Thread: [PoC] Reducing planning time when tables have many partitions
Hello,
I found a problem that planning takes too much time when the tables
have many child partitions. According to my observation, the planning
time increases in the order of O(n^2). Here, n is the number of child
partitions. I attached the patch to solve this problem. Please be
noted that this patch is a PoC.
1. Problem Statement
The problem arises in the next simple query. This query is modeled
after a university's grade system, joining tables about students,
scores, and their GPAs to output academic records for each student.
=====
SELECT students.name, gpas.gpa AS gpa, sum(scores.score) AS total_score
FROM students, scores, gpas
WHERE students.id = scores.student_id AND students.id = gpas.student_id
GROUP BY students.id, gpas.student_id;
=====
Here, since there are so many students enrolled in the university, we
will partition each table. If so, the planning time of the above query
increases very rapidly as the number of partitions increases.
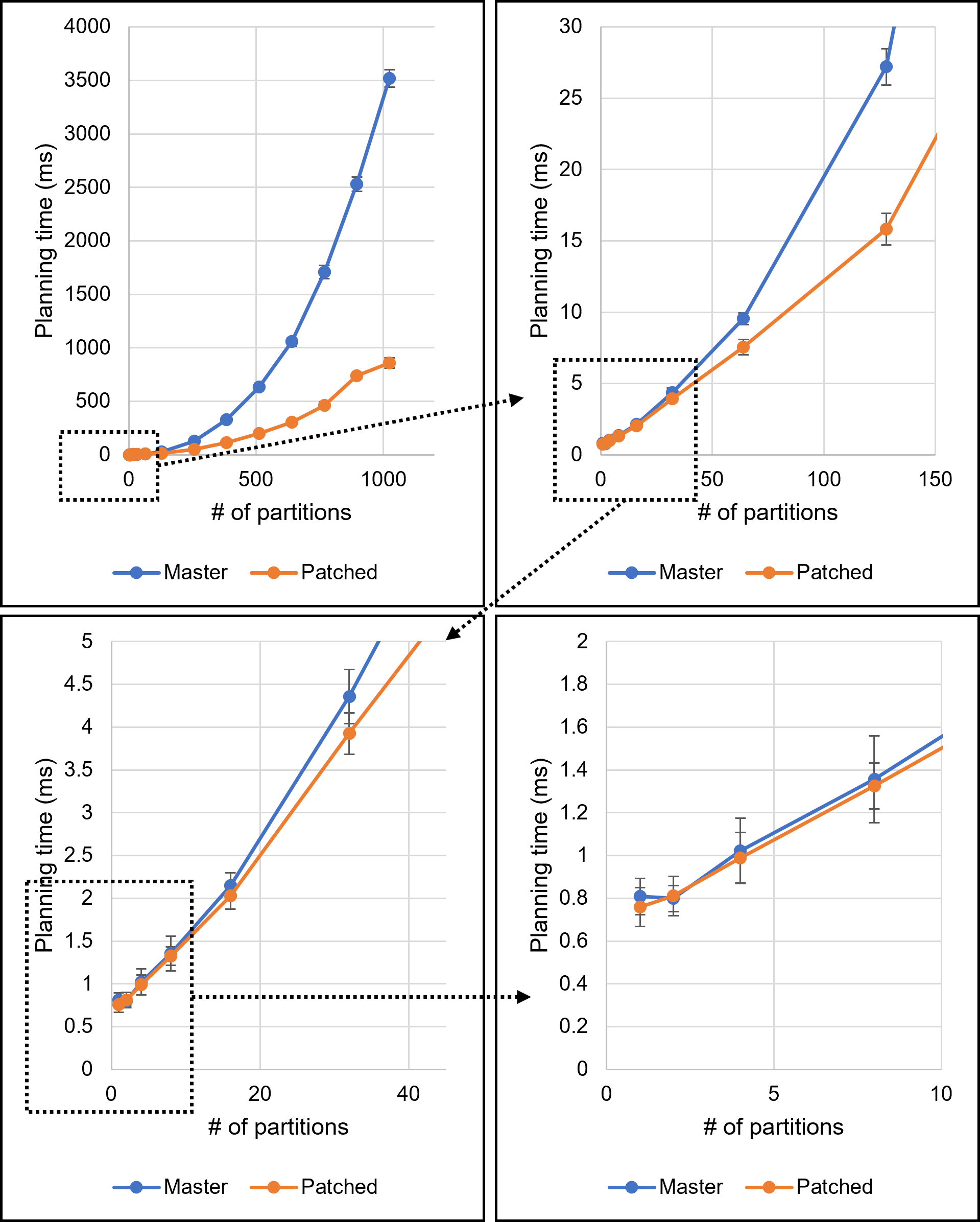
I conducted an experiment by varying the number of partitions of three
tables (students, scores, and gpas) from 2 to 1024. The attached
figure illustrates the result. The blue line annotated with "master"
stands for the result on the master branch. Obviously, its
computational complexity is large.
I attached SQL files to this e-mail as "sample-queries.zip". You can
reproduce my experiment by the next steps:
=====
$ unzip sample-queries.zip
$ cd sample-queries
# Create tables and insert sample data ('n' denotes the number of partitions)
$ psql -f create-table-n.sql
# Measure planning time
$ psql -f query-n.sql
=====
2. Where is Slow?
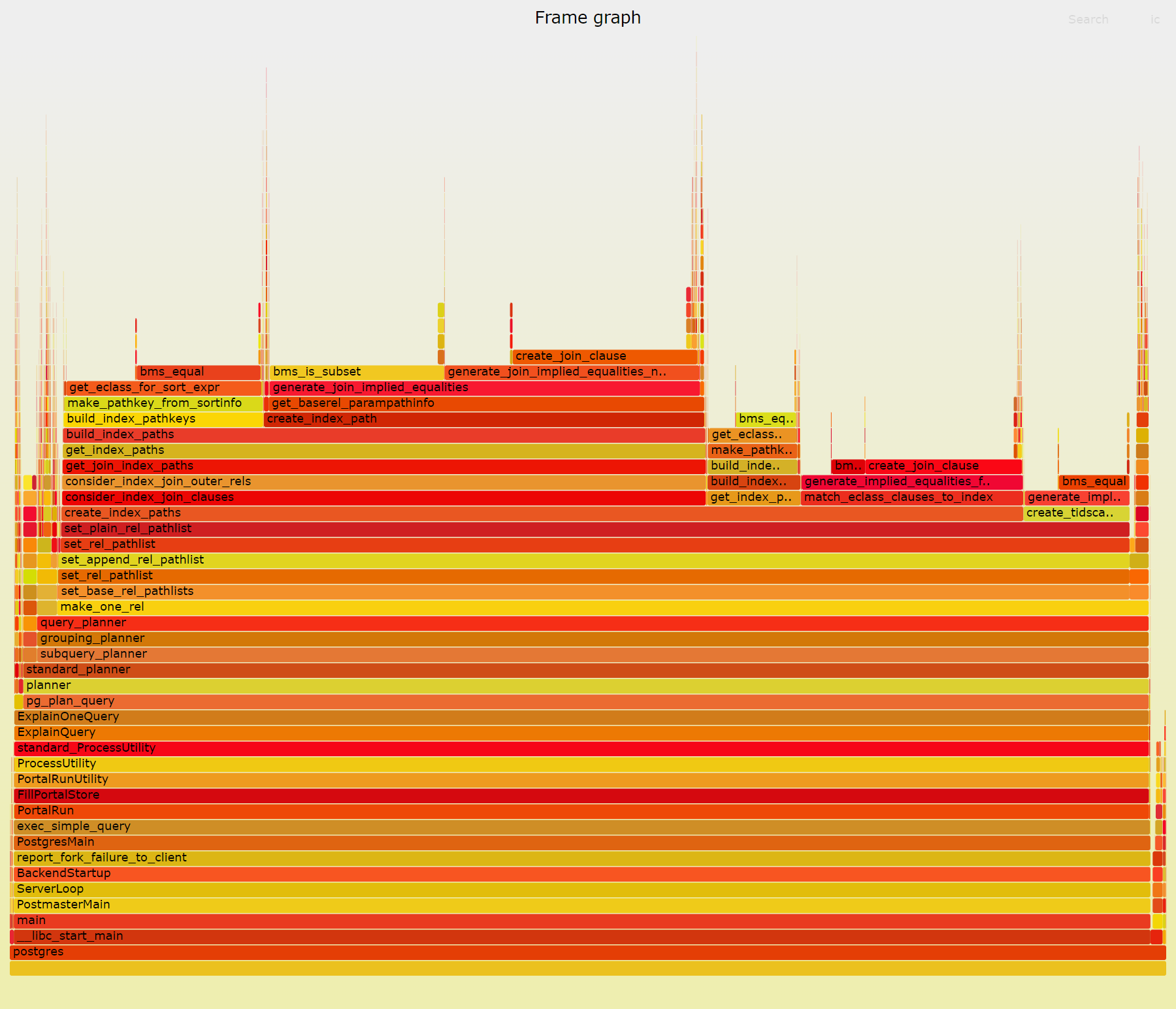
In order to identify bottlenecks, I ran a performance profiler(perf).
The "perf-master.png" is a call graph of planning of query-1024.sql.
From this figure, it can be seen that "bms_equal" and "bms_is_subset"
take up most of the running time. Most of these functions are called
when enumerating EquivalenceMembers in EquivalenceClass. The
enumerations exist in src/backend/optimizer/path/equivclass.c and have
the following form.
=====
EquivalenceClass *ec = /* given */;
EquivalenceMember *em;
ListCell *lc;
foreach(lc, ec->ec_members)
{
em = (EquivalenceMember *) lfirst(lc);
/* predicate is bms_equal or bms_is_subset, etc */
if (!predicate(em))
continue;
/* The predicate satisfies */
do something...;
}
=====
This foreach loop is a linear search, whose cost will become very high
when there are many EquivalenceMembers in ec_members. This is the case
when the number of partitions is large. Eliminating this heavy linear
search is a key to improving planning performance.
3. How to Solve?
In my patch, I made three different optimizations depending on the
predicate pattern.
3.1 When the predicate is "!em->em_is_child"
In equivclass.c, there are several processes performed when
em_is_child is false. If a table has many partitions, the number of
EquivalenceMembers which are not children is limited. Therefore, it is
useful to keep only the non-child members as a list in advance.
My patch adds the "ec_not_child_members" field to EquivalenceClass.
This field is a List containing non-child members. Taking advantage of
this, the previous loop can be rewritten as follows:
=====
foreach(lc, ec->ec_not_child_members)
{
em = (EquivalenceMember *) lfirst(lc);
Assert(!em->em_is_child);
do something...;
}
=====
3.2 When the predicate is "bms_equal(em->em_relids, relids)"
"bms_equal" is another example of the predicate. In this case,
processes will be done when the "em_relids" matches certain Relids.
This type of loop can be quickly handled by utilizing a hash table.
First, group EquivalenceMembers with the same Relids into a list.
Then, create an associative array whose key is Relids and whose value
is the list. In my patch, I added the "ec_members_htab" field to
EquivalenceClass, which plays a role of an associative array.
Based on this idea, the previous loop is transformed as follows. Here,
the FindEcMembersMatchingRelids function looks up the hash table and
returns the corresponding value, which is a list.
=====
foreach(lc, FindEcMembersMatchingRelids(ec, relids))
{
em = (EquivalenceMember *) lfirst(lc);
Assert(bms_equal(em->em_relids, relids));
do something...;
}
=====
3.3 When the predicate is "bms_is_subset(em->em_relids, relids)"
There are several processings performed on EquivalenceMembers whose
em_relids is a subset of the given "relids". In this case, the
predicate is "bms_is_subset". Optimizing this search is not as easy as
with bms_equal, but the technique above by hash tables can be applied.
There are 2^m subsets if the number of elements of the "relids" is m.
The key here is that m is not so large in most cases. For example, m
is up to 3 in the sample query, meaning that the number of subsets is
at most 2^3=8. Therefore, we can enumerate all subsets within a
realistic time. Looking up the hash table with each subset as a key
will drastically reduce unnecessary searches. My patch's optimization
is based on this notion.
This technique can be illustrated as the next pseudo-code. The code
iterates over all subsets and looks up the corresponding
EquivalenceMembers from the hash table. The actual code is more
complicated for performance reasons.
===
EquivalenceClass *ec = /* given */;
Relids relids = /* given */;
int num_members_in_relids = bms_num_members(relids);
for (int bit = 0; bit < (1 << num_members_in_relids); bit++)
{
EquivalenceMember *em;
ListCell *lc;
Relids subset = construct subset from 'bit';
foreach(lc, FindEcMembersMatchingRelids(ec, subset))
{
em = (EquivalenceMember *) lfirst(lc);
Assert(bms_is_subset(em->em_relids, relids));
do something...;
}
}
===
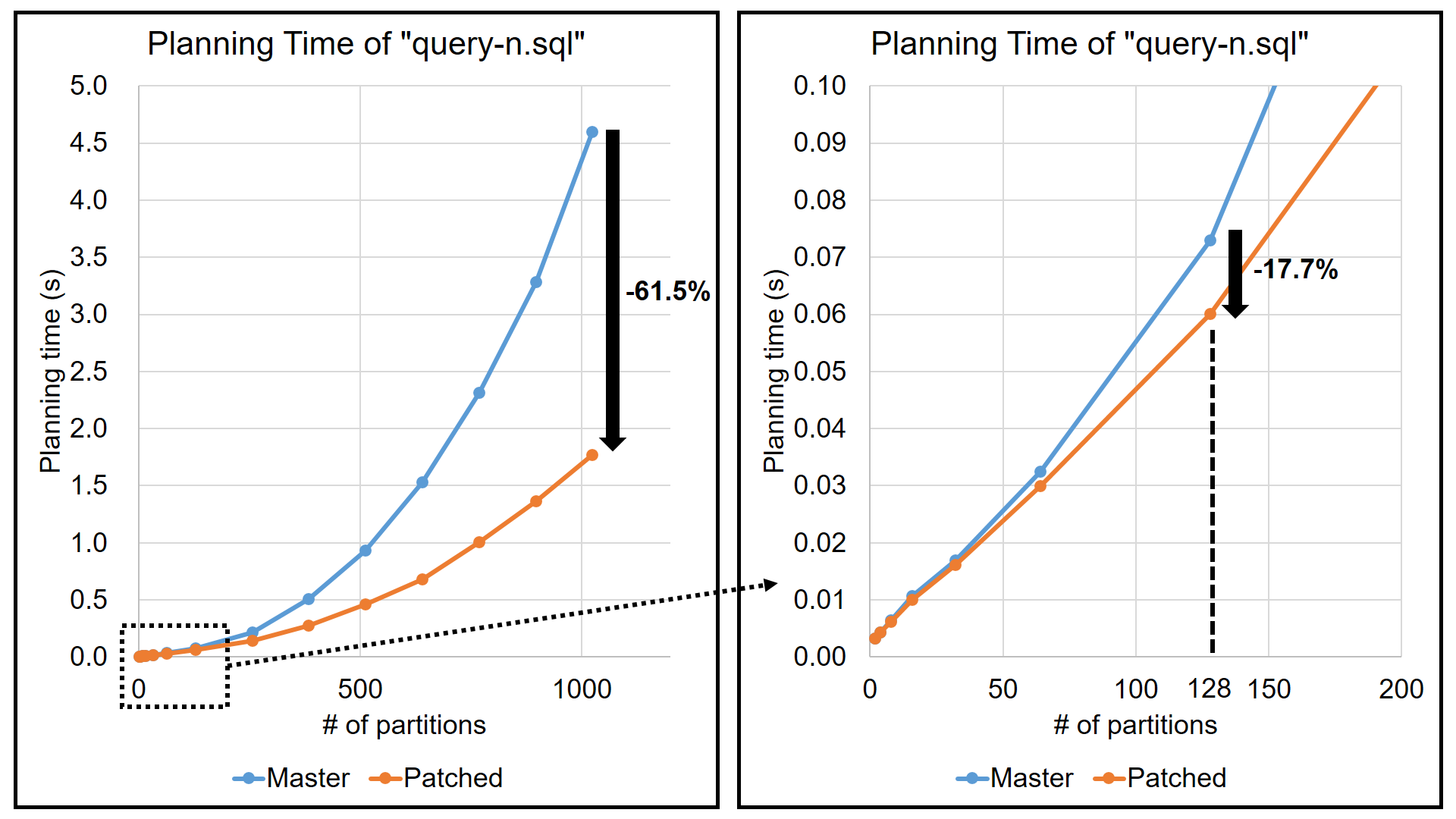
4. Experimental Result
The red line in the attached figure is the planning time with my
patch. The chart indicates that planning performance has been greatly
improved. The exact values are shown below.
Planning time of "query-n.sql" (n = number of partitions):
n | Master (s) | Patched (s) | Speed up
------------------------------------------
2 | 0.003 | 0.003 | 0.9%
4 | 0.004 | 0.004 | 1.0%
8 | 0.006 | 0.006 | 4.6%
16 | 0.011 | 0.010 | 5.3%
32 | 0.017 | 0.016 | 4.7%
64 | 0.032 | 0.030 | 8.0%
128 | 0.073 | 0.060 | 17.7%
256 | 0.216 | 0.142 | 34.2%
384 | 0.504 | 0.272 | 46.1%
512 | 0.933 | 0.462 | 50.4%
640 | 1.529 | 0.678 | 55.7%
768 | 2.316 | 1.006 | 56.6%
896 | 3.280 | 1.363 | 58.5%
1024 | 4.599 | 1.770 | 61.5%
With 1024 partitions, the planning time was reduced by 61.5%. Besides,
with 128 partitions, which is a realistic use case, the performance
increased by 17.7%.
5. Things to Be Discussed
5.1 Regressions
While my approach is effective for tables with a large number of
partitions, it may cause performance degradation otherwise. For small
cases, it is necessary to switch to a conventional algorithm. However,
its threshold is not self-evident.
5.2 Enumeration order
My patch may change the order in which members are enumerated. This
affects generated plans.
5.3 Code Quality
Source code quality should be improved.
=====
Again, I posted this patch as a PoC. I would appreciate it if you
would discuss the effectiveness of these optimizations with me.
Best regards,
Yuya Watari
Attachment
{kind=link}
{kind=link}
{kind=link}
On Fri, 18 Mar 2022 at 23:32, Yuya Watari <watari.yuya@gmail.com> wrote:
> I found a problem that planning takes too much time when the tables
> have many child partitions. According to my observation, the planning
> time increases in the order of O(n^2). Here, n is the number of child
> partitions. I attached the patch to solve this problem. Please be
> noted that this patch is a PoC.
> 3. How to Solve?
I think a better way to solve this would be just to have a single hash
table over all EquivalenceClasses that allows fast lookups of
EquivalenceMember->em_expr. I think there's no reason that a given
Expr should appear in more than one non-merged EquivalenceClass. The
EquivalenceClass a given Expr belongs to would need to be updated
during the merge process.
For functions such as get_eclass_for_sort_expr() and
process_equivalence(), that would become a fairly fast hashtable
lookup instead of having nested loops to find if an EquivalenceMember
already exists for the given Expr. We might not want to build the hash
table for all queries. Maybe we could just do it if we get to
something like ~16 EquivalenceMember in total.
As of now, we don't have any means to hash Exprs, so all that
infrastructure would need to be built first. Peter Eisentraut is
working on a patch [1] which is a step towards having this.
Here's a simple setup to show the pain of this problem:
create table lp (a int, b int) partition by list(a);
select 'create table lp'||x::text|| ' partition of lp for values
in('||x::text||');' from generate_Series(0,4095)x;
\gexec
explain analyze select * from lp where a=b order by a;
Planning Time: 510.248 ms
Execution Time: 264.659 ms
David
[1] https://commitfest.postgresql.org/37/3182/
Dear David,
Thank you for your comments on my patch. I really apologize for my
late response.
On Thu, Mar 24, 2022 at 11:03 AM David Rowley <dgrowleyml@gmail.com> wrote:
> I think a better way to solve this would be just to have a single hash
> table over all EquivalenceClasses that allows fast lookups of
> EquivalenceMember->em_expr. I think there's no reason that a given
> Expr should appear in more than one non-merged EquivalenceClass. The
> EquivalenceClass a given Expr belongs to would need to be updated
> during the merge process.
Thank you for your idea. However, I think building a hash table whose
key is EquivalenceMember->em_expr does not work for this case.
What I am trying to optimize in this patch is the following code.
=====
EquivalenceClass *ec = /* given */;
EquivalenceMember *em;
ListCell *lc;
foreach(lc, ec->ec_members)
{
em = (EquivalenceMember *) lfirst(lc);
/* predicate is bms_equal or bms_is_subset, etc */
if (!predicate(em))
continue;
/* The predicate satisfies */
do something...;
}
=====
From my observation, the predicates above will be false in most cases
and the subsequent processes are not executed. My optimization is
based on this notion and utilizes hash tables to eliminate calls of
predicates.
If the predicate were "em->em_expr == something", the hash table whose
key is em_expr would be effective. However, the actual predicates are
not of this type but the following.
// Find EquivalenceMembers whose relids is equal to the given relids
(1) bms_equal(em->em_relids, relids)
// Find EquivalenceMembers whose relids is a subset of the given relids
(2) bms_is_subset(em->em_relids, relids)
Since these predicates perform a match search for not em_expr but
em_relids, we need to build a hash table with em_relids as key. If so,
we can drastically reduce the planning time for the pattern (1).
Besides, by enumerating all subsets of relids, pattern (2) can be
optimized. The detailed algorithm is described in the first email.
I show an example of the pattern (1). The next code is in
src/backend/optimizer/path/equivclass.c. As can be seen from this
code, the foreach loop tries to find an EquivalenceMember whose
cur_em->em_relids is equal to rel->relids. If found, subsequent
processing will be performed.
== Before patched ==
List *
generate_implied_equalities_for_column(PlannerInfo *root,
RelOptInfo *rel,
ec_matches_callback_type callback,
void *callback_arg,
Relids prohibited_rels)
{
...
EquivalenceClass *cur_ec = (EquivalenceClass *)
list_nth(root->eq_classes, i);
EquivalenceMember *cur_em;
ListCell *lc2;
cur_em = NULL;
foreach(lc2, cur_ec->ec_members)
{
cur_em = (EquivalenceMember *) lfirst(lc2);
if (bms_equal(cur_em->em_relids, rel->relids) &&
callback(root, rel, cur_ec, cur_em, callback_arg))
break;
cur_em = NULL;
}
if (!cur_em)
continue;
...
}
===
My patch modifies this code as follows. The em_foreach_relids_equals
is a newly defined macro that finds EquivalenceMember satisfying the
bms_equal. The macro looks up a hash table using rel->relids as a key.
This type of optimization cannot be achieved without using hash tables
whose key is em->em_relids.
== After patched ==
List *
generate_implied_equalities_for_column(PlannerInfo *root,
RelOptInfo *rel,
ec_matches_callback_type callback,
void *callback_arg,
Relids prohibited_rels)
{
...
EquivalenceClass *cur_ec = (EquivalenceClass *)
list_nth(root->eq_classes, i);
EquivalenceMember *cur_em;
EquivalenceMember *other_em;
cur_em = NULL;
em_foreach_relids_equals(cur_em, cur_ec, rel->relids)
{
Assert(bms_equal(cur_em->em_relids, rel->relids));
if (callback(root, rel, cur_ec, cur_em, callback_arg))
break;
cur_em = NULL;
}
if (!cur_em)
continue;
...
}
===
> We might not want to build the hash table for all queries.
I agree with you. Building a lot of hash tables will consume much
memory. My idea for this problem is to let the hash table's key be a
pair of EquivalenceClass and Relids. However, this approach may lead
to increasing looking up time of the hash table.
==========
I noticed that the previous patch does not work with the current HEAD.
I attached the modified one to this email.
Additionally, I added my patch to the current commit fest [1].
[1] https://commitfest.postgresql.org/38/3701/
--
Best regards,
Yuya Watari
Attachment
Yuya Watari <watari.yuya@gmail.com> writes:
> On Thu, Mar 24, 2022 at 11:03 AM David Rowley <dgrowleyml@gmail.com> wrote:
>> I think a better way to solve this would be just to have a single hash
>> table over all EquivalenceClasses that allows fast lookups of
>> EquivalenceMember->em_expr.
> If the predicate were "em->em_expr == something", the hash table whose
> key is em_expr would be effective. However, the actual predicates are
> not of this type but the following.
> // Find EquivalenceMembers whose relids is equal to the given relids
> (1) bms_equal(em->em_relids, relids)
> // Find EquivalenceMembers whose relids is a subset of the given relids
> (2) bms_is_subset(em->em_relids, relids)
Yeah, that's a really interesting observation, and I agree that
David's suggestion doesn't address it. Maybe after we fix this
problem, matching of em_expr would be the next thing to look at,
but your results say it isn't the first thing.
I'm not real thrilled with trying to throw hashtables at the problem,
though. As David noted, they'd be counterproductive for simple
queries. Sure, we could address that with duplicate code paths,
but that's a messy and hard-to-tune approach. Also, I find the
idea of hashing on all subsets of relids to be outright scary.
"m is not so large in most cases" does not help when m *is* large.
For the bms_equal class of lookups, I wonder if we could get anywhere
by adding an additional List field to every RelOptInfo that chains
all EquivalenceMembers that match that RelOptInfo's relids.
The trick here would be to figure out when to build those lists.
The simple answer would be to do it lazily on-demand, but that
would mean a separate scan of all the EquivalenceMembers for each
RelOptInfo; I wonder if there's a way to do better?
Perhaps the bms_is_subset class could be handled in a similar
way, ie do a one-time pass to make a List of all EquivalenceMembers
that use a RelOptInfo.
regards, tom lane
Dear Tom,
Thank you for replying to my email.
On Mon, Jul 4, 2022 at 6:28 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> I'm not real thrilled with trying to throw hashtables at the problem,
> though. As David noted, they'd be counterproductive for simple
> queries.
As you said, my approach that utilizes hash tables has some overheads,
leading to degradation in query planning time.
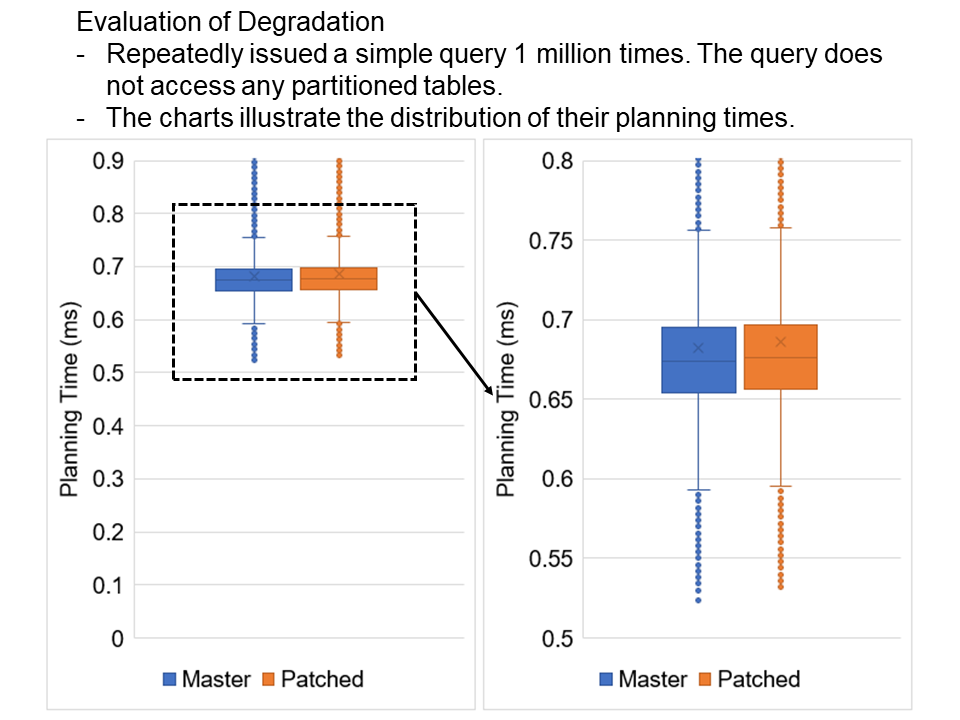
I tested the degradation by a brief experiment. In this experiment, I
used a simple query shown below.
===
SELECT students.name, gpas.gpa AS gpa, sum(scores.score) AS total_score
FROM students, scores, gpas
WHERE students.id = scores.student_id AND students.id = gpas.student_id
GROUP BY students.id, gpas.student_id;
===
Here, students, scores, and gpas tables have no partitions, i.e., they
are regular tables. Therefore, my techniques do not work for this
query and instead may lead to some regression. I repeatedly issued
this query 1 million times and measured their planning times.
The attached figure describes the distribution of the planning times.
The figure indicates that my patch has no severe negative impacts on
the planning performance. However, there seems to be a slight
degradation.
I show the mean and median of planning times below. With my patch, the
planning time became 0.002-0.004 milliseconds slower. We have to deal
with this problem, but reducing time complexity while keeping
degradation to zero is significantly challenging.
Planning time (ms)
| Mean | Median
------------------------------
Master | 0.682 | 0.674
Patched | 0.686 | 0.676
------------------------------
Degradation | 0.004 | 0.002
Of course, the attached result is just an example. Significant
regression might occur in other types of queries.
> For the bms_equal class of lookups, I wonder if we could get anywhere
> by adding an additional List field to every RelOptInfo that chains
> all EquivalenceMembers that match that RelOptInfo's relids.
> The trick here would be to figure out when to build those lists.
> The simple answer would be to do it lazily on-demand, but that
> would mean a separate scan of all the EquivalenceMembers for each
> RelOptInfo; I wonder if there's a way to do better?
>
> Perhaps the bms_is_subset class could be handled in a similar
> way, ie do a one-time pass to make a List of all EquivalenceMembers
> that use a RelOptInfo.
Thank you for giving your idea. I will try to polish up my algorithm
based on your suggestion.
--
Best regards,
Yuya Watari
Attachment
{kind=link}
On 7/5/22 13:57, Yuya Watari wrote: > On Mon, Jul 4, 2022 at 6:28 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: >> Perhaps the bms_is_subset class could be handled in a similar >> way, ie do a one-time pass to make a List of all EquivalenceMembers >> that use a RelOptInfo. > > Thank you for giving your idea. I will try to polish up my algorithm > based on your suggestion. This work has significant interest for highly partitioned configurations. Are you still working on this patch? According to the current state of the thread, changing the status to 'Waiting on author' may be better until the next version. Feel free to reverse the status if you need more feedback. -- Regards Andrey Lepikhov Postgres Professional
Dear Andrey Lepikhov, Thank you for replying and being a reviewer for this patch. I really appreciate it. > Are you still working on this patch? Yes, I’m working on improving this patch. It is not easy to address the problems that this patch has, but I’m hoping to send a new version of it in a few weeks. -- Best regards, Yuya Watari
On Mon, 4 Jul 2022 at 09:28, Tom Lane <tgl@sss.pgh.pa.us> wrote: > For the bms_equal class of lookups, I wonder if we could get anywhere > by adding an additional List field to every RelOptInfo that chains > all EquivalenceMembers that match that RelOptInfo's relids. > The trick here would be to figure out when to build those lists. > The simple answer would be to do it lazily on-demand, but that > would mean a separate scan of all the EquivalenceMembers for each > RelOptInfo; I wonder if there's a way to do better? How about, instead of EquivalenceClass having a List field named ec_members, it has a Bitmapset field named ec_member_indexes and we just keep a List of all EquivalenceMembers in PlannerInfo and mark which ones are in the class by setting the bit in the class's ec_member_indexes field. That would be teamed up with a new eclass_member_indexes field in RelOptInfo to store the index into PlannerInfo's List of EquivalenceMembers that belong to the given RelOptInfo. For searching: If you want to get all EquivalenceMembers in an EquivalenceClass, you bms_next_member loop over the EC's ec_member_indexes field. If you want to get all EquivalenceMembers for a given RelOptInfo, you bms_next_member loop over the RelOptInfo's eclass_member_indexes field. If you want to get all EquivalenceMembers for a given EquivalenceClass and RelOptInfo you need to do some bms_intersect() calls for the rel's eclass_member_indexes and EC's ec_member_indexes. I'm unsure if we'd want to bms_union the RelOptInfo's ec_member_indexes field for join rels. Looking at get_eclass_indexes_for_relids() we didn't do it that way for eclass_indexes. Maybe that's because we're receiving RelIds in a few places without a RelOptInfo. Certainly, the CPU cache locality is not going to be as good as if we had a List with all elements together, but for simple queries, there's not going to be many EquivalenceClasses anyway, and for complex queries, this should be a win. David
Dear David, Thank you for sharing your new idea. I agree that introducing a Bitmapset field may solve this problem. I will try this approach in addition to previous ones. Thank you again for helping me. -- Best regards, Yuya Watari
On Wed, 27 Jul 2022 at 18:07, Yuya Watari <watari.yuya@gmail.com> wrote: > I agree that introducing a Bitmapset field may solve this problem. I > will try this approach in addition to previous ones. I've attached a very half-done patch that might help you get started on this. There are still 2 failing regression tests which seem to be due to plan changes. I didn't expend any effort looking into why these plans changed. The attached does not contain any actual optimizations to find the minimal set of EMs to loop through by masking the Bitmapsets that I mentioned in my post last night. I just quickly put it together to see if there's some hole in the idea. I don't think there is. I've not really considered all of the places that we'll want to do the bit twiddling to get the minimal set of EquivalenceMember. I did see there's a couple more functions in postgres_fdw.c that could be optimized. One thing I've only partially thought about is what if you want to also find EquivalenceMembers with a constant value. If there's a Const, then you'll lose the bit for that when you mask the ec's ec_member_indexes with the RelOptInfos. If there are some places where we need to keep those then I think we'll need to add another field to EquivalenceClass to mark the index into PlannerInfo's eq_members for the EquivalenceMember with the Const. That bit would have to be bms_add_member()ed back into the Bitmapset of matching EquivalenceMembers after masking out RelOptInfo's ec_member_indexes. When adding the optimizations to find the minimal set of EM bits to search through, you should likely add some functions similar to the get_eclass_indexes_for_relids() and get_common_eclass_indexes() functions to help you find the minimal set of bits. You can also probably get some other inspiration from [1], in general. David [1] https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=3373c715535
Attachment
Hello,
On Thu, Jul 28, 2022 at 6:35 AM David Rowley <dgrowleyml@gmail.com> wrote:
> I've attached a very half-done patch that might help you get started
> on this.
Thank you so much for creating the patch. I have implemented your
approach and attached a new version of the patch to this email.
If you have already applied David's patch, please start the 'git am'
command from 0002-Fix-bugs.patch. All regression tests passed with
this patch on my environment.
1. Optimizations
The new optimization techniques utilizing Bitmapsets are implemented
as the following functions in src/include/optimizer/paths.h.
* get_eclass_members_indexes_for_relids()
* get_eclass_members_indexes_for_not_children()
* get_eclass_members_indexes_for_relids_or_not_children()
* get_eclass_members_indexes_for_subsets_of_relids()
* get_eclass_members_indexes_for_subsets_of_relids_or_not_children()
// I think the names of these functions need to be reconsidered.
These functions intersect ec->ec_member_indexes and some Bitmapset and
return indexes of EquivalenceMembers that we want to get.
The implementation of the first three functions listed above is
simple. However, the rest functions regarding the bms_is_subset()
condition are a bit more complicated. I have optimized this case based
on Tom's idea. The detailed steps are as follows.
I. Intersect ec->ec_member_indexes and the Bitmapset in RelOptInfo.
This intersection set is a candidate for the EquivalenceMembers to be
retrieved.
II. Remove from the candidate set the members that do not satisfy the
bms_is_subset().
Optimization for EquivalenceMembers with a constant value is one of
the future works.
2. Experimental Results
I conducted an experiment by using the original query, which is
attached to this email. You can reproduce this experiment by the
following commands.
=====
psql -f create-tables.sql
psql -f query.sql
=====
The following table and the attached figure describe the experimental result.
Planning time of "query.sql" (n = the number of partitions)
----------------------------------------------------------------
n | Master (ms) | Patched (ms) | Speedup (%) | Speedup (ms)
----------------------------------------------------------------
1 | 0.809 | 0.760 | 6.09% | 0.049
2 | 0.799 | 0.811 | -1.53% | -0.012
4 | 1.022 | 0.989 | 3.20% | 0.033
8 | 1.357 | 1.325 | 2.32% | 0.032
16 | 2.149 | 2.026 | 5.69% | 0.122
32 | 4.357 | 3.925 | 9.91% | 0.432
64 | 9.543 | 7.543 | 20.96% | 2.000
128 | 27.195 | 15.823 | 41.82% | 11.372
256 | 130.207 | 52.664 | 59.55% | 77.542
384 | 330.642 | 112.324 | 66.03% | 218.318
512 | 632.009 | 197.957 | 68.68% | 434.052
640 | 1057.193 | 306.861 | 70.97% | 750.333
768 | 1709.914 | 463.628 | 72.89% | 1246.287
896 | 2531.685 | 738.827 | 70.82% | 1792.858
1024 | 3516.592 | 858.211 | 75.60% | 2658.381
----------------------------------------------------------------
-------------------------------------------------------
n | Stddev of Master (ms) | Stddev of Patched (ms)
-------------------------------------------------------
1 | 0.085 | 0.091
2 | 0.061 | 0.091
4 | 0.153 | 0.118
8 | 0.203 | 0.107
16 | 0.150 | 0.153
32 | 0.313 | 0.242
64 | 0.411 | 0.531
128 | 1.263 | 1.109
256 | 5.592 | 4.714
384 | 17.423 | 6.625
512 | 20.172 | 7.188
640 | 40.964 | 26.246
768 | 61.924 | 31.741
896 | 66.481 | 27.819
1024 | 80.950 | 49.162
-------------------------------------------------------
The speed up with the new patch was up to 75.6% and 2.7 seconds. The
patch achieved a 21.0% improvement even with 64 partitions, which is a
realistic size. We can conclude that this optimization is very
effective in workloads with highly partitioned tables.
Performance degradation occurred only when the number of partitions
was 2, and its degree was 1.53% or 12 microseconds. This degradation
is the difference between the average planning times of 10000 runs.
Their standard deviations far exceed the difference in averages. It is
unclear whether this degradation is an error.
=====
I'm looking forward to your comments.
--
Best regards,
Yuya Watari
Attachment
{kind=link}
On Mon, 8 Aug 2022 at 23:28, Yuya Watari <watari.yuya@gmail.com> wrote: > If you have already applied David's patch, please start the 'git am' > command from 0002-Fix-bugs.patch. All regression tests passed with > this patch on my environment. Thanks for fixing those scope bugs. In regards to the 0002 patch, you have; + * TODO: "bms_add_members(ec1->ec_member_indexes, ec2->ec_member_indexes)" + * did not work to combine two EquivalenceClasses. This is probably because + * the order of the EquivalenceMembers is different from the previous + * implementation, which added the ec2's EquivalenceMembers to the end of + * the list. as far as I can see, the reason the code I that wrote caused the following regression test failure; - Index Cond: ((ff = '42'::bigint) AND (ff = '42'::bigint)) + Index Cond: (ff = '42'::bigint) was down to how generate_base_implied_equalities_const() marks the EC as ec_broken = true without any regard to cleaning up the work it's partially already complete. Because the loop inside generate_base_implied_equalities_const() just breaks as soon as we're unable to find a valid equality operator for the two given types, with my version, since the EquivalenceMember's order has effectively changed, we just discover the EC is broken before we call process_implied_equality() -> distribute_restrictinfo_to_rels(). In the code you've added, the EquivalenceMembers are effectively still in the original order and the process_implied_equality() -> distribute_restrictinfo_to_rels() gets done before we discover the broken EC. The same qual is just added again during generate_base_implied_equalities_broken(), which is why the plan has a duplicate ff=42. This is all just down to the order that the ECs are merged. If you'd just swapped the order of the items in the query's WHERE clause to become: where ec1.ff = 42::int8 and ss1.x = ec1.f1 and ec1.ff = ec1.f1; then my version would keep the duplicate qual. For what you've changed the code to, the planner would not have produced the duplicate ff=42 qual if you'd written the WHERE clause as follows: where ss1.x = ec1.f1 and ec1.ff = ec1.f1 and ec1.ff = 42::int8; In short, I think the code I had for that was fine and it's just the expected plan that you should be editing. If we wanted to this behaviour to be consistent then the fix should be to make generate_base_implied_equalities_const() better at only distributing the quals down to the relations after it has discovered that the EC is not broken, or at least cleaning up the partial work that it's done if it discovers a broken EC. The former seems better to me, but I doubt that it matters too much as broken ECs should be pretty rare and it does not seem worth spending too much effort making this work better. I've not had a chance to look at the 0003 patch yet. David
esOn Tue, 9 Aug 2022 at 19:10, David Rowley <dgrowleyml@gmail.com> wrote:
> I've not had a chance to look at the 0003 patch yet.
I've looked at the 0003 patch now.
The performance numbers look quite impressive, however, there were a
few things about the patch that I struggled to figure what they were
done the way you did them:
+ root->eq_not_children_indexes = bms_add_member(root->eq_not_children_indexes,
Why is that in PlannerInfo rather than in the EquivalenceClass?
if (bms_equal(rel->relids, em->em_relids))
{
rel->eclass_member_indexes =
bms_add_member(rel->eclass_member_indexes, em_index);
}
Why are you only adding the eclass_member_index to the RelOptInfo when
the em_relids contain a singleton relation?
I ended up going and fixing the patch to be more how I imagined it.
I've ended up with 3 Bitmapset fields in EquivalenceClass;
ec_member_indexes, ec_nonchild_indexes, ec_norel_indexes. I also
trimmed the number of helper functions down for obtaining the minimal
set of matching EquivalenceMember indexes to just:
Bitmapset *
get_ecmember_indexes(PlannerInfo *root, EquivalenceClass *ec, Relids relids,
bool with_children, bool with_norel_members)
Bitmapset *
get_ecmember_indexes_strict(PlannerInfo *root, EquivalenceClass *ec,
Relids relids, bool with_children,
bool with_norel_members)
I'm not so much a fan of the bool parameters, but it seemed better
than having 8 different functions with each combination of the bool
paramters instead of 2.
The "strict" version of the function takes the intersection of
eclass_member_indexes for each rel mentioned in relids, whereas the
non-strict version does a union of those. Each then intersect that
with all members in the 'ec', or just the non-child members when
'with_children' is false. They both then optionally bms_add_members()
the ec_norel_members if with_norel_members is true. I found it
difficult to figure out the best order to do the intersection. That
really depends on if the particular query has many EquivalenceClasses
with few EquivalenceMembers or few EquivalenceClasses with many
EquivalenceMembers. bms_int_members() always recycles the left input.
Ideally, that would always be the smallest Bitmapset. Maybe it's worth
inventing a new version of bms_int_members() that recycles the input
with the least nwords. That would give the subsequent
bms_next_member() calls an easier time. Right now they'll need to loop
over a bunch of 0 words at the end for many queries.
A few problems I ran into along the way:
1. generate_append_tlist() generates Vars with varno=0. That causes
problems when we add Exprs from those in add_eq_member() as there is
no element at root->simple_rel_array[0] to add eclass_member_indexes
to.
2. The existing comment for EquivalenceMember.em_relids claims "all
relids appearing in em_expr", but that's just not true when it comes
to em_is_child members.
So far, I fixed #1 by adding a hack to setup_simple_rel_arrays() to do
"root->simple_rel_array[0] = makeNode(RelOptInfo);" I'm not suggesting
that's the correct fix. It might be possible to set the varnos to the
varnos from the first Append child instead.
The fact that #2 is not true adds quite a bit of complexity to the
patch and I think the patch might even misbehave as a result. It seems
there are cases where a child em_relids can contain additional relids
that are not present in the em_expr. For example, when a UNION ALL
child has a Const in the targetlist, as explained in a comment in
add_child_rel_equivalences(). However, there also seem to be cases
where the opposite is true. I had to add the following code in
add_eq_member() to stop a regression test failing:
if (is_child)
expr_relids = bms_add_members(expr_relids, relids);
That's to make sure we add eclass_member_indexes to each RelOptInfo
mentioned in the em_expr.
After doing all that, I noticed that your benchmark was showing that
create_join_clause() was the new bottleneck. This was due to having to
loop so many times over the ec_sources to find an already built
RestrictInfo. I went off and added some new code to optimize the
lookup of those in a similar way by adding a new Bitmapset field in
RelOptInfo to index which ec_sources it mentioned, which meant having
to move ec_sources into PlannerInfo. I don't think this part of the
patch is quite right yet as the code I have relies on em_relids being
the same as the ones mentioned in the RestrictInfo. That seems not
true for em_is_child EMs, so I think we probably need to add a new
field to EquivalenceMember that truly is just pull_varnos from
em_expr, or else look into some way to make em_relids mean that (like
the comment claims).
Here are my results from running your benchmark on master (@f6c750d31)
with and without the attached patch.
npart master (ms) patched (ms) speedup
2 0.28 0.29 95.92%
4 0.37 0.38 96.75%
8 0.53 0.56 94.43%
16 0.92 0.91 100.36%
32 1.82 1.70 107.57%
64 4.05 3.26 124.32%
128 10.83 6.69 161.89%
256 42.63 19.46 219.12%
512 194.31 42.60 456.14%
1024 1104.02 98.37 1122.33%
This resulted in some good additional gains in planner performance.
The 1024 partition case is now about 11x faster on my machine instead
of 4x. The 2 partition does regress slightly. There might be a few
things we can do about that, for example, move ec_collation up 1 to
shrink EquivalenceClass back down closer to the size it was before.
[1] might be enough to make up for the remainder.
I've attached a draft patch with my revisions.
