On Tue, Nov 3, 2020 at 12:44 PM Peter Geoghegan <pg@bowt.ie> wrote:
> v6 still needs more polishing -- my focus has still been on the
> algorithm itself. But I think I'm almost done with that part -- it
> seems unlikely that I'll be able to make any additional significant
> improvements in that area after v6.
Attached is v7, which tidies everything up. The project is now broken
up into multiple patches, which can be committed separately. Every
patch has a descriptive commit message. This should make it a lot
easier to review.
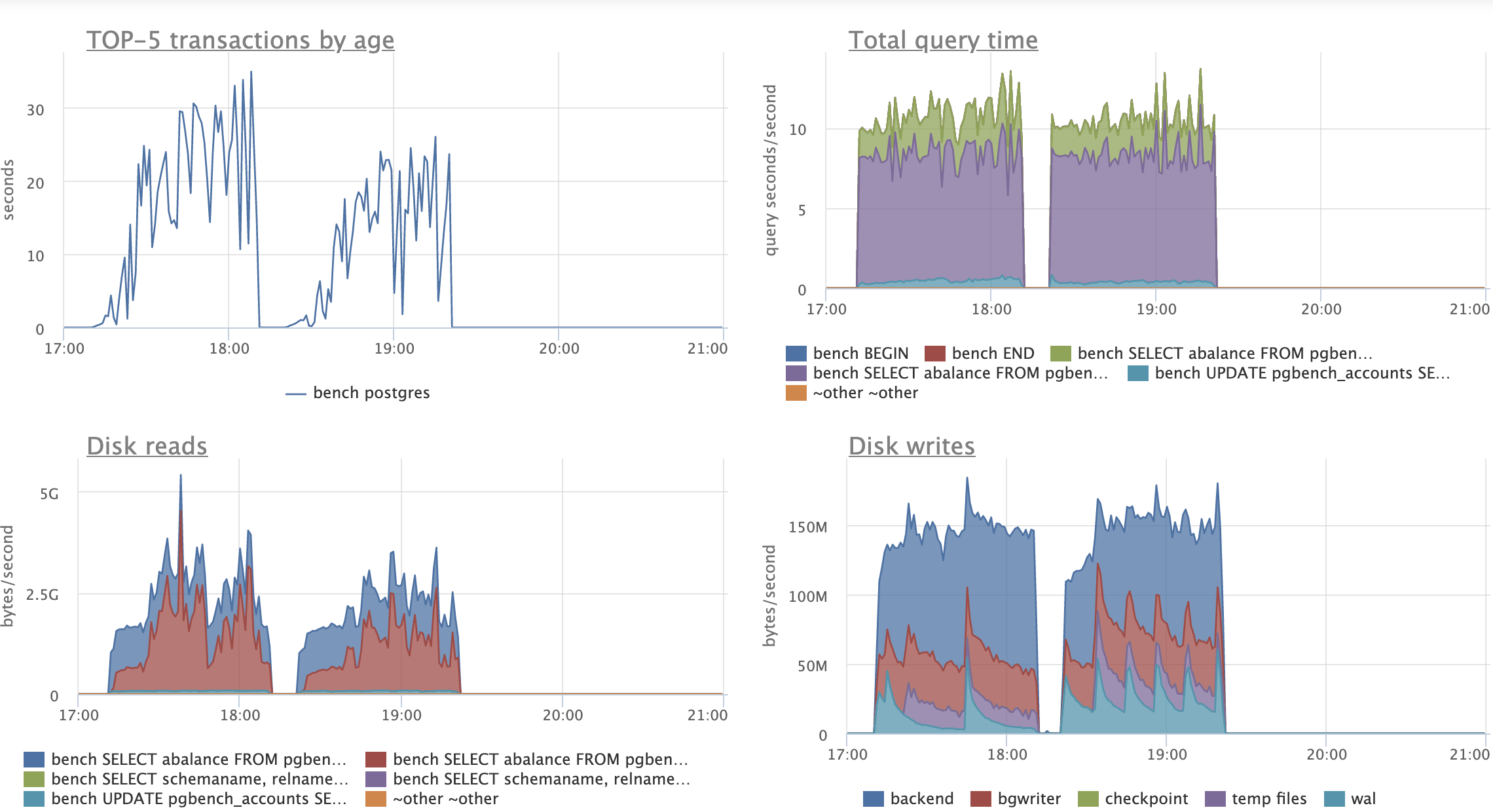
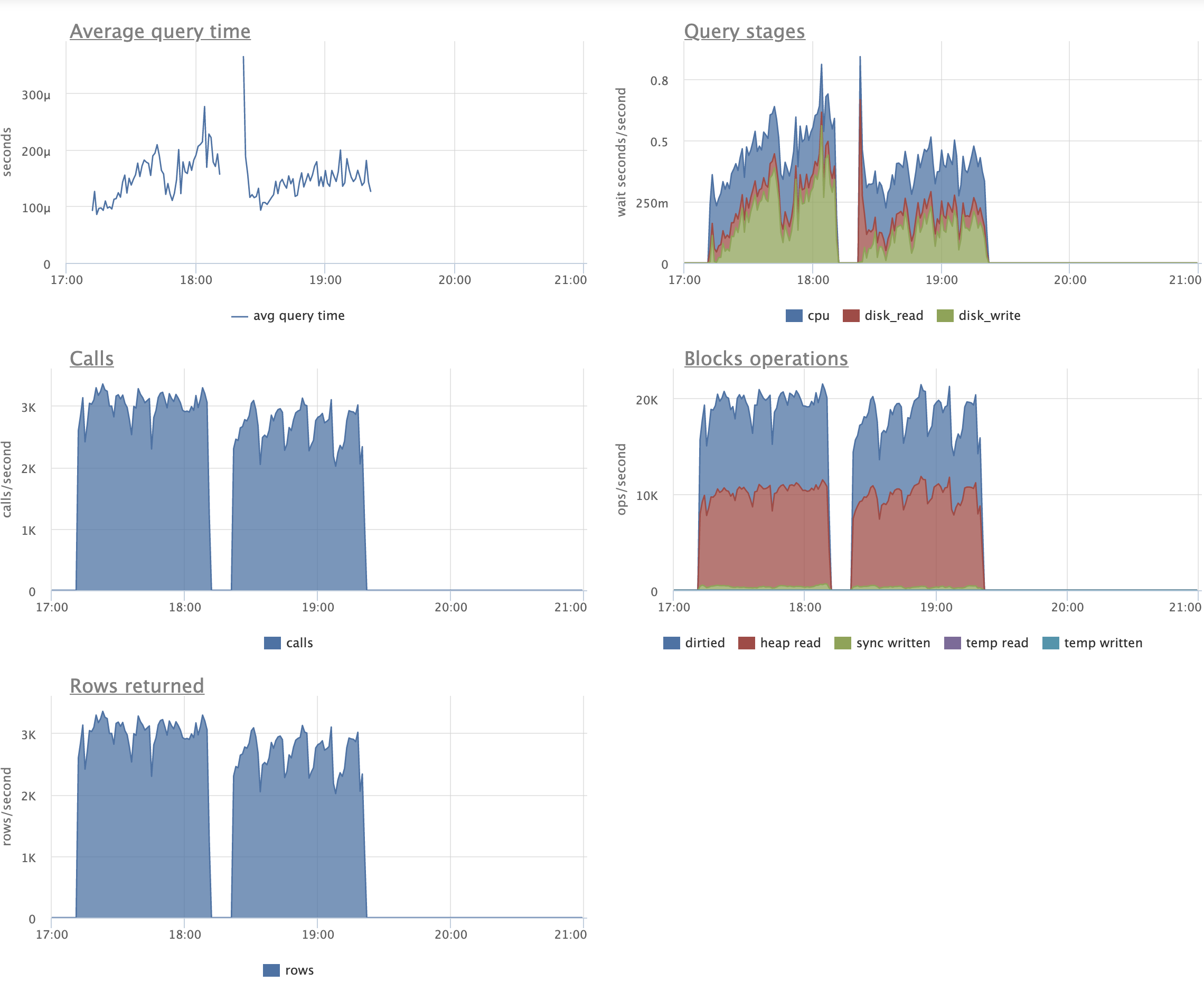
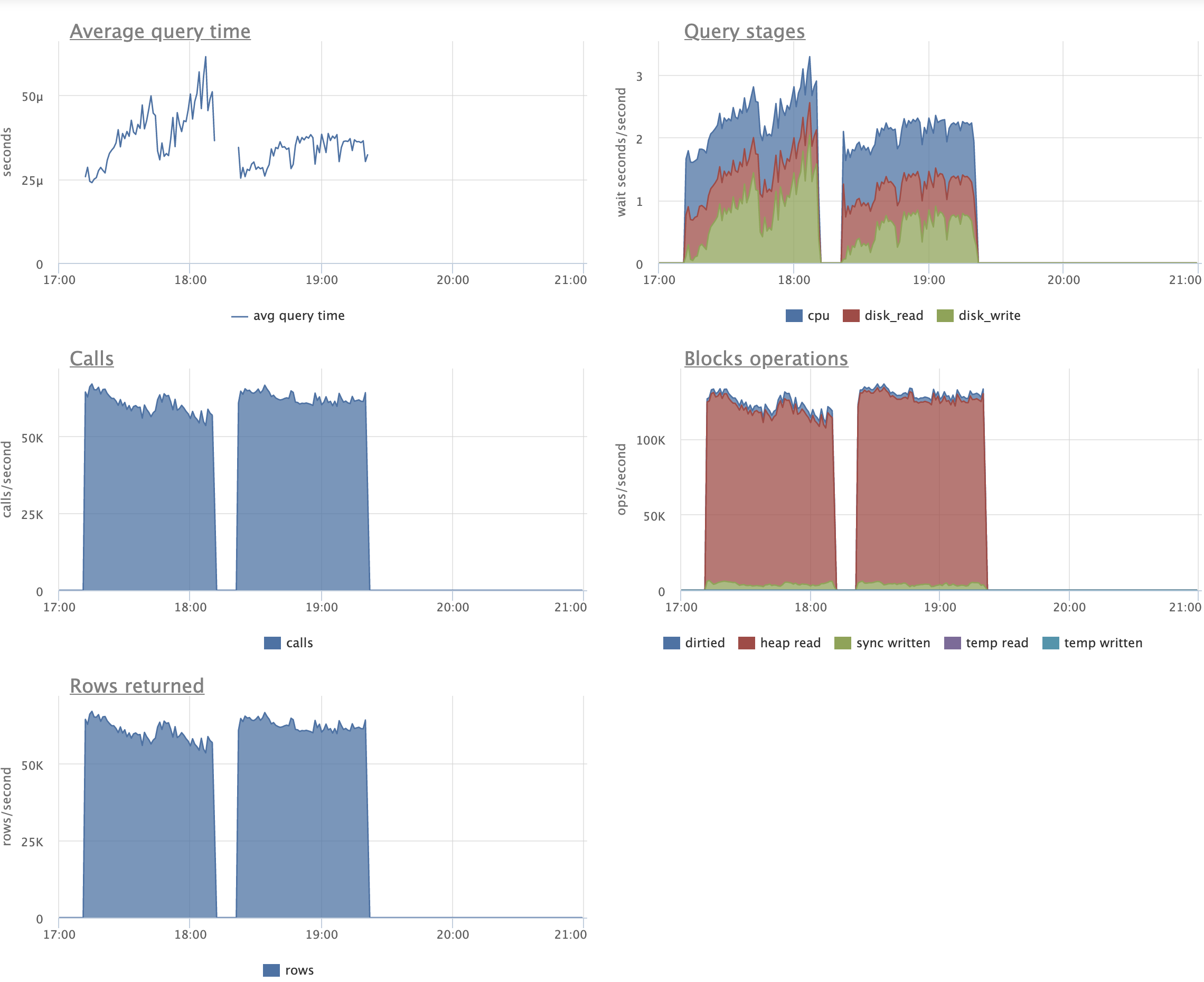
And another test session, this time with scale=2000 and shared_buffers=512MB
(vs scale=1000 and shared_buffers=16GB previously). The rest of the setup is the same:
- mtime column that is tracks update time
- index on (mtime, aid)
- tenner low cardinality index from Peter's earlier e-mail
- 3 pgbench scripts run in parallel on master and on v7 patchset (scripts from the previous e-mail used here).
(I just realized that the size-after figures in my previous e-mail are off, 'cos failed
to ANALYZE table after the tests.)
Master
------
relkind | relname | nrows | blk_before | mb_before | blk_after | mb_after | Diff
---------+-----------------------+-----------+------------+-----------+-----------+----------+-------
r | pgbench_accounts | 200000000 | 3278689 | 25614.8 | 3314951 | 25898.1 | +1.1%
i | accounts_mtime | 200000000 | 770080 | 6016.3 | 811946 | 6343.3 | +5.4%
i | pgbench_accounts_pkey | 200000000 | 548383 | 4284.2 | 548383 | 4284.2 | 0
i | tenner | 200000000 | 230701 | 1802.4 | 252346 | 1971.5 | +9.4%
(4 rows)
Patched
-------
relkind | relname | nrows | blk_before | mb_before | blk_after | mb_after | Diff
---------+-----------------------+-----------+------------+-----------+-----------+----------+-------
r | pgbench_accounts | 200000000 | 3278689 | 25614.8 | 3330788 | 26021.8 | +1.6%
i | accounts_mtime | 200000000 | 770080 | 6016.3 | 806920 | 6304.1 | +4.8%
i | pgbench_accounts_pkey | 200000000 | 548383 | 4284.2 | 548383 | 4284.2 | 0
i | tenner | 200000000 | 230701 | 1802.4 | 230701 | 1802.4 | 0
(4 rows)
TPS
---
query | Master TPS | Patched TPS | Diff
----------------+------------+-------------+------
UPDATE + SELECT | 3024 | 2661 | -12%
3 SELECT in txn | 19073 | 19852 | +4%
15min SELECT | 2.4 | 3.9 | +60%
We can see that the patched version does much less disk writes during UPDATEs and simple SELECTs and
eliminates write amplification for not involved indexes. (I'm really excited to see these figures.)
On the other hand, there's quite a big drop on the UPDATEs throughput. For sure, undersized shared_bufefrs
contribute to this drop. Still, my experience tells me that under conditions at hand (disabled HOT due to index
over update time column) tables will tend to accumulate bloat and produce unnecessary IO also from WAL.
Perhaps I need to conduct a longer test session, say 8+ hours to make obstacles appear more like in real life.
{kind=link}
{kind=link}
{kind=link}
{kind=link}