Locks in PostgreSQL: 1. Relation-level locks
The previous two series of articles covered isolation and multiversion concurrency control and logging.
In this series, we will discuss locks.
This series will consist of four articles:
- Relation-level locks (this article).
- Row-level locks.
- Locks on other objects and predicate locks.
- Locks in RAM.
The material of all the articles is based on training courses on administration that Pavel Luzanov and I are creating (see the "Training courses" section of our website), but does not repeat them verbatim and is intended for careful reading and self-experimenting.
Many thanks to Elena Indrupskaya for the translation of these articles into English.
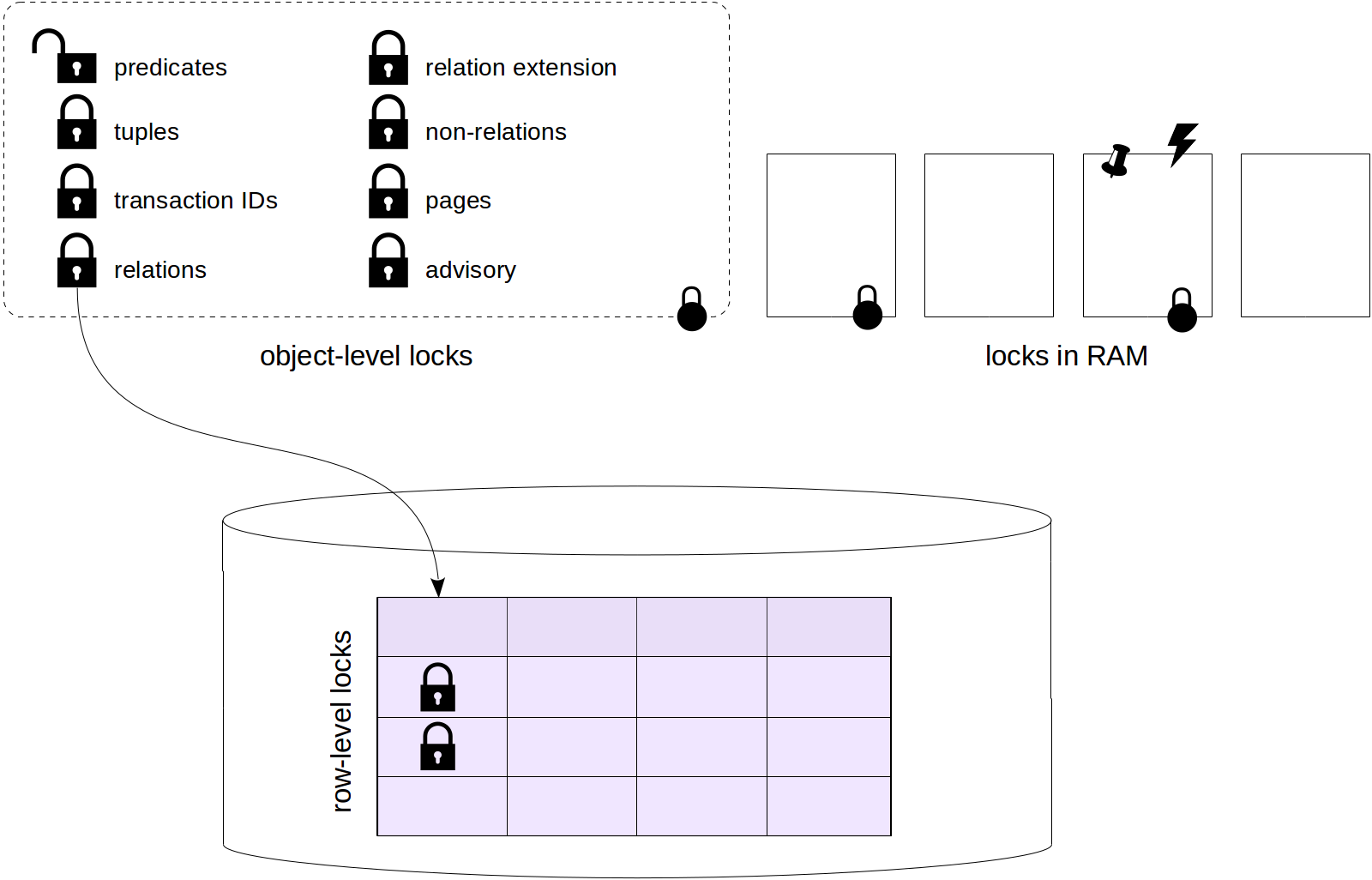
General information on locks
PostgreSQL has a wide variety of techniques that serve to lock something (or are at least called so). Therefore, I will first explain in the most general terms why locks are needed at all, what kinds of them are available and how they differ from one another. Then we will figure out what of this variety is used in PostgreSQL and only after that we will start discussing different kinds of locks in detail.
Locking is used to order concurrent access to shared resources.
By concurrent access, simultaneous access of several processes is meant. These processes themselves can run either in parallel (if the hardware permits) or sequentially in a time-sharing mode — it makes no difference.
Without concurrency, no locking is needed (for example: the shared buffer cache requires locking, while a local one does not).
Before accessing a resource, a process must acquire the lock associated with this resource. So this is a matter of certain discipline: everything works fine while processes conform to established rules of access to a shared resource. If a DBMS controls locking, it maintains order on its own; but if an application sets locks, the responsibility falls on it.
At a low level, a lock is an area in the shared memory with some indication of whether the lock is released or acquired (and maybe some additional information): the process number, acquisition time and so forth).
Note that this area in the shared memory itself is a resource that allows concurrent access. If we descend yet to a lower level, we will see that to regulate access, OS provides specialized synchronization primitives (such as semaphores or mutexes). Their purpose is to ensure that code accessing a shared resource is used only in one process. At the lowest level, these primitives are implemented through atomic processor instructions (such astest-and-setorcompare-and-swap).
When a resource is no longer needed to a process, the latter releases the lock so that other processes can use it.
Certainly, sometimes a lock cannot be acquired: the resource can be already in use by someone else. Then the process either stands in a wait queue (if the locking technique permits this) or repeats an attempt to acquire the lock some time later. Anyway, the process has to be idle in a wait for the resource to be free.
Sometimes, other, non-blocking, strategies can be used. For example: multiversion concurrency control in certain cases, allows several processes to work simultaneously with different versions of data without blocking one another.
In general, by the resource to be protected we mean anything that we can unambiguously identify and associate the lock address with it.
For example: a DBMS object such as a data page (identified by the filename and location inside the file), table (OID in the system catalog), or table row (the page and offset inside it) can be a resource. A memory structure such as a hash table, buffer and so forth (identified by a previously assigned number) can also be a resource. Sometimes it is even convenient to use abstract resources, which have no physical meaning (identified just by a unique number).
Many factors affect the efficiency of locking, of which we give prominence to two.
The granularity is critical when the resources are organized in a hierarchy.
For example: a table consists of pages, which contain table rows. All these objects can be resources. If processes are interested only in a few rows, but a lock is acquired at the table level, other processes will be unable to simultaneously work with different rows. Therefore, the higher the granularity, the better for enabling parallelization.
But this causes increase of the number of locks (for which the information needs to be stored in memory). In this case, escalation of locks can be applied: when the number of low-level high-granularity locks exceeds a certain limit, they are replaced with one higher-level lock.
Locks can be acquired in various modes.
The names of the modes can be any; what really matters is the matrix of their compatibility with each other. The mode that is incompatible with any mode (including itself) is usually called exclusive. If modes are compatible, several processes can acquire a lock simultaneously; modes like these are called shared. In general, the more modes compatible with each other can be distinguished, the more opportunities for concurrency occur.
By the duration, locks can be divided into long and short.
Long locks are acquired for a potentially long time (usually up to the end of the transaction) and most often relate to such resources as tables (relations) and rows. As a rule, PostgreSQL controls these locks automatically, but a user, however, has certain control over this process.
A large number of modes is typical of long locks to enable as many simultaneous data operations as possible. Usually an extensive infrastructure (for example: support of wait queues and detection of deadlocks) and monitoring tools are available for such locks since the maintenance cost of all these convenient features is anyway incomparably less than the cost of operations over data being protected.
Short locks are acquired for a short time (from a few processor instructions to fractions of seconds) and usually relate to data structures in the shared memory. PostgreSQL controls such locks in a fully automatic fashion — you only need to be aware of their existence.
The minimum of modes (exclusive and shared) and a simple infrastructure are typical of short locks. Sometimes there can even be no monitoring tools.
PostgreSQL uses different kinds of locks.
Object-level locks pertain to long, "heavy-weight" locking. Relations and other objects are resources here. If in this article you come across the word "lock" or "locking" without clarification, it means just this, "normal" locking.
Among long locks, row-level locks stand out separately. They are implemented differently from other long locks because they are potentially huge in number (imagine an update of a million of rows in one transaction). We will discuss these locks in the next article.
The third article of the series will cover the remaining object-level locks, as well as predicate locks (since the information on all these locks is uniformly stored in RAM).
Short locks comprise various locks on RAM structures. We will discuss them in the last article of the series.
Object-level locks
So, we are starting with object-level locks. By an object here we primarily mean relations, that is, tables, indexes, sequences and materialized views, but also some other entities. These locks are normally used to protect objects against simultaneous changes or against use when the object is being changed, but also for other needs.
The wording is vague, isn't it? Exactly so, since locks in this group are used for various purposes. The only thing that unites them is how they are organized.
Organization
Object locks are stored in the shared memory of the server. The number of them is limited by the product of two parameter values: max_locks_per_transaction × max_connections.
The pool of locks is one for all transactions, that is, a transaction can acquire more locks than max_locks_per_transaction: the only important thing is that the total number of locks in the system does not exceed the number specified. The pool is created at startup, so to change any of the two above parameters a server restart is required.
You can see all the locks in the pg_locks view.
If a resource is already locked in an incompatible mode, the transaction that tries to acquire the lock is queued to wait until the lock is released. Waiting transactions do not consume processor resources: backend processes involved "fall asleep" and are waked up by the OS when the resource gets free.
When to continue the work, one transaction needs a resource that is in use by another transaction, while the second one needs a resource that is in use by the first, a deadlock occurs. In general, a deadlock of more than two transactions can arise. In such a case, the wait will last infinitely, therefore, PostgreSQL detects such situations automatically and aborts one of the transactions to enable the others continue. (We will discuss deadlocks in detail in the next article.)
Object types
The following is a list of lock types (or, if you like, object types) that we will deal with in this and next articles. The names are provided according to the locktype column of the pg_locks view.
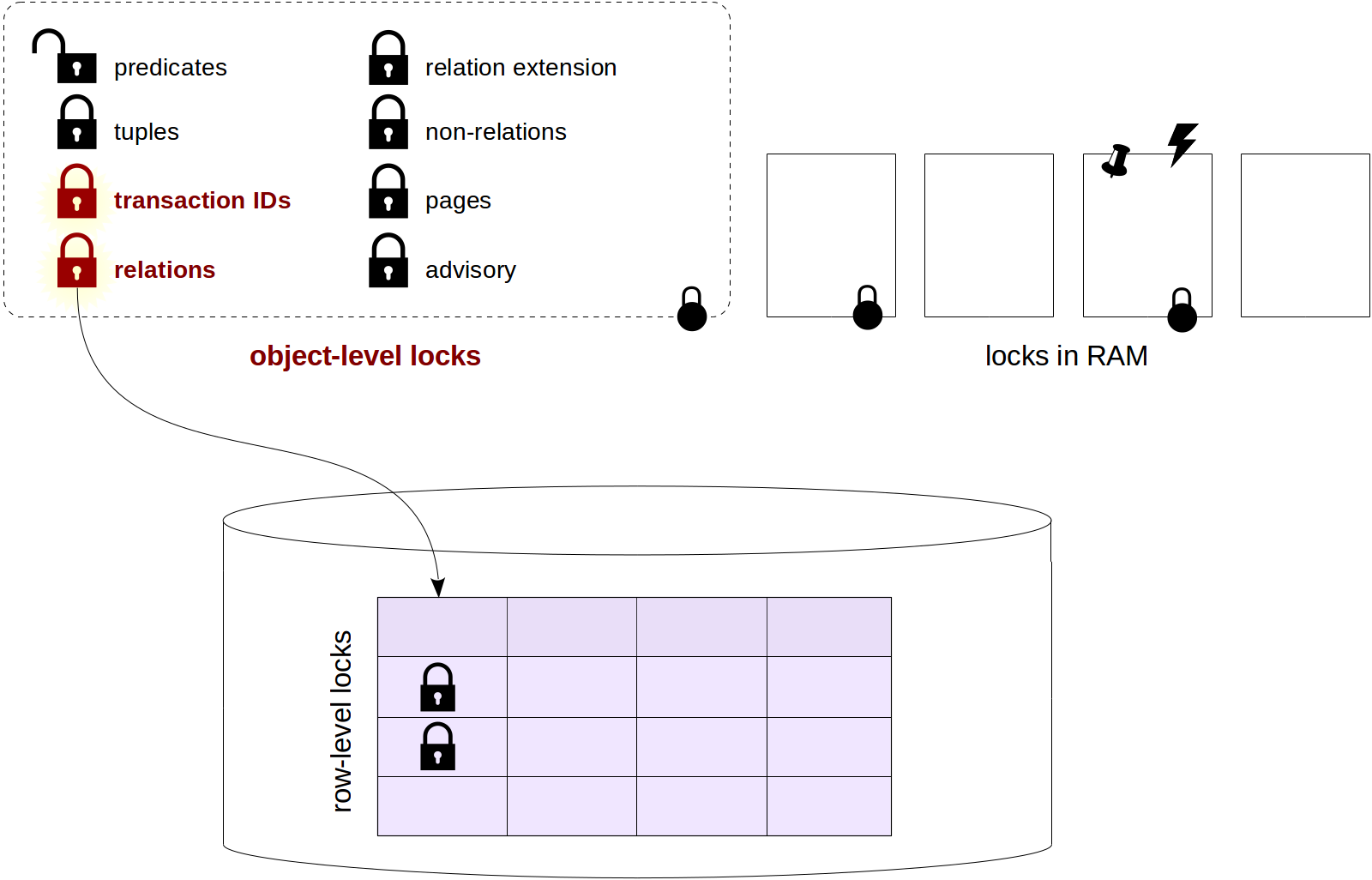
relation
Locks on relations.
transactionid и virtualxid
Locks on the transaction ID (actual or virtual). Each transaction itself holds an exclusive lock on its own ID, therefore, such locks are convenient to use when we need to wait until completion of another transaction.
tuple
Locks on a tuple. Used in some instances to prioritize several transactions waiting for a lock on the same row.
We will put off a talk on other types of locks until the third article of this series. All of them are acquired either in the exclusive or in the share/exclusive mode.
extend
Used when adding pages to a file of some relation.
object
Locks on objects different from relations (databases, schemas, subscriptions and so forth).
page
Locks on a page — used infrequently and only by certain types of indexes.
advisory
Advisory locks — a user has them acquired manually.
Relation-level locks
In order not to fall out of context, in a figure like this, I will mark those types of locks that will be discussed further.
Modes
Unless a relation-level lock is the most important among locks, it is mostly rich in modes for sure. As many as 8 different modes are defined for it. That many are needed to enable simultaneous execution of the maximum possible number of commands related to one table.
There is no point in committing these modes to your memory or trying to get an insight into their names; what is really important is to have near at hand the matrix that shows which locks conflict each other. For convenience, it is provided here along with examples of commands that require the corresponding levels of locking:
| Locking mode | AS | RS | RE | SUE | S | SRE | E | AE | Example of SQL commands |
| Access Share | X | SELECT | |||||||
| Row Share | X | X | SELECT FOR UPDATE/SHARE | ||||||
| Row Exclusive | X | X | X | X | INSERT, UPDATE, DELETE | ||||
| Share Update Exclusive | X | X | X | X | X | VACUUM, ALTER TABLE*, СREATE INDEX CONCURRENTLY | |||
| Share | X | X | X | X | X | CREATE INDEX | |||
| Share Row Exclusive | X | X | X | X | X | X | CREATE TRIGGER, ALTER TABLE* | ||
| Exclusive | X | X | X | X | X | X | X | REFRESH MAT. VIEW CONCURRENTLY | |
| Access Exclusive | X | X | X | X | X | X | X | X | DROP, TRUNCATE, VACUUM FULL, LOCK TABLE, ALTER TABLE*, REFRESH MAT. VIEW |
A few comments:
- First 4 modes allow concurrent changes of the table data, while the next 4 do not.
- The first mode (Access Share) is the weakest, it is compatible with any other but the last (Access Exclusive). This last mode is exclusive, it is incompatible with any other.
- The ALTER TABLE command has many flavors, and different flavors require different-level locks. Therefore, this command occurs in different rows of the matrix and is marked with an asterisk.
To illustrate
Let's consider an example. What happens if we execute the CREATE INDEX command?
We learn from the documentation that this command acquires a Share lock. From the matrix, we learn that the command is compatible with itself (that is, several indexes can be created simultaneously) and with read commands. So, SELECT command will continue working, while UPDATE, DELETE and INSERT will be blocked.
And vice versa: non-completed transactions that change table data will block execution of the CREATE INDEX command. It's for this reason that the CREATE INDEX CONCURRENTLY flavor of the command is available. Its execution takes longer (and it can even fail with an error), but it allows concurrent data updates.
You can make sure of this in practice. For experiments we will use the table of "bank" accounts, which is familiar to us since the first series and in which will store the account number and amount.
=> CREATE TABLE accounts(
acc_no integer PRIMARY KEY,
amount numeric
);
=> INSERT INTO accounts
VALUES (1,1000.00), (2,2000.00), (3,3000.00);
In the second session, we'll start a transaction. We will need the process ID of the backend process.
| => SELECT pg_backend_pid();
| pg_backend_pid
| ----------------
| 4746
| (1 row)
What locks does the transaction that just started hold? Looking into pg_locks:
=> SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted
FROM pg_locks WHERE pid = 4746;
locktype | relation | virtxid | xid | mode | granted
------------+----------+---------+-----+---------------+---------
virtualxid | | 5/15 | | ExclusiveLock | t
(1 row)
As I said before, a transaction always holds an Exclusive lock on its own ID, which is virtual in this case. This process has no other locks.
Now let's update a table row. How will the situation change?
| => UPDATE accounts SET amount = amount + 100 WHERE acc_no = 1;
=> \g
locktype | relation | virtxid | xid | mode | granted
---------------+---------------+---------+--------+------------------+---------
relation | accounts_pkey | | | RowExclusiveLock | t
relation | accounts | | | RowExclusiveLock | t
virtualxid | | 5/15 | | ExclusiveLock | t
transactionid | | | 529404 | ExclusiveLock | t
(4 rows)
Locks on the table being changed and on the index (created for the primary key) being used by the UPDATE command appeared. Both locks acquired are Row Exclusive. Besides, an exclusive lock on the actual transaction ID was added (the ID appeared as soon as the transaction started changing data).
Now we'll try to create an index on the table in yet another session.
|| => SELECT pg_backend_pid();
|| pg_backend_pid
|| ----------------
|| 4782
|| (1 row)
|| => CREATE INDEX ON accounts(acc_no);
The command "hangs" waiting for the resource to be free. What lock in particular does it try to acquire? Let's figure this out:
=> SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted
FROM pg_locks WHERE pid = 4782;
locktype | relation | virtxid | xid | mode | granted
------------+----------+---------+-----+---------------+---------
virtualxid | | 6/15 | | ExclusiveLock | t
relation | accounts | | | ShareLock | f
(2 rows)
It's clear now that the transaction tries to acquire a Share lock on the table, but cannot (granted = f).
In order to find the process ID (pid) of the locking process, and in general, several pids, it is convenient to use the function that appeared in version 9.6 (before that, the conclusions had to be made by carefully examining all the contents of pg_locks):
=> SELECT pg_blocking_pids(4782);
pg_blocking_pids
------------------
{4746}
(1 row)
And then, to understand the situation, we can get information on the sessions to which the pids found pertain:
=> SELECT * FROM pg_stat_activity
WHERE pid = ANY(pg_blocking_pids(4782)) \gx
-[ RECORD 1 ]----+------------------------------------------------------------
datid | 16386
datname | test
pid | 4746
usesysid | 16384
usename | student
application_name | psql
client_addr |
client_hostname |
client_port | -1
backend_start | 2019-08-07 15:02:53.811842+03
xact_start | 2019-08-07 15:02:54.090672+03
query_start | 2019-08-07 15:02:54.10621+03
state_change | 2019-08-07 15:02:54.106965+03
wait_event_type | Client
wait_event | ClientRead
state | idle in transaction
backend_xid | 529404
backend_xmin |
query | UPDATE accounts SET amount = amount + 100 WHERE acc_no = 1;
backend_type | client backend
When the transaction is completed, the locks are released and index is created.
| => COMMIT;
| COMMIT
|| CREATE INDEX
Join the queue!..
To better understand what occurrence of an incompatible lock entails, let's see what will happen if we execute the VACUUM FULL command during system operation.
Let SELECT be the first command executed on the above table. It acquires a weakest-level, Access Share, lock. To control the time of releasing the lock, we execute this command inside the transaction — the lock won't be released until the transaction completes. Actually several commands can read (and update) a table, and execution of some queries can take pretty long.
=> BEGIN;
=> SELECT * FROM accounts;
acc_no | amount
--------+---------
2 | 2000.00
3 | 3000.00
1 | 1100.00
(3 rows)
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for
FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for
----------+-----------------+---------+------+----------
relation | AccessShareLock | t | 4710 | {}
(1 row)
Then the administrator executes the VACUUM FULL command, which requires a lock that has the Access Exclusive level and that is inconsistent with everything, even with Access Share. (The LOCK TABLE command requires the same lock.) And the transaction is queued.
| => BEGIN;
| => LOCK TABLE accounts; -- the same lock mode as for VACUUM FULL
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for
FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for
----------+---------------------+---------+------+----------
relation | AccessShareLock | t | 4710 | {}
relation | AccessExclusiveLock | f | 4746 | {4710}
(2 rows)
But the application continues to issue queries, and so the SELECT command also occurs in the system. Hypothetically, it could "make it through" while VACUUM FULL is waiting, but no — it honestly stands in a queue for VACUUM FULL.
|| => SELECT * FROM accounts;
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for
FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for
----------+---------------------+---------+------+----------
relation | AccessShareLock | t | 4710 | {}
relation | AccessExclusiveLock | f | 4746 | {4710}
relation | AccessShareLock | f | 4782 | {4746}
(3 rows)
When the first transaction with the SELECT command completes and releases the lock, the VACUUM FULL command (which we simulated by the LOCK TABLE command) starts.
=> COMMIT;
COMMIT
| LOCK TABLE
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for
FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for
----------+---------------------+---------+------+----------
relation | AccessExclusiveLock | t | 4746 | {}
relation | AccessShareLock | f | 4782 | {4746}
(2 rows)
And it's only after VACUUM FULL completes and releases the lock, all the queued commands (SELECT in this example) will be able to acquire appropriate locks (Access Share) and execute.
| => COMMIT;
| COMMIT
|| acc_no | amount
|| --------+---------
|| 2 | 2000.00
|| 3 | 3000.00
|| 1 | 1100.00
|| (3 rows)
So, an improperly executed command can paralyze work of the system for the time interval that is way longer than it takes to execute the command itself.
Monitoring tools
It's beyond doubt that locks are needed for correct work, but they can cause undesirable waits. These waits can be tracked in order to figure out their root cause and eliminate it whenever possible (for example: by changing the algorithm of the application).
We are already acquainted with one way to do this: when a long lock occurs, we can query the pg_locks view, look at locked and locking transactions (using the pg_blocking_pids function) and interpret the data using pg_stat_activity.
Another way is to turn the log_lock_waits parameter on. In this case, information will get into the server message log if a transaction waited longer than deadlock_timeout (although the parameter is used for deadlocks, normal waits are meant here).
Let's try.
=> ALTER SYSTEM SET log_lock_waits = on;
=> SELECT pg_reload_conf();
The default value of the deadlock_timeout parameter is one second:
=> SHOW deadlock_timeout;
deadlock_timeout
------------------
1s
(1 row)
Let's reproduce a lock.
=> BEGIN;
=> UPDATE accounts SET amount = amount - 100.00 WHERE acc_no = 1;
UPDATE 1
| => BEGIN;
| => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
The second UPDATE command is waiting for the lock. Let's wait for a second and complete the first transaction.
=> SELECT pg_sleep(1);
=> COMMIT;
COMMIT
Now the second transaction can be completed.
| UPDATE 1
| => COMMIT;
| COMMIT
And all the important information was logged:
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
2019-08-07 15:26:30.827 MSK [5898] student@test LOG: process 5898 still waiting for ShareLock on transaction 529427 after 1000.186 ms
2019-08-07 15:26:30.827 MSK [5898] student@test DETAIL: Process holding the lock: 5862. Wait queue: 5898.
2019-08-07 15:26:30.827 MSK [5898] student@test CONTEXT: while updating tuple (0,4) in relation "accounts"
2019-08-07 15:26:30.827 MSK [5898] student@test STATEMENT: UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
2019-08-07 15:26:30.836 MSK [5898] student@test LOG: process 5898 acquired ShareLock on transaction 529427 after 1009.536 ms
2019-08-07 15:26:30.836 MSK [5898] student@test CONTEXT: while updating tuple (0,4) in relation "accounts"
2019-08-07 15:26:30.836 MSK [5898] student@test STATEMENT: UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;