Thread: Why HDD performance is better than SSD in this case
Dear, Some of you can help me understand this. This query plan is executed in the query below (query 9 of TPC-H Benchmark, with scale 40, database with approximately 40 gb). The experiment consisted of running the query on a HDD (Raid zero). Then the same query is executed on an SSD (Raid Zero). Why did the HDD (7200 rpm) perform better? HDD - TIME 9 MINUTES SSD - TIME 15 MINUTES As far as I know, the SSD has a reading that is 300 times faster than SSD. --- Execution Plans--- ssd 40g https://explain.depesz.com/s/rHkh hdd 40g https://explain.depesz.com/s/l4sq Query ------------------------------------ select nation, o_year, sum(amount) as sum_profit from ( select n_name as nation, extract(year from o_orderdate) as o_year, l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity as amount from part, supplier, lineitem, partsupp, orders, nation where s_suppkey = l_suppkey and ps_suppkey = l_suppkey and ps_partkey = l_partkey and p_partkey = l_partkey and o_orderkey = l_orderkey and s_nationkey = n_nationkey and p_name like '%orchid%' ) as profit group by nation, o_year order by nation, o_year desc
What's the on disk cache size for each drive? The better HDD performance problem won't be sustained with large amounts of data and several different queries.
- - Ben Scherrey
On Tue, Jul 17, 2018, 12:01 PM Neto pr <netopr9@gmail.com> wrote:
Dear,
Some of you can help me understand this.
This query plan is executed in the query below (query 9 of TPC-H
Benchmark, with scale 40, database with approximately 40 gb).
The experiment consisted of running the query on a HDD (Raid zero).
Then the same query is executed on an SSD (Raid Zero).
Why did the HDD (7200 rpm) perform better?
HDD - TIME 9 MINUTES
SSD - TIME 15 MINUTES
As far as I know, the SSD has a reading that is 300 times faster than SSD.
--- Execution Plans---
ssd 40g
https://explain.depesz.com/s/rHkh
hdd 40g
https://explain.depesz.com/s/l4sq
Query ------------------------------------
select
nation,
o_year,
sum(amount) as sum_profit
from
(
select
n_name as nation,
extract(year from o_orderdate) as o_year,
l_extendedprice * (1 - l_discount) - ps_supplycost *
l_quantity as amount
from
part,
supplier,
lineitem,
partsupp,
orders,
nation
where
s_suppkey = l_suppkey
and ps_suppkey = l_suppkey
and ps_partkey = l_partkey
and p_partkey = l_partkey
and o_orderkey = l_orderkey
and s_nationkey = n_nationkey
and p_name like '%orchid%'
) as profit
group by
nation,
o_year
order by
nation,
o_year desc
Can you show the configuration of postgresql.conf?
Query configuration method:
Select name, setting from pg_settings where name ~ 'buffers|cpu|^enable';
On 2018年07月17日 13:17, Benjamin Scherrey wrote:
What's the on disk cache size for each drive? The better HDD performance problem won't be sustained with large amounts of data and several different queries.- - Ben ScherreyOn Tue, Jul 17, 2018, 12:01 PM Neto pr <netopr9@gmail.com> wrote:Dear,
Some of you can help me understand this.
This query plan is executed in the query below (query 9 of TPC-H
Benchmark, with scale 40, database with approximately 40 gb).
The experiment consisted of running the query on a HDD (Raid zero).
Then the same query is executed on an SSD (Raid Zero).
Why did the HDD (7200 rpm) perform better?
HDD - TIME 9 MINUTES
SSD - TIME 15 MINUTES
As far as I know, the SSD has a reading that is 300 times faster than SSD.
--- Execution Plans---
ssd 40g
https://explain.depesz.com/s/rHkh
hdd 40g
https://explain.depesz.com/s/l4sq
Query ------------------------------------
select
nation,
o_year,
sum(amount) as sum_profit
from
(
select
n_name as nation,
extract(year from o_orderdate) as o_year,
l_extendedprice * (1 - l_discount) - ps_supplycost *
l_quantity as amount
from
part,
supplier,
lineitem,
partsupp,
orders,
nation
where
s_suppkey = l_suppkey
and ps_suppkey = l_suppkey
and ps_partkey = l_partkey
and p_partkey = l_partkey
and o_orderkey = l_orderkey
and s_nationkey = n_nationkey
and p_name like '%orchid%'
) as profit
group by
nation,
o_year
order by
nation,
o_year desc
-- <b>张文升</b> winston<br /> PostgreSQL DBA<br />
Can you post make and model of the SSD concerned? In general the cheaper consumer grade ones cannot do sustained read/writes at anything like their quoted max values. regards Mark On 17/07/18 17:00, Neto pr wrote: > Dear, > Some of you can help me understand this. > > This query plan is executed in the query below (query 9 of TPC-H > Benchmark, with scale 40, database with approximately 40 gb). > > The experiment consisted of running the query on a HDD (Raid zero). > Then the same query is executed on an SSD (Raid Zero). > > Why did the HDD (7200 rpm) perform better? > HDD - TIME 9 MINUTES > SSD - TIME 15 MINUTES > > As far as I know, the SSD has a reading that is 300 times faster than SSD. > > --- Execution Plans--- > ssd 40g > https://explain.depesz.com/s/rHkh > > hdd 40g > https://explain.depesz.com/s/l4sq > > Query ------------------------------------ > > select > nation, > o_year, > sum(amount) as sum_profit > from > ( > select > n_name as nation, > extract(year from o_orderdate) as o_year, > l_extendedprice * (1 - l_discount) - ps_supplycost * > l_quantity as amount > from > part, > supplier, > lineitem, > partsupp, > orders, > nation > where > s_suppkey = l_suppkey > and ps_suppkey = l_suppkey > and ps_partkey = l_partkey > and p_partkey = l_partkey > and o_orderkey = l_orderkey > and s_nationkey = n_nationkey > and p_name like '%orchid%' > ) as profit > group by > nation, > o_year > order by > nation, > o_year desc >
> Why did the HDD (7200 rpm) perform better? Are these different systems? Have you ruled out that during the HDD test the data was available in memory?
As already mentioned by Robert, please let us know if you made sure that nothing was fished from RAM, over the faster test. In other words, make sure that all caches are dropped between one test and another. Also,to better picture the situation, would be good to know: - which SSD (brand/model) are you using? - which HDD? - how are the disks configured? RAID? or not? - on which OS? - what are the mount options? SSD requires tuning - did you make sure that no other query was running at the time of the bench? - are you making a comparison on the same machine? - is it HW or VM? benchs should better run on bare metal to avoid results pollution (eg: other VMS on the same hypervisor using the disk, host caching and so on) - how many times did you run the tests? - did you change postgres configuration over tests? - can you post postgres config? - what about vacuums or maintenance tasks running in the background? Also, to benchmark disks i would not use a custom query but pgbench. Be aware: running benchmarks is a science, therefore needs a scientific approach :) regards fabio pardi On 07/17/2018 07:00 AM, Neto pr wrote: > Dear, > Some of you can help me understand this. > > This query plan is executed in the query below (query 9 of TPC-H > Benchmark, with scale 40, database with approximately 40 gb). > > The experiment consisted of running the query on a HDD (Raid zero). > Then the same query is executed on an SSD (Raid Zero). > > Why did the HDD (7200 rpm) perform better? > HDD - TIME 9 MINUTES > SSD - TIME 15 MINUTES > > As far as I know, the SSD has a reading that is 300 times faster than SSD. > > --- Execution Plans--- > ssd 40g > https://explain.depesz.com/s/rHkh > > hdd 40g > https://explain.depesz.com/s/l4sq > > Query ------------------------------------ > > select > nation, > o_year, > sum(amount) as sum_profit > from > ( > select > n_name as nation, > extract(year from o_orderdate) as o_year, > l_extendedprice * (1 - l_discount) - ps_supplycost * > l_quantity as amount > from > part, > supplier, > lineitem, > partsupp, > orders, > nation > where > s_suppkey = l_suppkey > and ps_suppkey = l_suppkey > and ps_partkey = l_partkey > and p_partkey = l_partkey > and o_orderkey = l_orderkey > and s_nationkey = n_nationkey > and p_name like '%orchid%' > ) as profit > group by > nation, > o_year > order by > nation, > o_year desc >
Sorry.. I replied in the wrong message before ... follows my response. ------------- Thanks all, but I still have not figured it out. This is really strange because the tests were done on the same machine (I use HP ML110 Proliant 8gb RAM - Xeon 2.8 ghz processor (4 cores), and POSTGRESQL 10.1. - Only the mentioned query running at the time of the test. - I repeated the query 7 times and did not change the results. - Before running each batch of 7 executions, I discarded the Operating System cache and restarted DBMS like this: (echo 3> / proc / sys / vm / drop_caches; discs: - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID) - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID) - The Operating System and the Postgresql DBMS are installed on the SSD disk. Best Regards [ ]`s Neto 2018-07-17 1:08 GMT-07:00 Fabio Pardi <f.pardi@portavita.eu>: > As already mentioned by Robert, please let us know if you made sure that > nothing was fished from RAM, over the faster test. > > In other words, make sure that all caches are dropped between one test > and another. > > Also,to better picture the situation, would be good to know: > > - which SSD (brand/model) are you using? > - which HDD? > - how are the disks configured? RAID? or not? > - on which OS? > - what are the mount options? SSD requires tuning > - did you make sure that no other query was running at the time of the > bench? > - are you making a comparison on the same machine? > - is it HW or VM? benchs should better run on bare metal to avoid > results pollution (eg: other VMS on the same hypervisor using the disk, > host caching and so on) > - how many times did you run the tests? > - did you change postgres configuration over tests? > - can you post postgres config? > - what about vacuums or maintenance tasks running in the background? > > Also, to benchmark disks i would not use a custom query but pgbench. > > Be aware: running benchmarks is a science, therefore needs a scientific > approach :) > > regards > > fabio pardi > > > > On 07/17/2018 07:00 AM, Neto pr wrote: >> Dear, >> Some of you can help me understand this. >> >> This query plan is executed in the query below (query 9 of TPC-H >> Benchmark, with scale 40, database with approximately 40 gb). >> >> The experiment consisted of running the query on a HDD (Raid zero). >> Then the same query is executed on an SSD (Raid Zero). >> >> Why did the HDD (7200 rpm) perform better? >> HDD - TIME 9 MINUTES >> SSD - TIME 15 MINUTES >> >> As far as I know, the SSD has a reading that is 300 times faster than SSD. >> >> --- Execution Plans--- >> ssd 40g >> https://explain.depesz.com/s/rHkh >> >> hdd 40g >> https://explain.depesz.com/s/l4sq >> >> Query ------------------------------------ >> >> select >> nation, >> o_year, >> sum(amount) as sum_profit >> from >> ( >> select >> n_name as nation, >> extract(year from o_orderdate) as o_year, >> l_extendedprice * (1 - l_discount) - ps_supplycost * >> l_quantity as amount >> from >> part, >> supplier, >> lineitem, >> partsupp, >> orders, >> nation >> where >> s_suppkey = l_suppkey >> and ps_suppkey = l_suppkey >> and ps_partkey = l_partkey >> and p_partkey = l_partkey >> and o_orderkey = l_orderkey >> and s_nationkey = n_nationkey >> and p_name like '%orchid%' >> ) as profit >> group by >> nation, >> o_year >> order by >> nation, >> o_year desc >> >
2018-07-17 10:04 GMT-03:00 Neto pr <netopr9@gmail.com>: > Sorry.. I replied in the wrong message before ... > follows my response. > ------------- > > Thanks all, but I still have not figured it out. > This is really strange because the tests were done on the same machine > (I use HP ML110 Proliant 8gb RAM - Xeon 2.8 ghz processor (4 > cores), and POSTGRESQL 10.1. > - Only the mentioned query running at the time of the test. > - I repeated the query 7 times and did not change the results. > - Before running each batch of 7 executions, I discarded the Operating > System cache and restarted DBMS like this: > (echo 3> / proc / sys / vm / drop_caches; > > discs: > - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID) > - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID) > > - The Operating System and the Postgresql DBMS are installed on the SSD disk. > One more information. I used default configuration to Postgresql.conf Only exception is to : random_page_cost on SSD is 1.1 > Best Regards > [ ]`s Neto > > 2018-07-17 1:08 GMT-07:00 Fabio Pardi <f.pardi@portavita.eu>: >> As already mentioned by Robert, please let us know if you made sure that >> nothing was fished from RAM, over the faster test. >> >> In other words, make sure that all caches are dropped between one test >> and another. >> >> Also,to better picture the situation, would be good to know: >> >> - which SSD (brand/model) are you using? >> - which HDD? >> - how are the disks configured? RAID? or not? >> - on which OS? >> - what are the mount options? SSD requires tuning >> - did you make sure that no other query was running at the time of the >> bench? >> - are you making a comparison on the same machine? >> - is it HW or VM? benchs should better run on bare metal to avoid >> results pollution (eg: other VMS on the same hypervisor using the disk, >> host caching and so on) >> - how many times did you run the tests? >> - did you change postgres configuration over tests? >> - can you post postgres config? >> - what about vacuums or maintenance tasks running in the background? >> >> Also, to benchmark disks i would not use a custom query but pgbench. >> >> Be aware: running benchmarks is a science, therefore needs a scientific >> approach :) >> >> regards >> >> fabio pardi >> >> >> >> On 07/17/2018 07:00 AM, Neto pr wrote: >>> Dear, >>> Some of you can help me understand this. >>> >>> This query plan is executed in the query below (query 9 of TPC-H >>> Benchmark, with scale 40, database with approximately 40 gb). >>> >>> The experiment consisted of running the query on a HDD (Raid zero). >>> Then the same query is executed on an SSD (Raid Zero). >>> >>> Why did the HDD (7200 rpm) perform better? >>> HDD - TIME 9 MINUTES >>> SSD - TIME 15 MINUTES >>> >>> As far as I know, the SSD has a reading that is 300 times faster than SSD. >>> >>> --- Execution Plans--- >>> ssd 40g >>> https://explain.depesz.com/s/rHkh >>> >>> hdd 40g >>> https://explain.depesz.com/s/l4sq >>> >>> Query ------------------------------------ >>> >>> select >>> nation, >>> o_year, >>> sum(amount) as sum_profit >>> from >>> ( >>> select >>> n_name as nation, >>> extract(year from o_orderdate) as o_year, >>> l_extendedprice * (1 - l_discount) - ps_supplycost * >>> l_quantity as amount >>> from >>> part, >>> supplier, >>> lineitem, >>> partsupp, >>> orders, >>> nation >>> where >>> s_suppkey = l_suppkey >>> and ps_suppkey = l_suppkey >>> and ps_partkey = l_partkey >>> and p_partkey = l_partkey >>> and o_orderkey = l_orderkey >>> and s_nationkey = n_nationkey >>> and p_name like '%orchid%' >>> ) as profit >>> group by >>> nation, >>> o_year >>> order by >>> nation, >>> o_year desc >>> >>
On Tue, Jul 17, 2018 at 1:00 AM, Neto pr <netopr9@gmail.com> wrote:
Dear,
Some of you can help me understand this.
This query plan is executed in the query below (query 9 of TPC-H
Benchmark, with scale 40, database with approximately 40 gb).
The experiment consisted of running the query on a HDD (Raid zero).
Then the same query is executed on an SSD (Raid Zero).
Why did the HDD (7200 rpm) perform better?
HDD - TIME 9 MINUTES
SSD - TIME 15 MINUTES
As far as I know, the SSD has a reading that is 300 times faster than SSD.
Is the 300 times faster comparing random to random, or sequential to sequential? Maybe your SSD simply fails to perform as advertised. This would not surprise me at all.
To remove some confounding variables, can you turn off parallelism and repeat the queries? (Yes, they will probably get slower. But is the relative timings still the same?) Also, turn on track_io_timings and repeat the "EXPLAIN (ANALYZE, BUFFERS)", perhaps with TIMINGS OFF.
Also, see how long it takes to read the entire database, or just the largest table, outside of postgres.
Something like:
time tar -f - $PGDATA/base | wc -c
or
time cat $PGDATA/base/<database oid>/<large table file node>* | wc -c
Cheers,
Jeff
Hi Neto, You should list the SSD model also - there are pleinty of Samsung EVO drives - and they are not professional grade. Among the the possible issues, the most likely (from my point of view) are: - TRIM command doesn't go through the RAID (which is really likely) - so the SSD controller think it's full, and keep pushing blocks around to level wear, causing massive perf degradation - please check this config on you RAID driver/adapter - TRIM is not configured on the OS level for the SSD - Partitions is not correctly aligned on the SSD blocks Without so little details on your system, we can only try to guess the real issues Nicolas Nicolas CHARLES Le 17/07/2018 à 15:19, Neto pr a écrit : > 2018-07-17 10:04 GMT-03:00 Neto pr <netopr9@gmail.com>: >> Sorry.. I replied in the wrong message before ... >> follows my response. >> ------------- >> >> Thanks all, but I still have not figured it out. >> This is really strange because the tests were done on the same machine >> (I use HP ML110 Proliant 8gb RAM - Xeon 2.8 ghz processor (4 >> cores), and POSTGRESQL 10.1. >> - Only the mentioned query running at the time of the test. >> - I repeated the query 7 times and did not change the results. >> - Before running each batch of 7 executions, I discarded the Operating >> System cache and restarted DBMS like this: >> (echo 3> / proc / sys / vm / drop_caches; >> >> discs: >> - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID) >> - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID) >> >> - The Operating System and the Postgresql DBMS are installed on the SSD disk. >> > One more information. > I used default configuration to Postgresql.conf > Only exception is to : > random_page_cost on SSD is 1.1 > > >> Best Regards >> [ ]`s Neto >> >> 2018-07-17 1:08 GMT-07:00 Fabio Pardi <f.pardi@portavita.eu>: >>> As already mentioned by Robert, please let us know if you made sure that >>> nothing was fished from RAM, over the faster test. >>> >>> In other words, make sure that all caches are dropped between one test >>> and another. >>> >>> Also,to better picture the situation, would be good to know: >>> >>> - which SSD (brand/model) are you using? >>> - which HDD? >>> - how are the disks configured? RAID? or not? >>> - on which OS? >>> - what are the mount options? SSD requires tuning >>> - did you make sure that no other query was running at the time of the >>> bench? >>> - are you making a comparison on the same machine? >>> - is it HW or VM? benchs should better run on bare metal to avoid >>> results pollution (eg: other VMS on the same hypervisor using the disk, >>> host caching and so on) >>> - how many times did you run the tests? >>> - did you change postgres configuration over tests? >>> - can you post postgres config? >>> - what about vacuums or maintenance tasks running in the background? >>> >>> Also, to benchmark disks i would not use a custom query but pgbench. >>> >>> Be aware: running benchmarks is a science, therefore needs a scientific >>> approach :) >>> >>> regards >>> >>> fabio pardi >>> >>> >>> >>> On 07/17/2018 07:00 AM, Neto pr wrote: >>>> Dear, >>>> Some of you can help me understand this. >>>> >>>> This query plan is executed in the query below (query 9 of TPC-H >>>> Benchmark, with scale 40, database with approximately 40 gb). >>>> >>>> The experiment consisted of running the query on a HDD (Raid zero). >>>> Then the same query is executed on an SSD (Raid Zero). >>>> >>>> Why did the HDD (7200 rpm) perform better? >>>> HDD - TIME 9 MINUTES >>>> SSD - TIME 15 MINUTES >>>> >>>> As far as I know, the SSD has a reading that is 300 times faster than SSD. >>>> >>>> --- Execution Plans--- >>>> ssd 40g >>>> https://explain.depesz.com/s/rHkh >>>> >>>> hdd 40g >>>> https://explain.depesz.com/s/l4sq >>>> >>>> Query ------------------------------------ >>>> >>>> select >>>> nation, >>>> o_year, >>>> sum(amount) as sum_profit >>>> from >>>> ( >>>> select >>>> n_name as nation, >>>> extract(year from o_orderdate) as o_year, >>>> l_extendedprice * (1 - l_discount) - ps_supplycost * >>>> l_quantity as amount >>>> from >>>> part, >>>> supplier, >>>> lineitem, >>>> partsupp, >>>> orders, >>>> nation >>>> where >>>> s_suppkey = l_suppkey >>>> and ps_suppkey = l_suppkey >>>> and ps_partkey = l_partkey >>>> and p_partkey = l_partkey >>>> and o_orderkey = l_orderkey >>>> and s_nationkey = n_nationkey >>>> and p_name like '%orchid%' >>>> ) as profit >>>> group by >>>> nation, >>>> o_year >>>> order by >>>> nation, >>>> o_year desc >>>>
On 17.07.2018 15:44, Nicolas Charles wrote: > - Partitions is not correctly aligned on the SSD blocks Does that really make a noticeable difference? If yes, have you got some further reading material on that?
If you have a RAID cache, i would disable it, since we are only focusing on the disks. Cache can give you inconsistent data (even it looks like is not the case here). Also, we can do a step backward, and exclude postgres from the picture for the moment. try to perform a dd test in reading from disk, and let us know. like: - create big_enough_file - empty OS cache - dd if=big_enough_file of=/dev/null and post the results for both disks. Also i think it makes not much sense testing on RAID 0. I would start performing tests on a single disk, bypassing RAID (or, as mentioned, at least disabling cache). The findings should narrow the focus regards, fabio pardi On 07/17/2018 03:19 PM, Neto pr wrote: > 2018-07-17 10:04 GMT-03:00 Neto pr <netopr9@gmail.com>: >> Sorry.. I replied in the wrong message before ... >> follows my response. >> ------------- >> >> Thanks all, but I still have not figured it out. >> This is really strange because the tests were done on the same machine >> (I use HP ML110 Proliant 8gb RAM - Xeon 2.8 ghz processor (4 >> cores), and POSTGRESQL 10.1. >> - Only the mentioned query running at the time of the test. >> - I repeated the query 7 times and did not change the results. >> - Before running each batch of 7 executions, I discarded the Operating >> System cache and restarted DBMS like this: >> (echo 3> / proc / sys / vm / drop_caches; >> >> discs: >> - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID) >> - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID) >> >> - The Operating System and the Postgresql DBMS are installed on the SSD disk. >> > > One more information. > I used default configuration to Postgresql.conf > Only exception is to : > random_page_cost on SSD is 1.1 > > >> Best Regards >> [ ]`s Neto >> >> 2018-07-17 1:08 GMT-07:00 Fabio Pardi <f.pardi@portavita.eu>: >>> As already mentioned by Robert, please let us know if you made sure that >>> nothing was fished from RAM, over the faster test. >>> >>> In other words, make sure that all caches are dropped between one test >>> and another. >>> >>> Also,to better picture the situation, would be good to know: >>> >>> - which SSD (brand/model) are you using? >>> - which HDD? >>> - how are the disks configured? RAID? or not? >>> - on which OS? >>> - what are the mount options? SSD requires tuning >>> - did you make sure that no other query was running at the time of the >>> bench? >>> - are you making a comparison on the same machine? >>> - is it HW or VM? benchs should better run on bare metal to avoid >>> results pollution (eg: other VMS on the same hypervisor using the disk, >>> host caching and so on) >>> - how many times did you run the tests? >>> - did you change postgres configuration over tests? >>> - can you post postgres config? >>> - what about vacuums or maintenance tasks running in the background? >>> >>> Also, to benchmark disks i would not use a custom query but pgbench. >>> >>> Be aware: running benchmarks is a science, therefore needs a scientific >>> approach :) >>> >>> regards >>> >>> fabio pardi >>> >>> >>> >>> On 07/17/2018 07:00 AM, Neto pr wrote: >>>> Dear, >>>> Some of you can help me understand this. >>>> >>>> This query plan is executed in the query below (query 9 of TPC-H >>>> Benchmark, with scale 40, database with approximately 40 gb). >>>> >>>> The experiment consisted of running the query on a HDD (Raid zero). >>>> Then the same query is executed on an SSD (Raid Zero). >>>> >>>> Why did the HDD (7200 rpm) perform better? >>>> HDD - TIME 9 MINUTES >>>> SSD - TIME 15 MINUTES >>>> >>>> As far as I know, the SSD has a reading that is 300 times faster than SSD. >>>> >>>> --- Execution Plans--- >>>> ssd 40g >>>> https://explain.depesz.com/s/rHkh >>>> >>>> hdd 40g >>>> https://explain.depesz.com/s/l4sq >>>> >>>> Query ------------------------------------ >>>> >>>> select >>>> nation, >>>> o_year, >>>> sum(amount) as sum_profit >>>> from >>>> ( >>>> select >>>> n_name as nation, >>>> extract(year from o_orderdate) as o_year, >>>> l_extendedprice * (1 - l_discount) - ps_supplycost * >>>> l_quantity as amount >>>> from >>>> part, >>>> supplier, >>>> lineitem, >>>> partsupp, >>>> orders, >>>> nation >>>> where >>>> s_suppkey = l_suppkey >>>> and ps_suppkey = l_suppkey >>>> and ps_partkey = l_partkey >>>> and p_partkey = l_partkey >>>> and o_orderkey = l_orderkey >>>> and s_nationkey = n_nationkey >>>> and p_name like '%orchid%' >>>> ) as profit >>>> group by >>>> nation, >>>> o_year >>>> order by >>>> nation, >>>> o_year desc >>>> >>>
2018-07-17 10:44 GMT-03:00 Nicolas Charles <nicolas.charles@normation.com>: > Hi Neto, > > You should list the SSD model also - there are pleinty of Samsung EVO drives > - and they are not professional grade. > > Among the the possible issues, the most likely (from my point of view) are: > > - TRIM command doesn't go through the RAID (which is really likely) - so the > SSD controller think it's full, and keep pushing blocks around to level > wear, causing massive perf degradation - please check this config on you > RAID driver/adapter > > - TRIM is not configured on the OS level for the SSD > > - Partitions is not correctly aligned on the SSD blocks > > > Without so little details on your system, we can only try to guess the real > issues > Thank you Nicolas, for your tips. I believe your assumption is right. This SSD really is not professional, even if Samsung's advertisement says yes. If I have to buy another SSD I will prefer INTEL SSDs. I had a previous problem with it (Sansung EVO) as it lost in performance to a SAS HDD, but however, the SAS HDD was a 12 Gb/s transfer rate and the SSD was 6 Gb/s. But now I tested against an HDD (7200 RPM) that has the same transfer rate as the SSD 6 Gb/sec. and could not lose in performance. Maybe it's the unconfigured trim. Could you give me some help on how I could check if my RAID is configured for this, I use Hardware RAID using HP software (HP Storage Provider on boot). And on Debian 8 Operating System, how could I check the TRIM configuration ? Best []'s Neto > > Nicolas > > Nicolas CHARLES > > Le 17/07/2018 à 15:19, Neto pr a écrit : >> >> 2018-07-17 10:04 GMT-03:00 Neto pr <netopr9@gmail.com>: >>> >>> Sorry.. I replied in the wrong message before ... >>> follows my response. >>> ------------- >>> >>> Thanks all, but I still have not figured it out. >>> This is really strange because the tests were done on the same machine >>> (I use HP ML110 Proliant 8gb RAM - Xeon 2.8 ghz processor (4 >>> cores), and POSTGRESQL 10.1. >>> - Only the mentioned query running at the time of the test. >>> - I repeated the query 7 times and did not change the results. >>> - Before running each batch of 7 executions, I discarded the Operating >>> System cache and restarted DBMS like this: >>> (echo 3> / proc / sys / vm / drop_caches; >>> >>> discs: >>> - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID) >>> - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID) >>> >>> - The Operating System and the Postgresql DBMS are installed on the SSD >>> disk. >>> >> One more information. >> I used default configuration to Postgresql.conf >> Only exception is to : >> random_page_cost on SSD is 1.1 >> >> >>> Best Regards >>> [ ]`s Neto >>> >>> 2018-07-17 1:08 GMT-07:00 Fabio Pardi <f.pardi@portavita.eu>: >>>> >>>> As already mentioned by Robert, please let us know if you made sure that >>>> nothing was fished from RAM, over the faster test. >>>> >>>> In other words, make sure that all caches are dropped between one test >>>> and another. >>>> >>>> Also,to better picture the situation, would be good to know: >>>> >>>> - which SSD (brand/model) are you using? >>>> - which HDD? >>>> - how are the disks configured? RAID? or not? >>>> - on which OS? >>>> - what are the mount options? SSD requires tuning >>>> - did you make sure that no other query was running at the time of the >>>> bench? >>>> - are you making a comparison on the same machine? >>>> - is it HW or VM? benchs should better run on bare metal to avoid >>>> results pollution (eg: other VMS on the same hypervisor using the disk, >>>> host caching and so on) >>>> - how many times did you run the tests? >>>> - did you change postgres configuration over tests? >>>> - can you post postgres config? >>>> - what about vacuums or maintenance tasks running in the background? >>>> >>>> Also, to benchmark disks i would not use a custom query but pgbench. >>>> >>>> Be aware: running benchmarks is a science, therefore needs a scientific >>>> approach :) >>>> >>>> regards >>>> >>>> fabio pardi >>>> >>>> >>>> >>>> On 07/17/2018 07:00 AM, Neto pr wrote: >>>>> >>>>> Dear, >>>>> Some of you can help me understand this. >>>>> >>>>> This query plan is executed in the query below (query 9 of TPC-H >>>>> Benchmark, with scale 40, database with approximately 40 gb). >>>>> >>>>> The experiment consisted of running the query on a HDD (Raid zero). >>>>> Then the same query is executed on an SSD (Raid Zero). >>>>> >>>>> Why did the HDD (7200 rpm) perform better? >>>>> HDD - TIME 9 MINUTES >>>>> SSD - TIME 15 MINUTES >>>>> >>>>> As far as I know, the SSD has a reading that is 300 times faster than >>>>> SSD. >>>>> >>>>> --- Execution Plans--- >>>>> ssd 40g >>>>> https://explain.depesz.com/s/rHkh >>>>> >>>>> hdd 40g >>>>> https://explain.depesz.com/s/l4sq >>>>> >>>>> Query ------------------------------------ >>>>> >>>>> select >>>>> nation, >>>>> o_year, >>>>> sum(amount) as sum_profit >>>>> from >>>>> ( >>>>> select >>>>> n_name as nation, >>>>> extract(year from o_orderdate) as o_year, >>>>> l_extendedprice * (1 - l_discount) - ps_supplycost * >>>>> l_quantity as amount >>>>> from >>>>> part, >>>>> supplier, >>>>> lineitem, >>>>> partsupp, >>>>> orders, >>>>> nation >>>>> where >>>>> s_suppkey = l_suppkey >>>>> and ps_suppkey = l_suppkey >>>>> and ps_partkey = l_partkey >>>>> and p_partkey = l_partkey >>>>> and o_orderkey = l_orderkey >>>>> and s_nationkey = n_nationkey >>>>> and p_name like '%orchid%' >>>>> ) as profit >>>>> group by >>>>> nation, >>>>> o_year >>>>> order by >>>>> nation, >>>>> o_year desc >>>>> >
2018-07-17 10:55 GMT-03:00 Fabio Pardi <f.pardi@portavita.eu>: > If you have a RAID cache, i would disable it, since we are only focusing > on the disks. Cache can give you inconsistent data (even it looks like > is not the case here). > > Also, we can do a step backward, and exclude postgres from the picture > for the moment. > > try to perform a dd test in reading from disk, and let us know. > > like: > > - create big_enough_file > - empty OS cache > - dd if=big_enough_file of=/dev/null > > and post the results for both disks. > > Also i think it makes not much sense testing on RAID 0. I would start > performing tests on a single disk, bypassing RAID (or, as mentioned, at > least disabling cache). > But in my case, both the 2 SSDs and the 2 HDDs are in RAID ZERO. This way it would not be a valid test ? Because the 2 environments are in RAID ZERO. > The findings should narrow the focus > > > regards, > > fabio pardi > > On 07/17/2018 03:19 PM, Neto pr wrote: >> 2018-07-17 10:04 GMT-03:00 Neto pr <netopr9@gmail.com>: >>> Sorry.. I replied in the wrong message before ... >>> follows my response. >>> ------------- >>> >>> Thanks all, but I still have not figured it out. >>> This is really strange because the tests were done on the same machine >>> (I use HP ML110 Proliant 8gb RAM - Xeon 2.8 ghz processor (4 >>> cores), and POSTGRESQL 10.1. >>> - Only the mentioned query running at the time of the test. >>> - I repeated the query 7 times and did not change the results. >>> - Before running each batch of 7 executions, I discarded the Operating >>> System cache and restarted DBMS like this: >>> (echo 3> / proc / sys / vm / drop_caches; >>> >>> discs: >>> - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID) >>> - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID) >>> >>> - The Operating System and the Postgresql DBMS are installed on the SSD disk. >>> >> >> One more information. >> I used default configuration to Postgresql.conf >> Only exception is to : >> random_page_cost on SSD is 1.1 >> >> >>> Best Regards >>> [ ]`s Neto >>> >>> 2018-07-17 1:08 GMT-07:00 Fabio Pardi <f.pardi@portavita.eu>: >>>> As already mentioned by Robert, please let us know if you made sure that >>>> nothing was fished from RAM, over the faster test. >>>> >>>> In other words, make sure that all caches are dropped between one test >>>> and another. >>>> >>>> Also,to better picture the situation, would be good to know: >>>> >>>> - which SSD (brand/model) are you using? >>>> - which HDD? >>>> - how are the disks configured? RAID? or not? >>>> - on which OS? >>>> - what are the mount options? SSD requires tuning >>>> - did you make sure that no other query was running at the time of the >>>> bench? >>>> - are you making a comparison on the same machine? >>>> - is it HW or VM? benchs should better run on bare metal to avoid >>>> results pollution (eg: other VMS on the same hypervisor using the disk, >>>> host caching and so on) >>>> - how many times did you run the tests? >>>> - did you change postgres configuration over tests? >>>> - can you post postgres config? >>>> - what about vacuums or maintenance tasks running in the background? >>>> >>>> Also, to benchmark disks i would not use a custom query but pgbench. >>>> >>>> Be aware: running benchmarks is a science, therefore needs a scientific >>>> approach :) >>>> >>>> regards >>>> >>>> fabio pardi >>>> >>>> >>>> >>>> On 07/17/2018 07:00 AM, Neto pr wrote: >>>>> Dear, >>>>> Some of you can help me understand this. >>>>> >>>>> This query plan is executed in the query below (query 9 of TPC-H >>>>> Benchmark, with scale 40, database with approximately 40 gb). >>>>> >>>>> The experiment consisted of running the query on a HDD (Raid zero). >>>>> Then the same query is executed on an SSD (Raid Zero). >>>>> >>>>> Why did the HDD (7200 rpm) perform better? >>>>> HDD - TIME 9 MINUTES >>>>> SSD - TIME 15 MINUTES >>>>> >>>>> As far as I know, the SSD has a reading that is 300 times faster than SSD. >>>>> >>>>> --- Execution Plans--- >>>>> ssd 40g >>>>> https://explain.depesz.com/s/rHkh >>>>> >>>>> hdd 40g >>>>> https://explain.depesz.com/s/l4sq >>>>> >>>>> Query ------------------------------------ >>>>> >>>>> select >>>>> nation, >>>>> o_year, >>>>> sum(amount) as sum_profit >>>>> from >>>>> ( >>>>> select >>>>> n_name as nation, >>>>> extract(year from o_orderdate) as o_year, >>>>> l_extendedprice * (1 - l_discount) - ps_supplycost * >>>>> l_quantity as amount >>>>> from >>>>> part, >>>>> supplier, >>>>> lineitem, >>>>> partsupp, >>>>> orders, >>>>> nation >>>>> where >>>>> s_suppkey = l_suppkey >>>>> and ps_suppkey = l_suppkey >>>>> and ps_partkey = l_partkey >>>>> and p_partkey = l_partkey >>>>> and o_orderkey = l_orderkey >>>>> and s_nationkey = n_nationkey >>>>> and p_name like '%orchid%' >>>>> ) as profit >>>>> group by >>>>> nation, >>>>> o_year >>>>> order by >>>>> nation, >>>>> o_year desc >>>>> >>>>
Le 17/07/2018 à 15:50, Robert Zenz a écrit : > On 17.07.2018 15:44, Nicolas Charles wrote: >> - Partitions is not correctly aligned on the SSD blocks > Does that really make a noticeable difference? If yes, have you got some further > reading material on that? I was pretty sure it was, but looking at the litterature, it's not that obvious. Especially https://blog.pgaddict.com/posts/postgresql-performance-on-ext4-and-xfs seems to mentions that it doesn't change a thing, while others stress out that it is mandatory ( https://www.alibabacloud.com/forum/read-415, https://www.thomas-krenn.com/en/wiki/Partition_Alignment ) Even on mecanical drives it's been reported to cause slowdown ( https://www.ibm.com/developerworks/library/l-linux-on-4kb-sector-disks/index.html ) Maybe the OS are more clever now, making it not so important as before ? Nicolas
Le 17/07/2018 à 16:00, Neto pr a écrit : > 2018-07-17 10:44 GMT-03:00 Nicolas Charles <nicolas.charles@normation.com>: >> Hi Neto, >> >> You should list the SSD model also - there are pleinty of Samsung EVO drives >> - and they are not professional grade. >> >> Among the the possible issues, the most likely (from my point of view) are: >> >> - TRIM command doesn't go through the RAID (which is really likely) - so the >> SSD controller think it's full, and keep pushing blocks around to level >> wear, causing massive perf degradation - please check this config on you >> RAID driver/adapter >> >> - TRIM is not configured on the OS level for the SSD >> >> - Partitions is not correctly aligned on the SSD blocks >> >> >> Without so little details on your system, we can only try to guess the real >> issues >> > Thank you Nicolas, for your tips. > I believe your assumption is right. > > This SSD really is not professional, even if Samsung's advertisement > says yes. If I have to buy another SSD I will prefer INTEL SSDs. > > I had a previous problem with it (Sansung EVO) as it lost in > performance to a SAS HDD, but however, the SAS HDD was a 12 Gb/s > transfer rate and the SSD was 6 Gb/s. > > But now I tested against an HDD (7200 RPM) that has the same transfer > rate as the SSD 6 Gb/sec. and could not lose in performance. > > Maybe it's the unconfigured trim. > > Could you give me some help on how I could check if my RAID is > configured for this, I use Hardware RAID using HP software (HP Storage > Provider on boot). > And on Debian 8 Operating System, how could I check the TRIM configuration ? > > Best > []'s Neto I'm no expert in HP system, but you can have a look at this thread and referenced links For the trim option in Debian, you need to define the mount options of your partition, in /etc/fstab, to include "discard" (see https://wiki.archlinux.org/index.php/Solid_State_Drive#Continuous_TRIM ) Regards, Nicolas >> Nicolas >> >> Nicolas CHARLES >> >> Le 17/07/2018 à 15:19, Neto pr a écrit : >>> 2018-07-17 10:04 GMT-03:00 Neto pr <netopr9@gmail.com>: >>>> Sorry.. I replied in the wrong message before ... >>>> follows my response. >>>> ------------- >>>> >>>> Thanks all, but I still have not figured it out. >>>> This is really strange because the tests were done on the same machine >>>> (I use HP ML110 Proliant 8gb RAM - Xeon 2.8 ghz processor (4 >>>> cores), and POSTGRESQL 10.1. >>>> - Only the mentioned query running at the time of the test. >>>> - I repeated the query 7 times and did not change the results. >>>> - Before running each batch of 7 executions, I discarded the Operating >>>> System cache and restarted DBMS like this: >>>> (echo 3> / proc / sys / vm / drop_caches; >>>> >>>> discs: >>>> - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID) >>>> - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID) >>>> >>>> - The Operating System and the Postgresql DBMS are installed on the SSD >>>> disk. >>>> >>> One more information. >>> I used default configuration to Postgresql.conf >>> Only exception is to : >>> random_page_cost on SSD is 1.1 >>> >>> >>>> Best Regards >>>> [ ]`s Neto >>>> >>>> 2018-07-17 1:08 GMT-07:00 Fabio Pardi <f.pardi@portavita.eu>: >>>>> As already mentioned by Robert, please let us know if you made sure that >>>>> nothing was fished from RAM, over the faster test. >>>>> >>>>> In other words, make sure that all caches are dropped between one test >>>>> and another. >>>>> >>>>> Also,to better picture the situation, would be good to know: >>>>> >>>>> - which SSD (brand/model) are you using? >>>>> - which HDD? >>>>> - how are the disks configured? RAID? or not? >>>>> - on which OS? >>>>> - what are the mount options? SSD requires tuning >>>>> - did you make sure that no other query was running at the time of the >>>>> bench? >>>>> - are you making a comparison on the same machine? >>>>> - is it HW or VM? benchs should better run on bare metal to avoid >>>>> results pollution (eg: other VMS on the same hypervisor using the disk, >>>>> host caching and so on) >>>>> - how many times did you run the tests? >>>>> - did you change postgres configuration over tests? >>>>> - can you post postgres config? >>>>> - what about vacuums or maintenance tasks running in the background? >>>>> >>>>> Also, to benchmark disks i would not use a custom query but pgbench. >>>>> >>>>> Be aware: running benchmarks is a science, therefore needs a scientific >>>>> approach :) >>>>> >>>>> regards >>>>> >>>>> fabio pardi >>>>> >>>>> >>>>> >>>>> On 07/17/2018 07:00 AM, Neto pr wrote: >>>>>> Dear, >>>>>> Some of you can help me understand this. >>>>>> >>>>>> This query plan is executed in the query below (query 9 of TPC-H >>>>>> Benchmark, with scale 40, database with approximately 40 gb). >>>>>> >>>>>> The experiment consisted of running the query on a HDD (Raid zero). >>>>>> Then the same query is executed on an SSD (Raid Zero). >>>>>> >>>>>> Why did the HDD (7200 rpm) perform better? >>>>>> HDD - TIME 9 MINUTES >>>>>> SSD - TIME 15 MINUTES >>>>>> >>>>>> As far as I know, the SSD has a reading that is 300 times faster than >>>>>> SSD. >>>>>> >>>>>> --- Execution Plans--- >>>>>> ssd 40g >>>>>> https://explain.depesz.com/s/rHkh >>>>>> >>>>>> hdd 40g >>>>>> https://explain.depesz.com/s/l4sq >>>>>> >>>>>> Query ------------------------------------ >>>>>> >>>>>> select >>>>>> nation, >>>>>> o_year, >>>>>> sum(amount) as sum_profit >>>>>> from >>>>>> ( >>>>>> select >>>>>> n_name as nation, >>>>>> extract(year from o_orderdate) as o_year, >>>>>> l_extendedprice * (1 - l_discount) - ps_supplycost * >>>>>> l_quantity as amount >>>>>> from >>>>>> part, >>>>>> supplier, >>>>>> lineitem, >>>>>> partsupp, >>>>>> orders, >>>>>> nation >>>>>> where >>>>>> s_suppkey = l_suppkey >>>>>> and ps_suppkey = l_suppkey >>>>>> and ps_partkey = l_partkey >>>>>> and p_partkey = l_partkey >>>>>> and o_orderkey = l_orderkey >>>>>> and s_nationkey = n_nationkey >>>>>> and p_name like '%orchid%' >>>>>> ) as profit >>>>>> group by >>>>>> nation, >>>>>> o_year >>>>>> order by >>>>>> nation, >>>>>> o_year desc >>>>>>
On 07/17/2018 04:05 PM, Neto pr wrote: > 2018-07-17 10:55 GMT-03:00 Fabio Pardi <f.pardi@portavita.eu>: >> Also i think it makes not much sense testing on RAID 0. I would start >> performing tests on a single disk, bypassing RAID (or, as mentioned, at >> least disabling cache). >> > > But in my case, both the 2 SSDs and the 2 HDDs are in RAID ZERO. > This way it would not be a valid test ? Because the 2 environments are > in RAID ZERO. > > in theory, probably yes and maybe not. In RAID 0, data is (usually) striped in a round robin fashion, so you should rely on the fact that, in average, data is spread 50% on each disk. For the sake of knowledge, you can check what your RAID controller is actually using as algorithm to spread data over RAID 0. But you might be in an unlucky case in which more data is on one disk than in another. Unlucky or created by the events, like you deleted the records which are on disk 0 and you only are querying those on disk 1, for instance. The fact is, that more complexity you add to your test, the less the results will be closer to your expectations. Since you are testing disks, and not RAID, i would start empirically and perform the test straight on 1 disk. A simple test, like dd i mentioned here above. If dd, or other more tailored tests on disks show that SSD is way slow, then you can focus on tuning your disk. or trashing it :) When you are satisfied with your results, you can build up complexity from the reliable/consolidated level you reached. As side note: why to run a test on a setup you can never use on production? regards, fabio pardi
Ok, so dropping the cache is good. How are you ensuring that you have one test setup on the HDDs and one on the SSDs? i.e do you have 2 postgres instances? or are you using one instance with tablespaces to locate the relevant tables? If the 2nd case then you will get pollution of shared_buffers if you don't restart between the HHD and SSD tests. If you have 2 instances then you need to carefully check the parameters are set the same (and probably shut the HDD instance down when testing the SSD etc). I can see a couple of things in your setup that might pessimize the SDD case: - you have OS on the SSD - if you tests make the system swap then this will wreck the SSD result - you have RAID 0 SSD...some of the cheaper ones slow down when you do this. maybe test with a single SSD regards Mark On 18/07/18 01:04, Neto pr wrote (note snippage): > (echo 3> / proc / sys / vm / drop_caches; > > discs: > - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID) > - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID) > > - The Operating System and the Postgresql DBMS are installed on the SSD disk. > >
Yeah, A +1 to telling us the model. In particular the later EVOs use TLC nand with a small SLC cache... and when you exhaust the SLC cache the performance can be worse than a HDD... On 18/07/18 01:44, Nicolas Charles wrote: > Hi Neto, > > You should list the SSD model also - there are pleinty of Samsung EVO > drives - and they are not professional grade. > > Among the the possible issues, the most likely (from my point of view) > are: > > - TRIM command doesn't go through the RAID (which is really likely) - > so the SSD controller think it's full, and keep pushing blocks around > to level wear, causing massive perf degradation - please check this > config on you RAID driver/adapter > > - TRIM is not configured on the OS level for the SSD > > - Partitions is not correctly aligned on the SSD blocks > > > Without so little details on your system, we can only try to guess the > real issues > > > Nicolas > > Nicolas CHARLES > Le 17/07/2018 à 15:19, Neto pr a écrit : >> 2018-07-17 10:04 GMT-03:00 Neto pr <netopr9@gmail.com>: >>> Sorry.. I replied in the wrong message before ... >>> follows my response. >>> ------------- >>> >>> Thanks all, but I still have not figured it out. >>> This is really strange because the tests were done on the same machine >>> (I use HP ML110 Proliant 8gb RAM - Xeon 2.8 ghz processor (4 >>> cores), and POSTGRESQL 10.1. >>> - Only the mentioned query running at the time of the test. >>> - I repeated the query 7 times and did not change the results. >>> - Before running each batch of 7 executions, I discarded the Operating >>> System cache and restarted DBMS like this: >>> (echo 3> / proc / sys / vm / drop_caches; >>> >>> discs: >>> - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID) >>> - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID) >>> >>> - The Operating System and the Postgresql DBMS are installed on the >>> SSD disk. >>> >> One more information. >> I used default configuration to Postgresql.conf >> Only exception is to : >> random_page_cost on SSD is 1.1 >> >> >>> Best Regards >>> [ ]`s Neto >>> >>> 2018-07-17 1:08 GMT-07:00 Fabio Pardi <f.pardi@portavita.eu>: >>>> As already mentioned by Robert, please let us know if you made sure >>>> that >>>> nothing was fished from RAM, over the faster test. >>>> >>>> In other words, make sure that all caches are dropped between one test >>>> and another. >>>> >>>> Also,to better picture the situation, would be good to know: >>>> >>>> - which SSD (brand/model) are you using? >>>> - which HDD? >>>> - how are the disks configured? RAID? or not? >>>> - on which OS? >>>> - what are the mount options? SSD requires tuning >>>> - did you make sure that no other query was running at the time of the >>>> bench? >>>> - are you making a comparison on the same machine? >>>> - is it HW or VM? benchs should better run on bare metal to avoid >>>> results pollution (eg: other VMS on the same hypervisor using the >>>> disk, >>>> host caching and so on) >>>> - how many times did you run the tests? >>>> - did you change postgres configuration over tests? >>>> - can you post postgres config? >>>> - what about vacuums or maintenance tasks running in the background? >>>> >>>> Also, to benchmark disks i would not use a custom query but pgbench. >>>> >>>> Be aware: running benchmarks is a science, therefore needs a >>>> scientific >>>> approach :) >>>> >>>> regards >>>> >>>> fabio pardi >>>> >>>> >>>> >>>> On 07/17/2018 07:00 AM, Neto pr wrote: >>>>> Dear, >>>>> Some of you can help me understand this. >>>>> >>>>> This query plan is executed in the query below (query 9 of TPC-H >>>>> Benchmark, with scale 40, database with approximately 40 gb). >>>>> >>>>> The experiment consisted of running the query on a HDD (Raid zero). >>>>> Then the same query is executed on an SSD (Raid Zero). >>>>> >>>>> Why did the HDD (7200 rpm) perform better? >>>>> HDD - TIME 9 MINUTES >>>>> SSD - TIME 15 MINUTES >>>>> >>>>> As far as I know, the SSD has a reading that is 300 times faster >>>>> than SSD. >>>>> >>>>> --- Execution Plans--- >>>>> ssd 40g >>>>> https://explain.depesz.com/s/rHkh >>>>> >>>>> hdd 40g >>>>> https://explain.depesz.com/s/l4sq >>>>> >>>>> Query ------------------------------------ >>>>> >>>>> select >>>>> nation, >>>>> o_year, >>>>> sum(amount) as sum_profit >>>>> from >>>>> ( >>>>> select >>>>> n_name as nation, >>>>> extract(year from o_orderdate) as o_year, >>>>> l_extendedprice * (1 - l_discount) - ps_supplycost * >>>>> l_quantity as amount >>>>> from >>>>> part, >>>>> supplier, >>>>> lineitem, >>>>> partsupp, >>>>> orders, >>>>> nation >>>>> where >>>>> s_suppkey = l_suppkey >>>>> and ps_suppkey = l_suppkey >>>>> and ps_partkey = l_partkey >>>>> and p_partkey = l_partkey >>>>> and o_orderkey = l_orderkey >>>>> and s_nationkey = n_nationkey >>>>> and p_name like '%orchid%' >>>>> ) as profit >>>>> group by >>>>> nation, >>>>> o_year >>>>> order by >>>>> nation, >>>>> o_year desc >>>>> > >
2018-07-17 20:04 GMT-03:00 Mark Kirkwood <mark.kirkwood@catalyst.net.nz>:
> Ok, so dropping the cache is good.
>
> How are you ensuring that you have one test setup on the HDDs and one on the
> SSDs? i.e do you have 2 postgres instances? or are you using one instance
> with tablespaces to locate the relevant tables? If the 2nd case then you
> will get pollution of shared_buffers if you don't restart between the HHD
> and SSD tests. If you have 2 instances then you need to carefully check the
> parameters are set the same (and probably shut the HDD instance down when
> testing the SSD etc).
>
Dear Mark
To ensure that the test is honest and has the same configuration the
O.S. and also DBMS, my O.S. is installed on the SSD and DBMS as well.
I have an instance only of DBMS and two database.
- a database called tpch40gnorhdd with tablespace on the HDD disk.
- a database called tpch40gnorssd with tablespace on the SSD disk.
See below:
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype |
Access privileges
---------------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
=c/postgres +
| | | | |
postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
=c/postgres +
| | | | |
postgres=CTc/postgres
tpch40gnorhdd | user1 | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
tpch40gnorssd | user1 | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
(5 rows)
postgres=#
After 7 query execution in a database tpch40gnorhdd I restart the DBMS
(/etc/init.d/pg101norssd restart and drop cache of the O.S.) and go to
execution test with the database tpch40gnorssd.
You think in this case there is pollution of shared_buffers?
Why do you think having O.S. on SSD is bad? Do you could explain better?
Best regards
[]`s Neto
> I can see a couple of things in your setup that might pessimize the SDD
> case:
> - you have OS on the SSD - if you tests make the system swap then this will
> wreck the SSD result
> - you have RAID 0 SSD...some of the cheaper ones slow down when you do this.
> maybe test with a single SSD
>
> regards
> Mark
>
> On 18/07/18 01:04, Neto pr wrote (note snippage):
>
>> (echo 3> / proc / sys / vm / drop_caches;
>>
>> discs:
>> - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID)
>> - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID)
>>
>> - The Operating System and the Postgresql DBMS are installed on the SSD
>> disk.
>>
>>
>
2018-07-17 22:13 GMT-03:00 Neto pr <netopr9@gmail.com>: > 2018-07-17 20:04 GMT-03:00 Mark Kirkwood <mark.kirkwood@catalyst.net.nz>: >> Ok, so dropping the cache is good. >> >> How are you ensuring that you have one test setup on the HDDs and one on the >> SSDs? i.e do you have 2 postgres instances? or are you using one instance >> with tablespaces to locate the relevant tables? If the 2nd case then you >> will get pollution of shared_buffers if you don't restart between the HHD >> and SSD tests. If you have 2 instances then you need to carefully check the >> parameters are set the same (and probably shut the HDD instance down when >> testing the SSD etc). >> > Dear Mark > To ensure that the test is honest and has the same configuration the > O.S. and also DBMS, my O.S. is installed on the SSD and DBMS as well. > I have an instance only of DBMS and two database. > - a database called tpch40gnorhdd with tablespace on the HDD disk. > - a database called tpch40gnorssd with tablespace on the SSD disk. > See below: > > postgres=# \l > List of databases > Name | Owner | Encoding | Collate | Ctype | > Access privileges > ---------------+----------+----------+-------------+-------------+----------------------- > postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | > template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | > =c/postgres + > | | | | | > postgres=CTc/postgres > template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | > =c/postgres + > | | | | | > postgres=CTc/postgres > tpch40gnorhdd | user1 | UTF8 | en_US.UTF-8 | en_US.UTF-8 | > tpch40gnorssd | user1 | UTF8 | en_US.UTF-8 | en_US.UTF-8 | > (5 rows) > > postgres=# > > After 7 query execution in a database tpch40gnorhdd I restart the DBMS > (/etc/init.d/pg101norssd restart and drop cache of the O.S.) and go to > execution test with the database tpch40gnorssd. > You think in this case there is pollution of shared_buffers? > Why do you think having O.S. on SSD is bad? Do you could explain better? > > Best regards > []`s Neto > +1 information about EVO SSD Samsung: Model: 850 Evo 500 GB SATA III 6Gb/s - http://www.samsung.com/semiconductor/minisite/ssd/product/consumer/850evo/ >> I can see a couple of things in your setup that might pessimize the SDD >> case: >> - you have OS on the SSD - if you tests make the system swap then this will >> wreck the SSD result >> - you have RAID 0 SSD...some of the cheaper ones slow down when you do this. >> maybe test with a single SSD >> >> regards >> Mark >> >> On 18/07/18 01:04, Neto pr wrote (note snippage): >> >>> (echo 3> / proc / sys / vm / drop_caches; >>> >>> discs: >>> - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID) >>> - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID) >>> >>> - The Operating System and the Postgresql DBMS are installed on the SSD >>> disk. >>> >>> >>
2018-07-17 11:43 GMT-03:00 Fabio Pardi <f.pardi@portavita.eu>: > > > On 07/17/2018 04:05 PM, Neto pr wrote: >> 2018-07-17 10:55 GMT-03:00 Fabio Pardi <f.pardi@portavita.eu>: > >>> Also i think it makes not much sense testing on RAID 0. I would start >>> performing tests on a single disk, bypassing RAID (or, as mentioned, at >>> least disabling cache). >>> >> >> But in my case, both the 2 SSDs and the 2 HDDs are in RAID ZERO. >> This way it would not be a valid test ? Because the 2 environments are >> in RAID ZERO. >> >> > > in theory, probably yes and maybe not. > In RAID 0, data is (usually) striped in a round robin fashion, so you > should rely on the fact that, in average, data is spread 50% on each > disk. For the sake of knowledge, you can check what your RAID controller > is actually using as algorithm to spread data over RAID 0. > > But you might be in an unlucky case in which more data is on one disk > than in another. > Unlucky or created by the events, like you deleted the records which are > on disk 0 and you only are querying those on disk 1, for instance. > > The fact is, that more complexity you add to your test, the less the > results will be closer to your expectations. > > Since you are testing disks, and not RAID, i would start empirically and > perform the test straight on 1 disk. > A simple test, like dd i mentioned here above. > If dd, or other more tailored tests on disks show that SSD is way slow, > then you can focus on tuning your disk. or trashing it :) > > When you are satisfied with your results, you can build up complexity > from the reliable/consolidated level you reached. > > As side note: why to run a test on a setup you can never use on production? > > regards, > > fabio pardi > Fabio, I understood and I agree with you about testing without RAID, this way it would be easier to avoid problems unrelated to my test on disks (SSD and HDD). Can you just explain why you said it below? "As side note: why to run a test on a setup you can never use on production?" You think that a RAID ZERO configuration for a DBMS is little used? Which one do you think would be good? I accept suggestions because I am in the middle of a work for my research of the postgraduate course and I can change the environment to something that is more useful and really used in real production environments. Best Regards []`s Neto >
Hi Neto, RAID 0 to store production data should never be used. Never a good idea, in my opinion. Simple reason is that when you lose one disk, you lose everything. If your goal is to bench the disk, go for single disk. If you want to be closer to a production setup, go for RAID 10, or pick a RAID setup close to what your needs and capabilitiesare (more reads? more writes? SSD? HDD? cache? ...? ) If you only have 2 disks, your obliged (redundant) choice is RAID 1. regards, fabio pardi On 18/07/18 03:24, Neto pr wrote: > >> As side note: why to run a test on a setup you can never use on production? >> >> regards, >> >> fabio pardi >> > > Can you just explain why you said it below? > > "As side note: why to run a test on a setup you can never use on production?" > > You think that a RAID ZERO configuration for a DBMS is little used? > Which one do you think would be good? I accept suggestions because I > am in the middle of a work for my > research of the postgraduate course and I can change the environment > to something that is more useful and really used in real production > environments. > > Best Regards > []`s Neto
Le 18/07/2018 à 03:16, Neto pr a écrit :
ATSB - The Destroyer (99th Percentile Write Latency) 99th Percentile Latency in Microseconds - Lower is Better 34923
Even average write latency of the Samsung 850 Evo is 3,3 ms in intensive workload
Why are you using this type of SSD for your benchmark ? What do you plan to achieve ?
As stated on his ML on january, Samsung 850 Evo is not a particularly fast SSD - especially it's not really consistent in term of performance ( see https://www.anandtech.com/show/8747/samsung-ssd-850-evo-review/5 and https://www.anandtech.com/bench/product/1913 ). This is not a product for professional usage, and you should not expect great performance from it - as reported by these benchmark, you can have a 34ms latency in very intensive usage:2018-07-17 22:13 GMT-03:00 Neto pr <netopr9@gmail.com>:2018-07-17 20:04 GMT-03:00 Mark Kirkwood <mark.kirkwood@catalyst.net.nz>:Ok, so dropping the cache is good. How are you ensuring that you have one test setup on the HDDs and one on the SSDs? i.e do you have 2 postgres instances? or are you using one instance with tablespaces to locate the relevant tables? If the 2nd case then you will get pollution of shared_buffers if you don't restart between the HHD and SSD tests. If you have 2 instances then you need to carefully check the parameters are set the same (and probably shut the HDD instance down when testing the SSD etc).Dear Mark To ensure that the test is honest and has the same configuration the O.S. and also DBMS, my O.S. is installed on the SSD and DBMS as well. I have an instance only of DBMS and two database. - a database called tpch40gnorhdd with tablespace on the HDD disk. - a database called tpch40gnorssd with tablespace on the SSD disk. See below: postgres=# \l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges ---------------+----------+----------+-------------+-------------+-----------------------postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgrestemplate1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgrestpch40gnorhdd | user1 | UTF8 | en_US.UTF-8 | en_US.UTF-8 |tpch40gnorssd | user1 | UTF8 | en_US.UTF-8 | en_US.UTF-8 | (5 rows) postgres=# After 7 query execution in a database tpch40gnorhdd I restart the DBMS (/etc/init.d/pg101norssd restart and drop cache of the O.S.) and go to execution test with the database tpch40gnorssd. You think in this case there is pollution of shared_buffers? Why do you think having O.S. on SSD is bad? Do you could explain better? Best regards []`s Neto+1 information about EVO SSD Samsung: Model: 850 Evo 500 GB SATA III 6Gb/s - http://www.samsung.com/semiconductor/minisite/ssd/product/consumer/850evo/
ATSB - The Destroyer (99th Percentile Write Latency) 99th Percentile Latency in Microseconds - Lower is Better 34923
Even average write latency of the Samsung 850 Evo is 3,3 ms in intensive workload
Why are you using this type of SSD for your benchmark ? What do you plan to achieve ?
I can see a couple of things in your setup that might pessimize the SDD case: - you have OS on the SSD - if you tests make the system swap then this will wreck the SSD result - you have RAID 0 SSD...some of the cheaper ones slow down when you do this. maybe test with a single SSD regards Mark On 18/07/18 01:04, Neto pr wrote (note snippage):(echo 3> / proc / sys / vm / drop_caches; discs: - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID) - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID) - The Operating System and the Postgresql DBMS are installed on the SSD disk.
Ok, so you are using 1 instance and tablespaces. Also I see you are restarting the instance between HDD and SSD tests, so all good there. The point I made about having the OS on the SSD's means that if these tests make your system swap, and your swap device is on the SSDs (which is probably is by default), then swap activity will compete with db access activity for IOPS on your SSDs and spoil the results of your test (i.e slow down your SSDs). You can check this using top, sar or iostat to see *if* you are swapping during the tests. Ideally you would design your setup to use 3 separate devices: - one device (or array) for os, swap, tmp etc - one device (HDD array) for you 'HDD' tablespace - one device (SDD array) for your 'SDD' tablespace regards Mark On 18/07/18 13:13, Neto pr wrote: > > Dear Mark > To ensure that the test is honest and has the same configuration the > O.S. and also DBMS, my O.S. is installed on the SSD and DBMS as well. > I have an instance only of DBMS and two database. > - a database called tpch40gnorhdd with tablespace on the HDD disk. > - a database called tpch40gnorssd with tablespace on the SSD disk. > See below: > > postgres=# \l > List of databases > Name | Owner | Encoding | Collate | Ctype | > Access privileges > ---------------+----------+----------+-------------+-------------+----------------------- > postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | > template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | > =c/postgres + > | | | | | > postgres=CTc/postgres > template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | > =c/postgres + > | | | | | > postgres=CTc/postgres > tpch40gnorhdd | user1 | UTF8 | en_US.UTF-8 | en_US.UTF-8 | > tpch40gnorssd | user1 | UTF8 | en_US.UTF-8 | en_US.UTF-8 | > (5 rows) > > postgres=# > > After 7 query execution in a database tpch40gnorhdd I restart the DBMS > (/etc/init.d/pg101norssd restart and drop cache of the O.S.) and go to > execution test with the database tpch40gnorssd. > You think in this case there is pollution of shared_buffers? > Why do you think having O.S. on SSD is bad? Do you could explain better? > >
On Wed, 18 Jul 2018 09:46:32 +0200, Fabio Pardi <f.pardi@portavita.eu> wrote: > RAID 0 to store production data should never be used. Never a good > idea, in my opinion. RAID 0 by itself should never be used. Combined with other RAID levels, it can boost performance without sacrificing reliability. https://en.wikipedia.org/wiki/Nested_RAID_levels Personally, I don't like RAID 0 + ? schemes because they use too many disks (with associated reliability issues). The required performance usually can be achieved in other ways. But YMMV. George
please check the SSD "DRIVE HEALTH STATUS" and the "S.M.A.R.T values of specified disk" ....
for example - with the "smartctl" tool ( https://www.smartmontools.org/ ) ( -x "Show all information for device" )
Expected output with "Samsung SSD 850 EVO 500GB" https://superuser.com/questions/1169810/smart-data-of-a-new-ssd
Regards,
Imre
Neto pr <netopr9@gmail.com> ezt írta (időpont: 2018. júl. 18., Sze, 3:17):
2018-07-17 22:13 GMT-03:00 Neto pr <netopr9@gmail.com>:
> 2018-07-17 20:04 GMT-03:00 Mark Kirkwood <mark.kirkwood@catalyst.net.nz>:
>> Ok, so dropping the cache is good.
>>
>> How are you ensuring that you have one test setup on the HDDs and one on the
>> SSDs? i.e do you have 2 postgres instances? or are you using one instance
>> with tablespaces to locate the relevant tables? If the 2nd case then you
>> will get pollution of shared_buffers if you don't restart between the HHD
>> and SSD tests. If you have 2 instances then you need to carefully check the
>> parameters are set the same (and probably shut the HDD instance down when
>> testing the SSD etc).
>>
> Dear Mark
> To ensure that the test is honest and has the same configuration the
> O.S. and also DBMS, my O.S. is installed on the SSD and DBMS as well.
> I have an instance only of DBMS and two database.
> - a database called tpch40gnorhdd with tablespace on the HDD disk.
> - a database called tpch40gnorssd with tablespace on the SSD disk.
> See below:
>
> postgres=# \l
> List of databases
> Name | Owner | Encoding | Collate | Ctype |
> Access privileges
> ---------------+----------+----------+-------------+-------------+-----------------------
> postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
> template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
> =c/postgres +
> | | | | |
> postgres=CTc/postgres
> template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
> =c/postgres +
> | | | | |
> postgres=CTc/postgres
> tpch40gnorhdd | user1 | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
> tpch40gnorssd | user1 | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
> (5 rows)
>
> postgres=#
>
> After 7 query execution in a database tpch40gnorhdd I restart the DBMS
> (/etc/init.d/pg101norssd restart and drop cache of the O.S.) and go to
> execution test with the database tpch40gnorssd.
> You think in this case there is pollution of shared_buffers?
> Why do you think having O.S. on SSD is bad? Do you could explain better?
>
> Best regards
> []`s Neto
>
+1 information about EVO SSD Samsung:
Model: 850 Evo 500 GB SATA III 6Gb/s -
http://www.samsung.com/semiconductor/minisite/ssd/product/consumer/850evo/
>> I can see a couple of things in your setup that might pessimize the SDD
>> case:
>> - you have OS on the SSD - if you tests make the system swap then this will
>> wreck the SSD result
>> - you have RAID 0 SSD...some of the cheaper ones slow down when you do this.
>> maybe test with a single SSD
>>
>> regards
>> Mark
>>
>> On 18/07/18 01:04, Neto pr wrote (note snippage):
>>
>>> (echo 3> / proc / sys / vm / drop_caches;
>>>
>>> discs:
>>> - 2 units of Samsung Evo SSD 500 GB (mounted on ZERO RAID)
>>> - 2 SATA 7500 Krpm HDD units - 1TB (mounted on ZERO RAID)
>>>
>>> - The Operating System and the Postgresql DBMS are installed on the SSD
>>> disk.
>>>
>>>
>>
One more thought on this: Query 9 does a lot pf sorting to disk - so there will be writes for that and all the reads for the table scans. Thus the location of your instance's pgsql_tmp directory(s) will significantly influence results. I'm wondering if in your HDD test the pgsql_tmp on the *SSD's* is being used. This would make the HDDs look faster (obviously - as they only need to do reads now). You can check this with iostat while the HDD test is being run, there should be *no* activity on the SSDs...if there is you have just found one reason for the results being quicker than it should be. FWIW: I had a play with this: ran two version 10.4 instances, one on a single 7200 rpm HDD, one on a (ahem slow) Intel 600p NVME. Running query 9 on the scale 40 databases I get: - SSD 30 minutes - HDD 70 minutes No I'm running these on an a Intel i7 3.4 Ghz 16 GB RAM setup. Also both postgres instances have default config apart from random_page_cost. Comparing my results with yours - the SSD one is consistent...if I had two SSDs in RAID0 I might halve the time (I might try this). However my HDD result is not at all like yours (mine makes more sense to be fair...would expect HDD to be slower in general). Cheers (thanks for an interesting puzzle)! Mark On 18/07/18 13:13, Neto pr wrote: > > Dear Mark > To ensure that the test is honest and has the same configuration the > O.S. and also DBMS, my O.S. is installed on the SSD and DBMS as well. > I have an instance only of DBMS and two database. > - a database called tpch40gnorhdd with tablespace on the HDD disk. > - a database called tpch40gnorssd with tablespace on the SSD disk. > See below: > >
FWIW: re-running query 9 using the SSD setup as 2x crucial M550 RAID0: 10 minutes. On 20/07/18 11:30, Mark Kirkwood wrote: > One more thought on this: > > Query 9 does a lot pf sorting to disk - so there will be writes for > that and all the reads for the table scans. Thus the location of your > instance's pgsql_tmp directory(s) will significantly influence results. > > I'm wondering if in your HDD test the pgsql_tmp on the *SSD's* is > being used. This would make the HDDs look faster (obviously - as they > only need to do reads now). You can check this with iostat while the > HDD test is being run, there should be *no* activity on the SSDs...if > there is you have just found one reason for the results being quicker > than it should be. > > FWIW: I had a play with this: ran two version 10.4 instances, one on a > single 7200 rpm HDD, one on a (ahem slow) Intel 600p NVME. Running > query 9 on the scale 40 databases I get: > > - SSD 30 minutes > > - HDD 70 minutes > > No I'm running these on an a Intel i7 3.4 Ghz 16 GB RAM setup. Also > both postgres instances have default config apart from random_page_cost. > > Comparing my results with yours - the SSD one is consistent...if I had > two SSDs in RAID0 I might halve the time (I might try this). However > my HDD result is not at all like yours (mine makes more sense to be > fair...would expect HDD to be slower in general). > > Cheers (thanks for an interesting puzzle)! > > Mark > > > > On 18/07/18 13:13, Neto pr wrote: >> >> Dear Mark >> To ensure that the test is honest and has the same configuration the >> O.S. and also DBMS, my O.S. is installed on the SSD and DBMS as well. >> I have an instance only of DBMS and two database. >> - a database called tpch40gnorhdd with tablespace on the HDD disk. >> - a database called tpch40gnorssd with tablespace on the SSD disk. >> See below: >> >> > >
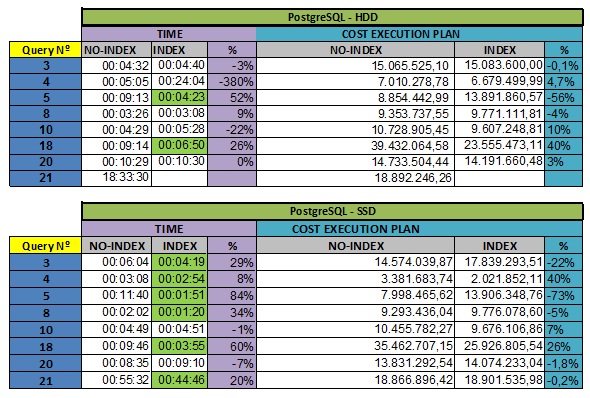
2018-07-19 21:33 GMT-03:00 Mark Kirkwood <mark.kirkwood@catalyst.net.nz>: > FWIW: > > re-running query 9 using the SSD setup as 2x crucial M550 RAID0: 10 minutes. > > > > On 20/07/18 11:30, Mark Kirkwood wrote: >> >> One more thought on this: >> >> Query 9 does a lot pf sorting to disk - so there will be writes for that >> and all the reads for the table scans. Thus the location of your instance's >> pgsql_tmp directory(s) will significantly influence results. >> >> I'm wondering if in your HDD test the pgsql_tmp on the *SSD's* is being >> used. This would make the HDDs look faster (obviously - as they only need to >> do reads now). You can check this with iostat while the HDD test is being >> run, there should be *no* activity on the SSDs...if there is you have just >> found one reason for the results being quicker than it should be. >> >> FWIW: I had a play with this: ran two version 10.4 instances, one on a >> single 7200 rpm HDD, one on a (ahem slow) Intel 600p NVME. Running query 9 >> on the scale 40 databases I get: >> >> - SSD 30 minutes >> >> - HDD 70 minutes >> >> No I'm running these on an a Intel i7 3.4 Ghz 16 GB RAM setup. Also both >> postgres instances have default config apart from random_page_cost. >> >> Comparing my results with yours - the SSD one is consistent...if I had two >> SSDs in RAID0 I might halve the time (I might try this). However my HDD >> result is not at all like yours (mine makes more sense to be fair...would >> expect HDD to be slower in general). >> >> Cheers (thanks for an interesting puzzle)! >> >> Mark >> Mark, This query 9 is very hard, see my results for other queries (attached - test with secondary index and without secondary index - only primary keys), the SSD always wins in performance. Only for this query that he was the loser, so I put this topic in the list. Today I will not be able to check your test information in more detail, but I will return with more information soon. Best Regards Neto >> >> >> On 18/07/18 13:13, Neto pr wrote: >>> >>> >>> Dear Mark >>> To ensure that the test is honest and has the same configuration the >>> O.S. and also DBMS, my O.S. is installed on the SSD and DBMS as well. >>> I have an instance only of DBMS and two database. >>> - a database called tpch40gnorhdd with tablespace on the HDD disk. >>> - a database called tpch40gnorssd with tablespace on the SSD disk. >>> See below: >>> >>> >> >> >
Attachment
{kind=link}
And perhaps more interesting: Re-running query 9 against the (single) HDD setup *but* with pgsql_tmp symlinked to the 2x SSD RAID0: 15 minutes I'm thinking that you have inadvertently configured your HDD test in this way (you get 9 minutes because you have 2x HDDs). Essentially most of the time taken for this query is in writing and reading files for sorting/hashing, so where pgsql_tmp is located hugely influences the overall time. regards Mark On 20/07/18 12:33, Mark Kirkwood wrote: > FWIW: > > re-running query 9 using the SSD setup as 2x crucial M550 RAID0: 10 > minutes. > > > On 20/07/18 11:30, Mark Kirkwood wrote: >> One more thought on this: >> >> Query 9 does a lot pf sorting to disk - so there will be writes for >> that and all the reads for the table scans. Thus the location of your >> instance's pgsql_tmp directory(s) will significantly influence results. >> >> I'm wondering if in your HDD test the pgsql_tmp on the *SSD's* is >> being used. This would make the HDDs look faster (obviously - as they >> only need to do reads now). You can check this with iostat while the >> HDD test is being run, there should be *no* activity on the SSDs...if >> there is you have just found one reason for the results being quicker >> than it should be. >> >> FWIW: I had a play with this: ran two version 10.4 instances, one on >> a single 7200 rpm HDD, one on a (ahem slow) Intel 600p NVME. Running >> query 9 on the scale 40 databases I get: >> >> - SSD 30 minutes >> >> - HDD 70 minutes >> >> No I'm running these on an a Intel i7 3.4 Ghz 16 GB RAM setup. Also >> both postgres instances have default config apart from random_page_cost. >> >> Comparing my results with yours - the SSD one is consistent...if I >> had two SSDs in RAID0 I might halve the time (I might try this). >> However my HDD result is not at all like yours (mine makes more sense >> to be fair...would expect HDD to be slower in general). >> >> Cheers (thanks for an interesting puzzle)! >> >> Mark >> >> >> >> On 18/07/18 13:13, Neto pr wrote: >>> >>> Dear Mark >>> To ensure that the test is honest and has the same configuration the >>> O.S. and also DBMS, my O.S. is installed on the SSD and DBMS as well. >>> I have an instance only of DBMS and two database. >>> - a database called tpch40gnorhdd with tablespace on the HDD disk. >>> - a database called tpch40gnorssd with tablespace on the SSD disk. >>> See below: >>> >>> >> >> > >
Hi Neto, In a great piece of timing my new experimental SSD arrived (WD Black 500 G 3D NAND MVME) [1]. Doing some runs of query 9: - default config: 7 minutes - work_mem=1G, max_parallel_workers_per_gather=4: 3-4 minutes Increasing either of these much more got me OOM errors (16 G of ram). Anyway, enjoy your benchmarking! Cheers Mark [1] Yeah - I know this is a 'do not use me in production' type of SSD. It is however fine for prototyping and DSS scenario run type use. On 20/07/18 12:52, Neto pr wrote: > > Mark, > This query 9 is very hard, see my results for other queries (attached > - test with secondary index and without secondary index - only primary > keys), the SSD always wins in performance. > Only for this query that he was the loser, so I put this topic in the list. > > Today I will not be able to check your test information in more > detail, but I will return with more information soon. > > Best Regards > Neto > > > > >