Thread: WIP: WAL prefetch (another approach)
Hello hackers, Based on ideas from earlier discussions[1][2], here is an experimental WIP patch to improve recovery speed by prefetching blocks. If you set wal_prefetch_distance to a positive distance, measured in bytes, then the recovery loop will look ahead in the WAL and call PrefetchBuffer() for referenced blocks. This can speed things up with cold caches (example: after a server reboot) and working sets that don't fit in memory (example: large scale pgbench). Results vary, but in contrived larger-than-memory pgbench crash recovery experiments on a Linux development system, I've seen recovery running as much as 20x faster with full_page_writes=off and wal_prefetch_distance=8kB. FPWs reduce the potential speed-up as discussed in the other thread. Some notes: * PrefetchBuffer() is only beneficial if your kernel and filesystem have a working POSIX_FADV_WILLNEED implementation. That includes Linux ext4 and xfs, but excludes macOS and Windows. In future we might use asynchronous I/O to bring data all the way into our own buffer pool; hopefully the PrefetchBuffer() interface wouldn't change much and this code would automatically benefit. * For now, for proof-of-concept purposes, the patch uses a second XLogReader to read ahead in the WAL. I am thinking about how to write a two-cursor XLogReader that reads and decodes each record just once. * It can handle simple crash recovery and streaming replication scenarios, but doesn't yet deal with complications like timeline changes (the way to do that might depend on how the previous point works out). The integration with WAL receiver probably needs some work, I've been testing pretty narrow cases so far, and the way I hijacked read_local_xlog_page() probably isn't right. * On filesystems with block size <= BLCKSZ, it's a waste of a syscall to try to prefetch a block that we have a FPW for, but otherwise it can avoid a later stall due to a read-before-write at pwrite() time, so I added a second GUC wal_prefetch_fpw to make that optional. Earlier work, and how this patch compares: * Sean Chittenden wrote pg_prefaulter[1], an external process that uses worker threads to pread() referenced pages some time before recovery does, and demonstrated very good speed-up, triggering a lot of discussion of this topic. My WIP patch differs mainly in that it's integrated with PostgreSQL, and it uses POSIX_FADV_WILLNEED rather than synchronous I/O from worker threads/processes. Sean wouldn't have liked my patch much because he was working on ZFS and that doesn't support POSIX_FADV_WILLNEED, but with a small patch to ZFS it works pretty well, and I'll try to get that upstreamed. * Konstantin Knizhnik proposed a dedicated PostgreSQL process that would do approximately the same thing[2]. My WIP patch differs mainly in that it does the prefetching work in the recovery loop itself, and uses PrefetchBuffer() rather than FilePrefetch() directly. This avoids a bunch of communication and complications, but admittedly does introduce new system calls into a hot loop (for now); perhaps I could pay for that by removing more lseek(SEEK_END) noise. It also deals with various edge cases relating to created, dropped and truncated relations a bit differently. It also tries to avoid generating sequential WILLNEED advice, based on experimental evidence[3] that that affects Linux's readahead heuristics negatively, though I don't understand the exact mechanism there. Here are some cases where I expect this patch to perform badly: * Your WAL has multiple intermixed sequential access streams (ie sequential access to N different relations), so that sequential access is not detected, and then all the WILLNEED advice prevents Linux's automagic readahead from working well. Perhaps that could be mitigated by having a system that can detect up to N concurrent streams, where N is more than the current 1, or by flagging buffers in the WAL as part of a sequential stream. I haven't looked into this. * The data is always found in our buffer pool, so PrefetchBuffer() is doing nothing useful and you might as well not be calling it or doing the extra work that leads up to that. Perhaps that could be mitigated with an adaptive approach: too many PrefetchBuffer() hits and we stop trying to prefetch, too many XLogReadBufferForRedo() misses and we start trying to prefetch. That might work nicely for systems that start out with cold caches but eventually warm up. I haven't looked into this. * The data is actually always in the kernel's cache, so the advice is a waste of a syscall. That might imply that you should probably be running with a larger shared_buffers (?). It's technically possible to ask the operating system if a region is cached on many systems, which could in theory be used for some kind of adaptive heuristic that would disable pointless prefetching, but I'm not proposing that. Ultimately this problem would be avoided by moving to true async I/O, where we'd be initiating the read all the way into our buffers (ie it replaces the later pread() so it's a wash, at worst). * The prefetch distance is set too low so that pread() waits are not avoided, or your storage subsystem can't actually perform enough concurrent I/O to get ahead of the random access pattern you're generating, so no distance would be far enough ahead. To help with the former case, perhaps we could invent something smarter than a user-supplied distance (something like "N cold block references ahead", possibly using effective_io_concurrency, rather than "N bytes ahead"). [1] https://www.pgcon.org/2018/schedule/track/Case%20Studies/1204.en.html [2] https://www.postgresql.org/message-id/flat/49df9cd2-7086-02d0-3f8d-535a32d44c82%40postgrespro.ru [3] https://github.com/macdice/some-io-tests
Attachment
On Thu, Jan 02, 2020 at 02:39:04AM +1300, Thomas Munro wrote: >Hello hackers, > >Based on ideas from earlier discussions[1][2], here is an experimental >WIP patch to improve recovery speed by prefetching blocks. If you set >wal_prefetch_distance to a positive distance, measured in bytes, then >the recovery loop will look ahead in the WAL and call PrefetchBuffer() >for referenced blocks. This can speed things up with cold caches >(example: after a server reboot) and working sets that don't fit in >memory (example: large scale pgbench). > Thanks, I only did a very quick review so far, but the patch looks fine. In general, I find it somewhat non-intuitive to configure prefetching by specifying WAL distance. I mean, how would you know what's a good value? If you know the storage hardware, you probably know the optimal queue depth i.e. you know you the number of requests to get best throughput. But how do you deduce the WAL distance from that? I don't know. Could we instead specify the number of blocks to prefetch? We'd probably need to track additional details needed to determine number of blocks to prefetch (essentially LSN for all prefetch requests). Another thing to consider might be skipping recently prefetched blocks. Consider you have a loop that does DML, where each statement creates a separate WAL record, but it can easily touch the same block over and over (say inserting to the same page). That means the prefetches are not really needed, but I'm not sure how expensive it really is. >Results vary, but in contrived larger-than-memory pgbench crash >recovery experiments on a Linux development system, I've seen recovery >running as much as 20x faster with full_page_writes=off and >wal_prefetch_distance=8kB. FPWs reduce the potential speed-up as >discussed in the other thread. > OK, so how did you test that? I'll do some tests with a traditional streaming replication setup, multiple sessions on the primary (and maybe a weaker storage system on the replica). I suppose that's another setup that should benefit from this. > ... > >Earlier work, and how this patch compares: > >* Sean Chittenden wrote pg_prefaulter[1], an external process that >uses worker threads to pread() referenced pages some time before >recovery does, and demonstrated very good speed-up, triggering a lot >of discussion of this topic. My WIP patch differs mainly in that it's >integrated with PostgreSQL, and it uses POSIX_FADV_WILLNEED rather >than synchronous I/O from worker threads/processes. Sean wouldn't >have liked my patch much because he was working on ZFS and that >doesn't support POSIX_FADV_WILLNEED, but with a small patch to ZFS it >works pretty well, and I'll try to get that upstreamed. > How long would it take to get the POSIX_FADV_WILLNEED to ZFS systems, if everything goes fine? I'm not sure what's the usual life-cycle, but I assume it may take a couple years to get it on most production systems. What other common filesystems are missing support for this? Presumably we could do what Sean's extension does, i.e. use a couple of bgworkers, each doing simple pread() calls. Of course, that's unnecessarily complicated on systems that have FADV_WILLNEED. > ... > >Here are some cases where I expect this patch to perform badly: > >* Your WAL has multiple intermixed sequential access streams (ie >sequential access to N different relations), so that sequential access >is not detected, and then all the WILLNEED advice prevents Linux's >automagic readahead from working well. Perhaps that could be >mitigated by having a system that can detect up to N concurrent >streams, where N is more than the current 1, or by flagging buffers in >the WAL as part of a sequential stream. I haven't looked into this. > Hmmm, wouldn't it be enough to prefetch blocks in larger batches (not one by one), and doing some sort of sorting? That should allow readahead to kick in. >* The data is always found in our buffer pool, so PrefetchBuffer() is >doing nothing useful and you might as well not be calling it or doing >the extra work that leads up to that. Perhaps that could be mitigated >with an adaptive approach: too many PrefetchBuffer() hits and we stop >trying to prefetch, too many XLogReadBufferForRedo() misses and we >start trying to prefetch. That might work nicely for systems that >start out with cold caches but eventually warm up. I haven't looked >into this. > I think the question is what's the cost of doing such unnecessary prefetch. Presumably it's fairly cheap, especially compared to the opposite case (not prefetching a block not in shared buffers). I wonder how expensive would the adaptive logic be on cases that never need a prefetch (i.e. datasets smaller than shared_buffers). >* The data is actually always in the kernel's cache, so the advice is >a waste of a syscall. That might imply that you should probably be >running with a larger shared_buffers (?). It's technically possible >to ask the operating system if a region is cached on many systems, >which could in theory be used for some kind of adaptive heuristic that >would disable pointless prefetching, but I'm not proposing that. >Ultimately this problem would be avoided by moving to true async I/O, >where we'd be initiating the read all the way into our buffers (ie it >replaces the later pread() so it's a wash, at worst). > Makes sense. >* The prefetch distance is set too low so that pread() waits are not >avoided, or your storage subsystem can't actually perform enough >concurrent I/O to get ahead of the random access pattern you're >generating, so no distance would be far enough ahead. To help with >the former case, perhaps we could invent something smarter than a >user-supplied distance (something like "N cold block references >ahead", possibly using effective_io_concurrency, rather than "N bytes >ahead"). > In general, I find it quite non-intuitive to configure prefetching by specifying WAL distance. I mean, how would you know what's a good value? If you know the storage hardware, you probably know the optimal queue depth i.e. you know you the number of requests to get best throughput. But how do you deduce the WAL distance from that? I don't know. Plus right after the checkpoint the WAL contains FPW, reducing the number of blocks in a given amount of WAL (compared to right before a checkpoint). So I expect users might pick unnecessarily high WAL distance. OTOH with FPW we don't quite need agressive prefetching, right? Could we instead specify the number of blocks to prefetch? We'd probably need to track additional details needed to determine number of blocks to prefetch (essentially LSN for all prefetch requests). Another thing to consider might be skipping recently prefetched blocks. Consider you have a loop that does DML, where each statement creates a separate WAL record, but it can easily touch the same block over and over (say inserting to the same page). That means the prefetches are not really needed, but I'm not sure how expensive it really is. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jan 3, 2020 at 7:10 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On Thu, Jan 02, 2020 at 02:39:04AM +1300, Thomas Munro wrote: > >Based on ideas from earlier discussions[1][2], here is an experimental > >WIP patch to improve recovery speed by prefetching blocks. If you set > >wal_prefetch_distance to a positive distance, measured in bytes, then > >the recovery loop will look ahead in the WAL and call PrefetchBuffer() > >for referenced blocks. This can speed things up with cold caches > >(example: after a server reboot) and working sets that don't fit in > >memory (example: large scale pgbench). > > > > Thanks, I only did a very quick review so far, but the patch looks fine. Thanks for looking! > >Results vary, but in contrived larger-than-memory pgbench crash > >recovery experiments on a Linux development system, I've seen recovery > >running as much as 20x faster with full_page_writes=off and > >wal_prefetch_distance=8kB. FPWs reduce the potential speed-up as > >discussed in the other thread. > > OK, so how did you test that? I'll do some tests with a traditional > streaming replication setup, multiple sessions on the primary (and maybe > a weaker storage system on the replica). I suppose that's another setup > that should benefit from this. Using a 4GB RAM 16 thread virtual machine running Linux debian10 4.19.0-6-amd64 with an ext4 filesystem on NVMe storage: postgres -D pgdata \ -c full_page_writes=off \ -c checkpoint_timeout=60min \ -c max_wal_size=10GB \ -c synchronous_commit=off # in another shell pgbench -i -s300 postgres psql postgres -c checkpoint pgbench -T60 -Mprepared -c4 -j4 postgres killall -9 postgres # save the crashed pgdata dir for repeated experiments mv pgdata pgdata-save # repeat this with values like wal_prefetch_distance=-1, 1kB, 8kB, 64kB, ... rm -fr pgdata cp -r pgdata-save pgdata postgres -D pgdata -c wal_prefetch_distance=-1 What I see on my desktop machine is around 10x speed-up: wal_prefetch_distance=-1 -> 62s (same number for unpatched) wal_prefetch_distance=8kb -> 6s wal_prefetch_distance=64kB -> 5s On another dev machine I managed to get a 20x speedup, using a much longer test. It's probably more interesting to try out some more realistic workloads rather than this cache-destroying uniform random stuff, though. It might be interesting to test on systems with high random read latency, but high concurrency; I can think of a bunch of network storage environments where that's the case, but I haven't looked into them, beyond some toy testing with (non-Linux) NFS over a slow network (results were promising). > >Earlier work, and how this patch compares: > > > >* Sean Chittenden wrote pg_prefaulter[1], an external process that > >uses worker threads to pread() referenced pages some time before > >recovery does, and demonstrated very good speed-up, triggering a lot > >of discussion of this topic. My WIP patch differs mainly in that it's > >integrated with PostgreSQL, and it uses POSIX_FADV_WILLNEED rather > >than synchronous I/O from worker threads/processes. Sean wouldn't > >have liked my patch much because he was working on ZFS and that > >doesn't support POSIX_FADV_WILLNEED, but with a small patch to ZFS it > >works pretty well, and I'll try to get that upstreamed. > > > > How long would it take to get the POSIX_FADV_WILLNEED to ZFS systems, if > everything goes fine? I'm not sure what's the usual life-cycle, but I > assume it may take a couple years to get it on most production systems. Assuming they like it enough to commit it (and initial informal feedback on the general concept has been positive -- it's not messing with their code at all, it's just boilerplate code to connect the relevant Linux and FreeBSD VFS callbacks), it could indeed be quite a while before it appear in conservative package repos, but I don't know, it depends where you get your OpenZFS/ZoL module from. > What other common filesystems are missing support for this? Using our build farm as a way to know which operating systems we care about as a community, in no particular order: * I don't know for exotic or network filesystems on Linux * AIX 7.2's manual says "Valid option, but this value does not perform any action" for every kind of advice except POSIX_FADV_NOWRITEBEHIND (huh, nonstandard advice). * Solaris's posix_fadvise() was a dummy libc function, as of 10 years ago when they closed the source; who knows after that. * FreeBSD's UFS and NFS support other advice through a default handler but unfortunately ignore WILLNEED (I have patches for those too, not good enough to send anywhere yet). * OpenBSD has no such syscall * NetBSD has the syscall, and I can see that it's hooked up to readahead code, so that's probably the only unqualified yes in this list * Windows has no equivalent syscall; the closest thing might be to use ReadFileEx() to initiate an async read into a dummy buffer; maybe you can use a zero event so it doesn't even try to tell you when the I/O completes, if you don't care? * macOS has no such syscall, but you could in theory do an aio_read() into a dummy buffer. On the other hand I don't think that interface is a general solution for POSIX systems, because on at least Linux and Solaris, aio_read() is emulated by libc with a whole bunch of threads and we are allergic to those things (and even if we weren't, we wouldn't want a whole threadpool in every PostgreSQL process, so you'd need to hand off to a worker process, and then why bother?). * HPUX, I don't know We could test any of those with a simple test I wrote[1], but I'm not likely to test any non-open-source OS myself due to lack of access. Amazingly, HPUX's posix_fadvise() doesn't appear to conform to POSIX: it sets errno and returns -1, while POSIX says that it should return an error number. Checking our source tree, I see that in pg_flush_data(), we also screwed that up and expect errno to be set, though we got it right in FilePrefetch(). In any case, Linux must be at the very least 90% of PostgreSQL installations. Incidentally, sync_file_range() without wait is a sort of opposite of WILLNEED (it means something like "POSIX_FADV_WILLSYNC"), and no one seem terribly upset that we really only have that on Linux (the emulations are pretty poor AFAICS). > Presumably we could do what Sean's extension does, i.e. use a couple of > bgworkers, each doing simple pread() calls. Of course, that's > unnecessarily complicated on systems that have FADV_WILLNEED. That is a good idea, and I agree. I have a patch set that does exactly that. It's nearly independent of the WAL prefetch work; it just changes how PrefetchBuffer() is implemented, affecting bitmap index scans, vacuum and any future user of PrefetchBuffer. If you apply these patches too then WAL prefetch will use it (just set max_background_readers = 4 or whatever): https://github.com/postgres/postgres/compare/master...macdice:bgreader That's simplified from an abandoned patch I had lying around because I was experimenting with prefetching all the way into shared buffers this way. The simplified version just does pread() into a dummy buffer, for the side effect of warming the kernel's cache, pretty much like pg_prefaulter. There are some tricky questions around whether it's better to wait or not when the request queue is full; the way I have that is far too naive, and that question is probably related to your point about being cleverer about how many prefetch blocks you should try to have in flight. A future version of PrefetchBuffer() might lock the buffer then tell the worker (or some kernel async I/O facility) to write the data into the buffer. If I understand correctly, to make that work we need Robert's IO lock/condition variable transplant[2], and Andres's scheme for a suitable interlocking protocol, and no doubt some bulletproof cleanup machinery. I'm not working on any of that myself right now because I don't want to step on Andres's toes. > >Here are some cases where I expect this patch to perform badly: > > > >* Your WAL has multiple intermixed sequential access streams (ie > >sequential access to N different relations), so that sequential access > >is not detected, and then all the WILLNEED advice prevents Linux's > >automagic readahead from working well. Perhaps that could be > >mitigated by having a system that can detect up to N concurrent > >streams, where N is more than the current 1, or by flagging buffers in > >the WAL as part of a sequential stream. I haven't looked into this. > > > > Hmmm, wouldn't it be enough to prefetch blocks in larger batches (not > one by one), and doing some sort of sorting? That should allow readahead > to kick in. Yeah, but I don't want to do too much work in the startup process, or get too opinionated about how the underlying I/O stack works. I think we'd need to do things like that in a direct I/O future, but we'd probably offload it (?). I figured the best approach for early work in this space would be to just get out of the way if we detect sequential access. > >* The data is always found in our buffer pool, so PrefetchBuffer() is > >doing nothing useful and you might as well not be calling it or doing > >the extra work that leads up to that. Perhaps that could be mitigated > >with an adaptive approach: too many PrefetchBuffer() hits and we stop > >trying to prefetch, too many XLogReadBufferForRedo() misses and we > >start trying to prefetch. That might work nicely for systems that > >start out with cold caches but eventually warm up. I haven't looked > >into this. > > > > I think the question is what's the cost of doing such unnecessary > prefetch. Presumably it's fairly cheap, especially compared to the > opposite case (not prefetching a block not in shared buffers). I wonder > how expensive would the adaptive logic be on cases that never need a > prefetch (i.e. datasets smaller than shared_buffers). Hmm. It's basically a buffer map probe. I think the adaptive logic would probably be some kind of periodically resetting counter scheme, but you're probably right to suspect that it might not even be worth bothering with, especially if a single XLogReader can be made to do the readahead with no real extra cost. Perhaps we should work on making the cost of all prefetching overheads as low as possible first, before trying to figure out whether it's worth building a system for avoiding it. > >* The prefetch distance is set too low so that pread() waits are not > >avoided, or your storage subsystem can't actually perform enough > >concurrent I/O to get ahead of the random access pattern you're > >generating, so no distance would be far enough ahead. To help with > >the former case, perhaps we could invent something smarter than a > >user-supplied distance (something like "N cold block references > >ahead", possibly using effective_io_concurrency, rather than "N bytes > >ahead"). > > > > In general, I find it quite non-intuitive to configure prefetching by > specifying WAL distance. I mean, how would you know what's a good value? > If you know the storage hardware, you probably know the optimal queue > depth i.e. you know you the number of requests to get best throughput. FWIW, on pgbench tests on flash storage I've found that 1KB only helps a bit, 8KB is great, and more than that doesn't get any better. Of course, this is meaningless in general; a zipfian workload might need to look a lot further head than a uniform one to find anything worth prefetching, and that's exactly what you're complaining about, and I agree. > But how do you deduce the WAL distance from that? I don't know. Plus > right after the checkpoint the WAL contains FPW, reducing the number of > blocks in a given amount of WAL (compared to right before a checkpoint). > So I expect users might pick unnecessarily high WAL distance. OTOH with > FPW we don't quite need agressive prefetching, right? Yeah, so you need to be touching blocks more than once between checkpoints, if you want to see speed-up on a system with blocks <= BLCKSZ and FPW on. If checkpoints are far enough apart you'll eventually run out of FPWs and start replaying non-FPW stuff. Or you could be on a filesystem with larger blocks than PostgreSQL. > Could we instead specify the number of blocks to prefetch? We'd probably > need to track additional details needed to determine number of blocks to > prefetch (essentially LSN for all prefetch requests). Yeah, I think you're right, we should probably try to make a little queue to track LSNs and count prefetch requests in and out. I think you'd also want PrefetchBuffer() to tell you if the block was already in the buffer pool, so that you don't count blocks that it decided not to prefetch. I guess PrefetchBuffer() needs to return an enum (I already had it returning a bool for another purpose relating to an edge case in crash recovery, when relations have been dropped by a later WAL record). I will think about that. > Another thing to consider might be skipping recently prefetched blocks. > Consider you have a loop that does DML, where each statement creates a > separate WAL record, but it can easily touch the same block over and > over (say inserting to the same page). That means the prefetches are > not really needed, but I'm not sure how expensive it really is. There are two levels of defence against repeatedly prefetching the same block: PrefetchBuffer() checks for blocks that are already in our cache, and before that, PrefetchState remembers the last block so that we can avoid fetching that block (or the following block). [1] https://github.com/macdice/some-io-tests [2] https://www.postgresql.org/message-id/CA%2BTgmoaj2aPti0yho7FeEf2qt-JgQPRWb0gci_o1Hfr%3DC56Xng%40mail.gmail.com
On Fri, Jan 3, 2020 at 5:57 PM Thomas Munro <thomas.munro@gmail.com> wrote: > On Fri, Jan 3, 2020 at 7:10 AM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: > > Could we instead specify the number of blocks to prefetch? We'd probably > > need to track additional details needed to determine number of blocks to > > prefetch (essentially LSN for all prefetch requests). Here is a new WIP version of the patch set that does that. Changes: 1. It now uses effective_io_concurrency to control how many concurrent prefetches to allow. It's possible that we should have a different GUC to control "maintenance" users of concurrency I/O as discussed elsewhere[1], but I'm staying out of that for now; if we agree to do that for VACUUM etc, we can change it easily here. Note that the value is percolated through the ComputeIoConcurrency() function which I think we should discuss, but again that's off topic, I just want to use the standard infrastructure here. 2. You can now change the relevant GUCs (wal_prefetch_distance, wal_prefetch_fpw, effective_io_concurrency) at runtime and reload for them to take immediate effect. For example, you can enable the feature on a running replica by setting wal_prefetch_distance=8kB (from the default of -1, which means off), and something like effective_io_concurrency=10, and telling the postmaster to reload. 3. The new code is moved out to a new file src/backend/access/transam/xlogprefetcher.c, to minimise new bloat in the mighty xlog.c file. Functions were renamed to make their purpose clearer, and a lot of comments were added. 4. The WAL receiver now exposes the current 'write' position via an atomic value in shared memory, so we don't need to hammer the WAL receiver's spinlock. 5. There is some rudimentary user documentation of the GUCs. [1] https://www.postgresql.org/message-id/13619.1557935593%40sss.pgh.pa.us
Attachment
- 0001-Allow-PrefetchBuffer-to-be-called-with-a-SMgrRela-v2.patch
- 0002-Rename-GetWalRcvWriteRecPtr-to-GetWalRcvFlushRecP-v2.patch
- 0003-Add-WalRcvGetWriteRecPtr-new-definition-v2.patch
- 0004-Allow-PrefetchBuffer-to-report-missing-file-in-re-v2.patch
- 0005-Prefetch-referenced-blocks-during-recovery-v2.patch
On Wed, Feb 12, 2020 at 7:52 PM Thomas Munro <thomas.munro@gmail.com> wrote:
> 1. It now uses effective_io_concurrency to control how many
> concurrent prefetches to allow. It's possible that we should have a
> different GUC to control "maintenance" users of concurrency I/O as
> discussed elsewhere[1], but I'm staying out of that for now; if we
> agree to do that for VACUUM etc, we can change it easily here. Note
> that the value is percolated through the ComputeIoConcurrency()
> function which I think we should discuss, but again that's off topic,
> I just want to use the standard infrastructure here.
I started a separate thread[1] to discuss that GUC, because it's
basically an independent question. Meanwhile, here's a new version of
the WAL prefetch patch, with the following changes:
1. A monitoring view:
postgres=# select * from pg_stat_wal_prefetcher ;
prefetch | skip_hit | skip_new | skip_fpw | skip_seq | distance | queue_depth
----------+----------+----------+----------+----------+----------+-------------
95854 | 291458 | 435 | 0 | 26245 | 261800 | 10
(1 row)
That shows a bunch of counters for blocks prefetched and skipped for
various reasons. It also shows the current read-ahead distance (in
bytes of WAL) and queue depth (an approximation of how many I/Os might
be in flight, used for rate limiting; I'm struggling to come up with a
better short name for this). This can be used to see the effects of
experiments with different settings, eg:
alter system set effective_io_concurrency = 20;
alter system set wal_prefetch_distance = '256kB';
select pg_reload_conf();
2. A log message when WAL prefetching begins and ends, so you can see
what it did during crash recovery:
LOG: WAL prefetch finished at 0/C5E98758; prefetch = 1112628,
skip_hit = 3607540,
skip_new = 45592, skip_fpw = 0, skip_seq = 177049, avg_distance =
247907.942532,
avg_queue_depth = 22.261352
3. A bit of general user documentation.
[1] https://www.postgresql.org/message-id/flat/CA%2BhUKGJUw08dPs_3EUcdO6M90GnjofPYrWp4YSLaBkgYwS-AqA%40mail.gmail.com
Attachment
I tried my luck at a quick read of this patchset.
I didn't manage to go over 0005 though, but I agree with Tomas that
having this be configurable in terms of bytes of WAL is not very
user-friendly.
First of all, let me join the crowd chanting that this is badly needed;
I don't need to repeat what Chittenden's talk showed. "WAL recovery is
now 10x-20x times faster" would be a good item for pg13 press release,
I think.
> From a61b4e00c42ace5db1608e02165f89094bf86391 Mon Sep 17 00:00:00 2001
> From: Thomas Munro <thomas.munro@gmail.com>
> Date: Tue, 3 Dec 2019 17:13:40 +1300
> Subject: [PATCH 1/5] Allow PrefetchBuffer() to be called with a SMgrRelation.
>
> Previously a Relation was required, but it's annoying to have
> to create a "fake" one in recovery.
LGTM.
It's a pity to have to include smgr.h in bufmgr.h. Maybe it'd be sane
to use a forward struct declaration and "struct SMgrRelation *" instead.
> From acbff1444d0acce71b0218ce083df03992af1581 Mon Sep 17 00:00:00 2001
> From: Thomas Munro <tmunro@postgresql.org>
> Date: Mon, 9 Dec 2019 17:10:17 +1300
> Subject: [PATCH 2/5] Rename GetWalRcvWriteRecPtr() to GetWalRcvFlushRecPtr().
>
> The new name better reflects the fact that the value it returns
> is updated only when received data has been flushed to disk.
>
> An upcoming patch will make use of the latest data that was
> written without waiting for it to be flushed, so use more
> precise function names.
Ugh. (Not for your patch -- I mean for the existing naming convention).
It would make sense to rename WalRcvData->receivedUpto in this commit,
maybe to flushedUpto.
> From d7fa7d82c5f68d0cccf441ce9e8dfa40f64d3e0d Mon Sep 17 00:00:00 2001
> From: Thomas Munro <tmunro@postgresql.org>
> Date: Mon, 9 Dec 2019 17:22:07 +1300
> Subject: [PATCH 3/5] Add WalRcvGetWriteRecPtr() (new definition).
>
> A later patch will read received WAL to prefetch referenced blocks,
> without waiting for the data to be flushed to disk. To do that,
> it needs to be able to see the write pointer advancing in shared
> memory.
>
> The function formerly bearing name was recently renamed to
> WalRcvGetFlushRecPtr(), which better described what it does.
> + pg_atomic_init_u64(&WalRcv->writtenUpto, 0);
Umm, how come you're using WalRcv here instead of walrcv? I would flag
this patch for sneaky nastiness if this weren't mostly harmless. (I
think we should do away with local walrcv pointers altogether. But that
should be a separate patch, I think.)
> + pg_atomic_uint64 writtenUpto;
Are we already using uint64s for XLogRecPtrs anywhere? This seems
novel. Given this, I wonder if the comment near "mutex" needs an
update ("except where atomics are used"), or perhaps just move the
member to after the line with mutex.
I didn't understand the purpose of inc_counter() as written. Why not
just pg_atomic_fetch_add_u64(..., 1)?
> /*
> * smgrprefetch() -- Initiate asynchronous read of the specified block of a relation.
> + *
> + * In recovery only, this can return false to indicate that a file
> + * doesn't exist (presumably it has been dropped by a later WAL
> + * record).
> */
> -void
> +bool
> smgrprefetch(SMgrRelation reln, ForkNumber forknum, BlockNumber blocknum)
I think this API, where the behavior of a low-level module changes
depending on InRecovery, is confusingly crazy. I'd rather have the
callers specifying whether they're OK with a file that doesn't exist.
> +extern PrefetchBufferResult SharedPrefetchBuffer(SMgrRelation smgr_reln,
> + ForkNumber forkNum,
> + BlockNumber blockNum);
> extern void PrefetchBuffer(Relation reln, ForkNumber forkNum,
> BlockNumber blockNum);
Umm, I would keep the return values of both these functions in sync.
It's really strange that PrefetchBuffer does not return
PrefetchBufferResult, don't you think?
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi Alvaro,
On Sat, Mar 14, 2020 at 10:15 AM Alvaro Herrera
<alvherre@2ndquadrant.com> wrote:
> I tried my luck at a quick read of this patchset.
Thanks! Here's a new patch set, and some inline responses to your feedback:
> I didn't manage to go over 0005 though, but I agree with Tomas that
> having this be configurable in terms of bytes of WAL is not very
> user-friendly.
The primary control is now maintenance_io_concurrency, which is
basically what Tomas suggested.
The byte-based control is just a cap to prevent it reading a crazy
distance ahead, that also functions as the on/off switch for the
feature. In this version I've added "max" to the name, to make that
clearer.
> First of all, let me join the crowd chanting that this is badly needed;
> I don't need to repeat what Chittenden's talk showed. "WAL recovery is
> now 10x-20x times faster" would be a good item for pg13 press release,
> I think.
We should be careful about over-promising here: Sean basically had a
best case scenario for this type of techology, partly due to his 16kB
filesystem blocks. Common results may be a lot more pedestrian,
though it could get more interesting if we figure out how to get rid
of FPWs...
> > From a61b4e00c42ace5db1608e02165f89094bf86391 Mon Sep 17 00:00:00 2001
> > From: Thomas Munro <thomas.munro@gmail.com>
> > Date: Tue, 3 Dec 2019 17:13:40 +1300
> > Subject: [PATCH 1/5] Allow PrefetchBuffer() to be called with a SMgrRelation.
> >
> > Previously a Relation was required, but it's annoying to have
> > to create a "fake" one in recovery.
>
> LGTM.
>
> It's a pity to have to include smgr.h in bufmgr.h. Maybe it'd be sane
> to use a forward struct declaration and "struct SMgrRelation *" instead.
OK, done.
While staring at this, I decided that SharedPrefetchBuffer() was a
weird word order, so I changed it to PrefetchSharedBuffer(). Then, by
analogy, I figured I should also change the pre-existing function
LocalPrefetchBuffer() to PrefetchLocalBuffer(). Do you think this is
an improvement?
> > From acbff1444d0acce71b0218ce083df03992af1581 Mon Sep 17 00:00:00 2001
> > From: Thomas Munro <tmunro@postgresql.org>
> > Date: Mon, 9 Dec 2019 17:10:17 +1300
> > Subject: [PATCH 2/5] Rename GetWalRcvWriteRecPtr() to GetWalRcvFlushRecPtr().
> >
> > The new name better reflects the fact that the value it returns
> > is updated only when received data has been flushed to disk.
> >
> > An upcoming patch will make use of the latest data that was
> > written without waiting for it to be flushed, so use more
> > precise function names.
>
> Ugh. (Not for your patch -- I mean for the existing naming convention).
> It would make sense to rename WalRcvData->receivedUpto in this commit,
> maybe to flushedUpto.
Ok, I renamed that variable and a related one. There are more things
you could rename if you pull on that thread some more, including
pg_stat_wal_receiver's received_lsn column, but I didn't do that in
this patch.
> > From d7fa7d82c5f68d0cccf441ce9e8dfa40f64d3e0d Mon Sep 17 00:00:00 2001
> > From: Thomas Munro <tmunro@postgresql.org>
> > Date: Mon, 9 Dec 2019 17:22:07 +1300
> > Subject: [PATCH 3/5] Add WalRcvGetWriteRecPtr() (new definition).
> >
> > A later patch will read received WAL to prefetch referenced blocks,
> > without waiting for the data to be flushed to disk. To do that,
> > it needs to be able to see the write pointer advancing in shared
> > memory.
> >
> > The function formerly bearing name was recently renamed to
> > WalRcvGetFlushRecPtr(), which better described what it does.
>
> > + pg_atomic_init_u64(&WalRcv->writtenUpto, 0);
>
> Umm, how come you're using WalRcv here instead of walrcv? I would flag
> this patch for sneaky nastiness if this weren't mostly harmless. (I
> think we should do away with local walrcv pointers altogether. But that
> should be a separate patch, I think.)
OK, done.
> > + pg_atomic_uint64 writtenUpto;
>
> Are we already using uint64s for XLogRecPtrs anywhere? This seems
> novel. Given this, I wonder if the comment near "mutex" needs an
> update ("except where atomics are used"), or perhaps just move the
> member to after the line with mutex.
Moved.
We use [u]int64 in various places in the replication code. Ideally
I'd have a magic way to say atomic<XLogRecPtr> so I didn't have to
assume that pg_atomic_uint64 is the right atomic integer width and
signedness, but here we are. In dsa.h I made a special typedef for
the atomic version of something else, but that's because the size of
that thing varied depending on the build, whereas our LSNs are of a
fixed width that ought to be en... <trails off>.
> I didn't understand the purpose of inc_counter() as written. Why not
> just pg_atomic_fetch_add_u64(..., 1)?
I didn't want counters that wrap at ~4 billion, but I did want to be
able to read and write concurrently without tearing. Instructions
like "lock xadd" would provide more guarantees that I don't need,
since only one thread is doing all the writing and there's no ordering
requirement. It's basically just counter++, but some platforms need a
spinlock to perform atomic read and write of 64 bit wide numbers, so
more hoop jumping is required.
> > /*
> > * smgrprefetch() -- Initiate asynchronous read of the specified block of a relation.
> > + *
> > + * In recovery only, this can return false to indicate that a file
> > + * doesn't exist (presumably it has been dropped by a later WAL
> > + * record).
> > */
> > -void
> > +bool
> > smgrprefetch(SMgrRelation reln, ForkNumber forknum, BlockNumber blocknum)
>
> I think this API, where the behavior of a low-level module changes
> depending on InRecovery, is confusingly crazy. I'd rather have the
> callers specifying whether they're OK with a file that doesn't exist.
Hmm. But... md.c has other code like that. It's true that I'm adding
InRecovery awareness to a function that didn't previously have it, but
that's just because we previously had no reason to prefetch stuff in
recovery.
> > +extern PrefetchBufferResult SharedPrefetchBuffer(SMgrRelation smgr_reln,
> > + ForkNumber forkNum,
> > + BlockNumber
blockNum);
> > extern void PrefetchBuffer(Relation reln, ForkNumber forkNum,
> > BlockNumber blockNum);
>
> Umm, I would keep the return values of both these functions in sync.
> It's really strange that PrefetchBuffer does not return
> PrefetchBufferResult, don't you think?
Agreed, and changed. I suspect that other users of the main
PrefetchBuffer() call will eventually want that, to do a better job of
keeping the request queue full, for example bitmap heap scan and
(hypothetical) btree scan with prefetch.
Attachment
On 2020-Mar-17, Thomas Munro wrote:
Hi Thomas
> On Sat, Mar 14, 2020 at 10:15 AM Alvaro Herrera
> <alvherre@2ndquadrant.com> wrote:
> > I didn't manage to go over 0005 though, but I agree with Tomas that
> > having this be configurable in terms of bytes of WAL is not very
> > user-friendly.
>
> The primary control is now maintenance_io_concurrency, which is
> basically what Tomas suggested.
> The byte-based control is just a cap to prevent it reading a crazy
> distance ahead, that also functions as the on/off switch for the
> feature. In this version I've added "max" to the name, to make that
> clearer.
Mumble. I guess I should wait to comment on this after reading 0005
more in depth.
> > First of all, let me join the crowd chanting that this is badly needed;
> > I don't need to repeat what Chittenden's talk showed. "WAL recovery is
> > now 10x-20x times faster" would be a good item for pg13 press release,
> > I think.
>
> We should be careful about over-promising here: Sean basically had a
> best case scenario for this type of techology, partly due to his 16kB
> filesystem blocks. Common results may be a lot more pedestrian,
> though it could get more interesting if we figure out how to get rid
> of FPWs...
Well, in my mind it's an established fact that our WAL replay uses far
too little of the available I/O speed. I guess if the system is
generating little WAL, then this change will show no benefit, but that's
not the kind of system that cares about this anyway -- for the others,
the parallelisation gains will be substantial, I'm sure.
> > > From a61b4e00c42ace5db1608e02165f89094bf86391 Mon Sep 17 00:00:00 2001
> > > From: Thomas Munro <thomas.munro@gmail.com>
> > > Date: Tue, 3 Dec 2019 17:13:40 +1300
> > > Subject: [PATCH 1/5] Allow PrefetchBuffer() to be called with a SMgrRelation.
> > >
> > > Previously a Relation was required, but it's annoying to have
> > > to create a "fake" one in recovery.
> While staring at this, I decided that SharedPrefetchBuffer() was a
> weird word order, so I changed it to PrefetchSharedBuffer(). Then, by
> analogy, I figured I should also change the pre-existing function
> LocalPrefetchBuffer() to PrefetchLocalBuffer(). Do you think this is
> an improvement?
Looks good. I doubt you'll break anything by renaming that routine.
> > > From acbff1444d0acce71b0218ce083df03992af1581 Mon Sep 17 00:00:00 2001
> > > From: Thomas Munro <tmunro@postgresql.org>
> > > Date: Mon, 9 Dec 2019 17:10:17 +1300
> > > Subject: [PATCH 2/5] Rename GetWalRcvWriteRecPtr() to GetWalRcvFlushRecPtr().
> > >
> > > The new name better reflects the fact that the value it returns
> > > is updated only when received data has been flushed to disk.
> > >
> > > An upcoming patch will make use of the latest data that was
> > > written without waiting for it to be flushed, so use more
> > > precise function names.
> >
> > Ugh. (Not for your patch -- I mean for the existing naming convention).
> > It would make sense to rename WalRcvData->receivedUpto in this commit,
> > maybe to flushedUpto.
>
> Ok, I renamed that variable and a related one. There are more things
> you could rename if you pull on that thread some more, including
> pg_stat_wal_receiver's received_lsn column, but I didn't do that in
> this patch.
+1 for that approach. Maybe we'll want to rename the SQL-visible name,
but I wouldn't burden this patch with that, lest we lose the entire
series to that :-)
> > > + pg_atomic_uint64 writtenUpto;
> >
> > Are we already using uint64s for XLogRecPtrs anywhere? This seems
> > novel. Given this, I wonder if the comment near "mutex" needs an
> > update ("except where atomics are used"), or perhaps just move the
> > member to after the line with mutex.
>
> Moved.
LGTM.
> We use [u]int64 in various places in the replication code. Ideally
> I'd have a magic way to say atomic<XLogRecPtr> so I didn't have to
> assume that pg_atomic_uint64 is the right atomic integer width and
> signedness, but here we are. In dsa.h I made a special typedef for
> the atomic version of something else, but that's because the size of
> that thing varied depending on the build, whereas our LSNs are of a
> fixed width that ought to be en... <trails off>.
Let's rewrite Postgres in Rust ...
> > I didn't understand the purpose of inc_counter() as written. Why not
> > just pg_atomic_fetch_add_u64(..., 1)?
>
> I didn't want counters that wrap at ~4 billion, but I did want to be
> able to read and write concurrently without tearing. Instructions
> like "lock xadd" would provide more guarantees that I don't need,
> since only one thread is doing all the writing and there's no ordering
> requirement. It's basically just counter++, but some platforms need a
> spinlock to perform atomic read and write of 64 bit wide numbers, so
> more hoop jumping is required.
Ah, I see, you don't want lock xadd ... That's non-obvious. I suppose
the function could use more commentary on *why* you're doing it that way
then.
> > > /*
> > > * smgrprefetch() -- Initiate asynchronous read of the specified block of a relation.
> > > + *
> > > + * In recovery only, this can return false to indicate that a file
> > > + * doesn't exist (presumably it has been dropped by a later WAL
> > > + * record).
> > > */
> > > -void
> > > +bool
> > > smgrprefetch(SMgrRelation reln, ForkNumber forknum, BlockNumber blocknum)
> >
> > I think this API, where the behavior of a low-level module changes
> > depending on InRecovery, is confusingly crazy. I'd rather have the
> > callers specifying whether they're OK with a file that doesn't exist.
>
> Hmm. But... md.c has other code like that. It's true that I'm adding
> InRecovery awareness to a function that didn't previously have it, but
> that's just because we previously had no reason to prefetch stuff in
> recovery.
True. I'm uncomfortable about it anyway. I also noticed that
_mdfd_getseg() already has InRecovery-specific behavior flags.
Clearly that ship has sailed. Consider my objection^W comment withdrawn.
> > Umm, I would keep the return values of both these functions in sync.
> > It's really strange that PrefetchBuffer does not return
> > PrefetchBufferResult, don't you think?
>
> Agreed, and changed. I suspect that other users of the main
> PrefetchBuffer() call will eventually want that, to do a better job of
> keeping the request queue full, for example bitmap heap scan and
> (hypothetical) btree scan with prefetch.
LGTM.
As before, I didn't get to reading 0005 in depth.
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Mar 18, 2020 at 2:47 PM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > On 2020-Mar-17, Thomas Munro wrote: > > I didn't want counters that wrap at ~4 billion, but I did want to be > > able to read and write concurrently without tearing. Instructions > > like "lock xadd" would provide more guarantees that I don't need, > > since only one thread is doing all the writing and there's no ordering > > requirement. It's basically just counter++, but some platforms need a > > spinlock to perform atomic read and write of 64 bit wide numbers, so > > more hoop jumping is required. > > Ah, I see, you don't want lock xadd ... That's non-obvious. I suppose > the function could use more commentary on *why* you're doing it that way > then. I updated the comment: +/* + * On modern systems this is really just *counter++. On some older systems + * there might be more to it, due to inability to read and write 64 bit values + * atomically. The counters will only be written to by one process, and there + * is no ordering requirement, so there's no point in using higher overhead + * pg_atomic_fetch_add_u64(). + */ +static inline void inc_counter(pg_atomic_uint64 *counter) > > > Umm, I would keep the return values of both these functions in sync. > > > It's really strange that PrefetchBuffer does not return > > > PrefetchBufferResult, don't you think? > > > > Agreed, and changed. I suspect that other users of the main > > PrefetchBuffer() call will eventually want that, to do a better job of > > keeping the request queue full, for example bitmap heap scan and > > (hypothetical) btree scan with prefetch. > > LGTM. Here's a new version that changes that part just a bit more, after a brief chat with Andres about his async I/O plans. It seems clear that returning an enum isn't very extensible, so I decided to try making PrefetchBufferResult a struct whose contents can be extended in the future. In this patch set it's still just used to distinguish 3 cases (hit, miss, no file), but it's now expressed as a buffer and a flag to indicate whether I/O was initiated. You could imagine that the second thing might be replaced by a pointer to an async I/O handle you can wait on or some other magical thing from the future. The concept here is that eventually we'll have just one XLogReader for both read ahead and recovery, and we could attach the prefetch results to the decoded records, and then recovery would try to use already looked up buffers to avoid a bit of work (and then recheck). In other words, the WAL would be decoded only once, and the buffers would hopefully be looked up only once, so you'd claw back all of the overheads of this patch. For now that's not done, and the buffer in the result is only compared with InvalidBuffer to check if there was a hit or not. Similar things could be done for bitmap heap scan and btree prefetch with this interface: their prefetch machinery could hold onto these results in their block arrays and try to avoid a more expensive ReadBuffer() call if they already have a buffer (though as before, there's a small chance it turns out to be the wrong one and they need to fall back to ReadBuffer()). > As before, I didn't get to reading 0005 in depth. Updated to account for the above-mentioned change, and with a couple of elog() calls changed to ereport().
Attachment
Hi,
On 2020-03-18 18:18:44 +1300, Thomas Munro wrote:
> From 1b03eb5ada24c3b23ab8ca6db50e0c5d90d38259 Mon Sep 17 00:00:00 2001
> From: Thomas Munro <tmunro@postgresql.org>
> Date: Mon, 9 Dec 2019 17:22:07 +1300
> Subject: [PATCH 3/5] Add WalRcvGetWriteRecPtr() (new definition).
>
> A later patch will read received WAL to prefetch referenced blocks,
> without waiting for the data to be flushed to disk. To do that, it
> needs to be able to see the write pointer advancing in shared memory.
>
> The function formerly bearing name was recently renamed to
> WalRcvGetFlushRecPtr(), which better described what it does.
Hm. I'm a bit weary of reusing the name with a different meaning. If
there's any external references, this'll hide that they need to
adapt. Perhaps, even if it's a bit clunky, name it GetUnflushedRecPtr?
> From c62fde23f70ff06833d743a1c85716e15f3c813c Mon Sep 17 00:00:00 2001
> From: Thomas Munro <thomas.munro@gmail.com>
> Date: Tue, 17 Mar 2020 17:26:41 +1300
> Subject: [PATCH 4/5] Allow PrefetchBuffer() to report what happened.
>
> Report whether a prefetch was actually initiated due to a cache miss, so
> that callers can limit the number of concurrent I/Os they try to issue,
> without counting the prefetch calls that did nothing because the page
> was already in our buffers.
>
> If the requested block was already cached, return a valid buffer. This
> might enable future code to avoid a buffer mapping lookup, though it
> will need to recheck the buffer before using it because it's not pinned
> so could be reclaimed at any time.
>
> Report neither hit nor miss when a relation's backing file is missing,
> to prepare for use during recovery. This will be used to handle cases
> of relations that are referenced in the WAL but have been unlinked
> already due to actions covered by WAL records that haven't been replayed
> yet, after a crash.
We probably should take this into account in nodeBitmapHeapscan.c
> diff --git a/src/backend/storage/buffer/bufmgr.c b/src/backend/storage/buffer/bufmgr.c
> index d30aed6fd9..4ceb40a856 100644
> --- a/src/backend/storage/buffer/bufmgr.c
> +++ b/src/backend/storage/buffer/bufmgr.c
> @@ -469,11 +469,13 @@ static int ts_ckpt_progress_comparator(Datum a, Datum b, void *arg);
> /*
> * Implementation of PrefetchBuffer() for shared buffers.
> */
> -void
> +PrefetchBufferResult
> PrefetchSharedBuffer(struct SMgrRelationData *smgr_reln,
> ForkNumber forkNum,
> BlockNumber blockNum)
> {
> + PrefetchBufferResult result = { InvalidBuffer, false };
> +
> #ifdef USE_PREFETCH
> BufferTag newTag; /* identity of requested block */
> uint32 newHash; /* hash value for newTag */
> @@ -497,7 +499,23 @@ PrefetchSharedBuffer(struct SMgrRelationData *smgr_reln,
>
> /* If not in buffers, initiate prefetch */
> if (buf_id < 0)
> - smgrprefetch(smgr_reln, forkNum, blockNum);
> + {
> + /*
> + * Try to initiate an asynchronous read. This returns false in
> + * recovery if the relation file doesn't exist.
> + */
> + if (smgrprefetch(smgr_reln, forkNum, blockNum))
> + result.initiated_io = true;
> + }
> + else
> + {
> + /*
> + * Report the buffer it was in at that time. The caller may be able
> + * to avoid a buffer table lookup, but it's not pinned and it must be
> + * rechecked!
> + */
> + result.buffer = buf_id + 1;
Perhaps it'd be better to name this "last_buffer" or such, to make it
clearer that it may be outdated?
> -void
> +PrefetchBufferResult
> PrefetchBuffer(Relation reln, ForkNumber forkNum, BlockNumber blockNum)
> {
> #ifdef USE_PREFETCH
> @@ -540,13 +564,17 @@ PrefetchBuffer(Relation reln, ForkNumber forkNum, BlockNumber blockNum)
> errmsg("cannot access temporary tables of other sessions")));
>
> /* pass it off to localbuf.c */
> - PrefetchLocalBuffer(reln->rd_smgr, forkNum, blockNum);
> + return PrefetchLocalBuffer(reln->rd_smgr, forkNum, blockNum);
> }
> else
> {
> /* pass it to the shared buffer version */
> - PrefetchSharedBuffer(reln->rd_smgr, forkNum, blockNum);
> + return PrefetchSharedBuffer(reln->rd_smgr, forkNum, blockNum);
> }
> +#else
> + PrefetchBuffer result = { InvalidBuffer, false };
> +
> + return result;
> #endif /* USE_PREFETCH */
> }
Hm. Now that results are returned indicating whether the buffer is in
s_b - shouldn't the return value be accurate regardless of USE_PREFETCH?
> +/*
> + * Type returned by PrefetchBuffer().
> + */
> +typedef struct PrefetchBufferResult
> +{
> + Buffer buffer; /* If valid, a hit (recheck needed!) */
I assume there's no user of this yet? Even if there's not, I wonder if
it still is worth adding and referencing a helper to do so correctly?
> From 42ba0a89260d46230ac0df791fae18bfdca0092f Mon Sep 17 00:00:00 2001
> From: Thomas Munro <thomas.munro@gmail.com>
> Date: Wed, 18 Mar 2020 16:35:27 +1300
> Subject: [PATCH 5/5] Prefetch referenced blocks during recovery.
>
> Introduce a new GUC max_wal_prefetch_distance. If it is set to a
> positive number of bytes, then read ahead in the WAL at most that
> distance, and initiate asynchronous reading of referenced blocks. The
> goal is to avoid I/O stalls and benefit from concurrent I/O. The number
> of concurrency asynchronous reads is capped by the existing
> maintenance_io_concurrency GUC. The feature is disabled by default.
>
> Reviewed-by: Tomas Vondra <tomas.vondra@2ndquadrant.com>
> Reviewed-by: Alvaro Herrera <alvherre@2ndquadrant.com>
> Discussion:
> https://postgr.es/m/CA%2BhUKGJ4VJN8ttxScUFM8dOKX0BrBiboo5uz1cq%3DAovOddfHpA%40mail.gmail.com
Why is it disabled by default? Just for "risk management"?
> + <varlistentry id="guc-max-wal-prefetch-distance" xreflabel="max_wal_prefetch_distance">
> + <term><varname>max_wal_prefetch_distance</varname> (<type>integer</type>)
> + <indexterm>
> + <primary><varname>max_wal_prefetch_distance</varname> configuration parameter</primary>
> + </indexterm>
> + </term>
> + <listitem>
> + <para>
> + The maximum distance to look ahead in the WAL during recovery, to find
> + blocks to prefetch. Prefetching blocks that will soon be needed can
> + reduce I/O wait times. The number of concurrent prefetches is limited
> + by this setting as well as <xref linkend="guc-maintenance-io-concurrency"/>.
> + If this value is specified without units, it is taken as bytes.
> + The default is -1, meaning that WAL prefetching is disabled.
> + </para>
> + </listitem>
> + </varlistentry>
Is it worth noting that a too large distance could hurt, because the
buffers might get evicted again?
> + <varlistentry id="guc-wal-prefetch-fpw" xreflabel="wal_prefetch_fpw">
> + <term><varname>wal_prefetch_fpw</varname> (<type>boolean</type>)
> + <indexterm>
> + <primary><varname>wal_prefetch_fpw</varname> configuration parameter</primary>
> + </indexterm>
> + </term>
> + <listitem>
> + <para>
> + Whether to prefetch blocks with full page images during recovery.
> + Usually this doesn't help, since such blocks will not be read. However,
> + on file systems with a block size larger than
> + <productname>PostgreSQL</productname>'s, prefetching can avoid a costly
> + read-before-write when a blocks are later written.
> + This setting has no effect unless
> + <xref linkend="guc-max-wal-prefetch-distance"/> is set to a positive number.
> + The default is off.
> + </para>
> + </listitem>
> + </varlistentry>
Hm. I think this needs more details - it's not clear enough what this
actually controls. I assume it's about prefetching for WAL records that
contain the FPW, but it also could be read to be about not prefetching
any pages that had FPWs before, or such?
> </variablelist>
> </sect2>
> <sect2 id="runtime-config-wal-archiving">
> diff --git a/doc/src/sgml/monitoring.sgml b/doc/src/sgml/monitoring.sgml
> index 987580d6df..df4291092b 100644
> --- a/doc/src/sgml/monitoring.sgml
> +++ b/doc/src/sgml/monitoring.sgml
> @@ -320,6 +320,13 @@ postgres 27093 0.0 0.0 30096 2752 ? Ss 11:34 0:00 postgres: ser
> </entry>
> </row>
>
> + <row>
> +
<entry><structname>pg_stat_wal_prefetcher</structname><indexterm><primary>pg_stat_wal_prefetcher</primary></indexterm></entry>
> + <entry>Only one row, showing statistics about blocks prefetched during recovery.
> + See <xref linkend="pg-stat-wal-prefetcher-view"/> for details.
> + </entry>
> + </row>
> +
'prefetcher' somehow sounds odd to me. I also suspect that we'll want to
have additional prefetching stat tables going forward. Perhaps
'pg_stat_prefetch_wal'?
> + <row>
> + <entry><structfield>distance</structfield></entry>
> + <entry><type>integer</type></entry>
> + <entry>How far ahead of recovery the WAL prefetcher is currently reading, in bytes</entry>
> + </row>
> + <row>
> + <entry><structfield>queue_depth</structfield></entry>
> + <entry><type>integer</type></entry>
> + <entry>How many prefetches have been initiated but are not yet known to have completed</entry>
> + </row>
> + </tbody>
> + </tgroup>
> + </table>
Is there a way we could have a "historical" version of at least some of
these? An average queue depth, or such?
It'd be useful to somewhere track the time spent initiating prefetch
requests. Otherwise it's quite hard to evaluate whether the queue is too
deep (and just blocks in the OS).
I think it'd be good to have a 'reset time' column.
> + <para>
> + The <structname>pg_stat_wal_prefetcher</structname> view will contain only
> + one row. It is filled with nulls if recovery is not running or WAL
> + prefetching is not enabled. See <xref linkend="guc-max-wal-prefetch-distance"/>
> + for more information. The counters in this view are reset whenever the
> + <xref linkend="guc-max-wal-prefetch-distance"/>,
> + <xref linkend="guc-wal-prefetch-fpw"/> or
> + <xref linkend="guc-maintenance-io-concurrency"/> setting is changed and
> + the server configuration is reloaded.
> + </para>
> +
So pg_stat_reset_shared() cannot be used? If so, why?
It sounds like the counters aren't persisted via the stats system - if
so, why?
> @@ -7105,6 +7114,31 @@ StartupXLOG(void)
> /* Handle interrupt signals of startup process */
> HandleStartupProcInterrupts();
>
> + /*
> + * The first time through, or if any relevant settings or the
> + * WAL source changes, we'll restart the prefetching machinery
> + * as appropriate. This is simpler than trying to handle
> + * various complicated state changes.
> + */
> + if (unlikely(reset_wal_prefetcher))
> + {
> + /* If we had one already, destroy it. */
> + if (prefetcher)
> + {
> + XLogPrefetcherFree(prefetcher);
> + prefetcher = NULL;
> + }
> + /* If we want one, create it. */
> + if (max_wal_prefetch_distance > 0)
> + prefetcher = XLogPrefetcherAllocate(xlogreader->ReadRecPtr,
> + currentSource == XLOG_FROM_STREAM);
> + reset_wal_prefetcher = false;
> + }
Do we really need all of this code in StartupXLOG() itself? Could it be
in HandleStartupProcInterrupts() or at least a helper routine called
here?
> + /* Peform WAL prefetching, if enabled. */
> + if (prefetcher)
> + XLogPrefetcherReadAhead(prefetcher, xlogreader->ReadRecPtr);
> +
> /*
> * Pause WAL replay, if requested by a hot-standby session via
> * SetRecoveryPause().
Personally, I'd rather have the if () be in
XLogPrefetcherReadAhead(). With an inline wrapper doing the check, if
the call bothers you (but I don't think it needs to).
> +/*-------------------------------------------------------------------------
> + *
> + * xlogprefetcher.c
> + * Prefetching support for PostgreSQL write-ahead log manager
> + *
An architectural overview here would be good.
> +struct XLogPrefetcher
> +{
> + /* Reader and current reading state. */
> + XLogReaderState *reader;
> + XLogReadLocalOptions options;
> + bool have_record;
> + bool shutdown;
> + int next_block_id;
> +
> + /* Book-keeping required to avoid accessing non-existing blocks. */
> + HTAB *filter_table;
> + dlist_head filter_queue;
> +
> + /* Book-keeping required to limit concurrent prefetches. */
> + XLogRecPtr *prefetch_queue;
> + int prefetch_queue_size;
> + int prefetch_head;
> + int prefetch_tail;
> +
> + /* Details of last prefetch to skip repeats and seq scans. */
> + SMgrRelation last_reln;
> + RelFileNode last_rnode;
> + BlockNumber last_blkno;
Do you have a comment somewhere explaining why you want to avoid
seqscans (I assume it's about avoiding regressions in linux, but only
because I recall chatting with you about it).
> +/*
> + * On modern systems this is really just *counter++. On some older systems
> + * there might be more to it, due to inability to read and write 64 bit values
> + * atomically. The counters will only be written to by one process, and there
> + * is no ordering requirement, so there's no point in using higher overhead
> + * pg_atomic_fetch_add_u64().
> + */
> +static inline void inc_counter(pg_atomic_uint64 *counter)
> +{
> + pg_atomic_write_u64(counter, pg_atomic_read_u64(counter) + 1);
> +}
Could be worthwhile to add to the atomics infrastructure itself - on the
platforms where this needs spinlocks this will lead to two acquisitions,
rather than one.
> +/*
> + * Create a prefetcher that is ready to begin prefetching blocks referenced by
> + * WAL that is ahead of the given lsn.
> + */
> +XLogPrefetcher *
> +XLogPrefetcherAllocate(XLogRecPtr lsn, bool streaming)
> +{
> + static HASHCTL hash_table_ctl = {
> + .keysize = sizeof(RelFileNode),
> + .entrysize = sizeof(XLogPrefetcherFilter)
> + };
> + XLogPrefetcher *prefetcher = palloc0(sizeof(*prefetcher));
> +
> + prefetcher->options.nowait = true;
> + if (streaming)
> + {
> + /*
> + * We're only allowed to read as far as the WAL receiver has written.
> + * We don't have to wait for it to be flushed, though, as recovery
> + * does, so that gives us a chance to get a bit further ahead.
> + */
> + prefetcher->options.read_upto_policy = XLRO_WALRCV_WRITTEN;
> + }
> + else
> + {
> + /* We're allowed to read as far as we can. */
> + prefetcher->options.read_upto_policy = XLRO_LSN;
> + prefetcher->options.lsn = (XLogRecPtr) -1;
> + }
> + prefetcher->reader = XLogReaderAllocate(wal_segment_size,
> + NULL,
> + read_local_xlog_page,
> + &prefetcher->options);
> + prefetcher->filter_table = hash_create("PrefetchFilterTable", 1024,
> + &hash_table_ctl,
> + HASH_ELEM | HASH_BLOBS);
> + dlist_init(&prefetcher->filter_queue);
> +
> + /*
> + * The size of the queue is based on the maintenance_io_concurrency
> + * setting. In theory we might have a separate queue for each tablespace,
> + * but it's not clear how that should work, so for now we'll just use the
> + * general GUC to rate-limit all prefetching.
> + */
> + prefetcher->prefetch_queue_size = maintenance_io_concurrency;
> + prefetcher->prefetch_queue = palloc0(sizeof(XLogRecPtr) * prefetcher->prefetch_queue_size);
> + prefetcher->prefetch_head = prefetcher->prefetch_tail = 0;
> +
> + /* Prepare to read at the given LSN. */
> + ereport(LOG,
> + (errmsg("WAL prefetch started at %X/%X",
> + (uint32) (lsn << 32), (uint32) lsn)));
> + XLogBeginRead(prefetcher->reader, lsn);
> +
> + XLogPrefetcherResetMonitoringStats();
> +
> + return prefetcher;
> +}
> +
> +/*
> + * Destroy a prefetcher and release all resources.
> + */
> +void
> +XLogPrefetcherFree(XLogPrefetcher *prefetcher)
> +{
> + double avg_distance = 0;
> + double avg_queue_depth = 0;
> +
> + /* Log final statistics. */
> + if (prefetcher->samples > 0)
> + {
> + avg_distance = prefetcher->distance_sum / prefetcher->samples;
> + avg_queue_depth = prefetcher->queue_depth_sum / prefetcher->samples;
> + }
> + ereport(LOG,
> + (errmsg("WAL prefetch finished at %X/%X; "
> + "prefetch = " UINT64_FORMAT ", "
> + "skip_hit = " UINT64_FORMAT ", "
> + "skip_new = " UINT64_FORMAT ", "
> + "skip_fpw = " UINT64_FORMAT ", "
> + "skip_seq = " UINT64_FORMAT ", "
> + "avg_distance = %f, "
> + "avg_queue_depth = %f",
> + (uint32) (prefetcher->reader->EndRecPtr << 32),
> + (uint32) (prefetcher->reader->EndRecPtr),
> + pg_atomic_read_u64(&MonitoringStats->prefetch),
> + pg_atomic_read_u64(&MonitoringStats->skip_hit),
> + pg_atomic_read_u64(&MonitoringStats->skip_new),
> + pg_atomic_read_u64(&MonitoringStats->skip_fpw),
> + pg_atomic_read_u64(&MonitoringStats->skip_seq),
> + avg_distance,
> + avg_queue_depth)));
> + XLogReaderFree(prefetcher->reader);
> + hash_destroy(prefetcher->filter_table);
> + pfree(prefetcher->prefetch_queue);
> + pfree(prefetcher);
> +
> + XLogPrefetcherResetMonitoringStats();
> +}
It's possibly overkill, but I think it'd be a good idea to do all the
allocations within a prefetch specific memory context. That makes
detecting potential leaks or such easier.
> + /* Can we drop any filters yet, due to problem records begin replayed? */
Odd grammar.
> + XLogPrefetcherCompleteFilters(prefetcher, replaying_lsn);
Hm, why isn't this part of the loop below?
> + /* Main prefetch loop. */
> + for (;;)
> + {
This kind of looks like a separate process' main loop. The name
indicates similar. And there's no architecture documentation
disinclining one from that view...
The loop body is quite long. I think it should be split into a number of
helper functions. Perhaps one to ensure a block is read, one to maintain
stats, and then one to process block references?
> + /*
> + * Scan the record for block references. We might already have been
> + * partway through processing this record when we hit maximum I/O
> + * concurrency, so start where we left off.
> + */
> + for (int i = prefetcher->next_block_id; i <= reader->max_block_id; ++i)
> + {
Super pointless nitpickery: For a loop-body this big I'd rather name 'i'
'blockid' or such.
Greetings,
Andres Freund
Hi,
Thanks for all that feedback. It's been a strange couple of weeks,
but I finally have a new version that addresses most of that feedback
(but punts on a couple of suggestions for later development, due to
lack of time).
It also fixes a couple of other problems I found with the previous version:
1. While streaming, whenever it hit the end of available data (ie LSN
written by WAL receiver), it would close and then reopen the WAL
segment. Fixed by the machinery in 0007 which allows for "would
block" as distinct from other errors.
2. During crash recovery, there were some edge cases where it would
try to read the next WAL segment when there isn't one. Also fixed by
0007.
3. It was maxing out at maintenance_io_concurrency - 1 due to a silly
circular buffer fence post bug.
Note that 0006 is just for illustration, it's not proposed for commit.
On Wed, Mar 25, 2020 at 11:31 AM Andres Freund <andres@anarazel.de> wrote:
> On 2020-03-18 18:18:44 +1300, Thomas Munro wrote:
> > From 1b03eb5ada24c3b23ab8ca6db50e0c5d90d38259 Mon Sep 17 00:00:00 2001
> > From: Thomas Munro <tmunro@postgresql.org>
> > Date: Mon, 9 Dec 2019 17:22:07 +1300
> > Subject: [PATCH 3/5] Add WalRcvGetWriteRecPtr() (new definition).
> >
> > A later patch will read received WAL to prefetch referenced blocks,
> > without waiting for the data to be flushed to disk. To do that, it
> > needs to be able to see the write pointer advancing in shared memory.
> >
> > The function formerly bearing name was recently renamed to
> > WalRcvGetFlushRecPtr(), which better described what it does.
>
> Hm. I'm a bit weary of reusing the name with a different meaning. If
> there's any external references, this'll hide that they need to
> adapt. Perhaps, even if it's a bit clunky, name it GetUnflushedRecPtr?
Well, at least external code won't compile due to the change in arguments:
extern XLogRecPtr GetWalRcvWriteRecPtr(XLogRecPtr *latestChunkStart,
TimeLineID *receiveTLI);
extern XLogRecPtr GetWalRcvWriteRecPtr(void);
Anyone who is using that for some kind of data integrity purposes
should hopefully be triggered to investigate, no? I tried to think of
a better naming scheme but...
> > From c62fde23f70ff06833d743a1c85716e15f3c813c Mon Sep 17 00:00:00 2001
> > From: Thomas Munro <thomas.munro@gmail.com>
> > Date: Tue, 17 Mar 2020 17:26:41 +1300
> > Subject: [PATCH 4/5] Allow PrefetchBuffer() to report what happened.
> >
> > Report whether a prefetch was actually initiated due to a cache miss, so
> > that callers can limit the number of concurrent I/Os they try to issue,
> > without counting the prefetch calls that did nothing because the page
> > was already in our buffers.
> >
> > If the requested block was already cached, return a valid buffer. This
> > might enable future code to avoid a buffer mapping lookup, though it
> > will need to recheck the buffer before using it because it's not pinned
> > so could be reclaimed at any time.
> >
> > Report neither hit nor miss when a relation's backing file is missing,
> > to prepare for use during recovery. This will be used to handle cases
> > of relations that are referenced in the WAL but have been unlinked
> > already due to actions covered by WAL records that haven't been replayed
> > yet, after a crash.
>
> We probably should take this into account in nodeBitmapHeapscan.c
Indeed. The naive version would be something like:
diff --git a/src/backend/executor/nodeBitmapHeapscan.c
b/src/backend/executor/nodeBitmapHeapscan.c
index 726d3a2d9a..3cd644d0ac 100644
--- a/src/backend/executor/nodeBitmapHeapscan.c
+++ b/src/backend/executor/nodeBitmapHeapscan.c
@@ -484,13 +484,11 @@ BitmapPrefetch(BitmapHeapScanState *node,
TableScanDesc scan)
node->prefetch_iterator = NULL;
break;
}
- node->prefetch_pages++;
/*
* If we expect not to have to
actually read this heap page,
* skip this prefetch call, but
continue to run the prefetch
- * logic normally. (Would it be
better not to increment
- * prefetch_pages?)
+ * logic normally.
*
* This depends on the assumption that
the index AM will
* report the same recheck flag for
this future heap page as
@@ -504,7 +502,13 @@ BitmapPrefetch(BitmapHeapScanState *node,
TableScanDesc scan)
&node->pvmbuffer));
if (!skip_fetch)
- PrefetchBuffer(scan->rs_rd,
MAIN_FORKNUM, tbmpre->blockno);
+ {
+ PrefetchBufferResult prefetch;
+
+ prefetch =
PrefetchBuffer(scan->rs_rd, MAIN_FORKNUM, tbmpre->blockno);
+ if (prefetch.initiated_io)
+ node->prefetch_pages++;
+ }
}
}
... but that might get arbitrarily far ahead, so it probably needs
some kind of cap, and the parallel version is a bit more complicated.
Something for later, along with more prefetching opportunities.
> > diff --git a/src/backend/storage/buffer/bufmgr.c b/src/backend/storage/buffer/bufmgr.c
> > index d30aed6fd9..4ceb40a856 100644
> > --- a/src/backend/storage/buffer/bufmgr.c
> > +++ b/src/backend/storage/buffer/bufmgr.c
> > @@ -469,11 +469,13 @@ static int ts_ckpt_progress_comparator(Datum a, Datum b, void *arg);
> > /*
> > * Implementation of PrefetchBuffer() for shared buffers.
> > */
> > -void
> > +PrefetchBufferResult
> > PrefetchSharedBuffer(struct SMgrRelationData *smgr_reln,
> > ForkNumber forkNum,
> > BlockNumber blockNum)
> > {
> > + PrefetchBufferResult result = { InvalidBuffer, false };
> > +
> > #ifdef USE_PREFETCH
> > BufferTag newTag; /* identity of requested block */
> > uint32 newHash; /* hash value for newTag */
> > @@ -497,7 +499,23 @@ PrefetchSharedBuffer(struct SMgrRelationData *smgr_reln,
> >
> > /* If not in buffers, initiate prefetch */
> > if (buf_id < 0)
> > - smgrprefetch(smgr_reln, forkNum, blockNum);
> > + {
> > + /*
> > + * Try to initiate an asynchronous read. This returns false in
> > + * recovery if the relation file doesn't exist.
> > + */
> > + if (smgrprefetch(smgr_reln, forkNum, blockNum))
> > + result.initiated_io = true;
> > + }
> > + else
> > + {
> > + /*
> > + * Report the buffer it was in at that time. The caller may be able
> > + * to avoid a buffer table lookup, but it's not pinned and it must be
> > + * rechecked!
> > + */
> > + result.buffer = buf_id + 1;
>
> Perhaps it'd be better to name this "last_buffer" or such, to make it
> clearer that it may be outdated?
OK. Renamed to "recent_buffer".
> > -void
> > +PrefetchBufferResult
> > PrefetchBuffer(Relation reln, ForkNumber forkNum, BlockNumber blockNum)
> > {
> > #ifdef USE_PREFETCH
> > @@ -540,13 +564,17 @@ PrefetchBuffer(Relation reln, ForkNumber forkNum, BlockNumber blockNum)
> > errmsg("cannot access temporary tables of other sessions")));
> >
> > /* pass it off to localbuf.c */
> > - PrefetchLocalBuffer(reln->rd_smgr, forkNum, blockNum);
> > + return PrefetchLocalBuffer(reln->rd_smgr, forkNum, blockNum);
> > }
> > else
> > {
> > /* pass it to the shared buffer version */
> > - PrefetchSharedBuffer(reln->rd_smgr, forkNum, blockNum);
> > + return PrefetchSharedBuffer(reln->rd_smgr, forkNum, blockNum);
> > }
> > +#else
> > + PrefetchBuffer result = { InvalidBuffer, false };
> > +
> > + return result;
> > #endif /* USE_PREFETCH */
> > }
>
> Hm. Now that results are returned indicating whether the buffer is in
> s_b - shouldn't the return value be accurate regardless of USE_PREFETCH?
Yeah. Done.
> > +/*
> > + * Type returned by PrefetchBuffer().
> > + */
> > +typedef struct PrefetchBufferResult
> > +{
> > + Buffer buffer; /* If valid, a hit (recheck needed!) */
>
> I assume there's no user of this yet? Even if there's not, I wonder if
> it still is worth adding and referencing a helper to do so correctly?
It *is* used, but only to see if it's valid. 0006 is a not-for-commit
patch to show how you might use it later to read a buffer. To
actually use this for something like bitmap heap scan, you'd first
need to fix the modularity violations in that code (I mean we have
PrefetchBuffer() in nodeBitmapHeapscan.c, but the corresponding
[ReleaseAnd]ReadBuffer() in heapam.c, and you'd need to get these into
the same module and/or to communicate in some graceful way).
> > From 42ba0a89260d46230ac0df791fae18bfdca0092f Mon Sep 17 00:00:00 2001
> > From: Thomas Munro <thomas.munro@gmail.com>
> > Date: Wed, 18 Mar 2020 16:35:27 +1300
> > Subject: [PATCH 5/5] Prefetch referenced blocks during recovery.
> >
> > Introduce a new GUC max_wal_prefetch_distance. If it is set to a
> > positive number of bytes, then read ahead in the WAL at most that
> > distance, and initiate asynchronous reading of referenced blocks. The
> > goal is to avoid I/O stalls and benefit from concurrent I/O. The number
> > of concurrency asynchronous reads is capped by the existing
> > maintenance_io_concurrency GUC. The feature is disabled by default.
> >
> > Reviewed-by: Tomas Vondra <tomas.vondra@2ndquadrant.com>
> > Reviewed-by: Alvaro Herrera <alvherre@2ndquadrant.com>
> > Discussion:
> > https://postgr.es/m/CA%2BhUKGJ4VJN8ttxScUFM8dOKX0BrBiboo5uz1cq%3DAovOddfHpA%40mail.gmail.com
>
> Why is it disabled by default? Just for "risk management"?
Well, it's not free, and might not help you, so not everyone would
want it on. I think the overheads can be mostly removed with more
work in a later release. Perhaps we could commit it enabled by
default, and then discuss it before release after looking at some more
data? On that basis I have now made it default to on, with
max_wal_prefetch_distance = 256kB, if your build has USE_PREFETCH.
Obviously this number can be discussed.
> > + <varlistentry id="guc-max-wal-prefetch-distance" xreflabel="max_wal_prefetch_distance">
> > + <term><varname>max_wal_prefetch_distance</varname> (<type>integer</type>)
> > + <indexterm>
> > + <primary><varname>max_wal_prefetch_distance</varname> configuration parameter</primary>
> > + </indexterm>
> > + </term>
> > + <listitem>
> > + <para>
> > + The maximum distance to look ahead in the WAL during recovery, to find
> > + blocks to prefetch. Prefetching blocks that will soon be needed can
> > + reduce I/O wait times. The number of concurrent prefetches is limited
> > + by this setting as well as <xref linkend="guc-maintenance-io-concurrency"/>.
> > + If this value is specified without units, it is taken as bytes.
> > + The default is -1, meaning that WAL prefetching is disabled.
> > + </para>
> > + </listitem>
> > + </varlistentry>
>
> Is it worth noting that a too large distance could hurt, because the
> buffers might get evicted again?
OK, I tried to explain that.
> > + <varlistentry id="guc-wal-prefetch-fpw" xreflabel="wal_prefetch_fpw">
> > + <term><varname>wal_prefetch_fpw</varname> (<type>boolean</type>)
> > + <indexterm>
> > + <primary><varname>wal_prefetch_fpw</varname> configuration parameter</primary>
> > + </indexterm>
> > + </term>
> > + <listitem>
> > + <para>
> > + Whether to prefetch blocks with full page images during recovery.
> > + Usually this doesn't help, since such blocks will not be read. However,
> > + on file systems with a block size larger than
> > + <productname>PostgreSQL</productname>'s, prefetching can avoid a costly
> > + read-before-write when a blocks are later written.
> > + This setting has no effect unless
> > + <xref linkend="guc-max-wal-prefetch-distance"/> is set to a positive number.
> > + The default is off.
> > + </para>
> > + </listitem>
> > + </varlistentry>
>
> Hm. I think this needs more details - it's not clear enough what this
> actually controls. I assume it's about prefetching for WAL records that
> contain the FPW, but it also could be read to be about not prefetching
> any pages that had FPWs before, or such?
Ok, I have elaborated.
> > </variablelist>
> > </sect2>
> > <sect2 id="runtime-config-wal-archiving">
> > diff --git a/doc/src/sgml/monitoring.sgml b/doc/src/sgml/monitoring.sgml
> > index 987580d6df..df4291092b 100644
> > --- a/doc/src/sgml/monitoring.sgml
> > +++ b/doc/src/sgml/monitoring.sgml
> > @@ -320,6 +320,13 @@ postgres 27093 0.0 0.0 30096 2752 ? Ss 11:34 0:00 postgres: ser
> > </entry>
> > </row>
> >
> > + <row>
> > +
<entry><structname>pg_stat_wal_prefetcher</structname><indexterm><primary>pg_stat_wal_prefetcher</primary></indexterm></entry>
> > + <entry>Only one row, showing statistics about blocks prefetched during recovery.
> > + See <xref linkend="pg-stat-wal-prefetcher-view"/> for details.
> > + </entry>
> > + </row>
> > +
>
> 'prefetcher' somehow sounds odd to me. I also suspect that we'll want to
> have additional prefetching stat tables going forward. Perhaps
> 'pg_stat_prefetch_wal'?
Works for me, though while thinking about this I realised that the
"WAL" part was bothering me. It sounds like we're prefetching WAL
itself, which would be a different thing. So I renamed this view to
pg_stat_prefetch_recovery.
Then I renamed the main GUCs that control this thing to:
max_recovery_prefetch_distance
recovery_prefetch_fpw
> > + <row>
> > + <entry><structfield>distance</structfield></entry>
> > + <entry><type>integer</type></entry>
> > + <entry>How far ahead of recovery the WAL prefetcher is currently reading, in bytes</entry>
> > + </row>
> > + <row>
> > + <entry><structfield>queue_depth</structfield></entry>
> > + <entry><type>integer</type></entry>
> > + <entry>How many prefetches have been initiated but are not yet known to have completed</entry>
> > + </row>
> > + </tbody>
> > + </tgroup>
> > + </table>
>
> Is there a way we could have a "historical" version of at least some of
> these? An average queue depth, or such?
Ok, I added simple online averages for distance and queue depth that
take a sample every time recovery advances by 256kB.
> It'd be useful to somewhere track the time spent initiating prefetch
> requests. Otherwise it's quite hard to evaluate whether the queue is too
> deep (and just blocks in the OS).
I agree that that sounds useful, and I thought about various ways to
do that that involved new views, until I eventually found myself
wondering: why isn't recovery's I/O already tracked via the existing
stats views? For example, why can't I see blks_read, blks_hit,
blk_read_time etc moving in pg_stat_database due to recovery activity?
I seems like if you made that work first, or created a new view
pgstatio view for that, then you could add prefetching counters and
timing (if track_io_timing is on) to the existing machinery so that
bufmgr.c would automatically capture it, and then not only recovery
but also stuff like bitmap heap scan could also be measured the same
way.
However, time is short, so I'm not attempting to do anything like that
now. You can measure the posix_fadvise() times with OS facilities in
the meantime.
> I think it'd be good to have a 'reset time' column.
Done, as stats_reset following other examples.
> > + <para>
> > + The <structname>pg_stat_wal_prefetcher</structname> view will contain only
> > + one row. It is filled with nulls if recovery is not running or WAL
> > + prefetching is not enabled. See <xref linkend="guc-max-wal-prefetch-distance"/>
> > + for more information. The counters in this view are reset whenever the
> > + <xref linkend="guc-max-wal-prefetch-distance"/>,
> > + <xref linkend="guc-wal-prefetch-fpw"/> or
> > + <xref linkend="guc-maintenance-io-concurrency"/> setting is changed and
> > + the server configuration is reloaded.
> > + </para>
> > +
>
> So pg_stat_reset_shared() cannot be used? If so, why?
Hmm. OK, I made pg_stat_reset_shared('prefetch_recovery') work.
> It sounds like the counters aren't persisted via the stats system - if
> so, why?
Ok, I made it persist the simple counters by sending to the to stats
collector periodically. The view still shows data straight out of
shmem though, not out of the stats file. Now I'm wondering if I
should have the view show it from the stats file, more like other
things, now that I understand that a bit better... hmm.
> > @@ -7105,6 +7114,31 @@ StartupXLOG(void)
> > /* Handle interrupt signals of startup process */
> > HandleStartupProcInterrupts();
> >
> > + /*
> > + * The first time through, or if any relevant settings or the
> > + * WAL source changes, we'll restart the prefetching machinery
> > + * as appropriate. This is simpler than trying to handle
> > + * various complicated state changes.
> > + */
> > + if (unlikely(reset_wal_prefetcher))
> > + {
> > + /* If we had one already, destroy it. */
> > + if (prefetcher)
> > + {
> > + XLogPrefetcherFree(prefetcher);
> > + prefetcher = NULL;
> > + }
> > + /* If we want one, create it. */
> > + if (max_wal_prefetch_distance > 0)
> > + prefetcher = XLogPrefetcherAllocate(xlogreader->ReadRecPtr,
> > +
currentSource == XLOG_FROM_STREAM);
> > + reset_wal_prefetcher = false;
> > + }
>
> Do we really need all of this code in StartupXLOG() itself? Could it be
> in HandleStartupProcInterrupts() or at least a helper routine called
> here?
It's now done differently, so that StartupXLOG() only has three new
lines: XLogPrefetchBegin() before the loop, XLogPrefetch() in the
loop, and XLogPrefetchEnd() after the loop.
> > + /* Peform WAL prefetching, if enabled. */
> > + if (prefetcher)
> > + XLogPrefetcherReadAhead(prefetcher, xlogreader->ReadRecPtr);
> > +
> > /*
> > * Pause WAL replay, if requested by a hot-standby session via
> > * SetRecoveryPause().
>
> Personally, I'd rather have the if () be in
> XLogPrefetcherReadAhead(). With an inline wrapper doing the check, if
> the call bothers you (but I don't think it needs to).
Done.
> > +/*-------------------------------------------------------------------------
> > + *
> > + * xlogprefetcher.c
> > + * Prefetching support for PostgreSQL write-ahead log manager
> > + *
>
> An architectural overview here would be good.
OK, added.
> > +struct XLogPrefetcher
> > +{
> > + /* Reader and current reading state. */
> > + XLogReaderState *reader;
> > + XLogReadLocalOptions options;
> > + bool have_record;
> > + bool shutdown;
> > + int next_block_id;
> > +
> > + /* Book-keeping required to avoid accessing non-existing blocks. */
> > + HTAB *filter_table;
> > + dlist_head filter_queue;
> > +
> > + /* Book-keeping required to limit concurrent prefetches. */
> > + XLogRecPtr *prefetch_queue;
> > + int prefetch_queue_size;
> > + int prefetch_head;
> > + int prefetch_tail;
> > +
> > + /* Details of last prefetch to skip repeats and seq scans. */
> > + SMgrRelation last_reln;
> > + RelFileNode last_rnode;
> > + BlockNumber last_blkno;
>
> Do you have a comment somewhere explaining why you want to avoid
> seqscans (I assume it's about avoiding regressions in linux, but only
> because I recall chatting with you about it).
I've added a note to the new architectural comments.
> > +/*
> > + * On modern systems this is really just *counter++. On some older systems
> > + * there might be more to it, due to inability to read and write 64 bit values
> > + * atomically. The counters will only be written to by one process, and there
> > + * is no ordering requirement, so there's no point in using higher overhead
> > + * pg_atomic_fetch_add_u64().
> > + */
> > +static inline void inc_counter(pg_atomic_uint64 *counter)
> > +{
> > + pg_atomic_write_u64(counter, pg_atomic_read_u64(counter) + 1);
> > +}
>
> Could be worthwhile to add to the atomics infrastructure itself - on the
> platforms where this needs spinlocks this will lead to two acquisitions,
> rather than one.
Ok, I added pg_atomic_unlocked_add_fetch_XXX(). (Could also be
"fetch_add", I don't care, I don't use the result).
> > +/*
> > + * Create a prefetcher that is ready to begin prefetching blocks referenced by
> > + * WAL that is ahead of the given lsn.
> > + */
> > +XLogPrefetcher *
> > +XLogPrefetcherAllocate(XLogRecPtr lsn, bool streaming)
> > +{
> > + static HASHCTL hash_table_ctl = {
> > + .keysize = sizeof(RelFileNode),
> > + .entrysize = sizeof(XLogPrefetcherFilter)
> > + };
> > + XLogPrefetcher *prefetcher = palloc0(sizeof(*prefetcher));
> > +
> > + prefetcher->options.nowait = true;
> > + if (streaming)
> > + {
> > + /*
> > + * We're only allowed to read as far as the WAL receiver has written.
> > + * We don't have to wait for it to be flushed, though, as recovery
> > + * does, so that gives us a chance to get a bit further ahead.
> > + */
> > + prefetcher->options.read_upto_policy = XLRO_WALRCV_WRITTEN;
> > + }
> > + else
> > + {
> > + /* We're allowed to read as far as we can. */
> > + prefetcher->options.read_upto_policy = XLRO_LSN;
> > + prefetcher->options.lsn = (XLogRecPtr) -1;
> > + }
> > + prefetcher->reader = XLogReaderAllocate(wal_segment_size,
> > + NULL,
> > + read_local_xlog_page,
> > + &prefetcher->options);
> > + prefetcher->filter_table = hash_create("PrefetchFilterTable", 1024,
> > + &hash_table_ctl,
> > + HASH_ELEM | HASH_BLOBS);
> > + dlist_init(&prefetcher->filter_queue);
> > +
> > + /*
> > + * The size of the queue is based on the maintenance_io_concurrency
> > + * setting. In theory we might have a separate queue for each tablespace,
> > + * but it's not clear how that should work, so for now we'll just use the
> > + * general GUC to rate-limit all prefetching.
> > + */
> > + prefetcher->prefetch_queue_size = maintenance_io_concurrency;
> > + prefetcher->prefetch_queue = palloc0(sizeof(XLogRecPtr) * prefetcher->prefetch_queue_size);
> > + prefetcher->prefetch_head = prefetcher->prefetch_tail = 0;
> > +
> > + /* Prepare to read at the given LSN. */
> > + ereport(LOG,
> > + (errmsg("WAL prefetch started at %X/%X",
> > + (uint32) (lsn << 32), (uint32) lsn)));
> > + XLogBeginRead(prefetcher->reader, lsn);
> > +
> > + XLogPrefetcherResetMonitoringStats();
> > +
> > + return prefetcher;
> > +}
> > +
> > +/*
> > + * Destroy a prefetcher and release all resources.
> > + */
> > +void
> > +XLogPrefetcherFree(XLogPrefetcher *prefetcher)
> > +{
> > + double avg_distance = 0;
> > + double avg_queue_depth = 0;
> > +
> > + /* Log final statistics. */
> > + if (prefetcher->samples > 0)
> > + {
> > + avg_distance = prefetcher->distance_sum / prefetcher->samples;
> > + avg_queue_depth = prefetcher->queue_depth_sum / prefetcher->samples;
> > + }
> > + ereport(LOG,
> > + (errmsg("WAL prefetch finished at %X/%X; "
> > + "prefetch = " UINT64_FORMAT ", "
> > + "skip_hit = " UINT64_FORMAT ", "
> > + "skip_new = " UINT64_FORMAT ", "
> > + "skip_fpw = " UINT64_FORMAT ", "
> > + "skip_seq = " UINT64_FORMAT ", "
> > + "avg_distance = %f, "
> > + "avg_queue_depth = %f",
> > + (uint32) (prefetcher->reader->EndRecPtr << 32),
> > + (uint32) (prefetcher->reader->EndRecPtr),
> > + pg_atomic_read_u64(&MonitoringStats->prefetch),
> > + pg_atomic_read_u64(&MonitoringStats->skip_hit),
> > + pg_atomic_read_u64(&MonitoringStats->skip_new),
> > + pg_atomic_read_u64(&MonitoringStats->skip_fpw),
> > + pg_atomic_read_u64(&MonitoringStats->skip_seq),
> > + avg_distance,
> > + avg_queue_depth)));
> > + XLogReaderFree(prefetcher->reader);
> > + hash_destroy(prefetcher->filter_table);
> > + pfree(prefetcher->prefetch_queue);
> > + pfree(prefetcher);
> > +
> > + XLogPrefetcherResetMonitoringStats();
> > +}
>
> It's possibly overkill, but I think it'd be a good idea to do all the
> allocations within a prefetch specific memory context. That makes
> detecting potential leaks or such easier.
I looked into that, but in fact it's already pretty clear how much
memory this thing is using, if you call
MemoryContextStats(TopMemoryContext), because it's almost all in a
named hash table:
TopMemoryContext: 155776 total in 6 blocks; 18552 free (8 chunks); 137224 used
XLogPrefetcherFilterTable: 16384 total in 2 blocks; 4520 free (3
chunks); 11864 used
SP-GiST temporary context: 8192 total in 1 blocks; 7928 free (0
chunks); 264 used
GiST temporary context: 8192 total in 1 blocks; 7928 free (0 chunks); 264 used
GIN recovery temporary context: 8192 total in 1 blocks; 7928 free (0
chunks); 264 used
Btree recovery temporary context: 8192 total in 1 blocks; 7928 free
(0 chunks); 264 used
RecoveryLockLists: 8192 total in 1 blocks; 2584 free (0 chunks); 5608 used
PrivateRefCount: 8192 total in 1 blocks; 2584 free (0 chunks); 5608 used
MdSmgr: 8192 total in 1 blocks; 7928 free (0 chunks); 264 used
Pending ops context: 8192 total in 1 blocks; 7928 free (0 chunks); 264 used
LOCALLOCK hash: 8192 total in 1 blocks; 512 free (0 chunks); 7680 used
Timezones: 104128 total in 2 blocks; 2584 free (0 chunks); 101544 used
ErrorContext: 8192 total in 1 blocks; 7928 free (4 chunks); 264 used
Grand total: 358208 bytes in 20 blocks; 86832 free (15 chunks); 271376 used
The XLogPrefetcher struct itself is not measured seperately, but I
don't think that's a problem, it's small and there's only ever one at
a time. It's that XLogPrefetcherFilterTable that is of variable size
(though it's often empty). While thinking about this, I made
prefetch_queue into a flexible array rather than a pointer to palloc'd
memory, which seemed a bit tidier.
> > + /* Can we drop any filters yet, due to problem records begin replayed? */
>
> Odd grammar.
Rewritten.
> > + XLogPrefetcherCompleteFilters(prefetcher, replaying_lsn);
>
> Hm, why isn't this part of the loop below?
It only needs to run when replaying_lsn has advanced (ie when records
have been replayed). I hope the new comment makes that clearer.
> > + /* Main prefetch loop. */
> > + for (;;)
> > + {
>
> This kind of looks like a separate process' main loop. The name
> indicates similar. And there's no architecture documentation
> disinclining one from that view...
OK, I have updated the comment.
> The loop body is quite long. I think it should be split into a number of
> helper functions. Perhaps one to ensure a block is read, one to maintain
> stats, and then one to process block references?
I've broken the function up. It's now:
StartupXLOG()
-> XLogPrefetch()
-> XLogPrefetcherReadAhead()
-> XLogPrefetcherScanRecords()
-> XLogPrefetcherScanBlocks()
> > + /*
> > + * Scan the record for block references. We might already have been
> > + * partway through processing this record when we hit maximum I/O
> > + * concurrency, so start where we left off.
> > + */
> > + for (int i = prefetcher->next_block_id; i <= reader->max_block_id; ++i)
> > + {
>
> Super pointless nitpickery: For a loop-body this big I'd rather name 'i'
> 'blockid' or such.
Done.
Attachment
- v6-0001-Allow-PrefetchBuffer-to-be-called-with-a-SMgrRela.patch
- v6-0002-Rename-GetWalRcvWriteRecPtr-to-GetWalRcvFlushRecP.patch
- v6-0003-Add-GetWalRcvWriteRecPtr-new-definition.patch
- v6-0004-Add-pg_atomic_unlocked_add_fetch_XXX.patch
- v6-0005-Allow-PrefetchBuffer-to-report-what-happened.patch
- v6-0006-Add-ReadBufferPrefetched-POC-only.patch
- v6-0007-Allow-XLogReadRecord-to-be-non-blocking.patch
- v6-0008-Prefetch-referenced-blocks-during-recovery.patch
On Wed, Apr 8, 2020 at 4:24 AM Thomas Munro <thomas.munro@gmail.com> wrote: > Thanks for all that feedback. It's been a strange couple of weeks, > but I finally have a new version that addresses most of that feedback > (but punts on a couple of suggestions for later development, due to > lack of time). Here's an executive summary of an off-list chat with Andres: * he withdrew his objection to the new definition of GetWalRcvWriteRecPtr() based on my argument that any external code will fail to compile anyway * he doesn't like the naive code that detects sequential access and skips prefetching; I agreed to rip it out for now and revisit if/when we have better evidence that that's worth bothering with; the code path that does that and the pg_stat_recovery_prefetch.skip_seq counter will remain, but be used only to skip prefetching of repeated access to the *same* block for now * he gave some feedback on the read_local_xlog_page() modifications: I probably need to reconsider the change to logical.c that passes NULL instead of cxt to the read_page callback; and the switch statement in read_local_xlog_page() probably should have a case for the preexisting mode * he +1s the plan to commit with the feature enabled, and revisit before release * he thinks the idea of a variant of ReadBuffer() that takes a PrefetchBufferResult (as sketched by the v6 0006 patch) broadly makes sense as a stepping stone towards his asychronous I/O proposal, but there's no point in committing something like 0006 without a user I'm going to go and commit the first few patches in this series, and come back in a bit with a new version of the main patch to fix the above and a compiler warning reported by cfbot.
On Wed, Apr 8, 2020 at 12:52 PM Thomas Munro <thomas.munro@gmail.com> wrote: > * he gave some feedback on the read_local_xlog_page() modifications: I > probably need to reconsider the change to logical.c that passes NULL > instead of cxt to the read_page callback; and the switch statement in > read_local_xlog_page() probably should have a case for the preexisting > mode So... logical.c wants to give its LogicalDecodingContext to any XLogPageReadCB you give it, via "private_data"; that is, it really only accepts XLogPageReadCB implementations that understand that (or ignore it). What I want to do is give every XLogPageReadCB the chance to have its own state that it is control of (to receive settings specific to the implementation, or whatever), that you supply along with it. We can't do both kinds of things with private_data, so I have added a second member read_page_data to XLogReaderState. If you pass in read_local_xlog_page as read_page, then you can optionally install a pointer to XLogReadLocalOptions as reader->read_page_data, to activate the new behaviours I added for prefetching purposes. While working on that, I realised the readahead XLogReader was breaking a rule expressed in XLogReadDetermineTimeLine(). Timelines are really confusing and there were probably several subtle or not to subtle bugs there. So I added an option to skip all of that logic, and just say "I command you to read only from TLI X". It reads the same TLI as recovery is reading, until it hits the end of readable data and that causes prefetching to shut down. Then the main recovery loop resets the prefetching module when it sees a TLI switch, so then it starts up again. This seems to work reliably, but I've obviously had limited time to test. Does this scheme sound sane? I think this is basically committable (though of course I wish I had more time to test and review). Ugh. Feature freeze in half an hour.
Attachment
On Wed, Apr 8, 2020 at 11:27 PM Thomas Munro <thomas.munro@gmail.com> wrote:
> On Wed, Apr 8, 2020 at 12:52 PM Thomas Munro <thomas.munro@gmail.com> wrote:
> > * he gave some feedback on the read_local_xlog_page() modifications: I
> > probably need to reconsider the change to logical.c that passes NULL
> > instead of cxt to the read_page callback; and the switch statement in
> > read_local_xlog_page() probably should have a case for the preexisting
> > mode
>
> So... logical.c wants to give its LogicalDecodingContext to any
> XLogPageReadCB you give it, via "private_data"; that is, it really
> only accepts XLogPageReadCB implementations that understand that (or
> ignore it). What I want to do is give every XLogPageReadCB the chance
> to have its own state that it is control of (to receive settings
> specific to the implementation, or whatever), that you supply along
> with it. We can't do both kinds of things with private_data, so I
> have added a second member read_page_data to XLogReaderState. If you
> pass in read_local_xlog_page as read_page, then you can optionally
> install a pointer to XLogReadLocalOptions as reader->read_page_data,
> to activate the new behaviours I added for prefetching purposes.
>
> While working on that, I realised the readahead XLogReader was
> breaking a rule expressed in XLogReadDetermineTimeLine(). Timelines
> are really confusing and there were probably several subtle or not to
> subtle bugs there. So I added an option to skip all of that logic,
> and just say "I command you to read only from TLI X". It reads the
> same TLI as recovery is reading, until it hits the end of readable
> data and that causes prefetching to shut down. Then the main recovery
> loop resets the prefetching module when it sees a TLI switch, so then
> it starts up again. This seems to work reliably, but I've obviously
> had limited time to test. Does this scheme sound sane?
>
> I think this is basically committable (though of course I wish I had
> more time to test and review). Ugh. Feature freeze in half an hour.
Ok, so the following parts of this work have been committed:
b09ff536: Simplify the effective_io_concurrency setting.
fc34b0d9: Introduce a maintenance_io_concurrency setting.
3985b600: Support PrefetchBuffer() in recovery.
d140f2f3: Rationalize GetWalRcv{Write,Flush}RecPtr().
However, I didn't want to push the main patch into the tree at
(literally) the last minute after doing such much work on it in the
last few days, without more review from recovery code experts and some
independent testing. Judging by the comments made in this thread and
elsewhere, I think the feature is in demand so I hope there is a way
we could get it into 13 in the next couple of days, but I totally
accept the release management team's prerogative on that.
On 4/8/20 8:12 AM, Thomas Munro wrote:
>
> Ok, so the following parts of this work have been committed:
>
> b09ff536: Simplify the effective_io_concurrency setting.
> fc34b0d9: Introduce a maintenance_io_concurrency setting.
> 3985b600: Support PrefetchBuffer() in recovery.
> d140f2f3: Rationalize GetWalRcv{Write,Flush}RecPtr().
>
> However, I didn't want to push the main patch into the tree at
> (literally) the last minute after doing such much work on it in the
> last few days, without more review from recovery code experts and some
> independent testing.
I definitely think that was the right call.
> Judging by the comments made in this thread and
> elsewhere, I think the feature is in demand so I hope there is a way
> we could get it into 13 in the next couple of days, but I totally
> accept the release management team's prerogative on that.
That's up to the RMT, of course, but we did already have an extra week.
Might be best to just get this in at the beginning of the PG14 cycle.
FWIW, I do think the feature is really valuable.
Looks like you'll need to rebase, so I'll move this to the next CF in
WoA state.
Regards,
--
-David
david@pgmasters.net
On Thu, Apr 9, 2020 at 12:27 AM David Steele <david@pgmasters.net> wrote: > On 4/8/20 8:12 AM, Thomas Munro wrote: > > Judging by the comments made in this thread and > > elsewhere, I think the feature is in demand so I hope there is a way > > we could get it into 13 in the next couple of days, but I totally > > accept the release management team's prerogative on that. > > That's up to the RMT, of course, but we did already have an extra week. > Might be best to just get this in at the beginning of the PG14 cycle. > FWIW, I do think the feature is really valuable. > > Looks like you'll need to rebase, so I'll move this to the next CF in > WoA state. Thanks. Here's a rebase.
Attachment
> On Thu, Apr 09, 2020 at 09:55:25AM +1200, Thomas Munro wrote:
> Thanks. Here's a rebase.
Thanks for working on this patch, it seems like a great feature. I'm
probably a bit late to the party, but still want to make couple of
commentaries.
The patch indeed looks good, I couldn't find any significant issues so
far and almost all my questions I had while reading it were actually
answered in this thread. I'm still busy with benchmarking, mostly to see
how prefetching would work with different workload distributions and how
much the kernel will actually prefetch.
In the meantime I have a few questions:
> On Wed, Feb 12, 2020 at 07:52:42PM +1300, Thomas Munro wrote:
> > On Fri, Jan 3, 2020 at 7:10 AM Tomas Vondra
> > <tomas.vondra@2ndquadrant.com> wrote:
> > > Could we instead specify the number of blocks to prefetch? We'd probably
> > > need to track additional details needed to determine number of blocks to
> > > prefetch (essentially LSN for all prefetch requests).
>
> Here is a new WIP version of the patch set that does that. Changes:
>
> 1. It now uses effective_io_concurrency to control how many
> concurrent prefetches to allow. It's possible that we should have a
> different GUC to control "maintenance" users of concurrency I/O as
> discussed elsewhere[1], but I'm staying out of that for now; if we
> agree to do that for VACUUM etc, we can change it easily here. Note
> that the value is percolated through the ComputeIoConcurrency()
> function which I think we should discuss, but again that's off topic,
> I just want to use the standard infrastructure here.
This totally makes sense, I believe the question "how much to prefetch"
eventually depends equally on a type of workload (correlates with how
far in WAL to read) and how much resources are available for prefetching
(correlates with queue depth). But in the documentation it looks like
maintenance-io-concurrency is just an "unimportant" option, and I'm
almost sure will be overlooked by many readers:
The maximum distance to look ahead in the WAL during recovery, to find
blocks to prefetch. Prefetching blocks that will soon be needed can
reduce I/O wait times. The number of concurrent prefetches is limited
by this setting as well as
<xref linkend="guc-maintenance-io-concurrency"/>. Setting it too high
might be counterproductive, if it means that data falls out of the
kernel cache before it is needed. If this value is specified without
units, it is taken as bytes. A setting of -1 disables prefetching
during recovery.
Maybe it makes also sense to emphasize that maintenance-io-concurrency
directly affects resource consumption and it's a "primary control"?
> On Wed, Mar 18, 2020 at 06:18:44PM +1300, Thomas Munro wrote:
>
> Here's a new version that changes that part just a bit more, after a
> brief chat with Andres about his async I/O plans. It seems clear that
> returning an enum isn't very extensible, so I decided to try making
> PrefetchBufferResult a struct whose contents can be extended in the
> future. In this patch set it's still just used to distinguish 3 cases
> (hit, miss, no file), but it's now expressed as a buffer and a flag to
> indicate whether I/O was initiated. You could imagine that the second
> thing might be replaced by a pointer to an async I/O handle you can
> wait on or some other magical thing from the future.
I like the idea of extensible PrefetchBufferResult. Just one commentary,
if I understand correctly the way how it is being used together with
prefetch_queue assumes one IO operation at a time. This limits potential
extension of the underlying code, e.g. one can't implement some sort of
buffering of requests and submitting an iovec to a sycall, then
prefetch_queue will no longer correctly represent inflight IO. Also,
taking into account that "we don't have any awareness of when I/O really
completes", maybe in the future it makes to reconsider having queue in
the prefetcher itself and rather ask for this information from the
underlying code?
> On Wed, Apr 08, 2020 at 04:24:21AM +1200, Thomas Munro wrote:
> > Is there a way we could have a "historical" version of at least some of
> > these? An average queue depth, or such?
>
> Ok, I added simple online averages for distance and queue depth that
> take a sample every time recovery advances by 256kB.
Maybe it was discussed in the past in other threads. But if I understand
correctly, this implementation weights all the samples. Since at the
moment it depends directly on replaying speed (so a lot of IO involved),
couldn't it lead to a single outlier at the beginning skewing this value
and make it less useful? Does it make sense to decay old values?
On Sun, Apr 19, 2020 at 11:46 PM Dmitry Dolgov <9erthalion6@gmail.com> wrote:
> Thanks for working on this patch, it seems like a great feature. I'm
> probably a bit late to the party, but still want to make couple of
> commentaries.
Hi Dmitry,
Thanks for your feedback and your interest in this work!
> The patch indeed looks good, I couldn't find any significant issues so
> far and almost all my questions I had while reading it were actually
> answered in this thread. I'm still busy with benchmarking, mostly to see
> how prefetching would work with different workload distributions and how
> much the kernel will actually prefetch.
Cool.
One report I heard recently said that if you get rid of I/O stalls,
pread() becomes cheap enough that the much higher frequency lseek()
calls I've complained about elsewhere[1] become the main thing
recovery is doing, at least on some systems, but I haven't pieced
together the conditions required yet. I'd be interested to know if
you see that.
> In the meantime I have a few questions:
>
> > 1. It now uses effective_io_concurrency to control how many
> > concurrent prefetches to allow. It's possible that we should have a
> > different GUC to control "maintenance" users of concurrency I/O as
> > discussed elsewhere[1], but I'm staying out of that for now; if we
> > agree to do that for VACUUM etc, we can change it easily here. Note
> > that the value is percolated through the ComputeIoConcurrency()
> > function which I think we should discuss, but again that's off topic,
> > I just want to use the standard infrastructure here.
>
> This totally makes sense, I believe the question "how much to prefetch"
> eventually depends equally on a type of workload (correlates with how
> far in WAL to read) and how much resources are available for prefetching
> (correlates with queue depth). But in the documentation it looks like
> maintenance-io-concurrency is just an "unimportant" option, and I'm
> almost sure will be overlooked by many readers:
>
> The maximum distance to look ahead in the WAL during recovery, to find
> blocks to prefetch. Prefetching blocks that will soon be needed can
> reduce I/O wait times. The number of concurrent prefetches is limited
> by this setting as well as
> <xref linkend="guc-maintenance-io-concurrency"/>. Setting it too high
> might be counterproductive, if it means that data falls out of the
> kernel cache before it is needed. If this value is specified without
> units, it is taken as bytes. A setting of -1 disables prefetching
> during recovery.
>
> Maybe it makes also sense to emphasize that maintenance-io-concurrency
> directly affects resource consumption and it's a "primary control"?
You're right. I will add something in the next version to emphasise that.
> > On Wed, Mar 18, 2020 at 06:18:44PM +1300, Thomas Munro wrote:
> >
> > Here's a new version that changes that part just a bit more, after a
> > brief chat with Andres about his async I/O plans. It seems clear that
> > returning an enum isn't very extensible, so I decided to try making
> > PrefetchBufferResult a struct whose contents can be extended in the
> > future. In this patch set it's still just used to distinguish 3 cases
> > (hit, miss, no file), but it's now expressed as a buffer and a flag to
> > indicate whether I/O was initiated. You could imagine that the second
> > thing might be replaced by a pointer to an async I/O handle you can
> > wait on or some other magical thing from the future.
>
> I like the idea of extensible PrefetchBufferResult. Just one commentary,
> if I understand correctly the way how it is being used together with
> prefetch_queue assumes one IO operation at a time. This limits potential
> extension of the underlying code, e.g. one can't implement some sort of
> buffering of requests and submitting an iovec to a sycall, then
> prefetch_queue will no longer correctly represent inflight IO. Also,
> taking into account that "we don't have any awareness of when I/O really
> completes", maybe in the future it makes to reconsider having queue in
> the prefetcher itself and rather ask for this information from the
> underlying code?
Yeah, you're right that it'd be good to be able to do some kind of
batching up of these requests to reduce system calls. Of course
posix_fadvise() doesn't support that, but clearly in the AIO future[2]
it would indeed make sense to buffer up a few of these and then make a
single call to io_uring_enter() on Linux[3] or lio_listio() on a
hypothetical POSIX AIO implementation[4]. (I'm not sure if there is a
thing like that on Windows; at a glance, ReadFileScatter() is
asynchronous ("overlapped") but works only on a single handle so it's
like a hypothetical POSIX aio_readv(), not like POSIX lio_list()).
Perhaps there could be an extra call PrefetchBufferSubmit() that you'd
call at appropriate times, but you obviously can't call it too
infrequently.
As for how to make the prefetch queue a reusable component, rather
than having a custom thing like that for each part of our system that
wants to support prefetching: that's a really good question. I didn't
see how to do it, but maybe I didn't try hard enough. I looked at the
three users I'm aware of, namely this patch, a btree prefetching patch
I haven't shared yet, and the existing bitmap heap scan code, and they
all needed to have their own custom book keeping for this, and I
couldn't figure out how to share more infrastructure. In the case of
this patch, you currently need to do LSN based book keeping to
simulate "completion", and that doesn't make sense for other users.
Maybe it'll become clearer when we have support for completion
notification?
Some related questions are why all these parts of our system that know
how to prefetch are allowed to do so independently without any kind of
shared accounting, and why we don't give each tablespace (= our model
of a device?) its own separate queue. I think it's OK to put these
questions off a bit longer until we have more infrastructure and
experience. Our current non-answer is at least consistent with our
lack of an approach to system-wide memory and CPU accounting... I
personally think that a better XLogReader that can be used for
prefetching AND recovery would be a higher priority than that.
> > On Wed, Apr 08, 2020 at 04:24:21AM +1200, Thomas Munro wrote:
> > > Is there a way we could have a "historical" version of at least some of
> > > these? An average queue depth, or such?
> >
> > Ok, I added simple online averages for distance and queue depth that
> > take a sample every time recovery advances by 256kB.
>
> Maybe it was discussed in the past in other threads. But if I understand
> correctly, this implementation weights all the samples. Since at the
> moment it depends directly on replaying speed (so a lot of IO involved),
> couldn't it lead to a single outlier at the beginning skewing this value
> and make it less useful? Does it make sense to decay old values?
Hmm.
I wondered about a reporting one or perhaps three exponential moving
averages (like Unix 1/5/15 minute load averages), but I didn't propose
it because: (1) In crash recovery, you can't query it, you just get
the log message at the end, and mean unweighted seems OK in that case,
no? (you are not more interested in the I/O saturation at the end of
the recovery compared to the start of recovery are you?), and (2) on a
streaming replica, if you want to sample the instantaneous depth and
compute an exponential moving average or some more exotic statistical
concoction in your monitoring tool, you're free to do so. I suppose
(2) is an argument for removing the existing average completely from
the stat view; I put it in there at Andres's suggestion, but I'm not
sure I really believe in it. Where is our average replication lag,
and why don't we compute the stddev of X, Y or Z? I think we should
provide primary measurements and let people compute derived statistics
from those.
I suppose the reason for this request was the analogy with Linux
iostat -x's "aqu-sz", which is the primary way that people understand
device queue depth on that OS. This number is actually computed by
iostat, not the kernel, so by analogy I could argue that a
hypothetical pg_iostat program compute that for you from raw
ingredients. AFAIK iostat computes the *unweighted* average queue
depth during the time between output lines, by observing changes in
the "aveq" ("the sum of how long all requests have spent in flight, in
milliseconds") and "use" ("how many milliseconds there has been at
least one IO in flight") fields of /proc/diskstats. But it's OK that
it's unweighted, because it computes a new value for every line it
output (ie every 5 seconds or whatever you asked for). It's not too
clear how to do something like that here, but all suggestions are
weclome.
Or maybe we'll have something more general that makes this more
specific thing irrelevant, in future AIO infrastructure work.
On a more superficial note, one thing I don't like about the last
version of the patch is the difference in the ordering of the words in
the GUC recovery_prefetch_distance and the view
pg_stat_prefetch_recovery. Hrmph.
[1] https://www.postgresql.org/message-id/CA%2BhUKG%2BNPZeEdLXAcNr%2Bw0YOZVb0Un0_MwTBpgmmVDh7No2jbg%40mail.gmail.com
[2] https://anarazel.de/talks/2020-01-31-fosdem-aio/aio.pdf
[3] https://kernel.dk/io_uring.pdf
[4] https://pubs.opengroup.org/onlinepubs/009695399/functions/lio_listio.html
> On Tue, Apr 21, 2020 at 05:26:52PM +1200, Thomas Munro wrote:
>
> One report I heard recently said that if you get rid of I/O stalls,
> pread() becomes cheap enough that the much higher frequency lseek()
> calls I've complained about elsewhere[1] become the main thing
> recovery is doing, at least on some systems, but I haven't pieced
> together the conditions required yet. I'd be interested to know if
> you see that.
At the moment I've performed couple of tests for the replication in case
when almost everything is in memory (mostly by mistake, I was expecting
that a postgres replica within a badly memory limited cgroup will cause
more IO, but looks like kernel do not evict pages anyway). Not sure if
that's what you mean by getting rid of IO stalls, but in these tests
profiling shows lseek & pread appear in similar amount of samples.
If I understand correctly, eventually one can measure prefetching
influence by looking at different redo function execution time (assuming
that data they operate with is already prefetched they should be
faster). I still have to clarify what is the exact reason, but even in
the situation described above (in memory) there is some visible
difference, e.g.
# with prefetch
Function = b'heap2_redo' [8064]
nsecs : count distribution
4096 -> 8191 : 1213 | |
8192 -> 16383 : 66639 |****************************************|
16384 -> 32767 : 27846 |**************** |
32768 -> 65535 : 873 | |
# without prefetch
Function = b'heap2_redo' [17980]
nsecs : count distribution
4096 -> 8191 : 1 | |
8192 -> 16383 : 66997 |****************************************|
16384 -> 32767 : 30966 |****************** |
32768 -> 65535 : 1602 | |
# with prefetch
Function = b'btree_redo' [8064]
nsecs : count distribution
2048 -> 4095 : 0 | |
4096 -> 8191 : 246 |****************************************|
8192 -> 16383 : 5 | |
16384 -> 32767 : 2 | |
# without prefetch
Function = b'btree_redo' [17980]
nsecs : count distribution
2048 -> 4095 : 0 | |
4096 -> 8191 : 82 |******************** |
8192 -> 16383 : 19 |**** |
16384 -> 32767 : 160 |****************************************|
Of course it doesn't take into account time we spend doing extra
syscalls for prefetching, but still can give some interesting
information.
> > I like the idea of extensible PrefetchBufferResult. Just one commentary,
> > if I understand correctly the way how it is being used together with
> > prefetch_queue assumes one IO operation at a time. This limits potential
> > extension of the underlying code, e.g. one can't implement some sort of
> > buffering of requests and submitting an iovec to a sycall, then
> > prefetch_queue will no longer correctly represent inflight IO. Also,
> > taking into account that "we don't have any awareness of when I/O really
> > completes", maybe in the future it makes to reconsider having queue in
> > the prefetcher itself and rather ask for this information from the
> > underlying code?
>
> Yeah, you're right that it'd be good to be able to do some kind of
> batching up of these requests to reduce system calls. Of course
> posix_fadvise() doesn't support that, but clearly in the AIO future[2]
> it would indeed make sense to buffer up a few of these and then make a
> single call to io_uring_enter() on Linux[3] or lio_listio() on a
> hypothetical POSIX AIO implementation[4]. (I'm not sure if there is a
> thing like that on Windows; at a glance, ReadFileScatter() is
> asynchronous ("overlapped") but works only on a single handle so it's
> like a hypothetical POSIX aio_readv(), not like POSIX lio_list()).
>
> Perhaps there could be an extra call PrefetchBufferSubmit() that you'd
> call at appropriate times, but you obviously can't call it too
> infrequently.
