Thread: Improving spin-lock implementation on ARM.
Improving spin-lock implementation on ARM.
------------------------------------------------------------
* Spin-Lock is known to have a significant effect on performance
with increasing scalability.
* Existing Spin-Lock implementation for ARM is sub-optimal due to
use of TAS (test and swap)
* TAS is implemented on ARM as load-store so even if the lock is not free,
store operation will execute to replace the same value.
This redundant operation (mainly store) is costly.
* CAS is implemented on ARM as load-check-store-check that means if the
lock is not free, check operation, post-load will cause the loop to
return there-by saving on costlier store operation. [1]
* x86 uses optimized xchg operation.
ARM too started supporting it (using Large System Extension) with
ARM-v8.1 but since it not supported with ARM-v8, GCC default tends
to roll more generic load-store assembly code.
* gcc-9.4+ onwards there is support for outline-atomics that could emit
both the variants of the code (load-store and cas/swp) and based on
underlying supported architecture proper variant it used but still a lot
of distros don't support GCC-9.4 as the default compiler.
* In light of this, we would like to propose a CAS-based approach based on
our local testing has shown improvement in the range of 10-40%.
(attaching graph).
* Patch enables CAS based approach if the CAS is supported depending on
existing compiled flag HAVE_GCC__ATOMIC_INT32_CAS
(Thanks to Amit Khandekar for rigorously performance testing this patch
with different combinations).
[1]: https://godbolt.org/z/jqbEsa
P.S: Sorry if I missed any standard pgsql protocol since I am just starting with pgsql.
---
Krunal Bauskar
#mysqlonarm
Huawei Technologies
Attachment
{kind=link}
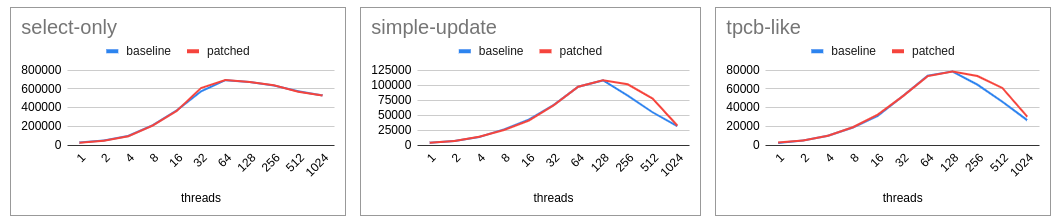
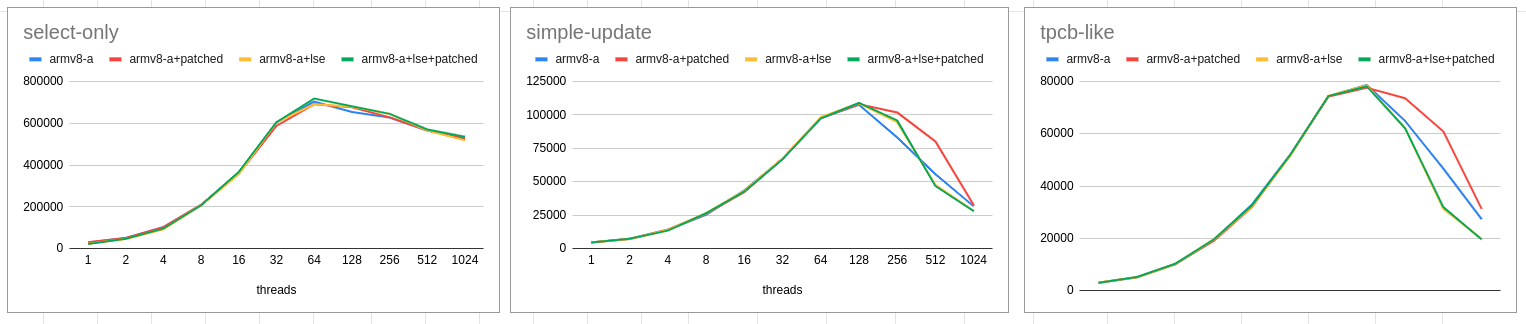
On Thu, Nov 26, 2020 at 10:00:50AM +0530, Krunal Bauskar wrote: > (Thanks to Amit Khandekar for rigorously performance testing this patch > with different combinations). For the simple-update and tpcb-like graphs, do you have any actual numbers to share between 128 and 1024 connections? The blue lines look like they are missing some measurements in-between, so it is hard to tell if this is an actual improvement or just some lack of data. -- Michael
Attachment
scalability baseline patched
----------- --------- ----------
update tpcb update tpcb
--------------------------------------------------------------
128 107932 78554 108081 78569
256 82877 64682 101543 73774
512 55174 46494 77886 61105
1024 32267 27020 33170 30597
configuration: https://github.com/mysqlonarm/benchmark-suites/blob/master/pgsql-pbench/conf/pgsql.cnf/postgresql.conf
On Thu, 26 Nov 2020 at 10:36, Michael Paquier <michael@paquier.xyz> wrote:
On Thu, Nov 26, 2020 at 10:00:50AM +0530, Krunal Bauskar wrote:
> (Thanks to Amit Khandekar for rigorously performance testing this patch
> with different combinations).
For the simple-update and tpcb-like graphs, do you have any actual
numbers to share between 128 and 1024 connections? The blue lines
look like they are missing some measurements in-between, so it is hard
to tell if this is an actual improvement or just some lack of data.
--
Michael
Regards,
Krunal Bauskar
Krunal Bauskar
Michael Paquier <michael@paquier.xyz> writes:
> On Thu, Nov 26, 2020 at 10:00:50AM +0530, Krunal Bauskar wrote:
>> (Thanks to Amit Khandekar for rigorously performance testing this patch
>> with different combinations).
> For the simple-update and tpcb-like graphs, do you have any actual
> numbers to share between 128 and 1024 connections?
Also, exactly what hardware/software platform were these curves
obtained on?
regards, tom lane
On Thu, 26 Nov 2020 at 10:50, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Michael Paquier <michael@paquier.xyz> writes:
> On Thu, Nov 26, 2020 at 10:00:50AM +0530, Krunal Bauskar wrote:
>> (Thanks to Amit Khandekar for rigorously performance testing this patch
>> with different combinations).
> For the simple-update and tpcb-like graphs, do you have any actual
> numbers to share between 128 and 1024 connections?
Also, exactly what hardware/software platform were these curves
obtained on?
Hardware: ARM Kunpeng 920 BareMetal Server 2.6 GHz. 64 cores (56 cores for server and 8 for client) [2 numa nodes]
Storage: 3.2 TB NVMe SSD
OS: CentOS Linux release 7.6
PGSQL: baseline = Release Tag 13.1
Invocation suite: https://github.com/mysqlonarm/benchmark-suites/tree/master/pgsql-pbench (Uses pgbench)
regards, tom lane
Regards,
Krunal Bauskar
Krunal Bauskar
On Thu, 26 Nov 2020 at 10:55, Krunal Bauskar <krunalbauskar@gmail.com> wrote: > Hardware: ARM Kunpeng 920 BareMetal Server 2.6 GHz. 64 cores (56 cores for server and 8 for client) [2 numa nodes] > Storage: 3.2 TB NVMe SSD > OS: CentOS Linux release 7.6 > PGSQL: baseline = Release Tag 13.1 > Invocation suite: https://github.com/mysqlonarm/benchmark-suites/tree/master/pgsql-pbench (Uses pgbench) Using the same hardware, attached are my improvement figures, which are pretty much in line with your figures. Except that, I did not run for more than 400 number of clients. And, I am getting some improvement even for select-only workloads, in case of 200-400 clients. For read-write load, I had seen that the s_lock() contention was caused when the XLogFlush() uses the spinlock. But for read-only case, I have not analyzed where the improvement occurred. The .png files in the attached tar have the graphs for head versus patch. The GUCs that I changed : work_mem=64MB shared_buffers=128GB maintenance_work_mem = 1GB min_wal_size = 20GB max_wal_size = 100GB checkpoint_timeout = 60min checkpoint_completion_target = 0.9 full_page_writes = on synchronous_commit = on effective_io_concurrency = 200 log_checkpoints = on For backends, 64 CPUs were allotted (covering 2 NUMA nodes) , and for pgbench clients a separate set of 28 CPUs were allotted on a different socket. Server was pre_warmed().
Attachment
On 26/11/2020 06:30, Krunal Bauskar wrote: > Improving spin-lock implementation on ARM. > ------------------------------------------------------------ > > * Spin-Lock is known to have a significant effect on performance > with increasing scalability. > > * Existing Spin-Lock implementation for ARM is sub-optimal due to > use of TAS (test and swap) > > * TAS is implemented on ARM as load-store so even if the lock is not free, > store operation will execute to replace the same value. > This redundant operation (mainly store) is costly. > > * CAS is implemented on ARM as load-check-store-check that means if the > lock is not free, check operation, post-load will cause the loop to > return there-by saving on costlier store operation. [1] Can you add some code comments to explain that why CAS is cheaper than TAS on ARM? Is there some official ARM documentation, like a programmer's reference manual or something like that, that would show a reference implementation of a spinlock on ARM? It would be good to refer to an authoritative source on this. - Heikki
On Thu, Nov 26, 2020 at 1:32 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote:
> On 26/11/2020 06:30, Krunal Bauskar wrote:
> > Improving spin-lock implementation on ARM.
> > ------------------------------------------------------------
> >
> > * Spin-Lock is known to have a significant effect on performance
> > with increasing scalability.
> >
> > * Existing Spin-Lock implementation for ARM is sub-optimal due to
> > use of TAS (test and swap)
> >
> > * TAS is implemented on ARM as load-store so even if the lock is not free,
> > store operation will execute to replace the same value.
> > This redundant operation (mainly store) is costly.
> >
> > * CAS is implemented on ARM as load-check-store-check that means if the
> > lock is not free, check operation, post-load will cause the loop to
> > return there-by saving on costlier store operation. [1]
>
> Can you add some code comments to explain that why CAS is cheaper than
> TAS on ARM?
>
> Is there some official ARM documentation, like a programmer's reference
> manual or something like that, that would show a reference
> implementation of a spinlock on ARM? It would be good to refer to an
> authoritative source on this.
Let me add my 2 cents.
I've compared assembly output of gcc implementations of CAS and TAS.
The sample C-program is attached. I've compiled it on raspberry pi 4
using gcc 9.3.0.
The inner loop of CAS is as follows. So, if the value loaded by ldaxr
doesn't match expected value, then we immediately quit the loop.
.L3:
ldxr w3, [x0]
cmp w3, w1
bne .L4
stlxr w4, w2, [x0]
cbnz w4, .L3
.L4:
The inner loop of TAS is as follows. So it really does "stxr"
unconditionally. In principle, it could check if a new value matches
the observed value and there is nothing to do, but it doesn't.
Moreover, stxr might fail, then we can spend multiple loops of
ldxr/stxr due to concurrent memory access. AFAIK, those concurrent
accesses could reflect not only lock release, but also other
unsuccessful lock attempts. So, good chance for extra loops to be
useless.
.L7:
ldxr w2, [x0]
stxr w3, w1, [x0]
cbnz w3, .L7
I've also googled for spinlock implementation on arm and found a blog
post about spinlock implementation in linux kernel [1]. Surprisingly
it doesn't use the trick to skip stxr if the lock is busy. Instead,
they use some arm-specific power-saving option called WFE.
So, I think it's quite clear that switching from TAS to CAS on arm
would be a win. But there could be other options to do this even
better.
Links
1. https://linux-concepts.blogspot.com/2018/05/spinlock-implementation-in-arm.html
------
Regards,
Alexander Korotkov
Attachment
On Thu, 26 Nov 2020 at 16:02, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
On 26/11/2020 06:30, Krunal Bauskar wrote:
> Improving spin-lock implementation on ARM.
> ------------------------------------------------------------
>
> * Spin-Lock is known to have a significant effect on performance
> with increasing scalability.
>
> * Existing Spin-Lock implementation for ARM is sub-optimal due to
> use of TAS (test and swap)
>
> * TAS is implemented on ARM as load-store so even if the lock is not free,
> store operation will execute to replace the same value.
> This redundant operation (mainly store) is costly.
>
> * CAS is implemented on ARM as load-check-store-check that means if the
> lock is not free, check operation, post-load will cause the loop to
> return there-by saving on costlier store operation. [1]
Can you add some code comments to explain that why CAS is cheaper than
TAS on ARM?
1. As Alexey too pointed out in followup email
CAS = load value -> check if the value is expected -> if yes then replace (store new value) -> else exit/break
TAS = load value -> store new value
This means each TAS would be converted to 2 operations that are LOAD and STORE and of-course
STORE is costlier in terms of latency. CAS ensures optimization in this regard with an early check.
Let's look at some micro-benchmarking. I implemented a simple spin-loop using both approaches and
as expected with increase scalability, CAS continues to out-perform TAS by a margin up to 50%.
---- TAS ----
Running 128 parallelism
Elapsed time: 1.34271 s
Running 256 parallelism
Elapsed time: 3.6487 s
Running 512 parallelism
Elapsed time: 11.3725 s
Running 1024 parallelism
Elapsed time: 43.5376 s
---- CAS ----
Running 128 parallelism
Elapsed time: 1.00131 s
Running 256 parallelism
Elapsed time: 2.53202 s
Running 512 parallelism
Elapsed time: 7.66829 s
Running 1024 parallelism
Elapsed time: 22.6294 s
Running 128 parallelism
Elapsed time: 1.34271 s
Running 256 parallelism
Elapsed time: 3.6487 s
Running 512 parallelism
Elapsed time: 11.3725 s
Running 1024 parallelism
Elapsed time: 43.5376 s
---- CAS ----
Running 128 parallelism
Elapsed time: 1.00131 s
Running 256 parallelism
Elapsed time: 2.53202 s
Running 512 parallelism
Elapsed time: 7.66829 s
Running 1024 parallelism
Elapsed time: 22.6294 s
This could be also observed from the perf profiling
TAS:
15.57 │44: ldxr w0, [x19]
83.93 │ stxr w1, w21, [x19]
83.93 │ stxr w1, w21, [x19]
CAS:
81.29 │58: ↓ b.ne cc
....
In TAS: STORE is pretty costly.
2. I have added the needed comment in the patch. Updated patch attached.
----------------------
Thanks for taking look at this and surely let me know if any more info is needed.
Is there some official ARM documentation, like a programmer's reference
manual or something like that, that would show a reference
implementation of a spinlock on ARM? It would be good to refer to an
authoritative source on this.
- Heikki
Regards,
Krunal Bauskar
Krunal Bauskar
Attachment
Krunal Bauskar <krunalbauskar@gmail.com> writes:
> On Thu, 26 Nov 2020 at 10:50, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Also, exactly what hardware/software platform were these curves
>> obtained on?
> Hardware: ARM Kunpeng 920 BareMetal Server 2.6 GHz. 64 cores (56 cores for
> server and 8 for client) [2 numa nodes]
> Storage: 3.2 TB NVMe SSD
> OS: CentOS Linux release 7.6
> PGSQL: baseline = Release Tag 13.1
Hmm, might not be the sort of hardware ordinary mortals can get their
hands on. What's likely to be far more common ARM64 hardware in the
near future is Apple's new gear. So I thought I'd try this on the new
M1 mini I just got.
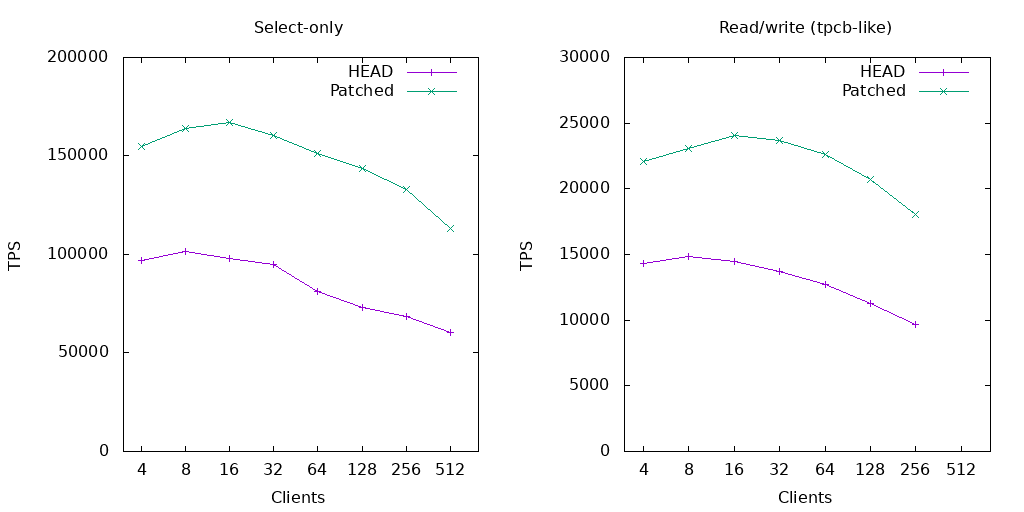
... and, after retrieving my jaw from the floor, I present the
attached. Apple's chips evidently like this style of spinlock a LOT
better. The difference is so remarkable that I wonder if I made a
mistake somewhere. Can anyone else replicate these results?
Test conditions are absolutely brain dead:
Today's HEAD (dcfff74fb), no special build options
All server parameters are out-of-the-box defaults, except
I had to raise max_connections for the larger client counts
pgbench scale factor 100
Read-only tests are like
pgbench -S -T 60 -c 32 -j 16 bench
Quoted figure is median of three runs; except for the lowest
client count, results were quite repeatable. (I speculate that
at -c 4, the scheduler might've been doing something funny about
sometimes using the slow cores instead of fast cores.)
Read-write tests are like
pgbench -T 300 -c 16 -j 8 bench
I didn't have the patience to run three full repetitions,
but again the numbers seemed pretty repeatable.
I used -j equal to half -c, except I could not get -j above 128
to work, so the larger client counts have -j 128. Did not try
to run down that problem yet, but I'm probably hitting some ulimit
somewhere. (I did have to raise "ulimit -n" to get these results.)
Anyway, this seems to be a slam-dunk win on M1.
regards, tom lane
Attachment
{kind=link}
Alexander Korotkov <aekorotkov@gmail.com> writes:
> On Thu, Nov 26, 2020 at 1:32 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote:
>> Is there some official ARM documentation, like a programmer's reference
>> manual or something like that, that would show a reference
>> implementation of a spinlock on ARM? It would be good to refer to an
>> authoritative source on this.
> I've compared assembly output of gcc implementations of CAS and TAS.
FWIW, I see quite different assembly using Apple's clang on their M1
processor. What I get for SpinLockAcquire on HEAD is (lock pointer
initially in x0):
mov x19, x0
mov w8, #1
swpal w8, w8, [x0]
cbz w8, LBB0_2
adrp x1, l_.str@PAGE
add x1, x1, l_.str@PAGEOFF
adrp x3, l___func__.foo@PAGE
add x3, x3, l___func__.foo@PAGEOFF
mov x0, x19
mov w2, #12
bl _s_lock
LBB0_2:
... lock is acquired
while SpinLockRelease is just
stlr wzr, [x19]
With the patch, I get
mov x19, x0
mov w8, #0
mov w9, #1
casa w8, w9, [x0]
cmp w8, #0 ; =0
b.eq LBB0_2
adrp x1, l_.str@PAGE
add x1, x1, l_.str@PAGEOFF
adrp x3, l___func__.foo@PAGE
add x3, x3, l___func__.foo@PAGEOFF
mov x0, x19
mov w2, #12
bl _s_lock
LBB0_2:
... lock is acquired
and SpinLockRelease is the same.
Don't know much of anything about ARM assembly, so I don't
know if these instructions are late-model-only.
regards, tom lane
On Fri, Nov 27, 2020 at 1:55 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Krunal Bauskar <krunalbauskar@gmail.com> writes: > > On Thu, 26 Nov 2020 at 10:50, Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> Also, exactly what hardware/software platform were these curves > >> obtained on? > > > Hardware: ARM Kunpeng 920 BareMetal Server 2.6 GHz. 64 cores (56 cores for > > server and 8 for client) [2 numa nodes] > > Storage: 3.2 TB NVMe SSD > > OS: CentOS Linux release 7.6 > > PGSQL: baseline = Release Tag 13.1 > > Hmm, might not be the sort of hardware ordinary mortals can get their > hands on. What's likely to be far more common ARM64 hardware in the > near future is Apple's new gear. So I thought I'd try this on the new > M1 mini I just got. > > ... and, after retrieving my jaw from the floor, I present the > attached. Apple's chips evidently like this style of spinlock a LOT > better. The difference is so remarkable that I wonder if I made a > mistake somewhere. Can anyone else replicate these results? Results look very surprising to me. I didn't expect there would be any very busy spin-lock when the number of clients is as low as 4. Especially in read-only pgbench. I don't have an M1 at hand. Could you do some profiling to identify the source of such a huge difference. ------ Regards, Alexander Korotkov
On Fri, Nov 27, 2020 at 2:20 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Alexander Korotkov <aekorotkov@gmail.com> writes: > > On Thu, Nov 26, 2020 at 1:32 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > >> Is there some official ARM documentation, like a programmer's reference > >> manual or something like that, that would show a reference > >> implementation of a spinlock on ARM? It would be good to refer to an > >> authoritative source on this. > > > I've compared assembly output of gcc implementations of CAS and TAS. > > FWIW, I see quite different assembly using Apple's clang on their M1 > processor. What I get for SpinLockAcquire on HEAD is (lock pointer > initially in x0): Yep, arm v8.1 implements single-instruction atomic operations swpal and casa, which much more look like x86 atomic instructions rather than loops of ldxr/stlxr. So, all the reasoning upthread shouldn't work here, but the advantage is much more huge. ------ Regards, Alexander Korotkov
Alexander Korotkov <aekorotkov@gmail.com> writes:
> On Fri, Nov 27, 2020 at 1:55 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> ... and, after retrieving my jaw from the floor, I present the
>> attached. Apple's chips evidently like this style of spinlock a LOT
>> better. The difference is so remarkable that I wonder if I made a
>> mistake somewhere. Can anyone else replicate these results?
> Results look very surprising to me. I didn't expect there would be
> any very busy spin-lock when the number of clients is as low as 4.
Yeah, that wasn't making sense to me either. The most likely explanation
seems to be that I messed up the test somehow ... but I don't see where.
So, again, I'm wondering if anyone else can replicate or refute this.
I can't be the only geek around here who sprang for an M1.
regards, tom lane
On Fri, Nov 27, 2020 at 02:50:30AM -0500, Tom Lane wrote: > Yeah, that wasn't making sense to me either. The most likely explanation > seems to be that I messed up the test somehow ... but I don't see where. > So, again, I'm wondering if anyone else can replicate or refute this. I do find your results extremely surprising not only for 4, but for all tests with connection numbers lower than 32. With a scale factor of 100 that's suspiciously a lot of difference. > I can't be the only geek around here who sprang for an M1. Not planning to buy one here, anything I have read on that tells that it is worth a performance study. -- Michael
Attachment
On Fri, Nov 27, 2020 at 11:55 AM Michael Paquier <michael@paquier.xyz> wrote: > Not planning to buy one here, anything I have read on that tells that > it is worth a performance study. Another interesting area for experiments is AWS graviton2 instances. Specification says it supports arm v8.2, so it should have swpal/casa instructions as well. ------ Regards, Alexander Korotkov
On 2020-11-26 23:55, Tom Lane wrote: > ... and, after retrieving my jaw from the floor, I present the > attached. Apple's chips evidently like this style of spinlock a LOT > better. The difference is so remarkable that I wonder if I made a > mistake somewhere. Can anyone else replicate these results? I tried this on a M1 MacBook Air. I cannot reproduce these results. The unpatched numbers are about in the neighborhood of what you showed, but the patched numbers are only about a few percent better, not the 1.5x or 2x change that you showed.
Peter Eisentraut <peter.eisentraut@enterprisedb.com> writes:
> I tried this on a M1 MacBook Air. I cannot reproduce these results.
> The unpatched numbers are about in the neighborhood of what you showed,
> but the patched numbers are only about a few percent better, not the
> 1.5x or 2x change that you showed.
After redoing the test, I can't find any outside-the-noise difference
at all between HEAD and the patch. So clearly, I screwed up yesterday.
The most likely theory is that I managed to measure an assert-enabled
build of HEAD.
It might be that this hardware is capable of showing a difference with a
better-tuned pgbench test, but with an untuned pgbench run, we just aren't
sufficiently sensitive to the spinlock properties. (Which I guess is good
news, really.)
One thing that did hold up is that the thermal performance of this box
is pretty ridiculous. After being beat on for a solid hour, the fan
still hasn't turned on to any noticeable level, and the enclosure is
only a little warm to the touch. Try that with Intel hardware ;-)
regards, tom lane
I wrote:
> It might be that this hardware is capable of showing a difference with a
> better-tuned pgbench test, but with an untuned pgbench run, we just aren't
> sufficiently sensitive to the spinlock properties. (Which I guess is good
> news, really.)
It occurred to me that if we don't insist on a semi-realistic test case,
it's not that hard to just pound on a spinlock and see what happens.
I made up a simple C function (attached) to repeatedly call
XLogGetLastRemovedSegno, which is basically just a spinlock
acquire/release. Using this as a "transaction":
$ cat bench.sql
select drive_spinlocks(50000);
I get this with HEAD:
$ pgbench -f bench.sql -n -T 60 -c 1 bench
transaction type: bench.sql
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
duration: 60 s
number of transactions actually processed: 127597
latency average = 0.470 ms
tps = 2126.479699 (including connections establishing)
tps = 2126.595015 (excluding connections establishing)
$ pgbench -f bench.sql -n -T 60 -c 2 bench
transaction type: bench.sql
scaling factor: 1
query mode: simple
number of clients: 2
number of threads: 1
duration: 60 s
number of transactions actually processed: 108979
latency average = 1.101 ms
tps = 1816.051930 (including connections establishing)
tps = 1816.150556 (excluding connections establishing)
$ pgbench -f bench.sql -n -T 60 -c 4 bench
transaction type: bench.sql
scaling factor: 1
query mode: simple
number of clients: 4
number of threads: 1
duration: 60 s
number of transactions actually processed: 42862
latency average = 5.601 ms
tps = 714.202152 (including connections establishing)
tps = 714.237301 (excluding connections establishing)
(With only 4 high-performance cores, it's probably not
interesting to go further; involving the slower cores
will just confuse matters.) And this with the patch:
$ pgbench -f bench.sql -n -T 60 -c 1 bench
transaction type: bench.sql
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
duration: 60 s
number of transactions actually processed: 130455
latency average = 0.460 ms
tps = 2174.098284 (including connections establishing)
tps = 2174.217097 (excluding connections establishing)
$ pgbench -f bench.sql -n -T 60 -c 2 bench
transaction type: bench.sql
scaling factor: 1
query mode: simple
number of clients: 2
number of threads: 1
duration: 60 s
number of transactions actually processed: 51533
latency average = 2.329 ms
tps = 858.765176 (including connections establishing)
tps = 858.811132 (excluding connections establishing)
$ pgbench -f bench.sql -n -T 60 -c 4 bench
transaction type: bench.sql
scaling factor: 1
query mode: simple
number of clients: 4
number of threads: 1
duration: 60 s
number of transactions actually processed: 31154
latency average = 7.705 ms
tps = 519.116788 (including connections establishing)
tps = 519.144375 (excluding connections establishing)
So at least on Apple's hardware, it seems like the CAS
implementation might be a shade faster when uncontended,
but it's very clearly worse when there is contention for
the spinlock. That's interesting, because the argument
that CAS should involve strictly less work seems valid ...
but that's what I'm getting.
