Thread: website doc search is extremely SLOW
Trying to use the 'search' in the docs section of PostgreSQL.org
is extremely SLOW. Considering this is a website for a database
and databases are supposed to be good for indexing content, I'd
expect a much faster performance.
I submitted my search over two minutes ago. I just finished this
email to the list. The results have still not come back. I only
searched for:
SECURITY INVOKER
Perhaps this should be worked on?
Dante
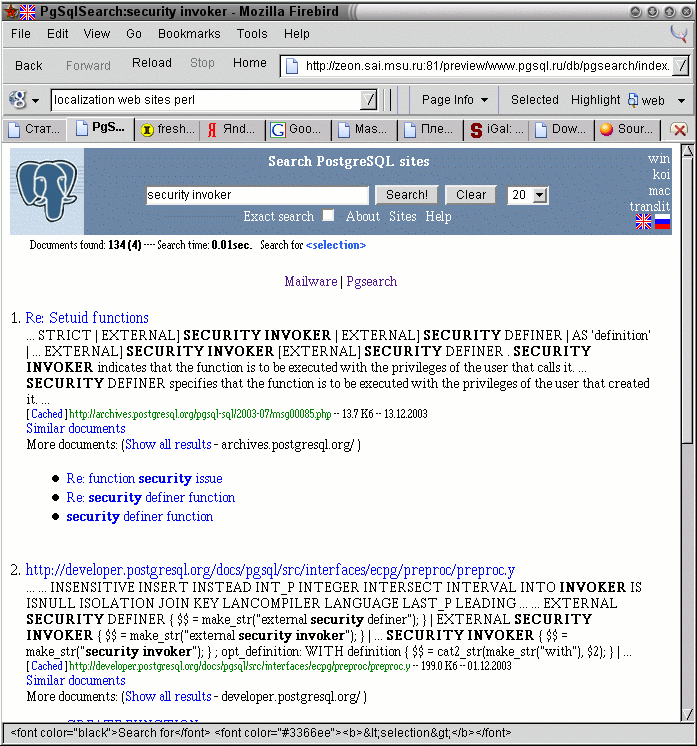
On Mon, 29 Dec 2003, D. Dante Lorenso wrote: > Trying to use the 'search' in the docs section of PostgreSQL.org > is extremely SLOW. Considering this is a website for a database > and databases are supposed to be good for indexing content, I'd > expect a much faster performance. > > I submitted my search over two minutes ago. I just finished this > email to the list. The results have still not come back. I only > searched for: > > SECURITY INVOKER > > Perhaps this should be worked on? Your query takes 0.01 sec to complete (134 documents found) on my development server I hope to present to the community soon after New Year. We've crawled 27 postgresql related sites. Screenshot is available http://www.sai.msu.su/~megera/postgres/pgsql.ru.gif > > Dante > > > > ---------------------------(end of broadcast)--------------------------- > TIP 9: the planner will ignore your desire to choose an index scan if your > joining column's datatypes do not match > Regards, Oleg _____________________________________________________________ Oleg Bartunov, sci.researcher, hostmaster of AstroNet, Sternberg Astronomical Institute, Moscow University (Russia) Internet: oleg@sai.msu.su, http://www.sai.msu.su/~megera/ phone: +007(095)939-16-83, +007(095)939-23-83
{kind=link}
On Mon, 29 Dec 2003, D. Dante Lorenso wrote: > Trying to use the 'search' in the docs section of PostgreSQL.org > is extremely SLOW. Considering this is a website for a database > and databases are supposed to be good for indexing content, I'd > expect a much faster performance. What is the full URL for the page you are looking at? Just the 'search link' at the top of the page? > Perhaps this should be worked on? Looking into it right now ... ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
On Tue, 30 Dec 2003, Marc G. Fournier wrote: > On Mon, 29 Dec 2003, D. Dante Lorenso wrote: > > > Trying to use the 'search' in the docs section of PostgreSQL.org > > is extremely SLOW. Considering this is a website for a database > > and databases are supposed to be good for indexing content, I'd > > expect a much faster performance. > > What is the full URL for the page you are looking at? Just the 'search > link' at the top of the page? > > > Perhaps this should be worked on? > > Looking into it right now ... just ran it from archives.postgresql.org (security invoker) and it comes back in 10 seconds ... I think it might be a problem with doing a search while indexing is happening ... am looking at that ... ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
When you got to docs and then click static, it has the ability to search. It is slowwwwwwwww.... Sincerely, Joshua D. Drake On Tue, 2003-12-30 at 19:05, Marc G. Fournier wrote: > On Mon, 29 Dec 2003, D. Dante Lorenso wrote: > > > Trying to use the 'search' in the docs section of PostgreSQL.org > > is extremely SLOW. Considering this is a website for a database > > and databases are supposed to be good for indexing content, I'd > > expect a much faster performance. > > What is the full URL for the page you are looking at? Just the 'search > link' at the top of the page? > > > Perhaps this should be worked on? > > Looking into it right now ... > > ---- > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > > ---------------------------(end of broadcast)--------------------------- > TIP 7: don't forget to increase your free space map settings -- Command Prompt, Inc., home of Mammoth PostgreSQL - S/ODBC and S/JDBC Postgresql support, programming shared hosting and dedicated hosting. +1-503-667-4564 - jd@commandprompt.com - http://www.commandprompt.com Mammoth PostgreSQL Replicator. Integrated Replication for PostgreSQL
Marc G. Fournier wrote:
>On Mon, 29 Dec 2003, D. Dante Lorenso wrote:
>
>>Trying to use the 'search' in the docs section of PostgreSQL.org
>>is extremely SLOW. Considering this is a website for a database
>>and databases are supposed to be good for indexing content, I'd
>>expect a much faster performance.
>>
>>
>What is the full URL for the page you are looking at? Just the 'search
>link' at the top of the page?
>
>
>>Perhaps this should be worked on?
>>
>>
>Looking into it right now ...
>
>
http://www.postgresql.org/ *click Docs on top of page*
http://www.postgresql.org/docs/ * click PostgreSQL static
documentation *
Search this document set: [ SECURITY INVOKER ] Search!
http://www.postgresql.org/search.cgi?ul=http://www.postgresql.org/docs/7.4/static/&q=SECURITY+INVOKER
I loaded that URL on IE and I wait like 2 minutes or more for a response.
then, it usually returns with 1 result. I click the Search! button again
to refresh and it came back a little faster with 0 results?
Searched again from the top and it's a little faster now:
* click search *
> date
Wed Dec 31 22:52:01 CST 2003
* results come back *
> date
Wed Dec 31 22:52:27 CST 2003
Still one result:
PostgreSQL 7.4 Documentation (SQL Key Words)
<http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html>
[*0.087%*]
http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html
Size: 65401 bytes, modified: Tue, 25 Nov 2003, 15:02:33 AST
However, the page that I SHOULD have found was this one:
http://www.postgresql.org/docs/current/static/sql-createfunction.html
That page has SECURITY INVOKER in a whole section:
[EXTERNAL] SECURITY INVOKER
[EXTERNAL] SECURITY DEFINER
SECURITY INVOKER indicates that the function is to be executed with
the privileges of the user that calls it. That is the default.
SECURITY DEFINER specifies that the function is to be executed with
the privileges of the user that created it.
Dante
----------
D. Dante Lorenso
dante@lorenso.com
search for create index took 59 seconds ? I've got a fairly (< 1 second for the same search) fast search engine on the docs at http://postgresintl.com/search?query=create index if that link doesn't work, try postgres.fastcrypt.com/search?query=create index for now you will have to type it, I'm working on indexing it then making it pretty Dave On Tue, 2003-12-30 at 22:39, D. Dante Lorenso wrote: > Marc G. Fournier wrote: > > >On Mon, 29 Dec 2003, D. Dante Lorenso wrote: > > > >>Trying to use the 'search' in the docs section of PostgreSQL.org > >>is extremely SLOW. Considering this is a website for a database > >>and databases are supposed to be good for indexing content, I'd > >>expect a much faster performance. > >> > >> > >What is the full URL for the page you are looking at? Just the 'search > >link' at the top of the page? > > > > > >>Perhaps this should be worked on? > >> > >> > >Looking into it right now ... > > > > > > http://www.postgresql.org/ *click Docs on top of page* > http://www.postgresql.org/docs/ * click PostgreSQL static > documentation * > > Search this document set: [ SECURITY INVOKER ] Search! > > > http://www.postgresql.org/search.cgi?ul=http://www.postgresql.org/docs/7.4/static/&q=SECURITY+INVOKER > > I loaded that URL on IE and I wait like 2 minutes or more for a response. > then, it usually returns with 1 result. I click the Search! button again > to refresh and it came back a little faster with 0 results? > > Searched again from the top and it's a little faster now: > > * click search * > > date > Wed Dec 31 22:52:01 CST 2003 > > * results come back * > > date > Wed Dec 31 22:52:27 CST 2003 > > Still one result: > > PostgreSQL 7.4 Documentation (SQL Key Words) > <http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html> > [*0.087%*] > http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html > Size: 65401 bytes, modified: Tue, 25 Nov 2003, 15:02:33 AST > > However, the page that I SHOULD have found was this one: > > http://www.postgresql.org/docs/current/static/sql-createfunction.html > > That page has SECURITY INVOKER in a whole section: > > [EXTERNAL] SECURITY INVOKER > [EXTERNAL] SECURITY DEFINER > > SECURITY INVOKER indicates that the function is to be executed with > the privileges of the user that calls it. That is the default. > SECURITY DEFINER specifies that the function is to be executed with > the privileges of the user that created it. > > Dante > > ---------- > D. Dante Lorenso > dante@lorenso.com > > > > ---------------------------(end of broadcast)--------------------------- > TIP 3: if posting/reading through Usenet, please send an appropriate > subscribe-nomail command to majordomo@postgresql.org so that your > message can get through to the mailing list cleanly > -- Dave Cramer 519 939 0336 ICQ # 1467551
does anyone know anything better then mnogosearch, that works with
PostgreSQL, for doing indexing? the database server is a Dual Xeon 2.4G,
4G of RAM, and a load avg right now of a lowly 1.5 ... the file system is
3x72G drive in a RAID5 configuration, and the database server is 7.4 ...
the mnogosearch folk use mysql for their development, so its possible
there is something they are doing that is slowing this process down, to
compensate for a fault in mysql, but this is ridiculous ...
note that I have it setup with what the mnogosearch folk lists as being
'the fastest schema for large indexes' or 'crc-multi' ...
right now, we're running only 373k docs:
isvr5# indexer -S
Database statistics
Status Expired Total
-----------------------------
415 0 311 Unsupported Media Type
302 0 1171 Moved Temporarily
502 0 43 Bad Gateway
414 0 3 Request-URI Too Long
301 0 307 Moved Permanently
404 0 1960 Not found
410 0 1 Gone
401 0 51 Unauthorized
304 0 16591 Not Modified
200 0 373015 OK
504 0 48 Gateway Timeout
400 0 3 Bad Request
0 2 47 Not indexed yet
-----------------------------
Total 2 393551
and a vacuum analyze runs nightly ...
anyone with suggestions/ideas? has to be something client/server, like
mnogosearch, as we're dealing with multiple servers searching against the
same database ... so I don't *think* that ht/Dig is a solution, but may be
wrong there ...
On Wed, 30 Dec 2003, Dave Cramer wrote:
> search for create index took 59 seconds ?
>
> I've got a fairly (< 1 second for the same search) fast search engine on
> the docs at
>
> http://postgresintl.com/search?query=create index
>
> if that link doesn't work, try
>
> postgres.fastcrypt.com/search?query=create index
>
> for now you will have to type it, I'm working on indexing it then making
> it pretty
>
> Dave
>
> On Tue, 2003-12-30 at 22:39, D. Dante Lorenso wrote:
> > Marc G. Fournier wrote:
> >
> > >On Mon, 29 Dec 2003, D. Dante Lorenso wrote:
> > >
> > >>Trying to use the 'search' in the docs section of PostgreSQL.org
> > >>is extremely SLOW. Considering this is a website for a database
> > >>and databases are supposed to be good for indexing content, I'd
> > >>expect a much faster performance.
> > >>
> > >>
> > >What is the full URL for the page you are looking at? Just the 'search
> > >link' at the top of the page?
> > >
> > >
> > >>Perhaps this should be worked on?
> > >>
> > >>
> > >Looking into it right now ...
> > >
> > >
> >
> > http://www.postgresql.org/ *click Docs on top of page*
> > http://www.postgresql.org/docs/ * click PostgreSQL static
> > documentation *
> >
> > Search this document set: [ SECURITY INVOKER ] Search!
> >
> >
> > http://www.postgresql.org/search.cgi?ul=http://www.postgresql.org/docs/7.4/static/&q=SECURITY+INVOKER
> >
> > I loaded that URL on IE and I wait like 2 minutes or more for a response.
> > then, it usually returns with 1 result. I click the Search! button again
> > to refresh and it came back a little faster with 0 results?
> >
> > Searched again from the top and it's a little faster now:
> >
> > * click search *
> > > date
> > Wed Dec 31 22:52:01 CST 2003
> >
> > * results come back *
> > > date
> > Wed Dec 31 22:52:27 CST 2003
> >
> > Still one result:
> >
> > PostgreSQL 7.4 Documentation (SQL Key Words)
> > <http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html>
> > [*0.087%*]
> > http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html
> > Size: 65401 bytes, modified: Tue, 25 Nov 2003, 15:02:33 AST
> >
> > However, the page that I SHOULD have found was this one:
> >
> > http://www.postgresql.org/docs/current/static/sql-createfunction.html
> >
> > That page has SECURITY INVOKER in a whole section:
> >
> > [EXTERNAL] SECURITY INVOKER
> > [EXTERNAL] SECURITY DEFINER
> >
> > SECURITY INVOKER indicates that the function is to be executed with
> > the privileges of the user that calls it. That is the default.
> > SECURITY DEFINER specifies that the function is to be executed with
> > the privileges of the user that created it.
> >
> > Dante
> >
> > ----------
> > D. Dante Lorenso
> > dante@lorenso.com
> >
> >
> >
> > ---------------------------(end of broadcast)---------------------------
> > TIP 3: if posting/reading through Usenet, please send an appropriate
> > subscribe-nomail command to majordomo@postgresql.org so that your
> > message can get through to the mailing list cleanly
> >
> --
> Dave Cramer
> 519 939 0336
> ICQ # 1467551
>
>
----
Marc G. Fournier Hub.Org Networking Services (http://www.hub.org)
Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
Why are their multiple servers hitting the same db what servers are searching through the db? Dave On Wed, 2003-12-31 at 00:04, Marc G. Fournier wrote: > does anyone know anything better then mnogosearch, that works with > PostgreSQL, for doing indexing? the database server is a Dual Xeon 2.4G, > 4G of RAM, and a load avg right now of a lowly 1.5 ... the file system is > 3x72G drive in a RAID5 configuration, and the database server is 7.4 ... > the mnogosearch folk use mysql for their development, so its possible > there is something they are doing that is slowing this process down, to > compensate for a fault in mysql, but this is ridiculous ... > > note that I have it setup with what the mnogosearch folk lists as being > 'the fastest schema for large indexes' or 'crc-multi' ... > > right now, we're running only 373k docs: > > isvr5# indexer -S > > Database statistics > > Status Expired Total > ----------------------------- > 415 0 311 Unsupported Media Type > 302 0 1171 Moved Temporarily > 502 0 43 Bad Gateway > 414 0 3 Request-URI Too Long > 301 0 307 Moved Permanently > 404 0 1960 Not found > 410 0 1 Gone > 401 0 51 Unauthorized > 304 0 16591 Not Modified > 200 0 373015 OK > 504 0 48 Gateway Timeout > 400 0 3 Bad Request > 0 2 47 Not indexed yet > ----------------------------- > Total 2 393551 > > and a vacuum analyze runs nightly ... > > anyone with suggestions/ideas? has to be something client/server, like > mnogosearch, as we're dealing with multiple servers searching against the > same database ... so I don't *think* that ht/Dig is a solution, but may be > wrong there ... > > On Wed, 30 Dec 2003, Dave Cramer wrote: > > > search for create index took 59 seconds ? > > > > I've got a fairly (< 1 second for the same search) fast search engine on > > the docs at > > > > http://postgresintl.com/search?query=create index > > > > if that link doesn't work, try > > > > postgres.fastcrypt.com/search?query=create index > > > > for now you will have to type it, I'm working on indexing it then making > > it pretty > > > > Dave > > > > On Tue, 2003-12-30 at 22:39, D. Dante Lorenso wrote: > > > Marc G. Fournier wrote: > > > > > > >On Mon, 29 Dec 2003, D. Dante Lorenso wrote: > > > > > > > >>Trying to use the 'search' in the docs section of PostgreSQL.org > > > >>is extremely SLOW. Considering this is a website for a database > > > >>and databases are supposed to be good for indexing content, I'd > > > >>expect a much faster performance. > > > >> > > > >> > > > >What is the full URL for the page you are looking at? Just the 'search > > > >link' at the top of the page? > > > > > > > > > > > >>Perhaps this should be worked on? > > > >> > > > >> > > > >Looking into it right now ... > > > > > > > > > > > > > > http://www.postgresql.org/ *click Docs on top of page* > > > http://www.postgresql.org/docs/ * click PostgreSQL static > > > documentation * > > > > > > Search this document set: [ SECURITY INVOKER ] Search! > > > > > > > > > http://www.postgresql.org/search.cgi?ul=http://www.postgresql.org/docs/7.4/static/&q=SECURITY+INVOKER > > > > > > I loaded that URL on IE and I wait like 2 minutes or more for a response. > > > then, it usually returns with 1 result. I click the Search! button again > > > to refresh and it came back a little faster with 0 results? > > > > > > Searched again from the top and it's a little faster now: > > > > > > * click search * > > > > date > > > Wed Dec 31 22:52:01 CST 2003 > > > > > > * results come back * > > > > date > > > Wed Dec 31 22:52:27 CST 2003 > > > > > > Still one result: > > > > > > PostgreSQL 7.4 Documentation (SQL Key Words) > > > <http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html> > > > [*0.087%*] > > > http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html > > > Size: 65401 bytes, modified: Tue, 25 Nov 2003, 15:02:33 AST > > > > > > However, the page that I SHOULD have found was this one: > > > > > > http://www.postgresql.org/docs/current/static/sql-createfunction.html > > > > > > That page has SECURITY INVOKER in a whole section: > > > > > > [EXTERNAL] SECURITY INVOKER > > > [EXTERNAL] SECURITY DEFINER > > > > > > SECURITY INVOKER indicates that the function is to be executed with > > > the privileges of the user that calls it. That is the default. > > > SECURITY DEFINER specifies that the function is to be executed with > > > the privileges of the user that created it. > > > > > > Dante > > > > > > ---------- > > > D. Dante Lorenso > > > dante@lorenso.com > > > > > > > > > > > > ---------------------------(end of broadcast)--------------------------- > > > TIP 3: if posting/reading through Usenet, please send an appropriate > > > subscribe-nomail command to majordomo@postgresql.org so that your > > > message can get through to the mailing list cleanly > > > > > -- > > Dave Cramer > > 519 939 0336 > > ICQ # 1467551 > > > > > > ---- > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > -- Dave Cramer 519 939 0336 ICQ # 1467551