>
> As for how to make the prefetch queue a reusable component, rather
> than having a custom thing like that for each part of our system that
> wants to support prefetching: that's a really good question. I didn't
> see how to do it, but maybe I didn't try hard enough. I looked at the
> three users I'm aware of, namely this patch, a btree prefetching patch
> I haven't shared yet, and the existing bitmap heap scan code, and they
> all needed to have their own custom book keeping for this, and I
> couldn't figure out how to share more infrastructure. In the case of
> this patch, you currently need to do LSN based book keeping to
> simulate "completion", and that doesn't make sense for other users.
> Maybe it'll become clearer when we have support for completion
> notification?
Yes, definitely.
> Some related questions are why all these parts of our system that know
> how to prefetch are allowed to do so independently without any kind of
> shared accounting, and why we don't give each tablespace (= our model
> of a device?) its own separate queue. I think it's OK to put these
> questions off a bit longer until we have more infrastructure and
> experience. Our current non-answer is at least consistent with our
> lack of an approach to system-wide memory and CPU accounting... I
> personally think that a better XLogReader that can be used for
> prefetching AND recovery would be a higher priority than that.
Sure, this patch is quite valuable as it is, and those questions I've
mentioned are targeting mostly future development.
> > Maybe it was discussed in the past in other threads. But if I understand
> > correctly, this implementation weights all the samples. Since at the
> > moment it depends directly on replaying speed (so a lot of IO involved),
> > couldn't it lead to a single outlier at the beginning skewing this value
> > and make it less useful? Does it make sense to decay old values?
>
> Hmm.
>
> I wondered about a reporting one or perhaps three exponential moving
> averages (like Unix 1/5/15 minute load averages), but I didn't propose
> it because: (1) In crash recovery, you can't query it, you just get
> the log message at the end, and mean unweighted seems OK in that case,
> no? (you are not more interested in the I/O saturation at the end of
> the recovery compared to the start of recovery are you?), and (2) on a
> streaming replica, if you want to sample the instantaneous depth and
> compute an exponential moving average or some more exotic statistical
> concoction in your monitoring tool, you're free to do so. I suppose
> (2) is an argument for removing the existing average completely from
> the stat view; I put it in there at Andres's suggestion, but I'm not
> sure I really believe in it. Where is our average replication lag,
> and why don't we compute the stddev of X, Y or Z? I think we should
> provide primary measurements and let people compute derived statistics
> from those.
For once I disagree, since I believe this very approach, widely applied,
leads to a slightly chaotic situation with monitoring. But of course
you're right, it has nothing to do with the patch itself. I also would
be in favour of removing the existing averages, unless Andres has more
arguments to keep it.
> On Sat, Apr 25, 2020 at 09:19:35PM +0200, Dmitry Dolgov wrote:
> > On Tue, Apr 21, 2020 at 05:26:52PM +1200, Thomas Munro wrote:
> >
> > One report I heard recently said that if you get rid of I/O stalls,
> > pread() becomes cheap enough that the much higher frequency lseek()
> > calls I've complained about elsewhere[1] become the main thing
> > recovery is doing, at least on some systems, but I haven't pieced
> > together the conditions required yet. I'd be interested to know if
> > you see that.
>
> At the moment I've performed couple of tests for the replication in case
> when almost everything is in memory (mostly by mistake, I was expecting
> that a postgres replica within a badly memory limited cgroup will cause
> more IO, but looks like kernel do not evict pages anyway). Not sure if
> that's what you mean by getting rid of IO stalls, but in these tests
> profiling shows lseek & pread appear in similar amount of samples.
>
> If I understand correctly, eventually one can measure prefetching
> influence by looking at different redo function execution time (assuming
> that data they operate with is already prefetched they should be
> faster). I still have to clarify what is the exact reason, but even in
> the situation described above (in memory) there is some visible
> difference, e.g.
I've finally performed couple of tests involving more IO. The
not-that-big dataset of 1.5 GB for the replica with the memory allowing
fitting ~ 1/6 of it, default prefetching parameters and an update
workload with uniform distribution. Rather a small setup, but causes
stable reading into the page cache on the replica and allows to see a
visible influence of the patch (more measurement samples tend to happen
at lower latencies):
# with patch
Function = b'heap_redo' [206]
nsecs : count distribution
1024 -> 2047 : 0 | |
2048 -> 4095 : 32833 |********************** |
4096 -> 8191 : 59476 |****************************************|
8192 -> 16383 : 18617 |************ |
16384 -> 32767 : 3992 |** |
32768 -> 65535 : 425 | |
65536 -> 131071 : 5 | |
131072 -> 262143 : 326 | |
262144 -> 524287 : 6 | |
# without patch
Function = b'heap_redo' [130]
nsecs : count distribution
1024 -> 2047 : 0 | |
2048 -> 4095 : 20062 |*********** |
4096 -> 8191 : 70662 |****************************************|
8192 -> 16383 : 12895 |******* |
16384 -> 32767 : 9123 |***** |
32768 -> 65535 : 560 | |
65536 -> 131071 : 1 | |
131072 -> 262143 : 460 | |
262144 -> 524287 : 3 | |
Not that there were any doubts, but at the same time it was surprising
to me how good linux readahead works in this situation. The results
above are shown with disabled readahead for filesystem and device, and
without that there was almost no difference, since a lot of IO was
avoided by readahead (which was in fact the majority of all reads):
# with patch
flags = Read
usecs : count distribution
16 -> 31 : 0 | |
32 -> 63 : 1 |******** |
64 -> 127 : 5 |****************************************|
flags = ReadAhead-Read
usecs : count distribution
32 -> 63 : 0 | |
64 -> 127 : 131 |****************************************|
128 -> 255 : 12 |*** |
256 -> 511 : 6 |* |
# without patch
flags = Read
usecs : count distribution
16 -> 31 : 0 | |
32 -> 63 : 0 | |
64 -> 127 : 4 |****************************************|
flags = ReadAhead-Read
usecs : count distribution
32 -> 63 : 0 | |
64 -> 127 : 143 |****************************************|
128 -> 255 : 20 |***** |
Numbers of reads in this case were similar with and without patch, which
means it couldn't be attributed to the situation when a page was read
too early, then evicted and read again later.
On Sun, May 3, 2020 at 3:12 AM Dmitry Dolgov <9erthalion6@gmail.com> wrote: > I've finally performed couple of tests involving more IO. The > not-that-big dataset of 1.5 GB for the replica with the memory allowing > fitting ~ 1/6 of it, default prefetching parameters and an update > workload with uniform distribution. Rather a small setup, but causes > stable reading into the page cache on the replica and allows to see a > visible influence of the patch (more measurement samples tend to happen > at lower latencies): Thanks for these tests Dmitry. You didn't mention the details of the workload, but one thing I'd recommend for a uniform/random workload that's generating a lot of misses on the primary server using N backends is to make sure that maintenance_io_concurrency is set to a number like N*2 or higher, and to look at the queue depth on both systems with iostat -x 1. Then you can experiment with ALTER SYSTEM SET maintenance_io_concurrency = X; SELECT pg_reload_conf(); to try to understand the way it works; there is a point where you've set it high enough and the replica is able to handle the same rate of concurrent I/Os as the primary. The default of 10 is actually pretty low unless you've only got ~4 backends generating random updates on the primary. That's with full_page_writes=off; if you leave it on, it takes a while to get into a scenario where it has much effect. Here's a rebase, after the recent XLogReader refactoring.
Attachment
Thomas Munro escribió:
> @@ -1094,8 +1103,16 @@ WALRead(XLogReaderState *state,
> XLByteToSeg(recptr, nextSegNo, state->segcxt.ws_segsize);
> state->routine.segment_open(state, nextSegNo, &tli);
>
> - /* This shouldn't happen -- indicates a bug in segment_open */
> - Assert(state->seg.ws_file >= 0);
> + /* callback reported that there was no such file */
> + if (state->seg.ws_file < 0)
> + {
> + errinfo->wre_errno = errno;
> + errinfo->wre_req = 0;
> + errinfo->wre_read = 0;
> + errinfo->wre_off = startoff;
> + errinfo->wre_seg = state->seg;
> + return false;
> + }
Ah, this is what Michael was saying ... we need to fix WALRead so that
it doesn't depend on segment_open alway returning a good FD. This needs
a fix everywhere, not just here, and improve the error report interface.
Maybe it does make sense to get it fixed in pg13 and avoid a break
later.
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi,
I've spent some time testing this, mostly from the performance point of
view. I've done a very simple thing, in order to have reproducible test:
1) I've initialized pgbench with scale 8000 (so ~120GB on a machine with
only 64GB of RAM)
2) created a physical backup, enabled WAL archiving
3) did 1h pgbench run with 32 clients
4) disabled full-page writes and did another 1h pgbench run
Once I had this, I did a recovery using the physical backup and WAL
archive, measuring how long it took to apply each WAL segment. First
without any prefetching (current master), then twice with prefetching.
First with default values (m_io_c=10, distance=256kB) and then with
higher values (100 + 2MB).
I did this on two storage systems I have in the system - NVME SSD and
SATA RAID (3 x 7.2k drives). So, a fast one and slow one.
1) NVME
On the NVME, this generates ~26k WAL segments (~400GB), and each of the
pgbench runs generates ~120M transactions (~33k tps). Of course, wast
majority of the WAL segments ~16k comes from the first run, because
there's a lot of FPI due to the random nature of the workload.
I have not expected a significant improvement from the prefetching, as
the NVME is pretty good in handling random I/O. The total duration looks
like this:
no prefetch prefetch prefetch2
10618 10385 9403
So the default is a tiny bit faster, and the more aggressive config
makes it about 10% faster. Not bad, considering the expectations.
Attached is a chart comparing the three runs. There are three clearly
visible parts - first the 1h run with f_p_w=on, with two checkpoints.
That's first ~16k segments. Then there's a bit of a gap before the
second pgbench run was started - I think it's mostly autovacuum etc. And
then at segment ~23k the second pgbench (f_p_w=off) starts.
I think this shows the prefetching starts to help as the number of FPIs
decreases. It's subtle, but it's there.
2) SATA
On SATA it's just ~550 segments (~8.5GB), and the pgbench runs generate
only about 1M transactions. Again, vast majority of the segments comes
from the first run, due to FPI.
In this case, I don't have complete results, but after processing 542
segments (out of the ~550) it looks like this:
no prefetch prefetch prefetch2
6644 6635 8282
So the no prefetch and "default" prefetch are roughly on par, but the
"aggressive" prefetch is way slower. I'll get back to this shortly, but
I'd like to point out this is entirely due to the "no FPI" pgbench,
because after the first ~525 initial segments it looks like this:
no prefetch prefetch prefetch2
58 65 57
So it goes very fast by the initial segments with plenty of FPIs, and
then we get to the "no FPI" segments and the prefetch either does not
help or makes it slower.
Looking at how long it takes to apply the last few segments, it looks
like this:
no prefetch prefetch prefetch2
280 298 478
which is not particularly great, I guess. There however seems to be
something wrong, because with the prefetching I see this in the log:
prefetch:
2020-06-05 02:47:25.970 CEST 1591318045.970 [22961] LOG: recovery no
longer prefetching: unexpected pageaddr 108/E8000000 in log segment
0000000100000108000000FF, offset 0
prefetch2:
2020-06-05 15:29:23.895 CEST 1591363763.895 [26676] LOG: recovery no
longer prefetching: unexpected pageaddr 108/E8000000 in log segment
000000010000010900000001, offset 0
Which seems pretty suspicious, but I have no idea what's wrong. I admit
the archive/restore commands are a bit hacky, but I've only seen this
with prefetching on the SATA storage, while all other cases seem to be
just fine. I haven't seen in on NVME (which processes much more WAL).
And the SATA baseline (no prefetching) also worked fine.
Moreover, the pageaddr value is the same in both cases, but the WAL
segments are different (but just one segment apart). Seems strange.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
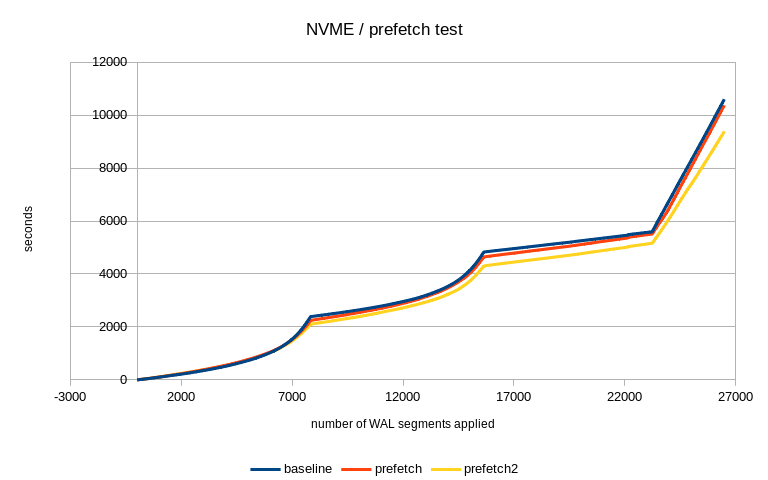{kind=link}
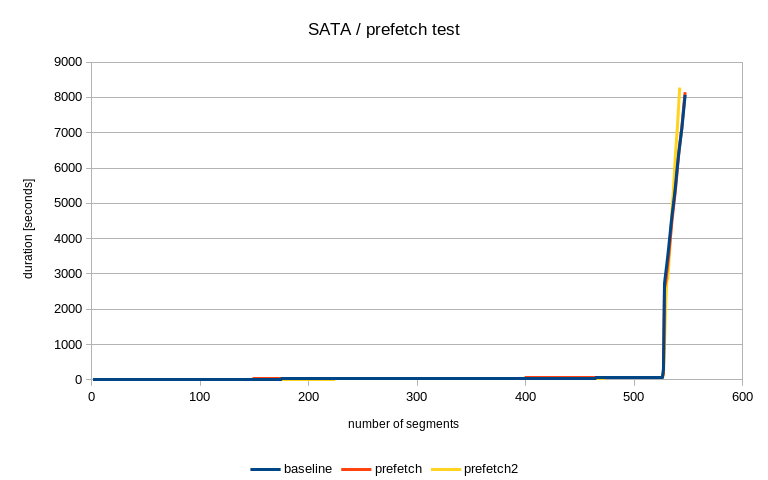{kind=link}
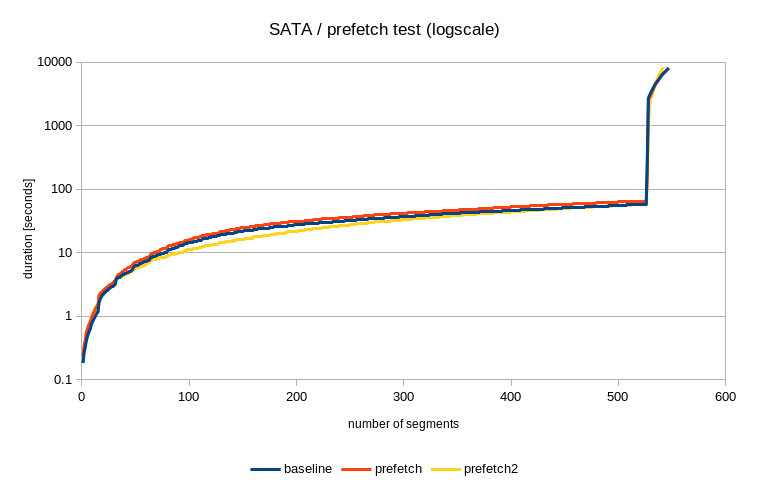{kind=link}
On Fri, Jun 05, 2020 at 05:20:52PM +0200, Tomas Vondra wrote:
>
> ...
>
>which is not particularly great, I guess. There however seems to be
>something wrong, because with the prefetching I see this in the log:
>
>prefetch:
>2020-06-05 02:47:25.970 CEST 1591318045.970 [22961] LOG: recovery no
>longer prefetching: unexpected pageaddr 108/E8000000 in log segment
>0000000100000108000000FF, offset 0
>
>prefetch2:
>2020-06-05 15:29:23.895 CEST 1591363763.895 [26676] LOG: recovery no
>longer prefetching: unexpected pageaddr 108/E8000000 in log segment
>000000010000010900000001, offset 0
>
>Which seems pretty suspicious, but I have no idea what's wrong. I admit
>the archive/restore commands are a bit hacky, but I've only seen this
>with prefetching on the SATA storage, while all other cases seem to be
>just fine. I haven't seen in on NVME (which processes much more WAL).
>And the SATA baseline (no prefetching) also worked fine.
>
>Moreover, the pageaddr value is the same in both cases, but the WAL
>segments are different (but just one segment apart). Seems strange.
>
I suspected it might be due to a somewhat hackish restore_command that
prefetches some of the WAL segments, so I tried again with a much
simpler restore_command - essentially just:
restore_command = 'cp /archive/%f %p.tmp && mv %p.tmp %p'
which I think should be fine for testing purposes. And I got this:
LOG: recovery no longer prefetching: unexpected pageaddr 108/57000000
in log segment 0000000100000108000000FF, offset 0
LOG: restored log file "0000000100000108000000FF" from archive
which is the same segment as in the earlier examples, but with a
different pageaddr value. Of course, there's no such pageaddr in the WAL
segment (and recovery of that segment succeeds).
So I think there's something broken ...
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jun 05, 2020 at 10:04:14PM +0200, Tomas Vondra wrote:
>On Fri, Jun 05, 2020 at 05:20:52PM +0200, Tomas Vondra wrote:
>>
>>...
>>
>>which is not particularly great, I guess. There however seems to be
>>something wrong, because with the prefetching I see this in the log:
>>
>>prefetch:
>>2020-06-05 02:47:25.970 CEST 1591318045.970 [22961] LOG: recovery no
>>longer prefetching: unexpected pageaddr 108/E8000000 in log segment
>>0000000100000108000000FF, offset 0
>>
>>prefetch2:
>>2020-06-05 15:29:23.895 CEST 1591363763.895 [26676] LOG: recovery no
>>longer prefetching: unexpected pageaddr 108/E8000000 in log segment
>>000000010000010900000001, offset 0
>>
>>Which seems pretty suspicious, but I have no idea what's wrong. I admit
>>the archive/restore commands are a bit hacky, but I've only seen this
>>with prefetching on the SATA storage, while all other cases seem to be
>>just fine. I haven't seen in on NVME (which processes much more WAL).
>>And the SATA baseline (no prefetching) also worked fine.
>>
>>Moreover, the pageaddr value is the same in both cases, but the WAL
>>segments are different (but just one segment apart). Seems strange.
>>
>
>I suspected it might be due to a somewhat hackish restore_command that
>prefetches some of the WAL segments, so I tried again with a much
>simpler restore_command - essentially just:
>
> restore_command = 'cp /archive/%f %p.tmp && mv %p.tmp %p'
>
>which I think should be fine for testing purposes. And I got this:
>
> LOG: recovery no longer prefetching: unexpected pageaddr 108/57000000
> in log segment 0000000100000108000000FF, offset 0
> LOG: restored log file "0000000100000108000000FF" from archive
>
>which is the same segment as in the earlier examples, but with a
>different pageaddr value. Of course, there's no such pageaddr in the WAL
>segment (and recovery of that segment succeeds).
>
>So I think there's something broken ...
>
BTW in all three cases it happens right after the first restart point in
the WAL stream:
LOG: restored log file "0000000100000108000000FD" from archive
LOG: restartpoint starting: time
LOG: restored log file "0000000100000108000000FE" from archive
LOG: restartpoint complete: wrote 236092 buffers (22.5%); 0 WAL ...
LOG: recovery restart point at 108/FC000028
DETAIL: Last completed transaction was at log time 2020-06-04
15:27:00.95139+02.
LOG: recovery no longer prefetching: unexpected pageaddr
108/57000000 in log segment 0000000100000108000000FF, offset 0
LOG: restored log file "0000000100000108000000FF" from archive
It looks exactly like this in case of all 3 failures ...
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Jun 6, 2020 at 8:41 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > BTW in all three cases it happens right after the first restart point in > the WAL stream: > > LOG: restored log file "0000000100000108000000FD" from archive > LOG: restartpoint starting: time > LOG: restored log file "0000000100000108000000FE" from archive > LOG: restartpoint complete: wrote 236092 buffers (22.5%); 0 WAL ... > LOG: recovery restart point at 108/FC000028 > DETAIL: Last completed transaction was at log time 2020-06-04 > 15:27:00.95139+02. > LOG: recovery no longer prefetching: unexpected pageaddr > 108/57000000 in log segment 0000000100000108000000FF, offset 0 > LOG: restored log file "0000000100000108000000FF" from archive > > It looks exactly like this in case of all 3 failures ... Huh. Thanks! I'll try to reproduce this here.
Hi, I wonder if we can collect some stats to measure how effective the prefetching actually is. Ultimately we want something like cache hit ratio, but we're only preloading into page cache, so we can't easily measure that. Perhaps we could measure I/O timings in redo, though? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Greetings, * Tomas Vondra (tomas.vondra@2ndquadrant.com) wrote: > I wonder if we can collect some stats to measure how effective the > prefetching actually is. Ultimately we want something like cache hit > ratio, but we're only preloading into page cache, so we can't easily > measure that. Perhaps we could measure I/O timings in redo, though? That would certainly be interesting, particularly as this optimization seems likely to be useful on some platforms (eg, zfs, where the filesystem block size is larger than ours..) and less on others (traditional systems which have a smaller block size). Thanks, Stephen
Attachment
On Sat, Jun 6, 2020 at 12:36 PM Stephen Frost <sfrost@snowman.net> wrote: > * Tomas Vondra (tomas.vondra@2ndquadrant.com) wrote: > > I wonder if we can collect some stats to measure how effective the > > prefetching actually is. Ultimately we want something like cache hit > > ratio, but we're only preloading into page cache, so we can't easily > > measure that. Perhaps we could measure I/O timings in redo, though? > > That would certainly be interesting, particularly as this optimization > seems likely to be useful on some platforms (eg, zfs, where the > filesystem block size is larger than ours..) and less on others > (traditional systems which have a smaller block size). I know one way to get information about cache hit ratios without the page cache fuzz factor: if you combine this patch with Andres's still-in-development AIO prototype and tell it to use direct IO, you get the undiluted truth about hits and misses by looking at the "prefetch" and "skip_hit" columns of the stats view. I'm hoping to have a bit more to say about how this patch works as a client of that new magic soon, but I also don't want to make this dependent on that (it's mostly orthogonal, apart from the "how deep is the queue" part which will improve with better information). FYI I am still trying to reproduce and understand the problem Tomas reported; more soon.
On Thu, Jul 02, 2020 at 03:09:29PM +1200, Thomas Munro wrote: >On Sat, Jun 6, 2020 at 12:36 PM Stephen Frost <sfrost@snowman.net> wrote: >> * Tomas Vondra (tomas.vondra@2ndquadrant.com) wrote: >> > I wonder if we can collect some stats to measure how effective the >> > prefetching actually is. Ultimately we want something like cache hit >> > ratio, but we're only preloading into page cache, so we can't easily >> > measure that. Perhaps we could measure I/O timings in redo, though? >> >> That would certainly be interesting, particularly as this optimization >> seems likely to be useful on some platforms (eg, zfs, where the >> filesystem block size is larger than ours..) and less on others >> (traditional systems which have a smaller block size). > >I know one way to get information about cache hit ratios without the >page cache fuzz factor: if you combine this patch with Andres's >still-in-development AIO prototype and tell it to use direct IO, you >get the undiluted truth about hits and misses by looking at the >"prefetch" and "skip_hit" columns of the stats view. I'm hoping to >have a bit more to say about how this patch works as a client of that >new magic soon, but I also don't want to make this dependent on that >(it's mostly orthogonal, apart from the "how deep is the queue" part >which will improve with better information). > >FYI I am still trying to reproduce and understand the problem Tomas >reported; more soon. Any luck trying to reproduce thigs? Should I try again and collect some additional debug info? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Aug 4, 2020 at 3:47 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On Thu, Jul 02, 2020 at 03:09:29PM +1200, Thomas Munro wrote: > >FYI I am still trying to reproduce and understand the problem Tomas > >reported; more soon. > > Any luck trying to reproduce thigs? Should I try again and collect some > additional debug info? No luck. I'm working on it now, and also trying to reduce the overheads so that we're not doing extra work when it doesn't help. By the way, I also looked into recovery I/O stalls *other* than relation buffer cache misses, and created https://commitfest.postgresql.org/29/2669/ to fix what I found. If you avoid both kinds of stalls then crash recovery is finally CPU bound (to go faster after that we'll need parallel replay).
On Thu, Aug 06, 2020 at 02:58:44PM +1200, Thomas Munro wrote: >On Tue, Aug 4, 2020 at 3:47 AM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> On Thu, Jul 02, 2020 at 03:09:29PM +1200, Thomas Munro wrote: >> >FYI I am still trying to reproduce and understand the problem Tomas >> >reported; more soon. >> >> Any luck trying to reproduce thigs? Should I try again and collect some >> additional debug info? > >No luck. I'm working on it now, and also trying to reduce the >overheads so that we're not doing extra work when it doesn't help. > OK, I'll see if I can still reproduce it. >By the way, I also looked into recovery I/O stalls *other* than >relation buffer cache misses, and created >https://commitfest.postgresql.org/29/2669/ to fix what I found. If >you avoid both kinds of stalls then crash recovery is finally CPU >bound (to go faster after that we'll need parallel replay). Yeah, I noticed. I'll take a look and do some testing in the next CF. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Aug 6, 2020 at 10:47 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On Thu, Aug 06, 2020 at 02:58:44PM +1200, Thomas Munro wrote: > >On Tue, Aug 4, 2020 at 3:47 AM Tomas Vondra > >> Any luck trying to reproduce thigs? Should I try again and collect some > >> additional debug info? > > > >No luck. I'm working on it now, and also trying to reduce the > >overheads so that we're not doing extra work when it doesn't help. > > OK, I'll see if I can still reproduce it. Since someone else ask me off-list, here's a rebase, with no functional changes. Soon I'll post a new improved version, but this version just fixes the bitrot and hopefully turns cfbot green.
Attachment
I have run some benchmarks for this patch. Overall it seems that there is a good improvement with the patch on recovery
times:
The VMs I used have 32GB RAM, pgbench is initialized with a scale factor 3000(so it doesn’t fit to memory, ~45GB).
In order to avoid checkpoints during benchmark, max_wal_size(200GB) and checkpoint_timeout(200 mins) are set to a high
value.
The run is cancelled when there is a reasonable amount of WAL ( > 25GB). The recovery times are measured from the REDO
logs.
I have tried combination of SSD, HDD, full_page_writes = on/off and max_io_concurrency = 10/50, the recovery times are
asfollows (in seconds):
No prefetch | Default prefetch values | Default + max_io_concurrency = 50
SSD, full_page_writes = on 852 301 197
SSD, full_page_writes = off 1642 1359 1391
HDD, full_page_writes = on 6027 6345 6390
HDD, full_page_writes = off 738 275 192
Default prefetch values:
- Max_recovery_prefetch_distance = 256KB
- Max_io_concurrency = 10
It probably makes sense to compare each row separately as the size of WAL can be different.
Talha.
-----Original Message-----
From: Thomas Munro <thomas.munro@gmail.com>
Sent: Thursday, August 13, 2020 9:57 AM
To: Tomas Vondra <tomas.vondra@2ndquadrant.com>
Cc: Stephen Frost <sfrost@snowman.net>; Dmitry Dolgov <9erthalion6@gmail.com>; David Steele <david@pgmasters.net>;
AndresFreund <andres@anarazel.de>; Alvaro Herrera <alvherre@2ndquadrant.com>; pgsql-hackers
<pgsql-hackers@postgresql.org>
Subject: [EXTERNAL] Re: WIP: WAL prefetch (another approach)
On Thu, Aug 6, 2020 at 10:47 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
> On Thu, Aug 06, 2020 at 02:58:44PM +1200, Thomas Munro wrote:
> >On Tue, Aug 4, 2020 at 3:47 AM Tomas Vondra
> >> Any luck trying to reproduce thigs? Should I try again and collect
> >> some additional debug info?
> >
> >No luck. I'm working on it now, and also trying to reduce the
> >overheads so that we're not doing extra work when it doesn't help.
>
> OK, I'll see if I can still reproduce it.
Since someone else ask me off-list, here's a rebase, with no functional changes. Soon I'll post a new improved
version,but this version just fixes the bitrot and hopefully turns cfbot green.
On Wed, Aug 26, 2020 at 9:42 AM Sait Talha Nisanci <Sait.Nisanci@microsoft.com> wrote: > I have tried combination of SSD, HDD, full_page_writes = on/off and max_io_concurrency = 10/50, the recovery times areas follows (in seconds): > > No prefetch | Default prefetch values | Default + max_io_concurrency= 50 > SSD, full_page_writes = on 852 301 197 > SSD, full_page_writes = off 1642 1359 1391 > HDD, full_page_writes = on 6027 6345 6390 > HDD, full_page_writes = off 738 275 192 The regression on HDD with full_page_writes=on is interesting. I don't know why that should happen, and I wonder if there is anything that can be done to mitigate it. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Greetings, * Sait Talha Nisanci (Sait.Nisanci@microsoft.com) wrote: > I have run some benchmarks for this patch. Overall it seems that there is a good improvement with the patch on recoverytimes: Maybe I missed it somewhere, but what's the OS/filesystem being used here..? What's the filesystem block size..? Thanks, Stephen
Attachment
Hi Stephen, OS version is Ubuntu 18.04.5 LTS. Filesystem is ext4 and block size is 4KB. Talha. -----Original Message----- From: Stephen Frost <sfrost@snowman.net> Sent: Thursday, August 27, 2020 4:56 PM To: Sait Talha Nisanci <Sait.Nisanci@microsoft.com> Cc: Thomas Munro <thomas.munro@gmail.com>; Tomas Vondra <tomas.vondra@2ndquadrant.com>; Dmitry Dolgov <9erthalion6@gmail.com>;David Steele <david@pgmasters.net>; Andres Freund <andres@anarazel.de>; Alvaro Herrera <alvherre@2ndquadrant.com>;pgsql-hackers <pgsql-hackers@postgresql.org> Subject: Re: [EXTERNAL] Re: WIP: WAL prefetch (another approach) Greetings, * Sait Talha Nisanci (Sait.Nisanci@microsoft.com) wrote: > I have run some benchmarks for this patch. Overall it seems that there is a good improvement with the patch on recoverytimes: Maybe I missed it somewhere, but what's the OS/filesystem being used here..? What's the filesystem block size..? Thanks, Stephen
Greetings, * Sait Talha Nisanci (Sait.Nisanci@microsoft.com) wrote: > OS version is Ubuntu 18.04.5 LTS. > Filesystem is ext4 and block size is 4KB. [...] * Sait Talha Nisanci (Sait.Nisanci@microsoft.com) wrote: > I have run some benchmarks for this patch. Overall it seems that there is a good improvement with the patch on recoverytimes: > > The VMs I used have 32GB RAM, pgbench is initialized with a scale factor 3000(so it doesn’t fit to memory, ~45GB). > > In order to avoid checkpoints during benchmark, max_wal_size(200GB) and checkpoint_timeout(200 mins) are set to a highvalue. > > The run is cancelled when there is a reasonable amount of WAL ( > 25GB). The recovery times are measured from the REDOlogs. > > I have tried combination of SSD, HDD, full_page_writes = on/off and max_io_concurrency = 10/50, the recovery times areas follows (in seconds): > > No prefetch | Default prefetch values | Default + max_io_concurrency = 50 > SSD, full_page_writes = on 852 301 197 > SSD, full_page_writes = off 1642 1359 1391 > HDD, full_page_writes = on 6027 6345 6390 > HDD, full_page_writes = off 738 275 192 > > Default prefetch values: > - Max_recovery_prefetch_distance = 256KB > - Max_io_concurrency = 10 > > It probably makes sense to compare each row separately as the size of WAL can be different. Is WAL FPW compression enabled..? I'm trying to figure out how, given what's been shared here, that replaying 25GB of WAL is being helped out by 2.5x thanks to prefetch in the SSD case. That prefetch is hurting in the HDD case entirely makes sense to me- we're spending time reading pages from the HDD, which is entirely pointless work given that we're just going to write over those pages entirely with FPWs. Further, if there's 32GB of RAM, and WAL compression isn't enabled and the WAL is only 25GB, then it's very likely that every page touched by the WAL ends up in memory (shared buffers or fs cache), and with FPWs we shouldn't ever need to actually read from the storage to get those pages, right? So how is prefetch helping so much..? I'm not sure that the 'full_page_writes = off' tests are very interesting in this case, since you're going to get torn pages and therefore corruption and hopefully no one is running with that configuration with this OS/filesystem. Thanks, Stephen
Attachment
Hi, On August 27, 2020 11:26:42 AM PDT, Stephen Frost <sfrost@snowman.net> wrote: >Is WAL FPW compression enabled..? I'm trying to figure out how, given >what's been shared here, that replaying 25GB of WAL is being helped out >by 2.5x thanks to prefetch in the SSD case. That prefetch is hurting >in >the HDD case entirely makes sense to me- we're spending time reading >pages from the HDD, which is entirely pointless work given that we're >just going to write over those pages entirely with FPWs. Hm? At least earlier versions didn't do prefetching for records with an fpw, and only for subsequent records affecting thesame or if not in s_b anymore. Andres -- Sent from my Android device with K-9 Mail. Please excuse my brevity.
Greetings, * Andres Freund (andres@anarazel.de) wrote: > On August 27, 2020 11:26:42 AM PDT, Stephen Frost <sfrost@snowman.net> wrote: > >Is WAL FPW compression enabled..? I'm trying to figure out how, given > >what's been shared here, that replaying 25GB of WAL is being helped out > >by 2.5x thanks to prefetch in the SSD case. That prefetch is hurting > >in > >the HDD case entirely makes sense to me- we're spending time reading > >pages from the HDD, which is entirely pointless work given that we're > >just going to write over those pages entirely with FPWs. > > Hm? At least earlier versions didn't do prefetching for records with an fpw, and only for subsequent records affectingthe same or if not in s_b anymore. We don't actually read the page when we're replaying an FPW though..? If we don't read it, and we entirely write the page from the FPW, how is pre-fetching helping..? I understood how it could be helpful for filesystems which have a larger block size than ours (eg: zfs w/ 16kb block sizes where the kernel needs to get the whole 16kb block when we only write 8kb to it), but that's apparently not the case here. So- what is it that pre-fetching is doing to result in such an improvement? Is there something lower level where the SSD physical block size is coming into play, which is typically larger..? I wouldn't have thought so, but perhaps that's the case.. Thanks, Stephen
Attachment
On Thu, Aug 27, 2020 at 2:51 PM Stephen Frost <sfrost@snowman.net> wrote: > > Hm? At least earlier versions didn't do prefetching for records with an fpw, and only for subsequent records affectingthe same or if not in s_b anymore. > > We don't actually read the page when we're replaying an FPW though..? > If we don't read it, and we entirely write the page from the FPW, how is > pre-fetching helping..? Suppose there is a checkpoint. Then we replay a record with an FPW, pre-fetching nothing. Then the buffer gets evicted from shared_buffers, and maybe the OS cache too. Then, before the next checkpoint, we again replay a record for the same page. At this point, pre-fetching should be helpful. Admittedly, I don't quite understand whether that is what is happening in this test case, or why SDD vs. HDD should make any difference. But there doesn't seem to be any reason why it doesn't make sense in theory. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Greetings, * Robert Haas (robertmhaas@gmail.com) wrote: > On Thu, Aug 27, 2020 at 2:51 PM Stephen Frost <sfrost@snowman.net> wrote: > > > Hm? At least earlier versions didn't do prefetching for records with an fpw, and only for subsequent records affectingthe same or if not in s_b anymore. > > > > We don't actually read the page when we're replaying an FPW though..? > > If we don't read it, and we entirely write the page from the FPW, how is > > pre-fetching helping..? > > Suppose there is a checkpoint. Then we replay a record with an FPW, > pre-fetching nothing. Then the buffer gets evicted from > shared_buffers, and maybe the OS cache too. Then, before the next > checkpoint, we again replay a record for the same page. At this point, > pre-fetching should be helpful. Sure- but if we're talking about 25GB of WAL, on a server that's got 32GB, then why would those pages end up getting evicted from memory entirely? Particularly, enough of them to end up with such a huge difference in replay time.. I do agree that if we've got more outstanding WAL between checkpoints than the system's got memory then that certainly changes things, but that wasn't what I understood the case to be here. > Admittedly, I don't quite understand whether that is what is happening > in this test case, or why SDD vs. HDD should make any difference. But > there doesn't seem to be any reason why it doesn't make sense in > theory. I agree that this could be a reason, but it doesn't seem to quite fit in this particular case given the amount of memory and WAL. I'm suspecting that it's something else and I'd very much like to know if it's a general "this applies to all (most? a lot of?) SSDs because the hardware has a larger than 8KB page size and therefore the kernel has to read it", or if it's something odd about this particular system and doesn't apply generally. Thanks, Stephen
Attachment
On Thu, Aug 27, 2020 at 04:28:54PM -0400, Stephen Frost wrote: >Greetings, > >* Robert Haas (robertmhaas@gmail.com) wrote: >> On Thu, Aug 27, 2020 at 2:51 PM Stephen Frost <sfrost@snowman.net> wrote: >> > > Hm? At least earlier versions didn't do prefetching for records with an fpw, and only for subsequent records affectingthe same or if not in s_b anymore. >> > >> > We don't actually read the page when we're replaying an FPW though..? >> > If we don't read it, and we entirely write the page from the FPW, how is >> > pre-fetching helping..? >> >> Suppose there is a checkpoint. Then we replay a record with an FPW, >> pre-fetching nothing. Then the buffer gets evicted from >> shared_buffers, and maybe the OS cache too. Then, before the next >> checkpoint, we again replay a record for the same page. At this point, >> pre-fetching should be helpful. > >Sure- but if we're talking about 25GB of WAL, on a server that's got >32GB, then why would those pages end up getting evicted from memory >entirely? Particularly, enough of them to end up with such a huge >difference in replay time.. > >I do agree that if we've got more outstanding WAL between checkpoints >than the system's got memory then that certainly changes things, but >that wasn't what I understood the case to be here. > I don't think it's very clear how much WAL there actually was in each case - the message only said there was more than 25GB, but who knows how many checkpoints that covers? In the cases with FPW=on this may easily be much less than one checkpoint (because with scale 45GB an update to every page will log 45GB of full-page images). It'd be interesting to see some stats from pg_waldump etc. >> Admittedly, I don't quite understand whether that is what is happening >> in this test case, or why SDD vs. HDD should make any difference. But >> there doesn't seem to be any reason why it doesn't make sense in >> theory. > >I agree that this could be a reason, but it doesn't seem to quite fit in >this particular case given the amount of memory and WAL. I'm suspecting >that it's something else and I'd very much like to know if it's a >general "this applies to all (most? a lot of?) SSDs because the >hardware has a larger than 8KB page size and therefore the kernel has to >read it", or if it's something odd about this particular system and >doesn't apply generally. > Not sure. I doubt it has anything to do with the hardware page size, that's mostly transparent to the kernel anyway. But it might be that the prefetching on a particular SSD has more overhead than what it saves. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Greetings, * Tomas Vondra (tomas.vondra@2ndquadrant.com) wrote: > On Thu, Aug 27, 2020 at 04:28:54PM -0400, Stephen Frost wrote: > >* Robert Haas (robertmhaas@gmail.com) wrote: > >>On Thu, Aug 27, 2020 at 2:51 PM Stephen Frost <sfrost@snowman.net> wrote: > >>> > Hm? At least earlier versions didn't do prefetching for records with an fpw, and only for subsequent records affectingthe same or if not in s_b anymore. > >>> > >>> We don't actually read the page when we're replaying an FPW though..? > >>> If we don't read it, and we entirely write the page from the FPW, how is > >>> pre-fetching helping..? > >> > >>Suppose there is a checkpoint. Then we replay a record with an FPW, > >>pre-fetching nothing. Then the buffer gets evicted from > >>shared_buffers, and maybe the OS cache too. Then, before the next > >>checkpoint, we again replay a record for the same page. At this point, > >>pre-fetching should be helpful. > > > >Sure- but if we're talking about 25GB of WAL, on a server that's got > >32GB, then why would those pages end up getting evicted from memory > >entirely? Particularly, enough of them to end up with such a huge > >difference in replay time.. > > > >I do agree that if we've got more outstanding WAL between checkpoints > >than the system's got memory then that certainly changes things, but > >that wasn't what I understood the case to be here. > > I don't think it's very clear how much WAL there actually was in each > case - the message only said there was more than 25GB, but who knows how > many checkpoints that covers? In the cases with FPW=on this may easily > be much less than one checkpoint (because with scale 45GB an update to > every page will log 45GB of full-page images). It'd be interesting to > see some stats from pg_waldump etc. Also in the message was this: -- In order to avoid checkpoints during benchmark, max_wal_size(200GB) and checkpoint_timeout(200 mins) are set to a high value. -- Which lead me to suspect, at least, that this was much less than a checkpoint, as you suggest. Also, given that the comment was 'run is cancelled when there is a reasonable amount of WAL (>25GB), seems likely that it's at least *around* there. Ultimately though, there just isn't enough information provided to really be able to understand what's going on. I agree, pg_waldump stats would be useful. > >>Admittedly, I don't quite understand whether that is what is happening > >>in this test case, or why SDD vs. HDD should make any difference. But > >>there doesn't seem to be any reason why it doesn't make sense in > >>theory. > > > >I agree that this could be a reason, but it doesn't seem to quite fit in > >this particular case given the amount of memory and WAL. I'm suspecting > >that it's something else and I'd very much like to know if it's a > >general "this applies to all (most? a lot of?) SSDs because the > >hardware has a larger than 8KB page size and therefore the kernel has to > >read it", or if it's something odd about this particular system and > >doesn't apply generally. > > Not sure. I doubt it has anything to do with the hardware page size, > that's mostly transparent to the kernel anyway. But it might be that the > prefetching on a particular SSD has more overhead than what it saves. Right- I wouldn't have thought the hardware page size would matter either, but it's entirely possible that assumption is wrong and that it does matter for some reason- perhaps with just some SSDs, or maybe with a lot of them, or maybe there's something else entirely going on. About all I feel like I can say at the moment is that I'm very interested in ways to make WAL replay go faster and it'd be great to get more information about what's going on here to see if there's something we can do to generally improve WAL replay. Thanks, Stephen
Attachment
Hi, The WAL size for "SSD, full_page_writes=on" was 36GB. I currently don't have the exact size for the other rows because mytest VMs got auto-deleted. I can possibly redo the benchmark to get pg_waldump stats for each row. Best, Talha. -----Original Message----- From: Stephen Frost <sfrost@snowman.net> Sent: Sunday, August 30, 2020 3:24 PM To: Tomas Vondra <tomas.vondra@2ndquadrant.com> Cc: Robert Haas <robertmhaas@gmail.com>; Andres Freund <andres@anarazel.de>; Sait Talha Nisanci <Sait.Nisanci@microsoft.com>;Thomas Munro <thomas.munro@gmail.com>; Dmitry Dolgov <9erthalion6@gmail.com>; David Steele <david@pgmasters.net>;Alvaro Herrera <alvherre@2ndquadrant.com>; pgsql-hackers <pgsql-hackers@postgresql.org> Subject: Re: [EXTERNAL] Re: WIP: WAL prefetch (another approach) Greetings, * Tomas Vondra (tomas.vondra@2ndquadrant.com) wrote: > On Thu, Aug 27, 2020 at 04:28:54PM -0400, Stephen Frost wrote: > >* Robert Haas (robertmhaas@gmail.com) wrote: > >>On Thu, Aug 27, 2020 at 2:51 PM Stephen Frost <sfrost@snowman.net> wrote: > >>> > Hm? At least earlier versions didn't do prefetching for records with an fpw, and only for subsequent records affectingthe same or if not in s_b anymore. > >>> > >>> We don't actually read the page when we're replaying an FPW though..? > >>> If we don't read it, and we entirely write the page from the FPW, > >>> how is pre-fetching helping..? > >> > >>Suppose there is a checkpoint. Then we replay a record with an FPW, > >>pre-fetching nothing. Then the buffer gets evicted from > >>shared_buffers, and maybe the OS cache too. Then, before the next > >>checkpoint, we again replay a record for the same page. At this > >>point, pre-fetching should be helpful. > > > >Sure- but if we're talking about 25GB of WAL, on a server that's got > >32GB, then why would those pages end up getting evicted from memory > >entirely? Particularly, enough of them to end up with such a huge > >difference in replay time.. > > > >I do agree that if we've got more outstanding WAL between checkpoints > >than the system's got memory then that certainly changes things, but > >that wasn't what I understood the case to be here. > > I don't think it's very clear how much WAL there actually was in each > case - the message only said there was more than 25GB, but who knows > how many checkpoints that covers? In the cases with FPW=on this may > easily be much less than one checkpoint (because with scale 45GB an > update to every page will log 45GB of full-page images). It'd be > interesting to see some stats from pg_waldump etc. Also in the message was this: -- In order to avoid checkpoints during benchmark, max_wal_size(200GB) and checkpoint_timeout(200 mins) are set to a high value. -- Which lead me to suspect, at least, that this was much less than a checkpoint, as you suggest. Also, given that the commentwas 'run is cancelled when there is a reasonable amount of WAL (>25GB), seems likely that it's at least *around* there. Ultimately though, there just isn't enough information provided to really be able to understand what's going on. I agree,pg_waldump stats would be useful. > >>Admittedly, I don't quite understand whether that is what is > >>happening in this test case, or why SDD vs. HDD should make any > >>difference. But there doesn't seem to be any reason why it doesn't > >>make sense in theory. > > > >I agree that this could be a reason, but it doesn't seem to quite fit > >in this particular case given the amount of memory and WAL. I'm > >suspecting that it's something else and I'd very much like to know if > >it's a general "this applies to all (most? a lot of?) SSDs because > >the hardware has a larger than 8KB page size and therefore the kernel > >has to read it", or if it's something odd about this particular > >system and doesn't apply generally. > > Not sure. I doubt it has anything to do with the hardware page size, > that's mostly transparent to the kernel anyway. But it might be that > the prefetching on a particular SSD has more overhead than what it saves. Right- I wouldn't have thought the hardware page size would matter either, but it's entirely possible that assumption iswrong and that it does matter for some reason- perhaps with just some SSDs, or maybe with a lot of them, or maybe there'ssomething else entirely going on. About all I feel like I can say at the moment is that I'm very interested in waysto make WAL replay go faster and it'd be great to get more information about what's going on here to see if there's somethingwe can do to generally improve WAL replay. Thanks, Stephen
On Thu, Aug 13, 2020 at 06:57:20PM +1200, Thomas Munro wrote:
>On Thu, Aug 6, 2020 at 10:47 PM Tomas Vondra
><tomas.vondra@2ndquadrant.com> wrote:
>> On Thu, Aug 06, 2020 at 02:58:44PM +1200, Thomas Munro wrote:
>> >On Tue, Aug 4, 2020 at 3:47 AM Tomas Vondra
>> >> Any luck trying to reproduce thigs? Should I try again and collect some
>> >> additional debug info?
>> >
>> >No luck. I'm working on it now, and also trying to reduce the
>> >overheads so that we're not doing extra work when it doesn't help.
>>
>> OK, I'll see if I can still reproduce it.
>
>Since someone else ask me off-list, here's a rebase, with no
>functional changes. Soon I'll post a new improved version, but this
>version just fixes the bitrot and hopefully turns cfbot green.
I've decided to do some tests with this patch version, but I immediately
ran into issues. What I did was initializing a 32GB pgbench database,
backed it up (shutdown + tar) and then ran 2h pgbench with archiving.
And then I restored the backed-up data directory and instructed it to
replay WAL from the archive. There's about 16k WAL segments, so about
256GB of WAL.
Unfortunately, the very first thing that happens after starting the
recovery is this:
LOG: starting archive recovery
LOG: restored log file "000000010000001600000080" from archive
LOG: consistent recovery state reached at 16/800000A0
LOG: redo starts at 16/800000A0
LOG: database system is ready to accept read only connections
LOG: recovery started prefetching on timeline 1 at 0/800000A0
LOG: recovery no longer prefetching: unexpected pageaddr 8/84000000 in log segment 000000010000001600000081,
offset0
LOG: restored log file "000000010000001600000081" from archive
LOG: restored log file "000000010000001600000082" from archive
So we start applying 000000010000001600000081 and it fails almost
immediately on the first segment. This is confirmed by prefetch stats,
which look like this:
-[ RECORD 1 ]---+-----------------------------
stats_reset | 2020-09-01 15:02:31.18766+02
prefetch | 1044
skip_hit | 1995
skip_new | 87
skip_fpw | 2108
skip_seq | 27
distance | 0
queue_depth | 0
avg_distance | 135838.95
avg_queue_depth | 8.852459
So we do a little bit of prefetching and then it gets disabled :-(
The segment looks perfectly fine when inspected using pg_waldump, see
the attached file.
I've tested this applied on 6ca547cf75ef6e922476c51a3fb5e253eef5f1b6,
and the failure seems fairly similar to what I reported before, except
that now it happened right at the very beginning.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On Wed, Sep 2, 2020 at 1:14 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > from the archive Ahh, so perhaps that's the key. > I've tested this applied on 6ca547cf75ef6e922476c51a3fb5e253eef5f1b6, > and the failure seems fairly similar to what I reported before, except > that now it happened right at the very beginning. Thanks, will see if I can work out why. My newer version probably has the same problem.
On Wed, Sep 02, 2020 at 02:05:10AM +1200, Thomas Munro wrote: >On Wed, Sep 2, 2020 at 1:14 AM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> from the archive > >Ahh, so perhaps that's the key. > Maybe. For the record, the commands look like this: archive_command = 'gzip -1 -c %p > /mnt/raid/wal-archive/%f.gz' restore_command = 'gunzip -c /mnt/raid/wal-archive/%f.gz > %p.tmp && mv %p.tmp %p' >> I've tested this applied on 6ca547cf75ef6e922476c51a3fb5e253eef5f1b6, >> and the failure seems fairly similar to what I reported before, except >> that now it happened right at the very beginning. > >Thanks, will see if I can work out why. My newer version probably has >the same problem. OK. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Sep 2, 2020 at 2:18 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On Wed, Sep 02, 2020 at 02:05:10AM +1200, Thomas Munro wrote: > >On Wed, Sep 2, 2020 at 1:14 AM Tomas Vondra > ><tomas.vondra@2ndquadrant.com> wrote: > >> from the archive > > > >Ahh, so perhaps that's the key. > > Maybe. For the record, the commands look like this: > > archive_command = 'gzip -1 -c %p > /mnt/raid/wal-archive/%f.gz' > > restore_command = 'gunzip -c /mnt/raid/wal-archive/%f.gz > %p.tmp && mv %p.tmp %p' Yeah, sorry, I goofed here by not considering archive recovery properly. I have special handling for crash recovery from files in pg_wal (XLRO_END, means read until you run out of files) and streaming replication (XLRO_WALRCV_WRITTEN, means read only as far as the wal receiver has advertised as written in shared memory), as a way to control the ultimate limit on how far ahead to read when maintenance_io_concurrency and max_recovery_prefetch_distance don't limit you first. But if you recover from a base backup with a WAL archive, it uses the XLRO_END policy which can run out of files just because a new file hasn't been restored yet, so it gives up prefetching too soon, as you're seeing. That doesn't cause any damage, but it stops doing anything useful because the prefetcher thinks its job is finished. It'd be possible to fix this somehow in the two-XLogReader design, but since I'm testing a new version that has a unified XLogReader-with-read-ahead I'm not going to try to do that. I've added a basebackup-with-archive recovery to my arsenal of test workloads to make sure I don't forget about archive recovery mode again, but I think it's actually harder to get this wrong in the new design. In the meantime, if you are still interested in studying the potential speed-up from WAL prefetching using the most recently shared two-XLogReader patch, you'll need to unpack all your archived WAL files into pg_wal manually beforehand.
On Sat, Sep 05, 2020 at 12:05:52PM +1200, Thomas Munro wrote: >On Wed, Sep 2, 2020 at 2:18 AM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> On Wed, Sep 02, 2020 at 02:05:10AM +1200, Thomas Munro wrote: >> >On Wed, Sep 2, 2020 at 1:14 AM Tomas Vondra >> ><tomas.vondra@2ndquadrant.com> wrote: >> >> from the archive >> > >> >Ahh, so perhaps that's the key. >> >> Maybe. For the record, the commands look like this: >> >> archive_command = 'gzip -1 -c %p > /mnt/raid/wal-archive/%f.gz' >> >> restore_command = 'gunzip -c /mnt/raid/wal-archive/%f.gz > %p.tmp && mv %p.tmp %p' > >Yeah, sorry, I goofed here by not considering archive recovery >properly. I have special handling for crash recovery from files in >pg_wal (XLRO_END, means read until you run out of files) and streaming >replication (XLRO_WALRCV_WRITTEN, means read only as far as the wal >receiver has advertised as written in shared memory), as a way to >control the ultimate limit on how far ahead to read when >maintenance_io_concurrency and max_recovery_prefetch_distance don't >limit you first. But if you recover from a base backup with a WAL >archive, it uses the XLRO_END policy which can run out of files just >because a new file hasn't been restored yet, so it gives up >prefetching too soon, as you're seeing. That doesn't cause any >damage, but it stops doing anything useful because the prefetcher >thinks its job is finished. > >It'd be possible to fix this somehow in the two-XLogReader design, but >since I'm testing a new version that has a unified >XLogReader-with-read-ahead I'm not going to try to do that. I've >added a basebackup-with-archive recovery to my arsenal of test >workloads to make sure I don't forget about archive recovery mode >again, but I think it's actually harder to get this wrong in the new >design. In the meantime, if you are still interested in studying the >potential speed-up from WAL prefetching using the most recently shared >two-XLogReader patch, you'll need to unpack all your archived WAL >files into pg_wal manually beforehand. OK, thanks for looking into this. I guess I'll wait for an updated patch before testing this further. The storage has limited capacity so I'd have to either reduce the amount of data/WAL or juggle with the WAL segments somehow. Doesn't seem worth it. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Sep 9, 2020 at 11:16 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > OK, thanks for looking into this. I guess I'll wait for an updated patch > before testing this further. The storage has limited capacity so I'd > have to either reduce the amount of data/WAL or juggle with the WAL > segments somehow. Doesn't seem worth it. Here's a new WIP version that works for archive-based recovery in my tests. The main change I have been working on is that there is now just a single XLogReaderState, so no more double-reading and double-decoding of the WAL. It provides XLogReadRecord(), as before, but now you can also read further ahead with XLogReadAhead(). The user interface is much like before, except that the GUCs changed a bit. They are now: recovery_prefetch=on recovery_prefetch_fpw=off wal_decode_buffer_size=256kB maintenance_io_concurrency=10 I recommend setting maintenance_io_concurrency and wal_decode_buffer_size much higher than those defaults. There are a few TODOs and questions remaining. One issue I'm wondering about is whether it is OK that bulky FPI data is now memcpy'd into the decode buffer, whereas before we avoided that sometimes, when it didn't happen to cross a page boundary; I have some ideas on how to do better (basically two levels of ring buffer) but I haven't looked into that yet. Another issue is the new 'nowait' API for the page-read callback; I'm trying to figure out if that is sufficient, or something more sophisticated including perhaps a different return value is required. Another thing I'm wondering about is whether I have timeline changes adequately handled. This design opens up a lot of possibilities for future performance improvements. Some example: 1. By adding some workspace to decoded records, the prefetcher can leave breadcrumbs for XLogReadBufferForRedoExtended(), so that it usually avoids the need for a second buffer mapping table lookup. Incidentally this also skips the hot smgropen() calls that Jakub complained about. I have an added an experimental patch like that, but I need to look into the interlocking some more. 2. By inspecting future records in the record->next chain, a redo function could merge work in various ways in quite a simple and localised way. A couple of examples: 2.1. If there is a sequence of records of the same type touching the same page, you could process all of them while you have the page lock. 2.2. If there is a sequence of relation extensions (say, a sequence of multi-tuple inserts to the end of a relation, as commonly seen in bulk data loads) then instead of generating a many pwrite(8KB of zeroes) syscalls record-by-record to extend the relation, a single posix_fallocate(1MB) could extend the file in one shot. Assuming the bgwriter is running and doing a good job, this would remove most of the system calls from bulk-load-recovery. 3. More sophisticated analysis could find records to merge that are a bit further apart, under carefully controlled conditions; for example if you have a sequence like heap-insert, btree-insert, heap-insert, btree-insert, ... then a simple next-record system like 2 won't see the opportunities, but something a teensy bit smarter could. 4. Since the decoding buffer can be placed in shared memory (decoded records contain pointers but only don't point to any other memory region, with the exception of clearly marked oversized records), we could begin to contemplate handing work off to other processes, given a clever dependency analysis scheme and some more infrastructure.
Attachment
On Thu, Sep 24, 2020 at 11:38 AM Thomas Munro <thomas.munro@gmail.com> wrote: > On Wed, Sep 9, 2020 at 11:16 AM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: > > OK, thanks for looking into this. I guess I'll wait for an updated patch > > before testing this further. The storage has limited capacity so I'd > > have to either reduce the amount of data/WAL or juggle with the WAL > > segments somehow. Doesn't seem worth it. > > Here's a new WIP version that works for archive-based recovery in my tests. Rebased over recent merge conflicts in xlog.c. I also removed a stray debugging message. One problem the current patch has is that if you use something like pg_standby, that is, a restore command that waits for more data, then it'll block waiting for WAL when it's trying to prefetch, which means that replay is delayed. I'm not sure what to think about that yet.
Attachment
On Thu, Sep 24, 2020 at 11:38:45AM +1200, Thomas Munro wrote: >On Wed, Sep 9, 2020 at 11:16 AM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> OK, thanks for looking into this. I guess I'll wait for an updated patch >> before testing this further. The storage has limited capacity so I'd >> have to either reduce the amount of data/WAL or juggle with the WAL >> segments somehow. Doesn't seem worth it. > >Here's a new WIP version that works for archive-based recovery in my tests. > >The main change I have been working on is that there is now just a >single XLogReaderState, so no more double-reading and double-decoding >of the WAL. It provides XLogReadRecord(), as before, but now you can >also read further ahead with XLogReadAhead(). The user interface is >much like before, except that the GUCs changed a bit. They are now: > > recovery_prefetch=on > recovery_prefetch_fpw=off > wal_decode_buffer_size=256kB > maintenance_io_concurrency=10 > >I recommend setting maintenance_io_concurrency and >wal_decode_buffer_size much higher than those defaults. > I think you've left the original GUC (replaced by the buffer size) in the postgresql.conf.sample file. Confused me for a bit ;-) I've done a bit of testing and so far it seems to work with WAL archive, so I'll do more testing and benchmarking over the next couple days. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi,
I repeated the same testing I did before - I started with a 32GB pgbench
database with archiving, run a pgbench for 1h to generate plenty of WAL,
and then performed recovery from a snapshot + archived WAL on different
storage types. The instance was running on NVMe SSD, allowing it ro
generate ~200GB of WAL in 1h.
The recovery was done on two storage types - SATA RAID0 with 3 x 7.2k
spinning drives and NVMe SSD. On each storage I tested three configs -
disabled prefetching, defaults and increased values:
wal_decode_buffer_size = 4MB (so 8x the default)
maintenance_io_concurrency = 100 (so 10x the default)
FWIW there's a bunch of issues with the GUCs - the .conf.sample file
does not include e.g. recovery_prefetch, and instead includes
#max_recovery_prefetch_distance which was however replaced by
wal_decode_buffer_size. Another thing is that the actual default value
differ from the docs - e.g. the docs say that wal_decode_buffer_size is
256kB by default, when in fact it's 512kB.
Now, some results ...
1) NVMe
Fro the fast storage, there's a modest improvement. The time it took to
recover the ~13k WAL segments are these
no prefetch: 5532s
default: 4613s
increased: 4549s
So the speedup from enabled prefetch is ~20% but increasing the values
to make it more aggressive has little effect. Fair enough, the NVMe
is probably fast enough to not benefig from longer I/O queues here.
This is a bit misleading though, because the effectivity of prfetching
very much depends on the fraction of FPI in the WAL stream - and right
after checkpoint that's most of the WAL, which makes the prefetching
less efficient. We still have to parse the WAL etc. without actually
prefetching anything, so it's pure overhead.
So I've also generated a chart showing time (in milliseconds) needed to
apply individual WAL segments. It clearly shows that there are 3
checkpoints, and that for each checkpoint it's initially very cheap
(thanks to FPI) and as the fraction of FPIs drops the redo gets more
expensive. At which point the prefetch actually helps, by up to 30% in
some cases (so a bit more than the overall speedup). All of this is
expected, of course.
2) 3 x 7.2k SATA RAID0
For the spinning rust, I had to make some compromises. It's not feasible
to apply all the 200GB of WAL - it would take way too long. I only
applied ~2600 segments for each configuration (so not even one whole
checkpoint), and even that took ~20h in each case.
The durations look like this:
no prefetch: 72446s
default: 73653s
increased: 55409s
So in this case the default settings is way too low - it actually makes
the recovery a bit slower, while with increased values there's ~25%
speedup, which is nice. I assume that if larger number of WAL segments
was applied (e.g. the whole checkpoint), the prefetch numbers would be
a bit better - the initial FPI part would play smaller role.
From the attached "average per segment" chart you can see that the basic
behavior is about the same as for NVMe - initially it's slower due to
FPIs in the WAL stream, and then it gets ~30% faster.
Overall I think it looks good. I haven't looked at the code very much,
and I can't comment on the potential optimizations mentioned a couple
days ago yet.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
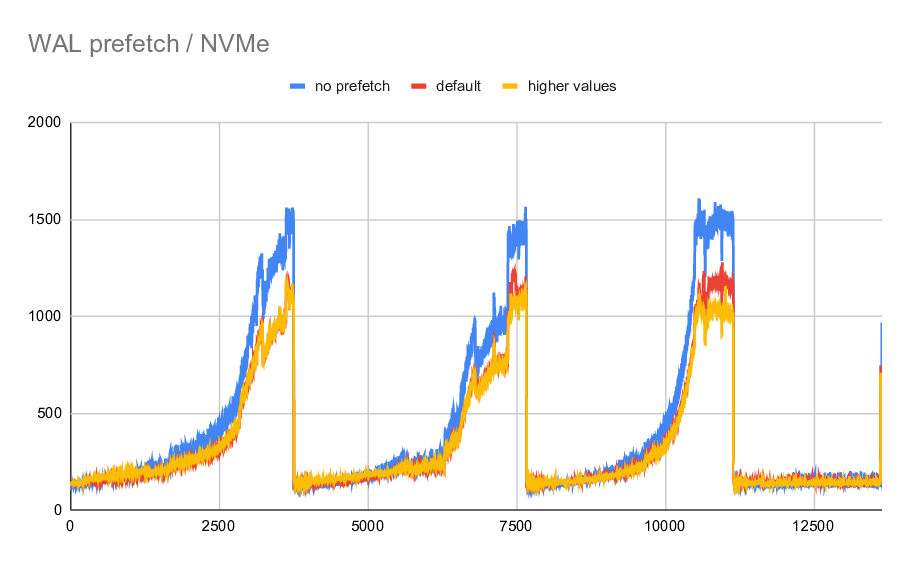{kind=link}
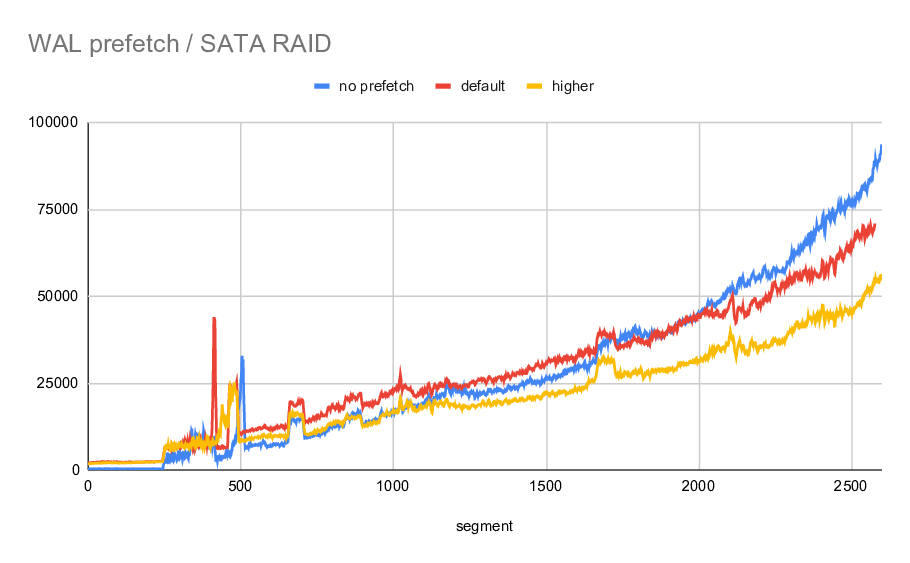{kind=link}
On Sun, Oct 11, 2020 at 12:29 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > I repeated the same testing I did before - I started with a 32GB pgbench > database with archiving, run a pgbench for 1h to generate plenty of WAL, > and then performed recovery from a snapshot + archived WAL on different > storage types. The instance was running on NVMe SSD, allowing it ro > generate ~200GB of WAL in 1h. Thanks for running these tests! And sorry for the delay in replying. > The recovery was done on two storage types - SATA RAID0 with 3 x 7.2k > spinning drives and NVMe SSD. On each storage I tested three configs - > disabled prefetching, defaults and increased values: > > wal_decode_buffer_size = 4MB (so 8x the default) > maintenance_io_concurrency = 100 (so 10x the default) > > FWIW there's a bunch of issues with the GUCs - the .conf.sample file > does not include e.g. recovery_prefetch, and instead includes > #max_recovery_prefetch_distance which was however replaced by > wal_decode_buffer_size. Another thing is that the actual default value > differ from the docs - e.g. the docs say that wal_decode_buffer_size is > 256kB by default, when in fact it's 512kB. Oops. Fixed, and rebased. > Now, some results ... > > 1) NVMe > > Fro the fast storage, there's a modest improvement. The time it took to > recover the ~13k WAL segments are these > > no prefetch: 5532s > default: 4613s > increased: 4549s > > So the speedup from enabled prefetch is ~20% but increasing the values > to make it more aggressive has little effect. Fair enough, the NVMe > is probably fast enough to not benefig from longer I/O queues here. > > This is a bit misleading though, because the effectivity of prfetching > very much depends on the fraction of FPI in the WAL stream - and right > after checkpoint that's most of the WAL, which makes the prefetching > less efficient. We still have to parse the WAL etc. without actually > prefetching anything, so it's pure overhead. Yeah. I've tried to reduce that overhead as much as possible, decoding once and looking up the buffer only once. The extra overhead caused by making posix_fadvise() calls is unfortunate (especially if they aren't helping due to small shared buffers but huge page cache), but should be fixed by switching to proper AIO, independently of this patch, which will batch those and remove the pread(). > So I've also generated a chart showing time (in milliseconds) needed to > apply individual WAL segments. It clearly shows that there are 3 > checkpoints, and that for each checkpoint it's initially very cheap > (thanks to FPI) and as the fraction of FPIs drops the redo gets more > expensive. At which point the prefetch actually helps, by up to 30% in > some cases (so a bit more than the overall speedup). All of this is > expected, of course. That is a nice way to see the effect of FPI on recovery. > 2) 3 x 7.2k SATA RAID0 > > For the spinning rust, I had to make some compromises. It's not feasible > to apply all the 200GB of WAL - it would take way too long. I only > applied ~2600 segments for each configuration (so not even one whole > checkpoint), and even that took ~20h in each case. > > The durations look like this: > > no prefetch: 72446s > default: 73653s > increased: 55409s > > So in this case the default settings is way too low - it actually makes > the recovery a bit slower, while with increased values there's ~25% > speedup, which is nice. I assume that if larger number of WAL segments > was applied (e.g. the whole checkpoint), the prefetch numbers would be > a bit better - the initial FPI part would play smaller role. Huh. Interesting. > From the attached "average per segment" chart you can see that the basic > behavior is about the same as for NVMe - initially it's slower due to > FPIs in the WAL stream, and then it gets ~30% faster. Yeah. I expect that one day not too far away we'll figure out how to get rid of FPIs (through a good enough double-write log or O_ATOMIC)... > Overall I think it looks good. I haven't looked at the code very much, > and I can't comment on the potential optimizations mentioned a couple > days ago yet. Thanks! I'm not really sure what to do about achive restore scripts that block. That seems to be fundamentally incompatible with what I'm doing here.
Attachment
On 11/13/20 3:20 AM, Thomas Munro wrote: > > ... > > I'm not really sure what to do about achive restore scripts that > block. That seems to be fundamentally incompatible with what I'm > doing here. > IMHO we can't do much about that, except for documenting it - if the prefetch can't work because of blocking restore script, someone has to fix/improve the script. No way around that, I'm afraid. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Greetings, * Tomas Vondra (tomas.vondra@enterprisedb.com) wrote: > On 11/13/20 3:20 AM, Thomas Munro wrote: > > I'm not really sure what to do about achive restore scripts that > > block. That seems to be fundamentally incompatible with what I'm > > doing here. > > IMHO we can't do much about that, except for documenting it - if the > prefetch can't work because of blocking restore script, someone has to > fix/improve the script. No way around that, I'm afraid. I'm a bit confused about what the issue here is- is the concern that a restore_command is specified that isn't allowed to run concurrently but this patch is intending to run more than one concurrently..? There's another patch that I was looking at for doing pre-fetching of WAL segments, so if this is also doing that we should figure out which patch we want.. I don't know that it's needed, but it feels likely that we could provide a better result if we consider making changes to the restore_command API (eg: have a way to say "please fetch this many segments ahead, and you can put them in this directory with these filenames" or something). I would think we'd be able to continue supporting the existing API and accept that it might not be as performant. Thanks, Stephen
Attachment
On Sat, Nov 14, 2020 at 4:13 AM Stephen Frost <sfrost@snowman.net> wrote: > * Tomas Vondra (tomas.vondra@enterprisedb.com) wrote: > > On 11/13/20 3:20 AM, Thomas Munro wrote: > > > I'm not really sure what to do about achive restore scripts that > > > block. That seems to be fundamentally incompatible with what I'm > > > doing here. > > > > IMHO we can't do much about that, except for documenting it - if the > > prefetch can't work because of blocking restore script, someone has to > > fix/improve the script. No way around that, I'm afraid. > > I'm a bit confused about what the issue here is- is the concern that a > restore_command is specified that isn't allowed to run concurrently but > this patch is intending to run more than one concurrently..? There's > another patch that I was looking at for doing pre-fetching of WAL > segments, so if this is also doing that we should figure out which > patch we want.. The problem is that the recovery loop tries to look further ahead in between applying individual records, which causes the restore script to run, and if that blocks, we won't apply records that we already have, because we're waiting for the next WAL file to appear. This behaviour is on by default with my patch, so pg_standby will introduce a weird replay delays. We could think of some ways to fix that, with meaningful return codes and periodic polling or something, I suppose, but something feels a bit weird about it. > I don't know that it's needed, but it feels likely that we could provide > a better result if we consider making changes to the restore_command API > (eg: have a way to say "please fetch this many segments ahead, and you > can put them in this directory with these filenames" or something). I > would think we'd be able to continue supporting the existing API and > accept that it might not be as performant. Hmm. Every time I try to think of a protocol change for the restore_command API that would be acceptable, I go around the same circle of thoughts about event flow and realise that what we really need for this is ... a WAL receiver... Here's a rebase over the recent commit "Get rid of the dedicated latch for signaling the startup process." just to fix cfbot; no other changes.
Attachment
Greetings, * Thomas Munro (thomas.munro@gmail.com) wrote: > On Sat, Nov 14, 2020 at 4:13 AM Stephen Frost <sfrost@snowman.net> wrote: > > * Tomas Vondra (tomas.vondra@enterprisedb.com) wrote: > > > On 11/13/20 3:20 AM, Thomas Munro wrote: > > > > I'm not really sure what to do about achive restore scripts that > > > > block. That seems to be fundamentally incompatible with what I'm > > > > doing here. > > > > > > IMHO we can't do much about that, except for documenting it - if the > > > prefetch can't work because of blocking restore script, someone has to > > > fix/improve the script. No way around that, I'm afraid. > > > > I'm a bit confused about what the issue here is- is the concern that a > > restore_command is specified that isn't allowed to run concurrently but > > this patch is intending to run more than one concurrently..? There's > > another patch that I was looking at for doing pre-fetching of WAL > > segments, so if this is also doing that we should figure out which > > patch we want.. > > The problem is that the recovery loop tries to look further ahead in > between applying individual records, which causes the restore script > to run, and if that blocks, we won't apply records that we already > have, because we're waiting for the next WAL file to appear. This > behaviour is on by default with my patch, so pg_standby will introduce > a weird replay delays. We could think of some ways to fix that, with > meaningful return codes and periodic polling or something, I suppose, > but something feels a bit weird about it. Ah, yeah, that's clearly an issue that should be addressed. There's a nearby thread which is talking about doing exactly that, so, perhaps this doesn't need to be worried about here..? > > I don't know that it's needed, but it feels likely that we could provide > > a better result if we consider making changes to the restore_command API > > (eg: have a way to say "please fetch this many segments ahead, and you > > can put them in this directory with these filenames" or something). I > > would think we'd be able to continue supporting the existing API and > > accept that it might not be as performant. > > Hmm. Every time I try to think of a protocol change for the > restore_command API that would be acceptable, I go around the same > circle of thoughts about event flow and realise that what we really > need for this is ... a WAL receiver... A WAL receiver, or an independent process which goes out ahead and fetches WAL..? Still, I wonder about having a way to inform the command that's run by the restore_command of what it is we really want, eg: restore_command = 'somecommand --async=%a --target=%t --target-name=%n --target-xid=%x --target-lsn=%l --target-timeline=%i--dest-dir=%d' Such that '%a' is either yes, or no, indicating if the restore command should operate asyncronously and pre-fetch WAL, %t is either empty (or mabye 'unset') or 'immediate', %n/%x/%l are similar to %t, %i is either a specific timeline or 'immediate' (somecommand should be understanding of timelines and know how to parse history files to figure out the right timeline to fetch along, based on the destination requested), and %d is a directory for somecommand to place WAL files into (perhaps with an alternative naming scheme, if we feel we need one). The amount pre-fetching which 'somecommand' would do, and how many processes it would use to do so, could either be configured as part of the options passed to 'somecommand', which we would just pass through, or through its own configuration file. A restore_command which is set but doesn't include a %a or %d or such would be assumed to work in the same manner as today. For my part, at least, I don't think this is really that much of a stretch, to expect a restore_command to be able to pre-populate a directory with WAL files- certainly there's at least one that already does this, even though it doesn't have all the information directly passed to it.. Would be nice if it did. :) Thanks, Stephen
Attachment
On Thu, Nov 19, 2020 at 10:00 AM Stephen Frost <sfrost@snowman.net> wrote: > * Thomas Munro (thomas.munro@gmail.com) wrote: > > Hmm. Every time I try to think of a protocol change for the > > restore_command API that would be acceptable, I go around the same > > circle of thoughts about event flow and realise that what we really > > need for this is ... a WAL receiver... > > A WAL receiver, or an independent process which goes out ahead and > fetches WAL..? What I really meant was: why would you want this over streaming rep? I just noticed this thread proposing to retire pg_standby on that basis: https://www.postgresql.org/message-id/flat/20201029024412.GP5380%40telsasoft.com I'd be happy to see that land, to fix this problem with my plan. But are there other people writing restore scripts that block that would expect them to work on PG14?
Greetings, * Thomas Munro (thomas.munro@gmail.com) wrote: > On Thu, Nov 19, 2020 at 10:00 AM Stephen Frost <sfrost@snowman.net> wrote: > > * Thomas Munro (thomas.munro@gmail.com) wrote: > > > Hmm. Every time I try to think of a protocol change for the > > > restore_command API that would be acceptable, I go around the same > > > circle of thoughts about event flow and realise that what we really > > > need for this is ... a WAL receiver... > > > > A WAL receiver, or an independent process which goes out ahead and > > fetches WAL..? > > What I really meant was: why would you want this over streaming rep? I have to admit to being pretty confused as to this question and maybe I'm just not understanding. Why wouldn't change patch be helpful for streaming replication too..? If I follow correctly, this patch will scan ahead in the WAL and let the kernel know that certain blocks will be needed soon. Ideally, though I don't think it does yet, we'd only do that for blocks that aren't already in shared buffers, and only for non-FPIs (even better if we can skip past pages for which we already, recently, passed an FPI). The biggest caveat here, it seems to me anyway, is that for this to actually help you need to be running with checkpoints that are larger than shared buffers, as otherwise all the pages we need will be in shared buffers already, thanks to FPIs bringing them in, except when running with hot standby, right? In the hot standby case, other random pages could be getting pulled in to answer user queries and therefore this would be quite helpful to minimize the amount of time required to replay WAL, I would think. Naturally, this isn't very interesting if we're just always able to keep up with the primary, but that's certainly not always the case. > I just noticed this thread proposing to retire pg_standby on that > basis: > > https://www.postgresql.org/message-id/flat/20201029024412.GP5380%40telsasoft.com > > I'd be happy to see that land, to fix this problem with my plan. But > are there other people writing restore scripts that block that would > expect them to work on PG14? Ok, I think I finally get the concern that you're raising here- basically that if a restore command was written to sit around and wait for WAL segments to arrive, instead of just returning to PG and saying "WAL segment not found", that this would be a problem if we are running out ahead of the applying process and asking for WAL. The thing is- that's an outright broken restore command script in the first place. If PG is in standby mode, we'll ask again if we get an error result indicating that the WAL file wasn't found. The restore command documentation is quite clear on this point: The command will be asked for file names that are not present in the archive; it must return nonzero when so asked. There's no "it can wait around for the next file to show up if it wants to" in there- it *must* return nonzero when asked for files that don't exist. So, I don't think that we really need to stress over this. The fact that pg_standby offers options to have it wait instead of just returning a non-zero error-code and letting the loop that we already do in the core code seems like it's really just a legacy thing from before we were doing that and probably should have been ripped out long ago... Even more reason to get rid of pg_standby tho, imv, we haven't been properly adjusting it when we've been making changes to the core code, it seems. Thanks, Stephen
Attachment
Hi, On 2020-12-04 13:27:38 -0500, Stephen Frost wrote: > If I follow correctly, this patch will scan ahead in the WAL and let > the kernel know that certain blocks will be needed soon. Ideally, > though I don't think it does yet, we'd only do that for blocks that > aren't already in shared buffers, and only for non-FPIs (even better if > we can skip past pages for which we already, recently, passed an FPI). The patch uses PrefetchSharedBuffer(), which only initiates a prefetch if the page isn't already in s_b. And once we have AIO, it can actually initiate IO into s_b at that point, rather than fetching it just into the kernel page cache. Greetings, Andres Freund
Greetings, * Andres Freund (andres@anarazel.de) wrote: > On 2020-12-04 13:27:38 -0500, Stephen Frost wrote: > > If I follow correctly, this patch will scan ahead in the WAL and let > > the kernel know that certain blocks will be needed soon. Ideally, > > though I don't think it does yet, we'd only do that for blocks that > > aren't already in shared buffers, and only for non-FPIs (even better if > > we can skip past pages for which we already, recently, passed an FPI). > > The patch uses PrefetchSharedBuffer(), which only initiates a prefetch > if the page isn't already in s_b. Great, glad that's already been addressed in this, that's certainly good. I think I knew that and forgot it while composing that response over the past rather busy week. :) > And once we have AIO, it can actually initiate IO into s_b at that > point, rather than fetching it just into the kernel page cache. Sure. Thanks, Stephen
Attachment
Thomas wrote:
> Here's a rebase over the recent commit "Get rid of the dedicated latch for
> signaling the startup process." just to fix cfbot; no other changes.
I wanted to contribute my findings - after dozens of various lengthy runs here - so far with WAL (asynchronous)
recoveryperformance in the hot-standby case. TL;DR; this patch is awesome even on NVMe 😉
This email is a little bit larger topic than prefetching patch itself, but I did not want to loose context. Maybe it'll
helpsomebody in operations or just to add to the general pool of knowledge amongst hackers here, maybe all of this
stuffwas already known to you. My plan is to leave it here like that as I'm probably lacking understanding, time,
energyand ideas how to tweak it more.
SETUP AND TEST:
---------------
There might be many different workloads, however I've only concentrated on single one namely - INSERT .. SELECT 100
rows- one that was predictible enough for me, quite generic and allows to uncover some deterministic hotspots. The
resultis that in such workload it is possible to replicate ~750Mbit/s of small rows traffic in stable conditions
(catching-upis a different matter).
- two i3.4xlarge AWS VMs with 14devel, see [0] for specs. 14devel already contains major optimizations of reducing
lseeks()and SLRU CLOG flushing[1]
- WIP WAL prefetching [2] by Thomas Munro applied, v14_000[12345] patches, especially v14_0005 is important here as it
reducesdynahash calls.
- FPWs were disabled to avoid hitting >2.5Gbps traffic spikes
- hash_search_with_hash_value_memcmpopt() is my very poor man's copycat optimization of dynahash.c's
hash_search_with_hash_value()to avoid indirect function calls of calling match() [3]
- VDSO clock_gettime() just in case fix on AWS, tsc for clocksource0 instead of "xen" OR one could use
track_io_timing=offto reduce syscalls
Primary tuning:
in order to reliably measure standby WAL recovery performance, one needs to setup *STABLE* generator over time/size, on
primary.In my case it was 2 indexes and 1 table: pgbench -n -f inserts.pgb -P 1 -T 86400 -c 16 -j 2 -R 4000
--latency-limit=50db.
VFS-CACHE-FITTING WORKLOAD @ 4k TPS:
------------------------------------
create sequence s1;
create table tid (id bigint primary key, j bigint not null, blah text not null) partition by hash (id);
create index j_tid on tid (j); -- to put some more realistic stress
create table tid_h1 partition of tid FOR VALUES WITH (MODULUS 16, REMAINDER 0);
[..]
create table tid_h16 partition of tid FOR VALUES WITH (MODULUS 16, REMAINDER 15);
The clients (-c 16) needs to aligned with hash-partitioning to avoid LWLock/BufferContent. inserts.pgb was looking
like:
insert into tid select nextval('s1'), g, 'some garbage text' from generate_series(1,100) g.
The sequence is of the key importance here. "g" is more or less randomly hitting here (the j_tid btree might quite grow
onstandby too).
Additionally due to drops on primary, I've disabled fsync as a stopgap measure because at least what to my
understandingI was affected by global freezes of my insertion workload due to Lock/extends as one of the sessions was
alwaysin: mdextend() -> register_dirty_segment() -> RegisterSyncRequest() (fsync pg_usleep 0.01s), which caused
frequentdips of performance even at the begginig (visible thanks to pgbench -P 1) and I wanted something completely
linear.The fsync=off was simply a shortcut just in order to measure stuff properly on the standby (I needed this
deterministic"producer").
The WAL recovery is not really single threaded thanks to prefetches with posix_fadvises() - performed by other (?)
CPUs/kernelthreads I suppose, CLOG flushing by checkpointer and the bgwriter itself. The walsender/walreciever were not
thebottlenecks, but bgwriter and checkpointer needs to be really tuned on *standby* side too.
So, the above workload is CPU bound on the standby side for long time. I would classify it as
"standby-recovery-friendly"as the IO-working-set of the main redo loop does NOT degrade over time/dbsize that much, so
thereis no lag till certain point. In order to classify the startup/recovery process one could use recent pidstat(1) -d
"iodelay"metric. If one gets stable >= 10 centiseconds over more than few seconds, then one has probably I/O driven
bottleneck.If iodelay==0 then it is completely VFS-cached I/O workload.
In such setup, primary can generate - without hiccups - 6000-6500 TPS (insert 100 rows) @ ~25% CPU util using 16 DB
sessions.Of course it could push more, but we are using pgbench throttling. Standby can follow up to @ ~4000 TPS on
theprimary, without lag (@ 4500 TPS was having some lag even at start). The startup/recovering gets into CPU 95%
utilizationterritory with ~300k (?) hash_search_with_hash_value_memcmpopt() executions per second (measured using
perf-probe).The shorter the WAL record the more CPU-bound the WAL recovery performance is going to be. In my case ~220k
WALrecords @ WAL segment 16MB and I was running at stable 750Mbit/s. What is important - at least on my HW - due to
dynahashsthere's hard limit of this ~300..400 k WAL records/s (perf probe/stat reports that i'm having 300k of
hash_search_with_hash_value_memcmpopt()/ s, while my workload is 4k [rate] * 100 [rows] * 3 [table + 2 indexes] =
400k/sand no lag, discrepancy that I admit do not understand, maybe it's the Thomas's recent_buffer_fastpath from
v14_0005prefetcher). On some other OLTP production systems I've seen that there's 10k..120k WAL records/16MB segment.
Theperf picture looks like one in [4]. The "tidseq-*" graphs are about this scenario.
One could say that with lesser amount of bigger rows one could push more on the network and that's true however
unrealisticin real-world systems (again with FPW=off, I was able to push up to @ 2.5Gbit/s stable without lag, but
twiceless rate and much bigger rows - ~270 WAL records/16MB segment and primary being the bottleneck). The top#1 CPU
functionwas quite unexpectedly again the BufTableLookup() -> hash_search_with_hash_value_memcmpopt() even at such
relativelylow-records rate, which illustrates that even with a lot of bigger memcpy()s being done by recovery, those
arenot the problem as one would typically expect.
VFS-CACHE-MISSES WORKLOAD @ 1.5k TPS:
-------------------------------------
Interesting behavior is that for the very similar data-loading scheme as described above, but for uuid PK and
uuid_generate_v4()*random* UUIDs (pretty common pattern amongst developers), instead of bigint sequence, so something
verysimilar to above like:
create table trandomuuid (id uuid primary key , j bigint not null, t text not null) partition by hash (id);
... picture radically changes if the active-working-I/O-set doesn't fit VFS cache and it's I/O bound on recovery side
(againthis is with prefetching already). This can checked via iodelay: if it goes let's say >= 10-20 centiseconds or
BCC'scachetop(1) shows "relatively low" READ_HIT% for recovering (poking at it was ~40-45% in my case when recovery
startedto be really I/O heavy):
DBsize@112GB , 1s sample:
13:00:16 Buffers MB: 200 / Cached MB: 88678 / Sort: HITS / Order: descending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
1849 postgres postgres 160697 67405 65794 41.6% 1.2% -- recovering
1853 postgres postgres 37011 36864 24576 16.8% 16.6% -- walreciever
1851 postgres postgres 15961 13968 14734 4.1% 0.0% -- bgwriter
On 128GB RAM, when DB size gets near the ~80-90GB boundary (128-32 for huge pages - $binaries - $kernel - $etc =~ 90GB
freepage cache) SOMETIMES in my experiments it started getting lag, but also at the same time even the primary cannot
keepat rate of 1500TPS (IO/DataFileRead|Write may happen or still Lock/extend) and struggles of course this is well
knownbehavior [5]. Also in this almost-pathological-INSERT-rate had pgstat_bgwriter.buffers_backend like 90% of
buffers_allocand I couldn't do much anything about it (small s_b on primary, tuning bgwriter settings to the max, even
withbgwriter_delay=0 hack, BM_MAX_USAGE_COUNT=1). Any suggestion on how to make such $workload deterministic after
certainDBsize under pgbench -P1 is welcome :)
So in order to deterministically - in multiple runs - demonstrate the impact of WAL prefetching by Thomas in such
scenario(where primary was bottleneck itself), see "trandomuuid-*" graphs, one of the graphs has same commentary as
here:
- the system is running with WAL prefetching disabled (maitenance_io_concurrency=0)
- once the DBsize >85-90GB primary cannot keep up, so there's drop of data produced - rxNET KB/s. At this stage I've
didecho 3> drop_caches, to shock the system (there's very little jump of Lag, buit it goes to 0 again -- good, standby
canstill manage)
- once the DBsize got near ~275GB standby couldn't follow even-the-chocked-primary (lag starts rising to >3000s,
IOdelayindicates that startup/recovering is wasting like 70% of it's time on synchronous preads())
- at DBsize ~315GB I've did set maitenance_io_concurrency=10 (enable the WAL prefetching/posix_fadvise()), lags starts
dropping,and IOdelay is reduced to ~53, %CPU (not %sys) of the process jumps from 28% -> 48% (efficiency grows)
- at DBsize ~325GB I've did set maitenance_io_concurrency=128 (give kernel more time to pre-read for us), lags starts
droppingeven faster, and IOdelay is reduced to ~30, %CPU part (not %sys) of the process jumps from 48% -> 70% (it's
efficiencygrows again, 2.5x more from baseline)
Another interesting observation is that standby's bgwriter is much more stressed and important than the recovery itself
andseveral times more active than the one on primary. I've rechecked using Tomas Vondra's sequuid extension [6] and of
courseproblem doesn't exist if the UUIDs are not that random (much more localized, so this small workload adjustment
makesit behave like in "VFS-CACHE-fitting" scenario).
Also just in case for the patch review process: also I can confirm that data inserted in primary and standby did match
onmultiple occasions (sums of columns) after those tests (some of those were run up to 3TB mark).
Random thoughts:
----------------
1) Even with all those optimizations, I/O prefetching (posix_fadvise()) or even IO_URING in future there's going be the
BufTableLookup()->dynahashsingle-threaded CPU limitation bottleneck. It may be that with IO_URING in future and proper
HW,all workloads will start to be CPU-bound on standby ;) I do not see a simple way to optimize such fundamental pillar
-other than parallelizing it ? I hope I'm wrong.
1b) With the above patches I need to disappoint Alvaro Herrera, I was unable to reproduce the top#1 smgropen() ->
hash_search_with_hash_value()in any way as I think right now v14_0005 simply kind of solves the problem.
2) I'm kind of thinking that flushing dirty pages on standby should be much more aggressive than on primary, in order
tounlock the startup/recovering potential. What I'm trying to say it might be even beneficial to spot if FlushBuffer()
ishappening too fast from inside the main redo recovery loop, and if it is then issue LOG/HINT from time to time
(similarto famous "checkpoints are occurring too frequently") to tune the background writer on slave or investigate
workloaditself on primary. Generally speaking those "bgwriter/checkpointer" GUCs might be kind of artificial during the
standby-processingscenario.
3) The WAL recovery could (?) have some protection from noisy neighboring backends. As the hot standby is often used in
readoffload configurations it could be important to protect it's VFS cache (active, freshly replicated data needed for
WALrecovery) from being polluted by some other backends issuing random SQL SELECTs.
4) Even for scenarios with COPY/heap_multi_insert()-based-statements it emits a lot of interleaved Btree/INSERT_LEAF
recordsthat are CPU heavy if the table is indexed.
6) I don't think walsender/walreciever are in any danger right now, as they at least in my case they had plenty of
headroom(even @ 2.5Gbps walreciever was ~30-40% CPU) while issuing I/O writes of 8kB (but this was with fsync=off and
onNVMe). Walsender was even in better shape mainly due to sendto(128kB). YMMV.
7) As uuid-osp extension is present in the contrib and T.V.'s sequential-uuids is unfortunately NOT, developers more
oftenthan not, might run into those pathological scenarios. Same applies to any cloud-hosted database where one cannot
deployhis extensions.
What was not tested and what are further research questions:
-----------------------------------------------------------
a) Impact of vacuum WAL records: I suspect that it might be that additional vacuum-generated workload that was added to
themix, during the VFS-cache-fitting workload that overwhelmed the recovering loop and it started catching lag.
b) Impact of the noisy-neighboring-SQL queries on hot-standby:
b1) research the impact of contention LWLock buffer_mappings between readers and recovery itself.
b2) research/experiments maybe with cgroups2 VFS-cache memory isolation for processes.
c) Impact of WAL prefetching's "maintenance_io_concurrency" VS iodelay for startup/recovering preads() is also unknown.
Theykey question there is how far ahead to issue those posix_fadvise() so that pread() is nearly free. Some I/O
calibrationtool to set maitenance_io_concurrency would be nice.
-J.
[0] - specs: 2x AWS i3.4xlarge (1s8c16t, 128GB RAM, Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GH), 2xNVMe in lvm striped
VG,ext4. Tuned parameters: bgwriter_*, s_b=24GB with huge pages, checkpoint_completion_target=0.9, commit_delay=100000,
commit_siblings=20,synchronous_commit=off, fsync=off, max_wal_size=40GB, recovery_prefetch=on, track_io_timing=on ,
wal_block_size=8192(default), wal_decode_buffer_size=512kB (default WIP WAL prefetching), wal_buffers=256MB. Schema was
always16-way hash-parititoned to avoid LWLock/BufferContent waits.
[1] -
https://www.postgresql.org/message-id/flat/CA%2BhUKGLJ%3D84YT%2BNvhkEEDAuUtVHMfQ9i-N7k_o50JmQ6Rpj_OQ%40mail.gmail.com
[2] - https://commitfest.postgresql.org/31/2410/
[3] - hash_search_with_hash_value() spends a lot of time near "callq *%r14" in tight loop assembly in my case (indirect
callto hash comparision function). This hash_search_with_hash_value_memcmpopt() is just copycat function and instead
directlycalls memcmp() where it matters (smgr.c, buf_table.c). Blind shot at gcc's -flto also didn't help to gain a lot
there(I was thinking it could optimize it by building many instances of hash_search_with_hash_value of per-match() use,
butno). I did not quantify the benefit, I think it just failed optimization experiment, as it is still top#1 in my
profiles,it could be even noise.
[4] - 10s perf image of CPU-bound 14devel with all the mentioned patches:
17.38% postgres postgres [.] hash_search_with_hash_value_memcmpopt
---hash_search_with_hash_value_memcmpopt
|--11.16%--BufTableLookup
| |--9.44%--PrefetchSharedBuffer
| | XLogPrefetcherReadAhead
| | StartupXLOG
| --1.72%--ReadBuffer_common
| ReadBufferWithoutRelcache
| XLogReadBufferExtended
| --1.29%--XLogReadBufferForRedoExtended
| --0.64%--XLogInitBufferForRedo
|--3.86%--smgropen
| |--2.79%--XLogPrefetcherReadAhead
| | StartupXLOG
| --0.64%--XLogReadBufferExtended
--2.15%--XLogPrefetcherReadAhead
StartupXLOG
10.30% postgres postgres [.] MarkBufferDirty
---MarkBufferDirty
|--5.58%--btree_xlog_insert
| btree_redo
| StartupXLOG
--4.72%--heap_xlog_insert
6.22% postgres postgres [.] ReadPageInternal
---ReadPageInternal
XLogReadRecordInternal
XLogReadAhead
XLogPrefetcherReadAhead
StartupXLOG
5.36% postgres postgres [.] hash_bytes
---hash_bytes
|--3.86%--hash_search_memcmpopt
[5] -
https://www.2ndquadrant.com/en/blog/on-the-impact-of-full-page-writes/
https://www.2ndquadrant.com/en/blog/sequential-uuid-generators/
https://www.2ndquadrant.com/en/blog/sequential-uuid-generators-ssd/
[6] - https://github.com/tvondra/sequential-uuids
Attachment
- tidseq-without-FPW-4kTPS_cpuOverSize.csv.png
- tidseq-without-FPW-4kTPS_iodelayOverSize.csv.png
- tidseq-without-FPW-4kTPS_lagOverSize.csv.png
- tidseq-without-FPW-4kTPS_lagOverTime.csv.png
- trandomuuids-without-FPW-1.5kTPS_cpuOverSize.csv.png
- trandomuuids-without-FPW-1.5kTPS_iodelayOverSize.csv.png
- trandomuuids-without-FPW-1.5kTPS_lagOverSize.csv.png
- trandomuuids-without-FPW-1.5kTPS_lagOverSize.csv-comments.png
- trandomuuids-without-FPW-1.5kTPS_lagOverTime.csv.png
{kind=link}
{kind=link}
{kind=link}
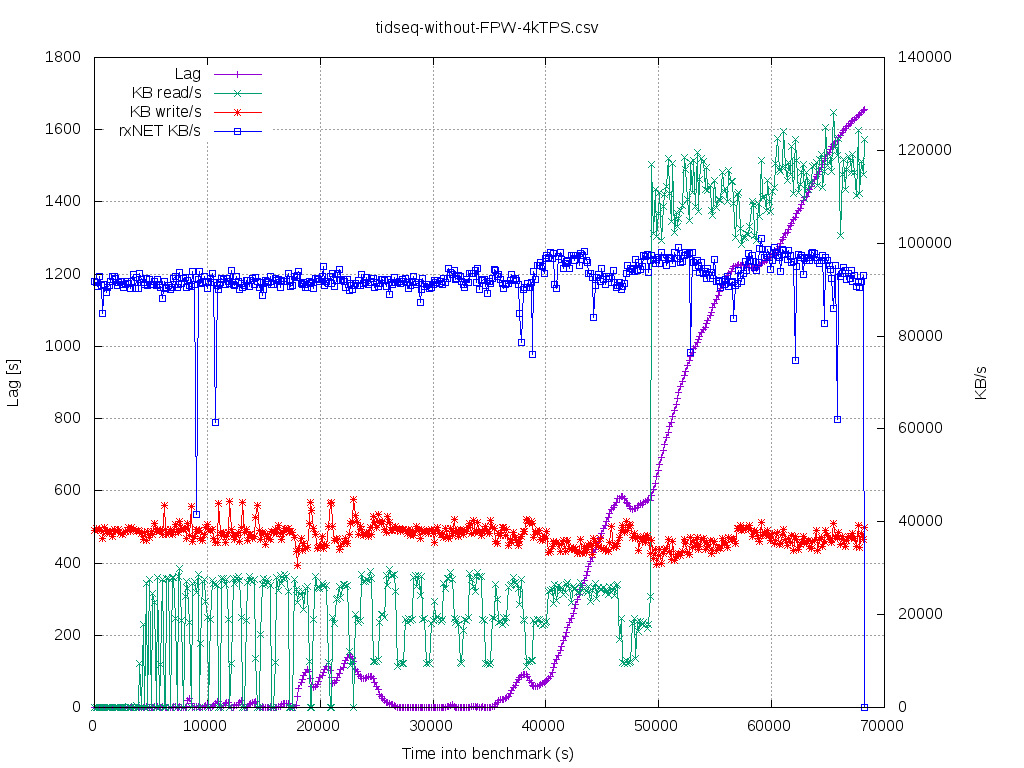{kind=link}
{kind=link}
{kind=link}
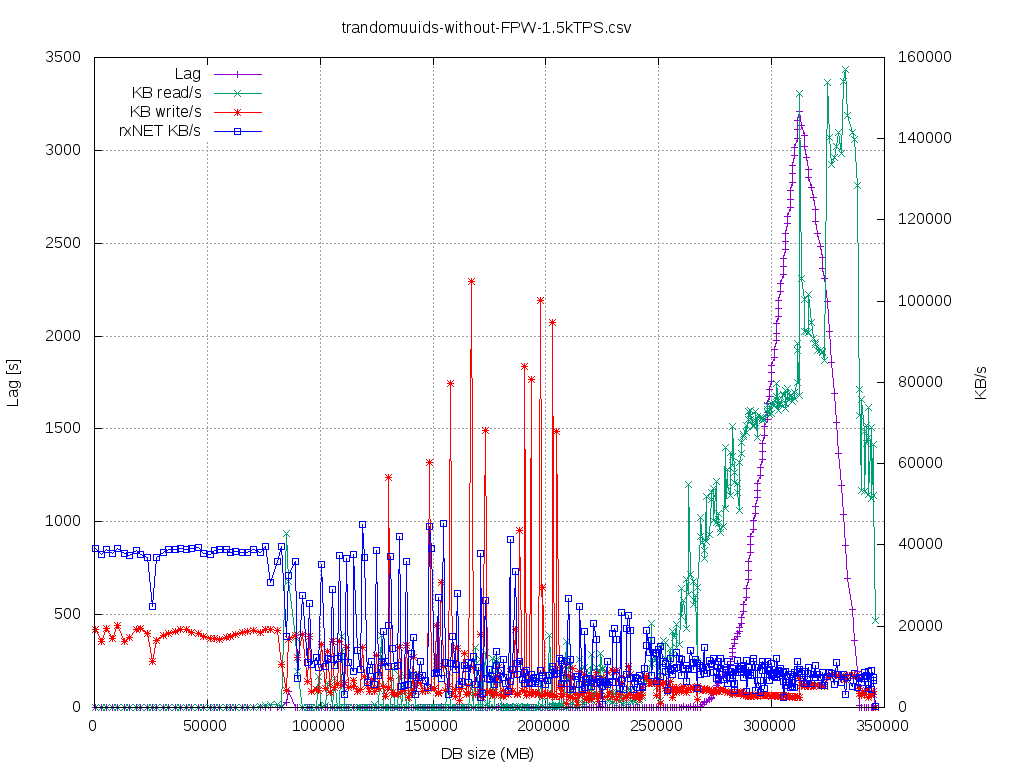{kind=link}
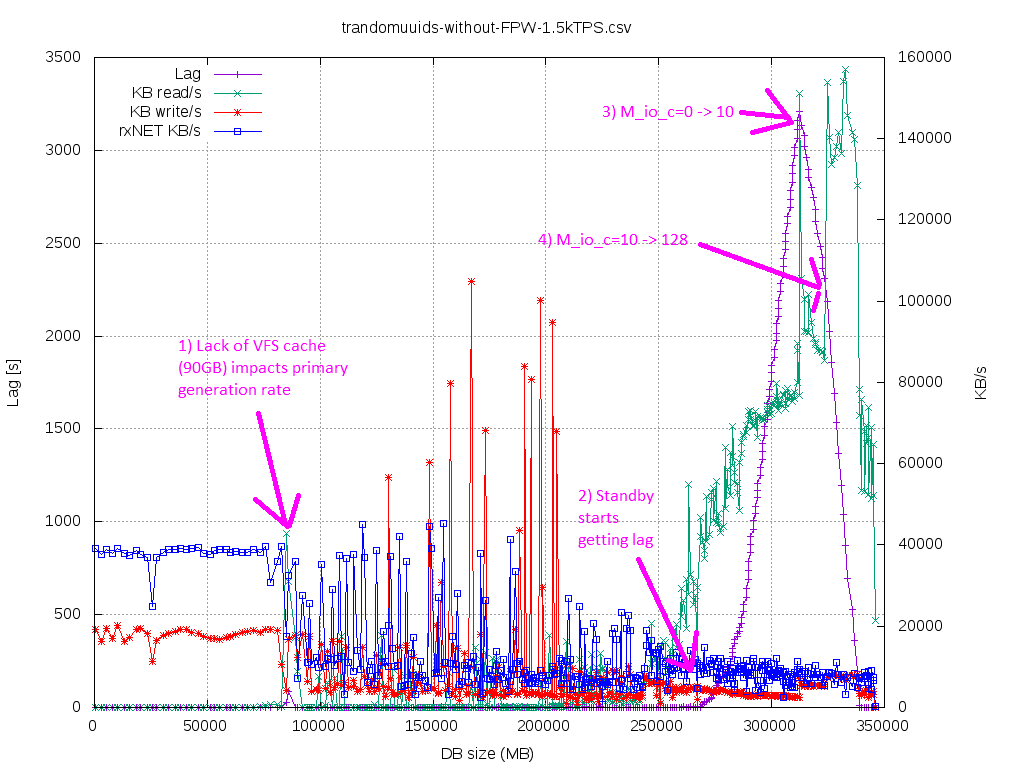{kind=link}
{kind=link}
On Sat, Dec 12, 2020 at 1:24 AM Jakub Wartak <Jakub.Wartak@tomtom.com> wrote: > I wanted to contribute my findings - after dozens of various lengthy runs here - so far with WAL (asynchronous) recoveryperformance in the hot-standby case. TL;DR; this patch is awesome even on NVMe Thanks Jakub! Some interesting, and nice, results. > The startup/recovering gets into CPU 95% utilization territory with ~300k (?) hash_search_with_hash_value_memcmpopt() executionsper second (measured using perf-probe). I suppose it's possible that this is caused by memory stalls that could be improved by teaching the prefetching pipeline to prefetch the relevant cachelines of memory (but it seems like it should be a pretty microscopic concern compared to the I/O). > [3] - hash_search_with_hash_value() spends a lot of time near "callq *%r14" in tight loop assembly in my case (indirectcall to hash comparision function). This hash_search_with_hash_value_memcmpopt() is just copycat function and insteaddirectly calls memcmp() where it matters (smgr.c, buf_table.c). Blind shot at gcc's -flto also didn't help to gaina lot there (I was thinking it could optimize it by building many instances of hash_search_with_hash_value of per-match()use, but no). I did not quantify the benefit, I think it just failed optimization experiment, as it is still top#1in my profiles, it could be even noise. Nice. A related specialisation is size (key and object). Of course, simplehash.h already does that, but it also makes some other choices that make it unusable for the buffer mapping table. So I think that we should either figure out how to fix that, or consider specialising the dynahash lookup path with a similar template scheme. Rebase attached.
Attachment
Hi,
On 2020-12-24 16:06:38 +1300, Thomas Munro wrote:
> From 85187ee6a1dd4c68ba70cfbce002a8fa66c99925 Mon Sep 17 00:00:00 2001
> From: Thomas Munro <thomas.munro@gmail.com>
> Date: Sat, 28 Mar 2020 11:42:59 +1300
> Subject: [PATCH v15 1/6] Add pg_atomic_unlocked_add_fetch_XXX().
>
> Add a variant of pg_atomic_add_fetch_XXX with no barrier semantics, for
> cases where you only want to avoid the possibility that a concurrent
> pg_atomic_read_XXX() sees a torn/partial value. On modern
> architectures, this is simply value++, but there is a fallback to
> spinlock emulation.
Wouldn't it be sufficient to implement this as one function implemented as
pg_atomic_write_u32(val, pg_atomic_read_u32(val) + 1)
then we'd not need any ifdefs?
> + * pg_atomic_unlocked_add_fetch_u32 - atomically add to variable
It's really not adding "atomically"...
> + * Like pg_atomic_unlocked_write_u32, guarantees only that partial values
> + * cannot be observed.
Maybe add a note saying that that in particularly means that
modifications could be lost when used concurrently?
Greetings,
Andres Freund
On Sat, Dec 5, 2020 at 7:27 AM Stephen Frost <sfrost@snowman.net> wrote: > * Thomas Munro (thomas.munro@gmail.com) wrote: > > I just noticed this thread proposing to retire pg_standby on that > > basis: > > > > https://www.postgresql.org/message-id/flat/20201029024412.GP5380%40telsasoft.com > > > > I'd be happy to see that land, to fix this problem with my plan. But > > are there other people writing restore scripts that block that would > > expect them to work on PG14? > > Ok, I think I finally get the concern that you're raising here- > basically that if a restore command was written to sit around and wait > for WAL segments to arrive, instead of just returning to PG and saying > "WAL segment not found", that this would be a problem if we are running > out ahead of the applying process and asking for WAL. > > The thing is- that's an outright broken restore command script in the > first place. If PG is in standby mode, we'll ask again if we get an > error result indicating that the WAL file wasn't found. The restore > command documentation is quite clear on this point: > > The command will be asked for file names that are not present in the > archive; it must return nonzero when so asked. > > There's no "it can wait around for the next file to show up if it wants > to" in there- it *must* return nonzero when asked for files that don't > exist. Well the manual does actually describe how to write your own version of pg_standby, referred to as a "waiting restore script": https://www.postgresql.org/docs/13/log-shipping-alternative.html I've now poked that other thread threatening to commit the removal of pg_standby, and while I was there, also to remove the section on how to write your own (it's possible that I missed some other reference to the concept elsewhere, I'll need to take another look). > So, I don't think that we really need to stress over this. The fact > that pg_standby offers options to have it wait instead of just returning > a non-zero error-code and letting the loop that we already do in the > core code seems like it's really just a legacy thing from before we were > doing that and probably should have been ripped out long ago... Even > more reason to get rid of pg_standby tho, imv, we haven't been properly > adjusting it when we've been making changes to the core code, it seems. So far I haven't heard from anyone who thinks we should keep this old facility (as useful as it was back then when it was the only way), so I hope we can now quietly drop it. It's not strictly an obstacle to this recovery prefetching work, but it'd interact confusingly in hard to describe ways, and it seems strange to perpetuate something that many were already proposing to drop due to obsolescence. Thanks for the comments/sanity check.
Hi, I did a bunch of tests on v15, mostly to asses how much could the prefetching help. The most interesting test I did was this: 1) primary instance on a box with 16/32 cores, 64GB RAM, NVMe SSD 2) replica on small box with 4 cores, 8GB RAM, SSD RAID 3) pause replication on the replica (pg_wal_replay_pause) 4) initialize pgbench scale 2000 (fits into RAM on primary, while on replica it's about 4x RAM) 5) run 1h pgbench: pgbench -N -c 16 -j 4 -T 3600 test 6) resume replication (pg_wal_replay_resume) 7) measure how long it takes to catch up, monitor lag This is nicely reproducible test case, it eliminates influence of network speed and so on. Attached is a chart showing the lag with and without the prefetching. In both cases we start with ~140GB of redo lag, and the chart shows how quickly the replica applies that. The "waves" are checkpoints, where right after a checkpoint the redo gets much faster thanks to FPIs and then slows down as it gets to parts without them (having to do synchronous random reads). With master, it'd take ~16000 seconds to catch up. I don't have the exact number, because I got tired of waiting, but the estimate is likely accurate (judging by other tests and how regular the progress is). With WAL prefetching enabled (I bumped up the buffer to 2MB, and prefetch limit to 500, but that was mostly just arbitrary choice), it finishes in ~3200 seconds. This includes replication of the pgbench initialization, which took ~200 seconds and where prefetching is mostly useless. That's a damn pretty improvement, I guess! In a way, this means the tiny replica would be able to keep up with a much larger machine, where everything is in memory. One comment about the patch - the postgresql.conf.sample change says: #recovery_prefetch = on # whether to prefetch pages logged with FPW #recovery_prefetch_fpw = off # whether to prefetch pages logged with FPW but clearly that comment is only for recovery_prefetch_fpw, the first GUC enables prefetching in general. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
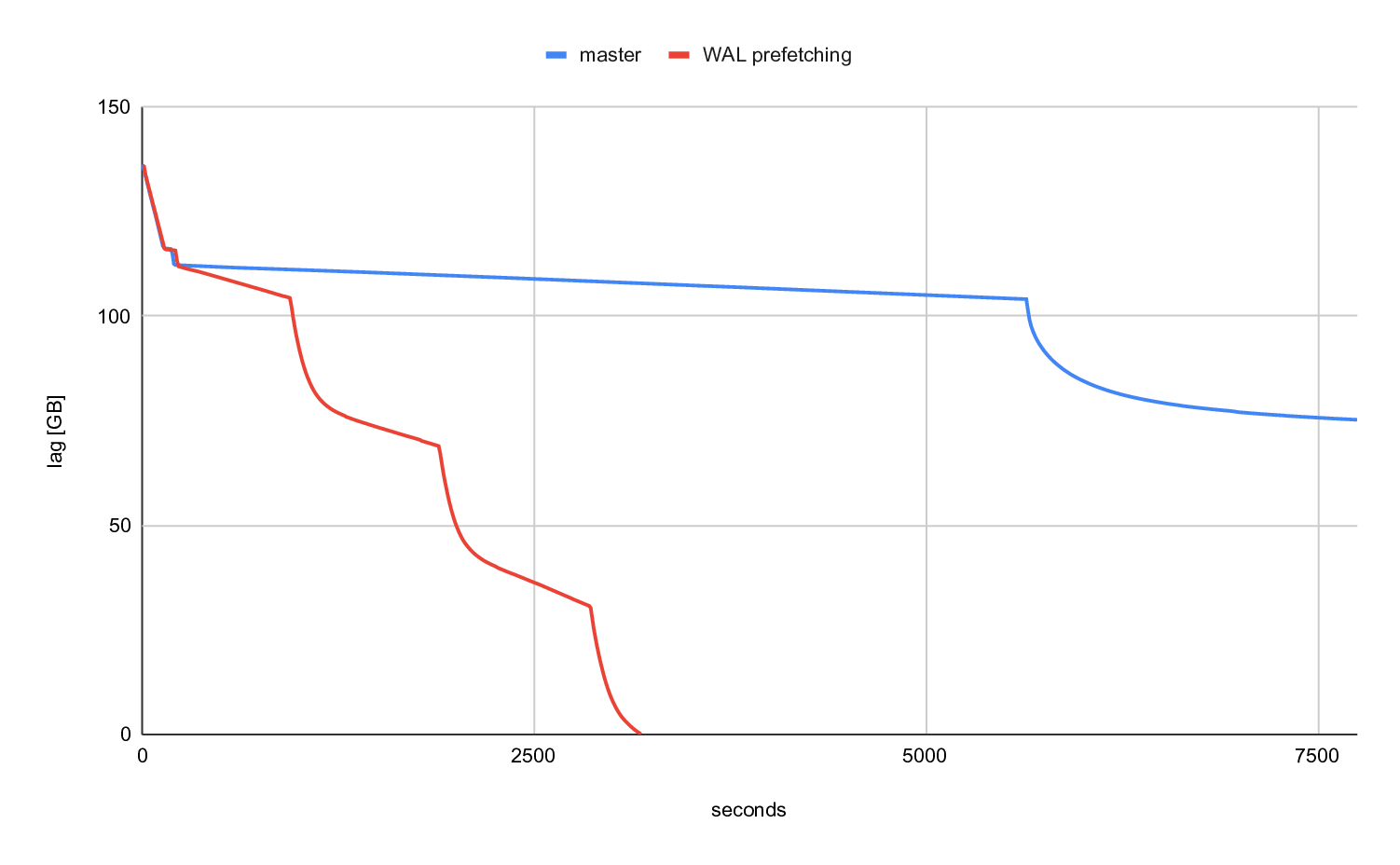{kind=link}
On Thu, Feb 4, 2021 at 1:40 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > With master, it'd take ~16000 seconds to catch up. I don't have the > exact number, because I got tired of waiting, but the estimate is likely > accurate (judging by other tests and how regular the progress is). > > With WAL prefetching enabled (I bumped up the buffer to 2MB, and > prefetch limit to 500, but that was mostly just arbitrary choice), it > finishes in ~3200 seconds. This includes replication of the pgbench > initialization, which took ~200 seconds and where prefetching is mostly > useless. That's a damn pretty improvement, I guess! Hi Tomas, Sorry for my slow response -- I've been catching up after some vacation time. Thanks very much for doing all this testing work! Those results are very good, and it's nice to see such compelling cases even with FPI enabled. I'm hoping to commit this in the next few weeks. There are a few little todos to tidy up, and I need to do some more review/testing of the error handling and edge cases. Any ideas on how to battle test it are very welcome. I'm also currently testing how it interacts with some other patches that are floating around. More soon. > #recovery_prefetch = on # whether to prefetch pages logged with FPW > #recovery_prefetch_fpw = off # whether to prefetch pages logged with FPW > > but clearly that comment is only for recovery_prefetch_fpw, the first > GUC enables prefetching in general. Ack, thanks.
Greetings,
* Thomas Munro (thomas.munro@gmail.com) wrote:
> Rebase attached.
> Subject: [PATCH v15 4/6] Prefetch referenced blocks during recovery.
> diff --git a/doc/src/sgml/config.sgml b/doc/src/sgml/config.sgml
> index 4b60382778..ac27392053 100644
> --- a/doc/src/sgml/config.sgml
> +++ b/doc/src/sgml/config.sgml
> @@ -3366,6 +3366,64 @@ include_dir 'conf.d'
[...]
> + <varlistentry id="guc-recovery-prefetch-fpw" xreflabel="recovery_prefetch_fpw">
> + <term><varname>recovery_prefetch_fpw</varname> (<type>boolean</type>)
> + <indexterm>
> + <primary><varname>recovery_prefetch_fpw</varname> configuration parameter</primary>
> + </indexterm>
> + </term>
> + <listitem>
> + <para>
> + Whether to prefetch blocks that were logged with full page images,
> + during recovery. Often this doesn't help, since such blocks will not
> + be read the first time they are needed and might remain in the buffer
The "might" above seems slightly confusing- such blocks will remain in
shared buffers until/unless they're forced out, right?
> + pool after that. However, on file systems with a block size larger
> + than
> + <productname>PostgreSQL</productname>'s, prefetching can avoid a
> + costly read-before-write when a blocks are later written.
> + The default is off.
"when a blocks" above doesn't sound quite right, maybe reword this as:
"prefetching can avoid a costly read-before-write when WAL replay
reaches the block that needs to be written."
> diff --git a/doc/src/sgml/wal.sgml b/doc/src/sgml/wal.sgml
> index d1c3893b14..c51c431398 100644
> --- a/doc/src/sgml/wal.sgml
> +++ b/doc/src/sgml/wal.sgml
> @@ -720,6 +720,23 @@
> <acronym>WAL</acronym> call being logged to the server log. This
> option might be replaced by a more general mechanism in the future.
> </para>
> +
> + <para>
> + The <xref linkend="guc-recovery-prefetch"/> parameter can
> + be used to improve I/O performance during recovery by instructing
> + <productname>PostgreSQL</productname> to initiate reads
> + of disk blocks that will soon be needed but are not currently in
> + <productname>PostgreSQL</productname>'s buffer pool.
> + The <xref linkend="guc-maintenance-io-concurrency"/> and
> + <xref linkend="guc-wal-decode-buffer-size"/> settings limit prefetching
> + concurrency and distance, respectively. The
> + prefetching mechanism is most likely to be effective on systems
> + with <varname>full_page_writes</varname> set to
> + <varname>off</varname> (where that is safe), and where the working
> + set is larger than RAM. By default, prefetching in recovery is enabled
> + on operating systems that have <function>posix_fadvise</function>
> + support.
> + </para>
> </sect1>
> diff --git a/src/backend/access/transam/xlog.c b/src/backend/access/transam/xlog.c
> @@ -3697,7 +3699,6 @@ XLogFileRead(XLogSegNo segno, int emode, TimeLineID tli,
> snprintf(activitymsg, sizeof(activitymsg), "waiting for %s",
> xlogfname);
> set_ps_display(activitymsg);
> -
> restoredFromArchive = RestoreArchivedFile(path, xlogfname,
> "RECOVERYXLOG",
> wal_segment_size,
> @@ -12566,6 +12585,7 @@ WaitForWALToBecomeAvailable(XLogRecPtr RecPtr, bool randAccess,
> else
> havedata = false;
> }
> +
> if (havedata)
> {
> /*
Random whitespace change hunks..?
> diff --git a/src/backend/access/transam/xlogprefetch.c b/src/backend/access/transam/xlogprefetch.c
> + * The size of the queue is based on the maintenance_io_concurrency
> + * setting. In theory we might have a separate queue for each tablespace,
> + * but it's not clear how that should work, so for now we'll just use the
> + * general GUC to rate-limit all prefetching. The queue has space for up
> + * the highest possible value of the GUC + 1, because our circular buffer
> + * has a gap between head and tail when full.
Seems like "to" is missing- "The queue has space for up *to* the highest
possible value of the GUC + 1" ? Maybe also "between the head and the
tail when full".
> +/*
> + * Scan the current record for block references, and consider prefetching.
> + *
> + * Return true if we processed the current record to completion and still have
> + * queue space to process a new record, and false if we saturated the I/O
> + * queue and need to wait for recovery to advance before we continue.
> + */
> +static bool
> +XLogPrefetcherScanBlocks(XLogPrefetcher *prefetcher)
> +{
> + DecodedXLogRecord *record = prefetcher->record;
> +
> + Assert(!XLogPrefetcherSaturated(prefetcher));
> +
> + /*
> + * We might already have been partway through processing this record when
> + * our queue became saturated, so we need to start where we left off.
> + */
> + for (int block_id = prefetcher->next_block_id;
> + block_id <= record->max_block_id;
> + ++block_id)
> + {
> + DecodedBkpBlock *block = &record->blocks[block_id];
> + PrefetchBufferResult prefetch;
> + SMgrRelation reln;
> +
> + /* Ignore everything but the main fork for now. */
> + if (block->forknum != MAIN_FORKNUM)
> + continue;
> +
> + /*
> + * If there is a full page image attached, we won't be reading the
> + * page, so you might think we should skip it. However, if the
> + * underlying filesystem uses larger logical blocks than us, it
> + * might still need to perform a read-before-write some time later.
> + * Therefore, only prefetch if configured to do so.
> + */
> + if (block->has_image && !recovery_prefetch_fpw)
> + {
> + pg_atomic_unlocked_add_fetch_u64(&Stats->skip_fpw, 1);
> + continue;
> + }
FPIs in the stream aren't going to just avoid reads when the
filesystem's block size matches PG's- they're also going to avoid
subsequent modifications to the block, provided we don't end up pushing
that block out of shared buffers, rights?
That is, if you have an empty shared buffers and see:
Block 5 FPI
Block 6 FPI
Block 5 Update
Block 6 Update
it seems like, with this patch, we're going to Prefetch Block 5 & 6,
even though we almost certainly won't actually need them.
> + /* Fast path for repeated references to the same relation. */
> + if (RelFileNodeEquals(block->rnode, prefetcher->last_rnode))
> + {
> + /*
> + * If this is a repeat access to the same block, then skip it.
> + *
> + * XXX We could also check for last_blkno + 1 too, and also update
> + * last_blkno; it's not clear if the kernel would do a better job
> + * of sequential prefetching.
> + */
> + if (block->blkno == prefetcher->last_blkno)
> + {
> + pg_atomic_unlocked_add_fetch_u64(&Stats->skip_seq, 1);
> + continue;
> + }
I'm sure this will help with some cases, but it wouldn't help with the
case that I mention above, as I understand it.
> + {"recovery_prefetch", PGC_SIGHUP, WAL_SETTINGS,
> + gettext_noop("Prefetch referenced blocks during recovery"),
> + gettext_noop("Read ahead of the currenty replay position to find uncached blocks.")
extra 'y' at the end of 'current', and "find uncached blocks" might be
misleading, maybe:
"Read out ahead of the current replay position and prefetch blocks."
> diff --git a/src/backend/utils/misc/postgresql.conf.sample b/src/backend/utils/misc/postgresql.conf.sample
> index b7fb2ec1fe..4288f2f37f 100644
> --- a/src/backend/utils/misc/postgresql.conf.sample
> +++ b/src/backend/utils/misc/postgresql.conf.sample
> @@ -234,6 +234,12 @@
> #checkpoint_flush_after = 0 # measured in pages, 0 disables
> #checkpoint_warning = 30s # 0 disables
>
> +# - Prefetching during recovery -
> +
> +#wal_decode_buffer_size = 512kB # lookahead window used for prefetching
> +#recovery_prefetch = on # whether to prefetch pages logged with FPW
> +#recovery_prefetch_fpw = off # whether to prefetch pages logged with FPW
Think this was already mentioned, but the above comments shouldn't be
the same. :)
> From 2f6d690cefc0cad8cbd8b88dbed4d688399c6916 Mon Sep 17 00:00:00 2001
> From: Thomas Munro <thomas.munro@gmail.com>
> Date: Mon, 14 Sep 2020 23:20:55 +1200
> Subject: [PATCH v15 5/6] WIP: Avoid extra buffer lookup when prefetching WAL
> blocks.
>
> Provide a some workspace in decoded WAL records, so that we can remember
> which buffer recently contained we found a block cached in, for later
> use when replaying the record. Provide a new way to look up a
> recently-known buffer and check if it's still valid and has the right
> tag.
"Provide a place in decoded WAL records to remember which buffer we
found a block cached in, to hopefully avoid having to look it up again
when we replay the record. Provide a way to look up a recently-known
buffer and check if it's still valid and has the right tag."
> XXX Needs review to figure out if it's safe or steamrolling over subtleties
... that's a great question. :) Not sure that I can really answer it
conclusively, but I can't think of any reason, given the buffer tag
check that's included, that it would be an issue. I'm glad to see this
though since it addresses some of the concern about this patch slowing
down replay in cases where there are FPIs and checkpoints are less than
the size of shared buffers, which seems much more common than cases
where FPIs have been disabled and/or checkpoints are larger than SB.
Further effort to avoid having likely-unnecessary prefetching done for
blocks which recently had an FPI would further reduce the risk of this
change slowing down replay for common deployments, though I'm not sure
how much of an impact that likely has or what the cost would be to avoid
the prefetching (and it's complicated by hot standby, I imagine...).
Thanks,
Stephen
Attachment
On 2/10/21 10:50 PM, Stephen Frost wrote:
>
> ...
>
>> +/*
>> + * Scan the current record for block references, and consider prefetching.
>> + *
>> + * Return true if we processed the current record to completion and still have
>> + * queue space to process a new record, and false if we saturated the I/O
>> + * queue and need to wait for recovery to advance before we continue.
>> + */
>> +static bool
>> +XLogPrefetcherScanBlocks(XLogPrefetcher *prefetcher)
>> +{
>> + DecodedXLogRecord *record = prefetcher->record;
>> +
>> + Assert(!XLogPrefetcherSaturated(prefetcher));
>> +
>> + /*
>> + * We might already have been partway through processing this record when
>> + * our queue became saturated, so we need to start where we left off.
>> + */
>> + for (int block_id = prefetcher->next_block_id;
>> + block_id <= record->max_block_id;
>> + ++block_id)
>> + {
>> + DecodedBkpBlock *block = &record->blocks[block_id];
>> + PrefetchBufferResult prefetch;
>> + SMgrRelation reln;
>> +
>> + /* Ignore everything but the main fork for now. */
>> + if (block->forknum != MAIN_FORKNUM)
>> + continue;
>> +
>> + /*
>> + * If there is a full page image attached, we won't be reading the
>> + * page, so you might think we should skip it. However, if the
>> + * underlying filesystem uses larger logical blocks than us, it
>> + * might still need to perform a read-before-write some time later.
>> + * Therefore, only prefetch if configured to do so.
>> + */
>> + if (block->has_image && !recovery_prefetch_fpw)
>> + {
>> + pg_atomic_unlocked_add_fetch_u64(&Stats->skip_fpw, 1);
>> + continue;
>> + }
>
> FPIs in the stream aren't going to just avoid reads when the
> filesystem's block size matches PG's- they're also going to avoid
> subsequent modifications to the block, provided we don't end up pushing
> that block out of shared buffers, rights?
>
> That is, if you have an empty shared buffers and see:
>
> Block 5 FPI
> Block 6 FPI
> Block 5 Update
> Block 6 Update
>
> it seems like, with this patch, we're going to Prefetch Block 5 & 6,
> even though we almost certainly won't actually need them.
>
Yeah, that's a good point. I think it'd make sense to keep track of
recent FPIs and skip prefetching such blocks. But how exactly should we
implement that, how many blocks do we need to track? If you get an FPI,
how long should we skip prefetching of that block?
I don't think the history needs to be very long, for two reasons.
Firstly, the usual pattern is that we have FPI + several changes for
that block shortly after it. Secondly, maintenance_io_concurrency limits
this naturally - after crossing that, redo should place the FPI into
shared buffers, allowing us to skip the prefetch.
So I think using maintenance_io_concurrency is sufficient. We might
track more buffers to allow skipping prefetches of blocks that were
evicted from shared buffers, but that seems like an overkill.
However, maintenance_io_concurrency can be quite high, so just a simple
queue is not very suitable - searching it linearly for each block would
be too expensive. But I think we can use a simple hash table, tracking
(relfilenode, block, LSN), over-sized to minimize collisions.
Imagine it's a simple array with (2 * maintenance_io_concurrency)
elements, and whenever we prefetch a block or find an FPI, we simply add
the block to the array as determined by hash(relfilenode, block)
hashtable[hash(...)] = {relfilenode, block, LSN}
and then when deciding whether to prefetch a block, we look at that one
position. If the (relfilenode, block) match, we check the LSN and skip
the prefetch if it's sufficiently recent. Otherwise we prefetch.
We may issue some extra prefetches due to collisions, but that's fine I
think. There should not be very many of them, thanks to having the hash
table oversized.
The good thing is this is quite simple, fixed-sized data structure,
there's no need for allocations etc.
>> + /* Fast path for repeated references to the same relation. */
>> + if (RelFileNodeEquals(block->rnode, prefetcher->last_rnode))
>> + {
>> + /*
>> + * If this is a repeat access to the same block, then skip it.
>> + *
>> + * XXX We could also check for last_blkno + 1 too, and also update
>> + * last_blkno; it's not clear if the kernel would do a better job
>> + * of sequential prefetching.
>> + */
>> + if (block->blkno == prefetcher->last_blkno)
>> + {
>> + pg_atomic_unlocked_add_fetch_u64(&Stats->skip_seq, 1);
>> + continue;
>> + }
>
> I'm sure this will help with some cases, but it wouldn't help with the
> case that I mention above, as I understand it.
>
It won't but it's a pretty effective check. I've done some experiments
recently, and with random pgbench this eliminates ~15% of prefetches.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi,
On 2021-02-12 00:42:04 +0100, Tomas Vondra wrote:
> Yeah, that's a good point. I think it'd make sense to keep track of recent
> FPIs and skip prefetching such blocks. But how exactly should we implement
> that, how many blocks do we need to track? If you get an FPI, how long
> should we skip prefetching of that block?
>
> I don't think the history needs to be very long, for two reasons. Firstly,
> the usual pattern is that we have FPI + several changes for that block
> shortly after it. Secondly, maintenance_io_concurrency limits this naturally
> - after crossing that, redo should place the FPI into shared buffers,
> allowing us to skip the prefetch.
>
> So I think using maintenance_io_concurrency is sufficient. We might track
> more buffers to allow skipping prefetches of blocks that were evicted from
> shared buffers, but that seems like an overkill.
>
> However, maintenance_io_concurrency can be quite high, so just a simple
> queue is not very suitable - searching it linearly for each block would be
> too expensive. But I think we can use a simple hash table, tracking
> (relfilenode, block, LSN), over-sized to minimize collisions.
>
> Imagine it's a simple array with (2 * maintenance_io_concurrency) elements,
> and whenever we prefetch a block or find an FPI, we simply add the block to
> the array as determined by hash(relfilenode, block)
>
> hashtable[hash(...)] = {relfilenode, block, LSN}
>
> and then when deciding whether to prefetch a block, we look at that one
> position. If the (relfilenode, block) match, we check the LSN and skip the
> prefetch if it's sufficiently recent. Otherwise we prefetch.
I'm a bit doubtful this is really needed at this point. Yes, the
prefetching will do a buffer table lookup - but it's a lookup that
already happens today. And the patch already avoids doing a second
lookup after prefetching (by optimistically caching the last Buffer id,
and re-checking).
I think there's potential for some significant optimization going
forward, but I think it's basically optimization over what we're doing
today. As this is already a nontrivial patch, I'd argue for doing so
separately.
Regards,
Andres
On 2/12/21 5:46 AM, Andres Freund wrote:
> Hi,
>
> On 2021-02-12 00:42:04 +0100, Tomas Vondra wrote:
>> Yeah, that's a good point. I think it'd make sense to keep track of recent
>> FPIs and skip prefetching such blocks. But how exactly should we implement
>> that, how many blocks do we need to track? If you get an FPI, how long
>> should we skip prefetching of that block?
>>
>> I don't think the history needs to be very long, for two reasons. Firstly,
>> the usual pattern is that we have FPI + several changes for that block
>> shortly after it. Secondly, maintenance_io_concurrency limits this naturally
>> - after crossing that, redo should place the FPI into shared buffers,
>> allowing us to skip the prefetch.
>>
>> So I think using maintenance_io_concurrency is sufficient. We might track
>> more buffers to allow skipping prefetches of blocks that were evicted from
>> shared buffers, but that seems like an overkill.
>>
>> However, maintenance_io_concurrency can be quite high, so just a simple
>> queue is not very suitable - searching it linearly for each block would be
>> too expensive. But I think we can use a simple hash table, tracking
>> (relfilenode, block, LSN), over-sized to minimize collisions.
>>
>> Imagine it's a simple array with (2 * maintenance_io_concurrency) elements,
>> and whenever we prefetch a block or find an FPI, we simply add the block to
>> the array as determined by hash(relfilenode, block)
>>
>> hashtable[hash(...)] = {relfilenode, block, LSN}
>>
>> and then when deciding whether to prefetch a block, we look at that one
>> position. If the (relfilenode, block) match, we check the LSN and skip the
>> prefetch if it's sufficiently recent. Otherwise we prefetch.
>
> I'm a bit doubtful this is really needed at this point. Yes, the
> prefetching will do a buffer table lookup - but it's a lookup that
> already happens today. And the patch already avoids doing a second
> lookup after prefetching (by optimistically caching the last Buffer id,
> and re-checking).
>
> I think there's potential for some significant optimization going
> forward, but I think it's basically optimization over what we're doing
> today. As this is already a nontrivial patch, I'd argue for doing so
> separately.
>
I agree with treating this as an improvement - it's not something that
needs to be solved in the first verson. OTOH I think Stephen has a point
that just skipping FPIs like we do now has limited effect, because the
WAL usually contains additional changes to the same block.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Greetings,
* Andres Freund (andres@anarazel.de) wrote:
> On 2021-02-12 00:42:04 +0100, Tomas Vondra wrote:
> > Yeah, that's a good point. I think it'd make sense to keep track of recent
> > FPIs and skip prefetching such blocks. But how exactly should we implement
> > that, how many blocks do we need to track? If you get an FPI, how long
> > should we skip prefetching of that block?
> >
> > I don't think the history needs to be very long, for two reasons. Firstly,
> > the usual pattern is that we have FPI + several changes for that block
> > shortly after it. Secondly, maintenance_io_concurrency limits this naturally
> > - after crossing that, redo should place the FPI into shared buffers,
> > allowing us to skip the prefetch.
> >
> > So I think using maintenance_io_concurrency is sufficient. We might track
> > more buffers to allow skipping prefetches of blocks that were evicted from
> > shared buffers, but that seems like an overkill.
> >
> > However, maintenance_io_concurrency can be quite high, so just a simple
> > queue is not very suitable - searching it linearly for each block would be
> > too expensive. But I think we can use a simple hash table, tracking
> > (relfilenode, block, LSN), over-sized to minimize collisions.
> >
> > Imagine it's a simple array with (2 * maintenance_io_concurrency) elements,
> > and whenever we prefetch a block or find an FPI, we simply add the block to
> > the array as determined by hash(relfilenode, block)
> >
> > hashtable[hash(...)] = {relfilenode, block, LSN}
> >
> > and then when deciding whether to prefetch a block, we look at that one
> > position. If the (relfilenode, block) match, we check the LSN and skip the
> > prefetch if it's sufficiently recent. Otherwise we prefetch.
>
> I'm a bit doubtful this is really needed at this point. Yes, the
> prefetching will do a buffer table lookup - but it's a lookup that
> already happens today. And the patch already avoids doing a second
> lookup after prefetching (by optimistically caching the last Buffer id,
> and re-checking).
I agree that when a page is looked up, and found, in the buffer table
that the subsequent cacheing of the buffer id in the WAL records does a
good job of avoiding having to re-do that lookup. However, that isn't
the case which was being discussed here or what Tomas's suggestion was
intended to address.
What I pointed out up-thread and what's being discussed here is what
happens when the WAL contains a few FPIs and a few regular WAL records
which are mixed up and not in ideal order. When that happens, with this
patch, the FPIs will be ignored, the regular WAL records will reference
blocks which aren't found in shared buffers (yet) and then we'll both
issue pre-fetches for those and end up having spent effort doing a
buffer lookup that we'll later re-do.
To address the unnecessary syscalls we really just need to keep track of
any FPIs that we've seen between where the point where the prefetching
is happening and the point where the replay is being done- once replay
has replayed an FPI, our buffer lookup will succeed and we'll cache the
buffer that the FPI is at- in other words, only wal_decode_buffer_size
amount of WAL needs to be considered.
We could further leverage this tracking of FPIs, to skip the prefetch
syscalls, by cacheing what later records address the blocks that have
FPIs earlier in the queue with the FPI record and then when replay hits
the FPI and loads it into shared_buffers, it could update the other WAL
records in the queue with the buffer id of the page, allowing us to very
likely avoid having to do another lookup later on.
> I think there's potential for some significant optimization going
> forward, but I think it's basically optimization over what we're doing
> today. As this is already a nontrivial patch, I'd argue for doing so
> separately.
This seems like a great optimization, albeit a fair bit of code, for a
relatively uncommon use-case, specifically where full page writes are
disabled or very large checkpoints. As that's the case though, I would
think it's reasonable to ask that it go out of its way to avoid slowing
down the more common configurations, particularly since it's proposed to
have it on by default (which I agree with, provided it ends up improving
the common cases, which I think the suggestions above would certainly
make it more likely to do).
Perhaps this already improves the common cases and is worth the extra
code on that basis, but I don't recall seeing much in the way of
benchmarking in this thread for that case- that is, where FPIs are
enabled and checkpoints are smaller than shared buffers. Jakub's
testing was done with FPWs disabled and Tomas's testing used checkpoints
which were much larger than the size of shared buffers on the system
doing the replay. While it's certainly good that this patch improves
those cases, we should also be looking out for the worst case and make
sure that the patch doesn't degrade performance in that case.
Thanks,
Stephen
Attachment
On 2/13/21 10:39 PM, Stephen Frost wrote:
> Greetings,
>
> * Andres Freund (andres@anarazel.de) wrote:
>> On 2021-02-12 00:42:04 +0100, Tomas Vondra wrote:
>>> Yeah, that's a good point. I think it'd make sense to keep track of recent
>>> FPIs and skip prefetching such blocks. But how exactly should we implement
>>> that, how many blocks do we need to track? If you get an FPI, how long
>>> should we skip prefetching of that block?
>>>
>>> I don't think the history needs to be very long, for two reasons. Firstly,
>>> the usual pattern is that we have FPI + several changes for that block
>>> shortly after it. Secondly, maintenance_io_concurrency limits this naturally
>>> - after crossing that, redo should place the FPI into shared buffers,
>>> allowing us to skip the prefetch.
>>>
>>> So I think using maintenance_io_concurrency is sufficient. We might track
>>> more buffers to allow skipping prefetches of blocks that were evicted from
>>> shared buffers, but that seems like an overkill.
>>>
>>> However, maintenance_io_concurrency can be quite high, so just a simple
>>> queue is not very suitable - searching it linearly for each block would be
>>> too expensive. But I think we can use a simple hash table, tracking
>>> (relfilenode, block, LSN), over-sized to minimize collisions.
>>>
>>> Imagine it's a simple array with (2 * maintenance_io_concurrency) elements,
>>> and whenever we prefetch a block or find an FPI, we simply add the block to
>>> the array as determined by hash(relfilenode, block)
>>>
>>> hashtable[hash(...)] = {relfilenode, block, LSN}
>>>
>>> and then when deciding whether to prefetch a block, we look at that one
>>> position. If the (relfilenode, block) match, we check the LSN and skip the
>>> prefetch if it's sufficiently recent. Otherwise we prefetch.
>>
>> I'm a bit doubtful this is really needed at this point. Yes, the
>> prefetching will do a buffer table lookup - but it's a lookup that
>> already happens today. And the patch already avoids doing a second
>> lookup after prefetching (by optimistically caching the last Buffer id,
>> and re-checking).
>
> I agree that when a page is looked up, and found, in the buffer table
> that the subsequent cacheing of the buffer id in the WAL records does a
> good job of avoiding having to re-do that lookup. However, that isn't
> the case which was being discussed here or what Tomas's suggestion was
> intended to address.
>
> What I pointed out up-thread and what's being discussed here is what
> happens when the WAL contains a few FPIs and a few regular WAL records
> which are mixed up and not in ideal order. When that happens, with this
> patch, the FPIs will be ignored, the regular WAL records will reference
> blocks which aren't found in shared buffers (yet) and then we'll both
> issue pre-fetches for those and end up having spent effort doing a
> buffer lookup that we'll later re-do.
>
The question is how common this pattern actually is - I don't know. As
noted, the non-FPI would have to be fairly close to the FPI, i.e. within
the wal_decode_buffer_size, to actually cause measurable harm.
> To address the unnecessary syscalls we really just need to keep track of
> any FPIs that we've seen between where the point where the prefetching
> is happening and the point where the replay is being done- once replay
> has replayed an FPI, our buffer lookup will succeed and we'll cache the
> buffer that the FPI is at- in other words, only wal_decode_buffer_size
> amount of WAL needs to be considered.
>
Yeah, that's essentially what I proposed.
> We could further leverage this tracking of FPIs, to skip the prefetch
> syscalls, by cacheing what later records address the blocks that have
> FPIs earlier in the queue with the FPI record and then when replay hits
> the FPI and loads it into shared_buffers, it could update the other WAL
> records in the queue with the buffer id of the page, allowing us to very
> likely avoid having to do another lookup later on.
>
This seems like an over-engineering, at least for v1.
>> I think there's potential for some significant optimization going
>> forward, but I think it's basically optimization over what we're doing
>> today. As this is already a nontrivial patch, I'd argue for doing so
>> separately.
>
> This seems like a great optimization, albeit a fair bit of code, for a
> relatively uncommon use-case, specifically where full page writes are
> disabled or very large checkpoints. As that's the case though, I would
> think it's reasonable to ask that it go out of its way to avoid slowing
> down the more common configurations, particularly since it's proposed to
> have it on by default (which I agree with, provided it ends up improving
> the common cases, which I think the suggestions above would certainly
> make it more likely to do).
>
I'm OK to do some benchmarking, but it's not quite clear to me why does
it matter if the checkpoints are smaller than shared buffers? IMO what
matters is how "localized" the updates are, i.e. how likely it is to hit
the same page repeatedly (in a short amount of time). Regular pgbench is
not very suitable for that, but some non-uniform distribution should do
the trick, I think.
> Perhaps this already improves the common cases and is worth the extra
> code on that basis, but I don't recall seeing much in the way of
> benchmarking in this thread for that case- that is, where FPIs are
> enabled and checkpoints are smaller than shared buffers. Jakub's
> testing was done with FPWs disabled and Tomas's testing used checkpoints
> which were much larger than the size of shared buffers on the system
> doing the replay. While it's certainly good that this patch improves
> those cases, we should also be looking out for the worst case and make
> sure that the patch doesn't degrade performance in that case.
>
I'm with Andres on this. It's fine to leave some possible optimizations
on the table for the future. And even if some workloads are affected
negatively, it's still possible to disable the prefetching.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Greetings,
* Tomas Vondra (tomas.vondra@enterprisedb.com) wrote:
> On 2/13/21 10:39 PM, Stephen Frost wrote:
> >* Andres Freund (andres@anarazel.de) wrote:
> >>On 2021-02-12 00:42:04 +0100, Tomas Vondra wrote:
> >>>Yeah, that's a good point. I think it'd make sense to keep track of recent
> >>>FPIs and skip prefetching such blocks. But how exactly should we implement
> >>>that, how many blocks do we need to track? If you get an FPI, how long
> >>>should we skip prefetching of that block?
> >>>
> >>>I don't think the history needs to be very long, for two reasons. Firstly,
> >>>the usual pattern is that we have FPI + several changes for that block
> >>>shortly after it. Secondly, maintenance_io_concurrency limits this naturally
> >>>- after crossing that, redo should place the FPI into shared buffers,
> >>>allowing us to skip the prefetch.
> >>>
> >>>So I think using maintenance_io_concurrency is sufficient. We might track
> >>>more buffers to allow skipping prefetches of blocks that were evicted from
> >>>shared buffers, but that seems like an overkill.
> >>>
> >>>However, maintenance_io_concurrency can be quite high, so just a simple
> >>>queue is not very suitable - searching it linearly for each block would be
> >>>too expensive. But I think we can use a simple hash table, tracking
> >>>(relfilenode, block, LSN), over-sized to minimize collisions.
> >>>
> >>>Imagine it's a simple array with (2 * maintenance_io_concurrency) elements,
> >>>and whenever we prefetch a block or find an FPI, we simply add the block to
> >>>the array as determined by hash(relfilenode, block)
> >>>
> >>> hashtable[hash(...)] = {relfilenode, block, LSN}
> >>>
> >>>and then when deciding whether to prefetch a block, we look at that one
> >>>position. If the (relfilenode, block) match, we check the LSN and skip the
> >>>prefetch if it's sufficiently recent. Otherwise we prefetch.
> >>
> >>I'm a bit doubtful this is really needed at this point. Yes, the
> >>prefetching will do a buffer table lookup - but it's a lookup that
> >>already happens today. And the patch already avoids doing a second
> >>lookup after prefetching (by optimistically caching the last Buffer id,
> >>and re-checking).
> >
> >I agree that when a page is looked up, and found, in the buffer table
> >that the subsequent cacheing of the buffer id in the WAL records does a
> >good job of avoiding having to re-do that lookup. However, that isn't
> >the case which was being discussed here or what Tomas's suggestion was
> >intended to address.
> >
> >What I pointed out up-thread and what's being discussed here is what
> >happens when the WAL contains a few FPIs and a few regular WAL records
> >which are mixed up and not in ideal order. When that happens, with this
> >patch, the FPIs will be ignored, the regular WAL records will reference
> >blocks which aren't found in shared buffers (yet) and then we'll both
> >issue pre-fetches for those and end up having spent effort doing a
> >buffer lookup that we'll later re-do.
>
> The question is how common this pattern actually is - I don't know. As
> noted, the non-FPI would have to be fairly close to the FPI, i.e. within the
> wal_decode_buffer_size, to actually cause measurable harm.
Yeah, so it'll depend on how big wal_decode_buffer_size is. Increasing
that would certainly help to show if there ends up being a degredation
with this patch due to the extra prefetching being done.
> >To address the unnecessary syscalls we really just need to keep track of
> >any FPIs that we've seen between where the point where the prefetching
> >is happening and the point where the replay is being done- once replay
> >has replayed an FPI, our buffer lookup will succeed and we'll cache the
> >buffer that the FPI is at- in other words, only wal_decode_buffer_size
> >amount of WAL needs to be considered.
>
> Yeah, that's essentially what I proposed.
Glad I captured it correctly.
> >We could further leverage this tracking of FPIs, to skip the prefetch
> >syscalls, by cacheing what later records address the blocks that have
> >FPIs earlier in the queue with the FPI record and then when replay hits
> >the FPI and loads it into shared_buffers, it could update the other WAL
> >records in the queue with the buffer id of the page, allowing us to very
> >likely avoid having to do another lookup later on.
>
> This seems like an over-engineering, at least for v1.
Perhaps, though it didn't seem like it'd be very hard to do with the
already proposed changes to stash the buffer id in the WAL records.
> >>I think there's potential for some significant optimization going
> >>forward, but I think it's basically optimization over what we're doing
> >>today. As this is already a nontrivial patch, I'd argue for doing so
> >>separately.
> >
> >This seems like a great optimization, albeit a fair bit of code, for a
> >relatively uncommon use-case, specifically where full page writes are
> >disabled or very large checkpoints. As that's the case though, I would
> >think it's reasonable to ask that it go out of its way to avoid slowing
> >down the more common configurations, particularly since it's proposed to
> >have it on by default (which I agree with, provided it ends up improving
> >the common cases, which I think the suggestions above would certainly
> >make it more likely to do).
>
> I'm OK to do some benchmarking, but it's not quite clear to me why does it
> matter if the checkpoints are smaller than shared buffers? IMO what matters
> is how "localized" the updates are, i.e. how likely it is to hit the same
> page repeatedly (in a short amount of time). Regular pgbench is not very
> suitable for that, but some non-uniform distribution should do the trick, I
> think.
I suppose strictly speaking it'd be
Min(wal_decode_buffer_size,checkpoint_size), but yes, you're right that
it's more about the wal_decode_buffer_size than the checkpoint's size.
Apologies for the confusion. As suggested above, one way to benchmark
this to really see if there's any issue would be to increase
wal_decode_buffer_size to some pretty big size and then compare the
performance vs. unpatched. I'd think that could even be done with
pgbench, so you're not having to arrange for the same pages to get
updated over and over.
> >Perhaps this already improves the common cases and is worth the extra
> >code on that basis, but I don't recall seeing much in the way of
> >benchmarking in this thread for that case- that is, where FPIs are
> >enabled and checkpoints are smaller than shared buffers. Jakub's
> >testing was done with FPWs disabled and Tomas's testing used checkpoints
> >which were much larger than the size of shared buffers on the system
> >doing the replay. While it's certainly good that this patch improves
> >those cases, we should also be looking out for the worst case and make
> >sure that the patch doesn't degrade performance in that case.
>
> I'm with Andres on this. It's fine to leave some possible optimizations on
> the table for the future. And even if some workloads are affected
> negatively, it's still possible to disable the prefetching.
While I'm generally in favor of this argument, that a feature is
particularly important and that it's worth slowing down the common cases
to enable it, I dislike that it's applied inconsistently. I'd certainly
feel better about it if we had actual performance numbers to consider.
I don't doubt the possibility that the extra prefetch's just don't
amount to enough to matter but I have a hard time seeing them as not
having some cost and without actually measuring it, it's hard to say
what that cost is.
Without looking farther back than the last record, we could end up
repeatedly asking for the same blocks to be prefetched too-
FPI for block 1
FPI for block 2
WAL record for block 1
WAL record for block 2
WAL record for block 1
WAL record for block 2
WAL record for block 1
WAL record for block 2
... etc.
Entirely possible my math is off, but seems like the worst case
situation right now might end up with some 4500 unnecessary prefetch
syscalls even with the proposed default wal_decode_buffer_size of
512k and 56-byte WAL records ((524,288 - 16,384) / 56 / 2 = ~4534).
Issuing unnecessary prefetches for blocks we've already sent a prefetch
for is arguably a concern even if FPWs are off but the benefit of doing
the prefetching almost certainly will outweight that and mean that
finding a way to address it is something we could certainly do later as
a future improvement. I wouldn't have any issue with that. Just
doesn't seem as clear-cut to me when thinking about the FPW-enabled
case. Ultimately, if you, Andres and Munro are all not concerned about
it and no one else speaks up then I'm not going to pitch a fuss over it
being committed, but, as you said above, it seemed like a good point to
raise for everyone to consider.
Thanks,
Stephen
Attachment
Greetings, * Tomas Vondra (tomas.vondra@enterprisedb.com) wrote: > Right, I was just going to point out the FPIs are not necessary - what > matters is the presence of long streaks of WAL records touching the same > set of blocks. But people with workloads where this is common likely > don't need the WAL prefetching at all - the replica can keep up just > fine, because it doesn't need to do much I/O anyway (and if it can't > then prefetching won't help much anyway). So just don't enable the > prefetching, and there'll be no overhead. Isn't this exactly the common case though..? Checkpoints happening every 5 minutes, the replay of the FPI happens first and then the record is updated and everything's in SB for the later changes? You mentioned elsewhere that this would improve 80% of cases but that doesn't seem to be backed up by anything and certainly doesn't seem likely to be the case if we're talking about across all PG deployments. I also disagree that asking the kernel to go do random I/O for us, even as a prefetch, is entirely free simply because we won't actually need those pages. At the least, it potentially pushes out pages that we might need shortly from the filesystem cache, no? > If it was up to me, I'd just get the patch committed as is. Delaying the > feature because of concerns that it might have some negative effect in > some cases, when that can be simply mitigated by disabling the feature, > is not really beneficial for our users. I don't know that we actually know how many cases it might have a negative effect on or what the actual amount of such negative case there might be- that's really why we should probably try to actually benchmark it and get real numbers behind it, particularly when the chances of running into such a negative effect with the default configuration (that is, FPWs enabled) on the more typical platforms (as in, not ZFS) is more likely to occur in the field than the cases where FPWs are disabled and someone's running on ZFS. Perhaps more to the point, it'd be nice to see how this change actually improves the caes where PG is running with more-or-less the defaults on the more commonly deployed filesystems. If it doesn't then maybe it shouldn't be the default..? Surely the folks running on ZFS and running with FPWs disabled would be able to manage to enable it if they wished to and we could avoid entirely the question of if this has a negative impact on the more common cases. Guess I'm just not a fan of pushing out a change that will impact everyone by default, in a possibly negative way (or positive, though that doesn't seem terribly likely, but who knows), without actually measuring what that impact will look like in those more common cases. Showing that it's a great win when you're on ZFS or running with FPWs disabled is good and the expected best case, but we should be considering the worst case too when it comes to performance improvements. Anyhow, ultimately I don't know that there's much more to discuss on this thread with regard to this particular topic, at least. As I said before, if everyone else is on board and not worried about it then so be it; I feel that at least the concern that I raised has been heard. Thanks, Stephen
Attachment
Hi,
On 3/17/21 10:43 PM, Stephen Frost wrote:
> Greetings,
>
> * Tomas Vondra (tomas.vondra@enterprisedb.com) wrote:
>> Right, I was just going to point out the FPIs are not necessary - what
>> matters is the presence of long streaks of WAL records touching the same
>> set of blocks. But people with workloads where this is common likely
>> don't need the WAL prefetching at all - the replica can keep up just
>> fine, because it doesn't need to do much I/O anyway (and if it can't
>> then prefetching won't help much anyway). So just don't enable the
>> prefetching, and there'll be no overhead.
>
> Isn't this exactly the common case though..? Checkpoints happening
> every 5 minutes, the replay of the FPI happens first and then the record
> is updated and everything's in SB for the later changes?
Well, as I said before, the FPIs are not very significant - you'll have
mostly the same issue with any repeated changes to the same block. It
does not matter much if you do
FPI for block 1
WAL record for block 2
WAL record for block 1
WAL record for block 2
WAL record for block 1
or just
WAL record for block 1
WAL record for block 2
WAL record for block 1
WAL record for block 2
WAL record for block 1
In both cases some of the prefetches are probably unnecessary. But the
frequency of checkpoints does not really matter, the important bit is
repeated changes to the same block(s).
If you have active set much larger than RAM, this is quite unlikely. And
we know from the pgbench tests that prefetching has a huge positive
effect in this case.
On smaller active sets, with frequent updates to the same block, we may
issue unnecessary prefetches - that's true. But (a) you have not shown
any numbers suggesting this is actually an issue, and (b) those cases
don't really need prefetching because all the data is already either in
shared buffers or in page cache. So if it happens to be an issue, the
user can simply disable it.
So how exactly would a problematic workload look like?
> You mentioned elsewhere that this would improve 80% of cases but that
> doesn't seem to be backed up by anything and certainly doesn't seem
> likely to be the case if we're talking about across all PG
> deployments.
Obviously, the 80% was just a figure of speech, illustrating my belief
that the proposed patch is beneficial for most users who currently have
issues with replication lag. That is based on my experience with support
customers who have such issues - it's almost invariably an OLTP workload
with large active set, and we know (from the benchmarks) that in these
cases it helps.
Users who don't have issues with replication lag can disable (or not
enable) the prefetching, and won't get any negative effects.
Perhaps there are users with weird workloads that have replication lag
issues but this patch won't help them - bummer, we can't solve
everything in one go. Also, no one actually demonstrated such workload
in this thread so far.
But as you're suggesting we don't have data to support the claim that
this actually helps many users (with no risk to others), I'd point out
you have not actually provided any numbers showing that it actually is
an issue in practice.
> I also disagree that asking the kernel to go do random I/O for us,
> even as a prefetch, is entirely free simply because we won't
> actually need those pages. At the least, it potentially pushes out
> pages that we might need shortly from the filesystem cache, no?
Where exactly did I say it's free? I said that workloads where this
happens a lot most likely don't need the prefetching at all, so it can
be simply disabled, eliminating all negative effects.
Moreover, looking at a limited number of recently prefetched blocks
won't eliminate this problem anyway - imagine a random OLTP on large
data set that however fits into RAM. After a while no read I/O needs to
be done, but you'd need pretty much infinite list of prefetched blocks
to eliminate that, and with smaller lists you'll still do 99% of the
prefetches.
Just disabling prefetching on such instances seems quite reasonable.
>> If it was up to me, I'd just get the patch committed as is. Delaying the
>> feature because of concerns that it might have some negative effect in
>> some cases, when that can be simply mitigated by disabling the feature,
>> is not really beneficial for our users.
>
> I don't know that we actually know how many cases it might have a
> negative effect on or what the actual amount of such negative case there
> might be- that's really why we should probably try to actually benchmark
> it and get real numbers behind it, particularly when the chances of
> running into such a negative effect with the default configuration (that
> is, FPWs enabled) on the more typical platforms (as in, not ZFS) is more
> likely to occur in the field than the cases where FPWs are disabled and
> someone's running on ZFS.
>
> Perhaps more to the point, it'd be nice to see how this change actually
> improves the caes where PG is running with more-or-less the defaults on
> the more commonly deployed filesystems. If it doesn't then maybe it
> shouldn't be the default..? Surely the folks running on ZFS and running
> with FPWs disabled would be able to manage to enable it if they
> wished to and we could avoid entirely the question of if this has a
> negative impact on the more common cases.
>
> Guess I'm just not a fan of pushing out a change that will impact
> everyone by default, in a possibly negative way (or positive, though
> that doesn't seem terribly likely, but who knows), without actually
> measuring what that impact will look like in those more common cases.
> Showing that it's a great win when you're on ZFS or running with FPWs
> disabled is good and the expected best case, but we should be
> considering the worst case too when it comes to performance
> improvements.
>
Well, maybe it'll behave differently on systems with ZFS. I don't know,
and I have no such machine to test that at the moment. My argument
however remains the same - if if happens to be a problem, just don't
enable (or disable) the prefetching, and you get the current behavior.
FWIW I'm not sure there was a discussion or argument about what should
be the default setting (enabled or disabled). I'm fine with not enabling
this by default, so that people have to enable it explicitly.
In a way that'd be consistent with effective_io_concurrency being 1 by
default, which almost disables regular prefetching.
> Anyhow, ultimately I don't know that there's much more to discuss on
> this thread with regard to this particular topic, at least. As I said
> before, if everyone else is on board and not worried about it then so be
> it; I feel that at least the concern that I raised has been heard.
>
OK, thanks for the discussions.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, Mar 18, 2021 at 12:00 PM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
> On 3/17/21 10:43 PM, Stephen Frost wrote:
> > Guess I'm just not a fan of pushing out a change that will impact
> > everyone by default, in a possibly negative way (or positive, though
> > that doesn't seem terribly likely, but who knows), without actually
> > measuring what that impact will look like in those more common cases.
> > Showing that it's a great win when you're on ZFS or running with FPWs
> > disabled is good and the expected best case, but we should be
> > considering the worst case too when it comes to performance
> > improvements.
> >
>
> Well, maybe it'll behave differently on systems with ZFS. I don't know,
> and I have no such machine to test that at the moment. My argument
> however remains the same - if if happens to be a problem, just don't
> enable (or disable) the prefetching, and you get the current behavior.
I see the road map for this feature being to get it working on every
OS via the AIO patchset, in later work, hopefully not very far in the
future (in the most portable mode, you get I/O worker processes doing
pread() or preadv() calls on behalf of recovery). So I'll be glad to
get this infrastructure in, even though it's maybe only useful for
some people in the first release.
> FWIW I'm not sure there was a discussion or argument about what should
> be the default setting (enabled or disabled). I'm fine with not enabling
> this by default, so that people have to enable it explicitly.
>
> In a way that'd be consistent with effective_io_concurrency being 1 by
> default, which almost disables regular prefetching.
Yeah, I'm not sure but I'd be fine with disabling it by default in the
initial release. The current patch set has it enabled, but that's
mostly for testing, it's not an opinion on how it should ship.
I've attached a rebased patch set with a couple of small changes:
1. I abandoned the patch that proposed
pg_atomic_unlocked_add_fetch_u{32,64}() and went for a simple function
local to xlogprefetch.c that just does pg_atomic_write_u64(counter,
pg_atomic_read_u64(counter) + 1), in response to complaints from
Andres[1].
2. I fixed a bug in ReadRecentBuffer(), and moved it into its own
patch for separate review.
I'm now looking at Horiguchi-san and Heikki's patch[2] to remove
XLogReader's callbacks, to try to understand how these two patch sets
are related. I don't really like the way those callbacks work, and
I'm afraid had to make them more complicated. But I don't yet know
very much about that other patch set. More soon.
[1] https://www.postgresql.org/message-id/20201230035736.qmyrtrpeewqbidfi%40alap3.anarazel.de
[2] https://www.postgresql.org/message-id/flat/20190418.210257.43726183.horiguchi.kyotaro@lab.ntt.co.jp
Attachment
- v16-0001-Provide-ReadRecentBuffer-to-re-pin-buffers-by-ID.patch
- v16-0002-Improve-information-about-received-WAL.patch
- v16-0003-Provide-XLogReadAhead-to-decode-future-WAL-recor.patch
- v16-0004-Prefetch-referenced-blocks-during-recovery.patch
- v16-0005-Avoid-extra-buffer-lookup-when-prefetching-WAL-b.patch
On 3/18/21 1:54 AM, Thomas Munro wrote:
> On Thu, Mar 18, 2021 at 12:00 PM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>> On 3/17/21 10:43 PM, Stephen Frost wrote:
>>> Guess I'm just not a fan of pushing out a change that will impact
>>> everyone by default, in a possibly negative way (or positive, though
>>> that doesn't seem terribly likely, but who knows), without actually
>>> measuring what that impact will look like in those more common cases.
>>> Showing that it's a great win when you're on ZFS or running with FPWs
>>> disabled is good and the expected best case, but we should be
>>> considering the worst case too when it comes to performance
>>> improvements.
>>>
>>
>> Well, maybe it'll behave differently on systems with ZFS. I don't know,
>> and I have no such machine to test that at the moment. My argument
>> however remains the same - if if happens to be a problem, just don't
>> enable (or disable) the prefetching, and you get the current behavior.
>
> I see the road map for this feature being to get it working on every
> OS via the AIO patchset, in later work, hopefully not very far in the
> future (in the most portable mode, you get I/O worker processes doing
> pread() or preadv() calls on behalf of recovery). So I'll be glad to
> get this infrastructure in, even though it's maybe only useful for
> some people in the first release.
>
+1 to that
>> FWIW I'm not sure there was a discussion or argument about what should
>> be the default setting (enabled or disabled). I'm fine with not enabling
>> this by default, so that people have to enable it explicitly.
>>
>> In a way that'd be consistent with effective_io_concurrency being 1 by
>> default, which almost disables regular prefetching.
>
> Yeah, I'm not sure but I'd be fine with disabling it by default in the
> initial release. The current patch set has it enabled, but that's
> mostly for testing, it's not an opinion on how it should ship.
>
+1 to that too. Better to have it disabled by default than not at all.
> I've attached a rebased patch set with a couple of small changes:
>
> 1. I abandoned the patch that proposed
> pg_atomic_unlocked_add_fetch_u{32,64}() and went for a simple function
> local to xlogprefetch.c that just does pg_atomic_write_u64(counter,
> pg_atomic_read_u64(counter) + 1), in response to complaints from
> Andres[1].
>
> 2. I fixed a bug in ReadRecentBuffer(), and moved it into its own
> patch for separate review.
>
> I'm now looking at Horiguchi-san and Heikki's patch[2] to remove
> XLogReader's callbacks, to try to understand how these two patch sets
> are related. I don't really like the way those callbacks work, and
> I'm afraid had to make them more complicated. But I don't yet know
> very much about that other patch set. More soon.
>
OK. Do you think we should get both of those patches in, or do we need
to commit them in a particular order? Or what is your concern?
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Fri, Mar 19, 2021 at 2:29 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > On 3/18/21 1:54 AM, Thomas Munro wrote: > > I'm now looking at Horiguchi-san and Heikki's patch[2] to remove > > XLogReader's callbacks, to try to understand how these two patch sets > > are related. I don't really like the way those callbacks work, and > > I'm afraid had to make them more complicated. But I don't yet know > > very much about that other patch set. More soon. > > OK. Do you think we should get both of those patches in, or do we need > to commit them in a particular order? Or what is your concern? I would like to commit the callback-removal patch first, and then the WAL decoder and prefetcher patches become simpler and cleaner on top of that. I will post the rebase and explanation shortly.
Here's rebase, on top of Horiguchi-san's v19 patch set. My patches start at 0007. Previously, there was a "nowait" flag that was passed into all the callbacks so that XLogReader could wait for new WAL in some cases but not others. This new version uses the proposed XLREAD_NEED_DATA protocol, and the caller deals with waiting for data to arrive when appropriate. This seems tidier to me. I made one other simplifying change: previously, the prefetch module would read the WAL up to the "written" LSN (so, allowing itself to read data that had been written but not yet flushed to disk by the walreceiver), though it still waited until a record's LSN was "flushed" before replaying. That allowed prefetching to happen concurrently with the WAL flush, which was nice, but it felt a little too "special". I decided to remove that part for now, and I plan to look into making standbys work more like primary servers, using WAL buffers, the WAL writer and optionally the standard log-before-data rule.
Attachment
- v17-0001-Move-callback-call-from-ReadPageInternal-to-XLog.patch
- v17-0002-Move-page-reader-out-of-XLogReadRecord.patch
- v17-0003-Remove-globals-readOff-readLen-and-readSegNo.patch
- v17-0004-Make-XLogFindNextRecord-not-use-callback-functio.patch
- v17-0005-Split-readLen-and-reqLen-of-XLogReaderState.patch
- v17-0006-fixup.patch
- v17-0007-Add-circular-WAL-decoding-buffer.patch
- v17-0008-Prefetch-referenced-blocks-during-recovery.patch
- v17-0009-Provide-ReadRecentBuffer-to-re-pin-buffers-by-ID.patch
- v17-0010-Avoid-extra-buffer-lookup-when-prefetching-WAL-b.patch
On 4/7/21 1:24 PM, Thomas Munro wrote: > Here's rebase, on top of Horiguchi-san's v19 patch set. My patches > start at 0007. Previously, there was a "nowait" flag that was passed > into all the callbacks so that XLogReader could wait for new WAL in > some cases but not others. This new version uses the proposed > XLREAD_NEED_DATA protocol, and the caller deals with waiting for data > to arrive when appropriate. This seems tidier to me. > OK, seems reasonable. > I made one other simplifying change: previously, the prefetch module > would read the WAL up to the "written" LSN (so, allowing itself to > read data that had been written but not yet flushed to disk by the > walreceiver), though it still waited until a record's LSN was > "flushed" before replaying. That allowed prefetching to happen > concurrently with the WAL flush, which was nice, but it felt a little > too "special". I decided to remove that part for now, and I plan to > look into making standbys work more like primary servers, using WAL > buffers, the WAL writer and optionally the standard log-before-data > rule. > Not sure, but the removal seems unnecessary. I'm worried that this will significantly reduce the amount of data that we'll be able to prefetch. How likely it is that we have data that is written but not flushed? Let's assume the replica is lagging and network bandwidth is not the bottleneck - how likely is this "has to be flushed" a limit for the prefetching? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Apr 8, 2021 at 3:27 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > On 4/7/21 1:24 PM, Thomas Munro wrote: > > I made one other simplifying change: previously, the prefetch module > > would read the WAL up to the "written" LSN (so, allowing itself to > > read data that had been written but not yet flushed to disk by the > > walreceiver), though it still waited until a record's LSN was > > "flushed" before replaying. That allowed prefetching to happen > > concurrently with the WAL flush, which was nice, but it felt a little > > too "special". I decided to remove that part for now, and I plan to > > look into making standbys work more like primary servers, using WAL > > buffers, the WAL writer and optionally the standard log-before-data > > rule. > > Not sure, but the removal seems unnecessary. I'm worried that this will > significantly reduce the amount of data that we'll be able to prefetch. > How likely it is that we have data that is written but not flushed? > Let's assume the replica is lagging and network bandwidth is not the > bottleneck - how likely is this "has to be flushed" a limit for the > prefetching? Yeah, it would have been nice to include that but it'll have to be for v15 due to lack of time to convince myself that it was correct. I do intend to look into more concurrency of that kind for v15. I have pushed these patches, updated to be disabled by default. I will look into how I can run a BF animal that has it enabled during the recovery tests for coverage. Thanks very much to everyone on this thread for all the discussion and testing so far.
On 4/8/21 1:46 PM, Thomas Munro wrote: > On Thu, Apr 8, 2021 at 3:27 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> On 4/7/21 1:24 PM, Thomas Munro wrote: >>> I made one other simplifying change: previously, the prefetch module >>> would read the WAL up to the "written" LSN (so, allowing itself to >>> read data that had been written but not yet flushed to disk by the >>> walreceiver), though it still waited until a record's LSN was >>> "flushed" before replaying. That allowed prefetching to happen >>> concurrently with the WAL flush, which was nice, but it felt a little >>> too "special". I decided to remove that part for now, and I plan to >>> look into making standbys work more like primary servers, using WAL >>> buffers, the WAL writer and optionally the standard log-before-data >>> rule. >> >> Not sure, but the removal seems unnecessary. I'm worried that this will >> significantly reduce the amount of data that we'll be able to prefetch. >> How likely it is that we have data that is written but not flushed? >> Let's assume the replica is lagging and network bandwidth is not the >> bottleneck - how likely is this "has to be flushed" a limit for the >> prefetching? > > Yeah, it would have been nice to include that but it'll have to be for > v15 due to lack of time to convince myself that it was correct. I do > intend to look into more concurrency of that kind for v15. I have > pushed these patches, updated to be disabled by default. I will look > into how I can run a BF animal that has it enabled during the recovery > tests for coverage. Thanks very much to everyone on this thread for > all the discussion and testing so far. > OK, understood. I'll rerun the benchmarks on this version, and if there's a significant negative impact we can look into that during the stabilization phase. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Here's some little language fixes.
BTW, before beginning "recovery", PG syncs all the data dirs.
This can be slow, and it seems like the slowness is frequently due to file
metadata. For example, that's an obvious consequence of an OS crash, after
which the page cache is empty. I've made a habit of running find /zfs -ls |wc
to pre-warm it, which can take a little bit, but then the recovery process
starts moments later. I don't have any timing measurements, but I expect that
starting to stat() all data files as soon as possible would be a win.
commit cc9707de333fe8242607cde9f777beadc68dbf04
Author: Justin Pryzby <pryzbyj@telsasoft.com>
Date: Thu Apr 8 10:43:14 2021 -0500
WIP: doc review: Optionally prefetch referenced data in recovery.
1d257577e08d3e598011d6850fd1025858de8c8c
diff --git a/doc/src/sgml/config.sgml b/doc/src/sgml/config.sgml
index bc4a8b2279..139dee7aa2 100644
--- a/doc/src/sgml/config.sgml
+++ b/doc/src/sgml/config.sgml
@@ -3621,7 +3621,7 @@ include_dir 'conf.d'
pool after that. However, on file systems with a block size larger
than
<productname>PostgreSQL</productname>'s, prefetching can avoid a
- costly read-before-write when a blocks are later written.
+ costly read-before-write when blocks are later written.
The default is off.
</para>
</listitem>
diff --git a/doc/src/sgml/wal.sgml b/doc/src/sgml/wal.sgml
index 24cf567ee2..36e00c92c2 100644
--- a/doc/src/sgml/wal.sgml
+++ b/doc/src/sgml/wal.sgml
@@ -816,9 +816,7 @@
prefetching mechanism is most likely to be effective on systems
with <varname>full_page_writes</varname> set to
<varname>off</varname> (where that is safe), and where the working
- set is larger than RAM. By default, prefetching in recovery is enabled
- on operating systems that have <function>posix_fadvise</function>
- support.
+ set is larger than RAM. By default, prefetching in recovery is disabled.
</para>
</sect1>
diff --git a/src/backend/access/transam/xlogprefetch.c b/src/backend/access/transam/xlogprefetch.c
index 28764326bc..363c079964 100644
--- a/src/backend/access/transam/xlogprefetch.c
+++ b/src/backend/access/transam/xlogprefetch.c
@@ -31,7 +31,7 @@
* stall; this is counted with "skip_fpw".
*
* The only way we currently have to know that an I/O initiated with
- * PrefetchSharedBuffer() has that recovery will eventually call ReadBuffer(),
+ * PrefetchSharedBuffer() has that recovery will eventually call ReadBuffer(), XXX: what ??
* and perform a synchronous read. Therefore, we track the number of
* potentially in-flight I/Os by using a circular buffer of LSNs. When it's
* full, we have to wait for recovery to replay records so that the queue
@@ -660,7 +660,7 @@ XLogPrefetcherScanBlocks(XLogPrefetcher *prefetcher)
/*
* I/O has possibly been initiated (though we don't know if it was
* already cached by the kernel, so we just have to assume that it
- * has due to lack of better information). Record this as an I/O
+ * was due to lack of better information). Record this as an I/O
* in progress until eventually we replay this LSN.
*/
XLogPrefetchIncrement(&SharedStats->prefetch);
diff --git a/src/backend/utils/misc/guc.c b/src/backend/utils/misc/guc.c
index 090abdad8b..8c72ba1f1a 100644
--- a/src/backend/utils/misc/guc.c
+++ b/src/backend/utils/misc/guc.c
@@ -2774,7 +2774,7 @@ static struct config_int ConfigureNamesInt[] =
{
{"wal_decode_buffer_size", PGC_POSTMASTER, WAL_ARCHIVE_RECOVERY,
gettext_noop("Maximum buffer size for reading ahead in the WAL during recovery."),
- gettext_noop("This controls the maximum distance we can read ahead n the WAL to prefetch referenced
blocks."),
+ gettext_noop("This controls the maximum distance we can read ahead in the WAL to prefetch referenced
blocks."),
GUC_UNIT_BYTE
},
&wal_decode_buffer_size,
On Fri, Apr 9, 2021 at 3:37 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > Here's some little language fixes. Thanks! Done. I rewrote the gibberish comment that made you say "XXX: what?". Pushed. > BTW, before beginning "recovery", PG syncs all the data dirs. > This can be slow, and it seems like the slowness is frequently due to file > metadata. For example, that's an obvious consequence of an OS crash, after > which the page cache is empty. I've made a habit of running find /zfs -ls |wc > to pre-warm it, which can take a little bit, but then the recovery process > starts moments later. I don't have any timing measurements, but I expect that > starting to stat() all data files as soon as possible would be a win. Did you see commit 61752afb, "Provide recovery_init_sync_method=syncfs"? Actually I believe it's safe to skip that phase completely and do a tiny bit more work during recovery, which I'd like to work on for v15[1]. [1] https://www.postgresql.org/message-id/flat/CA%2BhUKG%2B8Wm8TSfMWPteMEHfh194RytVTBNoOkggTQT1p5NTY7Q%40mail.gmail.com
On Sat, Apr 10, 2021 at 08:27:42AM +1200, Thomas Munro wrote: > On Fri, Apr 9, 2021 at 3:37 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > Here's some little language fixes. > > Thanks! Done. I rewrote the gibberish comment that made you say > "XXX: what?". Pushed. > > > BTW, before beginning "recovery", PG syncs all the data dirs. > > This can be slow, and it seems like the slowness is frequently due to file > > metadata. For example, that's an obvious consequence of an OS crash, after > > which the page cache is empty. I've made a habit of running find /zfs -ls |wc > > to pre-warm it, which can take a little bit, but then the recovery process > > starts moments later. I don't have any timing measurements, but I expect that > > starting to stat() all data files as soon as possible would be a win. > > Did you see commit 61752afb, "Provide > recovery_init_sync_method=syncfs"? Actually I believe it's safe to > skip that phase completely and do a tiny bit more work during > recovery, which I'd like to work on for v15[1]. Yes, I have it in my list for v14 deployment. Thanks for that. Did you see this? https://www.postgresql.org/message-id/GV0P278MB0483490FEAC879DCA5ED583DD2739%40GV0P278MB0483.CHEP278.PROD.OUTLOOK.COM I meant to mail you so you could include it in the same commit, but forgot until now. -- Justin
On Sat, Apr 10, 2021 at 8:37 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > Did you see this? > https://www.postgresql.org/message-id/GV0P278MB0483490FEAC879DCA5ED583DD2739%40GV0P278MB0483.CHEP278.PROD.OUTLOOK.COM > > I meant to mail you so you could include it in the same commit, but forgot > until now. Done, thanks.
Hi, Thank you for developing a great feature. I tested this feature and checked the documentation. Currently, the documentation for the pg_stat_prefetch_recovery view is included in the description for the pg_stat_subscriptionview. https://www.postgresql.org/docs/devel/monitoring-stats.html#MONITORING-PG-STAT-SUBSCRIPTION It is also not displayed in the list of "28.2. The Statistics Collector". https://www.postgresql.org/docs/devel/monitoring.html The attached patch modifies the pg_stat_prefetch_recovery view to appear as a separate view. Regards, Noriyoshi Shinoda -----Original Message----- From: Thomas Munro [mailto:thomas.munro@gmail.com] Sent: Saturday, April 10, 2021 5:46 AM To: Justin Pryzby <pryzby@telsasoft.com> Cc: Tomas Vondra <tomas.vondra@enterprisedb.com>; Stephen Frost <sfrost@snowman.net>; Andres Freund <andres@anarazel.de>;Jakub Wartak <Jakub.Wartak@tomtom.com>; Alvaro Herrera <alvherre@2ndquadrant.com>; Tomas Vondra <tomas.vondra@2ndquadrant.com>;Dmitry Dolgov <9erthalion6@gmail.com>; David Steele <david@pgmasters.net>; pgsql-hackers <pgsql-hackers@postgresql.org> Subject: Re: WIP: WAL prefetch (another approach) On Sat, Apr 10, 2021 at 8:37 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > Did you see this? > INVALID URI REMOVED > 278MB0483490FEAC879DCA5ED583DD2739*40GV0P278MB0483.CHEP278.PROD.OUTLOO > K.COM__;JQ!!NpxR!wcPrhiB2CaHRtywGoh9Ap0M-kH1m07hGI37-ycYRGCPgCqGs30lRS > KicsXacduEXHxI$ > > I meant to mail you so you could include it in the same commit, but > forgot until now. Done, thanks.
Attachment
On Sat, Apr 10, 2021 at 2:16 AM Thomas Munro <thomas.munro@gmail.com> wrote: > In commit 1d257577e08d3e598011d6850fd1025858de8c8c, there is a change in file format for stats, won't it require bumping PGSTAT_FILE_FORMAT_ID? Actually, I came across this while working on my today's commit f5fc2f5b23 where I forgot to bump PGSTAT_FILE_FORMAT_ID. So, I thought maybe we can bump it just once if required? -- With Regards, Amit Kapila.
Thomas Munro <thomas.munro@gmail.com> writes:
> Yeah, it would have been nice to include that but it'll have to be for
> v15 due to lack of time to convince myself that it was correct. I do
> intend to look into more concurrency of that kind for v15. I have
> pushed these patches, updated to be disabled by default.
I have a fairly bad feeling about these patches. I've already fixed
one critical bug (see 9e4114822), but I am still seeing random, hard
to reproduce failures in WAL replay testing. It looks like sometimes
the "decoded" version of a WAL record doesn't match what I see in
the on-disk data, which I'm having no luck tracing down.
Another interesting failure I just came across is
2021-04-21 11:32:14.280 EDT [14606] LOG: incorrect resource manager data checksum in record at F/438000A4
TRAP: FailedAssertion("state->decoding", File: "xlogreader.c", Line: 845, PID: 14606)
2021-04-21 11:38:23.066 EDT [14603] LOG: startup process (PID 14606) was terminated by signal 6: Abort trap
with stack trace
#0 0x90b669f0 in kill ()
#1 0x90c01bfc in abort ()
#2 0x0057a6a0 in ExceptionalCondition (conditionName=<value temporarily unavailable, due to optimizations>,
errorType=<valuetemporarily unavailable, due to optimizations>, fileName=<value temporarily unavailable, due to
optimizations>,lineNumber=<value temporarily unavailable, due to optimizations>) at assert.c:69
#3 0x000f5cf4 in XLogDecodeOneRecord (state=0x1000640, allow_oversized=1 '\001') at xlogreader.c:845
#4 0x000f682c in XLogNextRecord (state=0x1000640, record=0xbfffba38, errormsg=0xbfffba9c) at xlogreader.c:466
#5 0x000f695c in XLogReadRecord (state=<value temporarily unavailable, due to optimizations>, record=0xbfffba98,
errormsg=<valuetemporarily unavailable, due to optimizations>) at xlogreader.c:352
#6 0x000e61a0 in ReadRecord (xlogreader=0x1000640, emode=15, fetching_ckpt=0 '\0') at xlog.c:4398
#7 0x000ea320 in StartupXLOG () at xlog.c:7567
#8 0x00362218 in StartupProcessMain () at startup.c:244
#9 0x000fc170 in AuxiliaryProcessMain (argc=<value temporarily unavailable, due to optimizations>, argv=<value
temporarilyunavailable, due to optimizations>) at bootstrap.c:447
#10 0x0035c740 in StartChildProcess (type=StartupProcess) at postmaster.c:5439
#11 0x00360f4c in PostmasterMain (argc=5, argv=0xa006a0) at postmaster.c:1406
#12 0x0029737c in main (argc=<value temporarily unavailable, due to optimizations>, argv=<value temporarily
unavailable,due to optimizations>) at main.c:209
I am not sure whether the checksum failure itself is real or a variant
of the seeming bad-reconstruction problem, but what I'm on about right
at this moment is that the error handling logic for this case seems
quite broken. Why is a checksum failure only worthy of a LOG message?
Why is ValidXLogRecord() issuing a log message for itself, rather than
being tied into the report_invalid_record() mechanism? Why are we
evidently still trying to decode records afterwards?
In general, I'm not too pleased with the apparent attitude in this
thread that it's okay to push a patch that only mostly works on the
last day of the dev cycle and plan to stabilize it later.
regards, tom lane
On 4/21/21 6:30 PM, Tom Lane wrote:
> Thomas Munro <thomas.munro@gmail.com> writes:
>> Yeah, it would have been nice to include that but it'll have to be for
>> v15 due to lack of time to convince myself that it was correct. I do
>> intend to look into more concurrency of that kind for v15. I have
>> pushed these patches, updated to be disabled by default.
>
> I have a fairly bad feeling about these patches. I've already fixed
> one critical bug (see 9e4114822), but I am still seeing random, hard
> to reproduce failures in WAL replay testing. It looks like sometimes
> the "decoded" version of a WAL record doesn't match what I see in
> the on-disk data, which I'm having no luck tracing down.
>
> Another interesting failure I just came across is
>
> 2021-04-21 11:32:14.280 EDT [14606] LOG: incorrect resource manager data checksum in record at F/438000A4
> TRAP: FailedAssertion("state->decoding", File: "xlogreader.c", Line: 845, PID: 14606)
> 2021-04-21 11:38:23.066 EDT [14603] LOG: startup process (PID 14606) was terminated by signal 6: Abort trap
>
> with stack trace
>
> #0 0x90b669f0 in kill ()
> #1 0x90c01bfc in abort ()
> #2 0x0057a6a0 in ExceptionalCondition (conditionName=<value temporarily unavailable, due to optimizations>,
errorType=<valuetemporarily unavailable, due to optimizations>, fileName=<value temporarily unavailable, due to
optimizations>,lineNumber=<value temporarily unavailable, due to optimizations>) at assert.c:69
> #3 0x000f5cf4 in XLogDecodeOneRecord (state=0x1000640, allow_oversized=1 '\001') at xlogreader.c:845
> #4 0x000f682c in XLogNextRecord (state=0x1000640, record=0xbfffba38, errormsg=0xbfffba9c) at xlogreader.c:466
> #5 0x000f695c in XLogReadRecord (state=<value temporarily unavailable, due to optimizations>, record=0xbfffba98,
errormsg=<valuetemporarily unavailable, due to optimizations>) at xlogreader.c:352
> #6 0x000e61a0 in ReadRecord (xlogreader=0x1000640, emode=15, fetching_ckpt=0 '\0') at xlog.c:4398
> #7 0x000ea320 in StartupXLOG () at xlog.c:7567
> #8 0x00362218 in StartupProcessMain () at startup.c:244
> #9 0x000fc170 in AuxiliaryProcessMain (argc=<value temporarily unavailable, due to optimizations>, argv=<value
temporarilyunavailable, due to optimizations>) at bootstrap.c:447
> #10 0x0035c740 in StartChildProcess (type=StartupProcess) at postmaster.c:5439
> #11 0x00360f4c in PostmasterMain (argc=5, argv=0xa006a0) at postmaster.c:1406
> #12 0x0029737c in main (argc=<value temporarily unavailable, due to optimizations>, argv=<value temporarily
unavailable,due to optimizations>) at main.c:209
>
>
> I am not sure whether the checksum failure itself is real or a variant
> of the seeming bad-reconstruction problem, but what I'm on about right
> at this moment is that the error handling logic for this case seems
> quite broken. Why is a checksum failure only worthy of a LOG message?
> Why is ValidXLogRecord() issuing a log message for itself, rather than
> being tied into the report_invalid_record() mechanism? Why are we
> evidently still trying to decode records afterwards?
>
Yeah, that seems suspicious.
> In general, I'm not too pleased with the apparent attitude in this
> thread that it's okay to push a patch that only mostly works on the
> last day of the dev cycle and plan to stabilize it later.
>
Was there such attitude? I don't think people were arguing for pushing a
patch's not working correctly. The discussion was mostly about getting
it committed even and leaving some optimizations for v15.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, Apr 22, 2021 at 8:07 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > On 4/21/21 6:30 PM, Tom Lane wrote: > > Thomas Munro <thomas.munro@gmail.com> writes: > >> Yeah, it would have been nice to include that but it'll have to be for > >> v15 due to lack of time to convince myself that it was correct. I do > >> intend to look into more concurrency of that kind for v15. I have > >> pushed these patches, updated to be disabled by default. > > > > I have a fairly bad feeling about these patches. I've already fixed > > one critical bug (see 9e4114822), but I am still seeing random, hard > > to reproduce failures in WAL replay testing. It looks like sometimes > > the "decoded" version of a WAL record doesn't match what I see in > > the on-disk data, which I'm having no luck tracing down. Ugh. Looking into this now. Also, this week I have been researching a possible problem with eg ALTER TABLE SET TABLESPACE in the higher level patch, which I'll write about soon. > > I am not sure whether the checksum failure itself is real or a variant > > of the seeming bad-reconstruction problem, but what I'm on about right > > at this moment is that the error handling logic for this case seems > > quite broken. Why is a checksum failure only worthy of a LOG message? > > Why is ValidXLogRecord() issuing a log message for itself, rather than > > being tied into the report_invalid_record() mechanism? Why are we > > evidently still trying to decode records afterwards? > > Yeah, that seems suspicious. I may have invited trouble by deciding to rebase on the other proposal late in the cycle. That interfaces around there. > > In general, I'm not too pleased with the apparent attitude in this > > thread that it's okay to push a patch that only mostly works on the > > last day of the dev cycle and plan to stabilize it later. > > Was there such attitude? I don't think people were arguing for pushing a > patch's not working correctly. The discussion was mostly about getting > it committed even and leaving some optimizations for v15. That wasn't my plan, but I admit that the timing was non-ideal. In any case, I'll dig into these failures and then consider options. More soon.
On Thu, Apr 22, 2021 at 8:16 AM Thomas Munro <thomas.munro@gmail.com> wrote: > That wasn't my plan, but I admit that the timing was non-ideal. In > any case, I'll dig into these failures and then consider options. > More soon. Yeah, this clearly needs more work. xlogreader.c is difficult to work with and I think we need to keep trying to improve it, but I made a bad call here trying to combine this with other refactoring work up against a deadline and I made some dumb mistakes. I could of course debug it in-tree, and I know that this has been an anticipated feature. Personally I think the right thing to do now is to revert it and re-propose for 15 early in the cycle, supported with some better testing infrastructure.
Greetings,
On Wed, Apr 21, 2021 at 19:17 Thomas Munro <thomas.munro@gmail.com> wrote:
On Thu, Apr 22, 2021 at 8:16 AM Thomas Munro <thomas.munro@gmail.com> wrote:
> That wasn't my plan, but I admit that the timing was non-ideal. In
> any case, I'll dig into these failures and then consider options.
> More soon.
Yeah, this clearly needs more work. xlogreader.c is difficult to work
with and I think we need to keep trying to improve it, but I made a
bad call here trying to combine this with other refactoring work up
against a deadline and I made some dumb mistakes. I could of course
debug it in-tree, and I know that this has been an anticipated
feature. Personally I think the right thing to do now is to revert it
and re-propose for 15 early in the cycle, supported with some better
testing infrastructure.
I tend to agree with the idea to revert it, perhaps a +0 on that, but if others argue it should be fixed in-place, I wouldn’t complain about it.
I very much encourage the idea of improving testing in this area and would be happy to try and help do so in the 15 cycle.
Thanks,
Stephen
Stephen Frost <sfrost@snowman.net> writes:
> On Wed, Apr 21, 2021 at 19:17 Thomas Munro <thomas.munro@gmail.com> wrote:
>> ... Personally I think the right thing to do now is to revert it
>> and re-propose for 15 early in the cycle, supported with some better
>> testing infrastructure.
> I tend to agree with the idea to revert it, perhaps a +0 on that, but if
> others argue it should be fixed in-place, I wouldn’t complain about it.
FWIW, I've so far only been able to see problems on two old PPC Macs,
one of which has been known to be a bit flaky in the past. So it's
possible that what I'm looking at is a hardware glitch. But it's
consistent enough that I rather doubt that.
What I'm doing is running the core regression tests with a single
standby (on the same machine) and wal_consistency_checking = all.
Fairly reproducibly (more than one run in ten), what I get on the
slightly-flaky machine is consistency check failures like
2021-04-21 17:42:56.324 EDT [42286] PANIC: inconsistent page found, rel 1663/354383/357033, forknum 0, blkno 9, byte
offset2069: replay 0x00 primary 0x03
2021-04-21 17:42:56.324 EDT [42286] CONTEXT: WAL redo at 24/121C97B0 for Heap/INSERT: off 107 flags 0x00; blkref #0:
rel1663/354383/357033, blk 9 FPW
2021-04-21 17:45:11.662 EDT [42284] LOG: startup process (PID 42286) was terminated by signal 6: Abort trap
2021-04-21 11:25:30.091 EDT [38891] PANIC: inconsistent page found, rel 1663/229880/237980, forknum 0, blkno 108, byte
offset3845: replay 0x00 primary 0x99
2021-04-21 11:25:30.091 EDT [38891] CONTEXT: WAL redo at 17/A99897FC for SPGist/ADD_LEAF: add leaf to page; off 241;
headoff171; parentoff 0; blkref #0: rel 1663/229880/237980, blk 108 FPW
2021-04-21 11:26:59.371 EDT [38889] LOG: startup process (PID 38891) was terminated by signal 6: Abort trap
2021-04-20 19:20:16.114 EDT [34405] PANIC: inconsistent page found, rel 1663/189216/197311, forknum 0, blkno 115, byte
offset6149: replay 0x37 primary 0x03
2021-04-20 19:20:16.114 EDT [34405] CONTEXT: WAL redo at 13/3CBFED00 for SPGist/ADD_LEAF: add leaf to page; off 241;
headoff171; parentoff 0; blkref #0: rel 1663/189216/197311, blk 115 FPW
2021-04-20 19:21:54.421 EDT [34403] LOG: startup process (PID 34405) was terminated by signal 6: Abort trap
2021-04-20 17:44:09.356 EDT [24106] FATAL: inconsistent page found, rel 1663/135419/143843, forknum 0, blkno 101, byte
offset6152: replay 0x40 primary 0x00
2021-04-20 17:44:09.356 EDT [24106] CONTEXT: WAL redo at D/5107D8A8 for Gist/PAGE_UPDATE: ; blkref #0: rel
1663/135419/143843,blk 101 FPW
(Note I modified checkXLogConsistency to PANIC on failure, so I could get
a core dump to analyze; and it's also printing the first-mismatch location.)
I have not analyzed each one of these failures exhaustively, but on the
ones I have looked at closely, the replay_image_masked version of the page
appears correct while the primary_image_masked version is *not*.
Moreover, the primary_image_masked version does not match the full-page
image that I see in the on-disk WAL file. It did however seem to match
the in-memory WAL record contents that the decoder is operating on.
So unless you want to believe the buggy-hardware theory, something's
occasionally messing up while loading WAL records from disk. All of the
trouble cases involve records that span across WAL pages (unsurprising
since they contain FPIs), so maybe there's something not quite right
in there.
In the cases that I looked at closely, it appeared that there was a
block of 32 wrong bytes somewhere within the page image, with the data
before and after that being correct. I'm not sure if that pattern
holds in all cases though.
BTW, if I restart the failed standby, it plows through the same data
just fine, confirming that the on-disk WAL is not corrupt.
The other PPC machine (with no known history of trouble) is the one
that had the CRC failure I showed earlier. That one does seem to be
actual bad data in the stored WAL, because the problem was also seen
by pg_waldump, and trying to restart the standby got the same failure
again. I've not been able to duplicate the consistency-check failures
there. But because that machine is a laptop with a much inferior disk
drive, the speeds are enough different that it's not real surprising
if it doesn't hit the same problem.
I've also tried to reproduce on 32-bit and 64-bit Intel, without
success. So if this is real, maybe it's related to being big-endian
hardware? But it's also quite sensitive to $dunno-what, maybe the
history of WAL records that have already been replayed.
regards, tom lane
Hi,
On 2021-04-21 21:21:05 -0400, Tom Lane wrote:
> What I'm doing is running the core regression tests with a single
> standby (on the same machine) and wal_consistency_checking = all.
Do you run them over replication, or sequentially by storing data into
an archive? Just curious, because its so painful to run that scenario in
the replication case due to the tablespace conflicting between
primary/standby, unless one disables the tablespace tests.
> The other PPC machine (with no known history of trouble) is the one
> that had the CRC failure I showed earlier. That one does seem to be
> actual bad data in the stored WAL, because the problem was also seen
> by pg_waldump, and trying to restart the standby got the same failure
> again.
It seems like that could also indicate an xlogreader bug that is
reliably hit? Once it gets confused about record lengths or such I'd
expect CRC failures...
If it were actually wrong WAL contents I don't think any of the
xlogreader / prefetching changes could be responsible...
Have you tried reproducing it on commits before the recent xlogreader
changes?
commit 1d257577e08d3e598011d6850fd1025858de8c8c
Author: Thomas Munro <tmunro@postgresql.org>
Date: 2021-04-08 23:03:43 +1200
Optionally prefetch referenced data in recovery.
commit f003d9f8721b3249e4aec8a1946034579d40d42c
Author: Thomas Munro <tmunro@postgresql.org>
Date: 2021-04-08 23:03:34 +1200
Add circular WAL decoding buffer.
Discussion: https://postgr.es/m/CA+hUKGJ4VJN8ttxScUFM8dOKX0BrBiboo5uz1cq=AovOddfHpA@mail.gmail.com
commit 323cbe7c7ddcf18aaf24b7f6d682a45a61d4e31b
Author: Thomas Munro <tmunro@postgresql.org>
Date: 2021-04-08 23:03:23 +1200
Remove read_page callback from XLogReader.
Trying 323cbe7c7ddcf18aaf24b7f6d682a45a61d4e31b^ is probably the most
interesting bit.
> I've not been able to duplicate the consistency-check failures
> there. But because that machine is a laptop with a much inferior disk
> drive, the speeds are enough different that it's not real surprising
> if it doesn't hit the same problem.
>
> I've also tried to reproduce on 32-bit and 64-bit Intel, without
> success. So if this is real, maybe it's related to being big-endian
> hardware? But it's also quite sensitive to $dunno-what, maybe the
> history of WAL records that have already been replayed.
It might just be disk speed influencing how long the tests take, which
in turn increase the number of times checkpoints during the test,
increasing the number of FPIs?
Greetings,
Andres Freund
On Thu, Apr 22, 2021 at 1:21 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > I've also tried to reproduce on 32-bit and 64-bit Intel, without > success. So if this is real, maybe it's related to being big-endian > hardware? But it's also quite sensitive to $dunno-what, maybe the > history of WAL records that have already been replayed. Ah, that's interesting. There are a couple of sparc64 failures and a ppc64 failure in the build farm, but I couldn't immediately spot what was wrong with them or whether it might be related to this stuff. Thanks for the clues. I'll see what unusual systems I can find to try this on....
Andres Freund <andres@anarazel.de> writes:
> On 2021-04-21 21:21:05 -0400, Tom Lane wrote:
>> What I'm doing is running the core regression tests with a single
>> standby (on the same machine) and wal_consistency_checking = all.
> Do you run them over replication, or sequentially by storing data into
> an archive? Just curious, because its so painful to run that scenario in
> the replication case due to the tablespace conflicting between
> primary/standby, unless one disables the tablespace tests.
No, live over replication. I've been skipping the tablespace test.
> Have you tried reproducing it on commits before the recent xlogreader
> changes?
Nope.
regards, tom lane
Hi, On 2021-04-22 13:59:58 +1200, Thomas Munro wrote: > On Thu, Apr 22, 2021 at 1:21 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > I've also tried to reproduce on 32-bit and 64-bit Intel, without > > success. So if this is real, maybe it's related to being big-endian > > hardware? But it's also quite sensitive to $dunno-what, maybe the > > history of WAL records that have already been replayed. > > Ah, that's interesting. There are a couple of sparc64 failures and a > ppc64 failure in the build farm, but I couldn't immediately spot what > was wrong with them or whether it might be related to this stuff. > > Thanks for the clues. I'll see what unusual systems I can find to try > this on.... FWIW, I've run 32 and 64 bit x86 through several hundred regression cycles, without hitting an issue. For a lot of them I set checkpoint_timeout to a lower value as I thought that might make it more likely to reproduce an issue. Tom, any chance you could check if your machine repros the issue before these commits? Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> Tom, any chance you could check if your machine repros the issue before
> these commits?
Wilco, but it'll likely take a little while to get results ...
regards, tom lane
On Thu, Apr 29, 2021 at 4:45 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Andres Freund <andres@anarazel.de> writes: > > Tom, any chance you could check if your machine repros the issue before > > these commits? > > Wilco, but it'll likely take a little while to get results ... FWIW I also chewed through many megawatts trying to reproduce this on a PowerPC system in 64 bit big endian mode, with an emulator. No cigar. However, it's so slow that I didn't make it to 10 runs...
Thomas Munro <thomas.munro@gmail.com> writes:
> FWIW I also chewed through many megawatts trying to reproduce this on
> a PowerPC system in 64 bit big endian mode, with an emulator. No
> cigar. However, it's so slow that I didn't make it to 10 runs...
Speaking of megawatts ... my G4 has now finished about ten cycles of
installcheck-parallel without a failure, which isn't really enough
to draw any conclusions yet. But I happened to notice the
accumulated CPU time for the background processes:
USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND
tgl 19048 0.0 4.4 229952 92196 ?? Ss 3:19PM 19:59.19 postgres: startup recovering
000000010000001400000022
tgl 19051 0.0 0.1 229656 1696 ?? Ss 3:19PM 27:09.14 postgres: walreceiver streaming 14/227D8F14
tgl 19052 0.0 0.1 229904 2516 ?? Ss 3:19PM 17:38.17 postgres: walsender tgl [local] streaming
14/227D8F14
IOW, we've spent over twice as many CPU cycles shipping data to the
standby as we did in applying the WAL on the standby. Is this
expected? I've got wal_consistency_checking = all, which is bloating
the WAL volume quite a bit, but still it seems like the walsender and
walreceiver have little excuse for spending more cycles per byte
than the startup process.
(This is testing b3ee4c503, so if Thomas' WAL changes improved
efficiency of the replay process at all, the discrepancy could be
even worse in HEAD.)
regards, tom lane
Hi, On 2021-04-28 19:24:53 -0400, Tom Lane wrote: > But I happened to notice the accumulated CPU time for the background > processes: > > USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND > tgl 19048 0.0 4.4 229952 92196 ?? Ss 3:19PM 19:59.19 postgres: startup recovering 000000010000001400000022 > tgl 19051 0.0 0.1 229656 1696 ?? Ss 3:19PM 27:09.14 postgres: walreceiver streaming 14/227D8F14 > tgl 19052 0.0 0.1 229904 2516 ?? Ss 3:19PM 17:38.17 postgres: walsender tgl [local] streaming 14/227D8F14 > > IOW, we've spent over twice as many CPU cycles shipping data to the > standby as we did in applying the WAL on the standby. Is this > expected? I've got wal_consistency_checking = all, which is bloating > the WAL volume quite a bit, but still it seems like the walsender and > walreceiver have little excuse for spending more cycles per byte > than the startup process. I don't really know how the time calculation works on mac. Is there a chance it includes time spent doing IO? On the primary the WAL IO is done by a lot of backends, but on the standby it's all going to be the walreceiver. And the walreceiver does fsyncs in a not particularly efficient manner. FWIW, on my linux workstation no such difference is visible: USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND andres 2910540 9.4 0.0 2237252 126680 ? Ss 16:55 0:20 postgres: dev assert standby: startup recovering 00000001000000020000003F andres 2910544 5.2 0.0 2236724 9260 ? Ss 16:55 0:11 postgres: dev assert standby: walreceiver streaming 2/3FDCF118 andres 2910545 2.1 0.0 2237036 10672 ? Ss 16:55 0:04 postgres: dev assert: walsender andres [local] streaming2/3FDCF118 > (This is testing b3ee4c503, so if Thomas' WAL changes improved > efficiency of the replay process at all, the discrepancy could be > even worse in HEAD.) The prefetching isn't enabled by default, so I'd not expect meaningful differences... And even with the prefetching enabled, our normal regression tests largely are resident in s_b, so there shouldn't be much prefetching. Oh! I was about to ask how much shared buffers your primary / standby have. And I think I may actually have reproduce a variant of the issue! I previously had played around with different settings that I thought might increase the likelihood of reproducing the problem. But this time I set shared_buffers lower than before, and got: 2021-04-28 17:03:22.174 PDT [2913840][] LOG: database system was shut down in recovery at 2021-04-28 17:03:11 PDT 2021-04-28 17:03:22.174 PDT [2913840][] LOG: entering standby mode 2021-04-28 17:03:22.178 PDT [2913840][1/0] LOG: redo starts at 2/416C6278 2021-04-28 17:03:37.628 PDT [2913840][1/0] LOG: consistent recovery state reached at 4/7F5C3200 2021-04-28 17:03:37.628 PDT [2913840][1/0] FATAL: invalid memory alloc request size 3053455757 2021-04-28 17:03:37.628 PDT [2913839][] LOG: database system is ready to accept read only connections 2021-04-28 17:03:37.636 PDT [2913839][] LOG: startup process (PID 2913840) exited with exit code 1 This reproduces across restarts. Yay, I guess. Isn't it off that we get a "database system is ready to accept read only connections"? Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2021-04-28 19:24:53 -0400, Tom Lane wrote:
>> IOW, we've spent over twice as many CPU cycles shipping data to the
>> standby as we did in applying the WAL on the standby.
> I don't really know how the time calculation works on mac. Is there a
> chance it includes time spent doing IO?
I'd be pretty astonished if it did. This is basically a NetBSD system
remember (in fact, this ancient macOS release is a good deal closer
to those roots than modern versions). BSDen have never accounted for
time that way AFAIK. Also, the "ps" man page says specifically that
that column is CPU time.
> Oh! I was about to ask how much shared buffers your primary / standby
> have. And I think I may actually have reproduce a variant of the issue!
Default configurations, so 128MB each.
regards, tom lane
Hi, On 2021-04-28 20:24:43 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > Oh! I was about to ask how much shared buffers your primary / standby > > have. > Default configurations, so 128MB each. I thought that possibly initdb would detect less or something... I assume this is 32bit? I did notice that a 32bit test took a lot longer than a 64bit test. But didn't investigate so far. > And I think I may actually have reproduce a variant of the issue! Unfortunately I had not set up things in a way that the primary retains the WAL, making it harder to compare whether it's the WAL that got corrupted or whether it's a decoding bug. I can however say that pg_waldump on the standby's pg_wal does also fail. The failure as part of the backend is "invalid memory alloc request size", whereas in pg_waldump I get the much more helpful: pg_waldump: fatal: error in WAL record at 4/7F5C31C8: record with incorrect prev-link 416200FF/FF000000 at 4/7F5C3200 In frontend code that allocation actually succeeds, because there is no size check. But in backend code we run into the size check, and thus don't even display a useful error. In 13 the header is validated before allocating space for the record(except if header is spread across pages) - it seems inadvisable to turn that around? Greetings, Andres Freund
Hi, On 2021-04-28 17:59:22 -0700, Andres Freund wrote: > I can however say that pg_waldump on the standby's pg_wal does also > fail. The failure as part of the backend is "invalid memory alloc > request size", whereas in pg_waldump I get the much more helpful: > pg_waldump: fatal: error in WAL record at 4/7F5C31C8: record with incorrect prev-link 416200FF/FF000000 at 4/7F5C3200 There's definitely something broken around continuation records, in XLogFindNextRecord(). Which means that it's not the cause for the server side issue, but obviously still not good. The conversion of XLogFindNextRecord() to be state machine based basically only works in a narrow set of circumstances. Whenever the end of the first record read is on a different page than the start of the record, we'll endlessly loop. We'll go into XLogFindNextRecord(), and return until we've successfully read the page header. Then we'll enter the second loop. Which will try to read until the end of the first record. But after returning the first loop will again ask for page header. Even if that's fixed, the second loop alone has the same problem: As XLogBeginRead() is called unconditionally we'll start read the start of the record, discover that it needs data on a second page, return, and do the same thing again. I think it needs something roughly like the attached. Greetings, Andres Freund
Attachment
Hi,
On 2021-04-28 17:59:22 -0700, Andres Freund wrote:
> I can however say that pg_waldump on the standby's pg_wal does also
> fail. The failure as part of the backend is "invalid memory alloc
> request size", whereas in pg_waldump I get the much more helpful:
> pg_waldump: fatal: error in WAL record at 4/7F5C31C8: record with incorrect prev-link 416200FF/FF000000 at
4/7F5C3200
>
> In frontend code that allocation actually succeeds, because there is no
> size check. But in backend code we run into the size check, and thus
> don't even display a useful error.
>
> In 13 the header is validated before allocating space for the
> record(except if header is spread across pages) - it seems inadvisable
> to turn that around?
I was now able to reproduce the problem again, and I'm afraid that the
bug I hit is likely separate from Tom's. The allocation thing above is
the issue in my case:
The walsender connection ended (I restarted the primary), thus the
startup switches to replaying locally. For some reason the end of the
WAL contains non-zero data (I think it's because walreceiver doesn't
zero out pages - that's bad!). Because the allocation happen before the
header is validated, we reproducably end up in the mcxt.c ERROR path,
failing recovery.
To me it looks like a smaller version of the problem is present in < 14,
albeit only when the page header is at a record boundary. In that case
we don't validate the page header immediately, only once it's completely
read. But we do believe the total size, and try to allocate
that.
There's a really crufty escape hatch (from 70b4f82a4b) to that:
/*
* Note that in much unlucky circumstances, the random data read from a
* recycled segment can cause this routine to be called with a size
* causing a hard failure at allocation. For a standby, this would cause
* the instance to stop suddenly with a hard failure, preventing it to
* retry fetching WAL from one of its sources which could allow it to move
* on with replay without a manual restart. If the data comes from a past
* recycled segment and is still valid, then the allocation may succeed
* but record checks are going to fail so this would be short-lived. If
* the allocation fails because of a memory shortage, then this is not a
* hard failure either per the guarantee given by MCXT_ALLOC_NO_OOM.
*/
if (!AllocSizeIsValid(newSize))
return false;
but it looks to me like that's pretty much the wrong fix, at least in
the case where we've not yet validated the rest of the header. We don't
need to allocate all that data before we've read the rest of the
*fixed-size* header.
It also seems to me that 70b4f82a4b should also have changed walsender
to pad out the received data to an 8KB boundary?
Greetings,
Andres Freund
Andres Freund <andres@anarazel.de> writes:
> I was now able to reproduce the problem again, and I'm afraid that the
> bug I hit is likely separate from Tom's.
Yeah, I think so --- the symptoms seem quite distinct.
My score so far today on the G4 is:
12 error-free regression test cycles on b3ee4c503
(plus one more with shared_buffers set to 16MB, on the strength
of your previous hunch --- didn't fail for me though)
HEAD failed on the second run with the same symptom as before:
2021-04-28 22:57:17.048 EDT [50479] FATAL: inconsistent page found, rel 1663/58183/69545, forknum 0, blkno 696
2021-04-28 22:57:17.048 EDT [50479] CONTEXT: WAL redo at 4/B72D408 for Heap/INSERT: off 77 flags 0x00; blkref #0: rel
1663/58183/69545,blk 696 FPW
This seems to me to be pretty strong evidence that I'm seeing *something*
real. I'm currently trying to isolate a specific commit to pin it on.
A straight "git bisect" isn't going to work because so many people had
broken so many different things right around that date :-(, so it may
take awhile to get a good answer.
regards, tom lane
On Thu, Apr 29, 2021 at 3:14 PM Andres Freund <andres@anarazel.de> wrote: > To me it looks like a smaller version of the problem is present in < 14, > albeit only when the page header is at a record boundary. In that case > we don't validate the page header immediately, only once it's completely > read. But we do believe the total size, and try to allocate > that. > > There's a really crufty escape hatch (from 70b4f82a4b) to that: Right, I made that problem worse, and that could probably be changed to be no worse than 13 by reordering those operations. PS Sorry for my intermittent/slow responses on this thread this week, as I'm mostly away from the keyboard due to personal commitments. I'll be back in the saddle next week to tidy this up, most likely by reverting. The main thought I've been having about this whole area is that, aside from the lack of general testing of recovery, which we should definitely address[1], what it really needs is a decent test harness to drive it through all interesting scenarios and states at a lower level, independently. [1] https://www.postgresql.org/message-id/flat/CA%2BhUKGKpRWQ9SxdxxDmTBCJoR0YnFpMBe7kyzY8SUQk%2BHeskxg%40mail.gmail.com
Thomas Munro <thomas.munro@gmail.com> writes:
> On Thu, Apr 29, 2021 at 4:45 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Andres Freund <andres@anarazel.de> writes:
>>> Tom, any chance you could check if your machine repros the issue before
>>> these commits?
>> Wilco, but it'll likely take a little while to get results ...
> FWIW I also chewed through many megawatts trying to reproduce this on
> a PowerPC system in 64 bit big endian mode, with an emulator. No
> cigar. However, it's so slow that I didn't make it to 10 runs...
So I've expended a lot of kilowatt-hours over the past several days,
and I've got results that are interesting but don't really get us
any closer to a resolution.
To recap, the test lashup is:
* 2003 PowerMac G4 (1.25GHz PPC 7455, 7200 rpm spinning-rust drive)
* Standard debug build (--enable-debug --enable-cassert)
* Out-of-the-box configuration, except add wal_consistency_checking = all
and configure a wal-streaming standby on the same machine
* Repeatedly run "make installcheck-parallel", but skip the tablespace
test to avoid issues with the standby trying to use the same directory
* Delay long enough after each installcheck-parallel to let the
standby catch up (the run proper is ~24 min, plus 2 min for catchup)
The failures I'm seeing generally look like
2021-05-01 15:33:10.968 EDT [8281] FATAL: inconsistent page found, rel 1663/58186/66338, forknum 0, blkno 19
2021-05-01 15:33:10.968 EDT [8281] CONTEXT: WAL redo at 3/4CE905B8 for Gist/PAGE_UPDATE: ; blkref #0: rel
1663/58186/66338,blk 19 FPW
with a variety of WAL record types being named, so it doesn't seem
to be specific to any particular record type. I've twice gotten the
bogus-checksum-and-then-assertion-failure I reported before:
2021-05-01 17:07:52.992 EDT [17464] LOG: incorrect resource manager data checksum in record at 3/E0073EA4
TRAP: FailedAssertion("state->recordRemainLen > 0", File: "xlogreader.c", Line: 567, PID: 17464)
In both of those cases, the WAL on disk was perfectly fine, and the same
is true of most of the "inconsistent page" complaints. So the issue
definitely seems to be about the startup process mis-reading data that
was correctly shipped over.
Anyway, the new and interesting data concerns the relative failure rates
of different builds:
* Recent HEAD (from 4-28 and 5-1): 4 failures in 8 test cycles
* Reverting 1d257577e: 1 failure in 8 test cycles
* Reverting 1d257577e and f003d9f87: 3 failures in 28 cycles
* Reverting 1d257577e, f003d9f87, and 323cbe7c7: 2 failures in 93 cycles
That last point means that there was some hard-to-hit problem even
before any of the recent WAL-related changes. However, 323cbe7c7
(Remove read_page callback from XLogReader) increased the failure
rate by at least a factor of 5, and 1d257577e (Optionally prefetch
referenced data) seems to have increased it by another factor of 4.
But it looks like f003d9f87 (Add circular WAL decoding buffer)
didn't materially change the failure rate.
Considering that 323cbe7c7 was supposed to be just refactoring,
and 1d257577e is allegedly disabled-by-default, these are surely
not the results I was expecting to get.
It seems like it's still an open question whether all this is
a real bug, or flaky hardware. I have seen occasional kernel
freezeups (or so I think -- machine stops responding to keyboard
or network input) over the past year or two, so I cannot in good
conscience rule out the flaky-hardware theory. But it doesn't
smell like that kind of problem to me. I think what we're looking
at is a timing-sensitive bug that was there before (maybe long
before?) and these commits happened to make it occur more often
on this particular hardware. This hardware is enough unlike
anything made in the past decade that it's not hard to credit
that it'd show a timing problem that nobody else can reproduce.
(I did try the time-honored ritual of reseating all the machine's
RAM, partway through this. Doesn't seem to have changed anything.)
Anyway, I'm not sure where to go from here. I'm for sure nowhere
near being able to identify the bug --- and if there really is
a bug that formerly had a one-in-fifty reproduction rate, I have
zero interest in trying to identify where it started by bisecting.
It'd take at least a day per bisection step, and even that might
not be accurate enough. (But, if anyone has ideas of specific
commits to test, I'd be willing to try a few.)
regards, tom lane
On Thu, Apr 29, 2021 at 12:24 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Andres Freund <andres@anarazel.de> writes: > > On 2021-04-28 19:24:53 -0400, Tom Lane wrote: > >> IOW, we've spent over twice as many CPU cycles shipping data to the > >> standby as we did in applying the WAL on the standby. > > > I don't really know how the time calculation works on mac. Is there a > > chance it includes time spent doing IO? For comparison, on a modern Linux system I see numbers like this, while running that 025_stream_rep_regress.pl test I posted in a nearby thread: USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND tmunro 2150863 22.5 0.0 55348 6752 ? Ss 12:59 0:07 postgres: standby_1: startup recovering 00000001000000020000003C tmunro 2150867 17.5 0.0 55024 6364 ? Ss 12:59 0:05 postgres: standby_1: walreceiver streaming 2/3C675D80 tmunro 2150868 11.7 0.0 55296 7192 ? Ss 12:59 0:04 postgres: primary: walsender tmunro [local] streaming 2/3C675D80 Those ratios are better but it's still hard work, and perf shows the CPU time is all in page cache schlep: 22.44% postgres [kernel.kallsyms] [k] copy_user_enhanced_fast_string 20.12% postgres [kernel.kallsyms] [k] __add_to_page_cache_locked 7.30% postgres [kernel.kallsyms] [k] iomap_set_page_dirty That was with all three patches reverted, so it's nothing new. Definitely room for improvement... there have been a few discussions about not using a buffered file for high-frequency data exchange and relaxing various timing rules, which we should definitely look into, but I wouldn't be at all surprised if HFS+ was just much worse at this. Thinking more about good old HFS+... I guess it's remotely possible that there might have been coherency bugs in that could be exposed by our usage pattern, but then that doesn't fit too well with the clues I have from light reading: this is a non-SMP system, and it's said that HFS+ used to serialise pretty much everything on big filesystem locks anyway.
On Sun, May 2, 2021 at 3:16 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > That last point means that there was some hard-to-hit problem even > before any of the recent WAL-related changes. However, 323cbe7c7 > (Remove read_page callback from XLogReader) increased the failure > rate by at least a factor of 5, and 1d257577e (Optionally prefetch > referenced data) seems to have increased it by another factor of 4. > But it looks like f003d9f87 (Add circular WAL decoding buffer) > didn't materially change the failure rate. Oh, wow. There are several surprising results there. Thanks for running those tests for so long so that we could see the rarest failures. Even if there are somehow *two* causes of corruption, one preexisting and one added by the refactoring or decoding patches, I'm struggling to understand how the chance increases with 1d2575, since that only adds code that isn't reached when not enabled (though I'm going to re-review that). > Considering that 323cbe7c7 was supposed to be just refactoring, > and 1d257577e is allegedly disabled-by-default, these are surely > not the results I was expecting to get. +1 > It seems like it's still an open question whether all this is > a real bug, or flaky hardware. I have seen occasional kernel > freezeups (or so I think -- machine stops responding to keyboard > or network input) over the past year or two, so I cannot in good > conscience rule out the flaky-hardware theory. But it doesn't > smell like that kind of problem to me. I think what we're looking > at is a timing-sensitive bug that was there before (maybe long > before?) and these commits happened to make it occur more often > on this particular hardware. This hardware is enough unlike > anything made in the past decade that it's not hard to credit > that it'd show a timing problem that nobody else can reproduce. Hmm, yeah that does seem plausible. It would be nice to see a report from any other system though. I'm still trying, and reviewing...
On 5/3/21 7:42 AM, Thomas Munro wrote: > On Sun, May 2, 2021 at 3:16 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: >> That last point means that there was some hard-to-hit problem even >> before any of the recent WAL-related changes. However, 323cbe7c7 >> (Remove read_page callback from XLogReader) increased the failure >> rate by at least a factor of 5, and 1d257577e (Optionally prefetch >> referenced data) seems to have increased it by another factor of 4. >> But it looks like f003d9f87 (Add circular WAL decoding buffer) >> didn't materially change the failure rate. > > Oh, wow. There are several surprising results there. Thanks for > running those tests for so long so that we could see the rarest > failures. > > Even if there are somehow *two* causes of corruption, one preexisting > and one added by the refactoring or decoding patches, I'm struggling > to understand how the chance increases with 1d2575, since that only > adds code that isn't reached when not enabled (though I'm going to > re-review that). > >> Considering that 323cbe7c7 was supposed to be just refactoring, >> and 1d257577e is allegedly disabled-by-default, these are surely >> not the results I was expecting to get. > > +1 > >> It seems like it's still an open question whether all this is >> a real bug, or flaky hardware. I have seen occasional kernel >> freezeups (or so I think -- machine stops responding to keyboard >> or network input) over the past year or two, so I cannot in good >> conscience rule out the flaky-hardware theory. But it doesn't >> smell like that kind of problem to me. I think what we're looking >> at is a timing-sensitive bug that was there before (maybe long >> before?) and these commits happened to make it occur more often >> on this particular hardware. This hardware is enough unlike >> anything made in the past decade that it's not hard to credit >> that it'd show a timing problem that nobody else can reproduce. > > Hmm, yeah that does seem plausible. It would be nice to see a report > from any other system though. I'm still trying, and reviewing... > FWIW I've ran the test (make installcheck-parallel in a loop) on four different machines - two x86_64 ones, and two rpi4. The x86 boxes did ~1000 rounds each (and one of them had 5 local replicas) without any issue. The rpi4 machines did ~50 rounds each, also without failures. Obviously, it's possible there's something that neither of those (very different systems) triggers, but I'd say it might also be a hint that this really is a hw issue on the old ppc macs. Or maybe something very specific to that arch. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> On 5/3/21 7:42 AM, Thomas Munro wrote:
>> Hmm, yeah that does seem plausible. It would be nice to see a report
>> from any other system though. I'm still trying, and reviewing...
> FWIW I've ran the test (make installcheck-parallel in a loop) on four
> different machines - two x86_64 ones, and two rpi4. The x86 boxes did
> ~1000 rounds each (and one of them had 5 local replicas) without any
> issue. The rpi4 machines did ~50 rounds each, also without failures.
Yeah, I have also spent a fair amount of time trying to reproduce it
elsewhere, without success so far. Notably, I've been trying on a
PPC Mac laptop that has a fairly similar CPU to what's in the G4,
though a far slower disk drive. So that seems to exclude theories
based on it being PPC-specific.
I suppose that if we're unable to reproduce it on at least one other box,
we have to write it off as hardware flakiness. I'm not entirely
comfortable with that answer, but I won't push for reversion of the WAL
patches without more evidence that there's a real issue.
regards, tom lane
I wrote: > I suppose that if we're unable to reproduce it on at least one other box, > we have to write it off as hardware flakiness. BTW, that conclusion shouldn't distract us from the very real bug that Andres identified. I was just scraping the buildfarm logs concerning recent failures, and I found several recent cases that match the symptom he reported: https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=chipmunk&dt=2021-04-23%2022%3A27%3A41 https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=hornet&dt=2021-04-21%2005%3A15%3A24 https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=mandrill&dt=2021-04-20%2002%3A03%3A08 https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=tern&dt=2021-05-04%2004%3A07%3A41 https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=wrasse&dt=2021-04-20%2021%3A08%3A59 They all show the standby in recovery/019_replslot_limit.pl failing with symptoms like 2021-05-04 07:42:00.968 UTC [24707406:1] LOG: database system was shut down in recovery at 2021-05-04 07:41:39 UTC 2021-05-04 07:42:00.968 UTC [24707406:2] LOG: entering standby mode 2021-05-04 07:42:01.050 UTC [24707406:3] LOG: redo starts at 0/1C000D8 2021-05-04 07:42:01.079 UTC [24707406:4] LOG: consistent recovery state reached at 0/1D00000 2021-05-04 07:42:01.079 UTC [24707406:5] FATAL: invalid memory alloc request size 1476397045 2021-05-04 07:42:01.080 UTC [13238274:3] LOG: database system is ready to accept read only connections 2021-05-04 07:42:01.082 UTC [13238274:4] LOG: startup process (PID 24707406) exited with exit code 1 (BTW, the behavior seen here where the failure occurs *immediately* after reporting "consistent recovery state reached" is seen in the other reports as well, including Andres' version. I wonder if that means anything.) regards, tom lane
Hi,
On 2021-05-04 15:47:41 -0400, Tom Lane wrote:
> BTW, that conclusion shouldn't distract us from the very real bug
> that Andres identified. I was just scraping the buildfarm logs
> concerning recent failures, and I found several recent cases
> that match the symptom he reported:
> [...]
> They all show the standby in recovery/019_replslot_limit.pl failing
> with symptoms like
>
> 2021-05-04 07:42:00.968 UTC [24707406:1] LOG: database system was shut down in recovery at 2021-05-04 07:41:39 UTC
> 2021-05-04 07:42:00.968 UTC [24707406:2] LOG: entering standby mode
> 2021-05-04 07:42:01.050 UTC [24707406:3] LOG: redo starts at 0/1C000D8
> 2021-05-04 07:42:01.079 UTC [24707406:4] LOG: consistent recovery state reached at 0/1D00000
> 2021-05-04 07:42:01.079 UTC [24707406:5] FATAL: invalid memory alloc request size 1476397045
> 2021-05-04 07:42:01.080 UTC [13238274:3] LOG: database system is ready to accept read only connections
> 2021-05-04 07:42:01.082 UTC [13238274:4] LOG: startup process (PID 24707406) exited with exit code 1
Yea, that's the pre-existing end-of-log-issue that got more likely as
well as more consequential (by accident) in Thomas' patch. It's easy to
reach parity with the state in 13, it's just changing the order in one
place.
But I think we need to do something for all branches here. The bandaid
that was added to allocate_recordbuf() does doesn't really seems
sufficient to me. This is
commit 70b4f82a4b5cab5fc12ff876235835053e407155
Author: Michael Paquier <michael@paquier.xyz>
Date: 2018-06-18 10:43:27 +0900
Prevent hard failures of standbys caused by recycled WAL segments
In <= 13 the current state is that we'll allocate effectively random
bytes as long as the random number is below 1GB whenever we reach the
end of the WAL with the record on a page boundary (because there we
don't. That allocation is then not freed for the lifetime of the
xlogreader. And for FRONTEND uses of xlogreader we'll just happily
allocate 4GB. The specific problem here is that we don't validate the
record header before allocating when the record header is split across a
page boundary - without much need as far as I can tell? Until we've read
the entire header, we actually don't need to allocate the record buffer?
This seems like an issue that needs to be fixed to be more robust in
crash recovery scenarios where obviously we could just have failed with
half written records.
But the issue that 70b4f82a4b is trying to address seems bigger to
me. The reason it's so easy to hit the issue is that walreceiver does <
8KB writes into recycled WAL segments *without* zero-filling the tail
end of the page - which will commonly be filled with random older
contents, because we'll use a recycled segments. I think that
*drastically* increases the likelihood of finding something that looks
like a valid record header compared to the situation on a primary where
the zeroing pages before use makes that pretty unlikely.
> (BTW, the behavior seen here where the failure occurs *immediately*
> after reporting "consistent recovery state reached" is seen in the
> other reports as well, including Andres' version. I wonder if that
> means anything.)
That's to be expected, I think. There's not a lot of data that needs to
be replayed, and we'll always reach consistency before the end of the
WAL unless you're dealing with starting from an in-progress base-backup
that hasn't yet finished or such. The test causes replication to fail
shortly after that, so we'll always switch to doing recovery from
pg_wal, which then will hit the end of the WAL, hitting this issue with,
I think, ~25% likelihood (data from recycled WAL data is probably
*roughly* evenly distributed, and any 4byte value above 1GB will hit
this error in 14).
Greetings,
Andres Freund
Hi, On 2021-05-04 09:46:12 -0400, Tom Lane wrote: > Yeah, I have also spent a fair amount of time trying to reproduce it > elsewhere, without success so far. Notably, I've been trying on a > PPC Mac laptop that has a fairly similar CPU to what's in the G4, > though a far slower disk drive. So that seems to exclude theories > based on it being PPC-specific. > > I suppose that if we're unable to reproduce it on at least one other box, > we have to write it off as hardware flakiness. I wonder if there's a chance what we're seeing is an OS memory ordering bug, or a race between walreceiver writing data and the startup process reading it. When the startup process is able to keep up, there often will be a very small time delta between the startup process reading a page that the walreceiver just wrote. And if the currently read page was the tail page written to by a 'w' message, it'll often be written to again in short order - potentially while the startup process is reading it. It'd not terribly surprise me if an old OS version on an old processor had some issues around that. Were there any cases of walsender terminating and reconnecting around the failures? It looks suspicious that XLogPageRead() does not invalidate the xlogreader state when retrying. Normally that's xlogreader's responsibility, but there is that whole XLogReaderValidatePageHeader() business. But I don't quite see how it'd actually cause problems. Greetings, Andres Freund
Hi,
On 2021-05-04 18:08:35 -0700, Andres Freund wrote:
> But the issue that 70b4f82a4b is trying to address seems bigger to
> me. The reason it's so easy to hit the issue is that walreceiver does <
> 8KB writes into recycled WAL segments *without* zero-filling the tail
> end of the page - which will commonly be filled with random older
> contents, because we'll use a recycled segments. I think that
> *drastically* increases the likelihood of finding something that looks
> like a valid record header compared to the situation on a primary where
> the zeroing pages before use makes that pretty unlikely.
I've written an experimental patch to deal with this and, as expected,
it does make the end-of-wal detection a lot more predictable and
reliable. There's only two types of possible errors outside of crashes:
A record length of 0 (the end of WAL is within a page), and the page
header LSN mismatching (the end of WAL is at a page boundary).
This seems like a significant improvement.
However: It's nontrivial to do this nicely and in a backpatchable way in
XLogWalRcvWrite(). Or at least I haven't found a good way:
- We can't extend the input buffer to XLogWalRcvWrite(), it's from
libpq.
- We don't want to copy the the entire buffer (commonly 128KiB) to a new
buffer that we then can extend by 0-BLCKSZ of zeroes to cover the
trailing part of the last page.
- In PG13+ we can do this utilizing pg_writev(), adding another IOV
entry covering the trailing space to be padded.
- It's nicer to avoid increasign the number of write() calls, but it's
not as crucial as the earlier points.
I'm also a bit uncomfortable with another aspect, although I can't
really see a problem: When switch to receiving WAL via walreceiver, we
always start at a segment boundary, even if we had received most of that
segment before. Currently that won't end up with any trailing space that
needs to be zeroed, because the server always will send 128KB chunks,
but there's no formal guarantee for that. It seems a bit odd that we
could end up zeroing trailing space that already contains valid data,
just to overwrite it with valid data again. But it ought to always be
fine.
The least offensive way I could come up with is for XLogWalRcvWrite() to
always write partial pages in a separate pg_pwrite(). When writing a
partial page, and the previous write position was not already on that
same page, copy the buffer into a local XLOG_BLCKSZ sized buffer
(although we'll never use more than XLOG_BLCKSZ-1 I think), and (re)zero
out the trailing part. One thing that does not yet handle is if we were
to get a partial write - we'd not again notice that we need to pad the
end of the page.
Does anybody have a better idea?
I really wish we had a version of pg_p{read,write}[v] that internally
handled partial IOs, retrying as long as they see > 0 bytes written.
Greetings,
Andres Freund
On Thu, Apr 22, 2021 at 11:22 AM Stephen Frost <sfrost@snowman.net> wrote: > On Wed, Apr 21, 2021 at 19:17 Thomas Munro <thomas.munro@gmail.com> wrote: >> On Thu, Apr 22, 2021 at 8:16 AM Thomas Munro <thomas.munro@gmail.com> wrote: >> ... Personally I think the right thing to do now is to revert it >> and re-propose for 15 early in the cycle, supported with some better >> testing infrastructure. > > I tend to agree with the idea to revert it, perhaps a +0 on that, but if others argue it should be fixed in-place, I wouldn’tcomplain about it. Reverted. Note: eelpout may return a couple of failures because it's set up to run with recovery_prefetch=on (now an unknown GUC), and it'll be a few hours before I can access that machine to adjust that... > I very much encourage the idea of improving testing in this area and would be happy to try and help do so in the 15 cycle. Cool. I'm going to try out some ideas.
> On 10 May 2021, at 06:11, Thomas Munro <thomas.munro@gmail.com> wrote: > On Thu, Apr 22, 2021 at 11:22 AM Stephen Frost <sfrost@snowman.net> wrote: >> I tend to agree with the idea to revert it, perhaps a +0 on that, but if others argue it should be fixed in-place, I wouldn’tcomplain about it. > > Reverted. > > Note: eelpout may return a couple of failures because it's set up to > run with recovery_prefetch=on (now an unknown GUC), and it'll be a few > hours before I can access that machine to adjust that... > >> I very much encourage the idea of improving testing in this area and would be happy to try and help do so in the 15 cycle. > > Cool. I'm going to try out some ideas. Skimming this thread without all the context it's not entirely clear which patch the CF entry relates to (I assume it's the one from April 7 based on attached mail-id but there is a revert from May?), and the CF app and CF bot are also in disagreement which is the latest one. Could you post an updated version of the patch which is for review? -- Daniel Gustafsson https://vmware.com/
On Mon, Nov 15, 2021 at 11:31 PM Daniel Gustafsson <daniel@yesql.se> wrote: > Could you post an updated version of the patch which is for review? Sorry for taking so long to come back; I learned some new things that made me want to restructure this code a bit (see below). Here is an updated pair of patches that I'm currently testing. Old problems: 1. Last time around, an infinite loop was reported in pg_waldump. I believe Horiguchi-san has fixed that[1], but I'm no longer depending on that patch. I thought his patch set was a good idea, but it's complicated and there's enough going on here already... let's consider that independently. This version goes back to what I had earlier, though (I hope) it is better about how "nonblocking" states are communicated. In this version, XLogPageRead() has a way to give up part way through a record if it doesn't have enough data and there are queued up records that could be replayed right now. In that case, we'll go back to the beginning of the record (and occasionally, back a WAL page) next time we try. That's the cost of not maintaining intra-record decoding state. 2. Last time around, we could try to allocate a crazy amount of memory when reading garbage past the end of the WAL. Fixed, by validating first, like in master. New work: Since last time, I went away and worked on a "real" AIO version of this feature. That's ongoing experimental work for a future proposal, but I have a working prototype and I aim to share that soon, when that branch is rebased to catch up with recent changes. In that version, the prefetcher starts actual reads into the buffer pool, and recovery receives already pinned buffers attached to the stream of records it's replaying. That inspired a couple of refactoring changes to this non-AIO version, to minimise the difference and anticipate the future work better: 1. The logic for deciding which block to start prefetching next is moved into a new callback function in a sort of standard form (this is approximately how all/most prefetching code looks in the AIO project, ie sequential scans, bitmap heap scan, etc). 2. The logic for controlling how many IOs are running and deciding when to call the above is in a separate component. In this non-AIO version, it works using a simple ring buffer of LSNs to estimate the number of in flight I/Os, just like before. This part would be thrown away and replaced with the AIO branch's centralised "streaming read" mechanism which tracks I/O completions based on a stream of completion events from the kernel (or I/O worker processes). 3. In this version, the prefetcher still doesn't pin buffers, for simplicity. That work did force me to study places where WAL streams need prefetching "barriers", though, so in this patch you can see that it's now a little more careful than it probably needs to be. (It doesn't really matter much if you call posix_fadvise() on a non-existent file region, or the wrong file after OID wraparound and reuse, but it would matter if you actually read it into a buffer, and if an intervening record might be trying to drop something you have pinned). Some other changes: 1. I dropped the GUC recovery_prefetch_fpw. I think it was a possibly useful idea but it's a niche concern and not worth worrying about for now. 2. I simplified the stats. Coming up with a good running average system seemed like a problem for another day (the numbers before were hard to interpret). The new stats are super simple counters and instantaneous values: postgres=# select * from pg_stat_prefetch_recovery ; -[ RECORD 1 ]--+------------------------------ stats_reset | 2021-11-10 09:02:08.590217+13 prefetch | 13605674 <- times we called posix_fadvise() hit | 24185289 <- times we found pages already cached skip_init | 217215 <- times we did nothing because init, not read skip_new | 192347 <- times we skipped because relation too small skip_fpw | 27429 <- times we skipped because fpw, not read wal_distance | 10648 <- how far ahead in WAL bytes block_distance | 134 <- how far ahead in block references io_depth | 50 <- fadvise() calls not yet followed by pread() I also removed the code to save and restore the stats via the stats collector, for now. I figured that persistent stats could be a later feature, perhaps after the shared memory stats stuff? 3. I dropped the code that was caching an SMgrRelation pointer to avoid smgropen() calls that showed up in some profiles. That probably lacked invalidation that could be done with some more WAL analysis, but I decided to leave it out completely for now for simplicity. 4. I dropped the verbose logging. I think it might make sense to integrate with the new "recovery progress" system, but I think that should be a separate discussion. If you want to see the counters after crash recovery finishes, you can look at the stats view. [1] https://commitfest.postgresql.org/34/2113/
Attachment
Hi,
It's great you posted a new version of this patch, so I took a look a
brief look at it. The code seems in pretty good shape, I haven't found
any real issues - just two minor comments:
This seems a bit strange:
#define DEFAULT_DECODE_BUFFER_SIZE 0x10000
Why not to define this as a simple decimal value? Is there something
special about this particular value, or is it arbitrary? I guess it's
simply the minimum for wal_decode_buffer_size GUC, but why not to use
the GUC for all places decoding WAL?
FWIW I don't think we include updates to typedefs.list in patches.
I also repeated the benchmarks I did at the beginning of the year [1].
Attached is a chart with four different configurations:
1) master (f79962d826)
2) patched (with prefetching disabled)
3) patched (with default configuration)
4) patched (with I/O concurrency 256 and 2MB decode buffer)
For all configs the shared buffers were set to 64GB, checkpoints every
20 minutes, etc.
The results are pretty good / similar to previous results. Replaying the
1h worth of work on a smaller machine takes ~5:30h without prefetching
(master or with prefetching disabled). With prefetching enabled this
drops to ~2h (default config) and ~1h (with tuning).
regards
[1]
https://www.postgresql.org/message-id/c5d52837-6256-0556-ac8c-d6d3d558820a%40enterprisedb.com
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
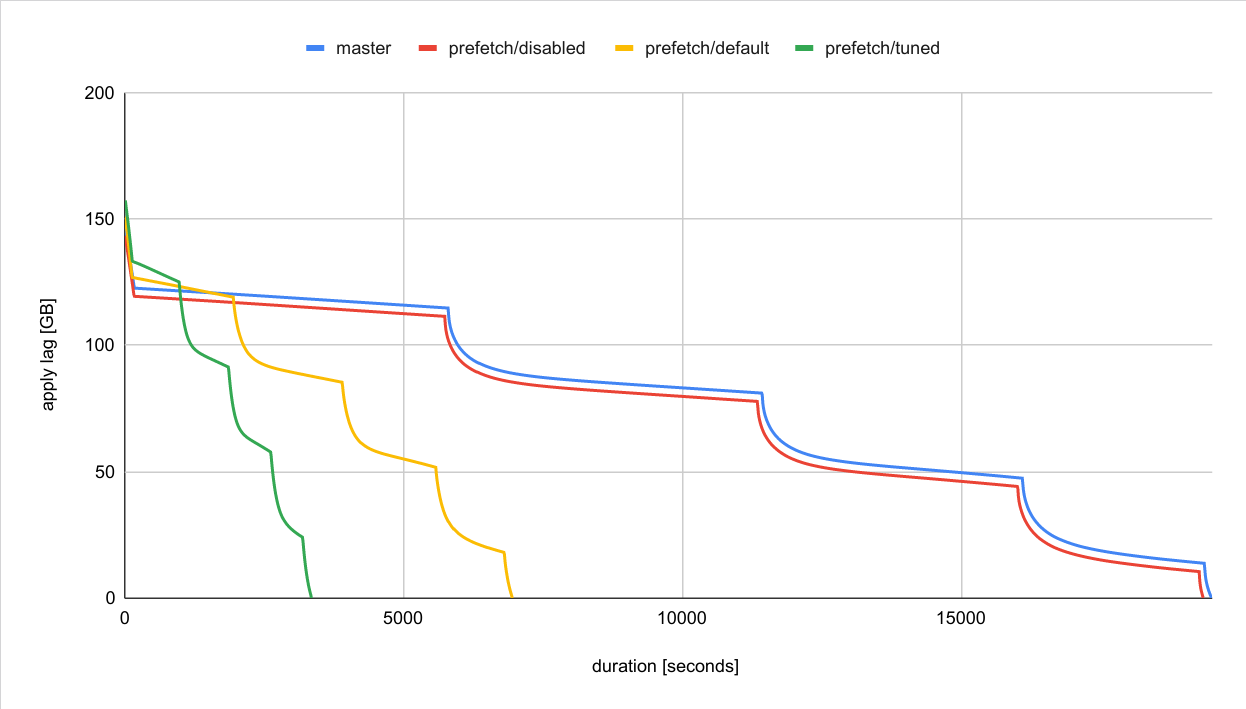{kind=link}
On Fri, Nov 26, 2021 at 11:32 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > The results are pretty good / similar to previous results. Replaying the > 1h worth of work on a smaller machine takes ~5:30h without prefetching > (master or with prefetching disabled). With prefetching enabled this > drops to ~2h (default config) and ~1h (with tuning). Thanks for testing! Wow, that's a nice graph. This has bit-rotted already due to Robert's work on ripping out globals, so I'll post a rebase early next week, and incorporate your code feedback.
On 11/26/21 22:16, Thomas Munro wrote: > On Fri, Nov 26, 2021 at 11:32 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> The results are pretty good / similar to previous results. Replaying the >> 1h worth of work on a smaller machine takes ~5:30h without prefetching >> (master or with prefetching disabled). With prefetching enabled this >> drops to ~2h (default config) and ~1h (with tuning). > > Thanks for testing! Wow, that's a nice graph. > > This has bit-rotted already due to Robert's work on ripping out > globals, so I'll post a rebase early next week, and incorporate your > code feedback. > One thing that's not clear to me is what happened to the reasons why this feature was reverted in the PG14 cycle? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Nov 27, 2021 at 12:34 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > One thing that's not clear to me is what happened to the reasons why > this feature was reverted in the PG14 cycle? Reasons for reverting: 1. A bug in commit 323cbe7c, "Remove read_page callback from XLogReader.". I couldn't easily revert just that piece. This new version doesn't depend on that change anymore, to try to keep things simple. (That particular bug has been fixed in a newer version of that patch[1], which I still think was a good idea incidentally.) 2. A bug where allocation for large records happened before validation. Concretely, you can see that this patch does XLogReadRecordAlloc() after validating the header (usually, same as master), but commit f003d9f8 did it first. (Though Andres pointed out[2] that more work is needed on that to make that logic more robust, and I'm keen to look into that, but that's independent of this work). 3. A wild goose chase for bugs on Tom Lane's antique 32 bit PPC machine. Tom eventually reproduced it with the patches reverted, which seemed to exonerate them but didn't leave a good feeling: what was happening, and why did the patches hugely increase the likelihood of the failure mode? I have no new information on that, but I know that several people spent a huge amount of time and effort trying to reproduce it on various types of systems, as did I, so despite not reaching a conclusion of a bug, this certainly contributed to a feeling that the patch had run out of steam for the 14 cycle. This week I'll have another crack at getting that TAP test I proposed that runs the regression tests with a streaming replica to work on Windows. That does approximately what Tom was doing when he saw problem #3, which I'd like to have as standard across the build farm. [1] https://www.postgresql.org/message-id/20211007.172820.1874635561738958207.horikyota.ntt%40gmail.com [2] https://www.postgresql.org/message-id/20210505010835.umylslxgq4a6rbwg%40alap3.anarazel.de
Thomas Munro <thomas.munro@gmail.com> writes:
> On Sat, Nov 27, 2021 at 12:34 PM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>> One thing that's not clear to me is what happened to the reasons why
>> this feature was reverted in the PG14 cycle?
> 3. A wild goose chase for bugs on Tom Lane's antique 32 bit PPC
> machine. Tom eventually reproduced it with the patches reverted,
> which seemed to exonerate them but didn't leave a good feeling: what
> was happening, and why did the patches hugely increase the likelihood
> of the failure mode? I have no new information on that, but I know
> that several people spent a huge amount of time and effort trying to
> reproduce it on various types of systems, as did I, so despite not
> reaching a conclusion of a bug, this certainly contributed to a
> feeling that the patch had run out of steam for the 14 cycle.
Yeah ... on the one hand, that machine has shown signs of
hard-to-reproduce flakiness, so it's easy to write off the failures
I saw as hardware issues. On the other hand, the flakiness I've
seen has otherwise manifested as kernel crashes, which is nothing
like the consistent test failures I was seeing with the patch.
Andres speculated that maybe we were seeing a kernel bug that
affects consistency of concurrent reads and writes. That could
be an explanation; but it's just evidence-free speculation so far,
so I don't feel real convinced by that idea either.
Anyway, I hope to find time to see if the issue still reproduces
with Thomas' new patch set.
regards, tom lane
Hi Thomas,
I am unable to apply these new set of patches on HEAD. Can you please share the rebased patch or if you have any work branch can you please point it out, I will refer to it for the changes.
--
With Regards,
Ashutosh sharma.
On Tue, Nov 23, 2021 at 3:44 PM Thomas Munro <thomas.munro@gmail.com> wrote:
On Mon, Nov 15, 2021 at 11:31 PM Daniel Gustafsson <daniel@yesql.se> wrote:
> Could you post an updated version of the patch which is for review?
Sorry for taking so long to come back; I learned some new things that
made me want to restructure this code a bit (see below). Here is an
updated pair of patches that I'm currently testing.
Old problems:
1. Last time around, an infinite loop was reported in pg_waldump. I
believe Horiguchi-san has fixed that[1], but I'm no longer depending
on that patch. I thought his patch set was a good idea, but it's
complicated and there's enough going on here already... let's consider
that independently.
This version goes back to what I had earlier, though (I hope) it is
better about how "nonblocking" states are communicated. In this
version, XLogPageRead() has a way to give up part way through a record
if it doesn't have enough data and there are queued up records that
could be replayed right now. In that case, we'll go back to the
beginning of the record (and occasionally, back a WAL page) next time
we try. That's the cost of not maintaining intra-record decoding
state.
2. Last time around, we could try to allocate a crazy amount of
memory when reading garbage past the end of the WAL. Fixed, by
validating first, like in master.
New work:
Since last time, I went away and worked on a "real" AIO version of
this feature. That's ongoing experimental work for a future proposal,
but I have a working prototype and I aim to share that soon, when that
branch is rebased to catch up with recent changes. In that version,
the prefetcher starts actual reads into the buffer pool, and recovery
receives already pinned buffers attached to the stream of records it's
replaying.
That inspired a couple of refactoring changes to this non-AIO version,
to minimise the difference and anticipate the future work better:
1. The logic for deciding which block to start prefetching next is
moved into a new callback function in a sort of standard form (this is
approximately how all/most prefetching code looks in the AIO project,
ie sequential scans, bitmap heap scan, etc).
2. The logic for controlling how many IOs are running and deciding
when to call the above is in a separate component. In this non-AIO
version, it works using a simple ring buffer of LSNs to estimate the
number of in flight I/Os, just like before. This part would be thrown
away and replaced with the AIO branch's centralised "streaming read"
mechanism which tracks I/O completions based on a stream of completion
events from the kernel (or I/O worker processes).
3. In this version, the prefetcher still doesn't pin buffers, for
simplicity. That work did force me to study places where WAL streams
need prefetching "barriers", though, so in this patch you can
see that it's now a little more careful than it probably needs to be.
(It doesn't really matter much if you call posix_fadvise() on a
non-existent file region, or the wrong file after OID wraparound and
reuse, but it would matter if you actually read it into a buffer, and
if an intervening record might be trying to drop something you have
pinned).
Some other changes:
1. I dropped the GUC recovery_prefetch_fpw. I think it was a
possibly useful idea but it's a niche concern and not worth worrying
about for now.
2. I simplified the stats. Coming up with a good running average
system seemed like a problem for another day (the numbers before were
hard to interpret). The new stats are super simple counters and
instantaneous values:
postgres=# select * from pg_stat_prefetch_recovery ;
-[ RECORD 1 ]--+------------------------------
stats_reset | 2021-11-10 09:02:08.590217+13
prefetch | 13605674 <- times we called posix_fadvise()
hit | 24185289 <- times we found pages already cached
skip_init | 217215 <- times we did nothing because init, not read
skip_new | 192347 <- times we skipped because relation too small
skip_fpw | 27429 <- times we skipped because fpw, not read
wal_distance | 10648 <- how far ahead in WAL bytes
block_distance | 134 <- how far ahead in block references
io_depth | 50 <- fadvise() calls not yet followed by pread()
I also removed the code to save and restore the stats via the stats
collector, for now. I figured that persistent stats could be a later
feature, perhaps after the shared memory stats stuff?
3. I dropped the code that was caching an SMgrRelation pointer to
avoid smgropen() calls that showed up in some profiles. That probably
lacked invalidation that could be done with some more WAL analysis,
but I decided to leave it out completely for now for simplicity.
4. I dropped the verbose logging. I think it might make sense to
integrate with the new "recovery progress" system, but I think that
should be a separate discussion. If you want to see the counters
after crash recovery finishes, you can look at the stats view.
[1] https://commitfest.postgresql.org/34/2113/
On Fri, Nov 26, 2021 at 9:47 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Yeah ... on the one hand, that machine has shown signs of > hard-to-reproduce flakiness, so it's easy to write off the failures > I saw as hardware issues. On the other hand, the flakiness I've > seen has otherwise manifested as kernel crashes, which is nothing > like the consistent test failures I was seeing with the patch. > > Andres speculated that maybe we were seeing a kernel bug that > affects consistency of concurrent reads and writes. That could > be an explanation; but it's just evidence-free speculation so far, > so I don't feel real convinced by that idea either. > > Anyway, I hope to find time to see if the issue still reproduces > with Thomas' new patch set. Honestly, all the reasons that Thomas articulated for the revert seem relatively unimpressive from my point of view. Perhaps they are sufficient justification for a revert so near to the end of the development cycle, but that's just an argument for committing things a little sooner so we have time to work out the kinks. This kind of work is too valuable to get hung up for a year or three because of a couple of minor preexisting bugs and/or preexisting maybe-bugs. -- Robert Haas EDB: http://www.enterprisedb.com
On Fri, 26 Nov 2021 at 21:47, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Yeah ... on the one hand, that machine has shown signs of > hard-to-reproduce flakiness, so it's easy to write off the failures > I saw as hardware issues. On the other hand, the flakiness I've > seen has otherwise manifested as kernel crashes, which is nothing > like the consistent test failures I was seeing with the patch. Hm. I asked around and found a machine I can use that can run PPC binaries, but it's actually, well, confusing. I think this is an x86 machine running Leopard which uses JIT to transparently run PPC binaries. I'm not sure this is really a good test. But if you're interested and can explain the tests to run I can try to get the tests running on this machine: IBUILD:~ gsstark$ uname -a Darwin IBUILD.MIT.EDU 9.8.0 Darwin Kernel Version 9.8.0: Wed Jul 15 16:55:01 PDT 2009; root:xnu-1228.15.4~1/RELEASE_I386 i386 IBUILD:~ gsstark$ sw_vers ProductName: Mac OS X ProductVersion: 10.5.8 BuildVersion: 9L31a
The actual hardware of this machine is a Mac Mini Core 2 Duo. I'm not
really clear how the emulation is done and whether it makes a
reasonable test environment or not.
Hardware Overview:
Model Name: Mac mini
Model Identifier: Macmini2,1
Processor Name: Intel Core 2 Duo
Processor Speed: 2 GHz
Number Of Processors: 1
Total Number Of Cores: 2
L2 Cache: 4 MB
Memory: 2 GB
Bus Speed: 667 MHz
Boot ROM Version: MM21.009A.B00
Greg Stark <stark@mit.edu> writes:
> But if you're interested and can explain the tests to run I can try to
> get the tests running on this machine:
I'm not sure that machine is close enough to prove much, but by all
means give it a go if you wish. My test setup was explained in [1]:
>> To recap, the test lashup is:
>> * 2003 PowerMac G4 (1.25GHz PPC 7455, 7200 rpm spinning-rust drive)
>> * Standard debug build (--enable-debug --enable-cassert)
>> * Out-of-the-box configuration, except add wal_consistency_checking = all
>> and configure a wal-streaming standby on the same machine
>> * Repeatedly run "make installcheck-parallel", but skip the tablespace
>> test to avoid issues with the standby trying to use the same directory
>> * Delay long enough after each installcheck-parallel to let the
>> standby catch up (the run proper is ~24 min, plus 2 min for catchup)
Remember also that the code in question is not in HEAD; you'd
need to apply Munro's patches, or check out some commit from
around 2021-04-22.
regards, tom lane
[1] https://www.postgresql.org/message-id/3502526.1619925367%40sss.pgh.pa.us
What tools and tool versions are you using to build? Is it just GCC for PPC? There aren't any special build processes to make a fat binary involved? On Thu, 16 Dec 2021 at 23:11, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Greg Stark <stark@mit.edu> writes: > > But if you're interested and can explain the tests to run I can try to > > get the tests running on this machine: > > I'm not sure that machine is close enough to prove much, but by all > means give it a go if you wish. My test setup was explained in [1]: > > >> To recap, the test lashup is: > >> * 2003 PowerMac G4 (1.25GHz PPC 7455, 7200 rpm spinning-rust drive) > >> * Standard debug build (--enable-debug --enable-cassert) > >> * Out-of-the-box configuration, except add wal_consistency_checking = all > >> and configure a wal-streaming standby on the same machine > >> * Repeatedly run "make installcheck-parallel", but skip the tablespace > >> test to avoid issues with the standby trying to use the same directory > >> * Delay long enough after each installcheck-parallel to let the > >> standby catch up (the run proper is ~24 min, plus 2 min for catchup) > > Remember also that the code in question is not in HEAD; you'd > need to apply Munro's patches, or check out some commit from > around 2021-04-22. > > regards, tom lane > > [1] https://www.postgresql.org/message-id/3502526.1619925367%40sss.pgh.pa.us -- greg
Greg Stark <stark@mit.edu> writes:
> What tools and tool versions are you using to build? Is it just GCC for PPC?
> There aren't any special build processes to make a fat binary involved?
Nope, just "configure; make" using that macOS version's regular gcc.
regards, tom lane
I have IBUILD:postgresql gsstark$ ls /usr/bin/*gcc* /usr/bin/gcc /usr/bin/gcc-4.0 /usr/bin/gcc-4.2 /usr/bin/i686-apple-darwin9-gcc-4.0.1 /usr/bin/i686-apple-darwin9-gcc-4.2.1 /usr/bin/powerpc-apple-darwin9-gcc-4.0.1 /usr/bin/powerpc-apple-darwin9-gcc-4.2.1 I'm guessing I should do CC=/usr/bin/powerpc-apple-darwin9-gcc-4.2.1 or maybe 4.0.1. What version is on your G4?
Greg Stark <stark@mit.edu> writes:
> I'm guessing I should do CC=/usr/bin/powerpc-apple-darwin9-gcc-4.2.1
> or maybe 4.0.1. What version is on your G4?
$ gcc -v
Using built-in specs.
Target: powerpc-apple-darwin9
Configured with: /var/tmp/gcc/gcc-5493~1/src/configure --disable-checking -enable-werror --prefix=/usr
--mandir=/share/man--enable-languages=c,objc,c++,obj-c++ --program-transform-name=/^[cg][^.-]*$/s/$/-4.0/
--with-gxx-include-dir=/include/c++/4.0.0--with-slibdir=/usr/lib --build=i686-apple-darwin9 --program-prefix=
--host=powerpc-apple-darwin9--target=powerpc-apple-darwin9
Thread model: posix
gcc version 4.0.1 (Apple Inc. build 5493)
I see that gcc 4.2.1 is also present on this machine, but I've
never used it.
regards, tom lane
Hm. I seem to have picked a bad checkout. I took the last one before
the revert (45aa88fe1d4028ea50ba7d26d390223b6ef78acc). Or there's some
incompatibility with the emulation and the IPC stuff parallel workers
use.
2021-12-17 17:51:51.688 EST [50955] LOG: background worker "parallel
worker" (PID 54073) was terminated by signal 10: Bus error
2021-12-17 17:51:51.688 EST [50955] DETAIL: Failed process was
running: SELECT variance(unique1::int4), sum(unique1::int8),
regr_count(unique1::float8, unique1::float8)
FROM (SELECT * FROM tenk1
UNION ALL SELECT * FROM tenk1
UNION ALL SELECT * FROM tenk1
UNION ALL SELECT * FROM tenk1) u;
2021-12-17 17:51:51.690 EST [50955] LOG: terminating any other active
server processes
2021-12-17 17:51:51.748 EST [54078] FATAL: the database system is in
recovery mode
2021-12-17 17:51:51.761 EST [50955] LOG: all server processes
terminated; reinitializing
On 12/17/21 23:56, Greg Stark wrote: > Hm. I seem to have picked a bad checkout. I took the last one before > the revert (45aa88fe1d4028ea50ba7d26d390223b6ef78acc). Or there's some > incompatibility with the emulation and the IPC stuff parallel workers > use. > > > 2021-12-17 17:51:51.688 EST [50955] LOG: background worker "parallel > worker" (PID 54073) was terminated by signal 10: Bus error > 2021-12-17 17:51:51.688 EST [50955] DETAIL: Failed process was > running: SELECT variance(unique1::int4), sum(unique1::int8), > regr_count(unique1::float8, unique1::float8) > FROM (SELECT * FROM tenk1 > UNION ALL SELECT * FROM tenk1 > UNION ALL SELECT * FROM tenk1 > UNION ALL SELECT * FROM tenk1) u; > 2021-12-17 17:51:51.690 EST [50955] LOG: terminating any other active > server processes > 2021-12-17 17:51:51.748 EST [54078] FATAL: the database system is in > recovery mode > 2021-12-17 17:51:51.761 EST [50955] LOG: all server processes > terminated; reinitializing > Interesting. In my experience SIGBUS on PPC tends to be due to incorrect alignment, but I'm not sure how that works with the emulation. Can you get a backtrace? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Greg Stark <stark@mit.edu> writes:
> Hm. I seem to have picked a bad checkout. I took the last one before
> the revert (45aa88fe1d4028ea50ba7d26d390223b6ef78acc).
FWIW, I think that's the first one *after* the revert.
> 2021-12-17 17:51:51.688 EST [50955] LOG: background worker "parallel
> worker" (PID 54073) was terminated by signal 10: Bus error
I'm betting on weird emulation issue. None of my real PPC machines
showed such things.
regards, tom lane
On Fri, 17 Dec 2021 at 18:40, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Greg Stark <stark@mit.edu> writes: > > Hm. I seem to have picked a bad checkout. I took the last one before > > the revert (45aa88fe1d4028ea50ba7d26d390223b6ef78acc). > > FWIW, I think that's the first one *after* the revert. Doh But the bigger question is. Are we really concerned about this flaky problem? Is it worth investing time and money on? I can get money to go buy a G4 or G5 and spend some time on it. It just seems a bit... niche. But if it's a real bug that represents something broken on other architectures that just happens to be easier to trigger here it might be worthwhile. -- greg
Greg Stark <stark@mit.edu> writes:
> But the bigger question is. Are we really concerned about this flaky
> problem? Is it worth investing time and money on? I can get money to
> go buy a G4 or G5 and spend some time on it. It just seems a bit...
> niche. But if it's a real bug that represents something broken on
> other architectures that just happens to be easier to trigger here it
> might be worthwhile.
TBH, I don't know. There seem to be three plausible explanations:
1. Flaky hardware in my unit.
2. Ancient macOS bug, as Andres suggested upthread.
3. Actual PG bug.
If it's #1 or #2 then we're just wasting our time here. I'm not
sure how to estimate the relative probabilities, but I suspect
#3 is the least likely of the lot.
FWIW, I did just reproduce the problem on that machine with current HEAD:
2021-12-17 18:40:40.293 EST [21369] FATAL: inconsistent page found, rel 1663/167772/2673, forknum 0, blkno 26
2021-12-17 18:40:40.293 EST [21369] CONTEXT: WAL redo at C/3DE3F658 for Btree/INSERT_LEAF: off 208; blkref #0: rel
1663/167772/2673,blk 26 FPW
2021-12-17 18:40:40.522 EST [21365] LOG: startup process (PID 21369) exited with exit code 1
That was after only five loops of the regression tests, so either
I got lucky or the failure probability has increased again.
In any case, it seems clear that the problem exists independently of
Munro's patches, so I don't really think this question should be
considered a blocker for those.
regards, tom lane
[Replies to two emails] On Fri, Dec 10, 2021 at 9:40 PM Ashutosh Sharma <ashu.coek88@gmail.com> wrote: > I am unable to apply these new set of patches on HEAD. Can you please share the rebased patch or if you have any work branchcan you please point it out, I will refer to it for the changes. Hi Ashutosh, Sorry I missed this. Rebase attached, and I also have a public working branch at https://github.com/macdice/postgres/tree/recovery-prefetch-ii . On Fri, Nov 26, 2021 at 11:32 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > It's great you posted a new version of this patch, so I took a look a > brief look at it. The code seems in pretty good shape, I haven't found > any real issues - just two minor comments: > > This seems a bit strange: > > #define DEFAULT_DECODE_BUFFER_SIZE 0x10000 > > Why not to define this as a simple decimal value? Changed to (64 * 1024). > Is there something > special about this particular value, or is it arbitrary? It should be large enough for most records, without being ridiculously large. This means that typical users of XLogReader (pg_waldump, ...) are unlikely to fall back to the "oversized" code path for records that don't fit in the decoding buffer. Comment added. > I guess it's > simply the minimum for wal_decode_buffer_size GUC, but why not to use > the GUC for all places decoding WAL? The GUC is used only by xlog.c for replay (and has a larger default since it can usefully see into the future), but frontend tools and other kinds of backend WAL decoding things (2PC, logical decoding) don't or can't respect the GUC and it didn't seem worth choosing a number for each user, so I needed to pick a default. > FWIW I don't think we include updates to typedefs.list in patches. Seems pretty harmless? And useful to keep around in development branches because I like to pgindent stuff...
Attachment
Thomas Munro <thomas.munro@gmail.com> writes: >> FWIW I don't think we include updates to typedefs.list in patches. > Seems pretty harmless? And useful to keep around in development > branches because I like to pgindent stuff... As far as that goes, my habit is to pull down https://buildfarm.postgresql.org/cgi-bin/typedefs.pl on a regular basis and pgindent against that. There have been some discussions about formalizing that process a bit more, but we've not come to any conclusions. regards, tom lane
Hi, On 2021-12-29 17:29:52 +1300, Thomas Munro wrote: > > FWIW I don't think we include updates to typedefs.list in patches. > > Seems pretty harmless? And useful to keep around in development > branches because I like to pgindent stuff... I think it's even helpful. As long as it's done with a bit of manual oversight, I don't see a meaningful downside of doing so. One needs to be careful to not remove platform dependant typedefs, but that's it. And especially for long-lived feature branches it's much less work to keep the typedefs.list changes in the tree, rather than coming up with them locally over and over / across multiple people working on a branch. Greetings, Andres Freund
On Wed, Dec 29, 2021 at 5:29 PM Thomas Munro <thomas.munro@gmail.com> wrote: > https://github.com/macdice/postgres/tree/recovery-prefetch-ii Here's a rebase. This mostly involved moving hunks over to the new xlogrecovery.c file. One thing that seemed a little strange to me with the new layout is that xlogreader is now a global variable. I followed that pattern and made xlogprefetcher a global variable too, for now. There is one functional change: now I block readahead at records that might change the timeline ID. This removes the need to think about scenarios where "replay TLI" and "read TLI" might differ. I don't know of a concrete problem in that area with the previous version, but the recent introduction of the variable(s) "replayTLI" and associated comments in master made me realise I hadn't analysed the hazards here enough. Since timelines are tricky things and timeline changes are extremely infrequent, it seemed better to simplify matters by putting up a big road block there. I'm now starting to think about committing this soon.
Attachment
On 3/8/22 06:15, Thomas Munro wrote: > On Wed, Dec 29, 2021 at 5:29 PM Thomas Munro <thomas.munro@gmail.com> wrote: >> https://github.com/macdice/postgres/tree/recovery-prefetch-ii > > Here's a rebase. This mostly involved moving hunks over to the new > xlogrecovery.c file. One thing that seemed a little strange to me > with the new layout is that xlogreader is now a global variable. I > followed that pattern and made xlogprefetcher a global variable too, > for now. > > There is one functional change: now I block readahead at records that > might change the timeline ID. This removes the need to think about > scenarios where "replay TLI" and "read TLI" might differ. I don't > know of a concrete problem in that area with the previous version, but > the recent introduction of the variable(s) "replayTLI" and associated > comments in master made me realise I hadn't analysed the hazards here > enough. Since timelines are tricky things and timeline changes are > extremely infrequent, it seemed better to simplify matters by putting > up a big road block there. > > I'm now starting to think about committing this soon. +1. I don't have the capacity/hardware to do more testing at the moment, but all of this looks reasonable. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2022-03-08 18:15:43 +1300, Thomas Munro wrote: > I'm now starting to think about committing this soon. +1 Are you thinking of committing both patches at once, or with a bit of distance? I think something in the regression tests ought to enable recovery_prefetch. 027_stream_regress or 001_stream_rep seem like the obvious candidates? - Andres
Hi, On Tue, Mar 08, 2022 at 06:15:43PM +1300, Thomas Munro wrote: > On Wed, Dec 29, 2021 at 5:29 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > https://github.com/macdice/postgres/tree/recovery-prefetch-ii > > Here's a rebase. This mostly involved moving hunks over to the new > xlogrecovery.c file. One thing that seemed a little strange to me > with the new layout is that xlogreader is now a global variable. I > followed that pattern and made xlogprefetcher a global variable too, > for now. I for now went through 0001, TL;DR the patch looks good to me. I have a few minor comments though, mostly to make things a bit clearer (at least to me). diff --git a/src/bin/pg_waldump/pg_waldump.c b/src/bin/pg_waldump/pg_waldump.c index 2340dc247b..c129df44ac 100644 --- a/src/bin/pg_waldump/pg_waldump.c +++ b/src/bin/pg_waldump/pg_waldump.c @@ -407,10 +407,10 @@ XLogDumpRecordLen(XLogReaderState *record, uint32 *rec_len, uint32 *fpi_len) * add an accessor macro for this. */ *fpi_len = 0; + for (block_id = 0; block_id <= XLogRecMaxBlockId(record); block_id++) { if (XLogRecHasBlockImage(record, block_id)) - *fpi_len += record->blocks[block_id].bimg_len; + *fpi_len += record->record->blocks[block_id].bimg_len; } (and similar in that file, xlogutils.c and xlogreader.c) This could use XLogRecGetBlock? Note that this macro is for now never used. xlogreader.c also has some similar forgotten code that could use XLogRecMaxBlockId. + * See if we can release the last record that was returned by + * XLogNextRecord(), to free up space. + */ +void +XLogReleasePreviousRecord(XLogReaderState *state) The comment seems a bit misleading, as I first understood it as it could be optional even if the record exists. Maybe something more like "Release the last record if any"? + * Remove it from the decoded record queue. It must be the oldest item + * decoded, decode_queue_tail. + */ + record = state->record; + Assert(record == state->decode_queue_tail); + state->record = NULL; + state->decode_queue_tail = record->next; The naming is a bit counter intuitive to me, as before reading the rest of the code I wasn't expecting the item at the tail of the queue to have a next element. Maybe just inverting tail and head would make it clearer? +DecodedXLogRecord * +XLogNextRecord(XLogReaderState *state, char **errormsg) +{ [...] + /* + * state->EndRecPtr is expected to have been set by the last call to + * XLogBeginRead() or XLogNextRecord(), and is the location of the + * error. + */ + + return NULL; The comment should refer to XLogFindNextRecord, not XLogNextRecord? Also, is it worth an assert (likely at the top of the function) for that? XLogRecord * XLogReadRecord(XLogReaderState *state, char **errormsg) +{ [...] + if (decoded) + { + /* + * XLogReadRecord() returns a pointer to the record's header, not the + * actual decoded record. The caller will access the decoded record + * through the XLogRecGetXXX() macros, which reach the decoded + * recorded as xlogreader->record. + */ + Assert(state->record == decoded); + return &decoded->header; I find it a bit weird to mention XLogReadRecord() as it's the current function. +/* + * Allocate space for a decoded record. The only member of the returned + * object that is initialized is the 'oversized' flag, indicating that the + * decoded record wouldn't fit in the decode buffer and must eventually be + * freed explicitly. + * + * Return NULL if there is no space in the decode buffer and allow_oversized + * is false, or if memory allocation fails for an oversized buffer. + */ +static DecodedXLogRecord * +XLogReadRecordAlloc(XLogReaderState *state, size_t xl_tot_len, bool allow_oversized) Is it worth clearly stating that it's the reponsability of the caller to update the decode_buffer_head (with the real size) after a successful decoding of this buffer? + if (unlikely(state->decode_buffer == NULL)) + { + if (state->decode_buffer_size == 0) + state->decode_buffer_size = DEFAULT_DECODE_BUFFER_SIZE; + state->decode_buffer = palloc(state->decode_buffer_size); + state->decode_buffer_head = state->decode_buffer; + state->decode_buffer_tail = state->decode_buffer; + state->free_decode_buffer = true; + } Maybe change XLogReaderSetDecodeBuffer to also handle allocation and use it here too? Otherwise XLogReaderSetDecodeBuffer should probably go in 0002 as the only caller is the recovery prefetching. + return decoded; +} I would find it a bit clearer to explicitly return NULL here. readOff = ReadPageInternal(state, targetPagePtr, Min(targetRecOff + SizeOfXLogRecord, XLOG_BLCKSZ)); - if (readOff < 0) + if (readOff == XLREAD_WOULDBLOCK) + return XLREAD_WOULDBLOCK; + else if (readOff < 0) ReadPageInternal comment should be updated to mention the new XLREAD_WOULDBLOCK possible return value. It's also not particulary obvious why XLogFindNextRecord() doesn't check for this value. AFAICS callers don't (and should never) call it with a nonblocking == true state, maybe add an assert for that? @@ -468,7 +748,7 @@ restart: if (pageHeader->xlp_info & XLP_FIRST_IS_OVERWRITE_CONTRECORD) { state->overwrittenRecPtr = RecPtr; - ResetDecoder(state); + //ResetDecoder(state); AFAICS this is indeed not necessary anymore, so it can be removed? static void ResetDecoder(XLogReaderState *state) { [...] + /* Reset the decoded record queue, freeing any oversized records. */ + while ((r = state->decode_queue_tail)) nit: I think it's better to explicitly check for the assignment being != NULL, and existing code is more frequently written this way AFAICS. +/* Return values from XLogPageReadCB. */ +typedef enum XLogPageReadResultResult typo
On Wed, Mar 9, 2022 at 7:47 PM Julien Rouhaud <rjuju123@gmail.com> wrote:
> I for now went through 0001, TL;DR the patch looks good to me. I have a few
> minor comments though, mostly to make things a bit clearer (at least to me).
Hi Julien,
Thanks for your review of 0001! It gave me a few things to think
about and some good improvements.
> diff --git a/src/bin/pg_waldump/pg_waldump.c b/src/bin/pg_waldump/pg_waldump.c
> index 2340dc247b..c129df44ac 100644
> --- a/src/bin/pg_waldump/pg_waldump.c
> +++ b/src/bin/pg_waldump/pg_waldump.c
> @@ -407,10 +407,10 @@ XLogDumpRecordLen(XLogReaderState *record, uint32 *rec_len, uint32 *fpi_len)
> * add an accessor macro for this.
> */
> *fpi_len = 0;
> + for (block_id = 0; block_id <= XLogRecMaxBlockId(record); block_id++)
> {
> if (XLogRecHasBlockImage(record, block_id))
> - *fpi_len += record->blocks[block_id].bimg_len;
> + *fpi_len += record->record->blocks[block_id].bimg_len;
> }
> (and similar in that file, xlogutils.c and xlogreader.c)
>
> This could use XLogRecGetBlock? Note that this macro is for now never used.
Yeah, I think that is a good idea for pg_waldump.c and xlogutils.c. Done.
> xlogreader.c also has some similar forgotten code that could use
> XLogRecMaxBlockId.
That is true, but I was thinking of it like this: most of the existing
code that interacts with xlogreader.c is working with the old model,
where the XLogReader object holds only one "current" record. For that
reason the XLogRecXXX() macros continue to work as before, implicitly
referring to the record that XLogReadRecord() most recently returned.
For xlogreader.c code, I prefer not to use the XLogRecXXX() macros,
even when referring to the "current" record, since xlogreader.c has
switched to a new multi-record model. In other words, they're sort of
'old API' accessors provided for continuity. Does this make sense?
> + * See if we can release the last record that was returned by
> + * XLogNextRecord(), to free up space.
> + */
> +void
> +XLogReleasePreviousRecord(XLogReaderState *state)
>
> The comment seems a bit misleading, as I first understood it as it could be
> optional even if the record exists. Maybe something more like "Release the
> last record if any"?
Done.
> + * Remove it from the decoded record queue. It must be the oldest item
> + * decoded, decode_queue_tail.
> + */
> + record = state->record;
> + Assert(record == state->decode_queue_tail);
> + state->record = NULL;
> + state->decode_queue_tail = record->next;
>
> The naming is a bit counter intuitive to me, as before reading the rest of the
> code I wasn't expecting the item at the tail of the queue to have a next
> element. Maybe just inverting tail and head would make it clearer?
Yeah, after mulling this over for a day, I agree. I've flipped it around.
Explanation: You're quite right, singly-linked lists traditionally
have a 'tail' that points to null, so it makes sense for new items to
be added there and older items to be consumed from the 'head' end, as
you expected. But... it's also typical (I think?) in ring buffers AKA
circular buffers to insert at the 'head', and remove from the 'tail'.
This code has both a linked-list (the chain of decoded records with a
->next pointer), and the underlying storage, which is a circular
buffer of bytes. I didn't want them to use opposite terminology, and
since I started by writing the ring buffer part, that's where I
finished up... I agree that it's an improvement to flip them.
> +DecodedXLogRecord *
> +XLogNextRecord(XLogReaderState *state, char **errormsg)
> +{
> [...]
> + /*
> + * state->EndRecPtr is expected to have been set by the last call to
> + * XLogBeginRead() or XLogNextRecord(), and is the location of the
> + * error.
> + */
> +
> + return NULL;
>
> The comment should refer to XLogFindNextRecord, not XLogNextRecord?
No, it does mean to refer to the XLogNextRecord() (ie the last time
you called XLogNextRecord and successfully dequeued a record, we put
its end LSN there, so if there is a deferred error, that's the
corresponding LSN). Make sense?
> Also, is it worth an assert (likely at the top of the function) for that?
How could I assert that EndRecPtr has the right value?
> XLogRecord *
> XLogReadRecord(XLogReaderState *state, char **errormsg)
> +{
> [...]
> + if (decoded)
> + {
> + /*
> + * XLogReadRecord() returns a pointer to the record's header, not the
> + * actual decoded record. The caller will access the decoded record
> + * through the XLogRecGetXXX() macros, which reach the decoded
> + * recorded as xlogreader->record.
> + */
> + Assert(state->record == decoded);
> + return &decoded->header;
>
> I find it a bit weird to mention XLogReadRecord() as it's the current function.
Changed to "This function ...".
> +/*
> + * Allocate space for a decoded record. The only member of the returned
> + * object that is initialized is the 'oversized' flag, indicating that the
> + * decoded record wouldn't fit in the decode buffer and must eventually be
> + * freed explicitly.
> + *
> + * Return NULL if there is no space in the decode buffer and allow_oversized
> + * is false, or if memory allocation fails for an oversized buffer.
> + */
> +static DecodedXLogRecord *
> +XLogReadRecordAlloc(XLogReaderState *state, size_t xl_tot_len, bool allow_oversized)
>
> Is it worth clearly stating that it's the reponsability of the caller to update
> the decode_buffer_head (with the real size) after a successful decoding of this
> buffer?
Comment added.
> + if (unlikely(state->decode_buffer == NULL))
> + {
> + if (state->decode_buffer_size == 0)
> + state->decode_buffer_size = DEFAULT_DECODE_BUFFER_SIZE;
> + state->decode_buffer = palloc(state->decode_buffer_size);
> + state->decode_buffer_head = state->decode_buffer;
> + state->decode_buffer_tail = state->decode_buffer;
> + state->free_decode_buffer = true;
> + }
>
> Maybe change XLogReaderSetDecodeBuffer to also handle allocation and use it
> here too? Otherwise XLogReaderSetDecodeBuffer should probably go in 0002 as
> the only caller is the recovery prefetching.
I don't think it matters much?
> + return decoded;
> +}
>
> I would find it a bit clearer to explicitly return NULL here.
Done.
> readOff = ReadPageInternal(state, targetPagePtr,
> Min(targetRecOff + SizeOfXLogRecord, XLOG_BLCKSZ));
> - if (readOff < 0)
> + if (readOff == XLREAD_WOULDBLOCK)
> + return XLREAD_WOULDBLOCK;
> + else if (readOff < 0)
>
> ReadPageInternal comment should be updated to mention the new XLREAD_WOULDBLOCK
> possible return value.
Yeah. Done.
> It's also not particulary obvious why XLogFindNextRecord() doesn't check for
> this value. AFAICS callers don't (and should never) call it with a
> nonblocking == true state, maybe add an assert for that?
Fair point. I have now explicitly cleared that flag. (I don't much
like state->nonblocking, which might be better as an argument to
page_read(), but in fact I don't like the fact that page_read
callbacks are blocking in the first place, which is why I liked
Horiguchi-san's patch to get rid of that... but that can be a subject
for later work.)
> @@ -468,7 +748,7 @@ restart:
> if (pageHeader->xlp_info & XLP_FIRST_IS_OVERWRITE_CONTRECORD)
> {
> state->overwrittenRecPtr = RecPtr;
> - ResetDecoder(state);
> + //ResetDecoder(state);
>
> AFAICS this is indeed not necessary anymore, so it can be removed?
Oops, yeah I use C++ comments when there's something I intended to
remove. Done.
> static void
> ResetDecoder(XLogReaderState *state)
> {
> [...]
> + /* Reset the decoded record queue, freeing any oversized records. */
> + while ((r = state->decode_queue_tail))
>
> nit: I think it's better to explicitly check for the assignment being != NULL,
> and existing code is more frequently written this way AFAICS.
I think it's perfectly normal idiomatic C, but if you think it's
clearer that way, OK, done like that.
> +/* Return values from XLogPageReadCB. */
> +typedef enum XLogPageReadResultResult
>
> typo
Fixed.
I realised that this version has broken -DWAL_DEBUG. I'll fix that
shortly, but I wanted to post this update ASAP, so here's a new
version. The other thing I need to change is that I should turn on
recovery_prefetch for platforms that support it (ie Linux and maybe
NetBSD only for now), in the tests. Right now you need to put
recovery_prefetch=on in a file and then run the tests with
"TEMP_CONFIG=path_to_that make -C src/test/recovery check" to
excercise much of 0002.
Attachment
On Fri, Mar 11, 2022 at 6:31 PM Thomas Munro <thomas.munro@gmail.com> wrote: > Thanks for your review of 0001! It gave me a few things to think > about and some good improvements. And just in case it's useful, here's what changed between v21 and v22..
Attachment
On March 10, 2022 9:31:13 PM PST, Thomas Munro <thomas.munro@gmail.com> wrote: > The other thing I need to change is that I should turn on >recovery_prefetch for platforms that support it (ie Linux and maybe >NetBSD only for now), in the tests. Could a setting of "try" make sense? -- Sent from my Android device with K-9 Mail. Please excuse my brevity.
On Fri, Mar 11, 2022 at 06:31:13PM +1300, Thomas Munro wrote:
> On Wed, Mar 9, 2022 at 7:47 PM Julien Rouhaud <rjuju123@gmail.com> wrote:
> >
> > This could use XLogRecGetBlock? Note that this macro is for now never used.
> > xlogreader.c also has some similar forgotten code that could use
> > XLogRecMaxBlockId.
>
> That is true, but I was thinking of it like this: most of the existing
> code that interacts with xlogreader.c is working with the old model,
> where the XLogReader object holds only one "current" record. For that
> reason the XLogRecXXX() macros continue to work as before, implicitly
> referring to the record that XLogReadRecord() most recently returned.
> For xlogreader.c code, I prefer not to use the XLogRecXXX() macros,
> even when referring to the "current" record, since xlogreader.c has
> switched to a new multi-record model. In other words, they're sort of
> 'old API' accessors provided for continuity. Does this make sense?
Ah I see, it does make sense. I'm wondering if there should be some comment
somewhere on the top of the file to mention it, as otherwise someone may be
tempted to change it to avoid some record->record->xxx usage.
> > +DecodedXLogRecord *
> > +XLogNextRecord(XLogReaderState *state, char **errormsg)
> > +{
> > [...]
> > + /*
> > + * state->EndRecPtr is expected to have been set by the last call to
> > + * XLogBeginRead() or XLogNextRecord(), and is the location of the
> > + * error.
> > + */
> > +
> > + return NULL;
> >
> > The comment should refer to XLogFindNextRecord, not XLogNextRecord?
>
> No, it does mean to refer to the XLogNextRecord() (ie the last time
> you called XLogNextRecord and successfully dequeued a record, we put
> its end LSN there, so if there is a deferred error, that's the
> corresponding LSN). Make sense?
It does, thanks!
>
> > Also, is it worth an assert (likely at the top of the function) for that?
>
> How could I assert that EndRecPtr has the right value?
Sorry, I meant to assert that some value was assigned (!XLogRecPtrIsInvalid).
It can only make sure that the first call is done after XLogBeginRead /
XLogFindNextRecord, but that's better than nothing and consistent with the top
comment.
> > + if (unlikely(state->decode_buffer == NULL))
> > + {
> > + if (state->decode_buffer_size == 0)
> > + state->decode_buffer_size = DEFAULT_DECODE_BUFFER_SIZE;
> > + state->decode_buffer = palloc(state->decode_buffer_size);
> > + state->decode_buffer_head = state->decode_buffer;
> > + state->decode_buffer_tail = state->decode_buffer;
> > + state->free_decode_buffer = true;
> > + }
> >
> > Maybe change XLogReaderSetDecodeBuffer to also handle allocation and use it
> > here too? Otherwise XLogReaderSetDecodeBuffer should probably go in 0002 as
> > the only caller is the recovery prefetching.
>
> I don't think it matters much?
The thing is that for now the only caller to XLogReaderSetDecodeBuffer (in
0002) only uses it to set the length, so a buffer is actually never passed to
that function. Since frontend code can rely on a palloc emulation, is there
really a use case to use e.g. some stack buffer there, or something in a
specific memory context? It seems to be the only use cases for having
XLogReaderSetDecodeBuffer() rather than simply a
XLogReaderSetDecodeBufferSize(). But overall I agree it doesn't matter much,
so no objection to keep it as-is.
> > It's also not particulary obvious why XLogFindNextRecord() doesn't check for
> > this value. AFAICS callers don't (and should never) call it with a
> > nonblocking == true state, maybe add an assert for that?
>
> Fair point. I have now explicitly cleared that flag. (I don't much
> like state->nonblocking, which might be better as an argument to
> page_read(), but in fact I don't like the fact that page_read
> callbacks are blocking in the first place, which is why I liked
> Horiguchi-san's patch to get rid of that... but that can be a subject
> for later work.)
Agreed.
> > static void
> > ResetDecoder(XLogReaderState *state)
> > {
> > [...]
> > + /* Reset the decoded record queue, freeing any oversized records. */
> > + while ((r = state->decode_queue_tail))
> >
> > nit: I think it's better to explicitly check for the assignment being != NULL,
> > and existing code is more frequently written this way AFAICS.
>
> I think it's perfectly normal idiomatic C, but if you think it's
> clearer that way, OK, done like that.
The thing I don't like about this form is that you can never be sure that an
assignment was really meant unless you read the rest of the nearby code. Other
than that agreed, if perfectly normal idiomatic C.
> I realised that this version has broken -DWAL_DEBUG. I'll fix that
> shortly, but I wanted to post this update ASAP, so here's a new
> version.
+ * Returns XLREAD_WOULDBLOCK if he requested data can't be read without
+ * waiting. This can be returned only if the installed page_read callback
typo: "the" requested data.
Other than that it all looks good to me!
> The other thing I need to change is that I should turn on
> recovery_prefetch for platforms that support it (ie Linux and maybe
> NetBSD only for now), in the tests. Right now you need to put
> recovery_prefetch=on in a file and then run the tests with
> "TEMP_CONFIG=path_to_that make -C src/test/recovery check" to
> excercise much of 0002.
+1 with Andres' idea to have a "try" setting.
On Fri, Mar 11, 2022 at 9:27 PM Julien Rouhaud <rjuju123@gmail.com> wrote: > > > Also, is it worth an assert (likely at the top of the function) for that? > > > > How could I assert that EndRecPtr has the right value? > > Sorry, I meant to assert that some value was assigned (!XLogRecPtrIsInvalid). > It can only make sure that the first call is done after XLogBeginRead / > XLogFindNextRecord, but that's better than nothing and consistent with the top > comment. Done. > + * Returns XLREAD_WOULDBLOCK if he requested data can't be read without > + * waiting. This can be returned only if the installed page_read callback > > typo: "the" requested data. Fixed. > Other than that it all looks good to me! Thanks! > > The other thing I need to change is that I should turn on > > recovery_prefetch for platforms that support it (ie Linux and maybe > > NetBSD only for now), in the tests. Right now you need to put > > recovery_prefetch=on in a file and then run the tests with > > "TEMP_CONFIG=path_to_that make -C src/test/recovery check" to > > excercise much of 0002. > > +1 with Andres' idea to have a "try" setting. Done. The default is still "off" for now, but in 027_stream_regress.pl I set it to "try". I also fixed the compile failure with -DWAL_DEBUG, and checked that output looks sane with wal_debug=on.
Attachment
On Mon, Mar 14, 2022 at 06:15:59PM +1300, Thomas Munro wrote: > On Fri, Mar 11, 2022 at 9:27 PM Julien Rouhaud <rjuju123@gmail.com> wrote: > > > > Also, is it worth an assert (likely at the top of the function) for that? > > > > > > How could I assert that EndRecPtr has the right value? > > > > Sorry, I meant to assert that some value was assigned (!XLogRecPtrIsInvalid). > > It can only make sure that the first call is done after XLogBeginRead / > > XLogFindNextRecord, but that's better than nothing and consistent with the top > > comment. > > Done. Just a small detail: I would move that assert at the top of the function as it should always be valid. > > I also fixed the compile failure with -DWAL_DEBUG, and checked that > output looks sane with wal_debug=on. Great! I'm happy with 0001 and I think it's good to go! > > > > The other thing I need to change is that I should turn on > > > recovery_prefetch for platforms that support it (ie Linux and maybe > > > NetBSD only for now), in the tests. Right now you need to put > > > recovery_prefetch=on in a file and then run the tests with > > > "TEMP_CONFIG=path_to_that make -C src/test/recovery check" to > > > excercise much of 0002. > > > > +1 with Andres' idea to have a "try" setting. > > Done. The default is still "off" for now, but in > 027_stream_regress.pl I set it to "try". Great too! Unless you want to commit both patches right now I'd like to review 0002 too (this week), as I barely look into it for now.
On Mon, Mar 14, 2022 at 8:17 PM Julien Rouhaud <rjuju123@gmail.com> wrote: > Great! I'm happy with 0001 and I think it's good to go! I'll push 0001 today to let the build farm chew on it for a few days before moving to 0002.
On Fri, Mar 18, 2022 at 9:59 AM Thomas Munro <thomas.munro@gmail.com> wrote: > I'll push 0001 today to let the build farm chew on it for a few days > before moving to 0002. Clearly 018_wal_optimize.pl is flapping and causing recoveryCheck to fail occasionally, but that predates the above commit. I didn't follow the existing discussion on that, so I'll try to look into that tomorrow. Here's a rebase of the 0002 patch, now called 0001
Attachment
On Sun, Mar 20, 2022 at 5:36 PM Thomas Munro <thomas.munro@gmail.com> wrote: > Clearly 018_wal_optimize.pl is flapping Correction, 019_replslot_limit.pl, discussed at https://www.postgresql.org/message-id/flat/83b46e5f-2a52-86aa-fa6c-8174908174b8%40iki.fi .
Hi,
On Sun, Mar 20, 2022 at 05:36:38PM +1300, Thomas Munro wrote:
> On Fri, Mar 18, 2022 at 9:59 AM Thomas Munro <thomas.munro@gmail.com> wrote:
> > I'll push 0001 today to let the build farm chew on it for a few days
> > before moving to 0002.
>
> Clearly 018_wal_optimize.pl is flapping and causing recoveryCheck to
> fail occasionally, but that predates the above commit. I didn't
> follow the existing discussion on that, so I'll try to look into that
> tomorrow.
>
> Here's a rebase of the 0002 patch, now called 0001
So I finally finished looking at this patch. Here again, AFAICS the feature is
working as expected and I didn't find any problem. I just have some minor
comments, like for the previous patch.
For the docs:
+ Whether to try to prefetch blocks that are referenced in the WAL that
+ are not yet in the buffer pool, during recovery. Valid values are
+ <literal>off</literal> (the default), <literal>on</literal> and
+ <literal>try</literal>. The setting <literal>try</literal> enables
+ prefetching only if the operating system provides the
+ <function>posix_fadvise</function> function, which is currently used
+ to implement prefetching. Note that some operating systems provide the
+ function, but don't actually perform any prefetching.
Is there any reason not to change it to try? I'm wondering if some system says
that the function exists but simply raise an error if you actually try to use
it. I think that at least WSL does that for some functions.
+ <para>
+ The <xref linkend="guc-recovery-prefetch"/> parameter can
+ be used to improve I/O performance during recovery by instructing
+ <productname>PostgreSQL</productname> to initiate reads
+ of disk blocks that will soon be needed but are not currently in
+ <productname>PostgreSQL</productname>'s buffer pool.
+ The <xref linkend="guc-maintenance-io-concurrency"/> and
+ <xref linkend="guc-wal-decode-buffer-size"/> settings limit prefetching
+ concurrency and distance, respectively.
+ By default, prefetching in recovery is disabled.
+ </para>
I think that "improving I/O performance" is a bit misleading, maybe reduce I/O
wait time or something like that? Also, I don't know if we need to be that
precise, but maybe we should say that it's the underlying kernel that will
(asynchronously) initiate the reads, and postgres will simply notifies it.
+ <para>
+ The <structname>pg_stat_prefetch_recovery</structname> view will contain only
+ one row. It is filled with nulls if recovery is not running or WAL
+ prefetching is not enabled. See <xref linkend="guc-recovery-prefetch"/>
+ for more information.
+ </para>
That's not the implemented behavior as far as I can see. It just prints whatever is in SharedStats
regardless of the recovery state or the prefetch_wal setting (assuming that
there's no pending reset request). Similarly, there's a mention that
pg_stat_reset_shared('wal') will reset the stats, but I don't see anything
calling XLogPrefetchRequestResetStats().
Finally, I think we should documented what are the cumulated counters in that
view (that should get reset) and the dynamic counters (that shouldn't get
reset).
For the code:
bool
XLogRecGetBlockTag(XLogReaderState *record, uint8 block_id,
RelFileNode *rnode, ForkNumber *forknum, BlockNumber *blknum)
+{
+ return XLogRecGetBlockInfo(record, block_id, rnode, forknum, blknum, NULL);
+}
+
+bool
+XLogRecGetBlockInfo(XLogReaderState *record, uint8 block_id,
+ RelFileNode *rnode, ForkNumber *forknum,
+ BlockNumber *blknum,
+ Buffer *prefetch_buffer)
{
It's missing comments on that function. XLogRecGetBlockTag comments should
probably be reworded at the same time.
+ReadRecord(XLogPrefetcher *xlogprefetcher, int emode,
bool fetching_ckpt, TimeLineID replayTLI)
{
XLogRecord *record;
+ XLogReaderState *xlogreader = XLogPrefetcherReader(xlogprefetcher);
nit: maybe name it XLogPrefetcherGetReader()?
* containing it (if not open already), and returns true. When end of standby
* mode is triggered by the user, and there is no more WAL available, returns
* false.
+ *
+ * If nonblocking is true, then give up immediately if we can't satisfy the
+ * request, returning XLREAD_WOULDBLOCK instead of waiting.
*/
-static bool
+static XLogPageReadResult
WaitForWALToBecomeAvailable(XLogRecPtr RecPtr, bool randAccess,
The comment still mentions a couple of time returning true/false rather than
XLREAD_*, same for at least XLogPageRead().
@@ -3350,6 +3392,14 @@ WaitForWALToBecomeAvailable(XLogRecPtr RecPtr, bool randAccess,
*/
if (lastSourceFailed)
{
+ /*
+ * Don't allow any retry loops to occur during nonblocking
+ * readahead. Let the caller process everything that has been
+ * decoded already first.
+ */
+ if (nonblocking)
+ return XLREAD_WOULDBLOCK;
Is that really enough? I'm wondering if the code path in ReadRecord() that
forces lastSourceFailed to False while it actually failed when switching into
archive recovery (xlogrecovery.c around line 3044) can be problematic here.
{"wal_decode_buffer_size", PGC_POSTMASTER, WAL_ARCHIVE_RECOVERY,
gettext_noop("Maximum buffer size for reading ahead in the WAL during recovery."),
gettext_noop("This controls the maximum distance we can read ahead in the WAL to prefetch referenced
blocks."),
GUC_UNIT_BYTE
},
&wal_decode_buffer_size,
512 * 1024, 64 * 1024, INT_MAX,
Should the max be MaxAllocSize?
+ /* Do we have a clue where the buffer might be already? */
+ if (BufferIsValid(recent_buffer) &&
+ mode == RBM_NORMAL &&
+ ReadRecentBuffer(rnode, forknum, blkno, recent_buffer))
+ {
+ buffer = recent_buffer;
+ goto recent_buffer_fast_path;
+ }
Should this increment (local|shared)_blks_hit, since ReadRecentBuffer doesn't?
Missed in the previous patch: XLogDecodeNextRecord() isn't a trivial function,
so some comments would be helpful.
xlogprefetcher.c:
+ * data. XLogRecBufferForRedo() cooperates uses information stored in the
+ * decoded record to find buffers efficiently.
I'm not sure what you wanted to say here. Also, I don't see any
XLogRecBufferForRedo() anywhere, I'm assuming it's
XLogReadBufferForRedo?
+/*
+ * A callback that reads ahead in the WAL and tries to initiate one IO.
+ */
+static LsnReadQueueNextStatus
+XLogPrefetcherNextBlock(uintptr_t pgsr_private, XLogRecPtr *lsn)
Should there be a bit more comments about what this function is supposed to
enforce?
I'm wondering if it's a bit overkill to implement this as a callback. Do you
have near future use cases in mind? For now no other code could use the
infrastructure at all as the lrq is private, so some changes will be needed to
make it truly configurable anyway.
If we keep it as a callback, I think it would make sense to extract some part,
like the main prefetch filters / global-limit logic, so other possible
implementations can use it if needed. It would also help to reduce this
function a bit, as it's somewhat long.
Also, about those filters:
+ if (rmid == RM_XLOG_ID)
+ {
+ if (record_type == XLOG_CHECKPOINT_SHUTDOWN ||
+ record_type == XLOG_END_OF_RECOVERY)
+ {
+ /*
+ * These records might change the TLI. Avoid potential
+ * bugs if we were to allow "read TLI" and "replay TLI" to
+ * differ without more analysis.
+ */
+ prefetcher->no_readahead_until = record->lsn;
+ }
+ }
Should there be a note that it's still ok to process this record in the loop
just after, as it won't contain any prefetchable data, or simply jump to the
end of that loop?
+/*
+ * Increment a counter in shared memory. This is equivalent to *counter++ on a
+ * plain uint64 without any memory barrier or locking, except on platforms
+ * where readers can't read uint64 without possibly observing a torn value.
+ */
+static inline void
+XLogPrefetchIncrement(pg_atomic_uint64 *counter)
+{
+ Assert(AmStartupProcess() || !IsUnderPostmaster);
+ pg_atomic_write_u64(counter, pg_atomic_read_u64(counter) + 1);
+}
I'm curious about this one. Is it to avoid expensive locking on platforms that
don't have a lockless pg_atomic_fetch_add_u64?
Also, it's only correct because there can only be a single prefetcher, so you
can't have concurrent increment of the same counter right?
+Datum
+pg_stat_get_prefetch_recovery(PG_FUNCTION_ARGS)
+{
[...]
This function could use the new SetSingleFuncCall() function introduced in
9e98583898c.
And finally:
diff --git a/src/backend/utils/misc/postgresql.conf.sample b/src/backend/utils/misc/postgresql.conf.sample
index 4cf5b26a36..0a6c7bd83e 100644
--- a/src/backend/utils/misc/postgresql.conf.sample
+++ b/src/backend/utils/misc/postgresql.conf.sample
@@ -241,6 +241,11 @@
#max_wal_size = 1GB
#min_wal_size = 80MB
+# - Prefetching during recovery -
+
+#wal_decode_buffer_size = 512kB # lookahead window used for prefetching
This one should be documented as "(change requires restart)"
On Mon, Mar 21, 2022 at 9:29 PM Julien Rouhaud <rjuju123@gmail.com> wrote:
> So I finally finished looking at this patch. Here again, AFAICS the feature is
> working as expected and I didn't find any problem. I just have some minor
> comments, like for the previous patch.
Thanks very much for the review. I've attached a new version
addressing most of your feedback, and also rebasing over the new
WAL-logged CREATE DATABASE. I've also fixed a couple of bugs (see
end).
> For the docs:
>
> + Whether to try to prefetch blocks that are referenced in the WAL that
> + are not yet in the buffer pool, during recovery. Valid values are
> + <literal>off</literal> (the default), <literal>on</literal> and
> + <literal>try</literal>. The setting <literal>try</literal> enables
> + prefetching only if the operating system provides the
> + <function>posix_fadvise</function> function, which is currently used
> + to implement prefetching. Note that some operating systems provide the
> + function, but don't actually perform any prefetching.
>
> Is there any reason not to change it to try? I'm wondering if some system says
> that the function exists but simply raise an error if you actually try to use
> it. I think that at least WSL does that for some functions.
Yeah, we could just default it to try. Whether we should ship that
way is another question, but done for now.
I don't think there are any supported systems that have a
posix_fadvise() that fails with -1, or we'd know about it, because
we already use it in other places. We do support one OS that provides
a dummy function in libc that does nothing at all (Solaris/illumos),
and at least a couple that enter the kernel but are known to do
nothing at all for WILLNEED (AIX, FreeBSD).
> + <para>
> + The <xref linkend="guc-recovery-prefetch"/> parameter can
> + be used to improve I/O performance during recovery by instructing
> + <productname>PostgreSQL</productname> to initiate reads
> + of disk blocks that will soon be needed but are not currently in
> + <productname>PostgreSQL</productname>'s buffer pool.
> + The <xref linkend="guc-maintenance-io-concurrency"/> and
> + <xref linkend="guc-wal-decode-buffer-size"/> settings limit prefetching
> + concurrency and distance, respectively.
> + By default, prefetching in recovery is disabled.
> + </para>
>
> I think that "improving I/O performance" is a bit misleading, maybe reduce I/O
> wait time or something like that? Also, I don't know if we need to be that
> precise, but maybe we should say that it's the underlying kernel that will
> (asynchronously) initiate the reads, and postgres will simply notifies it.
Updated with this new text:
The <xref linkend="guc-recovery-prefetch"/> parameter can be used to reduce
I/O wait times during recovery by instructing the kernel to initiate reads
of disk blocks that will soon be needed but are not currently in
<productname>PostgreSQL</productname>'s buffer pool and will soon be read.
> + <para>
> + The <structname>pg_stat_prefetch_recovery</structname> view will contain only
> + one row. It is filled with nulls if recovery is not running or WAL
> + prefetching is not enabled. See <xref linkend="guc-recovery-prefetch"/>
> + for more information.
> + </para>
>
> That's not the implemented behavior as far as I can see. It just prints whatever is in SharedStats
> regardless of the recovery state or the prefetch_wal setting (assuming that
> there's no pending reset request).
Yeah. Updated text: "It is filled with nulls if recovery has not run
or ...".
> Similarly, there's a mention that
> pg_stat_reset_shared('wal') will reset the stats, but I don't see anything
> calling XLogPrefetchRequestResetStats().
It's 'prefetch_recovery', not 'wal', but yeah, oops, it looks like I
got carried away between v18 and v19 while simplifying the stats and
lost a hunk I should have kept. Fixed.
> Finally, I think we should documented what are the cumulated counters in that
> view (that should get reset) and the dynamic counters (that shouldn't get
> reset).
OK, done.
> For the code:
>
> bool
> XLogRecGetBlockTag(XLogReaderState *record, uint8 block_id,
> RelFileNode *rnode, ForkNumber *forknum, BlockNumber *blknum)
> +{
> + return XLogRecGetBlockInfo(record, block_id, rnode, forknum, blknum, NULL);
> +}
> +
> +bool
> +XLogRecGetBlockInfo(XLogReaderState *record, uint8 block_id,
> + RelFileNode *rnode, ForkNumber *forknum,
> + BlockNumber *blknum,
> + Buffer *prefetch_buffer)
> {
>
> It's missing comments on that function. XLogRecGetBlockTag comments should
> probably be reworded at the same time.
New comment added for XLogRecGetBlockInfo(). Wish I could come up
with a better name for that... Not quite sure what you thought I should
change about XLogRecGetBlockTag().
> +ReadRecord(XLogPrefetcher *xlogprefetcher, int emode,
> bool fetching_ckpt, TimeLineID replayTLI)
> {
> XLogRecord *record;
> + XLogReaderState *xlogreader = XLogPrefetcherReader(xlogprefetcher);
>
> nit: maybe name it XLogPrefetcherGetReader()?
OK.
> * containing it (if not open already), and returns true. When end of standby
> * mode is triggered by the user, and there is no more WAL available, returns
> * false.
> + *
> + * If nonblocking is true, then give up immediately if we can't satisfy the
> + * request, returning XLREAD_WOULDBLOCK instead of waiting.
> */
> -static bool
> +static XLogPageReadResult
> WaitForWALToBecomeAvailable(XLogRecPtr RecPtr, bool randAccess,
>
> The comment still mentions a couple of time returning true/false rather than
> XLREAD_*, same for at least XLogPageRead().
Fixed.
> @@ -3350,6 +3392,14 @@ WaitForWALToBecomeAvailable(XLogRecPtr RecPtr, bool randAccess,
> */
> if (lastSourceFailed)
> {
> + /*
> + * Don't allow any retry loops to occur during nonblocking
> + * readahead. Let the caller process everything that has been
> + * decoded already first.
> + */
> + if (nonblocking)
> + return XLREAD_WOULDBLOCK;
>
> Is that really enough? I'm wondering if the code path in ReadRecord() that
> forces lastSourceFailed to False while it actually failed when switching into
> archive recovery (xlogrecovery.c around line 3044) can be problematic here.
I don't see the problem scenario, could you elaborate?
> {"wal_decode_buffer_size", PGC_POSTMASTER, WAL_ARCHIVE_RECOVERY,
> gettext_noop("Maximum buffer size for reading ahead in the WAL during recovery."),
> gettext_noop("This controls the maximum distance we can read ahead in the WAL to prefetch
referencedblocks."),
> GUC_UNIT_BYTE
> },
> &wal_decode_buffer_size,
> 512 * 1024, 64 * 1024, INT_MAX,
>
> Should the max be MaxAllocSize?
Hmm. OK, done.
> + /* Do we have a clue where the buffer might be already? */
> + if (BufferIsValid(recent_buffer) &&
> + mode == RBM_NORMAL &&
> + ReadRecentBuffer(rnode, forknum, blkno, recent_buffer))
> + {
> + buffer = recent_buffer;
> + goto recent_buffer_fast_path;
> + }
>
> Should this increment (local|shared)_blks_hit, since ReadRecentBuffer doesn't?
Hmm. I guess ReadRecentBuffer() should really do that. Done.
> Missed in the previous patch: XLogDecodeNextRecord() isn't a trivial function,
> so some comments would be helpful.
OK, I'll come back to that.
> xlogprefetcher.c:
>
> + * data. XLogRecBufferForRedo() cooperates uses information stored in the
> + * decoded record to find buffers ently.
>
> I'm not sure what you wanted to say here. Also, I don't see any
> XLogRecBufferForRedo() anywhere, I'm assuming it's
> XLogReadBufferForRedo?
Yeah, typos. I rewrote that comment.
> +/*
> + * A callback that reads ahead in the WAL and tries to initiate one IO.
> + */
> +static LsnReadQueueNextStatus
> +XLogPrefetcherNextBlock(uintptr_t pgsr_private, XLogRecPtr *lsn)
>
> Should there be a bit more comments about what this function is supposed to
> enforce?
I have added a comment to explain.
> I'm wondering if it's a bit overkill to implement this as a callback. Do you
> have near future use cases in mind? For now no other code could use the
> infrastructure at all as the lrq is private, so some changes will be needed to
> make it truly configurable anyway.
Yeah. Actually, in the next step I want to throw away the lrq part,
and keep just the XLogPrefetcherNextBlock() function, with some small
modifications.
Admittedly the control flow is a little confusing, but the point of
this architecture is to separate "how to prefetch one more thing" from
"when to prefetch, considering I/O depth and related constraints".
The first thing, "how", is represented by XLogPrefetcherNextBlock().
The second thing, "when", is represented here by the
LsnReadQueue/lrq_XXX stuff that is private in this file for now, but
later I will propose to replace that second thing with the
pg_streaming_read facility of commitfest entry 38/3316. This is a way
of getting there step by step. I also wrote briefly about that here:
https://www.postgresql.org/message-id/CA%2BhUKGJ7OqpdnbSTq5oK%3DdjSeVW2JMnrVPSm8JC-_dbN6Y7bpw%40mail.gmail.com
> If we keep it as a callback, I think it would make sense to extract some part,
> like the main prefetch filters / global-limit logic, so other possible
> implementations can use it if needed. It would also help to reduce this
> function a bit, as it's somewhat long.
I can't imagine reusing any of those filtering things anywhere else.
I admit that the function is kinda long...
> Also, about those filters:
>
> + if (rmid == RM_XLOG_ID)
> + {
> + if (record_type == XLOG_CHECKPOINT_SHUTDOWN ||
> + record_type == XLOG_END_OF_RECOVERY)
> + {
> + /*
> + * These records might change the TLI. Avoid potential
> + * bugs if we were to allow "read TLI" and "replay TLI" to
> + * differ without more analysis.
> + */
> + prefetcher->no_readahead_until = record->lsn;
> + }
> + }
>
> Should there be a note that it's still ok to process this record in the loop
> just after, as it won't contain any prefetchable data, or simply jump to the
> end of that loop?
Comment added.
> +/*
> + * Increment a counter in shared memory. This is equivalent to *counter++ on a
> + * plain uint64 without any memory barrier or locking, except on platforms
> + * where readers can't read uint64 without possibly observing a torn value.
> + */
> +static inline void
> +XLogPrefetchIncrement(pg_atomic_uint64 *counter)
> +{
> + Assert(AmStartupProcess() || !IsUnderPostmaster);
> + pg_atomic_write_u64(counter, pg_atomic_read_u64(counter) + 1);
> +}
>
> I'm curious about this one. Is it to avoid expensive locking on platforms that
> don't have a lockless pg_atomic_fetch_add_u64?
My goal here is only to make sure that systems without
PG_HAVE_8BYTE_SINGLE_COPY_ATOMICITY don't see bogus/torn values. On
more typical systems, I just want plain old counter++, for the CPU to
feel free to reorder, without the overheads of LOCK XADD.
> +Datum
> +pg_stat_get_prefetch_recovery(PG_FUNCTION_ARGS)
> +{
> [...]
>
> This function could use the new SetSingleFuncCall() function introduced in
> 9e98583898c.
Oh, yeah, that looks much nicer!
> +# - Prefetching during recovery -
> +
> +#wal_decode_buffer_size = 512kB # lookahead window used for prefetching
>
> This one should be documented as "(change requires restart)"
Done.
Other changes:
1. The logic for handling relations and blocks that don't exist
(presumably, yet) wasn't quite right. The previous version could
raise an error in smgrnblocks() if a referenced relation doesn't exist
at all on disk. I don't know how to actually reach that case
(considering the analysis this thing does of SMGR create etc to avoid
touching relations that haven't been created yet), but if it is
possible somehow, then it will handle this gracefully.
To check for missing relations I use smgrexists(). To make that fast,
I changed it to not close segments when in recovery, which is OK
because recovery already closes SMGR relations when replaying anything
that would unlink files.
2. The logic for filtering out access to an entire database wasn't
quite right. In this new version, that's necessary only for
file-based CREATE DATABASE, since that does bulk creation of relations
without any individual WAL records to analyse. This works by using
{inv, dbNode, inv} as a key in the filter hash table, but I was trying
to look things up by {spcNode, dbNode, inv}. Fixed.
3. The handling for XLOG_SMGR_CREATE was firing for every fork, but
it really only needed to fire for the main fork, for now. (There's no
reason at all this thing shouldn't prefetch other forks, that's just
left for later).
4. To make it easier to see the filtering logic at work, I added code
to log messages about that if you #define XLOGPREFETCHER_DEBUG_LEVEL.
Could be extended to show more internal state and events...
5. While retesting various scenarios, it bothered me that big seq
scan UPDATEs would repeatedly issue posix_fadvise() for the same block
(because multiple rows in a page are touched by consecutive records,
and the page doesn't make it into the buffer pool until a bit later).
I resurrected the defences I had against that a few versions back
using a small window of recent prefetches, which I'd originally
developed as a way to avoid explicit prefetches of sequential scans
(prefetch 1, 2, 3, ...). That turned out to be useless superstition
based on ancient discussions in this mailing list, but I think it's
still useful to avoid obviously stupid sequences of repeat system
calls (prefetch 1, 1, 1, ...). So now it has a little one-cache-line
sized window of history, to avoid doing that.
I need to re-profile a few workloads after these changes, and then
there are a couple of bikeshed-colour items:
1. It's completely arbitrary that it limits its lookahead to
maintenance_io_concurrency * 4 blockrefs ahead in the WAL. I have no
principled reason to choose 4. In the AIO version of this (to
follow), that number of blocks finishes up getting pinned at the same
time, so more thought might be needed on that, but that doesn't apply
here yet, so it's a bit arbitrary.
2. Defaults for wal_decode_buffer_size and maintenance_io_concurrency
are likewise arbitrary.
3. At some point in this long thread I was convinced to name the view
pg_stat_prefetch_recovery, but the GUC is called recovery_prefetch.
That seems silly...
Attachment
On Thu, Mar 31, 2022 at 10:49:32PM +1300, Thomas Munro wrote:
> On Mon, Mar 21, 2022 at 9:29 PM Julien Rouhaud <rjuju123@gmail.com> wrote:
> > So I finally finished looking at this patch. Here again, AFAICS the feature is
> > working as expected and I didn't find any problem. I just have some minor
> > comments, like for the previous patch.
>
> Thanks very much for the review. I've attached a new version
> addressing most of your feedback, and also rebasing over the new
> WAL-logged CREATE DATABASE. I've also fixed a couple of bugs (see
> end).
>
> > For the docs:
> >
> > + Whether to try to prefetch blocks that are referenced in the WAL that
> > + are not yet in the buffer pool, during recovery. Valid values are
> > + <literal>off</literal> (the default), <literal>on</literal> and
> > + <literal>try</literal>. The setting <literal>try</literal> enables
> > + prefetching only if the operating system provides the
> > + <function>posix_fadvise</function> function, which is currently used
> > + to implement prefetching. Note that some operating systems provide the
> > + function, but don't actually perform any prefetching.
> >
> > Is there any reason not to change it to try? I'm wondering if some system says
> > that the function exists but simply raise an error if you actually try to use
> > it. I think that at least WSL does that for some functions.
>
> Yeah, we could just default it to try. Whether we should ship that
> way is another question, but done for now.
Should there be an associated pg15 open item for that, when the patch will be
committed? Note that in wal.sgml, the patch still says:
+ [...] By default, prefetching in
+ recovery is disabled.
I guess this should be changed even if we eventually choose to disable it by
default?
> I don't think there are any supported systems that have a
> posix_fadvise() that fails with -1, or we'd know about it, because
> we already use it in other places. We do support one OS that provides
> a dummy function in libc that does nothing at all (Solaris/illumos),
> and at least a couple that enter the kernel but are known to do
> nothing at all for WILLNEED (AIX, FreeBSD).
Ah, I didn't know that, thanks for the info!
> > bool
> > XLogRecGetBlockTag(XLogReaderState *record, uint8 block_id,
> > RelFileNode *rnode, ForkNumber *forknum, BlockNumber *blknum)
> > +{
> > + return XLogRecGetBlockInfo(record, block_id, rnode, forknum, blknum, NULL);
> > +}
> > +
> > +bool
> > +XLogRecGetBlockInfo(XLogReaderState *record, uint8 block_id,
> > + RelFileNode *rnode, ForkNumber *forknum,
> > + BlockNumber *blknum,
> > + Buffer *prefetch_buffer)
> > {
> >
> > It's missing comments on that function. XLogRecGetBlockTag comments should
> > probably be reworded at the same time.
>
> New comment added for XLogRecGetBlockInfo(). Wish I could come up
> with a better name for that... Not quite sure what you thought I should
> change about XLogRecGetBlockTag().
Since XLogRecGetBlockTag is now a wrapper for XLogRecGetBlockInfo, I thought it
would be better to document only the specific behavior for this one (so no
prefetch_buffer), rather than duplicating the whole description in both places.
It seems like a good recipe to miss one of the comments the next time something
is changed there.
For the name, why not the usual XLogRecGetBlockTagExtended()?
> > @@ -3350,6 +3392,14 @@ WaitForWALToBecomeAvailable(XLogRecPtr RecPtr, bool randAccess,
> > */
> > if (lastSourceFailed)
> > {
> > + /*
> > + * Don't allow any retry loops to occur during nonblocking
> > + * readahead. Let the caller process everything that has been
> > + * decoded already first.
> > + */
> > + if (nonblocking)
> > + return XLREAD_WOULDBLOCK;
> >
> > Is that really enough? I'm wondering if the code path in ReadRecord() that
> > forces lastSourceFailed to False while it actually failed when switching into
> > archive recovery (xlogrecovery.c around line 3044) can be problematic here.
>
> I don't see the problem scenario, could you elaborate?
Sorry, I missed that in standby mode ReadRecord would keep going until a record
is found, so no problem indeed.
> > + /* Do we have a clue where the buffer might be already? */
> > + if (BufferIsValid(recent_buffer) &&
> > + mode == RBM_NORMAL &&
> > + ReadRecentBuffer(rnode, forknum, blkno, recent_buffer))
> > + {
> > + buffer = recent_buffer;
> > + goto recent_buffer_fast_path;
> > + }
> >
> > Should this increment (local|shared)_blks_hit, since ReadRecentBuffer doesn't?
>
> Hmm. I guess ReadRecentBuffer() should really do that. Done.
Ah, I also thought it be be better there but was assuming that there was some
possible usage where it's not wanted. Good then!
Should ReadRecentBuffer comment be updated to mention that pgBufferUsage is
incremented as appropriate? FWIW that's the first place I looked when checking
if the stats would be incremented.
> > Missed in the previous patch: XLogDecodeNextRecord() isn't a trivial function,
> > so some comments would be helpful.
>
> OK, I'll come back to that.
Ok!
>
> > +/*
> > + * A callback that reads ahead in the WAL and tries to initiate one IO.
> > + */
> > +static LsnReadQueueNextStatus
> > +XLogPrefetcherNextBlock(uintptr_t pgsr_private, XLogRecPtr *lsn)
> >
> > Should there be a bit more comments about what this function is supposed to
> > enforce?
>
> I have added a comment to explain.
small typos:
+ * Returns LRQ_NEXT_IO if the next block reference and it isn't in the buffer
+ * pool, [...]
I guess s/if the next block/if there's a next block/ or s/and it//.
+ * Returns LRQ_NO_IO if we examined the next block reference and found that it
+ * was already in the buffer pool.
should be LRQ_NEXT_NO_IO, and also this is returned if prefetching is disabled
or it the next block isn't prefetchable.
> > I'm wondering if it's a bit overkill to implement this as a callback. Do you
> > have near future use cases in mind? For now no other code could use the
> > infrastructure at all as the lrq is private, so some changes will be needed to
> > make it truly configurable anyway.
>
> Yeah. Actually, in the next step I want to throw away the lrq part,
> and keep just the XLogPrefetcherNextBlock() function, with some small
> modifications.
Ah I see, that makes sense then.
>
> Admittedly the control flow is a little confusing, but the point of
> this architecture is to separate "how to prefetch one more thing" from
> "when to prefetch, considering I/O depth and related constraints".
> The first thing, "how", is represented by XLogPrefetcherNextBlock().
> The second thing, "when", is represented here by the
> LsnReadQueue/lrq_XXX stuff that is private in this file for now, but
> later I will propose to replace that second thing with the
> pg_streaming_read facility of commitfest entry 38/3316. This is a way
> of getting there step by step. I also wrote briefly about that here:
>
> https://www.postgresql.org/message-id/CA%2BhUKGJ7OqpdnbSTq5oK%3DdjSeVW2JMnrVPSm8JC-_dbN6Y7bpw%40mail.gmail.com
I unsurprisingly didn't read the direct IO patch, and also joined the
prefetching thread quite recently so I missed that mail. Thanks for the
pointer!
>
> > If we keep it as a callback, I think it would make sense to extract some part,
> > like the main prefetch filters / global-limit logic, so other possible
> > implementations can use it if needed. It would also help to reduce this
> > function a bit, as it's somewhat long.
>
> I can't imagine reusing any of those filtering things anywhere else.
> I admit that the function is kinda long...
Yeah, I thought your plan was to provide custom prefetching method or something
like that. As-is, apart from making the function less long it wouldn't do
much.
> Other changes:
> [...]
> 3. The handling for XLOG_SMGR_CREATE was firing for every fork, but
> it really only needed to fire for the main fork, for now. (There's no
> reason at all this thing shouldn't prefetch other forks, that's just
> left for later).
Ah indeed. While at it, should there some comments on top of the file
mentioning that only the main fork is prefetched?
> 4. To make it easier to see the filtering logic at work, I added code
> to log messages about that if you #define XLOGPREFETCHER_DEBUG_LEVEL.
> Could be extended to show more internal state and events...
FTR I also tested the patch defining this. I will probably define it on my
buildfarm animal when the patch is committed to make sure it doesn't get
broken.
> 5. While retesting various scenarios, it bothered me that big seq
> scan UPDATEs would repeatedly issue posix_fadvise() for the same block
> (because multiple rows in a page are touched by consecutive records,
> and the page doesn't make it into the buffer pool until a bit later).
> I resurrected the defences I had against that a few versions back
> using a small window of recent prefetches, which I'd originally
> developed as a way to avoid explicit prefetches of sequential scans
> (prefetch 1, 2, 3, ...). That turned out to be useless superstition
> based on ancient discussions in this mailing list, but I think it's
> still useful to avoid obviously stupid sequences of repeat system
> calls (prefetch 1, 1, 1, ...). So now it has a little one-cache-line
> sized window of history, to avoid doing that.
Nice!
+ * To detect repeat access to the same block and skip useless extra system
+ * calls, we remember a small windows of recently prefetched blocks.
Should it be "repeated" access, and small window (singular)?
Also, I'm wondering if the "seq" part of the related pieces is a bit too much
specific, as there could be other workloads that lead to repeated update of the
same blocks. Maybe it's ok to use it for internal variables, but the new
skip_seq field seems a bit too obscure for some user facing thing. Maybe
skip_same, skip_repeated or something like that?
> I need to re-profile a few workloads after these changes, and then
> there are a couple of bikeshed-colour items:
>
> 1. It's completely arbitrary that it limits its lookahead to
> maintenance_io_concurrency * 4 blockrefs ahead in the WAL. I have no
> principled reason to choose 4. In the AIO version of this (to
> follow), that number of blocks finishes up getting pinned at the same
> time, so more thought might be needed on that, but that doesn't apply
> here yet, so it's a bit arbitrary.
Yeah, I don't see that as a blocker for now. Maybe use some #define to make it
more obvious though, as it's a bit hidden in the code right now?
> 3. At some point in this long thread I was convinced to name the view
> pg_stat_prefetch_recovery, but the GUC is called recovery_prefetch.
> That seems silly...
FWIW I prefer recovery_prefetch to prefetch_recovery.
On Mon, Apr 4, 2022 at 3:12 PM Julien Rouhaud <rjuju123@gmail.com> wrote: > [review] Thanks! I took almost all of your suggestions about renaming things, comments, docs and moving a magic number into a macro. Minor changes: 1. Rebased over the shmem stats changes and others that have just landed today (woo!). The way my simple SharedStats object works and is reset looks a little primitive next to the shiny new stats infrastructure, but I can always adjust that in a follow-up patch if required. 2. It was a bit annoying that the pg_stat_recovery_prefetch view would sometimes show stale numbers when waiting for WAL to be streamed, since that happens at arbitrary points X bytes apart in the WAL. Now it also happens before sleeping/waiting and when recovery ends. 3. Last year, commit a55a9847 synchronised config.sgml with guc.c's categories. A couple of hunks in there that modified the previous version of this work before it all got reverted. So I've re-added the WAL_RECOVERY GUC category, to match the new section in config.sgml. About test coverage, the most interesting lines of xlogprefetcher.c that stand out as unreached in a gcov report are in the special handling for the new CREATE DATABASE in file-copy mode -- but that's probably something to raise in the thread that introduced that new functionality without a test. I've tested that code locally; if you define XLOGPREFETCHER_DEBUG_LEVEL you'll see that it won't touch anything in the new database until recovery has replayed the file-copy. As for current CI-vs-buildfarm blind spots that recently bit me and others, I also tested -m32 and -fsanitize=undefined,unaligned builds. I reran one of the quick pgbench/crash/drop-caches/recover tests I had lying around and saw a 17s -> 6s speedup with FPW off (you need much longer tests to see speedup with them on, so this is a good way for quick sanity checks -- see Tomas V's results for long runs with FPWs and curved effects). With that... I've finally pushed the 0002 patch and will be watching the build farm.
The docs seem to be wrong about the default.
+ are not yet in the buffer pool, during recovery. Valid values are
+ <literal>off</literal> (the default), <literal>on</literal> and
+ <literal>try</literal>. The setting <literal>try</literal> enables
+ concurrency and distance, respectively. By default, it is set to
+ <literal>try</literal>, which enabled the feature on systems where
+ <function>posix_fadvise</function> is available.
Should say "which enables".
+ {
+ {"recovery_prefetch", PGC_SIGHUP, WAL_RECOVERY,
+ gettext_noop("Prefetch referenced blocks during recovery"),
+ gettext_noop("Look ahead in the WAL to find references to uncached data.")
+ },
+ &recovery_prefetch,
+ RECOVERY_PREFETCH_TRY, recovery_prefetch_options,
+ check_recovery_prefetch, assign_recovery_prefetch, NULL
+ },
Curiously, I reported a similar issue last year.
On Thu, Apr 08, 2021 at 10:37:04PM -0500, Justin Pryzby wrote:
> --- a/doc/src/sgml/wal.sgml
> +++ b/doc/src/sgml/wal.sgml
> @@ -816,9 +816,7 @@
> prefetching mechanism is most likely to be effective on systems
> with <varname>full_page_writes</varname> set to
> <varname>off</varname> (where that is safe), and where the working
> - set is larger than RAM. By default, prefetching in recovery is enabled
> - on operating systems that have <function>posix_fadvise</function>
> - support.
> + set is larger than RAM. By default, prefetching in recovery is disabled.
> </para>
> </sect1>
On Fri, Apr 8, 2022 at 12:55 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > The docs seem to be wrong about the default. > > + are not yet in the buffer pool, during recovery. Valid values are > + <literal>off</literal> (the default), <literal>on</literal> and > + <literal>try</literal>. The setting <literal>try</literal> enables Fixed. > + concurrency and distance, respectively. By default, it is set to > + <literal>try</literal>, which enabled the feature on systems where > + <function>posix_fadvise</function> is available. > > Should say "which enables". Fixed. > Curiously, I reported a similar issue last year. Sorry. I guess both times we only agreed on what the default should be in the final review round before commit, and I let the docs get out of sync (well, the default is mentioned in two places and I apparently ended my search too soon, changing only one). I also found another recently obsoleted sentence: the one about showing nulls sometimes was no longer true. Removed.
Hi, Thank you for developing the great feature. I tested this feature and checked the documentation. Currently, the documentationfor the pg_stat_prefetch_recovery view is included in the description for the pg_stat_subscription view. https://www.postgresql.org/docs/devel/monitoring-stats.html#MONITORING-PG-STAT-SUBSCRIPTION It is also not displayed in the list of "28.2. The Statistics Collector". https://www.postgresql.org/docs/devel/monitoring.html The attached patch modifies the pg_stat_prefetch_recovery view to appear as a separate view. Regards, Noriyoshi Shinoda -----Original Message----- From: Thomas Munro <thomas.munro@gmail.com> Sent: Friday, April 8, 2022 10:47 AM To: Justin Pryzby <pryzby@telsasoft.com> Cc: Tomas Vondra <tomas.vondra@enterprisedb.com>; Stephen Frost <sfrost@snowman.net>; Andres Freund <andres@anarazel.de>;Jakub Wartak <Jakub.Wartak@tomtom.com>; Alvaro Herrera <alvherre@2ndquadrant.com>; Tomas Vondra <tomas.vondra@2ndquadrant.com>;Dmitry Dolgov <9erthalion6@gmail.com>; David Steele <david@pgmasters.net>; pgsql-hackers <pgsql-hackers@postgresql.org> Subject: Re: WIP: WAL prefetch (another approach) On Fri, Apr 8, 2022 at 12:55 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > The docs seem to be wrong about the default. > > + are not yet in the buffer pool, during recovery. Valid values are > + <literal>off</literal> (the default), <literal>on</literal> and > + <literal>try</literal>. The setting <literal>try</literal> > + enables Fixed. > + concurrency and distance, respectively. By default, it is set to > + <literal>try</literal>, which enabled the feature on systems where > + <function>posix_fadvise</function> is available. > > Should say "which enables". Fixed. > Curiously, I reported a similar issue last year. Sorry. I guess both times we only agreed on what the default should be in the final review round before commit, and I letthe docs get out of sync (well, the default is mentioned in two places and I apparently ended my search too soon, changingonly one). I also found another recently obsoleted sentence: the one about showing nulls sometimes was no longertrue. Removed.
Attachment
On Tue, Apr 12, 2022 at 9:03 PM Shinoda, Noriyoshi (PN Japan FSIP) <noriyoshi.shinoda@hpe.com> wrote: > Thank you for developing the great feature. I tested this feature and checked the documentation. Currently, the documentationfor the pg_stat_prefetch_recovery view is included in the description for the pg_stat_subscription view. > > https://www.postgresql.org/docs/devel/monitoring-stats.html#MONITORING-PG-STAT-SUBSCRIPTION Hi! Thanks. I had just committed a fix before I saw your message, because there was already another report here: https://www.postgresql.org/message-id/flat/CAKrAKeVk-LRHMdyT6x_p33eF6dCorM2jed5h_eHdRdv0reSYTA%40mail.gmail.com
Hi, Thank you for your reply. I missed the message, sorry. Regards, Noriyoshi Shinoda -----Original Message----- From: Thomas Munro <thomas.munro@gmail.com> Sent: Tuesday, April 12, 2022 6:28 PM To: Shinoda, Noriyoshi (PN Japan FSIP) <noriyoshi.shinoda@hpe.com> Cc: Justin Pryzby <pryzby@telsasoft.com>; Tomas Vondra <tomas.vondra@enterprisedb.com>; Stephen Frost <sfrost@snowman.net>;Andres Freund <andres@anarazel.de>; Jakub Wartak <Jakub.Wartak@tomtom.com>; Alvaro Herrera <alvherre@2ndquadrant.com>;Tomas Vondra <tomas.vondra@2ndquadrant.com>; Dmitry Dolgov <9erthalion6@gmail.com>; David Steele<david@pgmasters.net>; pgsql-hackers <pgsql-hackers@postgresql.org> Subject: Re: WIP: WAL prefetch (another approach) On Tue, Apr 12, 2022 at 9:03 PM Shinoda, Noriyoshi (PN Japan FSIP) <noriyoshi.shinoda@hpe.com> wrote: > Thank you for developing the great feature. I tested this feature and checked the documentation. Currently, the documentationfor the pg_stat_prefetch_recovery view is included in the description for the pg_stat_subscription view. > > INVALID URI REMOVED > toring-stats.html*MONITORING-PG-STAT-SUBSCRIPTION__;Iw!!NpxR!xRu7zc4Hc > ZppB-32Fp3YfESPqJ7B4AOP_RF7QuYP-kCWidoiJ5txu9CW8sX61TfwddE$ Hi! Thanks. I had just committed a fix before I saw your message, because there was already another report here: https://www.postgresql.org/message-id/flat/CAKrAKeVk-LRHMdyT6x_p33eF6dCorM2jed5h_eHdRdv0reSYTA@mail.gmail.com
On Thu, 7 Apr 2022 at 08:46, Thomas Munro <thomas.munro@gmail.com> wrote: > With that... I've finally pushed the 0002 patch and will be watching > the build farm. This is a nice feature if it is safe to turn off full_page_writes. When is it safe to do that? On which platform? I am not aware of any released software that allows full_page_writes to be safely disabled. Perhaps something has been released recently that allows this? I think we have substantial documentation about safety of other settings, so we should carefully document things here also. -- Simon Riggs http://www.EnterpriseDB.com/
On 4/12/22 15:58, Simon Riggs wrote: > On Thu, 7 Apr 2022 at 08:46, Thomas Munro <thomas.munro@gmail.com> wrote: > >> With that... I've finally pushed the 0002 patch and will be watching >> the build farm. > > This is a nice feature if it is safe to turn off full_page_writes. > > When is it safe to do that? On which platform? > > I am not aware of any released software that allows full_page_writes > to be safely disabled. Perhaps something has been released recently > that allows this? I think we have substantial documentation about > safety of other settings, so we should carefully document things here > also. > I don't see why/how would an async prefetch make FPW unnecessary. Did anyone claim that be the case? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, 12 Apr 2022 at 16:41, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 4/12/22 15:58, Simon Riggs wrote: > > On Thu, 7 Apr 2022 at 08:46, Thomas Munro <thomas.munro@gmail.com> wrote: > > > >> With that... I've finally pushed the 0002 patch and will be watching > >> the build farm. > > > > This is a nice feature if it is safe to turn off full_page_writes. > > > > When is it safe to do that? On which platform? > > > > I am not aware of any released software that allows full_page_writes > > to be safely disabled. Perhaps something has been released recently > > that allows this? I think we have substantial documentation about > > safety of other settings, so we should carefully document things here > > also. > > > > I don't see why/how would an async prefetch make FPW unnecessary. Did > anyone claim that be the case? Other way around. FPWs make prefetch unnecessary. Therefore you would only want prefetch with FPW=off, AFAIK. Or put this another way: when is it safe and sensible to use recovery_prefetch != off? -- Simon Riggs http://www.EnterpriseDB.com/
Simon Riggs <simon.riggs@enterprisedb.com> writes: > On Thu, 7 Apr 2022 at 08:46, Thomas Munro <thomas.munro@gmail.com> wrote: > >> With that... I've finally pushed the 0002 patch and will be watching >> the build farm. > > This is a nice feature if it is safe to turn off full_page_writes. > > When is it safe to do that? On which platform? > > I am not aware of any released software that allows full_page_writes > to be safely disabled. Perhaps something has been released recently > that allows this? I think we have substantial documentation about > safety of other settings, so we should carefully document things here > also. Our WAL reliability docs claim that ZFS is safe against torn pages: https://www.postgresql.org/docs/current/wal-reliability.html: If you have file-system software that prevents partial page writes (e.g., ZFS), you can turn off this page imaging by turning off the full_page_writes parameter. - ilmari
On 4/12/22 17:46, Simon Riggs wrote: > On Tue, 12 Apr 2022 at 16:41, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 4/12/22 15:58, Simon Riggs wrote: >>> On Thu, 7 Apr 2022 at 08:46, Thomas Munro <thomas.munro@gmail.com> wrote: >>> >>>> With that... I've finally pushed the 0002 patch and will be watching >>>> the build farm. >>> >>> This is a nice feature if it is safe to turn off full_page_writes. >>> >>> When is it safe to do that? On which platform? >>> >>> I am not aware of any released software that allows full_page_writes >>> to be safely disabled. Perhaps something has been released recently >>> that allows this? I think we have substantial documentation about >>> safety of other settings, so we should carefully document things here >>> also. >>> >> >> I don't see why/how would an async prefetch make FPW unnecessary. Did >> anyone claim that be the case? > > Other way around. FPWs make prefetch unnecessary. > Therefore you would only want prefetch with FPW=off, AFAIK. > > Or put this another way: when is it safe and sensible to use > recovery_prefetch != off? > That assumes the FPI stays in memory until the next modification, and that can be untrue for a number of reasons. Long checkpoint interval with enough random accesses in between is a nice example. See the benchmarks I did a year ago (regular pgbench). Or imagine a r/o replica used to run analytics queries, that access so much data it evicts the buffers initialized by the FPI records. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Other way around. FPWs make prefetch unnecessary.
Therefore you would only want prefetch with FPW=off, AFAIK.
A few scenarios I can imagine page prefetch can help are, 1/ A DR replica instance that is smaller instance size than primary. Page prefetch can bring the pages back into memory in advance when they are evicted. This speeds up the replay and is cost effective. 2/ Allows larger checkpoint_timeout for the same recovery SLA and perhaps improved performance? 3/ WAL prefetch (not pages by itself) can improve replay by itself (not sure if it was measured in isolation, Tomas V can comment on it). 4/ Read replica running analytical workload scenario Tomas V mentioned earlier.
Or put this another way: when is it safe and sensible to use
recovery_prefetch != off?
When checkpoint_timeout is set large and under heavy write activity, on a read replica that has working set higher than the memory and receiving constant updates from primary. This covers 1 & 4 above.
--
Simon Riggs http://www.EnterpriseDB.com/
On Wed, Apr 13, 2022 at 3:57 AM Dagfinn Ilmari Mannsåker <ilmari@ilmari.org> wrote: > Simon Riggs <simon.riggs@enterprisedb.com> writes: > > This is a nice feature if it is safe to turn off full_page_writes. As other have said/shown, it does also help if a block with FPW is evicted and then read back in during one checkpoint cycle, in other words if the working set is larger than shared buffers. This also provides infrastructure for proposals in the next cycle, as part of commitfest #3316: * in direct I/O mode, I/O stalls become more likely due to lack of kernel prefetching/double-buffering, so prefetching becomes more essential * even in buffered I/O mode when benefiting from free double-buffering, the copy from kernel buffer to user space buffer can be finished in the background instead of calling pread() when you need the page, but you need to start it sooner * adjacent blocks accessed by nearby records can be merged into a single scatter-read, for example with preadv() in the background * repeated buffer lookups, pins, locks (and maybe eventually replay) to the same page can be consolidated Pie-in-the-sky ideas: * someone might eventually want to be able to replay in parallel (hard, but certainly requires lookahead) * I sure hope we'll eventually use different techniques for torn-page protection to avoid the high online costs of FPW > > When is it safe to do that? On which platform? > > > > I am not aware of any released software that allows full_page_writes > > to be safely disabled. Perhaps something has been released recently > > that allows this? I think we have substantial documentation about > > safety of other settings, so we should carefully document things here > > also. > > Our WAL reliability docs claim that ZFS is safe against torn pages: > > https://www.postgresql.org/docs/current/wal-reliability.html: > > If you have file-system software that prevents partial page writes > (e.g., ZFS), you can turn off this page imaging by turning off the > full_page_writes parameter. Unfortunately, posix_fadvise(WILLNEED) doesn't do anything on ZFS right now :-(. I have some patches to fix that on Linux[1] and FreeBSD and it seems like there's a good chance of getting them committed based on feedback, but it needs some more work on tests and mmap integration. If anyone's interested in helping get that landed faster, please ping me off-list. [1] https://github.com/openzfs/zfs/pull/9807
I believe that the WAL prefetch patch probably accounts for the
intermittent errors that buildfarm member topminnow has shown
since it went in, eg [1]:
diff -U3 /home/nm/ext4/HEAD/pgsql/contrib/pg_walinspect/expected/pg_walinspect.out
/home/nm/ext4/HEAD/pgsql.build/contrib/pg_walinspect/results/pg_walinspect.out
--- /home/nm/ext4/HEAD/pgsql/contrib/pg_walinspect/expected/pg_walinspect.out 2022-04-10 03:05:15.972622440 +0200
+++ /home/nm/ext4/HEAD/pgsql.build/contrib/pg_walinspect/results/pg_walinspect.out 2022-04-25 05:09:49.861642059
+0200
@@ -34,11 +34,7 @@
(1 row)
SELECT COUNT(*) >= 0 AS ok FROM pg_get_wal_records_info_till_end_of_wal(:'wal_lsn1');
- ok
-----
- t
-(1 row)
-
+ERROR: could not read WAL at 0/1903E40
SELECT COUNT(*) >= 0 AS ok FROM pg_get_wal_stats(:'wal_lsn1', :'wal_lsn2');
ok
----
@@ -46,11 +42,7 @@
(1 row)
SELECT COUNT(*) >= 0 AS ok FROM pg_get_wal_stats_till_end_of_wal(:'wal_lsn1');
- ok
-----
- t
-(1 row)
-
+ERROR: could not read WAL at 0/1903E40
-- ===================================================================
-- Test for filtering out WAL records of a particular table
-- ===================================================================
I've reproduced this manually on that machine, and confirmed that the
proximate cause is that XLogNextRecord() is returning NULL because
state->decode_queue_head == NULL, without bothering to provide an errormsg
(which doesn't seem very well thought out in itself). I obtained the
contents of the xlogreader struct at failure:
(gdb) p *xlogreader
$1 = {routine = {page_read = 0x594270 <read_local_xlog_page_no_wait>,
segment_open = 0x593b44 <wal_segment_open>,
segment_close = 0x593d38 <wal_segment_close>}, system_identifier = 0,
private_data = 0x0, ReadRecPtr = 26230672, EndRecPtr = 26230752,
abortedRecPtr = 26230752, missingContrecPtr = 26230784,
overwrittenRecPtr = 0, DecodeRecPtr = 26230672, NextRecPtr = 26230752,
PrevRecPtr = 0, record = 0x0, decode_buffer = 0xf25428 "\240",
decode_buffer_size = 65536, free_decode_buffer = true,
decode_buffer_head = 0xf25428 "\240", decode_buffer_tail = 0xf25428 "\240",
decode_queue_head = 0x0, decode_queue_tail = 0x0,
readBuf = 0xf173f0 "\020\321\005", readLen = 0, segcxt = {
ws_dir = '\000' <repeats 1023 times>, ws_segsize = 16777216}, seg = {
ws_file = 25, ws_segno = 0, ws_tli = 1}, segoff = 0,
latestPagePtr = 26222592, latestPageTLI = 1, currRecPtr = 26230752,
currTLI = 1, currTLIValidUntil = 0, nextTLI = 0,
readRecordBuf = 0xf1b3f8 "<", readRecordBufSize = 40960,
errormsg_buf = 0xef3270 "", errormsg_deferred = false, nonblocking = false}
I don't have an intuition about where to look beyond that, any
suggestions?
What I do know so far is that while the failure reproduces fairly
reliably under "make check" (more than half the time, which squares
with topminnow's history), it doesn't reproduce at all under "make
installcheck" (after removing NO_INSTALLCHECK), which seems odd.
Maybe it's dependent on how much WAL history the installation has
accumulated?
It could be that this is a bug in pg_walinspect or a fault in its
test case; hard to tell since that got committed at about the same
time as the prefetch changes.
regards, tom lane
[1] https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=topminnow&dt=2022-04-25%2001%3A48%3A47
Oh, one more bit of data: here's an excerpt from pg_waldump output after
the failed test:
rmgr: Btree len (rec/tot): 72/ 72, tx: 727, lsn: 0/01903BC8, prev 0/01903B70, desc: INSERT_LEAF off
111,blkref #0: rel 1663/16384/2673 blk 9
rmgr: Btree len (rec/tot): 72/ 72, tx: 727, lsn: 0/01903C10, prev 0/01903BC8, desc: INSERT_LEAF off
141,blkref #0: rel 1663/16384/2674 blk 7
rmgr: Standby len (rec/tot): 42/ 42, tx: 727, lsn: 0/01903C58, prev 0/01903C10, desc: LOCK xid 727 db
16384rel 16391
rmgr: Transaction len (rec/tot): 437/ 437, tx: 727, lsn: 0/01903C88, prev 0/01903C58, desc: COMMIT
2022-04-2520:16:03.374197 CEST; inval msgs: catcache 80 catcache 79 catcache 80 catcache 79 catcache 55 catcache 54
catcache7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7
catcache6 catcache 7 catcache 6 catcache 7 catcache 6 snapshot 2608 relcache 16391
rmgr: Heap len (rec/tot): 59/ 59, tx: 728, lsn: 0/01903E40, prev 0/01903C88, desc: INSERT+INIT off
1flags 0x00, blkref #0: rel 1663/16384/16391 blk 0
rmgr: Heap len (rec/tot): 59/ 59, tx: 728, lsn: 0/01903E80, prev 0/01903E40, desc: INSERT off 2
flags0x00, blkref #0: rel 1663/16384/16391 blk 0
rmgr: Transaction len (rec/tot): 34/ 34, tx: 728, lsn: 0/01903EC0, prev 0/01903E80, desc: COMMIT
2022-04-2520:16:03.379323 CEST
rmgr: Heap len (rec/tot): 59/ 59, tx: 729, lsn: 0/01903EE8, prev 0/01903EC0, desc: INSERT off 3
flags0x00, blkref #0: rel 1663/16384/16391 blk 0
rmgr: Heap len (rec/tot): 59/ 59, tx: 729, lsn: 0/01903F28, prev 0/01903EE8, desc: INSERT off 4
flags0x00, blkref #0: rel 1663/16384/16391 blk 0
rmgr: Transaction len (rec/tot): 34/ 34, tx: 729, lsn: 0/01903F68, prev 0/01903F28, desc: COMMIT
2022-04-2520:16:03.381720 CEST
The error is complaining about not being able to read 0/01903E40,
which AFAICT is from the first "INSERT INTO sample_tbl" command,
which most certainly ought to be down to disk at this point.
Also, I modified the test script to see what WAL LSNs it thought
it was dealing with, and got
+\echo 'wal_lsn1 = ' :wal_lsn1
+wal_lsn1 = 0/1903E40
+\echo 'wal_lsn2 = ' :wal_lsn2
+wal_lsn2 = 0/1903EE8
confirming that idea of where 0/01903E40 is in the WAL history.
So this is sure looking like a bug somewhere in xlogreader.c,
not in pg_walinspect.
regards, tom lane
On Tue, Apr 26, 2022 at 6:11 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > I believe that the WAL prefetch patch probably accounts for the > intermittent errors that buildfarm member topminnow has shown > since it went in, eg [1]: > > diff -U3 /home/nm/ext4/HEAD/pgsql/contrib/pg_walinspect/expected/pg_walinspect.out /home/nm/ext4/HEAD/pgsql.build/contrib/pg_walinspect/results/pg_walinspect.out Hmm, maybe but I suspect not. I think I might see what's happening here. > +ERROR: could not read WAL at 0/1903E40 > I've reproduced this manually on that machine, and confirmed that the > proximate cause is that XLogNextRecord() is returning NULL because > state->decode_queue_head == NULL, without bothering to provide an errormsg > (which doesn't seem very well thought out in itself). I obtained the Thanks for doing that. After several hours of trying I also managed to reproduce it on that gcc23 system (not at all sure why it doesn't show up elsewhere; MIPS 32 bit layout may be a factor), and added some trace to get some more clues. Still looking into it, but here is the current hypothesis I'm testing: 1. The reason there's a messageless ERROR in this case is because there is new read_page callback logic introduced for pg_walinspect, called via read_local_xlog_page_no_wait(), which is like the old read_local_xlog_page() except that it returns -1 if you try to read past the current "flushed" LSN, and we have no queued message. An error is then reported by XLogReadRecord(), and appears to the user. 2. The reason pg_walinspect tries to read WAL data past the flushed LSN is because its GetWALRecordsInfo() function keeps calling XLogReadRecord() until EndRecPtr >= end_lsn, where end_lsn is taken from a snapshot of the flushed LSN, but I don't see where it takes into account that the flushed LSN might momentarily fall in the middle of a record. In that case, xlogreader.c will try to read the next page, which fails because it's past the flushed LSN (see point 1). I will poke some more tomorrow to try to confirm this and try to come up with a fix.
On Tue, Apr 26, 2022 at 6:11 PM Thomas Munro <thomas.munro@gmail.com> wrote: > I will poke some more tomorrow to try to confirm this and try to come > up with a fix. Done, and moved over to the pg_walinspect commit thread to reach the right eyeballs: https://www.postgresql.org/message-id/CA%2BhUKGLtswFk9ZO3WMOqnDkGs6dK5kCdQK9gxJm0N8gip5cpiA%40mail.gmail.com
On Wed, Apr 13, 2022 at 8:05 AM Thomas Munro <thomas.munro@gmail.com> wrote: > On Wed, Apr 13, 2022 at 3:57 AM Dagfinn Ilmari Mannsåker > <ilmari@ilmari.org> wrote: > > Simon Riggs <simon.riggs@enterprisedb.com> writes: > > > This is a nice feature if it is safe to turn off full_page_writes. > > > When is it safe to do that? On which platform? > > > > > > I am not aware of any released software that allows full_page_writes > > > to be safely disabled. Perhaps something has been released recently > > > that allows this? I think we have substantial documentation about > > > safety of other settings, so we should carefully document things here > > > also. > > > > Our WAL reliability docs claim that ZFS is safe against torn pages: > > > > https://www.postgresql.org/docs/current/wal-reliability.html: > > > > If you have file-system software that prevents partial page writes > > (e.g., ZFS), you can turn off this page imaging by turning off the > > full_page_writes parameter. > > Unfortunately, posix_fadvise(WILLNEED) doesn't do anything on ZFS > right now :-(. Update: OpenZFS now has this working in its master branch (Linux only for now), so fingers crossed for the next release.