It might be useful to try this on other ARM platforms,
but I lack the energy right now (plus the only other
thing I've got is a Raspberry Pi, which might not be
something we particularly care about performance-wise).
regards, tom lane
/*
create function drive_spinlocks(count int) returns void
strict volatile language c as '.../spinlocktest.so';
*/
#include "postgres.h"
#include "access/xlog.h"
#include "fmgr.h"
#include "miscadmin.h"
PG_MODULE_MAGIC;
/*
* drive_spinlocks(count int) returns void
*/
PG_FUNCTION_INFO_V1(drive_spinlocks);
Datum
drive_spinlocks(PG_FUNCTION_ARGS)
{
int32 count = PG_GETARG_INT32(0);
while (count-- > 0)
{
XLogGetLastRemovedSegno();
CHECK_FOR_INTERRUPTS();
}
PG_RETURN_VOID();
}
On Sat, Nov 28, 2020 at 5:36 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > So at least on Apple's hardware, it seems like the CAS > implementation might be a shade faster when uncontended, > but it's very clearly worse when there is contention for > the spinlock. That's interesting, because the argument > that CAS should involve strictly less work seems valid ... > but that's what I'm getting. > > It might be useful to try this on other ARM platforms, > but I lack the energy right now (plus the only other > thing I've got is a Raspberry Pi, which might not be > something we particularly care about performance-wise). I guess that might depend on the implementation of CAS and TAS. I bet usage of CAS in spinlock gives advantage when ldxr/stxr are used, but not when swpal/casa are used. I found out that I can force clang to use swpal/casa by setting "-march=armv8-a+lse". I'm going to make some experiments on a multicore AWS graviton2 instance with different atomic implementation. ------ Regards, Alexander Korotkov
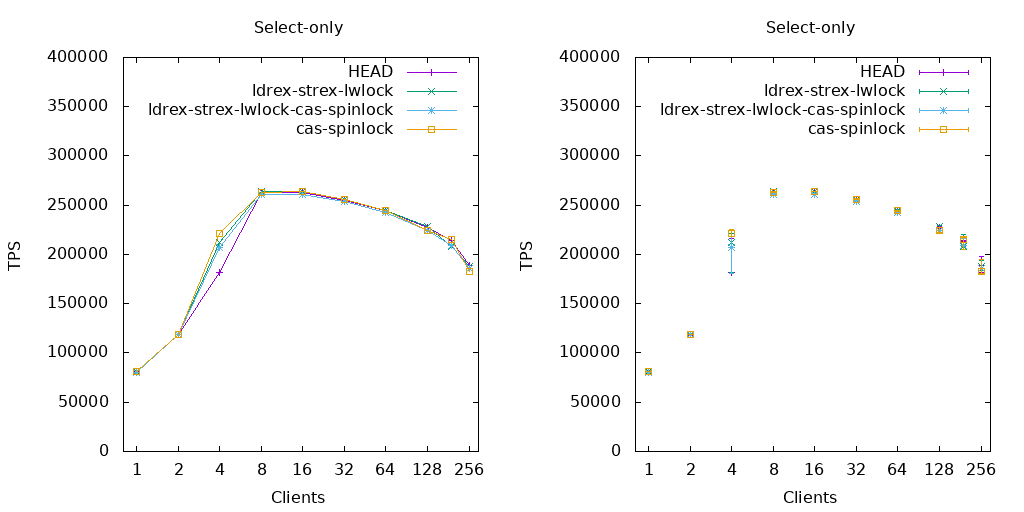
On Sat, Nov 28, 2020 at 1:31 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > I guess that might depend on the implementation of CAS and TAS. I bet > usage of CAS in spinlock gives advantage when ldxr/stxr are used, but > not when swpal/casa are used. I found out that I can force clang to > use swpal/casa by setting "-march=armv8-a+lse". I'm going to make > some experiments on a multicore AWS graviton2 instance with different > atomic implementation. I've made some benchmarks on c6gd.16xlarge ec2 instance with graviton2 processor of 64 virtual CPUs (graphs and raw results are attached). I've analyzed two patches: spinlock using cas by Krunal Bauskar, and my implementation of lwlock using lwrex/strex. My arm lwlock patch has the same idea as my previous patch for power: we can put lwlock attempt logic between lwrex and strex. In spite of my previous power patch, the arm patch doesn't contain assembly: instead I've used C-wrappers over lwrex/strex. The first series of experiments I've made using standard compiling options. So, LSE instructions from ARM v8.1 weren't used. Atomics were implemented using lwrex/strex pair. In the read-only benchmark, both spinlock (cas-spinlock graph) and lwlock (ldrew-strex-lwlock graph) patches give observable performance gain of similar value. However, performance of combination of these patches (ldrew-strex-lwlock-cas-spinlock graph) is close to performance of unpatched version. That could be counterintuitive, but I've rechecked that multiple times. In the read-write benchmark, both spinlock and lwlock patches give more significant performance gain, and lwlock patch gives more effect than spinlock patch. Noticeable, that combination of patches now gives some cumulative effect instead of counterintuitive slowdown. Then I've tried to compile postgres with LSE instruction using "-march=armv8-a+lse" flag with clang (graphs with -lse suffix). The effect of LSE is HUGE!!! Unpatched version with LSE is times faster than any version without LSE on high concurrency. In the both read-only and read-write benchmarks spinlock patch doesn't show any significant difference. The lwlock patch shows a great slowdown with LSE. Noticeable, in read-write benchmark, lwlock patch shows worse results than unpatched version without LSE. Probably, combining different atomics implementations isn't a good idea. It seems that ARM Kunpeng 920 should support ARM v8.1. I wonder if the published benchmarks results were made with LSE. I suspect that it was not. It would be nice to repeat the same benchmarks with LSE. I'd like to ask Krunal Bauskar and Amit Khandekar to repeat these benchmarks with LSE. My preliminary conclusions are so: 1) Since the effect of LSE is so huge, we should advise users of multicore ARM servers to compile PostgreSQL with LSE support. We probably should provide separate packaging for ARM v8.1 and higher (packages for ARM v8 are still needed for raspberry etc). 2) It seems that atomics in ARM v8.1 becomes very similar to x86 atomics, and it doesn't need special optimizations. And I think ARM v8 processors don't have so many cores and aren't so heavily used in high-concurrent environments. So, special optimizations for ARM v8 probably aren't worth it. Links 1. https://www.postgresql.org/message-id/CAB10pyamDkTFWU_BVGeEVmkc8%3DEhgCjr6QBk02SCdJtKpHkdFw%40mail.gmail.com 2. https://www.postgresql.org/message-id/CAPpHfdsKrh7c7P8-5eG-qW3VQobybbwqH%3DgL5Ck%2BdOES-gBbFg%40mail.gmail.com ------ Regards, Alexander Korotkov
Attachment
{kind=link}
{kind=link}
On Thu, Nov 26, 2020 at 7:35 AM Krunal Bauskar <krunalbauskar@gmail.com> wrote: > * x86 uses optimized xchg operation. > ARM too started supporting it (using Large System Extension) with > ARM-v8.1 but since it not supported with ARM-v8, GCC default tends > to roll more generic load-store assembly code. > > * gcc-9.4+ onwards there is support for outline-atomics that could emit > both the variants of the code (load-store and cas/swp) and based on > underlying supported architecture proper variant it used but still a lot > of distros don't support GCC-9.4 as the default compiler. I've checked that gcc 9.3 with "-march=armv8-a+lse" option uses LSE atomics... ------ Regards, Alexander Korotkov
On Sun, 29 Nov 2020 at 22:23, Alexander Korotkov <aekorotkov@gmail.com> wrote:
On Sat, Nov 28, 2020 at 1:31 PM Alexander Korotkov <aekorotkov@gmail.com> wrote:
> I guess that might depend on the implementation of CAS and TAS. I bet
> usage of CAS in spinlock gives advantage when ldxr/stxr are used, but
> not when swpal/casa are used. I found out that I can force clang to
> use swpal/casa by setting "-march=armv8-a+lse". I'm going to make
> some experiments on a multicore AWS graviton2 instance with different
> atomic implementation.
I've made some benchmarks on c6gd.16xlarge ec2 instance with graviton2
processor of 64 virtual CPUs (graphs and raw results are attached).
I've analyzed two patches: spinlock using cas by Krunal Bauskar, and
my implementation of lwlock using lwrex/strex. My arm lwlock patch
has the same idea as my previous patch for power: we can put lwlock
attempt logic between lwrex and strex. In spite of my previous power
patch, the arm patch doesn't contain assembly: instead I've used
C-wrappers over lwrex/strex.
The first series of experiments I've made using standard compiling
options. So, LSE instructions from ARM v8.1 weren't used. Atomics
were implemented using lwrex/strex pair.
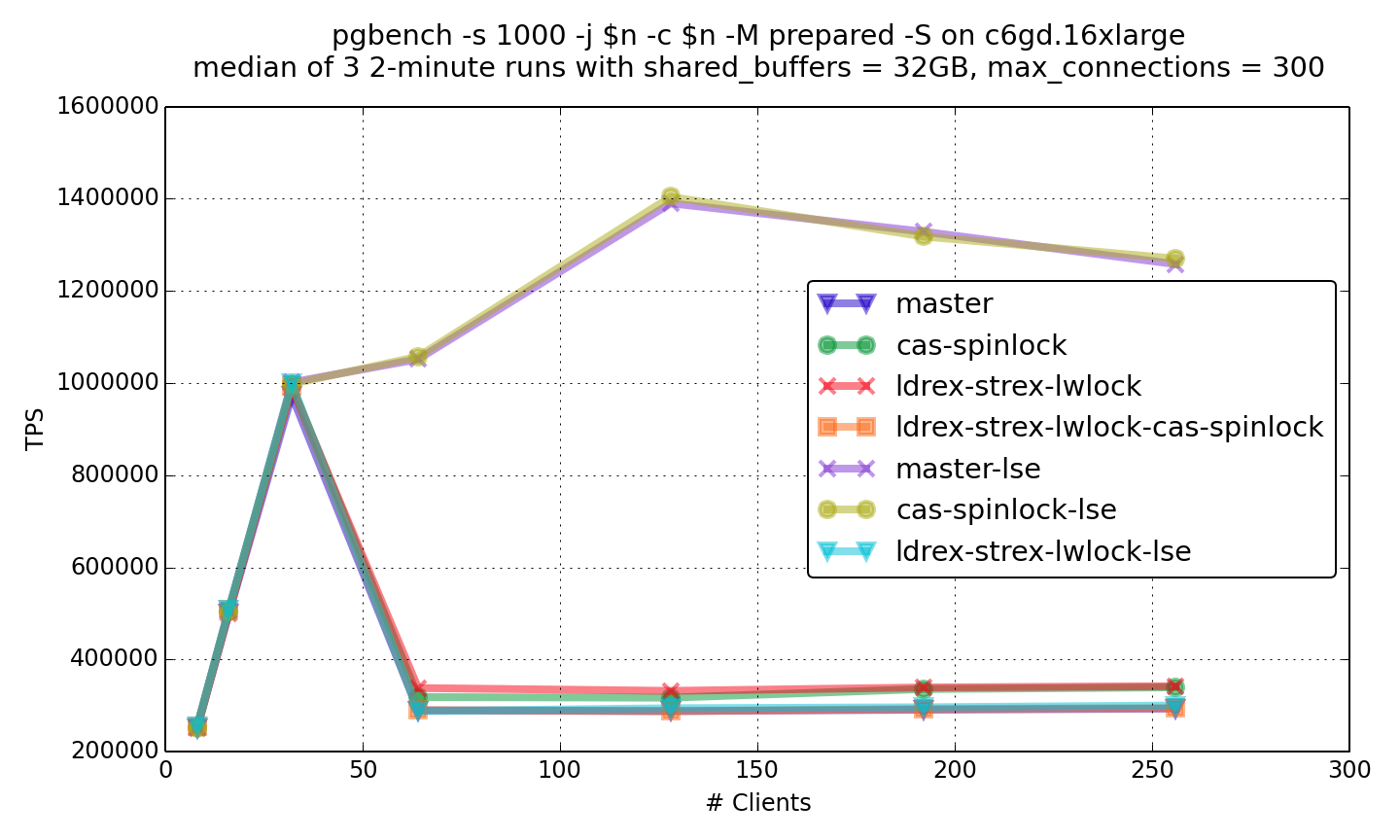
In the read-only benchmark, both spinlock (cas-spinlock graph) and
lwlock (ldrew-strex-lwlock graph) patches give observable performance
gain of similar value. However, performance of combination of these
patches (ldrew-strex-lwlock-cas-spinlock graph) is close to
performance of unpatched version. That could be counterintuitive, but
I've rechecked that multiple times.
In the read-write benchmark, both spinlock and lwlock patches give
more significant performance gain, and lwlock patch gives more effect
than spinlock patch. Noticeable, that combination of patches now
gives some cumulative effect instead of counterintuitive slowdown.
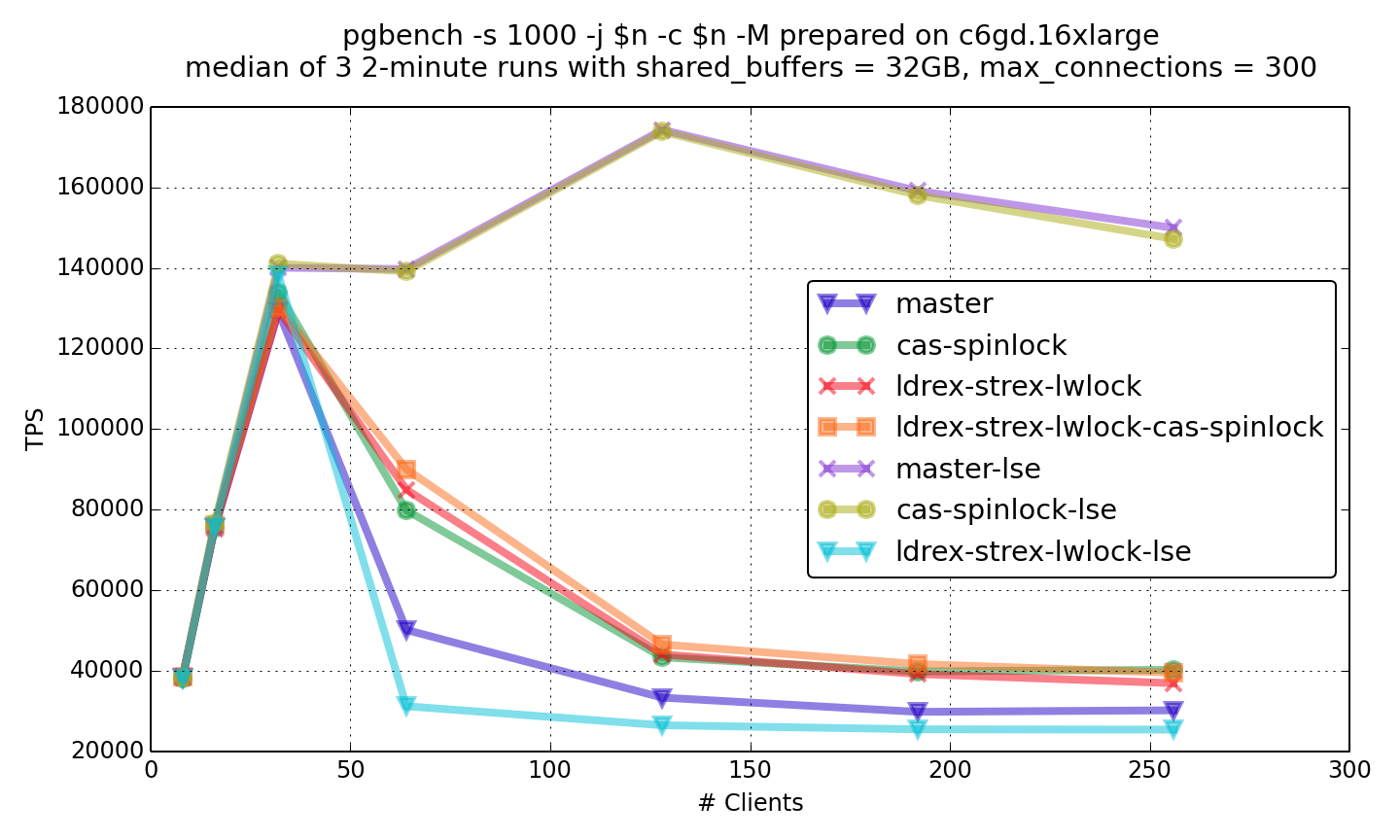
Then I've tried to compile postgres with LSE instruction using
"-march=armv8-a+lse" flag with clang (graphs with -lse suffix). The
effect of LSE is HUGE!!! Unpatched version with LSE is times faster
than any version without LSE on high concurrency. In the both
read-only and read-write benchmarks spinlock patch doesn't show any
significant difference. The lwlock patch shows a great slowdown with
LSE. Noticeable, in read-write benchmark, lwlock patch shows worse
results than unpatched version without LSE. Probably, combining
different atomics implementations isn't a good idea.
