Thread: SSI patch version 14
Attached.
Dan and I have spent many, many hours desk-check and testing,
including pounding for many hours in DBT-2 at high concurrency
factors on a 16 processor box. In doing so, we found and fixed a few
issues. Neither of us is aware of any bugs or deficiencies
remaining, even after a solid day of pounding in DBT-2, other than
the failure to extend any new functionality to hot standby.
At Heikki's suggestion I have included a test to throw an error on an
attempt to switch to serializable mode during recovery. Anything
more to address that issue can be a small follow-up patch -- probably
mainly a few notes in the docs.
-Kevin
Dan and I have spent many, many hours desk-check and testing,
including pounding for many hours in DBT-2 at high concurrency
factors on a 16 processor box. In doing so, we found and fixed a few
issues. Neither of us is aware of any bugs or deficiencies
remaining, even after a solid day of pounding in DBT-2, other than
the failure to extend any new functionality to hot standby.
At Heikki's suggestion I have included a test to throw an error on an
attempt to switch to serializable mode during recovery. Anything
more to address that issue can be a small follow-up patch -- probably
mainly a few notes in the docs.
-Kevin
Attachment
On Mon, 2011-01-24 at 21:30 -0600, Kevin Grittner wrote: > Attached. > > Dan and I have spent many, many hours desk-check and testing, > including pounding for many hours in DBT-2 at high concurrency > factors on a 16 processor box. In doing so, we found and fixed a few > issues. Neither of us is aware of any bugs or deficiencies > remaining, even after a solid day of pounding in DBT-2, other than > the failure to extend any new functionality to hot standby. > > At Heikki's suggestion I have included a test to throw an error on an > attempt to switch to serializable mode during recovery. Anything > more to address that issue can be a small follow-up patch -- probably > mainly a few notes in the docs. Here is my first crack at a review: First of all, I am very impressed with the patch. I was pleased to see that both READ ONLY DEFERRABLE and 2PC work! Also, I found the patch very usable and did not encounter any bugs or big surprises. Second, I do not understand this patch entirely, so the following statements can be considered questions as much as answers. At a high level, there is a nice conceptual simplicity. Let me try to summarize it as I understand it: * RW dependencies are detected using predicate locking. * RW dependencies are tracked fromthe reading transaction (as an "out") conflict; and from the writing transaction (as an "in" conflict). * Beforecommitting a transaction, then by looking only at the RW dependencies (and predicate locks) for current and past transactions, you can determine if committing this transaction will result in a cycle (and therefore a serializationanomaly); and if so, abort it. That's where the simplicity ends, however ;) For starters, the above structures require unlimited memory, while we have fixed amounts of memory. The predicate locks are referenced by a global shared hash table as well as per-process SHMQueues. It can adapt memory usage downward in three ways: * increase lock granularity -- e.g. change N page locks into a table lock * "summarization"-- fold multiple locks on the same object across many old committed transactions into a single lock * usethe SLRU Tracking of RW conflicts of current and past transactions is more complex. Obviously, it doesn't keep _all_ past transactions, but only ones that overlap with a currently-running transaction. It does all of this management using SHMQueue. There isn't much of an attempt to gracefully handle OOM here as far as I can tell, it just throws an error if there's not enough room to track a new transaction (which is reasonable, considering that it should be quite rare and can be mitigated by increasing max_connections). The heavy use of SHMQueue is quite reasonable, but for some reason I find the API very difficult to read. I think it would help (at least me) quite a lot to annotate (i.e. with a comment in the struct) the various lists and links with the types of data being held. The actual checking of conflicts isn't quite so simple, either, because we want to detect problems before the victim transaction has done too much work. So, checking is done along the way in several places, and it's a little difficult to follow exactly how those smaller checks add up to the overall serialization-anomaly check (the third point in my simple model). There are also optimizations around transactions declared READ ONLY. Some of these are a little difficult to follow as well, and I haven't followed them all. There is READ ONLY DEFERRABLE, which is a nice feature that waits for a "safe" snapshot, so that the transaction will never be aborted. Now, on to my code comments (non-exhaustive): * I see that you use a union as well as using "outLinks" to also be a free list. I suppose you did this to conserve shared memory space, right? * In RegisterSerializableTransactionInt(), for a RO xact, it considers any concurrent RW xact a possible conflict. It seems like it would be possible to know whether a RW transaction may have overlapped with any committed RW transaction (in finishedLink queue), and only add those as potential conflicts. Would that work? If so, that would make more snapshots safe. * When a transaction finishes, then PID should probably be set to zero. You only use it for waking up a deferrable RO xact waiting for a snapshot, right? * Still some compiler warnings: twophase.c: In function ‘FinishPreparedTransaction’: twophase.c:1360: warning: implicit declaration of function ‘PredicateLockTwoPhaseFinish’ * You have a function called CreatePredTran. We are already using "Transaction" and "Xact" -- we probably don't need "Tran" as well. * HS error has a typo: "ERROR: cannot set transaction isolationn level to serializable during recovery" * I'm a little unclear on summarization and writing to the SLRU. I don't see where it's determining that the predicate locks can be safely released. Couldn't the oldest transaction still have relevant predicate locks? * In RegisterSerializableTransactionInt, if it doesn't get an sxact, it goes into summarization. But summarization assumes that it has at least one finished xact. Is that always true? If you have enough memory to hold a transaction for each connection, plus max_prepared_xacts, plus one, I think that's true. But maybe that could be made more clear? I'll keep working on this patch. I hope I can be of some help getting this committed, because I'm looking forward to this feature. And I certainly think that you and Dan have applied the amount of planning, documentation, and careful implementation necessary for a feature like this. Regards,Jeff Davis
Thanks for working your way through this patch. I'm certainly well aware that that's not a trivial task! I'm suffering through a bout of insomnia, so I'll respond to some of your high-level comments in hopes that serializability will help put me to sleep (as it often does). I'll leave the more detailed code comments for later when I'm actually looking at the code, or better yet Kevin will take care of them and I won't have to. ;-) On Tue, Jan 25, 2011 at 01:07:39AM -0800, Jeff Davis wrote: > At a high level, there is a nice conceptual simplicity. Let me try to > summarize it as I understand it: > * RW dependencies are detected using predicate locking. > * RW dependencies are tracked from the reading transaction (as an > "out") conflict; and from the writing transaction (as an "in" > conflict). > * Before committing a transaction, then by looking only at the RW > dependencies (and predicate locks) for current and past > transactions, you can determine if committing this transaction will > result in a cycle (and therefore a serialization anomaly); and if > so, abort it. This summary is right on. I would add one additional detail or clarification to the last point, which is that rather than checking for a cycle, we're checking for a transaction with both "in" and "out" conflicts, which every cycle must contain. > That's where the simplicity ends, however ;) Indeed! > Tracking of RW conflicts of current and past transactions is more > complex. Obviously, it doesn't keep _all_ past transactions, but only > ones that overlap with a currently-running transaction. It does all of > this management using SHMQueue. There isn't much of an attempt to > gracefully handle OOM here as far as I can tell, it just throws an error > if there's not enough room to track a new transaction (which is > reasonable, considering that it should be quite rare and can be > mitigated by increasing max_connections). If the OOM condition you're referring to is the same one from the following comment, then it can't happen: (Apologies if I've misunderstood what you're referring to.) > * In RegisterSerializableTransactionInt, if it doesn't get an sxact, it > goes into summarization. But summarization assumes that it has at least > one finished xact. Is that always true? If you have enough memory to > hold a transaction for each connection, plus max_prepared_xacts, plus > one, I think that's true. But maybe that could be made more clear? Yes -- the SerializableXact pool is allocated up front and it definitely has to be bigger than the number of possible active transactions. In fact, it's much larger: 10 * (MaxBackends + max_prepared_xacts) to allow some room for the committed transactions we still have to track. > * In RegisterSerializableTransactionInt(), for a RO xact, it considers > any concurrent RW xact a possible conflict. It seems like it would be > possible to know whether a RW transaction may have overlapped with any > committed RW transaction (in finishedLink queue), and only add those as > potential conflicts. Would that work? If so, that would make more > snapshots safe. Interesting idea. That's worth some careful thought. I think it's related to the condition that the RW xact needs to commit with a conflict out to a transaction earlier than the RO xact. My first guess is that this wouldn't make more transactions safe, but could detect safe snapshots faster. > * When a transaction finishes, then PID should probably be set to zero. > You only use it for waking up a deferrable RO xact waiting for a > snapshot, right? Correct. It probably wouldn't hurt to clear that field when releasing the transaction, but we don't use it after. > * I'm a little unclear on summarization and writing to the SLRU. I don't > see where it's determining that the predicate locks can be safely > released. Couldn't the oldest transaction still have relevant predicate > locks? When a SerializableXact gets summarized to the SLRU, its predicate locks aren't released; they're transferred to the dummy OldCommittedSxact. > I'll keep working on this patch. I hope I can be of some help getting > this committed, because I'm looking forward to this feature. And I > certainly think that you and Dan have applied the amount of planning, > documentation, and careful implementation necessary for a feature like > this. Hopefully my comments here will help clarify the patch. It's not lost on me that there's no shortage of complexity in the patch, so if you found anything particularly confusing we should probably add some documentation to README-SSI. Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
Thanks for the review, Jeff! Dan Ports wrote: > On Tue, Jan 25, 2011 at 01:07:39AM -0800, Jeff Davis wrote: >> At a high level, there is a nice conceptual simplicity. Let me >> try to summarize it as I understand it: >> * RW dependencies are detected using predicate locking. >> * RW dependencies are tracked from the reading transaction (as an >> "out") conflict; and from the writing transaction (as an "in" >> conflict). >> * Before committing a transaction, then by looking only at the RW >> dependencies (and predicate locks) for current and past >> transactions, you can determine if committing this transaction >> will result in a cycle (and therefore a serialization anomaly); >> and if so, abort it. > > This summary is right on. I would add one additional detail or > clarification to the last point, which is that rather than > checking for a cycle, we're checking for a transaction with both > "in" and "out" conflicts, which every cycle must contain. Yep. For the visual thinkers out there, the whole concept can be understood by looking at the jpeg file that's in the Wiki page: http://wiki.postgresql.org/images/e/eb/Serialization-Anomalies-in-Snapshot-Isolation.png >> * In RegisterSerializableTransactionInt(), for a RO xact, it >> considers any concurrent RW xact a possible conflict. It seems >> like it would be possible to know whether a RW transaction may >> have overlapped with any committed RW transaction (in >> finishedLink queue), and only add those as potential conflicts. >> Would that work? If so, that would make more snapshots safe. > > Interesting idea. That's worth some careful thought. I think it's > related to the condition that the RW xact needs to commit with a > conflict out to a transaction earlier than the RO xact. My first > guess is that this wouldn't make more transactions safe, but could > detect safe snapshots faster. Yes, that would work. It would lower one type of overhead a little and allow RO transactions to be released from SSI tracking earlier. The question is how to determine it without taking too much time scanning the finished transaction list for every active read write transaction every time you start a RO transaction. I don't think that it's a trivial enough issue to consider for 9.1; it's certainly one to put on the list to look at for 9.2. >> * When a transaction finishes, then PID should probably be set to >> zero. You only use it for waking up a deferrable RO xact waiting >> for a snapshot, right? > > Correct. It probably wouldn't hurt to clear that field when > releasing the transaction, but we don't use it after. I thought they might show up in the pid column of pg_locks, but I see they don't. Should they? If so, should we still see the pid after a commit, for as long as the lock survives? -Kevin
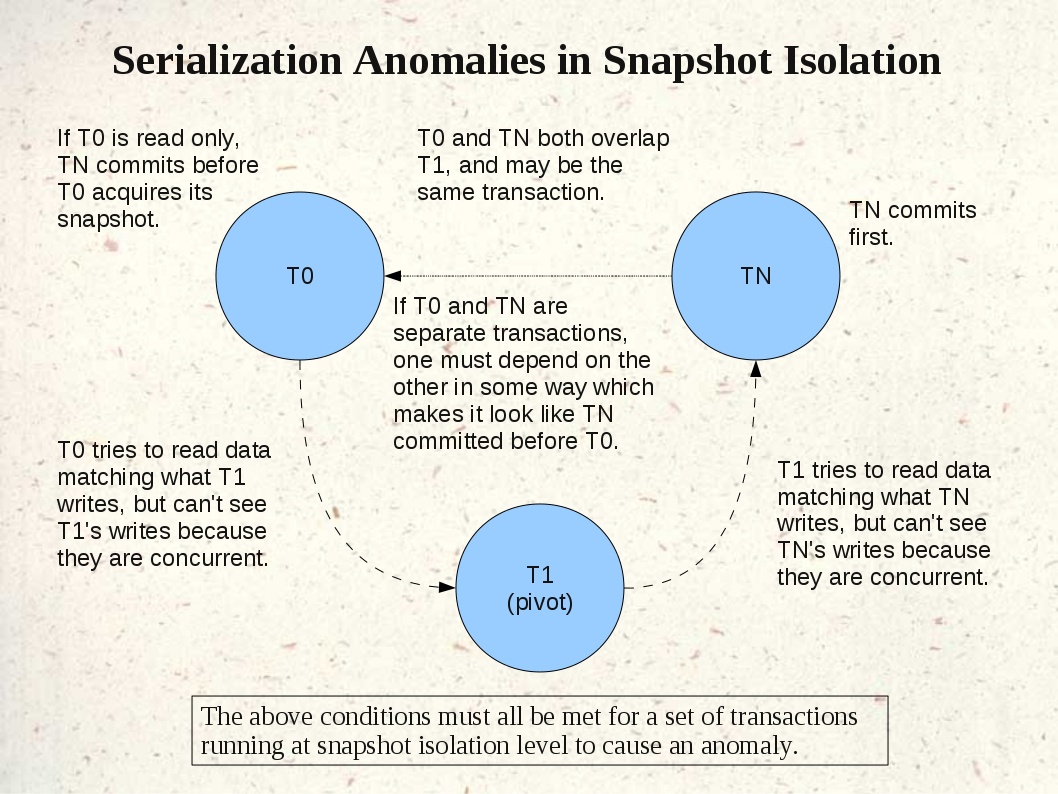{kind=link}
Jeff Davis <pgsql@j-davis.com> wrote: > For starters, the above structures require unlimited memory, while > we have fixed amounts of memory. The predicate locks are > referenced by a global shared hash table as well as per-process > SHMQueues. It can adapt memory usage downward in three ways: > * increase lock granularity -- e.g. change N page locks into a > table lock > * "summarization" -- fold multiple locks on the same object > across many old committed transactions into a single lock > * use the SLRU Those last two are related -- the summarization process takes the oldest committed-but-still-significant transaction and does two things with it: (1) We move predicate locks to the "dummy" transaction, kept just for this purpose. We combine locks against the same lock target, using the more recent commit point to determine when the resulting lock can be removed. (2) We use SLRU to keep track of the top level xid of the old committed transaction, and the earliest commit point of any transactions to which it had an out-conflict. The above reduces the information available to avoid serialization failure in certain corner cases, and is more expensive to access than the other structures, but it keeps us running in pessimal circumstances, even if at a degraded level of performance. > The heavy use of SHMQueue is quite reasonable, but for some reason > I find the API very difficult to read. I think it would help (at > least me) quite a lot to annotate (i.e. with a comment in the > struct) the various lists and links with the types of data being > held. We've tried to comment enough, but when you have your head buried in code you don't always recognize how mysterious something can look. Can you suggest some particular places where more comments would be helpful? > The actual checking of conflicts isn't quite so simple, either, > because we want to detect problems before the victim transaction > has done too much work. So, checking is done along the way in > several places, and it's a little difficult to follow exactly how > those smaller checks add up to the overall serialization-anomaly > check (the third point in my simple model). > > There are also optimizations around transactions declared READ > ONLY. Some of these are a little difficult to follow as well, and > I haven't followed them all. Yeah. After things were basically working correctly, in terms of not allowing any anomalies, we still had a lot of false positives. Checks around the order and timing of commits, as well as read-only status, helped bring these down. The infamous receipting example was my main guide here. There are 210 permutations in the way the statements can be interleaved, of which only six can result in anomalies. At first we only managed to commit a couple dozen permutations. As we added code to cover optimizations for various special cases the false positive rate dropped a little at a time, until that test hit 204 commits, six rollbacks. Although, all the tests in the dcheck target are useful -- if I made a mistake in implementing an optimization there would sometimes be just one or two of the other tests which would fail. Looking at which permutations got it right and which didn't was a really good way to figure out what I did wrong. > There is READ ONLY DEFERRABLE, which is a nice feature that waits > for a "safe" snapshot, so that the transaction will never be > aborted. *And* will not contribute to causing any other transaction to be rolled back, *and* dodges the overhead of predicate locking and conflict checking. Glad you like it! ;-) > Now, on to my code comments (non-exhaustive): > > * I see that you use a union as well as using "outLinks" to also > be a free list. I suppose you did this to conserve shared memory > space, right? Yeah, we tried to conserve shared memory space where we could do so without hurting performance. Some of it gets to be a little bit- twiddly, but it seemed like a good idea at the time. Does any of it seem like it creates a confusion factor which isn't worth it compared to the shared memory savings? > * Still some compiler warnings: > twophase.c: In function *FinishPreparedTransaction*: > twophase.c:1360: warning: implicit declaration of function > *PredicateLockTwoPhaseFinish* Ouch! That could cause bugs, since the implicit declaration didn't actually *match* the actual definition. Don't know how we missed that. I strongly recommend that anyone who wants to test 2PC with the patch add this commit to it: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=8e020d97bc7b8c72731688515b6d895f7e243e27 > * You have a function called CreatePredTran. We are already using > "Transaction" and "Xact" -- we probably don't need "Tran" as well. OK. Will rename if you like. Since that creates the PredTran structure, I assume you want that renamed, too? > * HS error has a typo: > "ERROR: cannot set transaction isolationn level to serializable > during recovery" Will fix. > I'll keep working on this patch. I hope I can be of some help > getting this committed, because I'm looking forward to this > feature. And I certainly think that you and Dan have applied the > amount of planning, documentation, and careful implementation > necessary for a feature like this. Thanks much! This effort was driven, for my part, by the needs of my employer; but I have to admit it was kinda fun to do some serious coding on innovative ideas again. It's been a while. I'm ready to kick back and party a bit when this gets done, though. ;-) -Kevin
On Tue, 2011-01-25 at 11:17 -0600, Kevin Grittner wrote: > > The heavy use of SHMQueue is quite reasonable, but for some reason > > I find the API very difficult to read. I think it would help (at > > least me) quite a lot to annotate (i.e. with a comment in the > > struct) the various lists and links with the types of data being > > held. > > We've tried to comment enough, but when you have your head buried in > code you don't always recognize how mysterious something can look. > Can you suggest some particular places where more comments would be > helpful? I think just annotating RWConflict.in/outLink and PredTranList.available/activeList with the types of things they hold would be a help. Also, you say something about RWConflict and "when the structure is not in use". Can you elaborate on that a bit? I'll address the rest of your comments in a later email. Regards,Jeff Davis
On Tue, 2011-01-25 at 09:41 -0600, Kevin Grittner wrote: > Yep. For the visual thinkers out there, the whole concept can be > understood by looking at the jpeg file that's in the Wiki page: > > http://wiki.postgresql.org/images/e/eb/Serialization-Anomalies-in-Snapshot-Isolation.png Yes, that helped a lot throughout the review process. Good job keeping it up-to-date! > Yes, that would work. It would lower one type of overhead a little > and allow RO transactions to be released from SSI tracking earlier. > The question is how to determine it without taking too much time > scanning the finished transaction list for every active read write > transaction every time you start a RO transaction. I don't think > that it's a trivial enough issue to consider for 9.1; it's certainly > one to put on the list to look at for 9.2. It's OK to leave it to 9.2. But if it's a RO deferrable transaction, it's just going to go to sleep in that case anyway; so why not look for an opportunity to get a safe snapshot right away? Regards,Jeff Davis
On 25.01.2011 05:30, Kevin Grittner wrote: > Attached. The readme says this: > + 4. PostgreSQL supports subtransactions -- an issue not mentioned > +in the papers. But I don't see any mention anywhere else on how subtransactions are handled. If a subtransaction aborts, are its predicate locks immediately released? -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > On 25.01.2011 05:30, Kevin Grittner wrote: > The readme says this: >> 4. PostgreSQL supports subtransactions -- an issue not mentioned >> in the papers. > > But I don't see any mention anywhere else on how subtransactions > are handled. If a subtransaction aborts, are its predicate locks > immediately released? No. Here's the reasoning. Within a top level transaction, you might start a subtransaction, read some data, and then decide based on what you read that the subtransaction should be rolled back. If the decision as to what is part of the top level transaction can depend on what is read in the subtransaction, predicate locks taken by the subtransaction must survive rollback of the subtransaction. Does that make sense to you? Is there somewhere you would like to see that argument documented? -Kevin
Jeff Davis <pgsql@j-davis.com> wrote: > I think just annotating RWConflict.in/outLink and > PredTranList.available/activeList with the types of things they > hold would be a help. > > Also, you say something about RWConflict and "when the structure > is not in use". Can you elaborate on that a bit? Please let me know whether this works for you: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=325ec55e8c9e5179e2e16ff303af6afc1d6e732b -Kevin
Jeff Davis <pgsql@j-davis.com> wrote: > It's OK to leave it to 9.2. But if it's a RO deferrable > transaction, it's just going to go to sleep in that case anyway; > so why not look for an opportunity to get a safe snapshot right > away? If you're talking about doing this only for DEFERRABLE transactions it *might* make sense for 9.1. I'd need to look at what's involved. We make similar checks for all read only transactions, so they can withdraw from SSI while running, if their snapshot *becomes* safe. I don't think I'd want to consider messing with that code at this point. -Kevin
On 25.01.2011 22:53, Kevin Grittner wrote: > Heikki Linnakangas<heikki.linnakangas@enterprisedb.com> wrote: >> On 25.01.2011 05:30, Kevin Grittner wrote: > >> The readme says this: >>> 4. PostgreSQL supports subtransactions -- an issue not mentioned >>> in the papers. >> >> But I don't see any mention anywhere else on how subtransactions >> are handled. If a subtransaction aborts, are its predicate locks >> immediately released? > > No. Here's the reasoning. Within a top level transaction, you > might start a subtransaction, read some data, and then decide based > on what you read that the subtransaction should be rolled back. If > the decision as to what is part of the top level transaction can > depend on what is read in the subtransaction, predicate locks taken > by the subtransaction must survive rollback of the subtransaction. > > Does that make sense to you? Yes, that's what I suspected. And I gather that all the data structures in predicate.c work with top-level xids, not subxids. When looking at an xid that comes from a tuple's xmin or xmax, for example, you always call SubTransGetTopmostTransaction() before doing much else with it. > Is there somewhere you would like to > see that argument documented? README-SSI . -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
On Mon, 2011-01-24 at 21:30 -0600, Kevin Grittner wrote: > Dan and I have spent many, many hours desk-check and testing, > including pounding for many hours in DBT-2 at high concurrency > factors on a 16 processor box. In doing so, we found and fixed a few > issues. Neither of us is aware of any bugs or deficiencies > remaining, even after a solid day of pounding in DBT-2, other than > the failure to extend any new functionality to hot standby. A couple of comments on this. I looked at the patch to begin a review and immediately saw "dtest". There's no docs to explain what it is, but a few comments fill me in a little more. Can we document that please? And/or explain why its an essential part of this commit? Could we keep it out of core, or if not, just commit that part separately? I notice the code is currently copyright someone else than PGDG. Pounding for hours on 16 CPU box sounds good. What diagnostics or instrumentation are included with the patch? How will we know whether pounding for hours is actually touching all relevant parts of code? I've done such things myself only to later realise I wasn't actually testing the right piece of code. When this runs in production, how will we know whether SSI is stuck or is consuming too much memory? e.g. Is there a dynamic view e.g. pg_prepared_xacts, or is there a log mode log_ssi_impact, etc?? -- Simon Riggs http://www.2ndQuadrant.com/books/PostgreSQL Development, 24x7 Support, Training and Services
On Wed, 2011-01-26 at 11:36 +0000, Simon Riggs wrote: > Pounding for hours on 16 CPU box sounds good. What diagnostics or > instrumentation are included with the patch? How will we know whether > pounding for hours is actually touching all relevant parts of code? I've > done such things myself only to later realise I wasn't actually testing > the right piece of code. An example of this is the XIDCACHE_DEBUG code used in procarray.c to validate TransactionIdIsInProgress(). -- Simon Riggs http://www.2ndQuadrant.com/books/PostgreSQL Development, 24x7 Support, Training and Services
Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > On 25.01.2011 22:53, Kevin Grittner wrote: >> Is there somewhere you would like to >> see that argument documented? > > README-SSI . Done (borrowing some of your language). http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=470abc51c5626cf3c7cbd734b1944342973d0d47 Let me know if you think more is needed. -Kevin
Simon Riggs <simon@2ndQuadrant.com> wrote: > On Wed, 2011-01-26 at 11:36 +0000, Simon Riggs wrote: > >> Pounding for hours on 16 CPU box sounds good. What diagnostics or >> instrumentation are included with the patch? How will we know >> whether pounding for hours is actually touching all relevant >> parts of code? I've done such things myself only to later realise >> I wasn't actually testing the right piece of code. > > An example of this is the XIDCACHE_DEBUG code used in procarray.c > to validate TransactionIdIsInProgress(). It isn't exactly equivalent, but on a conceptually similar note some of the hours of DBT-2 pounding were done with #ifdef statements to force code into code paths which are normally rarely used. We left one of them in the codebase with the #define commented out, although I know that's not strictly necessary. (It does provide a convenient place to put a comment about what it's for, though.) In looking at it just now, I noticed that after trying it in a couple different places what was left in the repository was not the optimal version for code coverage. I've put this back to the version which did a better job, for reasons described in the commit comment: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=8af1bc84318923ba0ec3d4413f374a3beb10bc70 Dan, did you have some others which should maybe be included? I'm not sure I see any counts we could get from SSI which would be useful beyond what we might get from a code coverage tool or profiling, but I'm open to suggestions. -Kevin
Simon Riggs <simon@2ndQuadrant.com> wrote: > I looked at the patch to begin a review and immediately saw > "dtest". There's no docs to explain what it is, but a few comments > fill me in a little more. Can we document that please? And/or > explain why its an essential part of this commit? Could we keep it > out of core, or if not, just commit that part separately? I notice > the code is currently copyright someone else than PGDG. I'm including Markus on this reply, because he's the only one who can address the copyright issue. I will say that while the dcheck make target is not required for a proper build, and the tests run for too long to consider including this in the check target, I would not recommend that anybody hack on SSI without regularly running these tests or some equivalent.. When I suggested breaking this out of the patch, everybody who spoke up said not to do so. How the eventual committer commits it is of course up to that person. > Pounding for hours on 16 CPU box sounds good. What diagnostics or > instrumentation are included with the patch? How will we know > whether pounding for hours is actually touching all relevant parts > of code? I've done such things myself only to later realise I > wasn't actually testing the right piece of code. We've looked at distributions of failed transactions by ereport statement. This confirms that we are indeed exercising the vast majority of the code. See separate post for how we pushed execution into the summarization path to test code related to that. I do have some concern that the 2PC testing hasn't yet covered all code paths. I don't see how the problem found by Jeff during review could have survived thorough testing there. > When this runs in production, how will we know whether SSI is > stuck Stuck? I'm not sure what you mean by that. Other than LW locking (which I believe is always appropriately brief, with rules for order of acquisition which should prevent deadlocks), the only blocking introduced by SSI is when there is an explicit request for DEFERRABLE READ ONLY transactions. Such a transaction may take a while to start. Is that what you're talking about? > or is consuming too much memory? Relevant shared memory is allocated at startup, with strategies for living within that as suggested by Heikki and summarized in a recent post by Jeff. It's theoretically possible to run out of certain objects, in which case there is an ereport, but we haven't seen anything like that since the mitigation and graceful degradation changes were implemented. > e.g. Is there a dynamic view e.g. pg_prepared_xacts, We show predicate locks in the pg_locks view with mode SIReadLock. > is there a log mode log_ssi_impact, etc?? Don't have that. What would you expect that to show? -Kevin
Kevin, thanks for your heads-up. On 01/26/2011 06:07 PM, Kevin Grittner wrote: > Simon Riggs <simon@2ndQuadrant.com> wrote: > >> I looked at the patch to begin a review and immediately saw >> "dtest". There's no docs to explain what it is, but a few comments >> fill me in a little more. Can we document that please? And/or >> explain why its an essential part of this commit? Could we keep it >> out of core, or if not, just commit that part separately? I notice >> the code is currently copyright someone else than PGDG. > > I'm including Markus on this reply, because he's the only one who > can address the copyright issue. I certainly agree to change the copyright notice for my parts of the code in Kevin's SSI to say "Copyright ... Postgres Global Development Group". However, it's also worth mentioning that 'make dcheck' requires my dtester python package to be installed. See [1]. I put that under the Boost license, which seems very similar to the Postgres license. > When I suggested breaking this out of the patch, everybody who spoke > up said not to do so. How the eventual committer commits it is of > course up to that person. If the committer decides not to commit the dtests, I'm happy to add these dtests to the "official" postgres-dtests repository [2]. There I could let it follow the development of dtester. If Kevin's dtests gets committed, either dtester needs to be backwards compatible or the Postgres sources need to follow development of dtester, which I'm not satisfied with, yet. (However, note that I didn't have any time to work on dtester, recently, so that is somewhat hypothetical anyway). If you have any more questions, I'm happy to help. Regards Markus Wanner [1]: dtester project site: http://www.bluegap.ch/projects/dtester/ [2]: postgres dtests: http://git.postgres-r.org/?p=postgres-dtests;a=summary
On Wed, 2011-01-26 at 11:07 -0600, Kevin Grittner wrote: > > When this runs in production, how will we know whether SSI is > > stuck > > Stuck? I'm not sure what you mean by that. Other than LW locking > (which I believe is always appropriately brief, with rules for order > of acquisition which should prevent deadlocks), the only blocking > introduced by SSI is when there is an explicit request for > DEFERRABLE READ ONLY transactions. Such a transaction may take a > while to start. Is that what you're talking about? I'm thinking of a general requirement for diagnostics. What has been done so far looks great to me, so talking about this subject is in no way meant to be negative. Everything has bugs and we find them quicker if there are some ways of getting out more information about what is happening in the guts of the system. For HS, I put in a special debug mode and various information functions. For HOT, I produced a set of page inspection functions. I'm keen to have some ways where we can find out various metrics about what is happening, so we can report back to you to check if there are bugs. I foresee that some applications will be more likely to generate serialization errors than others. People will ask questions and they may claim there are bugs. I would like to be able to say "there is no bug - look at XYZ and see that the errors you are getting are because of ABC". > > or is consuming too much memory? > > Relevant shared memory is allocated at startup, with strategies for > living within that as suggested by Heikki and summarized in a recent > post by Jeff. It's theoretically possible to run out of certain > objects, in which case there is an ereport, but we haven't seen > anything like that since the mitigation and graceful degradation > changes were implemented. > > > e.g. Is there a dynamic view e.g. pg_prepared_xacts, > > We show predicate locks in the pg_locks view with mode SIReadLock. OK, that's good. > > is there a log mode log_ssi_impact, etc?? > > Don't have that. What would you expect that to show? > > -Kevin -- Simon Riggs http://www.2ndQuadrant.com/books/PostgreSQL Development, 24x7 Support, Training and Services
Excerpts from Kevin Grittner's message of mié ene 26 14:07:18 -0300 2011: > Simon Riggs <simon@2ndQuadrant.com> wrote: > > Pounding for hours on 16 CPU box sounds good. What diagnostics or > > instrumentation are included with the patch? How will we know > > whether pounding for hours is actually touching all relevant parts > > of code? I've done such things myself only to later realise I > > wasn't actually testing the right piece of code. > > We've looked at distributions of failed transactions by ereport > statement. This confirms that we are indeed exercising the vast > majority of the code. See separate post for how we pushed execution > into the summarization path to test code related to that. BTW did you try "make coverage" and friends? See http://www.postgresql.org/docs/9.0/static/regress-coverage.html and http://developer.postgresql.org/~petere/coverage/ -- Álvaro Herrera <alvherre@commandprompt.com> The PostgreSQL Company - Command Prompt, Inc. PostgreSQL Replication, Consulting, Custom Development, 24x7 support
Alvaro Herrera <alvherre@commandprompt.com> wrote: > BTW did you try "make coverage" and friends? See > http://www.postgresql.org/docs/9.0/static/regress-coverage.html > and > http://developer.postgresql.org/~petere/coverage/ I had missed that; thanks for pointing it out! I'm doing a coverage build now, to see what coverage we get from `make check` (probably not much) and `make dcheck`. Dan, do you still have access to that machine you were using for the DBT-2 runs? Could we get a coverage run with and without TEST_OLDSERXID defined? -Kevin
"Kevin Grittner" <Kevin.Grittner@wicourts.gov> wrote: > Alvaro Herrera <alvherre@commandprompt.com> wrote: > >> BTW did you try "make coverage" and friends? See >> http://www.postgresql.org/docs/9.0/static/regress-coverage.html >> and >> http://developer.postgresql.org/~petere/coverage/ > > I had missed that; thanks for pointing it out! > > I'm doing a coverage build now, to see what coverage we get from > `make check` (probably not much) and `make dcheck`. Well, that was a bit better than I expected. While the overall code coverage for PostgreSQL source code is: Overall coverage rate: lines......: 64.8% (130296 of 201140 lines) functions..: 72.0% (7997 of 11109 functions) The coverage for predicate.c, after running both check and dcheck, was (formatted to match above): lines......: 69.8% (925 of 1325 lines) functions..: 85.7% (48 of 56 functions) Most of what was missed was in the SLRU or 2PC code, which is expected. I'll bet that the DBT-2 runs, between the "normal" and TEST_OLDSERXID flavors, would get us about 2/3 of the way from those numbers toward 100%, with almost all the residual being in 2PC. Does anyone have suggestions for automated 2PC tests? -Kevin
