Thread: PG replication across DataCenters
Hi,
I have read on the web that Postgresql DB supports replication across data centers. Any real life usecase examples if it has been implemented by anyone. Please also help me understand the caveats i need to take care if i implement this setup.
Regards,
Kaushal
Kaushal Shriyan wrote: > I have read on the web that Postgresql DB supports replication across data centers. Any real life > usecase examples if it has been implemented by anyone. Well, we replicate a 1 TB database between two locations. It is a fairly active OLTP application, but certainly not pushing the limits of what PostgreSQL can do in transactions per second. But I get the impression that replication is widely accepted and used by now. > Please also help me understand the caveats i > need to take care if i implement this setup. Don't use synchronous replication if you have a high transaction rate and a noticable network latency between the sites. Wait for the next bugfix release, since a nasty bug has just been discovered. Yours, Laurenz Albe
Em 22/11/2013 08:43, Kaushal Shriyan escreveu: > Hi, > > I have read on the web that Postgresql DB supports replication across > data centers. Any real life usecase examples if it has been > implemented by anyone. Please also help me understand the caveats i > need to take care if i implement this setup. > > Regards, > > Kaushal We have used asynchronous replication across datacenters with 100% success since 9.1. Currently we use 9.2. Our setup involves a internet tunnel between servers. Servers have about 2.000km of distance from each other. The only points you need to take attention is tuning number of wal_keep_segments and timeout, and the initial load (that can be huge, depends on your data). Regards, Edson
On 22/11/13 11:57, Albe Laurenz wrote: > Don't use synchronous replication if you have a high transaction > rate and a noticable network latency between the sites. > > Wait for the next bugfix release, since a nasty bug has just > been discovered. Can you please explain or provide a pointer for more information? We have recently started to use sync replication over a line with >80ms latency. It works for small transactions with a relatively low transaction rate. Avoid transactions using NOTIFY. Those acquire an exclusive lock during commit that is released only when the remote host has also done its commit. So, only one such transaction can be committing at time. Async replication works just fine. Torsten
Torsten Förtsch wrote: >> Don't use synchronous replication if you have a high transaction >> rate and a noticable network latency between the sites. >> >> Wait for the next bugfix release, since a nasty bug has just >> been discovered. > > Can you please explain or provide a pointer for more information? If you mean the bug I mentioned, see this thread: http://www.postgresql.org/message-id/20131119142001.GA10498@alap2.anarazel.de Yours, Laurenz Albe
On Fri, Nov 22, 2013 at 6:14 PM, Albe Laurenz <laurenz.albe@wien.gv.at> wrote:
Torsten Förtsch wrote:If you mean the bug I mentioned, see this thread:
>> Don't use synchronous replication if you have a high transaction
>> rate and a noticable network latency between the sites.
>>
>> Wait for the next bugfix release, since a nasty bug has just
>> been discovered.
>
> Can you please explain or provide a pointer for more information?
http://www.postgresql.org/message-id/20131119142001.GA10498@alap2.anarazel.de
Yours,
Laurenz Albe
Hi,
I am not sure i understand the difference between async and sync replication and on what scenarios i should use async or sync replication. Does it mean if it is within same DC then sync replication is the best and if it is across DC replication async is better than sync. Please help me understand.
Regards,
Kaushal
On Fri, Nov 22, 2013 at 10:03 PM, Kaushal Shriyan <kaushalshriyan@gmail.com> wrote: > I am not sure i understand the difference between async and sync replication > and on what scenarios i should use async or sync replication. Does it mean > if it is within same DC then sync replication is the best and if it is > across DC replication async is better than sync. Please help me understand. In the case of synchronous replication, master node waits for the confirmation that a given transaction has committed on slave side before committing itself. This wait period can cause some delay, hence it is preferable to use sync replication with nodes that far from each other. -- Michael
On Fri, Nov 22, 2013 at 9:44 PM, Albe Laurenz <laurenz.albe@wien.gv.at> wrote: > Torsten Förtsch wrote: >>> Don't use synchronous replication if you have a high transaction >>> rate and a noticable network latency between the sites. >>> >>> Wait for the next bugfix release, since a nasty bug has just >>> been discovered. >> >> Can you please explain or provide a pointer for more information? > > If you mean the bug I mentioned, see this thread: > http://www.postgresql.org/message-id/20131119142001.GA10498@alap2.anarazel.de Bug that has just been fixed btw: http://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=98f58a30c1beb6ec0870d6520f49fb40d9d0b566 Regards, -- Michael
Michael Paquier wrote: > On Fri, Nov 22, 2013 at 10:03 PM, Kaushal Shriyan <kaushalshriyan@gmail.com> wrote: >> I am not sure i understand the difference between async and sync replication >> and on what scenarios i should use async or sync replication. Does it mean >> if it is within same DC then sync replication is the best and if it is >> across DC replication async is better than sync. Please help me understand. > In the case of synchronous replication, master node waits for the > confirmation that a given transaction has committed on slave side > before committing itself. This wait period can cause some delay, hence > it is preferable to use sync replication with nodes that far from each > other. I am sure that you wanted to say "with nodes *not* that far from each other". Basically, you have to choose between these options: - Slow down processing, but don't lose a transaction on failover (this would be synchronous, nodes close to each other) - Replicate over longer distances, but possibly lose some transactions on failover (that would be asynchronous). Yours, Laurenz Albe
On Fri, Nov 22, 2013 at 11:46 PM, Albe Laurenz <laurenz.albe@wien.gv.at> wrote: > Michael Paquier wrote: >> On Fri, Nov 22, 2013 at 10:03 PM, Kaushal Shriyan <kaushalshriyan@gmail.com> wrote: >>> I am not sure i understand the difference between async and sync replication >>> and on what scenarios i should use async or sync replication. Does it mean >>> if it is within same DC then sync replication is the best and if it is >>> across DC replication async is better than sync. Please help me understand. > >> In the case of synchronous replication, master node waits for the >> confirmation that a given transaction has committed on slave side >> before committing itself. This wait period can cause some delay, hence >> it is preferable to use sync replication with nodes that far from each >> other. > > I am sure that you wanted to say > "with nodes *not* that far from each other". Oops sorry for the typo. Yes I meant of course "not that far". -- Michael
On 11/22/2013 5:57 AM, Albe Laurenz wrote: > Kaushal Shriyan wrote: >> I have read on the web that Postgresql DB supports replication >> across data centers. Any real life usecase examples if it has been >> implemented by anyone. > > Well, we replicate a 1 TB database between two locations. It is a > fairly active OLTP application, but certainly not pushing the limits > of what PostgreSQL can do in transactions per second. > Something that section 25 in the pgsql documentation is not clear about for hot-standby with WAL log shipping using the built-in streaming: Can you choose which databases / tables on the master server get streamed to the hot-standby read-only server at the remote site? If not, I suspect we'll have to go with either Slony or Bucardo.
On Dec 9, 2013, at 8:09 AM, Thomas Harold wrote:
On 11/22/2013 5:57 AM, Albe Laurenz wrote:Kaushal Shriyan wrote:I have read on the web that Postgresql DB supports replicationacross data centers. Any real life usecase examples if it has beenimplemented by anyone.Well, we replicate a 1 TB database between two locations. It is afairly active OLTP application, but certainly not pushing the limitsof what PostgreSQL can do in transactions per second.
Something that section 25 in the pgsql documentation is not clear about for hot-standby with WAL log shipping using the built-in streaming:
Can you choose which databases / tables on the master server get streamed to the hot-standby read-only server at the remote site? If not, I suspect we'll have to go with either Slony or Bucardo.
No, with the built-in binary replication, it's all or nothing, and the slaves have to have the exact same schema as the master (no adding or removing indices, for example.)
Out of curiosity what did you find unclear about http://www.postgresql.org/docs/9.3/static/different-replication-solutions.html?
Thomas Harold <thomas-lists@nybeta.com> wrote: > On 11/22/2013 5:57 AM, Albe Laurenz wrote: >> Kaushal Shriyan wrote: >>> I have read on the web that Postgresql DB supports replication >>> across data centers. Any real life usecase examples if it has been >>> implemented by anyone. >> >> Well, we replicate a 1 TB database between two locations. It is a >> fairly active OLTP application, but certainly not pushing the limits >> of what PostgreSQL can do in transactions per second. >> > > Something that section 25 in the pgsql documentation is not clear about > for hot-standby with WAL log shipping using the built-in streaming: > > Can you choose which databases / tables on the master server get > streamed to the hot-standby read-only server at the remote site? If > not, I suspect we'll have to go with either Slony or Bucardo. WAL's contains transaction informations for the whole cluster, you can't choose particular databases or tables. Andreas -- Really, I'm not out to destroy Microsoft. That will just be a completely unintentional side effect. (Linus Torvalds) "If I was god, I would recompile penguin with --enable-fly." (unknown) Kaufbach, Saxony, Germany, Europe. N 51.05082°, E 13.56889°
On 12/9/2013 11:24 AM, Ben Chobot wrote: > > Out of curiosity what did you find unclear about > http://www.postgresql.org/docs/9.3/static/different-replication-solutions.html? Perhaps the "Per-table granularity" line in the matrix (Table 25-1) might be better written as: "Synchronization Granularity" Columns 1-3 and 5 could say "Entire Cluster". Column 4 might say "Selected tables (Slony)", and I'm not sure off-hand what granularity #6 (Bucardo) is capable of. Column #7 might just say "Varies". For someone not familiar with what exactly WAL files are, it's not clear that solution #3 is an all-or-nothing approaches at the cluster level. Now that I've refreshed my memory on how WAL files work (and at what level in the pgsql cluster), I understand why #3 works the way it does.
On Mon, 09 Dec 2013 11:09:21 -0500 Thomas Harold <thomas-lists@nybeta.com> wrote: > On 11/22/2013 5:57 AM, Albe Laurenz wrote: > > Kaushal Shriyan wrote: > >> I have read on the web that Postgresql DB supports replication > >> across data centers. Any real life usecase examples if it has been > >> implemented by anyone. > > > > Well, we replicate a 1 TB database between two locations. It is a > > fairly active OLTP application, but certainly not pushing the limits > > of what PostgreSQL can do in transactions per second. > > > > Something that section 25 in the pgsql documentation is not clear about > for hot-standby with WAL log shipping using the built-in streaming: > > Can you choose which databases / tables on the master server get > streamed to the hot-standby read-only server at the remote site? If > not, I suspect we'll have to go with either Slony or Bucardo. Go with Slony. Trust me. People seem to shy away from the comlexity of slony, only to realize later that they're hurting because the solution they chose instead doesn't have the features they need. Keep in mind some things that slony does that aren't yet available with streaming: * Cascading replication chains (a really big deal when you want multiple slaves in the secondary facility and don't want to hog your bandwidth) * Quick and easy movement of the master to any of the database in the cluster without destroying replication. * Seeding of new slaves without interrupting existing nodes (assuming your hardware has a little free capacity) * Selective replication of tables, potentially in complex arrangements where some tables are replicated to only to A and some only to B and some to A and B, etc, etc. I was about to go on and type more, but really, those three things make a huge difference in day to day operations, when problems occur, and when the unexpected (but joyful) "we never expected this much activity" happens. Streaming replication is great, but unless you're 100% sure you'll be OK with the restrictions it imposes, I recommend taking the time to learn how to manage slony, as the advantages far outweigh the additional management overhead. -- Bill Moran <wmoran@potentialtech.com>
-----BEGIN PGP SIGNED MESSAGE----- Hash: RIPEMD160 > Columns 1-3 and 5 could say "Entire Cluster". Column 4 might say > "Selected tables (Slony)", and I'm not sure off-hand what granularity #6 > (Bucardo) is capable of. Column #7 might just say "Varies". Bucardo and Slony are both table-based and trigger-driven. - -- Greg Sabino Mullane greg@turnstep.com End Point Corporation http://www.endpoint.com/ PGP Key: 0x14964AC8 201312100859 http://biglumber.com/x/web?pk=2529DF6AB8F79407E94445B4BC9B906714964AC8 -----BEGIN PGP SIGNATURE----- iEYEAREDAAYFAlKnHmAACgkQvJuQZxSWSsiD9QCdFzrd+VfM18dGa6btzbZ5Bc9G oBsAn3O4Y4g74w3WxMK3mQsJjjHOIQ5g =m+o0 -----END PGP SIGNATURE-----
> http://www.postgresql.org/docs/9.3/static/different-replication-solutions.html? > Synchronous Multimaster Replication *snip* > PostgreSQL does not offer this type of replication (...) Now I compare that statement with: http://wiki.postgresql.org/wiki/Postgres-XC > Project Overview *snip* > Features of PG-XC include: *snip* > 2. Synchronous multi-master configuration Seems to me that the editing process of the different parts of postgresql.org somewhat lacks transactional semantics. >;-> Sincerely, Wolfgang
On Dec 10, 2013, at 8:47 AM, Wolfgang Keller <feliphil@gmx.net> wrote: >> http://www.postgresql.org/docs/9.3/static/different-replication-solutions.html? > >> Synchronous Multimaster Replication > > *snip* > >> PostgreSQL does not offer this type of replication (...) > > Now I compare that statement with: > > http://wiki.postgresql.org/wiki/Postgres-XC > >> Project Overview > > *snip* > >> Features of PG-XC include: > > *snip* > >> 2. Synchronous multi-master configuration > > Seems to me that the editing process of the different parts of > postgresql.org somewhat lacks transactional semantics. Postgres-XC isn't PostgreSQL. Entirely different product. Anyone can add pages to the wiki, and there's lots of information there about things that aren't postgresql, Postgres-XC is just one of those. Cheers, Steve
On 12/10/2013 8:47 AM, Wolfgang Keller wrote: > Seems to me that the editing process of the different parts of > postgresql.org somewhat lacks transactional semantics. postgresql-xc is not postgresql, its a fork. there's other forks that offer distributed databases, such as greenplum. -- john r pierce 37N 122W somewhere on the middle of the left coast
> > Seems to me that the editing process of the different parts of > > postgresql.org somewhat lacks transactional semantics. > > postgresql-xc is not postgresql, its a fork. As an end-user, why would I care. Since, besides that it's still open-source (even same license as PostgreSQL itself...?), it's following the PostgreSQL releases pretty closely. According to their roadmap, version 1.1 has been merged with PostgreSQL 9.2 and version 1.2 will be merged with 9.3. It would at least merit being mentioned in the doc, just like other "forks" or whatever you may call it, as long as they're open-source. Sincerely, Wolfgang
Wolfgang Keller <feliphil@gmx.net> writes:
>> postgresql-xc is not postgresql, its a fork.
> It would at least merit being mentioned in the doc, just like other
> "forks" or whatever you may call it, as long as they're open-source.
You seem to not realize how many forks of Postgres there are.
There's no way that we can even track them all, let alone cater
for them in our documentation.
regards, tom lane
Tom Lane <tgl@sss.pgh.pa.us> wrote: > Wolfgang Keller <feliphil@gmx.net> writes: >>> postgresql-xc is not postgresql, its a fork. > >> It would at least merit being mentioned in the doc, just like >> other "forks" or whatever you may call it, as long as they're >> open-source. > > You seem to not realize how many forks of Postgres there are. > There's no way that we can even track them all, let alone cater > for them in our documentation. Just to give the OP a view onto some of the forks we do know about: https://raw.github.com/daamien/artwork/master/inkscape/PostgreSQL_timeline/timeline_postgresql.png -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
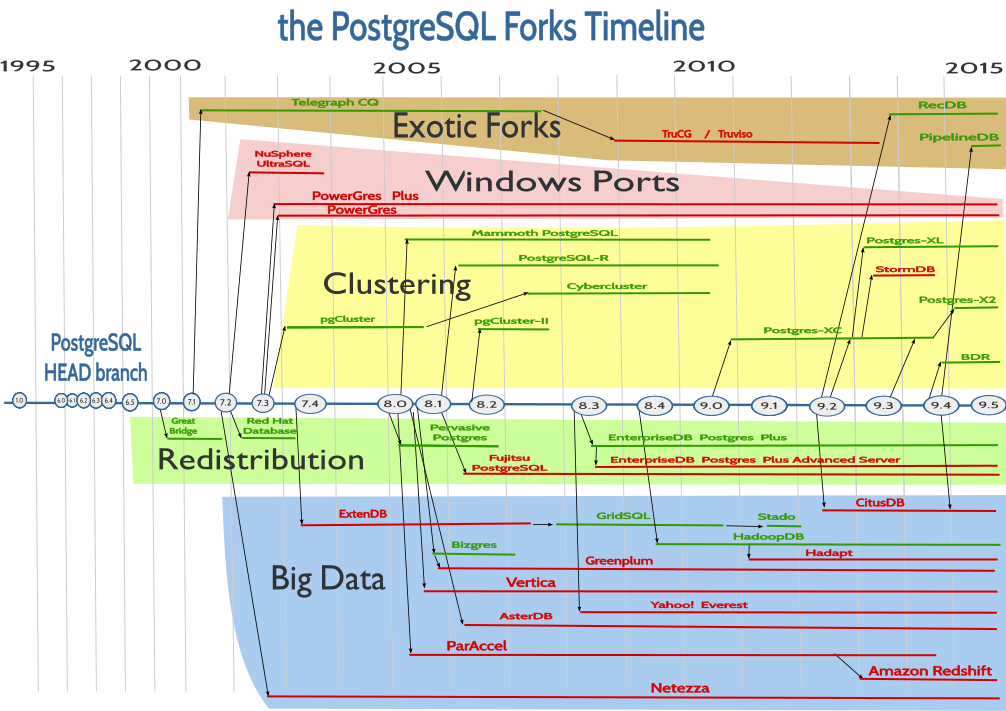{kind=link}
> >> postgresql-xc is not postgresql, its a fork. > > > It would at least merit being mentioned in the doc, just like other > > "forks" or whatever you may call it, as long as they're open-source. > > You seem to not realize how many forks of Postgres there are. I had mentioned just one. And that one does not only fill in a functionality gap that is pretty important when it comes to competition/advocacy vs. e.g. that database with the capital "O", but it is also mentioned already on postgresql.org. Honestly, don't try to tell me that the majority of the developers working on PostgreSQL are not aware of PostgreSQL-XC. > There's no way that we can even track them all, let alone cater > for them in our documentation. Just putting one single URL into the doc instead of the misleading statement that there's no such thing should have been less work than replying to me. >;-> Disclaimer: I have nothing to do with PostgreSQL-XC, I don't even use it myself, I just happen to know that it exists, even though I am just a "casual" user of PostgreSQL. Sincerely, Wolfgang
To be honest your request/demand expectation is quite unfair.
have you seen cross link on Suse and Red Hat and Ubuntu and SE Linux and Debian and... (well I would need a google search for adding more here)
By far I guess PostgreSQL community documentation is the one of the most organized doc stores (and the best dox when you need to see products limitation. No one else is so vocal). Only other better doc repository I have come across is MSDN. Well even there I can't recollect SQL server doc corss linking to SQL Azure.
Postgres-XC is a fork-serves different purpose, once it forked out it has nothing to do with PostgreSQL (to my knowledge the dev group as well is different).
Regards
Sameer
On Thu, Dec 12, 2013 at 3:19 AM, Wolfgang Keller <feliphil@gmx.net> wrote: >> >> postgresql-xc is not postgresql, its a fork. >> >> > It would at least merit being mentioned in the doc, just like other >> > "forks" or whatever you may call it, as long as they're open-source. >> >> You seem to not realize how many forks of Postgres there are. > > I had mentioned just one. > > And that one does not only fill in a functionality gap that is pretty > important when it comes to competition/advocacy vs. e.g. that database > with the capital "O", but it is also mentioned already on > postgresql.org. > > Honestly, don't try to tell me that the majority of the developers > working on PostgreSQL are not aware of PostgreSQL-XC. > >> There's no way that we can even track them all, let alone cater >> for them in our documentation. > > Just putting one single URL into the doc instead of the misleading > statement that there's no such thing should have been less work than > replying to me. Knowing the number of forks/projects based on Postgres, maintaining a list on a wiki list the one below is just easier for everybody: http://wiki.postgresql.org/wiki/Replication,_Clustering,_and_Connection_Pooling Perhaps this list is not completely up-to-date, but not adding that in the core documentation facilitates the work of core maintainers. It gives you all the information you need as well. Regards, -- Michael
Postgres-XC isn't PostgreSQL. Entirely different product.
Anyone can add pages to the wiki, and there's lots of information
there about things that aren't postgresql, Postgres-XC is just
one of those.
I think "entirely different product" is not really accurate. It isn't just a fork, but a closely related one, which continues to work closely with the community. That's different from Greenplum these days. At any rate it is far less an "entirely different product" than Illustra was, or EDB's Postgres Plus, or countless others.
Why should a user care? Because it means that there is better compatibility than there would be for a typical fork. It is still a much more complex product, and for a much more complex niche. However there will be areas where they are not the same, particularly when it comes to performance.
Best Wishes,
Chris Travers
Cheers,
Steve
--
Sent via pgsql-general mailing list (pgsql-general@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-general
Best Wishes,
Chris Travers
Efficito: Hosted Accounting and ERP. Robust and Flexible. No vendor lock-in.
I should have cross-posted this to pgsql-docs from the beginning, sorry for the mistake. For pgsql-docs readers: The issue is that the official documentation misleadingly omits the existence of Postgresql-XC: http://www.postgresql.org/docs/9.3/static/different-replication-solutions.html? > Synchronous Multimaster Replication *snip* > PostgreSQL does not offer this type of replication (...) Whereas the wiki says in http://wiki.postgresql.org/wiki/Postgres-XC > Project Overview *snip* > Features of PG-XC include: *snip* > 2. Synchronous multi-master configuration Now back to the original thread: > Knowing the number of forks/projects based on Postgres, maintaining a > list on a wiki list the one below is just easier for everybody: > http://wiki.postgresql.org/wiki/Replication,_Clustering,_and_Connection_Pooling That one doesn't even list PostgreSQL-XC. For how man years has it been around now... Can't even remember any more. Instead it lists Postgres-R, which has been in koma for how long now... Can't even remember any more. BTW; No, I don't suffer from that brain disease that makes you lose your memory (can't remember the name of it any more... ;-). > Perhaps this list is not completely up-to-date, To call that an understatement would be an euphemism. It's simply misleading. And misleading potential users in search of solutions for their needs is *bad* for the PostgreSQL project. > but not adding that in the core documentation facilitates the work of > core maintainers. It gives you all the information you need as well. Guys, are you really not aware to *that* point how badly you shoot yourself (and the PostgreSQL project as a whole) in the foot with that single - wrong - phrase in the "official" documentation: "PostgreSQL does not offer this type of replication" Reading that phrase, the average O***** DBA looking for a cheaper replacement will stop considering PostgreSQL and that's it. You're out of business. They won't look any further. Just stop arguing and put *one* *single* *phrase* in the official documentation instead like: "PostgreSQL itself does not provide this as a built-in functionality at the current stage, but there is an open-source "fork" freely available under the same license as PostgreSQL that does, for details read: http://wiki.postgresql.org/wiki/Postgres-XC" Is that really too much work? Heck, give me write-authority on the documentation and I'll do it for you then. You've already wasted *way* more brain bandwidth and precious time arguing why that phrase is *not* there than it would take to put it there once for good. That's the kind of pointy-haired dysfunctionality I'd expect from a managed corporation, not from an open-source project. In fact I would guess that given how closely PostgreSQL-XC follows the releases of "pure" PostgreSQL and the fact that they use the same license, at some stage it may be merged entirely. Sincerely, Wolfgang
Re: [DOCS] Re: postgresql.org inconsistent (Re: PG replication across DataCenters)
From
"Joshua D. Drake"
Date:
On 12/12/2013 08:18 AM, Wolfgang Keller wrote: > >> 2. Synchronous multi-master configuration > > Now back to the original thread: > >> Knowing the number of forks/projects based on Postgres, maintaining a >> list on a wiki list the one below is just easier for everybody: >> http://wiki.postgresql.org/wiki/Replication,_Clustering,_and_Connection_Pooling > > That one doesn't even list PostgreSQL-XC. Then update the page? It is a wiki. > > For how man years has it been around now... > Can't even remember any more. > > Instead it lists Postgres-R, which has been in koma for how long now... > Can't even remember any more. Nope, it is actively developed and sponsored by Translattice. > >> Perhaps this list is not completely up-to-date, > > To call that an understatement would be an euphemism. > > It's simply misleading. And misleading potential users in search of > solutions for their needs is *bad* for the PostgreSQL project. Why are you arguing about this instead of just fixing it? > Guys, are you really not aware to *that* point how badly you shoot > yourself (and the PostgreSQL project as a whole) in the foot with that > single - wrong - phrase in the "official" documentation: > > "PostgreSQL does not offer this type of replication" > > Reading that phrase, the average O***** DBA looking for a cheaper > replacement will stop considering PostgreSQL and that's it. You're out > of business. They won't look any further. I agree. > "PostgreSQL itself does not provide this as a built-in functionality at > the current stage, but there is an open-source "fork" freely available > under the same license as PostgreSQL that does, for details read: > > http://wiki.postgresql.org/wiki/Postgres-XC" > > Is that really too much work? Heck, give me write-authority on the > documentation and I'll do it for you then. You've already wasted *way* Submit a patch. Is that so hard? I don't understand why you are up in arms about this. Sincerely, Joshua D. Drake -- Command Prompt, Inc. - http://www.commandprompt.com/ 509-416-6579 PostgreSQL Support, Training, Professional Services and Development High Availability, Oracle Conversion, Postgres-XC, @cmdpromptinc For my dreams of your image that blossoms a rose in the deeps of my heart. - W.B. Yeats
Re: [DOCS] Re: postgresql.org inconsistent (Re: PG replication across DataCenters)
From
Wolfgang Keller
Date:
> > Instead it lists Postgres-R, which has been in koma for how long > > now... Can't even remember any more. > > Nope, it is actively developed and sponsored by Translattice. "Actively developed"? http://www.postgres-r.org/ lists the last entry in the column "News" on the right with a date of 2010-07-14. http://git.postgres-r.org/ lists the "Last Change" to Postgres-R as "2 years ago". http://www.postgres-r.org/downloads/ lists the last "Snapshot patch" with a date from 2010-08-29. The "Postgres-R Live-CD" has a date from 2006-07-04! Sincerely, Wolfgang
Re: [DOCS] Re: postgresql.org inconsistent (Re: PG replication across DataCenters)
From
"Christofer C. Bell"
Date:
On Sun, Dec 15, 2013 at 9:40 AM, Wolfgang Keller <feliphil@gmx.net> wrote: > > > > Instead it lists Postgres-R, which has been in koma for how long > > > now... Can't even remember any more. > > > > Nope, it is actively developed and sponsored by Translattice. > > "Actively developed"? > > http://www.postgres-r.org/ lists the last entry in the column "News" on > the right with a date of 2010-07-14. > > http://git.postgres-r.org/ lists the "Last Change" to Postgres-R as "2 > years ago". > > http://www.postgres-r.org/downloads/ lists the last "Snapshot patch" > with a date from 2010-08-29. > > The "Postgres-R Live-CD" has a date from 2006-07-04! > > Sincerely, > > Wolfgang It looks like it's been morphed into TED, the TransLattice Elastic Database. From their FAQ[1]: TransLattice Elastic Database (TED) What’s the basis of TED? Did you write it from scratch? We started TED from PostgreSQL, a very robust, open-source, ACID-compliant, fully transactional RDBMS and Postgres-R, a PostgreSQL extension that provides efficient, fast and consistent database replication . Extensive engineering enhancements allows TED to maintain ACID semantic transactions while operating in a geographically distributed cluster. [1] http://www.translattice.com/faq.shtml -- Chris "If you wish to make an apple pie from scratch, you must first invent the Universe." -- Carl Sagan
Re: [DOCS] Re: postgresql.org inconsistent (Re: PG replication across DataCenters)
From
Wolfgang Keller
Date:
> It looks like it's been morphed into TED, the TransLattice Elastic > Database. From their FAQ[1]: > > TransLattice Elastic Database (TED) > > What’s the basis of TED? Did you write it from scratch? > > We started TED from PostgreSQL, a very robust, open-source, > ACID-compliant, fully transactional RDBMS and Postgres-R, a PostgreSQL > extension that provides efficient, fast and consistent database > replication . Extensive engineering enhancements allows TED to > maintain ACID semantic transactions while operating in a > geographically distributed cluster. > > [1] http://www.translattice.com/faq.shtml I could not find any valid technical information on that site that would give details about what version of PostgreSQL they are based on etc. And if they have anything more recent than postgres-r.org, their product doesn't appear to be open source, since I couldn't find anything to download there. In fact their entire site reads to me just like the usual salespromotionspeak nonsense written for pointy-haired morons. Excuse me, but I can't take those people really serious. If Bettina Kemme is working with them, she should at least make sure to get them a reasonably useful WWW site. Sincerely, Wolfgang
Though I will agree that slony is a nice and a great tool w.r.t. replication (specifically selective replication). But I would dis-agree on below points:
* Cascading replication chains (a really big deal when you wantmultiple slaves in the secondary facility and don't want to hogyour bandwidth)
Really? which version of Postgres are we talking about? I think cascaded replication facility is available since v9.2
* Quick and easy movement of the master to any of the database inthe cluster without destroying replication.
Again, which version? Re-mastering is made simple in v9.3.
* Seeding of new slaves without interrupting existing nodes (assumingyour hardware has a little free capacity)
AFAIK, streaming replication does not cause any interruption while you add a new node.
* Selective replication of tables, potentially in complex arrangementswhere some tables are replicated to only to A and some only to Band some to A and B, etc, etc.
Agree.
In general I do not like trigger based (replication) solutions for huge clusters [this is my personal opinion and does not necessarily indicate my employer's opinion ;-)] and for databases which has huge write volume specifically if you do bulk insert/delete/update operations.
I think if it's slony or streaming replication will depend on below factors:
1) The change-set that you want to replicate contributes how much of your total change set? e.g. on a per minute basis if it's 70% or above, I will recommend you to go for streaming replication
2) Do you have too many tables to be added to replication set? lets say above 70% of your total tables needs to be replication (unless rest 30% have high write operations), then go for streaming replication
3) Do you too many bulk operations happening on the tables which needs to be replicated
4) To some extent your choice will be influenced by the motivation behind replication, DR, HA, reporting application (esp if you are particular about replicating only selective tables for reports)
There are few easier ways of managing a slony cluster:
2) I think even pgadmin supports slony replication (not sure if its slony-I or slony-II)
Regards
Sameer
On Tue, 24 Dec 2013 14:39:42 +0800 Sameer Kumar <sameer.kumar@ashnik.com> wrote: > > * Cascading replication chains (a really big deal when you want > > multiple slaves in the secondary facility and don't want to hog > > your bandwidth) > > Really? which version of Postgres are we talking about? I think cascaded > replication facility is available since v9.2 > http://www.postgresql.org/docs/9.2/static/warm-standby.html#CASCADING-REPLICATION Nice. Seems it's been longer than I realized since I last evaluated what streaming replication is capble of. > * Quick and easy movement of the master to any of the database in > > the cluster without destroying replication. > > Again, which version? Re-mastering is made simple in v9.3. I'm not seeing that in the documentation. In fact, what I'm finding seems to suggest the opposite: that each node's master is configured in a config file, so in the case of a complicated replication setup, I would have to run around editing config files on multiple servers to move the master ... unless I'm missing something in the documentation. > * Seeding of new slaves without interrupting existing nodes (assuming > > your hardware has a little free capacity) > > AFAIK, streaming replication does not cause any interruption while you add > a new node. The process is still significantly more involved than Slony's subscription commands. In our lab setups, I've watched junior DBA's fail time and time again to get a proper seed with streaming replication. > In general I do not like trigger based (replication) solutions for huge > clusters [this is my personal opinion and does not necessarily indicate my > employer's opinion ;-)] and for databases which has huge write volume > specifically if you do bulk insert/delete/update operations. There are definitely drawbacks, I'll grant you that. If it's raw throughput you need, Slony probably isn't going to cut it for you. > I think if it's slony or streaming replication will depend on below factors: > > 1) The change-set that you want to replicate contributes how much of your > total change set? e.g. on a per minute basis if it's 70% or above, I will > recommend you to go for streaming replication While this is a strong argument in favor of streaming over Slony, the 70% number seems rather arbitrary, and you're advocating that this point alone is enough to outweight the other advantages of Slony, which may be more important in a particular case. > 2) Do you have too many tables to be added to replication set? lets say > above 70% of your total tables needs to be replication (unless rest 30% > have high write operations), then go for streaming replication Again, this seems arbitrary. If the management that Slony provides is needed, then why would I care what percentage of tables are involved? > 3) Do you too many bulk operations happening on the tables which needs to > be replicated This is arguably a shortcoming of trigger-based replication that trumps just about everything else. If Slony just can't keep up, then you don't have much choice. > 4) To some extent your choice will be influenced by the motivation behind > replication, DR, HA, reporting application (esp if you are particular about > replicating only selective tables for reports) In my experience, this is usually the largest factor. Once argument in favor of streaming that you missed is when you have no control over the schema (for example, when it's 3rd party, like an openfire database). In those cases, the application frequently omits things like primary keys (which are required for slony) and has an upgrade process that assumes it can change database tables without impacting anything else. > There are few easier ways of managing a slony cluster: > > 1) > http://shoaibmir.wordpress.com/2009/08/05/setting-up-slony-cluster-with-perltools/<http://shoaibmir.wordpress.com/2009/08/05/setting-up-slony-cluster-with-perltools/> > > 2) I think even pgadmin supports slony replication (not sure if its slony-I > or slony-II) I'll add dbsteward to this list, as we wrote it (in part) to make slony management easier on systems that experience frequent change. -- Bill Moran <wmoran@potentialtech.com>
>> > * Quick and easy movement of the master to any of the database in
>> >
>> > the cluster without destroying replication.
>> >
>> > Again, which version? Re-mastering is made simple in v9.3.
>> I'm not seeing that in the documentation. In fact, what I'm finding
>> seems to suggest the opposite: that each node's master is configured
>> in a config file, so in the case of a complicated replication setup,
>> I would have to run around editing config files on multiple servers
>> to move the master ... unless I'm missing something in the documentation.
Well, the pain can be minimized if you can write some simple shell scripts for this. Or if you can have a floating/virtual IP.
>>> * Seeding of new slaves without interrupting existing nodes (assuming
>>>
>>> your hardware has a little free capacity)
>>>
>>> AFAIK, streaming replication does not cause any interruption while you add
>>> a new node.
>>The process is still significantly more involved than Slony's subscription
>>commands. In our lab setups, I've watched junior DBA's fail time and time
>>again to get a proper seed with streaming replication.
Try the pg_basebackup options in v9.3. Creating a streaming replica has been made easy. It's still a little painful if you want to move your WALs to a different LUW/HDD on your replica
>>> I think if it's slony or streaming replication will depend on below factors:
>>>
>>> 1) The change-set that you want to replicate contributes how much of your
>>> total change set? e.g. on a per minute basis if it's 70% or above, I will
>>> recommend you to go for streaming replication
>>While this is a strong argument in favor of streaming over Slony, the
>>70% number seems rather arbitrary, and you're advocating that this point
>>alone is enough to outweight the other advantages of Slony, which may be
>>more important in a particular case.
I gave an example. It will definately vary from case to case and implementation to implementation.
>>> 4) To some extent your choice will be influenced by the motivation behind
>>> replication, DR, HA, reporting application (esp if you are particular about
>>> replicating only selective tables for reports)
>>In my experience, this is usually the largest factor.
>>>To some extent your choice will be influenced <<<
Let me correct myself:
To a large extent your choice will be influnced :)
>>Once argument in favor of streaming that you missed is when you have no
>>control over the schema (for example, when it's 3rd party, like an openfire
>>database). In those cases, the application frequently omits things like
>>primary keys (which are required for slony) and has an upgrade process that
>>assumes it can change database tables without impacting anything else.
That's a good one and quite apt too!
Regards
Sameer
Ashnik Pte. Ltd.
Singapore
On Mon, 30 Dec 2013 00:15:37 +0800 Sameer Kumar <sameer.kumar@ashnik.com> wrote: > >> > * Quick and easy movement of the master to any of the database in > >> > > >> > the cluster without destroying replication. > >> > > >> > Again, which version? Re-mastering is made simple in v9.3. > > >> I'm not seeing that in the documentation. In fact, what I'm finding > >> seems to suggest the opposite: that each node's master is configured > >> in a config file, so in the case of a complicated replication setup, > >> I would have to run around editing config files on multiple servers > >> to move the master ... unless I'm missing something in the documentation. > > Well, the pain can be minimized if you can write some simple shell scripts > for this. Or if you can have a floating/virtual IP. This is probably the only point that we're not seeing eye to eye on. Take a real scenario I have to maintain. There is a single master and 11 replicas spread across 2 datacenters. Some of these replicas are read-only for the application, 1 is for analytics, another supports development, another is a dedicated backup system. The rest are purely for DR.. Now, in a facility failure scenario, all is well, we just promote the DR master in the secondary datacenter and go back to work -- this should be equally easy with either Slony or streaming What I don't see streaming working for is DR drills. I need to, in a controlled manner, move the entire application to the secondary datacenter, while keeping all the nodes in sync, make sure everything operates properly from there (which means allowing database updates), then move it all back to the primary datacenter, without losing sync on any slaves (this is a 2T database, which I'm sure isn't the largest anyone has dealt with, but it means that reseeding slaves is a multi-hour endeavour). With Slony, these drills are easy: a single slonik command relocates the master to the DR datacenter while keeping everything in sync, and when testing is complete, another slonik command puts everything back the way it was, without any data loss and with minimal chance for human error. If you feel that the current implementation of streaming replication is able to do that task, then I'll have to move up my timetable to re-evaluate it. It _has_ been a few versions since I've taken a good look at it. -- Bill Moran <wmoran@potentialtech.com>
What I don't see streaming working for is DR drills. I need to, in a
controlled manner, move the entire application to the secondary datacenter,
while keeping all the nodes in sync, make sure everything operates properly
from there (which means allowing database updates), then move it all back
to the primary datacenter, without losing sync on any slaves (this is a 2T
database, which I'm sure isn't the largest anyone has dealt with, but it
means that reseeding slaves is a multi-hour endeavour). With Slony, these
drills are easy: a single slonik command relocates the master to the DR
datacenter while keeping everything in sync, and when testing is complete,
another slonik command puts everything back the way it was, without any
data loss and with minimal chance for human error.
I guess I got your point :)
Agree to you now! :)
With v9.3 I think I would be easy to swap the roles for primary and DR. (I need to test this before I can say for sure).
But still it will be a pain if one needs to shift all the operations to DR (which is a a valid case, e.g. you would do that for testing the readiness of your DR site by doing a mock failover) and then shift back to Primary Site (assuming while operations were going on on DR site, primary site was kept down purposefully). This will involve taking a backup from DR to primary and then swapping the roles.
I guess this limitation will be soon waived off. I guess v9.4 or next one should have this feature (no backups as long as your wal_keep_segment is high enough to cater to your testing/mock failover window).
I agree slonik and few other utilities/tool around it administration/management is quite easy.
If you feel that the current implementation of streaming replication is
able to do that task, then I'll have to move up my timetable to re-evaluate
it. It _has_ been a few versions since I've taken a good look at it.
Given your expectation above, v9.3 is a good candidate. But you can afford to give it a miss.
You must try once v9.4 is out.
Regards
Sameer
Ashnik Pte. Ltd.
Singapore