It seems that ARM Kunpeng 920 should support ARM v8.1. I wonder if
the published benchmarks results were made with LSE. I suspect that
it was not. It would be nice to repeat the same benchmarks with LSE.
I'd like to ask Krunal Bauskar and Amit Khandekar to repeat these
benchmarks with LSE.
My preliminary conclusions are so:
1) Since the effect of LSE is so huge, we should advise users of
multicore ARM servers to compile PostgreSQL with LSE support. We
probably should provide separate packaging for ARM v8.1 and higher
(packages for ARM v8 are still needed for raspberry etc).
2) It seems that atomics in ARM v8.1 becomes very similar to x86
atomics, and it doesn't need special optimizations. And I think ARM
v8 processors don't have so many cores and aren't so heavily used in
high-concurrent environments. So, special optimizations for ARM v8
probably aren't worth it.
Thanks for the detailed results.
1. Results we shared are w/o lse enabled so using traditional store/load approach.
2. As you pointed out LSE is enabled starting only with arm-v8.1 but not all aarch64 tag machines are arm-v8.1 compatible.
This means we would need a separate package or a more optimal way would be to compile pgsql with gcc-9.4 (or gcc-10.x (default)) with
-moutline-atomics that would emit both traditional and lse code and flow would dynamically select depending on the target machine
(I have blogged about it in MySQL context https://mysqlonarm.github.io/ARM-LSE-and-MySQL/)
3. Problem with GCC approach is still a lot of distro don't support gcc 9.4 as default.
To use this approach:
* PGSQL will have to roll out its packages using gcc-9.4+ only so that they are compatible with all aarch64 machines
* but this continues to affect all other users who tend to build pgsql using standard distro based compiler. (unless they upgrade compiler).
--------------------
So given all the permutations and combinations, I think we could approach the problem as follows:
* Enable use of CAS as it is known to have optimal performance (vs TAS)
* Even with LSE enabled, CAS to continue to perform (on par or marginally better than TAS)
* Add a patch to compile pgsql with outline-atomics if set GCC supports it so the dynamic 2-way compatible code is emitted.
--------------------
Alexander,
We will surely benchmark using LSE on Kunpeng 920 and share the result.
I am a bit surprised to see things scale by 4-5x times just by switching to LSE.
(my working experience with lse (in mysql context and micro-benchmarking) didn't show that great improvement by switching to lse).
Maybe some more hotspots (beyond s_lock) are getting addressed with the use of lse.
Links
1. https://www.postgresql.org/message-id/CAB10pyamDkTFWU_BVGeEVmkc8%3DEhgCjr6QBk02SCdJtKpHkdFw%40mail.gmail.com
2. https://www.postgresql.org/message-id/CAPpHfdsKrh7c7P8-5eG-qW3VQobybbwqH%3DgL5Ck%2BdOES-gBbFg%40mail.gmail.com
------
Regards,
Alexander Korotkov
Regards,
Krunal Bauskar
Krunal Bauskar
Krunal Bauskar <krunalbauskar@gmail.com> writes:
> So given all the permutations and combinations, I think we could approach
> the problem as follows:
> * Enable use of CAS as it is known to have optimal performance (vs TAS)
The results I posted at [1] seem to contradict this for Apple's new
machines.
In general, I'm pretty skeptical of *all* the results posted so far on
this thread, because everybody seems to be testing exactly one machine.
If there's one thing that it's safe to assume about ARM, it's that
there are a lot of different implementations; and this area seems very
very likely to differ across implementations.
I don't have a big problem with catering for a few different spinlock
implementations on ARM ... but it's sure unclear how we could decide
which one to use.
regards, tom lane
[1] https://www.postgresql.org/message-id/741389.1606530957@sss.pgh.pa.us
On Mon, 30 Nov 2020 at 10:14, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Krunal Bauskar <krunalbauskar@gmail.com> writes:
> So given all the permutations and combinations, I think we could approach
> the problem as follows:
> * Enable use of CAS as it is known to have optimal performance (vs TAS)
The results I posted at [1] seem to contradict this for Apple's new
machines.
In general, I'm pretty skeptical of *all* the results posted so far on
this thread, because everybody seems to be testing exactly one machine.
If there's one thing that it's safe to assume about ARM, it's that
there are a lot of different implementations; and this area seems very
very likely to differ across implementations.
For the results you saw on Mac-Mini was LSE enabled by default.
Maybe clang does it on mac by default to harvest performance.
If that is the case then your results are still inline with what Alexander posted.
On other hand, Peter saw some % improvement on M1 MacBook.
------
* Can you please check/confirm the LSE enable status on MAC (default).
* Also, if possible run some quick micro-benchmark to help understand how TAS and CAS perform
on MAC. It would be a big surprise to learn that M1 can execute TAS better than CAS (without lse).
* I would also suggest if possible try with higher scalability (more than 4 to check if with increase scalability CAS out-perform).
Results I have seen to date (in different contexts too), CAS has outperformed on Kunpeng, Graviton2, (Other ARM arch), ... (matches with theory too unless LSE is enabled).
If M1 goes the other way around that would be a big surprise for the arm community too.
I don't have a big problem with catering for a few different spinlock
implementations on ARM ... but it's sure unclear how we could decide
which one to use.
regards, tom lane
[1] https://www.postgresql.org/message-id/741389.1606530957@sss.pgh.pa.us
Regards,
Krunal Bauskar
Krunal Bauskar
Krunal Bauskar <krunalbauskar@gmail.com> writes:
> On Mon, 30 Nov 2020 at 10:14, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> The results I posted at [1] seem to contradict this for Apple's new
>> machines.
> For the results you saw on Mac-Mini was LSE enabled by default.
Hmm, I don't know how to get Apple's clang to admit what its default
settings are ... anybody?
However, it does accept "-march=armv8-a+lse", and that seems to
not be the default, because I get different results from my spinlock-
pounding test than I did yesterday. Abbreviating into a table:
--- CFLAGS=-O2 --- --- CFLAGS="-O2 -march=armv8-a+lse" ---
TPS HEAD CAS patch HEAD CAS patch
clients=1 2127 2174 2612 2722
clients=2 1816 859 892 950
clients=4 714 519 610 468
clients=8 - - 108 185
Unfortunately, that still doesn't lead me to think that either LSE
or CAS are net wins on this hardware. It's quite clear that LSE
makes the uncontended case a good bit faster, but the contended case
is a lot worse, so is that really a tradeoff we want?
> * I would also suggest if possible try with higher scalability (more than 4
> to check if with increase scalability CAS out-perform).
As I said yesterday, running more than 4 processes is just going
to bring the low-performance cores into the equation, which is likely
to swamp any interesting comparison. I did run the test with "-c 8"
today, as shown in the right-hand columns, and the results seem
to bear that out.
regards, tom lane
On Mon, 30 Nov 2020 at 11:38, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Krunal Bauskar <krunalbauskar@gmail.com> writes:
> On Mon, 30 Nov 2020 at 10:14, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> The results I posted at [1] seem to contradict this for Apple's new
>> machines.
> For the results you saw on Mac-Mini was LSE enabled by default.
Hmm, I don't know how to get Apple's clang to admit what its default
settings are ... anybody?
However, it does accept "-march=armv8-a+lse", and that seems to
not be the default, because I get different results from my spinlock-
pounding test than I did yesterday. Abbreviating into a table:
--- CFLAGS=-O2 --- --- CFLAGS="-O2 -march=armv8-a+lse" ---
TPS HEAD CAS patch HEAD CAS patch
clients=1 2127 2174 2612 2722
clients=2 1816 859 892 950
clients=4 714 519 610 468
clients=8 - - 108 185
Thanks for trying this Tom.
---------
Some of us may be surprised by the fact that enabling lse is causing regression (1816 -> 892 or 714 -> 610) with HEAD itself.
While lse is meant to improve the performance. This, unfortunately, is not always the case at-least based on my previous experience with LSE.too.
I am still wondering why CAS is slower than TAS on M1. What is special on M1 that other ARM archs has not picked up.
Tom, Sorry to bother you again but this is arising a lot of curiosity about M1.
Whenever you get time can do some micro-benchmarking on M1 (to understand TAS vs CAS).
Also, if you can share assembly code is emitted for the TAS vs CAS.
Unfortunately, that still doesn't lead me to think that either LSE
or CAS are net wins on this hardware. It's quite clear that LSE
makes the uncontended case a good bit faster, but the contended case
is a lot worse, so is that really a tradeoff we want?
> * I would also suggest if possible try with higher scalability (more than 4
> to check if with increase scalability CAS out-perform).
As I said yesterday, running more than 4 processes is just going
to bring the low-performance cores into the equation, which is likely
to swamp any interesting comparison. I did run the test with "-c 8"
today, as shown in the right-hand columns, and the results seem
to bear that out.
regards, tom lane
Regards,
Krunal Bauskar
Krunal Bauskar
On Mon, Nov 30, 2020 at 9:20 AM Krunal Bauskar <krunalbauskar@gmail.com> wrote: > Some of us may be surprised by the fact that enabling lse is causing regression (1816 -> 892 or 714 -> 610) with HEAD itself. > While lse is meant to improve the performance. This, unfortunately, is not always the case at-least based on my previousexperience with LSE.too. I doubt this is correct. As Tom shown upthread, Apple clang have LSE enabled by default [1]. It might happen that --CFLAGS="-O2 -march=armv8-a+lse" disables some other optimizations, which are enabled by default in Apple clang... Links 1. https://www.postgresql.org/message-id/663376.1606432828%40sss.pgh.pa.us ------ Regards, Alexander Korotkov
On Mon, Nov 30, 2020 at 9:08 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Krunal Bauskar <krunalbauskar@gmail.com> writes: > > On Mon, 30 Nov 2020 at 10:14, Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> The results I posted at [1] seem to contradict this for Apple's new > >> machines. > > > For the results you saw on Mac-Mini was LSE enabled by default. > > Hmm, I don't know how to get Apple's clang to admit what its default > settings are ... anybody? > > However, it does accept "-march=armv8-a+lse", and that seems to > not be the default, because I get different results from my spinlock- > pounding test than I did yesterday. Abbreviating into a table: > > --- CFLAGS=-O2 --- --- CFLAGS="-O2 -march=armv8-a+lse" --- > > TPS HEAD CAS patch HEAD CAS patch > > clients=1 2127 2174 2612 2722 > clients=2 1816 859 892 950 > clients=4 714 519 610 468 > clients=8 - - 108 185 > > Unfortunately, that still doesn't lead me to think that either LSE > or CAS are net wins on this hardware. It's quite clear that LSE > makes the uncontended case a good bit faster, but the contended case > is a lot worse, so is that really a tradeoff we want? I tend to think that LSE is enabled by default in Apple's clang based on your previous message[1]. In order to dispel the doubts could you please provide assembly of SpinLockAcquire for following clang options. "-O2" "-O2 -march=armv8-a+lse" "-O2 -march=armv8-a" Thank you! Links 1. https://www.postgresql.org/message-id/663376.1606432828%40sss.pgh.pa.us ------ Regards, Alexander Korotkov
Alexander Korotkov <aekorotkov@gmail.com> writes:
> I tend to think that LSE is enabled by default in Apple's clang based
> on your previous message[1]. In order to dispel the doubts could you
> please provide assembly of SpinLockAcquire for following clang
> options.
> "-O2"
> "-O2 -march=armv8-a+lse"
> "-O2 -march=armv8-a"
Huh. Those options make exactly zero difference to the code generated
for SpinLockAcquire/SpinLockRelease; it's the same as I showed upthread,
for either the HEAD definition of TAS() or the CAS patch's version.
So now I'm at a loss as to the reason for the performance difference
I got. -march=armv8-a+lse does make a difference to code generation
someplace, because the overall size of the postgres executable changes
by 16kB or so. One might argue that the performance difference is due
to better code elsewhere than the spinlocks ... but the test I'm running
is basically just
while (count-- > 0)
{
XLogGetLastRemovedSegno();
CHECK_FOR_INTERRUPTS();
}
so it's hard to see where a non-spinlock-related code change would come
in. That loop itself definitely generates the same code either way.
I did find this interesting output from "clang -v":
-target-cpu vortex -target-feature +v8.3a -target-feature +fp-armv8 -target-feature +neon -target-feature +crc
-target-feature+crypto -target-feature +fullfp16 -target-feature +ras -target-feature +lse -target-feature +rdm
-target-feature+rcpc -target-feature +zcm -target-feature +zcz -target-feature +sha2 -target-feature +aes
whereas adding -march=armv8-a+lse changes that to just
-target-cpu vortex -target-feature +neon -target-feature +lse -target-feature +zcm -target-feature +zcz
On the whole, that would make one think that -march=armv8-a+lse
should produce worse code than the default settings.
regards, tom lane
On Mon, Nov 30, 2020 at 9:21 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> Alexander Korotkov <aekorotkov@gmail.com> writes:
> > I tend to think that LSE is enabled by default in Apple's clang based
> > on your previous message[1]. In order to dispel the doubts could you
> > please provide assembly of SpinLockAcquire for following clang
> > options.
> > "-O2"
> > "-O2 -march=armv8-a+lse"
> > "-O2 -march=armv8-a"
>
> Huh. Those options make exactly zero difference to the code generated
> for SpinLockAcquire/SpinLockRelease; it's the same as I showed upthread,
> for either the HEAD definition of TAS() or the CAS patch's version.
>
> So now I'm at a loss as to the reason for the performance difference
> I got. -march=armv8-a+lse does make a difference to code generation
> someplace, because the overall size of the postgres executable changes
> by 16kB or so. One might argue that the performance difference is due
> to better code elsewhere than the spinlocks ... but the test I'm running
> is basically just
>
> while (count-- > 0)
> {
> XLogGetLastRemovedSegno();
>
> CHECK_FOR_INTERRUPTS();
> }
>
> so it's hard to see where a non-spinlock-related code change would come
> in. That loop itself definitely generates the same code either way.
>
> I did find this interesting output from "clang -v":
>
> -target-cpu vortex -target-feature +v8.3a -target-feature +fp-armv8 -target-feature +neon -target-feature +crc
-target-feature+crypto -target-feature +fullfp16 -target-feature +ras -target-feature +lse -target-feature +rdm
-target-feature+rcpc -target-feature +zcm -target-feature +zcz -target-feature +sha2 -target-feature +aes
>
> whereas adding -march=armv8-a+lse changes that to just
>
> -target-cpu vortex -target-feature +neon -target-feature +lse -target-feature +zcm -target-feature +zcz
>
> On the whole, that would make one think that -march=armv8-a+lse
> should produce worse code than the default settings.
Great, thanks.
So, I think the following hypothesis isn't disproved yet.
1) On ARM with LSE support, PostgreSQL built with LSE is faster than
PostgreSQL built without LSE. Even if the latter is patched with
anything considered in this thread.
2) None of the patches considered in this thread give a clear
advantage for PostgreSQL built with LSE.
To further confirm this let's wait for Kunpeng 920 tests by Krunal
Bauskar and Amit Khandekar. Also it would be nice if someone will run
benchmarks similar to [1] on Apple M1.
Links
1. https://www.postgresql.org/message-id/CAPpHfdsGqVd6EJ4mr_RZVE5xSiCNBy4MuSvdTrKmTpM0eyWGpg%40mail.gmail.com
------
Regards,
Alexander Korotkov
On Mon, Nov 30, 2020 at 7:00 AM Krunal Bauskar <krunalbauskar@gmail.com> wrote: > 3. Problem with GCC approach is still a lot of distro don't support gcc 9.4 as default. > To use this approach: > * PGSQL will have to roll out its packages using gcc-9.4+ only so that they are compatible with all aarch64 machines > * but this continues to affect all other users who tend to build pgsql using standard distro based compiler. (unlessthey upgrade compiler). I think if a user, who runs PostgreSQL on a multicore machine with high-concurrent load, can take care about installing the appropriate package/using the appropriate compiler (especially if we publish explicit instructions for that). In the same way such advanced users tune Linux kernel etc. BTW, how do you get that required gcc version is 9.4? I've managed to use LSE with gcc 9.3. ------ Regards, Alexander Korotkov
On Tue, 1 Dec 2020 at 02:31, Alexander Korotkov <aekorotkov@gmail.com> wrote:
On Mon, Nov 30, 2020 at 7:00 AM Krunal Bauskar <krunalbauskar@gmail.com> wrote:
> 3. Problem with GCC approach is still a lot of distro don't support gcc 9.4 as default.
> To use this approach:
> * PGSQL will have to roll out its packages using gcc-9.4+ only so that they are compatible with all aarch64 machines
> * but this continues to affect all other users who tend to build pgsql using standard distro based compiler. (unless they upgrade compiler).
I think if a user, who runs PostgreSQL on a multicore machine with
high-concurrent load, can take care about installing the appropriate
package/using the appropriate compiler (especially if we publish
explicit instructions for that). In the same way such advanced users
tune Linux kernel etc.
BTW, how do you get that required gcc version is 9.4? I've managed to
use LSE with gcc 9.3.
Did they backported it to 9.3?
I am just looking at the gcc guide.
GCC 9.4
Target Specific Changes
AArch64
- The option
-moutline-atomicshas been added to aid deployment of the Large System Extensions (LSE)
------
Regards,
Alexander Korotkov
Regards,
Krunal Bauskar
Krunal Bauskar
Alexander Korotkov <aekorotkov@gmail.com> writes:
> 2) None of the patches considered in this thread give a clear
> advantage for PostgreSQL built with LSE.
Yeah, I think so.
> To further confirm this let's wait for Kunpeng 920 tests by Krunal
> Bauskar and Amit Khandekar. Also it would be nice if someone will run
> benchmarks similar to [1] on Apple M1.
I did what I could in this department. It's late and I'm not going to
have time to run read/write benchmarks before bed, but here are some
results for the "pgbench -S" cases. I tried to match your testing
choices, but could not entirely:
* Configure options are --enable-debug, --disable-cassert, no other
special configure options or CFLAG choices.
* I have not been able to find a way to make Apple's compiler not
use the LSE spinlock instructions, so all of these correspond to
your LSE cases.
* I used shared_buffers = 1GB, because this machine only has 16GB
RAM so 32GB is clearly out of reach. Also I used pgbench scale
factor 100 not 1000. Since we're trying to measure contention
effects not I/O speed, I don't think a huge test case is appropriate.
* I still haven't gotten pgbench to work with -j settings above 128,
so these runs use -j equal to half -c. Shouldn't really affect
conclusions about scaling. (BTW, I see a similar limitation on
macOS Catalina x86_64, so whatever that is, it's not new.)
* Otherwise, the first plot shows median of three results from
"pgbench -S -M prepared -T 120 -c $n -j $j", as you had it.
The right-hand plot shows all three of the values in yerrorbars
format, just to give a sense of the noise level.
Clearly, there is something weird going on at -c 4. There's a cluster
of results around 180K TPS, and another cluster around 210-220K TPS,
and nothing in between. I suspect that the scheduler is doing
something bogus with sometimes putting pgbench onto the slow cores.
Anyway, I believe that the apparent gap between HEAD and the other
curves at -c 4 is probably an artifact: HEAD had two 180K-ish results
and one 220K-ish result, while the other curves had the reverse, so
the medians are different but there's probably not any non-chance
effect there.
Bottom line is that these patches don't appear to do much of
anything on M1, as you surmised.
regards, tom lane
Attachment
{kind=link}
On Tue, Dec 1, 2020 at 6:26 AM Krunal Bauskar <krunalbauskar@gmail.com> wrote: > On Tue, 1 Dec 2020 at 02:31, Alexander Korotkov <aekorotkov@gmail.com> wrote: >> BTW, how do you get that required gcc version is 9.4? I've managed to >> use LSE with gcc 9.3. > > Did they backported it to 9.3? > I am just looking at the gcc guide. > https://gcc.gnu.org/gcc-9/changes.html > > GCC 9.4 > > Target Specific Changes > > AArch64 > > The option -moutline-atomics has been added to aid deployment of the Large System Extensions (LSE) No, you've misread this release notes item. This item relates to a new option for LSE support. See the rest of the description. "When the option is specified code is emitted to detect the presence of LSE instructions at runtime and use them for standard atomic operations. For more information please refer to the documentation." LSE support itself was introduced in gcc 6. https://gcc.gnu.org/gcc-6/changes.html * The ARMv8.1-A architecture and the Large System Extensions are now supported. They can be used by specifying the -march=armv8.1-a option. Additionally, the +lse option extension can be used in a similar fashion to other option extensions. The Large System Extensions introduce new instructions that are used in the implementation of atomic operations. But, -moutline-atomics looks very interesting itself. I think we should add this option to our arm64 packages if we haven't already. ------ Regards, Alexander Korotkov
On Tue, Dec 1, 2020 at 9:01 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > I did what I could in this department. It's late and I'm not going to > have time to run read/write benchmarks before bed, but here are some > results for the "pgbench -S" cases. I tried to match your testing > choices, but could not entirely: > > * Configure options are --enable-debug, --disable-cassert, no other > special configure options or CFLAG choices. > > * I have not been able to find a way to make Apple's compiler not > use the LSE spinlock instructions, so all of these correspond to > your LSE cases. > > * I used shared_buffers = 1GB, because this machine only has 16GB > RAM so 32GB is clearly out of reach. Also I used pgbench scale > factor 100 not 1000. Since we're trying to measure contention > effects not I/O speed, I don't think a huge test case is appropriate. > > * I still haven't gotten pgbench to work with -j settings above 128, > so these runs use -j equal to half -c. Shouldn't really affect > conclusions about scaling. (BTW, I see a similar limitation on > macOS Catalina x86_64, so whatever that is, it's not new.) > > * Otherwise, the first plot shows median of three results from > "pgbench -S -M prepared -T 120 -c $n -j $j", as you had it. > The right-hand plot shows all three of the values in yerrorbars > format, just to give a sense of the noise level. > > Clearly, there is something weird going on at -c 4. There's a cluster > of results around 180K TPS, and another cluster around 210-220K TPS, > and nothing in between. I suspect that the scheduler is doing > something bogus with sometimes putting pgbench onto the slow cores. > Anyway, I believe that the apparent gap between HEAD and the other > curves at -c 4 is probably an artifact: HEAD had two 180K-ish results > and one 220K-ish result, while the other curves had the reverse, so > the medians are different but there's probably not any non-chance > effect there. > > Bottom line is that these patches don't appear to do much of > anything on M1, as you surmised. Great, thank you for your research! ------ Regards, Alexander Korotkov
On Tue, 1 Dec 2020 at 15:16, Alexander Korotkov <aekorotkov@gmail.com> wrote:
On Tue, Dec 1, 2020 at 6:26 AM Krunal Bauskar <krunalbauskar@gmail.com> wrote:
> On Tue, 1 Dec 2020 at 02:31, Alexander Korotkov <aekorotkov@gmail.com> wrote:
>> BTW, how do you get that required gcc version is 9.4? I've managed to
>> use LSE with gcc 9.3.
>
> Did they backported it to 9.3?
> I am just looking at the gcc guide.
> https://gcc.gnu.org/gcc-9/changes.html
>
> GCC 9.4
>
> Target Specific Changes
>
> AArch64
>
> The option -moutline-atomics has been added to aid deployment of the Large System Extensions (LSE)
No, you've misread this release notes item. This item relates to a
new option for LSE support. See the rest of the description.
Some confusion here.
What I meant was outline-atomics support was added in GCC-9.4 and was made default in gcc-10.
LSE support is present for quite some time.
In one of my up-thread reply I mentioned about the outline atomic that would help us enable lse if underline architecture support it.
<snippet from reply>
2. As you pointed out LSE is enabled starting only with arm-v8.1 but not all aarch64 tag machines are arm-v8.1 compatible.
This means we would need a separate package or a more optimal way would be to compile pgsql with gcc-9.4 (or gcc-10.x (default)) with
-moutline-atomics that would emit both traditional and lse code and flow would dynamically select depending on the target machine
(I have blogged about it in MySQL context https://mysqlonarm.github.io/ARM-LSE-and-MySQL/)
</snippet from reply>
Problem with this approach is it would need gcc-9.4+ (I also ready gcc-9.3.1 would do) or gcc10.x but most of the distro doesn't support it so user using old compiler especially
default one shipped with OS would not be able to take advantage of this.
"When the option is specified code is emitted to detect the presence
of LSE instructions at runtime and use them for standard atomic
operations. For more information please refer to the documentation."
LSE support itself was introduced in gcc 6.
https://gcc.gnu.org/gcc-6/changes.html
* The ARMv8.1-A architecture and the Large System Extensions are now
supported. They can be used by specifying the -march=armv8.1-a option.
Additionally, the +lse option extension can be used in a similar
fashion to other option extensions. The Large System Extensions
introduce new instructions that are used in the implementation of
atomic operations.
But, -moutline-atomics looks very interesting itself. I think we
should add this option to our arm64 packages if we haven't already.
------
Regards,
Alexander Korotkov
Regards,
Krunal Bauskar
Krunal Bauskar
On Tue, 1 Dec 2020 at 15:33, Krunal Bauskar <krunalbauskar@gmail.com> wrote: > What I meant was outline-atomics support was added in GCC-9.4 and was made default in gcc-10. > LSE support is present for quite some time. FWIW, here is an earlier discussion on the same (also added the proposal author here) : https://www.postgresql.org/message-id/flat/099F69EE-51D3-4214-934A-1F28C0A1A7A7%40amazon.com
On Tue, 1 Dec 2020 at 02:16, Alexander Korotkov <aekorotkov@gmail.com> wrote:
On Mon, Nov 30, 2020 at 9:21 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> Alexander Korotkov <aekorotkov@gmail.com> writes:
> > I tend to think that LSE is enabled by default in Apple's clang based
> > on your previous message[1]. In order to dispel the doubts could you
> > please provide assembly of SpinLockAcquire for following clang
> > options.
> > "-O2"
> > "-O2 -march=armv8-a+lse"
> > "-O2 -march=armv8-a"
>
> Huh. Those options make exactly zero difference to the code generated
> for SpinLockAcquire/SpinLockRelease; it's the same as I showed upthread,
> for either the HEAD definition of TAS() or the CAS patch's version.
>
> So now I'm at a loss as to the reason for the performance difference
> I got. -march=armv8-a+lse does make a difference to code generation
> someplace, because the overall size of the postgres executable changes
> by 16kB or so. One might argue that the performance difference is due
> to better code elsewhere than the spinlocks ... but the test I'm running
> is basically just
>
> while (count-- > 0)
> {
> XLogGetLastRemovedSegno();
>
> CHECK_FOR_INTERRUPTS();
> }
>
> so it's hard to see where a non-spinlock-related code change would come
> in. That loop itself definitely generates the same code either way.
>
> I did find this interesting output from "clang -v":
>
> -target-cpu vortex -target-feature +v8.3a -target-feature +fp-armv8 -target-feature +neon -target-feature +crc -target-feature +crypto -target-feature +fullfp16 -target-feature +ras -target-feature +lse -target-feature +rdm -target-feature +rcpc -target-feature +zcm -target-feature +zcz -target-feature +sha2 -target-feature +aes
>
> whereas adding -march=armv8-a+lse changes that to just
>
> -target-cpu vortex -target-feature +neon -target-feature +lse -target-feature +zcm -target-feature +zcz
>
> On the whole, that would make one think that -march=armv8-a+lse
> should produce worse code than the default settings.
Great, thanks.
So, I think the following hypothesis isn't disproved yet.
1) On ARM with LSE support, PostgreSQL built with LSE is faster than
PostgreSQL built without LSE. Even if the latter is patched with
anything considered in this thread.
2) None of the patches considered in this thread give a clear
advantage for PostgreSQL built with LSE.
To further confirm this let's wait for Kunpeng 920 tests by Krunal
Bauskar and Amit Khandekar. Also it would be nice if someone will run
benchmarks similar to [1] on Apple M1.
------------------------------------------------------------------------------------------------------------------------------------------
I have completed benchmarking with lse.
Graph attached.
* For me, lse failed to perform. With lse enabled performance with higher scalability was infact less than baseline (with TAS).
[This is true with and without patch (cas)]. So lse is unable to push things.
* Graph traces all 4 lines (baseline (tas), baseline-patched (cas), baseline-lse (tas+lse), baseline-patched-lse (cas+lse))
- for select, there is no clear winner but baseline-patched-lse (cas+lse) perform better than others (2-4%).
- for update/tpcb like baseline-patched (cas) continue to outperform all the 3 options (10-40%).
In fact, with lse enabled a regression (compared to baseline/head) is observed.
[I am not surprised since MySQL showed the same behavior with lse of-course with a lesser percentage].
I have repeated the test 2 times to confirm the behavior.
Also, to reduce noise I normally run 4 rounds discarding 1st round and taking the median of the last 3 rounds.
In all, I see consistent numbers.
-----------------------------------------------------------------------------------------------------------------------------------------------
From all the observations till now following points are clear:
* Patch doesn't seem to make a significant difference with lse enabled.
Ir-respective of the machine (Kunpeng, Graviton2, M1). [infact introduces regression with Kunpeng].
* Patch helps generate significant +ve difference in performace with lse disabled.
Observed and Confirmed with both Kunpeng, Graviton2.
(not possible to disable lse on m1).
* Does the patch makes things worse with lse enabled.
* Graviton2: No (based on Alexander graph)
* M1: No (based on Tom's graph. Wondering why was debug build used (--enable-debug?))
* Kunpeng: regression observed.
--------------
Should we enable lse?
Based on the comment from [1] I see pgsql aligns with decision made by
compiler/distribution vendors. If the compiler/distribution vendors
has not made something default then there could be reason for it.
-------------
Without lse as we have seen patch continue to score.
Effect of LSE needs to be wide studied. Scaling on some arch and regressing
on some needs to be understood may be at CPU vendor level.
------------------------------------------------------------------------------------------------------------------------------------------
* Patch doesn't seem to make a significant difference with lse enabled.
Ir-respective of the machine (Kunpeng, Graviton2, M1). [infact introduces regression with Kunpeng].
* Patch helps generate significant +ve difference in performace with lse disabled.
Observed and Confirmed with both Kunpeng, Graviton2.
(not possible to disable lse on m1).
* Does the patch makes things worse with lse enabled.
* Graviton2: No (based on Alexander graph)
* M1: No (based on Tom's graph. Wondering why was debug build used (--enable-debug?))
* Kunpeng: regression observed.
--------------
Should we enable lse?
Based on the comment from [1] I see pgsql aligns with decision made by
compiler/distribution vendors. If the compiler/distribution vendors
has not made something default then there could be reason for it.
-------------
Without lse as we have seen patch continue to score.
Effect of LSE needs to be wide studied. Scaling on some arch and regressing
on some needs to be understood may be at CPU vendor level.
------------------------------------------------------------------------------------------------------------------------------------------
Links:
[1] https://www.postgresql.org/message-id/flat/099F69EE-51D3-4214-934A-1F28C0A1A7A7%40amazon.com
[1] https://www.postgresql.org/message-id/flat/099F69EE-51D3-4214-934A-1F28C0A1A7A7%40amazon.com
Links
1. https://www.postgresql.org/message-id/CAPpHfdsGqVd6EJ4mr_RZVE5xSiCNBy4MuSvdTrKmTpM0eyWGpg%40mail.gmail.com
------
Regards,
Alexander Korotkov
Regards,
Krunal Bauskar
Krunal Bauskar
Attachment
{kind=link}
On Tue, Dec 1, 2020 at 3:44 PM Krunal Bauskar <krunalbauskar@gmail.com> wrote: > I have completed benchmarking with lse. > > Graph attached. Thank you for benchmarking. Now I agree with this comment by Tom Lane > In general, I'm pretty skeptical of *all* the results posted so far on > this thread, because everybody seems to be testing exactly one machine. > If there's one thing that it's safe to assume about ARM, it's that > there are a lot of different implementations; and this area seems very > very likely to differ across implementations. Different ARM implementations look too different. As you pointed out, LSE is enabled in gcc-10 by default. I doubt we can accept a patch, which gives benefits for specific platform and only when the compiler isn't very modern. Also, we didn't cover all ARM planforms. Given they are so different, we can't guarantee that patch doesn't cause regression of some ARM. Additionally, the effect of the CAS patch even for Kunpeng seems modest. It makes the drop off of TPS more smooth, but it doesn't change the trend. ------ Regards, Alexander Korotkov
On Tue, Dec 1, 2020 at 1:10 PM Amit Khandekar <amitdkhan.pg@gmail.com> wrote: > On Tue, 1 Dec 2020 at 15:33, Krunal Bauskar <krunalbauskar@gmail.com> wrote: > > What I meant was outline-atomics support was added in GCC-9.4 and was made default in gcc-10. > > LSE support is present for quite some time. > > FWIW, here is an earlier discussion on the same (also added the > proposal author here) : > > https://www.postgresql.org/message-id/flat/099F69EE-51D3-4214-934A-1F28C0A1A7A7%40amazon.com Thank you for pointing! I wonder why the effect of LSE on Graviton2 observed by Tsahi Zidenberg is so modest. It's probably because he runs the tests with a low number of clients. ------ Regards, Alexander Korotkov
On Tue, 1 Dec 2020 at 20:25, Alexander Korotkov <aekorotkov@gmail.com> wrote:
On Tue, Dec 1, 2020 at 3:44 PM Krunal Bauskar <krunalbauskar@gmail.com> wrote:
> I have completed benchmarking with lse.
>
> Graph attached.
Thank you for benchmarking.
Now I agree with this comment by Tom Lane
> In general, I'm pretty skeptical of *all* the results posted so far on
> this thread, because everybody seems to be testing exactly one machine.
> If there's one thing that it's safe to assume about ARM, it's that
> there are a lot of different implementations; and this area seems very
> very likely to differ across implementations.
Different ARM implementations look too different. As you pointed out,
LSE is enabled in gcc-10 by default. I doubt we can accept a patch,
which gives benefits for specific platform and only when the compiler
isn't very modern. Also, we didn't cover all ARM planforms. Given
they are so different, we can't guarantee that patch doesn't cause
regression of some ARM. Additionally, the effect of the CAS patch
even for Kunpeng seems modest. It makes the drop off of TPS more
smooth, but it doesn't change the trend.
There are 2 parts:
* Does CAS patch help scale PGSQL. Yes.
* Is LSE beneficial for all architectures. Probably No.
The patch addresses only the former one which is true for all cases.
(Enabling LSE should be an independent process).
gcc-10 made it default but when I read [1] it quotes that canonical decided to remove it as default
as part of Ubuntu-20.04 which means LSE has not proven the test of canonical (probably).
Also, most of the distro has not yet started shipping GCC-10 which is way far before it makes it to all distro.
So if we keep the LSE effect aside and just look at the patch from performance improvement it surely helps
achieve a good gain. I see an improvement in the range of 10-40%.
Amit during his independent testing also observed the gain in the same range and your testing with G-2 has re-attested the same point.
Pardon me if this is modest as per pgsql standards.
With 1024 scalability PGSQL on other arches (beyond ARM) struggle to scale so there is something more
inherent that needs to be addressed from a generic perspective.
Also, the said patch non-only helps pgbench kind of workload but other workloads too.
--------------
I would request you guys to re-think it from this perspective to help ensure that PGSQL can scale well on ARM.
s_lock becomes a top-most function and LSE is not a universal solution but CAS surely helps ease the main bottleneck.
And surely let me know if more data is needed.
Link:
------
Regards,
Alexander Korotkov
Regards,
Krunal Bauskar
Krunal Bauskar
On Tue, Dec 1, 2020 at 6:19 PM Krunal Bauskar <krunalbauskar@gmail.com> wrote: > I would request you guys to re-think it from this perspective to help ensure that PGSQL can scale well on ARM. > s_lock becomes a top-most function and LSE is not a universal solution but CAS surely helps ease the main bottleneck. CAS patch isn't proven to be a universal solution as well. We have tested the patch on just a few processors, and Tom has seen the regression [1]. The benchmark used by Tom was artificial, but the results may be relevant for some real-life workload. I'm expressing just my personal opinion, other committers can have different opinions. I don't particularly think this topic is necessarily a non-starter. But I do think that given ambiguity we've observed in the benchmark, much more research is needed to push this topic forward. Links. 1. https://www.postgresql.org/message-id/741389.1606530957%40sss.pgh.pa.us ------ Regards, Alexander Korotkov
> On 01/12/2020, 16:59, "Alexander Korotkov" <aekorotkov@gmail.com> wrote: > On Tue, Dec 1, 2020 at 1:10 PM Amit Khandekar <amitdkhan.pg@gmail.com> wrote: > > FWIW, here is an earlier discussion on the same (also added the > > proposal author here) : Thanks for looping me in! > > > > https://www.postgresql.org/message-id/flat/099F69EE-51D3-4214-934A-1F28C0A1A7A7%40amazon.com > > > Thank you for pointing! I wonder why the effect of LSE on Graviton2 > observed by Tsahi Zidenberg is so modest. It's probably because he > runs the tests with a low number of clients. There are multiple possible reasons why I saw a smaller effect of LSE, but I think an important one was that I used a 32-core instance rather than a 64-core one. The reason I did so, was that 32-cores gave me better absolute results than 64 cores, and I didn't want to feel like I could misguide anyone. The 64-core instance results is a good example for the benefit of LSE. LSE becomes most important in edges, and with adversarial workloads. If multiple CPUs try to acquire a lock simultaneously - LSE ensures one CPU will indeed get the lock (with just one transaction), while LDRX/STRX could have multiple CPUS looping and no-one acquiring a lock. This is why I believe just looking at "reasonable" benchmarks misses out on effects real customers will run into. Happy to see another arm-optimization thread so quickly :) Thank you! Tsahi.
Alexander Korotkov <aekorotkov@gmail.com> writes:
> On Tue, Dec 1, 2020 at 6:19 PM Krunal Bauskar <krunalbauskar@gmail.com> wrote:
>> I would request you guys to re-think it from this perspective to help ensure that PGSQL can scale well on ARM.
>> s_lock becomes a top-most function and LSE is not a universal solution but CAS surely helps ease the main
bottleneck.
> CAS patch isn't proven to be a universal solution as well. We have
> tested the patch on just a few processors, and Tom has seen the
> regression [1]. The benchmark used by Tom was artificial, but the
> results may be relevant for some real-life workload.
Yeah. I think that the main conclusion from what we've seen here is
that on smaller machines like M1, a standard pgbench benchmark just
isn't capable of driving PG into serious spinlock contention. (That
reflects very well on the work various people have done over the years
to get rid of spinlock contention, because ten or so years ago it was
a huge problem on this size of machine. But evidently, not any more.)
Per the results others have posted, nowadays you need dozens of cores
and hundreds of client threads to measure any such issue with pgbench.
So that is why I experimented with a special test that does nothing
except pound on one spinlock. Sure it's artificial, but if you want
to see the effects of different spinlock implementations then it's
just too hard to get any results with pgbench's regular scripts.
And that's why it disturbs me that the CAS-spinlock patch showed up
worse in that environment. The fact that it's not visible in the
regular pgbench test just means that the effect is too small to
measure in that test. But in a test where we *can* measure an effect,
it's not looking good.
It would be interesting to see some results from the same test I did
on other processors. I suspect the results would look a lot different
from mine ... but we won't know unless someone does it. Or, if someone
wants to propose some other test case, let's have a look.
> I'm expressing just my personal opinion, other committers can have
> different opinions. I don't particularly think this topic is
> necessarily a non-starter. But I do think that given ambiguity we've
> observed in the benchmark, much more research is needed to push this
> topic forward.
Yeah. I'm not here to say "do nothing". But I think we need results
from more machines and more test cases to convince ourselves whether
there's a consistent, worthwhile win from any specific patch.
regards, tom lane
On Tue, Dec 1, 2020 at 7:57 PM Zidenberg, Tsahi <tsahee@amazon.com> wrote: > > On 01/12/2020, 16:59, "Alexander Korotkov" <aekorotkov@gmail.com> wrote: > > On Tue, Dec 1, 2020 at 1:10 PM Amit Khandekar <amitdkhan.pg@gmail.com> wrote: > > > FWIW, here is an earlier discussion on the same (also added the > > > proposal author here) : > > Thanks for looping me in! > > > > > > > https://www.postgresql.org/message-id/flat/099F69EE-51D3-4214-934A-1F28C0A1A7A7%40amazon.com > > > > > > Thank you for pointing! I wonder why the effect of LSE on Graviton2 > > observed by Tsahi Zidenberg is so modest. It's probably because he > > runs the tests with a low number of clients. > > There are multiple possible reasons why I saw a smaller effect of LSE, but I think an important one was that I > used a 32-core instance rather than a 64-core one. The reason I did so, was that 32-cores gave me better > absolute results than 64 cores, and I didn't want to feel like I could misguide anyone. BTW, what number of clients did you use? I can't find it in your message. ------ Regards, Alexander Korotkov
> On 01/12/2020, 19:08, "Alexander Korotkov" <aekorotkov@gmail.com> wrote: > BTW, what number of clients did you use? I can't find it in your message. Sure. Important params seem to be: Pgbench: Clients: 256 pgbench_jobs : 32 Scale: 1000 fill_factor: 90 Postgresql: shared buffers: 31GB max_connections: 1024 Thanks! Tsahi.
On Tue, 1 Dec 2020 at 22:19, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Alexander Korotkov <aekorotkov@gmail.com> writes:
> On Tue, Dec 1, 2020 at 6:19 PM Krunal Bauskar <krunalbauskar@gmail.com> wrote:
>> I would request you guys to re-think it from this perspective to help ensure that PGSQL can scale well on ARM.
