Re: [PoC] Reducing planning time when tables have many partitions - Mailing list pgsql-hackers
| From | Yuya Watari |
|---|---|
| Subject | Re: [PoC] Reducing planning time when tables have many partitions |
| Date | |
| Msg-id | CAJ2pMka2PBXNNzUfe0-ksFsxVN+gmfKq7aGQ5v35TcpjFG3Ggg@mail.gmail.com Whole thread |
| In response to | Re: [PoC] Reducing planning time when tables have many partitions (David Rowley <dgrowleyml@gmail.com>) |
| Responses |
Re: [PoC] Reducing planning time when tables have many partitions
|
| List | pgsql-hackers |
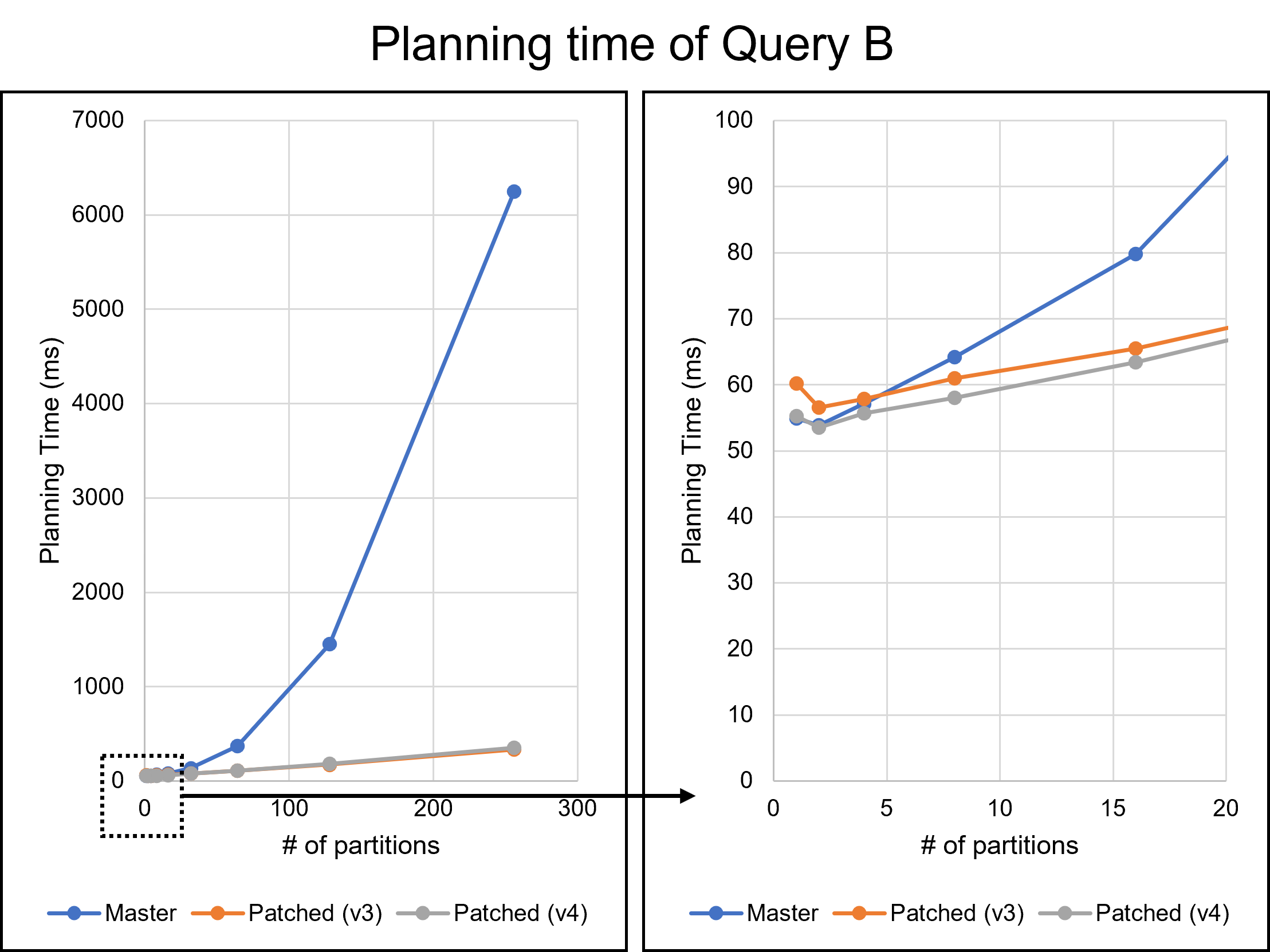
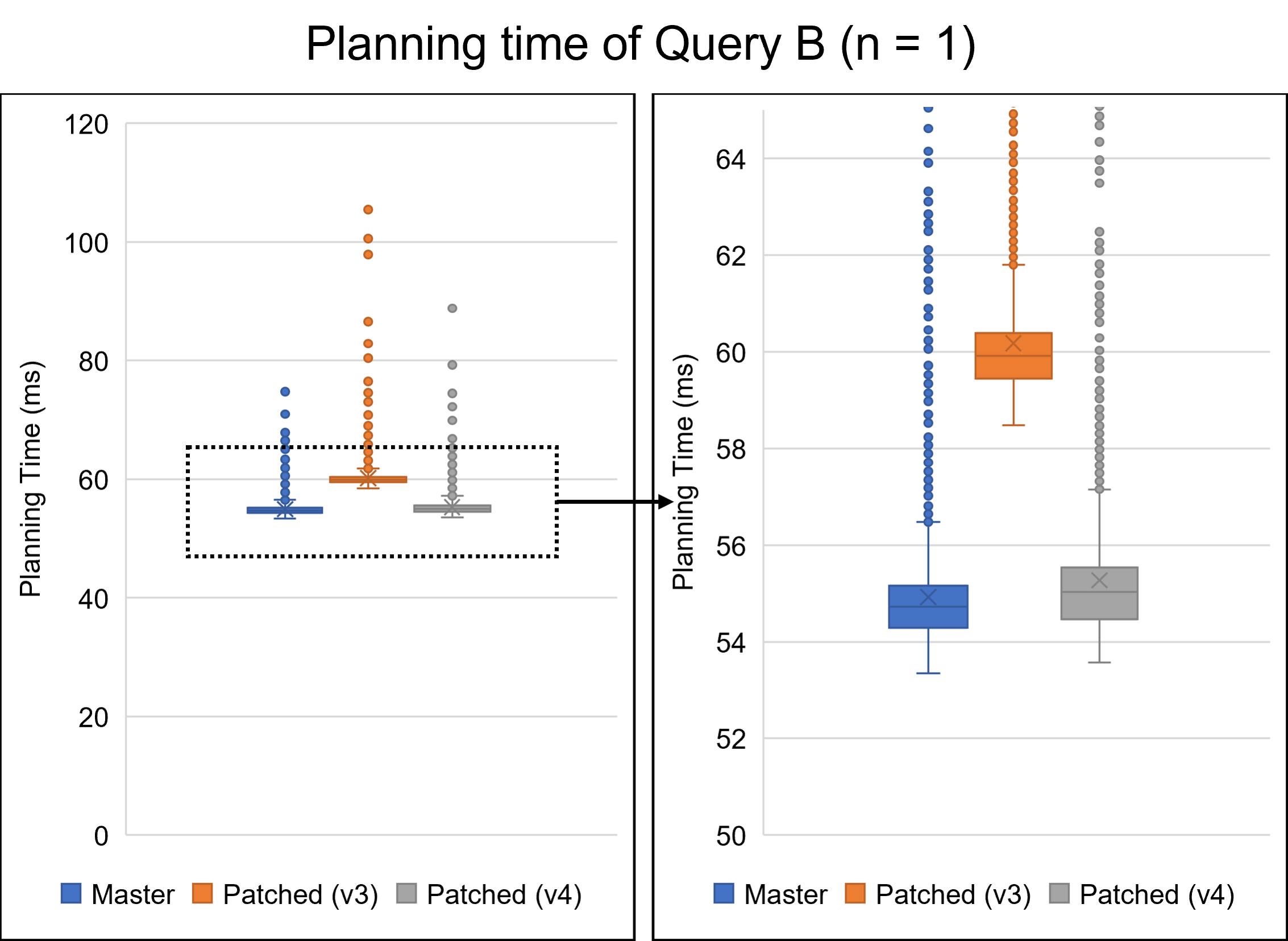
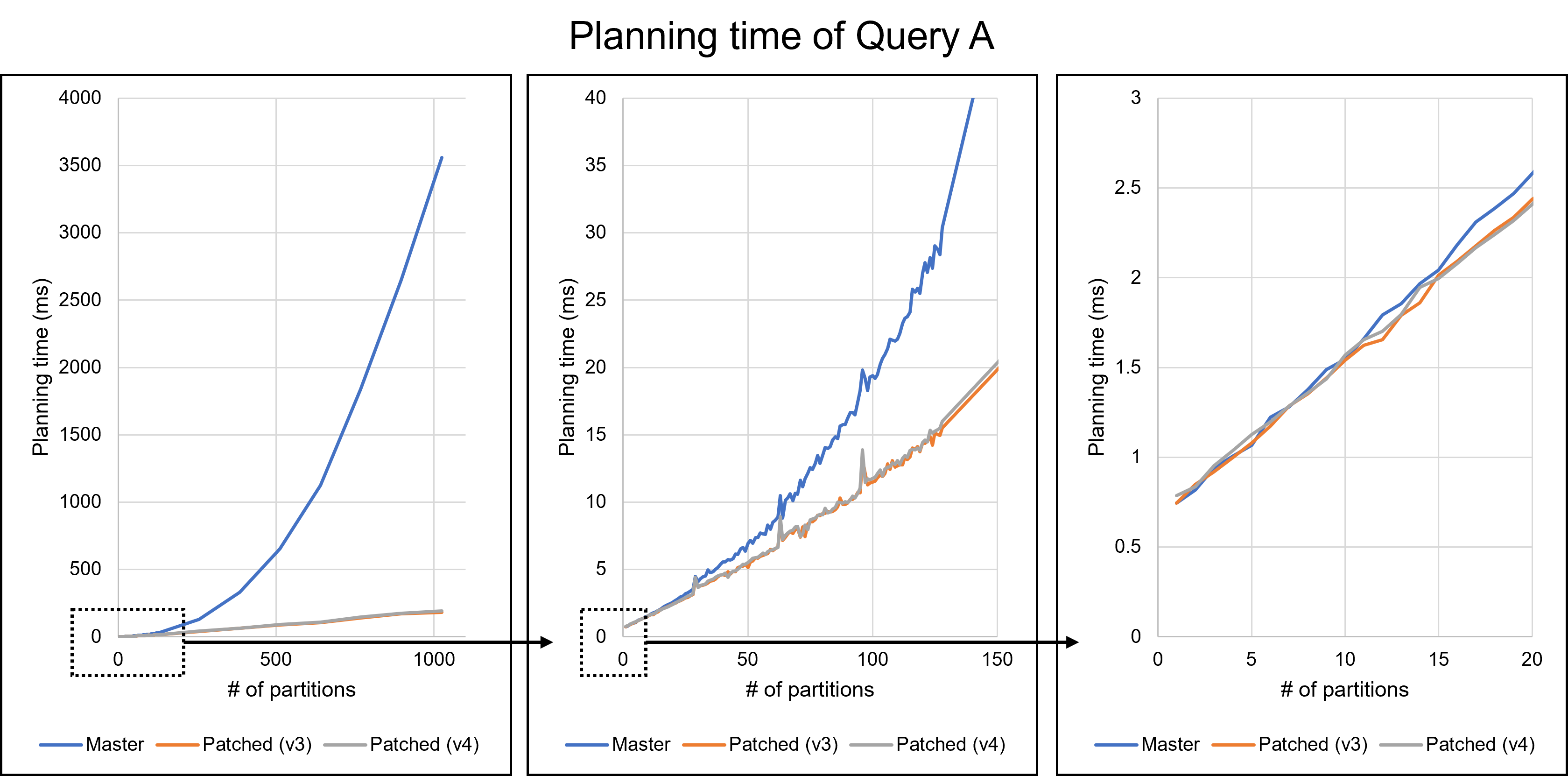
Dear David, I really appreciate your reply and your modifying the patch. The performance improvements are quite impressive. I believe these improvements will help PostgreSQL users. Thank you again. > The 2 partition does regress slightly. There might be a few > things we can do about that I tried to solve this regression problem. From here, I will refer to the patch you sent on August 16th as the v3 patch. I will also call my patch attached to this email the v4 patch. I will discuss the v4 patch later. Additionally, I give names to queries. * Query A: The query we have been using in previous emails, which joins students, scores, and gpas tables. * Query B: The query which is attached to this email. Query B is as follows: === SELECT * FROM testtable_1, testtable_2, testtable_3, testtable_4, testtable_5, testtable_6, testtable_7, testtable_8 WHERE testtable_1.x = testtable_2.x AND testtable_1.x = testtable_3.x AND testtable_1.x = testtable_4.x AND testtable_1.x = testtable_5.x AND testtable_1.x = testtable_6.x AND testtable_1.x = testtable_7.x AND testtable_1.x = testtable_8.x; === Query A joins three tables, whereas