Krunal Bauskar <krunalbauskar@gmail.com> writes:
> On Thu, 26 Nov 2020 at 10:50, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Also, exactly what hardware/software platform were these curves
>> obtained on?
> Hardware: ARM Kunpeng 920 BareMetal Server 2.6 GHz. 64 cores (56 cores for
> server and 8 for client) [2 numa nodes]
> Storage: 3.2 TB NVMe SSD
> OS: CentOS Linux release 7.6
> PGSQL: baseline = Release Tag 13.1
Hmm, might not be the sort of hardware ordinary mortals can get their
hands on. What's likely to be far more common ARM64 hardware in the
near future is Apple's new gear. So I thought I'd try this on the new
M1 mini I just got.
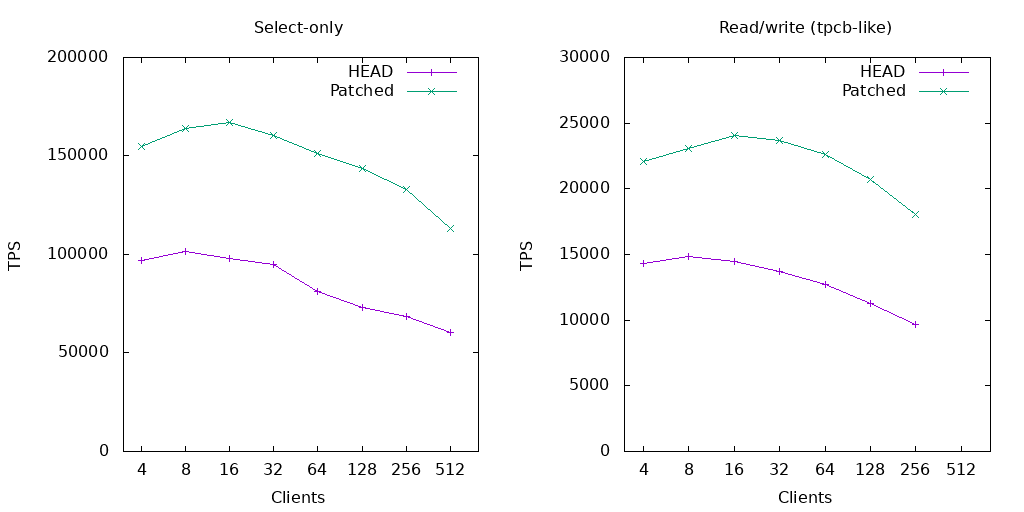
... and, after retrieving my jaw from the floor, I present the
attached. Apple's chips evidently like this style of spinlock a LOT
better. The difference is so remarkable that I wonder if I made a
mistake somewhere. Can anyone else replicate these results?
Test conditions are absolutely brain dead:
Today's HEAD (dcfff74fb), no special build options
All server parameters are out-of-the-box defaults, except
I had to raise max_connections for the larger client counts
pgbench scale factor 100
Read-only tests are like
pgbench -S -T 60 -c 32 -j 16 bench
Quoted figure is median of three runs; except for the lowest
client count, results were quite repeatable. (I speculate that
at -c 4, the scheduler might've been doing something funny about
sometimes using the slow cores instead of fast cores.)
Read-write tests are like
pgbench -T 300 -c 16 -j 8 bench
I didn't have the patience to run three full repetitions,
but again the numbers seemed pretty repeatable.
I used -j equal to half -c, except I could not get -j above 128
to work, so the larger client counts have -j 128. Did not try
to run down that problem yet, but I'm probably hitting some ulimit
somewhere. (I did have to raise "ulimit -n" to get these results.)
Anyway, this seems to be a slam-dunk win on M1.
regards, tom lane
{kind=link}