Thread: [HACKERS] Checksums by default?
Is it time to enable checksums by default, and give initdb a switch to turn it off instead?
--
I keep running into situations where people haven't enabled it, because (a) they didn't know about it, or (b) their packaging system ran initdb for them so they didn't even know they could. And of course they usually figure this out once the db has enough data and traffic that the only way to fix it is to set up something like slony/bucardo/pglogical and a whole new server to deal with it.. (Which is something that would also be good to fix -- but having the default changed would be useful as well)
* Magnus Hagander (magnus@hagander.net) wrote: > Is it time to enable checksums by default, and give initdb a switch to turn > it off instead? Yes, please. We've already agreed to make changes to have a better user experience and ask those who really care about certain performance aspects to have to configure for performance instead (see: wal_level changes), I view this as being very much in that same vein. I know one argument in the past has been that we don't have a tool that can be used to check all of the checksums, but that's also changed now that pgBackRest supports verifying checksums during backups. I'm all for adding a tool to core to perform a validation too, of course, though it does make a lot of sense to validate checksums during backup since you're reading all the pages anyway. Thanks! Stephen
On Sat, Jan 21, 2017 at 7:39 PM, Magnus Hagander <magnus@hagander.net> wrote: > Is it time to enable checksums by default, and give initdb a switch to turn > it off instead? > > I keep running into situations where people haven't enabled it, because (a) > they didn't know about it, or (b) their packaging system ran initdb for them > so they didn't even know they could. And of course they usually figure this > out once the db has enough data and traffic that the only way to fix it is > to set up something like slony/bucardo/pglogical and a whole new server to > deal with it.. (Which is something that would also be good to fix -- but > having the default changed would be useful as well) Perhaps that's not mandatory, but I think that one obstacle in changing this default is to be able to have pg_upgrade work from a checksum-disabled old instance to a checksum-enabled instance. That would really help with its adoption. -- Michael
On Sat, Jan 21, 2017 at 3:05 PM, Michael Paquier <michael.paquier@gmail.com> wrote:
That's a different usecase though.
On Sat, Jan 21, 2017 at 7:39 PM, Magnus Hagander <magnus@hagander.net> wrote:
> Is it time to enable checksums by default, and give initdb a switch to turn
> it off instead?
>
> I keep running into situations where people haven't enabled it, because (a)
> they didn't know about it, or (b) their packaging system ran initdb for them
> so they didn't even know they could. And of course they usually figure this
> out once the db has enough data and traffic that the only way to fix it is
> to set up something like slony/bucardo/pglogical and a whole new server to
> deal with it.. (Which is something that would also be good to fix -- but
> having the default changed would be useful as well)
Perhaps that's not mandatory, but I think that one obstacle in
changing this default is to be able to have pg_upgrade work from a
checksum-disabled old instance to a checksum-enabled instance. That
would really help with its adoption.
That's a different usecase though.
If we just change the default, then we'd have to teach pg_upgrade to initialize the upgraded cluster without checksums. We still need to keep that *option*, just reverse the default.
Being able to enable checksums on the fly is a different feature. Which I'd really like to have. I have some unfinished code for it, but it's a bit too unfinished so far :)
* Michael Paquier (michael.paquier@gmail.com) wrote: > On Sat, Jan 21, 2017 at 7:39 PM, Magnus Hagander <magnus@hagander.net> wrote: > > Is it time to enable checksums by default, and give initdb a switch to turn > > it off instead? > > > > I keep running into situations where people haven't enabled it, because (a) > > they didn't know about it, or (b) their packaging system ran initdb for them > > so they didn't even know they could. And of course they usually figure this > > out once the db has enough data and traffic that the only way to fix it is > > to set up something like slony/bucardo/pglogical and a whole new server to > > deal with it.. (Which is something that would also be good to fix -- but > > having the default changed would be useful as well) > > Perhaps that's not mandatory, but I think that one obstacle in > changing this default is to be able to have pg_upgrade work from a > checksum-disabled old instance to a checksum-enabled instance. That > would really help with its adoption. That's moving the goal-posts here about 3000 miles away and I don't believe it's necessary to have that to make this change. I agree that it'd be great to have, of course, and we're looking at if we could do something like: backup a checksum-disabled system, perform a restore which adds checksums and marks the cluster as now having checksums. If we can work out a good way to do that *and* have it work with incremental backup/restore, then we could possibly provide a small-downtime-window way to upgrade to a database with checksums. Thanks! Stephen
Magnus, * Magnus Hagander (magnus@hagander.net) wrote: > On Sat, Jan 21, 2017 at 3:05 PM, Michael Paquier <michael.paquier@gmail.com> > wrote: > > > On Sat, Jan 21, 2017 at 7:39 PM, Magnus Hagander <magnus@hagander.net> > > wrote: > > > Is it time to enable checksums by default, and give initdb a switch to > > turn > > > it off instead? > > > > > > I keep running into situations where people haven't enabled it, because > > (a) > > > they didn't know about it, or (b) their packaging system ran initdb for > > them > > > so they didn't even know they could. And of course they usually figure > > this > > > out once the db has enough data and traffic that the only way to fix it > > is > > > to set up something like slony/bucardo/pglogical and a whole new server > > to > > > deal with it.. (Which is something that would also be good to fix -- but > > > having the default changed would be useful as well) > > > > Perhaps that's not mandatory, but I think that one obstacle in > > changing this default is to be able to have pg_upgrade work from a > > checksum-disabled old instance to a checksum-enabled instance. That > > would really help with its adoption. > > That's a different usecase though. Agreed. > If we just change the default, then we'd have to teach pg_upgrade to > initialize the upgraded cluster without checksums. We still need to keep > that *option*, just reverse the default. Just to clarify- pg_upgrade doesn't init the new database, the user (or a distribution script) does. As such *pg_upgradecluster* would have to know to init the new cluster correctly based on the options the old cluster was init'd with, but it might actually already do that (not sure off-hand), and, even if it doesn't, it shouldn't be too hard to make it to that. > Being able to enable checksums on the fly is a different feature. Which I'd > really like to have. I have some unfinished code for it, but it's a bit too > unfinished so far :) Agreed. Thanks! Stephen
On 21/01/17 11:39, Magnus Hagander wrote: > Is it time to enable checksums by default, and give initdb a switch to > turn it off instead? I'd like to see benchmark first, both in terms of CPU and in terms of produced WAL (=network traffic) given that it turns on logging of hint bits. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Petr, * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > On 21/01/17 11:39, Magnus Hagander wrote: > > Is it time to enable checksums by default, and give initdb a switch to > > turn it off instead? > > I'd like to see benchmark first, both in terms of CPU and in terms of > produced WAL (=network traffic) given that it turns on logging of hint bits. Benchmarking was done previously, but I don't think it's really all that relevant, we should be checksum'ing by default because we care about the data and it's hard to get checksums enabled on a running system. If this is going to be a serious argument made against making this change (and, frankly, I don't believe that it should be) then what we should do is simply provide a way for users to disable checksums. It would be one-way and require a restart, of course, but it wouldn't be hard to do. Thanks! Stephen
On Sun, Jan 22, 2017 at 12:18 AM, Petr Jelinek <petr.jelinek@2ndquadrant.com> wrote: > On 21/01/17 11:39, Magnus Hagander wrote: >> Is it time to enable checksums by default, and give initdb a switch to >> turn it off instead? > > I'd like to see benchmark first, both in terms of CPU and in terms of > produced WAL (=network traffic) given that it turns on logging of hint bits. +1 If the performance overhead by the checksums is really negligible, we may be able to get rid of wal_log_hints parameter, as well. Regards, -- Fujii Masao
* Fujii Masao (masao.fujii@gmail.com) wrote: > On Sun, Jan 22, 2017 at 12:18 AM, Petr Jelinek > <petr.jelinek@2ndquadrant.com> wrote: > > On 21/01/17 11:39, Magnus Hagander wrote: > >> Is it time to enable checksums by default, and give initdb a switch to > >> turn it off instead? > > > > I'd like to see benchmark first, both in terms of CPU and in terms of > > produced WAL (=network traffic) given that it turns on logging of hint bits. > > +1 > > If the performance overhead by the checksums is really negligible, > we may be able to get rid of wal_log_hints parameter, as well. Prior benchmarks showed it to be on the order of a few percent, as I recall, so I'm not sure that we can say it's negligible (and that's not why Magnus was proposing changing the default). Thanks! Stephen
Magnus Hagander <magnus@hagander.net> writes:
> Is it time to enable checksums by default, and give initdb a switch to turn
> it off instead?
Have we seen *even one* report of checksums catching problems in a useful
way?
I think this will be making the average user pay X% for nothing.
regards, tom lane
* Tom Lane (tgl@sss.pgh.pa.us) wrote: > Magnus Hagander <magnus@hagander.net> writes: > > Is it time to enable checksums by default, and give initdb a switch to turn > > it off instead? > > Have we seen *even one* report of checksums catching problems in a useful > way? This isn't the right question. The right question is "have we seen reports of corruption which checksums *would* have caught?" Admittedly, that's a much harder question to answer, but I've definitely seen various reports of corruption in the field, but it's reasonably rare (which I am sure we can all be thankful for). I can't say for sure which of those cases would have been caught if checksums had been enabled, but I have a hard time believing that none of them would have been caught sooner if checksums had been enabled and regular checksum validation was being performed. Given our current default and the relative rarity that it happens, it'll be a great deal longer until we see such a report- but when we do (and I don't doubt that we will, eventually) what are we going to do about it? Tell the vast majority of people who still don't have checksums enabled because it wasn't the default that they need to pg_dump/reload? That's not a good way to treat our users. > I think this will be making the average user pay X% for nothing. Have we seen *even one* report of someone having to disable checksums for performance reasons? If so, that's an argument for giving a way for users who really trust their hardware, virtualization system, kernel, storage network, and everything else involved, to disable checksums (as I suggested elsewhere), not a reason to keep the current default. Thanks! Stephen
On 21/01/17 16:40, Stephen Frost wrote: > Petr, > > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: >> On 21/01/17 11:39, Magnus Hagander wrote: >>> Is it time to enable checksums by default, and give initdb a switch to >>> turn it off instead? >> >> I'd like to see benchmark first, both in terms of CPU and in terms of >> produced WAL (=network traffic) given that it turns on logging of hint bits. > > Benchmarking was done previously, but I don't think it's really all that > relevant, we should be checksum'ing by default because we care about the > data and it's hard to get checksums enabled on a running system. > I do think that performance implications are very relevant. And I haven't seen any serious benchmark that would incorporate all current differences between using and not using checksums. The change of wal_level was supported by benchmark, I think it's reasonable to ask for this to be as well. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Petr, * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > On 21/01/17 16:40, Stephen Frost wrote: > > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > >> On 21/01/17 11:39, Magnus Hagander wrote: > >>> Is it time to enable checksums by default, and give initdb a switch to > >>> turn it off instead? > >> > >> I'd like to see benchmark first, both in terms of CPU and in terms of > >> produced WAL (=network traffic) given that it turns on logging of hint bits. > > > > Benchmarking was done previously, but I don't think it's really all that > > relevant, we should be checksum'ing by default because we care about the > > data and it's hard to get checksums enabled on a running system. > > I do think that performance implications are very relevant. And I > haven't seen any serious benchmark that would incorporate all current > differences between using and not using checksums. This is just changing the *default*, not requiring checksums to always be enabled. We do not hold the same standards for our defaults as we do for always-enabled code, for clear reasons- not every situation is the same and that's why we have defaults that people can change. There are interesting arguments to be made about if checksum'ing is every worthwhile at all (some seem to see that the feature is entirely useless and we should just rip that code out, but I don't agree with that), or if we should just always enable it (because fewer options is a good thing and we care about our user's data and checksum'ing is worth the performance hit if it's a small hit; I'm more on the fence when it comes to this one as I have heard people say that they've run into cases where it does enough of a difference in performance to matter for them). We don't currently configure the defaults for any system to be the fastest possible performance, or we wouldn't have changed wal_level and we would have move aggressive settings for things like default work_mem, maintenance_work_mem, shared_buffers, max_wal_size, checkpoint_completion_target, all of the autovacuum settings, effective_io_concurrency, effective_cache_size, etc, etc. > The change of wal_level was supported by benchmark, I think it's > reasonable to ask for this to be as well. No, it wasn't, it was that people felt the cases where changing wal_level would seriously hurt performance didn't out-weigh the value of making the change to the default. Thanks! Stephen
Stephen Frost <sfrost@snowman.net> writes:
> * Tom Lane (tgl@sss.pgh.pa.us) wrote:
>> Have we seen *even one* report of checksums catching problems in a useful
>> way?
> This isn't the right question.
I disagree. If they aren't doing something useful for people who have
turned them on, what's the reason to think they'd do something useful
for the rest?
> The right question is "have we seen reports of corruption which
> checksums *would* have caught?"
Sure, that's also a useful question, one which hasn't been answered.
A third useful question is "have we seen any reports of false-positive
checksum failures?". Even one false positive, IMO, would have costs that
likely outweigh any benefits for typical installations with reasonably
reliable storage hardware.
I really do not believe that there's a case for turning on checksums by
default, and I *certainly* won't go along with turning them on without
somebody actually making that case. "Is it time yet" is not an argument.
regards, tom lane
On 21/01/17 17:31, Stephen Frost wrote: > Petr, > > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: >> On 21/01/17 16:40, Stephen Frost wrote: >>> * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: >>>> On 21/01/17 11:39, Magnus Hagander wrote: >>>>> Is it time to enable checksums by default, and give initdb a switch to >>>>> turn it off instead? >>>> >>>> I'd like to see benchmark first, both in terms of CPU and in terms of >>>> produced WAL (=network traffic) given that it turns on logging of hint bits. >>> >>> Benchmarking was done previously, but I don't think it's really all that >>> relevant, we should be checksum'ing by default because we care about the >>> data and it's hard to get checksums enabled on a running system. >> >> I do think that performance implications are very relevant. And I >> haven't seen any serious benchmark that would incorporate all current >> differences between using and not using checksums. > > This is just changing the *default*, not requiring checksums to always > be enabled. We do not hold the same standards for our defaults as we do > for always-enabled code, for clear reasons- not every situation is the > same and that's why we have defaults that people can change. I can buy that. If it's possible to turn checksums off without recreating data directory then I think it would be okay to have default on. >> The change of wal_level was supported by benchmark, I think it's >> reasonable to ask for this to be as well. > > No, it wasn't, it was that people felt the cases where changing > wal_level would seriously hurt performance didn't out-weigh the value of > making the change to the default. > Really? https://www.postgresql.org/message-id/d34ce5b5-131f-66ce-f7c5-eb406dbe026f@2ndquadrant.com https://www.postgresql.org/message-id/83b33502-1bf8-1ffb-7c73-5b61ddeb68ab@2ndquadrant.com -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On 01/21/2017 04:48 PM, Stephen Frost wrote: > * Fujii Masao (masao.fujii@gmail.com) wrote: >> If the performance overhead by the checksums is really negligible, >> we may be able to get rid of wal_log_hints parameter, as well. > > Prior benchmarks showed it to be on the order of a few percent, as I > recall, so I'm not sure that we can say it's negligible (and that's not > why Magnus was proposing changing the default). It might be worth looking into using the CRC CPU instruction to reduce this overhead, like we do for the WAL checksums. Since that is a different algorithm it would be a compatibility break and we would need to support the old algorithm for upgraded clusters.. Andreas
Stephen Frost <sfrost@snowman.net> writes:
> * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote:
>> The change of wal_level was supported by benchmark, I think it's
>> reasonable to ask for this to be as well.
> No, it wasn't, it was that people felt the cases where changing
> wal_level would seriously hurt performance didn't out-weigh the value of
> making the change to the default.
It was "supported" in the sense that somebody took the trouble to measure
the impact, so that we had some facts on which to base the value judgment
that the cost was acceptable. In the case of checksums, you seem to be in
a hurry to arrive at a conclusion without any supporting evidence.
regards, tom lane
* Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > On 21/01/17 17:31, Stephen Frost wrote: > > This is just changing the *default*, not requiring checksums to always > > be enabled. We do not hold the same standards for our defaults as we do > > for always-enabled code, for clear reasons- not every situation is the > > same and that's why we have defaults that people can change. > > I can buy that. If it's possible to turn checksums off without > recreating data directory then I think it would be okay to have default on. I'm glad to hear that. > >> The change of wal_level was supported by benchmark, I think it's > >> reasonable to ask for this to be as well. > > > > No, it wasn't, it was that people felt the cases where changing > > wal_level would seriously hurt performance didn't out-weigh the value of > > making the change to the default. > > Really? Yes. > https://www.postgresql.org/message-id/d34ce5b5-131f-66ce-f7c5-eb406dbe026f@2ndquadrant.com From the above link: > So while it'd be trivial to construct workloads demonstrating the > optimizations in wal_level=minimal (e.g. initial loads doing CREATE > TABLE + COPY + CREATE INDEX in a single transaction), but that would be > mostly irrelevant I guess. > Instead, I've decided to run regular pgbench TPC-B-like workload on a > bunch of different scales, and measure throughput + some xlog stats with > each of the three wal_level options. In other words, there was no performance testing of the cases where wal_level=minimal (the old default) optimizations would have been compared against wal_level > minimal. I'm quite sure that the performance numbers for the CREATE TABLE + COPY case with wal_level=minimal would have been *far* better than for wal_level > minimal. That case was entirely punted on as "mostly irrelevant" even though there are known production environments where those optimizations make a huge difference. Those are OLAP cases though, and not nearly enough folks around here seem to care one bit about them, which I continue to be disappointed by. Even so, I *did* agree with the change to the default of wal_level, based on an understanding of its value and that users could change to wal_level=minimal if they wished to, just as I am arguing that same thing here when it comes to checksums. Thanks! Stephen
* Tom Lane (tgl@sss.pgh.pa.us) wrote: > Stephen Frost <sfrost@snowman.net> writes: > > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > >> The change of wal_level was supported by benchmark, I think it's > >> reasonable to ask for this to be as well. > > > No, it wasn't, it was that people felt the cases where changing > > wal_level would seriously hurt performance didn't out-weigh the value of > > making the change to the default. > > It was "supported" in the sense that somebody took the trouble to measure > the impact, so that we had some facts on which to base the value judgment > that the cost was acceptable. In the case of checksums, you seem to be in > a hurry to arrive at a conclusion without any supporting evidence. No, no one measured the impact in the cases where wal_level=minimal makes a big difference, that I saw, at least. Further info with links to what was done are in my reply to Petr. As for checksums, I do see value in them and I'm pretty sure that the author of that particular feature did as well, or we wouldn't even have it as an option. You seem to be of the opinion that we might as well just rip all of that code and work out as being useless. Thanks! Stephen
* Andreas Karlsson (andreas@proxel.se) wrote: > On 01/21/2017 04:48 PM, Stephen Frost wrote: > >* Fujii Masao (masao.fujii@gmail.com) wrote: > >>If the performance overhead by the checksums is really negligible, > >>we may be able to get rid of wal_log_hints parameter, as well. > > > >Prior benchmarks showed it to be on the order of a few percent, as I > >recall, so I'm not sure that we can say it's negligible (and that's not > >why Magnus was proposing changing the default). > > It might be worth looking into using the CRC CPU instruction to > reduce this overhead, like we do for the WAL checksums. Since that > is a different algorithm it would be a compatibility break and we > would need to support the old algorithm for upgraded clusters.. +1. I'd be all for removing the option and requiring checksums if we do that and it turns out that the performance hit ends up being less than 1%. Thanks! Stephen
On 2017-01-21 11:39:18 +0100, Magnus Hagander wrote: > Is it time to enable checksums by default, and give initdb a switch to turn > it off instead? -1 - the WAL overhead is quite massive, and in contrast to the other GUCs recently changed you can't just switch this around. Andres
On 2017-01-22 00:41:55 +0900, Fujii Masao wrote: > On Sun, Jan 22, 2017 at 12:18 AM, Petr Jelinek > <petr.jelinek@2ndquadrant.com> wrote: > > On 21/01/17 11:39, Magnus Hagander wrote: > >> Is it time to enable checksums by default, and give initdb a switch to > >> turn it off instead? > > > > I'd like to see benchmark first, both in terms of CPU and in terms of > > produced WAL (=network traffic) given that it turns on logging of hint bits. > > +1 > > If the performance overhead by the checksums is really negligible, > we may be able to get rid of wal_log_hints parameter, as well. It's not just the performance overhead, but also the volume of WAL due to the additional FPIs... Andres
On 21/01/17 17:51, Stephen Frost wrote: > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: >> On 21/01/17 17:31, Stephen Frost wrote: >>> This is just changing the *default*, not requiring checksums to always >>> be enabled. We do not hold the same standards for our defaults as we do >>> for always-enabled code, for clear reasons- not every situation is the >>> same and that's why we have defaults that people can change. >> >> I can buy that. If it's possible to turn checksums off without >> recreating data directory then I think it would be okay to have default on. > > I'm glad to hear that. > >>>> The change of wal_level was supported by benchmark, I think it's >>>> reasonable to ask for this to be as well. >>> >>> No, it wasn't, it was that people felt the cases where changing >>> wal_level would seriously hurt performance didn't out-weigh the value of >>> making the change to the default. >> >> Really? > > Yes. > >> https://www.postgresql.org/message-id/d34ce5b5-131f-66ce-f7c5-eb406dbe026f@2ndquadrant.com > > From the above link: > >> So while it'd be trivial to construct workloads demonstrating the >> optimizations in wal_level=minimal (e.g. initial loads doing CREATE >> TABLE + COPY + CREATE INDEX in a single transaction), but that would be >> mostly irrelevant I guess. > >> Instead, I've decided to run regular pgbench TPC-B-like workload on a >> bunch of different scales, and measure throughput + some xlog stats with >> each of the three wal_level options. > > In other words, there was no performance testing of the cases where > wal_level=minimal (the old default) optimizations would have been > compared against wal_level > minimal. > > I'm quite sure that the performance numbers for the CREATE TABLE + COPY > case with wal_level=minimal would have been *far* better than for > wal_level > minimal. Which is random usecase very few people do on regular basis. Checksums affect *everybody*. What the benchmarks gave us is a way to do informed decision for common use. All I am asking for here is to be able to do informed decision as well. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Stephen Frost <sfrost@snowman.net> writes:
> As for checksums, I do see value in them and I'm pretty sure that the
> author of that particular feature did as well, or we wouldn't even have
> it as an option. You seem to be of the opinion that we might as well
> just rip all of that code and work out as being useless.
Not at all; I just think that it's not clear that they are a net win
for the average user, and so I'm unconvinced that turning them on by
default is a good idea. I could be convinced otherwise by suitable
evidence. What I'm objecting to is turning them on without making
any effort to collect such evidence.
Also, if we do decide to do that, there's the question of timing.
As I mentioned, one of the chief risks I see is the possibility of
false-positive checksum failures due to bugs; I think that code has seen
sufficiently little field use that we should have little confidence that
no such bugs remain. So if we're gonna do it, I'd prefer to do it at the
very start of a devel cycle, so as to have the greatest opportunity to
find bugs before we ship the new default.
regards, tom lane
* Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > On 21/01/17 17:51, Stephen Frost wrote: > > I'm quite sure that the performance numbers for the CREATE TABLE + COPY > > case with wal_level=minimal would have been *far* better than for > > wal_level > minimal. > > Which is random usecase very few people do on regular basis. Checksums > affect *everybody*. It's not a 'random usecase very few people do on a regular basis', it's a different usecase which a subset of our users do. I agree that changing the default for checksums would affect everyone who uses just the defaults. What I think is different about checksums, really, is that you have to pass an option to initdb to enable them. That's right from a technical perspective, but I seriously doubt everyone re-reads the 'man' page for initdb when they're setting up a new cluster, and if they didn't read the release notes for that particular release where checksums were introduced, they might not be aware that they exist or that they're defaulted to off. Values in postgresql.conf, at least in my experience, get a lot more regular review as there's always things changing there from release-to-release and anyone even slightly experienced with PG knows that our defaults in postgresql.conf pretty much suck and have to be adjusted. I expect we'd see a lot more people using checksums if they were in postgresql.conf somehow. I don't have any particular answer to that problem, just thought it interesting to consider how flags to initdb differ from postgresql.conf configuration options. > What the benchmarks gave us is a way to do informed decision for common > use. All I am asking for here is to be able to do informed decision as > well. From above: > >>>> The change of wal_level was supported by benchmark, I think it's > >>>> reasonable to ask for this to be as well. > >>> > >>> No, it wasn't, it was that people felt the cases where changing > >>> wal_level would seriously hurt performance didn't out-weigh the value of > >>> making the change to the default. In other words, the change of the *default* for checksums, at least in my view, is well worth the performance impact, and I came to that conclusion based on the previously published work when the feature was being developed, which was a few percent, as I recall, though I'd be fine with having it be the default even if it was 5%. At what point would you say we shouldn't have the default be to have checksums enabled? 1%? 5%? 10%? All that said, to be clear, I don't have any objection to Tomas (or whomever) doing performance testing of this case if he's interested and has time, but that I don't feel we really need a huge analysis of this. We did an analysis when the feature was developed and I doubt we would have been able to even get it included if it resulted in a 10% or more performance hit, though it wasn't that high, as I recall. Thanks! Stephen
On 2017-01-21 12:09:53 -0500, Tom Lane wrote: > Also, if we do decide to do that, there's the question of timing. > As I mentioned, one of the chief risks I see is the possibility of > false-positive checksum failures due to bugs; I think that code has seen > sufficiently little field use that we should have little confidence that > no such bugs remain. So if we're gonna do it, I'd prefer to do it at the > very start of a devel cycle, so as to have the greatest opportunity to > find bugs before we ship the new default. What wouldn't hurt is enabling it by default in pg_regress on master for a while. That seems like a good thing to do independent of flipping the default. Andres
* Tom Lane (tgl@sss.pgh.pa.us) wrote: > Stephen Frost <sfrost@snowman.net> writes: > > As for checksums, I do see value in them and I'm pretty sure that the > > author of that particular feature did as well, or we wouldn't even have > > it as an option. You seem to be of the opinion that we might as well > > just rip all of that code and work out as being useless. > > Not at all; I just think that it's not clear that they are a net win > for the average user, and so I'm unconvinced that turning them on by > default is a good idea. I could be convinced otherwise by suitable > evidence. What I'm objecting to is turning them on without making > any effort to collect such evidence. > Also, if we do decide to do that, there's the question of timing. > As I mentioned, one of the chief risks I see is the possibility of > false-positive checksum failures due to bugs; I think that code has seen > sufficiently little field use that we should have little confidence that > no such bugs remain. So if we're gonna do it, I'd prefer to do it at the > very start of a devel cycle, so as to have the greatest opportunity to > find bugs before we ship the new default. I can agree with a goal to make sure we aren't enabling code that a bunch of people are going to be seeing false positives due to, as that would certainly be bad. I also agree that further testing is generally a good idea, I just dislike the idea that we would prevent this change to the default due to performance concerns of a few percent in a default install. I'll ask around with some of the big PG installed bases (RDS, Heroku, etc) and see if they're a) enabling checksums already (and therefore doing a lot of testing of those code paths), and b) if they are, if they have seen any true or false positive reports from it. If we hear back that the large installed bases in those environments are already running with checksums enabled, without issues, then I'm not sure that we need to wait until the start of the next devel cycle to change the default. Alternativly, if we end up wanting to change the on-disk format, as discussed elsewhere on this thread, then we might want to wait and make that change at the same time as a change to the default, or at least not change the default right before we decide to change the format. Thanks! Stephen
* Andres Freund (andres@anarazel.de) wrote: > On 2017-01-21 12:09:53 -0500, Tom Lane wrote: > > Also, if we do decide to do that, there's the question of timing. > > As I mentioned, one of the chief risks I see is the possibility of > > false-positive checksum failures due to bugs; I think that code has seen > > sufficiently little field use that we should have little confidence that > > no such bugs remain. So if we're gonna do it, I'd prefer to do it at the > > very start of a devel cycle, so as to have the greatest opportunity to > > find bugs before we ship the new default. > > What wouldn't hurt is enabling it by default in pg_regress on master for > a while. That seems like a good thing to do independent of flipping the > default. Oh. I like that idea, a lot. +1. Thanks! Stephen
Andres Freund <andres@anarazel.de> writes:
> What wouldn't hurt is enabling it by default in pg_regress on master for
> a while. That seems like a good thing to do independent of flipping the
> default.
Yeah, I could get behind that. I'm not certain how much the regression
tests really stress checksumming: most of the tests work with small
amounts of data that probably never leave shared buffers. But it'd be
some hard evidence at least.
regards, tom lane
On 21/01/17 18:15, Stephen Frost wrote: > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: >> On 21/01/17 17:51, Stephen Frost wrote: >>> I'm quite sure that the performance numbers for the CREATE TABLE + COPY >>> case with wal_level=minimal would have been *far* better than for >>> wal_level > minimal. >> >> Which is random usecase very few people do on regular basis. Checksums >> affect *everybody*. > > It's not a 'random usecase very few people do on a regular basis', it's > a different usecase which a subset of our users do. I agree that > changing the default for checksums would affect everyone who uses just > the defaults. > > What I think is different about checksums, really, is that you have to > pass an option to initdb to enable them. That's right from a technical > perspective, but I seriously doubt everyone re-reads the 'man' page for > initdb when they're setting up a new cluster, and if they didn't read > the release notes for that particular release where checksums were > introduced, they might not be aware that they exist or that they're > defaulted to off. > > Values in postgresql.conf, at least in my experience, get a lot more > regular review as there's always things changing there from > release-to-release and anyone even slightly experienced with PG knows > that our defaults in postgresql.conf pretty much suck and have to be > adjusted. I expect we'd see a lot more people using checksums if they > were in postgresql.conf somehow. I don't have any particular answer to > that problem, just thought it interesting to consider how flags to > initdb differ from postgresql.conf configuration options. So in summary "postgresql.conf options are easy to change" while "initdb options are hard to change", I can see this argument used both for enabling or disabling checksums by default. As I said I would be less worried if it was easy to turn off, but we are not there afaik. And even then I'd still want benchmark first. > >> What the benchmarks gave us is a way to do informed decision for common >> use. All I am asking for here is to be able to do informed decision as >> well. > > From above: > >>>>>> The change of wal_level was supported by benchmark, I think it's >>>>>> reasonable to ask for this to be as well. >>>>> >>>>> No, it wasn't, it was that people felt the cases where changing >>>>> wal_level would seriously hurt performance didn't out-weigh the value of >>>>> making the change to the default. > > In other words, the change of the *default* for checksums, at least in > my view, is well worth the performance impact. > As we don't know the performance impact is (there was no benchmark done on reasonably current code base) I really don't understand how you can judge if it's worth it or not. I stand by the opinion that changing default which affect performance without any benchmark is bad idea. And for the record, I care much less about overall TPS, I care a lot more about amount of WAL produced because in 90%+ environments that I work with any increase in WAL amount means at least double the increase in network bandwidth due to replication. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
* Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > As we don't know the performance impact is (there was no benchmark done > on reasonably current code base) I really don't understand how you can > judge if it's worth it or not. Because I see having checksums as, frankly, something we always should have had (as most other databases do, for good reason...) and because they will hopefully prevent data loss. I'm willing to give us a fair bit to minimize the risk of losing data. > I stand by the opinion that changing default which affect performance > without any benchmark is bad idea. I'd be surprised if the performance impact has really changed all that much since the code went in. Perhaps that's overly optimistic of me. > And for the record, I care much less about overall TPS, I care a lot > more about amount of WAL produced because in 90%+ environments that I > work with any increase in WAL amount means at least double the increase > in network bandwidth due to replication. Do you run with all defaults in those environments? Thanks! Stephen
On 21/01/17 18:46, Stephen Frost wrote: > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: >> As we don't know the performance impact is (there was no benchmark done >> on reasonably current code base) I really don't understand how you can >> judge if it's worth it or not. > > Because I see having checksums as, frankly, something we always should > have had (as most other databases do, for good reason...) and because > they will hopefully prevent data loss. I'm willing to give us a fair > bit to minimize the risk of losing data. > >> I stand by the opinion that changing default which affect performance >> without any benchmark is bad idea. > > I'd be surprised if the performance impact has really changed all that > much since the code went in. Perhaps that's overly optimistic of me. > My problem is that we are still only guessing. And while my gut also tells me that the TPS difference will not be big, it also tells me that changes like this in important software like PostgreSQL should not be made based purely on it. >> And for the record, I care much less about overall TPS, I care a lot >> more about amount of WAL produced because in 90%+ environments that I >> work with any increase in WAL amount means at least double the increase >> in network bandwidth due to replication. > > Do you run with all defaults in those environments? > For initdb? Mostly yes. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On 2017-01-21 12:46:05 -0500, Stephen Frost wrote: > > I stand by the opinion that changing default which affect performance > > without any benchmark is bad idea. > > I'd be surprised if the performance impact has really changed all that > much since the code went in. Perhaps that's overly optimistic of me. Back then there were cases with well over 20% overhead. More edge cases, but that's a lot. And our scalability back then was a lot worse than where we are today. > > And for the record, I care much less about overall TPS, I care a lot > > more about amount of WAL produced because in 90%+ environments that I > > work with any increase in WAL amount means at least double the increase > > in network bandwidth due to replication. > > Do you run with all defaults in those environments? Irrelevant - changing requires re-initdb'ing. That's unrealistic. Greetings, Andres Freund
* Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > > Do you run with all defaults in those environments? > > For initdb? Mostly yes. Ok, fine, but you probably wouldn't if this change went in. For me, it's the other way- I have to go enable checksums at initdb time unless there's an excuse not to, and that's only when I get to be involved at initdb time, which is often not the case, sadly. There's certainly lots and lots of environments where the extra CPU and WAL aren't even remotely close to being an issue. * Andres Freund (andres@anarazel.de) wrote: > On 2017-01-21 12:46:05 -0500, Stephen Frost wrote: > > Do you run with all defaults in those environments? > > Irrelevant - changing requires re-initdb'ing. That's unrealistic. I disagree. Further, we can add an option to be able to disable checksums without needing to re-initdb pretty trivially, which addresses the case where someone's having a problem because it's enabled, as discussed. Thanks! Stephen
Andres Freund <andres@anarazel.de> writes:
> On 2017-01-21 12:46:05 -0500, Stephen Frost wrote:
>> Do you run with all defaults in those environments?
> Irrelevant - changing requires re-initdb'ing. That's unrealistic.
If you can't turn checksums *off* without re-initdb, that raises the
stakes for this enormously. But why is that so hard? Seems like if
you just stop checking them, you're done. I see that we have the
state recorded in pg_control, but surely we could teach some utility
or other to update that file while the postmaster is stopped.
I think a reasonable prerequisite before we even consider this change
is a patch to make it possible to turn off checksumming.
regards, tom lane
Stephen Frost <sfrost@snowman.net> writes:
> Because I see having checksums as, frankly, something we always should
> have had (as most other databases do, for good reason...) and because
> they will hopefully prevent data loss. I'm willing to give us a fair
> bit to minimize the risk of losing data.
To be perfectly blunt, that's just magical thinking. Checksums don't
prevent data loss in any way, shape, or form. In fact, they can *cause*
data loss, or at least make it harder for you to retrieve your data,
in the event of bugs causing false-positive checksum failures.
What checksums can do for you, perhaps, is notify you in a reasonably
timely fashion if you've already lost data due to storage-subsystem
problems. But in a pretty high percentage of cases, that fact would
be extremely obvious anyway, because of visible data corruption.
I think the only really clear benefit accruing from checksums is that
they make it easier to distinguish storage-subsystem failures from
Postgres bugs. That can certainly be a benefit to some users, but
I remain dubious that the average user will find it worth any noticeable
amount of overhead.
regards, tom lane
On 2017-01-21 13:03:52 -0500, Stephen Frost wrote: > * Andres Freund (andres@anarazel.de) wrote: > > On 2017-01-21 12:46:05 -0500, Stephen Frost wrote: > > > Do you run with all defaults in those environments? > > > > Irrelevant - changing requires re-initdb'ing. That's unrealistic. > > I disagree. Further, we can add an option to be able to disable > checksums without needing to re-initdb pretty trivially, which addresses > the case where someone's having a problem because it's enabled, as > discussed. Sure, it might be easy, but we don't have it. Personally I think checksums just aren't even ready for prime time. If we had: - ability to switch on/off at runtime (early patches for that have IIRC been posted) - *builtin* tooling to check checksums for everything - *builtin* tooling to compute checksums after changing setting - configurable background sweeps for checksums then the story would look differently. Right now checksums just aren't particularly useful due to not having the above. Just checking recent data doesn't really guarantee much - failures are more likely in old data, and the data might even be read from ram. Greetings, Andres Freund
On 2017-01-21 13:04:18 -0500, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > On 2017-01-21 12:46:05 -0500, Stephen Frost wrote: > >> Do you run with all defaults in those environments? > > > Irrelevant - changing requires re-initdb'ing. That's unrealistic. > > If you can't turn checksums *off* without re-initdb, that raises the > stakes for this enormously. Not right now, no. > But why is that so hard? Don't think it is, it's just that nobody has done it ;) Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> Sure, it might be easy, but we don't have it. Personally I think
> checksums just aren't even ready for prime time. If we had:
> - ability to switch on/off at runtime (early patches for that have IIRC
> been posted)
> - *builtin* tooling to check checksums for everything
> - *builtin* tooling to compute checksums after changing setting
> - configurable background sweeps for checksums
Yeah, and there's a bunch of usability tooling that we don't have,
centered around "what do you do after you get a checksum error?".
AFAIK there's no way to check or clear such an error; but without
such tools, I'm afraid that checksums are as much of a foot-gun
as a benefit.
I think developing all this stuff is a good long-term activity,
but I'm hesitant about turning checksums loose on the average
user before we have it.
To draw a weak analogy, our checksums right now are more or less
where our replication was in 9.1 --- we had it, but there were still
an awful lot of rough edges. It was only just in this past release
cycle that we started to change default settings towards the idea
that they should support replication by default. I think the checksum
tooling likewise needs years of maturation before we can say that it's
realistically ready to be the default.
regards, tom lane
* Tom Lane (tgl@sss.pgh.pa.us) wrote: > Stephen Frost <sfrost@snowman.net> writes: > > Because I see having checksums as, frankly, something we always should > > have had (as most other databases do, for good reason...) and because > > they will hopefully prevent data loss. I'm willing to give us a fair > > bit to minimize the risk of losing data. > > To be perfectly blunt, that's just magical thinking. Checksums don't > prevent data loss in any way, shape, or form. In fact, they can *cause* > data loss, or at least make it harder for you to retrieve your data, > in the event of bugs causing false-positive checksum failures. This is not a new argument, at least to me, and I don't agree with it. > What checksums can do for you, perhaps, is notify you in a reasonably > timely fashion if you've already lost data due to storage-subsystem > problems. But in a pretty high percentage of cases, that fact would > be extremely obvious anyway, because of visible data corruption. Exactly, and that awareness will allow a user to prevent further data loss or corruption. Slow corruption over time is a very much known and accepted real-world case that people do experience, as well as bit flipping enough for someone to write a not-that-old blog post about them: https://blogs.oracle.com/ksplice/entry/attack_of_the_cosmic_rays1 A really nice property of checksums on pages is that they also tell you what data you *didn't* lose, which can be extremely valuable. > I think the only really clear benefit accruing from checksums is that > they make it easier to distinguish storage-subsystem failures from > Postgres bugs. That can certainly be a benefit to some users, but > I remain dubious that the average user will find it worth any noticeable > amount of overhead. Or memory errors, or kernel bugs, or virtualization bugs, if they happen at the right time. We keep adding to the bits between the DB and the storage and to think they're all perfect is certainly a step farther than I'd go. Thanks! Stephen
* Andres Freund (andres@anarazel.de) wrote: > On 2017-01-21 13:03:52 -0500, Stephen Frost wrote: > > * Andres Freund (andres@anarazel.de) wrote: > > > On 2017-01-21 12:46:05 -0500, Stephen Frost wrote: > > > > Do you run with all defaults in those environments? > > > > > > Irrelevant - changing requires re-initdb'ing. That's unrealistic. > > > > I disagree. Further, we can add an option to be able to disable > > checksums without needing to re-initdb pretty trivially, which addresses > > the case where someone's having a problem because it's enabled, as > > discussed. > > Sure, it might be easy, but we don't have it. Personally I think > checksums just aren't even ready for prime time. If we had: > - ability to switch on/off at runtime (early patches for that have IIRC > been posted) > - *builtin* tooling to check checksums for everything > - *builtin* tooling to compute checksums after changing setting > - configurable background sweeps for checksums I'm certainly all for adding, well, all of that. I don't think we need *all* of it before considering enabling checksums by default, but I do think it'd be great if we had people working on adding those. > then the story would look differently. Right now checksums just aren't > particularly useful due to not having the above. Just checking recent > data doesn't really guarantee much - failures are more likely in old > data, and the data might even be read from ram. I agree that failures tend to be more likely in old data, though, as with everything, "it depends." Thanks! Stephen
* Tom Lane (tgl@sss.pgh.pa.us) wrote: > Andres Freund <andres@anarazel.de> writes: > > Sure, it might be easy, but we don't have it. Personally I think > > checksums just aren't even ready for prime time. If we had: > > - ability to switch on/off at runtime (early patches for that have IIRC > > been posted) > > - *builtin* tooling to check checksums for everything > > - *builtin* tooling to compute checksums after changing setting > > - configurable background sweeps for checksums > > Yeah, and there's a bunch of usability tooling that we don't have, > centered around "what do you do after you get a checksum error?". > AFAIK there's no way to check or clear such an error; but without > such tools, I'm afraid that checksums are as much of a foot-gun > as a benefit. Uh, ignore_checksum_failure and zero_damanged_pages ...? Not that I'd suggest flipping those on for your production database the first time you see a checksum failure, but we aren't completely without a way to address such cases. Or the to-be-implemented ability to disable checksums for a cluster. > I think developing all this stuff is a good long-term activity, > but I'm hesitant about turning checksums loose on the average > user before we have it. What I dislike about this stance is that it just means we're going to have more and more systems out there that won't have checksums enabled, and there's not going to be an easy way to fix that. > To draw a weak analogy, our checksums right now are more or less > where our replication was in 9.1 --- we had it, but there were still > an awful lot of rough edges. It was only just in this past release > cycle that we started to change default settings towards the idea > that they should support replication by default. I think the checksum > tooling likewise needs years of maturation before we can say that it's > realistically ready to be the default. Well, checksums were introduced in 9.3, which would mean that this is really only being proposed a year earlier than the replication timeline case, if I'm following correctly. I do agree that checksums have not seen quite as much love as the replicaiton work, though I'm tempted to argue that's because they aren't an "interesting" feature now that we've got them- but even those uninteresting features really need someone to champion them when they're important. Unfortunately, our situation with checksums does make me feel a bit like they were added to satisfy a check-box requirement and then not really developed very much further. Following your weak analogy though, it's not like users are going to have to dump/restore their entire cluster to change their systems to take advantage of the new replication capabilities. Thanks! Stephen
On Sat, Jan 21, 2017 at 6:41 PM, Andreas Karlsson <andreas@proxel.se> wrote: > On 01/21/2017 04:48 PM, Stephen Frost wrote: >> >> * Fujii Masao (masao.fujii@gmail.com) wrote: >>> >>> If the performance overhead by the checksums is really negligible, >>> we may be able to get rid of wal_log_hints parameter, as well. >> >> >> Prior benchmarks showed it to be on the order of a few percent, as I >> recall, so I'm not sure that we can say it's negligible (and that's not >> why Magnus was proposing changing the default). > > > It might be worth looking into using the CRC CPU instruction to reduce this > overhead, like we do for the WAL checksums. Since that is a different > algorithm it would be a compatibility break and we would need to support the > old algorithm for upgraded clusters.. We looked at that when picking the algorithm. At that point it seemed that CRC CPU instructions were not universal enough to rely on them. The algorithm we ended up on was designed to be fast on SIMD hardware. Unfortunately on x86-64 that required SSE4.1 integer instructions, so with default compiles there is a lot of performance left on table. A low hanging fruit would be to do CPU detection like the CRC case and enable a SSE4.1 optimized variant when those instructions are available. IIRC it was actually a lot faster than the naive hardware CRC that is used for WAL and about on par with interleaved CRC. That said the actual checksum calculation was not a big issue for performance. The only way to make it really matter was with a larger than shared buffers smaller than RAM workload with tiny per page execution overhead. My test case was SELECT COUNT(*) on wide rows with a small fill factor. Having to WAL log hint bits is the major issue. Regards, Ants Aasma
On Sat, Jan 21, 2017 at 7:39 PM, Petr Jelinek <petr.jelinek@2ndquadrant.com> wrote: > So in summary "postgresql.conf options are easy to change" while "initdb > options are hard to change", I can see this argument used both for > enabling or disabling checksums by default. As I said I would be less > worried if it was easy to turn off, but we are not there afaik. And even > then I'd still want benchmark first. Adding support for disabling checksums is almost trivial as it only requires flipping a value in the control file. And I have somewhere sitting around a similarly simple tool for turning on checksums while the database is offline. FWIW, based on customers and fellow conference goers I have talked to most would gladly take the performance hit, but not the downtime to turn it on on an existing database. Regards, Ants Aasma
* Ants Aasma (ants.aasma@eesti.ee) wrote: > On Sat, Jan 21, 2017 at 7:39 PM, Petr Jelinek > <petr.jelinek@2ndquadrant.com> wrote: > > So in summary "postgresql.conf options are easy to change" while "initdb > > options are hard to change", I can see this argument used both for > > enabling or disabling checksums by default. As I said I would be less > > worried if it was easy to turn off, but we are not there afaik. And even > > then I'd still want benchmark first. > > Adding support for disabling checksums is almost trivial as it only > requires flipping a value in the control file. And I have somewhere > sitting around a similarly simple tool for turning on checksums while > the database is offline. FWIW, based on customers and fellow > conference goers I have talked to most would gladly take the > performance hit, but not the downtime to turn it on on an existing > database. I've had the same reaction from folks I've talked to, unless it was the cases where they were just floored that we didn't have them enabled by default and now they felt the need to go get them enabled on all their systems... Thanks! Stephen
-----BEGIN PGP SIGNED MESSAGE----- Hash: RIPEMD160 tl;dr +1 from me for changing the default, it is worth it. Tom Lane wrote: > Have we seen *even one* report of checksums catching > problems in a usefuld way? Sort of chicken-and-egg, as most places don't have it enabled. Which leads us to: Stephen Frost replies: > This isn't the right question. > > The right question is "have we seen reports of corruption which > checksums *would* have caught?" Well, I've seen corruption that almost certainly would have got caught much earlier than stumbling upon it later on when the corruption happened to finally trigger an error. I don't normally report such things to the list: it's almost always a hardware bug or bad RAM. I would only post if it were caused by a Postgres bug. Tom Lane wrote: > I think this will be making the average user pay X% for nothing. I think you mean "the average user who doesn't check what initdb options are available". And we can certainly post a big notice about this in the release notes, so people can use the initdb option - --disable-data-checksums if they want. > ... pay X% for nothing. It is not for nothing, it is for increasing reliability by detecting (and pinpointing!) corruption as early as possible. - -- Greg Sabino Mullane greg@turnstep.com End Point Corporation http://www.endpoint.com/ PGP Key: 0x14964AC8 201701211513 http://biglumber.com/x/web?pk=2529DF6AB8F79407E94445B4BC9B906714964AC8 -----BEGIN PGP SIGNATURE----- iEYEAREDAAYFAliDwU4ACgkQvJuQZxSWSsi06QCgpPUg4SljERHMWP9tTJnoIRic U2cAoLZINh2rSECNYOwjldlD4dK00FiV =pYQ/ -----END PGP SIGNATURE-----
On Sat, Jan 21, 2017 at 09:02:25PM +0200, Ants Aasma wrote: > On Sat, Jan 21, 2017 at 6:41 PM, Andreas Karlsson <andreas@proxel.se> wrote: > > It might be worth looking into using the CRC CPU instruction to reduce this > > overhead, like we do for the WAL checksums. Since that is a different > > algorithm it would be a compatibility break and we would need to support the > > old algorithm for upgraded clusters.. > > We looked at that when picking the algorithm. At that point it seemed > that CRC CPU instructions were not universal enough to rely on them. > The algorithm we ended up on was designed to be fast on SIMD hardware. > Unfortunately on x86-64 that required SSE4.1 integer instructions, so > with default compiles there is a lot of performance left on table. A > low hanging fruit would be to do CPU detection like the CRC case and > enable a SSE4.1 optimized variant when those instructions are > available. IIRC it was actually a lot faster than the naive hardware > CRC that is used for WAL and about on par with interleaved CRC. I am afraid that won't fly with most end-user packages, cause distributions can't just built packages on their newest machine and then users get SIGILL or whatever cause their 2014 server doesn't have that instruction, or would they still work? So you would have to do runtime detection of the CPU features, and use the appropriate code if they are available. Which also makes regression testing harder, as not all codepaths would get exercised all the time. Michael -- Michael Banck Projektleiter / Senior Berater Tel.: +49 2166 9901-171 Fax: +49 2166 9901-100 Email: michael.banck@credativ.de credativ GmbH, HRB Mönchengladbach 12080 USt-ID-Nummer: DE204566209 Trompeterallee 108, 41189 Mönchengladbach Geschäftsführung: Dr. Michael Meskes, Jörg Folz, Sascha Heuer
-----BEGIN PGP SIGNED MESSAGE----- Hash: RIPEMD160 Tom Lane points out: > Yeah, and there's a bunch of usability tooling that we don't have, > centered around "what do you do after you get a checksum error?". I've asked myself this as well, and came up with a proof of conecpt repair tool called pg_healer: http://blog.endpoint.com/2016/09/pghealer-repairing-postgres-problems.html It's very rough, but my vision is that someday Postgres will have a background process akin to autovacuum that constantly sniffs out corruption problems and (optionally) repairs them. The ability to self-repair is very limited unless checksums are enabled. I agree that there is work needed and problems to be solved with our checksum implementation (e.g. what if cosmic ray hits the checksum itself!?), but I would love to see what we do have enabled by default so we dramatically increase the pool of people with checksums enabled. - -- Greg Sabino Mullane greg@turnstep.com End Point Corporation http://www.endpoint.com/ PGP Key: 0x14964AC8 201701211522 http://biglumber.com/x/web?pk=2529DF6AB8F79407E94445B4BC9B906714964AC8 -----BEGIN PGP SIGNATURE----- iEYEAREDAAYFAliDw5oACgkQvJuQZxSWSshy4QCfXokvagoishfTUnmujjpBNTUT q7IAn0dR74bFy0mj0EMoTU7Taj0db3Sh =qBEJ -----END PGP SIGNATURE-----
On Sat, Jan 21, 2017 at 10:16 PM, Michael Banck <michael.banck@credativ.de> wrote: > On Sat, Jan 21, 2017 at 09:02:25PM +0200, Ants Aasma wrote: >> On Sat, Jan 21, 2017 at 6:41 PM, Andreas Karlsson <andreas@proxel.se> wrote: >> > It might be worth looking into using the CRC CPU instruction to reduce this >> > overhead, like we do for the WAL checksums. Since that is a different >> > algorithm it would be a compatibility break and we would need to support the >> > old algorithm for upgraded clusters.. >> >> We looked at that when picking the algorithm. At that point it seemed >> that CRC CPU instructions were not universal enough to rely on them. >> The algorithm we ended up on was designed to be fast on SIMD hardware. >> Unfortunately on x86-64 that required SSE4.1 integer instructions, so >> with default compiles there is a lot of performance left on table. A >> low hanging fruit would be to do CPU detection like the CRC case and >> enable a SSE4.1 optimized variant when those instructions are >> available. IIRC it was actually a lot faster than the naive hardware >> CRC that is used for WAL and about on par with interleaved CRC. > > I am afraid that won't fly with most end-user packages, cause > distributions can't just built packages on their newest machine and then > users get SIGILL or whatever cause their 2014 server doesn't have that > instruction, or would they still work? > > So you would have to do runtime detection of the CPU features, and use > the appropriate code if they are available. Which also makes regression > testing harder, as not all codepaths would get exercised all the time. Runtime detection is exactly what I had in mind. The code path would also be the same as at least the two most important compilers only need a compilation flag change. And the required instruction was introduced in 2007 so I think anybody who is concerned about performance is covered. Regards, Ants Aasma
On Sun, Jan 22, 2017 at 7:37 AM, Stephen Frost <sfrost@snowman.net> wrote: > Exactly, and that awareness will allow a user to prevent further data > loss or corruption. Slow corruption over time is a very much known and > accepted real-world case that people do experience, as well as bit > flipping enough for someone to write a not-that-old blog post about > them: > > https://blogs.oracle.com/ksplice/entry/attack_of_the_cosmic_rays1 I have no doubt that low frequency cosmic ray bit flipping in main memory is a real phenomenon, having worked at a company that runs enough computers to see ECC messages in kernel logs on a regular basis. But our checksums can't actually help with that, can they? We verify checksums on the way into shared buffers, and compute new checksums on the way back to disk, so any bit-flipping that happens in between those two times -- while your data is a sitting duck in shared buffers -- would not be detected by this scheme. That's ECC's job. So the risk being defended against is corruption while in the disk subsystem, whatever that might consist of (and certainly that includes more buffers in strange places that themselves are susceptible to memory faults etc, and hopefully they have their own error detection and correction). Certainly the ZFS community thinks that pile of turtles can't be trusted and that extra checks are worthwhile, and you can find anecdotal reports and studies about filesystem corruption being detected, for example in the links from https://en.wikipedia.org/wiki/ZFS#Data_integrity . So +1 for enabling it by default. I always turn that on. -- Thomas Munro http://www.enterprisedb.com
Thomas, * Thomas Munro (thomas.munro@enterprisedb.com) wrote: > On Sun, Jan 22, 2017 at 7:37 AM, Stephen Frost <sfrost@snowman.net> wrote: > > Exactly, and that awareness will allow a user to prevent further data > > loss or corruption. Slow corruption over time is a very much known and > > accepted real-world case that people do experience, as well as bit > > flipping enough for someone to write a not-that-old blog post about > > them: > > > > https://blogs.oracle.com/ksplice/entry/attack_of_the_cosmic_rays1 > > I have no doubt that low frequency cosmic ray bit flipping in main > memory is a real phenomenon, having worked at a company that runs > enough computers to see ECC messages in kernel logs on a regular > basis. But our checksums can't actually help with that, can they? We > verify checksums on the way into shared buffers, and compute new > checksums on the way back to disk, so any bit-flipping that happens in > between those two times -- while your data is a sitting duck in shared > buffers -- would not be detected by this scheme. That's ECC's job. Ideally, everyone's gonna run with ECC and have that handle it. That said, there's still the possibility that the bit is flipped after we've calculated the checksum but before it's hit disk, or before it's actually been written out to the storage system underneath. You're correct that if the bit is flipped before we go to write the buffer out that we won't detect that case, but there's not much help for that without compromising performance more than even I'd be ok with. > So the risk being defended against is corruption while in the disk > subsystem, whatever that might consist of (and certainly that includes > more buffers in strange places that themselves are susceptible to > memory faults etc, and hopefully they have their own error detection > and correction). Certainly the ZFS community thinks that pile of > turtles can't be trusted and that extra checks are worthwhile, and you > can find anecdotal reports and studies about filesystem corruption > being detected, for example in the links from > https://en.wikipedia.org/wiki/ZFS#Data_integrity . Agreed. wrt your point above, if you consider "everything that happens after we have passed over a given bit to incorporate its value into our CRC" to be "disk subsystem" then I think we're in agreement on this point and that there's a bunch of stuff that happens then which could be caught by checking our CRC. I've seen some other funny things out there in the wild too though, like a page suddenly being half-zero'd because the virtualization system ran out of memory and barfed. I realize that our CRC might not catch such a case if it's in our shared buffers before we write the page out, but if it happens in the kernel's write buffer after we pushed it from shared buffers then our CRC would detect it. Which actually brings up another point when it comes to if CRCs save from data-loss: they certainly do if you catch it happening before you have expired the WAL and the WAL data is clean. > So +1 for enabling it by default. I always turn that on. Ditto. Thanks! Stephen
Tom, * Tom Lane (tgl@sss.pgh.pa.us) wrote: > Not at all; I just think that it's not clear that they are a net win > for the average user, and so I'm unconvinced that turning them on by > default is a good idea. I could be convinced otherwise by suitable > evidence. What I'm objecting to is turning them on without making > any effort to collect such evidence. As it happens, rather unexpectedly, we had evidence of a bit-flip happening on a 9.1.24 install show up on IRC today: https://paste.fedoraproject.org/533186/85041907/ What that shows is the output from: select * from heap_page_items(get_raw_page('theirtable', 4585)); With a row whose t_ctid is (134222313,18). Looking at the base-2 format of 4585 and 134222313: 0000 0000 0000 0000 0001 0001 1110 1001 0000 1000 0000 0000 0001 0001 1110 1001 There appears to be other issues with the page also but this was discovered through a pg_dump where the user was trying to get data out to upgrade to something more recent. Not clear if the errors on the page all happened at once or if it was over time, of course, but it's at least possible that this particular area of storage has been degrading over time and that identifying an error when it was just the bit-flip in the t_ctid (thanks to a checksum) might have allowed the user to pull out the data. During the discussion on IRC, someone else mentioned a similar problem which was due to not having ECC memory in their server. As discussed, that might mean that we wouldn't have caught the corruption since we only calculate the checksum on the way out of shared_buffers, but it's also entirely possible that we would have because it could have happened in kernel space too. We're still working with the user to see if we can get their data out, but that looks like pretty good evidence that maybe we should care about enabling checksums to catch corruption before it causes undo pain for our users. The raw page is here: https://paste.fedoraproject.org/533195/48504224/ if anyone is curious to look at it further (we're looking through it too). Thanks! Stephen
On 1/21/17 10:02 AM, Tom Lane wrote: > Magnus Hagander <magnus@hagander.net> writes: >> Is it time to enable checksums by default, and give initdb a switch to turn >> it off instead? > Have we seen *even one* report of checksums catching problems in a useful > way? I've experienced multiple corruption events that were ultimately tracked down to storage problems. These first manifested as corruption to PG page structures, and I have no way to know how much user data might have been corrupted. Obviously I can't prove that checksums would have caught all of those errors, but there's one massive benefit they would have given us: we'd know that Postgres was not the source of the corruption. That would have eliminated a lot of guesswork. So that we can stop guessing about performance, I did a simple benchmark on my laptop. Stock config except for synchronous_commit=off and checkpoint_timeout=1min, with the idea being that we want to test flushing buffers. Both databases initialized with scale=50, or 800MB. shared_buffers was 128MB. After a couple runs in each database to create dead tuples, runs were performed with pgbench -rT 300 & sleep 2 && PGPORT=5444 pgbench -rT 300 No checksums checksums 818 tps 758 tps 821 tps 877 tps 879 tps 799 tps 739 tps 808 tps 867 tps 845 tps 854 tps 831 tps Looking at per-statement latency, the variation is always in the update to branches. I'll try to get some sequential runs tonight. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
On 01/21/2017 05:35 PM, Tom Lane wrote: > Stephen Frost <sfrost@snowman.net> writes: >> * Tom Lane (tgl@sss.pgh.pa.us) wrote: >>> Have we seen *even one* report of checksums catching problems in >>> auseful way? > >> This isn't the right question. > > I disagree. If they aren't doing something useful for people who > have turned them on, what's the reason to think they'd do something > useful for the rest? > I believe Stephen is right. The fact that you don't see something, e.g. reports about checksums catching something in production deployments, proves nothing because of "survivorship bias" discovered by Abraham Wald during WWW II [1]. Not seeing bombers with bullet holes in engines does not mean you don't need to armor engines. Quite the opposite. [1] https://medium.com/@penguinpress/an-excerpt-from-how-not-to-be-wrong-by-jordan-ellenberg-664e708cfc3d#.j9d9c35mb Applied to checksums, we're quite unlikely to see reports about data corruption caught by checksums because "ERROR: invalid page in block X" is such a clear sign of data corruption that people don't even ask us about that. Combine that with the fact that most people are running with defaults (i.e. no checksums) and that data corruption is a rare event by nature, and we're bound to have no such reports. What we got, however, are reports about strange errors from instances without checksums enabled, that were either determined to be data corruption, or disappeared after dump/restore or reindexing. It's hard to say for sure whether those were cases of data corruption (where checksums might have helped) or some other bug (resulting in a corrupted page with the checksum computed on the corrupted page). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 01/21/2017 05:51 PM, Stephen Frost wrote: > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: >> On 21/01/17 17:31, Stephen Frost wrote: >>> This is just changing the *default*, not requiring checksums to always >>> be enabled. We do not hold the same standards for our defaults as we do >>> for always-enabled code, for clear reasons- not every situation is the >>> same and that's why we have defaults that people can change. >> >> I can buy that. If it's possible to turn checksums off without >> recreating data directory then I think it would be okay to have default on. > > I'm glad to hear that. > >>>> The change of wal_level was supported by benchmark, I think it's >>>> reasonable to ask for this to be as well. >>> >>> No, it wasn't, it was that people felt the cases where changing >>> wal_level would seriously hurt performance didn't out-weigh the value of >>> making the change to the default. >> >> Really? > > Yes. > >> https://www.postgresql.org/message-id/d34ce5b5-131f-66ce-f7c5-eb406dbe026f@2ndquadrant.com > > From the above link: > >> So while it'd be trivial to construct workloads demonstrating the >> optimizations in wal_level=minimal (e.g. initial loads doing >> CREATE TABLE + COPY + CREATE INDEX in a single transaction), but >> that would be mostly irrelevant I guess. > >> Instead, I've decided to run regular pgbench TPC-B-like workload on >> a bunch of different scales, and measure throughput + some xlog >> stats with each of the three wal_level options. > > In other words, there was no performance testing of the cases where > wal_level=minimal (the old default) optimizations would have been > compared against wal_level > minimal. > > I'm quite sure that the performance numbers for the CREATE TABLE + > COPY case with wal_level=minimal would have been *far* better than > for wal_level > minimal. > > That case was entirely punted on as "mostly irrelevant" even though > there are known production environments where those optimizations > make a huge difference. Those are OLAP cases though, and not nearly > enough folks around here seem to care one bit about them, which I > continue to be disappointed by. > You make it look as if we swept that case under the carpet, despite there being quite a bit of relevant discussion in that thread. We might argue how many deployments benefit from the Wal_level=minimal optimization (I'm sure some of our customers do benefit from it too), and whether it makes it 'common workload' or not. It's trivial to construct a workload demonstrating pretty arbitrary performance advantage of the wal_level=minimal case. Hence no point in wasting time on demonstrating it, making the case rather irrelevant for the benchmarking. Moreover, there are quite a few differences between enabling checksums by default, and switching to wal_level=minimal: - There are reasonable workaround that give you wal_level=minimal back (UNLOGGED tables). And those work even when you actually need a standby, which is pretty common these days. With checksums there's nothing like that. - You can switch between wal_level values by merely restarting the cluster, while checksums may only be enabled/disabled by initdb. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 01/21/2017 05:53 PM, Stephen Frost wrote: > * Tom Lane (tgl@sss.pgh.pa.us) wrote: >> Stephen Frost <sfrost@snowman.net> writes: >>> * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: >>>> The change of wal_level was supported by benchmark, I think it's >>>> reasonable to ask for this to be as well. >> >>> No, it wasn't, it was that people felt the cases where changing >>> wal_level would seriously hurt performance didn't out-weigh the value of >>> making the change to the default. >> >> It was "supported" in the sense that somebody took the trouble to >> measure the impact, so that we had some facts on which to base the >> value judgment that the cost was acceptable. In the case of >> checksums, you seem to be in a hurry to arrive at a conclusion >> without any supporting evidence. > Exactly. > No, no one measured the impact in the cases where wal_level=minimal > makes a big difference, that I saw, at least. > We already knew we can construct data-loading workloads relying on the wal_level=minimal optimization and demonstrating pretty arbitrary benefits, so there was no point in benchmarking them. That does not mean those cases were not considered, though. > > Further info with links to what was done are in my reply to Petr. > > As for checksums, I do see value in them and I'm pretty sure that > the author of that particular feature did as well, or we wouldn't > even have it as an option. You seem to be of the opinion that we > might as well just rip all of that code and work out as being > useless. > I do see value in them too, and if turning then off again would be as simple as reverting back to wal_level=minimal, I would be strongly in favor of enabling then to 'on' by default (after a bit of benchmarking, similar to what we did in the wal_level=minimal case). The fact that disabling them requires initdb makes the reasoning much trickier, though. That being said, I'm ready to do some benchmarking on this, so that we have at least some numbers to argue about. Can we agree on a set of workloads that we want to benchmark in the first round? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 01/21/2017 04:18 PM, Petr Jelinek wrote: > On 21/01/17 11:39, Magnus Hagander wrote: >> Is it time to enable checksums by default, and give initdb a switch to >> turn it off instead? > > I'd like to see benchmark first, both in terms of CPU and in terms of > produced WAL (=network traffic) given that it turns on logging of hint bits. > ... and those hint bits may easily trigger full-page writes, resulting in significant write amplification. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Jan 21, 2017 at 8:16 PM, Ants Aasma <ants.aasma@eesti.ee> wrote:
On Sat, Jan 21, 2017 at 7:39 PM, Petr Jelinek
<petr.jelinek@2ndquadrant.com> wrote:
> So in summary "postgresql.conf options are easy to change" while "initdb
> options are hard to change", I can see this argument used both for
> enabling or disabling checksums by default. As I said I would be less
> worried if it was easy to turn off, but we are not there afaik. And even
> then I'd still want benchmark first.
Adding support for disabling checksums is almost trivial as it only
requires flipping a value in the control file. And I have somewhere
sitting around a similarly simple tool for turning on checksums while
the database is offline. FWIW, based on customers and fellow
conference goers I have talked to most would gladly take the
performance hit, but not the downtime to turn it on on an existing
database.
This is exactly the scenario I've been exposed to over and over again. If it can be turned on/off online, then the default matters a lot less. But it has to be online.
Yes, you can set up a replica (which today requires third party products like slony, bucardo or pglogical -- at least we'll hopefully have pglogical fully in 10, but it's still a very expensive way to fix the problem).
If we can make it cheap and easy to turn them off, that makes a change of the default a lot cheaper. Did you have a tool for that sitting around as well?
From: pgsql-hackers-owner@postgresql.org > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Magnus Hagander > Is it time to enable checksums by default, and give initdb a switch to turn > it off instead? > > I keep running into situations where people haven't enabled it, because > (a) they didn't know about it, or (b) their packaging system ran initdb > for them so they didn't even know they could. And of course they usually > figure this out once the db has enough data and traffic that the only way > to fix it is to set up something like slony/bucardo/pglogical and a whole > new server to deal with it.. (Which is something that would also be good > to fix -- but having the default changed would be useful as well) +10 I was wondering why the community had decided to turn it off by default. IIRC, the reason was that the performance overheadwas 20-30% when the entire data directory was placed on the tmpfs, but it's not as important as the data protectionby default. Regards Takayuki Tsunakawa
> 21 янв. 2017 г., в 18:18, Petr Jelinek <petr.jelinek@2ndquadrant.com> написал(а): > > On 21/01/17 11:39, Magnus Hagander wrote: >> Is it time to enable checksums by default, and give initdb a switch to >> turn it off instead? +1 > > I'd like to see benchmark first, both in terms of CPU and in terms of > produced WAL (=network traffic) given that it turns on logging of hint bits. Here are the results of my testing for 9.4 in December 2014. The benchmark was done on a production like use case when allthe data fits in memory (~ 20 GB) and doesn’t fit into shared_buffers (it was intentionally small - 128 MB on stress stend),so that shared_blk_read / shared_blk_hit = 1/4. The workload was a typical OLTP but with mostly write queries (80%writes, 20% reads). Here are the number of WALs written during the test: Defaults 263 wal_log_hints 410 checksums 367 I couldn’t find the answer why WAL write amplification is even worse for wal_log_hints than for checksums but I checked severaltimes and it always reproduced. As for CPU I couldn’t see the overhead [1]. And perf top showed me less then 2% in calculating CRC. For all new DBs we now enable checksums at initdb and several dozens of our shards use checksums now. I don’t see any performancedifference for them comparing with non-checksumed clusters. And we have already had one case when we caught datacorruption with checksums. [1] https://yadi.sk/i/VAiWjv6t3AQCs2?lang=en -- May the force be with you… https://simply.name
On Sun, Jan 22, 2017 at 3:43 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > That being said, I'm ready to do some benchmarking on this, so that we have > at least some numbers to argue about. Can we agree on a set of workloads > that we want to benchmark in the first round? > I think if we can get data for pgbench read-write workload when data doesn't fit in shared buffers but fit in RAM, that can give us some indication. We can try by varying the ratio of shared buffers w.r.t data. This should exercise the checksum code both when buffers are evicted and at next read. I think it also makes sense to check the WAL data size for each of those runs. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 01/23/2017 08:30 AM, Amit Kapila wrote: > On Sun, Jan 22, 2017 at 3:43 PM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> >> That being said, I'm ready to do some benchmarking on this, so that we have >> at least some numbers to argue about. Can we agree on a set of workloads >> that we want to benchmark in the first round? >> > > I think if we can get data for pgbench read-write workload when data > doesn't fit in shared buffers but fit in RAM, that can give us some > indication. We can try by varying the ratio of shared buffers w.r.t > data. This should exercise the checksum code both when buffers are > evicted and at next read. I think it also makes sense to check the > WAL data size for each of those runs. > Yes, I'm thinking that's pretty much the worst case for OLTP-like workload, because it has to evict buffers from shared buffers, generating a continuous stream of writes. Doing that on good storage (e.g. PCI-e SSD or possibly tmpfs) will further limit the storage overhead, making the time spent computing checksums much more significant. Makes sense? What about other types of workload? I think we should not look just at write-heavy workloads - I wonder what is the overhead of verifying the checksums in read-only workloads (again, with data that fits into RAM). What about large data loads simulating OLAP, and exports (e.g. pg_dump)? That leaves us with 4 workload types, I guess: 1) read-write OLTP (shared buffers < data < RAM) 2) read-only OLTP (shared buffers < data < RAM) 3) large data loads (COPY) 4) large data exports (pg_dump) Anything else? The other question is of course hardware - IIRC there are differences between CPUs. I do have a new e5-2620v4, but perhaps it'd be good to also do some testing on a Power machine, or an older Intel CPU. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jan 23, 2017 at 1:18 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 01/23/2017 08:30 AM, Amit Kapila wrote: >> >> >> I think if we can get data for pgbench read-write workload when data >> doesn't fit in shared buffers but fit in RAM, that can give us some >> indication. We can try by varying the ratio of shared buffers w.r.t >> data. This should exercise the checksum code both when buffers are >> evicted and at next read. I think it also makes sense to check the >> WAL data size for each of those runs. >> > > Yes, I'm thinking that's pretty much the worst case for OLTP-like workload, > because it has to evict buffers from shared buffers, generating a continuous > stream of writes. Doing that on good storage (e.g. PCI-e SSD or possibly > tmpfs) will further limit the storage overhead, making the time spent > computing checksums much more significant. Makes sense? > Yeah, I think that can be helpful with respect to WAL, but for data, if we are considering the case where everything fits in RAM, then faster storage might or might not help. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 01/23/2017 09:57 AM, Amit Kapila wrote: > On Mon, Jan 23, 2017 at 1:18 PM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> On 01/23/2017 08:30 AM, Amit Kapila wrote: >>> >>> >>> I think if we can get data for pgbench read-write workload when data >>> doesn't fit in shared buffers but fit in RAM, that can give us some >>> indication. We can try by varying the ratio of shared buffers w.r.t >>> data. This should exercise the checksum code both when buffers are >>> evicted and at next read. I think it also makes sense to check the >>> WAL data size for each of those runs. >>> >> >> Yes, I'm thinking that's pretty much the worst case for OLTP-like workload, >> because it has to evict buffers from shared buffers, generating a continuous >> stream of writes. Doing that on good storage (e.g. PCI-e SSD or possibly >> tmpfs) will further limit the storage overhead, making the time spent >> computing checksums much more significant. Makes sense? >> > > Yeah, I think that can be helpful with respect to WAL, but for data, > if we are considering the case where everything fits in RAM, then > faster storage might or might not help. > I'm not sure I understand. Why wouldn't faster storage help? It's only a matter of generating enough dirty buffers (that get evicted from shared buffers) to saturate the storage. With some storage you'll hit that at 100 MB/s, with PCI-e it might be more like 1GB/s. Of course, if the main bottleneck is somewhere else (e.g. hitting 100% CPU utilization before putting any pressure on storage), that's not going to make much difference. Or perhaps I missed something important? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jan 23, 2017 at 3:56 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 01/23/2017 09:57 AM, Amit Kapila wrote: >> >> On Mon, Jan 23, 2017 at 1:18 PM, Tomas Vondra >> <tomas.vondra@2ndquadrant.com> wrote: >>> >>> On 01/23/2017 08:30 AM, Amit Kapila wrote: >>>> >>>> >>>> >>>> I think if we can get data for pgbench read-write workload when data >>>> doesn't fit in shared buffers but fit in RAM, that can give us some >>>> indication. We can try by varying the ratio of shared buffers w.r.t >>>> data. This should exercise the checksum code both when buffers are >>>> evicted and at next read. I think it also makes sense to check the >>>> WAL data size for each of those runs. >>>> >>> >>> Yes, I'm thinking that's pretty much the worst case for OLTP-like >>> workload, >>> because it has to evict buffers from shared buffers, generating a >>> continuous >>> stream of writes. Doing that on good storage (e.g. PCI-e SSD or possibly >>> tmpfs) will further limit the storage overhead, making the time spent >>> computing checksums much more significant. Makes sense? >>> >> >> Yeah, I think that can be helpful with respect to WAL, but for data, >> if we are considering the case where everything fits in RAM, then >> faster storage might or might not help. >> > > I'm not sure I understand. Why wouldn't faster storage help? It's only a > matter of generating enough dirty buffers (that get evicted from shared > buffers) to saturate the storage. > When the page gets evicted from shared buffer, it is just pushed to kernel; the real write to disk won't happen until the kernel feels like it.They are written to storage later when a checkpoint occurs. So, now if we have fast storage subsystem then it can improve the writes from kernel to disk, but not sure how much that can help in improving TPS. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 01/23/2017 01:40 PM, Amit Kapila wrote: > On Mon, Jan 23, 2017 at 3:56 PM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> On 01/23/2017 09:57 AM, Amit Kapila wrote: >>> >>> On Mon, Jan 23, 2017 at 1:18 PM, Tomas Vondra >>> <tomas.vondra@2ndquadrant.com> wrote: >>>> >>>> On 01/23/2017 08:30 AM, Amit Kapila wrote: >>>>> >>>>> >>>>> >>>>> I think if we can get data for pgbench read-write workload when data >>>>> doesn't fit in shared buffers but fit in RAM, that can give us some >>>>> indication. We can try by varying the ratio of shared buffers w.r.t >>>>> data. This should exercise the checksum code both when buffers are >>>>> evicted and at next read. I think it also makes sense to check the >>>>> WAL data size for each of those runs. >>>>> >>>> >>>> Yes, I'm thinking that's pretty much the worst case for OLTP-like >>>> workload, >>>> because it has to evict buffers from shared buffers, generating a >>>> continuous >>>> stream of writes. Doing that on good storage (e.g. PCI-e SSD or possibly >>>> tmpfs) will further limit the storage overhead, making the time spent >>>> computing checksums much more significant. Makes sense? >>>> >>> >>> Yeah, I think that can be helpful with respect to WAL, but for data, >>> if we are considering the case where everything fits in RAM, then >>> faster storage might or might not help. >>> >> >> I'm not sure I understand. Why wouldn't faster storage help? It's only a >> matter of generating enough dirty buffers (that get evicted from shared >> buffers) to saturate the storage. >> > > When the page gets evicted from shared buffer, it is just pushed to > kernel; the real write to disk won't happen until the kernel feels > like it.They are written to storage later when a checkpoint occurs. > So, now if we have fast storage subsystem then it can improve the > writes from kernel to disk, but not sure how much that can help in > improving TPS. > I don't think that's quite true. If the pages are evicted by bgwriter, since 9.6 there's a flush every 512kB. This will also flush data written by backends, of course. But even without the flushing, the OS does not wait with the flush until the very last moment - that'd be a huge I/O spike. Instead, the OS will write the dirty data to disk after 30 seconds, of after accumulating some predefined amount of dirty data. So the system will generally get into a "stable state" where it writes about the same amount of data to disk on average. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jan 23, 2017 at 6:57 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 01/23/2017 01:40 PM, Amit Kapila wrote: >> >> On Mon, Jan 23, 2017 at 3:56 PM, Tomas Vondra >> <tomas.vondra@2ndquadrant.com> wrote: >>> >>> On 01/23/2017 09:57 AM, Amit Kapila wrote: >>>> >>>> >>>> On Mon, Jan 23, 2017 at 1:18 PM, Tomas Vondra >>>> <tomas.vondra@2ndquadrant.com> wrote: >>>>> >>>>> >>>>> On 01/23/2017 08:30 AM, Amit Kapila wrote: >>>>>> >>>>>> >>>>>> >>>>>> >>>>>> I think if we can get data for pgbench read-write workload when data >>>>>> doesn't fit in shared buffers but fit in RAM, that can give us some >>>>>> indication. We can try by varying the ratio of shared buffers w.r.t >>>>>> data. This should exercise the checksum code both when buffers are >>>>>> evicted and at next read. I think it also makes sense to check the >>>>>> WAL data size for each of those runs. >>>>>> >>>>> >>>>> Yes, I'm thinking that's pretty much the worst case for OLTP-like >>>>> workload, >>>>> because it has to evict buffers from shared buffers, generating a >>>>> continuous >>>>> stream of writes. Doing that on good storage (e.g. PCI-e SSD or >>>>> possibly >>>>> tmpfs) will further limit the storage overhead, making the time spent >>>>> computing checksums much more significant. Makes sense? >>>>> >>>> >>>> Yeah, I think that can be helpful with respect to WAL, but for data, >>>> if we are considering the case where everything fits in RAM, then >>>> faster storage might or might not help. >>>> >>> >>> I'm not sure I understand. Why wouldn't faster storage help? It's only a >>> matter of generating enough dirty buffers (that get evicted from shared >>> buffers) to saturate the storage. >>> >> >> When the page gets evicted from shared buffer, it is just pushed to >> kernel; the real write to disk won't happen until the kernel feels >> like it.They are written to storage later when a checkpoint occurs. >> So, now if we have fast storage subsystem then it can improve the >> writes from kernel to disk, but not sure how much that can help in >> improving TPS. >> > > I don't think that's quite true. If the pages are evicted by bgwriter, since > 9.6 there's a flush every 512kB. > Right, but backend flush after is zero by default. > This will also flush data written by > backends, of course. But even without the flushing, the OS does not wait > with the flush until the very last moment - that'd be a huge I/O spike. > Instead, the OS will write the dirty data to disk after 30 seconds, of after > accumulating some predefined amount of dirty data. > This is the reason I told it might or might not help. I think there is no point in having too much discussion on this point, if you access to fast storage system, then go ahead and perform the tests on same, if not, then also we can try without that. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Sat, Jan 21, 2017 at 9:09 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Not at all; I just think that it's not clear that they are a net win > for the average user, and so I'm unconvinced that turning them on by > default is a good idea. I could be convinced otherwise by suitable > evidence. What I'm objecting to is turning them on without making > any effort to collect such evidence. +1 One insight Jim Gray has in the classic paper "Why Do Computers Stop and What Can Be Done About It?" [1] is that fault-tolerant hardware is table stakes, and so most failures are related to operator error, and to a lesser extent software bugs. The paper is about 30 years old. I don't recall ever seeing a checksum failure on a Heroku Postgres database, even though they were enabled as soon as the feature became available. I have seen a few corruption problems brought to light by amcheck, though, all of which were due to bugs in software. Apparently, before I joined Heroku there were real reliability problems with the storage subsystem that Heroku Postgres runs on (it's a pluggable storage service from a popular cloud provider -- the "pluggable" functionality would have made it fairly novel at the time). These problems were something that the Heroku Postgres team dealt with about 6 years ago. However, anecdotal evidence suggests that the reliability of the same storage system *vastly* improved roughly a year or two later. We still occasionally lose drives, but drives seem to fail fast in a fashion that lets us recover without data loss easily. In practice, Postgres checksums do *not* seem to catch problems. That's been my experience, at least. Obviously every additional check helps, and it may be something we can do without any appreciable downside. I'd like to see a benchmark. [1] http://www.hpl.hp.com/techreports/tandem/TR-85.7.pdf -- Peter Geoghegan
On Sat, Jan 21, 2017 at 12:35 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Andres Freund <andres@anarazel.de> writes: >> Sure, it might be easy, but we don't have it. Personally I think >> checksums just aren't even ready for prime time. If we had: >> - ability to switch on/off at runtime (early patches for that have IIRC >> been posted) >> - *builtin* tooling to check checksums for everything >> - *builtin* tooling to compute checksums after changing setting >> - configurable background sweeps for checksums > > Yeah, and there's a bunch of usability tooling that we don't have, > centered around "what do you do after you get a checksum error?". > AFAIK there's no way to check or clear such an error; but without > such tools, I'm afraid that checksums are as much of a foot-gun > as a benefit. I see your point here, but they sure saved my ass with that pl/sh issue. So I'm inclined to lightly disagree; there are good arguments either way. merlin
On 1/23/17 1:30 AM, Amit Kapila wrote: > On Sun, Jan 22, 2017 at 3:43 PM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> >> That being said, I'm ready to do some benchmarking on this, so that we have >> at least some numbers to argue about. Can we agree on a set of workloads >> that we want to benchmark in the first round? >> > > I think if we can get data for pgbench read-write workload when data > doesn't fit in shared buffers but fit in RAM, that can give us some > indication. We can try by varying the ratio of shared buffers w.r.t > data. This should exercise the checksum code both when buffers are > evicted and at next read. I think it also makes sense to check the > WAL data size for each of those runs. I tried testing this (and thought I sent an email about it but don't see it now :/). Unfortunately, on my laptop I wasn't getting terribly consistent runs; I was seeing +/- ~8% TPS. Sometimes checksumps appeared to add ~10% overhead, but it was hard to tell. If someone has a more stable (is in, dedicated) setup, testing would be useful. BTW, I ran the test with small (default 128MB) shared_buffers, scale 50 (800MB database), sync_commit = off, checkpoint_timeout = 1min, to try and significantly increase the rate of buffers being written out. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
On 1/23/17 6:14 PM, Peter Geoghegan wrote: > In practice, Postgres checksums do *not* seem to > catch problems. That's been my experience, at least. For someone running on a bunch of AWS hardware that doesn't really surprise me. Presumably, anyone operating at that scale would be quickly overwhelmed if odd hardware errors were even remotely common. (Note that odd errors aren't the same as an outright failure.) Where I'd expect this to help is with anyone running a moderate-sized data center that doesn't have the kind of monitoring resources a cloud provider does. As for collecting data, I don't really know what more data we can get. We get data corruption reports on a fairly regular basis. I think it's a very safe bet that CRCs would identify somewhere between 20% and 80%. Maybe that number could be better refined, but that's still going to be guesswork. As others have mentioned, right now practically no one enables this, so we've got zero data on how useful it might actually be. If the patch to make this a GUC goes through then at least we could tell people that have experienced corruption to enable this. That might provide some data, though the horse is already well out of the barn by then. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
Jim, * Jim Nasby (Jim.Nasby@BlueTreble.com) wrote: > As others have mentioned, right now practically no one enables this, > so we've got zero data on how useful it might actually be. Uhm, Peter G just said that Heroku enables this on all their databases and have yet to see a false-positive report or an issue with having it enabled. That, plus the reports and evidence we've seen in the past couple days, look like a pretty ringing endorsement for having them. I'll ping the RDS crowd and see if they'll tell me what they're doing and what their thoughts are on it. Thanks! Stephen
Stephen Frost <sfrost@snowman.net> writes:
> * Jim Nasby (Jim.Nasby@BlueTreble.com) wrote:
>> As others have mentioned, right now practically no one enables this,
>> so we've got zero data on how useful it might actually be.
> Uhm, Peter G just said that Heroku enables this on all their databases
> and have yet to see a false-positive report or an issue with having it
> enabled.
> That, plus the reports and evidence we've seen in the past couple days,
> look like a pretty ringing endorsement for having them.
You must have read a different Peter G than I did. What I read was
>> I don't recall ever seeing a checksum failure on a Heroku Postgres
>> database,
which did not sound like an endorsement to me.
regards, tom lane
On 1/23/17 6:55 PM, Stephen Frost wrote: > * Jim Nasby (Jim.Nasby@BlueTreble.com) wrote: >> As others have mentioned, right now practically no one enables this, >> so we've got zero data on how useful it might actually be. > Uhm, Peter G just said that Heroku enables this on all their databases > and have yet to see a false-positive report or an issue with having it > enabled. > > That, plus the reports and evidence we've seen in the past couple days, > look like a pretty ringing endorsement for having them. > > I'll ping the RDS crowd and see if they'll tell me what they're doing > and what their thoughts are on it. Oh, I read the thread as "there's no data to support checksums are useful", not "there's no data to support there's little risk of bugs or false-positives". I certainly agree that Heroku is a good test of both of those. IIRC Grant's mentioned in one of his presentations that they enable checksums, but getting more explicit info would be good. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
* Tom Lane (tgl@sss.pgh.pa.us) wrote: > Stephen Frost <sfrost@snowman.net> writes: > > * Jim Nasby (Jim.Nasby@BlueTreble.com) wrote: > >> As others have mentioned, right now practically no one enables this, > >> so we've got zero data on how useful it might actually be. > > > Uhm, Peter G just said that Heroku enables this on all their databases > > and have yet to see a false-positive report or an issue with having it > > enabled. > > > That, plus the reports and evidence we've seen in the past couple days, > > look like a pretty ringing endorsement for having them. > > You must have read a different Peter G than I did. What I read was > > >> I don't recall ever seeing a checksum failure on a Heroku Postgres > >> database, Not sure how this part of that sentence was missed: ----- ... even though they were enabled as soon as the feature became available. ----- Which would seem to me to say "the code's been running for a long time on a *lot* of systems without throwing a false positive or surfacing a bug." Given your up-thread concerns that enabling checksums could lead to false positives and might surface bugs, that's pretty good indication that those concerns are unfounded. In addition, it shows that big hosting providers were anxious to get the feature and enabled it immediately for their users, while we debate if it might be useful for *our* users. I certainly don't believe that Heroku or Amazon have all the right answers for everything, but I do think we should consider that they enabled checksums immediately, along with the other consultants on this thread who have said the same. Lastly, I've already pointed out that there were 2 cases recently reported on IRC of corruption on reasonably modern gear, with a third comment following that up from Merlin. These notions that corruption doesn't happen today, or that we would have heard about it if it had, also look unfounded from my perspective. Thanks! Stephen
Jim, * Jim Nasby (Jim.Nasby@BlueTreble.com) wrote: > On 1/23/17 6:55 PM, Stephen Frost wrote: > >* Jim Nasby (Jim.Nasby@BlueTreble.com) wrote: > >>As others have mentioned, right now practically no one enables this, > >>so we've got zero data on how useful it might actually be. > >Uhm, Peter G just said that Heroku enables this on all their databases > >and have yet to see a false-positive report or an issue with having it > >enabled. > > > >That, plus the reports and evidence we've seen in the past couple days, > >look like a pretty ringing endorsement for having them. > > > >I'll ping the RDS crowd and see if they'll tell me what they're doing > >and what their thoughts are on it. > > Oh, I read the thread as "there's no data to support checksums are > useful", There's been multiple reports on this thread that corruption does happen. Sure, it'd be nice if we had a report of it happening with checksums enabled and where checksums caught it, but I don't see any basis for an argument that they wouldn't ever catch real-world bit-flipping corruption. > IIRC Grant's mentioned in one of his presentations that they enable > checksums, but getting more explicit info would be good. Frankly, my recollection is that they wouldn't use PG until it had page-level checksums, and that they run it on all of their instances, but I'd like to get confirmation of that, if I can, and also hear if they've got examples of the checksums we have catching real issues. Thanks! Stephen
On 1/23/17 7:15 PM, Tom Lane wrote: >> Uhm, Peter G just said that Heroku enables this on all their databases >> and have yet to see a false-positive report or an issue with having it >> enabled. >> That, plus the reports and evidence we've seen in the past couple days, >> look like a pretty ringing endorsement for having them. > You must have read a different Peter G than I did. What I read was > >>> I don't recall ever seeing a checksum failure on a Heroku Postgres >>> database, > which did not sound like an endorsement to me. Well, it is pretty good evidence that there's no bugs and that false positives aren't a problem. As I mentioned earlier, my bet is that any significantly large cloud provider has a ton of things going on behind the scenes to prevent oddball (as in non-repeating) errors. When you've got 1M+ servers even small probability bugs can become really big problems. In any case, how can we go about collecting data that checksums help? We certainly know people suffer data corruption. We can only guess at how many of those incidents would be caught by checksums. I don't see how we can get data on that unless we get a lot more users running checksums. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
On Mon, Jan 23, 2017 at 5:26 PM, Stephen Frost <sfrost@snowman.net> wrote: > Not sure how this part of that sentence was missed: > > ----- > ... even though they were enabled as soon as the feature became > available. > ----- > > Which would seem to me to say "the code's been running for a long time > on a *lot* of systems without throwing a false positive or surfacing a > bug." I think you've both understood what I said correctly. Note that I remain neutral on the question of whether or not checksums should be enabled by default. Perhaps I've missed the point entirely, but, I have to ask: How could there ever be false positives? With checksums, false positives are simply not allowed. Therefore, there cannot be a false positive, unless we define checksums as a mechanism that should only find problems that originate somewhere at or below the filesystem. We clearly have not done that, so ISTM that checksums could legitimately find bugs in the checksum code. I am not being facetious. -- Peter Geoghegan
On Tue, Jan 24, 2017 at 10:26 AM, Stephen Frost <sfrost@snowman.net> wrote: > * Tom Lane (tgl@sss.pgh.pa.us) wrote: >> >> I don't recall ever seeing a checksum failure on a Heroku Postgres >> >> database, > > Not sure how this part of that sentence was missed: > > ----- > ... even though they were enabled as soon as the feature became > available. > ----- > > Which would seem to me to say "the code's been running for a long time > on a *lot* of systems without throwing a false positive or surfacing a > bug." I am reading that similarly to what Tom is seeing: enabling it has proved Heroku that it did not catch problems in years, meaning that the performance cost induced by enabling it has paid nothing in practive, except the insurance to catch up problems should they happen. > Given your up-thread concerns that enabling checksums could lead to > false positives and might surface bugs, that's pretty good indication > that those concerns are unfounded. FWIW, I have seen failures that could have been as hardware failures or where enabling checksums may have helped, but they were on pre-9.3 instances. Now there is a performance penalty in enabling them, but it solely depends on the page eviction from shared buffers, which is pretty high for some load patterns I work with, still even with that we saw a 1~2% output penalty in measurements. Perhaps not everybody would like to pay this price. FWIW, we are thinking about paying it as VMs are more sensitive to vmdk-like class of bugs. I am not sure that everybody would like to pay that. By seeing this thread -hackers likely are fine with the cost induced. -- Michael
* Peter Geoghegan (pg@heroku.com) wrote: > On Mon, Jan 23, 2017 at 5:26 PM, Stephen Frost <sfrost@snowman.net> wrote: > > Not sure how this part of that sentence was missed: > > > > ----- > > ... even though they were enabled as soon as the feature became > > available. > > ----- > > > > Which would seem to me to say "the code's been running for a long time > > on a *lot* of systems without throwing a false positive or surfacing a > > bug." > > I think you've both understood what I said correctly. Note that I > remain neutral on the question of whether or not checksums should be > enabled by default. > > Perhaps I've missed the point entirely, but, I have to ask: How could > there ever be false positives? With checksums, false positives are > simply not allowed. Therefore, there cannot be a false positive, > unless we define checksums as a mechanism that should only find > problems that originate somewhere at or below the filesystem. We > clearly have not done that, so ISTM that checksums could legitimately > find bugs in the checksum code. I am not being facetious. I'm not sure I'm following your question here. A false positive would be a case where the checksum code throws an error on a page whose checksum is correct, or where the checksum has failed but nothing is actually wrong/different on the page. As for the purpose of checksums, it's exactly to identify cases where the page has been changed since we wrote it out, due to corruption in the kernel, filesystem, storage system, etc. As we only check them when we read in a page and calculate them when we go to write the page out, they aren't helpful for shared_buffers corruption, generally speaking. It might be interesting to consider checking them in 'clean' pages in shared_buffers in a background process, as that, presumably, *would* detect shared buffers corruption. Thanks! Stephen
On 24/01/17 02:39, Michael Paquier wrote: > On Tue, Jan 24, 2017 at 10:26 AM, Stephen Frost <sfrost@snowman.net> wrote: >> * Tom Lane (tgl@sss.pgh.pa.us) wrote: >>>>> I don't recall ever seeing a checksum failure on a Heroku Postgres >>>>> database, >> >> Not sure how this part of that sentence was missed: >> >> ----- >> ... even though they were enabled as soon as the feature became >> available. >> ----- >> >> Which would seem to me to say "the code's been running for a long time >> on a *lot* of systems without throwing a false positive or surfacing a >> bug." > > I am reading that similarly to what Tom is seeing: enabling it has > proved Heroku that it did not catch problems in years, meaning that > the performance cost induced by enabling it has paid nothing in > practive, except the insurance to catch up problems should they > happen. > +1 -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Mon, Jan 23, 2017 at 5:47 PM, Stephen Frost <sfrost@snowman.net> wrote: >> Perhaps I've missed the point entirely, but, I have to ask: How could >> there ever be false positives? With checksums, false positives are >> simply not allowed. Therefore, there cannot be a false positive, >> unless we define checksums as a mechanism that should only find >> problems that originate somewhere at or below the filesystem. We >> clearly have not done that, so ISTM that checksums could legitimately >> find bugs in the checksum code. I am not being facetious. > > I'm not sure I'm following your question here. A false positive would > be a case where the checksum code throws an error on a page whose > checksum is correct, or where the checksum has failed but nothing is > actually wrong/different on the page. I thought that checksums went in in part because we thought that there was some chance that they'd find bugs in Postgres. I was under the impression that that was at least a secondary goal of checksums. > As for the purpose of checksums, it's exactly to identify cases where > the page has been changed since we wrote it out, due to corruption in > the kernel, filesystem, storage system, etc. As we only check them when > we read in a page and calculate them when we go to write the page out, > they aren't helpful for shared_buffers corruption, generally speaking. I'd have guessed that they might catch a bug in recovery itself, even when the filesystem maintains the guarantees Postgres requires. In any case, it seems exceedingly unlikely that the checksum code itself would fail. -- Peter Geoghegan
Peter Geoghegan <pg@heroku.com> writes:
> Perhaps I've missed the point entirely, but, I have to ask: How could
> there ever be false positives?
Bugs. For example, checksum is computed while somebody else is setting
a hint bit in the page, so that what is written out is completely valid
except that the checksum doesn't match. (I realize that that specific
scenario should be impossible given our implementation, but I hope you
aren't going to claim that bugs in the checksum code are impossible.)
Maybe this is a terminology problem. I'm taking "false positive" to mean
"checksum reports a failure, but in fact there is no observable data
corruption". Depending on why the false positive occurred, that might
help alert you to underlying storage problems, but it isn't helping you
with respect to being able to access your perfectly valid data.
regards, tom lane
On Mon, Jan 23, 2017 at 6:01 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Maybe this is a terminology problem. I'm taking "false positive" to mean > "checksum reports a failure, but in fact there is no observable data > corruption". Depending on why the false positive occurred, that might > help alert you to underlying storage problems, but it isn't helping you > with respect to being able to access your perfectly valid data. It was a terminology problem. Thank you for the clarification. -- Peter Geoghegan
Peter Geoghegan <pg@heroku.com> writes:
> I thought that checksums went in in part because we thought that there
> was some chance that they'd find bugs in Postgres.
Not really. AFAICS the only point is to catch storage-system malfeasance.
It's barely possible that checksumming would help detect cases where
we'd written data meant for block A into block B, but I don't rate
that as being significantly more probable than bugs in the checksum
code itself. Also, if that case did happen, the checksum code might
"detect" it in some sense, but it would be remarkably unhelpful at
identifying the actual cause.
regards, tom lane
On 1/23/17 7:47 PM, Stephen Frost wrote: > It might be interesting to consider checking them in 'clean' pages in > shared_buffers in a background process, as that, presumably, *would* > detect shared buffers corruption. Hmm... that would be interesting. Assuming the necessary functions are exposed it presumably wouldn't be difficult to do that in an extension, as a bgworker. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
Jim Nasby <Jim.Nasby@bluetreble.com> writes:
> On 1/23/17 7:47 PM, Stephen Frost wrote:
>> It might be interesting to consider checking them in 'clean' pages in
>> shared_buffers in a background process, as that, presumably, *would*
>> detect shared buffers corruption.
> Hmm... that would be interesting. Assuming the necessary functions are
> exposed it presumably wouldn't be difficult to do that in an extension,
> as a bgworker.
But we don't maintain the checksum of a page while it sits in shared
buffers. Trying to do so would break, eg, concurrent hint-bit updates.
regards, tom lane
On 1/23/17 8:24 PM, Tom Lane wrote: > Jim Nasby <Jim.Nasby@bluetreble.com> writes: >> On 1/23/17 7:47 PM, Stephen Frost wrote: >>> It might be interesting to consider checking them in 'clean' pages in >>> shared_buffers in a background process, as that, presumably, *would* >>> detect shared buffers corruption. > >> Hmm... that would be interesting. Assuming the necessary functions are >> exposed it presumably wouldn't be difficult to do that in an extension, >> as a bgworker. > > But we don't maintain the checksum of a page while it sits in shared > buffers. Trying to do so would break, eg, concurrent hint-bit updates. Hrm, I thought the checksum would be valid if the buffer is marked clean? -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
* Tom Lane (tgl@sss.pgh.pa.us) wrote: > Jim Nasby <Jim.Nasby@bluetreble.com> writes: > > On 1/23/17 7:47 PM, Stephen Frost wrote: > >> It might be interesting to consider checking them in 'clean' pages in > >> shared_buffers in a background process, as that, presumably, *would* > >> detect shared buffers corruption. > > > Hmm... that would be interesting. Assuming the necessary functions are > > exposed it presumably wouldn't be difficult to do that in an extension, > > as a bgworker. > > But we don't maintain the checksum of a page while it sits in shared > buffers. Trying to do so would break, eg, concurrent hint-bit updates. Hence why I said 'clean' pages.. Perhaps I'm missing something here, but with checksums enabled, a hint bit update is going to dirty the page (and we're going to write it into the WAL and write it out to the heap), no? We'd have to accept that checking the checksum on a page would require a read lock on each page as it goes through, I imagine, though we could do something like check if the page is clean, obtain a read lock, then check if it's still clean and if so calculate the checksum and then let the lock go, then at least we're avoiding trying to lock dirty pages. Thanks! Stephen
Stephen Frost <sfrost@snowman.net> writes:
> * Tom Lane (tgl@sss.pgh.pa.us) wrote:
>> But we don't maintain the checksum of a page while it sits in shared
>> buffers. Trying to do so would break, eg, concurrent hint-bit updates.
> Hence why I said 'clean' pages..
When we write out a page, we copy it into private memory and compute the
checksum there, right? We don't copy the checksum back into the page's
shared-buffer image, and if we did, that would defeat the point because we
would've had to maintain exclusive lock on the buffer or else the checksum
might be out of date. So I don't see how this works without throwing away
a lot of carefully-designed behavior.
regards, tom lane
On 2017-01-23 21:40:53 -0500, Stephen Frost wrote: > Perhaps I'm missing something here, but with checksums enabled, a hint > bit update is going to dirty the page (and we're going to write it into > the WAL and write it out to the heap), no? No. We only WAL log hint bits the first time a page is modified after a checkpoint. It's quite likely that you'll set hint bits in the same checkpoint cycle as the row has been modified last (necessating the hint bit change). So we can't just pessimize this. I'm a bit confused about the amount of technically wrong arguments in this thread. Greetings, Andres Freund
On Mon, Jan 23, 2017 at 8:07 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Peter Geoghegan <pg@heroku.com> writes: >> I thought that checksums went in in part because we thought that there >> was some chance that they'd find bugs in Postgres. > > Not really. AFAICS the only point is to catch storage-system malfeasance. > > It's barely possible that checksumming would help detect cases where > we'd written data meant for block A into block B, but I don't rate > that as being significantly more probable than bugs in the checksum > code itself. Also, if that case did happen, the checksum code might > "detect" it in some sense, but it would be remarkably unhelpful at > identifying the actual cause. Hm, but at least in some cases wouldn't it protect people from further damage? End user data damage ought to prevented at all costs IMO. merlin
Merlin Moncure <mmoncure@gmail.com> writes:
> Hm, but at least in some cases wouldn't it protect people from further
> damage? End user data damage ought to prevented at all costs IMO.
Well ... not directly. Disallowing you from accessing busted block A
doesn't in itself prevent the same thing from happening to block B.
The argument seems to be that checksum failure complaints might prompt
users to, say, replace a failing disk drive before it goes dead completely.
But I think there's a whole lot of wishful thinking in that, particularly
when it comes to the sort of low-information users who would actually
be affected by a change in the default checksum setting.
regards, tom lane
On 2017-01-23 21:11:37 -0600, Merlin Moncure wrote: > End user data damage ought to prevented at all costs IMO. Really, really, really not. We should do a lot, but if that'd be the only priority we'd enable all the expensive as shit stuff and be so slow that there'd be no users. We'd never add new scalability/performance features, because they'll initially have more bugs / increase complexity. Etc. Andres
On 21.01.2017 19:35, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: >> Sure, it might be easy, but we don't have it. Personally I think >> checksums just aren't even ready for prime time. If we had: >> - ability to switch on/off at runtime (early patches for that have IIRC >> been posted) >> - *builtin* tooling to check checksums for everything >> - *builtin* tooling to compute checksums after changing setting >> - configurable background sweeps for checksums > > Yeah, and there's a bunch of usability tooling that we don't have, > centered around "what do you do after you get a checksum error?". > AFAIK there's no way to check or clear such an error; but without > such tools, I'm afraid that checksums are as much of a foot-gun > as a benefit. I wanted to raise the same issue. A "something is broken" flag is fine to avoid more things get broken. But if you can't repair them, its not very useful. Since i'm a heavy user of ZFS: there are checksums and if you enable shadow-copies or using a raid, checksums are helpful, since the allow to recover from the problems. I personally would prefer to enable checksums manually and than get the possibility to repair damages. Manually because this would at least double the needed space. Greetings, Torsten
On 21.01.2017 19:37, Stephen Frost wrote: > * Tom Lane (tgl@sss.pgh.pa.us) wrote: >> Stephen Frost <sfrost@snowman.net> writes: >>> Because I see having checksums as, frankly, something we always should >>> have had (as most other databases do, for good reason...) and because >>> they will hopefully prevent data loss. I'm willing to give us a fair >>> bit to minimize the risk of losing data. >> >> To be perfectly blunt, that's just magical thinking. Checksums don't >> prevent data loss in any way, shape, or form. In fact, they can *cause* >> data loss, or at least make it harder for you to retrieve your data, >> in the event of bugs causing false-positive checksum failures. > > This is not a new argument, at least to me, and I don't agree with it. I don't agree also. Yes, statistically it is more likely that checksum causes data-loss. The IO is greater, therefore the disc has more to do and breaks faster. But the same is true for RAID: adding more disk increases the odds of an disk-fallout. So: yes. If you use checksums at a single disc its more likely to cause problems. But if you managed it right (like ZFS for example) its an overall gain. >> What checksums can do for you, perhaps, is notify you in a reasonably >> timely fashion if you've already lost data due to storage-subsystem >> problems. But in a pretty high percentage of cases, that fact would >> be extremely obvious anyway, because of visible data corruption. > > Exactly, and that awareness will allow a user to prevent further data > loss or corruption. Slow corruption over time is a very much known and > accepted real-world case that people do experience, as well as bit > flipping enough for someone to write a not-that-old blog post about > them: > > https://blogs.oracle.com/ksplice/entry/attack_of_the_cosmic_rays1 > > A really nice property of checksums on pages is that they also tell you > what data you *didn't* lose, which can be extremely valuable. Indeed! Greetings, Torsten
On Tue, Jan 24, 2017 at 4:07 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Peter Geoghegan <pg@heroku.com> writes: >> I thought that checksums went in in part because we thought that there >> was some chance that they'd find bugs in Postgres. > > Not really. AFAICS the only point is to catch storage-system malfeasance. This matches my understanding. Actual physical media errors are caught by lower level checksums/error correction codes, and memory errors are caught by ECC RAM. Checksums do very little for PostgreSQL bugs, which leaves only filesystem and storage firmware bugs. However the latter are still reasonably common faults. I have seen multiple cases where, after reviewing the corruption with a hex editor, the only reasonable conclusion was a bug in the storage system. Data shifted around by non-page size amounts, non-page aligned extents that are zeroed out, etc. Unfortunately none of those customers had checksums turned on at the time. I feel that reacting to such errors with a non-cryptic and easily debuggable checksum error is much better than erroring out with huge memory allocations, crashing or returning bogus data. Timely reaction to data corruption is really important for minimizing data loss. Regards, Ants Aasma
Greetings, * Ants Aasma (ants.aasma@eesti.ee) wrote: > On Tue, Jan 24, 2017 at 4:07 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Peter Geoghegan <pg@heroku.com> writes: > >> I thought that checksums went in in part because we thought that there > >> was some chance that they'd find bugs in Postgres. > > > > Not really. AFAICS the only point is to catch storage-system malfeasance. > > This matches my understanding. Actual physical media errors are caught > by lower level checksums/error correction codes, and memory errors are > caught by ECC RAM. Not everyone runs with ECC, sadly. > Checksums do very little for PostgreSQL bugs, which > leaves only filesystem and storage firmware bugs. However the latter > are still reasonably common faults. Agreed, but in additional to filesystem and storage firmware bugs, virtualization systems can have bugs as well and if those bugs hit the kernel's cache (which is actually the more likely case- that's what the VM system is going to think it can monkey with, as long as it works with the kernel) then you can have cases which PG's checksum would likely catch since we check the checksum when we read from the kernel's read cache, and calculate the checksum before we push the page to the kernel's write cache. > I have seen multiple cases where, > after reviewing the corruption with a hex editor, the only reasonable > conclusion was a bug in the storage system. Data shifted around by > non-page size amounts, non-page aligned extents that are zeroed out, > etc. Right, I've seen similar kinds of things happening in memory of virtualized systems; things like random chunks of memory suddenly being zero'd. > Unfortunately none of those customers had checksums turned on at > the time. I feel that reacting to such errors with a non-cryptic and > easily debuggable checksum error is much better than erroring out with > huge memory allocations, crashing or returning bogus data. Timely > reaction to data corruption is really important for minimizing data > loss. Agreed. In addition to that, in larger environments where there are multiple databases involved for the explicit purpose of fail-over, a system which is going south because of bad memory or storage could be detected and pulled out, potentially with zero data loss. Of course, to minimize data loss, it'd be extremely important for the fail-over system to identify a checksum error more-or-less immediately and take the bad node out. Thanks! Stephen
On 01/21/2017 09:09 AM, Tom Lane wrote: > Stephen Frost <sfrost@snowman.net> writes: >> As for checksums, I do see value in them and I'm pretty sure that the >> author of that particular feature did as well, or we wouldn't even have >> it as an option. You seem to be of the opinion that we might as well >> just rip all of that code and work out as being useless. > > Not at all; I just think that it's not clear that they are a net win > for the average user, Tom is correct here. They are not a net win for the average user. We tend to forget that although we collectively have a lot of enterprise installs where this does matter, we collectively do not equal near the level of average user installs. From an advocacy perspective, the average user install is the one that we tend most because that tending (in theory) will grow something that is more fruitful e.g; the enterprise install over time because we constantly and consistently provided a reasonable and expected experience to the average user. Sincerely, JD -- Command Prompt, Inc. http://the.postgres.company/ +1-503-667-4564 PostgreSQL Centered full stack support, consulting and development. Everyone appreciates your honesty, until you are honest with them. Unless otherwise stated, opinions are my own.
On 1/24/17 10:30 AM, Joshua D. Drake wrote: > > Tom is correct here. They are not a net win for the average user. We > tend to forget that although we collectively have a lot of enterprise > installs where this does matter, we collectively do not equal near the > level of average user installs. > > From an advocacy perspective, the average user install is the one that > we tend most because that tending (in theory) will grow something that > is more fruitful e.g; the enterprise install over time because we > constantly and consistently provided a reasonable and expected > experience to the average user. I'm not completely grokking your second paragraph, but I would think that an average user would love got get a heads-up that their hardware is failing. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
On Sat, Jan 21, 2017 at 11:57 AM, Andres Freund <andres@anarazel.de> wrote: > On 2017-01-21 11:39:18 +0100, Magnus Hagander wrote: >> Is it time to enable checksums by default, and give initdb a switch to turn >> it off instead? > > -1 - the WAL overhead is quite massive, and in contrast to the other > GUCs recently changed you can't just switch this around. I agree. I bet that if somebody does the test suggested by Amit downthread, it'll turn out that the performance is just awful. And those cases are common. I think the people saying "well, the overhead is worth it" must be people whose systems (or whose customer's systems) aren't processing continuous heavy OLTP workloads. If you've got a data warehousing workload, checksums are probably pretty cheap. If you've got a low-velocity OLTP workload, or an OLTP workload that fits in shared_buffers, it's probably bearable. But if you've got 8GB of shared_buffers and 100GB of data, and you've got 100 or so backends continuously doing random updates, I think checksums are going nail you to the wall. And EnterpriseDB, at least, has lots of customers that do exactly that sort of thing. Having said that, I've certain run into situations where I speculated that a customer had a hardware problem and they speculated that we had given them buggy database software. In a pretty significant number of cases, the customer turned out to be right; for example, some of those people were suffering from multixact bugs that resulted in unexplainable corruption. Now, would it have been useful to know that checksums were passing (suggesting a PostgreSQL problem) rather than failing (suggesting an OS problem)? Yes, that would have been great. I could have given those customers better support. On the other hand, I think I've run into MORE cases where the customer was desperately seeking options to improve write performance, which remains a pretty significant problem for PostgreSQL. I can't see taking a significant hit in that area for my convenience in understanding what's going on in data corruption situations. The write performance penalty is paid by everybody all the time, whereas data corruption is a rare event even among support cases. And even when you do have corruption, whether or not the data corruption is accompanied by a checksum failure is only ONE extra bit of useful data. A failure doesn't guarantee a hardware problem; it could be caused by a faulty backup procedure, like forgetting to run pg_start_backup(). The lack of a failure doesn't guarantee a software problem; it could be caused by a faulty backup procedure, like using an OS-level snapshot facility that isn't exactly simultaneous across tablespaces. What you really need to do when a customer has corruption is figure out why they have corruption, and the leading cause by far is neither the hardware nor the software but some kind of user error. Checksums are at best a very modest assist in figuring out whether an error has been made and if so of what type. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Jan 25, 2017 at 12:02 AM, Jim Nasby <Jim.Nasby@bluetreble.com> wrote: > I'm not completely grokking your second paragraph, but I would think that an > average user would love got get a heads-up that their hardware is failing. Sure. If the database runs fast enough with checksums enabled, there's basically no reason to have them turned off. The issue is when it doesn't. Also, it's not as if there are no other ways of checking whether your disks are failing. SMART, for example, is supposed to tell you about incipient hardware failures before PostgreSQL ever sees a bit flip. Surely an average user would love to get a heads-up that their hardware is failing even when that hardware is not being used to power PostgreSQL, yet many people don't bother to configure SMART (or similar proprietary systems provided by individual vendors). Trying to force those people to use checksums is just masterminding; they've made their own decision that it's not worth bothering with. When something goes wrong, WE still care about distinguishing hardware failure from PostgreSQL failure. Our pride is on the line. But the customer often doesn't. The DBA isn't the same person as the operating system guy, and the operating system guy isn't going to listen to the DBA even if the DBA complains of checksum failures. Or the customer has 100 things on the same piece of hardware and PostgreSQL is the only one that failed; or alternatively they all failed around the same time; either way the culprit is obvious. Or the remedy is to restore from backup[1] whether the problem is hardware or software and regardless of whose software is to blame. Or their storage cost a million dollars and is a year old and they simply won't believe that it's failing. Or their storage cost a hundred dollars and is 8 years old and they're looking for an excuse to replace it whether it's responsible for the problem du jour or not. I think it's great that we have a checksum feature and I think it's great for people who want to use it and are willing to pay the cost of it to turn it on. I don't accept the argument that all of our users, or even most of them, fall into that category. I also think it's disappointing that there's such a vigorous argument for changing the default when so little follow-on development has gone into this feature. If we had put any real effort into making this easier to turn on and off, for example, the default value would be less important, because people could change it more easily. But nobody's making that effort. I suggest that the people who think this a super-high-value feature should be willing to put some real work into improving it instead of trying to force it down everybody's throat as-is. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company [1] Alternatively, sometimes the remedy is to wish the had a usable backup while frantically running pg_resetxlog.
On Wed, Jan 25, 2017 at 10:18 AM, Robert Haas <robertmhaas@gmail.com> wrote: > Trying to force those people to use checksums is just masterminding; > they've made their own decision that it's not worth bothering with. > When something goes wrong, WE still care about distinguishing hardware > failure from PostgreSQL failure. Our pride is on the line. But the > customer often doesn't. The DBA isn't the same person as the > operating system guy, and the operating system guy isn't going to > listen to the DBA even if the DBA complains of checksum failures. We need to invest in corruption detection/verification tools that are run on an as-needed basis. They are available to users of every other major database system. -- Peter Geoghegan
On Wed, Jan 25, 2017 at 1:37 PM, Peter Geoghegan <pg@heroku.com> wrote: > On Wed, Jan 25, 2017 at 10:18 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> Trying to force those people to use checksums is just masterminding; >> they've made their own decision that it's not worth bothering with. >> When something goes wrong, WE still care about distinguishing hardware >> failure from PostgreSQL failure. Our pride is on the line. But the >> customer often doesn't. The DBA isn't the same person as the >> operating system guy, and the operating system guy isn't going to >> listen to the DBA even if the DBA complains of checksum failures. > > We need to invest in corruption detection/verification tools that are > run on an as-needed basis. They are available to users of every other > major database system. +1, but the trick is (a) figuring out exactly what to develop and (b) finding the time to develop it. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert, * Robert Haas (robertmhaas@gmail.com) wrote: > On Wed, Jan 25, 2017 at 12:02 AM, Jim Nasby <Jim.Nasby@bluetreble.com> wrote: > > I'm not completely grokking your second paragraph, but I would think that an > > average user would love got get a heads-up that their hardware is failing. > > Sure. If the database runs fast enough with checksums enabled, > there's basically no reason to have them turned off. The issue is > when it doesn't. I don't believe we're talking about forcing every user to have checksums enabled. We are discussing the default. Would you say that most user's databases run fast enough with checksums enabled? Or more than most, maybe 70%? 80%? In today's environment, I'd probably say that it's more like 90+%. Yet, our default is to have them disabled and *really* hard to enable. I agree that it's unfortunate that we haven't put more effort into fixing that- I'm all for it, but it's disappointing to see that people are not in favor of changing the default as I believe it would both help our users and encourage more development of the feature. Thanks! Stephen
* Peter Geoghegan (pg@heroku.com) wrote: > On Wed, Jan 25, 2017 at 10:18 AM, Robert Haas <robertmhaas@gmail.com> wrote: > > Trying to force those people to use checksums is just masterminding; > > they've made their own decision that it's not worth bothering with. > > When something goes wrong, WE still care about distinguishing hardware > > failure from PostgreSQL failure. Our pride is on the line. But the > > customer often doesn't. The DBA isn't the same person as the > > operating system guy, and the operating system guy isn't going to > > listen to the DBA even if the DBA complains of checksum failures. > > We need to invest in corruption detection/verification tools that are > run on an as-needed basis. They are available to users of every other > major database system. Agreed. Thanks! Stephen
Stephen Frost <sfrost@snowman.net> writes:
> Would you say that most user's databases run fast enough with checksums
> enabled? Or more than most, maybe 70%? 80%? In today's environment,
> I'd probably say that it's more like 90+%.
It would be nice if there were some actual evidence about this, rather
than numbers picked out of the air.
> I agree that it's unfortunate that we haven't put more effort into
> fixing that- I'm all for it, but it's disappointing to see that people
> are not in favor of changing the default as I believe it would both help
> our users and encourage more development of the feature.
I think the really key point is that a whole lot of infrastructure work
needs to be done still, and changing the default before that work has been
done is not going to be user-friendly. The most pressing issue being the
difficulty of changing the setting after the fact. It would be a *whole*
lot easier to sell default-on if there were a way to turn it off, and yet
you want us to buy into default-on before that way exists. Come back
after that feature is in, and we can talk.
regards, tom lane
On 01/25/2017 11:41 AM, Tom Lane wrote: > Stephen Frost <sfrost@snowman.net> writes: >> Would you say that most user's databases run fast enough with checksums >> enabled? Or more than most, maybe 70%? 80%? In today's environment, >> I'd probably say that it's more like 90+%. > > It would be nice if there were some actual evidence about this, rather > than numbers picked out of the air. > >> I agree that it's unfortunate that we haven't put more effort into >> fixing that- I'm all for it, but it's disappointing to see that people >> are not in favor of changing the default as I believe it would both help >> our users and encourage more development of the feature. > > I think the really key point is that a whole lot of infrastructure work > needs to be done still, and changing the default before that work has been > done is not going to be user-friendly. The most pressing issue being the > difficulty of changing the setting after the fact. It would be a *whole* > lot easier to sell default-on if there were a way to turn it off, and yet > you want us to buy into default-on before that way exists. Come back > after that feature is in, and we can talk. +1 Sincerely, JD -- Command Prompt, Inc. http://the.postgres.company/ +1-503-667-4564 PostgreSQL Centered full stack support, consulting and development. Everyone appreciates your honesty, until you are honest with them. Unless otherwise stated, opinions are my own.
On Wed, Jan 25, 2017 at 8:18 PM, Robert Haas <robertmhaas@gmail.com> wrote: > Also, it's not as if there are no other ways of checking whether your > disks are failing. SMART, for example, is supposed to tell you about > incipient hardware failures before PostgreSQL ever sees a bit flip. > Surely an average user would love to get a heads-up that their > hardware is failing even when that hardware is not being used to power > PostgreSQL, yet many people don't bother to configure SMART (or > similar proprietary systems provided by individual vendors). You really can't rely on SMART to tell you about hardware failures. 1 in 4 drives fail completely with 0 SMART indication [1]. And for the 1 in 1000 annual checksum failure rate other indicators except system restarts only had a weak correlation[2]. And this is without filesystem and other OS bugs that SMART knows nothing about. My view may be biased by mostly seeing the cases where things have already gone wrong, but I recommend support clients to turn checksums on unless it's known that write IO is going to be an issue. Especially because I know that if it turns out to be a problem I can go in and quickly hack together a tool to help them turn it off. I do agree that to change the PostgreSQL default at least some tool turn it off online should be included. [1] https://www.backblaze.com/blog/what-smart-stats-indicate-hard-drive-failures/ [2] https://www.usenix.org/legacy/event/fast08/tech/full_papers/bairavasundaram/bairavasundaram.pdf Regards, Ants Aasma
On Wed, Jan 25, 2017 at 2:23 PM, Stephen Frost <sfrost@snowman.net> wrote: >> Sure. If the database runs fast enough with checksums enabled, >> there's basically no reason to have them turned off. The issue is >> when it doesn't. > > I don't believe we're talking about forcing every user to have checksums > enabled. We are discussing the default. I never said otherwise. > Would you say that most user's databases run fast enough with checksums > enabled? Or more than most, maybe 70%? 80%? In today's environment, > I'd probably say that it's more like 90+%. I don't have statistics on that, but I'd certainly agree that it's over 90%. However, I estimate that the number of percentage of people who wouldn't be helped by checksums is also over 90%. I don't think it's easy to say whether there are more people who would benefit from checksums than would be hurt by the performance penalty or visca versa. My own feeling is the second, but I understand that yours is the first. > Yet, our default is to have them disabled and *really* hard to enable. First of all, that could be fixed by further development. Second, really hard to enable is a relative term. I accept that enabling checksums is not a pleasant process. Right now, you'd have to do a dump/restore, or use logical replication to replicate the data to a new cluster and then switch over. On the other hand, if checksums are really a critical feature, how are people getting to the point where they've got a mission-critical production system and only then discovering that they want to enable checksums? If you tell somebody "we have an optional feature called checksums and you should really use it" and they respond "well, I'd like to, but I already put my system into critical production use and it's not worth it to me to take downtime to get them enabled", that sounds to me like the feature is nice-to-have, not absolutely essential. When something is essential, you find a way to get it done, whether it's painful or not, because that's what essential means. And if checksums are not essential, then they shouldn't be enabled by default unless they're very cheap -- and I think we already know that's not true in all workloads. > I agree that it's unfortunate that we haven't put more effort into > fixing that- I'm all for it, but it's disappointing to see that people > are not in favor of changing the default as I believe it would both help > our users and encourage more development of the feature. I think it would help some users and hurt others. I do agree that it would encourage more development of the feature -- almost of necessity. In particular, I bet it would spur development of an efficient way of turning checksums off -- but I'd rather see us approach it from the other direction: let's develop an efficient way of turning the feature on and off FIRST. Deciding that the feature has to be on for everyone because turning it on later is too hard for the people who later decide they want it is letting the tail wag the dog. Also, I think that one of the big problems with the way checksums work is that you don't find problems with your archived data until it's too late. Suppose that in February bits get flipped in a block. You don't access the data until July[1]. Well, it's nice to have the system tell you that the data is corrupted, but what are you going to do about it? By that point, all of your backups are probably corrupted. So it's basically: ERROR: you're screwed It's nice to know that (maybe?) but without a recovery strategy a whole lot of people who get that message are going to immediately start asking "How do I ignore the fact that I'm screwed and try to read the data anyway?". And then you wonder what the point of having the feature turned on is, especially if it's costly. It's almost an attractive nuisance at that point - nobody wants to be the user that turns off checksums because they sound good on paper, but when you actually have a problem an awful lot of people are NOT going to want to try to restore from backup and maybe lose recent transactions. They're going to want to ignore the checksum failures. That's kind of awful. Peter's comments upthread get at this: "We need to invest in corruption detection/verification tools that are run on an as-needed basis." Exactly. If we could verify that our data is good before throwing away our old backups, that'd be good. If we could verify that our indexes were structurally sane, that would be superior to anything checksums can ever give us because it catches not only storage failures but also software failures within PostgreSQL itself and user malfeasance above the PostgreSQL layer (e.g. redefining the supposedly-immutable function to give different answers) and damage inflicted inadvertently by environmental changes (e.g. upgrading glibc and having strcoll() change its mind). If we could verify that every XID and MXID in the heap points to a clog or multixact record that still exists, that'd catch more than just bit flips. I'm not trying to downplay the usefulness of checksums *in a certain context*. It's a good feature, and I'm glad we have it. But I think you're somewhat inflating the utility of it while discounting the very real costs. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company [1] of the following year, maybe.
On Wed, Jan 25, 2017 at 12:23 PM, Robert Haas <robertmhaas@gmail.com> wrote: > Also, I think that one of the big problems with the way checksums work > is that you don't find problems with your archived data until it's too > late. Suppose that in February bits get flipped in a block. You > don't access the data until July[1]. Well, it's nice to have the > system tell you that the data is corrupted, but what are you going to > do about it? By that point, all of your backups are probably > corrupted. So it's basically: > > ERROR: you're screwed > > It's nice to know that (maybe?) but without a recovery strategy a > whole lot of people who get that message are going to immediately > start asking "How do I ignore the fact that I'm screwed and try to > read the data anyway?". That's also how I tend to think about it. I understand that my experience with storage devices is unusually narrow compared to everyone else here. That's why I remain neutral on the high level question of whether or not we ought to enable checksums by default. I'll ask other hackers to answer what may seem like a very naive question, while bearing what I just said in mind. The question is: Have you ever actually seen a checksum failure in production? And, if so, how helpful was it? I myself have not, despite the fact that Heroku uses checksums wherever possible, and has the technical means to detect problems like this across the entire fleet of customer databases. Not even once. This is not what I would have expected myself several years ago. -- Peter Geoghegan
Robert, * Robert Haas (robertmhaas@gmail.com) wrote: > On Wed, Jan 25, 2017 at 2:23 PM, Stephen Frost <sfrost@snowman.net> wrote: > > Yet, our default is to have them disabled and *really* hard to enable. > > First of all, that could be fixed by further development. I'm certainly all for doing so, but I don't agree that it necessairly is required before we flip the default. That said, if the way to get checksums enabled by default is providing a relativly easy way to turn them off, then that's something which I'll do what I can to help work towards. In other words, I'm not going to continue to argue, given the various opinions of the group, that we should just flip it tomorrow. I hope to discuss it further after we have the ability to turn it off easily. > Second, really hard to enable is a relative term. I accept that > enabling checksums is not a pleasant process. Right now, you'd have > to do a dump/restore, or use logical replication to replicate the data > to a new cluster and then switch over. On the other hand, if > checksums are really a critical feature, how are people getting to the > point where they've got a mission-critical production system and only > then discovering that they want to enable checksums? I truely do wish everyone would come talk to me before building out a database. Perhaps that's been your experience, in which case, I envy you, but I tend to get a reaction more along the lines of "wait, what do you mean I had to pass some option to initdb to enable checksum?!?!". The fact that we've got a WAL implementation and clearly understand fsync requirements, why full page writes make sense, and that our WAL has its own CRCs which isn't possible to disable, tends to lead people to think we really know what we're doing and that we care a lot about their data. > > I agree that it's unfortunate that we haven't put more effort into > > fixing that- I'm all for it, but it's disappointing to see that people > > are not in favor of changing the default as I believe it would both help > > our users and encourage more development of the feature. > > I think it would help some users and hurt others. I do agree that it > would encourage more development of the feature -- almost of > necessity. In particular, I bet it would spur development of an > efficient way of turning checksums off -- but I'd rather see us > approach it from the other direction: let's develop an efficient way > of turning the feature on and off FIRST. Deciding that the feature > has to be on for everyone because turning it on later is too hard for > the people who later decide they want it is letting the tail wag the > dog. As I have said, I don't believe it has to be on for everyone. > Also, I think that one of the big problems with the way checksums work > is that you don't find problems with your archived data until it's too > late. Suppose that in February bits get flipped in a block. You > don't access the data until July[1]. Well, it's nice to have the > system tell you that the data is corrupted, but what are you going to > do about it? By that point, all of your backups are probably > corrupted. So it's basically: If your backup system is checking the checksums when backing up PG, which I think every backup system *should* be doing, then guess what? You've got a backup which you can go back to immediately, possibly with the ability to restore all of the data from WAL. That won't always be the case, naturally, but it's a much better position than simply having a system which continues to degrade until you've actually reached the "you're screwed" level because PG will no longer read a page or perhaps can't even start up, *and* you no longer have any backups. As it is, there are backup solutions which *do* check the checksum when backing up PG. This is no longer, thankfully, some hypothetical thing, but something which really exists and will hopefully keep users from losing data. > It's nice to know that (maybe?) but without a recovery strategy a > whole lot of people who get that message are going to immediately > start asking "How do I ignore the fact that I'm screwed and try to > read the data anyway?". And we have options for that. > And then you wonder what the point of having > the feature turned on is, especially if it's costly. It's almost an > attractive nuisance at that point - nobody wants to be the user that > turns off checksums because they sound good on paper, but when you > actually have a problem an awful lot of people are NOT going to want > to try to restore from backup and maybe lose recent transactions. > They're going to want to ignore the checksum failures. That's kind of > awful. Presently, last I checked at least, the database system doesn't fall over and die if a single page's checksum fails. I agree entirely that we want the system to fail gracefully (unless the user instructs us otherwise, perhaps because they have a redundant system that they can flip to immediately). > Peter's comments upthread get at this: "We need to invest in > corruption detection/verification tools that are run on an as-needed > basis." Exactly. If we could verify that our data is good before > throwing away our old backups, that'd be good. Ok. We have that. I admit that it's not in PG proper, yet, but I can't turn back the clock and make that happen, but we *do* have the ability to verify that our backups are free of checksum errors, on checksum enabled databases, before we throw away the old backup. > If we could verify > that our indexes were structurally sane, that would be superior to > anything checksums can ever give us because it catches not only > storage failures but also software failures within PostgreSQL itself > and user malfeasance above the PostgreSQL layer (e.g. redefining the > supposedly-immutable function to give different answers) and damage > inflicted inadvertently by environmental changes (e.g. upgrading glibc > and having strcoll() change its mind). We have a patch for that and I would love to see it in core already. If it's possible to make that run against a backup, then I'd be happy to see about integrating it into a backup solution. > If we could verify that every > XID and MXID in the heap points to a clog or multixact record that > still exists, that'd catch more than just bit flips. Interesting idea... That might not be too hard to implement on systems with enough memory to pull all of clog in and then check as the pages go by. I can't promise anything, but I'm definitely going to discuss the idea with David. > I'm not trying to downplay the usefulness of checksums *in a certain > context*. It's a good feature, and I'm glad we have it. But I think > you're somewhat inflating the utility of it while discounting the very > real costs. The costs for checksums don't bother me any more than the costs for WAL or WAL CRCs or full page writes. They may not be required on every system, but they're certainly required on more than 'zero' entirely reasonable systems which people deploy in their production environments. I'd rather walk into an engagement where the user is saying "yeah, we enabled checksums and it caught this corruption issue" than having to break the bad news, which I've had to do over and over, that their existing system hasn't got checksums enabled. This isn't hypothetical, it's what I run into regularly with entirely reasonable and skilled engineers who have been deploying PG. Thanks! Stephen
On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: > As it is, there are backup solutions which *do* check the checksum when > backing up PG. This is no longer, thankfully, some hypothetical thing, > but something which really exists and will hopefully keep users from > losing data. Wouldn't that have issues with torn pages? -- Peter Geoghegan
On Thu, Jan 26, 2017 at 9:14 AM, Peter Geoghegan <pg@heroku.com> wrote: > On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: >> As it is, there are backup solutions which *do* check the checksum when >> backing up PG. This is no longer, thankfully, some hypothetical thing, >> but something which really exists and will hopefully keep users from >> losing data. > > Wouldn't that have issues with torn pages? Why? What do you foresee here? I would think such backup solutions are careful enough to ensure correctly the durability of pages so as they are not partially written. -- Michael
On 2017-01-26 09:19:28 +0900, Michael Paquier wrote: > On Thu, Jan 26, 2017 at 9:14 AM, Peter Geoghegan <pg@heroku.com> wrote: > > On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: > >> As it is, there are backup solutions which *do* check the checksum when > >> backing up PG. This is no longer, thankfully, some hypothetical thing, > >> but something which really exists and will hopefully keep users from > >> losing data. > > > > Wouldn't that have issues with torn pages? > > Why? What do you foresee here? I would think such backup solutions are > careful enough to ensure correctly the durability of pages so as they > are not partially written. That means you have to replay enough WAL to get into a consistent state... - Andres
On Wed, Jan 25, 2017 at 6:30 PM, Stephen Frost <sfrost@snowman.net> wrote: > I hope to discuss it further after we have the ability to turn it off > easily. I think we should have the ability to flip it in BOTH directions easily. >> Second, really hard to enable is a relative term. I accept that >> enabling checksums is not a pleasant process. Right now, you'd have >> to do a dump/restore, or use logical replication to replicate the data >> to a new cluster and then switch over. On the other hand, if >> checksums are really a critical feature, how are people getting to the >> point where they've got a mission-critical production system and only >> then discovering that they want to enable checksums? > > I truely do wish everyone would come talk to me before building out a > database. Perhaps that's been your experience, in which case, I envy > you, but I tend to get a reaction more along the lines of "wait, what do > you mean I had to pass some option to initdb to enable checksum?!?!". > The fact that we've got a WAL implementation and clearly understand > fsync requirements, why full page writes make sense, and that our WAL > has its own CRCs which isn't possible to disable, tends to lead people > to think we really know what we're doing and that we care a lot about > their data. It sounds to me like you are misleading users about the positives and negatives of checksums, which then causes them to be shocked that they are not the default. > As I have said, I don't believe it has to be on for everyone. For the second time, I didn't say that. But the default has a powerful influence on behavior. If it didn't, you wouldn't be trying to get it changed. > [ unsolicited bragging about an unspecified backup tool, presumably pgbackrest ] Great. > Presently, last I checked at least, the database system doesn't fall > over and die if a single page's checksum fails. This is another thing that I never said. > [ more unsolicited bragging an unspecified backup tool, presumably still pgbackrest ] Swell. >> I'm not trying to downplay the usefulness of checksums *in a certain >> context*. It's a good feature, and I'm glad we have it. But I think >> you're somewhat inflating the utility of it while discounting the very >> real costs. > > The costs for checksums don't bother me any more than the costs for WAL > or WAL CRCs or full page writes. Obviously. But I think they should. Frankly, I think the costs for full page writes should bother the heck out of all of us, but the solution isn't to shut them off any more than it is to enable checksums despite the cost. It's to find a way to reduce the costs. > They may not be required on every > system, but they're certainly required on more than 'zero' entirely > reasonable systems which people deploy in their production environments. Nobody said otherwise. > I'd rather walk into an engagement where the user is saying "yeah, we > enabled checksums and it caught this corruption issue" than having to > break the bad news, which I've had to do over and over, that their > existing system hasn't got checksums enabled. This isn't hypothetical, > it's what I run into regularly with entirely reasonable and skilled > engineers who have been deploying PG. Maybe you should just stop telling them and use the time thus freed up to work on improving the checksum feature. I'm skeptical of this whole discussion because you seem to be filled with unalloyed confidence that checksums have little performance impact and will do wonderful things to prevent data loss, whereas I think they have significant performance impact and will only very slightly help to prevent data loss. I admit that the idea of having pgbackrest verify checksums while backing up seems like it could greatly improve the chances of checksums being useful, but I'm not going to endorse changing PostgreSQL's default for pgbackrest's benefit. It's got to be to the benefit of PostgreSQL users broadly, not just the subset of those people who use one particular backup tool. Also, the massive hit that will probably occur on high-concurrency OLTP workloads larger than shared_buffers is going to be had to justify for any amount of backup security. I think that problem's got to be solved or at least mitigated before we think about changing this. I realize that not everyone would set the bar that high, but I see far too many customers with exactly that workload to dismiss it lightly. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Jan 26, 2017 at 9:22 AM, Andres Freund <andres@anarazel.de> wrote: > On 2017-01-26 09:19:28 +0900, Michael Paquier wrote: >> On Thu, Jan 26, 2017 at 9:14 AM, Peter Geoghegan <pg@heroku.com> wrote: >> > On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: >> >> As it is, there are backup solutions which *do* check the checksum when >> >> backing up PG. This is no longer, thankfully, some hypothetical thing, >> >> but something which really exists and will hopefully keep users from >> >> losing data. >> > >> > Wouldn't that have issues with torn pages? >> >> Why? What do you foresee here? I would think such backup solutions are >> careful enough to ensure correctly the durability of pages so as they >> are not partially written. > > That means you have to replay enough WAL to get into a consistent > state... Ah, OK I got the point. Yes that would be a problem to check this field on raw backups except if the page size matches the kernel's one at 4k. -- Michael
On Wed, Jan 25, 2017 at 7:19 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Thu, Jan 26, 2017 at 9:14 AM, Peter Geoghegan <pg@heroku.com> wrote: >> On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: >>> As it is, there are backup solutions which *do* check the checksum when >>> backing up PG. This is no longer, thankfully, some hypothetical thing, >>> but something which really exists and will hopefully keep users from >>> losing data. >> >> Wouldn't that have issues with torn pages? > > Why? What do you foresee here? I would think such backup solutions are > careful enough to ensure correctly the durability of pages so as they > are not partially written. Well, you'd have to keep a read(fd, buf, 8192) performed by the backup tool from overlapping with a write(fd, buf, 8192) performed by the backend. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
* Peter Geoghegan (pg@heroku.com) wrote: > On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: > > As it is, there are backup solutions which *do* check the checksum when > > backing up PG. This is no longer, thankfully, some hypothetical thing, > > but something which really exists and will hopefully keep users from > > losing data. > > Wouldn't that have issues with torn pages? No, why would it? The page has either been written out by PG to the OS, in which case the backup s/w will see the new page, or it hasn't been. Our testing has not turned up any issues as yet. That said, it's relatively new and I wouldn't be surprised if we need to do some adjustments in that area, which might be system-dependent even. We could certainly check the WAL for the page that had a checksum error (we currently simply report them, though don't throw away a prior backup if we detect one). This isn't like a case where only half the page made it to the disk because of a system failure though; everything is online and working properly during an online backup. Thanks! Stephen
* Michael Paquier (michael.paquier@gmail.com) wrote: > On Thu, Jan 26, 2017 at 9:14 AM, Peter Geoghegan <pg@heroku.com> wrote: > > On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: > >> As it is, there are backup solutions which *do* check the checksum when > >> backing up PG. This is no longer, thankfully, some hypothetical thing, > >> but something which really exists and will hopefully keep users from > >> losing data. > > > > Wouldn't that have issues with torn pages? > > Why? What do you foresee here? I would think such backup solutions are > careful enough to ensure correctly the durability of pages so as they > are not partially written. I believe his concern was that the backup sw might see a partially-updated page when it reads the file while PG is writing it. In other words, would the kernel return some intermediate state of data while an fwrite() is in progress. Thanks! Stephen
* Robert Haas (robertmhaas@gmail.com) wrote: > On Wed, Jan 25, 2017 at 7:19 PM, Michael Paquier > <michael.paquier@gmail.com> wrote: > > On Thu, Jan 26, 2017 at 9:14 AM, Peter Geoghegan <pg@heroku.com> wrote: > >> On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: > >>> As it is, there are backup solutions which *do* check the checksum when > >>> backing up PG. This is no longer, thankfully, some hypothetical thing, > >>> but something which really exists and will hopefully keep users from > >>> losing data. > >> > >> Wouldn't that have issues with torn pages? > > > > Why? What do you foresee here? I would think such backup solutions are > > careful enough to ensure correctly the durability of pages so as they > > are not partially written. > > Well, you'd have to keep a read(fd, buf, 8192) performed by the backup > tool from overlapping with a write(fd, buf, 8192) performed by the > backend. As Michael mentioned, that'd depend on if things are atomic from a user's perspective at certain sizes (perhaps 4k, which wouldn't be too surprising, but may also be system-dependent), in which case verifying that the page is in the WAL would be sufficient. Thanks! Stephen
On 2017-01-25 19:30:08 -0500, Stephen Frost wrote: > * Peter Geoghegan (pg@heroku.com) wrote: > > On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: > > > As it is, there are backup solutions which *do* check the checksum when > > > backing up PG. This is no longer, thankfully, some hypothetical thing, > > > but something which really exists and will hopefully keep users from > > > losing data. > > > > Wouldn't that have issues with torn pages? > > No, why would it? The page has either been written out by PG to the OS, > in which case the backup s/w will see the new page, or it hasn't been. Uh. Writes aren't atomic on that granularity. That means you very well *can* see a torn page (in linux you can e.g. on 4KB os page boundaries of a 8KB postgres page). Just read a page while it's being written out. You simply can't reliably verify checksums without replaying WAL (or creating a manual version of replay, as in checking the WAL for a FPW). > This isn't like a case where only half the page made it to the disk > because of a system failure though; everything is online and working > properly during an online backup. I don't think that really changes anything. Greetings, Andres Freund
On Thu, Jan 26, 2017 at 9:32 AM, Stephen Frost <sfrost@snowman.net> wrote: > * Robert Haas (robertmhaas@gmail.com) wrote: >> On Wed, Jan 25, 2017 at 7:19 PM, Michael Paquier >> <michael.paquier@gmail.com> wrote: >> > On Thu, Jan 26, 2017 at 9:14 AM, Peter Geoghegan <pg@heroku.com> wrote: >> >> On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: >> >>> As it is, there are backup solutions which *do* check the checksum when >> >>> backing up PG. This is no longer, thankfully, some hypothetical thing, >> >>> but something which really exists and will hopefully keep users from >> >>> losing data. >> >> >> >> Wouldn't that have issues with torn pages? >> > >> > Why? What do you foresee here? I would think such backup solutions are >> > careful enough to ensure correctly the durability of pages so as they >> > are not partially written. >> >> Well, you'd have to keep a read(fd, buf, 8192) performed by the backup >> tool from overlapping with a write(fd, buf, 8192) performed by the >> backend. > > As Michael mentioned, that'd depend on if things are atomic from a > user's perspective at certain sizes (perhaps 4k, which wouldn't be too > surprising, but may also be system-dependent), in which case verifying > that the page is in the WAL would be sufficient. That would be enough. It should also be rare enough that there would not be that many pages to track when looking at records from the backup start position to minimum recovery point. It could be also simpler, though more time-consuming, to just let a backup recover up to the minimum recovery point (recovery_target = 'immediate'), and then run the checksum sanity checks. There are other checks usually needed on a backup anyway like being sure that index pages are in good shape even with a correct checksum, etc. But here I am really high-jacking the thread, so I'll stop.. -- Michael
* Andres Freund (andres@anarazel.de) wrote: > On 2017-01-25 19:30:08 -0500, Stephen Frost wrote: > > * Peter Geoghegan (pg@heroku.com) wrote: > > > On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: > > > > As it is, there are backup solutions which *do* check the checksum when > > > > backing up PG. This is no longer, thankfully, some hypothetical thing, > > > > but something which really exists and will hopefully keep users from > > > > losing data. > > > > > > Wouldn't that have issues with torn pages? > > > > No, why would it? The page has either been written out by PG to the OS, > > in which case the backup s/w will see the new page, or it hasn't been. > > Uh. Writes aren't atomic on that granularity. That means you very well > *can* see a torn page (in linux you can e.g. on 4KB os page boundaries > of a 8KB postgres page). Just read a page while it's being written out. > > You simply can't reliably verify checksums without replaying WAL (or > creating a manual version of replay, as in checking the WAL for a FPW). Looking through the WAL isn't any surprise and is something we've been planning to do for other reasons anyway. Thanks! Stephen
Michael, * Michael Paquier (michael.paquier@gmail.com) wrote: > That would be enough. It should also be rare enough that there would > not be that many pages to track when looking at records from the > backup start position to minimum recovery point. It could be also > simpler, though more time-consuming, to just let a backup recover up > to the minimum recovery point (recovery_target = 'immediate'), and > then run the checksum sanity checks. There are other checks usually > needed on a backup anyway like being sure that index pages are in good > shape even with a correct checksum, etc. Belive me, I'm all for *all* of that. > But here I am really high-jacking the thread, so I'll stop.. If you have further thoughts, I'm all ears. This is all relatively new, and I don't expect to have all of the answer or solutions. Obviously, having to bring up a full database is an extra step (one we try to make easy to do), but, sadly, we don't have any way to ask PG to verify all the checksums with released versions, so that's what we're working with. Thanks! Stephen
* Robert Haas (robertmhaas@gmail.com) wrote: > On Wed, Jan 25, 2017 at 6:30 PM, Stephen Frost <sfrost@snowman.net> wrote: > > I hope to discuss it further after we have the ability to turn it off > > easily. > > I think we should have the ability to flip it in BOTH directions easily. Presumably you imply this to mean "before we enable it by default." I'm not sure that I can agree with that, but we haven't got it in either direction yet, so it's not terribly interesting to discuss that particular "what if." > It sounds to me like you are misleading users about the positives and > negatives of checksums, which then causes them to be shocked that they > are not the default. I don't try to claim that they are without downsides or performance impacts, if that's the implication here. > > [ more unsolicited bragging an unspecified backup tool, presumably still pgbackrest ] It was explicitly to counter the claim that there aren't things out there which are working to actively check the checksums. > > I'd rather walk into an engagement where the user is saying "yeah, we > > enabled checksums and it caught this corruption issue" than having to > > break the bad news, which I've had to do over and over, that their > > existing system hasn't got checksums enabled. This isn't hypothetical, > > it's what I run into regularly with entirely reasonable and skilled > > engineers who have been deploying PG. > > Maybe you should just stop telling them and use the time thus freed up > to work on improving the checksum feature. I'm working to improve the usefulness of our checksum feature in a way which will produce practical and much more immediate results than anything I could do today in PG. That said, I do plan to also support working on checksums as I'm able to. At the moment, that's supporting Magnus' thread about enabling them by default. I'd be a bit surprised if he was trying to force a change on PG because he thinks it's going to improve things for pgbackrest, but if so, I'm not going to complain when it seems like an entirely sensible and good change which will benefit PG's users too. Even better would be if we had an independent tool to check checksums endorsed by the PG community, but that won't happen for a release cycle. I'd also be extremely happy if the other backup tools out there grew the ability to check checksums in PG pages; frankly, I hope that adding it to pgbackrest will push them to do so. > I'm skeptical of this whole discussion because you seem to be filled > with unalloyed confidence that checksums have little performance > impact and will do wonderful things to prevent data loss, whereas I > think they have significant performance impact and will only very > slightly help to prevent data loss. I admit that they'll have a significant performance impact in some environments, but I think the vast majority of installations won't see anything different, while some of them may be saved by it, including, as likely as not, a number of actual corruption issues that have been brought up on these lists in the past few days, simply because reports were asked for. > I admit that the idea of having > pgbackrest verify checksums while backing up seems like it could > greatly improve the chances of checksums being useful, but I'm not > going to endorse changing PostgreSQL's default for pgbackrest's > benefit. I'm glad to hear that you generally endorse the idea of having a backup tool verify checksums. I'd love it if all of them did and I'm not going to apologize for, as far as I'm aware, being the first to even make an effort in that direction. > It's got to be to the benefit of PostgreSQL users broadly, > not just the subset of those people who use one particular backup > tool. Hopefully, other backup solutions will add similar capability, and perhaps someone will also write an independent tool, and eventually those will get out in released versions, and maybe PG will grow a tool to check checksums too, but I can't make other tool authors implement it, nor can I make other committers work on it and while I'm doing what I can, as I'm sure you understand, we all have a lot of different hats. > Also, the massive hit that will probably occur on > high-concurrency OLTP workloads larger than shared_buffers is going to > be had to justify for any amount of backup security. I think that > problem's got to be solved or at least mitigated before we think about > changing this. I realize that not everyone would set the bar that > high, but I see far too many customers with exactly that workload to > dismiss it lightly. I have a sneaking suspicion that the customers which you get directly involved with tend to be at a different level than the majority of PG users which exist out in the wild (I can't say that it's really any different for me). I don't think that's a bad thing, but I do think users at all levels deserve consideration and not just those running close to the limits of their gear. Thanks! Stephen
On Wed, Jan 25, 2017 at 1:22 PM, Peter Geoghegan <pg@heroku.com> wrote: > I understand that my experience with storage devices is unusually > narrow compared to everyone else here. That's why I remain neutral on > the high level question of whether or not we ought to enable checksums > by default. I'll ask other hackers to answer what may seem like a very > naive question, while bearing what I just said in mind. The question > is: Have you ever actually seen a checksum failure in production? And, > if so, how helpful was it? I'm surprised that nobody has answered my question yet. I'm not claiming that not actually seeing any corruption in the wild due to a failing checksum invalidates any argument. I *do* think that data points like this can be helpful, though. -- Peter Geoghegan
Peter, * Peter Geoghegan (pg@heroku.com) wrote: > On Wed, Jan 25, 2017 at 1:22 PM, Peter Geoghegan <pg@heroku.com> wrote: > > I understand that my experience with storage devices is unusually > > narrow compared to everyone else here. That's why I remain neutral on > > the high level question of whether or not we ought to enable checksums > > by default. I'll ask other hackers to answer what may seem like a very > > naive question, while bearing what I just said in mind. The question > > is: Have you ever actually seen a checksum failure in production? And, > > if so, how helpful was it? > > I'm surprised that nobody has answered my question yet. > > I'm not claiming that not actually seeing any corruption in the wild > due to a failing checksum invalidates any argument. I *do* think that > data points like this can be helpful, though. Sadly, without having them enabled by default, there's not a huge corpus of example cases to draw from. There have been a few examples already posted about corruption failures with PG, but one can't say with certainty that they would have been caught sooner if checksums had been enabled. Thanks! Stephen
On Thu, Jan 26, 2017 at 2:28 PM, Stephen Frost <sfrost@snowman.net> wrote: > Sadly, without having them enabled by default, there's not a huge corpus > of example cases to draw from. > > There have been a few examples already posted about corruption failures > with PG, but one can't say with certainty that they would have been > caught sooner if checksums had been enabled. I don't know how comparable it is to our checksum technology, but MySQL seems to have some kind of checksums on table data, and you can find public emails, blogs etc lamenting corrupted databases by searching Google for the string "InnoDB: uncompressed page, stored checksum in field1" (that's the start of a longer error message that includes actual and expected checksums). -- Thomas Munro http://www.enterprisedb.com
On Wed, Jan 25, 2017 at 7:37 PM, Andres Freund <andres@anarazel.de> wrote: > On 2017-01-25 19:30:08 -0500, Stephen Frost wrote: >> * Peter Geoghegan (pg@heroku.com) wrote: >> > On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: >> > > As it is, there are backup solutions which *do* check the checksum when >> > > backing up PG. This is no longer, thankfully, some hypothetical thing, >> > > but something which really exists and will hopefully keep users from >> > > losing data. >> > >> > Wouldn't that have issues with torn pages? >> >> No, why would it? The page has either been written out by PG to the OS, >> in which case the backup s/w will see the new page, or it hasn't been. > > Uh. Writes aren't atomic on that granularity. That means you very well > *can* see a torn page (in linux you can e.g. on 4KB os page boundaries > of a 8KB postgres page). Just read a page while it's being written out. Yeah. This is also why backups force full page writes on even if they're turned off in general. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 26 January 2017 at 01:58, Thomas Munro <thomas.munro@enterprisedb.com> wrote: > > I don't know how comparable it is to our checksum technology, but > MySQL seems to have some kind of checksums on table data, and you can > find public emails, blogs etc lamenting corrupted databases by > searching Google for the string "InnoDB: uncompressed page, stored > checksum in field1" (that's the start of a longer error message that > includes actual and expected checksums). I'm not sure what exactly that teaches us however. I see these were often associated with software bugs (Apparently MySQL long assumed that a checksum of 0 never happened for example). In every non software case I stumbled across seemed to be following a power failure. Apparently MySQL uses a "doublewrite buffer" to protect against torn pages but when I search for that I get tons of people inquiring how to turn it off... So even without software bugs in the checksum code I don't know that the frequency of the error necessarily teaches us anything about the frequency of hardware corruption either. And more to the point it seems what people are asking for in all those lamentations is how they can convince MySQL to continue and ignore the corruption. A typical response was "We slightly modified innochecksum and added option -f that means if the checksum of a page is wrong, rewrite it in the InnoDB page header." Which begs the question... -- greg
* Robert Haas (robertmhaas@gmail.com) wrote: > On Wed, Jan 25, 2017 at 7:37 PM, Andres Freund <andres@anarazel.de> wrote: > > On 2017-01-25 19:30:08 -0500, Stephen Frost wrote: > >> * Peter Geoghegan (pg@heroku.com) wrote: > >> > On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: > >> > > As it is, there are backup solutions which *do* check the checksum when > >> > > backing up PG. This is no longer, thankfully, some hypothetical thing, > >> > > but something which really exists and will hopefully keep users from > >> > > losing data. > >> > > >> > Wouldn't that have issues with torn pages? > >> > >> No, why would it? The page has either been written out by PG to the OS, > >> in which case the backup s/w will see the new page, or it hasn't been. > > > > Uh. Writes aren't atomic on that granularity. That means you very well > > *can* see a torn page (in linux you can e.g. on 4KB os page boundaries > > of a 8KB postgres page). Just read a page while it's being written out. > > Yeah. This is also why backups force full page writes on even if > they're turned off in general. I've got a question into David about this, I know we chatted about the risk at one point, I just don't recall what we ended up doing (I can imagine a few different possible things- re-read the page, which isn't a guarantee but reduces the chances a fair bit, or check the LSN, or perhaps the plan was to just check if it's in the WAL, as I mentioned) or if we ended up concluding it wasn't a risk for some, perhaps incorrect, reason and need to revisit it. Thanks! Stephen
On 01/25/2017 05:25 PM, Peter Geoghegan wrote: > On Wed, Jan 25, 2017 at 1:22 PM, Peter Geoghegan <pg@heroku.com> wrote: >> I understand that my experience with storage devices is unusually >> narrow compared to everyone else here. That's why I remain neutral on >> the high level question of whether or not we ought to enable checksums >> by default. I'll ask other hackers to answer what may seem like a very >> naive question, while bearing what I just said in mind. The question >> is: Have you ever actually seen a checksum failure in production? And, >> if so, how helpful was it? No. JD -- Command Prompt, Inc. http://the.postgres.company/ +1-503-667-4564 PostgreSQL Centered full stack support, consulting and development. Everyone appreciates your honesty, until you are honest with them.
On 1/25/17 10:38 PM, Stephen Frost wrote: > * Robert Haas (robertmhaas@gmail.com) wrote: >> On Wed, Jan 25, 2017 at 7:37 PM, Andres Freund <andres@anarazel.de> wrote: >>> On 2017-01-25 19:30:08 -0500, Stephen Frost wrote: >>>> * Peter Geoghegan (pg@heroku.com) wrote: >>>>> On Wed, Jan 25, 2017 at 3:30 PM, Stephen Frost <sfrost@snowman.net> wrote: >>>>>> As it is, there are backup solutions which *do* check the checksum when >>>>>> backing up PG. This is no longer, thankfully, some hypothetical thing, >>>>>> but something which really exists and will hopefully keep users from >>>>>> losing data. >>>>> >>>>> Wouldn't that have issues with torn pages? >>>> >>>> No, why would it? The page has either been written out by PG to the OS, >>>> in which case the backup s/w will see the new page, or it hasn't been. >>> >>> Uh. Writes aren't atomic on that granularity. That means you very well >>> *can* see a torn page (in linux you can e.g. on 4KB os page boundaries >>> of a 8KB postgres page). Just read a page while it's being written out. >> >> Yeah. This is also why backups force full page writes on even if >> they're turned off in general. > > I've got a question into David about this, I know we chatted about the > risk at one point, I just don't recall what we ended up doing (I can > imagine a few different possible things- re-read the page, which isn't a > guarantee but reduces the chances a fair bit, or check the LSN, or > perhaps the plan was to just check if it's in the WAL, as I mentioned) > or if we ended up concluding it wasn't a risk for some, perhaps > incorrect, reason and need to revisit it. The solution was to simply ignore the checksums of any pages with an LSN >= the LSN returned by pg_start_backup(). This means that hot blocks may never be checked during backup, but if they are active then any problems should be caught directly by PostgreSQL. This technique assumes that blocks can be consistently read in the order they were written. If the second 4k (or 512 byte, etc.) block of the fwrite is visible before the first 4k block then there would a false positive. I have a hard time imagining any sane buffering system working this way, but I can't discount it. It's definitely possible for pages on disk to have this characteristic (i.e., the first block is not written first) but that should be fixed during recovery before it is possible to take a backup. Note that reports of page checksum errors are informational only and do not have any effect on the backup process. Even so we would definitely prefer to avoid false positives. If anybody can poke a hole in this solution then I would like to hear it. -- -David david@pgmasters.net
Hi,
I've been running a bunch of benchmarks to measure the overhead of data
checksums. I'm not sure if we're still considering this change for 10,
but let me post the results anyway.
The benchmark was fairly simple - run a few simple workloads, measure
tps, amount of WAL generated etc. The scripts and results (including sar
data etc) is available here:
https://bitbucket.org/tvondra/checksum-bench
I encourage others to validate the results, see if I made some stupid
mistakes and perhaps do additional analysis of the data. There's quite a
bit of data, including pg_stat_* snapshots collected every second, etc.
The workloads benchmarked were
* regular pgbench
* 'skewed' pgbench (simulating workloads that frequently access only
small subset of data)
* 'skewed-n' (same as before, but skipping updates on tiny tables, to
prevent concurrency issues, just like "pgbench -N")
* pgbench with 90% reads, 10% writes
All of this on three different scales:
* 100 - fits into shared buffers
* 1000 - fits into RAM
* 10000 - exceeds RAM
This was done on a machine with 2 x 8/16 cores, with 32 clients, each
run taking 2h. The machine has PCIe SSD drive (Intel 750), so fairly
powerful both for reads and writes.
The TPS results look like this (charts and spreadsheet attached):
test scale checksums no-checksums ratio
-----------------------------------------------------------------
pgbench 100 20888 21166 98.69%
1000 15578 16036 97.14%
10000 5205 5352 97.25%
test scale checksums no-checksums ratio
-----------------------------------------------------------------
read-write 100 151228 152330 99.28%
1000 95396 96755 98.60%
10000 13067 14514 90.03%
test scale checksums no-checksums ratio
------------------------------------------------------------------
skewed 100 20957 20805 100.73%
1000 20865 20744 100.58%
10000 8855 9482 93.39%
test scale checksums no-checksums ratio
-----------------------------------------------------------------
skewed-n 100 29226 28104 103.99%
1000 28011 27612 101.45%
10000 9363 10109 92.62%
So it seems with smaller scales, the overhead is fairly low (~2%, so
within noise). On the large data the throughput drops by ~10% with some
of the workloads.
The amount of WAL generated (over the 2h run with checkpoints triggered
every 30 minutes) looks like this:
test scale checksums no-checksums ratio
-------------------------------------------------------------
pgbench 100 66.11 66.48 99.45%
1000 119.77 119.55 100.19%
10000 375.05 350.63 106.97%
test scale checksums no-checksums ratio
---------------------------------------------------------------
read-write 100 26.06 26.26 99.26%
1000 70.37 70.01 100.51%
10000 147.54 154.78 95.33%
test scale checksums no-checksums ratio
-----------------------------------------------------------------
skewed 100 65.64 64.88 101.18%
1000 117.20 114.79 102.10%
10000 370.15 346.39 106.86%
test scale checksums no-checksums ratio
----------------------------------------------------------------
skewed-n 100 61.00 56.53 107.92%
1000 106.85 102.48 104.26%
10000 372.03 348.29 106.82%
Those numbers should be probably corrected a bit to compensate for the
tps difference (if you to ~10% more TPS, you expect ~10% more WAL), but
I think it's clear the WAL overhead is roughly +10% or so.
I'm not suggesting this means we should or should not enable data
checksums by default, but hopefully it provides some actual data
measuring the impact. If needed, I can do more tests with other
workloads, and it should be difficult to use the scripts on other
systems if you want to run some benchmarks yourself.
regards
regards
Tomas Vondra
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
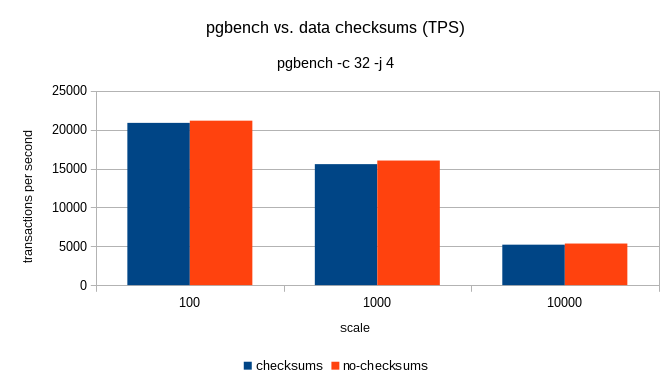{kind=link}
{kind=link}
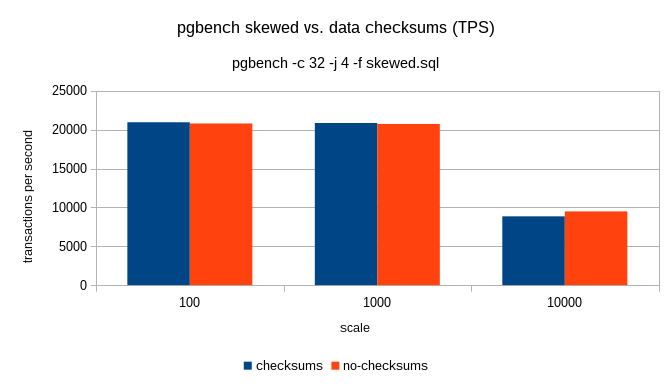{kind=link}
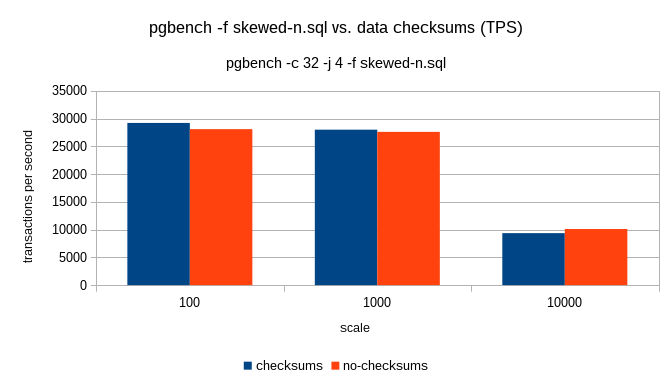{kind=link}
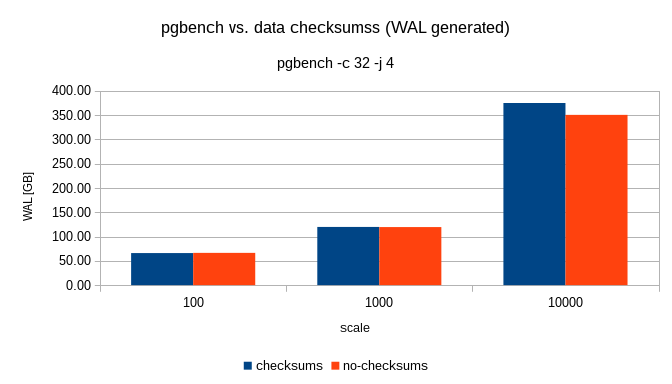{kind=link}
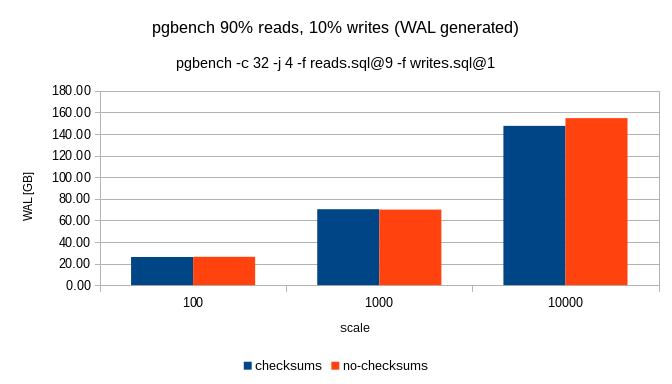{kind=link}
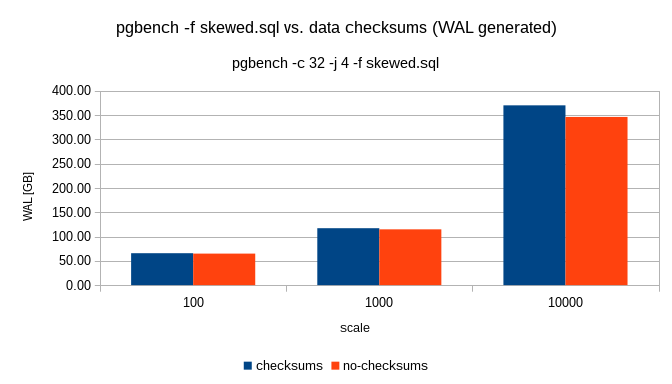{kind=link}
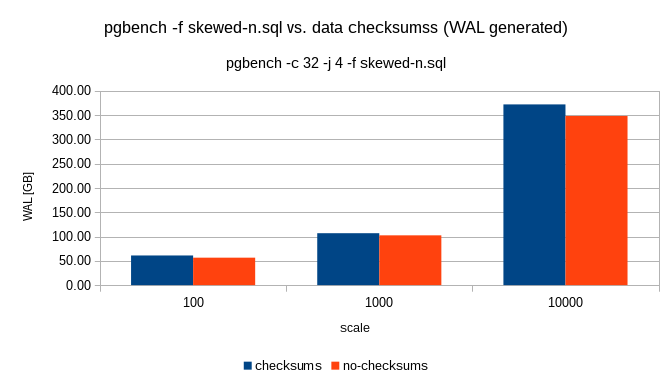{kind=link}
On 1/25/17 6:40 PM, Stephen Frost wrote: > Obviously, having to bring up a full database is an extra step (one we > try to make easy to do), but, sadly, we don't have any way to ask PG to > verify all the checksums with released versions, so that's what we're > working with. Wouldn't it be fairly trivial to write an extension that did that though? foreach r in pg_class where relkind in (...) for (b = 0; b < r.relpages; b++) ReadBufferExtended(..., BAS_BULKREAD); -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
On 2017-02-03 17:23:15 -0600, Jim Nasby wrote: > On 1/25/17 6:40 PM, Stephen Frost wrote: > > Obviously, having to bring up a full database is an extra step (one we > > try to make easy to do), but, sadly, we don't have any way to ask PG to > > verify all the checksums with released versions, so that's what we're > > working with. > > Wouldn't it be fairly trivial to write an extension that did that though? > > foreach r in pg_class where relkind in (...) > for (b = 0; b < r.relpages; b++) > ReadBufferExtended(..., BAS_BULKREAD); You can't really see things from other databases that way tho. So you need to write a tool that iterates all databases and such. Not that that's a huge problem, but it doesn't make things easier at least. (and you need to deal with things like forks, but that's not a huge issue) - Andres
On Mon, Jan 30, 2017 at 12:29 PM, David Steele <david@pgmasters.net> wrote: > The solution was to simply ignore the checksums of any pages with an LSN >>= the LSN returned by pg_start_backup(). This means that hot blocks > may never be checked during backup, but if they are active then any > problems should be caught directly by PostgreSQL. I feel like this doesn't fix the problem. Suppose the backup process reads part of a block that hasn't been modified in a while, and then PostgreSQL writes the block, and then the backup process reads the rest of the block. The LSN test will not prevent the checksum from being verified, but the checksum will fail to match. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2/3/17 5:31 PM, Andres Freund wrote: > You can't really see things from other databases that way tho. So you > need to write a tool that iterates all databases and such. Not that > that's a huge problem, but it doesn't make things easier at least. True. Not terribly hard to iterate though, and if the author of this mythical extension really wanted to they could probably use a bgworker that was free to iterate through the databases. > (and you need to deal with things like forks, but that's not a huge > issue) Yeah, which maybe requires version-specific hard-coded knowledge of how many forks you might have. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
Hi,
I've repeated those benchmarks on a much smaller/older machine, with
only minimal changes (mostly related to RAM and cores available). I've
expected to see more significant differences, assuming that newer CPUs
will handle the checksumming better, but to my surprise the impact of
enabling checksums on this machine is ~2%.
As usual, full results and statistics are available for review here:
https://bitbucket.org/tvondra/checksum-bench-i5
Looking at average TPS (measured over 2 hours, with a checkpoints every
30 minutes), I see this:
test scale checksums no-checksums
-----------------------------------------------------------
pgbench 50 7444 7518 99.02%
300 6863 6936 98.95%
1000 4195 4295 97.67%
read-write 50 48858 48832 100.05%
300 41999 42302 99.28%
1000 16539 16666 99.24%
skewed 50 7485 7480 100.07%
300 7245 7280 99.52%
1000 5950 6050 98.35%
skewed-n 50 10234 10226 100.08%
300 9618 9649 99.68%
1000 7371 7393 99.70%
And the amount of WAL produced looks like this:
test scale checksums no-checksums
-----------------------------------------------------------------
pgbench 50 24.89 24.67 100.89%
300 37.94 37.54 101.07%
1000 65.91 64.88 101.58%
read-write 50 10.00 9.98 100.11%
300 23.28 23.35 99.66%
1000 54.20 53.20 101.89%
skewed 50 24.35 24.01 101.43%
300 35.12 34.51 101.77%
1000 52.14 51.15 101.93%
skewed-n 50 21.71 21.13 102.73%
300 32.23 31.54 102.18%
1000 53.24 51.94 102.50%
Again, this is hardly a proof of non-existence of a workload where data
checksums have much worse impact, but I've expected to see a much more
significant impact on those workloads.
Incidentally, I've been dealing with a checksum failure reported by a
customer last week, and based on the experience I tend to agree that we
don't have the tools needed to deal with checksum failures. I think such
tooling should be a 'must have' for enabling checksums by default.
In this particular case the checksum failure is particularly annoying
because it happens during recovery (on a standby, after a restart),
during startup, so FATAL means shutdown.
I've managed to inspect the page in different way (dd and pageinspect
from another instance), and it looks fine - no obvious data corruption,
the only thing that seems borked is the checksum itself, and only three
consecutive bits are flipped in the checksum. So this doesn't seem like
a "stale checksum" - hardware issue is a possibility (the machine has
ECC RAM though), but it might just as easily be a bug in PostgreSQL,
when something scribbles over the checksum due to a buffer overflow,
just before we write the buffer to the OS. So 'false failures' are not
entirely impossible thing.
And no, backups may not be a suitable solution - the failure happens on
a standby, and the page (luckily) is not corrupted on the master. Which
means that perhaps the standby got corrupted by a WAL, which would
affect the backups too. I can't verify this, though, because the WAL got
removed from the archive, already. But it's a possibility.
So I think we're not ready to enable checksums by default for everyone,
not until we can provide tools to deal with failures like this (I don't
think users will be amused if we tell them to use 'dd' and inspect the
pages in a hex editor).
ISTM the way forward is to keep the current default (disabled), but to
allow enabling checksums on the fly. That will mostly fix the issue for
people who actually want checksums but don't realize they need to enable
them at initdb time (and starting from scratch is not an option for
them), are running on good hardware and are capable of dealing with
checksum errors if needed, even without more built-in tooling.
Being able to disable checksums on the fly is nice, but it only really
solves the issue of extra overhead - it does really help with the
failures (particularly when you can't even start the database, because
of a checksum failure in the startup phase).
So, shall we discuss what tooling would be useful / desirable?
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Fri, Feb 10, 2017 at 7:38 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Incidentally, I've been dealing with a checksum failure reported by a > customer last week, and based on the experience I tend to agree that we > don't have the tools needed to deal with checksum failures. I think such > tooling should be a 'must have' for enabling checksums by default. > > In this particular case the checksum failure is particularly annoying > because it happens during recovery (on a standby, after a restart), during > startup, so FATAL means shutdown. > > I've managed to inspect the page in different way (dd and pageinspect from > another instance), and it looks fine - no obvious data corruption, the only > thing that seems borked is the checksum itself, and only three consecutive > bits are flipped in the checksum. So this doesn't seem like a "stale > checksum" - hardware issue is a possibility (the machine has ECC RAM > though), but it might just as easily be a bug in PostgreSQL, when something > scribbles over the checksum due to a buffer overflow, just before we write > the buffer to the OS. So 'false failures' are not entirely impossible thing. > > And no, backups may not be a suitable solution - the failure happens on a > standby, and the page (luckily) is not corrupted on the master. Which means > that perhaps the standby got corrupted by a WAL, which would affect the > backups too. I can't verify this, though, because the WAL got removed from > the archive, already. But it's a possibility. > > So I think we're not ready to enable checksums by default for everyone, not > until we can provide tools to deal with failures like this (I don't think > users will be amused if we tell them to use 'dd' and inspect the pages in a > hex editor). > > ISTM the way forward is to keep the current default (disabled), but to allow > enabling checksums on the fly. That will mostly fix the issue for people who > actually want checksums but don't realize they need to enable them at initdb > time (and starting from scratch is not an option for them), are running on > good hardware and are capable of dealing with checksum errors if needed, > even without more built-in tooling. > > Being able to disable checksums on the fly is nice, but it only really > solves the issue of extra overhead - it does really help with the failures > (particularly when you can't even start the database, because of a checksum > failure in the startup phase). > > So, shall we discuss what tooling would be useful / desirable? FWIW, I appreciate this analysis and I think it's exactly the kind of thing we need to set a strategy for moving forward. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2/10/17 6:38 PM, Tomas Vondra wrote: > And no, backups may not be a suitable solution - the failure happens on > a standby, and the page (luckily) is not corrupted on the master. Which > means that perhaps the standby got corrupted by a WAL, which would > affect the backups too. I can't verify this, though, because the WAL got > removed from the archive, already. But it's a possibility. Possibly related... I've got a customer that periodically has SR replias stop in their tracks due to WAL checksum failure. I don't think there's any hardware correlation (they've seen this on multiple machines). Studying the code, it occurred to me that if there's any bugs in the handling of individual WAL record sizes or pointers during SR then you could get CRC failures. So far every one of these occurrences has been repairable by replacing the broken WAL file on the replica. I've requested that next time this happens they save the bad WAL. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
On 02/13/2017 02:29 AM, Jim Nasby wrote: > On 2/10/17 6:38 PM, Tomas Vondra wrote: >> And no, backups may not be a suitable solution - the failure happens on >> a standby, and the page (luckily) is not corrupted on the master. Which >> means that perhaps the standby got corrupted by a WAL, which would >> affect the backups too. I can't verify this, though, because the WAL got >> removed from the archive, already. But it's a possibility. > > Possibly related... I've got a customer that periodically has SR replias > stop in their tracks due to WAL checksum failure. I don't think there's > any hardware correlation (they've seen this on multiple machines). > Studying the code, it occurred to me that if there's any bugs in the > handling of individual WAL record sizes or pointers during SR then you > could get CRC failures. So far every one of these occurrences has been > repairable by replacing the broken WAL file on the replica. I've > requested that next time this happens they save the bad WAL. I don't follow. You're talking about WAL checksums, this thread is about data checksums. I'm not seeing any WAL checksum failure, but when the standby attempts to apply the WAL (in particular a Btree/DELETE WAL record), it detects an incorrect data checksum in the underlying table. So either there's a hardware issue, or the heap got corrupted by some preceding WAL. Or maybe one of the tiny gnomes in the CPU got tired and punched the bits wrong. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 02/11/2017 01:38 AM, Tomas Vondra wrote: > > Incidentally, I've been dealing with a checksum failure reported by a > customer last week, and based on the experience I tend to agree that we > don't have the tools needed to deal with checksum failures. I think such > tooling should be a 'must have' for enabling checksums by default. > > In this particular case the checksum failure is particularly annoying > because it happens during recovery (on a standby, after a restart), > during startup, so FATAL means shutdown. > > I've managed to inspect the page in different way (dd and pageinspect > from another instance), and it looks fine - no obvious data corruption, > the only thing that seems borked is the checksum itself, and only three > consecutive bits are flipped in the checksum. So this doesn't seem like > a "stale checksum" - hardware issue is a possibility (the machine has > ECC RAM though), but it might just as easily be a bug in PostgreSQL, > when something scribbles over the checksum due to a buffer overflow, > just before we write the buffer to the OS. So 'false failures' are not > entirely impossible thing. > Not to leave this without any resolution, it seems the issue has been caused by a SAN. Some configuration changes or something was being done at the time of the issue, and the SAN somehow ended up writing a page into a different relfilenode, into a different block. The page was from a btree index and got written into a heap relfilenode, but otherwise it was correct - the only thing that changed seems to be the block number, which explains the minimal difference in the checksum. I don't think we'll learn much more, but it seems the checksums did their work in detecting the issue. > > So I think we're not ready to enable checksums by default for everyone, > not until we can provide tools to deal with failures like this (I don't > think users will be amused if we tell them to use 'dd' and inspect the > pages in a hex editor). > > ISTM the way forward is to keep the current default (disabled), but to > allow enabling checksums on the fly. That will mostly fix the issue for > people who actually want checksums but don't realize they need to enable > them at initdb time (and starting from scratch is not an option for > them), are running on good hardware and are capable of dealing with > checksum errors if needed, even without more built-in tooling. > > Being able to disable checksums on the fly is nice, but it only really > solves the issue of extra overhead - it does really help with the > failures (particularly when you can't even start the database, because > of a checksum failure in the startup phase). > > So, shall we discuss what tooling would be useful / desirable? > Although the checksums did detect the issue (we might never notice without them, or maybe the instance would mysteriously crash), I still think better tooling is neeed. I've posted some minor pageinspect improvements I hacked together while investigating this, but I don't think pageinspect is a very good tool for investigating checksum / data corruption issues, for a number of reasons: 1) It does not work at all when the instance does not even start - you have to manually dump the pages and try inspecting them from another instance. 2) Even then it assumes the pages are not corrupted, and may easily cause segfaults or other issues if that's not the case. 3) Works on a manual page-by-page basis. 4) It does not even try to resolve the issue somehow. For example I think it'd be great to have a tool that work even on instances that are not running. For example, something that recursively walks through all files in a data directory, verifies checksums on everything, lists/dumps pages with broken checksums for further inspection. I have an alpha-alpha versions of something along those lines, written before the root cause was identified. It'd be nice to have something that could help with fixing the issues (e.g. by fetching the last FPI from the backup, or so). But that's clearly way more difficult. There are probably some other tools that might be useful when dealing with data corruption (e.g. scrubbing to detect it). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Jan 21, 2017 at 12:46:05PM -0500, Stephen Frost wrote: > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > > As we don't know the performance impact is (there was no benchmark done > > on reasonably current code base) I really don't understand how you can > > judge if it's worth it or not. > > Because I see having checksums as, frankly, something we always should > have had (as most other databases do, for good reason...) and because > they will hopefully prevent data loss. I'm willing to give us a fair > bit to minimize the risk of losing data. Do these other databases do checksums because they don't do full_page_writes? They just detect torn pages rather than repair them like we do? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Thu, Feb 23, 2017 at 10:37 PM, Bruce Momjian <bruce@momjian.us> wrote:
On Sat, Jan 21, 2017 at 12:46:05PM -0500, Stephen Frost wrote:
> * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote:
> > As we don't know the performance impact is (there was no benchmark done
> > on reasonably current code base) I really don't understand how you can
> > judge if it's worth it or not.
>
> Because I see having checksums as, frankly, something we always should
> have had (as most other databases do, for good reason...) and because
> they will hopefully prevent data loss. I'm willing to give us a fair
> bit to minimize the risk of losing data.
Do these other databases do checksums because they don't do
full_page_writes? They just detect torn pages rather than repair them
like we do?
Torn page detection is usually/often done by other means than checksums. I don't think those are necessarily related.
On Sat, Jan 21, 2017 at 09:02:25PM +0200, Ants Aasma wrote: > > It might be worth looking into using the CRC CPU instruction to reduce this > > overhead, like we do for the WAL checksums. Since that is a different > > algorithm it would be a compatibility break and we would need to support the > > old algorithm for upgraded clusters.. > > We looked at that when picking the algorithm. At that point it seemed > that CRC CPU instructions were not universal enough to rely on them. > The algorithm we ended up on was designed to be fast on SIMD hardware. > Unfortunately on x86-64 that required SSE4.1 integer instructions, so > with default compiles there is a lot of performance left on table. A > low hanging fruit would be to do CPU detection like the CRC case and > enable a SSE4.1 optimized variant when those instructions are > available. IIRC it was actually a lot faster than the naive hardware > CRC that is used for WAL and about on par with interleaved CRC. Uh, I thought already did compile-time testing for SSE4.1 and used them if present. Why do you say "with default compiles there is a lot of performance left on table?" -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On 02/24/2017 06:47 PM, Bruce Momjian wrote: > On Sat, Jan 21, 2017 at 09:02:25PM +0200, Ants Aasma wrote: >>> It might be worth looking into using the CRC CPU instruction to reduce this >>> overhead, like we do for the WAL checksums. Since that is a different >>> algorithm it would be a compatibility break and we would need to support the >>> old algorithm for upgraded clusters.. >> >> We looked at that when picking the algorithm. At that point it seemed >> that CRC CPU instructions were not universal enough to rely on them. >> The algorithm we ended up on was designed to be fast on SIMD hardware. >> Unfortunately on x86-64 that required SSE4.1 integer instructions, so >> with default compiles there is a lot of performance left on table. A >> low hanging fruit would be to do CPU detection like the CRC case and >> enable a SSE4.1 optimized variant when those instructions are >> available. IIRC it was actually a lot faster than the naive hardware >> CRC that is used for WAL and about on par with interleaved CRC. > > Uh, I thought already did compile-time testing for SSE4.1 and used them > if present. Why do you say "with default compiles there is a lot of > performance left on table?" > Compile-time is not enough - we build binary packages that may then be installed on machines without the SSE4.1 instructions available. On Intel this may not be a huge issue - the first microarchitecture with SSE4.1 was "Nehalem", announced in 2007, so we're only left with very old boxes based on "Intel Core" (and perhaps the even older P6). On AMD, it's a bit worse - the first micro-architecture with SSE4.1 was Bulldozer (late 2011). So quite a few CPUs out there, even if most people use Intel. In any case, we can't just build x86-64 packages with compile-time SSE4.1 checks. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Feb 24, 2017 at 7:47 PM, Bruce Momjian <bruce@momjian.us> wrote: > On Sat, Jan 21, 2017 at 09:02:25PM +0200, Ants Aasma wrote: >> > It might be worth looking into using the CRC CPU instruction to reduce this >> > overhead, like we do for the WAL checksums. Since that is a different >> > algorithm it would be a compatibility break and we would need to support the >> > old algorithm for upgraded clusters.. >> >> We looked at that when picking the algorithm. At that point it seemed >> that CRC CPU instructions were not universal enough to rely on them. >> The algorithm we ended up on was designed to be fast on SIMD hardware. >> Unfortunately on x86-64 that required SSE4.1 integer instructions, so >> with default compiles there is a lot of performance left on table. A >> low hanging fruit would be to do CPU detection like the CRC case and >> enable a SSE4.1 optimized variant when those instructions are >> available. IIRC it was actually a lot faster than the naive hardware >> CRC that is used for WAL and about on par with interleaved CRC. > > Uh, I thought already did compile-time testing for SSE4.1 and used them > if present. Why do you say "with default compiles there is a lot of > performance left on table?" Compile time checks don't help because the compiled binary could be run on a different host that does not have SSE4.1 (as extremely unlikely as it is at this point of time). A runtime check is done for WAL checksums that use a special CRC32 instruction. Block checksums predate that and use a different algorithm that was picked because it could be accelerated with vectorized execution on non-Intel architectures. We just never got around to adding runtime checks for the architecture to enable this speedup. The attached test runs 1M iterations of the checksum about 3x faster when compiled with SSE4.1 and vectorization, 4x if AVX2 is added into the mix. Test: gcc $CFLAGS -Isrc/include -DN=1000000 testchecksum.c -o testchecksum && time ./testchecksum Results: CFLAGS="-O2": 2.364s CFLAGS="-O2 -msse4.1 -ftree-vectorize": 0.752s CFLAGS="-O2 -mavx2 -ftree-vectorize": 0.552s That 0.552s is 15GB/s per core on a 3 year old laptop. Regards, Ants Aasma -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Fri, Feb 24, 2017 at 08:31:09PM +0200, Ants Aasma wrote: > >> We looked at that when picking the algorithm. At that point it seemed > >> that CRC CPU instructions were not universal enough to rely on them. > >> The algorithm we ended up on was designed to be fast on SIMD hardware. > >> Unfortunately on x86-64 that required SSE4.1 integer instructions, so > >> with default compiles there is a lot of performance left on table. A > >> low hanging fruit would be to do CPU detection like the CRC case and > >> enable a SSE4.1 optimized variant when those instructions are > >> available. IIRC it was actually a lot faster than the naive hardware > >> CRC that is used for WAL and about on par with interleaved CRC. > > > > Uh, I thought already did compile-time testing for SSE4.1 and used them > > if present. Why do you say "with default compiles there is a lot of > > performance left on table?" > > Compile time checks don't help because the compiled binary could be > run on a different host that does not have SSE4.1 (as extremely > unlikely as it is at this point of time). A runtime check is done for Right. > WAL checksums that use a special CRC32 instruction. Block checksums > predate that and use a different algorithm that was picked because it > could be accelerated with vectorized execution on non-Intel > architectures. We just never got around to adding runtime checks for > the architecture to enable this speedup. Oh, that's why we will hopefully eventually change the page checksum algorithm to use the special CRC32 instruction, and set a new checksum version --- got it. I assume there is currently no compile-time way to do this. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On 2/24/17 12:30 PM, Tomas Vondra wrote: > In any case, we can't just build x86-64 packages with compile-time > SSE4.1 checks. Dumb question... since we're already discussing llvm for the executor, would that potentially be an option here? AIUI that also opens the possibility of using the GPU as well. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com 855-TREBLE2 (855-873-2532)
On Fri, Feb 24, 2017 at 01:49:07PM -0600, Jim Nasby wrote: > On 2/24/17 12:30 PM, Tomas Vondra wrote: > >In any case, we can't just build x86-64 packages with compile-time > >SSE4.1 checks. > > Dumb question... since we're already discussing llvm for the executor, would > that potentially be an option here? AIUI that also opens the possibility of > using the GPU as well. Uh, as far as I know, the best you are going to get from llvm is standard assembly, while the SSE4.1 instructions use special assembly instructions, so they would be faster, and in a way they are a GPU built into CPUs. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Fri, Feb 24, 2017 at 9:37 PM, Bruce Momjian <bruce@momjian.us> wrote: > Oh, that's why we will hopefully eventually change the page checksum > algorithm to use the special CRC32 instruction, and set a new checksum > version --- got it. I assume there is currently no compile-time way to > do this. Using CRC32 as implemented now for the WAL would be significantly slower than what we have now due to instruction latency. Even the best theoretical implementation using the CRC32 instruction would still be about the same speed than what we have now. I haven't seen anybody working on swapping out the current algorithm. And I don't really see a reason to, it would introduce a load of headaches for no real gain. Regards, Ants Aasma
On Fri, Feb 24, 2017 at 9:49 PM, Jim Nasby <Jim.Nasby@bluetreble.com> wrote: > On 2/24/17 12:30 PM, Tomas Vondra wrote: >> >> In any case, we can't just build x86-64 packages with compile-time >> SSE4.1 checks. > > > Dumb question... since we're already discussing llvm for the executor, would > that potentially be an option here? AIUI that also opens the possibility of > using the GPU as well. Just transferring the block to the GPU would be slower than what we have now. Theoretically LLVM could be used to JIT the checksum calculation, but just precompiling a couple of versions and swithcing between them at runtime would be simpler and would give the same speedup. Regards, Ants saasma
On Fri, Feb 24, 2017 at 10:02 PM, Bruce Momjian <bruce@momjian.us> wrote: > Uh, as far as I know, the best you are going to get from llvm is > standard assembly, while the SSE4.1 instructions use special assembly > instructions, so they would be faster, and in a way they are a GPU built > into CPUs. Both LLVM and GCC are capable of compiling the code that we have to a vectorized loop using SSE4.1 or AVX2 instructions given the proper compilation flags. This is exactly what was giving the speedup in the test I showed in my e-mail. Regards, Ants Aasma
On Fri, Feb 24, 2017 at 10:09:50PM +0200, Ants Aasma wrote: > On Fri, Feb 24, 2017 at 9:37 PM, Bruce Momjian <bruce@momjian.us> wrote: > > Oh, that's why we will hopefully eventually change the page checksum > > algorithm to use the special CRC32 instruction, and set a new checksum > > version --- got it. I assume there is currently no compile-time way to > > do this. > > Using CRC32 as implemented now for the WAL would be significantly > slower than what we have now due to instruction latency. Even the best > theoretical implementation using the CRC32 instruction would still be > about the same speed than what we have now. I haven't seen anybody > working on swapping out the current algorithm. And I don't really see > a reason to, it would introduce a load of headaches for no real gain. Uh, I am confused. I thought you said we were leaving some performance on the table. What is that? I though CRC32 was SSE4.1. Why is CRC32 good for the WAL but bad for the page checksums? What about the WAL page images? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Fri, Feb 24, 2017 at 10:30 PM, Bruce Momjian <bruce@momjian.us> wrote: > On Fri, Feb 24, 2017 at 10:09:50PM +0200, Ants Aasma wrote: >> On Fri, Feb 24, 2017 at 9:37 PM, Bruce Momjian <bruce@momjian.us> wrote: >> > Oh, that's why we will hopefully eventually change the page checksum >> > algorithm to use the special CRC32 instruction, and set a new checksum >> > version --- got it. I assume there is currently no compile-time way to >> > do this. >> >> Using CRC32 as implemented now for the WAL would be significantly >> slower than what we have now due to instruction latency. Even the best >> theoretical implementation using the CRC32 instruction would still be >> about the same speed than what we have now. I haven't seen anybody >> working on swapping out the current algorithm. And I don't really see >> a reason to, it would introduce a load of headaches for no real gain. > > Uh, I am confused. I thought you said we were leaving some performance > on the table. What is that? I though CRC32 was SSE4.1. Why is CRC32 > good for the WAL but bad for the page checksums? What about the WAL > page images? The page checksum algorithm was designed to take advantage of CPUs that provide vectorized 32bit integer multiplication. On x86 this was introduced with SSE4.1 extensions. This means that by default we can't take advantage of the design. The code is written in a way that compiler auto vectorization works on it, so only using appropriate compilation flags are needed to compile a version that does use vector instructions. However to enable it on generic builds, a runtime switch between different levels of vectorization support is needed. This is what is leaving the performance on the table. The page checksum algorithm we have is extremely fast, memcpy fast. Even without vectorization it is right up there with Murmurhash3a and xxHash. With vectorization it's 4x faster. And it works this fast on most modern CPUs, not only Intel. The downside is that it only works well for large blocks, and only fixed power-of-2 size with the current implementation. WAL page images have the page hole removed so can't easily take advantage of this. That said, I haven't really seen either the hardware accelerated CRC32 calculation nor the non-vectorized page checksum take a noticeable amount of time on real world workloads. The benchmarks presented in this thread seem to corroborate this observation. Regards, Ants Aasma