David
[1] https://commitfest.postgresql.org/39/3810/
Attachment
Dear David, I really appreciate your reply and your modifying the patch. The performance improvements are quite impressive. I believe these improvements will help PostgreSQL users. Thank you again. > The 2 partition does regress slightly. There might be a few > things we can do about that I tried to solve this regression problem. From here, I will refer to the patch you sent on August 16th as the v3 patch. I will also call my patch attached to this email the v4 patch. I will discuss the v4 patch later. Additionally, I give names to queries. * Query A: The query we have been using in previous emails, which joins students, scores, and gpas tables. * Query B: The query which is attached to this email. Query B is as follows: === SELECT * FROM testtable_1, testtable_2, testtable_3, testtable_4, testtable_5, testtable_6, testtable_7, testtable_8 WHERE testtable_1.x = testtable_2.x AND testtable_1.x = testtable_3.x AND testtable_1.x = testtable_4.x AND testtable_1.x = testtable_5.x AND testtable_1.x = testtable_6.x AND testtable_1.x = testtable_7.x AND testtable_1.x = testtable_8.x; === Query A joins three tables, whereas Query B joins eight tables. Since EquivalenceClass is used when handling chained join conditions, I thought queries joining many tables, such as Query B, would have greater performance impacts. I have investigated the v3 patch with these queries. As a result, I did not observe any regressions in Query A in my environment. However, the v3 patch showed significant degradation in Query B. The following table and Figures 1 and 2 describe the result. The v3 patch resulted in a regression of 8.7% for one partition and 4.8% for two partitions. Figure 2 shows the distribution of planning times for the 1-partition case, indicating that the 8.7% regression is not an error. Table 1: Planning time of Query B (n: number of partitions) (milliseconds) ---------------------------------------------------------------- n | Master | v3 | v4 | Master / v3 | Master / v4 ---------------------------------------------------------------- 1 | 54.926 | 60.178 | 55.275 | 91.3% | 99.4% 2 | 53.853 | 56.554 | 53.519 | 95.2% | 100.6% 4 | 57.115 | 57.829 | 55.648 | 98.8% | 102.6% 8 | 64.208 | 60.945 | 58.025 | 105.4% | 110.7% 16 | 79.818 | 65.526 | 63.365 | 121.8% | 126.0% 32 | 136.981 | 77.813 | 76.526 | 176.0% | 179.0% 64 | 371.991 | 108.058 | 110.202 | 344.2% | 337.6% 128 | 1449.063 | 173.326 | 181.302 | 836.0% | 799.3% 256 | 6245.577 | 333.480 | 354.961 | 1872.8% | 1759.5% ---------------------------------------------------------------- This performance degradation is due to the heavy processing of the get_ec***_indexes***() functions. These functions are the core part of the optimization we are working on in this thread, but they are relatively heavy when the number of partitions is small. I noticed that these functions were called repeatedly with the same arguments. During planning Query B with one partition, the get_ec_source_indexes_strict() function was called 2087 times with exactly the same parameters. Such repeated calls occurred many times in a single query. To address this problem, I introduced a caching mechanism in the v4 patch. This patch caches the Bitmapset once it has been computed. After that, we only have to read the cached value instead of performing the same process. Of course, we cannot devote much time to the caching itself. Hash tables are a simple solution to accomplish this but are not available under the current case where microsecond performance degradation is a problem. Therefore, my patch adopts another approach. I will use the following function as an example to explain it. === Bitmapset *get_ecmember_indexes(PlannerInfo *root, EquivalenceClass *ec, Relids relids, bool with_children, bool with_norel_members); === My idea is "caching the returned Bitmapset into Relids." If the Relids has the result Bitmapset, we can access it quickly via the pointer. Of course, I understand this description is not accurate. Relids is just an alias of Bitmapset, so we cannot change the layout. I will describe the precise mechanism. In the v4 patch, I changed the signature of the get_ecmember_indexes() function as follows. === Bitmapset *get_ecmember_indexes(PlannerInfo *root, EquivalenceClass *ec, Relids relids, bool with_children, bool with_norel_members, ECIndexCache *cache); === ECIndexCache is storage for caching returned values. ECIndexCache has a one-to-one relationship with Relids. This relationship is achieved by placing the ECIndexCache just alongside the Relids. For example, ECIndexCache corresponding to some RelOptInfo's relids exists in the same RelOptInfo. When calling the get_ecmember_indexes() function with a RelOptInfo, we pass RelOptInfo->ECIndexCache together. On the other hand, since Relids appear in various places, it is sometimes difficult to prepare a corresponding ECIndexCache. In such cases, we give up caching and pass NULL. Besides, one ECIndexCache can only map to one EquivalenceClass. ECIndexCache only caches for the first EquivalenceClass it encounters and does not cache for another EC. My method abandons full caching to prevent overhead. However, it overcame the regression problem for Query B. As can be seen from Figure 2, the regression with the v4 patch is either non-existent or negligible. Furthermore, the v4 patch is faster than the v3 patch when the number of partitions is 32 or less. In addition to Query B, the results with Query A are shown in Figure 3. I cannot recognize any regression from Figure 3. Please be noted that these results are done on my machine and may differ in other environments. However, when the number of partitions was relatively large, my patch was slightly slower than the v3 patch. This may be due to too frequent memory allocation. ECIndexCache is a large struct containing 13 pointers. In the current implementation, ECIndexCache exists within commonly used structs such as RelOptInfo. Therefore, ECIndexCache is allocated even if no one uses it. When there were 256 partitions of Query B, 88509 ECIndexCache instances were allocated, but only 2295 were actually used. This means that 95.4% were wasted. I think on-demand allocation would solve this problem. Similar problems could also occur with other workloads, including OLTP. I'm going to try this approach soon. I really apologize for not commenting on the rest of your reply. I will continue to consider them. -- Best regards, Yuya Watari
Attachment
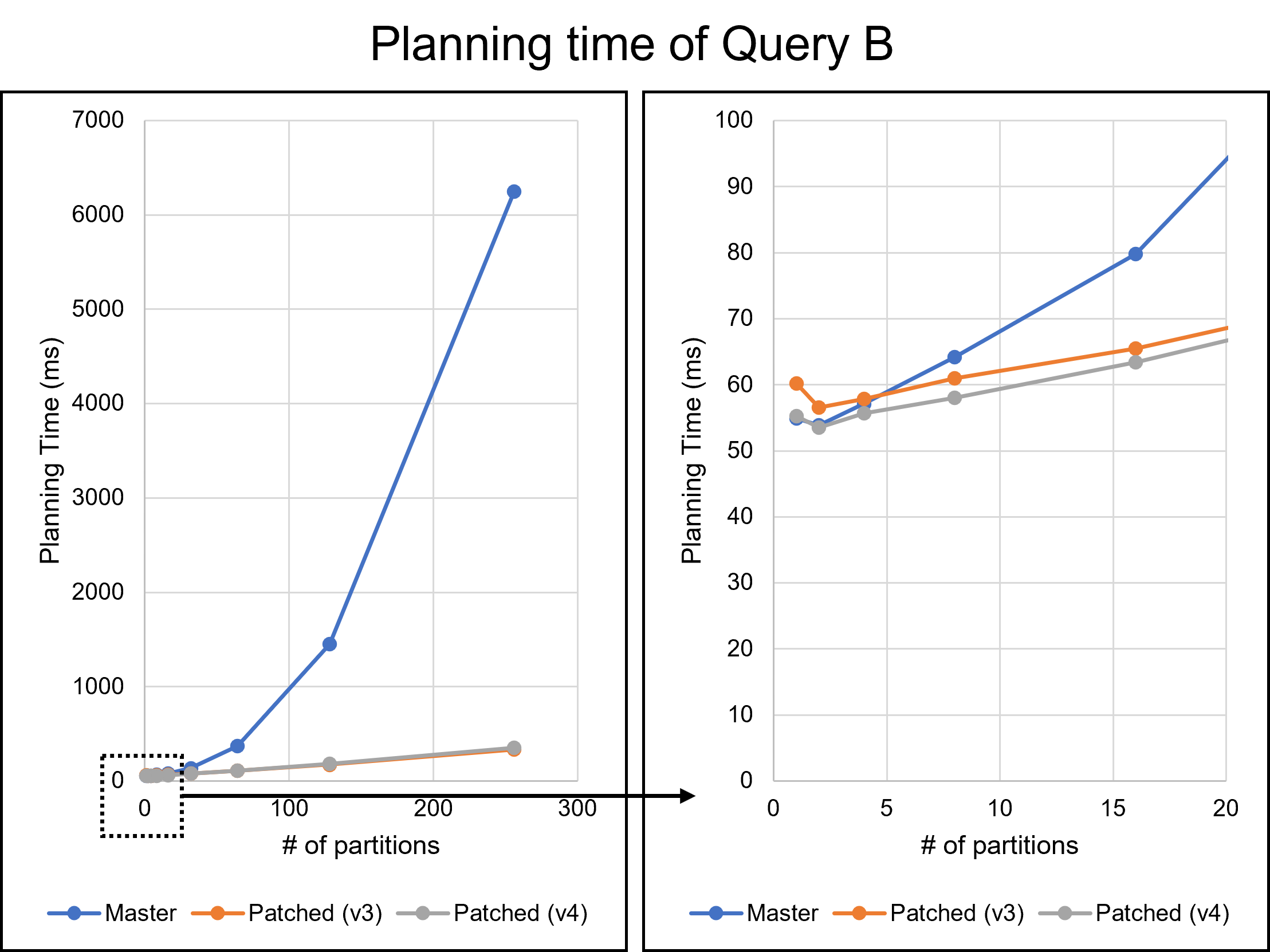{kind=link}
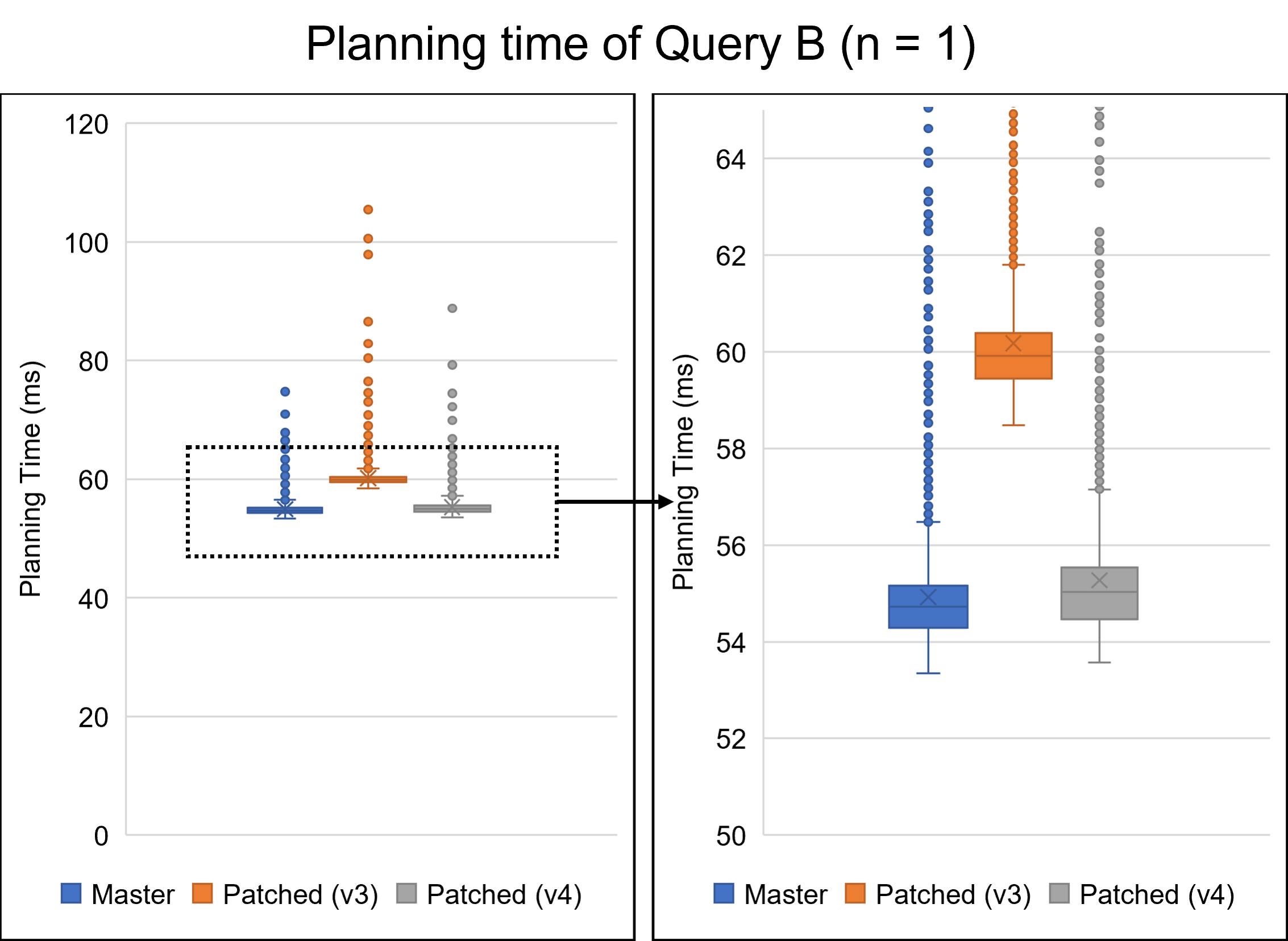{kind=link}
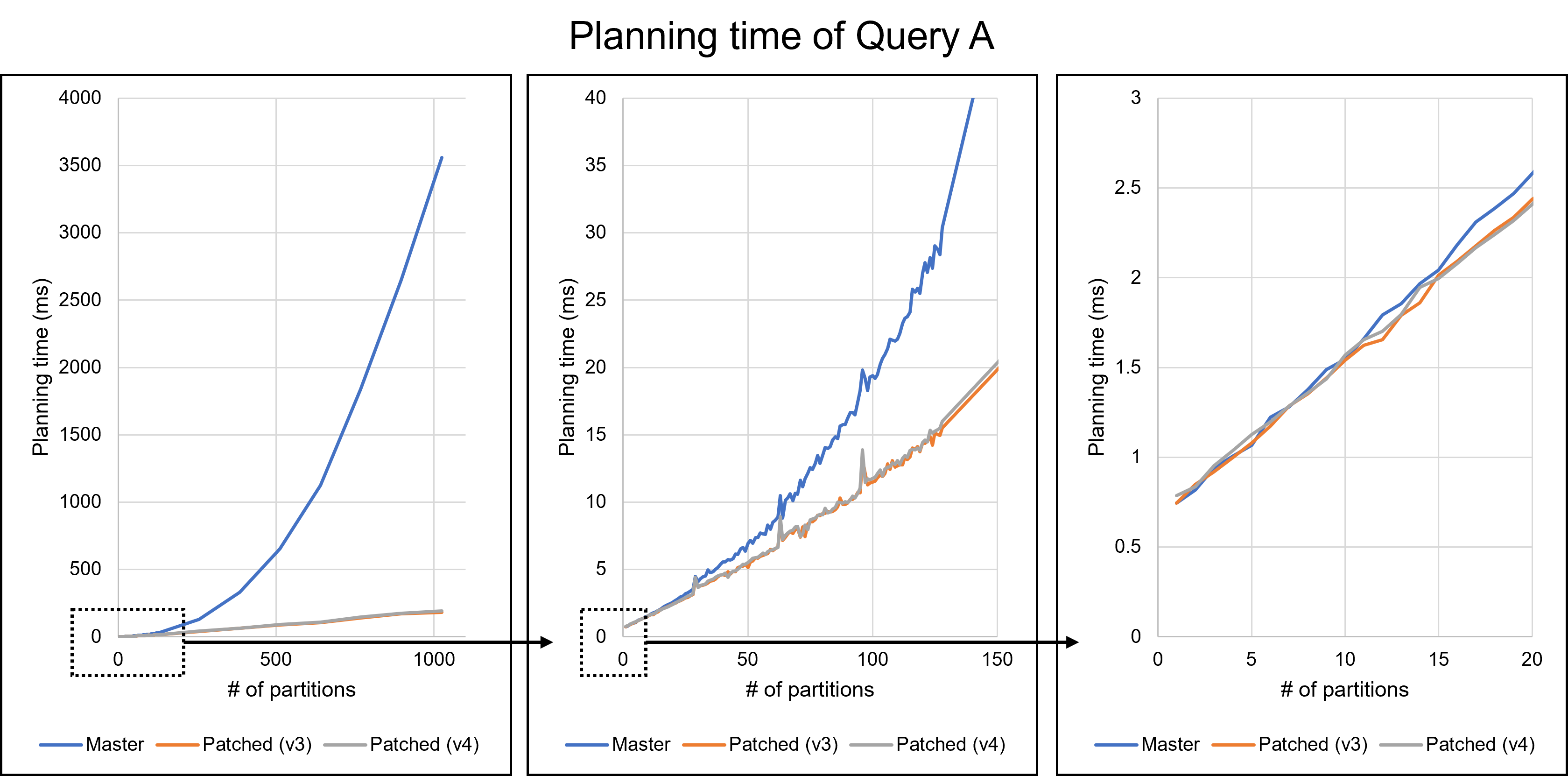{kind=link}
On Fri, 26 Aug 2022 at 12:40, Yuya Watari <watari.yuya@gmail.com> wrote:
> This performance degradation is due to the heavy processing of the
> get_ec***_indexes***() functions. These functions are the core part of
> the optimization we are working on in this thread, but they are
> relatively heavy when the number of partitions is small.
>
> I noticed that these functions were called repeatedly with the same
> arguments. During planning Query B with one partition, the
> get_ec_source_indexes_strict() function was called 2087 times with
> exactly the same parameters. Such repeated calls occurred many times
> in a single query.
How about instead of doing this caching like this, why don't we code
up some iterators that we can loop over to fetch the required EMs.
I'll attempt to type out my thoughts here without actually trying to
see if this works:
typedef struct EquivalenceMemberIterator
{
EquivalenceClass *ec;
Relids relids;
Bitmapset *em_matches;
int position; /* last found index of em_matches or -1 */
bool use_index;
bool with_children;
bool with_norel_members;
} EquivalenceMemberIterator;
We'd then have functions like:
static void
get_ecmember_indexes_iterator(EquivalenceMemberIterator *it,
PlannerInfo *root, EquivalenceClass *ec, Relids relids, bool
with_children, bool with_norel_members)
{
it->ec = ec;
it->relids = relids;
it->position = -1;
it->use_index = (root->simple_rel_array_size > 32); /* or whatever
threshold is best */
it->with_children = with_children;
it->with_norel_members = with_norel_members;
if (it->use_index)
it->em_matches = get_ecmember_indexes(root, ec, relids,
with_children, with_norel_members);
else
it->em_matches = NULL;
}
static EquivalenceMember *
get_next_matching_member(PlannerInfo *root, EquivalenceMemberIterator *it)
{
if (it->use_index)
{
it->position = bms_next_member(it->ec_matches, it->position);
if (it->position >= 0)
return list_nth(root->eq_members, it->position);
return NULL;
}
else
{
int i = it->position;
while ((i = bms_next_member(it->ec->ec_member_indexes, i) >= 0)
{
/* filter out the EMs we don't want here "break" when
we find a match */
}
it->position = i;
if (i >= 0)
return list_nth(root->eq_members, i);
return NULL;
}
}
Then the consuming code will do something like:
EquivalenceMemberIterator iterator;
get_ecmember_indexes_iterator(&iterator, root, ec, relids, true, false);
while ((cur_em = get_next_matching_member(root, &it)) != NULL)
{
// do stuff
}
David
Dear David, On Fri, Aug 26, 2022 at 12:18 PM David Rowley <dgrowleyml@gmail.com> wrote: > How about instead of doing this caching like this, why don't we code > up some iterators that we can loop over to fetch the required EMs. Thank you very much for your quick reply and for sharing your idea with code. I also think introducing EquivalenceMemberIterator is one good alternative solution. I will try to implement and test it. Thank you again for helping me. -- Best regards, Yuya Watari
Hello, On Fri, Aug 26, 2022 at 5:53 PM Yuya Watari <watari.yuya@gmail.com> wrote: > Thank you very much for your quick reply and for sharing your idea > with code. I also think introducing EquivalenceMemberIterator is one > good alternative solution. I will try to implement and test it. I apologize for my late response. I have implemented several approaches and tested them. 1. Changes I will describe how I modified our codes. I tested five versions: * v1: The first draft patch by David with bug fixes by me. This patch does not perform any optimizations based on Bitmapset operations. * v3: The past patch * v5 (v3 with revert): The v3 with revert of one of our optimizations * v6 (Iterator): An approach using iterators to enumerate over EquivalenceMembers. This approach is David's suggestion in the previous email. * v7 (Cache): My approach to caching the result of get_ec***indexes***() Please be noted that there is no direct parent-child relationship between v6 and v7; they are v5's children, i.e., siblings. I'm sorry for the confusing versioning. 1.1. Revert one of our optimizations (v5) As I mentioned in the comment in v[5|6|7]-0002-Revert-one-of-the-optimizations.patch, I reverted one of our optimizations. This code tries to find EquivalenceMembers that do not satisfy the bms_overlap condition. We encounter such members early in the loop, so the linear search is enough, and our optimization is too excessive here. As a result of experiments, I found this optimization was a bottleneck, so I reverted it. v6 (Iterator) and v7 (Cache) include this revert. 1.2. Iterator (v6) I have implemented the iterator approach. The code is based on what David advised, but I customized it a bit. I added the "bool caller_needs_recheck" argument to get_ecmember_indexes_iterator() and other similar functions. If this argument is true, the iterator enumerates all EquivalenceMembers without checking conditions such as bms_is_subset or bms_overlap. This change is because callers of these iterators sometimes recheck desired conditions after calling it. For example, if some caller wants EquivalenceMembers whose Relids is equal to some value, it calls get_ecmember_indexes(). However, since the result may have false positives, the caller has to recheck the result by the bms_equal() condition. In this case, if the threshold is below and we don't perform our optimization, checking bms_overlap() in the iterator does not make sense. We can solve this problem by passing true to the "caller_needs_recheck" argument to skip redundant checking. 1.3. Cache (v7) I have improved my caching approach. First, I introduced the on-demand allocation approach I mentioned in the previous email. ECIndexCache is allocated not together with RelOptInfo but when using it. In addition to this, a new version of the patch can handle multiple EquivalenceClasses. In the previous version, caching was only possible for one EquivalenceClass. This limitation is to prevent overhead but reduces caching opportunities. So, I have improved it so that it can handle all EquivalenceClasses. I made this change on the advice of Fujita-san. Thank you, Fujita-san. 2. Experimental Results I conducted experiments to test these methods. 2.1. Query A Figure 1 illustrates the planning times of Query A. Please see the previous email for what Query A refers to. The performance of all methods except master and v1 are almost the same. I cannot observe any degradation from this figure. 2.2. Query B Query B joins eight tables. In the previous email, I mentioned that the v3 patch has significant degradation for this query. Figure 2 and Table 1 show the results. The three approaches of v5, v6 (Iterator), and v7 (Cache) showed good overall performance. In particular, v7 (Cache) performed best for the smaller number of partitions. Table 1: Planning Time of Query B (ms) ------------------------------------- n | Master | v1 | v3 ------------------------------------- 1 | 55.459 | 57.376 | 58.849 2 | 54.162 | 56.454 | 57.615 4 | 56.491 | 59.742 | 57.108 8 | 62.694 | 67.920 | 59.591 16 | 79.547 | 90.589 | 64.954 32 | 134.623 | 160.452 | 76.626 64 | 368.716 | 439.894 | 107.278 128 | 1374.000 | 1598.748 | 170.909 256 | 5955.762 | 6921.668 | 324.113 ------------------------------------- -------------------------------------------------------- n | v5 (v3 with revert) | v6 (Iterator) | v7 (Cache) -------------------------------------------------------- 1 | 56.268 | 57.520 | 56.703 2 | 55.511 | 55.212 | 54.395 4 | 55.643 | 55.025 | 54.996 8 | 57.770 | 57.519 | 57.114 16 | 63.075 | 63.117 | 63.161 32 | 74.788 | 74.369 | 75.801 64 | 104.027 | 104.787 | 105.450 128 | 169.473 | 169.019 | 174.919 256 | 321.450 | 322.739 | 342.601 -------------------------------------------------------- 2.3. Join Order Benchmark It is essential to test real workloads, so I used the Join Order Benchmark [1]. This benchmark contains many complicated queries joining a lot of tables. I partitioned fact tables by 'id' columns and measured query planning times. Figure 3 and Table 2 describe the results. The results showed that all methods produced some degradations when there were not so many partitions. However, the degradation of v7 (cache) was relatively small. It was 0.8% with two partitions, while the other methods' degradation was at least 1.6%. Table 2: Speedup of Join Order Benchmark (higher is better) ----------------------------------------------------------------- n | v3 | v5 (v3 with revert) | v6 (Iterator) | v7 (Cache) ----------------------------------------------------------------- 2 | 95.8% | 97.3% | 97.3% | 97.7% 4 | 96.9% | 98.4% | 98.0% | 99.2% 8 | 102.2% | 102.9% | 98.1% | 103.0% 16 | 107.6% | 109.5% | 110.1% | 109.4% 32 | 123.5% | 125.4% | 125.5% | 125.0% 64 | 165.2% | 165.9% | 164.6% | 165.9% 128 | 308.2% | 309.2% | 312.1% | 311.4% 256 | 770.1% | 772.3% | 776.6% | 773.2% ----------------------------------------------------------------- 2.4. pgbench Our optimizations must not cause negative impacts on OLTP workloads. I conducted pgbench, and Figure 4 and Table 3 show its result. Table 3: The result of pgbench (tps) ------------------------------------------------------------------------ n | Master | v3 | v5 (v3 with revert) | v6 (Iterator) | v7 (Cache) ------------------------------------------------------------------------ 1 | 7617 | 7510 | 7484 | 7599 | 7561 2 | 7613 | 7487 | 7503 | 7609 | 7560 4 | 7559 | 7497 | 7453 | 7560 | 7553 8 | 7506 | 7429 | 7405 | 7523 | 7503 16 | 7584 | 7481 | 7466 | 7558 | 7508 32 | 7556 | 7456 | 7448 | 7558 | 7521 64 | 7555 | 7452 | 7435 | 7541 | 7504 128 | 7542 | 7430 | 7442 | 7558 | 7517 ------------------------------------------------------------------------ Avg | 7566 | 7468 | 7455 | 7563 | 7528 ------------------------------------------------------------------------ This result indicates that v3 and v5 (v3 with revert) had a significant negative impact on the pgbench workload. Their tps decreased by 1.3% or more. On the other hand, degradations of v6 (Iterator) and v7 (Cache) are non-existent or negligible. 3. Causes of Degression We could not avoid degradation with the Join Order Benchmark. The leading cause of this problem is that Bitmapset operation, especially bms_next_member(), is relatively slower than simple enumeration over List. It is easy to imagine that bms_next_member(), which has complex bit operations, is a little heavier than List enumerations simply advancing a pointer. The fact that even the v1, where we don't perform any optimizations, slowed down supports this notion. I think preventing this regression is very hard. To do so, we must have both List and Bitmapset representations of EquivalenceMembers. However, I don't prefer this solution because it is redundant and leads to less code maintainability. Reducing Bitmapset->nwords is another possible solution. I will try it, but it will likely not solve the significant degradation in pgbench for v3 and v5. This is because such degradation did not occur with v6 and v7, with also use Bitmapset. 4. Which Method is The Best? First of all, it is hard to adopt v3 and v5 (v3 with revert) because they degrade performance on OLTP workloads. Therefore, v6 (Iterator) and v7 (Cache) are possible candidates. Of these methods, I prefer v7 (Cache). Actually, I don't think an approach to introducing thresholds is a good idea because the best threshold is unclear. If we become conservative to avoid degradation, we must increase the threshold, but that takes away the opportunity for optimization. The opposite is true. In contrast, v7 (Cache) is an essential solution in terms of reducing the cost of repeated function calls and does not require the introduction of a threshold. Besides, it performs better on almost all workloads, including the Join Order Benchmark. It also has no negative impacts on OLTP. In conclusion, I think v7 (Cache) is the most desirable. Of course, the method may have some problems, but it is worth considering. [1] https://github.com/winkyao/join-order-benchmark -- Best regards, Yuya Watari
Attachment
- figure-1.png
- figure-2.png
- figure-3.png
- figure-4.png
- v5-0001-Apply-eclass_member_speedup_v3.patch.patch
- v5-0002-Revert-one-of-the-optimizations.patch
- v6-0001-Apply-eclass_member_speedup_v3.patch.patch
- v6-0002-Revert-one-of-the-optimizations.patch
- v6-0003-Implement-iterators.patch
- v7-0001-Apply-eclass_member_speedup_v3.patch.patch
- v7-0002-Revert-one-of-the-optimizations.patch
- v7-0003-Implement-ECIndexCache.patch
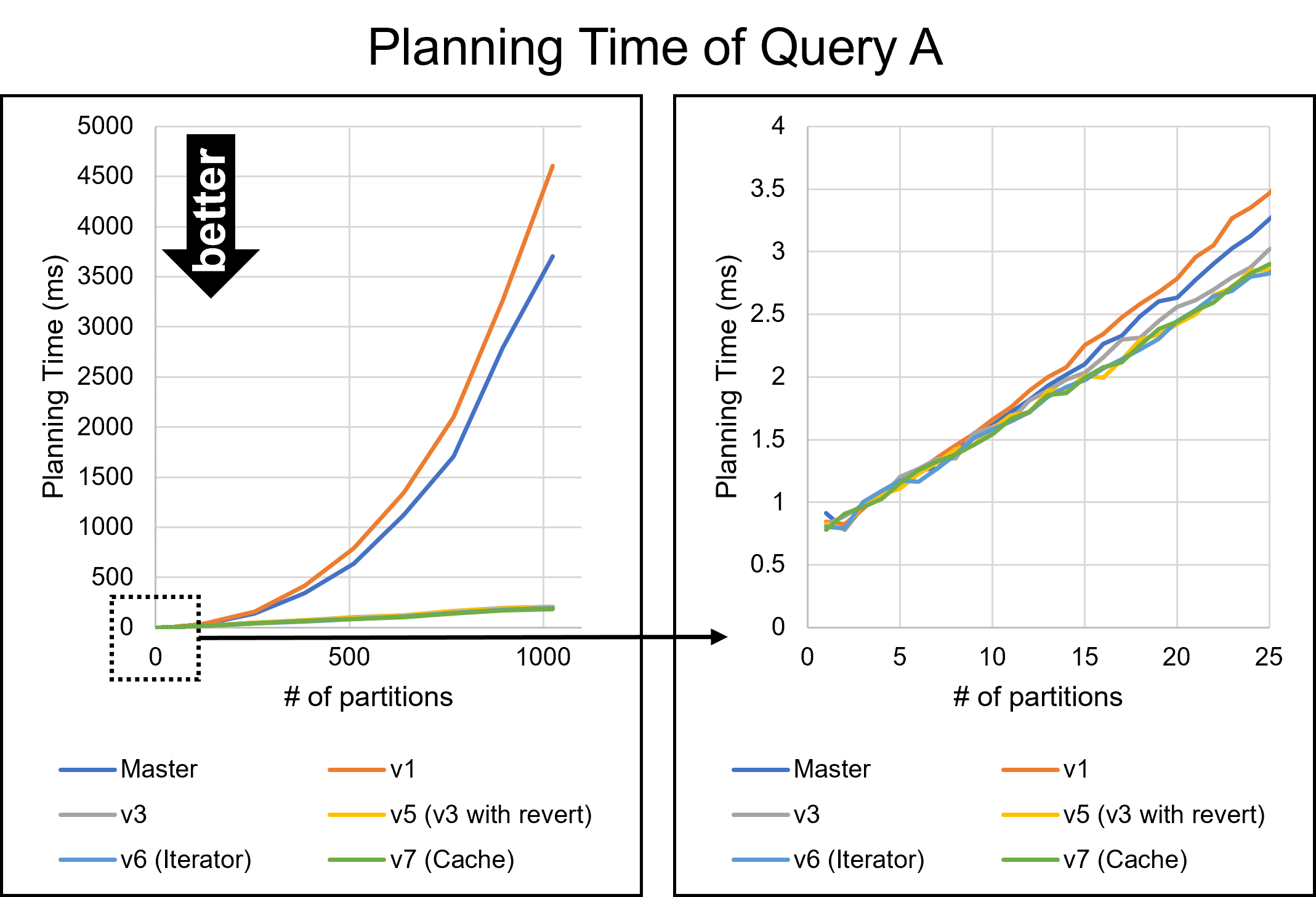{kind=link}
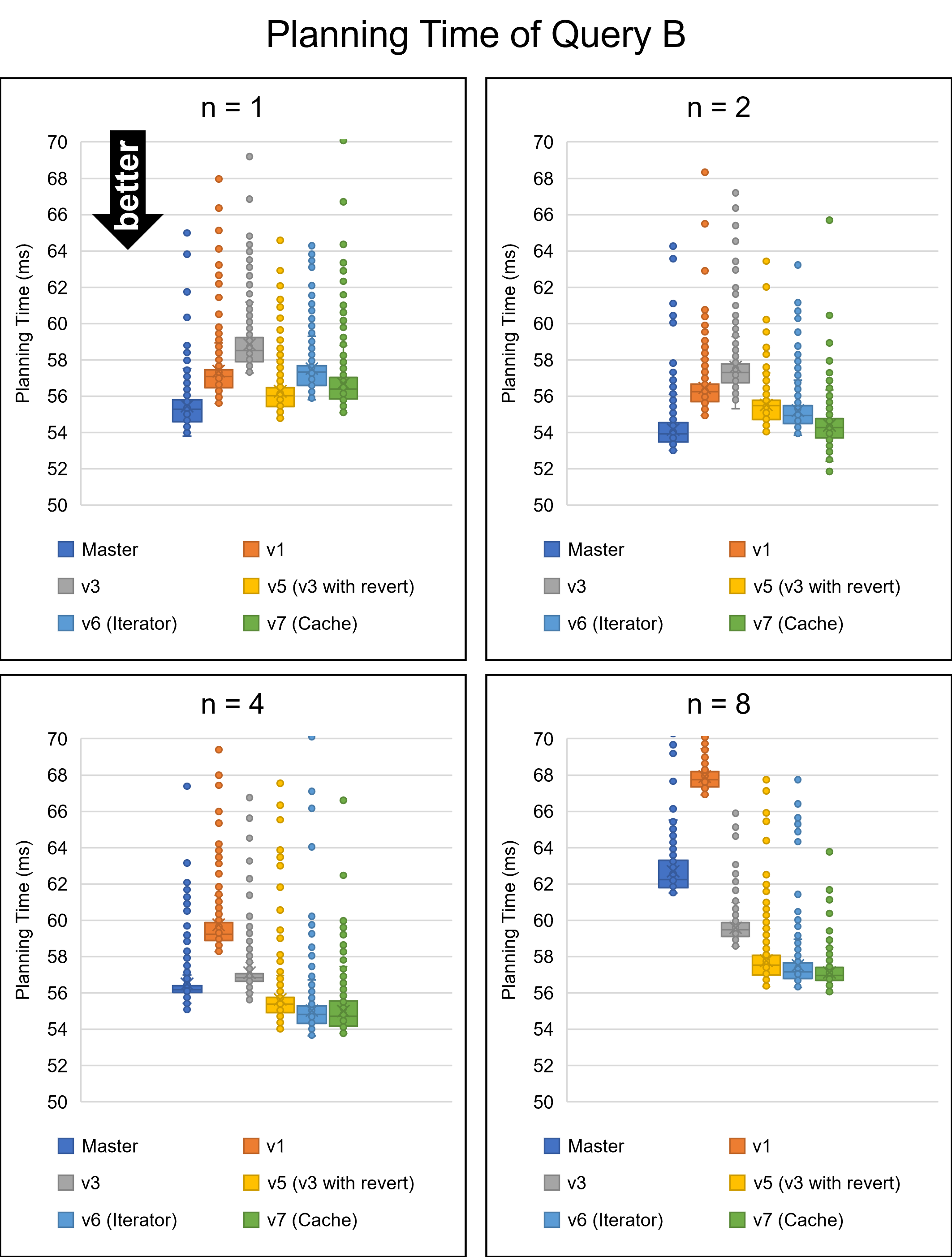{kind=link}
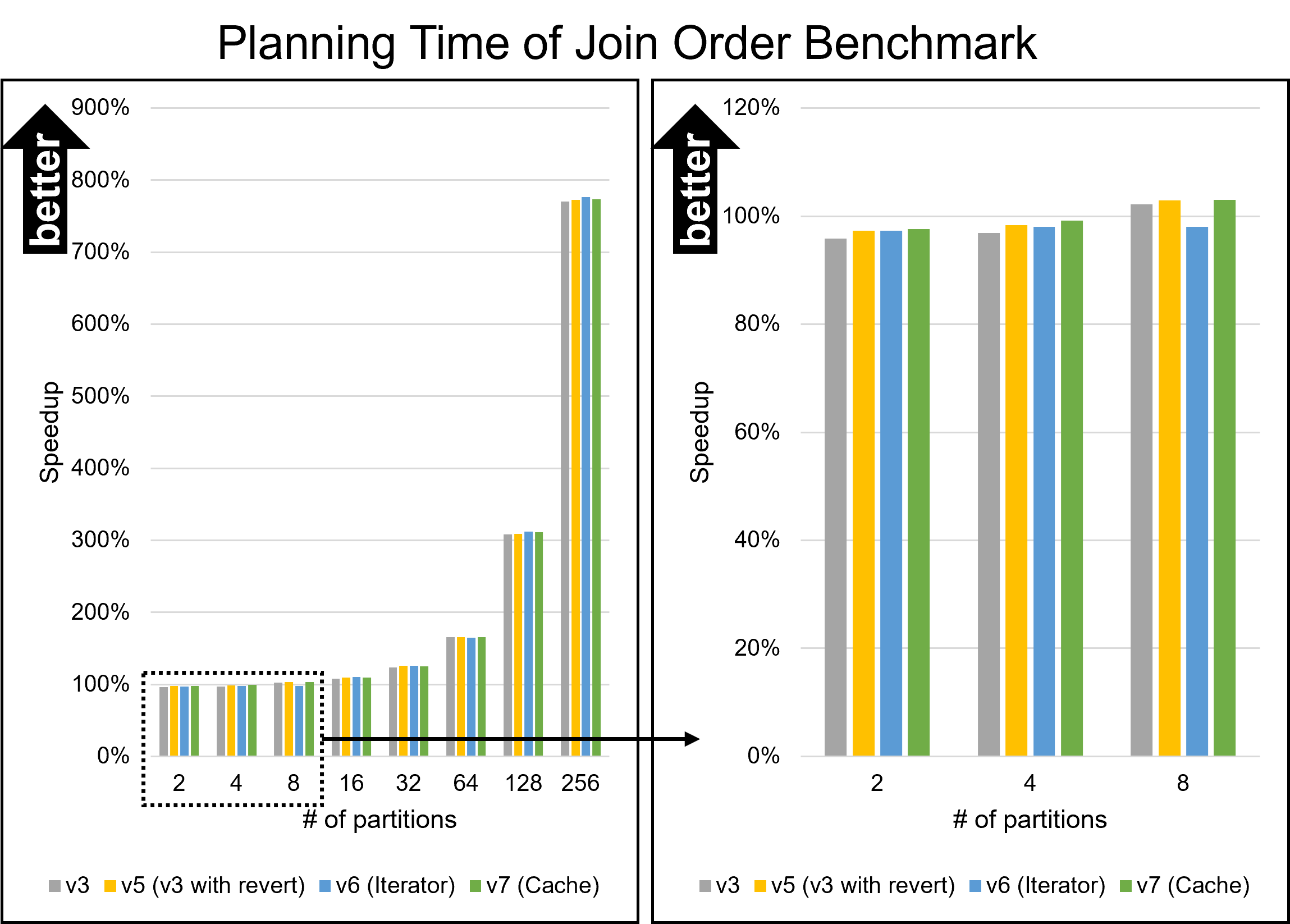{kind=link}
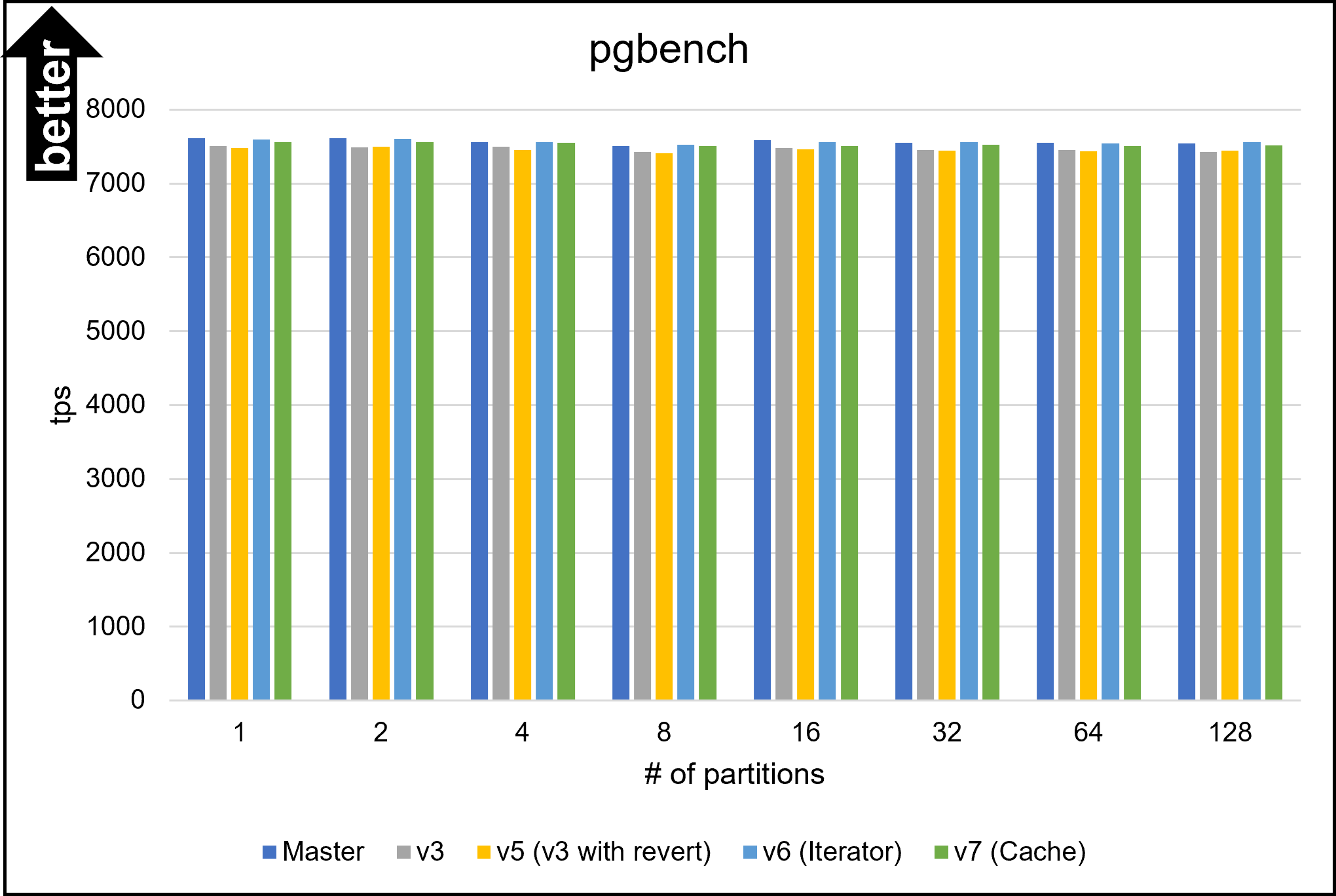{kind=link}
Hello, On Wed, Sep 21, 2022 at 6:43 PM Yuya Watari <watari.yuya@gmail.com> wrote: > 1.1. Revert one of our optimizations (v5) > > As I mentioned in the comment in > v[5|6|7]-0002-Revert-one-of-the-optimizations.patch, I reverted one of > our optimizations. This code tries to find EquivalenceMembers that do > not satisfy the bms_overlap condition. We encounter such members early > in the loop, so the linear search is enough, and our optimization is > too excessive here. As a result of experiments, I found this > optimization was a bottleneck, so I reverted it. In the previous mail, I proposed a revert of one excessive optimization. In addition, I found a new bottleneck and attached a new version of the patch solving it to this email. The new bottleneck exists in the select_outer_pathkeys_for_merge() function. At the end of this function, we count EquivalenceMembers that satisfy the specific condition. To count them, we have used Bitmapset operations. Through experiments, I concluded that this optimization is effective for larger cases but leads to some degradation for the smaller number of partitions. The new patch switches two algorithms depending on the problem sizes. 1. Experimental result 1.1. Join Order Benchmark As in the previous email, I used the Join Order Benchmark to evaluate the patches' performance. The correspondence between each version and patches is as follows. v3: v8-0001-*.patch v5 (v3 with revert): v8-0001-*.patch + v8-0002-*.patch v8 (v5 with revert): v8-0001-*.patch + v8-0002-*.patch + v8-0003-*.patch I show the speed-up of each method compared with the master branch in Table 1. When the number of partitions is 1, performance degradation is kept to 1.1% in v8, while they are 4.2% and 1.8% in v3 and v5. This result indicates that a newly introduced revert is effective. Table 1: Speedup of Join Order Benchmark (higher is better) (n = the number of partitions) ---------------------------------------------------------- n | v3 | v5 (v3 with revert) | v8 (v5 with revert) ---------------------------------------------------------- 2 | 95.8% | 98.2% | 98.9% 4 | 97.2% | 99.7% | 99.3% 8 | 101.4% | 102.5% | 103.4% 16 | 108.7% | 111.4% | 110.2% 32 | 127.1% | 127.6% | 128.8% 64 | 169.5% | 172.1% | 172.4% 128 | 330.1% | 335.2% | 332.3% 256 | 815.1% | 826.4% | 821.8% ---------------------------------------------------------- 1.2. pgbench The following table describes the result of pgbench. The v5 and v8 performed clearly better than the v3 patch. The difference between v5 and v8 is not so significant, but v8's performance is close to the master branch. Table 2: The result of pgbench (tps) ----------------------------------------------------------------- n | Master | v3 | v5 (v3 with revert) | v8 (v5 with revert) ----------------------------------------------------------------- 1 | 7550 | 7422 | 7474 | 7521 2 | 7594 | 7381 | 7536 | 7529 4 | 7518 | 7362 | 7461 | 7524 8 | 7459 | 7340 | 7424 | 7460 ----------------------------------------------------------------- Avg | 7531 | 7377 | 7474 | 7509 ----------------------------------------------------------------- 2. Conclusion and future works The revert in the v8-0003-*.patch is effective in preventing performance degradation for the smaller number of partitions. However, I don't think what I have done in the patch is the best or ideal solution. As I mentioned in the comments in the patch, switching two algorithms may be ugly because it introduces code duplication. We need a wiser solution to this problem. -- Best regards, Yuya Watari
Attachment
Hello, I noticed that the previous patch does not apply to the current HEAD. I attached the rebased version to this email. -- Best regards, Yuya Watari
Attachment
On 2/11/2022 15:27, Yuya Watari wrote: > Hello, > > I noticed that the previous patch does not apply to the current HEAD. > I attached the rebased version to this email. > I'm still in review of your patch now. At most it seems ok, but are you really need both eq_sources and eq_derives lists now? As I see, everywhere access to these lists guides by eclass_source_indexes and eclass_derive_indexes correspondingly. Maybe to merge them? -- regards, Andrey Lepikhov Postgres Professional
Andrey Lepikhov <a.lepikhov@postgrespro.ru> writes:
> I'm still in review of your patch now. At most it seems ok, but are you
> really need both eq_sources and eq_derives lists now?
Didn't we just have this conversation? eq_sources needs to be kept
separate to support the "broken EC" logic. We don't want to be
regurgitating derived clauses as well as originals in that path.
regards, tom lane
Andrey Lepikhov <a.lepikhov@postgrespro.ru> writes:I'm still in review of your patch now. At most it seems ok, but are you
really need both eq_sources and eq_derives lists now?
Didn't we just have this conversation? eq_sources needs to be kept
separate to support the "broken EC" logic. We don't want to be
regurgitating derived clauses as well as originals in that path.
) : https://www.postgresql.org/message-id/644164.1666877342%40sss.pgh.pa.us
On 2/11/2022 15:27, Yuya Watari wrote: > I noticed that the previous patch does not apply to the current HEAD. > I attached the rebased version to this email. Looking into find_em_for_rel() changes I see that you replaced if (bms_is_subset(em->em_relids, rel->relids) with assertion statement. According of get_ecmember_indexes(), the em_relids field of returned equivalence members can contain relids, not mentioned in the relation. I don't understand, why it works now? For example, we can sort by t1.x, but have an expression t1.x=t1.y*t2.z. Or I've missed something? If it is not a mistake, maybe to add a comment why assertion here isn't failed? -- regards, Andrey Lepikhov Postgres Professional
On Mon, 7 Nov 2022 at 06:33, Zhang Mingli <zmlpostgres@gmail.com> wrote: > > HI, > > Regards, > Zhang Mingli > On Nov 7, 2022, 14:26 +0800, Tom Lane <tgl@sss.pgh.pa.us>, wrote: > > Andrey Lepikhov <a.lepikhov@postgrespro.ru> writes: > > I'm still in review of your patch now. At most it seems ok, but are you > really need both eq_sources and eq_derives lists now? > > > Didn't we just have this conversation? eq_sources needs to be kept > separate to support the "broken EC" logic. We don't want to be > regurgitating derived clauses as well as originals in that path. > > Aha, we have that conversation in another thread(Reducing duplicativeness of EquivalenceClass-derived clauses > ) : https://www.postgresql.org/message-id/644164.1666877342%40sss.pgh.pa.us Once the issue Tom identified has been resolved, I'd like to test drive newer patches. Thom
On 2022-Nov-16, Thom Brown wrote: > Once the issue Tom identified has been resolved, I'd like to test > drive newer patches. What issue? If you mean the one from the thread "Reducing duplicativeness of EquivalenceClass-derived clauses", that patch is already applied (commit a5fc46414deb), and Yuya Watari's v8 series applies fine to current master. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "Having your biases confirmed independently is how scientific progress is made, and hence made our great society what it is today" (Mary Gardiner)
On Thu, 17 Nov 2022 at 09:31, Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2022-Nov-16, Thom Brown wrote: > > > Once the issue Tom identified has been resolved, I'd like to test > > drive newer patches. > > What issue? If you mean the one from the thread "Reducing > duplicativeness of EquivalenceClass-derived clauses", that patch is > already applied (commit a5fc46414deb), and Yuya Watari's v8 series > applies fine to current master. Ah, I see.. I'll test the v8 patches. Thanks Thom
On Thu, 17 Nov 2022 at 11:20, Thom Brown <thom@linux.com> wrote: > > On Thu, 17 Nov 2022 at 09:31, Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > > > On 2022-Nov-16, Thom Brown wrote: > > > > > Once the issue Tom identified has been resolved, I'd like to test > > > drive newer patches. > > > > What issue? If you mean the one from the thread "Reducing > > duplicativeness of EquivalenceClass-derived clauses", that patch is > > already applied (commit a5fc46414deb), and Yuya Watari's v8 series > > applies fine to current master. > > Ah, I see.. I'll test the v8 patches. No issues with applying. Created 1024 partitions, each of which is partitioned into 64 partitions. I'm getting a generic planning time of 1415ms. Is that considered reasonable in this situation? Bear in mind that the planning time prior to this patch was 282311ms, so pretty much a 200x speedup. Thom
Dear Andrey and Thom, Thank you for reviewing and testing the patch. I really apologize for my late response. On Tue, Nov 8, 2022 at 8:31 PM Andrey Lepikhov <a.lepikhov@postgrespro.ru> wrote: > Looking into find_em_for_rel() changes I see that you replaced > if (bms_is_subset(em->em_relids, rel->relids) > with assertion statement. > According of get_ecmember_indexes(), the em_relids field of returned > equivalence members can contain relids, not mentioned in the relation. > I don't understand, why it works now? For example, we can sort by t1.x, > but have an expression t1.x=t1.y*t2.z. Or I've missed something? If it > is not a mistake, maybe to add a comment why assertion here isn't failed? As you pointed out, changing the bms_is_subset() condition to an assertion is logically incorrect here. Thank you for telling me about it. I fixed it and attached the modified patch to this email. On Thu, Nov 17, 2022 at 9:05 PM Thom Brown <thom@linux.com> wrote: > No issues with applying. Created 1024 partitions, each of which is > partitioned into 64 partitions. > > I'm getting a generic planning time of 1415ms. Is that considered > reasonable in this situation? Bear in mind that the planning time > prior to this patch was 282311ms, so pretty much a 200x speedup. Thank you for testing the patch with an actual query. This speedup is very impressive. When I used an original query with 1024 partitions, its planning time was about 200ms. Given that each partition is also partitioned in your workload, I think the result of 1415ms is reasonable. -- Best regards, Yuya Watari
Attachment
On Tue, 29 Nov 2022 at 21:59, Yuya Watari <watari.yuya@gmail.com> wrote:
> Thank you for testing the patch with an actual query. This speedup is
> very impressive. When I used an original query with 1024 partitions,
> its planning time was about 200ms. Given that each partition is also
> partitioned in your workload, I think the result of 1415ms is
> reasonable.
I was looking again at the v9-0001 patch and I think we can do a
little better when building the Bitmapset of matching EMs. For
example, in the v9 patch, the code for get_ecmember_indexes_strict()
is doing:
+ if (!with_children)
+ matching_ems = bms_copy(ec->ec_nonchild_indexes);
+ else
+ matching_ems = bms_copy(ec->ec_member_indexes);
+
+ i = -1;
+ while ((i = bms_next_member(relids, i)) >= 0)
+ {
+ RelOptInfo *rel = root->simple_rel_array[i];
+
+ matching_ems = bms_int_members(matching_ems, rel->eclass_member_indexes);
+ }
It seems reasonable that if there are a large number of partitions
then ec_member_indexes will have a large number of Bitmapwords. When
we do bms_int_members() on that, we're going to probably end up with a
bunch of trailing zero words in the set. In the v10 patch, I've
changed this to become:
+ int i = bms_next_member(relids, -1);
+
+ if (i >= 0)
+ {
+ RelOptInfo *rel = root->simple_rel_array[i];
+
+ /*
+ * bms_intersect to the first relation to try to keep the resulting
+ * Bitmapset as small as possible. This saves having to make a
+ * complete bms_copy() of one of them. One may contain significantly
+ * more words than the other.
+ */
+ if (!with_children)
+ matching_ems = bms_intersect(rel->eclass_member_indexes,
+ ec->ec_nonchild_indexes);
+ else
+ matching_ems = bms_intersect(rel->eclass_member_indexes,
+ ec->ec_member_indexes);
+
+ while ((i = bms_next_member(relids, i)) >= 0)
+ {
+ rel = root->simple_rel_array[i];
+ matching_ems = bms_int_members(matching_ems,
+ rel->eclass_member_indexes);
+ }
+ }
so, effectively we first bms_intersect to the first member of relids
before masking out the bits for the remaining ones. This should mean
we'll have a Bitmapset with fewer words in many complex planning
problems. There's no longer the dilemma of having to decide if we
should start with RelOptInfo's eclass_member_indexes or the
EquivalenceClass's member indexes. When using bms_int_member, we
really want to start with the smallest of those so we get the smallest
resulting set. With bms_intersect(), it will always make a copy of
the smallest set. v10 does that instead of bms_copy()ing the
EquivalenceClass's member's Bitmapset.
I also wondered how much we're losing to the fact that
bms_int_members() zeros the trailing words and does not trim the
Bitmapset down.
The problem there is 2-fold;
1) we have to zero the trailing words on the left input. That'll
pollute the CPU cache a bit as it may have to fetch a bunch of extra
cache lines, and;
2) subsequent bms_int_members() done afterwards may have to mask out
additional words. If we can make the shortest input really short, then
subsequent bms_int_members() are going to be very fast.