On Wed, 31 Dec 2003, Dave Cramer wrote: > Why are their multiple servers hitting the same db > > what servers are searching through the db? www.postgresql.org and archives.postgresql.org both hit the same DB ... the point is more that whatever alternative that someone can suggest, it has to be able to be accessed centrally from several different machines ... when I just tried a search, I was the only one hitting the database, and the search was dreadful, so it isn't a problem with multiple connections :( Just as an FYI, the database server has sufficient RAM on her, so it isn't a swapping issue ... swap usuage right now, after 77 days uptime: Device 1K-blocks Used Avail Capacity Type /dev/da0s1b 8388480 17556 8370924 0% Interleaved > > Dave > On Wed, 2003-12-31 at 00:04, Marc G. Fournier wrote: > > does anyone know anything better then mnogosearch, that works with > > PostgreSQL, for doing indexing? the database server is a Dual Xeon 2.4G, > > 4G of RAM, and a load avg right now of a lowly 1.5 ... the file system is > > 3x72G drive in a RAID5 configuration, and the database server is 7.4 ... > > the mnogosearch folk use mysql for their development, so its possible > > there is something they are doing that is slowing this process down, to > > compensate for a fault in mysql, but this is ridiculous ... > > > > note that I have it setup with what the mnogosearch folk lists as being > > 'the fastest schema for large indexes' or 'crc-multi' ... > > > > right now, we're running only 373k docs: > > > > isvr5# indexer -S > > > > Database statistics > > > > Status Expired Total > > ----------------------------- > > 415 0 311 Unsupported Media Type > > 302 0 1171 Moved Temporarily > > 502 0 43 Bad Gateway > > 414 0 3 Request-URI Too Long > > 301 0 307 Moved Permanently > > 404 0 1960 Not found > > 410 0 1 Gone > > 401 0 51 Unauthorized > > 304 0 16591 Not Modified > > 200 0 373015 OK > > 504 0 48 Gateway Timeout > > 400 0 3 Bad Request > > 0 2 47 Not indexed yet > > ----------------------------- > > Total 2 393551 > > > > and a vacuum analyze runs nightly ... > > > > anyone with suggestions/ideas? has to be something client/server, like > > mnogosearch, as we're dealing with multiple servers searching against the > > same database ... so I don't *think* that ht/Dig is a solution, but may be > > wrong there ... > > > > On Wed, 30 Dec 2003, Dave Cramer wrote: > > > > > search for create index took 59 seconds ? > > > > > > I've got a fairly (< 1 second for the same search) fast search engine on > > > the docs at > > > > > > http://postgresintl.com/search?query=create index > > > > > > if that link doesn't work, try > > > > > > postgres.fastcrypt.com/search?query=create index > > > > > > for now you will have to type it, I'm working on indexing it then making > > > it pretty > > > > > > Dave > > > > > > On Tue, 2003-12-30 at 22:39, D. Dante Lorenso wrote: > > > > Marc G. Fournier wrote: > > > > > > > > >On Mon, 29 Dec 2003, D. Dante Lorenso wrote: > > > > > > > > > >>Trying to use the 'search' in the docs section of PostgreSQL.org > > > > >>is extremely SLOW. Considering this is a website for a database > > > > >>and databases are supposed to be good for indexing content, I'd > > > > >>expect a much faster performance. > > > > >> > > > > >> > > > > >What is the full URL for the page you are looking at? Just the 'search > > > > >link' at the top of the page? > > > > > > > > > > > > > > >>Perhaps this should be worked on? > > > > >> > > > > >> > > > > >Looking into it right now ... > > > > > > > > > > > > > > > > > > http://www.postgresql.org/ *click Docs on top of page* > > > > http://www.postgresql.org/docs/ * click PostgreSQL static > > > > documentation * > > > > > > > > Search this document set: [ SECURITY INVOKER ] Search! > > > > > > > > > > > > http://www.postgresql.org/search.cgi?ul=http://www.postgresql.org/docs/7.4/static/&q=SECURITY+INVOKER > > > > > > > > I loaded that URL on IE and I wait like 2 minutes or more for a response. > > > > then, it usually returns with 1 result. I click the Search! button again > > > > to refresh and it came back a little faster with 0 results? > > > > > > > > Searched again from the top and it's a little faster now: > > > > > > > > * click search * > > > > > date > > > > Wed Dec 31 22:52:01 CST 2003 > > > > > > > > * results come back * > > > > > date > > > > Wed Dec 31 22:52:27 CST 2003 > > > > > > > > Still one result: > > > > > > > > PostgreSQL 7.4 Documentation (SQL Key Words) > > > > <http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html> > > > > [*0.087%*] > > > > http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html > > > > Size: 65401 bytes, modified: Tue, 25 Nov 2003, 15:02:33 AST > > > > > > > > However, the page that I SHOULD have found was this one: > > > > > > > > http://www.postgresql.org/docs/current/static/sql-createfunction.html > > > > > > > > That page has SECURITY INVOKER in a whole section: > > > > > > > > [EXTERNAL] SECURITY INVOKER > > > > [EXTERNAL] SECURITY DEFINER > > > > > > > > SECURITY INVOKER indicates that the function is to be executed with > > > > the privileges of the user that calls it. That is the default. > > > > SECURITY DEFINER specifies that the function is to be executed with > > > > the privileges of the user that created it. > > > > > > > > Dante > > > > > > > > ---------- > > > > D. Dante Lorenso > > > > dante@lorenso.com > > > > > > > > > > > > > > > > ---------------------------(end of broadcast)--------------------------- > > > > TIP 3: if posting/reading through Usenet, please send an appropriate > > > > subscribe-nomail command to majordomo@postgresql.org so that your > > > > message can get through to the mailing list cleanly > > > > > > > -- > > > Dave Cramer > > > 519 939 0336 > > > ICQ # 1467551 > > > > > > > > > > ---- > > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > > > -- > Dave Cramer > 519 939 0336 > ICQ # 1467551 > > ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
I can modify mine to be client server if you want? It is a java app, so we need to be able to run jdk1.3 at least? Dave On Wed, 2003-12-31 at 00:04, Marc G. Fournier wrote: > does anyone know anything better then mnogosearch, that works with > PostgreSQL, for doing indexing? the database server is a Dual Xeon 2.4G, > 4G of RAM, and a load avg right now of a lowly 1.5 ... the file system is > 3x72G drive in a RAID5 configuration, and the database server is 7.4 ... > the mnogosearch folk use mysql for their development, so its possible > there is something they are doing that is slowing this process down, to > compensate for a fault in mysql, but this is ridiculous ... > > note that I have it setup with what the mnogosearch folk lists as being > 'the fastest schema for large indexes' or 'crc-multi' ... > > right now, we're running only 373k docs: > > isvr5# indexer -S > > Database statistics > > Status Expired Total > ----------------------------- > 415 0 311 Unsupported Media Type > 302 0 1171 Moved Temporarily > 502 0 43 Bad Gateway > 414 0 3 Request-URI Too Long > 301 0 307 Moved Permanently > 404 0 1960 Not found > 410 0 1 Gone > 401 0 51 Unauthorized > 304 0 16591 Not Modified > 200 0 373015 OK > 504 0 48 Gateway Timeout > 400 0 3 Bad Request > 0 2 47 Not indexed yet > ----------------------------- > Total 2 393551 > > and a vacuum analyze runs nightly ... > > anyone with suggestions/ideas? has to be something client/server, like > mnogosearch, as we're dealing with multiple servers searching against the > same database ... so I don't *think* that ht/Dig is a solution, but may be > wrong there ... > > On Wed, 30 Dec 2003, Dave Cramer wrote: > > > search for create index took 59 seconds ? > > > > I've got a fairly (< 1 second for the same search) fast search engine on > > the docs at > > > > http://postgresintl.com/search?query=create index > > > > if that link doesn't work, try > > > > postgres.fastcrypt.com/search?query=create index > > > > for now you will have to type it, I'm working on indexing it then making > > it pretty > > > > Dave > > > > On Tue, 2003-12-30 at 22:39, D. Dante Lorenso wrote: > > > Marc G. Fournier wrote: > > > > > > >On Mon, 29 Dec 2003, D. Dante Lorenso wrote: > > > > > > > >>Trying to use the 'search' in the docs section of PostgreSQL.org > > > >>is extremely SLOW. Considering this is a website for a database > > > >>and databases are supposed to be good for indexing content, I'd > > > >>expect a much faster performance. > > > >> > > > >> > > > >What is the full URL for the page you are looking at? Just the 'search > > > >link' at the top of the page? > > > > > > > > > > > >>Perhaps this should be worked on? > > > >> > > > >> > > > >Looking into it right now ... > > > > > > > > > > > > > > http://www.postgresql.org/ *click Docs on top of page* > > > http://www.postgresql.org/docs/ * click PostgreSQL static > > > documentation * > > > > > > Search this document set: [ SECURITY INVOKER ] Search! > > > > > > > > > http://www.postgresql.org/search.cgi?ul=http://www.postgresql.org/docs/7.4/static/&q=SECURITY+INVOKER > > > > > > I loaded that URL on IE and I wait like 2 minutes or more for a response. > > > then, it usually returns with 1 result. I click the Search! button again > > > to refresh and it came back a little faster with 0 results? > > > > > > Searched again from the top and it's a little faster now: > > > > > > * click search * > > > > date > > > Wed Dec 31 22:52:01 CST 2003 > > > > > > * results come back * > > > > date > > > Wed Dec 31 22:52:27 CST 2003 > > > > > > Still one result: > > > > > > PostgreSQL 7.4 Documentation (SQL Key Words) > > > <http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html> > > > [*0.087%*] > > > http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html > > > Size: 65401 bytes, modified: Tue, 25 Nov 2003, 15:02:33 AST > > > > > > However, the page that I SHOULD have found was this one: > > > > > > http://www.postgresql.org/docs/current/static/sql-createfunction.html > > > > > > That page has SECURITY INVOKER in a whole section: > > > > > > [EXTERNAL] SECURITY INVOKER > > > [EXTERNAL] SECURITY DEFINER > > > > > > SECURITY INVOKER indicates that the function is to be executed with > > > the privileges of the user that calls it. That is the default. > > > SECURITY DEFINER specifies that the function is to be executed with > > > the privileges of the user that created it. > > > > > > Dante > > > > > > ---------- > > > D. Dante Lorenso > > > dante@lorenso.com > > > > > > > > > > > > ---------------------------(end of broadcast)--------------------------- > > > TIP 3: if posting/reading through Usenet, please send an appropriate > > > subscribe-nomail command to majordomo@postgresql.org so that your > > > message can get through to the mailing list cleanly > > > > > -- > > Dave Cramer > > 519 939 0336 > > ICQ # 1467551 > > > > > > ---- > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > > ---------------------------(end of broadcast)--------------------------- > TIP 3: if posting/reading through Usenet, please send an appropriate > subscribe-nomail command to majordomo@postgresql.org so that your > message can get through to the mailing list cleanly > -- Dave Cramer 519 939 0336 ICQ # 1467551
On Wed, 31 Dec 2003, Dave Cramer wrote: > I can modify mine to be client server if you want? > > It is a java app, so we need to be able to run jdk1.3 at least? jdk1.4 is available on the VMs ... does your spider? for instance, you mention that you have the docs indexed right now, but we are currently indexing: Server http://archives.postgresql.org/ Server http://advocacy.postgresql.org/ Server http://developer.postgresql.org/ Server http://gborg.postgresql.org/ Server http://pgadmin.postgresql.org/ Server http://techdocs.postgresql.org/ Server http://www.postgresql.org/ will it be able to handle: 186_archives=# select count(*) from url; count -------- 393551 (1 row) as fast as you are finding with just the docs? ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
Hello, Why are we not using Tsearch2? Besides the obvious of getting everything into the database? Sincerely, Joshua D. Drake On Tue, 2003-12-30 at 21:24, Marc G. Fournier wrote: > On Wed, 31 Dec 2003, Dave Cramer wrote: > > > Why are their multiple servers hitting the same db > > > > what servers are searching through the db? > > www.postgresql.org and archives.postgresql.org both hit the same DB ... > the point is more that whatever alternative that someone can suggest, it > has to be able to be accessed centrally from several different machines > ... when I just tried a search, I was the only one hitting the database, > and the search was dreadful, so it isn't a problem with multiple > connections :( > > Just as an FYI, the database server has sufficient RAM on her, so it isn't > a swapping issue ... swap usuage right now, after 77 days uptime: > > Device 1K-blocks Used Avail Capacity Type > /dev/da0s1b 8388480 17556 8370924 0% Interleaved > > > > > > Dave > > On Wed, 2003-12-31 at 00:04, Marc G. Fournier wrote: > > > does anyone know anything better then mnogosearch, that works with > > > PostgreSQL, for doing indexing? the database server is a Dual Xeon 2.4G, > > > 4G of RAM, and a load avg right now of a lowly 1.5 ... the file system is > > > 3x72G drive in a RAID5 configuration, and the database server is 7.4 ... > > > the mnogosearch folk use mysql for their development, so its possible > > > there is something they are doing that is slowing this process down, to > > > compensate for a fault in mysql, but this is ridiculous ... > > > > > > note that I have it setup with what the mnogosearch folk lists as being > > > 'the fastest schema for large indexes' or 'crc-multi' ... > > > > > > right now, we're running only 373k docs: > > > > > > isvr5# indexer -S > > > > > > Database statistics > > > > > > Status Expired Total > > > ----------------------------- > > > 415 0 311 Unsupported Media Type > > > 302 0 1171 Moved Temporarily > > > 502 0 43 Bad Gateway > > > 414 0 3 Request-URI Too Long > > > 301 0 307 Moved Permanently > > > 404 0 1960 Not found > > > 410 0 1 Gone > > > 401 0 51 Unauthorized > > > 304 0 16591 Not Modified > > > 200 0 373015 OK > > > 504 0 48 Gateway Timeout > > > 400 0 3 Bad Request > > > 0 2 47 Not indexed yet > > > ----------------------------- > > > Total 2 393551 > > > > > > and a vacuum analyze runs nightly ... > > > > > > anyone with suggestions/ideas? has to be something client/server, like > > > mnogosearch, as we're dealing with multiple servers searching against the > > > same database ... so I don't *think* that ht/Dig is a solution, but may be > > > wrong there ... > > > > > > On Wed, 30 Dec 2003, Dave Cramer wrote: > > > > > > > search for create index took 59 seconds ? > > > > > > > > I've got a fairly (< 1 second for the same search) fast search engine on > > > > the docs at > > > > > > > > http://postgresintl.com/search?query=create index > > > > > > > > if that link doesn't work, try > > > > > > > > postgres.fastcrypt.com/search?query=create index > > > > > > > > for now you will have to type it, I'm working on indexing it then making > > > > it pretty > > > > > > > > Dave > > > > > > > > On Tue, 2003-12-30 at 22:39, D. Dante Lorenso wrote: > > > > > Marc G. Fournier wrote: > > > > > > > > > > >On Mon, 29 Dec 2003, D. Dante Lorenso wrote: > > > > > > > > > > > >>Trying to use the 'search' in the docs section of PostgreSQL.org > > > > > >>is extremely SLOW. Considering this is a website for a database > > > > > >>and databases are supposed to be good for indexing content, I'd > > > > > >>expect a much faster performance. > > > > > >> > > > > > >> > > > > > >What is the full URL for the page you are looking at? Just the 'search > > > > > >link' at the top of the page? > > > > > > > > > > > > > > > > > >>Perhaps this should be worked on? > > > > > >> > > > > > >> > > > > > >Looking into it right now ... > > > > > > > > > > > > > > > > > > > > > > http://www.postgresql.org/ *click Docs on top of page* > > > > > http://www.postgresql.org/docs/ * click PostgreSQL static > > > > > documentation * > > > > > > > > > > Search this document set: [ SECURITY INVOKER ] Search! > > > > > > > > > > > > > > > http://www.postgresql.org/search.cgi?ul=http://www.postgresql.org/docs/7.4/static/&q=SECURITY+INVOKER > > > > > > > > > > I loaded that URL on IE and I wait like 2 minutes or more for a response. > > > > > then, it usually returns with 1 result. I click the Search! button again > > > > > to refresh and it came back a little faster with 0 results? > > > > > > > > > > Searched again from the top and it's a little faster now: > > > > > > > > > > * click search * > > > > > > date > > > > > Wed Dec 31 22:52:01 CST 2003 > > > > > > > > > > * results come back * > > > > > > date > > > > > Wed Dec 31 22:52:27 CST 2003 > > > > > > > > > > Still one result: > > > > > > > > > > PostgreSQL 7.4 Documentation (SQL Key Words) > > > > > <http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html> > > > > > [*0.087%*] > > > > > http://www.postgresql.org/docs/7.4/static/sql-keywords-appendix.html > > > > > Size: 65401 bytes, modified: Tue, 25 Nov 2003, 15:02:33 AST > > > > > > > > > > However, the page that I SHOULD have found was this one: > > > > > > > > > > http://www.postgresql.org/docs/current/static/sql-createfunction.html > > > > > > > > > > That page has SECURITY INVOKER in a whole section: > > > > > > > > > > [EXTERNAL] SECURITY INVOKER > > > > > [EXTERNAL] SECURITY DEFINER > > > > > > > > > > SECURITY INVOKER indicates that the function is to be executed with > > > > > the privileges of the user that calls it. That is the default. > > > > > SECURITY DEFINER specifies that the function is to be executed with > > > > > the privileges of the user that created it. > > > > > > > > > > Dante > > > > > > > > > > ---------- > > > > > D. Dante Lorenso > > > > > dante@lorenso.com > > > > > > > > > > > > > > > > > > > > ---------------------------(end of broadcast)--------------------------- > > > > > TIP 3: if posting/reading through Usenet, please send an appropriate > > > > > subscribe-nomail command to majordomo@postgresql.org so that your > > > > > message can get through to the mailing list cleanly > > > > > > > > > -- > > > > Dave Cramer > > > > 519 939 0336 > > > > ICQ # 1467551 > > > > > > > > > > > > > > ---- > > > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > > > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > > > > > -- > > Dave Cramer > > 519 939 0336 > > ICQ # 1467551 > > > > > > ---- > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > > ---------------------------(end of broadcast)--------------------------- > TIP 7: don't forget to increase your free space map settings -- Command Prompt, Inc., home of Mammoth PostgreSQL - S/ODBC and S/JDBC Postgresql support, programming shared hosting and dedicated hosting. +1-503-667-4564 - jd@commandprompt.com - http://www.commandprompt.com Mammoth PostgreSQL Replicator. Integrated Replication for PostgreSQL
Marc, At our website we had a "in database" search as well... It was terribly slow (it was a custom built vector space model implemented in mysql+php so that explains a bit). We replaced it by the Xapian library (www.xapian.org) with its Omega frontend as a middle end. I.e. we call with our php-scripts the omega search frontend and postprocess the results with the scripts (some rights double checks and so on), from the results we build a very simpel SELECT ... FROM documents ... WHERE docid IN implode($docids_array) (you understand enough php to understand this, I suppose) With our 10GB of tekst, we have a 14GB (uncompressed, 9G compressed orso) xapian database (the largest part is for the 6.7G positional table), I'm pretty sure that if we'd store that information in something like tsearch it'd be more than that 14GB... Searches take less than a second (unless you do phrase searches of course, that takes a few seconds and sometimes a few minutes). I did a query on 'ext3 undelete' just a few minutes ago and it did the search in 827150 documents in only 0.027 (a second run 0.006) seconds (ext3 was found in 753 and undelete in 360 documents). Of course that is excluding the results parsing, the total time to create the webpage was "much" longer (0.43 seconds orso) due to the fact that the results needs to be transferred via xinetd and the results needs to be extracted from mysql (which is terrible with the "search supporting queries" we issue :/ ) Our search machine is very similar the machine you use as database, but it doesn't do much heavy work apart from running the xapian/omega search combination. If you are interested in this, I can provide (much) more information about our implementation. Since you don't need right-checks, you could even get away with just the omega front end all by itself (it has a nice scripting language, but can't interface with anything but xapian). The main advantage of taking this out of your sql database is that it runs on its own custom built storage system (and you could offload it to another machine, like we did). Btw, if you really need an "in database" solution, read back the postings of Eric Ridge at 26-12-2003 20:54 on the hackers list (he's working on integrating xapian in postgresql as a FTI) Best regards, Arjen van der Meijden Marc G. Fournier wrote: > does anyone know anything better then mnogosearch, that works with > PostgreSQL, for doing indexing? the database server is a Dual Xeon 2.4G, > 4G of RAM, and a load avg right now of a lowly 1.5 ... the file system is > 3x72G drive in a RAID5 configuration, and the database server is 7.4 ... > the mnogosearch folk use mysql for their development, so its possible > there is something they are doing that is slowing this process down, to > compensate for a fault in mysql, but this is ridiculous ... > > note that I have it setup with what the mnogosearch folk lists as being > 'the fastest schema for large indexes' or 'crc-multi' ... > > right now, we're running only 373k docs: > > isvr5# indexer -S > > Database statistics > > Status Expired Total > ----------------------------- > 415 0 311 Unsupported Media Type > 302 0 1171 Moved Temporarily > 502 0 43 Bad Gateway > 414 0 3 Request-URI Too Long > 301 0 307 Moved Permanently > 404 0 1960 Not found > 410 0 1 Gone > 401 0 51 Unauthorized > 304 0 16591 Not Modified > 200 0 373015 OK > 504 0 48 Gateway Timeout > 400 0 3 Bad Request > 0 2 47 Not indexed yet > ----------------------------- > Total 2 393551 > > and a vacuum analyze runs nightly ... > > anyone with suggestions/ideas? has to be something client/server, like > mnogosearch, as we're dealing with multiple servers searching against the > same database ... so I don't *think* that ht/Dig is a solution, but may be > wrong there ...
Marc, No it doesn't spider, it is a specialized tool for searching documents. I'm curious, what value is there to being able to count the number of url's ? It does do things like query all documents where CREATE AND TABLE are n words apart, just as fast, I would think these are more valuable to document searching? I think the challenge here is what do we want to search. I am betting that folks use this page as they would man? ie. what is the command for create trigger? As I said my offer stands to help out, but I think if the goal is to search the entire website, then this particular tool is not useful. At this point I am working on indexing the sgml directly as it has less cruft in it. For instance all the links that appear in every summary are just noise. Dave On Wed, 2003-12-31 at 00:44, Marc G. Fournier wrote: > On Wed, 31 Dec 2003, Dave Cramer wrote: > > > I can modify mine to be client server if you want? > > > > It is a java app, so we need to be able to run jdk1.3 at least? > > jdk1.4 is available on the VMs ... does your spider? for instance, you > mention that you have the docs indexed right now, but we are currently > indexing: > > Server http://archives.postgresql.org/ > Server http://advocacy.postgresql.org/ > Server http://developer.postgresql.org/ > Server http://gborg.postgresql.org/ > Server http://pgadmin.postgresql.org/ > Server http://techdocs.postgresql.org/ > Server http://www.postgresql.org/ > > will it be able to handle: > > 186_archives=# select count(*) from url; > count > -------- > 393551 > (1 row) > > as fast as you are finding with just the docs? > > ---- > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > -- Dave Cramer 519 939 0336 ICQ # 1467551
I think that Oleg's new search offering looks really good and fast. (I can't wait till I have some task that needs tsearch!). I agree with Dave that searching the docs is more important for me than the sites - but it would be really nice to have both, in one tool. I built something similar for the Tate Gallery in the UK - here you can select the type of content that you want returned, either static pages or dynamic. You can see the idea at http://www.tate.org.uk/search/default.jsp?terms=sunset%20oil&action=new This is custom built (using java/Oracle), supports stemming, boolean operators, exact phrase matching, relevancy and matched term highlighting. You can switch on/off the types of documents that you are not interested in. Using this analogy, a search facility that could offer you results from i) the docs and/or ii) the postgres sites static pages would be very useful. John Sidney-Woollett Dave Cramer said: > Marc, > > No it doesn't spider, it is a specialized tool for searching documents. > > I'm curious, what value is there to being able to count the number of > url's ? > > It does do things like query all documents where CREATE AND TABLE are n > words apart, just as fast, I would think these are more valuable to > document searching? > > I think the challenge here is what do we want to search. I am betting > that folks use this page as they would man? ie. what is the command for > create trigger? > > As I said my offer stands to help out, but I think if the goal is to > search the entire website, then this particular tool is not useful. > > At this point I am working on indexing the sgml directly as it has less > cruft in it. For instance all the links that appear in every summary are > just noise. > > > Dave > > On Wed, 2003-12-31 at 00:44, Marc G. Fournier wrote: >> On Wed, 31 Dec 2003, Dave Cramer wrote: >> >> > I can modify mine to be client server if you want? >> > >> > It is a java app, so we need to be able to run jdk1.3 at least? >> >> jdk1.4 is available on the VMs ... does your spider? for instance, you >> mention that you have the docs indexed right now, but we are currently >> indexing: >> >> Server http://archives.postgresql.org/ >> Server http://advocacy.postgresql.org/ >> Server http://developer.postgresql.org/ >> Server http://gborg.postgresql.org/ >> Server http://pgadmin.postgresql.org/ >> Server http://techdocs.postgresql.org/ >> Server http://www.postgresql.org/ >> >> will it be able to handle: >> >> 186_archives=# select count(*) from url; >> count >> -------- >> 393551 >> (1 row) >> >> as fast as you are finding with just the docs? >> >> ---- >> Marc G. Fournier Hub.Org Networking Services >> (http://www.hub.org) >> Email: scrappy@hub.org Yahoo!: yscrappy ICQ: >> 7615664 >> > -- > Dave Cramer > 519 939 0336 > ICQ # 1467551 > > > ---------------------------(end of broadcast)--------------------------- > TIP 9: the planner will ignore your desire to choose an index scan if your > joining column's datatypes do not match >
You should probably take a look at the Swish project. For a certain project, we tried Tsearch2/Tsearch, even (gasp) MySQL fulltext search, but with over 600,000 documents to index, both took too long to conduct searches, especially as the database was swapped in and out of memory based on search segment. MySQL full text was the most unusable. Swish uses its own internal DB format, and comes with a simple spider as well. You can make it search by category, date and other nifty criteria also. http://swish-e.org You can take a look over at the project and do some searches to see what I mean: http://cbd-net.com Warmest regards, Ericson Smith Tracking Specialist/DBA +-----------------------+----------------------------+ | http://www.did-it.com | "When I'm paid, I always | | eric@did-it.com | follow the job through. | | 516-255-0500 | You know that." -Angel Eyes| +-----------------------+----------------------------+ John Sidney-Woollett wrote: >I think that Oleg's new search offering looks really good and fast. (I >can't wait till I have some task that needs tsearch!). > >I agree with Dave that searching the docs is more important for me than >the sites - but it would be really nice to have both, in one tool. > >I built something similar for the Tate Gallery in the UK - here you can >select the type of content that you want returned, either static pages or >dynamic. You can see the idea at >http://www.tate.org.uk/search/default.jsp?terms=sunset%20oil&action=new > >This is custom built (using java/Oracle), supports stemming, boolean >operators, exact phrase matching, relevancy and matched term highlighting. > >You can switch on/off the types of documents that you are not interested >in. Using this analogy, a search facility that could offer you results >from i) the docs and/or ii) the postgres sites static pages would be very >useful. > >John Sidney-Woollett > >Dave Cramer said: > > >>Marc, >> >>No it doesn't spider, it is a specialized tool for searching documents. >> >>I'm curious, what value is there to being able to count the number of >>url's ? >> >>It does do things like query all documents where CREATE AND TABLE are n >>words apart, just as fast, I would think these are more valuable to >>document searching? >> >>I think the challenge here is what do we want to search. I am betting >>that folks use this page as they would man? ie. what is the command for >>create trigger? >> >>As I said my offer stands to help out, but I think if the goal is to >>search the entire website, then this particular tool is not useful. >> >>At this point I am working on indexing the sgml directly as it has less >>cruft in it. For instance all the links that appear in every summary are >>just noise. >> >> >>Dave >> >>On Wed, 2003-12-31 at 00:44, Marc G. Fournier wrote: >> >> >>>On Wed, 31 Dec 2003, Dave Cramer wrote: >>> >>> >>> >>>>I can modify mine to be client server if you want? >>>> >>>>It is a java app, so we need to be able to run jdk1.3 at least? >>>> >>>> >>>jdk1.4 is available on the VMs ... does your spider? for instance, you >>>mention that you have the docs indexed right now, but we are currently >>>indexing: >>> >>>Server http://archives.postgresql.org/ >>>Server http://advocacy.postgresql.org/ >>>Server http://developer.postgresql.org/ >>>Server http://gborg.postgresql.org/ >>>Server http://pgadmin.postgresql.org/ >>>Server http://techdocs.postgresql.org/ >>>Server http://www.postgresql.org/ >>> >>>will it be able to handle: >>> >>>186_archives=# select count(*) from url; >>> count >>>-------- >>> 393551 >>>(1 row) >>> >>>as fast as you are finding with just the docs? >>> >>>---- >>>Marc G. Fournier Hub.Org Networking Services >>>(http://www.hub.org) >>>Email: scrappy@hub.org Yahoo!: yscrappy ICQ: >>>7615664 >>> >>> >>> >>-- >>Dave Cramer >>519 939 0336 >>ICQ # 1467551 >> >> >>---------------------------(end of broadcast)--------------------------- >>TIP 9: the planner will ignore your desire to choose an index scan if your >> joining column's datatypes do not match >> >> >> > > >---------------------------(end of broadcast)--------------------------- >TIP 2: you can get off all lists at once with the unregister command > (send "unregister YourEmailAddressHere" to majordomo@postgresql.org) > > >
Attachment
Wow, you're right - I could have probably saved myself a load of time! :) Although you do learn a lot reinventing the wheel... ...or at least you hit the same issues and insights others did before... John Ericson Smith said: > You should probably take a look at the Swish project. For a certain > project, we tried Tsearch2/Tsearch, even (gasp) MySQL fulltext search, > but with over 600,000 documents to index, both took too long to conduct > searches, especially as the database was swapped in and out of memory > based on search segment. MySQL full text was the most unusable. > > Swish uses its own internal DB format, and comes with a simple spider as > well. You can make it search by category, date and other nifty criteria > also. > http://swish-e.org > > You can take a look over at the project and do some searches to see what > I mean: > http://cbd-net.com > > Warmest regards, > Ericson Smith > Tracking Specialist/DBA > +-----------------------+----------------------------+ > | http://www.did-it.com | "When I'm paid, I always | > | eric@did-it.com | follow the job through. | > | 516-255-0500 | You know that." -Angel Eyes| > +-----------------------+----------------------------+ > > > > John Sidney-Woollett wrote: > >>I think that Oleg's new search offering looks really good and fast. (I >>can't wait till I have some task that needs tsearch!). >> >>I agree with Dave that searching the docs is more important for me than >>the sites - but it would be really nice to have both, in one tool. >> >>I built something similar for the Tate Gallery in the UK - here you can >>select the type of content that you want returned, either static pages or >>dynamic. You can see the idea at >>http://www.tate.org.uk/search/default.jsp?terms=sunset%20oil&action=new >> >>This is custom built (using java/Oracle), supports stemming, boolean >>operators, exact phrase matching, relevancy and matched term >> highlighting. >> >>You can switch on/off the types of documents that you are not interested >>in. Using this analogy, a search facility that could offer you results >>from i) the docs and/or ii) the postgres sites static pages would be very >>useful. >> >>John Sidney-Woollett >> >>Dave Cramer said: >> >> >>>Marc, >>> >>>No it doesn't spider, it is a specialized tool for searching documents. >>> >>>I'm curious, what value is there to being able to count the number of >>>url's ? >>> >>>It does do things like query all documents where CREATE AND TABLE are n >>>words apart, just as fast, I would think these are more valuable to >>>document searching? >>> >>>I think the challenge here is what do we want to search. I am betting >>>that folks use this page as they would man? ie. what is the command for >>>create trigger? >>> >>>As I said my offer stands to help out, but I think if the goal is to >>>search the entire website, then this particular tool is not useful. >>> >>>At this point I am working on indexing the sgml directly as it has less >>>cruft in it. For instance all the links that appear in every summary are >>>just noise. >>> >>> >>>Dave >>> >>>On Wed, 2003-12-31 at 00:44, Marc G. Fournier wrote: >>> >>> >>>>On Wed, 31 Dec 2003, Dave Cramer wrote: >>>> >>>> >>>> >>>>>I can modify mine to be client server if you want? >>>>> >>>>>It is a java app, so we need to be able to run jdk1.3 at least? >>>>> >>>>> >>>>jdk1.4 is available on the VMs ... does your spider? for instance, you >>>>mention that you have the docs indexed right now, but we are currently >>>>indexing: >>>> >>>>Server http://archives.postgresql.org/ >>>>Server http://advocacy.postgresql.org/ >>>>Server http://developer.postgresql.org/ >>>>Server http://gborg.postgresql.org/ >>>>Server http://pgadmin.postgresql.org/ >>>>Server http://techdocs.postgresql.org/ >>>>Server http://www.postgresql.org/ >>>> >>>>will it be able to handle: >>>> >>>>186_archives=# select count(*) from url; >>>> count >>>>-------- >>>> 393551 >>>>(1 row) >>>> >>>>as fast as you are finding with just the docs? >>>> >>>>---- >>>>Marc G. Fournier Hub.Org Networking Services >>>>(http://www.hub.org) >>>>Email: scrappy@hub.org Yahoo!: yscrappy ICQ: >>>>7615664 >>>> >>>> >>>> >>>-- >>>Dave Cramer >>>519 939 0336 >>>ICQ # 1467551 >>> >>> >>>---------------------------(end of broadcast)--------------------------- >>>TIP 9: the planner will ignore your desire to choose an index scan if >>> your >>> joining column's datatypes do not match >>> >>> >>> >> >> >>---------------------------(end of broadcast)--------------------------- >>TIP 2: you can get off all lists at once with the unregister command >> (send "unregister YourEmailAddressHere" to majordomo@postgresql.org) >> >> >> >
The search engine I am using is lucene http://jakarta.apache.org/lucene/docs/index.html it too uses it's own internal database format, optimized for searching, it is quite flexible, and allow searching on arbitrary fields as well. The section on querying explains more http://jakarta.apache.org/lucene/docs/queryparsersyntax.html It is even possible to index text data inside a database. Dave On Wed, 2003-12-31 at 08:44, John Sidney-Woollett wrote: > Wow, you're right - I could have probably saved myself a load of time! :) > > Although you do learn a lot reinventing the wheel... ...or at least you > hit the same issues and insights others did before... > > John > > Ericson Smith said: > > You should probably take a look at the Swish project. For a certain > > project, we tried Tsearch2/Tsearch, even (gasp) MySQL fulltext search, > > but with over 600,000 documents to index, both took too long to conduct > > searches, especially as the database was swapped in and out of memory > > based on search segment. MySQL full text was the most unusable. > > > > Swish uses its own internal DB format, and comes with a simple spider as > > well. You can make it search by category, date and other nifty criteria > > also. > > http://swish-e.org > > > > You can take a look over at the project and do some searches to see what > > I mean: > > http://cbd-net.com > > > > Warmest regards, > > Ericson Smith > > Tracking Specialist/DBA > > +-----------------------+----------------------------+ > > | http://www.did-it.com | "When I'm paid, I always | > > | eric@did-it.com | follow the job through. | > > | 516-255-0500 | You know that." -Angel Eyes| > > +-----------------------+----------------------------+ > > > > > > > > John Sidney-Woollett wrote: > > > >>I think that Oleg's new search offering looks really good and fast. (I > >>can't wait till I have some task that needs tsearch!). > >> > >>I agree with Dave that searching the docs is more important for me than > >>the sites - but it would be really nice to have both, in one tool. > >> > >>I built something similar for the Tate Gallery in the UK - here you can > >>select the type of content that you want returned, either static pages or > >>dynamic. You can see the idea at > >>http://www.tate.org.uk/search/default.jsp?terms=sunset%20oil&action=new > >> > >>This is custom built (using java/Oracle), supports stemming, boolean > >>operators, exact phrase matching, relevancy and matched term > >> highlighting. > >> > >>You can switch on/off the types of documents that you are not interested > >>in. Using this analogy, a search facility that could offer you results > >>from i) the docs and/or ii) the postgres sites static pages would be very > >>useful. > >> > >>John Sidney-Woollett > >> > >>Dave Cramer said: > >> > >> > >>>Marc, > >>> > >>>No it doesn't spider, it is a specialized tool for searching documents. > >>> > >>>I'm curious, what value is there to being able to count the number of > >>>url's ? > >>> > >>>It does do things like query all documents where CREATE AND TABLE are n > >>>words apart, just as fast, I would think these are more valuable to > >>>document searching? > >>> > >>>I think the challenge here is what do we want to search. I am betting > >>>that folks use this page as they would man? ie. what is the command for > >>>create trigger? > >>> > >>>As I said my offer stands to help out, but I think if the goal is to > >>>search the entire website, then this particular tool is not useful. > >>> > >>>At this point I am working on indexing the sgml directly as it has less > >>>cruft in it. For instance all the links that appear in every summary are > >>>just noise. > >>> > >>> > >>>Dave > >>> > >>>On Wed, 2003-12-31 at 00:44, Marc G. Fournier wrote: > >>> > >>> > >>>>On Wed, 31 Dec 2003, Dave Cramer wrote: > >>>> > >>>> > >>>> > >>>>>I can modify mine to be client server if you want? > >>>>> > >>>>>It is a java app, so we need to be able to run jdk1.3 at least? > >>>>> > >>>>> > >>>>jdk1.4 is available on the VMs ... does your spider? for instance, you > >>>>mention that you have the docs indexed right now, but we are currently > >>>>indexing: > >>>> > >>>>Server http://archives.postgresql.org/ > >>>>Server http://advocacy.postgresql.org/ > >>>>Server http://developer.postgresql.org/ > >>>>Server http://gborg.postgresql.org/ > >>>>Server http://pgadmin.postgresql.org/ > >>>>Server http://techdocs.postgresql.org/ > >>>>Server http://www.postgresql.org/ > >>>> > >>>>will it be able to handle: > >>>> > >>>>186_archives=# select count(*) from url; > >>>> count > >>>>-------- > >>>> 393551 > >>>>(1 row) > >>>> > >>>>as fast as you are finding with just the docs? > >>>> > >>>>---- > >>>>Marc G. Fournier Hub.Org Networking Services > >>>>(http://www.hub.org) > >>>>Email: scrappy@hub.org Yahoo!: yscrappy ICQ: > >>>>7615664 > >>>> > >>>> > >>>> > >>>-- > >>>Dave Cramer > >>>519 939 0336 > >>>ICQ # 1467551 > >>> > >>> > >>>---------------------------(end of broadcast)--------------------------- > >>>TIP 9: the planner will ignore your desire to choose an index scan if > >>> your > >>> joining column's datatypes do not match > >>> > >>> > >>> > >> > >> > >>---------------------------(end of broadcast)--------------------------- > >>TIP 2: you can get off all lists at once with the unregister command > >> (send "unregister YourEmailAddressHere" to majordomo@postgresql.org) > >> > >> > >> > > > -- Dave Cramer 519 939 0336 ICQ # 1467551
Well it appears there are quite a few solutions to use so the next question should be what are we trying to accomplish here? One thing that I think is that the documentation search should be limited to the documentation. Who is in a position to make the decision of which solution to use? Dave On Wed, 2003-12-31 at 08:44, John Sidney-Woollett wrote: > Wow, you're right - I could have probably saved myself a load of time! :) > > Although you do learn a lot reinventing the wheel... ...or at least you > hit the same issues and insights others did before... > > John > > Ericson Smith said: > > You should probably take a look at the Swish project. For a certain > > project, we tried Tsearch2/Tsearch, even (gasp) MySQL fulltext search, > > but with over 600,000 documents to index, both took too long to conduct > > searches, especially as the database was swapped in and out of memory > > based on search segment. MySQL full text was the most unusable. > > > > Swish uses its own internal DB format, and comes with a simple spider as > > well. You can make it search by category, date and other nifty criteria > > also. > > http://swish-e.org > > > > You can take a look over at the project and do some searches to see what > > I mean: > > http://cbd-net.com > > > > Warmest regards, > > Ericson Smith > > Tracking Specialist/DBA > > +-----------------------+----------------------------+ > > | http://www.did-it.com | "When I'm paid, I always | > > | eric@did-it.com | follow the job through. | > > | 516-255-0500 | You know that." -Angel Eyes| > > +-----------------------+----------------------------+ > > > > > > > > John Sidney-Woollett wrote: > > > >>I think that Oleg's new search offering looks really good and fast. (I > >>can't wait till I have some task that needs tsearch!). > >> > >>I agree with Dave that searching the docs is more important for me than > >>the sites - but it would be really nice to have both, in one tool. > >> > >>I built something similar for the Tate Gallery in the UK - here you can > >>select the type of content that you want returned, either static pages or > >>dynamic. You can see the idea at > >>http://www.tate.org.uk/search/default.jsp?terms=sunset%20oil&action=new > >> > >>This is custom built (using java/Oracle), supports stemming, boolean > >>operators, exact phrase matching, relevancy and matched term > >> highlighting. > >> > >>You can switch on/off the types of documents that you are not interested > >>in. Using this analogy, a search facility that could offer you results > >>from i) the docs and/or ii) the postgres sites static pages would be very > >>useful. > >> > >>John Sidney-Woollett > >> > >>Dave Cramer said: > >> > >> > >>>Marc, > >>> > >>>No it doesn't spider, it is a specialized tool for searching documents. > >>> > >>>I'm curious, what value is there to being able to count the number of > >>>url's ? > >>> > >>>It does do things like query all documents where CREATE AND TABLE are n > >>>words apart, just as fast, I would think these are more valuable to > >>>document searching? > >>> > >>>I think the challenge here is what do we want to search. I am betting > >>>that folks use this page as they would man? ie. what is the command for > >>>create trigger? > >>> > >>>As I said my offer stands to help out, but I think if the goal is to > >>>search the entire website, then this particular tool is not useful. > >>> > >>>At this point I am working on indexing the sgml directly as it has less > >>>cruft in it. For instance all the links that appear in every summary are > >>>just noise. > >>> > >>> > >>>Dave > >>> > >>>On Wed, 2003-12-31 at 00:44, Marc G. Fournier wrote: > >>> > >>> > >>>>On Wed, 31 Dec 2003, Dave Cramer wrote: > >>>> > >>>> > >>>> > >>>>>I can modify mine to be client server if you want? > >>>>> > >>>>>It is a java app, so we need to be able to run jdk1.3 at least? > >>>>> > >>>>> > >>>>jdk1.4 is available on the VMs ... does your spider? for instance, you > >>>>mention that you have the docs indexed right now, but we are currently > >>>>indexing: > >>>> > >>>>Server http://archives.postgresql.org/ > >>>>Server http://advocacy.postgresql.org/ > >>>>Server http://developer.postgresql.org/ > >>>>Server http://gborg.postgresql.org/ > >>>>Server http://pgadmin.postgresql.org/ > >>>>Server http://techdocs.postgresql.org/ > >>>>Server http://www.postgresql.org/ > >>>> > >>>>will it be able to handle: > >>>> > >>>>186_archives=# select count(*) from url; > >>>> count > >>>>-------- > >>>> 393551 > >>>>(1 row) > >>>> > >>>>as fast as you are finding with just the docs? > >>>> > >>>>---- > >>>>Marc G. Fournier Hub.Org Networking Services > >>>>(http://www.hub.org) > >>>>Email: scrappy@hub.org Yahoo!: yscrappy ICQ: > >>>>7615664 > >>>> > >>>> > >>>> > >>>-- > >>>Dave Cramer > >>>519 939 0336 > >>>ICQ # 1467551 > >>> > >>> > >>>---------------------------(end of broadcast)--------------------------- > >>>TIP 9: the planner will ignore your desire to choose an index scan if > >>> your > >>> joining column's datatypes do not match > >>> > >>> > >>> > >> > >> > >>---------------------------(end of broadcast)--------------------------- > >>TIP 2: you can get off all lists at once with the unregister command > >> (send "unregister YourEmailAddressHere" to majordomo@postgresql.org) > >> > >> > >> > > > -- Dave Cramer 519 939 0336 ICQ # 1467551
> Hello, > > Why are we not using Tsearch2? > > Besides the obvious of getting everything into the database? > > Sincerely, > > Joshua D. Drake Oleg Bartunov, an author of tsearch2, is working on indexing the docs. See: http://archives.postgresql.org/pgsql-general/2003-12/msg01520.php I agree it makes the most sense to use a solution thats ships with the PostgreSQL source code. George Essig
On Dec 31, 2003, at 5:40 AM, Arjen van der Meijden wrote: > The main advantage of taking this out of your sql database is that it > runs on its own custom built storage system (and you could offload it > to another machine, like we did). > Btw, if you really need an "in database" solution, read back the > postings of Eric Ridge at 26-12-2003 20:54 on the hackers list (he's > working on integrating xapian in postgresql as a FTI) Hi, that's me! I'm working it right now, and it's coming along really well. I actually hope to have it integrated with Postgres' storage subsystem by the end of the day and to have it returning useful results. eric
On Wed, 31 Dec 2003, Dave Cramer wrote: > Marc, > > No it doesn't spider, it is a specialized tool for searching documents. > > I'm curious, what value is there to being able to count the number of > url's ? Sorry, that was just an example of the # of docs that have to be searched through ... again, the *biggest* thing that is searched is the mailing list archives, so without spidering, not sure how we'll be able to pull that in ... ? ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
On Tue, 30 Dec 2003, Joshua D. Drake wrote: > Hello, > > Why are we not using Tsearch2? Because nobody has built it yet? Oleg's stuff is nice, but we want something that we can build into the existing web sites, not a standalone site ... I keep searching the web hoping someone has come up with a 'tsearch2' based search engine that does the spidering, but, unless its sitting right in front of my eyes and I'm not seeing it, I haven't found it yet :( Out of everything I've found so far, mnogosearch is one of the best ... I just wish I could figure out where the bottleneck for it was, since, from reading their docs, their method of storing the data doesn't appear to be particularly off. I'm tempted to try their caching storage manager, and getting away from SQL totally, but I *really* want to showcase PostgreSQL on this :( ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
Marc G. Fournier wrote: > On Tue, 30 Dec 2003, Joshua D. Drake wrote: > > > Hello, > > > > Why are we not using Tsearch2? > > Because nobody has built it yet? Oleg's stuff is nice, but we want > something that we can build into the existing web sites, not a standalone > site ... > > I keep searching the web hoping someone has come up with a 'tsearch2' > based search engine that does the spidering, but, unless its sitting right > in front of my eyes and I'm not seeing it, I haven't found it yet :( > > Out of everything I've found so far, mnogosearch is one of the best ... I > just wish I could figure out where the bottleneck for it was, since, from > reading their docs, their method of storing the data doesn't appear to be > particularly off. I'm tempted to try their caching storage manager, and > getting away from SQL totally, but I *really* want to showcase PostgreSQL > on this :( Well, PostgreSQL is being un-showcased in the current setup, that's for sure. :-( -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 359-1001 + If your life is a hard drive, | 13 Roberts Road + Christ can be your backup. | Newtown Square, Pennsylvania 19073
On Wed, 31 Dec 2003, Bruce Momjian wrote: > > Out of everything I've found so far, mnogosearch is one of the best ... I > > just wish I could figure out where the bottleneck for it was, since, from > > reading their docs, their method of storing the data doesn't appear to be > > particularly off. I'm tempted to try their caching storage manager, and > > getting away from SQL totally, but I *really* want to showcase PostgreSQL > > on this :( > > Well, PostgreSQL is being un-showcased in the current setup, that's for > sure. :-( Agreed ... I could install the MySQL backend, whichits designed for, and advertise it as PostgreSQL? :) ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
Marc G. Fournier wrote: > On Wed, 31 Dec 2003, Bruce Momjian wrote: > > > > Out of everything I've found so far, mnogosearch is one of the best ... I > > > just wish I could figure out where the bottleneck for it was, since, from > > > reading their docs, their method of storing the data doesn't appear to be > > > particularly off. I'm tempted to try their caching storage manager, and > > > getting away from SQL totally, but I *really* want to showcase PostgreSQL > > > on this :( > > > > Well, PostgreSQL is being un-showcased in the current setup, that's for > > sure. :-( > > Agreed ... I could install the MySQL backend, whichits designed for, and > advertise it as PostgreSQL? :) I would be curious to know if it is faster --- that would tell use if it is tuned only for MySQL. Have you tried CLUSTER? I think the MySQL ISAM files are auto-clustered, and clustering is usually important for full-text searches. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 359-1001 + If your life is a hard drive, | 13 Roberts Road + Christ can be your backup. | Newtown Square, Pennsylvania 19073
On Wed, 2003-12-31 at 18:43, Bruce Momjian wrote: > Marc G. Fournier wrote: > > On Tue, 30 Dec 2003, Joshua D. Drake wrote: > > > > > Hello, > > > > > > Why are we not using Tsearch2? > > > > Because nobody has built it yet? Oleg's stuff is nice, but we want > > something that we can build into the existing web sites, not a standalone > > site ... > > > > I keep searching the web hoping someone has come up with a 'tsearch2' > > based search engine that does the spidering, but, unless its sitting right > > in front of my eyes and I'm not seeing it, I haven't found it yet :( > > > > Out of everything I've found so far, mnogosearch is one of the best ... I > > just wish I could figure out where the bottleneck for it was, since, from > > reading their docs, their method of storing the data doesn't appear to be > > particularly off. I'm tempted to try their caching storage manager, and > > getting away from SQL totally, but I *really* want to showcase PostgreSQL > > on this :( > > Well, PostgreSQL is being un-showcased in the current setup, that's for > sure. :-( In fact this is a very bad advertisement for postgres -- Dave Cramer 519 939 0336 ICQ # 1467551
On Wed, 31 Dec 2003, Bruce Momjian wrote: > Marc G. Fournier wrote: > > On Wed, 31 Dec 2003, Bruce Momjian wrote: > > > > > > Out of everything I've found so far, mnogosearch is one of the best ... I > > > > just wish I could figure out where the bottleneck for it was, since, from > > > > reading their docs, their method of storing the data doesn't appear to be > > > > particularly off. I'm tempted to try their caching storage manager, and > > > > getting away from SQL totally, but I *really* want to showcase PostgreSQL > > > > on this :( > > > > > > Well, PostgreSQL is being un-showcased in the current setup, that's for > > > sure. :-( > > > > Agreed ... I could install the MySQL backend, whichits designed for, and > > advertise it as PostgreSQL? :) > > I would be curious to know if it is faster --- that would tell use if it > is tuned only for MySQL. > > Have you tried CLUSTER? I think the MySQL ISAM files are > auto-clustered, and clustering is usually important for full-text > searches. Actually, check out http://www.mnogosearch.com ... the way they do the indexing doesn't (at least, as far as I can tell) make use of full-text searching. Simplistically, it appears to take the web page, sort -u all the words it finds, removes all 'stopwords' (and, the, in, etc) from the result, and then dumps the resultant words to the database, link'd to the URL ... We're using crc-multi, so a CRC value of the word is what is stored in the database, not the actual word itself ... the '-multi' part spreads the words across several tables depending on the word size, to keep total # of rows down ... The slow part on the database is finding those words, as can be seen by the following search on 'SECURITY INVOKER': Jan 1 01:21:05 pgsql74 postgres[59959]: [44-1] LOG: statement: SELECT ndict8.url_id,ndict8.intag FROM ndict8, url WHEREndict8.word_id=417851441 AND url.rec_id=ndict8 .url_id Jan 1 01:21:05 pgsql74 postgres[59959]: [44-2] AND ((url.url || '') LIKE 'http://archives.postgresql.org/%%') Jan 1 01:22:00 pgsql74 postgres[59959]: [45-1] LOG: duration: 55015.644 ms Jan 1 01:22:00 pgsql74 postgres[59959]: [46-1] LOG: statement: SELECT ndict7.url_id,ndict7.intag FROM ndict7, url WHEREndict7.word_id=-509484498 AND url.rec_id=ndict 7.url_id Jan 1 01:22:00 pgsql74 postgres[59959]: [46-2] AND ((url.url || '') LIKE 'http://archives.postgresql.org/%%') Jan 1 01:22:01 pgsql74 postgres[59959]: [47-1] LOG: duration: 1167.407 ms ndict8 looks like: 186_archives=# select count(1) from ndict8; count --------- 6320380 (1 row) rchives=# select count(1) from ndict8 where word_id=417851441; count ------- 15532 (1 row) 186_archives=# \d ndict8 Table "public.ndict8" Column | Type | Modifiers ---------+---------+-------------------- url_id | integer | not null default 0 word_id | integer | not null default 0 intag | integer | not null default 0 Indexes: "n8_url" btree (url_id) "n8_word" btree (word_id) and ndict7 looks like: 186_archives=# select count(1) from ndict7; count --------- 8400616 (1 row) 186_archives=# select count(1) from ndict7 where word_id=-509484498; count ------- 333 (1 row) 186_archives=# \d ndict7 Table "public.ndict7" Column | Type | Modifiers ---------+---------+-------------------- url_id | integer | not null default 0 word_id | integer | not null default 0 intag | integer | not null default 0 Indexes: "n7_url" btree (url_id) "n7_word" btree (word_id) The slowdown is the LIKE condition, as the ndict[78] word_id conditions return near instantly when run individually, and when I run the 'url/LIKE' condition, it takes "forever" ... 186_archives-# ; count -------- 304811 (1 row) 186_archives=# explain analyze select count(1) from url where ((url.url || '') LIKE 'http://archives.postgresql.org/%%'); QUERY PLAN ------------------------------------------------------------------------------------------------------------------ Aggregate (cost=93962.19..93962.19 rows=1 width=0) (actual time=5833.084..5833.088 rows=1 loops=1) -> Seq Scan on url (cost=0.00..93957.26 rows=1968 width=0) (actual time=0.069..4387.378 rows=304811 loops=1) Filter: ((url || ''::text) ~~ 'http://archives.postgresql.org/%%'::text) Total runtime: 5833.179 ms (4 rows) Hrmmm ... I don't have much (any) experience with tsearch, but could it be used to replace the LIKE? Then again, when its returning 300k rows out of 393k, it wouldn't help much on the above, would it? The full first query: SELECT ndict8.url_id,ndict8.intag FROM ndict8, url WHERE ndict8.word_id=417851441 AND url.rec_id=ndict8.url_id AND ((url.url || '') LIKE 'http://archives.postgresql.org/%%'); returns 13415 rows, and explain analyze shows: ----------------------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..30199.82 rows=17 width=8) (actual time=0.312..1459.504 rows=13415 loops=1) -> Index Scan using n8_word on ndict8 (cost=0.00..12616.09 rows=3219 width=8) (actual time=0.186..387.673 rows=15532loops=1) Index Cond: (word_id = 417851441) -> Index Scan using url_rec_id on url (cost=0.00..5.45 rows=1 width=4) (actual time=0.029..0.050 rows=1 loops=15532) Index Cond: (url.rec_id = "outer".url_id) Filter: ((url || ''::text) ~~ 'http://archives.postgresql.org/%%'::text) Total runtime: 1520.145 ms (7 rows) Which, of course, doesn't come close to matching what the duration showed in the original, most likely due to catching :( The server that the database is on rarely jumps abov a loadavg of 1, isn't using any swap (after 77 days up, used swap is 0% -or- 17meg) and the database itself is on a strip'd file system ... I'm open to ideas/things to try here ... The whole 'process' of the search shows the following times for the queries: pgsql74# grep 59959 /var/log/pgsql | grep duration Jan 1 01:21:05 pgsql74 postgres[59959]: [39-1] LOG: duration: 25.663 ms Jan 1 01:21:05 pgsql74 postgres[59959]: [41-1] LOG: duration: 4.376 ms Jan 1 01:21:05 pgsql74 postgres[59959]: [43-1] LOG: duration: 11.179 ms Jan 1 01:22:00 pgsql74 postgres[59959]: [45-1] LOG: duration: 55015.644 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [47-1] LOG: duration: 1167.407 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [49-1] LOG: duration: 7.886 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [51-1] LOG: duration: 1.516 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [53-1] LOG: duration: 3.539 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [55-1] LOG: duration: 109.890 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [57-1] LOG: duration: 15.582 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [59-1] LOG: duration: 1.631 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [61-1] LOG: duration: 0.838 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [63-1] LOG: duration: 2.148 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [65-1] LOG: duration: 0.810 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [67-1] LOG: duration: 1.211 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [69-1] LOG: duration: 0.798 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [71-1] LOG: duration: 0.861 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [73-1] LOG: duration: 0.748 ms Jan 1 01:22:01 pgsql74 postgres[59959]: [75-1] LOG: duration: 0.555 ms With the two >1000ms queries being the above two ndict[78] queries ... Doing two subsequent searches, on "setuid functions" and "privilege rules", just so that caching isn't involved, shows pretty much the same distribution: grep 61697 /var/log/pgsql | grep duration Jan 1 01:44:25 pgsql74 postgres[61697]: [41-1] LOG: duration: 1.244 ms Jan 1 01:44:25 pgsql74 postgres[61697]: [43-1] LOG: duration: 21.868 ms Jan 1 01:44:25 pgsql74 postgres[61697]: [45-1] LOG: duration: 17.956 ms Jan 1 01:44:29 pgsql74 postgres[61697]: [47-1] LOG: duration: 4452.326 ms Jan 1 01:44:57 pgsql74 postgres[61697]: [49-1] LOG: duration: 27992.581 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [51-1] LOG: duration: 357.158 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [53-1] LOG: duration: 1.338 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [55-1] LOG: duration: 11.438 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [57-1] LOG: duration: 63.389 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [59-1] LOG: duration: 134.941 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [61-1] LOG: duration: 0.570 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [63-1] LOG: duration: 0.489 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [65-1] LOG: duration: 0.477 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [67-1] LOG: duration: 0.470 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [69-1] LOG: duration: 0.471 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [71-1] LOG: duration: 0.468 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [73-1] LOG: duration: 0.473 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [75-1] LOG: duration: 0.466 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [77-1] LOG: duration: 0.469 ms Jan 1 01:44:58 pgsql74 postgres[61697]: [79-1] LOG: duration: 0.515 ms and: grep 61869 /var/log/pgsql | grep duration Jan 1 01:46:50 pgsql74 postgres[61869]: [41-1] LOG: duration: 19.776 ms Jan 1 01:46:50 pgsql74 postgres[61869]: [43-1] LOG: duration: 58.352 ms Jan 1 01:46:50 pgsql74 postgres[61869]: [45-1] LOG: duration: 0.897 ms Jan 1 01:46:53 pgsql74 postgres[61869]: [47-1] LOG: duration: 2859.331 ms Jan 1 01:47:47 pgsql74 postgres[61869]: [49-1] LOG: duration: 54774.241 ms Jan 1 01:47:47 pgsql74 postgres[61869]: [51-1] LOG: duration: 14.926 ms Jan 1 01:47:47 pgsql74 postgres[61869]: [53-1] LOG: duration: 1.502 ms Jan 1 01:47:47 pgsql74 postgres[61869]: [55-1] LOG: duration: 3.865 ms Jan 1 01:47:48 pgsql74 postgres[61869]: [57-1] LOG: duration: 110.435 ms Jan 1 01:47:48 pgsql74 postgres[61869]: [59-1] LOG: duration: 0.646 ms Jan 1 01:47:48 pgsql74 postgres[61869]: [61-1] LOG: duration: 0.503 ms Jan 1 01:47:48 pgsql74 postgres[61869]: [63-1] LOG: duration: 0.498 ms Jan 1 01:47:48 pgsql74 postgres[61869]: [65-1] LOG: duration: 0.484 ms Jan 1 01:47:48 pgsql74 postgres[61869]: [67-1] LOG: duration: 0.487 ms Jan 1 01:47:48 pgsql74 postgres[61869]: [69-1] LOG: duration: 0.478 ms Jan 1 01:47:48 pgsql74 postgres[61869]: [71-1] LOG: duration: 0.479 ms Jan 1 01:47:48 pgsql74 postgres[61869]: [73-1] LOG: duration: 0.480 ms Jan 1 01:47:48 pgsql74 postgres[61869]: [75-1] LOG: duration: 0.478 ms Jan 1 01:47:48 pgsql74 postgres[61869]: [77-1] LOG: duration: 0.477 ms So it looks like its those joins that are really killing things ... Note that I haven't made many changes to the postgresql.conf file, so there might be something really obvious I've overlooked, but here are the uncommented ones (ie. ones I've modified from defaults): tcpip_socket = true max_connections = 512 shared_buffers = 10000 # min 16, at least max_connections*2, 8KB each sort_mem = 10240 # min 64, size in KB vacuum_mem = 81920 # min 1024, size in KB syslog = 2 # range 0-2; 0=stdout; 1=both; 2=syslog syslog_facility = 'LOCAL0' syslog_ident = 'postgres' log_connections = true log_duration = false log_statement = false lc_messages = 'C' # locale for system error message strings lc_monetary = 'C' # locale for monetary formatting lc_numeric = 'C' # locale for number formatting lc_time = 'C' # locale for time formatting ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
On Wed, 31 Dec 2003, Dave Cramer wrote: > In fact this is a very bad advertisement for postgres I just posted a very very long email of what I'm seeing in the logs, as well as various query runs ... it may just be something that I need to tune that I'm overlooking:( the queries aren't particularly complex :( ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
What is the locale of the database? like won't use an index, unless it is 'C' locale, or you use 7.4 and change the operator of the index. Dave On Wed, 2003-12-31 at 20:49, Marc G. Fournier wrote: > On Wed, 31 Dec 2003, Bruce Momjian wrote: > > > Marc G. Fournier wrote: > > > On Wed, 31 Dec 2003, Bruce Momjian wrote: > > > > > > > > Out of everything I've found so far, mnogosearch is one of the best ... I > > > > > just wish I could figure out where the bottleneck for it was, since, from > > > > > reading their docs, their method of storing the data doesn't appear to be > > > > > particularly off. I'm tempted to try their caching storage manager, and > > > > > getting away from SQL totally, but I *really* want to showcase PostgreSQL > > > > > on this :( > > > > > > > > Well, PostgreSQL is being un-showcased in the current setup, that's for > > > > sure. :-( > > > > > > Agreed ... I could install the MySQL backend, whichits designed for, and > > > advertise it as PostgreSQL? :) > > > > I would be curious to know if it is faster --- that would tell use if it > > is tuned only for MySQL. > > > > Have you tried CLUSTER? I think the MySQL ISAM files are > > auto-clustered, and clustering is usually important for full-text > > searches. > > Actually, check out http://www.mnogosearch.com ... the way they do the > indexing doesn't (at least, as far as I can tell) make use of full-text > searching. Simplistically, it appears to take the web page, sort -u all > the words it finds, removes all 'stopwords' (and, the, in, etc) from the > result, and then dumps the resultant words to the database, link'd to the > URL ... > > We're using crc-multi, so a CRC value of the word is what is stored in the > database, not the actual word itself ... the '-multi' part spreads the > words across several tables depending on the word size, to keep total # of > rows down ... > > The slow part on the database is finding those words, as can be seen by > the following search on 'SECURITY INVOKER': > > Jan 1 01:21:05 pgsql74 postgres[59959]: [44-1] LOG: statement: SELECT ndict8.url_id,ndict8.intag FROM ndict8, url WHEREndict8.word_id=417851441 AND url.rec_id=ndict8 > .url_id > Jan 1 01:21:05 pgsql74 postgres[59959]: [44-2] AND ((url.url || '') LIKE 'http://archives.postgresql.org/%%') > Jan 1 01:22:00 pgsql74 postgres[59959]: [45-1] LOG: duration: 55015.644 ms > Jan 1 01:22:00 pgsql74 postgres[59959]: [46-1] LOG: statement: SELECT ndict7.url_id,ndict7.intag FROM ndict7, url WHEREndict7.word_id=-509484498 AND url.rec_id=ndict > 7.url_id > Jan 1 01:22:00 pgsql74 postgres[59959]: [46-2] AND ((url.url || '') LIKE 'http://archives.postgresql.org/%%') > Jan 1 01:22:01 pgsql74 postgres[59959]: [47-1] LOG: duration: 1167.407 ms > > ndict8 looks like: > > 186_archives=# select count(1) from ndict8; > count > --------- > 6320380 > (1 row) > rchives=# select count(1) from ndict8 where word_id=417851441; > count > ------- > 15532 > (1 row) > > 186_archives=# \d ndict8 > Table "public.ndict8" > Column | Type | Modifiers > ---------+---------+-------------------- > url_id | integer | not null default 0 > word_id | integer | not null default 0 > intag | integer | not null default 0 > Indexes: > "n8_url" btree (url_id) > "n8_word" btree (word_id) > > > and ndict7 looks like: > > 186_archives=# select count(1) from ndict7; > count > --------- > 8400616 > (1 row) > 186_archives=# select count(1) from ndict7 where word_id=-509484498; > count > ------- > 333 > (1 row) > > 186_archives=# \d ndict7 > Table "public.ndict7" > Column | Type | Modifiers > ---------+---------+-------------------- > url_id | integer | not null default 0 > word_id | integer | not null default 0 > intag | integer | not null default 0 > Indexes: > "n7_url" btree (url_id) > "n7_word" btree (word_id) > > > The slowdown is the LIKE condition, as the ndict[78] word_id conditions > return near instantly when run individually, and when I run the 'url/LIKE' > condition, it takes "forever" ... > > 186_archives-# ; > count > -------- > 304811 > (1 row) > > 186_archives=# explain analyze select count(1) from url where ((url.url || '') LIKE 'http://archives.postgresql.org/%%'); > QUERY PLAN > ------------------------------------------------------------------------------------------------------------------ > Aggregate (cost=93962.19..93962.19 rows=1 width=0) (actual time=5833.084..5833.088 rows=1 loops=1) > -> Seq Scan on url (cost=0.00..93957.26 rows=1968 width=0) (actual time=0.069..4387.378 rows=304811 loops=1) > Filter: ((url || ''::text) ~~ 'http://archives.postgresql.org/%%'::text) > Total runtime: 5833.179 ms > (4 rows) > > > Hrmmm ... I don't have much (any) experience with tsearch, but could it be > used to replace the LIKE? Then again, when its returning 300k rows out of > 393k, it wouldn't help much on the above, would it? > > The full first query: > > SELECT ndict8.url_id,ndict8.intag > FROM ndict8, url > WHERE ndict8.word_id=417851441 > AND url.rec_id=ndict8.url_id > AND ((url.url || '') LIKE 'http://archives.postgresql.org/%%'); > > returns 13415 rows, and explain analyze shows: > > ----------------------------------------------------------------------------------------------------------------------------------- > Nested Loop (cost=0.00..30199.82 rows=17 width=8) (actual time=0.312..1459.504 rows=13415 loops=1) > -> Index Scan using n8_word on ndict8 (cost=0.00..12616.09 rows=3219 width=8) (actual time=0.186..387.673 rows=15532loops=1) > Index Cond: (word_id = 417851441) > -> Index Scan using url_rec_id on url (cost=0.00..5.45 rows=1 width=4) (actual time=0.029..0.050 rows=1 loops=15532) > Index Cond: (url.rec_id = "outer".url_id) > Filter: ((url || ''::text) ~~ 'http://archives.postgresql.org/%%'::text) > Total runtime: 1520.145 ms > (7 rows) > > Which, of course, doesn't come close to matching what the duration showed > in the original, most likely due to catching :( > > The server that the database is on rarely jumps abov a loadavg of 1, isn't > using any swap (after 77 days up, used swap is 0% -or- 17meg) and the > database itself is on a strip'd file system ... > > I'm open to ideas/things to try here ... > > The whole 'process' of the search shows the following times for the > queries: > > pgsql74# grep 59959 /var/log/pgsql | grep duration > Jan 1 01:21:05 pgsql74 postgres[59959]: [39-1] LOG: duration: 25.663 ms > Jan 1 01:21:05 pgsql74 postgres[59959]: [41-1] LOG: duration: 4.376 ms > Jan 1 01:21:05 pgsql74 postgres[59959]: [43-1] LOG: duration: 11.179 ms > Jan 1 01:22:00 pgsql74 postgres[59959]: [45-1] LOG: duration: 55015.644 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [47-1] LOG: duration: 1167.407 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [49-1] LOG: duration: 7.886 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [51-1] LOG: duration: 1.516 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [53-1] LOG: duration: 3.539 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [55-1] LOG: duration: 109.890 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [57-1] LOG: duration: 15.582 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [59-1] LOG: duration: 1.631 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [61-1] LOG: duration: 0.838 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [63-1] LOG: duration: 2.148 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [65-1] LOG: duration: 0.810 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [67-1] LOG: duration: 1.211 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [69-1] LOG: duration: 0.798 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [71-1] LOG: duration: 0.861 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [73-1] LOG: duration: 0.748 ms > Jan 1 01:22:01 pgsql74 postgres[59959]: [75-1] LOG: duration: 0.555 ms > > With the two >1000ms queries being the above two ndict[78] queries ... > > Doing two subsequent searches, on "setuid functions" and "privilege > rules", just so that caching isn't involved, shows pretty much the same > distribution: > > grep 61697 /var/log/pgsql | grep duration > Jan 1 01:44:25 pgsql74 postgres[61697]: [41-1] LOG: duration: 1.244 ms > Jan 1 01:44:25 pgsql74 postgres[61697]: [43-1] LOG: duration: 21.868 ms > Jan 1 01:44:25 pgsql74 postgres[61697]: [45-1] LOG: duration: 17.956 ms > Jan 1 01:44:29 pgsql74 postgres[61697]: [47-1] LOG: duration: 4452.326 ms > Jan 1 01:44:57 pgsql74 postgres[61697]: [49-1] LOG: duration: 27992.581 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [51-1] LOG: duration: 357.158 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [53-1] LOG: duration: 1.338 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [55-1] LOG: duration: 11.438 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [57-1] LOG: duration: 63.389 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [59-1] LOG: duration: 134.941 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [61-1] LOG: duration: 0.570 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [63-1] LOG: duration: 0.489 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [65-1] LOG: duration: 0.477 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [67-1] LOG: duration: 0.470 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [69-1] LOG: duration: 0.471 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [71-1] LOG: duration: 0.468 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [73-1] LOG: duration: 0.473 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [75-1] LOG: duration: 0.466 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [77-1] LOG: duration: 0.469 ms > Jan 1 01:44:58 pgsql74 postgres[61697]: [79-1] LOG: duration: 0.515 ms > > and: > > grep 61869 /var/log/pgsql | grep duration > Jan 1 01:46:50 pgsql74 postgres[61869]: [41-1] LOG: duration: 19.776 ms > Jan 1 01:46:50 pgsql74 postgres[61869]: [43-1] LOG: duration: 58.352 ms > Jan 1 01:46:50 pgsql74 postgres[61869]: [45-1] LOG: duration: 0.897 ms > Jan 1 01:46:53 pgsql74 postgres[61869]: [47-1] LOG: duration: 2859.331 ms > Jan 1 01:47:47 pgsql74 postgres[61869]: [49-1] LOG: duration: 54774.241 ms > Jan 1 01:47:47 pgsql74 postgres[61869]: [51-1] LOG: duration: 14.926 ms > Jan 1 01:47:47 pgsql74 postgres[61869]: [53-1] LOG: duration: 1.502 ms > Jan 1 01:47:47 pgsql74 postgres[61869]: [55-1] LOG: duration: 3.865 ms > Jan 1 01:47:48 pgsql74 postgres[61869]: [57-1] LOG: duration: 110.435 ms > Jan 1 01:47:48 pgsql74 postgres[61869]: [59-1] LOG: duration: 0.646 ms > Jan 1 01:47:48 pgsql74 postgres[61869]: [61-1] LOG: duration: 0.503 ms > Jan 1 01:47:48 pgsql74 postgres[61869]: [63-1] LOG: duration: 0.498 ms > Jan 1 01:47:48 pgsql74 postgres[61869]: [65-1] LOG: duration: 0.484 ms > Jan 1 01:47:48 pgsql74 postgres[61869]: [67-1] LOG: duration: 0.487 ms > Jan 1 01:47:48 pgsql74 postgres[61869]: [69-1] LOG: duration: 0.478 ms > Jan 1 01:47:48 pgsql74 postgres[61869]: [71-1] LOG: duration: 0.479 ms > Jan 1 01:47:48 pgsql74 postgres[61869]: [73-1] LOG: duration: 0.480 ms > Jan 1 01:47:48 pgsql74 postgres[61869]: [75-1] LOG: duration: 0.478 ms > Jan 1 01:47:48 pgsql74 postgres[61869]: [77-1] LOG: duration: 0.477 ms > > So it looks like its those joins that are really killing things ... > > Note that I haven't made many changes to the postgresql.conf file, so > there might be something really obvious I've overlooked, but here are the > uncommented ones (ie. ones I've modified from defaults): > > tcpip_socket = true > max_connections = 512 > shared_buffers = 10000 # min 16, at least max_connections*2, 8KB each > sort_mem = 10240 # min 64, size in KB > vacuum_mem = 81920 # min 1024, size in KB > syslog = 2 # range 0-2; 0=stdout; 1=both; 2=syslog > syslog_facility = 'LOCAL0' > syslog_ident = 'postgres' > log_connections = true > log_duration = false > log_statement = false > lc_messages = 'C' # locale for system error message strings > lc_monetary = 'C' # locale for monetary formatting > lc_numeric = 'C' # locale for number formatting > lc_time = 'C' # locale for time formatting > > > ---- > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > > ---------------------------(end of broadcast)--------------------------- > TIP 6: Have you searched our list archives? > > http://archives.postgresql.org > -- Dave Cramer 519 939 0336 ICQ # 1467551
On Wed, 31 Dec 2003, Dave Cramer wrote: > What is the locale of the database? > > like won't use an index, unless it is 'C' locale, or you use 7.4 and > change the operator of the index. one thing I failed to note ... this is all running on 7.4 ... under 7.3, it was much much worse :) ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
Marc G. Fournier wrote: > 186_archives=# \d ndict7 > Table "public.ndict7" > Column | Type | Modifiers > ---------+---------+-------------------- > url_id | integer | not null default 0 > word_id | integer | not null default 0 > intag | integer | not null default 0 > Indexes: > "n7_url" btree (url_id) > "n7_word" btree (word_id) > > > The slowdown is the LIKE condition, as the ndict[78] word_id conditions > return near instantly when run individually, and when I run the 'url/LIKE' > condition, it takes "forever" ... Does it help to CLUSTER url.url? Is your data being loaded in so identical values used by LIKE are next to each other? -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 359-1001 + If your life is a hard drive, | 13 Roberts Road + Christ can be your backup. | Newtown Square, Pennsylvania 19073
On Thu, 1 Jan 2004, Bruce Momjian wrote:
> Marc G. Fournier wrote:
> > 186_archives=# \d ndict7
> > Table "public.ndict7"
> > Column | Type | Modifiers
> > ---------+---------+--------------------
> > url_id | integer | not null default 0
> > word_id | integer | not null default 0
> > intag | integer | not null default 0
> > Indexes:
> > "n7_url" btree (url_id)
> > "n7_word" btree (word_id)
> >
> >
> > The slowdown is the LIKE condition, as the ndict[78] word_id conditions
> > return near instantly when run individually, and when I run the 'url/LIKE'
> > condition, it takes "forever" ...
>
> Does it help to CLUSTER url.url? Is your data being loaded in so
> identical values used by LIKE are next to each other?
Just tried CLUSTER, and no difference, but ... chat'd with Dave on ICQ
this evening, and was thinking of something ... and it comes back to
something that I mentioned awhile back ...
Taking the ndict8 query that I originally presented, now post CLUSTER, and
an explain analyze looks like:
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=13918.23..26550.58 rows=17 width=8) (actual time=4053.403..83481.769 rows=13415 loops=1)
Hash Cond: ("outer".url_id = "inner".rec_id)
-> Index Scan using n8_word on ndict8 (cost=0.00..12616.09 rows=3219 width=8) (actual time=113.645..79163.431
rows=15533loops=1)
Index Cond: (word_id = 417851441)
-> Hash (cost=13913.31..13913.31 rows=1968 width=4) (actual time=3920.597..3920.597 rows=0 loops=1)
-> Seq Scan on url (cost=0.00..13913.31 rows=1968 width=4) (actual time=3.837..2377.853 rows=304811 loops=1)
Filter: ((url || ''::text) ~~ 'http://archives.postgresql.org/%%'::text)
Total runtime: 83578.572 ms
(8 rows)
Now, if I knock off the LIKE, so that I'm returning all rows from ndict8,
join'd to all the URLs that contain them, you get:
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.00..30183.13 rows=3219 width=8) (actual time=0.299..1217.116 rows=15533 loops=1)
-> Index Scan using n8_word on ndict8 (cost=0.00..12616.09 rows=3219 width=8) (actual time=0.144..458.891
rows=15533loops=1)
Index Cond: (word_id = 417851441)
-> Index Scan using url_rec_id on url (cost=0.00..5.44 rows=1 width=4) (actual time=0.024..0.029 rows=1
loops=15533)
Index Cond: (url.rec_id = "outer".url_id)
Total runtime: 1286.647 ms
(6 rows)
So, there are 15333 URLs that contain that word ... now, what I want to
find out is how many of those 15333 URLs contain
'http://archives.postgresql.org/%%', which is 13415 ...
The problem is that right now, we look at the LIKE first, giving us ~300k
rows, and then search through those for those who have the word matching
... is there some way of reducing the priority of the LIKE part of the
query, as far as the planner is concerned, so that it will "resolve" the =
first, and then work the LIKE on the resultant set, instead of the other
way around? So that the query is only checking 15k records for the 13k
that match, instead of searching through 300k?
I'm guessing that the reason that the LIKE is taking precidence(sp?) is
because the URL table has less rows in it then ndict8?
----
Marc G. Fournier Hub.Org Networking Services (http://www.hub.org)
Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
Might be worth trying a larger statistics target (say 100), in the hope that the planner then has better information to work with. best wishes Mark Marc G. Fournier wrote: > >he problem is that right now, we look at the LIKE first, giving us ~300k >rows, and then search through those for those who have the word matching >... is there some way of reducing the priority of the LIKE part of the >query, as far as the planner is concerned, so that it will "resolve" the = >first, and then work the LIKE on the resultant set, instead of the other >way around? So that the query is only checking 15k records for the 13k >that match, instead of searching through 300k? > >I'm guessing that the reason that the LIKE is taking precidence(sp?) is >because the URL table has less rows in it then ndict8? > > > >
Marc G. Fournier wrote: > > Now, if I knock off the LIKE, so that I'm returning all rows from ndict8, > join'd to all the URLs that contain them, you get: Can't you build seperate databases for each domain you want to index? Than you wouldn't need the like operator at all. The like-operator doesn't seem to allow a very scalable production environment. And besides that point, I don't really believe a "record per word/document-couple" is very scalable (not in SQL, not anywhere). Anyway, that doesn't help you much, perhaps decreasing the size of the index-tables can help, are they with OIDs ? If so, wouldn't it help to recreate them without, so you save yourselves 4 bytes per word-document couple, therefore allowing it to fit in less pages and by that speeding up the seqscans. Are _all_ your queries with the like on the url? Wouldn't it help to create an index on both the wordid and the urlid for ndict8? Perhaps you can create your own 'host table' (which could be filled using a trigger or a slightly adjusted indexer), and a foreign key from your url table to that, so you can search on url.hostid = X (or a join with that host table) instead of the like that is used now? By the way, can a construction like (tablefield || '') ever use an index in postgresql? Best regards and good luck, Arjen van der Meijden
On Thu, 1 Jan 2004, Arjen van der Meijden wrote: > Marc G. Fournier wrote: > > > > Now, if I knock off the LIKE, so that I'm returning all rows from ndict8, > > join'd to all the URLs that contain them, you get: > > Can't you build seperate databases for each domain you want to index? > Than you wouldn't need the like operator at all. First off, that would make searching across multiple domains difficult, no? Second, the LIKE is still required ... the LIKE allows the search to "group" URLs ... for instance, if I wanted to just search on the docs, the LIKE would look for all URLs that contain: http://www.postgresql.org/docs/%% whereas searching the whole site would be: http://www.postgresql.org/%% > Anyway, that doesn't help you much, perhaps decreasing the size of the > index-tables can help, are they with OIDs ? If so, wouldn't it help to > recreate them without, so you save yourselves 4 bytes per word-document > couple, therefore allowing it to fit in less pages and by that speeding > up the seqscans. This one I hadn't thought about ... for some reason, I thought that WITHOUT OIDs was now the default ... looking at that one now ... > Are _all_ your queries with the like on the url? Wouldn't it help to > create an index on both the wordid and the urlid for ndict8? as mentioned in a previous email, the schema for ndict8 is: 186_archives=# \d ndict8 Table "public.ndict8" Column | Type | Modifiers ---------+---------+-------------------- url_id | integer | not null default 0 word_id | integer | not null default 0 intag | integer | not null default 0 Indexes: "n8_url" btree (url_id) "n8_word" btree (word_id) > By the way, can a construction like (tablefield || '') ever use an index > in postgresql? again, as shown in a previous email, the index is being used for the LIKE query ... the big problem as I see it is that the result set from the LIKE is ~20x larger then the result set for the the = ... if there was some way to telling the planner that going the LIKE route was the more expensive of the two (even though table size seems to indicate the other way around), I suspect that that would improve things also ... ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
Mark Kirkwood <markir@paradise.net.nz> writes:
> Might be worth trying a larger statistics target (say 100), in the hope
> that the planner then has better information to work with.
I concur with that suggestion. Looking at Marc's problem:
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=13918.23..26550.58 rows=17 width=8) (actual time=4053.403..83481.769 rows=13415 loops=1)
Hash Cond: ("outer".url_id = "inner".rec_id)
-> Index Scan using n8_word on ndict8 (cost=0.00..12616.09 rows=3219 width=8) (actual time=113.645..79163.431
rows=15533loops=1)
Index Cond: (word_id = 417851441)
-> Hash (cost=13913.31..13913.31 rows=1968 width=4) (actual time=3920.597..3920.597 rows=0 loops=1)
-> Seq Scan on url (cost=0.00..13913.31 rows=1968 width=4) (actual time=3.837..2377.853 rows=304811 loops=1)
Filter: ((url || ''::text) ~~ 'http://archives.postgresql.org/%%'::text)
Total runtime: 83578.572 ms
(8 rows)
the slowness is not really in the LIKE, it's in the indexscan on
ndict8 (79 out of 83 seconds spent there). The planner probably would
not have chosen this plan if it hadn't been off by a factor of 5 on the
rows estimate. So try knocking up the stats target for ndict8.word_id,
re-analyze, and see what happens.
regards, tom lane
On Thu, 1 Jan 2004, Tom Lane wrote:
> Mark Kirkwood <markir@paradise.net.nz> writes:
> > Might be worth trying a larger statistics target (say 100), in the hope
> > that the planner then has better information to work with.
>
> I concur with that suggestion. Looking at Marc's problem:
>
> QUERY PLAN
>
---------------------------------------------------------------------------------------------------------------------------------------
> Hash Join (cost=13918.23..26550.58 rows=17 width=8) (actual time=4053.403..83481.769 rows=13415 loops=1)
> Hash Cond: ("outer".url_id = "inner".rec_id)
> -> Index Scan using n8_word on ndict8 (cost=0.00..12616.09 rows=3219 width=8) (actual time=113.645..79163.431
rows=15533loops=1)
> Index Cond: (word_id = 417851441)
> -> Hash (cost=13913.31..13913.31 rows=1968 width=4) (actual time=3920.597..3920.597 rows=0 loops=1)
> -> Seq Scan on url (cost=0.00..13913.31 rows=1968 width=4) (actual time=3.837..2377.853 rows=304811
loops=1)
> Filter: ((url || ''::text) ~~ 'http://archives.postgresql.org/%%'::text)
> Total runtime: 83578.572 ms
> (8 rows)
>
> the slowness is not really in the LIKE, it's in the indexscan on ndict8
> (79 out of 83 seconds spent there). The planner probably would not have
> chosen this plan if it hadn't been off by a factor of 5 on the rows
> estimate. So try knocking up the stats target for ndict8.word_id,
> re-analyze, and see what happens.
'k, and for todays question ... how does one 'knock up the stats target'?
This is stuff I've not played with yet, so a URL to read up on this would
be nice, vs just how to do it?
----
Marc G. Fournier Hub.Org Networking Services (http://www.hub.org)
Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
"Marc G. Fournier" <scrappy@postgresql.org> writes:
> 'k, and for todays question ... how does one 'knock up the stats target'?
ALTER TABLE [ ONLY ] name [ * ]
ALTER [ COLUMN ] column SET STATISTICS integer
The default is 10; try 100, or even 1000 (don't think it will let you
go higher than 1000).
regards, tom lane
On Thu, 1 Jan 2004, Bruce Momjian wrote: > Marc G. Fournier wrote: > > 186_archives=# \d ndict7 > > Table "public.ndict7" > > Column | Type | Modifiers > > ---------+---------+-------------------- > > url_id | integer | not null default 0 > > word_id | integer | not null default 0 > > intag | integer | not null default 0 > > Indexes: > > "n7_url" btree (url_id) > > "n7_word" btree (word_id) > > > > > > The slowdown is the LIKE condition, as the ndict[78] word_id conditions > > return near instantly when run individually, and when I run the 'url/LIKE' > > condition, it takes "forever" ... > > Does it help to CLUSTER url.url? Is your data being loaded in so > identical values used by LIKE are next to each other? I'm loading up a MySQL 4.1 database right now, along side of a PgSQL 7.4 one WITHOUT OIDs ... should take several days to fully load, but it will be interesting to compare them all ... ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
On Thu, 1 Jan 2004, Tom Lane wrote:
> "Marc G. Fournier" <scrappy@postgresql.org> writes:
> > 'k, and for todays question ... how does one 'knock up the stats target'?
>
> ALTER TABLE [ ONLY ] name [ * ]
> ALTER [ COLUMN ] column SET STATISTICS integer
>
> The default is 10; try 100, or even 1000 (don't think it will let you
> go higher than 1000).
k, so:
186_archives=# alter table ndict8 alter column word_id set statistics 1000;
ALTER TABLE
followed by an 'vacuum verbose analyze ndict8', which showed an analyze
of:
INFO: analyzing "public.ndict8"
INFO: "ndict8": 34718 pages, 300000 rows sampled, 6354814 estimated total rows
vs when set at 10:
INFO: analyzing "public.ndict8"
INFO: "ndict8": 34718 pages, 3000 rows sampled, 6229711 estimated total rows
The query @ 1000:
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=13918.23..76761.02 rows=81 width=8) (actual time=5199.443..5835.444 rows=13415 loops=1)
Hash Cond: ("outer".url_id = "inner".rec_id)
-> Index Scan using n8_word on ndict8 (cost=0.00..62761.60 rows=16075 width=8) (actual time=0.230..344.485
rows=15533loops=1)
Index Cond: (word_id = 417851441)
-> Hash (cost=13913.31..13913.31 rows=1968 width=4) (actual time=5198.289..5198.289 rows=0 loops=1)
-> Seq Scan on url (cost=0.00..13913.31 rows=1968 width=4) (actual time=3.933..3414.657 rows=304811 loops=1)
Filter: ((url || ''::text) ~~ 'http://archives.postgresql.org/%%'::text)
Total runtime: 5908.778 ms
(8 rows)
Same query @ 10:
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=13918.23..26502.18 rows=17 width=8) (actual time=3657.984..4293.529 rows=13415 loops=1)
Hash Cond: ("outer".url_id = "inner".rec_id)
-> Index Scan using n8_word on ndict8 (cost=0.00..12567.73 rows=3210 width=8) (actual time=0.239..362.375
rows=15533loops=1)
Index Cond: (word_id = 417851441)
-> Hash (cost=13913.31..13913.31 rows=1968 width=4) (actual time=3657.480..3657.480 rows=0 loops=1)
-> Seq Scan on url (cost=0.00..13913.31 rows=1968 width=4) (actual time=2.646..2166.632 rows=304811 loops=1)
Filter: ((url || ''::text) ~~ 'http://archives.postgresql.org/%%'::text)
Total runtime: 4362.375 ms
(8 rows)
I don't see a difference between the two, other then time changes, but
that could just be that runA had a server a bit more idle then runB ...
something I'm not seeing here?
----
Marc G. Fournier Hub.Org Networking Services (http://www.hub.org)
Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
Marc G. Fournier wrote: > On Thu, 1 Jan 2004, Arjen van der Meijden wrote: > > >>Marc G. Fournier wrote: >> >>>Now, if I knock off the LIKE, so that I'm returning all rows from ndict8, >>>join'd to all the URLs that contain them, you get: >> >>Can't you build seperate databases for each domain you want to index? >>Than you wouldn't need the like operator at all. > > > First off, that would make searching across multiple domains difficult, > no? If mnogosearch would allow searching in multiple databases; no. But it doesn't seem to feature that and indeed; yes that might become a bit difficult. It was something I thought of because our solution allows it, but that is no solution for you, I checked the mnogosearch features after sending that email, instead of before. Perhaps I should've turned that around. > Second, the LIKE is still required ... the LIKE allows the search to > "group" URLs ... for instance, if I wanted to just search on the docs, the > LIKE would look for all URLs that contain: > > http://www.postgresql.org/docs/%% > > whereas searching the whole site would be: > > http://www.postgresql.org/%% That depends. If it were possible, you could decide from the search usage stats to split /docs from the "the rest" of www.postgresql.org and by that avoiding quite a bit of like's. >>Anyway, that doesn't help you much, perhaps decreasing the size of the >>index-tables can help, are they with OIDs ? If so, wouldn't it help to >>recreate them without, so you save yourselves 4 bytes per word-document >>couple, therefore allowing it to fit in less pages and by that speeding >>up the seqscans. > > > This one I hadn't thought about ... for some reason, I thought that > WITHOUT OIDs was now the default ... looking at that one now ... No, it's still the default to do it with oids. >>By the way, can a construction like (tablefield || '') ever use an index >>in postgresql? > > > again, as shown in a previous email, the index is being used for the LIKE > query ... the big problem as I see it is that the result set from the LIKE > is ~20x larger then the result set for the the = ... if there was some way > to telling the planner that going the LIKE route was the more expensive of > the two (even though table size seems to indicate the other way around), I > suspect that that would improve things also ... Yeah, I noticed. Hopefully Tom's suggestion will work to achieve that. I can imagine how you feel about all this, I had to do a similar job a year ago, but was less restricted by a preference like the "it'd be a nice postgresql showcase". But then again, our search engine is loaded with an average of 24 queries per minute (peaking to over 100/m in the afternoon and evenings) and we didn't have any working solution (not even a slow one). Good luck, Arjen van der Meijden
"Marc G. Fournier" <scrappy@postgresql.org> writes:
> I don't see a difference between the two, other then time changes, but
> that could just be that runA had a server a bit more idle then runB ...
> something I'm not seeing here?
Well, the difference I was hoping for was a more accurate rows estimate
for the indexscan, which indeed we got (estimate went from 3210 to
16075, vs reality of 15533). But it didn't change the plan :-(.
Looking more closely, I see the rows estimate for the seqscan on "url"
is pretty awful too (1968 vs reality of 304811). I think it would get
better if you were doing just
AND (url.url LIKE 'http://archives.postgresql.org/%%');
without the concatenation of an empty string. Is there a reason for the
concatenation part of the expression?
regards, tom lane
On Thu, 1 Jan 2004, Arjen van der Meijden wrote: > That depends. If it were possible, you could decide from the search > usage stats to split /docs from the "the rest" of www.postgresql.org and > by that avoiding quite a bit of like's. then what if you want to search: http://www.postgresql.org/docs/7.4/%% vs http://www.postgresql.org/docs/7.3/%% :) ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
"Marc G. Fournier" <scrappy@postgresql.org> writes: > The full first query: > SELECT ndict8.url_id,ndict8.intag > FROM ndict8, url > WHERE ndict8.word_id=417851441 > AND url.rec_id=ndict8.url_id > AND ((url.url || '') LIKE 'http://archives.postgresql.org/%%'); > returns 13415 rows, and explain analyze shows: > Nested Loop (cost=0.00..30199.82 rows=17 width=8) (actual time=0.312..1459.504 rows=13415 loops=1) > -> Index Scan using n8_word on ndict8 (cost=0.00..12616.09 rows=3219 width=8) (actual time=0.186..387.673 rows=15532loops=1) > Index Cond: (word_id = 417851441) > -> Index Scan using url_rec_id on url (cost=0.00..5.45 rows=1 width=4) (actual time=0.029..0.050 rows=1 loops=15532) > Index Cond: (url.rec_id = "outer".url_id) > Filter: ((url || ''::text) ~~ 'http://archives.postgresql.org/%%'::text) > Total runtime: 1520.145 ms > (7 rows) The more I look at it, the more it seems that this is the best plan for the query. Since the URL condition is very unselective (and will probably be so in most all variants of this query), it just doesn't pay to try to apply it before doing the join. What we want is to make the join happen quickly, and not even bother applying the URL test until after we have a joinable url entry. (In the back of my mind here is the knowledge that mnogosearch is optimized for mysql, which is too stupid to do the query in any way other than a plan like the above.) I think Bruce's original suggestion of clustering was right on, except he guessed wrong about what to cluster. The slow part is the scan on ndict8, as we saw in the later message: -> Index Scan using n8_word on ndict8 (cost=0.00..12616.09 rows=3219 width=8) (actual time=113.645..79163.431 rows=15533loops=1) Index Cond: (word_id = 417851441) Presumably, the first EXPLAIN shows the behavior when this portion of ndict8 and its index have been cached, while the second EXPLAIN shows what happens when they're not in cache. So my suggestion is to CLUSTER ndict8 on n8_word. It might also help to CLUSTER url on url_rec_id. Make sure the plan goes back to the nested indexscan as above (you might need to undo the statistics-target changes). regards, tom lane
On Thu, 1 Jan 2004, Tom Lane wrote: > "Marc G. Fournier" <scrappy@postgresql.org> writes: > > I don't see a difference between the two, other then time changes, but > > that could just be that runA had a server a bit more idle then runB ... > > something I'm not seeing here? > > Well, the difference I was hoping for was a more accurate rows estimate > for the indexscan, which indeed we got (estimate went from 3210 to > 16075, vs reality of 15533). But it didn't change the plan :-(. > > Looking more closely, I see the rows estimate for the seqscan on "url" > is pretty awful too (1968 vs reality of 304811). I think it would get > better if you were doing just > AND (url.url LIKE 'http://archives.postgresql.org/%%'); > without the concatenation of an empty string. Is there a reason for the > concatenation part of the expression? Believe it or not, the concatenation was based on a discussion *way* back (2 years, maybe?) when we first started using Mnogosearch, in which you suggested going that route ... in fact, at the time (bear in mind, this is back in 7.2 days), it actually sped things up ... Ok, with statistics set to 10, we now have: QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..31672.49 rows=1927 width=8) (actual time=117.064..54476.806 rows=13415 loops=1) -> Index Scan using n8_word on ndict8 (cost=0.00..12567.73 rows=3210 width=8) (actual time=80.230..47844.752 rows=15533loops=1) Index Cond: (word_id = 417851441) -> Index Scan using url_rec_id on url (cost=0.00..5.94 rows=1 width=4) (actual time=0.392..0.398 rows=1 loops=15533) Index Cond: (url.rec_id = "outer".url_id) Filter: (url ~~ 'http://archives.postgresql.org/%%'::text) Total runtime: 54555.011 ms (7 rows) And, at 1000 (and appropriate vacuum analyze on ndict8): QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------------------- Merge Join (cost=91613.33..92959.41 rows=9026 width=8) (actual time=12834.316..16726.018 rows=13415 loops=1) Merge Cond: ("outer".url_id = "inner".rec_id) -> Sort (cost=59770.57..59808.18 rows=15043 width=8) (actual time=776.823..849.798 rows=15533 loops=1) Sort Key: ndict8.url_id -> Index Scan using n8_word on ndict8 (cost=0.00..58726.82 rows=15043 width=8) (actual time=0.296..680.139 rows=15533loops=1) Index Cond: (word_id = 417851441) -> Sort (cost=31842.76..32433.09 rows=236133 width=4) (actual time=12056.594..14159.852 rows=311731 loops=1) Sort Key: url.rec_id -> Index Scan using url_url on url (cost=0.00..10768.79 rows=236133 width=4) (actual time=225.243..8353.024 rows=304811loops=1) Index Cond: ((url >= 'http://archives.postgresql.org/'::text) AND (url < 'http://archives.postgresql.org0'::text)) Filter: (url ~~ 'http://archives.postgresql.org/%%'::text) Total runtime: 16796.932 ms (12 rows) Closer to what you were looking/hoping for? Second run, @1000, shows: Total runtime: 12194.016 ms (12 rows) Second run, after knocking her back down to 10, shows: Total runtime: 58119.150 ms (7 rows) so we're definitely improved ... if this is the kinda results you were hoping to see, then I guess next step would be to increase/reanalyze all the word_id columns ... what about the url.url column? should that be done as well? what does that setting affect, *just* the time it takes to analyze the table? from the verbose output, it looks like it is scanning more rows on an analyze then @ 10 ... is this something that can be set database wide, before loading data? and/or something that the default is currently just too low? ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
On Thu, 1 Jan 2004, Tom Lane wrote: > "Marc G. Fournier" <scrappy@postgresql.org> writes: > > The full first query: > > > SELECT ndict8.url_id,ndict8.intag > > FROM ndict8, url > > WHERE ndict8.word_id=417851441 > > AND url.rec_id=ndict8.url_id > > AND ((url.url || '') LIKE 'http://archives.postgresql.org/%%'); > > > returns 13415 rows, and explain analyze shows: > > > Nested Loop (cost=0.00..30199.82 rows=17 width=8) (actual time=0.312..1459.504 rows=13415 loops=1) > > -> Index Scan using n8_word on ndict8 (cost=0.00..12616.09 rows=3219 width=8) (actual time=0.186..387.673 rows=15532loops=1) > > Index Cond: (word_id = 417851441) > > -> Index Scan using url_rec_id on url (cost=0.00..5.45 rows=1 width=4) (actual time=0.029..0.050 rows=1 loops=15532) > > Index Cond: (url.rec_id = "outer".url_id) > > Filter: ((url || ''::text) ~~ 'http://archives.postgresql.org/%%'::text) > > Total runtime: 1520.145 ms > > (7 rows) > > The more I look at it, the more it seems that this is the best plan for > the query. Since the URL condition is very unselective (and will > probably be so in most all variants of this query), it just doesn't pay > to try to apply it before doing the join. What we want is to make the > join happen quickly, and not even bother applying the URL test until > after we have a joinable url entry. > > (In the back of my mind here is the knowledge that mnogosearch is > optimized for mysql, which is too stupid to do the query in any way > other than a plan like the above.) > > I think Bruce's original suggestion of clustering was right on, except > he guessed wrong about what to cluster. The slow part is the scan on > ndict8, as we saw in the later message: > > -> Index Scan using n8_word on ndict8 (cost=0.00..12616.09 rows=3219 width=8) (actual time=113.645..79163.431 rows=15533loops=1) > Index Cond: (word_id = 417851441) > > Presumably, the first EXPLAIN shows the behavior when this portion of > ndict8 and its index have been cached, while the second EXPLAIN shows > what happens when they're not in cache. So my suggestion is to CLUSTER > ndict8 on n8_word. It might also help to CLUSTER url on url_rec_id. > Make sure the plan goes back to the nested indexscan as above (you might > need to undo the statistics-target changes). k, so return statistics to the default, and run a CLUSTER on n8_word and url_rec_id ... now, question I asked previously, but I think Bruce might have overlooked it ... what sort of impact does CLUSTER have on the system? For instance, an index happens nightly, so I'm guessing that I'll have to CLUSTER each right after? Will successive CLUSTERs take less time then the initial one? I'm guessing so, since the initial one will have 100% to sort, while subsequent ones will have a smaller set to work with, but figured I'd ask ... from the man page, all I figure I need to do (other then the initial time) is: VACUUM; CLUSTER; With 7.4, VACUUM full isn't a requirement, but is it if I'm going to do a CLUSTER after? ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
"Marc G. Fournier" <scrappy@postgresql.org> writes: > On Thu, 1 Jan 2004, Tom Lane wrote: >> Is there a reason for the >> concatenation part of the expression? > Believe it or not, the concatenation was based on a discussion *way* back > (2 years, maybe?) when we first started using Mnogosearch, in which you > suggested going that route ... in fact, at the time (bear in mind, this is > back in 7.2 days), it actually sped things up ... Hmm, I vaguely remember that ... I think we were deliberately trying to fool the planner at that time, because it was making some stupid assumption about the selectivity of the LIKE clause. It looks like that problem is now mostly fixed, since your second example shows estimate of 236133 vs reality of 304811 rows for the URL condition: > -> Index Scan using url_url on url (cost=0.00..10768.79 rows=236133 width=4) (actual time=225.243..8353.024rows=304811 loops=1) > Index Cond: ((url >= 'http://archives.postgresql.org/'::text) AND (url < 'http://archives.postgresql.org0'::text)) > Filter: (url ~~ 'http://archives.postgresql.org/%%'::text) > Total runtime: 16796.932 ms > (12 rows) > Closer to what you were looking/hoping for? This probably says that we can stop using the concatenation hack, at least. I'd still suggest clustering the two tables as per my later message. (Note that clustering would help this mergejoin plan too, so it could come out to be a win relative to the nestloop indexscan, but we ought to try both and see.) > what does that setting affect, *just* the time it takes to > analyze the table? Well, it will also bloat pg_statistic and slow down planning a little. Can you try 100 and see if that gives reasonable estimates? 1000 is a rather extreme setting I think; I'd go for 100 to start with. > is this something that can be set database wide, Yeah, see default_statistics_target in postgresql.conf. regards, tom lane
"Marc G. Fournier" <scrappy@postgresql.org> writes:
> what sort of impact does CLUSTER have on the system? For instance, an
> index happens nightly, so I'm guessing that I'll have to CLUSTER each
> right after?
Depends; what does the "index" process do --- are ndict8 and friends
rebuilt from scratch?
regards, tom lane
On Thu, 1 Jan 2004, Tom Lane wrote: > "Marc G. Fournier" <scrappy@postgresql.org> writes: > > what sort of impact does CLUSTER have on the system? For instance, an > > index happens nightly, so I'm guessing that I'll have to CLUSTER each > > right after? > > Depends; what does the "index" process do --- are ndict8 and friends > rebuilt from scratch? nope, but heavily updated ... basically, the indexer looks at url for what urls need to be 're-indexed' ... if it does, it removed all words from the ndict# tables that belong to that url, and re-adds accordingly ... ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
While you are in there - consider looking at effective_cache_size too. Set it to something like your average buffer cache memory. As I understand this, it only effects the choices of possible plans - so with the default (1000) some good ones that use more memory may be ignored (mind you - some really bad ones may be ignored too). best wishes Mark Tom Lane wrote: > > >>is this something that can be set database wide, >> >> > >Yeah, see default_statistics_target in postgresql.conf. > > > >
"Marc G. Fournier" <scrappy@postgresql.org> writes:
> On Thu, 1 Jan 2004, Tom Lane wrote:
>> "Marc G. Fournier" <scrappy@postgresql.org> writes:
>>> what sort of impact does CLUSTER have on the system? For instance, an
>>> index happens nightly, so I'm guessing that I'll have to CLUSTER each
>>> right after?
>>
>> Depends; what does the "index" process do --- are ndict8 and friends
>> rebuilt from scratch?
> nope, but heavily updated ... basically, the indexer looks at url for what
> urls need to be 're-indexed' ... if it does, it removed all words from the
> ndict# tables that belong to that url, and re-adds accordingly ...
Hmm, but in practice only a small fraction of the pages on the site
change in any given day, no? I'd think the typical nightly run changes
only a small fraction of the entries in the tables, if it is smart
enough not to re-index pages that did not change.
My guess is that it'd be enough to re-cluster once a week or so.
But this is pointless speculation until we find out whether clustering
helps enough to make it worth maintaining clustered-ness at all. Did
you get any results yet?
regards, tom lane
On Thu, 1 Jan 2004, Tom Lane wrote: > "Marc G. Fournier" <scrappy@postgresql.org> writes: > > On Thu, 1 Jan 2004, Tom Lane wrote: > >> "Marc G. Fournier" <scrappy@postgresql.org> writes: > >>> what sort of impact does CLUSTER have on the system? For instance, an > >>> index happens nightly, so I'm guessing that I'll have to CLUSTER each > >>> right after? > >> > >> Depends; what does the "index" process do --- are ndict8 and friends > >> rebuilt from scratch? > > > nope, but heavily updated ... basically, the indexer looks at url for what > > urls need to be 're-indexed' ... if it does, it removed all words from the > > ndict# tables that belong to that url, and re-adds accordingly ... > > Hmm, but in practice only a small fraction of the pages on the site > change in any given day, no? I'd think the typical nightly run changes > only a small fraction of the entries in the tables, if it is smart > enough not to re-index pages that did not change. that is correct, and I further restrict it to 10000 URLs a night ... > My guess is that it'd be enough to re-cluster once a week or so. > > But this is pointless speculation until we find out whether clustering > helps enough to make it worth maintaining clustered-ness at all. Did > you get any results yet? Its doing the CLUSTERing right now ... will post results once finished ... ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
On Thu, 1 Jan 2004, Tom Lane wrote:
> "Marc G. Fournier" <scrappy@postgresql.org> writes:
> > On Thu, 1 Jan 2004, Tom Lane wrote:
> >> "Marc G. Fournier" <scrappy@postgresql.org> writes:
> >>> what sort of impact does CLUSTER have on the system? For instance, an
> >>> index happens nightly, so I'm guessing that I'll have to CLUSTER each
> >>> right after?
> >>
> >> Depends; what does the "index" process do --- are ndict8 and friends
> >> rebuilt from scratch?
>
> > nope, but heavily updated ... basically, the indexer looks at url for what
> > urls need to be 're-indexed' ... if it does, it removed all words from the
> > ndict# tables that belong to that url, and re-adds accordingly ...
>
> Hmm, but in practice only a small fraction of the pages on the site
> change in any given day, no? I'd think the typical nightly run changes
> only a small fraction of the entries in the tables, if it is smart
> enough not to re-index pages that did not change.
>
> My guess is that it'd be enough to re-cluster once a week or so.
>
> But this is pointless speculation until we find out whether clustering
> helps enough to make it worth maintaining clustered-ness at all. Did
> you get any results yet?
Here is post-CLUSTER:
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.00..19470.40 rows=1952 width=8) (actual time=39.639..4200.376 rows=13415 loops=1)
-> Index Scan using n8_word on ndict8 (cost=0.00..70.90 rows=3253 width=8) (actual time=37.047..2802.400
rows=15533loops=1)
Index Cond: (word_id = 417851441)
-> Index Scan using url_rec_id on url (cost=0.00..5.95 rows=1 width=4) (actual time=0.061..0.068 rows=1
loops=15533)
Index Cond: (url.rec_id = "outer".url_id)
Filter: (url ~~ 'http://archives.postgresql.org/%%'::text)
Total runtime: 4273.799 ms
(7 rows)
And ... shit ... just tried a search on 'security invoker', and results
back in 2 secs ... 'multi version', 18 secs ... 'mnogosearch', .32sec ...
'mnogosearch performance', 18secs ...
this is closer to what I expect from PostgreSQL ...
I'm still loading the 'WITHOUT OIDS' database ... should I expect that,
with CLUSTERing, its performance would be slightly better yet, or would
the difference be negligible?
----
Marc G. Fournier Hub.Org Networking Services (http://www.hub.org)
Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
"Marc G. Fournier" <scrappy@postgresql.org> writes:
> I'm still loading the 'WITHOUT OIDS' database ... should I expect that,
> with CLUSTERing, its performance would be slightly better yet, or would
> the difference be negligible?
I think the difference will be marginal, but worth doing; you're
reducing the row size from 40 bytes to 36 if I counted correctly,
so circa-10% I/O saving, no?
24 bytes minimum 7.4 HeapTupleHeader
4 bytes OID
12 bytes three int4 fields
On a machine with 8-byte MAXALIGN, this would not help, but on
Intel hardware it should.
regards, tom lane
On Thu, 1 Jan 2004, Tom Lane wrote: > "Marc G. Fournier" <scrappy@postgresql.org> writes: > > I'm still loading the 'WITHOUT OIDS' database ... should I expect that, > > with CLUSTERing, its performance would be slightly better yet, or would > > the difference be negligible? > > I think the difference will be marginal, but worth doing; you're > reducing the row size from 40 bytes to 36 if I counted correctly, > so circa-10% I/O saving, no? > > 24 bytes minimum 7.4 HeapTupleHeader > 4 bytes OID > 12 bytes three int4 fields > > On a machine with 8-byte MAXALIGN, this would not help, but on > Intel hardware it should. I take it there is no way of drop'ng OIDs after the fact, eh? :) ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
"Marc G. Fournier" <scrappy@postgresql.org> writes:
> I take it there is no way of drop'ng OIDs after the fact, eh? :)
I think we have an ALTER TABLE DROP OIDS command, but it won't instantly
remove the OIDS from the table --- removal happens incrementally as rows
get updated. Maybe that's good enough for your situation though.
regards, tom lane
On Thu, 1 Jan 2004, Tom Lane wrote: > "Marc G. Fournier" <scrappy@postgresql.org> writes: > > I take it there is no way of drop'ng OIDs after the fact, eh? :) > > I think we have an ALTER TABLE DROP OIDS command, but it won't instantly > remove the OIDS from the table --- removal happens incrementally as rows > get updated. Maybe that's good enough for your situation though. actually, that would be perfect ... saves having to spend the many many hours to re-index all the URLs, and will at least give a gradual improvement :) ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
> >Note that I haven't made many changes to the postgresql.conf file, so >there might be something really obvious I've overlooked, but here are the >uncommented ones (ie. ones I've modified from defaults): > >tcpip_socket = true >max_connections = 512 >shared_buffers = 10000 # min 16, at least max_connections*2, 8KB each >sort_mem = 10240 # min 64, size in KB >vacuum_mem = 81920 # min 1024, size in KB > > what about effective_cache_size and random_page_cost? Sincerely, Joshua D. Drake >syslog = 2 # range 0-2; 0=stdout; 1=both; 2=syslog >syslog_facility = 'LOCAL0' >syslog_ident = 'postgres' >log_connections = true >log_duration = false >log_statement = false >lc_messages = 'C' # locale for system error message strings >lc_monetary = 'C' # locale for monetary formatting >lc_numeric = 'C' # locale for number formatting >lc_time = 'C' # locale for time formatting > > >---- >Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) >Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > >---------------------------(end of broadcast)--------------------------- >TIP 6: Have you searched our list archives? > > http://archives.postgresql.org > > -- Command Prompt, Inc., home of Mammoth PostgreSQL - S/ODBC and S/JDBC Postgresql support, programming shared hosting and dedicated hosting. +1-503-222-2783 - jd@commandprompt.com - http://www.commandprompt.com Editor-N-Chief - PostgreSQl.Org - http://www.postgresql.org
BricolageA content management system is long overdue I think, do you have any good recommendations?
-- Command Prompt, Inc., home of Mammoth PostgreSQL - S/ODBC and S/JDBC Postgresql support, programming shared hosting and dedicated hosting. +1-503-222-2783 - jd@commandprompt.com - http://www.commandprompt.com
On Sat, 3 Jan 2004, Dave Cramer wrote:
> On Sat, 2004-01-03 at 09:49, Oleg Bartunov wrote:
> > Hi there,
> >
> > I hoped to release pilot version of www.pgsql.ru with full text search
> > of postgresql related resources (currently we've crawled 27 sites, about
> > 340K pages) but we started celebration NY too early :)
> > Expect it tomorrow or monday.
> Fantastic!
I'm just working on web interface to give people possibility to choose
collection of documents to search, for example: 7.1 documentation, 7.4 documentation
> >
> >
> > I'm not sure is there are some kind of CMS on www.postgresql.org, but
> > if it's there the best way is to embed tsearch2 into CMS. You'll have
> > fast, incremental search engine. There are many users of tsearch2 and I think
> > embedding isn't very difficult problem. I estimate there are maximum
> > 10-20K pages of documentation, nothing for tsearch2.
>
> A content management system is long overdue I think, do you have any
> good recommendations?
>
*.postgresql.org likes PHP, so let's see in Google for 'php cms' :)
> >
>
Regards,
Oleg
_____________________________________________________________
Oleg Bartunov, sci.researcher, hostmaster of AstroNet,
Sternberg Astronomical Institute, Moscow University (Russia)
Internet: oleg@sai.msu.su, http://www.sai.msu.su/~megera/
phone: +007(095)939-16-83, +007(095)939-23-83
On Thu, 1 Jan 2004, Marc G. Fournier wrote:
> On Thu, 1 Jan 2004, Bruce Momjian wrote:
>
> > Marc G. Fournier wrote:
> > > 186_archives=# \d ndict7
> > > Table "public.ndict7"
> > > Column | Type | Modifiers
> > > ---------+---------+--------------------
> > > url_id | integer | not null default 0
> > > word_id | integer | not null default 0
> > > intag | integer | not null default 0
> > > Indexes:
> > > "n7_url" btree (url_id)
> > > "n7_word" btree (word_id)
> > >
> > >
> > > The slowdown is the LIKE condition, as the ndict[78] word_id conditions
> > > return near instantly when run individually, and when I run the 'url/LIKE'
> > > condition, it takes "forever" ...
> >
> > Does it help to CLUSTER url.url? Is your data being loaded in so
> > identical values used by LIKE are next to each other?
>
> Just tried CLUSTER, and no difference, but ... chat'd with Dave on ICQ
> this evening, and was thinking of something ... and it comes back to
> something that I mentioned awhile back ...
>
> Taking the ndict8 query that I originally presented, now post CLUSTER, and
> an explain analyze looks like:
>
> QUERY PLAN
>
---------------------------------------------------------------------------------------------------------------------------------------
> Hash Join (cost=13918.23..26550.58 rows=17 width=8) (actual time=4053.403..83481.769 rows=13415 loops=1)
> Hash Cond: ("outer".url_id = "inner".rec_id)
> -> Index Scan using n8_word on ndict8 (cost=0.00..12616.09 rows=3219 width=8) (actual time=113.645..79163.431
rows=15533loops=1)
> Index Cond: (word_id = 417851441)
> -> Hash (cost=13913.31..13913.31 rows=1968 width=4) (actual time=3920.597..3920.597 rows=0 loops=1)
> -> Seq Scan on url (cost=0.00..13913.31 rows=1968 width=4) (actual time=3.837..2377.853 rows=304811
loops=1)
> Filter: ((url || ''::text) ~~ 'http://archives.postgresql.org/%%'::text)
> Total runtime: 83578.572 ms
> (8 rows)
>
> Now, if I knock off the LIKE, so that I'm returning all rows from ndict8,
> join'd to all the URLs that contain them, you get:
>
> QUERY PLAN
>
-----------------------------------------------------------------------------------------------------------------------------------
> Nested Loop (cost=0.00..30183.13 rows=3219 width=8) (actual time=0.299..1217.116 rows=15533 loops=1)
> -> Index Scan using n8_word on ndict8 (cost=0.00..12616.09 rows=3219 width=8) (actual time=0.144..458.891
rows=15533loops=1)
> Index Cond: (word_id = 417851441)
> -> Index Scan using url_rec_id on url (cost=0.00..5.44 rows=1 width=4) (actual time=0.024..0.029 rows=1
loops=15533)
> Index Cond: (url.rec_id = "outer".url_id)
> Total runtime: 1286.647 ms
> (6 rows)
>
> So, there are 15333 URLs that contain that word ... now, what I want to
> find out is how many of those 15333 URLs contain
> 'http://archives.postgresql.org/%%', which is 13415 ...
what's the need for such query ? Are you trying to restrict search to
archives ? Why not just have site attribute for document and use simple
join ?
>
> The problem is that right now, we look at the LIKE first, giving us ~300k
> rows, and then search through those for those who have the word matching
> ... is there some way of reducing the priority of the LIKE part of the
> query, as far as the planner is concerned, so that it will "resolve" the =
> first, and then work the LIKE on the resultant set, instead of the other
> way around? So that the query is only checking 15k records for the 13k
> that match, instead of searching through 300k?
>
> I'm guessing that the reason that the LIKE is taking precidence(sp?) is
> because the URL table has less rows in it then ndict8?
>
> ----
> Marc G. Fournier Hub.Org Networking Services (http://www.hub.org)
> Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
>
> ---------------------------(end of broadcast)---------------------------
> TIP 8: explain analyze is your friend
>
Regards,
Oleg
_____________________________________________________________
Oleg Bartunov, sci.researcher, hostmaster of AstroNet,
Sternberg Astronomical Institute, Moscow University (Russia)
Internet: oleg@sai.msu.su, http://www.sai.msu.su/~megera/
phone: +007(095)939-16-83, +007(095)939-23-83
Hi there,
I hoped to release pilot version of www.pgsql.ru with full text search
of postgresql related resources (currently we've crawled 27 sites, about
340K pages) but we started celebration NY too early :)
Expect it tomorrow or monday.
We have developed many search engines, some of them are based on
PostgreSQL like tsearch2, OpenFTS and are best to be embedded into
CMS for true online updating. Their power comes from access to documents attributes
stored in database, so one could perform categorized search, restricted
search (different rights, different document status, etc). The most close
example would be search on archive of mailing lists, which should be
embed such kind of full text search engine. fts.postgresql.org in his best
time was one of implementation of such system. This is what I hope to have on
www.pgsql.ru, if Marc will give us access to mailing list archives :)
Another search engines we use are based on standard technology of
inverted indices, they are best suited for indexing of semi-static collections
od documents. We've full-fledged crawler, indexer and searcher. Online
update of inverted indices is rather complex technological task and I'm
not sure there are databases which have true online update. On www.pgsql.ru
we use GTSearch which is generic text search engine we developed for
vertical searches (for example, postgresql related resources). It has
common set of features like phrase search, proximity ranking, site search,
morphology, stemming support, cached documents, spell checking, similar search
etc.
I see several separate tasks:
* official documents (documentation mostly)
I'm not sure is there are some kind of CMS on www.postgresql.org, but
if it's there the best way is to embed tsearch2 into CMS. You'll have
fast, incremental search engine. There are many users of tsearch2 and I think
embedding isn't very difficult problem. I estimate there are maximum
10-20K pages of documentation, nothing for tsearch2.
* mailing lists archive
mailing lists archive, which is constantly growing and
also required incremental update, so tsearch2 also needed. Nice hardware
like Marc has described would be more than enough. We have moderate dual
PIII 1Ggz server and I hope it would be enough.
* postgresql related resources
I think this task should be solved using standard technique - crawler,
indexer, searcher. Due to limited number of sites it's possible to
keep indices more actual than major search engines, for example
crawl once a week. This is what we currently have on pgsql.ru because
it doesn't require any permissions and interaction with sites officials.
Regards,
Oleg
On Wed, 31 Dec 2003, Marc G. Fournier wrote:
> On Tue, 30 Dec 2003, Joshua D. Drake wrote:
>
> > Hello,
> >
> > Why are we not using Tsearch2?
>
> Because nobody has built it yet? Oleg's stuff is nice, but we want
> something that we can build into the existing web sites, not a standalone
> site ...
>
> I keep searching the web hoping someone has come up with a 'tsearch2'
> based search engine that does the spidering, but, unless its sitting right
> in front of my eyes and I'm not seeing it, I haven't found it yet :(
>
> Out of everything I've found so far, mnogosearch is one of the best ... I
> just wish I could figure out where the bottleneck for it was, since, from
> reading their docs, their method of storing the data doesn't appear to be
> particularly off. I'm tempted to try their caching storage manager, and
> getting away from SQL totally, but I *really* want to showcase PostgreSQL
> on this :(
>
> ----
> Marc G. Fournier Hub.Org Networking Services (http://www.hub.org)
> Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
>
> ---------------------------(end of broadcast)---------------------------
> TIP 2: you can get off all lists at once with the unregister command
> (send "unregister YourEmailAddressHere" to majordomo@postgresql.org)
>
Regards,
Oleg
_____________________________________________________________
Oleg Bartunov, sci.researcher, hostmaster of AstroNet,
Sternberg Astronomical Institute, Moscow University (Russia)
Internet: oleg@sai.msu.su, http://www.sai.msu.su/~megera/
phone: +007(095)939-16-83, +007(095)939-23-83
On Sat, 2004-01-03 at 09:49, Oleg Bartunov wrote: > Hi there, > > I hoped to release pilot version of www.pgsql.ru with full text search > of postgresql related resources (currently we've crawled 27 sites, about > 340K pages) but we started celebration NY too early :) > Expect it tomorrow or monday. Fantastic! > > We have developed many search engines, some of them are based on > PostgreSQL like tsearch2, OpenFTS and are best to be embedded into > CMS for true online updating. Their power comes from access to documents attributes > stored in database, so one could perform categorized search, restricted > search (different rights, different document status, etc). The most close > example would be search on archive of mailing lists, which should be > embed such kind of full text search engine. fts.postgresql.org in his best > time was one of implementation of such system. This is what I hope to have on > www.pgsql.ru, if Marc will give us access to mailing list archives :) I too would like access to the archives. > > Another search engines we use are based on standard technology of > inverted indices, they are best suited for indexing of semi-static collections > od documents. We've full-fledged crawler, indexer and searcher. Online > update of inverted indices is rather complex technological task and I'm > not sure there are databases which have true online update. On www.pgsql.ru > we use GTSearch which is generic text search engine we developed for > vertical searches (for example, postgresql related resources). It has > common set of features like phrase search, proximity ranking, site search, > morphology, stemming support, cached documents, spell checking, similar search > etc. > > I see several separate tasks: > > * official documents (documentation mostly) > > I'm not sure is there are some kind of CMS on www.postgresql.org, but > if it's there the best way is to embed tsearch2 into CMS. You'll have > fast, incremental search engine. There are many users of tsearch2 and I think > embedding isn't very difficult problem. I estimate there are maximum > 10-20K pages of documentation, nothing for tsearch2. A content management system is long overdue I think, do you have any good recommendations? > > * mailing lists archive > > mailing lists archive, which is constantly growing and > also required incremental update, so tsearch2 also needed. Nice hardware > like Marc has described would be more than enough. We have moderate dual > PIII 1Ggz server and I hope it would be enough. > > * postgresql related resources > > I think this task should be solved using standard technique - crawler, > indexer, searcher. Due to limited number of sites it's possible to > keep indices more actual than major search engines, for example > crawl once a week. This is what we currently have on pgsql.ru because > it doesn't require any permissions and interaction with sites officials. > > > Regards, > Oleg > > > On Wed, 31 Dec 2003, Marc G. Fournier wrote: > > > On Tue, 30 Dec 2003, Joshua D. Drake wrote: > > > > > Hello, > > > > > > Why are we not using Tsearch2? > > > > Because nobody has built it yet? Oleg's stuff is nice, but we want > > something that we can build into the existing web sites, not a standalone > > site ... > > > > I keep searching the web hoping someone has come up with a 'tsearch2' > > based search engine that does the spidering, but, unless its sitting right > > in front of my eyes and I'm not seeing it, I haven't found it yet :( > > > > Out of everything I've found so far, mnogosearch is one of the best ... I > > just wish I could figure out where the bottleneck for it was, since, from > > reading their docs, their method of storing the data doesn't appear to be > > particularly off. I'm tempted to try their caching storage manager, and > > getting away from SQL totally, but I *really* want to showcase PostgreSQL > > on this :( > > > > ---- > > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > > > > ---------------------------(end of broadcast)--------------------------- > > TIP 2: you can get off all lists at once with the unregister command > > (send "unregister YourEmailAddressHere" to majordomo@postgresql.org) > > > > Regards, > Oleg > _____________________________________________________________ > Oleg Bartunov, sci.researcher, hostmaster of AstroNet, > Sternberg Astronomical Institute, Moscow University (Russia) > Internet: oleg@sai.msu.su, http://www.sai.msu.su/~megera/ > phone: +007(095)939-16-83, +007(095)939-23-83 > -- Dave Cramer 519 939 0336 ICQ # 1467551
Well I know that the advocacy site is looking at implementing Bricolage. It seems that if weIt's good Mason driven CMS, but Marc seems is a PHP fun :)
were smart about it, we would pick a platform (application wise) and stick with it.
Sincerely,
Joshua D. Drake
Regards, Oleg _____________________________________________________________ Oleg Bartunov, sci.researcher, hostmaster of AstroNet, Sternberg Astronomical Institute, Moscow University (Russia) Internet: oleg@sai.msu.su, http://www.sai.msu.su/~megera/ phone: +007(095)939-16-83, +007(095)939-23-83
-- Command Prompt, Inc., home of Mammoth PostgreSQL - S/ODBC and S/JDBC Postgresql support, programming shared hosting and dedicated hosting. +1-503-222-2783 - jd@commandprompt.com - http://www.commandprompt.com Editor-N-Chief - PostgreSQl.Org - http://www.postgresql.org
On Sat, 3 Jan 2004, Joshua D. Drake wrote:
> >
> >
> >
> >A content management system is long overdue I think, do you have any
> >good recommendations?
> >
> >
> >
> Bricolage
>
It's good Mason driven CMS, but Marc seems is a PHP fun :)
>
>
Regards,
Oleg
_____________________________________________________________
Oleg Bartunov, sci.researcher, hostmaster of AstroNet,
Sternberg Astronomical Institute, Moscow University (Russia)
Internet: oleg@sai.msu.su, http://www.sai.msu.su/~megera/
phone: +007(095)939-16-83, +007(095)939-23-83
On Sat, 3 Jan 2004, Oleg Bartunov wrote: > > So, there are 15333 URLs that contain that word ... now, what I want to > > find out is how many of those 15333 URLs contain > > 'http://archives.postgresql.org/%%', which is 13415 ... > > what's the need for such query ? Are you trying to restrict search to > archives ? Why not just have site attribute for document and use simple > join ? The searches are designed so that you can do sub-section searches ... ie. if you only wanted to search hackers, the LIKE would be: 'http://archives.postgresql.org/pgsql-hackers/%%' while: 'http://archives.postgresql.org/%%' would give you a search of *all* the mailing lists ... In theory, you could go smaller and search on: 'http://archives.postgresql.org/pgsql-hackers/2003-11/%% for all messages in November of 2003 ... ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
On Sat, 3 Jan 2004, Oleg Bartunov wrote: > time was one of implementation of such system. This is what I hope to have on > www.pgsql.ru, if Marc will give us access to mailing list archives :) Access to the archives was provided before New Years *puzzled look* I sent Teodor the rsync command that he needs to run to download it all from the IP he provided me previously ... ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
On Sat, 3 Jan 2004, Marc G. Fournier wrote: > On Sat, 3 Jan 2004, Oleg Bartunov wrote: > > > time was one of implementation of such system. This is what I hope to have on > > www.pgsql.ru, if Marc will give us access to mailing list archives :) > > Access to the archives was provided before New Years *puzzled look* I sent > Teodor the rsync command that he needs to run to download it all from the > IP he provided me previously ... Hmm, what's the secret rsync command you didn't share with me :) > > > ---- > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > > ---------------------------(end of broadcast)--------------------------- > TIP 5: Have you checked our extensive FAQ? > > http://www.postgresql.org/docs/faqs/FAQ.html > Regards, Oleg _____________________________________________________________ Oleg Bartunov, sci.researcher, hostmaster of AstroNet, Sternberg Astronomical Institute, Moscow University (Russia) Internet: oleg@sai.msu.su, http://www.sai.msu.su/~megera/ phone: +007(095)939-16-83, +007(095)939-23-83
Yup,
So slow in fact that I never use it. I did once or twice and gave up.
It is ironic! I only come to the online docs when I already know the
<where> part of my search and just go to that part or section. For
everything else, there's google!
SECURITY INVOKER site:postgresql.org
Searched pages from postgresql.org for SECURITY INVOKER. Results 1 -
10 of about 141. Search took 0.23 seconds.
Ahhh, that's better.
Or use site:www.postgresql.org to avoid the archive listings, etc.
== Ezra Epstein
""D. Dante Lorenso"" <dante@lorenso.com> wrote in message
news:3FF0A316.7090300@lorenso.com...
> Trying to use the 'search' in the docs section of PostgreSQL.org
> is extremely SLOW. Considering this is a website for a database
> and databases are supposed to be good for indexing content, I'd
> expect a much faster performance.
>
> I submitted my search over two minutes ago. I just finished this
> email to the list. The results have still not come back. I only
> searched for:
>
> SECURITY INVOKER
>
> Perhaps this should be worked on?
>
> Dante
>
>
>
> ---------------------------(end of broadcast)---------------------------
> TIP 9: the planner will ignore your desire to choose an index scan if your
> joining column's datatypes do not match
>
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 > I keep searching the web hoping someone has come up with a 'tsearch2' > based search engine that does the spidering, but, unless its sitting right > in front of my eyes and I'm not seeing it, I haven't found it yet :( I wrote my own search engine for the docs back when the site was having problems last year, and myself and some others needed a searchable interface. It actually spidered the raw sgml pages themselves, and was fairly quick. I can resurrect this if anyone is interested. It runs with Perl and PostgreSQL and nothing else. :) Of course, it could probably be modified to feed it's sgml parsing output to tsearch as well. In the meantime, could we please switch to a simple google search? It would require changing one or two lines of HTML source, and at least there would be *something* until we get everything sorted out. - -- Greg Sabino Mullane greg@turnstep.com PGP Key: 0x14964AC8 200401041439 -----BEGIN PGP SIGNATURE----- iD8DBQE/+GwIvJuQZxSWSsgRAkOgAJ9lmXwd/h/d+HzPiaPUVvO/Gq1O9wCeNbmn CidSrTYP0sc5pp/hdlIS19o= =YPWw -----END PGP SIGNATURE-----
On Wed, 31 Dec 2003, Dave Cramer wrote: > Well it appears there are quite a few solutions to use so the next > question should be what are we trying to accomplish here? > > One thing that I think is that the documentation search should be > limited to the documentation. > > Who is in a position to make the decision of which solution to use? I'm the one that is going to end up implementing whatever we go with ... If we pull out the mailing list archives from the database, I can't imagine mnogosearch being powerful enough to do it, as there really aren't that many pages ... its the archives that kill the process ... so maybe we'll just go with that as a first step, make 'site search' seperate from 'archives' search ... DaveP? Sound reasonable to try first? ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
On Sat, 3 Jan 2004, Oleg Bartunov wrote: > On Sat, 3 Jan 2004, Joshua D. Drake wrote: > > > > > > > > > > > > >A content management system is long overdue I think, do you have any > > >good recommendations? > > > > > > > > > > > Bricolage > > > > It's good Mason driven CMS, but Marc seems is a PHP fun :) Ummm, where do you derive that from? As the -www team all know (or should), they need something installed, they ask for it ... we have OACS, Jakarta-Tomcat, mod_perl, mod_python, etc now as it is. I personally use PHP, but I don't use CMSs, so don't even know of a PHPbased CMS to think to recommend ... Personally, I use what fits the situation ... web based stuff, I generally do in PHP ... command line, all in perl *shrug* ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
On Sun, 4 Jan 2004, Oleg Bartunov wrote: > On Sat, 3 Jan 2004, Marc G. Fournier wrote: > > > On Sat, 3 Jan 2004, Oleg Bartunov wrote: > > > > > time was one of implementation of such system. This is what I hope to have on > > > www.pgsql.ru, if Marc will give us access to mailing list archives :) > > > > Access to the archives was provided before New Years *puzzled look* I sent > > Teodor the rsync command that he needs to run to download it all from the > > IP he provided me previously ... > > Hmm, what's the secret rsync command you didn't share with me :) Its no secret, else I wouldn't have sent it to Teodor :) ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
Send it to me too please? Dave On Sun, 2004-01-04 at 04:34, Oleg Bartunov wrote: > On Sat, 3 Jan 2004, Marc G. Fournier wrote: > > > On Sat, 3 Jan 2004, Oleg Bartunov wrote: > > > > > time was one of implementation of such system. This is what I hope to have on > > > www.pgsql.ru, if Marc will give us access to mailing list archives :) > > > > Access to the archives was provided before New Years *puzzled look* I sent > > Teodor the rsync command that he needs to run to download it all from the > > IP he provided me previously ... > > Hmm, what's the secret rsync command you didn't share with me :) > > > > > > > ---- > > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > > > > ---------------------------(end of broadcast)--------------------------- > > TIP 5: Have you checked our extensive FAQ? > > > > http://www.postgresql.org/docs/faqs/FAQ.html > > > > Regards, > Oleg > _____________________________________________________________ > Oleg Bartunov, sci.researcher, hostmaster of AstroNet, > Sternberg Astronomical Institute, Moscow University (Russia) > Internet: oleg@sai.msu.su, http://www.sai.msu.su/~megera/ > phone: +007(095)939-16-83, +007(095)939-23-83 > > ---------------------------(end of broadcast)--------------------------- > TIP 3: if posting/reading through Usenet, please send an appropriate > subscribe-nomail command to majordomo@postgresql.org so that your > message can get through to the mailing list cleanly > -- Dave Cramer 519 939 0336 ICQ # 1467551
Marc, Can you please send it again, I can't seem to find the original message? Dave On Sun, 2004-01-04 at 10:03, Marc G. Fournier wrote: > On Sun, 4 Jan 2004, Oleg Bartunov wrote: > > > On Sat, 3 Jan 2004, Marc G. Fournier wrote: > > > > > On Sat, 3 Jan 2004, Oleg Bartunov wrote: > > > > > > > time was one of implementation of such system. This is what I hope to have on > > > > www.pgsql.ru, if Marc will give us access to mailing list archives :) > > > > > > Access to the archives was provided before New Years *puzzled look* I sent > > > Teodor the rsync command that he needs to run to download it all from the > > > IP he provided me previously ... > > > > Hmm, what's the secret rsync command you didn't share with me :) > > Its no secret, else I wouldn't have sent it to Teodor :) > > ---- > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > -- Dave Cramer 519 939 0336 ICQ # 1467551
Dave Cramer wrote: >Well it appears there are quite a few solutions to use so the next >question should be what are we trying to accomplish here? > >One thing that I think is that the documentation search should be >limited to the documentation. > >Who is in a position to make the decision of which solution to use? > > If I can weigh in on this one I'd just like to say... After all, it IS a website for a database. Shouldn't you be using PostgreSQL for the job? I mean it just seems silly if the PHP.net website were being run on ASP. Or the java.sun.com was run on Coldfusion. You just can't (or SHOULDN'T) use anything other than PostgreSQL, can you? I think the search engine should be a demo of PostgreSQL's database speed and abilities. Dante ---------- D. Dante Lorenso
Check it out now and let me know what you searched on, and whether or not you see an improvement over what it was ... Tom -and- Bruce suggested some changes that, from my tests, show a dramatic change in speed *compared to what it was* ... but that could just be that I'm getting lucky ... On Thu, 1 Jan 2004, ezra epstein wrote: > Yup, > > So slow in fact that I never use it. I did once or twice and gave up. > It is ironic! I only come to the online docs when I already know the > <where> part of my search and just go to that part or section. For > everything else, there's google! > > SECURITY INVOKER site:postgresql.org > > Searched pages from postgresql.org for SECURITY INVOKER. Results 1 - > 10 of about 141. Search took 0.23 seconds. > > > Ahhh, that's better. > > Or use site:www.postgresql.org to avoid the archive listings, etc. > > == Ezra Epstein > > ""D. Dante Lorenso"" <dante@lorenso.com> wrote in message > news:3FF0A316.7090300@lorenso.com... > > Trying to use the 'search' in the docs section of PostgreSQL.org > > is extremely SLOW. Considering this is a website for a database > > and databases are supposed to be good for indexing content, I'd > > expect a much faster performance. > > > > I submitted my search over two minutes ago. I just finished this > > email to the list. The results have still not come back. I only > > searched for: > > > > SECURITY INVOKER > > > > Perhaps this should be worked on? > > > > Dante > > > > > > > > ---------------------------(end of broadcast)--------------------------- > > TIP 9: the planner will ignore your desire to choose an index scan if your > > joining column's datatypes do not match > > > > > > ---------------------------(end of broadcast)--------------------------- > TIP 7: don't forget to increase your free space map settings > ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
On Sun, 4 Jan 2004, Greg Sabino Mullane wrote: > ------------------------------------------------------------------------------ > /usr/local/libexec/ppf_verify: pgp command failed > > gpg: WARNING: using insecure memory! > gpg: please see http://www.gnupg.org/faq.html for more information > gpg: Signature made Sun Jan 4 15:39:52 2004 AST using DSA key ID 14964AC8 > gpg: Can't check signature: public key not found > ------------------------------------------------------------------------------ > > > -----BEGIN PGP SIGNED MESSAGE----- > Hash: SHA1 > > > > I keep searching the web hoping someone has come up with a 'tsearch2' > > based search engine that does the spidering, but, unless its sitting right > > in front of my eyes and I'm not seeing it, I haven't found it yet :( > > I wrote my own search engine for the docs back when the site was having > problems last year, and myself and some others needed a searchable > interface. It actually spidered the raw sgml pages themselves, and was > fairly quick. I can resurrect this if anyone is interested. It runs > with Perl and PostgreSQL and nothing else. :) Of course, it could probably > be modified to feed it's sgml parsing output to tsearch as well. > > In the meantime, could we please switch to a simple google search? It > would require changing one or two lines of HTML source, and at least > there would be *something* until we get everything sorted out. Have you checked things out since Tom -and- Bruce's suggestions? ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 > Have you checked things out since Tom -and- Bruce's suggestions? Yes, and while they are better, they still reflect badly on PostgreSQL: Searching for "partial index" in the docs only: 12.26 seconds Searching from that result page (which defaults to the while site) for the word "index": 16.32 seconds By comparison, the mysql site (which claims to be running Mnogosearch) returns instantly, no matter the query. I like the idea of separating the archives into their own search, which I agree with Marc should help quite a bit. - -- Greg Sabino Mullane greg@turnstep.com PGP Key: 0x14964AC8 200401041533 -----BEGIN PGP SIGNATURE----- iD8DBQE/+HmHvJuQZxSWSsgRAmV0AJsHQ1lisSj4ur1WWyylYUjUWONU/QCgzk5p UeN+njNAiWFA/u2+AajuC4k= =qWcr -----END PGP SIGNATURE-----
I searched only the 7.4 docs for create table, and it returned in 10 seconds, much better Dave On Sun, 2004-01-04 at 15:02, Marc G. Fournier wrote: > Check it out now and let me know what you searched on, and whether or not > you see an improvement over what it was ... Tom -and- Bruce suggested some > changes that, from my tests, show a dramatic change in speed *compared to > what it was* ... but that could just be that I'm getting lucky ... > > On Thu, 1 Jan 2004, ezra epstein wrote: > > > Yup, > > > > So slow in fact that I never use it. I did once or twice and gave up. > > It is ironic! I only come to the online docs when I already know the > > <where> part of my search and just go to that part or section. For > > everything else, there's google! > > > > SECURITY INVOKER site:postgresql.org > > > > Searched pages from postgresql.org for SECURITY INVOKER. Results 1 - > > 10 of about 141. Search took 0.23 seconds. > > > > > > Ahhh, that's better. > > > > Or use site:www.postgresql.org to avoid the archive listings, etc. > > > > == Ezra Epstein > > > > ""D. Dante Lorenso"" <dante@lorenso.com> wrote in message > > news:3FF0A316.7090300@lorenso.com... > > > Trying to use the 'search' in the docs section of PostgreSQL.org > > > is extremely SLOW. Considering this is a website for a database > > > and databases are supposed to be good for indexing content, I'd > > > expect a much faster performance. > > > > > > I submitted my search over two minutes ago. I just finished this > > > email to the list. The results have still not come back. I only > > > searched for: > > > > > > SECURITY INVOKER > > > > > > Perhaps this should be worked on? > > > > > > Dante > > > > > > > > > > > > ---------------------------(end of broadcast)--------------------------- > > > TIP 9: the planner will ignore your desire to choose an index scan if your > > > joining column's datatypes do not match > > > > > > > > > > > ---------------------------(end of broadcast)--------------------------- > > TIP 7: don't forget to increase your free space map settings > > > > ---- > Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) > Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664 > > ---------------------------(end of broadcast)--------------------------- > TIP 1: subscribe and unsubscribe commands go to majordomo@postgresql.org > -- Dave Cramer 519 939 0336 ICQ # 1467551
I just tried : i) "wal" in "7.4 docs" -> 5 seconds ii) "partial index" in "All Sites" -> 3 seconds iii) "column statistics" in "All Sites" -> 2 seconds iv) "fork exec" in "All Sites" -> 2 seconds These results seem pretty good to me... regards Mark
> The searches are designed so that you can do sub-section searches ... ie. > if you only wanted to search hackers, the LIKE would be: > > 'http://archives.postgresql.org/pgsql-hackers/%%' > > while: > > 'http://archives.postgresql.org/%%' > > would give you a search of *all* the mailing lists ... > > In theory, you could go smaller and search on: > > 'http://archives.postgresql.org/pgsql-hackers/2003-11/%% for all messages > in November of 2003 ... > That doesn't stop you from using an extra site attribute to speed up the typical cases of documentation searches. You could just have an int field or something (basically enumerating the most important sites) and have the default set to be the result of a function. Then just make a functional index, and maybe even cluster by that attribute. The function I am describing would have the basic form: function site_type(url text) returns int as ' if url like 'archives.postgresql.org%' then return 1 else if url like 'www.postgresql.org/docs/%' then return 2 ... ' That way you shouldn't have to change the code that inserts into the table, only the code that does the search. If the table was clustered at the time of each change to the documentation, I couldn't imagine that the documentation searches would even take a second. Also, even though it's kind of a performance optimization hack, it doesn't seem unreasonable to store the smaller document sets in a seperate table, and then have a view of the union of the two tables. That might help the server cache the right files for quick access. Neither of these ideas would seem to have much impact on the flexibility of the system you designed. Both are just some optimization things that would give a good impression to the people doing quick documentation searches. Regards, Jeff
Mark Kirkwood <markir@paradise.net.nz> writes: > These results seem pretty good to me... FWIW, I see pretty decent search speed when I go to http://www.postgresql.org/search.cgi but pretty lousy search speed when I try a similar query at http://archives.postgresql.org/ Could we get the latter search engine cranked up? regards, tom lane
Try www.pgsql.ru. I just released pilot version with full text searching
postgresql related resources. Search for security invoker takes 0.03 sec :)
Oleg
On Thu, 1 Jan 2004, ezra epstein wrote:
> Yup,
>
> So slow in fact that I never use it. I did once or twice and gave up.
> It is ironic! I only come to the online docs when I already know the
> <where> part of my search and just go to that part or section. For
> everything else, there's google!
>
> SECURITY INVOKER site:postgresql.org
>
> Searched pages from postgresql.org for SECURITY INVOKER. Results 1 -
> 10 of about 141. Search took 0.23 seconds.
>
>
> Ahhh, that's better.
>
> Or use site:www.postgresql.org to avoid the archive listings, etc.
>
> == Ezra Epstein
>
> ""D. Dante Lorenso"" <dante@lorenso.com> wrote in message
> news:3FF0A316.7090300@lorenso.com...
> > Trying to use the 'search' in the docs section of PostgreSQL.org
> > is extremely SLOW. Considering this is a website for a database
> > and databases are supposed to be good for indexing content, I'd
> > expect a much faster performance.
> >
> > I submitted my search over two minutes ago. I just finished this
> > email to the list. The results have still not come back. I only
> > searched for:
> >
> > SECURITY INVOKER
> >
> > Perhaps this should be worked on?
> >
> > Dante
> >
> >
> >
> > ---------------------------(end of broadcast)---------------------------
> > TIP 9: the planner will ignore your desire to choose an index scan if your
> > joining column's datatypes do not match
> >
>
>
>
> ---------------------------(end of broadcast)---------------------------
> TIP 7: don't forget to increase your free space map settings
>
Regards,
Oleg
_____________________________________________________________
Oleg Bartunov, sci.researcher, hostmaster of AstroNet,
Sternberg Astronomical Institute, Moscow University (Russia)
Internet: oleg@sai.msu.su, http://www.sai.msu.su/~megera/
phone: +007(095)939-16-83, +007(095)939-23-83
On Mon, 5 Jan 2004, Tom Lane wrote: > Mark Kirkwood <markir@paradise.net.nz> writes: > > These results seem pretty good to me... > > FWIW, I see pretty decent search speed when I go to > http://www.postgresql.org/search.cgi > but pretty lousy search speed when I try a similar query at > http://archives.postgresql.org/ > > Could we get the latter search engine cranked up? Odd ... I'm doing all my searches using archives ... note that both use the same backend database, so the only thing I can think of is that when you use search.cgi, its not including everything on http://archives.*, which will cut down the # of URLs found by ~300k out of 390k ... smaller result set ... ---- Marc G. Fournier Hub.Org Networking Services (http://www.hub.org) Email: scrappy@hub.org Yahoo!: yscrappy ICQ: 7615664
On Wed, 31 Dec 2003, D. Dante Lorenso wrote:
> Dave Cramer wrote:
>
> >Well it appears there are quite a few solutions to use so the next
> >question should be what are we trying to accomplish here?
> >
> >One thing that I think is that the documentation search should be
> >limited to the documentation.
> >
> >Who is in a position to make the decision of which solution to use?
> >
> >
> If I can weigh in on this one I'd just like to say... After all, it IS
> a website for a database. Shouldn't you be using PostgreSQL for the
> job? I mean it just seems silly if the PHP.net website were being run
> on ASP. Or the java.sun.com was run on Coldfusion. You just can't
> (or SHOULDN'T) use anything other than PostgreSQL, can you?
>
> I think the search engine should be a demo of PostgreSQL's database
> speed and abilities.
I agree with you. That's what we've done for fts.postgresql.org in the past.
We just launched www.pgsql.ru which has indices for 27 postgresql related
resources and search is very fast. But, it doesn't use postgresql - it's
generic full text search engine with crawler. We plan to setup separate
search on archives of mailing lists based on tsearch2.postgresql.
>
> Dante
> ----------
> D. Dante Lorenso
>
>
>
> ---------------------------(end of broadcast)---------------------------
> TIP 8: explain analyze is your friend
>
Regards,
Oleg
_____________________________________________________________
Oleg Bartunov, sci.researcher, hostmaster of AstroNet,
Sternberg Astronomical Institute, Moscow University (Russia)
Internet: oleg@sai.msu.su, http://www.sai.msu.su/~megera/
phone: +007(095)939-16-83, +007(095)939-23-83