>> s_lock becomes a top-most function and LSE is not a universal solution but CAS surely helps ease the main bottleneck.
> CAS patch isn't proven to be a universal solution as well. We have
> tested the patch on just a few processors, and Tom has seen the
> regression [1]. The benchmark used by Tom was artificial, but the
> results may be relevant for some real-life workload.
Yeah. I think that the main conclusion from what we've seen here is
that on smaller machines like M1, a standard pgbench benchmark just
isn't capable of driving PG into serious spinlock contention. (That
reflects very well on the work various people have done over the years
to get rid of spinlock contention, because ten or so years ago it was
a huge problem on this size of machine. But evidently, not any more.)
Per the results others have posted, nowadays you need dozens of cores
and hundreds of client threads to measure any such issue with pgbench.
So that is why I experimented with a special test that does nothing
except pound on one spinlock. Sure it's artificial, but if you want
to see the effects of different spinlock implementations then it's
just too hard to get any results with pgbench's regular scripts.
And that's why it disturbs me that the CAS-spinlock patch showed up
worse in that environment. The fact that it's not visible in the
regular pgbench test just means that the effect is too small to
measure in that test. But in a test where we *can* measure an effect,
it's not looking good.
It would be interesting to see some results from the same test I did
on other processors. I suspect the results would look a lot different
from mine ... but we won't know unless someone does it. Or, if someone
wants to propose some other test case, let's have a look.
> I'm expressing just my personal opinion, other committers can have
> different opinions. I don't particularly think this topic is
> necessarily a non-starter. But I do think that given ambiguity we've
> observed in the benchmark, much more research is needed to push this
> topic forward.
Yeah. I'm not here to say "do nothing". But I think we need results
from more machines and more test cases to convince ourselves whether
there's a consistent, worthwhile win from any specific patch.
I think there is an ambiguity with lse and that has been the
source of some confusion so let's make another attempt to
understand all the observations and then define the next steps.
-----------------------------------------------------------------
1. CAS patch (applied on the baseline)
- Kunpeng: 10-45% improvement observed [1]
- Graviton2: 30-50% improvement observed [2]
- M1: Only select results are available cas continue to maintain a marginal gain but not significant. [3]
[inline with what we observed with Kunpeng and Graviton2 for select results too].
2. Let's ignore CAS for a sec and just think of LSE independently
- Kunpeng: regression observed
- Graviton2: gain observed
- M1: regression observed
[while lse probably is default explicitly enabling it with +lse causes regression on the head itself [4].
client=2/4: 1816/714 ---- vs ---- 892/610]
There is enough reason not to immediately consider enabling LSE given its unable to perform consistently on all hardware.
-----------------------------------------------------------------
With those 2 aspects clear let's evaluate what options we have in hand
1. Enable CAS approach
- What we gain: pgsql scale on Kunpeng/Graviton2
(m1 awaiting read-write result but may marginally scale [[5]: "but the patched numbers are only about a few percent better"])
- What we lose: Nothing for now.
2. LSE:
- What we gain: Scaled workload with Graviton2
- What we lose: regression on M1 and Kunpeng.
Let's think of both approaches independently.
- Enabling CAS would help us scale on all hardware (Kunpeng/Graviton2/M1)
- Enabling LSE would help us scale only on some but regress on others.
[LSE could be considered in the future once it stabilizes and all hardware adapts to it]
understand all the observations and then define the next steps.
-----------------------------------------------------------------
1. CAS patch (applied on the baseline)
- Kunpeng: 10-45% improvement observed [1]
- Graviton2: 30-50% improvement observed [2]
- M1: Only select results are available cas continue to maintain a marginal gain but not significant. [3]
[inline with what we observed with Kunpeng and Graviton2 for select results too].
2. Let's ignore CAS for a sec and just think of LSE independently
- Kunpeng: regression observed
- Graviton2: gain observed
- M1: regression observed
[while lse probably is default explicitly enabling it with +lse causes regression on the head itself [4].
client=2/4: 1816/714 ---- vs ---- 892/610]
There is enough reason not to immediately consider enabling LSE given its unable to perform consistently on all hardware.
-----------------------------------------------------------------
With those 2 aspects clear let's evaluate what options we have in hand
1. Enable CAS approach
- What we gain: pgsql scale on Kunpeng/Graviton2
(m1 awaiting read-write result but may marginally scale [[5]: "but the patched numbers are only about a few percent better"])
- What we lose: Nothing for now.
2. LSE:
- What we gain: Scaled workload with Graviton2
- What we lose: regression on M1 and Kunpeng.
Let's think of both approaches independently.
- Enabling CAS would help us scale on all hardware (Kunpeng/Graviton2/M1)
- Enabling LSE would help us scale only on some but regress on others.
[LSE could be considered in the future once it stabilizes and all hardware adapts to it]
-------------------------------------------------------------------
Let me know what do you think about this analysis and any specific direction that we should consider to help move forward.
-------------------------------------------------------------------
Links:
[1]: https://www.postgresql.org/message-id/attachment/116612/Screenshot%20from%202020-12-01%2017-55-21.png
{kind=link}
[2]: https://www.postgresql.org/message-id/attachment/116521/arm-rw.png
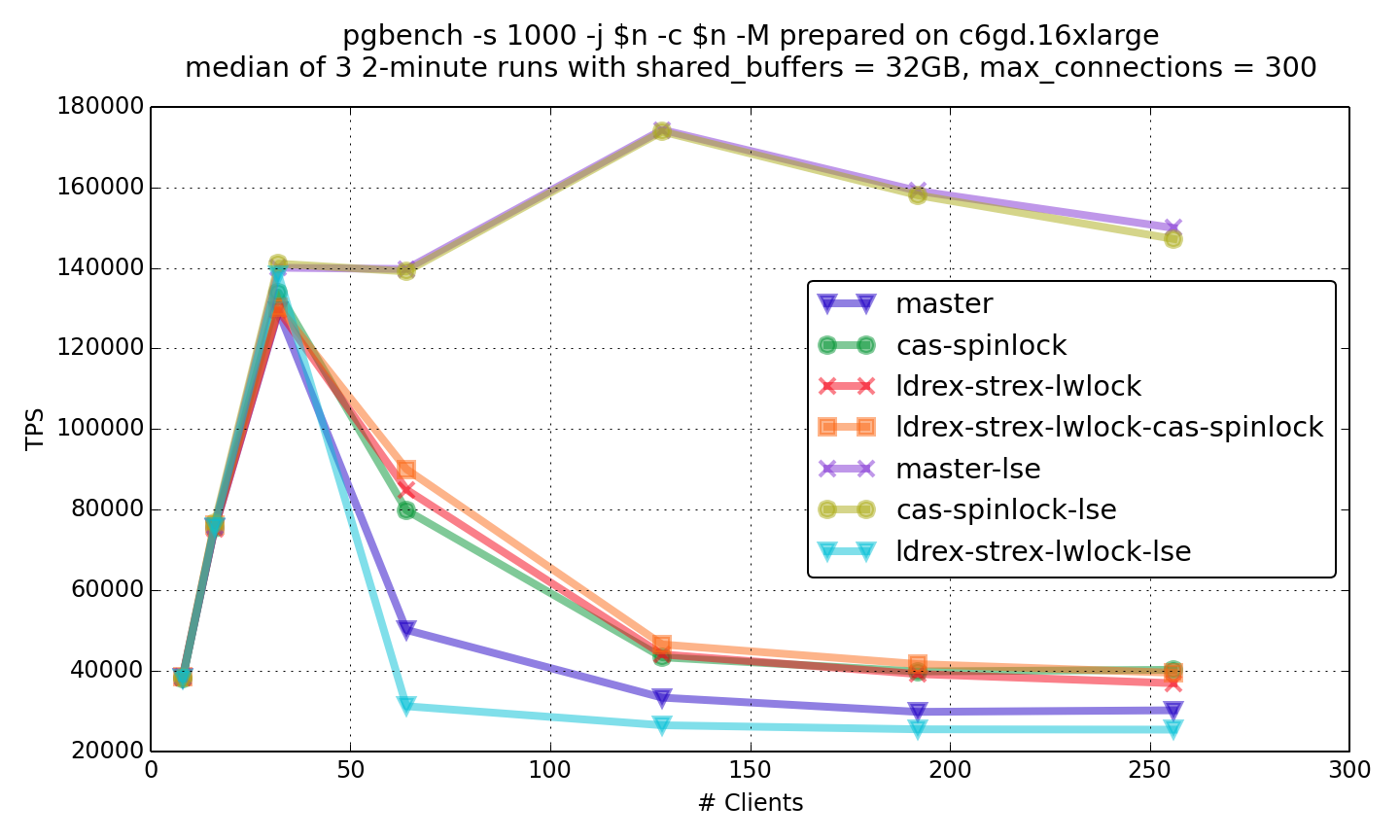{kind=link}
[3]: https://www.postgresql.org/message-id/1367116.1606802480%40sss.pgh.pa.us
[4]: https://www.postgresql.org/message-id/1158478.1606716507%40sss.pgh.pa.us
[5]: https://www.postgresql.org/message-id/51e2f75b-3742-7f28-4438-0425b11cf410%40enterprisedb.com
regards, tom lane
Regards,
Krunal Bauskar
Krunal Bauskar
Any updates or further inputs on this.
On Wed, 2 Dec 2020 at 09:27, Krunal Bauskar <krunalbauskar@gmail.com> wrote:
On Tue, 1 Dec 2020 at 22:19, Tom Lane <tgl@sss.pgh.pa.us> wrote:Alexander Korotkov <aekorotkov@gmail.com> writes:
> On Tue, Dec 1, 2020 at 6:19 PM Krunal Bauskar <krunalbauskar@gmail.com> wrote:
>> I would request you guys to re-think it from this perspective to help ensure that PGSQL can scale well on ARM.
>> s_lock becomes a top-most function and LSE is not a universal solution but CAS surely helps ease the main bottleneck.
> CAS patch isn't proven to be a universal solution as well. We have
> tested the patch on just a few processors, and Tom has seen the
> regression [1]. The benchmark used by Tom was artificial, but the
> results may be relevant for some real-life workload.
Yeah. I think that the main conclusion from what we've seen here is
that on smaller machines like M1, a standard pgbench benchmark just
isn't capable of driving PG into serious spinlock contention. (That
reflects very well on the work various people have done over the years
to get rid of spinlock contention, because ten or so years ago it was
a huge problem on this size of machine. But evidently, not any more.)
Per the results others have posted, nowadays you need dozens of cores
and hundreds of client threads to measure any such issue with pgbench.
So that is why I experimented with a special test that does nothing
except pound on one spinlock. Sure it's artificial, but if you want
to see the effects of different spinlock implementations then it's
just too hard to get any results with pgbench's regular scripts.
And that's why it disturbs me that the CAS-spinlock patch showed up
worse in that environment. The fact that it's not visible in the
regular pgbench test just means that the effect is too small to
measure in that test. But in a test where we *can* measure an effect,
it's not looking good.
It would be interesting to see some results from the same test I did
on other processors. I suspect the results would look a lot different
from mine ... but we won't know unless someone does it. Or, if someone
wants to propose some other test case, let's have a look.
> I'm expressing just my personal opinion, other committers can have
> different opinions. I don't particularly think this topic is
> necessarily a non-starter. But I do think that given ambiguity we've
> observed in the benchmark, much more research is needed to push this
> topic forward.
Yeah. I'm not here to say "do nothing". But I think we need results
from more machines and more test cases to convince ourselves whether
there's a consistent, worthwhile win from any specific patch.I think there is an ambiguity with lse and that has been thesource of some confusion so let's make another attempt to
understand all the observations and then define the next steps.
-----------------------------------------------------------------
1. CAS patch (applied on the baseline)
- Kunpeng: 10-45% improvement observed [1]
- Graviton2: 30-50% improvement observed [2]
- M1: Only select results are available cas continue to maintain a marginal gain but not significant. [3]
[inline with what we observed with Kunpeng and Graviton2 for select results too].
2. Let's ignore CAS for a sec and just think of LSE independently
- Kunpeng: regression observed
- Graviton2: gain observed
- M1: regression observed
[while lse probably is default explicitly enabling it with +lse causes regression on the head itself [4].
client=2/4: 1816/714 ---- vs ---- 892/610]
There is enough reason not to immediately consider enabling LSE given its unable to perform consistently on all hardware.
-----------------------------------------------------------------
With those 2 aspects clear let's evaluate what options we have in hand
1. Enable CAS approach
- What we gain: pgsql scale on Kunpeng/Graviton2
(m1 awaiting read-write result but may marginally scale [[5]: "but the patched numbers are only about a few percent better"])
- What we lose: Nothing for now.
2. LSE:
- What we gain: Scaled workload with Graviton2
- What we lose: regression on M1 and Kunpeng.
Let's think of both approaches independently.
- Enabling CAS would help us scale on all hardware (Kunpeng/Graviton2/M1)
- Enabling LSE would help us scale only on some but regress on others.
[LSE could be considered in the future once it stabilizes and all hardware adapts to it]-------------------------------------------------------------------Let me know what do you think about this analysis and any specific direction that we should consider to help move forward.
-------------------------------------------------------------------
Links:
[1]: https://www.postgresql.org/message-id/attachment/116612/Screenshot%20from%202020-12-01%2017-55-21.png
[2]: https://www.postgresql.org/message-id/attachment/116521/arm-rw.png
[3]: https://www.postgresql.org/message-id/1367116.1606802480%40sss.pgh.pa.us
[4]: https://www.postgresql.org/message-id/1158478.1606716507%40sss.pgh.pa.us
[5]: https://www.postgresql.org/message-id/51e2f75b-3742-7f28-4438-0425b11cf410%40enterprisedb.com
regards, tom lane--Regards,
Krunal Bauskar
Regards,
Krunal Bauskar
Krunal Bauskar
Krunal Bauskar <krunalbauskar@gmail.com> writes:
> Any updates or further inputs on this.
As far as LSE goes: my take is that tampering with the
compiler/platform's default optimization options requires *very*
strong evidence, which we have not got and likely won't get. Users
who are building for specific hardware can choose to supply custom
CFLAGS, of course. But we shouldn't presume to do that for them,
because we don't know what they are building for, or with what.
I'm very willing to consider the CAS spinlock patch, but it still
feels like there's not enough evidence to show that it's a universal
win. The way to move forward on that is to collect more measurements
on additional ARM-based platforms. And I continue to think that
pgbench is only a very crude tool for testing spinlock performance;
we should look at other tests.
From a system structural standpoint, I seriously dislike that lwlock.c
patch: putting machine-specific variant implementations into that file
seems like a disaster for maintainability. So it would need to show a
very significant gain across a range of hardware before I'd want to
consider adopting it ... and it has not shown that.
regards, tom lane
On Thu, Dec 3, 2020 at 7:02 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > From a system structural standpoint, I seriously dislike that lwlock.c > patch: putting machine-specific variant implementations into that file > seems like a disaster for maintainability. So it would need to show a > very significant gain across a range of hardware before I'd want to > consider adopting it ... and it has not shown that. The current shape of the lwlock patch is experimental. I had quite a beautiful (in my opinion) idea to wrap platform-dependent parts of CAS-loops into macros. Then we could provide different low-level implementations of CAS-loops for Power, ARM and rest platforms with single code for LWLockAttempLock() and others. However, I see that modern ARM tends to efficiently implement LSE. Power doesn't seem to be very popular. So, I'm going to give up with this for now. ------ Regards, Alexander Korotkov
On Wed, Dec 2, 2020 at 6:58 AM Krunal Bauskar <krunalbauskar@gmail.com> wrote: > 1. CAS patch (applied on the baseline) > - Kunpeng: 10-45% improvement observed [1] > - Graviton2: 30-50% improvement observed [2] What does lower boundary of improvement mean? Does it mean minimal improvement observed? Obviously not, because there is no improvement with a low number of clients or read-only benchmark. > - M1: Only select results are available cas continue to maintain a marginal gain but not significant. [3] Read-only benchmark doesn't involve spinlocks (I've just rechecked this). So, this difference is purely speculative. Also, Tom observed the regression [1]. The benchmark is artificial, but it may correspond to some real workload with heavily-loaded spinlocks. And that might have an explanation. ldrex/strex themselves don't work as memory barrier (this is why compiler adds explicit memory barrier afterwards). And I bet ldrex unpaired with strex could see an outdated value. On high-contended spinlocks that may cause too pessimistic waits. > 2. Let's ignore CAS for a sec and just think of LSE independently > - Kunpeng: regression observed Yeah, it's sad that there are ARM chips, where making the same action in a single instruction is slower than the same actions in multiple instructions. > - Graviton2: gain observed Have to say it's 5.5x improvement, which is dramatically more than CAS-loop patch can give. > - M1: regression observed > [while lse probably is default explicitly enabling it with +lse causes regression on the head itself [4]. > client=2/4: 1816/714 ---- vs ---- 892/610] This is plain false. LSE was enabled in all the versions tested in M1 [2]. So not LSE instructions or +lse option caused the regression, but lack of other options enabled by default in Apple's clang. > Let me know what do you think about this analysis and any specific direction that we should consider to help move forward. In order to move forward with ARM-optimized spinlocks I would investigate other options (at least [3]). Regarding CAS spinlock patch I can propose the following steps to clarify the things. 1. Run Tom's spinlock test on ARM machines other than M1. 2. Try to construct a pgbench script, which produces heavily-loaded spinlock without custom C-function, and also run it across various ARM machines. Links 1. https://www.postgresql.org/message-id/741389.1606530957%40sss.pgh.pa.us 2. https://www.postgresql.org/message-id/1274781.1606760475%40sss.pgh.pa.us 3. https://linux-concepts.blogspot.com/2018/05/spinlock-implementation-in-arm.html ------ Regards, Alexander Korotkov
On Wed, Dec 2, 2020 at 6:58 AM Krunal Bauskar <krunalbauskar@gmail.com> wrote: > Let me know what do you think about this analysis and any specific direction that we should consider to help move forward. BTW, it would be also nice to benchmark my lwlock patch on the Kunpeng. I'm very optimistic about this patch, but it wouldn't be fair to completely throw it away. It still might be useful for LSE-disabled builds. ------ Regards, Alexander Korotkov
On Sat, 5 Dec 2020 at 02:55, Alexander Korotkov <aekorotkov@gmail.com> wrote: > > On Wed, Dec 2, 2020 at 6:58 AM Krunal Bauskar <krunalbauskar@gmail.com> wrote: > > Let me know what do you think about this analysis and any specific direction that we should consider to help move forward. > > BTW, it would be also nice to benchmark my lwlock patch on the > Kunpeng. I'm very optimistic about this patch, but it wouldn't be > fair to completely throw it away. It still might be useful for > LSE-disabled builds. Coincidentally I was also looking at some hotspot locations around LWLockAcquire() and LWLockAttempt() for read-only work-loads on both arm64 and x86, and had narrowed down to the place where pg_atomic_compare_exchange_u32() is called. So it's likely we are working on the same hotspot area. When I get a chance, I do plan to look at your patch while I myself am trying to see if we can do some optimizations. Although, this is unrelated to the optimization of this mail thread, so this will need a different mail thread. -- Thanks, -Amit Khandekar Huawei Technologies
On Thu, 3 Dec 2020 at 21:32, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Krunal Bauskar <krunalbauskar@gmail.com> writes:
> Any updates or further inputs on this.
As far as LSE goes: my take is that tampering with the
compiler/platform's default optimization options requires *very*
strong evidence, which we have not got and likely won't get. Users
who are building for specific hardware can choose to supply custom
CFLAGS, of course. But we shouldn't presume to do that for them,
because we don't know what they are building for, or with what.
I'm very willing to consider the CAS spinlock patch, but it still
feels like there's not enough evidence to show that it's a universal
win. The way to move forward on that is to collect more measurements
on additional ARM-based platforms. And I continue to think that
pgbench is only a very crude tool for testing spinlock performance;
we should look at other tests.
Thanks Tom.
Given pg-bench limited option I decided to try things with sysbench to expose
the real contention using zipfian type (zipfian pattern causes part of the database
to get updated there-by exposing main contention point).
----------------------------------------------------------------------------
Baseline for 256 threads update-index use-case:
- 44.24% 174935 postgres postgres [.] s_lock
transactions:
transactions: 5587105 (92988.40 per sec.)
Patched for 256 threads update-index use-case:
0.02% 80 postgres postgres [.] s_lock
transactions:
transactions: 10288781 (171305.24 per sec.)
perf diff
0.02% +44.22% postgres [.] s_lock
----------------------------------------------------------------------------
As we see from the above result s_lock is exposing major contention that could be relaxed using the
----------------------------------------------------------------------------
As we see from the above result s_lock is exposing major contention that could be relaxed using the
said cas patch. Performance improvement in range of 80% is observed.
Taking this guideline we decided to run it for all scalability for update and non-update use-case.
Check the attached graph. Consistent improvement is observed.
I presume this should help re-establish that for major contention cases existing tas approach will always give up.
-------------------------------------------------------------------------------------------
Unfortunately, I don't have access to different ARM arch except for Kunpeng or Graviton2 where
we have already proved the value of the patch.
[ref: Apple M1 as per your evaluation patch doesn't show regression for select. Maybe if possible can you try update scenarios too].
Do you know anyone from the community who has access to other ARM arches we can request them to evaluate?
But since it is has proven on 2 independent ARM arch I am pretty confident it will scale with other ARM arches too.
From a system structural standpoint, I seriously dislike that lwlock.c
patch: putting machine-specific variant implementations into that file
seems like a disaster for maintainability. So it would need to show a
very significant gain across a range of hardware before I'd want to
consider adopting it ... and it has not shown that.
regards, tom lane
Regards,
Krunal Bauskar
Krunal Bauskar
Attachment
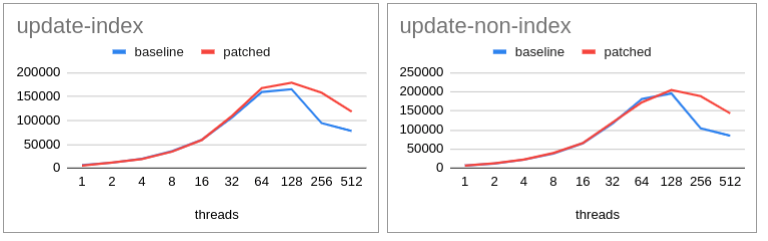{kind=link}
On Tue, 8 Dec 2020 at 14:33, Krunal Bauskar <krunalbauskar@gmail.com> wrote:
On Thu, 3 Dec 2020 at 21:32, Tom Lane <tgl@sss.pgh.pa.us> wrote:Krunal Bauskar <krunalbauskar@gmail.com> writes:
> Any updates or further inputs on this.
As far as LSE goes: my take is that tampering with the
compiler/platform's default optimization options requires *very*
strong evidence, which we have not got and likely won't get. Users
who are building for specific hardware can choose to supply custom
CFLAGS, of course. But we shouldn't presume to do that for them,
because we don't know what they are building for, or with what.
I'm very willing to consider the CAS spinlock patch, but it still
feels like there's not enough evidence to show that it's a universal
win. The way to move forward on that is to collect more measurements
on additional ARM-based platforms. And I continue to think that
pgbench is only a very crude tool for testing spinlock performance;
we should look at other tests.Thanks Tom.Given pg-bench limited option I decided to try things with sysbench to exposethe real contention using zipfian type (zipfian pattern causes part of the databaseto get updated there-by exposing main contention point).
----------------------------------------------------------------------------
Baseline for 256 threads update-index use-case:
- 44.24% 174935 postgres postgres [.] s_lock
transactions:
transactions: 5587105 (92988.40 per sec.)
Patched for 256 threads update-index use-case:
0.02% 80 postgres postgres [.] s_lock
transactions:
transactions: 10288781 (171305.24 per sec.)
perf diff0.02% +44.22% postgres [.] s_lock
----------------------------------------------------------------------------
As we see from the above result s_lock is exposing major contention that could be relaxed using thesaid cas patch. Performance improvement in range of 80% is observed.
Taking this guideline we decided to run it for all scalability for update and non-update use-case.Check the attached graph. Consistent improvement is observed.I presume this should help re-establish that for major contention cases existing tas approach will always give up.-------------------------------------------------------------------------------------------Unfortunately, I don't have access to different ARM arch except for Kunpeng or Graviton2 wherewe have already proved the value of the patch.[ref: Apple M1 as per your evaluation patch doesn't show regression for select. Maybe if possible can you try update scenarios too].Do you know anyone from the community who has access to other ARM arches we can request them to evaluate?But since it is has proven on 2 independent ARM arch I am pretty confident it will scale with other ARM arches too.
Any direction on how we can proceed on this?
* We have tested it with both cloud vendors that provide ARM instances.
* We have tested it with Apple M1 (partially at-least)
* Ampere use to provide instance on packet.com but now it is an evaluation program only.
No other active arm instance offering a cloud provider.
Given our evaluation so far has proven to be +ve can we think of considering it on basis of the available
data which is quite encouraging with 80% improvement seen for heavy contention use-cases.
From a system structural standpoint, I seriously dislike that lwlock.c
patch: putting machine-specific variant implementations into that file
seems like a disaster for maintainability. So it would need to show a
very significant gain across a range of hardware before I'd want to
consider adopting it ... and it has not shown that.
regards, tom lane--Regards,
Krunal Bauskar
Regards,
Krunal Bauskar
Krunal Bauskar
Wondering if we can take this to completion (any idea what more we could do?).
On Thu, 10 Dec 2020 at 14:48, Krunal Bauskar <krunalbauskar@gmail.com> wrote:
On Tue, 8 Dec 2020 at 14:33, Krunal Bauskar <krunalbauskar@gmail.com> wrote:On Thu, 3 Dec 2020 at 21:32, Tom Lane <tgl@sss.pgh.pa.us> wrote:Krunal Bauskar <krunalbauskar@gmail.com> writes:
> Any updates or further inputs on this.
As far as LSE goes: my take is that tampering with the
compiler/platform's default optimization options requires *very*
strong evidence, which we have not got and likely won't get. Users
who are building for specific hardware can choose to supply custom
CFLAGS, of course. But we shouldn't presume to do that for them,
because we don't know what they are building for, or with what.
I'm very willing to consider the CAS spinlock patch, but it still
feels like there's not enough evidence to show that it's a universal
win. The way to move forward on that is to collect more measurements
on additional ARM-based platforms. And I continue to think that
pgbench is only a very crude tool for testing spinlock performance;
we should look at other tests.Thanks Tom.Given pg-bench limited option I decided to try things with sysbench to exposethe real contention using zipfian type (zipfian pattern causes part of the databaseto get updated there-by exposing main contention point).
----------------------------------------------------------------------------
Baseline for 256 threads update-index use-case:
- 44.24% 174935 postgres postgres [.] s_lock
transactions:
transactions: 5587105 (92988.40 per sec.)
Patched for 256 threads update-index use-case:
0.02% 80 postgres postgres [.] s_lock
transactions:
transactions: 10288781 (171305.24 per sec.)
perf diff0.02% +44.22% postgres [.] s_lock
----------------------------------------------------------------------------
As we see from the above result s_lock is exposing major contention that could be relaxed using thesaid cas patch. Performance improvement in range of 80% is observed.
Taking this guideline we decided to run it for all scalability for update and non-update use-case.Check the attached graph. Consistent improvement is observed.I presume this should help re-establish that for major contention cases existing tas approach will always give up.-------------------------------------------------------------------------------------------Unfortunately, I don't have access to different ARM arch except for Kunpeng or Graviton2 wherewe have already proved the value of the patch.[ref: Apple M1 as per your evaluation patch doesn't show regression for select. Maybe if possible can you try update scenarios too].Do you know anyone from the community who has access to other ARM arches we can request them to evaluate?But since it is has proven on 2 independent ARM arch I am pretty confident it will scale with other ARM arches too.Any direction on how we can proceed on this?* We have tested it with both cloud vendors that provide ARM instances.* We have tested it with Apple M1 (partially at-least)* Ampere use to provide instance on packet.com but now it is an evaluation program only.No other active arm instance offering a cloud provider.Given our evaluation so far has proven to be +ve can we think of considering it on basis of the availabledata which is quite encouraging with 80% improvement seen for heavy contention use-cases.
From a system structural standpoint, I seriously dislike that lwlock.c
patch: putting machine-specific variant implementations into that file
seems like a disaster for maintainability. So it would need to show a
very significant gain across a range of hardware before I'd want to
consider adopting it ... and it has not shown that.
regards, tom lane--Regards,
Krunal Bauskar--Regards,
Krunal Bauskar
Regards,
Krunal Bauskar
Krunal Bauskar