[PoC] Reducing planning time when tables have many partitions - Mailing list pgsql-hackers
| From | Yuya Watari |
|---|---|
| Subject | [PoC] Reducing planning time when tables have many partitions |
| Date | |
| Msg-id | CAJ2pMkZNCgoUKSE+_5LthD+KbXKvq6h2hQN8Esxpxd+cxmgomg@mail.gmail.com Whole thread |
| Responses |
Re: [PoC] Reducing planning time when tables have many partitions
|
| List | pgsql-hackers |
Hello,
I found a problem that planning takes too much time when the tables
have many child partitions. According to my observation, the planning
time increases in the order of O(n^2). Here, n is the number of child
partitions. I attached the patch to solve this problem. Please be
noted that this patch is a PoC.
1. Problem Statement
The problem arises in the next simple query. This query is modeled
after a university's grade system, joining tables about students,
scores, and their GPAs to output academic records for each student.
=====
SELECT students.name, gpas.gpa AS gpa, sum(scores.score) AS total_score
FROM students, scores, gpas
WHERE students.id = scores.student_id AND students.id = gpas.student_id
GROUP BY students.id, gpas.student_id;
=====
Here, since there are so many students enrolled in the university, we
will partition each table. If so, the planning time of the above query
increases very rapidly as the number of partitions increases.
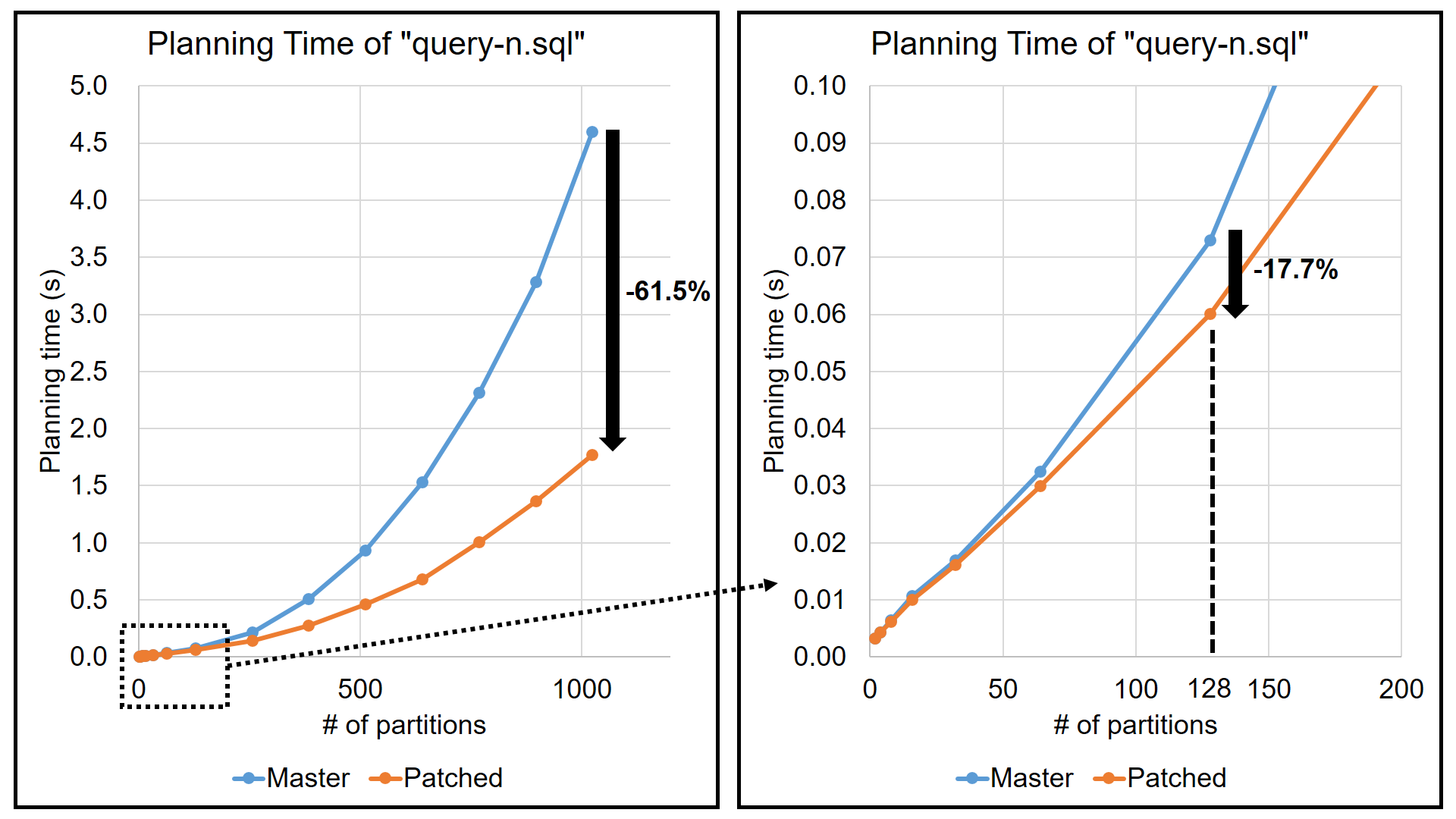
I conducted an experiment by varying the number of partitions of three
tables (students, scores, and gpas) from 2 to 1024. The attached
figure illustrates the result. The blue line annotated with "master"
stands for the result on the master branch. Obviously, its
computational complexity is large.
