Thread: Deleting older versions in unique indexes to avoid page splits
Attached is a POC patch that teaches nbtree to delete old duplicate versions from unique indexes. The optimization targets non-HOT duplicate version bloat. Although the patch is rather rough, it nevertheless manages to more or less eliminate a whole class of index bloat: Unique index bloat from non-HOT updates in workloads where no transaction lasts for more than a few seconds. For example, it eliminates index bloat with a custom pgbench workload that uses an INCLUDE unique index on pgbench_accounts.aid (with abalance as the non-key attribute), instead of the usual accounts primary key. Similarly, with a standard pgbench_accounts primary key alongside an extra non-unique index on abalance, the primary key will never have any page splits with the patch applied. It's almost as if the updates were actually HOT updates, at least if you focus on the unique index (assuming that there are no long-running transactions). The patch repurposes the deduplication infrastructure to delete duplicates within unique indexes, provided they're actually safe to VACUUM. This is somewhat different to the _bt_unique_check() LP_DEAD bit setting stuff, in that we have to access heap pages that we probably would not have to access otherwise -- it's something that we go out of our way to make happen at the point that the page is about to split, not something that happens in passing at no extra cost. The general idea is to exploit the fact that duplicates in unique indexes are usually deadwood. We only need to "stay one step ahead" of the bloat to avoid all page splits in many important cases. So we usually only have to access a couple of heap pages to avoid a page split in each case. In traditional serial/identity column primary key indexes, any page split that happens that isn't a split of the current rightmost page must be caused by version churn. It should be possible to avoid these "unnecessary" page splits altogether (again, barring long-running transactions). I would like to get early feedback on high level direction. While the patch seems quite promising, I am uncertain about my general approach, and how it might fit into some much broader effort to control bloat in general. There are some clear downsides to my approach. The patch has grotty heuristics that try to limit the extra work performed to avoid page splits -- the cost of accessing additional heap pages while a buffer lock is held on the leaf page needs to be kept. under control. No doubt this regresses some workloads without giving them a clear benefit. Also, the optimization only ever gets used with unique indexes, since they're the only case where a duplicate naturally suggests version churn, which can be targeted fairly directly, and without wasting too many cycles when it doesn't work out. It's not at all clear how we could do something like this with non-unique indexes. One related-though-distinct idea that might be worth considering occurs to me: teach nbtree to try to set LP_DEAD bits in non-unique indexes, in about the same way as it will in _bt_check_unique() for unique indexes. Perhaps the executor could hint to btinsert()/aminsert() that it's inserting a duplicate caused by a non-HOT update, so it's worth trying to LP_DEAD nearby duplicates -- especially if they're on the same heap page as the incoming item. There is a wholly separate question about index bloat that is of long term strategic importance to the Postgres project: what should we do about long running transactions? I tend to think that we can address problems in that area by indicating that it is safe to delete "intermediate" versions -- tuples that are not too old to be seen by the oldest transaction, that are nevertheless not needed (they're too new to be interesting to the old transaction's snapshot, but also too old to be interesting to any other snapshot). Perhaps this optimization could be pursued in a phased fashion, starting with index AMs, where it seems less scary. I recently read a paper that had some ideas about what we could do here [1]. IMV it is past time that we thrashed together a "remove useless intermediate versions" design that is compatible with the current heapam design. [1] https://dl.acm.org/doi/pdf/10.1145/3318464.3389714 -- Peter Geoghegan
Attachment
On Tue, Jun 30, 2020 at 5:03 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached is a POC patch that teaches nbtree to delete old duplicate > versions from unique indexes. The optimization targets non-HOT > duplicate version bloat. Although the patch is rather rough, it > nevertheless manages to more or less eliminate a whole class of index > bloat: Unique index bloat from non-HOT updates in workloads where no > transaction lasts for more than a few seconds. I'm slightly surprised that this thread didn't generate more interest back in June. After all, maintaining the pristine initial state of (say) a primary key index even after many high throughput non-HOT updates (i.e. avoiding "logically unnecessary" page splits entirely) is quite appealing. It arguably goes some way towards addressing long held criticisms of our approach to MVCC. Especially if it can be generalized to all b-tree indexes -- the Uber blog post mentioned tables that have several indexes, which presumably means that there can be no HOT updates (the author of the blog post didn't seem to be aware of HOT at all). I've been trying to generalize my approach to work with all indexes. I think that I can find a strategy that is largely effective at preventing version churn page splits that take place with workloads that have many non-HOT updates, without any serious downsides for workloads that do not benefit. I want to get feedback on that now, since I expect that it will be controversial. Teaching indexes about how tuples are versioned or chaining tuples seems like a non-starter, so the trick will be to come up with something that behaves in approximately the same way as that in cases where it helps. The approach I have in mind is to pass down a hint from the executor to btinsert(), which lets nbtree know that the index tuple insert is in fact associated with a non-HOT update. This hint is only given when the update did not logically modify the columns that the index covers (so presumably the majority of unchanged indexes get the hint, but not the one or two indexes whose columns were modified by our update statement -- or maybe the non-HOT update was caused by not being able to fit a new version on the same heap page, in which case all the btinsert() calls/all the indexes on the table get the hint). Of course, this hint makes it all but certain that the index tuple is the successor for some other index tuple located on the same leaf page. We don't actually include information about which other existing tuple it is, since it pretty much doesn't matter. Even if we did, we definitely cannot opportunistically delete it, because it needs to stay in the index at least until our transaction commits (this should be obvious). Actually, we already try to delete it from within _bt_check_unique() today for unique indexes -- we just never opportunistically mark it dead at that point (as I said, it's needed until the xact commits at the earliest). Here is the maybe-controversial part: The algorithm initially assumes that all indexes more or less have the same properties as unique indexes from a versioning point of view, even though that's clearly not true. That is, it initially assumes that the only reason why there can be duplicates on any leaf page it looks at is because some previous transaction also did a non-HOT update that added a new, unchanged index tuple. The new algorithm only runs when the hint is passed down from the executor and when the only alternative is to split the page (or have a deduplication pass), so clearly there is some justification for this assumption -- it really is highly unlikely that this update (which is on the verge of splitting the page) just so happened to be the first such update that affected the page. It's extremely likely that there will be at least a couple of other tuples like that on the page, and probably quite a few more. And even if we only manage to free one or two tuples, that'll still generally be enough to fit the incoming tuple. In general that is usually quite valuable. Even with a busy database, that might buy us minutes or hours before the question of splitting the same leaf page arises again. By the time that happens, longer running transactions may have committed, VACUUM may have run, etc. Like unique index deduplication, this isn't about freeing space -- it's about buying time. To be blunt: It may be controversial that we're accessing multiple heap pages while holding an exclusive lock on a leaf page, in the hopes that we can avoid a page split, but without any certainty that it'll work out. Sometimes (maybe even most of the time), this assumption turns out to be mostly correct, and we benefit in the obvious way -- no "unnecessary" page splits for affected non-unique indexes. Other times it won't work out, usually because the duplicates are in fact logical duplicates from distinct logical rows. When the new deletion thing doesn't work out, the situation works itself out in the obvious way: we get a deduplication pass. If that doesn't work out we get a page split. So we have three legitimate strategies for resolving the "pressure" against a leaf page: last minute emergency duplicate checks + deletion (the new thing), a deduplication pass, or a page split. The strategies are in competition with each other (though only when we have non-HOT updates). We're only willing to access a fixed number of heap pages (heap pages pointed to by duplicate index tuples) to try to delete some index tuples and avoid a split, and only in the specific context of the hint being received at the point a leaf page fills and it looks like we might have to split it. I think that we should probably avoid doing anything with posting list tuples left behind by deduplication, except maybe if there are only 2 or 3 TIDs -- just skip over them. That way, cases with duplicates across logical rows (not version churn) tend to get made into a posting list early (e.g. during an index build), so we don't even bother trying to delete from them later. Non-posting-list duplicates suggest recency, which suggests version churn -- those dups must at least have come after the most recent deduplication pass. Plus we have heuristics that maximize the chances of finding versions to kill. And we tend to look at the same blocks again and again -- like in the patch I posted, we look at the value with the most dups for things to kill first, and so on. So repeated version deletion passes won't end up accessing totally different heap blocks each time, unless they're successful at killing old versions. (I think that this new feature should be framed as extending the deduplication infrastructure to do deletes -- so it can only be used on indexes that use deduplication.) Even if this new mechanism ends up slowing down non-HOT updates noticeably -- which is *not* something that I can see with my benchmarks now -- then that could still be okay. I think that there is something sensible about imposing a penalty on non-HOT update queries that can cause problems for everybody today. Why shouldn't they have to clean up their own mess? I think that it buys us a lot to condition cleanup on avoiding page splits, because any possible penalty is only paid in cases where there isn't something else that keeps the bloat under control. If something like the kill_prior_tuple mechanism mostly keeps bloat under control already, then we'll resolve the situation that way instead. An important point about this technique is that it's just a back stop, so it can run very infrequently while still preventing an index from growing -- an index that can double in size today. If existing mechanisms against "logically unnecessary" page splits are 99% effective today, then they may still almost be useless to users -- your index still doubles in size. It just takes a little longer in Postgres 13 (with deduplication) compared to Postgres 12. So there is a really huge asymmetry that we still aren't doing enough about, even with deduplication. Deduplication cannot prevent the first "wave" of page splits with primary key style indexes due to the dimensions of the index tuples on the page. The first wave may be all that matters (deduplication does help more when things get really bad, but I'd like to avoid "merely bad" performance characteristics, too). Consider the simplest possible real world example. If we start out with 366 items on a leaf page initially (the actual number with default fillfactor + 64-bit alignment for the pgbench indexes), we can store another 40 non-HOT dups on the same leaf page before the page splits. We only save 4 bytes by merging a dup into one of the 366 original tuples. It's unlikely that many of the 40 dups that go on the page will be duplicates of *each other*, and deduplication only really starts to save space when posting list tuples have 4 or 5 TIDs each. So eventually all of the original leaf pages split when they really shouldn't, despite the availability of deduplication. -- Peter Geoghegan
> 8 окт. 2020 г., в 04:48, Peter Geoghegan <pg@bowt.ie> написал(а): > > On Tue, Jun 30, 2020 at 5:03 PM Peter Geoghegan <pg@bowt.ie> wrote: >> Attached is a POC patch that teaches nbtree to delete old duplicate >> versions from unique indexes. The optimization targets non-HOT >> duplicate version bloat. Although the patch is rather rough, it >> nevertheless manages to more or less eliminate a whole class of index >> bloat: Unique index bloat from non-HOT updates in workloads where no >> transaction lasts for more than a few seconds. > > I'm slightly surprised that this thread didn't generate more interest > back in June. The idea looks very interesting. It resembles GiST microvacuum: GiST tries to vacuum single page before split. I'm curious how cost of page deduplication is compared to cost of page split? Should we do deduplication of page will stillremain 99% full? Best regards, Andrey Borodin.
On Mon, Oct 12, 2020 at 3:47 AM Andrey Borodin <x4mmm@yandex-team.ru> wrote: > The idea looks very interesting. > It resembles GiST microvacuum: GiST tries to vacuum single page before split. AFAICT the GiST microvacuum mechanism is based on the one in nbtree, which is based on setting LP_DEAD bits when index scans find that the TIDs are dead-to-all. That's easy to justify, because it is easy and cheap to save future index scans the trouble of following the TIDs just to discover the same thing for themselves. The difference here is that we're simply making an intelligent guess -- there have been no index scans, but we're going to do a kind of special index scan at the last minute to see if we can avoid a page split. I think that this is okay because in practice we can do it in a reasonably targeted way. We will never do it with INSERTs, for example (except in unique indexes, though only when we know that there are duplicates because we saw them in _bt_check_unique()). In the worst case we make non-HOT updates a bit slower...and I'm not even sure that that's a bad thing when we don't manage to delete anything. After all, non-HOT updates impose a huge cost on the system. They have "negative externalities". Another way to look at it is that the mechanism I propose to add takes advantage of "convexity" [1]. (Actually, several of my indexing ideas are based on similar principles -- like the nbtsplitloc.c stuff.) Attached is v2. It controls the cost of visiting the heap by finding the heap page that has the most TIDs that we might be able to kill (among those that are duplicates on a leaf page). It also adds a hinting mechanism to the executor to avoid uselessly applying the optimization with INSERTs. > I'm curious how cost of page deduplication is compared to cost of page split? Should we do deduplication of page will stillremain 99% full? It depends on how you measure it, but in general I would say that the cost of traditional Postgres 13 deduplication is much lower. Especially as measured in WAL volume. I also believe that the same is true for this new delete deduplication mechanism. The way we determine which heap pages to visit maximizes the chances that we'll get lucky while minimizing the cost (currently we don't visit more than 2 heap pages unless we get at least one kill -- I think I could be more conservative here without losing much). A page split also has to exclusive lock two other pages (the right sibling page and parent page), so even the locking is perhaps better. The attached patch can completely or almost completely avoid index bloat in extreme cases with non-HOT updates. This can easily increase throughput by 2x or more, depending on how extreme you make it (i.e. how many indexes you have). It seems like the main problem caused by non-HOT updates is in fact page splits themselves. It is not so much a problem with dirtying of pages. You can test this with a benchmark like the one that was used for WARM back in 2017: https://www.postgresql.org/message-id/flat/CABOikdMNy6yowA%2BwTGK9RVd8iw%2BCzqHeQSGpW7Yka_4RSZ_LOQ%40mail.gmail.com I suspect that it's maybe even more effective than WARM was with this benchmark. [1] https://fooledbyrandomness.com/ConvexityScience.pdf -- Peter Geoghegan
Attachment
On 08.10.2020 02:48, Peter Geoghegan wrote:
The idea seems very promising, especially when extended to handle non-unique indexes too.On Tue, Jun 30, 2020 at 5:03 PM Peter Geoghegan <pg@bowt.ie> wrote:Attached is a POC patch that teaches nbtree to delete old duplicate versions from unique indexes. The optimization targets non-HOT duplicate version bloat. Although the patch is rather rough, it nevertheless manages to more or less eliminate a whole class of index bloat: Unique index bloat from non-HOT updates in workloads where no transaction lasts for more than a few seconds.I'm slightly surprised that this thread didn't generate more interest back in June. After all, maintaining the pristine initial state of (say) a primary key index even after many high throughput non-HOT updates (i.e. avoiding "logically unnecessary" page splits entirely) is quite appealing. It arguably goes some way towards addressing long held criticisms of our approach to MVCC. Especially if it can be generalized to all b-tree indexes -- the Uber blog post mentioned tables that have several indexes, which presumably means that there can be no HOT updates (the author of the blog post didn't seem to be aware of HOT at all).
That's exactly what I wanted to discuss after the first letter. If we could make (non)HOT-updates index specific, I think it could improve performance a lot.I've been trying to generalize my approach to work with all indexes. I think that I can find a strategy that is largely effective at preventing version churn page splits that take place with workloads that have many non-HOT updates, without any serious downsides for workloads that do not benefit. I want to get feedback on that now, since I expect that it will be controversial. Teaching indexes about how tuples are versioned or chaining tuples seems like a non-starter, so the trick will be to come up with something that behaves in approximately the same way as that in cases where it helps. The approach I have in mind is to pass down a hint from the executor to btinsert(), which lets nbtree know that the index tuple insert is in fact associated with a non-HOT update. This hint is only given when the update did not logically modify the columns that the index covers
Here is the maybe-controversial part: The algorithm initially assumes that all indexes more or less have the same properties as unique indexes from a versioning point of view, even though that's clearly not true. That is, it initially assumes that the only reason why there can be duplicates on any leaf page it looks at is because some previous transaction also did a non-HOT update that added a new, unchanged index tuple. The new algorithm only runs when the hint is passed down from the executor and when the only alternative is to split the page (or have a deduplication pass), so clearly there is some justification for this assumption -- it really is highly unlikely that this update (which is on the verge of splitting the page) just so happened to be the first such update that affected the page.
I think that this optimization can affect low cardinality indexes negatively, but it is hard to estimate impact without tests. Maybe it won't be a big deal, given that we attempt to eliminate old copies not very often and that low cardinality b-trees are already not very useful. Besides, we can always make this thing optional, so that users could tune it to their workload.To be blunt: It may be controversial that we're accessing multiple heap pages while holding an exclusive lock on a leaf page, in the hopes that we can avoid a page split, but without any certainty that it'll work out. Sometimes (maybe even most of the time), this assumption turns out to be mostly correct, and we benefit in the obvious way -- no "unnecessary" page splits for affected non-unique indexes. Other times it won't work out, usually because the duplicates are in fact logical duplicates from distinct logical rows.
I wonder, how this new feature will interact with physical replication? Replica may have quite different performance profile. For example, there can be long running queries, that now prevent vacuum from removing recently-dead rows. How will we handle same situation with this optimized deletion?
-- Anastasia Lubennikova Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Wed, Oct 14, 2020 at 7:07 AM Anastasia Lubennikova <a.lubennikova@postgrespro.ru> wrote: > The idea seems very promising, especially when extended to handle non-unique indexes too. Thanks! > That's exactly what I wanted to discuss after the first letter. If we could make (non)HOT-updates index specific, I thinkit could improve performance a lot. Do you mean accomplishing the same goal in heapam, by making the optimization more intelligent about which indexes need new versions? We did have a patch that did that in 2007, as you may recall -- this was called WARM: https://www.postgresql.org/message-id/flat/CABOikdMNy6yowA%2BwTGK9RVd8iw%2BCzqHeQSGpW7Yka_4RSZ_LOQ%40mail.gmail.com This didn't go anywhere. I think that this solution in more pragmatic. It's cheap enough to remove it if a better solution becomes available in the future. But this is a pretty good solution by all important measures. > I think that this optimization can affect low cardinality indexes negatively, but it is hard to estimate impact withouttests. Maybe it won't be a big deal, given that we attempt to eliminate old copies not very often and that low cardinalityb-trees are already not very useful. Besides, we can always make this thing optional, so that users could tuneit to their workload. Right. The trick is to pay only a fixed low cost (maybe as low as one heap page access) when we start out, and ratchet it up only if the first heap page access looks promising. And to avoid posting list tuples. Regular deduplication takes place when this fails. It's useful for the usual reasons, but also because this new mechanism learns not to try the posting list TIDs. > I wonder, how this new feature will interact with physical replication? Replica may have quite different performance profile. I think of that as equivalent to having a long running transaction on the primary. When I first started working on this patch I thought about having "long running transaction detection". But I quickly realized that that isn't a meaningful concept. A transaction is only truly long running relative to the writes that take place that have obsolete row versions that cannot be cleaned up. It has to be something we can deal with, but it cannot be meaningfully special-cased. -- Peter Geoghegan
On Wed, Oct 14, 2020 at 7:40 AM Peter Geoghegan <pg@bowt.ie> wrote:
> Right. The trick is to pay only a fixed low cost (maybe as low as one
> heap page access) when we start out, and ratchet it up only if the
> first heap page access looks promising.
Just as an example of how the patch can help, consider the following
pgbench variant script:
\set aid1 random_gaussian(1, 100000 * :scale, 2.0)
\set aid2 random_gaussian(1, 100000 * :scale, 2.5)
\set aid3 random_gaussian(1, 100000 * :scale, 2.2)
\set bid random(1, 1 * :scale)
\set tid random(1, 10 * :scale)
\set delta random(-5000, 5000)
BEGIN;
UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid1;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
END;
(These details you see here are a bit arbitrary; don't worry about the
specifics too much.)
Before running the script with pgbench, I initialized pgbench to scale
1500, and made some changes to the indexing (in order to actually test
the patch). There was no standard pgbench_accounts PK. Instead, I
created a unique index that had an include column, which is enough to
make every update a non-HOT update. I also added two more redundant
non-unique indexes to create more overhead from non-HOT updates. It
looked like this:
create unique index aid_pkey_include_abalance on pgbench_accounts
(aid) include (abalance);
create index one on pgbench_accounts (aid);
create index two on pgbench_accounts (aid);
So 3 indexes on the accounts table.
I ran the script for two hours and 16 clients with the patch, then for
another two hours with master. After that time, all 3 indexes were
exactly the same size with the patch, but had almost doubled in size
on master:
aid_pkey_include_abalance: 784,264 pages (or ~5.983 GiB)
one: 769,545 pages (or ~5.871 GiB)
two: 770,295 pages (or ~5.876 GiB)
(With the patch, all three indexes were 100% pristine -- they remained
precisely 411,289 pages in size by the end, which is ~3.137 GiB.)
Note that traditional deduplication is used by the indexes I've called
"one" and "two" here, but not the include index called
"aid_pkey_include_abalance". But it makes little difference, for
reasons that will be obvious if you think about what this looks like
at the leaf page level. Cases that Postgres 13 deduplication does
badly with are often the ones that this new mechanism does well with.
Deduplication by deleting and by merging are truly complementary -- I
haven't just structured the code that way because it was convenient to
use dedup infrastructure just to get the dups at the start. (Yes, it
*was* convenient, but there clearly are cases where each mechanism
competes initially, before nbtree converges on the best strategy at
the local level. So FWIW this patch is a natural and logical extension
of the deduplication work in my mind.)
The TPS/throughput is about what you'd expect for the two hour run:
18,988.762398 TPS for the patch
11,123.551707 TPS for the master branch.
This is a ~1.7x improvement, but I can get more than 3x by changing
the details at the start -- just add more indexes. I don't think that
the precise throughput difference you see here matters. The important
point is that we've more or less fixed a pathological set of behaviors
that have poorly understood cascading effects. Full disclosure: I rate
limited pgbench to 20k for this run, which probably wasn't significant
because neither patch nor master hit that limit for long.
Big latency improvements for that same run, too:
Patch:
statement latencies in milliseconds:
0.001 \set aid1 random_gaussian(1, 100000 * :scale, 2.0)
0.000 \set aid2 random_gaussian(1, 100000 * :scale, 2.5)
0.000 \set aid3 random_gaussian(1, 100000 * :scale, 2.2)
0.000 \set bid random(1, 1 * :scale)
0.000 \set tid random(1, 10 * :scale)
0.000 \set delta random(-5000, 5000)
0.057 BEGIN;
0.294 UPDATE pgbench_accounts SET abalance = abalance +
:delta WHERE aid = :aid1;
0.204 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.195 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
0.090 END;
Master:
statement latencies in milliseconds:
0.002 \set aid1 random_gaussian(1, 100000 * :scale, 2.0)
0.001 \set aid2 random_gaussian(1, 100000 * :scale, 2.5)
0.001 \set aid3 random_gaussian(1, 100000 * :scale, 2.2)
0.001 \set bid random(1, 1 * :scale)
0.000 \set tid random(1, 10 * :scale)
0.001 \set delta random(-5000, 5000)
0.084 BEGIN;
0.604 UPDATE pgbench_accounts SET abalance = abalance +
:delta WHERE aid = :aid1;
0.317 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.311 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
0.120 END;
Note that the mechanism added by the patch naturally limits the number
of versions that are in the index for each logical row, which seems
much more important than the total amount of garbage tuples cleaned
up. It's great that the index is half its original size, but even that
is less important than the effect of more or less bounding the worst
case number of heap pages accessed by point index scans. Even though
this patch shows big performance improvements (as well as very small
performance regressions for small indexes with skew), the patch is
mostly about stability. I believe that Postgres users want greater
stability and predictability in this area more than anything else.
The behavior of the system as a whole that we see for the master
branch here is not anywhere near linear. Page splits are of course
expensive, but they also occur in distinct waves [1] and have lasting
consequences. They're very often highly correlated, with clear tipping
points, so you see relatively sudden slow downs in the real world.
Worse still, with skew the number of hot pages that you have can
double in a short period of time. This very probably happens at the
worst possible time for the user, since the database was likely
already organically experiencing very high index writes at the point
of experiencing the first wave of splits (splits correlated both
within and across indexes on the same table). And, from that point on,
the number of FPIs for the same workload also doubles forever (or at
least until REINDEX).
[1] https://btw.informatik.uni-rostock.de/download/tagungsband/B2-2.pdf
--
Peter Geoghegan
пт, 16 окт. 2020 г. в 21:12, Peter Geoghegan <pg@bowt.ie>:
I ran the script for two hours and 16 clients with the patch, then for
another two hours with master. After that time, all 3 indexes were
exactly the same size with the patch, but had almost doubled in size
on master:
aid_pkey_include_abalance: 784,264 pages (or ~5.983 GiB)
one: 769,545 pages (or ~5.871 GiB)
two: 770,295 pages (or ~5.876 GiB)
(With the patch, all three indexes were 100% pristine -- they remained
precisely 411,289 pages in size by the end, which is ~3.137 GiB.)
…
The TPS/throughput is about what you'd expect for the two hour run:
18,988.762398 TPS for the patch
11,123.551707 TPS for the master branch.
I really like these results, great work!
I'm also wondering how IO numbers changed due to these improvements, shouldn't be difficult to look into.
Peter, according to cfbot patch no longer compiles.
Can you send and update, please?
Peter, according to cfbot patch no longer compiles.
Can you send and update, please?
Victor Yegorov
On Fri, Oct 16, 2020 at 1:00 PM Victor Yegorov <vyegorov@gmail.com> wrote:
> I really like these results, great work!
Thanks Victor!
> I'm also wondering how IO numbers changed due to these improvements, shouldn't be difficult to look into.
Here is the pg_statio_user_indexes for patch for the same run:
schemaname | relname | indexrelname |
idx_blks_read | idx_blks_hit
------------+------------------+---------------------------+---------------+---------------
public | pgbench_accounts | aid_pkey_include_abalance |
12,828,736 | 534,819,826
public | pgbench_accounts | one |
12,750,275 | 534,486,742
public | pgbench_accounts | two |
2,474,893 | 2,216,047,568
(3 rows)
And for master:
schemaname | relname | indexrelname |
idx_blks_read | idx_blks_hit
------------+------------------+---------------------------+---------------+---------------
public | pgbench_accounts | aid_pkey_include_abalance |
29,526,568 | 292,705,432
public | pgbench_accounts | one |
28,239,187 | 293,164,160
public | pgbench_accounts | two |
6,505,615 | 1,318,164,692
(3 rows)
Here is pg_statio_user_tables patch:
schemaname | relname | heap_blks_read | heap_blks_hit |
idx_blks_read | idx_blks_hit | toast_blks_read | toast_blks_hit |
tidx_blks_read | tidx_blks_hit
------------+------------------+----------------+---------------+---------------+---------------+-----------------+----------------+----------------+---------------
public | pgbench_accounts | 123,195,496 | 696,805,485 |
28,053,904 | 3,285,354,136 | | |
|
public | pgbench_branches | 11 | 1,553 |
| | | |
|
public | pgbench_history | 0 | 0 |
| | | |
|
public | pgbench_tellers | 86 | 15,416 |
| | | |
|
(4 rows)
And the pg_statio_user_tables for master:
schemaname | relname | heap_blks_read | heap_blks_hit |
idx_blks_read | idx_blks_hit | toast_blks_read | toast_blks_hit |
tidx_blks_read | tidx_blks_hit
------------+------------------+----------------+---------------+---------------+---------------+-----------------+----------------+----------------+---------------
public | pgbench_accounts | 106,502,089 | 334,875,058 |
64,271,370 | 1,904,034,284 | | |
|
public | pgbench_branches | 11 | 1,553 |
| | | |
|
public | pgbench_history | 0 | 0 |
| | | |
|
public | pgbench_tellers | 86 | 15,416 |
| | | |
|
(4 rows)
Of course, it isn't fair to make a direct comparison because we're
doing ~1.7x times more work with the patch. But even still, the
idx_blks_read is less than half with the patch.
BTW, the extra heap_blks_hit from the patch are not only due to the
fact that the system does more directly useful work. It's also due to
the extra garbage collection triggered in indexes. The same is
probably *not* true with heap_blks_read, though. I minimize the number
of heap pages accessed by the new cleamup mechanism each time, and
temporal locality will help a lot. I think that we delete index
entries pointing to garbage in the heap at pretty predictable
intervals. Heap pages full of LP_DEAD line pointer garbage only get
processed with a few times close together in time, after which they're
bound to either get VACUUM'd or get evicted from shared buffers.
> Peter, according to cfbot patch no longer compiles.
> Can you send and update, please?
Attached is v3, which is rebased against the master branch as of
today. No real changes, though.
--
Peter Geoghegan
Attachment
On Fri, Oct 16, 2020 at 1:58 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached is v3, which is rebased against the master branch as of > today. No real changes, though. And now here's v4. This version adds handling of posting list tuples, which I was skipping over before. Highly contended leaf pages with posting list tuples could still sometimes get "logically unnecessary" page splits in v3, which this seems to fix (barring the most extreme cases of version churn, where the patch cannot and should not prevent page splits). Actually, posting list tuple handling was something that we had in v1 but lost in v2, because v2 changed our general strategy to focus on what is convenient to the heap/tableam, which is the most important thing by far (the cost of failing must be a low, fixed, well understood and well targeted cost). The fix was to include TIDs from posting lists, while marking them "non-promising". Only plain tuples that are duplicates are considered promising. Only promising tuples influence where we look for tuples to kill most of the time. The exception is when there is an even number of promising tuples on two heap pages, where we tiebreak on the total number of TIDs that point to the heap page from the leaf page. I seem to be able to cap the costs paid when the optimization doesn't work out to the extent that we can get away with visiting only *one* heap page before giving up. And, we now never visit more than 3 total (2 is the common case when the optimization is really effective). This may sound conservative -- because it is -- but it seems to work in practice. I may change my mind about that and decide to be less conservative, but so far all of the evidence I've seen suggests that it doesn't matter -- the heuristics seem to really work. Might as well be completely conservative. I'm *sure* that we can afford one heap access here -- we currently *always* visit at least one heap tuple in roughly the same way during each and every unique index tuple insert (not just when the page fills). Posting list TIDs are not the only kind of TIDs that are marked non-promising. We now also include TIDs from non-duplicate tuples. So we're prepared to kill any of the TIDs on the page, though we only really expect it to happen with the "promising" tuples (duplicates). But why not be open to the possibility of killing some extra TIDs in passing? We don't have to visit any extra heap pages to do so, so it's practically free. Empirical evidence shows that this happens quite often. Here's why this posting list tuple strategy is a good one: we consider posting list tuple TIDs non-promising to represent that we think that there are probably actually multiple logical rows involved, or at least to represent that they didn't work -- simple trial and error suggests that they aren't very "promising", whatever the true reason happens to be. But why not "keep an open mind" about the TIDs not each being for distinct logical rows? If it just so happens that the posting list TIDs really were multiple versions of the same logical row all along, then there is a reasonable chance that there'll be even more versions on that same heap page later on. When this happens and when we end up back on the same B-Tree leaf page to think about dedup deletion once again, it's pretty likely that we'll also naturally end up looking into the later additional versions on this same heap page from earlier. At which point we won't miss the opportunity to check the posting lists TIDs in passing. So we get to delete the posting list after all! (If you're thinking "but we probably won't get lucky like that", then consider that it doesn't have to happen on the next occasion when delete deduplication happens on the same leaf page. Just at some point in the future. This is due to the way we visit the heap pages that look most promising first. It might take a couple of rounds of dedup deletion to get back to the same heap page, but that's okay. The simple heuristics proposed in the patch seem to have some really interesting and useful consequences in practice. It's hard to quantify how important these kinds of accidents of locality will be. I haven't targeted this or that effect -- my heuristics are dead simple, and based almost entirely on keeping costs down. You can think of it as "increase the number of TIDs to increase our chances of success" if you prefer.) The life cycle of logical rows/heap tuples seems to naturally lead to these kinds of opportunities. Obviously heapam is naturally very keen on storing related versions on the same heap block already, without any input from this patch. The patch is still evolving, and the overall structure and interface certainly still needs work -- I've focussed on the algorithm so far. I could really use some feedback on high level direction, though. It's a relatively short patch, even with all of my README commentary. But...it's not an easy concept to digest. Note: I'm not really sure if it's necessary to provide specialized qsort routines for the sorting we do to lists of TIDs, etc. I did do some experimentation with that, and it's an open question. So for now I rely on the patch that Thomas Munro posted to do that a little while back, which is why that's included here. The question of whether this is truly needed is unsettled. -- Peter Geoghegan
Attachment
On Wed, Oct 7, 2020 at 7:48 PM Peter Geoghegan <pg@bowt.ie> wrote: > To be blunt: It may be controversial that we're accessing multiple > heap pages while holding an exclusive lock on a leaf page, in the > hopes that we can avoid a page split, but without any certainty that > it'll work out. That certainly isn't great. I mean, it might be not be too terrible, because it's a leaf index page isn't nearly as potentially hot as a VM page or a clog page, but it hurts interruptibility and risks hurting concurrency, but if it were possible to arrange to hold only a pin on the page during all this rather than a lock, it would be better. I'm not sure how realistic that is, though. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Oct 21, 2020 at 8:25 AM Robert Haas <robertmhaas@gmail.com> wrote: > That certainly isn't great. I mean, it might be not be too terrible, > because it's a leaf index page isn't nearly as potentially hot as a VM > page or a clog page, but it hurts interruptibility and risks hurting > concurrency, but if it were possible to arrange to hold only a pin on > the page during all this rather than a lock, it would be better. I'm > not sure how realistic that is, though. I don't think that it's realistic. Well, technically you could do something like that, but you'd end up with some logically equivalent mechanism which would probably be slower. As you know, in nbtree pins are generally much less helpful than within heapam (you cannot read a page without a shared buffer lock, no matter what). Holding a pin only provides a very weak guarantee about VACUUM and TID recycling that usually doesn't come up. Bear in mind that we actually do practically the same thing all the time with the current LP_DEAD setting stuff, where we need to call compute_xid_horizon_for_tuples/heap_compute_xid_horizon_for_tuples with a leaf buffer lock held in almost the same way. That's actually potentially far worse if you look at it in isolation, because you could potentially have hundreds of heap pages, whereas this is just 1 - 3. (BTW, next version will also do that work in passing, so you're practically guaranteed to do less with a buffer lock held compared to the typical case of nbtree LP_DEAD setting, even without counting how the LP_DEAD bits get set in the first place.) I could also point out that something very similar happens in _bt_check_unique(). Also bear in mind that the alternative is pretty much a page split, which means: * Locking the leaf page * Then obtaining relation extension lock * Locking to create new right sibling * Releasing relation extension lock * Locking original right sibling page * Release original right sibling page * Release new right sibling page * Lock parent page * Release original now-split page * Release parent page (I will refrain from going into all of the absurd and near-permanent secondary costs that just giving up and splitting the page imposes for now. I didn't even include all of the information about locking -- there is one thing that didn't seem worth mentioning.) The key concept here is of course asymmetry. The asymmetry here is not only favorable; it's just outrageous. The other key concept is it's fundamentally impossible to pay more than a very small fixed cost without getting a benefit. That said, I accept that there is still some uncertainty that all workloads that get a benefit will be happy with the trade-off. I am still fine tuning how this works in cases with high contention. I welcome any help with that part. But note that this doesn't necessarily have much to do with the heap page accesses. It's not always strictly better to never have any bloat at all (it's pretty close to that, but not quite). We saw this with the Postgres 12 work, where small TPC-C test cases had some queries go slower simply because a small highly contended index did not get bloated due to a smarter split algorithm. There is no reason to believe that it had anything to do with the cost of making better decisions. It was the decisions themselves. I don't want to completely prevent "version driven page splits" (though a person could reasonably imagine that that is in fact my precise goal); rather, I want to make non-hot updates work to prove that it's almost certainly necessary to split the page due to version churn - then and only then should it be accepted. Currently we meekly roll over and let non-hot updaters impose negative externalities on the system as a whole. The patch usually clearly benefits even workloads that consist entirely of non-hot updaters. Negative externalities are only good for the individual trying to impose costs on the collective when they can be a true freeloader. It's always bad for the collective, but it's even bad for the bad actors once they're more than a small minority. Currently non-hot updaters are not merely selfish to the extent that they impose a downside on the collective or the system as a whole that is roughly proportionate to the upside benefit they get. Not cleaning up their mess as they go creates a downside that is a huge multiple of any possible upside for them. To me this seems incontrovertible. Worrying about the precise extent to which this is true in each situation doesn't seem particularly productive to me. Whatever the actual extent of the imbalance is, the solution is that you don't let them do that. This patch is not really about overall throughput. It could be justified on that basis, but that's not how I like to think of it. Rather, it's about providing a stabilizing backstop mechanism, which tends to bound the amount of index bloat and the number of versions in each index for each *logical row* -- that's the most important benefit of the patch. There are workloads that will greatly benefit despite only invoking the new mechanism very occasionally, as a backstop. And even cases with a fair amount of contention don't really use it that often (which is why the heap page access cost is pretty much a question about specific high contention patterns only). The proposed new cleanup mechanism may only be used in certain parts of the key space for certain indexes at certain times, in a bottom-up fashion. We don't have to be eager about cleaning up bloat most of the time, but it's also true that there are cases where we ought to work very hard at it in a localized way. This explanation may sound unlikely, but the existing behaviors taken together present us with outrageous cost/benefit asymmetry, arguably in multiple dimensions. I think that having this backstop cleanup mechanism (and likely others in other areas) will help to make the assumptions underlying autovacuum scheduling much more reasonable in realistic settings. Now it really is okay that autovacuum doesn't really care about the needs of queries, and is largely concerned with macro level things like free space management. It's top down approach isn't so bad once it has true bottom up complementary mechanisms. The LP_DEAD microvacuum stuff is nice because it marks things as dead in passing, pretty much for free. That's not enough on its own -- it's no backstop. The current LP_DEAD stuff appears to work rather well, until one day it suddenly doesn't and you curse Postgres for it. I could go on about the non-linear nature of the system as a whole, hidden tipping points, and other stuff like that. But I won't right now. -- Peter Geoghegan
On Wed, Oct 21, 2020 at 3:36 PM Peter Geoghegan <pg@bowt.ie> wrote: > Bear in mind that we actually do practically the same thing all the > time with the current LP_DEAD setting stuff, where we need to call > compute_xid_horizon_for_tuples/heap_compute_xid_horizon_for_tuples > with a leaf buffer lock held in almost the same way. That's actually > potentially far worse if you look at it in isolation, because you > could potentially have hundreds of heap pages, whereas this is just 1 > - 3. (BTW, next version will also do that work in passing, so you're > practically guaranteed to do less with a buffer lock held compared to > the typical case of nbtree LP_DEAD setting, even without counting how > the LP_DEAD bits get set in the first place.) That's fair. It's not that I'm trying to enforce some absolute coding rule, as if I even had the right to do such a thing. But, people have sometimes proposed patches which would have caused major regression in this area and I think it's really important that we avoid that. Normally, it doesn't matter: I/O requests complete quickly and everything is fine. But, on a system where things are malfunctioning, it makes a big difference whether you can regain control by hitting ^C. I expect you've probably at some point had the experience of being unable to recover control of a terminal window because some process was stuck in wait state D on the kernel level, and you probably thought, "well, this sucks." It's even worse if the kernel's entire process table fills up with such processes. This kind of thing is essentially the same issue at the database level, and it's smart to do what we can to mitigate it. But that being said, I'm not trying to derail this patch. It isn't, and shouldn't be, the job of this patch to solve that problem. It's just better if it doesn't regress things, or maybe even (as you say) makes them a little better. I think the idea you've got here is basically good, and a lot of it comes down to how well it works in practice. I completely agree that looking at amortized cost rather than worst-case cost is a reasonable principle here; you can't take that to a ridiculous extreme because people also care about consistently of performance, but it seems pretty clear from your description that your patch should not create any big problem in that area, because the worst-case number of extra buffer accesses for a single operation is tightly bounded. And, of course, containing index bloat is its own reward. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, 16 Oct 2020 at 20:12, Peter Geoghegan <pg@bowt.ie> wrote: > The TPS/throughput is about what you'd expect for the two hour run: > > 18,988.762398 TPS for the patch > 11,123.551707 TPS for the master branch. Very good. > Patch: > > statement latencies in milliseconds: > 0.294 UPDATE pgbench_accounts SET abalance = abalance + > :delta WHERE aid = :aid1; > > Master: > > statement latencies in milliseconds: > 0.604 UPDATE pgbench_accounts SET abalance = abalance + > :delta WHERE aid = :aid1; The average latency is x2. What is the distribution of latencies? Occasional very long or all uniformly x2? I would guess that holding the page locks will also slow down SELECT workload, so I think you should also report that workload as well. Hopefully that will be better in the latest version. I wonder whether we can put this work into a background process rather than pay the cost in the foreground? Perhaps that might not need us to hold page locks?? -- Simon Riggs http://www.EnterpriseDB.com/
On Thu, Oct 22, 2020 at 10:12 AM Simon Riggs <simon@2ndquadrant.com> wrote: > > 18,988.762398 TPS for the patch > > 11,123.551707 TPS for the master branch. > > Very good. I'm happy with this result, but as I said it's not really the point. I can probably get up to a 5x or more improvement in TPS if I simply add enough indexes. The point is that we're preventing pathological behavior. The patch does not so much add something helpful as subtract something harmful. You can contrive a case that has as much of that harmful element as you like. > The average latency is x2. What is the distribution of latencies? > Occasional very long or all uniformly x2? The latency is generally very even with the patch. There is a constant hum of cleanup by the new mechanism in the case of the benchmark workload. As opposed to a cascade of page splits, which occur in clearly distinct correlated waves. > I would guess that holding the page locks will also slow down SELECT > workload, so I think you should also report that workload as well. > > Hopefully that will be better in the latest version. But the same benchmark that you're asking about here has two SELECT statements and only one UPDATE. It already is read-heavy in that sense. And we see that the latency is also significantly improved for the SELECT queries. Even if there was often a performance hit rather than a benefit (which is definitely not what we see), it would still probably be worth it. Users create indexes for a reason. I believe that we are obligated to maintain the indexes to a reasonable degree, and not just when it happens to be convenient to do so in passing. > I wonder whether we can put this work into a background process rather > than pay the cost in the foreground? Perhaps that might not need us to > hold page locks?? Holding a lock on the leaf page is unavoidable. This patch is very effective because it intervenes at precisely the right moment in precisely the right place only. We don't really have to understand anything about workload characteristics to be sure of this, because it's all based on the enormous asymmetries I've described, which are so huge that it just seems impossible that anything else could matter. Trying to do any work in a background process works against this local-first, bottom-up laissez faire strategy. The strength of the design is in how clever it isn't. -- Peter Geoghegan
heapam and bottom-up garbage collection, keeping version chains short (Was: Deleting older versions in unique indexes to avoid page splits)
From
Peter Geoghegan
Date:
On Thu, Oct 22, 2020 at 6:18 AM Robert Haas <robertmhaas@gmail.com> wrote: > But that being said, I'm not trying to derail this patch. It isn't, > and shouldn't be, the job of this patch to solve that problem. It's > just better if it doesn't regress things, or maybe even (as you say) > makes them a little better. I think the idea you've got here is > basically good, and a lot of it comes down to how well it works in > practice. Thanks. I would like to have a more general conversation about how some of the principles embodied by this patch could be generalized to heapam in the future. I think that we could do something similar with pruning, or at least with the truncation of HOT chains. Here are a few of the principles I'm thinking of, plus some details of how they might be applied in heapam: * The most important metric is not the total amount of dead tuples in the whole table. Rather, it's something like the 90th + 99th percentile length of version chains for each logical row, or maybe only those logical rows actually accessed by index scans recently. (Not saying that we should try to target this in some explicit way - just that it should be kept low with real workloads as a natural consequence of the design.) * Have a variety of strategies for dealing with pruning that compete with each other. Allow them to fight it out organically. Start with the cheapest thing and work your way up. So for example, truncation of HOT chains is always preferred, and works in just the same way as it does today. Then it gets more complicated and more expensive, but in a way that is a natural adjunct of the current proven design. I believe that this creates a bit more pain earlier on, but avoids much more pain later. There is no point powering ahead if we'll end up hopelessly indebted with garbage tuples in the end. For heapam we could escalate from regular pruning by using an old version store for versions that were originally part of HOT chains, but were found to not fit on the same page at the point of opportunistic pruning. The old version store is for committed versions only -- it isn't really much like UNDO. We leave forwarding information on the original heap page. We add old committed versions to the version store at the point when a heap page is about to experience an event that is roughly the equivalent of a B-Tree page split -- for heapam a "split" is being unable to keep the same logical row on the same heap page over time in the presence of many updates. This is our last line of defense against this so-called page split situation. It occurs after regular pruning (which is an earlier line of defense) fails to resolve the situation inexpensively. We can make moving tuples into the old version store WAL efficient by making it work like an actual B-Tree page split -- it can describe the changes in a way that's mostly logical, and based on the existing page image. And like an actual page split, we're amortizing costs in a localized way. It is also possible to apply differential compression to whole HOT chains rather than storing them in the old version store, for example, if that happens to look favorable (think of rows with something like a pgbench_accounts.filler column -- not uncommon). We have options, we can add new options in the future as new requirements come to light. We allow the best option to present itself to us in a bottom-up fashion. Sometimes the best strategy at the local level is actually a combination of two different strategies applied alternately over time. For example, we use differential compression first when we fail to prune, then we prune the same page later (a little like merge deduplication in my recent nbtree delete dedup patch). Maybe each of these two strategies (differential compression + traditional heap HOT chain truncation) get applied alternately against the same heap page over time, in a tick-tock fashion. We naturally avoid availing of the old version store structure, which is good, since that is a relatively expensive strategy that we should apply only as a last resort. This tick-tock behavior is an emergent property of the workload rather than something planned or intelligent, and yet it kind of appears to be an intelligent strategy. (Maybe it works that way permanently in some parts of the heap, or maybe the same heap blocks only tick-tock like this on Tuesdays. It may be possible for stuff like that to happen sanely with well chosen simple heuristics that exploit asymmetry.) * Work with (not against) the way that Postgres strongly decouples the physical representation of data from the logical contents of the database compared to other DB systems. But at the same time, work hard to make the physical representation of the data as close as is practically possible to an idealized, imaginary logical version of the data. Do this because it makes queries faster, not because it's strictly necessary for concurrency control/recovery/whatever. Concretely, this mostly means that we try our best to keep each logical row (i.e. the latest physical version or two of each row) located on the same physical heap block over time, using the escalation strategy I described or something like it. Notice that we're imposing a cost on queries that are arguably responsible for creating garbage, but only when we really can't tolerate more garbage collection debt. But if it doesn't work out that's okay -- we tried. I have a feeling that it will in fact mostly work out. Why shouldn't it be possible to have no more than one or two uncommitted row versions in a heap page at any given time, just like with my nbtree patch? (I think that the answer to that question is "weird workloads", but I'm okay with the idea that they're a little slower or whatever.) Notice that this makes the visibility map work better in practice. I also think that the FSM needs to be taught that it isn't a good thing to reuse a little fragment of space on its own, because it works against our goal of trying to avoid relocating rows. The current logic seems focussed on using every little scrap of free space no matter what, which seems pretty misguided. Penny-wise, pound-foolish. Also notice that fighting to keep the same logical row on the same block has a non-linear payoff. We don't need to give up on that goal at the first sign of trouble. If it's hard to do a conventional prune after succeeding a thousand times then it's okay to work harder. Only a sucker gives up at the first sign of trouble. We're playing a long game here. If it becomes so hard that even applying a more aggressive strategy fails, then it's probably also true that it has become inherently impossible to sustain the original layout. We graciously accept defeat and cut our losses, having only actually wasted a little effort to learn that we need to move our incoming successor version to some other heap block (especially because the cost is amortized across versions that live on the same heap block). * Don't try to completely remove VACUUM. Treat its top down approach as complementary to the new bottom-up approaches we add. There is nothing wrong with taking a long time to clean up garbage tuples in heap pages that have very little garbage total. In fact I think that it might be a good thing. Why be in a hurry to dirty the page again? If it becomes a real problem in the short term then the bottom-up stuff can take care of it. Under this old-but-new paradigm, maybe VACUUM has to visit indexes a lot less (maybe it just decides not to sometimes, based on stats about the indexes, like we see today with vacuum_index_cleanup = off). VACUUM is for making infrequent "clean sweeps", though it typically leaves most of the work to new bottom-up approaches, that are well placed to understand the needs of queries that touch nearby data. Autovacuum does not presume to understand the needs of queries at all. It would also be possible for VACUUM to make more regular sweeps over the version store without disturbing the main relation under this model. The version store isn't that different to a separate heap relation, but naturally doesn't require traditional index cleanup or freezing, and naturally stores things in approximately temporal order. So we recycle space in the version store in a relatively eager, circular fashion, because it naturally contains data that favors such an approach. We make up the fixed cost of using the separate old version store structure by reducing deferred costs like this. And by only using it when it is demonstrably helpful. It might also make sense for us to prioritize putting heap tuples that represent versions whose indexed columns were changed by update (basically a non-hot update) in the version store -- we work extra hard on that (and just leave behind an LP_DEAD line pointer). That way VACUUM can do retail index tuple deletion for the index whose columns were modified when it finds them in the version store (presumably this nbtree patch of mine works well enough with the logically unchanged index entries for other indexes that we don't need to go out of our way). I'm sure that there are more than a few holes in this sketch of mine. It's not really worked out, but it has certain properties that are generally under appreciated -- especially the thing about the worst case number of versions per logical row being extremely important, as well as the idea that back pressure can be a good thing when push comes to shove -- provided it is experienced locally, and only by queries that update the same very hot logical rows. Back pressure needs to be proportionate and approximately fair. Another important point that I want to call out again here is that we should try to exploit cost/benefit asymmetry opportunistically. That seems to have worked out extremely well in my recent B-Tree delete dedup patch. I don't really expect anybody to take this seriously -- especially as a total blueprint. Maybe some elements of what I've sketched can be used as part of some future big effort. You've got to start somewhere. It has to be incremental. -- Peter Geoghegan
On Thu, 22 Oct 2020 at 18:42, Peter Geoghegan <pg@bowt.ie> wrote: > > The average latency is x2. What is the distribution of latencies? > > Occasional very long or all uniformly x2? > > The latency is generally very even with the patch. There is a constant > hum of cleanup by the new mechanism in the case of the benchmark > workload. As opposed to a cascade of page splits, which occur in > clearly distinct correlated waves. Please publish details of how long a pre-split cleaning operation takes and what that does to transaction latency. It *might* be true that the cost of avoiding splits is worth it in balance against the cost of splitting, but it might not. You've shown us a very nice paper analysing the page split waves, but we need a similar detailed analysis so we can understand if what you propose is better or not (and in what situations). > > I would guess that holding the page locks will also slow down SELECT > > workload, so I think you should also report that workload as well. > > > > Hopefully that will be better in the latest version. > > But the same benchmark that you're asking about here has two SELECT > statements and only one UPDATE. It already is read-heavy in that > sense. And we see that the latency is also significantly improved for > the SELECT queries. > > Even if there was often a performance hit rather than a benefit (which > is definitely not what we see), it would still probably be worth it. > Users create indexes for a reason. I believe that we are obligated to > maintain the indexes to a reasonable degree, and not just when it > happens to be convenient to do so in passing. The leaf page locks are held for longer, so we need to perform sensible tests that show if this has a catastrophic effect on related workloads, or not. The SELECT tests proposed need to be aimed at the same table, at the same time. > The strength of the design is in how clever it isn't. What it doesn't do could be good or bad so we need to review more details on behavior. Since the whole idea of the patch is to change behavior, that seems a reasonable ask. I don't have any doubt about the validity of the approach or coding. What you've done so far is very good and I am very positive about this, well done. -- Simon Riggs http://www.EnterpriseDB.com/
On Fri, Oct 23, 2020 at 9:03 AM Simon Riggs <simon@2ndquadrant.com> wrote: > Please publish details of how long a pre-split cleaning operation > takes and what that does to transaction latency. It *might* be true > that the cost of avoiding splits is worth it in balance against the > cost of splitting, but it might not. I don't think that you understand how the patch works. I cannot very well isolate that cost because the patch is designed to only pay it when there is a strong chance of getting a much bigger reward, and when the only alternative is to split the page. When it fails the question naturally doesn't come up again for the same two pages that follow from the page split. As far as I know the only cases that are regressed all involve small indexes with lots of contention, which is not surprising. And not necessarily due to the heap page accesses - making indexes smaller sometimes has that effect, even when it happens due to things like better page split heuristics. If anybody finds a serious problem with my patch then it'll be a weakness or hole in the argument I just made -- it won't have much to do with how expensive any of these operations are in isolation. It usually isn't sensible to talk about page splits as isolated things. Most of my work on B-Trees in the past couple of years built on the observation that sometimes successive page splits are related to each other in one way or another. It is a fallacy of composition to think of the patch as a thing that prevents some page splits. The patch is valuable because it more or less eliminates *unnecessary* page splits (and makes it so that there cannot be very many TIDs for each logical row in affected indexes). The overall effect is not linear. If you added code to artificially make the mechanism fail randomly 10% of the time (at the point where it becomes clear that the current operation would otherwise be successful) that wouldn't make the resulting code 90% as useful as the original. It would actually make it approximately 0% as useful. On human timescales the behavioral difference between this hobbled version of my patch and the master branch would be almost imperceptible. It's obvious that a page split is more expensive than the delete operation (when it works out). It doesn't need a microbenchmark (and I really can't think of one that would make any sense). Page splits typically have WAL records that are ~4KB in size, whereas the opportunistic delete records are almost always less than 100 bytes, and typically close to 64 bytes -- which is the same size as most individual leaf page insert WAL records. Plus you have almost double the FPIs going forward with the page split. > You've shown us a very nice paper analysing the page split waves, but > we need a similar detailed analysis so we can understand if what you > propose is better or not (and in what situations). That paper was just referenced in passing. It isn't essential to the main argument. > The leaf page locks are held for longer, so we need to perform > sensible tests that show if this has a catastrophic effect on related > workloads, or not. > > The SELECT tests proposed need to be aimed at the same table, at the same time. But that's exactly what I did the first time! I had two SELECT statements against the same table. They use almost the same distribution as the UPDATE, so that they'd hit the same part of the key space without it being exactly the same as the UPDATE from the same xact in each case (I thought that if it was exactly the same part of the table then that might unfairly favor my patch). > > The strength of the design is in how clever it isn't. > > What it doesn't do could be good or bad so we need to review more > details on behavior. Since the whole idea of the patch is to change > behavior, that seems a reasonable ask. I don't have any doubt about > the validity of the approach or coding. I agree, but the patch isn't the sum of its parts. You need to talk about a workload or a set of conditions, and how things develop over time. -- Peter Geoghegan
On Fri, 23 Oct 2020 at 18:14, Peter Geoghegan <pg@bowt.ie> wrote: > It's obvious that a page split is more expensive than the delete > operation (when it works out). The problem I highlighted is that the average UPDATE latency is x2 what it is on current HEAD. That is not consistent with the reported TPS, so it remains an issue and that isn't obvious. > It doesn't need a microbenchmark (and I > really can't think of one that would make any sense). I'm asking for detailed timings so we can understand the latency issue. I didn't ask for a microbenchmark. I celebrate your results, but we do need to understand the issue, somehow. -- Simon Riggs http://www.EnterpriseDB.com/
On Sat, Oct 24, 2020 at 2:55 AM Simon Riggs <simon@2ndquadrant.com> wrote: > The problem I highlighted is that the average UPDATE latency is x2 > what it is on current HEAD. That is not consistent with the reported > TPS, so it remains an issue and that isn't obvious. Why do you say that? I reported that the UPDATE latency is less than half for the benchmark. There probably are some workloads with worse latency and throughput, but generally only with high contention/small indexes. I'll try to fine tune those, but some amount of it is probably inevitable. On average query latency is quite a lot lower with the patch (where it is affected at all - the mechanism is only used with non-hot updates). -- Peter Geoghegan
On Sat, Oct 24, 2020 at 8:01 AM Peter Geoghegan <pg@bowt.ie> wrote:
> There probably are some workloads with worse latency and throughput,
> but generally only with high contention/small indexes. I'll try to
> fine tune those, but some amount of it is probably inevitable. On
> average query latency is quite a lot lower with the patch (where it is
> affected at all - the mechanism is only used with non-hot updates).
Attached is v5, which has changes that are focused on two important
high level goals:
1. Keeping costs down generally, especially in high contention cases
where costs are most noticeable.
2. Making indexes on low cardinality columns that naturally really
benefit from merge deduplication in Postgres 13 receive largely the
same benefits that you've already seen with high cardinality indexes
(at least outside of the extreme cases where it isn't sensible to
try).
CPU costs (especially from sorting temp work arrays) seem to be the
big cost overall. It turns out that the costs of accessing heap pages
within the new mechanism is not really noticeable. This isn't all that
surprising, though. The heap pages are accessed in a way that
naturally exploits locality across would-be page splits in different
indexes.
To some degree the two goals that I describe conflict with each other.
If merge deduplication increases the number of logical rows that "fit
on each leaf page" (by increasing the initial number of TIDs on each
leaf page by over 3x when the index is in the pristine CREATE INDEX
state), then naturally the average amount of work required to maintain
indexes in their pristine state is increased. We cannot expect to pay
nothing to avoid "unnecessary page splits" -- we can only expect to
come out ahead over time.
The main new thing that allowed me to more or less accomplish the
second goal is granular deletion in posting list tuples. That is, v5
teaches the delete mechanism to do VACUUM-style granular TID deletion
within posting lists. This factor turned out to matter a lot.
Here is an extreme benchmark that I ran this morning for this patch,
which shows both strengths and weaknesses:
pgbench scale 1000 (with customizations to indexing that I go into
below), 16 + 32 clients, 30 minutes per run (so 2 hours total
excluding initial data loading). Same queries as last time:
\set aid1 random_gaussian(1, 100000 * :scale, 4.0)
\set aid2 random_gaussian(1, 100000 * :scale, 4.5)
\set aid3 random_gaussian(1, 100000 * :scale, 4.2)
\set bid random(1, 1 * :scale)
\set tid random(1, 10 * :scale)
\set delta random(-5000, 5000)
BEGIN;
UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid1;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
END;
And just like last time, we replace the usual pgbench_accounts index
with an INCLUDE index to artificially make every UPDATE a non-HOT
UPDATE:
create unique index aid_pkey_include_abalance on pgbench_accounts
(aid) include(abalance);
Unlike last time we have a variety of useless-to-us *low cardinality*
indexes. These are much smaller than aid_pkey_include_abalance due to
merge deduplication, but are still quite similar to it:
create index fiver on pgbench_accounts ((aid - (aid%5)));
create index tenner on pgbench_accounts ((aid - (aid%10)));
create index score on pgbench_accounts ((aid - (aid%20)));
The silly indexes this time around are designed to have the same skew
as the PK, but with low cardinality data. So, for example "score", has
twenty distinct logical rows for each distinct aid value. Which is
pretty extreme as far as the delete mechanism is concerned. That's why
this is more of a mixed picture compared to the earlier benchmark. I'm
trying to really put the patch through its paces, not make it look
good.
First the good news. The patch held up perfectly in one important way
-- the size of the indexes didn't change at all compared to the
original pristine size. That looked like this at the start for both
patch + master:
aid_pkey_include_abalance: 274,194 pages/2142 MB
fiver: 142,348 pages/1112 MB
tenner: 115,352 pages/901 MB
score: 94,677 pages/740 MB
By the end, master looked like this:
aid_pkey_include_abalance: 428,759 pages (~1.56x original size)
fiver: 220,114 pages (~1.54x original size)
tenner: 176,983 pages (~1.53x original size)
score: 178,165 pages (~1.88x original size)
(As I said, no change in the size of indexes with the patch -- not
even one single page split.)
Now for the not-so-good news. The TPS numbers looked like this
(results in original chronological order of the runs, which I've
interleaved):
patch_1_run_16.out: "tps = 30452.530518 (including connections establishing)"
master_1_run_16.out: "tps = 35101.867559 (including connections establishing)"
patch_1_run_32.out: "tps = 26000.991486 (including connections establishing)"
master_1_run_32.out: "tps = 32582.129545 (including connections establishing)"
The latency numbers aren't great for the patch, either. Take the 16 client case:
number of transactions actually processed: 54814992
latency average = 0.525 ms
latency stddev = 0.326 ms
tps = 30452.530518 (including connections establishing)
tps = 30452.612796 (excluding connections establishing)
statement latencies in milliseconds:
0.001 \set aid1 random_gaussian(1, 100000 * :scale, 4.0)
0.000 \set aid2 random_gaussian(1, 100000 * :scale, 4.5)
0.000 \set aid3 random_gaussian(1, 100000 * :scale, 4.2)
0.000 \set bid random(1, 1 * :scale)
0.000 \set tid random(1, 10 * :scale)
0.000 \set delta random(-5000, 5000)
0.046 BEGIN;
0.159 UPDATE pgbench_accounts SET abalance = abalance +
:delta WHERE aid = :aid1;
0.153 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.091 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
0.075 END;
vs master's 16 client case:
number of transactions actually processed: 63183870
latency average = 0.455 ms
latency stddev = 0.307 ms
tps = 35101.867559 (including connections establishing)
tps = 35101.914573 (excluding connections establishing)
statement latencies in milliseconds:
0.001 \set aid1 random_gaussian(1, 100000 * :scale, 4.0)
0.000 \set aid2 random_gaussian(1, 100000 * :scale, 4.5)
0.000 \set aid3 random_gaussian(1, 100000 * :scale, 4.2)
0.000 \set bid random(1, 1 * :scale)
0.000 \set tid random(1, 10 * :scale)
0.000 \set delta random(-5000, 5000)
0.049 BEGIN;
0.117 UPDATE pgbench_accounts SET abalance = abalance +
:delta WHERE aid = :aid1;
0.120 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.091 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
0.077 END;
Earlier variations of this same workload that were run with a 10k TPS
rate limit had SELECT statements that had somewhat lower latency with
the patch, while the UPDATE statements were slower by roughly the same
amount as you see here. Here we see that at least the aid3 SELECT is
just as fast with the patch. (Don't have a proper example of this
rate-limited phenomenon close at hand now, since I saw it happen back
when the patch was less well optimized.)
This benchmark is designed to be extreme, and to really stress the
patch. For one thing we have absolutely no index scans for all but one
of the four indexes, so controlling the bloat there isn't going to
give you the main expected benefit. Which is that index scans don't
even have to visit heap pages from old versions, since they're not in
the index for very long (unless there aren't very many versions for
the logical rows in question, which isn't really a problem for us).
For another the new mechanism is constantly needed, which just isn't
very realistic. It seems as if the cost is mostly paid by non-HOT
updaters, which seems exactly right to me.
I probably could have cheated by making the aid_pkey_include_abalance
index a non-unique index, denying the master branch the benefit of
LP_DEAD setting within _bt_check_unique(). Or I could have cheated
(perhaps I should just say "gone for something a bit more
sympathetic") by not having skew on all the indexes (say by hashing on
aid in the indexes that use merge deduplication). I also think that
the TPS gap would have been smaller if I'd spent more time on each
run, but I didn't have time for that today. In the past I've seen it
take a couple of hours or more for the advantages of the patch to come
through (it takes that long for reasons that should be obvious).
Even the overhead we see here is pretty tolerable IMV. I believe that
it will be far more common for the new mechanism to hardly get used at
all, and yet have a pretty outsized effect on index bloat. To give you
a simple example of how that can happen, consider that if this did
happen in a real workload it would probably be caused by a surge in
demand -- now we don't have to live with the bloat consequences of an
isolated event forever (or until the next REINDEX). I can make more
sophisticated arguments than that one, but it doesn't seem useful
right now so I'll refrain.
The patch adds a backstop. It seems to me that that's really what we
need here. Predictability over time and under a large variety of
different conditions. Real workloads constantly fluctuate.
Even if people end up not buying my argument that it's worth it for
workloads like this, there are various options. And, I bet I can
further improve the high contention cases without losing the valuable
part -- there are a number of ways in which I can get the CPU costs
down further that haven't been fully explored (yes, it really does
seem to be CPU costs, especially due to TID sorting). Again, this
patch is all about extreme pathological workloads, system stability,
and system efficiency over time -- it is not simply about increasing
system throughput. There are some aspects of this design (that come up
with extreme workloads) that may in the end come down to value
judgments. I'm not going to tell somebody that they're wrong for
prioritizing different things (within reason, at least). In my opinion
almost all of the problems we have with VACUUM are ultimately
stability problems, not performance problems per se. And, I suspect
that we do very well with stupid benchmarks like this compared to
other DB systems precisely because we currently allow non-HOT updaters
to "live beyond their means" (which could in theory be great if you
frame it a certain way that seems pretty absurd to me). This suggests
we can "afford" to go a bit slower here as far as the competitive
pressures determine what we should do (notice that this is a distinct
argument to my favorite argument, which is that we cannot afford to
*not* go a bit slower in certain extreme cases).
I welcome debate about this.
--
Peter Geoghegan
Attachment
On Mon, 26 Oct 2020 at 21:15, Peter Geoghegan <pg@bowt.ie> wrote: > Now for the not-so-good news. The TPS numbers looked like this > (results in original chronological order of the runs, which I've > interleaved): While it is important we investigate the worst cases, I don't see this is necessarily bad. HOT was difficult to measure, but on a 2+ hour run on a larger table, the latency graph was what showed it was a winner. Short runs and in-memory data masked the benefits in our early analyses. So I suggest not looking at the totals and averages but on the peaks and the long term trend. Showing that in graphical form is best. > The patch adds a backstop. It seems to me that that's really what we > need here. Predictability over time and under a large variety of > different conditions. Real workloads constantly fluctuate. Yeh, agreed. This is looking like a winner now, but lets check. > Even if people end up not buying my argument that it's worth it for > workloads like this, there are various options. And, I bet I can > further improve the high contention cases without losing the valuable > part -- there are a number of ways in which I can get the CPU costs > down further that haven't been fully explored (yes, it really does > seem to be CPU costs, especially due to TID sorting). Again, this > patch is all about extreme pathological workloads, system stability, > and system efficiency over time -- it is not simply about increasing > system throughput. There are some aspects of this design (that come up > with extreme workloads) that may in the end come down to value > judgments. I'm not going to tell somebody that they're wrong for > prioritizing different things (within reason, at least). In my opinion > almost all of the problems we have with VACUUM are ultimately > stability problems, not performance problems per se. And, I suspect > that we do very well with stupid benchmarks like this compared to > other DB systems precisely because we currently allow non-HOT updaters > to "live beyond their means" (which could in theory be great if you > frame it a certain way that seems pretty absurd to me). This suggests > we can "afford" to go a bit slower here as far as the competitive > pressures determine what we should do (notice that this is a distinct > argument to my favorite argument, which is that we cannot afford to > *not* go a bit slower in certain extreme cases). > > I welcome debate about this. Agreed, we can trade initial speed for long term consistency. I guess there are some heuristics there on that tradeoff. -- Simon Riggs http://www.EnterpriseDB.com/
On Tue, Oct 27, 2020 at 2:44 AM Simon Riggs <simon@2ndquadrant.com> wrote:
> While it is important we investigate the worst cases, I don't see this
> is necessarily bad.
I looked at "perf top" a few times when the test from yesterday ran. I
saw that the proposed delete mechanism was the top consumer of CPU
cycles. It seemed as if the mechanism was very expensive. However,
that's definitely the wrong conclusion about what happens in the
general case, or even in slightly less extreme cases. It at least
needs to be put in context.
I reran exactly the same benchmark overnight, but added a 10k TPS rate
limit this time (so about a third of the TPS that's possible without a
limit). I also ran it for longer, and saw much improved latency. (More
on the latency aspect below, for now I want to talk about "perf top").
The picture with "perf top" changed significantly with a 10k TPS rate
limit, even though the workload itself is very similar. Certainly the
new mechanism/function is still quite close to the top consumer of CPU
cycles. But it no longer uses more cycles than the familiar super hot
functions that you expect to see right at the top with pgbench (e.g.
_bt_compare(), hash_search_with_hash_value()). It's now something like
the 4th or 5th hottest function (I think that that means that the cost
in cycles is more than an order of magnitude lower, but I didn't
check). Just adding this 10k TPS rate limit makes the number of CPU
cycles consumed by the new mechanism seem quite reasonable. The
benefits that the patch brings are not diminished at all compared to
the original no-rate-limit variant -- the master branch now only takes
slightly longer to completely bloat all its indexes with this 10k TPS
limit (while the patch avoids even a single page split -- no change
there).
Again, this is because the mechanism is a backstop. It only works as
hard as needed to avoid unnecessary page splits. When the system is
working as hard as possible to add version churn to indexes (which is
what the original/unthrottled test involved), then the mechanism also
works quite hard. In this artificial and contrived scenario, any
cycles we can save from cleaning up bloat (by micro optimizing the
code in the patch) go towards adding even more bloat instead...which
necessitates doing more cleanup. This is why optimizing the code in
the patch with this unrealistic scenario in mind is subject to sharp
diminishing returns. It's also why you can get a big benefit from the
patch when the new mechanism is barely ever used. I imagine that if I
ran the same test again but with a 1k TPS limit I would hardly see the
new mechanism in "perf top" at all....but in the end the bloat
situation would be very similar.
I think that you could model this probabilistically if you had the
inclination. Yes, the more you throttle throughput (by lowering the
pgbench rate limit further), the less chance you have of any given
leaf page splitting moment to moment (for the master branch). But in
the long run every original leaf page splits at least once anyway,
because each leaf page still only has to be unlucky once. It is still
inevitable that they'll all get split eventually (and probably not
before too long), unless and until you *drastically* throttle pgbench.
I believe that things like opportunistic HOT chain truncation (heap
pruning) and index tuple LP_DEAD bit setting are very effective much
of the time. The problem is that it's easy to utterly rely on them
without even realizing it, which creates hidden risk that may or may
not result in big blow ups down the line. There is nothing inherently
wrong with being lazy or opportunistic about cleaning up garbage
tuples -- I think that there are significant advantages, in fact. But
only if it isn't allowed to create systemic risk. More concretely,
bloat cannot be allowed to become concentrated in any one place -- no
individual query should have to deal with more than 2 or 3 versions
for any given logical row. If we're focussed on the *average* number
of physical versions per logical row then we may reach dramatically
wrong conclusions about what to do (which is a problem in a world
where autovacuum is supposed to do most garbage collection...unless
your app happens to look like standard pgbench!).
And now back to latency with this 10k TPS limited variant I ran last
night. After 16 hours we have performed 8 runs, each lasting 2 hours.
In the original chronological order, these runs are:
patch_1_run_16.out: "tps = 10000.095914 (including connections establishing)"
master_1_run_16.out: "tps = 10000.171945 (including connections establishing)"
patch_1_run_32.out: "tps = 10000.082975 (including connections establishing)"
master_1_run_32.out: "tps = 10000.533370 (including connections establishing)"
patch_2_run_16.out: "tps = 10000.076865 (including connections establishing)"
master_2_run_16.out: "tps = 9997.933215 (including connections establishing)"
patch_2_run_32.out: "tps = 9999.911988 (including connections establishing)"
master_2_run_32.out: "tps = 10000.864031 (including connections establishing)"
Here is what I see at the end of "patch_2_run_32.out" (i.e. at the end
of the final 2 hour run for the patch):
number of transactions actually processed: 71999872
latency average = 0.265 ms
latency stddev = 0.110 ms
rate limit schedule lag: avg 0.046 (max 30.274) ms
tps = 9999.911988 (including connections establishing)
tps = 9999.915766 (excluding connections establishing)
statement latencies in milliseconds:
0.001 \set aid1 random_gaussian(1, 100000 * :scale, 4.0)
0.000 \set aid2 random_gaussian(1, 100000 * :scale, 4.5)
0.000 \set aid3 random_gaussian(1, 100000 * :scale, 4.2)
0.000 \set bid random(1, 1 * :scale)
0.000 \set tid random(1, 10 * :scale)
0.000 \set delta random(-5000, 5000)
0.023 BEGIN;
0.099 UPDATE pgbench_accounts SET abalance = abalance +
:delta WHERE aid = :aid1;
0.036 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.034 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
0.025 END;
Here is what I see at the end of "master_2_run_32.out" (i.e. at the
end of the final run for master):
number of transactions actually processed: 72006803
latency average = 0.266 ms
latency stddev = 2.722 ms
rate limit schedule lag: avg 0.074 (max 396.853) ms
tps = 10000.864031 (including connections establishing)
tps = 10000.868545 (excluding connections establishing)
statement latencies in milliseconds:
0.001 \set aid1 random_gaussian(1, 100000 * :scale, 4.0)
0.000 \set aid2 random_gaussian(1, 100000 * :scale, 4.5)
0.000 \set aid3 random_gaussian(1, 100000 * :scale, 4.2)
0.000 \set bid random(1, 1 * :scale)
0.000 \set tid random(1, 10 * :scale)
0.000 \set delta random(-5000, 5000)
0.022 BEGIN;
0.073 UPDATE pgbench_accounts SET abalance = abalance +
:delta WHERE aid = :aid1;
0.036 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.034 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
0.025 END;
Notice the following:
1. The overall "latency average" for the patch is very slightly lower.
2. The overall "latency stddev" for the patch is far far lower -- over
20x lower, in fact.
3. The patch's latency for the UPDATE statement is still somewhat
higher, but it's not so bad. We're still visibly paying a price in
some sense, but at least we're imposing the new costs squarely on the
query that is responsible for all of our problems.
4. The patch's latency for the SELECT statements is exactly the same
for the patch. We're not imposing any new cost on "innocent" SELECT
statements that didn't create the problem, even if they didn't quite
manage to benefit here. (Without LP_DEAD setting in _bt_check_unique()
I'm sure that the SELECT latency would be significantly lower for the
patch.)
The full results (with lots of details pulled from standard system
views after each run) can be downloaded as a .tar.gz archive from:
https://drive.google.com/file/d/1Dn8rSifZqT7pOOIgyKstl-tdACWH-hqO/view?usp=sharing
(It's probably not that interesting to drill down any further, but I
make the full set of results available just in case. There are loads
of things included just because I automatically capture them when
benchmarking anything at all.)
> HOT was difficult to measure, but on a 2+ hour run on a larger table,
> the latency graph was what showed it was a winner. Short runs and
> in-memory data masked the benefits in our early analyses.
Yeah, that's what was nice about working on sorting -- almost instant
feedback. Who wants to spend at least 2 hours to test out every little
theory? :-)
> So I suggest not looking at the totals and averages but on the peaks
> and the long term trend. Showing that in graphical form is best.
I think that you're right that a graphical representation with an
X-axis that shows how much time has passed would be very useful. I'll
try to find a way of incorporating that into my benchmarking workflow.
This is especially likely to help when modelling how cases with a long
running xact/snapshot behave. That isn't a specific goal of mine here,
but I expect that it'll help with that a lot too. For now I'm just
focussing on downsides and not upsides, for the usual reasons.
> Agreed, we can trade initial speed for long term consistency. I guess
> there are some heuristics there on that tradeoff.
Right. Another way of looking at it is this: it should be possible for
reasonably good DBAs to develop good intuitions about how the system
will hold up over time, based on past experience and common sense --
no chaos theory required. Whatever the cost of the mechanism is, at
least it's only something that gets shaved off the top minute to
minute. It seems almost impossible for the cost to cause sudden
surprises (except maybe once, after an initial upgrade to Postgres 14,
though I doubt it). Whereas it seems very likely to prevent many large
and unpleasant surprises caused by hidden, latent risk.
I believe that approximately 100% of DBAs would gladly take that
trade-off, even if the total cost in cycles was higher. It happens to
also be true that they're very likely to use far fewer cycles over
time, but that's really just a bonus.
--
Peter Geoghegan
пн, 26 окт. 2020 г. в 22:15, Peter Geoghegan <pg@bowt.ie>:
Attached is v5, which has changes that are focused on two important
high level goals:
I've reviewed v5 of the patch and did some testing.
First things first, the niceties must be observed:
Patch applies, compiles and passes checks without any issues.
It has a good amount of comments that describe the changes very well.
Now to its contents.
I now see what you mean by saying that this patch is a natural and logical
extension of the deduplication v13 work. I agree with this.
Basically, 2 major deduplication strategies exist now:
- by merging duplicates into a posting list; suits non-unique indexes better,
'cos actual duplicates come from the logically different tuples. This is
existing functionality.
- by deleting dead tuples and reducing need for deduplication at all; suits
unique indexes mostly. This is a subject of this patch and it (to some
extent) undoes v13 functionality around unique indexes, making it better.
Some comments on the patch.
1. In the following comment:
+ * table_index_batch_check() is a variant that is specialized to garbage
+ * collection of dead tuples in index access methods. Duplicates are
+ * commonly caused by MVCC version churn when an optimization like
+ * heapam's HOT cannot be applied. It can make sense to opportunistically
+ * guess that many index tuples are dead versions, particularly in unique
+ * indexes.
I don't quite like the last sentence. Given that this code is committed,
I would rather make it:
… cannot be applied. Therefore we opportunistically check for dead tuples
and reuse the space, delaying leaf page splits.
I understand that "we" shouldn't be used here, but I fail to think of a
proper way to express this.
2. in _bt_dedup_delete_pass() and heap_index_batch_check() you're using some
constants, like:
- expected score of 25
- nblocksaccessed checks for 1, 2 and 3 blocks
- maybe more, but the ones above caught my attention.
Perhaps, it'd be better to use #define-s here instead?
3. Do we really need to touch another heap page, if all conditions are met?
+ if (uniqueindex && nblocksaccessed == 1 && score == 0)
+ break;
+ if (!uniqueindex && nblocksaccessed == 2 && score == 0)
+ break;
+ if (nblocksaccessed == 3)
+ break;
I was really wondering why to look into 2 heap pages. By not doing it straight away,
we just delay the work for the next occasion that'll work on the same page we're
processing. I've modified this piece and included it in my tests (see below), I reduced
2nd condition to just 1 block and limited the 3rd case to 2 blocks (just a quick hack).
Now for the tests.
I used an i3en.6xlarge EC2 instance with EBS disks attached (24 cores, 192GB RAM).
I've employed the same tests Peter described on Oct 16 (right after v2 of the patch).
There were some config changes (attached), mostly to produce more logs and enable
proper query monitoring with pg_stat_statements.
This server is used also for other tests, therefore I am not able to utilize all core/RAM.
I'm interested in doing so though, subject for the next run of tests.
I've used scale factor 10 000, adjusted indexes (resulting in a 189GB size database)
and run the following pgbench:
First things first, the niceties must be observed:
Patch applies, compiles and passes checks without any issues.
It has a good amount of comments that describe the changes very well.
Now to its contents.
I now see what you mean by saying that this patch is a natural and logical
extension of the deduplication v13 work. I agree with this.
Basically, 2 major deduplication strategies exist now:
- by merging duplicates into a posting list; suits non-unique indexes better,
'cos actual duplicates come from the logically different tuples. This is
existing functionality.
- by deleting dead tuples and reducing need for deduplication at all; suits
unique indexes mostly. This is a subject of this patch and it (to some
extent) undoes v13 functionality around unique indexes, making it better.
Some comments on the patch.
1. In the following comment:
+ * table_index_batch_check() is a variant that is specialized to garbage
+ * collection of dead tuples in index access methods. Duplicates are
+ * commonly caused by MVCC version churn when an optimization like
+ * heapam's HOT cannot be applied. It can make sense to opportunistically
+ * guess that many index tuples are dead versions, particularly in unique
+ * indexes.
I don't quite like the last sentence. Given that this code is committed,
I would rather make it:
… cannot be applied. Therefore we opportunistically check for dead tuples
and reuse the space, delaying leaf page splits.
I understand that "we" shouldn't be used here, but I fail to think of a
proper way to express this.
2. in _bt_dedup_delete_pass() and heap_index_batch_check() you're using some
constants, like:
- expected score of 25
- nblocksaccessed checks for 1, 2 and 3 blocks
- maybe more, but the ones above caught my attention.
Perhaps, it'd be better to use #define-s here instead?
3. Do we really need to touch another heap page, if all conditions are met?
+ if (uniqueindex && nblocksaccessed == 1 && score == 0)
+ break;
+ if (!uniqueindex && nblocksaccessed == 2 && score == 0)
+ break;
+ if (nblocksaccessed == 3)
+ break;
I was really wondering why to look into 2 heap pages. By not doing it straight away,
we just delay the work for the next occasion that'll work on the same page we're
processing. I've modified this piece and included it in my tests (see below), I reduced
2nd condition to just 1 block and limited the 3rd case to 2 blocks (just a quick hack).
Now for the tests.
I used an i3en.6xlarge EC2 instance with EBS disks attached (24 cores, 192GB RAM).
I've employed the same tests Peter described on Oct 16 (right after v2 of the patch).
There were some config changes (attached), mostly to produce more logs and enable
proper query monitoring with pg_stat_statements.
This server is used also for other tests, therefore I am not able to utilize all core/RAM.
I'm interested in doing so though, subject for the next run of tests.
I've used scale factor 10 000, adjusted indexes (resulting in a 189GB size database)
and run the following pgbench:
pgbench -f testcase.pgbench -r -c32 -j8 -T 3600 bench
Results (see also attachment):
/* 1, master */
latency average = 16.482 ms
tps = 1941.513487 (excluding connections establishing)
statement latencies in milliseconds:
4.476 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid1;
2.084 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
2.090 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
/* 2, v5-patch */
latency average = 12.509 ms
tps = 2558.119453 (excluding connections establishing)
statement latencies in milliseconds:
2.009 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid1;
0.868 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.893 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
/* 3, v5-restricted */
latency average = 12.338 ms
tps = 2593.519240 (excluding connections establishing)
statement latencies in milliseconds:
1.955 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid1;
0.846 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.866 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
I can see a clear benefit from this patch *under specified conditions, YMMW*
- 32% increase in TPS
- 24% drop in average latency
- most important — stable index size!
Looking at the attached graphs (including statement specific ones):
- CPU activity, Disk reads (reads, not hits) and Transaction throughput are very
stable for patched version
- CPU's "iowait" is stable and reduced for patched version (expected)
- CPU's "user" peaks out when master starts to split leafs, no such peaks
for the patched version
- there's expected increase in amount of "Disk reads" for patched versions,
although on master we start pretty much on the same level and by the end of
the test we seem to climb up on reads
- on master, UPDATEs are spending 2x more time on average, reading 3x more
pages than on patched versions
- in fact, "Average query time" and "Query stages" graphs show very nice caching
effect for patched UPDATEs, a bit clumsy for SELECTs, but still visible
Comparing original and restricted patch versions:
- there's no visible difference in amount of "Disk reads"
- on restricted version UPDATEs behave more gradually, I like this pattern
more, as it feels more stable and predictable
In my opinion, patch provides clear benefits from IO reduction and index size
control perspective. I really like the stability of operations on patched
version. I would rather stick to the "restricted" version of the patch though.
Hope this helps. I'm open to do more tests if necessary.
P.S. I am using automated monitoring for graphs, do not have metrics around, sorry.
Victor Yegorov
Attachment
- 20201028-v5-results.txt
- 20201028-v5-cpu.png
- 20201028-v5-dr.png
- 20201028-v5-txn.png
- 20201028-v5-tqt.png
- 20201028-v5-update-1-master.png
- 20201028-v5-update-2-patch.png
- 20201028-v5-update-3-restricted.png
- 20201028-v5-select-1-master.png
- 20201028-v5-select-2-patch.png
- 20201028-v5-select-3-restricted.png
- testcase.pgbench
- postgresql.auto.conf
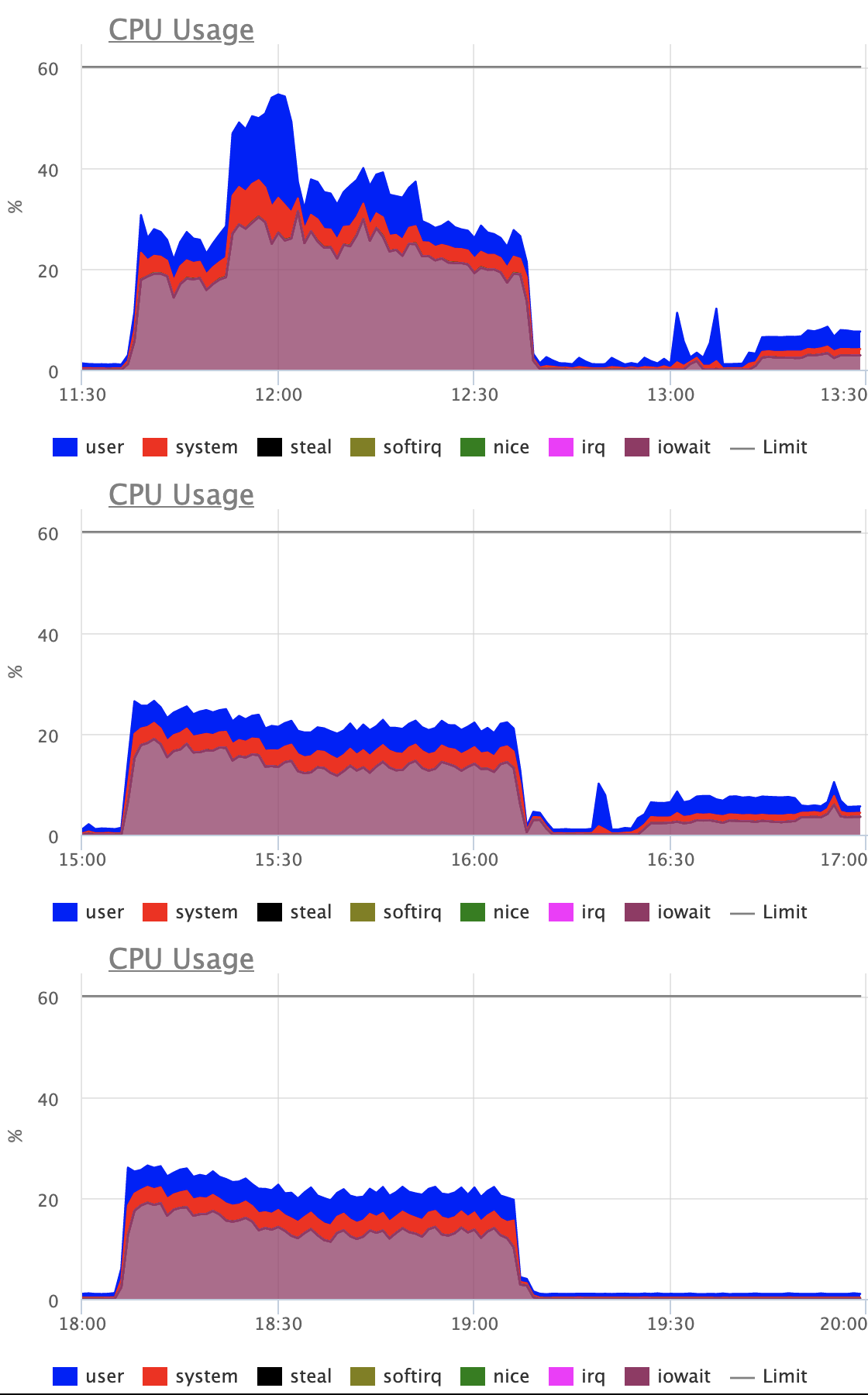{kind=link}
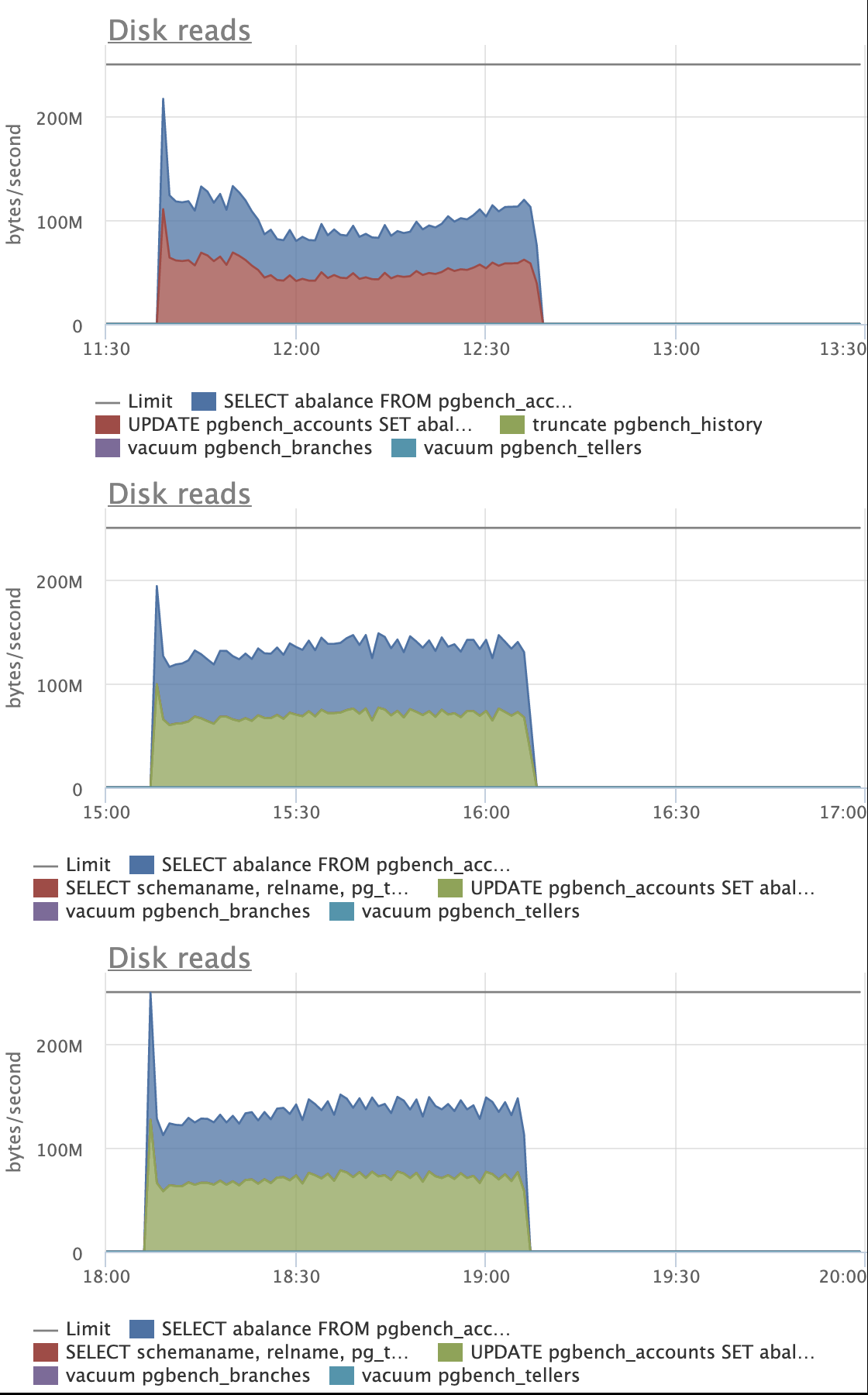{kind=link}
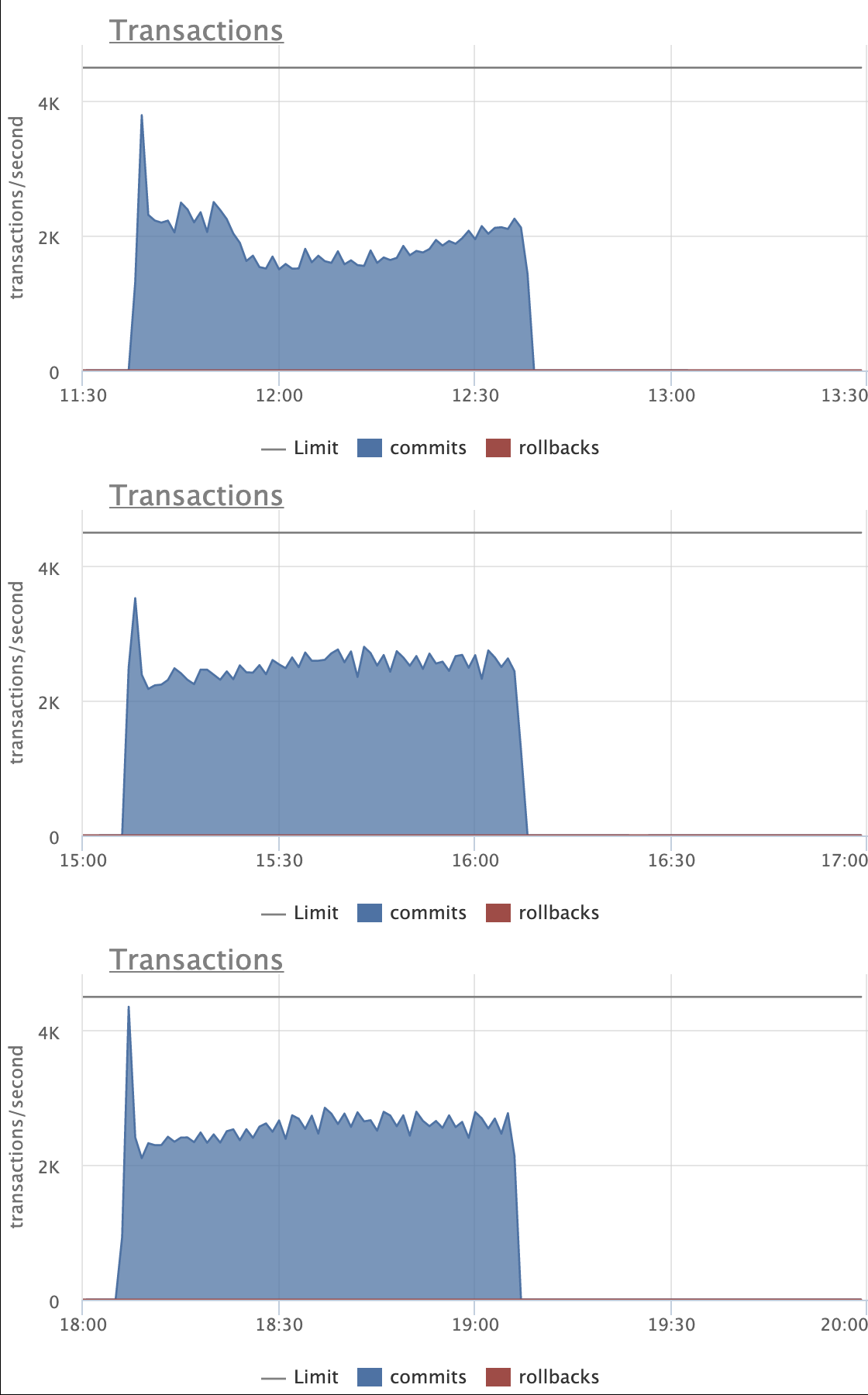{kind=link}
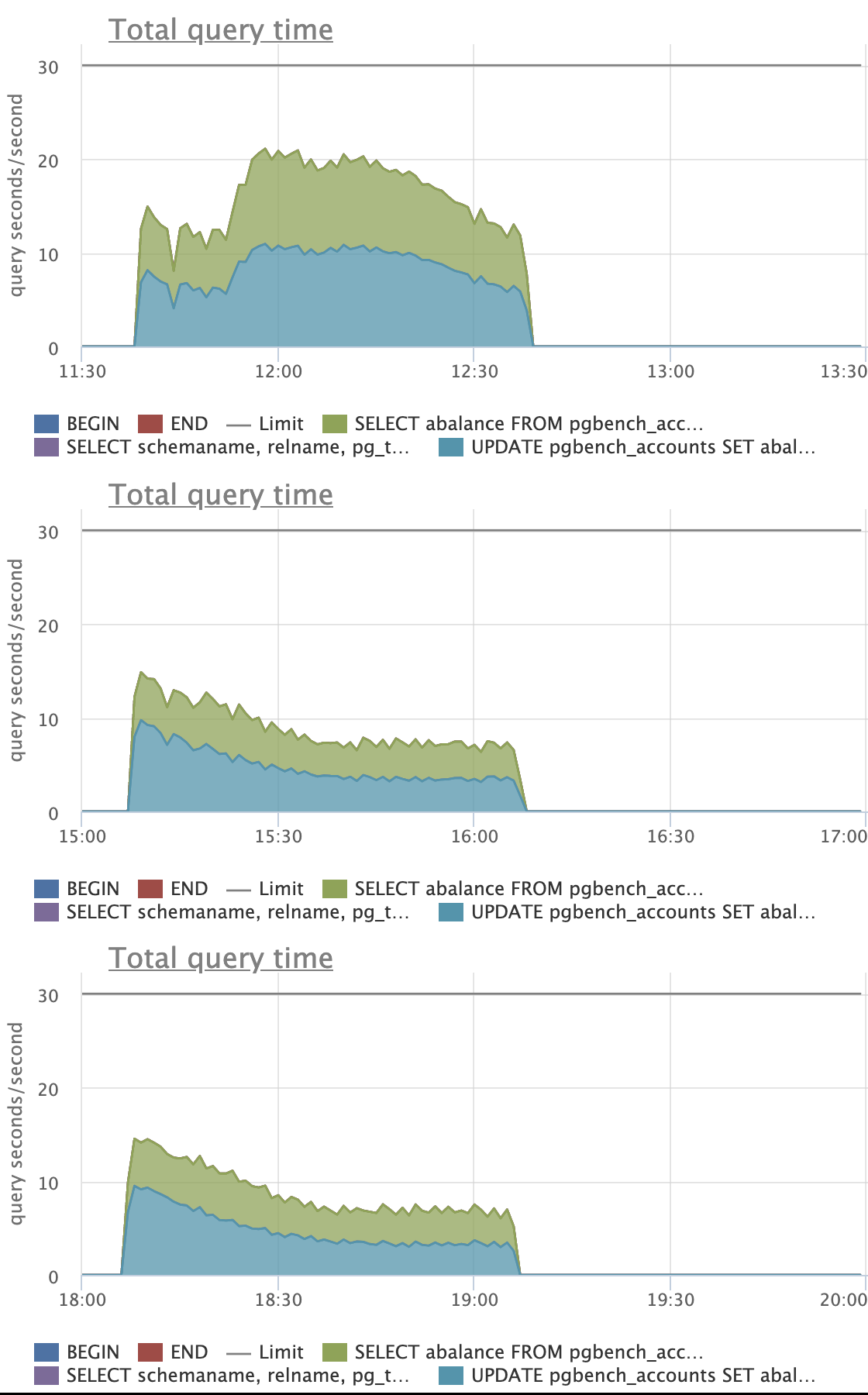{kind=link}
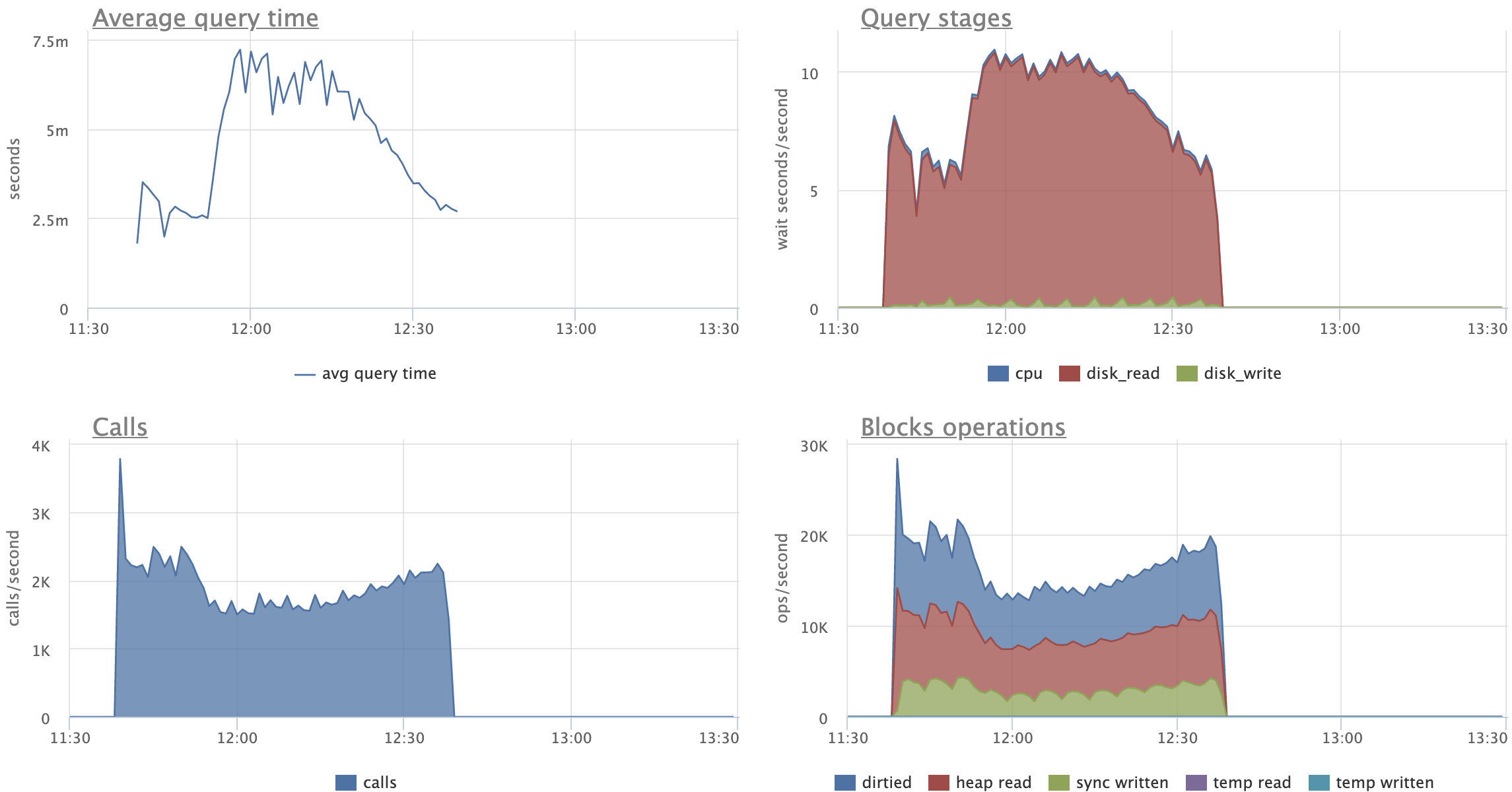{kind=link}
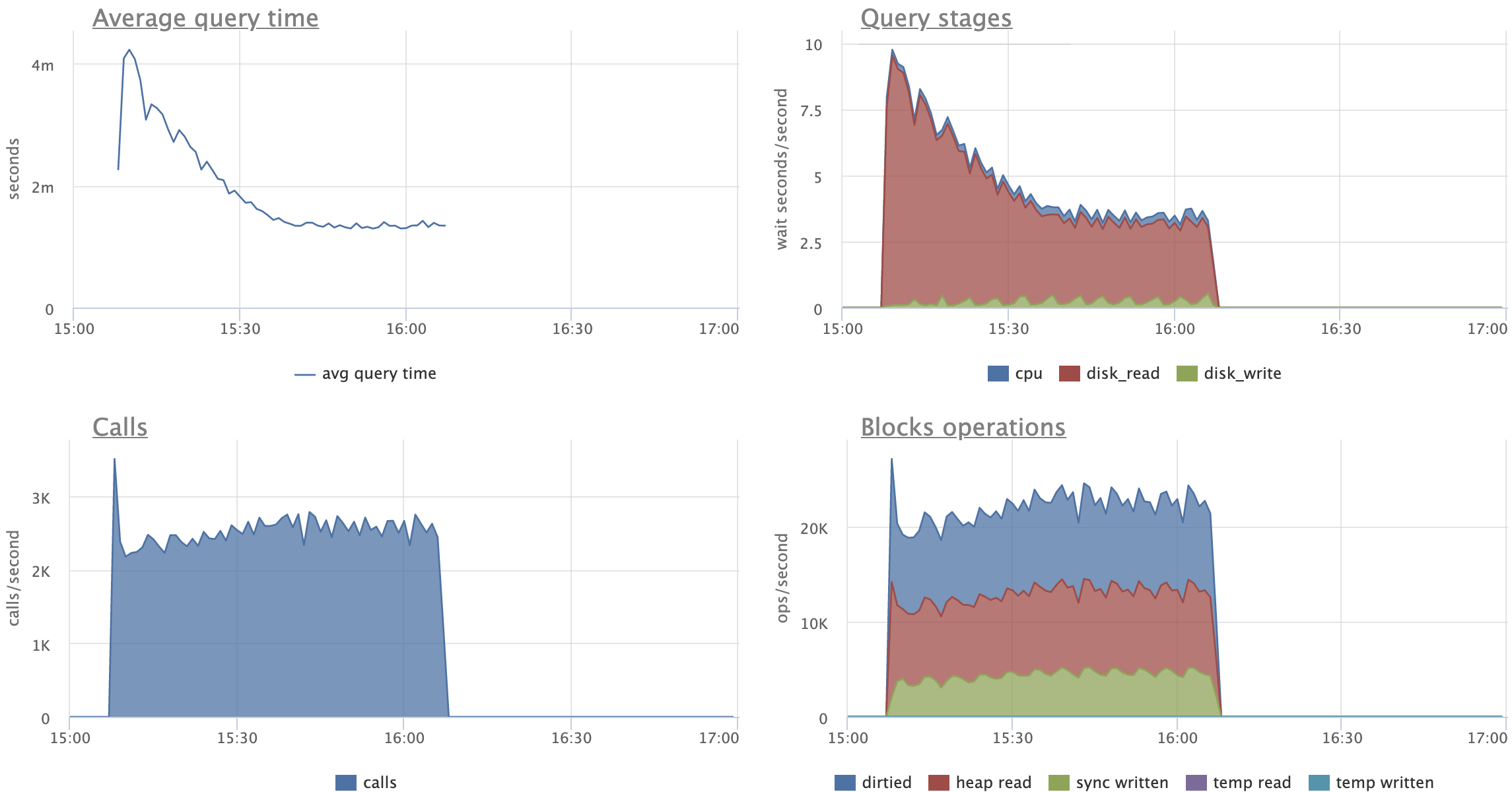{kind=link}
{kind=link}
{kind=link}
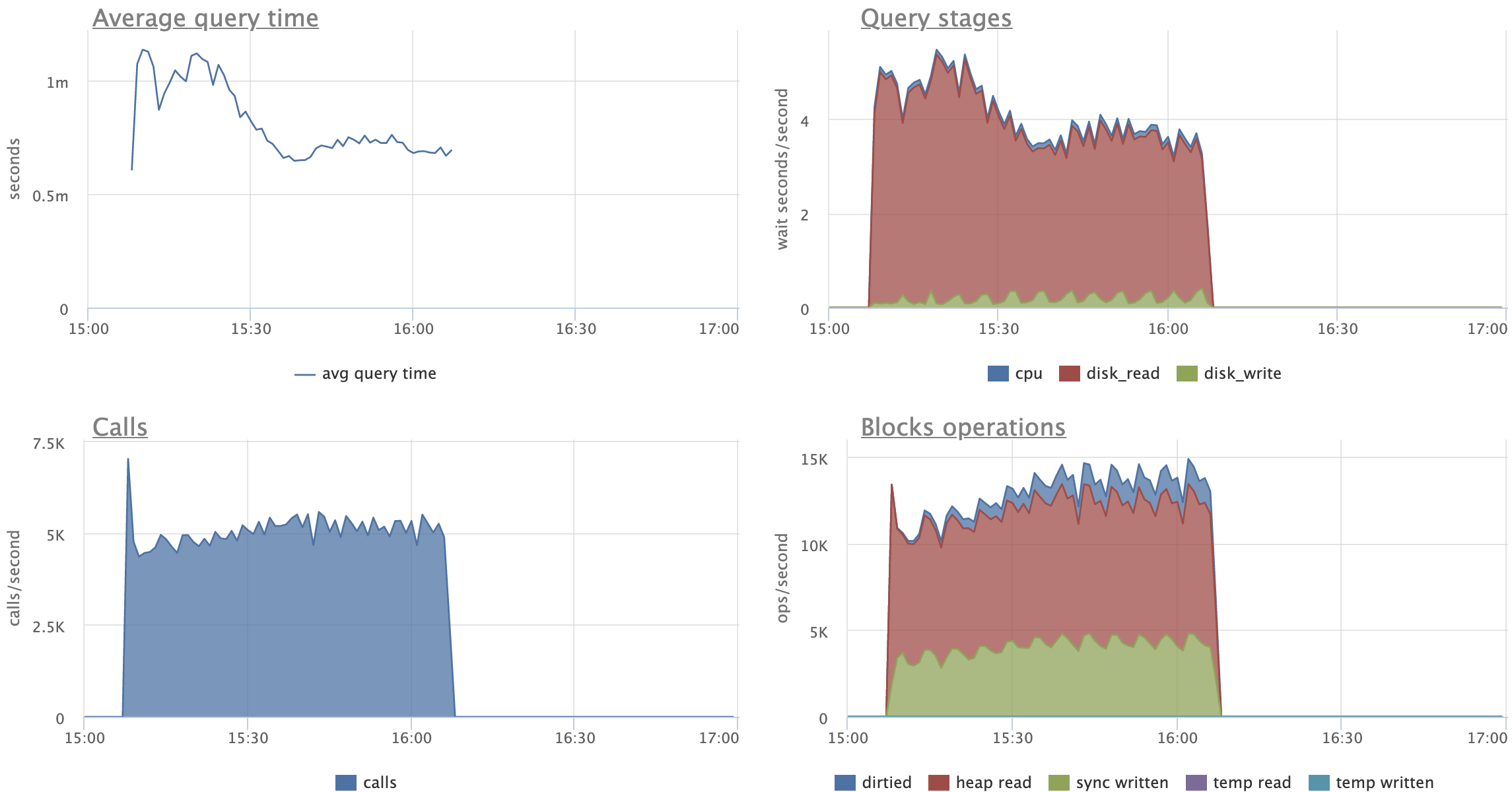{kind=link}
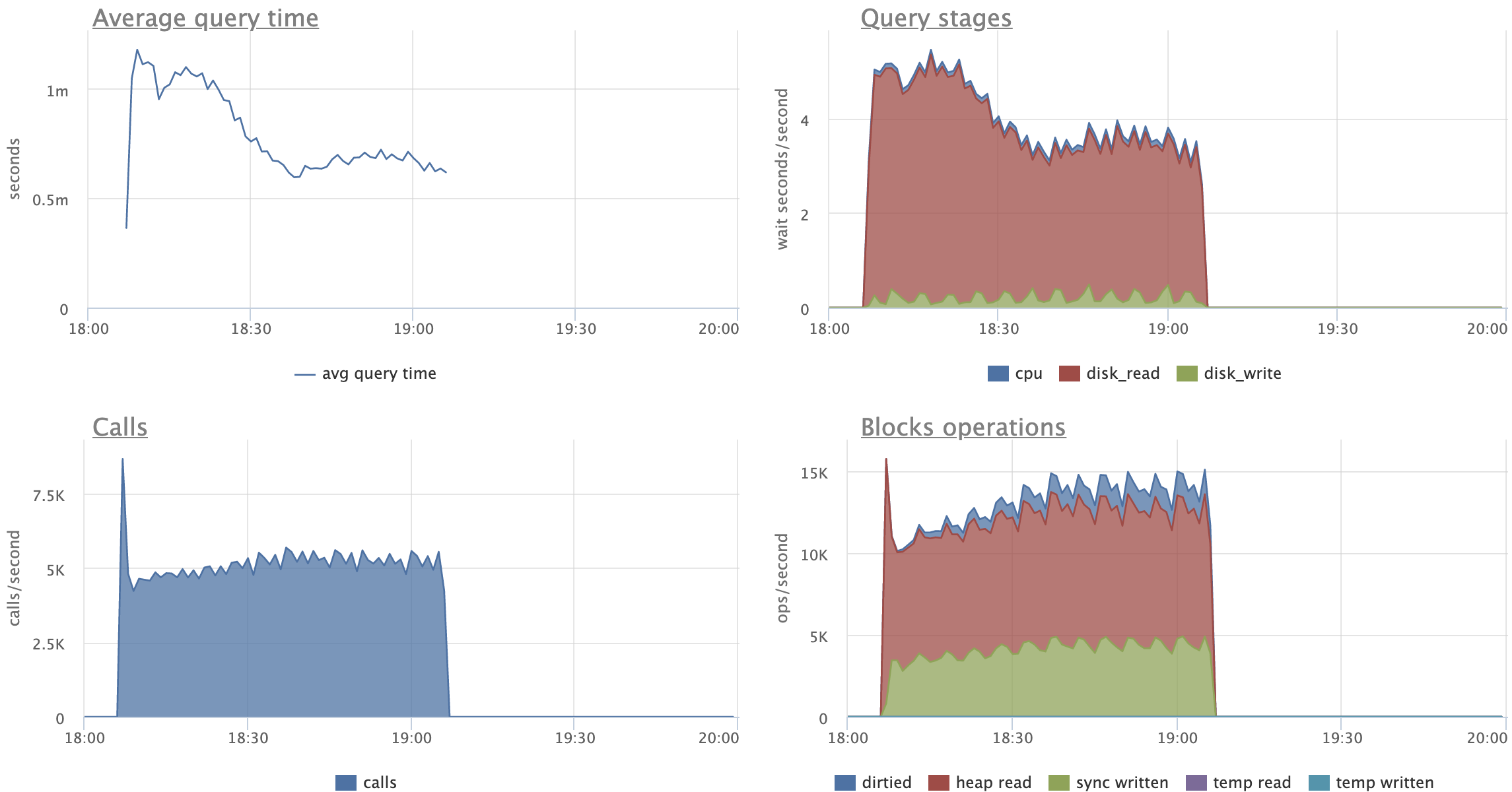{kind=link}
пн, 26 окт. 2020 г. в 22:15, Peter Geoghegan <pg@bowt.ie>:
Attached is v5, which has changes that are focused on two important
high level goals:
And some more comments after another round of reading the patch.
1. Looks like UNIQUE_CHECK_NO_WITH_UNCHANGED is used for HOT updates,
should we use UNIQUE_CHECK_NO_HOT here? It is better understood like this.
2. You're modifying the table_tuple_update() function on 1311 line of include/access/tableam.h,
adding modified_attrs_hint. There's a large comment right before it describing parameters,
I think there should be a note about modified_attrs_hint parameter in that comment, 'cos
it is referenced from other places in tableam.h and also from backend/access/heap/heapam.c
3. Can you elaborate on the scoring model you're using?
Why do we expect a score of 25, what's the rationale behind this number?
And should it be #define-d ?
4. heap_compute_xid_horizon_for_tuples contains duplicate logic. Is it possible to avoid this?
5. In this comment
+ * heap_index_batch_check() helper function. Sorts deltids array in the
+ * order needed for useful processing.
perhaps it is better to replace "useful" with more details? Or point to the place
where "useful processing" is described.
6. In this snippet in _bt_dedup_delete_pass()
+ else if (_bt_keep_natts_fast(rel, state->base, itup) > nkeyatts &&
+ _bt_dedup_save_htid(state, itup))
+ {
+
+ }
I would rather add a comment, explaining that the empty body of the clause is actually expected.
7. In the _bt_dedup_delete_finish_pending() you're setting ispromising to false for both
posting and non-posting tuples. This contradicts comments before function.
Victor Yegorov
On Wed, Oct 28, 2020 at 4:05 PM Victor Yegorov <vyegorov@gmail.com> wrote: > I've reviewed v5 of the patch and did some testing. Thanks! > I now see what you mean by saying that this patch is a natural and logical > extension of the deduplication v13 work. I agree with this. I tried the patch out with a long running transaction yesterday. I think that the synergy with the v13 deduplication work really helped. It took a really long time for an old snapshot to lead to pgbench page splits (relative to the master branch, running a benchmark like the one I talked about recently -- the fiver, tenner, score, etc index benchmark). When the page splits finally started, they seemed much more gradual -- I don't think that I saw the familiar pattern of distinct waves of page splits that are clearly all correlated. I think that the indexes grew at a low steady rate, which looked like the rate that heap relations usually grow at. We see a kind of "tick tock" pattern with this new mechanism + v13 deduplication: even when we don't delete very many TIDs, we still free a few, and then merge the remaining TIDs to buy more time. Very possibly enough time that a long running transaction goes away by the time the question of splitting the page comes up again. Maybe there is another long running transaction by then, but deleting just a few of the TIDs the last time around is enough to not waste time on that block this time around, and therefore to actually succeed despite the second, newer long running transaction (we can delete older TIDs, just not the now-oldest TIDs that the newer long running xact might still need). If this scenario sounds unlikely, bear in mind that "unnecessary" page splits (which are all we really care about here) are usually only barely necessary today, if you think about it in a localized/page level way. What the master branch shows is that most individual "unnecessary" page splits are in a sense *barely* unnecessary (which of course doesn't make the consequences any better). We could buy many hours until the next time the question of splitting a page comes up by just freeing a small number of tuples -- even on a very busy database. I found that the "fiver" and "tenner" indexes in particular took a very long time to have even one page split with a long running transaction. Another interesting effect was that all page splits suddenly stopped when my one hour 30 minute long transaction/snapshot finally went away -- the indexes stopped growing instantly when I killed the psql session. But on the master branch the cascading version driven page splits took at least several minutes to stop when I killed the psql session/snapshot at that same point of the benchmark (maybe longer). With the master branch, we can get behind on LP_DEAD index tuple bit setting, and then have no chance of catching up. Whereas the patch gives us a second chance for each page. (I really have only started to think about long running transactions this week, so my understanding is still very incomplete, and based on guesses and intuitions.) > I don't quite like the last sentence. Given that this code is committed, > I would rather make it: > > … cannot be applied. Therefore we opportunistically check for dead tuples > and reuse the space, delaying leaf page splits. > > I understand that "we" shouldn't be used here, but I fail to think of a > proper way to express this. Makes sense. > 2. in _bt_dedup_delete_pass() and heap_index_batch_check() you're using some > constants, like: > - expected score of 25 > - nblocksaccessed checks for 1, 2 and 3 blocks > - maybe more, but the ones above caught my attention. > > Perhaps, it'd be better to use #define-s here instead? Yeah. It's still evolving, which is why it's still rough. It's not easy to come up with a good interface here. Not because it's very important and subtle. It's actually very *unimportant*, in a way. nbtree cannot really expect too much from heapam here (though it might get much more than expected too, when it happens to be easy for heapam). The important thing is always what happens to be possible at the local/page level -- the exact preferences of nbtree are not so important. Beggars cannot be choosers. It only makes sense to have a "score" like this because sometimes the situation is so favorable (i.e. there are so many TIDs that can be killed) that we want to avoid vastly exceeding what is likely to be useful to nbtree. Actually, this situation isn't that rare (which maybe means I was wrong to say the score thing was unimportant, but hopefully you get the idea). Easily hitting our target score of 25 on the first heap page probably happens almost all the time when certain kinds of unique indexes use the mechanism, for example. And when that happens it is nice to only have to visit one heap block. We're almost sure that it isn't worth visiting a second, regardless of how many TIDs we're likely to find there. > 3. Do we really need to touch another heap page, if all conditions are met? > > + if (uniqueindex && nblocksaccessed == 1 && score == 0) > + break; > + if (!uniqueindex && nblocksaccessed == 2 && score == 0) > + break; > + if (nblocksaccessed == 3) > + break; > > I was really wondering why to look into 2 heap pages. By not doing it straight away, > we just delay the work for the next occasion that'll work on the same page we're > processing. I've modified this piece and included it in my tests (see below), I reduced > 2nd condition to just 1 block and limited the 3rd case to 2 blocks (just a quick hack). The benchmark that you ran involved indexes that are on a column whose values are already unique, pgbench_accounts.aid (the extra indexes are not actually unique indexes, but they could work as unique indexes). If you actually made them unique indexes then you would have seen the same behavior anyway. The 2 heap pages thing is useful with low cardinality indexes. Maybe that could be better targeted - not sure. Things are still moving quite fast, and I'm still working on the patch by solving the biggest problem I see on the horizon. So I will probably change this and then change it again in the next week anyway. I've had further success microoptimizing the sorts in heapam.c in the past couple of days. I think that the regression that I reported can be further shrunk. To recap, we saw a ~15% lost of throughput/TPS with 16 clients, extreme contention (no rate limiting), several low cardinality indexes, with everything still fitting in shared_buffers. It now looks like I can get that down to ~7%, which seems acceptable to me given the extreme nature of the workload (and given the fact that we still win on efficiency here -- no index growth). > I've used scale factor 10 000, adjusted indexes (resulting in a 189GB size database) > and run the following pgbench: > > pgbench -f testcase.pgbench -r -c32 -j8 -T 3600 bench > I can see a clear benefit from this patch *under specified conditions, YMMW* > - 32% increase in TPS > - 24% drop in average latency > - most important — stable index size! Nice. When I did a similar test on October 16th it was on a much smaller database. I think that I saw a bigger improvement because the initial DB size was close to shared_buffers. So not going over shared_buffers makes a much bigger difference. Whereas here the DB size is several times larger, so there is no question about significantly exceeding shared_buffers -- it's going to happen for the master branch as well as the patch. (This is kind of obvious, but pointing it out just in case.) > In my opinion, patch provides clear benefits from IO reduction and index size > control perspective. I really like the stability of operations on patched > version. I would rather stick to the "restricted" version of the patch though. You're using EBS here, which probably has much higher latency than what I have here (an NVME SSD). What you have is probably more relevant to the real world, though. > Hope this helps. I'm open to do more tests if necessary. It's great, thanks! -- Peter Geoghegan
On Thu, Oct 29, 2020 at 3:05 PM Victor Yegorov <vyegorov@gmail.com> wrote:
> And some more comments after another round of reading the patch.
>
> 1. Looks like UNIQUE_CHECK_NO_WITH_UNCHANGED is used for HOT updates,
> should we use UNIQUE_CHECK_NO_HOT here? It is better understood like this.
This would probably get me arrested by the tableam police, though.
FWIW the way that that works is still kind of a hack. I think that I
actually need a new boolean flag, rather than overloading the enum
like this.
> 2. You're modifying the table_tuple_update() function on 1311 line of include/access/tableam.h,
> adding modified_attrs_hint. There's a large comment right before it describing parameters,
> I think there should be a note about modified_attrs_hint parameter in that comment, 'cos
> it is referenced from other places in tableam.h and also from backend/access/heap/heapam.c
Okay, makes sense.
> 3. Can you elaborate on the scoring model you're using?
> Why do we expect a score of 25, what's the rationale behind this number?
> And should it be #define-d ?
See my remarks on this from the earlier e-mail.
> 4. heap_compute_xid_horizon_for_tuples contains duplicate logic. Is it possible to avoid this?
Maybe? I think that duplicating code is sometimes the lesser evil.
Like in tuplesort.c, for example. I'm not sure if that's true here,
but it certainly can be true. This is the kind of thing that I usually
only make my mind up about at the last minute. It's a matter of taste.
> 5. In this comment
>
> + * heap_index_batch_check() helper function. Sorts deltids array in the
> + * order needed for useful processing.
>
> perhaps it is better to replace "useful" with more details? Or point to the place
> where "useful processing" is described.
Okay.
> + else if (_bt_keep_natts_fast(rel, state->base, itup) > nkeyatts &&
> + _bt_dedup_save_htid(state, itup))
> + {
> +
> + }
>
> I would rather add a comment, explaining that the empty body of the clause is actually expected.
Okay. Makes sense.
> 7. In the _bt_dedup_delete_finish_pending() you're setting ispromising to false for both
> posting and non-posting tuples. This contradicts comments before function.
The idea is that we can have plain tuples (non-posting list tuples)
that are non-promising when they're duplicates. Because why not?
Somebody might have deleted them (rather than updating them). It is
fine to have an open mind about this possibility despite the fact that
it is close to zero (in the general case). Including these TIDs
doesn't increase the amount of work we do in heapam. Even when we
don't succeed in finding any of the non-dup TIDs as dead (which is
very much the common case), telling heapam about their existence could
help indirectly (which is somewhat more common). This factor alone
could influence which heap pages heapam visits when there is no
concentration of promising tuples on heap pages (since the total
number of TIDs on each block is the tie-breaker condition when
comparing heap blocks with an equal number of promising tuples during
the block group sort in heapam.c). I believe that this approach tends
to result in heapam going after older TIDs when it wouldn't otherwise,
at least in some cases.
You're right, though -- this is still unclear. Actually, I think that
I should move the handling of promising/duplicate tuples into
_bt_dedup_delete_finish_pending(), too (move it from
_bt_dedup_delete_pass()). That would allow me to talk about all of the
TIDs that get added to the deltids array (promising and non-promising)
in one central function. I'll do it that way soon.
--
Peter Geoghegan
On Thu, Oct 29, 2020 at 4:30 PM Peter Geoghegan <pg@bowt.ie> wrote: > I found that the "fiver" and "tenner" indexes in particular took a > very long time to have even one page split with a long running > transaction. Another interesting effect was that all page splits > suddenly stopped when my one hour 30 minute long transaction/snapshot > finally went away -- the indexes stopped growing instantly when I > killed the psql session. But on the master branch the cascading > version driven page splits took at least several minutes to stop when > I killed the psql session/snapshot at that same point of the benchmark > (maybe longer). With the master branch, we can get behind on LP_DEAD > index tuple bit setting, and then have no chance of catching up. > Whereas the patch gives us a second chance for each page. I forgot to say that this long running xact/snapshot test I ran yesterday was standard pgbench (more or less) -- no custom indexes. Unlike my other testing, the only possible source of non-HOT updates here was not being able to fit a heap tuple on the same heap page (typically because we couldn't truncate HOT chains in time due to a long running xact holding back cleanup). The normal state (without a long running xact/snapshot) is no page splits, both with the patch and with master. But when you introduce a long running xact, both master and patch will get page splits. The difference with the patch is that it'll take much longer to start up compared to master, the page splits are more gradual and smoother with the patch, and the patch will stop having page splits just as soon as the xact goes away -- the same second. With the master branch we're reliant on LP_DEAD bit setting, and if that gets temporarily held back by a long snapshot then we have little chance of catching up after the snapshot goes away but before some pages have unnecessary version-driven page splits. -- Peter Geoghegan
On Mon, Oct 26, 2020 at 2:15 PM Peter Geoghegan <pg@bowt.ie> wrote:
> Now for the not-so-good news.
> The latency numbers aren't great for the patch, either. Take the 16 client case:
Attached is v6, which more or less totally fixes the problem we saw
with this silly "lots of low cardinality indexes" benchmark.
I wasn't really expecting this to happen -- the benchmark in question
is extreme and rather unrealistic -- but I had some new insights that
made it possible (more details on the code changes towards the end of
this email). Now I don't have to convince anyone that the performance
hit for extreme cases is worth it in order to realize big benefits for
other workloads. There pretty much isn't a performance hit to speak of
now (or so it would seem). I've managed to take this small loss of
performance and turn it into a small gain. And without having to make
any compromises on the core goal of the patch ("no unnecessary page
splits caused by version churn").
With the same indexes ("score", "tenner", "fiver", etc) as before on
pgbench_accounts, and same pgbench-variant queries, we once again see
lots of index bloat with master, but no index bloat at all with v6 of
the patch (no change there). The raw latency numbers are where we see
new improvements for v6. Summary:
2020-11-02 17:35:29 -0800 - Start of initial data load for run
"patch.r1c16" (DB is also used by later runs)
2020-11-02 17:40:21 -0800 - End of initial data load for run "patch.r1c16"
2020-11-02 17:40:21 -0800 - Start of pgbench run "patch.r1c16"
2020-11-02 19:40:31 -0800 - End of pgbench run "patch.r1c16":
patch.r1c16.bench.out: "tps = 9998.129224 (including connections
establishing)" "latency average = 0.243 ms" "latency stddev = 0.088
ms"
2020-11-02 19:40:46 -0800 - Start of initial data load for run
"master.r1c16" (DB is also used by later runs)
2020-11-02 19:45:42 -0800 - End of initial data load for run "master.r1c16"
2020-11-02 19:45:42 -0800 - Start of pgbench run "master.r1c16"
2020-11-02 21:45:52 -0800 - End of pgbench run "master.r1c16":
master.r1c16.bench.out: "tps = 9998.674505 (including connections
establishing)" "latency average = 0.231 ms" "latency stddev = 0.717
ms"
2020-11-02 21:46:10 -0800 - Start of pgbench run "patch.r1c32"
2020-11-02 23:46:23 -0800 - End of pgbench run "patch.r1c32":
patch.r1c32.bench.out: "tps = 9999.968794 (including connections
establishing)" "latency average = 0.256 ms" "latency stddev = 0.104
ms"
2020-11-02 23:46:39 -0800 - Start of pgbench run "master.r1c32"
2020-11-03 01:46:54 -0800 - End of pgbench run "master.r1c32":
master.r1c32.bench.out: "tps = 10001.097045 (including connections
establishing)" "latency average = 0.250 ms" "latency stddev = 1.858
ms"
2020-11-03 01:47:32 -0800 - Start of pgbench run "patch.r2c16"
2020-11-03 03:47:45 -0800 - End of pgbench run "patch.r2c16":
patch.r2c16.bench.out: "tps = 9999.290688 (including connections
establishing)" "latency average = 0.247 ms" "latency stddev = 0.103
ms"
2020-11-03 03:48:04 -0800 - Start of pgbench run "master.r2c16"
2020-11-03 05:48:18 -0800 - End of pgbench run "master.r2c16":
master.r2c16.bench.out: "tps = 10000.424117 (including connections
establishing)" "latency average = 0.241 ms" "latency stddev = 1.587
ms"
2020-11-03 05:48:39 -0800 - Start of pgbench run "patch.r2c32"
2020-11-03 07:48:52 -0800 - End of pgbench run "patch.r2c32":
patch.r2c32.bench.out: "tps = 9999.539730 (including connections
establishing)" "latency average = 0.258 ms" "latency stddev = 0.125
ms"
2020-11-03 07:49:11 -0800 - Start of pgbench run "master.r2c32"
2020-11-03 09:49:26 -0800 - End of pgbench run "master.r2c32":
master.r2c32.bench.out: "tps = 10000.833754 (including connections
establishing)" "latency average = 0.250 ms" "latency stddev = 0.997
ms"
These are 2 hour runs, 16 and 32 clients -- same as last time (though
note the 10k TPS limit). So 4 pairs of runs (each pair of runs is a
pair of patch/master runs) making 8 runs total, lasting 16 hours total
(not including initial data loading).
Notice that the final pair of runs shows that the master branch
eventually gets to the point of having far higher latency stddev. The
stddev starts high and gets higher as time goes on. Here is the
latency breakdown for the final pair of runs:
patch.r2c32.bench.out:
scaling factor: 1000
query mode: prepared
number of clients: 32
number of threads: 8
duration: 7200 s
number of transactions actually processed: 71997119
latency average = 0.258 ms
latency stddev = 0.125 ms
rate limit schedule lag: avg 0.046 (max 39.151) ms
tps = 9999.539730 (including connections establishing)
tps = 9999.544743 (excluding connections establishing)
statement latencies in milliseconds:
0.001 \set aid1 random_gaussian(1, 100000 * :scale, 4.0)
0.000 \set aid2 random_gaussian(1, 100000 * :scale, 4.5)
0.000 \set aid3 random_gaussian(1, 100000 * :scale, 4.2)
0.000 \set bid random(1, 1 * :scale)
0.000 \set tid random(1, 10 * :scale)
0.000 \set delta random(-5000, 5000)
0.022 BEGIN;
0.091 UPDATE pgbench_accounts SET abalance = abalance +
:delta WHERE aid = :aid1;
0.036 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.034 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
0.025 END;
master.r2c32.bench.out:
query mode: prepared
number of clients: 32
number of threads: 8
duration: 7200 s
number of transactions actually processed: 72006667
latency average = 0.250 ms
latency stddev = 0.997 ms
rate limit schedule lag: avg 0.053 (max 233.045) ms
tps = 10000.833754 (including connections establishing)
tps = 10000.839935 (excluding connections establishing)
statement latencies in milliseconds:
0.001 \set aid1 random_gaussian(1, 100000 * :scale, 4.0)
0.000 \set aid2 random_gaussian(1, 100000 * :scale, 4.5)
0.000 \set aid3 random_gaussian(1, 100000 * :scale, 4.2)
0.000 \set bid random(1, 1 * :scale)
0.000 \set tid random(1, 10 * :scale)
0.000 \set delta random(-5000, 5000)
0.023 BEGIN;
0.075 UPDATE pgbench_accounts SET abalance = abalance +
:delta WHERE aid = :aid1;
0.037 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.035 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
0.026 END;
There is only one aspect of this that the master branch still wins on
by the end -- the latency on the UPDATE is still a little lower on
master. This happens for the obvious reason: the UPDATE doesn't clean
up after itself on the master branch (to the extent that the average
xact latency is still a tiny bit higher with the patch). But the
SELECT queries are never actually slower with the patch, even during
earlier runs -- they're just as fast as the master branch (and faster
than the master branch by the end). Only the UPDATEs can ever be made
slower, so AFAICT any new cost is only experienced by the queries that
create the problem for the system as a whole. We're imposing new costs
fairly.
Performance with the patch is consistently much more stable. We don't
get overwhelmed by FPIs in the way we see with the master branch,
which causes sudden gluts that are occasionally very severe (notice
that master.r2c16.bench.out was a big stddev outlier). Maybe the most
notable thing is the max rate limit schedule lag. In the last run we
see max 39.151 ms for the patch vs max 233.045 ms for master.
Now for a breakdown of the code enhancements behind the improved
benchmark numbers. They are:
* The most notable improvement is to the sort order of the heap block
groups within heapam.c. We now round up to the next power of two when
sorting candidate heap blocks (this is the sort used to decide which
heap blocks to visit, and in what order). The "number of promising
TIDs" field (as well as the "number of TIDs total" tiebreaker) is
rounded up so that we ignore relatively small differences. We now tend
to process related groups of contiguous pages in relatively big
batches -- though only where appropriate.
* A closely related optimization was also added to heapam.c:
"favorable blocks". That is, we recognize groups of related heap
blocks that are contiguous. When we encounter these blocks we make
heapam.c effectively increase its per-call batch size, so that it
processes more blocks in the short term but does less absolute work in
the long run.
The key insight behind both of these enhancements is that physically
close heap blocks are generally also close together in time, and
generally share similar characteristics (mostly LP_DEAD items vs
mostly live items, already in shared_buffers, etc). So we're focussing
more on heap locality when the hint we get from nbtree isn't giving us
a very strong signal about what to do (we need to be very judicious
because we are still only willing to access a small number of heap
blocks at a time). While in general the best information heapam has to
go on comes from nbtree, heapam should not care about noise-level
variations in that information -- better to focus on heap locality
(IOW heapam.c needs to have a sophisticated understanding of the
limitations of the hints it receives from nbtree). As a result of
these two changes, heapam.c tends to process earlier blocks/records
first, in order, in a way that is correlated across time and across
indexes -- with more sequential I/O and more confidence in a
successful outcome when we undertake work. (Victor should note that
heapam.c no longer has any patience when it encounters even a single
heap block with no dead TIDs -- he was right about that. The new
heapam.c stuff works well enough that there is no possible upside to
"being patient", even with indexes on low cardinality data that
experience lots of version churn, a workload that my recent
benchmarking exemplifies.)
* nbtdedup.c will now give heapam.c an accurate idea about its
requirements -- it now expresses those in terms of space freed, which
heapam.c now cares about directly. This matters a lot with low
cardinality data, where freeing an entire index tuple is a lot more
valuable to nbtree than freeing just one TID in a posting list
(because the former case frees up 20 bytes at a minimum, while the
latter case usually only frees up 6 bytes).
I said something to Victor about nbtree's wishes not being important
here -- heapam.c is in charge. But that now seems like the wrong
mental model. After all, how can nbtree not be important if it is
entitled to call heapam.c as many times as it feels like, without
caring about the cost of thrashing (as we saw with low cardinality
data prior to v6)? With v6 of the patch I took my own advice about not
thinking of each operation as an isolated event. So now heapam.c has a
more nuanced understanding of the requirements of nbtree, and can be
either more eager or more lazy according to 1) nbtree requirements,
and 2.) conditions local to heapam.c.
* Improved handling of low cardinality data in nbtdedup.c -- we now
always merge together items with low cardinality data, regardless of
how well we do with deleting TIDs. This buys more time before the next
delete attempt for the same page.
* Specialized shellsort implementations for heapam.c.
Shellsort is sometimes used as a lightweight system qsort in embedded
systems. It has many of the same useful properties as a well optimized
quicksort for smaller datasets, and also has the merit of compiling to
far fewer instructions when specialized like this. Specializing on
qsort (as in v5) results in machine code that seems rather heavyweight
given the heapam.c requirements. Instruction cache matters here
(although that's easy to miss when profiling).
v6 still needs more polishing -- my focus has still been on the
algorithm itself. But I think I'm almost done with that part -- it
seems unlikely that I'll be able to make any additional significant
improvements in that area after v6. The new bucketized heap block
sorting behavior seems to be really effective, especially with low
cardinality data, and especially over time, as the heap naturally
becomes more fragmented. We're now blending together locality from
nbtree and heapam in an adaptive way.
I'm pretty sure that the performance on sympathetic cases (such as the
case Victor tested) will also be a lot better, though I didn't look
into that on v6. If Victor is in a position to run further benchmarks
on v6, that would certainly be welcome (independent validation always
helps).
I'm not aware of any remaining cases that it would be fair to describe
as being regressed by the patch -- can anybody else think of any
possible candidates?
BTW, I will probably rename the mechanism added by the patch to
"bottom-up index vacuuming", or perhaps "bottom-up index deletion" --
that seems to capture the general nature of what the patch does quite
well. Now regular index vacuuming can be thought of as a top-down
complementary mechanism that takes care of remaining diffuse spots of
garbage tuples that queries happen to miss (more or less). Also, while
it is true that there are some ways in which the patch is related to
deduplication, it doesn't seem useful to emphasize that part anymore.
Plus clarifying which kind of deduplication I'm talking about in code
comments is starting to become really annoying.
--
Peter Geoghegan
Attachment
On Tue, Nov 3, 2020 at 12:44 PM Peter Geoghegan <pg@bowt.ie> wrote: > v6 still needs more polishing -- my focus has still been on the > algorithm itself. But I think I'm almost done with that part -- it > seems unlikely that I'll be able to make any additional significant > improvements in that area after v6. Attached is v7, which tidies everything up. The project is now broken up into multiple patches, which can be committed separately. Every patch has a descriptive commit message. This should make it a lot easier to review. I've renamed the feature to "bottom-up index deletion" in this latest revision. This seems like a better name than "dedup deletion". This name suggests that the feature complements "top-down index deletion" by VACUUM. This name is descriptive of what the new mechanism is supposed to do at a high level. Other changes in v7 include: * We now fully use the tableam interface -- see the first patch. The bottom-up index deletion API has been fully worked out. There is now an optional callback/shim function. The bottom-up index deletion caller (nbtree) is decoupled from the callee (heapam) by the tableam shim. This was what allowed me to break the patch into multiple pieces/patches. * The executor no longer uses a IndexUniqueCheck-enum-constant as a hint to nbtree. Rather, we have a new aminsert() bool argument/flag that hints to the index AM -- see the second patch. To recap, the hint tells nbtree that the incoming tuple is a duplicate of an existing tuple caused by an UPDATE, without any logical changes for the indexed columns. Bottom-up deletion is effective when there is a local concentration of these index tuples that become garbage quickly. A dedicated aminsert() argument seems a lot cleaner. Though I wonder if this approach can be generalized a bit further, so that we can support other similar aminsert() hints in the future without adding even more arguments. Maybe some new enum instead of a boolean? * Code cleanup for the nbtdedup.c changes. Better explanation of when and how posting list TIDs are marked promising, and why. * Streamlined handling of the various strategies that nbtinsert.c uses to avoid a page split (e.g. traditional LP_DEAD deletion, deduplication). A new unified function in nbtinsert.c was added. This organization is a lot cleaner -- it greatly simplifies _bt_findinsertloc(), which became more complicated than it really needed to be due to the changes needed for deduplication in PostgreSQL 13. This change almost seems like an independently useful piece of work. -- Peter Geoghegan
Attachment
пн, 9 нояб. 2020 г. в 18:21, Peter Geoghegan <pg@bowt.ie>:
On Tue, Nov 3, 2020 at 12:44 PM Peter Geoghegan <pg@bowt.ie> wrote:
> v6 still needs more polishing -- my focus has still been on the
> algorithm itself. But I think I'm almost done with that part -- it
> seems unlikely that I'll be able to make any additional significant
> improvements in that area after v6.
Attached is v7, which tidies everything up. The project is now broken
up into multiple patches, which can be committed separately. Every
patch has a descriptive commit message. This should make it a lot
easier to review.
I've looked at the latest (v7) patchset.
I've decided to use a quite common (in my practice) setup with an indexed mtime column over scale 1000 set:
alter table pgbench_accounts add mtime timestamp default now();
create or replace function fill_mtime() returns trigger as $$begin NEW.mtime=now(); return NEW; END;$$ language plpgsql;
create trigger t_accounts_mtime before update on pgbench_accounts for each row execute function fill_mtime();
create index accounts_mtime on pgbench_accounts (mtime, aid);
create index tenner on pgbench_accounts ((aid - (aid%10)));
ANALYZE pgbench_accounts;
create or replace function fill_mtime() returns trigger as $$begin NEW.mtime=now(); return NEW; END;$$ language plpgsql;
create trigger t_accounts_mtime before update on pgbench_accounts for each row execute function fill_mtime();
create index accounts_mtime on pgbench_accounts (mtime, aid);
create index tenner on pgbench_accounts ((aid - (aid%10)));
ANALYZE pgbench_accounts;
For the test, I've used 3 pgbench scripts (started in parallel sessions):
1. UPDATE + single PK SELECT in a transaction
2. three PK SELECTs in a transaction
3. SELECT of all modifications for the last 15 minutes
Given the size of the set, all data was cached and UPDATEs were fast enough to make 3rd query sit on disk-based sorting.
1. UPDATE + single PK SELECT in a transaction
2. three PK SELECTs in a transaction
3. SELECT of all modifications for the last 15 minutes
Given the size of the set, all data was cached and UPDATEs were fast enough to make 3rd query sit on disk-based sorting.
Some figures follow.
Master sizes
------------
relkind | relname | nrows | blk_before | mb_before | blk_after | mb_after
---------+-----------------------+-----------+------------+-----------+-----------+----------
r | pgbench_accounts | 100000000 | 1639345 | 12807.4 | 1677861 | 13182.8
i | accounts_mtime | 100000000 | 385042 | 3008.1 | 424413 | 3565.6
i | pgbench_accounts_pkey | 100000000 | 274194 | 2142.1 | 274194 | 2142.3
i | tenner | 100000000 | 115352 | 901.2 | 128513 | 1402.9
(4 rows)
Patchset v7 sizes
-----------------
relkind | relname | nrows | blk_before | mb_before | blk_after | mb_after
---------+-----------------------+-----------+------------+-----------+-----------+----------
r | pgbench_accounts | 100000000 | 1639345 | 12807.4 | 1676887 | 13170.2
i | accounts_mtime | 100000000 | 385042 | 3008.1 | 424521 | 3536.4
i | pgbench_accounts_pkey | 100000000 | 274194 | 2142.1 | 274194 | 2142.1
i | tenner | 100000000 | 115352 | 901.2 | 115352 | 901.2
(4 rows)
TPS
---
query | Master TPS | Patched TPS
----------------+------------+-------------
UPDATE + SELECT | 5150 | 4884
3 SELECT in txn | 23133 | 23193
15min SELECT | 0.75 | 0.78
------------
relkind | relname | nrows | blk_before | mb_before | blk_after | mb_after
---------+-----------------------+-----------+------------+-----------+-----------+----------
r | pgbench_accounts | 100000000 | 1639345 | 12807.4 | 1677861 | 13182.8
i | accounts_mtime | 100000000 | 385042 | 3008.1 | 424413 | 3565.6
i | pgbench_accounts_pkey | 100000000 | 274194 | 2142.1 | 274194 | 2142.3
i | tenner | 100000000 | 115352 | 901.2 | 128513 | 1402.9
(4 rows)
Patchset v7 sizes
-----------------
relkind | relname | nrows | blk_before | mb_before | blk_after | mb_after
---------+-----------------------+-----------+------------+-----------+-----------+----------
r | pgbench_accounts | 100000000 | 1639345 | 12807.4 | 1676887 | 13170.2
i | accounts_mtime | 100000000 | 385042 | 3008.1 | 424521 | 3536.4
i | pgbench_accounts_pkey | 100000000 | 274194 | 2142.1 | 274194 | 2142.1
i | tenner | 100000000 | 115352 | 901.2 | 115352 | 901.2
(4 rows)
TPS
---
query | Master TPS | Patched TPS
----------------+------------+-------------
UPDATE + SELECT | 5150 | 4884
3 SELECT in txn | 23133 | 23193
15min SELECT | 0.75 | 0.78
- unused index is not suffering from not-HOT updates at all, which is the point of the patch
- we have ordinary queries performing on the same level as on master
- we have 5,2% slowdown in UPDATE speed
Looking at graphs (attached), I can see that on the patched version we're doing some IO (which is expected) during UPADTEs.
We're also reading quite a lot from disks for simple SELECTs, compared to the master version.
I'm not sure if this should be counted as regression, though, as graphs go on par pretty much.
Still, I would like to understand why this combination of indexes and queries slows down UPDATEs.
During compilation I got one warning for make -C contrib:
blutils.c: In function ‘blhandler’:
blutils.c:133:22: warning: assignment from incompatible pointer type [-Wincompatible-pointer-types]
amroutine->aminsert = blinsert;
Looking at graphs (attached), I can see that on the patched version we're doing some IO (which is expected) during UPADTEs.
We're also reading quite a lot from disks for simple SELECTs, compared to the master version.
I'm not sure if this should be counted as regression, though, as graphs go on par pretty much.
Still, I would like to understand why this combination of indexes and queries slows down UPDATEs.
During compilation I got one warning for make -C contrib:
blutils.c: In function ‘blhandler’:
blutils.c:133:22: warning: assignment from incompatible pointer type [-Wincompatible-pointer-types]
amroutine->aminsert = blinsert;
I agree with the rename to "bottom-up index deletion", using "vacuuming" generally makes users think
that functionality is used only during VACUUM (misleading).
I haven't looked at the code yet.
Victor Yegorov
Attachment
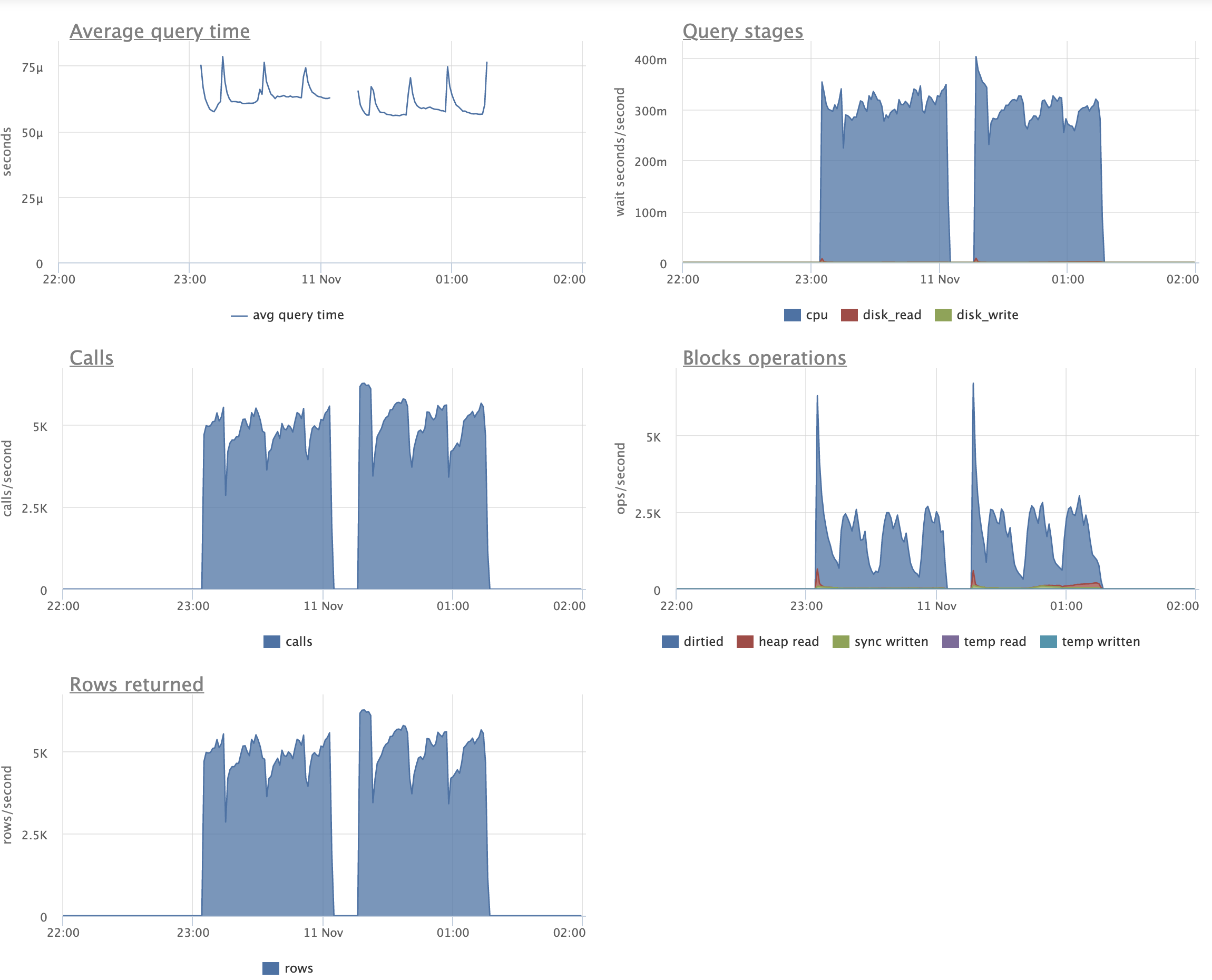{kind=link}
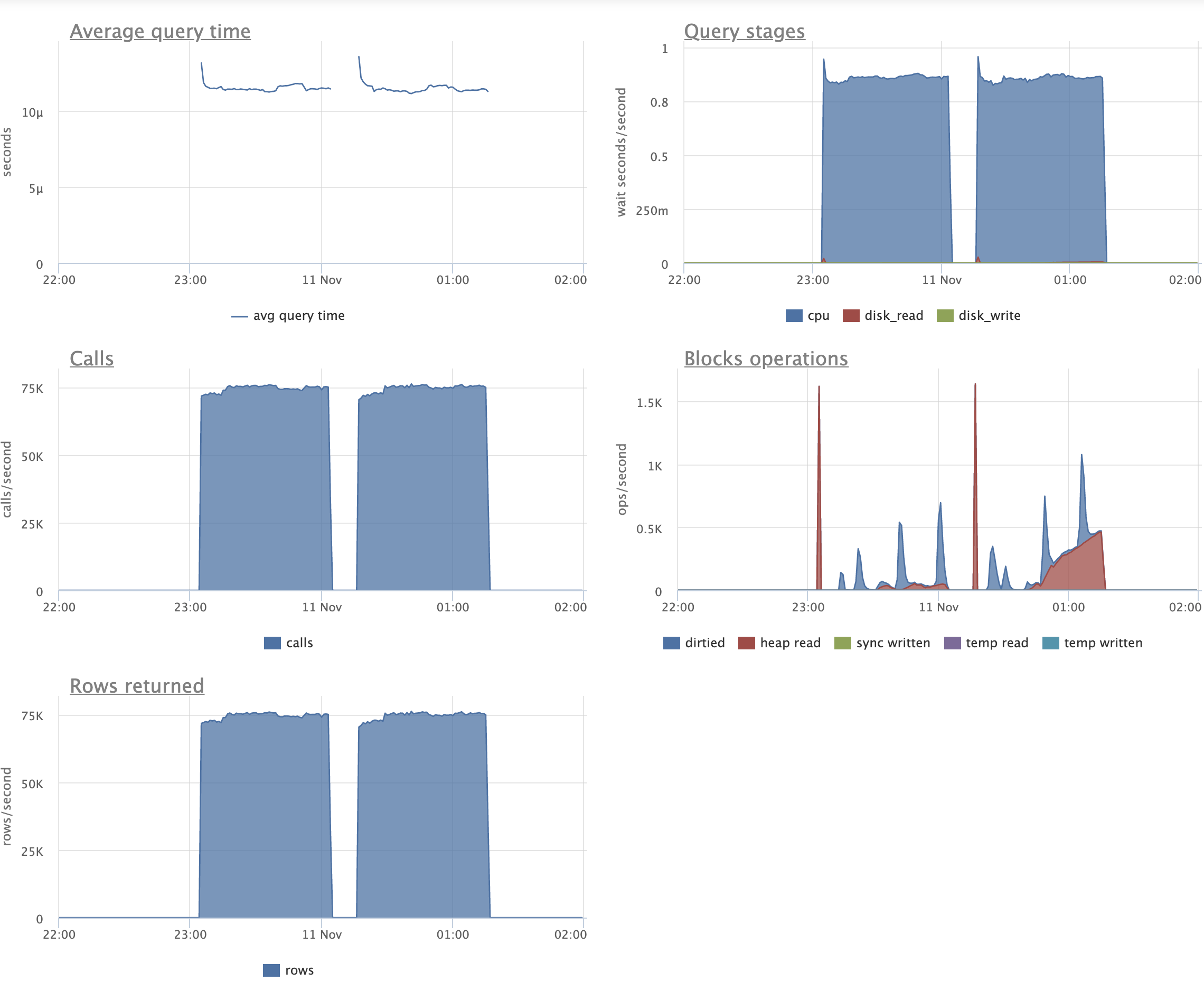{kind=link}
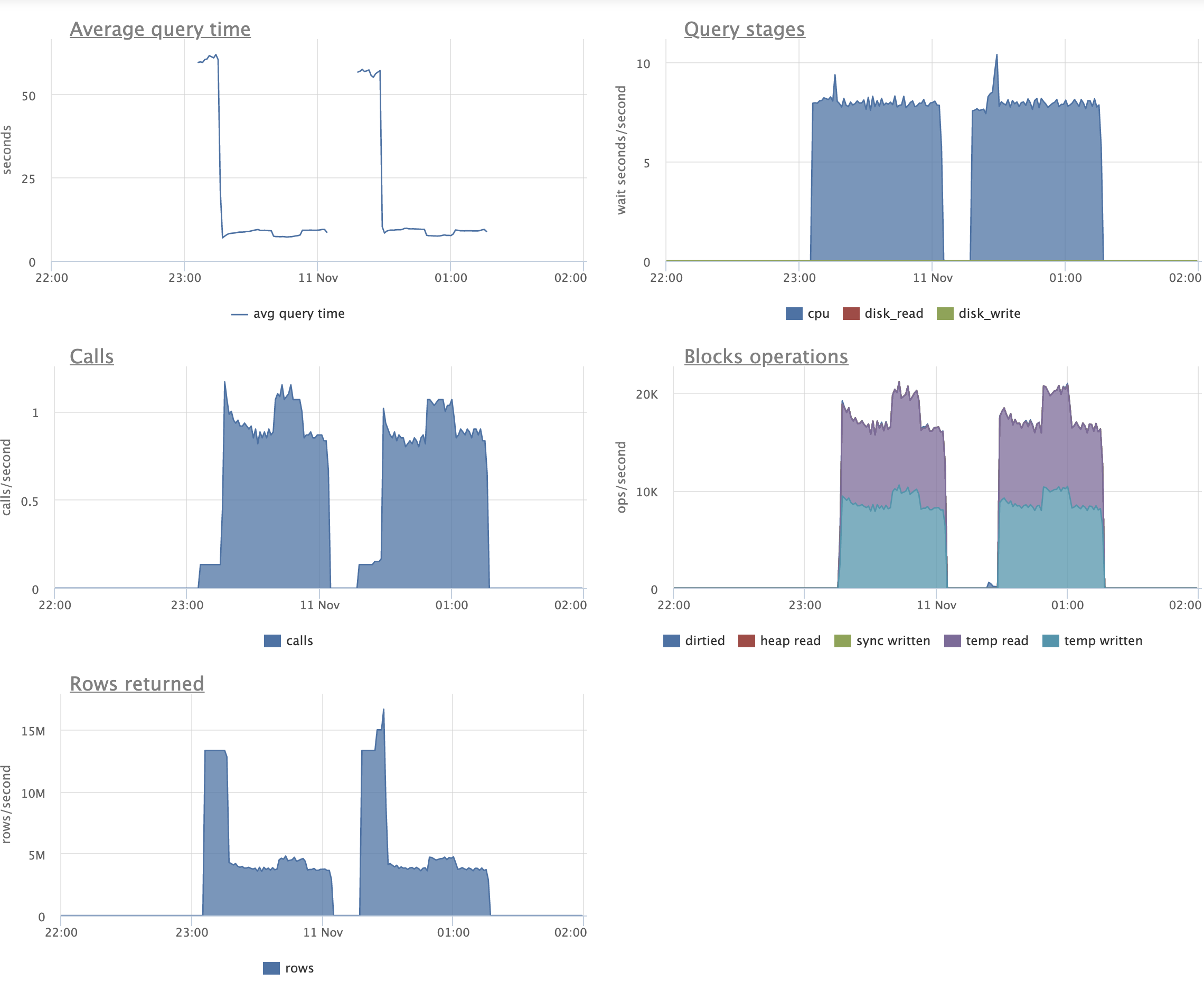{kind=link}
пн, 9 нояб. 2020 г. в 18:21, Peter Geoghegan <pg@bowt.ie>:
On Tue, Nov 3, 2020 at 12:44 PM Peter Geoghegan <pg@bowt.ie> wrote:
> v6 still needs more polishing -- my focus has still been on the
> algorithm itself. But I think I'm almost done with that part -- it
> seems unlikely that I'll be able to make any additional significant
> improvements in that area after v6.
Attached is v7, which tidies everything up. The project is now broken
up into multiple patches, which can be committed separately. Every
patch has a descriptive commit message. This should make it a lot
easier to review.
And another test session, this time with scale=2000 and shared_buffers=512MB
(vs scale=1000 and shared_buffers=16GB previously). The rest of the setup is the same:
- mtime column that is tracks update time
- index on (mtime, aid)
- tenner low cardinality index from Peter's earlier e-mail
- 3 pgbench scripts run in parallel on master and on v7 patchset (scripts from the previous e-mail used here).
(vs scale=1000 and shared_buffers=16GB previously). The rest of the setup is the same:
- mtime column that is tracks update time
- index on (mtime, aid)
- tenner low cardinality index from Peter's earlier e-mail
- 3 pgbench scripts run in parallel on master and on v7 patchset (scripts from the previous e-mail used here).
(I just realized that the size-after figures in my previous e-mail are off, 'cos failed
to ANALYZE table after the tests.)
Master
------
relkind | relname | nrows | blk_before | mb_before | blk_after | mb_after | Diff
---------+-----------------------+-----------+------------+-----------+-----------+----------+-------
r | pgbench_accounts | 200000000 | 3278689 | 25614.8 | 3314951 | 25898.1 | +1.1%
i | accounts_mtime | 200000000 | 770080 | 6016.3 | 811946 | 6343.3 | +5.4%
i | pgbench_accounts_pkey | 200000000 | 548383 | 4284.2 | 548383 | 4284.2 | 0
i | tenner | 200000000 | 230701 | 1802.4 | 252346 | 1971.5 | +9.4%
(4 rows)
------
relkind | relname | nrows | blk_before | mb_before | blk_after | mb_after | Diff
---------+-----------------------+-----------+------------+-----------+-----------+----------+-------
r | pgbench_accounts | 200000000 | 3278689 | 25614.8 | 3314951 | 25898.1 | +1.1%
i | accounts_mtime | 200000000 | 770080 | 6016.3 | 811946 | 6343.3 | +5.4%
i | pgbench_accounts_pkey | 200000000 | 548383 | 4284.2 | 548383 | 4284.2 | 0
i | tenner | 200000000 | 230701 | 1802.4 | 252346 | 1971.5 | +9.4%
(4 rows)
Patched
-------
relkind | relname | nrows | blk_before | mb_before | blk_after | mb_after | Diff
---------+-----------------------+-----------+------------+-----------+-----------+----------+-------
r | pgbench_accounts | 200000000 | 3278689 | 25614.8 | 3330788 | 26021.8 | +1.6%
i | accounts_mtime | 200000000 | 770080 | 6016.3 | 806920 | 6304.1 | +4.8%
i | pgbench_accounts_pkey | 200000000 | 548383 | 4284.2 | 548383 | 4284.2 | 0
i | tenner | 200000000 | 230701 | 1802.4 | 230701 | 1802.4 | 0
(4 rows)
-------
relkind | relname | nrows | blk_before | mb_before | blk_after | mb_after | Diff
---------+-----------------------+-----------+------------+-----------+-----------+----------+-------
r | pgbench_accounts | 200000000 | 3278689 | 25614.8 | 3330788 | 26021.8 | +1.6%
i | accounts_mtime | 200000000 | 770080 | 6016.3 | 806920 | 6304.1 | +4.8%
i | pgbench_accounts_pkey | 200000000 | 548383 | 4284.2 | 548383 | 4284.2 | 0
i | tenner | 200000000 | 230701 | 1802.4 | 230701 | 1802.4 | 0
(4 rows)
TPS
---
query | Master TPS | Patched TPS | Diff
----------------+------------+-------------+------
UPDATE + SELECT | 3024 | 2661 | -12%
3 SELECT in txn | 19073 | 19852 | +4%
15min SELECT | 2.4 | 3.9 | +60%
---
query | Master TPS | Patched TPS | Diff
----------------+------------+-------------+------
UPDATE + SELECT | 3024 | 2661 | -12%
3 SELECT in txn | 19073 | 19852 | +4%
15min SELECT | 2.4 | 3.9 | +60%
We can see that the patched version does much less disk writes during UPDATEs and simple SELECTs and
eliminates write amplification for not involved indexes. (I'm really excited to see these figures.)
On the other hand, there's quite a big drop on the UPDATEs throughput. For sure, undersized shared_bufefrs
contribute to this drop. Still, my experience tells me that under conditions at hand (disabled HOT due to index
over update time column) tables will tend to accumulate bloat and produce unnecessary IO also from WAL.
over update time column) tables will tend to accumulate bloat and produce unnecessary IO also from WAL.
Perhaps I need to conduct a longer test session, say 8+ hours to make obstacles appear more like in real life.
Victor Yegorov
Attachment
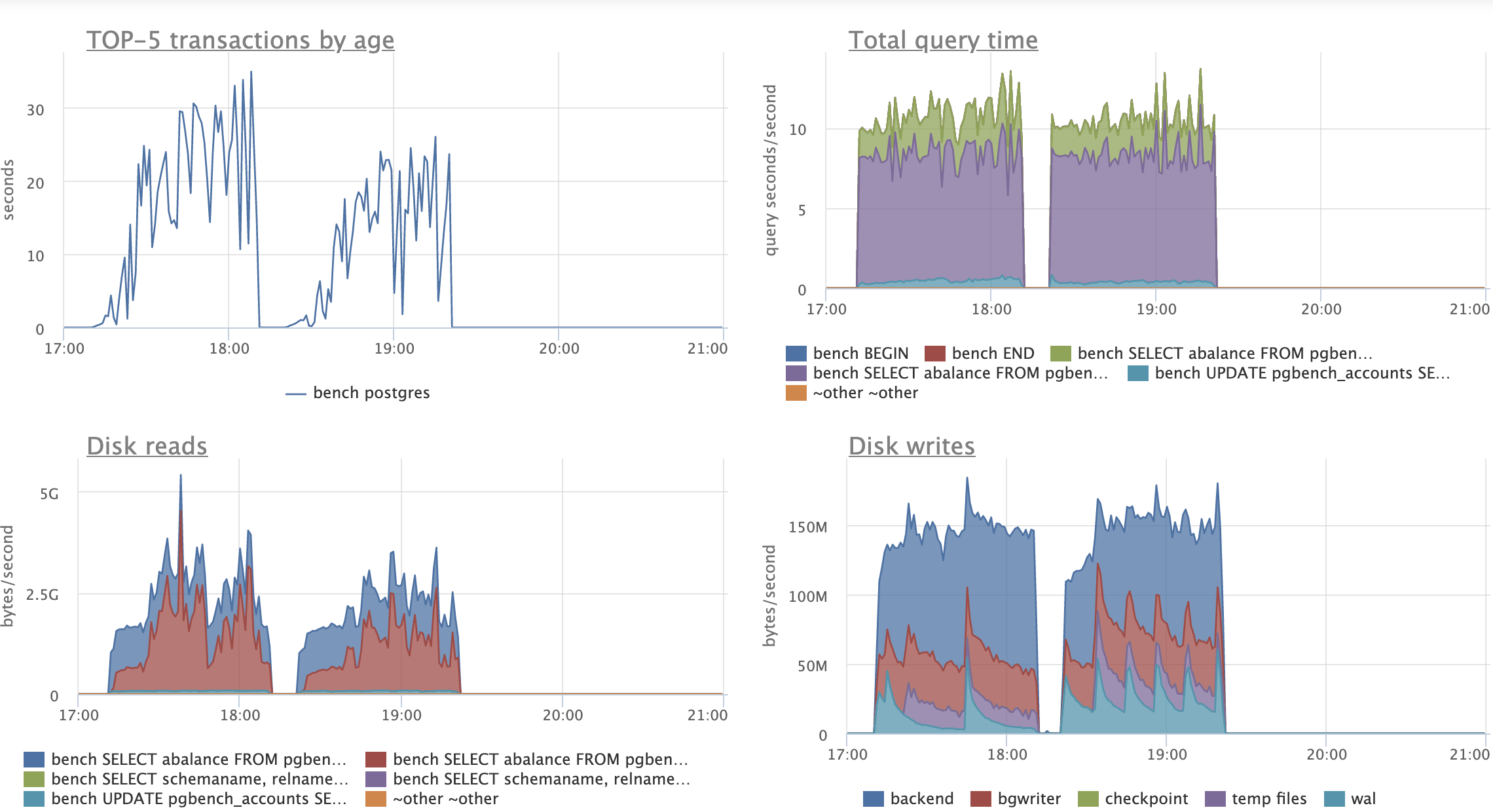{kind=link}
{kind=link}
{kind=link}
{kind=link}
On Wed, Nov 11, 2020 at 6:17 AM Victor Yegorov <vyegorov@gmail.com> wrote: > I've looked at the latest (v7) patchset. > I've decided to use a quite common (in my practice) setup with an indexed mtime column over scale 1000 set: Thanks for testing! > We can see that: > - unused index is not suffering from not-HOT updates at all, which is the point of the patch > - we have ordinary queries performing on the same level as on master > - we have 5,2% slowdown in UPDATE speed I think that I made a mistake with v7: I changed the way that we detect low cardinality data during bottom-up deletion, which made us do extra/early deduplication in more cases than we really should. I suspect that this partially explains the slowdown in UPDATE latency that you reported. I will fix this in v8. I don't think that the solution is to go back to the v6 behavior in this area, though. I now believe that this whole "proactive deduplication for low cardinality data" thing only made sense as a way of compensating for deficiencies in earlier versions of the patch. Deficiencies that I've since fixed anyway. The best solution now is to simplify. We can have generic criteria for "should we dedup the page early after bottom-up deletion finishes without freeing up very much space?". This seemed to work well during my latest testing. Probably because heapam.c is now smart about the requirements from nbtree, as well as the cost of accessing heap pages. > I'm not sure if this should be counted as regression, though, as graphs go on par pretty much. > Still, I would like to understand why this combination of indexes and queries slows down UPDATEs. Another thing that I'll probably add to v8: Prefetching. This is probably necessary just so I can have parity with the existing heapam.c function that the new code is based on, heap_compute_xid_horizon_for_tuples(). That will probably help here, too. > During compilation I got one warning for make -C contrib: Oops. > I agree with the rename to "bottom-up index deletion", using "vacuuming" generally makes users think > that functionality is used only during VACUUM (misleading). Yeah. That's kind of a problem already, because sometimes we use the word VACUUM when talking about the long established LP_DEAD deletion stuff. But I see that as a problem to be fixed. Actually, I would like to fix it very soon. > I haven't looked at the code yet. It would be helpful if you could take a look at the nbtree patch -- particularly the changes related to deprecating the page-level BTP_HAS_GARBAGE flag. I would like to break those parts out into a separate patch, and commit it in the next week or two. It's just refactoring, really. (This commit can also make nbtree only use the word VACUUM for things that strictly involve VACUUM. For example, it'll rename _bt_vacuum_one_page() to _bt_delete_or_dedup_one_page().) We almost don't care about the flag already, so there is almost no behavioral change from deprecated BTP_HAS_GARBAGE in this way. Indexes that use deduplication already don't rely on BTP_HAS_GARBAGE being set ever since deduplication was added to Postgres 13 (the deduplication code doesn't want to deal with LP_DEAD bits, and cannot trust that no LP_DEAD bits can be set just because BTP_HAS_GARBAGE isn't set in the special area). Trusting the BTP_HAS_GARBAGE flag can cause us to miss out on deleting items with their LP_DEAD bits set -- we're better off "assuming that BTP_HAS_GARBAGE is always set", and finding out if there really are LP_DEAD bits set for ourselves each time. Missing LP_DEAD bits like this can happen when VACUUM unsets the page-level flag without actually deleting the items at the same time, which is expected when the items became garbage (and actually had their LP_DEAD bits set) after VACUUM began, but before VACUUM reached the leaf pages. That's really wasteful, and doesn't actually have any upside -- we're scanning all of the line pointers only when we're about to split (or dedup) the same page anyway, so the extra work is practically free. -- Peter Geoghegan
On Wed, Nov 11, 2020 at 12:58 PM Victor Yegorov <vyegorov@gmail.com> wrote: > On the other hand, there's quite a big drop on the UPDATEs throughput. For sure, undersized shared_bufefrs > contribute to this drop. Still, my experience tells me that under conditions at hand (disabled HOT due to index > over update time column) tables will tend to accumulate bloat and produce unnecessary IO also from WAL. I think that the big SELECT statement with an "ORDER BY mtime ... " was a good way of demonstrating the advantages of the patch. Attached is v8, which has the enhancements for low cardinality data that I mentioned earlier today. It also simplifies the logic for dealing with posting lists that we need to delete some TIDs from. These posting list simplifications also make the code a bit more efficient, which might be noticeable during benchmarking. Perhaps your "we have 5,2% slowdown in UPDATE speed" issue will be at least somewhat fixed by the enhancements to v8? Another consideration when testing the patch is the behavioral differences we see between cases where system throughput is as high as possible, versus similar cases where we have a limit in place (i.e. pgbench --rate=? was used). These two cases are quite different with the patch because the patch can no longer be lazy without a limit -- we tend to see noticeably more CPU cycles spent doing bottom-up deletion, though everything else about the profile looks similar (I generally use "perf top" to keep an eye on these things). It's possible to sometimes see increases in latency (regressions) when running without a limit, at least in the short term. These increases can go away when a rate limit is imposed that is perhaps as high as 50% of the max TPS. In general, I think that it makes sense to focus on latency when we have some kind of limit in place. A non-rate-limited case is less realistic. > Perhaps I need to conduct a longer test session, say 8+ hours to make obstacles appear more like in real life. That would be ideal. It is inconvenient to run longer benchmarks, but it's an important part of performance validation. BTW, another related factor is that the patch takes longer to "warm up". I notice this "warm-up" effect on the second or subsequent runs, where we have lots of garbage in indexes even with the patch, and even in the first 5 seconds of execution. The extra I/Os for heap page accesses end up being buffer misses instead of buffer hits, until the cache warms. This is not really a problem with fewer longer runs, because there is relatively little "special warm-up time". (We rarely experience heap page misses during ordinary execution because the heapam.c code is smart about locality of access.) I noticed that the pgbench_accounts_pkey index doesn't grow at all on the master branch in 20201111-results-master.txt. But it's always just a matter of time until that happens without the patch. The PK/unique index takes longer to bloat because it alone benefits from LP_DEAD setting, especially within _bt_check_unique(). But this advantage will naturally erode over time. It'll probably take a couple of hours or more with larger scale factors -- I'm thinking of pgbench scale factors over 2000. When the LP_DEAD bit setting isn't very effective (say it's 50% effective), it's only a matter of time until every original page splits. But that's also true when LP_DEAD setting is 99% effective. While it is much less likely that any individual page will split when LP_DEAD bits are almost always set, the fundamental problem remains, even with 99% effectiveness. That problem is: each page only has to be unlucky once. On a long enough timeline, the difference between 50% effective and 99% effective may be very small. And "long enough timeline" may not actually be very long, at least to a human. Of course, the patch still benefits from LP_DEAD bits getting set by queries -- no change there. It just doesn't *rely* on LP_DEAD bits keeping up with transactions that create bloat on every leaf page. Maybe the patch will behave exactly the same way as the master branch -- it's workload dependent. Actually, it behaves in exactly the same way for about the first 5 - 15 minutes following pgbench initialization. This is roughly how long it takes before the master branch has even one page split. You could say that the patch "makes the first 5 minutes last forever". (Not sure if any of this is obvious to you by now, just saying.) Thanks! -- Peter Geoghegan
Attachment
On Thu, Nov 12, 2020 at 3:00 PM Peter Geoghegan <pg@bowt.ie> wrote:
> Attached is v8, which has the enhancements for low cardinality data
> that I mentioned earlier today. It also simplifies the logic for
> dealing with posting lists that we need to delete some TIDs from.
> These posting list simplifications also make the code a bit more
> efficient, which might be noticeable during benchmarking.
One more thing: I repeated a pgbench test that was similar to my
earlier low cardinality tests -- same indexes (fiver, tenner, score,
aid_pkey_include_abalance). And same queries. But longer runs: 4 hours
each. Plus a larger DB: scale 2,500. Plus a rate-limit of 5000 TPS.
Here is the high level report, with 4 runs -- one pair with 16
clients, another pair with 32 clients:
2020-11-11 19:03:26 -0800 - Start of initial data load for run
"patch.r1c16" (DB is also used by later runs)
2020-11-11 19:18:16 -0800 - End of initial data load for run "patch.r1c16"
2020-11-11 19:18:16 -0800 - Start of pgbench run "patch.r1c16"
2020-11-11 23:18:43 -0800 - End of pgbench run "patch.r1c16":
patch.r1c16.bench.out: "tps = 4999.100006 (including connections
establishing)" "latency average = 3.355 ms" "latency stddev = 58.455
ms"
2020-11-11 23:19:12 -0800 - Start of initial data load for run
"master.r1c16" (DB is also used by later runs)
2020-11-11 23:34:33 -0800 - End of initial data load for run "master.r1c16"
2020-11-11 23:34:33 -0800 - Start of pgbench run "master.r1c16"
2020-11-12 03:35:01 -0800 - End of pgbench run "master.r1c16":
master.r1c16.bench.out: "tps = 5000.061623 (including connections
establishing)" "latency average = 8.591 ms" "latency stddev = 64.851
ms"
2020-11-12 03:35:41 -0800 - Start of pgbench run "patch.r1c32"
2020-11-12 07:36:10 -0800 - End of pgbench run "patch.r1c32":
patch.r1c32.bench.out: "tps = 5000.141420 (including connections
establishing)" "latency average = 1.253 ms" "latency stddev = 9.935
ms"
2020-11-12 07:36:40 -0800 - Start of pgbench run "master.r1c32"
2020-11-12 11:37:19 -0800 - End of pgbench run "master.r1c32":
master.r1c32.bench.out: "tps = 5000.542942 (including connections
establishing)" "latency average = 3.069 ms" "latency stddev = 24.640
ms"
2020-11-12 11:38:18 -0800 - Start of pgbench run "patch.r2c16"
We see a very significant latency advantage for the patch here. Here
is the breakdown on query latency from the final patch run,
patch.r1c32:
scaling factor: 2500
query mode: prepared
number of clients: 32
number of threads: 8
duration: 14400 s
number of transactions actually processed: 72002280
latency average = 1.253 ms
latency stddev = 9.935 ms
rate limit schedule lag: avg 0.406 (max 694.645) ms
tps = 5000.141420 (including connections establishing)
tps = 5000.142503 (excluding connections establishing)
statement latencies in milliseconds:
0.002 \set aid1 random_gaussian(1, 100000 * :scale, 4.0)
0.001 \set aid2 random_gaussian(1, 100000 * :scale, 4.5)
0.001 \set aid3 random_gaussian(1, 100000 * :scale, 4.2)
0.001 \set bid random(1, 1 * :scale)
0.001 \set tid random(1, 10 * :scale)
0.001 \set delta random(-5000, 5000)
0.063 BEGIN;
0.361 UPDATE pgbench_accounts SET abalance = abalance +
:delta WHERE aid = :aid1;
0.171 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.172 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
0.074 END;
Here is the equivalent for master:
scaling factor: 2500
query mode: prepared
number of clients: 32
number of threads: 8
duration: 14400 s
number of transactions actually processed: 72008125
latency average = 3.069 ms
latency stddev = 24.640 ms
rate limit schedule lag: avg 1.695 (max 1097.628) ms
tps = 5000.542942 (including connections establishing)
tps = 5000.544213 (excluding connections establishing)
statement latencies in milliseconds:
0.002 \set aid1 random_gaussian(1, 100000 * :scale, 4.0)
0.001 \set aid2 random_gaussian(1, 100000 * :scale, 4.5)
0.001 \set aid3 random_gaussian(1, 100000 * :scale, 4.2)
0.001 \set bid random(1, 1 * :scale)
0.001 \set tid random(1, 10 * :scale)
0.001 \set delta random(-5000, 5000)
0.078 BEGIN;
0.560 UPDATE pgbench_accounts SET abalance = abalance +
:delta WHERE aid = :aid1;
0.320 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.308 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
0.102 END;
So even the UPDATE is much faster here.
This is also something we see with pg_statio_tables, which looked like
this by the end for patch:
-[ RECORD 1 ]---+-----------------
schemaname | public
relname | pgbench_accounts
heap_blks_read | 117,384,599
heap_blks_hit | 1,051,175,835
idx_blks_read | 24,761,513
idx_blks_hit | 4,024,776,723
For the patch:
-[ RECORD 1 ]---+-----------------
schemaname | public
relname | pgbench_accounts
heap_blks_read | 191,947,522
heap_blks_hit | 904,536,584
idx_blks_read | 65,653,885
idx_blks_hit | 4,002,061,803
Notice that heap_blks_read is down from 191,947,522 on master, to
117,384,599 with the patch -- so it's ~0.611x with the patch. A huge
reduction like this is possible with the patch because it effectively
amortizes the cost of accessing heap blocks to find garbage to clean
up ("nipping the [index bloat] problem in the bud" is much cheaper
than letting it get out of hand for many reasons, locality in
shared_buffers is one more reason). The patch accesses garbage tuples
in heap blocks close together in time for all indexes, at a point in
time when the blocks are still likely to be found in shared_buffers.
Also notice that idx_blks_read is ~0.38x with the patch. That's less
important, but still significant.
--
Peter Geoghegan
пт, 13 нояб. 2020 г. в 00:01, Peter Geoghegan <pg@bowt.ie>:
On Wed, Nov 11, 2020 at 12:58 PM Victor Yegorov <vyegorov@gmail.com> wrote:
> On the other hand, there's quite a big drop on the UPDATEs throughput. For sure, undersized shared_bufefrs
> contribute to this drop. Still, my experience tells me that under conditions at hand (disabled HOT due to index
> over update time column) tables will tend to accumulate bloat and produce unnecessary IO also from WAL.
I think that the big SELECT statement with an "ORDER BY mtime ... "
was a good way of demonstrating the advantages of the patch.
Attached is v8, which has the enhancements for low cardinality data
that I mentioned earlier today. It also simplifies the logic for
dealing with posting lists that we need to delete some TIDs from.
These posting list simplifications also make the code a bit more
efficient, which might be noticeable during benchmarking.
Perhaps your "we have 5,2% slowdown in UPDATE speed" issue will be at
least somewhat fixed by the enhancements to v8?
Yes, v8 looks very nice!
I've done two 8 hour long sessions with scale=2000 and shared_buffers=512MB
(previously sent postgresql.auto.conf used here with no changes).
The rest of the setup is the same:(previously sent postgresql.auto.conf used here with no changes).
- mtime column that is tracks update time
- index on (mtime, aid)
- tenner low cardinality index from Peter's earlier e-mail
- 3 pgbench scripts run in parallel on master and on v8 patchset (scripts from the previous e-mail used here).
Master
------
relname | nrows | blk_before | mb_before | blk_after | mb_after | diff
-----------------------+-----------+------------+-----------+-----------+----------+--------
pgbench_accounts | 300000000 | 4918033 | 38422.1 | 5066589 | 39582.7 | +3.0%
accounts_mtime | 300000000 | 1155119 | 9024.4 | 1422354 | 11112.1 | +23.1%
pgbench_accounts_pkey | 300000000 | 822573 | 6426.4 | 822573 | 6426.4 | 0
tenner | 300000000 | 346050 | 2703.5 | 563101 | 4399.2 | +62.7%
(4 rows)
DB size: 59.3..64.5 (+5.2GB / +8.8%)
------
relname | nrows | blk_before | mb_before | blk_after | mb_after | diff
-----------------------+-----------+------------+-----------+-----------+----------+--------
pgbench_accounts | 300000000 | 4918033 | 38422.1 | 5066589 | 39582.7 | +3.0%
accounts_mtime | 300000000 | 1155119 | 9024.4 | 1422354 | 11112.1 | +23.1%
pgbench_accounts_pkey | 300000000 | 822573 | 6426.4 | 822573 | 6426.4 | 0
tenner | 300000000 | 346050 | 2703.5 | 563101 | 4399.2 | +62.7%
(4 rows)
DB size: 59.3..64.5 (+5.2GB / +8.8%)
Patched
-------
relname | nrows | blk_before | mb_before | blk_after | mb_after | diff
-----------------------+-----------+------------+-----------+-----------+----------+--------
pgbench_accounts | 300000000 | 4918033 | 38422.1 | 5068092 | 39594.5 | +3.0%
accounts_mtime | 300000000 | 1155119 | 9024.4 | 1428972 | 11163.8 | +23.7%
pgbench_accounts_pkey | 300000000 | 822573 | 6426.4 | 822573 | 6426.4 | 0
tenner | 300000000 | 346050 | 2703.5 | 346050 | 2703.5 | 0
(4 rows)
DB size: 59.3..62.8 (+3.5GB / +5.9%)
-------
relname | nrows | blk_before | mb_before | blk_after | mb_after | diff
-----------------------+-----------+------------+-----------+-----------+----------+--------
pgbench_accounts | 300000000 | 4918033 | 38422.1 | 5068092 | 39594.5 | +3.0%
accounts_mtime | 300000000 | 1155119 | 9024.4 | 1428972 | 11163.8 | +23.7%
pgbench_accounts_pkey | 300000000 | 822573 | 6426.4 | 822573 | 6426.4 | 0
tenner | 300000000 | 346050 | 2703.5 | 346050 | 2703.5 | 0
(4 rows)
DB size: 59.3..62.8 (+3.5GB / +5.9%)
TPS
---
query | Master TPS | Patched TPS | diff
----------------+------------+-------------+-------
UPDATE + SELECT | 2413 | 2473 | +2.5%
3 SELECT in txn | 19737 | 19545 | -0.9%
15min SELECT | 0.74 | 1.03 | +39%
---
query | Master TPS | Patched TPS | diff
----------------+------------+-------------+-------
UPDATE + SELECT | 2413 | 2473 | +2.5%
3 SELECT in txn | 19737 | 19545 | -0.9%
15min SELECT | 0.74 | 1.03 | +39%
Based on the figures and also on the graphs attached, I can tell v8 has no visible regression
in terms of TPS, IO pattern changes slightly, but the end result is worth it.
In my view, this patch can be applied from a performance POV.
I wanted to share these before I'll finish with the code review, I'm planning to send it tomorrow.
In my view, this patch can be applied from a performance POV.
I wanted to share these before I'll finish with the code review, I'm planning to send it tomorrow.
Victor Yegorov
Attachment
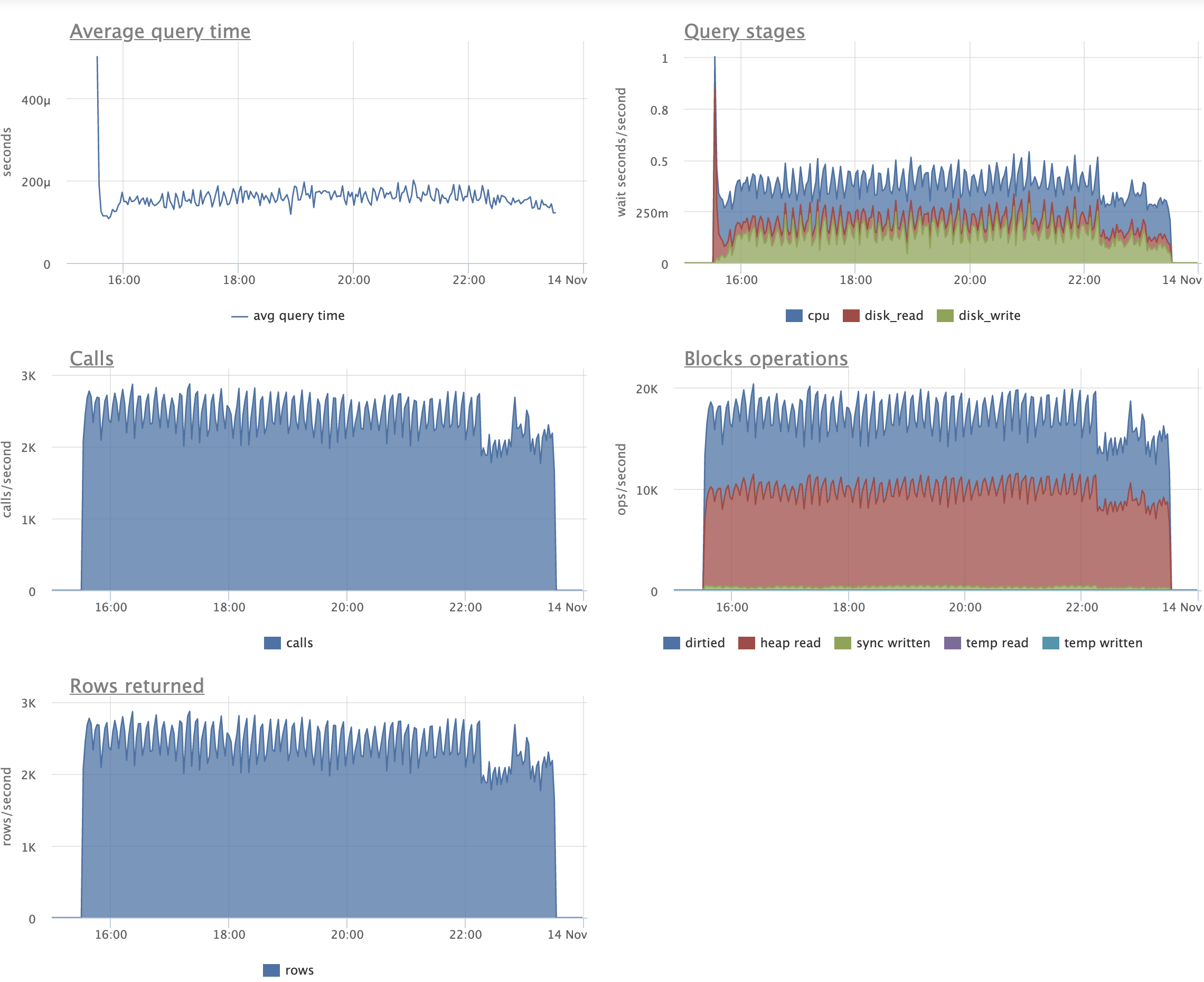{kind=link}
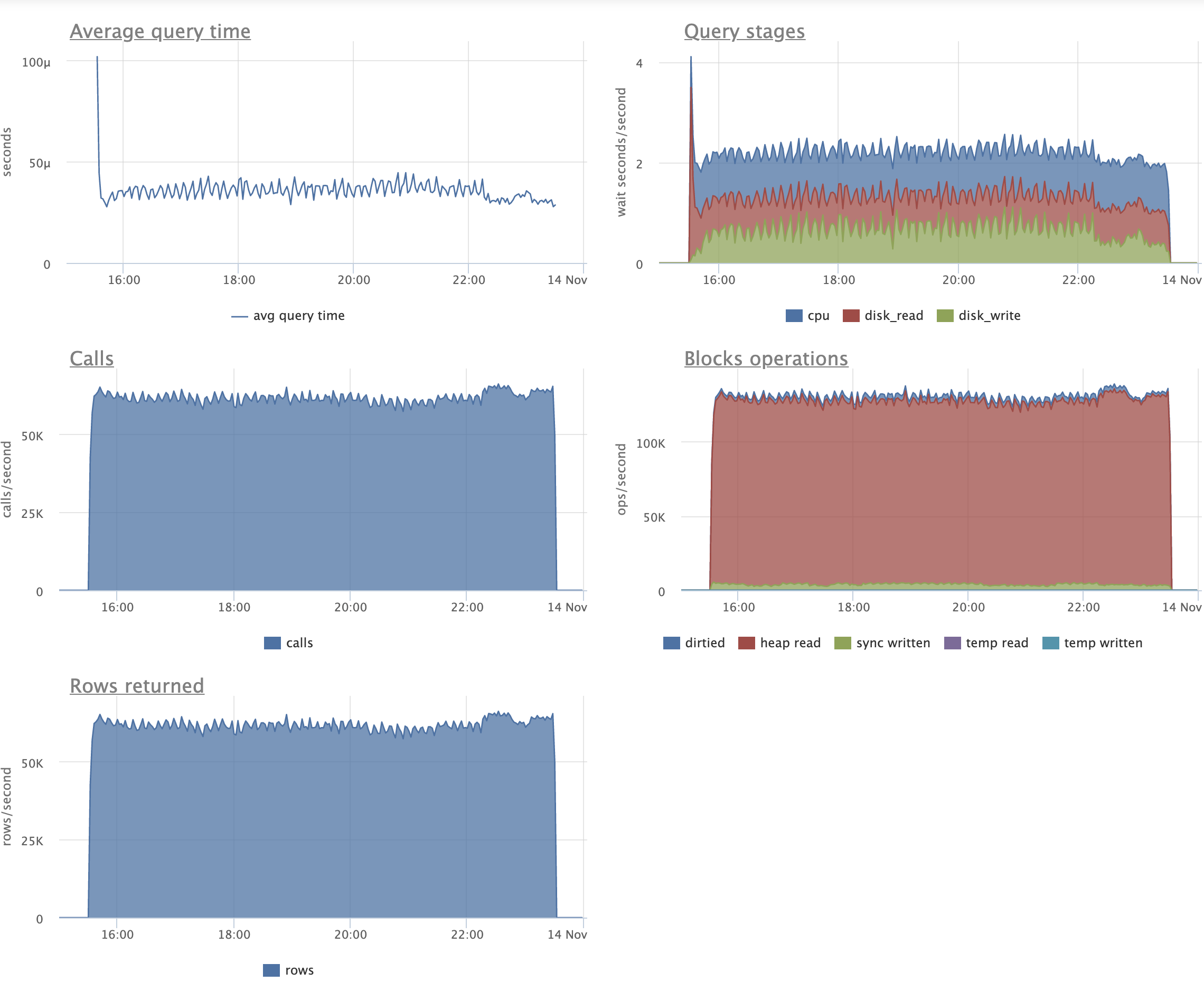{kind=link}
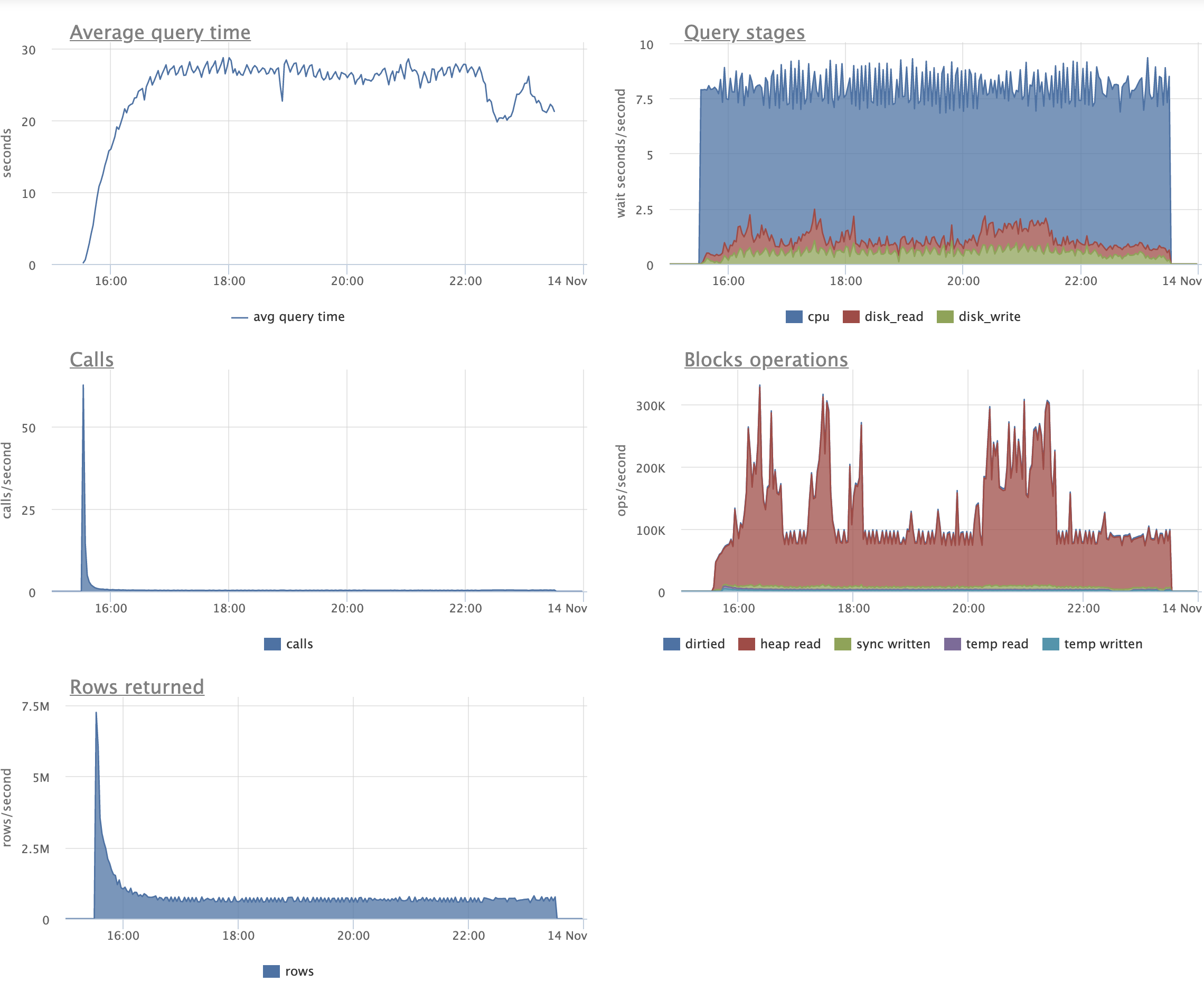{kind=link}
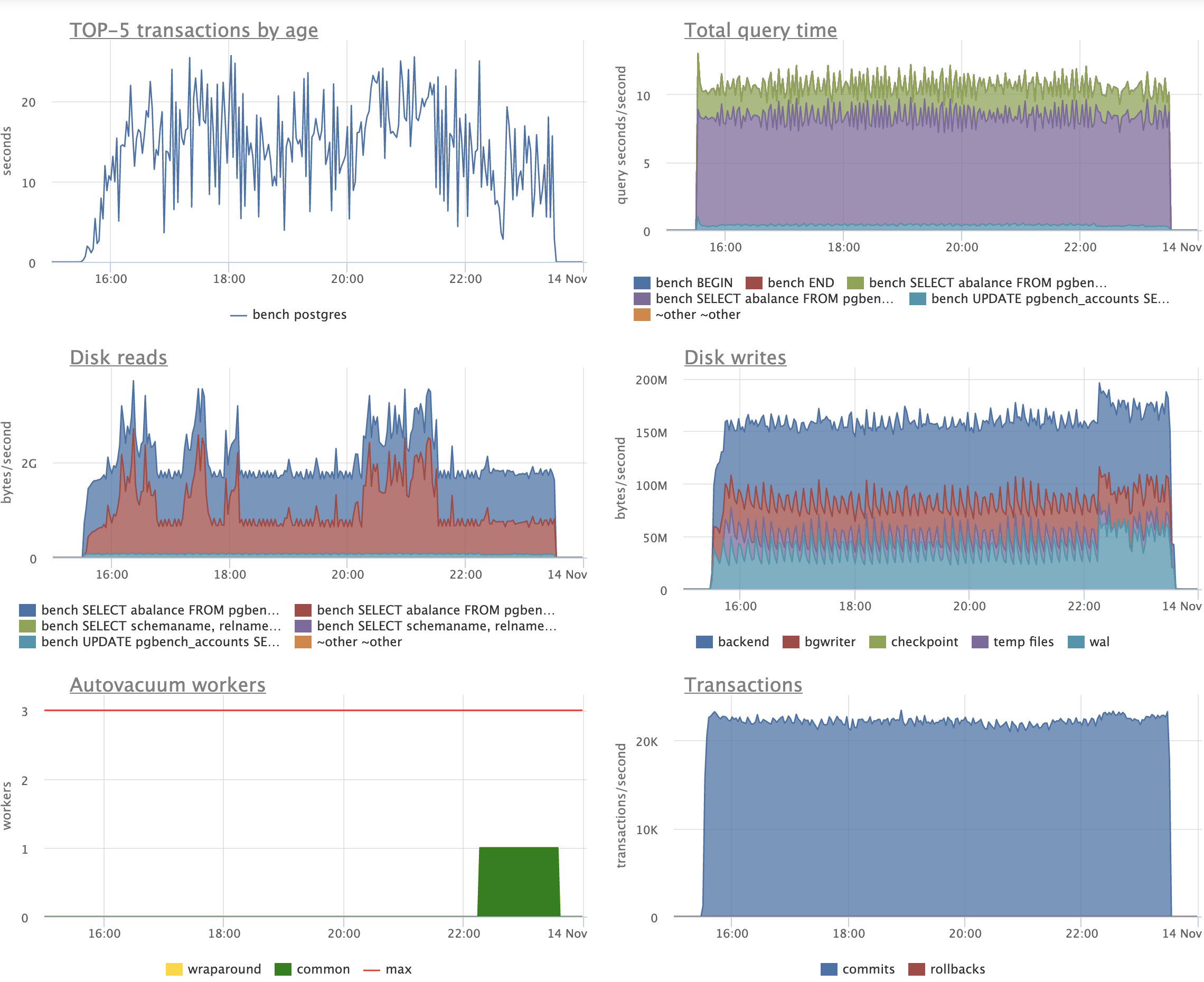{kind=link}
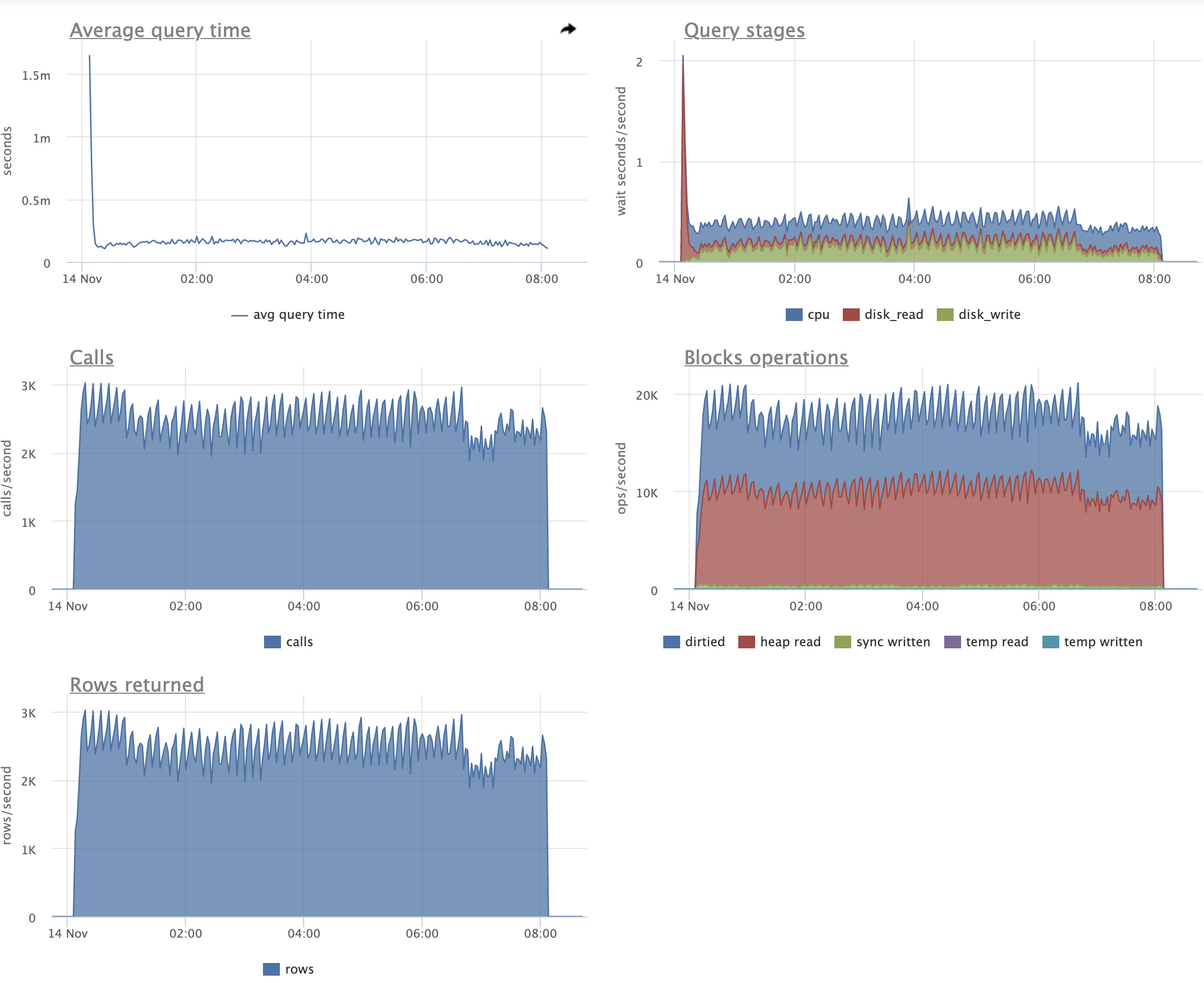{kind=link}
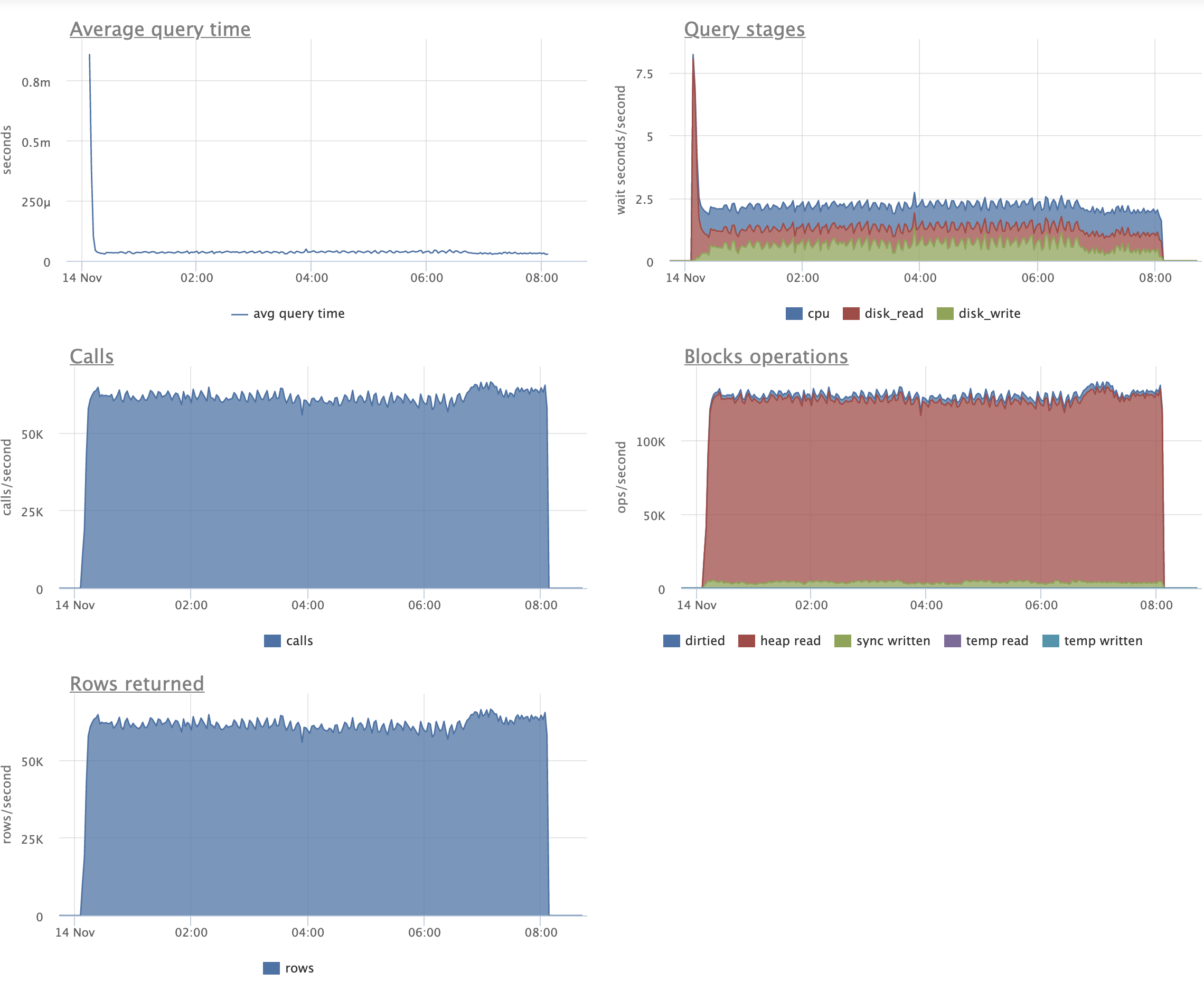{kind=link}
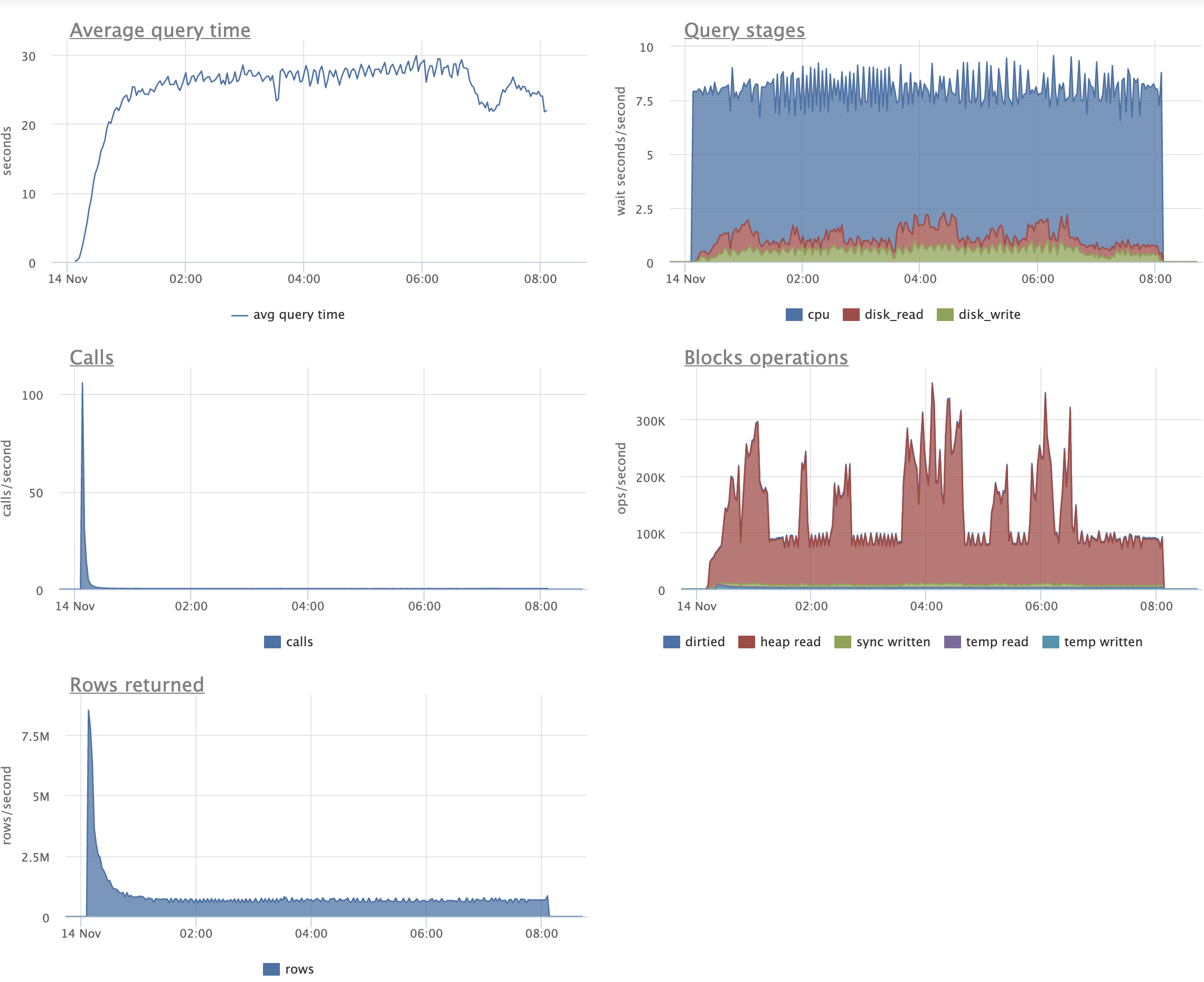{kind=link}
{kind=link}
On Sun, Nov 15, 2020 at 2:29 PM Victor Yegorov <vyegorov@gmail.com> wrote: > TPS > --- > query | Master TPS | Patched TPS | diff > ----------------+------------+-------------+------- > UPDATE + SELECT | 2413 | 2473 | +2.5% > 3 SELECT in txn | 19737 | 19545 | -0.9% > 15min SELECT | 0.74 | 1.03 | +39% > > Based on the figures and also on the graphs attached, I can tell v8 has no visible regression > in terms of TPS, IO pattern changes slightly, but the end result is worth it. > In my view, this patch can be applied from a performance POV. Great, thanks for testing! -- Peter Geoghegan
чт, 12 нояб. 2020 г. в 23:00, Peter Geoghegan <pg@bowt.ie>:
It would be helpful if you could take a look at the nbtree patch --
particularly the changes related to deprecating the page-level
BTP_HAS_GARBAGE flag. I would like to break those parts out into a
separate patch, and commit it in the next week or two. It's just
refactoring, really. (This commit can also make nbtree only use the
word VACUUM for things that strictly involve VACUUM. For example,
it'll rename _bt_vacuum_one_page() to _bt_delete_or_dedup_one_page().)
We almost don't care about the flag already, so there is almost no
behavioral change from deprecated BTP_HAS_GARBAGE in this way.
Indexes that use deduplication already don't rely on BTP_HAS_GARBAGE
being set ever since deduplication was added to Postgres 13 (the
deduplication code doesn't want to deal with LP_DEAD bits, and cannot
trust that no LP_DEAD bits can be set just because BTP_HAS_GARBAGE
isn't set in the special area). Trusting the BTP_HAS_GARBAGE flag can
cause us to miss out on deleting items with their LP_DEAD bits set --
we're better off "assuming that BTP_HAS_GARBAGE is always set", and
finding out if there really are LP_DEAD bits set for ourselves each
time.
Missing LP_DEAD bits like this can happen when VACUUM unsets the
page-level flag without actually deleting the items at the same time,
which is expected when the items became garbage (and actually had
their LP_DEAD bits set) after VACUUM began, but before VACUUM reached
the leaf pages. That's really wasteful, and doesn't actually have any
upside -- we're scanning all of the line pointers only when we're
about to split (or dedup) the same page anyway, so the extra work is
practically free.
I've looked over the BTP_HAS_GARBAGE modifications, they look sane.
I've double checked that heapkeyspace indexes don't use this flag (don't rely on it),
while pre-v4 ones still use it.
I have a question. This flag is raised in the _bt_check_unique() and in _bt_killitems().
If we're deprecating this flag, perhaps it'd be good to either avoid raising it at least for
If we're deprecating this flag, perhaps it'd be good to either avoid raising it at least for
_bt_check_unique(), as it seems to me that conditions are dealing with postings, therefore
we are speaking of heapkeyspace indexes here.
If we'll conditionally raise this flag in the functions above, we can get rid of blocks that drop it
in _bt_delitems_delete(), I think.
Victor Yegorov
чт, 12 нояб. 2020 г. в 23:00, Peter Geoghegan <pg@bowt.ie>:
Another thing that I'll probably add to v8: Prefetching. This is
probably necessary just so I can have parity with the existing
heapam.c function that the new code is based on,
heap_compute_xid_horizon_for_tuples(). That will probably help here,
too.
I don't quite see this part. Do you mean top_block_groups_favorable() here?
Victor Yegorov
пт, 13 нояб. 2020 г. в 00:01, Peter Geoghegan <pg@bowt.ie>:
Attached is v8, which has the enhancements for low cardinality data
that I mentioned earlier today. It also simplifies the logic for
dealing with posting lists that we need to delete some TIDs from.
These posting list simplifications also make the code a bit more
efficient, which might be noticeable during benchmarking.
I've looked through the code and it looks very good from my end:
- plenty comments, good description of what's going on
- I found no loose ends in terms of AM integration
- magic constants replaced with defines
Code looks good. Still, it'd be good if somebody with more experience could look into this patch.
Question: why in the comments you're using double spaces after dots?
Is this a convention of the project?
I am thinking of two more scenarios that require testing:
- queue in the table, with a high rate of INSERTs+DELETEs and a long transaction.
Currently I've seen such conditions yield indexes of several GB in size wil holding less
Code looks good. Still, it'd be good if somebody with more experience could look into this patch.
Question: why in the comments you're using double spaces after dots?
Is this a convention of the project?
I am thinking of two more scenarios that require testing:
- queue in the table, with a high rate of INSERTs+DELETEs and a long transaction.
Currently I've seen such conditions yield indexes of several GB in size wil holding less
than a thousand of live records.
- upgraded cluster with !heapkeyspace indexes.
- upgraded cluster with !heapkeyspace indexes.
Victor Yegorov
On Tue, Nov 17, 2020 at 7:05 AM Victor Yegorov <vyegorov@gmail.com> wrote: > I've looked over the BTP_HAS_GARBAGE modifications, they look sane. > I've double checked that heapkeyspace indexes don't use this flag (don't rely on it), > while pre-v4 ones still use it. Cool. > I have a question. This flag is raised in the _bt_check_unique() and in _bt_killitems(). > If we're deprecating this flag, perhaps it'd be good to either avoid raising it at least for > _bt_check_unique(), as it seems to me that conditions are dealing with postings, therefore > we are speaking of heapkeyspace indexes here. Well, we still want to mark LP_DEAD bits set in all cases, just as before. The difference is that heapkeyspace indexes won't rely on the page-level flag later on. > If we'll conditionally raise this flag in the functions above, we can get rid of blocks that drop it > in _bt_delitems_delete(), I think. I prefer to continue to maintain the flag in the same way, regardless of which B-Tree version is in use (i.e. if it's heapkeyspace or not). Maintaining the flag is not expensive, may have some small value for forensic or debugging purposes, and saves callers the trouble of telling _bt_delitems_delete() (and code like it) whether or not this is a heapkeyspace index. -- Peter Geoghegan
вт, 17 нояб. 2020 г. в 17:24, Peter Geoghegan <pg@bowt.ie>:
I prefer to continue to maintain the flag in the same way, regardless
of which B-Tree version is in use (i.e. if it's heapkeyspace or not).
Maintaining the flag is not expensive, may have some small value for
forensic or debugging purposes, and saves callers the trouble of
telling _bt_delitems_delete() (and code like it) whether or not this
is a heapkeyspace index.
OK. Can you explain what deprecation means here?
If this functionality is left as is, it is not really deprecation?..
If this functionality is left as is, it is not really deprecation?..
Victor Yegorov
On Tue, Nov 17, 2020 at 9:19 AM Victor Yegorov <vyegorov@gmail.com> wrote: > OK. Can you explain what deprecation means here? > If this functionality is left as is, it is not really deprecation?.. It just means that we only keep it around for compatibility purposes. We would like to remove it, but can't right now. If we ever stop supporting version 3 indexes, then we can probably remove it entirely. I would like to avoid special cases across B-Tree index versions. Simply maintaining the page flag in the same way as we always have is the simplest approach. Pushed the BTP_HAS_GARBAGE patch just now. I'll post a rebased version of the patch series later on today. Thanks -- Peter Geoghegan
On Tue, Nov 17, 2020 at 7:24 AM Victor Yegorov <vyegorov@gmail.com> wrote: > I've looked through the code and it looks very good from my end: > - plenty comments, good description of what's going on > - I found no loose ends in terms of AM integration > - magic constants replaced with defines > Code looks good. Still, it'd be good if somebody with more experience could look into this patch. Great, thank you. > Question: why in the comments you're using double spaces after dots? > Is this a convention of the project? Not really. It's based on my habit of trying to be as consistent as possible with existing code. There seems to be a weak consensus among English speakers on this question, which is: the two space convention is antiquated, and only ever made sense in the era of mechanical typewriters. I don't really care either way, and I doubt that any other committer pays much attention to these things. You may have noticed that I use only one space in my e-mails. Actually, I probably shouldn't care about it myself. It's just what I decided to do at some point. I find it useful to decide that this or that practice is now a best practice, and then stick to it without thinking about it very much (this frees up space in my head to think about more important things). But this particular habit of mine around spaces is definitely not something I'd insist on from other contributors. It's just that: a habit. > I am thinking of two more scenarios that require testing: > - queue in the table, with a high rate of INSERTs+DELETEs and a long transaction. I see your point. This is going to be hard to make work outside of unique indexes, though. Unique indexes are already not dependent on the executor hint -- they can just use the "uniquedup" hint. The code for unique indexes is prepared to notice duplicates in _bt_check_unique() in passing, and apply the optimization for that reason. Maybe there is some argument to forgetting about the hint entirely, and always assuming that we should try to find tuples to delete at the point that a page is about to be split. I think that that argument is a lot harder to make, though. And it can be revisited in the future. It would be nice to do better with INSERTs+DELETEs, but that's surely not the big problem for us right now. I realize that this unique indexes/_bt_check_unique() thing is not even really a partial fix to the problem you describe. The indexes that have real problems with such an INSERTs+DELETEs workload will naturally not be unique indexes -- _bt_check_unique() already does a fairly good job of controlling bloat without bottom-up deletion. > - upgraded cluster with !heapkeyspace indexes. I do have a patch that makes that easy to test, that I used for the Postgres 13 deduplication work -- I can rebase it and post it if you like. You will be able to apply the patch, and run the regression tests with a !heapkeyspace index. This works with only one or two tweaks to the tests (IIRC the amcheck tests need to be tweaked in one place for this to work). I don't anticipate that !heapkeyspace indexes will be a problem, because they won't use any of the new stuff anyway, and because nothing about the on-disk format is changed by bottom-up index deletion. -- Peter Geoghegan
On Tue, Nov 17, 2020 at 7:17 AM Victor Yegorov <vyegorov@gmail.com> wrote: > чт, 12 нояб. 2020 г. в 23:00, Peter Geoghegan <pg@bowt.ie>: >> Another thing that I'll probably add to v8: Prefetching. This is >> probably necessary just so I can have parity with the existing >> heapam.c function that the new code is based on, >> heap_compute_xid_horizon_for_tuples(). That will probably help here, >> too. > > I don't quite see this part. Do you mean top_block_groups_favorable() here? I meant to add prefetching to the version of the patch that became v8, but that didn't happen because I ran out of time. I wanted to get out a version with the low cardinality fix, to see if that helped with the regression you talked about last week. (Prefetching seems to make a small difference when we're I/O bound, so it may not be that important.) Attached is v9 of the patch series. This actually has prefetching in heapam.c. Prefetching is not just applied to favorable blocks, though -- it's applied to all the blocks that we might visit, even though we often won't really visit the last few blocks in line. This needs more testing. The specific choices I made around prefetching were definitely a bit arbitrary. To be honest, it was a bit of a box-ticking thing (parity with similar code for its own sake). But maybe I failed to consider particular scenarios in which prefetching really is important. My high level goal for v9 was to do cleanup of v8. There isn't very much that you could call a new enhancement (just the prefetching thing). Other changes in v9 include: * Much simpler approach to passing down an aminsert() hint from the executor in v9-0002* patch. Rather than exposing some HOT implementation details from heap_update(), we use executor state that tracks updated columns. Now all we have to do is tell ExecInsertIndexTuples() "this round of index tuple inserts is for an UPDATE statement". It then figures out the specific details (whether it passes the hint or not) on an index by index basis. This interface feels much more natural to me. This also made it easy to handle expression indexes sensibly. And, we get support for the logical replication UPDATE caller to ExecInsertIndexTuples(). It only has to say "this is for an UPDATE", in the usual way, without any special effort (actually I need to test logical replication, just to be sure, but I think that it works fine in v9). * New B-Tree sgml documentation in v9-0003* patch. I've added an extensive user-facing description of the feature to the end of "Chapter 64. B-Tree Indexes", near the existing discussion of deduplication. * New delete_items storage parameter. This makes it possible to disable the optimization. Like deduplicate_items in Postgres 13, it is not expected to be set to "off" very often. I'm not yet 100% sure that a storage parameter is truly necessary -- I might still change my mind and remove it later. Thanks -- Peter Geoghegan
Attachment
On Tue, Nov 17, 2020 at 12:45 PM Peter Geoghegan <pg@bowt.ie> wrote: > > I am thinking of two more scenarios that require testing: > > - queue in the table, with a high rate of INSERTs+DELETEs and a long transaction. > > I see your point. This is going to be hard to make work outside of > unique indexes, though. Unique indexes are already not dependent on > the executor hint -- they can just use the "uniquedup" hint. The code > for unique indexes is prepared to notice duplicates in > _bt_check_unique() in passing, and apply the optimization for that > reason. I thought about this some more. My first idea was to simply always try out bottom-up deletion (i.e. behave as if the hint from the executor always indicates that it's favorable). I couldn't really justify that approach, though. It results in many bottom-up deletion passes that end up wasting cycles (and unnecessarily accessing heap blocks). Then I had a much better idea: Make the existing LP_DEAD stuff a little more like bottom-up index deletion. We usually have to access heap blocks that the index tuples point to today, in order to have a latestRemovedXid cutoff (to generate recovery conflicts). It's worth scanning the leaf page for index tuples with TIDs whose heap block matches the index tuples that actually have their LP_DEAD bits set. This only consumes a few more CPU cycles. We don't have to access any more heap blocks to try these extra TIDs, so it seems like a very good idea to try them out. I ran the regression tests with an enhanced version of the patch, with this LP_DEAD-deletion-with-extra-TIDs thing. It also had custom instrumentation that showed exactly what happens in each case. We manage to delete at least a small number of extra index tuples in almost all cases -- so we get some benefit in practically all cases. And in the majority of cases we can delete significantly more. It's not uncommon to increase the number of index tuples deleted. It could go from 1 - 10 or so without the enhancement to LP_DEAD deletion, to 50 - 250 with the LP_DEAD enhancement. Some individual LP_DEAD deletion calls can free more than 50% of the space on the leaf page. I believe that this is a lower risk way of doing better when there is a high rate of INSERTs+DELETEs. Most of the regression test cases I looked at were in the larger system catalog indexes, which often look like that. We don't have to be that lucky for a passing index scan to set at least one or two LP_DEAD bits. If there is any kind of physical/logical correlation, then we're bound to also end up deleting some extra index tuples by the time that the page looks like it might need to be split. -- Peter Geoghegan
ср, 25 нояб. 2020 г. в 05:35, Peter Geoghegan <pg@bowt.ie>:
Then I had a much better idea: Make the existing LP_DEAD stuff a
little more like bottom-up index deletion. We usually have to access
heap blocks that the index tuples point to today, in order to have a
latestRemovedXid cutoff (to generate recovery conflicts). It's worth
scanning the leaf page for index tuples with TIDs whose heap block
matches the index tuples that actually have their LP_DEAD bits set.
This only consumes a few more CPU cycles. We don't have to access any
more heap blocks to try these extra TIDs, so it seems like a very good
idea to try them out.
I don't seem to understand this.
Is it: we're scanning the leaf page for all LP_DEAD tuples that point to the same
heap block? Which heap block we're talking about here, the one that holds
entry we're about to add (the one that triggered bottom-up-deletion due to lack
of space I mean)?
of space I mean)?
I ran the regression tests with an enhanced version of the patch, with
this LP_DEAD-deletion-with-extra-TIDs thing. It also had custom
instrumentation that showed exactly what happens in each case. We
manage to delete at least a small number of extra index tuples in
almost all cases -- so we get some benefit in practically all cases.
And in the majority of cases we can delete significantly more. It's
not uncommon to increase the number of index tuples deleted. It could
go from 1 - 10 or so without the enhancement to LP_DEAD deletion, to
50 - 250 with the LP_DEAD enhancement. Some individual LP_DEAD
deletion calls can free more than 50% of the space on the leaf page.
I am missing a general perspective here.
Is it true, that despite the long (vacuum preventing) transaction we can re-use space,
as after the DELETE statements commits, IndexScans are setting LP_DEAD hints after
they check the state of the corresponding heap tuple?
they check the state of the corresponding heap tuple?
If my thinking is correct for both cases — nature of LP_DEAD hint bits and the mechanics of
suggested optimization — then I consider this a very promising improvement!
I haven't done any testing so far since sending my last e-mail.
If you'll have a chance to send a new v10 version with LP_DEAD-deletion-with-extra-TIDs thing,
I will do some tests (planned).
If you'll have a chance to send a new v10 version with LP_DEAD-deletion-with-extra-TIDs thing,
I will do some tests (planned).
Victor Yegorov
On Wed, Nov 25, 2020 at 4:43 AM Victor Yegorov <vyegorov@gmail.com> wrote: >> Then I had a much better idea: Make the existing LP_DEAD stuff a >> little more like bottom-up index deletion. We usually have to access >> heap blocks that the index tuples point to today, in order to have a >> latestRemovedXid cutoff (to generate recovery conflicts). It's worth >> scanning the leaf page for index tuples with TIDs whose heap block >> matches the index tuples that actually have their LP_DEAD bits set. >> This only consumes a few more CPU cycles. We don't have to access any >> more heap blocks to try these extra TIDs, so it seems like a very good >> idea to try them out. > > > I don't seem to understand this. > > Is it: we're scanning the leaf page for all LP_DEAD tuples that point to the same > heap block? Which heap block we're talking about here, the one that holds > entry we're about to add (the one that triggered bottom-up-deletion due to lack > of space I mean)? No, the incoming tuple isn't significant. As you know, bottom-up index deletion uses heuristics that are concerned with duplicates on the page, and the "logically unchanged by an UPDATE" hint that the executor passes to btinsert(). Bottom-up deletion runs when all LP_DEAD bits have been cleared (either because there never were any LP_DEAD bits set, or because they were set and then deleted, which wasn't enough). But before bottom-up deletion may run, traditional deletion of LP_DEAD index tuples runs -- this is always our preferred strategy because index tuples with their LP_DEAD bits set are already known to be deletable. We can make this existing process (which has been around since PostgreSQL 8.2) better by applying similar principles. We have promising tuples for bottom-up deletion. Why not have "promising heap blocks" for traditional LP_DEAD index tuple deletion? Or if you prefer, we can consider index tuples that *don't* have their LP_DEAD bits set already but happen to point to the *same heap block* as other tuples that *do* have their LP_DEAD bits set promising. (The tuples with their LP_DEAD bits set are not just promising -- they're already a sure thing.) This means that traditional LP_DEAD deletion is now slightly more speculative in one way (it speculates about what is likely to be true using heuristics). But it's much less speculative than bottom-up index deletion. We are required to visit these heap blocks anyway, since a call to _bt_delitems_delete() for LP_DEAD deletion must already call table_compute_xid_horizon_for_tuples(), which has to access the blocks to get a latestRemovedXid for the WAL record. The only thing that we have to lose here is a few CPU cycles to find extra TIDs to consider. We'll visit exactly the same number of heap blocks as before. (Actually, _bt_delitems_delete() does not have to do that in all cases, actually, but it has to do it with a logged table with wal_level >= replica, which is the vast majority of cases in practice.) This means that traditional LP_DEAD deletion reuses some of the bottom-up index deletion infrastructure. So maybe nbtree never calls table_compute_xid_horizon_for_tuples() now, since everything goes through the new heapam stuff instead (which knows how to check extra TIDs that might not be dead at all). > I am missing a general perspective here. > > Is it true, that despite the long (vacuum preventing) transaction we can re-use space, > as after the DELETE statements commits, IndexScans are setting LP_DEAD hints after > they check the state of the corresponding heap tuple? The enhancement to traditional LP_DEAD deletion that I just described does not affect the current restrictions on setting LP_DEAD bits in the presence of a long-running transaction, or anything like that. That seems like an unrelated project. The value of this enhancement is purely its ability to delete *extra* index tuples that could have had their LP_DEAD bits set already (it was possible in principle), but didn't. And only when they are nearby to index tuples that really do have their LP_DEAD bits set. > I haven't done any testing so far since sending my last e-mail. > If you'll have a chance to send a new v10 version with LP_DEAD-deletion-with-extra-TIDs thing, > I will do some tests (planned). Thanks! I think that it will be next week. It's a relatively big change. -- Peter Geoghegan
ср, 25 нояб. 2020 г. в 19:41, Peter Geoghegan <pg@bowt.ie>:
We have promising tuples for bottom-up deletion. Why not have
"promising heap blocks" for traditional LP_DEAD index tuple deletion?
Or if you prefer, we can consider index tuples that *don't* have their
LP_DEAD bits set already but happen to point to the *same heap block*
as other tuples that *do* have their LP_DEAD bits set promising. (The
tuples with their LP_DEAD bits set are not just promising -- they're
already a sure thing.)
In the _bt_delete_or_dedup_one_page() we start with the simple loop over items on the page and
if there're any LP_DEAD tuples, we're kicking off _bt_delitems_delete().
So if I understood you right, you plan to make this loop (or a similar one somewhere around)
So if I understood you right, you plan to make this loop (or a similar one somewhere around)
to track TIDs of the LP_DEAD tuples and then (perhaps on a second loop over the page) compare all other
currently-not-LP_DEAD tuples and mark those pages, that have at least 2 TIDs pointing at (one LP_DEAD and other not)
as a promising one.
Later, should we require to kick deduplication, we'll go visit promising pages first.
Is my understanding correct?
Later, should we require to kick deduplication, we'll go visit promising pages first.
Is my understanding correct?
> I am missing a general perspective here.
>
> Is it true, that despite the long (vacuum preventing) transaction we can re-use space,
> as after the DELETE statements commits, IndexScans are setting LP_DEAD hints after
> they check the state of the corresponding heap tuple?
The enhancement to traditional LP_DEAD deletion that I just described
does not affect the current restrictions on setting LP_DEAD bits in
the presence of a long-running transaction, or anything like that.
That seems like an unrelated project. The value of this enhancement is
purely its ability to delete *extra* index tuples that could have had
their LP_DEAD bits set already (it was possible in principle), but
didn't. And only when they are nearby to index tuples that really do
have their LP_DEAD bits set.
I wasn't considering improvements here, that was a general question about how this works
(trying to clear up gaps in my understanding).
What I meant to ask — will LP_DEAD be set by IndexScan in the presence of the long transaction?
Victor Yegorov
On Wed, Nov 25, 2020 at 1:20 PM Victor Yegorov <vyegorov@gmail.com> wrote: > In the _bt_delete_or_dedup_one_page() we start with the simple loop over items on the page and > if there're any LP_DEAD tuples, we're kicking off _bt_delitems_delete(). Right. > So if I understood you right, you plan to make this loop (or a similar one somewhere around) > to track TIDs of the LP_DEAD tuples and then (perhaps on a second loop over the page) compare all other > currently-not-LP_DEAD tuples and mark those pages, that have at least 2 TIDs pointing at (one LP_DEAD and other not) > as a promising one. Yes. We notice extra TIDs that can be included in our heapam test "for free". The cost is low, but the benefits are also often quite high: in practice there are *natural* correlations that we can exploit. For example: maybe there were non-HOT updates, and some but not all of the versions got marked LP_DEAD. We can get them all in one go, avoiding a true bottom-up index deletion pass for much longer (compared to doing LP_DEAD deletion the old way, which is what happens in v9 of the patch). We're better off doing the deletions all at once. It's cheaper. (We still really need to have bottom-up deletion passes, of course, because that covers the important case where there are no LP_DEAD bits set at all, which is an important goal of this project.) Minor note: Technically there aren't any promising tuples involved, because that only makes sense when we are not going to visit every possible heap page (just the "most promising" heap pages). But we are going to visit every possible heap page with the new LP_DEAD bit deletion code (which could occasionally mean visiting 10 or more heap pages, which is a lot more than bottom-up index deletion will ever visit). All we need to do with the new LP_DEAD deletion logic is to include all possible matching TIDs (not just those that are marked LP_DEAD already). > What I meant to ask — will LP_DEAD be set by IndexScan in the presence of the long transaction? That works in the same way as before, even with the new LP_DEAD deletion code. The new code uses the same information as before (set LP_DEAD bits), which is generated in the same way as before. The difference is in how the information is actually used during LP_DEAD deletion -- we can now delete some extra things in certain common cases. In practice this (and bottom-up deletion) make nbtree more robust against disruption caused by long running transactions that hold a snapshot open. It's hard to give a simple explanation of why that is, because it's a second order effect. The patch is going to make it possible to recover when LP_DEAD bits suddenly stop being set because of an old snapshot -- now we'll have a "second chance", and maybe even a third chance. But if the snapshot is held open *forever*, then a second chance has no value. Here is a thought experiment that might be helpful: Imagine Postgres just as it is today (without the patch), except that VACUUM runs very frequently, and is infinitely fast (this is a magical version of VACUUM). This solves many problems, but does not solve all problems. Magic Postgres will become just as slow as earthly Postgres when there is a snapshot that is held open for a very long time. That will take longer to happen compared to earthly/mortal Postgres, but eventually there will be no difference between the two at all. But, when you don't have such an extreme problem, magic Postgres really is much faster. I think that it will be possible to approximate the behavior of magic Postgres using techniques like bottom-up deletion, the new LP_DEAD deletion thing we've been talking today, and maybe other enhancements in other areas (like in heap pruning). It doesn't matter that we don't physically remove garbage immediately, as long as we "logically" remove it immediately. The actually physical removal can occur in a just in time, incremental fashion, creating the illusion that VACUUM really does run infinitely fast. No magic required. Actually, in a way this isn't new; we have always "logically" removed garbage at the earliest opportunity (by which I mean we allow that it can be physically removed according to an oldestXmin style cutoff, which can be reacquired/updated the second the oldest MVCC snapshot goes away). We don't think of useless old versions as being "logically removed" the instant an old snapshot goes away. But maybe we should -- it's a useful mental model. It will also be very helpful to add "remove useless intermediate versions" logic at some point. This is quite a distinct area to what I just described, but it's also important. We need both, I think. -- Peter Geoghegan
On Wed, Nov 25, 2020 at 10:41 AM Peter Geoghegan <pg@bowt.ie> wrote: > We have promising tuples for bottom-up deletion. Why not have > "promising heap blocks" for traditional LP_DEAD index tuple deletion? > Or if you prefer, we can consider index tuples that *don't* have their > LP_DEAD bits set already but happen to point to the *same heap block* > as other tuples that *do* have their LP_DEAD bits set promising. (The > tuples with their LP_DEAD bits set are not just promising -- they're > already a sure thing.) > > This means that traditional LP_DEAD deletion is now slightly more > speculative in one way (it speculates about what is likely to be true > using heuristics). But it's much less speculative than bottom-up index > deletion. We are required to visit these heap blocks anyway, since a > call to _bt_delitems_delete() for LP_DEAD deletion must already call > table_compute_xid_horizon_for_tuples(), which has to access the blocks > to get a latestRemovedXid for the WAL record. > > The only thing that we have to lose here is a few CPU cycles to find > extra TIDs to consider. We'll visit exactly the same number of heap > blocks as before. (Actually, _bt_delitems_delete() does not have to do > that in all cases, actually, but it has to do it with a logged table > with wal_level >= replica, which is the vast majority of cases in > practice.) > > This means that traditional LP_DEAD deletion reuses some of the > bottom-up index deletion infrastructure. So maybe nbtree never calls > table_compute_xid_horizon_for_tuples() now, since everything goes > through the new heapam stuff instead (which knows how to check extra > TIDs that might not be dead at all). Attached is v10, which has this LP_DEAD deletion enhancement I described. (It also fixed bitrot -- v9 no longer applies.) This revision does a little refactoring to make this possible. Now there is less new code in nbtdedup.c, and more code in nbtpage.c, because some of the logic used by bottom-up deletion has been generalized (in order to be used by the new-to-v10 LP_DEAD deletion enhancement). Other than that, no big changes between this v10 and v9. Just polishing and refactoring. I decided to make it mandatory for tableams to support the new interface that heapam implements, since it's hardly okay for them to not allow LP_DEAD deletion in nbtree (which is what making supporting the interface optional would imply, given the LP_DEAD changes). So now the heapam and tableam changes are including in one patch/commit, which is to be applied first among patches in the series. -- Peter Geoghegan
Attachment
This is a wholly new concept with a lot of heuristics. It's a lot of
swallow. But here are a few quick comments after a first read-through:
On 30/11/2020 21:50, Peter Geoghegan wrote:
> +/*
> + * State used when calling table_index_delete_check() to perform "bottom up"
> + * deletion of duplicate index tuples. State is intialized by index AM
> + * caller, while state is finalized by tableam, which modifies state.
> + */
> +typedef struct TM_IndexDelete
> +{
> + ItemPointerData tid; /* table TID from index tuple */
> + int16 id; /* Offset into TM_IndexStatus array */
> +} TM_IndexDelete;
> +
> +typedef struct TM_IndexStatus
> +{
> + OffsetNumber idxoffnum; /* Index am page offset number */
> + int16 tupsize; /* Space freed in index if tuple deleted */
> + bool ispromising; /* Duplicate in index? */
> + bool deleteitup; /* Known dead-to-all? */
> +} TM_IndexStatus;
> ...
> + * The two arrays are conceptually one single array. Two arrays/structs are
> + * used for performance reasons. (We really need to keep the TM_IndexDelete
> + * struct small so that the tableam can do an initial sort by TID as quickly
> + * as possible.)
Is it really significantly faster to have two arrays? If you had just
one array, each element would be only 12 bytes long. That's not much
smaller than TM_IndexDeletes, which is 8 bytes.
> + /* First sort caller's array by TID */
> + heap_tid_shellsort(delstate->deltids, delstate->ndeltids);
> +
> + /* alltids caller visits all blocks, so make sure that happens */
> + if (delstate->alltids)
> + return delstate->ndeltids;
> +
> + /* Calculate per-heap-block count of TIDs */
> + blockcounts = palloc(sizeof(IndexDeleteCounts) * delstate->ndeltids);
> + for (int i = 0; i < delstate->ndeltids; i++)
> + {
> + ItemPointer deltid = &delstate->deltids[i].tid;
> + TM_IndexStatus *dstatus = delstate->status + delstate->deltids[i].id;
> + bool ispromising = dstatus->ispromising;
> +
> + if (curblock != ItemPointerGetBlockNumber(deltid))
> + {
> + /* New block group */
> + nblockgroups++;
> +
> + Assert(curblock < ItemPointerGetBlockNumber(deltid) ||
> + !BlockNumberIsValid(curblock));
> +
> + curblock = ItemPointerGetBlockNumber(deltid);
> + blockcounts[nblockgroups - 1].ideltids = i;
> + blockcounts[nblockgroups - 1].ntids = 1;
> + blockcounts[nblockgroups - 1].npromisingtids = 0;
> + }
> + else
> + {
> + blockcounts[nblockgroups - 1].ntids++;
> + }
> +
> + if (ispromising)
> + blockcounts[nblockgroups - 1].npromisingtids++;
> + }
Instead of sorting the array by TID, wouldn't it be enough to sort by
just the block numbers?
> * While in general the presence of promising tuples (the hint that index
> + * AMs provide) is the best information that we have to go on, it is based
> + * on simple heuristics about duplicates in indexes that are understood to
> + * have specific flaws. We should not let the most promising heap pages
> + * win or lose on the basis of _relatively_ small differences in the total
> + * number of promising tuples. Small differences between the most
> + * promising few heap pages are effectively ignored by applying this
> + * power-of-two bucketing scheme.
> + *
What are the "specific flaws"?
I understand that this is all based on rough heuristics, but is there
any advantage to rounding/bucketing the numbers like this? Even if small
differences in the total number of promising tuple is essentially noise
that can be safely ignored, is there any harm in letting those small
differences guide the choice? Wouldn't it be the essentially the same as
picking at random, or are those small differences somehow biased?
- Heikki
On Tue, Dec 1, 2020 at 1:50 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > This is a wholly new concept with a lot of heuristics. It's a lot of > swallow. Thanks for taking a look! Yes, it's a little unorthodox. Ideally, you'd find time to grok the patch and help me codify the design in some general kind of way. If there are general lessons to be learned here (and I suspect that there are), then this should not be left to chance. The same principles can probably be applied in heapam, for example. Even if I'm wrong about the techniques being highly generalizable, it should still be interesting! (Something to think about a little later.) Some of the intuitions behind the design might be vaguely familiar to you as the reviewer of my earlier B-Tree work. In particular, the whole way that we reason about how successive related operations (in this case bottom-up deletion passes) affect individual leaf pages over time might give you a feeling of déjà vu. It's a little like the nbtsplitloc.c stuff that we worked on together during the Postgres 12 cycle. We can make what might seem like rather bold assumptions about what's going on, and adapt to the workload. This is okay because we're sure that the downside of our being wrong is a fixed, low performance penalty. (To a lesser degree it's okay because the empirical evidence shows that we're almost always right, because we apply the optimization again and again precisely because it worked out last time.) I like to compare it to the familiar "rightmost leaf page applies leaf fillfactor" heuristic, which applies an assumption that is wrong in the general case, but nevertheless obviously helps enormously as a practical matter. Of course it's still true that anybody reviewing this patch ought to start with a principled skepticism of this claim -- that's how you review any patch. I can say for sure that that's the idea behind the patch, though. I want to be clear about that up front, to save you time -- if this claim is wrong, then I'm wrong about everything. Generational garbage collection influenced this work, too. It also applies pragmatic assumptions about where garbage is likely to appear. Assumptions that are based on nothing more than empirical observations about what is likely to happen in the real world, that are validated by experience and by benchmarking. > On 30/11/2020 21:50, Peter Geoghegan wrote: > > +} TM_IndexDelete; > > +} TM_IndexStatus; > Is it really significantly faster to have two arrays? If you had just > one array, each element would be only 12 bytes long. That's not much > smaller than TM_IndexDeletes, which is 8 bytes. Yeah, but the swap operations really matter here. At one point I found that to be the case, anyway. That might no longer be true, though. It might be that the code became less performance critical because other parts of the design improved, resulting in the code getting called less frequently. But if that is true then it has a lot to do with the power-of-two bucketing that you go on to ask about -- that helped performance a lot in certain specific cases (as I go into below). I will add a TODO item for myself, to look into this again. You may well be right. > > + /* First sort caller's array by TID */ > > + heap_tid_shellsort(delstate->deltids, delstate->ndeltids); > Instead of sorting the array by TID, wouldn't it be enough to sort by > just the block numbers? I don't understand. Yeah, I guess that we could do our initial sort of the deltids array (the heap_tid_shellsort() call) just using BlockNumber (not TID). But OTOH there might be some small locality benefit to doing a proper TID sort at the level of each heap page. And even if there isn't any such benefit, does it really matter? If you are asking about the later sort of the block counts array (which helps us sort the deltids array a second time, leaving it in its final order for bottom-up deletion heapam.c processing), then the answer is no. This block counts metadata array sort is useful because it allows us to leave the deltids array in what I believe to be the most useful order for processing. We'll access heap blocks primarily based on the number of promising tuples (though as I go into below, sometimes the number of promising tuples isn't a decisive influence on processing order). > > * While in general the presence of promising tuples (the hint that index > > + * AMs provide) is the best information that we have to go on, it is based > > + * on simple heuristics about duplicates in indexes that are understood to > > + * have specific flaws. We should not let the most promising heap pages > > + * win or lose on the basis of _relatively_ small differences in the total > > + * number of promising tuples. Small differences between the most > > + * promising few heap pages are effectively ignored by applying this > > + * power-of-two bucketing scheme. > > + * > > What are the "specific flaws"? I just meant the obvious: the index AM doesn't actually know for sure that there are any old versions on the leaf page that it will ultimately be able to delete. This uncertainty needs to be managed, including inside heapam.c. Feel free to suggest a better way of expressing that sentiment. > I understand that this is all based on rough heuristics, but is there > any advantage to rounding/bucketing the numbers like this? Even if small > differences in the total number of promising tuple is essentially noise > that can be safely ignored, is there any harm in letting those small > differences guide the choice? Wouldn't it be the essentially the same as > picking at random, or are those small differences somehow biased? Excellent question! It actually helps enormously, especially with low cardinality data that makes good use of the deduplication optimization (where it is especially important to keep the costs and the benefits in balance). This has been validated by benchmarking. This design naturally allows the heapam.c code to take advantage of both temporal and spatial locality. For example, let's say that you have several indexes all on the same table, which get lots of non-HOT UPDATEs, which are skewed. Naturally, the heap TIDs will match across each index -- these are index entries that are needed to represent successor versions (which are logically unchanged/version duplicate index tuples from the point of view of nbtree/nbtdedup.c). Introducing a degree of determinism to the order in which heap blocks are processed naturally takes advantage of the correlated nature of the index bloat. It naturally makes it much more likely that the also-correlated bottom-up index deletion passes (that occur across indexes on the same table) each process the same heap blocks close together in time -- with obvious performance benefits. In the extreme (but not particularly uncommon) case of non-HOT UPDATEs with many low cardinality indexes, each heapam.c call will end up doing *almost the same thing* across indexes. So we're making the correlated nature of the bloat (which is currently a big problem) work in our favor -- turning it on its head, you could say. Highly correlated bloat is not the exception -- it's actually the norm in the cases we're targeting here. If it wasn't highly correlated then it would already be okay to rely on VACUUM to get around to cleaning it later. This power-of-two bucketing design probably also helps when there is only one index. I could go into more detail on that, plus other variations, but perhaps the multiple index example suffices for now. I believe that there are a few interesting kinds of correlations here -- I bet you can think of some yourself. (Of course it's also possible and even likely that heap block correlation won't be important at all, but my response is "what specifically is the harm in being open to the possibility?".) BTW, I tried to make the tableam interface changes more or less compatible with Zedstore, which is notable for not using TIDs in the same way as heapam (or zheap). Let me know what you think about that. I can go into detail about it if it isn't obvious to you. -- Peter Geoghegan
On Tue, Dec 1, 2020 at 2:18 PM Peter Geoghegan <pg@bowt.ie> wrote: > On Tue, Dec 1, 2020 at 1:50 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > > This is a wholly new concept with a lot of heuristics. It's a lot of > > swallow. Attached is v11, which cleans everything up around the tableam interface. There are only two patches in v11, since the tableam refactoring made it impossible to split the second patch into a heapam patch and nbtree patch (there is no reduction in functionality compared to v10). Most of the real changes in v11 (compared to v10) are in heapam.c. I've completely replaced the table_compute_xid_horizon_for_tuples() interface with a new interface that supports all existing requirements (from index deletions that support LP_DEAD deletion), while also supporting these new requirements (e.g. bottom-up index deletion). So now heap_compute_xid_horizon_for_tuples() becomes heap_compute_delete_for_tuples(), which has different arguments but the same overall structure. All of the new requirements can now be thought of as additive things that we happen to use for nbtree callers, that could easily also be used in other index AMs later on. This means that there is a lot less new code in heapam.c. Prefetching of heap blocks for the new bottom-up index deletion caller now works in the same way as it has worked in heap_compute_xid_horizon_for_tuples() since Postgres 12 (more or less). This is a significant improvement compared to my original approach. Chaning heap_compute_xid_horizon_for_tuples() rather than adding a sibling function started to make sense when v10 of the patch taught regular nbtree LP_DEAD deletion (the thing that has been around since PostgreSQL 8.2) to add "extra" TIDs to check in passing, just in case we find that they're also deletable -- why not just have one function? It also means that hash indexes and GiST indexes now use the heap_compute_delete_for_tuples() function, though they get the same behavior as before. I imagine that it would be pretty straightforward to bring that same benefit to those other index AMs, since their implementations are already derived from the nbtree implementation of LP_DEAD deletion (and because adding extra TIDs to check in passing in these other index AMs should be fairly easy). > > > +} TM_IndexDelete; > > > > +} TM_IndexStatus; > > > Is it really significantly faster to have two arrays? If you had just > > one array, each element would be only 12 bytes long. That's not much > > smaller than TM_IndexDeletes, which is 8 bytes. I kept this facet of the design in v11, following some deliberation. I found that the TID sort operation appeared quite prominently in profiles, and so the optimizations mostly seemed to still make sense. I also kept one shellsort specialization. However, I removed the second specialized sort implementation, so at least there is only one specialization now (which is small anyway). I found that the second sort specialization (added to heapam.c in v10) really wasn't pulling its weight, even in more extreme cases of the kind that justified the optimizations in the first place. -- Peter Geoghegan
Attachment
Hi,
In v11-0001-Pass-down-logically-unchanged-index-hint.patch :
+ if (hasexpression)
+ return false;
+
+ return true;
+ return false;
+
+ return true;
The above can be written as 'return !hasexpression;'
For +index_unchanged_by_update_var_walker:
+ * Returns true when Var that appears within allUpdatedCols located.
the sentence seems incomplete.
Currently the return value of index_unchanged_by_update_var_walker() is the reverse of index_unchanged_by_update().
Maybe it is easier to read the code if their return values have the same meaning.
Cheers
On Wed, Dec 9, 2020 at 5:13 PM Peter Geoghegan <pg@bowt.ie> wrote:
On Tue, Dec 1, 2020 at 2:18 PM Peter Geoghegan <pg@bowt.ie> wrote:
> On Tue, Dec 1, 2020 at 1:50 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote:
> > This is a wholly new concept with a lot of heuristics. It's a lot of
> > swallow.
Attached is v11, which cleans everything up around the tableam
interface. There are only two patches in v11, since the tableam
refactoring made it impossible to split the second patch into a heapam
patch and nbtree patch (there is no reduction in functionality
compared to v10).
Most of the real changes in v11 (compared to v10) are in heapam.c.
I've completely replaced the table_compute_xid_horizon_for_tuples()
interface with a new interface that supports all existing requirements
(from index deletions that support LP_DEAD deletion), while also
supporting these new requirements (e.g. bottom-up index deletion). So
now heap_compute_xid_horizon_for_tuples() becomes
heap_compute_delete_for_tuples(), which has different arguments but
the same overall structure. All of the new requirements can now be
thought of as additive things that we happen to use for nbtree
callers, that could easily also be used in other index AMs later on.
This means that there is a lot less new code in heapam.c.
Prefetching of heap blocks for the new bottom-up index deletion caller
now works in the same way as it has worked in
heap_compute_xid_horizon_for_tuples() since Postgres 12 (more or
less). This is a significant improvement compared to my original
approach.
Chaning heap_compute_xid_horizon_for_tuples() rather than adding a
sibling function started to make sense when v10 of the patch taught
regular nbtree LP_DEAD deletion (the thing that has been around since
PostgreSQL 8.2) to add "extra" TIDs to check in passing, just in case
we find that they're also deletable -- why not just have one function?
It also means that hash indexes and GiST indexes now use the
heap_compute_delete_for_tuples() function, though they get the same
behavior as before. I imagine that it would be pretty straightforward
to bring that same benefit to those other index AMs, since their
implementations are already derived from the nbtree implementation of
LP_DEAD deletion (and because adding extra TIDs to check in passing in
these other index AMs should be fairly easy).
> > > +} TM_IndexDelete;
>
> > > +} TM_IndexStatus;
>
> > Is it really significantly faster to have two arrays? If you had just
> > one array, each element would be only 12 bytes long. That's not much
> > smaller than TM_IndexDeletes, which is 8 bytes.
I kept this facet of the design in v11, following some deliberation. I
found that the TID sort operation appeared quite prominently in
profiles, and so the optimizations mostly seemed to still make sense.
I also kept one shellsort specialization. However, I removed the
second specialized sort implementation, so at least there is only one
specialization now (which is small anyway). I found that the second
sort specialization (added to heapam.c in v10) really wasn't pulling
its weight, even in more extreme cases of the kind that justified the
optimizations in the first place.
--
Peter Geoghegan
On Wed, Dec 9, 2020 at 5:12 PM Peter Geoghegan <pg@bowt.ie> wrote: > Most of the real changes in v11 (compared to v10) are in heapam.c. > I've completely replaced the table_compute_xid_horizon_for_tuples() > interface with a new interface that supports all existing requirements > (from index deletions that support LP_DEAD deletion), while also > supporting these new requirements (e.g. bottom-up index deletion). I came up with a microbenchmark that is designed to give some general sense of how helpful it is to include "extra" TIDs alongside LP_DEAD-in-index TIDs (when they happen to point to the same table block as the LP_DEAD-in-index TIDs, which we'll have to visit anyway). The basic idea is simple: Add custom instrumentation that summarizes each B-Tree index deletion in LOG output, and then run the regression tests. Attached in the result of this for a "make installcheck-world". If you're just looking at this thread for the first time in a while: note that what I'm about to go into isn't technically bottom-up deletion (though you will see some of that in the full log output if you look). It's a closely related optimization that only appeared in recent versions of the patch. So I'm comparing the current approach to simple deletion of LP_DEAD-marked index tuples to a new enhanced approach (that makes it a little more like bottom-up deletion, but only a little). Here is some sample output (selected almost at random from a text file consisting of 889 lines of similar output): ... exact TIDs deleted 17, LP_DEAD tuples 4, LP_DEAD-related table blocks 2 ) ... exact TIDs deleted 38, LP_DEAD tuples 28, LP_DEAD-related table blocks 1 ) ... exact TIDs deleted 39, LP_DEAD tuples 1, LP_DEAD-related table blocks 1 ) ... exact TIDs deleted 44, LP_DEAD tuples 42, LP_DEAD-related table blocks 3 ) ... exact TIDs deleted 6, LP_DEAD tuples 2, LP_DEAD-related table blocks 2 ) (The initial contents of each line were snipped here, to focus on the relevant metrics.) Here we see that the actual number of TIDs/index tuples deleted often *vastly* exceeds the number of LP_DEAD-marked tuples (which are all we would have been able to delete with the existing approach of just deleting LP_DEAD items). It's pretty rare for us to fail to at least delete a couple of extra TIDs. Clearly this technique is broadly effective, because in practice there are significant locality-related effects that we can benefit from. It doesn't really matter that it's hard to precisely describe all of these locality effects. IMV the question that really matters is whether or not the cost of trying is consistently very low (relative to the cost of our current approach to simple LP_DEAD deletion). We do need to understand that fully. It's tempting to think about this quantitatively (and it also bolsters the case for the patch), but that misses the point. The right way to think about this is as a *qualitative* thing. The presence of LP_DEAD bits gives us certain reliable information about the nature of the index tuple (that it is dead-to-all, and therefore safe to delete), but it also *suggests* quite a lot more than that. In practice bloat is usually highly correlated/concentrated, especially when we limit our consideration to workloads where bloat is noticeable in any practical sense. So we're very well advised to look for nearby deletable index tuples in passing -- especially since it's practically free to do so. (Which is what the patch does here, of course.) Let's compare this to an extreme variant of my patch that runs the same test, to see what changes. Consider a variant that exhaustively checks every index tuple on the page at the point of a simple LP_DEAD deletion operation, no matter what. Rather than only including those TIDs that happen to be on the same heap/table blocks (and thus are practically free to check), we include all of them. This design isn't acceptable in the real world because it does a lot of unnecessary I/O, but that shouldn't invalidate any comparison I make here. This is still a reasonable approximation of a version of the patch with magical foreknowledge of where to find dead TIDs. It's an Oracle (ahem) that we can sensibly compare to the real patch within certain constraints. The results of this comparative analysis seem to suggest something important about the general nature of what's going on. The results are: There are only 844 deletion operations total with the Oracle. While this is less than the actual patch's 889 deletion operations, you would expect a bigger improvement from using what is after all supposed to apply magic! This suggests to me that the precise intervention of the patch here (the new LP_DEAD deletion stuff) has an outsized impact. The correlations that naturally exist make this asymmetrical payoff-to-cost situation possible. Simple cheap heuristics once again go a surprisingly long way, kind of like bottom-up deletion itself. -- Peter Geoghegan
Attachment
On Wed, Dec 9, 2020 at 5:12 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached is v11, which cleans everything up around the tableam > interface. There are only two patches in v11, since the tableam > refactoring made it impossible to split the second patch into a heapam > patch and nbtree patch (there is no reduction in functionality > compared to v10). Attached is v12, which fixed bitrot against the master branch. This version has significant comment and documentation revisions. It is functionally equivalent to v11, though. I intend to commit the patch in the next couple of weeks. While it certainly would be nice to get a more thorough review, I don't feel that it is strictly necessary. The patch provides very significant benefits with certain workloads that have traditionally been considered an Achilles' heel for Postgres. Even zheap doesn't provide a solution to these problems. The only thing that I can think of that might reasonably be considered in competition with this design is WARM, which hasn't been under active development since 2017 (I assume that it has been abandoned by those involved). I should also point out that the design doesn't change the on-disk format in any way, and so doesn't commit us to supporting something that might become onerous in the event of somebody else finding a better way to address at least some of the same problems. -- Peter Geoghegan
Attachment
чт, 31 дек. 2020 г. в 03:55, Peter Geoghegan <pg@bowt.ie>:
Attached is v12, which fixed bitrot against the master branch. This
version has significant comment and documentation revisions. It is
functionally equivalent to v11, though.
I intend to commit the patch in the next couple of weeks. While it
certainly would be nice to get a more thorough review, I don't feel
that it is strictly necessary. The patch provides very significant
benefits with certain workloads that have traditionally been
considered an Achilles' heel for Postgres. Even zheap doesn't provide
a solution to these problems. The only thing that I can think of that
might reasonably be considered in competition with this design is
WARM, which hasn't been under active development since 2017 (I assume
that it has been abandoned by those involved).
I am planning to look into this patch in the next few days.
Victor Yegorov
Hi, Peter:
Happy New Year.
For v12-0001-Pass-down-logically-unchanged-index-hint.patch
+ if (hasexpression)
+ return false;
+
+ return true;
+ return false;
+
+ return true;
The above can be written as return !hasexpression;
The negation is due to the return value from index_unchanged_by_update_var_walker() is inverse of index unchanged.
If you align the meaning of return value from index_unchanged_by_update_var_walker() the same way as index_unchanged_by_update(), negation is not needed.
For v12-0002-Add-bottom-up-index-deletion.patch :
For struct xl_btree_delete:
+ /* DELETED TARGET OFFSET NUMBERS FOLLOW */
+ /* UPDATED TARGET OFFSET NUMBERS FOLLOW */
+ /* UPDATED TUPLES METADATA (xl_btree_update) ARRAY FOLLOWS */
+ /* UPDATED TARGET OFFSET NUMBERS FOLLOW */
+ /* UPDATED TUPLES METADATA (xl_btree_update) ARRAY FOLLOWS */
I guess the comment is for illustration purposes. Maybe you can write the comment in lower case.
+#define BOTTOMUP_FAVORABLE_STRIDE 3
Adding a comment on why the number 3 is chosen would be helpful for people to understand the code.
Cheers
On Wed, Dec 30, 2020 at 6:55 PM Peter Geoghegan <pg@bowt.ie> wrote:
On Wed, Dec 9, 2020 at 5:12 PM Peter Geoghegan <pg@bowt.ie> wrote:
> Attached is v11, which cleans everything up around the tableam
> interface. There are only two patches in v11, since the tableam
> refactoring made it impossible to split the second patch into a heapam
> patch and nbtree patch (there is no reduction in functionality
> compared to v10).
Attached is v12, which fixed bitrot against the master branch. This
version has significant comment and documentation revisions. It is
functionally equivalent to v11, though.
I intend to commit the patch in the next couple of weeks. While it
certainly would be nice to get a more thorough review, I don't feel
that it is strictly necessary. The patch provides very significant
benefits with certain workloads that have traditionally been
considered an Achilles' heel for Postgres. Even zheap doesn't provide
a solution to these problems. The only thing that I can think of that
might reasonably be considered in competition with this design is
WARM, which hasn't been under active development since 2017 (I assume
that it has been abandoned by those involved).
I should also point out that the design doesn't change the on-disk
format in any way, and so doesn't commit us to supporting something
that might become onerous in the event of somebody else finding a
better way to address at least some of the same problems.
--
Peter Geoghegan
чт, 31 дек. 2020 г. в 20:01, Zhihong Yu <zyu@yugabyte.com>:
For v12-0001-Pass-down-logically-unchanged-index-hint.patch+ if (hasexpression)
+ return false;
+
+ return true;The above can be written as return !hasexpression;
To be honest, I prefer the way Peter has it in his patch.
Yes, it's possible to shorten this part. But readability is hurt — for current code I just read it, for the suggested change I need to think about it.
Victor Yegorov
On Thu, Dec 31, 2020 at 11:01 AM Zhihong Yu <zyu@yugabyte.com> wrote: > Happy New Year. Happy New Year. > For v12-0001-Pass-down-logically-unchanged-index-hint.patch > > + if (hasexpression) > + return false; > + > + return true; > > The above can be written as return !hasexpression; > The negation is due to the return value from index_unchanged_by_update_var_walker() is inverse of index unchanged. > If you align the meaning of return value from index_unchanged_by_update_var_walker() the same way as index_unchanged_by_update(),negation is not needed. I don't think that that represents an improvement. The negation seems clearer to me because we're negating the *absence* of something that we search for more or less linearly (a modified column from the index). This happens when determining whether to do an extra thing (provide the "logically unchanged" hint to this particular index/aminsert() call). To me, the negation reflects that high level structure. > For struct xl_btree_delete: > > + /* DELETED TARGET OFFSET NUMBERS FOLLOW */ > + /* UPDATED TARGET OFFSET NUMBERS FOLLOW */ > + /* UPDATED TUPLES METADATA (xl_btree_update) ARRAY FOLLOWS */ > > I guess the comment is for illustration purposes. Maybe you can write the comment in lower case. The comment is written like this (in higher case) to be consistent with an existing convention. If this was a green field situation I suppose I might not write it that way, but that's not how I assess these things. I always try to give the existing convention the benefit of the doubt. In this case I don't think that it matters very much, and so I'm inclined to stick with the existing style. > +#define BOTTOMUP_FAVORABLE_STRIDE 3 > > Adding a comment on why the number 3 is chosen would be helpful for people to understand the code. Noted - I will add something about that to the next revision. -- Peter Geoghegan
On 02/12/2020 00:18, Peter Geoghegan wrote: > On Tue, Dec 1, 2020 at 1:50 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> On 30/11/2020 21:50, Peter Geoghegan wrote: >>> +} TM_IndexDelete; > >>> +} TM_IndexStatus; > >> Is it really significantly faster to have two arrays? If you had just >> one array, each element would be only 12 bytes long. That's not much >> smaller than TM_IndexDeletes, which is 8 bytes. > > Yeah, but the swap operations really matter here. At one point I found > that to be the case, anyway. That might no longer be true, though. It > might be that the code became less performance critical because other > parts of the design improved, resulting in the code getting called > less frequently. But if that is true then it has a lot to do with the > power-of-two bucketing that you go on to ask about -- that helped > performance a lot in certain specific cases (as I go into below). > > I will add a TODO item for myself, to look into this again. You may > well be right. > >>> + /* First sort caller's array by TID */ >>> + heap_tid_shellsort(delstate->deltids, delstate->ndeltids); > >> Instead of sorting the array by TID, wouldn't it be enough to sort by >> just the block numbers? > > I don't understand. Yeah, I guess that we could do our initial sort of > the deltids array (the heap_tid_shellsort() call) just using > BlockNumber (not TID). But OTOH there might be some small locality > benefit to doing a proper TID sort at the level of each heap page. And > even if there isn't any such benefit, does it really matter? You said above that heap_tid_shellsort() is very performance critical, and that's why you use the two arrays approach. If it's so performance critical that swapping 8 bytes vs 12 byte array elements makes a difference, I would guess that comparing TID vs just the block numbers would also make a difference. If you really want to shave cycles, you could also store BlockNumber and OffsetNumber in the TM_IndexDelete array, instead of ItemPointerData. What's the difference, you might ask? ItemPointerData stores the block number as two 16 bit integers that need to be reassembled into a 32 bit integer in the ItemPointerGetBlockNumber() macro. My argument here is two-pronged: If this is performance critical, you could do these additional optimizations. If it's not, then you don't need the two-arrays trick; one array would be simpler. I'm not sure how performance critical this really is, or how many instructions each of these optimizations might shave off, so of course I might be wrong and the tradeoff you have in the patch now really is the best. However, my intuition would be to use a single array, because that's simpler, and do all the other optimizations instead: store the tid in the struct as separate BlockNumber and OffsetNumber fields, and sort only by the block number. Those optimizations are very deep in the low level functions and won't add much to the mental effort of understanding the algorithm at a high level. >>> * While in general the presence of promising tuples (the hint that index >>> + * AMs provide) is the best information that we have to go on, it is based >>> + * on simple heuristics about duplicates in indexes that are understood to >>> + * have specific flaws. We should not let the most promising heap pages >>> + * win or lose on the basis of _relatively_ small differences in the total >>> + * number of promising tuples. Small differences between the most >>> + * promising few heap pages are effectively ignored by applying this >>> + * power-of-two bucketing scheme. >>> + * >> >> What are the "specific flaws"? > > I just meant the obvious: the index AM doesn't actually know for sure > that there are any old versions on the leaf page that it will > ultimately be able to delete. This uncertainty needs to be managed, > including inside heapam.c. Feel free to suggest a better way of > expressing that sentiment. Hmm, maybe: "... is the best information that we have to go on, it is just a guess based on simple heuristics about duplicates in indexes". >> I understand that this is all based on rough heuristics, but is there >> any advantage to rounding/bucketing the numbers like this? Even if small >> differences in the total number of promising tuple is essentially noise >> that can be safely ignored, is there any harm in letting those small >> differences guide the choice? Wouldn't it be the essentially the same as >> picking at random, or are those small differences somehow biased? > > Excellent question! It actually helps enormously, especially with low > cardinality data that makes good use of the deduplication optimization > (where it is especially important to keep the costs and the benefits > in balance). This has been validated by benchmarking. > > This design naturally allows the heapam.c code to take advantage of > both temporal and spatial locality. For example, let's say that you > have several indexes all on the same table, which get lots of non-HOT > UPDATEs, which are skewed. Naturally, the heap TIDs will match across > each index -- these are index entries that are needed to represent > successor versions (which are logically unchanged/version duplicate > index tuples from the point of view of nbtree/nbtdedup.c). Introducing > a degree of determinism to the order in which heap blocks are > processed naturally takes advantage of the correlated nature of the > index bloat. It naturally makes it much more likely that the > also-correlated bottom-up index deletion passes (that occur across > indexes on the same table) each process the same heap blocks close > together in time -- with obvious performance benefits. > > In the extreme (but not particularly uncommon) case of non-HOT UPDATEs > with many low cardinality indexes, each heapam.c call will end up > doing *almost the same thing* across indexes. So we're making the > correlated nature of the bloat (which is currently a big problem) work > in our favor -- turning it on its head, you could say. Highly > correlated bloat is not the exception -- it's actually the norm in the > cases we're targeting here. If it wasn't highly correlated then it > would already be okay to rely on VACUUM to get around to cleaning it > later. > > This power-of-two bucketing design probably also helps when there is > only one index. I could go into more detail on that, plus other > variations, but perhaps the multiple index example suffices for now. I > believe that there are a few interesting kinds of correlations here -- > I bet you can think of some yourself. (Of course it's also possible > and even likely that heap block correlation won't be important at all, > but my response is "what specifically is the harm in being open to the > possibility?".) I see. Would be good to explain that pattern with multiple indexes in the comment. - Heikki
чт, 31 дек. 2020 г. в 03:55, Peter Geoghegan <pg@bowt.ie>:
Attached is v12, which fixed bitrot against the master branch. This
version has significant comment and documentation revisions. It is
functionally equivalent to v11, though.
I intend to commit the patch in the next couple of weeks. While it
certainly would be nice to get a more thorough review, I don't feel
that it is strictly necessary. The patch provides very significant
benefits with certain workloads that have traditionally been
considered an Achilles' heel for Postgres. Even zheap doesn't provide
a solution to these problems. The only thing that I can think of that
might reasonably be considered in competition with this design is
WARM, which hasn't been under active development since 2017 (I assume
that it has been abandoned by those involved).
I've looked through the v12 patch.
I like the new outline:
- _bt_delete_or_dedup_one_page() is the main entry for the new code
- first we try _bt_simpledel_pass() does improved cleanup of LP_DEAD entries
- then (if necessary) _bt_bottomupdel_pass() for bottomup deletion
- finally, we perform _bt_dedup_pass() to deduplication
- finally, we perform _bt_dedup_pass() to deduplication
We split the leaf page only if all the actions above failed to provide enough space.
Some comments on the code.
v12-0001
--------
1. For the following comment
+ * Only do this for key columns. A change to a non-key column within an
+ * INCLUDE index should not be considered because that's just payload to
+ * the index (they're not unlike table TIDs to the index AM).
The last part of it (in the parenthesis) is difficult to grasp due to
the double negation (not unlike). I think it's better to rephrase it.
2. After reading the patch, I also think, that fact, that index_unchanged_by_update()
and index_unchanged_by_update_var_walker() return different bool states
(i.e. when the latter returns true, the first one returns false) is a bit misleading.
Although logic as it is looks fine, maybe index_unchanged_by_update_var_walker()
can be renamed to avoid this confusion, to smth like index_expression_changed_walker() ?
v12-0001
--------
1. For the following comment
+ * Only do this for key columns. A change to a non-key column within an
+ * INCLUDE index should not be considered because that's just payload to
+ * the index (they're not unlike table TIDs to the index AM).
The last part of it (in the parenthesis) is difficult to grasp due to
the double negation (not unlike). I think it's better to rephrase it.
2. After reading the patch, I also think, that fact, that index_unchanged_by_update()
and index_unchanged_by_update_var_walker() return different bool states
(i.e. when the latter returns true, the first one returns false) is a bit misleading.
Although logic as it is looks fine, maybe index_unchanged_by_update_var_walker()
can be renamed to avoid this confusion, to smth like index_expression_changed_walker() ?
v12-0002
--------
1. Thanks for the comments, they're well made and do help to read the code.
2. I'm not sure the bottomup_delete_items parameter is very helpful. In order to disable
bottom-up deletion, DBA needs somehow to measure it's impact on a particular index.
Currently I do not see how to achieve this. Not sure if this is overly important, though, as
--------
1. Thanks for the comments, they're well made and do help to read the code.
2. I'm not sure the bottomup_delete_items parameter is very helpful. In order to disable
bottom-up deletion, DBA needs somehow to measure it's impact on a particular index.
Currently I do not see how to achieve this. Not sure if this is overly important, though, as
you have a similar parameter for the deduplication.
3. It feels like indexUnchanged is better to make indexChanged and negate its usage in the code.
3. It feels like indexUnchanged is better to make indexChanged and negate its usage in the code.
As !indexChanged reads more natural than !indexUnchanged, at least to me.
This is all I have. I agree, that this code is pretty close to being committed.
Now for the tests.
This is all I have. I agree, that this code is pretty close to being committed.
Now for the tests.
First, I run a 2-hour long case with the same setup as I used in my e-mail from 15 of November.
I found no difference between patch and master whatsoever. Which makes me think, that current
I found no difference between patch and master whatsoever. Which makes me think, that current
master is quite good at keeping better bloat control (not sure if this is an effect of
4228817449 commit or deduplication).
I created another setup (see attached testcases). Basically, I emulated queue operations(INSERT at the end and DELETE
I created another setup (see attached testcases). Basically, I emulated queue operations(INSERT at the end and DELETE
Victor Yegorov
пн, 4 янв. 2021 г. в 17:28, Victor Yegorov <vyegorov@gmail.com>:
I created another setup (see attached testcases). Basically, I emulated queue operations(INSERT at the end and DELETE
Sorry, hit Send too early.
So, I emulated queue operations(INSERT at the end and DELETE from the head). And also made 5-minute transactions
appear in the background for the whole duration of the test. 3 pgbench were run in parallel on a scale 3000 bench database
with modifications (attached).
Master
------
relname | nrows | blk_before | mb_before | blk_after | mb_after | diff
-----------------------+-----------+------------+-----------+-----------+----------+--------
pgbench_accounts | 300000000 | 4918033 | 38422.1 | 5065575 | 39574.8 | +3.0%
accounts_mtime | 300000000 | 1155119 | 9024.4 | 1287656 | 10059.8 | +11.5%
fiver | 300000000 | 427039 | 3336.2 | 567755 | 4435.6 | +33.0%
pgbench_accounts_pkey | 300000000 | 822573 | 6426.4 | 1033344 | 8073.0 | +25.6%
score | 300000000 | 284022 | 2218.9 | 458502 | 3582.0 | +61.4%
tenner | 300000000 | 346050 | 2703.5 | 417985 | 3265.5 | +20.8%
(6 rows)
DB size: 65.2..72.3 (+7.1GB / +10.9%)
TPS: 2297 / 495
Patched
------
relname | nrows | blk_before | mb_before | blk_after | mb_after | diff
-----------------------+-----------+------------+-----------+-----------+----------+--------
pgbench_accounts | 300000000 | 4918033 | 38422.1 | 5067500 | 39589.8 | +3.0%
accounts_mtime | 300000000 | 1155119 | 9024.4 | 1283441 | 10026.9 | +11.1%
fiver | 300000000 | 427039 | 3336.2 | 429101 | 3352.4 | +0.5%
pgbench_accounts_pkey | 300000000 | 822573 | 6426.4 | 826056 | 6453.6 | +0.4%
score | 300000000 | 284022 | 2218.9 | 285465 | 2230.2 | +0.5%
tenner | 300000000 | 346050 | 2703.5 | 347695 | 2716.4 | +0.5%
(6 rows)
DB size: 65.2..67.5 (+2.3GB / +3.5%)
So, I emulated queue operations(INSERT at the end and DELETE from the head). And also made 5-minute transactions
appear in the background for the whole duration of the test. 3 pgbench were run in parallel on a scale 3000 bench database
with modifications (attached).
Master
------
relname | nrows | blk_before | mb_before | blk_after | mb_after | diff
-----------------------+-----------+------------+-----------+-----------+----------+--------
pgbench_accounts | 300000000 | 4918033 | 38422.1 | 5065575 | 39574.8 | +3.0%
accounts_mtime | 300000000 | 1155119 | 9024.4 | 1287656 | 10059.8 | +11.5%
fiver | 300000000 | 427039 | 3336.2 | 567755 | 4435.6 | +33.0%
pgbench_accounts_pkey | 300000000 | 822573 | 6426.4 | 1033344 | 8073.0 | +25.6%
score | 300000000 | 284022 | 2218.9 | 458502 | 3582.0 | +61.4%
tenner | 300000000 | 346050 | 2703.5 | 417985 | 3265.5 | +20.8%
(6 rows)
DB size: 65.2..72.3 (+7.1GB / +10.9%)
TPS: 2297 / 495
Patched
------
relname | nrows | blk_before | mb_before | blk_after | mb_after | diff
-----------------------+-----------+------------+-----------+-----------+----------+--------
pgbench_accounts | 300000000 | 4918033 | 38422.1 | 5067500 | 39589.8 | +3.0%
accounts_mtime | 300000000 | 1155119 | 9024.4 | 1283441 | 10026.9 | +11.1%
fiver | 300000000 | 427039 | 3336.2 | 429101 | 3352.4 | +0.5%
pgbench_accounts_pkey | 300000000 | 822573 | 6426.4 | 826056 | 6453.6 | +0.4%
score | 300000000 | 284022 | 2218.9 | 285465 | 2230.2 | +0.5%
tenner | 300000000 | 346050 | 2703.5 | 347695 | 2716.4 | +0.5%
(6 rows)
DB size: 65.2..67.5 (+2.3GB / +3.5%)
As you can see, TPS are very much similar, but the fact that we have no bloat for the patched version makes me very happy!
On the graphs, you can clearly see extra write activity performed by the backedns of the patched version.
Victor Yegorov
Attachment
- 20210103-pg_bench-alterations.txt
- 20210103-master-overview.png
- 20210103-master-dbsize.png
- 20210103-v12-overview.png
- 20210103-v12-dbsize.png
- 20210103-postgresql.auto.conf
- 20210103-testcase1.pgbench
- 20210103-testcase2.pgbench
- 20210103-testcase3.pgbench
- 20210103-results-master.txt
- 20210103-results-patched.txt
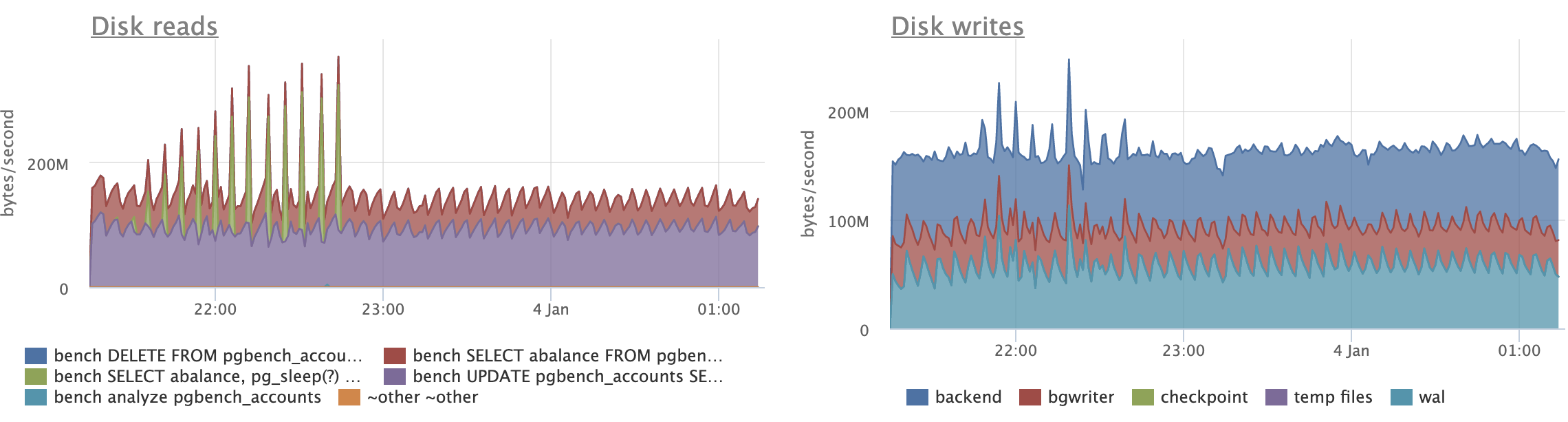{kind=link}
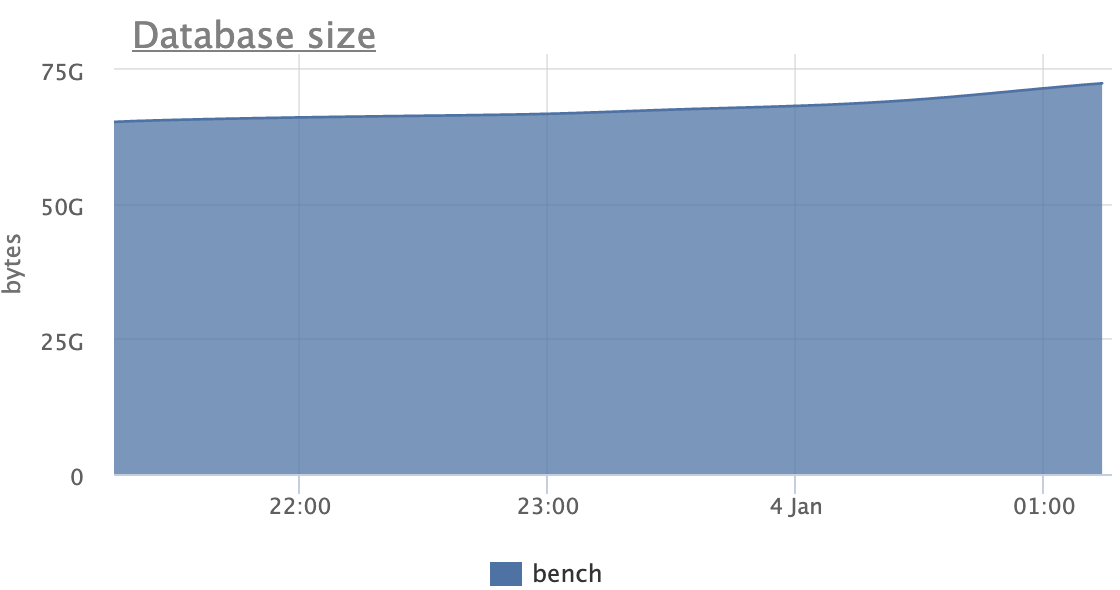{kind=link}
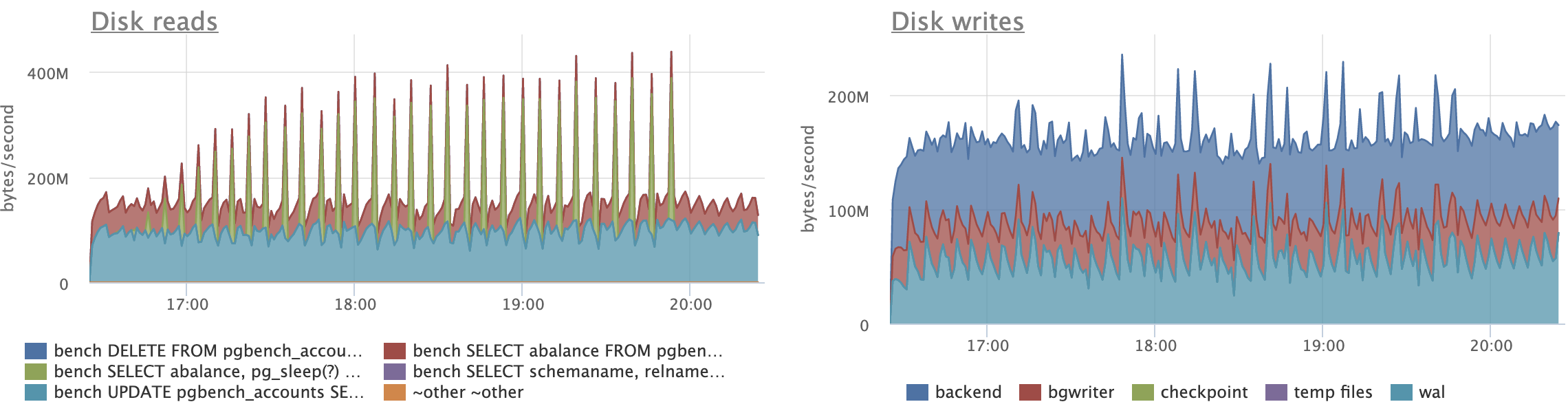{kind=link}
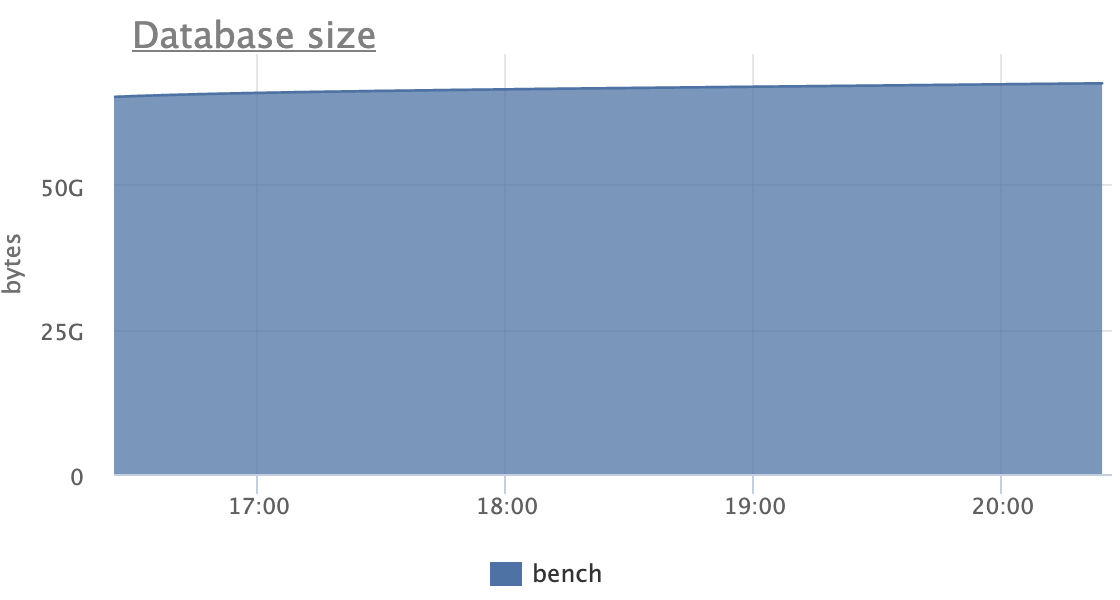{kind=link}
On Mon, Jan 4, 2021 at 4:08 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > You said above that heap_tid_shellsort() is very performance critical, > and that's why you use the two arrays approach. If it's so performance > critical that swapping 8 bytes vs 12 byte array elements makes a > difference, I would guess that comparing TID vs just the block numbers > would also make a difference. > > If you really want to shave cycles, you could also store BlockNumber and > OffsetNumber in the TM_IndexDelete array, instead of ItemPointerData. > What's the difference, you might ask? ItemPointerData stores the block > number as two 16 bit integers that need to be reassembled into a 32 bit > integer in the ItemPointerGetBlockNumber() macro. > > My argument here is two-pronged: If this is performance critical, you > could do these additional optimizations. If it's not, then you don't > need the two-arrays trick; one array would be simpler. That's reasonable. The reason why I haven't been more decisive here is because the question of whether or not it matters is actually very complicated, for reasons that have little to do with sorting. The more effective the mechanism is each time (the more bytes it allows nbtree to free from each leaf page), the less often it is called, and the less performance critical the overhead per operation is. On the other hand there are a couple of other questions about what we do in heapam.c that aren't quite resolved yet (e.g. exact "favorable blocks"/prefetching behavior in bottom-up case), that probably affect how important the heap_tid_shellsort() microoptimisations are. I think that it makes sense to make a final decision on this at the last minute, once everything else is resolved, since the implicit dependencies make any other approach much too complicated. I agree that this kind of microoptimization is best avoided, but I really don't want to have to worry about regressions in workloads that I now understand fully. I think that the sort became less important on perhaps 2 or 3 occasions during development, even though that was never really the goal that I had in mind in each case. I'll do my best to avoid it. > Hmm, maybe: "... is the best information that we have to go on, it is > just a guess based on simple heuristics about duplicates in indexes". I'll add something like that to the next revision. > I see. Would be good to explain that pattern with multiple indexes in > the comment. Will do -- it is the single best example of how heap block locality can matter with a real workload, so it makes sense to go with it in explanatory comments. -- Peter Geoghegan
On Mon, Jan 4, 2021 at 8:28 AM Victor Yegorov <vyegorov@gmail.com> wrote: > I've looked through the v12 patch. > > I like the new outline: > > - _bt_delete_or_dedup_one_page() is the main entry for the new code > - first we try _bt_simpledel_pass() does improved cleanup of LP_DEAD entries > - then (if necessary) _bt_bottomupdel_pass() for bottomup deletion > - finally, we perform _bt_dedup_pass() to deduplication > > We split the leaf page only if all the actions above failed to provide enough space. I'm thinking of repeating the LP_DEAD enhancement within GiST and hash shortly after this, as follow-up work. Their implementation of LP_DEAD deletion was always based on the nbtree original, and I think that it makes sense to keep everything in sync. The simple deletion enhancement probably makes just as much sense in these other places. > + * Only do this for key columns. A change to a non-key column within an > + * INCLUDE index should not be considered because that's just payload to > + * the index (they're not unlike table TIDs to the index AM). > > The last part of it (in the parenthesis) is difficult to grasp due to > the double negation (not unlike). I think it's better to rephrase it. Okay, will do. > 2. After reading the patch, I also think, that fact, that index_unchanged_by_update() > and index_unchanged_by_update_var_walker() return different bool states > (i.e. when the latter returns true, the first one returns false) is a bit misleading. > Although logic as it is looks fine, maybe index_unchanged_by_update_var_walker() > can be renamed to avoid this confusion, to smth like index_expression_changed_walker() ? I agree. I'll use the name index_expression_changed_walker() in the next revision. > 2. I'm not sure the bottomup_delete_items parameter is very helpful. In order to disable > bottom-up deletion, DBA needs somehow to measure it's impact on a particular index. > Currently I do not see how to achieve this. Not sure if this is overly important, though, as > you have a similar parameter for the deduplication. I'll take bottomup_delete_items out, since I think that you may be right about that. It can be another "decision to recheck mid-beta" thing (on the PostgreSQL 14 open items list), so we can delay making a final decision on it until after it gets tested by the broadest possible group of people. > 3. It feels like indexUnchanged is better to make indexChanged and negate its usage in the code. > As !indexChanged reads more natural than !indexUnchanged, at least to me. I don't want to do that because then we're negating "indexChanged" as part of our gating condition to the bottom-up deletion pass code. To me this feels wrong, since the hint only exists to be used to trigger index tuple deletion. This is unlikely to ever change. > First, I run a 2-hour long case with the same setup as I used in my e-mail from 15 of November. > I found no difference between patch and master whatsoever. Which makes me think, that current > master is quite good at keeping better bloat control (not sure if this is an effect of > 4228817449 commit or deduplication). Commit 4228817449 can't have improved the performance of the master branch -- that commit was just about providing a *correct* latestRemovedXid value. It cannot affect how many index tuples get deleted per pass, or anything like that. Not surprised that you didn't see many problems with the master branch on your first attempt. It's normal for there to be non-linear effects with this stuff, and these are very hard (maybe even impossible) to model. For example, even with artificial test data you often see distinct "waves" of page splits, which is a phenomenon pretty well described by the "Waves of misery after index creation" paper [1]. It's likely that your original stress test case (the 15 November one) would have shown significant bloat if you just kept it up for long enough. One goal for this project is to make the performance characteristics more predictable. The performance characteristics are unpredictable precisely because they're pathological. B-Trees will always have non-linear performance characteristics, but they can be made a lot less chaotic in practice. To be honest, I was slightly surprised that your more recent stress test (the queue thing) worked out so well for the patch. But not too surprised, because I don't necessarily expect to understand how the patch can help for any given workload -- this is dynamic behavior that's part of a complex system. I first thought that maybe the presence of the INSERTs and DELETEs would mess things up. But I was wrong -- everything still worked well, probably because bottom-up index deletion "cooperated" with deduplication. The INSERTs could not trigger a bottom-up deletion (which might have been useful for these particular INSERTs), but that didn't actually matter because deduplication was triggered instead, which "held the line" for long enough for bottom-up deletion to eventually get triggered (by non-HOT UPDATEs). As I've said before, I believe that the workload should "figure out the best strategy for handling bloat on its own". A diversity of strategies are available, which can adapt to many different kinds of workloads organically. That kind of approach is sometimes necessary with a complex system IMV. [1] https://btw.informatik.uni-rostock.de/download/tagungsband/B2-2.pdf -- Peter Geoghegan
On Thu, Jan 7, 2021 at 3:07 PM Peter Geoghegan <pg@bowt.ie> wrote: > I agree. I'll use the name index_expression_changed_walker() in the > next revision. Attached is v13, which has this tweak, and other miscellaneous cleanup based on review from both Victor and Heikki. I consider this version of the patch to be committable. I intend to commit something close to it in the next week, probably no later than Thursday. I still haven't got to the bottom of the shellsort question raised by Heikki. I intend to do further performance validation before committing the patch. I will look into the shellsort thing again as part of this final performance validation work -- perhaps I can get rid of the specialized shellsort implementation entirely, simplifying the state structs added to tableam.h. (As I said before, it seems best to address this last of all to avoid making performance validation even more complicated.) This version of the patch is notable for removing the index storage param, and for having lots of comment updates and documentation consolidation, particularly in heapam.c. Many of the latter changes are based on feedback from Heikki. Note that all of the discussion of heapam level locality has been consolidated, and is now mostly confined to a fairly large comment block over bottomup_nblocksfavorable() in heapam.c. I also cut down on redundancy among comments about the design at the whole-patch level. A small amount of redundancy in design docs/comments is a good thing IMV. It was hard to get the balance exactly right, since bottom-up index deletion is by its very nature a mechanism that requires the index AM and the tableam to closely cooperate -- which is a novel thing. This isn't 100% housekeeping changes, though. I did add one new minor optimization to v13: We now count the heap block of the incoming new item index tuple's TID (the item that won't fit on the leaf page as-is) as an LP_DEAD-related block for the purposes of determining which heap blocks will be visited during simple index tuple deletion. The extra cost of doing this is low: when the new item heap block is visited purely due to this new behavior, we're still practically guaranteed to not get a buffer miss to read from the heap page. The reason should be obvious: the executor is currently in the process of modifying that same heap page anyway. The benefits are also high relative to the cost. This heap block in particular seems to be very promising as a place to look for deletable TIDs (I tested this with custom instrumentation and microbenchmarks). I believe that this effect exists because by its very nature garbage is often concentrated in recently modified pages. This is per the generational hypothesis, an important part of the theory behind GC algorithms for automated memory management (GC theory seems to have real practical relevance to the GC/VACUUM problems in Postgres, at least at a high level). Of course we still won't do any simple deletion operations unless there is at least one index tuple with its LP_DEAD bit set in the first place at the point that it looks like the page will overflow (no change there). As always, we're just piggy-backing some extra work on top of an expensive operation that needed to take place anyway. I couldn't resist adding this new minor optimization at this late stage, because it is such a bargain. Thanks -- Peter Geoghegan
Attachment
пн, 11 янв. 2021 г. в 01:07, Peter Geoghegan <pg@bowt.ie>:
Attached is v13, which has this tweak, and other miscellaneous cleanup
based on review from both Victor and Heikki. I consider this version
of the patch to be committable. I intend to commit something close to
it in the next week, probably no later than Thursday. I still haven't
got to the bottom of the shellsort question raised by Heikki. I intend
to do further performance validation before committing the patch. I
will look into the shellsort thing again as part of this final
performance validation work -- perhaps I can get rid of the
specialized shellsort implementation entirely, simplifying the state
structs added to tableam.h. (As I said before, it seems best to
address this last of all to avoid making performance validation even
more complicated.)
I've checked this version quickly. It applies and compiles without issues.
`make check` and `make check-world` reported no issue.
But `make installcheck-world` failed on:
…
test explain ... FAILED 22 ms
test event_trigger ... ok 178 ms
test fast_default ... ok 262 ms
test stats ... ok 586 ms
========================
1 of 202 tests failed.
========================
(see attached diff). It doesn't look like the fault of this patch, though.
I suppose you plan to send another revision before committing this.
Therefore I didn't perform any tests here, will wait for the next version.
But `make installcheck-world` failed on:
…
test explain ... FAILED 22 ms
test event_trigger ... ok 178 ms
test fast_default ... ok 262 ms
test stats ... ok 586 ms
========================
1 of 202 tests failed.
========================
(see attached diff). It doesn't look like the fault of this patch, though.
I suppose you plan to send another revision before committing this.
Therefore I didn't perform any tests here, will wait for the next version.
Victor Yegorov
Attachment
On Mon, Jan 11, 2021 at 12:19 PM Victor Yegorov <vyegorov@gmail.com> wrote: > (see attached diff). It doesn't look like the fault of this patch, though. > > I suppose you plan to send another revision before committing this. > Therefore I didn't perform any tests here, will wait for the next version. I imagine that this happened because you have track_io_timing=on in postgresql.conf. Doesn't the same failure take place with the current master branch? I have my own way of running the locally installed Postgres when I want "make installcheck" to pass that specifically accounts for this (and a few other similar things). -- Peter Geoghegan
пн, 11 янв. 2021 г. в 22:10, Peter Geoghegan <pg@bowt.ie>:
I imagine that this happened because you have track_io_timing=on in
postgresql.conf. Doesn't the same failure take place with the current
master branch?
I have my own way of running the locally installed Postgres when I
want "make installcheck" to pass that specifically accounts for this
(and a few other similar things).
Oh, right, haven't thought of this. Thanks for pointing that out.
Now everything looks good!
Victor Yegorov
On Sun, Jan 10, 2021 at 4:06 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached is v13, which has this tweak, and other miscellaneous cleanup > based on review from both Victor and Heikki. I consider this version > of the patch to be committable. I intend to commit something close to > it in the next week, probably no later than Thursday. I still haven't > got to the bottom of the shellsort question raised by Heikki. I intend > to do further performance validation before committing the patch. I benchmarked the patch with one array and without the shellsort specialization using two patches on top of v13, both of which are attached. This benchmark was similar to other low cardinality index benchmarks I've run in the past (with indexes named fiver, tenner, score, plus a pgbench_accounts INCLUDE unique index instead of the regular primary key). I used pgbench scale 500, for 30 minutes, no rate limit. One run with 16 clients, another with 32 clients. Original v13: patch.r1c32.bench.out: "tps = 32709.772257 (including connections establishing)" "latency average = 0.974 ms" "latency stddev = 0.514 ms" patch.r1c16.bench.out: "tps = 34670.929998 (including connections establishing)" "latency average = 0.461 ms" "latency stddev = 0.314 ms" v13 + attached simplifying patches: patch.r1c32.bench.out: "tps = 31848.632770 (including connections establishing)" "latency average = 1.000 ms" "latency stddev = 0.548 ms" patch.r1c16.bench.out: "tps = 33864.099333 (including connections establishing)" "latency average = 0.472 ms" "latency stddev = 0.399 ms" Clearly the optimization work still has some value, since we're looking at about a 2% - 3% increase in throughput here. This seems like it makes the cost of retaining the optimizations acceptable. The difference is much less visible with a rate-limit, which is rather more realistic. To some extent the sort is hot here because the patched version of Postgres updates tuples as fast as it can, and must therefore delete from the index as fast as it can. The sort itself was consistently near the top consumer of CPU cycles according to "perf top", even if it didn't get as bad as what I saw in earlier versions of the patch months ago. There are actually two sorts involved here (not just the heapam.c shellsort). We need to sort the deltids array twice -- once in heapam.c, and a second time (to restore the original leaf-page-wise order) in nbtpage.c, using qsort(). I'm pretty sure that the latter sort also matters, though it matters less than the heapam.c shellsort. I'm going to proceed with committing the original version of the patch -- I feel that this settles it. The code would be a bit tidier without two arrays or the shellsort, but it really doesn't make that much difference. Whereas the benefit is quite visible, and will be something that all varieties of index tuple deletion see a performance benefit from (not just bottom-up deletion). -- Peter Geoghegan
Attachment
On Mon, Jan 11, 2021 at 9:26 PM Peter Geoghegan <pg@bowt.ie> wrote: > I'm going to proceed with committing the original version of the patch > -- I feel that this settles it. Pushed both patches from the patch series just now. Thanks for the code reviews and benchmarking work! -- Peter Geoghegan
On Wed, Jan 13, 2021 at 11:16 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Mon, Jan 11, 2021 at 9:26 PM Peter Geoghegan <pg@bowt.ie> wrote: > > I'm going to proceed with committing the original version of the patch > > -- I feel that this settles it. > > Pushed both patches from the patch series just now. > Nice work! I briefly read the commits and have a few questions. Do we do this optimization (bottom-up deletion) only when the last item which can lead to page split has indexUnchanged set to true? If so, what if the last tuple doesn't have indexUnchanged but the previous ones do have? Why are we using terminology bottom-up deletion and why not simply duplicate version deletion or something on those lines? There is the following comment in the code: 'Index AM/tableam coordination is central to the design of bottom-up index deletion. The index AM provides hints about where to look to the tableam by marking some entries as "promising". Index AM does this with duplicate index tuples that are strongly suspected to be old versions left behind by UPDATEs that did not logically modify indexed values.' How do we distinguish between version duplicate tuples (added due to the reason that some other index column is updated) or duplicate tuples (added because a user has inserted a row with duplicate value) for the purpose of bottom-up deletion? I think we need to distinguish between them because in the earlier case we can remove the old version of the tuple in the index but not in later. Or is it the case that indexAm doesn't differentiate between them but relies on heapAM to give the correct answer? -- With Regards, Amit Kapila.
On Sat, Jan 16, 2021 at 9:55 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > Do we do this optimization (bottom-up deletion) only when the last > item which can lead to page split has indexUnchanged set to true? If > so, what if the last tuple doesn't have indexUnchanged but the > previous ones do have? Using the indexUnchanged hint as a triggering condition makes sure that non-HOT updaters are the ones that pay the cost of a bottom-up deletion pass. We create backpressure for non-HOT updaters (in indexes that are logically unchanged) specifically. (Of course it's also true that the presence of the indexUnchanged hint is highly suggestive of there being more version churn duplicates on the leaf page already, which is not actually certain.) It's possible that there will be some mixture of inserts and non-hot updates on the same leaf page, and as you say the implementation might fail to do a bottom-up pass based on the fact that an incoming item at the point of a would-be page split was a plain insert (and so didn't receive the hint). The possibility of these kinds of "missed opportunities" are okay because a page split was inevitable either way. You can imagine a case where that isn't true (i.e. a missed opportunity to avoid a page split), but that's kind of like imagining a fair coin flip taking place 100 times and coming up heads each time. It just isn't realistic for such an "mixed tendencies" leaf page to stay in flux (i.e. not ever split) forever, with the smartest triggering condition in the world -- it's too unstable. An important part of understanding the design is to imagine things at the leaf page level, while thinking about how what that actually looks like differs from an ideal physical representation of the same leaf page that is much closer to the logical contents of the database. We're only interested in leaf pages where the number of logical rows is basically fixed over time (when there is version churn). Usually this just means that there are lots of non-HOT updates, but it can also work with lots of queue-like inserts and deletes in a unique index. Ultimately, the thing that determines whether or not the bottom-up deletion optimization is effective for any given leaf page is the fact that it actually prevents the page from splitting despite lots of version churn -- this happens again and again. Another key concept here is that bottom-up deletion passes for the same leaf page are related in important ways -- it is often a mistake to think of individual bottom-up passes as independent events. > Why are we using terminology bottom-up deletion and why not simply > duplicate version deletion or something on those lines? Why is that simpler? Also, it doesn't exactly delete duplicates. See my later remarks. > How do we distinguish between version duplicate tuples (added due to > the reason that some other index column is updated) or duplicate > tuples (added because a user has inserted a row with duplicate value) > for the purpose of bottom-up deletion? I think we need to distinguish > between them because in the earlier case we can remove the old version > of the tuple in the index but not in later. Or is it the case that > indexAm doesn't differentiate between them but relies on heapAM to > give the correct answer? Bottom-up deletion uses the presence of duplicates as a starting point for determining which heap pages to visit, based on the assumption that at least some are obsolete versions. But heapam.c has additional heap-level heuristics that help too. It is quite possible and even likely that we will delete some non-duplicate tuples in passing, just because they're checked in passing -- they might turn out to be deletable, for whatever reason. We're also concerned (on the heapam.c side) about which heap pages have the most TIDs (any kind of TID, not just one marked promising in index AM), so this kind of "serendipity" is quite common in practice. Often the total number of heap pages that are pointed to by all index tuples on the page just isn't that many (8 - 10). And often cases with lots of HOT pruning can have hundreds of LP_DEAD item pointers on a heap page, which we'll tend to get to before too long anyway (with or without many duplicates). The nbtree/caller side makes inferences about what is likely to be true about the "logical contents" of the physical leaf page, as a starting point for the heuristic-driven search for deletable index tuples. There are various ways in which each inference (considered individually) might be wrong, including the one that you pointed out: inserts of duplicates will look like update version churn. But that particular issue won't matter if the inserted duplicates are on mostly-distinct heap blocks (which is likely), because then they'll only make a noise level contribution to the behavior in heapam.c. Also, we can fall back on deduplication when bottom-up deletion fails, which will merge together the duplicates-from-insert, so now any future bottom-up deletion pass over the same leaf page won't have the same problem. Bear in mind that heapam.c is only looking for a select few heap blocks, and doesn't even need to get the order exactly right. We're only concerned about extremes, which are actually what we see in cases that we're interested in helping. We only have to be very approximately right, or right on average. Sure, there might be some tiny cost in marginal cases, but that's not something that I've been able to quantify in any practical way. Because once we fail we fail for good -- the page splits and the question of doing a bottom-up deletion pass for that same leaf page ends. Another important concept is the cost asymmetry -- the asymmetry here is huge. Leaf page splits driven by version churn are very expensive in the short term and in the long term. Our previous behavior was to assume that they were necessary. Now we're initially assuming that they're unnecessary, and requiring non-HOT updaters to do some work that shows (with some margin of error) that such a split is in fact necessary. This is a form of backpressure. Bottom-up deletion doesn't intervene unless and until that happens. It is only interested in pages where version churn is concentrated -- it is absolutely fine to leave it up to VACUUM to get to any "floating garbage" tuples later. This is a pathological condition, and as such isn't hard to spot, regardless of workload conditions. If you or anyone else can think of a gap in my reasoning, or a workload in which the heuristics either fail to prevent page splits where that might be expected or impose too high a cost, do let me know. I admit that my design is unorthodox, but the results speak for themselves. -- Peter Geoghegan
On Mon, Jan 18, 2021 at 12:43 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Sat, Jan 16, 2021 at 9:55 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > Do we do this optimization (bottom-up deletion) only when the last > > item which can lead to page split has indexUnchanged set to true? If > > so, what if the last tuple doesn't have indexUnchanged but the > > previous ones do have? > > Using the indexUnchanged hint as a triggering condition makes sure > that non-HOT updaters are the ones that pay the cost of a bottom-up > deletion pass. We create backpressure for non-HOT updaters (in indexes > that are logically unchanged) specifically. (Of course it's also true > that the presence of the indexUnchanged hint is highly suggestive of > there being more version churn duplicates on the leaf page already, > which is not actually certain.) > > It's possible that there will be some mixture of inserts and non-hot > updates on the same leaf page, and as you say the implementation might > fail to do a bottom-up pass based on the fact that an incoming item at > the point of a would-be page split was a plain insert (and so didn't > receive the hint). > or it would do the scan when that is the only time for this leaf page to receive such a hint. > The possibility of these kinds of "missed > opportunities" are okay because a page split was inevitable either > way. You can imagine a case where that isn't true (i.e. a missed > opportunity to avoid a page split), but that's kind of like imagining > a fair coin flip taking place 100 times and coming up heads each time. > It just isn't realistic for such an "mixed tendencies" leaf page to > stay in flux (i.e. not ever split) forever, with the smartest > triggering condition in the world -- it's too unstable. > But even if we don't want to avoid it forever delaying it will also have advantages depending upon the workload. Let's try to see by some example, say the item and page size are such that it would require 12 items to fill the page completely. Case-1, where we decide based on the hint received in the last item, and Case-2 where we decide based on whether we ever received such a hint for the leaf page. Case-1: ======== 12 new items (6 inserts 6 non-HOT updates) Page-1: 12 items - no split would be required because we received the hint (indexUnchanged) with the last item, so page-1 will have 6 items after clean up. 6 new items (3 inserts, 3 non-HOT updates) Page-1: 12 items (9 inserts, 3 non-HOT updates) lead to split because we received the last item without a hint. The SPLIT-1 happens after 18 operations (6 after the initial 12). After this split (SPLIT-1), we will have 2 pages with the below state: Page-1: 6 items (4 inserts, 2 non-HOT updates) Page-2: 6 items (5 inserts, 1 non-HOT updates) 6 new items (3 inserts, 3 non-HOT updates) Page-1 got 3 new items 1 insert and 2 non-HOT updates; Page-1: 9 items (5 inserts, 4 non-HOT updates) Page-2 got 3 new items 2 inserts and 1 non-HOT update; Page-2: 9 items (7 inserts, 2 non-HOT updates) 6 new items (3 inserts, 3 non-HOT updates) Page-1 got 3 new items 1 insert and 2 non-HOT updates; Page-1: 12 items (6 inserts, 6 non-HOT updates) doesn't lead to split Page-2 got 3 new items 2 inserts and 1 non-HOT update; Page-2: 9 items (9 inserts, 3 non-HOT updates) lead to split (split-2) The SPLIT-2 happens after 30 operations (12 new operations after the previous split). Case-2: ======== 12 new items (6 inserts 6 non-HOT updates) Page-1: 12 items - no split would be required because we received the hint (indexUnchanged) with at least one of the item, so page-1 will have 6 items after clean up. 6 new items (3 inserts, 3 non-HOT updates) Page-1: 12 items (9 inserts, 3 non-HOT updates), cleanup happens and Page-1 will have 9 items. 6 new items (3 inserts, 3 non-HOT updates), at this stage in whichever order the new items are received one split can't be avoided. The SPLIT-1 happens after 24 new operations (12 new ops after initial 12). Page-1: 6 items (6 inserts) Page-2: 6 items (6 inserts) 6 new items (3 inserts, 3 non-HOT updates) Page-1 got 3 new items 1 insert and 2 non-HOT updates; Page-1: 9 items (7 inserts, 2 non-HOT updates) Page-2 got 3 new items 2 inserts and 1 non-HOT update; Page-2: 9 items (8 inserts, 1 non-HOT updates) 6 new items (3 inserts, 3 non-HOT updates) Page-1 got 3 new items 1 insert and 2 non-HOT updates; Page-1: 12 items (8 inserts, 4 non-HOT updates) clean up happens and page-1 will have 8 items. Page-2 got 3 new items 2 inserts and 1 non-HOT update; Page-2: 9 items (10 inserts, 2 non-HOT updates) clean up happens and page-2 will have 10 items. 6 new items (3 inserts, 3 non-HOT updates) Page-1 got 3 new items, 1 insert and 2 non-HOT updates; Page-1: 11 items (9 inserts, 2 non-HOT updates) Page-2 got 3 new items, 2 inserts and 1 non-HOT update; Page-2: 12 items (12 inserts, 0 non-HOT updates) cleanup happens for one of the non-HOT updates 6 new items (3 inserts, 3 non-HOT updates) Page-1 got 3 new items, 1 insert, and 2 non-HOT updates; Page-1: 12 items (12 inserts, 0 non-HOT updates) cleanup happens for one of the non-HOT updates Page-2 got 3 new items, 2 inserts, and 1 non-HOT update; Page-2: split happens After split Page-1: 12 items (12 inserts) Page-2: 6 items (6 inserts) Page-3: 6 items (6 inserts) The SPLIT-2 happens after 48 operations (24 new operations) The summary of the above is that with Case-1 (clean-up based on hint received with the last item on the page) it takes fewer operations to cause a page split as compared to Case-2 (clean-up based on hint received with at least of the items on the page) for a mixed workload. How can we say that it doesn't matter? > An important part of understanding the design is to imagine things at > the leaf page level, while thinking about how what that actually looks > like differs from an ideal physical representation of the same leaf > page that is much closer to the logical contents of the database. > We're only interested in leaf pages where the number of logical rows > is basically fixed over time (when there is version churn). > With the above example, it seems like it would also help when this is not true. > Usually > this just means that there are lots of non-HOT updates, but it can > also work with lots of queue-like inserts and deletes in a unique > index. > > Ultimately, the thing that determines whether or not the bottom-up > deletion optimization is effective for any given leaf page is the fact > that it actually prevents the page from splitting despite lots of > version churn -- this happens again and again. Another key concept > here is that bottom-up deletion passes for the same leaf page are > related in important ways -- it is often a mistake to think of > individual bottom-up passes as independent events. > > > Why are we using terminology bottom-up deletion and why not simply > > duplicate version deletion or something on those lines? > > Why is that simpler? > I am not sure what I proposed fits here but the bottom-up sounds like we are starting from the leaf level and move upwards to root level which I think is not true here. > Also, it doesn't exactly delete duplicates. See > my later remarks. > > > How do we distinguish between version duplicate tuples (added due to > > the reason that some other index column is updated) or duplicate > > tuples (added because a user has inserted a row with duplicate value) > > for the purpose of bottom-up deletion? I think we need to distinguish > > between them because in the earlier case we can remove the old version > > of the tuple in the index but not in later. Or is it the case that > > indexAm doesn't differentiate between them but relies on heapAM to > > give the correct answer? > > Bottom-up deletion uses the presence of duplicates as a starting point > for determining which heap pages to visit, based on the assumption > that at least some are obsolete versions. But heapam.c has additional > heap-level heuristics that help too. > > It is quite possible and even likely that we will delete some > non-duplicate tuples in passing, just because they're checked in > passing -- they might turn out to be deletable, for whatever reason. > How is that working? Does heapam.c can someway indicate additional tuples (extra to what has been marked/sent by IndexAM as promising) as deletable? I see in heap_index_delete_tuples that we mark the status of the passed tuples as delectable (by setting knowndeletable flag for them). -- With Regards, Amit Kapila.
пн, 18 янв. 2021 г. в 07:44, Amit Kapila <amit.kapila16@gmail.com>:
The summary of the above is that with Case-1 (clean-up based on hint
received with the last item on the page) it takes fewer operations to
cause a page split as compared to Case-2 (clean-up based on hint
received with at least of the items on the page) for a mixed workload.
How can we say that it doesn't matter?
I cannot understand this, perhaps there's a word missing in the brackets?..
Thinking of your proposal to undertake bottom-up deletion also on the last-to-fit tuple insertion,
I'd like to start with my understanding of the design:
* we try to avoid index bloat, but we do it in the “lazy” way (for a reason, see below)
* we try to avoid index bloat, but we do it in the “lazy” way (for a reason, see below)
* it means, that if there is enough space on the leaf page to fit new index tuple,
we just fit it there
* if there's not enough space, we first look at the presence of LP_DEAD tuples,
and if they do exits, we scan the whole (index) page to re-check all tuples in order
to find others, not-yet-marked-but-actually-being-LP_DEAD tuples and clean all those up.
* if still not enough space, only now we try bottom-up-deletion. This is heavy operation and
can cause extra IO (tests do show this), therefore this operation is undertaken at the point,
when we can justify extra IO against leaf page split.
* if no space also after bottom-up-deletion, we perform deduplication (if possible)
* finally, we split the page.
* finally, we split the page.
Should we try bottom-up-deletion pass in a situation where we're inserting the last possible tuple
into the page (enough space for *current* insert, but likely no space for the next),
then (among others) exists the following possibilities:
- no new tuples ever comes to this page anymore (happy accident), which means that
then (among others) exists the following possibilities:
- no new tuples ever comes to this page anymore (happy accident), which means that
we've wasted IO cycles
- we undertake bottom-up-deletion pass without success and we're asked to insert new tuple in this
- we undertake bottom-up-deletion pass without success and we're asked to insert new tuple in this
fully packed index page. This can unroll to:
- due to the delay, we've managed to find some space either due to LP_DEAD or bottom-up-cleanup.
which means we've wasted IO cycles on the previous iteration (too early attempt).
- due to the delay, we've managed to find some space either due to LP_DEAD or bottom-up-cleanup.
which means we've wasted IO cycles on the previous iteration (too early attempt).
- we still failed to find any space and are forced to split the page.
in this case we've wasted IO cycles twice.
In my view these cases when we generated wasted IO cycles (producing no benefit) should be avoided.
And this is main reason for current approach.
Again, this is my understanding and I hope I got it right.
--
in this case we've wasted IO cycles twice.
In my view these cases when we generated wasted IO cycles (producing no benefit) should be avoided.
And this is main reason for current approach.
Again, this is my understanding and I hope I got it right.
Victor Yegorov
On Mon, Jan 18, 2021 at 5:11 PM Victor Yegorov <vyegorov@gmail.com> wrote: > > пн, 18 янв. 2021 г. в 07:44, Amit Kapila <amit.kapila16@gmail.com>: >> >> The summary of the above is that with Case-1 (clean-up based on hint >> received with the last item on the page) it takes fewer operations to >> cause a page split as compared to Case-2 (clean-up based on hint >> received with at least of the items on the page) for a mixed workload. >> How can we say that it doesn't matter? > > > I cannot understand this, perhaps there's a word missing in the brackets?.. > There is a missing word (one) in Case-2, let me write it again to avoid any confusion. Case-2 (clean-up based on hint received with at least one of the items on the page). > > Thinking of your proposal to undertake bottom-up deletion also on the last-to-fit tuple insertion, > I think there is some misunderstanding in what I am trying to say and your conclusion of the same. See below. > I'd like to start with my understanding of the design: > > * we try to avoid index bloat, but we do it in the “lazy” way (for a reason, see below) > > * it means, that if there is enough space on the leaf page to fit new index tuple, > we just fit it there > > * if there's not enough space, we first look at the presence of LP_DEAD tuples, > and if they do exits, we scan the whole (index) page to re-check all tuples in order > to find others, not-yet-marked-but-actually-being-LP_DEAD tuples and clean all those up. > > * if still not enough space, only now we try bottom-up-deletion. This is heavy operation and > can cause extra IO (tests do show this), therefore this operation is undertaken at the point, > when we can justify extra IO against leaf page split. > > * if no space also after bottom-up-deletion, we perform deduplication (if possible) > > * finally, we split the page. > > Should we try bottom-up-deletion pass in a situation where we're inserting the last possible tuple > into the page (enough space for *current* insert, but likely no space for the next), > I am saying that we try bottom-up deletion when the new insert item didn't find enough space on the page and there was previously some indexUnchanged tuple(s) inserted into that page. Of course, like now it will be attempted after an attempt to remove LP_DEAD items. > then (among others) exists the following possibilities: > > - no new tuples ever comes to this page anymore (happy accident), which means that > we've wasted IO cycles > > - we undertake bottom-up-deletion pass without success and we're asked to insert new tuple in this > fully packed index page. This can unroll to: > - due to the delay, we've managed to find some space either due to LP_DEAD or bottom-up-cleanup. > which means we've wasted IO cycles on the previous iteration (too early attempt). > - we still failed to find any space and are forced to split the page. > in this case we've wasted IO cycles twice. > > In my view these cases when we generated wasted IO cycles (producing no benefit) should be avoided. > I don't think any of these can happen in what I am actually saying. Do you still have the same feeling after reading this email? Off-hand, I don't see any downsides as compared to the current approach and it will have fewer splits in some other workloads like when there is a mix of inserts and non-HOT updates (that doesn't logically change the index). -- With Regards, Amit Kapila.
пн, 18 янв. 2021 г. в 13:42, Amit Kapila <amit.kapila16@gmail.com>:
I don't think any of these can happen in what I am actually saying. Do
you still have the same feeling after reading this email? Off-hand, I
don't see any downsides as compared to the current approach and it
will have fewer splits in some other workloads like when there is a
mix of inserts and non-HOT updates (that doesn't logically change the
index).
If I understand you correctly, you suggest to track _all_ the hints that came
from the executor for possible non-HOT logical duplicates somewhere on
the page. And when we hit the no-space case, we'll check not only the last
item being hinted, but all items on the page, which makes it more probable
item being hinted, but all items on the page, which makes it more probable
to kick in and do something.
Sounds interesting. And judging on the Peter's tests of extra LP_DEAD tuples
Sounds interesting. And judging on the Peter's tests of extra LP_DEAD tuples
found on the page (almost always being more, than actually flagged), this can
have some positive effects.
have some positive effects.
Also, I'm not sure where to put it. We've deprecated the BTP_HAS_GARBAGE
flag, maybe it can be reused for this purpose?
Victor Yegorov
On Sun, Jan 17, 2021 at 10:44 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > With the above example, it seems like it would also help when this is not true. I'll respond to your remarks here separately, in a later email. > I am not sure what I proposed fits here but the bottom-up sounds like > we are starting from the leaf level and move upwards to root level > which I think is not true here. I guess that that's understandable, because it is true that B-Trees are maintained in a bottom-up fashion. However, it's also true that you can have top-down and bottom-up approaches in query optimizers, and many other things (it's even something that is used to describe governance models). The whole point of the term "bottom-up" is to suggest that bottom-up deletion complements top-down cleanup by VACUUM. I think that this design embodies certain principles that can be generalized to other areas, such as heap pruning. I recall that Robert Haas hated the name deduplication. I'm not about to argue that my choice of "deduplication" was objectively better than whatever he would have preferred. Same thing applies here - I more or less chose a novel name because the concept is itself novel (unlike deduplication). Reasonable people can disagree about what exact name might have been better, but it's not like we're going to arrive at something that everybody can be happy with. And whatever we arrive at probably won't matter that much - the vast majority of users will never need to know what either thing is. They may be important things, but that doesn't mean that many people will ever think about them (in fact I specifically hope that they don't ever need to think about them). > How is that working? Does heapam.c can someway indicate additional > tuples (extra to what has been marked/sent by IndexAM as promising) as > deletable? I see in heap_index_delete_tuples that we mark the status > of the passed tuples as delectable (by setting knowndeletable flag for > them). The bottom-up nbtree caller to heap_index_delete_tuples()/table_index_delete_tuple() (not to be confused with the simple/LP_DEAD heap_index_delete_tuples() caller) always provides heapam.c with a complete picture of the index page, in the sense that it exhaustively has a delstate.deltids entry for each and every TID on the page, no matter what. This is the case even though in practice there is usually no possible way to check even 20% of the deltids entries within heapam.c. In general, the goal during a bottom-up pass is *not* to maximize expected utility (i.e. the number of deleted index tuples/space freed/whatever), exactly. The goal is to lower the variance across related calls, so that we'll typically manage to free a fair number of index tuples when we need to. In general it is much better for heapam.c to make its decisions based on 2 or 3 good reasons rather than just 1 excellent reason. And so heapam.c applies a power-of-two bucketing scheme, never truly giving too much weight to what nbtree tells it about duplicates. See comments above bottomup_nblocksfavorable(), and bottomup_sort_and_shrink() comments (both are from heapam.c). -- Peter Geoghegan
On Mon, Jan 18, 2021 at 6:11 AM Victor Yegorov <vyegorov@gmail.com> wrote: > If I understand you correctly, you suggest to track _all_ the hints that came > from the executor for possible non-HOT logical duplicates somewhere on > the page. And when we hit the no-space case, we'll check not only the last > item being hinted, but all items on the page, which makes it more probable > to kick in and do something. > Also, I'm not sure where to put it. We've deprecated the BTP_HAS_GARBAGE > flag, maybe it can be reused for this purpose? There actually was a similar flag (named BTP_UNCHANGED_UPDATE and later BTP_HAS_DUPS) that appeared in earlier versions of the patch (several versions in total, up to and including v6). This was never discussed on the list because I assumed that that wouldn't be helpful (I was already writing too many overlong e-mails). It was unsettled in my mind at the time, so it didn't make sense to start discussing. I changed my mind at some point, and so it never came up until now, when Amit raised the question. Looking back on my personal notes, I am reminded that I debated this exact question with myself at length. The argument for keeping the nbtree flag (i.e. what Amit is arguing for now) involved an isolated example that seems very similar to the much more recent example from Amit (that he arrived at independently). I am at least sympathetic to this view of things, even now. Let me go into why I changed my mind after a couple of months of on and off deliberation. In general, the highly speculative nature of the extra work that heapam.c does for index deleters in the bottom-up caller case can only be justified because the cost is paid by non-HOT updaters that are definitely about to split the page just to fit another version, and because we only risk wasting one heap page access at any given point of the entire process (the latter point about risk/cost is not 100% true, because you have additional fixed CPU costs and stuff like that, but it's at least true in spirit). We can justify "gambling" like this only because the game is rigged in our favor to an *absurd* degree: there are many ways to win big (relative to the likely version churn page split baseline case), and we only have to put down relatively small "bets" at any given point -- heapam.c will give up everything when it encounters one whole heap page that lacks a single deletable entry, no matter what the reason is. The algorithm *appears* to behave very intelligently when seen from afar, but is in fact stupid and opportunistic when you look at it up close. It's possible to be so permissive about the upside benefit by also being very conservative about the downside cost. Almost all of our individual inferences can be wrong, and yet we still win in the end. And the effect is robust over time. You could say that it is an organic approach: it adapts to the workload, rather than trying to make the workload adapt to it. This is less radical than you'd think -- in some sense this is how B-Trees have always worked. In the end, I couldn't justify imposing this cost on anything other than a non-HOT updater, which is what the flag proposal would require me to do -- then it's not 100% clear that the relative cost of each "bet" placed in heapam.c really is extremely low (we can no longer say for sure that we have very little to lose, given the certain alternative that is a version churn page split). The fact is that "version chains in indexes" still cannot get very long. Plus there are other subtle ways in which it's unlikely to be a problem (e.g. the LP_DEAD deletion stuff also got much better, deduplication can combine with bottom-up deletion so that we'll trigger a useful bottom-up deletion pass sooner or later without much downside, and possibly other things I haven't even thought of). It's possible that I have been too conservative. I admit that my decision on this point is at least a little arbitrary, but I stand by it for now. I cannot feel too bad about theoretically leaving some gains on the table, given that we're only talking about deleting a group of related versions a little later than we would otherwise, and only in some circumstances, and in a way that seems likely to be imperceptible to users. I reserve the right to change my mind about it, but for now it doesn't look like an absurdly good deal, and those are the kind of deals that it makes sense to focus on here. I am very happy about the fact that it is relatively easy to understand why the worst case for bottom-up index deletion cannot be that bad. -- Peter Geoghegan
пн, 18 янв. 2021 г. в 21:43, Peter Geoghegan <pg@bowt.ie>:
In the end, I couldn't justify imposing this cost on anything other
than a non-HOT updater, which is what the flag proposal would require
me to do -- then it's not 100% clear that the relative cost of each
"bet" placed in heapam.c really is extremely low (we can no longer say
for sure that we have very little to lose, given the certain
alternative that is a version churn page split).
I must admit, that it's a bit difficult to understand you here (at least for me).
I assume that by "bet" you mean flagged tuple, that we marked as such
(should we implement the suggested case).
As heapam will give up early in case there are no deletable tuples, why do say,
that "bet" is no longer low? At the end, we still decide between page split (and
index bloat) vs a beneficial space cleanup.
index bloat) vs a beneficial space cleanup.
The fact is that
"version chains in indexes" still cannot get very long. Plus there are
other subtle ways in which it's unlikely to be a problem (e.g. the
LP_DEAD deletion stuff also got much better, deduplication can combine
with bottom-up deletion so that we'll trigger a useful bottom-up
deletion pass sooner or later without much downside, and possibly
other things I haven't even thought of).
I agree with this, except for "version chains" not being long. It all really depends
on the data distribution. It's perfectly common to find indexes supporting FK constraints
on highly skewed sets, with 80% of the index belonging to a single value (say, huge business
customer vs several thousands of one-time buyers).
customer vs several thousands of one-time buyers).
Victor Yegorov
On Mon, Jan 18, 2021 at 1:10 PM Victor Yegorov <vyegorov@gmail.com> wrote: > I must admit, that it's a bit difficult to understand you here (at least for me). > > I assume that by "bet" you mean flagged tuple, that we marked as such > (should we implement the suggested case). > As heapam will give up early in case there are no deletable tuples, why do say, > that "bet" is no longer low? At the end, we still decide between page split (and > index bloat) vs a beneficial space cleanup. Well, as I said, there are various ways in which our inferences (say the ones in nbtdedup.c) are likely to be wrong. You understand this already. For example, obviously if there are two duplicate index tuples pointing to the same heap page then it's unlikely that both will be deletable, and there is even a fair chance that neither will be (for many reasons). I think that it's important to justify why we use stuff like that to drive our decisions -- the reasoning really matters. It's very much not like the usual optimization problem thing. It's a tricky thing to discuss. I don't assume that I understand all workloads, or how I might introduce regressions. It follows that I should be extremely conservative about imposing new costs here. It's good that we currently know of no workloads that the patch is likely to regress, but absence of evidence isn't evidence of absence. I personally will never vote for a theoretical risk with only a theoretical benefit. And right now that's what the idea of doing bottom-up deletions in more marginal cases (the page flag thing) looks like. -- Peter Geoghegan
On Tue, Jan 19, 2021 at 3:03 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Mon, Jan 18, 2021 at 1:10 PM Victor Yegorov <vyegorov@gmail.com> wrote: > > I must admit, that it's a bit difficult to understand you here (at least for me). > > > > I assume that by "bet" you mean flagged tuple, that we marked as such > > (should we implement the suggested case). > > As heapam will give up early in case there are no deletable tuples, why do say, > > that "bet" is no longer low? At the end, we still decide between page split (and > > index bloat) vs a beneficial space cleanup. > > Well, as I said, there are various ways in which our inferences (say > the ones in nbtdedup.c) are likely to be wrong. You understand this > already. For example, obviously if there are two duplicate index > tuples pointing to the same heap page then it's unlikely that both > will be deletable, and there is even a fair chance that neither will > be (for many reasons). I think that it's important to justify why we > use stuff like that to drive our decisions -- the reasoning really > matters. It's very much not like the usual optimization problem thing. > It's a tricky thing to discuss. > > I don't assume that I understand all workloads, or how I might > introduce regressions. It follows that I should be extremely > conservative about imposing new costs here. It's good that we > currently know of no workloads that the patch is likely to regress, > but absence of evidence isn't evidence of absence. > The worst cases could be (a) when there is just one such duplicate (indexval logically unchanged) on the page and that happens to be the last item and others are new insertions, (b) same as (a) and along with it lets say there is an open transaction due to which we can't remove even that duplicate version. Have we checked the overhead or results by simulating such workloads? I feel unlike LP_DEAD optimization this new bottom-up scheme can cost us extra CPU and I/O because there seems to be not much consideration given to the fact that we might not be able to delete any item (or very few) due to long-standing open transactions except that we limit ourselves when we are not able to remove even one tuple from any particular heap page. Now, say due to open transactions, we are able to remove very few tuples (for the sake of argument say there is only 'one' such tuple) from the heap page then we will keep on accessing the heap pages without much benefit. I feel extending the deletion mechanism based on the number of LP_DEAD items sounds more favorable than giving preference to duplicate items. Sure, it will give equally good or better results if there are no long-standing open transactions. > I personally will > never vote for a theoretical risk with only a theoretical benefit. And > right now that's what the idea of doing bottom-up deletions in more > marginal cases (the page flag thing) looks like. > I don't think we can say that it is purely theoretical because I have dome shown some basic computation where it can lead to fewer splits. -- With Regards, Amit Kapila.
Hi, On 2021-01-20 09:24:35 +0530, Amit Kapila wrote: > I feel extending the deletion mechanism based on the number of LP_DEAD > items sounds more favorable than giving preference to duplicate > items. Sure, it will give equally good or better results if there are > no long-standing open transactions. There's a lot of workloads that never set LP_DEAD because all scans are bitmap index scans. And there's no obvious way to address that. So I don't think it's wise to purely rely on LP_DEAD. Greetings, Andres Freund
On Tue, Jan 19, 2021 at 7:54 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > The worst cases could be (a) when there is just one such duplicate > (indexval logically unchanged) on the page and that happens to be the > last item and others are new insertions, (b) same as (a) and along > with it lets say there is an open transaction due to which we can't > remove even that duplicate version. Have we checked the overhead or > results by simulating such workloads? There is no such thing as a workload that has page splits caused by non-HOT updaters, but almost no actual version churn from the same non-HOT updaters. It's possible that a small number of individual page splits will work out like that, of course, but they'll be extremely rare, and impossible to see in any kind of consistent way. That just leaves long running transactions. Of course it's true that eventually a long-running transaction will make it impossible to perform any cleanup, for the usual reasons. And at that point this mechanism is bound to fail (which costs additional cycles -- the wasted access to a single heap page, some CPU cycles). But it's still a bargain to try. Even with a long running transactions there will be a great many bottom-up deletion passes that still succeed earlier on (because at least some of the dups are deletable, and we can still delete those that became garbage right before the long running snapshot was acquired). Victor independently came up with a benchmark that ran over several hours, with cleanup consistently held back by ~5 minutes by a long running transaction: https://www.postgresql.org/message-id/CAGnEbogATZS1mWMVX8FzZHMXzuDEcb10AnVwwhCtXtiBpg3XLQ@mail.gmail.com This was actually one of the most favorable cases of all for the patch -- the patch prevented logically unchanged indexes from growing (this is a mix of inserts, updates, and deletes, not just updates, so it was less than perfect -- we did see the indexes grow by a half of one percent). Whereas without the patch each of the same 3 indexes grew by 30% - 60%. So yes, I did think about long running transactions, and no, the possibility of wasting one heap block access here and there when the database is melting down anyway doesn't seem like a big deal to me. > I feel unlike LP_DEAD optimization this new bottom-up scheme can cost > us extra CPU and I/O because there seems to be not much consideration > given to the fact that we might not be able to delete any item (or > very few) due to long-standing open transactions except that we limit > ourselves when we are not able to remove even one tuple from any > particular heap page. There was plenty of consideration given to that. It was literally central to the design, and something I poured over at length. Why don't you go read some of that now? Or, why don't you demonstrate an actual regression using a tool like pgbench? I do not appreciate being accused of having acted carelessly. You don't have a single shred of evidence. The design is counter-intuitive. I think that you simply don't understand it. > Now, say due to open transactions, we are able > to remove very few tuples (for the sake of argument say there is only > 'one' such tuple) from the heap page then we will keep on accessing > the heap pages without much benefit. I feel extending the deletion > mechanism based on the number of LP_DEAD items sounds more favorable > than giving preference to duplicate items. Sure, it will give equally > good or better results if there are no long-standing open > transactions. As Andres says, LP_DEAD bits need to be set by index scans. Otherwise nothing happens. The simple deletion case can do nothing without that happening. It's good that it's possible to reuse work from index scans opportunistically, but it's not reliable. > > I personally will > > never vote for a theoretical risk with only a theoretical benefit. And > > right now that's what the idea of doing bottom-up deletions in more > > marginal cases (the page flag thing) looks like. > > > > I don't think we can say that it is purely theoretical because I have > dome shown some basic computation where it can lead to fewer splits. I'm confused. You realize that this makes it *more* likely that bottom-up deletion passes will take place, right? It sounds like you're arguing both sides of the issue at the same time. -- Peter Geoghegan
On Wed, Jan 20, 2021 at 10:58 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Tue, Jan 19, 2021 at 7:54 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > The worst cases could be (a) when there is just one such duplicate > > (indexval logically unchanged) on the page and that happens to be the > > last item and others are new insertions, (b) same as (a) and along > > with it lets say there is an open transaction due to which we can't > > remove even that duplicate version. Have we checked the overhead or > > results by simulating such workloads? > > There is no such thing as a workload that has page splits caused by > non-HOT updaters, but almost no actual version churn from the same > non-HOT updaters. It's possible that a small number of individual page > splits will work out like that, of course, but they'll be extremely > rare, and impossible to see in any kind of consistent way. > > That just leaves long running transactions. Of course it's true that > eventually a long-running transaction will make it impossible to > perform any cleanup, for the usual reasons. And at that point this > mechanism is bound to fail (which costs additional cycles -- the > wasted access to a single heap page, some CPU cycles). But it's still > a bargain to try. Even with a long running transactions there will be > a great many bottom-up deletion passes that still succeed earlier on > (because at least some of the dups are deletable, and we can still > delete those that became garbage right before the long running > snapshot was acquired). > How many of the dups are deletable till there is an open long-running transaction in the system before the transaction that has performed an update? I tried a simple test to check this. create table t1(c1 int, c2 int, c3 char(10)); create index idx_t1 on t1(c1); create index idx_t2 on t1(c2); insert into t1 values(generate_series(1,5000),1,'aaaaaa'); update t1 set c2 = 2; The update will try to remove the tuples via bottom-up cleanup mechanism for index 'idx_t1' and won't be able to remove any tuple because the duplicates are from the same transaction. > Victor independently came up with a benchmark that ran over several > hours, with cleanup consistently held back by ~5 minutes by a long > running transaction: > AFAICS, the long-running transaction used in the test is below: SELECT abalance, pg_sleep(300) FROM pgbench_accounts WHERE mtime > now() - INTERVAL '15min' ORDER BY aid LIMIT 1; This shouldn't generate a transaction id so would it be sufficient to hold back the clean-up? > https://www.postgresql.org/message-id/CAGnEbogATZS1mWMVX8FzZHMXzuDEcb10AnVwwhCtXtiBpg3XLQ@mail.gmail.com > > This was actually one of the most favorable cases of all for the patch > -- the patch prevented logically unchanged indexes from growing (this > is a mix of inserts, updates, and deletes, not just updates, so it was > less than perfect -- we did see the indexes grow by a half of one > percent). Whereas without the patch each of the same 3 indexes grew by > 30% - 60%. > > So yes, I did think about long running transactions, and no, the > possibility of wasting one heap block access here and there when the > database is melting down anyway doesn't seem like a big deal to me. > First, it is not clear to me if that has properly simulated the long-running test but even if it is what I intend to say was to have an open long-running transaction possibly for the entire duration of the test? If we do that, we will come to know if there is any overhead and if so how much? > > I feel unlike LP_DEAD optimization this new bottom-up scheme can cost > > us extra CPU and I/O because there seems to be not much consideration > > given to the fact that we might not be able to delete any item (or > > very few) due to long-standing open transactions except that we limit > > ourselves when we are not able to remove even one tuple from any > > particular heap page. > > There was plenty of consideration given to that. It was literally > central to the design, and something I poured over at length. Why > don't you go read some of that now? Or, why don't you demonstrate an > actual regression using a tool like pgbench? > > I do not appreciate being accused of having acted carelessly. You > don't have a single shred of evidence. > I think you have done a good job and I am just trying to see if there are any loose ends which we can tighten-up. Anyway, here are results from some simple performance tests: Test with 2 un-modified indexes =============================== create table t1(c1 int, c2 int, c3 int, c4 char(10)); create index idx_t1 on t1(c1); create index idx_t2 on t1(c2); create index idx_t3 on t1(c3); insert into t1 values(generate_series(1,5000000), 1, 10, 'aaaaaa'); update t1 set c2 = 2; Without nbree mod (without commit d168b66682) =================================================== postgres=# update t1 set c2 = 2; UPDATE 5000000 Time: 46533.530 ms (00:46.534) With HEAD ========== postgres=# update t1 set c2 = 2; UPDATE 5000000 Time: 52529.839 ms (00:52.530) I have dropped and recreated the table after each update in the test. Some non-default configurations: autovacuum = off; checkpoint_timeout = 35min; shared_buffers = 10GB; min_wal_size = 10GB; max_wal_size = 20GB; There seems to 12-13% of regression in the above test and I think we can reproduce similar or higher regression with a long-running open transaction. At this moment, I don't have access to any performance machine so done these tests on CentOS VM. The results could vary but I have repeated these enough times to reduce such a possibility. > The design is counter-intuitive. I think that you simply don't understand it. > I have read your patch and have some decent understanding but obviously, you and Victor will have a better idea. I am not sure what I wrote in my previous email which made you say so. Anyway, I hope I have made my point clear this time. > > > > I personally will > > > never vote for a theoretical risk with only a theoretical benefit. And > > > right now that's what the idea of doing bottom-up deletions in more > > > marginal cases (the page flag thing) looks like. > > > > > > > I don't think we can say that it is purely theoretical because I have > > dome shown some basic computation where it can lead to fewer splits. > > I'm confused. You realize that this makes it *more* likely that > bottom-up deletion passes will take place, right? > Yes. > It sounds like > you're arguing both sides of the issue at the same time. > No, I am sure the bottom-up deletion is a good technique to get rid of bloat and just trying to see if there are more cases where we can take its advantage and also try to avoid regression if there is any. -- With Regards, Amit Kapila.
On Wed, Jan 20, 2021 at 7:03 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Jan 20, 2021 at 10:58 AM Peter Geoghegan <pg@bowt.ie> wrote: > > > > On Tue, Jan 19, 2021 at 7:54 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > The worst cases could be (a) when there is just one such duplicate > > > (indexval logically unchanged) on the page and that happens to be the > > > last item and others are new insertions, (b) same as (a) and along > > > with it lets say there is an open transaction due to which we can't > > > remove even that duplicate version. Have we checked the overhead or > > > results by simulating such workloads? > > > > There is no such thing as a workload that has page splits caused by > > non-HOT updaters, but almost no actual version churn from the same > > non-HOT updaters. It's possible that a small number of individual page > > splits will work out like that, of course, but they'll be extremely > > rare, and impossible to see in any kind of consistent way. > > > > That just leaves long running transactions. Of course it's true that > > eventually a long-running transaction will make it impossible to > > perform any cleanup, for the usual reasons. And at that point this > > mechanism is bound to fail (which costs additional cycles -- the > > wasted access to a single heap page, some CPU cycles). But it's still > > a bargain to try. Even with a long running transactions there will be > > a great many bottom-up deletion passes that still succeed earlier on > > (because at least some of the dups are deletable, and we can still > > delete those that became garbage right before the long running > > snapshot was acquired). > > > > How many ... > Typo. /many/any -- With Regards, Amit Kapila.
On Wed, Jan 20, 2021 at 10:50 AM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > On 2021-01-20 09:24:35 +0530, Amit Kapila wrote: > > I feel extending the deletion mechanism based on the number of LP_DEAD > > items sounds more favorable than giving preference to duplicate > > items. Sure, it will give equally good or better results if there are > > no long-standing open transactions. > > There's a lot of workloads that never set LP_DEAD because all scans are > bitmap index scans. And there's no obvious way to address that. So I > don't think it's wise to purely rely on LP_DEAD. > Right, I understand this point. The point I was trying to make was that in this new technique we might not be able to delete any tuple (or maybe very few) if there are long-running open transactions in the system and still incur a CPU and I/O cost. I am completely in favor of this technique and patch, so don't get me wrong. As mentioned in my reply to Peter, I am just trying to see if there are more ways we can use this optimization and reduce the chances of regression (if there is any). -- With Regards, Amit Kapila.
On Wed, Jan 20, 2021 at 5:33 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > Victor independently came up with a benchmark that ran over several > > hours, with cleanup consistently held back by ~5 minutes by a long > > running transaction: > > > > AFAICS, the long-running transaction used in the test is below: > SELECT abalance, pg_sleep(300) FROM pgbench_accounts WHERE mtime > > now() - INTERVAL '15min' ORDER BY aid LIMIT 1; > > This shouldn't generate a transaction id so would it be sufficient to > hold back the clean-up? It will hold back clean-up because it holds open a snapshot. Whether or not the long running transaction has been allocated a true XID (not just a VXID) is irrelevant. Victor's test case is perfectly valid. In general there are significant benefits for cases with long-running transactions, which will be quite apparent if you do something simple like run pgbench (a script with non-HOT updates) while a REPEATABLE READ transaction runs in psql (and has actually acquired a snapshot by running a simple query -- the xact snapshot is acquired lazily). I understand that this will be surprising if you believe that the problem in these cases is strictly that there are too many "recently dead" versions that still need to be stored (i.e. versions that cleanup simply isn't able to remove, given the xmin horizon invariant). But it's now clear that that's not what really happens in most cases with a long running transaction. What we actually see is that local page-level inefficiencies in cleanup were (and perhaps to some degree still are) a much bigger problem than the inherent inability of cleanup to remove even one or two tuples. This is at least true until the bloat problem becomes a full-blown disaster (because cleanup really is inherently restricted by the global xmin horizon, and therefore hopelessly behind). In reality there are seldom that many individual logical rows that get updated more than a few times in (say) any given one hour period. This is true even with skewed updates -- the skew is almost never visible at the level of an individual leaf page. The behavior we see now that we have bottom-up index deletion is much closer to the true optimal behavior for the general approach Postgres takes to cleanup of garbage tuples, since it tends to make the number of versions for any given logical row as low as possible (within the confines of the global xmin horizon limitations for cleanup). Of course it would also be helpful to have something like zheap -- some mechanism that can store "recently dead" versions some place where they at least don't bloat up the main relation structures. But that's only one part of the big picture for Postgres MVCC garbage. We should not store garbage tuples (i.e. those that are dead rather than just recently dead) *anywhere*. > First, it is not clear to me if that has properly simulated the > long-running test but even if it is what I intend to say was to have > an open long-running transaction possibly for the entire duration of > the test? If we do that, we will come to know if there is any overhead > and if so how much? I am confident that you are completely wrong about regressing cases with long-running transactions, except perhaps in some very narrow sense that is of little practical relevance. Victor's test case did result in a small loss of throughput, for example, but that's a small price to pay to not have your indexes explode (note also that most of the indexes weren't even used for reads, so in the real world it would probably also improve throughput even in the short term). FWIW the small drop in TPS probably had little to do with the cost of visiting the heap for visibility information. Workloads must be made to "live within their means". You can call that a regression if you like, but I think that almost anybody else would take issue with that characterization. Slowing down non-HOT updaters in these extreme cases may actually be a good thing, even when bottom-up deletion finally becomes ineffective. It can be thought of as backpressure. I am not worried about slowing down something that is already hopelessly inefficient and unsustainable. I'd go even further than that, in fact -- I now wonder if we should *deliberately* slow them down some more! > Test with 2 un-modified indexes > =============================== > create table t1(c1 int, c2 int, c3 int, c4 char(10)); > create index idx_t1 on t1(c1); > create index idx_t2 on t1(c2); > create index idx_t3 on t1(c3); > > insert into t1 values(generate_series(1,5000000), 1, 10, 'aaaaaa'); > update t1 set c2 = 2; > postgres=# update t1 set c2 = 2; > UPDATE 5000000 > Time: 46533.530 ms (00:46.534) > > With HEAD > ========== > postgres=# update t1 set c2 = 2; > UPDATE 5000000 > Time: 52529.839 ms (00:52.530) > > I have dropped and recreated the table after each update in the test. Good thing that you remembered to drop and recreate the table, since otherwise bottom-up index deletion would look really good! Besides, this test case is just ludicrous. I bet that Postgres was always faster than other RDBMSs here, because Postgres is relatively unconcerned about making updates like this sustainable. > I have read your patch and have some decent understanding but > obviously, you and Victor will have a better idea. I am not sure what > I wrote in my previous email which made you say so. Anyway, I hope I > have made my point clear this time. I don't think that you fully understand the insights behind the patch. Understanding how the patch works mechanistically is not enough. This patch is unusual in that you really need to think about emergent behaviors to understand it. That is certainly a difficult thing to do, and it's understandable that even an expert might not grok it without considering it carefully. What annoys me here is that you didn't seem to seriously consider the *possibility* that something like that *might* be true, even after I pointed it out several times. If I was looking at a project that you'd worked on just after it was committed, and something seemed *obviously* wrong, I know that I would think long and hard about the possibility that my understanding was faulty in some subtle though important way. I try to always do this when the apparent problem is too simple and obvious -- I know it's unlikely that a respected colleague would make such a basic error (which is not to say that there cannot still be some error). -- Peter Geoghegan
On Wed, Jan 20, 2021 at 10:53 AM Peter Geoghegan <pg@bowt.ie> wrote: > This patch is unusual in that you really need to think about emergent > behaviors to understand it. That is certainly a difficult thing to do, > and it's understandable that even an expert might not grok it without > considering it carefully. I happened to stumble upon a recent blog post that seems like a light, approachable introduction to some of the key concepts here: https://jessitron.com/2021/01/18/when-costs-are-nonlinear-keep-it-small/ Bottom-up index deletion enhances a complex system whose maintenance costs are *dramatically* nonlinear, at least in many important cases. If you apply linear thinking to such a system then you'll probably end up with a bad design. The system as a whole is made efficient by making sure that we're lazy when that makes sense, while also making sure that we're eager when that makes sense. So it almost *has* to be structured as a bottom-up, reactive mechanism -- no other approach is able to ramp up or down in exactly the right way. Talking about small cost differences (things that can easily be empirically measured, perhaps with a microbenchmark) is almost irrelevant to the big picture. It's even irrelevant to the "medium picture". What's more, it's basically a mistake to think of heap page accesses that don't yield any deletable index tuples as wasted effort (even though that's how I describe them myself!). Here's why: we have to access the heap page to learn that it has nothing for us in the first place place! If we somehow knew ahead of time that some useless-to-us heap block was useless, then the whole system wouldn't be bottom-up (by definition). In other words, failing to get any index tuple deletes from an entire heap page *is itself a form of feedback* at the local level -- it guides the entire system's behavior over time. Why should we expect to get that information at zero cost? This is somehow both simple and complicated, which creates huge potential for miscommunications. I tried to describe this in various ways at various points. Perhaps I could have done better with that. -- Peter Geoghegan
On Thu, Jan 21, 2021 at 12:23 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Wed, Jan 20, 2021 at 5:33 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > Victor independently came up with a benchmark that ran over several > > > hours, with cleanup consistently held back by ~5 minutes by a long > > > running transaction: > > > > > > > AFAICS, the long-running transaction used in the test is below: > > SELECT abalance, pg_sleep(300) FROM pgbench_accounts WHERE mtime > > > now() - INTERVAL '15min' ORDER BY aid LIMIT 1; > > > > This shouldn't generate a transaction id so would it be sufficient to > > hold back the clean-up? > > It will hold back clean-up because it holds open a snapshot. > Okay, that makes sense. It skipped from my mind. > > Slowing down non-HOT updaters in these extreme cases may actually be a > good thing, even when bottom-up deletion finally becomes ineffective. > It can be thought of as backpressure. I am not worried about slowing > down something that is already hopelessly inefficient and > unsustainable. I'd go even further than that, in fact -- I now wonder > if we should *deliberately* slow them down some more! > Do you have something specific in mind for this? > > Test with 2 un-modified indexes > > =============================== > > create table t1(c1 int, c2 int, c3 int, c4 char(10)); > > create index idx_t1 on t1(c1); > > create index idx_t2 on t1(c2); > > create index idx_t3 on t1(c3); > > > > insert into t1 values(generate_series(1,5000000), 1, 10, 'aaaaaa'); > > update t1 set c2 = 2; > > > postgres=# update t1 set c2 = 2; > > UPDATE 5000000 > > Time: 46533.530 ms (00:46.534) > > > > With HEAD > > ========== > > postgres=# update t1 set c2 = 2; > > UPDATE 5000000 > > Time: 52529.839 ms (00:52.530) > > > > I have dropped and recreated the table after each update in the test. > > Good thing that you remembered to drop and recreate the table, since > otherwise bottom-up index deletion would look really good! > I have briefly tried that but numbers were not consistent probably because at that time autovacuum was also 'on'. So, I tried switching off autovacuum and dropping/recreating the tables. > Besides, this test case is just ludicrous. > I think it might be okay to say that in such cases we can expect regression especially because we see benefits in many other cases so paying some cost in such cases is acceptable or such scenarios are less common or probably such cases are already not efficient so it doesn't matter much but I am not sure if we can say they are completely unreasonable. I think this test case depicts the behavior with bulk updates. I am not saying that we need to definitely do anything but acknowledging that we can regress in some cases without actually removing bloat is not necessarily a bad thing because till now none of the tests done has shown any such behavior (where we are not able to help with bloat but still the performance is reduced). > > I have read your patch and have some decent understanding but > > obviously, you and Victor will have a better idea. I am not sure what > > I wrote in my previous email which made you say so. Anyway, I hope I > > have made my point clear this time. > > I don't think that you fully understand the insights behind the patch. > Understanding how the patch works mechanistically is not enough. > > This patch is unusual in that you really need to think about emergent > behaviors to understand it. That is certainly a difficult thing to do, > and it's understandable that even an expert might not grok it without > considering it carefully. What annoys me here is that you didn't seem > to seriously consider the *possibility* that something like that > *might* be true, even after I pointed it out several times. > I am not denying that I could be missing your point but OTOH you are also completely refuting the points raised even though I have shown them by test and by sharing an example. For example, I understand that you want to be conservative in triggering the bottom-up clean up so you choose to do it in fewer cases but we might still want to add a 'Note' in the code (or README) suggesting something like we have considered the alternative for page-level-flag (to be aggressive in triggering this optimization) but not pursued with that for so-and-so reasons. I think this can help future developers to carefully think about it even if they want to attempt something like that. You have considered it during the early development phase and then the same thing occurred to Victor and me as an interesting optimization to explore so the same can occur to someone else as well. -- With Regards, Amit Kapila.
On Thu, Jan 21, 2021 at 9:23 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > Slowing down non-HOT updaters in these extreme cases may actually be a > > good thing, even when bottom-up deletion finally becomes ineffective. > > It can be thought of as backpressure. I am not worried about slowing > > down something that is already hopelessly inefficient and > > unsustainable. I'd go even further than that, in fact -- I now wonder > > if we should *deliberately* slow them down some more! > > > > Do you have something specific in mind for this? Maybe something a bit like the VACUUM cost delay stuff could be applied at the point that we realize that a given bottom-up deletion pass is entirely effective purely due to a long running transaction, that gets applied by nbtree caller once it splits the page. This isn't something that I plan to work on anytime soon. My point was mostly that it really would make sense to deliberately throttle non-hot updates at the point that they trigger page splits that are believed to be more or less caused by a long running transaction. They're so incredibly harmful to the general responsiveness of the system that having a last line of defense like that (backpressure/throttling) really does make sense. > I have briefly tried that but numbers were not consistent probably > because at that time autovacuum was also 'on'. So, I tried switching > off autovacuum and dropping/recreating the tables. It's not at all surprising that they weren't consistent. Clearly bottom-up deletion wastes cycles on the first execution (it is wasted effort in at least one sense) -- you showed that already. Subsequent executions will actually manage to delete some tuples (probably a great many tuples), and so will have totally different performance profiles/characteristics. Isn't that obvious? > > Besides, this test case is just ludicrous. > > > > I think it might be okay to say that in such cases we can expect > regression especially because we see benefits in many other cases so > paying some cost in such cases is acceptable or such scenarios are > less common or probably such cases are already not efficient so it > doesn't matter much but I am not sure if we can say they are > completely unreasonable. I think this test case depicts the behavior > with bulk updates. Sincere question: What do you want me to do about it? You're asking me about two separate though very closely related issues at the same time here (this bulk update regression thing, plus the question of doing bottom-up passes when the incoming item isn't from a HOT updater). While your positions on these closely related issues are not incompatible, exactly, it's difficult for me to get to any underlying substantive point. In effect, you are pulling the patch in two separate directions at the same time. In practical terms, it's very likely that I cannot move the bottom-up deletion code closer to one of your ideals without simultaneously moving it further away from the other ideal. I will say the following about your bulk update example now, just in case you feel that I gave you the impression of never having taken it seriously: 1. I accept that the effect that you've described is real. It is a pretty narrow effect in practice, though, and will be of minimal concern to real applications (especially relative to the benefits they receive). I happen to believe that the kind of bulk update that you showed is naturally very rare, and will naturally cause horrible problems with any RDBMS -- and that's why I'm not too worried (about this specific sequence that you showed, or one like it that somehow artfully avoids receiving any performance benefit). I just cannot buy the idea that any real world user will do a bulk update like that exactly once, and be frustrated by the fact that it's ~12% slower in Postgres 14. If they do it more than once the story changes, of course (the technique starts to win). You have to do something more than once to notice a change in its performance in the first place, of course -- so it just doesn't seem plausible to me. Of course it's still possible to imagine a way that that could happen. This is a risk that I am willing to live with, given the benefits. 2. If there was some simple way of avoiding the relative loss of performance without hurting other cases I would certainly take it -- in general I prefer to not have to rely on anybody's opinion of what is or is not a reasonable price to pay for something. I strongly doubt that I can do anything about your first/bulk update complaint (without causing much greater harm elsewhere), and so I won't be pursuing it. I did not deny the existence of cases like this at any point. In fact, the entire discussion was ~50% me agonizing over regressions (though never this precise case). Discussion of possible regressions happened over many months and many dense emails. So I refuse to be lectured about my supposed indifference to regressions -- not by you, and not by anyone else. In general I consistently *bend over backwards* to avoid regressions, and never assume that I didn't miss something. This came up recently, in fact: https://smalldatum.blogspot.com/2021/01/insert-benchmark-postgres-is-still.html See the "Updates" section of this recent blog post. No regressions could be attributed to any of the nbtree projects I was involved with in the past few years. There was a tiny (IMV quite acceptable) regression attributed to insert-driven autovacuum in Postgres 13. Deduplication didn't lead to any appreciable loss of performance, even though most of the benchmarks were rather unsympathetic towards it (no low cardinality data). I specifically asked Mark Callaghan to isolate the small regression that he thought might be attributable to the deduplication feature (via deduplicate_items storage param) -- even though at the time I myself imagined that that would *confirm* his original suspicion that nbtree deduplication was behind the issue. I don't claim to be objective when it comes to my own work, but I have at least been very conscientious. > I am not denying that I could be missing your point but OTOH you are > also completely refuting the points raised even though I have shown > them by test and by sharing an example. Actually, I quite specifically and directly said that I was *sympathetic* to your second point (the one about doing bottom-up deletion in more marginal cases not directly involving non-HOT updaters). I also said that I struggled with it myself for a long time. I just don't think that it is worth pursuing at this time -- but that shouldn't stop anyone else that's interested in it. > 'Note' in the code (or README) suggesting something like we have > considered the alternative for page-level-flag (to be aggressive in > triggering this optimization) but not pursued with that for so-and-so > reasons. Good news, then: I pretty much *did* document it in the nbtree README! The following aside concerns this *exact* theoretical limitation, and appears in parenthesis as part of commentary on the wider issue of how bottom-up passes are triggered: "(in theory a small amount of version churn could make a page split occur earlier than strictly necessary, but that's pretty harmless)" The "breadcrumbs" *are* there. You'd notice that if you actually looked for them. > I think this can help future developers to carefully think > about it even if they want to attempt something like that. You have > considered it during the early development phase and then the same > thing occurred to Victor and me as an interesting optimization to > explore so the same can occur to someone else as well. I would not document the idea in the README unless perhaps I had high confidence that it would work out. I have an open mind about that as a possibility, but that alone doesn't seem like a good enough reason to do it. Though I am now prepared to say that this does not seem like an amazing opportunity to make the feature much better. That's why it's not a priority for me right now. There actually *are* things that I would describe that way (Sawada-san's complementary work on VACUUM). And so that's what I'll be focussing on in the weeks ahead. -- Peter Geoghegan
On Sat, Jan 23, 2021 at 5:27 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Thu, Jan 21, 2021 at 9:23 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > Slowing down non-HOT updaters in these extreme cases may actually be a > > > good thing, even when bottom-up deletion finally becomes ineffective. > > > It can be thought of as backpressure. I am not worried about slowing > > > down something that is already hopelessly inefficient and > > > unsustainable. I'd go even further than that, in fact -- I now wonder > > > if we should *deliberately* slow them down some more! > > > > > > > Do you have something specific in mind for this? > > Maybe something a bit like the VACUUM cost delay stuff could be > applied at the point that we realize that a given bottom-up deletion > pass is entirely effective purely due to a long running transaction, > that gets applied by nbtree caller once it splits the page. > > This isn't something that I plan to work on anytime soon. My point was > mostly that it really would make sense to deliberately throttle > non-hot updates at the point that they trigger page splits that are > believed to be more or less caused by a long running transaction. > They're so incredibly harmful to the general responsiveness of the > system that having a last line of defense like that > (backpressure/throttling) really does make sense. > > > I have briefly tried that but numbers were not consistent probably > > because at that time autovacuum was also 'on'. So, I tried switching > > off autovacuum and dropping/recreating the tables. > > It's not at all surprising that they weren't consistent. Clearly > bottom-up deletion wastes cycles on the first execution (it is wasted > effort in at least one sense) -- you showed that already. Subsequent > executions will actually manage to delete some tuples (probably a > great many tuples), and so will have totally different performance > profiles/characteristics. Isn't that obvious? > Yeah, that sounds obvious but what I remembered happening was that at some point during/before the second update, the autovacuum kicks in and removes the bloat incurred by the previous update. In few cases, the autovacuum seems to clean up the bloat and still we seem to be taking additional time maybe because of some non-helpful cycles by bottom-up clean-up in the new pass (like second bulk-update for which we can't clean up anything). Now, this is more of speculation based on the few runs so I don't expect any response or any action based on it. I need to spend more time on benchmarking to study the behavior and I think without that it would be difficult to make a conclusion in this regard. So, let's not consider any action on this front till I spend more time to find the details. I agree with the other points mentioned by you in the email. -- With Regards, Amit Kapila.
On Mon, Jan 25, 2021 at 10:48 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > I need to spend more time on benchmarking to study the behavior and I > think without that it would be difficult to make a conclusion in this > regard. So, let's not consider any action on this front till I spend > more time to find the details. It is true that I committed the patch without thorough review, which was less than ideal. I welcome additional review from you now. I will say one more thing about it for now: Start with a workload, not with the code. Without bottom-up deletion (e.g. when using Postgres 13) with a simple though extreme workload that will experience version churn in indexes after a while, it still takes quite a few minutes for the first page to split (when the table is at least a few GB in size to begin with). When I was testing the patch I would notice that it could take 10 or 15 minutes for the deletion mechanism to kick in for the first time -- the patch really didn't do anything at all until perhaps 15 minutes into the benchmark, despite helping *enormously* by the 60 minute mark. And this is with significant skew, so presumably the first page that would split (in the absence of the bottom-up deletion feature) was approximately the page with the most skew -- most individual pages might have taken 30 minutes or more to split without the intervention of bottom-up deletion. Relatively rare events (in this case would-be page splits) can have very significant long term consequences for the sustainability of a workload, so relatively simple targeted interventions can make all the difference. The idea behind bottom-up deletion is to allow the workload to figure out the best way of fixing its bloat problems *naturally*. The heuristics must be simple precisely because workloads are so varied and complicated. We must be willing to pay small fixed costs for negative feedback -- it has to be okay for the mechanism to occasionally fail in order to learn what works. I freely admit that I don't understand all workloads. But I don't think anybody can. This holistic/organic approach has a lot of advantages, especially given the general uncertainty about workload characteristics. Your suspicion of the simple nature of the heuristics actually makes a lot of sense to me. I do get it. -- Peter Geoghegan
Hi Peter, Sorry for bringing up so old thread since I have some troubles to understand what is going on here. I'd start with something I can understand then raise my question I have right now. > > The difference here is that we're simply making an intelligent guess > -- there have been no index scans, but we're going to do a kind of > special index scan at the last minute to see if we can avoid a page > split. "Index scans" would cause the "simple index deletion" work and this "bottom-to-up" deletion works for the cases where the index scan doesn't happen. Index page split is expensive. Before the index page split, if we can remove the tuples which are invisible to all the clients, then some room may be saved, then the saved room may avoid the index page split totally. This is the general goal of this patch. IIUC, to detect some tuples, we have to go to heap page for the MVCC check, this is not free. So a important part of this patch is to intelligent guess which leaf page needs the "bottom-to-up deletion". This is the place I start to confuse. By checking the commits message / README, looks two metrics are used here. One is "logically unchanged index" hint, from "Each bottom-up deletion pass is triggered lazily in response to a flood of versions on an nbtree leaf page. This usually involves a "logically unchanged index" hint (these are produced by the executor mechanism added by commit 9dc718bd)." The other one is latestRemovedXid. from "The LP_DEAD deletion process (which is now called "simple deletion" to clearly distinguish it from bottom-up deletion) won't usually need to visit any extra table blocks to check these extra tuples. We have to visit the same table blocks anyway to generate a latestRemovedXid value (at least in the common case where the index deletion operation's WAL record needs such a value)." So my questions are: (a) How does the "logically unchanged index" hint can be helpful for this purpose? (b). What does the latestRemovedXid means, and which variable in code is used for this purpose. I searched "latestRemovedXid" but nothing is found. (c) What is the relationship between a and b. I mean if we *have to visit" the same table blocks (in the case of index-split?), then the IO-cost is paid anyway, do we still need the "logically unchanged index hint"? At last, appreciated for your effort on making this part much better! -- Best Regards Andy Fan
Hi Andy, On Thu, Nov 7, 2024 at 3:05 AM Andy Fan <zhihuifan1213@163.com> wrote: > So my questions are: (a) How does the "logically unchanged index" hint > can be helpful for this purpose? It's the main trigger for bottom-up index deletion. It is taken as a signal that the leaf page might have garbage duplicates from non-HOT updates. What the hint *actually* indicates is that the incoming index tuple is a new, unchanged version duplicate. But it's reasonable to guess that this will also be true of existing tuples located on the same leaf page as the one that the new, incoming tuple will go on. It's especially worth making that guess when the only alternative is to split the page (most of the time the hint isn't used at all, since the incoming item already fits on its leaf page). > (b). What does the latestRemovedXid > means, and which variable in code is used for this purpose. I searched > "latestRemovedXid" but nothing is found. That's because the symbol name changed a year or two after this commit went in. It is now snapshotConflictHorizon, but it has the same purpose as before (to generate conflicts on hot standys when needed). The commit message points out that simple deletion inherently requires that we visit the heap to generate this snapshotConflictHorizon value for the WAL record. And so the cost of considering whether we can delete additional index tuples (not just those index tuples already marked LP_DEAD in the index leaf page) is very low. We were already visiting the heap pages that are used to check the "extra" index tuples (if we weren't then those index tuples wouldn't be checked at all). In short, since the *added* cost of checking extra related index tuples is very low, then it doesn't really matter if there are few or no extra tuples that actually turn out to be deletable. We can be aggressive because the cost of being wrong is hardly noticeable at all. > (c) What is the relationship > between a and b. I mean if we *have to visit" the same table blocks (in > the case of index-split?), then the IO-cost is paid anyway, do we still > need the "logically unchanged index hint"? Well, the commit message was written at a time when the only form of deletion was deletion of index tuples marked LP_DEAD (now called simple deletion). Prior to this work, we didn't attempt to delete any extra tuples in passing during simple deletion. It is easy to justify checking those extra index tuples/batching up work in that context. It is a little harder to justify bottom-up index deletion (or was at the time), because it will do work that is totally speculative -- the entire process might not even delete a single index tuple. It is important that we give up quickly when it isn't possible to delete a single index tuple. We're better off falling back on nbtree index deduplication. That way another bottom-up index deletion pass over the same leaf page may succeed in the future (or may never be required). > At last, appreciated for your effort on making this part much better! Thanks -- Peter Geoghegan
Peter Geoghegan <pg@bowt.ie> writes: Hi Peter, I think I understand the main idea now with your help, I'd like to repeat my understanding for your double check. > On Thu, Nov 7, 2024 at 3:05 AM Andy Fan <zhihuifan1213@163.com> wrote: >> So my questions are: (a) How does the "logically unchanged index" hint >> can be helpful for this purpose? > > It's the main trigger for bottom-up index deletion. It is taken as a > signal that the leaf page might have garbage duplicates from non-HOT > updates. > What the hint *actually* indicates is that the incoming index tuple is > a new, unchanged version duplicate. But it's reasonable to guess that > this will also be true of existing tuples located on the same leaf > page as the one that the new, incoming tuple will go on. We triggered with this style(non-hot + unchanged index + update) because: (1). HOT UPDATE doesn't duplicate the index entry, so it should be safely ignored. (2). INSERT doesn't generate old tuples, so it should be safely ignored. (3). DELETE does generate new index entry, but we might not touch the indexes at all during deletes (except the index we used for index scan), so we have no chances to mark the "logically unchanged index" hint. With the (1) (2) (3), only non-hot UPDATE is considered. Then why do we need "unchanged index" as a prerequisite? that is because it is reasonable to guess that the "unchanged version" will be in the same leaf page as the old one (Let's call it as leaf page A). Otherwise even there are some old index entries, they are likely in a different leaf page (leaf page B), and even they are deletable, but such deletes would not be helpful for delay the current leaf page(A) from splitting. So it is not considered now. AND since we doesn't touch leaf page B at all during "changed index datum" update, so we have no chances to mark any hint on page B, so we can do nothing for it. > It's > especially worth making that guess when the only alternative is to > split the page (most of the time the hint isn't used at all, since the > incoming item already fits on its leaf page). OK. >> (b). What does the latestRemovedXid >> means, and which variable in code is used for this purpose. I searched >> "latestRemovedXid" but nothing is found. > > That's because the symbol name changed a year or two after this commit > went in. It is now snapshotConflictHorizon, but it has the same > purpose as before (to generate conflicts on hot standys when needed). OK. I'd try to understand why we need such snapshotConflictHorizon logic later. So can I understand the relationship between "snapshotConflictHorizon" and "(non-hot + unchanged index + update)" is [OR], which means *either* of them is true, bottom-to-up deletes will be triggered. > The commit message points out that simple deletion inherently requires > that we visit the heap to generate this snapshotConflictHorizon value > for the WAL record. And so the cost of considering whether we can > delete additional index tuples (not just those index tuples already > marked LP_DEAD in the index leaf page) is very low. We were already > visiting the heap pages that are used to check the "extra" index > tuples (if we weren't then those index tuples wouldn't be checked at > all). OK. > In short, since the *added* cost of checking extra related index > tuples is very low, then it doesn't really matter if there are few or > no extra tuples that actually turn out to be deletable. We can be > aggressive because the cost of being wrong is hardly noticeable at > all. OK. >> (c) What is the relationship >> between a and b. I mean if we *have to visit" the same table blocks (in >> the case of index-split?), then the IO-cost is paid anyway, do we still >> need the "logically unchanged index hint"? > > Well, the commit message was written at a time when the only form of > deletion was deletion of index tuples marked LP_DEAD (now called > simple deletion). Prior to this work, we didn't attempt to delete any > extra tuples in passing during simple deletion. It is easy to justify > checking those extra index tuples/batching up work in that context. OK. > It is a little harder to justify bottom-up index deletion (or was at > the time), because it will do work that is totally speculative -- the > entire process might not even delete a single index tuple. I understand this as some activities blocked OldestXmin to advacne. e.g. long transactions. > It is > important that we give up quickly when it isn't possible to delete a > single index tuple. We're better off falling back on nbtree index > deduplication. That way another bottom-up index deletion pass over the > same leaf page may succeed in the future (or may never be required). OK. Thanks for your answering! -- Best Regards Andy Fan
Andy Fan <zhihuifan1213@163.com> writes: > (3). DELETE does generate new index entry, but we might not touch > the indexes at all during deletes (*except the index we used for index > scan*). I still not check the code right now (it may still take times for me even I understand the overall design). So do we need to mark the "garbage" hints for DELETE with a index scan? The case in my mind is: CREATE TABLE t(a INT, B int); CREATE INDEX t_a_idx on t(a); CREATE INDEX t_b_idx on t(b); DELETE FROM t WHERE b = 1; If the delete goes with Index Scan of t_b_idx, we still have the chances to mark hints on t_b_idx, so that it can be useful during index split? -- Best Regards Andy Fan
On Thu, Nov 7, 2024 at 7:31 PM Andy Fan <zhihuifan1213@163.com> wrote: > With the (1) (2) (3), only non-hot UPDATE is considered. > > Then why do we need "unchanged index" as a prerequisite? How else is the nbtree code ever supposed to know when it might be a good idea to do a bottom-up index deletion pass? You could do it every time the page looked like it might have to be split, but that would be quite wasteful. > OK. I'd try to understand why we need such snapshotConflictHorizon logic > later. So can I understand the relationship between > "snapshotConflictHorizon" and "(non-hot + unchanged index + update)" is > [OR], which means *either* of them is true, bottom-to-up deletes > will be triggered. The need to generate a snapshotConflictHorizon exists for both kinds of index deletion (and for HOT pruning, and for freezing). It's just that we have to do external heap page accesses in the case of index tuples. That cost is fixed (we need it to correctly perform deletion), so we should "get the most out of" these heap page accesses (by attempting to delete extra index tuples that happen to point to the heap pages, and that are on the same leaf page as a page with LP_DEAD bits set for some other index tuples). -- Peter Geoghegan
On Thu, Nov 7, 2024 at 7:38 PM Andy Fan <zhihuifan1213@163.com> wrote: > If the delete goes with Index Scan of t_b_idx, we still have the chances > to mark hints on t_b_idx, so that it can be useful during index split? See for yourself, by using pageinspect. The bt_page_items function returns a "dead" column, which will be true for index tuples that already have their LP_DEAD bit set. The exact rules for when LP_DEAD bits are set are a bit complicated, and are hard to describe precisely. I don't think that your DELETE statement will set any LP_DEAD bits, because the tuples won't be dead until some time after the xact for the DELETE statement actually commits -- it'd have to be some later SELECT statement that runs after the DELETE commits (could be a DELETE statement instead of a SELECT statement but SELECT is more typical). This also has to happen during an index scan or an index-only scan -- bitmap scans don't do it. Plus there are some other obscure rules. -- Peter Geoghegan
Peter Geoghegan <pg@bowt.ie> writes: > On Thu, Nov 7, 2024 at 7:38 PM Andy Fan <zhihuifan1213@163.com> wrote: >> If the delete goes with Index Scan of t_b_idx, we still have the chances >> to mark hints on t_b_idx, so that it can be useful during index split? > > The exact rules for when LP_DEAD bits are set are a bit complicated, > and are hard to describe precisely. I don't think that your DELETE > statement will set any LP_DEAD bits, because the tuples won't be dead > until some time after the xact for the DELETE statement actually > commits -- it'd have to be some later SELECT statement that runs after > the DELETE commits (could be a DELETE statement instead of a SELECT > statement but SELECT is more typical). > > This also has to happen during an index scan or an index-only scan -- > bitmap scans don't do it. Plus there are some other obscure rules. Yes, I can understand the above fact:) So I'm *not* talking about "Simple deletion". I'm thinking if we can use "Bottom-Up deletion" algirithom in some more places. IIUC, the key factor of "bottom-up deletion" should be trigged (likely) when *we know* there are some garbage in the leaf page, even we are not sure these garbage can be clean at the index split time. So in my above example, "simple deletion" doesn't work, but it is true that *we know* there are some garbage in the leaf, should we consider "Bottom-Up deletion" algirithom for that as well during index split? Per the commit message or btree/README, looks such sistuation is not considered yet, not sure how is the code. -- Best Regards Andy Fan