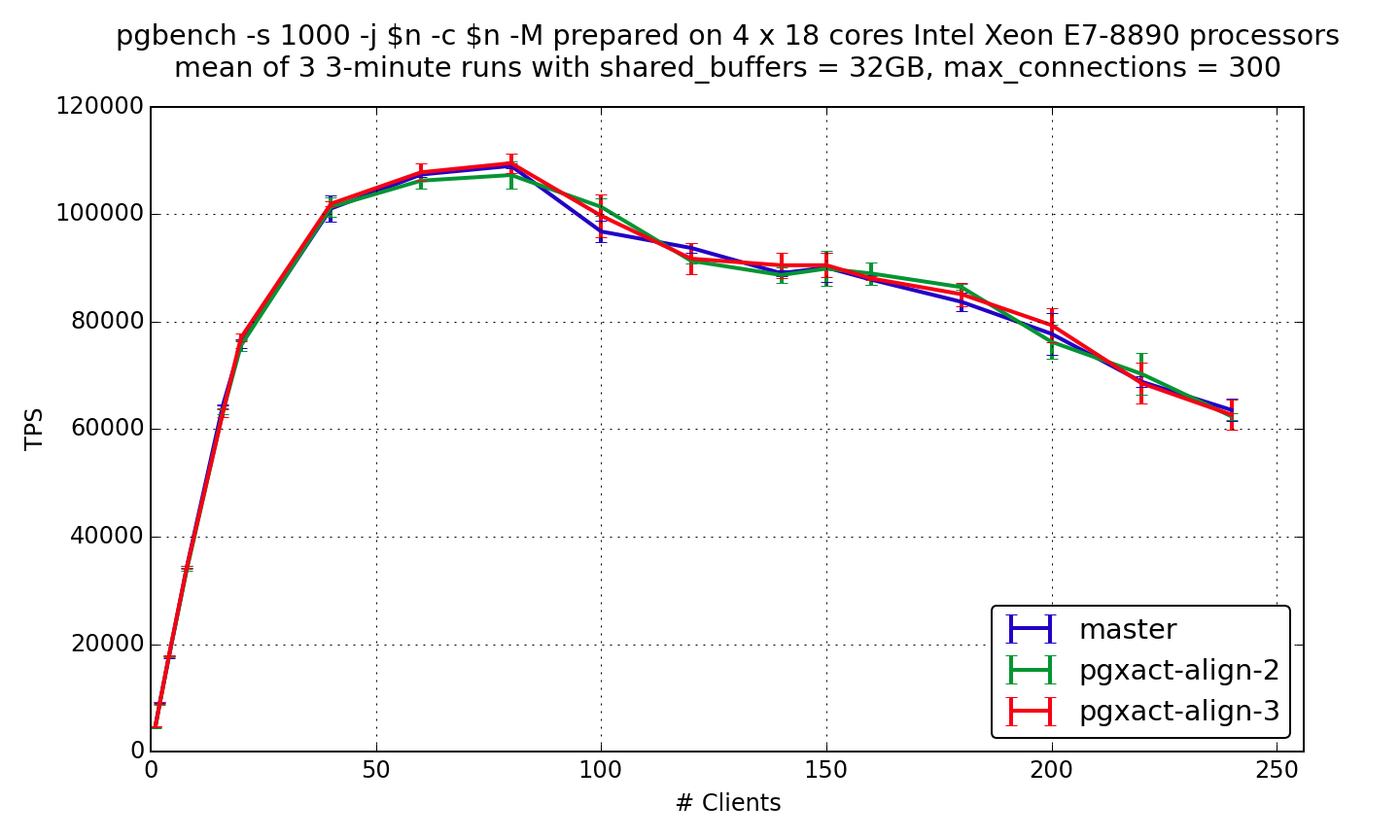
According to Andres comment [1] I made a version of patch (pgxact-align-3.patch) which align PGXACT to 16 bytes.
That excludes situation when single PGXACT is spread over 2 cache lines.
Results of read-only tests are attached. We can see that 16-byte alignment gives speedup in read-only tests, but it's a bit less than speedup of cache line alignment version.
Read-write tests are now running. Hopefully 16-byte alignment version of patch wouldn't cause regression in read-write benchmark.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
{kind=link}
On Wed, Feb 15, 2017 at 11:49 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Mon, Feb 13, 2017 at 8:02 PM, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:I too have performed benchmarking of this patch on a large machine
(with 128 CPU(s), 520GB RAM, intel x86-64 architecture) and would like
to share my observations for the same (Please note that, as I had to
reverify readings on few client counts, it did take some time for me
to share these test-results.)Great! Thank you very much for testing.Case3: Data fits in shared buffer, Read-write workload:
------------------------------------------------------------ -----------------
In this case, I could see that the tps on head and patch are very
close to each other with a small variation of (+-)3-4% which i assume
is a run-to-run variation. PFA result sheet
'results-readwrite-300-1000-SF' containing the test-results. I wouldn't say it's just a variation. It looks like relatively small but noticeable regression in the patch.According to Andres comment [1] I made a version of patch (pgxact-align-3.patch) which align PGXACT to 16 bytes.That excludes situation when single PGXACT is spread over 2 cache lines.Results of read-only tests are attached. We can see that 16-byte alignment gives speedup in read-only tests, but it's a bit less than speedup of cache line alignment version.Read-write tests are now running. Hopefully 16-byte alignment version of patch wouldn't cause regression in read-write benchmark.
RW-benchmark on 72-cores machine is completed.
+-----------+--------+--------
| | master | pgxact-align-2 | pgxact-align-3 |
| clients | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 |
|-----------+--------+--------
| 1 | 4696 | 4773 | 4777 | 4449 | 4766 | 4731 | 4658 | 4670 | 4807 |
| 2 | 9127 | 9154 | 9300 | 9224 | 8801 | 9055 | 9278 | 9245 | 8902 |
| 4 | 17377 | 17779 | 17740 | 17936 | 17560 | 17900 | 17806 | 17782 | 17934 |
| 8 | 34348 | 34233 | 34656 | 34204 | 33617 | 34226 | 34446 | 34105 | 34554 |
| 16 | 64350 | 64530 | 64574 | 63474 | 62852 | 63622 | 63942 | 62268 | 63396 |
| 20 | 76648 | 76515 | 75026 | 75123 | 74624 | 76461 | 77756 | 77245 | 76263 |
| 40 | 98566 | 100429 | 103499 | 103118 | 100186 | 99550 | 101489 | 102363 | 102015 |
| 60 | 106871 | 107842 | 107724 | 107168 | 107645 | 104791 | 109388 | 109367 | 106146 |
| 80 | 109461 | 108467 | 108913 | 104780 | 109742 | 106929 | 111254 | 107688 | 109581 |
| 100 | 98772 | 98641 | 94742 | 100390 | 102977 | 99691 | 99296 | 95699 | 103675 |
| 120 | 92740 | 94659 | 93876 | 91856 | 90732 | 91560 | 92334 | 88746 | 94663 |
| 140 | 88400 | 89448 | 89600 | 87173 | 90152 | 88190 | 88174 | 92784 | 91788 |
| 150 | 87292 | 92834 | 89714 | 86626 | 93090 | 88887 | 89407 | 88234 | 92760 |
| 160 | 88704 | 86890 | 87668 | 91025 | 89734 | 86875 | 88398 | 87846 | 87659 |
| 180 | 85451 | 84611 | 81913 | 86939 | 85888 | 86000 | 87287 | 85644 | 82915 |
| 200 | 73796 | 81149 | 81674 | 76179 | 73104 | 79381 | 82456 | 79920 | 76239 |
| 220 | 68113 | 69765 | 67871 | 67611 | 74125 | 66436 | 64810 | 72282 | 71387 |
| 240 | 63528 | 61462 | 65662 | 61711 | 61697 | 63032 | 65435 | 61804 | 59918 |
+-----------+--------+--------
Difference between master, pgxact-align-2 and pgxact-align-3 doesn't exceed per run variation.
Thus, at this test we can't confirm neither regression in pgxact-align-2, neither improvement in pgxact-align-3.
Ashutosh, could you please repeat your benchmarks with pgxact-align-3?
The Russian Postgres Company
Attachment
{kind=link}
On Mon, Feb 13, 2017 at 11:07 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > It seems to me that Andres comments here were largely ignored: > https://www.postgresql.org/message-id/20160822021747.u5bqx2xwwjzac5u5@alap3.anarazel.de > He was suggesting to increase the struct size to 16 bytes rather than > going all the way up to 128. Did anybody test this? So, I think that going up to 128 bytes can't really make sense. If that's the best-performing solution here, then maybe what we ought to be doing is reverting the PGXACT/PGPROC separation, sticking these critical members at the beginning, and padding the whole PGXACT out to a multiple of the cache line size. Something that only touches the PGXACT fields will touch the exact same number of cache lines with that design, but cases that touch more than just the PGXACT fields should perform better. The point of moving PGXACT into a separate structure was to reduce the number of cache lines required to build a snapshot. If that's going to go back up to 1 per PGPROC anyway, we might as well at least use the rest of that cache line to store something else that might be useful instead of pad bytes. I think, anyway. If padding to 16 bytes is sufficient to get the performance improvement (or as much as we care about), that seems more reasonable. But it's still possible we may be gaining on one hand (because now you'll never touch multiple cache lines for your own PGXACT) and losing on the other (because now you're scanning 4/3 as many cache lines to construct a snapshot). Which of those is better might be workload-dependent or hardware-dependent. > Re the coding of the padding computation, seems it'd be better to use > our standard "offsetof(last-struct-member) + sizeof(last-struct-member)" > rather than adding each of the members' sizes individually. I think our now-standard way of doing this is to have a "Padded" version that is a union between the unpadded struct and char[]. c.f. BufferDescPadded, LWLockPadded. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes: > On Mon, Feb 13, 2017 at 11:07 AM, Alvaro Herrera > <alvherre@2ndquadrant.com> wrote: >> It seems to me that Andres comments here were largely ignored: >> https://www.postgresql.org/message-id/20160822021747.u5bqx2xwwjzac5u5@alap3.anarazel.de >> He was suggesting to increase the struct size to 16 bytes rather than >> going all the way up to 128. Did anybody test this? > So, I think that going up to 128 bytes can't really make sense. If > that's the best-performing solution here, then maybe what we ought to > be doing is reverting the PGXACT/PGPROC separation, sticking these > critical members at the beginning, and padding the whole PGXACT out to > a multiple of the cache line size. Yes. That separation was never more than a horribly ugly kluge. I would love to see it go away. But keeping it *and* padding PGXACT to something >= the size of PGPROC borders on insanity. regards, tom lane
On Wed, Feb 15, 2017 at 12:14 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Mon, Feb 13, 2017 at 11:07 AM, Alvaro Herrera >> <alvherre@2ndquadrant.com> wrote: >>> It seems to me that Andres comments here were largely ignored: >>> https://www.postgresql.org/message-id/20160822021747.u5bqx2xwwjzac5u5@alap3.anarazel.de >>> He was suggesting to increase the struct size to 16 bytes rather than >>> going all the way up to 128. Did anybody test this? > >> So, I think that going up to 128 bytes can't really make sense. If >> that's the best-performing solution here, then maybe what we ought to >> be doing is reverting the PGXACT/PGPROC separation, sticking these >> critical members at the beginning, and padding the whole PGXACT out to >> a multiple of the cache line size. > > Yes. That separation was never more than a horribly ugly kluge. > I would love to see it go away. But keeping it *and* padding > PGXACT to something >= the size of PGPROC borders on insanity. I don't think it would be bigger than a PGPROC. PGPROCs are really big, 816 bytes on my MacBook Pro. But if you did what I suggested, you could take a snapshot by touching 1 cache line per backend. They wouldn't be consecutive; it would be an upward pattern, with skips. If you pad PGXACT out to one cache line, you could likewise take a snapshot by touching 1 cache line per backend, and they'd be consecutive. Maybe that difference matters to the memory prefetching controller, I dunno, but it seems funny that we did the PGXACT work to reduce the number of cache lines that had to be touched in order to take a snapshot to improve performance, and now we're talking about increasing it again, also to improve performance. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> ... Maybe that difference matters to the memory prefetching
> controller, I dunno, but it seems funny that we did the PGXACT work to
> reduce the number of cache lines that had to be touched in order to
> take a snapshot to improve performance, and now we're talking about
> increasing it again, also to improve performance.
Yes. I was skeptical that the original change was adequately proven
to be a good idea, and I'm even more skeptical this time. I think
every single number that's been reported about this is completely
machine-specific, and likely workload-specific too, and should not
be taken as a reason to do anything.
My druthers at this point would be to revert the separation on code
cleanliness grounds and call it a day, more or less independently of any
claims about performance. I'd be willing to talk about padding PGPROC
to some reasonable stride, but I remain dubious that any changes of
that sort would have a half-life worth complicating the code for.
regards, tom lane
Alexander Korotkov wrote: > Difference between master, pgxact-align-2 and pgxact-align-3 doesn't exceed > per run variation. FWIW this would be more visible if you added error bars to each data point. Should be simple enough in gnuplot ... -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Feb 15, 2017 at 12:48 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> ... Maybe that difference matters to the memory prefetching >> controller, I dunno, but it seems funny that we did the PGXACT work to >> reduce the number of cache lines that had to be touched in order to >> take a snapshot to improve performance, and now we're talking about >> increasing it again, also to improve performance. > > Yes. I was skeptical that the original change was adequately proven > to be a good idea, and I'm even more skeptical this time. I think > every single number that's been reported about this is completely > machine-specific, and likely workload-specific too, and should not > be taken as a reason to do anything. The original change definitely worked on read-only pgbench workloads on both x86 and Itanium, and the gains were pretty significant at higher client counts. I don't know whether we tested POWER. Read-only pgbench throughput is not the world, of course, but it's a reasonable proxy for high-concurrency, read-mostly workloads involving short transactions, so it's not nothing, either. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2017-02-15 11:43:17 -0500, Robert Haas wrote: > On Mon, Feb 13, 2017 at 11:07 AM, Alvaro Herrera > <alvherre@2ndquadrant.com> wrote: > > It seems to me that Andres comments here were largely ignored: > > https://www.postgresql.org/message-id/20160822021747.u5bqx2xwwjzac5u5@alap3.anarazel.de > > He was suggesting to increase the struct size to 16 bytes rather than > > going all the way up to 128. Did anybody test this? > > So, I think that going up to 128 bytes can't really make sense. If > that's the best-performing solution here, then maybe what we ought to > be doing is reverting the PGXACT/PGPROC separation, sticking these > critical members at the beginning, and padding the whole PGXACT out to > a multiple of the cache line size. Something that only touches the > PGXACT fields will touch the exact same number of cache lines with > that design, but cases that touch more than just the PGXACT fields > should perform better. I don't think that's true for several reasons. Separating out PGXACT didn't just mean reducing the stride size of the access / preventing sharing. It also meant that frequently changing fields in PGPROC aren't on the same cache-line as fields in PGXACT. That makes quite a difference, because with the split a lot of the cachelines "backing" PGPROC can stay in 'shared' mode in several CPU caches, while modifications to PGPROC largely can stay in 'exclusive' mode locally on the CPU the backend is currently running on. I think I previously mentioned, even just removing the MyPgXact->xmin assignment in SnapshotResetXmin() is measurable performance wise and cache-hit ratio wise. While Nasby is right that going to multiple of the actual line size can cause problems due to the N-way associativity of caches, it's not like unused padding memory >= cacheline-size actually causes cache to be wasted; it just gets used for other things. FWIW, I however think we should just set the cacheline size based on the architecture, rather than defaulting to 128 - it's not like that actually changes particularly frequently. I doubt a special-case for each of x86, arm, power, itanium, and the rest will cause us a lot of maintenance issues. > The point of moving PGXACT into a separate > structure was to reduce the number of cache lines required to build a > snapshot. If that's going to go back up to 1 per PGPROC anyway, we > might as well at least use the rest of that cache line to store > something else that might be useful instead of pad bytes. I think, > anyway. I don't think that's true, due to the aforementioned dirtyness issue, which causes inter-node cache coherency traffic (busier bus & latency). > I think our now-standard way of doing this is to have a "Padded" > version that is a union between the unpadded struct and char[]. c.f. > BufferDescPadded, LWLockPadded. That's what my original POC patch did IIRC, but somebody complained it changed a lot of accesses. - Andres
Hi, On 2017-02-15 12:24:44 -0500, Robert Haas wrote: > If you pad PGXACT out to one cache line, you could likewise take a > snapshot by touching 1 cache line per backend, and they'd be > consecutive. Maybe that difference matters to the memory prefetching > controller, I dunno, Unfortunately it's currently *not* consecutively accessed afaik. We're not iterating PGXACT sequentially, we're doing it in pgprocno order. The reason is that otherwise we have to scan unused PGXACT entries. I've previously played around with using actual sequential access, and it was a good bit faster as long as nearly all connections are used - but slower when only a few are in use, which is quite common... > but it seems funny that we did the PGXACT work to > reduce the number of cache lines that had to be touched in order to > take a snapshot to improve performance, and now we're talking about > increasing it again, also to improve performance. I don't think it's that weird that aligning things properly is important for performance, nor that reducing the amount of memory accessed is beneficial. Engineering is tradeoffs, and we might just have erred a bit too far in this case. Greetings, Andres Freund
On Wed, Feb 15, 2017 at 2:15 PM, Andres Freund <andres@anarazel.de> wrote: > I don't think that's true for several reasons. Separating out PGXACT > didn't just mean reducing the stride size of the access / preventing > sharing. It also meant that frequently changing fields in PGPROC aren't > on the same cache-line as fields in PGXACT. That makes quite a > difference, because with the split a lot of the cachelines "backing" > PGPROC can stay in 'shared' mode in several CPU caches, while > modifications to PGPROC largely can stay in 'exclusive' mode locally on > the CPU the backend is currently running on. I think I previously > mentioned, even just removing the MyPgXact->xmin assignment in > SnapshotResetXmin() is measurable performance wise and cache-hit ratio > wise. Oh, hmm. I didn't think about that angle. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Feb 15, 2017 at 8:49 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Good point.
Alexander Korotkov wrote:
> Difference between master, pgxact-align-2 and pgxact-align-3 doesn't exceed
> per run variation.
FWIW this would be more visible if you added error bars to each data
point. Should be simple enough in gnuplot ...
Please find graph of mean and errors in attachment.
The Russian Postgres Company
Attachment
{kind=link}
On Thu, Feb 16, 2017 at 5:07 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > On Wed, Feb 15, 2017 at 8:49 PM, Alvaro Herrera <alvherre@2ndquadrant.com> > wrote: >> Alexander Korotkov wrote: >> >> > Difference between master, pgxact-align-2 and pgxact-align-3 doesn't >> > exceed >> > per run variation. >> >> FWIW this would be more visible if you added error bars to each data >> point. Should be simple enough in gnuplot ... > > Good point. > Please find graph of mean and errors in attachment. So ... no difference? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Feb 16, 2017 at 4:58 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Thu, Feb 16, 2017 at 5:07 AM, Alexander Korotkov
<a.korotkov@postgrespro.ru> wrote:
> On Wed, Feb 15, 2017 at 8:49 PM, Alvaro Herrera <alvherre@2ndquadrant.com>
> wrote:
>> Alexander Korotkov wrote:
>>
>> > Difference between master, pgxact-align-2 and pgxact-align-3 doesn't
>> > exceed
>> > per run variation.
>>
>> FWIW this would be more visible if you added error bars to each data
>> point. Should be simple enough in gnuplot ...
>
> Good point.
> Please find graph of mean and errors in attachment.
So ... no difference?
Yeah, nothing surprising. It's just another graph based on the same data.
I wonder how pgxact-align-3 would work on machine of Ashutosh Sharma, because I observed regression there in write-heavy benchmark of pgxact-align-2.
The Russian Postgres Company
Hi, >> On Thu, Feb 16, 2017 at 5:07 AM, Alexander Korotkov >> <a.korotkov@postgrespro.ru> wrote: >> > On Wed, Feb 15, 2017 at 8:49 PM, Alvaro Herrera >> > <alvherre@2ndquadrant.com> >> > wrote: >> >> Alexander Korotkov wrote: >> >> >> >> > Difference between master, pgxact-align-2 and pgxact-align-3 doesn't >> >> > exceed >> >> > per run variation. >> >> >> >> FWIW this would be more visible if you added error bars to each data >> >> point. Should be simple enough in gnuplot ... >> > >> > Good point. >> > Please find graph of mean and errors in attachment. >> >> So ... no difference? > > > Yeah, nothing surprising. It's just another graph based on the same data. > I wonder how pgxact-align-3 would work on machine of Ashutosh Sharma, > because I observed regression there in write-heavy benchmark of > pgxact-align-2. I am yet to benchmark pgxact-align-3 patch on a read-write workload. I could not do it as our benchmarking machine was already reserved for some other test work. But, I am planning to do it on this weekend. Will try to post my results by Monday evening. Thank you and sorry for the delayed response.
On Fri, Feb 17, 2017 at 12:44 PM, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
>> On Thu, Feb 16, 2017 at 5:07 AM, Alexander Korotkov
>> <a.korotkov@postgrespro.ru> wrote:
>> > On Wed, Feb 15, 2017 at 8:49 PM, Alvaro Herrera
>> > <alvherre@2ndquadrant.com>
>> > wrote:
>> >> Alexander Korotkov wrote:
>> >>
>> >> > Difference between master, pgxact-align-2 and pgxact-align-3 doesn't
>> >> > exceed
>> >> > per run variation.
>> >>
>> >> FWIW this would be more visible if you added error bars to each data
>> >> point. Should be simple enough in gnuplot ...
>> >
>> > Good point.
>> > Please find graph of mean and errors in attachment.
>>
>> So ... no difference?
>
>
> Yeah, nothing surprising. It's just another graph based on the same data.
> I wonder how pgxact-align-3 would work on machine of Ashutosh Sharma,
> because I observed regression there in write-heavy benchmark of
> pgxact-align-2.
I am yet to benchmark pgxact-align-3 patch on a read-write workload. I
could not do it as our benchmarking machine was already reserved for
some other test work. But, I am planning to do it on this weekend.
Will try to post my results by Monday evening. Thank you and sorry for
the delayed response.
Cool, thank you very much!
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Hi,
Following are the pgbench results for read-write workload, I got with pgxact-align-3 patch. The results are for 300 scale factor with 8GB of shared buffer i.e. when data fits into the shared buffer. For 1000 scale factor with 8GB shared buffer the test is still running, once it is completed I will share the results for that as well.
pgbench settings:
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres
where, time_for_reading = 30mins
non default GUC param:
shared_buffers=8GB
max_connections=300
pg_xlog is located in SSD.
>> On Thu, Feb 16, 2017 at 5:07 AM, Alexander Korotkov
>> <a.korotkov@postgrespro.ru> wrote:
>> > On Wed, Feb 15, 2017 at 8:49 PM, Alvaro Herrera
>> > <alvherre@2ndquadrant.com>
>> > wrote:
>> >> Alexander Korotkov wrote:
>> >>
>> >> > Difference between master, pgxact-align-2 and pgxact-align-3 doesn't
>> >> > exceed
>> >> > per run variation.
>> >>
>> >> FWIW this would be more visible if you added error bars to each data
>> >> point. Should be simple enough in gnuplot ...
>> >
>> > Good point.
>> > Please find graph of mean and errors in attachment.
>>
>> So ... no difference?
>
>
> Yeah, nothing surprising. It's just another graph based on the same data.
> I wonder how pgxact-align-3 would work on machine of Ashutosh Sharma,
> because I observed regression there in write-heavy benchmark of
> pgxact-align-2.
I am yet to benchmark pgxact-align-3 patch on a read-write workload. I
could not do it as our benchmarking machine was already reserved for
some other test work. But, I am planning to do it on this weekend.
Will try to post my results by Monday evening. Thank you and sorry for
the delayed response.
Following are the pgbench results for read-write workload, I got with pgxact-align-3 patch. The results are for 300 scale factor with 8GB of shared buffer i.e. when data fits into the shared buffer. For 1000 scale factor with 8GB shared buffer the test is still running, once it is completed I will share the results for that as well.
pgbench settings:
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres
where, time_for_reading = 30mins
non default GUC param:
shared_buffers=8GB
max_connections=300
pg_xlog is located in SSD.
Machine details:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 8
NUMA node(s): 8
Vendor ID: GenuineIntel
CPU family: 6
Model: 47
Model name: Intel(R) Xeon(R) CPU E7- 8830 @ 2.13GHz
Also, Excel sheet (results-read-write-300-SF) containing the results for all the 3 runs is attached.
--
With Regards,
Ashutosh Sharma
EnterpriseDB:http://www.
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 8
NUMA node(s): 8
Vendor ID: GenuineIntel
CPU family: 6
Model: 47
Model name: Intel(R) Xeon(R) CPU E7- 8830 @ 2.13GHz
| CLIENT COUNT | TPS (HEAD) | TPS (PATCH) | % IMPROVEMENT |
| 4 | 4283 | 4220 | -1.47093159 |
| 8 | 7291 | 7261 | -0.4114661912 |
| 16 | 11909 | 12149 | 2.015282559 |
| 32 | 20789 | 20745 | -0.211650392 |
| 64 | 28412 | 27831 | -2.044910601 |
| 128 | 29369 | 28765 | -2.056590282 |
| 156 | 27949 | 27189 | -2.719238613 |
| 180 | 27876 | 27171 | -2.529057254 |
| 196 | 28849 | 27872 | -3.386599189 |
| 256 | 30321 | 28188 | -7.034728406 |
Also, Excel sheet (results-read-write-300-SF) containing the results for all the 3 runs is attached.
--
With Regards,
Ashutosh Sharma
EnterpriseDB:http://www.
Attachment
On 15 February 2017 at 19:15, Andres Freund <andres@anarazel.de> wrote: > I think I previously > mentioned, even just removing the MyPgXact->xmin assignment in > SnapshotResetXmin() is measurable performance wise and cache-hit ratio > wise. Currently, we issue SnapshotResetXmin() pointlessly at end of xact, so patch attached to remove that call, plus some comments to explain that. This reduces the cause. Also, another patch to reduce the calls to SnapshotResetXmin() using a simple heuristic to reduce the effects. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Mon, Feb 20, 2017 at 6:02 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > On 15 February 2017 at 19:15, Andres Freund <andres@anarazel.de> wrote: > >> I think I previously >> mentioned, even just removing the MyPgXact->xmin assignment in >> SnapshotResetXmin() is measurable performance wise and cache-hit ratio >> wise. > > Currently, we issue SnapshotResetXmin() pointlessly at end of xact, so > patch attached to remove that call, plus some comments to explain > that. This reduces the cause. > > Also, another patch to reduce the calls to SnapshotResetXmin() using a > simple heuristic to reduce the effects. I think skip_SnapshotResetXmin_if_idle_timeout.v1.patch isn't a good idea, because it could have the surprising result that setting idle_in_transaction_timeout to a non-zero value makes bloat worse. I don't think users will like that. Regarding reduce_pgxact_access_AtEOXact.v1.patch, it took me a few minutes to figure out that the comment was referring to ProcArrayEndTransaction(), so it might be good to be more explicit about that if we go forward with this. Have you checked whether this patch makes any noticeable performance difference? It's sure surprising that we go to all of this trouble to clean things up in AtEOXact_Snapshot() when we've already nuked MyPgXact->xmin from orbit. (Instead of changing AtEOXact_Snapshot, should we think about removing the xid clear logic from ProcArrayEndTransaction and only doing it here, or would that be wrong-headed?) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 20 February 2017 at 16:53, Robert Haas <robertmhaas@gmail.com> wrote: > On Mon, Feb 20, 2017 at 6:02 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >> On 15 February 2017 at 19:15, Andres Freund <andres@anarazel.de> wrote: >> >>> I think I previously >>> mentioned, even just removing the MyPgXact->xmin assignment in >>> SnapshotResetXmin() is measurable performance wise and cache-hit ratio >>> wise. >> >> Currently, we issue SnapshotResetXmin() pointlessly at end of xact, so >> patch attached to remove that call, plus some comments to explain >> that. This reduces the cause. >> >> Also, another patch to reduce the calls to SnapshotResetXmin() using a >> simple heuristic to reduce the effects. > > I think skip_SnapshotResetXmin_if_idle_timeout.v1.patch isn't a good > idea, because it could have the surprising result that setting > idle_in_transaction_timeout to a non-zero value makes bloat worse. I > don't think users will like that. > > Regarding reduce_pgxact_access_AtEOXact.v1.patch, it took me a few > minutes to figure out that the comment was referring to > ProcArrayEndTransaction(), so it might be good to be more explicit > about that if we go forward with this. Sure, attached. > Have you checked whether this > patch makes any noticeable performance difference? No, but then we're reducing the number of calls to PgXact directly; there is no heuristic involved, its just a pure saving. > It's sure > surprising that we go to all of this trouble to clean things up in > AtEOXact_Snapshot() when we've already nuked MyPgXact->xmin from > orbit. (Instead of changing AtEOXact_Snapshot, should we think about > removing the xid clear logic from ProcArrayEndTransaction and only > doing it here, or would that be wrong-headed?) If anything, I'd move the call to PgXact->xmin = InvalidTransactionId into a function inside procarray.c, so we only touch snapshots in snapmgr.c and all procarray stuff is isolated. (Not done here, yet). -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Mon, Feb 20, 2017 at 10:49 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >> Regarding reduce_pgxact_access_AtEOXact.v1.patch, it took me a few >> minutes to figure out that the comment was referring to >> ProcArrayEndTransaction(), so it might be good to be more explicit >> about that if we go forward with this. > > Sure, attached. Looks better, thanks. >> Have you checked whether this >> patch makes any noticeable performance difference? > > No, but then we're reducing the number of calls to PgXact directly; > there is no heuristic involved, its just a pure saving. Well, it's adding a branch where there wasn't one. Maybe that costs essentially nothing and the saved write to shared memory saves something noticeable, but for all I know it's the reverse. If I had to guess, it would be that neither the costs nor the savings from this are in the slightest way noticeable on a macrobenchmark, and therefore there's not much point in changing it, but that could be 100% wrong. >> It's sure >> surprising that we go to all of this trouble to clean things up in >> AtEOXact_Snapshot() when we've already nuked MyPgXact->xmin from >> orbit. (Instead of changing AtEOXact_Snapshot, should we think about >> removing the xid clear logic from ProcArrayEndTransaction and only >> doing it here, or would that be wrong-headed?) > > If anything, I'd move the call to PgXact->xmin = InvalidTransactionId > into a function inside procarray.c, so we only touch snapshots in > snapmgr.c and all procarray stuff is isolated. (Not done here, yet). I'm not convinced that really buys us anything except more function-call overhead. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 20 February 2017 at 17:32, Robert Haas <robertmhaas@gmail.com> wrote: >>> Have you checked whether this >>> patch makes any noticeable performance difference? >> >> No, but then we're reducing the number of calls to PgXact directly; >> there is no heuristic involved, its just a pure saving. > > Well, it's adding a branch where there wasn't one. A branch that is avoided in almost all cases, so easy to predict. > Maybe that costs > essentially nothing and the saved write to shared memory saves > something noticeable, but for all I know it's the reverse. If I had > to guess, it would be that neither the costs nor the savings from this > are in the slightest way noticeable on a macrobenchmark, and therefore > there's not much point in changing it, but that could be 100% wrong. Given Andres' earlier measurements, it seems worth testing to me. Hopefully someone can recheck. Thanks in advance. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, Ashutosh!
On Mon, Feb 20, 2017 at 1:20 PM, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
Following are the pgbench results for read-write workload, I got with pgxact-align-3 patch. The results are for 300 scale factor with 8GB of shared buffer i.e. when data fits into the shared buffer. For 1000 scale factor with 8GB shared buffer the test is still running, once it is completed I will share the results for that as well.
pgbench settings:
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres
where, time_for_reading = 30mins
non default GUC param:
shared_buffers=8GB
max_connections=300
pg_xlog is located in SSD.
Thank you for testing.
It seems that there is still regression. While padding was reduced from 116 bytes to 4 bytes, it makes me think that probably there is something wrong in testing methodology.
Are you doing re-initdb and pgbench -i before each run? I would ask you to do the both.
Also, if regression would still exist, let's change the order of versions. Thus, if you run master before patched version, I would ask you to run patched version before master.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Tue, Feb 21, 2017 at 4:21 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > Hi, Ashutosh! > On Mon, Feb 20, 2017 at 1:20 PM, Ashutosh Sharma <ashu.coek88@gmail.com> wrote: >> >> Following are the pgbench results for read-write workload, I got with pgxact-align-3 patch. The results are for 300 scalefactor with 8GB of shared buffer i.e. when data fits into the shared buffer. For 1000 scale factor with 8GB shared bufferthe test is still running, once it is completed I will share the results for that as well. >> >> pgbench settings: >> pgbench -i -s 300 postgres >> pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres >> >> where, time_for_reading = 30mins >> >> non default GUC param: >> shared_buffers=8GB >> max_connections=300 >> >> pg_xlog is located in SSD. > > > Thank you for testing. > It seems that there is still regression. While padding was reduced from 116 bytes to 4 bytes, it makes me think that probablythere is something wrong in testing methodology. > Are you doing re-initdb and pgbench -i before each run? I would ask you to do the both. > Also, if regression would still exist, let's change the order of versions. Thus, if you run master before patched version,I would ask you to run patched version before master. Yes, there is still some regression however it has come down by a small margin. I am not doing initdb for each run instead I am doing, dropdb-->createdb-->pgbench -i. Is dropping old database and creating a new one for every run not okay, Do I have to do initdb every time. Okay, I can change the order of reading and let you know the results.
Hi, On 2017-02-21 16:57:36 +0530, Ashutosh Sharma wrote: > Yes, there is still some regression however it has come down by a > small margin. I am not doing initdb for each run instead I am doing, > dropdb-->createdb-->pgbench -i. Is dropping old database and creating > a new one for every run not okay, Do I have to do initdb every time. > Okay, I can change the order of reading and let you know the results. That does make a difference. Primarily because WAL writes in a new cluster are a more expensive than in an old one, because of segment recycling. - Andres
On Tue, Feb 21, 2017 at 2:37 PM, Andres Freund <andres@anarazel.de> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On 2017-02-21 16:57:36 +0530, Ashutosh Sharma wrote:
> Yes, there is still some regression however it has come down by a
> small margin. I am not doing initdb for each run instead I am doing,
> dropdb-->createdb-->pgbench -i. Is dropping old database and creating
> a new one for every run not okay, Do I have to do initdb every time.
> Okay, I can change the order of reading and let you know the results.
That does make a difference. Primarily because WAL writes in a new
cluster are a more expensive than in an old one, because of segment
recycling.
+1
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Tue, Feb 21, 2017 at 5:52 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > On Tue, Feb 21, 2017 at 2:37 PM, Andres Freund <andres@anarazel.de> wrote: >> >> On 2017-02-21 16:57:36 +0530, Ashutosh Sharma wrote: >> > Yes, there is still some regression however it has come down by a >> > small margin. I am not doing initdb for each run instead I am doing, >> > dropdb-->createdb-->pgbench -i. Is dropping old database and creating >> > a new one for every run not okay, Do I have to do initdb every time. >> > Okay, I can change the order of reading and let you know the results. >> >> That does make a difference. Primarily because WAL writes in a new >> cluster are a more expensive than in an old one, because of segment >> recycling. > > > +1 okay, understood. Will take care of it when I start with next round of testing. Thanks.
I wonder if this "perf c2c" tool with Linux 4.10 might be useful in studying this problem. https://joemario.github.io/blog/2016/09/01/c2c-blog/ -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Okay. As suggested by Alexander, I have changed the order of reading and doing initdb for each pgbench run. With these changes, I got following results at 300 scale factor with 8GB of shared buffer.
pgbench settings:
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres
where, time_for_reading = 30mins
non default GUC param
shared_buffers=8GB
max_connections=300
pg_xlog is located in SSD.
The test machine details are as follows,
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 8
NUMA node(s): 8
Vendor ID: GenuineIntel
CPU family: 6
Model: 47
Model name: Intel(R) Xeon(R) CPU E7- 8830 @ 2.13GHz
Also, Excel sheet (results-readwrite-300-SF) containing the results for all the 3 runs is attached.pgbench settings:
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres
where, time_for_reading = 30mins
non default GUC param
shared_buffers=8GB
max_connections=300
pg_xlog is located in SSD.
| CLIENT COUNT | TPS (HEAD) | TPS (PATCH) | % IMPROVEMENT |
| 4 | 2803 | 2843 | 1.427042455 |
| 8 | 5315 | 5225 | -1.69332079 |
| 32 | 19755 | 19669 | -0.4353328271 |
| 64 | 28679 | 27980 | -2.437323477 |
| 128 | 28887 | 28008 | -3.042891266 |
| 156 | 27465 | 26728 | -2.683415256 |
| 180 | 27425 | 26697 | -2.654512306 |
| 196 | 28826 | 27396 | -4.960799278 |
| 256 | 29787 | 28107 | -5.640044315 |
The test machine details are as follows,
Machine details:
Architecture: x86_64CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 8
NUMA node(s): 8
Vendor ID: GenuineIntel
CPU family: 6
Model: 47
Model name: Intel(R) Xeon(R) CPU E7- 8830 @ 2.13GHz
--
With Regards,
Ashutosh Sharma
EnterpriseDB:http://www.
On Thu, Feb 23, 2017 at 2:44 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
I wonder if this "perf c2c" tool with Linux 4.10 might be useful in
studying this problem.
https://joemario.github.io/blog/2016/09/01/c2c-blog/
--
Álvaro Herrera https://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On 24 February 2017 at 04:41, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
--
Okay. As suggested by Alexander, I have changed the order of reading and doing initdb for each pgbench run. With these changes, I got following results at 300 scale factor with 8GB of shared buffer.
Would you be able to test my patch also please?
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Feb 24, 2017 at 10:41 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > On 24 February 2017 at 04:41, Ashutosh Sharma <ashu.coek88@gmail.com> wrote: >> >> Okay. As suggested by Alexander, I have changed the order of reading and >> doing initdb for each pgbench run. With these changes, I got following >> results at 300 scale factor with 8GB of shared buffer. > > > Would you be able to test my patch also please? > Sure, I can do that and share the results by early next week. Thanks.
Hi,
On Fri, Feb 24, 2017 at 12:22 PM, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
So, Here are the pgbench results I got with 'reduce_pgxact_access_AtEOXact.v2.patch' on a read-write workload.
pgbench settings:
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres
where, time_for_reading = 30mins
non default GUC param
shared_buffers=8GB
max_connections=300
pg_wal is located in SSD.
Also, Excel sheet (results-readwrite-300-SF.xlsx) containing the results for all the 3 runs is attached.
On Fri, Feb 24, 2017 at 12:22 PM, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
On Fri, Feb 24, 2017 at 10:41 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
> On 24 February 2017 at 04:41, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
>>
>> Okay. As suggested by Alexander, I have changed the order of reading and
>> doing initdb for each pgbench run. With these changes, I got following
>> results at 300 scale factor with 8GB of shared buffer.
>
>
> Would you be able to test my patch also please?
>
Sure, I can do that and share the results by early next week. Thanks.
So, Here are the pgbench results I got with 'reduce_pgxact_access_AtEOXact.v2.patch' on a read-write workload.
pgbench settings:
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres
where, time_for_reading = 30mins
non default GUC param
shared_buffers=8GB
max_connections=300
pg_wal is located in SSD.
| CLIENT COUNT | TPS (HEAD) | TPS (PATCH) | % IMPROVEMENT |
| 4 | 2588 | 2601 | 0.5023183926 |
| 8 | 5094 | 5098 | 0.0785237534 |
| 16 | 10294 | 10307 | 0.1262871576 |
| 32 | 19779 | 19815 | 0.182011224 |
| 64 | 27908 | 28346 | 1.569442454 |
| 72 | 27823 | 28416 | 2.131330194 |
| 128 | 28455 | 28618 | 0.5728342998 |
| 180 | 26739 | 26879 | 0.5235797898 |
| 196 | 27820 | 27963 | 0.5140186916 |
| 256 | 28763 | 28969 | 0.7161978931 |
Also, Excel sheet (results-readwrite-300-SF.xlsx) containing the results for all the 3 runs is attached.
Attachment
On 28 February 2017 at 11:34, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
--
So, Here are the pgbench results I got with 'reduce_pgxact_access_AtEOXact.v2.patch' on a read-write workload.
Thanks for performing a test.
I see a low yet noticeable performance gain across the board on that workload.
That is quite surprising to see a gain on that workload. The main workload we have been discussing was the full read-only test (-S). For that case the effect should be much more noticeable based upon Andres' earlier comments.
Would it be possible to re-run the test using only the -S workload? Thanks very much.
pgbench settings:
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres
where, time_for_reading = 30mins
non default GUC param
shared_buffers=8GB
max_connections=300
pg_wal is located in SSD.
CLIENT COUNT TPS (HEAD) TPS (PATCH) % IMPROVEMENT 4 2588 2601 0.5023183926 8 5094 5098 0.0785237534 16 10294 10307 0.1262871576 32 19779 19815 0.182011224 64 27908 28346 1.569442454 72 27823 28416 2.131330194 128 28455 28618 0.5728342998 180 26739 26879 0.5235797898 196 27820 27963 0.5140186916 256 28763 28969 0.7161978931
Also, Excel sheet (results-readwrite-300-SF.xlsx) containing the results for all the 3 runs is attached.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Feb 28, 2017 at 11:44 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
Okay, I already had the results for read-oly workload but just forgot to share it along with the results for read-write test. Here are the results for read-only
test,
On 28 February 2017 at 11:34, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:So, Here are the pgbench results I got with 'reduce_pgxact_access_AtEOXact.v2.patch' on a read-write workload. Thanks for performing a test.I see a low yet noticeable performance gain across the board on that workload.That is quite surprising to see a gain on that workload. The main workload we have been discussing was the full read-only test (-S). For that case the effect should be much more noticeable based upon Andres' earlier comments.Would it be possible to re-run the test using only the -S workload? Thanks very much.
Okay, I already had the results for read-oly workload but just forgot to share it along with the results for read-write test. Here are the results for read-only
test,
| CLIENT COUNT | TPS (HEAD) | TPS (PATCH) | % IMPROVEMENT |
| 4 | 26322 | 31259 | 18.75617354 |
| 8 | 63499 | 69472 | 9.406447346 |
| 16 | 181155 | 186534 | 2.96928045 |
| 32 | 333504 | 337533 | 1.208081462 |
| 64 | 350341 | 353747 | 0.9721956608 |
| 72 | 366339 | 373898 | 2.063389374 |
| 128 | 443381 | 478562 | 7.934710779 |
| 180 | 299875 | 334118 | 11.41909129 |
| 196 | 269194 | 275525 | 2.351835479 |
| 256 | 220027 | 235995 | 7.257291151 |
The pgbench settings and non-default params are,
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading -S postgres
where, time_for_reading = 10mins
non default param:
shared_buffers=8GB
max_connections=300
--
With Regards,
Ashutosh Sharma
EnterpriseDB:http://www.
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading -S postgres
where, time_for_reading = 10mins
non default param:
shared_buffers=8GB
max_connections=300
--
With Regards,
Ashutosh Sharma
EnterpriseDB:http://www.
pgbench settings:
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres
where, time_for_reading = 30mins
non default GUC param
shared_buffers=8GB
max_connections=300
pg_wal is located in SSD.
CLIENT COUNT TPS (HEAD) TPS (PATCH) % IMPROVEMENT 4 2588 2601 0.5023183926 8 5094 5098 0.0785237534 16 10294 10307 0.1262871576 32 19779 19815 0.182011224 64 27908 28346 1.569442454 72 27823 28416 2.131330194 128 28455 28618 0.5728342998 180 26739 26879 0.5235797898 196 27820 27963 0.5140186916 256 28763 28969 0.7161978931
Also, Excel sheet (results-readwrite-300-SF.xlsx) containing the results for all the 3 runs is attached. --Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 1 March 2017 at 04:50, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
--
On Tue, Feb 28, 2017 at 11:44 PM, Simon Riggs <simon@2ndquadrant.com> wrote:On 28 February 2017 at 11:34, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:So, Here are the pgbench results I got with 'reduce_pgxact_access_AtEOXact.v2.patch' on a read-write workload. Thanks for performing a test.I see a low yet noticeable performance gain across the board on that workload.That is quite surprising to see a gain on that workload. The main workload we have been discussing was the full read-only test (-S). For that case the effect should be much more noticeable based upon Andres' earlier comments.Would it be possible to re-run the test using only the -S workload? Thanks very much.
Okay, I already had the results for read-oly workload but just forgot to share it along with the results for read-write test. Here are the results for read-only
test,
Thanks for conducting those comparisons.
So we have variable and sometimes significant gains, with no regressions.
By the shape of the results this helps in different places to the alignment patch. Do we have evidence to commit both?
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Mar 1, 2017 at 5:29 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > > On 1 March 2017 at 04:50, Ashutosh Sharma <ashu.coek88@gmail.com> wrote: >> >> On Tue, Feb 28, 2017 at 11:44 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >>> >>> On 28 February 2017 at 11:34, Ashutosh Sharma <ashu.coek88@gmail.com> wrote: >>> >>>> >>>> So, Here are the pgbench results I got with 'reduce_pgxact_access_AtEOXact.v2.patch' on a read-write workload. >>> >>> >>> Thanks for performing a test. >>> >>> I see a low yet noticeable performance gain across the board on that workload. >>> >>> That is quite surprising to see a gain on that workload. The main workload we have been discussing was the full read-onlytest (-S). For that case the effect should be much more noticeable based upon Andres' earlier comments. >>> >>> Would it be possible to re-run the test using only the -S workload? Thanks very much. >> >> >> Okay, I already had the results for read-oly workload but just forgot to share it along with the results for read-writetest. Here are the results for read-only >> test, > > > Thanks for conducting those comparisons. > > So we have variable and sometimes significant gains, with no regressions. > > By the shape of the results this helps in different places to the alignment patch. Do we have evidence to commit both? Well, We have seen some regression in read-write test with pgxact alignment patch - [1]. I may need to run the test with both the patches to see the combined effect on performance. [1] - https://www.postgresql.org/message-id/CAE9k0Pk%2BrCuNY%2B7O5XwVXHPuki9t8%3DM7jr4kevxw-hdkpFhS2A%40mail.gmail.com
On Wed, Mar 1, 2017 at 6:44 PM, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
On Wed, Mar 1, 2017 at 5:29 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
>
> On 1 March 2017 at 04:50, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
>>
>> On Tue, Feb 28, 2017 at 11:44 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
>>>
>>> On 28 February 2017 at 11:34, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
>>>
>>>>
>>>> So, Here are the pgbench results I got with 'reduce_pgxact_access_AtEOXact.v2.patch' on a read-write workload.
>>>
>>>
>>> Thanks for performing a test.
>>>
>>> I see a low yet noticeable performance gain across the board on that workload.
>>>
>>> That is quite surprising to see a gain on that workload. The main workload we have been discussing was the full read-only test (-S). For that case the effect should be much more noticeable based upon Andres' earlier comments.
>>>
>>> Would it be possible to re-run the test using only the -S workload? Thanks very much.
>>
>>
>> Okay, I already had the results for read-oly workload but just forgot to share it along with the results for read-write test. Here are the results for read-only
>> test,
>
>
> Thanks for conducting those comparisons.
>
> So we have variable and sometimes significant gains, with no regressions.
>
> By the shape of the results this helps in different places to the alignment patch. Do we have evidence to commit both?
Well, We have seen some regression in read-write test with pgxact
alignment patch - [1]. I may need to run the test with both the
patches to see the combined effect on performance.
[1] - https://www.postgresql.org/message-id/CAE9k0Pk%2BrCuNY% 2B7O5XwVXHPuki9t8% 3DM7jr4kevxw-hdkpFhS2A%40mail. gmail.com
I agree. Probably Simon's patch for reducing pgxact access could negate regression in pgxact alignment patch.
Ashutosh, could please you run read-write and read-only tests when both these patches applied?
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Hi,
>
> I agree. Probably Simon's patch for reducing pgxact access could negate
> regression in pgxact alignment patch.
> Ashutosh, could please you run read-write and read-only tests when both
> these patches applied?
I already had the results with both the patches applied. But, as I was not quite
able to understand on how Simon's patch for reducing pgxact access could
negate the regression on read-write workload that we saw with pgxact-align-3
patch earlier, I was slightly hesitant to share the results. Anyways, here are
the results with combined patches on readonly and readwrite workload:
1) Results for read-only workload:
========================
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading -S postgres
where, time_for_reading = 10mins
non default param:
shared_buffers=8GB
max_connections=300
2) Results for read-write workload:
=========================
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres
where, time_for_reading = 30mins
non default param:
shared_buffers=8GB
max_connections=300
HEAD is basically referring to the following git commit in master branch,>
> I agree. Probably Simon's patch for reducing pgxact access could negate
> regression in pgxact alignment patch.
> Ashutosh, could please you run read-write and read-only tests when both
> these patches applied?
I already had the results with both the patches applied. But, as I was not quite
able to understand on how Simon's patch for reducing pgxact access could
negate the regression on read-write workload that we saw with pgxact-align-3
patch earlier, I was slightly hesitant to share the results. Anyways, here are
the results with combined patches on readonly and readwrite workload:
1) Results for read-only workload:
========================
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading -S postgres
where, time_for_reading = 10mins
non default param:
shared_buffers=8GB
max_connections=300
| CLIENT COUNT | TPS (HEAD) | TPS (PATCH) | % IMPROVEMENT |
| 4 | 36333 | 36835 | 1.381664052 |
| 8 | 70179 | 72496 | 3.301557446 |
| 16 | 169303 | 175743 | 3.803831001 |
| 32 | 328837 | 341093 | 3.727074508 |
| 64 | 363352 | 399847 | 10.04397939 |
| 72 | 372011 | 413437 | 11.13569222 |
| 128 | 443979 | 578355 | 30.26629638 |
| 180 | 321420 | 552373 | 71.85396055 |
| 196 | 276780 | 558896 | 101.927885 |
| 256 | 234563 | 568951 | 142.5578629 |
2) Results for read-write workload:
=========================
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres
where, time_for_reading = 30mins
non default param:
shared_buffers=8GB
max_connections=300
| CLIENT COUNT | TPS (HEAD) | TPS (PATCH) | % IMPROVEMENT |
| 4 | 2683 | 2690 | 0.2609019754 |
| 8 | 5321 | 5332 | 0.2067280586 |
| 16 | 10348 | 10387 | 0.3768844221 |
| 32 | 19446 | 19754 | 1.58387329 |
| 64 | 28178 | 28198 | 0.0709773582 |
| 72 | 28296 | 28639 | 1.212185468 |
| 128 | 28577 | 28600 | 0.0804843056 |
| 180 | 26665 | 27525 | 3.225201575 |
| 196 | 27628 | 28511 | 3.19603301 |
| 256 | 28467 | 28529 | 0.2177960445 |
commit 5dbdb2f799232cb1b6df7d7a85d59ade3234d30c
Author: Robert Haas <rhaas@postgresql.org>
Date: Fri Feb 24 12:21:46 2017 +0530
Make tablesample work with partitioned tables.
This was an oversight in the original partitioning commit.
Amit Langote, reviewed by David Fetter
--
With Regards,
Ashutosh Sharma
EnterpriseDB:http://www.
On Fri, Mar 10, 2017 at 4:01 PM, Ashutosh Sharma <ashu.coek88@gmail.com> wrote:
> I agree. Probably Simon's patch for reducing pgxact access could negate
> regression in pgxact alignment patch.
> Ashutosh, could please you run read-write and read-only tests when both
> these patches applied?
I already had the results with both the patches applied. But, as I was not quite
able to understand on how Simon's patch for reducing pgxact access could
negate the regression on read-write workload that we saw with pgxact-align-3
patch earlier, I was slightly hesitant to share the results. Anyways, here are
the results with combined patches on readonly and readwrite workload:
1) Results for read-only workload:
========================
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading -S postgres
where, time_for_reading = 10mins
non default param:
shared_buffers=8GB
max_connections=300
CLIENT COUNT TPS (HEAD) TPS (PATCH) % IMPROVEMENT 4 36333 36835 1.381664052 8 70179 72496 3.301557446 16 169303 175743 3.803831001 32 328837 341093 3.727074508 64 363352 399847 10.04397939 72 372011 413437 11.13569222 128 443979 578355 30.26629638 180 321420 552373 71.85396055 196 276780 558896 101.927885 256 234563 568951 142.5578629
2) Results for read-write workload:
=========================
pgbench -i -s 300 postgres
pgbench -M prepared -c $thread -j $thread -T $time_for_reading postgres
where, time_for_reading = 30mins
non default param:
shared_buffers=8GB
max_connections=300
CLIENT COUNT TPS (HEAD) TPS (PATCH) % IMPROVEMENT 4 2683 2690 0.2609019754 8 5321 5332 0.2067280586 16 10348 10387 0.3768844221 32 19446 19754 1.58387329 64 28178 28198 0.0709773582 72 28296 28639 1.212185468 128 28577 28600 0.0804843056 180 26665 27525 3.225201575 196 27628 28511 3.19603301 256 28467 28529 0.2177960445
Results look good for me. Idea of committing both of patches looks attractive.
We have pretty much acceleration for read-only case and small acceleration for read-write case.
I'll run benchmark on 72-cores machine as well.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Hi Alexander On 3/10/17 8:08 AM, Alexander Korotkov wrote: > Results look good for me. Idea of committing both of patches looks > attractive. > We have pretty much acceleration for read-only case and small > acceleration for read-write case. > I'll run benchmark on 72-cores machine as well. Have you had a chance to run those tests yet? Thanks, -- -David david@pgmasters.net
On 10 March 2017 at 13:08, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
--
Results look good for me. Idea of committing both of patches looks attractive.
I'll commit mine since I understand what it does. I'll look at the other one also, but won't commit yet.
We have pretty much acceleration for read-only case and small acceleration for read-write case.I'll run benchmark on 72-cores machine as well.
No need to wait for that.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Mar 24, 2017 at 10:12 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > On 10 March 2017 at 13:08, Alexander Korotkov <a.korotkov@postgrespro.ru> > wrote: >> Results look good for me. Idea of committing both of patches looks >> attractive. > > I'll commit mine since I understand what it does. I'll look at the other one > also, but won't commit yet. Might've been nice to include reviewers, testers, and a link to the mailing list discussion in the commit message. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Mar 22, 2017 at 12:23 AM, David Steele <david@pgmasters.net> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
Hi Alexander
On 3/10/17 8:08 AM, Alexander Korotkov wrote:Results look good for me. Idea of committing both of patches looks
attractive.
We have pretty much acceleration for read-only case and small
acceleration for read-write case.
I'll run benchmark on 72-cores machine as well.
Have you had a chance to run those tests yet?
I discovered an interesting issue.
I found that ccce90b3 (which was reverted) gives almost same effect as PGXACT alignment on read-only test on 72-cores machine.
That shouldn't be related to the functionality of ccce90b3 itself, because read-only test don't do anything with clog. And that appears to be true. Padding of PGPROC gives same positive effect as ccce90b3. Padding patch (pgproc-pad.patch) is attached. It's curious that padding changes size of PGPROC from 816 bytes to 848 bytes. So, size of PGPROC remains 16-byte aligned. So, probably effect is related to distance between PGPROC members...
See comparison of 16-bytes alignment of PGXACT + reduce PGXACT access vs. padding of PGPROC.
+-----------+-----------------------------+-----------------------------+-----------------------------+
| | master |pgxact-align16+reduce-access | pgproc-pad |
| clients | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 |
|-----------+---------+---------+---------+---------+---------+---------+---------+---------+---------|
| 1 | 31765 | 31100 | 32961 | 32744 | 30024 | 32165 | 31831 | 31710 | 32063 |
| 2 | 58784 | 60347 | 59438 | 58900 | 60846 | 58578 | 57006 | 58875 | 59738 |
| 4 | 112786 | 116346 | 116513 | 114393 | 115238 | 116982 | 112964 | 112910 | 114248 |
| 8 | 216363 | 217180 | 220492 | 220160 | 213277 | 222844 | 219578 | 217326 | 221533 |
| 16 | 430783 | 428994 | 405667 | 441594 | 437152 | 434521 | 429309 | 430169 | 425734 |
| 20 | 531794 | 530932 | 530881 | 546216 | 536639 | 538384 | 537205 | 529382 | 535287 |
| 40 | 951640 | 930171 | 915583 | 958039 | 831028 | 932284 | 951259 | 960069 | 955081 |
| 60 | 1087248 | 1085500 | 1082603 | 1108364 | 1117380 | 1119477 | 1123136 | 1108958 | 1121190 |
| 80 | 1249524 | 1253363 | 1254437 | 1256894 | 1241449 | 1277724 | 1258509 | 1270440 | 1261364 |
| 100 | 1384761 | 1390181 | 1390948 | 1370966 | 1365666 | 1361546 | 1424189 | 1404768 | 1417215 |
| 120 | 1440615 | 1442773 | 1434149 | 1545179 | 1527888 | 1533981 | 1577170 | 1569765 | 1566950 |
| 140 | 1400715 | 1411922 | 1406841 | 1692305 | 1695125 | 1661440 | 1726416 | 1707735 | 1713590 |
| 150 | 1335935 | 1342888 | 1340833 | 1662310 | 1655399 | 1695437 | 1737758 | 1731811 | 1748215 |
| 160 | 1299769 | 1293409 | 1299178 | 1702658 | 1701668 | 1732576 | 1718459 | 1725853 | 1714432 |
| 180 | 1088828 | 1096198 | 1085467 | 1641713 | 1652604 | 1619376 | 1682716 | 1684590 | 1674715 |
| 200 | 994350 | 989267 | 996982 | 1636544 | 1650192 | 1629450 | 1654997 | 1647421 | 1646110 |
| 220 | 920877 | 922182 | 927801 | 1613027 | 1630249 | 1635628 | 1579957 | 1570928 | 1576457 |
| 240 | 887654 | 890656 | 881243 | 1565544 | 1574255 | 1570622 | 1486611 | 1496031 | 1497658 |
+-----------+---------+---------+---------+---------+---------+---------+---------+---------+---------+
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
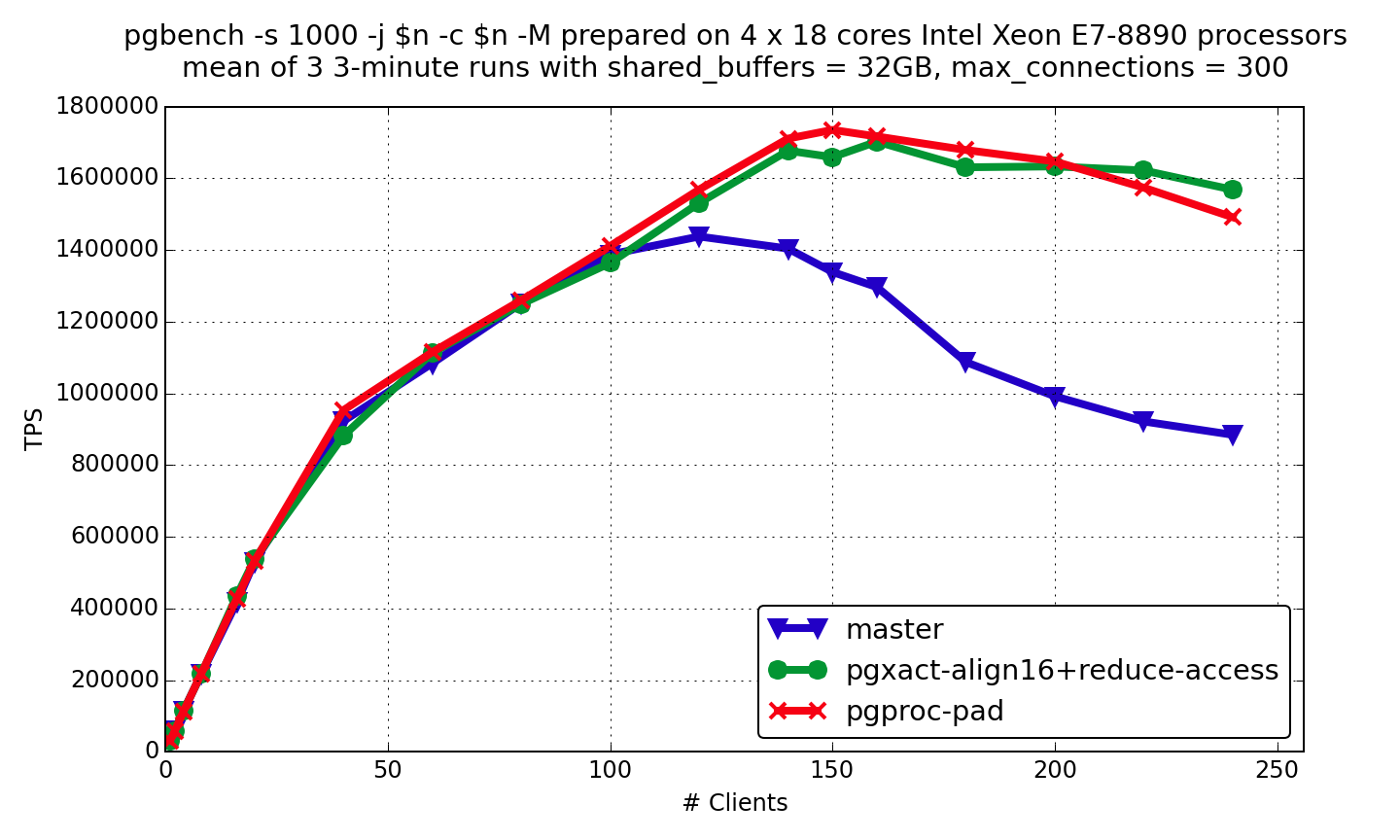{kind=link}
On 2017-03-25 19:35:35 +0300, Alexander Korotkov wrote: > On Wed, Mar 22, 2017 at 12:23 AM, David Steele <david@pgmasters.net> wrote: > > > Hi Alexander > > > > On 3/10/17 8:08 AM, Alexander Korotkov wrote: > > > > Results look good for me. Idea of committing both of patches looks > >> attractive. > >> We have pretty much acceleration for read-only case and small > >> acceleration for read-write case. > >> I'll run benchmark on 72-cores machine as well. > >> > > > > Have you had a chance to run those tests yet? > > > > I discovered an interesting issue. > I found that ccce90b3 (which was reverted) gives almost same effect as > PGXACT alignment on read-only test on 72-cores machine. That's possibly because it changes alignment? > That shouldn't be related to the functionality of ccce90b3 itself, because > read-only test don't do anything with clog. And that appears to be true. > Padding of PGPROC gives same positive effect as ccce90b3. Padding patch > (pgproc-pad.patch) is attached. It's curious that padding changes size of > PGPROC from 816 bytes to 848 bytes. So, size of PGPROC remains 16-byte > aligned. So, probably effect is related to distance between PGPROC > members... > > See comparison of 16-bytes alignment of PGXACT + reduce PGXACT access vs. > padding of PGPROC. My earlier testing had showed that padding everything is the best approach :/ I'm inclined to push this to the next CF, it seems we need a lot more benchmarking here. Greetings, Andres Freund
pgsql-hackers-owner@postgresql.org wrote on 04/03/2017 01:58:03 PM:
> From: Andres Freund <andres@anarazel.de>
> To: Alexander Korotkov <a.korotkov@postgrespro.ru>
> Cc: David Steele <david@pgmasters.net>, Ashutosh Sharma
> <ashu.coek88@gmail.com>, Simon Riggs <simon@2ndquadrant.com>, Alvaro
> Herrera <alvherre@2ndquadrant.com>, Robert Haas
> <robertmhaas@gmail.com>, Bernd Helmle <mailings@oopsware.de>, Tomas
> Vondra <tomas.vondra@2ndquadrant.com>, pgsql-hackers <pgsql-
> hackers@postgresql.org>
> Date: 04/03/2017 01:59 PM
> Subject: Re: [HACKERS] Should we cacheline align PGXACT?
> Sent by: pgsql-hackers-owner@postgresql.org
>
> On 2017-03-25 19:35:35 +0300, Alexander Korotkov wrote:
> > On Wed, Mar 22, 2017 at 12:23 AM, David Steele <david@pgmasters.net> wrote:
> >
> > > Hi Alexander
> > >
> > > On 3/10/17 8:08 AM, Alexander Korotkov wrote:
> > >
> > > Results look good for me. Idea of committing both of patches looks
> > >> attractive.
> > >> We have pretty much acceleration for read-only case and small
> > >> acceleration for read-write case.
> > >> I'll run benchmark on 72-cores machine as well.
> > >>
> > >
> > > Have you had a chance to run those tests yet?
> > >
> >
> > I discovered an interesting issue.
> > I found that ccce90b3 (which was reverted) gives almost same effect as
> > PGXACT alignment on read-only test on 72-cores machine.
>
> That's possibly because it changes alignment?
>
>
> > That shouldn't be related to the functionality of ccce90b3 itself, because
> > read-only test don't do anything with clog. And that appears to be true.
> > Padding of PGPROC gives same positive effect as ccce90b3. Padding patch
> > (pgproc-pad.patch) is attached. It's curious that padding changes size of
> > PGPROC from 816 bytes to 848 bytes. So, size of PGPROC remains 16-byte
> > aligned. So, probably effect is related to distance between PGPROC
> > members...
> >
> > See comparison of 16-bytes alignment of PGXACT + reduce PGXACT access vs.
> > padding of PGPROC.
>
> My earlier testing had showed that padding everything is the best
> approach :/
>
My approach has been to, generally, pad "everything" as well. In my testing on power, I padded PGXACT to 16 bytes. To my surprise, with the padding in isolation, the performance (on hammerdb) was slightly degraded.
Jim Van Fleet
>
> I'm inclined to push this to the next CF, it seems we need a lot more
> benchmarking here.
>
> Greetings,
>
> Andres Freund
>
>
> --
> Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackers
>
On Mon, Apr 3, 2017 at 9:58 PM, Andres Freund <andres@anarazel.de> wrote:
No objections.
On 2017-03-25 19:35:35 +0300, Alexander Korotkov wrote:
> On Wed, Mar 22, 2017 at 12:23 AM, David Steele <david@pgmasters.net> wrote:
>
> > Hi Alexander
> >
> > On 3/10/17 8:08 AM, Alexander Korotkov wrote:
> >
> > Results look good for me. Idea of committing both of patches looks
> >> attractive.
> >> We have pretty much acceleration for read-only case and small
> >> acceleration for read-write case.
> >> I'll run benchmark on 72-cores machine as well.
> >>
> >
> > Have you had a chance to run those tests yet?
> >
>
> I discovered an interesting issue.
> I found that ccce90b3 (which was reverted) gives almost same effect as
> PGXACT alignment on read-only test on 72-cores machine.
That's possibly because it changes alignment?
Probably, that needs to be checked.
> That shouldn't be related to the functionality of ccce90b3 itself, because
> read-only test don't do anything with clog. And that appears to be true.
> Padding of PGPROC gives same positive effect as ccce90b3. Padding patch
> (pgproc-pad.patch) is attached. It's curious that padding changes size of
> PGPROC from 816 bytes to 848 bytes. So, size of PGPROC remains 16-byte
> aligned. So, probably effect is related to distance between PGPROC
> members...
>
> See comparison of 16-bytes alignment of PGXACT + reduce PGXACT access vs.
> padding of PGPROC.
My earlier testing had showed that padding everything is the best
approach :/
I'm inclined to push this to the next CF, it seems we need a lot more
benchmarking here.
The Russian Postgres Company
On 4/4/17 8:55 AM, Alexander Korotkov wrote: > On Mon, Apr 3, 2017 at 9:58 PM, Andres Freund <andres@anarazel.de > > I'm inclined to push this to the next CF, it seems we need a lot more > benchmarking here. > > > No objections. This submission has been moved to CF 2017-07. Thanks, -- -David david@pgmasters.net
On 4 April 2017 at 08:58, David Steele <david@pgmasters.net> wrote: > On 4/4/17 8:55 AM, Alexander Korotkov wrote: >> On Mon, Apr 3, 2017 at 9:58 PM, Andres Freund <andres@anarazel.de >> >> I'm inclined to push this to the next CF, it seems we need a lot more >> benchmarking here. >> >> >> No objections. > > This submission has been moved to CF 2017-07. Please note that I'm expecting to re-commit my earlier patch once fixed up, since it had all-positive test results. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
> On 04 Apr 2017, at 14:58, David Steele <david@pgmasters.net> wrote: > > On 4/4/17 8:55 AM, Alexander Korotkov wrote: >> On Mon, Apr 3, 2017 at 9:58 PM, Andres Freund <andres@anarazel.de >> >> I'm inclined to push this to the next CF, it seems we need a lot more >> benchmarking here. >> >> No objections. > > This submission has been moved to CF 2017-07. This CF has now started (well, 201709 but that’s what was meant in above), can we reach closure on this patch in this CF? cheers ./daniel
On Tue, Sep 5, 2017 at 2:47 PM, Daniel Gustafsson <daniel@yesql.se> wrote:
> On 04 Apr 2017, at 14:58, David Steele <david@pgmasters.net> wrote:
>
> On 4/4/17 8:55 AM, Alexander Korotkov wrote:
>> On Mon, Apr 3, 2017 at 9:58 PM, Andres Freund <andres@anarazel.de
>>
>> I'm inclined to push this to the next CF, it seems we need a lot more
>> benchmarking here.
>>
>> No objections.
>
> This submission has been moved to CF 2017-07.
This CF has now started (well, 201709 but that’s what was meant in above), can
we reach closure on this patch in this CF?
During previous commitfest I come to doubts if this patch is really needed when same effect could be achieved by another (perhaps random) change of alignment. The thing I can do now is to retry my benchmark on current master and check what effect this patch has now.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
> On 16 Sep 2017, at 01:51, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > On Tue, Sep 5, 2017 at 2:47 PM, Daniel Gustafsson <daniel@yesql.se <mailto:daniel@yesql.se>> wrote: > > On 04 Apr 2017, at 14:58, David Steele <david@pgmasters.net <mailto:david@pgmasters.net>> wrote: > > > > On 4/4/17 8:55 AM, Alexander Korotkov wrote: > >> On Mon, Apr 3, 2017 at 9:58 PM, Andres Freund <andres@anarazel.de <mailto:andres@anarazel.de> > >> > >> I'm inclined to push this to the next CF, it seems we need a lot more > >> benchmarking here. > >> > >> No objections. > > > > This submission has been moved to CF 2017-07. > > This CF has now started (well, 201709 but that’s what was meant in above), can > we reach closure on this patch in this CF? > > During previous commitfest I come to doubts if this patch is really needed when same effect could be achieved by another(perhaps random) change of alignment. The thing I can do now is to retry my benchmark on current master and checkwhat effect this patch has now. Considering this I’ll mark this as Waiting on Author, in case you come to conclusion that another patch is required then we’ll bump to a return status. cheers ./daniel -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Mon, Sep 18, 2017 at 12:41 PM, Daniel Gustafsson <daniel@yesql.se> wrote:
I'm going to make some experiments with read-write and mixed workloads too.
> On 16 Sep 2017, at 01:51, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
>
> On Tue, Sep 5, 2017 at 2:47 PM, Daniel Gustafsson <daniel@yesql.se <mailto:daniel@yesql.se>> wrote:
> > On 04 Apr 2017, at 14:58, David Steele <david@pgmasters.net <mailto:david@pgmasters.net>> wrote:
> >
> > On 4/4/17 8:55 AM, Alexander Korotkov wrote:
> >> On Mon, Apr 3, 2017 at 9:58 PM, Andres Freund <andres@anarazel.de <mailto:andres@anarazel.de>
> >>
> >> I'm inclined to push this to the next CF, it seems we need a lot more
> >> benchmarking here.
> >>
> >> No objections.
> >
> > This submission has been moved to CF 2017-07.
>
> This CF has now started (well, 201709 but that’s what was meant in above), can
> we reach closure on this patch in this CF?
>
> During previous commitfest I come to doubts if this patch is really needed when same effect could be achieved by another (perhaps random) change of alignment. The thing I can do now is to retry my benchmark on current master and check what effect this patch has now.
Considering this I’ll mark this as Waiting on Author, in case you come to
conclusion that another patch is required then we’ll bump to a return status.
I've made some read-only benchmarking. There is clear win in this case. The only point where median of master is higher than median of patched version is 40 clients.
In this point observations are following:
master: 982432 939483 932075
pgxact-align: 913151 921300 938132
So, groups of observations form the overlapping ranges, and this anomaly can be explained by statistical error.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
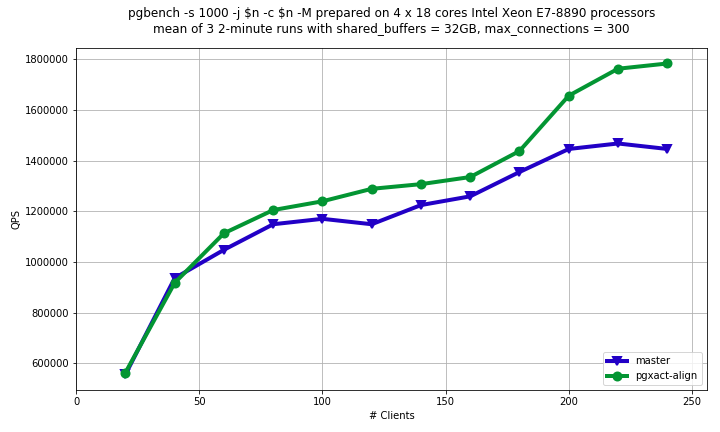{kind=link}
On Thu, Sep 21, 2017 at 12:08 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Mon, Sep 18, 2017 at 12:41 PM, Daniel Gustafsson <daniel@yesql.se> wrote:> On 16 Sep 2017, at 01:51, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
>
> On Tue, Sep 5, 2017 at 2:47 PM, Daniel Gustafsson <daniel@yesql.se <mailto:daniel@yesql.se>> wrote:
> > On 04 Apr 2017, at 14:58, David Steele <david@pgmasters.net <mailto:david@pgmasters.net>> wrote:
> >
> > On 4/4/17 8:55 AM, Alexander Korotkov wrote:
> >> On Mon, Apr 3, 2017 at 9:58 PM, Andres Freund <andres@anarazel.de <mailto:andres@anarazel.de>
> >>
> >> I'm inclined to push this to the next CF, it seems we need a lot more
> >> benchmarking here.
> >>
> >> No objections.
> >
> > This submission has been moved to CF 2017-07.
>
> This CF has now started (well, 201709 but that’s what was meant in above), can
> we reach closure on this patch in this CF?
>
> During previous commitfest I come to doubts if this patch is really needed when same effect could be achieved by another (perhaps random) change of alignment. The thing I can do now is to retry my benchmark on current master and check what effect this patch has now.
Considering this I’ll mark this as Waiting on Author, in case you come to
conclusion that another patch is required then we’ll bump to a return status.I've made some read-only benchmarking. There is clear win in this case. The only point where median of master is higher than median of patched version is 40 clients.In this point observations are following:master: 982432 939483 932075pgxact-align: 913151 921300 938132So, groups of observations form the overlapping ranges, and this anomaly can be explained by statistical error.I'm going to make some experiments with read-write and mixed workloads too.
I've made benchmarks with two more workloads.
scalability-rw.png – read-write tcpb-like workload (pgbench default)
scalability-rrw.png – 90% read-only transactions 10% read-write transactions (-btpcb-like@1 -bselect-only@9)
It became clear that this patch causes regression. On pure read-write workload, it's not so evident due to high variability of observations. However, on mixed workload it's very clear regression.
I would be ridiculous to consider patch which improves read-only performance but degrades read-write performance in nearly same degree. Thus, this topic needs more investigation if it's possible to at least get the same benefit on read-only workload without penalty on read-write workload (ideally read-write workload should benefit too). I'm going to mark this patch as "returned with feedback".
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
{kind=link}
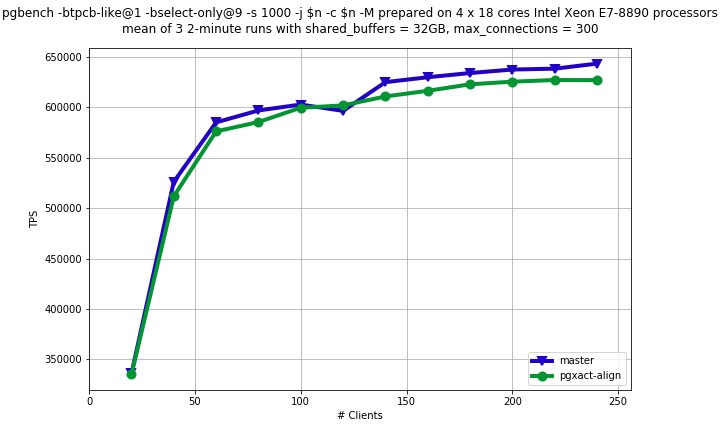{kind=link}