Egor Rogov's Blog
Recent posts

PostgreSQL 14 Internals for print on demand

A quick note to let you know that the PostgreSQL 14 Internals book is now available for orders on a worldwide print-on-demand service. You can buy hardcover or paperback version. PDF is still freely available on our website.
PostgreSQL 14 Internals
I’m excited to announce that the translation of the “PostgreSQL 14 Internals” book is finally complete thanks to the amazing work of Liudmila Mantrova.
The final part of the book considers each of the index types in great detail. It explains and demonstrates how access methods, operator classes, and data types work together to serve a variety of distinct needs.
You can download a PDF version of this book for free. We are also working on making it available on a print-on-demand service.
Your comments are very welcome. Contact us at edu@postgrespro.ru.

PostgreSQL 14 Internals, Part IV

I’m excited to announce that the translation of Part IV of the “PostgreSQL 14 Internals” book is published. This part delves into the inner workings of the planner and the executor, and it took me a couple of hundred pages to get through all the magic that covers this advanced technology.
You can download the book freely in PDF. The last part is yet to come, stay tuned!
I’d like to thank Alejandro García Montoro, Goran Pulevic, and Japin Li for their feedback and suggestions. Your comments are much appreciated. Contact us at edu@postgrespro.ru.

Queries in PostgreSQL: 7. Sort and merge
In the previous articles, covered query execution stages, statistics, sequential and index scan, and two of the three join methods: nested loop and hash join. This last article of the series will cover the merge algorithm and sorting. I will also demonstrate how the three join methods compare against each other.
Merge join
The merge join algorithm takes two data sets that are sorted by the merge key and returns an ordered output. The input data sets may be pre-sorted by an index scan or be sorted explicitly.
Merging sorted sets
Below is an example of a merge join. Note the Merge Join node in the plan.
...
PostgreSQL 14 Internals, Part III
I’m excited to announce that the translation of Part III of the “PostgreSQL 14 Internals” book is finished. This part is about a diverse world of locks, which includes a variety of heavyweight locks used for all kinds of purposes, several types of locks on memory structures, row locks which are not exactly locks, and even predicate locks which are not locks at all.
Please download the book freely in PDF. We have two more parts to come, so stay tuned!
Your comments are much appreciated. Contact us at edu@postgrespro.ru.
PostgreSQL 14 Internals, Part II
I’m pleased to announce that Part II of the “PostgreSQL 14 Internals” book is available now. This part explores the purpose and design of the buffer cache and explains the need for write-ahead logging.
Please download the book freely in PDF. There are three more parts to come, so stay tuned!
Thanks to Matthew Daniel who has spotted a blunder in typesetting of Part I. Your comments are much appreciated; write us to edu@postgrespro.ru.
So far we have covered query execution stages, statistics, sequential and index scan, and have moved on to joins.
The previous article focused on the nested loop join, and in this one I will explain the hash join. I will also briefly mention group-bys and distincs.
One-pass hash join
The hash join looks for matching pairs using a hash table, which has to be prepared in advance. Here's an example of a plan with a hash join:
EXPLAIN (costs off) SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Hash Join
Hash Cond: (tf.ticket_no = t.ticket_no)
−> Seq Scan on ticket_flights tf
−> Hash
−> Seq Scan on tickets t (5 rows)
First, the Hash Join node calls the Hash node. The Hash node fetches all the inner set rows from its child node and arranges them into a hash table.
A hash table stores data as hash key and value pairs. This makes key-value search time constant and unaffected by hash table size. A hash function distributes hash keys randomly and evenly across a limited number of buckets. The total number of buckets is always two to the power N, and the bucket number for a given hash key is the last N bits of its hash function result.
So, during the first stage, the hash join begins by scanning all the inner set rows. The hash value of each row is computed by applying a hash function to the join attributes (Hash Cond), and all the fields from the row required for the query are stored in a hash table.
...
PostgreSQL 14 Internals
This is a short note to inform that we are translating my book “PostgreSQL 14 Internals,” recently published in Russian. Liudmila Mantrova, who helped me a lot with the editing of the original, is working on the translation, too. My gratitude to her is beyond words.
The book is largely based on the articles I’ve published here and training courses my colleagues and I are developing. It dives deep into the problems of data consistency and isolation, explaining implementation details of multiversion concurrency control and snapshot isolation, buffer cache and write-ahead log, and then moves on to the twists and turns of the locking system. The book also covers the questions of planning and executing SQL queries, including the discussion of data access and join methods, statistics, and various index types.
The book is freely available in PDF. The translation is in progress, and for now only Part I of the book is ready. Other parts will follow soon, so stay tuned!
So far we've discussed query execution stages, statistics, and the two basic data access methods: Sequential scan and Index scan.
The next item on the list is join methods. This article will remind you what logical join types are out there, and then discuss one of three physical join methods, the Nested loop join. Additionally, we will check out the row memoization feature introduced in PostgreSQL 14.
Joins
Joins are the primary feature of SQL, the foundation that enables its power and agility. Sets of rows (whether pulled directly from a table or formed as a result of an operation) are always joined together in pairs. There are several types of joins.
...
In previous articles we discussed query execution stages and statistics. Last time, I started on data access methods, namely Sequential scan. Today we will cover Index Scan. This article requires a basic understanding of the index method interface. If words like "operator class" and "access method properties" don't ring a bell, check out my article on indexes from a while back for a refresher.
Plain Index Scan
Indexes return row version IDs (tuple IDs, or TIDs for short), which can be handled in one of two ways. The first one is Index scan. Most (but not all) index methods have the INDEX SCAN property and support this approach. The operation is represented in the plan with an Index Scan node
...
In previous articles we discussed how the system plans a query execution and how it collects statistics to select the best plan. The following articles, starting with this one, will focus on what a plan actually is, what it consists of and how it is executed.
In this article, I will demonstrate how the planner calculates execution costs. I will also discuss access methods and how they affect these costs, and use the sequential scan method as an illustration. Lastly, I will talk about parallel execution in PostgreSQL, how it works and when to use it.
I will use several seemingly complicated math formulas later in the article. You don't have to memorize any of them to get to the bottom of how the planner works; they are merely there to show where I get my numbers from.
Pluggable storage engines
The PostgreSQL's approach to storing data on disk will not be optimal for every possible type of load. Thankfully, you have options. Delivering on its promise of extensibility, PostgreSQL 12 and higher supports custom table access methods (storage engines), although it ships only with the stock one, heap:
...
Despite the ongoing tragic events, we continue the series. In the last article we reviewed the stages of query execution. Before we move on to plan node operations (data access and join methods), let's discuss the bread and butter of the cost optimizer: statistics.
As usual, I use the demo database for all my examples. You can download it and follow along.
You will see a lot of execution plans here today. We will discuss how the plans work in more detail in later articles. For now just pay attention to the numbers that you see in the first line of each plan, next to the word rows. These are row number estimates, or cardinality.
...
Hello! I'm kicking off another article series about the internals of PostgreSQL. This one will focus on query planning and execution mechanics.
This series will cover: query execution stages (this article), statistics, sequential and index scans, nested-loop, hash, and merge joins.
Many thanks to Alexander Meleshko for the translation of this series into English.
This article borrows from our course QPT Query Optimization (available in English soon), but focuses mostly on the internal mechanisms of query execution, leaving the optimization aspect aside. Please also note that this article series is written with PostgreSQL 14 in mind.
Simple query protocol
The fundamental purpose of the PostgreSQL client-server protocol is twofold: it sends SQL queries to the server, and it receives the entire execution result in response. The query received by the server for execution goes through several stages.
Parsing
First, the query text is parsed, so that the server understands exactly what needs to be done.
Lexer and parser. The lexer is responsible for recognizing lexemes in the query string (such as SQL keywords, string and numeric literals, etc.), and the parser makes sure that the resulting set of lexemes is grammatically valid. The parser and lexer are implemented using the standard tools Bison and Flex.
The parsed query is represented as an abstract syntax tree.
...
To remind you, we've already talked about relation-level locks, row-level locks, locks on other objects (including predicate locks) and interrelationships of different types of locks.
The following discussion of locks in RAM finishes this series of articles. We will consider spinlocks, lightweight locks and buffer pins, as well as events monitoring tools and sampling.
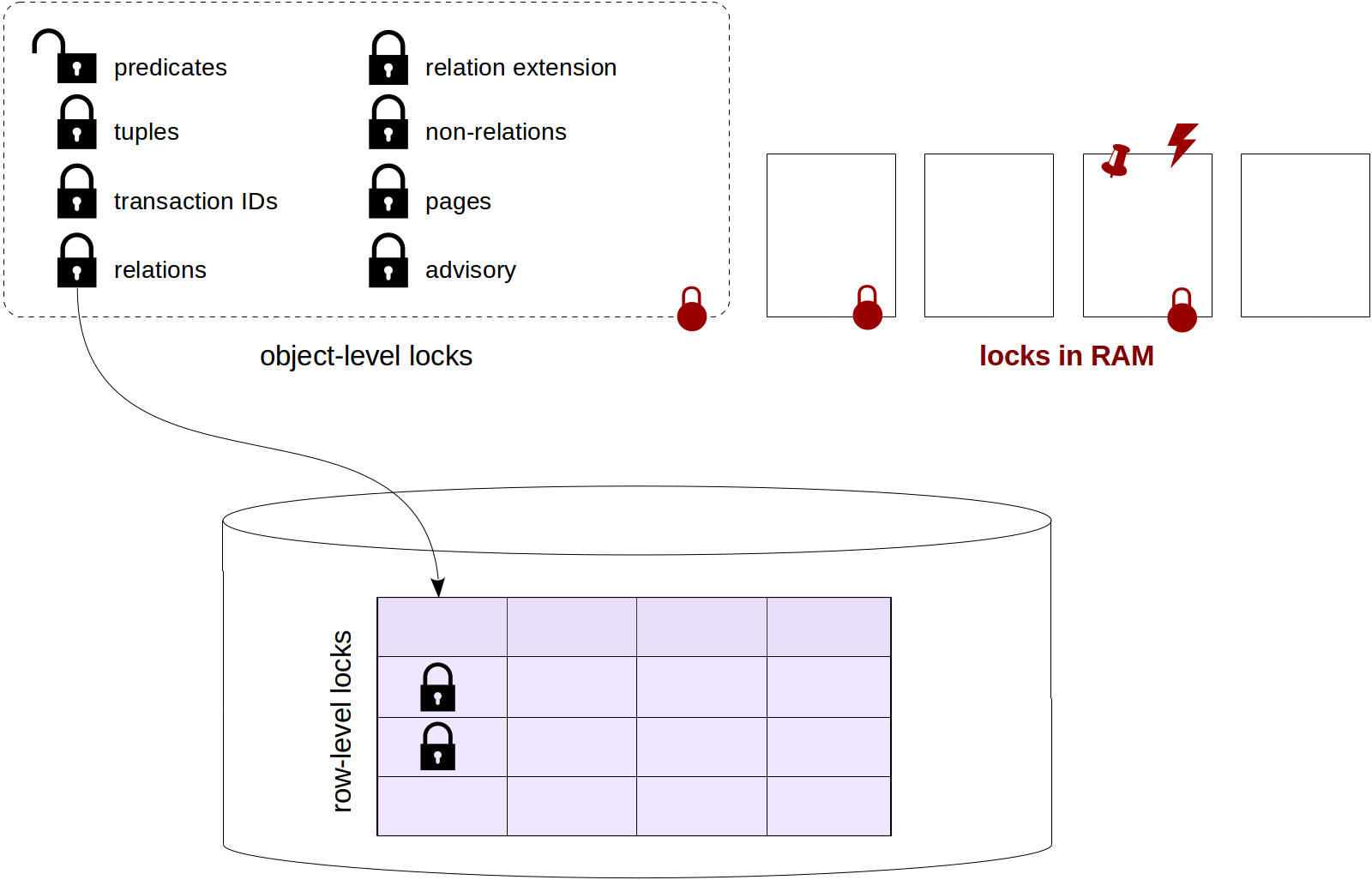
...