Thread: pgbench - allow to create partitioned tables
Hello devs, While doing some performance tests and reviewing patches, I needed to create partitioned tables. Given the current syntax this is time consumming. The attached patch adds two options to create a partitioned "account" table in pgbench. It allows to answer quickly simple questions, eg "what is the overhead of hash partitioning on a simple select on my laptop"? Answer: # N=0..? sh> pgench -i -s 1 --partition-number=$N --partition-type=hash # then run sh> pgench -S -M prepared -P 1 -T 10 # and look at latency: # no parts = 0.071 ms # 1 hash = 0.071 ms (did someone optimize this case?!) # 2 hash ~ 0.126 ms (+ 0.055 ms) # 50 hash ~ 0.155 ms # 100 hash ~ 0.178 ms # 150 hash ~ 0.232 ms # 200 hash ~ 0.279 ms # overhead ~ (0.050 + [0.0005-0.0008] * nparts) ms -- Fabien.
Attachment
On Tue, 23 Jul 2019 at 19:26, Fabien COELHO <coelho@cri.ensmp.fr> wrote:
Hello devs,
While doing some performance tests and reviewing patches, I needed to
create partitioned tables. Given the current syntax this is time
consumming.
Good idea. I wonder why we didn't have it already.
The attached patch adds two options to create a partitioned "account"
table in pgbench.
It allows to answer quickly simple questions, eg "what is the overhead of
hash partitioning on a simple select on my laptop"? Answer:
# N=0..?
sh> pgench -i -s 1 --partition-number=$N --partition-type=hash
Given current naming of options, I would call this --partitions=number-of-partitions and --partition-method=hash
# then run
sh> pgench -S -M prepared -P 1 -T 10
# and look at latency:
# no parts = 0.071 ms
# 1 hash = 0.071 ms (did someone optimize this case?!)
# 2 hash ~ 0.126 ms (+ 0.055 ms)
# 50 hash ~ 0.155 ms
# 100 hash ~ 0.178 ms
# 150 hash ~ 0.232 ms
# 200 hash ~ 0.279 ms
# overhead ~ (0.050 + [0.0005-0.0008] * nparts) ms
It is linear?
Hello Simon, >> While doing some performance tests and reviewing patches, I needed to >> create partitioned tables. Given the current syntax this is time >> consumming. > > Good idea. I wonder why we didn't have it already. Probably because I did not have to create partitioned table for some testing:-) >> sh> pgench -i -s 1 --partition-number=$N --partition-type=hash > > Given current naming of options, I would call this > --partitions=number-of-partitions and --partition-method=hash Ok. >> # then run >> sh> pgench -S -M prepared -P 1 -T 10 >> >> # and look at latency: >> # no parts = 0.071 ms >> # 1 hash = 0.071 ms (did someone optimize this case?!) >> # 2 hash ~ 0.126 ms (+ 0.055 ms) >> # 50 hash ~ 0.155 ms >> # 100 hash ~ 0.178 ms >> # 150 hash ~ 0.232 ms >> # 200 hash ~ 0.279 ms >> # overhead ~ (0.050 + [0.0005-0.0008] * nparts) ms > > It is linear? Good question. I would have hoped affine, but this is not very clear on these data, which are the median of about five runs, hence the bracket on the slope factor. At least it is increasing with the number of partitions. Maybe it would be clearer on the minimum of five runs. -- Fabien.
Attachment
>>> # and look at latency:
>>> # no parts = 0.071 ms
>>> # 1 hash = 0.071 ms (did someone optimize this case?!)
>>> # 2 hash ~ 0.126 ms (+ 0.055 ms)
>>> # 50 hash ~ 0.155 ms
>>> # 100 hash ~ 0.178 ms
>>> # 150 hash ~ 0.232 ms
>>> # 200 hash ~ 0.279 ms
>>> # overhead ~ (0.050 + [0.0005-0.0008] * nparts) ms
>>
>> It is linear?
>
> Good question. I would have hoped affine, but this is not very clear on these
> data, which are the median of about five runs, hence the bracket on the slope
> factor. At least it is increasing with the number of partitions. Maybe it
> would be clearer on the minimum of five runs.
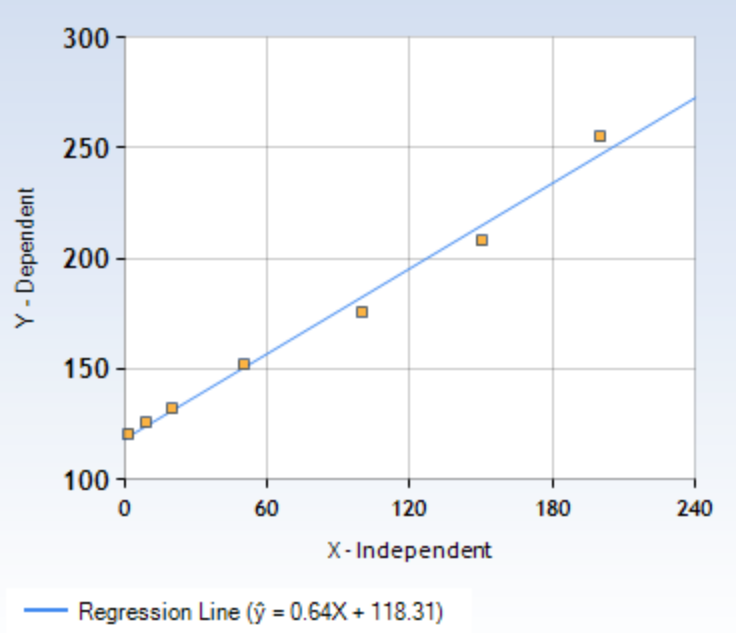
Here is a fellow up.
On the minimum of all available runs the query time on hash partitions is
about:
0.64375 nparts + 118.30979 (in µs).
So the overhead is about 47.30979 + 0.64375 nparts, and it is indeed
pretty convincingly linear as suggested by the attached figure.
--
Fabien.
Attachment
{kind=link}
Attached v3 fixes strcasecmp non portability on windows, per postgresql patch tester. -- Fabien.
Attachment
The following review has been posted through the commitfest application: make installcheck-world: tested, passed Implements feature: tested, passed Spec compliant: not tested Documentation: not tested Hi, The patch looks good to me, Just one suggestion --partition-method option should be made dependent on --partitions, becauseit has no use unless used with --partitions. What do you think? Regards, Asif The new status of this patch is: Waiting on Author
> Just one suggestion --partition-method option should be made dependent > on --partitions, because it has no use unless used with --partitions. > What do you think? Why not. V4 attached. -- Fabien.
Attachment
The following review has been posted through the commitfest application: make installcheck-world: tested, passed Implements feature: tested, passed Spec compliant: not tested Documentation: not tested Thanks. All looks good, making it ready for committer. Regards, Asif The new status of this patch is: Ready for Committer
On Mon, Aug 26, 2019 at 11:04 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
>
> > Just one suggestion --partition-method option should be made dependent
> > on --partitions, because it has no use unless used with --partitions.
> > What do you think?
>
Some comments:
*
+ case 11: /* partitions */
+ initialization_option_set = true;
+ partitions = atoi(optarg);
+ if (partitions < 0)
+ {
+ fprintf(stderr, "invalid number of partitions: \"%s\"\n",
+ optarg);
+ exit(1);
+ }
+ break;
Is there a reason why we treat "partitions = 0" as a valid value?
Also, shouldn't we keep some max limit for this parameter as well?
Forex. how realistic it will be if the user gives the value of
partitions the same or greater than the number of rows in
pgbench_accounts table? I understand it is not sensible to give such
a value, but I guess the API should behave sanely in such cases as
well. I am not sure what will be the good max value for it, but I
think there should be one. Anyone else have any better suggestions
for this?
*
@@ -3625,6 +3644,7 @@ initCreateTables(PGconn *con)
const char *bigcols; /* column decls if accountIDs are 64 bits */
int declare_fillfactor;
};
+
static const struct ddlinfo DDLs[] = {
Spurious line change.
*
+ " --partitions=NUM partition account table in NUM parts
(defaults: 0)\n"
+ " --partition-method=(range|hash)\n"
+ " partition account table with this
method (default: range)\n"
Refer complete table name like pgbench_accounts instead of just
account. It will be clear and in sync with what we display in some
other options like --skip-some-updates.
*
+ " --partitions=NUM partition account table in NUM parts
(defaults: 0)\n"
/defaults/default.
*
I think we should print the information about partitions in
printResults. It can help users while analyzing results.
*
+enum { PART_NONE, PART_RANGE, PART_HASH }
+ partition_method = PART_NONE;
+
I think it is better to follow the style of QueryMode enum by using
typedef here, that will make look code in sync with nearby code.
*
- int i;
fprintf(stderr, "creating tables...\n");
- for (i = 0; i < lengthof(DDLs); i++)
+ for (int i = 0; i < lengthof(DDLs); i++)
This is unnecessary change as far as this patch is concerned. I
understand there is no problem in writing either way, but let's not
change the coding pattern here as part of this patch.
*
+ if (partitions >= 1)
+ {
+ int64 part_size = (naccounts * (int64) scale + partitions - 1) / partitions;
+ char ff[64];
+ ff[0] = '\0';
+ append_fillfactor(ff, sizeof(ff));
+
+ fprintf(stderr, "creating %d partitions...\n", partitions);
+
+ for (int p = 1; p <= partitions; p++)
+ {
+ char query[256];
+
+ if (partition_method == PART_RANGE)
+ {
part_size can be defined inside "if (partition_method == PART_RANGE)"
as it is used here. In general, this part of the code can use some
comments.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Hello Amit,
Thanks for the feedback.
> + case 11: /* partitions */
> + initialization_option_set = true;
> + partitions = atoi(optarg);
> + if (partitions < 0)
> + {
> + fprintf(stderr, "invalid number of partitions: \"%s\"\n",
> + optarg);
> + exit(1);
> + }
> + break;
>
> Is there a reason why we treat "partitions = 0" as a valid value?
Yes. It is an explicit "do not create partitioned tables", which differ
from 1 which says "create a partitionned table with just one partition".
> Also, shouldn't we keep some max limit for this parameter as well?
I do not think so. If someone wants to test how terrible it is to use
100000 partitions, we should not prevent it.
> Forex. how realistic it will be if the user gives the value of
> partitions the same or greater than the number of rows in
> pgbench_accounts table?
Although I agree that it does not make much sense, for testing purposes
why not, to test overheads in critical cases for instance.
> I understand it is not sensible to give such a value, but I guess the
> API should behave sanely in such cases as well.
Yep, it should work.
> I am not sure what will be the good max value for it, but I
> think there should be one.
I disagree. Pgbench is a tool for testing performance for given
parameters. If postgres accepts a parameter there is no reason why pgbench
should reject it.
> @@ -3625,6 +3644,7 @@ initCreateTables(PGconn *con)
> const char *bigcols; /* column decls if accountIDs are 64 bits */
> int declare_fillfactor;
> };
> +
> static const struct ddlinfo DDLs[] = {
>
> Spurious line change.
Indeed.
> *
> + " --partitions=NUM partition account table in NUM parts
> (defaults: 0)\n"
> + " --partition-method=(range|hash)\n"
> + " partition account table with this
> method (default: range)\n"
>
> Refer complete table name like pgbench_accounts instead of just account.
> It will be clear and in sync with what we display in some other options
> like --skip-some-updates.
Ok.
> *
> + " --partitions=NUM partition account table in NUM parts
> (defaults: 0)\n"
>
> /defaults/default.
Ok.
> I think we should print the information about partitions in
> printResults. It can help users while analyzing results.
Hmmm. Why not, with some hocus-pocus to get the information out of
pg_catalog, and trying to fail gracefully so that if pgbench is run
against a no partitioning-support version.
> *
> +enum { PART_NONE, PART_RANGE, PART_HASH }
> + partition_method = PART_NONE;
> +
>
> I think it is better to follow the style of QueryMode enum by using
> typedef here, that will make look code in sync with nearby code.
Hmmm. Why not. This means inventing a used-once type name for
partition_method. My great creativity lead to partition_method_t.
> *
> - int i;
>
> fprintf(stderr, "creating tables...\n");
>
> - for (i = 0; i < lengthof(DDLs); i++)
> + for (int i = 0; i < lengthof(DDLs); i++)
>
> This is unnecessary change as far as this patch is concerned. I
> understand there is no problem in writing either way, but let's not
> change the coding pattern here as part of this patch.
The reason I did that is that I had a stupid bug in a development version
which was due to an accidental reuse of this index, which would have been
prevented by this declaration style. Removed anyway.
> + if (partitions >= 1)
> + {
> + int64 part_size = (naccounts * (int64) scale + partitions - 1) / partitions;
> + char ff[64];
> + ff[0] = '\0';
> + append_fillfactor(ff, sizeof(ff));
> +
> + fprintf(stderr, "creating %d partitions...\n", partitions);
> +
> + for (int p = 1; p <= partitions; p++)
> + {
> + char query[256];
> +
> + if (partition_method == PART_RANGE)
> + {
>
> part_size can be defined inside "if (partition_method == PART_RANGE)"
> as it is used here.
I just wanted to avoid recomputing the value in the loop, but indeed it
may be computed needlessly. Moved.
> In general, this part of the code can use some comments.
Ok.
Attached an updated version.
--
Fabien.
Attachment
On Wed, Sep 11, 2019 at 6:08 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
> Attached an updated version.
I have reviewed the patch and done some basic testing. It works as
per the expectation
I have a few cosmetic comments
1.
+ if (partitions >= 1)
+ {
+ char ff[64];
+ ff[0] = '\0';
+ append_fillfactor(ff, sizeof(ff));
Generally, we give one blank line between the variable declaration and
the first statement of the block.
2.
+ if (p == 1)
+ sprintf(minvalue, "minvalue");
+ else
+ sprintf(minvalue, INT64_FORMAT, (p-1) * part_size + 1);
(p-1) -> (p - 1)
I am just wondering will it be a good idea to expand it to support
multi-level partitioning?
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Wed, Sep 11, 2019 at 6:08 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
>
I would like to take inputs from others as well for the display part
of this patch. After this patch, for a simple-update pgbench test,
the changed output will be as follows (note: partition method and
partitions):
pgbench.exe -c 4 -j 4 -T 10 -N postgres
starting vacuum...end.
transaction type: <builtin: simple update>
scaling factor: 1
partition method: hash
partitions: 3
query mode: simple
number of clients: 4
number of threads: 4
duration: 10 s
number of transactions actually processed: 14563
latency average = 2.749 ms
tps = 1454.899150 (including connections establishing)
tps = 1466.689412 (excluding connections establishing)
What do others think about this? This will be the case when the user
has used --partitions option in pgbench, otherwise, it won't change.
>
> > + case 11: /* partitions */
> > + initialization_option_set = true;
> > + partitions = atoi(optarg);
> > + if (partitions < 0)
> > + {
> > + fprintf(stderr, "invalid number of partitions: \"%s\"\n",
> > + optarg);
> > + exit(1);
> > + }
> > + break;
> >
> > Is there a reason why we treat "partitions = 0" as a valid value?
>
> Yes. It is an explicit "do not create partitioned tables", which differ
> from 1 which says "create a partitionned table with just one partition".
>
Why would anyone want to use --partitions option in the first case
("do not create partitioned tables")?
>
> > I think we should print the information about partitions in
> > printResults. It can help users while analyzing results.
>
> Hmmm. Why not, with some hocus-pocus to get the information out of
> pg_catalog, and trying to fail gracefully so that if pgbench is run
> against a no partitioning-support version.
>
+ res = PQexec(con,
+ "select p.partstrat, count(*) "
+ "from pg_catalog.pg_class as c "
+ "left join pg_catalog.pg_partitioned_table as p on (p.partrelid = c.oid) "
+ "left join pg_catalog.pg_inherits as i on (c.oid = i.inhparent) "
+ "where c.relname = 'pgbench_accounts' "
+ "group by 1, c.oid");
Can't we write this query with inner join instead of left join? What
additional purpose you are trying to serve by using left join?
> > *
> > +enum { PART_NONE, PART_RANGE, PART_HASH }
> > + partition_method = PART_NONE;
> > +
> >
> > I think it is better to follow the style of QueryMode enum by using
> > typedef here, that will make look code in sync with nearby code.
>
> Hmmm. Why not. This means inventing a used-once type name for
> partition_method. My great creativity lead to partition_method_t.
>
+partition_method_t partition_method = PART_NONE;
It is better to make this static.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Hello Dilip, > Generally, we give one blank line between the variable declaration and > the first statement of the block. Ok. > (p-1) -> (p - 1) Ok. > I am just wondering will it be a good idea to expand it to support > multi-level partitioning? ISTM that how the user could specify multi-level parameters is pretty unclear, so I would let that as a possible extension if someone wants it enough. Attached v6 implements the two cosmetic changes outlined above. -- Fabien.
Attachment
On Fri, Sep 13, 2019 at 1:35 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote: Thanks for the updated version of the patch. > > Generally, we give one blank line between the variable declaration and > > the first statement of the block. > > Ok. > > > (p-1) -> (p - 1) > > Ok. > > > I am just wondering will it be a good idea to expand it to support > > multi-level partitioning? > > ISTM that how the user could specify multi-level parameters is pretty > unclear, so I would let that as a possible extension if someone wants it > enough. Ok > > Attached v6 implements the two cosmetic changes outlined above. + /* For RANGE, we use open-ended partitions at the beginning and end */ + if (p == 1) + sprintf(minvalue, "minvalue"); + else + sprintf(minvalue, INT64_FORMAT, (p-1) * part_size + 1); + + if (p < partitions) + sprintf(maxvalue, INT64_FORMAT, p * part_size + 1); + else + sprintf(maxvalue, "maxvalue"); I do not understand the reason why first partition need to be open-ended? Because we are clear that the minimum value of the aid is 1 in pgbench_accout. So if you directly use sprintf(minvalue, INT64_FORMAT, (p-1) * part_size + 1); then also it will give 1 as minvalue for the first partition and that will be the right thing to do. Am I missing something here? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Hello Amit,
>>> Is there a reason why we treat "partitions = 0" as a valid value?
>>
>> Yes. It is an explicit "do not create partitioned tables", which differ
>> from 1 which says "create a partitionned table with just one partition".
>
> Why would anyone want to use --partitions option in the first case
> ("do not create partitioned tables")?
Having an explicit value for the default is generally a good idea, eg for
a script to tests various partitioning settings:
for nparts in 0 1 2 3 4 5 6 7 8 9 ; do
pgbench -i --partitions=$nparts ... ;
...
done
Otherwise you would need significant kludging to add/remove the option.
Allowing 0 does not harm anyone.
Now if the consensus is to remove an explicit 0, it is simple enough to
change it, but my opinion is that it is better to have it.
>>> I think we should print the information about partitions in
>>> printResults. It can help users while analyzing results.
>
> + res = PQexec(con,
> + "select p.partstrat, count(*) "
> + "from pg_catalog.pg_class as c "
> + "left join pg_catalog.pg_partitioned_table as p on (p.partrelid = c.oid) "
> + "left join pg_catalog.pg_inherits as i on (c.oid = i.inhparent) "
> + "where c.relname = 'pgbench_accounts' "
> + "group by 1, c.oid");
>
> Can't we write this query with inner join instead of left join? What
> additional purpose you are trying to serve by using left join?
I'm ensuring that there is always a one line answer, whether it is
partitioned or not. Maybe the count(*) should be count(something in p) to
get 0 instead of 1 on non partitioned tables, though, but this is hidden
in the display anyway.
> +partition_method_t partition_method = PART_NONE;
>
> It is better to make this static.
I do agree, but this would depart from all other global variables around
which are currently not static. Maybe a separate patch could turn them all
as static, but ISTM that this patch should not change the current style.
--
Fabien.
Hello Dilip, > + /* For RANGE, we use open-ended partitions at the beginning and end */ > + if (p == 1) > + sprintf(minvalue, "minvalue"); > + else > + sprintf(minvalue, INT64_FORMAT, (p-1) * part_size + 1); > + > + if (p < partitions) > + sprintf(maxvalue, INT64_FORMAT, p * part_size + 1); > + else > + sprintf(maxvalue, "maxvalue"); > > I do not understand the reason why first partition need to be > open-ended? Because we are clear that the minimum value of the aid is 1 > in pgbench_accout. So if you directly use sprintf(minvalue, > INT64_FORMAT, (p-1) * part_size + 1); then also it will give 1 as > minvalue for the first partition and that will be the right thing to do. > Am I missing something here? This is simply for the principle that any value allowed for the primary key type has a corresponding partition, and also that it exercices these special values. It also probably reduces the cost of checking whether a value belongs to the first partition because one test is removed, so there is a small additional performance benefit beyond principle and coverage. -- Fabien.
On Fri, Sep 13, 2019 at 2:05 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > > Hello Dilip, > > > + /* For RANGE, we use open-ended partitions at the beginning and end */ > > + if (p == 1) > > + sprintf(minvalue, "minvalue"); > > + else > > + sprintf(minvalue, INT64_FORMAT, (p-1) * part_size + 1); > > + > > + if (p < partitions) > > + sprintf(maxvalue, INT64_FORMAT, p * part_size + 1); > > + else > > + sprintf(maxvalue, "maxvalue"); > > > > I do not understand the reason why first partition need to be > > open-ended? Because we are clear that the minimum value of the aid is 1 > > in pgbench_accout. So if you directly use sprintf(minvalue, > > INT64_FORMAT, (p-1) * part_size + 1); then also it will give 1 as > > minvalue for the first partition and that will be the right thing to do. > > Am I missing something here? > > This is simply for the principle that any value allowed for the primary > key type has a corresponding partition, and also that it exercices these > special values. IMHO, the primary key values for the pgbench_accout tables are always within the defined range minvalue=1 and maxvalue=scale*100000, right? > > It also probably reduces the cost of checking whether a value belongs to > the first partition because one test is removed, so there is a small > additional performance benefit beyond principle and coverage. Ok, I agree that it will slightly reduce the cost for the tuple falling in the first and the last partition. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Fri, Sep 13, 2019 at 1:50 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
> >>> Is there a reason why we treat "partitions = 0" as a valid value?
> >>
> >> Yes. It is an explicit "do not create partitioned tables", which differ
> >> from 1 which says "create a partitionned table with just one partition".
> >
> > Why would anyone want to use --partitions option in the first case
> > ("do not create partitioned tables")?
>
> Having an explicit value for the default is generally a good idea, eg for
> a script to tests various partitioning settings:
>
> for nparts in 0 1 2 3 4 5 6 7 8 9 ; do
> pgbench -i --partitions=$nparts ... ;
> ...
> done
>
> Otherwise you would need significant kludging to add/remove the option.
> Allowing 0 does not harm anyone.
>
> Now if the consensus is to remove an explicit 0, it is simple enough to
> change it, but my opinion is that it is better to have it.
>
Fair enough, let us see if anyone else wants to weigh in.
> >>> I think we should print the information about partitions in
> >>> printResults. It can help users while analyzing results.
> >
> > + res = PQexec(con,
> > + "select p.partstrat, count(*) "
> > + "from pg_catalog.pg_class as c "
> > + "left join pg_catalog.pg_partitioned_table as p on (p.partrelid = c.oid) "
> > + "left join pg_catalog.pg_inherits as i on (c.oid = i.inhparent) "
> > + "where c.relname = 'pgbench_accounts' "
> > + "group by 1, c.oid");
> >
> > Can't we write this query with inner join instead of left join? What
> > additional purpose you are trying to serve by using left join?
>
> I'm ensuring that there is always a one line answer, whether it is
> partitioned or not. Maybe the count(*) should be count(something in p) to
> get 0 instead of 1 on non partitioned tables, though, but this is hidden
> in the display anyway.
>
Sure, but I feel the code will be simplified. I see no reason for
using left join here.
> > +partition_method_t partition_method = PART_NONE;
> >
> > It is better to make this static.
>
> I do agree, but this would depart from all other global variables around
> which are currently not static.
>
Check QueryMode.
> Maybe a separate patch could turn them all
> as static, but ISTM that this patch should not change the current style.
>
No need to change others, but we can do it for this one.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On 2019-Sep-13, Amit Kapila wrote:
> On Fri, Sep 13, 2019 at 1:50 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
> > >>> Is there a reason why we treat "partitions = 0" as a valid value?
> > >>
> > >> Yes. It is an explicit "do not create partitioned tables", which differ
> > >> from 1 which says "create a partitionned table with just one partition".
> > >
> > > Why would anyone want to use --partitions option in the first case
> > > ("do not create partitioned tables")?
> >
> > Having an explicit value for the default is generally a good idea, eg for
> > a script to tests various partitioning settings:
> >
> > for nparts in 0 1 2 3 4 5 6 7 8 9 ; do
> > pgbench -i --partitions=$nparts ... ;
> > ...
> > done
> >
> > Otherwise you would need significant kludging to add/remove the option.
> > Allowing 0 does not harm anyone.
> >
> > Now if the consensus is to remove an explicit 0, it is simple enough to
> > change it, but my opinion is that it is better to have it.
>
> Fair enough, let us see if anyone else wants to weigh in.
It seems convenient UI -- I vote to keep it.
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2019-Sep-13, Amit Kapila wrote: > I would like to take inputs from others as well for the display part > of this patch. After this patch, for a simple-update pgbench test, > the changed output will be as follows (note: partition method and > partitions): > pgbench.exe -c 4 -j 4 -T 10 -N postgres > starting vacuum...end. > transaction type: <builtin: simple update> > scaling factor: 1 > partition method: hash > partitions: 3 > query mode: simple > number of clients: 4 > number of threads: 4 > duration: 10 s > number of transactions actually processed: 14563 > latency average = 2.749 ms > tps = 1454.899150 (including connections establishing) > tps = 1466.689412 (excluding connections establishing) > > What do others think about this? This will be the case when the user > has used --partitions option in pgbench, otherwise, it won't change. I wonder what's the intended usage of this output ... it seems to be getting a bit too long. Is this intended for machine processing? I would rather have more things per line in a more compact header. But then I'm not the kind of person who automates multiple pgbench runs. Maybe we can get some input from Tomas, who does -- how do you automate extracting data from collected pgbench output, or do you instead just redirect the output to a file whose path/name indicates the parameters that were used? (I do the latter.) I mean, if we changed it like this (and I'm not proposing to do it in this patch, this is only an example), would it bother anyone? $ pgbench -x -y -z ... starting vacuum...end. scaling factor: 1 partition method: hash partitions: 1 transaction type: <builtin: simple update> query mode: simple number of clients: 4 number of threads: 4 duration: 10s number of transactions actually processed: 14563 latency average = 2.749 ms tps = 1454.899150 (including connections establishing) tps = 1466.689412 (excluding connections establishing) If this output doesn't bother people, then I suggest that this patch should put the partition information in the line together with scaling factor. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hello Amit, >>> + res = PQexec(con, >>> + "select p.partstrat, count(*) " >>> + "from pg_catalog.pg_class as c " >>> + "left join pg_catalog.pg_partitioned_table as p on (p.partrelid = c.oid) " >>> + "left join pg_catalog.pg_inherits as i on (c.oid = i.inhparent) " >>> + "where c.relname = 'pgbench_accounts' " >>> + "group by 1, c.oid"); >>> >>> Can't we write this query with inner join instead of left join? What >>> additional purpose you are trying to serve by using left join? >> >> I'm ensuring that there is always a one line answer, whether it is >> partitioned or not. Maybe the count(*) should be count(something in p) to >> get 0 instead of 1 on non partitioned tables, though, but this is hidden >> in the display anyway. > > Sure, but I feel the code will be simplified. I see no reason for > using left join here. Without a left join, the query result is empty if there are no partitions, whereas there is one line with it. This fact simplifies managing the query result afterwards because we are always expecting 1 row in the "normal" case, whether partitioned or not. >>> +partition_method_t partition_method = PART_NONE; >>> >>> It is better to make this static. >> >> I do agree, but this would depart from all other global variables around >> which are currently not static. > > Check QueryMode. Indeed, there is a mix of static (about 8) and non static (29 cases). I think static is better anyway, so why not. Attached a v7. -- Fabien.
Attachment
On Fri, Sep 13, 2019 at 6:36 PM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > > On 2019-Sep-13, Amit Kapila wrote: > > > I would like to take inputs from others as well for the display part > > of this patch. After this patch, for a simple-update pgbench test, > > the changed output will be as follows (note: partition method and > > partitions): > > > pgbench.exe -c 4 -j 4 -T 10 -N postgres > > starting vacuum...end. > > transaction type: <builtin: simple update> > > scaling factor: 1 > > partition method: hash > > partitions: 3 > > query mode: simple > > number of clients: 4 > > number of threads: 4 > > duration: 10 s > > number of transactions actually processed: 14563 > > latency average = 2.749 ms > > tps = 1454.899150 (including connections establishing) > > tps = 1466.689412 (excluding connections establishing) > > > > What do others think about this? This will be the case when the user > > has used --partitions option in pgbench, otherwise, it won't change. > > I wonder what's the intended usage of this output ... it seems to be > getting a bit too long. Is this intended for machine processing? I > would rather have more things per line in a more compact header. > But then I'm not the kind of person who automates multiple pgbench runs. > Maybe we can get some input from Tomas, who does -- how do you automate > extracting data from collected pgbench output, or do you instead just > redirect the output to a file whose path/name indicates the parameters > that were used? (I do the latter.) > > I mean, if we changed it like this (and I'm not proposing to do it in > this patch, this is only an example), would it bother anyone? > > $ pgbench -x -y -z ... > starting vacuum...end. > scaling factor: 1 partition method: hash partitions: 1 > transaction type: <builtin: simple update> query mode: simple > number of clients: 4 number of threads: 4 duration: 10s > number of transactions actually processed: 14563 > latency average = 2.749 ms > tps = 1454.899150 (including connections establishing) > tps = 1466.689412 (excluding connections establishing) > > > If this output doesn't bother people, then I suggest that this patch > should put the partition information in the line together with scaling > factor. > IIUC, there are two things here (a) you seem to be fine displaying 'partitions' and 'partition method' information, (b) you would prefer to put it along with 'scaling factor' line. I personally prefer each parameter to be displayed in a separate line, but I am fine if more people would like to see the 'multiple parameters information in a single line'. I think it is better to that (point (b)) as a separate patch even if we agree on changing the display format. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Fri, Sep 13, 2019 at 11:06 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > Hello Amit, > > >>> + res = PQexec(con, > >>> + "select p.partstrat, count(*) " > >>> + "from pg_catalog.pg_class as c " > >>> + "left join pg_catalog.pg_partitioned_table as p on (p.partrelid = c.oid) " > >>> + "left join pg_catalog.pg_inherits as i on (c.oid = i.inhparent) " > >>> + "where c.relname = 'pgbench_accounts' " > >>> + "group by 1, c.oid"); > >>> > >>> Can't we write this query with inner join instead of left join? What > >>> additional purpose you are trying to serve by using left join? > >> > >> I'm ensuring that there is always a one line answer, whether it is > >> partitioned or not. Maybe the count(*) should be count(something in p) to > >> get 0 instead of 1 on non partitioned tables, though, but this is hidden > >> in the display anyway. > > > > Sure, but I feel the code will be simplified. I see no reason for > > using left join here. > > Without a left join, the query result is empty if there are no partitions, > whereas there is one line with it. This fact simplifies managing the query > result afterwards because we are always expecting 1 row in the "normal" > case, whether partitioned or not. > Why can't we change it as attached? I find using left join to always get one row as an ugly way to manipulate the results later. We shouldn't go in that direction unless we can't handle this with some simple code. Some more comments: * - '--initialize --init-steps=dtpvg --scale=1 --unlogged-tables --fillfactor=98 --foreign-keys --quiet --tablespace=pg_default --index-tablespace=pg_default', + '--initialize --init-steps=dtpvg --scale=1 --unlogged-tables --fillfactor=98 --foreign-keys --quiet --tablespace=regress_pgbench_tap_1_ts --index-tablespace=regress_pgbench_tap_1_ts --partitions=2 --partition-method=hash', What is the need of using regress_pgbench_tap_1_ts in this test? I think we don't need to change existing tests unless required for the new functionality. * - 'pgbench scale 1 initialization'); + 'pgbench scale 1 initialization with options'); Similar to the above, it is not clear to me why we need to change this? *pgbench( - # given the expected rate and the 2 ms tx duration, at most one is executed '-t 10 --rate=100000 --latency-limit=1 -n -r', 0, The above appears to be a spurious line change. * I think we need to change the docs [1] to indicate the new step for partitioning. See section --init-steps=init_steps [1] - https://www.postgresql.org/docs/devel/pgbench.html -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Attachment
Hello Amit, >>>> I'm ensuring that there is always a one line answer, whether it is >>>> partitioned or not. Maybe the count(*) should be count(something in p) to >>>> get 0 instead of 1 on non partitioned tables, though, but this is hidden >>>> in the display anyway. >>> >>> Sure, but I feel the code will be simplified. I see no reason for >>> using left join here. >> >> Without a left join, the query result is empty if there are no partitions, >> whereas there is one line with it. This fact simplifies managing the query >> result afterwards because we are always expecting 1 row in the "normal" >> case, whether partitioned or not. > > Why can't we change it as attached? I think that your version works, but I do not like much the condition for the normal case which is implicitely assumed. The solution I took has 3 clear-cut cases: 1 error against a server without partition support, detect multiple pgbench_accounts table -- argh, and then the normal expected case, whether partitioned or not. Your solution has 4 cases because of the last implicit zero-row select that relies on default, which would need some explanations. > I find using left join to always get one row as an ugly way to > manipulate the results later. Hmmm. It is really a matter of taste. I do not share your distate for left join on principle. In the case at hand, I find that getting one row in all cases pretty elegant because there is just one code for handling them all. > We shouldn't go in that direction unless we can't handle this with some > simple code. Hmmm. Left join does not strike me as over complex code. I wish my student would remember that this thing exists:-) > What is the need of using regress_pgbench_tap_1_ts in this test? I wanted to check that tablespace options work appropriately with partition tables, as I changed the create table stuff significantly, and just using "pg_default" is kind of cheating. > I think we don't need to change existing tests unless required for the > new functionality. I do agree, but there was a motivation behind the addition. > * > - 'pgbench scale 1 initialization'); > + 'pgbench scale 1 initialization with options'); > > Similar to the above, it is not clear to me why we need to change this? Because I noticed that it had the same description as the previous one, so I made the test name distinct and more precise, while I was adding options on it. > *pgbench( > - > # given the expected rate and the 2 ms tx duration, at most one is executed > '-t 10 --rate=100000 --latency-limit=1 -n -r', > 0, > > The above appears to be a spurious line change. Indeed. I think that this empty line is a typo, but I can let it as it is. > * I think we need to change the docs [1] to indicate the new step for > partitioning. See section --init-steps=init_steps > > [1] - https://www.postgresql.org/docs/devel/pgbench.html The partitioned table generation is integrated into the existing create table step, it is not a separate step because I cannot see an interest to do something in between the table creations. Patch v8 attached adds some comments around partition detection, ensures that 0 is returned for the no partition case and let the spurious empty line where it is. -- Fabien.
Attachment
On Sat, Sep 14, 2019 at 6:35 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
> >>>> I'm ensuring that there is always a one line answer, whether it is
> >>>> partitioned or not. Maybe the count(*) should be count(something in p) to
> >>>> get 0 instead of 1 on non partitioned tables, though, but this is hidden
> >>>> in the display anyway.
> >>>
> >>> Sure, but I feel the code will be simplified. I see no reason for
> >>> using left join here.
> >>
> >> Without a left join, the query result is empty if there are no partitions,
> >> whereas there is one line with it. This fact simplifies managing the query
> >> result afterwards because we are always expecting 1 row in the "normal"
> >> case, whether partitioned or not.
> >
> > Why can't we change it as attached?
>
> I think that your version works, but I do not like much the condition for
> the normal case which is implicitely assumed. The solution I took has 3
> clear-cut cases: 1 error against a server without partition support,
> detect multiple pgbench_accounts table -- argh, and then the normal
> expected case, whether partitioned or not. Your solution has 4 cases
> because of the last implicit zero-row select that relies on default, which
> would need some explanations.
>
Why? Here, we are fetching the partitioning information. If it
exists, then we remember that to display for later, otherwise, the
default should apply.
> > I find using left join to always get one row as an ugly way to
> > manipulate the results later.
>
> Hmmm. It is really a matter of taste. I do not share your distate for left
> join on principle.
>
Oh no, I am not generally against using left join, but here it appears
like using it without much need. If nothing else, it will consume
more cycles to fetch one extra row when we can avoid it.
Irrespective of whether we use left join or not, I think the below
change from my patch is important.
- /* only print partitioning information if some partitioning was detected */
- if (partition_method != PART_NONE && partition_method != PART_UNKNOWN)
+ /* print partitioning information only if there exists any partition */
+ if (partitions > 0)
Basically, it would be good if we just rely on 'partitions' to decide
whether we have partitions or not.
> In the case at hand, I find that getting one row in all
> cases pretty elegant because there is just one code for handling them all.
>
Hmm, I would be fine if you can show some other place in code where
such a method is used or if someone else also shares your viewpoint.
>
> > What is the need of using regress_pgbench_tap_1_ts in this test?
>
> I wanted to check that tablespace options work appropriately with
> partition tables, as I changed the create table stuff significantly, and
> just using "pg_default" is kind of cheating.
>
I think your change will be tested if there is a '--tablespace'
option. Even if you want to test win non-default tablespace, then
also, adding additional test would make more sense rather than
changing existing one which is testing a valid thing. Also, there is
an existing way to create tablespace location in
"src/bin/pg_checksums/t/002_actions". I think we can use the same. I
don't find any problem with your way, but why having multiple ways of
doing same thing in code. We need to test this on windows also once
as this involves some path creation which might vary, although I don't
think there should be any problem in that especially if we use
existing way.
> > I think we don't need to change existing tests unless required for the
> > new functionality.
>
> I do agree, but there was a motivation behind the addition.
>
> > *
> > - 'pgbench scale 1 initialization');
> > + 'pgbench scale 1 initialization with options');
> >
> > Similar to the above, it is not clear to me why we need to change this?
>
> Because I noticed that it had the same description as the previous one, so
> I made the test name distinct and more precise, while I was adding options
> on it.
>
Good observation, but better be done separately. I think in general
the more unrelated changes are present in patch, the more time it
takes to review.
One more comment:
+typedef enum { PART_NONE, PART_RANGE, PART_HASH, PART_UNKNOWN }
+ partition_method_t;
See, if we can eliminate PART_UNKNOWN. I don't see much use of same.
It is used at one place where we can set PART_NONE without much loss.
Having lesser invalid values makes code easier to follow.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Tue, Sep 17, 2019 at 4:24 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Sat, Sep 14, 2019 at 6:35 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
> One more comment:
> +typedef enum { PART_NONE, PART_RANGE, PART_HASH, PART_UNKNOWN }
> + partition_method_t;
>
> See, if we can eliminate PART_UNKNOWN. I don't see much use of same.
> It is used at one place where we can set PART_NONE without much loss.
> Having lesser invalid values makes code easier to follow.
>
Looking more closely at this case:
+ else if (PQntuples(res) != 1)
+ {
+ /* unsure because multiple (or no) pgbench_accounts found */
+ partition_method = PART_UNKNOWN;
+ partitions = 0;
+ }
Is it ever possible to have multiple pgbench_accounts considering we
have unique index on (relname, relnamespace) for pg_class?
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Hello Amit,
>> One more comment:
>> +typedef enum { PART_NONE, PART_RANGE, PART_HASH, PART_UNKNOWN }
>> + partition_method_t;
>>
>> See, if we can eliminate PART_UNKNOWN.
I'm not very happy with this one, but I wanted to differentiate "we do
know that it is not partitioned" from "we do not know if it is
partitioned", and I did not have a better idea.
> I don't see much use of same.
Although it is not used afterwards, we could display the partitioning
information differently between the two cases. This is not done because I
did not want to add more lines on the "normal" case.
>> It is used at one place where we can set PART_NONE without much loss.
>> Having lesser invalid values makes code easier to follow.
>
> Looking more closely at this case:
> + else if (PQntuples(res) != 1)
> + {
> + /* unsure because multiple (or no) pgbench_accounts found */
> + partition_method = PART_UNKNOWN;
> + partitions = 0;
> + }
>
> Is it ever possible to have multiple pgbench_accounts considering we
> have unique index on (relname, relnamespace) for pg_class?
The issue is that it is not directly obvious which relnamespace will be
used by the queries which rely on non schema qualified "pgbench_accounts".
Each schema could theoretically hold a pgbench_accounts table. As this is
pretty unlikely, I did not attempt to add complexity to resolve taking
into account the search_path, but just skipped to unknown in this case,
which I expect nobody would hit in normal circumstances.
Another possible and unlikely issue is that pgbench_accounts could have
been deleted but not pgbench_branches which is used earlier to get the
current "scale". If so, the queries will fail later on anyway.
--
Fabien.
Hello Amit,
>>> Why can't we change it as attached?
>>
>> I think that your version works, but I do not like much the condition for
>> the normal case which is implicitely assumed. The solution I took has 3
>> clear-cut cases: 1 error against a server without partition support,
>> detect multiple pgbench_accounts table -- argh, and then the normal
>> expected case, whether partitioned or not. Your solution has 4 cases
>> because of the last implicit zero-row select that relies on default, which
>> would need some explanations.
>
> Why?
Hmmm. This is a coding-philosophy question:-)
To be nice to the code reader?
You have several if cases, but the last one is to keep the default *which
means something*. ISTM that the default is kept in two cases: when there
is a pgbench_accounts without partitioning, and when no pgbench_accounts
was found, in which case the defaults are plain false. I could be okay of
the default say "we do not know", but for me having all cases explicitely
covered in one place helps understand the behavior of a code.
> Here, we are fetching the partitioning information. If it exists, then
> we remember that to display for later, otherwise, the default should
> apply.
Yep, but the default is also kept if nothing is found, whereas the left
join solution would give one row when found and empty when not found,
which for me are quite distinct cases.
> Oh no, I am not generally against using left join, but here it appears
> like using it without much need. If nothing else, it will consume
> more cycles to fetch one extra row when we can avoid it.
As pointed out, the left join allows to distinguish "not found" from "not
partitioned" logically, even if no explicit use of that is done
afterwards.
> Irrespective of whether we use left join or not, I think the below
> change from my patch is important.
> - /* only print partitioning information if some partitioning was detected */
> - if (partition_method != PART_NONE && partition_method != PART_UNKNOWN)
> + /* print partitioning information only if there exists any partition */
> + if (partitions > 0)
>
> Basically, it would be good if we just rely on 'partitions' to decide
> whether we have partitions or not.
Could be, although I was thinking of telling the user that we do not know
on unknown. I'll think about this one.
>> In the case at hand, I find that getting one row in all cases pretty
>> elegant because there is just one code for handling them all.
>
> Hmm, I would be fine if you can show some other place in code where
> such a method is used
No problem:-) Although there are no other catalog queries in "pgbench",
there are plenty in "psql" and "pg_dump", and also in some other commands,
and they often rely on "LEFT" joins:
sh> grep LEFT src/bin/psql/*.c | wc -l # 58
sh> grep LEFT src/bin/pg_dump/*.c | wc -l # 54
Note that there are no "RIGHT" nor "FULL" joins…
>>> What is the need of using regress_pgbench_tap_1_ts in this test?
>>
>> I wanted to check that tablespace options work appropriately with
>> partition tables, as I changed the create table stuff significantly, and
>> just using "pg_default" is kind of cheating.
>
> I think your change will be tested if there is a '--tablespace'
> option.
Yes. There is just one, really.
> Even if you want to test win non-default tablespace, then also, adding
> additional test would make more sense rather than changing existing one
> which is testing a valid thing.
Tom tends to think that there are already too many tests, so I try to keep
them as compact/combined as possible. Moreover, the spirit of this test is
to cover "all possible options", so it made also sense to add the new
options there, and it achieves both coverage and testing my changes with
an explicit tablespace.
> Also, there is an existing way to create tablespace location in
> "src/bin/pg_checksums/t/002_actions". I think we can use the same. I
> don't find any problem with your way, but why having multiple ways of
> doing same thing in code. We need to test this on windows also once as
> this involves some path creation which might vary, although I don't
> think there should be any problem in that especially if we use existing
> way.
Ok, I'll look at the pg_checksums way to do that.
>>> - 'pgbench scale 1 initialization');
>>> + 'pgbench scale 1 initialization with options');
>>>
>>> Similar to the above, it is not clear to me why we need to change this?
>>
>> Because I noticed that it had the same description as the previous one,
>> so I made the test name distinct and more precise, while I was adding
>> options on it.
Hmmm. Keeping the same name is really a copy paste error, and I wanted to
avoid a distinct commit for more than very minor thing.
> Good observation, but better be done separately. I think in general
> the more unrelated changes are present in patch, the more time it
> takes to review.
Then let's keep the same name.
> One more comment:
> +typedef enum { PART_NONE, PART_RANGE, PART_HASH, PART_UNKNOWN }
> + partition_method_t;
>
> See, if we can eliminate PART_UNKNOWN. I don't see much use of same.
> It is used at one place where we can set PART_NONE without much loss.
> Having lesser invalid values makes code easier to follow.
Discussed in other mail.
--
Fabien.
On Tue, Sep 17, 2019 at 6:38 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
>
> >> It is used at one place where we can set PART_NONE without much loss.
> >> Having lesser invalid values makes code easier to follow.
> >
> > Looking more closely at this case:
> > + else if (PQntuples(res) != 1)
> > + {
> > + /* unsure because multiple (or no) pgbench_accounts found */
> > + partition_method = PART_UNKNOWN;
> > + partitions = 0;
> > + }
> >
> > Is it ever possible to have multiple pgbench_accounts considering we
> > have unique index on (relname, relnamespace) for pg_class?
>
> The issue is that it is not directly obvious which relnamespace will be
> used by the queries which rely on non schema qualified "pgbench_accounts".
>
It seems to me the patch already uses namespace in the query, so this
should not be a problem here. The part of query is as below:
+ res = PQexec(con,
+ "select p.partstrat, count(p.partrelid) "
+ "from pg_catalog.pg_class as c "
This uses pg_catalog, so it should not have multiple entries for
"pgbench_accounts".
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Attached v9:
- remove the PART_UNKNOWN and use partitions = -1 to tell
that there is an error, and partitions >= 1 to print info
- use search_path to find at most one pgbench_accounts
It still uses left join because I still think that it is appropriate.
I added a lateral to avoid repeating the array_position call
to manage the search_path, and use explicit pg_catalog everywhere.
- let the wrongly repeated test name as is
- somehow use pg_checksums tablespace creation method, however:
- I kept testing that mkdir succeeds
- I kept escaping single quotes, if the path contains a "'"
so the only difference is that on some msys platform it may
avoid some unclear issue.
--
Fabien.
Attachment
On 2019-09-17 20:49, Fabien COELHO wrote: > Attached v9: > > [pgbench-init-partitioned-9.patch] Turns out this patch needed a dos2unix treatment. It's easy to do but it takes time to figure it out (I'm dumb). I for one would be happy to receive patches not so encumbered :) thanks, Erik Rijkers
Hello Erikjan, >> [pgbench-init-partitioned-9.patch] > > Turns out this patch needed a dos2unix treatment. > It's easy to do but it takes time to figure it out (I'm dumb). I for one > would be happy to receive patches not so encumbered :) AFAICR this is usually because your mailer does not conform to MIME spec, which *requires* that text files be sent over with \r\n terminations, so my mailer does it for text/x-diff, and your mailer should translate back EOL for your platform, but it does not, so you have to do it manually. I could edit my /etc/mime.types file to switch patch files to some binary mime type, but it may have side effects on my system, so I refrained. Hoping that mailer writers read and conform to MIME seems desperate. Last time this discussion occured there was no obvious solution beside me switching to another bug-compatible mailer, but this is not really convenient for me. ISTM that the "patch" command accepts these files with warnings. -- Fabien.
Hi Fabien, On Wed, Sep 18, 2019 at 3:49 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote: > Attached v9: Thanks. This seems to work well. Couple of nitpicks on parameter error messages. + fprintf(stderr, "invalid partition type, expecting \"range\" or \"hash\"," How about "partitioning method" instead of "partition type"? + fprintf(stderr, "--partition-method requires actual partitioning with --partitions\n"); Assuming that this error message is to direct the user to fix a mistake they might have inadvertently made in specifying --partitions, I don't think the message is very clear. How about: "--partition-method requires --partitions to be greater than zero" but this wording might suggest to some users that some partitioning methods do allow zero partitions. So, maybe: "specifying --partition-method requires --partitions to be greater than zero" Thanks, Amit
Hello Amit, > + fprintf(stderr, "invalid partition type, > expecting \"range\" or \"hash\"," > > How about "partitioning method" instead of "partition type"? Indeed, this is a left over from a previous version. > + fprintf(stderr, "--partition-method requires actual > partitioning with --partitions\n"); > > [...] "--partition-method requires --partitions to be greater than zero" I think the first suggestion is clear enough. I've put a shorter variant in the same spirit: "--partitions-method requires greater than zero --partitions" Attached v10 fixes both messages. -- Fabien.
Attachment
On Wed, Sep 18, 2019 at 1:02 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote: > */ + res = PQexec(con, + "select o.n, p.partstrat, pg_catalog.count(p.partrelid) " + "from pg_catalog.pg_class as c " + "join pg_catalog.pg_namespace as n on (n.oid = c.relnamespace) " + "cross join lateral (select pg_catalog.array_position(pg_catalog.current_schemas(true), n.nspname)) as o(n) " + "left join pg_catalog.pg_partitioned_table as p on (p.partrelid = c.oid) " + "left join pg_catalog.pg_inherits as i on (c.oid = i.inhparent) " + /* right name and schema in search_path */ + "where c.relname = 'pgbench_accounts' and o.n is not null " + "group by 1, 2 " + "order by 1 asc " I have a question, wouldn't it be sufficient to just group by 1? Are you expecting multiple pgbench_account tables partitioned by different strategy under the same schema? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Sep 18, 2019 at 12:19 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
>
> Attached v9:
>
> - remove the PART_UNKNOWN and use partitions = -1 to tell
> that there is an error, and partitions >= 1 to print info
> - use search_path to find at most one pgbench_accounts
> It still uses left join because I still think that it is appropriate.
> I added a lateral to avoid repeating the array_position call
> to manage the search_path, and use explicit pg_catalog everywhere.
It would be good if you can add some more comments to explain the
intent of query.
Few more comments:
*
else
+ {
+ /* PQntupes(res) == 1: normal case, extract the partition status */
+ char *ps = PQgetvalue(res, 0, 1);
+
+ if (ps == NULL)
+ partition_method = PART_NONE;
When can we expect ps as NULL? If this is not a valid case, then
probably and Assert would be better.
*
+ else if (PQntuples(res) == 0)
+ {
+ /* no pgbench_accounts found, builtin script should fail later */
+ partition_method = PART_NONE;
+ partitions = -1;
+ }
If we don't find pgbench_accounts, let's give error here itself rather
than later unless you have a valid case in mind.
*
+
+ /*
+ * Partition information. Assume no partitioning on any failure, so as
+ * to avoid failing on an older version.
+ */
..
+ if (PQresultStatus(res) != PGRES_TUPLES_OK)
+ {
+ /* probably an older version, coldly assume no partitioning */
+ partition_method = PART_NONE;
+ partitions = 0;
+ }
So, here we are silently absorbing the error when pgbench is executed
against older server version which doesn't support partitioning. If
that is the case, then I think if user gives --partitions for the old
server version, it will also give an error? It is not clear in
documentation whether we support or not using pgbench with older
server versions. I guess it didn't matter, but with this feature, it
can matter. Do we need to document this?
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
> + "group by 1, 2 " > > I have a question, wouldn't it be sufficient to just group by 1? Conceptually yes, it is what is happening in practice, but SQL requires that non aggregated columns must appear explicitely in the GROUP BY clause, so I have to put it even if it will not change groups. -- Fabien.
Hello Amit,
>> - use search_path to find at most one pgbench_accounts
>> It still uses left join because I still think that it is appropriate.
>> I added a lateral to avoid repeating the array_position call
>> to manage the search_path, and use explicit pg_catalog everywhere.
>
> It would be good if you can add some more comments to explain the
> intent of query.
Indeed, I put too few comments on the query.
> + if (ps == NULL)
> + partition_method = PART_NONE;
>
> When can we expect ps as NULL? If this is not a valid case, then
> probably and Assert would be better.
No, ps is really NULL if there is no partitioning, because of the LEFT
JOIN and pg_partitioned_table is just empty in that case.
The last else where there is an unexpected entry is different, see
comments about v11 below.
> + else if (PQntuples(res) == 0)
> + {
> + /* no pgbench_accounts found, builtin script should fail later */
> + partition_method = PART_NONE;
> + partitions = -1;
>
> If we don't find pgbench_accounts, let's give error here itself rather
> than later unless you have a valid case in mind.
I thought of it, but decided not to: Someone could add a builtin script
which does not use pgbench_accounts, or a parallel running script could
create a table dynamically, whatever, so I prefer the error to be raised
by the script itself, rather than deciding that it will fail before even
trying.
> + /*
> + * Partition information. Assume no partitioning on any failure, so as
> + * to avoid failing on an older version.
> + */
> ..
> + if (PQresultStatus(res) != PGRES_TUPLES_OK)
> + {
> + /* probably an older version, coldly assume no partitioning */
> + partition_method = PART_NONE;
> + partitions = 0;
> + }
>
> So, here we are silently absorbing the error when pgbench is executed
> against older server version which doesn't support partitioning.
Yes, exactly.
> If that is the case, then I think if user gives --partitions for the old
> server version, it will also give an error?
Yes, on -i it will fail because the syntax will not be recognized.
> It is not clear in documentation whether we support or not using pgbench
> with older server versions.
Indeed. We more or less do in practice. Command "psql" works back to 8
AFAICR, and pgbench as well.
> I guess it didn't matter, but with this feature, it can matter. Do we
> need to document this?
This has been discussed in the past, and the conclusion was that it was
not worth the effort. We just try not to break things if it is avoidable.
On this regard, the patch slightly changes FILLFACTOR output, which is
removed if the value is 100 (%) as it is the default, which means that
table creation would work on very very old version which did not support
fillfactor, unless you specify a lower percentage.
Attached v11:
- add quite a few comments on the pg_catalog query
- reverts the partitions >= 1 test; If some new partition method is
added that pgbench does not know about, the failure mode will be that
nothing is printed rather than printing something strange like
"method none with 2 partitions".
--
Fabien.
Attachment
Hi Fabien,
On Thu, Sep 19, 2019 at 2:03 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
> > If that is the case, then I think if user gives --partitions for the old
> > server version, it will also give an error?
>
> Yes, on -i it will fail because the syntax will not be recognized.
Maybe we should be checking the server version, which would allow to
produce more useful error messages when these options are used against
older servers, like
if (sversion < 10000)
fprintf(stderr, "cannot use --partitions/--partitions-method
against servers older than 10");
We would also have to check that partition-method=hash is not used against v10.
Maybe overkill?
Thanks,
Amit
Hello Amit, >> Yes, on -i it will fail because the syntax will not be recognized. > > Maybe we should be checking the server version, which would allow to > produce more useful error messages when these options are used against > older servers, like > > if (sversion < 10000) > fprintf(stderr, "cannot use --partitions/--partitions-method > against servers older than 10"); > > We would also have to check that partition-method=hash is not used against v10. > > Maybe overkill? Yes, I think so: the error detection and messages would be more or less replicated from the server and would vary from version to version. I do not think that it is worth going this path because the use case is virtually void as people in 99.9% of cases would use a pgbench matching the server version. For those who do not, the error message should be clear enough to let them guess what the issue is. Also, it would be untestable. One thing we could eventually do is just to check pgbench version against the server version like psql does and output a generic warning if they differ, but franckly I do not think it is worth the effort: ISTM that nobody ever complained about such issues. Also, that would be matter for another patch. -- Fabien.
On Wed, Sep 18, 2019 at 10:33 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
>
> Hello Amit,
>
> >> - use search_path to find at most one pgbench_accounts
> >> It still uses left join because I still think that it is appropriate.
> >> I added a lateral to avoid repeating the array_position call
> >> to manage the search_path, and use explicit pg_catalog everywhere.
> >
> > It would be good if you can add some more comments to explain the
> > intent of query.
>
> Indeed, I put too few comments on the query.
>
> > + if (ps == NULL)
> > + partition_method = PART_NONE;
> >
> > When can we expect ps as NULL? If this is not a valid case, then
> > probably and Assert would be better.
>
> No, ps is really NULL if there is no partitioning, because of the LEFT
> JOIN and pg_partitioned_table is just empty in that case.
>
'ps' itself won't be NULL in that case, the value it contains is NULL.
I have debugged this case as well. 'ps' itself can be NULL only when
you pass wrong column number or something like that to PQgetvalue.
> The last else where there is an unexpected entry is different, see
> comments about v11 below.
>
> > + else if (PQntuples(res) == 0)
> > + {
> > + /* no pgbench_accounts found, builtin script should fail later */
> > + partition_method = PART_NONE;
> > + partitions = -1;
> >
> > If we don't find pgbench_accounts, let's give error here itself rather
> > than later unless you have a valid case in mind.
>
> I thought of it, but decided not to: Someone could add a builtin script
> which does not use pgbench_accounts, or a parallel running script could
> create a table dynamically, whatever, so I prefer the error to be raised
> by the script itself, rather than deciding that it will fail before even
> trying.
>
I think this is not a possibility today and I don't know of the
future. I don't think it is a good idea to add code which we can't
reach today. You can probably add Assert if required.
> > + /*
> > + * Partition information. Assume no partitioning on any failure, so as
> > + * to avoid failing on an older version.
> > + */
> > ..
> > + if (PQresultStatus(res) != PGRES_TUPLES_OK)
> > + {
> > + /* probably an older version, coldly assume no partitioning */
> > + partition_method = PART_NONE;
> > + partitions = 0;
> > + }
> >
> > So, here we are silently absorbing the error when pgbench is executed
> > against older server version which doesn't support partitioning.
>
> Yes, exactly.
>
> > If that is the case, then I think if user gives --partitions for the old
> > server version, it will also give an error?
>
> Yes, on -i it will fail because the syntax will not be recognized.
>
> > It is not clear in documentation whether we support or not using pgbench
> > with older server versions.
>
> Indeed. We more or less do in practice. Command "psql" works back to 8
> AFAICR, and pgbench as well.
>
> > I guess it didn't matter, but with this feature, it can matter. Do we
> > need to document this?
>
> This has been discussed in the past, and the conclusion was that it was
> not worth the effort. We just try not to break things if it is avoidable.
> On this regard, the patch slightly changes FILLFACTOR output, which is
> removed if the value is 100 (%) as it is the default, which means that
> table creation would work on very very old version which did not support
> fillfactor, unless you specify a lower percentage.
>
Hmm, why you need to change the fill factor behavior? If it is not
specifically required for the functionality of this patch, then I
suggest keeping that behavior as it is.
> Attached v11:
>
> - add quite a few comments on the pg_catalog query
>
> - reverts the partitions >= 1 test; If some new partition method is
> added that pgbench does not know about, the failure mode will be that
> nothing is printed rather than printing something strange like
> "method none with 2 partitions".
>
but how will that new partition method will be associated with a table
created via pgbench? I think the previous check was good because it
makes partition checking consistent throughout the patch.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Thu, Sep 19, 2019 at 10:25 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote: > Hello Amit, > > >> Yes, on -i it will fail because the syntax will not be recognized. > > > > Maybe we should be checking the server version, which would allow to > > produce more useful error messages when these options are used against > > older servers, like > > > > if (sversion < 10000) > > fprintf(stderr, "cannot use --partitions/--partitions-method > > against servers older than 10"); > > > > We would also have to check that partition-method=hash is not used against v10. > > > > Maybe overkill? > > Yes, I think so: the error detection and messages would be more or less > replicated from the server and would vary from version to version. > Yeah, but I think Amit L's point is worth considering. I think it would be good if a few other people can also share their suggestion on this point. Alvaro, Dilip, anybody else following this thread, would like to comment? It is important to know others opinion on this because this will change how pgbench behaves with prior versions. > I do not think that it is worth going this path because the use case is > virtually void as people in 99.9% of cases would use a pgbench matching > the server version. Fair enough, but there is no restriction of using it with prior versions. In fact some people might want to use this with v11 where partitioning was present. So, we shouldn't ignore this point. > One thing we could eventually do is just to check pgbench version against > the server version like psql does and output a generic warning if they > differ, but franckly I do not think it is worth the effort: > Yeah and even if we want to do something like that, it should not be part of this patch. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Hi Fabien, On Thu, Sep 19, 2019 at 1:55 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote: > Hello Amit, > > >> Yes, on -i it will fail because the syntax will not be recognized. > > > > Maybe we should be checking the server version, which would allow to > > produce more useful error messages when these options are used against > > older servers, like > > > > if (sversion < 10000) > > fprintf(stderr, "cannot use --partitions/--partitions-method > > against servers older than 10"); > > > > We would also have to check that partition-method=hash is not used against v10. > > > > Maybe overkill? > > Yes, I think so: the error detection and messages would be more or less > replicated from the server and would vary from version to version. > > I do not think that it is worth going this path because the use case is > virtually void as people in 99.9% of cases would use a pgbench matching > the server version. For those who do not, the error message should be > clear enough to let them guess what the issue is. Also, it would be > untestable. Okay, I can understand the desire to not add code for rarely occurring situations where the server's error is a good enough clue. > One thing we could eventually do is just to check pgbench version against > the server version like psql does and output a generic warning if they > differ, but franckly I do not think it is worth the effort: ISTM that > nobody ever complained about such issues. Agree. Thanks, Amit
On Thu, Sep 19, 2019 at 11:47 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Sep 19, 2019 at 10:25 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > Hello Amit, > > > > >> Yes, on -i it will fail because the syntax will not be recognized. > > > > > > Maybe we should be checking the server version, which would allow to > > > produce more useful error messages when these options are used against > > > older servers, like > > > > > > if (sversion < 10000) > > > fprintf(stderr, "cannot use --partitions/--partitions-method > > > against servers older than 10"); > > > > > > We would also have to check that partition-method=hash is not used against v10. > > > > > > Maybe overkill? > > > > Yes, I think so: the error detection and messages would be more or less > > replicated from the server and would vary from version to version. > > > > Yeah, but I think Amit L's point is worth considering. I think it > would be good if a few other people can also share their suggestion on > this point. Alvaro, Dilip, anybody else following this thread, would > like to comment? It is important to know others opinion on this > because this will change how pgbench behaves with prior versions. IMHO, we don't need to invent the error handling at the pgbench instead we can rely on the server's error. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Hello Amit, > [...] 'ps' itself won't be NULL in that case, the value it contains is > NULL. I have debugged this case as well. 'ps' itself can be NULL only > when you pass wrong column number or something like that to PQgetvalue. Argh, you are right! I mixed up C NULL and SQL NULL:-( >>> If we don't find pgbench_accounts, let's give error here itself rather >>> than later unless you have a valid case in mind. >> >> I thought of it, but decided not to: Someone could add a builtin script >> which does not use pgbench_accounts, or a parallel running script could >> create a table dynamically, whatever, so I prefer the error to be raised >> by the script itself, rather than deciding that it will fail before even >> trying. > > I think this is not a possibility today and I don't know of the > future. I don't think it is a good idea to add code which we can't > reach today. You can probably add Assert if required. I added a fail on an unexpected partition method, i.e. not 'r' or 'h', and an Assert of PQgetvalue returns NULL. I fixed the query so that it counts actual partitions, otherwise I was getting one for a partitioned table without partitions attached, which does not generate an error by the way. I just figured out that pgbench does not check that UPDATE updates anything. Hmmm. > Hmm, why you need to change the fill factor behavior? If it is not > specifically required for the functionality of this patch, then I > suggest keeping that behavior as it is. The behavior is not actually changed, but I had to move fillfactor away because it cannot be declared on partitioned tables, it must be declared on partitions only. Once there is a function to handle that it is pretty easy to add the test. I can remove it but franckly there are only benefits: the default is now tested by pgbench, the create query is smaller, and it would work with older versions of pg, which does not matter but is good on principle. >> added that pgbench does not know about, the failure mode will be that >> nothing is printed rather than printing something strange like >> "method none with 2 partitions". > > but how will that new partition method will be associated with a table > created via pgbench? The user could do a -i with a version of pgbench and bench with another one. I do that often while developing… > I think the previous check was good because it makes partition checking > consistent throughout the patch. This case now generates a fail. v12: - fixes NULL vs NULL - works correctly with a partitioned table without partitions attached - generates an error if the partition method is unknown - adds an assert -- Fabien.
Attachment
On Fri, Sep 20, 2019 at 12:41 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > This case now generates a fail. > > v12: > - fixes NULL vs NULL > - works correctly with a partitioned table without partitions attached > - generates an error if the partition method is unknown > - adds an assert > You seem to have attached some previous version (v2) of this patch. I could see old issues in the patch which we have sorted out in the review. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Fri, Sep 20, 2019 at 12:41 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
>
> Hello Amit,
>
> > [...] 'ps' itself won't be NULL in that case, the value it contains is
> > NULL. I have debugged this case as well. 'ps' itself can be NULL only
> > when you pass wrong column number or something like that to PQgetvalue.
>
> Argh, you are right! I mixed up C NULL and SQL NULL:-(
>
> >>> If we don't find pgbench_accounts, let's give error here itself rather
> >>> than later unless you have a valid case in mind.
> >>
> >> I thought of it, but decided not to: Someone could add a builtin script
> >> which does not use pgbench_accounts, or a parallel running script could
> >> create a table dynamically, whatever, so I prefer the error to be raised
> >> by the script itself, rather than deciding that it will fail before even
> >> trying.
> >
> > I think this is not a possibility today and I don't know of the
> > future. I don't think it is a good idea to add code which we can't
> > reach today. You can probably add Assert if required.
>
> I added a fail on an unexpected partition method, i.e. not 'r' or 'h',
> and an Assert of PQgetvalue returns NULL.
>
> I fixed the query so that it counts actual partitions, otherwise I was
> getting one for a partitioned table without partitions attached, which
> does not generate an error by the way. I just figured out that pgbench
> does not check that UPDATE updates anything. Hmmm.
>
> > Hmm, why you need to change the fill factor behavior? If it is not
> > specifically required for the functionality of this patch, then I
> > suggest keeping that behavior as it is.
>
> The behavior is not actually changed, but I had to move fillfactor away
> because it cannot be declared on partitioned tables, it must be declared
> on partitions only. Once there is a function to handle that it is pretty
> easy to add the test.
>
> I can remove it but franckly there are only benefits: the default is now
> tested by pgbench, the create query is smaller, and it would work with
> older versions of pg, which does not matter but is good on principle.
>
I am not saying that it is a bad check on its own, rather it might be
good, but let's not do any unrelated change as that will delay the
main patch. Once, we are done with the main patch, you can propose
these as improvements.
> >> added that pgbench does not know about, the failure mode will be that
> >> nothing is printed rather than printing something strange like
> >> "method none with 2 partitions".
> >
> > but how will that new partition method will be associated with a table
> > created via pgbench?
>
> The user could do a -i with a version of pgbench and bench with another
> one. I do that often while developing…
>
I am not following what you want to say here especially ("pgbench and
bench with another one"). Can you explain with some example?
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
>> v12: >> - fixes NULL vs NULL >> - works correctly with a partitioned table without partitions attached >> - generates an error if the partition method is unknown >> - adds an assert > > You seem to have attached some previous version (v2) of this patch. I > could see old issues in the patch which we have sorted out in the > review. Indeed. This is a change from forgetting the attachement. Here is v12. Hopefully. -- Fabien.
Attachment
>> The behavior is not actually changed, but I had to move fillfactor away
>> because it cannot be declared on partitioned tables, it must be declared
>> on partitions only. Once there is a function to handle that it is pretty
>> easy to add the test.
>>
>> I can remove it but franckly there are only benefits: the default is now
>> tested by pgbench, the create query is smaller, and it would work with
>> older versions of pg, which does not matter but is good on principle.
>
> I am not saying that it is a bad check on its own, rather it might be
> good, but let's not do any unrelated change as that will delay the
> main patch. Once, we are done with the main patch, you can propose
> these as improvements.
I would not bother to create a patch for so small an improvement. This
makes sense in passing because the created function makes it very easy,
but otherwise I'll just drop it.
>> The user could do a -i with a version of pgbench and bench with another
>> one. I do that often while developing…
>
> I am not following what you want to say here especially ("pgbench and
> bench with another one"). Can you explain with some example?
While developing, I often run pgbench under development client against an
already created set of tables on an already created cluster, and usually
the server side on my laptop is the last major release from pgdg (ie 11.5)
while the pgbench I'm testing is from sources (ie 12dev). If I type
"pgbench" I run 11.5, and in the sources "./pgbench" runs the dev version.
--
Fabien.
On Fri, Sep 20, 2019 at 10:29 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
> >> The behavior is not actually changed, but I had to move fillfactor away
> >> because it cannot be declared on partitioned tables, it must be declared
> >> on partitions only. Once there is a function to handle that it is pretty
> >> easy to add the test.
> >>
> >> I can remove it but franckly there are only benefits: the default is now
> >> tested by pgbench, the create query is smaller, and it would work with
> >> older versions of pg, which does not matter but is good on principle.
> >
> > I am not saying that it is a bad check on its own, rather it might be
> > good, but let's not do any unrelated change as that will delay the
> > main patch. Once, we are done with the main patch, you can propose
> > these as improvements.
>
> I would not bother to create a patch for so small an improvement. This
> makes sense in passing because the created function makes it very easy,
> but otherwise I'll just drop it.
>
I would prefer to drop for now.
> >> The user could do a -i with a version of pgbench and bench with another
> >> one. I do that often while developing…
> >
> > I am not following what you want to say here especially ("pgbench and
> > bench with another one"). Can you explain with some example?
>
> While developing, I often run pgbench under development client against an
> already created set of tables on an already created cluster, and usually
> the server side on my laptop is the last major release from pgdg (ie 11.5)
> while the pgbench I'm testing is from sources (ie 12dev). If I type
> "pgbench" I run 11.5, and in the sources "./pgbench" runs the dev version.
>
Hmm, I think some such thing is possible when you are running pgbench
of lower version with tables initialized by some higher version of
pgbench. Because higher version pgbench must be a superset of lower
version unless we drop support for one of the partitioning method. I
think even if there is some unknown partition method, it should be
detected much earlier rather than reaching the stage of printing the
results like after the query for partitions in below code.
+ else
+ {
+ fprintf(stderr, "unexpected partition method: \"%s\"\n", ps);
+ exit(1);
+ }
If we can't catch that earlier, then it might be better to have some
version-specific checks rather than such obscure code which is
difficult to understand for others.
I have made a few modifications in the attached patch.
* move the create partitions related code into a separate function.
* make the check related to number of partitions consistent i.e check
partitions > 0 apart from where we print which I also want to change
but let us first discuss one of the above points
* when we don't found pgbench_accounts table, error out instead of continuing
* ensure append_fillfactor doesn't assume that it has to append
fillfactor and removed fillfactor < 100 check from it.
* improve the comments around query to fetch partitions
* improve the comments in the patch and make the code look like nearby code
* pgindent the patch
I think we should try to add some note or comment that why we only
choose to partition pgbench_accounts table when the user has given
--partitions option.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Attachment
Hello Amit,
>> I would not bother to create a patch for so small an improvement. This
>> makes sense in passing because the created function makes it very easy,
>> but otherwise I'll just drop it.
>
> I would prefer to drop for now.
Attached v13 does that, I added a comment instead. I do not think that it
is an improvement.
> + else
> + {
> + fprintf(stderr, "unexpected partition method: \"%s\"\n", ps);
> + exit(1);
> + }
>
> If we can't catch that earlier, then it might be better to have some
> version-specific checks rather than such obscure code which is
> difficult to understand for others.
Hmmm. The code simply checks for the current partitioning and fails if the
result is unknown, which I understood was what you asked, the previous
version was just ignoring the result.
The likelyhood of postgres dropping support for range or hash partitions
seems unlikely.
This issue rather be raised if an older partition-enabled pgbench is run
against a newer postgres which adds a new partition method. But then I
cannot guess when a new partition method will be added, so I cannot put a
guard with a version about something in the future. Possibly, if no new
method is ever added, the code will never be triggered.
> I have made a few modifications in the attached patch.
> * move the create partitions related code into a separate function.
Why not. Not sure it is an improvement.
> * make the check related to number of partitions consistent i.e check
> partitions > 0 apart from where we print which I also want to change
> but let us first discuss one of the above points
I switched two instances of >= 1 to > 0, which had 1 instance before.
> * when we don't found pgbench_accounts table, error out instead of continuing
I do not think that it is a a good idea, but I did it anyway to move
things forward.
> * ensure append_fillfactor doesn't assume that it has to append
> fillfactor and removed fillfactor < 100 check from it.
Done, which is too bad.
> * improve the comments around query to fetch partitions
What? How?
There are already quite a few comments compared to the length of the
query.
> * improve the comments in the patch and make the code look like nearby
> code
This requirement is to fuzzy. I re-read the changes, and both code and
comments look okay to me.
> * pgindent the patch
Done.
> I think we should try to add some note or comment that why we only
> choose to partition pgbench_accounts table when the user has given
> --partitions option.
Added as a comment on the initPartition function.
--
Fabien.
Attachment
On Sat, Sep 21, 2019 at 12:26 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
> >> I would not bother to create a patch for so small an improvement. This
> >> makes sense in passing because the created function makes it very easy,
> >> but otherwise I'll just drop it.
> >
> > I would prefer to drop for now.
>
> Attached v13 does that, I added a comment instead. I do not think that it
> is an improvement.
>
> > + else
> > + {
> > + fprintf(stderr, "unexpected partition method: \"%s\"\n", ps);
> > + exit(1);
> > + }
> >
> > If we can't catch that earlier, then it might be better to have some
> > version-specific checks rather than such obscure code which is
> > difficult to understand for others.
>
> Hmmm. The code simply checks for the current partitioning and fails if the
> result is unknown, which I understood was what you asked, the previous
> version was just ignoring the result.
>
Yes, this code is correct. I am not sure if you understood the point,
so let me try again. I am bothered about below code in the patch:
+ /* only print partitioning information if some partitioning was detected */
+ if (partition_method != PART_NONE)
This is the only place now where we check 'whether there are any
partitions' differently. I am suggesting to make this similar to
other checks (if (partitions > 0)).
> The likelyhood of postgres dropping support for range or hash partitions
> seems unlikely.
>
> This issue rather be raised if an older partition-enabled pgbench is run
> against a newer postgres which adds a new partition method. But then I
> cannot guess when a new partition method will be added, so I cannot put a
> guard with a version about something in the future. Possibly, if no new
> method is ever added, the code will never be triggered.
>
Sure, even in that case your older version of pgbench will be able to
detect by below code:
+ else
+ {
+ fprintf(stderr, "unexpected partition method: \"%s\"\n", ps);
+ exit(1);
+ }
>
> > * improve the comments around query to fetch partitions
>
> What? How?
>
> There are already quite a few comments compared to the length of the
> query.
>
Hmm, you have just written what each part of the query is doing which
I think one can identify if we write some general comment as I have in
the patch to explain the overall intent. Even if we write what each
part of the statement is doing, the comment explaining overall intent
is required. I personally don't like writing a comment for each
sub-part of the query as that makes reading the query difficult. See
the patch sent by me in my previous email.
> > * improve the comments in the patch and make the code look like nearby
> > code
>
> This requirement is to fuzzy. I re-read the changes, and both code and
> comments look okay to me.
>
I have done that in some of the cases in the patch attached by me in
my last email. Have you looked at those changes? Try to make those
changes in the next version unless you see something wrong is written
in comments.
> > * pgindent the patch
>
> Done.
>
> > I think we should try to add some note or comment that why we only
> > choose to partition pgbench_accounts table when the user has given
> > --partitions option.
>
> Added as a comment on the initPartition function.
>
I am not sure if something like that is required in the docs, but we
can leave it for now.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Hello Amit, > Yes, this code is correct. I am not sure if you understood the point, > so let me try again. I am bothered about below code in the patch: > + /* only print partitioning information if some partitioning was detected */ > + if (partition_method != PART_NONE) > > This is the only place now where we check 'whether there are any > partitions' differently. I am suggesting to make this similar to > other checks (if (partitions > 0)). As I said somewhere up thread, you can have a partitioned table with zero partitions, and it works fine (yep! the update just does not do anything…) so partitions > 0 is not a good way to know whether there is a partitioned table when running a bench. It is a good way for initialization, though, because we are creating them. sh> pgbench -i --partitions=1 sh> psql -c 'DROP TABLE pgbench_accounts_1' sh> pgbench -T 10 ... transaction type: <builtin: TPC-B (sort of)> scaling factor: 1 partition method: hash partitions: 0 query mode: simple number of clients: 1 number of threads: 1 duration: 10 s number of transactions actually processed: 2314 latency average = 4.323 ms tps = 231.297122 (including connections establishing) tps = 231.549125 (excluding connections establishing) As postgres does not break, there is no good reason to forbid it. > [...] Sure, even in that case your older version of pgbench will be able > to detect by below code [...] "unexpected partition method: " [...]. Yes, that is what I was saying. > Hmm, you have just written what each part of the query is doing which I > think one can identify if we write some general comment as I have in the > patch to explain the overall intent. Even if we write what each part of > the statement is doing, the comment explaining overall intent is > required. There was some comments. > I personally don't like writing a comment for each sub-part of the query > as that makes reading the query difficult. See the patch sent by me in > my previous email. I did not notice there was an attachment. > I have done that in some of the cases in the patch attached by me in > my last email. Have you looked at those changes? Nope, as I was not expected one. > Try to make those changes in the next version unless you see something > wrong is written in comments. I incorporated most of them, although I made them terser, and fixed them when inaccurate. I did not buy moving the condition inside the fillfactor function. See attached v14. -- Fabien.
Attachment
On Sat, Sep 21, 2019 at 1:18 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > Yes, this code is correct. I am not sure if you understood the point, > > so let me try again. I am bothered about below code in the patch: > > + /* only print partitioning information if some partitioning was detected */ > > + if (partition_method != PART_NONE) > > > > This is the only place now where we check 'whether there are any > > partitions' differently. I am suggesting to make this similar to > > other checks (if (partitions > 0)). > > As I said somewhere up thread, you can have a partitioned table with zero > partitions, and it works fine (yep! the update just does not do anything…) > so partitions > 0 is not a good way to know whether there is a partitioned > table when running a bench. It is a good way for initialization, though, > because we are creating them. > > sh> pgbench -i --partitions=1 > sh> psql -c 'DROP TABLE pgbench_accounts_1' > sh> pgbench -T 10 > ... > transaction type: <builtin: TPC-B (sort of)> > scaling factor: 1 > partition method: hash > partitions: 0 > I am not sure how many users would be able to make out that it is a run where actual partitions are not present unless they beforehand know and detect such a condition in their scripts. What is the use of such a run which completes without actual updates? I think it is better if give an error for such a case rather than allowing to execute it and then give some information which doesn't make much sense. > > I incorporated most of them, although I made them terser, and fixed them > when inaccurate. > > I did not buy moving the condition inside the fillfactor function. > I also don't agree with your position. My main concern here is that we can't implicitly assume that fillfactor need to be appended. At the very least we should have a comment saying why we are always appending the fillfactor for partitions, something like I had in my patch. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Hello Amit, >> sh> pgbench -T 10 >> ... >> partitions: 0 > > I am not sure how many users would be able to make out that it is a > run where actual partitions are not present unless they beforehand > know and detect such a condition in their scripts. > What is the use of such a run which completes without actual updates? Why should we decide that they cannot do that? The user could be testing the overhead of no-op updates, which is something interesting, and check what happens with partitioning in this case. For that, they may delete pgbench_accounts contents or its partitions for partitioned version, or only some partitions, or whatever. A valid (future) case is that hopefully dynamic partitioning could be implemented, thus no partitions would be a perfectly legal state even with the standard benchmarking practice. Maybe the user just wrote a clever extension to do that with a trigger and wants to test the performance overhead with pgbench. Fine! IMHO we should not babysit the user by preventing them to run a bench which would not generate any error, so is fundamentaly legal. If running a bench should fail, it should fail while running it, not before even starting. I have already added at your request early failures modes to the patch about which I'm not very happy. Note that I'm mostly okay with warnings, but I know that I do not know what use may be done with pgbench, and I do not want to decide for users. In this case, franckly I would not bother to issue a warning which has a very low probability ever to be raised. > I think it is better if give an error for such a case rather than > allowing to execute it and then give some information which doesn't make > much sense. I strongly disagree, as explained above. >> I incorporated most of them, although I made them terser, and fixed them >> when inaccurate. >> >> I did not buy moving the condition inside the fillfactor function. > > I also don't agree with your position. My main concern here is that > we can't implicitly assume that fillfactor need to be appended. Sure. > At the very least we should have a comment saying why we are always > appending the fillfactor for partitions The patch does not do that, the condition is just before the call, not inside it with a boolean passed as an argument. AFAICS the behavior of v14 is exactly the same as your version and as the initial code. -- Fabien.
On Sun, Sep 22, 2019 at 12:22 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote: > >> sh> pgbench -T 10 > >> ... > >> partitions: 0 > > > > I am not sure how many users would be able to make out that it is a > > run where actual partitions are not present unless they beforehand > > know and detect such a condition in their scripts. > > > What is the use of such a run which completes without actual updates? > > Why should we decide that they cannot do that? > > The user could be testing the overhead of no-op updates, which is > something interesting, and check what happens with partitioning in this > case. For that, they may delete pgbench_accounts contents or its > partitions for partitioned version, or only some partitions, or whatever. > > A valid (future) case is that hopefully dynamic partitioning could be > implemented, thus no partitions would be a perfectly legal state even with > the standard benchmarking practice. Maybe the user just wrote a clever > extension to do that with a trigger and wants to test the performance > overhead with pgbench. Fine! > It is better for a user to write a custom script for such cases. Because after that "select-only" or "simple-update" script doesn't make any sense. In the "select-only" case why would anyone like test fetching zero rows, similarly in "simple-update" case, 2 out of 3 statements will be a no-op. In "tpcb-like" script, 2 out of 5 queries will be no-op and it won't be completely no-op updates as you are telling. Having said that, I see your point and don't mind allowing such cases until we don't have to write special checks in the code to support such cases. Now, we can have a detailed comment in printResults to explain why we have a different check there as compare to other code paths or change other code paths to have a similar check as printResults, but I am not convinced of any of those options. > >> > >> I did not buy moving the condition inside the fillfactor function. > > > > I also don't agree with your position. My main concern here is that > > we can't implicitly assume that fillfactor need to be appended. > > Sure. > > > At the very least we should have a comment saying why we are always > > appending the fillfactor for partitions > > The patch does not do that, the condition is just before the call, not > inside it with a boolean passed as an argument. AFAICS the behavior of v14 > is exactly the same as your version and as the initial code. > Here, I am talking about the call to append_fillfactor in createPartitions() function. See, in my version, there are some comments. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Hello Amit, > It is better for a user to write a custom script for such cases. I kind-of agree, but IMHO this is not for pgbench to decide what is better for the user and to fail on a script that would not fail. > Because after that "select-only" or "simple-update" script doesn't > make any sense. [...]. What make sense in a benchmarking context may not be what you think. For instance, AFAICR, I already removed benevolent but misplaced guards which were preventing running scripts without queries: if one wants to look at pgbench overheads because they are warry that it may be too high, they really need to be allowed to run such scripts. This not for us to decide, and as I already said they do if you want to test no-op overheads. Moreover the problem pre-exists: if the user deletes the contents of pgbench_accounts these scripts are no-op, and we do not complain. The no partition attached is just a particular case. > Having said that, I see your point and don't mind allowing such cases > until we don't have to write special checks in the code to support such > cases. Indeed, it is also simpler to not care about such issues in the code. > [...] Now, we can have a detailed comment in printResults to explain why > we have a different check there as compare to other code paths or change > other code paths to have a similar check as printResults, but I am not > convinced of any of those options. Yep. ISTM that the current version is reasonable. > [...] I am talking about the call to append_fillfactor in > createPartitions() function. See, in my version, there are some > comments. Ok, I understand that you want a comment. Patch v15 does that. -- Fabien.
Attachment
On Mon, Sep 23, 2019 at 11:58 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
>
> Hello Amit,
>
> > It is better for a user to write a custom script for such cases.
>
> I kind-of agree, but IMHO this is not for pgbench to decide what is better
> for the user and to fail on a script that would not fail.
>
> > Because after that "select-only" or "simple-update" script doesn't
> > make any sense. [...].
>
> What make sense in a benchmarking context may not be what you think. For
> instance, AFAICR, I already removed benevolent but misplaced guards which
> were preventing running scripts without queries: if one wants to look at
> pgbench overheads because they are warry that it may be too high, they
> really need to be allowed to run such scripts.
>
> This not for us to decide, and as I already said they do if you want to
> test no-op overheads. Moreover the problem pre-exists: if the user deletes
> the contents of pgbench_accounts these scripts are no-op, and we do not
> complain. The no partition attached is just a particular case.
>
> > Having said that, I see your point and don't mind allowing such cases
> > until we don't have to write special checks in the code to support such
> > cases.
>
> Indeed, it is also simpler to not care about such issues in the code.
>
If you agree with this, then why haven't you changed below check in patch:
+ if (partition_method != PART_NONE)
+ printf("partition method: %s\npartitions: %d\n",
+ PARTITION_METHOD[partition_method], partitions);
This is exactly the thing bothering me. It won't be easy for others
to understand why this check for partitioning information is different
from other checks. For you or me, it might be okay as we have
discussed this case, but it won't be apparent to others. This doesn't
buy us much, so it is better to keep this code consistent with other
places that check for partitions.
> > [...] Now, we can have a detailed comment in printResults to explain why
> > we have a different check there as compare to other code paths or change
> > other code paths to have a similar check as printResults, but I am not
> > convinced of any of those options.
>
> Yep. ISTM that the current version is reasonable.
>
> > [...] I am talking about the call to append_fillfactor in
> > createPartitions() function. See, in my version, there are some
> > comments.
>
> Ok, I understand that you want a comment. Patch v15 does that.
>
Thanks!
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Hello Amit,
> {...]
> If you agree with this, then why haven't you changed below check in patch:
>
> + if (partition_method != PART_NONE)
> + printf("partition method: %s\npartitions: %d\n",
> + PARTITION_METHOD[partition_method], partitions);
>
> This is exactly the thing bothering me. It won't be easy for others
> to understand why this check for partitioning information is different
> from other checks.
As I tried to explain with an example, using "partitions > 0" does not
work in this case because you can have a partitioned table with zero
partitions attached while benchmarking, but this cannot happen while
creating.
> For you or me, it might be okay as we have discussed this case, but it
> won't be apparent to others. This doesn't buy us much, so it is better
> to keep this code consistent with other places that check for
> partitions.
Attached uses "partition_method != PART_NONE" consistently, plus an assert
on "partitions > 0" for checking and for triggering the default method at
the end of option processing.
--
Fabien.
Attachment
On Tue, Sep 24, 2019 at 6:59 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
> > For you or me, it might be okay as we have discussed this case, but it
> > won't be apparent to others. This doesn't buy us much, so it is better
> > to keep this code consistent with other places that check for
> > partitions.
>
> Attached uses "partition_method != PART_NONE" consistently, plus an assert
> on "partitions > 0" for checking and for triggering the default method at
> the end of option processing.
>
Okay, I think making the check consistent is a step forward. The
latest patch is not compiling for me. You have used the wrong
variable name in below line:
+ /* Partition pgbench_accounts table */
+ if (partitions_method != PART_NONE && strcmp(ddl->table,
"pgbench_accounts") == 0)
Another point is:
+ else if (PQntuples(res) == 0)
+ {
+ /*
+ * This case is unlikely as pgbench already found "pgbench_branches"
+ * above to compute the scale.
+ */
+ fprintf(stderr,
+ "No pgbench_accounts table found in search_path. "
+ "Perhaps you need to do initialization (\"pgbench -i\") in database
\"%s\"\n", PQdb(con));
We don't recommend to start messages with a capital letter. See
"Upper Case vs. Lower Case" section in docs [1]. It is not that we
have not used it anywhere else, but I think we should try to avoid it.
[1] - https://www.postgresql.org/docs/devel/error-style-guide.html
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
> Okay, I think making the check consistent is a step forward. The > latest patch is not compiling for me. Argh, shame on me! > [...] We don't recommend to start messages with a capital letter. See > "Upper Case vs. Lower Case" section in docs [1]. It is not that we have > not used it anywhere else, but I think we should try to avoid it. Ok. Patch v17 makes both above changes, compiles and passes pgbench TAP tests on my laptop. -- Fabien.
Attachment
pgbench's main() is overly long already, and the new code being added seems to pollute it even more. Can we split it out into a static function that gets placed, say, just below disconnect_all() or maybe after runInitSteps? (Also, we seem to be afraid of function prototypes. Why not move the append_fillfactor() to *below* the functions that use it?) -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hello Alvaro, > pgbench's main() is overly long already, and the new code being added > seems to pollute it even more. Can we split it out into a static > function that gets placed, say, just below disconnect_all() or maybe > after runInitSteps? I agree that refactoring is a good idea, but I do not think it belongs to this patch. The file is pretty long too, probably some functions could be moved to distinct files (eg expression evaluation, variable management, ...). > (Also, we seem to be afraid of function prototypes. Why not move the > append_fillfactor() to *below* the functions that use it?) Because we avoid one more line for the function prototype? I try to put functions in def/use order if possible, especially for small functions like this one. -- Fabien.
On 2019-Sep-26, Fabien COELHO wrote: > > Hello Alvaro, > > > pgbench's main() is overly long already, and the new code being added > > seems to pollute it even more. Can we split it out into a static > > function that gets placed, say, just below disconnect_all() or maybe > > after runInitSteps? > > I agree that refactoring is a good idea, but I do not think it belongs to > this patch. The file is pretty long too, probably some functions could be > moved to distinct files (eg expression evaluation, variable management, > ...). I'm not suggesting to refactor anything as part of this patch -- just that instead of adding that new code to main(), you create a new function for it. > > (Also, we seem to be afraid of function prototypes. Why not move the > > append_fillfactor() to *below* the functions that use it?) > > Because we avoid one more line for the function prototype? I try to put > functions in def/use order if possible, especially for small functions like > this one. I can see that ... I used to do that too. But nowadays I think it's less messy to put important stuff first, secondary uninteresting stuff later. So I suggest to move that new function so that it appears below the code that uses it. Not a big deal anyhow. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Sep 27, 2019 at 2:36 AM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > On 2019-Sep-26, Fabien COELHO wrote: > > > pgbench's main() is overly long already, and the new code being added > > > seems to pollute it even more. Can we split it out into a static > > > function that gets placed, say, just below disconnect_all() or maybe > > > after runInitSteps? > > > > I agree that refactoring is a good idea, but I do not think it belongs to > > this patch. The file is pretty long too, probably some functions could be > > moved to distinct files (eg expression evaluation, variable management, > > ...). > > I'm not suggesting to refactor anything as part of this patch -- just > that instead of adding that new code to main(), you create a new > function for it. > > > > (Also, we seem to be afraid of function prototypes. Why not move the > > > append_fillfactor() to *below* the functions that use it?) > > > > Because we avoid one more line for the function prototype? I try to put > > functions in def/use order if possible, especially for small functions like > > this one. > > I can see that ... I used to do that too. But nowadays I think it's > less messy to put important stuff first, secondary uninteresting stuff > later. So I suggest to move that new function so that it appears below > the code that uses it. Not a big deal anyhow. > Thanks, Alvaro, both seem like good suggestions to me. However, there are a few more things where your feedback can help: a. With new options, we will partition pgbench_accounts and the reason is that because that is the largest table. Do we need to be explicit about the reason in docs? b. I am not comfortable with test modification in 001_pgbench_with_server.pl. Basically, it doesn't seem like we should modify the existing test to use non-default tablespaces as part of this patch. It might be a good idea in general, but I am not sure doing as part of this patch is a good idea as there is no big value addition with that modification as far as this patch is concerned. OTOH, as such there is no harm in testing with non-default tablespaces. The other thing is that the query used in patch to fetch partition information seems correct to me, but maybe there is a better way to get that information. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 2019-Sep-27, Amit Kapila wrote: > Thanks, Alvaro, both seem like good suggestions to me. However, there > are a few more things where your feedback can help: > a. With new options, we will partition pgbench_accounts and the > reason is that because that is the largest table. Do we need to be > explicit about the reason in docs? Hmm, I would document what is it that we do, and stop there without explaining why. Unless you have concrete reasons to want the reason documented? > b. I am not comfortable with test modification in > 001_pgbench_with_server.pl. Basically, it doesn't seem like we should > modify the existing test to use non-default tablespaces as part of > this patch. It might be a good idea in general, but I am not sure > doing as part of this patch is a good idea as there is no big value > addition with that modification as far as this patch is concerned. > OTOH, as such there is no harm in testing with non-default > tablespaces. Yeah, this change certainly is out of place in this patch. > The other thing is that the query used in patch to fetch partition > information seems correct to me, but maybe there is a better way to > get that information. I hadn't looked at that, but yeah it seems that it should be using pg_partition_tree(). -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Sep 27, 2019 at 7:05 PM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > > On 2019-Sep-27, Amit Kapila wrote: > > > The other thing is that the query used in patch to fetch partition > > information seems correct to me, but maybe there is a better way to > > get that information. > > I hadn't looked at that, but yeah it seems that it should be using > pg_partition_tree(). > I think we might also need to use pg_get_partkeydef along with pg_partition_tree to fetch the partition method information. However, I think to find reloid of pgbench_accounts in the current search path, we might need to use some part of query constructed by Fabien. Fabien, what do you think about Alvaro's suggestion? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Hello Amit,
> I think we might also need to use pg_get_partkeydef along with
> pg_partition_tree to fetch the partition method information. However,
> I think to find reloid of pgbench_accounts in the current search path,
> we might need to use some part of query constructed by Fabien.
>
> Fabien, what do you think about Alvaro's suggestion?
I think that the current straightforward SQL query is and works fine, and
I find it pretty elegant. No doubt other solutions could be implemented to
the same effect, with SQL or possibly through introspection functions.
Incidentally, ISTM that "pg_partition_tree" appears in v12, while
partitions exist in v11, so it would break uselessly backward
compatibility of the feature which currently work with v11, which I do not
find desirable.
Attached v18:
- remove the test tablespace
I had to work around a strange issue around partitioned tables and
the default tablespace.
- creates a separate function for setting scale, partitions and
partition_method
--
Fabien.
Attachment
On Sat, Sep 28, 2019 at 11:41 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
>
> Hello Amit,
>
> > I think we might also need to use pg_get_partkeydef along with
> > pg_partition_tree to fetch the partition method information. However,
> > I think to find reloid of pgbench_accounts in the current search path,
> > we might need to use some part of query constructed by Fabien.
> >
> > Fabien, what do you think about Alvaro's suggestion?
>
> I think that the current straightforward SQL query is and works fine, and
> I find it pretty elegant. No doubt other solutions could be implemented to
> the same effect, with SQL or possibly through introspection functions.
>
> Incidentally, ISTM that "pg_partition_tree" appears in v12, while
> partitions exist in v11, so it would break uselessly backward
> compatibility of the feature which currently work with v11, which I do not
> find desirable.
>
Fair enough. Alvaro, do let us know if you think this can be
simplified? I think even if we find some better way to get that
information as compare to what Fabien has done here, we can change it
later without any impact.
> Attached v18:
> - remove the test tablespace
> I had to work around a strange issue around partitioned tables and
> the default tablespace.
- if (tablespace != NULL)
+
+ if (tablespace != NULL && strcmp(tablespace, "pg_default") != 0)
{
- if (index_tablespace != NULL)
+ if (index_tablespace != NULL && strcmp(index_tablespace, "pg_default") != 0)
I don't think such a workaround is a good idea for two reasons (a)
having check on the name ("pg_default") is not advisable, we should
get the tablespace oid and then check if it is same as
DEFAULTTABLESPACE_OID, (b) this will change something which was
previously allowed i.e. to append default tablespace name for the
non-partitioned tables.
I don't think we need any such check, rather if the user gives
default_tablespace with 'partitions' option, then let it fail with an
error "cannot specify default tablespace for partitioned relations".
If we do that then one of the modified pgbench tests will start
failing. I think we have two options here:
(a) Don't test partitions with "all possible options" test and add a
comment on why we are not testing it there.
(b) Create a non-default tablespace to test partitions with "all
possible options" test as you have in your previous version. Also,
add a comment explaining why in that test we are using non-default
tablespace.
I am leaning towards approach (b) unless you and or Alvaro feels (a)
is good for now or if you have some other idea.
If we want to go with option (b), I have small comment in your previous test:
+# tablespace for testing
+my $ts = $node->basedir . '/regress_pgbench_tap_1_ts_dir';
+mkdir $ts or die "cannot create directory $ts";
+my $ets = TestLib::perl2host($ts);
+# add needed escaping!
+$ets =~ s/'/''/;
I am not sure if we really need this quote skipping stuff. Why can't
we write the test as below:
# tablespace for testing
my $basedir = $node->basedir;
my $ts = "$basedir/regress_pgbench_tap_1_ts_dir";
mkdir $ts or die "cannot create directory $ts";
$ts = TestLib::perl2host($ts);
$node->safe_psql('postgres',
"CREATE TABLESPACE regress_pgbench_tap_1_ts LOCATION '$ets';"
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Hello Amit,
>> Attached v18:
>> - remove the test tablespace
>> I had to work around a strange issue around partitioned tables and
>> the default tablespace.
>
> - if (tablespace != NULL)
> + if (tablespace != NULL && strcmp(tablespace, "pg_default") != 0)
>
> [...]
>
> I don't think we need any such check, rather if the user gives
> default_tablespace with 'partitions' option, then let it fail with an
> error "cannot specify default tablespace for partitioned relations".
That is the one I wanted to avoid, which is triggered by TAP tests, but
I'm fine with putting back a tablespace. Given partitioned table strange
constraints, ISTM desirable to check that it works with options such as
tablespace and fillfactor.
> (b) Create a non-default tablespace to test partitions with "all
> possible options" test as you have in your previous version.
> Also, add a comment explaining why in that test we are using non-default
> tablespace.
> I am leaning towards approach (b) unless you and or Alvaro feels (a)
> is good for now or if you have some other idea.
No other idea. I put back the tablespace creation which I just removed,
with comments about why it is there.
> If we want to go with option (b), I have small comment in your previous test:
> +# tablespace for testing
> +my $ts = $node->basedir . '/regress_pgbench_tap_1_ts_dir';
> +mkdir $ts or die "cannot create directory $ts";
> +my $ets = TestLib::perl2host($ts);
> +# add needed escaping!
> +$ets =~ s/'/''/;
>
> I am not sure if we really need this quote skipping stuff. Why can't
> we write the test as below:
>
> # tablespace for testing
> my $basedir = $node->basedir;
> my $ts = "$basedir/regress_pgbench_tap_1_ts_dir";
> mkdir $ts or die "cannot create directory $ts";
> $ts = TestLib::perl2host($ts);
> $node->safe_psql('postgres',
> "CREATE TABLESPACE regress_pgbench_tap_1_ts LOCATION '$ets';"
I think that this last command fails if the path contains a "'", so the
'-escaping is necessary. I had to make changes in TAP tests before because
it was not working when the path was a little bit strange, so now I'm
careful.
Attached v19:
- put back a local tablespace plus comments
- remove the pg_default doubtful workaround.
--
Fabien.
Attachment
On Mon, Sep 30, 2019 at 2:26 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
> > I am leaning towards approach (b) unless you and or Alvaro feels (a)
> > is good for now or if you have some other idea.
>
> No other idea. I put back the tablespace creation which I just removed,
> with comments about why it is there.
>
> > If we want to go with option (b), I have small comment in your previous test:
> > +# tablespace for testing
> > +my $ts = $node->basedir . '/regress_pgbench_tap_1_ts_dir';
> > +mkdir $ts or die "cannot create directory $ts";
> > +my $ets = TestLib::perl2host($ts);
> > +# add needed escaping!
> > +$ets =~ s/'/''/;
> >
> > I am not sure if we really need this quote skipping stuff. Why can't
> > we write the test as below:
> >
> > # tablespace for testing
> > my $basedir = $node->basedir;
> > my $ts = "$basedir/regress_pgbench_tap_1_ts_dir";
> > mkdir $ts or die "cannot create directory $ts";
> > $ts = TestLib::perl2host($ts);
> > $node->safe_psql('postgres',
> > "CREATE TABLESPACE regress_pgbench_tap_1_ts LOCATION '$ets';"
>
> I think that this last command fails if the path contains a "'", so the
> '-escaping is necessary. I had to make changes in TAP tests before because
> it was not working when the path was a little bit strange, so now I'm
> careful.
>
Hmm, I don't know what kind of issues you have earlier faced, but
tablespace creation doesn't allow quotes. See the message "tablespace
location cannot contain single quotes" in CreateTableSpace. Also,
there are other places in tests like
src/bin/pg_checksums/t/002_actions.pl which uses the way I have
mentioned. I don't think there is any need for escaping single-quotes
here and I am not seeing the use of same. I don't want to introduce a
new pattern in tests which people can then tomorrow copy at other
places even though such code is not required. OTOH, if there is a
genuine need for the same, then I am fine.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Hello Amit,
>>> $node->safe_psql('postgres',
>>> "CREATE TABLESPACE regress_pgbench_tap_1_ts LOCATION '$ets';"
>>
>> I think that this last command fails if the path contains a "'", so the
>> '-escaping is necessary. I had to make changes in TAP tests before because
>> it was not working when the path was a little bit strange, so now I'm
>> careful.
>
> Hmm, I don't know what kind of issues you have earlier faced,
AFAICR, path with shell-sensitive characters ($ ? * ...) which was
breaking something somewhere.
> but tablespace creation doesn't allow quotes. See the message
> "tablespace location cannot contain single quotes" in CreateTableSpace.
Hmmm. That is the problem of CreateTableSpace. From an SQL perspective,
escaping is required. If the command fails later, that is the problem of
the command implementation, but otherwise this is just a plain syntax
error at the SQL level.
> Also, there are other places in tests like
> src/bin/pg_checksums/t/002_actions.pl which uses the way I have
> mentioned.
Yes, I looked at it and imported the window-specific function to handle
the path. It does not do anything about escaping.
> I don't think there is any need for escaping single-quotes
> here
As said, this is required for SQL, or you must know that there are no
single quotes in the string.
> and I am not seeing the use of same.
Sure. It is probably buggy there too.
> I don't want to introduce a new pattern in tests which people can then
> tomorrow copy at other places even though such code is not required.
> OTOH, if there is a genuine need for the same, then I am fine.
Hmmm. The committer is right by definition. Here is a version without
escaping but with a comment instead.
--
Fabien.
Attachment
On Mon, Sep 30, 2019 at 5:17 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
>
> > I don't want to introduce a new pattern in tests which people can then
> > tomorrow copy at other places even though such code is not required.
> > OTOH, if there is a genuine need for the same, then I am fine.
>
> Hmmm. The committer is right by definition. Here is a version without
> escaping but with a comment instead.
>
Thanks, attached is a patch with minor modifications which I am
planning to push after one more round of review on Thursday morning
IST unless there are more comments by anyone else.
The changes include:
1. ran pgindent
2. As per Alvaro's suggestions move few function definitions.
3. Changed one or two comments and fixed spelling at one place.
The one place where some suggestion might help:
+ else if (PQntuples(res) == 0)
+ {
+ /*
+ * This case is unlikely as pgbench already found "pgbench_branches"
+ * above to compute the scale.
+ */
+ fprintf(stderr,
+ "no pgbench_accounts table found in search_path\n"
+ "Perhaps you need to do initialization (\"pgbench -i\") in database
\"%s\"\n", PQdb(con));
+ exit(1);
+ }
Can anyone else think of a better error message either in wording or
style for above case?
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Attachment
Hello Amit, > 1. ran pgindent > 2. As per Alvaro's suggestions move few function definitions. > 3. Changed one or two comments and fixed spelling at one place. Thanks for the improvements. Not sure why you put "XXX - " in front of "append_fillfactor" comment, though. > + fprintf(stderr, > + "no pgbench_accounts table found in search_path\n" > + "Perhaps you need to do initialization (\"pgbench -i\") in database > \"%s\"\n", PQdb(con)); > Can anyone else think of a better error message either in wording or > style for above case? No better idea from me. The second part is a duplicate from a earlier comment, when getting the scale fails. -- Fabien.
On Tue, Oct 1, 2019 at 11:51 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
Hello Amit,
> 1. ran pgindent
> 2. As per Alvaro's suggestions move few function definitions.
> 3. Changed one or two comments and fixed spelling at one place.
Thanks for the improvements.
Not sure why you put "XXX - " in front of "append_fillfactor" comment,
though.
It is to indicate that we can do this after further consideration.
> + fprintf(stderr,
> + "no pgbench_accounts table found in search_path\n"
> + "Perhaps you need to do initialization (\"pgbench -i\") in database
> \"%s\"\n", PQdb(con));
> Can anyone else think of a better error message either in wording or
> style for above case?
No better idea from me. The second part is a duplicate from a earlier
comment, when getting the scale fails.
Yeah, I know that, but this doesn't look quite right. I mean to say whatever we want to say via this message is correct, but I am not completely happy with the display part. How about something like: "pgbench_accounts is missing, you need to do initialization (\"pgbench -i\") in database \"%s\"\n"? Feel free to propose something else on similar lines? If possible, I want to convey this information in a single sentence.
On Tue, 1 Oct 2019 at 15:39, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Tue, Oct 1, 2019 at 11:51 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
Hello Amit,
> 1. ran pgindent
> 2. As per Alvaro's suggestions move few function definitions.
> 3. Changed one or two comments and fixed spelling at one place.
Thanks for the improvements.
Not sure why you put "XXX - " in front of "append_fillfactor" comment,
though.It is to indicate that we can do this after further consideration.> + fprintf(stderr,
> + "no pgbench_accounts table found in search_path\n"
> + "Perhaps you need to do initialization (\"pgbench -i\") in database
> \"%s\"\n", PQdb(con));
> Can anyone else think of a better error message either in wording or
> style for above case?
No better idea from me. The second part is a duplicate from a earlier
comment, when getting the scale fails.Yeah, I know that, but this doesn't look quite right. I mean to say whatever we want to say via this message is correct, but I am not completely happy with the display part. How about something like: "pgbench_accounts is missing, you need to do initialization (\"pgbench -i\") in database \"%s\"\n"? Feel free to propose something else on similar lines? If possible, I want to convey this information in a single sentence.
How about, "pgbench_accounts is missing, initialize (\"pgbench -i\") in database \"%s\"\n"?
Regards,
Rafia Sabih
Rafia Sabih
>> Yeah, I know that, but this doesn't look quite right. I mean to say >> whatever we want to say via this message is correct, but I am not >> completely happy with the display part. How about something like: >> "pgbench_accounts is missing, you need to do initialization (\"pgbench >> -i\") in database \"%s\"\n"? Feel free to propose something else on >> similar lines? If possible, I want to convey this information in a single >> sentence. >> >> How about, "pgbench_accounts is missing, initialize (\"pgbench -i\") in > database \"%s\"\n"? I think that we should not presume too much about the solution: perhaps the user did not specify the right database or host and it has nothing to do with initialization. Maybe something like: "pgbench_accounts is missing, perhaps you need to initialize (\"pgbench -i\") in database \"%s\"\n" The two sentences approach has the logic of "error" and a separate "hint" which is often used. -- Fabien.
On Tue, 1 Oct 2019 at 16:48, Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>> Yeah, I know that, but this doesn't look quite right. I mean to say
>> whatever we want to say via this message is correct, but I am not
>> completely happy with the display part. How about something like:
>> "pgbench_accounts is missing, you need to do initialization (\"pgbench
>> -i\") in database \"%s\"\n"? Feel free to propose something else on
>> similar lines? If possible, I want to convey this information in a single
>> sentence.
>>
>> How about, "pgbench_accounts is missing, initialize (\"pgbench -i\") in
> database \"%s\"\n"?
I think that we should not presume too much about the solution: perhaps
the user did not specify the right database or host and it has nothing to
do with initialization.
Maybe something like:
"pgbench_accounts is missing, perhaps you need to initialize (\"pgbench
-i\") in database \"%s\"\n"
The two sentences approach has the logic of "error" and a separate "hint"
which is often used.
+1 for error and hint separation.
Regards,
Rafia Sabih
Rafia Sabih
On Tue, Oct 1, 2019 at 8:45 PM Rafia Sabih <rafia.pghackers@gmail.com> wrote:
On Tue, 1 Oct 2019 at 16:48, Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>> Yeah, I know that, but this doesn't look quite right. I mean to say
>> whatever we want to say via this message is correct, but I am not
>> completely happy with the display part. How about something like:
>> "pgbench_accounts is missing, you need to do initialization (\"pgbench
>> -i\") in database \"%s\"\n"? Feel free to propose something else on
>> similar lines? If possible, I want to convey this information in a single
>> sentence.
>>
>> How about, "pgbench_accounts is missing, initialize (\"pgbench -i\") in
> database \"%s\"\n"?
I think that we should not presume too much about the solution: perhaps
the user did not specify the right database or host and it has nothing to
do with initialization.
Maybe something like:
"pgbench_accounts is missing, perhaps you need to initialize (\"pgbench
-i\") in database \"%s\"\n"
The two sentences approach has the logic of "error" and a separate "hint"
which is often used.+1 for error and hint separation.
Okay, if you people like the approach of two sentences for the separation of "hint" and "error", then I think the second line should end with a period. See below note in docs[1]:
"Grammar and PunctuationThe rules are different for primary error messages and for detail/hint messages:
Primary error messages: Do not capitalize the first letter. Do not end a message with a period. Do not even think about ending a message with an exclamation point.
Detail and hint messages: Use complete sentences, and end each with a period. Capitalize the first word of sentences. Put two spaces after the period if another sentence follows (for English text; might be inappropriate in other languages)."
Also, the similar style is used in other places in code, see contrib/oid2name/oid2name.c, contrib/pg_standby/pg_standby.c for similar usage.
I shall modify this before commit unless you disagree.
On Tue, Oct 1, 2019 at 10:20 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
On Mon, Sep 30, 2019 at 5:17 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
> > I don't want to introduce a new pattern in tests which people can then
> > tomorrow copy at other places even though such code is not required.
> > OTOH, if there is a genuine need for the same, then I am fine.
>
> Hmmm. The committer is right by definition. Here is a version without
> escaping but with a comment instead.
>
Thanks, attached is a patch with minor modifications which I am
planning to push after one more round of review on Thursday morning
IST unless there are more comments by anyone else.
>> Thanks, attached is a patch with minor modifications which I am >> planning to push after one more round of review on Thursday morning >> IST unless there are more comments by anyone else. > > Pushed. Thanks! -- Fabien.
Hi Fabien, Amit, I could see that when an invalid number of partitions is specified, sometimes pgbench fails with an error "invalid number of partitions: ..." whereas many a times it doesn't, instead it creates number of partitions that hasn't been specified by the user. As partitions is an integer type variable, the maximum value it can hold is "2147483647". But if I specify partitions as "3147483647", atoi function returns a value lesser than zero and pgbench terminates with an error. However, if the value for number of partitions specified is something like "5147483647", atoi returns a non-negative number and pgbench creates as many number of partitions as the value returned by atoi function. Have a look at the below examples, [ashu@localhost bin]$ ./pgbench -i -s 10 --partitions=2147483647 postgres dropping old tables... creating tables... creating 2147483647 partitions... ^C [ashu@localhost bin]$ ./pgbench -i -s 10 --partitions=3147483647 postgres invalid number of partitions: "3147483647" [ashu@localhost bin]$ ./pgbench -i -s 10 --partitions=5147483647 postgres dropping old tables... creating tables... creating 852516351 partitions... ^C This seems like a problem with atoi function, isn't it? atoi functions has been used at several places in pgbench script and I can see similar behaviour for all. For e.g. it has been used with scale factor and above observation is true for that as well. So, is this a bug or you guys feel that it isn't and can be ignored? Please let me know your thoughts on this. Thank you. -- With Regards, Ashutosh Sharma EnterpriseDB:http://www.enterprisedb.com On Thu, Oct 3, 2019 at 10:30 AM Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > > >> Thanks, attached is a patch with minor modifications which I am > >> planning to push after one more round of review on Thursday morning > >> IST unless there are more comments by anyone else. > > > > Pushed. > > Thanks! > > -- > Fabien. > >
Hello, > As partitions is an integer type variable, the maximum value it can > hold is "2147483647". But if I specify partitions as "3147483647", > atoi function returns a value lesser than zero and pgbench terminates > with an error. However, if the value for number of partitions > specified is something like "5147483647", atoi returns a non-negative > number and pgbench creates as many number of partitions as the value > returned by atoi function. > > This seems like a problem with atoi function, isn't it? Yes. > atoi functions has been used at several places in pgbench script and I > can see similar behaviour for all. For e.g. it has been used with > scale factor and above observation is true for that as well. So, is > this a bug or you guys feel that it isn't and can be ignored? Please > let me know your thoughts on this. Thank you. I think that it is a known bug (as you noted atoi is used more or less everywhere in pgbench and other commands) which shoud be addressed separately: all integer user inputs should be validated for syntax and overflow, everywhere, really. This is not currently the case, so I simply replicated the current bad practice when developing this feature. There is/was a current patch/discussion to improve integer parsing, which could address this. -- Fabien.
On Thu, Oct 3, 2019 at 1:53 PM Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > > Hello, > > > As partitions is an integer type variable, the maximum value it can > > hold is "2147483647". But if I specify partitions as "3147483647", > > atoi function returns a value lesser than zero and pgbench terminates > > with an error. However, if the value for number of partitions > > specified is something like "5147483647", atoi returns a non-negative > > number and pgbench creates as many number of partitions as the value > > returned by atoi function. > > > > This seems like a problem with atoi function, isn't it? > > Yes. > > > atoi functions has been used at several places in pgbench script and I > > can see similar behaviour for all. For e.g. it has been used with > > scale factor and above observation is true for that as well. So, is > > this a bug or you guys feel that it isn't and can be ignored? Please > > let me know your thoughts on this. Thank you. > > I think that it is a known bug (as you noted atoi is used more or less > everywhere in pgbench and other commands) which shoud be addressed > separately: all integer user inputs should be validated for syntax and > overflow, everywhere, really. This is not currently the case, so I simply > replicated the current bad practice when developing this feature. > Okay, I think we should possibly replace atoi with strtol function call for better error handling. It handles the erroneous inputs better than atoi. > There is/was a current patch/discussion to improve integer parsing, which > could address this. > It seems like you are trying to point out the following discussion on hackers, https://www.postgresql.org/message-id/flat/20190724040237.GB64205%40begriffs.com#5677c361d3863518b0db5d5baae72bbe -- With Regards, Ashutosh Sharma EnterpriseDB:http://www.enterprisedb.com
The documentation and pgbench --help output that accompanied this patch claims that the argument to pgbench --partition-method is optional and defaults to "range", but that is not actually the case, as the implementation requires an argument. Could you please sort this out? Personally, I think making the argument optional is unnecessary and confusing, so I'd just change the documentation. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jan 3, 2020 at 3:24 PM Peter Eisentraut <peter.eisentraut@2ndquadrant.com> wrote: > > The documentation and pgbench --help output that accompanied this patch > claims that the argument to pgbench --partition-method is optional and > defaults to "range", but that is not actually the case, as the > implementation requires an argument. Could you please sort this out? > AFAICS, if the user omits this argument, then the default is range as specified in docs. I tried by using something like 'pgbench.exe -i -s 1 --partitions=2 postgres' and then run 'pgbench -S postgres'. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 2020-01-03 11:04, Amit Kapila wrote: > On Fri, Jan 3, 2020 at 3:24 PM Peter Eisentraut > <peter.eisentraut@2ndquadrant.com> wrote: >> >> The documentation and pgbench --help output that accompanied this patch >> claims that the argument to pgbench --partition-method is optional and >> defaults to "range", but that is not actually the case, as the >> implementation requires an argument. Could you please sort this out? >> > > AFAICS, if the user omits this argument, then the default is range as > specified in docs. I tried by using something like 'pgbench.exe -i -s > 1 --partitions=2 postgres' and then run 'pgbench -S postgres'. Ah, the way I interpreted this is that the argument to --partition-method itself is optional. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hello Peter, >>> The documentation and pgbench --help output that accompanied this patch >>> claims that the argument to pgbench --partition-method is optional and >>> defaults to "range", but that is not actually the case, as the >>> implementation requires an argument. Could you please sort this out? >> >> AFAICS, if the user omits this argument, then the default is range as >> specified in docs. I tried by using something like 'pgbench.exe -i -s >> 1 --partitions=2 postgres' and then run 'pgbench -S postgres'. > > Ah, the way I interpreted this is that the argument to --partition-method > itself is optional. Yep. Optionnal stuff would be in [], where () is used for choices. Would the attached have improved your understanding? It is somehow more consistent with other help lines. -- Fabien.