You might argue there that setting nwords to the shortest length may
cause us to have to repalloc the Bitmapset if we need to later add
more members again, but if you look at the repalloc() code, it's
effectively a no-op when the allocated size >= the requested size, so
repalloc() should be very fast in this case. So, worst case, there's
an additional "no-op" repalloc() (which should be very fast) followed
by maybe a bms_add_members() which has to zero the words instead of
bms_int_members(). I changed this in the v10-0002 patch. I'm not sure
if we should do this or not.
I also changed v10-0001 so that we still store the EquivalenceClass's
members list. There were a few places where the code just wanted to
get the first member and having to look at the Bitmapset index and
fetch the first match from PlannerInfo seemed convoluted. If the
query is simple, it seems like it's not going to be very expensive to
add a few EquivalenceMembers to this list. When planning more complex
problems, there's probably enough other extra overhead that we're
unlikely to notice the extra lappend()s. This also allows v10-0003 to
work, see below.
In v10-0003, I experimented with the iterator concept that I mentioned
earlier. Since v10-0001 is now storing the EquivalenceMember list in
EquivalenceClass again, it's now quite simple to have the iterator
decide if it should be scanning the index or doing a loop over all
members to find the ones matching the search. We can make this
decision based on list_length(ec->ec_members). This should be a more
reliable check than checking root->simple_rel_array_size as we could
still have classes with just a few members even when there's a large
number of rels in simple_rel_array. I was hoping that v10-0003 would
allow us to maintain the same planner performance for simple queries.
It just does not seem to change the performance much. Perhaps it's not
worth the complexity if there are no performance benefits. It probably
needs more performance testing than what I've done to know if it helps
or hinders, however.
Overall, I'm not quite sure if this is any faster than your v9 patch.
I think more performance testing needs to be done. I think the
v10-0001 + v10-0002 is faster than v9-0001, but perhaps the changes
you've made in v9-0002 and v9-0003 are worth redoing. I didn't test. I
was hoping to keep the logic about which method to use to find the
members in the iterator code and not litter it around the tree.
I did run the test you mentioned in [1] and I got:
$ echo Master @ 29452de73 && ./partbench.sh | grep -E "^(Testing|latency)"
Master @ 29452de73
Testing with 2 partitions...
latency average = 0.231 ms
Testing with 4 partitions...
latency average = 0.303 ms
Testing with 8 partitions...
latency average = 0.454 ms
Testing with 16 partitions...
latency average = 0.777 ms
Testing with 32 partitions...
latency average = 1.576 ms
Testing with 64 partitions...
latency average = 3.574 ms
Testing with 128 partitions...
latency average = 9.504 ms
Testing with 256 partitions...
latency average = 37.321 ms
Testing with 512 partitions...
latency average = 171.660 ms
Testing with 1024 partitions...
latency average = 1021.990 ms
$ echo Master + v10-0001 && ./partbench.sh | grep -E "^(Testing|latency)"
Master + v10-0001
Testing with 2 partitions...
latency average = 0.239 ms
Testing with 4 partitions...
latency average = 0.315 ms
Testing with 8 partitions...
latency average = 0.463 ms
Testing with 16 partitions...
latency average = 0.757 ms
Testing with 32 partitions...
latency average = 1.481 ms
Testing with 64 partitions...
latency average = 2.563 ms
Testing with 128 partitions...
latency average = 5.618 ms
Testing with 256 partitions...
latency average = 16.229 ms
Testing with 512 partitions...
latency average = 38.855 ms
Testing with 1024 partitions...
latency average = 85.705 ms
$ echo Master + v10-0001 + v10-0002 && ./partbench.sh | grep -E
"^(Testing|latency)"
Master + v10-0001 + v10-0002
Testing with 2 partitions...
latency average = 0.241 ms
Testing with 4 partitions...
latency average = 0.312 ms
Testing with 8 partitions...
latency average = 0.459 ms
Testing with 16 partitions...
latency average = 0.755 ms
Testing with 32 partitions...
latency average = 1.464 ms
Testing with 64 partitions...
latency average = 2.580 ms
Testing with 128 partitions...
latency average = 5.652 ms
Testing with 256 partitions...
latency average = 16.464 ms
Testing with 512 partitions...
latency average = 37.674 ms
Testing with 1024 partitions...
latency average = 84.094 ms
$ echo Master + v10-0001 + v10-0002 + v10-0003 && ./partbench.sh |
grep -E "^(Testing|latency)"
Master + v10-0001 + v10-0002 + v10-0003
Testing with 2 partitions...
latency average = 0.240 ms
Testing with 4 partitions...
latency average = 0.318 ms
Testing with 8 partitions...
latency average = 0.465 ms
Testing with 16 partitions...
latency average = 0.763 ms
Testing with 32 partitions...
latency average = 1.486 ms
Testing with 64 partitions...
latency average = 2.858 ms
Testing with 128 partitions...
latency average = 5.764 ms
Testing with 256 partitions...
latency average = 16.995 ms
Testing with 512 partitions...
latency average = 38.012 ms
Testing with 1024 partitions...
latency average = 88.098 ms
$ echo Master + v9-* && ./partbench.sh | grep -E "^(Testing|latency)"
Master + v9-*
Testing with 2 partitions...
latency average = 0.237 ms
Testing with 4 partitions...
latency average = 0.313 ms
Testing with 8 partitions...
latency average = 0.460 ms
Testing with 16 partitions...
latency average = 0.780 ms
Testing with 32 partitions...
latency average = 1.468 ms
Testing with 64 partitions...
latency average = 2.701 ms
Testing with 128 partitions...
latency average = 5.275 ms
Testing with 256 partitions...
latency average = 17.208 ms
Testing with 512 partitions...
latency average = 37.183 ms
Testing with 1024 partitions...
latency average = 90.595 ms
David
[1] https://postgr.es/m/CAJ2pMkZNCgoUKSE%2B_5LthD%2BKbXKvq6h2hQN8Esxpxd%2Bcxmgomg%40mail.gmail.com
Attachment
On Sun, 4 Dec 2022 at 00:35, David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Tue, 29 Nov 2022 at 21:59, Yuya Watari <watari.yuya@gmail.com> wrote:
> > Thank you for testing the patch with an actual query. This speedup is
> > very impressive. When I used an original query with 1024 partitions,
> > its planning time was about 200ms. Given that each partition is also
> > partitioned in your workload, I think the result of 1415ms is
> > reasonable.
>
> I was looking again at the v9-0001 patch and I think we can do a
> little better when building the Bitmapset of matching EMs. For
> example, in the v9 patch, the code for get_ecmember_indexes_strict()
> is doing:
>
> + if (!with_children)
> + matching_ems = bms_copy(ec->ec_nonchild_indexes);
> + else
> + matching_ems = bms_copy(ec->ec_member_indexes);
> +
> + i = -1;
> + while ((i = bms_next_member(relids, i)) >= 0)
> + {
> + RelOptInfo *rel = root->simple_rel_array[i];
> +
> + matching_ems = bms_int_members(matching_ems, rel->eclass_member_indexes);
> + }
>
> It seems reasonable that if there are a large number of partitions
> then ec_member_indexes will have a large number of Bitmapwords. When
> we do bms_int_members() on that, we're going to probably end up with a
> bunch of trailing zero words in the set. In the v10 patch, I've
> changed this to become:
>
> + int i = bms_next_member(relids, -1);
> +
> + if (i >= 0)
> + {
> + RelOptInfo *rel = root->simple_rel_array[i];
> +
> + /*
> + * bms_intersect to the first relation to try to keep the resulting
> + * Bitmapset as small as possible. This saves having to make a
> + * complete bms_copy() of one of them. One may contain significantly
> + * more words than the other.
> + */
> + if (!with_children)
> + matching_ems = bms_intersect(rel->eclass_member_indexes,
> + ec->ec_nonchild_indexes);
> + else
> + matching_ems = bms_intersect(rel->eclass_member_indexes,
> + ec->ec_member_indexes);
> +
> + while ((i = bms_next_member(relids, i)) >= 0)
> + {
> + rel = root->simple_rel_array[i];
> + matching_ems = bms_int_members(matching_ems,
> + rel->eclass_member_indexes);
> + }
> + }
>
> so, effectively we first bms_intersect to the first member of relids
> before masking out the bits for the remaining ones. This should mean
> we'll have a Bitmapset with fewer words in many complex planning
> problems. There's no longer the dilemma of having to decide if we
> should start with RelOptInfo's eclass_member_indexes or the
> EquivalenceClass's member indexes. When using bms_int_member, we
> really want to start with the smallest of those so we get the smallest
> resulting set. With bms_intersect(), it will always make a copy of
> the smallest set. v10 does that instead of bms_copy()ing the
> EquivalenceClass's member's Bitmapset.
>
> I also wondered how much we're losing to the fact that
> bms_int_members() zeros the trailing words and does not trim the
> Bitmapset down.
>
> The problem there is 2-fold;
> 1) we have to zero the trailing words on the left input. That'll
> pollute the CPU cache a bit as it may have to fetch a bunch of extra
> cache lines, and;
> 2) subsequent bms_int_members() done afterwards may have to mask out
> additional words. If we can make the shortest input really short, then
> subsequent bms_int_members() are going to be very fast.
>
> You might argue there that setting nwords to the shortest length may
> cause us to have to repalloc the Bitmapset if we need to later add
> more members again, but if you look at the repalloc() code, it's
> effectively a no-op when the allocated size >= the requested size, so
> repalloc() should be very fast in this case. So, worst case, there's
> an additional "no-op" repalloc() (which should be very fast) followed
> by maybe a bms_add_members() which has to zero the words instead of
> bms_int_members(). I changed this in the v10-0002 patch. I'm not sure
> if we should do this or not.
>
> I also changed v10-0001 so that we still store the EquivalenceClass's
> members list. There were a few places where the code just wanted to
> get the first member and having to look at the Bitmapset index and
> fetch the first match from PlannerInfo seemed convoluted. If the
> query is simple, it seems like it's not going to be very expensive to
> add a few EquivalenceMembers to this list. When planning more complex
> problems, there's probably enough other extra overhead that we're
> unlikely to notice the extra lappend()s. This also allows v10-0003 to
> work, see below.
>
> In v10-0003, I experimented with the iterator concept that I mentioned
> earlier. Since v10-0001 is now storing the EquivalenceMember list in
> EquivalenceClass again, it's now quite simple to have the iterator
> decide if it should be scanning the index or doing a loop over all
> members to find the ones matching the search. We can make this
> decision based on list_length(ec->ec_members). This should be a more
> reliable check than checking root->simple_rel_array_size as we could
> still have classes with just a few members even when there's a large
> number of rels in simple_rel_array. I was hoping that v10-0003 would
> allow us to maintain the same planner performance for simple queries.
> It just does not seem to change the performance much. Perhaps it's not
> worth the complexity if there are no performance benefits. It probably
> needs more performance testing than what I've done to know if it helps
> or hinders, however.
>
> Overall, I'm not quite sure if this is any faster than your v9 patch.
> I think more performance testing needs to be done. I think the
> v10-0001 + v10-0002 is faster than v9-0001, but perhaps the changes
> you've made in v9-0002 and v9-0003 are worth redoing. I didn't test. I
> was hoping to keep the logic about which method to use to find the
> members in the iterator code and not litter it around the tree.
>
> I did run the test you mentioned in [1] and I got:
>
> $ echo Master @ 29452de73 && ./partbench.sh | grep -E "^(Testing|latency)"
> Master @ 29452de73
> Testing with 2 partitions...
> latency average = 0.231 ms
> Testing with 4 partitions...
> latency average = 0.303 ms
> Testing with 8 partitions...
> latency average = 0.454 ms
> Testing with 16 partitions...
> latency average = 0.777 ms
> Testing with 32 partitions...
> latency average = 1.576 ms
> Testing with 64 partitions...
> latency average = 3.574 ms
> Testing with 128 partitions...
> latency average = 9.504 ms
> Testing with 256 partitions...
> latency average = 37.321 ms
> Testing with 512 partitions...
> latency average = 171.660 ms
> Testing with 1024 partitions...
> latency average = 1021.990 ms
>
> $ echo Master + v10-0001 && ./partbench.sh | grep -E "^(Testing|latency)"
> Master + v10-0001
> Testing with 2 partitions...
> latency average = 0.239 ms
> Testing with 4 partitions...
> latency average = 0.315 ms
> Testing with 8 partitions...
> latency average = 0.463 ms
> Testing with 16 partitions...
> latency average = 0.757 ms
> Testing with 32 partitions...
> latency average = 1.481 ms
> Testing with 64 partitions...
> latency average = 2.563 ms
> Testing with 128 partitions...
> latency average = 5.618 ms
> Testing with 256 partitions...
> latency average = 16.229 ms
> Testing with 512 partitions...
> latency average = 38.855 ms
> Testing with 1024 partitions...
> latency average = 85.705 ms
>
> $ echo Master + v10-0001 + v10-0002 && ./partbench.sh | grep -E
> "^(Testing|latency)"
> Master + v10-0001 + v10-0002
> Testing with 2 partitions...
> latency average = 0.241 ms
> Testing with 4 partitions...
> latency average = 0.312 ms
> Testing with 8 partitions...
> latency average = 0.459 ms
> Testing with 16 partitions...
> latency average = 0.755 ms
> Testing with 32 partitions...
> latency average = 1.464 ms
> Testing with 64 partitions...
> latency average = 2.580 ms
> Testing with 128 partitions...
> latency average = 5.652 ms
> Testing with 256 partitions...
> latency average = 16.464 ms
> Testing with 512 partitions...
> latency average = 37.674 ms
> Testing with 1024 partitions...
> latency average = 84.094 ms
>
> $ echo Master + v10-0001 + v10-0002 + v10-0003 && ./partbench.sh |
> grep -E "^(Testing|latency)"
> Master + v10-0001 + v10-0002 + v10-0003
> Testing with 2 partitions...
> latency average = 0.240 ms
> Testing with 4 partitions...
> latency average = 0.318 ms
> Testing with 8 partitions...
> latency average = 0.465 ms
> Testing with 16 partitions...
> latency average = 0.763 ms
> Testing with 32 partitions...
> latency average = 1.486 ms
> Testing with 64 partitions...
> latency average = 2.858 ms
> Testing with 128 partitions...
> latency average = 5.764 ms
> Testing with 256 partitions...
> latency average = 16.995 ms
> Testing with 512 partitions...
> latency average = 38.012 ms
> Testing with 1024 partitions...
> latency average = 88.098 ms
>
> $ echo Master + v9-* && ./partbench.sh | grep -E "^(Testing|latency)"
> Master + v9-*
> Testing with 2 partitions...
> latency average = 0.237 ms
> Testing with 4 partitions...
> latency average = 0.313 ms
> Testing with 8 partitions...
> latency average = 0.460 ms
> Testing with 16 partitions...
> latency average = 0.780 ms
> Testing with 32 partitions...
> latency average = 1.468 ms
> Testing with 64 partitions...
> latency average = 2.701 ms
> Testing with 128 partitions...
> latency average = 5.275 ms
> Testing with 256 partitions...
> latency average = 17.208 ms
> Testing with 512 partitions...
> latency average = 37.183 ms
> Testing with 1024 partitions...
> latency average = 90.595 ms
Testing your patches with the same 1024 partitions, each with 64
sub-partitions, I get a planning time of 205.020 ms, which is now a
1,377x speedup. This has essentially reduced the planning time from a
catastrophe to a complete non-issue. Huge win!
--
Thom
On Tue, 6 Dec 2022 at 04:45, Thom Brown <thom@linux.com> wrote: > Testing your patches with the same 1024 partitions, each with 64 > sub-partitions, I get a planning time of 205.020 ms, which is now a > 1,377x speedup. This has essentially reduced the planning time from a > catastrophe to a complete non-issue. Huge win! Thanks for testing the v10 patches. I wouldn't have expected such additional gains from v10. I was mostly focused on trying to minimise any performance regression for simple queries that wouldn't benefit from indexing the EquivalenceMembers. Your query sounds like it does not fit into that category. Perhaps it is down to the fact that v9-0002 or v9-0003 reverts a couple of the optimisations that is causing v9 to be slower than v10 for your query. It's hard to tell without more details of what you're running. Is this a schema and query you're able to share? Or perhaps mock up a script of something similar enough to allow us to see why v9 and v10 are so different? Additionally, it would be interesting to see if patching with v10-0002 alone helps the performance of your query at all. I didn't imagine that change would give us anything easily measurable, but partition pruning makes extensive use of Bitmapsets, so perhaps you've found something. If you have then it might be worth considering v10-0002 independently of the EquivalenceMember indexing work. David
On Mon, 5 Dec 2022 at 21:28, David Rowley <dgrowleyml@gmail.com> wrote: > > On Tue, 6 Dec 2022 at 04:45, Thom Brown <thom@linux.com> wrote: > > Testing your patches with the same 1024 partitions, each with 64 > > sub-partitions, I get a planning time of 205.020 ms, which is now a > > 1,377x speedup. This has essentially reduced the planning time from a > > catastrophe to a complete non-issue. Huge win! > > Thanks for testing the v10 patches. > > I wouldn't have expected such additional gains from v10. I was mostly > focused on trying to minimise any performance regression for simple > queries that wouldn't benefit from indexing the EquivalenceMembers. > Your query sounds like it does not fit into that category. Perhaps it > is down to the fact that v9-0002 or v9-0003 reverts a couple of the > optimisations that is causing v9 to be slower than v10 for your query. > It's hard to tell without more details of what you're running. I celebrated prematurely as I neglected to wait for the 6th execution of the prepared statement, which shows the real result. With the v10 patches, it takes 5632.040 ms, a speedup of 50x. Testing the v9 patches, the same query takes 3388.173 ms, a speedup of 83x. And re-testing v8, I'm getting roughly the same times. These are all with a cold cache. So the result isn't as dramatic as I had initially interpreted it to have unfortunately. -- Thom
Hello, Thank you for creating the v10 patches. On Sun, Dec 4, 2022 at 9:34 AM David Rowley <dgrowleyml@gmail.com> wrote: > Overall, I'm not quite sure if this is any faster than your v9 patch. > I think more performance testing needs to be done. I think the > v10-0001 + v10-0002 is faster than v9-0001, but perhaps the changes > you've made in v9-0002 and v9-0003 are worth redoing. I didn't test. I > was hoping to keep the logic about which method to use to find the > members in the iterator code and not litter it around the tree. I tested the performance of v9, v10, and v10 + v9-0002 + v9-0003. The last one is v10 with v9-0002 and v9-0003 applied. 1. Join Order Benchmark I ran the Join Order Benchmark [1] and measured its planning times. The result is shown in Table 1. Table 1: Speedup of Join Order Benchmark (higher is better) (n = the number of partitions) ------------------------------------------------- n | v9 | v10 | v10 + v9-0002 + v9-0003 ------------------------------------------------- 2 | 97.2% | 95.7% | 97.5% 4 | 98.0% | 96.7% | 97.3% 8 | 101.2% | 99.6% | 100.3% 16 | 107.0% | 106.7% | 107.5% 32 | 123.1% | 122.0% | 123.7% 64 | 161.9% | 162.0% | 162.6% 128 | 307.0% | 311.7% | 313.4% 256 | 780.1% | 805.5% | 816.4% ------------------------------------------------- This result indicates that v10 degraded slightly more for the smaller number of partitions. The performances of v9 and v10 + v9-0002 + v9-0003 were almost the same, but the latter was faster when the number of partitions was large. 2. Query A (The query mentioned in [2]) I also ran Query A, which I shared in [2] and you used in ./partbench.sh. The attached figure illustrates the planning times of Query A. Our patches might have had some degradations, but they were not so significant. 3. Query B (The query mentioned in [3]) The following tables show the results of Query B. The results are close to the one of the Join Order Benchmark; v9 and v10 + v9-0002 + v9-0003 had fewer degradations than v10. Table 2: Planning Time of Query B (ms) -------------------------------------------------------------- n | Master | v9 | v10 | v10 + v9-0002 + v9-0003 -------------------------------------------------------------- 1 | 36.056 | 37.730 | 38.546 | 37.782 2 | 35.035 | 37.190 | 37.472 | 36.393 4 | 36.860 | 37.478 | 38.312 | 37.388 8 | 41.099 | 40.152 | 40.705 | 40.268 16 | 52.852 | 44.926 | 45.956 | 45.211 32 | 87.042 | 54.919 | 55.287 | 55.125 64 | 224.750 | 82.125 | 81.323 | 80.567 128 | 901.226 | 136.631 | 136.632 | 132.840 256 | 4166.045 | 263.913 | 260.295 | 258.453 -------------------------------------------------------------- Table 3: Speedup of Query B (higher is better) --------------------------------------------------- n | v9 | v10 | v10 + v9-0002 + v9-0003 --------------------------------------------------- 1 | 95.6% | 93.5% | 95.4% 2 | 94.2% | 93.5% | 96.3% 4 | 98.4% | 96.2% | 98.6% 8 | 102.4% | 101.0% | 102.1% 16 | 117.6% | 115.0% | 116.9% 32 | 158.5% | 157.4% | 157.9% 64 | 273.7% | 276.4% | 279.0% 128 | 659.6% | 659.6% | 678.4% 256 | 1578.6% | 1600.5% | 1611.9% --------------------------------------------------- ====== The above results show that the reverts I have made in v9-0002 and v9-0003 are very important in avoiding degradation. I think we should apply these changes again. It is unclear whether v9 or v10 + v9-0002 + v9-0003 is better, but the latter performed better in my experiments. [1] https://github.com/winkyao/join-order-benchmark [2] https://postgr.es/m/CAJ2pMkZNCgoUKSE%2B_5LthD%2BKbXKvq6h2hQN8Esxpxd%2Bcxmgomg%40mail.gmail.com [3] https://postgr.es/m/CAJ2pMka2PBXNNzUfe0-ksFsxVN%2BgmfKq7aGQ5v35TcpjFG3Ggg%40mail.gmail.com -- Best regards, Yuya Watari
Attachment
{kind=link}
Thank you for running all the benchmarks on v10. On Thu, 8 Dec 2022 at 00:31, Yuya Watari <watari.yuya@gmail.com> wrote: > The above results show that the reverts I have made in v9-0002 and > v9-0003 are very important in avoiding degradation. I think we should > apply these changes again. It is unclear whether v9 or v10 + v9-0002 + > v9-0003 is better, but the latter performed better in my experiments. I was hoping to keep the logic which decides to loop over ec_members or use the bitmap indexes all in equivclass.c, ideally in the iterator code. I've looked at the v9-0002 patch and I'm thinking maybe it's ok since it always loops over ec_nonchild_indexes. We process the base relations first, so all the EquivalenceMember in PlannerInfo for these will be at the start of the eq_members list and the Bitmapset won't have many bitmapwords to loop over. Additionally, it's only looping over the nonchild ones, so a large number of partitions existing has no effect on the number of loops performed. For v9-0003, I was really hoping to find some kind of workaround so we didn't need the "if (root->simple_rel_array_size < 32)". The problem I have with that is; 1) why is 32 a good choice?, and 2) simple_rel_array_size is just not a great thing to base the decision off of. For #1, we only need to look at the EquivalenceMembers belonging to base relations here and simple_rel_array_size includes all relations, including partitions, so even if there's just a few members belonging to base rels, we may still opt to use the Bitmapset method. Additionally, it does look like this patch should be looping over ec_nonchild_indexes rather than ec_member_indexes and filtering out the !em->em_is_const && !em->em_is_child EquivalenceMembers. Since both the changes made in v9-0002 and v9-0003 can just be made to loop over ec_nonchild_indexes, which isn't going to get big with large numbers of partitions, then I wonder if we're ok just to do the loop in all cases rather than conditionally try to do something more fanciful with counting bits like I had done in select_outer_pathkeys_for_merge(). I've made v11 work like what v9-0003 did and I've used v9-0002. I also found a stray remaining "bms_membership(eclass->ec_member_indexes) != BMS_MULTIPLE" in eclass_useful_for_merging() that should have been put back to "list_length(eclass->ec_members) <= 1". I've still got a couple of things in mind that I'd like to see done to this patch. a) I think the iterator code should have some additional sanity checks that the results of both methods match when building with USE_ASSERT_CHECKING. I've got some concerns that we might break something. The logic about what the em_relids is set to for child members is a little confusing. See add_eq_member(). b) We still need to think about if adding a RelOptInfo to PlannerInfo->simple_rel_array[0] is a good idea for solving the append relation issue. Ideally, we'd have a proper varno for these Vars instead of setting varno=0 per what's being done in generate_append_tlist(). I've attached the v11 set of patches. David
Attachment
Dear David, On Mon, Dec 12, 2022 at 1:50 PM David Rowley <dgrowleyml@gmail.com> wrote: > I've attached the v11 set of patches. Thanks for creating the v11 version. I think your patches look good to me. I really apologize for my late reply. > a) I think the iterator code should have some additional sanity checks > that the results of both methods match when building with > USE_ASSERT_CHECKING. I've got some concerns that we might break > something. The logic about what the em_relids is set to for child > members is a little confusing. See add_eq_member(). I added sanity checking code to check that two iteration results are the same. I have attached a new version of the patch, v12, to this email. The implementation of my sanity checking code (v12-0004) is not ideal and a little ugly. I understand that and will try to improve it. However, there is more bad news. Unfortunately, some regression tests are failing in my environment. I'm not sure why, but it could be that a) my sanity checking code (v12-0004) is wrong, or b) our patches have some bugs. I will investigate this issue further, and share the results when found. -- Best regards, Yuya Watari
Attachment
Hello,
On Fri, Jan 27, 2023 at 12:48 PM Yuya Watari <watari.yuya@gmail.com> wrote:
> However, there is more bad news. Unfortunately, some regression tests
> are failing in my environment. I'm not sure why, but it could be that
> a) my sanity checking code (v12-0004) is wrong, or b) our patches have
> some bugs.
>
> I will investigate this issue further, and share the results when found.
I have investigated this issue and concluded that b) our patches have
some bugs. I have attached the modified patches to this email. This
version passed regression tests in my environment.
1. v13-0005
The first bug is in eclass_member_iterator_strict_next(). As I
mentioned in the commit message, the original code incorrectly missed
EquivalenceMembers with empty em_relids when 'with_norel_members' is
true.
I show my changes as follows:
===
- if (!iter->with_children && em->em_is_child)
- continue;
- if (!iter->with_norel_members && bms_is_empty(em->em_relids))
- continue;
- if (!bms_is_subset(iter->with_relids, em->em_relids))
- continue;
- iter->current_index = foreach_current_index(lc);
+ if ((iter->with_norel_members && bms_is_empty(em->em_relids))
+ || (bms_is_subset(iter->with_relids, em->em_relids)
+ && (iter->with_children || !em->em_is_child)))
+ {
+ iter->current_index = foreach_current_index(lc);
===
EquivalenceMembers with empty em_relids will pass the second 'if'
condition when 'with_norel_members' is true. These members should be
returned. However, since the empty em_relids can never be superset of
any non-empty relids, the EMs may fail the last condition. Therefore,
the original code missed some members.
2. v13-0006
The second bug exists in get_ecmember_indexes_strict(). As I described
in the comment, if the empty relids is given, this function must
return all members because their em_relids are always superset. I am
concerned that this change may adversely affect performance.
Currently, I have not seen any degradation.
3. v13-0007
The last one is in add_eq_member(). I am not sure why this change is
working, but it is probably related to the concerns David mentioned in
the previous mail. The v13-0007 may be wrong, so it should be
reconsidered.
--
Best regards,
Yuya Watari
Attachment
- v13-0001-Add-Bitmapset-indexes-for-faster-lookup-of-Equiv.patch
- v13-0002-Adjust-bms_int_members-so-that-it-shortens-the-l.patch
- v13-0003-Add-iterators-for-looping-over-EquivalenceMember.patch
- v13-0004-Add-a-validation-to-check-that-two-iteration-res.patch
- v13-0005-Fix-incorrect-filtering-condition-in-iteration.patch
- v13-0006-Fix-a-bug-with-get_ecmember_indexes_strict-incor.patch
- v13-0007-Fix-a-bug.patch
isOn Mon, 30 Jan 2023 at 23:03, Yuya Watari <watari.yuya@gmail.com> wrote:
> 1. v13-0005
>
> The first bug is in eclass_member_iterator_strict_next(). As I
> mentioned in the commit message, the original code incorrectly missed
> EquivalenceMembers with empty em_relids when 'with_norel_members' is
> true.
Yeah, I was also looking at this today and found the same issues after
adding the verification code that checks we get the same members from
the index and via the looking method. I ended up making some changes
slightly different from what you had but wasn't quite ready to post
them yet.
I'm still a little unhappy with master's comments for the
EquivalenceMember.em_relids field. It claims to be the relids for the
em_expr, but that's not the case for em_is_child members. I've ended
up adding an additional field named em_norel_expr that gets set to
true when em_expr truly contains no Vars. I then adjusted the
conditions in the iterator's loops to properly include members with no
Vars when we ask for those.
> 2. v13-0006
>
> The second bug exists in get_ecmember_indexes_strict(). As I described
> in the comment, if the empty relids is given, this function must
> return all members because their em_relids are always superset. I am
> concerned that this change may adversely affect performance.
> Currently, I have not seen any degradation.
I fixed this by adding a new field to the iterator struct named
relids_empty. It's just set to bms_is_empty(iter->with_relids). The
loop condition then just becomes:
if (iter->relids_empty ||
!bms_is_subset(iter->with_relids, em->em_relids))
continue;
> 3. v13-0007
>
> The last one is in add_eq_member(). I am not sure why this change is
> working, but it is probably related to the concerns David mentioned in
> the previous mail. The v13-0007 may be wrong, so it should be
> reconsidered.
Unfortunately, we can't fix it that way. At a glance, what you have
would only find var-less child members if you requested that the
iterator also gave you with_norel_members==true. I've not looked,
perhaps all current code locations request with_norel_members, so your
change likely just words by accident.
I've attached what I worked on today. I still want to do more
cross-checking to make sure all code locations which use these new
iterators get the same members as they used to get.
In the attached I also changed the code that added a RelOptInfo to
root->simple_rel_array[0] to allow the varno=0 Vars made in
generate_append_tlist() to be indexed. That's now done via a new
function (setup_append_rel_entry()) which is only called during
plan_set_operations(). This means we're no longer wastefully creating
that entry during the planning of normal queries. We could maybe
consider giving this a more valid varno and expand simple_rel_array to
make more room, but I'm not sure it's worth it or not. I'm happier
that this simple_rel_array[0] entry now only exists when planning set
operations, but I'd probably feel better if there was some other way
that felt less like we're faking up a RelOptInfo to store
EquivalenceMembers in.
I've also included a slightly edited version of your code which checks
that the members match when using and not using the new indexes. All
the cross-checking seems to pass.
David
Attachment
Dear David,
On Mon, Jan 30, 2023 at 9:14 PM David Rowley <dgrowleyml@gmail.com> wrote:
> I've attached what I worked on today.
I really appreciate your quick response and the v15 patches. The bug
fixes in the v15 look good to me.
After receiving your email, I realized that this version does not
apply to the current master. This conflict is caused by commits of
2489d76c49 [1] and related. I have attached the rebased version, v16,
to this email. Resolving many conflicts was a bit of hard work, so I
may have made some mistakes.
Unfortunately, the rebased version did not pass regression tests. This
failure is due to segmentation faults regarding a null reference to
RelOptInfo. I show the code snippet that leads to the segfault as
follows.
=====
@@ -572,9 +662,31 @@ add_eq_member(EquivalenceClass *ec, Expr *expr,
Relids relids,
+ i = -1;
+ while ((i = bms_next_member(expr_relids, i)) >= 0)
+ {
+ RelOptInfo *rel = root->simple_rel_array[i];
+
+ rel->eclass_member_indexes =
bms_add_member(rel->eclass_member_indexes, em_index);
+ }
=====
The segfault occurred because root->simple_rel_array[i] is sometimes
NULL. This issue is similar to the one regarding
root->simple_rel_array[0]. Before the commit of 2489d76c49, we only
had to consider the nullability of root->simple_rel_array[0]. We
overcame this problem by creating the RelOptInfo in the
setup_append_rel_entry() function. However, after the commit,
root->simple_rel_array[i] with non-zero 'i' can also be NULL. I'm not
confident with its cause, but is this because non-base relations
appear in the expr_relids? Seeing the commit, I found the following
change in pull_varnos_walker():
=====
@@ -153,7 +161,11 @@ pull_varnos_walker(Node *node,
pull_varnos_context *context)
Var *var = (Var *) node;
if (var->varlevelsup == context->sublevels_up)
+ {
context->varnos = bms_add_member(context->varnos, var->varno);
+ context->varnos = bms_add_members(context->varnos,
+ var->varnullingrels);
+ }
return false;
}
if (IsA(node, CurrentOfExpr))
=====
We get the expr_relids by pull_varnos(). This commit adds
var->varnullingrels to its result. From my observations, indices 'i'
such that root->simple_rel_array[i] is null come from
var->varnullingrels. This change is probably related to the segfault.
I don't understand the commit well, so please let me know if I'm
wrong.
To address this problem, in v16-0003, I moved EquivalenceMember
indexes in RelOptInfo to PlannerInfo. This change allows us to store
indexes whose corresponding RelOptInfo is NULL.
> I'm happier
> that this simple_rel_array[0] entry now only exists when planning set
> operations, but I'd probably feel better if there was some other way
> that felt less like we're faking up a RelOptInfo to store
> EquivalenceMembers in.
Of course, I'm not sure if my approach in v16-0003 is ideal, but it
may help solve your concern above. Since simple_rel_array[0] is no
longer necessary with my patch, I removed the setup_append_rel_entry()
function in v16-0004. However, to work the patch, I needed to change
some assertions in v16-0005. For more details, please see the commit
message of v16-0005. After these works, the attached patches passed
all regression tests in my environment.
Instead of my approach, imitating the following change to
get_eclass_indexes_for_relids() is also a possible solution. Ignoring
NULL RelOptInfos enables us to avoid the segfault, but we have to
adjust EquivalenceMemberIterator to match the result, and I'm not sure
if this idea is correct.
=====
@@ -3204,6 +3268,12 @@ get_eclass_indexes_for_relids(PlannerInfo
*root, Relids relids)
{
RelOptInfo *rel = root->simple_rel_array[i];
+ if (rel == NULL) /* must be an outer join */
+ {
+ Assert(bms_is_member(i, root->outer_join_rels));
+ continue;
+ }
+
ec_indexes = bms_add_members(ec_indexes, rel->eclass_indexes);
}
return ec_indexes;
=====
[1] https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=2489d76c4906f4461a364ca8ad7e0751ead8aa0d
--
Best regards,
Yuya Watari
Attachment
On 2/6/23 06:47, Yuya Watari wrote: > Of course, I'm not sure if my approach in v16-0003 is ideal, but it > may help solve your concern above. Since simple_rel_array[0] is no > longer necessary with my patch, I removed the setup_append_rel_entry() > function in v16-0004. However, to work the patch, I needed to change > some assertions in v16-0005. For more details, please see the commit > message of v16-0005. After these works, the attached patches passed > all regression tests in my environment. > > Instead of my approach, imitating the following change to > get_eclass_indexes_for_relids() is also a possible solution. Ignoring > NULL RelOptInfos enables us to avoid the segfault, but we have to > adjust EquivalenceMemberIterator to match the result, and I'm not sure > if this idea is correct. As I see, You moved the indexes from RelOptInfo to PlannerInfo. May be better to move them into RangeTblEntry instead? -- Regards Andrey Lepikhov Postgres Professional
Dear Andrey, On Tue, Feb 14, 2023 at 7:01 PM Andrey Lepikhov <a.lepikhov@postgrespro.ru> wrote: > As I see, You moved the indexes from RelOptInfo to PlannerInfo. May be > better to move them into RangeTblEntry instead? I really appreciate your kind advice. I think your idea is very good. I have implemented it as the v17 patches, which are attached to this email. The v17 has passed all regression tests in my environment. -- Best regards, Yuya Watari
Attachment
Hello Watari-san, this patch does not currently apply. Could you please rebase? David, do you intend to continue to be involved in reviewing this one? Thanks to both, -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/ "All rings of power are equal, But some rings of power are more equal than others." (George Orwell's The Lord of the Rings)
On Thu, 9 Mar 2023 at 01:34, Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > David, do you intend to continue to be involved in reviewing this one? Yes. I'm currently trying to make a few Bitmapset improvements which include the change made in this thread's 0001 patch over on [1]. For the main patch, I've been starting to wonder if it should work completely differently. Instead of adding members for partitioned and inheritance children, we could just translate the Vars from child to top-level parent and find the member that way. I wondered if this method might be even faster as it would forego add_child_rel_equivalences(). I think we'd still need em_is_child for UNION ALL children. So far, I've not looked into this in detail. I was hoping to find an idea that would allow some means to have the planner realise that a LIST partition which allows a single Datum could skip pushing base quals which are constantly true. i.e: create table lp (a int) partition by list(a); create table lp1 partition of lp for values in(1); explain select * from lp where a = 1; Seq Scan on lp1 lp (cost=0.00..41.88 rows=13 width=4) Filter: (a = 1) David [1] https://postgr.es/m/CAApHDvq9eq0W_aFUGrb6ba28ieuQN4zM5Uwqxy7+LMZjJc+VGg@mail.gmail.com
Hello, On Wed, Mar 8, 2023 at 9:34 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > Hello Watari-san, this patch does not currently apply. Could you please > rebase? Thank you for pointing it out. I have attached the rebased version to this email. This version includes an additional change, v18-0005. The change relates to the Bitmapset operations that David mentioned: On Thu, Mar 9, 2023 at 6:23 AM David Rowley <dgrowleyml@gmail.com> wrote: > Yes. I'm currently trying to make a few Bitmapset improvements which > include the change made in this thread's 0001 patch over on [1]. As of v18-0005, the redundant loop to check if the result of bms_intersect() is empty has been removed. This change is almost the same as David's following idea in the [1] thread, but slightly different. On Fri, Mar 3, 2023 at 10:52 AM David Rowley <dgrowleyml@gmail.com> wrote: > The patch also optimizes sub-optimal newly added code which calls > bms_is_empty_internal() when we have other more optimal means to > determine if the set is empty or not. I conducted an experiment measuring the planning time of Query B [2]. In the experiment, I tested the next four versions: * Master * (A): v18-0001 + v18-0002 + v18-0003 + v18-0004 (= v17) * (B): v18-0001 + v18-0002 + v18-0003 + v18-0004 + v18-0005 * (C): v18-0002 + v18-0003 + v18-0004 + David's patches in [1] --> Since [1] includes v18-0001, (C) does not contain v18-0001. The following tables show the results. These show that when the number of partitions is large, (B) is faster than (A). This result indicates that the change in v18-0005 is effective on this workload. In addition, the patches in [1] slowed down the performance compared to (A) and (B). I am not sure of the cause of this degradation. I will investigate this issue further. I hope these results will help the discussion of [1]. Table 1: Planning time of Query B (ms) ---------------------------------------------- n | Master | (A) | (B) | (C) ---------------------------------------------- 1 | 37.780 | 38.836 | 38.354 | 38.187 2 | 36.222 | 37.067 | 37.416 | 37.068 4 | 38.001 | 38.410 | 37.980 | 38.005 8 | 42.384 | 41.159 | 41.601 | 42.218 16 | 53.906 | 47.277 | 47.080 | 59.466 32 | 88.271 | 58.842 | 58.762 | 69.474 64 | 229.445 | 91.675 | 91.194 | 115.348 128 | 896.418 | 166.251 | 161.182 | 335.121 256 | 4220.514 | 371.369 | 350.723 | 923.272 ---------------------------------------------- Table 2: Planning time speedup of Query B (higher is better) -------------------------------------------------------------------------- n | Master / (A) | Master / (B) | Master / (C) | (A) / (B) | (A) / (C) -------------------------------------------------------------------------- 1 | 97.3% | 98.5% | 98.9% | 101.3% | 101.7% 2 | 97.7% | 96.8% | 97.7% | 99.1% | 100.0% 4 | 98.9% | 100.1% | 100.0% | 101.1% | 101.1% 8 | 103.0% | 101.9% | 100.4% | 98.9% | 97.5% 16 | 114.0% | 114.5% | 90.7% | 100.4% | 79.5% 32 | 150.0% | 150.2% | 127.1% | 100.1% | 84.7% 64 | 250.3% | 251.6% | 198.9% | 100.5% | 79.5% 128 | 539.2% | 556.2% | 267.5% | 103.1% | 49.6% 256 | 1136.5% | 1203.4% | 457.1% | 105.9% | 40.2% -------------------------------------------------------------------------- On Thu, Mar 9, 2023 at 6:23 AM David Rowley <dgrowleyml@gmail.com> wrote: > For the main patch, I've been starting to wonder if it should work > completely differently. Instead of adding members for partitioned and > inheritance children, we could just translate the Vars from child to > top-level parent and find the member that way. I wondered if this > method might be even faster as it would forego > add_child_rel_equivalences(). I think we'd still need em_is_child for > UNION ALL children. So far, I've not looked into this in detail. I > was hoping to find an idea that would allow some means to have the > planner realise that a LIST partition which allows a single Datum > could skip pushing base quals which are constantly true. i.e: > > create table lp (a int) partition by list(a); > create table lp1 partition of lp for values in(1); > explain select * from lp where a = 1; > > Seq Scan on lp1 lp (cost=0.00..41.88 rows=13 width=4) > Filter: (a = 1) Thank you for considering this issue. I will look into this as well. [1] https://postgr.es/m/CAApHDvq9eq0W_aFUGrb6ba28ieuQN4zM5Uwqxy7+LMZjJc+VGg@mail.gmail.com [2] https://postgr.es/m/CAJ2pMka2PBXNNzUfe0-ksFsxVN%2BgmfKq7aGQ5v35TcpjFG3Ggg%40mail.gmail.com -- Best regards, Yuya Watari
Attachment
Hello, On Fri, Mar 10, 2023 at 5:38 PM Yuya Watari <watari.yuya@gmail.com> wrote: > Thank you for pointing it out. I have attached the rebased version to > this email. Recent commits, such as a8c09daa8b [1], have caused conflicts and compilation errors in these patches. I have attached the fixed version to this email. The v19-0004 adds an 'em_index' field representing the index within root->eq_members of the EquivalenceMember. This field is needed to delete EquivalenceMembers when iterating them using the ec_members list instead of the ec_member_indexes. [1] https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=a8c09daa8bb1d741bb8b3d31a12752448eb6fb7c -- Best regards, Yuya Watari
Attachment
On 5/7/2023 16:57, Yuya Watari wrote: > Hello, > > On Fri, Mar 10, 2023 at 5:38 PM Yuya Watari <watari.yuya@gmail.com> wrote: >> Thank you for pointing it out. I have attached the rebased version to >> this email. > > Recent commits, such as a8c09daa8b [1], have caused conflicts and > compilation errors in these patches. I have attached the fixed version > to this email. > > The v19-0004 adds an 'em_index' field representing the index within > root->eq_members of the EquivalenceMember. This field is needed to > delete EquivalenceMembers when iterating them using the ec_members > list instead of the ec_member_indexes. > > [1] https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=a8c09daa8bb1d741bb8b3d31a12752448eb6fb7c > Discovering quality of partition pruning at the stage of execution initialization and using your set of patches I have found some dubious results with performance degradation. Look into the test case in attachment. Here is three queries. Execution times: 1 - 8s; 2 - 30s; 3 - 131s (with your patch set). 1 - 5s; 2 - 10s; 3 - 33s (current master). Maybe it is a false alarm, but on my laptop I see this degradation at every launch. -- regards, Andrey Lepikhov Postgres Professional
Attachment
On 27/7/2023 14:58, Andrey Lepikhov wrote: > On 5/7/2023 16:57, Yuya Watari wrote: >> Hello, >> >> On Fri, Mar 10, 2023 at 5:38 PM Yuya Watari <watari.yuya@gmail.com> >> wrote: >>> Thank you for pointing it out. I have attached the rebased version to >>> this email. >> >> Recent commits, such as a8c09daa8b [1], have caused conflicts and >> compilation errors in these patches. I have attached the fixed version >> to this email. >> >> The v19-0004 adds an 'em_index' field representing the index within >> root->eq_members of the EquivalenceMember. This field is needed to >> delete EquivalenceMembers when iterating them using the ec_members >> list instead of the ec_member_indexes. >> >> [1] >> https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=a8c09daa8bb1d741bb8b3d31a12752448eb6fb7c >> > Discovering quality of partition pruning at the stage of execution > initialization and using your set of patches I have found some dubious > results with performance degradation. Look into the test case in > attachment. > Here is three queries. Execution times: > 1 - 8s; 2 - 30s; 3 - 131s (with your patch set). > 1 - 5s; 2 - 10s; 3 - 33s (current master). > > Maybe it is a false alarm, but on my laptop I see this degradation at > every launch. Sorry for this. It was definitely a false alarm. In this patch, assertion checking adds much overhead. After switching it off, I found out that this feature solves my problem with a quick pass through the members of an equivalence class. Planning time results for the queries from the previous letter: 1 - 0.4s, 2 - 1.3s, 3 - 1.3s; (with the patches applied) 1 - 5s; 2 - 8.7s; 3 - 22s; (current master). I have attached flamegraph that shows query 2 planning process after applying this set of patches. As you can see, overhead at the equivalence class routines has gone. -- regards, Andrey Lepikhov Postgres Professional
Attachment
{kind=link}
Hello, On Fri, Jul 28, 2023 at 1:27 PM Andrey Lepikhov <a.lepikhov@postgrespro.ru> wrote: > Sorry for this. It was definitely a false alarm. In this patch, > assertion checking adds much overhead. After switching it off, I found > out that this feature solves my problem with a quick pass through the > members of an equivalence class. Planning time results for the queries > from the previous letter: > 1 - 0.4s, 2 - 1.3s, 3 - 1.3s; (with the patches applied) > 1 - 5s; 2 - 8.7s; 3 - 22s; (current master). > > I have attached flamegraph that shows query 2 planning process after > applying this set of patches. As you can see, overhead at the > equivalence class routines has gone. I really appreciate testing the patches and sharing your results. The results are interesting because they show that our optimization effectively reduces planning time for your workload containing different queries than I have used in my benchmarks. Thank you again for reviewing this. -- Best regards, Yuya Watari
Hi Yuya, Andrey, On Fri, Jul 28, 2023 at 9:58 AM Andrey Lepikhov <a.lepikhov@postgrespro.ru> wrote: > >> > > Discovering quality of partition pruning at the stage of execution > > initialization and using your set of patches I have found some dubious > > results with performance degradation. Look into the test case in > > attachment. > > Here is three queries. Execution times: > > 1 - 8s; 2 - 30s; 3 - 131s (with your patch set). > > 1 - 5s; 2 - 10s; 3 - 33s (current master). > > > > Maybe it is a false alarm, but on my laptop I see this degradation at > > every launch. > Sorry for this. It was definitely a false alarm. In this patch, > assertion checking adds much overhead. After switching it off, I found > out that this feature solves my problem with a quick pass through the > members of an equivalence class. Planning time results for the queries > from the previous letter: > 1 - 0.4s, 2 - 1.3s, 3 - 1.3s; (with the patches applied) > 1 - 5s; 2 - 8.7s; 3 - 22s; (current master). I measured planning time using my scripts setup.sql and queries.sql attached to [1] with and without assert build using your patch. The timings are recorded in the attached spreadsheet. I have following observations 1. The patchset improves the planning time of queries involving partitioned tables by an integral factor. Both in case of partitionwise join and without it. The speedup is 5x to 21x in my experiment. That's huge. 2. There's slight degradation in planning time of queries involving unpartitioned tables. But I have seen that much variance usually. 3. assert and debug enabled build shows degradation in planning time in all the cases. 4. There is substantial memory increase in all the cases. It's percentage wise predominant when the partitionwise join is not used. Given that most of the developers run assert enabled builds it would be good to bring down the degradation there while keeping the excellent speedup in non-assert builds. Queries on partitioned tables eat a lot of memory anyways, increasing that further should be avoided. I have not studied the patches. But I think the memory increase has to do with our Bitmapset structure. It's space inefficient when there are thousands of partitions involved. See my comment at [2] [1] https://www.postgresql.org/message-id/CAExHW5stmOUobE55pMt83r8UxvfCph+Pvo5dNpdrVCsBgXEzDQ@mail.gmail.com [2] https://www.postgresql.org/message-id/CAExHW5s4EqY43oB%3Dne6B2%3D-xLgrs9ZGeTr1NXwkGFt2j-OmaQQ%40mail.gmail.com -- Best Wishes, Ashutosh Bapat
Attachment
Hello, I really appreciate sharing very useful scripts and benchmarking results. On Fri, Jul 28, 2023 at 6:51 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > Given that most of the developers run assert enabled builds it would > be good to bring down the degradation there while keeping the > excellent speedup in non-assert builds. From my observation, this degradation in assert enabled build is caused by verifying the iteration results of EquivalenceMembers. My patch uses Bitmapset-based indexes to speed up the iteration. When assertions are enabled, we verify that the result of the iteration is the same with and without the indexes. This verification results in executing a similar loop three times, which causes the degradation. I measured planning time by using your script without this verification. The results are as follows: Master: 144.55 ms Patched (v19): 529.85 ms Patched (v19) without verification: 78.84 ms (*) All runs are with assertions. As seen from the above, verifying iteration results was the cause of the performance degradation. I agree that we should avoid such degradation because it negatively affects the development of PostgreSQL. Removing the verification when committing this patch is one possible option. > Queries on partitioned tables eat a lot of memory anyways, increasing > that further should be avoided. > > I have not studied the patches. But I think the memory increase has to > do with our Bitmapset structure. It's space inefficient when there are > thousands of partitions involved. See my comment at [2] Thank you for pointing this out. I have never considered the memory usage impact of this patch. As you say, the Bitmapset structure caused this increase. I will try to look into this further. -- Best regards, Yuya Watari
On 2/8/2023 13:40, Yuya Watari wrote: > As seen from the above, verifying iteration results was the cause of > the performance degradation. I agree that we should avoid such > degradation because it negatively affects the development of > PostgreSQL. Removing the verification when committing this patch is > one possible option. You introduced list_ptr_cmp as an extern function of a List, but use it the only under USE_ASSERT_CHECKING ifdef. Maybe you hide it under USE_ASSERT_CHECKING or remove all the stuff? -- regards, Andrey Lepikhov Postgres Professional
Hello, On Wed, Aug 2, 2023 at 6:43 PM Andrey Lepikhov <a.lepikhov@postgrespro.ru> wrote: > You introduced list_ptr_cmp as an extern function of a List, but use it > the only under USE_ASSERT_CHECKING ifdef. > Maybe you hide it under USE_ASSERT_CHECKING or remove all the stuff? Thank you for your quick reply and for pointing that out. If we remove the verification code when committing this patch, we should also remove the list_ptr_cmp() function because nobody will use it. If we don't remove the verification, whether to hide it by USE_ASSERT_CHECKING is a difficult question. The list_ptr_cmp() can be used for generic use and is helpful even without assertions, so not hiding it is one option. However, I understand that it is not pretty to have the function compiled even though it is not referenced from anywhere when assertions are disabled. As you say, I think hiding it by USE_ASSERT_CHECKING is also a possible solution. -- Best regards, Yuya Watari
Hello,
I really appreciate sharing very useful scripts and benchmarking results.
