WAL in PostgreSQL: 2. Write-Ahead Log
Last time we got acquainted with the structure of an important component of the shared memory — the buffer cache. A risk of losing information from RAM is the main reason why we need techniques to recover data after failure. Now we will discuss these techniques.
The log
Sadly, there's no such thing as miracles: to survive the loss of information in RAM, everything needed must be duly saved to disk (or other nonvolatile media).
Therefore, the following was done. Along with changing data, the log of these changes is maintained. When we change something on a page in the buffer cache, we create a record of this change in the log. The record contains the minimum information sufficient to redo the change if the need arises.
For this to work, the log record must obligatory get to disk before the changed page gets there. And this explains the name: write-ahead log (WAL).
In case of failure, the data on disk appear to be inconsistent: some pages were written earlier, and others later. But WAL remains, which we can read and redo the operations that were performed before the failure but their result was late to reach the disk.
Why not force writing to disk the data pages themselves, why duplicate the work instead? It appears to be more efficient. First, WAL is a sequential stream of append-only data. Even HDD disks do the job of sequential writing fine. However, the data themselves are written in a random fashion since pages are spread across the disk more or less in disorder. Second, a WAL record can be way smaller than the page. Third, when writing to disk we do not need to take care of maintaining the consistency of data on disk at every point in time (this requirement makes life really difficult). And fourth, as we will see later, WAL (once it is available) can be used not only for recovery, but also for backup and replication.
All the operations must be WAL-logged that can result in inconsistent data on disk in case of failure. Specifically, the following operations are WAL-logged:
- Changes to pages in the buffer cache (mostly table and index pages) — since it takes some time for the page changed to get to disk.
- Transactions' commits and aborts — since a change of the status is done in XACT buffers and it also takes some time for the change to get to disk.
- File operations (creation and deletion of files and directories, such as creation of files during creation of a table) — since these operations must be synchronous with the changes to data.
The following is not WAL-logged:
- Operations with unlogged tables — their name is self-explanatory.
- Operations with temporary tables — logging makes no sense since the lifetime of such tables does not exceed the lifetime of the session that created them.
Before PostgreSQL 10, hash indexes were not WAL-logged (they served only to associate hash functions with different data types), but this has been corrected.
Logical structure
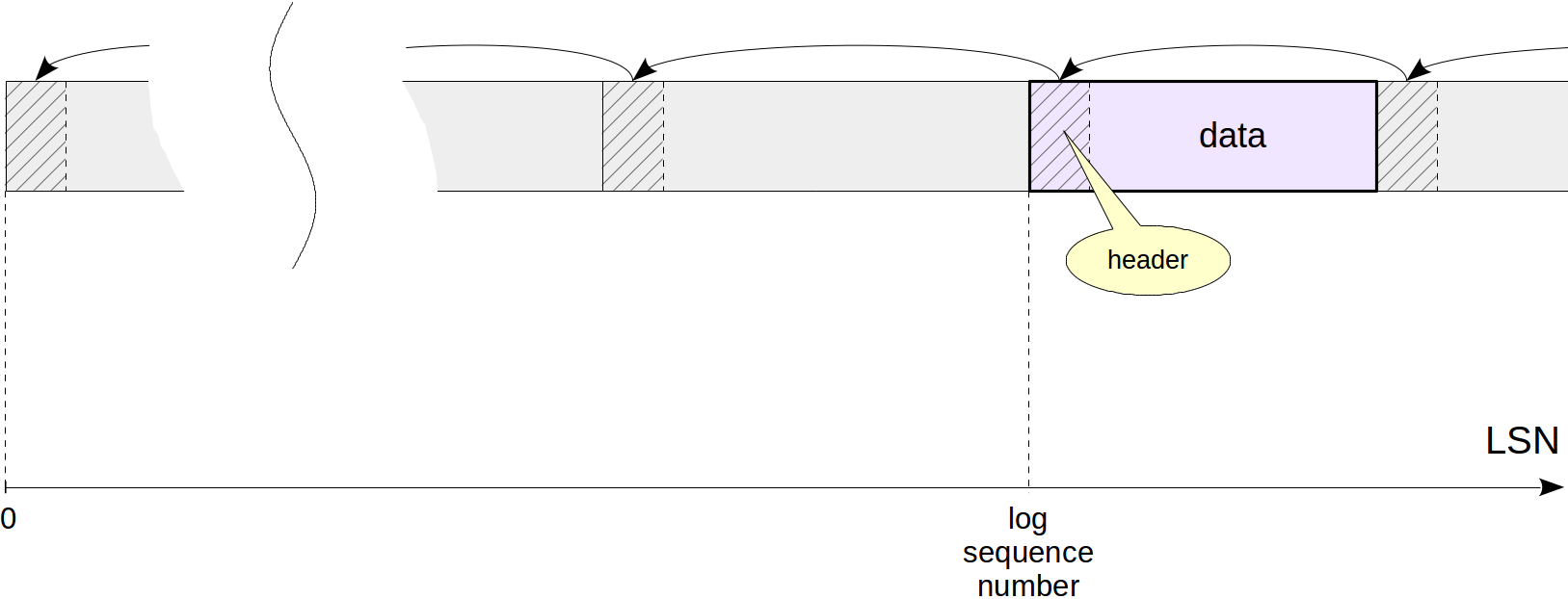
We can logically envisage WAL as a sequence of records of different lengths. Each record contains data on a certain operation, which are prefixed by a standard header. In the header, among the rest, the following is specified:
- The ID of the transaction that the record relates to.
- The resource manager — the system component responsible for the record.
- The checksum (CRC) — permits to detect data corruption.
- The length of the record and link to the preceding record.
As for the data, they can have different formats and meaning. For example: they can be represented by a page fragment that needs to be written on top of the page contents at a certain offset. The resource manager specified "understands" how to interpret the data in its record. There are separate managers for tables, each type of indexes, transaction statuses and so on. You can get the full list of them using the command
pg_waldump -r list
Physical structure
WAL is stored on disk as files in the $PGDATA/pg_wal directory. By default, each file is 16 MB. You can increase this size to avoid having many files in one catalog. Before PostgreSQL 11, you could do this only when compiling source codes, but now you can specify the size when initializing the cluster (use the --wal-segsize option).
WAL records get into the currently used file, and once it is over, the next one will be used.
In the shared memory of the server, special buffers are allocated for WAL. The wal_buffers parameter specifies the size of the WAL cache (the default value implies automatic setting: 1/32 of the buffer cache is allocated).
The WAL cache is structured similarly to the buffer cache, but works mainly in the circular buffer mode: records are added to the "head", but get written to disk starting with the "tail".
The pg_current_wal_lsn and pg_current_wal_insert_lsn functions return the write ("tail") and insert ("head") locations, respectively:
=> SELECT pg_current_wal_lsn(), pg_current_wal_insert_lsn();
pg_current_wal_lsn | pg_current_wal_insert_lsn
--------------------+---------------------------
0/331E4E64 | 0/331E4EA0
(1 row)
To reference a certain record, the pg_lsn data type is used: it is a 64-bit integer that represents the byte offset of the beginning of the record with respect to the beginning of WAL. LSN (log sequence number) is output as two 32-bit hexadecimal numbers separated by a slash.
We can get to know in what file we will find the location needed and at what offset from the beginning of the file:
=> SELECT file_name, upper(to_hex(file_offset)) file_offset
FROM pg_walfile_name_offset('0/331E4E64');
file_name | file_offset
--------------------------+-------------
000000010000000000000033 | 1E4E64
\ /\ /
time 0/331E4E64
line
The filename consists of two parts. 8 high-order hexadecimal digits show the number of the time line (it is used in restoring from backup) and the remainder corresponds to the high-order LSN digits (and the rest low-order LSN digits show the offset).
In the file system, you can see WAL files in the $PGDATA/pg_wal/ directory, but starting with PostgreSQL 10, you can also see them using a specialized function:
=> SELECT * FROM pg_ls_waldir() WHERE name = '000000010000000000000033';
name | size | modification
--------------------------+----------+------------------------
000000010000000000000033 | 16777216 | 2019-07-08 20:24:13+03
(1 row)
Write-ahead logging
Let's see how WAL-logging is done and how writing ahead is ensured. Let's create a table:
=> CREATE TABLE wal(id integer);
=> INSERT INTO wal VALUES (1);
We will be looking into the header of the table page. To do this, we will need a well-known extension:
=> CREATE EXTENSION pageinspect;
Let's start a transaction and remember the location of insertion into WAL:
=> BEGIN;
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
0/331F377C
(1 row)
Now we will perform some operation, for example, update a row:
=> UPDATE wal set id = id + 1;
This change was WAL-logged, and the insert location changed:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
0/331F37C4
(1 row)
To ensure the changed data page not to be flushed to disk prior to the WAL record, LSN of the last WAL record related to this page is stored in the page header:
=> SELECT lsn FROM page_header(get_raw_page('wal',0));
lsn
------------
0/331F37C4
(1 row)
Note that WAL is one for the entire cluster, and new records get there all the time. Therefore, LSN on the page can be less than the value just returned by the pg_current_wal_insert_lsn function. But since nothing is happening in our system, the numbers are the same.
Now let's commit the transaction.
=> COMMIT;
Commits are also WAL-logged, and the location changes again:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
0/331F37E8
(1 row)
Each commit changes the transaction status in the structure called XACT (we've already discussed it). Statuses are stored in files, but they also use their own cache, which occupies 128 pages in the shared memory. Therefore, for XACT pages, LSN of the last WAL record also has to be tracked. But this information is stored in RAM rather than in the page itself.
WAL records created will once be written to disk. We will discuss sometime later when exactly this happens, but in the above situation, it has already happened:
=> SELECT pg_current_wal_lsn(), pg_current_wal_insert_lsn();
pg_current_wal_lsn | pg_current_wal_insert_lsn
--------------------+---------------------------
0/331F37E8 | 0/331F37E8
(1 row)
Hereafter the data and XACT pages can be flushed to disk. But if we had to flush them earlier, it would be detected and the WAL records would be forced to get to disk first.
Having two LSN locations, we can get the amount of WAL records between them (in bytes) by simply subtracting one from the other. We only need to cast the locations to the pg_lsn type:
=> SELECT '0/331F37E8'::pg_lsn - '0/331F377C'::pg_lsn;
?column?
----------
108
(1 row)
In this case, the update of the row and commit required 108 bytes in WAL.
The same way we can evaluate the amount of WAL records that the server generates per unit of time at a certain load. This is important information, which will be needed for tuning (which we will discuss next time).
Now let's use the pg_waldump utility to look at the WAL records created.
The utility can also work with a range of LSNs (as in this example) and select the records for a transaction specified. You should run the utility as postgres OS user since it will need access to WAL files on disk.
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/331F377C -e 0/331F37E8 000000010000000000000033
rmgr: Heap len (rec/tot): 69/ 69, tx: 101085, lsn: 0/331F377C, prev 0/331F3014, desc: HOT_UPDATE off 1 xmax 101085 ; new off 2 xmax 0, blkref #0: rel 1663/16386/33081 blk 0
rmgr: Transaction len (rec/tot): 34/ 34, tx: 101085, lsn: 0/331F37C4, prev 0/331F377C, desc: COMMIT 2019-07-08 20:24:13.945435 MSK
Here we see the headers of two records.
The first one is the HOT_UPDATE operation, related to the Heap resource manager. The filename and page number are specified in the blkref field and are the same as of the updated table page:
=> SELECT pg_relation_filepath('wal');
pg_relation_filepath
----------------------
base/16386/33081
(1 row)
The second record is COMMIT, related to the Transaction resource manager.
This format is hardly easy-to-read, but allows us to clarify the things if needed.
Recovery
When we start the server, the postmaster process is launched first, which, in turn, launches the startup process, whose task is to ensure the recovery in case of failure.
To figure out a need for the recovery, startup looks at the cluster state in the specialized control file $PGDATA/global/pg_control. But we can also check the state on our own by means of the pg_controldata utility:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: in production
A server that was shut down in a regular way will have the "shut down" state. If a server is not working, but the state is still "in production", it means that the DBMS is down and the recovery will be done automatically.
For the recovery, the startup process will sequentially read WAL and apply records to the pages if needed. The need can be determined by comparing LSN of the page on disk with LSN of the WAL record. If LSN of the page appears to be greater, the record does not need to be applied. Actually, it even cannot be applied since the records are meant to be applied in a strictly sequential order.
But there are exceptions. Certain records are created as FPI (full page image), which overrides page contents and can therefore be applied to the page regardless of its state. A change to the transaction status can be applied to any version of a XACT page, so there is no need to store LSN inside such pages.
During a recovery, pages are changed in the buffer cache, as during regular work. To this end, postmaster launches the background processes needed.
WAL records are applied to files in a similar way: for example, if it is clear from a record that the file must exist, but it does not, the file is created.
And at the very end of the recovery process, respective initialization forks overwrite all unlogged tables to make them empty.
This is a very simplified description of the algorithm. Specifically, we haven't said a word so far on where to start reading WAL records (we have to put a talk on this off until we discuss a checkpoint).
And the last thing to clarify. "Classically", a recovery process consists of two phases. At the first (roll forward) phase, log records are applied and the server redoes all the work lost due to failure. At the second (roll back) phase, transactions that were not committed by the moment of failure are rolled back. But PostgreSQL does not need the second phase. As we discussed earlier, thanks to the implementation features of the multiversion concurrency control, transactions do not need to be physically rolled back — it is sufficient that the commit bit is not set in XACT.