Locks in PostgreSQL: 2. Row-level locks
Last time, we discussed object-level locks and in particular relation-level locks. In this article, we will see how row-level locks are organized in PostgreSQL and how they are used together with object-level locks. We will also talk of wait queues and of those who jumps the queue.
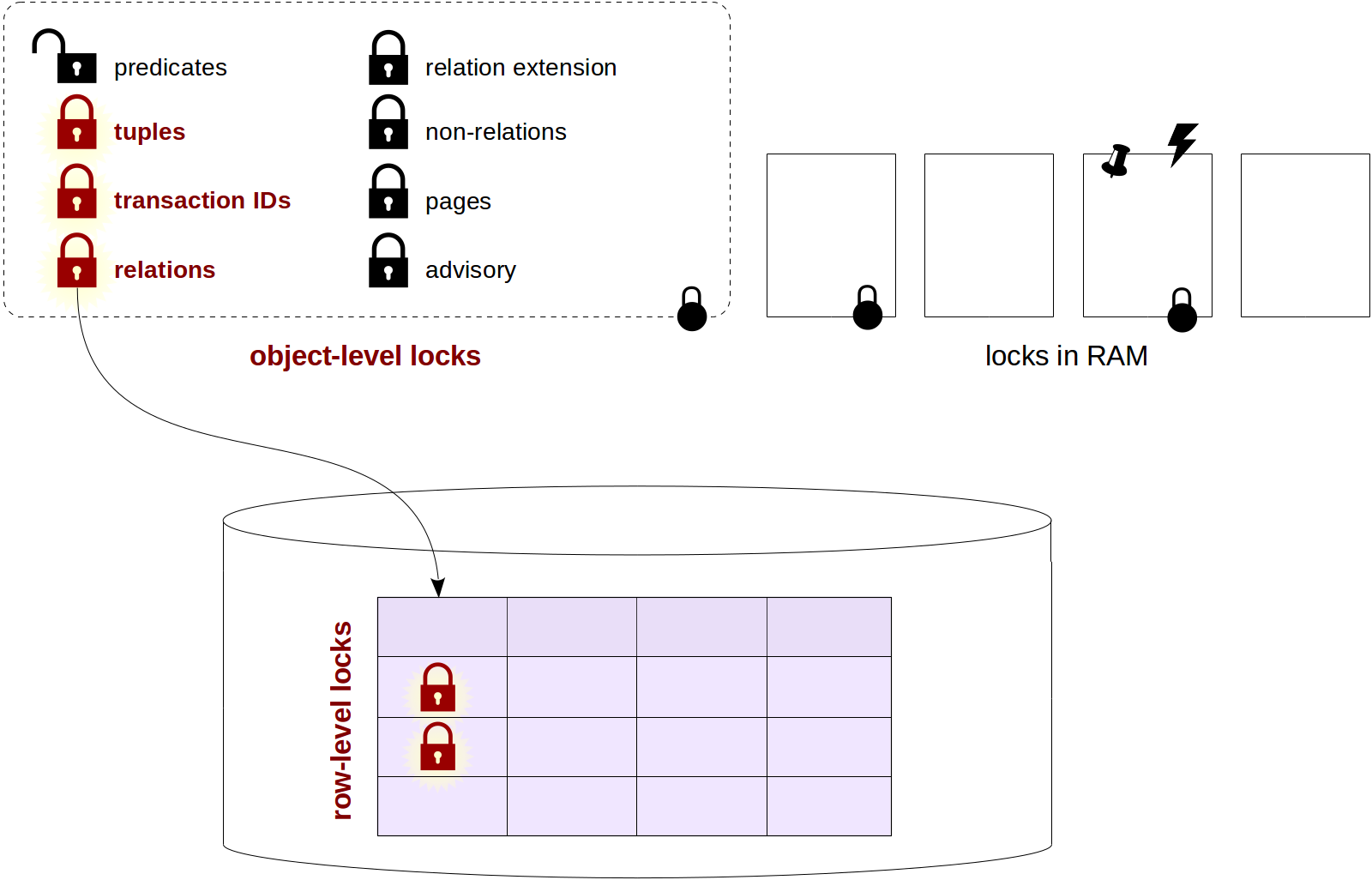
Row-level locks
Organization
Let's recall a few weighty conclusions of the previous article.
- A lock must be available somewhere in the shared memory of the server.
- The higher granularity of locks, the lower the contention among concurrent processes.
- On the other hand, the higher the granularity, the more of the memory is occupied by locks.
There is no doubt that we want a change of one row not block other rows of the same table. But we cannot afford to have its own lock for each row either.
There are different approaches to solving this problem. Some database management systems apply escalation of locks: if the number of row-level locks gets too high, they are replaced with one, more general lock (for example: a page-level or an entire table-level).
As we will see later, PostgreSQL also applies this technique, but only for predicate locks. The situation with row-level locks is different.
PostgreSQL stores information that a row is locked only and exclusively in the row version inside the data page (and not in RAM). It means that it is not a lock in a usual sense, but just some indicator. Actually, the ID of the xmax transaction, along with additional information bits, serves as the indicator; we will look at how this is organized in detail a little later.
A pro is that we can lock as many rows as we want without consuming any resources.
But there is also a con: since the information on the lock is not available in RAM, other processes cannot be queued. And monitoring is impossible either (to count the locks, all the table needs to be read).
Let alone monitoring, but something needs to be done for the queue. To this end, "normal" locks have yet to be used. If we need to wait for a row to be released, we actually need to wait until completion of the locking transaction: all locks are released at the transaction commit or roll back. And to this end, we can request a lock on the ID of the locking transaction (to remind you, the transaction itself holds this lock in an exclusive mode). So, the number of locks used is proportional to the number of simultaneously running processes rather than to the number of rows being updated.
Exclusive modes
There are 4 modes that allow locking a row. Two of them are exclusive locks, which only one transaction can hold at a time.
- FOR UPDATE mode assumes a total change (or delete) of a row.
- FOR NO KEY UPDATE mode assumes a change only to the fields that are not involved in unique indexes (in other words, this change does not affect foreign keys).
The UPDATE command itself selects the minimum appropriate locking mode; rows are usually locked in the FOR NO KEY UPDATE mode.
As you remember, when a row is updated or deleted, the ID of the current transaction is written to the xmax field of the current up-to-date version. This ID shows that the transaction deleted the tuple. And this very number xmax is used to indicate a lock. Indeed, if xmax in a tuple matches an active (not yet completed) transaction and we want to update this very row, we need to wait until the transaction completes, and no additional indicator is needed.
Let's take a look. And let's create a table of accounts, same as in the last article.
=> CREATE TABLE accounts(
acc_no integer PRIMARY KEY,
amount numeric
);
=> INSERT INTO accounts
VALUES (1, 100.00), (2, 200.00), (3, 300.00);
To look into pages, we need a pretty familiar pageinspect extension.
=> CREATE EXTENSION pageinspect;
For convenience, we will create a view that shows only the information of interest: xmax and some information bits.
=> CREATE VIEW accounts_v AS
SELECT '(0,'||lp||')' AS ctid,
t_xmax as xmax,
CASE WHEN (t_infomask & 128) > 0 THEN 't' END AS lock_only,
CASE WHEN (t_infomask & 4096) > 0 THEN 't' END AS is_multi,
CASE WHEN (t_infomask2 & 8192) > 0 THEN 't' END AS keys_upd,
CASE WHEN (t_infomask & 16) > 0 THEN 't' END AS keyshr_lock,
CASE WHEN (t_infomask & 16+64) = 16+64 THEN 't' END AS shr_lock
FROM heap_page_items(get_raw_page('accounts',0))
ORDER BY lp;
So, we start a transaction and update the amount in the first account (the key is unchanged) and the number of the second account (the key is changed):
=> BEGIN;
=> UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
=> UPDATE accounts SET acc_no = 20 WHERE acc_no = 2;
Let's look into the view:
=> SELECT * FROM accounts_v LIMIT 2;
ctid | xmax | lock_only | is_multi | keys_upd | keyshr_lock | shr_lock
-------+--------+-----------+----------+----------+-------------+----------
(0,1) | 530492 | | | | |
(0,2) | 530492 | | | t | |
(2 rows)
The keys_updated information bit determines the lock mode.
The same xmax field is involved in locking of a row by the SELECT FOR UPDATE command, but in this case, an additional information bit (xmax_lock_only) is set, which tells us that the tuple is only locked, but not deleted and is still live.
=> ROLLBACK;
=> BEGIN;
=> SELECT * FROM accounts WHERE acc_no = 1 FOR NO KEY UPDATE;
=> SELECT * FROM accounts WHERE acc_no = 2 FOR UPDATE;
=> SELECT * FROM accounts_v LIMIT 2;
ctid | xmax | lock_only | is_multi | keys_upd | keyshr_lock | shr_lock
-------+--------+-----------+----------+----------+-------------+----------
(0,1) | 530493 | t | | | |
(0,2) | 530493 | t | | t | |
(2 rows)
=> ROLLBACK;
Shared modes
Two more modes represent shared locks, which several transactions can be holding.
- FOR SHARE mode is used when we need to read a row, but no other transaction is permitted to change it.
- FOR KEY SHARE mode permits a change of a row, but only in its non-key fields. In particular, PostgreSQL automatically uses this mode when checking foreign keys.
Let's take a look.
=> BEGIN;
=> SELECT * FROM accounts WHERE acc_no = 1 FOR KEY SHARE;
=> SELECT * FROM accounts WHERE acc_no = 2 FOR SHARE;
In the tuples, we see:
=> SELECT * FROM accounts_v LIMIT 2;
ctid | xmax | lock_only | is_multi | keys_upd | keyshr_lock | shr_lock
-------+--------+-----------+----------+----------+-------------+----------
(0,1) | 530494 | t | | | t |
(0,2) | 530494 | t | | | t | t
(2 rows)
In both cases, the keyshr_lock bit is set, and the SHARE mode can be recognized by looking into one more information bit.
This is what the general matrix of modes compatibility looks like.
| Mode | FOR KEY SHARE | FOR SHARE | FOR NO KEY UPDATE | FOR UPDATE |
| FOR KEY SHARE | Х | |||
| FOR SHARE | Х | Х | ||
| FOR NO KEY UPDATE | Х | Х | Х | |
| FOR UPDATE | Х | Х | Х | Х |
From the matrix, it is clear that:
- Exclusive modes conflict each other.
- Shared modes are compatible with one another.
- The shared mode FOR KEY SHARE is compatible with the exclusive mode FOR NO KEY UPDATE (that is, we can update non-key fields simultaneously and be sure that the key won't change).
Multitransactions
Up to here, we considered the ID of the locking transaction in the xmax field to represent a lock. But shared locks can be held by multiple transactions, while we cannot write several IDs to one xmax field. What shall we do?
So-called multitransactions (MultiXact) are used for shared locks. This is a group of transactions to which a separate ID is assigned. This ID has the same bit depth as a normal transaction ID, but the IDs are assigned independently (that is, a system can have equal IDs of a transaction and multitransaction). To differentiate them, another information bit is used (xmax_is_multi), and detailed information on the participants of this group and locking modes is stored in files of the $PGDATA/pg_multixact/ directory. Naturally, the last used data are stored in buffers of the shared memory of the server for faster access.
Apart from existing locks, let's add one more exclusive lock, held by another transaction (we can do this since FOR KEY SHARE and FOR NO KEY UPDATE modes are compatible with each other):
| => BEGIN;
| => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
=> SELECT * FROM accounts_v LIMIT 2;
ctid | xmax | lock_only | is_multi | keys_upd | keyshr_lock | shr_lock
-------+--------+-----------+----------+----------+-------------+----------
(0,1) | 61 | | t | | |
(0,2) | 530494 | t | | | t | t
(2 rows)
In the first line, we see that the normal ID is replaced with the multitransaction ID — the xmax_is_multi bit indicates this.
To avoid exploring the internals of the multitransaction implementation, we can use one more extension, which allows us to get all the information on all types of locks in a user-friendly format.
=> CREATE EXTENSION pgrowlocks;
=> SELECT * FROM pgrowlocks('accounts') \gx
-[ RECORD 1 ]-----------------------------
locked_row | (0,1)
locker | 61
multi | t
xids | {530494,530495}
modes | {"Key Share","No Key Update"}
pids | {5892,5928}
-[ RECORD 2 ]-----------------------------
locked_row | (0,2)
locker | 530494
multi | f
xids | {530494}
modes | {"For Share"}
pids | {5892}
=> COMMIT;
| => ROLLBACK;
Setup of freezing
Since separate IDs are assigned to multitransactions, which are written to the xmax field of tuples, and because of the limitation on the bit depth of the IDs, the same xid wraparound issue can arise for them as for normal IDs.
Therefore, for multitransaction IDs, it is needed to perform something similar to freezing, that is, replace old IDs with new ones (or with a normal transaction ID if at the time of freezing, the lock is held by only one transaction).
Note that freezing of normal transaction IDs is performed only for the xmin field (since if a tuple has a non-empty xmax field, this is either a dead tuple, which will be vacuumed away, or the xmax transaction is rolled back and its ID is of no interest to us). But for multitransactions, this involves the xmax field of the live tuple, which can remain live, but be continuously locked by different transactions in the shared mode.
The parameters that are responsible for freezing multitransactions are similar to those of normal transactions: vacuum_multixact_freeze_min_age, vacuum_multixact_freeze_table_age, autovacuum_multixact_freeze_max_age.
Where is the end of the queue?
Gradually approaching the sweet. Let's see what picture of locks arises when several transactions are going to update the same row.
We'll start with creating a view over pg_locks. First, we'll make the output more compact, second, we'll consider only interesting locks (actually, we drop locks on the following: virtual transaction IDs, the index on the accounts table, pg_locks, and the view itself — in short, everything that is irrelevant and only distracts attention).
=> CREATE VIEW locks_v AS
SELECT pid,
locktype,
CASE locktype
WHEN 'relation' THEN relation::regclass::text
WHEN 'transactionid' THEN transactionid::text
WHEN 'tuple' THEN relation::regclass::text||':'||tuple::text
END AS lockid,
mode,
granted
FROM pg_locks
WHERE locktype in ('relation','transactionid','tuple')
AND (locktype != 'relation' OR relation = 'accounts'::regclass);
Now let's start the first transaction and update a row.
=> BEGIN;
=> SELECT txid_current(), pg_backend_pid();
txid_current | pg_backend_pid
--------------+----------------
530497 | 5892
(1 row)
=> UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
UPDATE 1
What's going on with locks?
=> SELECT * FROM locks_v WHERE pid = 5892;
pid | locktype | lockid | mode | granted
------+---------------+----------+------------------+---------
5892 | relation | accounts | RowExclusiveLock | t
5892 | transactionid | 530497 | ExclusiveLock | t
(2 rows)
The transaction holds the locks on its own ID and on the table. Everything is as expected so far.
Starting the second transaction and trying to update the same row.
| => BEGIN;
| => SELECT txid_current(), pg_backend_pid();
| txid_current | pg_backend_pid
| --------------+----------------
| 530498 | 5928
| (1 row)
| => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
What's going on with locks held by the second transaction?
=> SELECT * FROM locks_v WHERE pid = 5928;
pid | locktype | lockid | mode | granted
------+---------------+------------+------------------+---------
5928 | relation | accounts | RowExclusiveLock | t
5928 | transactionid | 530498 | ExclusiveLock | t
5928 | transactionid | 530497 | ShareLock | f
5928 | tuple | accounts:1 | ExclusiveLock | t
(4 rows)
It appears more interesting here. In addition to locks on the transaction's own ID and the table, we can see two more locks. The second transaction discovered that the row was locked by the first one and "hanged" waiting for its ID (granted = f). But where does the tuple lock (locktype = tuple) come from and what for?
Avoid confusing a tuple lock with a row lock. The first one is a regular lock of thetupletype, which is visible inpg_locks. But the second one is an indicator in the data page:xmaxand information bits.
When a transaction is going to change a row, it performs the following sequence of steps:
- Acquires an exclusive lock on the tuple to be updated.
- If
xmaxand information bits show that the row is locked, requests a lock on thexmaxtransaction ID. - Writes its own
xmaxand sets the required information bits. - Releases the tuple lock.
When the first transaction was updating the row, it also acquired a tuple lock (step 1), but immediately released it (step 4).
When the second transaction arrived, it acquired a tuple lock (step 1), but had to request a lock on the ID of the first transaction (step 2) and hanged ding this.
What will happen if the third similar transaction appears? It will try to acquire a tuple lock (step 1) and will hang as early as at this step. Let's check.
|| => BEGIN;
|| => SELECT txid_current(), pg_backend_pid();
|| txid_current | pg_backend_pid
|| --------------+----------------
|| 530499 | 5964
|| (1 row)
|| => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
=> SELECT * FROM locks_v WHERE pid = 5964;
pid | locktype | lockid | mode | granted
------+---------------+------------+------------------+---------
5964 | relation | accounts | RowExclusiveLock | t
5964 | tuple | accounts:1 | ExclusiveLock | f
5964 | transactionid | 530499 | ExclusiveLock | t
(3 rows)
Transactions four, five and others that try to update the same row will be no different from transaction three: all of them will be "hanging" on the same tuple lock.
To top it off, let's add one more transaction.
||| => BEGIN;
||| => SELECT txid_current(), pg_backend_pid();
||| txid_current | pg_backend_pid
||| --------------+----------------
||| 530500 | 6000
||| (1 row)
||| => UPDATE accounts SET amount = amount - 100.00 WHERE acc_no = 1;
=> SELECT * FROM locks_v WHERE pid = 6000;
pid | locktype | lockid | mode | granted
------+---------------+------------+------------------+---------
6000 | relation | accounts | RowExclusiveLock | t
6000 | transactionid | 530500 | ExclusiveLock | t
6000 | tuple | accounts:1 | ExclusiveLock | f
(3 rows)
We can see an integral picture of current waits in the pg_stat_activity view by adding information on the locking processes:
=> SELECT pid, wait_event_type, wait_event, pg_blocking_pids(pid)
FROM pg_stat_activity
WHERE backend_type = 'client backend';
pid | wait_event_type | wait_event | pg_blocking_pids
------+-----------------+---------------+------------------
5892 | | | {}
5928 | Lock | transactionid | {5892}
5964 | Lock | tuple | {5928}
6000 | Lock | tuple | {5928,5964}
(4 rows)
Sort of a "queue" arises here, with the first one (who holds the tuple lock) and the rest, queued up behind the first one.
What is this sophisticated structure needed for? Assume we did not have the tuple lock. Then the second, third (and next) transactions would wait for the lock on the ID of the first transaction. At the time of completion of the first transaction, the locked resource disappears, and what happens next depends on which of the waiting processes will be first waked up by the OS and therefore, will manage to lock the row. The rest of the processes will also be waked up, but will have to wait in a queue again, but behind another process now.
This is fraught with an issue: one of the transactions may wait its turn infinitely long if due to an unfortunate coincidence, other transactions persistently "overtake" it. This situation is called "lock starvation".
In our example, we confront something similar, but a little better though: the transaction that arrived second is guaranteed to be the next to get access to the resource. But what happens to the next transactions (third and so on)?
If the first transaction completes with a roll back, everything will be fine: the transactions that arrived will go in the same order as they are queued.
But — bad luck — if the first transaction completes with a commit, not only the transaction ID disappears, but also the tuple! I mean that the tuple is still in place, but it is no longer live, and quite a different, latest, version (of the same row) will need to be updated. The resource which the transactions were queueing up for no longer exists, and they start a race for the new resource.
Let the first transaction complete with a commit.
=> COMMIT;
The second transaction will be waked up and will perform steps 3 and 4.
| UPDATE 1
=> SELECT * FROM locks_v WHERE pid = 5928;
pid | locktype | lockid | mode | granted
------+---------------+----------+------------------+---------
5928 | relation | accounts | RowExclusiveLock | t
5928 | transactionid | 530498 | ExclusiveLock | t
(2 rows)
And what happens to the third transaction? It skips step 1 (since the resource is no longer available) and gets stuck on step 2:
=> SELECT * FROM locks_v WHERE pid = 5964;
pid | locktype | lockid | mode | granted
------+---------------+----------+------------------+---------
5964 | relation | accounts | RowExclusiveLock | t
5964 | transactionid | 530498 | ShareLock | f
5964 | transactionid | 530499 | ExclusiveLock | t
(3 rows)
The same happens to the fourth transaction:
=> SELECT * FROM locks_v WHERE pid = 6000;
pid | locktype | lockid | mode | granted
------+---------------+----------+------------------+---------
6000 | relation | accounts | RowExclusiveLock | t
6000 | transactionid | 530498 | ShareLock | f
6000 | transactionid | 530500 | ExclusiveLock | t
(3 rows)
That is, the third and fourth transactions are waiting for completion of the second one. The queue turned into a pumpkin crowd.
Completing all the started transactions.
| => COMMIT;
|| UPDATE 1
|| => COMMIT;
||| UPDATE 1
||| => COMMIT;
You can find more details of locking table rows in README.tuplock.
It's not your turn
So, the idea behind two-level locking is to reduce the probability of lock starvation for an "unlucky" transaction. Nevertheless, as we've already seen, this situation is not unlikely. And if an application uses shared locks, everything can be even more sad.
Let the first transaction lock a row in a shared mode.
=> BEGIN;
=> SELECT txid_current(), pg_backend_pid();
txid_current | pg_backend_pid
--------------+----------------
530501 | 5892
(1 row)
=> SELECT * FROM accounts WHERE acc_no = 1 FOR SHARE;
acc_no | amount
--------+--------
1 | 100.00
(1 row)
The second transaction tries to update the same row, but cannot: SHARE and NO KEY UPDATE modes are incompatible.
| => BEGIN;
| => SELECT txid_current(), pg_backend_pid();
| txid_current | pg_backend_pid
| --------------+----------------
| 530502 | 5928
| (1 row)
| => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
The second transaction waits for completion of the first one and holds the tuple lock — everything is the same as last time, so far.
=> SELECT * FROM locks_v WHERE pid = 5928;
pid | locktype | lockid | mode | granted
------+---------------+-------------+------------------+---------
5928 | relation | accounts | RowExclusiveLock | t
5928 | tuple | accounts:10 | ExclusiveLock | t
5928 | transactionid | 530501 | ShareLock | f
5928 | transactionid | 530502 | ExclusiveLock | t
(4 rows)
And here the third transaction shows up, which wants a shared lock. The trouble is that it does not attempt to acquire a tuple lock (since it does not want to change the row), but simply jumps the queue since the needed lock is compatible with the lock held by the first transaction.
|| BEGIN
|| => SELECT txid_current(), pg_backend_pid();
|| txid_current | pg_backend_pid
|| --------------+----------------
|| 530503 | 5964
|| (1 row)
|| => SELECT * FROM accounts WHERE acc_no = 1 FOR SHARE;
|| acc_no | amount
|| --------+--------
|| 1 | 100.00
|| (1 row)
And now two transactions lock the row:
=> SELECT * FROM pgrowlocks('accounts') \gx
-[ RECORD 1 ]---------------
locked_row | (0,10)
locker | 62
multi | t
xids | {530501,530503}
modes | {Share,Share}
pids | {5892,5964}
But what will happen now when the first transaction completes? The second transaction will be waked up, but will see that the row lock is still there and will "queue", this time, behind the third transaction:
=> COMMIT;
=> SELECT * FROM locks_v WHERE pid = 5928;
pid | locktype | lockid | mode | granted
------+---------------+-------------+------------------+---------
5928 | relation | accounts | RowExclusiveLock | t
5928 | tuple | accounts:10 | ExclusiveLock | t
5928 | transactionid | 530503 | ShareLock | f
5928 | transactionid | 530502 | ExclusiveLock | t
(4 rows)
And it's only when the third transaction completes (and if no other shared locks occur during that time), the second one will be able to perform the update.
|| => COMMIT;
| UPDATE 1
| => ROLLBACK;
It seems like it's time to make some practical conclusions.
- Simultaneous updates of the same table row in multiple concurrent processes is hardly the best idea.
- If you opt for using SHARE locks in an application, do this cautiously.
- A check of foreign keys can hardly hinder since foreign keys do not usually change and KEY SHARE and NO KEY UPDATE modes are compatible.
You are kindly asked not to queue
Usually SQL commands wait until resources they need get free. But sometimes we want to refrain from execution of the command if the lock cannot be acquired immediately. To this end, such commands as SELECT, LOCK and ALTER permit the NOWAIT clause.
For example:
=> BEGIN;
=> UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
| => SELECT * FROM accounts FOR UPDATE NOWAIT;
| ERROR: could not obtain lock on row in relation "accounts"
The command terminates with an error if the resource appears to be in use. Application code can catch and handle an error like this.
We cannot provide the NOWAIT clause for the UPDATE и DELETE commands, but we can first execute SELECT FOR UPDATE NOWAIT and then in the case of success, update or delete the row.
One more option to aviod waiting is to use the SELECT FOR command with the SKIP LOCKED clause. This command will skip locked rows, but process those that are free.
| => BEGIN;
| => DECLARE c CURSOR FOR
| SELECT * FROM accounts ORDER BY acc_no FOR UPDATE SKIP LOCKED;
| => FETCH c;
| acc_no | amount
| --------+--------
| 2 | 200.00
| (1 row)
In the above example, the first, locked, row was skipped and we immediately accessed (and locked) the second one.
In practice, this allows us to set up multithreaded processing of queues. It makes no sense to think of other use cases for this command — if you want to use it, you most likely missed a simpler solution.
=> ROLLBACK;
| => ROLLBACK;