On Fri, Jul 28, 2023 at 6:51 PM Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
> Given that most of the developers run assert enabled builds it would
> be good to bring down the degradation there while keeping the
> excellent speedup in non-assert builds.
From my observation, this degradation in assert enabled build is
caused by verifying the iteration results of EquivalenceMembers. My
patch uses Bitmapset-based indexes to speed up the iteration. When
assertions are enabled, we verify that the result of the iteration is
the same with and without the indexes. This verification results in
executing a similar loop three times, which causes the degradation. I
measured planning time by using your script without this verification.
The results are as follows:
Master: 144.55 ms
Patched (v19): 529.85 ms
Patched (v19) without verification: 78.84 ms
(*) All runs are with assertions.
As seen from the above, verifying iteration results was the cause of
the performance degradation. I agree that we should avoid such
degradation because it negatively affects the development of
PostgreSQL. Removing the verification when committing this patch is
one possible option.
> Queries on partitioned tables eat a lot of memory anyways, increasing
> that further should be avoided.
>
> I have not studied the patches. But I think the memory increase has to
> do with our Bitmapset structure. It's space inefficient when there are
> thousands of partitions involved. See my comment at [2]
Thank you for pointing this out. I have never considered the memory
usage impact of this patch. As you say, the Bitmapset structure caused
this increase. I will try to look into this further.
--
Hello, Thank you for your reply. On Thu, Aug 3, 2023 at 10:29 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > If you think that the verification is important to catch bugs, you may want to encapsulate it with an #ifdef .. #endifsuch that the block within is not compiled by default. See OPTIMIZER_DEBUG for example. In my opinion, verifying the iteration results is only necessary to avoid introducing bugs while developing this patch. The verification is too excessive for regular development of PostgreSQL. I agree that we should avoid a significant degradation in assert enabled builds, so I will consider removing it. > Do you think that the memory measurement patch I have shared in those threads is useful in itself? If so, I will startanother proposal to address it. For me, who is developing the planner in this thread, the memory measurement patch is useful. However, most users do not care about memory usage, so there is room for consideration. For example, making the metrics optional in EXPLAIN ANALYZE outputs might be better. -- Best regards, Yuya Watari
On 7/8/2023 15:19, Yuya Watari wrote:
> Hello,
>
> Thank you for your reply.
>
> On Thu, Aug 3, 2023 at 10:29 PM Ashutosh Bapat
> <ashutosh.bapat.oss@gmail.com> wrote:
>> If you think that the verification is important to catch bugs, you may want to encapsulate it with an #ifdef ..
#endifsuch that the block within is not compiled by default. See OPTIMIZER_DEBUG for example.
>
> In my opinion, verifying the iteration results is only necessary to
> avoid introducing bugs while developing this patch. The verification
> is too excessive for regular development of PostgreSQL. I agree that
> we should avoid a significant degradation in assert enabled builds, so
> I will consider removing it.
I should admit, these checks has helped me during backpatching this
feature to pg v.13 (users crave speed up of query planning a lot). Maybe
it is a sign of a lack of tests, but in-fact, it already has helped.
One more thing: I think, you should add comments to
add_child_rel_equivalences() and add_child_join_rel_equivalences()
on replacing of:
if (bms_is_subset(cur_em->em_relids, top_parent_relids) &&
!bms_is_empty(cur_em->em_relids))
and
if (bms_overlap(cur_em->em_relids, top_parent_relids))
with different logic. What was changed? It will be better to help future
developers realize this part of the code more easily by adding some
comments.
>
>> Do you think that the memory measurement patch I have shared in those threads is useful in itself? If so, I will
startanother proposal to address it.
>
> For me, who is developing the planner in this thread, the memory
> measurement patch is useful. However, most users do not care about
> memory usage, so there is room for consideration. For example, making
> the metrics optional in EXPLAIN ANALYZE outputs might be better.
>
+1. Any memory-related info in the output of EXPLAIN ANALYZE makes tests
more complex because of architecture dependency.
--
regards,
Andrey Lepikhov
Postgres Professional
>> Do you think that the memory measurement patch I have shared in those threads is useful in itself? If so, I will start another proposal to address it.
>
> For me, who is developing the planner in this thread, the memory
> measurement patch is useful. However, most users do not care about
> memory usage, so there is room for consideration. For example, making
> the metrics optional in EXPLAIN ANALYZE outputs might be better.
>
+1. Any memory-related info in the output of EXPLAIN ANALYZE makes tests
more complex because of architecture dependency.
--
On 7/8/2023 19:15, Ashutosh Bapat wrote: > > > On Mon, Aug 7, 2023 at 2:21 PM Andrey Lepikhov > <a.lepikhov@postgrespro.ru <mailto:a.lepikhov@postgrespro.ru>> wrote: > > >> Do you think that the memory measurement patch I have shared in > those threads is useful in itself? If so, I will start another > proposal to address it. > > > > For me, who is developing the planner in this thread, the memory > > measurement patch is useful. However, most users do not care about > > memory usage, so there is room for consideration. For example, making > > the metrics optional in EXPLAIN ANALYZE outputs might be better. > > > +1. Any memory-related info in the output of EXPLAIN ANALYZE makes > tests > more complex because of architecture dependency. > > > As far as the tests go, the same is the case with planning time and > execution time. They change even without changing the architecture. But > we have tests which mask the actual values. Something similar will be > done to the planning memory. It is a positive thing to access some planner internals from the console, of course. My point is dedicated to the structuration of an EXPLAIN output and is caused by two reasons: 1. I use the EXPLAIN command daily to identify performance issues and the optimiser's weak points. According to the experience, when you have an 'explain analyze' containing more than 100 strings, you try removing unnecessary information to improve observability. It would be better to have the possibility to see an EXPLAIN with different levels of the output details. Flexibility here reduces a lot of manual work, sometimes. 2. Writing extensions and having an explain analyze in the regression test, we must create masking functions just to make the test more stable. That additional work can be avoided with another option, like MEMUSAGE ON/OFF. So, in my opinion, it would be better to introduce this new output data guarded by additional option. > > I will propose it as a separate patch in the next commitfest and will > seek opinions from other hackers. Cool, good news. -- regards, Andrey Lepikhov Postgres Professional
Hi Andrey, On Tue, Aug 8, 2023 at 8:52 AM Andrey Lepikhov <a.lepikhov@postgrespro.ru> wrote: > It is a positive thing to access some planner internals from the > console, of course. My point is dedicated to the structuration of an > EXPLAIN output and is caused by two reasons: > 1. I use the EXPLAIN command daily to identify performance issues and > the optimiser's weak points. According to the experience, when you have > an 'explain analyze' containing more than 100 strings, you try removing > unnecessary information to improve observability. It would be better to > have the possibility to see an EXPLAIN with different levels of the > output details. Flexibility here reduces a lot of manual work, sometimes. I use the json output format to extract the interesting parts of EXPLAIN output. See my SQL scripts attached upthread. That way I can ignore new additions like this. > 2. Writing extensions and having an explain analyze in the regression > test, we must create masking functions just to make the test more > stable. That additional work can be avoided with another option, like > MEMUSAGE ON/OFF. We already have a masking function in-place. See changes to explain.out in my proposed patch at [1] > > I will propose it as a separate patch in the next commitfest and will > > seek opinions from other hackers. > Cool, good news. Done. Commitfest entry https://commitfest.postgresql.org/44/4492/ [1] https://www.postgresql.org/message-id/CAExHW5sZA=5LJ_ZPpRO-w09ck8z9p7eaYAqq3Ks9GDfhrxeWBw@mail.gmail.com -- Best Wishes, Ashutosh Bapat
Hello Andrey, Ashutosh, and David,
Thank you for your reply and for reviewing the patch.
On Mon, Aug 7, 2023 at 5:51 PM Andrey Lepikhov
<a.lepikhov@postgrespro.ru> wrote:
> One more thing: I think, you should add comments to
> add_child_rel_equivalences() and add_child_join_rel_equivalences()
> on replacing of:
>
> if (bms_is_subset(cur_em->em_relids, top_parent_relids) &&
> !bms_is_empty(cur_em->em_relids))
> and
> if (bms_overlap(cur_em->em_relids, top_parent_relids))
>
> with different logic. What was changed? It will be better to help future
> developers realize this part of the code more easily by adding some
> comments.
The following change in add_child_join_rel_equivalences():
- /* Does this member reference child's topmost parent rel? */
- if (bms_overlap(cur_em->em_relids, top_parent_relids))
is correct because EquivalenceMemberIterator guarantees that these two
Relids always overlap for the iterated results. The following code
does this iteration. As seen from the below code, the iteration
eliminates not overlapping Relids, so we do not need to check
bms_overlap() for the iterated results.
=====
/*
* eclass_member_iterator_next
* Fetch the next EquivalenceMember from an EquivalenceMemberIterator
* which was set up by setup_eclass_member_iterator(). Returns NULL when
* there are no more matching EquivalenceMembers.
*/
EquivalenceMember *
eclass_member_iterator_next(EquivalenceMemberIterator *iter)
{
...
ListCell *lc;
for_each_from(lc, iter->eclass->ec_members, iter->current_index + 1)
{
EquivalenceMember *em = lfirst_node(EquivalenceMember, lc);
...
/*
* Don't return members which have no common rels with with_relids
*/
if (!bms_overlap(em->em_relids, iter->with_relids))
continue;
return em;
}
return NULL;
...
}
=====
I agree with your opinion that my patch lacks some explanations, so I
will consider adding more comments. However, I received the following
message from David in March.
On Thu, Mar 9, 2023 at 6:23 AM David Rowley <dgrowleyml@gmail.com> wrote:
> For the main patch, I've been starting to wonder if it should work
> completely differently. Instead of adding members for partitioned and
> inheritance children, we could just translate the Vars from child to
> top-level parent and find the member that way. I wondered if this
> method might be even faster as it would forego
> add_child_rel_equivalences(). I think we'd still need em_is_child for
> UNION ALL children. So far, I've not looked into this in detail. I
> was hoping to find an idea that would allow some means to have the
> planner realise that a LIST partition which allows a single Datum
> could skip pushing base quals which are constantly true. i.e:
>
> create table lp (a int) partition by list(a);
> create table lp1 partition of lp for values in(1);
> explain select * from lp where a = 1;
>
> Seq Scan on lp1 lp (cost=0.00..41.88 rows=13 width=4)
> Filter: (a = 1)
I am concerned that fixing the current patch will conflict with
David's idea. Of course, I am now trying to experiment with the above
idea, but I should avoid the conflict if he is working on this. David,
what do you think about this? Is it OK to post a new patch to address
the review comments? I am looking forward to your reply.
--
Best regards,
Yuya Watari
On Wed, 5 Jul 2023 at 21:58, Yuya Watari <watari.yuya@gmail.com> wrote: > > Hello, > > On Fri, Mar 10, 2023 at 5:38 PM Yuya Watari <watari.yuya@gmail.com> wrote: > > Thank you for pointing it out. I have attached the rebased version to > > this email. > > Recent commits, such as a8c09daa8b [1], have caused conflicts and > compilation errors in these patches. I have attached the fixed version > to this email. > > The v19-0004 adds an 'em_index' field representing the index within > root->eq_members of the EquivalenceMember. This field is needed to > delete EquivalenceMembers when iterating them using the ec_members > list instead of the ec_member_indexes. If 0004 is adding an em_index to mark the index into PlannerInfo->eq_members, can't you use that in setup_eclass_member[_strict]_iterator to loop to verify that the two methods yield the same result? i.e: + Bitmapset *matching_ems = NULL; + memcpy(&idx_iter, iter, sizeof(EquivalenceMemberIterator)); + memcpy(&noidx_iter, iter, sizeof(EquivalenceMemberIterator)); + + idx_iter.use_index = true; + noidx_iter.use_index = false; + + while ((em = eclass_member_iterator_strict_next(&noidx_iter)) != NULL) + matching_ems = bms_add_member(matching_ems, em->em_index); + + Assert(bms_equal(matching_ems, iter->matching_ems)); That should void the complaint that the Assert checking is too slow. You can also delete the list_ptr_cmp function too (also noticed a complaint about that). For the 0003 patch. Can you explain why you think these fields should be in RangeTblEntry rather than RelOptInfo? I can only guess you might have done this for memory usage so that we don't have to carry those fields for join rels? I think RelOptInfo is the correct place to store fields that are only used in the planner. If you put them in RangeTblEntry they'll end up in pg_rewrite and be stored for all views. Seems very space inefficient and scary as it limits the scope for fixing bugs in back branches due to RangeTblEntries being serialized into the catalogues in various places. David
On Wed, 9 Aug 2023 at 22:28, David Rowley <dgrowleyml@gmail.com> wrote: > i.e: > > + Bitmapset *matching_ems = NULL; > + memcpy(&idx_iter, iter, sizeof(EquivalenceMemberIterator)); > + memcpy(&noidx_iter, iter, sizeof(EquivalenceMemberIterator)); > + > + idx_iter.use_index = true; > + noidx_iter.use_index = false; > + > + while ((em = eclass_member_iterator_strict_next(&noidx_iter)) != NULL) > + matching_ems = bms_add_member(matching_ems, em->em_index); > + > + Assert(bms_equal(matching_ems, iter->matching_ems)); Slight correction, you could just get rid of idx_iter completely. I only added that copy since the Assert code needed to iterate and I didn't want to change the position of the iterator that's actually being used. Since the updated code wouldn't be interesting over "iter", you could just use "iter" directly like I have in the Assert(bms_equals... code above. David
On Wed, 9 Aug 2023 at 20:15, Yuya Watari <watari.yuya@gmail.com> wrote:
> I agree with your opinion that my patch lacks some explanations, so I
> will consider adding more comments. However, I received the following
> message from David in March.
>
> On Thu, Mar 9, 2023 at 6:23 AM David Rowley <dgrowleyml@gmail.com> wrote:
> > For the main patch, I've been starting to wonder if it should work
> > completely differently. Instead of adding members for partitioned and
> > inheritance children, we could just translate the Vars from child to
> > top-level parent and find the member that way. I wondered if this
> > method might be even faster as it would forego
> > add_child_rel_equivalences(). I think we'd still need em_is_child for
> > UNION ALL children. So far, I've not looked into this in detail. I
> > was hoping to find an idea that would allow some means to have the
> > planner realise that a LIST partition which allows a single Datum
> > could skip pushing base quals which are constantly true. i.e:
> >
> > create table lp (a int) partition by list(a);
> > create table lp1 partition of lp for values in(1);
> > explain select * from lp where a = 1;
> >
> > Seq Scan on lp1 lp (cost=0.00..41.88 rows=13 width=4)
> > Filter: (a = 1)
>
> I am concerned that fixing the current patch will conflict with
> David's idea. Of course, I am now trying to experiment with the above
> idea, but I should avoid the conflict if he is working on this. David,
> what do you think about this? Is it OK to post a new patch to address
> the review comments? I am looking forward to your reply.
So, I have three concerns with this patch.
1) I really dislike the way eclass_member_iterator_next() has to check
bms_overlap() to filter out unwanted EMs. This is required because of
how add_child_rel_equivalences() does not pass the "relids" parameter
in add_eq_member() as equivalent to pull_varnos(expr). See this code
in master:
/*
* Transform em_relids to match. Note we do *not* do
* pull_varnos(child_expr) here, as for example the
* transformation might have substituted a constant, but we
* don't want the child member to be marked as constant.
*/
new_relids = bms_difference(cur_em->em_relids,
top_parent_relids);
new_relids = bms_add_members(new_relids, child_relids);
I understand this is done to support Consts in UNION ALL parents, e.g
the following query prunes the n=2 UNION ALL branch
postgres=# explain select * from (select 1 AS n,* from pg_Class c1
union all select 2 AS n,* from pg_Class c2) where n=1;
QUERY PLAN
----------------------------------------------------------------
Seq Scan on pg_class c1 (cost=0.00..18.13 rows=413 width=277)
(1 row)
... but the following (existing) comment is just a lie:
Relids em_relids; /* all relids appearing in em_expr */
This means that there's some weirdness on which RelOptInfos we set
eclass_member_indexes. Do we just set the EM in the RelOptInfos
mentioned in the em_expr, or should it be the ones in em_relids?
You can see the following code I wrote in the 0001 patch which tries
to work around this problem:
+ /*
+ * We must determine the exact set of relids in the expr for child
+ * EquivalenceMembers as what is given to us in 'relids' may differ from
+ * the relids mentioned in the expression. See add_child_rel_equivalences
+ */
+ if (parent != NULL)
+ expr_relids = pull_varnos(root, (Node *) expr);
+ else
+ {
+ expr_relids = relids;
+ /* We expect the relids to match for non-child members */
+ Assert(bms_equal(pull_varnos(root, (Node *) expr), relids));
+ }
So, you can see we go with the relids from the em_expr rather than
what's mentioned in em_relids. I believe this means we need the
following line:
+ /*
+ * Don't return members which have no common rels with with_relids
+ */
+ if (!bms_overlap(em->em_relids, iter->with_relids))
+ continue;
I don't quite recall if the em_expr can mention relids that are not in
em_relids or not or if em_expr's relids always is a subset of
em_relids.
I'm just concerned this adds complexity and the risk of mixing up the
meaning (even more than it is already in master). I'm not sure I'm
confident that all this is correct, and I wrote the 0001 patch.
Maybe this can be fixed by changing master so that em_relids always
matches pull_varnos(em_expr)? I'm unsure if there are any other
complexities other than having to ensure we don't set em_is_const for
child members.
2) The 2nd reason is what I hinted at that you quoted in the email I
sent you in March. I think if it wasn't for UNION ALL and perhaps
table inheritance and we only needed child EMs for partitions of
partitioned tables, then I think we might be able to get away with
just translating Exprs child -> parent before looking up the EM and
likewise when asked to get join quals for child rels, we'd translate
the child relids to their top level parents, find the quals then
translate those back to child form again. EquivalenceClasses would
then only contain a few members and there likely wouldn't be a great
need to do any indexing like we are in the 0001 patch. I'm sure
someone somewhere probably has a query that would go faster with them,
but it's likely going to be rare therefore probably not worth it.
Unfortunately, I'm not smart enough to just tell you this will or will
not work just off hand. The UNION ALL branch pruning adds complexity
that I don't recall the details of. To know, someone would either
need to tell me, or I'd need to go try to make it work myself and then
discover the reason it can't be made to work. I'm happy for you to try
this, but if you don't I'm not sure when I can do it. I think it
would need to be at least explored before I'd ever consider thinking
about committing this patch.
3) I just don't like the way the patch switches between methods of
looking up EMs as it means we could return EMs in a different order
depending on something like how many partitions were pruned or after
the DBA does ATTACH PARTITION. That could start causing weird
problems like plan changes due to a change in which columns were
selected in generate_implied_equalities_for_column(). I don't have
any examples of actual problems, but it's pretty difficult to prove
there aren't any.
Of course, I do recall the complaint about the regression for more
simple queries and that's why I wrote the iterator code to have it use
the linear search when the number of EMs is small, so we can't exactly
just delete the linear search method as we'd end up with that
performance regression again.
I think the best way to move this forward is to explore not putting
partitioned table partitions in EMs and instead see if we can
translate to top-level parent before lookups. This might just be too
complex to translate the Exprs all the time and it may add overhead
unless we can quickly determine somehow that we don't need to attempt
to translate the Expr when the given Expr is already from the
top-level parent. If that can't be made to work, then maybe that shows
the current patch has merit.
David
Hello David,
I really appreciate your quick reply.
On Wed, Aug 9, 2023 at 7:28 PM David Rowley <dgrowleyml@gmail.com> wrote:
> If 0004 is adding an em_index to mark the index into
> PlannerInfo->eq_members, can't you use that in
> setup_eclass_member[_strict]_iterator to loop to verify that the two
> methods yield the same result?
>
> i.e:
>
> + Bitmapset *matching_ems = NULL;
> + memcpy(&idx_iter, iter, sizeof(EquivalenceMemberIterator));
> + memcpy(&noidx_iter, iter, sizeof(EquivalenceMemberIterator));
> +
> + idx_iter.use_index = true;
> + noidx_iter.use_index = false;
> +
> + while ((em = eclass_member_iterator_strict_next(&noidx_iter)) != NULL)
> + matching_ems = bms_add_member(matching_ems, em->em_index);
> +
> + Assert(bms_equal(matching_ems, iter->matching_ems));
>
> That should void the complaint that the Assert checking is too slow.
> You can also delete the list_ptr_cmp function too (also noticed a
> complaint about that).
Thanks for sharing your idea regarding this verification. It looks
good to solve the degradation problem in assert-enabled builds. I will
try it.
> For the 0003 patch. Can you explain why you think these fields should
> be in RangeTblEntry rather than RelOptInfo? I can only guess you might
> have done this for memory usage so that we don't have to carry those
> fields for join rels? I think RelOptInfo is the correct place to
> store fields that are only used in the planner. If you put them in
> RangeTblEntry they'll end up in pg_rewrite and be stored for all
> views. Seems very space inefficient and scary as it limits the scope
> for fixing bugs in back branches due to RangeTblEntries being
> serialized into the catalogues in various places.
This change was not made for performance reasons but to avoid null
reference exceptions. The details are explained in my email [1]. In
brief, the earlier patch did not work because simple_rel_array[i]
could be NULL for some 'i', and we referenced such a RelOptInfo. For
example, the following code snippet in add_eq_member() does not work.
I inserted "Assert(rel != NULL)" into this code, and then the
assertion failed. So, I moved the indexes to RangeTblEntry to address
this issue, but I don't know if this solution is good. We may have to
solve this in a different way.
=====
@@ -572,9 +662,31 @@ add_eq_member(EquivalenceClass *ec, Expr *expr,
Relids relids,
+ i = -1;
+ while ((i = bms_next_member(expr_relids, i)) >= 0)
+ {
+ RelOptInfo *rel = root->simple_rel_array[i];
+
+ rel->eclass_member_indexes =
bms_add_member(rel->eclass_member_indexes, em_index);
+ }
=====
On Wed, Aug 9, 2023 at 8:54 PM David Rowley <dgrowleyml@gmail.com> wrote:
> So, I have three concerns with this patch.
> I think the best way to move this forward is to explore not putting
> partitioned table partitions in EMs and instead see if we can
> translate to top-level parent before lookups. This might just be too
> complex to translate the Exprs all the time and it may add overhead
> unless we can quickly determine somehow that we don't need to attempt
> to translate the Expr when the given Expr is already from the
> top-level parent. If that can't be made to work, then maybe that shows
> the current patch has merit.
I really appreciate your detailed advice. I am sorry that I will not
be able to respond for a week or two due to my vacation, but I will
explore and work on these issues. Thanks again for your kind reply.
[1] https://www.postgresql.org/message-id/CAJ2pMkYR_X-%3Dpq%2B39-W5kc0OG7q9u5YUwDBCHnkPur17DXnxuQ%40mail.gmail.com
--
Best regards,
Yuya Watari
Hello,
On Wed, Aug 9, 2023 at 8:54 PM David Rowley <dgrowleyml@gmail.com> wrote:
> I think the best way to move this forward is to explore not putting
> partitioned table partitions in EMs and instead see if we can
> translate to top-level parent before lookups. This might just be too
> complex to translate the Exprs all the time and it may add overhead
> unless we can quickly determine somehow that we don't need to attempt
> to translate the Expr when the given Expr is already from the
> top-level parent. If that can't be made to work, then maybe that shows
> the current patch has merit.
Based on your suggestion, I have experimented with not putting child
EquivalenceMembers in an EquivalenceClass. I have attached a new
patch, v20, to this email. The following is a summary of v20.
* v20 has been written from scratch.
* In v20, EquivalenceClass->ec_members no longer has any child
members. All of ec_members are now non-child. Instead, the child
EquivalenceMembers are in the RelOptInfos.
* When child EquivalenceMembers are required, 1) we translate the
given Relids to their top-level parents, and 2) if some parent
EquivalenceMembers' Relids match the translated top-level ones, we get
the child members from the RelOptInfo.
* With the above change, ec_members has a few members, which leads to
a significant performance improvement. This is the core part of the
v20 optimization.
* My experimental results show that v20 performs better for both small
and large sizes. For small sizes, v20 is clearly superior to v19. For
large sizes, v20 performs as well as v19.
* At this point, I don't know if we should switch to the v20 method.
v20 is just a new proof of concept with much room for improvement. It
is important to compare two different methods of v19 and v20 and
discuss the best strategy.
1. Key idea of v20
I have attached a patch series consisting of two patches. v20-0001 and
v20-0002 are for optimizations regarding EquivalenceClasses and
RestrictInfos, respectively. v20-0002 is picked up from v19. Most of
my new optimizations are in v20-0001.
As I wrote above, the main change in v20-0001 is that we don't add
child EquivalenceMembers to ec_members. I will describe how v20 works.
First of all, take a look at the code of get_eclass_for_sort_expr().
Its comments are helpful for understanding my idea. Traditionally, we
have searched EquivalenceMembers matching the request as follows. This
was a very slow linear search when there were many members in the
list.
===== Master =====
foreach(lc2, cur_ec->ec_members)
{
EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc2);
/*
* Ignore child members unless they match the request.
*/
if (cur_em->em_is_child &&
!bms_equal(cur_em->em_relids, rel))
continue;
/*
* Match constants only within the same JoinDomain (see
* optimizer/README).
*/
if (cur_em->em_is_const && cur_em->em_jdomain != jdomain)
continue;
if (opcintype == cur_em->em_datatype &&
equal(expr, cur_em->em_expr))
return cur_ec; /* Match! */
}
==================
v20 addressed this problem by not adding child members to ec_members.
Since there are few members in the list, we can speed up the search.
Of course, we still need child members. Previously, child members have
been made and added to ec_members in
add_child_[join_]rel_equivalences(). Now, in v20, we add them to
child_[join]rel instead of ec_members. The following is the v20's
change.
===== v20 =====
@@ -2718,9 +2856,20 @@ add_child_rel_equivalences(PlannerInfo *root,
top_parent_relids);
new_relids = bms_add_members(new_relids, child_relids);
- (void) add_eq_member(cur_ec, child_expr, new_relids,
- cur_em->em_jdomain,
- cur_em, cur_em->em_datatype);
+ child_em = make_eq_member(cur_ec, child_expr, new_relids,
+ cur_em->em_jdomain,
+ cur_em, cur_em->em_datatype);
+ child_rel->eclass_child_members = lappend(child_rel->eclass_child_members,
+ child_em);
+
+ /*
+ * We save the knowledge that 'child_em' can be translated from
+ * 'child_rel'. This knowledge is useful for
+ * add_transformed_child_version() to find child members from the
+ * given Relids.
+ */
+ cur_em->em_child_relids = bms_add_member(cur_em->em_child_relids,
+ child_rel->relid);
/* Record this EC index for the child rel */
child_rel->eclass_indexes = bms_add_member(child_rel->eclass_indexes, i);
===============
In many places, we need child EquivalenceMembers that match the given
Relids. To get them, we first find the top-level parents of the given
Relids by calling find_relids_top_parents(). find_relids_top_parents()
replaces all of the Relids as their top-level parents. During looping
over ec_members, we check if the children of an EquivalenceMember can
match the request (top-level parents are needed in this checking). If
the children can match, we get child members from RelOptInfos. These
techniques are the core of the v20 solution. The next change does what
I mentioned now.
===== v20 =====
@@ -599,6 +648,17 @@ get_eclass_for_sort_expr(PlannerInfo *root,
EquivalenceMember *newem;
ListCell *lc1;
MemoryContext oldcontext;
+ Relids top_parent_rel;
+
+ /*
+ * First, we translate the given Relids to their top-level parents. This is
+ * required because an EquivalenceClass contains only parent
+ * EquivalenceMembers, and we have to translate top-level ones to get child
+ * members. We can skip such translations if we now see top-level ones,
+ * i.e., when top_parent_rel is NULL. See the find_relids_top_parents()'s
+ * definition for more details.
+ */
+ top_parent_rel = find_relids_top_parents(root, rel);
/*
* Ensure the expression exposes the correct type and collation.
@@ -632,16 +694,35 @@ get_eclass_for_sort_expr(PlannerInfo *root,
if (!equal(opfamilies, cur_ec->ec_opfamilies))
continue;
- foreach(lc2, cur_ec->ec_members)
+ /*
+ * When we have to see child EquivalenceMembers, we get and add them to
+ * 'members'. We cannot use foreach() because the 'members' may be
+ * modified during iteration.
+ */
+ members = cur_ec->ec_members;
+ modified = false;
+ for (i = 0; i < list_length(members); i++)
{
- EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc2);
+ EquivalenceMember *cur_em =
list_nth_node(EquivalenceMember, members, i);
+
+ /*
+ * If child EquivalenceMembers may match the request, we add and
+ * iterate over them.
+ */
+ if (unlikely(top_parent_rel != NULL) && !cur_em->em_is_child &&
+ bms_equal(cur_em->em_relids, top_parent_rel))
+ add_child_rel_equivalences_to_list(root, cur_ec, cur_em, rel,
+ &members, &modified);
/*
* Ignore child members unless they match the request.
*/
- if (cur_em->em_is_child &&
- !bms_equal(cur_em->em_relids, rel))
- continue;
+ /*
+ * If this EquivalenceMember is a child, i.e., translated above,
+ * it should match the request. We cannot assert this if a request
+ * is bms_is_subset().
+ */
+ Assert(!cur_em->em_is_child || bms_equal(cur_em->em_relids, rel));
/*
* Match constants only within the same JoinDomain (see
===============
The main concern was the overhead of getting top-level parents. If the
given Relids are already top-level, such an operation can be a major
bottleneck. I addressed this issue with a simple null check. v20 saves
top-level parent Relids to PlannerInfo's array. If there are no
children, v20 sets this array to null, and find_relids_top_parents()
can quickly conclude that the given Relids are top-level. For more
details, see the find_relids_top_parents() in pathnode.h (partially
quoted below).
===== v20 =====
@@ -323,6 +323,24 @@ extern Relids min_join_parameterization(PlannerInfo *root,
+#define find_relids_top_parents(root, relids) \
+ (likely((root)->top_parent_relid_array == NULL) \
+ ? NULL : find_relids_top_parents_slow(root, relids))
+extern Relids find_relids_top_parents_slow(PlannerInfo *root, Relids relids);
===============
2. Experimental results
I conducted experiments to test the performance of v20.
2.1. Small size cases (make installcheck)
When I worked with you on optimizing Bitmapset operations, we used
'make installcheck' to check degradation in planning [1]. I did the
same for v19 and v20. Figure 1 and Tables 1 and 2 are the results.
They show that v20 is clearly superior to v19. The degradation of v20
was only 0.5%, while that of v19 was 2.1%. Figure 1 shows that the
0.5% slowdown is much smaller than its variance.
Table 1: Total Planning Time for installcheck (seconds)
-----------------------------------------
| Mean | Median | Stddev
-----------------------------------------
Master | 2.505161 | 2.503110 | 0.019775
v19 | 2.558466 | 2.558560 | 0.017320
v20 | 2.517806 | 2.516081 | 0.016932
-----------------------------------------
Table 2: Speedup for installcheck (higher is better)
----------------------
| Mean | Median
----------------------
v19 | 97.9% | 97.8%
v20 | 99.5% | 99.5%
----------------------
2.2. Large size cases (queries A and B)
I evaluated v20 with the same queries I have used in this thread. The
queries, Queries A and B, are attached in [2]. Both queries join
partitioned tables. Figures 2 and 3 and the following tables show the
results. v20 performed as well as v19 for large sizes. v20 achieved a
speedup of about x10. There seems to be some regression for small
sizes.
Table 3: Planning time of Query A
(n: the number of partitions of each table)
(lower is better)
------------------------------------------
n | Master (ms) | v19 (ms) | v20 (ms)
------------------------------------------
1 | 0.713 | 0.730 | 0.737
2 | 0.792 | 0.814 | 0.815
4 | 0.955 | 0.982 | 0.987
8 | 1.291 | 1.299 | 1.335
16 | 1.984 | 1.951 | 1.992
32 | 3.991 | 3.720 | 3.778
64 | 7.701 | 6.003 | 6.891
128 | 21.118 | 13.988 | 12.861
256 | 77.405 | 37.091 | 37.294
384 | 166.122 | 56.748 | 57.130
512 | 316.650 | 79.942 | 78.692
640 | 520.007 | 94.030 | 93.772
768 | 778.314 | 123.494 | 123.207
896 | 1182.477 | 185.422 | 179.266
1024 | 1547.897 | 161.104 | 155.761
------------------------------------------
Table 4: Speedup of Query A (higher is better)
------------------------
n | v19 | v20
------------------------
1 | 97.7% | 96.7%
2 | 97.3% | 97.2%
4 | 97.3% | 96.8%
8 | 99.4% | 96.7%
16 | 101.7% | 99.6%
32 | 107.3% | 105.6%
64 | 128.3% | 111.8%
128 | 151.0% | 164.2%
256 | 208.7% | 207.6%
384 | 292.7% | 290.8%
512 | 396.1% | 402.4%
640 | 553.0% | 554.5%
768 | 630.2% | 631.7%
896 | 637.7% | 659.6%
1024 | 960.8% | 993.8%
------------------------
Table 5: Planning time of Query B
-----------------------------------------
n | Master (ms) | v19 (ms) | v20 (ms)
-----------------------------------------
1 | 37.044 | 38.062 | 37.614
2 | 35.839 | 36.804 | 36.555
4 | 38.202 | 37.864 | 37.977
8 | 42.292 | 41.023 | 41.210
16 | 51.867 | 46.481 | 46.477
32 | 80.003 | 57.329 | 57.363
64 | 185.212 | 87.124 | 88.528
128 | 656.116 | 157.236 | 160.884
256 | 2883.258 | 343.035 | 340.285
-----------------------------------------
Table 6: Speedup of Query B (higher is better)
-----------------------
n | v19 | v20
-----------------------
1 | 97.3% | 98.5%
2 | 97.4% | 98.0%
4 | 100.9% | 100.6%
8 | 103.1% | 102.6%
16 | 111.6% | 111.6%
32 | 139.6% | 139.5%
64 | 212.6% | 209.2%
128 | 417.3% | 407.8%
256 | 840.5% | 847.3%
-----------------------
3. Future works
3.1. Redundant memory allocation of Lists
When we need child EquivalenceMembers in a loop over ec_members, v20
adds them to the list. However, since we cannot modify the ec_members,
v20 always copies it. In most cases, there are only one or two child
members, so this behavior is a waste of memory and time and not a good
idea. I didn't address this problem in v20 because doing so could add
much complexity to the code, but it is one of the major future works.
I suspect that the degradation of Queries A and B is due to this
problem. The difference between 'make installcheck' and Queries A and
B is whether there are partitioned tables. Most of the tests in 'make
installcheck' do not have partitions, so find_relids_top_parents()
could immediately determine the given Relids are already top-level and
keep degradation very small. However, since Queries A and B have
partitions, too frequent allocations of Lists may have caused the
regression. I hope we can reduce the degradation by avoiding these
memory allocations. I will continue to investigate and fix this
problem.
3.2. em_relids and pull_varnos
I'm sorry that v20 did not address your 1st concern regarding
em_relids and pull_varnos. I will try to look into this.
3.3. Indexes for RestrictInfos
Indexes for RestrictInfos are still in RangeTblEntry in v20-0002. I
will also investigate this issue.
3.4. Correctness
v20 has passed all regression tests in my environment, but I'm not so
sure if v20 is correct.
4. Conclusion
I wrote v20 based on a new idea. It may have a lot of problems, but it
has advantages. At least it solves your 3rd concern. Since we iterate
Lists instead of Bitmapsets, we don't have to introduce an iterator
mechanism. My experiment showed that the 'make installcheck'
degradation was very small. For the 2nd concern, v20 no longer adds
child EquivalenceMembers to ec_members. I'm sorry if this is not what
you intended, but it effectively worked. Again, v20 is a new proof of
concept. I hope the v20-based approach will be a good alternative
solution if we can overcome several problems, including what I
mentioned above.
[1] https://www.postgresql.org/message-id/CAApHDvo68m_0JuTHnEHFNsdSJEb2uPphK6BWXStj93u_QEi2rg%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAJ2pMkYcKHFBD_OMUSVyhYSQU0-j9T6NZ0pL6pwbZsUCohWc7Q%40mail.gmail.com
--
Best regards,
Yuya Watari
Attachment
{kind=link}
Hi Yuya, On Fri, Aug 25, 2023 at 1:09 PM Yuya Watari <watari.yuya@gmail.com> wrote: > > 3. Future works > > 3.1. Redundant memory allocation of Lists > > When we need child EquivalenceMembers in a loop over ec_members, v20 > adds them to the list. However, since we cannot modify the ec_members, > v20 always copies it. In most cases, there are only one or two child > members, so this behavior is a waste of memory and time and not a good > idea. I didn't address this problem in v20 because doing so could add > much complexity to the code, but it is one of the major future works. > > I suspect that the degradation of Queries A and B is due to this > problem. The difference between 'make installcheck' and Queries A and > B is whether there are partitioned tables. Most of the tests in 'make > installcheck' do not have partitions, so find_relids_top_parents() > could immediately determine the given Relids are already top-level and > keep degradation very small. However, since Queries A and B have > partitions, too frequent allocations of Lists may have caused the > regression. I hope we can reduce the degradation by avoiding these > memory allocations. I will continue to investigate and fix this > problem. > > 3.2. em_relids and pull_varnos > > I'm sorry that v20 did not address your 1st concern regarding > em_relids and pull_varnos. I will try to look into this. > > 3.3. Indexes for RestrictInfos > > Indexes for RestrictInfos are still in RangeTblEntry in v20-0002. I > will also investigate this issue. > > 3.4. Correctness > > v20 has passed all regression tests in my environment, but I'm not so > sure if v20 is correct. > > 4. Conclusion > > I wrote v20 based on a new idea. It may have a lot of problems, but it > has advantages. At least it solves your 3rd concern. Since we iterate > Lists instead of Bitmapsets, we don't have to introduce an iterator > mechanism. My experiment showed that the 'make installcheck' > degradation was very small. For the 2nd concern, v20 no longer adds > child EquivalenceMembers to ec_members. I'm sorry if this is not what > you intended, but it effectively worked. Again, v20 is a new proof of > concept. I hope the v20-based approach will be a good alternative > solution if we can overcome several problems, including what I > mentioned above. It seems that you are still investigating and fixing issues. But the CF entry is marked as "needs review". I think a better status is "WoA". Do you agree with that? -- Best Wishes, Ashutosh Bapat
On 25/8/2023 14:39, Yuya Watari wrote: > Hello, > > On Wed, Aug 9, 2023 at 8:54 PM David Rowley <dgrowleyml@gmail.com> wrote: >> I think the best way to move this forward is to explore not putting >> partitioned table partitions in EMs and instead see if we can >> translate to top-level parent before lookups. This might just be too >> complex to translate the Exprs all the time and it may add overhead >> unless we can quickly determine somehow that we don't need to attempt >> to translate the Expr when the given Expr is already from the >> top-level parent. If that can't be made to work, then maybe that shows >> the current patch has merit. > > Based on your suggestion, I have experimented with not putting child > EquivalenceMembers in an EquivalenceClass. I have attached a new > patch, v20, to this email. The following is a summary of v20. Working on self-join removal in the thread [1] nearby, I stuck into the problem, which made an additional argument to work in this new direction than a couple of previous ones. With indexing positions in the list of equivalence members, we make some optimizations like join elimination more complicated - it may need to remove some clauses and equivalence class members. For changing lists of derives or ec_members, we should go through all the index lists and fix them, which is a non-trivial operation. [1] https://www.postgresql.org/message-id/flat/64486b0b-0404-e39e-322d-0801154901f3%40postgrespro.ru -- regards, Andrey Lepikhov Postgres Professional
Hello Ashutosh and Andrey,
Thank you for your email, and I really apologize for my late response.
On Thu, Sep 7, 2023 at 3:43 PM Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
> It seems that you are still investigating and fixing issues. But the
> CF entry is marked as "needs review". I think a better status is
> "WoA". Do you agree with that?
Yes, I am now investigating and fixing issues. I agree with you and
changed the entry's status to "Waiting on Author". Thank you for your
advice.
On Tue, Sep 19, 2023 at 5:21 PM Andrey Lepikhov
<a.lepikhov@postgrespro.ru> wrote:
> Working on self-join removal in the thread [1] nearby, I stuck into the
> problem, which made an additional argument to work in this new direction
> than a couple of previous ones.
> With indexing positions in the list of equivalence members, we make some
> optimizations like join elimination more complicated - it may need to
> remove some clauses and equivalence class members.
> For changing lists of derives or ec_members, we should go through all
> the index lists and fix them, which is a non-trivial operation.
Thank you for looking into this and pointing that out. I understand
that this problem will occur somewhere like your patch [1] quoted
below because we need to modify RelOptInfo->eclass_child_members in
addition to ec_members. Is my understanding correct? (Of course, I
know ec_[no]rel_members, but I doubt we need them.)
=====
+static void
+update_eclass(EquivalenceClass *ec, int from, int to)
+{
+ List *new_members = NIL;
+ ListCell *lc;
+
+ foreach(lc, ec->ec_members)
+ {
+ EquivalenceMember *em = lfirst_node(EquivalenceMember, lc);
+ bool is_redundant = false;
+
...
+
+ if (!is_redundant)
+ new_members = lappend(new_members, em);
+ }
+
+ list_free(ec->ec_members);
+ ec->ec_members = new_members;
=====
I think we may be able to remove the eclass_child_members field by
making child members on demand. v20 makes child members at
add_[child_]join_rel_equivalences() and adds them into
RelOptInfo->eclass_child_members. Instead of doing that, if we
translate on demand when child members are requested,
RelOptInfo->eclass_child_members is no longer necessary. After that,
there is only ec_members, which consists of parent members, so
removing clauses will still be simple. Do you think this idea will
solve your problem? If so, I will experiment with this and share a new
patch version. The main concern with this idea is that the same child
member will be created many times, wasting time and memory. Some
techniques like caching might solve this.
[1] https://www.postgresql.org/message-id/flat/64486b0b-0404-e39e-322d-0801154901f3%40postgrespro.ru
--
Best regards,
Yuya Watari
On Wed, Sep 20, 2023 at 3:35 PM Yuya Watari <watari.yuya@gmail.com> wrote: > I think we may be able to remove the eclass_child_members field by > making child members on demand. v20 makes child members at > add_[child_]join_rel_equivalences() and adds them into > RelOptInfo->eclass_child_members. Instead of doing that, if we > translate on demand when child members are requested, > RelOptInfo->eclass_child_members is no longer necessary. After that, > there is only ec_members, which consists of parent members, so > removing clauses will still be simple. Do you think this idea will > solve your problem? If so, I will experiment with this and share a new > patch version. The main concern with this idea is that the same child > member will be created many times, wasting time and memory. Some > techniques like caching might solve this. > While working on RestrictInfo translations patch I was thinking on these lines. [1] uses hash table for storing translated RestrictInfo. An EC can have a hash table to store ec_member translations. The same patchset also has some changes in the code which generates RestrictInfo clauses from ECs. I think that code will be simplified by your approach. [1] https://www.postgresql.org/message-id/CAExHW5u0Yyyr2mwvLrvVy_QnLd65kpc9u-bO0Ox7bgLkgbac8A@mail.gmail.com -- Best Wishes, Ashutosh Bapat
On Wed, Sep 20, 2023, at 5:04 PM, Yuya Watari wrote: > On Tue, Sep 19, 2023 at 5:21 PM Andrey Lepikhov > <a.lepikhov@postgrespro.ru> wrote: >> Working on self-join removal in the thread [1] nearby, I stuck into the >> problem, which made an additional argument to work in this new direction >> than a couple of previous ones. >> With indexing positions in the list of equivalence members, we make some >> optimizations like join elimination more complicated - it may need to >> remove some clauses and equivalence class members. >> For changing lists of derives or ec_members, we should go through all >> the index lists and fix them, which is a non-trivial operation. > > Thank you for looking into this and pointing that out. I understand > that this problem will occur somewhere like your patch [1] quoted > below because we need to modify RelOptInfo->eclass_child_members in > addition to ec_members. Is my understanding correct? (Of course, I > know ec_[no]rel_members, but I doubt we need them.) It is okay if we talk about the self-join-removal feature specifically because joins are removed before an inheritance expansion. But ec_source_indexes and ec_derive_indexes point to specific places in eq_sources and eq_derives lists. If I removed anEquivalenceClass or a restriction during an optimisation, I would arrange all indexes, too. Right now, I use a workaround here and remove the index link without removing the element from the list. But I'm not surehow good this approach can be in perspective. So, having eq_sources and eq_derives localised in EC could make such optimisations a bit more simple. -- Regards, Andrei Lepikhov
Hello Ashutosh and Andrey, On Wed, Sep 20, 2023 at 8:03 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > While working on RestrictInfo translations patch I was thinking on > these lines. [1] uses hash table for storing translated RestrictInfo. > An EC can have a hash table to store ec_member translations. The same > patchset also has some changes in the code which generates > RestrictInfo clauses from ECs. I think that code will be simplified by > your approach. Thank you for sharing this. I agree that we have to avoid adding complexity to existing or future codes through my patch. As you say, this approach mentioned in the last email is helpful to simplify the code, so I will try it. On Fri, Sep 22, 2023 at 12:49 PM Lepikhov Andrei <a.lepikhov@postgrespro.ru> wrote: > It is okay if we talk about the self-join-removal feature specifically because joins are removed before an inheritanceexpansion. > But ec_source_indexes and ec_derive_indexes point to specific places in eq_sources and eq_derives lists. If I removed anEquivalenceClass or a restriction during an optimisation, I would arrange all indexes, too. > Right now, I use a workaround here and remove the index link without removing the element from the list. But I'm not surehow good this approach can be in perspective. > So, having eq_sources and eq_derives localised in EC could make such optimisations a bit more simple. Thank you for pointing it out. The ec_source_indexes and ec_derive_indexes are just picked up from the previous patch, and I have not changed their design. I think a similar approach to EquivalenceMembers may be applied to RestrictInfos. I will experiment with them and share a new patch. -- Best regards, Yuya Watari
Hi, all!
While I was reviewing the patches, I noticed that they needed some rebasing, and in one of the patches (Introduce-indexes-for-RestrictInfo.patch) there was a conflict with the recently added self-join-removal feature [1]. So, I rebased patches and resolved the conflicts. While I was doing this, I found a problem that I also fixed:
1. Due to the lack of ec_source_indexes, ec_derive_indexes, we could catch an error during the execution of atomic functions such as:
ERROR: unrecognized token: ")" Context: внедрённая в код SQL-функция "shobj_description"
I fixed it.
We save the current reading context before reading the field name, then check whether the field has been read and, if not, restore the context to allow the next macro reads the field name correctly.
I added the solution to the bug_related_atomic_function.diff file.
2. I added the solution to the conflict to the solved_conflict_with_self_join_removal.diff file.
All diff files have already been added to v21-0002-Introduce-indexes-for-RestrictInfo patch.
-- Regards, Alena Rybakina
Attachment
On Sat, Nov 18, 2023 at 4:04 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote: > > All diff files have already been added to v21-0002-Introduce-indexes-for-RestrictInfo patch. Unfortunately, the patch tester is too smart for its own good, and will try to apply .diff files as well. Since bug_related_to_atomic_function.diff is first in the alphabet, it comes first, which is the reason for the current CI failure.
John Naylor <johncnaylorls@gmail.com> writes: > On Sat, Nov 18, 2023 at 4:04 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote: >> All diff files have already been added to v21-0002-Introduce-indexes-for-RestrictInfo patch. > Unfortunately, the patch tester is too smart for its own good, and > will try to apply .diff files as well. Yeah --- see documentation here: https://wiki.postgresql.org/wiki/Cfbot That suggests using a .txt extension for anything you don't want to be taken as part of the patch set. regards, tom lane
On 18.11.2023 05:45, John Naylor wrote: > On Sat, Nov 18, 2023 at 4:04 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote: >> All diff files have already been added to v21-0002-Introduce-indexes-for-RestrictInfo patch. > Unfortunately, the patch tester is too smart for its own good, and > will try to apply .diff files as well. Since > bug_related_to_atomic_function.diff is first in the alphabet, it comes > first, which is the reason for the current CI failure. On 18.11.2023 06:13, Tom Lane wrote: > John Naylor <johncnaylorls@gmail.com> writes: >> On Sat, Nov 18, 2023 at 4:04 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote: >>> All diff files have already been added to v21-0002-Introduce-indexes-for-RestrictInfo patch. >> Unfortunately, the patch tester is too smart for its own good, and >> will try to apply .diff files as well. > Yeah --- see documentation here: > > https://wiki.postgresql.org/wiki/Cfbot > > That suggests using a .txt extension for anything you don't want to > be taken as part of the patch set. > > regards, tom lane Thank you for explanation. I fixed it. I have attached the previous diff files as txt so that they will not applied (they are already applied in the second patch "v21-0002-PATCH-PATCH-1-2-Introduce-indexes-for-RestrictInfo-T.patch"). Also, the previous time I missed the fact that the files conflict with each other - I fixed it too and everything seems to work fine now.
Attachment
On 27/9/2023 14:28, Yuya Watari wrote: > Thank you for pointing it out. The ec_source_indexes and > ec_derive_indexes are just picked up from the previous patch, and I > have not changed their design. I think a similar approach to > EquivalenceMembers may be applied to RestrictInfos. I will experiment > with them and share a new patch. During the work on committing the SJE feature [1], Alexander Korotkov pointed out the silver lining in this work [2]: he proposed that we shouldn't remove RelOptInfo from simple_rel_array at all but replace it with an 'Alias', which will refer the kept relation. It can simplify further optimizations on removing redundant parts of the query. [1] https://www.postgresql.org/message-id/flat/64486b0b-0404-e39e-322d-0801154901f3%40postgrespro.ru [2] https://www.postgresql.org/message-id/CAPpHfdsnAbg8CaK+NJ8AkiG_+_Tt07eCStkb1LOa50f0UsT5RQ@mail.gmail.com -- regards, Andrei Lepikhov Postgres Professional
Hello Alena, Andrei, and all, Thank you for reviewing this patch. I really apologize for not updating this thread for a while. On Sat, Nov 18, 2023 at 6:04 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote: > Hi, all! > > While I was reviewing the patches, I noticed that they needed some rebasing, and in one of the patches (Introduce-indexes-for-RestrictInfo.patch)there was a conflict with the recently added self-join-removal feature [1]. So,I rebased patches and resolved the conflicts. While I was doing this, I found a problem that I also fixed: Thank you very much for rebasing these patches and fixing the issue. The bug seemed to be caused because these indexes were in RangeTblEntry, and the handling of their serialization was not correct. Thank you for fixing it. On Mon, Nov 20, 2023 at 1:45 PM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > During the work on committing the SJE feature [1], Alexander Korotkov > pointed out the silver lining in this work [2]: he proposed that we > shouldn't remove RelOptInfo from simple_rel_array at all but replace it > with an 'Alias', which will refer the kept relation. It can simplify > further optimizations on removing redundant parts of the query. Thank you for sharing this information. I think the idea suggested by Alexander Korotkov is also helpful for our patch. As mentioned above, the indexes are in RangeTblEntry in the current implementation. However, I think RangeTblEntry is not the best place to store them. An 'alias' relids may help solve this and simplify fixing the above bug. I will try this approach soon. Unfortunately, I've been busy due to work, so I won't be able to respond for several weeks. I'm really sorry for not being able to see the patches. As soon as I'm not busy, I will look at them, consider the above approach, and reply to this thread. If there is no objection, I will move this CF entry forward to next CF. Again, thank you very much for looking at this thread, and I'm sorry for my late work. -- Best regards, Yuya Watari
Hello, On Wed, Nov 22, 2023 at 2:32 PM Yuya Watari <watari.yuya@gmail.com> wrote: > Unfortunately, I've been busy due to work, so I won't be able to > respond for several weeks. I'm really sorry for not being able to see > the patches. As soon as I'm not busy, I will look at them, consider > the above approach, and reply to this thread. If there is no > objection, I will move this CF entry forward to next CF. Since the end of this month is approaching, I moved this CF entry to the next CF (January CF). I will reply to this thread in a few weeks. Again, I appreciate your kind reviews and patches. -- Best regards, Yuya Watari
Hello Alena, Andrei, and all,
I am sorry for my late response. I found that the current patches do
not apply to the master, so I have rebased those patches. I have
attached v22. For this later discussion, I separated the rebasing and
bug fixing that Alena did in v21 into separate commits, v22-0003 and
v22-0004. I will merge these commits after the discussion.
1. v22-0003 (solved_conflict_with_self_join_removal.txt)
Thank you for your rebase. Looking at your rebasing patch, I thought
we could do this more simply. Your patch deletes (more precisely, sets
to null) non-redundant members from the root->eq_sources list and
re-adds them to the same list. However, this approach seems a little
waste of memory. Instead, we can update
EquivalenceClass->ec_source_indexes directly. Then, we can reuse the
members in root->eq_sources and don't need to extend root->eq_sources.
I did this in v22-0003. What do you think of this approach?
The main concern with this idea is that it does not fix
RangeTblEntry->eclass_source_indexes. The current code works fine even
if we don't fix the index because get_ec_source_indexes() always does
bms_intersect() for eclass_source_indexes and ec_source_indexes. If we
guaranteed this behavior of doing bms_intersect, then simply modifying
ec_source_indexes would be fine. Fortunately, such a guarantee is not
so difficult.
And your patch removes the following assertion code from the previous
patch. May I ask why you removed this code? I think this assertion is
helpful for sanity checks. Of course, I know that this kind of
assertion will slow down regression tests or assert-enabled builds.
So, we may have to discuss which assertions to keep and which to
discard.
=====
-#ifdef USE_ASSERT_CHECKING
- /* verify the results look sane */
- i = -1;
- while ((i = bms_next_member(rel_esis, i)) >= 0)
- {
- RestrictInfo *rinfo = list_nth_node(RestrictInfo, root->eq_sources,
- i);
-
- Assert(bms_overlap(relids, rinfo->clause_relids));
- }
-#endif
=====
Finally, your patch changes the name of the following function. I
understand the need for this change, but it has nothing to do with our
patches, so we should not include it and discuss it in another thread.
=====
-update_eclasses(EquivalenceClass *ec, int from, int to)
+update_eclass(PlannerInfo *root, EquivalenceClass *ec, int from, int to)
=====
2. v22-0004 (bug_related_to_atomic_function.txt)
Thank you for fixing the bug. As I wrote in the previous mail:
On Wed, Nov 22, 2023 at 2:32 PM Yuya Watari <watari.yuya@gmail.com> wrote:
> On Mon, Nov 20, 2023 at 1:45 PM Andrei Lepikhov
> <a.lepikhov@postgrespro.ru> wrote:
> > During the work on committing the SJE feature [1], Alexander Korotkov
> > pointed out the silver lining in this work [2]: he proposed that we
> > shouldn't remove RelOptInfo from simple_rel_array at all but replace it
> > with an 'Alias', which will refer the kept relation. It can simplify
> > further optimizations on removing redundant parts of the query.
>
> Thank you for sharing this information. I think the idea suggested by
> Alexander Korotkov is also helpful for our patch. As mentioned above,
> the indexes are in RangeTblEntry in the current implementation.
> However, I think RangeTblEntry is not the best place to store them. An
> 'alias' relids may help solve this and simplify fixing the above bug.
> I will try this approach soon.
I think that the best way to solve this issue is to move these indexes
from RangeTblEntry to RelOptInfo. Since they are related to planning
time, they should be in RelOptInfo. The reason why I put these indexes
in RangeTblEntry is because some RelOptInfos can be null and we cannot
store the indexes. This problem is similar to an issue regarding
'varno 0' Vars. I hope an alias RelOptInfo would help solve this
issue. I have attached the current proof of concept I am considering
as poc-alias-reloptinfo.txt. To test this patch, please follow the
procedure below.
1. Apply all *.patch files,
2. Apply Alexander Korotkov's alias_relids.patch [1], and
3. Apply poc-alias-reloptinfo.txt, which is attached to this email.
My patch creates a dummy (or an alias) RelOptInfo to store indexes if
the corresponding RelOptInfo is null. The following is the core change
in my patch.
=====
@@ -627,9 +627,19 @@ add_eq_source(PlannerInfo *root, EquivalenceClass
*ec, RestrictInfo *rinfo)
i = -1;
while ((i = bms_next_member(rinfo->clause_relids, i)) >= 0)
{
- RangeTblEntry *rte = root->simple_rte_array[i];
+ RelOptInfo *rel = root->simple_rel_array[i];
- rte->eclass_source_indexes = bms_add_member(rte->eclass_source_indexes,
+ /*
+ * If the corresponding RelOptInfo does not exist, we create a 'dummy'
+ * RelOptInfo for storing EquivalenceClass indexes.
+ */
+ if (rel == NULL)
+ {
+ rel = root->simple_rel_array[i] = makeNode(RelOptInfo);
+ rel->eclass_source_indexes = NULL;
+ rel->eclass_derive_indexes = NULL;
+ }
+ rel->eclass_source_indexes = bms_add_member(rel->eclass_source_indexes,
source_idx);
}
=====
At this point, I'm not sure if this approach is correct. It seems to
pass the regression tests, but we should doubt its correctness. I will
continue to experiment with this idea.
[1] https://www.postgresql.org/message-id/CAPpHfdseB13zJJPZuBORevRnZ0vcFyUaaJeSGfAysX7S5er%2BEQ%40mail.gmail.com
--
Best regards,
Yuya Watari
Attachment
Thank you!Hello Alena, Andrei, and all, I am sorry for my late response. I found that the current patches do not apply to the master, so I have rebased those patches. I have attached v22. For this later discussion, I separated the rebasing and bug fixing that Alena did in v21 into separate commits, v22-0003 and v22-0004. I will merge these commits after the discussion. 1. v22-0003 (solved_conflict_with_self_join_removal.txt)
I thought about this earlier and was worried that the index links of the equivalence classes might not be referenced correctly for outer joins,Thank you for your rebase. Looking at your rebasing patch, I thought we could do this more simply. Your patch deletes (more precisely, sets to null) non-redundant members from the root->eq_sources list and re-adds them to the same list. However, this approach seems a little waste of memory. Instead, we can update EquivalenceClass->ec_source_indexes directly. Then, we can reuse the members in root->eq_sources and don't need to extend root->eq_sources. I did this in v22-0003. What do you think of this approach?
so I decided to just overwrite them and reset the previous ones.
The main concern with this idea is that it does not fix
RangeTblEntry->eclass_source_indexes. The current code works fine even
if we don't fix the index because get_ec_source_indexes() always does
bms_intersect() for eclass_source_indexes and ec_source_indexes. If we
guaranteed this behavior of doing bms_intersect, then simply modifying
ec_source_indexes would be fine. Fortunately, such a guarantee is not
so difficult.
And your patch removes the following assertion code from the previous
patch. May I ask why you removed this code? I think this assertion is
helpful for sanity checks. Of course, I know that this kind of
assertion will slow down regression tests or assert-enabled builds.
So, we may have to discuss which assertions to keep and which to
discard.
=====
-#ifdef USE_ASSERT_CHECKING
- /* verify the results look sane */
- i = -1;
- while ((i = bms_next_member(rel_esis, i)) >= 0)
- {
- RestrictInfo *rinfo = list_nth_node(RestrictInfo, root->eq_sources,
- i);
-
- Assert(bms_overlap(relids, rinfo->clause_relids));
- }
-#endif
=====then this check is not correct either - since the zeroed value indicated by the index is correct.
That's why I removed this check.
I agree.Finally, your patch changes the name of the following function. I understand the need for this change, but it has nothing to do with our patches, so we should not include it and discuss it in another thread. ===== -update_eclasses(EquivalenceClass *ec, int from, int to) +update_eclass(PlannerInfo *root, EquivalenceClass *ec, int from, int to) =====
Yes, I also thought in this direction before and I agree that this is the best way to develop the patch.2. v22-0004 (bug_related_to_atomic_function.txt) Thank you for fixing the bug. As I wrote in the previous mail: On Wed, Nov 22, 2023 at 2:32 PM Yuya Watari <watari.yuya@gmail.com> wrote:On Mon, Nov 20, 2023 at 1:45 PM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote:During the work on committing the SJE feature [1], Alexander Korotkov pointed out the silver lining in this work [2]: he proposed that we shouldn't remove RelOptInfo from simple_rel_array at all but replace it with an 'Alias', which will refer the kept relation. It can simplify further optimizations on removing redundant parts of the query.Thank you for sharing this information. I think the idea suggested by Alexander Korotkov is also helpful for our patch. As mentioned above, the indexes are in RangeTblEntry in the current implementation. However, I think RangeTblEntry is not the best place to store them. An 'alias' relids may help solve this and simplify fixing the above bug. I will try this approach soon.I think that the best way to solve this issue is to move these indexes from RangeTblEntry to RelOptInfo. Since they are related to planning time, they should be in RelOptInfo. The reason why I put these indexes in RangeTblEntry is because some RelOptInfos can be null and we cannot store the indexes. This problem is similar to an issue regarding 'varno 0' Vars. I hope an alias RelOptInfo would help solve this issue. I have attached the current proof of concept I am considering as poc-alias-reloptinfo.txt. To test this patch, please follow the procedure below. 1. Apply all *.patch files, 2. Apply Alexander Korotkov's alias_relids.patch [1], and 3. Apply poc-alias-reloptinfo.txt, which is attached to this email. My patch creates a dummy (or an alias) RelOptInfo to store indexes if the corresponding RelOptInfo is null. The following is the core change in my patch. ===== @@ -627,9 +627,19 @@ add_eq_source(PlannerInfo *root, EquivalenceClass *ec, RestrictInfo *rinfo) i = -1; while ((i = bms_next_member(rinfo->clause_relids, i)) >= 0) { - RangeTblEntry *rte = root->simple_rte_array[i]; + RelOptInfo *rel = root->simple_rel_array[i]; - rte->eclass_source_indexes = bms_add_member(rte->eclass_source_indexes, + /* + * If the corresponding RelOptInfo does not exist, we create a 'dummy' + * RelOptInfo for storing EquivalenceClass indexes. + */ + if (rel == NULL) + { + rel = root->simple_rel_array[i] = makeNode(RelOptInfo); + rel->eclass_source_indexes = NULL; + rel->eclass_derive_indexes = NULL; + } + rel->eclass_source_indexes = bms_add_member(rel->eclass_source_indexes, source_idx); } ===== At this point, I'm not sure if this approach is correct. It seems to pass the regression tests, but we should doubt its correctness. I will continue to experiment with this idea. [1] https://www.postgresql.org/message-id/CAPpHfdseB13zJJPZuBORevRnZ0vcFyUaaJeSGfAysX7S5er%2BEQ%40mail.gmail.com
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hello Alena,
Thank you for your quick response, and I'm sorry for my delayed reply.
On Sun, Dec 17, 2023 at 12:41 AM Alena Rybakina
<lena.ribackina@yandex.ru> wrote:
> I thought about this earlier and was worried that the index links of the equivalence classes might not be referenced
correctlyfor outer joins,
> so I decided to just overwrite them and reset the previous ones.
Thank you for pointing this out. I have investigated this problem and
found a potential bug place. The code quoted below modifies
RestrictInfo's clause_relids. Here, our indexes, namely
eclass_source_indexes and eclass_derive_indexes, are based on
clause_relids, so they should be adjusted after the modification.
However, my patch didn't do that, so it may have missed some
references. The same problem occurs in places other than the quoted
one.
=====
/*
* Walker function for replace_varno()
*/
static bool
replace_varno_walker(Node *node, ReplaceVarnoContext *ctx)
{
...
else if (IsA(node, RestrictInfo))
{
RestrictInfo *rinfo = (RestrictInfo *) node;
...
if (bms_is_member(ctx->from, rinfo->clause_relids))
{
replace_varno((Node *) rinfo->clause, ctx->from, ctx->to);
replace_varno((Node *) rinfo->orclause, ctx->from, ctx->to);
rinfo->clause_relids = replace_relid(rinfo->clause_relids,
ctx->from, ctx->to);
...
}
...
}
...
}
=====
I have attached a new version of the patch, v23, to fix this problem.
v23-0006 adds a helper function called update_clause_relids(). This
function modifies RestrictInfo->clause_relids while adjusting its
related indexes. I have also attached a sanity check patch
(sanity-check.txt) to this email. This sanity check patch verifies
that there are no missing references between RestrictInfos and our
indexes. I don't intend to commit this patch, but it helps find
potential bugs. v23 passes this sanity check, but the v21 you
submitted before does not. This means that the adjustment by
update_clause_relids() is needed to prevent missing references after
modifying clause_relids. I'd appreciate your letting me know if v23
doesn't solve your concern.
One of the things I don't think is good about my approach is that it
adds some complexity to the code. In my approach, all modifications to
clause_relids must be done through the update_clause_relids()
function, but enforcing this rule is not so easy. In this sense, my
patch may need to be simplified more.
> this is due to the fact that I explained before: we zeroed the values indicated by the indexes,
> then this check is not correct either - since the zeroed value indicated by the index is correct.
> That's why I removed this check.
Thank you for letting me know. I fixed this in v23-0005 to adjust the
indexes in update_eclasses(). With this change, the assertion check
will be correct.
--
Best regards,
Yuya Watari
Attachment
- sanity-check.txt
- v23-0001-Speed-up-searches-for-child-EquivalenceMembers.patch
- v23-0002-Introduce-indexes-for-RestrictInfo.patch
- v23-0003-Solve-conflict-with-self-join-removal.patch
- v23-0004-Fix-a-bug-related-to-atomic-function.patch
- v23-0005-Remove-all-references-between-RestrictInfo-and-i.patch
- v23-0006-Introduce-update_clause_relids-for-updating-Rest.patch
Hi! Sorry my delayed reply too.
On 17.01.2024 12:33, Yuya Watari wrote:
> Hello Alena,
>
> Thank you for your quick response, and I'm sorry for my delayed reply.
>
> On Sun, Dec 17, 2023 at 12:41 AM Alena Rybakina
> <lena.ribackina@yandex.ru> wrote:
>> I thought about this earlier and was worried that the index links of the equivalence classes might not be referenced
correctlyfor outer joins,
>> so I decided to just overwrite them and reset the previous ones.
> Thank you for pointing this out. I have investigated this problem and
> found a potential bug place. The code quoted below modifies
> RestrictInfo's clause_relids. Here, our indexes, namely
> eclass_source_indexes and eclass_derive_indexes, are based on
> clause_relids, so they should be adjusted after the modification.
> However, my patch didn't do that, so it may have missed some
> references. The same problem occurs in places other than the quoted
> one.
>
> =====
> /*
> * Walker function for replace_varno()
> */
> static bool
> replace_varno_walker(Node *node, ReplaceVarnoContext *ctx)
> {
> ...
> else if (IsA(node, RestrictInfo))
> {
> RestrictInfo *rinfo = (RestrictInfo *) node;
> ...
>
> if (bms_is_member(ctx->from, rinfo->clause_relids))
> {
> replace_varno((Node *) rinfo->clause, ctx->from, ctx->to);
> replace_varno((Node *) rinfo->orclause, ctx->from, ctx->to);
> rinfo->clause_relids = replace_relid(rinfo->clause_relids,
> ctx->from, ctx->to);
> ...
> }
> ...
> }
> ...
> }
> =====
>
> I have attached a new version of the patch, v23, to fix this problem.
> v23-0006 adds a helper function called update_clause_relids(). This
> function modifies RestrictInfo->clause_relids while adjusting its
> related indexes. I have also attached a sanity check patch
> (sanity-check.txt) to this email. This sanity check patch verifies
> that there are no missing references between RestrictInfos and our
> indexes. I don't intend to commit this patch, but it helps find
> potential bugs. v23 passes this sanity check, but the v21 you
> submitted before does not. This means that the adjustment by
> update_clause_relids() is needed to prevent missing references after
> modifying clause_relids. I'd appreciate your letting me know if v23
> doesn't solve your concern.
>
> One of the things I don't think is good about my approach is that it
> adds some complexity to the code. In my approach, all modifications to
> clause_relids must be done through the update_clause_relids()
> function, but enforcing this rule is not so easy. In this sense, my
> patch may need to be simplified more.
>
>> this is due to the fact that I explained before: we zeroed the values indicated by the indexes,
>> then this check is not correct either - since the zeroed value indicated by the index is correct.
>> That's why I removed this check.
> Thank you for letting me know. I fixed this in v23-0005 to adjust the
> indexes in update_eclasses(). With this change, the assertion check
> will be correct.
>
Yes, it is working correctly now with the assertion check. I suppose
it's better to add this code with an additional comment and a
recommendation for other developers
to use it for checking in case of manipulations with the list of
equivalences.
--
Regards,
Alena Rybakina
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Hello, On Tue, Feb 13, 2024 at 6:19 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote: > > Yes, it is working correctly now with the assertion check. I suppose > it's better to add this code with an additional comment and a > recommendation for other developers > to use it for checking in case of manipulations with the list of > equivalences. Thank you for your reply and advice. I have added this assertion so that other developers can use it in the future. I also merged recent changes and attached a new version, v24. Since this thread is getting long, I will summarize the patches. 1. v24-0001 This patch is one of the main parts of my optimization. Traditionally, EquivalenceClass has both parent and child members. However, this leads to high iteration costs when there are many child partitions. In v24-0001, EquivalenceClasses no longer have child members. If we need to iterate over child EquivalenceMembers, we use the EquivalenceChildMemberIterator and access the children through the iterator. For more details, see [1] (please note that there are a few design changes from [1]). 2. v24-0002 This patch was made in the previous work with David. Like EquivalenceClass, there are many RestrictInfos in highly partitioned cases. This patch introduces an indexing mechanism to speed up searches for RestrictInfos. 3. v24-0003 v24-0002 adds its indexes to RangeTblEntry, but this is not a good idea. RelOptInfo is the best place. This problem is a workaround because some RelOptInfos can be NULL, so we cannot store indexes to such RelOptInfos. v24-0003 moves the indexes from RangeTblEntry to PlannerInfo. This is still a workaround, and I think it should be reconsidered. [1] https://www.postgresql.org/message-id/CAJ2pMkZk-Nr%3DyCKrGfGLu35gK-D179QPyxaqtJMUkO86y1NmSA%40mail.gmail.com -- Best regards, Yuya Watari
Attachment
Hello,
On Tue, Feb 13, 2024 at 6:19 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote:
>
> Yes, it is working correctly now with the assertion check. I suppose
> it's better to add this code with an additional comment and a
> recommendation for other developers
> to use it for checking in case of manipulations with the list of
> equivalences.
Thank you for your reply and advice. I have added this assertion so
that other developers can use it in the future.
I also merged recent changes and attached a new version, v24. Since
this thread is getting long, I will summarize the patches.
--
Hello Ashutosh, Thank you for your email and for reviewing the patch. I sincerely apologize for the delay in responding. On Wed, Mar 6, 2024 at 11:16 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > here's summary of observations > 1. The patch improves planning time significantly (3X to 20X) and the improvement increases with the number of tables beingjoined. > 2. In the assert enabled build the patch slows down (in comparison to HEAD) planning with higher number of tables in thejoin. You may want to investigate this. But this is still better than my earlier measurements. > 3. The patch increased memory consumption by planner. But the numbers have improved since my last measurement. Still itwill be good to investigate what causes this extra memory consumption. > 4. Generally with the assert enabled build planner consumes more memory with or without patch. From my previous experiencethis might be due to Bitmapset objects created within Assert() calls. Thank you for testing the patch and sharing the results. For comment #1, these results show the effectiveness of the patch. For comment #2, I agree that we should not slow down assert-enabled builds. The patch adds a lot of assertions to avoid adding bugs, but they might be too excessive. I will reconsider these assertions and remove unnecessary ones. For comments #3 and #4, while the patch improves time complexity, it has some negative impacts on space complexity. The patch uses a Bitmapset-based index to speed up searching for EquivalenceMembers and RestrictInfos. Reducing this memory consumption is a little hard, but this is a very important problem in committing this patch, so I will investigate this further. > Does v24-0002 have any relation/overlap with my patches to reduce memory consumed by RestrictInfos? Those patches havecode to avoid creating duplicate RestrictInfos (including commuted RestrictInfos) from ECs. [2] Thank you for sharing these patches. My patch may be related to your patches. My patch speeds up slow linear searches over EquivalenceMembers and RestrictInfos. It uses several approaches, one of which is the Bitmapset-based index. Bitmapsets are space inefficient, so if there are many EquivalenceMembers and RestrictInfos, this index becomes large. This is true for highly partitioned cases, where there are a lot of similar (or duplicate) elements. Eliminating such duplicate elements may help my patch reduce memory consumption. I will investigate this further. Unfortunately, I've been busy due to work, so I may not be able to respond soon. I really apologize for this. However, I will look into the patches, including yours, and share further information if found. Again, I apologize for my late response and appreciate your kind review. -- Best regards, Yuya Watari
On Thu, May 2, 2024 at 3:57 PM Yuya Watari <watari.yuya@gmail.com> wrote:
>
hi. sorry to bother you, maybe a dumb question.
trying to understand something under the hood.
currently I only applied
v24-0001-Speed-up-searches-for-child-EquivalenceMembers.patch.
on v24-0001:
+/*
+ * add_eq_member - build a new EquivalenceMember and add it to an EC
+ */
+static EquivalenceMember *
+add_eq_member(EquivalenceClass *ec, Expr *expr, Relids relids,
+ JoinDomain *jdomain, Oid datatype)
+{
+ EquivalenceMember *em = make_eq_member(ec, expr, relids, jdomain,
+ NULL, datatype);
+
+ ec->ec_members = lappend(ec->ec_members, em);
+ return em;
+}
+
this part seems so weird to me.
add_eq_member function was added very very long ago,
why do we create a function with the same function name?
also I didn't see deletion of original add_eq_member function
(https://git.postgresql.org/cgit/postgresql.git/tree/src/backend/optimizer/path/equivclass.c#n516)
in v24-0001.
Obviously, now I cannot compile it correctly.
What am I missing?
Hello,
Thank you for reviewing these patches.
On Thu, May 2, 2024 at 11:35 PM jian he <jian.universality@gmail.com> wrote:
> on v24-0001:
> +/*
> + * add_eq_member - build a new EquivalenceMember and add it to an EC
> + */
> +static EquivalenceMember *
> +add_eq_member(EquivalenceClass *ec, Expr *expr, Relids relids,
> + JoinDomain *jdomain, Oid datatype)
> +{
> + EquivalenceMember *em = make_eq_member(ec, expr, relids, jdomain,
> + NULL, datatype);
> +
> + ec->ec_members = lappend(ec->ec_members, em);
> + return em;
> +}
> +
> this part seems so weird to me.
> add_eq_member function was added very very long ago,
> why do we create a function with the same function name?
>
> also I didn't see deletion of original add_eq_member function
> (https://git.postgresql.org/cgit/postgresql.git/tree/src/backend/optimizer/path/equivclass.c#n516)
> in v24-0001.
Actually, this patch does not recreate the add_eq_member() function
but splits it into two functions: add_eq_member() and
make_eq_member().
The reason why planning takes so long time in the current
implementation is that EquivalenceClasses have a large number of child
EquivalenceMembers, and the linear search for them is time-consuming.
To solve this problem, the patch makes EquivalenceClasses have only
parent members. There are few parent members, so we can speed up the
search. In the patch, the child members are introduced when needed.
The add_eq_member() function originally created EquivalenceMembers and
added them to ec_members. In the patch, this function is split into
the following two functions.
1. make_eq_member
Creates a new (parent or child) EquivalenceMember and returns it
without adding it to ec_members.
2. add_eq_member
Creates a new parent (not child) EquivalenceMember and adds it to
ec_members. Internally calls make_eq_member.
When we create parent members, we simply call add_eq_member(). This is
the same as the current implementation. When we create child members,
we have to do something different. Look at the code below. The
add_child_rel_equivalences() function creates child members. The patch
creates child EquivalenceMembers by the make_eq_member() function and
stores them in RelOptInfo (child_rel->eclass_child_members) instead of
their parent EquivalenceClass->ec_members. When we need child
EquivalenceMembers, we get them via RelOptInfos.
=====
void
add_child_rel_equivalences(PlannerInfo *root,
AppendRelInfo *appinfo,
RelOptInfo *parent_rel,
RelOptInfo *child_rel)
{
...
i = -1;
while ((i = bms_next_member(parent_rel->eclass_indexes, i)) >= 0)
{
...
foreach(lc, cur_ec->ec_members)
{
...
if (bms_is_subset(cur_em->em_relids, top_parent_relids) &&
!bms_is_empty(cur_em->em_relids))
{
/* OK, generate transformed child version */
...
child_em = make_eq_member(cur_ec, child_expr, new_relids,
cur_em->em_jdomain,
cur_em, cur_em->em_datatype);
child_rel->eclass_child_members =
lappend(child_rel->eclass_child_members,
child_em);
...
}
}
}
}
=====
I didn't change the name of add_eq_member, but it might be better to
change it to something like add_parent_eq_member(). Alternatively,
creating a new function named add_child_eq_member() that adds child
members to RelOptInfo can be a solution. I will consider these changes
in the next version.
> Obviously, now I cannot compile it correctly.
> What am I missing?
Thank you for pointing this out. This is due to a conflict with a
recent commit [1]. This commit introduces a new function named
add_setop_child_rel_equivalences(), which is quoted below. This
function creates a new child EquivalenceMember by calling
add_eq_member(). We have to adjust this function to make my patch
work, but it is not so easy. I'm sorry it will take some time to solve
this conflict, but I will post a new version when it is fixed.
=====
/*
* add_setop_child_rel_equivalences
* Add equivalence members for each non-resjunk target in 'child_tlist'
* to the EquivalenceClass in the corresponding setop_pathkey's pk_eclass.
*
* 'root' is the PlannerInfo belonging to the top-level set operation.
* 'child_rel' is the RelOptInfo of the child relation we're adding
* EquivalenceMembers for.
* 'child_tlist' is the target list for the setop child relation. The target
* list expressions are what we add as EquivalenceMembers.
* 'setop_pathkeys' is a list of PathKeys which must contain an entry for each
* non-resjunk target in 'child_tlist'.
*/
void
add_setop_child_rel_equivalences(PlannerInfo *root, RelOptInfo *child_rel,
List *child_tlist, List *setop_pathkeys)
{
ListCell *lc;
ListCell *lc2 = list_head(setop_pathkeys);
foreach(lc, child_tlist)
{
TargetEntry *tle = lfirst_node(TargetEntry, lc);
EquivalenceMember *parent_em;
PathKey *pk;
if (tle->resjunk)
continue;
if (lc2 == NULL)
elog(ERROR, "too few pathkeys for set operation");
pk = lfirst_node(PathKey, lc2);
parent_em = linitial(pk->pk_eclass->ec_members);
/*
* We can safely pass the parent member as the first member in the
* ec_members list as this is added first in generate_union_paths,
* likewise, the JoinDomain can be that of the initial member of the
* Pathkey's EquivalenceClass.
*/
add_eq_member(pk->pk_eclass,
tle->expr,
child_rel->relids,
parent_em->em_jdomain,
parent_em,
exprType((Node *) tle->expr));
lc2 = lnext(setop_pathkeys, lc2);
}
/*
* transformSetOperationStmt() ensures that the targetlist never contains
* any resjunk columns, so all eclasses that exist in 'root' must have
* received a new member in the loop above. Add them to the child_rel's
* eclass_indexes.
*/
child_rel->eclass_indexes = bms_add_range(child_rel->eclass_indexes, 0,
list_length(root->eq_classes) - 1);
}
=====
[1] https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=66c0185a3d14bbbf51d0fc9d267093ffec735231
--
Best regards,
Yuya Watari
> On Tue, Oct 15, 2024 at 12:20:04PM GMT, Yuya Watari wrote:
>
> The previous patches do not apply to the current master, so I have
> attached the rebased version.
Thanks for keeping it up to date.
> v25-0001
> This patch is one of the main parts of my optimization. Traditionally,
> EquivalenceClass has both parent and child members. However, this
> leads to high iteration costs when there are many child partitions. In
> v25-0001, EquivalenceClasses no longer have child members. If we need
> to iterate over child EquivalenceMembers, we use the
> EquivalenceChildMemberIterator and access the children through the
> iterator. For more details, see [1] (note that there are some design
> changes from [1]).
The referenced email containst some benchmark results. But shouldn't the
benchmark be repeated after those design changes you're talking about?
Few random notes after quickly looking through the first patch:
* There are patterns like this scattered around, it looks somewhat confusing:
+ /* See the comments in get_eclass_for_sort_expr() to see how this works. */
+ top_parent_rel_relids = find_relids_top_parents(root, rel->relids);
It's not immediately clear which part of get_eclass_for_sort_expr is
relevant, or one have to read the whole function first. Probably better to
omit the superficial commentary on the call site, and instead expand the
commentary for the find_relids_top_parents itself?
* The patch series features likely/unlikely since v20, but don't see any
discussion about that. Did you notice any visible boost from that? I wonder
how necessary that is.
On Mon, Dec 2, 2024 at 2:22 PM Yuya Watari <watari.yuya@gmail.com> wrote: > > 4. Discussion > > First of all, tables 1, 2 and the figure attached to this email show > that likely and unlikely do not have the effect I expected. Rather, > tables 3, 4, 5 and 6 imply that they can have a negative effect on > queries A and B. So it is better to remove these likely and unlikely. > > For the design change, the benchmark results show that it may cause > some regression, especially for smaller sizes. However, Figure 1 also > shows that the regression is much smaller than its variance. This > design change is intended to improve code maintainability. The > regression is small enough that I think these results are acceptable. > What do you think about this? > > [1] https://www.postgresql.org/message-id/CAJ2pMkZk-Nr=yCKrGfGLu35gK-D179QPyxaqtJMUkO86y1NmSA@mail.gmail.com > [2] https://www.postgresql.org/message-id/CAJ2pMkYcKHFBD_OMUSVyhYSQU0-j9T6NZ0pL6pwbZsUCohWc7Q@mail.gmail.com > Hi Yuya, For one of the earlier versions, I had reported a large memory consumption in all cases and increase in planning time for Assert enabled builds. How does the latest version perform in those aspects? -- Best Wishes, Ashutosh Bapat
Hello, On 2024-Dec-03, Ashutosh Bapat wrote: > For one of the earlier versions, I had reported a large memory > consumption in all cases and increase in planning time for Assert > enabled builds. How does the latest version perform in those aspects? I don't think planning time in assert-enabled builds is something we should worry about, at all. Planning time in production builds is the important one. -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/ "Learn about compilers. Then everything looks like either a compiler or a database, and now you have two problems but one of them is fun." https://twitter.com/thingskatedid/status/1456027786158776329
On Tue, Dec 3, 2024 at 4:08 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > Hello, > > On 2024-Dec-03, Ashutosh Bapat wrote: > > > For one of the earlier versions, I had reported a large memory > > consumption in all cases and increase in planning time for Assert > > enabled builds. How does the latest version perform in those aspects? > > I don't think planning time in assert-enabled builds is something we > should worry about, at all. Planning time in production builds is the > important one. > This was discussed earlier. See a few emails from [1] going backwards. The degradation was Nx, if I am reading those emails right. That means somebody who is working with a large number of partitions has to spend Nx time in running their tests. Given that the planning time with thousands of partitions is already in seconds, slowing that further down, even in an assert build is slowing development down further. My suggestion of using OPTIMIZER_DEBUG will help us keep the sanity checks and also not slow down development. [1] https://www.postgresql.org/message-id/CAJ2pMkZrFS8EfvZpkw9CP0iqWk=EaAxzaKWS7dW+FTtqkUOWxA@mail.gmail.com -- Best Wishes, Ashutosh Bapat
Hello Yuya, On 2024-Dec-11, Yuya Watari wrote: > On Tue, Dec 3, 2024 at 7:38 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > > > I don't think planning time in assert-enabled builds is something we > > should worry about, at all. Planning time in production builds is the > > important one. > > Thank you for your reply. Making debug builds too slow is not good for > developers, I'm repeating myself, but I disagree that this is something we should spend _any_ time on. Developers running assertion-enabled builds do not care if a complicated query with one thousand partitions is planned in 500 ms instead of 300 ms. Heck, I bet nobody cares if it took 2000 ms either, because, you know what? The developers don't have a thousand partitions to begin with; if they do, it's precisely because they want to measure this kind of effect. This is not going to bother anyone ever, unless you stick a hundred of these queries in the regression tests. In regression tests you're going to have, say, 64 partitions at most, because having more than that doesn't test anything additional; having that go from 40 ms to 60 ms (or whatever) isn't going to bother anyone. If anything, you can add a note to remove the USE_ASSERTIONS blocks once we get past the beta process; by then any bugs will have been noticed and the asserts will be of less value. I would like to see this patch series get committed, and this concern about planning time in development builds under conditions that are unrealistic for testing is slowing the process down. (The process is slow enough. This patch has already missed two releases.) Please stop. Memory usage and planning time in production builds is important. You can better spend your energy there. Thanks -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/ "La gente vulgar sólo piensa en pasar el tiempo; el que tiene talento, en aprovecharlo"
Hello Alvaro, Thank you for your reply, and I'm sorry if my previous emails caused confusion or made it seem like I was ignoring more important issues. On Thu, Dec 12, 2024 at 9:09 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > I'm repeating myself, but I disagree that this is something we should > spend _any_ time on. Developers running assertion-enabled builds do not > care if a complicated query with one thousand partitions is planned in > 500 ms instead of 300 ms. Heck, I bet nobody cares if it took 2000 ms > either, because, you know what? The developers don't have a thousand > partitions to begin with; if they do, it's precisely because they want > to measure this kind of effect. This is not going to bother anyone > ever, unless you stick a hundred of these queries in the regression > tests. In regression tests you're going to have, say, 64 partitions at > most, because having more than that doesn't test anything additional; > having that go from 40 ms to 60 ms (or whatever) isn't going to bother > anyone. I agree that focusing too much on assert-enabled builds is not productive at this point. In my last email, I shared benchmark results for debug builds, but I understand your point that even a few seconds of regression is not practically important for debug builds. For context, there have been reports in the past of minute-order regressions in assert-enabled builds (100 seconds [1] and 50 seconds [2]). I mentioned these minute-order regressions not to refocus the discussion on debug builds right now, but to clarify why we have been concerned about them in the past. I should have shared this background and done appropriate benchmarks (not millisecond regressions, but minutes). My sincere apologies. Once we have addressed the primary goals (release build performance and memory usage), I will revisit these regressions. > If anything, you can add a note to remove the USE_ASSERTIONS blocks once > we get past the beta process; by then any bugs will have been noticed > and the asserts will be of less value. Thank you for your advice. I will consider removing these assertions after the beta process or using OPTIMIZER_DEBUG, which is Ashutosh's idea. > I would like to see this patch series get committed, and this concern > about planning time in development builds under conditions that are > unrealistic for testing is slowing the process down. (The process is > slow enough. This patch has already missed two releases.) Please stop. I will speed up the process for committing this patch series. > Memory usage and planning time in production builds is important. You > can better spend your energy there. As you said, we have another big problem, which is memory usage. I will focus on the memory usage problem first, as you suggested. After fixing those problems, we can revisit the assert-enabled build regressions as a final step if necessary. What do you think about this approach? [1] https://www.postgresql.org/message-id/d8db5b4e-e358-2567-8c56-a85d2d8013df%40postgrespro.ru [2] https://www.postgresql.org/message-id/CAExHW5uVZ3E5RT9cXHaxQ_DEK7tasaMN%3DD6rPHcao5gcXanY5w%40mail.gmail.com -- Best regards, Yuya Watari
Hello, On 2024-Dec-13, Yuya Watari wrote: > Thank you for your reply, and I'm sorry if my previous emails caused > confusion or made it seem like I was ignoring more important issues. Not to worry! > > Memory usage and planning time in production builds [are] important. > > You can better spend your energy there. > > As you said, we have another big problem, which is memory usage. I > will focus on the memory usage problem first, as you suggested. That's great, thanks. BTW I forgot to mention it yesterday, but I was surprised that you attached Ashutosh's old patch for planner memory usage reporting. This feature is already in EXPLAIN (MEMORY), so you don't need any patch to measure memory consumption ... or does your patch add some detail that isn't already in the code? > After fixing those problems, we can revisit the assert-enabled build > regressions as a final step if necessary. What do you think about this > approach? Sounds good. -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/ "I can't go to a restaurant and order food because I keep looking at the fonts on the menu. Five minutes later I realize that it's also talking about food" (Donald Knuth)
Hello, On Wed, Feb 19, 2025 at 4:33 PM Yuya Watari <watari.yuya@gmail.com> wrote: > > I noticed that the patches did not apply to the current HEAD, so I > have rebased them. The previous patches did not apply to the current master, so I have rebased them. -- Best regards, Yuya Watari
Attachment
Re: [PoC] Reducing planning time when tables have many partitions
The following review has been posted through the commitfest application: make installcheck-world: tested, failed Implements feature: tested, failed Spec compliant: tested, failed Documentation: tested, failed Hi Yuya, Tested this patch and noted that this patch significantly improves query planning time, especially as the number of partitionsincreases. While the impact is minimal for small partition counts (2–8), the improvement becomes substantial from16 partitions onward, reaching up to ~86.6% reduction at 768 partitions. Larger partitions (512–1024) see a dramaticspeedup, cutting planning time by over 2.7 seconds. The results confirm that the patch optimizes partitioned queryexecution efficiently. This enhancement is crucial for databases handling large partitioned tables, leading to betterperformance and scalability. Regards, NewtGlobal PostgreSQL contributors
On Sat, 1 Mar 2025 at 23:07, Yuya Watari <watari.yuya@gmail.com> wrote: > The previous patches did not apply to the current master, so I have > rebased them. Thank you for continuing to work on this. My apologies for having completely disappeared from this thread for so long. Looking at v33-0001, there are a few choices you've made that are not clear to me: 1) Can you describe the difference between PlannerInfo.top_parent_relid_array and RelOptInfo.top_parent_relids? If you've added the PlannerInfo field for performance reasons, then that needs to be documented. I think the bar for adding another field to do the same thing should be quite high. The RelOptInfo.top_parent_relids field already is commented with "redundant, but handy", so having another field in another struct that's also redundant leads me to think that some design needs more thought. If you need a cheap way to take the same shortcut as you're doing in setup_eclass_child_member_iterator() with "if (root->top_parent_relid_array == NULL)", then maybe PlannerInfo should have a boolean field to record if there are any other member rels 2) I think the naming of setup_eclass_child_member_iterator() and dispose_eclass_child_member_iterator() is confusing. From the names, I'd expect these to only be returning em_is_child == true members, but that's not the case. 3) The header comment for setup_eclass_child_member_iterator() does not seem concise enough. It claims "so that it can iterate over EquivalenceMembers in 'ec'.", but what does that mean? The definition of "EquivalenceMembers in 'ec'" isn't clear. Is that just the class's ec_members, or also the child members that are stored somewhere else. Users of this function need to know what they'll get so they know which members they need to ignore or which they can assume won't be returned. If you don't document that, then it's quite hard to determine where the faulty code is when we get bugs. The "relids" parameter needs to be documented too. 4) add_transformed_child_version sounds like it does some transformation, but all it does is add the EMs for the given RelOptInfo to the iterator's list. I don't quite follow what's being "transformed". Maybe there's a better name? That's all I have for now. David
Hello David, Thank you very much for your thorough review and valuable comments. I have refactored the patches based on your feedback and attached the updated versions (v34). Additionally, I have included a diff between v33 and v34 for your quick reference. On Thu, Mar 13, 2025 at 1:53 PM David Rowley <dgrowleyml@gmail.com> wrote: > > 1) Can you describe the difference between > PlannerInfo.top_parent_relid_array and RelOptInfo.top_parent_relids? > If you've added the PlannerInfo field for performance reasons, then > that needs to be documented. I think the bar for adding another field > to do the same thing should be quite high. The > RelOptInfo.top_parent_relids field already is commented with > "redundant, but handy", so having another field in another struct > that's also redundant leads me to think that some design needs more > thought. > > If you need a cheap way to take the same shortcut as you're doing in > setup_eclass_child_member_iterator() with "if > (root->top_parent_relid_array == NULL)", then maybe PlannerInfo should > have a boolean field to record if there are any other member rels Thank you for highlighting this. I initially introduced PlannerInfo.top_parent_relid_array primarily for performance reasons to quickly determine whether a relation is a parent or child, particularly in setup_eclass_child_member_iterator(). As you mentioned, earlier versions utilized the check "if (root->top_parent_relid_array == NULL)" to skip unnecessary operations when no child relations exist. However, I have realized that the same behavior can be achieved by using root->append_rel_array. Specifically, if a relation is a parent, the corresponding AppendRelInfo is NULL, and if there are no child relations at all, the entire array itself is NULL. So, PlannerInfo.top_parent_relid_array is no longer necessary. In v34-0001, I removed root->top_parent_relid_array and instead utilized root->append_rel_array. However, this caused issues in add_setop_child_rel_equivalences(), since this function adds a new child EquivalenceMember without building a parent-child relationship in root->append_rel_array. To address this, I have created a dummy AppendRelInfo object in v34-0002. This is just a workaround, and there may be a more elegant solution. I'd greatly appreciate any suggestions or alternative approaches you might have. > 2) I think the naming of setup_eclass_child_member_iterator() and > dispose_eclass_child_member_iterator() is confusing. From the names, > I'd expect these to only be returning em_is_child == true members, but > that's not the case. I agree the original naming was misleading. In v34-0001, I have renamed these functions to setup_eclass_all_member_iterator_for_relids() and dispose_eclass_all_member_iterator_for_relids(). To align with this change, I have also renamed EquivalenceChildMemberIterator to EquivalenceAllMemberIterator. Does this new naming better address your concern? > 3) The header comment for setup_eclass_child_member_iterator() does > not seem concise enough. It claims "so that it can iterate over > EquivalenceMembers in 'ec'.", but what does that mean? The definition > of "EquivalenceMembers in 'ec'" isn't clear. Is that just the class's > ec_members, or also the child members that are stored somewhere else. > Users of this function need to know what they'll get so they know > which members they need to ignore or which they can assume won't be > returned. If you don't document that, then it's quite hard to > determine where the faulty code is when we get bugs. The "relids" > parameter needs to be documented too. I have clarified the header comment in v34-0001. It now explicitly states that the iterator iterates over all parent members and child members whose em_relids are subsets of the given 'relids'. I have also clearly documented the parameters, including 'relids'. > 4) add_transformed_child_version sounds like it does some > transformation, but all it does is add the EMs for the given > RelOptInfo to the iterator's list. I don't quite follow what's being > "transformed". Maybe there's a better name? Thank you for highlighting this. The original name was indeed misleading. I have renamed this function to add_eclass_child_members_to_iterator(). -- Best regards, Yuya Watari
Attachment
On Fri, 14 Mar 2025 at 23:10, Yuya Watari <watari.yuya@gmail.com> wrote: > I have refactored the patches based on your feedback and attached the > updated versions (v34). Additionally, I have included a diff between > v33 and v34 for your quick reference. Thanks for updating the patch. I've looked at v34-0001. Here are my review comments: 1. There are various places in equivclass.c that Assert the member isn't a child which have a comment "/* no children yet */", e.g. generate_base_implied_equalities_const() there's "Assert(!cur_em->em_is_child); /* no children yet */". The comment implies that ec_members will later contain em_is_child members, but that's not true. What you've written in generate_implied_equalities_for_column() seems like the correct way to handle this, i.e. "Child members should not exist in ec_members" 2. There's a comment in setup_eclass_all_member_iterator_for_relids which says: * whose em_relids is a subset of the given 'child_relids'. The inverted is 'child_relids' meant to be 'relids'? Otherwise, I don't know what 'child_relids' is. 3. Can you explain why you've added the following assert to reconsider_full_join_clause()? Assert(!bms_is_empty(coal_em->em_relids)); There are no other changes to that function and I can't quite figure out why that Assert is relevant now if it wasn't before. Or is this a case of adding additional protection against this? If so, is there more risk now than there was before? 4. Is there any point in renaming add_eq_member() to add_parent_eq_member()? You don't have a function called add_child_eq_member() so is the "parent" word needed here? 5. In add_child_join_rel_equivalences() 'lc' can be moved into the scope of the while loop. 6. The following comment in add_child_join_rel_equivalences() should be deleted. That used to be above the "if (cur_em->em_is_child) continue;" statement and it does not seem relevant to the code you've replaced that with. /* * We consider only original EC members here, not * already-transformed child members. */ 7. EquivalenceAllMemberIterator's "modified" field does not seem like a great name. Is it better to call this something like "list_is_copy"? 8. It looks like most of the changes in createplan.c are there because you need to get the PlannerInfo down to a few functions where it's currently unavailable. I think you should break this out into another precursor patch which does this only. It'll be easier to review the main patch this way. 9. The new PlannerInfo parameter in prepare_sort_from_pathkeys() isn't documented in the "Input Parameters:" header comment. Likewise for make_sort_from_pathkeys() and make_incrementalsort_from_pathkeys() 10. The comment for PlannerInfo.eclass_indexes_array states it's for "faster lookups of RestrictInfo". Shouldn't it be "faster EquivalenceMember lookups"? /* * eclass_indexes_array is the same length as simple_rel_array and holds * the indexes of the corresponding rels for faster lookups of * RestrictInfo. See the EquivalenceClass comment for more details. */ struct EquivalenceClassIndexes *eclass_indexes_array pg_node_attr(read_write_ignore); I'm also not sure this comment would be accurate enough with only that fix as it looks like we don't store any indexes for base rels. 11. In setup_simple_rel_arrays(), is there any point in pallocing memory for eclass_indexes_array when root->append_rel_list is empty? 12. join_rel_list_index isn't being initialized in all the places that do makeNode(RelOptInfo); Maybe -1 is a good initial value? (See my next point) 13. RelOptInfo.join_rel_list_index is an index into PlannerInfo.join_rel_list. It shouldn't be of type "Index". "int" is the correct type for an index into a List. 14. In add_join_rel(), if you assign the join_rel_list_index before the lappend, you don't need to "- 1". > On Thu, Mar 13, 2025 at 1:53 PM David Rowley <dgrowleyml@gmail.com> wrote: > > > > 1) Can you describe the difference between > > PlannerInfo.top_parent_relid_array and RelOptInfo.top_parent_relids? > > If you've added the PlannerInfo field for performance reasons, then > > that needs to be documented. I think the bar for adding another field > > to do the same thing should be quite high. The > > RelOptInfo.top_parent_relids field already is commented with > > "redundant, but handy", so having another field in another struct > > that's also redundant leads me to think that some design needs more > > thought. > > > > If you need a cheap way to take the same shortcut as you're doing in > > setup_eclass_child_member_iterator() with "if > > (root->top_parent_relid_array == NULL)", then maybe PlannerInfo should > > have a boolean field to record if there are any other member rels > > Thank you for highlighting this. I initially introduced > PlannerInfo.top_parent_relid_array primarily for performance reasons > to quickly determine whether a relation is a parent or child, > particularly in setup_eclass_child_member_iterator(). As you > mentioned, earlier versions utilized the check "if > (root->top_parent_relid_array == NULL)" to skip unnecessary operations > when no child relations exist. > > However, I have realized that the same behavior can be achieved by > using root->append_rel_array. Specifically, if a relation is a parent, > the corresponding AppendRelInfo is NULL, and if there are no child > relations at all, the entire array itself is NULL. So, > PlannerInfo.top_parent_relid_array is no longer necessary. > > In v34-0001, I removed root->top_parent_relid_array and instead > utilized root->append_rel_array. However, this caused issues in > add_setop_child_rel_equivalences(), since this function adds a new > child EquivalenceMember without building a parent-child relationship > in root->append_rel_array. To address this, I have created a dummy > AppendRelInfo object in v34-0002. This is just a workaround, and there > may be a more elegant solution. I'd greatly appreciate any suggestions > or alternative approaches you might have. I don't currently have the answers you need here. The problem is down to how prepunion.c hacks together a targetlist with Vars having varno==0. For the union planner work I did last year, to make the union planner properly know if a union child had the required PathKeys, I had to add EquivalenceMembers for each union child. At the moment I don't really know if we could get away with classing union children's non-junk target entries as fully-fledged EMs, or if these should be child EMs. There's some contradiction as to how the RelOptInfo is set up without a parent in recurse_set_operations(), and making these child EMs as you're doing in the v34-0002 patch. The problem with building the RelOptInfo with a parent is that build_simple_rel() would try to apply the same base quals to the child as the parent has. That's not the correct thing to do for union children as each union child can have different quals. I just don't think we have the correct design for the union planner just yet. I don't currently have ideas on how to make this better. Maybe build_simple_rel() needs some way to distinguish "this rel has a parent" and "this rel should copy the parent's quals". However, redesigning how this works now likely is a bad idea as it just feels a bit late in the release cycle for that. You can see I chickened out doing that in 12933dc60, previously 66c0185a3. > > 2) I think the naming of setup_eclass_child_member_iterator() and > > dispose_eclass_child_member_iterator() is confusing. From the names, > > I'd expect these to only be returning em_is_child == true members, but > > that's not the case. > > I agree the original naming was misleading. In v34-0001, I have > renamed these functions to > setup_eclass_all_member_iterator_for_relids() and > dispose_eclass_all_member_iterator_for_relids(). To align with this > change, I have also renamed EquivalenceChildMemberIterator to > EquivalenceAllMemberIterator. Does this new naming better address your > concern? It's better. These names still feel very long. Also, I don't think the iterator struct's name needs to be specific to "AllMembers". Surely another setup function could have an iterator loop over any members it likes. Likewise, the dispose function does not seem very specific to "AllMembers". It's really the setup function that controls which members are going to be visited. I suggest the next function, the dispose function and the struct are given much more generic names. setup_eclass_all_member_iterator_for_relids() feels long. Maybe eclass_member_iterator_with_children and forget trying to include "relids" in the name? David
Hello David, Thank you for your prompt response and detailed review. I have addressed your comments and updated the patches accordingly (attached as v35). On Wed, Mar 19, 2025 at 7:48 PM David Rowley <dgrowleyml@gmail.com> wrote: > > 1. There are various places in equivclass.c that Assert the member > isn't a child which have a comment "/* no children yet */", e.g. > generate_base_implied_equalities_const() there's > "Assert(!cur_em->em_is_child); /* no children yet */". The comment > implies that ec_members will later contain em_is_child members, but > that's not true. What you've written in > generate_implied_equalities_for_column() seems like the correct way to > handle this, i.e. "Child members should not exist in ec_members" Thank you for pointing this out. I have updated these assertions and comments. > 2. There's a comment in setup_eclass_all_member_iterator_for_relids which says: > > * whose em_relids is a subset of the given 'child_relids'. The inverted > > is 'child_relids' meant to be 'relids'? Otherwise, I don't know what > 'child_relids' is. This was my mistake. I have corrected it to 'relids'. > 3. Can you explain why you've added the following assert to > reconsider_full_join_clause()? > > Assert(!bms_is_empty(coal_em->em_relids)); > > There are no other changes to that function and I can't quite figure > out why that Assert is relevant now if it wasn't before. Or is this a > case of adding additional protection against this? If so, is there > more risk now than there was before? I'm sorry, but I cannot recall exactly why I initially added this assertion. Upon review, I realized it was incorrect and unnecessary, so I have removed it. > 4. Is there any point in renaming add_eq_member() to > add_parent_eq_member()? You don't have a function called > add_child_eq_member() so is the "parent" word needed here? I agree with you. I have reverted to the original name, add_eq_member(). > 5. In add_child_join_rel_equivalences() 'lc' can be moved into the > scope of the while loop. Fixed. > 6. The following comment in add_child_join_rel_equivalences() should > be deleted. That used to be above the "if (cur_em->em_is_child) > continue;" statement and it does not seem relevant to the code you've > replaced that with. > > /* > * We consider only original EC members here, not > * already-transformed child members. > */ Removed as suggested. > 7. EquivalenceAllMemberIterator's "modified" field does not seem like > a great name. Is it better to call this something like > "list_is_copy"? Thank you for the suggestion. I have renamed it to "list_is_copy." > 8. It looks like most of the changes in createplan.c are there because > you need to get the PlannerInfo down to a few functions where it's > currently unavailable. I think you should break this out into another > precursor patch which does this only. It'll be easier to review the > main patch this way. I have separated these changes into a distinct precursor patch as suggested. > 9. The new PlannerInfo parameter in prepare_sort_from_pathkeys() isn't > documented in the "Input Parameters:" header comment. Likewise for > make_sort_from_pathkeys() and make_incrementalsort_from_pathkeys() I have updated the documentation in each of these functions. > 10. The comment for PlannerInfo.eclass_indexes_array states it's for > "faster lookups of RestrictInfo". Shouldn't it be "faster > EquivalenceMember lookups"? > > /* > * eclass_indexes_array is the same length as simple_rel_array and holds > * the indexes of the corresponding rels for faster lookups of > * RestrictInfo. See the EquivalenceClass comment for more details. > */ > struct EquivalenceClassIndexes *eclass_indexes_array > pg_node_attr(read_write_ignore); I have revised this comment accordingly. > I'm also not sure this comment would be accurate enough with only that > fix as it looks like we don't store any indexes for base rels. It is true that currently, indexes for EquivalenceMembers do not store information about base rels. However, the subsequent commit (v35-0004) introduces indexes for base rels to enable faster RestrictInfo lookups. Therefore, if we commit the later patch as well, the comment will remain accurate. What do you think about this? > 11. In setup_simple_rel_arrays(), is there any point in pallocing > memory for eclass_indexes_array when root->append_rel_list is empty? As you mentioned, there is no need to allocate the array in v35-0002 (faster lookups for EquivalenceMembers) when root->append_rel_list is empty. However, the allocation becomes necessary when introducing indexes for RestrictInfos in v35-0004. To allow committing only v35-0002 independently, I now avoid allocating the array when root->append_rel_list is empty in v35-0002 and instead ensure that it is always allocated in v35-0004. > 12. join_rel_list_index isn't being initialized in all the places that > do makeNode(RelOptInfo); Maybe -1 is a good initial value? (See my > next point) Fixed by initializing join_rel_list_index to -1. > 13. RelOptInfo.join_rel_list_index is an index into > PlannerInfo.join_rel_list. It shouldn't be of type "Index". "int" is > the correct type for an index into a List. Corrected to use "int". > 14. In add_join_rel(), if you assign the join_rel_list_index before > the lappend, you don't need to "- 1". Fixed as suggested. > I don't currently have the answers you need here. The problem is down > to how prepunion.c hacks together a targetlist with Vars having > varno==0. For the union planner work I did last year, to make the > union planner properly know if a union child had the required > PathKeys, I had to add EquivalenceMembers for each union child. At > the moment I don't really know if we could get away with classing > union children's non-junk target entries as fully-fledged EMs, or if > these should be child EMs. There's some contradiction as to how the > RelOptInfo is set up without a parent in recurse_set_operations(), and > making these child EMs as you're doing in the v34-0002 patch. The > problem with building the RelOptInfo with a parent is that > build_simple_rel() would try to apply the same base quals to the child > as the parent has. That's not the correct thing to do for union > children as each union child can have different quals. I just don't > think we have the correct design for the union planner just yet. I > don't currently have ideas on how to make this better. Maybe > build_simple_rel() needs some way to distinguish "this rel has a > parent" and "this rel should copy the parent's quals". However, > redesigning how this works now likely is a bad idea as it just feels a > bit late in the release cycle for that. You can see I chickened out > doing that in 12933dc60, previously 66c0185a3. I agree it's challenging to redesign the union planner at this stage of the release cycle. For now, I have proposed a workaround solution (v35-0003, previously v34-0002). Would this workaround be acceptable for the current release cycle? > It's better. These names still feel very long. Also, I don't think the > iterator struct's name needs to be specific to "AllMembers". Surely > another setup function could have an iterator loop over any members it > likes. Likewise, the dispose function does not seem very specific to > "AllMembers". It's really the setup function that controls which > members are going to be visited. I suggest the next function, the > dispose function and the struct are given much more generic names. > setup_eclass_all_member_iterator_for_relids() feels long. Maybe > eclass_member_iterator_with_children and forget trying to include > "relids" in the name? Following your advice, I have simplified the naming: * setup_eclass_all_member_iterator_for_relids() --> setup_eclass_member_iterator_with_children() * eclass_all_member_iterator_for_relids_next() --> eclass_member_iterator_next() * dispose_eclass_all_member_iterator() --> dispose_eclass_member_iterator() * EquivalenceAllMemberIterator --> EquivalenceMemberIterator === Thank you again for all your valuable feedback so far. -- Best regards, Yuya Watari
Attachment
- diff-v34-v35.txt
- v35-0001-Add-the-PlannerInfo-context-to-the-parameter-of-.patch
- v35-0002-Speed-up-searches-for-child-EquivalenceMembers.patch
- v35-0003-Resolve-conflict-with-commit-66c0185.patch
- v35-0004-Introduce-indexes-for-RestrictInfo.patch
- v35-0005-Introduce-RestrictInfoIterator-to-reduce-memory-.patch
Thank you for addressing those comments.
On Mon, 24 Mar 2025 at 12:24, Yuya Watari <watari.yuya@gmail.com> wrote:
> It is true that currently, indexes for EquivalenceMembers do not store
> information about base rels. However, the subsequent commit (v35-0004)
> introduces indexes for base rels to enable faster RestrictInfo
> lookups. Therefore, if we commit the later patch as well, the comment
> will remain accurate. What do you think about this?
I understand Ashutosh would like to handle the RestrictInfo speedup
another way, so there's additional review work to do there to
determine the merits of each method and figure out the best method.
I'm worried that means we don't get to fix this part for v18 and if
that happens and 0002 goes in alone, then we'd be left with a struct
with a single field. Maybe you should adjust the patch series and
only introduce the new struct in 0004 where it's required.
> I agree it's challenging to redesign the union planner at this stage
> of the release cycle. For now, I have proposed a workaround solution
> (v35-0003, previously v34-0002). Would this workaround be acceptable
> for the current release cycle?
I think something like that is probably ok. You have a problem with
your implementation as you're trying to add the AppendRelInfo once for
each child_tlist element rather than once per union child. Can you fix
this and incorporate into the 0002 patch please?
Here are some more review comments for v35-0002:
1. I don't think the header comment for eclass_member_iterator_next()
needs to mention setup_eclass_member_iterator_with_children(). The
renaming you did in v35 is meant to make it so the
eclass_member_iterator_next and dispose_eclass_member_iterator()
functions don't care about what set up the iterator. We might end up
with new ones in the future and this seems like a comment that might
not get updated when that happens.
2. You should use list_free() in the following:
/*
* XXX Should we use list_free()? I decided to use this style to take
* advantage of speculative execution.
*/
if (unlikely(it->list_is_copy))
pfree(it->ec_members);
The reason is that you're wrongly assuming that calling pfree on the
List pointer is enough to get rid of all memory used by the list. The
List may have a separately allocated elements[] array (this happens
when there's > 5 elements) which you're leaking with the current code.
I assume the speculative execution comment is there because you want
to omit the "list == NULL" check in list_free_private. Is this
measurable, performance-wise?
3. Maybe I'm missing something, but I'm confused about the need for
the eclass_indexes_array field in PlannerInfo. This array is indexed
by the relid, so why can't we get rid of the array and add a field to
RelOptInfo to store the EquivalenceClassIndexes?
4. Could you also please run another set of benchmarks against current
master with the the v36 patches: master, master + v36-0001 + 0002,
master + v36-0001 + 0002 + 0003 (0003 will be the v34-0004 patch), and
then also with v36-0004 (which is the same as v35-0005). The main
thing I'd like to understand here is if there's not enough time to get
the entire patch set committed, is there much benefit to just having
the EquivalenceMember index stuff in by itself without the
RestrictInfo changes.
David
David Rowley <dgrowleyml@gmail.com> writes:
> ... The main
> thing I'd like to understand here is if there's not enough time to get
> the entire patch set committed, is there much benefit to just having
> the EquivalenceMember index stuff in by itself without the
> RestrictInfo changes.
I finally made some time to look at this patchset, and I'm pretty
disappointed, because after 35 versions I'd expect to see something
that looks close to committable. This doesn't really. I like the
basic idea of taking child EC members out of ECs' main ec_members
lists, but there are too many weird details and
underexplained/overcomplicated/unmaintainable data structures.
One thing I don't love is putting the children into RelOptInfos.
That seems like an unrelated data structure. Have you thought
about instead having, in each EC that needs it, an array indexed
by RTI of per-relation child-member lists? I think this might
net out as less storage because there typically aren't that many
ECs in a query. But the main thing is to not have so many
interconnections between ECs and RelOptInfos.
Another thing I really don't like is the back-link from EMs to ECs:
+ EquivalenceClass *em_ec; /* EquivalenceClass which has this member */
That makes the data structure circular, which will cause pprint to
recurse infinitely. (The fact that you hadn't noticed that makes
me wonder how you debugged any of these data structure changes.)
We could prevent the recursion with suitable annotation on this field,
but I'd really rather not have the field in the first place. Circular
pointers are dangerous and best avoided. Also, it's bloating a node
type that you are concerned about supporting a lot of. Another point
is that I don't see any code to take care of updating these links
during an EC merge.
Some thoughts about the iterator stuff:
* setup_eclass_member_iterator_with_children is a carpal-tunnel-inducing
name. Could we drop the "_with_children" part? It doesn't seem to
add much, since there's no variant for "without children".
* The root parameter should be first; IMO there should be no
exceptions to that within the planner. Perhaps putting the target
iterator parameter last would make it read more nicely. Or you could
rely on struct assignment:
it = setup_eclass_member_iterator(root, ec, relids);
* Why did you define the iterator as possibly returning irrelevant
members? Doesn't that mean that every caller has to double-check?
Wouldn't it make for less code and fewer bugs for the iterator to
have that responsibility? If there is a good reason to do it like
that, the comments should explain why.
I don't really like the concept of 0004 at all. Putting *all*
the EC-related RelOptInfos into a root-stored list seems to be
doubling down very hard on the assumption that no performance-critical
operations will ever need to search that whole list. Is there a good
reason to do it like that, rather than say using the bitmap-index
concept separately within each EC? That might also alleviate the
problem you're having with the bitmapsets getting too big.
Given that we've only got a week left, I see little hope of getting
any of this into v18.
regards, tom lane
2. You should use list_free() in the following:
/*
* XXX Should we use list_free()? I decided to use this style to take
* advantage of speculative execution.
*/
if (unlikely(it->list_is_copy))
pfree(it->ec_members);
The reason is that you're wrongly assuming that calling pfree on the
List pointer is enough to get rid of all memory used by the list. The
List may have a separately allocated elements[] array (this happens
when there's > 5 elements) which you're leaking with the current code.
I assume the speculative execution comment is there because you want
to omit the "list == NULL" check in list_free_private. Is this
measurable, performance-wise?
-----------+---------------------------------+---------------------------------+---------------------------------+---------------------------------
0 | s=0.00%, mm=15 kB, pm=15 kB | s=0.00%, mm=21 kB, pm=21 kB | s=0.00%, mm=27 kB, pm=27 kB | s=0.00%, mm=34 kB, pm=34 kB
10 | s=0.00%, mm=231 kB, pm=231 kB | s=0.00%, mm=485 kB, pm=485 kB | s=0.00%, mm=924 kB, pm=924 kB | s=2.21%, mm=1901 kB, pm=1859 kB
100 | s=0.00%, mm=1965 kB, pm=1965 kB | s=0.00%, mm=4082 kB, pm=4082 kB | s=0.00%, mm=7115 kB, pm=7115 kB | s=3.35%, mm=12 MB, pm=12 MB
500 | s=0.00%, mm=10 MB, pm=10 MB | s=0.00%, mm=23 MB, pm=23 MB | s=0.00%, mm=42 MB, pm=42 MB | s=2.58%, mm=80 MB, pm=78 MB
1000 | s=0.00%, mm=22 MB, pm=22 MB | s=0.00%, mm=55 MB, pm=55 MB | s=0.00%, mm=107 MB, pm=107 MB | s=1.97%, mm=209 MB, pm=205 MB
-----------+---------------------------------+---------------------------------+---------------------------------+---------------------------------
0 | s=0.00%, mm=15 kB, pm=15 kB | s=0.00%, mm=21 kB, pm=21 kB | s=0.00%, mm=27 kB, pm=27 kB | s=0.00%, mm=34 kB, pm=34 kB
10 | s=0.00%, mm=379 kB, pm=379 kB | s=0.00%, mm=1228 kB, pm=1228 kB | s=0.00%, mm=3628 kB, pm=3628 kB | s=0.40%, mm=10 MB, pm=10 MB
100 | s=0.00%, mm=3478 kB, pm=3478 kB | s=0.00%, mm=11 MB, pm=11 MB | s=0.00%, mm=34 MB, pm=34 MB | s=0.41%, mm=99 MB, pm=99 MB
500 | s=0.00%, mm=18 MB, pm=18 MB | s=0.00%, mm=62 MB, pm=62 MB | s=0.00%, mm=186 MB, pm=186 MB | s=0.37%, mm=564 MB, pm=562 MB
1000 | s=0.00%, mm=38 MB, pm=38 MB | s=0.00%, mm=139 MB, pm=139 MB | s=0.00%, mm=420 MB, pm=420 MB | s=0.32%, mm=1297 MB, pm=1293 MB
-----------+----------------------------------+----------------------------------+-----------------------------------+----------------------------------
0 | s=0.00%, mm=15 kB, pm=15 kB | s=0.00%, mm=21 kB, pm=21 kB | s=0.00%, mm=27 kB, pm=27 kB | s=-3.03%, mm=33 kB, pm=34 kB
10 | s=-5.96%, mm=218 kB, pm=231 kB | s=-6.59%, mm=455 kB, pm=485 kB | s=-6.45%, mm=868 kB, pm=924 kB | s=-9.55%, mm=1697 kB, pm=1859 kB
100 | s=-7.73%, mm=1824 kB, pm=1965 kB | s=-9.79%, mm=3718 kB, pm=4082 kB | s=-11.17%, mm=6400 kB, pm=7115 kB | s=-19.04%, mm=10233 kB, pm=12 MB
500 | s=-10.91%, mm=9395 kB, pm=10 MB | s=-16.99%, mm=20 MB, pm=23 MB | s=-21.14%, mm=35 MB, pm=42 MB | s=-31.14%, mm=59 MB, pm=78 MB
1000 | s=-14.33%, mm=19 MB, pm=22 MB | s=-23.95%, mm=45 MB, pm=55 MB | s=-29.77%, mm=82 MB, pm=107 MB | s=-40.45%, mm=146 MB, pm=205 MB
-----------+----------------------------------+----------------------------------+----------------------------------+----------------------------------
0 | s=0.00%, mm=15 kB, pm=15 kB | s=0.00%, mm=21 kB, pm=21 kB | s=0.00%, mm=27 kB, pm=27 kB | s=-3.03%, mm=33 kB, pm=34 kB
10 | s=-3.84%, mm=365 kB, pm=379 kB | s=-2.50%, mm=1198 kB, pm=1228 kB | s=-1.60%, mm=3571 kB, pm=3628 kB | s=-1.55%, mm=10 MB, pm=10 MB
100 | s=-4.23%, mm=3337 kB, pm=3478 kB | s=-3.25%, mm=11 MB, pm=11 MB | s=-2.11%, mm=33 MB, pm=34 MB | s=-1.96%, mm=97 MB, pm=99 MB
500 | s=-5.96%, mm=17 MB, pm=18 MB | s=-5.71%, mm=59 MB, pm=62 MB | s=-4.12%, mm=179 MB, pm=186 MB | s=-3.40%, mm=544 MB, pm=562 MB
1000 | s=-7.88%, mm=35 MB, pm=38 MB | s=-8.33%, mm=128 MB, pm=139 MB | s=-6.19%, mm=395 MB, pm=420 MB | s=-4.79%, mm=1234 MB, pm=1293 MB
On Mon, Mar 24, 2025 at 11:08 AM David Rowley <dgrowleyml@gmail.com> wrote:2. You should use list_free() in the following:
/*
* XXX Should we use list_free()? I decided to use this style to take
* advantage of speculative execution.
*/
if (unlikely(it->list_is_copy))
pfree(it->ec_members);
The reason is that you're wrongly assuming that calling pfree on the
List pointer is enough to get rid of all memory used by the list. The
List may have a separately allocated elements[] array (this happens
when there's > 5 elements) which you're leaking with the current code.
I assume the speculative execution comment is there because you want
to omit the "list == NULL" check in list_free_private. Is this
measurable, performance-wise?Here are memory consumption numbers using list_free() instead of pfree(), using the same method as [1], using a binary without asserts and debug info. PFA the patchset where all the patches are the same as v35 but with an extra patch fixing memory leak. The memory leak is visible with a higher number of joins. At a lower number of joins, I expect that the memory saved is less than a KB or the leaked memory fits within 1 chunk of memory context and hence not visible.rows by number of partitionscolumns by number of joinseach cell is a triplet, s = memory saving in %, mm - memory consumed without fix, pm = memory consumed with fixwith PWJ = offnum_parts | 2 | 3 | 4 | 5
-----------+---------------------------------+---------------------------------+---------------------------------+---------------------------------
0 | s=0.00%, mm=15 kB, pm=15 kB | s=0.00%, mm=21 kB, pm=21 kB | s=0.00%, mm=27 kB, pm=27 kB | s=0.00%, mm=34 kB, pm=34 kB
10 | s=0.00%, mm=231 kB, pm=231 kB | s=0.00%, mm=485 kB, pm=485 kB | s=0.00%, mm=924 kB, pm=924 kB | s=2.21%, mm=1901 kB, pm=1859 kB
100 | s=0.00%, mm=1965 kB, pm=1965 kB | s=0.00%, mm=4082 kB, pm=4082 kB | s=0.00%, mm=7115 kB, pm=7115 kB | s=3.35%, mm=12 MB, pm=12 MB
500 | s=0.00%, mm=10 MB, pm=10 MB | s=0.00%, mm=23 MB, pm=23 MB | s=0.00%, mm=42 MB, pm=42 MB | s=2.58%, mm=80 MB, pm=78 MB
1000 | s=0.00%, mm=22 MB, pm=22 MB | s=0.00%, mm=55 MB, pm=55 MB | s=0.00%, mm=107 MB, pm=107 MB | s=1.97%, mm=209 MB, pm=205 MBwithout PWJ = onnum_parts | 2 | 3 | 4 | 5
-----------+---------------------------------+---------------------------------+---------------------------------+---------------------------------
0 | s=0.00%, mm=15 kB, pm=15 kB | s=0.00%, mm=21 kB, pm=21 kB | s=0.00%, mm=27 kB, pm=27 kB | s=0.00%, mm=34 kB, pm=34 kB
10 | s=0.00%, mm=379 kB, pm=379 kB | s=0.00%, mm=1228 kB, pm=1228 kB | s=0.00%, mm=3628 kB, pm=3628 kB | s=0.40%, mm=10 MB, pm=10 MB
100 | s=0.00%, mm=3478 kB, pm=3478 kB | s=0.00%, mm=11 MB, pm=11 MB | s=0.00%, mm=34 MB, pm=34 MB | s=0.41%, mm=99 MB, pm=99 MB
500 | s=0.00%, mm=18 MB, pm=18 MB | s=0.00%, mm=62 MB, pm=62 MB | s=0.00%, mm=186 MB, pm=186 MB | s=0.37%, mm=564 MB, pm=562 MB
1000 | s=0.00%, mm=38 MB, pm=38 MB | s=0.00%, mm=139 MB, pm=139 MB | s=0.00%, mm=420 MB, pm=420 MB | s=0.32%, mm=1297 MB, pm=1293 MBBut overall the patches consume more memory than before as seen from measurements belowEach cell is a triplet (s, mm, pm) where s = memory saving in % (-ve indicates that memory consumption has increased), mm = memory consumption with no patches applied, pm = memory consumption with all patches appliedPWJ=offnum_parts | 2 | 3 | 4 | 5
-----------+----------------------------------+----------------------------------+-----------------------------------+----------------------------------
0 | s=0.00%, mm=15 kB, pm=15 kB | s=0.00%, mm=21 kB, pm=21 kB | s=0.00%, mm=27 kB, pm=27 kB | s=-3.03%, mm=33 kB, pm=34 kB
10 | s=-5.96%, mm=218 kB, pm=231 kB | s=-6.59%, mm=455 kB, pm=485 kB | s=-6.45%, mm=868 kB, pm=924 kB | s=-9.55%, mm=1697 kB, pm=1859 kB
100 | s=-7.73%, mm=1824 kB, pm=1965 kB | s=-9.79%, mm=3718 kB, pm=4082 kB | s=-11.17%, mm=6400 kB, pm=7115 kB | s=-19.04%, mm=10233 kB, pm=12 MB
500 | s=-10.91%, mm=9395 kB, pm=10 MB | s=-16.99%, mm=20 MB, pm=23 MB | s=-21.14%, mm=35 MB, pm=42 MB | s=-31.14%, mm=59 MB, pm=78 MB
1000 | s=-14.33%, mm=19 MB, pm=22 MB | s=-23.95%, mm=45 MB, pm=55 MB | s=-29.77%, mm=82 MB, pm=107 MB | s=-40.45%, mm=146 MB, pm=205 MBPWJ=onnum_parts | 2 | 3 | 4 | 5
-----------+----------------------------------+----------------------------------+----------------------------------+----------------------------------
0 | s=0.00%, mm=15 kB, pm=15 kB | s=0.00%, mm=21 kB, pm=21 kB | s=0.00%, mm=27 kB, pm=27 kB | s=-3.03%, mm=33 kB, pm=34 kB
10 | s=-3.84%, mm=365 kB, pm=379 kB | s=-2.50%, mm=1198 kB, pm=1228 kB | s=-1.60%, mm=3571 kB, pm=3628 kB | s=-1.55%, mm=10 MB, pm=10 MB
100 | s=-4.23%, mm=3337 kB, pm=3478 kB | s=-3.25%, mm=11 MB, pm=11 MB | s=-2.11%, mm=33 MB, pm=34 MB | s=-1.96%, mm=97 MB, pm=99 MB
500 | s=-5.96%, mm=17 MB, pm=18 MB | s=-5.71%, mm=59 MB, pm=62 MB | s=-4.12%, mm=179 MB, pm=186 MB | s=-3.40%, mm=544 MB, pm=562 MB
1000 | s=-7.88%, mm=35 MB, pm=38 MB | s=-8.33%, mm=128 MB, pm=139 MB | s=-6.19%, mm=395 MB, pm=420 MB | s=-4.79%, mm=1234 MB, pm=1293 MBIn the case of PWJ = on, the % wise memory consumption is less because memory consumption without fixes is huge and the patch adds on top of it. But without PWJ, the memory consumption is high, especially at higher number of joins and higher number of partitions.--Best Wishes,Ashutosh Bapat
Attachment
- 0003-Resolve-conflict-with-commit-66c0185-20250327.patch
- 0004-Introduce-indexes-for-RestrictInfo-20250327.patch
- 0005-Introduce-RestrictInfoIterator-to-reduce-me-20250327.patch
- 0001-Add-the-PlannerInfo-context-to-the-paramete-20250327.patch
- 0002-Speed-up-searches-for-child-EquivalenceMemb-20250327.patch
- 0006-Use-list_free-instead-of-pfree-20250327.patch
Hello David, Thank you for your prompt reply, and apologies for my late response. On Mon, Mar 24, 2025 at 2:38 PM David Rowley <dgrowleyml@gmail.com> wrote: > > I understand Ashutosh would like to handle the RestrictInfo speedup > another way, so there's additional review work to do there to > determine the merits of each method and figure out the best method. > I'm worried that means we don't get to fix this part for v18 and if > that happens and 0002 goes in alone, then we'd be left with a struct > with a single field. Maybe you should adjust the patch series and > only introduce the new struct in 0004 where it's required. Thank you for your advice. I agree that introducing a struct with only one field is not a good design, so adjusting the patch series to avoid this issue is necessary. > I think something like that is probably ok. You have a problem with > your implementation as you're trying to add the AppendRelInfo once for > each child_tlist element rather than once per union child. Can you fix > this and incorporate into the 0002 patch please? Thank you for pointing this out. This was indeed my mistake, and I will correct it in the next version of the patch series. > 1. I don't think the header comment for eclass_member_iterator_next() > needs to mention setup_eclass_member_iterator_with_children(). The > renaming you did in v35 is meant to make it so the > eclass_member_iterator_next and dispose_eclass_member_iterator() > functions don't care about what set up the iterator. We might end up > with new ones in the future and this seems like a comment that might > not get updated when that happens. I agree. I will fix this comment in the next version. > 2. You should use list_free() in the following: > > /* > * XXX Should we use list_free()? I decided to use this style to take > * advantage of speculative execution. > */ > if (unlikely(it->list_is_copy)) > pfree(it->ec_members); > > The reason is that you're wrongly assuming that calling pfree on the > List pointer is enough to get rid of all memory used by the list. The > List may have a separately allocated elements[] array (this happens > when there's > 5 elements) which you're leaking with the current code. > > I assume the speculative execution comment is there because you want > to omit the "list == NULL" check in list_free_private. Is this > measurable, performance-wise? Thank you for clarifying this. It was my oversight. Regarding speculative execution, I have never measured its impact. I added "unlikely" based on an assumption that non-partitioned cases would be common. However, whether this assumption is correct needs to be discussed. > 3. Maybe I'm missing something, but I'm confused about the need for > the eclass_indexes_array field in PlannerInfo. This array is indexed > by the relid, so why can't we get rid of the array and add a field to > RelOptInfo to store the EquivalenceClassIndexes? The reason is that some RelOptInfos can be NULL. Further details were explained in [1]. To be honest, I don't fully understand the architectural details. Initially, I addressed this by moving the indexes into RangeTblEntry, but this was not an ideal solution. Therefore, I moved them into PlannerInfo by introducing a new struct, "EquivalenceClassIndexes". > 4. Could you also please run another set of benchmarks against current > master with the the v36 patches: master, master + v36-0001 + 0002, > master + v36-0001 + 0002 + 0003 (0003 will be the v34-0004 patch), and > then also with v36-0004 (which is the same as v35-0005). The main > thing I'd like to understand here is if there's not enough time to get > the entire patch set committed, is there much benefit to just having > the EquivalenceMember index stuff in by itself without the > RestrictInfo changes. Thank you for your suggestion. Running the benchmarks themselves should be possible, but given Tom's feedback and the limited time remaining before feature freeze, it is unlikely that even a partial integration into v18 is realistic, and a detailed evaluation will likely need to be deferred until v19. I apologize again for my slow progress. Given this situation, I plan to carefully reconsider the overall design and propose a refined patch set for v19. What do you think about this approach? Thank you again for your extensive contributions to this patch so far. I'm sorry that I couldn't get it ready in time for v18. [1] https://www.postgresql.org/message-id/CAJ2pMkYR_X-%3Dpq%2B39-W5kc0OG7q9u5YUwDBCHnkPur17DXnxuQ%40mail.gmail.com -- Best regards, Yuya Watari
Hello Tom, Thank you for your detailed review, and apologies for my late response. On Tue, Mar 25, 2025 at 2:49 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > One thing I don't love is putting the children into RelOptInfos. > That seems like an unrelated data structure. Have you thought > about instead having, in each EC that needs it, an array indexed > by RTI of per-relation child-member lists? I think this might > net out as less storage because there typically aren't that many > ECs in a query. But the main thing is to not have so many > interconnections between ECs and RelOptInfos. Thank you for your suggestion. Storing EquivalenceMembers in RelOptInfos indeed complicates the data structures involved. In the next version, I will explore alternative approaches, including the one you have suggested. > Another thing I really don't like is the back-link from EMs to ECs: > > + EquivalenceClass *em_ec; /* EquivalenceClass which has this member */ > > That makes the data structure circular, which will cause pprint to > recurse infinitely. (The fact that you hadn't noticed that makes > me wonder how you debugged any of these data structure changes.) > We could prevent the recursion with suitable annotation on this field, > but I'd really rather not have the field in the first place. Circular > pointers are dangerous and best avoided. Also, it's bloating a node > type that you are concerned about supporting a lot of. Another point > is that I don't see any code to take care of updating these links > during an EC merge. I apologize for missing this critical point. It is clear that avoiding circular dependencies would be preferable, so I will reconsider this aspect of the design. > * setup_eclass_member_iterator_with_children is a carpal-tunnel-inducing > name. Could we drop the "_with_children" part? It doesn't seem to > add much, since there's no variant for "without children". Thank you for this suggestion. I will remove "_with_children" in the next version. > * The root parameter should be first; IMO there should be no > exceptions to that within the planner. Perhaps putting the target > iterator parameter last would make it read more nicely. Or you could > rely on struct assignment: > > it = setup_eclass_member_iterator(root, ec, relids); I agree with your point. I will adjust the parameter order in the next version to match your suggestion. > * Why did you define the iterator as possibly returning irrelevant > members? Doesn't that mean that every caller has to double-check? > Wouldn't it make for less code and fewer bugs for the iterator to > have that responsibility? If there is a good reason to do it like > that, the comments should explain why. This design was chosen for performance reasons. If the iterator always filtered out irrelevant members, it would need to repeatedly check each element against "bms_is_subset". However, some callers require stricter conditions, such as "bms_equals", resulting in redundant checks. Therefore, the iterator intentionally returns some false positives, leaving it to callers to perform additional checks for the exact conditions they require. As you pointed out, I failed to clearly document this, and I will fix this oversight in the next version. > I don't really like the concept of 0004 at all. Putting *all* > the EC-related RelOptInfos into a root-stored list seems to be > doubling down very hard on the assumption that no performance-critical > operations will ever need to search that whole list. Is there a good > reason to do it like that, rather than say using the bitmap-index > concept separately within each EC? That might also alleviate the > problem you're having with the bitmapsets getting too big. Thank you for this suggestion. The patch series indeed has issues with memory consumption. Your suggestion to manage bitmap indexes separately within each EC seems worth exploring, and I will investigate this approach further. > Given that we've only got a week left, I see little hope of getting > any of this into v18. I agree that addressing these issues within the remaining time is challenging. The design clearly needs reconsideration. Therefore, I will postpone these changes and submit a fully revised version for v19. Would this approach be acceptable to you? -- Best regards, Yuya Watari
Hello Ashutosh, Thank you for your detailed review, and apologies for my delayed response. On Thu, Mar 27, 2025 at 1:42 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > > Here are memory consumption numbers using list_free() instead of pfree(), using the same method as [1], using a binarywithout asserts and debug info. PFA the patchset where all the patches are the same as v35 but with an extra patchfixing memory leak. The memory leak is visible with a higher number of joins. At a lower number of joins, I expect thatthe memory saved is less than a KB or the leaked memory fits within 1 chunk of memory context and hence not visible. Thank you for conducting your benchmarks. Your results clearly show increased memory consumption with my patches. As Tom also suggested, we may reduce memory usage by adopting a different design. I will reconsider alternative approaches and compare the memory usage to the current version. Thank you once again for conducting the benchmarks. -- Best regards, Yuya Watari
On Tue, 25 Mar 2025 at 06:49, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I finally made some time to look at this patchset, and I'm pretty > disappointed, because after 35 versions I'd expect to see something > that looks close to committable. This doesn't really. I like the > basic idea of taking child EC members out of ECs' main ec_members > lists, but there are too many weird details and > underexplained/overcomplicated/unmaintainable data structures. > > One thing I don't love is putting the children into RelOptInfos. > That seems like an unrelated data structure. Have you thought > about instead having, in each EC that needs it, an array indexed > by RTI of per-relation child-member lists? I think this might > net out as less storage because there typically aren't that many > ECs in a query. But the main thing is to not have so many > interconnections between ECs and RelOptInfos. I think that's quite a good idea. One drawback of that method is that we'd need to duplicate the EquivalenceMembers into each relid making up the joinrels in add_child_join_rel_equivalences(). That could mean finding the same EM multiple times when iterating over the set. I don't think that causes issues other than wasted effort. > Another thing I really don't like is the back-link from EMs to ECs: > > + EquivalenceClass *em_ec; /* EquivalenceClass which has this member */ > > That makes the data structure circular, which will cause pprint to > recurse infinitely. (The fact that you hadn't noticed that makes > me wonder how you debugged any of these data structure changes.) > We could prevent the recursion with suitable annotation on this field, > but I'd really rather not have the field in the first place. Circular > pointers are dangerous and best avoided. Also, it's bloating a node > type that you are concerned about supporting a lot of. Another point > is that I don't see any code to take care of updating these links > during an EC merge. > > Some thoughts about the iterator stuff: > > * setup_eclass_member_iterator_with_children is a carpal-tunnel-inducing > name. Could we drop the "_with_children" part? It doesn't seem to > add much, since there's no variant for "without children". > > * The root parameter should be first; IMO there should be no > exceptions to that within the planner. Perhaps putting the target > iterator parameter last would make it read more nicely. Or you could > rely on struct assignment: > > it = setup_eclass_member_iterator(root, ec, relids); > > * Why did you define the iterator as possibly returning irrelevant > members? Doesn't that mean that every caller has to double-check? > Wouldn't it make for less code and fewer bugs for the iterator to > have that responsibility? If there is a good reason to do it like > that, the comments should explain why. I've attached 2 patches, which I think addresses most of this, aside from the last point. These do need more work. I've just attached what I have so far before I head off for the day. I am planning on running some performance tests tomorrow and doing a round on the comments. > I don't really like the concept of 0004 at all. Putting *all* > the EC-related RelOptInfos into a root-stored list seems to be > doubling down very hard on the assumption that no performance-critical > operations will ever need to search that whole list. Is there a good > reason to do it like that, rather than say using the bitmap-index > concept separately within each EC? That might also alleviate the > problem you're having with the bitmapsets getting too big. I've dropped this patch out of the set for now. There's other work going on that might solve the issue that patch was aiming to solve. > Given that we've only got a week left, I see little hope of getting > any of this into v18. I am keen on not giving up quite yet. I'd very much value any further input you have. It doesn't seem excessively complex to have quite a large impact on the performance of the planner here. David
Attachment
On Fri, 4 Apr 2025 at 00:34, David Rowley <dgrowleyml@gmail.com> wrote:
> I've attached 2 patches, which I think addresses most of this, aside
> from the last point.
>
> These do need more work. I've just attached what I have so far before
> I head off for the day. I am planning on running some performance
> tests tomorrow and doing a round on the comments.
I've done some further work on this, mostly relating to the code
comments. I also removed the now-empty
dispose_eclass_member_iterator() function.
A couple of things which I'm still uncertain of:
1. How to handle the ec_childmembers array in _outEquivalenceClass().
There's no field to know the size of the array. Maybe I should add one
and then print out the non-empty lists.
2. When processing RELOPT_OTHER_JOINREL in add_child_eq_member(), I'm
adding the member to each List for all individual relid mentioned in
child_relids. This will result in the member going on multiple Lists
and cause the iterator to possibly return the member multiple times.
That might matter in a few places, e.g.
generate_join_implied_equalities_normal() keeps some scoring based on
the number of members.
For #2, Yuya's Bitmapset approach didn't suffer from this issue as the
Bitmapsets would be unioned to get the non-duplicative members. I
wondered about doing list_append_unique() instead of lappend() in
generate_join_implied_equalities_normal(). Unsure. The only other
thing I can think of is to do something else with members for
RELOPT_OTHER_JOINREL and store them elsewhere.
I also did some benchmarking using the attached script. I've attached
the results of running that on my AMD Zen2 machine. See the end of the
script for the CREATE TABLE statement for loading that into postgres.
The results look pretty good. v37 came out slightly faster than v36,
either noise or because of dispose_eclass_member_iterator() removal.
-- overall plan time.
select testname,sum(plan_time)::int as plan_ms from bench_results
group by 1 order by 2;
testname | plan_ms
------------------+---------
v37_patch | 6806
v36_patch | 6891
v35_patch | 6917
master_1aff1dc8d | 21113
-- plan time by number of joins for 1024 parts
select testname,joins,sum(plan_time)::int as "plan_ms" from
bench_results where parts=1024 group by 1,2 order by 2,1;
testname | joins | plan_ms
------------------+-------+---------
master_1aff1dc8d | 0 | 239
v35_patch | 0 | 120
v36_patch | 0 | 120
v37_patch | 0 | 119
master_1aff1dc8d | 1 | 485
v35_patch | 1 | 181
v36_patch | 1 | 184
v37_patch | 1 | 180
master_1aff1dc8d | 2 | 832
v35_patch | 2 | 252
v36_patch | 2 | 253
v37_patch | 2 | 249
master_1aff1dc8d | 3 | 1284
v35_patch | 3 | 342
v36_patch | 3 | 338
v37_patch | 3 | 337
master_1aff1dc8d | 4 | 1909
v35_patch | 4 | 427
v36_patch | 4 | 435
v37_patch | 4 | 435
master_1aff1dc8d | 5 | 2830
v35_patch | 5 | 530
v36_patch | 5 | 540
v37_patch | 5 | 535
master_1aff1dc8d | 6 | 4759
v35_patch | 6 | 685
v36_patch | 6 | 691
v37_patch | 6 | 681
-- The memory used is about the same as before:
select testname,joins,sum(mem_alloc)::int as mem_alloc from
bench_results group by 1,2 order by 2,1;
testname | joins | mem_alloc
------------------+-------+-----------
master_1aff1dc8d | 0 | 231110
v35_patch | 0 | 233662
v36_patch | 0 | 233662
v37_patch | 0 | 233662
master_1aff1dc8d | 1 | 432685
v35_patch | 1 | 435369
v36_patch | 1 | 435369
v37_patch | 1 | 435369
master_1aff1dc8d | 2 | 476916
v35_patch | 2 | 476300
v36_patch | 2 | 476300
v37_patch | 2 | 476300
master_1aff1dc8d | 3 | 801834
v35_patch | 3 | 801372
v36_patch | 3 | 801372
v37_patch | 3 | 801372
master_1aff1dc8d | 4 | 917312
v35_patch | 4 | 917015
v36_patch | 4 | 917015
v37_patch | 4 | 917015
master_1aff1dc8d | 5 | 1460833
v35_patch | 5 | 1460701
v36_patch | 5 | 1460701
v37_patch | 5 | 1460701
master_1aff1dc8d | 6 | 2550570
v35_patch | 6 | 2639395
v36_patch | 6 | 2639395
v37_patch | 6 | 2639395
David
Attachment
Hello David,
Thank you very much for your continuous contributions to this patch
series, and especially for providing these new patches despite the
time constraints.
On Fri, Apr 4, 2025 at 3:04 PM David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Fri, 4 Apr 2025 at 00:34, David Rowley <dgrowleyml@gmail.com> wrote:
> > I've attached 2 patches, which I think addresses most of this, aside
> > from the last point.
> >
> > These do need more work. I've just attached what I have so far before
> > I head off for the day. I am planning on running some performance
> > tests tomorrow and doing a round on the comments.
>
> I've done some further work on this, mostly relating to the code
> comments. I also removed the now-empty
> dispose_eclass_member_iterator() function.
I agree with this new approach. It significantly simplifies the
overall architecture of the patch series while still maintaining
excellent performance. Thank you again for your effort here.
> A couple of things which I'm still uncertain of:
>
> 1. How to handle the ec_childmembers array in _outEquivalenceClass().
> There's no field to know the size of the array. Maybe I should add one
> and then print out the non-empty lists.
I'm also not certain about the best solution here. As you suggested,
adding a field representing the array size to EquivalenceClass seems
like a reasonable approach.
> 2. When processing RELOPT_OTHER_JOINREL in add_child_eq_member(), I'm
> adding the member to each List for all individual relid mentioned in
> child_relids. This will result in the member going on multiple Lists
> and cause the iterator to possibly return the member multiple times.
> That might matter in a few places, e.g.
> generate_join_implied_equalities_normal() keeps some scoring based on
> the number of members.
>
> For #2, Yuya's Bitmapset approach didn't suffer from this issue as the
> Bitmapsets would be unioned to get the non-duplicative members. I
> wondered about doing list_append_unique() instead of lappend() in
> generate_join_implied_equalities_normal(). Unsure. The only other
> thing I can think of is to do something else with members for
> RELOPT_OTHER_JOINREL and store them elsewhere.
Another approach I have in mind is adding an iterator pointer to each
EquivalenceMember to track the iterator that last returned each
member. When the iterator is about to return a member, it would first
check if that member's iterator pointer matches the current iterator.
If it does, we know this member has already been returned, so we skip
it. However, this approach does not work when iterators are called
recursively and leads to increased complexity in the data structure.
Your proposed solution using list_append_unique() instead of lappend()
seems practical since the number of EquivalenceMembers handled in
generate_join_implied_equalities_normal() is usually limited.
> I also did some benchmarking using the attached script. I've attached
> the results of running that on my AMD Zen2 machine. See the end of the
> script for the CREATE TABLE statement for loading that into postgres.
>
> The results look pretty good. v37 came out slightly faster than v36,
> either noise or because of dispose_eclass_member_iterator() removal.
Thank you for running your benchmarks as well. Your results look
promising, demonstrating both reduced planning time and lower memory
consumption.
I have also conducted benchmarks using queries A and B, which I have
used previously and are in [1]. Here is a quick summary:
* The new patch (v37) shows better performance improvements compared
to previous versions (v35 and v36).
* The performance gains are significant and worth committing.
* Performance regressions are negligible or non-existent, even with a
small number of partitions.
* Memory usage in v37 is lower than v35 and almost identical to the master.
Detailed results are as follows:
The following tables and attached figures indicate that v37 achieves
up to 415.4% and 280.3% speedups for queries A and B, respectively.
These improvements are better than those seen in v35 and v36.
Importantly, v37 does not appear to introduce any regressions. Its
speedups exceeded 100% in all tested cases except for the one with two
partitions in query A. Even in that case, the performance remained at
99.9% of the master, demonstrating that the regression is negligible.
Moreover, Table 5 and the attached figure show v37 consumes no
additional memory compared to the master.
Table 1: Planning time for query A (ms)
-------------------------------------------
n | Master | v35 | v36 | v37
-------------------------------------------
1 | 0.274 | 0.273 | 0.274 | 0.270
2 | 0.285 | 0.288 | 0.286 | 0.286
4 | 0.381 | 0.378 | 0.368 | 0.372
8 | 0.477 | 0.468 | 0.471 | 0.471
16 | 0.698 | 0.671 | 0.667 | 0.650
32 | 1.251 | 1.190 | 1.169 | 1.149
64 | 2.848 | 2.550 | 2.463 | 2.444
128 | 6.051 | 4.692 | 4.669 | 4.588
256 | 16.812 | 10.851 | 10.784 | 10.742
384 | 30.985 | 16.640 | 16.354 | 16.243
512 | 50.548 | 23.174 | 22.981 | 22.940
640 | 72.046 | 28.725 | 28.679 | 28.296
768 | 102.668 | 34.975 | 34.759 | 34.280
896 | 150.563 | 46.764 | 46.313 | 46.006
1024 | 197.559 | 48.243 | 47.777 | 47.553
-------------------------------------------
Table 2: Speedup of query A (higher is better)
---------------------------------
n | v35 | v36 | v37
---------------------------------
1 | 100.6% | 100.2% | 101.5%
2 | 99.2% | 99.9% | 99.9%
4 | 100.6% | 103.3% | 102.3%
8 | 101.8% | 101.2% | 101.2%
16 | 104.0% | 104.6% | 107.4%
32 | 105.1% | 107.0% | 108.9%
64 | 111.7% | 115.6% | 116.5%
128 | 129.0% | 129.6% | 131.9%
256 | 154.9% | 155.9% | 156.5%
384 | 186.2% | 189.5% | 190.8%
512 | 218.1% | 220.0% | 220.4%
640 | 250.8% | 251.2% | 254.6%
768 | 293.5% | 295.4% | 299.5%
896 | 322.0% | 325.1% | 327.3%
1024 | 409.5% | 413.5% | 415.4%
---------------------------------
Table 3: Planning time for query B (ms)
------------------------------------------
n | Master | v35 | v36 | v37
------------------------------------------
1 | 12.300 | 12.419 | 12.219 | 12.209
2 | 11.741 | 11.761 | 11.652 | 11.639
4 | 12.573 | 12.376 | 12.390 | 12.418
8 | 13.653 | 13.242 | 13.074 | 13.081
16 | 15.693 | 14.717 | 14.503 | 14.416
32 | 20.957 | 17.890 | 17.732 | 17.675
64 | 35.914 | 25.772 | 25.633 | 25.495
128 | 79.154 | 42.826 | 42.441 | 42.407
256 | 243.880 | 88.246 | 87.626 | 87.011
------------------------------------------
Table 4: Speedup of query B (higher is better)
--------------------------------
n | v35 | v36 | v37
--------------------------------
1 | 99.0% | 100.7% | 100.7%
2 | 99.8% | 100.8% | 100.9%
4 | 101.6% | 101.5% | 101.2%
8 | 103.1% | 104.4% | 104.4%
16 | 106.6% | 108.2% | 108.9%
32 | 117.1% | 118.2% | 118.6%
64 | 139.4% | 140.1% | 140.9%
128 | 184.8% | 186.5% | 186.7%
256 | 276.4% | 278.3% | 280.3%
--------------------------------
Table 5: Memory usage (MB)
(n: number of partitions per table; PWJ: partition-wise join)
----------------------------------------------------------------
Query | n | PWJ | Master | v35 | v36 | v37
----------------------------------------------------------------
A | 1024 | OFF | 48.138 | 49.606 | 48.341 | 48.341
A | 1024 | ON | 127.483 | 128.952 | 127.687 | 127.687
B | 256 | OFF | 92.507 | 96.882 | 92.632 | 92.632
B | 256 | ON | 5803.316 | 5807.691 | 5803.441 | 5803.441
----------------------------------------------------------------
Again, I greatly appreciate your taking the time to significantly
improve this patch. I'd also like to thank Tom once again for his
valuable feedback, which greatly contributed to these improvements.
[1] https://www.postgresql.org/message-id/CAJ2pMkYcKHFBD_OMUSVyhYSQU0-j9T6NZ0pL6pwbZsUCohWc7Q@mail.gmail.com
--
Best regards,
Yuya Watari
Attachment
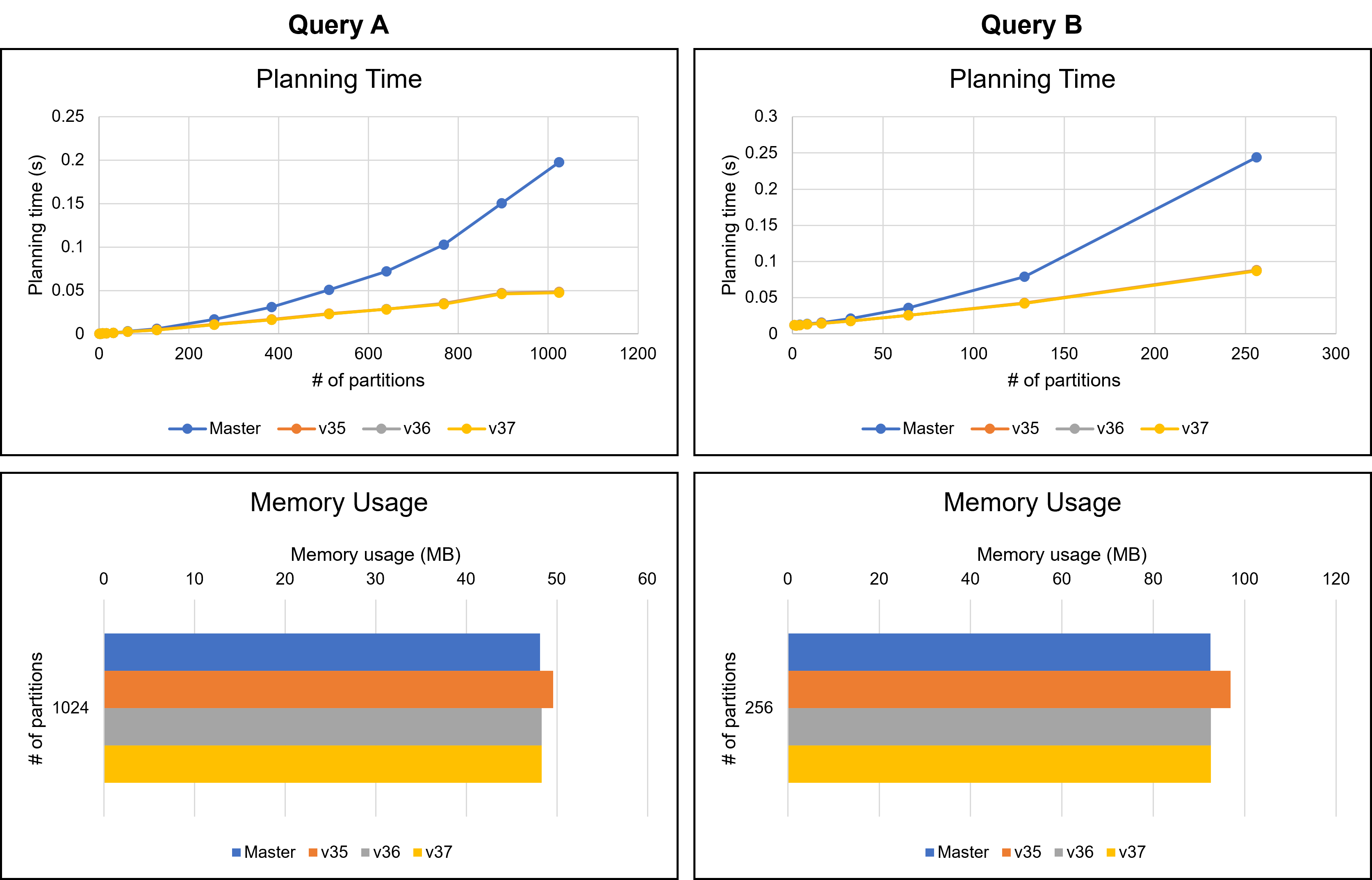{kind=link}
Hi David,
Impressive results!
On Fri, Apr 4, 2025 at 3:05 PM David Rowley <dgrowleyml@gmail.com> wrote:
> I've done some further work on this, mostly relating to the code
> comments.
It looks to me like the following hunks in 0002 probably belong in
0001, unless you’re planning to commit the patches together anyway:
diff --git a/src/backend/optimizer/path/indxpath.c
b/src/backend/optimizer/path/indxpath.c
index 6386ce82253..5c6410e0631 100644
--- a/src/backend/optimizer/path/indxpath.c
+++ b/src/backend/optimizer/path/indxpath.c
@@ -190,7 +190,7 @@ static IndexClause
*expand_indexqual_rowcompare(PlannerInfo *root,
IndexOptInfo *index,
Oid expr_op,
bool var_on_left);
-static void match_pathkeys_to_index(IndexOptInfo *index, List *pathkeys,
+static void match_pathkeys_to_index(PlannerInfo *root, IndexOptInfo
*index, List *pathkeys,
List **orderby_clauses_p,
List **clause_columns_p);
static Expr *match_clause_to_ordering_op(IndexOptInfo *index,
@@ -934,7 +934,7 @@ build_index_paths(PlannerInfo *root, RelOptInfo *rel,
* query_pathkeys will allow an incremental sort to be considered on
* the index's partially sorted results.
*/
- match_pathkeys_to_index(index, root->query_pathkeys,
+ match_pathkeys_to_index(root, index, root->query_pathkeys,
&orderbyclauses,
&orderbyclausecols);
if (list_length(root->query_pathkeys) == list_length(orderbyclauses))
The comment on EquivalenceMember might benefit from a mention of how
ec_childmembers now fits into the picture -- do you think it’s worth
updating?
/*
* EquivalenceMember - one member expression of an EquivalenceClass
*
* em_is_child signifies that this element was built by transposing a member
* for an appendrel parent relation to represent the corresponding expression
* for an appendrel child.
...
+ /* XXX ec_childmembers? */
Maybe we don’t need to print these, since the comment on em_is_child
suggests they aren’t really full-fledged EC members and are meant to
be ignored by most operations?
--
Thanks, Amit Langote
Hi David,
On Fri, Apr 4, 2025 at 11:34 AM David Rowley <dgrowleyml@gmail.com> wrote:
>
> I also did some benchmarking using the attached script. I've attached
> the results of running that on my AMD Zen2 machine. See the end of the
> script for the CREATE TABLE statement for loading that into postgres.
>
> The results look pretty good. v37 came out slightly faster than v36,
> either noise or because of dispose_eclass_member_iterator() removal.
Here are my benchmarking results
Planning time: columns correspond to number of joins, rows to number
of partitions, each cell is a triplet (s, md, pd) where
s is improvement as percentage of planning time without patch (higher
the better)
md and pd are standard deviation in planning time with and without
patch respectively as % of respective averages.
planning time improvement with PWJ=off
num_parts | 2 | 3
| 4 | 5
-----------+------------------------------+----------------------------+----------------------------+----------------------------
0 | s=-4.43% md=16.72% pd=16.41% | s=-2.93% md=5.33% pd=5.27%
| s=-0.10% md=4.28% pd=4.49% | s=-2.60% md=4.80% pd=4.28%
10 | s=1.32% md=9.93% pd=9.13% | s=2.70% md=1.90% pd=1.90%
| s=4.53% md=1.55% pd=1.59% | s=4.96% md=0.99% pd=0.94%
100 | s=29.15% md=3.96% pd=4.66% | s=38.11% md=0.43% pd=1.22%
| s=44.17% md=1.19% pd=1.21% | s=43.97% md=0.37% pd=0.27%
500 | s=63.12% md=1.39% pd=3.80% | s=69.57% md=1.76% pd=0.73%
| s=71.73% md=0.88% pd=0.81% | s=66.08% md=0.72% pd=0.57%
1000 | s=76.33% md=0.82% pd=1.72% | s=80.37% md=0.30% pd=0.82%
| s=75.30% md=1.23% pd=0.64% | s=67.06% md=0.83% pd=0.19%
(5 rows)
planning time improvement with PWJ=on
num_parts | 2 | 3 |
4 | 5
-----------+----------------------------+----------------------------+----------------------------+----------------------------
0 | s=-2.08% md=5.87% pd=6.16% | s=-2.22% md=4.70% pd=5.29% |
s=-1.77% md=5.40% pd=4.23% | s=-3.96% md=3.96% pd=3.89%
10 | s=-0.93% md=3.34% pd=2.89% | s=0.06% md=0.96% pd=0.52% |
s=2.09% md=0.43% pd=0.60% | s=2.03% md=0.39% pd=0.66%
100 | s=20.31% md=1.70% pd=1.19% | s=16.98% md=1.28% pd=1.70% |
s=13.35% md=0.32% pd=0.77% | s=14.12% md=1.19% pd=0.43%
500 | s=51.98% md=3.12% pd=4.25% | s=50.85% md=0.45% pd=0.48% |
s=47.27% md=0.16% pd=0.82% | s=40.60% md=0.30% pd=0.57%
1000 | s=67.34% md=1.67% pd=1.16% | s=69.54% md=0.20% pd=0.44% |
s=61.31% md=1.13% pd=0.63% | s=54.66% md=0.38% pd=0.57%
(5 rows)
The deviations are mostly within noise range so the results are
reliable. There are some cells, corresponding to lower number of
partitions and join, which show regression in planning time but that's
within noise range. I think that can be ignored. For a higher number
of partitions and joins the improvements are impressive.
planning memory improvement with PWJ=off
num_parts | 2 | 3
| 4 | 5
-----------+----------------------------------+----------------------------------+----------------------------------+----------------------------------
0 | s=0.00%, mm=15 kB, pm=15 kB | s=0.00%, mm=21 kB,
pm=21 kB | s=0.00%, mm=27 kB, pm=27 kB | s=0.00%, mm=33 kB,
pm=33 kB
10 | s=-0.46%, mm=218 kB, pm=219 kB | s=-0.44%, mm=455 kB,
pm=457 kB | s=-0.35%, mm=868 kB, pm=871 kB | s=-0.24%, mm=1697 kB,
pm=1701 kB
100 | s=-0.88%, mm=1824 kB, pm=1840 kB | s=-0.62%, mm=3718 kB,
pm=3741 kB | s=-0.50%, mm=6400 kB, pm=6432 kB | s=-0.38%, mm=10233 kB,
pm=10 MB
500 | s=-0.83%, mm=9395 kB, pm=9473 kB | s=-0.56%, mm=20 MB,
pm=20 MB | s=-0.44%, mm=35 MB, pm=35 MB | s=-0.30%, mm=59 MB,
pm=60 MB
1000 | s=-0.79%, mm=19 MB, pm=20 MB | s=-0.49%, mm=45 MB,
pm=45 MB | s=-0.37%, mm=82 MB, pm=83 MB | s=-0.24%, mm=146 MB,
pm=147 MB
(5 rows)
planning memory improvement with PWJ=on
num_parts | 2 | 3
| 4 | 5
-----------+----------------------------------+----------------------------------+----------------------------------+----------------------------------
0 | s=0.00%, mm=15 kB, pm=15 kB | s=0.00%, mm=21 kB,
pm=21 kB | s=0.00%, mm=27 kB, pm=27 kB | s=0.00%, mm=33 kB,
pm=33 kB
10 | s=-0.55%, mm=365 kB, pm=367 kB | s=-0.25%, mm=1198 kB,
pm=1201 kB | s=-0.08%, mm=3571 kB, pm=3574 kB | s=-0.04%, mm=10 MB,
pm=10 MB
100 | s=-0.48%, mm=3337 kB, pm=3353 kB | s=-0.20%, mm=11 MB,
pm=11 MB | s=-0.09%, mm=33 MB, pm=33 MB | s=-0.04%, mm=97 MB,
pm=97 MB
500 | s=-0.45%, mm=17 MB, pm=17 MB | s=-0.19%, mm=59 MB,
pm=59 MB | s=-0.08%, mm=179 MB, pm=179 MB | s=-0.03%, mm=544 MB,
pm=544 MB
1000 | s=-0.43%, mm=35 MB, pm=35 MB | s=-0.17%, mm=128 MB,
pm=129 MB | s=-0.08%, mm=395 MB, pm=396 MB | s=-0.03%, mm=1234 MB,
pm=1234 MB
(5 rows)
The memory profile too is impressive. There's almost no impact on
memory consumption. The increase in memory consumption is acceptable
given the significant improvements in planning time.
I have not reviewed patches though.
I haven't measured if the patches improve performance of simple scans
with thousands of partitions. Have you tried measuring that?
--
Best Wishes,
Ashutosh Bapat
On Sat, 5 Apr 2025 at 02:54, Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
> I haven't measured if the patches improve performance of simple scans
> with thousands of partitions. Have you tried measuring that?
I just tried 10k partitions on my Zen4 laptop.
create table lp (a int) partition by list(a);
select 'create table lp'||x||' partition of lp for values
in('||x||');' from generate_Series(1,10000)x;
\gexec
create index on lp(a);
explain (summary on) select * from lp order by a;
master:
Planning Time: 2296.227 ms
Planning Time: 2142.999 ms
Planning Time: 2089.924 ms
Memory: used=84701kB allocated=85292kB
59.34% postgres [.] bms_is_subset
17.09% postgres [.] find_ec_member_matching_expr
11.55% postgres [.] bms_equal
3.41% postgres [.] get_eclass_for_sort_expr
2.08% postgres [.] add_child_rel_equivalences
0.59% postgres [.] SearchCatCacheInternal
0.52% postgres [.] hash_search_with_hash_value
0.45% libc.so.6 [.] __memmove_avx512_unaligned_erms
0.23% postgres [.] AllocSetAlloc
0.16% postgres [.] ResourceOwnerForget
0.13% postgres [.] add_paths_to_append_rel
0.12% postgres [.] RelationIdGetRelation
0.11% postgres [.] create_scan_plan
0.11% libc.so.6 [.] __memset_avx512_unaligned_erms
0.10% postgres [.] uint32_hash
0.10% libc.so.6 [.] __memcmp_evex_movbe
0.10% postgres [.] lappend
patched:
Planning Time: 118.346 ms
Planning Time: 122.706 ms
Planning Time: 120.424 ms
Memory: used=77677kB allocated=84752kB
9.58% postgres [.] hash_search_with_hash_value
7.58% libc.so.6 [.] __memmove_avx512_unaligned_erms
6.41% postgres [.] SearchCatCacheInternal
3.35% postgres [.] AllocSetAlloc
3.15% postgres [.] bms_next_member
2.79% postgres [.] ResourceOwnerForget
2.07% postgres [.] RelationIdGetRelation
1.86% libc.so.6 [.] __memcmp_evex_movbe
1.78% postgres [.] add_paths_to_append_rel
1.57% postgres [.] LockAcquireExtended
1.35% postgres [.] uint32_hash
1.29% libc.so.6 [.] __memset_avx512_unaligned_erms
David
Thank you for having a look at this. On Fri, 4 Apr 2025 at 21:47, Amit Langote <amitlangote09@gmail.com> wrote: > It looks to me like the following hunks in 0002 probably belong in > 0001, unless you’re planning to commit the patches together anyway: Ah, yeah. Unsure about that as yet, but I've moved it over. > The comment on EquivalenceMember might benefit from a mention of how > ec_childmembers now fits into the picture -- do you think it’s worth > updating? > > /* > * EquivalenceMember - one member expression of an EquivalenceClass > * > * em_is_child signifies that this element was built by transposing a member > * for an appendrel parent relation to represent the corresponding expression > * for an appendrel child. > ... I've adjusted that a bit in the attached. > + /* XXX ec_childmembers? */ > > Maybe we don’t need to print these, since the comment on em_is_child > suggests they aren’t really full-fledged EC members and are meant to > be ignored by most operations? It is marked with pg_node_attr no_read, so I guess that means the writing is just for debugging since there's nothing else to read it. In the attached I added a field for the array length and am calling WRITE_NODE_ARRAY on it. I spent more time going over all the usages of ec_members. A few functions do something different to what they did before; 1) print_pathkeys() maybe this should also loop over all child members too. However, it doesn't seem too important since those are just or debugging. 2) in convert_subquery_pathkeys() there's some code doing "score = list_length(outer_ec->ec_members) - 1;", I think this might have become more correct now that the child members are not contributing to the score. I also added a series of Asserts in some places where child members are not expected yet. analyzejoins.c is doing some fiddling with the ec_members list, but that's always done before the children are added, so the Assert is there to make sure that remains true. I didn't see the sense in writing dead code to remove the child members. I'd feel more inclined to do that if that code was in equivclass.c I've attached the updated set of patches. I'm still uncertain what to do about the EquivalenceMemberIterator returning duplicate members for child join rels. I'll need to spend more time to see if this is an actual problem. David
Attachment
David Rowley <dgrowleyml@gmail.com> writes:
> I've attached the updated set of patches.
This patchset has a distinct whiff of unseemly haste.
1. The commit message for 0002 still claims that child EC members
are kept in RelOptInfos, precisely the point I objected to upthread.
I see that in fact that's untrue, but it'd be nice if the commit log
had some connection to what's being committed.
2. Because there is no longer any need to find RelOptInfos, the
EquivalenceMemberIterator stuff doesn't need a "root" pointer,
either in the struct or as an setup_eclass_member_iterator argument.
3. Because of #2, the 0001 patch is useless code churn and should
be dropped.
See attached (just a hasty root-ectomy, I've not really read much
else).
I do note that add_child_eq_member seems to have a considerable
amount of faith that root->simple_rel_array_size can't increase
after we start adding child members. That seems rather unsafe,
though the fact that it hasn't crashed in light testing suggests
that maybe there's something I'm missing. I would be much
happier if there were provision to expand the array at need.
regards, tom lane
diff --git a/contrib/postgres_fdw/postgres_fdw.c b/contrib/postgres_fdw/postgres_fdw.c
index b4e0e60928b..a7e0cc9f323 100644
--- a/contrib/postgres_fdw/postgres_fdw.c
+++ b/contrib/postgres_fdw/postgres_fdw.c
@@ -7847,14 +7847,13 @@ conversion_error_callback(void *arg)
EquivalenceMember *
find_em_for_rel(PlannerInfo *root, EquivalenceClass *ec, RelOptInfo *rel)
{
- ListCell *lc;
-
PgFdwRelationInfo *fpinfo = (PgFdwRelationInfo *) rel->fdw_private;
+ EquivalenceMemberIterator it;
+ EquivalenceMember *em;
- foreach(lc, ec->ec_members)
+ setup_eclass_member_iterator(&it, ec, rel->relids);
+ while ((em = eclass_member_iterator_next(&it)) != NULL)
{
- EquivalenceMember *em = (EquivalenceMember *) lfirst(lc);
-
/*
* Note we require !bms_is_empty, else we'd accept constant
* expressions which are not suitable for the purpose.
@@ -7908,7 +7907,10 @@ find_em_for_rel_target(PlannerInfo *root, EquivalenceClass *ec,
while (expr && IsA(expr, RelabelType))
expr = ((RelabelType *) expr)->arg;
- /* Locate an EquivalenceClass member matching this expr, if any */
+ /*
+ * Locate an EquivalenceClass member matching this expr, if any.
+ * Ignore child members.
+ */
foreach(lc2, ec->ec_members)
{
EquivalenceMember *em = (EquivalenceMember *) lfirst(lc2);
@@ -7918,9 +7920,8 @@ find_em_for_rel_target(PlannerInfo *root, EquivalenceClass *ec,
if (em->em_is_const)
continue;
- /* Ignore child members */
- if (em->em_is_child)
- continue;
+ /* Child members should not exist in ec_members */
+ Assert(!em->em_is_child);
/* Match if same expression (after stripping relabel) */
em_expr = em->em_expr;
diff --git a/src/backend/nodes/outfuncs.c b/src/backend/nodes/outfuncs.c
index 557f06e344f..ceac3fd8620 100644
--- a/src/backend/nodes/outfuncs.c
+++ b/src/backend/nodes/outfuncs.c
@@ -465,7 +465,9 @@ _outEquivalenceClass(StringInfo str, const EquivalenceClass *node)
WRITE_NODE_FIELD(ec_opfamilies);
WRITE_OID_FIELD(ec_collation);
+ WRITE_INT_FIELD(ec_childmembers_size);
WRITE_NODE_FIELD(ec_members);
+ WRITE_NODE_ARRAY(ec_childmembers, node->ec_childmembers_size);
WRITE_NODE_FIELD(ec_sources);
/* Only ec_derives_list is written; hash is not serialized. */
WRITE_NODE_FIELD(ec_derives_list);
diff --git a/src/backend/optimizer/path/equivclass.c b/src/backend/optimizer/path/equivclass.c
index 9cd54c573a8..089f196c958 100644
--- a/src/backend/optimizer/path/equivclass.c
+++ b/src/backend/optimizer/path/equivclass.c
@@ -34,11 +34,23 @@
#include "utils/lsyscache.h"
+static EquivalenceMember *make_eq_member(EquivalenceClass *ec,
+ Expr *expr, Relids relids,
+ JoinDomain *jdomain,
+ EquivalenceMember *parent,
+ Oid datatype);
static EquivalenceMember *add_eq_member(EquivalenceClass *ec,
Expr *expr, Relids relids,
JoinDomain *jdomain,
- EquivalenceMember *parent,
Oid datatype);
+static EquivalenceMember *add_child_eq_member(PlannerInfo *root,
+ EquivalenceClass *ec,
+ int ec_index, Expr *expr,
+ Relids relids,
+ JoinDomain *jdomain,
+ EquivalenceMember *parent_em,
+ Oid datatype,
+ Relids child_relids);
static void generate_base_implied_equalities_const(PlannerInfo *root,
EquivalenceClass *ec);
static void generate_base_implied_equalities_no_const(PlannerInfo *root,
@@ -314,11 +326,15 @@ process_equivalence(PlannerInfo *root,
if (!equal(opfamilies, cur_ec->ec_opfamilies))
continue;
+ /* We don't expect any children yet */
+ Assert(cur_ec->ec_childmembers == NULL);
+
foreach(lc2, cur_ec->ec_members)
{
EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc2);
- Assert(!cur_em->em_is_child); /* no children yet */
+ /* Child members should not exist in ec_members */
+ Assert(!cur_em->em_is_child);
/*
* Match constants only within the same JoinDomain (see
@@ -428,7 +444,7 @@ process_equivalence(PlannerInfo *root,
{
/* Case 3: add item2 to ec1 */
em2 = add_eq_member(ec1, item2, item2_relids,
- jdomain, NULL, item2_type);
+ jdomain, item2_type);
ec1->ec_sources = lappend(ec1->ec_sources, restrictinfo);
ec1->ec_min_security = Min(ec1->ec_min_security,
restrictinfo->security_level);
@@ -445,7 +461,7 @@ process_equivalence(PlannerInfo *root,
{
/* Case 3: add item1 to ec2 */
em1 = add_eq_member(ec2, item1, item1_relids,
- jdomain, NULL, item1_type);
+ jdomain, item1_type);
ec2->ec_sources = lappend(ec2->ec_sources, restrictinfo);
ec2->ec_min_security = Min(ec2->ec_min_security,
restrictinfo->security_level);
@@ -465,7 +481,9 @@ process_equivalence(PlannerInfo *root,
ec->ec_opfamilies = opfamilies;
ec->ec_collation = collation;
+ ec->ec_childmembers_size = 0;
ec->ec_members = NIL;
+ ec->ec_childmembers = NULL;
ec->ec_sources = list_make1(restrictinfo);
ec->ec_derives_list = NIL;
ec->ec_derives_hash = NULL;
@@ -478,9 +496,9 @@ process_equivalence(PlannerInfo *root,
ec->ec_max_security = restrictinfo->security_level;
ec->ec_merged = NULL;
em1 = add_eq_member(ec, item1, item1_relids,
- jdomain, NULL, item1_type);
+ jdomain, item1_type);
em2 = add_eq_member(ec, item2, item2_relids,
- jdomain, NULL, item2_type);
+ jdomain, item2_type);
root->eq_classes = lappend(root->eq_classes, ec);
@@ -566,11 +584,13 @@ canonicalize_ec_expression(Expr *expr, Oid req_type, Oid req_collation)
}
/*
- * add_eq_member - build a new EquivalenceMember and add it to an EC
+ * make_eq_member
+ * Build a new EquivalenceMember without adding it to an EC. If 'parent'
+ * is NULL, the result will be a parent member, otherwise a child member.
*/
static EquivalenceMember *
-add_eq_member(EquivalenceClass *ec, Expr *expr, Relids relids,
- JoinDomain *jdomain, EquivalenceMember *parent, Oid datatype)
+make_eq_member(EquivalenceClass *ec, Expr *expr, Relids relids,
+ JoinDomain *jdomain, EquivalenceMember *parent, Oid datatype)
{
EquivalenceMember *em = makeNode(EquivalenceMember);
@@ -597,11 +617,84 @@ add_eq_member(EquivalenceClass *ec, Expr *expr, Relids relids,
ec->ec_has_const = true;
/* it can't affect ec_relids */
}
- else if (!parent) /* child members don't add to ec_relids */
+
+ return em;
+}
+
+/*
+ * add_eq_member - build a new non-child EquivalenceMember and add it to 'ec'.
+ */
+static EquivalenceMember *
+add_eq_member(EquivalenceClass *ec, Expr *expr, Relids relids,
+ JoinDomain *jdomain, Oid datatype)
+{
+ EquivalenceMember *em = make_eq_member(ec, expr, relids, jdomain,
+ NULL, datatype);
+
+ /* add to the members list */
+ ec->ec_members = lappend(ec->ec_members, em);
+
+ /* record the relids for parent members */
+ ec->ec_relids = bms_add_members(ec->ec_relids, relids);
+
+ return em;
+}
+
+/*
+ * add_child_eq_member
+ * Create an em_is_child=true EquivalenceMember and add it to 'ec'.
+ *
+ * 'root' the PlannerInfo that 'ec' belongs to.
+ * 'ec' the EquivalenceClass to add the child member to.
+ * 'ec_index' the index of 'ec' within root->eq_classes, or -1 if maintaining
+ * the RelOptInfo.eclass_indexes isn't needed.
+ * 'expr' the em_expr for the new member.
+ * 'relids' the 'em_relids' for the new member.
+ * 'jdomain' the 'em_jdomain' for the new member.
+ * 'parent_em' the parent member of the child to create.
+ * 'datatype' the em_datatype of the new member.
+ * 'child_relids' defines which elements of ec_childmembers to add this member
+ * to.
+ */
+static EquivalenceMember *
+add_child_eq_member(PlannerInfo *root, EquivalenceClass *ec, int ec_index,
+ Expr *expr, Relids relids, JoinDomain *jdomain,
+ EquivalenceMember *parent_em, Oid datatype,
+ Relids child_relids)
+{
+ EquivalenceMember *em;
+ int relid;
+
+ Assert(parent_em != NULL);
+
+ /*
+ * Allocate member to store children. An array of Lists indexed by relid.
+ */
+ if (ec->ec_childmembers == NULL)
{
- ec->ec_relids = bms_add_members(ec->ec_relids, relids);
+ ec->ec_childmembers = (List **) palloc0(root->simple_rel_array_size *
+ sizeof(List *));
+ ec->ec_childmembers_size = root->simple_rel_array_size;
+ }
+
+ em = make_eq_member(ec, expr, relids, jdomain, parent_em, datatype);
+
+ /* Record this member in the ec_childmembers Lists for each relid */
+ relid = -1;
+ while ((relid = bms_next_member(child_relids, relid)) >= 0)
+ {
+
+ ec->ec_childmembers[relid] = lappend(ec->ec_childmembers[relid], em);
+
+ /* Record this EC index for the child rel */
+ if (ec_index >= 0)
+ {
+ RelOptInfo *child_rel = root->simple_rel_array[relid];
+
+ child_rel->eclass_indexes =
+ bms_add_member(child_rel->eclass_indexes, ec_index);
+ }
}
- ec->ec_members = lappend(ec->ec_members, em);
return em;
}
@@ -672,7 +765,8 @@ get_eclass_for_sort_expr(PlannerInfo *root,
foreach(lc1, root->eq_classes)
{
EquivalenceClass *cur_ec = (EquivalenceClass *) lfirst(lc1);
- ListCell *lc2;
+ EquivalenceMemberIterator it;
+ EquivalenceMember *cur_em;
/*
* Never match to a volatile EC, except when we are looking at another
@@ -687,10 +781,9 @@ get_eclass_for_sort_expr(PlannerInfo *root,
if (!equal(opfamilies, cur_ec->ec_opfamilies))
continue;
- foreach(lc2, cur_ec->ec_members)
+ setup_eclass_member_iterator(&it, cur_ec, rel);
+ while ((cur_em = eclass_member_iterator_next(&it)) != NULL)
{
- EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc2);
-
/*
* Ignore child members unless they match the request.
*/
@@ -725,7 +818,9 @@ get_eclass_for_sort_expr(PlannerInfo *root,
newec = makeNode(EquivalenceClass);
newec->ec_opfamilies = list_copy(opfamilies);
newec->ec_collation = collation;
+ newec->ec_childmembers_size = 0;
newec->ec_members = NIL;
+ newec->ec_childmembers = NULL;
newec->ec_sources = NIL;
newec->ec_derives_list = NIL;
newec->ec_derives_hash = NULL;
@@ -747,7 +842,7 @@ get_eclass_for_sort_expr(PlannerInfo *root,
expr_relids = pull_varnos(root, (Node *) expr);
newem = add_eq_member(newec, copyObject(expr), expr_relids,
- jdomain, NULL, opcintype);
+ jdomain, opcintype);
/*
* add_eq_member doesn't check for volatile functions, set-returning
@@ -821,15 +916,16 @@ find_ec_member_matching_expr(EquivalenceClass *ec,
Expr *expr,
Relids relids)
{
- ListCell *lc;
+ EquivalenceMemberIterator it;
+ EquivalenceMember *em;
/* We ignore binary-compatible relabeling on both ends */
while (expr && IsA(expr, RelabelType))
expr = ((RelabelType *) expr)->arg;
- foreach(lc, ec->ec_members)
+ setup_eclass_member_iterator(&it, ec, relids);
+ while ((em = eclass_member_iterator_next(&it)) != NULL)
{
- EquivalenceMember *em = (EquivalenceMember *) lfirst(lc);
Expr *emexpr;
/*
@@ -898,7 +994,8 @@ find_computable_ec_member(PlannerInfo *root,
bool require_parallel_safe)
{
List *exprvars;
- ListCell *lc;
+ EquivalenceMemberIterator it;
+ EquivalenceMember *em;
/*
* Pull out the Vars and quasi-Vars present in "exprs". In the typical
@@ -912,9 +1009,9 @@ find_computable_ec_member(PlannerInfo *root,
PVC_INCLUDE_PLACEHOLDERS |
PVC_INCLUDE_CONVERTROWTYPES);
- foreach(lc, ec->ec_members)
+ setup_eclass_member_iterator(&it, ec, relids);
+ while ((em = eclass_member_iterator_next(&it)) != NULL)
{
- EquivalenceMember *em = (EquivalenceMember *) lfirst(lc);
List *emvars;
ListCell *lc2;
@@ -1193,6 +1290,9 @@ generate_base_implied_equalities_const(PlannerInfo *root,
return;
}
+ /* We don't expect any children yet */
+ Assert(ec->ec_childmembers == NULL);
+
/*
* Find the constant member to use. We prefer an actual constant to
* pseudo-constants (such as Params), because the constraint exclusion
@@ -1219,7 +1319,8 @@ generate_base_implied_equalities_const(PlannerInfo *root,
Oid eq_op;
RestrictInfo *rinfo;
- Assert(!cur_em->em_is_child); /* no children yet */
+ Assert(!cur_em->em_is_child); /* Child members should not exist in
+ * ec_members */
if (cur_em == const_em)
continue;
eq_op = select_equality_operator(ec,
@@ -1283,12 +1384,16 @@ generate_base_implied_equalities_no_const(PlannerInfo *root,
prev_ems = (EquivalenceMember **)
palloc0(root->simple_rel_array_size * sizeof(EquivalenceMember *));
+ /* We don't expect any children yet */
+ Assert(ec->ec_childmembers == NULL);
+
foreach(lc, ec->ec_members)
{
EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc);
int relid;
- Assert(!cur_em->em_is_child); /* no children yet */
+ Assert(!cur_em->em_is_child); /* Child members should not exist in
+ * ec_members */
if (!bms_get_singleton_member(cur_em->em_relids, &relid))
continue;
Assert(relid < root->simple_rel_array_size);
@@ -1621,7 +1726,8 @@ generate_join_implied_equalities_normal(PlannerInfo *root,
List *new_members = NIL;
List *outer_members = NIL;
List *inner_members = NIL;
- ListCell *lc1;
+ EquivalenceMemberIterator it;
+ EquivalenceMember *cur_em;
/*
* First, scan the EC to identify member values that are computable at the
@@ -1632,10 +1738,9 @@ generate_join_implied_equalities_normal(PlannerInfo *root,
* as well as to at least one input member, plus enforce at least one
* outer-rel member equal to at least one inner-rel member.
*/
- foreach(lc1, ec->ec_members)
+ setup_eclass_member_iterator(&it, ec, join_relids);
+ while ((cur_em = eclass_member_iterator_next(&it)) != NULL)
{
- EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc1);
-
/*
* We don't need to check explicitly for child EC members. This test
* against join_relids will cause them to be ignored except when
@@ -1668,6 +1773,7 @@ generate_join_implied_equalities_normal(PlannerInfo *root,
Oid best_eq_op = InvalidOid;
int best_score = -1;
RestrictInfo *rinfo;
+ ListCell *lc1;
foreach(lc1, outer_members)
{
@@ -1742,6 +1848,7 @@ generate_join_implied_equalities_normal(PlannerInfo *root,
List *old_members = list_concat(outer_members, inner_members);
EquivalenceMember *prev_em = NULL;
RestrictInfo *rinfo;
+ ListCell *lc1;
/* For now, arbitrarily take the first old_member as the one to use */
if (old_members)
@@ -1749,7 +1856,7 @@ generate_join_implied_equalities_normal(PlannerInfo *root,
foreach(lc1, new_members)
{
- EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc1);
+ cur_em = (EquivalenceMember *) lfirst(lc1);
if (prev_em != NULL)
{
@@ -2189,6 +2296,9 @@ reconsider_outer_join_clause(PlannerInfo *root, OuterJoinClauseInfo *ojcinfo,
bool match;
ListCell *lc2;
+ /* We don't expect any children yet */
+ Assert(cur_ec->ec_childmembers == NULL);
+
/* Ignore EC unless it contains pseudoconstants */
if (!cur_ec->ec_has_const)
continue;
@@ -2206,7 +2316,8 @@ reconsider_outer_join_clause(PlannerInfo *root, OuterJoinClauseInfo *ojcinfo,
{
EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc2);
- Assert(!cur_em->em_is_child); /* no children yet */
+ Assert(!cur_em->em_is_child); /* Child members should not exist
+ * in ec_members */
if (equal(outervar, cur_em->em_expr))
{
match = true;
@@ -2304,6 +2415,9 @@ reconsider_full_join_clause(PlannerInfo *root, OuterJoinClauseInfo *ojcinfo)
ListCell *lc2;
int coal_idx = -1;
+ /* We don't expect any children yet */
+ Assert(cur_ec->ec_childmembers == NULL);
+
/* Ignore EC unless it contains pseudoconstants */
if (!cur_ec->ec_has_const)
continue;
@@ -2333,7 +2447,8 @@ reconsider_full_join_clause(PlannerInfo *root, OuterJoinClauseInfo *ojcinfo)
foreach(lc2, cur_ec->ec_members)
{
coal_em = (EquivalenceMember *) lfirst(lc2);
- Assert(!coal_em->em_is_child); /* no children yet */
+ Assert(!coal_em->em_is_child); /* Child members should not exist
+ * in ec_members */
if (IsA(coal_em->em_expr, CoalesceExpr))
{
CoalesceExpr *cexpr = (CoalesceExpr *) coal_em->em_expr;
@@ -2462,6 +2577,9 @@ rebuild_eclass_attr_needed(PlannerInfo *root)
{
EquivalenceClass *ec = (EquivalenceClass *) lfirst(lc);
+ /* We don't expect any children yet */
+ Assert(ec->ec_childmembers == NULL);
+
/* Need do anything only for a multi-member, no-const EC. */
if (list_length(ec->ec_members) > 1 && !ec->ec_has_const)
{
@@ -2547,12 +2665,13 @@ exprs_known_equal(PlannerInfo *root, Node *item1, Node *item2, Oid opfamily)
!list_member_oid(ec->ec_opfamilies, opfamily))
continue;
+ /* Ignore children here */
foreach(lc2, ec->ec_members)
{
EquivalenceMember *em = (EquivalenceMember *) lfirst(lc2);
- if (em->em_is_child)
- continue; /* ignore children here */
+ Assert(!em->em_is_child); /* Child members should not exist in
+ * ec_members */
if (equal(item1, em->em_expr))
item1member = true;
else if (equal(item2, em->em_expr))
@@ -2616,15 +2735,18 @@ match_eclasses_to_foreign_key_col(PlannerInfo *root,
/* Never match to a volatile EC */
if (ec->ec_has_volatile)
continue;
- /* It's okay to consider "broken" ECs here, see exprs_known_equal */
+ /*
+ * It's okay to consider "broken" ECs here, see exprs_known_equal.
+ * Ignore children here.
+ */
foreach(lc2, ec->ec_members)
{
EquivalenceMember *em = (EquivalenceMember *) lfirst(lc2);
Var *var;
- if (em->em_is_child)
- continue; /* ignore children here */
+ /* Child members should not exist in ec_members */
+ Assert(!em->em_is_child);
/* EM must be a Var, possibly with RelabelType */
var = (Var *) em->em_expr;
@@ -2710,6 +2832,7 @@ add_child_rel_equivalences(PlannerInfo *root,
Relids top_parent_relids = child_rel->top_parent_relids;
Relids child_relids = child_rel->relids;
int i;
+ ListCell *lc;
/*
* EC merging should be complete already, so we can use the parent rel's
@@ -2722,7 +2845,6 @@ add_child_rel_equivalences(PlannerInfo *root,
while ((i = bms_next_member(parent_rel->eclass_indexes, i)) >= 0)
{
EquivalenceClass *cur_ec = (EquivalenceClass *) list_nth(root->eq_classes, i);
- int num_members;
/*
* If this EC contains a volatile expression, then generating child
@@ -2735,29 +2857,15 @@ add_child_rel_equivalences(PlannerInfo *root,
/* Sanity check eclass_indexes only contain ECs for parent_rel */
Assert(bms_is_subset(top_parent_relids, cur_ec->ec_relids));
- /*
- * We don't use foreach() here because there's no point in scanning
- * newly-added child members, so we can stop after the last
- * pre-existing EC member.
- */
- num_members = list_length(cur_ec->ec_members);
- for (int pos = 0; pos < num_members; pos++)
+ foreach(lc, cur_ec->ec_members)
{
- EquivalenceMember *cur_em = (EquivalenceMember *) list_nth(cur_ec->ec_members, pos);
+ EquivalenceMember *cur_em = lfirst_node(EquivalenceMember, lc);
if (cur_em->em_is_const)
continue; /* ignore consts here */
- /*
- * We consider only original EC members here, not
- * already-transformed child members. Otherwise, if some original
- * member expression references more than one appendrel, we'd get
- * an O(N^2) explosion of useless derived expressions for
- * combinations of children. (But add_child_join_rel_equivalences
- * may add targeted combinations for partitionwise-join purposes.)
- */
- if (cur_em->em_is_child)
- continue; /* ignore children here */
+ /* Child members should not exist in ec_members */
+ Assert(!cur_em->em_is_child);
/*
* Consider only members that reference and can be computed at
@@ -2802,12 +2910,15 @@ add_child_rel_equivalences(PlannerInfo *root,
top_parent_relids);
new_relids = bms_add_members(new_relids, child_relids);
- (void) add_eq_member(cur_ec, child_expr, new_relids,
- cur_em->em_jdomain,
- cur_em, cur_em->em_datatype);
-
- /* Record this EC index for the child rel */
- child_rel->eclass_indexes = bms_add_member(child_rel->eclass_indexes, i);
+ add_child_eq_member(root,
+ cur_ec,
+ i,
+ child_expr,
+ new_relids,
+ cur_em->em_jdomain,
+ cur_em,
+ cur_em->em_datatype,
+ child_rel->relids);
}
}
}
@@ -2854,7 +2965,7 @@ add_child_join_rel_equivalences(PlannerInfo *root,
while ((i = bms_next_member(matching_ecs, i)) >= 0)
{
EquivalenceClass *cur_ec = (EquivalenceClass *) list_nth(root->eq_classes, i);
- int num_members;
+ ListCell *lc;
/*
* If this EC contains a volatile expression, then generating child
@@ -2867,25 +2978,15 @@ add_child_join_rel_equivalences(PlannerInfo *root,
/* Sanity check on get_eclass_indexes_for_relids result */
Assert(bms_overlap(top_parent_relids, cur_ec->ec_relids));
- /*
- * We don't use foreach() here because there's no point in scanning
- * newly-added child members, so we can stop after the last
- * pre-existing EC member.
- */
- num_members = list_length(cur_ec->ec_members);
- for (int pos = 0; pos < num_members; pos++)
+ foreach(lc, cur_ec->ec_members)
{
- EquivalenceMember *cur_em = (EquivalenceMember *) list_nth(cur_ec->ec_members, pos);
+ EquivalenceMember *cur_em = lfirst_node(EquivalenceMember, lc);
if (cur_em->em_is_const)
continue; /* ignore consts here */
- /*
- * We consider only original EC members here, not
- * already-transformed child members.
- */
- if (cur_em->em_is_child)
- continue; /* ignore children here */
+ /* Child members should not exist in ec_members */
+ Assert(!cur_em->em_is_child);
/*
* We may ignore expressions that reference a single baserel,
@@ -2930,9 +3031,15 @@ add_child_join_rel_equivalences(PlannerInfo *root,
top_parent_relids);
new_relids = bms_add_members(new_relids, child_relids);
- (void) add_eq_member(cur_ec, child_expr, new_relids,
- cur_em->em_jdomain,
- cur_em, cur_em->em_datatype);
+ add_child_eq_member(root,
+ cur_ec,
+ -1,
+ child_expr,
+ new_relids,
+ cur_em->em_jdomain,
+ cur_em,
+ cur_em->em_datatype,
+ child_joinrel->relids);
}
}
}
@@ -2979,14 +3086,18 @@ add_setop_child_rel_equivalences(PlannerInfo *root, RelOptInfo *child_rel,
* We can safely pass the parent member as the first member in the
* ec_members list as this is added first in generate_union_paths,
* likewise, the JoinDomain can be that of the initial member of the
- * Pathkey's EquivalenceClass.
+ * Pathkey's EquivalenceClass. We pass -1 for ec_index since we
+ * maintain the eclass_indexes for the child_rel after the loop.
*/
- add_eq_member(pk->pk_eclass,
- tle->expr,
- child_rel->relids,
- parent_em->em_jdomain,
- parent_em,
- exprType((Node *) tle->expr));
+ add_child_eq_member(root,
+ pk->pk_eclass,
+ -1,
+ tle->expr,
+ child_rel->relids,
+ parent_em->em_jdomain,
+ parent_em,
+ exprType((Node *) tle->expr),
+ child_rel->relids);
lc2 = lnext(setop_pathkeys, lc2);
}
@@ -3001,6 +3112,83 @@ add_setop_child_rel_equivalences(PlannerInfo *root, RelOptInfo *child_rel,
list_length(root->eq_classes) - 1);
}
+/*
+ * setup_eclass_member_iterator
+ * Setup an EquivalenceMemberIterator 'it' to iterate over all parent
+ * EquivalenceMembers and child members belonging to the given 'ec'.
+ *
+ * This iterator returns:
+ * - All parent members stored directly in ec_members for 'ec', and;
+ * - Any child member added to the given ec by add_child_eq_member() where
+ * the child_relids specified in the add_child_eq_member() overlap with
+ * the child_relids in the setup_eclass_member_iterator() call.
+ *
+ * Note:
+ * - The given 'child_relids' must remain allocated and not be changed for
+ * the lifetime of the iterator.
+ *
+ * Parameters:
+ * it - A pointer to the iterator to set up.
+ * ec - The EquivalenceClass from which to iterate members.
+ * child_relids - The relids to return child members for.
+ */
+void
+setup_eclass_member_iterator(EquivalenceMemberIterator *it,
+ EquivalenceClass *ec, Relids child_relids)
+{
+ it->ec = ec;
+ /* no need to set this if the class has no child members */
+ it->child_relids = ec->ec_childmembers ? child_relids : NULL;
+ it->current_relid = -1;
+ it->current_list = ec->ec_members;
+ it->current_cell = list_head(it->current_list);
+}
+
+/*
+ * eclass_member_iterator_next
+ * Get a next EquivalenceMember from an EquivalenceMemberIterator 'it'
+ * that was setup by setup_eclass_member_iterator(). NULL is
+ * returned if there are no members left, in which case callers must not
+ * call eclass_member_iterator_next() again for the given iterator.
+ */
+EquivalenceMember *
+eclass_member_iterator_next(EquivalenceMemberIterator *it)
+{
+ EquivalenceMember *em = NULL;
+
+ while (it->current_list != NULL)
+ {
+nextcell:
+ while (it->current_cell != NULL)
+ {
+ em = lfirst_node(EquivalenceMember, it->current_cell);
+ it->current_cell = lnext(it->current_list, it->current_cell);
+ goto end;
+ }
+
+ /* Search for the next list to return members from */
+ while ((it->current_relid = bms_next_member(it->child_relids, it->current_relid)) > 0)
+ {
+ it->current_list = it->ec->ec_childmembers[it->current_relid];
+
+ /*
+ * If there are members in this list, use it, this will exclude
+ * RELOPT_BASERELs as ec_childmembers[] are not populated for
+ * those.
+ */
+ if (it->current_list != NIL)
+ {
+ /* point current_cell to the head of this list */
+ it->current_cell = list_head(it->current_list);
+ goto nextcell;
+ }
+ }
+ goto end;
+ }
+
+end:
+ return em;
+}
/*
* generate_implied_equalities_for_column
@@ -3053,6 +3241,7 @@ generate_implied_equalities_for_column(PlannerInfo *root,
while ((i = bms_next_member(rel->eclass_indexes, i)) >= 0)
{
EquivalenceClass *cur_ec = (EquivalenceClass *) list_nth(root->eq_classes, i);
+ EquivalenceMemberIterator it;
EquivalenceMember *cur_em;
ListCell *lc2;
@@ -3076,14 +3265,12 @@ generate_implied_equalities_for_column(PlannerInfo *root,
* corner cases, so for now we live with just reporting the first
* match. See also get_eclass_for_sort_expr.)
*/
- cur_em = NULL;
- foreach(lc2, cur_ec->ec_members)
+ setup_eclass_member_iterator(&it, cur_ec, rel->relids);
+ while ((cur_em = eclass_member_iterator_next(&it)) != NULL)
{
- cur_em = (EquivalenceMember *) lfirst(lc2);
if (bms_equal(cur_em->em_relids, rel->relids) &&
callback(root, rel, cur_ec, cur_em, callback_arg))
break;
- cur_em = NULL;
}
if (!cur_em)
@@ -3091,7 +3278,7 @@ generate_implied_equalities_for_column(PlannerInfo *root,
/*
* Found our match. Scan the other EC members and attempt to generate
- * joinclauses.
+ * joinclauses. Ignore children here.
*/
foreach(lc2, cur_ec->ec_members)
{
@@ -3099,8 +3286,8 @@ generate_implied_equalities_for_column(PlannerInfo *root,
Oid eq_op;
RestrictInfo *rinfo;
- if (other_em->em_is_child)
- continue; /* ignore children here */
+ /* Child members should not exist in ec_members */
+ Assert(!other_em->em_is_child);
/* Make sure it'll be a join to a different rel */
if (other_em == cur_em ||
@@ -3313,13 +3500,15 @@ eclass_useful_for_merging(PlannerInfo *root,
if (bms_is_subset(eclass->ec_relids, relids))
return false;
- /* To join, we need a member not in the given rel */
+ /*
+ * To join, we need a member not in the given rel. Ignore children here.
+ */
foreach(lc, eclass->ec_members)
{
EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc);
- if (cur_em->em_is_child)
- continue; /* ignore children here */
+ /* Child members should not exist in ec_members */
+ Assert(!cur_em->em_is_child);
if (!bms_overlap(cur_em->em_relids, relids))
return true;
diff --git a/src/backend/optimizer/path/indxpath.c b/src/backend/optimizer/path/indxpath.c
index 4cabb358abc..601354ea3e0 100644
--- a/src/backend/optimizer/path/indxpath.c
+++ b/src/backend/optimizer/path/indxpath.c
@@ -3755,7 +3755,8 @@ match_pathkeys_to_index(IndexOptInfo *index, List *pathkeys,
{
PathKey *pathkey = (PathKey *) lfirst(lc1);
bool found = false;
- ListCell *lc2;
+ EquivalenceMemberIterator it;
+ EquivalenceMember *member;
/* Pathkey must request default sort order for the target opfamily */
@@ -3774,9 +3775,10 @@ match_pathkeys_to_index(IndexOptInfo *index, List *pathkeys,
* be considered to match more than one pathkey list, which is OK
* here. See also get_eclass_for_sort_expr.)
*/
- foreach(lc2, pathkey->pk_eclass->ec_members)
+ setup_eclass_member_iterator(&it, pathkey->pk_eclass,
+ index->rel->relids);
+ while ((member = eclass_member_iterator_next(&it)) != NULL)
{
- EquivalenceMember *member = (EquivalenceMember *) lfirst(lc2);
int indexcol;
/* No possibility of match if it references other relations */
diff --git a/src/backend/optimizer/path/pathkeys.c b/src/backend/optimizer/path/pathkeys.c
index 6fac08cb0d9..4e8923e383e 100644
--- a/src/backend/optimizer/path/pathkeys.c
+++ b/src/backend/optimizer/path/pathkeys.c
@@ -1143,6 +1143,7 @@ convert_subquery_pathkeys(PlannerInfo *root, RelOptInfo *rel,
int best_score = -1;
ListCell *j;
+ /* Ignore children here */
foreach(j, sub_eclass->ec_members)
{
EquivalenceMember *sub_member = (EquivalenceMember *) lfirst(j);
@@ -1151,8 +1152,8 @@ convert_subquery_pathkeys(PlannerInfo *root, RelOptInfo *rel,
Oid sub_expr_coll = sub_eclass->ec_collation;
ListCell *k;
- if (sub_member->em_is_child)
- continue; /* ignore children here */
+ /* Child members should not exist in ec_members */
+ Assert(!sub_member->em_is_child);
foreach(k, subquery_tlist)
{
@@ -1709,8 +1710,11 @@ select_outer_pathkeys_for_merge(PlannerInfo *root,
{
EquivalenceMember *em = (EquivalenceMember *) lfirst(lc2);
+ /* Child members should not exist in ec_members */
+ Assert(!em->em_is_child);
+
/* Potential future join partner? */
- if (!em->em_is_const && !em->em_is_child &&
+ if (!em->em_is_const &&
!bms_overlap(em->em_relids, joinrel->relids))
score++;
}
diff --git a/src/backend/optimizer/plan/analyzejoins.c b/src/backend/optimizer/plan/analyzejoins.c
index ae20691ca91..c9f3b7f08ef 100644
--- a/src/backend/optimizer/plan/analyzejoins.c
+++ b/src/backend/optimizer/plan/analyzejoins.c
@@ -710,6 +710,13 @@ remove_rel_from_eclass(EquivalenceClass *ec, SpecialJoinInfo *sjinfo,
ec->ec_relids = adjust_relid_set(ec->ec_relids,
sjinfo->ojrelid, subst);
+ /*
+ * We don't expect any EC child members to exist at this point. Ensure
+ * that's the case, otherwise we might be getting asked to do something
+ * this function hasn't been coded for.
+ */
+ Assert(ec->ec_childmembers == NULL);
+
/*
* Fix up the member expressions. Any non-const member that ends with
* empty em_relids must be a Var or PHV of the removed relation. We don't
@@ -1509,6 +1516,13 @@ update_eclasses(EquivalenceClass *ec, int from, int to)
List *new_members = NIL;
List *new_sources = NIL;
+ /*
+ * We don't expect any EC child members to exist at this point. Ensure
+ * that's the case, otherwise we might be getting asked to do something
+ * this function hasn't been coded for.
+ */
+ Assert(ec->ec_childmembers == NULL);
+
foreach_node(EquivalenceMember, em, ec->ec_members)
{
bool is_redundant = false;
diff --git a/src/include/nodes/pathnodes.h b/src/include/nodes/pathnodes.h
index 4c466f76778..59ddafca1cf 100644
--- a/src/include/nodes/pathnodes.h
+++ b/src/include/nodes/pathnodes.h
@@ -1414,6 +1414,22 @@ typedef struct JoinDomain
* In contrast, ec_sources holds equality clauses that appear directly in the
* query. These are typically few and do not require a hash table for lookup.
*
+ * 'ec_members' is a List of all EquivalenceMembers belonging to
+ * RELOPT_BASERELs. EquivalenceMembers for any RELOPT_OTHER_MEMBER_REL and
+ * RELOPT_OTHER_JOINREL relations are stored in the 'ec_childmembers' array in
+ * the index corresponding to the relid. 'ec_childmembers' may be NULL if the
+ * class has no child EquivalenceMembers.
+ *
+ * For code wishing to look at EquivalenceMembers, if only parent-level
+ * members are needed, then a simple foreach loop over ec_members is
+ * sufficient. When child members are also required, it is best to use the
+ * functionality provided by EquivalenceMemberIterator. The reason for this
+ * is because large numbers of child EquivalenceMembers can exist in queries
+ * to partitioned tables with many partitions. The functionality provided by
+ * EquivalenceMemberIterator allows efficient access to EquivalenceMembers
+ * which belong to specific child relids. See the header comments for
+ * EquivalenceMemberIterator below for further details.
+ *
* NB: if ec_merged isn't NULL, this class has been merged into another, and
* should be ignored in favor of using the pointed-to class.
*
@@ -1431,7 +1447,10 @@ typedef struct EquivalenceClass
List *ec_opfamilies; /* btree operator family OIDs */
Oid ec_collation; /* collation, if datatypes are collatable */
+ int ec_childmembers_size; /* # elements in ec_childmembers */
List *ec_members; /* list of EquivalenceMembers */
+ List **ec_childmembers; /* array of Lists of child
+ * EquivalenceMembers */
List *ec_sources; /* list of generating RestrictInfos */
List *ec_derives_list; /* list of derived RestrictInfos */
struct derives_hash *ec_derives_hash; /* optional hash table for fast
@@ -1465,12 +1484,17 @@ typedef struct EquivalenceClass
* child when necessary to build a MergeAppend path for the whole appendrel
* tree. An em_is_child member has no impact on the properties of the EC as a
* whole; in particular the EC's ec_relids field does NOT include the child
- * relation. An em_is_child member should never be marked em_is_const nor
- * cause ec_has_const or ec_has_volatile to be set, either. Thus, em_is_child
+ * relation. em_is_child members aren't stored in the ec_members List of the
+ * EC and instead they're stored and indexed by the relids of the child
+ * relation(s) they represent equivalence for in ec_childmembers. An
+ * em_is_child member should never be marked em_is_const nor cause
+ * ec_has_const or ec_has_volatile to be set, either. Thus, em_is_child
* members are not really full-fledged members of the EC, but just reflections
* or doppelgangers of real members. Most operations on EquivalenceClasses
- * should ignore em_is_child members, and those that don't should test
- * em_relids to make sure they only consider relevant members.
+ * should ignore em_is_child members by only inspecting members in the
+ * ec_members list. Callers that require inspecting child members should do
+ * so using an EquivalenceMemberIterator and should test em_relids to make
+ * sure they only consider relevant members.
*
* em_datatype is usually the same as exprType(em_expr), but can be
* different when dealing with a binary-compatible opfamily; in particular
@@ -1493,6 +1517,70 @@ typedef struct EquivalenceMember
struct EquivalenceMember *em_parent pg_node_attr(read_write_ignore);
} EquivalenceMember;
+/*
+ * EquivalenceMemberIterator
+ *
+ * EquivalenceMemberIterator allows efficient access to sets of
+ * EquivalenceMembers for callers which require access to child members.
+ * Because partitioning workloads can result in large numbers of child
+ * members, the child members are not stored in the EquivalenceClass's
+ * ec_members List. Instead, these are stored in the EquivalenceClass's
+ * ec_childmembers array of Lists. The functionality provided by
+ * EquivalenceMemberIterator aims to provide efficient access to parent
+ * members and child members belonging to specific child relids.
+ *
+ * Currently, there is only one way to initialize and iterate over an
+ * EquivalenceMemberIterator and that is via the setup_eclass_member_iterator
+ * and eclass_member_iterator_next functions. The iterator object is
+ * generally a local variable which is passed by address to
+ * setup_eclass_member_iterator. The calling function defines which
+ * EquivalenceClass the iterator should be looking at and which child
+ * relids to also include the members for. child_relids can be passed as NULL
+ * but the caller may as well just perform a foreach loop over ec_members as
+ * only parent-level members will be returned in that case.
+ *
+ * When calling the next function on an EquivalenceMemberIterator, all
+ * parent-level EquivalenceMembers are returned first, followed by any
+ * child members for the relids specified by the child_relids parameter as
+ * specified when calling setup_eclass_member_iterator. The child members
+ * returned are members which have any of the relids mentioned in
+ * child_relids. That's not to be confused with returning members which
+ * contain *all* of the child relids specified when calling
+ * setup_eclass_member_iterator. It is up to the calling function to ensure
+ * that the returned member matches what is required for the purpose.
+ *
+ * It is also important to note that when dealing with child
+ * EquivalenceMembers for RELOPT_OTHER_JOINRELs that it's possible for the
+ * same EquivalenceMembers to be returned more than once by the next function.
+ * This is currently not seen to be a problem, but some callers may want to be
+ * aware of it.
+ *
+ * The most common way to use this iterator is as follows:
+ * -----
+ * EquivalenceMemberIterator it;
+ * EquivalenceMember *em;
+ *
+ * setup_eclass_member_iterator(&it, ec, child_relids);
+ * while ((em = eclass_member_iterator_next(&it)) != NULL)
+ * {
+ * ...
+ * }
+ * -----
+ * It is not valid to call eclass_member_iterator_next() after it has returned
+ * NULL for any given EquivalenceMemberIterator.
+ */
+typedef struct
+{
+ EquivalenceClass *ec; /* The EquivalenceClass to iterate over */
+ int current_relid; /* Current relid position within 'relids'. -1
+ * when still looping over ec_members and -2
+ * at the end of iteration */
+ Relids child_relids; /* Relids of child relations of interest.
+ * Non-child rels are ignored */
+ ListCell *current_cell; /* Next cell to return within current_list */
+ List *current_list; /* Current list of members being returned */
+} EquivalenceMemberIterator;
+
/*
* PathKeys
*
diff --git a/src/include/optimizer/paths.h b/src/include/optimizer/paths.h
index b1a76816442..a48c9721797 100644
--- a/src/include/optimizer/paths.h
+++ b/src/include/optimizer/paths.h
@@ -183,6 +183,10 @@ extern void add_setop_child_rel_equivalences(PlannerInfo *root,
RelOptInfo *child_rel,
List *child_tlist,
List *setop_pathkeys);
+extern void setup_eclass_member_iterator(EquivalenceMemberIterator *it,
+ EquivalenceClass *ec,
+ Relids child_relids);
+extern EquivalenceMember *eclass_member_iterator_next(EquivalenceMemberIterator *it);
extern List *generate_implied_equalities_for_column(PlannerInfo *root,
RelOptInfo *rel,
ec_matches_callback_type callback,
diff --git a/src/tools/pgindent/typedefs.list b/src/tools/pgindent/typedefs.list
index c3f05796a7c..1513b247d9d 100644
--- a/src/tools/pgindent/typedefs.list
+++ b/src/tools/pgindent/typedefs.list
@@ -711,6 +711,7 @@ EphemeralNamedRelationMetadata
EphemeralNamedRelationMetadataData
EquivalenceClass
EquivalenceMember
+EquivalenceMemberIterator
ErrorContextCallback
ErrorData
ErrorSaveContext
On Sat, 5 Apr 2025 at 04:05, Tom Lane <tgl@sss.pgh.pa.us> wrote: > This patchset has a distinct whiff of unseemly haste. hmm, yes. I would like to give this patch as good a chance at making v18 as I can, and I admit to having optimised for that. Seemingly, we've got a few other good partitioning performance patches in v18, and more workloads are now bottlenecked on what this patch aims to fix than ever before. What I'm aiming to avoid here is tuning those optimisations to cloud my judgment on the quality of the patch. So, I'm happy to have your 2nd opinion here. > 1. The commit message for 0002 still claims that child EC members > are kept in RelOptInfos, precisely the point I objected to upthread. > I see that in fact that's untrue, but it'd be nice if the commit log > had some connection to what's being committed. Now adjusted. > 2. Because there is no longer any need to find RelOptInfos, the > EquivalenceMemberIterator stuff doesn't need a "root" pointer, > either in the struct or as an setup_eclass_member_iterator argument. > > 3. Because of #2, the 0001 patch is useless code churn and should > be dropped. I'm glad that's not needed now. Thanks for noticing. Fixed. > I do note that add_child_eq_member seems to have a considerable > amount of faith that root->simple_rel_array_size can't increase > after we start adding child members. That seems rather unsafe, > though the fact that it hasn't crashed in light testing suggests > that maybe there's something I'm missing. I would be much > happier if there were provision to expand the array at need. I think it's probably worth making that safer. add_child_rel_equivalences() is currently called after add_other_rels_to_query(). It is a similar story in the union planner for add_setop_child_rel_equivalences(), but that's likely no reason to not be a bit more cautious. I am still thinking about the duplicate members being returned from the iterator for child join rels due to them being duplicated into each component relid element in ec_childmembers. I did consider if these could just not be duplicated and instead just put into the ec_childmember element according to their lowest component relid. For that to work, all callers that need these would need to ensure they never pass some subset of child_relids when setting up the EquivalenceMemberIterator. I need to study a bit more to understand if that's doable. In the meantime, I've attached v40 with a rewritten commit message, a bit more adjustment to comments and a slightly revised version of eclass_member_iterator_next() to get rid of some gotos and hopefully make it easier to follow the logic. Thank you for looking. David
Attachment
On Sat, 5 Apr 2025 at 16:55, David Rowley <dgrowleyml@gmail.com> wrote: > I am still thinking about the duplicate members being returned from > the iterator for child join rels due to them being duplicated into > each component relid element in ec_childmembers. I did consider if > these could just not be duplicated and instead just put into the > ec_childmember element according to their lowest component relid. For > that to work, all callers that need these would need to ensure they > never pass some subset of child_relids when setting up the > EquivalenceMemberIterator. I need to study a bit more to understand if > that's doable. It looks like the child members added by add_child_join_rel_equivalences() are only required for pathkey requirements. The EquivalenceMember mentions: * for an appendrel child. These members are used for determining the * pathkeys of scans on the child relation and for explicitly sorting the * child when necessary to build a MergeAppend path for the whole appendrel * tree. An em_is_child member has no impact on the properties of the EC as a I used the attached .txt file to highlight the places where the iterator returned the same member twice and saw only that find_ec_member_matching_expr() does this. Because during createplan, we'll have the specific RelOptInfo that we need the EquivalenceMember for, we'll be passing the "relids" of that RelOptInfo to setup_eclass_member_iterator(), in which case, I think it's fine to store the member in just one of the ec_childmembers[] array slots for just one of the relids making up the RELOPT_OTHER_JOINREL's component relids as that means it'll be found once only due to how eclass_member_iterator_next() looks at all of the ec_childmembers[] elements for the given relids. Doing this also allows the code in add_child_eq_member() to be simplified. I made this happen in the attached v41 patch, and that's the last outstanding issue that I had for this. I think this is worthy of getting into v18. Does anyone else think differently? It'd be good to know that soon. David
Attachment
Hello David, Thank you very much for updating the patches and clearly addressing these points. On Mon, Apr 7, 2025 at 8:04 AM David Rowley <dgrowleyml@gmail.com> wrote: > > I used the attached .txt file to highlight the places where the > iterator returned the same member twice and saw only that > find_ec_member_matching_expr() does this. > > Because during createplan, we'll have the specific RelOptInfo that we > need the EquivalenceMember for, we'll be passing the "relids" of that > RelOptInfo to setup_eclass_member_iterator(), in which case, I think > it's fine to store the member in just one of the ec_childmembers[] > array slots for just one of the relids making up the > RELOPT_OTHER_JOINREL's component relids as that means it'll be found > once only due to how eclass_member_iterator_next() looks at all of the > ec_childmembers[] elements for the given relids. > > Doing this also allows the code in add_child_eq_member() to be simplified. I agree with you. Using the first member of relids as the array index is simple, clear, and effective, significantly simplifying the logic and implementation. > I made this happen in the attached v41 patch, and that's the last > outstanding issue that I had for this. > > I think this is worthy of getting into v18. Does anyone else think > differently? It'd be good to know that soon. Thank you very much for sharing this new patch. It looks good to me, and I'd also be very happy to see this committed in v18. -- Best regards, Yuya Watari
David Rowley <dgrowleyml@gmail.com> writes:
> I think this is worthy of getting into v18. Does anyone else think
> differently? It'd be good to know that soon.
v41 passes an eyeball check for me.
regards, tom lane
On Mon, Apr 7, 2025 at 4:34 AM David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Sat, 5 Apr 2025 at 16:55, David Rowley <dgrowleyml@gmail.com> wrote:
> > I am still thinking about the duplicate members being returned from
> > the iterator for child join rels due to them being duplicated into
> > each component relid element in ec_childmembers. I did consider if
> > these could just not be duplicated and instead just put into the
> > ec_childmember element according to their lowest component relid. For
> > that to work, all callers that need these would need to ensure they
> > never pass some subset of child_relids when setting up the
> > EquivalenceMemberIterator. I need to study a bit more to understand if
> > that's doable.
>
> It looks like the child members added by
> add_child_join_rel_equivalences() are only required for pathkey
> requirements. The EquivalenceMember mentions:
>
> * for an appendrel child. These members are used for determining the
> * pathkeys of scans on the child relation and for explicitly sorting the
> * child when necessary to build a MergeAppend path for the whole appendrel
> * tree. An em_is_child member has no impact on the properties of the EC as a
>
> I used the attached .txt file to highlight the places where the
> iterator returned the same member twice and saw only that
> find_ec_member_matching_expr() does this.
>
> Because during createplan, we'll have the specific RelOptInfo that we
> need the EquivalenceMember for, we'll be passing the "relids" of that
> RelOptInfo to setup_eclass_member_iterator(), in which case, I think
> it's fine to store the member in just one of the ec_childmembers[]
> array slots for just one of the relids making up the
> RELOPT_OTHER_JOINREL's component relids as that means it'll be found
> once only due to how eclass_member_iterator_next() looks at all of the
> ec_childmembers[] elements for the given relids.
>
> Doing this also allows the code in add_child_eq_member() to be simplified.
>
> I made this happen in the attached v41 patch, and that's the last
> outstanding issue that I had for this.
>
> I think this is worthy of getting into v18. Does anyone else think
> differently? It'd be good to know that soon.
I took a quick look at patch 0001. I have some questions and cosmetic comments
- foreach(lc2, cur_ec->ec_members)
+ setup_eclass_member_iterator(&it, cur_ec, rel);
+ while ((cur_em = eclass_member_iterator_next(&it)) != NULL)
{
- EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc2);
-
/*
* Ignore child members unless they match the request.
*/
Can this step be executed in the iterator itself?
find_ec_member_matching_expr() also does something similar but uses
bms_is_subset() instead of bms_equal(). The BMS comparison operation
to use itself could be an argument to the iterator. The iterator knows
when it has started looking for child members and it also scans the
ec_members by relids, so I guess we could eliminate many comparisons
and boolean variable check.
generate_join_implied_equalities_normal() also compares relids but it
performs three comparisons, probably one of the comparisons can be
pushed into the iterator.
Scanning the code further I see why we can't do relids comparison in
the iterator itself - because we don't store ec_member in the array
elements correspodning each of relids participating in it. Let's say
an EM has em_relids (10, 11, 12) all child rels, but the EM is stored
only in list of array element corresponding to 10. If someone searches
EMs with em_relids containing 11, 12 only, this EM will be missed.
* the iterator
* will return members where the em_relids overlaps the child_relids specified
* when calling setup_eclass_member_iterator(). The caller may wish to ensure
* the em_relids is a subset of the relids they're searching for.
em_relids should be subset of or equal to child_relids specified,
otherwise it may be missed as explained above. We should rephrase the
sentence as " The caller should ensure ...". "May wish to" indicates
an optional thing, but it doesn't look optional to me.
@@ -725,7 +819,9 @@ get_eclass_for_sort_expr(PlannerInfo *root,
newec = makeNode(EquivalenceClass);
newec->ec_opfamilies = list_copy(opfamilies);
newec->ec_collation = collation;
+ newec->ec_childmembers_size = 0;
newec->ec_members = NIL;
How about renaming ec_members to ec_parent_members to make it
explicit. That might break extensions that use ec_members but that way
they would know that the purpose of this list has changed and it will
nudge them to use ec_parent_member of EC iterator appropriately.
@@ -2461,6 +2577,9 @@ rebuild_eclass_attr_needed(PlannerInfo *root)
{
EquivalenceClass *ec = (EquivalenceClass *) lfirst(lc);
+ /* We don't expect any children yet */
+ Assert(ec->ec_childmembers == NULL);
+
This function's prologue or comments inside it do not mention this.
Also the loop over ec_members prior to your change didn't exclude
child ec_members explicitly. So, I guess, we need to add a comment
mentioning why child ec members are not expected here.
- /*
- * We don't use foreach() here because there's no point in scanning
- * newly-added child members, so we can stop after the last
- * pre-existing EC member.
- */
- num_members = list_length(cur_ec->ec_members);
- for (int pos = 0; pos < num_members; pos++)
+ foreach(lc, cur_ec->ec_members)
Since you are adding a new foreach loop, does it make sense to use
foreach_node() instead?
- /*
- * We don't use foreach() here because there's no point in scanning
- * newly-added child members, so we can stop after the last
- * pre-existing EC member.
- */
- num_members = list_length(cur_ec->ec_members);
- for (int pos = 0; pos < num_members; pos++)
+ foreach(lc, cur_ec->ec_members)
foreach_node instead of foreach?
+ /*
+ * We don't expect any EC child members to exist at this point. Ensure
+ * that's the case, otherwise we might be getting asked to do something
+ * this function hasn't been coded for.
+ */
+ Assert(ec->ec_childmembers == NULL);
+
In find_em_for_rel_target() we have Assert(!em->em_is_child), but here
it's different Assert for the same purpose. It would be good to be
consistent in all such places either Asserting !em->em_is_child in the
loop or Assert(ec->ec_childmembers) OR both as you have done in
process_equivalence().
I am also surprised that the function does not have any comment or
Assert about child ec_members. It might be good to explain why we
don't expect any child members in this function. Or do you think that
the explanation is unnecessary.
@@ -1509,6 +1516,13 @@ update_eclasses(EquivalenceClass *ec, int from, int to)
List *new_members = NIL;
List *new_sources = NIL;
+ /*
+ * We don't expect any EC child members to exist at this point. Ensure
+ * that's the case, otherwise we might be getting asked to do something
+ * this function hasn't been coded for.
+ */
+ Assert(ec->ec_childmembers == NULL);
+
Similar to above.
--
Best Wishes,
Ashutosh Bapat
On Tue, 8 Apr 2025 at 04:54, Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
> - foreach(lc2, cur_ec->ec_members)
> + setup_eclass_member_iterator(&it, cur_ec, rel);
> + while ((cur_em = eclass_member_iterator_next(&it)) != NULL)
> {
> - EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc2);
> -
> /*
> * Ignore child members unless they match the request.
> */
>
> Can this step be executed in the iterator itself?
Yes, all the filtering requested *could* be done within the iterator.
The problem with doing that is that there's not even nearly a single
pattern to what callers need. Here's a summary of all 7 users of it:
1. get_eclass_for_sort_expr: CHILD members must have em_relids EQUAL
to rel (TYPE 1)
2. generate_join_implied_equalities_normal: ALL members must be a
SUBSET of join_relids (TYPE 2)
3. generate_implied_equalities_for_column: ALL members must have
em_relids EQUAL to rel->relids (TYPE 3)
4. find_em_for_rel: ALL members must be a SUBSET of rel->relids (TYPE 2)
5. find_ec_member_matching_expr: CHILD members must have em_relids
SUBSET of relids (TYPE 4)
6. find_computable_ec_member: CHILD members must have em_relids SUBSET
of relids (TYPE 4)
7. match_pathkeys_to_index: ALL members must have em_relids EQUAL to
index->rel->relids (TYPE 3)
So, 4 distinct requirements and only types 3 and 4 are repeated.
Certainly, we could code up the iterator to handle all those different
requirements, but would that code be easy to follow? Do you think 1
iterator should handle all those requirements with a set of IF
statements? I think that would be more difficult to read than how the
patch has it now.
An alternative that I did consider, and even put a comment on the 2nd
paragraph of the header comment for EquivalenceMemberIterator about,
is the possibility of having multiple iterators for different
purposes. That would save the spaghetti code of IF statements doing it
in 1 iterator and alleviate the performance overhead of the spaghetti
code too. The problem is that there's still not a common pattern
that's followed often enough. If I wrote 4 iterators, I'd need to give
them meaningful names. Names like
eclass_member_iterator_children_with_subset_of_next are a too long and
if I was writing new code that was to call some function like that,
I'd probably be happier just doing the filtering locally than trying
to find which of the 4 iterators is the one I want.
> find_ec_member_matching_expr() also does something similar but uses
> bms_is_subset() instead of bms_equal(). The BMS comparison operation
> to use itself could be an argument to the iterator. The iterator knows
> when it has started looking for child members and it also scans the
> ec_members by relids, so I guess we could eliminate many comparisons
> and boolean variable check.
Performance-wise, it would be nicer to filter within the iterator as
calling next() once per loop means an external function call on each
loop. Unfortunately, I don't think there's a common enough pattern to
warrant all the iterators that are needed. I feel we'd need to see
some demonstratable performance improvements to warrant adding
special-purpose iterators. I expect those will be quite small, but
happy if someone proves me wrong. I'd rather not hold up the patch for
a hypothetical 1-2% on some workload when the current patch as-is
gives 20x for some tested other workloads.
> generate_join_implied_equalities_normal() also compares relids but it
> performs three comparisons, probably one of the comparisons can be
> pushed into the iterator.
Could be. There's also the overhead of having to document each
iterator so that callers know what's handled and what they need to
handle themselves.
> Scanning the code further I see why we can't do relids comparison in
> the iterator itself - because we don't store ec_member in the array
> elements correspodning each of relids participating in it. Let's say
> an EM has em_relids (10, 11, 12) all child rels, but the EM is stored
> only in list of array element corresponding to 10. If someone searches
> EMs with em_relids containing 11, 12 only, this EM will be missed.
That currently won't happen as the only child members which have
multiple relids is em_relids are RELOPT_OTHER_JOINREL and they're only
searched during create plan. Those searches are always done with all
the relids belonging to that RELOPT_OTHER_JOINREL. This is the reason
I think it's ok to store the member for that in the slot for relid 10
(in this example)
> * the iterator
> * will return members where the em_relids overlaps the child_relids specified
> * when calling setup_eclass_member_iterator(). The caller may wish to ensure
> * the em_relids is a subset of the relids they're searching for.
>
> em_relids should be subset of or equal to child_relids specified,
> otherwise it may be missed as explained above. We should rephrase the
> sentence as " The caller should ensure ...". "May wish to" indicates
> an optional thing, but it doesn't look optional to me.
That comment does not know what the caller needs to do. That's up to
the caller. If every caller needed to do that, we might as well just
filter non-matching ones out in the iterator itself.
I did rewrite that comment quite a bit in the attached version as I
still wasn't quite happy with the wording. I still didn't make any
assumptions about what the caller wants, however.
> @@ -725,7 +819,9 @@ get_eclass_for_sort_expr(PlannerInfo *root,
> newec = makeNode(EquivalenceClass);
> newec->ec_opfamilies = list_copy(opfamilies);
> newec->ec_collation = collation;
> + newec->ec_childmembers_size = 0;
> newec->ec_members = NIL;
>
> How about renaming ec_members to ec_parent_members to make it
> explicit. That might break extensions that use ec_members but that way
> they would know that the purpose of this list has changed and it will
> nudge them to use ec_parent_member of EC iterator appropriately.
The reason I didn't rename that field is mainly because I'm fine with
the current name. In my view, I think of parent members as normal
members of the class and only the child members are 2nd class members.
You can see evidence of that line of thought in the patch with
add_eq_member() not being called add_parent_eq_member().
One reason that I did think about in favour of a rename was to
purposefully break any extension code using that field. I didn't
look, but I imagine that Citus and maybe Timescale could be extensions
that might have code that needs to be updated. However, I do imagine
it won't take them very long to notice their stuff isn't working. Do
you think we need to make it so their compiler prompts them to fix the
code? The rename is permanent, and breaking extensions is just a
transient thing between now and whenever extension authors release
their v18-supported extension. If I thought the breakage was something
subtle, I'd be more inclined to agree to the rename.
I certainly could get on board with renaming if there's consensus to
do so. I don't think that's going to happen in the next 9 hours. Is it
worth pushing this out to v19 because we can't agree on the name of a
struct field? I'd be disappointed if we miss this because of something
so trivial.
> @@ -2461,6 +2577,9 @@ rebuild_eclass_attr_needed(PlannerInfo *root)
> {
> EquivalenceClass *ec = (EquivalenceClass *) lfirst(lc);
> + /* We don't expect any children yet */
> + Assert(ec->ec_childmembers == NULL);
> +
>
> This function's prologue or comments inside it do not mention this.
> Also the loop over ec_members prior to your change didn't exclude
> child ec_members explicitly. So, I guess, we need to add a comment
> mentioning why child ec members are not expected here.
I've added some comments there. I had already done something similar
in analyzejoins.c
> - /*
> - * We don't use foreach() here because there's no point in scanning
> - * newly-added child members, so we can stop after the last
> - * pre-existing EC member.
> - */
> - num_members = list_length(cur_ec->ec_members);
> - for (int pos = 0; pos < num_members; pos++)
> + foreach(lc, cur_ec->ec_members)
>
> Since you are adding a new foreach loop, does it make sense to use
> foreach_node() instead?
OK. I am in favour of new code using those. It's a nicer API. I've
edited the patch
> + /*
> + * We don't expect any EC child members to exist at this point. Ensure
> + * that's the case, otherwise we might be getting asked to do something
> + * this function hasn't been coded for.
> + */
> + Assert(ec->ec_childmembers == NULL);
> +
>
> In find_em_for_rel_target() we have Assert(!em->em_is_child), but here
> it's different Assert for the same purpose. It would be good to be
> consistent in all such places either Asserting !em->em_is_child in the
> loop or Assert(ec->ec_childmembers) OR both as you have done in
> process_equivalence().
I think this might not be obvious when reading the patch, but I think
where the confusion might be starting is that
"Assert(!cur_em->em_is_child);" isn't asserting what it used to. In
unpatched master, there are a few places that do that to verify the
function is never called after child members have been added. The
patch changes the meaning of this Assert. The comment was updated in a
bid to try to make this more obvious. The Assert's new purpose is to
ensure no child members snuck into the ec_members list. For the
functions that fundamentally don't expect children to exist yet, I've
added an Assert(cur_ec->ec_childmembers == NULL) to ensure that
remains true. I believe I'm consistent with that and I believe that's
a worthwhile assert to make.
Occasionally, there are Asserts to check there are no child members in
ec_members elsewhere in places where ec_childmembers might contain
children. I believe all the Asserts doing this were all converted from
an "if (ec->em_is_child) continue;" statement. I don't feel the need
to add this assert everywhere that we loop over ec_members. It does
not seem likely that we'd get an em_is_child member in ec_members as
there's only a single place where the ec_members list is adjusted.
I'd be more easily convinced we can just delete all those Asserts than
I could be to add more.
> I am also surprised that the function does not have any comment or
> Assert about child ec_members. It might be good to explain why we
> don't expect any child members in this function. Or do you think that
> the explanation is unnecessary.
>
> @@ -1509,6 +1516,13 @@ update_eclasses(EquivalenceClass *ec, int from, int to)
> List *new_members = NIL;
> List *new_sources = NIL;
> + /*
> + * We don't expect any EC child members to exist at this point. Ensure
> + * that's the case, otherwise we might be getting asked to do something
> + * this function hasn't been coded for.
> + */
> + Assert(ec->ec_childmembers == NULL);
> +
>
> Similar to above.
The patch isn't adding any new reason for this. If you want this then
I'll need to go and figure out all the existing reasons and document
them. However, I think it's a simple case that these functions are
always called before children exist and are coded with that
assumption. I think the comment I added for this in analyzejoins.c
works ok. I think for cases such as process_equivalence(), it's much
more fundamental that children can't exist yet, as we're still working
on figuring out what the parent members are going to be. So it's not a
case of the function just not being coded to handle children as it is
in analyzejoins.c.
I've attached a version with the foreach_node() changes included. I've
also done some extensive work on the comments to try to make the API
of the interator easier to understand. There's also a small
optimisation made to eclass_member_iterator_next() to move a goto
label to save having to recheck if the ListCell is NULL when moving to
the next list. We're already pointing to the proven non-empty list
head at that point, so we don't need to check the ListCell is NULL
twice.
David
Attachment
David Rowley <dgrowleyml@gmail.com> writes:
> I certainly could get on board with renaming if there's consensus to
> do so. I don't think that's going to happen in the next 9 hours. Is it
> worth pushing this out to v19 because we can't agree on the name of a
> struct field? I'd be disappointed if we miss this because of something
> so trivial.
Renaming functions or struct fields is hardly something that's forbidden
post-feature-freeze. I think you could go ahead while agreeing to
change that stuff later if there's consensus for it. At this point it
seems much more useful to get some buildfarm mileage on the patch.
(FWIW, I buy your argument that there's a limit to how much complexity
we should shove into the iterator.)
regards, tom lane
On Tue, Apr 8, 2025 at 8:30 AM David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Tue, 8 Apr 2025 at 04:54, Ashutosh Bapat
> <ashutosh.bapat.oss@gmail.com> wrote:
> > - foreach(lc2, cur_ec->ec_members)
> > + setup_eclass_member_iterator(&it, cur_ec, rel);
> > + while ((cur_em = eclass_member_iterator_next(&it)) != NULL)
> > {
> > - EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc2);
> > -
> > /*
> > * Ignore child members unless they match the request.
> > */
> >
> > Can this step be executed in the iterator itself?
>
> Yes, all the filtering requested *could* be done within the iterator.
> The problem with doing that is that there's not even nearly a single
> pattern to what callers need. Here's a summary of all 7 users of it:
>
> 1. get_eclass_for_sort_expr: CHILD members must have em_relids EQUAL
> to rel (TYPE 1)
> 2. generate_join_implied_equalities_normal: ALL members must be a
> SUBSET of join_relids (TYPE 2)
> 3. generate_implied_equalities_for_column: ALL members must have
> em_relids EQUAL to rel->relids (TYPE 3)
> 4. find_em_for_rel: ALL members must be a SUBSET of rel->relids (TYPE 2)
> 5. find_ec_member_matching_expr: CHILD members must have em_relids
> SUBSET of relids (TYPE 4)
> 6. find_computable_ec_member: CHILD members must have em_relids SUBSET
> of relids (TYPE 4)
> 7. match_pathkeys_to_index: ALL members must have em_relids EQUAL to
> index->rel->relids (TYPE 3)
>
> So, 4 distinct requirements and only types 3 and 4 are repeated.
> Certainly, we could code up the iterator to handle all those different
> requirements, but would that code be easy to follow? Do you think 1
> iterator should handle all those requirements with a set of IF
> statements? I think that would be more difficult to read than how the
> patch has it now.
>
> An alternative that I did consider, and even put a comment on the 2nd
> paragraph of the header comment for EquivalenceMemberIterator about,
> is the possibility of having multiple iterators for different
> purposes. That would save the spaghetti code of IF statements doing it
> in 1 iterator and alleviate the performance overhead of the spaghetti
> code too. The problem is that there's still not a common pattern
> that's followed often enough. If I wrote 4 iterators, I'd need to give
> them meaningful names. Names like
> eclass_member_iterator_children_with_subset_of_next are a too long and
> if I was writing new code that was to call some function like that,
> I'd probably be happier just doing the filtering locally than trying
> to find which of the 4 iterators is the one I want.
Thanks for listing all the patterns. Creating four different iterators
is going to affect functionality and might require duplicate code. But
each of the patterns is using exactly one BMS operation on em_relids
and relids being used as search criteria. That BMS operation/function
pointer can be passed to the iterator. I have not looked into whether
each of those BMS functions return boolean or not OR whether all the
functions take arguments in the same order. But, those things can be
fixed. However, given that the feature freeze deadline is so close,
it's fine to do it later either during the beta phase or in PG 19. The
speed up would be small enough to be noticeable in PG 18 given this
and other improvements that have gone in.
>
> > * the iterator
> > * will return members where the em_relids overlaps the child_relids specified
> > * when calling setup_eclass_member_iterator(). The caller may wish to ensure
> > * the em_relids is a subset of the relids they're searching for.
> >
> > em_relids should be subset of or equal to child_relids specified,
> > otherwise it may be missed as explained above. We should rephrase the
> > sentence as " The caller should ensure ...". "May wish to" indicates
> > an optional thing, but it doesn't look optional to me.
>
> That comment does not know what the caller needs to do. That's up to
> the caller. If every caller needed to do that, we might as well just
> filter non-matching ones out in the iterator itself.
>
> I did rewrite that comment quite a bit in the attached version as I
> still wasn't quite happy with the wording. I still didn't make any
> assumptions about what the caller wants, however.
I have tried to improve it further in the attached diff. Please accept
the diff if you find it useful and if time permits.
>
> > @@ -725,7 +819,9 @@ get_eclass_for_sort_expr(PlannerInfo *root,
> > newec = makeNode(EquivalenceClass);
> > newec->ec_opfamilies = list_copy(opfamilies);
> > newec->ec_collation = collation;
> > + newec->ec_childmembers_size = 0;
> > newec->ec_members = NIL;
> >
> > How about renaming ec_members to ec_parent_members to make it
> > explicit. That might break extensions that use ec_members but that way
> > they would know that the purpose of this list has changed and it will
> > nudge them to use ec_parent_member of EC iterator appropriately.
>
> The reason I didn't rename that field is mainly because I'm fine with
> the current name. In my view, I think of parent members as normal
> members of the class and only the child members are 2nd class members.
> You can see evidence of that line of thought in the patch with
> add_eq_member() not being called add_parent_eq_member().
I think the distinction between parent and child is useful. So I will
still suggest renaming the field but it can be done
post-feature-freeze. Tom seems to be fine with that per his last email
on the thread. If we do earlier in the beta cycle like in April
itself, that will give enough time for the extension authors to adjust
their code, if necessary.
> > + /*
> > + * We don't expect any EC child members to exist at this point. Ensure
> > + * that's the case, otherwise we might be getting asked to do something
> > + * this function hasn't been coded for.
> > + */
> > + Assert(ec->ec_childmembers == NULL);
> > +
> >
> > In find_em_for_rel_target() we have Assert(!em->em_is_child), but here
> > it's different Assert for the same purpose. It would be good to be
> > consistent in all such places either Asserting !em->em_is_child in the
> > loop or Assert(ec->ec_childmembers) OR both as you have done in
> > process_equivalence().
>
> I think this might not be obvious when reading the patch, but I think
> where the confusion might be starting is that
> "Assert(!cur_em->em_is_child);" isn't asserting what it used to. In
> unpatched master, there are a few places that do that to verify the
> function is never called after child members have been added. The
> patch changes the meaning of this Assert. The comment was updated in a
> bid to try to make this more obvious. The Assert's new purpose is to
> ensure no child members snuck into the ec_members list. For the
> functions that fundamentally don't expect children to exist yet, I've
> added an Assert(cur_ec->ec_childmembers == NULL) to ensure that
> remains true. I believe I'm consistent with that and I believe that's
> a worthwhile assert to make.
>
> Occasionally, there are Asserts to check there are no child members in
> ec_members elsewhere in places where ec_childmembers might contain
> children. I believe all the Asserts doing this were all converted from
> an "if (ec->em_is_child) continue;" statement. I don't feel the need
> to add this assert everywhere that we loop over ec_members. It does
> not seem likely that we'd get an em_is_child member in ec_members as
> there's only a single place where the ec_members list is adjusted.
> I'd be more easily convinced we can just delete all those Asserts than
> I could be to add more.
Thanks for the clarification. That's very useful
Attached diff also brings ec_childmembers_size closer to
ec_childmembers - usual practice of keeping the array and its size
together.
Thanks for all your last minute work. I think this is good to go for PG 18.
--
Best Wishes,
Ashutosh Bapat
Attachment
On Tue, 8 Apr 2025 at 17:41, Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > Thanks for listing all the patterns. Creating four different iterators > is going to affect functionality and might require duplicate code. But > each of the patterns is using exactly one BMS operation on em_relids > and relids being used as search criteria. That BMS operation/function > pointer can be passed to the iterator. I have not looked into whether > each of those BMS functions return boolean or not OR whether all the > functions take arguments in the same order. But, those things can be > fixed. However, given that the feature freeze deadline is so close, > it's fine to do it later either during the beta phase or in PG 19. The > speed up would be small enough to be noticeable in PG 18 given this > and other improvements that have gone in. I'll be happy to see further speedups proposed here. I doubt we'll see much in the same league as this one, but a % here and there are often welcome, providing the added complexity is acceptable. > I think the distinction between parent and child is useful. So I will > still suggest renaming the field but it can be done > post-feature-freeze. Tom seems to be fine with that per his last email > on the thread. If we do earlier in the beta cycle like in April > itself, that will give enough time for the extension authors to adjust > their code, if necessary. That's fine for me. I did grep the Citus codebase earlier to look for ec_member usages and I did see one. So, let's see who complains first. > Attached diff also brings ec_childmembers_size closer to > ec_childmembers - usual practice of keeping the array and its size > together. The reason I put it where it was is because it was filling a 4-byte hole in the struct. I'd not tested any performance with it located in a place that would cause the struct to be enlarged. IMO, we should be allowed some flexibility here for such small struct. I don't think having it 1 field up is confusing. We could swap ec_members and ec_childmembers positions if you feel strongly. I've pushed the patch now. Thanks for all the reviews of my adjustments. Thanks to Yuya for persisting on this for so many years. I was impressed with that persistence and also with your very detailed and easy to understand performance benchmark results. This feels like (all going well) it's making v18 is big win for the big partitioning users of Postgres. I kind of feel the "up to a few thousand partitions fairly well" in [1] has been abused by many or taken without the caveat of "the query planner to prune all but a small number of partitions" over the years and the "Never just assume that more partitions are better than fewer partitions, nor vice-versa." has been ignored by too many. It's good that the people pushing these limits will no longer be getting as big an unwelcome surprise now (I hope). Or, at least, onto the next bottleneck. Maybe relcache :) I've attached a dump of the performance tests of v42 I did an hour or so ago with up to 8K partitions. That's where I got the 60x numbers I hinted at in the commit message. David [1] https://www.postgresql.org/docs/current/ddl-partitioning.html#DDL-PARTITIONING-DECLARATIVE-BEST-PRACTICES
Attachment
Hello David, On Tue, Apr 8, 2025 at 3:31 PM David Rowley <dgrowleyml@gmail.com> wrote: > > I've pushed the patch now. Thanks for all the reviews of my adjustments. Thank you very much for pushing the patch! I also wish to extend my deepest thanks to everyone who has contributed to reviewing and improving this patch. > Thanks to Yuya for persisting on this for so many years. I was > impressed with that persistence and also with your very detailed and > easy to understand performance benchmark results. This feels like > (all going well) it's making v18 is big win for the big partitioning > users of Postgres. I kind of feel the "up to a few thousand partitions > fairly well" in [1] has been abused by many or taken without the > caveat of "the query planner to prune all but a small number of > partitions" over the years and the "Never just assume that more > partitions are better than fewer partitions, nor vice-versa." has been > ignored by too many. It's good that the people pushing these limits > will no longer be getting as big an unwelcome surprise now (I hope). > Or, at least, onto the next bottleneck. Maybe relcache :) This work could not have been realized without your significant contributions. You have provided many valuable ideas and efforts since I first proposed the patch three years ago. I would like to express my sincere thanks for your continued and extensive support. I hope that this work we have done together will greatly benefit users managing highly partitioned configurations. It has truly been an honor for me to work closely with you and all the reviewers on this work. It would be my pleasure to continue contributing to PostgreSQL. -- Best regards, Yuya Watari
David Rowley <dgrowleyml@gmail.com> writes:
> I've pushed the patch now. Thanks for all the reviews of my adjustments.
Shouldn't the CF entry be marked committed?
> Thanks to Yuya for persisting on this for so many years. I was
> impressed with that persistence and also with your very detailed and
> easy to understand performance benchmark results.
+1
regards, tom lane
On Wed, 9 Apr 2025 at 02:24, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > I've pushed the patch now. Thanks for all the reviews of my adjustments. > > Shouldn't the CF entry be marked committed? I've done that now. 88f55bc97 added code to do faster lookups of ec_derives clauses, so I think that likely renders part of the remaining patches obsolete. The v35-0004 also had some indexing of ec_sources. It would be good to know if there's still any gains to be had from indexing those. If there's work to do, then a new CF entry can be made for that. David
Hi David,
On Wed, Apr 9, 2025 at 5:12 AM David Rowley <dgrowleyml@gmail.com> wrote:
> On Wed, 9 Apr 2025 at 02:24, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >
> > David Rowley <dgrowleyml@gmail.com> writes:
> > > I've pushed the patch now. Thanks for all the reviews of my adjustments.
> >
> > Shouldn't the CF entry be marked committed?
>
> I've done that now.
Should the following paragraph in src/backend/optimizer/README be
updated to reflect the new reality after recent changes?
An EquivalenceClass can contain "em_is_child" members, which are copies
of members that contain appendrel parent relation Vars, transposed to
contain the equivalent child-relation variables or expressions. These
members are not full-fledged members of the EquivalenceClass and do not
affect the class's overall properties at all. They are kept only to
simplify matching of child-relation expressions to EquivalenceClasses.
Most operations on EquivalenceClasses should ignore child members.
The part about these being in the EquivalenceClass might be worth
rewording now that we keep them in a separate array.
--
Thanks, Amit Langote
Amit Langote <amitlangote09@gmail.com> writes:
> Should the following paragraph in src/backend/optimizer/README be
> updated to reflect the new reality after recent changes?
> An EquivalenceClass can contain "em_is_child" members, which are copies
> of members that contain appendrel parent relation Vars, transposed to
> contain the equivalent child-relation variables or expressions.
Hm. They still are "in" the EquivalenceClass in a very real sense;
there is no other data structure that links to them. So this isn't
incorrect. I do get your feeling that maybe some rewording is
warranted, but I'm not sure what.
regards, tom lane
On Wed, 9 Apr 2025 at 17:09, Amit Langote <amitlangote09@gmail.com> wrote: > Should the following paragraph in src/backend/optimizer/README be > updated to reflect the new reality after recent changes? > > An EquivalenceClass can contain "em_is_child" members, which are copies > of members that contain appendrel parent relation Vars, transposed to > contain the equivalent child-relation variables or expressions. These > members are not full-fledged members of the EquivalenceClass and do not > affect the class's overall properties at all. They are kept only to > simplify matching of child-relation expressions to EquivalenceClasses. > Most operations on EquivalenceClasses should ignore child members. > > The part about these being in the EquivalenceClass might be worth > rewording now that we keep them in a separate array. I did read over that as part of the search I did for things that need to be updated, but I didn't see the need to adjust anything since the text doesn't talk about where the members are stored. The only thing I see as a hint to that is the final sentence. If the README is light on documentation about where members are stored, do we really need to start detailing that because of this change? I've tried to be fairly comprehensive about where members are stored in the header comment for struct EquivalenceClass. Wouldn't stating something similar in the README just be duplicating that? I always think of the READMEs as more of an overview on how things fit together with some high-level theory. I think talking about data structures might be a bit too much detail. I'm happy to view wording suggestions if you think we need to detail this further. Maybe there's something that can be adjusted without going into too much depth. David
On Wed, Apr 9, 2025 at 10:51 AM David Rowley <dgrowleyml@gmail.com> wrote: > > On Wed, 9 Apr 2025 at 17:09, Amit Langote <amitlangote09@gmail.com> wrote: > > Should the following paragraph in src/backend/optimizer/README be > > updated to reflect the new reality after recent changes? > > > > An EquivalenceClass can contain "em_is_child" members, which are copies > > of members that contain appendrel parent relation Vars, transposed to > > contain the equivalent child-relation variables or expressions. These > > members are not full-fledged members of the EquivalenceClass and do not > > affect the class's overall properties at all. They are kept only to > > simplify matching of child-relation expressions to EquivalenceClasses. > > Most operations on EquivalenceClasses should ignore child members. > > > > The part about these being in the EquivalenceClass might be worth > > rewording now that we keep them in a separate array. > > I did read over that as part of the search I did for things that need > to be updated, but I didn't see the need to adjust anything since the > text doesn't talk about where the members are stored. The only thing > I see as a hint to that is the final sentence. > > If the README is light on documentation about where members are > stored, do we really need to start detailing that because of this > change? I've tried to be fairly comprehensive about where members are > stored in the header comment for struct EquivalenceClass. Wouldn't > stating something similar in the README just be duplicating that? I > always think of the READMEs as more of an overview on how things fit > together with some high-level theory. I think talking about data > structures might be a bit too much detail. This change didn't require us to change the README indicates that the README is at the right level. The code changes internally reorganize how child EMs are stored within an EC, so changing the comments for relevant structures seems good enough, not a change that should bubble up to the README. The only change in the EC interface is the addition of a new iterator method - maybe we could document that in README but that too seems more detail than what README is about. -- Best Wishes, Ashutosh Bapat
On Wed, Apr 9, 2025 at 2:21 PM David Rowley <dgrowleyml@gmail.com> wrote: > On Wed, 9 Apr 2025 at 17:09, Amit Langote <amitlangote09@gmail.com> wrote: > > Should the following paragraph in src/backend/optimizer/README be > > updated to reflect the new reality after recent changes? > > > > An EquivalenceClass can contain "em_is_child" members, which are copies > > of members that contain appendrel parent relation Vars, transposed to > > contain the equivalent child-relation variables or expressions. These > > members are not full-fledged members of the EquivalenceClass and do not > > affect the class's overall properties at all. They are kept only to > > simplify matching of child-relation expressions to EquivalenceClasses. > > Most operations on EquivalenceClasses should ignore child members. > > > > The part about these being in the EquivalenceClass might be worth > > rewording now that we keep them in a separate array. > > I did read over that as part of the search I did for things that need > to be updated, but I didn't see the need to adjust anything since the > text doesn't talk about where the members are stored. The only thing > I see as a hint to that is the final sentence. > > If the README is light on documentation about where members are > stored, do we really need to start detailing that because of this > change? I've tried to be fairly comprehensive about where members are > stored in the header comment for struct EquivalenceClass. Wouldn't > stating something similar in the README just be duplicating that? I > always think of the READMEs as more of an overview on how things fit > together with some high-level theory. I think talking about data > structures might be a bit too much detail. > > I'm happy to view wording suggestions if you think we need to detail > this further. Maybe there's something that can be adjusted without > going into too much depth. Fair point that the current text isn't wrong (as Tom says) -- and we do have the storage details in the struct comment already as you say. Still, maybe a tiny tweak to the last line could help steer readers right without diving into storage. How about: Most operations on EquivalenceClasses should ignore child members, which are stored separately from normal members. No big deal either way -- just throwing it out there. -- Thanks, Amit Langote
On Wed, 9 Apr 2025 at 17:38, Amit Langote <amitlangote09@gmail.com> wrote: > Still, maybe a tiny tweak to the last line could help steer readers > right without diving into storage. How about: > > Most operations on EquivalenceClasses should ignore child members, > which are stored separately from normal members. I think the only part of the current text that makes me slightly uncomfortable is the "ignore child members". I don't mind your text, but it does introduce detail about how the members are stored, which isn't there before. I think the "ignore child members" part could be fixed with: --- a/src/backend/optimizer/README +++ b/src/backend/optimizer/README @@ -902,7 +902,7 @@ contain the equivalent child-relation variables or expressions. These members are *not* full-fledged members of the EquivalenceClass and do not affect the class's overall properties at all. They are kept only to simplify matching of child-relation expressions to EquivalenceClasses. -Most operations on EquivalenceClasses should ignore child members. +Most operations on EquivalenceClasses needn't look at child members. Would that be ok? David
On Thu, Apr 10, 2025 at 12:03 PM David Rowley <dgrowleyml@gmail.com> wrote: > On Wed, 9 Apr 2025 at 17:38, Amit Langote <amitlangote09@gmail.com> wrote: > > Still, maybe a tiny tweak to the last line could help steer readers > > right without diving into storage. How about: > > > > Most operations on EquivalenceClasses should ignore child members, > > which are stored separately from normal members. > > I think the only part of the current text that makes me slightly > uncomfortable is the "ignore child members". I don't mind your text, > but it does introduce detail about how the members are stored, which > isn't there before. > > I think the "ignore child members" part could be fixed with: > > --- a/src/backend/optimizer/README > +++ b/src/backend/optimizer/README > @@ -902,7 +902,7 @@ contain the equivalent child-relation variables or > expressions. These > members are *not* full-fledged members of the EquivalenceClass and do not > affect the class's overall properties at all. They are kept only to > simplify matching of child-relation expressions to EquivalenceClasses. > -Most operations on EquivalenceClasses should ignore child members. > +Most operations on EquivalenceClasses needn't look at child members. > > Would that be ok? Yeah, I think that wording works well. It avoids sounding too strict but still points things in the right direction. -- Thanks, Amit Langote
On Thu, 10 Apr 2025 at 16:57, Amit Langote <amitlangote09@gmail.com> wrote: > > On Thu, Apr 10, 2025 at 12:03 PM David Rowley <dgrowleyml@gmail.com> wrote: > > -Most operations on EquivalenceClasses should ignore child members. > > +Most operations on EquivalenceClasses needn't look at child members. > > > > Would that be ok? > > Yeah, I think that wording works well. It avoids sounding too strict > but still points things in the right direction. Thanks. Pushed. David
On Thu, Apr 10, 2025 at 2:35 PM David Rowley <dgrowleyml@gmail.com> wrote: > On Thu, 10 Apr 2025 at 16:57, Amit Langote <amitlangote09@gmail.com> wrote: > > > > On Thu, Apr 10, 2025 at 12:03 PM David Rowley <dgrowleyml@gmail.com> wrote: > > > -Most operations on EquivalenceClasses should ignore child members. > > > +Most operations on EquivalenceClasses needn't look at child members. > > > > > > Would that be ok? > > > > Yeah, I think that wording works well. It avoids sounding too strict > > but still points things in the right direction. > > Thanks. Pushed. Thank you. -- Thanks, Amit Langote