WAL in PostgreSQL: 3. Checkpoint
We already got acquainted with the structure of the buffer cache — one of the main objects of the shared memory — and concluded that to recover after failure when all the RAM contents get lost, the write-ahead log (WAL) must be maintained.
The problem yet unaddressed, where we left off last time, is that we are unaware of where to start playing back WAL records during the recovery. To begin from the beginning, as the King from Lewis Caroll's Alice advised, is not an option: it is impossible to keep all the WAL records from the server start — this is potentially both a huge memory size and equally huge duration of the recovery. We need such a point that is gradually moving forward and that we can start the recovery at (and safely remove all the previous WAL records, accordingly). And this is the checkpoint, to be discussed below.
Checkpoint
What features must the checkpoint have? We must be sure that all the WAL records starting with the checkpoint will be applied to the pages flushed to disk. If it were not the case, during recovery, we could read from disk a version of the page that is too old, apply the WAL record to it and by doing so, irreversibly hurt the data.
How can we get a checkpoint? The simplest option is to suspend the work of the system from time to time and flush all the dirty pages of the buffer and other caches to disk. (Note that pages are only written, but not evicted from the cache.) Such points will meet the above condition, but nobody will be happy to work with the system that continuously dies for some time, which is indefinite, but pretty significant.
So actually, this is a bit more complicated: a checkpoint turns from a point into an interval. First we start a checkpoint. After that we quietly flush dirty buffers to disk without interrupting the work or causing peak loads wherever possible.

When all the buffers that are dirty at the checkpoint start time are on disk, the checkpoint is considered to be complete. Now (but not earlier) we can use the start time as the point to start recovery at. And we no longer need WAL records created up to this point in time.
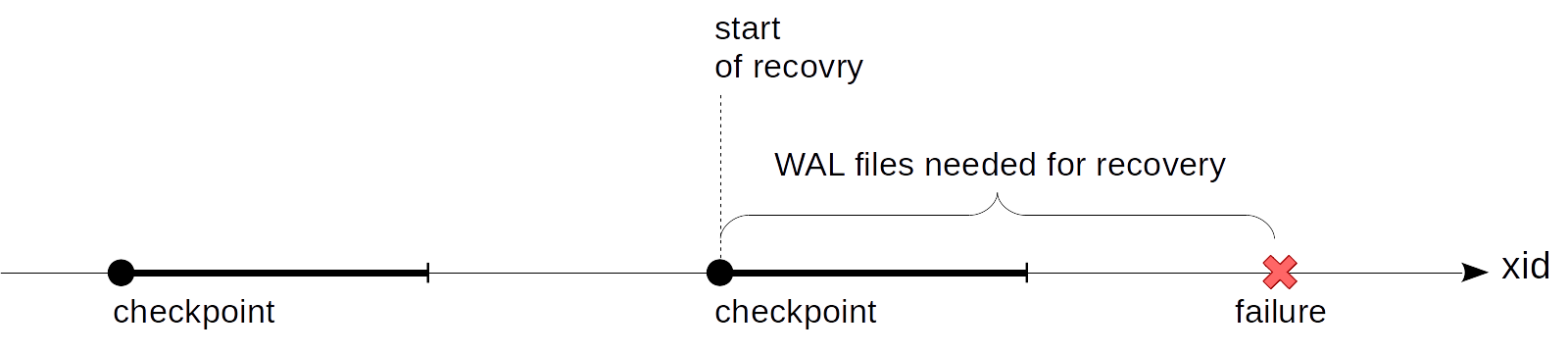
A specialized background process called checkpointer performs a checkpoint.
The duration of writing dirty buffers is defined by the value of the checkpoint_completion_target parameter. It shows the fraction of time between two neighboring checkpoints when writes are done. The default value is 0.5 (as in the figures above), that is, the writes take half the time between the checkpoints. Usually this value is increased up to 0.9 for more uniformity.
0.9 will become the default value in PostgreSQL 14.
Let's consider in more detail what happens when a checkpoint is performed.
First the checkpointer flushes XACT buffers to disk. Since there are few of them (only 128), they get written immediately.
Then the main task starts: flushing dirty pages from the buffer cache. As we already mentioned, all the pages cannot be flushed instantaneously since the size of the buffer cache can be large. Therefore, all pages that are currently dirty are marked in the buffer cache with a special flag in the headers.
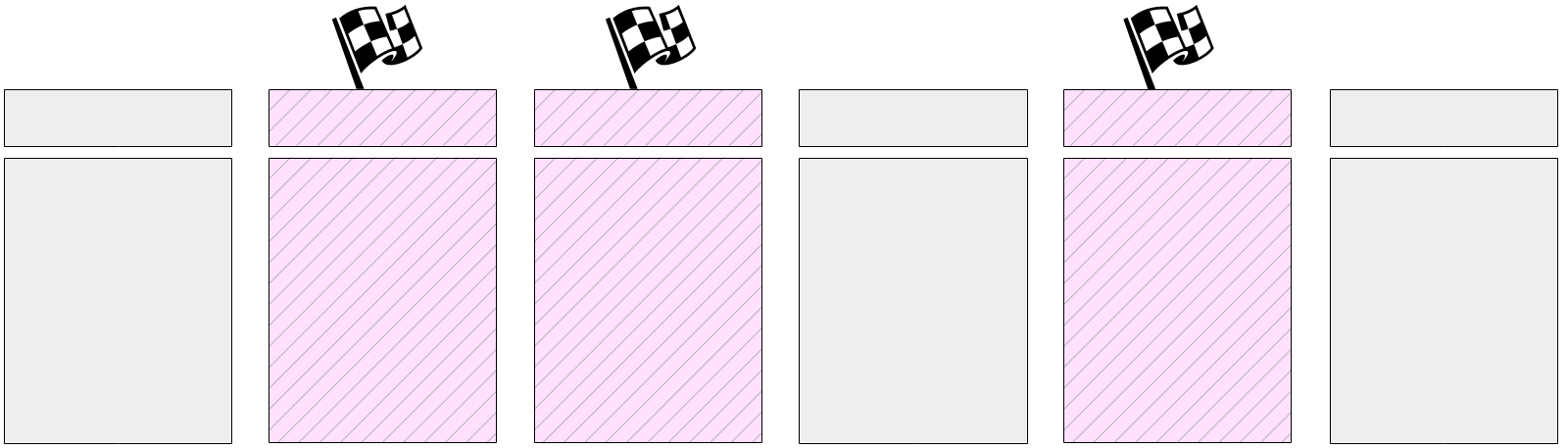
And then the checkpointer gradually walks through all the buffers and flushes those flagged to disk. To remind you, pages are not evicted from the cache, but are only written to disk; therefore, you need not pay attention either to the usage count of a buffer or to whether it is pinned.
The flagged buffers can also be written by server processes — whichever reaches the buffer first. Anyway, a write resets the flag set earlier, so (for the purpose of a checkpoint) the buffer will be written only once.
Naturally, while a checkpoint is performed, pages continue to change in the buffer cache. But new dirty buffers are not flagged, and the checkpointer will not write them.
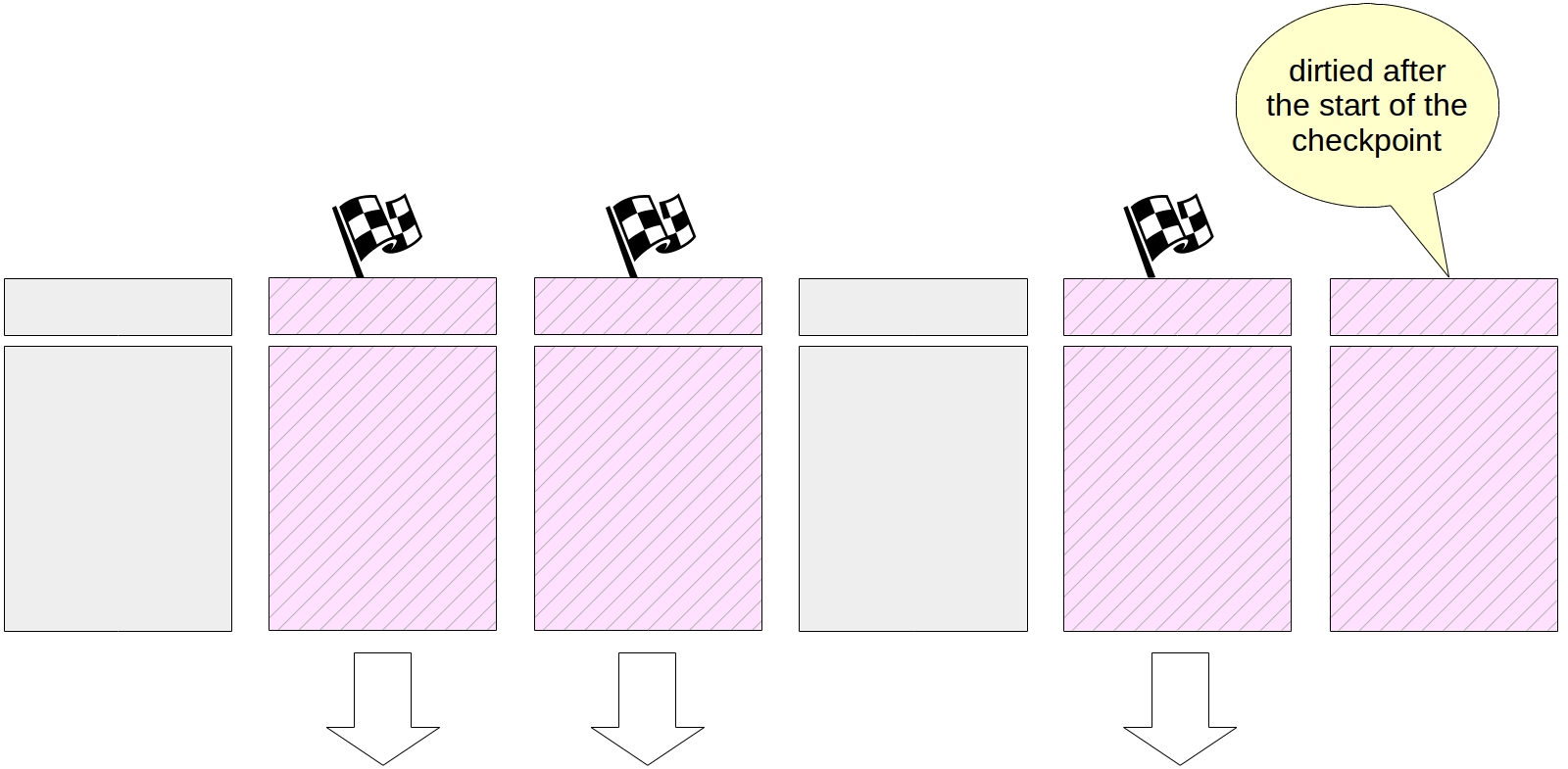
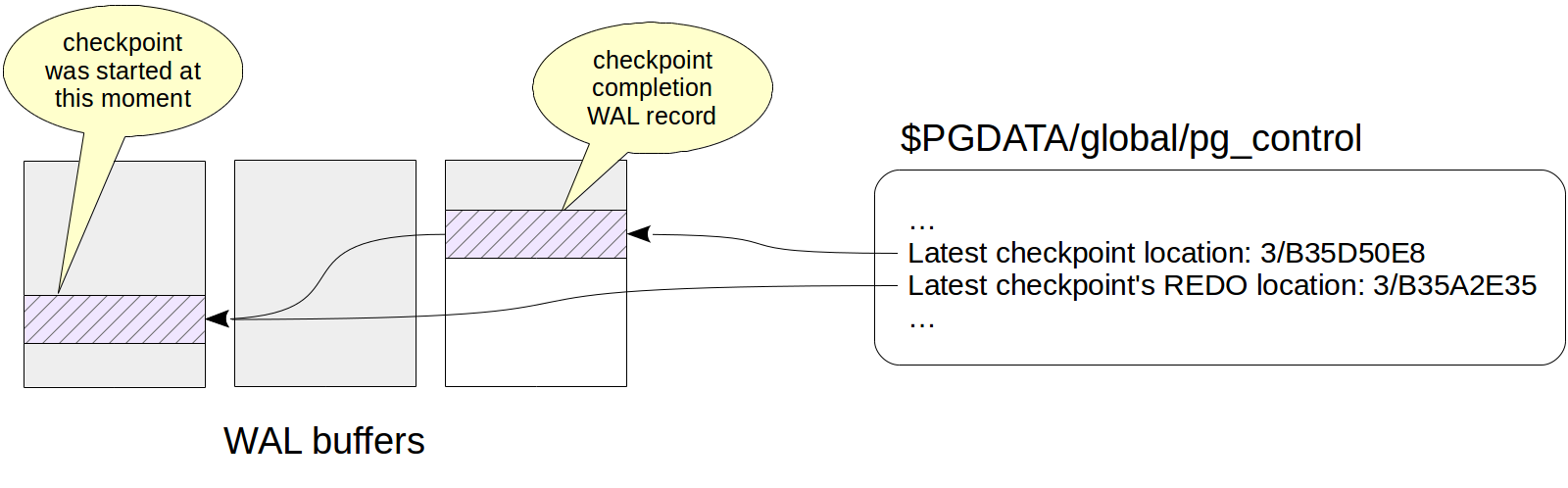
At the end of its work, the process creates a WAL record of the end of the checkpoint. This record contains LSN of the checkpoint start time. Since the checkpoint does not write anything to WAL when it starts, any log record can be located at this LSN.
Besides, the indication of the last completed checkpoint is updated in the $PGDATA/global/pg_control file. Before the checkpoint is completed, pg_control points to the previous checkpoint.
To watch the work of a checkpoint, let's create a table; its pages will get into the buffer cache and will be dirty:
=> CREATE TABLE chkpt AS SELECT * FROM generate_series(1,10000) AS g(n);
=> CREATE EXTENSION pg_buffercache;
=> SELECT count(*) FROM pg_buffercache WHERE isdirty;
count
-------
78
(1 row)
Let's remember the current WAL location:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
0/3514A048
(1 row)
Now let's perform the checkpoint manually to make sure that no dirty pages are left in the cache (as we already mentioned, new dirty pages can occur, but in the above situation there were no changes while the checkpoint was performed):
=> CHECKPOINT;
=> SELECT count(*) FROM pg_buffercache WHERE isdirty;
count
-------
0
(1 row)
Let's look how the checkpoint is reflected in WAL:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
0/3514A0E4
(1 row)
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A048 -e 0/3514A0E4
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/3514A048, prev 0/35149CEC, desc: RUNNING_XACTS nextXid 101105 latestCompletedXid 101104 oldestRunningXid 101105
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A07C, prev 0/3514A048, desc: CHECKPOINT_ONLINE redo 0/3514A048; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 101105; online
We see two records here. The last one is the record of the checkpoint completion (CHECKPOINT_ONLINE). LSN of the checkpoint start is output after the word "redo", and this location corresponds to the WAL record that was the last at the checkpoint start time.
We will find the same information in the control file:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | egrep 'Latest.*location'
Latest checkpoint location: 0/3514A07C
Latest checkpoint's REDO location: 0/3514A048
Recovery
We are now ready to state more exactly the recovery algorithm outlined in the previous article.
If the server fails, at the subsequent start, the startup process detects this by looking into the pg_control file to find the status different from "shut down". Automatic recovery is done in this case.
First the recovery process will read the checkpoint start location from the same pg_control file. (To complete the picture, note that if the backup_label file is available, the checkpoint record is read from there — this is needed to restore from backups, but it is a topic for a separate series.)
Then the process will read WAL starting at the location found and apply WAL records to the pages one by one (if the need arises, as we discussed last time).
In the end all unlogged tables are emptied by their initialization forks.
This is where the startup process finishes its work, and the checkpointer process immediately performs the checkpoint in order to secure the restored state on disk.
We can simulate a failure by forcing the server shutdown in the immediate mode.
student$ sudo pg_ctlcluster 11 main stop -m immediate --skip-systemctl-redirect
(The --skip-systemctl-redirect option is needed here since we use PostgreSQL installed on Ubuntu from the package. It is controlled by the pg_ctlcluster command, which actually calls systemctl, which, in its turn, calls pg_ctl. Because of all this wrapping, the name of the mode gets lost on the way. But the --skip-systemctl-redirect option enables us to do without systemctl and retain the important information.)
Let's check the state of the cluster:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: in production
At the start, PostgreSQL understands that a failure occurred and recovery is required.
student$ sudo pg_ctlcluster 11 main start
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:49.441 MSK [8865] LOG: database system was interrupted; last known up at 2019-07-17 15:27:48 MSK
2019-07-17 15:27:49.801 MSK [8865] LOG: database system was not properly shut down; automatic recovery in progress
2019-07-17 15:27:49.804 MSK [8865] LOG: redo starts at 0/3514A048
2019-07-17 15:27:49.804 MSK [8865] LOG: invalid record length at 0/3514A0E4: wanted 24, got 0
2019-07-17 15:27:49.804 MSK [8865] LOG: redo done at 0/3514A07C
2019-07-17 15:27:49.824 MSK [8864] LOG: database system is ready to accept connections
2019-07-17 15:27:50.409 MSK [8872] [unknown]@[unknown] LOG: incomplete startup packet
A need for recovery is reported in the message log: database system was not properly shut down; automatic recovery in progress. Then playback of WAL records starts at the "redo starts at" location and continues while it is possible to get next WAL records. This completes the recovery at the "redo done at" location, and the DBMS starts working with clients (database system is ready to accept connections).
And what happens at a normal shutdown of the server? To flush dirty pages to disk, PostgreSQL disconnects all the clients and then performs the final checkpoint.
Let's remember the current WAL location:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
0/3514A14C
(1 row)
Now we shut down the server in a regular way:
student$ sudo pg_ctlcluster 11 main stop
Let's check the cluster state:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: shut down
And WAL has the only record of the final checkpoint (CHECKPOINT_SHUTDOWN):
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A14C
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A14C, prev 0/3514A0E4, desc: CHECKPOINT_SHUTDOWN redo 0/3514A14C; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 0; shutdown
pg_waldump: FATAL: error in WAL record at 0/3514A14C: invalid record length at 0/3514A1B4: wanted 24, got 0
(By the fatal error message pg_waldump only wants to inform us that it read WAL to the end.)
Let's run the instance again.
student$ sudo pg_ctlcluster 11 main start
Background write
As we figured out, the checkpoint is one of the processes that flushes dirty pages from the buffer cache to disk. But it is not the only one.
If a backend process needs to flush a page from a buffer, but the page appears to be dirty, the process will have to write the page on disk on its own. And this situation is no good since it entails waits — it is much better when a write is done asynchronously, in the background.
Therefore, in addition to the checkpointer process, there is also the background writer process (also referred to as bgwriter or just writer). This process uses the same algorithm for searching buffers as the eviction technique. There are ultimately two differences.
- The writer's own pointer is used rather than the pointer to the "next victim". It can be ahead of the pointer to the "victim", but never behind it.
- In a walk through the buffers, the usage count is not reduced.
Those buffers are written for which all of this is true:
- They contain changed data (dirty).
- They are not pinned (pin count = 0).
- They have usage count = 0.
So, the background writer process sort of runs ahead of eviction and finds those buffers that are more likely to be evicted soon. Ideally, due to this, backend processes must be able to detect that the buffers they chose can be used without wasting time on writes.
Tuning
The checkpointer is usually set up from the following reasoning.
First, we need to determine what amount of WAL records we can afford keeping between two subsequent checkpoints (and what recovery time is acceptable to us). The more the better, but for obvious reasons, this value is limited.
Then we can count what time it takes to generate this amount at normal load. We've already discussed how to do this (we need to remember the locations in WAL and subtract one from the other).
It's this time that will be our usual interval between checkpoints. And we write it into the checkpoint_timeout parameter. The default value is 5 minutes, which is evidently too little; this time is usually increased, say, to half an hour. To reiterate: the less frequent checkpoints we can afford, the better — this reduces overhead costs.
But it is possible (and even likely) that sometimes the load will be higher than usual and a too large amount of WAL records will be generated within the time specified in the parameter. In this case, it is desirable to perform the checkpoint more often. To this end, we specify the total permissible amount of WAL files in the max_wal_size parameter. If the actual amount is greater, the server initiates an unplanned checkpoint.
The server needs to keep WAL files starting at the moment of the last completed checkpoint plus the files accumulated during the current checkpoint. So, the total amount can be estimated as amount in one checkpoint cycle multiplied by (1 + checkpoint_completion_target). Before version 11, we should multiply by (2 + checkpoint_completion_target) instead, as PostgreSQL also retained files from the last but one checkpoint.
So, most of checkpoints are performed on schedule: once every checkpoint_timeout units of time. But at an increased load, checkpoints are performed more often, when the amount of max_wal_size is reached.
It is important to understand that the value of max_wal_size parameter may be exceeded:
- The value of the max_wal_size parameter is only what's desirable rather than a strict limitation. The amount may happen to be greater.
- The server is not eligible to erase WAL files that haven't been passed through the replication slots yet and haven't been archived yet if continuous archiving is in place. If this functionality is used, continuous monitoring is needed to avoid the server memory grow full.
To complete the picture, not only the maximum, but the minimum amount can be specified by the min_wal_size parameter. The purpose of this setting is that the server does not delete files while their amount fits in min_wal_size, but only renames and reuses them. This allows saving on continuous creation and deletion of files.
It makes sense to tune the background writer only when the checkpointer is tuned. These processes together must manage to write dirty buffers before backend processes need them.
The background writer works in rounds of bgwriter_lru_maxpages pages at a maximum and sleeps between rounds for bgwriter_delay units of time.
The number of pages to be written in one round is determined from the average number of buffers that were requested by backend processes starting with the previous round (the moving average is used here to smooth over the non-uniformity between rounds, but not depend on the far-off history). The computed number of buffers is multiplied by the bgwriter_lru_multiplier coefficient (but anyway will not be greater than bgwriter_lru_maxpages).
The default values are: bgwriter_delay = 200 ms (most likely, too much — a lot of water will go under the bridge for 1/5 of a second), bgwriter_lru_maxpages = 100, bgwriter_lru_multiplier = 2.0 (let's try to respond to the demand in advance).
If the process did not find dirty buffers at all (that is, nothing is happening in the system), it "goes into hibernation", which it comes out of when a server process requests a buffer. After waking up, the process works as usual again.
Monitoring
You can and need to tune the checkpointer and background writer from the monitoring feedback.
The checkpoint_warning parameter outputs a warning if checkpoints caused by exceeding the amount of WAL files are performed too often. Its default value is 30 seconds, and we need to adjust it to the value of checkpoint_timeout.
The log_checkpoints parameter (turned off by default) enables us to get information on the checkpoints being performed from the message log of the server. Let's turn it on.
=> ALTER SYSTEM SET log_checkpoints = on;
=> SELECT pg_reload_conf();
Now let's change something in the data and perform the checkpoint.
=> UPDATE chkpt SET n = n + 1;
=> CHECKPOINT;
In the message log we will see the information such as:
postgres$ tail -n 2 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:55.248 MSK [8962] LOG: checkpoint starting: immediate force wait
2019-07-17 15:27:55.274 MSK [8962] LOG: checkpoint complete: wrote 79 buffers (0.5%); 0 WAL file(s) added, 0 removed, 0 recycled; write=0.001 s, sync=0.013 s, total=0.025 s; sync files=2, longest=0.011 s, average=0.006 s; distance=1645 kB, estimate=1645 kB
We can see here how many buffers were written, how the set of WAL files changed after the checkpoint, how long it took to perform the checkpoint and what the distance (in bytes) between the neighboring checkpoints is.
But probably the most useful information is the statistics for the checkpointer and background writer processes in the pg_stat_bgwriter view. The view is shared by the two since formerly one process performed both tasks, then the responsibilities were split, but the view remained.
=> SELECT * FROM pg_stat_bgwriter \gx
-[ RECORD 1 ]---------+------------------------------
checkpoints_timed | 0
checkpoints_req | 1
checkpoint_write_time | 1
checkpoint_sync_time | 13
buffers_checkpoint | 79
buffers_clean | 0
maxwritten_clean | 0
buffers_backend | 42
buffers_backend_fsync | 0
buffers_alloc | 363
stats_reset | 2019-07-17 15:27:49.826414+03
Here among the rest, we see the number of checkpoints performed:
checkpoints_timed— on schedule (on reaching checkpoint_timeout).checkpoints_req— on demand (including those performed on reaching max_wal_size).
A large value of checkpoint_req (compared to checkpoints_timed) indicates that checkpoints occur more often than expected.
The following is important information on the number of pages written:
buffers_checkpoint— by the checkpointer.buffers_backend— by backend processes.buffers_clean— by the background writer.
In a well-tuned system, the value of buffers_backend must be much less than the sum of buffers_checkpoint and buffers_clean.
The value of maxwritten_clean will also help to tune the background writer. It shows how many times the process stopped because of exceeding the value of bgwriter_lru_maxpages.
You can reset the collected statistics in the call:
=> SELECT pg_stat_reset_shared('bgwriter');