I attached SQL files to this e-mail as "sample-queries.zip". You can
reproduce my experiment by the next steps:
=====
$ unzip sample-queries.zip
$ cd sample-queries
# Create tables and insert sample data ('n' denotes the number of partitions)
$ psql -f create-table-n.sql
# Measure planning time
$ psql -f query-n.sql
=====
2. Where is Slow?
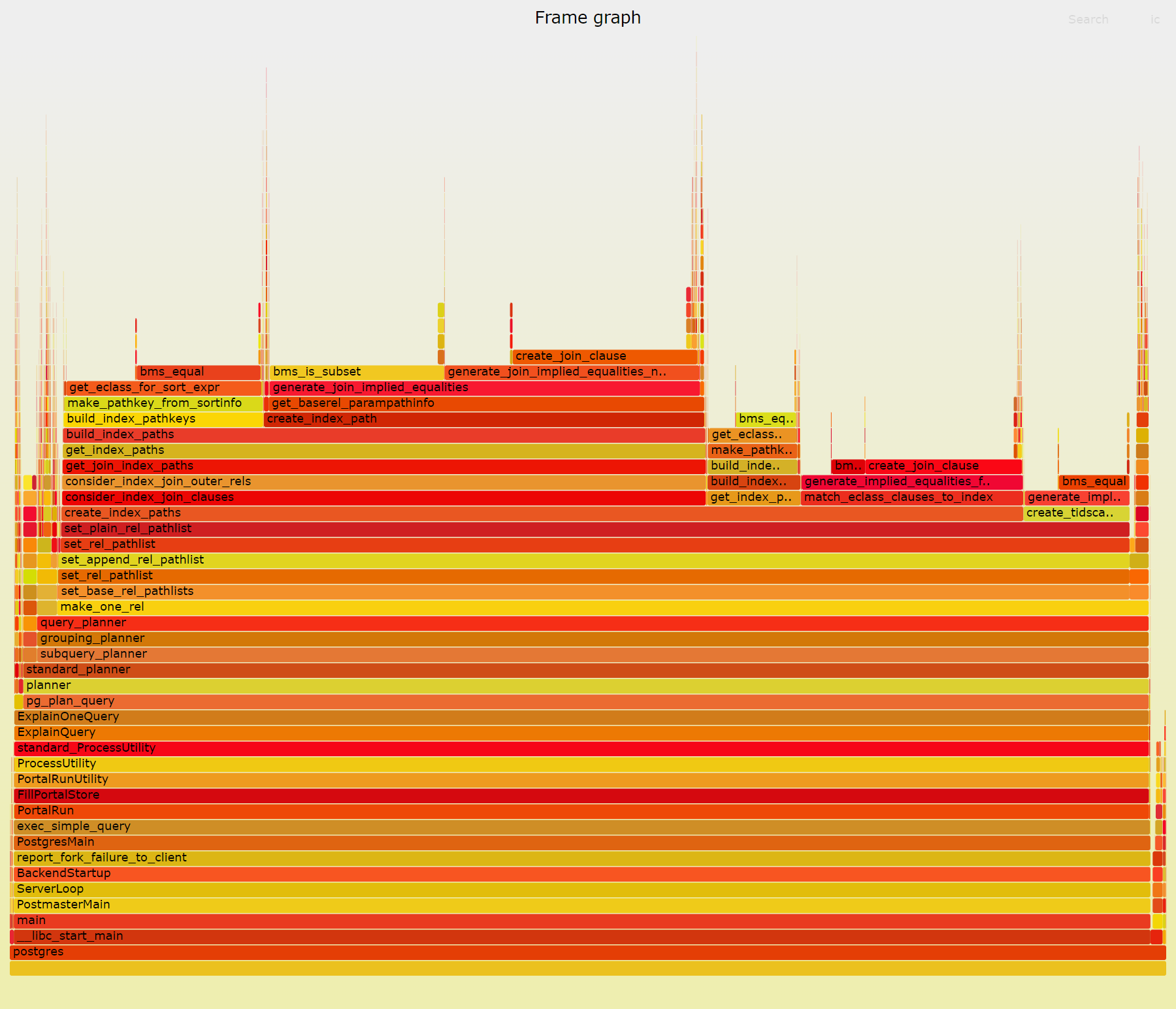
In order to identify bottlenecks, I ran a performance profiler(perf).
The "perf-master.png" is a call graph of planning of query-1024.sql.
From this figure, it can be seen that "bms_equal" and "bms_is_subset"
take up most of the running time. Most of these functions are called
when enumerating EquivalenceMembers in EquivalenceClass. The
enumerations exist in src/backend/optimizer/path/equivclass.c and have
the following form.