Query B joins eight tables. Since EquivalenceClass is used when handling chained join conditions, I thought queries joining many tables, such as Query B, would have greater performance impacts. I have investigated the v3 patch with these queries. As a result, I did not observe any regressions in Query A in my environment. However, the v3 patch showed significant degradation in Query B. The following table and Figures 1 and 2 describe the result. The v3 patch resulted in a regression of 8.7% for one partition and 4.8% for two partitions. Figure 2 shows the distribution of planning times for the 1-partition case, indicating that the 8.7% regression is not an error. Table 1: Planning time of Query B (n: number of partitions) (milliseconds) ---------------------------------------------------------------- n | Master | v3 | v4 | Master / v3 | Master / v4 ---------------------------------------------------------------- 1 | 54.926 | 60.178 | 55.275 | 91.3% | 99.4% 2 | 53.853 | 56.554 | 53.519 | 95.2% | 100.6% 4 | 57.115 | 57.829 | 55.648 | 98.8% | 102.6% 8 | 64.208 | 60.945 | 58.025 | 105.4% | 110.7% 16 | 79.818 | 65.526 | 63.365 | 121.8% | 126.0% 32 | 136.981 | 77.813 | 76.526 | 176.0% | 179.0% 64 | 371.991 | 108.058 | 110.202 | 344.2% | 337.6% 128 | 1449.063 | 173.326 | 181.302 | 836.0% | 799.3% 256 | 6245.577 | 333.480 | 354.961 | 1872.8% | 1759.5% ---------------------------------------------------------------- This performance degradation is due to the heavy processing of the get_ec***_indexes***() functions. These functions are the core part of the optimization we are working on in this thread, but they are relatively heavy when the number of partitions is small. I noticed that these functions were called repeatedly with the same arguments. During planning Query B with one partition, the get_ec_source_indexes_strict() function was called 2087 times with exactly the same parameters. Such repeated calls occurred many times in a single query. To address this problem, I introduced a caching mechanism in the v4 patch. This patch caches the Bitmapset once it has been computed. After that, we only have to read the cached value instead of performing the same process. Of course, we cannot devote much time to the caching itself. Hash tables are a simple solution to accomplish this but are not available under the current case where microsecond performance degradation is a problem. Therefore, my patch adopts another approach. I will use the following function as an example to explain it. === Bitmapset *get_ecmember_indexes(PlannerInfo *root, EquivalenceClass *ec, Relids relids, bool with_children, bool with_norel_members); === My idea is "caching the returned Bitmapset into Relids." If the Relids has the result Bitmapset, we can access it quickly via the pointer. Of course, I understand this description is not accurate. Relids is just an alias of Bitmapset, so we cannot change the layout. I will describe the precise mechanism. In the v4 patch, I changed the signature of the get_ecmember_indexes() function as follows. === Bitmapset *get_ecmember_indexes(PlannerInfo *root, EquivalenceClass *ec, Relids relids, bool with_children, bool with_norel_members, ECIndexCache *cache); === ECIndexCache is storage for caching returned values. ECIndexCache has a one-to-one relationship with Relids. This relationship is achieved by placing the ECIndexCache just alongside the Relids. For example, ECIndexCache corresponding to some RelOptInfo's relids exists in the same RelOptInfo. When calling the get_ecmember_indexes() function with a RelOptInfo, we pass RelOptInfo->ECIndexCache together. On the other hand, since Relids appear in various places, it is sometimes difficult to prepare a corresponding ECIndexCache. In such cases, we give up caching and pass NULL. Besides, one ECIndexCache can only map to one EquivalenceClass. ECIndexCache only caches for the first EquivalenceClass it encounters and does not cache for another EC. My method abandons full caching to prevent overhead. However, it overcame the regression problem for Query B. As can be seen from Figure 2, the regression with the v4 patch is either non-existent or negligible. Furthermore, the v4 patch is faster than the v3 patch when the number of partitions is 32 or less. In addition to Query B, the results with Query A are shown in Figure 3. I cannot recognize any regression from Figure 3. Please be noted that these results are done on my machine and may differ in other environments. However, when the number of partitions was relatively large, my patch was slightly slower than the v3 patch. This may be due to too frequent memory allocation. ECIndexCache is a large struct containing 13 pointers. In the current implementation, ECIndexCache exists within commonly used structs such as RelOptInfo. Therefore, ECIndexCache is allocated even if no one uses it. When there were 256 partitions of Query B, 88509 ECIndexCache instances were allocated, but only 2295 were actually used. This means that 95.4% were wasted. I think on-demand allocation would solve this problem. Similar problems could also occur with other workloads, including OLTP. I'm going to try this approach soon. I really apologize for not commenting on the rest of your reply. I will continue to consider them. -- Best regards, Yuya Watari
Attachment
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: