Thread: Improve WALRead() to suck data directly from WAL buffers when possible
Hi, WALRead() currently reads WAL from the WAL file on the disk, which means, the walsenders serving streaming and logical replication (callers of WALRead()) will have to hit the disk/OS's page cache for reading the WAL. This may increase the amount of read IO required for all the walsenders put together as one typically maintains many standbys/subscribers on production servers for high availability, disaster recovery, read-replicas and so on. Also, it may increase replication lag if all the WAL reads are always hitting the disk. It may happen that WAL buffers contain the requested WAL, if so, the WALRead() can attempt to read from the WAL buffers first before reading from the file. If the read hits the WAL buffers, then reading from the file on disk is avoided. This mainly reduces the read IO/read system calls. It also enables us to do other features specified elsewhere [1]. I'm attaching a patch that implements the idea which is also noted elsewhere [2]. I've run some tests [3]. The WAL buffers hit ratio with the patch stood at 95%, in other words, the walsenders avoided 95% of the time reading from the file. The benefit, if measured in terms of the amount of data - 79% (13.5GB out of total 17GB) of the requested WAL is read from the WAL buffers as opposed to 21% from the file. Note that the WAL buffers hit ratio can be very low for write-heavy workloads, in which case, file reads are inevitable. The patch introduces concurrent readers for the WAL buffers, so far only there are concurrent writers. In the patch, WALRead() takes just one lock (WALBufMappingLock) in shared mode to enable concurrent readers and does minimal things - checks if the requested WAL page is present in WAL buffers, if so, copies the page and releases the lock. I think taking just WALBufMappingLock is enough here as the concurrent writers depend on it to initialize and replace a page in WAL buffers. I'll add this to the next commitfest. Thoughts? [1] https://www.postgresql.org/message-id/CALj2ACXCSM%2BsTR%3D5NNRtmSQr3g1Vnr-yR91azzkZCaCJ7u4d4w%40mail.gmail.com [2] * XXX probably this should be improved to suck data directly from the * WAL buffers when possible. */ bool WALRead(XLogReaderState *state, [3] 1 primary, 1 sync standby, 1 async standby ./pgbench --initialize --scale=300 postgres ./pgbench --jobs=16 --progress=300 --client=32 --time=900 --username=ubuntu postgres PATCHED: -[ RECORD 1 ]----------+---------------- application_name | assb1 wal_read | 31005 wal_read_bytes | 3800607104 wal_read_time | 779.402 wal_read_buffers | 610611 wal_read_bytes_buffers | 14493226440 wal_read_time_buffers | 3033.309 sync_state | async -[ RECORD 2 ]----------+---------------- application_name | ssb1 wal_read | 31027 wal_read_bytes | 3800932712 wal_read_time | 696.365 wal_read_buffers | 610580 wal_read_bytes_buffers | 14492900832 wal_read_time_buffers | 2989.507 sync_state | sync HEAD: -[ RECORD 1 ]----+---------------- application_name | assb1 wal_read | 705627 wal_read_bytes | 18343480640 wal_read_time | 7607.783 sync_state | async -[ RECORD 2 ]----+------------ application_name | ssb1 wal_read | 705625 wal_read_bytes | 18343480640 wal_read_time | 4539.058 sync_state | sync -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Kyotaro Horiguchi
Date:
At Fri, 9 Dec 2022 14:33:39 +0530, Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote in > The patch introduces concurrent readers for the WAL buffers, so far > only there are concurrent writers. In the patch, WALRead() takes just > one lock (WALBufMappingLock) in shared mode to enable concurrent > readers and does minimal things - checks if the requested WAL page is > present in WAL buffers, if so, copies the page and releases the lock. > I think taking just WALBufMappingLock is enough here as the concurrent > writers depend on it to initialize and replace a page in WAL buffers. > > I'll add this to the next commitfest. > > Thoughts? This adds copying of the whole page (at least) at every WAL *record* read, fighting all WAL writers by taking WALBufMappingLock on a very busy page while the copying. I'm a bit doubtful that it results in an overall improvement. It seems to me almost all pread()s here happens on file buffer so it is unclear to me that copying a whole WAL page (then copying the target record again) wins over a pread() call that copies only the record to read. Do you have an actual number of how frequent WAL reads go to disk, or the actual number of performance gain or real I/O reduction this patch offers? This patch copies the bleeding edge WAL page without recording the (next) insertion point nor checking whether all in-progress insertion behind the target LSN have finished. Thus the copied page may have holes. That being said, the sequential-reading nature and the fact that WAL buffers are zero-initialized may make it work for recovery, but I don't think this also works for replication. I remember that the one of the advantage of reading the on-memory WAL records is that that allows walsender to presend the unwritten records. So perhaps we should manage how far the buffer is filled with valid content (or how far we can presend) in this feature. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Kyotaro Horiguchi
Date:
At Mon, 12 Dec 2022 11:57:17 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in > This patch copies the bleeding edge WAL page without recording the > (next) insertion point nor checking whether all in-progress insertion > behind the target LSN have finished. Thus the copied page may have > holes. That being said, the sequential-reading nature and the fact > that WAL buffers are zero-initialized may make it work for recovery, > but I don't think this also works for replication. Mmm. I'm a bit dim. Recovery doesn't read concurrently-written records. Please forget about recovery. > I remember that the one of the advantage of reading the on-memory WAL > records is that that allows walsender to presend the unwritten > records. So perhaps we should manage how far the buffer is filled with > valid content (or how far we can presend) in this feature. -- Kyotaro Horiguchi NTT Open Source Software Center
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Kyotaro Horiguchi
Date:
Sorry for the confusion. At Mon, 12 Dec 2022 12:06:36 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in > At Mon, 12 Dec 2022 11:57:17 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in > > This patch copies the bleeding edge WAL page without recording the > > (next) insertion point nor checking whether all in-progress insertion > > behind the target LSN have finished. Thus the copied page may have > > holes. That being said, the sequential-reading nature and the fact > > that WAL buffers are zero-initialized may make it work for recovery, > > but I don't think this also works for replication. > > Mmm. I'm a bit dim. Recovery doesn't read concurrently-written > records. Please forget about recovery. NO... Logical walsenders do that. So, please forget about this... > > I remember that the one of the advantage of reading the on-memory WAL > > records is that that allows walsender to presend the unwritten > > records. So perhaps we should manage how far the buffer is filled with > > valid content (or how far we can presend) in this feature. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Mon, Dec 12, 2022 at 8:27 AM Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote: > Thanks for providing thoughts. > At Fri, 9 Dec 2022 14:33:39 +0530, Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote in > > The patch introduces concurrent readers for the WAL buffers, so far > > only there are concurrent writers. In the patch, WALRead() takes just > > one lock (WALBufMappingLock) in shared mode to enable concurrent > > readers and does minimal things - checks if the requested WAL page is > > present in WAL buffers, if so, copies the page and releases the lock. > > I think taking just WALBufMappingLock is enough here as the concurrent > > writers depend on it to initialize and replace a page in WAL buffers. > > > > I'll add this to the next commitfest. > > > > Thoughts? > > This adds copying of the whole page (at least) at every WAL *record* > read, In the worst case yes, but that may not always be true. On a typical production server with decent write traffic, it happens that the callers of WALRead() read a full WAL page of size XLOG_BLCKSZ bytes or MAX_SEND_SIZE bytes. > fighting all WAL writers by taking WALBufMappingLock on a very > busy page while the copying. I'm a bit doubtful that it results in an > overall improvement. Well, the tests don't reflect that [1], I've run an insert work load [2]. The WAL is being read from WAL buffers 99% of the time, which is pretty cool. If you have any use-cases in mind, please share them and/or feel free to run at your end. > It seems to me almost all pread()s here happens > on file buffer so it is unclear to me that copying a whole WAL page > (then copying the target record again) wins over a pread() call that > copies only the record to read. That's not always guaranteed. Imagine a typical production server with decent write traffic and heavy analytical queries (which fills OS page cache with the table pages accessed for the queries), the WAL pread() calls turn to IOPS. Despite the WAL being present in WAL buffers, customers will be paying unnecessarily for these IOPS too. With the patch, we are basically avoiding the pread() system calls which may turn into IOPS on production servers (99% of the time for the insert use case [1][2], 95% of the time for pgbench use case specified upthread). With the patch, WAL buffers can act as L1 cache, if one calls OS page cache as L2 cache (of course this illustration is not related to the typical processor L1 and L2 ... caches). > Do you have an actual number of how > frequent WAL reads go to disk, or the actual number of performance > gain or real I/O reduction this patch offers? It might be a bit tough to generate such heavy traffic. An idea is to ensure the WAL page/file goes out of the OS page cache before WALRead() - these might help here - 0002 patch from https://www.postgresql.org/message-id/CA%2BhUKGLmeyrDcUYAty90V_YTcoo5kAFfQjRQ-_1joS_%3DX7HztA%40mail.gmail.com and tool https://github.com/klando/pgfincore. > This patch copies the bleeding edge WAL page without recording the > (next) insertion point nor checking whether all in-progress insertion > behind the target LSN have finished. Thus the copied page may have > holes. That being said, the sequential-reading nature and the fact > that WAL buffers are zero-initialized may make it work for recovery, > but I don't think this also works for replication. WALRead() callers are smart enough to take the flushed bytes only. Although they read the whole WAL page, they calculate the valid bytes. > I remember that the one of the advantage of reading the on-memory WAL > records is that that allows walsender to presend the unwritten > records. So perhaps we should manage how far the buffer is filled with > valid content (or how far we can presend) in this feature. Yes, the non-flushed WAL can be read and sent across if one wishes to to make replication faster and parallel flushing on primary and standbys at the cost of a bit of extra crash handling, that's mentioned here https://www.postgresql.org/message-id/CALj2ACXCSM%2BsTR%3D5NNRtmSQr3g1Vnr-yR91azzkZCaCJ7u4d4w%40mail.gmail.com. However, this can be a separate discussion. I also want to reiterate that the patch implemented a TODO item: * XXX probably this should be improved to suck data directly from the * WAL buffers when possible. */ bool WALRead(XLogReaderState *state, [1] PATCHED: 1 1470.329907 2 1437.096329 4 2966.096948 8 5978.441040 16 11405.538255 32 22933.546058 64 43341.870038 128 73623.837068 256 104754.248661 512 115746.359530 768 106106.691455 1024 91900.079086 2048 84134.278589 4096 62580.875507 -[ RECORD 1 ]----------+----------- application_name | assb1 sent_lsn | 0/1B8106A8 write_lsn | 0/1B8106A8 flush_lsn | 0/1B8106A8 replay_lsn | 0/1B8106A8 write_lag | flush_lag | replay_lag | wal_read | 104 wal_read_bytes | 10733008 wal_read_time | 1.845 wal_read_buffers | 76662 wal_read_bytes_buffers | 383598808 wal_read_time_buffers | 205.418 sync_state | async HEAD: 1 1312.054496 2 1449.429321 4 2717.496207 8 5913.361540 16 10762.978907 32 19653.449728 64 41086.124269 128 68548.061171 256 104468.415361 512 114328.943598 768 91751.279309 1024 96403.736757 2048 82155.140270 4096 66160.659511 -[ RECORD 1 ]----+----------- application_name | assb1 sent_lsn | 0/1AB5BCB8 write_lsn | 0/1AB5BCB8 flush_lsn | 0/1AB5BCB8 replay_lsn | 0/1AB5BCB8 write_lag | flush_lag | replay_lag | wal_read | 71967 wal_read_bytes | 381009080 wal_read_time | 243.616 sync_state | async [2] Test details: ./configure --prefix=$PWD/inst/ CFLAGS="-O3" > install.log && make -j 8 install > install.log 2>&1 & 1 primary, 1 async standby cd inst/bin ./pg_ctl -D data -l logfile stop ./pg_ctl -D assbdata -l logfile1 stop rm -rf data assbdata rm logfile logfile1 free -m sudo su -c 'sync; echo 3 > /proc/sys/vm/drop_caches' free -m ./initdb -D data rm -rf /home/ubuntu/archived_wal mkdir /home/ubuntu/archived_wal cat << EOF >> data/postgresql.conf shared_buffers = '8GB' wal_buffers = '1GB' max_wal_size = '16GB' max_connections = '5000' archive_mode = 'on' archive_command='cp %p /home/ubuntu/archived_wal/%f' track_wal_io_timing = 'on' EOF ./pg_ctl -D data -l logfile start ./psql -c "select pg_create_physical_replication_slot('assb1_repl_slot', true, false)" postgres ./pg_ctl -D data -l logfile restart ./pg_basebackup -D assbdata ./pg_ctl -D data -l logfile stop cat << EOF >> assbdata/postgresql.conf port=5433 primary_conninfo='host=localhost port=5432 dbname=postgres user=ubuntu application_name=assb1' primary_slot_name='assb1_repl_slot' restore_command='cp /home/ubuntu/archived_wal/%f %p' EOF touch assbdata/standby.signal ./pg_ctl -D data -l logfile start ./pg_ctl -D assbdata -l logfile1 start ./pgbench -i -s 1 -d postgres ./psql -d postgres -c "ALTER TABLE pgbench_accounts DROP CONSTRAINT pgbench_accounts_pkey;" cat << EOF >> insert.sql \set aid random(1, 10 * :scale) \set delta random(1, 100000 * :scale) INSERT INTO pgbench_accounts (aid, bid, abalance) VALUES (:aid, :aid, :delta); EOF ulimit -S -n 5000 for c in 1 2 4 8 16 32 64 128 256 512 768 1024 2048 4096; do echo -n "$c ";./pgbench -n -M prepared -U ubuntu postgres -f insert.sql -c$c -j$c -T5 2>&1|grep '^tps'|awk '{print $3}';done -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
On Fri, Dec 23, 2022 at 3:46 PM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > On Mon, Dec 12, 2022 at 8:27 AM Kyotaro Horiguchi > <horikyota.ntt@gmail.com> wrote: > > > > Thanks for providing thoughts. > > > At Fri, 9 Dec 2022 14:33:39 +0530, Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote in > > > The patch introduces concurrent readers for the WAL buffers, so far > > > only there are concurrent writers. In the patch, WALRead() takes just > > > one lock (WALBufMappingLock) in shared mode to enable concurrent > > > readers and does minimal things - checks if the requested WAL page is > > > present in WAL buffers, if so, copies the page and releases the lock. > > > I think taking just WALBufMappingLock is enough here as the concurrent > > > writers depend on it to initialize and replace a page in WAL buffers. > > > > > > I'll add this to the next commitfest. > > > > > > Thoughts? > > > > This adds copying of the whole page (at least) at every WAL *record* > > read, > > In the worst case yes, but that may not always be true. On a typical > production server with decent write traffic, it happens that the > callers of WALRead() read a full WAL page of size XLOG_BLCKSZ bytes or > MAX_SEND_SIZE bytes. I agree with this. > > This patch copies the bleeding edge WAL page without recording the > > (next) insertion point nor checking whether all in-progress insertion > > behind the target LSN have finished. Thus the copied page may have > > holes. That being said, the sequential-reading nature and the fact > > that WAL buffers are zero-initialized may make it work for recovery, > > but I don't think this also works for replication. > > WALRead() callers are smart enough to take the flushed bytes only. > Although they read the whole WAL page, they calculate the valid bytes. Right On first read the patch looks good, although it needs some more thoughts on 'XXX' comments in the patch. And also I do not like that XLogReadFromBuffers() is using 3 bools hit/partial hit/miss, instead of this we can use an enum or some tristate variable, I think that will be cleaner. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Sun, Dec 25, 2022 at 4:55 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > This adds copying of the whole page (at least) at every WAL *record* > > > read, > > > > In the worst case yes, but that may not always be true. On a typical > > production server with decent write traffic, it happens that the > > callers of WALRead() read a full WAL page of size XLOG_BLCKSZ bytes or > > MAX_SEND_SIZE bytes. > > I agree with this. > > > > This patch copies the bleeding edge WAL page without recording the > > > (next) insertion point nor checking whether all in-progress insertion > > > behind the target LSN have finished. Thus the copied page may have > > > holes. That being said, the sequential-reading nature and the fact > > > that WAL buffers are zero-initialized may make it work for recovery, > > > but I don't think this also works for replication. > > > > WALRead() callers are smart enough to take the flushed bytes only. > > Although they read the whole WAL page, they calculate the valid bytes. > > Right > > On first read the patch looks good, although it needs some more > thoughts on 'XXX' comments in the patch. Thanks a lot for reviewing. Here are some open points that I mentioned in v1 patch: 1. + * XXX: Perhaps, measuring the immediate lock availability and its impact + * on concurrent WAL writers is a good idea here. It was shown in my testng upthread [1] that the patch does no harm in this regard. It will be great if other members try testing in their respective environments and use cases. 2. + * XXX: Perhaps, returning if lock is not immediately available a good idea + * here. The caller can then go ahead with reading WAL from WAL file. After thinking a bit more on this, ISTM that doing the above is right to not cause any contention when the lock is busy. I've done so in the v2 patch. 3. + * XXX: Perhaps, quickly finding if the given WAL record is in WAL buffers + * a good idea here. This avoids unnecessary lock acquire-release cycles. + * One way to do that is by maintaining oldest WAL record that's currently + * present in WAL buffers. I think by doing the above we might end up creating a new point of contention. Because shared variables to track min and max available LSNs in the WAL buffers will need to be protected against all the concurrent writers. Also, with the change that's done in (2) above, that is, quickly exiting if the lock was busy, this comment seems unnecessary to worry about. Hence, I decided to leave it there. 4. + * XXX: Perhaps, we can further go and validate the found page header, + * record header and record at least in assert builds, something like + * the xlogreader.c does and return if any of those validity checks + * fail. Having said that, we stick to the minimal checks for now. I was being over-cautious initially. The fact that we acquire WALBufMappingLock while reading the needed WAL buffer page itself guarantees that no one else initializes it/makes it ready for next use in AdvanceXLInsertBuffer(). The checks that we have for page header (xlp_magic, xlp_pageaddr and xlp_tli) in the patch are enough for us to ensure that we're not reading a page that got just initialized. The callers will anyway perform extensive checks on page and record in XLogReaderValidatePageHeader() and ValidXLogRecordHeader() respectively. If any such failures occur after reading WAL from WAL buffers, then that must be treated as a bug IMO. Hence, I don't think we need to do the above. > And also I do not like that XLogReadFromBuffers() is using 3 bools > hit/partial hit/miss, instead of this we can use an enum or some > tristate variable, I think that will be cleaner. Yeah, that seems more verbose, all that information can be deduced from requested bytes and read bytes, I've done so in the v2 patch. Please review the attached v2 patch further. I'm also attaching two helper patches (as .txt files) herewith for testing that basically adds WAL read stats - USE-ON-HEAD-Collect-WAL-read-from-file-stats.txt - apply on HEAD and monitor pg_stat_replication for per-walsender WAL read from WAL file stats. USE-ON-PATCH-Collect-WAL-read-from-buffers-and-file-stats.txt - apply on v2 patch and monitor pg_stat_replication for per-walsender WAL read from WAL buffers and WAL file stats. [1] https://www.postgresql.org/message-id/CALj2ACXUbvON86vgwTkum8ab3bf1%3DHkMxQ5hZJZS3ZcJn8NEXQ%40mail.gmail.com -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
On Mon, 2022-12-26 at 14:20 +0530, Bharath Rupireddy wrote: > Please review the attached v2 patch further. I'm still unclear on the performance goals of this patch. I see that it will reduce syscalls, which sounds good, but to what end? Does it allow a greater number of walsenders? Lower replication latency? Less IO bandwidth? All of the above? -- Jeff Davis PostgreSQL Contributor Team - AWS
Hi, On 2023-01-14 00:48:52 -0800, Jeff Davis wrote: > On Mon, 2022-12-26 at 14:20 +0530, Bharath Rupireddy wrote: > > Please review the attached v2 patch further. > > I'm still unclear on the performance goals of this patch. I see that it > will reduce syscalls, which sounds good, but to what end? > > Does it allow a greater number of walsenders? Lower replication > latency? Less IO bandwidth? All of the above? One benefit would be that it'd make it more realistic to use direct IO for WAL - for which I have seen significant performance benefits. But when we afterwards have to re-read it from disk to replicate, it's less clearly a win. Greetings, Andres Freund
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
SATYANARAYANA NARLAPURAM
Date:
On Sat, Jan 14, 2023 at 12:34 PM Andres Freund <andres@anarazel.de> wrote:
Hi,
On 2023-01-14 00:48:52 -0800, Jeff Davis wrote:
> On Mon, 2022-12-26 at 14:20 +0530, Bharath Rupireddy wrote:
> > Please review the attached v2 patch further.
>
> I'm still unclear on the performance goals of this patch. I see that it
> will reduce syscalls, which sounds good, but to what end?
>
> Does it allow a greater number of walsenders? Lower replication
> latency? Less IO bandwidth? All of the above?
One benefit would be that it'd make it more realistic to use direct IO for WAL
- for which I have seen significant performance benefits. But when we
afterwards have to re-read it from disk to replicate, it's less clearly a win.
+1. Archive modules rely on reading the wal files for PITR. Direct IO for WAL requires reading these files from disk anyways for archival. However, Archiving using utilities like pg_receivewal can take advantage of this patch together with direct IO for WAL.
Thanks,
Satya
Hi, On 2023-01-14 12:34:03 -0800, Andres Freund wrote: > On 2023-01-14 00:48:52 -0800, Jeff Davis wrote: > > On Mon, 2022-12-26 at 14:20 +0530, Bharath Rupireddy wrote: > > > Please review the attached v2 patch further. > > > > I'm still unclear on the performance goals of this patch. I see that it > > will reduce syscalls, which sounds good, but to what end? > > > > Does it allow a greater number of walsenders? Lower replication > > latency? Less IO bandwidth? All of the above? > > One benefit would be that it'd make it more realistic to use direct IO for WAL > - for which I have seen significant performance benefits. But when we > afterwards have to re-read it from disk to replicate, it's less clearly a win. Satya's email just now reminded me of another important reason: Eventually we should add the ability to stream out WAL *before* it has locally been written out and flushed. Obviously the relevant positions would have to be noted in the relevant message in the streaming protocol, and we couldn't generally allow standbys to apply that data yet. That'd allow us to significantly reduce the overhead of synchronous replication, because instead of commonly needing to send out all the pending WAL at commit, we'd just need to send out the updated flush position. The reason this would lower the overhead is that: a) The reduced amount of data to be transferred reduces latency - it's easy to accumulate a few TCP packets worth of data even in a single small OLTP transaction b) The remote side can start to write out data earlier Of course this would require additional infrastructure on the receiver side. E.g. some persistent state indicating up to where WAL is allowed to be applied, to avoid the standby getting ahead of th eprimary, in case the primary crash-restarts (or has more severe issues). With a bit of work we could perform WAL replay on standby without waiting for the fdatasync of the received WAL - that only needs to happen when a) we need to confirm a flush position to the primary b) when we need to write back pages from the buffer pool (and some other things). Greetings, Andres Freund
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Thu, Jan 26, 2023 at 2:45 AM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > On 2023-01-14 12:34:03 -0800, Andres Freund wrote: > > On 2023-01-14 00:48:52 -0800, Jeff Davis wrote: > > > On Mon, 2022-12-26 at 14:20 +0530, Bharath Rupireddy wrote: > > > > Please review the attached v2 patch further. > > > > > > I'm still unclear on the performance goals of this patch. I see that it > > > will reduce syscalls, which sounds good, but to what end? > > > > > > Does it allow a greater number of walsenders? Lower replication > > > latency? Less IO bandwidth? All of the above? > > > > One benefit would be that it'd make it more realistic to use direct IO for WAL > > - for which I have seen significant performance benefits. But when we > > afterwards have to re-read it from disk to replicate, it's less clearly a win. > > Satya's email just now reminded me of another important reason: > > Eventually we should add the ability to stream out WAL *before* it has locally > been written out and flushed. Obviously the relevant positions would have to > be noted in the relevant message in the streaming protocol, and we couldn't > generally allow standbys to apply that data yet. > > That'd allow us to significantly reduce the overhead of synchronous > replication, because instead of commonly needing to send out all the pending > WAL at commit, we'd just need to send out the updated flush position. The > reason this would lower the overhead is that: > > a) The reduced amount of data to be transferred reduces latency - it's easy to > accumulate a few TCP packets worth of data even in a single small OLTP > transaction > b) The remote side can start to write out data earlier > > > Of course this would require additional infrastructure on the receiver > side. E.g. some persistent state indicating up to where WAL is allowed to be > applied, to avoid the standby getting ahead of th eprimary, in case the > primary crash-restarts (or has more severe issues). > > > With a bit of work we could perform WAL replay on standby without waiting for > the fdatasync of the received WAL - that only needs to happen when a) we need > to confirm a flush position to the primary b) when we need to write back pages > from the buffer pool (and some other things). Thanks Andres, Jeff and Satya for taking a look at the thread. Andres is right, the eventual plan is to do a bunch of other stuff as described above and we've discussed this in another thread (see below). I would like to once again clarify motivation behind this feature: 1. It enables WAL readers (callers of WALRead() - wal senders, pg_walinspect etc.) to use WAL buffers as first level cache which might reduce number of IOPS at a peak load especially when the pread() results in a disk read (WAL isn't available in OS page cache). I had earlier presented the buffer hit ratio/amount of pread() system calls reduced with wal senders in the first email of this thread (95% of the time wal senders are able to read from WAL buffers without impacting anybody). Now, here are the results with the WAL DIO patch [1] - where WAL pread() turns into a disk read, see the results [2] and attached graph. 2. As Andres rightly mentioned, it helps WAL DIO; since there's no OS page cache, using WAL buffers as read cache helps a lot. It is clearly evident from my experiment with WAL DIO patch [1], see the results [2] and attached graph. As expected, WAL DIO brings down the TPS, whereas WAL buffers read i.e. this patch brings it up. 3. As Andres rightly mentioned above, it enables flushing WAL in parallel on primary and all standbys [3]. I haven't yet started work on this, I will aim for PG 17. 4. It will make the work on - disallow async standbys or subscribers getting ahead of the sync standbys [3] possible. I haven't yet started work on this, I will aim for PG 17. 5. It implements the following TODO item specified near WALRead(): * XXX probably this should be improved to suck data directly from the * WAL buffers when possible. */ bool WALRead(XLogReaderState *state, That said, this feature is separately reviewable and perhaps can go separately as it has its own benefits. [1] https://www.postgresql.org/message-id/CA%2BhUKGLmeyrDcUYAty90V_YTcoo5kAFfQjRQ-_1joS_%3DX7HztA%40mail.gmail.com [2] Test case is an insert pgbench workload. clients HEAD WAL DIO WAL DIO & WAL BUFFERS READ WAL BUFFERS READ 1 1404 1070 1424 1375 2 1487 796 1454 1517 4 3064 1743 3011 3019 8 6114 3556 6026 5954 16 11560 7051 12216 12132 32 23181 13079 23449 23561 64 43607 26983 43997 45636 128 80723 45169 81515 81911 256 110925 90185 107332 114046 512 119354 109817 110287 117506 768 112435 105795 106853 111605 1024 107554 105541 105942 109370 2048 88552 79024 80699 90555 4096 61323 54814 58704 61743 [3] https://www.postgresql.org/message-id/20220309020123.sneaoijlg3rszvst@alap3.anarazel.de https://www.postgresql.org/message-id/CALj2ACXCSM%2BsTR%3D5NNRtmSQr3g1Vnr-yR91azzkZCaCJ7u4d4w%40mail.gmail.com -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
{kind=link}
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Masahiko Sawada
Date:
On Thu, Jan 26, 2023 at 2:33 PM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > On Thu, Jan 26, 2023 at 2:45 AM Andres Freund <andres@anarazel.de> wrote: > > > > Hi, > > > > On 2023-01-14 12:34:03 -0800, Andres Freund wrote: > > > On 2023-01-14 00:48:52 -0800, Jeff Davis wrote: > > > > On Mon, 2022-12-26 at 14:20 +0530, Bharath Rupireddy wrote: > > > > > Please review the attached v2 patch further. > > > > > > > > I'm still unclear on the performance goals of this patch. I see that it > > > > will reduce syscalls, which sounds good, but to what end? > > > > > > > > Does it allow a greater number of walsenders? Lower replication > > > > latency? Less IO bandwidth? All of the above? > > > > > > One benefit would be that it'd make it more realistic to use direct IO for WAL > > > - for which I have seen significant performance benefits. But when we > > > afterwards have to re-read it from disk to replicate, it's less clearly a win. > > > > Satya's email just now reminded me of another important reason: > > > > Eventually we should add the ability to stream out WAL *before* it has locally > > been written out and flushed. Obviously the relevant positions would have to > > be noted in the relevant message in the streaming protocol, and we couldn't > > generally allow standbys to apply that data yet. > > > > That'd allow us to significantly reduce the overhead of synchronous > > replication, because instead of commonly needing to send out all the pending > > WAL at commit, we'd just need to send out the updated flush position. The > > reason this would lower the overhead is that: > > > > a) The reduced amount of data to be transferred reduces latency - it's easy to > > accumulate a few TCP packets worth of data even in a single small OLTP > > transaction > > b) The remote side can start to write out data earlier > > > > > > Of course this would require additional infrastructure on the receiver > > side. E.g. some persistent state indicating up to where WAL is allowed to be > > applied, to avoid the standby getting ahead of th eprimary, in case the > > primary crash-restarts (or has more severe issues). > > > > > > With a bit of work we could perform WAL replay on standby without waiting for > > the fdatasync of the received WAL - that only needs to happen when a) we need > > to confirm a flush position to the primary b) when we need to write back pages > > from the buffer pool (and some other things). > > Thanks Andres, Jeff and Satya for taking a look at the thread. Andres > is right, the eventual plan is to do a bunch of other stuff as > described above and we've discussed this in another thread (see > below). I would like to once again clarify motivation behind this > feature: > > 1. It enables WAL readers (callers of WALRead() - wal senders, > pg_walinspect etc.) to use WAL buffers as first level cache which > might reduce number of IOPS at a peak load especially when the pread() > results in a disk read (WAL isn't available in OS page cache). I had > earlier presented the buffer hit ratio/amount of pread() system calls > reduced with wal senders in the first email of this thread (95% of the > time wal senders are able to read from WAL buffers without impacting > anybody). Now, here are the results with the WAL DIO patch [1] - where > WAL pread() turns into a disk read, see the results [2] and attached > graph. > > 2. As Andres rightly mentioned, it helps WAL DIO; since there's no OS > page cache, using WAL buffers as read cache helps a lot. It is clearly > evident from my experiment with WAL DIO patch [1], see the results [2] > and attached graph. As expected, WAL DIO brings down the TPS, whereas > WAL buffers read i.e. this patch brings it up. > > [2] Test case is an insert pgbench workload. > clients HEAD WAL DIO WAL DIO & WAL BUFFERS READ WAL BUFFERS READ > 1 1404 1070 1424 1375 > 2 1487 796 1454 1517 > 4 3064 1743 3011 3019 > 8 6114 3556 6026 5954 > 16 11560 7051 12216 12132 > 32 23181 13079 23449 23561 > 64 43607 26983 43997 45636 > 128 80723 45169 81515 81911 > 256 110925 90185 107332 114046 > 512 119354 109817 110287 117506 > 768 112435 105795 106853 111605 > 1024 107554 105541 105942 109370 > 2048 88552 79024 80699 90555 > 4096 61323 54814 58704 61743 If I'm understanding this result correctly, it seems to me that your patch works well with the WAL DIO patch (WALDIO vs. WAL DIO & WAL BUFFERS READ), but there seems no visible performance gain with only your patch (HEAD vs. WAL BUFFERS READ). So it seems to me that your patch should be included in the WAL DIO patch rather than applying it alone. Am I missing something? Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Hi,
On 2023-01-27 14:24:51 +0900, Masahiko Sawada wrote:
> If I'm understanding this result correctly, it seems to me that your
> patch works well with the WAL DIO patch (WALDIO vs. WAL DIO & WAL
> BUFFERS READ), but there seems no visible performance gain with only
> your patch (HEAD vs. WAL BUFFERS READ). So it seems to me that your
> patch should be included in the WAL DIO patch rather than applying it
> alone. Am I missing something?
We already support using DIO for WAL - it's just restricted in a way that
makes it practically not usable. And the reason for that is precisely that
walsenders need to read the WAL. See get_sync_bit():
/*
* Optimize writes by bypassing kernel cache with O_DIRECT when using
* O_SYNC and O_DSYNC. But only if archiving and streaming are disabled,
* otherwise the archive command or walsender process will read the WAL
* soon after writing it, which is guaranteed to cause a physical read if
* we bypassed the kernel cache. We also skip the
* posix_fadvise(POSIX_FADV_DONTNEED) call in XLogFileClose() for the same
* reason.
*
* Never use O_DIRECT in walreceiver process for similar reasons; the WAL
* written by walreceiver is normally read by the startup process soon
* after it's written. Also, walreceiver performs unaligned writes, which
* don't work with O_DIRECT, so it is required for correctness too.
*/
if (!XLogIsNeeded() && !AmWalReceiverProcess())
o_direct_flag = PG_O_DIRECT;
Even if that weren't the case, splitting up bigger commits in incrementally
committable chunks is a good idea.
Greetings,
Andres Freund
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Masahiko Sawada
Date:
On Fri, Jan 27, 2023 at 3:17 PM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > On 2023-01-27 14:24:51 +0900, Masahiko Sawada wrote: > > If I'm understanding this result correctly, it seems to me that your > > patch works well with the WAL DIO patch (WALDIO vs. WAL DIO & WAL > > BUFFERS READ), but there seems no visible performance gain with only > > your patch (HEAD vs. WAL BUFFERS READ). So it seems to me that your > > patch should be included in the WAL DIO patch rather than applying it > > alone. Am I missing something? > > We already support using DIO for WAL - it's just restricted in a way that > makes it practically not usable. And the reason for that is precisely that > walsenders need to read the WAL. See get_sync_bit(): > > /* > * Optimize writes by bypassing kernel cache with O_DIRECT when using > * O_SYNC and O_DSYNC. But only if archiving and streaming are disabled, > * otherwise the archive command or walsender process will read the WAL > * soon after writing it, which is guaranteed to cause a physical read if > * we bypassed the kernel cache. We also skip the > * posix_fadvise(POSIX_FADV_DONTNEED) call in XLogFileClose() for the same > * reason. > * > * Never use O_DIRECT in walreceiver process for similar reasons; the WAL > * written by walreceiver is normally read by the startup process soon > * after it's written. Also, walreceiver performs unaligned writes, which > * don't work with O_DIRECT, so it is required for correctness too. > */ > if (!XLogIsNeeded() && !AmWalReceiverProcess()) > o_direct_flag = PG_O_DIRECT; > > > Even if that weren't the case, splitting up bigger commits in incrementally > committable chunks is a good idea. Agreed. I was wondering about the fact that the test result doesn't show things to satisfy the first motivation of this patch, which is to improve performance by reducing disk I/O and system calls regardless of the DIO patch. But it makes sense to me that this patch is a part of the DIO patch series. I'd like to confirm whether there is any performance regression caused by this patch in some cases, especially when not using DIO. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Fri, Jan 27, 2023 at 12:16 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> I'd like to confirm whether there is any performance regression caused
> by this patch in some cases, especially when not using DIO.
Thanks. I ran some insert tests with primary and 1 async standby.
Please see the numbers below and attached graphs. I've not noticed a
regression as such, in fact, with patch, there's a slight improvement.
Note that there's no WAL DIO involved here.
test-case 1:
clients HEAD PATCHED
1 139 156
2 624 599
4 3113 3410
8 6194 6433
16 11255 11722
32 22455 21658
64 46072 47103
128 80255 85970
256 110067 111488
512 114043 118094
768 109588 111892
1024 106144 109361
2048 85808 90745
4096 55911 53755
test-case 2:
clients HEAD PATCHED
1 177 128
2 186 425
4 2114 2946
8 5835 5840
16 10654 11199
32 14071 13959
64 18092 17519
128 27298 28274
256 24600 24843
512 17139 19450
768 16778 20473
1024 18294 20209
2048 12898 13920
4096 6399 6815
test-case 3:
clients HEAD PATCHED
1 148 191
2 302 317
4 3415 3243
8 5864 6193
16 9573 10267
32 14069 15819
64 17424 18453
128 24493 29192
256 33180 38250
512 35568 36551
768 29731 30317
1024 32291 32124
2048 27964 28933
4096 13702 15034
[1]
cat << EOF >> data/postgresql.conf
shared_buffers = '8GB'
wal_buffers = '1GB'
max_wal_size = '16GB'
max_connections = '5000'
archive_mode = 'on'
archive_command='cp %p /home/ubuntu/archived_wal/%f'
EOF
test-case 1:
./pgbench -i -s 300 -d postgres
./psql -d postgres -c "ALTER TABLE pgbench_accounts DROP CONSTRAINT
pgbench_accounts_pkey;"
cat << EOF >> insert.sql
\set aid random(1, 10 * :scale)
\set delta random(1, 100000 * :scale)
INSERT INTO pgbench_accounts (aid, bid, abalance) VALUES (:aid, :aid, :delta);
EOF
for c in 1 2 4 8 16 32 64 128 256 512 768 1024 2048 4096; do echo -n
"$c ";./pgbench -n -M prepared -U ubuntu postgres -f insert.sql -c$c
-j$c -T5 2>&1|grep '^tps'|awk '{print $3}';done
test-case 2:
./pgbench --initialize --scale=300 postgres
for c in 1 2 4 8 16 32 64 128 256 512 768 1024 2048 4096; do echo -n
"$c ";./pgbench -n -M prepared -U ubuntu postgres -b tpcb-like -c$c
-j$c -T5 2>&1|grep '^tps'|awk '{print $3}';done
test-case 3:
./pgbench --initialize --scale=300 postgres
for c in 1 2 4 8 16 32 64 128 256 512 768 1024 2048 4096; do echo -n
"$c ";./pgbench -n -M prepared -U ubuntu postgres -b simple-update
-c$c -j$c -T5 2>&1|grep '^tps'|awk '{print $3}';done
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Attachment
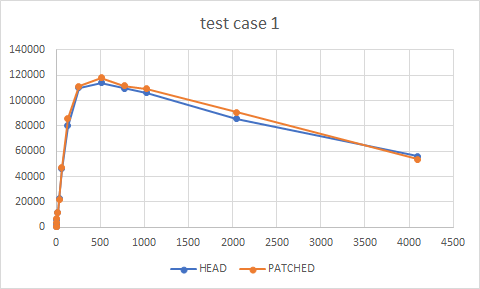{kind=link}
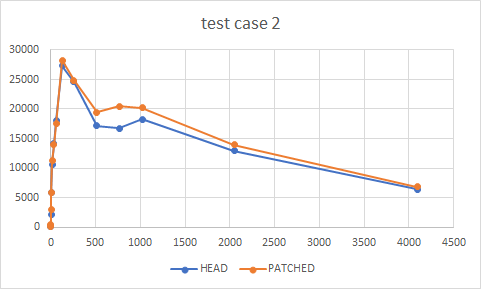{kind=link}
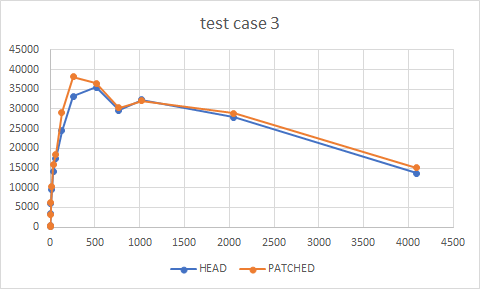{kind=link}
On Mon, Dec 26, 2022 at 2:20 PM Bharath Rupireddy
<bharath.rupireddyforpostgres@gmail.com> wrote:
>
I have gone through this patch, I have some comments (mostly cosmetic
and comments)
1.
+ /*
+ * We have found the WAL buffer page holding the given LSN. Read from a
+ * pointer to the right offset within the page.
+ */
+ memcpy(page, (XLogCtl->pages + idx * (Size) XLOG_BLCKSZ),
+ (Size) XLOG_BLCKSZ);
From the above comments, it appears that we are reading from the exact
pointer we are interested to read, but actually, we are reading
the complete page. I think this comment needs to be fixed and we can
also explain why we read the complete page here.
2.
+static char *
+GetXLogBufferForRead(XLogRecPtr ptr, TimeLineID tli, char *page)
+{
+ XLogRecPtr expectedEndPtr;
+ XLogRecPtr endptr;
+ int idx;
+ char *recptr = NULL;
Generally, we use the name 'recptr' to represent XLogRecPtr type of
variable, but in your case, it is actually data at that recptr, so
better use some other name like 'buf' or 'buffer'.
3.
+ if ((recptr + nbytes) <= (page + XLOG_BLCKSZ))
+ {
+ /* All the bytes are in one page. */
+ memcpy(dst, recptr, nbytes);
+ dst += nbytes;
+ *read_bytes += nbytes;
+ ptr += nbytes;
+ nbytes = 0;
+ }
+ else if ((recptr + nbytes) > (page + XLOG_BLCKSZ))
+ {
+ /* All the bytes are not in one page. */
+ Size bytes_remaining;
Why do you have this 'else if ((recptr + nbytes) > (page +
XLOG_BLCKSZ))' check in the else part? why it is not directly else
without a condition in 'if'?
4.
+XLogReadFromBuffers(XLogRecPtr startptr,
+ TimeLineID tli,
+ Size count,
+ char *buf,
+ Size *read_bytes)
I think we do not need 2 separate variables 'count' and '*read_bytes',
just one variable for input/output is sufficient. The original value
can always be stored in some temp variable
instead of the function argument.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Tue, Feb 7, 2023 at 4:12 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Mon, Dec 26, 2022 at 2:20 PM Bharath Rupireddy
> <bharath.rupireddyforpostgres@gmail.com> wrote:
>
> I have gone through this patch, I have some comments (mostly cosmetic
> and comments)
Thanks a lot for reviewing.
> From the above comments, it appears that we are reading from the exact
> pointer we are interested to read, but actually, we are reading
> the complete page. I think this comment needs to be fixed and we can
> also explain why we read the complete page here.
I modified it. Please see the attached v3 patch.
> Generally, we use the name 'recptr' to represent XLogRecPtr type of
> variable, but in your case, it is actually data at that recptr, so
> better use some other name like 'buf' or 'buffer'.
Changed it to use 'data' as it seemed more appropriate than just a
buffer to not confuse with the WAL buffer page.
> 3.
> + if ((recptr + nbytes) <= (page + XLOG_BLCKSZ))
> + {
> + }
> + else if ((recptr + nbytes) > (page + XLOG_BLCKSZ))
> + {
>
> Why do you have this 'else if ((recptr + nbytes) > (page +
> XLOG_BLCKSZ))' check in the else part? why it is not directly else
> without a condition in 'if'?
Changed.
> I think we do not need 2 separate variables 'count' and '*read_bytes',
> just one variable for input/output is sufficient. The original value
> can always be stored in some temp variable
> instead of the function argument.
We could do that, but for the sake of readability and not cluttering
the API, I kept it as-is.
Besides addressing the above review comments, I've made some more
changes - 1) I optimized the patch a bit by removing an extra memcpy.
Up until v2 patch, the entire WAL buffer page is returned and the
caller takes what is wanted from it. This adds an extra memcpy, so I
changed it to avoid extra memcpy and just copy what is wanted. 2) I
improved the comments.
I can also do a few other things, but before working on them, I'd like
to hear from others:
1. A separate wait event (WAIT_EVENT_WAL_READ_FROM_BUFFERS) for
reading from WAL buffers - right now, WAIT_EVENT_WAL_READ is being
used both for reading from WAL buffers and WAL files. Given the fact
that we won't wait for a lock or do a time-taking task while reading
from buffers, it seems unnecessary.
2. A separate TAP test for verifying that the WAL is actually read
from WAL buffers - right now, existing tests for recovery,
subscription, pg_walinspect already cover the code, see [1]. However,
if needed, I can add a separate TAP test.
3. Use the oldest initialized WAL buffer page to quickly tell if the
given LSN is present in WAL buffers without taking any lock - right
now, WALBufMappingLock is acquired to do so. While this doesn't seem
to impact much, it's good to optimize it away. But, the oldest
initialized WAL buffer page isn't tracked, so I've put up a patch and
sent in another thread [2]. Irrespective of [2], we are still good
with what we have in this patch.
[1]
recovery tests:
PATCHED: WAL buffers hit - 14759, misses - 3371
subscription tests:
PATCHED: WAL buffers hit - 1972, misses - 32616
pg_walinspect tests:
PATCHED: WAL buffers hit - 8, misses - 8
[2] https://www.postgresql.org/message-id/CALj2ACVgi6LirgLDZh%3DFdfdvGvKAD%3D%3DWTOSWcQy%3DAtNgPDVnKw%40mail.gmail.com
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Attachment
On Wed, Feb 8, 2023 at 9:57 AM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > I can also do a few other things, but before working on them, I'd like > to hear from others: > 1. A separate wait event (WAIT_EVENT_WAL_READ_FROM_BUFFERS) for > reading from WAL buffers - right now, WAIT_EVENT_WAL_READ is being > used both for reading from WAL buffers and WAL files. Given the fact > that we won't wait for a lock or do a time-taking task while reading > from buffers, it seems unnecessary. Yes, we do not need this separate wait event and we also don't need WAIT_EVENT_WAL_READ wait event while reading from the buffer. Because we are not performing any IO so no specific wait event is needed and for reading from the WAL buffer we are acquiring WALBufMappingLock so that lwlock event will be tracked under that lock. > 2. A separate TAP test for verifying that the WAL is actually read > from WAL buffers - right now, existing tests for recovery, > subscription, pg_walinspect already cover the code, see [1]. However, > if needed, I can add a separate TAP test. Can we write a test that can actually validate that we have read from a WAL Buffer? If so then it would be good to have such a test to avoid any future breakage in that logic. But if it is just for hitting the code but no guarantee that whether we can validate as part of the test whether it has hit the WAL buffer or not then I think the existing cases are sufficient. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Wed, Feb 8, 2023 at 10:33 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Wed, Feb 8, 2023 at 9:57 AM Bharath Rupireddy > <bharath.rupireddyforpostgres@gmail.com> wrote: > > > > I can also do a few other things, but before working on them, I'd like > > to hear from others: > > 1. A separate wait event (WAIT_EVENT_WAL_READ_FROM_BUFFERS) for > > reading from WAL buffers - right now, WAIT_EVENT_WAL_READ is being > > used both for reading from WAL buffers and WAL files. Given the fact > > that we won't wait for a lock or do a time-taking task while reading > > from buffers, it seems unnecessary. > > Yes, we do not need this separate wait event and we also don't need > WAIT_EVENT_WAL_READ wait event while reading from the buffer. Because > we are not performing any IO so no specific wait event is needed and > for reading from the WAL buffer we are acquiring WALBufMappingLock so > that lwlock event will be tracked under that lock. Nope, LWLockConditionalAcquire doesn't wait, so no lock wait event (no LWLockReportWaitStart) there. I agree to not have any wait event for reading from WAL buffers as no IO is involved there. I removed it in the attached v4 patch. > > 2. A separate TAP test for verifying that the WAL is actually read > > from WAL buffers - right now, existing tests for recovery, > > subscription, pg_walinspect already cover the code, see [1]. However, > > if needed, I can add a separate TAP test. > > Can we write a test that can actually validate that we have read from > a WAL Buffer? If so then it would be good to have such a test to avoid > any future breakage in that logic. But if it is just for hitting the > code but no guarantee that whether we can validate as part of the test > whether it has hit the WAL buffer or not then I think the existing > cases are sufficient. We could set up a standby or a logical replication subscriber or pg_walinspect extension and verify if the code got hit with the help of the server log (DEBUG1) message added by the patch. However, this can make the test volatile. Therefore, I came up with a simple and small test module/extension named test_wal_read_from_buffers under src/test/module. It basically exposes a SQL-function given an LSN, it calls XLogReadFromBuffers() and returns true if it hits WAL buffers, otherwise false. And the simple TAP test of this module verifies if the function returns true. I attached the test module as v4-0002 here. The test module looks specific and also helps as demonstration of how one can possibly use the new XLogReadFromBuffers(). Thoughts? -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Nathan Bossart
Date:
On Wed, Feb 08, 2023 at 08:00:00PM +0530, Bharath Rupireddy wrote: > + /* > + * We read some of the requested bytes. Continue to read remaining > + * bytes. > + */ > + ptr += nread; > + nbytes -= nread; > + dst += nread; > + *read_bytes += nread; Why do we only read a page at a time in XLogReadFromBuffersGuts()? What is preventing us from copying all the data we need in one go? -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Tue, Feb 28, 2023 at 6:14 AM Nathan Bossart <nathandbossart@gmail.com> wrote: > > On Wed, Feb 08, 2023 at 08:00:00PM +0530, Bharath Rupireddy wrote: > > + /* > > + * We read some of the requested bytes. Continue to read remaining > > + * bytes. > > + */ > > + ptr += nread; > > + nbytes -= nread; > > + dst += nread; > > + *read_bytes += nread; > > Why do we only read a page at a time in XLogReadFromBuffersGuts()? What is > preventing us from copying all the data we need in one go? Note that most of the WALRead() callers request a single page of XLOG_BLCKSZ bytes even if the server has less or more available WAL pages. It's the streaming replication wal sender that can request less than XLOG_BLCKSZ bytes and upto MAX_SEND_SIZE (16 * XLOG_BLCKSZ). And, if we read, say, MAX_SEND_SIZE at once while holding WALBufMappingLock, that might impact concurrent inserters (at least, I can say it in theory) - one of the main intentions of this patch is not to impact inserters much. Therefore, I feel reading one WAL buffer page at a time, which works for most of the cases, without impacting concurrent inserters much is better - https://www.postgresql.org/message-id/CALj2ACWXHP6Ha1BfDB14txm%3DXP272wCbOV00mcPg9c6EXbnp5A%40mail.gmail.com. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
On Tue, Feb 28, 2023 at 10:38 AM Bharath Rupireddy
<bharath.rupireddyforpostgres@gmail.com> wrote:
>
+/*
+ * Guts of XLogReadFromBuffers().
+ *
+ * Read 'count' bytes into 'buf', starting at location 'ptr', from WAL
+ * fetched WAL buffers on timeline 'tli' and return the read bytes.
+ */
s/fetched WAL buffers/fetched from WAL buffers
+ else if (nread < nbytes)
+ {
+ /*
+ * We read some of the requested bytes. Continue to read remaining
+ * bytes.
+ */
+ ptr += nread;
+ nbytes -= nread;
+ dst += nread;
+ *read_bytes += nread;
+ }
The 'if' condition should always be true. You can replace the same
with an assertion instead.
s/Continue to read remaining/Continue to read the remaining
The good thing about this patch is that it reduces read IO calls
without impacting the write performance (at least not that
noticeable). It also takes us one step forward towards the
enhancements mentioned in the thread. If performance is a concern, we
can introduce a GUC to enable/disable this feature.
--
Thanks & Regards,
Kuntal Ghosh
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Nathan Bossart
Date:
On Tue, Feb 28, 2023 at 10:38:31AM +0530, Bharath Rupireddy wrote: > On Tue, Feb 28, 2023 at 6:14 AM Nathan Bossart <nathandbossart@gmail.com> wrote: >> Why do we only read a page at a time in XLogReadFromBuffersGuts()? What is >> preventing us from copying all the data we need in one go? > > Note that most of the WALRead() callers request a single page of > XLOG_BLCKSZ bytes even if the server has less or more available WAL > pages. It's the streaming replication wal sender that can request less > than XLOG_BLCKSZ bytes and upto MAX_SEND_SIZE (16 * XLOG_BLCKSZ). And, > if we read, say, MAX_SEND_SIZE at once while holding > WALBufMappingLock, that might impact concurrent inserters (at least, I > can say it in theory) - one of the main intentions of this patch is > not to impact inserters much. Perhaps we should test both approaches to see if there is a noticeable difference. It might not be great for concurrent inserts to repeatedly take the lock, either. If there's no real difference, we might be able to simplify the code a bit. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Wed, Mar 1, 2023 at 12:06 AM Kuntal Ghosh <kuntalghosh.2007@gmail.com> wrote:
>
> On Tue, Feb 28, 2023 at 10:38 AM Bharath Rupireddy
> <bharath.rupireddyforpostgres@gmail.com> wrote:
> >
> +/*
> + * Guts of XLogReadFromBuffers().
> + *
> + * Read 'count' bytes into 'buf', starting at location 'ptr', from WAL
> + * fetched WAL buffers on timeline 'tli' and return the read bytes.
> + */
> s/fetched WAL buffers/fetched from WAL buffers
Modified that comment a bit and moved it to the XLogReadFromBuffers.
> + else if (nread < nbytes)
> + {
> + /*
> + * We read some of the requested bytes. Continue to read remaining
> + * bytes.
> + */
> + ptr += nread;
> + nbytes -= nread;
> + dst += nread;
> + *read_bytes += nread;
> + }
>
> The 'if' condition should always be true. You can replace the same
> with an assertion instead.
Yeah, added an assert and changed that else if (nread < nbytes) to
else only condition.
> s/Continue to read remaining/Continue to read the remaining
Done.
> The good thing about this patch is that it reduces read IO calls
> without impacting the write performance (at least not that
> noticeable). It also takes us one step forward towards the
> enhancements mentioned in the thread.
Right.
> If performance is a concern, we
> can introduce a GUC to enable/disable this feature.
I didn't see any performance issues from my testing so far with 3
different pgbench cases
https://www.postgresql.org/message-id/CALj2ACWXHP6Ha1BfDB14txm%3DXP272wCbOV00mcPg9c6EXbnp5A%40mail.gmail.com.
While adding a GUC to enable/disable a feature sounds useful, IMHO it
isn't good for the user. Because we already have too many GUCs for the
user and we may not want all features to be defensive and add their
own GUCs. If at all, any bugs arise due to some corner-case we missed
to count in, we can surely help fix them. Having said this, I'm open
to suggestions here.
Please find the attached v5 patch set for further review.
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Wed, Mar 1, 2023 at 2:39 PM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > Please find the attached v5 patch set for further review. I simplified the code largely by moving the logic of reading the WAL buffer page from a separate function to the main while loop. This enabled me to get rid of XLogReadFromBuffersGuts() that v5 and other previous patches have. Please find the attached v6 patch set for further review. Meanwhile, I'll continue to work on the review comment raised upthread - https://www.postgresql.org/message-id/20230301041523.GA1453450%40nathanxps13. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Wed, Mar 1, 2023 at 9:45 AM Nathan Bossart <nathandbossart@gmail.com> wrote:
>
> On Tue, Feb 28, 2023 at 10:38:31AM +0530, Bharath Rupireddy wrote:
> > On Tue, Feb 28, 2023 at 6:14 AM Nathan Bossart <nathandbossart@gmail.com> wrote:
> >> Why do we only read a page at a time in XLogReadFromBuffersGuts()? What is
> >> preventing us from copying all the data we need in one go?
> >
> > Note that most of the WALRead() callers request a single page of
> > XLOG_BLCKSZ bytes even if the server has less or more available WAL
> > pages. It's the streaming replication wal sender that can request less
> > than XLOG_BLCKSZ bytes and upto MAX_SEND_SIZE (16 * XLOG_BLCKSZ). And,
> > if we read, say, MAX_SEND_SIZE at once while holding
> > WALBufMappingLock, that might impact concurrent inserters (at least, I
> > can say it in theory) - one of the main intentions of this patch is
> > not to impact inserters much.
>
> Perhaps we should test both approaches to see if there is a noticeable
> difference. It might not be great for concurrent inserts to repeatedly
> take the lock, either. If there's no real difference, we might be able to
> simplify the code a bit.
I took a stab at this - acquire WALBufMappingLock separately for each
requested WAL buffer page vs acquire WALBufMappingLock once for all
requested WAL buffer pages. I chose the pgbench tpcb-like benchmark
that has 3 UPDATE statements and 1 INSERT statement. I ran pgbench for
30min with scale factor 100 and 4096 clients with primary and 1 async
standby, see [1]. I captured wait_events to see the contention on
WALBufMappingLock. I haven't noticed any contention on the lock and no
difference in TPS too, see [2] for results on HEAD, see [3] for
results on v6 patch which has "acquire WALBufMappingLock separately
for each requested WAL buffer page" strategy and see [4] for results
on v7 patch (attached herewith) which has "acquire WALBufMappingLock
once for all requested WAL buffer pages" strategy. Another thing to
note from the test results is that reduction in WALRead IO wait events
from 136 on HEAD to 1 on v6 or v7 patch. So, the read from WAL buffers
is really helping here.
With these observations, I'd like to use the approach that acquires
WALBufMappingLock once for all requested WAL buffer pages unlike v6
and the previous patches.
I'm attaching the v7 patch set with this change for further review.
[1]
shared_buffers = '8GB'
wal_buffers = '1GB'
max_wal_size = '16GB'
max_connections = '5000'
archive_mode = 'on'
archive_command='cp %p /home/ubuntu/archived_wal/%f'
./pgbench --initialize --scale=100 postgres
./pgbench -n -M prepared -U ubuntu postgres -b tpcb-like -c4096 -j4096 -T1800
[2]
HEAD:
done in 20.03 s (drop tables 0.00 s, create tables 0.01 s, client-side
generate 15.53 s, vacuum 0.19 s, primary keys 4.30 s).
tps = 11654.475345 (without initial connection time)
50950253 Lock | transactionid
16472447 Lock | tuple
3869523 LWLock | LockManager
739283 IPC | ProcArrayGroupUpdate
718549 |
439877 LWLock | WALWrite
130737 Client | ClientRead
121113 LWLock | BufferContent
70778 LWLock | WALInsert
43346 IPC | XactGroupUpdate
18547
18546 Activity | LogicalLauncherMain
18545 Activity | AutoVacuumMain
18272 Activity | ArchiverMain
17627 Activity | WalSenderMain
17207 Activity | WalWriterMain
15455 IO | WALSync
14963 LWLock | ProcArray
14747 LWLock | XactSLRU
13943 Timeout | CheckpointWriteDelay
10519 Activity | BgWriterHibernate
8022 Activity | BgWriterMain
4486 Timeout | SpinDelay
4443 Activity | CheckpointerMain
1435 Lock | extend
670 LWLock | XidGen
373 IO | WALWrite
283 Timeout | VacuumDelay
268 IPC | ArchiveCommand
249 Timeout | VacuumTruncate
136 IO | WALRead
115 IO | WALInitSync
74 IO | DataFileWrite
67 IO | WALInitWrite
36 IO | DataFileFlush
35 IO | DataFileExtend
17 IO | DataFileRead
4 IO | SLRUWrite
3 IO | BufFileWrite
2 IO | DataFileImmediateSync
1 Tuples only is on.
1 LWLock | SInvalWrite
1 LWLock | LockFastPath
1 IO | ControlFileSyncUpdate
[3]
done in 19.99 s (drop tables 0.00 s, create tables 0.01 s, client-side
generate 15.52 s, vacuum 0.18 s, primary keys 4.28 s).
tps = 11689.584538 (without initial connection time)
50678977 Lock | transactionid
16252048 Lock | tuple
4146827 LWLock | LockManager
768256 |
719923 IPC | ProcArrayGroupUpdate
432836 LWLock | WALWrite
140354 Client | ClientRead
124203 LWLock | BufferContent
74355 LWLock | WALInsert
39852 IPC | XactGroupUpdate
30728
30727 Activity | LogicalLauncherMain
30726 Activity | AutoVacuumMain
30420 Activity | ArchiverMain
29881 Activity | WalSenderMain
29418 Activity | WalWriterMain
23428 Activity | BgWriterHibernate
15960 Timeout | CheckpointWriteDelay
15840 IO | WALSync
15066 LWLock | ProcArray
14577 Activity | CheckpointerMain
14377 LWLock | XactSLRU
7291 Activity | BgWriterMain
4336 Timeout | SpinDelay
1707 Lock | extend
720 LWLock | XidGen
362 Timeout | VacuumTruncate
360 IO | WALWrite
304 Timeout | VacuumDelay
301 IPC | ArchiveCommand
106 IO | WALInitSync
82 IO | DataFileWrite
66 IO | WALInitWrite
45 IO | DataFileFlush
25 IO | DataFileExtend
18 IO | DataFileRead
5 LWLock | LockFastPath
2 IO | DataFileSync
2 IO | DataFileImmediateSync
1 Tuples only is on.
1 LWLock | BufferMapping
1 IO | WALRead
1 IO | SLRUWrite
1 IO | SLRURead
1 IO | ReplicationSlotSync
1 IO | BufFileRead
[4]
done in 19.92 s (drop tables 0.00 s, create tables 0.01 s, client-side
generate 15.53 s, vacuum 0.23 s, primary keys 4.16 s).
tps = 11671.869074 (without initial connection time)
50614021 Lock | transactionid
16482561 Lock | tuple
4086451 LWLock | LockManager
777507 |
714329 IPC | ProcArrayGroupUpdate
420593 LWLock | WALWrite
138142 Client | ClientRead
125381 LWLock | BufferContent
75283 LWLock | WALInsert
38759 IPC | XactGroupUpdate
20283
20282 Activity | LogicalLauncherMain
20281 Activity | AutoVacuumMain
20002 Activity | ArchiverMain
19467 Activity | WalSenderMain
19036 Activity | WalWriterMain
15836 IO | WALSync
15708 Timeout | CheckpointWriteDelay
15346 LWLock | ProcArray
15095 LWLock | XactSLRU
11852 Activity | BgWriterHibernate
8424 Activity | BgWriterMain
4636 Timeout | SpinDelay
4415 Activity | CheckpointerMain
2048 Lock | extend
1457 Timeout | VacuumTruncate
646 LWLock | XidGen
402 IO | WALWrite
306 Timeout | VacuumDelay
278 IPC | ArchiveCommand
117 IO | WALInitSync
74 IO | DataFileWrite
66 IO | WALInitWrite
35 IO | DataFileFlush
29 IO | DataFileExtend
24 LWLock | LockFastPath
14 IO | DataFileRead
2 IO | SLRUWrite
2 IO | DataFileImmediateSync
2 IO | BufFileWrite
1 Tuples only is on.
1 LWLock | BufferMapping
1 IO | WALRead
1 IO | SLRURead
1 IO | BufFileRead
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Nathan Bossart
Date:
+void
+XLogReadFromBuffers(XLogRecPtr startptr,
+ TimeLineID tli,
+ Size count,
+ char *buf,
+ Size *read_bytes)
Since this function presently doesn't return anything, can we have it
return the number of bytes read instead of storing it in a pointer
variable?
+ ptr = startptr;
+ nbytes = count;
+ dst = buf;
These variables seem superfluous.
+ /*
+ * Requested WAL isn't available in WAL buffers, so return with
+ * what we have read so far.
+ */
+ break;
nitpick: I'd move this to the top so that you can save a level of
indentation.
if (expectedEndPtr != endptr)
break;
... logic for when the data is found in the WAL buffers ...
+ /*
+ * All the bytes are not in one page. Read available bytes on
+ * the current page, copy them over to output buffer and
+ * continue to read remaining bytes.
+ */
Is it possible to memcpy more than a page at a time?
+ /*
+ * The fact that we acquire WALBufMappingLock while reading the WAL
+ * buffer page itself guarantees that no one else initializes it or
+ * makes it ready for next use in AdvanceXLInsertBuffer().
+ *
+ * However, we perform basic page header checks for ensuring that
+ * we are not reading a page that just got initialized. Callers
+ * will anyway perform extensive page-level and record-level
+ * checks.
+ */
Hm. I wonder if we should make these assertions instead.
+ elog(DEBUG1, "read %zu bytes out of %zu bytes from WAL buffers for given LSN %X/%X, Timeline ID %u",
+ *read_bytes, count, LSN_FORMAT_ARGS(startptr), tli);
I definitely don't think we should put an elog() in this code path.
Perhaps this should be guarded behind WAL_DEBUG.
+ /*
+ * Check if we have read fully (hit), partially (partial hit) or
+ * nothing (miss) from WAL buffers. If we have read either partially or
+ * nothing, then continue to read the remaining bytes the usual way,
+ * that is, read from WAL file.
+ */
+ if (count == read_bytes)
+ {
+ /* Buffer hit, so return. */
+ return true;
+ }
+ else if (read_bytes > 0 && count > read_bytes)
+ {
+ /*
+ * Buffer partial hit, so reset the state to count the read bytes
+ * and continue.
+ */
+ buf += read_bytes;
+ startptr += read_bytes;
+ count -= read_bytes;
+ }
+
+ /* Buffer miss i.e., read_bytes = 0, so continue */
I think we can simplify this. We effectively take the same action any time
"count" doesn't equal "read_bytes", so there's no need for the "else if".
if (count == read_bytes)
return true;
buf += read_bytes;
startptr += read_bytes;
count -= read_bytes;
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Tue, Mar 7, 2023 at 3:30 AM Nathan Bossart <nathandbossart@gmail.com> wrote: > > +void > +XLogReadFromBuffers(XLogRecPtr startptr, > > Since this function presently doesn't return anything, can we have it > return the number of bytes read instead of storing it in a pointer > variable? Done. > + ptr = startptr; > + nbytes = count; > + dst = buf; > > These variables seem superfluous. Needed startptr and count for DEBUG1 message and assertion at the end. Removed dst and used buf in the new patch now. > + /* > + * Requested WAL isn't available in WAL buffers, so return with > + * what we have read so far. > + */ > + break; > > nitpick: I'd move this to the top so that you can save a level of > indentation. Done. > + /* > + * All the bytes are not in one page. Read available bytes on > + * the current page, copy them over to output buffer and > + * continue to read remaining bytes. > + */ > > Is it possible to memcpy more than a page at a time? It would complicate things a lot there; the logic to figure out the last page bytes that may or may not fit in the whole page gets complicated. Also, the logic to verify each page's header gets complicated. We might lose out if we memcpy all the pages at once and start verifying each page's header in another loop. I would like to keep it simple - read a single page from WAL buffers, verify it and continue. > + /* > + * The fact that we acquire WALBufMappingLock while reading the WAL > + * buffer page itself guarantees that no one else initializes it or > + * makes it ready for next use in AdvanceXLInsertBuffer(). > + * > + * However, we perform basic page header checks for ensuring that > + * we are not reading a page that just got initialized. Callers > + * will anyway perform extensive page-level and record-level > + * checks. > + */ > > Hm. I wonder if we should make these assertions instead. Okay. I added XLogReaderValidatePageHeader for assert-only builds which will help catch any issues there. But we can't perform record level checks here because this function doesn't know where the record starts from, it knows only pages. This change required us to pass in XLogReaderState to XLogReadFromBuffers. I marked it as PG_USED_FOR_ASSERTS_ONLY and did page header checks only when it is passed as non-null so that someone who doesn't have XLogReaderState can still read from buffers. > + elog(DEBUG1, "read %zu bytes out of %zu bytes from WAL buffers for given LSN %X/%X, Timeline ID %u", > + *read_bytes, count, LSN_FORMAT_ARGS(startptr), tli); > > I definitely don't think we should put an elog() in this code path. > Perhaps this should be guarded behind WAL_DEBUG. Placing it behind WAL_DEBUG doesn't help users/developers. My intention was to let users know that the WAL read hit the buffers, it'll help them report if any issue occurs and also help developers to debug that issue. On a different note - I was recently looking at the code around WAL_DEBUG macro and the wal_debug GUC. It looks so complex that one needs to build source code with the WAL_DEBUG macro and enable the GUC to see the extended logs for WAL. IMO, the best way there is either: 1) unify all the code under WAL_DEBUG macro and get rid of wal_debug GUC, or 2) unify all the code under wal_debug GUC (it is developer-only and superuser-only so there shouldn't be a problem even if we ship it out of the box). If someone is concerned about the GUC being enabled on production servers knowingly or unknowingly with option (2), we can go ahead with option (1). I will discuss this separately to see what others think. > I think we can simplify this. We effectively take the same action any time > "count" doesn't equal "read_bytes", so there's no need for the "else if". > > if (count == read_bytes) > return true; > > buf += read_bytes; > startptr += read_bytes; > count -= read_bytes; I wanted to avoid setting these unnecessarily for buffer misses. Thanks a lot for reviewing. I'm attaching the v8 patch for further review. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Nathan Bossart
Date:
On Tue, Mar 07, 2023 at 12:39:13PM +0530, Bharath Rupireddy wrote: > On Tue, Mar 7, 2023 at 3:30 AM Nathan Bossart <nathandbossart@gmail.com> wrote: >> Is it possible to memcpy more than a page at a time? > > It would complicate things a lot there; the logic to figure out the > last page bytes that may or may not fit in the whole page gets > complicated. Also, the logic to verify each page's header gets > complicated. We might lose out if we memcpy all the pages at once and > start verifying each page's header in another loop. Doesn't the complicated logic you describe already exist to some extent in the patch? You are copying a page at a time, which involves calculating various addresses and byte counts. >> + elog(DEBUG1, "read %zu bytes out of %zu bytes from WAL buffers for given LSN %X/%X, Timeline ID %u", >> + *read_bytes, count, LSN_FORMAT_ARGS(startptr), tli); >> >> I definitely don't think we should put an elog() in this code path. >> Perhaps this should be guarded behind WAL_DEBUG. > > Placing it behind WAL_DEBUG doesn't help users/developers. My > intention was to let users know that the WAL read hit the buffers, > it'll help them report if any issue occurs and also help developers to > debug that issue. I still think an elog() is mighty expensive for this code path, even when it doesn't actually produce any messages. And when it does, I think it has the potential to be incredibly noisy. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
> [1] > subscription tests: > PATCHED: WAL buffers hit - 1972, misses - 32616 Can you share more details about the test here? I went through the v8 patch. Following are my thoughts to improve the WAL buffer hit ratio. Currently the no-longer-needed WAL data present in WAL buffers gets cleared in XLogBackgroundFlush() which is called based on the wal_writer_delay config setting. Once the data is flushed to the disk, it is treated as no-longer-needed and it will be cleared as soon as possible based on some config settings. I have done some testing by tweaking the wal_writer_delay config setting to confirm the behaviour. We can see that the WAL buffer hit ratio is good when the wal_writer_delay is big enough [2] compared to smaller wal_writer_delay [1]. So irrespective of the wal_writer_delay settings, we should keep the WAL data in the WAL buffers as long as possible so that all the readers (Mainly WAL senders) can take advantage of this. The WAL page should be evicted from the WAL buffers only when the WAL buffer is full and we need room for the new page. The patch attached takes care of this. We can see the improvements in WAL buffer hit ratio even when the wal_writer_delay is set to lower value [3]. Second, In WALRead(), we try to read the data from disk whenever we don't find the data from WAL buffers. We don't store this data in the WAL buffer. We just read the data, use it and leave it. If we store this data to the WAL buffer, then we may avoid a few disk reads. [1]: wal_buffers=1GB wal_writer_delay=1ms ./pgbench --initialize --scale=300 postgres WAL buffers hit=5046 WAL buffers miss=56767 [2]: wal_buffers=1GB wal_writer_delay=10s ./pgbench --initialize --scale=300 postgres WAL buffers hit=45454 WAL buffers miss=14064 [3]: wal_buffers=1GB wal_writer_delay=1ms ./pgbench --initialize --scale=300 postgres WAL buffers hit=37214 WAL buffers miss=844 Please share your thoughts. Thanks & Regards, Nitin Jadhav On Tue, Mar 7, 2023 at 12:39 PM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > On Tue, Mar 7, 2023 at 3:30 AM Nathan Bossart <nathandbossart@gmail.com> wrote: > > > > +void > > +XLogReadFromBuffers(XLogRecPtr startptr, > > > > Since this function presently doesn't return anything, can we have it > > return the number of bytes read instead of storing it in a pointer > > variable? > > Done. > > > + ptr = startptr; > > + nbytes = count; > > + dst = buf; > > > > These variables seem superfluous. > > Needed startptr and count for DEBUG1 message and assertion at the end. > Removed dst and used buf in the new patch now. > > > + /* > > + * Requested WAL isn't available in WAL buffers, so return with > > + * what we have read so far. > > + */ > > + break; > > > > nitpick: I'd move this to the top so that you can save a level of > > indentation. > > Done. > > > + /* > > + * All the bytes are not in one page. Read available bytes on > > + * the current page, copy them over to output buffer and > > + * continue to read remaining bytes. > > + */ > > > > Is it possible to memcpy more than a page at a time? > > It would complicate things a lot there; the logic to figure out the > last page bytes that may or may not fit in the whole page gets > complicated. Also, the logic to verify each page's header gets > complicated. We might lose out if we memcpy all the pages at once and > start verifying each page's header in another loop. > > I would like to keep it simple - read a single page from WAL buffers, > verify it and continue. > > > + /* > > + * The fact that we acquire WALBufMappingLock while reading the WAL > > + * buffer page itself guarantees that no one else initializes it or > > + * makes it ready for next use in AdvanceXLInsertBuffer(). > > + * > > + * However, we perform basic page header checks for ensuring that > > + * we are not reading a page that just got initialized. Callers > > + * will anyway perform extensive page-level and record-level > > + * checks. > > + */ > > > > Hm. I wonder if we should make these assertions instead. > > Okay. I added XLogReaderValidatePageHeader for assert-only builds > which will help catch any issues there. But we can't perform record > level checks here because this function doesn't know where the record > starts from, it knows only pages. This change required us to pass in > XLogReaderState to XLogReadFromBuffers. I marked it as > PG_USED_FOR_ASSERTS_ONLY and did page header checks only when it is > passed as non-null so that someone who doesn't have XLogReaderState > can still read from buffers. > > > + elog(DEBUG1, "read %zu bytes out of %zu bytes from WAL buffers for given LSN %X/%X, Timeline ID %u", > > + *read_bytes, count, LSN_FORMAT_ARGS(startptr), tli); > > > > I definitely don't think we should put an elog() in this code path. > > Perhaps this should be guarded behind WAL_DEBUG. > > Placing it behind WAL_DEBUG doesn't help users/developers. My > intention was to let users know that the WAL read hit the buffers, > it'll help them report if any issue occurs and also help developers to > debug that issue. > > On a different note - I was recently looking at the code around > WAL_DEBUG macro and the wal_debug GUC. It looks so complex that one > needs to build source code with the WAL_DEBUG macro and enable the GUC > to see the extended logs for WAL. IMO, the best way there is either: > 1) unify all the code under WAL_DEBUG macro and get rid of wal_debug GUC, or > 2) unify all the code under wal_debug GUC (it is developer-only and > superuser-only so there shouldn't be a problem even if we ship it out > of the box). > > If someone is concerned about the GUC being enabled on production > servers knowingly or unknowingly with option (2), we can go ahead with > option (1). I will discuss this separately to see what others think. > > > I think we can simplify this. We effectively take the same action any time > > "count" doesn't equal "read_bytes", so there's no need for the "else if". > > > > if (count == read_bytes) > > return true; > > > > buf += read_bytes; > > startptr += read_bytes; > > count -= read_bytes; > > I wanted to avoid setting these unnecessarily for buffer misses. > > Thanks a lot for reviewing. I'm attaching the v8 patch for further review. > > -- > Bharath Rupireddy > PostgreSQL Contributors Team > RDS Open Source Databases > Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Sun, Mar 12, 2023 at 12:52 AM Nitin Jadhav
<nitinjadhavpostgres@gmail.com> wrote:
>
> I went through the v8 patch.
Thanks for looking at it. Please post the responses in-line, not above
the entire previous message for better readability.
> Following are my thoughts to improve the
> WAL buffer hit ratio.
Note that the motive of this patch is to read WAL from WAL buffers
*when possible* without affecting concurrent WAL writers.
> Currently the no-longer-needed WAL data present in WAL buffers gets
> cleared in XLogBackgroundFlush() which is called based on the
> wal_writer_delay config setting. Once the data is flushed to the disk,
> it is treated as no-longer-needed and it will be cleared as soon as
> possible based on some config settings.
Being opportunistic in pre-initializing as many possible WAL buffer
pages as is there for a purpose. There's an illuminating comment [1],
so that's done for a purpose, so removing it fully is a no-go IMO. For
instance, it'll make WAL buffer pages available for concurrent writers
so there will be less work for writers in GetXLogBuffer. I'm sure
removing the opportunistic pre-initialization of the WAL buffer pages
will hurt performance in a highly concurrent-write workload.
/*
* Great, done. To take some work off the critical path, try to initialize
* as many of the no-longer-needed WAL buffers for future use as we can.
*/
AdvanceXLInsertBuffer(InvalidXLogRecPtr, insertTLI, true);
> Second, In WALRead(), we try to read the data from disk whenever we
> don't find the data from WAL buffers. We don't store this data in the
> WAL buffer. We just read the data, use it and leave it. If we store
> this data to the WAL buffer, then we may avoid a few disk reads.
Again this is going to hurt concurrent writers. Note that wal_buffers
aren't used as full cache per-se, there'll be multiple writers to it,
*when possible* readers will try to read from it without hurting
writers.
> The patch attached takes care of this.
Please post the new proposal as a text file (not a .patch file) or as
a plain text in the email itself if the change is small or attach all
the patches if the patch is over-and-above the proposed patches.
Attaching a single over-and-above patch will make CFBot unhappy and
will force authors to repost the original patches. Typically, we
follow this. Having said, I have some review comments to fix on
v8-0001, so, I'll be sending out v9 patch-set soon.
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Sun, Mar 12, 2023 at 11:00 PM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > I have some review comments to fix on > v8-0001, so, I'll be sending out v9 patch-set soon. Please find the attached v9 patch set for further review. I moved the check for just-initialized WAL buffer pages before reading the page. Up until now, it's the other way around, meaning, read the page and then check the header if it is just-initialized, which is wrong. The attached v9 patch set corrects it. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Tue, Mar 7, 2023 at 11:14 PM Nathan Bossart <nathandbossart@gmail.com> wrote: > > On Tue, Mar 07, 2023 at 12:39:13PM +0530, Bharath Rupireddy wrote: > > On Tue, Mar 7, 2023 at 3:30 AM Nathan Bossart <nathandbossart@gmail.com> wrote: > >> Is it possible to memcpy more than a page at a time? > > > > It would complicate things a lot there; the logic to figure out the > > last page bytes that may or may not fit in the whole page gets > > complicated. Also, the logic to verify each page's header gets > > complicated. We might lose out if we memcpy all the pages at once and > > start verifying each page's header in another loop. > > Doesn't the complicated logic you describe already exist to some extent in > the patch? You are copying a page at a time, which involves calculating > various addresses and byte counts. Okay here I am with the v10 patch set attached that avoids multiple memcpy calls which must benefit the callers who want to read more than 1 WAL buffer page (streaming replication WAL sender for instance). > >> + elog(DEBUG1, "read %zu bytes out of %zu bytes from WAL buffers for given LSN %X/%X, Timeline ID %u", > >> + *read_bytes, count, LSN_FORMAT_ARGS(startptr), tli); > >> > >> I definitely don't think we should put an elog() in this code path. > >> Perhaps this should be guarded behind WAL_DEBUG. > > > > Placing it behind WAL_DEBUG doesn't help users/developers. My > > intention was to let users know that the WAL read hit the buffers, > > it'll help them report if any issue occurs and also help developers to > > debug that issue. > > I still think an elog() is mighty expensive for this code path, even when > it doesn't actually produce any messages. And when it does, I think it has > the potential to be incredibly noisy. Well, my motive was to have a way for the user to know WAL buffer hits and misses to report any found issues. However, I have a plan later to add WAL buffer stats (hits/misses). I understand that even if someone enables DEBUG1, this message can bloat server log files and make recovery slower, especially on a standby. Hence, I agree to keep these logs behind the WAL_DEBUG macro like others and did so in the attached v10 patch set. Please review the attached v10 patch set further. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
On Sat, 2023-01-14 at 12:34 -0800, Andres Freund wrote:
> One benefit would be that it'd make it more realistic to use direct
> IO for WAL
> - for which I have seen significant performance benefits. But when we
> afterwards have to re-read it from disk to replicate, it's less
> clearly a win.
Does this patch still look like a good fit for your (or someone else's)
plans for direct IO here? If so, would committing this soon make it
easier to make progress on that, or should we wait until it's actually
needed?
If I recall, this patch does not provide a perforance benefit as-is
(correct me if things have changed) and I don't know if a reduction in
syscalls alone is enough to justify it. But if it paves the way for
direct IO for WAL, that does seem worth it.
Regards,
Jeff Davis
Hi, On 2023-10-03 16:05:32 -0700, Jeff Davis wrote: > On Sat, 2023-01-14 at 12:34 -0800, Andres Freund wrote: > > One benefit would be that it'd make it more realistic to use direct > > IO for WAL > > - for which I have seen significant performance benefits. But when we > > afterwards have to re-read it from disk to replicate, it's less > > clearly a win. > > Does this patch still look like a good fit for your (or someone else's) > plans for direct IO here? If so, would committing this soon make it > easier to make progress on that, or should we wait until it's actually > needed? I think it'd be quite useful to have. Even with the code as of 16, I see better performance in some workloads with debug_io_direct=wal, wal_sync_method=open_datasync compared to any other configuration. Except of course that it makes walsenders more problematic, as they suddenly require read IO. Thus having support for walsenders to send directly from wal buffers would be beneficial, even without further AIO infrastructure. I also think there are other quite desirable features that are made easier by this patch. One of the primary problems with using synchronous replication is the latency increase, obviously. We can't send out WAL before it has locally been wirten out and flushed to disk. For some workloads, we could substantially lower synchronous commit latency if we were able to send WAL to remote nodes *before* WAL has been made durable locally, even if the receiving systems wouldn't be allowed to write that data to disk yet: It takes less time to send just "write LSN: %X/%X, flush LSNL: %X/%X" than also having to send all the not-yet-durable WAL. In many OLTP workloads there won't be WAL flushes between generating WAL for DML and commit, which means that the amount of WAL that needs to be sent out at commit can be of nontrivial size. E.g. for pgbench, normally a transaction is about ~550 bytes (fitting in a single tcp/ip packet), but a pgbench transaction that needs to emit FPIs for everything is a lot larger: ~45kB (not fitting in a single packet). Obviously many real world workloads OLTP workloads actually do more writes than pgbench. Making the commit latency of the latter be closer to the commit latency of the former when using syncrep would obviously be great. Of course this patch is just a relatively small step towards that: We'd also need in-memory buffering on the receiving side, the replication protocol would need to be improved, we'd likely need an option to explicitly opt into receiving unflushed data. But it's still a pretty much required step. Greetings, Andres Freund
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Thu, Oct 12, 2023 at 4:13 AM Andres Freund <andres@anarazel.de> wrote: > > On 2023-10-03 16:05:32 -0700, Jeff Davis wrote: > > > > Does this patch still look like a good fit for your (or someone else's) > > plans for direct IO here? If so, would committing this soon make it > > easier to make progress on that, or should we wait until it's actually > > needed? > > I think it'd be quite useful to have. Even with the code as of 16, I see > better performance in some workloads with debug_io_direct=wal, > wal_sync_method=open_datasync compared to any other configuration. Except of > course that it makes walsenders more problematic, as they suddenly require > read IO. Thus having support for walsenders to send directly from wal buffers > would be beneficial, even without further AIO infrastructure. Right. Tests show the benefit with WAL DIO + this patch - https://www.postgresql.org/message-id/CALj2ACV6rS%2B7iZx5%2BoAvyXJaN4AG-djAQeM1mrM%3DYSDkVrUs7g%40mail.gmail.com. Also, irrespective of WAL DIO, the WAL buffers hit ratio with the patch stood at 95% for 1 primary, 1 sync standby, 1 async standby, pgbench --scale=300 --client=32 --time=900. In other words, the walsenders avoided 95% of the time reading from the file/avoided pread system calls - https://www.postgresql.org/message-id/CALj2ACXKKK%3DwbiG5_t6dGao5GoecMwRkhr7GjVBM_jg54%2BNa%3DQ%40mail.gmail.com. > I also think there are other quite desirable features that are made easier by > this patch. One of the primary problems with using synchronous replication is > the latency increase, obviously. We can't send out WAL before it has locally > been wirten out and flushed to disk. For some workloads, we could > substantially lower synchronous commit latency if we were able to send WAL to > remote nodes *before* WAL has been made durable locally, even if the receiving > systems wouldn't be allowed to write that data to disk yet: It takes less time > to send just "write LSN: %X/%X, flush LSNL: %X/%X" than also having to send > all the not-yet-durable WAL. > > In many OLTP workloads there won't be WAL flushes between generating WAL for > DML and commit, which means that the amount of WAL that needs to be sent out > at commit can be of nontrivial size. > > E.g. for pgbench, normally a transaction is about ~550 bytes (fitting in a > single tcp/ip packet), but a pgbench transaction that needs to emit FPIs for > everything is a lot larger: ~45kB (not fitting in a single packet). Obviously > many real world workloads OLTP workloads actually do more writes than > pgbench. Making the commit latency of the latter be closer to the commit > latency of the former when using syncrep would obviously be great. > > Of course this patch is just a relatively small step towards that: We'd also > need in-memory buffering on the receiving side, the replication protocol would > need to be improved, we'd likely need an option to explicitly opt into > receiving unflushed data. But it's still a pretty much required step. Yes, this patch can pave the way for all of the above features in future. However, I'm looking forward to getting this in for now. Later, I'll come up with more concrete thoughts on the above. Having said above, the latest v10 patch after addressing some of the review comments is at https://www.postgresql.org/message-id/CALj2ACU3ZYzjOv4vZTR%2BLFk5PL4ndUnbLS6E1vG2dhDBjQGy2A%40mail.gmail.com. Any further thoughts on the patch is welcome. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Thu, Oct 12, 2023 at 4:13 AM Andres Freund <andres@anarazel.de> wrote: > > On 2023-10-03 16:05:32 -0700, Jeff Davis wrote: > > On Sat, 2023-01-14 at 12:34 -0800, Andres Freund wrote: > > > One benefit would be that it'd make it more realistic to use direct > > > IO for WAL > > > - for which I have seen significant performance benefits. But when we > > > afterwards have to re-read it from disk to replicate, it's less > > > clearly a win. > > > > Does this patch still look like a good fit for your (or someone else's) > > plans for direct IO here? If so, would committing this soon make it > > easier to make progress on that, or should we wait until it's actually > > needed? > > I think it'd be quite useful to have. Even with the code as of 16, I see > better performance in some workloads with debug_io_direct=wal, > wal_sync_method=open_datasync compared to any other configuration. Except of > course that it makes walsenders more problematic, as they suddenly require > read IO. Thus having support for walsenders to send directly from wal buffers > would be beneficial, even without further AIO infrastructure. I'm attaching the v11 patch set with the following changes: - Improved input validation in the function that reads WAL from WAL buffers in 0001 patch. - Improved test module's code in 0002 patch. - Modernized meson build file in 0002 patch. - Added commit messages for both the patches. - Ran pgindent on both the patches. Any thoughts are welcome. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Fri, Oct 20, 2023 at 10:19 PM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > On Thu, Oct 12, 2023 at 4:13 AM Andres Freund <andres@anarazel.de> wrote: > > > > On 2023-10-03 16:05:32 -0700, Jeff Davis wrote: > > > On Sat, 2023-01-14 at 12:34 -0800, Andres Freund wrote: > > > > One benefit would be that it'd make it more realistic to use direct > > > > IO for WAL > > > > - for which I have seen significant performance benefits. But when we > > > > afterwards have to re-read it from disk to replicate, it's less > > > > clearly a win. > > > > > > Does this patch still look like a good fit for your (or someone else's) > > > plans for direct IO here? If so, would committing this soon make it > > > easier to make progress on that, or should we wait until it's actually > > > needed? > > > > I think it'd be quite useful to have. Even with the code as of 16, I see > > better performance in some workloads with debug_io_direct=wal, > > wal_sync_method=open_datasync compared to any other configuration. Except of > > course that it makes walsenders more problematic, as they suddenly require > > read IO. Thus having support for walsenders to send directly from wal buffers > > would be beneficial, even without further AIO infrastructure. > > I'm attaching the v11 patch set with the following changes: > - Improved input validation in the function that reads WAL from WAL > buffers in 0001 patch. > - Improved test module's code in 0002 patch. > - Modernized meson build file in 0002 patch. > - Added commit messages for both the patches. > - Ran pgindent on both the patches. > > Any thoughts are welcome. I'm attaching v12 patch set with just pgperltidy ran on the new TAP test added in 0002. No other changes from that of v11 patch set. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
On Sat, 2023-10-21 at 23:59 +0530, Bharath Rupireddy wrote:
> I'm attaching v12 patch set with just pgperltidy ran on the new TAP
> test added in 0002. No other changes from that of v11 patch set.
Thank you.
Comments:
* It would be good to document that this is partially an optimization
(read from memory first) and partially an API difference that allows
reading unflushed data. For instance, walsender may benefit
performance-wise (and perhaps later with the ability to read unflushed
data) whereas pg_walinspect benefits primarily from reading unflushed
data.
* Shouldn't there be a new method in XLogReaderRoutine (e.g.
read_unflushed_data), rather than having logic in WALRead()? The
callers can define the method if it makes sense (and that would be a
good place to document why); or leave it NULL if not.
* I'm not clear on the "partial hit" case. Wouldn't that mean you found
the earliest byte in the buffers, but not the latest byte requested? Is
that possible, and if so under what circumstances? I added an
"Assert(nread == 0 || nread == count)" in WALRead() after calling
XLogReadFromBuffers(), and it wasn't hit.
* If the partial hit case is important, wouldn't XLogReadFromBuffers()
fill in the end of the buffer rather than the beginning?
* Other functions that use xlblocks, e.g. GetXLogBuffer(), use more
effort to avoid acquiring WALBufMappingLock. Perhaps you can avoid it,
too? One idea is to check that XLogCtl->xlblocks[idx] is equal to
expectedEndPtr both before and after the memcpy(), with appropriate
barriers. That could mitigate concerns expressed by Kyotaro Horiguchi
and Masahiko Sawada.
* Are you sure that reducing the number of calls to memcpy() is a win?
I would expect that to be true only if the memcpy()s are tiny, but here
they are around XLOG_BLCKSZ. I believe this was done based on a comment
from Nathan Bossart, but I didn't really follow why that's important.
Also, if we try to use one memcpy for all of the data, it might not
interact well with my idea above to avoid taking the lock.
* Style-wise, the use of "unlikely" seems excessive, unless there's a
reason to think it matters.
Regards,
Jeff Davis
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Nathan Bossart
Date:
On Tue, Oct 24, 2023 at 05:15:19PM -0700, Jeff Davis wrote: > * Are you sure that reducing the number of calls to memcpy() is a win? > I would expect that to be true only if the memcpy()s are tiny, but here > they are around XLOG_BLCKSZ. I believe this was done based on a comment > from Nathan Bossart, but I didn't really follow why that's important. > Also, if we try to use one memcpy for all of the data, it might not > interact well with my idea above to avoid taking the lock. I don't recall exactly why I suggested this, but if additional memcpy()s help in some way and don't negatively impact performance, then I retract my previous comment. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Wed, Oct 25, 2023 at 5:45 AM Jeff Davis <pgsql@j-davis.com> wrote: > > Comments: Thanks for reviewing. > * It would be good to document that this is partially an optimization > (read from memory first) and partially an API difference that allows > reading unflushed data. For instance, walsender may benefit > performance-wise (and perhaps later with the ability to read unflushed > data) whereas pg_walinspect benefits primarily from reading unflushed > data. Commit message has these things covered in detail. However, I think adding some info in the code comments is a good idea and done around the WALRead() function in the attached v13 patch set. > * Shouldn't there be a new method in XLogReaderRoutine (e.g. > read_unflushed_data), rather than having logic in WALRead()? The > callers can define the method if it makes sense (and that would be a > good place to document why); or leave it NULL if not. I've designed the new function XLogReadFromBuffers to read from WAL buffers in such a way that one can easily embed it in page_read callbacks if it makes sense. Almost all the available backend page_read callbacks read_local_xlog_page_no_wait, read_local_xlog_page, logical_read_xlog_page except XLogPageRead (which is used for recovery when WAL buffers aren't used at all) have one thing in common, that is, WALRead(). Therefore, it seemed a natural choice for me to call XLogReadFromBuffers. In other words, I'd say it's the responsibility of page_read callback implementers to decide if they want to read from WAL buffers or not and hence I don't think we need a separate XLogReaderRoutine. If someone wants to read unflushed WAL, the typical way to implement it is to write a new page_read callback read_local_unflushed_xlog_page/logical_read_unflushed_xlog_page or similar without WALRead() but just the new function XLogReadFromBuffers to read from WAL buffers and return. > * I'm not clear on the "partial hit" case. Wouldn't that mean you found > the earliest byte in the buffers, but not the latest byte requested? Is > that possible, and if so under what circumstances? I added an > "Assert(nread == 0 || nread == count)" in WALRead() after calling > XLogReadFromBuffers(), and it wasn't hit. > > * If the partial hit case is important, wouldn't XLogReadFromBuffers() > fill in the end of the buffer rather than the beginning? Partial hit was possible when the requested WAL pages are read one page at a time from WAL buffers with WALBufMappingLock acquisition-release for each page as the requested page can be replaced by the time the lock is released and reacquired. This was the case up until the v6 patch - https://www.postgresql.org/message-id/CALj2ACWTNneq2EjMDyUeWF-BnwpewuhiNEfjo9bxLwFU9iPF0w%40mail.gmail.com. Now that the approach has been changed to read multiple pages at once under one WALBufMappingLock acquisition-release. . We can either keep the partial hit handling (just to not miss anything) or turn the following partial hit case to an error or an Assert(false);. I prefer to keep the partial hit handling as-is just in case: + else if (count > nread) + { + /* + * Buffer partial hit, so reset the state to count the read bytes + * and continue. + */ + buf += nread; + startptr += nread; + count -= nread; + } > * Other functions that use xlblocks, e.g. GetXLogBuffer(), use more > effort to avoid acquiring WALBufMappingLock. Perhaps you can avoid it, > too? One idea is to check that XLogCtl->xlblocks[idx] is equal to > expectedEndPtr both before and after the memcpy(), with appropriate > barriers. That could mitigate concerns expressed by Kyotaro Horiguchi > and Masahiko Sawada. Yes, I proposed that idea in another thread - https://www.postgresql.org/message-id/CALj2ACVFSirOFiABrNVAA6JtPHvA9iu%2Bwp%3DqkM9pdLZ5mwLaFg%40mail.gmail.com. If that looks okay, I can add it to the next version of this patch set. > * Are you sure that reducing the number of calls to memcpy() is a win? > I would expect that to be true only if the memcpy()s are tiny, but here > they are around XLOG_BLCKSZ. I believe this was done based on a comment > from Nathan Bossart, but I didn't really follow why that's important. > Also, if we try to use one memcpy for all of the data, it might not > interact well with my idea above to avoid taking the lock. Up until the v6 patch - https://www.postgresql.org/message-id/CALj2ACWTNneq2EjMDyUeWF-BnwpewuhiNEfjo9bxLwFU9iPF0w%40mail.gmail.com, the requested WAL was being read one page at a time from WAL buffers into output buffer with one memcpy call for each page. Now that the approach has been changed to read multiple pages at once under one WALBufMappingLock acquisition-release with comparatively lesser number of memcpy calls. I honestly haven't seen any difference between the two approaches - https://www.postgresql.org/message-id/CALj2ACUpQGiwQTzmoSMOFk5%3DWiJc06FcYpxzBX0SEej4ProRzg%40mail.gmail.com. The new approach of reading multiple pages at once under one WALBufMappingLock acquisition-release clearly wins over reading one page at a time with multiple lock acquisition-release cycles. > * Style-wise, the use of "unlikely" seems excessive, unless there's a > reason to think it matters. Given the current use of XLogReadFromBuffers, the input parameters are passed as expected, IOW, these are unlikely events. The comments [1] say that the unlikely() is to be used in hot code paths; I think reading WAL from buffers is a hot code path especially when called from (logical, physical) walsenders. If there's any stronger reason than the appearance/style-wise, I'm okay to not use them. For now, I've retained them. FWIW, I found heapam.c using unlikely() extensively for safety checks. [1] * Hints to the compiler about the likelihood of a branch. Both likely() and * unlikely() return the boolean value of the contained expression. * * These should only be used sparingly, in very hot code paths. It's very easy * to mis-estimate likelihoods. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
On Fri, 2023-10-27 at 03:46 +0530, Bharath Rupireddy wrote: > > Almost all the available backend > page_read callbacks read_local_xlog_page_no_wait, > read_local_xlog_page, logical_read_xlog_page except XLogPageRead > (which is used for recovery when WAL buffers aren't used at all) have > one thing in common, that is, WALRead(). Therefore, it seemed a > natural choice for me to call XLogReadFromBuffers. In other words, > I'd > say it's the responsibility of page_read callback implementers to > decide if they want to read from WAL buffers or not and hence I don't > think we need a separate XLogReaderRoutine. I think I see what you are saying: WALRead() is at a lower level than the XLogReaderRoutine callbacks, because it's used by the .page_read callbacks. That makes sense, but my first interpretation was that WALRead() is above the XLogReaderRoutine callbacks because it calls .segment_open and .segment_close. To me that sounds like a layering violation, but it exists today without your patch. I suppose the question is: should reading from the WAL buffers an intentional thing that the caller does explicitly by specific callers? Or is it an optimization that should be hidden from the caller? I tend toward the former, at least for now. I suspect that when we do some more interesting things, like replicating unflushed data, we will want reading from buffers to be a separate step, not combined with WALRead(). After things in this area settle a bit then we might want to refactor and combine them again. > If someone wants to read unflushed WAL, the typical way to implement > it is to write a new page_read callback > read_local_unflushed_xlog_page/logical_read_unflushed_xlog_page or > similar without WALRead() but just the new function > XLogReadFromBuffers to read from WAL buffers and return. Then why is it being called from WALRead() at all? > > I prefer to keep the partial hit handling as-is just > in case: > So a "partial hit" is essentially a narrow race condition where one page is read from buffers, and it's valid; and by the time it gets to the next page, it has already been evicted (along with the previously read page)? In other words, I think you are describing a case where eviction is happening faster than the memcpy()s in a loop, which is certainly possible due to scheduling or whatever, but doesn't seem like the common case. The case I'd expect for a partial read is when the startptr points to an evicted page, but some later pages in the requested range are still present in the buffers. I'm not really sure whether either of these cases matters, but if we implement one and not the other, there should be some explanation. > Yes, I proposed that idea in another thread - > https://www.postgresql.org/message-id/CALj2ACVFSirOFiABrNVAA6JtPHvA9iu%2Bwp%3DqkM9pdLZ5mwLaFg%40mail.gmail.com > . > If that looks okay, I can add it to the next version of this patch > set. The code in the email above still shows a call to: /* * Requested WAL is available in WAL buffers, so recheck the existence * under the WALBufMappingLock and read if the page still exists, otherwise * return. */ LWLockAcquire(WALBufMappingLock, LW_SHARED); and I don't think that's required. How about something like: endptr1 = XLogCtl->xlblocks[idx]; /* Requested WAL isn't available in WAL buffers. */ if (expectedEndPtr != endptr1) break; pg_read_barrier(); ... memcpy(buf, data, bytes_read_this_loop); ... pg_read_barrier(); endptr2 = XLogCtl->xlblocks[idx]; if (expectedEndPtr != endptr2) break; ntotal += bytes_read_this_loop; /* success; move on to next page */ I'm not sure why GetXLogBuffer() doesn't just use pg_atomic_read_u64(). I suppose because xlblocks are not guaranteed to be 64-bit aligned? Should we just align it to 64 bits so we can use atomics? (I don't think it matters in this case, but atomics would avoid the need to think about it.) > > > FWIW, I found heapam.c using unlikely() extensively for safety > checks. OK, I won't object to the use of unlikely(), though I typically don't use it without a fairly strong reason to think I should override what the compiler thinks and/or what branch predictors can handle. In this case, I think some of those errors are not really necessary anyway, though: * XLogReadFromBuffers shouldn't take a timeline argument just to demand that it's always equal to the wal insertion timeline. * Why check that startptr is earlier than the flush pointer, but not startptr+count? Also, given that we intend to support reading unflushed data, it would be good to comment that the function still works past the flush pointer, and that it will be safe to remove later (right?). * An "Assert(!RecoveryInProgress())" would be more appropriate than an error. Perhaps we will remove even that check in the future to achieve cascaded replication of unflushed data. Regards, Jeff Davis
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Sat, Oct 28, 2023 at 2:22 AM Jeff Davis <pgsql@j-davis.com> wrote:
>
> I think I see what you are saying: WALRead() is at a lower level than
> the XLogReaderRoutine callbacks, because it's used by the .page_read
> callbacks.
>
> That makes sense, but my first interpretation was that WALRead() is
> above the XLogReaderRoutine callbacks because it calls .segment_open
> and .segment_close. To me that sounds like a layering violation, but it
> exists today without your patch.
Right. WALRead() is a common function used by most if not all
page_read callbacks. Typically, the page_read callbacks code has 2
parts - first determine the target/start LSN and second read WAL (via
WALRead() for instance).
> I suppose the question is: should reading from the WAL buffers an
> intentional thing that the caller does explicitly by specific callers?
> Or is it an optimization that should be hidden from the caller?
>
> I tend toward the former, at least for now.
Yes, it's an optimization that must be hidden from the caller.
> I suspect that when we do
> some more interesting things, like replicating unflushed data, we will
> want reading from buffers to be a separate step, not combined with
> WALRead(). After things in this area settle a bit then we might want to
> refactor and combine them again.
As said previously, the new XLogReadFromBuffers() function is generic
and extensible in the way that anyone with a target/start LSN
(corresponding to flushed or written-but-not-yet-flushed WAL) and TLI
can call it to read from WAL buffers. It's just that the patch
currently uses it where it makes sense i.e. in WALRead(). But, it's
usable in, say, a page_read callback reading unflushed WAL from WAL
buffers.
> > If someone wants to read unflushed WAL, the typical way to implement
> > it is to write a new page_read callback
> > read_local_unflushed_xlog_page/logical_read_unflushed_xlog_page or
> > similar without WALRead() but just the new function
> > XLogReadFromBuffers to read from WAL buffers and return.
>
> Then why is it being called from WALRead() at all?
The patch focuses on reading flushed WAL from WAL buffers if
available, not the unflushed WAL at all; that's why it's in WALRead()
before reading from the WAL file using pg_pread().
I'm trying to make a point that the XLogReadFromBuffers() enables one
to read unflushed WAL from WAL buffers (if really wanted for future
features like replicate from WAL buffers as a new opt-in feature to
improve the replication performance).
> > I prefer to keep the partial hit handling as-is just
> > in case:
>
> So a "partial hit" is essentially a narrow race condition where one
> page is read from buffers, and it's valid; and by the time it gets to
> the next page, it has already been evicted (along with the previously
> read page)?
>
> In other words, I think you are describing a case where
> eviction is happening faster than the memcpy()s in a loop, which is
> certainly possible due to scheduling or whatever, but doesn't seem like
> the common case.
>
> The case I'd expect for a partial read is when the startptr points to
> an evicted page, but some later pages in the requested range are still
> present in the buffers.
>
> I'm not really sure whether either of these cases matters, but if we
> implement one and not the other, there should be some explanation.
At any given point of time, WAL buffer pages are maintained as a
circularly sorted array in an ascending order from
OldestInitializedPage to InitializedUpTo (new pages are inserted at
this end). Also, the current patch holds WALBufMappingLock while
reading the buffer pages, meaning, no one can replace the buffer pages
until reading is finished. Therefore, the above two described partial
hit cases can't happen - when reading multiple pages if the first page
is found to be existing in the buffer pages, it means the other pages
must exist too because of the circular and sortedness of the WAL
buffer page array.
Here's an illustration with WAL buffers circular array (idx, LSN) of
size 10 elements with contents as {(0, 160), (1, 170), (2, 180), (3,
90), (4, 100), (5, 110), (6, 120), (7, 130), (8, 140), (9, 150)} and
current InitializedUpTo pointing to page at LSN 180, idx 2.
- Read 6 pages starting from LSN 80. Nothing is read from WAL buffers
as the page at LSN 80 doesn't exist despite other 5 pages starting
from LSN 90 exist.
- Read 6 pages starting from LSN 90. All the pages exist and are read
from WAL buffers.
- Read 6 pages starting from LSN 150. Note that WAL is currently
flushed only up to page at LSN 180 and the callers won't ask for
unflushed WAL read. If a caller asks for an unflushed WAL read
intentionally or unintentionally, XLogReadFromBuffers() reads only 4
pages starting from LSN 150 to LSN 180 and will leave the remaining 2
pages for the caller to deal with. This is the partial hit that can
happen. Therefore, retaining the partial hit code in WALRead() as-is
in the current patch is needed IMV.
> > Yes, I proposed that idea in another thread -
> > https://www.postgresql.org/message-id/CALj2ACVFSirOFiABrNVAA6JtPHvA9iu%2Bwp%3DqkM9pdLZ5mwLaFg%40mail.gmail.com
> > .
> > If that looks okay, I can add it to the next version of this patch
> > set.
>
> The code in the email above still shows a call to:
>
> /*
> * Requested WAL is available in WAL buffers, so recheck the
> existence
> * under the WALBufMappingLock and read if the page still exists,
> otherwise
> * return.
> */
> LWLockAcquire(WALBufMappingLock, LW_SHARED);
>
> and I don't think that's required. How about something like:
>
> endptr1 = XLogCtl->xlblocks[idx];
> /* Requested WAL isn't available in WAL buffers. */
> if (expectedEndPtr != endptr1)
> break;
>
> pg_read_barrier();
> ...
> memcpy(buf, data, bytes_read_this_loop);
> ...
> pg_read_barrier();
> endptr2 = XLogCtl->xlblocks[idx];
> if (expectedEndPtr != endptr2)
> break;
>
> ntotal += bytes_read_this_loop;
> /* success; move on to next page */
>
> I'm not sure why GetXLogBuffer() doesn't just use pg_atomic_read_u64().
> I suppose because xlblocks are not guaranteed to be 64-bit aligned?
> Should we just align it to 64 bits so we can use atomics? (I don't
> think it matters in this case, but atomics would avoid the need to
> think about it.)
WALBufMappingLock protects both xlblocks and WAL buffer pages [1][2].
I'm not sure how using the memory barrier, not WALBufMappingLock,
prevents writers from replacing WAL buffer pages while readers reading
the pages. FWIW, GetXLogBuffer() reads the xlblocks value without the
lock but it confirms the WAL existence under the lock and gets the WAL
buffer page under the lock [3].
I'll reiterate the WALBufMappingLock thing for this patch - the idea
is to know whether or not the WAL at a given LSN exists in WAL buffers
without acquiring WALBufMappingLock; if exists acquire the lock in
shared mode, read from WAL buffers and then release. WAL buffer pages
are organized as a circular array with the InitializedUpTo as the
latest filled WAL buffer page. If there's a way to track the oldest
filled WAL buffer page (OldestInitializedPage), at any given point of
time, the elements of the circular array are sorted in an ascending
order from OldestInitializedPage to InitializedUpTo. With this
approach, no lock is required to know if the WAL at given LSN exists
in WAL buffers, we can just do this if lsn >=
XLogCtl->OldestInitializedPage && lsn < XLogCtl->InitializedUpTo. I
proposed this idea here
https://www.postgresql.org/message-id/CALj2ACVgi6LirgLDZh%3DFdfdvGvKAD%3D%3DWTOSWcQy%3DAtNgPDVnKw%40mail.gmail.com.
I've pulled that patch in here as 0001 to showcase its use for this
feature.
> * Why check that startptr is earlier than the flush pointer, but not
> startptr+count? Also, given that we intend to support reading unflushed
> data, it would be good to comment that the function still works past
> the flush pointer, and that it will be safe to remove later (right?).
That won't work, see the comment below. Actual flushed LSN may not
always be greater than startptr+count. GetFlushRecPtr() check in
XLogReadFromBuffers() is similar to what pg_walinspect has in
GetCurrentLSN().
/*
* Even though we just determined how much of the page can be validly read
* as 'count', read the whole page anyway. It's guaranteed to be
* zero-padded up to the page boundary if it's incomplete.
*/
if (!WALRead(state, cur_page, targetPagePtr, XLOG_BLCKSZ, tli,
&errinfo))
> * An "Assert(!RecoveryInProgress())" would be more appropriate than
> an error. Perhaps we will remove even that check in the future to
> achieve cascaded replication of unflushed data.
>
> In this case, I think some of those errors are not really necessary
> anyway, though:
>
> * XLogReadFromBuffers shouldn't take a timeline argument just to
> demand that it's always equal to the wal insertion timeline.
I've changed XLogReadFromBuffers() to return as-if nothing was read
(cache miss) when the server is in recovery or the requested TLI is
not the current server's insertion TLI. It is better than failing with
ERRORs so that the callers don't have to have any checks for recovery
or TLI.
PSA v14 patch set.
[1]
* WALBufMappingLock: must be held to replace a page in the WAL buffer cache.
[2]
* and xlblocks values certainly do. xlblocks values are protected by
* WALBufMappingLock.
*/
char *pages; /* buffers for unwritten XLOG pages */
XLogRecPtr *xlblocks; /* 1st byte ptr-s + XLOG_BLCKSZ */
[3]
* However, we don't hold a lock while we read the value. If someone has
* just initialized the page, it's possible that we get a "torn read" of
* the XLogRecPtr if 64-bit fetches are not atomic on this platform. In
* that case we will see a bogus value. That's ok, we'll grab the mapping
* lock (in AdvanceXLInsertBuffer) and retry if we see anything else than
* the page we're looking for. But it means that when we do this unlocked
* read, we might see a value that appears to be ahead of the page we're
* looking for. Don't PANIC on that, until we've verified the value while
* holding the lock.
*/
expectedEndPtr = ptr;
expectedEndPtr += XLOG_BLCKSZ - ptr % XLOG_BLCKSZ;
endptr = XLogCtl->xlblocks[idx];
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Attachment
On Thu, 2023-11-02 at 22:38 +0530, Bharath Rupireddy wrote:
> > I suppose the question is: should reading from the WAL buffers an
> > intentional thing that the caller does explicitly by specific
> > callers?
> > Or is it an optimization that should be hidden from the caller?
> >
> > I tend toward the former, at least for now.
>
> Yes, it's an optimization that must be hidden from the caller.
As I said, I tend toward the opposite: that specific callers should
read from the buffers explicitly in the cases where it makes sense.
I don't think this is the most important point right now though, let's
sort out the other details.
> >
> At any given point of time, WAL buffer pages are maintained as a
> circularly sorted array in an ascending order from
> OldestInitializedPage to InitializedUpTo (new pages are inserted at
> this end).
I don't see any reference to OldestInitializedPage or anything like it,
with or without your patch. Am I missing something?
> - Read 6 pages starting from LSN 80. Nothing is read from WAL buffers
> as the page at LSN 80 doesn't exist despite other 5 pages starting
> from LSN 90 exist.
This is what I imagined a "partial hit" was: read the 5 pages starting
at 90. The caller would then need to figure out how to read the page at
LSN 80 from the segment files.
I am not saying we should support this case; perhaps it doesn't matter.
I'm just describing why that term was confusing for me.
> If a caller asks for an unflushed WAL read
> intentionally or unintentionally, XLogReadFromBuffers() reads only 4
> pages starting from LSN 150 to LSN 180 and will leave the remaining 2
> pages for the caller to deal with. This is the partial hit that can
> happen.
To me that's more like an EOF case. "Partial hit" sounds to me like the
data exists but is not available in the cache (i.e. go to the segment
files); whereas if it encountered the end, the data is not available at
all.
> >
> WALBufMappingLock protects both xlblocks and WAL buffer pages [1][2].
> I'm not sure how using the memory barrier, not WALBufMappingLock,
> prevents writers from replacing WAL buffer pages while readers
> reading
> the pages.
It doesn't *prevent* that case, but it does *detect* that case. We
don't want to prevent writers from replacing WAL buffers, because that
would mean we are slowing down the critical WAL writing path.
Let me explain the potential problem cases, and how the barriers
prevent them:
Potential problem 1: the page is not yet resident in the cache at the
time the memcpy begins. In this case, the first read barrier would
ensure that the page is also not yet resident at the time xlblocks[idx]
is read into endptr1, and we'd break out of the loop.
Potential problem 2: the page is evicted before the memcpy finishes. In
this case, the second read barrier would ensure that the page was also
evicted before xlblocks[idx] is read into endptr2, and again we'd
detect the problem and break out of the loop.
I assume here that, if xlblocks[idx] holds the endPtr of the desired
page, all of the bytes for that page are resident at that moment. I
don't think that's true right now: AdvanceXLInsertBuffers() zeroes the
old page before updating xlblocks[nextidx]. I think it needs something
like:
pg_atomic_write_u64(&XLogCtl->xlblocks[nextidx], InvalidXLogRecPtr);
pg_write_barrier();
before the MemSet.
I didn't review your latest v14 patch yet.
Regards,
Jeff Davis
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Fri, Nov 3, 2023 at 12:35 PM Jeff Davis <pgsql@j-davis.com> wrote:
>
> On Thu, 2023-11-02 at 22:38 +0530, Bharath Rupireddy wrote:
> > > I suppose the question is: should reading from the WAL buffers an
> > > intentional thing that the caller does explicitly by specific
> > > callers?
> > > Or is it an optimization that should be hidden from the caller?
> > >
> > > I tend toward the former, at least for now.
> >
> > Yes, it's an optimization that must be hidden from the caller.
>
> As I said, I tend toward the opposite: that specific callers should
> read from the buffers explicitly in the cases where it makes sense.
How about adding a bool flag (read_from_wal_buffers) to
XLogReaderState so that the callers can set it if they want this
facility via XLogReaderAllocate()?
> > At any given point of time, WAL buffer pages are maintained as a
> > circularly sorted array in an ascending order from
> > OldestInitializedPage to InitializedUpTo (new pages are inserted at
> > this end).
>
> I don't see any reference to OldestInitializedPage or anything like it,
> with or without your patch. Am I missing something?
OldestInitializedPage is introduced in v14-0001 patch. Please have a look.
> > - Read 6 pages starting from LSN 80. Nothing is read from WAL buffers
> > as the page at LSN 80 doesn't exist despite other 5 pages starting
> > from LSN 90 exist.
>
> This is what I imagined a "partial hit" was: read the 5 pages starting
> at 90. The caller would then need to figure out how to read the page at
> LSN 80 from the segment files.
>
> I am not saying we should support this case; perhaps it doesn't matter.
> I'm just describing why that term was confusing for me.
Okay. Current patch doesn't support this case.
> > If a caller asks for an unflushed WAL read
> > intentionally or unintentionally, XLogReadFromBuffers() reads only 4
> > pages starting from LSN 150 to LSN 180 and will leave the remaining 2
> > pages for the caller to deal with. This is the partial hit that can
> > happen.
>
> To me that's more like an EOF case. "Partial hit" sounds to me like the
> data exists but is not available in the cache (i.e. go to the segment
> files); whereas if it encountered the end, the data is not available at
> all.
Right. We can tweak the comments around "partial hit" if required.
> > WALBufMappingLock protects both xlblocks and WAL buffer pages [1][2].
> > I'm not sure how using the memory barrier, not WALBufMappingLock,
> > prevents writers from replacing WAL buffer pages while readers
> > reading
> > the pages.
>
> It doesn't *prevent* that case, but it does *detect* that case. We
> don't want to prevent writers from replacing WAL buffers, because that
> would mean we are slowing down the critical WAL writing path.
>
> Let me explain the potential problem cases, and how the barriers
> prevent them:
>
> Potential problem 1: the page is not yet resident in the cache at the
> time the memcpy begins. In this case, the first read barrier would
> ensure that the page is also not yet resident at the time xlblocks[idx]
> is read into endptr1, and we'd break out of the loop.
>
> Potential problem 2: the page is evicted before the memcpy finishes. In
> this case, the second read barrier would ensure that the page was also
> evicted before xlblocks[idx] is read into endptr2, and again we'd
> detect the problem and break out of the loop.
Understood.
> I assume here that, if xlblocks[idx] holds the endPtr of the desired
> page, all of the bytes for that page are resident at that moment. I
> don't think that's true right now: AdvanceXLInsertBuffers() zeroes the
> old page before updating xlblocks[nextidx].
Right.
> I think it needs something like:
>
> pg_atomic_write_u64(&XLogCtl->xlblocks[nextidx], InvalidXLogRecPtr);
> pg_write_barrier();
>
> before the MemSet.
I think it works. First, xlblocks needs to be turned to an array of
64-bit atomics and then the above change. With this, all those who
reads xlblocks with or without WALBufMappingLock also need to check if
xlblocks[idx] is ever InvalidXLogRecPtr and take appropriate action.
I'm sure you have seen the following. It looks like I'm leaning
towards the claim that it's safe to read xlblocks without
WALBufMappingLock. I'll put up a patch for these changes separately.
/*
* Make sure the initialization of the page becomes visible to others
* before the xlblocks update. GetXLogBuffer() reads xlblocks without
* holding a lock.
*/
pg_write_barrier();
*((volatile XLogRecPtr *) &XLogCtl->xlblocks[nextidx]) = NewPageEndPtr;
I think the 3 things that helps read from WAL buffers without
WALBufMappingLock are: 1) couple of the read barriers in
XLogReadFromBuffers, 2) atomically initializing xlblocks[idx] to
InvalidXLogRecPtr plus a write barrier in AdvanceXLInsertBuffer(), 3)
the following sanity check to see if the read page is valid in
XLogReadFromBuffers(). If it sounds sensible, I'll work towards coding
it up. Thoughts?
+ , we
+ * need to ensure that we are not reading a page that just got
+ * initialized. For this, we look at the needed page header.
+ */
+ phdr = (XLogPageHeader) page;
+
+ /* Return, if WAL buffer page doesn't look valid. */
+ if (!(phdr->xlp_magic == XLOG_PAGE_MAGIC &&
+ phdr->xlp_pageaddr == (ptr - (ptr % XLOG_BLCKSZ)) &&
+ phdr->xlp_tli == tli))
+ break;
+
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
On Fri, 2023-11-03 at 20:23 +0530, Bharath Rupireddy wrote: > > > OldestInitializedPage is introduced in v14-0001 patch. Please have a > look. I don't see why that's necessary if we move to the algorithm I suggested below that doesn't require a lock. > > > Okay. Current patch doesn't support this [partial hit of newer pages] > case. OK, no need to support it until you see a reason. > > > > > > I think it needs something like: > > > > pg_atomic_write_u64(&XLogCtl->xlblocks[nextidx], > > InvalidXLogRecPtr); > > pg_write_barrier(); > > > > before the MemSet. > > I think it works. First, xlblocks needs to be turned to an array of > 64-bit atomics and then the above change. Does anyone see a reason we shouldn't move to atomics here? > > pg_write_barrier(); > > *((volatile XLogRecPtr *) &XLogCtl->xlblocks[nextidx]) = > NewPageEndPtr; I am confused why the "volatile" is required on that line (not from your patch). I sent a separate message about that: https://www.postgresql.org/message-id/784f72ac09061fe5eaa5335cc347340c367c73ac.camel@j-davis.com > I think the 3 things that helps read from WAL buffers without > WALBufMappingLock are: 1) couple of the read barriers in > XLogReadFromBuffers, 2) atomically initializing xlblocks[idx] to > InvalidXLogRecPtr plus a write barrier in AdvanceXLInsertBuffer(), 3) > the following sanity check to see if the read page is valid in > XLogReadFromBuffers(). If it sounds sensible, I'll work towards > coding > it up. Thoughts? I like it. I think it will ultimately be a fairly simple loop. And by moving to atomics, we won't need the delicate comment in GetXLogBuffer(). Regards, Jeff Davis
Hi, On 2023-11-03 20:23:30 +0530, Bharath Rupireddy wrote: > On Fri, Nov 3, 2023 at 12:35 PM Jeff Davis <pgsql@j-davis.com> wrote: > > > > On Thu, 2023-11-02 at 22:38 +0530, Bharath Rupireddy wrote: > > > > I suppose the question is: should reading from the WAL buffers an > > > > intentional thing that the caller does explicitly by specific > > > > callers? > > > > Or is it an optimization that should be hidden from the caller? > > > > > > > > I tend toward the former, at least for now. > > > > > > Yes, it's an optimization that must be hidden from the caller. > > > > As I said, I tend toward the opposite: that specific callers should > > read from the buffers explicitly in the cases where it makes sense. > > How about adding a bool flag (read_from_wal_buffers) to > XLogReaderState so that the callers can set it if they want this > facility via XLogReaderAllocate()? That seems wrong architecturally - why should xlogreader itself know about any of this? What would it mean in frontend code if read_from_wal_buffers were set? IMO this is something that should happen purely within the read function. Greetings, Andres Freund
Hi,
On 2023-11-02 22:38:38 +0530, Bharath Rupireddy wrote:
> From 5b5469d7dcd8e98bfcaf14227e67356bbc1f5fe8 Mon Sep 17 00:00:00 2001
> From: Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com>
> Date: Thu, 2 Nov 2023 15:10:51 +0000
> Subject: [PATCH v14] Track oldest initialized WAL buffer page
>
> ---
> src/backend/access/transam/xlog.c | 170 ++++++++++++++++++++++++++++++
> src/include/access/xlog.h | 1 +
> 2 files changed, 171 insertions(+)
>
> diff --git a/src/backend/access/transam/xlog.c b/src/backend/access/transam/xlog.c
> index b541be8eec..fdf2ef310b 100644
> --- a/src/backend/access/transam/xlog.c
> +++ b/src/backend/access/transam/xlog.c
> @@ -504,6 +504,45 @@ typedef struct XLogCtlData
> XLogRecPtr *xlblocks; /* 1st byte ptr-s + XLOG_BLCKSZ */
> int XLogCacheBlck; /* highest allocated xlog buffer index */
>
> + /*
> + * Start address of oldest initialized page in XLog buffers.
> + *
> + * We mainly track oldest initialized page explicitly to quickly tell if a
> + * given WAL record is available in XLog buffers. It also can be used for
> + * other purposes, see notes below.
> + *
> + * OldestInitializedPage gives XLog buffers following properties:
> + *
> + * 1) At any given point of time, pages in XLog buffers array are sorted
> + * in an ascending order from OldestInitializedPage till InitializedUpTo.
> + * Note that we verify this property for assert-only builds, see
> + * IsXLogBuffersArraySorted() for more details.
This is true - but also not, if you look at it a bit too literally. The
buffers in xlblocks itself obviously aren't ordered when wrapping around
between XLogRecPtrToBufIdx(OldestInitializedPage) and
XLogRecPtrToBufIdx(InitializedUpTo).
> + * 2) OldestInitializedPage is monotonically increasing (by virtue of how
> + * postgres generates WAL records), that is, its value never decreases.
> + * This property lets someone read its value without a lock. There's no
> + * problem even if its value is slightly stale i.e. concurrently being
> + * updated. One can still use it for finding if a given WAL record is
> + * available in XLog buffers. At worst, one might get false positives
> + * (i.e. OldestInitializedPage may tell that the WAL record is available
> + * in XLog buffers, but when one actually looks at it, it isn't really
> + * available). This is more efficient and performant than acquiring a lock
> + * for reading. Note that we may not need a lock to read
> + * OldestInitializedPage but we need to update it holding
> + * WALBufMappingLock.
I'd
s/may not need/do not need/
But perhaps rephrase it a bit more, to something like:
To update OldestInitializedPage, WALBufMappingLock needs to be held
exclusively, for reading no lock is required.
> + *
> + * 3) One can start traversing XLog buffers from OldestInitializedPage
> + * till InitializedUpTo to list out all valid WAL records and stats, and
> + * expose them via SQL-callable functions to users.
> + *
> + * 4) XLog buffers array is inherently organized as a circular, sorted and
> + * rotated array with OldestInitializedPage as pivot with the property
> + * where LSN of previous buffer page (if valid) is greater than
> + * OldestInitializedPage and LSN of next buffer page (if valid) is greater
> + * than OldestInitializedPage.
> + */
> + XLogRecPtr OldestInitializedPage;
It seems a bit odd to name a LSN containing variable *Page...
> /*
> * InsertTimeLineID is the timeline into which new WAL is being inserted
> * and flushed. It is zero during recovery, and does not change once set.
> @@ -590,6 +629,10 @@ static ControlFileData *ControlFile = NULL;
> #define NextBufIdx(idx) \
> (((idx) == XLogCtl->XLogCacheBlck) ? 0 : ((idx) + 1))
>
> +/* Macro to retreat to previous buffer index. */
> +#define PreviousBufIdx(idx) \
> + (((idx) == 0) ? XLogCtl->XLogCacheBlck : ((idx) - 1))
I think it might be worth making these inlines and adding assertions that idx
is not bigger than XLogCtl->XLogCacheBlck?
> /*
> * XLogRecPtrToBufIdx returns the index of the WAL buffer that holds, or
> * would hold if it was in cache, the page containing 'recptr'.
> @@ -708,6 +751,10 @@ static void WALInsertLockAcquireExclusive(void);
> static void WALInsertLockRelease(void);
> static void WALInsertLockUpdateInsertingAt(XLogRecPtr insertingAt);
>
> +#ifdef USE_ASSERT_CHECKING
> +static bool IsXLogBuffersArraySorted(void);
> +#endif
> +
> /*
> * Insert an XLOG record represented by an already-constructed chain of data
> * chunks. This is a low-level routine; to construct the WAL record header
> @@ -1992,6 +2039,52 @@ AdvanceXLInsertBuffer(XLogRecPtr upto, TimeLineID tli, bool opportunistic)
> XLogCtl->InitializedUpTo = NewPageEndPtr;
>
> npages++;
> +
> + /*
> + * Try updating oldest initialized XLog buffer page.
> + *
> + * Update it if we are initializing an XLog buffer page for the first
> + * time or if XLog buffers are full and we are wrapping around.
> + */
> + if (XLogRecPtrIsInvalid(XLogCtl->OldestInitializedPage) ||
> + XLogRecPtrToBufIdx(XLogCtl->OldestInitializedPage) == nextidx)
> + {
> + Assert(XLogCtl->OldestInitializedPage < NewPageBeginPtr);
> +
> + XLogCtl->OldestInitializedPage = NewPageBeginPtr;
> + }
Wait, isn't this too late? At this point the buffer can already be used by
GetXLogBuffers(). I think thi sneeds to happen at the latest just before
*((volatile XLogRecPtr *) &XLogCtl->xlblocks[nextidx]) = NewPageEndPtr;
Why is it legal to get here with XLogCtl->OldestInitializedPage being invalid?
> +
> +/*
> + * Returns whether or not a given WAL record is available in XLog buffers.
> + *
> + * Note that we don't read OldestInitializedPage under a lock, see description
> + * near its definition in xlog.c for more details.
> + *
> + * Note that caller needs to pass in an LSN known to the server, not a future
> + * or unwritten or unflushed LSN.
> + */
> +bool
> +IsWALRecordAvailableInXLogBuffers(XLogRecPtr lsn)
> +{
> + if (!XLogRecPtrIsInvalid(lsn) &&
> + !XLogRecPtrIsInvalid(XLogCtl->OldestInitializedPage) &&
> + lsn >= XLogCtl->OldestInitializedPage &&
> + lsn < XLogCtl->InitializedUpTo)
> + {
> + return true;
> + }
> +
> + return false;
> +}
> diff --git a/src/include/access/xlog.h b/src/include/access/xlog.h
> index a14126d164..35235010e6 100644
> --- a/src/include/access/xlog.h
> +++ b/src/include/access/xlog.h
> @@ -261,6 +261,7 @@ extern void ReachedEndOfBackup(XLogRecPtr EndRecPtr, TimeLineID tli);
> extern void SetInstallXLogFileSegmentActive(void);
> extern bool IsInstallXLogFileSegmentActive(void);
> extern void XLogShutdownWalRcv(void);
> +extern bool IsWALRecordAvailableInXLogBuffers(XLogRecPtr lsn);
>
> /*
> * Routines to start, stop, and get status of a base backup.
> --
> 2.34.1
>
> From db027d8f1dcb53ebceef0135287f120acf67cc21 Mon Sep 17 00:00:00 2001
> From: Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com>
> Date: Thu, 2 Nov 2023 15:36:11 +0000
> Subject: [PATCH v14] Allow WAL reading from WAL buffers
>
> This commit adds WALRead() the capability to read WAL from WAL
> buffers when possible. When requested WAL isn't available in WAL
> buffers, the WAL is read from the WAL file as usual. It relies on
> WALBufMappingLock so that no one replaces the WAL buffer page that
> we're reading from. It skips reading from WAL buffers if
> WALBufMappingLock can't be acquired immediately. In other words,
> it doesn't wait for WALBufMappingLock to be available. This helps
> reduce the contention on WALBufMappingLock.
>
> This commit benefits the callers of WALRead(), that are walsenders
> and pg_walinspect. They can now avoid reading WAL from the WAL
> file (possibly avoiding disk IO). Tests show that the WAL buffers
> hit ratio stood at 95% for 1 primary, 1 sync standby, 1 async
> standby, with pgbench --scale=300 --client=32 --time=900. In other
> words, the walsenders avoided 95% of the time reading from the
> file/avoided pread system calls:
> https://www.postgresql.org/message-id/CALj2ACXKKK%3DwbiG5_t6dGao5GoecMwRkhr7GjVBM_jg54%2BNa%3DQ%40mail.gmail.com
>
> This commit also benefits when direct IO is enabled for WAL.
> Reading WAL from WAL buffers puts back the performance close to
> that of without direct IO for WAL:
> https://www.postgresql.org/message-id/CALj2ACV6rS%2B7iZx5%2BoAvyXJaN4AG-djAQeM1mrM%3DYSDkVrUs7g%40mail.gmail.com
>
> This commit also paves the way for the following features in
> future:
> - Improves synchronous replication performance by replicating
> directly from WAL buffers.
> - A opt-in way for the walreceivers to receive unflushed WAL.
> More details here:
> https://www.postgresql.org/message-id/20231011224353.cl7c2s222dw3de4j%40awork3.anarazel.de
>
> Author: Bharath Rupireddy
> Reviewed-by: Dilip Kumar, Andres Freund
> Reviewed-by: Nathan Bossart, Kuntal Ghosh
> Discussion:
https://www.postgresql.org/message-id/CALj2ACXKKK%3DwbiG5_t6dGao5GoecMwRkhr7GjVBM_jg54%2BNa%3DQ%40mail.gmail.com
> ---
> src/backend/access/transam/xlog.c | 205 ++++++++++++++++++++++++
> src/backend/access/transam/xlogreader.c | 41 ++++-
> src/include/access/xlog.h | 6 +
> 3 files changed, 250 insertions(+), 2 deletions(-)
>
> diff --git a/src/backend/access/transam/xlog.c b/src/backend/access/transam/xlog.c
> index fdf2ef310b..ff5dccaaa7 100644
> --- a/src/backend/access/transam/xlog.c
> +++ b/src/backend/access/transam/xlog.c
> @@ -1753,6 +1753,211 @@ GetXLogBuffer(XLogRecPtr ptr, TimeLineID tli)
> return cachedPos + ptr % XLOG_BLCKSZ;
> }
>
> +/*
> + * Read WAL from WAL buffers.
> + *
> + * Read 'count' bytes of WAL from WAL buffers into 'buf', starting at location
> + * 'startptr', on timeline 'tli' and return total read bytes.
> + *
> + * This function returns quickly in the following cases:
> + * - When passed-in timeline is different than server's current insertion
> + * timeline as WAL is always inserted into WAL buffers on insertion timeline.
> + * - When server is in recovery as WAL buffers aren't currently used in
> + * recovery.
> + *
> + * Note that this function reads as much as it can from WAL buffers, meaning,
> + * it may not read all the requested 'count' bytes. Caller must be aware of
> + * this and deal with it.
> + *
> + * Note that this function is not available for frontend code as WAL buffers is
> + * an internal mechanism to the server.
>
> + */
> +Size
> +XLogReadFromBuffers(XLogReaderState *state,
> + XLogRecPtr startptr,
> + TimeLineID tli,
> + Size count,
> + char *buf)
> +{
> + XLogRecPtr ptr;
> + XLogRecPtr cur_lsn;
> + Size nbytes;
> + Size ntotal;
> + Size nbatch;
> + char *batchstart;
> +
> + if (RecoveryInProgress())
> + return 0;
>
> + if (tli != GetWALInsertionTimeLine())
> + return 0;
> +
> + Assert(!XLogRecPtrIsInvalid(startptr));
> +
> + cur_lsn = GetFlushRecPtr(NULL);
> + if (unlikely(startptr > cur_lsn))
> + elog(ERROR, "WAL start LSN %X/%X specified for reading from WAL buffers must be less than current database
systemWAL LSN %X/%X",
> + LSN_FORMAT_ARGS(startptr), LSN_FORMAT_ARGS(cur_lsn));
Hm, why does this check belong here? For some tools it might be legitimate to
read the WAL before it was fully flushed.
> + /*
> + * Holding WALBufMappingLock ensures inserters don't overwrite this value
> + * while we are reading it. We try to acquire it in shared mode so that
> + * the concurrent WAL readers are also allowed. We try to do as less work
> + * as possible while holding the lock to not impact concurrent WAL writers
> + * much. We quickly exit to not cause any contention, if the lock isn't
> + * immediately available.
> + */
> + if (!LWLockConditionalAcquire(WALBufMappingLock, LW_SHARED))
> + return 0;
That seems problematic - that lock is often heavily contended. We could
instead check IsWALRecordAvailableInXLogBuffers() once before reading the
page, then read the page contents *without* holding a lock, and then check
IsWALRecordAvailableInXLogBuffers() again - if the page was replaced in the
interim we read bogus data, but that's a bit of a wasted effort.
> + ptr = startptr;
> + nbytes = count; /* Total bytes requested to be read by caller. */
> + ntotal = 0; /* Total bytes read. */
> + nbatch = 0; /* Bytes to be read in single batch. */
> + batchstart = NULL; /* Location to read from for single batch. */
What does "batch" mean?
> + while (nbytes > 0)
> + {
> + XLogRecPtr expectedEndPtr;
> + XLogRecPtr endptr;
> + int idx;
> + char *page;
> + char *data;
> + XLogPageHeader phdr;
> +
> + idx = XLogRecPtrToBufIdx(ptr);
> + expectedEndPtr = ptr;
> + expectedEndPtr += XLOG_BLCKSZ - ptr % XLOG_BLCKSZ;
> + endptr = XLogCtl->xlblocks[idx];
> +
> + /* Requested WAL isn't available in WAL buffers. */
> + if (expectedEndPtr != endptr)
> + break;
> +
> + /*
> + * We found WAL buffer page containing given XLogRecPtr. Get starting
> + * address of the page and a pointer to the right location of given
> + * XLogRecPtr in that page.
> + */
> + page = XLogCtl->pages + idx * (Size) XLOG_BLCKSZ;
> + data = page + ptr % XLOG_BLCKSZ;
> +
> + /*
> + * The fact that we acquire WALBufMappingLock while reading the WAL
> + * buffer page itself guarantees that no one else initializes it or
> + * makes it ready for next use in AdvanceXLInsertBuffer(). However, we
> + * need to ensure that we are not reading a page that just got
> + * initialized. For this, we look at the needed page header.
> + */
> + phdr = (XLogPageHeader) page;
> +
> + /* Return, if WAL buffer page doesn't look valid. */
> + if (!(phdr->xlp_magic == XLOG_PAGE_MAGIC &&
> + phdr->xlp_pageaddr == (ptr - (ptr % XLOG_BLCKSZ)) &&
> + phdr->xlp_tli == tli))
> + break;
I don't think this code should ever encounter a page where this is not the
case? We particularly shouldn't do so silently, seems that could hide all
kinds of problems.
> + /*
> + * Note that we don't perform all page header checks here to avoid
> + * extra work in production builds; callers will anyway do those
> + * checks extensively. However, in an assert-enabled build, we perform
> + * all the checks here and raise an error if failed.
> + */
Why?
> + /* Count what is wanted, not the whole page. */
> + if ((data + nbytes) <= (page + XLOG_BLCKSZ))
> + {
> + /* All the bytes are in one page. */
> + nbatch += nbytes;
> + ntotal += nbytes;
> + nbytes = 0;
> + }
> + else
> + {
> + Size navailable;
> +
> + /*
> + * All the bytes are not in one page. Deduce available bytes on
> + * the current page, count them and continue to look for remaining
> + * bytes.
> + */
s/deducate/deduct/? Perhaps better subtract?
Greetings,
Andres Freund
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Sat, Nov 4, 2023 at 1:17 AM Jeff Davis <pgsql@j-davis.com> wrote: > > > > I think it needs something like: > > > > > > pg_atomic_write_u64(&XLogCtl->xlblocks[nextidx], > > > InvalidXLogRecPtr); > > > pg_write_barrier(); > > > > > > before the MemSet. > > > > I think it works. First, xlblocks needs to be turned to an array of > > 64-bit atomics and then the above change. > > Does anyone see a reason we shouldn't move to atomics here? > > > > > pg_write_barrier(); > > > > *((volatile XLogRecPtr *) &XLogCtl->xlblocks[nextidx]) = > > NewPageEndPtr; > > I am confused why the "volatile" is required on that line (not from > your patch). I sent a separate message about that: > > https://www.postgresql.org/message-id/784f72ac09061fe5eaa5335cc347340c367c73ac.camel@j-davis.com > > > I think the 3 things that helps read from WAL buffers without > > WALBufMappingLock are: 1) couple of the read barriers in > > XLogReadFromBuffers, 2) atomically initializing xlblocks[idx] to > > InvalidXLogRecPtr plus a write barrier in AdvanceXLInsertBuffer(), 3) > > the following sanity check to see if the read page is valid in > > XLogReadFromBuffers(). If it sounds sensible, I'll work towards > > coding > > it up. Thoughts? > > I like it. I think it will ultimately be a fairly simple loop. And by > moving to atomics, we won't need the delicate comment in > GetXLogBuffer(). I'm attaching the v15 patch set implementing the above ideas. Please have a look. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
On Sat, 2023-11-04 at 20:55 +0530, Bharath Rupireddy wrote:
> + XLogRecPtr EndPtr =
> pg_atomic_read_u64(&XLogCtl->xlblocks[curridx]);
> +
> + /*
> + * xlblocks value can be InvalidXLogRecPtr before
> the new WAL buffer
> + * page gets initialized in AdvanceXLInsertBuffer.
> In such a case
> + * re-read the xlblocks value under the lock to
> ensure the correct
> + * value is read.
> + */
> + if (unlikely(XLogRecPtrIsInvalid(EndPtr)))
> + {
> + LWLockAcquire(WALBufMappingLock,
> LW_EXCLUSIVE);
> + EndPtr = pg_atomic_read_u64(&XLogCtl-
> >xlblocks[curridx]);
> + LWLockRelease(WALBufMappingLock);
> + }
> +
> + Assert(!XLogRecPtrIsInvalid(EndPtr));
Can that really happen? If the EndPtr is invalid, that means the page
is in the process of being cleared, so the contents of the page are
undefined at that time, right?
Regards,
Jeff Davis
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Sun, Nov 5, 2023 at 2:57 AM Jeff Davis <pgsql@j-davis.com> wrote:
>
> On Sat, 2023-11-04 at 20:55 +0530, Bharath Rupireddy wrote:
> > + XLogRecPtr EndPtr =
> > pg_atomic_read_u64(&XLogCtl->xlblocks[curridx]);
> > +
> > + /*
> > + * xlblocks value can be InvalidXLogRecPtr before
> > the new WAL buffer
> > + * page gets initialized in AdvanceXLInsertBuffer.
> > In such a case
> > + * re-read the xlblocks value under the lock to
> > ensure the correct
> > + * value is read.
> > + */
> > + if (unlikely(XLogRecPtrIsInvalid(EndPtr)))
> > + {
> > + LWLockAcquire(WALBufMappingLock,
> > LW_EXCLUSIVE);
> > + EndPtr = pg_atomic_read_u64(&XLogCtl-
> > >xlblocks[curridx]);
> > + LWLockRelease(WALBufMappingLock);
> > + }
> > +
> > + Assert(!XLogRecPtrIsInvalid(EndPtr));
>
> Can that really happen? If the EndPtr is invalid, that means the page
> is in the process of being cleared, so the contents of the page are
> undefined at that time, right?
My initial thoughts were this way - xlblocks is being read without
holding WALBufMappingLock in XLogWrite() and since we write
InvalidXLogRecPtr to xlblocks array elements temporarily before
MemSet-ting the page in AdvanceXLInsertBuffer(), the PANIC "xlog write
request %X/%X is past end of log %X/%X" might get hit if EndPtr read
from xlblocks is InvalidXLogRecPtr. FWIW, an Assert(false); within the
if (unlikely(XLogRecPtrIsInvalid(EndPtr))) block didn't hit in make
check-world.
It looks like my above understanding isn't correct because it can
never happen that the page that's being written to the WAL file gets
initialized in AdvanceXLInsertBuffer(). I'll remove this piece of code
in next version of the patch unless there are any other thoughts.
[1]
/*
* Within the loop, curridx is the cache block index of the page to
* consider writing. Begin at the buffer containing the next unwritten
* page, or last partially written page.
*/
curridx = XLogRecPtrToBufIdx(LogwrtResult.Write);
while (LogwrtResult.Write < WriteRqst.Write)
{
/*
* Make sure we're not ahead of the insert process. This could happen
* if we're passed a bogus WriteRqst.Write that is past the end of the
* last page that's been initialized by AdvanceXLInsertBuffer.
*/
XLogRecPtr EndPtr = pg_atomic_read_u64(&XLogCtl->xlblocks[curridx]);
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Sat, Nov 4, 2023 at 6:13 AM Andres Freund <andres@anarazel.de> wrote: > > > + cur_lsn = GetFlushRecPtr(NULL); > > + if (unlikely(startptr > cur_lsn)) > > + elog(ERROR, "WAL start LSN %X/%X specified for reading from WAL buffers must be less than current databasesystem WAL LSN %X/%X", > > + LSN_FORMAT_ARGS(startptr), LSN_FORMAT_ARGS(cur_lsn)); > > Hm, why does this check belong here? For some tools it might be legitimate to > read the WAL before it was fully flushed. Agreed and removed the check. > > + /* > > + * Holding WALBufMappingLock ensures inserters don't overwrite this value > > + * while we are reading it. We try to acquire it in shared mode so that > > + * the concurrent WAL readers are also allowed. We try to do as less work > > + * as possible while holding the lock to not impact concurrent WAL writers > > + * much. We quickly exit to not cause any contention, if the lock isn't > > + * immediately available. > > + */ > > + if (!LWLockConditionalAcquire(WALBufMappingLock, LW_SHARED)) > > + return 0; > > That seems problematic - that lock is often heavily contended. We could > instead check IsWALRecordAvailableInXLogBuffers() once before reading the > page, then read the page contents *without* holding a lock, and then check > IsWALRecordAvailableInXLogBuffers() again - if the page was replaced in the > interim we read bogus data, but that's a bit of a wasted effort. In the new approach described upthread here https://www.postgresql.org/message-id/c3455ab9da42e09ca9d059879b5c512b2d1f9681.camel%40j-davis.com, there's no lock required for reading from WAL buffers. PSA patches for more details. > > + /* > > + * The fact that we acquire WALBufMappingLock while reading the WAL > > + * buffer page itself guarantees that no one else initializes it or > > + * makes it ready for next use in AdvanceXLInsertBuffer(). However, we > > + * need to ensure that we are not reading a page that just got > > + * initialized. For this, we look at the needed page header. > > + */ > > + phdr = (XLogPageHeader) page; > > + > > + /* Return, if WAL buffer page doesn't look valid. */ > > + if (!(phdr->xlp_magic == XLOG_PAGE_MAGIC && > > + phdr->xlp_pageaddr == (ptr - (ptr % XLOG_BLCKSZ)) && > > + phdr->xlp_tli == tli)) > > + break; > > I don't think this code should ever encounter a page where this is not the > case? We particularly shouldn't do so silently, seems that could hide all > kinds of problems. I think it's possible to read a "just got initialized" page with the new approach to read WAL buffer pages without WALBufMappingLock if the page is read right after it is initialized and xlblocks is filled in AdvanceXLInsertBuffer() but before actual WAL is written. > > + /* > > + * Note that we don't perform all page header checks here to avoid > > + * extra work in production builds; callers will anyway do those > > + * checks extensively. However, in an assert-enabled build, we perform > > + * all the checks here and raise an error if failed. > > + */ > > Why? Minimal page header checks are performed to ensure we don't read the page that just got initialized unlike what XLogReaderValidatePageHeader(). Are you suggesting to remove page header checks with XLogReaderValidatePageHeader() for assert-enabled builds? Or are you suggesting to do page header checks with XLogReaderValidatePageHeader() for production builds too? PSA v16 patch set. Note that 0004 patch adds support for WAL read stats (both from WAL file and WAL buffers) to walsenders and may not necessarily the best approach to capture WAL read stats in light of https://www.postgresql.org/message-id/CALj2ACU_f5_c8F%2BxyNR4HURjG%3DJziiz07wCpQc%3DAqAJUFh7%2B8w%40mail.gmail.com which adds WAL read/write/fsync stats to pg_stat_io. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Hi, On 2023-11-08 13:10:34 +0530, Bharath Rupireddy wrote: > > > + /* > > > + * The fact that we acquire WALBufMappingLock while reading the WAL > > > + * buffer page itself guarantees that no one else initializes it or > > > + * makes it ready for next use in AdvanceXLInsertBuffer(). However, we > > > + * need to ensure that we are not reading a page that just got > > > + * initialized. For this, we look at the needed page header. > > > + */ > > > + phdr = (XLogPageHeader) page; > > > + > > > + /* Return, if WAL buffer page doesn't look valid. */ > > > + if (!(phdr->xlp_magic == XLOG_PAGE_MAGIC && > > > + phdr->xlp_pageaddr == (ptr - (ptr % XLOG_BLCKSZ)) && > > > + phdr->xlp_tli == tli)) > > > + break; > > > > I don't think this code should ever encounter a page where this is not the > > case? We particularly shouldn't do so silently, seems that could hide all > > kinds of problems. > > I think it's possible to read a "just got initialized" page with the > new approach to read WAL buffer pages without WALBufMappingLock if the > page is read right after it is initialized and xlblocks is filled in > AdvanceXLInsertBuffer() but before actual WAL is written. I think the code needs to make sure that *never* happens. That seems unrelated to holding or not holding WALBufMappingLock. Even if the page header is already valid, I don't think it's ok to just read/parse WAL data that's concurrently being modified. We can never allow WAL being read that's past XLogBytePosToRecPtr(XLogCtl->Insert->CurrBytePos) as it does not exist. And if the to-be-read LSN is between XLogCtl->LogwrtResult->Write and XLogBytePosToRecPtr(Insert->CurrBytePos) we need to call WaitXLogInsertionsToFinish() before copying the data. Greetings, Andres Freund
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Fri, Nov 10, 2023 at 2:28 AM Andres Freund <andres@anarazel.de> wrote: > > On 2023-11-08 13:10:34 +0530, Bharath Rupireddy wrote: > > > > + /* > > > > + * The fact that we acquire WALBufMappingLock while reading the WAL > > > > + * buffer page itself guarantees that no one else initializes it or > > > > + * makes it ready for next use in AdvanceXLInsertBuffer(). However, we > > > > + * need to ensure that we are not reading a page that just got > > > > + * initialized. For this, we look at the needed page header. > > > > + */ > > > > + phdr = (XLogPageHeader) page; > > > > + > > > > + /* Return, if WAL buffer page doesn't look valid. */ > > > > + if (!(phdr->xlp_magic == XLOG_PAGE_MAGIC && > > > > + phdr->xlp_pageaddr == (ptr - (ptr % XLOG_BLCKSZ)) && > > > > + phdr->xlp_tli == tli)) > > > > + break; > > > > > > I don't think this code should ever encounter a page where this is not the > > > case? We particularly shouldn't do so silently, seems that could hide all > > > kinds of problems. > > > > I think it's possible to read a "just got initialized" page with the > > new approach to read WAL buffer pages without WALBufMappingLock if the > > page is read right after it is initialized and xlblocks is filled in > > AdvanceXLInsertBuffer() but before actual WAL is written. > > I think the code needs to make sure that *never* happens. That seems unrelated > to holding or not holding WALBufMappingLock. Even if the page header is > already valid, I don't think it's ok to just read/parse WAL data that's > concurrently being modified. > > We can never allow WAL being read that's past > XLogBytePosToRecPtr(XLogCtl->Insert->CurrBytePos) > as it does not exist. Agreed. Erroring out in XLogReadFromBuffers() if passed in WAL is past the CurrBytePos is an option. Another cleaner way is to just let the caller decide what it needs to do (retry or error out) - fill an error message in XLogReadFromBuffers() and return as-if nothing was read or return a special negative error code like XLogDecodeNextRecord so that the caller can deal with it. Also, reading CurrBytePos with insertpos_lck spinlock can come in the way of concurrent inserters. A possible way is to turn both CurrBytePos and PrevBytePos 64-bit atomics so that XLogReadFromBuffers() can read CurrBytePos without any lock atomically and leave it to the caller to deal with non-existing WAL reads. > And if the to-be-read LSN is between > XLogCtl->LogwrtResult->Write and XLogBytePosToRecPtr(Insert->CurrBytePos) > we need to call WaitXLogInsertionsToFinish() before copying the data. Agree to wait for all in-flight insertions to the pages we're about to read to finish. But, reading XLogCtl->LogwrtRqst.Write requires either XLogCtl->info_lck spinlock or WALWriteLock. Maybe turn XLogCtl->LogwrtRqst.Write a 64-bit atomic and read it without any lock, rely on WaitXLogInsertionsToFinish()'s return value i.e. if WaitXLogInsertionsToFinish() returns a value >= Insert->CurrBytePos, then go read that page from WAL buffers. Thoughts? -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Mon, Nov 13, 2023 at 7:02 PM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > On Fri, Nov 10, 2023 at 2:28 AM Andres Freund <andres@anarazel.de> wrote: > > > I think the code needs to make sure that *never* happens. That seems unrelated > > to holding or not holding WALBufMappingLock. Even if the page header is > > already valid, I don't think it's ok to just read/parse WAL data that's > > concurrently being modified. > > > > We can never allow WAL being read that's past > > XLogBytePosToRecPtr(XLogCtl->Insert->CurrBytePos) > > as it does not exist. > > Agreed. Erroring out in XLogReadFromBuffers() if passed in WAL is past > the CurrBytePos is an option. Another cleaner way is to just let the > caller decide what it needs to do (retry or error out) - fill an error > message in XLogReadFromBuffers() and return as-if nothing was read or > return a special negative error code like XLogDecodeNextRecord so that > the caller can deal with it. In the attached v17 patch, I've ensured that the XLogReadFromBuffers returns when the caller requests a WAL that's past the current insert position at the moment. > Also, reading CurrBytePos with insertpos_lck spinlock can come in the > way of concurrent inserters. A possible way is to turn both > CurrBytePos and PrevBytePos 64-bit atomics so that > XLogReadFromBuffers() can read CurrBytePos without any lock atomically > and leave it to the caller to deal with non-existing WAL reads. > > > And if the to-be-read LSN is between > > XLogCtl->LogwrtResult->Write and XLogBytePosToRecPtr(Insert->CurrBytePos) > > we need to call WaitXLogInsertionsToFinish() before copying the data. > > Agree to wait for all in-flight insertions to the pages we're about to > read to finish. But, reading XLogCtl->LogwrtRqst.Write requires either > XLogCtl->info_lck spinlock or WALWriteLock. Maybe turn > XLogCtl->LogwrtRqst.Write a 64-bit atomic and read it without any > lock, rely on > WaitXLogInsertionsToFinish()'s return value i.e. if > WaitXLogInsertionsToFinish() returns a value >= Insert->CurrBytePos, > then go read that page from WAL buffers. In the attached v17 patch, I've ensured that the XLogReadFromBuffers waits for all in-progress insertions to finish when the caller requests WAL that's past the current write position and before the current insert position. I've also ensured that the XLogReadFromBuffers returns special return codes for various scenarios (when asked to read in recovery, read on a different TLI, read a non-existent WAL and so on.) instead of it erroring out. This gives flexibility to the caller to decide what to do. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
On Thu, 2023-12-07 at 15:59 +0530, Bharath Rupireddy wrote:
> In the attached v17 patch
0001 could impact performance could be impacted in a few ways:
* There's one additional write barrier inside
AdvanceXLInsertBuffer()
* AdvanceXLInsertBuffer() already holds WALBufMappingLock, so
the atomic access inside of it is somewhat redundant
* On some platforms, the XLogCtlData structure size will change
The patch has been out for a while and nobody seems concerned about
those things, and they look fine to me, so I assume these are not real
problems. I just wanted to highlight them.
Also, the description and the comments seem off. The patch does two
things: (a) make it possible to read a page without a lock, which means
we need to mark with InvalidXLogRecPtr while it's being initialized;
and (b) use 64-bit atomics to make it safer (or at least more
readable).
(a) feels like the most important thing, and it's a hard requirement
for the rest of the work, right?
(b) seems like an implementation choice, and I agree with it on
readability grounds.
Also:
+ * But it means that when we do this
+ * unlocked read, we might see a value that appears to be ahead of
the
+ * page we're looking for. Don't PANIC on that, until we've verified
the
+ * value while holding the lock.
Is that still true even without a torn read?
The code for 0001 itself looks good. These are minor concerns and I am
inclined to commit something like it fairly soon.
Regards,
Jeff Davis
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Fri, Dec 8, 2023 at 6:04 AM Jeff Davis <pgsql@j-davis.com> wrote: > > On Thu, 2023-12-07 at 15:59 +0530, Bharath Rupireddy wrote: > > In the attached v17 patch > > The code for 0001 itself looks good. These are minor concerns and I am > inclined to commit something like it fairly soon. Thanks. Attaching remaining patches as v18 patch-set after commits c3a8e2a7cb16 and 766571be1659. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
On Wed, 2023-12-20 at 15:36 +0530, Bharath Rupireddy wrote:
> Thanks. Attaching remaining patches as v18 patch-set after commits
> c3a8e2a7cb16 and 766571be1659.
Comments:
I still think the right thing for this patch is to call
XLogReadFromBuffers() directly from the callers who need it, and not
change WALRead(). I am open to changing this later, but for now that
makes sense to me so that we can clearly identify which callers benefit
and why. I have brought this up a few times before[1][2], so there must
be some reason that I don't understand -- can you explain it?
The XLogReadFromBuffersResult is never used. I can see how it might be
useful for testing or asserts, but it's not used even in the test
module. I don't think we should clutter the API with that kind of thing
-- let's just return the nread.
I also do not like the terminology "partial hit" to be used in this
way. Perhaps "short read" or something about hitting the end of
readable WAL would be better?
I like how the callers of WALRead() are being more precise about the
bytes they are requesting.
You've added several spinlock acquisitions to the loop. Two explicitly,
and one implicitly in WaitXLogInsertionsToFinish(). These may allow you
to read slightly further, but introduce performance risk. Was this
discussed?
The callers are not checking for XLREADBUGS_UNINITIALIZED_WAL, so it
seems like there's a risk of getting partially-written data? And it's
not clear to me the check of the wal page headers is the right one
anyway.
It seems like all of this would be simpler if you checked first how far
you can safely read data, and then just loop and read that far. I'm not
sure that it's worth it to try to mix the validity checks with the
reading of the data.
Regards,
Jeff Davis
[1] https://www.postgresql.org/message-id/4132fe48f831ed6f73a9eb191af5fe475384969c.camel%40j-davis.com
[2]
https://www.postgresql.org/message-id/2ef04861c0f77e7ae78b703770cc2bbbac3d85e6.camel@j-davis.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Fri, Jan 5, 2024 at 7:20 AM Jeff Davis <pgsql@j-davis.com> wrote: > > On Wed, 2023-12-20 at 15:36 +0530, Bharath Rupireddy wrote: > > Thanks. Attaching remaining patches as v18 patch-set after commits > > c3a8e2a7cb16 and 766571be1659. > > Comments: Thanks for reviewing. > I still think the right thing for this patch is to call > XLogReadFromBuffers() directly from the callers who need it, and not > change WALRead(). I am open to changing this later, but for now that > makes sense to me so that we can clearly identify which callers benefit > and why. I have brought this up a few times before[1][2], so there must > be some reason that I don't understand -- can you explain it? IMO, WALRead() is the best place to have XLogReadFromBuffers() for 2 reasons: 1) All of the WALRead() callers (except FRONTEND tools) will benefit if WAL is read from WAL buffers. I don't see any reason for a caller to skip reading from WAL buffers. If there's a caller (in future) wanting to skip reading from WAL buffers, I'm open to adding a flag in XLogReaderState to skip. 2) The amount of code is reduced if XLogReadFromBuffers() sits in WALRead(). > The XLogReadFromBuffersResult is never used. I can see how it might be > useful for testing or asserts, but it's not used even in the test > module. I don't think we should clutter the API with that kind of thing > -- let's just return the nread. Removed. > I also do not like the terminology "partial hit" to be used in this > way. Perhaps "short read" or something about hitting the end of > readable WAL would be better? "short read" seems good. Done that way in the new patch. > I like how the callers of WALRead() are being more precise about the > bytes they are requesting. > > You've added several spinlock acquisitions to the loop. Two explicitly, > and one implicitly in WaitXLogInsertionsToFinish(). These may allow you > to read slightly further, but introduce performance risk. Was this > discussed? I opted to read slightly further thinking that the loops aren't going to get longer for spinlocks to appear costly. Basically, I wasn't sure which approach was the best. Now that there's an opinion to keep them outside, I'd agree with it. Done that way in the new patch. > The callers are not checking for XLREADBUGS_UNINITIALIZED_WAL, so it > seems like there's a risk of getting partially-written data? And it's > not clear to me the check of the wal page headers is the right one > anyway. > > It seems like all of this would be simpler if you checked first how far > you can safely read data, and then just loop and read that far. I'm not > sure that it's worth it to try to mix the validity checks with the > reading of the data. XLogReadFromBuffers needs the page header check in after reading the page from WAL buffers. Typically, we must not read a WAL buffer page that just got initialized. Because we waited enough for the in-progress WAL insertions to finish above. However, there can exist a slight window after the above wait finishes in which the read buffer page can get replaced especially under high WAL generation rates. After all, we are reading from WAL buffers without any locks here. So, let's not count such a page in. I've addressed the above review comments and attached v19 patch-set. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
On Wed, 2024-01-10 at 19:59 +0530, Bharath Rupireddy wrote:
> I've addressed the above review comments and attached v19 patch-set.
Regarding:
- if (!WALRead(state, cur_page, targetPagePtr, XLOG_BLCKSZ, tli,
- &errinfo))
+ if (!WALRead(state, cur_page, targetPagePtr, count, tli,
&errinfo))
I'd like to understand the reason it was using XLOG_BLCKSZ before. Was
it a performance optimization? Or was it to zero the remainder of the
caller's buffer (readBuf)? Or something else?
If it was to zero the remainder of the caller's buffer, then we should
explicitly make that the caller's responsibility.
Regards,
Jeff Davis
Hi Bharath,
Thanks for working on this. It seems like a nice improvement to have.
Here are some comments on 0001 patch.
1- xlog.c
+ /*
+ * Fast paths for the following reasons: 1) WAL buffers aren't in use when
+ * server is in recovery. 2) WAL is inserted into WAL buffers on current
+ * server's insertion TLI. 3) Invalid starting WAL location.
+ */
Shouldn't the comment be something like "2) WAL is *not* inserted into WAL buffers on current server's insertion TLI" since the condition to break is tli != GetWALInsertionTimeLine()
2-
+ /*
+ * WAL being read doesn't yet exist i.e. past the current insert position.
+ */
+ if ((startptr + count) > reservedUpto)
+ return ntotal;
This question may not even make sense but I wonder whether we can read from startptr only to reservedUpto in case of startptr+count exceeds reservedUpto?
3-
+ /* Wait for any in-progress WAL insertions to WAL buffers to finish. */
+ if ((startptr + count) > LogwrtResult.Write &&
+ (startptr + count) <= reservedUpto)
+ WaitXLogInsertionsToFinish(startptr + count);
Do we need to check if (startptr + count) <= reservedUpto as we already verified this condition a few lines above?
4-
+ Assert(nread > 0);
+ memcpy(dst, data, nread);
+
+ /*
+ * Make sure we don't read xlblocks down below before the page
+ * contents up above.
+ */
+ pg_read_barrier();
+
+ /* Recheck if the read page still exists in WAL buffers. */
+ endptr = pg_atomic_read_u64(&XLogCtl->xlblocks[idx]);
+
+ /* Return if the page got initalized while we were reading it. */
+ if (expectedEndPtr != endptr)
+ break;
+
+ /*
+ * Typically, we must not read a WAL buffer page that just got
+ * initialized. Because we waited enough for the in-progress WAL
+ * insertions to finish above. However, there can exist a slight
+ * window after the above wait finishes in which the read buffer page
+ * can get replaced especially under high WAL generation rates. After
+ * all, we are reading from WAL buffers without any locks here. So,
+ * let's not count such a page in.
+ */
+ phdr = (XLogPageHeader) page;
+ if (!(phdr->xlp_magic == XLOG_PAGE_MAGIC &&
+ phdr->xlp_pageaddr == (ptr - (ptr % XLOG_BLCKSZ)) &&
+ phdr->xlp_tli == tli))
+ break;
I see that you recheck if the page still exists and so at the end. What would you think about memcpy'ing only after being sure that we will need and use the recently read data? If we break the loop during the recheck, we simply discard the data read in the latest attempt. I guess that this may not be a big deal but the data would be unnecessarily copied into the destination in such a case.
5- xlogreader.c
+ nread = XLogReadFromBuffers(startptr, tli, count, buf);
+
+ if (nread > 0)
+ {
+ /*
+ * Check if its a full read, short read or no read from WAL buffers.
+ * For short read or no read, continue to read the remaining bytes
+ * from WAL file.
+ *
+ * XXX: It might be worth to expose WAL buffer read stats.
+ */
+ if (nread == count) /* full read */
+ return true;
+ else if (nread < count) /* short read */
+ {
+ buf += nread;
+ startptr += nread;
+ count -= nread;
+ }
Typo in the comment. Should be like "Check if *it's* a full read, short read or no read from WAL buffers."
Also I don't think XLogReadFromBuffers() returns anything less than 0 and more than count. Is verifying nread > 0 necessary? I think if nread does not equal to count, we can simply assume that it's a short read. (or no read at all in case nread is 0 which we don't need to handle specifically)
6-
+ /*
+ * We determined how much of the page can be validly read as 'count', read
+ * that much only, not the entire page. Since WALRead() can read the page
+ * from WAL buffers, in which case, the page is not guaranteed to be
+ * zero-padded up to the page boundary because of the concurrent
+ * insertions.
+ */
I'm not sure about pasting this into the most places we call WalRead(). Wouldn't it be better if we mention this somewhere around WALRead() only once?
Best,
Melih Mutlu
Microsoft
Hi, On 2024-01-10 19:59:29 +0530, Bharath Rupireddy wrote: > + /* > + * Typically, we must not read a WAL buffer page that just got > + * initialized. Because we waited enough for the in-progress WAL > + * insertions to finish above. However, there can exist a slight > + * window after the above wait finishes in which the read buffer page > + * can get replaced especially under high WAL generation rates. After > + * all, we are reading from WAL buffers without any locks here. So, > + * let's not count such a page in. > + */ > + phdr = (XLogPageHeader) page; > + if (!(phdr->xlp_magic == XLOG_PAGE_MAGIC && > + phdr->xlp_pageaddr == (ptr - (ptr % XLOG_BLCKSZ)) && > + phdr->xlp_tli == tli)) > + break; I still think that anything that requires such checks shouldn't be merged. It's completely bogus to check page contents for validity when we should have metadata telling us which range of the buffers is valid and which not. Greetings, Andres Freund
On Mon, 2024-01-22 at 12:12 -0800, Andres Freund wrote:
> I still think that anything that requires such checks shouldn't be
> merged. It's completely bogus to check page contents for validity
> when we
> should have metadata telling us which range of the buffers is valid
> and which
> not.
The check seems entirely unnecessary, to me. A leftover from v18?
I have attached a new patch (version "19j") to illustrate some of my
previous suggestions. I didn't spend a lot of time on it so it's not
ready for commit, but I believe my suggestions are easier to understand
in code form.
Note that, right now, it only works for XLogSendPhysical(). I believe
it's best to just make it work for 1-3 callers that we understand well,
and we can generalize later if it makes sense.
I'm still not clear on why some callers are reading XLOG_BLCKSZ
(expecting zeros at the end), and if it's OK to just change them to use
the exact byte count.
Also, if we've detected that the first requested buffer has been
evicted, is there any value in continuing the loop to see if more
recent buffers are available? For example, if the requested LSNs range
over buffers 4, 5, and 6, and 4 has already been evicted, should we try
to return LSN data from 5 and 6 at the proper offset in the dest
buffer? If so, we'd need to adjust the API so the caller knows what
parts of the dest buffer were filled in.
Regards,
Jeff Davis
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Tue, Jan 23, 2024 at 9:37 AM Jeff Davis <pgsql@j-davis.com> wrote: > > On Mon, 2024-01-22 at 12:12 -0800, Andres Freund wrote: > > I still think that anything that requires such checks shouldn't be > > merged. It's completely bogus to check page contents for validity > > when we > > should have metadata telling us which range of the buffers is valid > > and which > > not. > > The check seems entirely unnecessary, to me. A leftover from v18? > > I have attached a new patch (version "19j") to illustrate some of my > previous suggestions. I didn't spend a lot of time on it so it's not > ready for commit, but I believe my suggestions are easier to understand > in code form. > Note that, right now, it only works for XLogSendPhysical(). I believe > it's best to just make it work for 1-3 callers that we understand well, > and we can generalize later if it makes sense. +1 to do it for XLogSendPhysical() first. Enabling it for others can just be done as something like the attached v20-0003. > I'm still not clear on why some callers are reading XLOG_BLCKSZ > (expecting zeros at the end), and if it's OK to just change them to use > the exact byte count. "expecting zeros at the end" - this can't always be true as the WAL can get flushed after determining the flush ptr before reading it from the WAL file. FWIW, here's what I've tried previoulsy - https://github.com/BRupireddy2/postgres/tree/ensure_extra_read_WAL_page_is_zero_padded_at_the_end_WIP, the tests hit the Assert(false); added. Which means, the zero-padding comment around WALRead() call-sites isn't quite right. /* * Even though we just determined how much of the page can be validly read * as 'count', read the whole page anyway. It's guaranteed to be * zero-padded up to the page boundary if it's incomplete. */ if (!WALRead(state, cur_page, targetPagePtr, XLOG_BLCKSZ, tli, I think this needs to be discussed separately. If okay, I'll start a new thread. > Also, if we've detected that the first requested buffer has been > evicted, is there any value in continuing the loop to see if more > recent buffers are available? For example, if the requested LSNs range > over buffers 4, 5, and 6, and 4 has already been evicted, should we try > to return LSN data from 5 and 6 at the proper offset in the dest > buffer? If so, we'd need to adjust the API so the caller knows what > parts of the dest buffer were filled in. I'd second this capability for now to keep the API simple and clear, but we can consider expanding it as needed. I reviewed the v19j and attached v20 patch set: 1. * The caller must ensure that it's reasonable to read from the WAL buffers, * i.e. that the requested data is from the current timeline, that we're not * in recovery, etc. I still think the XLogReadFromBuffers can just return in any of the above cases instead of comments. I feel we must assume the caller is going to ask the WAL from a different timeline and/or in recovery and design the API to deal with it. Done that way in v20 patch. 2. Fixed some typos, reworded a few comments (i.e. used "current insert/write position" instead of "Insert/Write pointer" like elsewhere), ran pgindent. 3. - * XXX probably this should be improved to suck data directly from the - * WAL buffers when possible. Removed the above comment before WALRead() since we have that facility now. Perhaps, we can say the callers can suck data directly from the WAL buffers using XLogReadFromBuffers. But I have no strong opinion on this. 4. + * Most callers will have already updated LogwrtResult when determining + * how far to read, but it's OK if it's out of date. (XXX: is it worth + * taking a spinlock to update LogwrtResult and check again before calling + * WaitXLogInsertionsToFinish()?) If the callers use GetFlushRecPtr() to determine how far to read, LogwrtResult will be *reasonably* latest, otherwise not. If LogwrtResult is a bit old, XLogReadFromBuffers will call WaitXLogInsertionsToFinish which will just loop over all insertion locks and return. As far as the current WAL readers are concerned, we don't need an explicit spinlock to determine LogwrtResult because all of them use GetFlushRecPtr() to determine how far to read. If there's any caller that's not updating LogwrtResult at all, we can consider reading LogwrtResult it ourselves in future. 5. I think the two requirements specified at https://www.postgresql.org/message-id/20231109205836.zjoawdrn4q77yemv%40awork3.anarazel.de still hold with the v19j. 5.1 Never allow WAL being read that's past XLogBytePosToRecPtr(XLogCtl->Insert->CurrBytePos) as it does not exist. 5.2 If the to-be-read LSN is between XLogCtl->LogwrtResult->Write and XLogBytePosToRecPtr(Insert->CurrBytePos) we need to call WaitXLogInsertionsToFinish() before copying the data. + if (upto > LogwrtResult.Write) + { + XLogRecPtr writtenUpto = WaitXLogInsertionsToFinish(upto, false); + + upto = Min(upto, writtenUpto); + nbytes = upto - startptr; + } XLogReadFromBuffers ensures the above two with adjusting upto based on Min(upto, writtenUpto) as WaitXLogInsertionsToFinish returns the oldest insertion that is still in-progress. For instance, the current write LSN is 100, current insert LSN is 150 and upto is 200 - we only read upto 150 if startptr is < 150; we don't read anything if startptr is > 150. 6. I've modified the test module in v20-0002 patch as follows: 6.1 Renamed the module to read_wal_from_buffers stripping "test_" which otherwise is making the name longer. Longer names can cause failures on some Windows BF members if the PATH/FILE name is too long. 6.2 Tweaked tests to hit WaitXLogInsertionsToFinish() and upto = Min(upto, writtenUpto); in XLogReadFromBuffers. PSA v20 patch set. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
On Thu, 2024-01-25 at 14:35 +0530, Bharath Rupireddy wrote: > > "expecting zeros at the end" - this can't always be true as the WAL > ... > I think this needs to be discussed separately. If okay, I'll start a > new thread. Thank you for investigating. When the above issue is handled, I'll be more comfortable expanding the call sites for XLogReadFromBuffers(). > > Also, if we've detected that the first requested buffer has been > > evicted, is there any value in continuing the loop to see if more > > recent buffers are available? For example, if the requested LSNs > > range > > over buffers 4, 5, and 6, and 4 has already been evicted, should we > > try > > to return LSN data from 5 and 6 at the proper offset in the dest > > buffer? If so, we'd need to adjust the API so the caller knows what > > parts of the dest buffer were filled in. > > I'd second this capability for now to keep the API simple and clear, > but we can consider expanding it as needed. Agreed. This case doesn't seem important; I just thought I'd ask about it. > If the callers use GetFlushRecPtr() to determine how far to read, > LogwrtResult will be *reasonably* latest It will be up-to-date enough that we'd never go through WaitXLogInsertionsToFinish(), which is all we care about. > As far as the current WAL readers are concerned, we don't need an > explicit spinlock to determine LogwrtResult because all of them use > GetFlushRecPtr() to determine how far to read. If there's any caller > that's not updating LogwrtResult at all, we can consider reading > LogwrtResult it ourselves in future. So we don't actually need that path yet, right? > 5. I think the two requirements specified at > https://www.postgresql.org/message-id/20231109205836.zjoawdrn4q77yemv%40awork3.anarazel.de > still hold with the v19j. Agreed. > PSA v20 patch set. 0001 is very close. I have the following suggestions: * Don't just return zero. If the caller is doing something we don't expect, we want to fix the caller. I understand you'd like this to be more like a transparent optimization, and we may do that later, but I don't think it's a good idea to do that now. * There's currently no use for reading LSNs between Write and Insert, so remove the WaitXLogInsertionsToFinish() code path. That also means we don't need the extra emitLog parameter, so we can remove that. When we have a use case, we can bring it all back. If you agree, I can just make those adjustments (and do some final checking) and commit 0001. Otherwise let me know what you think. 0002: How does the test control whether the data requested is before the Flush pointer, the Write pointer, or the Insert pointer? What if the walwriter comes in and moves one of those pointers before the next statement is executed? Also, do you think a test module is required for the basic functionality in 0001, or only when we start doing more complex things like reading past the Flush pointer? 0003: can you explain why this is useful for wal summarizer to read from the buffers? Regards, Jeff Davis
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Fri, Jan 26, 2024 at 8:31 AM Jeff Davis <pgsql@j-davis.com> wrote: > > > PSA v20 patch set. > > 0001 is very close. I have the following suggestions: > > * Don't just return zero. If the caller is doing something we don't > expect, we want to fix the caller. I understand you'd like this to be > more like a transparent optimization, and we may do that later, but I > don't think it's a good idea to do that now. + if (RecoveryInProgress() || + tli != GetWALInsertionTimeLine()) + return ntotal; + + Assert(!XLogRecPtrIsInvalid(startptr)); Are you suggesting to error out instead of returning 0? If yes, I disagree with it. Because, failure to read due to unmet pre-conditions doesn't necessarily have to be to error out. If we error out, the immediate failure we see is in the src/bin/psql TAP test for calling XLogReadFromBuffers when the server is in recovery. How about returning a negative value instead of just 0 or returning true/false just like WALRead? > * There's currently no use for reading LSNs between Write and Insert, > so remove the WaitXLogInsertionsToFinish() code path. That also means > we don't need the extra emitLog parameter, so we can remove that. When > we have a use case, we can bring it all back. I disagree with this. I don't see anything wrong with XLogReadFromBuffers having the capability to wait for in-progress insertions to finish. In fact, it makes the function near-complete. Imagine, implementing an extension (may be for fun or learning or educational or production purposes) to read unflushed WAL directly from WAL buffers using XLogReadFromBuffers as page_read callback with xlogreader facility. AFAICT, I don't see a problem with WaitXLogInsertionsToFinish logic in XLogReadFromBuffers. FWIW, one important aspect of XLogReadFromBuffers is its ability to read the unflushed WAL from WAL buffers. Also, see a note from Andres here https://www.postgresql.org/message-id/20231109205836.zjoawdrn4q77yemv%40awork3.anarazel.de. > If you agree, I can just make those adjustments (and do some final > checking) and commit 0001. Otherwise let me know what you think. Thanks. Please see my responses above. > 0002: How does the test control whether the data requested is before > the Flush pointer, the Write pointer, or the Insert pointer? What if > the walwriter comes in and moves one of those pointers before the next > statement is executed? Tried to keep wal_writer quiet with wal_writer_delay=10000ms and wal_writer_flush_after = 1GB to not to flush WAL in the background. Also, disabled autovacuum, and set checkpoint_timeout to a higher value. All of this is done to generate minimal WAL so that WAL buffers don't get overwritten. Do you see any problems with it? > Also, do you think a test module is required for > the basic functionality in 0001, or only when we start doing more > complex things like reading past the Flush pointer? With WaitXLogInsertionsToFinish in XLogReadFromBuffers, we have that capability already in. Having a separate test module ensures the code is tested properly. As far as the test is concerned, it verifies 2 cases: 1. Check if WAL is successfully read from WAL buffers. For this, the test generates minimal WAL and reads from WAL buffers from the start LSN = current insert LSN captured before the WAL generation. 2. Check with a WAL that doesn't yet exist. For this, the test reads from WAL buffers from the start LSN = current flush LSN+16MB (a randomly chosen higher value). > 0003: can you explain why this is useful for wal summarizer to read > from the buffers? Can the WAL summarizer ever read the WAL on current TLI? I'm not so sure about it, I haven't explored it in detail. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
On Fri, 2024-01-26 at 19:31 +0530, Bharath Rupireddy wrote:
> Are you suggesting to error out instead of returning 0?
We'd do neither of those things, because no caller should actually call
it while RecoveryInProgress() or on a different timeline.
> How about
> returning a negative value instead of just 0 or returning true/false
> just like WALRead?
All of these things are functionally equivalent -- the same thing is
happening at the end. This is just a discussion about API style and how
that will interact with hypothetical callers that don't exist today.
And it can also be easily changed later, so we aren't stuck with
whatever decision happens here.
>
> Imagine, implementing an extension (may be for fun or learning or
> educational or production purposes) to read unflushed WAL directly
> from WAL buffers using XLogReadFromBuffers as page_read callback with
> xlogreader facility.
That makes sense, I didn't realize you intended to use this fron an
extension. I'm fine considering that as a separate patch that could
potentially be committed soon after this one.
I'd like some more details, but can I please just commit the basic
functionality now-ish?
> Tried to keep wal_writer quiet with wal_writer_delay=10000ms and
> wal_writer_flush_after = 1GB to not to flush WAL in the background.
> Also, disabled autovacuum, and set checkpoint_timeout to a higher
> value. All of this is done to generate minimal WAL so that WAL
> buffers
> don't get overwritten. Do you see any problems with it?
Maybe check it against pg_current_wal_lsn(), and see if the Write
pointer moved ahead? Perhaps even have a (limited) loop that tries
again to catch it at the right time?
> Can the WAL summarizer ever read the WAL on current TLI? I'm not so
> sure about it, I haven't explored it in detail.
Let's just not call XLogReadFromBuffers from there.
Regards,
Jeff Davis
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Sat, Jan 27, 2024 at 1:04 AM Jeff Davis <pgsql@j-davis.com> wrote: > > All of these things are functionally equivalent -- the same thing is > happening at the end. This is just a discussion about API style and how > that will interact with hypothetical callers that don't exist today. > And it can also be easily changed later, so we aren't stuck with > whatever decision happens here. I'll leave that up to you. I'm okay either ways - 1) ensure the caller doesn't use XLogReadFromBuffers, 2) XLogReadFromBuffers returning as-if nothing was read when in recovery or on a different timeline. > > Imagine, implementing an extension (may be for fun or learning or > > educational or production purposes) to read unflushed WAL directly > > from WAL buffers using XLogReadFromBuffers as page_read callback with > > xlogreader facility. > > That makes sense, I didn't realize you intended to use this fron an > extension. I'm fine considering that as a separate patch that could > potentially be committed soon after this one. Yes, I've turned that into 0002 patch. > I'd like some more details, but can I please just commit the basic > functionality now-ish? +1. > > Tried to keep wal_writer quiet with wal_writer_delay=10000ms and > > wal_writer_flush_after = 1GB to not to flush WAL in the background. > > Also, disabled autovacuum, and set checkpoint_timeout to a higher > > value. All of this is done to generate minimal WAL so that WAL > > buffers > > don't get overwritten. Do you see any problems with it? > > Maybe check it against pg_current_wal_lsn(), and see if the Write > pointer moved ahead? Perhaps even have a (limited) loop that tries > again to catch it at the right time? Adding a loop seems to be reasonable here and done in v21-0003. Also, I've added wal_level = minimal per src/test/recovery/t/039_end_of_wal.pl introduced by commit bae868caf22 which also tries to keep WAL activity to minimum. > > Can the WAL summarizer ever read the WAL on current TLI? I'm not so > > sure about it, I haven't explored it in detail. > > Let's just not call XLogReadFromBuffers from there. Removed. PSA v21 patch set. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Alvaro Herrera
Date:
Hmm, this looks quite nice and simple. My only comment is that a
sequence like this
/* Read from WAL buffers, if available. */
rbytes = XLogReadFromBuffers(&output_message.data[output_message.len],
startptr, nbytes, xlogreader->seg.ws_tli);
output_message.len += rbytes;
startptr += rbytes;
nbytes -= rbytes;
if (!WALRead(xlogreader,
&output_message.data[output_message.len],
startptr,
leaves you wondering if WALRead() should be called at all or not, in the
case when all bytes were read by XLogReadFromBuffers. I think in many
cases what's going to happen is that nbytes is going to be zero, and
then WALRead is going to return having done nothing in its inner loop.
I think this warrants a comment somewhere. Alternatively, we could
short-circuit the 'if' expression so that WALRead() is not called in
that case (but I'm not sure it's worth the loss of code clarity).
Also, but this is really quite minor, it seems sad to add more functions
with the prefix XLog, when we have renamed things to use the prefix WAL,
and we have kept the old names only to avoid backpatchability issues.
I mean, if we have WALRead() already, wouldn't it make perfect sense to
name the new routine WALReadFromBuffers?
--
Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
"Tiene valor aquel que admite que es un cobarde" (Fernandel)
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Tue, Jan 30, 2024 at 11:01 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
>
> Hmm, this looks quite nice and simple.
Thanks for looking at it.
> My only comment is that a
> sequence like this
>
> /* Read from WAL buffers, if available. */
> rbytes = XLogReadFromBuffers(&output_message.data[output_message.len],
> startptr, nbytes, xlogreader->seg.ws_tli);
> output_message.len += rbytes;
> startptr += rbytes;
> nbytes -= rbytes;
>
> if (!WALRead(xlogreader,
> &output_message.data[output_message.len],
> startptr,
>
> leaves you wondering if WALRead() should be called at all or not, in the
> case when all bytes were read by XLogReadFromBuffers. I think in many
> cases what's going to happen is that nbytes is going to be zero, and
> then WALRead is going to return having done nothing in its inner loop.
> I think this warrants a comment somewhere. Alternatively, we could
> short-circuit the 'if' expression so that WALRead() is not called in
> that case (but I'm not sure it's worth the loss of code clarity).
It might help avoid a function call in case reading from WAL buffers
satisfies the read fully. And, it's not that clumsy with the change,
see following. I've changed it in the attached v22 patch set.
if (nbytes > 0 &&
!WALRead(xlogreader,
> Also, but this is really quite minor, it seems sad to add more functions
> with the prefix XLog, when we have renamed things to use the prefix WAL,
> and we have kept the old names only to avoid backpatchability issues.
> I mean, if we have WALRead() already, wouldn't it make perfect sense to
> name the new routine WALReadFromBuffers?
WALReadFromBuffers looks better. Used that in v22 patch.
Please see the attached v22 patch set.
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Alvaro Herrera
Date:
Looking at 0003, where an XXX comment is added about taking a spinlock to read LogwrtResult, I suspect the answer is probably not, because it is likely to slow down the other uses of LogwrtResult. But I wonder if a better path forward would be to base further work on my older uncommitted patch to make LogwrtResult use atomics. With that, you wouldn't have to block others in order to read the value. I last posted that patch in [1] in case you're curious. [1] https://postgr.es/m/20220728065920.oleu2jzsatchakfj@alvherre.pgsql The reason I abandoned that patch is that the performance problem that I was fixing no longer existed -- it was fixed in a different way. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "In fact, the basic problem with Perl 5's subroutines is that they're not crufty enough, so the cruft leaks out into user-defined code instead, by the Conservation of Cruft Principle." (Larry Wall, Apocalypse 6)
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Wed, Jan 31, 2024 at 3:01 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > Looking at 0003, where an XXX comment is added about taking a spinlock > to read LogwrtResult, I suspect the answer is probably not, because it > is likely to slow down the other uses of LogwrtResult. We avoided keeping LogwrtResult latest as the current callers for WALReadFromBuffers() all determine the flush LSN using GetFlushRecPtr(), see comment #4 from https://www.postgresql.org/message-id/CALj2ACV%3DC1GZT9XQRm4iN1NV1T%3DhLA_hsGWNx2Y5-G%2BmSwdhNg%40mail.gmail.com. > But I wonder if > a better path forward would be to base further work on my older > uncommitted patch to make LogwrtResult use atomics. With that, you > wouldn't have to block others in order to read the value. I last posted > that patch in [1] in case you're curious. > > [1] https://postgr.es/m/20220728065920.oleu2jzsatchakfj@alvherre.pgsql > > The reason I abandoned that patch is that the performance problem that I > was fixing no longer existed -- it was fixed in a different way. Nice. I'll respond in that thread. FWIW, there's been a recent attempt at turning unloggedLSN to 64-bit atomic - https://commitfest.postgresql.org/46/4330/ and that might need pg_atomic_monotonic_advance_u64. I guess we would have to bring your patch and the unloggedLSN into a single thread to have a better discussion. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
On Wed, 2024-01-31 at 14:30 +0530, Bharath Rupireddy wrote: > Please see the attached v22 patch set. Committed 0001. For 0002 & 0003, I'd like more clarity on how they will actually be used by an extension. For 0004, we need to resolve why callers are using XLOG_BLCKSZ and we can fix that independently, as discussed here: https://www.postgresql.org/message-id/CALj2ACV=C1GZT9XQRm4iN1NV1T=hLA_hsGWNx2Y5-G+mSwdhNg@mail.gmail.com Regards, Jeff Davis
Hi, On 2024-02-12 11:33:24 -0800, Jeff Davis wrote: > On Wed, 2024-01-31 at 14:30 +0530, Bharath Rupireddy wrote: > > Please see the attached v22 patch set. > > Committed 0001. Yay, I think this is very cool. There are plenty other improvements than can be based on this... One thing I'm a bit confused in the code is the following: + /* + * Don't read past the available WAL data. + * + * Check using local copy of LogwrtResult. Ordinarily it's been updated by + * the caller when determining how far to read; but if not, it just means + * we'll read less data. + * + * XXX: the available WAL could be extended to the WAL insert pointer by + * calling WaitXLogInsertionsToFinish(). + */ + upto = Min(startptr + count, LogwrtResult.Write); + nbytes = upto - startptr; Shouldn't it pretty much be a bug to ever encounter this? There aren't equivalent checks in WALRead(), so any user of WALReadFromBuffers() that then falls back to WALRead() is just going to send unwritten data. ISTM that this should be an assertion or error. Greetings, Andres Freund
On Mon, 2024-02-12 at 12:18 -0800, Andres Freund wrote:
> + upto = Min(startptr + count, LogwrtResult.Write);
> + nbytes = upto - startptr;
>
> Shouldn't it pretty much be a bug to ever encounter this?
In the current code it's impossible, though Bharath hinted at an
extension which could reach that path.
What I committed was a bit of a compromise -- earlier versions of the
patch supported reading right up to the Insert pointer (which requires
a call to WaitXLogInsertionsToFinish()). I wasn't ready to commit that
code without seeing a more about how that would be used, but I thought
it was reasonable to have some simple code in there to allow reading up
to the Write pointer.
It seems closer to the structure that we will ultimately need to
replicate unflushed data, right?
Regards,
Jeff Davis
[1]
https://www.postgresql.org/message-id/CALj2ACW65mqn6Ukv57SqDTMzAJgd1N_AdQtDgy+gMDqu6v618Q@mail.gmail.com
Hi, On 2024-02-12 12:46:00 -0800, Jeff Davis wrote: > On Mon, 2024-02-12 at 12:18 -0800, Andres Freund wrote: > > + upto = Min(startptr + count, LogwrtResult.Write); > > + nbytes = upto - startptr; > > > > Shouldn't it pretty much be a bug to ever encounter this? > > In the current code it's impossible, though Bharath hinted at an > extension which could reach that path. > > What I committed was a bit of a compromise -- earlier versions of the > patch supported reading right up to the Insert pointer (which requires > a call to WaitXLogInsertionsToFinish()). I wasn't ready to commit that > code without seeing a more about how that would be used, but I thought > it was reasonable to have some simple code in there to allow reading up > to the Write pointer. I doubt there's a sane way to use WALRead() without *first* ensuring that the range of data is valid. I think we're better of moving that responsibility explicitly to the caller and adding an assertion verifying that. > It seems closer to the structure that we will ultimately need to > replicate unflushed data, right? It doesn't really seem like a necessary, or even particularly useful, part. You couldn't just call WALRead() for that, since the caller would need to know the range up to which WAL is valid but not yet flushed as well. Thus the caller would need to first use WaitXLogInsertionsToFinish() or something like it anyway - and then there's no point in doing the WALRead() anymore. Note that for replicating unflushed data, we *still* might need to fall back to reading WAL data from disk. In which case not asserting in WALRead() would just make it hard to find bugs, because not using WaitXLogInsertionsToFinish() would appear to work as long as data is in wal buffers, but as soon as we'd fall back to on-disk (but unflushed) data, we'd send bogus WAL. Greetings, Andres Freund
On Mon, 2024-02-12 at 11:33 -0800, Jeff Davis wrote:
> For 0002 & 0003, I'd like more clarity on how they will actually be
> used by an extension.
In patch 0002, I'm concerned about calling
WaitXLogInsertionsToFinish(). It loops through all the locks, but
doesn't have any early return path or advance any state.
So if it's repeatedly called with the same or similar values it seems
like it would be doing a lot of extra work.
I'm not sure of the best fix. We could add something to LogwrtResult to
track a new LSN that represents the highest known point where all
inserters are finished (in other words, the latest return value of
WaitXLogInsertionsToFinish()). That seems invasive, though.
Regards,
Jeff Davis
Hi, On 2024-02-12 15:56:19 -0800, Jeff Davis wrote: > On Mon, 2024-02-12 at 11:33 -0800, Jeff Davis wrote: > > For 0002 & 0003, I'd like more clarity on how they will actually be > > used by an extension. > > In patch 0002, I'm concerned about calling > WaitXLogInsertionsToFinish(). It loops through all the locks, but > doesn't have any early return path or advance any state. I doubt it'd be too bad - we call that at much much higher frequency during write heavy OLTP workloads (c.f. XLogFlush()). It can be a performance issue there, but only after increasing NUM_XLOGINSERT_LOCKS - before that the limited number of writers is the limit. Compared to that walsender shouldn't be a significant factor. However, I think it's a very bad idea to call WALReadFromBuffers() from WALReadFromBuffers(). This needs to be at the caller, not down in WALReadFromBuffers(). I don't see why we would want to weaken the error condition in WaitXLogInsertionsToFinish() - I suspect it'd not work correctly to wait for insertions that aren't yet in progress and it just seems like an API misuse. > So if it's repeatedly called with the same or similar values it seems like > it would be doing a lot of extra work. > > I'm not sure of the best fix. We could add something to LogwrtResult to > track a new LSN that represents the highest known point where all > inserters are finished (in other words, the latest return value of > WaitXLogInsertionsToFinish()). That seems invasive, though. FWIW, I think LogwrtResult is an anti-pattern, perhaps introduced due to misunderstanding how cache coherency works. It's not fundamentally faster to access non-shared memory. It'd make far more sense to allow lock-free access to the shared LogwrtResult and Greetings, Andres Freund
On Mon, 2024-02-12 at 15:36 -0800, Andres Freund wrote:
>
> It doesn't really seem like a necessary, or even particularly useful,
> part. You couldn't just call WALRead() for that, since the caller
> would need
> to know the range up to which WAL is valid but not yet flushed as
> well. Thus
> the caller would need to first use WaitXLogInsertionsToFinish() or
> something
> like it anyway - and then there's no point in doing the WALRead()
> anymore.
I follow until the last part. Did you mean "and then there's no point
in doing the WaitXLogInsertionsToFinish() in WALReadFromBuffers()
anymore"?
For now, should I assert that the requested WAL data is before the
Flush pointer or assert that it's before the Write pointer?
> Note that for replicating unflushed data, we *still* might need to
> fall back
> to reading WAL data from disk. In which case not asserting in
> WALRead() would
> just make it hard to find bugs, because not using
> WaitXLogInsertionsToFinish()
> would appear to work as long as data is in wal buffers, but as soon
> as we'd
> fall back to on-disk (but unflushed) data, we'd send bogus WAL.
That makes me wonder whether my previous idea[1] might matter: when
some buffers have been evicted, should WALReadFromBuffers() keep going
through the loop and return the end portion of the requested data
rather than the beginning?
We can sort that out when we get closer to replicating unflushed WAL.
Regards,
Jeff Davis
[1]
https://www.postgresql.org/message-id/2b36bf99e762e65db0dafbf8d338756cf5fa6ece.camel@j-davis.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Tue, Feb 13, 2024 at 1:03 AM Jeff Davis <pgsql@j-davis.com> wrote: > > For 0004, we need to resolve why callers are using XLOG_BLCKSZ and we > can fix that independently, as discussed here: > > https://www.postgresql.org/message-id/CALj2ACV=C1GZT9XQRm4iN1NV1T=hLA_hsGWNx2Y5-G+mSwdhNg@mail.gmail.com Thanks. I started a new thread for this - https://www.postgresql.org/message-id/CALj2ACWBRFac2TingD3PE3w2EBHXUHY3%3DAEEZPJmqhpEOBGExg%40mail.gmail.com. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Tue, Feb 13, 2024 at 5:06 AM Andres Freund <andres@anarazel.de> wrote:
>
> I doubt there's a sane way to use WALRead() without *first* ensuring that the
> range of data is valid. I think we're better of moving that responsibility
> explicitly to the caller and adding an assertion verifying that.
>
> It doesn't really seem like a necessary, or even particularly useful,
> part. You couldn't just call WALRead() for that, since the caller would need
> to know the range up to which WAL is valid but not yet flushed as well. Thus
> the caller would need to first use WaitXLogInsertionsToFinish() or something
> like it anyway - and then there's no point in doing the WALRead() anymore.
>
> Note that for replicating unflushed data, we *still* might need to fall back
> to reading WAL data from disk. In which case not asserting in WALRead() would
> just make it hard to find bugs, because not using WaitXLogInsertionsToFinish()
> would appear to work as long as data is in wal buffers, but as soon as we'd
> fall back to on-disk (but unflushed) data, we'd send bogus WAL.
Callers of WALRead() do a good amount of work to figure out what's
been flushed out but they read the un-flushed and/or invalid data see
the comment [1] around WALRead() call sites as well as a recent thread
[2] for more details.
IIUC, here's the summary of the discussion that has happened so far:
a) If only replicating flushed data, then ensure all the WALRead()
callers read how much ever is valid out of startptr+count. Fix
provided in [2] can help do that.
b) If only replicating flushed data, then ensure all the
WALReadFromBuffers() callers read how much ever is valid out of
startptr+count. Current and expected WALReadFromBuffers() callers will
anyway determine how much of it is flushed and can validly be read.
c) If planning to replicate unflushed data, then ensure all the
WALRead() callers wait until startptr+count is past the current insert
position with WaitXLogInsertionsToFinish().
d) If planning to replicate unflushed data, then ensure all the
WALReadFromBuffers() callers wait until startptr+count is past the
current insert position with WaitXLogInsertionsToFinish().
Adding an assertion or error in WALReadFromBuffers() for ensuring the
callers do follow the above set of rules is easy. We can just do
Assert(startptr+count <= LogwrtResult.Flush).
However, adding a similar assertion or error in WALRead() gets
trickier as it's being called from many places - walsenders, backends,
external tools etc. even when the server is in recovery. Therefore,
determining the actual valid LSN is a bit of a challenge.
What I think is the best way:
- Try and get the fix provided for (a) at [2].
- Implement both (c) and (d).
- Have the assertion in WALReadFromBuffers() ensuring the callers wait
until startptr+count is past the current insert position with
WaitXLogInsertionsToFinish().
- Have a comment around WALRead() to ensure the callers are requesting
the WAL that's written to the disk because it's hard to determine
what's written to disk as this gets called in many scenarios - when
server is in recovery, for walsummarizer etc.
- In the new test module, demonstrate how one can implement reading
unflushed data with WALReadFromBuffers() and/or WALRead() +
WaitXLogInsertionsToFinish().
Thoughts?
[1]
/*
* Even though we just determined how much of the page can be validly read
* as 'count', read the whole page anyway. It's guaranteed to be
* zero-padded up to the page boundary if it's incomplete.
*/
if (!WALRead(state, cur_page, targetPagePtr, XLOG_BLCKSZ, tli,
&errinfo))
[2] https://www.postgresql.org/message-id/CALj2ACWBRFac2TingD3PE3w2EBHXUHY3%3DAEEZPJmqhpEOBGExg%40mail.gmail.com
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Attached 2 patches. Per Andres's suggestion, 0001 adds an: Assert(startptr + count <= LogwrtResult.Write) Though if we want to allow the caller (e.g. in an extension) to determine the valid range, perhaps using WaitXLogInsertionsToFinish(), then the check is wrong. Maybe we should just get rid of that code entirely and trust the caller to request a reasonable range? On Mon, 2024-02-12 at 17:33 -0800, Jeff Davis wrote: > That makes me wonder whether my previous idea[1] might matter: when > some buffers have been evicted, should WALReadFromBuffers() keep > going > through the loop and return the end portion of the requested data > rather than the beginning? > [1] > https://www.postgresql.org/message-id/2b36bf99e762e65db0dafbf8d338756cf5fa6ece.camel@j-davis.com 0002 is to illustrate the above idea. It's a strange API so I don't intend to commit it in this form, but I think we will ultimately need to do something like it when we want to replicate unflushed data. The idea is that data past the Write pointer is always (and only) available in the WAL buffers, so WALReadFromBuffers() should always return it. That way we can always safely fall through to ordinary WALRead(), which can only see before the Write pointer. There's also data before the Write pointer that could be in the WAL buffers, and we might as well copy that, too, if it's not evicted. If some buffers are evicted, it will fill in the *end* of the buffer, leaving a gap at the beginning. The nice thing is that if there is any gap, it will be before the Write pointer, so we can always fall back to WALRead() to fill the gap and it should always succeed. Regards, Jeff Davis
Attachment
On Tue, 2024-02-13 at 22:47 +0530, Bharath Rupireddy wrote:
> c) If planning to replicate unflushed data, then ensure all the
> WALRead() callers wait until startptr+count is past the current
> insert
> position with WaitXLogInsertionsToFinish().
WALRead() can't read past the Write pointer, so there's no point in
calling WaitXLogInsertionsToFinish(), right?
Regards,
Jeff Davis
Hi, On 2024-02-12 17:33:24 -0800, Jeff Davis wrote: > On Mon, 2024-02-12 at 15:36 -0800, Andres Freund wrote: > > > > It doesn't really seem like a necessary, or even particularly useful, > > part. You couldn't just call WALRead() for that, since the caller > > would need > > to know the range up to which WAL is valid but not yet flushed as > > well. Thus > > the caller would need to first use WaitXLogInsertionsToFinish() or > > something > > like it anyway - and then there's no point in doing the WALRead() > > anymore. > > I follow until the last part. Did you mean "and then there's no point > in doing the WaitXLogInsertionsToFinish() in WALReadFromBuffers() > anymore"? Yes, not sure what happened in my brain there. > For now, should I assert that the requested WAL data is before the > Flush pointer or assert that it's before the Write pointer? Yes, I think that'd be good. > > Note that for replicating unflushed data, we *still* might need to > > fall back > > to reading WAL data from disk. In which case not asserting in > > WALRead() would > > just make it hard to find bugs, because not using > > WaitXLogInsertionsToFinish() > > would appear to work as long as data is in wal buffers, but as soon > > as we'd > > fall back to on-disk (but unflushed) data, we'd send bogus WAL. > > That makes me wonder whether my previous idea[1] might matter: when > some buffers have been evicted, should WALReadFromBuffers() keep going > through the loop and return the end portion of the requested data > rather than the beginning? I still doubt that that will help very often, but it'll take some experimentation to figure it out, I guess. > We can sort that out when we get closer to replicating unflushed WAL. +1 Greetings, Andres Freund
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Wed, Feb 14, 2024 at 6:59 AM Jeff Davis <pgsql@j-davis.com> wrote: > > Attached 2 patches. > > Per Andres's suggestion, 0001 adds an: > Assert(startptr + count <= LogwrtResult.Write) > > Though if we want to allow the caller (e.g. in an extension) to > determine the valid range, perhaps using WaitXLogInsertionsToFinish(), > then the check is wrong. Right. > Maybe we should just get rid of that code > entirely and trust the caller to request a reasonable range? I'd suggest we strike a balance here - error out in assert builds if startptr+count is past the current insert position and trust the callers for production builds. It has a couple of advantages over doing just Assert(startptr + count <= LogwrtResult.Write): 1) It allows the caller to read unflushed WAL directly from WAL buffers, see the attached 0005 for an example. 2) All the existing callers where WALReadFromBuffers() is thought to be used are ensuring WAL availability by reading upto the flush position so no problem with it. Also, a note before WALRead() stating the caller must request the WAL at least that's written out (upto LogwrtResult.Write). I'm not so sure about this, perhaps, we don't need this comment at all. Here, I'm with v23 patch set: 0001 - Adds assertion in WALReadFromBuffers() to ensure the requested WAL isn't beyond the current insert position. 0002 - Adds a new test module to demonstrate how one can use WALReadFromBuffers() ensuring WaitXLogInsertionsToFinish() if need be. 0003 - Uses WALReadFromBuffers in more places like logical walsenders and backends. 0004 - Removes zero-padding related stuff as discussed in https://www.postgresql.org/message-id/CALj2ACWBRFac2TingD3PE3w2EBHXUHY3=AEEZPJmqhpEOBGExg@mail.gmail.com. This is needed in this patch set otherwise the assertion added in 0001 fails after 0003. 0005 - Adds a page_read callback for reading from WAL buffers in the new test module added in 0002. Also, adds tests. Thoughts? -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
- v23-0002-Add-test-module-for-verifying-read-from-WAL-buff.patch
- v23-0004-Do-away-with-zero-padding-assumption-before-WALR.patch
- v23-0003-Use-WALReadFromBuffers-in-more-places.patch
- v23-0001-Add-check-in-WALReadFromBuffers-against-requeste.patch
- v23-0005-Demonstrate-page_read-callback-for-reading-from-.patch
On Fri, 2024-02-16 at 13:08 +0530, Bharath Rupireddy wrote:
> I'd suggest we strike a balance here - error out in assert builds if
> startptr+count is past the current insert position and trust the
> callers for production builds.
It's not reasonable to have divergent behavior between assert-enabled
builds and production. I think for now I will just commit the Assert as
Andres suggested until we work out a few more details.
One idea is to use Álvaro's work to eliminate the spinlock, and then
add a variable to represent the last known point returned by
WaitXLogInsertionsToFinish(). Then we can cheaply Assert that the
caller requested something before that point.
> Here, I'm with v23 patch set:
Thank you, I'll look at these.
Regards,
Jeff Davis
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Fri, Feb 16, 2024 at 11:01 PM Jeff Davis <pgsql@j-davis.com> wrote: > > > Here, I'm with v23 patch set: > > Thank you, I'll look at these. Thanks. Here's the v24 patch set after rebasing. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Sat, Feb 17, 2024 at 10:27 AM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > On Fri, Feb 16, 2024 at 11:01 PM Jeff Davis <pgsql@j-davis.com> wrote: > > > > > Here, I'm with v23 patch set: > > > > Thank you, I'll look at these. > > Thanks. Here's the v24 patch set after rebasing. Ran pgperltidy on the new TAP test file added. Please see the attached v25 patch set. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Tue, Feb 20, 2024 at 11:40 AM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > Ran pgperltidy on the new TAP test file added. Please see the attached > v25 patch set. Please find the v26 patches after rebasing. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Thu, Mar 21, 2024 at 11:33 PM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > Please find the v26 patches after rebasing. Commit f3ff7bf83b added a check in WALReadFromBuffers to ensure the requested WAL is not past the WAL that's copied to WAL buffers. So, I've dropped v26-0001 patch. I've attached v27 patches for further review. 0001 adds a test module to demonstrate reading from WAL buffers patterns like the caller ensuring the requested WAL is fully copied to WAL buffers using WaitXLogInsertionsToFinish and an implementation of xlogreader page_read callback to read unflushed/not-yet-flushed WAL directly from WAL buffers. 0002 Use WALReadFromBuffers in more places like for logical walsenders, logical decoding functions, backends reading WAL. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
"Andrey M. Borodin"
Date:
> On 8 Apr 2024, at 08:17, Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: Hi Bharath! As far as I understand CF entry [0] is committed? I understand that there are some open followups, but I just want to determinecorrect CF item status... Thanks! Best regards, Andrey Borodin. [0] https://commitfest.postgresql.org/47/4060/
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Michael Paquier
Date:
On Tue, Apr 09, 2024 at 09:33:49AM +0300, Andrey M. Borodin wrote: > As far as I understand CF entry [0] is committed? I understand that > there are some open followups, but I just want to determine correct > CF item status... So much work has happened on this thread with things that has been committed, so switching the entry to committed makes sense to me. I have just done that. Bharath, could you create a new thread with the new things you are proposing? All that should be v18 work, particularly v27-0002: https://www.postgresql.org/message-id/CALj2ACWCibnX2jcnRreBHFesFeQ6vbKiFstML=w-JVTvUKD_EA@mail.gmail.com -- Michael
Attachment
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Bharath Rupireddy
Date:
On Thu, Apr 11, 2024 at 6:31 AM Michael Paquier <michael@paquier.xyz> wrote: > > On Tue, Apr 09, 2024 at 09:33:49AM +0300, Andrey M. Borodin wrote: > > As far as I understand CF entry [0] is committed? I understand that > > there are some open followups, but I just want to determine correct > > CF item status... > > So much work has happened on this thread with things that has been > committed, so switching the entry to committed makes sense to me. I > have just done that. > > Bharath, could you create a new thread with the new things you are > proposing? All that should be v18 work, particularly v27-0002: > https://www.postgresql.org/message-id/CALj2ACWCibnX2jcnRreBHFesFeQ6vbKiFstML=w-JVTvUKD_EA@mail.gmail.com Thanks. I started a new thread https://www.postgresql.org/message-id/CALj2ACVfF2Uj9NoFy-5m98HNtjHpuD17EDE9twVeJng-jTAe7A%40mail.gmail.com. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Re: Improve WALRead() to suck data directly from WAL buffers when possible
From
Michael Paquier
Date:
On Wed, Apr 24, 2024 at 09:46:20PM +0530, Bharath Rupireddy wrote: > Thanks. I started a new thread > https://www.postgresql.org/message-id/CALj2ACVfF2Uj9NoFy-5m98HNtjHpuD17EDE9twVeJng-jTAe7A%40mail.gmail.com. Cool, thanks. -- Michael