Re: [PoC] Reducing planning time when tables have many partitions - Mailing list pgsql-hackers
| From | Yuya Watari |
|---|---|
| Subject | Re: [PoC] Reducing planning time when tables have many partitions |
| Date | |
| Msg-id | CAJ2pMkYohJofeEvu7N_QmbGncjQ+4H4e1cL+Crii9z9x2=b3Sg@mail.gmail.com Whole thread |
| In response to | Re: [PoC] Reducing planning time when tables have many partitions (Yuya Watari <watari.yuya@gmail.com>) |
| Responses |
Re: [PoC] Reducing planning time when tables have many partitions
|
| List | pgsql-hackers |
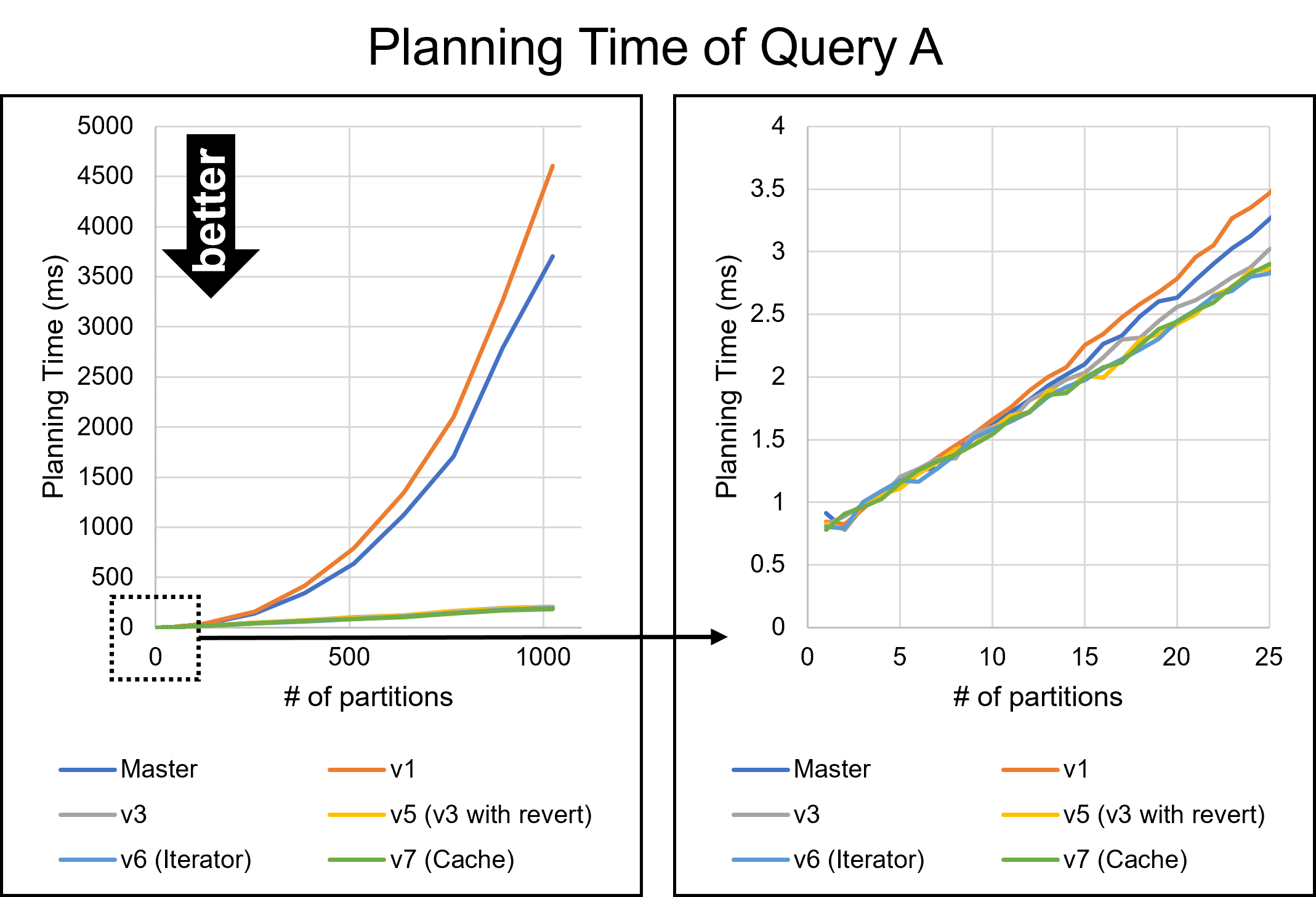
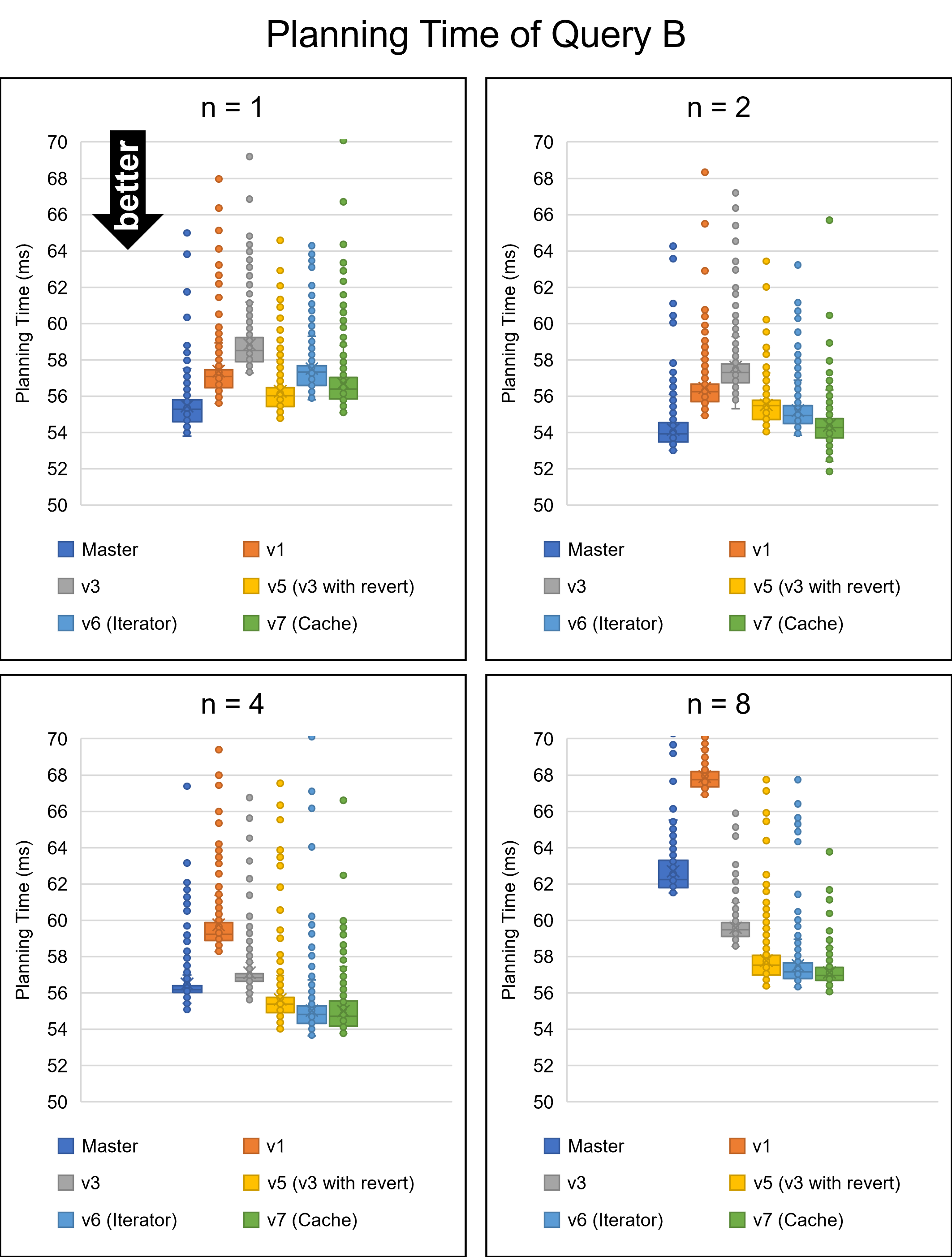
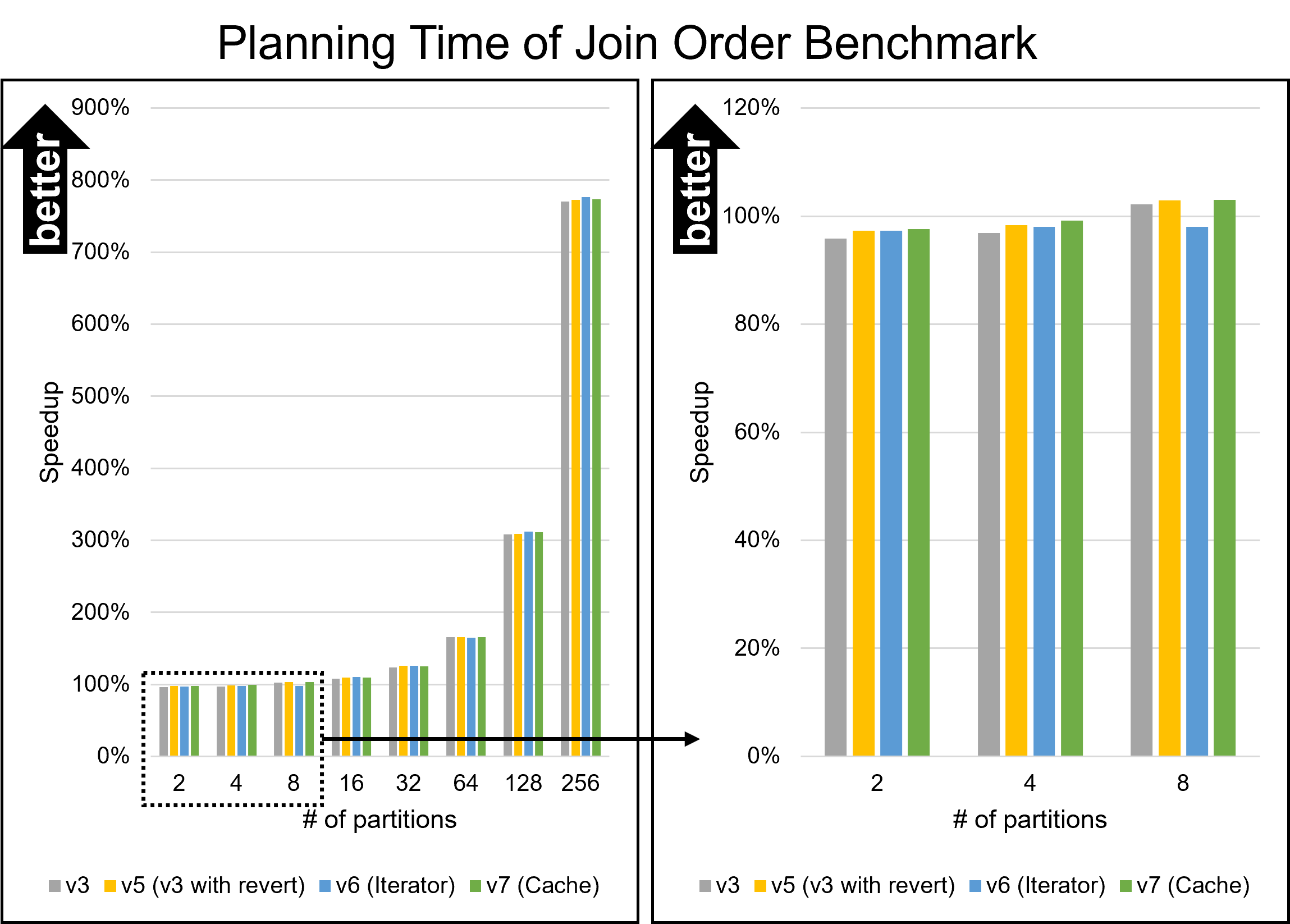
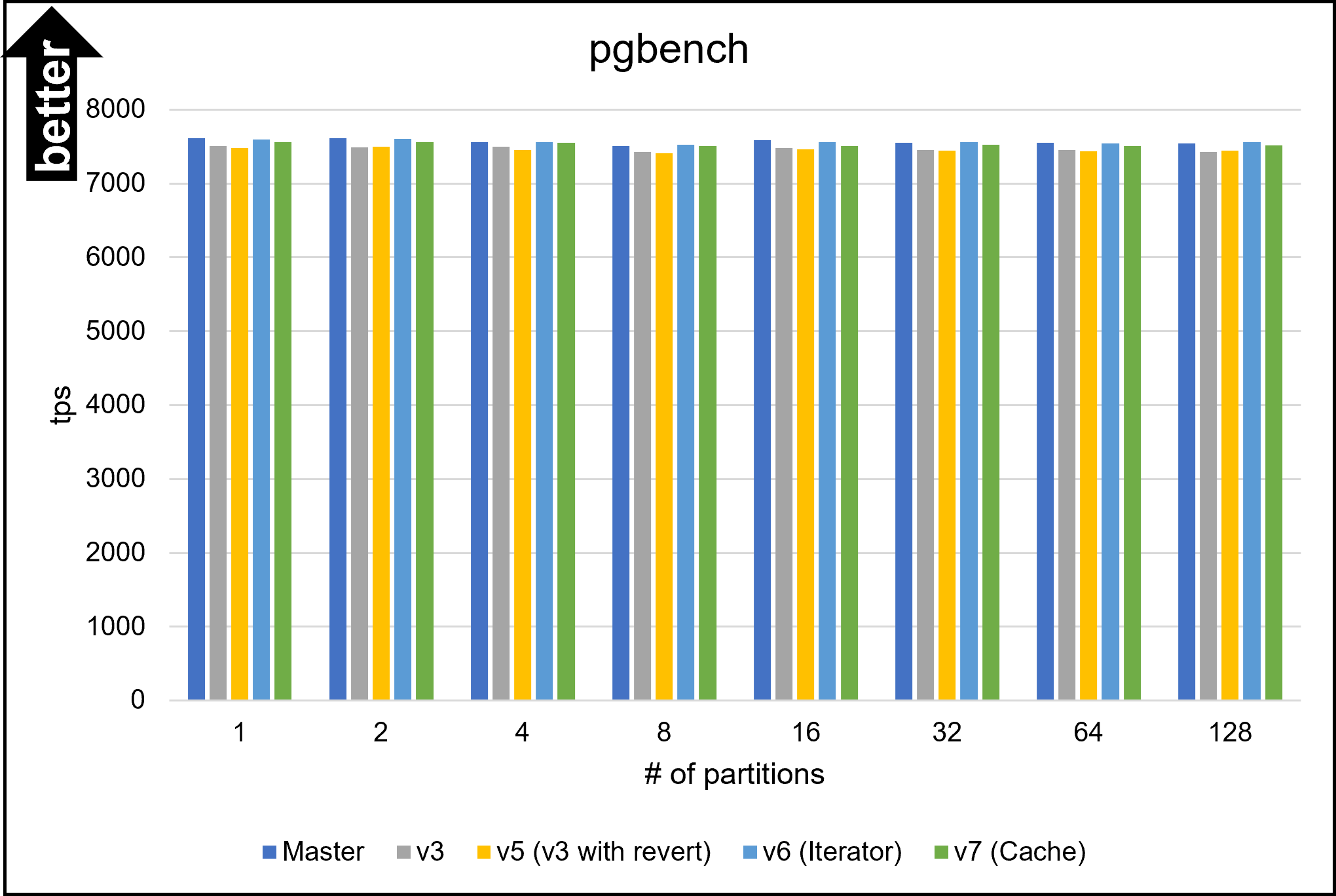
Hello, On Fri, Aug 26, 2022 at 5:53 PM Yuya Watari <watari.yuya@gmail.com> wrote: > Thank you very much for your quick reply and for sharing your idea > with code. I also think introducing EquivalenceMemberIterator is one > good alternative solution. I will try to implement and test it. I apologize for my late response. I have implemented several approaches and tested them. 1. Changes I will describe how I modified our codes. I tested five versions: * v1: The first draft patch by David with bug fixes by me. This patch does not perform any optimizations based on Bitmapset operations. * v3: The past patch * v5 (v3 with revert): The v3 with revert of one of our optimizations * v6 (Iterator): An approach using iterators to enumerate over EquivalenceMembers. This approach is David's suggestion in the previous email. * v7 (Cache): My approach to caching the result of get_ec***indexes***() Please be noted that there is no direct parent-child relationship between v6 and v7; they are v5's children, i.e., siblings. I'm sorry for the confusing versioning. 1.1. Revert one of our optimizations (v5) As I mentioned in the comment in v[5|6|7]-0002-Revert-one-of-the-optimizations.patch, I reverted one of our optimizations. This code tries to find EquivalenceMembers that do not satisfy the bms_overlap condition. We encounter such members early in the loop, so the linear search is enough, and our optimization is too excessive here. As a result of experiments, I found this optimization was a bottleneck, so I reverted it. v6 (Iterator) and v7 (Cache) include this revert. 1.2. Iterator (v6) I have implemented the iterator approach. The code is based on what David advised, but I customized it a bit. I added the "bool caller_needs_recheck" argument to get_ecmember_indexes_iterator() and other similar functions. If this argument is true, the iterator enumerates all EquivalenceMembers without checking conditions such as bms_is_subset or bms_overlap. This change is because callers of these iterators sometimes recheck desired conditions after calling it. For example, if some caller wants EquivalenceMembers whose Relids is equal to some value, it calls get_ecmember_indexes(). However, since the result may have false positives, the caller has to recheck the result by the bms_equal() condition. In this case, if the threshold is below and we don't perform our optimization, checking bms_overlap() in the iterator does not make sense. We can solve this problem by passing true to the "caller_needs_recheck" argument to skip redundant checking. 1.3. Cache (v7) I have improved my caching approach. First, I introduced the on-demand allocation approach I mentioned in the previous email. ECIndexCache is allocated not together with RelOptInfo but when using it. In addition to this, a new version of the patch can handle multiple EquivalenceClasses. In the previous version, caching was only possible for one EquivalenceClass. This limitation is to prevent overhead but reduces caching opportunities. So, I have improved it so that it can handle all EquivalenceClasses. I made this change on the advice of Fujita-san. Thank you, Fujita-san. 2. Experimental Results I conducted experiments to test these methods. 2.1. Query A Figure 1 illustrates the planning times of Query A. Please see the previous email for what Query A refers to. The performance of all methods except master and v1 are almost the same. I cannot observe any degradation from this figure. 2.2. Query B Query B joins eight tables. In the previous email, I mentioned that the v3 patch has significant degradation for this query. Figure 2 and Table 1 show the results. The three approaches of v5, v6 (Iterator), and v7 (Cache) showed good overall performance. In particular, v7 (Cache) performed best for the smaller number of partitions. Table 1: Planning Time of Query B (ms) ------------------------------------- n | Master | v1 | v3 ------------------------------------- 1 | 55.459 | 57.376 | 58.849 2 | 54.162 | 56.454 | 57.615 4 | 56.491 | 59.742 | 57.108 8 | 62.694 | 67.920 | 59.591 16 | 79.547 | 90.589 | 64.954 32 | 134.623 | 160.452 | 76.626 64 | 368.716 | 439.894 | 107.278 128 | 1374.000 | 1598.748 | 170.909 256 | 5955.762 | 6921.668 | 324.113 ------------------------------------- -------------------------------------------------------- n | v5 (v3 with revert) | v6 (Iterator) | v7 (Cache) -------------------------------------------------------- 1 | 56.268 | 57.520 | 56.703 2 | 55.511 | 55.212 | 54.395 4 | 55.643 | 55.025 | 54.996 8 | 57.770 | 57.519 | 57.114 16 | 63.075 | 63.117 | 63.161 32 | 74.788 | 74.369 | 75.801 64 | 104.027 | 104.787 | 105.450 128 | 169.473 | 169.019 | 174.919 256 | 321.450 | 322.739 | 342.601 -------------------------------------------------------- 2.3. Join Order Benchmark It is essential to test real workloads, so I used the Join Order Benchmark [1]. This benchmark contains many complicated queries joining a lot of tables. I partitioned fact tables by 'id' columns and measured query planning times. Figure 3 and Table 2 describe the results. The results showed that all methods produced some degradations when there were not so many partitions. However, the degradation of v7 (cache) was relatively small. It was 0.8% with two partitions, while the other methods' degradation was at least 1.6%. Table 2: Speedup of Join Order Benchmark (higher is better) ----------------------------------------------------------------- n | v3 | v5 (v3 with revert) | v6 (Iterator) | v7 (Cache) ----------------------------------------------------------------- 2 | 95.8% | 97.3% | 97.3% | 97.7% 4 | 96.9% | 98.4% | 98.0% | 99.2% 8 | 102.2% | 102.9% | 98.1% | 103.0% 16 | 107.6% | 109.5% | 110.1% | 109.4% 32 | 123.5% | 125.4% | 125.5% | 125.0% 64 | 165.2% | 165.9% | 164.6% | 165.9% 128 | 308.2% | 309.2% | 312.1% | 311.4% 256 | 770.1% | 772.3% | 776.6% | 773.2% ----------------------------------------------------------------- 2.4. pgbench Our optimizations must not cause negative impacts on OLTP workloads. I conducted pgbench, and Figure 4 and Table 3 show its result. Table 3: The result of pgbench (tps) ------------------------------------------------------------------------ n | Master | v3 | v5 (v3 with revert) | v6 (Iterator) | v7 (Cache) ------------------------------------------------------------------------ 1 | 7617 | 7510 | 7484 | 7599 | 7561 2 | 7613 | 7487 | 7503 | 7609 | 7560 4 | 7559 | 7497 | 7453 | 7560 | 7553 8 | 7506 | 7429 | 7405 | 7523 | 7503 16 | 7584 | 7481 | 7466 | 7558 | 7508 32 | 7556 | 7456 | 7448 | 7558 | 7521 64 | 7555 | 7452 | 7435 | 7541 | 7504 128 | 7542 | 7430 | 7442 | 7558 | 7517 ------------------------------------------------------------------------ Avg | 7566 | 7468 | 7455 | 7563 | 7528 ------------------------------------------------------------------------ This result indicates that v3 and v5 (v3 with revert) had a significant negative impact on the pgbench workload. Their tps decreased by 1.3% or more. On the other hand, degradations of v6 (Iterator) and v7 (Cache) are non-existent or negligible. 3. Causes of Degression We could not avoid degradation with the Join Order Benchmark. The leading cause of this problem is that Bitmapset operation, especially bms_next_member(), is relatively slower than simple enumeration over List. It is easy to imagine that bms_next_member(), which has complex bit operations, is a little heavier than List enumerations simply advancing a pointer. The fact that even the v1, where we don't perform any optimizations, slowed down supports this notion. I think preventing this regression is very hard. To do so, we must have both List and Bitmapset representations of EquivalenceMembers. However, I don't prefer this solution because it is redundant and leads to less code maintainability. Reducing Bitmapset->nwords is another possible solution. I will try it, but it will likely not solve the significant degradation in pgbench for v3 and v5. This is because such degradation did not occur with v6 and v7, with also use Bitmapset. 4. Which Method is The Best? First of all, it is hard to adopt v3 and v5 (v3 with revert) because they degrade performance on OLTP workloads. Therefore, v6 (Iterator) and v7 (Cache) are possible candidates. Of these methods, I prefer v7 (Cache). Actually, I don't think an approach to introducing thresholds is a good idea because the best threshold is unclear. If we become conservative to avoid degradation, we must increase the threshold, but that takes away the opportunity for optimization. The opposite is true. In contrast, v7 (Cache) is an essential solution in terms of reducing the cost of repeated function calls and does not require the introduction of a threshold. Besides, it performs better on almost all workloads, including the Join Order Benchmark. It also has no negative impacts on OLTP. In conclusion, I think v7 (Cache) is the most desirable. Of course, the method may have some problems, but it is worth considering. [1] https://github.com/winkyao/join-order-benchmark -- Best regards, Yuya Watari
Attachment
- figure-1.png
- figure-2.png
- figure-3.png
- figure-4.png
- v5-0001-Apply-eclass_member_speedup_v3.patch.patch
- v5-0002-Revert-one-of-the-optimizations.patch
- v6-0001-Apply-eclass_member_speedup_v3.patch.patch
- v6-0002-Revert-one-of-the-optimizations.patch
- v6-0003-Implement-iterators.patch
- v7-0001-Apply-eclass_member_speedup_v3.patch.patch
- v7-0002-Revert-one-of-the-optimizations.patch
- v7-0003-Implement-ECIndexCache.patch
{kind=link}
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: