пн, 9 нояб. 2020 г. в 18:21, Peter Geoghegan <
pg@bowt.ie>:
On Tue, Nov 3, 2020 at 12:44 PM Peter Geoghegan <pg@bowt.ie> wrote:
> v6 still needs more polishing -- my focus has still been on the
> algorithm itself. But I think I'm almost done with that part -- it
> seems unlikely that I'll be able to make any additional significant
> improvements in that area after v6.
Attached is v7, which tidies everything up. The project is now broken
up into multiple patches, which can be committed separately. Every
patch has a descriptive commit message. This should make it a lot
easier to review.
I've looked at the latest (v7) patchset.
I've decided to use a quite common (in my practice) setup with an indexed mtime column over scale 1000 set:
alter table pgbench_accounts add mtime timestamp default now();
create or replace function fill_mtime() returns trigger as $$begin NEW.mtime=now(); return NEW; END;$$ language plpgsql;
create trigger t_accounts_mtime before update on pgbench_accounts for each row execute function fill_mtime();
create index accounts_mtime on pgbench_accounts (mtime, aid);
create index tenner on pgbench_accounts ((aid - (aid%10)));
ANALYZE pgbench_accounts;
For the test, I've used 3 pgbench scripts (started in parallel sessions):
1. UPDATE + single PK SELECT in a transaction
2. three PK SELECTs in a transaction
3. SELECT of all modifications for the last 15 minutes
Given the size of the set, all data was cached and UPDATEs were fast enough to make 3rd query sit on disk-based sorting.
Some figures follow.
Master sizes
------------
relkind | relname | nrows | blk_before | mb_before | blk_after | mb_after
---------+-----------------------+-----------+------------+-----------+-----------+----------
r | pgbench_accounts | 100000000 | 1639345 | 12807.4 | 1677861 | 13182.8
i | accounts_mtime | 100000000 | 385042 | 3008.1 | 424413 | 3565.6
i | pgbench_accounts_pkey | 100000000 | 274194 | 2142.1 | 274194 | 2142.3
i | tenner | 100000000 | 115352 | 901.2 | 128513 | 1402.9
(4 rows)
Patchset v7 sizes
-----------------
relkind | relname | nrows | blk_before | mb_before | blk_after | mb_after
---------+-----------------------+-----------+------------+-----------+-----------+----------
r | pgbench_accounts | 100000000 | 1639345 | 12807.4 | 1676887 | 13170.2
i | accounts_mtime | 100000000 | 385042 | 3008.1 | 424521 | 3536.4
i | pgbench_accounts_pkey | 100000000 | 274194 | 2142.1 | 274194 | 2142.1
i | tenner | 100000000 | 115352 | 901.2 | 115352 | 901.2
(4 rows)
TPS
---
query | Master TPS | Patched TPS
----------------+------------+-------------
UPDATE + SELECT | 5150 | 4884
3 SELECT in txn | 23133 | 23193
15min SELECT | 0.75 | 0.78
We can see that:
- unused index is not suffering from not-HOT updates at all, which is the point of the patch
- we have ordinary queries performing on the same level as on master
- we have 5,2% slowdown in UPDATE speed
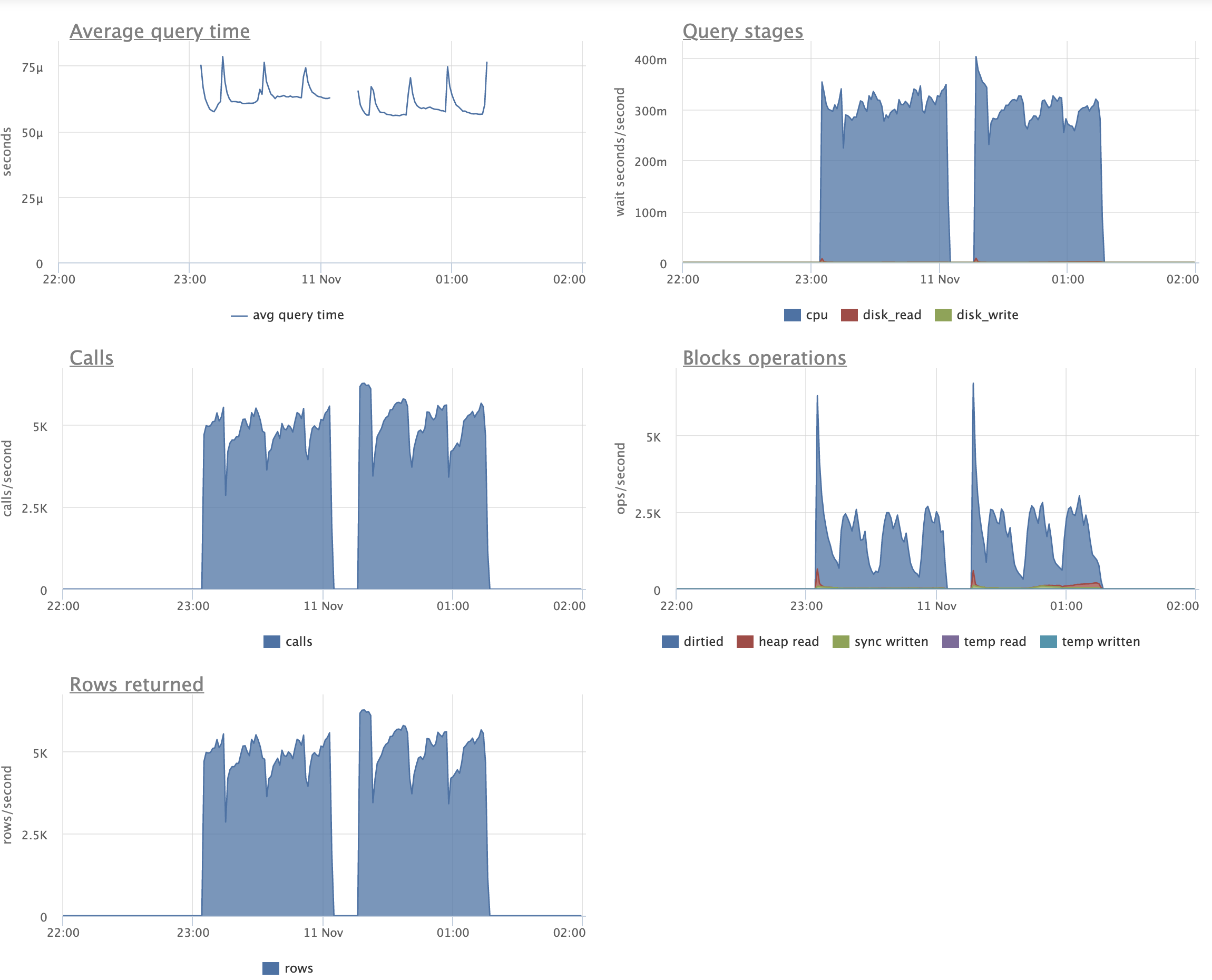
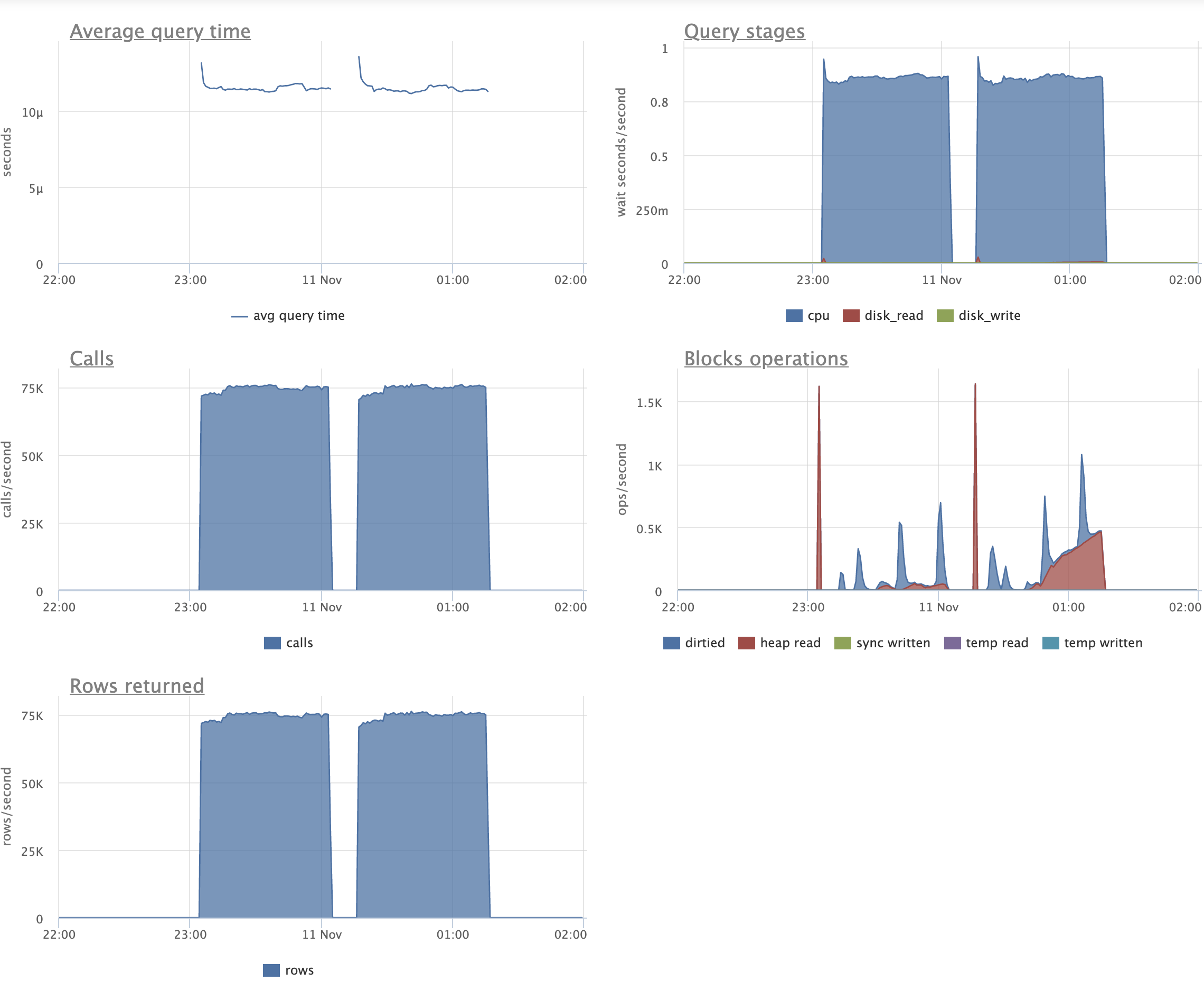
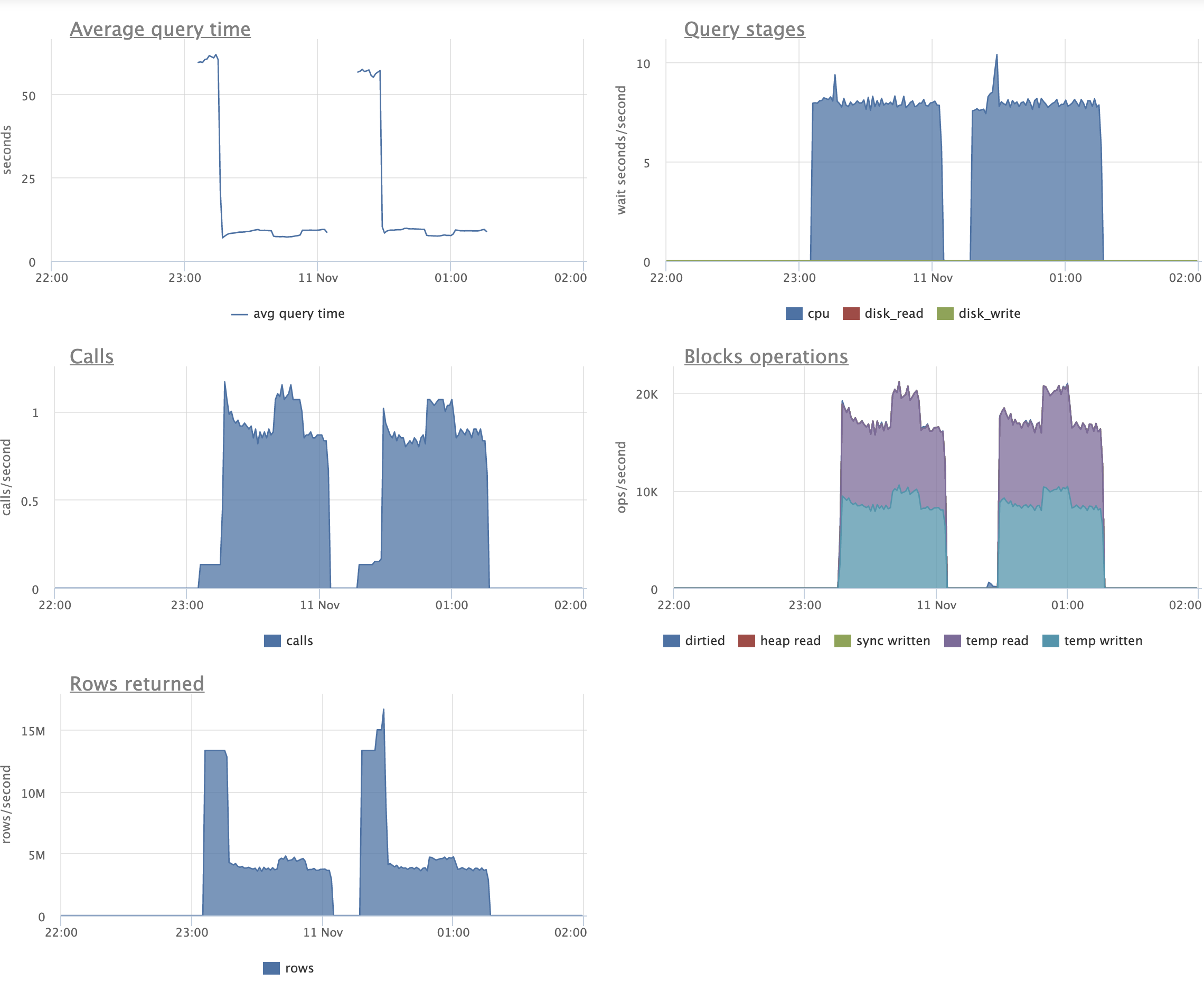
Looking at graphs (attached), I can see that on the patched version we're doing some IO (which is expected) during UPADTEs.
We're also reading quite a lot from disks for simple SELECTs, compared to the master version.
I'm not sure if this should be counted as regression, though, as graphs go on par pretty much.
Still, I would like to understand why this combination of indexes and queries slows down UPDATEs.
During compilation I got one warning for make -C contrib:
blutils.c: In function ‘blhandler’:
blutils.c:133:22: warning: assignment from incompatible pointer type [-Wincompatible-pointer-types]
amroutine->aminsert = blinsert;
I agree with the rename to "bottom-up index deletion", using "vacuuming" generally makes users think
that functionality is used only during VACUUM (misleading).
I haven't looked at the code yet.
{kind=link}
{kind=link}
{kind=link}