On Wed, Jan 26, 2011 at 10:01:28AM -0600, Kevin Grittner wrote: > In looking at it just now, I noticed that after trying it in a > couple different places what was left in the repository was not the > optimal version for code coverage. I've put this back to the > version which did a better job, for reasons described in the commit > comment: Isn't this placement the same as the version we had before that didn't work? Specifically, aren't we going to have problems running with TEST_OLDSERXID enabled because CreatePredTran succeeds and links a new SerializableXact into the active list, but we don't initialize it before we drop SerializableXactHashLock to call SummarizeOldestCommittedSxact? I seem to recall SummarizeOldestCommittedSxact failing before because of the uninitialized entry, but more generally since we drop the lock something else might scan the list. (This isn't a problem in the non-test case because we'd only do that if CreatePredTran fails.) Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
On Wed, Jan 26, 2011 at 01:42:23PM -0600, Kevin Grittner wrote: > Dan, do you still have access to that machine you were using for the > DBT-2 runs? Could we get a coverage run with and without > TEST_OLDSERXID defined? Sure, I'll give it a shot (once I figure out how to enable coverage...) Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
Dan Ports <drkp@csail.mit.edu> wrote: > Isn't this placement the same as the version we had before that > didn't work? You're right. How about this?: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=86b839291e2588e59875fb87d05432f8049575f6 Same benefit in terms of exercising more lines of code, but *without* exposing the uninitialized structure to other threads. -Kevin
I wrote: > You're right. How about this?: That's even worse. I'm putting back to where you had it and taking a break before I do anything else that dumb. -Kevin
On Wed, Jan 26, 2011 at 02:36:25PM -0600, Kevin Grittner wrote: > Same benefit in terms of exercising more lines of code, but > *without* exposing the uninitialized structure to other threads. Won't this cause a deadlock because locks are being acquired out of order? Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
I wrote: > While the overall code coverage for PostgreSQL source code is: > > Overall coverage rate: > lines......: 64.8% (130296 of 201140 lines) > functions..: 72.0% (7997 of 11109 functions) By the way, I discovered that the above is lower if you just run the check target. The dcheck target helps with overall PostgreSQL code coverage, even though it was targeted at the SSI code. > The coverage for predicate.c, after running both check and dcheck, > was (formatted to match above): > > lines......: 69.8% (925 of 1325 lines) > functions..: 85.7% (48 of 56 functions) Some minor tweaks to the regression tests boosts that to: lines......: 73.1% (968 of 1325 lines) functions..: 89.3% (50 of56 functions) Most of the code not covered in the regular build (above) is in the OldSerXidXxxxx functions, which are covered well in a build with TEST_OLDSERXID defined. The 2PC code is very well covered now, except for the recovery-time function. We don't have a way to test that in the `make check` process, do we? There is some code which is not covered just because it is so hard to hit -- for example, code which is only executed if vacuum cleans up an index page when we are right at the edge of running out of the memory used to track predicate locks. It would be hard to include a test for that in the normal regression tests. The regression test changes are here: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=d4c1005d731c81049cc2622e50b7a2ebb99bbcac -Kevin
On Tue, 2011-01-25 at 05:57 -0500, Dan Ports wrote: > This summary is right on. I would add one additional detail or > clarification to the last point, which is that rather than checking for > a cycle, we're checking for a transaction with both "in" and "out" > conflicts, which every cycle must contain. To clarify, this means that it will get some false positives, right? For instance: T1: get snapshot T2: get snapshot insert R1 commit T1: read R1 write R2 T3: get snapshot read R2 T3: commit T1: commit -- throws error T1 has a conflict out to T2, and T1 has a conflict in from T3. T2 has a conflict in from T1. T3 has a conflict out to T1. T1 is canceled because it has both a conflict in and a conflict out. But the results are the same as a serial order of execution: T3, T1, T2. Is there a reason we can't check for a real cycle, which would let T1 succeed? Regards,Jeff Davis
Jeff Davis <pgsql@j-davis.com> wrote: > To clarify, this means that it will get some false positives, > right? Yes. But the example you're about to get into isn't one of them. > For instance: > > T1: > get snapshot > > T2: > get snapshot > insert R1 > commit > > T1: > read R1 > write R2 > > T3: > get snapshot > read R2 > > T3: > commit > > T1: > commit -- throws error > > > T1 has a conflict out to T2, and T1 has a conflict in from T3. > T2 has a conflict in from T1. > T3 has a conflict out to T1. > > T1 is canceled because it has both a conflict in and a conflict > out. But the results are the same as a serial order of execution: > T3, T1, T2. > > Is there a reason we can't check for a real cycle, which would let > T1 succeed? Yes. Because T2 committed before T3 started, it's entirely possible that there is knowledge outside the database server that the work of T2 was done and committed before the start of T3, which makes the order of execution: T2, T3, T1, T2. So you can have anomalies. Let me give you a practical example. Pretend there are receipting terminals in public places for the organization. In most financial systems, those receipts are assigned to batches of some type. Let's say that's done by an insert for the new batch ID, which closes the old batch. Receipts are always added with the maximum batch ID, reflecting the open batch. Your above example could be: -- setup test=# create table ctl (batch_id int not null primary key); NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "ctl_pkey" for table "ctl" CREATE TABLE test=# create table receipt (batch_id int not null, amt numeric(13,2) not null); CREATE TABLE test=# insert into ctl values (1),(2),(3); INSERT 0 3 test=# insert into receipt values ((select max(batch_id) from ctl), 50),((select max(batch_id) from ctl), 100); INSERT 0 2 -- receipting workstation -- T1 starts working on receipt insert transaction test=# begin transaction isolation level repeatable read; BEGIN test=# select 1; -- to grab snapshot, per above?column? ---------- 1 (1 row) -- accounting workstation -- T2 closes old receipt batch; opens new test=# begin transaction isolation level repeatable read; BEGIN test=# insert into ctl values (4); INSERT 0 1 test=# commit; COMMIT -- receipting workstation -- T1 continues work on receipt test=# select max(batch_id) from ctl;max ----- 3 (1 row) test=# insert into receipt values (3, 1000); INSERT 0 1 -- accounting workstation -- T3 lists receipts from the closed batch -- (Hey, we inserted a new batch_id and successfully -- committed, right? The old batch is closed.) test=# begin transaction isolation level repeatable read; BEGIN test=# select * from receipt where batch_id = 3;batch_id | amt ----------+-------- 3 | 50.00 3 | 100.00 (2 rows) test=# commit; COMMIT -- receipting workstation -- T1 receipt insert transaction commits test=# commit; COMMIT Now, with serializable transactions, as you saw, T1 will be rolled back. With a decent software framework, it will be automatically retried, without any user interaction. It will select max(batch_id) of 4 this time, and the insert will succeed and be committed. Accounting's list is accurate. -Kevin
"Kevin Grittner" <Kevin.Grittner@wicourts.gov> wrote: > Now, with serializable transactions, as you saw, T1 will be rolled > back. I should probably have mentioned, that if all the transactions were SERIALIZABLE and the report of transactions from the batch was run as SERIALIZABLE READ ONLY DEFERRABLE, the start of the report would block until it was certain that it had a snapshot which could not lead to an anomaly, so the BEGIN for T3 would wait until the COMMIT of T1, get a new snapshot which it would determine to be safe, and proceed. This would allow that last receipt to land in batch 3 and show up on accounting's receipt list with no rollbacks *or* anomalies. -Kevin
On Tue, 2011-01-25 at 15:22 -0600, Kevin Grittner wrote: > Jeff Davis <pgsql@j-davis.com> wrote: > > > I think just annotating RWConflict.in/outLink and > > PredTranList.available/activeList with the types of things they > > hold would be a help. > > > > Also, you say something about RWConflict and "when the structure > > is not in use". Can you elaborate on that a bit? > > Please let me know whether this works for you: > > http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=325ec55e8c9e5179e2e16ff303af6afc1d6e732b Looks good. Jeff
On Thu, Jan 27, 2011 at 09:18:23AM -0800, Jeff Davis wrote: > On Tue, 2011-01-25 at 05:57 -0500, Dan Ports wrote: > > This summary is right on. I would add one additional detail or > > clarification to the last point, which is that rather than checking for > > a cycle, we're checking for a transaction with both "in" and "out" > > conflicts, which every cycle must contain. > > To clarify, this means that it will get some false positives, right? Yes, this is correct. > Is there a reason we can't check for a real cycle, which would let T1 > succeed? I talked today with someone who experimented with doing exactly that in MySQL as part of a research project (Perfectly Serializable Snapshot Isolation, paper forthcoming in ICDE) It confirmed my intuition that this is possible but not as straightforward as it sounds. Some complications I thought of in adapting that to what we're doing: 1) it requires tracking all edges in the serialization graph; besides the rw-conflicts we track there are also the moremundane rw-dependencies (if T2 sees an update made by T1, then T2 has to come after T1) and ww-dependencies (if T2'swrite modifies a tuple created by T1, then T2 has to come after T1). We are taking advantage of the fact that anycycle must have two adjacent rw-conflict edges, but the rest of the cycle can be composed of other types. It would certainlybe possible to track the others, but it would add a bit more complexity and use more memory. 2) it requires doing a depth-first search to check for a cycle, which is more expensive than just detecting two edges. Thatseems OK if you only want to check it on commit, but maybe not if you want to detect serialization failures at thetime of the conflicting read/write (as we do). 3) it doesn't seem to interact very well with our memory mitigation efforts, wherein we discard lots of data about committed transactions that we know we won't need. If we were checking for cycles, we'd need to keep more of it. I suspectsummarization (when we combine two transactions' predicate locks to save memory) would also cause problems. None of these seem particularly insurmountable, but they suggest it isn't a clear win to try to find an entire cycle. Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
> Dan Ports wrote:
> On Thu, Jan 27, 2011 at 09:18:23AM -0800, Jeff Davis wrote:
>
>> Is there a reason we can't check for a real cycle, which would let
>> T1 succeed?
>
> I talked today with someone who experimented with doing exactly
> that in MySQL as part of a research project (Perfectly Serializable
> Snapshot Isolation, paper forthcoming in ICDE)
I'm wondering how this differs from what is discussed in Section 2.7
("Serialization Graph Testing") of Cahill's doctoral thesis. That
discusses a technique for trying to avoid false positives by testing
the full graph for cycles, with the apparent conclusion that the
costs of doing so are prohibitive. The failure of attempts to
implement that technique seem to have been part of the impetus to
develop the SSI technique, where a particular structure involving two
to three transactions has been proven to exist in all graphs which
form such a cycle.
I've been able to identify four causes for false positives in the
current SSI implementation:
(1) Collateral reads. In particular, data skew caused by inserts
past the end of an index between an ANALYZE and subsequent data
access was a recurring source of performance complaints. This was
fixed by having the planner probe the ends of an index to correct the
costs in such situations. This has been effective at correcting the
target problem, but we haven't yet excluded such index probes from
predicate locking.
(2) Lock granularity. This includes vertical granularity issues,
such as granularity promotion to conserve shared memory and page
locking versus next-key locking; and it also includes the possibility
of column locking. Many improvements are still possible in this area;
although each should be treated as a performance enhancement patch
and subject to the appropriate performance testing to justify the
extra code and complexity. In some cases the work needed to effect
the reduction in serialization failures may cost more than retrying
the failed transactions.
(3) Dependencies other than read-write. SSI relies on current
PostgreSQL MVCC handling of write-write conflicts -- when one of
these occurs between two transactions running at this level, one of
the transactions must fail with a serialization failure; since only
one runs to successful completion, there is no question of which ran
*first*. Write-read dependencies (where one transaction *can* see
the work of another because they *don't* overlap) is handled in SSI
by assuming that if T1 commits before T2 acquires its snapshot, T1
will appear to have run before T2. I won't go into it at length on
this thread, but one has to be very careful about assuming anything
else; trying to explicitly track these conflicts and consider that T2
may have appeared to run before T1 can fall apart completely in the
face of some common and reasonable programming practices.
(4) Length of read-write dependency (a/k/a rw-conflict) chains.
Basically, it is a further extension from the Cahill papers in the
direction of work which apparently failed because of the overhead of
full cycle-checking. The 2008 paper (which was "best paper" at the
2008 ACM SIGMOD), just used inConflict and outConflict flag bits.
The 2009 paper extended this to pointers by those names, with NULL
meaning "no conflict", and a self-reference meaning "couldn't track
the detail; consider it to conflict with *all* concurrent
transactions". The latter brought the false positive rate down
without adding too much overhead. In the PostgreSQL effort, we
replaced those pointers with *lists* of conflicts. We only get to
"conflict with all concurrent transactions" in certain circumstances
after summarizing transaction data to avoid blowing out shared
memory.
The lists allowed avoidance of many false positives, facilitated
earlier cleanup of much information from shared memory, and led to a
cleaner implementation of the summarization logic. They also, as it
happens, provide enough data to fully trace the read-write
dependencies and avoid some false positives where the "dangerous
structure" SSI is looking for exists, but there is neither a complete
rw-conflict cycle, nor any transaction in the graph which committed
early enough to make a write-read conflict possible to any
transaction in the graph. Whether such rigorous tracing prevents
enough false positives to justify the programming effort, code
complexity, and run-time cost is anybody's guess.
I only raise these to clarify the issue for the Jeff (who is
reviewing the patch), since he asked. I strongly feel that none of
them are issues which need to be addressed for 9.1, nor do I think
they can be properly addressed within the time frame of this CF.
On the other hand, perhaps an addition to the README-SSI file is
warranted?
-Kevin
1. In CheckForSerializableConflictIn(), I think the comment above may be out of date. It says: "A tuple insert is in conflict only if there is a predicate lock against the entire relation." That doesn't appear to be true if, for example, there's a predicate lock on the index page that the tuple goes into. I examined it with gdb, and it calls the function, and the function does identify the conflict. 2. Also in the comment above CheckForSerializableConflictIn(), I see: "The call to this function also indicates that we need an entry in the serializable transaction hash table, so that this write's conflicts can be detected for the proper lifetime, which is until this transaction and all overlapping serializable transactions have completed." which doesn't make sense to me. The transaction should already have an entry in the hash table at this point, right? 3. The comment above CheckForSerializableConflictOut() seems to trail off, as though you may have meant to write more. It also seems to be out of date. And why are you reading the infomask directly? Do the existing visibility functions not suffice? I have made it through predicate.c, and I have a much better understanding of what it's actually doing. I can't claim that I have a clear understanding of everything involved, but the code looks like it's in good shape (given the complexity involved) and well-commented. I am marking the patch Ready For Committer, because any committer will need time to go through the patch; and the authors have clearly applied the thought, care, and testing required for something of this complexity. I will continue to work on it, though. The biggest issue on my mind is what to do about Hot Standby. The authors have a plan, but there is also some resistance to it: http://archives.postgresql.org/message-id/23698.1295566621@sss.pgh.pa.us We don't need a perfect solution for 9.1, but it would be nice if we had a viable plan for 9.2. Regards,Jeff Davis
On Sun, Jan 30, 2011 at 04:01:56PM -0600, Kevin Grittner wrote:
> I'm wondering how this differs from what is discussed in Section 2.7
> ("Serialization Graph Testing") of Cahill's doctoral thesis. That
> discusses a technique for trying to avoid false positives by testing
> the full graph for cycles, with the apparent conclusion that the
> costs of doing so are prohibitive. The failure of attempts to
> implement that technique seem to have been part of the impetus to
> develop the SSI technique, where a particular structure involving two
> to three transactions has been proven to exist in all graphs which
> form such a cycle.
I'm not sure. My very limited understanding is that people have tried
to do concurrency control via serialization graph testing but it's (at
least thought to be) too expensive to actually use. This seems to be
saying the opposite of that, so there must be some difference...
> I've been able to identify four causes for false positives in the
> current SSI implementation:
>
> (1) Collateral reads. In particular, data skew caused by inserts
> past the end of an index between an ANALYZE and subsequent data
> access was a recurring source of performance complaints. This was
> fixed by having the planner probe the ends of an index to correct the
> costs in such situations. This has been effective at correcting the
> target problem, but we haven't yet excluded such index probes from
> predicate locking.
I wasn't aware of this one (which probably means you mentioned it at
some point and I dropped that packet). Seems like it would not be too
difficult to exclude these -- for 9.2.
> (3) Dependencies other than read-write.
[...]
> one has to be very careful about assuming anything
> else; trying to explicitly track these conflicts and consider that T2
> may have appeared to run before T1 can fall apart completely in the
> face of some common and reasonable programming practices.
Yes. If you want to do precise cycle testing you'll have to track these
dependencies also, and I believe that would require quite a different
design from what we're doing.
> (4) Length of read-write dependency (a/k/a rw-conflict) chains.
[...]
> They also, as it
> happens, provide enough data to fully trace the read-write
> dependencies and avoid some false positives where the "dangerous
> structure" SSI is looking for exists, but there is neither a complete
> rw-conflict cycle, nor any transaction in the graph which committed
> early enough to make a write-read conflict possible to any
> transaction in the graph. Whether such rigorous tracing prevents
> enough false positives to justify the programming effort, code
> complexity, and run-time cost is anybody's guess.
I think I understand what you're getting at here, and it does sound
quite complicated for a benefit that is not clear.
> I only raise these to clarify the issue for the Jeff (who is
> reviewing the patch), since he asked. I strongly feel that none of
> them are issues which need to be addressed for 9.1, nor do I think
> they can be properly addressed within the time frame of this CF.
Absolutely, no question about it!
Dan
--
Dan R. K. Ports MIT CSAIL http://drkp.net/
Jeff Davis wrote: > 1. In CheckForSerializableConflictIn(), I think the comment above > may be out of date. It says: > 2. Also in the comment above CheckForSerializableConflictIn(), I > see: > 3. The comment above CheckForSerializableConflictOut() seems to > trail off, as though you may have meant to write more. It also > seems to be out of date. Will fix and post a patch version 15, along with the other fixes based on feedback to v14 (mostly to comments and docs) within a few hours. I'll also do that global change from using "tran" as an abbreviation for transaction in some places to consistently using xact whenever it is abbreviated. > And why are you reading the infomask directly? Do the existing > visibility functions not suffice? It's possible we re-invented some code somewhere, but I'm not clear on what code from this patch might use what existing function. Could you provide specifics? > I have made it through predicate.c, and I have a much better > understanding of what it's actually doing. I can't claim that I > have a clear understanding of everything involved, but the code > looks like it's in good shape (given the complexity involved) and > well-commented. Thanks! I know that's a lot of work, and I appreciate you pointing out where comments have not kept up with coding. > I am marking the patch Ready For Committer, because any committer > will need time to go through the patch; and the authors have > clearly applied the thought, care, and testing required for > something of this complexity. I will continue to work on it, > though. Thanks! > The biggest issue on my mind is what to do about Hot Standby. The > authors have a plan, but there is also some resistance to it: > > http://archives.postgresql.org/message-id/23698.1295566621@sss.pgh.pa.us > > We don't need a perfect solution for 9.1, but it would be nice if > we had a viable plan for 9.2. I don't recall any real opposition to what I sketched out in this post, which came after the above-referenced one: http://archives.postgresql.org/message-id/4D39D5EC0200002500039A19@gw.wicourts.gov Also, that opposition appears to be based on a misunderstanding of the first alternative, which was for sending at most one snapshot per commit or rollback of a serializable read write transaction, with possible throttling. The alternative needs at most two bits per commit or rollback of a serializable read write transaction; although I haven't checked whether that can be scared up without adding a whole byte. Read only transactions have nothing to do with the traffic under either alternative. -Kevin
Jeff Davis <pgsql@j-davis.com> wrote: > 1. [& 2.] In CheckForSerializableConflictIn() All of that was obsolete and could just be deleted. I did. > 3. The comment above CheckForSerializableConflictOut() I reworked the comment there. Hopefully it is now more clear. > I am marking the patch Ready For Committer Patch v15 is attached with fixes for all issues identified in v14. There was one (two-line) bug fix. No other logic changes. We had an addition to the README-SSI file, comment changes, doc changes, changes to the text of a few messages, and some structure/field renames to avoid using Tran as an abbreviation for transaction in addition to the use of Xact as an abbreviation. Pretty minimal differences from V14, but I figured it would save the committer some work if I rolled them all up here. -Kevin
Attachment
On Mon, Jan 31, 2011 at 12:31 PM, Kevin Grittner <Kevin.Grittner@wicourts.gov> wrote: > Pretty minimal differences from V14, but I figured it would save the > committer some work if I rolled them all up here. Sounds good. I believe Heikki is planning to work on this one. Hopefully that will happen soon, since we are running short on time. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, 2011-01-31 at 07:26 -0600, Kevin Grittner wrote: > > And why are you reading the infomask directly? Do the existing > > visibility functions not suffice? > > It's possible we re-invented some code somewhere, but I'm not clear > on what code from this patch might use what existing function. Could > you provide specifics? In CheckForSerializableConflictOut(), it takes a boolean "valid". Then within the function, it tries to differentiate: 1. Valid with no indication that it will be deleted. 2. Valid, but delete in progress 3. Invalid For #1, you are using the hint bit (not the real transaction status), and manually checking whether it's just a lock or a real delete. For #2 you are assuming any other xmax means that the transaction is in progress (which it may not be, because the hint bit might not be set for some time). I assume that will cause additional false positives. If you used HeapTupleSatisfiesVacuum(), you could do something like: case HEAPTUPLE_LIVE: return; case HEAPTUPLE_RECENTLY_DEAD: case HEAPTUPLE_DELETE_IN_PROGRESS: xid = HeapTupleHeaderGetXmax(tuple->t_data); break; case HEAPTUPLE_INSERT_IN_PROGRESS: xid = HeapTupleHeaderGetXmin(tuple->t_data); break; case HEAPTUPLE_DEAD: return; This is not identical to what's happening currently, and I haven't thought this through thoroughly yet. For instance, "recently dead and invalid" would be checking on the xmax instead of the xmin. Perhaps you could exit early in that case (if you still keep the "valid" flag), but that will happen soon enough anyway. I don't think this function really cares about the visibility with respect to the current snapshot, right? It really cares about what other transactions are interacting with the tuple and how. And I think HTSV meets that need a little better. > > The biggest issue on my mind is what to do about Hot Standby. The > > authors have a plan, but there is also some resistance to it: > > > > > http://archives.postgresql.org/message-id/23698.1295566621@sss.pgh.pa.us > > > > We don't need a perfect solution for 9.1, but it would be nice if > > we had a viable plan for 9.2. > > I don't recall any real opposition to what I sketched out in this > post, which came after the above-referenced one: > > http://archives.postgresql.org/message-id/4D39D5EC0200002500039A19@gw.wicourts.gov > > Also, that opposition appears to be based on a misunderstanding of > the first alternative, which was for sending at most one snapshot per > commit or rollback of a serializable read write transaction, with > possible throttling. The alternative needs at most two bits per > commit or rollback of a serializable read write transaction; although > I haven't checked whether that can be scared up without adding a > whole byte. Read only transactions have nothing to do with the > traffic under either alternative. Ok, great. When I read that before I thought that WAL might need to be sent for implicit RO transactions. I will read it more carefully again. Regards,Jeff Davis
Jeff Davis <pgsql@j-davis.com> wrote: > On Mon, 2011-01-31 at 07:26 -0600, Kevin Grittner wrote: >>> And why are you reading the infomask directly? Do the existing >>> visibility functions not suffice? >> >> It's possible we re-invented some code somewhere, but I'm not >> clear on what code from this patch might use what existing >> function. Could you provide specifics? > > In CheckForSerializableConflictOut(), it takes a boolean "valid". Ah, now I see what you're talking about. Take a look at where that "valid" flag come from -- the CheckForSerializableConflictOut are all place right after calls to HeapTupleSatisfiesVisibility. The "valid" value is what HeapTupleSatisfiesVisibility returned. Is it possible that the hint bits will not be accurate right after that? With that in mind, do you still see a problem with how things are currently done? -Kevin
On Mon, 2011-01-31 at 13:32 -0600, Kevin Grittner wrote: > Ah, now I see what you're talking about. Take a look at where that > "valid" flag come from -- the CheckForSerializableConflictOut are > all place right after calls to HeapTupleSatisfiesVisibility. The > "valid" value is what HeapTupleSatisfiesVisibility returned. Is it > possible that the hint bits will not be accurate right after that? > With that in mind, do you still see a problem with how things are > currently done? Oh, ok. The staleness of the hint bit was a fairly minor point though. Really, I think this should be using HTSV to separate concerns better and improve readability. My first reaction was to try to find out what the function was doing that's special. If it is doing something special, and HTSV is not what you're really looking for, a comment to explain would be helpful. As an example, consider that Robert Haas recently suggested using an infomask bit to mean frozen, rather than actually removing the xid, to save the xid as forensic information. If that were to happen, your code would be reading an xid that may have been re-used. Regards,Jeff Davis
Jeff Davis <pgsql@j-davis.com> wrote: > I don't think this function really cares about the visibility with > respect to the current snapshot, right? What it cares about is whether some other particular top level transaction wrote a tuple which we *would* read except that it is not visible to us because that other top level transaction is concurrent with ours. If so, we want to flag a read-write conflict out from our transaction and in to that other transaction. -Kevin
Jeff Davis <pgsql@j-davis.com> wrote: > Really, I think this should be using HTSV to separate concerns > better and improve readability. My first reaction was to try to > find out what the function was doing that's special. If it is > doing something special, and HTSV is not what you're really > looking for, a comment to explain would be helpful. It does seem that at least a comment would be needed. I'm not at all confident that there isn't some macro or function which would yield what I need. I just sent an email clarifying exactly what I want to check, so if you can see a better way to determine that, I'm all ears. > As an example, consider that Robert Haas recently suggested using > an infomask bit to mean frozen, rather than actually removing the > xid, to save the xid as forensic information. If that were to > happen, your code would be reading an xid that may have been > re-used. Yeah, clearly if the code remains as it is, it would be sensitive to changes in how hint bits or the xid values are used. If we can abstract that, it's clearly a Good Thing to do so. -Kevin
On Mon, 2011-01-31 at 13:55 -0600, Kevin Grittner wrote: > Jeff Davis <pgsql@j-davis.com> wrote: > > > I don't think this function really cares about the visibility with > > respect to the current snapshot, right? > > What it cares about is whether some other particular top level > transaction wrote a tuple which we *would* read except that it is > not visible to us because that other top level transaction is > concurrent with ours. Or a tuple that you *are* reading, but is being deleted concurrently, right? Or has been deleted by an overlapping transaction? > If so, we want to flag a read-write conflict > out from our transaction and in to that other transaction. It still seems like HTSV would suffice, unless I'm missing something. I think "visible" is still needed though: it matters in the cases HEAPTUPLE_RECENTLY_DEAD and HEAPTUPLE_LIVE. For the former, it only allows an early exit (if !visible); but for the latter, I think it's required. Regards,Jeff Davis
Jeff Davis <pgsql@j-davis.com> wrote:
> On Mon, 2011-01-31 at 13:55 -0600, Kevin Grittner wrote:
>> What it cares about is whether some other particular top level
>> transaction wrote a tuple which we *would* read except that it is
>> not visible to us because that other top level transaction is
>> concurrent with ours.
>
> Or a tuple that you *are* reading, but is being deleted
> concurrently, right? Or has been deleted by an overlapping
> transaction?
Right. I guess that wasn't as precise a statement as I thought. I
was trying to say that the effects of some write (insert, update,
delete to a permanent table) would not be visible to us because the
writing transaction is concurrent, for some tuple under
consideration.
>> If so, we want to flag a read-write conflict
>> out from our transaction and in to that other transaction.
>
> It still seems like HTSV would suffice, unless I'm missing
> something.
It is at least as likely that I'm missing something. If I'm
following you, we're talking about these 24 lines of code, where
"valid" is the what was just returned from
HeapTupleSatisfiesVisibility: if (valid) { /* * We may bail out if previous xmax aborted, or if it
committed but * only locked the tuple without updating it. */ if (tuple->t_data->t_infomask &
(HEAP_XMAX_INVALID|
HEAP_IS_LOCKED)) return;
/* * If there's a valid xmax, it must be from a concurrent
transaction, * since it deleted a tuple which is visible to us. */ xid =
HeapTupleHeaderGetXmax(tuple->t_data); if (!TransactionIdIsValid(xid)) return; } else { /*
* We would read this row, but it isn't visible to us. */ xid = HeapTupleHeaderGetXmin(tuple->t_data);
}
We follow this by a check for the top-level xid, and return if
that's early enough to have overlapped our transaction.
This seems to work as intended for a all known tests. I guess my
questions would be:
(1) Do you see a case where this would do the wrong thing? Can you
describe that or (even better) provide a test case to demonstrate
it?
(2) I haven't gotten my head around how HTSV helps or is even the
right thing. If I want to try the switch statement from your recent
post, what should I use as the OldestXmin value on the call to HTSV?
-Kevin
I wrote: > We follow this by a check for the top-level xid, and return if > that's early enough to have overlapped our transaction. s/early enough to have overlapped/early enough not to have overlapped/ -Kevin
On Mon, 2011-01-31 at 14:38 -0600, Kevin Grittner wrote: > It is at least as likely that I'm missing something. If I'm > following you, we're talking about these 24 lines of code, where > "valid" is the what was just returned from > HeapTupleSatisfiesVisibility: Yes. > (1) Do you see a case where this would do the wrong thing? Can you > describe that or (even better) provide a test case to demonstrate > it? No, I don't see any incorrect results. > (2) I haven't gotten my head around how HTSV helps or is even the > right thing. It primarily just encapsulates the access to the tuple header fields. I think that avoiding the messy logic of hint bits, tuple locks, etc., is a significant win for readability and maintainability. > If I want to try the switch statement from your recent > post, what should I use as the OldestXmin value on the call to HTSV? I believe RecentGlobalXmin should work. And I don't think the original switch statement I posted did the right thing for HEAPTUPLE_LIVE. I think that case needs to account for the visible flag (if it's live but not visible, that's the same as insert-in-progress for your purposes). Regards,Jeff Davis
Jeff Davis <pgsql@j-davis.com> wrote: > Ok, great. When I read that before I thought that WAL might need > to be sent for implicit RO transactions. I will read it more > carefully again. In looking back over recent posts to see what I might have missed or misinterpreted, I now see your point. Either of these alternatives would involve potentially sending something through the WAL on commit or rollback of some serializable transactions which *did not* write anything, if they were not *declared* to be READ ONLY. If that is not currently happening (again, I confess to not having yet delved into the mysteries of writing WAL records), then we would need a new WAL record type for writing these. That said, the logic would not make it at all useful to send something for *every* such transaction, and I've rather assumed that we would want some heuristic for setting a minimum interval between notifications, whether we sent the snapshots themselves or just flags to indicate it was time to build or validate a candidate snapshot. Sorry for misunderstanding the concerns. -Kevin
Jeff Davis <pgsql@j-davis.com> wrote: > On Mon, 2011-01-31 at 14:38 -0600, Kevin Grittner wrote: >> If I want to try the switch statement from your recent >> post, what should I use as the OldestXmin value on the call to >> HTSV? > > I believe RecentGlobalXmin should work. > > And I don't think the original switch statement I posted did the > right thing for HEAPTUPLE_LIVE. I think that case needs to account > for the visible flag (if it's live but not visible, that's the > same as insert-in-progress for your purposes). I'll try to set this up and see if I can get it to pass the check and dcheck make targets. Can we assume that the performance impact would be too small to matter when we know for sure that hint bits have already been set? -Kevin
On 31.01.2011 20:05, Robert Haas wrote: > On Mon, Jan 31, 2011 at 12:31 PM, Kevin Grittner > <Kevin.Grittner@wicourts.gov> wrote: >> Pretty minimal differences from V14, but I figured it would save the >> committer some work if I rolled them all up here. > > Sounds good. I believe Heikki is planning to work on this one. > Hopefully that will happen soon, since we are running short on time. Yeah, I can commit this. Jeff, are you satisfied with this patch now? I'm glad you're reviewing this, more eyeballs helps a lot with a big patch like this. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
On Mon, 2011-01-31 at 15:30 -0600, Kevin Grittner wrote: > I'll try to set this up and see if I can get it to pass the check > and dcheck make targets. Can we assume that the performance impact > would be too small to matter when we know for sure that hint bits > have already been set? I think that's a safe assumption. If there is some kind of noticeable difference in conflict rates or runtime, that probably indicates a bug in the new or old code. Regards,Jeff Davis
On Mon, 2011-01-31 at 23:35 +0200, Heikki Linnakangas wrote: > Yeah, I can commit this. Jeff, are you satisfied with this patch now? > I'm glad you're reviewing this, more eyeballs helps a lot with a big > patch like this. I think the patch is very close. I am doing my best in my free time to complete a thorough review. If you have other patches to review/commit then I will still be making progress reviewing SSI. However, I would recommend leaving yourself some time to think on this one if you don't already understand the design well. Regards,Jeff Davis
Jeff Davis <pgsql@j-davis.com> wrote: > On Mon, 2011-01-31 at 15:30 -0600, Kevin Grittner wrote: >> I'll try to set this up and see if I can get it to pass the check >> and dcheck make targets. Can we assume that the performance >> impact would be too small to matter when we know for sure that > hint bits have already been set? > > I think that's a safe assumption. If there is some kind of > noticeable difference in conflict rates or runtime, that probably > indicates a bug in the new or old code. That worked fine; passed check and dcheck targets. Here's the code: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=6360b0d4ca88c09cf590a75409cd29831afff58b With confidence that it works, I looked it over some more and now like this a lot. It is definitely more readable and should be less fragile in the face of changes to MVCC bit-twiddling techniques. Of course, any changes to the HTSV_Result enum will require changes to this code, but that seems easier to spot and fix than the alternative. Thanks for the suggestion! Having gotten my head around it, I embellished here: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=f9307a41c198a9aa4203eb529f9c6d1b55c5c6e1 Do those changes look reasonable? None of that is really *necessary*, but it seemed cleaner and clearer that way once I looked at the code with the changes you suggested. -Kevin
On Mon, 2011-01-31 at 17:55 -0600, Kevin Grittner wrote: > http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=6360b0d4ca88c09cf590a75409cd29831afff58b > > With confidence that it works, I looked it over some more and now > like this a lot. It is definitely more readable and should be less > fragile in the face of changes to MVCC bit-twiddling techniques. Of > course, any changes to the HTSV_Result enum will require changes to > this code, but that seems easier to spot and fix than the > alternative. Thanks for the suggestion! One thing that confused me a little about the code is the default case at the end. The enum is exhaustive, so the default doesn't really make sense. The compiler warning you are silencing is the uninitialized variable xid (right?), which is clearly a spurious warning. Since you have the "Assert(TransactionIdIsValid(xid))" there anyway, why not just initialize xid to InvalidTransactionId and get rid of the default case? I assume the "Assert(false)" is there to detect if someone adds a new enum value, but the compiler should issue a warning in that case anyway (and the comment next to Assert(false) is worded in a confusing way). This is all really minor stuff, obviously. Also, from a code standpoint, it might be possible to early return in the HEAPTUPLE_RECENTLY_DEAD case where visible=false. It looks like it will be handled quickly afterward (at TransactionIdPrecedes), so you don't have to change anything, but I thought I would mention it. > Having gotten my head around it, I embellished here: > > http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=f9307a41c198a9aa4203eb529f9c6d1b55c5c6e1 > > Do those changes look reasonable? None of that is really > *necessary*, but it seemed cleaner and clearer that way once I > looked at the code with the changes you suggested. Yes, I like those changes. Regards,Jeff Davis
Jeff Davis <pgsql@j-davis.com> wrote: > One thing that confused me a little about the code is the default > case at the end. The enum is exhaustive, so the default doesn't > really make sense. The compiler warning you are silencing is the > uninitialized variable xid (right?) Right. > Since you have the "Assert(TransactionIdIsValid(xid))" there > anyway, why not just initialize xid to InvalidTransactionId and > get rid of the default case? I feel a little better keeping even that trivial work out of the code path if possible, and it seems less confusing to me on the default case than up front. I'll improve the comment. > I assume the "Assert(false)" is there to detect if someone adds a > new enum value, but the compiler should issue a warning in that > case anyway My compiler doesn't. Would it make sense to elog here, rather than Assert? I'm not clear on the rules for that. I'll push something that way for review and comment. If it's wrong, I'll change it. > This is all really minor stuff, obviously. In a million line code base, I hate to call anything which affects readability minor. ;-) > Also, from a code standpoint, it might be possible to early return > in the HEAPTUPLE_RECENTLY_DEAD case where visible=false. Yeah, good point. It seems worth testing a bool there. A small push dealing with all the above issues and adding a little to comments: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=538ff57691256de0341e22513f59e9dc4dfd998f Let me know if any of that still needs work to avoid confusion and comply with PostgreSQL coding conventions. Like I said, I'm not totally clear whether elog is right here, but it seems to me a conceptually similar case to some I found elsewhere that elog was used. -Kevin
On Tue, 2011-02-01 at 11:01 -0600, Kevin Grittner wrote:
> My compiler doesn't.
Strange. Maybe it requires -O2?
> Would it make sense to elog here, rather than
> Assert? I'm not clear on the rules for that.
elog looks fine there to me, assuming we have the default case. I'm not
100% clear on the rules, either. I think invalid input/corruption are
usually elog (so they can be caught in non-assert builds); but other
switch statements have them as well ("unrecognized node...").
> A small push dealing with all the above issues and adding a little
> to comments:
>
>
http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=538ff57691256de0341e22513f59e9dc4dfd998f
>
> Let me know if any of that still needs work to avoid confusion and
> comply with PostgreSQL coding conventions. Like I said, I'm not
> totally clear whether elog is right here, but it seems to me a
> conceptually similar case to some I found elsewhere that elog was
> used.
Looks good. It also looks like it contains a bugfix for subtransactions,
right?
Regards,Jeff Davis
Jeff Davis <pgsql@j-davis.com> wrote: > On Tue, 2011-02-01 at 11:01 -0600, Kevin Grittner wrote: >> My compiler doesn't. > > Strange. Maybe it requires -O2? That's not it; I see -O2 in my compiles. At any rate, I think the default clause is the best place to quash the warning because that leaves us with a warning if changes leave a path through the other options without setting xid. In other words, unconditionally setting a value before the switch could prevent warnings on actual bugs, and I don't see such a risk when it's on the default. >> A small push dealing with all the above issues and adding a >> little to comments: > Looks good. It also looks like it contains a bugfix for > subtransactions, right? I think it fixes a bug introduced in the push from late yesterday. In reviewing what went into the last push yesterday, it looked like I might have introduced an assertion failure for the case where there is a write to a row within a subtransaction and then row is read again after leaving the subtransaction. I didn't actually confirm that through testing, because it looked like the safe approach was better from a performance standpoint, anyway. That last check for "our own xid" after finding the top level xid comes before acquiring the LW lock and doing an HTAB lookup which aren't necessary in that case. Re-reading a row within the same transaction seems likely enough to make it worth that quick test before doing more expensive things. It did throw a scare into me, though. The last thing I want to do is destabilize things at this juncture. I'll try to be more conservative with changes from here out. -Kevin
On 26.01.2011 13:36, Simon Riggs wrote: > I looked at the patch to begin a review and immediately saw "dtest". > There's no docs to explain what it is, but a few comments fill me in a > little more. Can we document that please? And/or explain why its an > essential part of this commit? Could we keep it out of core, or if not, > just commit that part separately? I notice the code is currently > copyright someone else than PGDG. We still haven't really resolved this.. Looking at the dtest suite, I'd really like to have those tests in the PostgreSQL repository. However, I'd really like not to require python to run them, and even less dtester (no offense Markus) and the dependencies it has. I couldn't get it to run on my basic Debian system, clearly I'm doing something wrong, but it will be even harder for people on more exotic platforms. The tests don't seem very complicated, and they don't seem to depend much on the dtester features. How hard would it be to rewrite the test engine in C or perl? I'm thinking of defining each test in a simple text file, and write a small test engine to parse that. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Heikki, On 02/02/2011 11:20 AM, Heikki Linnakangas wrote: > I couldn't get it to run on my basic Debian system, clearly I'm > doing something wrong, but it will be even harder for people on more > exotic platforms. On Debian you only need 'python-twisted' and the dtester sources [1], IIRC. What issue did you run into? > The tests don't seem very complicated, and they don't seem to depend > much on the dtester features. How hard would it be to rewrite the test > engine in C or perl? I've taken a quick look at a perl framework similar to twisted (POE). Doesn't seem too complicated, but I don't see the benefit of requiring one over the other. Another async, event-based framework that I've been playing with is asio (C++). I don't think it's feasible to write anything similar without basing on such a framework. (And twisted seems more mature and widespread (in terms of supported platforms) than POE, but that's probably just my subjective impression). However, the question here probably is whether or not you need all of the bells and whistles of dtester (as if there were that many) [2]. > I'm thinking of defining each test in a simple text file, and write a > small test engine to parse that. AFAIUI there are lots of possible permutations, so you don't want to have to edit files for each manually (several hundreds, IIRC). So using a scripting language to generate the permutations makes sense, IMO. Pretty much everything else that Kevin currently uses dtester for (i.e. initdb, running the postmaster, connecting with psql) is covered by the existing regression testing infrastructure already, I think. So it might be a matter of integrating the permutation generation and test running code into the existing infrastructure. Kevin? Regards Markus Wanner [1]: dtester project site: http://www.bluegap.ch/projects/dtester/ [2]: side note: Dtester mainly serves me to test Postgres-R, where the current regression testing infrastructure simply doesn't suffice. With dtester I tried to better structure the processes and services, their dependencies and the test environment.
On 02.02.2011 12:20, Heikki Linnakangas wrote: > On 26.01.2011 13:36, Simon Riggs wrote: >> I looked at the patch to begin a review and immediately saw "dtest". >> There's no docs to explain what it is, but a few comments fill me in a >> little more. Can we document that please? And/or explain why its an >> essential part of this commit? Could we keep it out of core, or if not, >> just commit that part separately? I notice the code is currently >> copyright someone else than PGDG. > > We still haven't really resolved this.. > > Looking at the dtest suite, I'd really like to have those tests in the > PostgreSQL repository. However, I'd really like not to require python to > run them, and even less dtester (no offense Markus) and the dependencies > it has. I couldn't get it to run on my basic Debian system, clearly I'm > doing something wrong, but it will be even harder for people on more > exotic platforms. > > The tests don't seem very complicated, and they don't seem to depend > much on the dtester features. How hard would it be to rewrite the test > engine in C or perl? > > I'm thinking of defining each test in a simple text file, and write a > small test engine to parse that. I took a stab at doing that. Attached, untar in the top source tree, and do "cd src/test/isolation; make check". It's like "installcheck", so it needs a postgres server to be running. Also available in my git repository at git://git.postgresql.org/git/users/heikki/postgres.git, branch "serializable". I think this will work. This is a rough first version, but it already works. We can extend the test framework later if we need more features, but I believe this is enough for all the existing tests. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Attachment
On 02.02.2011 14:48, Markus Wanner wrote: > Heikki, > > On 02/02/2011 11:20 AM, Heikki Linnakangas wrote: >> I couldn't get it to run on my basic Debian system, clearly I'm >> doing something wrong, but it will be even harder for people on more >> exotic platforms. > > On Debian you only need 'python-twisted' and the dtester sources [1], > IIRC. What issue did you run into? I installed dtester with: PYTHONPATH=~/pythonpath/lib/python2.6/site-packages/ python ./setup.py install --prefix=/home/heikki/pythonpath/ And that worked. But when I try to run Kevin's test suite, I get this: ~/git-sandbox/postgresql/src/test/regress (serializable)$ PYTHONPATH=~/pythonpath/lib/python2.6/site-packages/ make dcheck ./pg_dtester.py --temp-install --top-builddir=../../.. \ --multibyte= Postgres dtester suite Copyright (c) 2004-2010, by Markus Wanner Traceback (most recent call last): File "./pg_dtester.py", line 1376, in <module> main(sys.argv[1:]) File "./pg_dtester.py",line 1370, in main runner = Runner(reporter=TapReporter(sys.stdout, sys.stderr, showTimingInfo=True), TypeError: __init__() got an unexpected keyword argument 'showTimingInfo' make: *** [dcheck] Virhe 1 At that point I had no idea what's wrong. PS. I tried "python ./setup.py dtest", mentioned in the README, and it just said "invalid command 'dtest'". But I presume the installation worked anyway. > Pretty much everything else that Kevin currently uses dtester for (i.e. > initdb, running the postmaster, connecting with psql) is covered by the > existing regression testing infrastructure already, I think. So it > might be a matter of integrating the permutation generation and test > running code into the existing infrastructure. Kevin? Yeah, that was my impression too. (see my other post with WIP implementation of that) -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Heikki, On 02/02/2011 02:04 PM, Heikki Linnakangas wrote: > TypeError: __init__() got an unexpected keyword argument 'showTimingInfo' > make: *** [dcheck] Virhe 1 > > At that point I had no idea what's wrong. Hm.. looks like Kevin already uses the latest dtester code from git. You can either do that as well, or try to drop the 'showTimingInfo' argument from the call to Runner() in pg_dtester.py:1370. > PS. I tried "python ./setup.py dtest", mentioned in the README, and it > just said "invalid command 'dtest'". But I presume the installation > worked anyway. Yeah, that's a gotcha in dtester. setup.py dtest requires dtester to be installed - a classic chicken and egg problem. I certainly need to look into this. > Yeah, that was my impression too. (see my other post with WIP > implementation of that) I'd like to get Kevin's opinion on that, but it certainly sounds like a pragmatic approach for now. Regards Markus Wanner
Heikki Linnakangas wrote: > On 02.02.2011 12:20, Heikki Linnakangas wrote: >> The tests don't seem very complicated, and they don't seem to >> depend much on the dtester features. How hard would it be to >> rewrite the test engine in C or perl? >> >> I'm thinking of defining each test in a simple text file, and >> write a small test engine to parse that. > > I took a stab at doing that. Attached, untar in the top source > tree, and do "cd src/test/isolation; make check". It's like > "installcheck", so it needs a postgres server to be running. Also > available in my git repository at > git://git.postgresql.org/git/users/heikki/postgres.git, > branch "serializable". > > I think this will work. This is a rough first version, but it > already works. We can extend the test framework later if we need > more features, but I believe this is enough for all the existing > tests. Thanks for this. It does seem the way to go. I can fill it out with the rest of the tests, unless you'd rather. -Kevin
On 02.02.2011 16:11, Kevin Grittner wrote: > Heikki Linnakangas wrote: >> On 02.02.2011 12:20, Heikki Linnakangas wrote: > >>> The tests don't seem very complicated, and they don't seem to >>> depend much on the dtester features. How hard would it be to >>> rewrite the test engine in C or perl? >>> >>> I'm thinking of defining each test in a simple text file, and >>> write a small test engine to parse that. >> >> I took a stab at doing that. Attached, untar in the top source >> tree, and do "cd src/test/isolation; make check". It's like >> "installcheck", so it needs a postgres server to be running. Also >> available in my git repository at >> git://git.postgresql.org/git/users/heikki/postgres.git, >> branch "serializable". >> >> I think this will work. This is a rough first version, but it >> already works. We can extend the test framework later if we need >> more features, but I believe this is enough for all the existing >> tests. > > Thanks for this. It does seem the way to go. > > I can fill it out with the rest of the tests, unless you'd rather. Thanks, please do. I converted the next test, receipt-report, grab that from my git repository first. It produces over two hundred permutations, so it's going to be a bit tedious to check the output for that, but I think it's still acceptable so that we don't need more complicated rules for what is accepted. IOW, we can just print the output of all permutations and "diff", we won't need "if step X ran before step Y, commit should succeed" rules that the python version had. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Heikki Linnakangas wrote: > I converted the next test, receipt-report, grab that from my git > repository first. Will do. > It produces over two hundred permutations, so it's going to be a > bit tedious to check the output for that, but I think it's still > acceptable so that we don't need more complicated rules for what is > accepted. IOW, we can just print the output of all permutations and > "diff", we won't need "if step X ran before step Y, commit should > succeed" rules that the python version had. During initial development, I was very glad to have the one-line- per-permutation summary; however, lately I've been wishing for more detail, such as is available with this approach. At least for the moment, what this provides is exactly what is most useful. If there is ever a major refactoring (versus incremental enhancements), it might be worth developing a way to filter the detailed input into the sort of summary we were getting from dtester, but we can cross that bridge when (and if) we come to it. -Kevin
On 02.02.2011 16:27, Kevin Grittner wrote: > Heikki Linnakangas wrote: >> It produces over two hundred permutations, so it's going to be a >> bit tedious to check the output for that, but I think it's still >> acceptable so that we don't need more complicated rules for what is >> accepted. IOW, we can just print the output of all permutations and >> "diff", we won't need "if step X ran before step Y, commit should >> succeed" rules that the python version had. > > During initial development, I was very glad to have the one-line- > per-permutation summary; however, lately I've been wishing for more > detail, such as is available with this approach. At least for the > moment, what this provides is exactly what is most useful. If there > is ever a major refactoring (versus incremental enhancements), it > might be worth developing a way to filter the detailed input into the > sort of summary we were getting from dtester, but we can cross that > bridge when (and if) we come to it. Ok, great. Let's just add comments to the test specs to explain which permutations should succeed and which should fail, then. And which ones fail because they're false positives. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Heikki Linnakangas wrote: > I converted the next test, receipt-report, grab that from my git > repository first. It produces over two hundred permutations, so > it's going to be a bit tedious to check the output for that, but I > think it's still acceptable so that we don't need more complicated > rules for what is accepted. I was a bit disconcerted to see 48 permutations fail when dcheck had been seeing 6; but it turned out to be simple to fix -- the third connection was declared READ ONLY in the dcheck version. Measuring false positives for the READ WRITE version is probably valuable, but we also want to test the READ ONLY optimizations. The "two ids test" has similar dynamics, so I'll change one or the other so we cover both scenarios. > IOW, we can just print the output of all permutations and "diff", > we won't need "if step X ran before step Y, commit should succeed" > rules that the python version had. I found two problems with this, and I'm not sure how to handle either. If we can figure out an approach, I'm happy to work on it. (1) We don't have much in the way of detail yet. I put a different detail message on each, so that there is more evidence, hopefully at least somewhat comprehensible to an educated user, about how the cancelled transaction fit into the dangerous pattern of access among transactions. Ultimately, I hope we can improve these messages to include such detail as table names in many circumstances, but that's not 9.1 material. What I did include, when it was easily available, was another xid involved in the conflict. These are not matching from one test to the next. (2) The NOTICE lines for implicit index creation pop up at odd times in the output, like in the middle of a SQL statement. It looks like these are piling up in a buffer somewhere and getting dumped into the output when the buffer fills. They are actually showing up at exactly the same point on each run, but I doubt that we can count on that for all platforms, and even if we could -- it's kinda ugly. Perhaps we should change the client logging level to suppress these? They're not really important here. So, I think (2) is probably easy, but I don't see how we can deal with (1) as easily. Suppress detail? Filter to change the xid number to some literal? -Kevin
On 02.02.2011 17:52, Kevin Grittner wrote: > I found two problems with this, and I'm not sure how to handle > either. If we can figure out an approach, I'm happy to work on it. > > (1) We don't have much in the way of detail yet. I put a different > detail message on each, so that there is more evidence, hopefully at > least somewhat comprehensible to an educated user, about how the > cancelled transaction fit into the dangerous pattern of access among > transactions. Ultimately, I hope we can improve these messages to > include such detail as table names in many circumstances, but that's > not 9.1 material. What I did include, when it was easily available, > was another xid involved in the conflict. These are not matching > from one test to the next. > > (2) The NOTICE lines for implicit index creation pop up at odd times > in the output, like in the middle of a SQL statement. It looks like > these are piling up in a buffer somewhere and getting dumped into the > output when the buffer fills. They are actually showing up at > exactly the same point on each run, but I doubt that we can count on > that for all platforms, and even if we could -- it's kinda ugly. > Perhaps we should change the client logging level to suppress these? > They're not really important here. > > So, I think (2) is probably easy, but I don't see how we can deal > with (1) as easily. Suppress detail? Filter to change the xid > number to some literal? Suppressing detail seems easiest. AFAICS all the variable parts are in errdetail. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Heikki Linnakangas wrote: > Suppressing detail seems easiest. AFAICS all the variable parts are > in errdetail. I pushed that with some work on the tests. If you could review the changes to isolationtester.c to confirm that they look sane, I'd appreciate it. http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=2e0254b82a62ead25311f545b0626c97f9ac35b4#patch6 If that part is right, it shouldn't take me very long to finish the specs and capture the expected results. I really appreciate you putting this testing framework together. This is clearly the right way to do it, although we also clearly don't want this test in the check target at the root directory, because of the run time. -Kevin
On 02.02.2011 19:36, Kevin Grittner wrote: > Heikki Linnakangas wrote: > >> Suppressing detail seems easiest. AFAICS all the variable parts are >> in errdetail. > > I pushed that with some work on the tests. If you could review the > changes to isolationtester.c to confirm that they look sane, I'd > appreciate it. > > http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=2e0254b82a62ead25311f545b0626c97f9ac35b4#patch6 > > If that part is right, it shouldn't take me very long to finish the > specs and capture the expected results. Looks good. A comment would be in order to explain why we only print the primary message. (yeah, I know I didn't comment the tester code very well myself) -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Heikki Linnakangas wrote: > A comment would be in order to explain why we only print the > primary message. Done: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=ddeea22db06ed763b39f716b86db248008a3aa92 -Kevin
Heikki Linnakangas wrote: On 02.02.2011 19:36, Kevin Grittner wrote: >> If that part is right, it shouldn't take me very long to finish >> the specs and capture the expected results. > Looks good. First cut on the rest of it pushed. I'll want to go over it again to confirm, but I think all dcheck testing is now replicated there. I didn't eliminate dtester/dcheck code yet, in case either of us wanted to compare, but it can go any time now. -Kevin
On 02.02.2011 19:36, Kevin Grittner wrote: > I really appreciate you putting this testing framework together. > This is clearly the right way to do it, although we also clearly > don't want this test in the check target at the root directory, > because of the run time. It would be nice to get some buildfarm members to run them though. I'm reading through the patch again now, hoping to commit this weekend. There's still this one TODO item that you commented on earlier: > Then there's one still lurking outside the new predicate* files, in > heapam.c. It's about 475 lines into the heap_update function (25 > lines from the bottom). In reviewing where we needed to acquire > predicate locks, this struck me as a place where we might need to > duplicate the predicate lock from one tuple to another, but I wasn't > entirely sure. I tried for a few hours one day to construct a > scenario which would show a serialization anomaly if I didn't do > this, and failed create one. If someone who understands both the > patch and heapam.c wants to look at this and offer an opinion, I'd > be most grateful. I'll take another look and see if I can get my > head around it better, but failing that, I'm disinclined to either > add locking I'm not sure we need or to remove the comment that says > we *might* need it there. Have you convinced yourself that there's nothing to do? If so, we should replace the todo comment with a comment explaining why. PageIsPredicateLocked() is currently only called by one assertion in RecordFreeIndexPage(). The comment in PageIsPredicateLocked() says something about gist vacuuming; I presume this is something that will be needed to implement more fine-grained predicate locking in GiST. But we don't have that at the moment. The assertion in RecordFreeIndexPage() is a reasonable sanity check, but I'm inclined to move it to the caller instead: I don't think the FSM should need to access predicate lock manager, even for an assertion. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Heikki Linnakangas wrote: > On 02.02.2011 19:36, Kevin Grittner wrote: >> I really appreciate you putting this testing framework together. >> This is clearly the right way to do it, although we also clearly >> don't want this test in the check target at the root directory, >> because of the run time. > > It would be nice to get some buildfarm members to run them though. Maybe it could be included in the installcheck or installcheck-world target? > There's still this one TODO item that you commented on earlier: > >> Then there's one still lurking outside the new predicate* files, >> in heapam.c. It's about 475 lines into the heap_update function >> (25 lines from the bottom). In reviewing where we needed to >> acquire predicate locks, this struck me as a place where we might >> need to duplicate the predicate lock from one tuple to another, >> but I wasn't entirely sure. I tried for a few hours one day to >> construct a scenario which would show a serialization anomaly if I >> didn't do this, and failed create one. If someone who understands >> both the patch and heapam.c wants to look at this and offer an >> opinion, I'd be most grateful. I'll take another look and see if I >> can get my head around it better, but failing that, I'm >> disinclined to either add locking I'm not sure we need or to >> remove the comment that says we *might* need it there. > > Have you convinced yourself that there's nothing to do? If so, we > should replace the todo comment with a comment explaining why. I'll look at that today and tomorrow and try to resolve the issue one way or the other. > PageIsPredicateLocked() is currently only called by one assertion > in RecordFreeIndexPage(). The comment in PageIsPredicateLocked() > says something about gist vacuuming; I presume this is something > that will be needed to implement more fine-grained predicate > locking in GiST. But we don't have that at the moment. Yeah. We had something close at one point which we had to back out because it didn't cover page splits correctly in all cases. It's a near-certainty that we can have fine-grained coverage for the GiST AM covered with a small patch in 9.2, and I'm pretty sure we'll need that function for it. > The assertion in RecordFreeIndexPage() is a reasonable sanity > check, but I'm inclined to move it to the caller instead: I don't > think the FSM should need to access predicate lock manager, even > for an assertion. OK. So it looks like right now it will move to btvacuumpage(), right before the call to RecordFreeIndexPage(), and we will need to add it to one spot each in the GiST and GIN AMs, when we get to those. Would you like me to do that? -Kevin
On 04.02.2011 14:30, Kevin Grittner wrote: > Heikki Linnakangas wrote: >> The assertion in RecordFreeIndexPage() is a reasonable sanity >> check, but I'm inclined to move it to the caller instead: I don't >> think the FSM should need to access predicate lock manager, even >> for an assertion. > > OK. So it looks like right now it will move to btvacuumpage(), right > before the call to RecordFreeIndexPage(), and we will need to add it > to one spot each in the GiST and GIN AMs, when we get to those. > Would you like me to do that? Yeah, please do. Thanks! -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > On 04.02.2011 14:30, Kevin Grittner wrote: >> OK. So it looks like right now it will move to btvacuumpage(), >> right before the call to RecordFreeIndexPage(), and we will need >> to add it to one spot each in the GiST and GIN AMs, when we get >> to those. Would you like me to do that? > > Yeah, please do. Thanks! Done: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=69b1c072048fbae42dacb098d70f5e29fb8be63c Any objections to me taking out the dcheck target and scripts now? -Kevin
Heikki Linnakangas wrote: > On 02.02.2011 19:36, Kevin Grittner wrote: > >> Then there's one still lurking outside the new predicate* files, >> in heapam.c. It's about 475 lines into the heap_update function >> (25 lines from the bottom). In reviewing where we needed to >> acquire predicate locks, this struck me as a place where we might >> need to duplicate the predicate lock from one tuple to another, >> but I wasn't entirely sure. I tried for a few hours one day to >> construct a scenario which would show a serialization anomaly if I >> didn't do this, and failed create one. If someone who understands >> both the patch and heapam.c wants to look at this and offer an >> opinion, I'd be most grateful. I'll take another look and see if I >> can get my head around it better, but failing that, I'm >> disinclined to either add locking I'm not sure we need or to >> remove the comment that says we *might* need it there. > > Have you convinced yourself that there's nothing to do? If so, we > should replace the todo comment with a comment explaining why. It turns out that nagging doubt from my right-brain was on target. Here's the simplest example I was able to construct of a false negative due to the lack of some code there: -- setup create table t (id int not null, txt text) with (fillfactor=50); insert into t (id) select x from (select * from generate_series(1, 1000000)) a(x); alter table t add primary key (id); -- session 1 -- T1 begin transaction isolation level serializable; select * from t where id = 1000000; -- session 2 -- T2 begin transaction isolation level serializable; update t set txt = 'x' where id = 1000000; commit; -- T3 begin transaction isolation level serializable; update t set txt = 'y' where id = 1000000; select * from t where id = 500000; -- session 3 -- T4 begin transaction isolation level serializable; update t set txt = 'z' where id = 500000; select * from t where id = 1; commit; -- session 2 commit; -- session 1 update t set txt = 'a' where id = 1; commit; Based on visibility of work, there's a cycle in the apparent order of execution: T1 -> T2 -> T3 -> T4 -> T1 So now that I'm sure we actually do need code there, I'll add it. And I'll add the new test to the isolation suite. -Kevin
"Kevin Grittner" wrote: > So now that I'm sure we actually do need code there, I'll add it. In working on this I noticed the apparent need to move two calls to PredicateLockTuple a little bit to keep them inside the buffer lock. Without at least a share lock on the buffer, it seems that here is a window where a read could miss the MVCC from a write and the write could fail to see the predicate lock. Please see whether this seems reasonable: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=7841a22648c3f4ae46f674d7cf4a7c2673cf9ed2 > And I'll add the new test to the isolation suite. We don't need all permutations for this test, which is a good thing since it has such a long setup time. Is there an easy way to just run the one schedule of statements on three connections? -Kevin
"Kevin Grittner" wrote: > So now that I'm sure we actually do need code there, I'll add it. Hmmm... First cut at this here: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=3ccedeb451ee74ee78ef70735782f3550b621eeb It passes all the usual regression tests, the new isolation tests, and the example posted earlier in the thread of a test case which was allowing an anomaly. (That is to say, the anomaly is now prevented.) I didn't get timings, but it *seems* noticeably slower; hopefully that's either subjective or fixable. Any feedback on whether this seems a sane approach to the issue is welcome. -Kevin
I wrote: > First cut [of having predicate locks linked to later row versions > for conflict detection purposes] > It passes all the usual regression tests, the new isolation tests, > and the example posted earlier in the thread of a test case which > was allowing an anomaly. (That is to say, the anomaly is now > prevented.) > > I didn't get timings, but it *seems* noticeably slower; hopefully > that's either subjective or fixable. Any feedback on whether this > seems a sane approach to the issue is welcome. After sleeping on it and reviewing the patch this morning, I'm convinced that this is fundamentally right, but the recursion in RemoveTargetIfNoLongerUsed() can't work. I'll have to just break the linkage there and walk the HTAB in the general cleanup to eliminate orphaned targets. I'm working on it now, and hope to have it all settled down today. I fear I've messed up Heikki's goal of a commit this weekend, but I think this is a "must fix". -Kevin
"Kevin Grittner" wrote: > I'm working on it now, and hope to have it all settled down today. Done and pushed to the git repo. Branch serializable on: git://git.postgresql.org/git/users/kgrittn/postgres.git Heikki: I'm back to not having any outstanding work on the patch. Does anyone want me to post a new version of the patch with recent changes? -Kevin
On Sat, 2011-02-05 at 14:43 -0600, Kevin Grittner wrote: > "Kevin Grittner" wrote: > > > So now that I'm sure we actually do need code there, I'll add it. > > In working on this I noticed the apparent need to move two calls to > PredicateLockTuple a little bit to keep them inside the buffer lock. > Without at least a share lock on the buffer, it seems that here is a > window where a read could miss the MVCC from a write and the write > could fail to see the predicate lock. Please see whether this seems > reasonable: > > http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=7841a22648c3f4ae46f674d7cf4a7c2673cf9ed2 What does PredicateLockTuple do that needs a share lock? Does a pin suffice? Regards,Jeff Davis
Jeff Davis wrote: > On Sat, 2011-02-05 at 14:43 -0600, Kevin Grittner wrote: >> In working on this I noticed the apparent need to move two calls >> to PredicateLockTuple a little bit to keep them inside the buffer >> lock. Without at least a share lock on the buffer, it seems that >> here is a window where a read could miss the MVCC from a write and >> the write could fail to see the predicate lock. > What does PredicateLockTuple do that needs a share lock? Does a pin > suffice? If one process is reading a tuple and another is writing it (e.g., UPDATE or DELETE) the concern is that we need to be able to guarantee that either the predicate lock appears in time for the writer to see it on the call to CheckForSerializableConflictIn or the reader sees the MVCC changes in CheckForSerializableConflictOut. It's OK if the conflict is detected both ways, but if it's missed both ways then we could have a false negative, allowing anomalies to slip through. It didn't seem to me on review that acquiring the predicate lock after releasing the shared buffer lock (and just having the pin) would be enough to ensure that a write which followed that would see the predicate lock. reader has pin and shared lock writer increments pin count reader releases shared lock writer acquires exclusive lock writer checks predicate lock and fails to see one reader adds predicate lock we have a problem -Kevin
"Kevin Grittner" wrote: > Jeff Davis wrote: > >> What does PredicateLockTuple do that needs a share lock? Does a >> pin suffice? > > If one process is reading a tuple and another is writing it (e.g., > UPDATE or DELETE) the concern is that we need to be able to > guarantee that either the predicate lock appears in time for the > writer to see it on the call to CheckForSerializableConflictIn or > the reader sees the MVCC changes in > CheckForSerializableConflictOut. It's OK if the conflict is > detected both ways, but if it's missed both ways then we could have > a false negative, allowing anomalies to slip through. It didn't > seem to me on review that acquiring the predicate lock after > releasing the shared buffer lock (and just having the pin) would be > enough to ensure that a write which followed that would see the > predicate lock. > > reader has pin and shared lock > writer increments pin count > reader releases shared lock > writer acquires exclusive lock > writer checks predicate lock and fails to see one > reader adds predicate lock > we have a problem Hmmm... Or do we? If both sides were careful to record what they're doing before checking for a conflict, the pin might be enough. I'll check for that. In at least one of those moves I was moving the predicate lock acquisition from after the conflict check to before, but maybe I didn't need to move it quite so far.... -Kevin
On 05.02.2011 21:43, Kevin Grittner wrote: > "Kevin Grittner" wrote: > >> So now that I'm sure we actually do need code there, I'll add it. > > In working on this I noticed the apparent need to move two calls to > PredicateLockTuple a little bit to keep them inside the buffer lock. > Without at least a share lock on the buffer, it seems that here is a > window where a read could miss the MVCC from a write and the write > could fail to see the predicate lock. Please see whether this seems > reasonable: > > http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=7841a22648c3f4ae46f674d7cf4a7c2673cf9ed2 > >> And I'll add the new test to the isolation suite. > > We don't need all permutations for this test, which is a good thing > since it has such a long setup time. Is there an easy way to just > run the one schedule of statements on three connections? Not at the moment, but we can add that.. I added the capability to specify exact permutations like: permutation "rwx1" "rwx2" "c1" "c2" See my git repository at git://git.postgresql.org/git/users/heikki/postgres.git, branch "serializable". I also added a short README to explain what the isolation test suite is all about, as well as separate "make check" and "make installcheck" targets. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Kevin Grittner <kgrittn@wicourts.gov> wrote: > "Kevin Grittner" wrote: >> Jeff Davis wrote: >> >>> What does PredicateLockTuple do that needs a share lock? Does a >>> pin suffice? >> >> If one process is reading a tuple and another is writing it >> (e.g., UPDATE or DELETE) the concern is that we need to be able >> to guarantee that either the predicate lock appears in time for >> the writer to see it on the call to >> CheckForSerializableConflictIn or the reader sees the MVCC >> changes in CheckForSerializableConflictOut. It's OK if the >> conflict is detected both ways, but if it's missed both ways then >> we could have a false negative, allowing anomalies to slip >> through. It didn't seem to me on review that acquiring the >> predicate lock after releasing the shared buffer lock (and just >> having the pin) would be enough to ensure that a write which >> followed that would see the predicate lock. >> >> reader has pin and shared lock >> writer increments pin count >> reader releases shared lock >> writer acquires exclusive lock >> writer checks predicate lock and fails to see one >> reader adds predicate lock >> we have a problem > > Hmmm... Or do we? If both sides were careful to record what > they're doing before checking for a conflict, the pin might be > enough. I'll check for that. In at least one of those moves I was > moving the predicate lock acquisition from after the conflict > check to before, but maybe I didn't need to move it quite so > far.... Some of these calls are placed where there is no reasonable choice but to do them while holding a buffer lock. There are some which *might* be able to be moved out, but I'm inclined to say that should be on a list of possible performance improvements in future releases. My concern is that the code paths are complicated enough to make it hard to confidently desk-check such changes, we don't yet have a good way to test whether such a change is introducing a race condition. The src/test/isolation tests are good at proving the fundamental correctness of the logic in predicate.c, and the DBT-2 stress tests Dan ran are good at flushing out race conditions within predicate.c code; but we don't have a test which is good at pointing out race conditions based on *placement of the calls* to predicate.c from other code. Until we have such tests, I think we should be cautious about risking possible hard-to-reproduce correctness violations to shave a few nanoseconds off the time a shared buffer lock is held. Particularly since we're so close to the end of the release cycle. -Kevin
On 06.02.2011 20:30, Kevin Grittner wrote: > "Kevin Grittner" wrote: > >> I'm working on it now, and hope to have it all settled down today. > > Done and pushed to the git repo. Branch serializable on: > > git://git.postgresql.org/git/users/kgrittn/postgres.git > > Heikki: I'm back to not having any outstanding work on the patch. Ok, committed. Thank you for all this! It has been a huge effort from you and Dan, and a great feature as a result. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
On Mon, Feb 7, 2011 at 23:14, Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > On 06.02.2011 20:30, Kevin Grittner wrote: >> >> "Kevin Grittner" wrote: >> >>> I'm working on it now, and hope to have it all settled down today. >> >> Done and pushed to the git repo. Branch serializable on: >> >> git://git.postgresql.org/git/users/kgrittn/postgres.git >> >> Heikki: I'm back to not having any outstanding work on the patch. > > Ok, committed. > > Thank you for all this! It has been a huge effort from you and Dan, and a > great feature as a result. +1! (or more) -- Magnus Hagander Me: http://www.hagander.net/ Work: http://www.redpill-linpro.com/
On Mon, Feb 7, 2011 at 5:23 PM, Magnus Hagander <magnus@hagander.net> wrote: > On Mon, Feb 7, 2011 at 23:14, Heikki Linnakangas > <heikki.linnakangas@enterprisedb.com> wrote: >> On 06.02.2011 20:30, Kevin Grittner wrote: >>> >>> "Kevin Grittner" wrote: >>> >>>> I'm working on it now, and hope to have it all settled down today. >>> >>> Done and pushed to the git repo. Branch serializable on: >>> >>> git://git.postgresql.org/git/users/kgrittn/postgres.git >>> >>> Heikki: I'm back to not having any outstanding work on the patch. >> >> Ok, committed. >> >> Thank you for all this! It has been a huge effort from you and Dan, and a >> great feature as a result. > > +1! Indeed, congratulations Kevin! -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > Ok, committed. Thanks for that, and for all the suggestions along the way! Thanks also to Joe Conway for the review and partial commit in the first CF for this release; to Jeff Davis for the reviews, pointing out areas which needed work; and to Anssi Kääriäinen for testing thoroughly enough to find some issues to fix! And thanks especially to Dan Ports for joining me in this effort and co-authoring this with me! Besides the actual code contributions, the ability to pound on the result with DBT-2 for days at a time was invaluable. WOO-HOO! -Kevin
Heikki Linnakangas wrote: > Ok, committed. I see that at least three BuildFarm critters don't have UINT64_MAX defined. Not sure why coypu is running out of connections. -Kevin
On 08.02.2011 10:43, Kevin Grittner wrote: > Heikki Linnakangas wrote: > >> Ok, committed. > > I see that at least three BuildFarm critters don't have UINT64_MAX > defined. I guess we'll have to just #define it ourselves. Or could we just pick another magic value, do we actually rely on InvalidSerCommitSeqno being higher than all other values anywhere? > Not sure why coypu is running out of connections. Hmm, it seems to choose a smaller max_connections value now, 20 instead of 30. Looks like our shared memory usage went up by just enough to pass that threshold. Looks like our shared memory footprint grew by about 2MB with default configuration, from 37MB to 39MB. That's quite significant. Should we dial down the default of max_predicate_locks_per_transaction? Or tweak the sizing of the hash tables somehow? -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Kevin Grittner wrote: > Heikki Linnakangas wrote: > > > Ok, committed. > > I see that at least three BuildFarm critters don't have UINT64_MAX > defined. Not sure why coypu is running out of connections. Yes, I am seeing that failures here too on my BSD machine. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + It's impossible for everything to be true. +
> Heikki Linnakangas wrote: > On 08.02.2011 10:43, Kevin Grittner wrote: > >> I see that at least three BuildFarm critters don't have UINT64_MAX >> defined. > > I guess we'll have to just #define it ourselves. Or could we just > pick another magic value, do we actually rely on > InvalidSerCommitSeqno being higher than all other values anywhere? It seemed more robust than a low-end number, based on how it's used. >> Not sure why coypu is running out of connections. > > Hmm, it seems to choose a smaller max_connections value now, 20 > instead of 30. Looks like our shared memory usage went up by just > enough to pass that threshold. > > Looks like our shared memory footprint grew by about 2MB with > default configuration, from 37MB to 39MB. That's quite significant. > Should we dial down the default of > max_predicate_locks_per_transaction? Or tweak the sizing of the > hash tables somehow? Dialing down max_predicate_locks_per_transaction could cause the user to see "out of shared memory" errors sooner, so I'd prefer to stay away from that. Personally, I feel that max_connections is higher than it should be for machines which would have trouble with the RAM space, but I suspect I'd have trouble selling the notion that the default for that should be reduced. The multiplier of 10 PredXactList structures per connection is kind of arbitrary. It affects the point at which information is pushed to the lossy summary, so any number from 2 up will work correctly; it's a matter of performance and false positive rate. We might want to put that on a GUC and default it to something lower. -Kevin
On Tue, Feb 08, 2011 at 11:25:34AM +0200, Heikki Linnakangas wrote: > On 08.02.2011 10:43, Kevin Grittner wrote: > > I see that at least three BuildFarm critters don't have UINT64_MAX > > defined. > > I guess we'll have to just #define it ourselves. Or could we just pick > another magic value, do we actually rely on InvalidSerCommitSeqno being > higher than all other values anywhere? As far as I know we don't specifically rely on that anywhere, and indeed I did have it #defined to 1 at one point (with the other constants adjusted to match) and I don't recall any problems. But given that we most often use InvalidSerCommitSeqNo to mean "not committed yet", it made more sense to set it to UINT64_MAX so that if a comparison did sneak in it would do the right thing. I did dust off a copy of the ANSI standard at the time, and it was pretty explicit that UINT64_MAX is supposed to be defined in <stdint.h>. But that may just be a C99 requirement (I didn't have an older copy of the standard), and it's obviously no guarantee that it actually is defined. Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
Dan Ports <drkp@csail.mit.edu> wrote: > On Tue, Feb 08, 2011 at 11:25:34AM +0200, Heikki Linnakangas wrote: >> On 08.02.2011 10:43, Kevin Grittner wrote: >>> I see that at least three BuildFarm critters don't have >>> UINT64_MAX defined. >> >> I guess we'll have to just #define it ourselves. Or could we just >> pick another magic value, do we actually rely on >> InvalidSerCommitSeqno being higher than all other values >> anywhere? > > As far as I know we don't specifically rely on that anywhere, and > indeed I did have it #defined to 1 at one point (with the other > constants adjusted to match) and I don't recall any problems. But > given that we most often use InvalidSerCommitSeqNo to mean "not > committed yet", it made more sense to set it to UINT64_MAX so that > if a comparison did sneak in it would do the right thing. > > I did dust off a copy of the ANSI standard at the time, and it was > pretty explicit that UINT64_MAX is supposed to be defined in > <stdint.h>. But that may just be a C99 requirement (I didn't have > an older copy of the standard), and it's obviously no guarantee > that it actually is defined. Attached is something which will work. Whether people prefer this or a definition of UINT64_MAX in some header file (if it's missing) doesn't matter much to me. At any rate, if someone commits this one-liner, three critters should go back to green. -Kevin
Attachment
I wrote: > The multiplier of 10 PredXactList structures per connection is > kind of arbitrary. It affects the point at which information is > pushed to the lossy summary, so any number from 2 up will work > correctly; it's a matter of performance and false positive rate. > We might want to put that on a GUC and default it to something > lower. If the consensus is that we want to add this knob, I can code it up today. If we default it to something low, we can knock off a large part of the 2MB increase in shared memory used by SSI in the default configuration. For those not using SERIALIZABLE transactions the only impact is that less shared memory will be reserved for something they're not using. For those who try SERIALIZABLE transactions, the smaller the number, the sooner performance will start to drop off under load -- especially in the face of a long-running READ WRITE transaction. Since it determines shared memory allocation, it would have to be a restart-required GUC. I do have some concern that if this defaults to too low a number, those who try SSI without bumping it and restarting the postmaster will not like the performance under load very much. SSI performance would not be affected by a low setting under light load when there isn't a long-running READ WRITE transaction. -Kevin
On 08.02.2011 17:50, Kevin Grittner wrote: > Attached is something which will work. Whether people prefer this > or a definition of UINT64_MAX in some header file (if it's missing) > doesn't matter much to me. > > At any rate, if someone commits this one-liner, three critters > should go back to green. Thanks, committed. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
On Tue, Feb 08, 2011 at 10:14:44AM -0600, Kevin Grittner wrote: > I do have some concern that if this defaults to too low a number, > those who try SSI without bumping it and restarting the postmaster > will not like the performance under load very much. SSI performance > would not be affected by a low setting under light load when there > isn't a long-running READ WRITE transaction. If we're worried about this, we could add a log message the first time SummarizeOldestCommittedXact is called, to suggest increasing the GUC for number of SerializableXacts. This also has the potential benefit of alerting the user that there's a long-running transaction, in case that's unexpected (say, if it were caused by a wedged client) I don't have any particular opinion on what the default value of the GUC should be. Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
On 08.02.2011 18:14, Kevin Grittner wrote: > I wrote: > >> The multiplier of 10 PredXactList structures per connection is >> kind of arbitrary. It affects the point at which information is >> pushed to the lossy summary, so any number from 2 up will work >> correctly; it's a matter of performance and false positive rate. >> We might want to put that on a GUC and default it to something >> lower. > > If the consensus is that we want to add this knob, I can code it up > today. If we default it to something low, we can knock off a large > part of the 2MB increase in shared memory used by SSI in the default > configuration. For those not using SERIALIZABLE transactions the > only impact is that less shared memory will be reserved for > something they're not using. For those who try SERIALIZABLE > transactions, the smaller the number, the sooner performance will > start to drop off under load -- especially in the face of a > long-running READ WRITE transaction. Since it determines shared > memory allocation, it would have to be a restart-required GUC. > > I do have some concern that if this defaults to too low a number, > those who try SSI without bumping it and restarting the postmaster > will not like the performance under load very much. SSI performance > would not be affected by a low setting under light load when there > isn't a long-running READ WRITE transaction. Hmm, comparing InitPredicateLocks() and PredicateLockShmemSize(), it looks like RWConflictPool is missing altogether from the calculations in PredicateLockShmemSize(). I added an elog to InitPredicateLocks() and PredicateLockShmemSize(), to print the actual and estimated size. Here's what I got with max_predicate_locks_per_transaction=10 and max_connections=100: LOG: shmemsize 635467 LOG: actual 1194392 WARNING: out of shared memory FATAL: not enough shared memory for data structure "shmInvalBuffer" (67224 bytes requested) On the other hand, when I bumped max_predicate_locks_per_transaction to 100, I got: LOG: shmemsize 3153112 LOG: actual 2339864 Which is a pretty big overestimate, percentage-wise. Taking RWConflictPool into account in PredicateLockShmemSize() fixes the underestimate, but makes the overestimate correspondingly larger. I've never compared the actual and estimated shmem sizes of other parts of the backend, so I'm not sure how large discrepancies we usually have, but that seems quite big. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > Taking RWConflictPool into account in PredicateLockShmemSize() fixes the > underestimate, but makes the overestimate correspondingly larger. I've > never compared the actual and estimated shmem sizes of other parts of > the backend, so I'm not sure how large discrepancies we usually have, > but that seems quite big. Looking into it... -Kevin
One other nit re. the predicate lock table size GUCs: the out-of-memory case in RegisterPredicateLockingXid (predicate.c:1592 in my tree) gives the hint to increase max_predicate_locks_per_transaction. I don't think that's correct, since that GUC isn't used to size SerializableXidHash. In fact, that error shouldn't arise at all because if there was room in PredXact to register the transaction, then there should be room to register it's xid in SerializableXidHash. Except that it's possible for something else to allocate all of our shared memory and thus prevent SerializbleXidHash from reaching its intended max capacity. In general, it might be worth considering making a HTAB's max_size a hard limit, but that's a larger issue. Here, it's probably worth just removing the hint. Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > LOG: shmemsize 3153112 > LOG: actual 2339864 > > Which is a pretty big overestimate, percentage-wise. Taking > RWConflictPool into account in PredicateLockShmemSize() fixes the > underestimate, but makes the overestimate correspondingly larger. > I've never compared the actual and estimated shmem sizes of other > parts of the backend, so I'm not sure how large discrepancies we > usually have, but that seems quite big. I found two things which probably explain that: (1) When HTABs are created, there is the max_size, which is what the PredicateLockShmemSize function must use in its calculations, and the init_size, which is what will initially be allocated (and so, is probably what you see in the usage at the end of the InitPredLocks function). That's normally set to half the maximum. (2) The predicate lock and lock target initialization code was initially copied and modified from the code for heavyweight locks. The heavyweight lock code adds 10% to the calculated maximum size. So I wound up doing that for PredicateLockTargetHash and PredicateLockHash, but didn't do it for SerializableXidHassh. Should I eliminate this from the first two, add it to the third, or leave it alone? So if the space was all in HTABs, you might expect shmemsize to be 110% of the estimated maximum, and actual (at the end of the init function) to be 50% of the estimated maximum. So the shmemsize would be (2.2 * actual) at that point. The difference isn't that extreme because the list-based pools now used for some structures are allocated at full size without padding. In addition to the omission of the RWConflictPool (which is a biggie), the OldSerXidControlData estimate was only for a *pointer* to it, not the structure itself. The attached patch should correct the shmemsize numbers. -Kevin
Attachment
On Tue, Feb 08, 2011 at 04:04:39PM -0600, Kevin Grittner wrote: > (2) The predicate lock and lock target initialization code was > initially copied and modified from the code for heavyweight locks. > The heavyweight lock code adds 10% to the calculated maximum size. > So I wound up doing that for PredicateLockTargetHash and > PredicateLockHash, but didn't do it for SerializableXidHassh. > Should I eliminate this from the first two, add it to the third, or > leave it alone? Actually, I think for SerializableXidHash we should probably just initially allocate it at its maximum size. Then it'll match the PredXact list which is allocated in full upfront, and there's no risk of being able to allocate a transaction but not register its xid. In fact, I believe there would be no way for starting a new serializable transaction to fail. Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
On Tue, Feb 8, 2011 at 7:23 PM, Dan Ports <drkp@csail.mit.edu> wrote: > On Tue, Feb 08, 2011 at 04:04:39PM -0600, Kevin Grittner wrote: >> (2) The predicate lock and lock target initialization code was >> initially copied and modified from the code for heavyweight locks. >> The heavyweight lock code adds 10% to the calculated maximum size. >> So I wound up doing that for PredicateLockTargetHash and >> PredicateLockHash, but didn't do it for SerializableXidHassh. >> Should I eliminate this from the first two, add it to the third, or >> leave it alone? > > Actually, I think for SerializableXidHash we should probably just > initially allocate it at its maximum size. Then it'll match the > PredXact list which is allocated in full upfront, and there's no risk > of being able to allocate a transaction but not register its xid. In > fact, I believe there would be no way for starting a new serializable > transaction to fail. No way to fail is a tall order. If we don't allocate all the memory up front, does that allow memory to be dynamically shared between different hash tables in shared memory? I'm thinking not, but... Frankly, I think this is an example of how our current shared memory model is a piece of garbage. Our insistence on using sysv shm, and only sysv shm, is making it impossible for us to do things that other products can do easily. My first reaction to this whole discussion was "who gives a crap about 2MB of shared memory?" and then I said "oh, right, we do, because it might cause someone who was going to get 24MB of shared buffers to get 16MB instead, and then performance will suck even worse than it does already". But of course the person should really be running with 256MB or more, in all likelihood, and would be happy to have us do that right out of the box if it didn't require them to do tap-dance around their kernel settings and reboot. We really need to fix this. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Feb 08, 2011 at 09:09:48PM -0500, Robert Haas wrote: > No way to fail is a tall order. Well, no way to fail due to running out of shared memory in RegisterPredicateLock/RegisterPredicateLockingXid, but that doesn't have quite the same ring to it... > If we don't allocate all the memory up front, does that allow memory > to be dynamically shared between different hash tables in shared > memory? I'm thinking not, but... Not in a useful way. If we only allocate some of the memory up front, then the rest goes into the global shmem pool (actually, that has nothing to do with the hash table per se, just the ShmemSize calculations), and it's up for grabs for any hash table that wants to expand, even beyond its declared maximum capacity. But once it's claimed by a hash table it can't get returned. This doesn't sound like a feature to me. In particular, I'd worry that something that allocates a lot of locks (either of the heavyweight or predicate variety) would fill up the associated hash table, and then we're out of shared memory for the other hash tables -- and have no way to get it back short of restarting the whole system. > Frankly, I think this is an example of how our current shared memory > model is a piece of garbage. Our insistence on using sysv shm, and > only sysv shm, is making it impossible for us to do things that other > products can do easily. My first reaction to this whole discussion > was "who gives a crap about 2MB of shared memory?" and then I said > "oh, right, we do, because it might cause someone who was going to get > 24MB of shared buffers to get 16MB instead, and then performance will > suck even worse than it does already". But of course the person > should really be running with 256MB or more, in all likelihood, and > would be happy to have us do that right out of the box if it didn't > require them to do tap-dance around their kernel settings and reboot. I'm completely with you on this. Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
On 09.02.2011 00:04, Kevin Grittner wrote: > (1) When HTABs are created, there is the max_size, which is what > the PredicateLockShmemSize function must use in its calculations, > and the init_size, which is what will initially be allocated (and > so, is probably what you see in the usage at the end of the > InitPredLocks function). That's normally set to half the maximum. Oh, I see. > (2) The predicate lock and lock target initialization code was > initially copied and modified from the code for heavyweight locks. > The heavyweight lock code adds 10% to the calculated maximum size. > So I wound up doing that for PredicateLockTargetHash and > PredicateLockHash, but didn't do it for SerializableXidHassh. > Should I eliminate this from the first two, add it to the third, or > leave it alone? I'm inclined to eliminate it from the first two. Even in LockShmemSize(), it seems a bit weird to add a safety margin, the sizes of the lock and proclock hashes are just rough estimates anyway. > So if the space was all in HTABs, you might expect shmemsize to be > 110% of the estimated maximum, and actual (at the end of the init > function) to be 50% of the estimated maximum. So the shmemsize > would be (2.2 * actual) at that point. The difference isn't that > extreme because the list-based pools now used for some structures > are allocated at full size without padding. > > In addition to the omission of the RWConflictPool (which is a > biggie), the OldSerXidControlData estimate was only for a *pointer* > to it, not the structure itself. The attached patch should correct > the shmemsize numbers. The actual and estimated shmem sizes still didn't add up, I still saw actual usage much higher than estimated size, with max_connections=1000 and max_predicate_locks_per_transaction=10. It turned out to be because: * You missed that RWConflictPool is sized five times as large as SerializableXidHash, and * The allocation for RWConflictPool elements was wrong, while the estimate was correct. With these changes, the estimated and actual sizes match closely, so that actual hash table sizes are 50% of the estimated size as expected. I fixed those bugs, but this doesn't help with the buildfarm members with limited shared memory yet. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
On Tue, Feb 08, 2011 at 09:09:48PM -0500, Robert Haas wrote: > If we don't allocate all the memory up front, does that allow memory > to be dynamically shared between different hash tables in shared > memory? I'm thinking not, but... > > Frankly, I think this is an example of how our current shared memory > model is a piece of garbage. What other model(s) might work better? Cheers, David. -- David Fetter <david@fetter.org> http://fetter.org/ Phone: +1 415 235 3778 AIM: dfetter666 Yahoo!: dfetter Skype: davidfetter XMPP: david.fetter@gmail.com iCal: webcal://www.tripit.com/feed/ical/people/david74/tripit.ics Remember to vote! Consider donating to Postgres: http://www.postgresql.org/about/donate
Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: >> (2) The predicate lock and lock target initialization code was >> initially copied and modified from the code for heavyweight >> locks. The heavyweight lock code adds 10% to the calculated >> maximum size. So I wound up doing that for >> PredicateLockTargetHash and PredicateLockHash, but didn't do it >> for SerializableXidHassh. Should I eliminate this from the first >> two, add it to the third, or leave it alone? > > I'm inclined to eliminate it from the first two. Even in > LockShmemSize(), it seems a bit weird to add a safety margin, the > sizes of the lock and proclock hashes are just rough estimates > anyway. I'm fine with that. Trivial patch attached. > * You missed that RWConflictPool is sized five times as large as > SerializableXidHash, and > > * The allocation for RWConflictPool elements was wrong, while the > estimate was correct. > > With these changes, the estimated and actual sizes match closely, > so that actual hash table sizes are 50% of the estimated size as > expected. > > I fixed those bugs Thanks. Sorry for missing them. > but this doesn't help with the buildfarm members with limited > shared memory yet. Well, if dropping the 10% fudge factor on those two HTABs doesn't bring it down far enough (which seems unlikely), what do we do? We could, as I said earlier, bring down the multiplier for the number of transactions we track in SSI based on the maximum allowed connections connections, but I would really want a GUC on it if we do that. We could bring down the default number of predicate locks per transaction. We could make the default configuration more stingy about max_connections when memory is this tight. Other ideas? I do think that anyone using SSI with a heavy workload will need something like the current values to see decent performance, so it would be good if there was some way to do this which would tend to scale up as they increased something. Wild idea: make the multiplier equivalent to the bytes of shared memory divided by 100MB clamped to a minimum of 2 and a maximum of 10? -Kevin
Attachment
On 02/09/2011 04:16 PM, David Fetter wrote: > On Tue, Feb 08, 2011 at 09:09:48PM -0500, Robert Haas wrote: >> Frankly, I think this is an example of how our current shared memory >> model is a piece of garbage. > > What other model(s) might work better? Thread based, dynamically allocatable and resizeable shared memory, as most other projects and developers use, for example. My dynshmem work is a first attempt at addressing the allocation part of that. It would theoretically allow more dynamic use of the overall fixed amount of shared memory available (instead of requiring every subsystem to use a fixed fraction of the overall available shared memory, as is required now). It has dismissed from CF 2010-07 for good reasons (lacking evidence of usable performance, possible patent issues (on the allocator chosen), lots of work for questionable benefit (existing subsystems would have to be reworked to use that allocator)). For anybody interested, please search the archives for 'dynshmem'. Regards Markus Wanner
Dan Ports <drkp@csail.mit.edu> wrote: > I think for SerializableXidHash we should probably just initially > allocate it at its maximum size. Then it'll match the PredXact > list which is allocated in full upfront, and there's no risk of > being able to allocate a transaction but not register its xid. In > fact, I believe there would be no way for starting a new > serializable transaction to fail. To be more precise, it would prevent an out of shared memory error during an attempt to register an xid for an active serializable transaction. That seems like a good thing. Patch to remove the hint and initially allocate that HTAB at full size attached. I didn't attempt to address the larger general issue of one HTAB stealing shared memory from space calculated to belong to another, and then holding on to it until the postmaster is shut down. -Kevin
Attachment
On Wed, Feb 9, 2011 at 10:38 AM, Markus Wanner <markus@bluegap.ch> wrote: > On 02/09/2011 04:16 PM, David Fetter wrote: >> On Tue, Feb 08, 2011 at 09:09:48PM -0500, Robert Haas wrote: >>> Frankly, I think this is an example of how our current shared memory >>> model is a piece of garbage. >> >> What other model(s) might work better? > > Thread based, dynamically allocatable and resizeable shared memory, as > most other projects and developers use, for example. Or less invasively, a small sysv shm to prevent the double-postmaster problem, and allocate the rest using POSIX shm. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Feb 9, 2011, at 12:25 PM, Robert Haas wrote: > On Wed, Feb 9, 2011 at 10:38 AM, Markus Wanner <markus@bluegap.ch> wrote: >> On 02/09/2011 04:16 PM, David Fetter wrote: >>> On Tue, Feb 08, 2011 at 09:09:48PM -0500, Robert Haas wrote: >>>> Frankly, I think this is an example of how our current shared memory >>>> model is a piece of garbage. >>> >>> What other model(s) might work better? >> >> Thread based, dynamically allocatable and resizeable shared memory, as >> most other projects and developers use, for example. > > Or less invasively, a small sysv shm to prevent the double-postmaster > problem, and allocate the rest using POSIX shm. Such a patch was proposed and rejected: http://thread.gmane.org/gmane.comp.db.postgresql.devel.general/94791 Cheers, M
On Wed, Feb 9, 2011 at 2:16 PM, A.M. <agentm@themactionfaction.com> wrote: > On Feb 9, 2011, at 12:25 PM, Robert Haas wrote: >> On Wed, Feb 9, 2011 at 10:38 AM, Markus Wanner <markus@bluegap.ch> wrote: >>> On 02/09/2011 04:16 PM, David Fetter wrote: >>>> On Tue, Feb 08, 2011 at 09:09:48PM -0500, Robert Haas wrote: >>>>> Frankly, I think this is an example of how our current shared memory >>>>> model is a piece of garbage. >>>> >>>> What other model(s) might work better? >>> >>> Thread based, dynamically allocatable and resizeable shared memory, as >>> most other projects and developers use, for example. >> >> Or less invasively, a small sysv shm to prevent the double-postmaster >> problem, and allocate the rest using POSIX shm. > > Such a patch was proposed and rejected: > http://thread.gmane.org/gmane.comp.db.postgresql.devel.general/94791 I know. We need to revisit that for 9.2 and un-reject it. It's nice that PostgreSQL can run on my thermostat, but it isn't nice that that's the only place where it delivers the expected level of performance. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 02/09/2011 06:25 PM, Robert Haas wrote: > On Wed, Feb 9, 2011 at 10:38 AM, Markus Wanner <markus@bluegap.ch> wrote: >> Thread based, dynamically allocatable and resizeable shared memory, as >> most other projects and developers use, for example. I didn't mean to say we should switch to that model. It's just *the* other model that works (whether or not it's better in general or for Postgres is debatable). > Or less invasively, a small sysv shm to prevent the double-postmaster > problem, and allocate the rest using POSIX shm. ..which allows ftruncate() to resize, right? That's the main benefit over sysv shm which we currently use. ISTM that addresses the resizing-of-the-overall-shared-memory question, but doesn't that require dynamic allocation or some other kind of book-keeping? Or do you envision all subsystems to have to re-initialize their new (grown or shrunken) chunk of it? Regards Markus Wanner
On Wed, Feb 9, 2011 at 2:51 PM, Markus Wanner <markus@bluegap.ch> wrote: > On 02/09/2011 06:25 PM, Robert Haas wrote: >> On Wed, Feb 9, 2011 at 10:38 AM, Markus Wanner <markus@bluegap.ch> wrote: >>> Thread based, dynamically allocatable and resizeable shared memory, as >>> most other projects and developers use, for example. > > I didn't mean to say we should switch to that model. It's just *the* > other model that works (whether or not it's better in general or for > Postgres is debatable). > >> Or less invasively, a small sysv shm to prevent the double-postmaster >> problem, and allocate the rest using POSIX shm. > > ..which allows ftruncate() to resize, right? That's the main benefit > over sysv shm which we currently use. > > ISTM that addresses the resizing-of-the-overall-shared-memory question, > but doesn't that require dynamic allocation or some other kind of > book-keeping? Or do you envision all subsystems to have to > re-initialize their new (grown or shrunken) chunk of it? Basically, I'd be happy if all we got out of it was freedom from the oppressive system shared memory limits. On a modern system, it's hard to imagine that the default for shared_buffers should be less than 256MB, but that blows out the default POSIX shared memory allocation limits on every operating system I use, and some of those need a reboot to fix it. That's needlessly reducing performance and raising the barrier of entry for new users. I am waiting for the day when I have to explain to the guy with a terabyte of memory that the reason why his performance sucks so bad is because he's got a 16MB buffer cache. The percentage of memory we're allocating to shared_buffers should not need to be expressed in scientific notation. But once we get out from under that, I think there might well be some advantage to have certain subsystems allocate their own segments, and/or using ftruncate() for resizing. I don't have a concrete proposal in mind, though. It's very much non-trivial to resize shared_buffers, for example, even if you assume that the size of the shm can easily be changed. So I don't expect quick progress on this front; but it would be nice to have those options available. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 09.02.2011 17:58, Kevin Grittner wrote: > Dan Ports<drkp@csail.mit.edu> wrote: > >> I think for SerializableXidHash we should probably just initially >> allocate it at its maximum size. Then it'll match the PredXact >> list which is allocated in full upfront, and there's no risk of >> being able to allocate a transaction but not register its xid. In >> fact, I believe there would be no way for starting a new >> serializable transaction to fail. > > To be more precise, it would prevent an out of shared memory error > during an attempt to register an xid for an active serializable > transaction. That seems like a good thing. Patch to remove the > hint and initially allocate that HTAB at full size attached. Committed. Curiously, coypu has gone green again. It's now choosing 40 connections and 8 MB of shared_buffers, while it used to choose 30 connections and 24 MB of shared_buffers before the SSI patch. Looks like fixing the size estimation bugs helped that, but I'm not entirely sure how. Maybe it just failed with higher max_connections settings because of the misestimate. But why does it now choose a *higher* max_connections setting than before? -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
On 02/10/2011 05:09 AM, Heikki Linnakangas wrote: > On 09.02.2011 17:58, Kevin Grittner wrote: >> Dan Ports<drkp@csail.mit.edu> wrote: >> >>> I think for SerializableXidHash we should probably just initially >>> allocate it at its maximum size. Then it'll match the PredXact >>> list which is allocated in full upfront, and there's no risk of >>> being able to allocate a transaction but not register its xid. In >>> fact, I believe there would be no way for starting a new >>> serializable transaction to fail. >> >> To be more precise, it would prevent an out of shared memory error >> during an attempt to register an xid for an active serializable >> transaction. That seems like a good thing. Patch to remove the >> hint and initially allocate that HTAB at full size attached. > > Committed. > > Curiously, coypu has gone green again. It's now choosing 40 > connections and 8 MB of shared_buffers, while it used to choose 30 > connections and 24 MB of shared_buffers before the SSI patch. Looks > like fixing the size estimation bugs helped that, but I'm not entirely > sure how. Maybe it just failed with higher max_connections settings > because of the misestimate. But why does it now choose a *higher* > max_connections setting than before? Rémi might have increased its available resources. cheers andrew