=====
EquivalenceClass *ec = /* given */;
EquivalenceMember *em;
ListCell *lc;
foreach(lc, ec->ec_members)
{
em = (EquivalenceMember *) lfirst(lc);
/* predicate is bms_equal or bms_is_subset, etc */
if (!predicate(em))
continue;
/* The predicate satisfies */
do something...;
}
=====
This foreach loop is a linear search, whose cost will become very high
when there are many EquivalenceMembers in ec_members. This is the case
when the number of partitions is large. Eliminating this heavy linear
search is a key to improving planning performance.
3. How to Solve?
In my patch, I made three different optimizations depending on the
predicate pattern.
3.1 When the predicate is "!em->em_is_child"
In equivclass.c, there are several processes performed when
em_is_child is false. If a table has many partitions, the number of
EquivalenceMembers which are not children is limited. Therefore, it is
useful to keep only the non-child members as a list in advance.
My patch adds the "ec_not_child_members" field to EquivalenceClass.
This field is a List containing non-child members. Taking advantage of
this, the previous loop can be rewritten as follows:
=====
foreach(lc, ec->ec_not_child_members)
{
em = (EquivalenceMember *) lfirst(lc);
Assert(!em->em_is_child);
do something...;
}
=====
3.2 When the predicate is "bms_equal(em->em_relids, relids)"
"bms_equal" is another example of the predicate. In this case,
processes will be done when the "em_relids" matches certain Relids.
This type of loop can be quickly handled by utilizing a hash table.
First, group EquivalenceMembers with the same Relids into a list.
Then, create an associative array whose key is Relids and whose value
is the list. In my patch, I added the "ec_members_htab" field to
EquivalenceClass, which plays a role of an associative array.
Based on this idea, the previous loop is transformed as follows. Here,
the FindEcMembersMatchingRelids function looks up the hash table and
returns the corresponding value, which is a list.
=====
foreach(lc, FindEcMembersMatchingRelids(ec, relids))
{
em = (EquivalenceMember *) lfirst(lc);
Assert(bms_equal(em->em_relids, relids));
do something...;
}
=====
3.3 When the predicate is "bms_is_subset(em->em_relids, relids)"
There are several processings performed on EquivalenceMembers whose
em_relids is a subset of the given "relids". In this case, the
predicate is "bms_is_subset". Optimizing this search is not as easy as
with bms_equal, but the technique above by hash tables can be applied.
There are 2^m subsets if the number of elements of the "relids" is m.
The key here is that m is not so large in most cases. For example, m
is up to 3 in the sample query, meaning that the number of subsets is
at most 2^3=8. Therefore, we can enumerate all subsets within a
realistic time. Looking up the hash table with each subset as a key
will drastically reduce unnecessary searches. My patch's optimization
is based on this notion.
This technique can be illustrated as the next pseudo-code. The code
iterates over all subsets and looks up the corresponding
EquivalenceMembers from the hash table. The actual code is more
complicated for performance reasons.
===
EquivalenceClass *ec = /* given */;
Relids relids = /* given */;
int num_members_in_relids = bms_num_members(relids);
for (int bit = 0; bit < (1 << num_members_in_relids); bit++)
{
EquivalenceMember *em;
ListCell *lc;
Relids subset = construct subset from 'bit';
foreach(lc, FindEcMembersMatchingRelids(ec, subset))
{
em = (EquivalenceMember *) lfirst(lc);
Assert(bms_is_subset(em->em_relids, relids));
do something...;
}
}
===
4. Experimental Result
The red line in the attached figure is the planning time with my
patch. The chart indicates that planning performance has been greatly
improved. The exact values are shown below.
Planning time of "query-n.sql" (n = number of partitions):
n | Master (s) | Patched (s) | Speed up
------------------------------------------
2 | 0.003 | 0.003 | 0.9%
4 | 0.004 | 0.004 | 1.0%
8 | 0.006 | 0.006 | 4.6%
16 | 0.011 | 0.010 | 5.3%
32 | 0.017 | 0.016 | 4.7%
64 | 0.032 | 0.030 | 8.0%
128 | 0.073 | 0.060 | 17.7%
256 | 0.216 | 0.142 | 34.2%
384 | 0.504 | 0.272 | 46.1%
512 | 0.933 | 0.462 | 50.4%
640 | 1.529 | 0.678 | 55.7%
768 | 2.316 | 1.006 | 56.6%
896 | 3.280 | 1.363 | 58.5%
1024 | 4.599 | 1.770 | 61.5%
With 1024 partitions, the planning time was reduced by 61.5%. Besides,
with 128 partitions, which is a realistic use case, the performance
increased by 17.7%.
5. Things to Be Discussed
5.1 Regressions
While my approach is effective for tables with a large number of
partitions, it may cause performance degradation otherwise. For small
cases, it is necessary to switch to a conventional algorithm. However,
its threshold is not self-evident.
5.2 Enumeration order
My patch may change the order in which members are enumerated. This
affects generated plans.
5.3 Code Quality
Source code quality should be improved.
=====
Again, I posted this patch as a PoC. I would appreciate it if you
would discuss the effectiveness of these optimizations with me.
Best regards,
Yuya Watari
Attachment
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: