Re: Deleting older versions in unique indexes to avoid page splits - Mailing list pgsql-hackers
| From | Victor Yegorov |
|---|---|
| Subject | Re: Deleting older versions in unique indexes to avoid page splits |
| Date | |
| Msg-id | CAGnEboiJDPdYR4mRsbVZ_VXYXBFv553w3ZbXQKfQAd=9ihW8qg@mail.gmail.com Whole thread |
| In response to | Re: Deleting older versions in unique indexes to avoid page splits (Peter Geoghegan <pg@bowt.ie>) |
| Responses |
Re: Deleting older versions in unique indexes to avoid page splits
|
| List | pgsql-hackers |
пн, 26 окт. 2020 г. в 22:15, Peter Geoghegan <pg@bowt.ie>:
Attached is v5, which has changes that are focused on two important
high level goals:
I've reviewed v5 of the patch and did some testing.
First things first, the niceties must be observed:
Patch applies, compiles and passes checks without any issues.
It has a good amount of comments that describe the changes very well.
Now to its contents.
I now see what you mean by saying that this patch is a natural and logical
extension of the deduplication v13 work. I agree with this.
Basically, 2 major deduplication strategies exist now:
- by merging duplicates into a posting list; suits non-unique indexes better,
'cos actual duplicates come from the logically different tuples. This is
existing functionality.
- by deleting dead tuples and reducing need for deduplication at all; suits
unique indexes mostly. This is a subject of this patch and it (to some
extent) undoes v13 functionality around unique indexes, making it better.
Some comments on the patch.
1. In the following comment:
+ * table_index_batch_check() is a variant that is specialized to garbage
+ * collection of dead tuples in index access methods. Duplicates are
+ * commonly caused by MVCC version churn when an optimization like
+ * heapam's HOT cannot be applied. It can make sense to opportunistically
+ * guess that many index tuples are dead versions, particularly in unique
+ * indexes.
I don't quite like the last sentence. Given that this code is committed,
I would rather make it:
… cannot be applied. Therefore we opportunistically check for dead tuples
and reuse the space, delaying leaf page splits.
I understand that "we" shouldn't be used here, but I fail to think of a
proper way to express this.
2. in _bt_dedup_delete_pass() and heap_index_batch_check() you're using some
constants, like:
- expected score of 25
- nblocksaccessed checks for 1, 2 and 3 blocks
- maybe more, but the ones above caught my attention.
Perhaps, it'd be better to use #define-s here instead?
3. Do we really need to touch another heap page, if all conditions are met?
+ if (uniqueindex && nblocksaccessed == 1 && score == 0)
+ break;
+ if (!uniqueindex && nblocksaccessed == 2 && score == 0)
+ break;
+ if (nblocksaccessed == 3)
+ break;
I was really wondering why to look into 2 heap pages. By not doing it straight away,
we just delay the work for the next occasion that'll work on the same page we're
processing. I've modified this piece and included it in my tests (see below), I reduced
2nd condition to just 1 block and limited the 3rd case to 2 blocks (just a quick hack).
Now for the tests.
I used an i3en.6xlarge EC2 instance with EBS disks attached (24 cores, 192GB RAM).
I've employed the same tests Peter described on Oct 16 (right after v2 of the patch).
There were some config changes (attached), mostly to produce more logs and enable
proper query monitoring with pg_stat_statements.
This server is used also for other tests, therefore I am not able to utilize all core/RAM.
I'm interested in doing so though, subject for the next run of tests.
I've used scale factor 10 000, adjusted indexes (resulting in a 189GB size database)
and run the following pgbench:
First things first, the niceties must be observed:
Patch applies, compiles and passes checks without any issues.
It has a good amount of comments that describe the changes very well.
Now to its contents.
I now see what you mean by saying that this patch is a natural and logical
extension of the deduplication v13 work. I agree with this.
Basically, 2 major deduplication strategies exist now:
- by merging duplicates into a posting list; suits non-unique indexes better,
'cos actual duplicates come from the logically different tuples. This is
existing functionality.
- by deleting dead tuples and reducing need for deduplication at all; suits
unique indexes mostly. This is a subject of this patch and it (to some
extent) undoes v13 functionality around unique indexes, making it better.
Some comments on the patch.
1. In the following comment:
+ * table_index_batch_check() is a variant that is specialized to garbage
+ * collection of dead tuples in index access methods. Duplicates are
+ * commonly caused by MVCC version churn when an optimization like
+ * heapam's HOT cannot be applied. It can make sense to opportunistically
+ * guess that many index tuples are dead versions, particularly in unique
+ * indexes.
I don't quite like the last sentence. Given that this code is committed,
I would rather make it:
… cannot be applied. Therefore we opportunistically check for dead tuples
and reuse the space, delaying leaf page splits.
I understand that "we" shouldn't be used here, but I fail to think of a
proper way to express this.
2. in _bt_dedup_delete_pass() and heap_index_batch_check() you're using some
constants, like:
- expected score of 25
- nblocksaccessed checks for 1, 2 and 3 blocks
- maybe more, but the ones above caught my attention.
Perhaps, it'd be better to use #define-s here instead?
3. Do we really need to touch another heap page, if all conditions are met?
+ if (uniqueindex && nblocksaccessed == 1 && score == 0)
+ break;
+ if (!uniqueindex && nblocksaccessed == 2 && score == 0)
+ break;
+ if (nblocksaccessed == 3)
+ break;
I was really wondering why to look into 2 heap pages. By not doing it straight away,
we just delay the work for the next occasion that'll work on the same page we're
processing. I've modified this piece and included it in my tests (see below), I reduced
2nd condition to just 1 block and limited the 3rd case to 2 blocks (just a quick hack).
Now for the tests.
I used an i3en.6xlarge EC2 instance with EBS disks attached (24 cores, 192GB RAM).
I've employed the same tests Peter described on Oct 16 (right after v2 of the patch).
There were some config changes (attached), mostly to produce more logs and enable
proper query monitoring with pg_stat_statements.
This server is used also for other tests, therefore I am not able to utilize all core/RAM.
I'm interested in doing so though, subject for the next run of tests.
I've used scale factor 10 000, adjusted indexes (resulting in a 189GB size database)
and run the following pgbench:
pgbench -f testcase.pgbench -r -c32 -j8 -T 3600 bench
Results (see also attachment):
/* 1, master */
latency average = 16.482 ms
tps = 1941.513487 (excluding connections establishing)
statement latencies in milliseconds:
4.476 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid1;
2.084 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
2.090 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
/* 2, v5-patch */
latency average = 12.509 ms
tps = 2558.119453 (excluding connections establishing)
statement latencies in milliseconds:
2.009 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid1;
0.868 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.893 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
/* 3, v5-restricted */
latency average = 12.338 ms
tps = 2593.519240 (excluding connections establishing)
statement latencies in milliseconds:
1.955 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid1;
0.846 SELECT abalance FROM pgbench_accounts WHERE aid = :aid2;
0.866 SELECT abalance FROM pgbench_accounts WHERE aid = :aid3;
I can see a clear benefit from this patch *under specified conditions, YMMW*
- 32% increase in TPS
- 24% drop in average latency
- most important — stable index size!
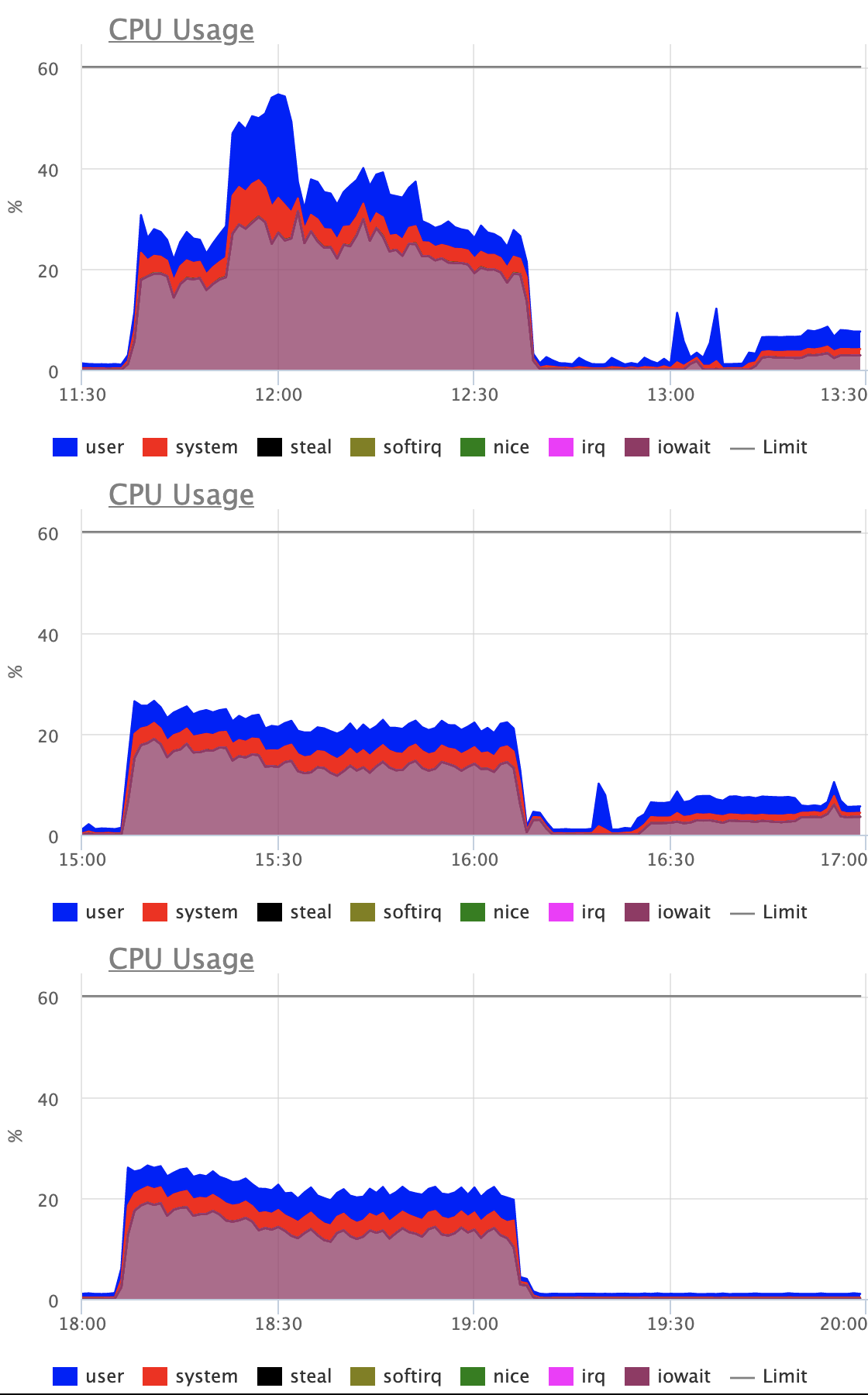
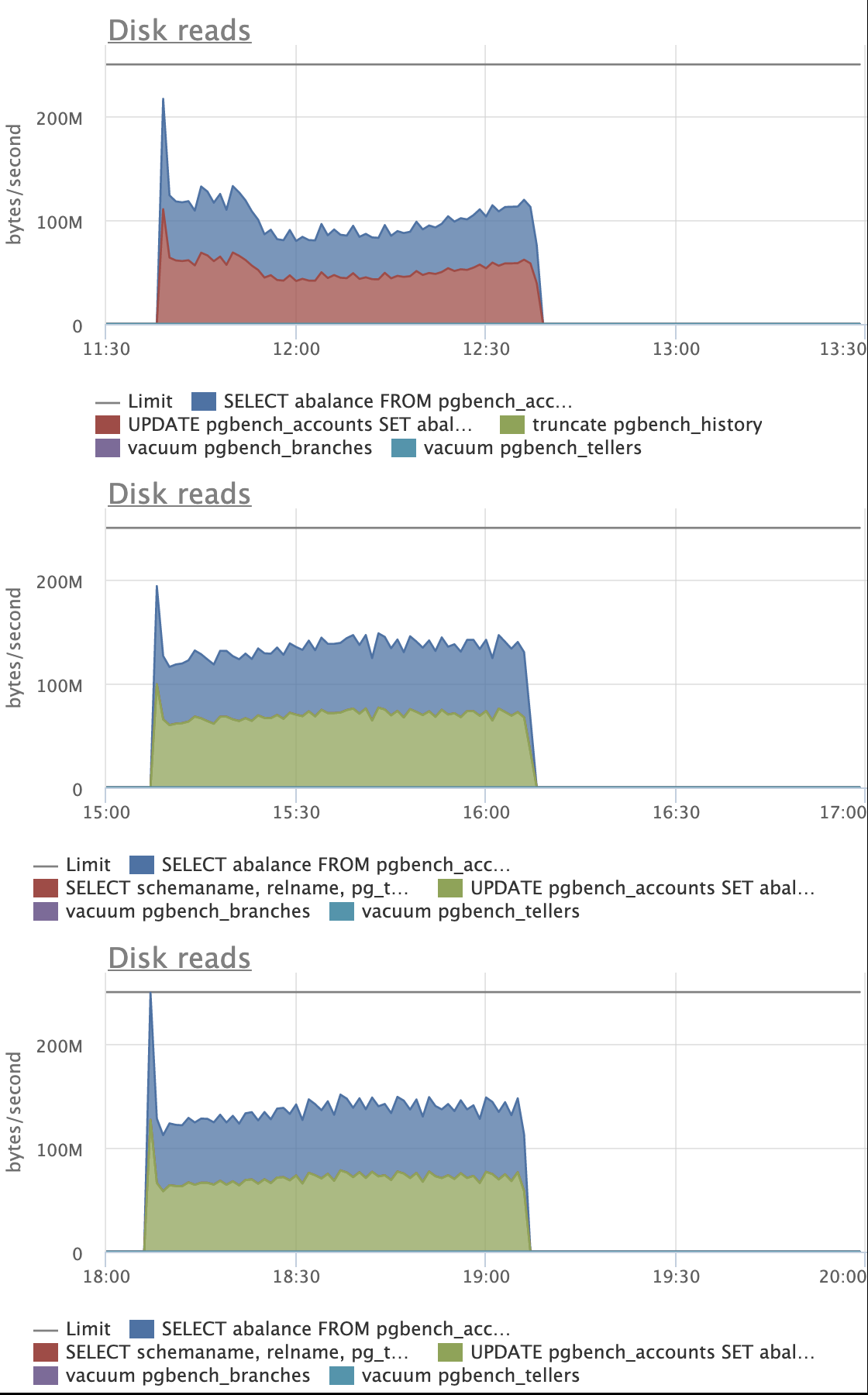
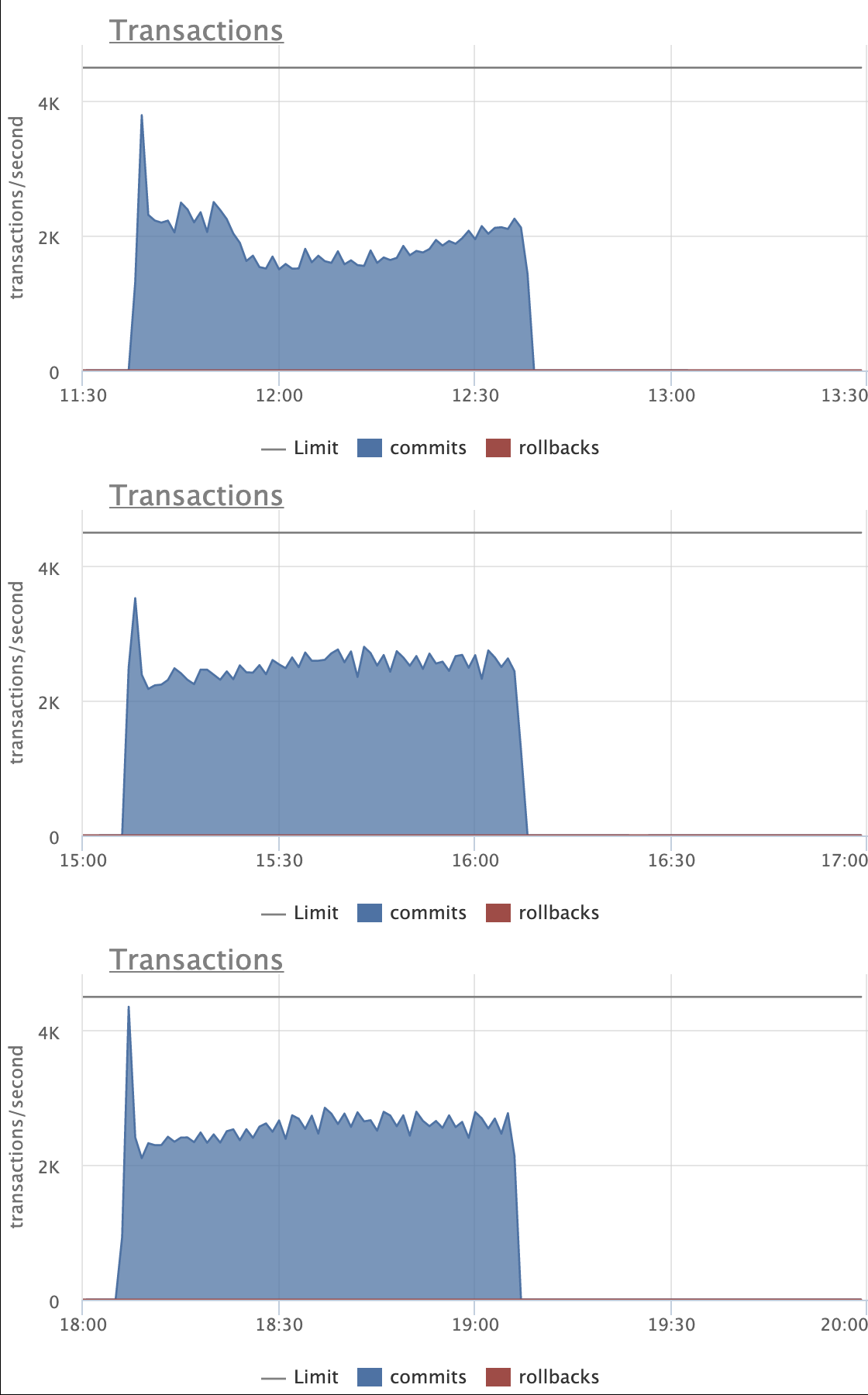
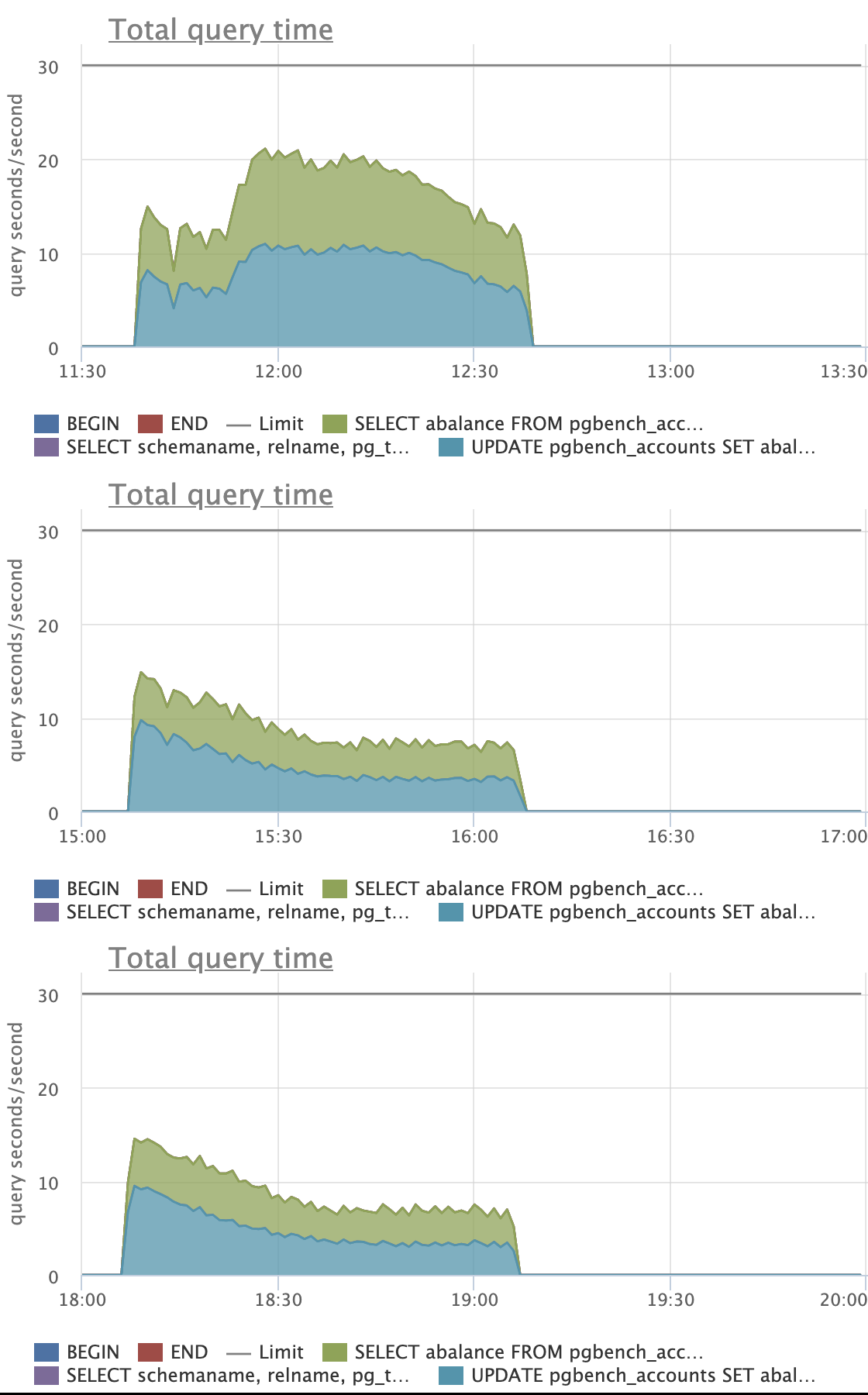
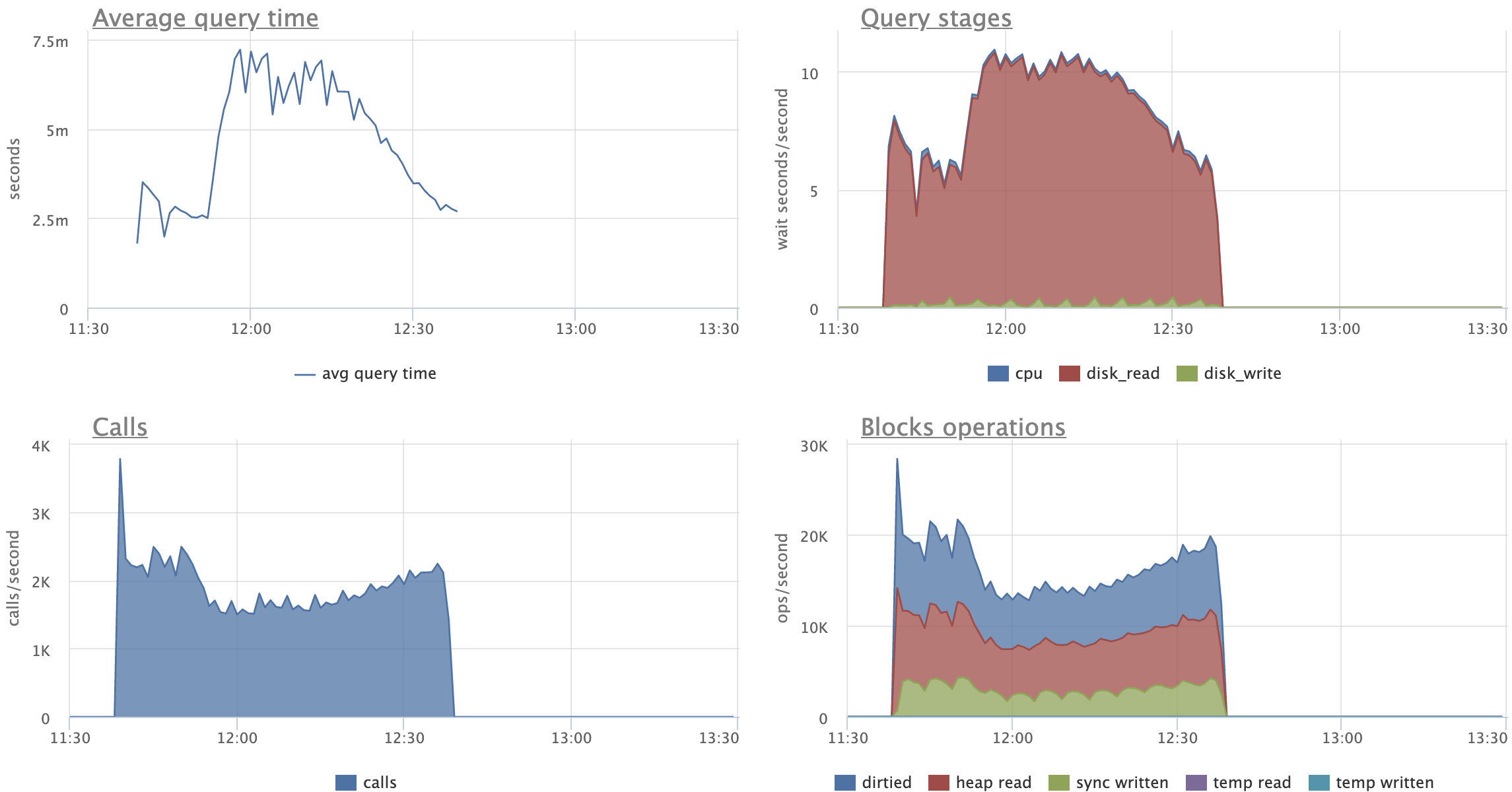
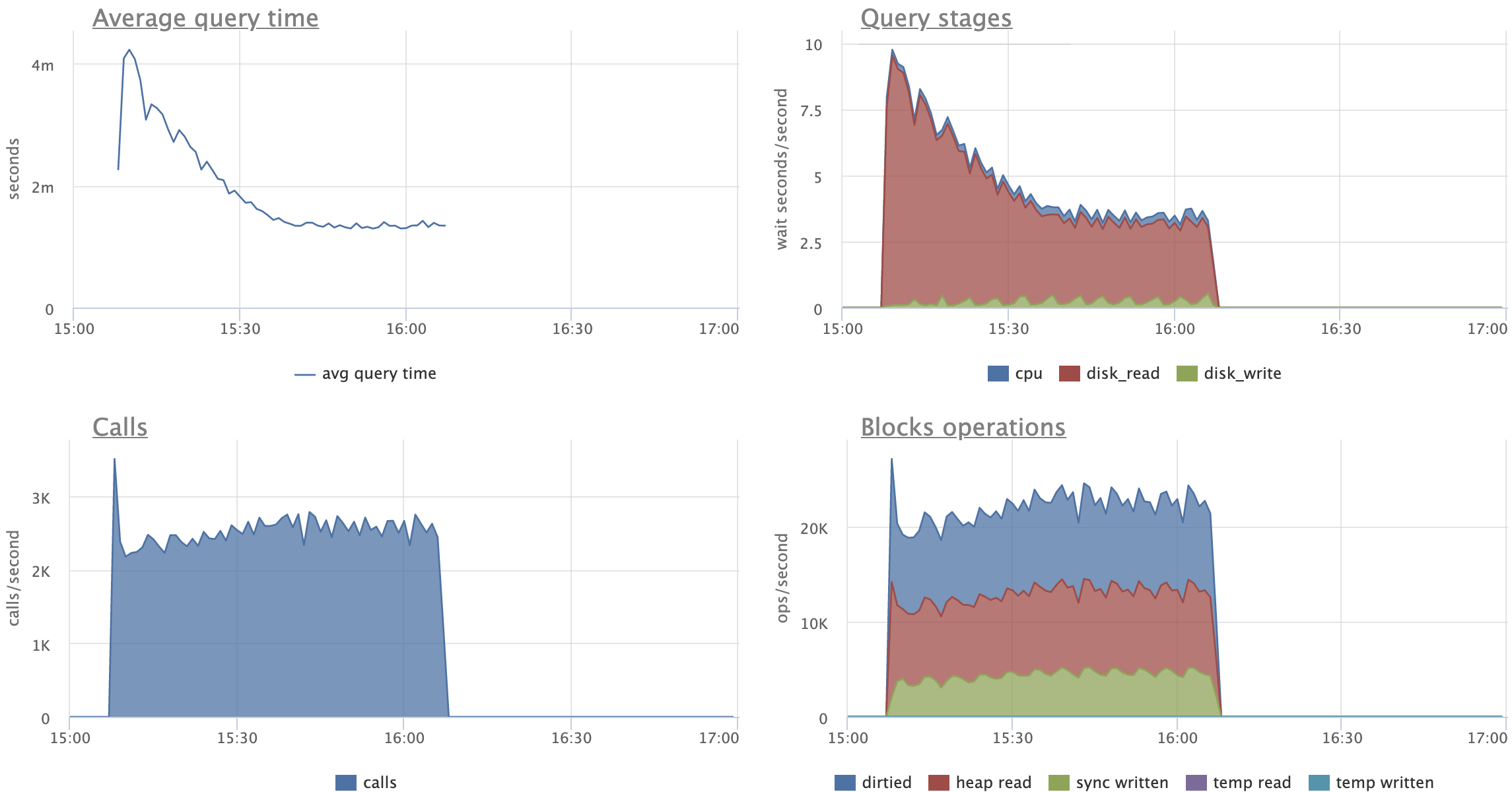
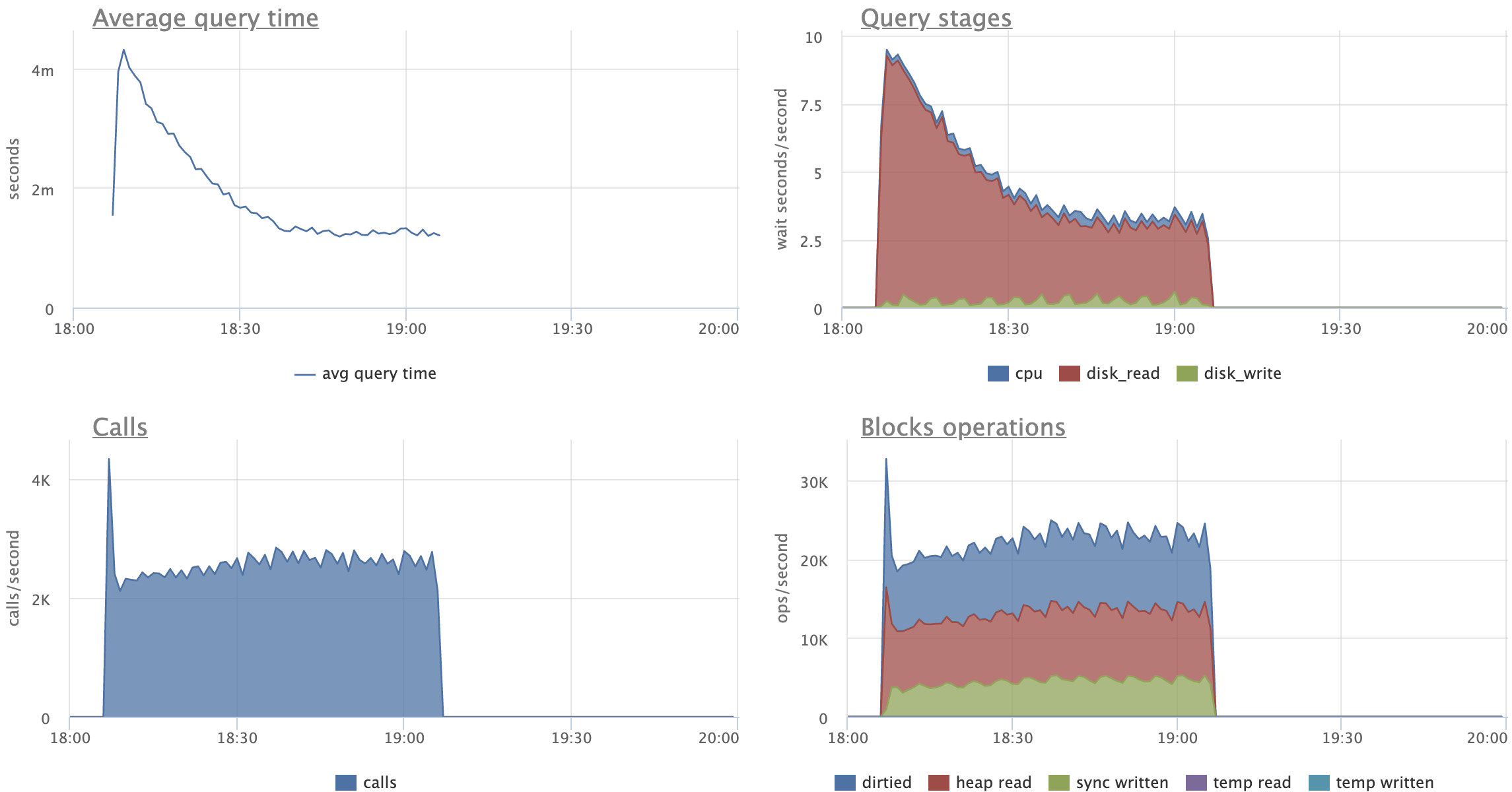
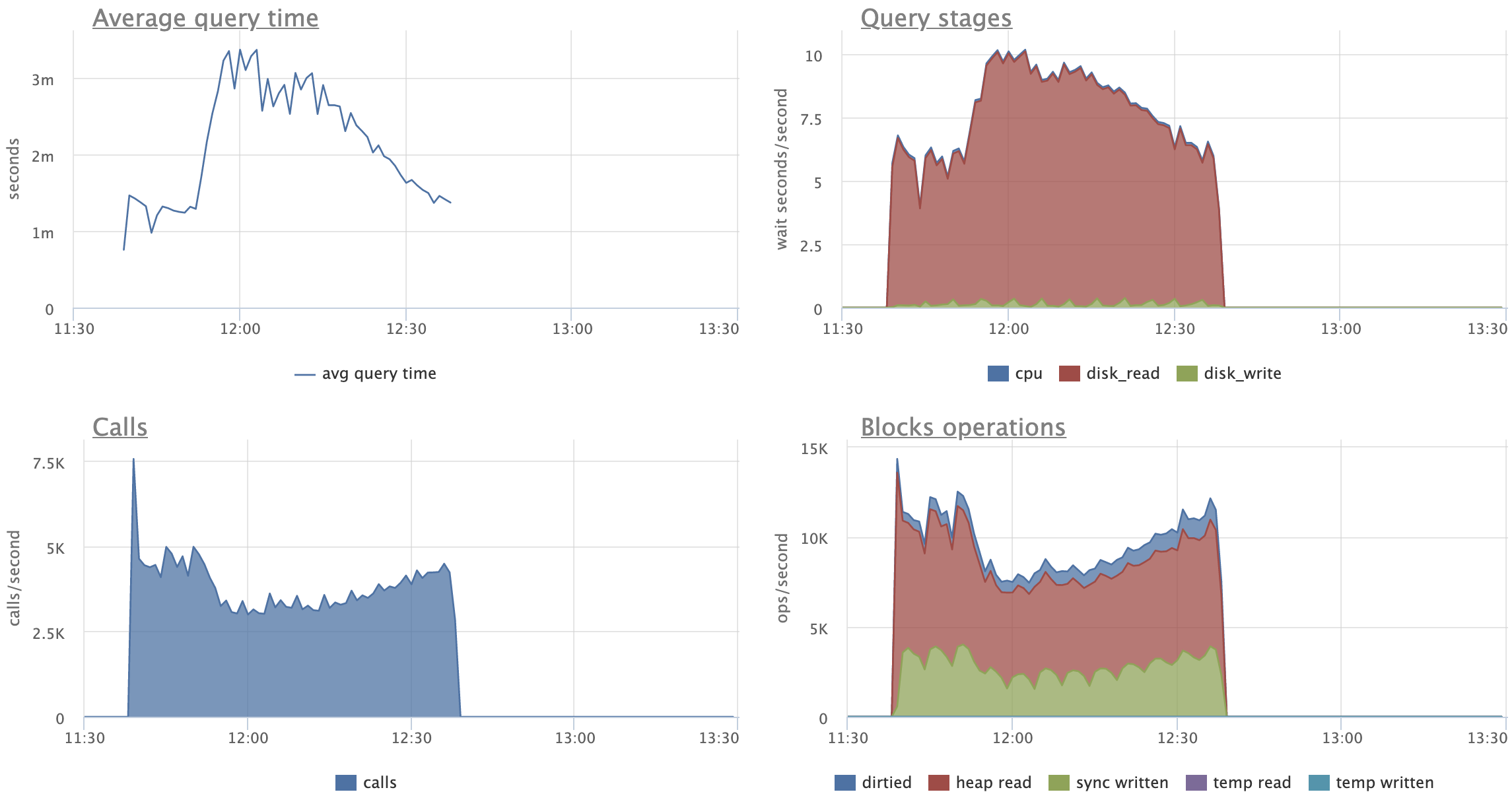
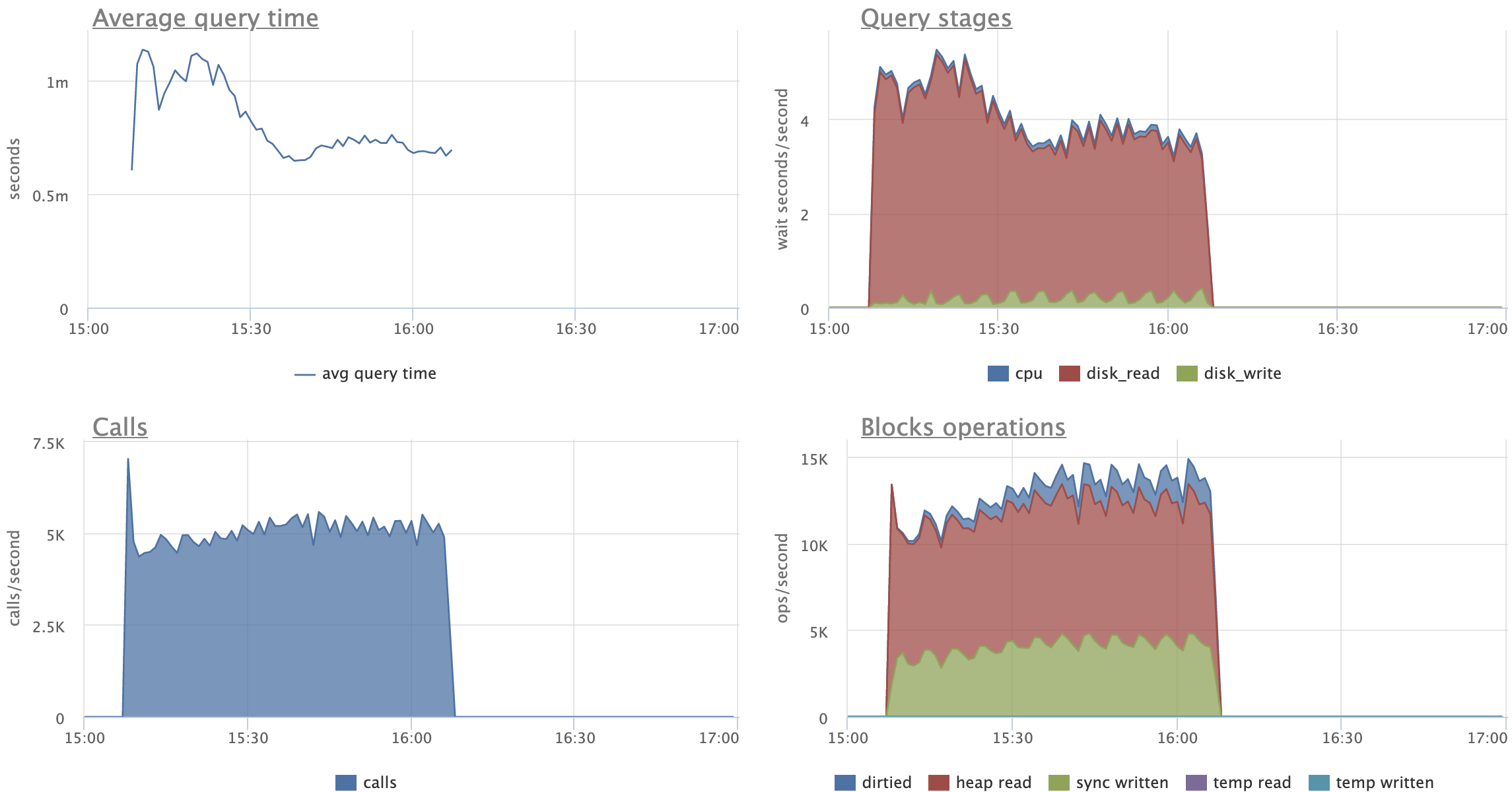
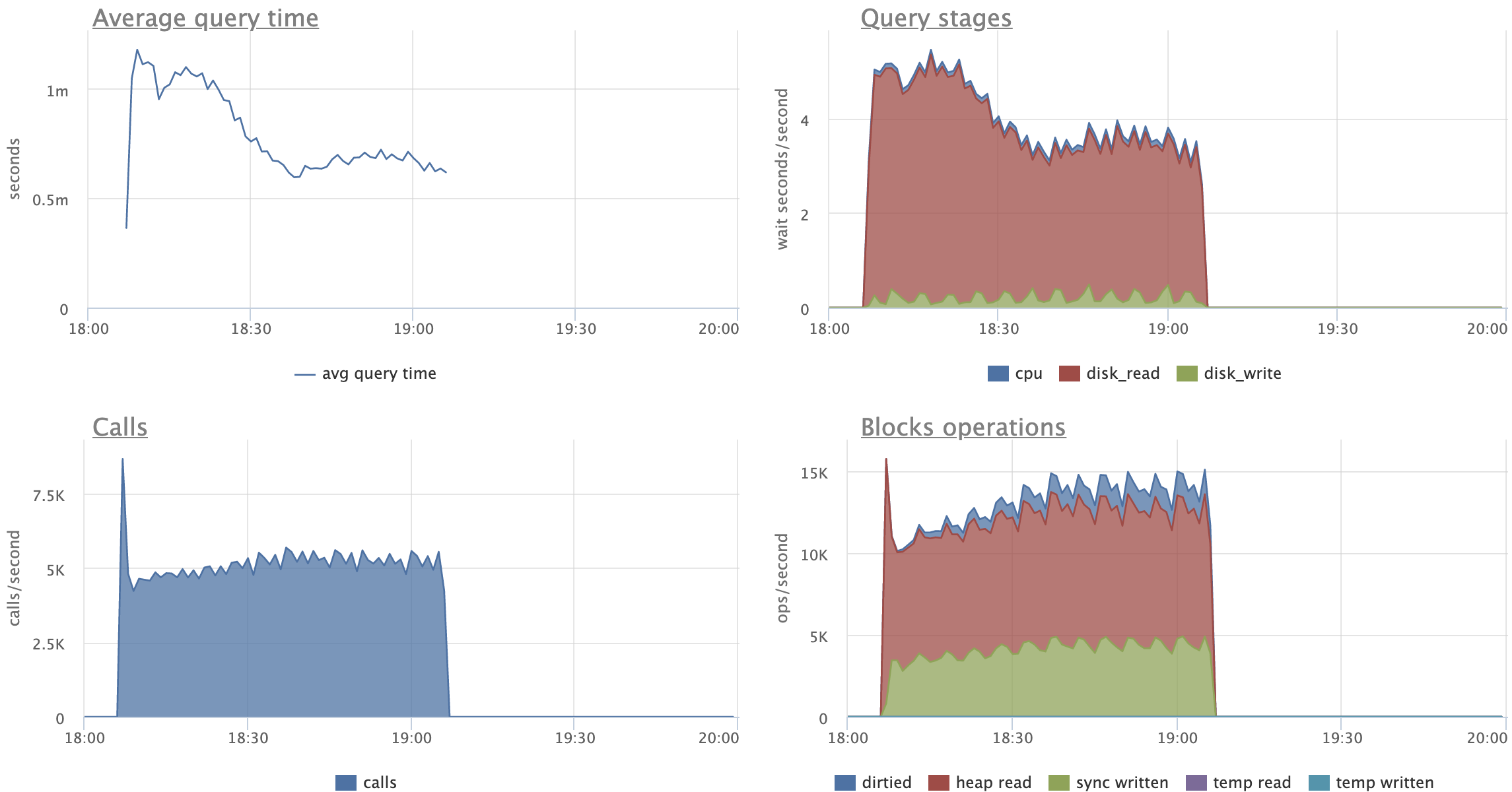
Looking at the attached graphs (including statement specific ones):
- CPU activity, Disk reads (reads, not hits) and Transaction throughput are very
stable for patched version
- CPU's "iowait" is stable and reduced for patched version (expected)
- CPU's "user" peaks out when master starts to split leafs, no such peaks
for the patched version
- there's expected increase in amount of "Disk reads" for patched versions,
although on master we start pretty much on the same level and by the end of
the test we seem to climb up on reads
- on master, UPDATEs are spending 2x more time on average, reading 3x more
pages than on patched versions
- in fact, "Average query time" and "Query stages" graphs show very nice caching
effect for patched UPDATEs, a bit clumsy for SELECTs, but still visible
Comparing original and restricted patch versions:
- there's no visible difference in amount of "Disk reads"
- on restricted version UPDATEs behave more gradually, I like this pattern
more, as it feels more stable and predictable
In my opinion, patch provides clear benefits from IO reduction and index size
control perspective. I really like the stability of operations on patched
version. I would rather stick to the "restricted" version of the patch though.
Hope this helps. I'm open to do more tests if necessary.
P.S. I am using automated monitoring for graphs, do not have metrics around, sorry.
Victor Yegorov
Attachment
- 20201028-v5-results.txt
- 20201028-v5-cpu.png
- 20201028-v5-dr.png
- 20201028-v5-txn.png
- 20201028-v5-tqt.png
- 20201028-v5-update-1-master.png
- 20201028-v5-update-2-patch.png
- 20201028-v5-update-3-restricted.png
- 20201028-v5-select-1-master.png
- 20201028-v5-select-2-patch.png
- 20201028-v5-select-3-restricted.png
- testcase.pgbench
- postgresql.auto.conf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: