Thread: GSoC project: K-medoids clustering in Madlib
I am "viod.len@gmail.com", but now writing with my "true" email address.
Note that I've sent this mail to both MADlib and PostgreSQL mailing lists, in order to synchronize the efforts. I've also sent it to everyone that was CC'ed in previous mails.
Where should I send mails regarding this project from now on? Sending on both mailing lists seems like a quite bad idea.
As I had lost hope of getting an answer from MADlib, I have recontacted Atri, as he was willing to mentor the MADlib projects.
Here is his answer:
On Mon, Apr 15, 2013 at 9:12 PM, viod <viod.len@gmail.com> wrote:
> Hello all!
>
>
>>
>> Do you have any interest in data analytics? I proposed a couple of
>> ideas in that field.If you are interested, we could talk over them.
>>
>> Regards,
>>
>> Atri
>
>
> I am pretty much interested in the ideas you posted on the mailing list
> (particularly in implementing the K-medoids algorithm). I've asked MADlib if
> they could mentor me, but unfortunately their org has not been accepted in
> GSoC, and they haven't answered since then.
No issues, I can try to help you out.
> Do you think I could still do it with PostgreSQL? I would really like to do
> this project, as an initiation to classification algorithms.
>
> Still, I don't really understand how this would be used by PostgreSQL?
MADLib is the de facto library for in database analytics in PostgreSQL.
Download,install MADLib, run a few programs, and think more about the
implementation and discuss here.
Regards,
Atri
Do you have any idea of stuff I could do to get familiar with the code?
I've already been through the doc to search for functions I already knew,
and found a little bit, I'll go and read the code by the end of the week.
My current training is actually called IT and Applied Mathematics (and I currently have some difficulties in mathematics, as all the other students, except for one, have done a very maths-intensive "preparatory course" before coming here). Still, I'm really interested into what I learn, and am very curious about many things.
At first, I wanted to apply for a PostgreSQL project, and, while lurking on their mailing list, I found a reference to the aforementioned project about K-medoids algorithm. I found this project in perfect fit with my centers of interest: a teacher made me love databases and want to learn more about their internals, and machine learning is a domain that's been attracting me for a while now.
As to my skills, I've learnt lots of programming languages (not exhaustive list: C, C++, Java, a bit of Matlab and Fortran, Bash, PHP, C#, VBA, Python, Caml...). I know how to learn by myself and quickly. During my courses, I've done a (very little) bit of classification: we had to determine the zone in which a pixel belongs via their maximum likelihood. This made me want to learn more about this domain.
--
Maxence Ahlouche
06 06 66 97 00
93 avenue Paul DOUMER
24100 Bergerac
Hi Akansha,I am confused about the question - MADlib is open-source and available from Github. If you're having trouble in fork/clone or have a specific question about a module, we would be glad to help you. Please be specific about your question.- Rahul---------------------------------------------------------
Rahul Iyer
Senior Software Engineer | Predictive Analytics
rahul.iyer@emc.comOn Apr 19, 2013, at 3:13 AM, Akansha Singh wrote:Hi, MADLib guys, Any Updates..? On my Part I am trying to understand the modules placed in Github .I a trying to get hands on it. http://madlib.net/ https://github.com/madlib/madlib/
--
Maxence Ahlouche
06 06 66 97 00
93 avenue Paul DOUMER
24100 Bergerac
Attachment
However, I couldn't guess how to assign a cluster to a point from the output of the algorithm, could someone give me an indication, please?Hi all!I've had a bit of fun with the k-means clustering, and have made a small script to visualize the result of the classification.My script is written in python3, and uses py-postgresql (http://python.projects.pgfoundry.org/) as PostgreSQL interface. It also requires Pillow (a PIL fork) which you can find here : https://pypi.python.org/pypi/Pillow/2.0.0.Before your first use, you may want to change the settings (on top of the file) to connect to your PostgreSQL server.The script will create a table in your database, populate it with random groups of points, and then call the k-means algorithm on it. Finally, it will generate a PNG image, displaying the points and the centroids.For a first run, use something like this:./k-means_test.py --regen -o clustered_data.pngYou can call "./k-means_test.py -h" for a list of available options.In attachment are my script and an example of its output.By the way, I'll have a lot of work next week, as I have several exams coming and a big project to do (about empirical orthogonal functions), so I'll probably be inactive for a few days! Then I'll be on holidays, so I will be able to focus on MADlib and GSoC :)Regards,Maxence2013/4/19 Iyer, Rahul <Rahul.Iyer@emc.com>Hi Akansha,I am confused about the question - MADlib is open-source and available from Github. If you're having trouble in fork/clone or have a specific question about a module, we would be glad to help you. Please be specific about your question.- Rahul---------------------------------------------------------
Rahul Iyer
Senior Software Engineer | Predictive Analytics
rahul.iyer@emc.comOn Apr 19, 2013, at 3:13 AM, Akansha Singh wrote:Hi, MADLib guys, Any Updates..? On my Part I am trying to understand the modules placed in Github .I a trying to get hands on it. http://madlib.net/ https://github.com/madlib/madlib/
--
Maxence Ahlouche
06 06 66 97 00
93 avenue Paul DOUMER
24100 Bergerac
--
Maxence Ahlouche
06 06 66 97 00
93 avenue Paul DOUMER
24100 Bergerac
Attachment
{kind=link}
Sent from my iPad
Oops, forgot to attach the output!2013/4/20 Maxence AHLOUCHE <maxence.ahlouche@gmail.com>However, I couldn't guess how to assign a cluster to a point from the output of the algorithm, could someone give me an indication, please?Hi all!I've had a bit of fun with the k-means clustering, and have made a small script to visualize the result of the classification.My script is written in python3, and uses py-postgresql (http://python.projects.pgfoundry.org/) as PostgreSQL interface. It also requires Pillow (a PIL fork) which you can find here : https://pypi.python.org/pypi/Pillow/2.0.0.Before your first use, you may want to change the settings (on top of the file) to connect to your PostgreSQL server.The script will create a table in your database, populate it with random groups of points, and then call the k-means algorithm on it. Finally, it will generate a PNG image, displaying the points and the centroids.For a first run, use something like this:./k-means_test.py --regen -o clustered_data.pngYou can call "./k-means_test.py -h" for a list of available options.In attachment are my script and an example of its output.By the way, I'll have a lot of work next week, as I have several exams coming and a big project to do (about empirical orthogonal functions), so I'll probably be inactive for a few days! Then I'll be on holidays, so I will be able to focus on MADlib and GSoC :)Regards,Maxence
On Sat, Apr 20, 2013 at 7:31 PM, Maxence AHLOUCHE <maxence.ahlouche@gmail.com> wrote: > > > > 2013/4/20 Atri Sharma <atri.jiit@gmail.com> >> >> Very interesting! The results look encouraging,although this is on Python >> :) >> >> Good work! >> >> Regards, >> >> Atri > > > Thanks :) > But do you know if there is a way to know the cluster that a point has been > assigned to? Can the objective function have something to do with it? I > haven't understood why it was returned yet! I didnt get your question. Could you please elaborate a bit more? Regards, Atri
What I mean is that, on the output, I would like to color the points with the same color as the centroid they "depend" on.
On Sat, Apr 20, 2013 at 7:31 PM, Maxence AHLOUCHEI didnt get your question. Could you please elaborate a bit more?
<maxence.ahlouche@gmail.com> wrote:
>
>
>
> 2013/4/20 Atri Sharma <atri.jiit@gmail.com>
>>
>> Very interesting! The results look encouraging,although this is on Python
>> :)
>>
>> Good work!
>>
>> Regards,
>>
>> Atri
>
>
> Thanks :)
> But do you know if there is a way to know the cluster that a point has been
> assigned to? Can the objective function have something to do with it? I
> haven't understood why it was returned yet!
Regards,
Atri
--
Maxence Ahlouche
06 06 66 97 00
93 avenue Paul DOUMER
24100 Bergerac
On Sat, Apr 20, 2013 at 8:11 PM, Maxence AHLOUCHE <maxence.ahlouche@gmail.com> wrote: > Sure! > > The k-means algorithms tries to group the points, but how can we know to > which group a point has been assigned? > What I mean is that, on the output, I would like to color the points with > the same color as the centroid they "depend" on. > > And another question, which I thought could be related to the first one, is > why does the algorithms returns the objective function? What's its use? > > Thanks ffor spending time for my questions :) No problem You can probably maintain a data structure for this purpose. A simple Vector would suffice, I think. You will need to empty the Vectors in each iteration of the algorithm, until the algorithm doesnt finish. Then, the vectors shall contain the final memberships. So, for each Vector, you designate the current centroid and put the points assigned to that centroid's groups in that Vector. Then, if another iteration of your algorithm shall run, you can empty the vectors and reassign the centroids. Atri -- Regards, Atri l'apprenant
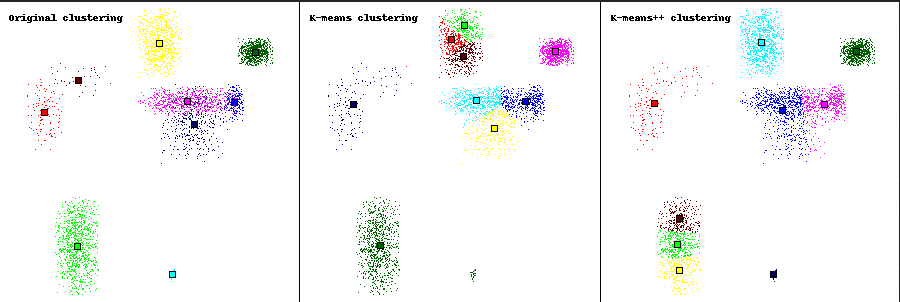
- It is now able to color the points according to their assigned cluster. It has occured to me last night that it was the main inconvenient of the k-means algorithm: a point is assigned to the nearest centroid's cluster, which is easy to compute.
- It's now able to load data from a file, if it has been previously generated, so it is no longer mandatory to specify the number of clusters wished when using "old" data.
- It displays the original clustering and the k-means++ clustering for comparison purposes, and it is very easy to add new clusterings.
- It is available on GitHub! https://github.com/viodlen/clustering_visualizer
Still, there is room for improvements:
- It only tests with 2-dimensional spaces. This won't evolve, as it would get difficult to visualize.
- It only uses the euclidean distance. This can be fixed, but would be heavy to implement, and probably ugly (a hashmap to match the python's distance function with the MADlib's one).
- For now, the points are reparted in the clusters folowing a gaussian law (not sure of my vocabulary here). This can be easily fixed, and will probably be in a future version.
In attachment is an output example. It shows the poor results of the k-means algorithm on contiguous clusters.
It also shows the interest of the k-means++ algorithm: the small light-blue cluster (in the original clustering) is correctly identified as a complete cluster by the k-means++ algorithm, when it was only a part of a bigger cluster with the simple k-means algorithm.
The characteristics of the k-means algorithm make it easy to calculate the clusters only from the points and the centroids, but this won't be true for the k-medoids algorithm. So, sadly, if I implement the latter, it won't be possible to keep the same function signature: some more data will have to be returned, along with the centroids list.
I've also wondered if it would be useful to implement the clustering algorithms for non-float vectors (for example, strings), provided the user gives a distance function for this type?
Maxence Ahlouche
06 06 66 97 00
93 avenue Paul DOUMER
24100 Bergerac
Attachment
{kind=link}
Sent from my iPad
Hello!I've pretty much improved my visualizer:
- It is now able to color the points according to their assigned cluster. It has occured to me last night that it was the main inconvenient of the k-means algorithm: a point is assigned to the nearest centroid's cluster, which is easy to compute.
- It's now able to load data from a file, if it has been previously generated, so it is no longer mandatory to specify the number of clusters wished when using "old" data.
- It displays the original clustering and the k-means++ clustering for comparison purposes, and it is very easy to add new clusterings.
- It is available on GitHub! https://github.com/viodlen/clustering_visualizer
Still, there is room for improvements:
- It only tests with 2-dimensional spaces. This won't evolve, as it would get difficult to visualize.
- It only uses the euclidean distance. This can be fixed, but would be heavy to implement, and probably ugly (a hashmap to match the python's distance function with the MADlib's one).
- For now, the points are reparted in the clusters folowing a gaussian law (not sure of my vocabulary here). This can be easily fixed, and will probably be in a future version.
In attachment is an output example. It shows the poor results of the k-means algorithm on contiguous clusters.
It also shows the interest of the k-means++ algorithm: the small light-blue cluster (in the original clustering) is correctly identified as a complete cluster by the k-means++ algorithm, when it was only a part of a bigger cluster with the simple k-means algorithm.
The characteristics of the k-means algorithm make it easy to calculate the clusters only from the points and the centroids, but this won't be true for the k-medoids algorithm. So, sadly, if I implement the latter, it won't be possible to keep the same function signature: some more data will have to be returned, along with the centroids list.
I've also wondered if it would be useful to implement the clustering algorithms for non-float vectors (for example, strings), provided the user gives a distance function for this type?
Interesting! Good work!Could you draw up a summary, giving your findings about the performance of different algorithms,and which one should be implemented,or both(k means++ vs k medoids).Regards,Atri
Very cool!May I suggest generating a visualization in a web toolkit? Perhaps the new vega library would be simplest (http://trifacta.github.io/vega/) or the more popular but lower-level D3.js?More generally, a project to connect MADlib outputs to vega vis specifications seems like it would be enormously useful!
Joe
--
Maxence Ahlouche
06 06 66 97 00
93 avenue Paul DOUMER
24100 Bergerac
--
Maxence Ahlouche
06 06 66 97 00
93 avenue Paul DOUMER
24100 Bergerac
On 4/21/13, hellerstein@cs.berkeley.edu <hellerstein@cs.berkeley.edu> wrote: > Very cool! > > > May I suggest generating a visualization in a web toolkit? Perhaps the new > vega library would be simplest (http://trifacta.github.io/vega/) or the more > popular but lower-level D3.js? > > > More generally, a project to connect MADlib outputs to vega vis > specifications seems like it would be enormously useful! Yes, the idea seems awesome. Generating these kind of results in a web toolkit should serve multiple purposes. Regards, Atri
Sent from my iPad On 02-May-2013, at 17:34, Maxence AHLOUCHE <maxence.ahlouche@gmail.com> wrote: > Hello! > > I've submitted my proposal on the GSoC website. > I've been inactive for the last few days, because I was setting up a server in order to make all my tests. As it is thefirst time I do this, I've met a bunch of (usually stupid) problems, but it's now almost entirely configured! I hope I'llsoon be able to provide a web visualization for the k-means algorithm, but it will probably be a simple png at first.It will allow you to test my work without having to download or install anything. > > Great.All the best and looking forward to the web visualisation. Regards, Atri
I don't think we have anyone from the madlib project signed up as a mentor currently. Is there someone in the madlib project that would be willing to mentor this? We'll need to get a mentor assigned for this ASAP, before we can even consider this.
I don't think we have anyone from the madlib project signed up as a mentor currently. Is there someone in the madlib project that would be willing to mentor this? We'll need to get a mentor assigned for this ASAP, before we can even consider this.So, would anyone from MADlib be interested in co-mentoring this project? I think Atri Sharma was willing to mentor this project, on the PostgreSQL side.
Thanks in advance!
Sent from my iPad
Hi!I'm pasting here the comment Heikki Linnakangas left on my GSoC proposal (available here: http://www.google-melange.com/gsoc/proposal/review/google/gsoc2013/viod/1):
I don't think we have anyone from the madlib project signed up as a mentor currently. Is there someone in the madlib project that would be willing to mentor this? We'll need to get a mentor assigned for this ASAP, before we can even consider this.I don't think we have anyone from the madlib project signed up as a mentor currently. Is there someone in the madlib project that would be willing to mentor this? We'll need to get a mentor assigned for this ASAP, before we can even consider this.So, would anyone from MADlib be interested in co-mentoring this project? I think Atri Sharma was willing to mentor this project, on the PostgreSQL side.
Thanks in advance!Regards,Maxence
HI, I would like to extend my help to mentor if possible.
Regards,
Maxence
----- Original Message -----
From: atri.jiit@gmail.com
To: maxence.ahlouche@gmail.com
Cc: Sujit.Philip@emc.com, devel@madlib.net, Rahul.Iyer@emc.com, pgsql-students@postgresql.org, hlinnakangas@vmware.com
Sent: Wednesday, May 8, 2013 5:52:11 PM GMT +05:30 Chennai, Kolkata, Mumbai, New Delhi
Subject: Re: [pgsql-students] GSoC project: K-medoids clustering in Madlib
Sent from my iPad
Hi!I'm pasting here the comment Heikki Linnakangas left on my GSoC proposal (available here: http://www.google-melange.com/gsoc/proposal/review/google/gsoc2013/viod/1):
I don't think we have anyone from the madlib project signed up as a mentor currently. Is there someone in the madlib project that would be willing to mentor this? We'll need to get a mentor assigned for this ASAP, before we can even consider this.I don't think we have anyone from the madlib project signed up as a mentor currently. Is there someone in the madlib project that would be willing to mentor this? We'll need to get a mentor assigned for this ASAP, before we can even consider this.So, would anyone from MADlib be interested in co-mentoring this project? I think Atri Sharma was willing to mentor this project, on the PostgreSQL side.
Thanks in advance!Regards,Maxence
On 8.5.2013 18:13, Akansha Singh wrote: > Hi All, Can i be allowed to mentor the project , i am very keen to > extend my hand and give surety about my sincerity . I'm a bit confused. AFAIK you've submitted two madlib-related proposals on your own. I don't think it's a good idea to work on a GSoC project and mentor another one at the same time. Tomas
Hi!I'm pasting here the comment Heikki Linnakangas left on my GSoC proposal (available here: http://www.google-melange.com/gsoc/proposal/review/google/gsoc2013/viod/1):I don't think we have anyone from the madlib project signed up as a mentor currently. Is there someone in the madlib project that would be willing to mentor this? We'll need to get a mentor assigned for this ASAP, before we can even consider this.So, would anyone from MADlib be interested in co-mentoring this project? I think Atri Sharma was willing to mentor this project, on the PostgreSQL side.I am still available as a co mentor.Rahul, would you be willing to be the mentor,please?
--
Maxence Ahlouche
06 06 66 97 00
93 avenue Paul DOUMER
24100 Bergerac
Hi, I will be obliged if given a chance to mentor.
--
Maxence Ahlouche
06 06 66 97 00
93 avenue Paul DOUMER
24100 Bergerac
On Tue, May 14, 2013 at 11:34 AM, Maxence AHLOUCHE <maxence.ahlouche@gmail.com> wrote: > Hello! > > Akansha Singh said: >> >> Hi, I will be obliged if given a chance to mentor. > > > On the MADlib side so? Just put a comment here then: > http://www.google-melange.com/gsoc/proposal/review/google/gsoc2013/viod/1 , > so that Heikki can be notified! > > Regards, > Maxence > > -- > Maxence Ahlouche > 06 06 66 97 00 > 93 avenue Paul DOUMER > 24100 Bergerac You cannot be a mentor and a student at the same time. I think a senior member of the community clearly expressed this to Ms. Akansha earlier. Maxence, we need a member of the MADLib community to be the mentor. I would suggest you to contact them for the same. Regards, Atri Regards, Atri -- Regards, Atri l'apprenant
On 14.05.2013 09:42, Atri Sharma wrote: > Maxence, we need a member of the MADLib community to be the mentor. I > would suggest you to contact them for the same. Well, Philip Sujit and Rahul Iyer are CC'd on this thread. Looking at the mailing list archives and commit history, I believe they are the two most active people working on Madlib. I would expect Philip or Rahul to mentor, or for them to point at someone else who knows the code and the community well enough to mentor. Philip, Rahul, is either one of you interested in mentoring any of the proposed GSoC projects, under the PostgreSQL umbrella? If you are, we need to get you signed up in the next couple of days, so that you can take part in reviewing and ranking the proposals. - Heikki
Well, the problem is that you needed to do it over a week ago. Google
has pretty strict deadlines for GSOC. As such, we had to reject all
proposals for work on Madlib this year.
Next year, we will get one or more of your team signed up early in the
GSOC process.
--
Maxence Ahlouche
06 06 66 97 00
93 avenue Paul DOUMER
24100 Bergerac