Blog , p.4
The Standard edition of Postgres Pro DBMS 14.1.1 has become available, along with new minor releases for the following versions: Std 9.6.24.1, Std 10.19.1, Std 11.14.1, Std 12.9.1 and Std 13.5.1.

PGConf.Russia Gathers 500+ IT Professionals at a Hybrid Online+Offline Event
25-26 October PGConf.Russia 2021 was held in a hybrid format to accommodate both online and offline participants. Postgres Professional organized this notable event for the 8th time; more than 500 people attended it virtually and in person. Software developers, database administrators, and top managers from the IT industry exchanged PostgreSQL best practices and shared their experience with the world’s most advanced open source database. Representatives of Intel, Yandex, EnterpriseDB, DBeaver Corp, Delivery Hero, and many other companies and organizations were speaking at PGConf.
This is a summary of Postgres Professional’s more than 6 years field experience of providing HA/DR solutions to our customers and it covers both PostgreSQL and Postgres Pro databases.
While most of our customers are making progress on their journeys to the cloud, many of the HA/DR solutions they use from the on-premises world can be used in the cloud as well.
During PostgreSQL maintenance, resource-consuming queries occur inevitably. Therefore, it's vital for every Database Engineer, DBA, or Software Developer to detect and fix them as soon as possible. In this article, we'll list various extensions and monitoring tools used to collect information about queries and display them in a human-readable way.
Then we will cover typical query writing mistakes and explain how to correct them. We will also consider cases where extended statistics are used for more accurate row count estimates. Finally, you will see an example of how PostgreSQL planner excludes redundant filter clauses during its work.
During our webinar on PostgreSQL query optimization, we found many of your questions interesting and helpful to the public, if properly answered. Get more useful links and working expert advice from Peter Petrov, our Database Engineer.
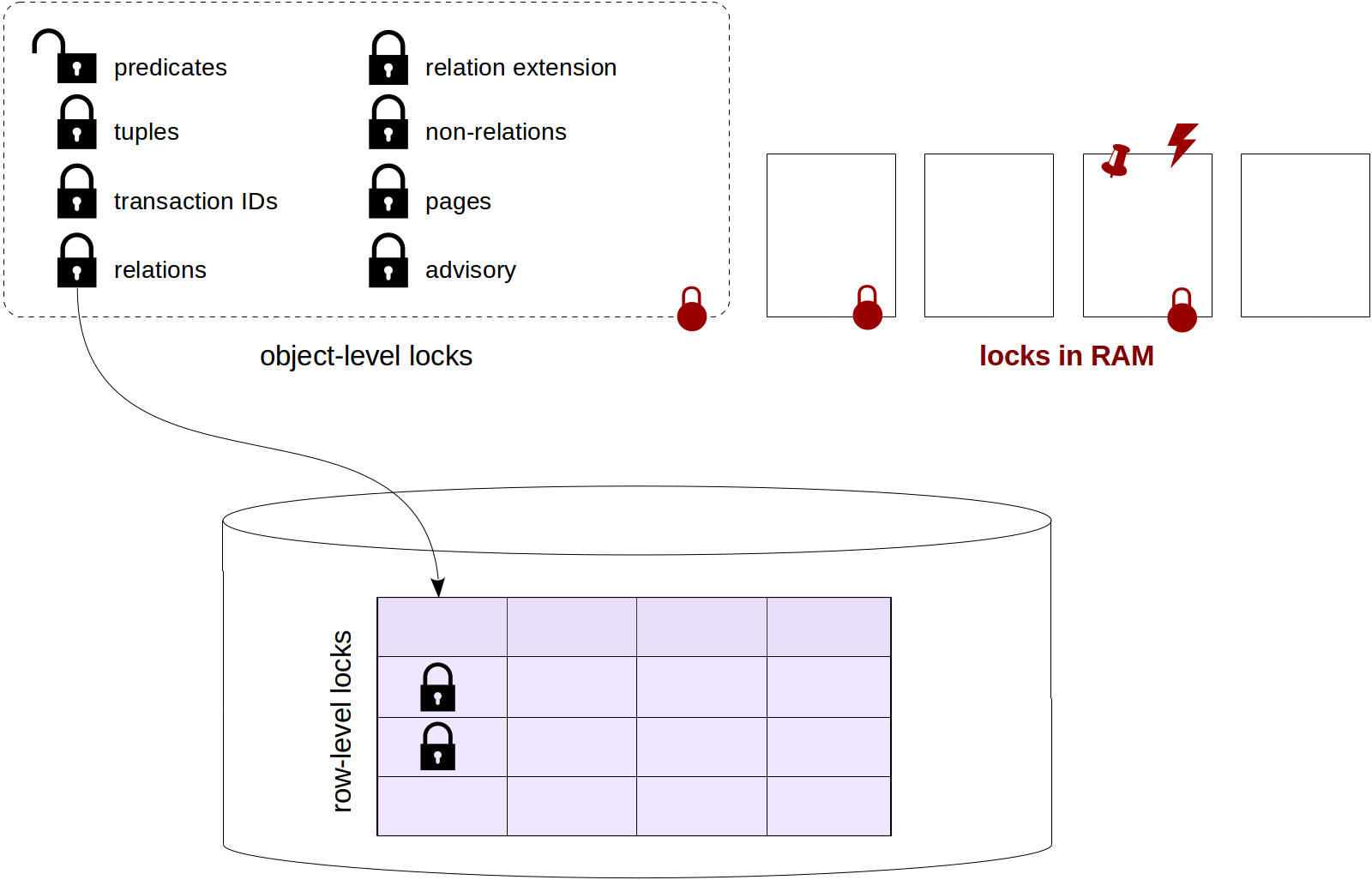
To remind you, we've already talked about relation-level locks, row-level locks, locks on other objects (including predicate locks) and interrelationships of different types of locks.
The following discussion of locks in RAM finishes this series of articles. We will consider spinlocks, lightweight locks and buffer pins, as well as events monitoring tools and sampling.
...
We've already discussed some object-level locks (specifically, relation-level locks), as well as row-level locks with their connection to object-level locks and also explored wait queues, which are not always fair.
We have a hodgepodge this time. We'll start with deadlocks (actually, I planned to discuss them last time, but that article was excessively long in itself), then briefly review object-level locks left and finally discuss predicate locks.
Last time, we discussed object-level locks and in particular relation-level locks. In this article, we will see how row-level locks are organized in PostgreSQL and how they are used together with object-level locks. We will also talk of wait queues and of those who jumps the queue.
The previous two series of articles covered isolation and multiversion concurrency control and logging.
In this series, we will discuss locks.
This series will consist of four articles:
- Relation-level locks (this article).
- Row-level locks.
- Locks on other objects and predicate locks.
- Locks in RAM.
In this blog post, we're explaining to those new to pg_profile why you might need this PostgreSQL extension in your daily work, on a real-world example.
So, we got acquainted with the structure of the buffer cache and in this context concluded that if all the RAM contents got lost due to failure, the write-ahead log (WAL) was required to recover. The size of the necessary WAL files and the recovery time are limited thanks to the checkpoint performed from time to time.
In the previous articles we already reviewed quite a few important settings that anyway relate to WAL. In this article (being the last in this series) we will discuss problems of WAL setup that are unaddressed yet: WAL levels and their purpose, as well as the reliability and performance of write-ahead logging.
We already got acquainted with the structure of the buffer cache — one of the main objects of the shared memory — and concluded that to recover after failure when all the RAM contents get lost, the write-ahead log (WAL) must be maintained.
The problem yet unaddressed, where we left off last time, is that we are unaware of where to start playing back WAL records during the recovery. To begin from the beginning, as the King from Lewis Caroll's Alice advised, is not an option: it is impossible to keep all the WAL records from the server start — this is potentially both a huge memory size and equally huge duration of the recovery. We need such a point that is gradually moving forward and that we can start the recovery at (and safely remove all the previous WAL records, accordingly). And this is the checkpoint, to be discussed below.
Last time we got acquainted with the structure of an important component of the shared memory — the buffer cache. A risk of losing information from RAM is the main reason why we need techniques to recover data after failure. Now we will discuss these techniques.
We started with problems related to isolation, made a digression about low-level data structure, discussed row versions in detail and observed how data snapshots are obtained from row versions.
Then we covered different vacuuming techniques: in-page vacuum (along with HOT updates), vacuum and autovacuum.
Now we've reached the last topic of this series. We will talk on the transaction id wraparound and freezing.
Transaction ID wraparound
PostgreSQL uses 32-bit transaction IDs. This is a pretty large number (about 4 billion), but with intensive work of the server, this number is not unlikely to get exhausted. For example: with the workload of 1000 transactions a second, this will happen as early as in one month and a half of continuous work.
But we've mentioned that multiversion concurrency control relies on the sequential numbering, which means that of two transactions the one with a smaller number can be considered to have started earlier. Therefore, it is clear that it is not an option to just reset the counter and start the numbering from scratch.
...