Re: WIP: WAL prefetch (another approach) - Mailing list pgsql-hackers
| From | Tomas Vondra |
|---|---|
| Subject | Re: WIP: WAL prefetch (another approach) |
| Date | |
| Msg-id | 20201010112935.qrhm572v4djrjljo@development Whole thread |
| In response to | Re: WIP: WAL prefetch (another approach) (Thomas Munro <thomas.munro@gmail.com>) |
| Responses |
Re: WIP: WAL prefetch (another approach)
|
| List | pgsql-hackers |
Hi,
I repeated the same testing I did before - I started with a 32GB pgbench
database with archiving, run a pgbench for 1h to generate plenty of WAL,
and then performed recovery from a snapshot + archived WAL on different
storage types. The instance was running on NVMe SSD, allowing it ro
generate ~200GB of WAL in 1h.
The recovery was done on two storage types - SATA RAID0 with 3 x 7.2k
spinning drives and NVMe SSD. On each storage I tested three configs -
disabled prefetching, defaults and increased values:
wal_decode_buffer_size = 4MB (so 8x the default)
maintenance_io_concurrency = 100 (so 10x the default)
FWIW there's a bunch of issues with the GUCs - the .conf.sample file
does not include e.g. recovery_prefetch, and instead includes
#max_recovery_prefetch_distance which was however replaced by
wal_decode_buffer_size. Another thing is that the actual default value
differ from the docs - e.g. the docs say that wal_decode_buffer_size is
256kB by default, when in fact it's 512kB.
Now, some results ...
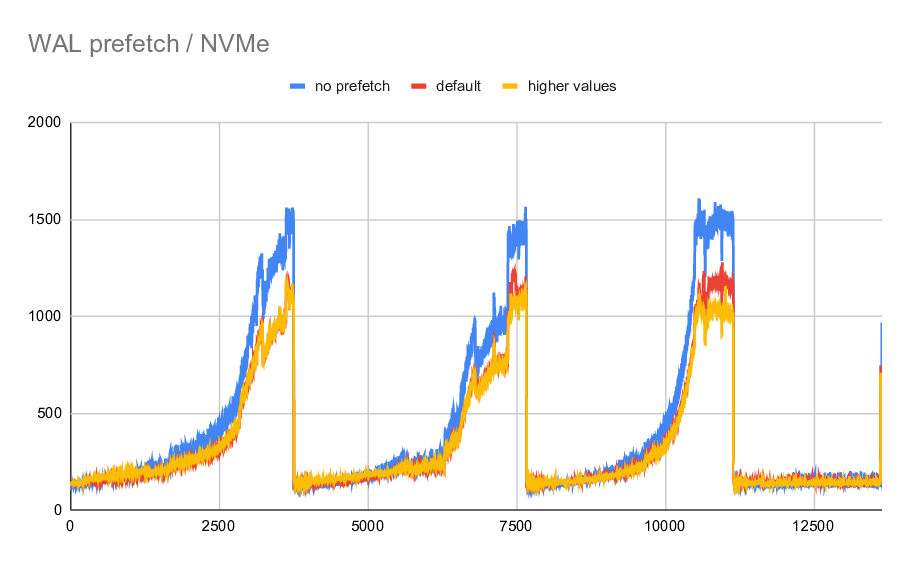
1) NVMe
Fro the fast storage, there's a modest improvement. The time it took to
recover the ~13k WAL segments are these
no prefetch: 5532s
default: 4613s
increased: 4549s
So the speedup from enabled prefetch is ~20% but increasing the values
to make it more aggressive has little effect. Fair enough, the NVMe
is probably fast enough to not benefig from longer I/O queues here.
This is a bit misleading though, because the effectivity of prfetching
very much depends on the fraction of FPI in the WAL stream - and right
after checkpoint that's most of the WAL, which makes the prefetching
less efficient. We still have to parse the WAL etc. without actually
prefetching anything, so it's pure overhead.
So I've also generated a chart showing time (in milliseconds) needed to
apply individual WAL segments. It clearly shows that there are 3
checkpoints, and that for each checkpoint it's initially very cheap
(thanks to FPI) and as the fraction of FPIs drops the redo gets more
expensive. At which point the prefetch actually helps, by up to 30% in
some cases (so a bit more than the overall speedup). All of this is
expected, of course.
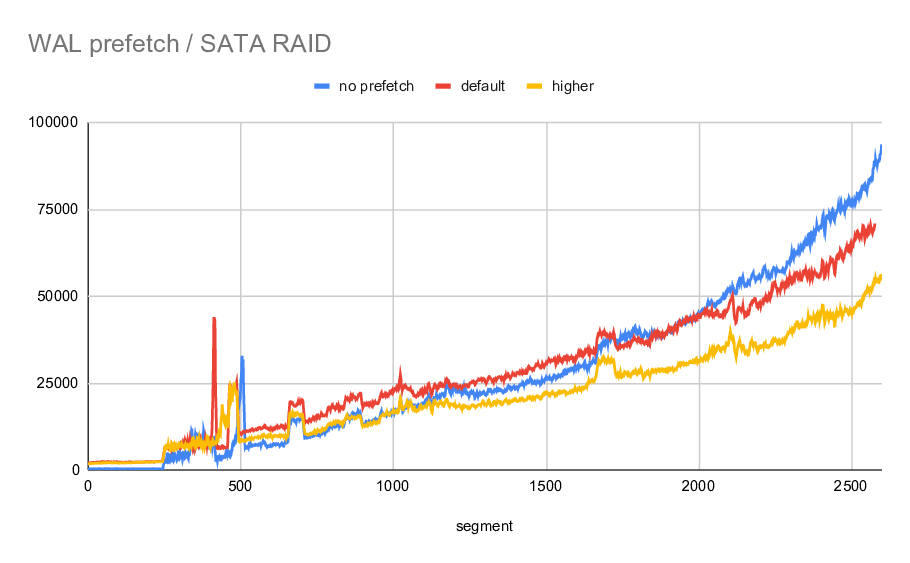
2) 3 x 7.2k SATA RAID0
For the spinning rust, I had to make some compromises. It's not feasible
to apply all the 200GB of WAL - it would take way too long. I only
applied ~2600 segments for each configuration (so not even one whole
checkpoint), and even that took ~20h in each case.
The durations look like this:
no prefetch: 72446s
default: 73653s
increased: 55409s
So in this case the default settings is way too low - it actually makes
the recovery a bit slower, while with increased values there's ~25%
speedup, which is nice. I assume that if larger number of WAL segments
was applied (e.g. the whole checkpoint), the prefetch numbers would be
a bit better - the initial FPI part would play smaller role.
From the attached "average per segment" chart you can see that the basic
behavior is about the same as for NVMe - initially it's slower due to
FPIs in the WAL stream, and then it gets ~30% faster.
Overall I think it looks good. I haven't looked at the code very much,
and I can't comment on the potential optimizations mentioned a couple
days ago yet.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
{kind=link}
{kind=link}
pgsql-hackers by date: