Thread: POC, WIP: OR-clause support for indexes
I'd like to present OR-clause support for indexes. Although OR-clauses could be
supported by bitmapOR index scan it isn't very effective and such scan lost any
order existing in index. We (with Alexander Korotkov) presented results on
Vienna's conference this year. In short, it provides performance improvement:
EXPLAIN ANALYZE
SELECT count(*) FROM tst WHERE id = 5 OR id = 500 OR id = 5000;
me=0.080..0.267 rows=173 loops=1)
Recheck Cond: ((id = 5) OR (id = 500) OR (id = 5000))
Heap Blocks: exact=172
-> Bitmap Index Scan on idx_gin (cost=0.00..57.50 rows=15000
width=0) (actual time=0.059..0.059 rows=147 loops=1)
Index Cond: ((id = 5) OR (id = 500) OR (id = 5000))
Planning time: 0.077 ms
Execution time: 0.308 ms <-------
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=51180.53..51180.54 rows=1 width=0) (actual
time=796.766..796.766 rows=1 loops=1)
-> Index Only Scan using idx_btree on tst (cost=0.42..51180.40 rows=55
width=0) (actual time=0.444..796.736 rows=173 loops=1)
Filter: ((id = 5) OR (id = 500) OR (id = 5000))
Rows Removed by Filter: 999829
Heap Fetches: 1000002
Planning time: 0.087 ms
Execution time: 796.798 ms <------
QUERY PLAN
-------------------------------------------------------------------------------------------------------------
Aggregate (cost=21925.63..21925.64 rows=1 width=0) (actual
time=160.412..160.412 rows=1 loops=1)
-> Seq Scan on tst (cost=0.00..21925.03 rows=237 width=0) (actual
time=0.535..160.362 rows=175 loops=1)
Filter: ((id = 5) OR (id = 500) OR (id = 5000))
Rows Removed by Filter: 999827
Planning time: 0.459 ms
Execution time: 160.451 ms
It also could work together with KNN feature of GiST and in this case
performance improvement could be up to several orders of magnitude, in
artificial example it was 37000 times faster.
Not all indexes can support oR-clause, patch adds support to GIN, GiST and BRIN
indexes. pg_am table is extended for adding amcanorclause column which indicates
possibility of executing of OR-clause by index.
indexqual and indexqualorig doesn't contain implicitly-ANDed list of index
qual expressions, now that lists could contain OR RestrictionInfo. Actually, the
patch just tries to convert BitmapOr node to IndexScan or IndexOnlyScan. Thats
significantly simplifies logic to find possible clause's list for index.
Index always gets a array of ScanKey but for indexes which support OR-clauses
array of ScanKey is actually exection tree in reversed polish notation form.
Transformation is done in ExecInitIndexScan().
The problems on the way which I see for now:
1 Calculating cost. Right now it's just a simple transformation of costs
computed for BitmapOr path. I'd like to hope that's possible and so index's
estimation function could be non-touched. So, they could believe that all
clauses are implicitly-ANDed
2 I'd like to add such support to btree but it seems that it should be a
separated patch. Btree search algorithm doesn't use any kind of stack of pages
and algorithm to walk over btree doesn't clear for me for now.
3 I could miss some places which still assumes implicitly-ANDed list of clauses
although regression tests passes fine.
Hope, hackers will not have an strong objections to do that. But obviously patch
requires further work and I'd like to see comments, suggestions and
recommendations. Thank you.
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
Attachment
I'd like to present OR-clause support for indexes. Although OR-clauses could be supported by bitmapOR index scan it isn't very effective and such scan lost any order existing in index. We (with Alexander Korotkov) presented results on Vienna's conference this year. In short, it provides performance improvement:
EXPLAIN ANALYZE
SELECT count(*) FROM tst WHERE id = 5 OR id = 500 OR id = 5000;
me=0.080..0.267 rows=173 loops=1)
Recheck Cond: ((id = 5) OR (id = 500) OR (id = 5000))
Heap Blocks: exact=172
-> Bitmap Index Scan on idx_gin (cost=0.00..57.50 rows=15000 width=0) (actual time=0.059..0.059 rows=147 loops=1)
Index Cond: ((id = 5) OR (id = 500) OR (id = 5000))
Planning time: 0.077 ms
Execution time: 0.308 ms <-------
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=51180.53..51180.54 rows=1 width=0) (actual time=796.766..796.766 rows=1 loops=1)
-> Index Only Scan using idx_btree on tst (cost=0.42..51180.40 rows=55 width=0) (actual time=0.444..796.736 rows=173 loops=1)
Filter: ((id = 5) OR (id = 500) OR (id = 5000))
Rows Removed by Filter: 999829
Heap Fetches: 1000002
Planning time: 0.087 ms
Execution time: 796.798 ms <------
QUERY PLAN
-------------------------------------------------------------------------------------------------------------
Aggregate (cost=21925.63..21925.64 rows=1 width=0) (actual time=160.412..160.412 rows=1 loops=1)
-> Seq Scan on tst (cost=0.00..21925.03 rows=237 width=0) (actual time=0.535..160.362 rows=175 loops=1)
Filter: ((id = 5) OR (id = 500) OR (id = 5000))
Rows Removed by Filter: 999827
Planning time: 0.459 ms
Execution time: 160.451 ms
It also could work together with KNN feature of GiST and in this case performance improvement could be up to several orders of magnitude, in artificial example it was 37000 times faster.
Not all indexes can support oR-clause, patch adds support to GIN, GiST and BRIN indexes. pg_am table is extended for adding amcanorclause column which indicates possibility of executing of OR-clause by index.
indexqual and indexqualorig doesn't contain implicitly-ANDed list of index qual expressions, now that lists could contain OR RestrictionInfo. Actually, the patch just tries to convert BitmapOr node to IndexScan or IndexOnlyScan. Thats significantly simplifies logic to find possible clause's list for index.
Index always gets a array of ScanKey but for indexes which support OR-clauses
array of ScanKey is actually exection tree in reversed polish notation form. Transformation is done in ExecInitIndexScan().
The problems on the way which I see for now:
1 Calculating cost. Right now it's just a simple transformation of costs computed for BitmapOr path. I'd like to hope that's possible and so index's estimation function could be non-touched. So, they could believe that all clauses are implicitly-ANDed
2 I'd like to add such support to btree but it seems that it should be a separated patch. Btree search algorithm doesn't use any kind of stack of pages and algorithm to walk over btree doesn't clear for me for now.
3 I could miss some places which still assumes implicitly-ANDed list of clauses although regression tests passes fine.
Hope, hackers will not have an strong objections to do that. But obviously patch
requires further work and I'd like to see comments, suggestions and recommendations. Thank you.
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
> This is great. I got a question, is it possible make btree index to support OR > as well? Is btree supports more invasive, in the sense that we need to do > enhance ScanKey to supports an array of values? Btree now works by follow: find the max/min tuple which satisfies condtions and then executes forward/backward scan over leaf pages. For complicated clauses it's not obvious how to find min/max tuple. Scanning whole index isn't an option from preformance point of view. -- Teodor Sigaev E-mail: teodor@sigaev.ru WWW: http://www.sigaev.ru/
I'd like to present OR-clause support for indexes. Although OR-clauses could be supported by bitmapOR index scan it isn't very effective and such scan lost any order existing in index. We (with Alexander Korotkov) presented results on Vienna's conference this year. In short, it provides performance improvement:
EXPLAIN ANALYZE
SELECT count(*) FROM tst WHERE id = 5 OR id = 500 OR id = 5000;
me=0.080..0.267 rows=173 loops=1)
Recheck Cond: ((id = 5) OR (id = 500) OR (id = 5000))
Heap Blocks: exact=172
-> Bitmap Index Scan on idx_gin (cost=0.00..57.50 rows=15000 width=0) (actual time=0.059..0.059 rows=147 loops=1)
Index Cond: ((id = 5) OR (id = 500) OR (id = 5000))
Planning time: 0.077 ms
Execution time: 0.308 ms <-------
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=51180.53..51180.54 rows=1 width=0) (actual time=796.766..796.766 rows=1 loops=1)
-> Index Only Scan using idx_btree on tst (cost=0.42..51180.40 rows=55 width=0) (actual time=0.444..796.736 rows=173 loops=1)
Filter: ((id = 5) OR (id = 500) OR (id = 5000))
Rows Removed by Filter: 999829
Heap Fetches: 1000002
Planning time: 0.087 ms
Execution time: 796.798 ms <------
QUERY PLAN
-------------------------------------------------------------------------------------------------------------
Aggregate (cost=21925.63..21925.64 rows=1 width=0) (actual time=160.412..160.412 rows=1 loops=1)
-> Seq Scan on tst (cost=0.00..21925.03 rows=237 width=0) (actual time=0.535..160.362 rows=175 loops=1)
Filter: ((id = 5) OR (id = 500) OR (id = 5000))
Rows Removed by Filter: 999827
Planning time: 0.459 ms
Execution time: 160.451 ms
It also could work together with KNN feature of GiST and in this case performance improvement could be up to several orders of magnitude, in artificial example it was 37000 times faster.
Not all indexes can support oR-clause, patch adds support to GIN, GiST and BRIN indexes. pg_am table is extended for adding amcanorclause column which indicates possibility of executing of OR-clause by index.
indexqual and indexqualorig doesn't contain implicitly-ANDed list of index qual expressions, now that lists could contain OR RestrictionInfo. Actually, the patch just tries to convert BitmapOr node to IndexScan or IndexOnlyScan. Thats significantly simplifies logic to find possible clause's list for index.
Index always gets a array of ScanKey but for indexes which support OR-clauses
array of ScanKey is actually exection tree in reversed polish notation form. Transformation is done in ExecInitIndexScan().
The problems on the way which I see for now:
1 Calculating cost. Right now it's just a simple transformation of costs computed for BitmapOr path. I'd like to hope that's possible and so index's estimation function could be non-touched. So, they could believe that all clauses are implicitly-ANDed
2 I'd like to add such support to btree but it seems that it should be a separated patch. Btree search algorithm doesn't use any kind of stack of pages and algorithm to walk over btree doesn't clear for me for now.
3 I could miss some places which still assumes implicitly-ANDed list of clauses although regression tests passes fine.
Hope, hackers will not have an strong objections to do that. But obviously patch
requires further work and I'd like to see comments, suggestions and recommendations. Thank you.
I think this is very exciting stuff, but since you didn't submit an updated patch after David's review, I'm closing it for now as returned-with-feedback. Please submit a new version once you have it. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Thank you for review!
> I'd like to see comments too! but more so in the code. :) I've had a look over
> this, and it seems like a great area in which we could improve on, and your
> reported performance improvements are certainly very interesting too. However
> I'm finding the code rather hard to follow, which might be a combination of my
> lack of familiarity with the index code, but more likely it's the lack of
I've added comments, fixed a found bugs.
> comments to explain what's going on. Let's just take 1 function as an example:
>
> Here there's not a single comment, so I'm just going to try to work out what's
> going on based on the code.
>
> +static void
> +compileScanKeys(IndexScanDesc scan)
> +{
> +GISTScanOpaqueso = (GISTScanOpaque) scan->opaque;
> +int*stack,
> +stackPos = -1,
> +i;
> +
> +if (scan->numberOfKeys <= 1 || so->useExec == false)
> +return;
> +
> +Assert(scan->numberOfKeys >=3);
>
> Why can numberOfKeys never be 2? I looked at what calls this and I can't really
Because here they are actually an expression, expression could contain 1 or tree
or more nodes but could not two (operation AND/OR plus two arguments)
> work it out. I'm really also not sure what useExec means as there's no comment
fixed. If useExec == false then SkanKeys are implicitly ANDed and stored in just
array.
> in that struct member, and what if numberOfKeys == 1 and useExec == false, won't
> this Assert() fail? If that's not a possible situation then why not?
fixed
> +ScanKey key = scan->keyData + i;
> Is there a reason not to use keyData[i]; ?
That's the same ScanKey key = &scan->keyData[i];
I prefer first form as more clear but I could be wrong - but there are other
places in code where pointer arithmetic is used.
> +if (stackPos >= 0 && (key->sk_flags & (SK_OR | SK_AND)))
> +{
> +Assert(stackPos >= 1 && stackPos < scan->numberOfKeys);
> stackPos >= 1? This seems unnecessary and confusing as the if test surely makes
> that impossible.
> +
> +so->leftArgs[i] = stack[stackPos - 1];
> Something is broken here as stackPos can be 0 (going by the if() not the
> Assert()), therefore that's stack[-1].
fixed
> stackPos is initialised to -1, so this appears to always skip the first element
> of the keyData array. If that's really the intention, then wouldn't it be better
> to just make the initial condition of the for() look i = 1 ?
done
> I'd like to review more, but it feels like a job that's more difficult than it
> needs to be due to lack of comments.
>
> Would it be possible to update the patch to try and explain things a little better?
Hope, I made cleaner..
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
Attachment
Hi Teodor,
I've looked into v2 of the patch you sent a few days ago. Firstly, I
definitely agree that being able to use OR conditions with an index is
definitely a cool idea.
I do however agree with David that the patch would definitely benefit
from comments documenting various bits that are less obvious to mere
mortals like me, with limited knowledge of the index internals.
I also wonder whether the patch should add explanation of OR-clauses
handling into the READMEs in src/backend/access/*
The patch would probably benefit from transforming it into a patch
series - one patch for the infrastructure shared by all the indexes,
then one patch per index type. That should make it easier to review, and
I seriously doubt we'd want to commit this in one huge chunk anyway.
Now, some review comments from eyeballing the patch. Some of those are
nitpicking, but well ...
1) fields in BrinOpaque are not following the naming convention (all the
existing fields start with bo_)
2) there's plenty of places violating the usual code style (e.g. for
single-command if branches) - not a big deal for WIP patch, but needs to
get fixed eventually
3) I wonder whether we really need both SK_OR and SK_AND, considering
they are mutually exclusive. Why not to assume SK_AND by default, and
only use SK_OR? If we really need them, perhaps an assert making sure
they are not set at the same time would be appropriate.
4) scanGetItem is a prime example of the "badly needs comments" issue,
particularly because the previous version of the function actually had
quite a lot of them while the new function has none.
5) scanGetItem() may end up using uninitialized 'cmp' - it only gets
initialized when (!leftFinished && !rightFinished), but then gets used
when either part of the condition evaluates to true. Probably should be
if (!leftFinished || !rightFinished) cmp = ...
6) the code in nodeIndexscan.c should not include call to abort()
{ abort(); elog(ERROR, "unsupported indexqual type: %d", (int) nodeTag(clause)); }
7) I find it rather ugly that the paths are built by converting BitmapOr
paths. Firstly, it means indexes without amgetbitmap can't benefit from
this change. Maybe that's reasonable limitation, though?
But more importantly, this design already has a bunch of unintended
consequences. For example, the current code completely ignores
enable_indexscan setting, because it merely copies the costs from the
bitmap path.
SET enable_indexscan = off; EXPLAIN SELECT * FROM t WHERE (c && ARRAY[1] OR c && ARRAY[2]);
QUERY PLAN
-------------------------------------------------------------------Index Scan using t_c_idx on t (cost=0.00..4.29
rows=0width=33) Index Cond: ((c && '{1}'::integer[]) OR (c && '{2}'::integer[]))
(2 rows)
That's pretty dubious, I guess. So this code probably needs to be made
aware of enable_indexscan - right now it entirely ignores startup_cost
in convert_bitmap_path_to_index_clause(). But of course if there are
multiple IndexPaths, the enable_indexscan=off will be included multiple
times.
9) This already breaks estimation for some reason. Consider this
example, using a table with int[] column, with gist index built using
intarray:
EXPLAIN SELECT * FROM t WHERE (c && ARRAY[1,2,3,4,5,6,7]);
QUERY PLAN
--------------------------------------------------------------------Index Scan using t_c_idx on t (cost=0.28..52.48
rows=12width=33) Index Cond: (c && '{1,2,3,4,5,6,7}'::integer[])
(2 rows)
EXPLAIN SELECT * FROM t WHERE (c && ARRAY[8,9,10,11,12,13,14]);
QUERY PLAN
--------------------------------------------------------------------Index Scan using t_c_idx on t (cost=0.28..44.45
rows=10width=33) Index Cond: (c && '{8,9,10,11,12,13,14}'::integer[])
(2 rows)
EXPLAIN SELECT * FROM t WHERE (c && ARRAY[1,2,3,4,5,6,7]) OR (c &&
ARRAY[8,9,10,11,12,13,14]);
QUERY PLAN
--------------------------------------------------------------------Index Scan using t_c_idx on t (cost=0.00..4.37
rows=0width=33) Index Cond: ((c && '{1,2,3,4,5,6,7}'::integer[]) OR (c &&
'{8,9,10,11,12,13,14}'::integer[]))
(2 rows)
So the OR-clause is estimated to match 0 rows, less than each of the
clauses independently. Needless to say that without the patch this works
just fine.
10) Also, this already breaks some regression tests, apparently because
it changes how 'width' is computed.
So I think this way of building the index path from a BitmapOr path is
pretty much a dead-end.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
> I also wonder whether the patch should add explanation of OR-clauses
> handling into the READMEs in src/backend/access/*
Oops, will add shortly.
>
> The patch would probably benefit from transforming it into a patch
> series - one patch for the infrastructure shared by all the indexes,
> then one patch per index type. That should make it easier to review, and
> I seriously doubt we'd want to commit this in one huge chunk anyway.
Ok, will do it.
> 1) fields in BrinOpaque are not following the naming convention (all the
> existing fields start with bo_)
fixed
>
> 2) there's plenty of places violating the usual code style (e.g. for
> single-command if branches) - not a big deal for WIP patch, but needs to
> get fixed eventually
hope, fixed
>
> 3) I wonder whether we really need both SK_OR and SK_AND, considering
> they are mutually exclusive. Why not to assume SK_AND by default, and
> only use SK_OR? If we really need them, perhaps an assert making sure
> they are not set at the same time would be appropriate.
In short: possible ambiguity and increasing stack machine complexity.
Let we have follow expression in reversed polish notation (letters represent a
condtion, | - OR, & - AND logical operation, ANDs are omitted):
a b c |
Is it ((a & b)| c) or (a & (b | c)) ?
Also, using both SK_ makes code more readable.
> 4) scanGetItem is a prime example of the "badly needs comments" issue,
> particularly because the previous version of the function actually had
> quite a lot of them while the new function has none.
Will add soon
>
> 5) scanGetItem() may end up using uninitialized 'cmp' - it only gets
> initialized when (!leftFinished && !rightFinished), but then gets used
> when either part of the condition evaluates to true. Probably should be
>
> if (!leftFinished || !rightFinished)
> cmp = ...
fixed
>
> 6) the code in nodeIndexscan.c should not include call to abort()
>
> {
> abort();
> elog(ERROR, "unsupported indexqual type: %d",
> (int) nodeTag(clause));
> }
fixed, just forgot to remove
>
> 7) I find it rather ugly that the paths are built by converting BitmapOr
> paths. Firstly, it means indexes without amgetbitmap can't benefit from
> this change. Maybe that's reasonable limitation, though?
I based on following thoughts:
1 code which tries to find OR-index path will be very similar to existing
generate_or_bitmap code. Obviously, it should not be duplicated.
2 all existsing indexes have amgetbitmap method, only a few don't. amgetbitmap
interface is simpler. Anyway, I can add an option for generate_or_bitmap
to use any index, but, in current state it will just repeat all work.
>
> But more importantly, this design already has a bunch of unintended
> consequences. For example, the current code completely ignores
> enable_indexscan setting, because it merely copies the costs from the
> bitmap path.
I'd like to add separate enable_indexorscan
> That's pretty dubious, I guess. So this code probably needs to be made
> aware of enable_indexscan - right now it entirely ignores startup_cost
> in convert_bitmap_path_to_index_clause(). But of course if there are
> multiple IndexPaths, the enable_indexscan=off will be included multiple
> times.
>
> 9) This already breaks estimation for some reason. Consider this
...
> So the OR-clause is estimated to match 0 rows, less than each of the
> clauses independently. Needless to say that without the patch this works
> just fine.
fixed
>
> 10) Also, this already breaks some regression tests, apparently because
> it changes how 'width' is computed.
fixed too
> So I think this way of building the index path from a BitmapOr path is
> pretty much a dead-end.
I don't think so because separate code path to support OR-clause in index will
significanlty duplicate BitmapOr generator.
Will send next version as soon as possible. Thank you for your attention!
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
Attachment
> I also wonder whether the patch should add explanation of OR-clauses
> handling into the READMEs in src/backend/access/*
Not yet, but will
> The patch would probably benefit from transforming it into a patch
> series - one patch for the infrastructure shared by all the indexes,
> then one patch per index type. That should make it easier to review, and
> I seriously doubt we'd want to commit this in one huge chunk anyway.
I splitted to two:
1 0001-idx_or_core - only planner and executor changes
2 0002-idx_or_indexes - BRIN/GIN/GiST changes with tests
I don't think that splitting of second patch adds readability but increase
management diffculties, but if your insist I will split.
> 4) scanGetItem is a prime example of the "badly needs comments" issue,
> particularly because the previous version of the function actually had
> quite a lot of them while the new function has none.
added
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
Attachment
I gave this patch a quick spin and noticed a strange query plan.
CREATE TABLE test (a int, b int, c int);
CREATE INDEX ON test USING gin (a, b, c);
INSERT INTO test SELECT i % 7, i % 9, i % 11 FROM generate_series(1,
1000000) i;
EXPLAIN ANALYZE SELECT * FROM test WHERE (a = 3 OR b = 5) AND c = 2;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------
BitmapHeap Scan on test (cost=829.45..4892.10 rows=21819 width=12)
(actual time=66.494..76.234 rows=21645 loops=1) Recheck Cond: ((((a = 3) AND (c = 2)) OR ((b = 5) AND (c = 2))) AND
(c = 2)) Heap Blocks: exact=5406 -> Bitmap Index Scan on test_a_b_c_idx (cost=0.00..824.00
rows=2100 width=0) (actual time=65.272..65.272 rows=21645 loops=1) Index Cond: ((((a = 3) AND (c = 2)) OR ((b =
5)AND (c = 2)))
AND (c = 2)) Planning time: 0.200 ms Execution time: 77.206 ms
(7 rows)
Shouldn't the index condition just be "((a = 3) AND (c = 2)) OR ((b = 5)
AND (c = 2))"?
Also when applying and reading the patch I noticed some minor
issues/nitpick.
- I get whitespace warnings from git apply when I apply the patches.
- You have any insconstent style for casts: I think "(Node*)clause"
should be "(Node *) clause".
- Same with pointers. "List* quals" should be "List *quals"
- I am personally not a fan of seeing the "isorderby == false &&
index->rd_amroutine->amcanorclause" clause twice. Feels like a risk for
diverging code paths. But it could be that there is no clean alternative.
Andreas
Hi Teodor,
Sadly the v4 does not work for me - I do get assertion failures. For
example with the example Andreas Karlsson posted in this thread:
CREATE EXTENSION btree_gin;
CREATE TABLE test (a int, b int, c int);
CREATE INDEX ON test USING gin (a, b, c);
INSERT INTO test SELECT i % 7, i % 9, i % 11 FROM generate_series(1,
1000000) i;
EXPLAIN ANALYZE SELECT * FROM test WHERE (a = 3 OR b = 5) AND c = 2;
It seems working, but only until I run ANALYZE on the table. Once I do
that, I start getting crashes at this line
*qualcols = list_concat(*qualcols, list_copy(idx_path->indexqualcols));
in convert_bitmap_path_to_index_clause. Apparently one of the lists is
T_List while the other one is T_IntList, so list_concat() errors out.
My guess is that the T_BitmapOrPath branch should do
oredqualcols = list_concat(oredqualcols, li_qualcols); ... *qualcols = list_concat(qualcols, oredqualcols);
instead of
oredqualcols = lappend(oredqualcols, li_qualcols); ... *qualcols = lappend(*qualcols, oredqualcols);
but once I fixed that I got some other assert failures further down,
that I haven't tried to fix.
So the patch seems to be broken, and I suspect this might be related to
the broken index condition reported by Andreas (although I don't see
that - I either see correct condition or assertion failures).
On 03/17/2016 06:19 PM, Teodor Sigaev wrote:
...
>>
>> 7) I find it rather ugly that the paths are built by converting BitmapOr
>> paths. Firstly, it means indexes without amgetbitmap can't benefit from
>> this change. Maybe that's reasonable limitation, though?
> I based on following thoughts:
> 1 code which tries to find OR-index path will be very similar to existing
> generate_or_bitmap code. Obviously, it should not be duplicated.
> 2 all existsing indexes have amgetbitmap method, only a few don't.
> amgetbitmap
> interface is simpler. Anyway, I can add an option for generate_or_bitmap
> to use any index, but, in current state it will just repeat all work.
I agree that the code should not be duplicated, but is this really a
good solution. Perhaps a refactoring that'd allow sharing most of the
code would be more appropriate.
>>
>> But more importantly, this design already has a bunch of unintended
>> consequences. For example, the current code completely ignores
>> enable_indexscan setting, because it merely copies the costs from the
>> bitmap path.>
> I'd like to add separate enable_indexorscan
That may be useful, but why shouldn't enable_indexscan=off also disable
indexorscan? I would find it rather surprising if after setting
enable_indexscan=off I'd still get index scans for OR-clauses.
>
>> That's pretty dubious, I guess. So this code probably needs to be made
>> aware of enable_indexscan - right now it entirely ignores startup_cost
>> in convert_bitmap_path_to_index_clause(). But of course if there are
>> multiple IndexPaths, the enable_indexscan=off will be included multiple
>> times.
... and it does not address this at all.
I really doubt a costing derived from the bitmap index scan nodes will
make much sense - you essentially need to revert unknown parts of the
costing to only include building the bitmap once, etc.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi Teador, On 3/19/16 8:44 PM, Tomas Vondra wrote: > Sadly the v4 does not work for me - I do get assertion failures. Time is growing short and there seem to be some serious concerns with this patch. Can you provide a new patch soon? If not, I think it might be be time to mark this "returned with feedback". Thanks, -- -David david@pgmasters.net
On 3/25/16 11:13 AM, David Steele wrote: > Time is growing short and there seem to be some serious concerns with > this patch. Can you provide a new patch soon? If not, I think it might > be be time to mark this "returned with feedback". I have marked this patch "returned with feedback". Please feel free to resubmit for 9.7! Thanks, -- -David david@pgmasters.net
On 12/26/15 23:04, Teodor Sigaev wrote: > I'd like to present OR-clause support for indexes. Although OR-clauses > could be supported by bitmapOR index scan it isn't very effective and > such scan lost any order existing in index. We (with Alexander Korotkov) > presented results on Vienna's conference this year. In short, it > provides performance improvement: > > EXPLAIN ANALYZE > SELECT count(*) FROM tst WHERE id = 5 OR id = 500 OR id = 5000; > ... > The problems on the way which I see for now: > 1 Calculating cost. Right now it's just a simple transformation of costs > computed for BitmapOr path. I'd like to hope that's possible and so > index's estimation function could be non-touched. So, they could believe > that all clauses are implicitly-ANDed > 2 I'd like to add such support to btree but it seems that it should be a > separated patch. Btree search algorithm doesn't use any kind of stack of > pages and algorithm to walk over btree doesn't clear for me for now. > 3 I could miss some places which still assumes implicitly-ANDed list of > clauses although regression tests passes fine. I support such a cunning approach. But this specific case, you demonstrated above, could be optimized independently at an earlier stage. If to convert: (F(A) = ConstStableExpr_1) OR (F(A) = ConstStableExpr_2) to F(A) IN (ConstStableExpr_1, ConstStableExpr_2) it can be seen significant execution speedup. For example, using the demo.sql to estimate maximum positive effect we see about 40% of execution and 100% of planning speedup. To avoid unnecessary overhead, induced by the optimization, such transformation may be made at the stage of planning (we have cardinality estimations and have pruned partitions) but before creation of a relation scan paths. So, we can avoid planning overhead and non-optimal BitmapOr in the case of many OR's possibly aggravated by many indexes on the relation. For example, such operation can be executed in create_index_paths() before passing rel->indexlist. -- Regards Andrey Lepikhov Postgres Professional
Attachment
I agree with your idea and try to implement it and will soon attach a patch with a solution.
I also have a really practical example confirming that such optimization can be useful.
A query was written that consisted of 50000 conditions due to the fact that the ORM framework couldn't work with a query having an ANY operator. In summary, we got a better plan that contained 50000 Bitmap Index Scan nodes with 50000 different conditions. Since approximately 27336 Bite of memory were required to initialize one BitmapOr Index Scan node, therefore, about 1.27 GB of memory was spent at the initialization step of the plan execution and query execution time was about 55756,053 ms (00:55,756).
psql -U postgres -c "CREATE DATABASE test_db" pgbench -U postgres -d test_db -i -s 10SELECT FORMAT('prepare x %s AS SELECT * FROM pgbench_accounts a WHERE %s', '(' || string_agg('int', ',') || ')', string_agg(FORMAT('aid = $%s', g.id), ' or ') ) AS cmd FROM generate_series(1, 50000) AS g(id) \gexecSELECT FORMAT('execute x %s;', '(' || string_agg(g.id::text, ',') || ')') AS cmd FROM generate_series(1, 50000) AS g(id) \gexec
I got the plan of this query:
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on pgbench_accounts a (cost=44.35..83.96 rows=10 width=97)
Recheck Cond: ((aid = 1) OR (aid = 2) OR (aid = 3) OR (aid = 4) OR (aid = 5) OR (aid = 6) OR (aid = 7) OR (aid = 8) OR (aid = 9) OR (aid = 10))
-> BitmapOr (cost=44.35..44.35 rows=10 width=0)
-> Bitmap Index Scan on pgbench_accounts_pkey (cost=0.00..4.43 rows=1 width=0)
Index Cond: (aid = 1)
-> Bitmap Index Scan on pgbench_accounts_pkey (cost=0.00..4.43 rows=1 width=0)
Index Cond: (aid = 2)
-> Bitmap Index Scan on pgbench_accounts_pkey (cost=0.00..4.43 rows=1 width=0)
Index Cond: (aid = 3)
-> Bitmap Index Scan on pgbench_accounts_pkey (cost=0.00..4.43 rows=1 width=0)
Index Cond: (aid = 4)
-> Bitmap Index Scan on pgbench_accounts_pkey (cost=0.00..4.43 rows=1 width=0)
Index Cond: (aid = 5)
-> Bitmap Index Scan on pgbench_accounts_pkey (cost=0.00..4.43 rows=1 width=0)
Index Cond: (aid = 6)
-> Bitmap Index Scan on pgbench_accounts_pkey (cost=0.00..4.43 rows=1 width=0)
Index Cond: (aid = 7)
-> Bitmap Index Scan on pgbench_accounts_pkey (cost=0.00..4.43 rows=1 width=0)
Index Cond: (aid = 8)
-> Bitmap Index Scan on pgbench_accounts_pkey (cost=0.00..4.43 rows=1 width=0)
Index Cond: (aid = 9)
-> Bitmap Index Scan on pgbench_accounts_pkey (cost=0.00..4.43 rows=1 width=0)
Index Cond: (aid = 10)
If I rewrite this query using ANY operator,
SELECT FORMAT('prepare x %s AS SELECT * FROM pgbench_accounts a WHERE aid = ANY(SELECT g.id FROM generate_series(1, 50000) AS g(id))', '(' || string_agg('int', ',') || ')' ) AS cmd FROM generate_series(1, 50000) AS g(id) \gexec
I will get a plan where the array comparison operator is used through ANY operator at the index scan stage. It's execution time is significantly lower as 339,764 ms.
QUERY PLAN
--------------------------------------------------------------------------------------------------- Index Scan using pgbench_accounts_pkey on pgbench_accounts a (cost=0.42..48.43 rows=10 width=97) Index Cond: (aid = ANY ('{1,2,3,4,5,6,7,8,9,10}'::integer[]))
(2 rows)SELECT FORMAT('prepare x %s AS SELECT * FROM pgbench_accounts a WHERE aid IN(%s)', '(' || string_agg('int', ',') || ')', string_agg(FORMAT('%s', g.id), ', ') ) AS cmd FROM generate_series(1, 50000) AS g(id) \gexec
QUERY PLAN
--------------------------------------------------------------------------------------------------- Index Scan using pgbench_accounts_pkey on pgbench_accounts a (cost=0.42..48.43 rows=10 width=97) Index Cond: (aid = ANY ('{1,2,3,4,5,6,7,8,9,10}'::integer[]))
(2 rows)On 12/26/15 23:04, Teodor Sigaev wrote:I'd like to present OR-clause support for indexes. Although OR-clauses could be supported by bitmapOR index scan it isn't very effective and such scan lost any order existing in index. We (with Alexander Korotkov) presented results on Vienna's conference this year. In short, it provides performance improvement:I support such a cunning approach. But this specific case, you demonstrated above, could be optimized independently at an earlier stage. If to convert:
EXPLAIN ANALYZE
SELECT count(*) FROM tst WHERE id = 5 OR id = 500 OR id = 5000;
...
The problems on the way which I see for now:
1 Calculating cost. Right now it's just a simple transformation of costs computed for BitmapOr path. I'd like to hope that's possible and so index's estimation function could be non-touched. So, they could believe that all clauses are implicitly-ANDed
2 I'd like to add such support to btree but it seems that it should be a separated patch. Btree search algorithm doesn't use any kind of stack of pages and algorithm to walk over btree doesn't clear for me for now.
3 I could miss some places which still assumes implicitly-ANDed list of clauses although regression tests passes fine.
(F(A) = ConstStableExpr_1) OR (F(A) = ConstStableExpr_2)
to
F(A) IN (ConstStableExpr_1, ConstStableExpr_2)
it can be seen significant execution speedup. For example, using the demo.sql to estimate maximum positive effect we see about 40% of execution and 100% of planning speedup.
To avoid unnecessary overhead, induced by the optimization, such transformation may be made at the stage of planning (we have cardinality estimations and have pruned partitions) but before creation of a relation scan paths. So, we can avoid planning overhead and non-optimal BitmapOr in the case of many OR's possibly aggravated by many indexes on the relation.
For example, such operation can be executed in create_index_paths() before passing rel->indexlist.
-- Alena Rybakina Postgres Professional
I agree with your idea and try to implement it and will soon attach a patch with a solution.
Index Cond: (id = 1)
Recheck Cond: ((id = 1) OR (id = 1) OR (id = 1) OR (id = 2))
-> BitmapOr (cost=17.73..17.73 rows=4 width=0)
-> Bitmap Index Scan on x_id (cost=0.00..4.43 rows=1 width=0)
Index Cond: (id = 1)
-> Bitmap Index Scan on x_id (cost=0.00..4.43 rows=1 width=0)
Index Cond: (id = 1)
-> Bitmap Index Scan on x_id (cost=0.00..4.43 rows=1 width=0)
Index Cond: (id = 1)
-> Bitmap Index Scan on x_id (cost=0.00..4.43 rows=1 width=0)
Index Cond: (id = 2)
Hi, all! Sorry I haven't written for a long time.
I finished writing the code patch for transformation "Or" expressions to "Any" expressions. I didn't see any problems in regression tests, even when I changed the constant at which the minimum or expression is replaced by any at 0. I ran my patch on sqlancer and so far the code has never fallen.
I agree with your idea and try to implement it and will soon attach a patch with a solution.
Additionally, if those OR constants repeat you'll see ...If all constants are the same value, fineexplain select * from x where ((ID = 1) OR (ID = 1) OR (ID = 1));Index Only Scan using x_id on x (cost=0.42..4.44 rows=1 width=4)
Index Cond: (id = 1)if all values are almost the same, opsexplain select * from x where ((ID = 1) OR (ID = 1) OR (ID = 1) OR (ID = 2));Bitmap Heap Scan on x (cost=17.73..33.45 rows=4 width=4)
Recheck Cond: ((id = 1) OR (id = 1) OR (id = 1) OR (id = 2))
-> BitmapOr (cost=17.73..17.73 rows=4 width=0)
-> Bitmap Index Scan on x_id (cost=0.00..4.43 rows=1 width=0)
Index Cond: (id = 1)
-> Bitmap Index Scan on x_id (cost=0.00..4.43 rows=1 width=0)
Index Cond: (id = 1)
-> Bitmap Index Scan on x_id (cost=0.00..4.43 rows=1 width=0)
Index Cond: (id = 1)
-> Bitmap Index Scan on x_id (cost=0.00..4.43 rows=1 width=0)
Index Cond: (id = 2)thanksMarcos
--
Regards,
Alena Rybakina
Attachment
Sorry, I wrote the last sentence in a confusing way, I meant that I formed transformations for any number of "or" expressions (const_transform_or_limit=1). in regression tests, I noticed only diff changes of transformations of "or" expressions to "any". I attach a file with diff.
Hi, all! Sorry I haven't written for a long time.
I finished writing the code patch for transformation "Or" expressions to "Any" expressions. I didn't see any problems in regression tests, even when I changed the constant at which the minimum or expression is replaced by any at 0. I ran my patch on sqlancer and so far the code has never fallen.
On 14.01.2023 18:45, Marcos Pegoraro wrote:I agree with your idea and try to implement it and will soon attach a patch with a solution.
Additionally, if those OR constants repeat you'll see ...If all constants are the same value, fineexplain select * from x where ((ID = 1) OR (ID = 1) OR (ID = 1));Index Only Scan using x_id on x (cost=0.42..4.44 rows=1 width=4)
Index Cond: (id = 1)if all values are almost the same, opsexplain select * from x where ((ID = 1) OR (ID = 1) OR (ID = 1) OR (ID = 2));Bitmap Heap Scan on x (cost=17.73..33.45 rows=4 width=4)
Recheck Cond: ((id = 1) OR (id = 1) OR (id = 1) OR (id = 2))
-> BitmapOr (cost=17.73..17.73 rows=4 width=0)
-> Bitmap Index Scan on x_id (cost=0.00..4.43 rows=1 width=0)
Index Cond: (id = 1)
-> Bitmap Index Scan on x_id (cost=0.00..4.43 rows=1 width=0)
Index Cond: (id = 1)
-> Bitmap Index Scan on x_id (cost=0.00..4.43 rows=1 width=0)
Index Cond: (id = 1)
-> Bitmap Index Scan on x_id (cost=0.00..4.43 rows=1 width=0)
Index Cond: (id = 2)thanksMarcos--
Regards,
Alena Rybakina
Attachment
On Sun, Jun 25, 2023 at 6:48 PM Alena Rybakina <lena.ribackina@yandex.ru> wrote: > I finished writing the code patch for transformation "Or" expressions to "Any" expressions. This seems interesting to me. I'm currently working on improving nbtree's "native execution of ScalarArrayOpExpr quals" (see commit 9e8da0f7 for background information). That is relevant to what you're trying to do here. Right now nbtree's handling of ScalarArrayOpExpr is rather inefficient. The executor does pass the index scan an array of constants, so the whole structure already allows the nbtree code to execute the ScalarArrayOpExpr in whatever way would be most efficient. There is only one problem: it doesn't really try to do so. It more or less just breaks down the large ScalarArrayOpExpr into "mini" queries -- one per constant. Internally, query execution isn't significantly different to executing many of these "mini" queries independently. We just sort and deduplicate the arrays. We don't intelligently decide which pages dynamically. This is related to skip scan. Attached is an example query that shows the problem. Right now the query needs to access a buffer containing an index page a total of 24 times. It's actually accessing the same 2 pages 12 times. My draft patch only requires 2 buffer accesses -- because it "coalesces the array constants together" dynamically at run time. That is a little extreme, but it's certainly possible. BTW, this project is related to skip scan. It's part of the same family of techniques -- MDAM techniques. (I suppose that that's already true for ScalarArrayOpExpr execution by nbtree, but without dynamic behavior it's not nearly as valuable as it could be.) If executing ScalarArrayOpExprs was less inefficient in these cases then the planner could be a lot more aggressive about using them. Seems like these executor improvements might go well together with what you're doing in the planner. Note that I have to "set random_page_cost=0.1" to get the planner to use all of the quals from the query as index quals. It thinks (correctly) that the query plan is very inefficient. That happens to match reality right now, but the underlying reality could change significantly. Something to think about. -- Peter Geoghegan
Attachment
Thank you for your feedback, your work is also very interesting and important, and I will be happy to review it. I learned something new from your letter, thank you very much for that!On Sun, Jun 25, 2023 at 6:48 PM Alena Rybakina <lena.ribackina@yandex.ru> wrote:I finished writing the code patch for transformation "Or" expressions to "Any" expressions.This seems interesting to me. I'm currently working on improving nbtree's "native execution of ScalarArrayOpExpr quals" (see commit 9e8da0f7 for background information). That is relevant to what you're trying to do here. Right now nbtree's handling of ScalarArrayOpExpr is rather inefficient. The executor does pass the index scan an array of constants, so the whole structure already allows the nbtree code to execute the ScalarArrayOpExpr in whatever way would be most efficient. There is only one problem: it doesn't really try to do so. It more or less just breaks down the large ScalarArrayOpExpr into "mini" queries -- one per constant. Internally, query execution isn't significantly different to executing many of these "mini" queries independently. We just sort and deduplicate the arrays. We don't intelligently decide which pages dynamically. This is related to skip scan. Attached is an example query that shows the problem. Right now the query needs to access a buffer containing an index page a total of 24 times. It's actually accessing the same 2 pages 12 times. My draft patch only requires 2 buffer accesses -- because it "coalesces the array constants together" dynamically at run time. That is a little extreme, but it's certainly possible. BTW, this project is related to skip scan. It's part of the same family of techniques -- MDAM techniques. (I suppose that that's already true for ScalarArrayOpExpr execution by nbtree, but without dynamic behavior it's not nearly as valuable as it could be.) If executing ScalarArrayOpExprs was less inefficient in these cases then the planner could be a lot more aggressive about using them. Seems like these executor improvements might go well together with what you're doing in the planner. Note that I have to "set random_page_cost=0.1" to get the planner to use all of the quals from the query as index quals. It thinks (correctly) that the query plan is very inefficient. That happens to match reality right now, but the underlying reality could change significantly. Something to think about. -- Peter Geoghegan
I analyzed the buffer consumption when I ran control regression tests using my patch. diff shows me that there is no difference between the number of buffer block scans without and using my patch, as far as I have seen. (regression.diffs)
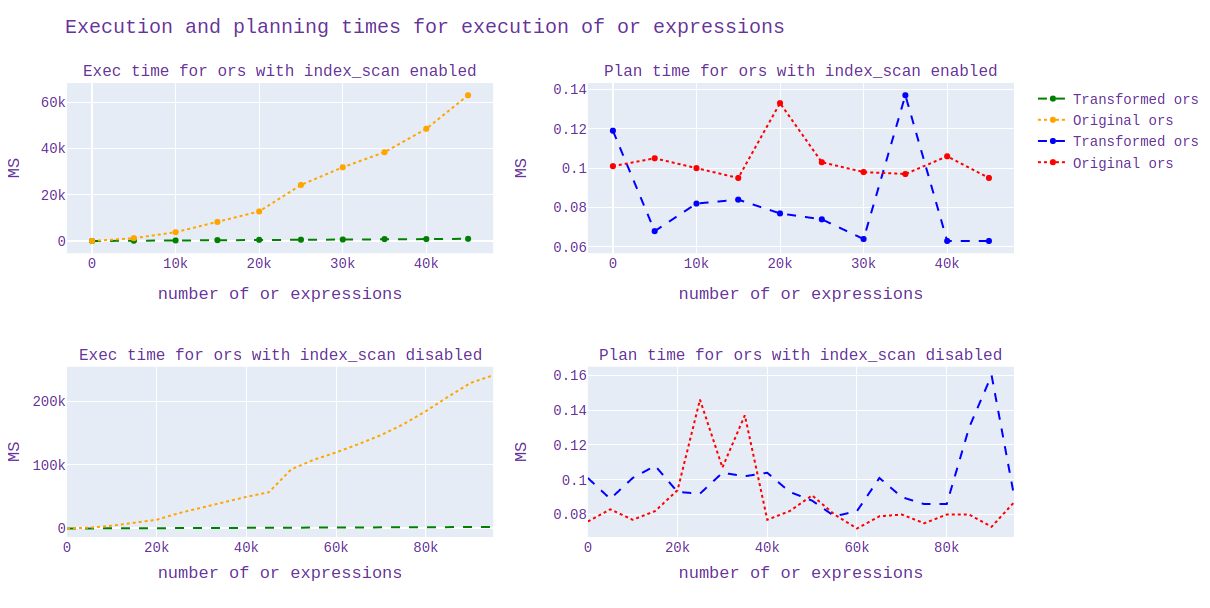
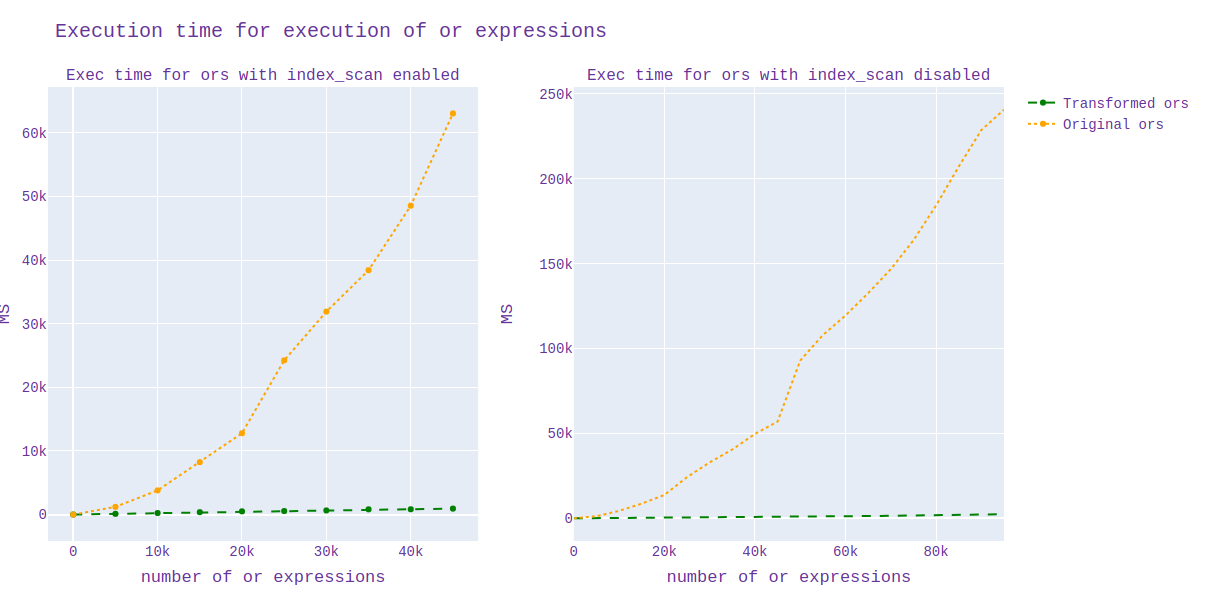
In addition, I analyzed the scheduling and duration of the execution time of the source code and with my applied patch. I generated 20 billion data from pgbench and plotted the scheduling and execution time depending on the number of "or" expressions.
By runtime, I noticed a clear acceleration for queries when using the index, but I can't say the same when the index is disabled.
At first I turned it off in this way:
1)enable_seqscan='off'
2)enable_indexonlyscan='off'
enable_indexscan='off'
Unfortunately, it is not yet clear which constant needs to be set when the transformation needs to be done, I will still study in detail. (the graph for all this is presented in graph1.svg)
-- Regards, Alena Rybakina
Attachment
{kind=link}
Thank you for your feedback, your work is also very interesting and important, and I will be happy to review it. I learned something new from your letter, thank you very much for that!Sorry, just now I noticed that there were incorrect names in the headings of the pictures, I corrected it. I also attach its html copy, because it may be more convenient for viewing it.
I analyzed the buffer consumption when I ran control regression tests using my patch. diff shows me that there is no difference between the number of buffer block scans without and using my patch, as far as I have seen. (regression.diffs)
In addition, I analyzed the scheduling and duration of the execution time of the source code and with my applied patch. I generated 20 billion data from pgbench and plotted the scheduling and execution time depending on the number of "or" expressions.
By runtime, I noticed a clear acceleration for queries when using the index, but I can't say the same when the index is disabled.
At first I turned it off in this way:
1)enable_seqscan='off'
2)enable_indexonlyscan='off'
enable_indexscan='off'
Unfortunately, it is not yet clear which constant needs to be set when the transformation needs to be done, I will still study in detail. (the graph for all this is presented in graph1.svg)\\-- Regards, Alena Rybakina
-- Regards, Alena Rybakina
Attachment
{kind=link}
>when I changed the constant at which the minimum or expression is
>replaced by any at 0. I ran my patch on sqlancer and so far the code has
I didn't compile or test it.
Please feel free to use them.
Attachment
On Tue, Jun 27, 2023 at 6:19 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote: > I learned something new from your letter, thank you very much for that! Cool. The MDAM paper is also worth a read: https://vldb.org/conf/1995/P710.PDF Some of the techniques it describes are already in Postgres. With varying degrees of maturity. The paper actually mentions OR optimization at one point, under "Duplicate Elimination". The general idea is that ScalarArrayOpExpr execution can "eliminate duplicates before the data is read". The important underlying principle is that it can be really useful to give the B-Tree code the context it requires to be clever about stuff like that. We can do this by (say) using one ScalarArrayOpExpr, rather than using two or more index scans that the B-Tree code will treat as independent things. So a lot of the value in your patch comes from the way that it can enable other optimizations (the immediate benefits are also nice). In the past, OR optimizations have been prototyped that were later withdrawn/rejected because the duplicate elimination aspect was...too scary [1]. It's very easy to see that ScalarArrayOpExpr index scans don't really have the same problem. "Giving the B-Tree code the required context" helps here too. > I analyzed the buffer consumption when I ran control regression tests using my patch. diff shows me that there is no differencebetween the number of buffer block scans without and using my patch, as far as I have seen. (regression.diffs) To be clear, I wasn't expecting that there'd be any regressions from your patch. Intuitively, it seems like this optimization should make the query plan do almost the same thing at execution time -- just slightly more efficiently on average, and much more efficiently in some individual cases. It would probably be very hard for the optimizer to model/predict how much work it can save by using a ScalarArrayOpExpr instead of an "equivalent" set of bitmap index scans, OR'd together. But it doesn't necessarily matter -- the only truly critical detail is understanding the worst case for the transformation optimization. It cannot be too bad (maybe it's ~zero added runtime overhead relative to not doing the transformation, even?). At the same time, nbtree can be clever about ScalarArrayOpExpr execution at runtime (once that's implemented), without ever needing to make any kind of up-front commitment to navigating through the index in any particular way. It's all dynamic, and can be driven by the actual observed characteristics of the index structure. In other words, we don't really need to gamble (in the planner, or at execution time). We're just keeping our options open in more cases. (My thinking on these topics was influenced by Goetz Graefe -- "choice is confusion" [2]). [1] https://www.postgresql.org/message-id/flat/1397.1486598083%40sss.pgh.pa.us#310f974a8dc84478d6d3c70f336807bb [2] https://sigmodrecord.org/publications/sigmodRecord/2009/pdfs/05_Profiles_Graefe.pdf -- Peter Geoghegan
On 6/27/23 20:55, Ranier Vilela wrote: > Hi, > >>I finished writing the code patch for transformation "Or" expressions to >>"Any" expressions. I didn't see any problems in regression tests, even >>when I changed the constant at which the minimum or expression is >>replaced by any at 0. I ran my patch on sqlancer and so far the code has >>never fallen. > Thanks for working on this. > > I took the liberty of making some modifications to the patch. > I didn't compile or test it. > Please feel free to use them. > I don't want to be rude, but this doesn't seem very helpful. - You made some changes, but you don't even attempt to explain what you changed or why you changed it. - You haven't even tried to compile the code, nor tested it. If it happens to compile, wow could others even know it actually behaves the way you wanted? - You responded in a way that breaks the original thread, so it's not clear which message you're responding to. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 6/27/23 20:55, Ranier Vilela wrote:
> Hi,
>
>>I finished writing the code patch for transformation "Or" expressions to
>>"Any" expressions. I didn't see any problems in regression tests, even
>>when I changed the constant at which the minimum or expression is
>>replaced by any at 0. I ran my patch on sqlancer and so far the code has
>>never fallen.
> Thanks for working on this.
>
> I took the liberty of making some modifications to the patch.
> I didn't compile or test it.
> Please feel free to use them.
>
I don't want to be rude, but this doesn't seem very helpful.
- You made some changes, but you don't even attempt to explain what you
changed or why you changed it.
- You haven't even tried to compile the code, nor tested it. If it
happens to compile, wow could others even know it actually behaves the
way you wanted?
- You responded in a way that breaks the original thread, so it's not
clear which message you're responding to.
Attachment
Hi!
I don't want to be rude, but this doesn't seem very helpful.Sorry, It was not my intention to cause interruptions.
- You made some changes, but you don't even attempt to explain what you
changed or why you changed it.1. Reduce scope2. Eliminate unnecessary variables3. Eliminate unnecessary expressions
- You haven't even tried to compile the code, nor tested it. If it
happens to compile, wow could others even know it actually behaves the
way you wanted?
Sorry I didn't answer right away. I will try not to do this in the future thank you for your participation and help.
Yes, the scope of this patch may be small, but I am sure that it will solve the worst case of memory consumption with large numbers of "or" expressions or reduce execution and planning time. As I have already said, I conducted a launch on a database with 20 billion data generated using a benchmark. Unfortunately, at that time I sent a not quite correct picture: the execution time, not the planning time, increases with the number of "or" expressions (execution_time.png). x is the number of or expressions, y is the execution/scheduling time.
I also throw memory consumption at 50,000 "or" expressions collected by HeapTrack (where memory consumption was recorded already at the initialization stage of the 1.27GB pic3.png). I think such a transformation will allow just the same to avoid such a worst case, since in comparison with ANY memory is much less and takes little time.
SELECT FORMAT('prepare x %s AS SELECT * FROM pgbench_accounts a WHERE %s', '(' || string_agg('int', ',') || ')', string_agg(FORMAT('aid = $%s', g.id), ' or ') ) AS cmd FROM generate_series(1, 50000) AS g(id) \gexec SELECT FORMAT('execute x %s;', '(' || string_agg(g.id::text, ',') || ')') AS cmd FROM generate_series(1, 50000) AS g(id) \gexec
I tried to add a transformation at the path formation stage before we form indexes (set_plain_rel_pathlist function) and at the stage when we have preprocessing of "or" expressions (getting rid of duplicates or useless conditions), but everywhere there was a problem of incorrect selectivity estimation.
CREATE TABLE tenk1 (unique1 int, unique2 int, ten int, hundred int); insert into tenk1 SELECT x,x,x,x FROM generate_series(1,50000) as x; CREATE INDEX a_idx1 ON tenk1(unique1); CREATE INDEX a_idx2 ON tenk1(unique2); CREATE INDEX a_hundred ON tenk1(hundred); postgres=# explain analyze select * from tenk1 a join tenk1 b on ((a.unique2 = 3 or a.unique2 = 7)) or (a.unique1 = 1); QUERY PLAN ---------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..140632434.50 rows=11250150000 width=32) (actual time=0.077..373.279 rows=1350000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..2311.00 rows=150000 width=16) (actual time=0.037..13.941 rows=150000 loops=1) -> Materialize (cost=0.00..3436.01 rows=75001 width=16) (actual time=0.000..0.001 rows=9 loops=150000) -> Seq Scan on tenk1 a (cost=0.00..3061.00 rows=75001 width=16) (actual time=0.027..59.174 rows=9 loops=1) Filter: ((unique2 = ANY (ARRAY[3, 7])) OR (unique1 = 1)) Rows Removed by Filter: 149991 Planning Time: 0.438 ms Execution Time: 407.144 ms (8 rows)
Only by converting the expression at this stage, we do not encounter this problem.
postgres=# set enable_bitmapscan ='off';
SET
postgres=# explain analyze
select * from tenk1 a join tenk1 b on a.unique2 = 3 or a.unique2 = 7 or a.unique1 = 1; QUERY PLAN
---------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..22247.02 rows=1350000 width=32) (actual time=0.094..373.627 rows=1350000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..2311.00 rows=150000 width=16) (actual time=0.051..14.667 rows=150000 loops=1) -> Materialize (cost=0.00..3061.05 rows=9 width=16) (actual time=0.000..0.001 rows=9 loops=150000) -> Seq Scan on tenk1 a (cost=0.00..3061.00 rows=9 width=16) (actual time=0.026..42.389 rows=9 loops=1) Filter: ((unique2 = ANY ('{3,7}'::integer[])) OR (unique1 = 1)) Rows Removed by Filter: 149991 Planning Time: 0.414 ms Execution Time: 409.154 ms
(8 rows)I compiled my original patch and there were no problems with regression tests. The only time there was a problem when I set the const_transform_or_limit variable to 0 (I have 15), as you have in the patch. To be honest, diff appears there because you had a different plan, specifically the expressions "or" are replaced by ANY (see regression.diffs).
Unfortunately, your patch version did not apply immediately, I did not understand the reasons, I applied it manually.
At the moment, I'm not sure that the constant is the right number for applying transformations, so I'm in search of it, to be honest. I will post my observations on this issue later. If you don't mind, I'll leave the constant equal to 15 for now.
Sorry, I don't understand well enough what is meant by points "Eliminate unnecessary variables" and "Eliminate unnecessary expressions". Can you explain in more detail?
Regarding the patch, there was a Warning at the compilation stage.
In file included from ../../../src/include/nodes/bitmapset.h:21, from ../../../src/include/nodes/parsenodes.h:26, from ../../../src/include/catalog/objectaddress.h:17, from ../../../src/include/catalog/pg_aggregate.h:24, from parse_expr.c:18: parse_expr.c: In function ‘transformBoolExprOr’: ../../../src/include/nodes/nodes.h:133:66: warning: ‘expr’ is used uninitialized [-Wuninitialized] 133 | #define nodeTag(nodeptr) (((const Node*)(nodeptr))->type) | ^~ parse_expr.c:116:29: note: ‘expr’ was declared here 116 | BoolExpr *expr; | ^~~~
I couldn't figure out how to fix it and went back to my original version. To be honest, I don't think anything needs to be changed here.
Unfortunately, I didn't understand the reasons why, with the available or expressions, you don't even try to convert to ANY by calling transformBoolExpr, as I saw. I went back to my version.
I think it's worth checking whether the or_statement variable is positive.
I think it's worth leaving the use of the or_statement variable in its original form.
switch (expr->boolop)
{
case AND_EXPR:
opname = "AND";
break;
case OR_EXPR:
opname = "OR";
or_statement = true;
break;
case NOT_EXPR:
opname = "NOT";
break;
default:
elog(ERROR, "unrecognized boolop: %d", (int) expr->boolop);
opname = NULL; /* keep compiler quiet */
break;
}
if (!or_statement || list_length(expr->args) < const_transform_or_limit)
return transformBoolExpr(pstate, (BoolExpr *)expr_orig);
The current version of the patch also works and all tests pass.
-- Regards, Alena Rybakina Postgres Professional
Attachment
{kind=link}
{kind=link}
Sorry for the possible duplicate. I have a suspicion that the previous email was not sent.
Hi!
Em qua., 28 de jun. de 2023 às 18:45, Tomas Vondra <tomas.vondra@enterprisedb.com> escreveu:On 6/27/23 20:55, Ranier Vilela wrote:
> Hi,
>
>>I finished writing the code patch for transformation "Or" expressions to
>>"Any" expressions. I didn't see any problems in regression tests, even
>>when I changed the constant at which the minimum or expression is
>>replaced by any at 0. I ran my patch on sqlancer and so far the code has
>>never fallen.
> Thanks for working on this.
>
> I took the liberty of making some modifications to the patch.
> I didn't compile or test it.
> Please feel free to use them.
>
I don't want to be rude, but this doesn't seem very helpful.Sorry, It was not my intention to cause interruptions.
- You made some changes, but you don't even attempt to explain what you
changed or why you changed it.1. Reduce scope2. Eliminate unnecessary variables3. Eliminate unnecessary expressions
- You haven't even tried to compile the code, nor tested it. If it
happens to compile, wow could others even know it actually behaves the
way you wanted?Attached v2 with make check pass all tests.Ubuntu 64 bitsgcc 64 bits
- You responded in a way that breaks the original thread, so it's not
clear which message you're responding to.It was a pretty busy day.Sorry for the noise, I hope I was of some help.regards,Ranier VilelaP.S.0001-Replace-clause-X-N1-OR-X-N2-.-with-X-ANY-N1-N2-on.patch fails with 4 tests.
Sorry I didn't answer right away. I will try not to do this in the future thank you for your participation and help.
Yes, the scope of this patch may be small, but I am sure that it will solve the worst case of memory consumption with large numbers of "or" expressions or reduce execution and planning time. As I have already said, I conducted a launch on a database with 20 billion data generated using a benchmark. Unfortunately, at that time I sent a not quite correct picture: the execution time, not the planning time, increases with the number of "or" expressions (https://www.dropbox.com/s/u7gt81blbv2adpi/execution_time.png?dl=0). x is the number of or expressions, y is the execution/scheduling time.
{kind=link}
I also throw memory consumption at 50,000 "or" expressions collected by HeapTrack (where memory consumption was recorded already at the initialization stage of the 1.27GB https://www.dropbox.com/s/vb827ya0193dlz0/pic3.png?dl=0). I think such a transformation will allow just the same to avoid such a worst case, since in comparison with ANY memory is much less and takes little time.
{kind=link}
SELECT FORMAT('prepare x %s AS SELECT * FROM pgbench_accounts a WHERE %s', '(' || string_agg('int', ',') || ')', string_agg(FORMAT('aid = $%s', g.id), ' or ') ) AS cmd FROM generate_series(1, 50000) AS g(id) \gexec SELECT FORMAT('execute x %s;', '(' || string_agg(g.id::text, ',') || ')') AS cmd FROM generate_series(1, 50000) AS g(id) \gexec
I tried to add a transformation at the path formation stage before we form indexes (set_plain_rel_pathlist function) and at the stage when we have preprocessing of "or" expressions (getting rid of duplicates or useless conditions), but everywhere there was a problem of incorrect selectivity estimation.
CREATE TABLE tenk1 (unique1 int, unique2 int, ten int, hundred int); insert into tenk1 SELECT x,x,x,x FROM generate_series(1,50000) as x; CREATE INDEX a_idx1 ON tenk1(unique1); CREATE INDEX a_idx2 ON tenk1(unique2); CREATE INDEX a_hundred ON tenk1(hundred); postgres=# explain analyze select * from tenk1 a join tenk1 b on ((a.unique2 = 3 or a.unique2 = 7)) or (a.unique1 = 1); QUERY PLAN ---------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..140632434.50 rows=11250150000 width=32) (actual time=0.077..373.279 rows=1350000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..2311.00 rows=150000 width=16) (actual time=0.037..13.941 rows=150000 loops=1) -> Materialize (cost=0.00..3436.01 rows=75001 width=16) (actual time=0.000..0.001 rows=9 loops=150000) -> Seq Scan on tenk1 a (cost=0.00..3061.00 rows=75001 width=16) (actual time=0.027..59.174 rows=9 loops=1) Filter: ((unique2 = ANY (ARRAY[3, 7])) OR (unique1 = 1)) Rows Removed by Filter: 149991 Planning Time: 0.438 ms Execution Time: 407.144 ms (8 rows)
Only by converting the expression at this stage, we do not encounter this problem.
postgres=# set enable_bitmapscan ='off';
SET
postgres=# explain analyze
select * from tenk1 a join tenk1 b on a.unique2 = 3 or a.unique2 = 7 or a.unique1 = 1; QUERY PLAN
---------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..22247.02 rows=1350000 width=32) (actual time=0.094..373.627 rows=1350000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..2311.00 rows=150000 width=16) (actual time=0.051..14.667 rows=150000 loops=1) -> Materialize (cost=0.00..3061.05 rows=9 width=16) (actual time=0.000..0.001 rows=9 loops=150000) -> Seq Scan on tenk1 a (cost=0.00..3061.00 rows=9 width=16) (actual time=0.026..42.389 rows=9 loops=1) Filter: ((unique2 = ANY ('{3,7}'::integer[])) OR (unique1 = 1)) Rows Removed by Filter: 149991 Planning Time: 0.414 ms Execution Time: 409.154 ms
(8 rows)I compiled my original patch and there were no problems with regression tests. The only time there was a problem when I set the const_transform_or_limit variable to 0 (I have 15), as you have in the patch. To be honest, diff appears there because you had a different plan, specifically the expressions "or" are replaced by ANY (see regression.diffs).
Unfortunately, your patch version did not apply immediately, I did not understand the reasons, I applied it manually.
At the moment, I'm not sure that the constant is the right number for applying transformations, so I'm in search of it, to be honest. I will post my observations on this issue later. If you don't mind, I'll leave the constant equal to 15 for now.
Sorry, I don't understand well enough what is meant by points "Eliminate unnecessary variables" and "Eliminate unnecessary expressions". Can you explain in more detail?
Regarding the patch, there was a Warning at the compilation stage.
In file included from ../../../src/include/nodes/bitmapset.h:21, from ../../../src/include/nodes/parsenodes.h:26, from ../../../src/include/catalog/objectaddress.h:17, from ../../../src/include/catalog/pg_aggregate.h:24, from parse_expr.c:18: parse_expr.c: In function ‘transformBoolExprOr’: ../../../src/include/nodes/nodes.h:133:66: warning: ‘expr’ is used uninitialized [-Wuninitialized] 133 | #define nodeTag(nodeptr) (((const Node*)(nodeptr))->type) | ^~ parse_expr.c:116:29: note: ‘expr’ was declared here 116 | BoolExpr *expr; | ^~~~
I couldn't figure out how to fix it and went back to my original version. To be honest, I don't think anything needs to be changed here.
Unfortunately, I didn't understand the reasons why, with the available or expressions, you don't even try to convert to ANY by calling transformBoolExpr, as I saw. I went back to my version.
I think it's worth checking whether the or_statement variable is positive.
I think it's worth leaving the use of the or_statement variable in its original form.
switch (expr->boolop)
{
case AND_EXPR:
opname = "AND";
break;
case OR_EXPR:
opname = "OR";
or_statement = true;
break;
case NOT_EXPR:
opname = "NOT";
break;
default:
elog(ERROR, "unrecognized boolop: %d", (int) expr->boolop);
opname = NULL; /* keep compiler quiet */
break;
}
if (!or_statement || list_length(expr->args) < const_transform_or_limit)
return transformBoolExpr(pstate, (BoolExpr *)expr_orig);
The current version of the patch also works and all tests pass.
-- Regards, Alena Rybakina Postgres Professional
Attachment
Hi! I'm sorry I didn't answer you right away, I was too busy with work.
On Tue, Jun 27, 2023 at 6:19 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote:I learned something new from your letter, thank you very much for that!Cool. The MDAM paper is also worth a read: https://vldb.org/conf/1995/P710.PDF Some of the techniques it describes are already in Postgres. With varying degrees of maturity. The paper actually mentions OR optimization at one point, under "Duplicate Elimination". The general idea is that ScalarArrayOpExpr execution can "eliminate duplicates before the data is read". The important underlying principle is that it can be really useful to give the B-Tree code the context it requires to be clever about stuff like that. We can do this by (say) using one ScalarArrayOpExpr, rather than using two or more index scans that the B-Tree code will treat as independent things. So a lot of the value in your patch comes from the way that it can enable other optimizations (the immediate benefits are also nice). In the past, OR optimizations have been prototyped that were later withdrawn/rejected because the duplicate elimination aspect was...too scary [1]. It's very easy to see that ScalarArrayOpExpr index scans don't really have the same problem. "Giving the B-Tree code the required context" helps here too.
Thank you for the explanation and the material provided) unfortunately, I am still only studying the article and at the moment I cannot write more. To be honest, I didn't think about the fact that my optimization can help eliminate duplicates before reading the data before.
I am still only in the process of familiarizing myself with the thread [1] (reference from your letter), but I have already seen that there are problems related, for example, to when "or" expressions refer to the parent element.
I think, I would face the similar problems if I complicate the current code, for example, so that not only or expressions standing on the same level are written in any, but also on different ones without violating the logic of the priority of executing operators.
For example, this query works now:
postgres=# EXPLAIN (analyze, COSTS OFF)
SELECT oid,relname FROM pg_class
WHERE
(oid = 13779 OR oid = 2) OR (oid = 4 OR oid = 5) OR
relname = 'pg_extension'
;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Seq Scan on pg_class (actual time=0.086..0.140 rows=1 loops=1)
Filter: ((oid = ANY ('{4,5}'::oid[])) OR (oid = ANY ('{13779,2}'::oid[])) OR (relname = 'pg_extension'::name))
Rows Removed by Filter: 412
Planning Time: 2.135 ms
Execution Time: 0.160 ms
(5 rows)
But I would like it works such as:
QUERY PLAN
--------------------------------------------------------------------------------------
Seq Scan on pg_class (actual time=0.279..0.496 rows=1 loops=1)
Filter: ((oid = ANY ('{13779,2,4,5}'::oid[])) OR (relname = 'pg_extension'::name))
Rows Removed by Filter: 412
Planning Time: 0.266 ms
Execution Time: 0.536 ms
(5 rows)
Yes, I agree with you and I have yet to analyze this.I analyzed the buffer consumption when I ran control regression tests using my patch. diff shows me that there is no difference between the number of buffer block scans without and using my patch, as far as I have seen. (regression.diffs)To be clear, I wasn't expecting that there'd be any regressions from your patch. Intuitively, it seems like this optimization should make the query plan do almost the same thing at execution time -- just slightly more efficiently on average, and much more efficiently in some individual cases. It would probably be very hard for the optimizer to model/predict how much work it can save by using a ScalarArrayOpExpr instead of an "equivalent" set of bitmap index scans, OR'd together. But it doesn't necessarily matter -- the only truly critical detail is understanding the worst case for the transformation optimization.
I haven't seen a major performance degradation so far, but to be honest, I have not conducted a detailed analysis on other types of queries other than x=1 or x=2 or x=1 or y=2, etc. As soon as something is known, I will provide the data, it is very interesting to me.It cannot be too bad (maybe it's ~zero added runtime overhead relative to not doing the transformation, even?).
At the same time, nbtree can be clever about ScalarArrayOpExpr execution at runtime (once that's implemented), without ever needing to make any kind of up-front commitment to navigating through the index in any particular way. It's all dynamic, and can be driven by the actual observed characteristics of the index structure. In other words, we don't really need to gamble (in the planner, or at execution time). We're just keeping our options open in more cases. (My thinking on these topics was influenced by Goetz Graefe -- "choice is confusion" [2]).
Unfortunately, when I tried to make a transformation at the stage of index formation, I encountered too incorrect an assessment of the selectivity of relation, which affected the incorrect calculation of the cost and cardinality. I couldn't solve this problem.
My diff (transform_or_v0.diff). I got this result:
CREATE TABLE tenk1 (unique1 int, unique2 int, ten int, hundred int); insert into tenk1 SELECT x,x,x,x FROM generate_series(1,50000) as x; CREATE INDEX a_idx1 ON tenk1(unique1); CREATE INDEX a_idx2 ON tenk1(unique2); CREATE INDEX a_hundred ON tenk1(hundred); postgres=# explain analyze select * from tenk1 a join tenk1 b on a.unique2 = 3 or a.unique2 = 7 or a.unique1 = 1; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..15627479.50 rows=1250050000 width=32) (actual time=0.040..75.531 rows=150000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..771.00 rows=50000 width=16) (actual time=0.022..5.467 rows=50000 loops=1) -> Materialize (cost=0.00..1146.01 rows=25001 width=16) (actual time=0.000..0.001 rows=3 loops=50000) -> Seq Scan on tenk1 a (cost=0.00..1021.00 rows=25001 width=16) (actual time=0.011..22.789 rows=3 loops=1) Filter: ((unique2 = ANY (ARRAY[3, 7])) OR (unique1 = 1)) Rows Removed by Filter: 49997 Planning Time: 0.427 ms Execution Time: 80.027 ms (8 rows)
The current patch's result:
postgres=# set enable_bitmapscan ='off';
SET
postgres=# explain analyze
select * from tenk1 a join tenk1 b on a.unique2 = 3 or a.unique2 = 7 or a.unique1 = 1; QUERY PLAN
---------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..22247.02 rows=1350000 width=32) (actual time=0.094..373.627 rows=1350000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..2311.00 rows=150000 width=16) (actual time=0.051..14.667 rows=150000 loops=1) -> Materialize (cost=0.00..3061.05 rows=9 width=16) (actual time=0.000..0.001 rows=9 loops=150000) -> Seq Scan on tenk1 a (cost=0.00..3061.00 rows=9 width=16) (actual time=0.026..42.389 rows=9 loops=1) Filter: ((unique2 = ANY ('{3,7}'::integer[])) OR (unique1 = 1)) Rows Removed by Filter: 149991 Planning Time: 0.414 ms Execution Time: 409.154 ms
(8 rows)Thank you again for the explanations and the material provided. I will carefully study everything as soon as possible and will write if there are any thoughts or if there are ideas about my patch.[1] https://www.postgresql.org/message-id/flat/1397.1486598083%40sss.pgh.pa.us#310f974a8dc84478d6d3c70f336807bb [2] https://sigmodrecord.org/publications/sigmodRecord/2009/pdfs/05_Profiles_Graefe.pdf
--
Regards, Alena Rybakina Postgres Professional
Attachment
I apologize for breaks the original thread. In my defense, I can say that I'm new to all this and I'm just learning. I will try to make as few mistakes as possible.
I try to fix it by forwarding this message to you, besides it might be interesting to you too. This message to you, because it might be interesting to you too.
I'm sorry if I didn't state my goals clearly at first, but it seemed to me that initially the problem I encountered was very similar to what is described in this thread, only I suggested a slightly different way to solve it.
I have described the problem more or less clearly here [1] and the worst case, as it seems to me, too, but if this is not the case, let me know. 1. https://www.mail-archive.com/pgsql-hackers@lists.postgresql.org/msg146230.html
On 29.06.2023 12:32, Alena Rybakina wrote:Hi! I'm sorry I didn't answer you right away, I was too busy with work.
On 27.06.2023 22:50, Peter Geoghegan wrote:On Tue, Jun 27, 2023 at 6:19 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote:I learned something new from your letter, thank you very much for that!Cool. The MDAM paper is also worth a read: https://vldb.org/conf/1995/P710.PDF Some of the techniques it describes are already in Postgres. With varying degrees of maturity. The paper actually mentions OR optimization at one point, under "Duplicate Elimination". The general idea is that ScalarArrayOpExpr execution can "eliminate duplicates before the data is read". The important underlying principle is that it can be really useful to give the B-Tree code the context it requires to be clever about stuff like that. We can do this by (say) using one ScalarArrayOpExpr, rather than using two or more index scans that the B-Tree code will treat as independent things. So a lot of the value in your patch comes from the way that it can enable other optimizations (the immediate benefits are also nice). In the past, OR optimizations have been prototyped that were later withdrawn/rejected because the duplicate elimination aspect was...too scary [1]. It's very easy to see that ScalarArrayOpExpr index scans don't really have the same problem. "Giving the B-Tree code the required context" helps here too.Thank you for the explanation and the material provided) unfortunately, I am still only studying the article and at the moment I cannot write more. To be honest, I didn't think about the fact that my optimization can help eliminate duplicates before reading the data before.
I am still only in the process of familiarizing myself with the thread [1] (reference from your letter), but I have already seen that there are problems related, for example, to when "or" expressions refer to the parent element.
I think, I would face the similar problems if I complicate the current code, for example, so that not only or expressions standing on the same level are written in any, but also on different ones without violating the logic of the priority of executing operators.
For example, this query works now:
postgres=# EXPLAIN (analyze, COSTS OFF)
SELECT oid,relname FROM pg_class
WHERE
(oid = 13779 OR oid = 2) OR (oid = 4 OR oid = 5) OR
relname = 'pg_extension'
;QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Seq Scan on pg_class (actual time=0.086..0.140 rows=1 loops=1)
Filter: ((oid = ANY ('{4,5}'::oid[])) OR (oid = ANY ('{13779,2}'::oid[])) OR (relname = 'pg_extension'::name))
Rows Removed by Filter: 412
Planning Time: 2.135 ms
Execution Time: 0.160 ms
(5 rows)But I would like it works such as:
QUERY PLAN
--------------------------------------------------------------------------------------
Seq Scan on pg_class (actual time=0.279..0.496 rows=1 loops=1)
Filter: ((oid = ANY ('{13779,2,4,5}'::oid[])) OR (relname = 'pg_extension'::name))
Rows Removed by Filter: 412
Planning Time: 0.266 ms
Execution Time: 0.536 ms
(5 rows)Yes, I agree with you and I have yet to analyze this.I analyzed the buffer consumption when I ran control regression tests using my patch. diff shows me that there is no difference between the number of buffer block scans without and using my patch, as far as I have seen. (regression.diffs)To be clear, I wasn't expecting that there'd be any regressions from your patch. Intuitively, it seems like this optimization should make the query plan do almost the same thing at execution time -- just slightly more efficiently on average, and much more efficiently in some individual cases. It would probably be very hard for the optimizer to model/predict how much work it can save by using a ScalarArrayOpExpr instead of an "equivalent" set of bitmap index scans, OR'd together. But it doesn't necessarily matter -- the only truly critical detail is understanding the worst case for the transformation optimization.I haven't seen a major performance degradation so far, but to be honest, I have not conducted a detailed analysis on other types of queries other than x=1 or x=2 or x=1 or y=2, etc. As soon as something is known, I will provide the data, it is very interesting to me.It cannot be too bad (maybe it's ~zero added runtime overhead relative to not doing the transformation, even?).At the same time, nbtree can be clever about ScalarArrayOpExpr execution at runtime (once that's implemented), without ever needing to make any kind of up-front commitment to navigating through the index in any particular way. It's all dynamic, and can be driven by the actual observed characteristics of the index structure. In other words, we don't really need to gamble (in the planner, or at execution time). We're just keeping our options open in more cases. (My thinking on these topics was influenced by Goetz Graefe -- "choice is confusion" [2]).Unfortunately, when I tried to make a transformation at the stage of index formation, I encountered too incorrect an assessment of the selectivity of relation, which affected the incorrect calculation of the cost and cardinality. I couldn't solve this problem.
My diff (transform_or_v0.diff). I got this result:
CREATE TABLE tenk1 (unique1 int, unique2 int, ten int, hundred int); insert into tenk1 SELECT x,x,x,x FROM generate_series(1,50000) as x; CREATE INDEX a_idx1 ON tenk1(unique1); CREATE INDEX a_idx2 ON tenk1(unique2); CREATE INDEX a_hundred ON tenk1(hundred); postgres=# explain analyze select * from tenk1 a join tenk1 b on a.unique2 = 3 or a.unique2 = 7 or a.unique1 = 1; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..15627479.50 rows=1250050000 width=32) (actual time=0.040..75.531 rows=150000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..771.00 rows=50000 width=16) (actual time=0.022..5.467 rows=50000 loops=1) -> Materialize (cost=0.00..1146.01 rows=25001 width=16) (actual time=0.000..0.001 rows=3 loops=50000) -> Seq Scan on tenk1 a (cost=0.00..1021.00 rows=25001 width=16) (actual time=0.011..22.789 rows=3 loops=1) Filter: ((unique2 = ANY (ARRAY[3, 7])) OR (unique1 = 1)) Rows Removed by Filter: 49997 Planning Time: 0.427 ms Execution Time: 80.027 ms (8 rows)The current patch's result:
postgres=# set enable_bitmapscan ='off'; SET postgres=# explain analyze select * from tenk1 a join tenk1 b on a.unique2 = 3 or a.unique2 = 7 or a.unique1 = 1; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..22247.02 rows=1350000 width=32) (actual time=0.094..373.627 rows=1350000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..2311.00 rows=150000 width=16) (actual time=0.051..14.667 rows=150000 loops=1) -> Materialize (cost=0.00..3061.05 rows=9 width=16) (actual time=0.000..0.001 rows=9 loops=150000) -> Seq Scan on tenk1 a (cost=0.00..3061.00 rows=9 width=16) (actual time=0.026..42.389 rows=9 loops=1) Filter: ((unique2 = ANY ('{3,7}'::integer[])) OR (unique1 = 1)) Rows Removed by Filter: 149991 Planning Time: 0.414 ms Execution Time: 409.154 ms (8 rows)Thank you again for the explanations and the material provided. I will carefully study everything as soon as possible and will write if there are any thoughts or if there are ideas about my patch.[1] https://www.postgresql.org/message-id/flat/1397.1486598083%40sss.pgh.pa.us#310f974a8dc84478d6d3c70f336807bb [2] https://sigmodrecord.org/publications/sigmodRecord/2009/pdfs/05_Profiles_Graefe.pdf
-- Regards, Alena Rybakina Postgres Professional
I apologize for breaks the original thread. In my defense, I can say that I'm new to all this and I'm just learning. I will try to make as few mistakes as possible.
Hi!
On 29.06.2023 04:36, Ranier Vilela wrote:I don't want to be rude, but this doesn't seem very helpful.Sorry, It was not my intention to cause interruptions.
- You made some changes, but you don't even attempt to explain what you
changed or why you changed it.1. Reduce scope2. Eliminate unnecessary variables3. Eliminate unnecessary expressions
- You haven't even tried to compile the code, nor tested it. If it
happens to compile, wow could others even know it actually behaves the
way you wanted?Sorry I didn't answer right away. I will try not to do this in the future thank you for your participation and help.
Yes, the scope of this patch may be small, but I am sure that it will solve the worst case of memory consumption with large numbers of "or" expressions or reduce execution and planning time.
As I have already said, I conducted a launch on a database with 20 billion data generated using a benchmark. Unfortunately, at that time I sent a not quite correct picture: the execution time, not the planning time, increases with the number of "or" expressions (execution_time.png). x is the number of or expressions, y is the execution/scheduling time.I also throw memory consumption at 50,000 "or" expressions collected by HeapTrack (where memory consumption was recorded already at the initialization stage of the 1.27GB pic3.png). I think such a transformation will allow just the same to avoid such a worst case, since in comparison with ANY memory is much less and takes little time.
SELECT FORMAT('prepare x %s AS SELECT * FROM pgbench_accounts a WHERE %s', '(' || string_agg('int', ',') || ')', string_agg(FORMAT('aid = $%s', g.id), ' or ') ) AS cmd FROM generate_series(1, 50000) AS g(id) \gexec SELECT FORMAT('execute x %s;', '(' || string_agg(g.id::text, ',') || ')') AS cmd FROM generate_series(1, 50000) AS g(id) \gexecI tried to add a transformation at the path formation stage before we form indexes (set_plain_rel_pathlist function) and at the stage when we have preprocessing of "or" expressions (getting rid of duplicates or useless conditions), but everywhere there was a problem of incorrect selectivity estimation.
CREATE TABLE tenk1 (unique1 int, unique2 int, ten int, hundred int); insert into tenk1 SELECT x,x,x,x FROM generate_series(1,50000) as x; CREATE INDEX a_idx1 ON tenk1(unique1); CREATE INDEX a_idx2 ON tenk1(unique2); CREATE INDEX a_hundred ON tenk1(hundred); postgres=# explain analyze select * from tenk1 a join tenk1 b on ((a.unique2 = 3 or a.unique2 = 7)) or (a.unique1 = 1); QUERY PLAN ---------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..140632434.50 rows=11250150000 width=32) (actual time=0.077..373.279 rows=1350000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..2311.00 rows=150000 width=16) (actual time=0.037..13.941 rows=150000 loops=1) -> Materialize (cost=0.00..3436.01 rows=75001 width=16) (actual time=0.000..0.001 rows=9 loops=150000) -> Seq Scan on tenk1 a (cost=0.00..3061.00 rows=75001 width=16) (actual time=0.027..59.174 rows=9 loops=1) Filter: ((unique2 = ANY (ARRAY[3, 7])) OR (unique1 = 1)) Rows Removed by Filter: 149991 Planning Time: 0.438 ms Execution Time: 407.144 ms (8 rows)Only by converting the expression at this stage, we do not encounter this problem.
postgres=# set enable_bitmapscan ='off'; SET postgres=# explain analyze select * from tenk1 a join tenk1 b on a.unique2 = 3 or a.unique2 = 7 or a.unique1 = 1; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..22247.02 rows=1350000 width=32) (actual time=0.094..373.627 rows=1350000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..2311.00 rows=150000 width=16) (actual time=0.051..14.667 rows=150000 loops=1) -> Materialize (cost=0.00..3061.05 rows=9 width=16) (actual time=0.000..0.001 rows=9 loops=150000) -> Seq Scan on tenk1 a (cost=0.00..3061.00 rows=9 width=16) (actual time=0.026..42.389 rows=9 loops=1) Filter: ((unique2 = ANY ('{3,7}'::integer[])) OR (unique1 = 1)) Rows Removed by Filter: 149991 Planning Time: 0.414 ms Execution Time: 409.154 ms (8 rows)I compiled my original patch and there were no problems with regression tests. The only time there was a problem when I set the const_transform_or_limit variable to 0 (I have 15), as you have in the patch. To be honest, diff appears there because you had a different plan, specifically the expressions "or" are replaced by ANY (see regression.diffs).
Unfortunately, your patch version did not apply immediately, I did not understand the reasons, I applied it manually.
At the moment, I'm not sure that the constant is the right number for applying transformations, so I'm in search of it, to be honest. I will post my observations on this issue later. If you don't mind, I'll leave the constant equal to 15 for now.
Sorry, I don't understand well enough what is meant by points "Eliminate unnecessary variables" and "Eliminate unnecessary expressions". Can you explain in more detail?
Regarding the patch, there was a Warning at the compilation stage.In file included from ../../../src/include/nodes/bitmapset.h:21, from ../../../src/include/nodes/parsenodes.h:26, from ../../../src/include/catalog/objectaddress.h:17, from ../../../src/include/catalog/pg_aggregate.h:24, from parse_expr.c:18: parse_expr.c: In function ‘transformBoolExprOr’: ../../../src/include/nodes/nodes.h:133:66: warning: ‘expr’ is used uninitialized [-Wuninitialized] 133 | #define nodeTag(nodeptr) (((const Node*)(nodeptr))->type) | ^~ parse_expr.c:116:29: note: ‘expr’ was declared here 116 | BoolExpr *expr; | ^~~~
I couldn't figure out how to fix it and went back to my original version. To be honest, I don't think anything needs to be changed here.
Unfortunately, I didn't understand the reasons why, with the available or expressions, you don't even try to convert to ANY by calling transformBoolExpr, as I saw. I went back to my version.
I think it's worth checking whether the or_statement variable is positive.
I think it's worth leaving the use of the or_statement variable in its original form.
switch (expr->boolop)
{
case AND_EXPR:
opname = "AND";
break;
case OR_EXPR:
opname = "OR";
or_statement = true;
break;
case NOT_EXPR:
opname = "NOT";
break;
default:
elog(ERROR, "unrecognized boolop: %d", (int) expr->boolop);
opname = NULL; /* keep compiler quiet */
break;
}
if (!or_statement || list_length(expr->args) < const_transform_or_limit)
return transformBoolExpr(pstate, (BoolExpr *)expr_orig);
Attachment
At the moment, I'm not sure that the constant is the right number for applying transformations, so I'm in search of it, to be honest. I will post my observations on this issue later. If you don't mind, I'll leave the constant equal to 15 for now.
It's hard to predict. Perhaps accounting for time on each benchmark could help decide.
I will try to test on JOB [1] (because queries are difficult for the optimizer due to the significant number of joins and correlations contained in the dataset) and
tpcds [2] (the benchmark I noticed contains a sufficient number of queries with "or" expressions).
Sorry, I don't understand well enough what is meant by points "Eliminate unnecessary variables" and "Eliminate unnecessary expressions". Can you explain in more detail?
One example is array_type.As you can see in v2 and v3 it no longer exists.
I get it. Honestly, I was guided by the example of converting "IN" to "ANY" (transformAExprIn), at least the part of the code when we specifically convert the expression to ScalarArrayOpExpr.
Both there and here, we first look for a common type for the collected constants, and if there is one, then we try to find the type for the array structure.
Only I think in my current patch it is also worth returning to the original version in this place, since if it is not found, the ScalarArrayOpExpr generation function will be processed incorrectly and
the request may not be executed at all, referring to the error that it is impossible to determine the type of node (ERROR: unrecognized node type. )
At the same time we are trying to do this transformation for each group. The group here implies that these are combined "or" expressions on the common left side, and at the same time we consider
only expressions that contain a constant and only equality.
What else should be taken into account is that we are trying to do this processing before forming a BoolExpr expression (if you notice, then after any outcome we call the makeBoolExpr function,
which just forms the "Or" expression, as in the original version, regardless of what type of expressions it combines.
Thank you again for your interest in this problem and help. Yes, I think so too)As I said earlier, these are just suggestions.But thinking about it now, I think they can be classified as bad early optimizations.
1. https://github.com/gregrahn/join-order-benchmark
2. https://github.com/Alena0704/s64da-benchmark-toolkit/tree/master/benchmarks/tpcds
-- Regards, Alena Rybakina Postgres Professional
Attachment
Em qui., 29 de jun. de 2023 às 06:56, Alena Rybakina <lena.ribackina@yandex.ru> escreveu:I apologize for breaks the original thread. In my defense, I can say that I'm new to all this and I'm just learning. I will try to make as few mistakes as possible.
By no means, your work is excellent and deserves all compliments.
Thank you, I will try to work in the same spirit, especially since there is still quite a lot of work left).
Thank you for your feedback.
-- Regards, Alena Rybakina Postgres Professional
HI, all! > On 27.06.2023 16:19, Alena Rybakina wrote: >> Thank you for your feedback, your work is also very interesting and >> important, and I will be happy to review it. I learned something new >> from your letter, thank you very much for that! >> >> I analyzed the buffer consumption when I ran control regression tests >> using my patch. diff shows me that there is no difference between the >> number of buffer block scans without and using my patch, as far as I >> have seen. (regression.diffs) >> >> >> In addition, I analyzed the scheduling and duration of the execution >> time of the source code and with my applied patch. I generated 20 >> billion data from pgbench and plotted the scheduling and execution >> time depending on the number of "or" expressions. >> By runtime, I noticed a clear acceleration for queries when using the >> index, but I can't say the same when the index is disabled. >> At first I turned it off in this way: >> 1)enable_seqscan='off' >> 2)enable_indexonlyscan='off' >> enable_indexscan='off' >> >> Unfortunately, it is not yet clear which constant needs to be set >> when the transformation needs to be done, I will still study in >> detail. (the graph for all this is presented in graph1.svg I finished comparing the performance of queries with converted or expressions and the original ones and found that about 500 "OR" expressions have significantly noticeable degradation of execution time, both using the index and without it (you can look at time_comsuption_with_indexes.png and time_comsuption_without_indexes.html ) The test was performed on the same benchmark database generated by 2 billion values. I corrected this constant in the patch. -- Regards, Alena Rybakina Postgres Professional
Attachment
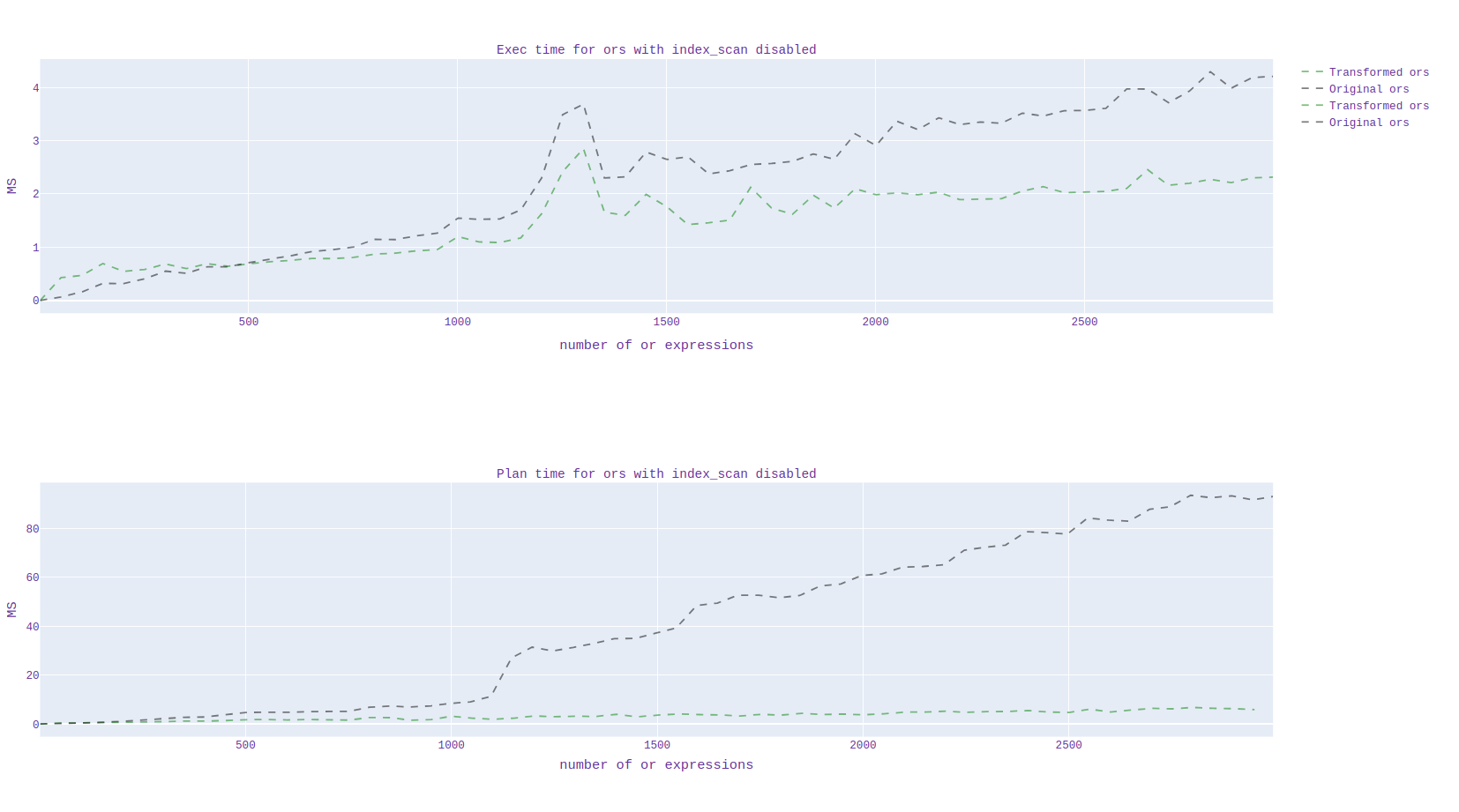{kind=link}
{kind=link}
Sorry, I threw off the wrong charts, I'm sending the right ones. On 05.07.2023 22:39, Alena Rybakina wrote: > HI, all! > >> On 27.06.2023 16:19, Alena Rybakina wrote: >>> Thank you for your feedback, your work is also very interesting and >>> important, and I will be happy to review it. I learned something new >>> from your letter, thank you very much for that! >>> >>> I analyzed the buffer consumption when I ran control regression >>> tests using my patch. diff shows me that there is no difference >>> between the number of buffer block scans without and using my patch, >>> as far as I have seen. (regression.diffs) >>> >>> >>> In addition, I analyzed the scheduling and duration of the execution >>> time of the source code and with my applied patch. I generated 20 >>> billion data from pgbench and plotted the scheduling and execution >>> time depending on the number of "or" expressions. >>> By runtime, I noticed a clear acceleration for queries when using >>> the index, but I can't say the same when the index is disabled. >>> At first I turned it off in this way: >>> 1)enable_seqscan='off' >>> 2)enable_indexonlyscan='off' >>> enable_indexscan='off' >>> >>> Unfortunately, it is not yet clear which constant needs to be set >>> when the transformation needs to be done, I will still study in >>> detail. (the graph for all this is presented in graph1.svg > > I finished comparing the performance of queries with converted or > expressions and the original ones and found that about 500 "OR" > expressions have significantly noticeable degradation of execution > time, both using the index and without it (you can look at > time_comsuption_with_indexes.png and > time_comsuption_without_indexes.html ) > > The test was performed on the same benchmark database generated by 2 > billion values. > > I corrected this constant in the patch. > -- Regards, Alena Rybakina Postgres Professional
Attachment
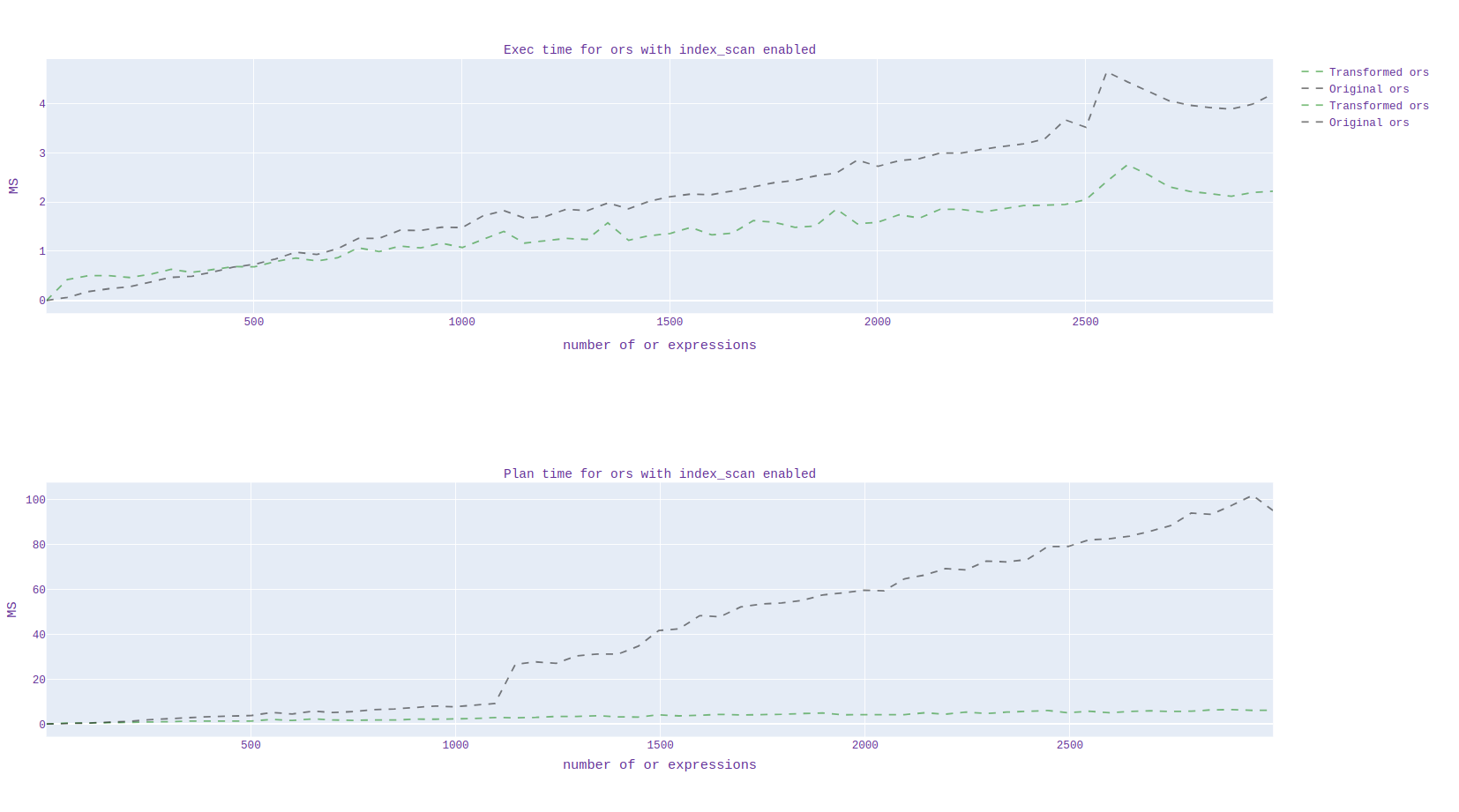{kind=link}
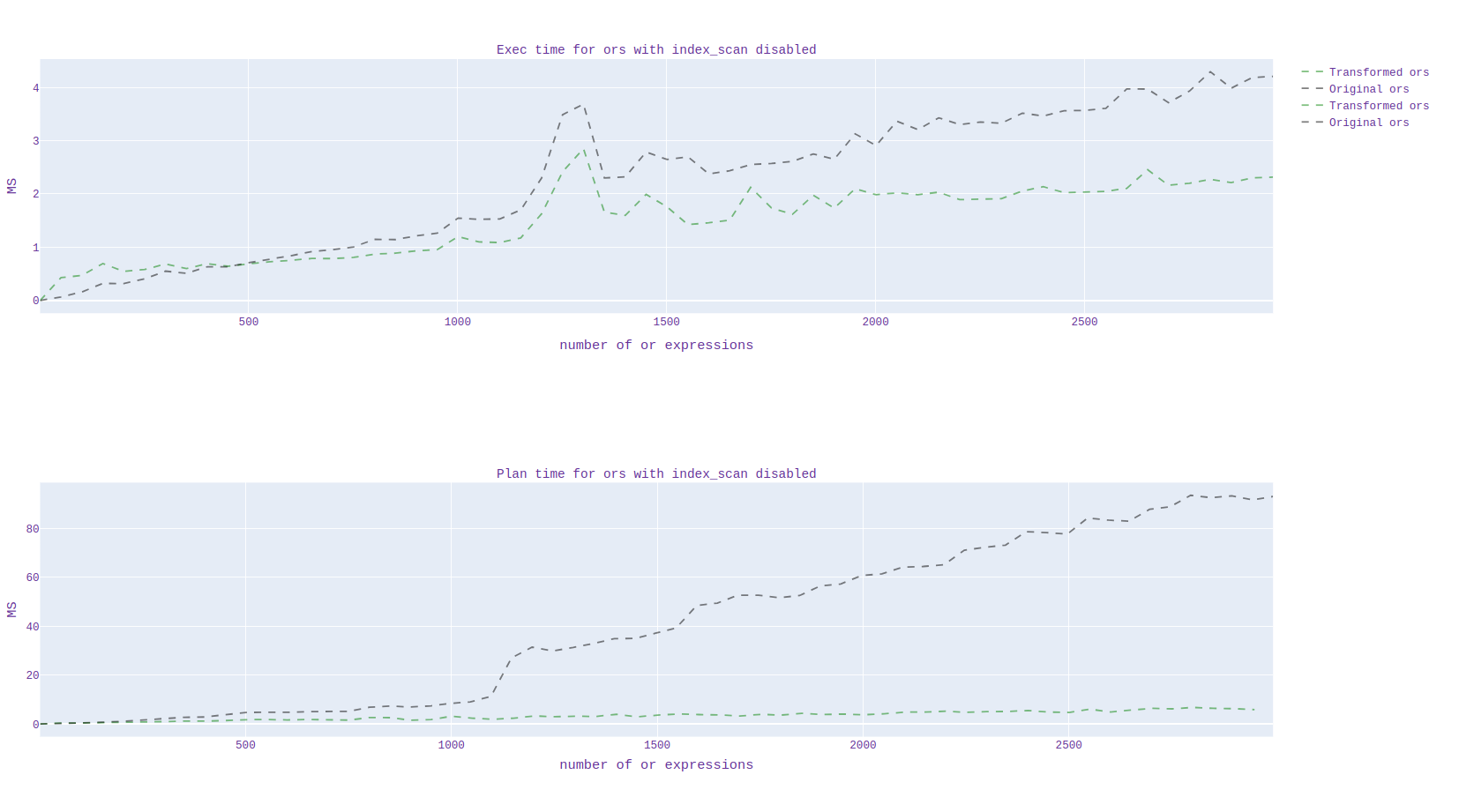{kind=link}
On 6/7/2023 03:06, Alena Rybakina wrote: >> I corrected this constant in the patch. The patch don't apply cleanly: it contains some trailing spaces. Also, quick glance into the code shows some weak points; 1. transformBoolExprOr should have input type BoolExpr. 2. You can avoid the switch operator at the beginning of the function, because you only need one option. 3. Stale comments: RestrictIinfos definitely not exists at this point. 4. I don't know, you really need to copy the expr or not, but it is better to do as late, as possible. 5. You assume, that leftop is non-constant and rightop - constant. Why? 6.I doubt about equivalence operator. Someone can invent a custom '=' operator with another semantics, than usual. May be better to check mergejoinability? 7. I don't know how to confidently identify constant expressions at this level. So, I guess, You can only merge here expressions like "F(X)=Const", not an 'F(X)=ConstExpression'. See delta.diff with mentioned changes in attachment. -- regards, Andrey Lepikhov Postgres Professional
Attachment
On 6/7/2023 03:06, Alena Rybakina wrote: >> The test was performed on the same benchmark database generated by 2 >> billion values. >> >> I corrected this constant in the patch. In attempt to resolve some issues had mentioned in my previous letter I used op_mergejoinable to detect mergejoinability of a clause. Constant side of the expression is detected by call of eval_const_expressions() and check each side on the Const type of node. See 'diff to diff' in attachment. -- regards, Andrey Lepikhov Postgres Professional
Attachment
Hi! Thank you for your detailed review, your changes have greatly helped
to improve this patch.
On 06.07.2023 13:20, Andrey Lepikhov wrote:
> On 6/7/2023 03:06, Alena Rybakina wrote:
>>> I corrected this constant in the patch.
> The patch don't apply cleanly: it contains some trailing spaces.
I fixed it.
>
> Also, quick glance into the code shows some weak points;
> 1. transformBoolExprOr should have input type BoolExpr.
Agreed.
> 2. You can avoid the switch operator at the beginning of the function,
> because you only need one option.
Agreed.
> 3. Stale comments: RestrictIinfos definitely not exists at this point.
Yes, unfortunately, I missed this from the previous version when I tried
to perform such a transformation at the index creation stage.
> 4. I don't know, you really need to copy the expr or not, but it is
> better to do as late, as possible.
Yes, I agree with you, copying "expr" is not necessary in this patch
> 5. You assume, that leftop is non-constant and rightop - constant. Why?
Agreed, It was too presumptuous on my part and I agree with your changes.
> 6.I doubt about equivalence operator. Someone can invent a custom '='
> operator with another semantics, than usual. May be better to check
> mergejoinability?
Yes, I agree with you, and I haven't thought about it before. But I
haven't found any functions to arrange this in PostgreSQL, but using
mergejoinability turns out to be more beautiful here.
> 7. I don't know how to confidently identify constant expressions at
> this level. So, I guess, You can only merge here expressions like
> "F(X)=Const", not an 'F(X)=ConstExpression'.
I see, you can find solution for this case, thank you for this, and I
think it's reliable enough.
On 07.07.2023 05:43, Andrey Lepikhov wrote:
> On 6/7/2023 03:06, Alena Rybakina wrote:
>>> The test was performed on the same benchmark database generated by 2
>>> billion values.
>>>
>>> I corrected this constant in the patch.
> In attempt to resolve some issues had mentioned in my previous letter
> I used op_mergejoinable to detect mergejoinability of a clause.
> Constant side of the expression is detected by call of
> eval_const_expressions() and check each side on the Const type of node.
>
> See 'diff to diff' in attachment.
I notices you remove condition for checking equal operation.
strcmp(strVal(linitial((arg)->name)), "=") == 0
Firstly, it is noticed me not correct, but a simple example convinced me
otherwise:
postgres=# explain analyze select x from a where x=1 or x>5 or x<3 or x=2;
QUERY PLAN
--------------------------------------------------------------------------------------------------------
Seq Scan on a (cost=0.00..2291.00 rows=97899 width=4) (actual
time=0.038..104.168 rows=99000 loops=1)
Filter: ((x > '5'::numeric) OR (x < '3'::numeric) OR (x = ANY
('{1,2}'::numeric[])))
Rows Removed by Filter: 1000
Planning Time: 9.938 ms
Execution Time: 113.457 ms
(5 rows)
It surprises me that such check I can write such similar way:
eval_const_expressions(NULL, orqual).
Yes, I see we can remove this code:
bare_orarg = transformExprRecurse(pstate, (Node *)arg);
bare_orarg = coerce_to_boolean(pstate, bare_orarg, "OR");
because we will provide similar manipulation in this:
foreach(l, gentry->consts)
{
Node *rexpr = (Node *) lfirst(l);
rexpr = coerce_to_common_type(pstate, rexpr,
scalar_type,
"IN");
aexprs = lappend(aexprs, rexpr);
}
--
Regards,
Alena Rybakina
Postgres Professional
Attachment
On 7/7/2023 15:20, Alena Rybakina wrote:
>
> because we will provide similar manipulation in this:
>
> foreach(l, gentry->consts)
> {
> Node *rexpr = (Node *) lfirst(l);
>
> rexpr = coerce_to_common_type(pstate, rexpr,
> scalar_type,
> "IN");
> aexprs = lappend(aexprs, rexpr);
> }
I'm not sure that it should be replaced.
In attachment - a bit more corrections to the patch.
The most important change - or_list contains already transformed
expression subtree. So, I think we don't need to free it at all.
--
regards,
Andrey Lepikhov
Postgres Professional
Attachment
I agreed with the changes. Thank you for your work.
I updated patch and added you to the authors.
I specified Ranier Vilela as a reviewer.
On 10.07.2023 06:12, Andrey Lepikhov wrote:
> On 7/7/2023 15:20, Alena Rybakina wrote:
>>
>> because we will provide similar manipulation in this:
>>
>> foreach(l, gentry->consts)
>> {
>> Node *rexpr = (Node *) lfirst(l);
>>
>> rexpr = coerce_to_common_type(pstate, rexpr,
>> scalar_type,
>> "IN");
>> aexprs = lappend(aexprs, rexpr);
>> }
> I'm not sure that it should be replaced.
> In attachment - a bit more corrections to the patch.
> The most important change - or_list contains already transformed
> expression subtree. So, I think we don't need to free it at all.
>
--
Regards,
Alena Rybakina
Postgres Professional
Attachment
I agreed with the changes. Thank you for your work.
I updated patch and added you to the authors.
I specified Ranier Vilela as a reviewer.
+ nconst_expr =get_rightop(orqual);
+ {
+ or_list = lappend(or_list, orqual);
+ continue;
+ }
+ newa->array_typeid = array_type;
+ list_free(gentry->consts);
+ continue;
Hi Alena,Em seg., 10 de jul. de 2023 às 05:38, Alena Rybakina <lena.ribackina@yandex.ru> escreveu:I agreed with the changes. Thank you for your work.
I updated patch and added you to the authors.
I specified Ranier Vilela as a reviewer.Is a good habit when post a new version of the patch, name it v1, v2, v3,etc.Makes it easy to follow development and references on the thread.Regarding the last patch.1. I think that variable const_is_left is not necessary.You can stick with:+ if (IsA(get_leftop(orqual), Const))
+ nconst_expr =get_rightop(orqual);+ const_expr = get_leftop(orqual) ;+ else if (IsA(get_rightop(orqual), Const))+ nconst_expr =get_leftop(orqual);+ const_expr = get_rightop(orqual) ;+ else
+ {
+ or_list = lappend(or_list, orqual);
+ continue;
+ }2. Test scalar_type != RECORDOID is more cheaper,mainly if OidIsValid were a function, we knows that is a macro.+ if (scalar_type != RECORDOID && OidIsValid(scalar_type))3. Sorry about wrong tip about array_type, but if really necessary,better use it.+ newa->element_typeid = scalar_type;
+ newa->array_typeid = array_type;4. Is a good habit, call free last, to avoid somebody accidentally using it.+ or_list = lappend(or_list, gentry->expr);
+ list_free(gentry->consts);
+ continue;5. list_make1(makeString((char *) "=")Is an invariant?
On 10/7/2023 15:38, Alena Rybakina wrote:
> I agreed with the changes. Thank you for your work.
>
> I updated patch and added you to the authors.
>
> I specified Ranier Vilela as a reviewer.
This patch looks much better than earlier. But it definitely needs some
covering with tests. As a first simple approximation, here you can see
the result of regression tests, where the transformation limit is set to
0. See in the attachment some test changes induced by these diffs.
Also, I see some impact of the transformation to other queries:
create_view.out:
(NOT x > z) ----> (x <= z)
inherit.out:
(((a)::text = 'ab'::text) OR ((a)::text = ANY ('{NULL,cd}'::text[])))
to
(((a)::text = ANY ('{NULL,cd}'::text[])) OR ((a)::text = 'ab'::text))
Transformations, mentioned above, are correct, of course. But it can be
a sign of possible unstable behavior.
--
regards,
Andrey Lepikhov
Postgres Professional
Attachment
Hi!
Sorry, I fixed it.Em seg., 10 de jul. de 2023 às 09:03, Ranier Vilela <ranier.vf@gmail.com> escreveu:Hi Alena,Em seg., 10 de jul. de 2023 às 05:38, Alena Rybakina <lena.ribackina@yandex.ru> escreveu:I agreed with the changes. Thank you for your work.
I updated patch and added you to the authors.
I specified Ranier Vilela as a reviewer.Is a good habit when post a new version of the patch, name it v1, v2, v3,etc.Makes it easy to follow development and references on the thread.
Agreed.Regarding the last patch.1. I think that variable const_is_left is not necessary.You can stick with:+ if (IsA(get_leftop(orqual), Const))
+ nconst_expr =get_rightop(orqual);+ const_expr = get_leftop(orqual) ;+ else if (IsA(get_rightop(orqual), Const))+ nconst_expr =get_leftop(orqual);+ const_expr = get_rightop(orqual) ;+ else
+ {
+ or_list = lappend(or_list, orqual);
+ continue;
+ }
Is it safe? Maybe we should first make sure that it can be checked on RECORDOID at all?2. Test scalar_type != RECORDOID is more cheaper,mainly if OidIsValid were a function, we knows that is a macro.+ if (scalar_type != RECORDOID && OidIsValid(scalar_type))
Agreed.3. Sorry about wrong tip about array_type, but if really necessary,better use it.+ newa->element_typeid = scalar_type;
+ newa->array_typeid = array_type;
4. Is a good habit, call free last, to avoid somebody accidentally using it.+ or_list = lappend(or_list, gentry->expr);
+ list_free(gentry->consts);
+ continue;
No, this is not necessary, because we add the original expression in these places to the resulting list and later
we will not use the list of constants for this group at all, otherwise it would be an error.
-- Regards, Alena Rybakina Postgres Professional
Attachment
Hi!
On 10.07.2023 15:15, Ranier Vilela wrote:Sorry, I fixed it.Em seg., 10 de jul. de 2023 às 09:03, Ranier Vilela <ranier.vf@gmail.com> escreveu:Hi Alena,Em seg., 10 de jul. de 2023 às 05:38, Alena Rybakina <lena.ribackina@yandex.ru> escreveu:I agreed with the changes. Thank you for your work.
I updated patch and added you to the authors.
I specified Ranier Vilela as a reviewer.Is a good habit when post a new version of the patch, name it v1, v2, v3,etc.Makes it easy to follow development and references on the thread.Agreed.Regarding the last patch.1. I think that variable const_is_left is not necessary.You can stick with:+ if (IsA(get_leftop(orqual), Const))
+ nconst_expr =get_rightop(orqual);+ const_expr = get_leftop(orqual) ;+ else if (IsA(get_rightop(orqual), Const))+ nconst_expr =get_leftop(orqual);+ const_expr = get_rightop(orqual) ;+ else
+ {
+ or_list = lappend(or_list, orqual);
+ continue;
+ }
.
Is it safe? Maybe we should first make sure that it can be checked on RECORDOID at all?2. Test scalar_type != RECORDOID is more cheaper,mainly if OidIsValid were a function, we knows that is a macro.+ if (scalar_type != RECORDOID && OidIsValid(scalar_type))
Yes, thank you. I fixed it.Em ter., 11 de jul. de 2023 às 09:29, Alena Rybakina <lena.ribackina@yandex.ru> escreveu:Hi!
On 10.07.2023 15:15, Ranier Vilela wrote:Sorry, I fixed it.Em seg., 10 de jul. de 2023 às 09:03, Ranier Vilela <ranier.vf@gmail.com> escreveu:Hi Alena,Em seg., 10 de jul. de 2023 às 05:38, Alena Rybakina <lena.ribackina@yandex.ru> escreveu:I agreed with the changes. Thank you for your work.
I updated patch and added you to the authors.
I specified Ranier Vilela as a reviewer.Is a good habit when post a new version of the patch, name it v1, v2, v3,etc.Makes it easy to follow development and references on the thread.Agreed.Regarding the last patch.1. I think that variable const_is_left is not necessary.You can stick with:+ if (IsA(get_leftop(orqual), Const))
+ nconst_expr =get_rightop(orqual);+ const_expr = get_leftop(orqual) ;+ else if (IsA(get_rightop(orqual), Const))+ nconst_expr =get_leftop(orqual);+ const_expr = get_rightop(orqual) ;+ else
+ {
+ or_list = lappend(or_list, orqual);
+ continue;
+ }You missed in removing the declaration- bool const_is_left = true;
Added it..Is it safe? Maybe we should first make sure that it can be checked on RECORDOID at all?2. Test scalar_type != RECORDOID is more cheaper,mainly if OidIsValid were a function, we knows that is a macro.+ if (scalar_type != RECORDOID && OidIsValid(scalar_type))Yes it's safe, because && connector.But you can leave as is in v5.
-- Regards, Alena Rybakina Postgres Professional
Attachment
Hi!
On 11.07.2023 11:47, Andrey Lepikhov wrote:
> This patch looks much better than earlier. But it definitely needs
> some covering with tests. As a first simple approximation, here you
> can see the result of regression tests, where the transformation limit
> is set to 0. See in the attachment some test changes induced by these
> diffs.
>
Yes, I think so too. I also added some tests. I have attached an
additional diff-5.diff where you can see the changes.
> Also, I see some impact of the transformation to other queries:
> create_view.out:
> (NOT x > z) ----> (x <= z)
> inherit.out:
> (((a)::text = 'ab'::text) OR ((a)::text = ANY ('{NULL,cd}'::text[])))
> to -
> (((a)::text = ANY ('{NULL,cd}'::text[])) OR ((a)::text = 'ab'::text))
>
> Transformations, mentioned above, are correct, of course. But it can
> be a sign of possible unstable behavior.
>
I think it can be made more stable if we always add the existing
transformed expressions first, and then the original ones, or vice versa. T
o do this, we will need two more lists, I think, and then we can combine
them, where the elements of the second will be written to the end of the
first.
But I suppose that this may not be the only unstable behavior - I
suppose we need sorting result elements on the left side, what do you think?
--
Regards,
Alena Rybakina
Postgres Professional
Attachment
Hi, all! I sent a patch to commitfest and noticed that the authors and the reviewer were incorrectly marked. Sorry about that. I fixed it and sent the current version of the patch. -- Regards, Alena Rybakina Postgres Professional
Attachment
On Thu, Jun 29, 2023 at 2:32 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote: > Hi! I'm sorry I didn't answer you right away, I was too busy with work. Same for me, this time. I was busy working on my patch, which I finally posted yesterday. > To be honest, I didn't think about the fact that my optimization can help eliminate duplicates before reading the databefore. I'm not surprised that you didn't specifically think of that, because it's very subtle. > I am still only in the process of familiarizing myself with the thread [1] (reference from your letter), but I have alreadyseen that there are problems related, for example, to when "or" expressions refer to the parent element. I didn't intend to imply that you might have the same problem here. I just meant that OR optimizations can have problems with duplicate elimination, in general. I suspect that your patch doesn't have that problem, because you are performing a transformation of one kind of OR into another kind of OR. > I think, I would face the similar problems if I complicate the current code, for example, so that not only or expressionsstanding on the same level are written in any, but also on different ones without violating the logic of the priorityof executing operators. I can't say that I am particularly experienced in this general area -- I have never tried to formally reason about how two different statements are equivalent. It just hasn't been something that I've needed to have a totally rigorous understanding of up until now. But my recent patch changes that. Now I need to study this area to make sure that I have a truly rigorous understanding. Jeff Davis suggested that I read "Logic and Databases", by C.J. Date. So now I have some homework to do. > Unfortunately, when I tried to make a transformation at the stage of index formation, I encountered too incorrect an assessmentof the selectivity of relation, which affected the incorrect calculation of the cost and cardinality. It's not surprising that a weird shift in the plan chosen by the optimizer is seen with some random test case, as a result of this added transformation. Even changes that are 100% strictly better (e.g. changes in a selectivity estimation function that is somehow guaranteed to be more accurate in all cases) might do that. Here is a recent example of that with another patch, involving a bitmap OR: https://postgr.es/m/CAH2-WznCDK9n2tZ6j_-iLN563_ePuC3NzP6VSVTL6jHzs6nRuQ@mail.gmail.com This example was *not* a regression, if you go by conventional measures. It was merely a less robust plan than the bitmap OR plan, because it didn't pass down both columns as index quals. BTW, there are various restrictions on the sort order of SAOPs that you might want to try to familiarize yourself with. I describe them (perhaps not very clearly) here: https://postgr.es/m/CAH2-Wz=ksvN_sjcnD1+Bt-WtifRA5ok48aDYnq3pkKhxgMQpcw@mail.gmail.com Currently, the optimizer doesn't recognize multi-column indexes with SAOPs on every column as having a valid sort order, except on the first column. It seems possible that that has consequences for your patch. (I'm really only guessing, though; don't trust anything that I say about the optimizer too much.) -- Peter Geoghegan
Hi!
On 26.07.2023 02:47, Peter Geoghegan wrote:
> On Thu, Jun 29, 2023 at 2:32 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote:
>> Hi! I'm sorry I didn't answer you right away, I was too busy with work.
> Same for me, this time. I was busy working on my patch, which I
> finally posted yesterday.
I'm glad to hear it, I've seen your thread ("Optimizing nbtree
ScalarArrayOp execution, allowing multi-column ordered scans, skip
scan"), but, unfortunately, I didn't have enough time to read it. I'll
review it soon!
>> To be honest, I didn't think about the fact that my optimization can help eliminate duplicates before reading the
databefore.
> I'm not surprised that you didn't specifically think of that, because
> it's very subtle.
>
>> I am still only in the process of familiarizing myself with the thread [1] (reference from your letter), but I have
alreadyseen that there are problems related, for example, to when "or" expressions refer to the parent element.
> I didn't intend to imply that you might have the same problem here. I
> just meant that OR optimizations can have problems with duplicate
> elimination, in general. I suspect that your patch doesn't have that
> problem, because you are performing a transformation of one kind of OR
> into another kind of OR.
Yes, you are right, but I studied this topic and two other sources to
accumulate my knowledge. It was an exciting experience for me)
I was especially inspired after studying the interview with Goetz Graf
[2], his life experience is the most inspiring, and from this article I
was able to get a broad understanding of the field of databases:
current problems, future development, how it works... Thank you for the
recommendation.
I discovered for myself that the idea described in the article [1] is
similar to the idea of representing grouped data in OLAP cubes, and
also, if I saw correctly, an algorithm like depth-first search is used
there, but for indexes.
I think it really helps to speed up the search with similar deep
filtering compared to cluster indexes, but do we have cases where we
don't use this algorithm because it takes longer than an usual index?
I thought about the situation with wide indexes (with a lot of multiple
columns) and having a lot of filtering predicates for them.
But I'm not sure about this, so it seems to me that this is a problem of
improper use of indexes rather.
>> I think, I would face the similar problems if I complicate the current code, for example, so that not only or
expressionsstanding on the same level are written in any, but also on different ones without violating the logic of the
priorityof executing operators.
> I can't say that I am particularly experienced in this general area --
> I have never tried to formally reason about how two different
> statements are equivalent. It just hasn't been something that I've
> needed to have a totally rigorous understanding of up until now. But
> my recent patch changes that. Now I need to study this area to make
> sure that I have a truly rigorous understanding.
>
> Jeff Davis suggested that I read "Logic and Databases", by C.J. Date.
> So now I have some homework to do.
I'll read this book too. Maybe I can finish work with the knowledge I
got from there. Thank you for sharing!
>> Unfortunately, when I tried to make a transformation at the stage of index formation, I encountered too incorrect an
assessmentof the selectivity of relation, which affected the incorrect calculation of the cost and cardinality.
> It's not surprising that a weird shift in the plan chosen by the
> optimizer is seen with some random test case, as a result of this
> added transformation. Even changes that are 100% strictly better (e.g.
> changes in a selectivity estimation function that is somehow
> guaranteed to be more accurate in all cases) might do that. Here is a
> recent example of that with another patch, involving a bitmap OR:
>
> https://postgr.es/m/CAH2-WznCDK9n2tZ6j_-iLN563_ePuC3NzP6VSVTL6jHzs6nRuQ@mail.gmail.com
At first, this surprised me very much. It took time to find a suitable
place to implement the transformation.
I have looked through this thread many times, I will study it in more
detail .
> This example was *not* a regression, if you go by conventional
> measures. It was merely a less robust plan than the bitmap OR plan,
> because it didn't pass down both columns as index quals.
>
> BTW, there are various restrictions on the sort order of SAOPs that
> you might want to try to familiarize yourself with. I describe them
> (perhaps not very clearly) here:
>
> https://postgr.es/m/CAH2-Wz=ksvN_sjcnD1+Bt-WtifRA5ok48aDYnq3pkKhxgMQpcw@mail.gmail.com
Thank you! Yes, I'll study it too)
> Currently, the optimizer doesn't recognize multi-column indexes with
> SAOPs on every column as having a valid sort order, except on the
> first column. It seems possible that that has consequences for your
> patch. (I'm really only guessing, though; don't trust anything that I
> say about the optimizer too much.)
>
Honestly, I couldn't understand your concerns very well, could you
describe it in more detail?
1. https://vldb.org/conf/1995/P710.PDF
2.
https://sigmodrecord.org/publications/sigmodRecord/2009/pdfs/05_Profiles_Graefe.pdf
--
Regards,
Alena Rybakina
Postgres Professional
On Wed, Jul 26, 2023 at 6:30 PM Alena Rybakina <lena.ribackina@yandex.ru> wrote: > > I didn't intend to imply that you might have the same problem here. I > > just meant that OR optimizations can have problems with duplicate > > elimination, in general. I suspect that your patch doesn't have that > > problem, because you are performing a transformation of one kind of OR > > into another kind of OR. > > Yes, you are right, but I studied this topic and two other sources to > accumulate my knowledge. It was an exciting experience for me) Cool! Yeah, a lot of the value with these sorts of things comes from the way that they can interact with each other. This is hard to describe exactly, but still important. > I was especially inspired after studying the interview with Goetz Graf > [2], his life experience is the most inspiring, and from this article I > was able to get a broad understanding of the field of databases: > current problems, future development, how it works... Thank you for the > recommendation. I also think that his perspective is very interesting. > I think it really helps to speed up the search with similar deep > filtering compared to cluster indexes, but do we have cases where we > don't use this algorithm because it takes longer than an usual index? > I thought about the situation with wide indexes (with a lot of multiple > columns) and having a lot of filtering predicates for them. I think that it should be possible for the optimizer to only use multi-column SAOP index paths when there is at least likely to be some small advantage -- that's definitely my goal. Importantly, we may not really need to accurately model the costs where the new approach turns out to be much faster. The only essential thing is that we avoid cases where the new approach is much slower than the old approach. Which is possible (in at least some cases) by making the runtime behavior adaptive. The best decision that the planner can make may be no decision at all. Better to wait until runtime where at all possible, since that gives us the latest and most accurate picture of things. > But I'm not sure about this, so it seems to me that this is a problem of > improper use of indexes rather. It's hard to say how true that is. Certainly, workloads similar to the TPC-DS benchmark kinda need something like MDAM. It's just not practical to have enough indexes to support every possible query -- the benchmark is deliberately designed to have unpredictable, hard-to-optimize access paths. It seems to require having fewer, more general indexes that can support multi-dimensional access reasonably efficiently. Of course, with OLTP it's much more likely that the workload will have predictable access patterns. That makes having exactly the right indexes much more practical. So maybe you're right there. But, I still see a lot of value in a design that is as forgiving as possible. Users really like that kind of thing in my experience. > > Currently, the optimizer doesn't recognize multi-column indexes with > > SAOPs on every column as having a valid sort order, except on the > > first column. It seems possible that that has consequences for your > > patch. (I'm really only guessing, though; don't trust anything that I > > say about the optimizer too much.) > > > Honestly, I couldn't understand your concerns very well, could you > describe it in more detail? Well, I'm not sure if there is any possible scenario where the transformation from your patch makes it possible to go from an access path that has a valid sort order (usually because there is an underlying index scan) into an access path that doesn't. In fact, the opposite situation seems more likely (which is good news) -- especially if you assume that my own patch is also present. Going from a bitmap OR (which cannot return sorted output) to a multi-column SAOP index scan (which now can) may have significant value in some specific circumstances. Most obviously, it's really useful when it enables us to feed tuples into a GroupAggregate without a separate sort step, and without a hash aggregate (that's why I see value in combining your patch with my own patch). You just need to be careful about allowing the opposite situation to take place. More generally, there is a need to think about strange second order effects. We want to be open to useful second order effects that make query execution much faster in some specific context, while avoiding harmful second order effects. Intuitively, I think that it should be possible to do this with the transformations performed by your patch. In other words, "helpful serendipity" is an important advantage, while "harmful anti-serendipity" is what we really want to avoid. Ideally by making the harmful cases impossible "by construction". -- Peter Geoghegan
Hi! >> I think it really helps to speed up the search with similar deep >> filtering compared to cluster indexes, but do we have cases where we >> don't use this algorithm because it takes longer than an usual index? >> I thought about the situation with wide indexes (with a lot of multiple >> columns) and having a lot of filtering predicates for them. > I think that it should be possible for the optimizer to only use > multi-column SAOP index paths when there is at least likely to be some > small advantage -- that's definitely my goal. Importantly, we may not > really need to accurately model the costs where the new approach turns > out to be much faster. The only essential thing is that we avoid cases > where the new approach is much slower than the old approach. Which is > possible (in at least some cases) by making the runtime behavior > adaptive. > > The best decision that the planner can make may be no decision at all. > Better to wait until runtime where at all possible, since that gives > us the latest and most accurate picture of things. > >> But I'm not sure about this, so it seems to me that this is a problem of >> improper use of indexes rather. > It's hard to say how true that is. > > Certainly, workloads similar to the TPC-DS benchmark kinda need > something like MDAM. It's just not practical to have enough indexes to > support every possible query -- the benchmark is deliberately designed > to have unpredictable, hard-to-optimize access paths. It seems to > require having fewer, more general indexes that can support > multi-dimensional access reasonably efficiently. > > Of course, with OLTP it's much more likely that the workload will have > predictable access patterns. That makes having exactly the right > indexes much more practical. So maybe you're right there. But, I still > see a lot of value in a design that is as forgiving as possible. Users > really like that kind of thing in my experience. I tend to agree with you, but a runtime estimate cannot give us an accurate picture when using indexes correctly or any other optimizations due to the unstable state of the environment in which the query is executed. I believe that a more complex analysis is needed here. >>> Currently, the optimizer doesn't recognize multi-column indexes with >>> SAOPs on every column as having a valid sort order, except on the >>> first column. It seems possible that that has consequences for your >>> patch. (I'm really only guessing, though; don't trust anything that I >>> say about the optimizer too much.) >>> >> Honestly, I couldn't understand your concerns very well, could you >> describe it in more detail? > Well, I'm not sure if there is any possible scenario where the > transformation from your patch makes it possible to go from an access > path that has a valid sort order (usually because there is an > underlying index scan) into an access path that doesn't. In fact, the > opposite situation seems more likely (which is good news) -- > especially if you assume that my own patch is also present. > > Going from a bitmap OR (which cannot return sorted output) to a > multi-column SAOP index scan (which now can) may have significant > value in some specific circumstances. Most obviously, it's really > useful when it enables us to feed tuples into a GroupAggregate without > a separate sort step, and without a hash aggregate (that's why I see > value in combining your patch with my own patch). You just need to be > careful about allowing the opposite situation to take place. > > More generally, there is a need to think about strange second order > effects. We want to be open to useful second order effects that make > query execution much faster in some specific context, while avoiding > harmful second order effects. Intuitively, I think that it should be > possible to do this with the transformations performed by your patch. > > In other words, "helpful serendipity" is an important advantage, while > "harmful anti-serendipity" is what we really want to avoid. Ideally by > making the harmful cases impossible "by construction". > I noticed only one thing there: when we have unsorted array values in SOAP, the query takes longer than when it has a sorted array. I'll double-check it just in case and write about the results later. I am also testing some experience with multi-column indexes using SAOPs. -- Regards, Alena Rybakina Postgres Professional
On Mon, Jul 31, 2023 at 9:38 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote:
> I noticed only one thing there: when we have unsorted array values in
> SOAP, the query takes longer than
> when it has a sorted array. I'll double-check it just in case and write
> about the results later.
I would expect the B-Tree preprocessing by _bt_preprocess_array_keys()
to be very slightly faster when the query is written with presorted,
duplicate-free constants. Sorting is faster when you don't really have
to sort. However, I would not expect the effect to be significant
enough to matter, except perhaps in very extreme cases.
Although...some of the cases you care about are very extreme cases.
> I am also testing some experience with multi-column indexes using SAOPs.
Have you thought about a similar transformation for when the row
constructor syntax happens to have been used?
Consider a query like the following, against a table with a composite
index on (a, b):
select * from multi_test where ( a, b ) in (( 1, 1 ), ( 2, 1 ));
This query will get a BitmapOr based plan that's similar to the plans
that OR-based queries affected by your transformation patch get today,
on HEAD. However, this equivalent spelling has the potential to be
significantly faster:
select * from multi_test where a = any('{1,2}') and b = 1;
(Of course, this is more likely to be true with my nbtree SAOP patch in place.)
Note that we currently won't use RowCompareExpr in many simple cases
where the row constructor syntax has been used. For example, a query
like this:
select * from multi_test where ( a, b ) = (( 2, 1 ));
This case already involves a transformation that is roughly comparable
to the one you're working on now. We'll remove the RowCompareExpr
during parsing. It'll be as if my example row constructor equality
query was written this way instead:
select * from multi_test where a = 2 and b = 1;
This can be surprisingly important, when combined with other things,
in more realistic examples.
The nbtree code has special knowledge of RowCompareExpr that makes the
rules for comparing index tuples different to those from other kinds
of index scans. However, due to the RowCompareExpr transformation
process I just described, we don't need to rely on that specialized
nbtree code when the row constructor syntax is used with a simple
equality clause -- which is what makes the normalization process have
real value. If the nbtree code cannot see RowCompareExpr index quals
then it cannot have this problem in the first place. In general it is
useful to "normalize to conjunctive normal form" when it might allow
scan key preprocessing in the nbtree code to come up with a much
faster approach to executing the scan.
It's easier to understand what I mean by showing a simple example. The
nbtree preprocessing code is smart enough to recognize that the
following query doesn't really need to do any work, due to having
quals that it recognizes as contradictory (it can set so->qual_okay to
false for unsatisfiable quals):
select * from multi_test where ( a, b ) = (( 2, 1 )) and a = -1;
However, it is not smart enough to perform the same trick if we change
one small detail with the query:
select * from multi_test where ( a, b ) >= (( 2, 1 )) and a = -1;
Ideally, the optimizer would canonicalize/normalize everything in a
way that made all of the nbtree preprocessing optimizations work just
as well, without introducing any new special cases. Obviously, there
is no reason why we can't perform the same trick with the second
variant. (Note also that the nbtree preprocessing code can be smart
about redundant quals, not just contradictory quals, so it matters
more than it may appear from this simple, unrealistic example of
mine.)
While these similar RowCompareExpr transformations are at least
somewhat important, that's not really why I bring them up now. I am
pointing them out now because I think that it might help you to
develop a more complete mental model of these transformations.
Ideally, your initial approach will generalize to other situations
later on. So it's worth considering the relationship between this
existing RowCompareExpr transformation, and the one that you're
working on currently. Plus other, future transformations.
This example might also give you some appreciation of why my SAOP
patch is confused about when we need to do normalization/safety
checks. Some things seem necessary when generating index paths in the
optimizer. Other things seem necessary during preprocessing, in the
nbtree code, at the start of the index scan. Unfortunately, it's not
obvious to me where the right place is to deal with each aspect of
setting up multi-column SAOP index quals. My mental model is very
incomplete.
--
Peter Geoghegan
Peter, I'm very glad to hear that you're researching this!
Will this include skip-scan optimizations for OR or IN predicates, or when the number of distinct values in a leading
non-constantindex column(s) is sufficiently small? e.g. suppose there is an ORDER BY b, and WHERE clause predicates (a
=1 AND b = 5) OR (c > 12 AND b BETWEEN 100 AND 200). Then a single index scan on an index with leading column b could
visitb = 5, and then the range b from 100:200, and deliver the rows in the order requested. Or if the predicate is (a
=1 AND b = 5) OR (c LIKE 'XYZ' AND b < 12), then you can scan just b < 12. Or if the index is defined on (a, b) and
youknow that b = 100, and that there are only 4 distinct values of column a, then you could skip each distinct value of
awhere b = 100, and so on.
If you have an ORDER BY clause and a lower and upper bound on the first column of the ORDER BY list, you have a
potentialto reduce search effort versus a full index scan, even when that upper and lower bound needs to be derived
froma complex predicate.
Of course, if you have an IN list you can either skip to the distinct values listed or scan the entire index, depending
onestimated cost.
/Jim F
On 8/1/23, 3:43 PM, "Peter Geoghegan" <pg@bowt.ie <mailto:pg@bowt.ie>> wrote:
CAUTION: This email originated from outside of the organization. Do not click links or open attachments unless you can
confirmthe sender and know the content is safe.
On Mon, Jul 31, 2023 at 9:38 AM Alena Rybakina <lena.ribackina@yandex.ru <mailto:lena.ribackina@yandex.ru>> wrote:
> I noticed only one thing there: when we have unsorted array values in
> SOAP, the query takes longer than
> when it has a sorted array. I'll double-check it just in case and write
> about the results later.
I would expect the B-Tree preprocessing by _bt_preprocess_array_keys()
to be very slightly faster when the query is written with presorted,
duplicate-free constants. Sorting is faster when you don't really have
to sort. However, I would not expect the effect to be significant
enough to matter, except perhaps in very extreme cases.
Although...some of the cases you care about are very extreme cases.
> I am also testing some experience with multi-column indexes using SAOPs.
Have you thought about a similar transformation for when the row
constructor syntax happens to have been used?
Consider a query like the following, against a table with a composite
index on (a, b):
select * from multi_test where ( a, b ) in (( 1, 1 ), ( 2, 1 ));
This query will get a BitmapOr based plan that's similar to the plans
that OR-based queries affected by your transformation patch get today,
on HEAD. However, this equivalent spelling has the potential to be
significantly faster:
select * from multi_test where a = any('{1,2}') and b = 1;
(Of course, this is more likely to be true with my nbtree SAOP patch in place.)
Note that we currently won't use RowCompareExpr in many simple cases
where the row constructor syntax has been used. For example, a query
like this:
select * from multi_test where ( a, b ) = (( 2, 1 ));
This case already involves a transformation that is roughly comparable
to the one you're working on now. We'll remove the RowCompareExpr
during parsing. It'll be as if my example row constructor equality
query was written this way instead:
select * from multi_test where a = 2 and b = 1;
This can be surprisingly important, when combined with other things,
in more realistic examples.
The nbtree code has special knowledge of RowCompareExpr that makes the
rules for comparing index tuples different to those from other kinds
of index scans. However, due to the RowCompareExpr transformation
process I just described, we don't need to rely on that specialized
nbtree code when the row constructor syntax is used with a simple
equality clause -- which is what makes the normalization process have
real value. If the nbtree code cannot see RowCompareExpr index quals
then it cannot have this problem in the first place. In general it is
useful to "normalize to conjunctive normal form" when it might allow
scan key preprocessing in the nbtree code to come up with a much
faster approach to executing the scan.
It's easier to understand what I mean by showing a simple example. The
nbtree preprocessing code is smart enough to recognize that the
following query doesn't really need to do any work, due to having
quals that it recognizes as contradictory (it can set so->qual_okay to
false for unsatisfiable quals):
select * from multi_test where ( a, b ) = (( 2, 1 )) and a = -1;
However, it is not smart enough to perform the same trick if we change
one small detail with the query:
select * from multi_test where ( a, b ) >= (( 2, 1 )) and a = -1;
Ideally, the optimizer would canonicalize/normalize everything in a
way that made all of the nbtree preprocessing optimizations work just
as well, without introducing any new special cases. Obviously, there
is no reason why we can't perform the same trick with the second
variant. (Note also that the nbtree preprocessing code can be smart
about redundant quals, not just contradictory quals, so it matters
more than it may appear from this simple, unrealistic example of
mine.)
While these similar RowCompareExpr transformations are at least
somewhat important, that's not really why I bring them up now. I am
pointing them out now because I think that it might help you to
develop a more complete mental model of these transformations.
Ideally, your initial approach will generalize to other situations
later on. So it's worth considering the relationship between this
existing RowCompareExpr transformation, and the one that you're
working on currently. Plus other, future transformations.
This example might also give you some appreciation of why my SAOP
patch is confused about when we need to do normalization/safety
checks. Some things seem necessary when generating index paths in the
optimizer. Other things seem necessary during preprocessing, in the
nbtree code, at the start of the index scan. Unfortunately, it's not
obvious to me where the right place is to deal with each aspect of
setting up multi-column SAOP index quals. My mental model is very
incomplete.
--
Peter Geoghegan
Jim, On Tue, Aug 1, 2023 at 1:11 PM Finnerty, Jim <jfinnert@amazon.com> wrote: > Peter, I'm very glad to hear that you're researching this! Glad to hear it! > Will this include skip-scan optimizations for OR or IN predicates, or when the number of distinct values in a leading non-constantindex column(s) is sufficiently small? Yes -- though perhaps not in the first iteration. As I go into on the thread associated with my own patch [1], my initial goal is to support efficient execution of multiple IN() lists for multiple columns from the same index, all while preserving index sort order on output, and avoiding a separate duplicate elimination step. Some of the most compelling cases for these MDAM techniques involve GroupAggregates, ORDER BY ... LIMIT, and DISTINCT -- I understand the importance of making the index scan appear to be a conventional index scan to the optimizer. > If you have an ORDER BY clause and a lower and upper bound on the first column of the ORDER BY list, you have a potentialto reduce search effort versus a full index scan, even when that upper and lower bound needs to be derived froma complex predicate. It sounds like your example is an attempt to ascertain whether or not my design considers the need to convert complicated predicates into disjuncts that can be executed as if by one single index scan, via CNF -> DNF transformations/preprocessing. That is certainly the plan, at least medium term -- I fully expect to be able to combine all of these techniques together, in ways that continue to work even with very complicated predicates. Like the really hairy example from the MDAM paper, or like your example. There are already some nbtree scan key preprocessing steps a little like the ones considered by the MDAM paper. These steps eliminate redundant and contradictory quals -- but they weren't specifically written with the very general MDAM DNF design requirements in mind. Plus there are already at least some transformations like the one that Alena is working on in the patch discussed on this thread -- these were also not written with MDAM stuff in mind. A major goal of mine for this project in the short term is to come up with a very general design. I must reconcile all this stuff, somehow or other, so that these very complicated cases will work just as well as simpler and more obvious cases. I really hate special cases. > Of course, if you have an IN list you can either skip to the distinct values listed or scan the entire index, dependingon estimated cost. Actually, I think that it should be possible to decide on how to skip dynamically, without needing an up-front decision around skipping from the optimizer. In other words, the scans can skip using an adaptive strategy. This is feasible provided I can make the overhead of a dynamic/adaptive approach negligible. When it turns out that a full index scan is appropriate, we'll just end up doing it that way at runtime. Nothing stops a given scan from needing to do skip a great deal in the first half of an index, while scanning everything in the second half of the index. Obviously, a static choice won't do well there, since it works at the level of the whole scan/index, which seems like the wrong framing to me. (Of course we'll still need to model skipping stuff in the planner -- just not so that we can decide between two index paths that are essentially identical, that should just be one index path.) [1] https://postgr.es/m/CAH2-Wz=ksvN_sjcnD1+Bt-WtifRA5ok48aDYnq3pkKhxgMQpcw@mail.gmail.com -- Peter Geoghegan
I fixed an error that caused the current optimization not to work with
prepared queries. I added a test to catch similar cases in the future.
I have attached a patch.
On 01.08.2023 22:42, Peter Geoghegan wrote:
> On Mon, Jul 31, 2023 at 9:38 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote:
>> I noticed only one thing there: when we have unsorted array values in
>> SOAP, the query takes longer than
>> when it has a sorted array. I'll double-check it just in case and write
>> about the results later.
> I would expect the B-Tree preprocessing by _bt_preprocess_array_keys()
> to be very slightly faster when the query is written with presorted,
> duplicate-free constants. Sorting is faster when you don't really have
> to sort. However, I would not expect the effect to be significant
> enough to matter, except perhaps in very extreme cases.
> Although...some of the cases you care about are very extreme cases.
I tested an optimization to compare execution time and scheduling with
sorting, shuffling, and reverse sorting constants in the simple case and
I didn't notice any significant changes (compare_sorted.png).
(I used a database with 100 million values generated by pgbench).
>> I am also testing some experience with multi-column indexes using SAOPs.
> Have you thought about a similar transformation for when the row
> constructor syntax happens to have been used?
>
> Consider a query like the following, against a table with a composite
> index on (a, b):
>
> select * from multi_test where ( a, b ) in (( 1, 1 ), ( 2, 1 ));
>
> This query will get a BitmapOr based plan that's similar to the plans
> that OR-based queries affected by your transformation patch get today,
> on HEAD. However, this equivalent spelling has the potential to be
> significantly faster:
>
> select * from multi_test where a = any('{1,2}') and b = 1;
>
> (Of course, this is more likely to be true with my nbtree SAOP patch in place.)
No, I haven't thought about it yet. I studied the example and it would
really be nice to add optimization here. I didn't notice any problems
with its implementation. I also have an obvious example with the "or"
operator, for example
, select * from multi_test, where (a, b ) = ( 1, 1 ) or (a, b ) = ( 2, 1
) ...;
Although I think such a case will be used less often.
Thank you for the example, I think I understand better why our patches
help each other, but I will review your patch again.
I tried another example to see the lack of optimization in the pgbench
database, but I also created an additional index:
create index ind1 on pgbench_accounts(aid,bid);
test_db=# explain analyze select * from pgbench_accounts where (aid,
bid) in ((2,1), (2,2), (2,3), (3,3));
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on pgbench_accounts (cost=17.73..33.66 rows=1
width=97) (actual time=0.125..0.133 rows=1 loops=1)
Recheck Cond: ((aid = 2) OR (aid = 2) OR (aid = 2) OR (aid = 3))
Filter: (((aid = 2) AND (bid = 1)) OR ((aid = 2) AND (bid = 2)) OR
((aid = 2) AND (bid = 3)) OR ((aid = 3) AND (bid = 3)))
Rows Removed by Filter: 1
Heap Blocks: exact=1
-> BitmapOr (cost=17.73..17.73 rows=4 width=0) (actual
time=0.100..0.102 rows=0 loops=1)
-> Bitmap Index Scan on pgbench_accounts_pkey
(cost=0.00..4.43 rows=1 width=0) (actual time=0.036..0.037 rows=1 loops=1)
Index Cond: (aid = 2)
-> Bitmap Index Scan on pgbench_accounts_pkey
(cost=0.00..4.43 rows=1 width=0) (actual time=0.021..0.022 rows=1 loops=1)
Index Cond: (aid = 2)
-> Bitmap Index Scan on pgbench_accounts_pkey
(cost=0.00..4.43 rows=1 width=0) (actual time=0.021..0.021 rows=1 loops=1)
Index Cond: (aid = 2)
-> Bitmap Index Scan on pgbench_accounts_pkey
(cost=0.00..4.43 rows=1 width=0) (actual time=0.019..0.020 rows=1 loops=1)
Index Cond: (aid = 3)
Planning Time: 0.625 ms
Execution Time: 0.227 ms
(16 rows)
I think such optimization would be useful here: aid =2 and bid in (1,2)
or (aid,bid)=((3,3))
> Note that we currently won't use RowCompareExpr in many simple cases
> where the row constructor syntax has been used. For example, a query
> like this:
>
> select * from multi_test where ( a, b ) = (( 2, 1 ));
>
> This case already involves a transformation that is roughly comparable
> to the one you're working on now. We'll remove the RowCompareExpr
> during parsing. It'll be as if my example row constructor equality
> query was written this way instead:
>
> select * from multi_test where a = 2 and b = 1;
>
> This can be surprisingly important, when combined with other things,
> in more realistic examples.
>
> The nbtree code has special knowledge of RowCompareExpr that makes the
> rules for comparing index tuples different to those from other kinds
> of index scans. However, due to the RowCompareExpr transformation
> process I just described, we don't need to rely on that specialized
> nbtree code when the row constructor syntax is used with a simple
> equality clause -- which is what makes the normalization process have
> real value. If the nbtree code cannot see RowCompareExpr index quals
> then it cannot have this problem in the first place. In general it is
> useful to "normalize to conjunctive normal form" when it might allow
> scan key preprocessing in the nbtree code to come up with a much
> faster approach to executing the scan.
>
> It's easier to understand what I mean by showing a simple example. The
> nbtree preprocessing code is smart enough to recognize that the
> following query doesn't really need to do any work, due to having
> quals that it recognizes as contradictory (it can set so->qual_okay to
> false for unsatisfiable quals):
>
> select * from multi_test where ( a, b ) = (( 2, 1 )) and a = -1;
>
> However, it is not smart enough to perform the same trick if we change
> one small detail with the query:
>
> select * from multi_test where ( a, b ) >= (( 2, 1 )) and a = -1;
Yes, I have run the examples and I see it.
((ROW(aid, bid) >= ROW(2, 1)) AND (aid = '-1'::integer))
As I see it, we can implement such a transformation:
'( a, b ) >= (( 2, 1 )) and a = -1' -> 'aid >= 2 and bid >= 1 and
aid =-1'
It seems to me the most difficult thing is to notice problematic cases
where the transformations are incorrect, but I think it can be implemented.
> Ideally, the optimizer would canonicalize/normalize everything in a
> way that made all of the nbtree preprocessing optimizations work just
> as well, without introducing any new special cases. Obviously, there
> is no reason why we can't perform the same trick with the second
> variant. (Note also that the nbtree preprocessing code can be smart
> about redundant quals, not just contradictory quals, so it matters
> more than it may appear from this simple, unrealistic example of
> mine.)
I agree with your position, but I still don't understand how to consider
transformations to generalized cases without relying on special cases.
As I understand it, you assume that it is possible to apply
transformations at the index creation stage, but there I came across the
selectivity overestimation problem.
I still haven't found a solution for this problem.
> While these similar RowCompareExpr transformations are at least
> somewhat important, that's not really why I bring them up now. I am
> pointing them out now because I think that it might help you to
> develop a more complete mental model of these transformations.
> Ideally, your initial approach will generalize to other situations
> later on. So it's worth considering the relationship between this
> existing RowCompareExpr transformation, and the one that you're
> working on currently. Plus other, future transformations.
I will consider my case more broadly, but for this I will need some
research work.
> This example might also give you some appreciation of why my SAOP
> patch is confused about when we need to do normalization/safety
> checks. Some things seem necessary when generating index paths in the
> optimizer. Other things seem necessary during preprocessing, in the
> nbtree code, at the start of the index scan. Unfortunately, it's not
> obvious to me where the right place is to deal with each aspect of
> setting up multi-column SAOP index quals. My mental model is very
> incomplete.
To be honest, I think that in your examples I understand better what you
mean by normalization to the conjunctive norm, because I only had a
theoretical idea from the logic course.
Hence, yes, normalization/security checks - now I understand why they
are necessary.
--
Regards,
Alena Rybakina
Postgres Professional
Attachment
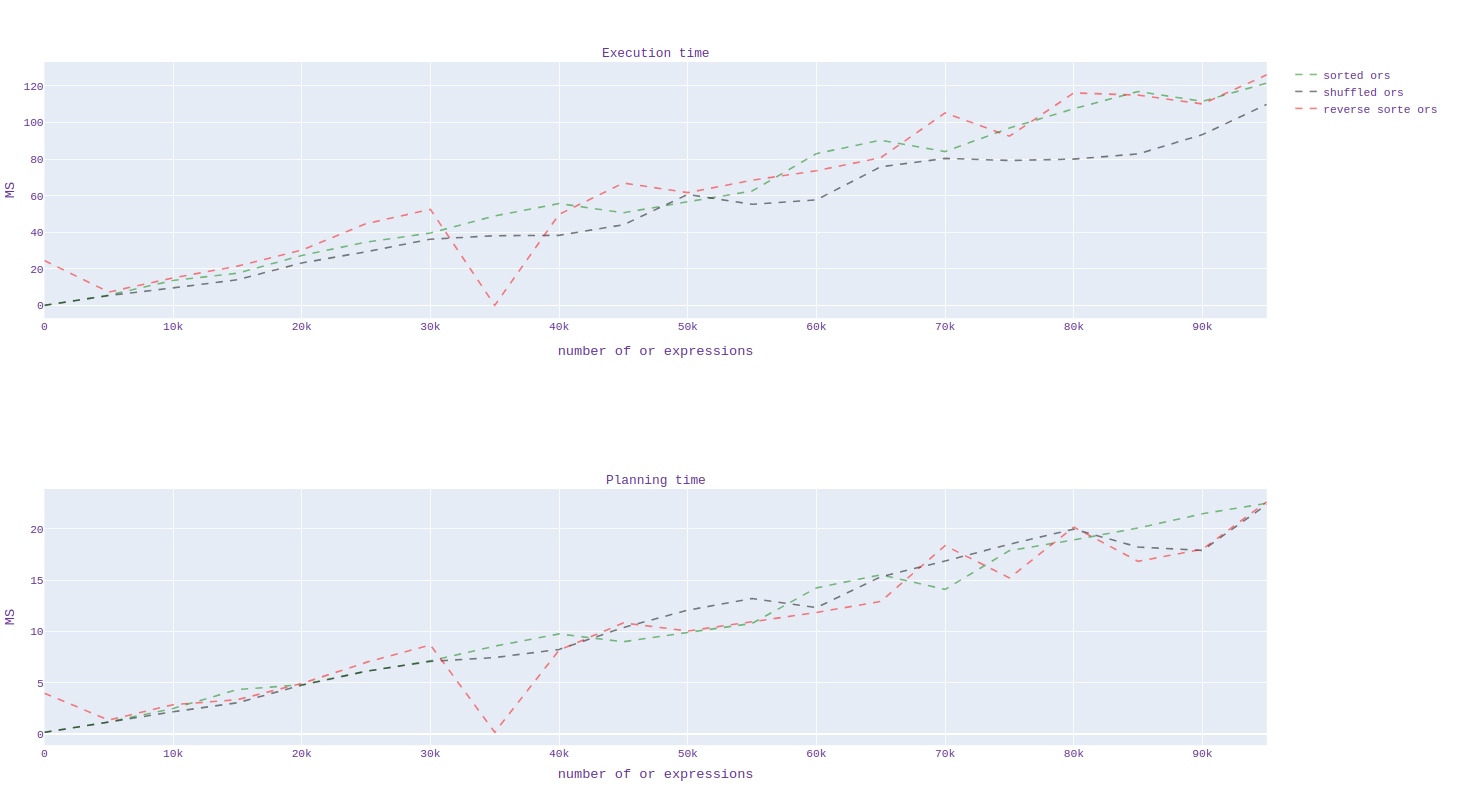{kind=link}
On Wed, Aug 2, 2023 at 8:58 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote: > No, I haven't thought about it yet. I studied the example and it would > really be nice to add optimization here. I didn't notice any problems > with its implementation. I also have an obvious example with the "or" > operator, for example > , select * from multi_test, where (a, b ) = ( 1, 1 ) or (a, b ) = ( 2, 1 > ) ...; > > Although I think such a case will be used less often. Right. As I said, I don't particularly care about the row constructor syntax -- it's not essential. In my experience patches like this one that ultimately don't succeed usually *don't* have specific problems that cannot be fixed. The real problem tends to be ambiguity about the general high level design. So more than anything else, ambiguity is the thing that you need to minimize to be successful here. This is the #1 practical problem, by far. This may be the only thing about your patch that I feel 100% sure of. In my experience it can actually be easier to expand the scope of a project, and to come up with a more general solution: https://en.wikipedia.org/wiki/Inventor%27s_paradox I'm not trying to make your work more difficult by expanding its scope. I'm actually trying to make your work *easier* by expanding its scope. I don't claim to know what the specific scope of your patch should be at all. Just that it might be possible to get a much clearer picture of what the ideal scope really is by *trying* to generalize it further -- that understanding is what we lack right now. Even if this exercise fails in some way, it won't really have been a failure. The reasons why it fails will still be interesting and practically relevant. > It seems to me the most difficult thing is to notice problematic cases > where the transformations are incorrect, but I think it can be implemented. Right. To be clear, I am sure that it won't be practical to come up with a 100% theoretically pure approach. If for no other reason than this: normalizing to CNF in all cases will run into problems with very complex predicates. It might even be computationally intractable (could just be very slow). So there is a clear need to keep theoretical purity in balance with practical considerations. There is a need for some kind of negotiation between those two things. Probably some set of heuristics will ultimately be required to keep costs and benefits in balance. > I agree with your position, but I still don't understand how to consider > transformations to generalized cases without relying on special cases. Me neither. I wish I could say something a bit less vague here. I don't expect you to determine what set of heuristics will ultimately be required to determine when and how to perform CNF conversions, in the general case. But having at least some vague idea seems like it might increase confidence in your design. > As I understand it, you assume that it is possible to apply > transformations at the index creation stage, but there I came across the > selectivity overestimation problem. > > I still haven't found a solution for this problem. Do you think that this problem is just an accidental side-effect? It isn't necessarily the responsibility of your patch to fix such things. If it's even possible for selectivity estimates to change, then it's already certain that sometimes they'll be worse than before -- if only because of chance interactions. The optimizer is often right for the wrong reasons, and wrong for the right reasons -- we cannot really expect any patch to completely avoid problems like that. > To be honest, I think that in your examples I understand better what you > mean by normalization to the conjunctive norm, because I only had a > theoretical idea from the logic course. > > Hence, yes, normalization/security checks - now I understand why they > are necessary. As I explained to Jim, I am trying to put things in this area on a more rigorous footing. For example, I have said that the way that the nbtree code executes SAOP quals is equivalent to DNF. That is basically true, but it's also my own slightly optimistic interpretation of history and of the design. That's a good start, but it's not enough on its own. My interpretation might still be wrong in some subtle way, that I have yet to discover. That's really what I'm concerned about with your patch, too. I'm currently trying to solve a problem that I don't yet fully understand, so for me "getting a properly working flow of information" seems like a good practical exercise. I'm trying to generalize the design of my own patch as far as I can, to see what breaks, and why it breaks. My intuition is that this will help me with my own patch by forcing me to gain a truly rigorous understanding of the problem. My suggestion about generalizing your approach to cover RowCompareExpr cases is what I would do, if I were you, and this was my patch. That's almost exactly what I'm doing with my own patch already, in fact. -- Peter Geoghegan
On 02.08.2023 21:58, Peter Geoghegan wrote: > On Wed, Aug 2, 2023 at 8:58 AM Alena Rybakina <lena.ribackina@yandex.ru> wrote: >> No, I haven't thought about it yet. I studied the example and it would >> really be nice to add optimization here. I didn't notice any problems >> with its implementation. I also have an obvious example with the "or" >> operator, for example >> , select * from multi_test, where (a, b ) = ( 1, 1 ) or (a, b ) = ( 2, 1 >> ) ...; >> >> Although I think such a case will be used less often. > Right. As I said, I don't particularly care about the row constructor > syntax -- it's not essential. > > In my experience patches like this one that ultimately don't succeed > usually *don't* have specific problems that cannot be fixed. The real > problem tends to be ambiguity about the general high level design. So > more than anything else, ambiguity is the thing that you need to > minimize to be successful here. This is the #1 practical problem, by > far. This may be the only thing about your patch that I feel 100% sure > of. > > In my experience it can actually be easier to expand the scope of a > project, and to come up with a more general solution: > > https://en.wikipedia.org/wiki/Inventor%27s_paradox > > I'm not trying to make your work more difficult by expanding its > scope. I'm actually trying to make your work *easier* by expanding its > scope. I don't claim to know what the specific scope of your patch > should be at all. Just that it might be possible to get a much clearer > picture of what the ideal scope really is by *trying* to generalize it > further -- that understanding is what we lack right now. Even if this > exercise fails in some way, it won't really have been a failure. The > reasons why it fails will still be interesting and practically > relevant. > > As I explained to Jim, I am trying to put things in this area on a > more rigorous footing. For example, I have said that the way that the > nbtree code executes SAOP quals is equivalent to DNF. That is > basically true, but it's also my own slightly optimistic > interpretation of history and of the design. That's a good start, but > it's not enough on its own. > > My interpretation might still be wrong in some subtle way, that I have > yet to discover. That's really what I'm concerned about with your > patch, too. I'm currently trying to solve a problem that I don't yet > fully understand, so for me "getting a properly working flow of > information" seems like a good practical exercise. I'm trying to > generalize the design of my own patch as far as I can, to see what > breaks, and why it breaks. My intuition is that this will help me with > my own patch by forcing me to gain a truly rigorous understanding of > the problem. > > My suggestion about generalizing your approach to cover RowCompareExpr > cases is what I would do, if I were you, and this was my patch. That's > almost exactly what I'm doing with my own patch already, in fact. It's all right. I understand your position) I also agree to try to find other optimization cases and generalize them. I read the wiki article, and as I understand it, in such a situation we see a difficult problem with finding expressions that need to be converted into a logically correct expression and simplify execution for the executor. For example, this is a ROW type. It can have a simpler expression with AND and OR operations, besides we can exclude duplicates. But some of these transformations may be incorrect or they will have a more complex representation. We can try to find the problematic expressions and try to combine them into groups and finally find a solutions for each groups or, conversely, discover that the existing transformation is uncorrected. If I understand correctly, we should first start searching for "ROW" expressions (define a group for them) and think about a solution for the group. >> It seems to me the most difficult thing is to notice problematic cases >> where the transformations are incorrect, but I think it can be implemented. > Right. To be clear, I am sure that it won't be practical to come up > with a 100% theoretically pure approach. If for no other reason than > this: normalizing to CNF in all cases will run into problems with very > complex predicates. It might even be computationally intractable > (could just be very slow). So there is a clear need to keep > theoretical purity in balance with practical considerations. There is > a need for some kind of negotiation between those two things. Probably > some set of heuristics will ultimately be required to keep costs and > benefits in balance. > > I don't expect you to determine what set of heuristics will ultimately > be required to determine when and how to perform CNF conversions, in > the general case. But having at least some vague idea seems like it > might increase confidence in your design. I agree, but I think this will be the second step after solutions are found. > Do you think that this problem is just an accidental side-effect? It > isn't necessarily the responsibility of your patch to fix such things. > If it's even possible for selectivity estimates to change, then it's > already certain that sometimes they'll be worse than before -- if only > because of chance interactions. The optimizer is often right for the > wrong reasons, and wrong for the right reasons -- we cannot really > expect any patch to completely avoid problems like that. To be honest, I tried to fix it many times by calling the function to calculate selectivity, and each time the result of the estimate did not change. I didn't have any problems in this part after moving the transformation to the parsing stage. I even tried to perform this transformation at the planning stage (to the preprocess_qual_conditions function), but I ran into the same problem there as well. To tell the truth, I think I'm ready to investigate this problem again (maybe I'll be able to see it differently or really find that I missed something in previous times). -- Regards, Alena Rybakina Postgres Professional
On Thu, Aug 3, 2023 at 12:47 PM Alena Rybakina <lena.ribackina@yandex.ru> wrote: > It's all right. I understand your position) Okay, good to know. :-) > I also agree to try to find other optimization cases and generalize them. Good idea. Since the real goal is to "get a working flow of information", the practical value of trying to get it working with other clauses seems to be of secondary importance. > To be honest, I tried to fix it many times by calling the function to > calculate selectivity, and each time the result of the estimate did not > change. I didn't have any problems in this part after moving the > transformation to the parsing stage. I even tried to perform this > transformation at the planning stage (to the preprocess_qual_conditions > function), but I ran into the same problem there as well. > > To tell the truth, I think I'm ready to investigate this problem again > (maybe I'll be able to see it differently or really find that I missed > something in previous times). The optimizer will itself do a limited form of "normalizing to CNF". Are you familiar with extract_restriction_or_clauses(), from orclauses.c? Comments above the function have an example of how this can work: * Although a join clause must reference multiple relations overall, * an OR of ANDs clause might contain sub-clauses that reference just one * relation and can be used to build a restriction clause for that rel. * For example consider * WHERE ((a.x = 42 AND b.y = 43) OR (a.x = 44 AND b.z = 45)); * We can transform this into * WHERE ((a.x = 42 AND b.y = 43) OR (a.x = 44 AND b.z = 45)) * AND (a.x = 42 OR a.x = 44) * AND (b.y = 43 OR b.z = 45); * which allows the latter clauses to be applied during the scans of a and b, * perhaps as index qualifications, and in any case reducing the number of * rows arriving at the join. In essence this is a partial transformation to * CNF (AND of ORs format). It is not complete, however, because we do not * unravel the original OR --- doing so would usually bloat the qualification * expression to little gain. Of course this immediately makes me wonder: shouldn't your patch be able to perform an additional transformation here? You know, by transforming "a.x = 42 OR a.x = 44" into "a IN (42, 44)"? Although I haven't checked for myself, I assume that this doesn't happen right now, since your patch currently performs all of its transformations during parsing. I also noticed that the same comment block goes on to say something about "clauselist_selectivity's inability to recognize redundant conditions". Perhaps that is relevant to the problems you were having with selectivity estimation, back when the code was in preprocess_qual_conditions() instead? I have no reason to believe that there should be any redundancy left behind by your transformation, so this is just one possibility to consider. Separately, the commit message of commit 25a9e54d2d says something about how the planner builds RestrictInfos, which seems possibly-relevant. That commit enhanced extended statistics for OR clauses, so the relevant paragraph describes a limitation of extended statistics with OR clauses specifically. I'm just guessing, but it still seems like it might be relevant to the problem you ran into with selectivity estimation. Another possibility to consider. BTW, I sometimes use RR to help improve my understanding of the planner: https://wiki.postgresql.org/wiki/Getting_a_stack_trace_of_a_running_PostgreSQL_backend_on_Linux/BSD#Recording_Postgres_using_rr_Record_and_Replay_Framework The planner has particularly complicated control flow, which has unique challenges -- just knowing where to begin can be difficult (unlike most other areas). I find that setting watchpoints to see when and where the planner modifies state using RR is far more useful than it would be with regular GDB. Once I record a query, I find that I can "map out" what happens in the planner relatively easily. -- Peter Geoghegan
On Sat, Aug 5, 2023 at 7:01 PM Peter Geoghegan <pg@bowt.ie> wrote: > Of course this immediately makes me wonder: shouldn't your patch be > able to perform an additional transformation here? You know, by > transforming "a.x = 42 OR a.x = 44" into "a IN (42, 44)"? Although I > haven't checked for myself, I assume that this doesn't happen right > now, since your patch currently performs all of its transformations > during parsing. Many interesting cases won't get SAOP transformation from the patch, simply because of the or_transform_limit GUC's default of 500. I don't think that that design makes too much sense. It made more sense back when the focus was on expression evaluation overhead. But that's only one of the benefits that we now expect from the patch, right? So it seems like something that should be revisited soon. I'm not suggesting that there is no need for some kind of limit. But it seems like a set of heuristics might be a better approach. Although I would like to get a better sense of the costs of the transformation to be able to say too much more. -- Peter Geoghegan
Hi! Thank you for your research, I'm sure it will help me to fix the problem of calculating selectivity faster) I'm sorry I didn't answer right away, to be honest, I had a full diary of urgent matters at work. For this reason, I didn't have enough time to work on this patch properly. > The optimizer will itself do a limited form of "normalizing to CNF". > Are you familiar with extract_restriction_or_clauses(), from > orclauses.c? Comments above the function have an example of how this > can work: > > * Although a join clause must reference multiple relations overall, > * an OR of ANDs clause might contain sub-clauses that reference just one > * relation and can be used to build a restriction clause for that rel. > * For example consider > * WHERE ((a.x = 42 AND b.y = 43) OR (a.x = 44 AND b.z = 45)); > * We can transform this into > * WHERE ((a.x = 42 AND b.y = 43) OR (a.x = 44 AND b.z = 45)) > * AND (a.x = 42 OR a.x = 44) > * AND (b.y = 43 OR b.z = 45); > * which allows the latter clauses to be applied during the scans of a and b, > * perhaps as index qualifications, and in any case reducing the number of > * rows arriving at the join. In essence this is a partial transformation to > * CNF (AND of ORs format). It is not complete, however, because we do not > * unravel the original OR --- doing so would usually bloat the qualification > * expression to little gain. This is an interesting feature. I didn't notice this function before, I studied many times consider_new_or_cause, which were called there. As far as I know, there is a selectivity calculation going on there, but as far as I remember, I called it earlier after my conversion, and unfortunately it didn't solve my problem with calculating selectivity. I'll reconsider it again, maybe I can find something I missed. > Of course this immediately makes me wonder: shouldn't your patch be > able to perform an additional transformation here? You know, by > transforming "a.x = 42 OR a.x = 44" into "a IN (42, 44)"? Although I > haven't checked for myself, I assume that this doesn't happen right > now, since your patch currently performs all of its transformations > during parsing. > > I also noticed that the same comment block goes on to say something > about "clauselist_selectivity's inability to recognize redundant > conditions". Perhaps that is relevant to the problems you were having > with selectivity estimation, back when the code was in > preprocess_qual_conditions() instead? I have no reason to believe that > there should be any redundancy left behind by your transformation, so > this is just one possibility to consider. > Separately, the commit message of commit 25a9e54d2d says something > about how the planner builds RestrictInfos, which seems > possibly-relevant. That commit enhanced extended statistics for OR > clauses, so the relevant paragraph describes a limitation of extended > statistics with OR clauses specifically. I'm just guessing, but it > still seems like it might be relevant to the problem you ran into with > selectivity estimation. Another possibility to consider. I understood what is said about AND clauses in this comment. It seems to me that AND clauses saved like (BoolExpr *) expr->args->(RestrictInfo *) clauseA->(RestrictInfo *)clauseB lists and OR clauses saved like (BoolExpr *) expr -> orclause->(RestrictInfo *)clause A->(RestrictInfo *)clause B. As I understand it, selectivity is calculated for each expression. But I'll exploring it deeper, because I think this place may contain the answer to the question, what's wrong with selectivity calculation in my patch. > BTW, I sometimes use RR to help improve my understanding of the planner: > > https://wiki.postgresql.org/wiki/Getting_a_stack_trace_of_a_running_PostgreSQL_backend_on_Linux/BSD#Recording_Postgres_using_rr_Record_and_Replay_Framework > The planner has particularly complicated control flow, which has > unique challenges -- just knowing where to begin can be difficult > (unlike most other areas). I find that setting watchpoints to see when > and where the planner modifies state using RR is far more useful than > it would be with regular GDB. Once I record a query, I find that I can > "map out" what happens in the planner relatively easily. Thank you for sharing this source! I didn't know about this before, and it will definitely make my life easier to understand the optimizer. I understand what you mean, and I researched the optimizer in a similar way through gdb and looked at the comments and code in postgresql. This is a complicated way and I didn't always understand correctly what this variable was doing in this place, and this created some difficulties for me. So, thank you for the link! > Many interesting cases won't get SAOP transformation from the patch, > simply because of the or_transform_limit GUC's default of 500. I don't > think that that design makes too much sense. It made more sense back > when the focus was on expression evaluation overhead. But that's only > one of the benefits that we now expect from the patch, right? So it > seems like something that should be revisited soon. > > I'm not suggesting that there is no need for some kind of limit. But > it seems like a set of heuristics might be a better approach. Although > I would like to get a better sense of the costs of the transformation > to be able to say too much more. Yes, this may be revised in the future after some transformations. Initially, I was solving the problem described here [0]. So, after testing [1], I come to the conclusion that 500 is the ideal value for or_transform_limit. [0] https://www.postgresql.org/message-id/919bfbcb-f812-758d-d687-71f89f0d9a68%40postgrespro.ru [1] https://www.postgresql.org/message-id/6b97b517-f36a-f0c6-3b3a-0cf8cfba220c%40yandex.ru -- Regards, Alena Rybakina Postgres Professional
The optimizer will itself do a limited form of "normalizing to CNF".This is an interesting feature. I didn't notice this function before, I studied many times consider_new_or_cause, which were called there. As far as I know, there is a selectivity calculation going on there, but as far as I remember, I called it earlier after my conversion, and unfortunately it didn't solve my problem with calculating selectivity. I'll reconsider it again, maybe I can find something I missed.
Are you familiar with extract_restriction_or_clauses(), from
orclauses.c? Comments above the function have an example of how this
can work:
* Although a join clause must reference multiple relations overall,
* an OR of ANDs clause might contain sub-clauses that reference just one
* relation and can be used to build a restriction clause for that rel.
* For example consider
* WHERE ((a.x = 42 AND b.y = 43) OR (a.x = 44 AND b.z = 45));
* We can transform this into
* WHERE ((a.x = 42 AND b.y = 43) OR (a.x = 44 AND b.z = 45))
* AND (a.x = 42 OR a.x = 44)
* AND (b.y = 43 OR b.z = 45);
* which allows the latter clauses to be applied during the scans of a and b,
* perhaps as index qualifications, and in any case reducing the number of
* rows arriving at the join. In essence this is a partial transformation to
* CNF (AND of ORs format). It is not complete, however, because we do not
* unravel the original OR --- doing so would usually bloat the qualification
* expression to little gain.Of course this immediately makes me wonder: shouldn't your patch be
able to perform an additional transformation here? You know, by
transforming "a.x = 42 OR a.x = 44" into "a IN (42, 44)"? Although I
haven't checked for myself, I assume that this doesn't happen right
now, since your patch currently performs all of its transformations
during parsing.
I also noticed that the same comment block goes on to say something
about "clauselist_selectivity's inability to recognize redundant
conditions". Perhaps that is relevant to the problems you were having
with selectivity estimation, back when the code was in
preprocess_qual_conditions() instead? I have no reason to believe that
there should be any redundancy left behind by your transformation, so
this is just one possibility to consider.
Separately, the commit message of commit 25a9e54d2d says something
about how the planner builds RestrictInfos, which seems
possibly-relevant. That commit enhanced extended statistics for OR
clauses, so the relevant paragraph describes a limitation of extended
statistics with OR clauses specifically. I'm just guessing, but it
still seems like it might be relevant to the problem you ran into with
selectivity estimation. Another possibility to consider.
I understood what is said about AND clauses in this comment. It seems to me that AND clauses saved like (BoolExpr *) expr->args->(RestrictInfo *) clauseA->(RestrictInfo *)clauseB lists and OR clauses saved like (BoolExpr *) expr -> orclause->(RestrictInfo *)clause A->(RestrictInfo *)clause B.
As I understand it, selectivity is calculated for each expression. But I'll exploring it deeper, because I think this place may contain the answer to the question, what's wrong with selectivity calculation in my patch.
I could move transformation in there (extract_restriction_or_clauses) and didn't have any problem with selectivity calculation, besides it also works on the redundant or duplicates stage. So, it looks like:
CREATE TABLE tenk1 (unique1 int, unique2 int, ten int, hundred int); insert into tenk1 SELECT x,x,x,x FROM generate_series(1,50000) as x; CREATE INDEX a_idx1 ON tenk1(unique1); CREATE INDEX a_idx2 ON tenk1(unique2); CREATE INDEX a_hundred ON tenk1(hundred);
explain analyze select * from tenk1 a join tenk1 b on ((a.unique2 = 3 or a.unique2 = 7));
PLAN ------------------------------------------------------------------------------------------------------------------------------ Nested Loop (cost=0.29..2033.62 rows=100000 width=32) (actual time=0.090..60.258 rows=100000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..771.00 rows=50000 width=16) (actual time=0.016..9.747 rows=50000 loops=1) -> Materialize (cost=0.29..12.62 rows=2 width=16) (actual time=0.000..0.000 rows=2 loops=50000) -> Index Scan using a_idx2 on tenk1 a (cost=0.29..12.62 rows=2 width=16) (actual time=0.063..0.068 rows=2 loops=1) Index Cond: (unique2 = ANY (ARRAY[3, 7])) Planning Time: 8.257 ms Execution Time: 64.453 ms (7 rows)
Overall, this was due to incorrectly defined types of elements in the array, and if we had applied the transformation with the definition of the tup operator, we could have avoided such problems (I used make_scalar_array_op and have not yet found an alternative to this).
When I moved the transformation on the index creation stage, it couldn't work properly and as a result I faced the same problem of selectivity calculation. I supposed that the selectivity values are also used there, and not recalculated all over again. perhaps we can solve this by forcibly recalculating the selectivity values, but I foresee other problems there.
explain analyze select * from tenk1 a join tenk1 b on ((a.unique2 = 3 or a.unique2 = 7));
QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=12.58..312942.91 rows=24950000 width=32) (actual time=0.040..47.582 rows=100000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..771.00 rows=50000 width=16) (actual time=0.009..7.039 rows=50000 loops=1) -> Materialize (cost=12.58..298.16 rows=499 width=16) (actual time=0.000..0.000 rows=2 loops=50000) -> Bitmap Heap Scan on tenk1 a (cost=12.58..295.66 rows=499 width=16) (actual time=0.025..0.028 rows=2 loops=1) Recheck Cond: ((unique2 = 3) OR (unique2 = 7)) Heap Blocks: exact=1 -> BitmapOr (cost=12.58..12.58 rows=500 width=0) (actual time=0.023..0.024 rows=0 loops=1) -> Bitmap Index Scan on a_idx2 (cost=0.00..6.17 rows=250 width=0) (actual time=0.019..0.019 rows=1 loops=1) Index Cond: (unique2 = 3) -> Bitmap Index Scan on a_idx2 (cost=0.00..6.17 rows=250 width=0) (actual time=0.003..0.003 rows=1 loops=1) Index Cond: (unique2 = 7) Planning Time: 0.401 ms Execution Time: 51.350 ms (13 rows)
I have attached a diff file so far, but it is very raw and did not pass all regression tests (I attached regression.diff) and even had bad conversion cases (some of the cases did not work at all, in other cases there were no non-converted nodes). But now I see an interesting transformation, which was the most interesting for me.
EXPLAIN (COSTS OFF) SELECT * FROM tenk1 WHERE thousand = 42 AND (tenthous = 1 OR tenthous = 3 OR tenthous = 42); - QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------ - Bitmap Heap Scan on tenk1 - Recheck Cond: (((thousand = 42) AND (tenthous = 1)) OR ((thousand = 42) AND (tenthous = 3)) OR ((thousand = 42) AND (tenthous = 42))) - -> BitmapOr - -> Bitmap Index Scan on tenk1_thous_tenthous - Index Cond: ((thousand = 42) AND (tenthous = 1)) - -> Bitmap Index Scan on tenk1_thous_tenthous - Index Cond: ((thousand = 42) AND (tenthous = 3)) - -> Bitmap Index Scan on tenk1_thous_tenthous - Index Cond: ((thousand = 42) AND (tenthous = 42)) -(9 rows) + QUERY PLAN +------------------------------------------------------------------------ + Index Scan using tenk1_thous_tenthous on tenk1 + Index Cond: ((thousand = 42) AND (tenthous = ANY (ARRAY[1, 3, 42]))) +(2 rows)
Attachment
Sorry, I didn't write correctly enough, about the second second place in the code where the conversion works well enough is the removal of duplicate OR expressions.
I attached patch to learn it in more detail.
Hi, all!The optimizer will itself do a limited form of "normalizing to CNF".This is an interesting feature. I didn't notice this function before, I studied many times consider_new_or_cause, which were called there. As far as I know, there is a selectivity calculation going on there, but as far as I remember, I called it earlier after my conversion, and unfortunately it didn't solve my problem with calculating selectivity. I'll reconsider it again, maybe I can find something I missed.
Are you familiar with extract_restriction_or_clauses(), from
orclauses.c? Comments above the function have an example of how this
can work:
* Although a join clause must reference multiple relations overall,
* an OR of ANDs clause might contain sub-clauses that reference just one
* relation and can be used to build a restriction clause for that rel.
* For example consider
* WHERE ((a.x = 42 AND b.y = 43) OR (a.x = 44 AND b.z = 45));
* We can transform this into
* WHERE ((a.x = 42 AND b.y = 43) OR (a.x = 44 AND b.z = 45))
* AND (a.x = 42 OR a.x = 44)
* AND (b.y = 43 OR b.z = 45);
* which allows the latter clauses to be applied during the scans of a and b,
* perhaps as index qualifications, and in any case reducing the number of
* rows arriving at the join. In essence this is a partial transformation to
* CNF (AND of ORs format). It is not complete, however, because we do not
* unravel the original OR --- doing so would usually bloat the qualification
* expression to little gain.Of course this immediately makes me wonder: shouldn't your patch be
able to perform an additional transformation here? You know, by
transforming "a.x = 42 OR a.x = 44" into "a IN (42, 44)"? Although I
haven't checked for myself, I assume that this doesn't happen right
now, since your patch currently performs all of its transformations
during parsing.
I also noticed that the same comment block goes on to say something
about "clauselist_selectivity's inability to recognize redundant
conditions". Perhaps that is relevant to the problems you were having
with selectivity estimation, back when the code was in
preprocess_qual_conditions() instead? I have no reason to believe that
there should be any redundancy left behind by your transformation, so
this is just one possibility to consider.
Separately, the commit message of commit 25a9e54d2d says something
about how the planner builds RestrictInfos, which seems
possibly-relevant. That commit enhanced extended statistics for OR
clauses, so the relevant paragraph describes a limitation of extended
statistics with OR clauses specifically. I'm just guessing, but it
still seems like it might be relevant to the problem you ran into with
selectivity estimation. Another possibility to consider.
I understood what is said about AND clauses in this comment. It seems to me that AND clauses saved like (BoolExpr *) expr->args->(RestrictInfo *) clauseA->(RestrictInfo *)clauseB lists and OR clauses saved like (BoolExpr *) expr -> orclause->(RestrictInfo *)clause A->(RestrictInfo *)clause B.
As I understand it, selectivity is calculated for each expression. But I'll exploring it deeper, because I think this place may contain the answer to the question, what's wrong with selectivity calculation in my patch.I could move transformation in there (extract_restriction_or_clauses) and didn't have any problem with selectivity calculation, besides it also works on the redundant or duplicates stage. So, it looks like:
CREATE TABLE tenk1 (unique1 int, unique2 int, ten int, hundred int); insert into tenk1 SELECT x,x,x,x FROM generate_series(1,50000) as x; CREATE INDEX a_idx1 ON tenk1(unique1); CREATE INDEX a_idx2 ON tenk1(unique2); CREATE INDEX a_hundred ON tenk1(hundred);
explain analyze select * from tenk1 a join tenk1 b on ((a.unique2 = 3 or a.unique2 = 7));
PLAN ------------------------------------------------------------------------------------------------------------------------------ Nested Loop (cost=0.29..2033.62 rows=100000 width=32) (actual time=0.090..60.258 rows=100000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..771.00 rows=50000 width=16) (actual time=0.016..9.747 rows=50000 loops=1) -> Materialize (cost=0.29..12.62 rows=2 width=16) (actual time=0.000..0.000 rows=2 loops=50000) -> Index Scan using a_idx2 on tenk1 a (cost=0.29..12.62 rows=2 width=16) (actual time=0.063..0.068 rows=2 loops=1) Index Cond: (unique2 = ANY (ARRAY[3, 7])) Planning Time: 8.257 ms Execution Time: 64.453 ms (7 rows)
Overall, this was due to incorrectly defined types of elements in the array, and if we had applied the transformation with the definition of the tup operator, we could have avoided such problems (I used make_scalar_array_op and have not yet found an alternative to this).
When I moved the transformation on the index creation stage, it couldn't work properly and as a result I faced the same problem of selectivity calculation. I supposed that the selectivity values are also used there, and not recalculated all over again. perhaps we can solve this by forcibly recalculating the selectivity values, but I foresee other problems there.
explain analyze select * from tenk1 a join tenk1 b on ((a.unique2 = 3 or a.unique2 = 7));
QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=12.58..312942.91 rows=24950000 width=32) (actual time=0.040..47.582 rows=100000 loops=1) -> Seq Scan on tenk1 b (cost=0.00..771.00 rows=50000 width=16) (actual time=0.009..7.039 rows=50000 loops=1) -> Materialize (cost=12.58..298.16 rows=499 width=16) (actual time=0.000..0.000 rows=2 loops=50000) -> Bitmap Heap Scan on tenk1 a (cost=12.58..295.66 rows=499 width=16) (actual time=0.025..0.028 rows=2 loops=1) Recheck Cond: ((unique2 = 3) OR (unique2 = 7)) Heap Blocks: exact=1 -> BitmapOr (cost=12.58..12.58 rows=500 width=0) (actual time=0.023..0.024 rows=0 loops=1) -> Bitmap Index Scan on a_idx2 (cost=0.00..6.17 rows=250 width=0) (actual time=0.019..0.019 rows=1 loops=1) Index Cond: (unique2 = 3) -> Bitmap Index Scan on a_idx2 (cost=0.00..6.17 rows=250 width=0) (actual time=0.003..0.003 rows=1 loops=1) Index Cond: (unique2 = 7) Planning Time: 0.401 ms Execution Time: 51.350 ms (13 rows)
I have attached a diff file so far, but it is very raw and did not pass all regression tests (I attached regression.diff) and even had bad conversion cases (some of the cases did not work at all, in other cases there were no non-converted nodes). But now I see an interesting transformation, which was the most interesting for me.
EXPLAIN (COSTS OFF) SELECT * FROM tenk1 WHERE thousand = 42 AND (tenthous = 1 OR tenthous = 3 OR tenthous = 42); - QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------ - Bitmap Heap Scan on tenk1 - Recheck Cond: (((thousand = 42) AND (tenthous = 1)) OR ((thousand = 42) AND (tenthous = 3)) OR ((thousand = 42) AND (tenthous = 42))) - -> BitmapOr - -> Bitmap Index Scan on tenk1_thous_tenthous - Index Cond: ((thousand = 42) AND (tenthous = 1)) - -> Bitmap Index Scan on tenk1_thous_tenthous - Index Cond: ((thousand = 42) AND (tenthous = 3)) - -> Bitmap Index Scan on tenk1_thous_tenthous - Index Cond: ((thousand = 42) AND (tenthous = 42)) -(9 rows) + QUERY PLAN +------------------------------------------------------------------------ + Index Scan using tenk1_thous_tenthous on tenk1 + Index Cond: ((thousand = 42) AND (tenthous = ANY (ARRAY[1, 3, 42]))) +(2 rows)
Attachment
On Thu, Aug 17, 2023 at 3:08 AM a.rybakina <a.rybakina@postgrespro.ru> wrote: > This is an interesting feature. I didn't notice this function before, I studied many times consider_new_or_cause, whichwere called there. As far as I know, there is a selectivity calculation going on there, but as far as I remember, Icalled it earlier after my conversion, and unfortunately it didn't solve my problem with calculating selectivity. I'll reconsiderit again, maybe I can find something I missed. Back in 2003, commit 9888192f removed (or at least simplified) what were then called "CNF/DNF CONVERSION ROUTINES". Prior to that point the optimizer README had something about leaving clause lists un-normalized leading to selectivity estimation problems. Bear in mind that this is a couple of years before ScalarArrayOpExpr was first invented. Apparently even back then "The OR-of-ANDs format is useful for indexscan implementation". It's possible that that old work will offer some hints on what to do now. In a way it's not surprising that work in this area would have some impact on selectivies. The surprising part is the extent of the problem, I suppose. I see that a lot of the things in this area are just used by BitmapOr clauses, such as build_paths_for_OR() -- but you're not necessarily able to use any of that stuff. Also, choose_bitmap_and() has some stuff about how it compensates to avoid "too-small selectivity that makes a redundant AND step look like it reduces the total cost". It also mentions some problems with match_join_clauses_to_index() + extract_restriction_or_clauses(). Again, this might be a good place to look for more clues. -- Peter Geoghegan
On Sun, Aug 20, 2023 at 3:11 PM Peter Geoghegan <pg@bowt.ie> wrote: > Back in 2003, commit 9888192f removed (or at least simplified) what > were then called "CNF/DNF CONVERSION ROUTINES". Prior to that point > the optimizer README had something about leaving clause lists > un-normalized leading to selectivity estimation problems. Bear in mind > that this is a couple of years before ScalarArrayOpExpr was first > invented. Apparently even back then "The OR-of-ANDs format is useful > for indexscan implementation". It's possible that that old work will > offer some hints on what to do now. There was actually support for OR lists in index AMs prior to ScalarArrayOpExpr. Even though ScalarArrayOpExpr don't really seem all that related to bitmap scans these days (since at least nbtree knows how to execute them "natively"), that wasn't always the case. ScalarArrayOpExpr were invented the same year that bitmap index scans were first added (2005), and seem more or less related to that work. See commits bc843d39, 5b051852, 1e9a6ba5, and 290166f9 (all from 2005). Particularly the last one, which has a commit message that heavily suggests that my interpretation is correct. I think that we currently over-rely on BitmapOr for OR clauses. It's useful that they're so general, of course, but ISTM that we shouldn't even try to use a BitmapOr in simple cases. Things like the "WHERE thousand = 42 AND (tenthous = 1 OR tenthous = 3 OR tenthous = 42)" tenk1 query that you brought up probably shouldn't even have a BitmapOr path (which I guess they don't with you patch). Note that I recently discussed the same query at length with Tomas Vondra on the ongoing thread for his index filter patch (you probably knew that already). -- Peter Geoghegan
On Thu, Aug 17, 2023 at 3:08 AM a.rybakina <a.rybakina@postgrespro.ru> wrote: > But now I see an interesting transformation, which was the most interesting for me. > > EXPLAIN (COSTS OFF) SELECT * FROM tenk1 WHERE thousand = 42 AND (tenthous = 1 OR tenthous = 3 OR tenthous = 42); It would be even more interesting if it could be an index-only scan as a result of the transformation. For example, we could use an index-only scan with this query (once your patch was in place): "SELECT thousand, tenthous FROM tenk1 WHERE thousand = 42 AND (tenthous = 1 OR tenthous = 3 OR tenthous = 42)" Index-only scans were the original motivation for adding native ScalarArrayExprOp support to nbtree (in 2011 commit 9e8da0f7), in fact. As I suggested earlier, I suspect that there is too much planner logic that targets BitmapOrs specifically -- maybe even selectivity estimation/restrictinfo stuff. PS I wonder if the correctness issues that you saw could be related to eval_const_expressions(), since "the planner assumes that this [eval_const_expressions] will always flatten nested AND and OR clauses into N-argument form". See its subroutines simplify_or_arguments() and simplify_and_arguments(). -- Peter Geoghegan
Thank you for your interest in this problem and help, and I'm sorry that I didn't respond to this email for a long time. To be honest, I wanted to investigate the problems in more detail and already answer more clearly, but unfortunately I have not found anything more significant yet.
I agree with your assumption about looking at the source of the error related to selectivity in these places. But honestly, no matter how many times I looked, until enough sensible thoughts appeared, which could cause a problem. I keep looking, maybe I'll find something.There was actually support for OR lists in index AMs prior to ScalarArrayOpExpr. Even though ScalarArrayOpExpr don't really seem all that related to bitmap scans these days (since at least nbtree knows how to execute them "natively"), that wasn't always the case. ScalarArrayOpExpr were invented the same year that bitmap index scans were first added (2005), and seem more or less related to that work. See commits bc843d39, 5b051852, 1e9a6ba5, and 290166f9 (all from 2005). Particularly the last one, which has a commit message that heavily suggests that my interpretation is correct. Back in 2003, commit 9888192f removed (or at least simplified) what were then called "CNF/DNF CONVERSION ROUTINES". Prior to that point the optimizer README had something about leaving clause lists un-normalized leading to selectivity estimation problems. Bear in mind that this is a couple of years before ScalarArrayOpExpr was first invented. Apparently even back then "The OR-of-ANDs format is useful for indexscan implementation". It's possible that that old work will offer some hints on what to do now. In a way it's not surprising that work in this area would have some impact on selectivies. The surprising part is the extent of the problem, I suppose. I see that a lot of the things in this area are just used by BitmapOr clauses, such as build_paths_for_OR() -- but you're not necessarily able to use any of that stuff. Also, choose_bitmap_and() has some stuff about how it compensates to avoid "too-small selectivity that makes a redundant AND step look like it reduces the total cost". It also mentions some problems with match_join_clauses_to_index() + extract_restriction_or_clauses(). Again, this might be a good place to look for more clues.
EXPLAIN (COSTS OFF) SELECT * FROM tenk1 WHERE thousand = 42 AND (tenthous = 1 OR tenthous = 3 OR tenthous = 42);
- QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------
- Bitmap Heap Scan on tenk1
- Recheck Cond: (((thousand = 42) AND (tenthous = 1)) OR ((thousand = 42) AND (tenthous = 3)) OR ((thousand = 42) AND (tenthous = 42)))
- -> BitmapOr
- -> Bitmap Index Scan on tenk1_thous_tenthous
- Index Cond: ((thousand = 42) AND (tenthous = 1))
- -> Bitmap Index Scan on tenk1_thous_tenthous
- Index Cond: ((thousand = 42) AND (tenthous = 3))
- -> Bitmap Index Scan on tenk1_thous_tenthous
- Index Cond: ((thousand = 42) AND (tenthous = 42))
-(9 rows)
+ QUERY PLAN
+------------------------------------------------------------------------
+ Index Scan using tenk1_thous_tenthous on tenk1
+ Index Cond: ((thousand = 42) AND (tenthous = ANY (ARRAY[1, 3, 42])))
+(2 rows)
I think that we currently over-rely on BitmapOr for OR clauses. It's
useful that they're so general, of course, but ISTM that we shouldn't
even try to use a BitmapOr in simple cases. Things like the "WHERE
thousand = 42 AND (tenthous = 1 OR tenthous = 3 OR tenthous = 42)"
tenk1 query that you brought up probably shouldn't even have a
BitmapOr path (which I guess they don't with you patch). Note that I
recently discussed the same query at length with Tomas Vondra on the
ongoing thread for his index filter patch (you probably knew that
already).
On 29.08.23 05:37, a.rybakina wrote: > Thank you for your interest in this problem and help, and I'm sorry that > I didn't respond to this email for a long time. To be honest, I wanted > to investigate the problems in more detail and already answer more > clearly, but unfortunately I have not found anything more significant yet. What is the status of this patch? It is registered in the commitfest. It looks like a stalled research project? The last posted patch doesn't contain any description or tests, so it doesn't look very ready.
Hi! When I sent the patch version to commitfest, I thought that the work on this topic was completed. Patch version and test results in [0]. But in the process of discussing this patch, we found out that there is another place where you can make a transformation, specifically, during the calculation of selectivity. I implemented the raw version [1], but unfortunately it didn't work in regression tests. I'm sorry that I didn't write about the status earlier, I was very overwhelmed with tasks at work due to releases and preparations for the conference. I returned to the work of this patch, today or tomorrow I'll drop the version. [0] https://www.postgresql.org/message-id/4bac271d-1700-db24-74ac-8414f2baf9fd%40postgrespro.ru https://www.postgresql.org/message-id/11403645-b342-c400-859e-47d0f41ec22a%40postgrespro.ru [1] https://www.postgresql.org/message-id/b301dce1-09fd-72b1-834a-527ca428db5e%40yandex.ru On 20.09.2023 12:37, Peter Eisentraut wrote: > On 29.08.23 05:37, a.rybakina wrote: >> Thank you for your interest in this problem and help, and I'm sorry >> that I didn't respond to this email for a long time. To be honest, I >> wanted to investigate the problems in more detail and already answer >> more clearly, but unfortunately I have not found anything more >> significant yet. > > What is the status of this patch? It is registered in the commitfest. > It looks like a stalled research project? The last posted patch > doesn't contain any description or tests, so it doesn't look very ready. >
I'm sorry I didn't write for a long time, but I really had a very difficult month, now I'm fully back to work.I was able to implement the patches to the end and moved the transformation of "OR" expressions to ANY. I haven't seen a big difference between them yet, one has a conversion before calculating selectivity (v7-v1-Replace-OR-clause-to-ANY.patch), the other after (v7-v2-Replace-OR-clause-to-ANY.patch). Regression tests are passing, I don't see any problems with selectivity, nothing has fallen into the coredump, but I found some incorrect transformations. What is the reason for these inaccuracies, I have not found, but, to be honest, they look unusual). Gave the error below.
In the patch, I don't like that I had to drag three libraries from parsing until I found a way around it.The advantage of this approach compared to the other (v7-v0-Replace-OR-clause-to-ANY.patch) is that at this stage all possible or transformations are performed, compared to the patch, where the transformation was done at the parsing stage. That is, here, for example, there are such optimizations in the transformation:
I took the common element out of the bracket and the rest is converted to ANY, while, as noted by Peter Geoghegan, we did not have several bitmapscans, but only one scan through the array.
postgres=# explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 AND prolang=1 OR prolang = 13 AND prolang = 2 OR prolang = 13 AND prolang = 3;
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..151.66 rows=1 width=68) (actual time=1.167..1.168 rows=0 loops=1)
Filter: ((prolang = '13'::oid) AND (prolang = ANY (ARRAY['1'::oid, '2'::oid, '3'::oid])))
Rows Removed by Filter: 3302
Planning Time: 0.146 ms
Execution Time: 1.191 ms
(5 rows)
While I was testing, I found some transformations that don't work, although in my opinion, they should:
1. First case:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 AND prolang=1 OR prolang = 2 AND prolang = 2 OR prolang = 13 AND prolang = 13;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..180.55 rows=2 width=68) (actual time=2.959..3.335 rows=89 loops=1)
Filter: (((prolang = '13'::oid) AND (prolang = '1'::oid)) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)) OR ((prolang = '13'::oid) AND (prolang = '13'::oid)))
Rows Removed by Filter: 3213
Planning Time: 1.278 ms
Execution Time: 3.486 ms
(5 rows)
Should have left only prolang = '13'::oid:
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..139.28 rows=1 width=68) (actual time=2.034..2.034 rows=0 loops=1)
Filter: ((prolang = '13'::oid ))
Rows Removed by Filter: 3302
Planning Time: 0.181 ms
Execution Time: 2.079 ms
(5 rows)
2. Also does not work:
postgres=# explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang = 2 AND prolang = 2 OR prolang = 13;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..164.04 rows=176 width=68) (actual time=2.422..2.686 rows=89 loops=1)
Filter: ((prolang = '13'::oid) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)) OR (prolang = '13'::oid))
Rows Removed by Filter: 3213
Planning Time: 1.370 ms
Execution Time: 2.799 ms
(5 rows)
Should have left:
Filter: ((prolang = '13'::oid) OR (prolang = '2'::oid))
3. Or another:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang=13 OR prolang = 2 AND prolang = 2;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..164.04 rows=176 width=68) (actual time=2.350..2.566 rows=89 loops=1)
Filter: ((prolang = '13'::oid) OR (prolang = '13'::oid) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)))
Rows Removed by Filter: 3213
Planning Time: 0.215 ms
Execution Time: 2.624 ms
(5 rows)
Should have left:
Filter: ((prolang = '13'::oid) OR (prolang = '2'::oid))
Falls into coredump at me:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang = 2 AND prolang = 2 OR prolang = 13;
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang=13 OR prolang = 2 AND prolang = 2;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..164.04 rows=176 width=68) (actual time=2.350..2.566 rows=89 loops=1)
Filter: ((prolang = '13'::oid) OR (prolang = '13'::oid) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)))
Rows Removed by Filter: 3213
Planning Time: 0.215 ms
Execution Time: 2.624 ms
(5 rows)
I remind that initially the task was to find an opportunity to optimize the case of processing a large number of "or" expressions to optimize memory consumption. The FlameGraph for executing 50,000 "or" expressionshas grown 1.4Gb and remains in this state until exiting the psql session (flamegraph1.png) and it sagged a lot in execution time. If this case is converted to ANY, the query is executed much faster and memory is optimized (flamegraph2.png). It may be necessary to use this approach if there is no support for the framework to process ANY, IN expressions.
Peter Geoghegan also noticed some development of this patch in terms of preparing some transformations to optimize the query at the stage of its execution [0].
Attachment
{kind=link}
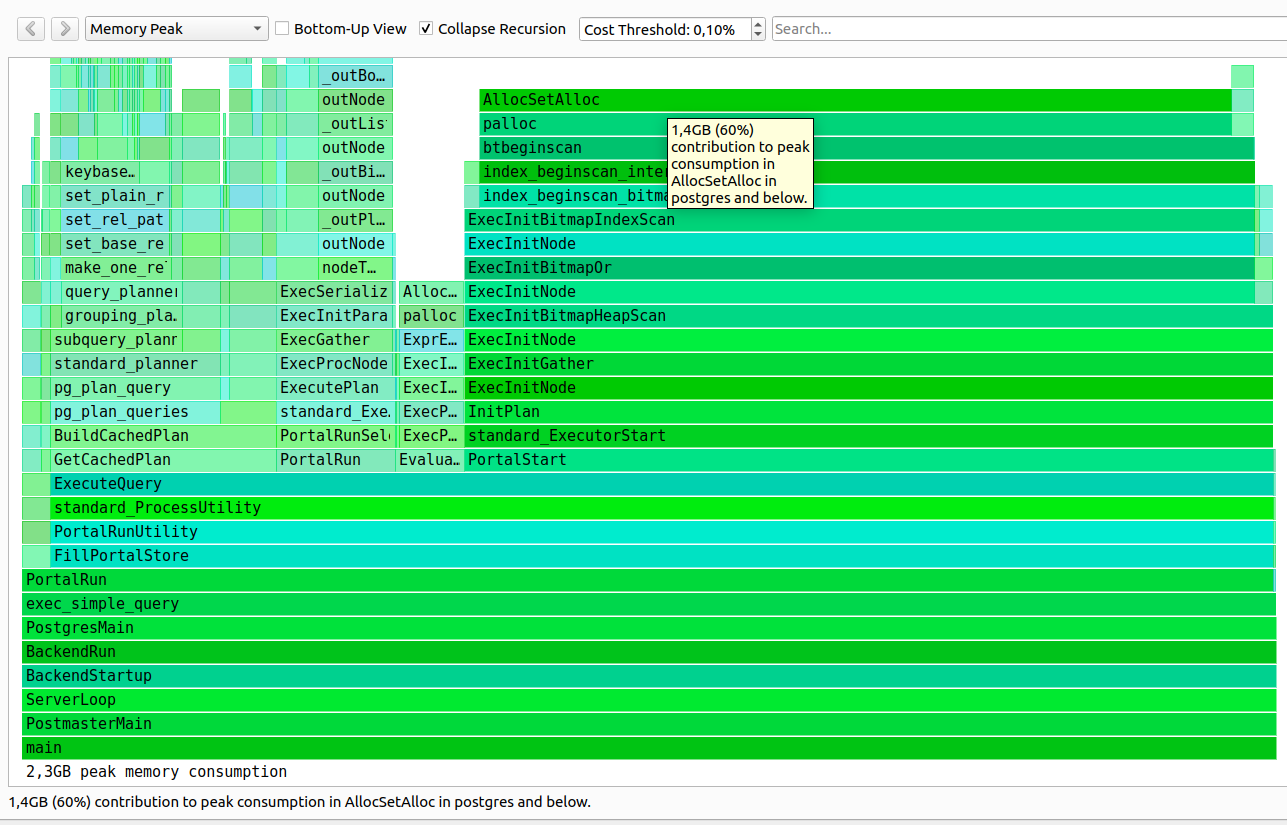{kind=link}
I'm sorry I didn't write for a long time, but I really had a very difficult month, now I'm fully back to work.I was able to implement the patches to the end and moved the transformation of "OR" expressions to ANY. I haven't seen a big difference between them yet, one has a transformation before calculating selectivity (v7.1-Replace-OR-clause-to-ANY.patch), the other after (v7.2-Replace-OR-clause-to-ANY.patch). Regression tests are passing, I don't see any problems with selectivity, nothing has fallen into the coredump, but I found some incorrect transformations. What is the reason for these inaccuracies, I have not found, but, to be honest, they look unusual). Gave the error below.
In the patch, I don't like that I had to drag three libraries from parsing until I found a way around it.The advantage of this approach compared to the other (v7.0-Replace-OR-clause-to-ANY.patch) is that at this stage all possible or transformations are performed, compared to the patch, where the transformation was done at the parsing stage. That is, here, for example, there are such optimizations in the transformation:
I took the common element out of the bracket and the rest is converted to ANY, while, as noted by Peter Geoghegan, we did not have several bitmapscans, but only one scan through the array.
postgres=# explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 AND prolang=1 OR prolang = 13 AND prolang = 2 OR prolang = 13 AND prolang = 3;
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..151.66 rows=1 width=68) (actual time=1.167..1.168 rows=0 loops=1)
Filter: ((prolang = '13'::oid) AND (prolang = ANY (ARRAY['1'::oid, '2'::oid, '3'::oid])))
Rows Removed by Filter: 3302
Planning Time: 0.146 ms
Execution Time: 1.191 ms
(5 rows)
While I was testing, I found some transformations that don't work, although in my opinion, they should:
1. First case:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 AND prolang=1 OR prolang = 2 AND prolang = 2 OR prolang = 13 AND prolang = 13;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..180.55 rows=2 width=68) (actual time=2.959..3.335 rows=89 loops=1)
Filter: (((prolang = '13'::oid) AND (prolang = '1'::oid)) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)) OR ((prolang = '13'::oid) AND (prolang = '13'::oid)))
Rows Removed by Filter: 3213
Planning Time: 1.278 ms
Execution Time: 3.486 ms
(5 rows)
Should have left only prolang = '13'::oid:
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..139.28 rows=1 width=68) (actual time=2.034..2.034 rows=0 loops=1)
Filter: ((prolang = '13'::oid ))
Rows Removed by Filter: 3302
Planning Time: 0.181 ms
Execution Time: 2.079 ms
(5 rows)
2. Also does not work:
postgres=# explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang = 2 AND prolang = 2 OR prolang = 13;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..164.04 rows=176 width=68) (actual time=2.422..2.686 rows=89 loops=1)
Filter: ((prolang = '13'::oid) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)) OR (prolang = '13'::oid))
Rows Removed by Filter: 3213
Planning Time: 1.370 ms
Execution Time: 2.799 ms
(5 rows)
Should have left:
Filter: ((prolang = '13'::oid) OR (prolang = '2'::oid))
3. Or another:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang=13 OR prolang = 2 AND prolang = 2;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..164.04 rows=176 width=68) (actual time=2.350..2.566 rows=89 loops=1)
Filter: ((prolang = '13'::oid) OR (prolang = '13'::oid) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)))
Rows Removed by Filter: 3213
Planning Time: 0.215 ms
Execution Time: 2.624 ms
(5 rows)
Should have left:
Filter: ((prolang = '13'::oid) OR (prolang = '2'::oid))
Falls into coredump at me:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang = 2 AND prolang = 2 OR prolang = 13;
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang=13 OR prolang = 2 AND prolang = 2;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..164.04 rows=176 width=68) (actual time=2.350..2.566 rows=89 loops=1)
Filter: ((prolang = '13'::oid) OR (prolang = '13'::oid) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)))
Rows Removed by Filter: 3213
Planning Time: 0.215 ms
Execution Time: 2.624 ms
(5 rows)
I remind that initially the task was to find an opportunity to optimize the case of processing a large number of "or" expressions to optimize memory consumption. The FlameGraph for executing 50,000 "or" expressionshas grown 1.4Gb and remains in this state until exiting the psql session (flamegraph1.png) and it sagged a lot in execution time. If this case is converted to ANY, the query is executed much faster and memory is optimized (flamegraph2.png). It may be necessary to use this approach if there is no support for the framework to process ANY, IN expressions.
Peter Geoghegan also noticed some development of this patch in terms of preparing some transformations to optimize the query at the stage of its execution [0].
Attachment
{kind=link}
{kind=link}
I'm sorry I didn't write for a long time, but I really had a very difficult month, now I'm fully back to work.I was able to implement the patches to the end and moved the transformation of "OR" expressions to ANY. I haven't seen a big difference between them yet, one has a transformation before calculating selectivity (v7.1-Replace-OR-clause-to-ANY.patch), the other after (v7.2-Replace-OR-clause-to-ANY.patch). Regression tests are passing, I don't see any problems with selectivity, nothing has fallen into the coredump, but I found some incorrect transformations. What is the reason for these inaccuracies, I have not found, but, to be honest, they look unusual). Gave the error below.
In the patch, I don't like that I had to drag three libraries from parsing until I found a way around it.The advantage of this approach compared to the other ([1]) is that at this stage all possible or transformations are performed, compared to the patch, where the transformation was done at the parsing stage. That is, here, for example, there are such optimizations in the transformation:
I took the common element out of the bracket and the rest is converted to ANY, while, as noted by Peter Geoghegan, we did not have several bitmapscans, but only one scan through the array.
postgres=# explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 AND prolang=1 OR prolang = 13 AND prolang = 2 OR prolang = 13 AND prolang = 3;
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..151.66 rows=1 width=68) (actual time=1.167..1.168 rows=0 loops=1)
Filter: ((prolang = '13'::oid) AND (prolang = ANY (ARRAY['1'::oid, '2'::oid, '3'::oid])))
Rows Removed by Filter: 3302
Planning Time: 0.146 ms
Execution Time: 1.191 ms
(5 rows)
While I was testing, I found some transformations that don't work, although in my opinion, they should:
1. First case:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 AND prolang=1 OR prolang = 2 AND prolang = 2 OR prolang = 13 AND prolang = 13;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..180.55 rows=2 width=68) (actual time=2.959..3.335 rows=89 loops=1)
Filter: (((prolang = '13'::oid) AND (prolang = '1'::oid)) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)) OR ((prolang = '13'::oid) AND (prolang = '13'::oid)))
Rows Removed by Filter: 3213
Planning Time: 1.278 ms
Execution Time: 3.486 ms
(5 rows)
Should have left only prolang = '13'::oid:
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..139.28 rows=1 width=68) (actual time=2.034..2.034 rows=0 loops=1)
Filter: ((prolang = '13'::oid ))
Rows Removed by Filter: 3302
Planning Time: 0.181 ms
Execution Time: 2.079 ms
(5 rows)
2. Also does not work:
postgres=# explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang = 2 AND prolang = 2 OR prolang = 13;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..164.04 rows=176 width=68) (actual time=2.422..2.686 rows=89 loops=1)
Filter: ((prolang = '13'::oid) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)) OR (prolang = '13'::oid))
Rows Removed by Filter: 3213
Planning Time: 1.370 ms
Execution Time: 2.799 ms
(5 rows)
Should have left:
Filter: ((prolang = '13'::oid) OR (prolang = '2'::oid))
3. Or another:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang=13 OR prolang = 2 AND prolang = 2;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..164.04 rows=176 width=68) (actual time=2.350..2.566 rows=89 loops=1)
Filter: ((prolang = '13'::oid) OR (prolang = '13'::oid) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)))
Rows Removed by Filter: 3213
Planning Time: 0.215 ms
Execution Time: 2.624 ms
(5 rows)
Should have left:
Filter: ((prolang = '13'::oid) OR (prolang = '2'::oid))
Falls into coredump at me:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang = 2 AND prolang = 2 OR prolang = 13;
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang=13 OR prolang = 2 AND prolang = 2;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..164.04 rows=176 width=68) (actual time=2.350..2.566 rows=89 loops=1)
Filter: ((prolang = '13'::oid) OR (prolang = '13'::oid) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)))
Rows Removed by Filter: 3213
Planning Time: 0.215 ms
Execution Time: 2.624 ms
(5 rows)
I remind that initially the task was to find an opportunity to optimize the case of processing a large number of "or" expressions to optimize memory consumption. The FlameGraph for executing 50,000 "or" expressionshas grown 1.4Gb and remains in this state until exiting the psql session (flamegraph1.png) and it sagged a lot in execution time. If this case is converted to ANY, the query is executed much faster and memory is optimized (flamegraph2.png). It may be necessary to use this approach if there is no support for the framework to process ANY, IN expressions.
Peter Geoghegan also noticed some development of this patch in terms of preparing some transformations to optimize the query at the stage of its execution [0].
Attachment
{kind=link}
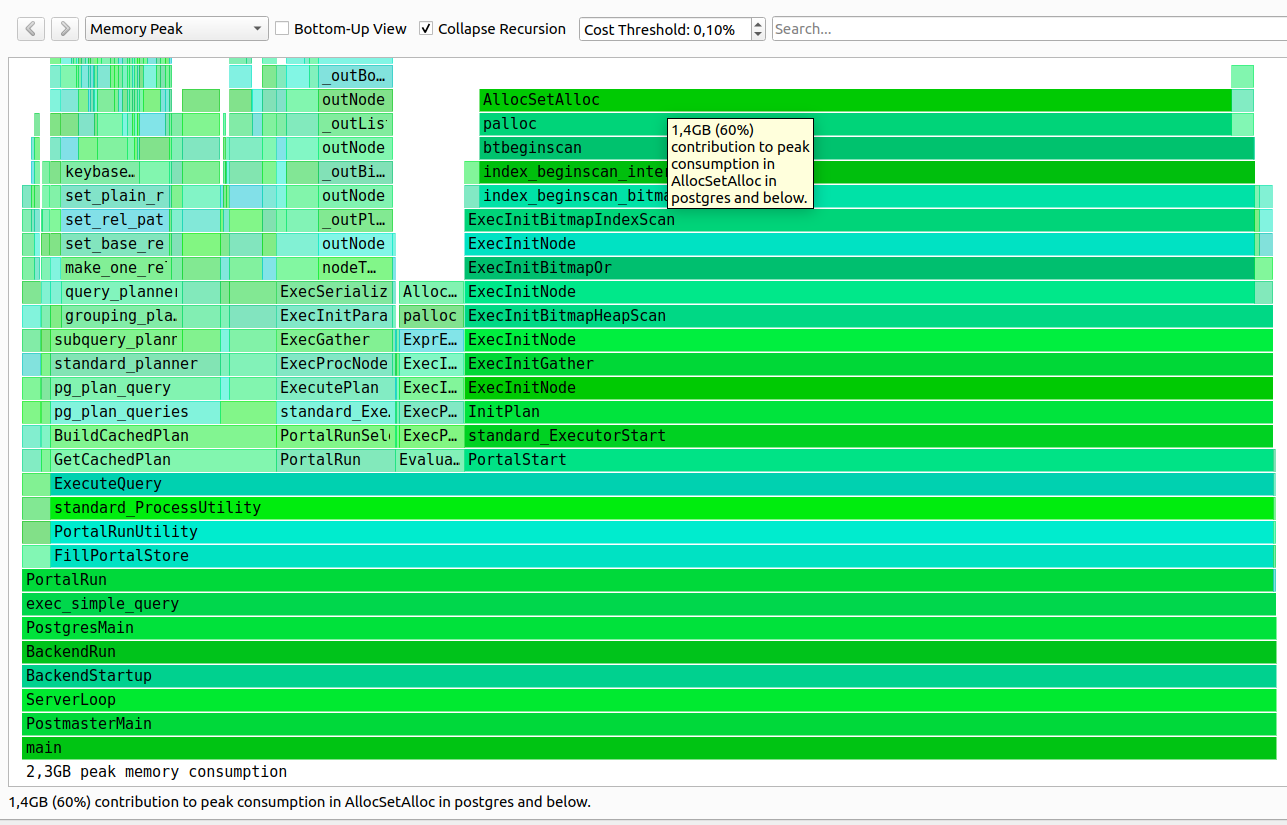{kind=link}
Sorry for the duplicates, I received a letter that my letter did not reach the addressee, I thought the design was incorrect.
I'm sorry I didn't write for a long time, but I really had a very difficult month, now I'm fully back to work.I was able to implement the patches to the end and moved the transformation of "OR" expressions to ANY. I haven't seen a big difference between them yet, one has a transformation before calculating selectivity (v7.1-Replace-OR-clause-to-ANY.patch), the other after (v7.2-Replace-OR-clause-to-ANY.patch). Regression tests are passing, I don't see any problems with selectivity, nothing has fallen into the coredump, but I found some incorrect transformations. What is the reason for these inaccuracies, I have not found, but, to be honest, they look unusual). Gave the error below.
In the patch, I don't like that I had to drag three libraries from parsing until I found a way around it.The advantage of this approach compared to the other ([1]) is that at this stage all possible or transformations are performed, compared to the patch, where the transformation was done at the parsing stage. That is, here, for example, there are such optimizations in the transformation:
I took the common element out of the bracket and the rest is converted to ANY, while, as noted by Peter Geoghegan, we did not have several bitmapscans, but only one scan through the array.
postgres=# explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 AND prolang=1 OR prolang = 13 AND prolang = 2 OR prolang = 13 AND prolang = 3;
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..151.66 rows=1 width=68) (actual time=1.167..1.168 rows=0 loops=1)
Filter: ((prolang = '13'::oid) AND (prolang = ANY (ARRAY['1'::oid, '2'::oid, '3'::oid])))
Rows Removed by Filter: 3302
Planning Time: 0.146 ms
Execution Time: 1.191 ms
(5 rows)
While I was testing, I found some transformations that don't work, although in my opinion, they should:
1. First case:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 AND prolang=1 OR prolang = 2 AND prolang = 2 OR prolang = 13 AND prolang = 13;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..180.55 rows=2 width=68) (actual time=2.959..3.335 rows=89 loops=1)
Filter: (((prolang = '13'::oid) AND (prolang = '1'::oid)) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)) OR ((prolang = '13'::oid) AND (prolang = '13'::oid)))
Rows Removed by Filter: 3213
Planning Time: 1.278 ms
Execution Time: 3.486 ms
(5 rows)
Should have left only prolang = '13'::oid:
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..139.28 rows=1 width=68) (actual time=2.034..2.034 rows=0 loops=1)
Filter: ((prolang = '13'::oid ))
Rows Removed by Filter: 3302
Planning Time: 0.181 ms
Execution Time: 2.079 ms
(5 rows)
2. Also does not work:
postgres=# explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang = 2 AND prolang = 2 OR prolang = 13;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..164.04 rows=176 width=68) (actual time=2.422..2.686 rows=89 loops=1)
Filter: ((prolang = '13'::oid) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)) OR (prolang = '13'::oid))
Rows Removed by Filter: 3213
Planning Time: 1.370 ms
Execution Time: 2.799 ms
(5 rows)
Should have left:
Filter: ((prolang = '13'::oid) OR (prolang = '2'::oid))
3. Or another:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang=13 OR prolang = 2 AND prolang = 2;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..164.04 rows=176 width=68) (actual time=2.350..2.566 rows=89 loops=1)
Filter: ((prolang = '13'::oid) OR (prolang = '13'::oid) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)))
Rows Removed by Filter: 3213
Planning Time: 0.215 ms
Execution Time: 2.624 ms
(5 rows)
Should have left:
Filter: ((prolang = '13'::oid) OR (prolang = '2'::oid))
Falls into coredump at me:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang = 2 AND prolang = 2 OR prolang = 13;
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang=13 OR prolang = 2 AND prolang = 2;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..164.04 rows=176 width=68) (actual time=2.350..2.566 rows=89 loops=1)
Filter: ((prolang = '13'::oid) OR (prolang = '13'::oid) OR ((prolang = '2'::oid) AND (prolang = '2'::oid)))
Rows Removed by Filter: 3213
Planning Time: 0.215 ms
Execution Time: 2.624 ms(5 rows)
I remind that initially the task was to find an opportunity to optimize the case of processing a large number of "or" expressions to optimize memory consumption. The FlameGraph for executing 50,000 "or" expressionshas grown 1.4Gb and remains in this state until exiting the psql session (flamegraph1.png) and it sagged a lot in execution time. If this case is converted to ANY, the query is executed much faster and memory is optimized (flamegraph2.png). It may be necessary to use this approach if there is no support for the framework to process ANY, IN expressions.
Peter Geoghegan also noticed some development of this patch in terms of preparing some transformations to optimize the query at the stage of its execution [0].
I'm sorry I didn't write for a long time, but I really had a very difficult month, now I'm fully back to work.I was able to implement the patches to the end and moved the transformation of "OR" expressions to ANY. I haven't seen a big difference between them yet, one has a transformation before calculating selectivity (v7.1-Replace-OR-clause-to-ANY.patch), the other after (v7.2-Replace-OR-clause-to-ANY.patch). Regression tests are passing, I don't see any problems with selectivity, nothing has fallen into the coredump, but I found some incorrect transformations. What is the reason for these inaccuracies, I have not found, but, to be honest, they look unusual). Gave the error below.
In the patch, I don't like that I had to drag three libraries from parsing until I found a way around it.The advantage of this approach compared to the other ([1]) is that at this stage all possible or transformations are performed, compared to the patch, where the transformation was done at the parsing stage. That is, here, for example, there are such optimizations in the transformation:
I took the common element out of the bracket and the rest is converted to ANY, while, as noted by Peter Geoghegan, we did not have several bitmapscans, but only one scan through the array.
postgres=# explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 AND prolang=1 OR prolang = 13 AND prolang = 2 OR prolang = 13 AND prolang = 3;
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..151.66 rows=1 width=68) (actual time=1.167..1.168 rows=0 loops=1)
Filter: ((prolang = '13'::oid) AND (prolang = ANY (ARRAY['1'::oid, '2'::oid, '3'::oid])))
Rows Removed by Filter: 3302
Planning Time: 0.146 ms
Execution Time: 1.191 ms
(5 rows)
Falls into coredump at me:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang = 2 AND prolang = 2 OR prolang = 13;
I continue to try to move transformations of "OR" expressions at the optimization stage, unfortunately I have not been able to figure out coredump yet, but I saw an important thing that it is already necessary to process RestrictInfo expressions here. I corrected it.
To be honest, despite some significant advantages in the fact that we are already processing pre-converted "or" expressions (logical transformations have been performed and duplicates have been removed), I have big doubts about this approach. We already have quite a lot of objects at this stage that can refer to the RestrictInfo variable in ReplOptInfo, and updating these links can be costly for us. By the way, right now I suspect that the current coredump appeared precisely because there is a link somewhere that refers to an un-updated RestrictInfo, but so far I can't find this place. coredump occurs at the request execution stage, looks like this:Core was generated by `postgres: alena regression [local] SELECT '.
--Type <RET> for more, q to quit, c to continue without paging--
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x00005565f3ec4947 in ExecInitExprRec (node=0x5565f530b290, state=0x5565f53383d8, resv=0x5565f53383e0, resnull=0x5565f53383dd) at execExpr.c:1331
1331 Expr *arg = (Expr *) lfirst(lc);
(gdb) bt
#0 0x00005565f3ec4947 in ExecInitExprRec (node=0x5565f530b290, state=0x5565f53383d8, resv=0x5565f53383e0, resnull=0x5565f53383dd) at execExpr.c:1331
#1 0x00005565f3ec2708 in ExecInitQual (qual=0x5565f531d950, parent=0x5565f5337948) at execExpr.c:258
#2 0x00005565f3f2f080 in ExecInitSeqScan (node=0x5565f5309700, estate=0x5565f5337700, eflags=32) at nodeSeqscan.c:172
#3 0x00005565f3ee70c9 in ExecInitNode (node=0x5565f5309700, estate=0x5565f5337700, eflags=32) at execProcnode.c:210
#4 0x00005565f3edbe3a in InitPlan (queryDesc=0x5565f53372f0, eflags=32) at execMain.c:968
#5 0x00005565f3edabe3 in standard_ExecutorStart (queryDesc=0x5565f53372f0, eflags=32) at execMain.c:266
#6 0x00005565f3eda927 in ExecutorStart (queryDesc=0x5565f53372f0, eflags=0) at execMain.c:145
#7 0x00005565f419921e in PortalStart (portal=0x5565f52ace90, params=0x0, eflags=0, snapshot=0x0) at pquery.c:517
#8 0x00005565f4192635 in exec_simple_query (
query_string=0x5565f5233af0 "SELECT p1.oid, p1.proname\nFROM pg_proc as p1\nWHERE prolang = 13 AND (probin IS NULL OR probin = '' OR probin = '-');") at postgres.c:1233
#9 0x00005565f41976ef in PostgresMain (dbname=0x5565f526ad10 "regression", username=0x5565f526acf8 "alena") at postgres.c:4652
#10 0x00005565f40b8417 in BackendRun (port=0x5565f525f830) at postmaster.c:4439
#11 0x00005565f40b7ca3 in BackendStartup (port=0x5565f525f830) at postmaster.c:4167
#12 0x00005565f40b40f1 in ServerLoop () at postmaster.c:1781
#13 0x00005565f40b399b in PostmasterMain (argc=8, argv=0x5565f522c110) at postmaster.c:1465
#14 0x00005565f3f6560e in main (argc=8, argv=0x5565f522c110) at main.c:198
I have saved my experimental version of the "or" transfer in the diff file, I am attaching the main patch in the ".patch" format so that the tests are checked against this version. Let me remind you that the main patch contains the code for converting "OR" expressions to "ANY" at the parsing stage.
Attachment
I'm sorry I didn't write for a long time, but I really had a very difficult month, now I'm fully back to work.I was able to implement the patches to the end and moved the transformation of "OR" expressions to ANY. I haven't seen a big difference between them yet, one has a transformation before calculating selectivity (v7.1-Replace-OR-clause-to-ANY.patch), the other after (v7.2-Replace-OR-clause-to-ANY.patch). Regression tests are passing, I don't see any problems with selectivity, nothing has fallen into the coredump, but I found some incorrect transformations. What is the reason for these inaccuracies, I have not found, but, to be honest, they look unusual). Gave the error below.
In the patch, I don't like that I had to drag three libraries from parsing until I found a way around it.The advantage of this approach compared to the other ([1]) is that at this stage all possible or transformations are performed, compared to the patch, where the transformation was done at the parsing stage. That is, here, for example, there are such optimizations in the transformation:
I took the common element out of the bracket and the rest is converted to ANY, while, as noted by Peter Geoghegan, we did not have several bitmapscans, but only one scan through the array.
postgres=# explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 AND prolang=1 OR prolang = 13 AND prolang = 2 OR prolang = 13 AND prolang = 3;
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Seq Scan on pg_proc p1 (cost=0.00..151.66 rows=1 width=68) (actual time=1.167..1.168 rows=0 loops=1)
Filter: ((prolang = '13'::oid) AND (prolang = ANY (ARRAY['1'::oid, '2'::oid, '3'::oid])))
Rows Removed by Filter: 3302
Planning Time: 0.146 ms
Execution Time: 1.191 ms
(5 rows)Falls into coredump at me:
explain analyze SELECT p1.oid, p1.proname
FROM pg_proc as p1
WHERE prolang = 13 OR prolang = 2 AND prolang = 2 OR prolang = 13;
Hi, all!
I fixed the kernel dump issue and all the regression tests were successful, but I discovered another problem when I added my own regression tests.
Some queries that contain "or" expressions do not convert to "ANY". I have described this in more detail using diff as expected and real results:diff -U3 /home/alena/postgrespro__copy6/src/test/regress/expected/create_index.out /home/alena/postgrespro__copy6/src/test/regress/results/create_index.out
--- /home/alena/postgrespro__copy6/src/test/regress/expected/create_index.out 2023-10-04 21:54:12.496282667 +0300
+++ /home/alena/postgrespro__copy6/src/test/regress/results/create_index.out 2023-10-04 21:55:41.665422459 +0300
@@ -1925,17 +1925,20 @@
EXPLAIN (COSTS OFF)
SELECT count(*) FROM tenk1
WHERE thousand = 42 AND (tenthous = 1 OR tenthous = 3) OR thousand = 41;
- QUERY PLAN
---------------------------------------------------------------------------------------------------------
+ QUERY PLAN
+---------------------------------------------------------------------------------------------------------------------------
Aggregate
-> Bitmap Heap Scan on tenk1
- Recheck Cond: (((thousand = 42) AND (tenthous = ANY ('{1,3}'::integer[]))) OR (thousand = 41))
+ Recheck Cond: ((((thousand = 42) AND (tenthous = 1)) OR ((thousand = 42) AND (tenthous = 3))) OR (thousand = 41))
-> BitmapOr
- -> Bitmap Index Scan on tenk1_thous_tenthous
- Index Cond: ((thousand = 42) AND (tenthous = ANY ('{1,3}'::integer[])))
+ -> BitmapOr
+ -> Bitmap Index Scan on tenk1_thous_tenthous
+ Index Cond: ((thousand = 42) AND (tenthous = 1))
+ -> Bitmap Index Scan on tenk1_thous_tenthous
+ Index Cond: ((thousand = 42) AND (tenthous = 3))
-> Bitmap Index Scan on tenk1_thous_tenthous
Index Cond: (thousand = 41)
-(8 rows)
+(11 rows)
@@ -1946,24 +1949,50 @@
EXPLAIN (COSTS OFF)
SELECT count(*) FROM tenk1
+ WHERE thousand = 42 OR tenthous = 1 AND thousand = 42 OR tenthous = 1;
+ QUERY PLAN
+---------------------------------------------------------------------------------------------------
+ Aggregate
+ -> Bitmap Heap Scan on tenk1
+ Recheck Cond: ((thousand = 42) OR ((thousand = 42) AND (tenthous = 1)) OR (tenthous = 1))
+ -> BitmapOr
+ -> Bitmap Index Scan on tenk1_thous_tenthous
+ Index Cond: (thousand = 42)
+ -> Bitmap Index Scan on tenk1_thous_tenthous
+ Index Cond: ((thousand = 42) AND (tenthous = 1))
+ -> Bitmap Index Scan on tenk1_thous_tenthous
+ Index Cond: (tenthous = 1)
+(10 rows)
+
+SELECT count(*) FROM tenk1
+ WHERE thousand = 42 OR tenthous = 1 AND thousand = 42 OR tenthous = 1;
+ count
+-------
+ 11
+(1 row)
+
+EXPLAIN (COSTS OFF)
+SELECT count(*) FROM tenk1
WHERE hundred = 42 AND (thousand = 42 OR thousand = 99 OR tenthous < 2) OR thousand = 41;
- QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
+ QUERY PLAN
+------------------------------------------------------------------------------------------------------------------------
Aggregate
-> Bitmap Heap Scan on tenk1
- Recheck Cond: (((hundred = 42) AND ((tenthous < 2) OR (thousand = ANY ('{42,99}'::integer[])))) OR (thousand = 41))
+ Recheck Cond: (((hundred = 42) AND ((thousand = 42) OR (thousand = 99) OR (tenthous < 2))) OR (thousand = 41))
-> BitmapOr
-> BitmapAnd
-> Bitmap Index Scan on tenk1_hundred
Index Cond: (hundred = 42)
-> BitmapOr
-> Bitmap Index Scan on tenk1_thous_tenthous
- Index Cond: (tenthous < 2)
+ Index Cond: (thousand = 42)
-> Bitmap Index Scan on tenk1_thous_tenthous
- Index Cond: (thousand = ANY ('{42,99}'::integer[]))
+ Index Cond: (thousand = 99)
+ -> Bitmap Index Scan on tenk1_thous_tenthous
+ Index Cond: (tenthous < 2)
-> Bitmap Index Scan on tenk1_thous_tenthous
Index Cond: (thousand = 41)
-(14 rows)
+(16 rows)
diff -U3 /home/alena/postgrespro__copy6/src/test/regress/expected/join.out /home/alena/postgrespro__copy6/src/test/regress/results/join.out
--- /home/alena/postgrespro__copy6/src/test/regress/expected/join.out 2023-10-04 21:53:55.632069079 +0300
+++ /home/alena/postgrespro__copy6/src/test/regress/results/join.out 2023-10-04 21:55:46.597485979 +0300
explain (costs off)
select * from tenk1 a join tenk1 b on
(a.unique1 < 20 or a.unique1 = 3 or a.unique1 = 1 and b.unique1 = 2) or
((a.unique2 = 3 or a.unique2 = 7) and b.hundred = 4);
- QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------
+ QUERY PLAN
+-------------------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop
- Join Filter: ((a.unique1 < 20) OR ((a.unique1 = 1) AND (b.unique1 = 2)) OR ((a.unique2 = ANY ('{3,7}'::integer[])) AND (b.hundred = 4)) OR (a.unique1 = 3))
+ Join Filter: ((a.unique1 < 20) OR (a.unique1 = 3) OR ((a.unique1 = 1) AND (b.unique1 = 2)) OR (((a.unique2 = 3) OR (a.unique2 = 7)) AND (b.hundred = 4)))
-> Seq Scan on tenk1 b
-> Materialize
-> Bitmap Heap Scan on tenk1 a
- Recheck Cond: ((unique1 < 20) OR (unique1 = 1) OR (unique2 = ANY ('{3,7}'::integer[])) OR (unique1 = 3))
+ Recheck Cond: ((unique1 < 20) OR (unique1 = 3) OR (unique1 = 1) OR (unique2 = 3) OR (unique2 = 7))
-> BitmapOr
-> Bitmap Index Scan on tenk1_unique1
Index Cond: (unique1 < 20)
-> Bitmap Index Scan on tenk1_unique1
+ Index Cond: (unique1 = 3)
+ -> Bitmap Index Scan on tenk1_unique1
Index Cond: (unique1 = 1)
-> Bitmap Index Scan on tenk1_unique2
- Index Cond: (unique2 = ANY ('{3,7}'::integer[]))
- -> Bitmap Index Scan on tenk1_unique1
- Index Cond: (unique1 = 3)
-(15 rows)
+ Index Cond: (unique2 = 3)
+ -> Bitmap Index Scan on tenk1_unique2
+ Index Cond: (unique2 = 7)
+(17 rows)
explain (costs off)
select * from tenk1 a join tenk1 b on
(a.unique1 < 20 or a.unique1 = 3 or a.unique1 = 1 and b.unique1 = 2) or
((a.unique2 = 3 or a.unique2 = 7) and b.hundred = 4);
- QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------
+ QUERY PLAN
+-------------------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop
- Join Filter: ((a.unique1 < 20) OR ((a.unique1 = 1) AND (b.unique1 = 2)) OR ((a.unique2 = ANY ('{3,7}'::integer[])) AND (b.hundred = 4)) OR (a.unique1 = 3))
+ Join Filter: ((a.unique1 < 20) OR (a.unique1 = 3) OR ((a.unique1 = 1) AND (b.unique1 = 2)) OR (((a.unique2 = 3) OR (a.unique2 = 7)) AND (b.hundred = 4)))
-> Seq Scan on tenk1 b
-> Materialize
-> Bitmap Heap Scan on tenk1 a
- Recheck Cond: ((unique1 < 20) OR (unique1 = 1) OR (unique2 = ANY ('{3,7}'::integer[])) OR (unique1 = 3))
+ Recheck Cond: ((unique1 < 20) OR (unique1 = 3) OR (unique1 = 1) OR (unique2 = 3) OR (unique2 = 7))
-> BitmapOr
-> Bitmap Index Scan on tenk1_unique1
Index Cond: (unique1 < 20)
-> Bitmap Index Scan on tenk1_unique1
+ Index Cond: (unique1 = 3)
+ -> Bitmap Index Scan on tenk1_unique1
Index Cond: (unique1 = 1)
-> Bitmap Index Scan on tenk1_unique2
- Index Cond: (unique2 = ANY ('{3,7}'::integer[]))
- -> Bitmap Index Scan on tenk1_unique1
- Index Cond: (unique1 = 3)
-(15 rows)
+ Index Cond: (unique2 = 3)
+ -> Bitmap Index Scan on tenk1_unique2
+ Index Cond: (unique2 = 7)
+(17 rows)
I haven't been able to fully deal with this problem yet
I have attached my experimental patch with the code.
Attachment
Hi, Alena!
Thank you for your work on the subject.
On Wed, Oct 4, 2023 at 10:21 PM a.rybakina <a.rybakina@postgrespro.ru> wrote:
> I fixed the kernel dump issue and all the regression tests were successful, but I discovered another problem when I
addedmy own regression tests.
> Some queries that contain "or" expressions do not convert to "ANY". I have described this in more detail using diff
asexpected and real results:
>
> diff -U3 /home/alena/postgrespro__copy6/src/test/regress/expected/create_index.out
/home/alena/postgrespro__copy6/src/test/regress/results/create_index.out
> --- /home/alena/postgrespro__copy6/src/test/regress/expected/create_index.out 2023-10-04 21:54:12.496282667 +0300
> +++ /home/alena/postgrespro__copy6/src/test/regress/results/create_index.out 2023-10-04 21:55:41.665422459 +0300
> @@ -1925,17 +1925,20 @@
> EXPLAIN (COSTS OFF)
> SELECT count(*) FROM tenk1
> WHERE thousand = 42 AND (tenthous = 1 OR tenthous = 3) OR thousand = 41;
> - QUERY PLAN
> ---------------------------------------------------------------------------------------------------------
> + QUERY PLAN
>
+---------------------------------------------------------------------------------------------------------------------------
> Aggregate
> -> Bitmap Heap Scan on tenk1
> - Recheck Cond: (((thousand = 42) AND (tenthous = ANY ('{1,3}'::integer[]))) OR (thousand = 41))
> + Recheck Cond: ((((thousand = 42) AND (tenthous = 1)) OR ((thousand = 42) AND (tenthous = 3))) OR (thousand
=41))
> -> BitmapOr
> - -> Bitmap Index Scan on tenk1_thous_tenthous
> - Index Cond: ((thousand = 42) AND (tenthous = ANY ('{1,3}'::integer[])))
> + -> BitmapOr
> + -> Bitmap Index Scan on tenk1_thous_tenthous
> + Index Cond: ((thousand = 42) AND (tenthous = 1))
> + -> Bitmap Index Scan on tenk1_thous_tenthous
> + Index Cond: ((thousand = 42) AND (tenthous = 3))
> -> Bitmap Index Scan on tenk1_thous_tenthous
> Index Cond: (thousand = 41)
> -(8 rows)
> +(11 rows)
I think this query is not converted, because you only convert
top-level ORs in the transform_ors() function. But in the example
given, the target OR lays under AND, which in turn lays under another
OR. I think you need to make transform_ors() recursive to handle
cases like this.
I wonder about the default value of the parameter or_transform_limit
of 500. In [1] and [2] you show the execution time degradation from 0
to ~500 OR clauses. I made a simple SQL script with the query "SELECT
* FROM pgbench_accounts a WHERE aid = 1 OR aid = 2 OR ... OR aid =
100;". The pgbench results for a single connection in prepared mode
are the following.
master: 936 tps
patched (or_transform_limit == 0) :1414 tps
So, transformation to ANY obviously accelerates the execution.
I think it's important to identify the cases where this patch causes
the degradation. Generally, I don't see why ANY could be executed
slower than the equivalent OR clause. So, the possible degradation
cases are slower plan generation and worse plans. I managed to find
both.
As you stated before, currently the OR transformation has a quadratic
complexity depending on the number of or-clause-groups. I made a
simple test to evaluate this. containing 10000 or-clause-groups.
SELECT * FROM pgbench_accounts a WHERE aid + 1 * bid = 1 OR aid + 2 *
bid = 1 OR ... OR aid + 10000 * bid = 1;
master: 316ms
patched: 7142ms
Note, that the current or_transform_limit GUC parameter is not capable
of cutting such cases, because it cuts cases lower than the limit not
higher than the limit. In the comment, you mention that we could
invent something like hash to handle this. Hash should be nice, but
the problem is that we currently don't have a generic facility to hash
nodes (or even order them). It would be nice to add this facility,
that would be quite a piece of work. I would propose to limit this
patch for now to handle just a single Var node as a non-const side of
the clause and implement a simple hash for Vars.
Another problem is the possible generation of worse plans. I made an
example table with two partial indexes.
create table test as (select (random()*10)::int x, (random()*1000) y
from generate_series(1,1000000) i);
create index test_x_1_y on test (y) where x = 1;
create index test_x_2_y on test (y) where x = 2;
vacuum analyze test;
Without the transformation of ORs to ANY, our planner manages to use
both indexes with a Bitmap scan.
# explain select * from test where (x = 1 or x = 2) and y = 100;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on test (cost=8.60..12.62 rows=1 width=12)
Recheck Cond: (((y = '100'::double precision) AND (x = 1)) OR ((y =
'100'::double precision) AND (x = 2)))
-> BitmapOr (cost=8.60..8.60 rows=1 width=0)
-> Bitmap Index Scan on test_x_1_y (cost=0.00..4.30 rows=1 width=0)
Index Cond: (y = '100'::double precision)
-> Bitmap Index Scan on test_x_2_y (cost=0.00..4.30 rows=1 width=0)
Index Cond: (y = '100'::double precision)
(7 rows)
With transformation, the planner can't use indexes.
# explain select * from test where (x = 1 or x = 2) and y = 100;
QUERY PLAN
-----------------------------------------------------------------------------
Gather (cost=1000.00..12690.10 rows=1 width=12)
Workers Planned: 2
-> Parallel Seq Scan on test (cost=0.00..11690.00 rows=1 width=12)
Filter: ((x = ANY (ARRAY[1, 2])) AND (y = '100'::double precision))
(4 rows)
The solution I see would be to tech Bitmap scan to handle ANY clause
in the same way as the OR clause. I think the entry point for the
relevant logic is the choose_bitmap_and() function.
Regarding the GUC parameter, I don't see we need a limit. It's not
yet clear whether a small number or a large number of OR clauses are
more favorable for transformation. I propose to have just a boolean
enable_or_transformation GUC.
Links
1. https://www.postgresql.org/message-id/6b97b517-f36a-f0c6-3b3a-0cf8cfba220c%40yandex.ru
2. https://www.postgresql.org/message-id/938d82e1-98df-6553-334c-9db7c4e288ae%40yandex.ru
------
Regards,
Alexander Korotkov
Yes, you are right, it seems that a recursive method is needed here.Hi, Alena! Thank you for your work on the subject. On Wed, Oct 4, 2023 at 10:21 PM a.rybakina <a.rybakina@postgrespro.ru> wrote:I fixed the kernel dump issue and all the regression tests were successful, but I discovered another problem when I added my own regression tests. Some queries that contain "or" expressions do not convert to "ANY". I have described this in more detail using diff as expected and real results: diff -U3 /home/alena/postgrespro__copy6/src/test/regress/expected/create_index.out /home/alena/postgrespro__copy6/src/test/regress/results/create_index.out --- /home/alena/postgrespro__copy6/src/test/regress/expected/create_index.out 2023-10-04 21:54:12.496282667 +0300 +++ /home/alena/postgrespro__copy6/src/test/regress/results/create_index.out 2023-10-04 21:55:41.665422459 +0300 @@ -1925,17 +1925,20 @@ EXPLAIN (COSTS OFF) SELECT count(*) FROM tenk1 WHERE thousand = 42 AND (tenthous = 1 OR tenthous = 3) OR thousand = 41; - QUERY PLAN --------------------------------------------------------------------------------------------------------- + QUERY PLAN +--------------------------------------------------------------------------------------------------------------------------- Aggregate -> Bitmap Heap Scan on tenk1 - Recheck Cond: (((thousand = 42) AND (tenthous = ANY ('{1,3}'::integer[]))) OR (thousand = 41)) + Recheck Cond: ((((thousand = 42) AND (tenthous = 1)) OR ((thousand = 42) AND (tenthous = 3))) OR (thousand = 41)) -> BitmapOr - -> Bitmap Index Scan on tenk1_thous_tenthous - Index Cond: ((thousand = 42) AND (tenthous = ANY ('{1,3}'::integer[]))) + -> BitmapOr + -> Bitmap Index Scan on tenk1_thous_tenthous + Index Cond: ((thousand = 42) AND (tenthous = 1)) + -> Bitmap Index Scan on tenk1_thous_tenthous + Index Cond: ((thousand = 42) AND (tenthous = 3)) -> Bitmap Index Scan on tenk1_thous_tenthous Index Cond: (thousand = 41) -(8 rows) +(11 rows)I think this query is not converted, because you only convert top-level ORs in the transform_ors() function. But in the example given, the target OR lays under AND, which in turn lays under another OR. I think you need to make transform_ors() recursive to handle cases like this.
I ran the query and saw that you were right, this place in the patch turns out to be very expensive. In addition to the hash, I saw a second solution to this problem - parameterize constants and store them in the list, but this will not be such a universal solution as hashing. If the variable, not the constant, changes, parameterization will not help.I wonder about the default value of the parameter or_transform_limit of 500. In [1] and [2] you show the execution time degradation from 0 to ~500 OR clauses. I made a simple SQL script with the query "SELECT * FROM pgbench_accounts a WHERE aid = 1 OR aid = 2 OR ... OR aid = 100;". The pgbench results for a single connection in prepared mode are the following. master: 936 tps patched (or_transform_limit == 0) :1414 tps So, transformation to ANY obviously accelerates the execution. I think it's important to identify the cases where this patch causes the degradation. Generally, I don't see why ANY could be executed slower than the equivalent OR clause. So, the possible degradation cases are slower plan generation and worse plans. I managed to find both. As you stated before, currently the OR transformation has a quadratic complexity depending on the number of or-clause-groups. I made a simple test to evaluate this. containing 10000 or-clause-groups. SELECT * FROM pgbench_accounts a WHERE aid + 1 * bid = 1 OR aid + 2 * bid = 1 OR ... OR aid + 10000 * bid = 1; master: 316ms patched: 7142ms Note, that the current or_transform_limit GUC parameter is not capable of cutting such cases, because it cuts cases lower than the limit not higher than the limit. In the comment, you mention that we could invent something like hash to handle this. Hash should be nice, but the problem is that we currently don't have a generic facility to hash nodes (or even order them). It would be nice to add this facility, that would be quite a piece of work. I would propose to limit this patch for now to handle just a single Var node as a non-const side of the clause and implement a simple hash for Vars.
I agree with your suggestion to try adding hashing. I'll take a closer look at this.
It's a good idea, I'll try.Another problem is the possible generation of worse plans. I made an example table with two partial indexes. create table test as (select (random()*10)::int x, (random()*1000) y from generate_series(1,1000000) i); create index test_x_1_y on test (y) where x = 1; create index test_x_2_y on test (y) where x = 2; vacuum analyze test; Without the transformation of ORs to ANY, our planner manages to use both indexes with a Bitmap scan. # explain select * from test where (x = 1 or x = 2) and y = 100; QUERY PLAN -------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on test (cost=8.60..12.62 rows=1 width=12) Recheck Cond: (((y = '100'::double precision) AND (x = 1)) OR ((y = '100'::double precision) AND (x = 2))) -> BitmapOr (cost=8.60..8.60 rows=1 width=0) -> Bitmap Index Scan on test_x_1_y (cost=0.00..4.30 rows=1 width=0) Index Cond: (y = '100'::double precision) -> Bitmap Index Scan on test_x_2_y (cost=0.00..4.30 rows=1 width=0) Index Cond: (y = '100'::double precision) (7 rows) With transformation, the planner can't use indexes. # explain select * from test where (x = 1 or x = 2) and y = 100; QUERY PLAN ----------------------------------------------------------------------------- Gather (cost=1000.00..12690.10 rows=1 width=12) Workers Planned: 2 -> Parallel Seq Scan on test (cost=0.00..11690.00 rows=1 width=12) Filter: ((x = ANY (ARRAY[1, 2])) AND (y = '100'::double precision)) (4 rows) The solution I see would be to tech Bitmap scan to handle ANY clause in the same way as the OR clause. I think the entry point for the relevant logic is the choose_bitmap_and() function.
But to be honest, I'm afraid that problems with selectivity may come up again and in order to solve them, additional processing of RestrictInfo may be required, which will be unnecessarily expensive. As far as I understand, at this stage we are creating indexes for AND expressions and there is a risk that its transformation may cause the need to change references in all possible places where it was referenced.
Regarding the GUC parameter, I don't see we need a limit. It's not yet clear whether a small number or a large number of OR clauses are more favorable for transformation. I propose to have just a boolean enable_or_transformation GUC. Links 1. https://www.postgresql.org/message-id/6b97b517-f36a-f0c6-3b3a-0cf8cfba220c%40yandex.ru 2. https://www.postgresql.org/message-id/938d82e1-98df-6553-334c-9db7c4e288ae%40yandex.ru
I tend to agree with you and I see that in some cases it really doesn't help.
Hi!
On 15.10.2023 01:34, Alexander Korotkov wrote:
> Hi, Alena!
>
> Thank you for your work on the subject.
>
> On Wed, Oct 4, 2023 at 10:21 PM a.rybakina <a.rybakina@postgrespro.ru> wrote:
>> I fixed the kernel dump issue and all the regression tests were successful, but I discovered another problem when I
addedmy own regression tests.
>> Some queries that contain "or" expressions do not convert to "ANY". I have described this in more detail using diff
asexpected and real results:
>>
>> diff -U3 /home/alena/postgrespro__copy6/src/test/regress/expected/create_index.out
/home/alena/postgrespro__copy6/src/test/regress/results/create_index.out
>> --- /home/alena/postgrespro__copy6/src/test/regress/expected/create_index.out 2023-10-04 21:54:12.496282667 +0300
>> +++ /home/alena/postgrespro__copy6/src/test/regress/results/create_index.out 2023-10-04 21:55:41.665422459 +0300
>> @@ -1925,17 +1925,20 @@
>> EXPLAIN (COSTS OFF)
>> SELECT count(*) FROM tenk1
>> WHERE thousand = 42 AND (tenthous = 1 OR tenthous = 3) OR thousand = 41;
>> - QUERY PLAN
>> ---------------------------------------------------------------------------------------------------------
>> + QUERY PLAN
>>
+---------------------------------------------------------------------------------------------------------------------------
>> Aggregate
>> -> Bitmap Heap Scan on tenk1
>> - Recheck Cond: (((thousand = 42) AND (tenthous = ANY ('{1,3}'::integer[]))) OR (thousand = 41))
>> + Recheck Cond: ((((thousand = 42) AND (tenthous = 1)) OR ((thousand = 42) AND (tenthous = 3))) OR (thousand
=41))
>> -> BitmapOr
>> - -> Bitmap Index Scan on tenk1_thous_tenthous
>> - Index Cond: ((thousand = 42) AND (tenthous = ANY ('{1,3}'::integer[])))
>> + -> BitmapOr
>> + -> Bitmap Index Scan on tenk1_thous_tenthous
>> + Index Cond: ((thousand = 42) AND (tenthous = 1))
>> + -> Bitmap Index Scan on tenk1_thous_tenthous
>> + Index Cond: ((thousand = 42) AND (tenthous = 3))
>> -> Bitmap Index Scan on tenk1_thous_tenthous
>> Index Cond: (thousand = 41)
>> -(8 rows)
>> +(11 rows)
> I think this query is not converted, because you only convert
> top-level ORs in the transform_ors() function. But in the example
> given, the target OR lays under AND, which in turn lays under another
> OR. I think you need to make transform_ors() recursive to handle
> cases like this.
>
> I wonder about the default value of the parameter or_transform_limit
> of 500. In [1] and [2] you show the execution time degradation from 0
> to ~500 OR clauses. I made a simple SQL script with the query "SELECT
> * FROM pgbench_accounts a WHERE aid = 1 OR aid = 2 OR ... OR aid =
> 100;". The pgbench results for a single connection in prepared mode
> are the following.
> master: 936 tps
> patched (or_transform_limit == 0) :1414 tps
> So, transformation to ANY obviously accelerates the execution.
>
> I think it's important to identify the cases where this patch causes
> the degradation. Generally, I don't see why ANY could be executed
> slower than the equivalent OR clause. So, the possible degradation
> cases are slower plan generation and worse plans. I managed to find
> both.
>
> As you stated before, currently the OR transformation has a quadratic
> complexity depending on the number of or-clause-groups. I made a
> simple test to evaluate this. containing 10000 or-clause-groups.
> SELECT * FROM pgbench_accounts a WHERE aid + 1 * bid = 1 OR aid + 2 *
> bid = 1 OR ... OR aid + 10000 * bid = 1;
> master: 316ms
> patched: 7142ms
> Note, that the current or_transform_limit GUC parameter is not capable
> of cutting such cases, because it cuts cases lower than the limit not
> higher than the limit. In the comment, you mention that we could
> invent something like hash to handle this. Hash should be nice, but
> the problem is that we currently don't have a generic facility to hash
> nodes (or even order them). It would be nice to add this facility,
> that would be quite a piece of work. I would propose to limit this
> patch for now to handle just a single Var node as a non-const side of
> the clause and implement a simple hash for Vars.
>
> Another problem is the possible generation of worse plans. I made an
> example table with two partial indexes.
> create table test as (select (random()*10)::int x, (random()*1000) y
> from generate_series(1,1000000) i);
> create index test_x_1_y on test (y) where x = 1;
> create index test_x_2_y on test (y) where x = 2;
> vacuum analyze test;
>
> Without the transformation of ORs to ANY, our planner manages to use
> both indexes with a Bitmap scan.
> # explain select * from test where (x = 1 or x = 2) and y = 100;
> QUERY PLAN
> --------------------------------------------------------------------------------------------------------------
> Bitmap Heap Scan on test (cost=8.60..12.62 rows=1 width=12)
> Recheck Cond: (((y = '100'::double precision) AND (x = 1)) OR ((y =
> '100'::double precision) AND (x = 2)))
> -> BitmapOr (cost=8.60..8.60 rows=1 width=0)
> -> Bitmap Index Scan on test_x_1_y (cost=0.00..4.30 rows=1 width=0)
> Index Cond: (y = '100'::double precision)
> -> Bitmap Index Scan on test_x_2_y (cost=0.00..4.30 rows=1 width=0)
> Index Cond: (y = '100'::double precision)
> (7 rows)
>
> With transformation, the planner can't use indexes.
> # explain select * from test where (x = 1 or x = 2) and y = 100;
> QUERY PLAN
> -----------------------------------------------------------------------------
> Gather (cost=1000.00..12690.10 rows=1 width=12)
> Workers Planned: 2
> -> Parallel Seq Scan on test (cost=0.00..11690.00 rows=1 width=12)
> Filter: ((x = ANY (ARRAY[1, 2])) AND (y = '100'::double precision))
> (4 rows)
>
> The solution I see would be to tech Bitmap scan to handle ANY clause
> in the same way as the OR clause. I think the entry point for the
> relevant logic is the choose_bitmap_and() function.
>
> Regarding the GUC parameter, I don't see we need a limit. It's not
> yet clear whether a small number or a large number of OR clauses are
> more favorable for transformation. I propose to have just a boolean
> enable_or_transformation GUC.
>
I removed the limit from the hook, left the option to enable it or not.
I replaced the data structure so that the groups were formed not in a
list, but in a hash table. It seems to work fine, but I haven't figured
out yet why in some cases the regression test results are different and
the function doesn't work.
So far, I have formed a patch for the version where the conversion takes
place in parsing, since so far this patch looks the most reliable for me
For convenience, I have formed a patch for the very first version so far.
I have a suspicion that the problem is in the part where we form a hash
from a string. I'm still figuring it out.
Attachment
On Sat, Oct 14, 2023 at 6:37 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > Regarding the GUC parameter, I don't see we need a limit. It's not > yet clear whether a small number or a large number of OR clauses are > more favorable for transformation. I propose to have just a boolean > enable_or_transformation GUC. That's a poor solution. So is the GUC patch currently has (or_transform_limit). What you need is a heuristic that figures out fairly reliably whether the transformation is going to be better or worse. Or else, do the whole thing in some other way that is always same-or-better. In general, adding GUCs makes sense when the user knows something that we can't know. For example, shared_buffers makes some sense because, even if we discovered how much memory the machine has, we can't know how much of it the user wants to devote to PostgreSQL as opposed to anything else. And track_io_timing makes sense because we can't know whether the user wants to pay the price of gathering that additional data. But GUCs are a poor way of handling cases where the real problem is that we don't know what code to write. In this case, some queries will be better with enable_or_transformation=on, and some will be better with enable_or_transformation=off. Since we don't know which will work out better, we make the user figure it out and set the GUC, possibly differently for each query. That's terrible. It's the query optimizer's whole job to figure out which transformations will speed up the query. It shouldn't turn around and punt the decision back to the user. Notice that superficially-similar GUCs like enable_seqscan aren't really the same thing at all. That's just for developer testing and debugging. Nobody expects that you have to adjust that GUC on a production system - ever. -- Robert Haas EDB: http://www.enterprisedb.com
Hi! Thank you for your feedback!
On Sat, Oct 14, 2023 at 6:37 PM Alexander Korotkov <aekorotkov@gmail.com> wrote:Regarding the GUC parameter, I don't see we need a limit. It's not yet clear whether a small number or a large number of OR clauses are more favorable for transformation. I propose to have just a boolean enable_or_transformation GUC.That's a poor solution. So is the GUC patch currently has (or_transform_limit). What you need is a heuristic that figures out fairly reliably whether the transformation is going to be better or worse. Or else, do the whole thing in some other way that is always same-or-better. In general, adding GUCs makes sense when the user knows something that we can't know. For example, shared_buffers makes some sense because, even if we discovered how much memory the machine has, we can't know how much of it the user wants to devote to PostgreSQL as opposed to anything else. And track_io_timing makes sense because we can't know whether the user wants to pay the price of gathering that additional data. But GUCs are a poor way of handling cases where the real problem is that we don't know what code to write. In this case, some queries will be better with enable_or_transformation=on, and some will be better with enable_or_transformation=off. Since we don't know which will work out better, we make the user figure it out and set the GUC, possibly differently for each query. That's terrible. It's the query optimizer's whole job to figure out which transformations will speed up the query. It shouldn't turn around and punt the decision back to the user. Notice that superficially-similar GUCs like enable_seqscan aren't really the same thing at all. That's just for developer testing and debugging. Nobody expects that you have to adjust that GUC on a production system - ever.
I noticed that the costs of expressions are different and it can help to assess when it is worth leaving the conversion, when not.
With small amounts of "OR" elements, the cost of orexpr is lower than with "ANY", on the contrary, higher.postgres=# SET or_transform_limit = 500;
EXPLAIN (analyze)
SELECT oid,relname FROM pg_class
WHERE
oid = 13779 AND (oid = 2 OR oid = 4 OR oid = 5)
;
SET
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Index Scan using pg_class_oid_index on pg_class (cost=0.27..8.30 rows=1 width=68) (actual time=0.105..0.106 rows=0 loops=1)
Index Cond: (oid = '13779'::oid)
Filter: ((oid = '2'::oid) OR (oid = '4'::oid) OR (oid = '5'::oid))
Planning Time: 0.323 ms
Execution Time: 0.160 ms
(5 rows)
postgres=# SET or_transform_limit = 0;
EXPLAIN (analyze)
SELECT oid,relname FROM pg_class
WHERE
oid = 13779 AND (oid = 2 OR oid = 4 OR oid = 5)
;
SET
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------
Index Scan using pg_class_oid_index on pg_class (cost=0.27..16.86 rows=1 width=68) (actual time=0.160..0.161 rows=0 loops=1)
Index Cond: ((oid = ANY (ARRAY['2'::oid, '4'::oid, '5'::oid])) AND (oid = '13779'::oid))
Planning Time: 4.515 ms
Execution Time: 0.313 ms
(4 rows)
Index Scan using pg_class_oid_index on pg_class (cost=0.27..2859.42 rows=414 width=68) (actual time=1.504..34.183 rows=260 loops=1)
Index Cond: (oid = ANY (ARRAY['1'::oid, '2'::oid, '3'::oid, '4'::oid, '5'::oid, '6'::oid, '7'::oid,
Bitmap Heap Scan on pg_class (cost=43835.00..54202.14 rows=414 width=68) (actual time=39.958..41.293 rows=260 loops=1)
Recheck Cond: ((oid = '1'::oid) OR (oid = '2'::oid) OR (oid = '3'::oid) OR (oid = '4'::oid) OR (oid =
I think we could see which value is lower, and if lower with expressions converted to ANY, then work with it further, otherwise work with the original "OR" expressions. But we still need to make this conversion to find out its cost.
In addition, I will definitely have to postpone the transformation of "OR" to "ANY" at the stage of creating indexes (?) or maybe a little earlier so that I have to count only the cost of the transformed expression.
On Thu, Oct 26, 2023 at 3:47 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > With small amounts of "OR" elements, the cost of orexpr is lower than with "ANY", on the contrary, higher. Alexander's example seems to show that it's not that simple. If I'm reading his example correctly, with things like aid = 1, the transformation usually wins even if the number of things in the OR expression is large, but with things like aid + 1 * bid = 1, the transformation seems to lose at least with larger numbers of items. So it's not JUST the number of OR elements but also what they contain, unless I'm misunderstanding his point. > Index Scan using pg_class_oid_index on pg_class (cost=0.27..2859.42 rows=414 width=68) (actual time=1.504..34.183 rows=260loops=1) > Index Cond: (oid = ANY (ARRAY['1'::oid, '2'::oid, '3'::oid, '4'::oid, '5'::oid, '6'::oid, '7'::oid, > > Bitmap Heap Scan on pg_class (cost=43835.00..54202.14 rows=414 width=68) (actual time=39.958..41.293 rows=260 loops=1) > Recheck Cond: ((oid = '1'::oid) OR (oid = '2'::oid) OR (oid = '3'::oid) OR (oid = '4'::oid) OR (oid = > > I think we could see which value is lower, and if lower with expressions converted to ANY, then work with it further, otherwisework with the original "OR" expressions. But we still need to make this conversion to find out its cost. To me, this sort of output suggests that perhaps the transformation is being done in the wrong place. I expect that we have to decide whether to convert from OR to = ANY(...) at a very early stage of the planner, before we have any idea what the selected path will ultimately be. But this output suggests that we want the answer to depend on which kind of path is going to be faster, which would seem to argue for doing this sort of transformation as part of path generation for only those paths that will benefit from it, rather than during earlier phases of expression processing/simplification. I'm not sure I have the full picture here, though, so I might have this all wrong. -- Robert Haas EDB: http://www.enterprisedb.com
On 26.10.2023 22:58, Robert Haas wrote: > On Thu, Oct 26, 2023 at 3:47 PM Alena Rybakina > <a.rybakina@postgrespro.ru> wrote: >> With small amounts of "OR" elements, the cost of orexpr is lower than with "ANY", on the contrary, higher. > Alexander's example seems to show that it's not that simple. If I'm > reading his example correctly, with things like aid = 1, the > transformation usually wins even if the number of things in the OR > expression is large, but with things like aid + 1 * bid = 1, the > transformation seems to lose at least with larger numbers of items. So > it's not JUST the number of OR elements but also what they contain, > unless I'm misunderstanding his point. Yes, I agree, with Alexander's example, this option will not help and here I need to look inside Expr itself. But I noticed that such a complex non-constant expression is always an OpExpr type, otherwise if the non-constant part contains only one variable, then it is a Var type. We can add a constraint that we will transform expressions with the simple variables like x=1 or x=2 or x=3, etc., but expressions like x*1+y=1 or x*2+y=2... we ignore. But then, we do not consider expressions when the nonconstant part is always the same for expressions. For example, we could transform x*1+y=1 or x*1+y=2... to x*1+y = ANY([1,2,...]). But I think it's not so critical, because such cases are rare. > >> Index Scan using pg_class_oid_index on pg_class (cost=0.27..2859.42 rows=414 width=68) (actual time=1.504..34.183 rows=260loops=1) >> Index Cond: (oid = ANY (ARRAY['1'::oid, '2'::oid, '3'::oid, '4'::oid, '5'::oid, '6'::oid, '7'::oid, >> >> Bitmap Heap Scan on pg_class (cost=43835.00..54202.14 rows=414 width=68) (actual time=39.958..41.293 rows=260 loops=1) >> Recheck Cond: ((oid = '1'::oid) OR (oid = '2'::oid) OR (oid = '3'::oid) OR (oid = '4'::oid) OR (oid = >> >> I think we could see which value is lower, and if lower with expressions converted to ANY, then work with it further,otherwise work with the original "OR" expressions. But we still need to make this conversion to find out its cost. > To me, this sort of output suggests that perhaps the transformation is > being done in the wrong place. I expect that we have to decide whether > to convert from OR to = ANY(...) at a very early stage of the planner, > before we have any idea what the selected path will ultimately be. But > this output suggests that we want the answer to depend on which kind > of path is going to be faster, which would seem to argue for doing > this sort of transformation as part of path generation for only those > paths that will benefit from it, rather than during earlier phases of > expression processing/simplification. > > I'm not sure I have the full picture here, though, so I might have > this all wrong. > This would be the most ideal option, and to be honest, I like the conversion at an early stage also because there are no problems with selectivity or link updates if we changed the structure of RestrictInfo of relation. But in terms of calculating which option is better to use transformed or original, I think this solution might be complicated, since we need not only to highlight the cases in which the transformation wins in principle, but also with which types of data it will work best and there is a risk of missing some cases and we may need the own evaluation model. Now it's hard for me to come up with something simple. The cost option seems simpler and clearer to me, but yes, it is difficult to decide when it is better to do the conversion for the most correct estimate. -- Regards, Alena Rybakina
On Thu, Oct 26, 2023 at 12:59 PM Robert Haas <robertmhaas@gmail.com> wrote: > Alexander's example seems to show that it's not that simple. If I'm > reading his example correctly, with things like aid = 1, the > transformation usually wins even if the number of things in the OR > expression is large, but with things like aid + 1 * bid = 1, the > transformation seems to lose at least with larger numbers of items. So > it's not JUST the number of OR elements but also what they contain, > unless I'm misunderstanding his point. Alexander said "Generally, I don't see why ANY could be executed slower than the equivalent OR clause". I understood that this was his way of expressing the following idea: "In principle, there is no reason to expect execution of ANY() to be slower than execution of an equivalent OR clause (except for noise-level differences). While it might not actually look that way for every single type of plan you can imagine right now, that doesn't argue for making a cost-based decision. It actually argues for fixing the underlying issue, which can't possibly be due to some kind of fundamental advantage enjoyed by expression evaluation with ORs". This is also what I think of all this. Alexander's partial index example had this quality to it. Obviously, the planner *could* be taught to do the right thing with such a case, with a little more work. The fact that it doesn't right now is definitely a problem, and should probably be treated as a blocker for this patch. But that doesn't really argue against the general idea behind the patch -- it just argues for fixing that one problem. There may also be a separate problem that comes from the added planner cycles required to do the transformation -- particularly in extreme or adversarial cases. We should worry about that, too. But, again, it doesn't change the basic fact, which is that having a standard/normalized representation of OR lists/DNF transformation is extremely useful in general, and *shouldn't* result in any real slowdowns at execution time if done well. > To me, this sort of output suggests that perhaps the transformation is > being done in the wrong place. I expect that we have to decide whether > to convert from OR to = ANY(...) at a very early stage of the planner, > before we have any idea what the selected path will ultimately be. But > this output suggests that we want the answer to depend on which kind > of path is going to be faster, which would seem to argue for doing > this sort of transformation as part of path generation for only those > paths that will benefit from it, rather than during earlier phases of > expression processing/simplification. I don't think that that's the right direction. They're semantically equivalent things. But a SAOP-based plan can be fundamentally better, since SAOPs enable passing down useful context to index AMs (at least nbtree). And because we can use a hash table for SAOP expression evaluation. It's a higher level, standardized, well optimized way of expressing exactly the same concept. I can come up with a case that'll be orders of magnitude more efficient with this patch, despite the transformation process only affecting a small OR list of 3 or 5 elements -- a 100x reduction in heap page accesses is quite possible. This is particularly likely to come up if you assume that the nbtree patch that I'm currently working on is also available. In general, I think that we totally over-rely on bitmap index scans, especially BitmapOrs. -- Peter Geoghegan
Hi!
I think it would be more correct to finalize the current approach to converting "OR" expressions to "ANY", since quite a few problems related to this patch have already been found here, I think you can solve them first, and then you can move on.On Thu, Oct 26, 2023 at 12:59 PM Robert Haas <robertmhaas@gmail.com> wrote:Alexander's example seems to show that it's not that simple. If I'm reading his example correctly, with things like aid = 1, the transformation usually wins even if the number of things in the OR expression is large, but with things like aid + 1 * bid = 1, the transformation seems to lose at least with larger numbers of items. So it's not JUST the number of OR elements but also what they contain, unless I'm misunderstanding his point.Alexander said "Generally, I don't see why ANY could be executed slower than the equivalent OR clause". I understood that this was his way of expressing the following idea: "In principle, there is no reason to expect execution of ANY() to be slower than execution of an equivalent OR clause (except for noise-level differences). While it might not actually look that way for every single type of plan you can imagine right now, that doesn't argue for making a cost-based decision. It actually argues for fixing the underlying issue, which can't possibly be due to some kind of fundamental advantage enjoyed by expression evaluation with ORs". This is also what I think of all this. Alexander's partial index example had this quality to it. Obviously, the planner *could* be taught to do the right thing with such a case, with a little more work. The fact that it doesn't right now is definitely a problem, and should probably be treated as a blocker for this patch. But that doesn't really argue against the general idea behind the patch -- it just argues for fixing that one problem. There may also be a separate problem that comes from the added planner cycles required to do the transformation -- particularly in extreme or adversarial cases. We should worry about that, too. But, again, it doesn't change the basic fact, which is that having a standard/normalized representation of OR lists/DNF transformation is extremely useful in general, and *shouldn't* result in any real slowdowns at execution time if done well.
Regarding the application of the transformation at an early stage, the patch is almost ready, except for solving cases related to queries that work slower. I haven't figured out how to exclude such requests without comparing the cost or parameter by the number of OR elements yet. The simplest option is not to process Expr types (already mentioned earlier) in the queries that Alexander gave as an example, but as I already said, I don't like this approach very much.To me, this sort of output suggests that perhaps the transformation is being done in the wrong place. I expect that we have to decide whether to convert from OR to = ANY(...) at a very early stage of the planner, before we have any idea what the selected path will ultimately be. But this output suggests that we want the answer to depend on which kind of path is going to be faster, which would seem to argue for doing this sort of transformation as part of path generation for only those paths that will benefit from it, rather than during earlier phases of expression processing/simplification.I don't think that that's the right direction. They're semantically equivalent things. But a SAOP-based plan can be fundamentally better, since SAOPs enable passing down useful context to index AMs (at least nbtree). And because we can use a hash table for SAOP expression evaluation. It's a higher level, standardized, well optimized way of expressing exactly the same concept. I can come up with a case that'll be orders of magnitude more efficient with this patch, despite the transformation process only affecting a small OR list of 3 or 5 elements -- a 100x reduction in heap page accesses is quite possible. This is particularly likely to come up if you assume that the nbtree patch that I'm currently working on is also available. In general, I think that we totally over-rely on bitmap index scans, especially BitmapOrs.
-- Regards, Alena Rybakina Postgres Professional
On Thu, Oct 26, 2023 at 5:05 PM Peter Geoghegan <pg@bowt.ie> wrote: > On Thu, Oct 26, 2023 at 12:59 PM Robert Haas <robertmhaas@gmail.com> wrote: > > Alexander's example seems to show that it's not that simple. If I'm > > reading his example correctly, with things like aid = 1, the > > transformation usually wins even if the number of things in the OR > > expression is large, but with things like aid + 1 * bid = 1, the > > transformation seems to lose at least with larger numbers of items. So > > it's not JUST the number of OR elements but also what they contain, > > unless I'm misunderstanding his point. > > Alexander said "Generally, I don't see why ANY could be executed > slower than the equivalent OR clause". I understood that this was his > way of expressing the following idea: > > "In principle, there is no reason to expect execution of ANY() to be > slower than execution of an equivalent OR clause (except for > noise-level differences). While it might not actually look that way > for every single type of plan you can imagine right now, that doesn't > argue for making a cost-based decision. It actually argues for fixing > the underlying issue, which can't possibly be due to some kind of > fundamental advantage enjoyed by expression evaluation with ORs". > > This is also what I think of all this. I agree with that, with some caveats, mainly that the reverse is to some extent also true. Maybe not completely, because arguably the ANY() formulation should just be straight-up easier to deal with, but in principle, the two are equivalent and it shouldn't matter which representation we pick. But practically, it may, and we need to be sure that we don't put in place a translation that is theoretically a win but in practice leads to large regressions. Avoiding regressions here is more important than capturing all the possible gains. A patch that wins in some scenarios and does nothing in others can be committed; a patch that wins in even more scenarios but causes serious regressions in some cases probably can't. -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Oct 30, 2023 at 3:40 PM Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Oct 26, 2023 at 5:05 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Thu, Oct 26, 2023 at 12:59 PM Robert Haas <robertmhaas@gmail.com> wrote: > > > Alexander's example seems to show that it's not that simple. If I'm > > > reading his example correctly, with things like aid = 1, the > > > transformation usually wins even if the number of things in the OR > > > expression is large, but with things like aid + 1 * bid = 1, the > > > transformation seems to lose at least with larger numbers of items. So > > > it's not JUST the number of OR elements but also what they contain, > > > unless I'm misunderstanding his point. > > > > Alexander said "Generally, I don't see why ANY could be executed > > slower than the equivalent OR clause". I understood that this was his > > way of expressing the following idea: > > > > "In principle, there is no reason to expect execution of ANY() to be > > slower than execution of an equivalent OR clause (except for > > noise-level differences). While it might not actually look that way > > for every single type of plan you can imagine right now, that doesn't > > argue for making a cost-based decision. It actually argues for fixing > > the underlying issue, which can't possibly be due to some kind of > > fundamental advantage enjoyed by expression evaluation with ORs". > > > > This is also what I think of all this. > > I agree with that, with some caveats, mainly that the reverse is to > some extent also true. Maybe not completely, because arguably the > ANY() formulation should just be straight-up easier to deal with, but > in principle, the two are equivalent and it shouldn't matter which > representation we pick. > > But practically, it may, and we need to be sure that we don't put in > place a translation that is theoretically a win but in practice leads > to large regressions. Avoiding regressions here is more important than > capturing all the possible gains. A patch that wins in some scenarios > and does nothing in others can be committed; a patch that wins in even > more scenarios but causes serious regressions in some cases probably > can't. +1 Sure, I've identified two cases where patch shows regression [1]. The first one (quadratic complexity of expression processing) should be already addressed by usage of hash. The second one (planning regression with Bitmap OR) is not yet addressed. Links 1. https://www.postgresql.org/message-id/CAPpHfduJtO0s9E%3DSHUTzrCD88BH0eik0UNog1_q3XBF2wLmH6g%40mail.gmail.com ------ Regards, Alexander Korotkov
On Mon, Oct 30, 2023 at 6:40 AM Robert Haas <robertmhaas@gmail.com> wrote: > I agree with that, with some caveats, mainly that the reverse is to > some extent also true. Maybe not completely, because arguably the > ANY() formulation should just be straight-up easier to deal with, but > in principle, the two are equivalent and it shouldn't matter which > representation we pick. I recently looked into MySQL's handling of these issues, which is more mature and better documented than what we can do. EXPLAIN ANALYZE will show an IN() list as if the query had been written as a list of ORs, even though it can efficiently execute an index scan that uses IN()/"OR var = constant" lists. So I agree with what you said here. It is perhaps just as accident of history that we're talking about converting to a ScalarArrayOpExpr, rather than talking about converting to some other clause type that we associate with OR lists. The essential point is that there ought to be one clause type that is easier to deal with. > But practically, it may, and we need to be sure that we don't put in > place a translation that is theoretically a win but in practice leads > to large regressions. Avoiding regressions here is more important than > capturing all the possible gains. A patch that wins in some scenarios > and does nothing in others can be committed; a patch that wins in even > more scenarios but causes serious regressions in some cases probably > can't. I agree. Most of the really big wins here will come from simple transformations. I see no reason why we can't take an incremental approach. In fact I think we almost have to do so, since as I understand it the transformations are just infeasible in certain extreme cases. -- Peter Geoghegan
On 30.10.2023 17:06, Alexander Korotkov wrote: > On Mon, Oct 30, 2023 at 3:40 PM Robert Haas <robertmhaas@gmail.com> wrote: >> On Thu, Oct 26, 2023 at 5:05 PM Peter Geoghegan <pg@bowt.ie> wrote: >>> On Thu, Oct 26, 2023 at 12:59 PM Robert Haas <robertmhaas@gmail.com> wrote: >>>> Alexander's example seems to show that it's not that simple. If I'm >>>> reading his example correctly, with things like aid = 1, the >>>> transformation usually wins even if the number of things in the OR >>>> expression is large, but with things like aid + 1 * bid = 1, the >>>> transformation seems to lose at least with larger numbers of items. So >>>> it's not JUST the number of OR elements but also what they contain, >>>> unless I'm misunderstanding his point. >>> Alexander said "Generally, I don't see why ANY could be executed >>> slower than the equivalent OR clause". I understood that this was his >>> way of expressing the following idea: >>> >>> "In principle, there is no reason to expect execution of ANY() to be >>> slower than execution of an equivalent OR clause (except for >>> noise-level differences). While it might not actually look that way >>> for every single type of plan you can imagine right now, that doesn't >>> argue for making a cost-based decision. It actually argues for fixing >>> the underlying issue, which can't possibly be due to some kind of >>> fundamental advantage enjoyed by expression evaluation with ORs". >>> >>> This is also what I think of all this. >> I agree with that, with some caveats, mainly that the reverse is to >> some extent also true. Maybe not completely, because arguably the >> ANY() formulation should just be straight-up easier to deal with, but >> in principle, the two are equivalent and it shouldn't matter which >> representation we pick. >> >> But practically, it may, and we need to be sure that we don't put in >> place a translation that is theoretically a win but in practice leads >> to large regressions. Avoiding regressions here is more important than >> capturing all the possible gains. A patch that wins in some scenarios >> and does nothing in others can be committed; a patch that wins in even >> more scenarios but causes serious regressions in some cases probably >> can't. > +1 > Sure, I've identified two cases where patch shows regression [1]. The > first one (quadratic complexity of expression processing) should be > already addressed by usage of hash. The second one (planning > regression with Bitmap OR) is not yet addressed. > > Links > 1. https://www.postgresql.org/message-id/CAPpHfduJtO0s9E%3DSHUTzrCD88BH0eik0UNog1_q3XBF2wLmH6g%40mail.gmail.com > I also support this approach. I have almost finished writing a patch that fixes the first problem related to the quadratic complexity of processing expressions by adding a hash table. I also added a check: if the number of groups is equal to the number of OR expressions, we assume that no expressions need to be converted and interrupt further execution. Now I am trying to fix the last problem in this patch: three tests have indicated a problem related to incorrect conversion. I don't think it can be serious, but I haven't figured out where the mistake is yet. I added log like that: ERROR: unrecognized node type: 0. -- Regards, Alena Rybakina Postgres Professional
Attachment
On 06.11.2023 16:51, Alena Rybakina wrote: > I also support this approach. I have almost finished writing a patch > that fixes the first problem related to the quadratic complexity of > processing expressions by adding a hash table. > > I also added a check: if the number of groups is equal to the number > of OR expressions, we assume that no expressions need to be converted > and interrupt further execution. > > Now I am trying to fix the last problem in this patch: three tests > have indicated a problem related to incorrect conversion. I don't > think it can be serious, but I haven't figured out where the mistake > is yet. > > I added log like that: ERROR: unrecognized node type: 0. I fixed this issue and added some cosmetic refactoring. The changes are presented in the or_patch_changes.diff file. -- Regards, Alena Rybakina Postgres Professional
Attachment
Hi, all! These days I was porting a patch for converting or expressions to ANY to the choose_bitmap_and function. Unfortunately, it is not possible to transfer the conversion there, since expressions are processed one by one, as far as I saw. Therefore, I tried to make the conversion earlier in the generate_bitmap_or_paths function, there is just a loop bypass. The patch turns out to be quite complicated, in my opinion, and to be honest, it does not work fully yet. Also, due to the fact that the index for the ScalarOpExpr expression is created earlier (approximately 344 lines in the src/backend/optimizer/path/indxpath.c file), we had to call the generate_bitmap_or_paths function earlier. I haven't seen yet what problems this could potentially lead to. Patch in the attached diff file. In the last letter, I had an incorrect numbering for the original patch, corrected, respectively, it is unclear whether the tests in CI were normal. Corrected it.
Attachment
On 10/11/2023 16:20, Alena Rybakina wrote: >> I added log like that: ERROR: unrecognized node type: 0. > I fixed this issue and added some cosmetic refactoring. > The changes are presented in the or_patch_changes.diff file. Looking into the patch, I found some trivial improvements (see attachment). Also, it is not obvious that using a string representation of the clause as a hash table key is needed here. Also, by making a copy of the node in the get_key_nconst_node(), you replace the location field, but in the case of complex expression, you don't do the same with other nodes. I propose to generate expression hash instead + prove the equality of two expressions by calling equal(). -- regards, Andrei Lepikhov Postgres Professional
Attachment
On 20.11.2023 11:52, Andrei Lepikhov wrote: > On 10/11/2023 16:20, Alena Rybakina wrote: >>> I added log like that: ERROR: unrecognized node type: 0. >> I fixed this issue and added some cosmetic refactoring. >> The changes are presented in the or_patch_changes.diff file. > > Looking into the patch, I found some trivial improvements (see > attachment). > Also, it is not obvious that using a string representation of the > clause as a hash table key is needed here. Also, by making a copy of > the node in the get_key_nconst_node(), you replace the location field, > but in the case of complex expression, you don't do the same with > other nodes. > I propose to generate expression hash instead + prove the equality of > two expressions by calling equal(). > Thank you! I agree with your changes.
On 20.11.2023 11:52, Andrei Lepikhov wrote: > Looking into the patch, I found some trivial improvements (see > attachment). > Also, it is not obvious that using a string representation of the > clause as a hash table key is needed here. Also, by making a copy of > the node in the get_key_nconst_node(), you replace the location field, > but in the case of complex expression, you don't do the same with > other nodes. > I propose to generate expression hash instead + prove the equality of > two expressions by calling equal(). > I was thinking about your last email and a possible error where the location field may not be cleared in complex expressions. Unfortunately, I didn't come up with any examples either, but I think I was able to handle this with a special function that removes location-related patterns. The alternative to this is to bypass this expression, but I think it will be more invasive. In addition, I have added changes related to the hash table: now the key is of type int. All changes are displayed in the attached v9-0001-Replace-OR-clause-to_ANY.diff.txt file. I haven't measured it yet. But what do you think about these changes? -- Regards, Alena Rybakina Postgres Professional
Attachment
On 21.11.2023 03:50, Alena Rybakina wrote: > On 20.11.2023 11:52, Andrei Lepikhov wrote: >> Looking into the patch, I found some trivial improvements (see >> attachment). >> Also, it is not obvious that using a string representation of the >> clause as a hash table key is needed here. Also, by making a copy of >> the node in the get_key_nconst_node(), you replace the location >> field, but in the case of complex expression, you don't do the same >> with other nodes. >> I propose to generate expression hash instead + prove the equality of >> two expressions by calling equal(). >> > I was thinking about your last email and a possible error where the > location field may not be cleared in complex expressions. > Unfortunately, I didn't come up with any examples either, but I think > I was able to handle this with a special function that removes > location-related patterns. The alternative to this is to bypass this > expression, but I think it will be more invasive. In addition, I have > added changes related to the hash table: now the key is of type int. > > All changes are displayed in the attached > v9-0001-Replace-OR-clause-to_ANY.diff.txt file. > > I haven't measured it yet. But what do you think about these changes? > > Sorry, I lost your changes during the revision process. I returned them. I raised the patch version just in case to run ci successfully. -- Regards, Alena Rybakina Postgres Professional
Attachment
On 21/11/2023 18:31, Alena Rybakina wrote: > Sorry, I lost your changes during the revision process. I returned > them. I raised the patch version just in case to run ci successfully. I think the usage of nodeToString for the generation of clause hash is too expensive and buggy. Also, in the code, you didn't resolve hash collisions. So, I've rewritten the patch a bit (see the attachment). One more thing: I propose to enable transformation by default at least for quick detection of possible issues. This code changes tests in many places. But, as I see it, it mostly demonstrates the positive effect of the transformation. -- regards, Andrei Lepikhov Postgres Professional
Attachment
On 23/11/2023 16:23, Andrei Lepikhov wrote: > This code changes tests in many places. But, as I see it, it mostly > demonstrates the positive effect of the transformation. I found out that the postgres_fdw tests were impacted by the feature. Fix it, because the patch is on the commitfest and passes buildfarm. Taking advantage of this, I suppressed the expression evaluation procedure to make regression test changes more clear. -- regards, Andrei Lepikhov Postgres Professional
Attachment
On 23.11.2023 12:23, Andrei Lepikhov wrote: > I think the usage of nodeToString for the generation of clause hash is > too expensive and buggy. > Also, in the code, you didn't resolve hash collisions. So, I've > rewritten the patch a bit (see the attachment). > One more thing: I propose to enable transformation by default at least > for quick detection of possible issues. > This code changes tests in many places. But, as I see it, it mostly > demonstrates the positive effect of the transformation. On 24.11.2023 06:30, Andrei Lepikhov wrote: > On 23/11/2023 16:23, Andrei Lepikhov wrote: >> This code changes tests in many places. But, as I see it, it mostly >> demonstrates the positive effect of the transformation. > > I found out that the postgres_fdw tests were impacted by the feature. > Fix it, because the patch is on the commitfest and passes buildfarm. > Taking advantage of this, I suppressed the expression evaluation > procedure to make regression test changes more clear. Thank you for your work. You are right, the patch with the current changes looks better and works more correctly. To be honest, I didn't think we could use JumbleExpr in this way. -- Regards, Alena Rybakina Postgres Professional
Hi! On Mon, Nov 13, 2023 at 9:48 PM a.rybakina <a.rybakina@postgrespro.ru> wrote: > These days I was porting a patch for converting or expressions to ANY to > the choose_bitmap_and function. Unfortunately, it is not possible to > transfer the conversion there, since expressions are processed one by > one, as far as I saw. Therefore, I tried to make the conversion earlier > in the generate_bitmap_or_paths function, there is just a loop bypass. > The patch turns out to be quite complicated, in my opinion, and to be > honest, it does not work fully yet. Also, due to the fact that the index > for the ScalarOpExpr expression is created earlier (approximately 344 > lines in the src/backend/optimizer/path/indxpath.c file), we had to call > the generate_bitmap_or_paths function earlier. I haven't seen yet what > problems this could potentially lead to. Patch in the attached diff file. It seems to me there is a confusion. I didn't mean we need to move conversion of OR-expressions to ANY into choose_bitmap_and() function or anything like this. My idea was to avoid degradation of plans, which I've seen in [1]. Current code for generation of bitmap paths considers the possibility to split OR-expressions into distinct bitmap index scans. But it doesn't consider this possibility for ANY-expressions. So, my idea was to enhance our bitmap scan generation to consider split values of ANY-expressions into distinct bitmap index scans. So, in the example [1] and similar queries conversion of OR-expressions to ANY wouldn't affect the generation of bitmap paths. Links 1. https://www.postgresql.org/message-id/CAPpHfduJtO0s9E=SHUTzrCD88BH0eik0UNog1_q3XBF2wLmH6g@mail.gmail.com ------ Regards, Alexander Korotkov
On Fri, Nov 24, 2023 at 7:05 AM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > On 23.11.2023 12:23, Andrei Lepikhov wrote: > > I think the usage of nodeToString for the generation of clause hash is > > too expensive and buggy. > > Also, in the code, you didn't resolve hash collisions. So, I've > > rewritten the patch a bit (see the attachment). > > One more thing: I propose to enable transformation by default at least > > for quick detection of possible issues. > > This code changes tests in many places. But, as I see it, it mostly > > demonstrates the positive effect of the transformation. > > On 24.11.2023 06:30, Andrei Lepikhov wrote: > > > On 23/11/2023 16:23, Andrei Lepikhov wrote: > >> This code changes tests in many places. But, as I see it, it mostly > >> demonstrates the positive effect of the transformation. > > > > I found out that the postgres_fdw tests were impacted by the feature. > > Fix it, because the patch is on the commitfest and passes buildfarm. > > Taking advantage of this, I suppressed the expression evaluation > > procedure to make regression test changes more clear. > > Thank you for your work. You are right, the patch with the current > changes looks better and works more correctly. > > To be honest, I didn't think we could use JumbleExpr in this way. I think patch certainly gets better in this aspect. One thing I can't understand is why do we use home-grown code for resolving hash-collisions. You can just define custom hash and match functions in HASHCTL. Even if we need to avoid repeated JumbleExpr calls, we still can save pre-calculated hash value into hash entry and use custom hash and match. This doesn't imply us to write our own collision-resolving code. ------ Regards, Alexander Korotkov
Thanks for the explanation, yes, I did not understand the idea correctly at first. I will try to implement something similar.It seems to me there is a confusion. I didn't mean we need to move conversion of OR-expressions to ANY into choose_bitmap_and() function or anything like this. My idea was to avoid degradation of plans, which I've seen in [1]. Current code for generation of bitmap paths considers the possibility to split OR-expressions into distinct bitmap index scans. But it doesn't consider this possibility for ANY-expressions. So, my idea was to enhance our bitmap scan generation to consider split values of ANY-expressions into distinct bitmap index scans. So, in the example [1] and similar queries conversion of OR-expressions to ANY wouldn't affect the generation of bitmap paths.
-- Regards, Alena Rybakina Postgres Professional
On Sat, Nov 25, 2023 at 1:10 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > On 25.11.2023 04:13, Alexander Korotkov wrote: > > It seems to me there is a confusion. I didn't mean we need to move > conversion of OR-expressions to ANY into choose_bitmap_and() function > or anything like this. My idea was to avoid degradation of plans, > which I've seen in [1]. Current code for generation of bitmap paths > considers the possibility to split OR-expressions into distinct bitmap > index scans. But it doesn't consider this possibility for > ANY-expressions. So, my idea was to enhance our bitmap scan > generation to consider split values of ANY-expressions into distinct > bitmap index scans. So, in the example [1] and similar queries > conversion of OR-expressions to ANY wouldn't affect the generation of > bitmap paths. > > Thanks for the explanation, yes, I did not understand the idea correctly at first. I will try to implement something similar. Alena, great, thank you. I'm looking forward to the updated patch. ------ Regards, Alexander Korotkov
On 25/11/2023 08:23, Alexander Korotkov wrote: > I think patch certainly gets better in this aspect. One thing I can't > understand is why do we use home-grown code for resolving > hash-collisions. You can just define custom hash and match functions > in HASHCTL. Even if we need to avoid repeated JumbleExpr calls, we > still can save pre-calculated hash value into hash entry and use > custom hash and match. This doesn't imply us to write our own > collision-resolving code. Thanks, it was an insightful suggestion. I implemented it, and the code has become shorter (see attachment). -- regards, Andrei Lepikhov Postgres Professional
Attachment
On Mon, Nov 27, 2023 at 3:02 AM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > On 25/11/2023 08:23, Alexander Korotkov wrote: > > I think patch certainly gets better in this aspect. One thing I can't > > understand is why do we use home-grown code for resolving > > hash-collisions. You can just define custom hash and match functions > > in HASHCTL. Even if we need to avoid repeated JumbleExpr calls, we > > still can save pre-calculated hash value into hash entry and use > > custom hash and match. This doesn't imply us to write our own > > collision-resolving code. > > Thanks, it was an insightful suggestion. > I implemented it, and the code has become shorter (see attachment). Neither the code comments nor the commit message really explain the design idea here. That's unfortunate, principally because it makes review difficult. I'm very skeptical about the idea of using JumbleExpr for any part of this. It seems fairly expensive, and it might produce false matches. If expensive is OK, then why not just use equal()? If it's not, then this probably isn't really OK either. But in any case there should be comments explaining why this strategy was chosen. The use of op_mergejoinable() seems pretty random to me. Why should we care about that? If somebody writes a<1 or a<2 or a<3 or a<4, you can transform that to a<any(array[1,2,3,4]) if you want. It might not be a good idea, but I think it's a legal transformation. The reader shouldn't be left to guess whether a rule like this was made for reasons of correctness or for reasons of efficiency or something else. Looking further, I see that the reason for this is likely that the operator for the transformation result is constructing using list_make1(makeString((char *) "=")), but trying to choose an operator based on the operator name is, I think, pretty clearly unacceptable. Tom has fired more than one hacker out of an airlock for such transgressions, and this violation seems less principled than some. The = operator that got chosen could be entirely unrelated to any operator in the original, untransformed query. It could be part of no operator class that was involved in the original query, in a different schema than the operator in the original query, and owned by a different user than the one who owned any operator referenced by the original query. I suspect that's not only incorrect but an exploitable security vulnerability. I am extremely dubious about the use of select_common_type() here. Why not do this only when the types already match exactly? Maybe the concern is unknown literals, but perhaps that should be handled in some other way. If you do this kind of thing, you need to justify why it can't fail or produce wrong answers. Honestly, it seems very hard to avoid the conclusion that this transformation is being done at too early a stage. Parse analysis is not the time to try to do query optimization. I can't really believe that there's a way to produce a committable patch along these lines. Ideally, a transformation like this should be done after we know what plan shape we're using (or considering using), so that we can make cost-based decisions about whether to transform or not. But at the very least it should happen somewhere in the planner. There's really no justification for parse analysis rewriting the SQL that the user entered. -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Nov 27, 2023 at 1:04 PM Robert Haas <robertmhaas@gmail.com> wrote: > The use of op_mergejoinable() seems pretty random to me. Why should we > care about that? If somebody writes a<1 or a<2 or a<3 or a<4, you can > transform that to a<any(array[1,2,3,4]) if you want. It might not be a > good idea, but I think it's a legal transformation. That kind of transformation is likely to be a very good idea, because nbtree's _bt_preprocess_array_keys() function knows how to perform preprocessing that makes the final index qual "a < 1". Obviously that could be far more efficient. Further suppose you have a machine generated query "a<1 or a<2 or a<3 or a<4 AND a = 2" -- same as before, except that I added "AND a = 2" to the end. Now _bt_preprocess_array_keys() will be able to do the aforementioned inequality preprocessing, just as before. But this time _bt_preprocess_keys() (a different function with a similar name) can see that the quals are contradictory. That makes the entire index scan end, before it ever really began. Obviously, this is an example of a more general principle: a great deal of the benefit of these transformations is indirect, in the sense that they come from enabling further transformations/optimizations, that apply in the context of some particular query. So you have to think holistically. It's perhaps a little unfortunate that all of this nbtree preprocessing stuff is totally opaque to the planner. Tom has expressed concerns about that in the past, FWIW: https://www.postgresql.org/message-id/2587523.1647982549@sss.pgh.pa.us (see the final paragraph for the reference) There might be some bigger picture to doing all of these transformations, in a way that maximizes opportunities to apply further transformations/optimizations. You know much more about the optimizer than I do, so maybe this is already very obvious. Just pointing it out. > Honestly, it seems very hard to avoid the conclusion that this > transformation is being done at too early a stage. Parse analysis is > not the time to try to do query optimization. I can't really believe > that there's a way to produce a committable patch along these lines. > Ideally, a transformation like this should be done after we know what > plan shape we're using (or considering using), so that we can make > cost-based decisions about whether to transform or not. But at the > very least it should happen somewhere in the planner. There's really > no justification for parse analysis rewriting the SQL that the user > entered. I am sure that there is a great deal of truth to this. The general conclusion about parse analysis being the wrong place for this seems very hard to argue with. But I'm much less sure that there needs to be a conventional cost model. The planner's cost model is supposed to have some basis in physical runtime costs, which is not the case for any of these transformations. Not in any general sense; they're just transformations that enable finding a cheaper way to execute the query. While they have to pay for themselves, in some sense, I think that that's purely a matter of managing the added planner cycles. In principle they shouldn't have any direct impact on the physical costs incurred by physical operators. No? As I keep pointing out, there is a sound theoretical basis to the idea of normalizing to conjunctive normal form as its own standard step in query processing. To some extent we do this already, but it's all rather ad-hoc. Even if (say) the nbtree preprocessing transformations that I described were something that the planner already knew about directly, they still wouldn't really need to be costed. They're pretty much strictly better at runtime (at most you only have to worry about the fixed cost of determining if they apply at all). -- Peter Geoghegan
On Mon, Nov 27, 2023 at 1:04 PM Robert Haas <robertmhaas@gmail.com> wrote:
> The use of op_mergejoinable() seems pretty random to me. Why should we
> care about that? If somebody writes a<1 or a<2 or a<3 or a<4, you can
> transform that to a<any(array[1,2,3,4]) if you want. It might not be a
> good idea, but I think it's a legal transformation.
That kind of transformation is likely to be a very good idea, because
nbtree's _bt_preprocess_array_keys() function knows how to perform
preprocessing that makes the final index qual "a < 1". Obviously that
could be far more efficient.
Further suppose you have a machine generated query "a<1 or a<2 or a<3
or a<4 AND a = 2" -- same as before, except that I added "AND a = 2"
to the end. Now _bt_preprocess_array_keys() will be able to do the
aforementioned inequality preprocessing, just as before. But this time
_bt_preprocess_keys() (a different function with a similar name) can
see that the quals are contradictory. That makes the entire index scan
end, before it ever really began.
On Mon, Nov 27, 2023 at 5:16 PM Peter Geoghegan <pg@bowt.ie> wrote: > [ various observations ] This all seems to make sense but I don't have anything particular to say about it. > I am sure that there is a great deal of truth to this. The general > conclusion about parse analysis being the wrong place for this seems > very hard to argue with. But I'm much less sure that there needs to be > a conventional cost model. I'm not sure about that part, either. The big reason we shouldn't do this in parse analysis is that parse analysis is supposed to produce an internal representation which is basically just a direct translation of what the user entered. The representation should be able to be deparsed to produce more or less what the user entered without significant transformations. References to objects like tables and operators do get resolved to OIDs at this stage, so deparsing results will vary if objects are renamed or the search_path changes and more or less schema-qualification is required or things like that, but the output of parse analysis is supposed to preserve the meaning of the query as entered by the user. The right place to do optimization is in the optimizer. But where in the optimizer to do it is an open question in my mind. Previous discussion suggests to me that we might not really have enough information at the beginning, because it seems like the right thing to do depends on which plan we ultimately choose to use, which gets to what you say here: > The planner's cost model is supposed to have some basis in physical > runtime costs, which is not the case for any of these transformations. > Not in any general sense; they're just transformations that enable > finding a cheaper way to execute the query. While they have to pay for > themselves, in some sense, I think that that's purely a matter of > managing the added planner cycles. In principle they shouldn't have > any direct impact on the physical costs incurred by physical > operators. No? Right. It's just that, as a practical matter, some of the operators deal with one form better than the other. So if we waited until we knew which operator we were using to decide on which form to pick, that would let us be smart. > As I keep pointing out, there is a sound theoretical basis to the idea > of normalizing to conjunctive normal form as its own standard step in > query processing. To some extent we do this already, but it's all > rather ad-hoc. Even if (say) the nbtree preprocessing transformations > that I described were something that the planner already knew about > directly, they still wouldn't really need to be costed. They're pretty > much strictly better at runtime (at most you only have to worry about > the fixed cost of determining if they apply at all). It's just a matter of figuring out where we can put the logic and have the result make sense. We'd like to put it someplace where it's not too expensive and gets the right answer. -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Nov 27, 2023 at 4:07 PM Robert Haas <robertmhaas@gmail.com> wrote: > > I am sure that there is a great deal of truth to this. The general > > conclusion about parse analysis being the wrong place for this seems > > very hard to argue with. But I'm much less sure that there needs to be > > a conventional cost model. > > I'm not sure about that part, either. The big reason we shouldn't do > this in parse analysis is that parse analysis is supposed to produce > an internal representation which is basically just a direct > translation of what the user entered. The representation should be > able to be deparsed to produce more or less what the user entered > without significant transformations. References to objects like tables > and operators do get resolved to OIDs at this stage, so deparsing > results will vary if objects are renamed or the search_path changes > and more or less schema-qualification is required or things like that, > but the output of parse analysis is supposed to preserve the meaning > of the query as entered by the user. One of the reasons why we shouldn't do this during parse analysis is because query rewriting might matter. But that doesn't mean that the transformation/normalization process must fundamentally be the responsibility of the optimizer, through process of elimination. Maybe it should be the responsibility of some other phase of query processing, invented solely to make life easier for the optimizer, but not formally part of query planning per se. > The right place to do > optimization is in the optimizer. Then why doesn't the optimizer do query rewriting? Isn't that also a kind of optimization, at least in part? > > The planner's cost model is supposed to have some basis in physical > > runtime costs, which is not the case for any of these transformations. > > Not in any general sense; they're just transformations that enable > > finding a cheaper way to execute the query. While they have to pay for > > themselves, in some sense, I think that that's purely a matter of > > managing the added planner cycles. In principle they shouldn't have > > any direct impact on the physical costs incurred by physical > > operators. No? > > Right. It's just that, as a practical matter, some of the operators > deal with one form better than the other. So if we waited until we > knew which operator we were using to decide on which form to pick, > that would let us be smart. ISTM that the real problem is that this is true in the first place. If the optimizer had only one representation for any two semantically equivalent spellings of the same qual, then it would always use the best available representation. That seems even smarter, because that way the planner can be dumb and still look fairly smart at runtime. I am trying to be pragmatic, too (at least I think so). If having only one representation turns out to be very hard, then maybe they weren't ever really equivalent -- meaning it really is an optimization problem, and the responsibility of the planner. It seems like it would be more useful to spend time on making the world simpler for the optimizer, rather than spending time on making the optimizer smarter. Especially if we're talking about teaching the optimizer about what are actually fairly accidental differences that come from implementation details. I understand that it'll never be black and white. There are practical constraints on how far you go with this. We throw around terms like "semantically equivalent" as if everybody agreed on precisely what that means, which isn't really true (users complain when their view definition has "<>" instead of "!="). Even still, I bet that we could bring things far closer to this theoretical ideal, to good effect. > > As I keep pointing out, there is a sound theoretical basis to the idea > > of normalizing to conjunctive normal form as its own standard step in > > query processing. To some extent we do this already, but it's all > > rather ad-hoc. Even if (say) the nbtree preprocessing transformations > > that I described were something that the planner already knew about > > directly, they still wouldn't really need to be costed. They're pretty > > much strictly better at runtime (at most you only have to worry about > > the fixed cost of determining if they apply at all). > > It's just a matter of figuring out where we can put the logic and have > the result make sense. We'd like to put it someplace where it's not > too expensive and gets the right answer. Agreed. -- Peter Geoghegan
On 25.11.2023 19:13, Alexander Korotkov wrote: > On Sat, Nov 25, 2023 at 1:10 PM Alena Rybakina > <a.rybakina@postgrespro.ru> wrote: >> On 25.11.2023 04:13, Alexander Korotkov wrote: >> >> It seems to me there is a confusion. I didn't mean we need to move >> conversion of OR-expressions to ANY into choose_bitmap_and() function >> or anything like this. My idea was to avoid degradation of plans, >> which I've seen in [1]. Current code for generation of bitmap paths >> considers the possibility to split OR-expressions into distinct bitmap >> index scans. But it doesn't consider this possibility for >> ANY-expressions. So, my idea was to enhance our bitmap scan >> generation to consider split values of ANY-expressions into distinct >> bitmap index scans. So, in the example [1] and similar queries >> conversion of OR-expressions to ANY wouldn't affect the generation of >> bitmap paths. >> >> Thanks for the explanation, yes, I did not understand the idea correctly at first. I will try to implement something similar. > Alena, great, thank you. I'm looking forward to the updated patch. > I wrote the patch (any_to_or.diff.txt), although it is still under development (not all regression tests have been successful so far), it is already clear that for a query where a bad plan was chosen before, it is now choosing a more optimal query plan. postgres=# set enable_or_transformation =on; SET postgres=# explain select * from test where (x = 1 or x = 2) and y = 100; QUERY PLAN -------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on test (cost=8.60..12.62 rows=1 width=12) Recheck Cond: (((y = '100'::double precision) AND (x = 1)) OR ((y = '100'::double precision) AND (x = 2))) -> BitmapOr (cost=8.60..8.60 rows=1 width=0) -> Bitmap Index Scan on test_x_1_y (cost=0.00..4.30 rows=1 width=0) Index Cond: (y = '100'::double precision) -> Bitmap Index Scan on test_x_2_y (cost=0.00..4.30 rows=1 width=0) Index Cond: (y = '100'::double precision) (7 rows) While I'm thinking how to combine it now. BTW, while I was figuring out how create_index_paths works and creating bitmapscan indexes, I think I found a bug with unallocated memory (fix patch is bugfix.diff.txt). Without a fix here, it falls into the crust at the stage of assigning a value to any of the variables, specifically, skip_lower_stop and skip_nonnative_saop. I discovered it when I forced to form a bitmapindex plan for ANY (any_to_or.diff.txt). I'm causing a problem with my OR->ANY conversion patch. -- Regards, Alena Rybakina Postgres Professional
Attachment
On Mon, Nov 27, 2023 at 5:07 PM Peter Geoghegan <pg@bowt.ie> wrote: > One of the reasons why we shouldn't do this during parse analysis is > because query rewriting might matter. But that doesn't mean that the > transformation/normalization process must fundamentally be the > responsibility of the optimizer, through process of elimination. > > Maybe it should be the responsibility of some other phase of query > processing, invented solely to make life easier for the optimizer, but > not formally part of query planning per se. Support for SEARCH and CYCLE clauses for recursive CTEs (added by commit 3696a600e2) works by literally rewriting a parse node into a form involving RowExpr and ScalarArrayOpExpr during rewriting. See rewriteSearchAndCycle(). These implementation details are even mentioned in user-facing docs. Separately, the planner has long relied on certain generic normalization steps from rewriteHandler.c. For example, it reorders the targetlist from INSERT and UPDATE statements into what it knows to be standard order within the planner, for the planner's convenience. I'm not suggesting that these are any kind of precedent to follow now. Just that they hint that rewriting/transformation prior to query planning proper could be the right general approach. AFAICT that really is what is needed. That, plus the work of fixing any undesirable/unintended side effects that the transformations lead to, which might be a difficult task in its own right (it likely requires work in the planner). -- Peter Geoghegan
On 28/11/2023 04:03, Robert Haas wrote: > On Mon, Nov 27, 2023 at 3:02 AM Andrei Lepikhov > <a.lepikhov@postgrespro.ru> wrote: >> On 25/11/2023 08:23, Alexander Korotkov wrote: >>> I think patch certainly gets better in this aspect. One thing I can't >>> understand is why do we use home-grown code for resolving >>> hash-collisions. You can just define custom hash and match functions >>> in HASHCTL. Even if we need to avoid repeated JumbleExpr calls, we >>> still can save pre-calculated hash value into hash entry and use >>> custom hash and match. This doesn't imply us to write our own >>> collision-resolving code. >> >> Thanks, it was an insightful suggestion. >> I implemented it, and the code has become shorter (see attachment). > > Neither the code comments nor the commit message really explain the > design idea here. That's unfortunate, principally because it makes > review difficult. Yeah, it is still an issue. We will think about how to improve this; any suggestions are welcome. > I'm very skeptical about the idea of using JumbleExpr for any part of > this. It seems fairly expensive, and it might produce false matches. > If expensive is OK, then why not just use equal()? If it's not, then > this probably isn't really OK either. But in any case there should be > comments explaining why this strategy was chosen. We used the equal() routine without hashing in earlier versions. Hashing resolves issues with many different OR clauses. Is it expensive? Maybe, but we assume this transformation should be applied to simple enough expressions. > The use of op_mergejoinable() seems pretty random to me. Why should we > care about that? If somebody writes a<1 or a<2 or a<3 or a<4, you can > transform that to a<any(array[1,2,3,4]) if you want. It might not be a > good idea, but I think it's a legal transformation. You are right. The only reason was to obtain a working patch to benchmark and look for corner cases. We would rewrite that place but still live with the equivalence operator. > The reader shouldn't be left to guess whether a rule like this was made for > reasons of correctness or for reasons of efficiency or something else. > Looking further, I see that the reason for this is likely that the > operator for the transformation result is constructing using > list_make1(makeString((char *) "=")), but trying to choose an operator > based on the operator name is, I think, pretty clearly unacceptable. Yes, it was a big mistake. It is fixed in the new version (I guess). > I am extremely dubious about the use of select_common_type() here. Why > not do this only when the types already match exactly? Maybe the > concern is unknown literals, but perhaps that should be handled in > some other way. If you do this kind of thing, you need to justify why > it can't fail or produce wrong answers. Perhaps. We implemented your approach in the next version. At least we could see consequences. > Honestly, it seems very hard to avoid the conclusion that this > transformation is being done at too early a stage. Parse analysis is > not the time to try to do query optimization. I can't really believe > that there's a way to produce a committable patch along these lines. > Ideally, a transformation like this should be done after we know what > plan shape we're using (or considering using), so that we can make > cost-based decisions about whether to transform or not. But at the > very least it should happen somewhere in the planner. There's really > no justification for parse analysis rewriting the SQL that the user > entered. Here, we assume that array operation is generally better than many ORs. As a result, it should be more effective to make OR->ANY transformation in the parser (it is a relatively lightweight operation here) and, as a second phase, decompose that in the optimizer. We implemented earlier prototypes in different places of the optimizer, and I'm convinced that only this approach resolves the issues we found. Does this approach look weird? Maybe. We can debate it in this thread. -- regards, Andrei Lepikhov Postgres Professional
Attachment
On Mon, Nov 27, 2023 at 8:08 PM Peter Geoghegan <pg@bowt.ie> wrote: > Maybe it should be the responsibility of some other phase of query > processing, invented solely to make life easier for the optimizer, but > not formally part of query planning per se. I don't really see why that would be useful. Adding more stages to the query pipeline adds cognitive burden for which there must be some corresponding benefit. Even if this happened very early in query planning as a completely separate pass over the query tree, that would minimize the need for code changes outside the optimizer to need to care about it. But I suspect that this shouldn't happen very early in query planning as a completely separate pass, but someplace later where it can be done together with other useful optimizations (e.g. eval_const_expressions, or even path construction). > > The right place to do > > optimization is in the optimizer. > > Then why doesn't the optimizer do query rewriting? Isn't that also a > kind of optimization, at least in part? I mean, I think rewriting mostly means applying rules. > ISTM that the real problem is that this is true in the first place. If > the optimizer had only one representation for any two semantically > equivalent spellings of the same qual, then it would always use the > best available representation. That seems even smarter, because that > way the planner can be dumb and still look fairly smart at runtime. Sure, well, that's another way of attacking the problem, but the in-array representation is more convenient to loop over than the or-clause representation, so if you get to a point where looping over all the values is a thing you want to do, you're going to want something that looks like that. If I just care about the fact that the values I'm looking for are 3, 4, and 6, I want someone to hand me 3, 4, and 6, not x = 3, x = 4, and x = 6, and then I have to skip over the x = part each time. -- Robert Haas EDB: http://www.enterprisedb.com
Hi! > >> Honestly, it seems very hard to avoid the conclusion that this >> transformation is being done at too early a stage. Parse analysis is >> not the time to try to do query optimization. I can't really believe >> that there's a way to produce a committable patch along these lines. >> Ideally, a transformation like this should be done after we know what >> plan shape we're using (or considering using), so that we can make >> cost-based decisions about whether to transform or not. But at the >> very least it should happen somewhere in the planner. There's really >> no justification for parse analysis rewriting the SQL that the user >> entered. > > Here, we assume that array operation is generally better than many ORs. > As a result, it should be more effective to make OR->ANY > transformation in the parser (it is a relatively lightweight operation > here) and, as a second phase, decompose that in the optimizer. > We implemented earlier prototypes in different places of the > optimizer, and I'm convinced that only this approach resolves the > issues we found. > Does this approach look weird? Maybe. We can debate it in this thread. I think this is incorrect, and the example of A. Korotkov confirms this. If we perform the conversion at the parsing stage, we will skip the more important conversion using OR expressions. I'll show you in the example below. First of all, I will describe my idea to combine two approaches to obtaining plans with OR to ANY transformation and ANY to OR transformation. I think they are both good, and we can't work with just one of them, we should consider both the option of OR expressions, and with ANY. I did this by creating a RelOptInfo with which has references from the original RelOptInfo, for which conversion is possible either from ANY->OR, or vice versa. After obtaining the necessary transformation, I started the procedure for obtaining the seq and index paths for both relations and then calculated their cost. The relation with the lowest cost is considered the best. I'm not sure if this is the best approach, but it's less complicated. I noticed that I got a lower cost for not the best plan, but I think this corresponds to another topic related to the wrong estimate calculation. 1. The first patch is a mixture of the original patch (when we perform the conversion of OR to ANY at the parsing stage), and when we perform the conversion at the index creation stage with the conversion to an OR expression. We can see that the query proposed by A.Korotkov did not have the best plan with ANY expression at all, and even despite receiving a query with OR expressions, we cannot get anything better than SeqScan, due to the lack of effective logical transformations that would have been performed if we had left the OR expressions. So, I got query plans using enable_or_transformation if it is enabled: postgres=# create table test as (select (random()*10)::int x, (random()*1000) y from generate_series(1,1000000) i); create index test_x_1_y on test (y) where x = 1; create index test_x_2_y on test (y) where x = 2; vacuum analyze test; SELECT 1000000 CREATE INDEX CREATE INDEX VACUUM postgres=# explain select * from test where (x = 1 or x = 2) and y = 100; WARNING: cost with original approach: - 20440.000000 WARNING: cost with OR to ANY applied transfomation: - 15440.000000 QUERY PLAN -------------------------------------------------------------------------- Gather (cost=1000.00..12690.10 rows=1 width=12) Workers Planned: 2 -> Parallel Seq Scan on test (cost=0.00..11690.00 rows=1 width=12) Filter: (((x = 1) OR (x = 2)) AND (y = '100'::double precision)) (4 rows) and if it is off: postgres=# set enable_or_transformation =off; SET postgres=# explain select * from test where (x = 1 or x = 2) and y = 100; QUERY PLAN -------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on test (cost=8.60..12.62 rows=1 width=12) Recheck Cond: (((y = '100'::double precision) AND (x = 1)) OR ((y = '100'::double precision) AND (x = 2))) -> BitmapOr (cost=8.60..8.60 rows=1 width=0) -> Bitmap Index Scan on test_x_1_y (cost=0.00..4.30 rows=1 width=0) Index Cond: (y = '100'::double precision) -> Bitmap Index Scan on test_x_2_y (cost=0.00..4.30 rows=1 width=0) Index Cond: (y = '100'::double precision) (7 rows) 2. The second patch is my patch version when I moved the OR transformation in the s index formation stage: So, I got the best query plan despite the possible OR to ANY transformation: postgres=# create table test as (select (random()*10)::int x, (random()*1000) y from generate_series(1,1000000) i); create index test_x_1_y on test (y) where x = 1; create index test_x_2_y on test (y) where x = 2; vacuum analyze test; SELECT 1000000 CREATE INDEX CREATE INDEX VACUUM postgres=# explain select * from test where (x = 1 or x = 2) and y = 100; WARNING: cost with original approach: - 12.618000 WARNING: cost with OR to ANY applied transfomation: - 15440.000000 QUERY PLAN -------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on test (cost=8.60..12.62 rows=1 width=12) Recheck Cond: (((y = '100'::double precision) AND (x = 1)) OR ((y = '100'::double precision) AND (x = 2))) -> BitmapOr (cost=8.60..8.60 rows=1 width=0) -> Bitmap Index Scan on test_x_1_y (cost=0.00..4.30 rows=1 width=0) Index Cond: (y = '100'::double precision) -> Bitmap Index Scan on test_x_2_y (cost=0.00..4.30 rows=1 width=0) Index Cond: (y = '100'::double precision) (7 rows) -- Regards, Alena Rybakina Postgres Professional
Sorry, I forgot to apply my patches. For the first experiment was 0001-OR-to-ANY-in-parser-and-ANY-to-OR-in-index.diff and for the second experiment was 0002-OR-to-ANY-in-index.diff. On 30.11.2023 11:00, Alena Rybakina wrote: > Hi! > >> >>> Honestly, it seems very hard to avoid the conclusion that this >>> transformation is being done at too early a stage. Parse analysis is >>> not the time to try to do query optimization. I can't really believe >>> that there's a way to produce a committable patch along these lines. >>> Ideally, a transformation like this should be done after we know what >>> plan shape we're using (or considering using), so that we can make >>> cost-based decisions about whether to transform or not. But at the >>> very least it should happen somewhere in the planner. There's really >>> no justification for parse analysis rewriting the SQL that the user >>> entered. >> >> Here, we assume that array operation is generally better than many ORs. >> As a result, it should be more effective to make OR->ANY >> transformation in the parser (it is a relatively lightweight >> operation here) and, as a second phase, decompose that in the optimizer. >> We implemented earlier prototypes in different places of the >> optimizer, and I'm convinced that only this approach resolves the >> issues we found. >> Does this approach look weird? Maybe. We can debate it in this thread. > > I think this is incorrect, and the example of A. Korotkov confirms > this. If we perform the conversion at the parsing stage, we will skip > the more important conversion using OR expressions. I'll show you in > the example below. > > First of all, I will describe my idea to combine two approaches to > obtaining plans with OR to ANY transformation and ANY to OR > transformation. I think they are both good, and we can't work with > just one of them, we should consider both the option of OR > expressions, and with ANY. > > I did this by creating a RelOptInfo with which has references from the > original RelOptInfo, for which conversion is possible either from > ANY->OR, or vice versa. After obtaining the necessary transformation, > I started the procedure for obtaining the seq and index paths for both > relations and then calculated their cost. The relation with the lowest > cost is considered the best. > > I'm not sure if this is the best approach, but it's less complicated. > > I noticed that I got a lower cost for not the best plan, but I think > this corresponds to another topic related to the wrong estimate > calculation. > > 1. The first patch is a mixture of the original patch (when we perform > the conversion of OR to ANY at the parsing stage), and when we perform > the conversion at the index creation stage with the conversion to an > OR expression. We can see that the query proposed by A.Korotkov did > not have the best plan with ANY expression at all, and even despite > receiving a query with OR expressions, we cannot get anything better > than SeqScan, due to the lack of effective logical transformations > that would have been performed if we had left the OR expressions. > > So, I got query plans using enable_or_transformation if it is enabled: > > postgres=# create table test as (select (random()*10)::int x, > (random()*1000) y > from generate_series(1,1000000) i); > create index test_x_1_y on test (y) where x = 1; > create index test_x_2_y on test (y) where x = 2; > vacuum analyze test; > SELECT 1000000 > CREATE INDEX > CREATE INDEX > VACUUM > postgres=# explain select * from test where (x = 1 or x = 2) and y = 100; > WARNING: cost with original approach: - 20440.000000 > WARNING: cost with OR to ANY applied transfomation: - 15440.000000 > QUERY PLAN > -------------------------------------------------------------------------- > > Gather (cost=1000.00..12690.10 rows=1 width=12) > Workers Planned: 2 > -> Parallel Seq Scan on test (cost=0.00..11690.00 rows=1 width=12) > Filter: (((x = 1) OR (x = 2)) AND (y = '100'::double precision)) > (4 rows) > > and if it is off: > > postgres=# set enable_or_transformation =off; > SET > postgres=# explain select * from test where (x = 1 or x = 2) and y = 100; > QUERY PLAN > -------------------------------------------------------------------------------------------------------------- > > Bitmap Heap Scan on test (cost=8.60..12.62 rows=1 width=12) > Recheck Cond: (((y = '100'::double precision) AND (x = 1)) OR ((y = > '100'::double precision) AND (x = 2))) > -> BitmapOr (cost=8.60..8.60 rows=1 width=0) > -> Bitmap Index Scan on test_x_1_y (cost=0.00..4.30 rows=1 > width=0) > Index Cond: (y = '100'::double precision) > -> Bitmap Index Scan on test_x_2_y (cost=0.00..4.30 rows=1 > width=0) > Index Cond: (y = '100'::double precision) > (7 rows) > > 2. The second patch is my patch version when I moved the OR > transformation in the s index formation stage: > > So, I got the best query plan despite the possible OR to ANY > transformation: > > postgres=# create table test as (select (random()*10)::int x, > (random()*1000) y > from generate_series(1,1000000) i); > create index test_x_1_y on test (y) where x = 1; > create index test_x_2_y on test (y) where x = 2; > vacuum analyze test; > SELECT 1000000 > CREATE INDEX > CREATE INDEX > VACUUM > postgres=# explain select * from test where (x = 1 or x = 2) and y = 100; > WARNING: cost with original approach: - 12.618000 > WARNING: cost with OR to ANY applied transfomation: - 15440.000000 > QUERY PLAN > -------------------------------------------------------------------------------------------------------------- > > Bitmap Heap Scan on test (cost=8.60..12.62 rows=1 width=12) > Recheck Cond: (((y = '100'::double precision) AND (x = 1)) OR ((y = > '100'::double precision) AND (x = 2))) > -> BitmapOr (cost=8.60..8.60 rows=1 width=0) > -> Bitmap Index Scan on test_x_1_y (cost=0.00..4.30 rows=1 > width=0) > Index Cond: (y = '100'::double precision) > -> Bitmap Index Scan on test_x_2_y (cost=0.00..4.30 rows=1 > width=0) > Index Cond: (y = '100'::double precision) > (7 rows) > > > -- Regards, Alena Rybakina Postgres Professional
Attachment
On 30/11/2023 15:00, Alena Rybakina wrote: > 2. The second patch is my patch version when I moved the OR > transformation in the s index formation stage: > > So, I got the best query plan despite the possible OR to ANY > transformation: If the user uses a clause like "x IN (1,2) AND y=100", it will break your 'good' solution. In my opinion, the general approach here is to stay with OR->ANY transformation at the parsing stage and invent one more way for picking an index by looking into the array and attempting to find a compound index. Having a shorter list of expressions, where uniform ORs are grouped into arrays, the optimizer will do such work with less overhead. -- regards, Andrei Lepikhov Postgres Professional
On 30.11.2023 11:30, Andrei Lepikhov wrote:
> On 30/11/2023 15:00, Alena Rybakina wrote:
>> 2. The second patch is my patch version when I moved the OR
>> transformation in the s index formation stage:
>>
>> So, I got the best query plan despite the possible OR to ANY
>> transformation:
>
> If the user uses a clause like "x IN (1,2) AND y=100", it will break
> your 'good' solution.
No, unfortunately I still see the plan with Seq scan node:
postgres=# explain analyze select * from test where x in (1,2) and y = 100;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..12690.10 rows=1 width=12) (actual
time=72.985..74.832 rows=0 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on test (cost=0.00..11690.00 rows=1 width=12)
(actual time=68.573..68.573 rows=0 loops=3)
Filter: ((x = ANY ('{1,2}'::integer[])) AND (y = '100'::double
precision))
Rows Removed by Filter: 333333
Planning Time: 0.264 ms
Execution Time: 74.887 ms
(8 rows)
> In my opinion, the general approach here is to stay with OR->ANY
> transformation at the parsing stage and invent one more way for
> picking an index by looking into the array and attempting to find a
> compound index.
> Having a shorter list of expressions, where uniform ORs are grouped
> into arrays, the optimizer will do such work with less overhead.
Looking at the current index generation code, implementing this approach
will require a lot of refactoring so that functions starting with
get_indexes do not rely on the current baserestrictinfo, but use only
the indexrestrictinfo, which is a copy of baserestrictinfo. And I think,
potentially, there may be complexity also with the equivalences that we
can get from OR expressions. All interesting transformations are
available only for OR expressions, not for ANY, that is, it makes sense
to try the last chance to find a suitable plan with the available OR
expressions and if that plan turns out to be better, use it.
--
Regards,
Alena Rybakina
Postgres Professional
On 30.11.2023 11:00, Alena Rybakina wrote: > Hi! > >> >>> Honestly, it seems very hard to avoid the conclusion that this >>> transformation is being done at too early a stage. Parse analysis is >>> not the time to try to do query optimization. I can't really believe >>> that there's a way to produce a committable patch along these lines. >>> Ideally, a transformation like this should be done after we know what >>> plan shape we're using (or considering using), so that we can make >>> cost-based decisions about whether to transform or not. But at the >>> very least it should happen somewhere in the planner. There's really >>> no justification for parse analysis rewriting the SQL that the user >>> entered. >> >> Here, we assume that array operation is generally better than many ORs. >> As a result, it should be more effective to make OR->ANY >> transformation in the parser (it is a relatively lightweight >> operation here) and, as a second phase, decompose that in the optimizer. >> We implemented earlier prototypes in different places of the >> optimizer, and I'm convinced that only this approach resolves the >> issues we found. >> Does this approach look weird? Maybe. We can debate it in this thread. > > I think this is incorrect, and the example of A. Korotkov confirms > this. If we perform the conversion at the parsing stage, we will skip > the more important conversion using OR expressions. I'll show you in > the example below. > > First of all, I will describe my idea to combine two approaches to > obtaining plans with OR to ANY transformation and ANY to OR > transformation. I think they are both good, and we can't work with > just one of them, we should consider both the option of OR > expressions, and with ANY. > Just in case, I have attached a patch or->any transformation where this happens at the index creation stage. I get diff file during make check, but judging by the changes, it shows that the transformation is going well. I also attached it. -- Regards, Alena Rybakina Postgres Professional
Attachment
Hi, Here is the next version of the patch where, I think, all of Roberts's claims related to the code have been fixed. For example, expression 'x < 1 OR x < 2' is transformed to 'x < ANY (1,2)'. Here, we still need to deal with the architectural issues. I like the approach mentioned by Peter: try to transform the expression tree to some 'normal' form, which is more laconic and simple; delay the search for any optimization ways to the following stages. Also, it doesn't pass pg_dump test. At first glance, it is a problem of regex expression, which should be corrected further. -- regards, Andrei Lepikhov Postgres Professional
Attachment
Here is fresh version with the pg_dump.pl regex fixed. Now it must pass buildfarm. Under development: 1. Explanation of the general idea in comments (Robert's note) 2. Issue with hiding some optimizations (Alexander's note and example with overlapping clauses on two partial indexes) -- regards, Andrei Lepikhov Postgres Professional
Attachment
On Tue, 5 Dec 2023 at 16:25, Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > > Here is fresh version with the pg_dump.pl regex fixed. Now it must pass > buildfarm. > > Under development: > 1. Explanation of the general idea in comments (Robert's note) > 2. Issue with hiding some optimizations (Alexander's note and example > with overlapping clauses on two partial indexes) CFBot shows that the patch does not apply anymore as in [1]: === Applying patches on top of PostgreSQL commit ID 64444ce071f6b04d3fc836f436fa08108a6d11e2 === === applying patch ./v14-1-0001-Transform-OR-clause-to-ANY-expressions.patch .... patching file src/test/regress/expected/sysviews.out Hunk #1 succeeded at 124 (offset 1 line). Hunk #2 FAILED at 134. 1 out of 2 hunks FAILED -- saving rejects to file src/test/regress/expected/sysviews.out.rej Please post an updated version for the same. [1] - http://cfbot.cputube.org/patch_46_4450.log Regards, Vignesh
On Tue, Dec 5, 2023 at 6:55 PM Andrei Lepikhov
<a.lepikhov@postgrespro.ru> wrote:
>
> Here is fresh version with the pg_dump.pl regex fixed. Now it must pass
> buildfarm.
+JumbleState *
+JumbleExpr(Expr *expr, uint64 *queryId)
+{
+ JumbleState *jstate = NULL;
+
+ Assert(queryId != NULL);
+
+ jstate = (JumbleState *) palloc(sizeof(JumbleState));
+
+ /* Set up workspace for query jumbling */
+ jstate->jumble = (unsigned char *) palloc(JUMBLE_SIZE);
+ jstate->jumble_len = 0;
+ jstate->clocations_buf_size = 32;
+ jstate->clocations = (LocationLen *)
+ palloc(jstate->clocations_buf_size * sizeof(LocationLen));
+ jstate->clocations_count = 0;
+ jstate->highest_extern_param_id = 0;
+
+ /* Compute query ID */
+ _jumbleNode(jstate, (Node *) expr);
+ *queryId = DatumGetUInt64(hash_any_extended(jstate->jumble,
+ jstate->jumble_len,
+ 0));
+
+ if (*queryId == UINT64CONST(0))
+ *queryId = UINT64CONST(1);
+
+ return jstate;
+}
+/*
+ * Hash function that's compatible with guc_name_compare
+ */
+static uint32
+orclause_hash(const void *data, Size keysize)
+{
+ OrClauseGroupKey *key = (OrClauseGroupKey *) data;
+ uint64 hash;
+
+ (void) JumbleExpr(key->expr, &hash);
+ hash += ((uint64) key->opno + (uint64) key->exprtype) % UINT64_MAX;
+ return hash;
+}
correct me if i am wrong:
in orclause_hash, you just want to return a uint32, then why does the
JumbleExpr function return struct JumbleState.
here JumbleExpr, we just simply hash part of a Query struct,
so JumbleExpr's queryId would be confused with JumbleQuery function's queryId.
not sure the purpose of the following:
+ if (*queryId == UINT64CONST(0))
+ *queryId = UINT64CONST(1);
even if *queryId is 0
`hash += ((uint64) key->opno + (uint64) key->exprtype) % UINT64_MAX;`
will make the hash return non-zero?
+ MemSet(&info, 0, sizeof(info));
i am not sure this is necessary.
Some comments on OrClauseGroupEntry would be great.
seems there is no doc.
create or replace function retint(int) returns int as
$func$
begin return $1 + round(10 * random()); end
$func$ LANGUAGE plpgsql;
set enable_or_transformation to on;
EXPLAIN (COSTS OFF)
SELECT count(*) FROM tenk1
WHERE thousand = 42 AND (tenthous * retint(1) = NULL OR tenthous *
retint(1) = 3) OR thousand = 41;
returns:
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Aggregate
-> Seq Scan on tenk1
Filter: (((thousand = 42) AND ((tenthous * retint(1)) = ANY
('{NULL,3}'::integer[]))) OR (thousand = 41))
(3 rows)
Based on the query plan, retint executed once, but here it should be
executed twice?
maybe we need to use contain_volatile_functions to check through the
other part of the operator expression.
+ if (IsA(leftop, Const))
+ {
+ opno = get_commutator(opno);
+
+ if (!OidIsValid(opno))
+ {
+ /* Commuter doesn't exist, we can't reverse the order */
+ or_list = lappend(or_list, orqual);
+ continue;
+ }
+
+ nconst_expr = get_rightop(orqual);
+ const_expr = get_leftop(orqual);
+ }
+ else if (IsA(rightop, Const))
+ {
+ const_expr = get_rightop(orqual);
+ nconst_expr = get_leftop(orqual);
+ }
+ else
+ {
+ or_list = lappend(or_list, orqual);
+ continue;
+ }
do we need to skip this transformation for the const type is anyarray?
+/*
+ * Hash function that's compatible with guc_name_compare
+ */
+static uint32
+orclause_hash(const void *data, Size keysize)
+{
+ OrClauseGroupKey *key = (OrClauseGroupKey *) data;
+ uint64 hash;
+
+ (void) JumbleExpr(key->expr, &hash);
+ hash += ((uint64) key->opno + (uint64) key->exprtype) % UINT64_MAX;
+ return hash;
+}
looks strange. `hash` is uint64, but here you return uint32.
based on my understanding of
https://www.postgresql.org/docs/current/xoper-optimization.html#XOPER-COMMUTATOR
I think you need move commutator check right after the `if
(get_op_rettype(opno) != BOOLOID)` branch
+ opno = ((OpExpr *) orqual)->opno;
+ if (get_op_rettype(opno) != BOOLOID)
+ {
+ /* Only operator returning boolean suits OR -> ANY transformation */
+ or_list = lappend(or_list, orqual);
+ continue;
+ }
select po.oprname,po.oprkind,po.oprcanhash,po.oprleft::regtype,po.oprright,po.oprresult,
po1.oprname
from pg_operator po join pg_operator po1
on po.oprcom = po1.oid
where po.oprresult = 16;
I am wondering, are all these types as long as the return type is bool
suitable for this transformation?
On Wed, Jan 31, 2024 at 10:55 AM jian he <jian.universality@gmail.com> wrote: > > based on my understanding of > https://www.postgresql.org/docs/current/xoper-optimization.html#XOPER-COMMUTATOR > I think you need move commutator check right after the `if > (get_op_rettype(opno) != BOOLOID)` branch > I was wrong about this part. sorry for the noise. I have made some changes (attachment). * if the operator expression left or right side type category is {array | domain | composite}, then don't do the transformation. (i am not 10% sure with composite) * if the left side of the operator expression node contains volatile functions, then don't do the transformation. * some other minor cosmetic changes.
Attachment
On Wed, Jan 31, 2024 at 10:55 AM jian he <jian.universality@gmail.com> wrote:based on my understanding of https://www.postgresql.org/docs/current/xoper-optimization.html#XOPER-COMMUTATOR I think you need move commutator check right after the `if (get_op_rettype(opno) != BOOLOID)` branchI was wrong about this part. sorry for the noise. I have made some changes (attachment). * if the operator expression left or right side type category is {array | domain | composite}, then don't do the transformation. (i am not 10% sure with composite)
To be honest, I'm not sure about this check, because we check the type of variable there:if (!IsA(orqual, OpExpr))
{
or_list = lappend(or_list, orqual);
continue;
}
And below:
if (IsA(leftop, Const))
{
opno = get_commutator(opno);
if (!OidIsValid(opno))
{
/* Commuter doesn't exist, we can't reverse the order */
or_list = lappend(or_list, orqual);
continue;
}
nconst_expr = get_rightop(orqual);
const_expr = get_leftop(orqual);
}
else if (IsA(rightop, Const))
{
const_expr = get_rightop(orqual);
nconst_expr = get_leftop(orqual);
}
else
{
or_list = lappend(or_list, orqual);
continue;
}
Isn't that enough?
Besides, some of examples (with ARRAY) works fine:
postgres=# CREATE TABLE sal_emp (
pay_by_quarter integer[],
pay_by_quater1 integer[]
);
CREATE TABLE
postgres=# INSERT INTO sal_emp
VALUES (
'{10000, 10000, 10000, 10000}',
'{1,2,3,4}');
INSERT 0 1
postgres=# select * from sal_emp where pay_by_quarter[1] = 10000 or pay_by_quarter[1]=2;
pay_by_quarter | pay_by_quater1
---------------------------+----------------
{10000,10000,10000,10000} | {1,2,3,4}
(1 row)
postgres=# explain select * from sal_emp where pay_by_quarter[1] = 10000 or pay_by_quarter[1]=2;
QUERY PLAN
--------------------------------------------------------------
Seq Scan on sal_emp (cost=0.00..21.00 rows=9 width=64)
Filter: (pay_by_quarter[1] = ANY ('{10000,2}'::integer[]))
(2 rows)
* if the left side of the operator expression node contains volatile functions, then don't do the transformation.
I'm also not sure about the volatility check function, because we perform such a conversion at the parsing stage, and at this stage we don't have a RelOptInfo variable and especially a RestictInfo such as PathTarget.
Speaking of NextValueExpr, I couldn't find any examples where the current patch wouldn't work. I wrote one of them below:
postgres=# create table foo (f1 int, f2 int generated always as identity);
CREATE TABLE
postgres=# insert into foo values(1);
INSERT 0 1
postgres=# explain verbose update foo set f1 = 2 where f1=1 or f1=2 ;
QUERY PLAN
-------------------------------------------------------------------
Update on public.foo (cost=0.00..38.25 rows=0 width=0)
-> Seq Scan on public.foo (cost=0.00..38.25 rows=23 width=10)
Output: 2, ctid
Filter: (foo.f1 = ANY ('{1,2}'::integer[]))
(4 rows)
Maybe I missed something. Do you have any examples?
Thank you, I agree with them.* some other minor cosmetic changes.
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Wed, Jan 31, 2024 at 7:10 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > > Hi, thank you for your review and interest in this subject. > > On 31.01.2024 13:15, jian he wrote: > > On Wed, Jan 31, 2024 at 10:55 AM jian he <jian.universality@gmail.com> wrote: > > based on my understanding of > https://www.postgresql.org/docs/current/xoper-optimization.html#XOPER-COMMUTATOR > I think you need move commutator check right after the `if > (get_op_rettype(opno) != BOOLOID)` branch > > I was wrong about this part. sorry for the noise. > > > I have made some changes (attachment). > * if the operator expression left or right side type category is > {array | domain | composite}, then don't do the transformation. > (i am not 10% sure with composite) > > To be honest, I'm not sure about this check, because we check the type of variable there: > > if (!IsA(orqual, OpExpr)) > { > or_list = lappend(or_list, orqual); > continue; > } > And below: > if (IsA(leftop, Const)) > { > opno = get_commutator(opno); > > if (!OidIsValid(opno)) > { > /* Commuter doesn't exist, we can't reverse the order */ > or_list = lappend(or_list, orqual); > continue; > } > > nconst_expr = get_rightop(orqual); > const_expr = get_leftop(orqual); > } > else if (IsA(rightop, Const)) > { > const_expr = get_rightop(orqual); > nconst_expr = get_leftop(orqual); > } > else > { > or_list = lappend(or_list, orqual); > continue; > } > > Isn't that enough? alter table tenk1 add column arr int[]; set enable_or_transformation to on; EXPLAIN (COSTS OFF) SELECT count(*) FROM tenk1 WHERE arr = '{1,2,3}' or arr = '{1,2}'; the above query will not do the OR transformation. because array type doesn't have array type. ` scalar_type = entry->key.exprtype; if (scalar_type != RECORDOID && OidIsValid(scalar_type)) array_type = get_array_type(scalar_type); else array_type = InvalidOid; ` If either side of the operator expression is array or array related type, we can be sure it cannot do the transformation (get_array_type will return InvalidOid for anyarray type). we can check it earlier, so hash related code will not be invoked for array related types. > Besides, some of examples (with ARRAY) works fine: > > postgres=# CREATE TABLE sal_emp ( > pay_by_quarter integer[], > pay_by_quater1 integer[] > ); > CREATE TABLE > postgres=# INSERT INTO sal_emp > VALUES ( > '{10000, 10000, 10000, 10000}', > '{1,2,3,4}'); > INSERT 0 1 > postgres=# select * from sal_emp where pay_by_quarter[1] = 10000 or pay_by_quarter[1]=2; > pay_by_quarter | pay_by_quater1 > ---------------------------+---------------- > {10000,10000,10000,10000} | {1,2,3,4} > (1 row) > > postgres=# explain select * from sal_emp where pay_by_quarter[1] = 10000 or pay_by_quarter[1]=2; > QUERY PLAN > -------------------------------------------------------------- > Seq Scan on sal_emp (cost=0.00..21.00 rows=9 width=64) > Filter: (pay_by_quarter[1] = ANY ('{10000,2}'::integer[])) > (2 rows) > > * if the left side of the operator expression node contains volatile > functions, then don't do the transformation. > > I'm also not sure about the volatility check function, because we perform such a conversion at the parsing stage, and atthis stage we don't have a RelOptInfo variable and especially a RestictInfo such as PathTarget. > see the example in here: https://www.postgresql.org/message-id/CACJufxGXhJ823cdAdp2Ho7qC-HZ3_-dtdj-myaAi_u9RQLn45g%40mail.gmail.com set enable_or_transformation to on; create or replace function retint(int) returns int as $func$ begin raise notice 'hello'; return $1 + round(10 * random()); end $func$ LANGUAGE plpgsql; SELECT count(*) FROM tenk1 WHERE thousand = 42; will return 10 rows. SELECT count(*) FROM tenk1 WHERE thousand = 42 AND (retint(1) = 4 OR retint(1) = 3); this query I should return 20 notices 'hello', but now only 10. EXPLAIN (COSTS OFF) SELECT count(*) FROM tenk1 WHERE thousand = 42 AND (retint(1) = 4 OR retint(1) = 3); QUERY PLAN ------------------------------------------------------------------------------ Aggregate -> Seq Scan on tenk1 Filter: ((thousand = 42) AND (retint(1) = ANY ('{4,3}'::integer[]))) (3 rows)
Agree.On Wed, Jan 31, 2024 at 7:10 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote:Hi, thank you for your review and interest in this subject. On 31.01.2024 13:15, jian he wrote: On Wed, Jan 31, 2024 at 10:55 AM jian he <jian.universality@gmail.com> wrote: based on my understanding of https://www.postgresql.org/docs/current/xoper-optimization.html#XOPER-COMMUTATOR I think you need move commutator check right after the `if (get_op_rettype(opno) != BOOLOID)` branch I was wrong about this part. sorry for the noise. I have made some changes (attachment). * if the operator expression left or right side type category is {array | domain | composite}, then don't do the transformation. (i am not 10% sure with composite) To be honest, I'm not sure about this check, because we check the type of variable there: if (!IsA(orqual, OpExpr)) { or_list = lappend(or_list, orqual); continue; } And below: if (IsA(leftop, Const)) { opno = get_commutator(opno); if (!OidIsValid(opno)) { /* Commuter doesn't exist, we can't reverse the order */ or_list = lappend(or_list, orqual); continue; } nconst_expr = get_rightop(orqual); const_expr = get_leftop(orqual); } else if (IsA(rightop, Const)) { const_expr = get_rightop(orqual); nconst_expr = get_leftop(orqual); } else { or_list = lappend(or_list, orqual); continue; } Isn't that enough?alter table tenk1 add column arr int[]; set enable_or_transformation to on; EXPLAIN (COSTS OFF) SELECT count(*) FROM tenk1 WHERE arr = '{1,2,3}' or arr = '{1,2}'; the above query will not do the OR transformation. because array type doesn't have array type. ` scalar_type = entry->key.exprtype; if (scalar_type != RECORDOID && OidIsValid(scalar_type)) array_type = get_array_type(scalar_type); else array_type = InvalidOid; ` If either side of the operator expression is array or array related type, we can be sure it cannot do the transformation (get_array_type will return InvalidOid for anyarray type). we can check it earlier, so hash related code will not be invoked for array related types.
Besides, some of examples (with ARRAY) works fine: postgres=# CREATE TABLE sal_emp ( pay_by_quarter integer[], pay_by_quater1 integer[] ); CREATE TABLE postgres=# INSERT INTO sal_emp VALUES ( '{10000, 10000, 10000, 10000}', '{1,2,3,4}'); INSERT 0 1 postgres=# select * from sal_emp where pay_by_quarter[1] = 10000 or pay_by_quarter[1]=2; pay_by_quarter | pay_by_quater1 ---------------------------+---------------- {10000,10000,10000,10000} | {1,2,3,4} (1 row) postgres=# explain select * from sal_emp where pay_by_quarter[1] = 10000 or pay_by_quarter[1]=2; QUERY PLAN -------------------------------------------------------------- Seq Scan on sal_emp (cost=0.00..21.00 rows=9 width=64) Filter: (pay_by_quarter[1] = ANY ('{10000,2}'::integer[])) (2 rows) * if the left side of the operator expression node contains volatile functions, then don't do the transformation. I'm also not sure about the volatility check function, because we perform such a conversion at the parsing stage, and at this stage we don't have a RelOptInfo variable and especially a RestictInfo such as PathTarget.see the example in here: https://www.postgresql.org/message-id/CACJufxGXhJ823cdAdp2Ho7qC-HZ3_-dtdj-myaAi_u9RQLn45g%40mail.gmail.com set enable_or_transformation to on; create or replace function retint(int) returns int as $func$ begin raise notice 'hello'; return $1 + round(10 * random()); end $func$ LANGUAGE plpgsql; SELECT count(*) FROM tenk1 WHERE thousand = 42; will return 10 rows. SELECT count(*) FROM tenk1 WHERE thousand = 42 AND (retint(1) = 4 OR retint(1) = 3); this query I should return 20 notices 'hello', but now only 10. EXPLAIN (COSTS OFF) SELECT count(*) FROM tenk1 WHERE thousand = 42 AND (retint(1) = 4 OR retint(1) = 3); QUERY PLAN ------------------------------------------------------------------------------ Aggregate -> Seq Scan on tenk1 Filter: ((thousand = 42) AND (retint(1) = ANY ('{4,3}'::integer[]))) (3 rows)
Agree.
I added your code to the patch.
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On 3/2/2024 02:06, Alena Rybakina wrote: > On 01.02.2024 08:00, jian he wrote: > I added your code to the patch. Thanks Alena and Jian for the detailed scrutiny! A couple of questions: 1. As I see, transformAExprIn uses the same logic as we invented but allows composite and domain types. Could you add a comment explaining why we forbid row types in general, in contrast to the transformAExprIn routine? 2. Could you provide the tests to check issues covered by the recent (in v.15) changes? Patch 0001-* in the attachment incorporates changes induced by Jian's notes from [1]. Patch 0002-* contains a transformation of the SAOP clause, which allows the optimizer to utilize partial indexes if they cover all values in this array. Also, it is an answer to Alexander's note [2] on performance degradation. This first version may be a bit raw, but I need your opinion: Does it resolve the issue? Skimming through the thread, I see that, in general, all issues have been covered for now. Only Robert's note on a lack of documentation is still needs to be resolved. [1] https://www.postgresql.org/message-id/CACJufxGXhJ823cdAdp2Ho7qC-HZ3_-dtdj-myaAi_u9RQLn45g%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAPpHfduJtO0s9E%3DSHUTzrCD88BH0eik0UNog1_q3XBF2wLmH6g%40mail.gmail.com -- regards, Andrei Lepikhov Postgres Professional
Attachment
On Thu, Feb 8, 2024 at 1:34 PM Andrei Lepikhov
<a.lepikhov@postgrespro.ru> wrote:
>
> On 3/2/2024 02:06, Alena Rybakina wrote:
> > On 01.02.2024 08:00, jian he wrote:
> > I added your code to the patch.
> Thanks Alena and Jian for the detailed scrutiny!
>
> A couple of questions:
> 1. As I see, transformAExprIn uses the same logic as we invented but
> allows composite and domain types. Could you add a comment explaining
> why we forbid row types in general, in contrast to the transformAExprIn
> routine?
> 2. Could you provide the tests to check issues covered by the recent (in
> v.15) changes?
>
> Patch 0001-* in the attachment incorporates changes induced by Jian's
> notes from [1].
> Patch 0002-* contains a transformation of the SAOP clause, which allows
> the optimizer to utilize partial indexes if they cover all values in
> this array. Also, it is an answer to Alexander's note [2] on performance
> degradation. This first version may be a bit raw, but I need your
> opinion: Does it resolve the issue?
yes. It resolved the partial index performance degradation issue.
The v16, 0002 extra code overhead is limited.
Here is how I test it.
drop table if exists test;
create table test as (select (random()*100)::int x, (random()*1000) y
from generate_series(1,1000000) i);
create index test_x_1_y on test (y) where x = 1;
create index test_x_2_y on test (y) where x = 2;
create index test_x_3_y on test (y) where x = 3;
create index test_x_4_y on test (y) where x = 4;
create index test_x_5_y on test (y) where x = 5;
create index test_x_6_y on test (y) where x = 6;
create index test_x_7_y on test (y) where x = 7;
create index test_x_8_y on test (y) where x = 8;
create index test_x_9_y on test (y) where x = 9;
create index test_x_10_y on test (y) where x = 10;
set enable_or_transformation to on;
explain(analyze, costs off)
select * from test
where (x = 1 or x = 2 or x = 3 or x = 4 or x = 5 or x = 6 or x = 7 or
x = 8 or x = 9 or x = 10);
set enable_or_transformation to off;
explain(analyze, costs off)
select * from test
where (x = 1 or x = 2 or x = 3 or x = 4 or x = 5 or x = 6 or x = 7 or
x = 8 or x = 9 or x = 10);
FAILED: src/backend/postgres_lib.a.p/optimizer_path_indxpath.c.o
ccache cc -Isrc/backend/postgres_lib.a.p -Isrc/include
-I../../Desktop/pg_src/src8/postgres/src/include
-I/usr/include/libxml2 -fdiagnostics-color=always --coverage
-D_FILE_OFFSET_BITS=64 -Wall -Winvalid-pch -Werror -O0 -g
-fno-strict-aliasing -fwrapv -fexcess-precision=standard -D_GNU_SOURCE
-Wmissing-prototypes -Wpointer-arith -Werror=vla -Wendif-labels
-Wmissing-format-attribute -Wimplicit-fallthrough=3
-Wcast-function-type -Wshadow=compatible-local -Wformat-security
-Wdeclaration-after-statement -Wno-format-truncation
-Wno-stringop-truncation -Wunused-variable -Wuninitialized
-Werror=maybe-uninitialized -Wreturn-type
-DWRITE_READ_PARSE_PLAN_TREES -DCOPY_PARSE_PLAN_TREES
-DREALLOCATE_BITMAPSETS -DRAW_EXPRESSION_COVERAGE_TEST
-fno-omit-frame-pointer -fPIC -pthread -DBUILDING_DLL -MD -MQ
src/backend/postgres_lib.a.p/optimizer_path_indxpath.c.o -MF
src/backend/postgres_lib.a.p/optimizer_path_indxpath.c.o.d -o
src/backend/postgres_lib.a.p/optimizer_path_indxpath.c.o -c
../../Desktop/pg_src/src8/postgres/src/backend/optimizer/path/indxpath.c
../../Desktop/pg_src/src8/postgres/src/backend/optimizer/path/indxpath.c:
In function ‘build_paths_for_SAOP’:
../../Desktop/pg_src/src8/postgres/src/backend/optimizer/path/indxpath.c:1267:33:
error: declaration of ‘pd’ shadows a previous local
[-Werror=shadow=compatible-local]
1267 | PredicatesData *pd = (PredicatesData *) lfirst(lc);
| ^~
../../Desktop/pg_src/src8/postgres/src/backend/optimizer/path/indxpath.c:1235:29:
note: shadowed declaration is here
1235 | PredicatesData *pd;
| ^~
cc1: all warnings being treated as errors
[32/126] Compiling C object src/backend/postgres_lib.a.p/utils_adt_ruleutils.c.o
ninja: build stopped: subcommand failed.
+ if (!predicate_implied_by(index->indpred, list_make1(rinfo1), true))
+ elog(ERROR, "Logical mistake in OR <-> ANY transformation code");
the error message seems not clear?
What is a "Logical mistake"?
static List *
build_paths_for_SAOP(PlannerInfo *root, RelOptInfo *rel, RestrictInfo *rinfo,
List *other_clauses)
I am not sure what's `other_clauses`, and `rinfo` refers to? adding
some comments would be great.
struct PredicatesData needs some comments, I think.
+bool
+saop_covered_by_predicates(ScalarArrayOpExpr *saop, List *predicate_lists)
+{
+ ListCell *lc;
+ PredIterInfoData clause_info;
+ bool result = false;
+ bool isConstArray;
+
+ Assert(IsA(saop, ScalarArrayOpExpr));
is this Assert necessary?
For the function build_paths_for_SAOP, I think I understand the first
part of the code.
But I am not 100% sure of the second part of the `foreach(lc,
predicate_lists)` code.
more comments in `foreach(lc, predicate_lists)` would be helpful.
do you need to add `PredicatesData` to src/tools/pgindent/typedefs.list?
I also did some minor refactoring of generate_saop_pathlist.
type_is_rowtype does not check if the type is array type.
transformBoolExprOr the OR QUAL, the Const part cannot be an array.
simple example:
alter table tenk1 add column arr int[];
set enable_or_transformation to on;
EXPLAIN (COSTS OFF)
SELECT count(*) FROM tenk1
WHERE arr = '{1,2,3}' or arr = '{1,2}';
instead of let it go to `foreach (lc, entries)`,
we can reject the Const array at `foreach(lc, expr->args)`
also `foreach(lc, expr->args)` do we need to reject cases like
`contain_subplans((Node *) nconst_expr)`?
maybe let the nconst_expr be a Var node would be far more easier.
Attachment
Thanks for the review!
It was the first version for discussion. Of course, refactoring and
polishing cycles will be needed, even so we can discuss the general idea
earlier.
On 10/2/2024 12:00, jian he wrote:
> On Thu, Feb 8, 2024 at 1:34 PM Andrei Lepikhov
> 1235 | PredicatesData *pd;
Thanks
> + if (!predicate_implied_by(index->indpred, list_make1(rinfo1), true))
> + elog(ERROR, "Logical mistake in OR <-> ANY transformation code");
> the error message seems not clear?
Yeah, have rewritten
> static List *
> build_paths_for_SAOP(PlannerInfo *root, RelOptInfo *rel, RestrictInfo *rinfo,
> List *other_clauses)
> I am not sure what's `other_clauses`, and `rinfo` refers to? adding
> some comments would be great.
>
> struct PredicatesData needs some comments, I think.
Added, not so much though
>
> +bool
> +saop_covered_by_predicates(ScalarArrayOpExpr *saop, List *predicate_lists)
> +{
> + ListCell *lc;
> + PredIterInfoData clause_info;
> + bool result = false;
> + bool isConstArray;
> +
> + Assert(IsA(saop, ScalarArrayOpExpr));
> is this Assert necessary?
Not sure. Moved it into another routine.
>
> For the function build_paths_for_SAOP, I think I understand the first
> part of the code.
> But I am not 100% sure of the second part of the `foreach(lc,
> predicate_lists)` code.
> more comments in `foreach(lc, predicate_lists)` would be helpful.
Done
>
> do you need to add `PredicatesData` to src/tools/pgindent/typedefs.list?
Done
>
> I also did some minor refactoring of generate_saop_pathlist.
Partially agree
>
> instead of let it go to `foreach (lc, entries)`,
> we can reject the Const array at `foreach(lc, expr->args)`
Yeah, I just think we can go further and transform two const arrays into
a new one if we have the same clause and operator. In that case, we
should allow it to pass through this cycle down to the classification stage.
>
> also `foreach(lc, expr->args)` do we need to reject cases like
> `contain_subplans((Node *) nconst_expr)`?
> maybe let the nconst_expr be a Var node would be far more easier.
It's contradictory. On the one hand, we simplify the comparison
procedure and can avoid expr jumbling at all. On the other hand - we
restrict the feature. IMO, it would be better to unite such clauses
complex_clause1 IN (..) OR complex_clause1 IN (..)
into
complex_clause1 IN (.., ..)
and don't do duplicated work computing complex clauses.
In the attachment - the next version of the second patch.
--
regards,
Andrei Lepikhov
Postgres Professional
Attachment
Hi!
I can't unnderstand this part of code:
/* Time to generate index paths */
MemSet(&clauseset, 0, sizeof(clauseset));
match_clauses_to_index(root, list_make1(rinfo1), index, &clauseset);
As I understand it, match_clauses_to_index is necessary if you have a RestrictInfo (rinfo1) variable, so maybe we should run it after the make_restrictonfo procedure, otherwise calling it, I think, is useless.
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 12/2/2024 15:55, Alena Rybakina wrote: > Hi! > > I can't unnderstand this part of code: > > /* Time to generate index paths */ > > MemSet(&clauseset, 0, sizeof(clauseset)); > match_clauses_to_index(root, list_make1(rinfo1), index, &clauseset); > > As I understand it, match_clauses_to_index is necessary if you have a > RestrictInfo (rinfo1) variable, so maybe we should run it after the > make_restrictonfo procedure, otherwise calling it, I think, is useless. I think you must explain your note in more detail. Before this call, we already called make_restrictinfo() and built rinfo1, haven't we? -- regards, Andrei Lepikhov Postgres Professional
On 12.02.2024 12:01, Andrei Lepikhov wrote:
> On 12/2/2024 15:55, Alena Rybakina wrote:
>> Hi!
>>
>> I can't unnderstand this part of code:
>>
>> /* Time to generate index paths */
>>
>> MemSet(&clauseset, 0, sizeof(clauseset));
>> match_clauses_to_index(root, list_make1(rinfo1), index, &clauseset);
>>
>> As I understand it, match_clauses_to_index is necessary if you have a
>> RestrictInfo (rinfo1) variable, so maybe we should run it after the
>> make_restrictonfo procedure, otherwise calling it, I think, is useless.
> I think you must explain your note in more detail. Before this call,
> we already called make_restrictinfo() and built rinfo1, haven't we?
>
I got it, I think, I was confused by the “else“ block when we can
process the index, otherwise we move on to the next element.
I think maybe “else“ block of creating restrictinfo with the indexpaths
list creation should be moved to a separate function or just remove "else"?
I think we need to check that rinfo->clause is not empty, because if it
is we can miss calling build_paths_for_OR function. We should add it there:
restriction_is_saop_clause(RestrictInfo *restrictinfo)
{
if (IsA(restrictinfo->clause, ScalarArrayOpExpr))
...
By the way, I think we need to add a check that the clauseset is not
empty (if (!clauseset.nonempty)) otherwise we could get an error. The
same check I noticed in build_paths_for_OR function.
--
Regards,
Alena Rybakina
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Thu, Feb 8, 2024 at 1:34 PM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > A couple of questions: > 1. As I see, transformAExprIn uses the same logic as we invented but > allows composite and domain types. Could you add a comment explaining > why we forbid row types in general, in contrast to the transformAExprIn > routine? > 2. Could you provide the tests to check issues covered by the recent (in > v.15) changes? > > Patch 0001-* in the attachment incorporates changes induced by Jian's > notes from [1]. > Patch 0002-* contains a transformation of the SAOP clause, which allows > the optimizer to utilize partial indexes if they cover all values in > this array. Also, it is an answer to Alexander's note [2] on performance > degradation. This first version may be a bit raw, but I need your > opinion: Does it resolve the issue? > + newa = makeNode(ArrayExpr); + /* array_collid will be set by parse_collate.c */ + newa->element_typeid = scalar_type; + newa->array_typeid = array_type; + newa->multidims = false; + newa->elements = aexprs; + newa->location = -1; I am confused by the comments `array_collid will be set by parse_collate.c`, can you further explain it? if OR expression right arm is not plain Const, but with collation specification, eg. `where a = 'a' collate "C" or a = 'b' collate "C";` then the rightop is not Const, it will be CollateExpr, it will not be used in transformation. --------------------------------------------------------------------------------------------------------------------- Maybe the previous thread mentioned it, but this thread is very long. after apply v16-0001-Transform-OR-clause-to-ANY-expressions.patch and 0002-Teach-generate_bitmap_or_paths-to-build-BitmapOr-pat-20240212.patch I found a performance degradation case: drop table if exists test; create table test as (select (random()*100)::int x, (random()*1000) y from generate_series(1,1000000) i); vacuum analyze test; set enable_or_transformation to off; explain(timing off, analyze, costs off) select * from test where (x = 1 or x = 2 or x = 3 or x = 4 or x = 5 or x = 6 or x = 7 or x = 8 or x = 9 ) \watch i=0.1 c=10 50.887 ms set enable_or_transformation to on; explain(timing off, analyze, costs off) select * from test where (x = 1 or x = 2 or x = 3 or x = 4 or x = 5 or x = 6 or x = 7 or x = 8 or x = 9 ) \watch i=0.1 c=10 92.001 ms --------------------------------------------------------------------------------------------------------------------- but for aggregate count(*), it indeed increased the performance: set enable_or_transformation to off; explain(timing off, analyze, costs off) select count(*) from test where (x = 1 or x = 2 or x = 3 or x = 4 or x = 5 or x = 6 or x = 7 or x = 8 or x = 9 ) \watch i=0.1 c=10 46.818 ms set enable_or_transformation to on; explain(timing off, analyze, costs off) select count(*) from test where (x = 1 or x = 2 or x = 3 or x = 4 or x = 5 or x = 6 or x = 7 or x = 8 or x = 9 ) \watch i=0.1 c=10 35.376 ms The time is the last result of the 10 iterations.
On 13/2/2024 07:00, jian he wrote:
> + newa = makeNode(ArrayExpr);
> + /* array_collid will be set by parse_collate.c */
> + newa->element_typeid = scalar_type;
> + newa->array_typeid = array_type;
> + newa->multidims = false;
> + newa->elements = aexprs;
> + newa->location = -1;
>
> I am confused by the comments `array_collid will be set by
> parse_collate.c`, can you further explain it?
I wonder if the second paragraph of comments on commit b310b6e will be
enough to dive into details.
> if OR expression right arm is not plain Const, but with collation
> specification, eg.
> `where a = 'a' collate "C" or a = 'b' collate "C";`
>
> then the rightop is not Const, it will be CollateExpr, it will not be
> used in transformation.
Yes, it is done for simplicity right now. I'm not sure about corner
cases of merging such expressions.
>
> set enable_or_transformation to on;
> explain(timing off, analyze, costs off)
> select count(*) from test where (x = 1 or x = 2 or x = 3 or x = 4 or x
> = 5 or x = 6 or x = 7 or x = 8 or x = 9 ) \watch i=0.1 c=10
> 35.376 ms
>
> The time is the last result of the 10 iterations.
The reason here - parallel workers.
If you see into the plan you will find parallel workers without
optimization and absence of them in the case of optimization:
Gather (cost=1000.00..28685.37 rows=87037 width=12)
(actual rows=90363 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on test
Filter: ((x = 1) OR (x = 2) OR (x = 3) OR (x = 4) OR (x = 5)
OR (x = 6) OR (x = 7) OR (x = 8) OR (x = 9))
Seq Scan on test (cost=0.02..20440.02 rows=90600 width=12)
(actual rows=90363 loops=1)
Filter: (x = ANY ('{1,2,3,4,5,6,7,8,9}'::integer[]))
Having 90600 tuples returned we estimate it into 87000 (less precisely)
without transformation and 90363 (more precisely) with the transformation.
But if you play with parallel_tuple_cost and parallel_setup_cost, you
will end up having these parallel workers:
Gather (cost=0.12..11691.03 rows=90600 width=12)
(actual rows=90363 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on test
Filter: (x = ANY ('{1,2,3,4,5,6,7,8,9}'::integer[]))
Rows Removed by Filter: 303212
And some profit about 25%, on my laptop.
I'm not sure about the origins of such behavior, but it seems to be an
issue of parallel workers, not this specific optimization.
--
regards,
Andrei Lepikhov
Postgres Professional
On 12/2/2024 17:51, Alena Rybakina wrote:
> On 12.02.2024 12:01, Andrei Lepikhov wrote:
>> On 12/2/2024 15:55, Alena Rybakina wrote:
>>> As I understand it, match_clauses_to_index is necessary if you have a
>>> RestrictInfo (rinfo1) variable, so maybe we should run it after the
>>> make_restrictonfo procedure, otherwise calling it, I think, is useless.
>> I think you must explain your note in more detail. Before this call,
>> we already called make_restrictinfo() and built rinfo1, haven't we?
>>
> I got it, I think, I was confused by the “else“ block when we can
> process the index, otherwise we move on to the next element.
>
> I think maybe “else“ block of creating restrictinfo with the indexpaths
> list creation should be moved to a separate function or just remove "else"?
IMO, it is a matter of taste. But if you are really confused, maybe it
will make understanding for someone else simpler. So, changed.
> I think we need to check that rinfo->clause is not empty, because if it
> is we can miss calling build_paths_for_OR function. We should add it there:
>
> restriction_is_saop_clause(RestrictInfo *restrictinfo)
> {
> if (IsA(restrictinfo->clause, ScalarArrayOpExpr))
I wonder if we should add here assertion, not NULL check. In what case
we could get NULL clause here? But added for surety.
> By the way, I think we need to add a check that the clauseset is not
> empty (if (!clauseset.nonempty)) otherwise we could get an error. The
> same check I noticed in build_paths_for_OR function.
I don't. Feel free to provide counterexample.
--
regards,
Andrei Lepikhov
Postgres Professional
Attachment
On 13/2/2024 17:03, Andrei Lepikhov wrote: > On 13/2/2024 07:00, jian he wrote: >> The time is the last result of the 10 iterations. > I'm not sure about the origins of such behavior, but it seems to be an > issue of parallel workers, not this specific optimization. Having written that, I'd got a backburner. And to close that issue, I explored get_restriction_qual_cost(). A close look shows us that "x IN (..)" cheaper than its equivalent "x=N1 OR ...". Just numbers: ANY: startup_cost = 0.0225; total_cost = 0.005 OR: startup_cost==0; total_cost = 0.0225 Expression total_cost is calculated per tuple. In your example, we have many tuples, so the low cost of expression per tuple dominates over the significant startup cost. According to the above, SAOP adds 6250 to the cost of SeqScan; OR - 13541. So, the total cost of the query with SAOP is less than with OR, and the optimizer doesn't choose heavy parallel workers. And it is the answer. So, this example is more about the subtle balance between parallel/sequential execution, which can vary from one platform to another. -- regards, Andrei Lepikhov Postgres Professional
On Wed, Feb 14, 2024 at 11:21 AM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > > So, this example is more about the subtle balance between > parallel/sequential execution, which can vary from one platform to another. > Hi, here I attached two files, expression_num_or_1_100.sql, expression_num_or_1_10000.sql it has step by step test cases, also with the tests output. For both sql files, I already set the max_parallel_workers_per_gather to 10, work_mem to 4GB. I think the parameters setting should be fine. in expression_num_or_1_100.sql: main test table: create table test_1_100 as (select (random()*1000)::int x, (random()*1000) y from generate_series(1,1_000_000) i); if the number of OR exceeds 29, the performance with enable_or_transformation (ON) begins to outpace enable_or_transformation (OFF). if the number of OR less than 29, the performance with enable_or_transformation (OFF) is better than enable_or_transformation (ON). expression_num_or_1_10000.sql enable_or_transformation (ON) is always better than enable_or_transformation (OFF). My OS: Ubuntu 22.04.3 LTS I already set the max_parallel_workers_per_gather to 10. So for all cases, it should use parallelism first? a better question would be: how to make the number of OR less than 29 still faster when enable_or_transformation is ON by only set parameters?
Attachment
On 16/2/2024 07:00, jian he wrote: > On Wed, Feb 14, 2024 at 11:21 AM Andrei Lepikhov > <a.lepikhov@postgrespro.ru> wrote: > My OS: Ubuntu 22.04.3 LTS > I already set the max_parallel_workers_per_gather to 10. > So for all cases, it should use parallelism first? > > a better question would be: > how to make the number of OR less than 29 still faster when > enable_or_transformation is ON by only set parameters? In my test environment this example gives some subtle supremacy to ORs over ANY with only 3 ors and less. Please, provide next EXPLAIN ANALYZE results for the case you want to discuss here: 1. with enable_or_transformation enabled 2. with enable_or_transformation disabled 3. with enable_or_transformation disabled but with manual transformation OR -> ANY done, to check the overhead of this optimization. -- regards, Andrei Lepikhov Postgres Professional
On Fri, Feb 16, 2024 at 1:32 PM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > > On 16/2/2024 07:00, jian he wrote: > > On Wed, Feb 14, 2024 at 11:21 AM Andrei Lepikhov > > <a.lepikhov@postgrespro.ru> wrote: > > My OS: Ubuntu 22.04.3 LTS > > I already set the max_parallel_workers_per_gather to 10. > > So for all cases, it should use parallelism first? > > > > a better question would be: > > how to make the number of OR less than 29 still faster when > > enable_or_transformation is ON by only set parameters? > In my test environment this example gives some subtle supremacy to ORs > over ANY with only 3 ors and less. > Please, provide next EXPLAIN ANALYZE results for the case you want to > discuss here: > 1. with enable_or_transformation enabled > 2. with enable_or_transformation disabled > 3. with enable_or_transformation disabled but with manual transformation > OR -> ANY done, to check the overhead of this optimization. > you previously mentioned playing with parallel_tuple_cost and parallel_setup_cost. (https://www.postgresql.org/message-id/e3338e82-a28d-4631-9eec-b9c0984b32d5%40postgrespro.ru) So I did by ` SET parallel_setup_cost = 0; SET parallel_tuple_cost = 0; ` After setting these parameters, overall enable_or_transformation ON is performance better. sorry for the noise. so now I didn't find any corner case where enable_or_transformation is ON peforms worse than when it's OFF. +typedef struct OrClauseGroupEntry +{ + OrClauseGroupKey key; + + Node *node; + List *consts; + Oid scalar_type; + List *exprs; +} OrClauseGroupEntry; I found that the field `scalar_type` was never used.
On 16/2/2024 19:54, jian he wrote:
> After setting these parameters, overall enable_or_transformation ON is
> performance better.
> sorry for the noise.
Don't worry, at least we know a weak point of partial paths estimation.
> so now I didn't find any corner case where enable_or_transformation is
> ON peforms worse than when it's OFF.
>
> +typedef struct OrClauseGroupEntry
> +{
> + OrClauseGroupKey key;
> +
> + Node *node;
> + List *consts;
> + Oid scalar_type;
> + List *exprs;
> +} OrClauseGroupEntry;
>
> I found that the field `scalar_type` was never used.
Thanks, fixed.
In attachment - v17 for both patches. As I see it, the only general
explanation of the idea is not addressed. I'm not sure how deeply we
should explain it.
--
regards,
Andrei Lepikhov
Postgres Professional
Attachment
On 16/2/2024 19:54, jian he wrote:
> After setting these parameters, overall enable_or_transformation ON is
> performance better.
> sorry for the noise.
Don't worry, at least we know a weak point of partial paths estimation.
> so now I didn't find any corner case where enable_or_transformation is
> ON peforms worse than when it's OFF.
>
> +typedef struct OrClauseGroupEntry
> +{
> + OrClauseGroupKey key;
> +
> + Node *node;
> + List *consts;
> + Oid scalar_type;
> + List *exprs;
> +} OrClauseGroupEntry;
>
> I found that the field `scalar_type` was never used.
Thanks, fixed.
+ ScalarArrayOpExpr *dest;
+
+ pd = (PredicatesData *) lfirst(lc);
+ if (pd->elems == NIL)
+ /* The index doesn't participate in this operation */
+ continue;
+ dest = makeNode(ScalarArrayOpExpr);
On 19/2/2024 19:53, Ranier Vilela wrote: > v17-0002 > 1) move the vars *arrayconst and *dest, to after if, to avoid makeNode > (palloc). > + Const *arrayconst; > + ScalarArrayOpExpr *dest; > + > + pd = (PredicatesData *) lfirst(lc); > + if (pd->elems == NIL) > + /* The index doesn't participate in this operation */ > + continue; > > + arrayconst = lsecond_node(Const, saop->args); > + dest = makeNode(ScalarArrayOpExpr); Thanks for the review! I'm not sure I understand you clearly. Does the patch in attachment fix the issue you raised? -- regards, Andrei Lepikhov Postgres Professional
Attachment
On Mon, Feb 19, 2024 at 4:35 PM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > > In attachment - v17 for both patches. As I see it, the only general > explanation of the idea is not addressed. I'm not sure how deeply we > should explain it. > On Tue, Nov 28, 2023 at 5:04 AM Robert Haas <robertmhaas@gmail.com> wrote: > > On Mon, Nov 27, 2023 at 3:02 AM Andrei Lepikhov > <a.lepikhov@postgrespro.ru> wrote: > > On 25/11/2023 08:23, Alexander Korotkov wrote: > > > I think patch certainly gets better in this aspect. One thing I can't > > > understand is why do we use home-grown code for resolving > > > hash-collisions. You can just define custom hash and match functions > > > in HASHCTL. Even if we need to avoid repeated JumbleExpr calls, we > > > still can save pre-calculated hash value into hash entry and use > > > custom hash and match. This doesn't imply us to write our own > > > collision-resolving code. > > > > Thanks, it was an insightful suggestion. > > I implemented it, and the code has become shorter (see attachment). > > Neither the code comments nor the commit message really explain the > design idea here. That's unfortunate, principally because it makes > review difficult. > > I'm very skeptical about the idea of using JumbleExpr for any part of > this. It seems fairly expensive, and it might produce false matches. > If expensive is OK, then why not just use equal()? If it's not, then > this probably isn't really OK either. But in any case there should be > comments explaining why this strategy was chosen. The above message (https://postgr.es/m/CA%2BTgmoZCgP6FrBQEusn4yaWm02XU8OPeoEMk91q7PRBgwaAkFw%40mail.gmail.com) seems still not answered. How can we evaluate whether JumbleExpr is expensive or not? I used this naive script to test, but didn't find a big difference when enable_or_transformation is ON or OFF. ` create table test_1_100 as (select (random()*1000)::int x, (random()*1000) y from generate_series(1,1_000_000) i); explain(costs off, analyze) select * from test where x = 1 or x + 2= 3 or x + 3= 4 or x + 4= 5 or x + 5= 6 or x + 6= 7 or x + 7= 8 or x + 8= 9 or x + 9=10 or x + 10= 11 or x + 11= 12 or x + 12= 13 or x + 13= 14 or x + 14= 15 or x + 15= 16 or x + 16= 17 or x + 17= 18 or x + 18=19 or x + 19= 20 or x + 20= 21 or x + 21= 22 or x + 22= 23 or x + 23= 24 or x + 24= 25 or x + 25= 26 or x + 26= 27 or x + 27=28 or x + 28= 29 or x + 29= 30 or x + 30= 31 \watch i=0.1 c=10 ` `leftop operator rightop` the operator can also be volatile. Do we need to check (op_volatile(opno) == PROVOLATILE_VOLATILE) within transformBoolExprOr?
On 20/2/2024 11:03, jian he wrote: >> Neither the code comments nor the commit message really explain the >> design idea here. That's unfortunate, principally because it makes >> review difficult. >> >> I'm very skeptical about the idea of using JumbleExpr for any part of >> this. It seems fairly expensive, and it might produce false matches. >> If expensive is OK, then why not just use equal()? If it's not, then >> this probably isn't really OK either. But in any case there should be >> comments explaining why this strategy was chosen. > > The above message > (https://postgr.es/m/CA%2BTgmoZCgP6FrBQEusn4yaWm02XU8OPeoEMk91q7PRBgwaAkFw%40mail.gmail.com) > seems still not answered. > How can we evaluate whether JumbleExpr is expensive or not? > I used this naive script to test, but didn't find a big difference > when enable_or_transformation is ON or OFF. First, I am open to discussion here. But IMO, equal() operation is quite expensive by itself. We should use the hash table approach to avoid quadratic behaviour when looking for similar clauses in the 'OR' list. Moreover, we use equal() in many places: selectivity estimations, proving of fitting the index, predtest, etc. So, by reducing the clause list, we eliminate many calls of the equal() routine, too. > `leftop operator rightop` > the operator can also be volatile. > Do we need to check (op_volatile(opno) == PROVOLATILE_VOLATILE) within > transformBoolExprOr? As usual, could you provide a test case to discuss it more objectively? -- regards, Andrei Lepikhov Postgres Professional
On 19/2/2024 19:53, Ranier Vilela wrote:
> v17-0002
> 1) move the vars *arrayconst and *dest, to after if, to avoid makeNode
> (palloc).
> + Const *arrayconst;
> + ScalarArrayOpExpr *dest;
> +
> + pd = (PredicatesData *) lfirst(lc);
> + if (pd->elems == NIL)
> + /* The index doesn't participate in this operation */
> + continue;
>
> + arrayconst = lsecond_node(Const, saop->args);
> + dest = makeNode(ScalarArrayOpExpr);
Thanks for the review!
I'm not sure I understand you clearly. Does the patch in attachment fix
the issue you raised?
What I meant is to move the initializations of the variables *arrayconst* and *dest*
for after the test (if (pd->elems == NIL)
To avoid unnecessary initialization if the test fails.
Hi. I wrote the first draft patch of the documentation. it's under the section: Planner Method Configuration (runtime-config-query.html) but this feature's main meat is in src/backend/parser/parse_expr.c so it may be slightly inconsistent, as mentioned by others. You can further furnish it.
Attachment
On 24.02.2024 14:28, jian he wrote: > Hi. > I wrote the first draft patch of the documentation. > it's under the section: Planner Method Configuration (runtime-config-query.html) > but this feature's main meat is in src/backend/parser/parse_expr.c > so it may be slightly inconsistent, as mentioned by others. > > You can further furnish it. Thank you for your work. I found a few spelling mistakes - I fixed this and added some information about generating a partial index plan. I attached it. -- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On 26/2/2024 11:10, Alena Rybakina wrote: > On 24.02.2024 14:28, jian he wrote: >> Hi. >> I wrote the first draft patch of the documentation. >> it's under the section: Planner Method Configuration >> (runtime-config-query.html) >> but this feature's main meat is in src/backend/parser/parse_expr.c >> so it may be slightly inconsistent, as mentioned by others. >> >> You can further furnish it. > > Thank you for your work. I found a few spelling mistakes - I fixed this > and added some information about generating a partial index plan. I > attached it. Thanks Jian and Alena, It is a good start for the documentation. But I think the runtime-config section needs only a condensed description of a feature underlying the GUC. The explanations in this section look a bit awkward. Having looked through the documentation for a better place for a detailed explanation, I found array.sgml as a candidate. Also, we have the parser's short overview section. I'm unsure about the best place but it is better when the server config section. What's more, there are some weak points in the documentation: 1. We choose constant and variable parts of an expression and don't require the constant to be on the right side. 2. We should describe the second part of the feature, where the optimiser can split an array to fit the optimal BitmapOr scan path. -- regards, Andrei Lepikhov Postgres Professional
On Wed, Feb 28, 2024 at 12:19 PM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > > On 26/2/2024 11:10, Alena Rybakina wrote: > > On 24.02.2024 14:28, jian he wrote: > >> Hi. > >> I wrote the first draft patch of the documentation. > >> it's under the section: Planner Method Configuration > >> (runtime-config-query.html) > >> but this feature's main meat is in src/backend/parser/parse_expr.c > >> so it may be slightly inconsistent, as mentioned by others. > >> > >> You can further furnish it. > > > > Thank you for your work. I found a few spelling mistakes - I fixed this > > and added some information about generating a partial index plan. I > > attached it. > Thanks Jian and Alena, > It is a good start for the documentation. But I think the runtime-config > section needs only a condensed description of a feature underlying the > GUC. The explanations in this section look a bit awkward. > Having looked through the documentation for a better place for a > detailed explanation, I found array.sgml as a candidate. Also, we have > the parser's short overview section. I'm unsure about the best place but > it is better when the server config section. doc/src/sgml/array.sgml corresponds to https://www.postgresql.org/docs/current/arrays.html. this GUC is related to parser|optimzier. adding a GUC to array.sgml seems strange. (I think). > 2. We should describe the second part of the feature, where the > optimiser can split an array to fit the optimal BitmapOr scan path. we can add a sentence explaining that: it may not do the expression transformation when the original expression can be utilized by index mechanism. I am not sure how to rephrase it.
On 28.02.2024 13:07, jian he wrote: > On Wed, Feb 28, 2024 at 12:19 PM Andrei Lepikhov > <a.lepikhov@postgrespro.ru> wrote: >> On 26/2/2024 11:10, Alena Rybakina wrote: >>> On 24.02.2024 14:28, jian he wrote: >>>> Hi. >>>> I wrote the first draft patch of the documentation. >>>> it's under the section: Planner Method Configuration >>>> (runtime-config-query.html) >>>> but this feature's main meat is in src/backend/parser/parse_expr.c >>>> so it may be slightly inconsistent, as mentioned by others. >>>> >>>> You can further furnish it. >>> Thank you for your work. I found a few spelling mistakes - I fixed this >>> and added some information about generating a partial index plan. I >>> attached it. >> Thanks Jian and Alena, >> It is a good start for the documentation. But I think the runtime-config >> section needs only a condensed description of a feature underlying the >> GUC. The explanations in this section look a bit awkward. >> Having looked through the documentation for a better place for a >> detailed explanation, I found array.sgml as a candidate. Also, we have >> the parser's short overview section. I'm unsure about the best place but >> it is better when the server config section. > doc/src/sgml/array.sgml corresponds to > https://www.postgresql.org/docs/current/arrays.html. > this GUC is related to parser|optimzier. > adding a GUC to array.sgml seems strange. (I think). I suggest describing our feature in array.sgml and mentioning a GUC there. We can describe a GUC in config.sgml. >> 2. We should describe the second part of the feature, where the >> optimiser can split an array to fit the optimal BitmapOr scan path. > we can add a sentence explaining that: > it may not do the expression transformation when the original > expression can be utilized by index mechanism. > I am not sure how to rephrase it. Maybe like that: It also considers the way to generate a path using BitmapScan indexes, converting the transformed expression into expressions separated by "OR" operations, and if it turns out to be the best and finally selects the best one. -- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 28/2/2024 17:07, jian he wrote: > doc/src/sgml/array.sgml corresponds to > https://www.postgresql.org/docs/current/arrays.html. > this GUC is related to parser|optimzier. > adding a GUC to array.sgml seems strange. (I think). Maybe. In that case, I suggest adding extended comments to functions transformBoolExprOr and generate_saop_pathlist (including cross-referencing each other). These are starting points to understand the transformation and, therefore, a good place for a detailed explanation. -- regards, Andrei Lepikhov Postgres Professional
On 28/2/2024 17:27, Alena Rybakina wrote: > Maybe like that: > > It also considers the way to generate a path using BitmapScan indexes, > converting the transformed expression into expressions separated by "OR" > operations, and if it turns out to be the best and finally selects the > best one. Thanks, I spent some time describing the feature with documentation. A condensed description of the GUC is in the runtime-config file. Feature description has spread between TransformOrExprToANY and generate_saop_pathlist routines. Also, I've made tiny changes in the code to look more smoothly. All modifications are integrated into the two new patches. Feel free to add, change or totally rewrite these changes. -- regards, Andrei Lepikhov Postgres Professional
Attachment
On 28/2/2024 17:27, Alena Rybakina wrote:
> Maybe like that:
>
> It also considers the way to generate a path using BitmapScan indexes,
> converting the transformed expression into expressions separated by "OR"
> operations, and if it turns out to be the best and finally selects the
> best one.
Thanks,
I spent some time describing the feature with documentation.
A condensed description of the GUC is in the runtime-config file.
Feature description has spread between TransformOrExprToANY and
generate_saop_pathlist routines.
Also, I've made tiny changes in the code to look more smoothly.
All modifications are integrated into the two new patches.
Feel free to add, change or totally rewrite these changes.
> * Transformation only works with both side type is not
> * { array | composite | domain | record }.
Regards,
Alexander Korotkov
I found that it was mentioned here - https://www.postgresql.org/message-id/CACJufxFrZS07oBHMk1_c8P3A84VZ3ysXiZV8NeU6gAnvu%2BHsVA%40mail.gmail.com.
To be honest, I couldn't find any explanation for that.
Hi, Andrei,Hi, Alena!On Thu, Feb 29, 2024 at 10:59 AM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote:On 28/2/2024 17:27, Alena Rybakina wrote:
> Maybe like that:
>
> It also considers the way to generate a path using BitmapScan indexes,
> converting the transformed expression into expressions separated by "OR"
> operations, and if it turns out to be the best and finally selects the
> best one.
Thanks,
I spent some time describing the feature with documentation.
A condensed description of the GUC is in the runtime-config file.
Feature description has spread between TransformOrExprToANY and
generate_saop_pathlist routines.
Also, I've made tiny changes in the code to look more smoothly.
All modifications are integrated into the two new patches.
Feel free to add, change or totally rewrite these changes.I'm going to review and revise the patch.One question I have yet.> /*
> * Transformation only works with both side type is not
> * { array | composite | domain | record }.Why do we limit transformation for these types? Also, it doesn't seem the current code restricts anything except composite/record.------
Regards,
Alexander Korotkov
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Sorry, I found explanation - https://www.postgresql.org/message-id/CACJufxFS-xcjaWq2Du2OyJUjRAyqCk12Q_zGOPxv61sgrdpw9w%40mail.gmail.com
I found that it was mentioned here - https://www.postgresql.org/message-id/CACJufxFrZS07oBHMk1_c8P3A84VZ3ysXiZV8NeU6gAnvu%2BHsVA%40mail.gmail.com.
To be honest, I couldn't find any explanation for that.
On 01.03.2024 18:33, Alexander Korotkov wrote:Hi, Andrei,Hi, Alena!On Thu, Feb 29, 2024 at 10:59 AM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote:On 28/2/2024 17:27, Alena Rybakina wrote:
> Maybe like that:
>
> It also considers the way to generate a path using BitmapScan indexes,
> converting the transformed expression into expressions separated by "OR"
> operations, and if it turns out to be the best and finally selects the
> best one.
Thanks,
I spent some time describing the feature with documentation.
A condensed description of the GUC is in the runtime-config file.
Feature description has spread between TransformOrExprToANY and
generate_saop_pathlist routines.
Also, I've made tiny changes in the code to look more smoothly.
All modifications are integrated into the two new patches.
Feel free to add, change or totally rewrite these changes.I'm going to review and revise the patch.One question I have yet.> /*
> * Transformation only works with both side type is not
> * { array | composite | domain | record }.Why do we limit transformation for these types? Also, it doesn't seem the current code restricts anything except composite/record.------
Regards,
Alexander Korotkov-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Thu, Feb 29, 2024 at 4:59 PM Andrei Lepikhov
<a.lepikhov@postgrespro.ru> wrote:
>
> On 28/2/2024 17:27, Alena Rybakina wrote:
> > Maybe like that:
> >
> > It also considers the way to generate a path using BitmapScan indexes,
> > converting the transformed expression into expressions separated by "OR"
> > operations, and if it turns out to be the best and finally selects the
> > best one.
> Thanks,
> I spent some time describing the feature with documentation.
> A condensed description of the GUC is in the runtime-config file.
> Feature description has spread between TransformOrExprToANY and
> generate_saop_pathlist routines.
> Also, I've made tiny changes in the code to look more smoothly.
> All modifications are integrated into the two new patches.
>
> Feel free to add, change or totally rewrite these changes.
diff --git a/src/backend/utils/misc/guc_tables.c
b/src/backend/utils/misc/guc_tables.c
index 93ded31ed9..7d3a1ca238 100644
--- a/src/backend/utils/misc/guc_tables.c
+++ b/src/backend/utils/misc/guc_tables.c
@@ -1026,6 +1026,17 @@ struct config_bool ConfigureNamesBool[] =
true,
NULL, NULL, NULL
},
+ {
+ {"enable_or_transformation", PGC_USERSET, QUERY_TUNING_OTHER,
+ gettext_noop("Transform a sequence of OR clauses to an IN expression."),
+ gettext_noop("The planner will replace clauses like 'x=c1 OR x=c2 .."
+ "to the clause 'x IN (c1,c2,...)'"),
+ GUC_EXPLAIN
+ },
+ &enable_or_transformation,
+ true,
+ NULL, NULL, NULL
+ },
I think it should be something like:
+ gettext_noop("Transform a sequence of OR expressions to an array
expression."),
+ gettext_noop("The planner will replace expression like 'x=c1 OR x=c2 "
+ "to the expression 'x = ANY( ARRAY[c1,c2])''"
+JumbleState *
+JumbleExpr(Expr *expr, uint64 *queryId)
+{
+ JumbleState *jstate = NULL;
+
+ Assert(queryId != NULL);
+
+ jstate = (JumbleState *) palloc(sizeof(JumbleState));
+
+ /* Set up workspace for query jumbling */
+ jstate->jumble = (unsigned char *) palloc(JUMBLE_SIZE);
+ jstate->jumble_len = 0;
+ jstate->clocations_buf_size = 32;
+ jstate->clocations = (LocationLen *)
+ palloc(jstate->clocations_buf_size * sizeof(LocationLen));
+ jstate->clocations_count = 0;
+ jstate->highest_extern_param_id = 0;
+
+ /* Compute query ID */
+ _jumbleNode(jstate, (Node *) expr);
+ *queryId = DatumGetUInt64(hash_any_extended(jstate->jumble,
+ jstate->jumble_len,
+ 0));
+
+ return jstate;
+}
queryId may not be a good variable name here?
comment `/* Compute query ID */`
seems not correct, here we are just hashing the expression?
+/*
+ * Dynahash match function to use in guc_hashtab
+ */
+static int
+orclause_match(const void *data1, const void *data2, Size keysize)
+{
+ OrClauseGroupKey *key1 = (OrClauseGroupKey *) data1;
+ OrClauseGroupKey *key2 = (OrClauseGroupKey *) data2;
+
+ Assert(sizeof(OrClauseGroupKey) == keysize);
+
+ if (key1->opno == key2->opno && key1->exprtype == key2->exprtype &&
+ equal(key1->expr, key2->expr))
+ return 0;
+
+ return 1;
+}
the above comments seem not correct?
<para>
Enables or disables the query planner's ability to lookup and
group multiple
similar OR expressions to ANY (<xref
linkend="functions-comparisons-any-some"/>) expressions.
The grouping technique of this transformation is based on the
similarity of variable sides.
It applies to equality expressions only. One side of such an expression
must be a constant clause, and the other must contain a variable clause.
The default is <literal>on</literal>.
Also, during BitmapScan paths generation it enables analysis of elements
of IN or ANY constant arrays to cover such clause with BitmapOr set of
partial index scans.
</para>
` It applies to equality expressions only.` seems not correct?
`select * from tenk1 where unique1 < 1 or unique1 < 2; ` can also do
the transformation.
`similarity of variable sides.` seems not correct,
should it be 'sameness of the variable sides`?
in [1], we can get:
expression IN (value [, ...])
is equivalent to
expression = value1
OR
expression = value2
OR
in [2], we can get:
SOME is a synonym for ANY. IN is equivalent to = ANY.
but still transforming OR to ANY is not intuitive.
a normal user may not know what is "transforming OR to ANY".
so maybe adding a simple example at
<varlistentry id="guc-enable-or-transformation"
xreflabel="enable_or_transformation">
would be great. which, I did at previous thread.
I also did some refactoring based on v18, attached.
[1] https://www.postgresql.org/docs/current/functions-comparisons.html#FUNCTIONS-COMPARISONS-IN-SCALAR
[2] https://www.postgresql.org/docs/current/functions-subquery.html#FUNCTIONS-SUBQUERY-ANY-SOME
Attachment
On 1/3/2024 22:33, Alexander Korotkov wrote:
> I'm going to review and revise the patch.
Nice!
>
> One question I have yet.
>
> > /*
> > * Transformation only works with both side type is not
> > * { array | composite | domain | record }.
>
> Why do we limit transformation for these types? Also, it doesn't seem
> the current code restricts anything except composite/record.
Answer can be a bit long. Let's try to see comment a4424c5 at first.
We forbid record types although they can have typarray. It is because of
the RowExpr comparison specific. Although we have the record_eq()
routine, all base types in comparing records must be strictly the same.
Let me show:
explain analyze
SELECT * FROM
(SELECT ROW(relpages,relnatts) AS x FROM pg_class LIMIT 10) AS q1,
(SELECT ROW(relpages,relallvisible) AS x FROM pg_class LIMIT 10) AS q2
WHERE q1.x=q2.x;
ERROR: cannot compare dissimilar column types smallint and integer at
record column 2
As you can see, we have smallint and integer in the second position of
RowExpr and it causes the ERROR. It is the reason, why PostgreSQL
transforms ROW expressions to the series of ORs, Look:
explain (costs off)
SELECT oid,relname FROM pg_class
WHERE (oid,relname) IN ((1, 'a'), (2,'b'));
Bitmap Heap Scan on pg_class
Recheck Cond: ((relname = 'a'::name) OR (relname = 'b'::name))
Filter: (((oid = '1'::oid) AND (relname = 'a'::name)) OR ((oid =
'2'::oid) AND (relname = 'b'::name)))
-> BitmapOr
...
So, transforming composite types to the ScalarArrayOpExpr expression
doesn't make sense. Am I wrong?
The same with domain. If it have composite base type we reject the
transformation according to the logic above.
What about arrays? As I see, arrays don't have typarray and we can avoid
to spend more cycles after detection of TYPCATEGORY_ARRAY. I haven't
done it yet because have a second thought: what if to combine arrays
into the larger one? I'm unsure on that, so we can forbid it too.
--
regards,
Andrei Lepikhov
Postgres Professional
On 4/3/2024 09:26, jian he wrote:
> On Thu, Feb 29, 2024 at 4:59 PM Andrei Lepikhov
>> Feel free to add, change or totally rewrite these changes.
On replacement of static ScalarArrayOpExpr dest with dynamic allocated one:
After discussion [1] I agree with that replacement.
Some style (and language) changes in comments I haven't applied because
it looks debatable for me.
> I think it should be something like:
> + gettext_noop("Transform a sequence of OR expressions to an array
> expression."),
> + gettext_noop("The planner will replace expression like 'x=c1 OR x=c2 "
> + "to the expression 'x = ANY( ARRAY[c1,c2])''"
Fixed
> queryId may not be a good variable name here?
Not sure. QueryId is a concept, part of queryjumble technique and can be
used by other tools. It just tells the developer what it is the same
thing as Query Jumbling but for a separate expression.
At least you don't insist on removing of JumbleState return pointer that
looks strange for a simple hash ...
>
> comment `/* Compute query ID */`
> seems not correct, here we are just hashing the expression?
The same as above.
> +/*
> + * Dynahash match function to use in guc_hashtab
> the above comments seem not correct?
Yes, fixed.
> ` It applies to equality expressions only.` seems not correct?
> `select * from tenk1 where unique1 < 1 or unique1 < 2; ` can also do
> the transformation.
Yes, I forgot it.
> `similarity of variable sides.` seems not correct,
> should it be 'sameness of the variable sides`?
The term 'equivalence' looks better *).
> in [2], we can get:
> SOME is a synonym for ANY. IN is equivalent to = ANY.
>
> but still transforming OR to ANY is not intuitive.
> a normal user may not know what is "transforming OR to ANY".
> so maybe adding a simple example at
> <varlistentry id="guc-enable-or-transformation"
> xreflabel="enable_or_transformation">
> would be great. which, I did at previous thread.
Not sure. Examples in that section are unusual things. What's more,
should a user who doesn't know what it means to change this setting?
Let's wait for other opinions.
[1] https://www.postgresql.org/message-id/2157387.1709068790@sss.pgh.pa.us
--
regards,
Andrei Lepikhov
Postgres Professional
On 5/3/2024 12:30, Andrei Lepikhov wrote: > On 4/3/2024 09:26, jian he wrote: ... and the new version of the patchset is attached. -- regards, Andrei Lepikhov Postgres Professional
Attachment
On Tue, Mar 5, 2024 at 9:59 AM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote:
> On 5/3/2024 12:30, Andrei Lepikhov wrote:
> > On 4/3/2024 09:26, jian he wrote:
> ... and the new version of the patchset is attached.
I made some revisions for the patchset.
1) Use hash_combine() to combine hash values.
2) Upper limit the number of array elements by MAX_SAOP_ARRAY_SIZE.
3) Better save the original order of clauses by putting hash entries and untransformable clauses to the same list. A lot of differences in regression tests output have gone.
One important issue I found.
# analyze t;
# explain select * from t where i = 1 or i = 1;
QUERY PLAN
-----------------------------------------------------
Seq Scan on t (cost=0.00..189.00 rows=200 width=4)
Filter: (i = ANY ('{1,1}'::integer[]))
(2 rows)
# set enable_or_transformation = false;
SET
# explain select * from t where i = 1 or i = 1;
QUERY PLAN
-----------------------------------------------------
Seq Scan on t (cost=0.00..189.00 rows=100 width=4)
Filter: (i = 1)
(2 rows)
We don't make array values unique. That might make query execution performance somewhat worse, and also makes selectivity estimation worse. I suggest Andrei and/or Alena should implement making array values unique.
------
Regards,
Alexander Korotkov
Attachment
Hi!
On 07.03.2024 17:51, Alexander Korotkov wrote:
> Hi!
>
> On Tue, Mar 5, 2024 at 9:59 AM Andrei Lepikhov
> <a.lepikhov@postgrespro.ru> wrote:
> > On 5/3/2024 12:30, Andrei Lepikhov wrote:
> > > On 4/3/2024 09:26, jian he wrote:
> > ... and the new version of the patchset is attached.
>
> I made some revisions for the patchset.
> 1) Use hash_combine() to combine hash values.
> 2) Upper limit the number of array elements by MAX_SAOP_ARRAY_SIZE.
> 3) Better save the original order of clauses by putting hash entries
> and untransformable clauses to the same list. A lot of differences in
> regression tests output have gone.
Thank you for your changes. I agree with them.
>
> One important issue I found.
>
> # create table t as (select i::int%100 i from generate_series(1,10000) i);
> # analyze t;
> # explain select * from t where i = 1 or i = 1;
> QUERY PLAN
> -----------------------------------------------------
> Seq Scan on t (cost=0.00..189.00 rows=200 width=4)
> Filter: (i = ANY ('{1,1}'::integer[]))
> (2 rows)
>
> # set enable_or_transformation = false;
> SET
> # explain select * from t where i = 1 or i = 1;
> QUERY PLAN
> -----------------------------------------------------
> Seq Scan on t (cost=0.00..189.00 rows=100 width=4)
> Filter: (i = 1)
> (2 rows)
>
> We don't make array values unique. That might make query execution
> performance somewhat worse, and also makes selectivity estimation
> worse. I suggest Andrei and/or Alena should implement making array
> values unique.
>
>
I have corrected this and some spelling mistakes. The
unique_any_elements_change.no-cfbot file contains changes.
While I was correcting the test results caused by such changes, I
noticed that the same behavior was when converting the IN expression,
and this can be seen in the result of the regression test:
EXPLAIN (COSTS OFF)
SELECT unique2 FROM onek2
WHERE stringu1 IN ('A', 'A') AND (stringu1 = 'A' OR stringu1 = 'A');
QUERY PLAN
---------------------------------------------------------------------------
Bitmap Heap Scan on onek2
Recheck Cond: (stringu1 < 'B'::name)
Filter: ((stringu1 = ANY ('{A,A}'::name[])) AND (stringu1 = 'A'::name))
-> Bitmap Index Scan on onek2_u2_prtl
(4 rows)
--
Regards,
Alena Rybakina
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
+ if (!IsA(lfirst(lc), Invalid))
+ {
+ or_list = lappend(or_list, lfirst(lc));
+ continue;
+ }
Currently `IsA(lfirst(lc)` works.
but is this generally OK? I didn't find any other examples.
do you need do cast, like `(Node *) lfirst(lc);`
If I understand the logic correctly:
In `foreach(lc, args) ` if everything goes well, it will reach
`hashkey.type = T_Invalid;`
which will make `IsA(lfirst(lc), Invalid)` be true.
adding some comments to the above code would be great.
On 7/3/2024 21:51, Alexander Korotkov wrote: > Hi! > > On Tue, Mar 5, 2024 at 9:59 AM Andrei Lepikhov > <a.lepikhov@postgrespro.ru <mailto:a.lepikhov@postgrespro.ru>> wrote: > > On 5/3/2024 12:30, Andrei Lepikhov wrote: > > > On 4/3/2024 09:26, jian he wrote: > > ... and the new version of the patchset is attached. > > I made some revisions for the patchset. Great! > 1) Use hash_combine() to combine hash values. Looks better > 2) Upper limit the number of array elements by MAX_SAOP_ARRAY_SIZE. I'm not convinced about this limit. The initial reason was to combine long lists of ORs into the array because such a transformation made at an early stage increases efficiency. I understand the necessity of this limit in the array decomposition routine but not in the creation one. > 3) Better save the original order of clauses by putting hash entries and > untransformable clauses to the same list. A lot of differences in > regression tests output have gone. I agree that reducing the number of changes in regression tests looks better. But to achieve this, you introduced a hack that increases the complexity of the code. Is it worth it? Maybe it would be better to make one-time changes in tests instead of getting this burden on board. Or have you meant something more introducing the node type? > We don't make array values unique. That might make query execution > performance somewhat worse, and also makes selectivity estimation > worse. I suggest Andrei and/or Alena should implement making array > values unique. The fix Alena has made looks correct. But I urge you to think twice: The optimizer doesn't care about duplicates, so why do we do it? What's more, this optimization is intended to speed up queries with long OR lists. Using the list_append_unique() comparator on such lists could impact performance. I suggest sticking to the common rule and leaving the responsibility on the user's shoulders. At least, we should do this optimization later, in one pass, with sorting elements before building the array. But what if we don't have a sort operator for the type? -- regards, Andrei Lepikhov Postgres Professional
Hi Andrei, Thank you for your response. On Mon, Mar 11, 2024 at 7:13 AM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > On 7/3/2024 21:51, Alexander Korotkov wrote: > > Hi! > > > > On Tue, Mar 5, 2024 at 9:59 AM Andrei Lepikhov > > <a.lepikhov@postgrespro.ru <mailto:a.lepikhov@postgrespro.ru>> wrote: > > > On 5/3/2024 12:30, Andrei Lepikhov wrote: > > > > On 4/3/2024 09:26, jian he wrote: > > > ... and the new version of the patchset is attached. > > > > I made some revisions for the patchset. > Great! > > 1) Use hash_combine() to combine hash values. > Looks better > > 2) Upper limit the number of array elements by MAX_SAOP_ARRAY_SIZE. > > I'm not convinced about this limit. The initial reason was to combine > long lists of ORs into the array because such a transformation made at > an early stage increases efficiency. > I understand the necessity of this limit in the array decomposition > routine but not in the creation one. The comment near MAX_SAOP_ARRAY_SIZE says that this limit is because N^2 algorithms could be applied to arrays. Are you sure that's not true for our case? > > 3) Better save the original order of clauses by putting hash entries and > > untransformable clauses to the same list. A lot of differences in > > regression tests output have gone. > I agree that reducing the number of changes in regression tests looks > better. But to achieve this, you introduced a hack that increases the > complexity of the code. Is it worth it? Maybe it would be better to make > one-time changes in tests instead of getting this burden on board. Or > have you meant something more introducing the node type? For me the reason is not just a regression test. The current code keeps the original order of quals as much as possible. The OR transformation code reorders quals even in cases when it doesn't eventually apply any optimization. I don't think that's acceptable. However, less hackery ways for this is welcome for sure. > > We don't make array values unique. That might make query execution > > performance somewhat worse, and also makes selectivity estimation > > worse. I suggest Andrei and/or Alena should implement making array > > values unique. > The fix Alena has made looks correct. But I urge you to think twice: > The optimizer doesn't care about duplicates, so why do we do it? > What's more, this optimization is intended to speed up queries with long > OR lists. Using the list_append_unique() comparator on such lists could > impact performance. I suggest sticking to the common rule and leaving > the responsibility on the user's shoulders. I don't see why the optimizer doesn't care about duplicates for OR lists. As I showed before in an example, it successfully removes the duplicate. So, currently OR transformation clearly introduces a regression in terms of selectivity estimation. I think we should evade that. > At least, we should do this optimization later, in one pass, with > sorting elements before building the array. But what if we don't have a > sort operator for the type? It was probably discussed before, but can we do our work later? There is a canonicalize_qual() which calls find_duplicate_ors(). This is the place where currently duplicate OR clauses are removed. Could our OR-to-ANY transformation be just another call from canonicalize_qual()? ------ Regards, Alexander Korotkov
On 11/3/2024 18:31, Alexander Korotkov wrote: >> I'm not convinced about this limit. The initial reason was to combine >> long lists of ORs into the array because such a transformation made at >> an early stage increases efficiency. >> I understand the necessity of this limit in the array decomposition >> routine but not in the creation one. > > The comment near MAX_SAOP_ARRAY_SIZE says that this limit is because > N^2 algorithms could be applied to arrays. Are you sure that's not > true for our case? When you operate an array, indeed. But when we transform ORs to an array, not. Just check all the places in the optimizer and even the executor where we would pass along the list of ORs. This is why I think we should use this optimization even more intensively for huge numbers of ORs in an attempt to speed up the overall query. >>> 3) Better save the original order of clauses by putting hash entries and >>> untransformable clauses to the same list. A lot of differences in >>> regression tests output have gone. >> I agree that reducing the number of changes in regression tests looks >> better. But to achieve this, you introduced a hack that increases the >> complexity of the code. Is it worth it? Maybe it would be better to make >> one-time changes in tests instead of getting this burden on board. Or >> have you meant something more introducing the node type? > > For me the reason is not just a regression test. The current code > keeps the original order of quals as much as possible. The OR > transformation code reorders quals even in cases when it doesn't > eventually apply any optimization. I don't think that's acceptable. > However, less hackery ways for this is welcome for sure. Why is it unacceptable? Can the user implement some order-dependent logic with clauses, and will it be correct? Otherwise, it is a matter of taste, and generally, this decision is up to you. > >>> We don't make array values unique. That might make query execution >>> performance somewhat worse, and also makes selectivity estimation >>> worse. I suggest Andrei and/or Alena should implement making array >>> values unique. >> The fix Alena has made looks correct. But I urge you to think twice: >> The optimizer doesn't care about duplicates, so why do we do it? >> What's more, this optimization is intended to speed up queries with long >> OR lists. Using the list_append_unique() comparator on such lists could >> impact performance. I suggest sticking to the common rule and leaving >> the responsibility on the user's shoulders. > > I don't see why the optimizer doesn't care about duplicates for OR > lists. As I showed before in an example, it successfully removes the > duplicate. So, currently OR transformation clearly introduces a > regression in terms of selectivity estimation. I think we should > evade that. I think you are right. It is probably a better place than any other to remove duplicates in an array. I just think we should sort and remove duplicates from entry->consts in one pass. Thus, this optimisation should be applied to sortable constants. > >> At least, we should do this optimization later, in one pass, with >> sorting elements before building the array. But what if we don't have a >> sort operator for the type? > > It was probably discussed before, but can we do our work later? There > is a canonicalize_qual() which calls find_duplicate_ors(). This is > the place where currently duplicate OR clauses are removed. Could our > OR-to-ANY transformation be just another call from > canonicalize_qual()? Hmm, we already tried to do it at that point. I vaguely recall some issues caused by this approach. Anyway, it should be done as quickly as possible to increase the effect of the optimization. -- regards, Andrei Lepikhov Postgres Professional
On Mon, Mar 11, 2024 at 2:43 PM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > On 11/3/2024 18:31, Alexander Korotkov wrote: > >> I'm not convinced about this limit. The initial reason was to combine > >> long lists of ORs into the array because such a transformation made at > >> an early stage increases efficiency. > >> I understand the necessity of this limit in the array decomposition > >> routine but not in the creation one. > > > > The comment near MAX_SAOP_ARRAY_SIZE says that this limit is because > > N^2 algorithms could be applied to arrays. Are you sure that's not > > true for our case? > When you operate an array, indeed. But when we transform ORs to an > array, not. Just check all the places in the optimizer and even the > executor where we would pass along the list of ORs. This is why I think > we should use this optimization even more intensively for huge numbers > of ORs in an attempt to speed up the overall query. Ok. > >>> 3) Better save the original order of clauses by putting hash entries and > >>> untransformable clauses to the same list. A lot of differences in > >>> regression tests output have gone. > >> I agree that reducing the number of changes in regression tests looks > >> better. But to achieve this, you introduced a hack that increases the > >> complexity of the code. Is it worth it? Maybe it would be better to make > >> one-time changes in tests instead of getting this burden on board. Or > >> have you meant something more introducing the node type? > > > > For me the reason is not just a regression test. The current code > > keeps the original order of quals as much as possible. The OR > > transformation code reorders quals even in cases when it doesn't > > eventually apply any optimization. I don't think that's acceptable. > > However, less hackery ways for this is welcome for sure. > Why is it unacceptable? Can the user implement some order-dependent > logic with clauses, and will it be correct? > Otherwise, it is a matter of taste, and generally, this decision is up > to you. I think this is an important property that the user sees the quals in the plan in the same order as they were in the query. And if some transformations are applied, then the order is saved as much as possible. I don't think we should sacrifice this property without strong reasons. A bit of code complexity is definitely not that reason for me. > >>> We don't make array values unique. That might make query execution > >>> performance somewhat worse, and also makes selectivity estimation > >>> worse. I suggest Andrei and/or Alena should implement making array > >>> values unique. > >> The fix Alena has made looks correct. But I urge you to think twice: > >> The optimizer doesn't care about duplicates, so why do we do it? > >> What's more, this optimization is intended to speed up queries with long > >> OR lists. Using the list_append_unique() comparator on such lists could > >> impact performance. I suggest sticking to the common rule and leaving > >> the responsibility on the user's shoulders. > > > > I don't see why the optimizer doesn't care about duplicates for OR > > lists. As I showed before in an example, it successfully removes the > > duplicate. So, currently OR transformation clearly introduces a > > regression in terms of selectivity estimation. I think we should > > evade that. > I think you are right. It is probably a better place than any other to > remove duplicates in an array. I just think we should sort and remove > duplicates from entry->consts in one pass. Thus, this optimisation > should be applied to sortable constants. Ok. > >> At least, we should do this optimization later, in one pass, with > >> sorting elements before building the array. But what if we don't have a > >> sort operator for the type? > > > > It was probably discussed before, but can we do our work later? There > > is a canonicalize_qual() which calls find_duplicate_ors(). This is > > the place where currently duplicate OR clauses are removed. Could our > > OR-to-ANY transformation be just another call from > > canonicalize_qual()? > Hmm, we already tried to do it at that point. I vaguely recall some > issues caused by this approach. Anyway, it should be done as quickly as > possible to increase the effect of the optimization. I think there were provided quite strong reasons why this shouldn't be implemented at the parse analysis stage [1], [2], [3]. The canonicalize_qual() looks quite appropriate place for that since it does similar transformations. Links. 1. https://www.postgresql.org/message-id/CA%2BTgmoZCgP6FrBQEusn4yaWm02XU8OPeoEMk91q7PRBgwaAkFw%40mail.gmail.com 2. https://www.postgresql.org/message-id/CAH2-Wzm2%3Dnf_JhiM3A2yetxRs8Nd2NuN3JqH%3Dfm_YWYd1oYoPg%40mail.gmail.com 3. https://www.postgresql.org/message-id/CA%2BTgmoaOiwMXBBTYknczepoZzKTp-Zgk5ss1%2BCuVQE-eFTqBmA%40mail.gmail.com ------ Regards, Alexander Korotkov
On 12/3/2024 22:20, Alexander Korotkov wrote: > On Mon, Mar 11, 2024 at 2:43 PM Andrei Lepikhov >> I think you are right. It is probably a better place than any other to >> remove duplicates in an array. I just think we should sort and remove >> duplicates from entry->consts in one pass. Thus, this optimisation >> should be applied to sortable constants. > > Ok. New version of the patch set implemented all we have agreed on for now. We can return MAX_SAOP_ARRAY_SIZE constraint and Alena's approach to duplicates deletion for non-sortable cases at the end. > >> Hmm, we already tried to do it at that point. I vaguely recall some >> issues caused by this approach. Anyway, it should be done as quickly as >> possible to increase the effect of the optimization. > > I think there were provided quite strong reasons why this shouldn't be > implemented at the parse analysis stage [1], [2], [3]. The > canonicalize_qual() looks quite appropriate place for that since it > does similar transformations. Ok. Let's discuss these reasons. In Robert's opinion [1,3], we should do the transformation based on the cost model. But in the canonicalize_qual routine, we still make the transformation blindly. Moreover, the second patch reduces the weight of this reason, doesn't it? Maybe we shouldn't think about that as about optimisation but some 'general form of expression'? Peter [2] worries about the possible transformation outcomes at this stage. But remember, we already transform clauses like ROW() IN (...) to a series of ORs here, so it is not an issue. Am I wrong? Why did we discard the attempt with canonicalize_qual on the previous iteration? - The stage of parsing is much more native for building SAOP quals. We can reuse make_scalar_array_op and other stuff, for example. During the optimisation stage, the only list partitioning machinery creates SAOP based on a list of constants. So, in theory, it is possible to implement. But do we really need to make the code more complex? > > Links. > 1. https://www.postgresql.org/message-id/CA%2BTgmoZCgP6FrBQEusn4yaWm02XU8OPeoEMk91q7PRBgwaAkFw%40mail.gmail.com > 2. https://www.postgresql.org/message-id/CAH2-Wzm2%3Dnf_JhiM3A2yetxRs8Nd2NuN3JqH%3Dfm_YWYd1oYoPg%40mail.gmail.com > 3. https://www.postgresql.org/message-id/CA%2BTgmoaOiwMXBBTYknczepoZzKTp-Zgk5ss1%2BCuVQE-eFTqBmA%40mail.gmail.com -- regards, Andrei Lepikhov Postgres Professional
Attachment
On Wed, Mar 13, 2024 at 7:52 AM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > On 12/3/2024 22:20, Alexander Korotkov wrote: > > On Mon, Mar 11, 2024 at 2:43 PM Andrei Lepikhov > >> I think you are right. It is probably a better place than any other to > >> remove duplicates in an array. I just think we should sort and remove > >> duplicates from entry->consts in one pass. Thus, this optimisation > >> should be applied to sortable constants. > > > > Ok. > New version of the patch set implemented all we have agreed on for now. > We can return MAX_SAOP_ARRAY_SIZE constraint and Alena's approach to > duplicates deletion for non-sortable cases at the end. > > > >> Hmm, we already tried to do it at that point. I vaguely recall some > >> issues caused by this approach. Anyway, it should be done as quickly as > >> possible to increase the effect of the optimization. > > > > I think there were provided quite strong reasons why this shouldn't be > > implemented at the parse analysis stage [1], [2], [3]. The > > canonicalize_qual() looks quite appropriate place for that since it > > does similar transformations. > Ok. Let's discuss these reasons. In Robert's opinion [1,3], we should do > the transformation based on the cost model. But in the canonicalize_qual > routine, we still make the transformation blindly. Moreover, the second > patch reduces the weight of this reason, doesn't it? Maybe we shouldn't > think about that as about optimisation but some 'general form of > expression'? > Peter [2] worries about the possible transformation outcomes at this > stage. But remember, we already transform clauses like ROW() IN (...) to > a series of ORs here, so it is not an issue. Am I wrong? > Why did we discard the attempt with canonicalize_qual on the previous > iteration? - The stage of parsing is much more native for building SAOP > quals. We can reuse make_scalar_array_op and other stuff, for example. > During the optimisation stage, the only list partitioning machinery > creates SAOP based on a list of constants. So, in theory, it is possible > to implement. But do we really need to make the code more complex? As we currently do OR-to-ANY transformation at the parse stage, the system catalog (including views, inheritance clauses, partial and expression indexes, and others) would have a form depending on enable_or_transformation at the moment of DDL execution. I think this is rather wrong. The enable_or_transformation should be run-time optimization which affects the resulting query plan, its result shouldn't be persistent. Regarding the ROW() IN (...) precedent. 1. AFAICS, this is not exactly an optimization. This transformation allows us to perform type matching individually for every value. Therefore it allows the execute some queries which otherwise would end up with error. 2. I don't think this is a sample of good design. This is rather hack, which is historically here, but we don't want to replicate this experience. Given all of the above, I think moving transformation to the canonicalize_qual() would be the right way to go. ------ Regards, Alexander Korotkov
On 13/3/2024 18:05, Alexander Korotkov wrote: > On Wed, Mar 13, 2024 at 7:52 AM Andrei Lepikhov > Given all of the above, I think moving transformation to the > canonicalize_qual() would be the right way to go. Ok, I will try to move the code. I have no idea about the timings so far. I recall the last time I got bogged down in tons of duplicated code. I hope with an almost-ready sketch, it will be easier. -- regards, Andrei Lepikhov Postgres Professional
> On 13/3/2024 18:05, Alexander Korotkov wrote:
> > On Wed, Mar 13, 2024 at 7:52 AM Andrei Lepikhov
> > Given all of the above, I think moving transformation to the
> > canonicalize_qual() would be the right way to go.
> Ok, I will try to move the code.
> I have no idea about the timings so far. I recall the last time I got
> bogged down in tons of duplicated code. I hope with an almost-ready
> sketch, it will be easier.
Thank you! I'll be looking forward to the updated patch.
I also have notes about the bitmap patch.
/*
* Building index paths over SAOP clause differs from the logic of OR clauses.
* Here we iterate across all the array elements and split them to SAOPs,
* corresponding to different indexes. We must match each element to an index.
*/
This covers the case I posted before. But in order to fix all possible cases we probably need to handle the SAOP clause in the same way as OR clauses. Check also this case.
insert into t (select i, 2, 2 from generate_series(1,10000) i);
create index t_a_b_idx on t (a, b);
create statistics t_b_c_stat (mcv) on b, c from t;
QUERY PLAN
------------------------------------------------------------------------------
Bitmap Heap Scan on t (cost=156.55..440.56 rows=5001 width=12)
Recheck Cond: (a = 1)
Filter: ((b = ANY ('{1,2}'::integer[])) AND (c = 2))
-> Bitmap Index Scan on t_a_b_idx (cost=0.00..155.29 rows=10001 width=0)
Index Cond: (a = 1)
(5 rows)
------------------------------------------------------------------------------
Bitmap Heap Scan on t (cost=11.10..18.32 rows=5001 width=12)
Recheck Cond: (((b = 1) AND (c = 2)) OR ((a = 1) AND (b = 2)))
Filter: ((a = 1) AND (c = 2))
-> BitmapOr (cost=11.10..11.10 rows=2 width=0)
-> Bitmap Index Scan on t_b_c_idx (cost=0.00..4.30 rows=1 width=0)
Index Cond: ((b = 1) AND (c = 2))
-> Bitmap Index Scan on t_a_b_idx (cost=0.00..4.30 rows=1 width=0)
Index Cond: ((a = 1) AND (b = 2))
(8 rows)
As you can see this case is not related to partial indexes. Just no index selective for the whole query. However, splitting scan by the OR qual lets use a combination of two selective indexes.
------
Regards,
Alexander Korotkov
On 14/3/2024 16:31, Alexander Korotkov wrote: > On Wed, Mar 13, 2024 at 2:16 PM Andrei Lepikhov > <a.lepikhov@postgrespro.ru <mailto:a.lepikhov@postgrespro.ru>> wrote: > > On 13/3/2024 18:05, Alexander Korotkov wrote: > > > On Wed, Mar 13, 2024 at 7:52 AM Andrei Lepikhov > > > Given all of the above, I think moving transformation to the > > > canonicalize_qual() would be the right way to go. > > Ok, I will try to move the code. > > I have no idea about the timings so far. I recall the last time I got > > bogged down in tons of duplicated code. I hope with an almost-ready > > sketch, it will be easier. > > Thank you! I'll be looking forward to the updated patch. Okay, I moved the 0001-* patch to the prepqual.c module. See it in the attachment. I treat it as a transient patch. It has positive outcomes as well as negative ones. The most damaging result you can see in the partition_prune test: partition pruning, in some cases, moved to the executor initialization stage. I guess, we should avoid it somehow in the next version. -- regards, Andrei Lepikhov Postgres Professional
Attachment
On Thu, Mar 14, 2024 at 12:11 PM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > > On 14/3/2024 16:31, Alexander Korotkov wrote: > > On Wed, Mar 13, 2024 at 2:16 PM Andrei Lepikhov > > <a.lepikhov@postgrespro.ru <mailto:a.lepikhov@postgrespro.ru>> wrote: > > > On 13/3/2024 18:05, Alexander Korotkov wrote: > > > > On Wed, Mar 13, 2024 at 7:52 AM Andrei Lepikhov > > > > Given all of the above, I think moving transformation to the > > > > canonicalize_qual() would be the right way to go. > > > Ok, I will try to move the code. > > > I have no idea about the timings so far. I recall the last time I got > > > bogged down in tons of duplicated code. I hope with an almost-ready > > > sketch, it will be easier. > > > > Thank you! I'll be looking forward to the updated patch. > Okay, I moved the 0001-* patch to the prepqual.c module. See it in the > attachment. I treat it as a transient patch. > It has positive outcomes as well as negative ones. > The most damaging result you can see in the partition_prune test: > partition pruning, in some cases, moved to the executor initialization > stage. I guess, we should avoid it somehow in the next version. Thank you, Andrei. Looks like a very undesirable side effect. Do you have any idea why it happens? Partition pruning should work correctly for both transformed and non-transformed quals, why does transformation hurt it? ------ Regards, Alexander Korotkov
On 14/3/2024 17:39, Alexander Korotkov wrote: > Thank you, Andrei. Looks like a very undesirable side effect. Do you > have any idea why it happens? Partition pruning should work correctly > for both transformed and non-transformed quals, why does > transformation hurt it? Now we have the v23-0001-* patch with all issues resolved. The last one which caused execution stage pruning was about necessity to evaluate SAOP expression right after transformation. In previous version the core executed it on transformed expressions. > As you can see this case is not related to partial indexes. Just no > index selective for the whole query. However, splitting scan by the > OR qual lets use a combination of two selective indexes. Thanks for the case. I will try to resolve it. -- regards, Andrei Lepikhov Postgres Professional
Attachment
On 14/3/2024 16:31, Alexander Korotkov wrote: > On Wed, Mar 13, 2024 at 2:16 PM Andrei Lepikhov > As you can see this case is not related to partial indexes. Just no > index selective for the whole query. However, splitting scan by the OR > qual lets use a combination of two selective indexes. I have rewritten the 0002-* patch according to your concern. A candidate and some thoughts are attached. As I see, we have a problem here: expanding each array and trying to apply an element to each index can result in a lengthy planning stage. Also, an index scan with the SAOP may potentially be more effective than with the list of OR clauses. Originally, the transformation's purpose was to reduce a query's complexity and the number of optimization ways to speed up planning and (sometimes) execution. Here, we reduce planning complexity only in the case of an array size larger than MAX_SAOP_ARRAY_SIZE. Maybe we can fall back to the previous version of the second patch, keeping in mind that someone who wants to get maximum profit from the BitmapOr scan of multiple indexes can just disable this optimization, enabling deep search of the most optimal scanning way? As a compromise solution, I propose adding one more option to the previous version: if an element doesn't fit any partial index, try to cover it with a plain index. In this case, we still do not guarantee the most optimal fit of elements to the set of indexes, but we speed up planning. Does that make sense? -- regards, Andrei Lepikhov Postgres Professional
Attachment
On Tue, Mar 19, 2024 at 7:17 AM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > On 14/3/2024 16:31, Alexander Korotkov wrote: > > On Wed, Mar 13, 2024 at 2:16 PM Andrei Lepikhov > > As you can see this case is not related to partial indexes. Just no > > index selective for the whole query. However, splitting scan by the OR > > qual lets use a combination of two selective indexes. > I have rewritten the 0002-* patch according to your concern. A candidate > and some thoughts are attached. > As I see, we have a problem here: expanding each array and trying to > apply an element to each index can result in a lengthy planning stage. > Also, an index scan with the SAOP may potentially be more effective than > with the list of OR clauses. > Originally, the transformation's purpose was to reduce a query's > complexity and the number of optimization ways to speed up planning and > (sometimes) execution. Here, we reduce planning complexity only in the > case of an array size larger than MAX_SAOP_ARRAY_SIZE. > Maybe we can fall back to the previous version of the second patch, > keeping in mind that someone who wants to get maximum profit from the > BitmapOr scan of multiple indexes can just disable this optimization, > enabling deep search of the most optimal scanning way? > As a compromise solution, I propose adding one more option to the > previous version: if an element doesn't fit any partial index, try to > cover it with a plain index. > In this case, we still do not guarantee the most optimal fit of elements > to the set of indexes, but we speed up planning. Does that make sense? Thank you for your research Andrei. Now things get more clear on the advantages and disadvantages of this transformation. The current patch has a boolean guc enable_or_transformation. However, when we have just a few ORs to be transformated, then we should get less performance gain from the transformation and higher chances to lose a good bitmap scan plan from that. When there is a huge list of ORs to be transformed, then the performance gain is greater and it is less likely we could lose a good bitmap scan plan. What do you think about introducing a GUC threshold value: the minimum size of list to do OR-to-ANY transformation? min_list_or_transformation or something. ------ Regards, Alexander Korotkov
On 28/3/2024 16:54, Alexander Korotkov wrote: > The current patch has a boolean guc enable_or_transformation. > However, when we have just a few ORs to be transformated, then we > should get less performance gain from the transformation and higher > chances to lose a good bitmap scan plan from that. When there is a > huge list of ORs to be transformed, then the performance gain is > greater and it is less likely we could lose a good bitmap scan plan. > > What do you think about introducing a GUC threshold value: the minimum > size of list to do OR-to-ANY transformation? > min_list_or_transformation or something. I labelled it or_transformation_limit (see in attachment). Feel free to rename it. It's important to note that the limiting GUC doesn't operate symmetrically for forward, OR -> SAOP, and backward SAOP -> OR operations. In the forward case, it functions as you've proposed. However, in the backward case, we only check whether the feature is enabled or not. This is due to our existing limitation, MAX_SAOP_ARRAY_SIZE, and the fact that we can't match the length of the original OR list with the sizes of the resulting SAOPs. For instance, a lengthy OR list with 100 elements can be transformed into 3 SAOPs, each with a size of around 30 elements. One aspect that requires attention is the potential inefficiency of our OR -> ANY transformation when we have a number of elements less than MAX_SAOP_ARRAY_SIZE. This is because we perform a reverse transformation ANY -> OR at the stage of generating bitmap scans. If the BitmapScan path dominates, we may have done unnecessary work. Is this an occurrence that we should address? But the concern above may just be a point of improvement later: We can add one more strategy to the optimizer: testing each array element as an OR clause; we can also provide a BitmapOr path, where SAOP is covered with a minimal number of partial indexes (likewise, previous version). -- regards, Andrei Lepikhov Postgres Professional
Attachment
Hi! On Mon, Apr 1, 2024 at 9:38 AM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > On 28/3/2024 16:54, Alexander Korotkov wrote: > > The current patch has a boolean guc enable_or_transformation. > > However, when we have just a few ORs to be transformated, then we > > should get less performance gain from the transformation and higher > > chances to lose a good bitmap scan plan from that. When there is a > > huge list of ORs to be transformed, then the performance gain is > > greater and it is less likely we could lose a good bitmap scan plan. > > > > What do you think about introducing a GUC threshold value: the minimum > > size of list to do OR-to-ANY transformation? > > min_list_or_transformation or something. > I labelled it or_transformation_limit (see in attachment). Feel free to > rename it. > It's important to note that the limiting GUC doesn't operate > symmetrically for forward, OR -> SAOP, and backward SAOP -> OR > operations. In the forward case, it functions as you've proposed. > However, in the backward case, we only check whether the feature is > enabled or not. This is due to our existing limitation, > MAX_SAOP_ARRAY_SIZE, and the fact that we can't match the length of the > original OR list with the sizes of the resulting SAOPs. For instance, a > lengthy OR list with 100 elements can be transformed into 3 SAOPs, each > with a size of around 30 elements. > One aspect that requires attention is the potential inefficiency of our > OR -> ANY transformation when we have a number of elements less than > MAX_SAOP_ARRAY_SIZE. This is because we perform a reverse transformation > ANY -> OR at the stage of generating bitmap scans. If the BitmapScan > path dominates, we may have done unnecessary work. Is this an occurrence > that we should address? > But the concern above may just be a point of improvement later: We can > add one more strategy to the optimizer: testing each array element as an > OR clause; we can also provide a BitmapOr path, where SAOP is covered > with a minimal number of partial indexes (likewise, previous version). I've revised the patch. Did some beautification, improvements for documentation, commit messages etc. I've pushed the 0001 patch without 0002. I think 0001 is good by itself given that there is the or_to_any_transform_limit GUC option. The more similar OR clauses are here the more likely grouping them into SOAP will be a win. But I've changed the default value to 5. This will make it less invasive and affect only queries with obvious repeating patterns. That also reduced the changes in the regression tests expected outputs. Regarding 0002, it seems questionable since it could cause a planning slowdown for SAOP's with large arrays. Also, it might reduce the win of transformation made by 0001. So, I think we should skip it for now. ------ Regards, Alexander Korotkov
On Mon, Apr 08, 2024 at 01:34:37AM +0300, Alexander Korotkov wrote: > Hi! > > On Mon, Apr 1, 2024 at 9:38 AM Andrei Lepikhov > <a.lepikhov@postgrespro.ru> wrote: > > On 28/3/2024 16:54, Alexander Korotkov wrote: > > > The current patch has a boolean guc enable_or_transformation. > > > However, when we have just a few ORs to be transformated, then we > > > should get less performance gain from the transformation and higher > > > chances to lose a good bitmap scan plan from that. When there is a > > > huge list of ORs to be transformed, then the performance gain is > > > greater and it is less likely we could lose a good bitmap scan plan. > > > > > > What do you think about introducing a GUC threshold value: the minimum > > > size of list to do OR-to-ANY transformation? > > > min_list_or_transformation or something. > > I labelled it or_transformation_limit (see in attachment). Feel free to > > rename it. > > It's important to note that the limiting GUC doesn't operate > > symmetrically for forward, OR -> SAOP, and backward SAOP -> OR > > operations. In the forward case, it functions as you've proposed. > > However, in the backward case, we only check whether the feature is > > enabled or not. This is due to our existing limitation, > > MAX_SAOP_ARRAY_SIZE, and the fact that we can't match the length of the > > original OR list with the sizes of the resulting SAOPs. For instance, a > > lengthy OR list with 100 elements can be transformed into 3 SAOPs, each > > with a size of around 30 elements. > > One aspect that requires attention is the potential inefficiency of our > > OR -> ANY transformation when we have a number of elements less than > > MAX_SAOP_ARRAY_SIZE. This is because we perform a reverse transformation > > ANY -> OR at the stage of generating bitmap scans. If the BitmapScan > > path dominates, we may have done unnecessary work. Is this an occurrence > > that we should address? > > But the concern above may just be a point of improvement later: We can > > add one more strategy to the optimizer: testing each array element as an > > OR clause; we can also provide a BitmapOr path, where SAOP is covered > > with a minimal number of partial indexes (likewise, previous version). > > I've revised the patch. Did some beautification, improvements for > documentation, commit messages etc. > > I've pushed the 0001 patch without 0002. I think 0001 is good by > itself given that there is the or_to_any_transform_limit GUC option. > The more similar OR clauses are here the more likely grouping them > into SOAP will be a win. But I've changed the default value to 5. The sample config file has the wrong default +#or_to_any_transform_limit = 0 We had a patch to catch this kind of error, but it was closed (which IMO was itself an error). -- Justin
On Mon, Apr 8, 2024 at 1:34 AM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > I've revised the patch. Did some beautification, improvements for > documentation, commit messages etc. > > I've pushed the 0001 patch without 0002. I think 0001 is good by > itself given that there is the or_to_any_transform_limit GUC option. > The more similar OR clauses are here the more likely grouping them > into SOAP will be a win. But I've changed the default value to 5. > This will make it less invasive and affect only queries with obvious > repeating patterns. That also reduced the changes in the regression > tests expected outputs. > > Regarding 0002, it seems questionable since it could cause a planning > slowdown for SAOP's with large arrays. Also, it might reduce the win > of transformation made by 0001. So, I think we should skip it for > now. The patch has been reverted from pg17. Let me propose a new version for pg18 based on the valuable feedback from Tom Lane [1][2]. * The transformation is moved to the stage of adding restrictinfos to the base relation (in particular add_base_clause_to_rel()). This leads to interesting consequences. While this allows IndexScans to use transformed clauses, BitmapScans and SeqScans seem unaffected. Therefore, I wasn't able to find a planning regression. * As soon as there is no planning regression anymore, I've removed or_to_any_transform_limit GUC, which was a source of critics. * Now, not only Consts allowed in the SAOP's list, but also Params. * The criticized hash based on expression jumbling has been removed. Now, the plain list is used instead. * OrClauseGroup now gets a legal node tag. That allows to mix it in the list with other nodes without hacks. I think this patch shouldn't be as good as before for optimizing performance of large OR lists, given that BitmapScans and SeqScans still deal with ORs. However, it allows IndexScans to handle more, doesn't seem to cause planning regression and therefore introduce no extra GUC. Overall, this seems like a good compromise. This patch could use some polishing, but I'd like to first hear some feedback on general design. Links 1. https://www.postgresql.org/message-id/3604469.1712628736%40sss.pgh.pa.us 2. https://www.postgresql.org/message-id/3649287.1712642139%40sss.pgh.pa.us ------ Regards, Alexander Korotkov Supabase
Attachment
On 6/14/24 19:00, Alexander Korotkov wrote: > This patch could use some polishing, but I'd like to first hear some > feedback on general design. Thanks for your time and efforts. I have skimmed through the code—there is a minor fix in the attachment. First and foremost, I think this approach can survive. But generally, I'm not happy with manipulations over a restrictinfo clause: 1. While doing that, we should remember the fields of the RestrictInfo clause. It may need to be changed, too, or it can require such a change in the future if someone adds new logic. 2. We should remember the link to the RestrictInfo: see how the caller of the distribute_restrictinfo_to_rels routine manipulates its fields right after the distribution. 3. Remember caches and cached decisions inside the RestrictInfo structure: replacing the clause should we change these fields too? These were the key reasons why we shifted the code to the earlier stages in the previous incarnation. So, going this way we should recheck all the fields of this structure and analyse how the transformation can [potentially] affect their values. -- regards, Andrei Lepikhov Postgres Professional
Attachment
Hi, thank you for your work with this subject!
On Mon, Apr 8, 2024 at 1:34 AM Alexander Korotkov <aekorotkov@gmail.com> wrote:I've revised the patch. Did some beautification, improvements for documentation, commit messages etc. I've pushed the 0001 patch without 0002. I think 0001 is good by itself given that there is the or_to_any_transform_limit GUC option. The more similar OR clauses are here the more likely grouping them into SOAP will be a win. But I've changed the default value to 5. This will make it less invasive and affect only queries with obvious repeating patterns. That also reduced the changes in the regression tests expected outputs. Regarding 0002, it seems questionable since it could cause a planning slowdown for SAOP's with large arrays. Also, it might reduce the win of transformation made by 0001. So, I think we should skip it for now.The patch has been reverted from pg17. Let me propose a new version for pg18 based on the valuable feedback from Tom Lane [1][2]. * The transformation is moved to the stage of adding restrictinfos to the base relation (in particular add_base_clause_to_rel()). This leads to interesting consequences. While this allows IndexScans to use transformed clauses, BitmapScans and SeqScans seem unaffected. Therefore, I wasn't able to find a planning regression. * As soon as there is no planning regression anymore, I've removed or_to_any_transform_limit GUC, which was a source of critics. * Now, not only Consts allowed in the SAOP's list, but also Params. * The criticized hash based on expression jumbling has been removed. Now, the plain list is used instead. * OrClauseGroup now gets a legal node tag. That allows to mix it in the list with other nodes without hacks. I think this patch shouldn't be as good as before for optimizing performance of large OR lists, given that BitmapScans and SeqScans still deal with ORs. However, it allows IndexScans to handle more, doesn't seem to cause planning regression and therefore introduce no extra GUC. Overall, this seems like a good compromise. This patch could use some polishing, but I'd like to first hear some feedback on general design. Links 1. https://www.postgresql.org/message-id/3604469.1712628736%40sss.pgh.pa.us 2. https://www.postgresql.org/message-id/3649287.1712642139%40sss.pgh.pa.us
I noticed that 7 libraries have been added to src/backend/optimizer/plan/initsplan.c, and as far as I remember, Tom Lane has already expressed doubts about the approach that requires adding a large number of libraries [0], but I'm afraid I'm out of ideas about alternative approach. In addition, I checked the fix in the previous cases that you wrote earlier [1] and noticed that SeqScan continues to generate, unfortunately, without converting expressions:
with patch:
create table test as (select (random()*10)::int x, (random()*1000) y from generate_series(1,1000000) i); create index test_x_1_y on test (y) where x = 1; create index test_x_2_y on test (y) where x = 2; vacuum analyze test; SELECT 1000000 CREATE INDEX CREATE INDEX VACUUM alena@postgres=# explain select * from test where (x = 1 or x = 2) and y = 100; QUERY PLAN -------------------------------------------------------------------------- Gather (cost=1000.00..12690.10 rows=1 width=12) Workers Planned: 2 -> Parallel Seq Scan on test (cost=0.00..11690.00 rows=1 width=12) Filter: (((x = 1) OR (x = 2)) AND (y = '100'::double precision)) (4 rows) alena@postgres=# set enable_seqscan =off; SET alena@postgres=# explain select * from test where (x = 1 or x = 2) and y = 100; QUERY PLAN ------------------------------------------------------------------------- Seq Scan on test (cost=10000000000.00..10000020440.00 rows=1 width=12) Filter: (((x = 1) OR (x = 2)) AND (y = '100'::double precision)) (2 rows)
without patch:
-------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on test (cost=8.60..12.62 rows=1 width=12) Recheck Cond: (((y = '100'::double precision) AND (x = 1)) OR ((y = '100'::double precision) AND (x = 2))) -> BitmapOr (cost=8.60..8.60 rows=1 width=0) -> Bitmap Index Scan on test_x_1_y (cost=0.00..4.30 rows=1 width=0) Index Cond: (y = '100'::double precision) -> Bitmap Index Scan on test_x_2_y (cost=0.00..4.30 rows=1 width=0) Index Cond: (y = '100'::double precision) (7 rows)
[0] https://www.postgresql.org/message-id/3604469.1712628736%40sss.pgh.pa.us
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Mon, Jun 17, 2024 at 1:33 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > I noticed that 7 libraries have been added to src/backend/optimizer/plan/initsplan.c, and as far as I remember, Tom Lanehas already expressed doubts about the approach that requires adding a large number of libraries [0], but I'm afraidI'm out of ideas about alternative approach. Thank you for pointing. Right, the number of extra headers included was one of points for criticism on this patch. I'll look to move this functionality elsewhere, while the stage of transformation could probably be the same. > In addition, I checked the fix in the previous cases that you wrote earlier [1] and noticed that SeqScan continues to generate,unfortunately, without converting expressions: I've rechecked and see I made wrong conclusion about this. The plan regression is still here. But I'm still looking to workaround this without extra GUC. I think we need to additionally do something like [1], but take further steps to avoid planning overhead when not necessary. In particular, I think we should only consider splitting SAOP for bitmap OR in the following cases: 1. There are partial indexes with predicates over target column. 2. There are multiple indexes covering target column and different subsets of other columns presented in restrictions. 3. There are indexes covreing target column without support of SAOP (amsearcharray == false). Hopefully this should skip generation of useless bitmap paths in majority cases. Thoughts? Links. 1. https://www.postgresql.org/message-id/67bd918d-285e-44d2-a207-f52d9a4c35e6%40postgrespro.ru ------ Regards, Alexander Korotkov Supabase
On Mon, Jun 17, 2024 at 7:02 AM Andrei Lepikhov <a.lepikhov@postgrespro.ru> wrote: > On 6/14/24 19:00, Alexander Korotkov wrote: > > This patch could use some polishing, but I'd like to first hear some > > feedback on general design. > Thanks for your time and efforts. I have skimmed through the code—there > is a minor fix in the attachment. > First and foremost, I think this approach can survive. > But generally, I'm not happy with manipulations over a restrictinfo clause: > 1. While doing that, we should remember the fields of the RestrictInfo > clause. It may need to be changed, too, or it can require such a change > in the future if someone adds new logic. > 2. We should remember the link to the RestrictInfo: see how the caller > of the distribute_restrictinfo_to_rels routine manipulates its fields > right after the distribution. > 3. Remember caches and cached decisions inside the RestrictInfo > structure: replacing the clause should we change these fields too? > > These were the key reasons why we shifted the code to the earlier stages > in the previous incarnation. So, going this way we should recheck all > the fields of this structure and analyse how the transformation can > [potentially] affect their values. I see your points. Making this at the stage of restrictinfos seems harder, and there are open questions in the patch. I'd like to hear how Tom feels about this. Is this the right direction, or should we try another way? ------ Regards, Alexander Korotkov Supabase
Yes, I thing so.On Mon, Jun 17, 2024 at 1:33 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote:I noticed that 7 libraries have been added to src/backend/optimizer/plan/initsplan.c, and as far as I remember, Tom Lane has already expressed doubts about the approach that requires adding a large number of libraries [0], but I'm afraid I'm out of ideas about alternative approach.Thank you for pointing. Right, the number of extra headers included was one of points for criticism on this patch. I'll look to move this functionality elsewhere, while the stage of transformation could probably be the same.
In addition, I checked the fix in the previous cases that you wrote earlier [1] and noticed that SeqScan continues to generate, unfortunately, without converting expressions:I've rechecked and see I made wrong conclusion about this. The plan regression is still here. But I'm still looking to workaround this without extra GUC. I think we need to additionally do something like [1], but take further steps to avoid planning overhead when not necessary.
Frankly, I see that we will need to split SAOP anyway to check it, right?In particular, I think we should only consider splitting SAOP for bitmap OR in the following cases: 1. There are partial indexes with predicates over target column.
I see two cases in one. First, we need to check whether there is an index for the columns specified in the restrictlist, and secondly, the index ranges for which the conditions fall into the "OR" expressions.2. There are multiple indexes covering target column and different subsets of other columns presented in restrictions.
I'm not sure I fully understand how useful this can be. Could you explain it to me in more detail?3. There are indexes covreing target column without support of SAOP (amsearcharray == false). Hopefully this should skip generation of useless bitmap paths in majority cases. Thoughts?
Links. 1. https://www.postgresql.org/message-id/67bd918d-285e-44d2-a207-f52d9a4c35e6%40postgrespro.ru
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
I'm confused, I have seen that we have two threads [1] and [2] about this thread and I haven't found any explanation for how they differ.
And I don't understand, why am I not listed as the author of the patch? I was developing the first part of the patch before Andrey came to review it [3] and his first part hasn't changed much since then.
If I wrote to the wrong person about it, then please tell me where.
[1] https://commitfest.postgresql.org/48/4450/
[2] https://commitfest.postgresql.org/48/5037/
[3] https://www.postgresql.org/message-id/b301dce1-09fd-72b1-834a-527ca428db5e%40yandex.ru
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Fri, Jun 21, 2024 at 1:05 PM Alena Rybakina
<a.rybakina@postgrespro.ru> wrote:
> I'm confused, I have seen that we have two threads [1] and [2] about this thread and I haven't found any explanation
forhow they differ.
>
> And I don't understand, why am I not listed as the author of the patch? I was developing the first part of the patch
beforeAndrey came to review it [3] and his first part hasn't changed much since then.
v25 still lists you as an author (in fact, the first author) but I
can't say why we have two CommitFest entries. Surely that's a mistake.
On the patch itself, I'm really glad we got to a design where this is
part of planning, not parsing. I'm not sure yet whether we're doing it
at the right time within the planner, but I think this *might* be
right, whereas the old way was definitely wrong.
What exactly is the strategy around OR-clauses with type differences?
If I'm reading the code correctly, the first loop requires an exact
opno match, which presumably implies that the constant-type elements
are of the same type. But then why does the second loop need to use
coerce_to_common_type?
Also, why is the array built with eval_const_expressions instead of
something like makeArrayResult? There should be no need for general
expression evaluation here if we are just dealing with constants.
+ foreach(lc2, entry->exprs)
+ {
+ RestrictInfo *rinfo = (RestrictInfo *) lfirst(lc2);
+
+ is_pushed_down = is_pushed_down || rinfo->is_pushed_down;
+ has_clone = has_clone || rinfo->is_pushed_down;
+ security_level = Max(security_level, rinfo->security_level);
+ required_relids = bms_union(required_relids, rinfo->required_relids);
+ incompatible_relids = bms_union(incompatible_relids,
rinfo->incompatible_relids);
+ outer_relids = bms_union(outer_relids, rinfo->outer_relids);
+ }
This seems like an extremely bad idea. Smushing together things with
different security levels (or a bunch of these other properties) seems
like it will break things. Presumably we wouldn't track these
properties on a per-RelOptInfo basis unless we needed an accurate idea
of the property value for each RelOptInfo. If the values are
guaranteed to match, then it's fine, but then we don't need this code
to merge possibly-different values. If they're not guaranteed to
match, then presumably we shouldn't merge into a single OR clause
unless they do.
On a related note, it looks to me like the tests focus too much on
simple cases. It seems like it's mostly testing cases where there are
no security quals, no weird operator classes, no type mismatches, and
few joins. In the cases where there are joins, it's an inner join and
there's no distinction between an ON-qual and a WHERE-qual. I strongly
suggest adding some test cases for weirder scenarios.
+ if (!OperatorIsVisible(entry->opno))
+ namelist = lappend(namelist,
makeString(get_namespace_name(operform->oprnamespace)));
+
+ namelist = lappend(namelist, makeString(pstrdup(NameStr(operform->oprname))));
+ ReleaseSysCache(opertup);
+
+ saopexpr =
+ (ScalarArrayOpExpr *)
+ make_scalar_array_op(NULL,
+ namelist,
+ true,
+ (Node *) entry->expr,
+ (Node *) newa,
+ -1);
I do not think this is acceptable. We should find a way to get the
right operator into the ScalarArrayOpExpr without translating the OID
back into a name and then back into an OID.
+ /* One more trick: assemble correct clause */
This comment doesn't seem to make much sense. Some other comments
contain spelling mistakes. The patch should have comments in more
places explaining key design decisions.
+extern JumbleState *JumbleExpr(Expr *expr, uint64 *exprId);
This is no longer needed.
--
Robert Haas
EDB: http://www.enterprisedb.com
Hi, Alena. On Fri, Jun 21, 2024 at 8:05 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > > I'm confused, I have seen that we have two threads [1] and [2] about this thread and I haven't found any explanation forhow they differ. > > And I don't understand, why am I not listed as the author of the patch? I was developing the first part of the patch beforeAndrey came to review it [3] and his first part hasn't changed much since then. > > If I wrote to the wrong person about it, then please tell me where. > > [1] https://commitfest.postgresql.org/48/4450/ > > [2] https://commitfest.postgresql.org/48/5037/ > > [3] https://www.postgresql.org/message-id/b301dce1-09fd-72b1-834a-527ca428db5e%40yandex.ru Sorry, I didn't notice that the [1] commitfest entry exists and created the [2] commitfest entry. I'm removed [2]. ------ Regards, Alexander Korotkov Supabase
On Fri, Jun 21, 2024 at 1:05 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote:I'm confused, I have seen that we have two threads [1] and [2] about this thread and I haven't found any explanation for how they differ. And I don't understand, why am I not listed as the author of the patch? I was developing the first part of the patch before Andrey came to review it [3] and his first part hasn't changed much since then.v25 still lists you as an author (in fact, the first author) but I can't say why we have two CommitFest entries. Surely that's a mistake.
Sorry, maybe I was overreacting.
Thank you very much for taking the time to do a detailed review!
Thank you!Sorry, I didn't notice that the [1] commitfest entry exists and created the [2] commitfest entry. I'm removed [2].
On the patch itself, I'm really glad we got to a design where this is part of planning, not parsing. I'm not sure yet whether we're doing it at the right time within the planner, but I think this *might* be right, whereas the old way was definitely wrong.
It's hard to tell, but I think it might be one of the good places to apply transformation. Let me describe a brief conclusion on the two approaches.
In the first approach, we definitely did not process the extra "OR" expressions in the first approach, since they were packaged as an Array. It could lead to the fact that less planning time would be spent on the optimizer.
Also the selectivity for Array expressions is estimated better, which could lead to the generation of a more optimal plan, but, to be honest, this is just an observation from changes in regression tests and, in general, how the process of calculating the selectivity of a complex expression works.
SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE (a = 1 OR a = 51) AND b = ''1''');
estimated | actual
-----------+--------
- 99 | 100
+ 100 | 100
(1 row)
SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE (a = 1 OR a = 51) AND (b = ''1'' OR b = ''2'')');
estimated | actual
-----------+--------
- 99 | 100
+ 100 | 100
(1 row)
SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE (a = 1 OR a = 2 OR a = 51 OR a = 52) AND (b = ''1'' OR b = ''2'')');
estimated | actual
-----------+--------
- 197 | 200
+ 200 | 200
In addition, we do not have new equivalence classes, since some “Or” expressions are not available for their formation. This can result in reduced memory and time spent generating the query plan, especially in partitions.
Speaking of the main disadvantages, we do not give the optimizer the opportunity to generate a plan using BitmapScan, which can lead to the generation of a suboptimal plan, but in the current approach the same thing happens [0].
And the second one might be related the lack of generation Equivalence Classes and generation of useful pathkeys as a result, so we could miss an optimal plan again. But I haven't caught something like this on practice. I see we won't have such problems if we apply the transformation later.
Overall, I have not yet noticed any very different parts from what was in the first approach: I didn’t see any significant degradation or improvement, which is good, but so far the main problem with the degradation of the plan has not yet been solved, that is, we have not escaped from the main problems.
Andrei mentioned the problem in the second approach about updating references to expressions in RestrictInfo [1] lists, because the can be used in different variables during the formation of the query plan. As the practice of Self-join removal [2] has shown, this can be expensive, but feasible.
By applying the transformation at the analysis stage in the first approach, because no links were created, so we did not encounter such problems, so this approach was more suitable than the others.
[0] https://www.postgresql.org/message-id/7d5aed92-d4cc-4b76-8ae0-051d182c9eec%40postgrespro.ru
[1] https://www.postgresql.org/message-id/6850c306-4e9d-40b7-8096-1f3c7d29cd9e%40postgrespro.ru
[2] https://commitfest.postgresql.org/48/5043/
What exactly is the strategy around OR-clauses with type differences? If I'm reading the code correctly, the first loop requires an exact opno match, which presumably implies that the constant-type elements are of the same type. But then why does the second loop need to use coerce_to_common_type?
It needs to transform all similar constants to one type, because some constants of "OR" expressions can belong others, like the numeric and int types. Due to the fact that array structure demands that all types must be belonged to one type, so for this reason we applied this procedure.
You can find the similar strategy in transformAExprIn function, when we transform "In" list to SaopArray expression. Frankly, initially, I took it as the main example to make my patch.
I don’t really understand the reason why it’s better not to do this. Can you explain please?+ if (!OperatorIsVisible(entry->opno)) + namelist = lappend(namelist, makeString(get_namespace_name(operform->oprnamespace))); + + namelist = lappend(namelist, makeString(pstrdup(NameStr(operform->oprname)))); + ReleaseSysCache(opertup); + + saopexpr = + (ScalarArrayOpExpr *) + make_scalar_array_op(NULL, + namelist, + true, + (Node *) entry->expr, + (Node *) newa, + -1); I do not think this is acceptable. We should find a way to get the right operator into the ScalarArrayOpExpr without translating the OID back into a name and then back into an OID.
I'm not ready to answer this question right now, I need time to study the use of the makeArrayResult function in the optimizer.Also, why is the array built with eval_const_expressions instead of something like makeArrayResult? There should be no need for general expression evaluation here if we are just dealing with constants.
+ foreach(lc2, entry->exprs)
+ {
+ RestrictInfo *rinfo = (RestrictInfo *) lfirst(lc2);
+
+ is_pushed_down = is_pushed_down || rinfo->is_pushed_down;
+ has_clone = has_clone || rinfo->is_pushed_down;
+ security_level = Max(security_level, rinfo->security_level);
+ required_relids = bms_union(required_relids, rinfo->required_relids);
+ incompatible_relids = bms_union(incompatible_relids,
rinfo->incompatible_relids);
+ outer_relids = bms_union(outer_relids, rinfo->outer_relids);
+ }This seems like an extremely bad idea. Smushing together things with different security levels (or a bunch of these other properties) seems like it will break things. Presumably we wouldn't track these properties on a per-RelOptInfo basis unless we needed an accurate idea of the property value for each RelOptInfo. If the values are guaranteed to match, then it's fine, but then we don't need this code to merge possibly-different values. If they're not guaranteed to match, then presumably we shouldn't merge into a single OR clause unless they do.
On a related note, it looks to me like the tests focus too much on simple cases. It seems like it's mostly testing cases where there are no security quals, no weird operator classes, no type mismatches, and few joins. In the cases where there are joins, it's an inner join and there's no distinction between an ON-qual and a WHERE-qual. I strongly suggest adding some test cases for weirder scenarios.
+ /* One more trick: assemble correct clause */ This comment doesn't seem to make much sense. Some other comments contain spelling mistakes. The patch should have comments in more places explaining key design decisions.
Agree.+extern JumbleState *JumbleExpr(Expr *expr, uint64 *exprId); This is no longer needed.
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Fri, Jun 21, 2024 at 6:52 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > It's hard to tell, but I think it might be one of the good places to apply transformation. Let me describe a brief conclusionon the two approaches. This explanation is somewhat difficult for me to follow. For example: > In the first approach, we definitely did not process the extra "OR" expressions in the first approach, since they werepackaged as an Array. It could lead to the fact that less planning time would be spent on the optimizer. I don't know what the "first approach" refers to, or what processing the extra "OR" expressions means, or what it would mean to package OR expressions as an array. If you made them into an SAOP then you'd have an array *instead of* OR expressions, not OR expressions "packaged as an array" but even then, they'd still be processed somewhere, unless the patch was just wrong. I think you should try writing this summary again and see if you can make it a lot clearer and more precise. I'm suspicious based that we should actually be postponing the transformation even further. If, for example, the transformation is advantageous for index scans and disadvantageous for bitmap scans, or the other way around, then this approach can't help much: it either does the transformation and all scan types are affected, or it doesn't do it and no scan types are affected. But if you decided for each scan whether to transform the quals, then you could handle that. Against that, there might be increased planning cost. But, perhaps that could be avoided somehow. > What exactly is the strategy around OR-clauses with type differences? > If I'm reading the code correctly, the first loop requires an exact > opno match, which presumably implies that the constant-type elements > are of the same type. But then why does the second loop need to use > coerce_to_common_type? > > It needs to transform all similar constants to one type, because some constants of "OR" expressions can belong others,like the numeric and int types. Due to the fact that array structure demands that all types must be belonged to onetype, so for this reason we applied this procedure. The alternative that should be considered is not combining things if the types don't match. If we're going to combine such things, we need to be absolutely certain that type conversion cannot fail. > I do not think this is acceptable. We should find a way to get the > right operator into the ScalarArrayOpExpr without translating the OID > back into a name and then back into an OID. > > I don’t really understand the reason why it’s better not to do this. Can you explain please? One reason is that it is extra work to convert things to a name and then back to an OID. It's got to be slower than using the OID you already have. The other reason is that it's error-prone. If somehow the second lookup doesn't produce the same OID as the first lookup, bad things will happen, possibly including security vulnerabilities. I see you've taken steps to avoid that, like nailing down the schema, and that's good, but it's not a good enough reason to do it like this. If we don't have a function that can construct the node we need with the OID rather than the name as an argument, we should invent one, not do this sort of thing. > Also, why is the array built with eval_const_expressions instead of > something like makeArrayResult? There should be no need for general > expression evaluation here if we are just dealing with constants. > > I'm not ready to answer this question right now, I need time to study the use of the makeArrayResult function in the optimizer. OK. An important consideration here is that eval_const_expressions() is prone to *fail* because it can call user-defined functions. We really don't want this optimization to cause planner failure (or queries to error out at any other stage, either). We also don't want to end up with any security problems, which is another possible danger when we call a function that can execute arbitrary code. It's better to keep it simple and only do things that we know are simple and safe, like assembling a bunch of datums that we already have into an array. -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Jun 24, 2024 at 11:28 AM Robert Haas <robertmhaas@gmail.com> wrote:
> > It needs to transform all similar constants to one type, because some constants of "OR" expressions can belong
others,like the numeric and int types. Due to the fact that array structure demands that all types must be belonged to
onetype, so for this reason we applied this procedure.
>
> The alternative that should be considered is not combining things if
> the types don't match. If we're going to combine such things, we need
> to be absolutely certain that type conversion cannot fail.
But what about cases like this:
SELECT * FROM mytable WHERE columna = 1_000_000_000 or columna =
5_000_000_000; -- columna is int4
This is using two types, of course. 1_000_000_000 is int4, while
5_000_000_000 is bigint. If the transformation suddenly failed to work
when a constant above INT_MAX was used for the first time, then I'd
say that that's pretty surprising. That's what happens currently if
you write the same query as "WHERE columna =
any('{1_000_000_000,5_000_000_000}')", due to the way the coercion
works. That seems less surprising to me, because the user is required
to construct their own array, and users expect arrays to always have
one element type.
It would probably be okay to make the optimization not combine
things/not apply when the user gratuitously mixes different syntaxes.
For example, if a numeric constant was used, rather than an integer
constant.
Maybe it would be practical to do something with the B-Tree operator
class for each of the types involved in the optimization. You could
probably find a way for a SAOP to work against a
"heterogeneously-typed array" while still getting B-Tree index scans
-- provided the types all came from the same operator family. I'm
assuming that the index has an index column whose input opclass was a
member of that same family. That would necessitate changing the
general definition of SAOP, and adding new code to nbtree that worked
with that. But that seems doable.
I was already thinking about doing something like this, to support
index scans for "IS NOT DISTINCT FROM", or on constructs like "columna
= 5 OR columna IS NULL". That is more or less a SAOP with two values,
except that one of the values in the value NULL. I've already
implemented "nbtree SAOPs where one of the elements is a NULL" for
skip scan, which could be generalized to support these other cases.
Admittedly I'm glossing over a lot of important details here. Does it
just work for the default opclass for the type, or can we expect it to
work with a non-default opclass when that's the salient opclass (the
one used by our index)? I don't know what you'd do about stuff like
that.
--
Peter Geoghegan
On Mon, Jun 24, 2024 at 12:09 PM Peter Geoghegan <pg@bowt.ie> wrote:
> But what about cases like this:
>
> SELECT * FROM mytable WHERE columna = 1_000_000_000 or columna =
> 5_000_000_000; -- columna is int4
>
> This is using two types, of course. 1_000_000_000 is int4, while
> 5_000_000_000 is bigint. If the transformation suddenly failed to work
> when a constant above INT_MAX was used for the first time, then I'd
> say that that's pretty surprising. That's what happens currently if
> you write the same query as "WHERE columna =
> any('{1_000_000_000,5_000_000_000}')", due to the way the coercion
> works. That seems less surprising to me, because the user is required
> to construct their own array, and users expect arrays to always have
> one element type.
I am not against handling this kind of case if we can do it, but it's
more important that the patch doesn't cause gratuitous failures than
that it handles more cases.
> Maybe it would be practical to do something with the B-Tree operator
> class for each of the types involved in the optimization. You could
> probably find a way for a SAOP to work against a
> "heterogeneously-typed array" while still getting B-Tree index scans
> -- provided the types all came from the same operator family. I'm
> assuming that the index has an index column whose input opclass was a
> member of that same family. That would necessitate changing the
> general definition of SAOP, and adding new code to nbtree that worked
> with that. But that seems doable.
I agree that something based on operator families might be viable. Why
would that require changing the definition of an SAOP?
> Admittedly I'm glossing over a lot of important details here. Does it
> just work for the default opclass for the type, or can we expect it to
> work with a non-default opclass when that's the salient opclass (the
> one used by our index)? I don't know what you'd do about stuff like
> that.
It seems to me that it just depends on the opclasses in the query. If
the user says
WHERE column op1 const1 AND column op2 const2
...then if op1 and op2 are in the same operator family and if we can
convert one of const1 and const2 to the type of the other without risk
of failure, then we can rewrite this as an SAOP with whichever of the
two operators pertains to the target type, e.g.
column1 op1 ANY[const1,converted_const2]
I don't think the default opclass matters here, or the index properties either.
--
Robert Haas
EDB: http://www.enterprisedb.com
On Mon, Jun 24, 2024 at 1:29 PM Robert Haas <robertmhaas@gmail.com> wrote: > I am not against handling this kind of case if we can do it, but it's > more important that the patch doesn't cause gratuitous failures than > that it handles more cases. I agree, with the proviso that "avoid gratuitous failures" should include cases where a query that got the optimization suddenly fails to get the optimization, due only to some very innocuous looking change. Such as a change from using a constant 1_000_000_000 to a constant 5_000_000_000 in the query text. That is a POLA violation. > > Maybe it would be practical to do something with the B-Tree operator > > class for each of the types involved in the optimization. You could > > probably find a way for a SAOP to work against a > > "heterogeneously-typed array" while still getting B-Tree index scans > > -- provided the types all came from the same operator family. I'm > > assuming that the index has an index column whose input opclass was a > > member of that same family. That would necessitate changing the > > general definition of SAOP, and adding new code to nbtree that worked > > with that. But that seems doable. > > I agree that something based on operator families might be viable. Why > would that require changing the definition of an SAOP? Maybe it doesn't. My point was only that the B-Tree code doesn't necessarily need to use just one rhs type for the same column input opclass. The definition of SOAP works (or could work) in basically the same way, provided the "OR condition" were provably disjunct. We could for example mix different operators for the same nbtree scan key (with some work in nbtutils.c), just as we could support "where mycol =5 OR mycol IS NULL" with much effort. BTW, did you know MySQL has long supported the latter? It has a <=> operator, which is basically a non-standard spelling of IS NOT DISTINCT FROM. Importantly, it is indexable, whereas right now Postgres doesn't support indexing IS NOT DISTINCT FROM. If you're interested in working on this problem within the scope of this patch, or some follow-up patch, I can take care of the nbtree side of things. > > Admittedly I'm glossing over a lot of important details here. Does it > > just work for the default opclass for the type, or can we expect it to > > work with a non-default opclass when that's the salient opclass (the > > one used by our index)? I don't know what you'd do about stuff like > > that. > > It seems to me that it just depends on the opclasses in the query. If > the user says > > WHERE column op1 const1 AND column op2 const2 > > ...then if op1 and op2 are in the same operator family and if we can > convert one of const1 and const2 to the type of the other without risk > of failure, then we can rewrite this as an SAOP with whichever of the > two operators pertains to the target type, e.g. > > column1 op1 ANY[const1,converted_const2] > > I don't think the default opclass matters here, or the index properties either. Okay, good. The docs do say "Another requirement for a multiple-data-type family is that any implicit or binary-coercion casts that are defined between data types included in the operator family must not change the associated sort ordering" [1]. There must be precedent for this sort of thing. Probably for merge joins. [1] https://www.postgresql.org/docs/devel/btree.html#BTREE-BEHAVIOR -- Peter Geoghegan
On Mon, Jun 24, 2024 at 1:46 PM Peter Geoghegan <pg@bowt.ie> wrote: > BTW, did you know MySQL has long supported the latter? It has a <=> > operator, which is basically a non-standard spelling of IS NOT > DISTINCT FROM. Importantly, it is indexable, whereas right now > Postgres doesn't support indexing IS NOT DISTINCT FROM. If you're > interested in working on this problem within the scope of this patch, > or some follow-up patch, I can take care of the nbtree side of things. To be clear, I meant that we could easily support "where mycol = 5 OR mycol IS NULL" and have nbtree handle that efficiently, by making it a SAOP internally. Separately, we could also make IS NOT DISTINCT FROM indexable, though that probably wouldn't need any work in nbtree. -- Peter Geoghegan
On Mon, Jun 24, 2024 at 1:47 PM Peter Geoghegan <pg@bowt.ie> wrote:
> I agree, with the proviso that "avoid gratuitous failures" should
> include cases where a query that got the optimization suddenly fails
> to get the optimization, due only to some very innocuous looking
> change. Such as a change from using a constant 1_000_000_000 to a
> constant 5_000_000_000 in the query text. That is a POLA violation.
Nope, I don't agree with that at all. If you imagine that we can
either have the optimization apply to one of those cases on the other,
or on the other hand we can have some cases that outright fail, I
think it's entirely clear that the former is better.
> Maybe it doesn't. My point was only that the B-Tree code doesn't
> necessarily need to use just one rhs type for the same column input
> opclass. The definition of SOAP works (or could work) in basically the
> same way, provided the "OR condition" were provably disjunct. We could
> for example mix different operators for the same nbtree scan key (with
> some work in nbtutils.c), just as we could support "where mycol =5 OR
> mycol IS NULL" with much effort.
>
> BTW, did you know MySQL has long supported the latter? It has a <=>
> operator, which is basically a non-standard spelling of IS NOT
> DISTINCT FROM. Importantly, it is indexable, whereas right now
> Postgres doesn't support indexing IS NOT DISTINCT FROM. If you're
> interested in working on this problem within the scope of this patch,
> or some follow-up patch, I can take care of the nbtree side of things.
I was assuming this patch shouldn't be changing the way indexes work
at all, just making use of the facilities that we have today. More
could be done, but that might make it harder to get anything
committed.
Before we get too deep into arguing about hypotheticals, I don't think
there's any problem here that we can't solve with the infrastructure
we already have. For instance, consider this:
robert.haas=# explain select * from foo where a in (1, 1000000000000000);
QUERY PLAN
-----------------------------------------------------------
Seq Scan on foo1 foo (cost=0.00..25.88 rows=13 width=36)
Filter: (a = ANY ('{1,1000000000000000}'::bigint[]))
(2 rows)
I don't know exactly what's happening here, but it seems very similar
to what we need to have happen for this patch to work. pg_typeof(1) is
integer, and pg_typeof(1000000000000000) is bigint, and we're able to
figure out that it's OK to put both of those in an array of a single
type and without having any type conversion failures. If you replace
1000000000000000 with 2, then the array ends up being of type
integer[] rather than type bigint[], so. clearly the system is able to
reason its way through these kinds of scenarios already.
It's even possible, in my mind at least, that the patch is already
doing exactly the right things here. Even if it isn't, the problem
doesn't seem to be fundamental, because if this example can work (and
it does) then what the patch is trying to do should be workable, too.
We just have to make sure we're plugging all the pieces properly
together, and that we have comments adequately explain what is
happening and test cases that verify it. My feeling is that the patch
doesn't meet that standard today, but I think that just means it needs
some more work. I'm not arguing we have to throw the whole thing out,
or invent a lot of new infrastructure, or anything like that.
--
Robert Haas
EDB: http://www.enterprisedb.com
On Mon, Jun 24, 2024 at 2:28 PM Robert Haas <robertmhaas@gmail.com> wrote:
> On Mon, Jun 24, 2024 at 1:47 PM Peter Geoghegan <pg@bowt.ie> wrote:
> > I agree, with the proviso that "avoid gratuitous failures" should
> > include cases where a query that got the optimization suddenly fails
> > to get the optimization, due only to some very innocuous looking
> > change. Such as a change from using a constant 1_000_000_000 to a
> > constant 5_000_000_000 in the query text. That is a POLA violation.
>
> Nope, I don't agree with that at all. If you imagine that we can
> either have the optimization apply to one of those cases on the other,
> or on the other hand we can have some cases that outright fail, I
> think it's entirely clear that the former is better.
I'm just saying that not having the optimization apply to a query very
similar to one where it does apply is a POLA violation. That's another
kind of failure, for all practical purposes. Weird performance cliffs
like that are bad. It's very easy to imagine code that generates a
query text, that at some point randomly and mysteriously gets a
sequential scan. Or a much less efficient index scan.
> I was assuming this patch shouldn't be changing the way indexes work
> at all, just making use of the facilities that we have today. More
> could be done, but that might make it harder to get anything
> committed.
I was just pointing out that there is currently no good way to make
nbtree efficiently execute a qual "WHERE a = 5 OR a IS NULL", which is
almost entirely (though not quite entirely) due to a lack of any way
of expressing that idea through SQL, in a way that'll get pushed down
to the index scan node. You can write "WHERE a = any('{5,NULL')", of
course, but that doesn't treat NULL as just another array element to
match against via an IS NULL qual (due to NULL semantics).
Yeah, this is nonessential. But it's quite a nice optimization, and
seems entirely doable within the framework of the patch. It would be a
natural follow-up.
All that I'd need on the nbtree side is to get an input scan key that
directly embodies "WHERE mycol = 5 OR mycol IS NULL". That would
probably just be a scan key with sk_flags "SK_SEARCHARRAY |
SK_SEARCHNULL", that was otherwise identical to the current
SK_SEARCHARRAY scan keys.
Adopting the nbtree array index scan code to work with this would be
straightforward. SK_SEARCHNULL scan keys basically already work like
regular equality scan keys at execution time, so all that this
optimization requires on the nbtree side is teaching
_bt_advance_array_keys to treat NULL as a distinct array condition
(evaluated as IS NULL, not as = NULL).
> It's even possible, in my mind at least, that the patch is already
> doing exactly the right things here. Even if it isn't, the problem
> doesn't seem to be fundamental, because if this example can work (and
> it does) then what the patch is trying to do should be workable, too.
> We just have to make sure we're plugging all the pieces properly
> together, and that we have comments adequately explain what is
> happening and test cases that verify it. My feeling is that the patch
> doesn't meet that standard today, but I think that just means it needs
> some more work. I'm not arguing we have to throw the whole thing out,
> or invent a lot of new infrastructure, or anything like that.
I feel like my point about the potential for POLA violations is pretty
much just common sense. I'm not particular about the exact mechanism
by which we avoid it; only that we avoid it.
--
Peter Geoghegan
Hi! Let me join the review process. I am no expert in execution plans, so there would not be much help in doing even better optimization. But I can read the code, as a person who is not familiar with this area and help making it clear even to a person like me. So, I am reading v25-0001-Transform-OR-clauses-to-ANY-expression.patch that have been posted some time ago, and especially transform_or_to_any function. > @@ -38,7 +45,6 @@ > int from_collapse_limit; > int join_collapse_limit; > > - > /* > * deconstruct_jointree requires multiple passes over the join tree, because we > * need to finish computing JoinDomains before we start distributing quals. Do not think that removing empty line should be part of the patch > + /* > + * If the const node's (right side of operator expression) type > + * don't have “true†array type, then we cannnot do the > + * transformation. We simply concatenate the expression node. > + */ Guess using unicode double quotes is not the best idea here... Now to the first part of `transform_or_to_any`
Attachment
Hi! Let me join the review process. I am no expert in execution plans, so there would not be much help in doing even better optimization. But I can read the code, as a person who is not familiar with this area and help making it clear even to a person like me. So, I am reading v25-0001-Transform-OR-clauses-to-ANY-expression.patch that have been posted some time ago, and especially transform_or_to_any function. > @@ -38,7 +45,6 @@ > int from_collapse_limit; > int join_collapse_limit; > > - > /* > * deconstruct_jointree requires multiple passes over the join tree, because we > * need to finish computing JoinDomains before we start distributing quals. Do not think that removing empty line should be part of the patch > + /* > + * If the const node's (right side of operator expression) type > + * don't have “true†array type, then we cannnot do the > + * transformation. We simply concatenate the expression node. > + */ Guess using unicode double quotes is not the best idea here... Now to the first part of `transform_or_to_any`: > + List *entries = NIL; I guess the idea of entries should be explained from the start. What kind of entries are accomulated there... I see they are added there all around the code, but what is the purpose of that is not quite clear when you read it. At the first part of `transform_or_to_any` function, you costanly repeat two lines, like a mantra: > + entries = lappend(entries, rinfo); > + continue; "If something is wrong -- do that mantra" From my perspective, if you have to repeat same code again and again, then most probably you have some issues with architecture of the code. If you repeat some code again and again, you need to try to rewrite the code, the way, that part is repeated only once. In that case I would try to move the most of the first loop of `transform_or_to_any` to a separate function (let's say its name is prepare_single_or), that will do all the checks, if this or is good for us; return NULL if it does not suits our purposes (and in this case we do "entries = lappend(entries, rinfo); continue" in the main code, but only once) or return pointer to some useful data if this or clause is good for our purposes. This, I guess will make that part more clear and easy to read, without repeating same "lappend mantra" again and again. Will continue digging into the code tomorrow. P.S. Sorry for sending partly finished email. Pressed Ctrl+Enter accidentally... With no way to make it back :-(((
Attachment
On Fri, Jun 21, 2024 at 6:52 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote:It's hard to tell, but I think it might be one of the good places to apply transformation. Let me describe a brief conclusion on the two approaches.This explanation is somewhat difficult for me to follow. For example:In the first approach, we definitely did not process the extra "OR" expressions in the first approach, since they were packaged as an Array. It could lead to the fact that less planning time would be spent on the optimizer.I don't know what the "first approach" refers to, or what processing the extra "OR" expressions means, or what it would mean to package OR expressions as an array. If you made them into an SAOP then you'd have an array *instead of* OR expressions, not OR expressions "packaged as an array" but even then, they'd still be processed somewhere, unless the patch was just wrong. I think you should try writing this summary again and see if you can make it a lot clearer and more precise. I'm suspicious based that we should actually be postponing the transformation even further. If, for example, the transformation is advantageous for index scans and disadvantageous for bitmap scans, or the other way around, then this approach can't help much: it either does the transformation and all scan types are affected, or it doesn't do it and no scan types are affected. But if you decided for each scan whether to transform the quals, then you could handle that. Against that, there might be increased planning cost. But, perhaps that could be avoided somehow.
Sorry, you are right and I'll try to explain more precisely. The first approach is the first part of the patch, where we made "Or" expressions into an SAOP at an early stage of plan generation [0], the second one was the one proposed by A.Korotkov [1].
So, when we made "OR" expressions into an SAOP at the post-parsing stage of the plan generation [0], we definitely did not process the redundant expressions "OR" expressions there (for example, duplicates), since they were transformed to SAOP expression. Furthermore, the list of OR expressions can be significantly reduced, since constants belonging to the same predicate will already be converted into an SAOP expression. I assume this may reduce planning time, as I know several places in the optimizer where these lists of "OR" expressions are scanned several times.
Also the selectivity for SAOP expressions is estimated better, which could lead to the generation of a more optimal plan, but, to be honest, this is just an observation from changes in regression tests and, in general, how the process of calculating the selectivity of a complex expression works. And I think it needs further consideration. SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE (a = 1 OR a = 51) AND b = ''1'''); estimated | actual -----------+-------- - 99 | 100 + 100 | 100 (1 row) SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE (a = 1 OR a = 51) AND (b = ''1'' OR b = ''2'')'); estimated | actual -----------+-------- - 99 | 100 + 100 | 100 (1 row) SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE (a = 1 OR a = 2 OR a = 51 OR a = 52) AND (b = ''1'' OR b = ''2'')'); estimated | actual -----------+-------- - 197 | 200 + 200 | 200 Speaking of the main disadvantages, we do not give the optimizer the opportunity to generate a plan using BitmapScan, which can lead to the generation of a suboptimal plan, but in the current approach the same thing happens [2]. And you mentioned about it before:
I'm suspicious based that we should actually be postponing the transformation even further. If, for example, the transformation is advantageous for index scans and disadvantageous for bitmap scans, or the other way around, then this approach can't help much: it either does the transformation and all scan types are affected, or it doesn't do it and no scan types are affected. But if you decided for each scan whether to transform the quals, then you could handle that. Against that, there might be increased planning cost. But, perhaps that could be avoided somehow.
Andrei mentioned the problem, which might be caused by the transformation on the later stage of optimization is updating references to expressions in RestrictInfo [3] lists, because they can be used in different parts during the formation of the query plan. As the practice of Self-join removal [4] has shown, this can be expensive, but feasible. By applying the transformation at the analysis stage [0], because no links were created, so we did not encounter such problems, so this approach was more suitable than the others.
If some things were not clear enough, let me know.
[0] https://www.postgresql.org/message-id/attachment/156971/v21-0001-Transform-OR-clauses-to-ANY-expression.patch [1] https://www.postgresql.org/message-id/CAPpHfduah1PLzajBJFDmp7%2BMZuaWYpie2p%2BGsV0r03fcGghQ-g%40mail.gmail.com [2] https://www.postgresql.org/message-id/7d5aed92-d4cc-4b76-8ae0-051d182c9eec%40postgrespro.ru [3] https://www.postgresql.org/message-id/6850c306-4e9d-40b7-8096-1f3c7d29cd9e%40postgrespro.ru [4] https://commitfest.postgresql.org/48/5043/
The alternative that should be considered is not combining things if the types don't match. If we're going to combine such things, we need to be absolutely certain that type conversion cannot fail.
Peter, Robert, thanks for the detailed discussion, I realized that here you need to look carefully at the patch. In general, it comes out, I need to pay attention and highlight the cases where POLA violation occurs
One reason is that it is extra work to convert things to a name and then back to an OID. It's got to be slower than using the OID you already have. The other reason is that it's error-prone. If somehow the second lookup doesn't produce the same OID as the first lookup, bad things will happen, possibly including security vulnerabilities. I see you've taken steps to avoid that, like nailing down the schema, and that's good, but it's not a good enough reason to do it like this. If we don't have a function that can construct the node we need with the OID rather than the name as an argument, we should invent one, not do this sort of thing.
I understood. I'll try to fix it.
В письме от понедельник, 24 июня 2024 г. 23:51:56 MSK пользователь Nikolay Shaplov написал: So, I continue reading the patch. I see there is `entries` variable in the code, that is the list of `RestrictInfo` objects and `entry` that is `OrClauseGroup` object. This naming is quite misguiding (at least for me). `entries` variable name can be used, as we deal only with RestrictInfo entries here. It is kind of "generic" type. Though naming it `restric_info_entry` might make te code more readable. But when we come to an `entry` variable, it is very specific entry, it should be `OrClauseGroup` entry, not just any entry. So I would suggest to name this variable `or_clause_group_entry`, or even `or_clause_group` , so when we meet this variable in the middle of the code, we can get the idea what we are dealing with, without scrolling code up. Variable naming is very important thing. It can drastically improve (or ruin) code readability. ======== Also I see some changes in the tests int this patch. There are should be tests that check that this new feature works well. And there are test whose behavior have been just accidentally affected. I whould suggest to split these tests into two patches, as they should be reviewed in different ways. Functionality tests should be thoroughly checked that all stuff we added is properly tested, and affected tests should be checked that nothing important is not broken. It would be more easy to check if these are two different patches. I would also suggest to add to the commit message of affected tests changes some explanation why this changes does not really breaks anything. This will do the checking more simple. To be continued. -- Nikolay Shaplov aka Nataraj Fuzzing Engineer at Postgres Professional Matrix IM: @dhyan:nataraj.su
Attachment
I think maybe replying to multiple emails with a single email is something you'd be better off doing less often. On Tue, Jun 25, 2024 at 7:14 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > Sorry, you are right and I'll try to explain more precisely. The first approach is the first part of the patch, where wemade "Or" expressions into an SAOP at an early stage of plan generation [0], the second one was the one proposed by A.Korotkov[1]. [0] isn't doing anything "at an early stage of plan generation". It's changing something in *the parser*. The parser and planner are VERY different stages of query parsing, and it's really important to keep them separate mentally and in discussions. We should not be changing anything about the query in the parser, because that will, as Alexander also pointed out, change what gets stored if the user does something like CREATE VIEW whatever AS SELECT ...; and we should, for the most part, be storing the query as the user entered it, not some transformed version of it. Further, at the parser stage, we do not know the cost of anything, so we can only transform things when the transformed version is always - or practically always - going to be cheaper than the untransformed version. > On 24.06.2024 18:28, Robert Haas wrote: > Andrei mentioned the problem, which might be caused by the transformation on the later stage of optimization is updatingreferences to expressions in RestrictInfo [3] lists, because they can be used in different parts during the formationof the query plan. As the practice of Self-join removal [4] has shown, this can be expensive, but feasible. By applyingthe transformation at the analysis stage [0], because no links were created, so we did not encounter such problems,so this approach was more suitable than the others. The link you provided for [3] doesn't show me exactly what code you're talking about, but I can see why mutating a RestrictInfo after creating it could be problematic. However, I'm not proposing that, and I don't think it's a good idea. Instead of mutating an existing data structure after it's been created, we want to get each data structure correct at the moment that it is created. What that means is that at each stage of processing, whenever we create a new in-memory data structure, we have an opportunity to make changes along the way. For instance, let's say we have a RestrictInfo and we are creating a Path, perhaps via create_index_path(). One argument to that function is a list of indexclauses. The indexclauses are derived from the RestrictInfo list associated with the RelOptInfo. We take some subset of those quals that are deemed to be indexable and we reorder them and maybe change a few things and we build this new list of indexclauses that is then passed to create_index_path(). The RelOptInfo's list of RestrictInfos is not changed -- only the new list of clauses derived from it is being built up here, without any mutation of the original structure. This is the kind of thing that this patch can and probably should do. Join removal is quite awkward, as you rightly point out, because we end up modifying existing data structures after they've been created, and that requires us to run around and fix up a bunch of stuff, and that can have bugs. Whenever possible, we don't want to do it that way. Instead, we want to pick points in the processing when we're anyway constructing some new structure and use that as an opportunity to do transformations when building the new structure that incorporate optimizations that make sense. -- Robert Haas EDB: http://www.enterprisedb.com
Ok, I won't do this in the future. After thinking it over, I realized that it turned out to be some kind of mess in the end.I think maybe replying to multiple emails with a single email is something you'd be better off doing less often.
On Tue, Jun 25, 2024 at 7:14 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote:Sorry, you are right and I'll try to explain more precisely. The first approach is the first part of the patch, where we made "Or" expressions into an SAOP at an early stage of plan generation [0], the second one was the one proposed by A.Korotkov [1].[0] isn't doing anything "at an early stage of plan generation". It's changing something in *the parser*. The parser and planner are VERY different stages of query parsing, and it's really important to keep them separate mentally and in discussions.
Thanks for the detailed explanation, I'm always glad to learn new things for myself)
To be honest, I had an intuitive feeling that the transformation was called in the analyzer stage, but I wasn't sure about it, so I tried to summarize it.
As for the fact that in general all this can be divided into two large stages, parsing and planner is a little new to me. I have reread the documentation [0] and I found information about it there.
Before that, I was guided by information from the Carnegie Mellon University lecture and the Bruce Mamjian report[1], which was wrong on my part.
By the way, it turns out that the query rewriting stage refers to an independent stage, which is located between the parser stage and the planner/optimizer. I found it from the documentation [2].
[0] https://www.postgresql.org/docs/current/planner-optimizer.html
[1] https://momjian.us/main/writings/pgsql/optimizer.pdf
[2] https://www.postgresql.org/docs/16/rule-system.html
We should not be changing anything about the query in the parser, because that will, as Alexander also pointed out, change what gets stored if the user does something like CREATE VIEW whatever AS SELECT ...; and we should, for the most part, be storing the query as the user entered it, not some transformed version of it. Further, at the parser stage, we do not know the cost of anything, so we can only transform things when the transformed version is always - or practically always - going to be cheaper than the untransformed version.
Thank you, now it has become clear to me why it is so important to leave the transformation at the planner stage.
On 24.06.2024 18:28, Robert Haas wrote: Andrei mentioned the problem, which might be caused by the transformation on the later stage of optimization is updating references to expressions in RestrictInfo [3] lists, because they can be used in different parts during the formation of the query plan. As the practice of Self-join removal [4] has shown, this can be expensive, but feasible. By applying the transformation at the analysis stage [0], because no links were created, so we did not encounter such problems, so this approach was more suitable than the others.The link you provided for [3] doesn't show me exactly what code you're talking about, but I can see why mutating a RestrictInfo after creating it could be problematic. However, I'm not proposing that, and I don't think it's a good idea. Instead of mutating an existing data structure after it's been created, we want to get each data structure correct at the moment that it is created. What that means is that at each stage of processing, whenever we create a new in-memory data structure, we have an opportunity to make changes along the way. For instance, let's say we have a RestrictInfo and we are creating a Path, perhaps via create_index_path(). One argument to that function is a list of indexclauses. The indexclauses are derived from the RestrictInfo list associated with the RelOptInfo. We take some subset of those quals that are deemed to be indexable and we reorder them and maybe change a few things and we build this new list of indexclauses that is then passed to create_index_path(). The RelOptInfo's list of RestrictInfos is not changed -- only the new list of clauses derived from it is being built up here, without any mutation of the original structure. This is the kind of thing that this patch can and probably should do. Join removal is quite awkward, as you rightly point out, because we end up modifying existing data structures after they've been created, and that requires us to run around and fix up a bunch of stuff, and that can have bugs. Whenever possible, we don't want to do it that way. Instead, we want to pick points in the processing when we're anyway constructing some new structure and use that as an opportunity to do transformations when building the new structure that incorporate optimizations that make sense.
Thanks for the idea! I hadn't thought in this direction before, but it really might just work and solve all our original problems.
By the way, I saw that the optimizer is smart enough to eliminate duplicates. Below I have conducted a couple of examples where he decides for himself which expression is more profitable for him to leave.
We just need to add this transformation, and the optimizer will choose the appropriate one)
alena@postgres=# explain select * from x where (a = 1 or a = 2) and a in (1,2);
QUERY PLAN
--------------------------------------------------------------------
Index Only Scan using a_idx on x (cost=0.28..8.61 rows=1 width=4)
Index Cond: (a = ANY ('{1,2}'::integer[]))
(2 rows)
alena@postgres=# explain select * from x where a < 3 and (a = 1 or a = 2) and a = ANY(ARRAY[1,2]);
QUERY PLAN
--------------------------------------------------------------------
Index Only Scan using a_idx on x (cost=0.28..8.60 rows=1 width=4)
Index Cond: ((a < 3) AND (a = ANY ('{1,2}'::integer[])))
(2 rows)
It works for Korotkov's case too, as I see it:
alena@postgres=# create table test as (select (random()*10)::int x, (random()*1000) y from generate_series(1,1000000) i); create index test_x_1_y on test (y) where x = 1; create index test_x_2_y on test (y) where x = 2; vacuum analyze test; SELECT 1000000 CREATE INDEX CREATE INDEX VACUUM alena@postgres=# explain select * from test where (x = 1 or x = 2) and y = 100 and x in (1,2); QUERY PLAN -------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on test (cost=8.60..12.62 rows=1 width=12) Recheck Cond: (((y = '100'::double precision) AND (x = 1)) OR ((y = '100'::double precision) AND (x = 2))) -> BitmapOr (cost=8.60..8.60 rows=1 width=0) -> Bitmap Index Scan on test_x_1_y (cost=0.00..4.30 rows=1 width=0) Index Cond: (y = '100'::double precision) -> Bitmap Index Scan on test_x_2_y (cost=0.00..4.30 rows=1 width=0) Index Cond: (y = '100'::double precision) (7 rows)
I noticed that the distribute_quals_to_rels function launches at the stage when it is necessary to generate RestrictInfo lists for relation - it might be a suitable place for applying transformation.
So, instead of completely replacing the list, we should form a complex BoolExpr structure with the "AND" operator, which should contain two expressions, where one of them is BoolExpr with the "OR" operator and the second is ScalarArrayOpExpr.
To be honest, I've already started writing code to do this, but I'm faced with a misunderstanding of how to correctly create a condition for "OR" expressions that are not subject to transformation. For example, the expressions b=1 in the query below:
alena@postgres=# explain select * from x where ( (a =5 or a=4) and a = ANY(ARRAY[5,4])) or (b=1); QUERY PLAN ---------------------------------------------------------------------------------- Seq Scan on x (cost=0.00..123.00 rows=1 width=8) Filter: ((((a = 5) OR (a = 4)) AND (a = ANY ('{5,4}'::integer[]))) OR (b = 1)) (2 rows)
I see that two expressions have remained unchanged and it only works for "AND" binary operations.
But I think it might be worth applying this together, where does the optimizer generate indexes (build_paths_for_OR function)?
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
For example, the expressions b=1 in the query below:
alena@postgres=# explain select * from x where ( (a =5 or a=4) and a = ANY(ARRAY[5,4])) or (b=1); QUERY PLAN ---------------------------------------------------------------------------------- Seq Scan on x (cost=0.00..123.00 rows=1 width=8) Filter: ((((a = 5) OR (a = 4)) AND (a = ANY ('{5,4}'::integer[]))) OR (b = 1)) (2 rows)
I see that two expressions have remained unchanged and it only works for "AND" binary operations.
But I think it might be worth applying this together, where does the optimizer generate indexes (build_paths_for_OR function)?
Sorry, it works) I needed to create one more index for b column.
Just in case, I gave an example of a complete case, otherwise it might not be entirely clear:
alena@postgres=# create table x (a int, b int);
CREATE TABLE
alena@postgres=# create index a_idx on x(a);
insert into x select id,id from generate_series(1, 5000) as id;
CREATE INDEX
INSERT 0 5000
alena@postgres=# analyze;
ANALYZE
alena@postgres=# explain select * from x where ( (a =5 or a=4) and a = ANY(ARRAY[5,4])) or (b=1); QUERY PLAN ---------------------------------------------------------------------------------- Seq Scan on x (cost=0.00..123.00 rows=1 width=8) Filter: ((((a = 5) OR (a = 4)) AND (a = ANY ('{5,4}'::integer[]))) OR (b = 1)) (2 rows)
alena@postgres=# create index b_idx on x(b);
CREATE INDEX
alena@postgres=# explain select * from x where ( (a =5 or a=4) and a = ANY(ARRAY[5,4])) or (b=1);
QUERY PLAN
--------------------------------------------------------------------------
Bitmap Heap Scan on x (cost=12.87..21.68 rows=1 width=8)
Recheck Cond: ((a = ANY ('{5,4}'::integer[])) OR (b = 1))
-> BitmapOr (cost=12.87..12.87 rows=3 width=0)
-> Bitmap Index Scan on a_idx (cost=0.00..8.58 rows=2 width=0)
Index Cond: (a = ANY ('{5,4}'::integer[]))
-> Bitmap Index Scan on b_idx (cost=0.00..4.29 rows=1 width=0)
Index Cond: (b = 1)
(7 rows)
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi! Thank you for your review! Sorry for the delay in responding.
I rewrote the patch as you requested, but now I'm faced with the problem of processing the elements of the or_entries list. For some reason, the pointer to the list is cleared and I couldn't find the place where it happened. Maybe I'm missing something simple in view of the heavy workload right now, but maybe you'll see a problem? I have displayed part of stack below.
#5 0x00005b0f6d9f6a6a in ExceptionalCondition (conditionName=0x5b0f6dbb74f7 "IsPointerList(list)", fileName=0x5b0f6dbb7418 "list.c", lineNumber=341) at assert.c:66 #6 0x00005b0f6d5dc3ba in lappend (list=0x5b0f6eec5ca0, datum=0x5b0f6eec0d90) at list.c:341 #7 0x00005b0f6d69230c in transform_or_to_any (root=0x5b0f6eeb13c8, orlist=0x5b0f6eec57c0) at initsplan.c:2818 #8 0x00005b0f6d692958 in add_base_clause_to_rel (root=0x5b0f6eeb13c8, relid=1, restrictinfo=0x5b0f6eec5990) at initsplan.c:2982 #9 0x00005b0f6d692e5f in distribute_restrictinfo_to_rels (root=0x5b0f6eeb13c8, restrictinfo=0x5b0f6eec5990) at initsplan.c:3175 #10 0x00005b0f6d691bf2 in distribute_qual_to_rels (root=0x5b0f6eeb13c8, clause=0x5b0f6eec0fc0, jtitem=0x5b0f6eec4330, sjinfo=0x0, security_level=0, qualscope=0x5b0f6eec4730, ojscope=0x0, outerjoin_nonnullable=0x0, incompatible_relids=0x0, allow_equivalence=true, has_clone=false, is_clone=false, postponed_oj_qual_list=0x0) at initsplan.c:2576 #11 0x00005b0f6d69146f in distribute_quals_to_rels (root=0x5b0f6eeb13c8, clauses=0x5b0f6eec0bb0, jtitem=0x5b0f6eec4330, sjinfo=0x0, security_level=0, qualscope=0x5b0f6eec4730, ojscope=0x0, outerjoin_nonnullable=0x0, incompatible_relids=0x0, allow_equivalence=true, has_clone=false, is_clone=false, postponed_oj_qual_list=0x0) at initsplan.c:2144
This is still the first iteration of the fixes you have proposed, so I have attached the patch in diff format. I rewrote it, as you suggested in the first letter [0]. I created a separate function that tries to form an OrClauseGroup node, but if it fails in this, it returns false, otherwise it processes the generated element according to what it found - either adds it to the list as new, or adds a constant to an existing one.
I also divided one general list of suitable for conversion and unsuitable into two different ones: appropriate_entries and or_entries. Now we are only looking in the list of suitable elements to form ANY expr.
This helps us to get rid of repetitions in the code you mentioned. Please write if this is not the logic that you have seen before.
[0] https://www.postgresql.org/message-id/3381819.e9J7NaK4W3%40thinkpad-pgpro
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
To be honest, I've already started writing code to do this, but I'm faced with a misunderstanding of how to correctly create a condition for "OR" expressions that are not subject to transformation.For example, the expressions b=1 in the query below:
alena@postgres=# explain select * from x where ( (a =5 or a=4) and a = ANY(ARRAY[5,4])) or (b=1); QUERY PLAN ---------------------------------------------------------------------------------- Seq Scan on x (cost=0.00..123.00 rows=1 width=8) Filter: ((((a = 5) OR (a = 4)) AND (a = ANY ('{5,4}'::integer[]))) OR (b = 1)) (2 rows)
I see that two expressions have remained unchanged and it only works for "AND" binary operations.
But I think it might be worth applying this together, where does the optimizer generate indexes (build_paths_for_OR function)?
I implemented such code, but at the analysis stage in planner, and it wasn't fully ready yet, but I was able to draw some important conclusions. First of all, I faced the problem of the inequality of the number of columns in the expression with the required one, at least some extra column appeared, judging by the crust. I haven't fully realized it yet and haven't fixed it.
#0 __pthread_kill_implementation (no_tid=0, signo=6, threadid=134300960061248)
at ./nptl/pthread_kill.c:44
#1 __pthread_kill_internal (signo=6, threadid=134300960061248) at ./nptl/pthread_kill.c:78
#2 __GI___pthread_kill (threadid=134300960061248, signo=signo@entry=6) at ./nptl/pthread_kill.c:89
#3 0x00007a2560042476 in __GI_raise (sig=sig@entry=6) at ../sysdeps/posix/raise.c:26
#4 0x00007a25600287f3 in __GI_abort () at ./stdlib/abort.c:79
#5 0x00005573f9df62a8 in ExceptionalCondition (
conditionName=0x5573f9fec4c8 "AttrNumberIsForUserDefinedAttr(list_attnums[i]) || !bms_is_member(attnum, clauses_attnums)", fileName=0x5573f9fec11c "dependencies.c", lineNumber=1525) at assert.c:66
#6 0x00005573f9b8b85f in dependencies_clauselist_selectivity (root=0x5573fad534e8,
clauses=0x5573fad0b2d8, varRelid=0, jointype=JOIN_INNER, sjinfo=0x0, rel=0x5573fad54b38,
estimatedclauses=0x7ffe2e43f178) at dependencies.c:1525
#7 0x00005573f9b8fed9 in statext_clauselist_selectivity (root=0x5573fad534e8, clauses=0x5573fad0b2d8,
varRelid=0, jointype=JOIN_INNER, sjinfo=0x0, rel=0x5573fad54b38, estimatedclauses=0x7ffe2e43f178,
is_or=false) at extended_stats.c:2035
--Type <RET> for more, q to quit, c to continue without paging--
#8 0x00005573f9a57f88 in clauselist_selectivity_ext (root=0x5573fad534e8, clauses=0x5573fad0b2d8,
varRelid=0, jointype=JOIN_INNER, sjinfo=0x0, use_extended_stats=true) at clausesel.c:153
#9 0x00005573f9a57e30 in clauselist_selectivity (root=0x5573fad534e8, clauses=0x5573fad0b2d8,
varRelid=0, jointype=JOIN_INNER, sjinfo=0x0) at clausesel.c:106
#10 0x00005573f9a62e03 in set_baserel_size_estimates (root=0x5573fad534e8, rel=0x5573fad54b38)
at costsize.c:5247
#11 0x00005573f9a51aa5 in set_plain_rel_size (root=0x5573fad534e8, rel=0x5573fad54b38,
rte=0x5573fad0ec58) at allpaths.c:581
#12 0x00005573f9a516ce in set_rel_size (root=0x5573fad534e8, rel=0x5573fad54b38, rti=1,
rte=0x5573fad0ec58) at allpaths.c:411
#13 0x00005573f9a514c7 in set_base_rel_sizes (root=0x5573fad534e8) at allpaths.c:322
#14 0x00005573f9a5119d in make_one_rel (root=0x5573fad534e8, joinlist=0x5573fad0adf8) at allpaths.c:183
#15 0x00005573f9a94d45 in query_planner (root=0x5573fad534e8,
qp_callback=0x5573f9a9b59e <standard_qp_callback>, qp_extra=0x7ffe2e43f540) at planmain.c:280
#16 0x00005573f9a977a8 in grouping_planner (root=0x5573fad534e8, tuple_fraction=0, setops=0x0)
at planner.c:1520
#17 0x00005573f9a96e47 in subquery_planner (glob=0x5573fad533d8, parse=0x5573fad0ea48, parent_root=0x0,
hasRecursion=false, tuple_fraction=0, setops=0x0) at planner.c:1089
#18 0x00005573f9a954aa in standard_planner (parse=0x5573fad0ea48,
query_string=0x5573fad8b3b0 "explain analyze SELECT * FROM functional_dependencies WHERE ((a * 2) = 2 OR (a * 2) = 102) AND upper(b) = '1'", cursorOptions=2048, boundParams=0x0) at planner.c:415
#19 0x00005573f9a951d4 in planner (parse=0x5573fad0ea48,
--Type <RET> for more, q to quit, c to continue without paging--
query_string=0x5573fad8b3b0 "explain analyze SELECT * FROM functional_dependencies WHERE ((a * 2) = 2 OR (a * 2) = 102) AND upper(b) = '1'", cursorOptions=2048, boundParams=0x0) at planner.c:282
#20 0x00005573f9bf4e2e in pg_plan_query (querytree=0x5573fad0ea48,
query_string=0x5573fad8b3b0 "explain analyze SELECT * FROM functional_dependencies WHERE ((a * 2) = 2 OR (a * 2) = 102) AND upper(b) = '1'", cursorOptions=2048, boundParams=0x0) at postgres.c:904
#21 0x00005573f98613e7 in standard_ExplainOneQuery (query=0x5573fad0ea48, cursorOptions=2048, into=0x0,
es=0x5573fad57da0,
queryString=0x5573fad8b3b0 "explain analyze SELECT * FROM functional_dependencies WHERE ((a * 2) = 2 OR (a * 2) = 102) AND upper(b) = '1'", params=0x0, queryEnv=0x0) at explain.c:489
#22 0x00005573f9861205 in ExplainOneQuery (query=0x5573fad0ea48, cursorOptions=2048, into=0x0,
es=0x5573fad57da0,
queryString=0x5573fad8b3b0 "explain analyze SELECT * FROM functional_dependencies WHERE ((a * 2) = 2 OR (a * 2) = 102) AND upper(b) = '1'", params=0x0, queryEnv=0x0) at explain.c:445
#23 0x00005573f9860e35 in ExplainQuery (pstate=0x5573fad57c90, stmt=0x5573fad8b5a0, params=0x0,
dest=0x5573fad57c00) at explain.c:341
#24 0x00005573f9bff3a8 in standard_ProcessUtility (pstmt=0x5573fad8b490,
queryString=0x5573fad8b3b0 "explain analyze SELECT * FROM functional_dependencies WHERE ((a * 2) = 2 OR (a * 2) = 102) AND upper(b) = '1'", readOnlyTree=false, context=PROCESS_UTILITY_QUERY, params=0x0,
queryEnv=0x0, dest=0x5573fad57c00, qc=0x7ffe2e43fcd0) at utility.c:863
#25 0x00005573f9bfe91a in ProcessUtility (pstmt=0x5573fad8b490,
queryString=0x5573fad8b3b0 "explain analyze SELECT * FROM functional_dependencies WHERE ((a * 2) = 2 OR (a * 2) = 102) AND upper(b) = '1'", readOnlyTree=false, context=PROCESS_UTILITY_QUERY, params=0x0,
--Type <RET> for more, q to quit, c to continue without paging--
queryEnv=0x0, dest=0x5573fad57c00, qc=0x7ffe2e43fcd0) at utility.c:523
#26 0x00005573f9bfd195 in PortalRunUtility (portal=0x5573fac6bcf0, pstmt=0x5573fad8b490,
isTopLevel=false, setHoldSnapshot=true, dest=0x5573fad57c00, qc=0x7ffe2e43fcd0) at pquery.c:1158
#27 0x00005573f9bfced2 in FillPortalStore (portal=0x5573fac6bcf0, isTopLevel=false) at pquery.c:1031
#28 0x00005573f9bfd778 in PortalRunFetch (portal=0x5573fac6bcf0, fdirection=FETCH_FORWARD, count=10,
dest=0x5573fa1d6880 <spi_printtupDR>) at pquery.c:1442
#29 0x00005573f9992675 in _SPI_cursor_operation (portal=0x5573fac6bcf0, direction=FETCH_FORWARD,
count=10, dest=0x5573fa1d6880 <spi_printtupDR>) at spi.c:3019
#30 0x00005573f9990849 in SPI_cursor_fetch (portal=0x5573fac6bcf0, forward=true, count=10) at spi.c:1805
#31 0x00007a25603e0aa5 in exec_for_query (estate=0x7ffe2e440200, stmt=0x5573fad067c8,
portal=0x5573fac6bcf0, prefetch_ok=true) at pl_exec.c:5889
#32 0x00007a25603de728 in exec_stmt_dynfors (estate=0x7ffe2e440200, stmt=0x5573fad067c8)
at pl_exec.c:4647
#33 0x00007a25603d8b1c in exec_stmts (estate=0x7ffe2e440200, stmts=0x5573fad06ec8) at pl_exec.c:2100
#34 0x00007a25603d8697 in exec_stmt_block (estate=0x7ffe2e440200, block=0x5573fad06f18) at pl_exec.c:1943
#35 0x00007a25603d7d9e in exec_toplevel_block (estate=0x7ffe2e440200, block=0x5573fad06f18)
at pl_exec.c:1634
#36 0x00007a25603d5a2e in plpgsql_exec_function (func=0x5573fac2c1e0, fcinfo=0x5573fad2af60,
simple_eval_estate=0x0, simple_eval_resowner=0x0, procedure_resowner=0x0, atomic=true)
at pl_exec.c:623
#37 0x00007a25603f277f in plpgsql_call_handler (fcinfo=0x5573fad2af60) at pl_handler.c:277
#38 0x00005573f993589a in ExecMakeTableFunctionResult (setexpr=0x5573facfd8c8, econtext=0x5573facfd798,
--Type <RET> for more, q to quit, c to continue without paging--
argContext=0x5573fad2ae60, expectedDesc=0x5573facfe130, randomAccess=false) at execSRF.c:234
#39 0x00005573f995299c in FunctionNext (node=0x5573facfd588) at nodeFunctionscan.c:94
#40 0x00005573f993735f in ExecScanFetch (node=0x5573facfd588, accessMtd=0x5573f99528e6 <FunctionNext>,
recheckMtd=0x5573f9952ced <FunctionRecheck>) at execScan.c:131
#41 0x00005573f99373d8 in ExecScan (node=0x5573facfd588, accessMtd=0x5573f99528e6 <FunctionNext>,
recheckMtd=0x5573f9952ced <FunctionRecheck>) at execScan.c:180
#42 0x00005573f9952d46 in ExecFunctionScan (pstate=0x5573facfd588) at nodeFunctionscan.c:269
#43 0x00005573f9932c7f in ExecProcNodeFirst (node=0x5573facfd588) at execProcnode.c:464
#44 0x00005573f9925df5 in ExecProcNode (node=0x5573facfd588)
at ../../../src/include/executor/executor.h:274
#45 0x00005573f9928bf9 in ExecutePlan (estate=0x5573facfd360, planstate=0x5573facfd588,
use_parallel_mode=false, operation=CMD_SELECT, sendTuples=true, numberTuples=0,
direction=ForwardScanDirection, dest=0x5573fad8f6e0, execute_once=true) at execMain.c:1646
#46 0x00005573f992653d in standard_ExecutorRun (queryDesc=0x5573fad87f70,
direction=ForwardScanDirection, count=0, execute_once=true) at execMain.c:363
#47 0x00005573f9926316 in ExecutorRun (queryDesc=0x5573fad87f70, direction=ForwardScanDirection,
count=0, execute_once=true) at execMain.c:304
#48 0x00005573f9bfcb7d in PortalRunSelect (portal=0x5573fac6bbe0, forward=true, count=0,
dest=0x5573fad8f6e0) at pquery.c:924
#49 0x00005573f9bfc7a5 in PortalRun (portal=0x5573fac6bbe0, count=9223372036854775807, isTopLevel=true,
run_once=true, dest=0x5573fad8f6e0, altdest=0x5573fad8f6e0, qc=0x7ffe2e440a60) at pquery.c:768
#50 0x00005573f9bf5512 in exec_simple_query (
--Type <RET> for more, q to quit, c to continue without paging--
query_string=0x5573fabea030 "SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE ((a * 2) = 2 OR (a * 2) = 102) AND upper(b) = ''1''');") at postgres.c:1274
#51 0x00005573f9bfa5b7 in PostgresMain (dbname=0x5573fab52240 "regression",
username=0x5573fac27c98 "alena") at postgres.c:4680
#52 0x00005573f9bf137e in BackendMain (startup_data=0x7ffe2e440ce4 "", startup_data_len=4)
at backend_startup.c:105
#53 0x00005573f9b06852 in postmaster_child_launch (child_type=B_BACKEND, startup_data=0x7ffe2e440ce4 "",
startup_data_len=4, client_sock=0x7ffe2e440d30) at launch_backend.c:265
#54 0x00005573f9b0cd66 in BackendStartup (client_sock=0x7ffe2e440d30) at postmaster.c:3593
#55 0x00005573f9b09db1 in ServerLoop () at postmaster.c:1674
#56 0x00005573f9b09678 in PostmasterMain (argc=8, argv=0x5573fab500d0) at postmaster.c:1372
#57 0x00005573f99b5f79 in main (argc=8, argv=0x5573fab500d0) at main.c:197
Secondly, I saw diff changes in queries that showed cases where the optimizer did not eliminate one of the redundant expressions and processed both of them. This indicates the problem that the optimizer has not learned how to handle it in all cases. I think I'll need to add some code to handle it. EXPLAIN (COSTS OFF)
SELECT count(*) FROM tenk1
WHERE hundred = 42 AND (thousand = 42 OR thousand = 99 OR tenthous < 2) OR thousand = 41;
- QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
+ QUERY PLAN
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate
-> Bitmap Heap Scan on tenk1
- Recheck Cond: (((hundred = 42) AND ((thousand = ANY ('{42,99}'::integer[])) OR (tenthous < 2))) OR (thousand = 41))
+ Recheck Cond: (((((thousand = 42) AND (thousand = ANY ('{42,99}'::integer[]))) OR ((thousand = 99) AND (thousand = ANY ('{42,99}'::integer[])))) OR (tenthous < 2)) OR (thousand = 41))
+ Filter: (((hundred = 42) AND ((((thousand = 42) OR (thousand = 99)) AND (thousand = ANY ('{42,99}'::integer[]))) OR (tenthous < 2))) OR (thousand = 41))
-> BitmapOr
- -> BitmapAnd
- -> Bitmap Index Scan on tenk1_hundred
- Index Cond: (hundred = 42)
+ -> BitmapOr
-> BitmapOr
-> Bitmap Index Scan on tenk1_thous_tenthous
- Index Cond: (thousand = ANY ('{42,99}'::integer[]))
+ Index Cond: ((thousand = 42) AND (thousand = ANY ('{42,99}'::integer[])))
-> Bitmap Index Scan on tenk1_thous_tenthous
- Index Cond: (tenthous < 2)
+ Index Cond: ((thousand = 99) AND (thousand = ANY ('{42,99}'::integer[])))
+ -> Bitmap Index Scan on tenk1_thous_tenthous
+ Index Cond: (tenthous < 2)
-> Bitmap Index Scan on tenk1_thous_tenthous
Index Cond: (thousand = 41)
-(14 rows)
+(15 rows)
SELECT count(*) FROM tenk1
WHERE hundred = 42 AND (thousand = 42 OR thousand = 99 OR tenthous < 2) OR thousand = 41;
@@ -1986,20 +1987,21 @@
EXPLAIN (COSTS OFF)
SELECT count(*) FROM tenk1
WHERE hundred = 42 AND (thousand = 42 OR thousand = 41 OR thousand = 99 AND tenthous = 2);
- QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------
+ QUERY PLAN
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate
-> Bitmap Heap Scan on tenk1
- Recheck Cond: ((hundred = 42) AND ((thousand = ANY ('{41,42}'::integer[])) OR ((thousand = 99) AND (tenthous = 2))))
- -> BitmapAnd
- -> Bitmap Index Scan on tenk1_hundred
- Index Cond: (hundred = 42)
+ Recheck Cond: ((((thousand = 42) AND (thousand = ANY ('{41,42}'::integer[]))) OR ((thousand = 41) AND (thousand = ANY ('{41,42}'::integer[])))) OR ((thousand = 99) AND (tenthous = 2)))
+ Filter: (hundred = 42)
+ -> BitmapOr
-> BitmapOr
-> Bitmap Index Scan on tenk1_thous_tenthous
- Index Cond: (thousand = ANY ('{41,42}'::integer[]))
+ Index Cond: ((thousand = 42) AND (thousand = ANY ('{41,42}'::integer[])))
-> Bitmap Index Scan on tenk1_thous_tenthous
- Index Cond: ((thousand = 99) AND (tenthous = 2))
-(11 rows)
+ Index Cond: ((thousand = 41) AND (thousand = ANY ('{41,42}'::integer[])))
+ -> Bitmap Index Scan on tenk1_thous_tenthous
+ Index Cond: ((thousand = 99) AND (tenthous = 2))
+(12 rows)
SELECT count(*) FROM tenk1
WHERE hundred = 42 AND (thousand = 42 OR thousand = 41 OR thousand = 99 AND tenthous = 2);
diff -U3 /home/alena/postgrespro5/src/test/regress/expected/inherit.out /home/alena/postgrespro5/src/test/regress/results/inherit.out
--- /home/alena/postgrespro5/src/test/regress/expected/inherit.out 2024-06-20 12:28:52.324011724 +0300
+++ /home/alena/postgrespro5/src/test/regress/results/inherit.out 2024-07-11 02:00:55.404006843 +0300
@@ -2126,7 +2126,7 @@
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on part_ab_cd list_parted
- Filter: (((a)::text = 'ab'::text) OR ((a)::text = ANY ('{NULL,cd}'::text[])))
+ Filter: (((a)::text = ANY ('{NULL,cd}'::text[])) OR ((a)::text = 'ab'::text))
(2 rows)
explain (costs off) select * from list_parted where a = 'ab';
diff -U3 /home/alena/postgrespro5/src/test/regress/expected/join.out /home/alena/postgrespro5/src/test/regress/results/join.out
--- /home/alena/postgrespro5/src/test/regress/expected/join.out 2024-06-28 11:05:44.304135987 +0300
+++ /home/alena/postgrespro5/src/test/regress/results/join.out 2024-07-11 02:00:58.152006921 +0300
@@ -4210,10 +4210,17 @@
select * from tenk1 a join tenk1 b on
(a.unique1 = 1 and b.unique1 = 2) or
((a.unique2 = 3 or a.unique2 = 7) and b.hundred = 4);
- QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
+ QUERY PLAN
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop
- Join Filter: (((a.unique1 = 1) AND (b.unique1 = 2)) OR ((a.unique2 = ANY ('{3,7}'::integer[])) AND (b.hundred = 4)))
+ Join Filter: (((a.unique1 = 1) AND (b.unique1 = 2)) OR (((a.unique2 = 3) OR (a.unique2 = 7)) AND (a.unique2 = ANY ('{3,7}'::integer[])) AND (b.hundred = 4)))
+ -> Bitmap Heap Scan on tenk1 a
+ Recheck Cond: ((unique1 = 1) OR (unique2 = ANY ('{3,7}'::integer[])))
+ -> BitmapOr
+ -> Bitmap Index Scan on tenk1_unique1
+ Index Cond: (unique1 = 1)
+ -> Bitmap Index Scan on tenk1_unique2
+ Index Cond: (unique2 = ANY ('{3,7}'::integer[]))
-> Bitmap Heap Scan on tenk1 b
Recheck Cond: ((unique1 = 2) OR (hundred = 4))
-> BitmapOr
@@ -4221,25 +4228,24 @@
Index Cond: (unique1 = 2)
-> Bitmap Index Scan on tenk1_hundred
Index Cond: (hundred = 4)
- -> Materialize
- -> Bitmap Heap Scan on tenk1 a
- Recheck Cond: ((unique1 = 1) OR (unique2 = ANY ('{3,7}'::integer[])))
- -> BitmapOr
- -> Bitmap Index Scan on tenk1_unique1
- Index Cond: (unique1 = 1)
- -> Bitmap Index Scan on tenk1_unique2
- Index Cond: (unique2 = ANY ('{3,7}'::integer[]))
-(17 rows)
+(16 rows)
SET enable_or_transformation = on;
explain (costs off)
select * from tenk1 a join tenk1 b on
(a.unique1 = 1 and b.unique1 = 2) or
((a.unique2 = 3 or a.unique2 = 7) and b.hundred = 4);
- QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
+ QUERY PLAN
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop
- Join Filter: (((a.unique1 = 1) AND (b.unique1 = 2)) OR ((a.unique2 = ANY ('{3,7}'::integer[])) AND (b.hundred = 4)))
+ Join Filter: (((a.unique1 = 1) AND (b.unique1 = 2)) OR (((a.unique2 = 3) OR (a.unique2 = 7)) AND (a.unique2 = ANY ('{3,7}'::integer[])) AND (b.hundred = 4)))
+ -> Bitmap Heap Scan on tenk1 a
+ Recheck Cond: ((unique1 = 1) OR (unique2 = ANY ('{3,7}'::integer[])))
+ -> BitmapOr
+ -> Bitmap Index Scan on tenk1_unique1
+ Index Cond: (unique1 = 1)
+ -> Bitmap Index Scan on tenk1_unique2
+ Index Cond: (unique2 = ANY ('{3,7}'::integer[]))
-> Bitmap Heap Scan on tenk1 b
Recheck Cond: ((unique1 = 2) OR (hundred = 4))
-> BitmapOr
@@ -4247,37 +4253,29 @@
Index Cond: (unique1 = 2)
-> Bitmap Index Scan on tenk1_hundred
Index Cond: (hundred = 4)
- -> Materialize
- -> Bitmap Heap Scan on tenk1 a
- Recheck Cond: ((unique1 = 1) OR (unique2 = ANY ('{3,7}'::integer[])))
- -> BitmapOr
- -> Bitmap Index Scan on tenk1_unique1
- Index Cond: (unique1 = 1)
- -> Bitmap Index Scan on tenk1_unique2
- Index Cond: (unique2 = ANY ('{3,7}'::integer[]))
-(17 rows)
+(16 rows)
explain (costs off)
select * from tenk1 a join tenk1 b on
(a.unique1 < 20 or a.unique1 = 3 or a.unique1 = 1 and b.unique1 = 2) or
((a.unique2 = 3 or a.unique2 = 7) and b.hundred = 4);
- QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------
+ QUERY PLAN
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop
- Join Filter: ((a.unique1 < 20) OR (a.unique1 = 3) OR ((a.unique1 = 1) AND (b.unique1 = 2)) OR ((a.unique2 = ANY ('{3,7}'::integer[])) AND (b.hundred = 4)))
+ Join Filter: (((a.unique1 = 1) AND (b.unique1 = 2)) OR (((a.unique2 = 3) OR (a.unique2 = 7)) AND (a.unique2 = ANY ('{3,7}'::integer[])) AND (b.hundred = 4)) OR (a.unique1 < 20) OR (a.unique1 = 3))
-> Seq Scan on tenk1 b
-> Materialize
-> Bitmap Heap Scan on tenk1 a
- Recheck Cond: ((unique1 < 20) OR (unique1 = 3) OR (unique1 = 1) OR (unique2 = ANY ('{3,7}'::integer[])))
+ Recheck Cond: ((unique1 = 1) OR (unique2 = ANY ('{3,7}'::integer[])) OR (unique1 < 20) OR (unique1 = 3))
-> BitmapOr
-> Bitmap Index Scan on tenk1_unique1
- Index Cond: (unique1 < 20)
- -> Bitmap Index Scan on tenk1_unique1
- Index Cond: (unique1 = 3)
- -> Bitmap Index Scan on tenk1_unique1
Index Cond: (unique1 = 1)
-> Bitmap Index Scan on tenk1_unique2
Index Cond: (unique2 = ANY ('{3,7}'::integer[]))
+ -> Bitmap Index Scan on tenk1_unique1
+ Index Cond: (unique1 < 20)
+ -> Bitmap Index Scan on tenk1_unique1
+ Index Cond: (unique1 = 3)
(15 rows)
Thirdly, I have evidence that this may affect the underestimation of power. I'll look into this in detail later.
diff -U3 /home/alena/postgrespro5/src/test/regress/expected/stats_ext.out /home/alena/postgrespro5/src/test/regress/results/stats_ext.out
--- /home/alena/postgrespro5/src/test/regress/expected/stats_ext.out 2024-06-28 11:05:44.304135987 +0300
+++ /home/alena/postgrespro5/src/test/regress/results/stats_ext.out 2024-07-11 02:01:06.596007159 +0300
@@ -1156,19 +1156,19 @@
SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE (a = 1 OR a = 51) AND b = ''1''');
estimated | actual
-----------+--------
- 2 | 100
+ 1 | 100
(1 row)
SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE (a = 1 OR a = 51) AND (b = ''1'' OR b = ''2'')');
estimated | actual
-----------+--------
- 4 | 100
+ 1 | 100
(1 row)
SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE (a = 1 OR a = 2 OR a = 51 OR a = 52) AND (b = ''1'' OR b = ''2'')');
estimated | actual
-----------+--------
- 8 | 200
+ 1 | 200
(1 row)
-- OR clauses referencing different attributes
@@ -1322,19 +1322,19 @@
SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE (a = 1 OR a = 51) AND b = ''1''');
estimated | actual
-----------+--------
- 100 | 100
+ 2 | 100
(1 row)
SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE (a = 1 OR a = 51) AND (b = ''1'' OR b = ''2'')');
estimated | actual
-----------+--------
- 100 | 100
+ 2 | 100
(1 row)
SELECT * FROM check_estimated_rows('SELECT * FROM functional_dependencies WHERE (a = 1 OR a = 2 OR a = 51 OR a = 52) AND (b = ''1'' OR b = ''2'')');
estimated | actual
-----------+--------
- 200 | 200
+ 8 | 200
(1 row)
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
Hi, again!
I have finished patch and processed almost your suggestions (from [0], [1], [2]). It remains only to add tests where the conversion should work, but I will add this in the next version.
[0] https://www.postgresql.org/message-id/3381819.e9J7NaK4W3%40thinkpad-pgpro
[1] https://www.postgresql.org/message-id/9736220.CDJkKcVGEf%40thinkpad-pgpro
[2] https://www.postgresql.org/message-id/2193851.QkHrqEjB74%40thinkpad-pgpro
The error was caused by the specifics of storing the "OR" clauses in the RestrictInfo structure. Scanning the orclauses list of the RestrictInfo variable, we could face not only the item with RestrictInfo type, but also the BoolExpr type.Hi! Thank you for your review! Sorry for the delay in responding.
I rewrote the patch as you requested, but now I'm faced with the problem of processing the elements of the or_entries list. For some reason, the pointer to the list is cleared and I couldn't find the place where it happened. Maybe I'm missing something simple in view of the heavy workload right now, but maybe you'll see a problem? I have displayed part of stack below.
#5 0x00005b0f6d9f6a6a in ExceptionalCondition (conditionName=0x5b0f6dbb74f7 "IsPointerList(list)", fileName=0x5b0f6dbb7418 "list.c", lineNumber=341) at assert.c:66 #6 0x00005b0f6d5dc3ba in lappend (list=0x5b0f6eec5ca0, datum=0x5b0f6eec0d90) at list.c:341 #7 0x00005b0f6d69230c in transform_or_to_any (root=0x5b0f6eeb13c8, orlist=0x5b0f6eec57c0) at initsplan.c:2818 #8 0x00005b0f6d692958 in add_base_clause_to_rel (root=0x5b0f6eeb13c8, relid=1, restrictinfo=0x5b0f6eec5990) at initsplan.c:2982 #9 0x00005b0f6d692e5f in distribute_restrictinfo_to_rels (root=0x5b0f6eeb13c8, restrictinfo=0x5b0f6eec5990) at initsplan.c:3175 #10 0x00005b0f6d691bf2 in distribute_qual_to_rels (root=0x5b0f6eeb13c8, clause=0x5b0f6eec0fc0, jtitem=0x5b0f6eec4330, sjinfo=0x0, security_level=0, qualscope=0x5b0f6eec4730, ojscope=0x0, outerjoin_nonnullable=0x0, incompatible_relids=0x0, allow_equivalence=true, has_clone=false, is_clone=false, postponed_oj_qual_list=0x0) at initsplan.c:2576 #11 0x00005b0f6d69146f in distribute_quals_to_rels (root=0x5b0f6eeb13c8, clauses=0x5b0f6eec0bb0, jtitem=0x5b0f6eec4330, sjinfo=0x0, security_level=0, qualscope=0x5b0f6eec4730, ojscope=0x0, outerjoin_nonnullable=0x0, incompatible_relids=0x0, allow_equivalence=true, has_clone=false, is_clone=false, postponed_oj_qual_list=0x0) at initsplan.c:2144
This is still the first iteration of the fixes you have proposed, so I have attached the patch in diff format. I rewrote it, as you suggested in the first letter [0]. I created a separate function that tries to form an OrClauseGroup node, but if it fails in this, it returns false, otherwise it processes the generated element according to what it found - either adds it to the list as new, or adds a constant to an existing one.
I also divided one general list of suitable for conversion and unsuitable into two different ones: appropriate_entries and or_entries. Now we are only looking in the list of suitable elements to form ANY expr.
This helps us to get rid of repetitions in the code you mentioned. Please write if this is not the logic that you have seen before.
[0] https://www.postgresql.org/message-id/3381819.e9J7NaK4W3%40thinkpad-pgpro
For example, when we have both or clauses and "AND" clauses together, like x = 1 and (y =1 or y=2 or y=3 and z = 1). The structure looks like:
RestrictInfo->orclauses = [RestrictInfo [x=1],
RestrictInfo->orclauses = [RestrictInfo[y=1],
RestrictInfo [y=2],
BoolExpr = [Restrictinfo [y=3], RestrictInfo [z=1]
]
]
It's working fine now.
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
The error was caused by the specifics of storing the "OR" clauses in the RestrictInfo structure. Scanning the orclauses list of the RestrictInfo variable, we could face not only the item with RestrictInfo type, but also the BoolExpr type.For example, when we have both or clauses and "AND" clauses together, like x = 1 and (y =1 or y=2 or y=3 and z = 1). The structure looks like:
RestrictInfo->orclauses = [RestrictInfo [x=1],
RestrictInfo->orclauses = [RestrictInfo[y=1],
RestrictInfo [y=2],
BoolExpr = [Restrictinfo [y=3], RestrictInfo [z=1]
]
]It's working fine now.
The error was caused by the specifics of storing the "OR" clauses in the RestrictInfo structure. When viewing the list of or offers, we could encounter not only the RestrictInfo type, but also the BoolExpr type. It's working fine now.
For example, when we have both or clauses and "AND" clauses together, like x = 1 and (y =1 or y=2 or y=3 and z = 1). The structure looks like:
RestrictInfo->orclauses = [RestrictInfo [x=1],
RestrictInfo->orclauses = [RestrictInfo[y=1],
RestrictInfo [y=2],
BoolExpr = [Restrictinfo [y=3], RestrictInfo [z=1]
]
]
It's working fine now.
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi, Alena! On Thu, Jul 11, 2024 at 7:17 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > I have finished patch and processed almost your suggestions (from [0], [1], [2]). It remains only to add tests where theconversion should work, but I will add this in the next version. > > [0] https://www.postgresql.org/message-id/3381819.e9J7NaK4W3%40thinkpad-pgpro > > [1] https://www.postgresql.org/message-id/9736220.CDJkKcVGEf%40thinkpad-pgpro > > [2] https://www.postgresql.org/message-id/2193851.QkHrqEjB74%40thinkpad-pgpro I dare making another revision of this patch. In this version I moved the transformation to match_clause_to_indexcol(). Therefore, this allows to successfully construct index scans with SAOP, but has no degradation in generation of bitmap scans which I observed in [1] and [2]. BTW, I found that my description in [2] lacks of t_b_c_idx index definition. Sorry for that. Given that now we're doing OR-to-ANY transformation solely to match an index we don't need complex analysis of OR-list, which potentially could take quadratic time. Instead, we're trying to match every OR element to an index and quit immediately on failure. I'd like to head a feedback on the new place to apply the transformation. It looks like significant simplification for me and the way to go. Also, I have addressed some of notes by Robert Haas [3]. In v27 we don't use expression evaluation, but directly construct an array constant when possible. Also we don't transform operator id to string and back, but directly construct SAOP instead. Links. 1. https://www.postgresql.org/message-id/CAPpHfduJtO0s9E%3DSHUTzrCD88BH0eik0UNog1_q3XBF2wLmH6g%40mail.gmail.com 2. https://www.postgresql.org/message-id/CAPpHfdtSXxhdv3mLOLjEewGeXJ%2BFtfhjqodn1WWuq5JLsKx48g%40mail.gmail.com 3. https://www.postgresql.org/message-id/CA%2BTgmobu0DUFCTF28DuAi975mEc4xYqX3xyt8RA0WbnyrYg%2BFw%40mail.gmail.com ------ Regards, Alexander Korotkov Supabase
Attachment
Hi! Thanks for your contribution to this topic! On 17.07.2024 03:03, Alexander Korotkov wrote: > Hi, Alena! > > On Thu, Jul 11, 2024 at 7:17 PM Alena Rybakina > <a.rybakina@postgrespro.ru> wrote: >> I have finished patch and processed almost your suggestions (from [0], [1], [2]). It remains only to add tests where theconversion should work, but I will add this in the next version. >> >> [0] https://www.postgresql.org/message-id/3381819.e9J7NaK4W3%40thinkpad-pgpro >> >> [1] https://www.postgresql.org/message-id/9736220.CDJkKcVGEf%40thinkpad-pgpro >> >> [2] https://www.postgresql.org/message-id/2193851.QkHrqEjB74%40thinkpad-pgpro > I dare making another revision of this patch. In this version I moved > the transformation to match_clause_to_indexcol(). Therefore, this > allows to successfully construct index scans with SAOP, but has no > degradation in generation of bitmap scans which I observed in [1] and > [2]. BTW, I found that my description in [2] lacks of t_b_c_idx index > definition. Sorry for that. > > Given that now we're doing OR-to-ANY transformation solely to match an > index we don't need complex analysis of OR-list, which potentially > could take quadratic time. Instead, we're trying to match every OR > element to an index and quit immediately on failure. Yes I see that. I will look at this in detail, but so far I have not found any unpleasant side effects indicating that the patch should be moved to another place and this is very good) The only thing that worries me so far is that most likely we will need to analyze the changes in rinfo and distribute them to others places where links about them are used. But I need to look at this in more detail separately before discussing it. Yes, I am ready to agree that there was no degradation in tests [1] and [2]. But just in case, I will do a review to rule out any other problems. > I'd like to head a feedback on the new place to apply the > transformation. It looks like significant simplification for me and > the way to go. > > Also, I have addressed some of notes by Robert Haas [3]. In v27 we > don't use expression evaluation, but directly construct an array > constant when possible. Also we don't transform operator id to string > and back, but directly construct SAOP instead. > > Links. > 1. https://www.postgresql.org/message-id/CAPpHfduJtO0s9E%3DSHUTzrCD88BH0eik0UNog1_q3XBF2wLmH6g%40mail.gmail.com > 2. https://www.postgresql.org/message-id/CAPpHfdtSXxhdv3mLOLjEewGeXJ%2BFtfhjqodn1WWuq5JLsKx48g%40mail.gmail.com > 3. https://www.postgresql.org/message-id/CA%2BTgmobu0DUFCTF28DuAi975mEc4xYqX3xyt8RA0WbnyrYg%2BFw%40mail.gmail.com Thanks for your effort and any help is welcome) Yesterday I finished a big project in my work and now I'm ready to continue working on this thread. I'll write the results one of these days. -- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 17.07.2024 03:03, Alexander Korotkov wrote:
> Hi, Alena!
>
> On Thu, Jul 11, 2024 at 7:17 PM Alena Rybakina
> <a.rybakina@postgrespro.ru> wrote:
>> I have finished patch and processed almost your suggestions (from [0], [1], [2]). It remains only to add tests where the conversion should work, but I will add this in the next version.
>>
>> [0] https://www.postgresql.org/message-id/3381819.e9J7NaK4W3%40thinkpad-pgpro
>>
>> [1] https://www.postgresql.org/message-id/9736220.CDJkKcVGEf%40thinkpad-pgpro
>>
>> [2] https://www.postgresql.org/message-id/2193851.QkHrqEjB74%40thinkpad-pgpro
> I dare making another revision of this patch. In this version I moved
> the transformation to match_clause_to_indexcol(). Therefore, this
> allows to successfully construct index scans with SAOP, but has no
> degradation in generation of bitmap scans which I observed in [1] and
> [2]. BTW, I found that my description in [2] lacks of t_b_c_idx index
> definition. Sorry for that.
>
> Given that now we're doing OR-to-ANY transformation solely to match an
> index we don't need complex analysis of OR-list, which potentially
> could take quadratic time. Instead, we're trying to match every OR
> element to an index and quit immediately on failure.
Yes I see that. I will look at this in detail, but so far I have not
found any unpleasant side effects indicating that the patch should be
moved to another place and this is very good)
The only thing that worries me so far is that most likely we will need
to analyze the changes in rinfo and distribute them to others places
where links about them are used.
But I need to look at this in more detail separately before discussing it.
Bitmap Heap Scan on t (cost=19.70..26.93 rows=5001 width=12)
Recheck Cond: (((b = 1) AND (b = ANY ('{1,2}'::integer[])) AND (c = 2)) OR ((a = 1) AND (b = 2) AND (b = ANY ('{1,2}'::integer[]))))
Filter: ((a = 1) AND (c = 2))
-> BitmapOr (cost=19.70..19.70 rows=2 width=0)
-> Bitmap Index Scan on t_b_c_idx (cost=0.00..8.60 rows=1 width=0)
Index Cond: ((b = 1) AND (b = ANY ('{1,2}'::integer[])) AND (c = 2))
-> Bitmap Index Scan on t_a_b_idx (cost=0.00..8.60 rows=1 width=0)
Index Cond: ((a = 1) AND (b = 2) AND (b = ANY ('{1,2}'::integer[])))
(8 rows)
Yes, I am ready to agree that there was no degradation in tests [1] and
[2]. But just in case, I will do a review to rule out any other problems.
> I'd like to head a feedback on the new place to apply the
> transformation. It looks like significant simplification for me and
> the way to go.
>
> Also, I have addressed some of notes by Robert Haas [3]. In v27 we
> don't use expression evaluation, but directly construct an array
> constant when possible. Also we don't transform operator id to string
> and back, but directly construct SAOP instead.
>
> Links.
> 1. https://www.postgresql.org/message-id/CAPpHfduJtO0s9E%3DSHUTzrCD88BH0eik0UNog1_q3XBF2wLmH6g%40mail.gmail.com
> 2. https://www.postgresql.org/message-id/CAPpHfdtSXxhdv3mLOLjEewGeXJ%2BFtfhjqodn1WWuq5JLsKx48g%40mail.gmail.com
> 3. https://www.postgresql.org/message-id/CA%2BTgmobu0DUFCTF28DuAi975mEc4xYqX3xyt8RA0WbnyrYg%2BFw%40mail.gmail.com
Thanks for your effort and any help is welcome)
Yesterday I finished a big project in my work and now I'm ready to
continue working on this thread. I'll write the results one of these days.
Regards,
Alexander Korotkov
В письме от среда, 17 июля 2024 г. 22:36:19 MSK пользователь Alexander
Korotkov написал:
Hi All!
I am continue reading the patch, now it's newer version
First main question:
As far a I can get, the entry point for OR->ANY convertation have been moved
to match_clause_to_indexcol funtion, that checks if some restriction can use
index for performance.
The thing I do not understand what match_clause_to_indexcol actually received
as arguments. Should this be set of expressions with OR in between grouped by
one of the expression argument?
If not I do not understand how this ever should work.
The rest is about code readability
> + if (bms_is_member(index->rel->relid, rinfo->right_relids))
> + return NULL;
This check it totally not obvious for person who is not deep into postgres
code. There should go comment explaining what are we checking for, and why it
does not suit our purposes
> + foreach(lc, orclause->args)
> + {
Being no great expert in postgres code, I am confused what are we iterating on
here? Two arguments of OR statement? (a>1) OR (b>2) those in brackets? Or
what? Comment explaining that would be a great help here.
> +if (sub_rinfo->is_pushed_down != rinfo->is_pushed_down ||
> + sub_rinfo->is_clone != rinfo->is_clone ||
> + sub_rinfo->security_level != rinfo->security_level ||
> + !bms_equal(sub_rinfo->required_relids, rinfo->required_relids) ||
> + !bms_equal(sub_rinfo->incompatible_relids, rinfo-
incompatible_relids) ||
> + !bms_equal(sub_rinfo->outer_relids, rinfo->outer_relids))
> + {
This check it totally mind-blowing... What in the name of existence is going
on here?
I would suggest to split these checks into parts (compiler optimizer should
take care about overhead) and give each part a sane explanation.
--
Nikolay Shaplov aka Nataraj
Fuzzing Engineer at Postgres Professional
Matrix IM: @dhyan:nataraj.su
Attachment
Hi! Thank you for your contribution to this thread!
To be honest,I saw a larger problem. Look at the query bellow:
master:
alena@postgres=# create table t (a int not null, b int not null, c int not null);
insert into t (select 1, 1, i from generate_series(1,10000) i);
insert into t (select i, 2, 2 from generate_series(1,10000) i);
create index t_a_b_idx on t (a, b);
create statistics t_a_b_stat (mcv) on a, b from t;
create statistics t_b_c_stat (mcv) on b, c from t;
vacuum analyze t;
CREATE TABLE
INSERT 0 10000
INSERT 0 10000
CREATE INDEX
CREATE STATISTICS
CREATE STATISTICS
VACUUM
alena@postgres=# explain select * from t where a = 1 and (b = 1 or b = 2) and c = 2;
QUERY PLAN
------------------------------------------------------------------------------
Bitmap Heap Scan on t (cost=156.55..465.57 rows=5001 width=12)
Recheck Cond: (a = 1)
Filter: ((c = 2) AND ((b = 1) OR (b = 2)))
-> Bitmap Index Scan on t_a_b_idx (cost=0.00..155.29 rows=10001 width=0)
Index Cond: (a = 1)
(5 rows)
The query plan if v26[0] and v27[1] versions are equal and wrong in my opinion -where is c=2 expression?
v27 [1]
alena@postgres=# explain select * from t where a = 1 and (b = 1 or b = 2) and c = 2;
QUERY PLAN
------------------------------------------------------------------------------
Bitmap Heap Scan on t (cost=165.85..474.87 rows=5001 width=12)
Recheck Cond: ((a = 1) AND (b = ANY ('{1,2}'::integer[])))
Filter: (c = 2)
-> Bitmap Index Scan on t_a_b_idx (cost=0.00..164.59 rows=10001 width=0)
Index Cond: ((a = 1) AND (b = ANY ('{1,2}'::integer[])))
(5 rows)
v26 [0]
alena@postgres=# explain select * from t where a = 1 and (b = 1 or b = 2) and c = 2;
QUERY PLAN
------------------------------------------------------------------------------
Bitmap Heap Scan on t (cost=165.85..449.86 rows=5001 width=12)
Recheck Cond: ((a = 1) AND (b = ANY ('{1,2}'::integer[])))
Filter: (c = 2)
-> Bitmap Index Scan on t_a_b_idx (cost=0.00..164.59 rows=10001 width=0)
Index Cond: ((a = 1) AND (b = ANY ('{1,2}'::integer[])))
(5 rows)
In addition, I noticed that the ANY expression will be formed only for first group and ignore for others, like in the sample bellow:
v26 version [0]:
alena@postgres=# explain select * from t where (b = 1 or b = 2) and (a = 2 or a=3);
QUERY PLAN
-----------------------------------------------------------------------------------
Index Scan using t_a_b_idx on t (cost=0.29..24.75 rows=2 width=12)
Index Cond: ((a = ANY ('{2,3}'::integer[])) AND (b = ANY ('{1,2}'::integer[])))
(2 rows)
v27 version [1]:
alena@postgres=# explain select * from t where (b = 1 or b = 2 or a = 2 or a=3);
QUERY PLAN
--------------------------------------------------------
Seq Scan on t (cost=0.00..509.00 rows=14999 width=12)
Filter: ((b = 1) OR (b = 2) OR (a = 2) OR (a = 3))
(2 rows)
alena@postgres=# create index a_idx on t(a);
CREATE INDEX
alena@postgres=# create index b_idx on t(b);
CREATE INDEX
alena@postgres=# analyze;
ANALYZE
v26:
alena@postgres=# explain select * from t where (b = 1 or b = 2 or a = 2 or a=3);
QUERY PLAN
------------------------------------------------------------------------------------
Bitmap Heap Scan on t (cost=17.18..30.94 rows=4 width=12)
Recheck Cond: ((a = ANY ('{2,3}'::integer[])) OR (a = ANY ('{2,3}'::integer[])))
-> BitmapOr (cost=17.18..17.18 rows=4 width=0)
-> Bitmap Index Scan on a_idx (cost=0.00..8.59 rows=2 width=0)
Index Cond: (a = ANY ('{2,3}'::integer[]))
-> Bitmap Index Scan on a_idx (cost=0.00..8.59 rows=2 width=0)
Index Cond: (a = ANY ('{2,3}'::integer[]))
(7 rows)
v27:
alena@postgres=# explain select * from t where (b = 1 or b = 2 or a = 2 or a=3);
QUERY PLAN
--------------------------------------------------------
Seq Scan on t (cost=0.00..509.00 rows=14999 width=12)
Filter: ((b = 1) OR (b = 2) OR (a = 2) OR (a = 3))
(2 rows)
The behavior in version 26 is incorrect, but in version 27, it does not select anything other than seqscan
Since Thursday I have been trying to add the code forming groups of identical "OR" expressions, as in version 26. I'm currently debugging errors.
The point is that we do the transformation for those columns that have an index, since this transformation is most useful in these cases. we pass the parameters index relation and column number to find out information about it.В письме от среда, 17 июля 2024 г. 22:36:19 MSK пользователь Alexander Korotkov написал: Hi All! I am continue reading the patch, now it's newer version First main question: As far a I can get, the entry point for OR->ANY convertation have been moved to match_clause_to_indexcol funtion, that checks if some restriction can use index for performance. The thing I do not understand what match_clause_to_indexcol actually received as arguments. Should this be set of expressions with OR in between grouped by one of the expression argument? If not I do not understand how this ever should work.
To be honest, I'm not sure that I understand your question. Could you explain me?The rest is about code readability+ if (bms_is_member(index->rel->relid, rinfo->right_relids)) + return NULL;
I'll add it, thank you.This check it totally not obvious for person who is not deep into postgres code. There should go comment explaining what are we checking for, and why it does not suit our purposes+ foreach(lc, orclause->args) + {
I'll add it.Being no great expert in postgres code, I am confused what are we iterating on here? Two arguments of OR statement? (a>1) OR (b>2) those in brackets? Or what? Comment explaining that would be a great help here.+if (sub_rinfo->is_pushed_down != rinfo->is_pushed_down || + sub_rinfo->is_clone != rinfo->is_clone || + sub_rinfo->security_level != rinfo->security_level || + !bms_equal(sub_rinfo->required_relids, rinfo->required_relids) || + !bms_equal(sub_rinfo->incompatible_relids, rinfo-incompatible_relids) ||+ !bms_equal(sub_rinfo->outer_relids, rinfo->outer_relids)) + {
This check it totally mind-blowing... What in the name of existence is going on here? I would suggest to split these checks into parts (compiler optimizer should take care about overhead) and give each part a sane explanation.
Alexander suggested moving the transformation to another place and it is correct in my opinion. All previous problems are now gone.
But he also cut the code - he made a transformation for one group of "OR" expressions. I agree, some parts don't yet
provide enough explanation of what's going on. I'm correcting this now.
Speaking of the changes according to your suggestions, I made them in version 26 [0] and just part of that code will end up in the current version of the patch to process all groups of "OR" expressions.
I'll try to do this as best I can, but it took me a while to figure out how to properly organize RestrictInfo in the index.
[0] https://www.postgresql.org/message-id/3b9bb831-da52-4779-8f3e-f8b6b83ba41f%40postgrespro.ru
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi, Alena!
Let me answer to some of your findings.
On Mon, Jul 22, 2024 at 12:53 AM Alena Rybakina
<a.rybakina@postgrespro.ru> wrote:
> To be honest,I saw a larger problem. Look at the query bellow:
>
> master:
>
> alena@postgres=# create table t (a int not null, b int not null, c int not null);
> insert into t (select 1, 1, i from generate_series(1,10000) i);
> insert into t (select i, 2, 2 from generate_series(1,10000) i);
> create index t_a_b_idx on t (a, b);
Just a side note. As I mention in [1], there is missing statement
create index t_a_b_idx on t (a, b);
to get same plan as in [2].
> create statistics t_a_b_stat (mcv) on a, b from t;
> create statistics t_b_c_stat (mcv) on b, c from t;
> vacuum analyze t;
> CREATE TABLE
> INSERT 0 10000
> INSERT 0 10000
> CREATE INDEX
> CREATE STATISTICS
> CREATE STATISTICS
> VACUUM
> alena@postgres=# explain select * from t where a = 1 and (b = 1 or b = 2) and c = 2;
> QUERY PLAN
> ------------------------------------------------------------------------------
> Bitmap Heap Scan on t (cost=156.55..465.57 rows=5001 width=12)
> Recheck Cond: (a = 1)
> Filter: ((c = 2) AND ((b = 1) OR (b = 2)))
> -> Bitmap Index Scan on t_a_b_idx (cost=0.00..155.29 rows=10001 width=0)
> Index Cond: (a = 1)
> (5 rows)
>
>
> The query plan if v26[0] and v27[1] versions are equal and wrong in my opinion -where is c=2 expression?
>
> v27 [1]
> alena@postgres=# explain select * from t where a = 1 and (b = 1 or b = 2) and c = 2;
> QUERY PLAN
> ------------------------------------------------------------------------------
> Bitmap Heap Scan on t (cost=165.85..474.87 rows=5001 width=12)
> Recheck Cond: ((a = 1) AND (b = ANY ('{1,2}'::integer[])))
> Filter: (c = 2)
> -> Bitmap Index Scan on t_a_b_idx (cost=0.00..164.59 rows=10001 width=0)
> Index Cond: ((a = 1) AND (b = ANY ('{1,2}'::integer[])))
> (5 rows)
> v26 [0]
> alena@postgres=# explain select * from t where a = 1 and (b = 1 or b = 2) and c = 2;
> QUERY PLAN
> ------------------------------------------------------------------------------
> Bitmap Heap Scan on t (cost=165.85..449.86 rows=5001 width=12)
> Recheck Cond: ((a = 1) AND (b = ANY ('{1,2}'::integer[])))
> Filter: (c = 2)
> -> Bitmap Index Scan on t_a_b_idx (cost=0.00..164.59 rows=10001 width=0)
> Index Cond: ((a = 1) AND (b = ANY ('{1,2}'::integer[])))
> (5 rows)
I think both v26 and v27 are correct here. The c = 2 condition is in
the Filter.
> In addition, I noticed that the ANY expression will be formed only for first group and ignore for others, like in the
samplebellow:
>
> v26 version [0]:
>
> alena@postgres=# explain select * from t where (b = 1 or b = 2) and (a = 2 or a=3);
> QUERY PLAN
> -----------------------------------------------------------------------------------
> Index Scan using t_a_b_idx on t (cost=0.29..24.75 rows=2 width=12)
> Index Cond: ((a = ANY ('{2,3}'::integer[])) AND (b = ANY ('{1,2}'::integer[])))
> (2 rows)
>
> v27 version [1]:
>
> alena@postgres=# explain select * from t where (b = 1 or b = 2 or a = 2 or a=3);
> QUERY PLAN
> --------------------------------------------------------
> Seq Scan on t (cost=0.00..509.00 rows=14999 width=12)
> Filter: ((b = 1) OR (b = 2) OR (a = 2) OR (a = 3))
> (2 rows)
Did you notice you're running different queries on v26 and v27 here?
If you will run ton v27 the same query you run on v26, the plan also
will be the same.
> alena@postgres=# create index a_idx on t(a);
> CREATE INDEX
> alena@postgres=# create index b_idx on t(b);
> CREATE INDEX
> alena@postgres=# analyze;
> ANALYZE
>
> v26:
>
> alena@postgres=# explain select * from t where (b = 1 or b = 2 or a = 2 or a=3);
> QUERY PLAN
> ------------------------------------------------------------------------------------
> Bitmap Heap Scan on t (cost=17.18..30.94 rows=4 width=12)
> Recheck Cond: ((a = ANY ('{2,3}'::integer[])) OR (a = ANY ('{2,3}'::integer[])))
> -> BitmapOr (cost=17.18..17.18 rows=4 width=0)
> -> Bitmap Index Scan on a_idx (cost=0.00..8.59 rows=2 width=0)
> Index Cond: (a = ANY ('{2,3}'::integer[]))
> -> Bitmap Index Scan on a_idx (cost=0.00..8.59 rows=2 width=0)
> Index Cond: (a = ANY ('{2,3}'::integer[]))
> (7 rows)
>
> v27:
>
> alena@postgres=# explain select * from t where (b = 1 or b = 2 or a = 2 or a=3);
> QUERY PLAN
> --------------------------------------------------------
> Seq Scan on t (cost=0.00..509.00 rows=14999 width=12)
> Filter: ((b = 1) OR (b = 2) OR (a = 2) OR (a = 3))
> (2 rows)
>
> The behavior in version 26 is incorrect, but in version 27, it does not select anything other than seqscan
Please, check that there is still possibility to the generate BitmapOr plan.
# explain select * from t where (b = 1 or b = 2 or a = 2 or a = 3);
QUERY PLAN
------------------------------------------------------------------------------------
Bitmap Heap Scan on t (cost=326.16..835.16 rows=14999 width=12)
Recheck Cond: ((b = 1) OR (b = 2) OR (a = 2) OR (a = 3))
-> BitmapOr (cost=326.16..326.16 rows=20000 width=0)
-> Bitmap Index Scan on t_b_c_idx (cost=0.00..151.29
rows=10000 width=0)
Index Cond: (b = 1)
-> Bitmap Index Scan on t_b_c_idx (cost=0.00..151.29
rows=10000 width=0)
Index Cond: (b = 2)
-> Bitmap Index Scan on t_a_b_idx (cost=0.00..4.29 rows=1 width=0)
Index Cond: (a = 2)
-> Bitmap Index Scan on t_a_b_idx (cost=0.00..4.29 rows=1 width=0)
Index Cond: (a = 3)
It has higher cost than SeqScan plan, but I think it would be selected
on larger tables. And yes, this is not ideal, because it fails to
generate BitmapOr over two IndexScans on SAOPs. But it's not worse
than what current master does. An optimization doesn't have to do
everything it could possible do. So, I think this could be improved
in a separate patch.
Links
1. https://www.postgresql.org/message-id/CAPpHfdvhWE5pArZhgJeLViLx3-A3rxEREZvfkTj3E%3Dh7q-Bx9w%40mail.gmail.com
2. https://www.postgresql.org/message-id/CAPpHfdtSXxhdv3mLOLjEewGeXJ%2BFtfhjqodn1WWuq5JLsKx48g%40mail.gmail.com
------
Regards,
Alexander Korotkov
Supabase
On Mon, Jul 22, 2024 at 3:52 AM Alexander Korotkov <aekorotkov@gmail.com> wrote: > Please, check that there is still possibility to the generate BitmapOr plan. > > # explain select * from t where (b = 1 or b = 2 or a = 2 or a = 3); > QUERY PLAN > ------------------------------------------------------------------------------------ > Bitmap Heap Scan on t (cost=326.16..835.16 rows=14999 width=12) > Recheck Cond: ((b = 1) OR (b = 2) OR (a = 2) OR (a = 3)) > -> BitmapOr (cost=326.16..326.16 rows=20000 width=0) > -> Bitmap Index Scan on t_b_c_idx (cost=0.00..151.29 > rows=10000 width=0) > Index Cond: (b = 1) > -> Bitmap Index Scan on t_b_c_idx (cost=0.00..151.29 > rows=10000 width=0) > Index Cond: (b = 2) > -> Bitmap Index Scan on t_a_b_idx (cost=0.00..4.29 rows=1 width=0) > Index Cond: (a = 2) > -> Bitmap Index Scan on t_a_b_idx (cost=0.00..4.29 rows=1 width=0) > Index Cond: (a = 3) Forgot to mention that I have to # set enable_seqscan = off; to get this plan. ------ Regards, Alexander Korotkov Supabase
Yes, I see it and agree with that.Hi, Alena! Let me answer to some of your findings. On Mon, Jul 22, 2024 at 12:53 AM Alena Rybakina <a.rybakina@postgrespro.ru> wrote:To be honest,I saw a larger problem. Look at the query bellow: master: alena@postgres=# create table t (a int not null, b int not null, c int not null); insert into t (select 1, 1, i from generate_series(1,10000) i); insert into t (select i, 2, 2 from generate_series(1,10000) i); create index t_a_b_idx on t (a, b);Just a side note. As I mention in [1], there is missing statement create index t_a_b_idx on t (a, b); to get same plan as in [2].create statistics t_a_b_stat (mcv) on a, b from t; create statistics t_b_c_stat (mcv) on b, c from t; vacuum analyze t; CREATE TABLE INSERT 0 10000 INSERT 0 10000 CREATE INDEX CREATE STATISTICS CREATE STATISTICS VACUUM alena@postgres=# explain select * from t where a = 1 and (b = 1 or b = 2) and c = 2; QUERY PLAN ------------------------------------------------------------------------------ Bitmap Heap Scan on t (cost=156.55..465.57 rows=5001 width=12) Recheck Cond: (a = 1) Filter: ((c = 2) AND ((b = 1) OR (b = 2))) -> Bitmap Index Scan on t_a_b_idx (cost=0.00..155.29 rows=10001 width=0) Index Cond: (a = 1) (5 rows) The query plan if v26[0] and v27[1] versions are equal and wrong in my opinion -where is c=2 expression? v27 [1] alena@postgres=# explain select * from t where a = 1 and (b = 1 or b = 2) and c = 2; QUERY PLAN ------------------------------------------------------------------------------ Bitmap Heap Scan on t (cost=165.85..474.87 rows=5001 width=12) Recheck Cond: ((a = 1) AND (b = ANY ('{1,2}'::integer[]))) Filter: (c = 2) -> Bitmap Index Scan on t_a_b_idx (cost=0.00..164.59 rows=10001 width=0) Index Cond: ((a = 1) AND (b = ANY ('{1,2}'::integer[]))) (5 rows) v26 [0] alena@postgres=# explain select * from t where a = 1 and (b = 1 or b = 2) and c = 2; QUERY PLAN ------------------------------------------------------------------------------ Bitmap Heap Scan on t (cost=165.85..449.86 rows=5001 width=12) Recheck Cond: ((a = 1) AND (b = ANY ('{1,2}'::integer[]))) Filter: (c = 2) -> Bitmap Index Scan on t_a_b_idx (cost=0.00..164.59 rows=10001 width=0) Index Cond: ((a = 1) AND (b = ANY ('{1,2}'::integer[]))) (5 rows)I think both v26 and v27 are correct here. The c = 2 condition is in the Filter.
It is fine, I think. The transformation works, but due to the fact that index columns are different for two indexes, the transformation hasn't been applied.In addition, I noticed that the ANY expression will be formed only for first group and ignore for others, like in the sample bellow: v26 version [0]: alena@postgres=# explain select * from t where (b = 1 or b = 2) and (a = 2 or a=3); QUERY PLAN ----------------------------------------------------------------------------------- Index Scan using t_a_b_idx on t (cost=0.29..24.75 rows=2 width=12) Index Cond: ((a = ANY ('{2,3}'::integer[])) AND (b = ANY ('{1,2}'::integer[]))) (2 rows) v27 version [1]: alena@postgres=# explain select * from t where (b = 1 or b = 2 or a = 2 or a=3); QUERY PLAN -------------------------------------------------------- Seq Scan on t (cost=0.00..509.00 rows=14999 width=12) Filter: ((b = 1) OR (b = 2) OR (a = 2) OR (a = 3)) (2 rows)Did you notice you're running different queries on v26 and v27 here? If you will run ton v27 the same query you run on v26, the plan also will be the same.alena@postgres=# create index a_idx on t(a); CREATE INDEX alena@postgres=# create index b_idx on t(b); CREATE INDEX alena@postgres=# analyze; ANALYZE v26: alena@postgres=# explain select * from t where (b = 1 or b = 2 or a = 2 or a=3); QUERY PLAN ------------------------------------------------------------------------------------ Bitmap Heap Scan on t (cost=17.18..30.94 rows=4 width=12) Recheck Cond: ((a = ANY ('{2,3}'::integer[])) OR (a = ANY ('{2,3}'::integer[]))) -> BitmapOr (cost=17.18..17.18 rows=4 width=0) -> Bitmap Index Scan on a_idx (cost=0.00..8.59 rows=2 width=0) Index Cond: (a = ANY ('{2,3}'::integer[])) -> Bitmap Index Scan on a_idx (cost=0.00..8.59 rows=2 width=0) Index Cond: (a = ANY ('{2,3}'::integer[])) (7 rows) v27: alena@postgres=# explain select * from t where (b = 1 or b = 2 or a = 2 or a=3); QUERY PLAN -------------------------------------------------------- Seq Scan on t (cost=0.00..509.00 rows=14999 width=12) Filter: ((b = 1) OR (b = 2) OR (a = 2) OR (a = 3)) (2 rows) The behavior in version 26 is incorrect, but in version 27, it does not select anything other than seqscanPlease, check that there is still possibility to the generate BitmapOr plan.
# explain select * from t where (b = 1 or b = 2 or a = 2 or a = 3); QUERY PLAN ------------------------------------------------------------------------------------ Bitmap Heap Scan on t (cost=326.16..835.16 rows=14999 width=12) Recheck Cond: ((b = 1) OR (b = 2) OR (a = 2) OR (a = 3)) -> BitmapOr (cost=326.16..326.16 rows=20000 width=0) -> Bitmap Index Scan on t_b_c_idx (cost=0.00..151.29 rows=10000 width=0) Index Cond: (b = 1) -> Bitmap Index Scan on t_b_c_idx (cost=0.00..151.29 rows=10000 width=0) Index Cond: (b = 2) -> Bitmap Index Scan on t_a_b_idx (cost=0.00..4.29 rows=1 width=0) Index Cond: (a = 2) -> Bitmap Index Scan on t_a_b_idx (cost=0.00..4.29 rows=1 width=0) Index Cond: (a = 3) It has higher cost than SeqScan plan, but I think it would be selected on larger tables. And yes, this is not ideal, because it fails to generate BitmapOr over two IndexScans on SAOPs. But it's not worse than what current master does. An optimization doesn't have to do everything it could possible do. So, I think this could be improved in a separate patch. Links 1. https://www.postgresql.org/message-id/CAPpHfdvhWE5pArZhgJeLViLx3-A3rxEREZvfkTj3E%3Dh7q-Bx9w%40mail.gmail.com 2. https://www.postgresql.org/message-id/CAPpHfdtSXxhdv3mLOLjEewGeXJ%2BFtfhjqodn1WWuq5JLsKx48g%40mail.gmail.com
Yes, I see and agree with you.
To be honest, I have found a big problem in this patch - we try to perform the transformation every time we examime a column:
for (indexcol = 0; indexcol < index->nkeycolumns; indexcol++) { ...
}
I have fixed it and moved the transformation before going through the loop.
I try to make an array expression for "OR" expr, but at the same time I form the result as an "AND" expression, consisting of an "Array" expression and "OR" expressions, and then I check whether there is an index for this column, if so, I save it and write down the transformation. I also had to return the previous part of the patch, where we formed "ANY" groups, since we could end up with several such groups. I hope I made my idea clear, but if not, please tell me.
Unfortunately, I have got the different result one of the query from regression tests and I'm not sure if it is correct:
diff -U3 /home/alena/postgrespro_or3/src/test/regress/expected/create_index.out /home/alena/postgrespro_or3/src/test/regress/results/create_index.out --- /home/alena/postgrespro_or3/src/test/regress/expected/create_index.out 2024-07-23 18:51:13.077311360 +0300 +++ /home/alena/postgrespro_or3/src/test/regress/results/create_index.out 2024-07-25 16:43:56.895132328 +0300 @@ -1860,13 +1860,14 @@ EXPLAIN (COSTS OFF) SELECT * FROM tenk1 WHERE thousand = 42 AND (tenthous = 1 OR tenthous = (SELECT 1 + 2) OR tenthous = 42); - QUERY PLAN ----------------------------------------------------------------------------------------- + QUERY PLAN +--------------------------------------------------------------------------------- Index Scan using tenk1_thous_tenthous on tenk1 - Index Cond: ((thousand = 42) AND (tenthous = ANY (ARRAY[1, (InitPlan 1).col1, 42]))) + Index Cond: ((thousand = 42) AND (tenthous = ANY ('{1,-1,42}'::integer[]))) + Filter: ((tenthous = 1) OR (tenthous = (InitPlan 1).col1) OR (tenthous = 42)) InitPlan 1 -> Result -(4 rows) +(5 rows) SELECT * FROM tenk1 WHERE thousand = 42 AND (tenthous = 1 OR tenthous = (SELECT 1 + 2) OR tenthous = 42);
I'm researching what's wrong here now.
-- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On Thu, Jul 25, 2024 at 5:04 PM Alena Rybakina
<a.rybakina@postgrespro.ru> wrote:
> To be honest, I have found a big problem in this patch - we try to perform the transformation every time we examime a
column:
>
> for (indexcol = 0; indexcol < index->nkeycolumns; indexcol++) { ...
>
> }
>
> I have fixed it and moved the transformation before going through the loop.
What makes you think there is a problem? Do you have a test case
illustrating a slow planning time?
When v27 performs transformation for a particular column, it just
stops facing the first unmatched OR entry. So,
match_orclause_to_indexcol() examines just the first OR entry for all
the columns excepts at most one. So, the check
match_orclause_to_indexcol() does is not much slower than other
match_*_to_indexcol() do.
I actually think this could help performance in many cases, not hurt
it. At least we get rid of O(n^2) complexity over the number of OR
entries, which could be very many.
------
Regards,
Alexander Korotkov
Supabase
On 27.07.2024 13:56, Alexander Korotkov wrote:
> On Thu, Jul 25, 2024 at 5:04 PM Alena Rybakina
> <a.rybakina@postgrespro.ru> wrote:
>> To be honest, I have found a big problem in this patch - we try to perform the transformation every time we examime
acolumn:
>>
>> for (indexcol = 0; indexcol < index->nkeycolumns; indexcol++) { ...
>>
>> }
>>
>> I have fixed it and moved the transformation before going through the loop.
> What makes you think there is a problem?
To be honest, I was bothered by the fact that we need to go through
expressions several times that obviously will not fit under other
conditions.
Just yesterday I thought that it would be worthwhile to create a list of
candidates - expressions that did not fit because the column did not
match the index (!match_index_to_operand(nconst_expr, indexcol, index)).
Another problem that is related to the first one that the boolexpr could
contain expressions referring to different operands, for example, both x
and y. that is, we may have the problem that the optimal "ANY"
expression may not be used, because the expression with x may come
earlier and the loop may end earlier.
alena@postgres=# create table b (x int, y int);
CREATE TABLE
alena@postgres=# insert into b select id, id from
generate_series(1,1000) as id;
INSERT 0 1000
alena@postgres=# create index x_idx on b(x);
CREATE INDEX
alena@postgres=# analyze;
ANALYZE
alena@postgres=# explain select * from b where y =3 or x =4 or x=5 or
x=6 or x = 7 or x=8 or x=9;
QUERY PLAN
---------------------------------------------------------------------------------------
Seq Scan on b (cost=0.00..32.50 rows=7 width=8)
Filter: ((y = 3) OR (x = 4) OR (x = 5) OR (x = 6) OR (x = 7) OR (x =
8) OR (x = 9))
(2 rows)
alena@postgres=# explain select * from b where x =4 or x=5 or x=6 or x =
7 or x=8 or x=9 or y=1;
QUERY PLAN
---------------------------------------------------------------------------------------
Seq Scan on b (cost=0.00..32.50 rows=7 width=8)
Filter: ((x = 4) OR (x = 5) OR (x = 6) OR (x = 7) OR (x = 8) OR (x =
9) OR (y = 1))
(2 rows)
alena@postgres=# explain select * from b where x =4 or x=5 or x=6 or x =
7 or x=8 or x=9;
QUERY PLAN
----------------------------------------------------------------
Index Scan using x_idx on b (cost=0.28..12.75 rows=6 width=8)
Index Cond: (x = ANY ('{4,5,6,7,8,9}'::integer[]))
(2 rows)
Furthermore expressions can be stored in a different order.
For example, first comes "AND" expr, and then group of "OR" expr, which
we can convert to "ANY" expr, but we won't do this due to the fact that
we will exit the loop early, according to this condition:
if (!IsA(sub_rinfo->clause, OpExpr))
return NULL;
or it may occur due to other conditions.
alena@postgres=# create index x_y_idx on b(x,y);
CREATE INDEX
alena@postgres=# analyze;
ANALYZE
alena@postgres=# explain select * from b where (x = 2 and y =3) or x =4
or x=5 or x=6 or x = 7 or x=8 or x=9;
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Seq Scan on b (cost=0.00..35.00 rows=6 width=8)
Filter: (((x = 2) AND (y = 3)) OR (x = 4) OR (x = 5) OR (x = 6) OR
(x = 7) OR (x = 8) OR (x = 9))
(2 rows)
Because of these reasons, I tried to save this and that transformation
together for each column and try to analyze for each expr separately
which method would be optimal.
> Do you have a test case
> illustrating a slow planning time?
No, I didn't have time to measure it and sorry for that. I'll do it.
> When v27 performs transformation for a particular column, it just
> stops facing the first unmatched OR entry. So,
> match_orclause_to_indexcol() examines just the first OR entry for all
> the columns excepts at most one. So, the check
> match_orclause_to_indexcol() does is not much slower than other
> match_*_to_indexcol() do.
>
> I actually think this could help performance in many cases, not hurt
> it. At least we get rid of O(n^2) complexity over the number of OR
> entries, which could be very many.
I agree with you that there is an overhead and your patch fixes this
problem, but optimizer needs to have a good ordering of expressions for
application.
I think we can try to move the transformation to another place where
there is already a loop pass, and also save two options "OR" expr and
"ANY" expr in one place (through BoolExpr) (like find_duplicate_ors
function) and teach the optimizer to determine which option is better,
for example, like now in match_orclause_to_indexcol() function.
What do you thing about it?
--
Regards,
Alena Rybakina
Postgres Professional:http://www.postgrespro.com
The Russian Postgres Company
On Sun, Jul 28, 2024 at 12:59 PM Alena Rybakina
<a.rybakina@postgrespro.ru> wrote:
> On 27.07.2024 13:56, Alexander Korotkov wrote:
> > On Thu, Jul 25, 2024 at 5:04 PM Alena Rybakina
> > <a.rybakina@postgrespro.ru> wrote:
> >> To be honest, I have found a big problem in this patch - we try to perform the transformation every time we
examimea column:
> >>
> >> for (indexcol = 0; indexcol < index->nkeycolumns; indexcol++) { ...
> >>
> >> }
> >>
> >> I have fixed it and moved the transformation before going through the loop.
> > What makes you think there is a problem?
>
> To be honest, I was bothered by the fact that we need to go through
> expressions several times that obviously will not fit under other
> conditions.
> Just yesterday I thought that it would be worthwhile to create a list of
> candidates - expressions that did not fit because the column did not
> match the index (!match_index_to_operand(nconst_expr, indexcol, index)).
I admit that this area probably could use some optimization,
especially for case of many clauses and many indexes. But in the
scope of this patch, I think this is enough to not make things worse
in this area.
> Another problem that is related to the first one that the boolexpr could
> contain expressions referring to different operands, for example, both x
> and y. that is, we may have the problem that the optimal "ANY"
> expression may not be used, because the expression with x may come
> earlier and the loop may end earlier.
>
> alena@postgres=# create table b (x int, y int);
> CREATE TABLE
> alena@postgres=# insert into b select id, id from
> generate_series(1,1000) as id;
> INSERT 0 1000
> alena@postgres=# create index x_idx on b(x);
> CREATE INDEX
> alena@postgres=# analyze;
> ANALYZE
> alena@postgres=# explain select * from b where y =3 or x =4 or x=5 or
> x=6 or x = 7 or x=8 or x=9;
> QUERY PLAN
> ---------------------------------------------------------------------------------------
> Seq Scan on b (cost=0.00..32.50 rows=7 width=8)
> Filter: ((y = 3) OR (x = 4) OR (x = 5) OR (x = 6) OR (x = 7) OR (x =
> 8) OR (x = 9))
> (2 rows)
> alena@postgres=# explain select * from b where x =4 or x=5 or x=6 or x =
> 7 or x=8 or x=9 or y=1;
> QUERY PLAN
> ---------------------------------------------------------------------------------------
> Seq Scan on b (cost=0.00..32.50 rows=7 width=8)
> Filter: ((x = 4) OR (x = 5) OR (x = 6) OR (x = 7) OR (x = 8) OR (x =
> 9) OR (y = 1))
> (2 rows)
> alena@postgres=# explain select * from b where x =4 or x=5 or x=6 or x =
> 7 or x=8 or x=9;
> QUERY PLAN
> ----------------------------------------------------------------
> Index Scan using x_idx on b (cost=0.28..12.75 rows=6 width=8)
> Index Cond: (x = ANY ('{4,5,6,7,8,9}'::integer[]))
> (2 rows)
>
> Furthermore expressions can be stored in a different order.
> For example, first comes "AND" expr, and then group of "OR" expr, which
> we can convert to "ANY" expr, but we won't do this due to the fact that
> we will exit the loop early, according to this condition:
>
> if (!IsA(sub_rinfo->clause, OpExpr))
> return NULL;
>
> or it may occur due to other conditions.
>
> alena@postgres=# create index x_y_idx on b(x,y);
> CREATE INDEX
> alena@postgres=# analyze;
> ANALYZE
>
> alena@postgres=# explain select * from b where (x = 2 and y =3) or x =4
> or x=5 or x=6 or x = 7 or x=8 or x=9;
> QUERY PLAN
> -----------------------------------------------------------------------------------------------------
> Seq Scan on b (cost=0.00..35.00 rows=6 width=8)
> Filter: (((x = 2) AND (y = 3)) OR (x = 4) OR (x = 5) OR (x = 6) OR
> (x = 7) OR (x = 8) OR (x = 9))
> (2 rows)
>
> Because of these reasons, I tried to save this and that transformation
> together for each column and try to analyze for each expr separately
> which method would be optimal.
Yes, with v27 of the patch, optimization wouldn't work in these cases.
However, you are using quite small table. If you will use larger
table or disable sequential scans, there would be bitmap plans to
handle these queries. So, v27 doesn't make the situation worse. It
just doesn't optimize all that it could potentially optimize and
that's OK.
I've written a separate 0002 patch to address this. Now, before
generation of paths for bitmap OR, similar OR entries are grouped
together. When considering a group of similar entries, they are
considered both together and one-by-one. Ideally we could consider
more sophisticated grouping, but that seems fine for now. You can
check how this patch handles the cases of above.
Also, 0002 address issue of duplicated bitmap scan conditions in
different forms. During generate_bitmap_or_paths() we need to exclude
considered condition for other clauses. It couldn't be as normal
filtered out in the latter stage, because could reach the index in
another form.
> > Do you have a test case
> > illustrating a slow planning time?
> No, I didn't have time to measure it and sorry for that. I'll do it.
> > When v27 performs transformation for a particular column, it just
> > stops facing the first unmatched OR entry. So,
> > match_orclause_to_indexcol() examines just the first OR entry for all
> > the columns excepts at most one. So, the check
> > match_orclause_to_indexcol() does is not much slower than other
> > match_*_to_indexcol() do.
> >
> > I actually think this could help performance in many cases, not hurt
> > it. At least we get rid of O(n^2) complexity over the number of OR
> > entries, which could be very many.
>
> I agree with you that there is an overhead and your patch fixes this
> problem, but optimizer needs to have a good ordering of expressions for
> application.
>
> I think we can try to move the transformation to another place where
> there is already a loop pass, and also save two options "OR" expr and
> "ANY" expr in one place (through BoolExpr) (like find_duplicate_ors
> function) and teach the optimizer to determine which option is better,
> for example, like now in match_orclause_to_indexcol() function.
>
> What do you thing about it?
find_duplicate_ors() and similar places were already tried before.
Please, check upthread. This approach receives severe critics. AFAIU,
the problem is that find_duplicate_ors() during preprocessing, a
cost-blind stage.
This is why I'd like to continue developing ideas of v27, because it
fits the existing framework.
------
Regards,
Alexander Korotkov
Supabase
Attachment
On Mon, Jul 29, 2024 at 5:36 AM Alexander Korotkov <aekorotkov@gmail.com> wrote: > On Sun, Jul 28, 2024 at 12:59 PM Alena Rybakina > > Because of these reasons, I tried to save this and that transformation > > together for each column and try to analyze for each expr separately > > which method would be optimal. > > Yes, with v27 of the patch, optimization wouldn't work in these cases. > However, you are using quite small table. If you will use larger > table or disable sequential scans, there would be bitmap plans to > handle these queries. So, v27 doesn't make the situation worse. It > just doesn't optimize all that it could potentially optimize and > that's OK. > > I've written a separate 0002 patch to address this. Now, before > generation of paths for bitmap OR, similar OR entries are grouped > together. When considering a group of similar entries, they are > considered both together and one-by-one. Ideally we could consider > more sophisticated grouping, but that seems fine for now. You can > check how this patch handles the cases of above. > > Also, 0002 address issue of duplicated bitmap scan conditions in > different forms. During generate_bitmap_or_paths() we need to exclude > considered condition for other clauses. It couldn't be as normal > filtered out in the latter stage, because could reach the index in > another form. > > > I agree with you that there is an overhead and your patch fixes this > > problem, but optimizer needs to have a good ordering of expressions for > > application. > > > > I think we can try to move the transformation to another place where > > there is already a loop pass, and also save two options "OR" expr and > > "ANY" expr in one place (through BoolExpr) (like find_duplicate_ors > > function) and teach the optimizer to determine which option is better, > > for example, like now in match_orclause_to_indexcol() function. > > > > What do you thing about it? > > find_duplicate_ors() and similar places were already tried before. > Please, check upthread. This approach receives severe critics. AFAIU, > the problem is that find_duplicate_ors() during preprocessing, a > cost-blind stage. > > This is why I'd like to continue developing ideas of v27, because it > fits the existing framework. The revised patchset is attached. There is no material changes in the logic, I found no issues here yet. But it comes with refactoring, cleanup, more comments and better commit messages. I think now this patchset is understandable and ready for review. ------ Regards, Alexander Korotkov Supabase
Attachment
Ok, thank you for your work) I think we can leave only the two added libraries in the first patch, others are superfluous. On 05.08.2024 22:48, Alexander Korotkov wrote: > On Mon, Jul 29, 2024 at 5:36 AM Alexander Korotkov <aekorotkov@gmail.com> wrote: >> On Sun, Jul 28, 2024 at 12:59 PM Alena Rybakina >>> Because of these reasons, I tried to save this and that transformation >>> together for each column and try to analyze for each expr separately >>> which method would be optimal. >> Yes, with v27 of the patch, optimization wouldn't work in these cases. >> However, you are using quite small table. If you will use larger >> table or disable sequential scans, there would be bitmap plans to >> handle these queries. So, v27 doesn't make the situation worse. It >> just doesn't optimize all that it could potentially optimize and >> that's OK. >> >> I've written a separate 0002 patch to address this. Now, before >> generation of paths for bitmap OR, similar OR entries are grouped >> together. When considering a group of similar entries, they are >> considered both together and one-by-one. Ideally we could consider >> more sophisticated grouping, but that seems fine for now. You can >> check how this patch handles the cases of above. >> >> Also, 0002 address issue of duplicated bitmap scan conditions in >> different forms. During generate_bitmap_or_paths() we need to exclude >> considered condition for other clauses. It couldn't be as normal >> filtered out in the latter stage, because could reach the index in >> another form. >> >>> I agree with you that there is an overhead and your patch fixes this >>> problem, but optimizer needs to have a good ordering of expressions for >>> application. >>> >>> I think we can try to move the transformation to another place where >>> there is already a loop pass, and also save two options "OR" expr and >>> "ANY" expr in one place (through BoolExpr) (like find_duplicate_ors >>> function) and teach the optimizer to determine which option is better, >>> for example, like now in match_orclause_to_indexcol() function. >>> >>> What do you thing about it? >> find_duplicate_ors() and similar places were already tried before. >> Please, check upthread. This approach receives severe critics. AFAIU, >> the problem is that find_duplicate_ors() during preprocessing, a >> cost-blind stage. >> >> This is why I'd like to continue developing ideas of v27, because it >> fits the existing framework. > The revised patchset is attached. There is no material changes in the > logic, I found no issues here yet. But it comes with refactoring, > cleanup, more comments and better commit messages. I think now this > patchset is understandable and ready for review. > > ------ > Regards, > Alexander Korotkov > Supabase -- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On Mon, Aug 5, 2024 at 11:24 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > Ok, thank you for your work) > > I think we can leave only the two added libraries in the first patch, > others are superfluous. Thank you. I also have fixed some grammar issues. ------ Regards, Alexander Korotkov Supabase
Attachment
On 07.08.2024 04:11, Alexander Korotkov wrote: > On Mon, Aug 5, 2024 at 11:24 PM Alena Rybakina > <a.rybakina@postgrespro.ru> wrote: >> Ok, thank you for your work) >> >> I think we can leave only the two added libraries in the first patch, >> others are superfluous. > Thank you. > I also have fixed some grammar issues. Thank you) I added some tests to test the functionality of queries using strange operator classes, type mismatches, and a small number of joins. At the same time, I faced an assertion when a request with an unusual operator was processed: EXPLAIN (COSTS OFF) SELECT COUNT(*) FROM guid1 WHERE guid_field <> '11111111111111111111111111111111' OR guid_field <> '3f3e3c3b-3a30-3938-3736-353433a2313e'; Coredump: #0 __pthread_kill_implementation (no_tid=0, signo=6, threadid=138035230913472) at ./nptl/pthread_kill.c:44 #1 __pthread_kill_internal (signo=6, threadid=138035230913472) at ./nptl/pthread_kill.c:78 #2 __GI___pthread_kill (threadid=138035230913472, signo=signo@entry=6) at ./nptl/pthread_kill.c:89 #3 0x00007d8ad3e42476 in __GI_raise (sig=sig@entry=6) at ../sysdeps/posix/raise.c:26 #4 0x00007d8ad3e287f3 in __GI_abort () at ./stdlib/abort.c:79 #5 0x000060ceb55be02f in ExceptionalCondition (conditionName=0x60ceb58058af "op_strategy != 0", fileName=0x60ceb58053e6 "selfuncs.c", lineNumber=6900) at assert.c:66 #6 0x000060ceb553ed48 in btcostestimate (root=0x60ceb6f9d2a8, path=0x60ceb6fbd2a8, loop_count=1, --Type <RET> for more, q to quit, c to continue without paging-- indexStartupCost=0x7fff7ea15380, indexTotalCost=0x7fff7ea15388, indexSelectivity=0x7fff7ea15390, indexCorrelation=0x7fff7ea15398, indexPages=0x7fff7ea153b0) at selfuncs.c:6900 #7 0x000060ceb521afca in cost_index (path=0x60ceb6fbd2a8, root=0x60ceb6f9d2a8, loop_count=1, partial_path=false) at costsize.c:618 #8 0x000060ceb5290c99 in create_index_path (root=0x60ceb6f9d2a8, index=0x60ceb6fbd5e8, indexclauses=0x60ceb6fbe4c8, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x0, indexscandir=ForwardScanDirection, indexonly=true, required_outer=0x0, loop_count=1, partial_path=false) at pathnode.c:1024 --Type <RET> for more, q to quit, c to continue without paging-- #9 0x000060ceb522df4d in build_index_paths (root=0x60ceb6f9d2a8, rel=0x60ceb70716c8, index=0x60ceb6fbd5e8, clauses=0x7fff7ea15790, useful_predicate=false, scantype=ST_ANYSCAN, skip_nonnative_saop=0x7fff7ea15607) at indxpath.c:970 #10 0x000060ceb522d905 in get_index_paths (root=0x60ceb6f9d2a8, rel=0x60ceb70716c8, index=0x60ceb6fbd5e8, clauses=0x7fff7ea15790, bitindexpaths=0x7fff7ea15678) at indxpath.c:729 #11 0x000060ceb522c846 in create_index_paths (root=0x60ceb6f9d2a8, rel=0x60ceb70716c8) at indxpath.c:286 #12 0x000060ceb5212d29 in set_plain_rel_pathlist (root=0x60ceb6f9d2a8, rel=0x60ceb70716c8, rte=0x60ceb6f63768) at allpaths.c:794 #13 0x000060ceb5212852 in set_rel_pathlist (root=0x60ceb6f9d2a8, rel=0x60ceb70716c8, rti=1, rte=0x60ceb6f63768) at allpaths.c:499 #14 0x000060ceb521248c in set_base_rel_pathlists (root=0x60ceb6f9d2a8) at allpaths.c:351 #15 0x000060ceb52121af in make_one_rel (root=0x60ceb6f9d2a8, joinlist=0x60ceb6fbdea8) at allpaths.c:221 #16 0x000060ceb5257a8d in query_planner (root=0x60ceb6f9d2a8, qp_callback=0x60ceb525e2e6 <standard_qp_callback>, qp_extra=0x7fff7ea15d90) at planmain.c:280 #17 0x000060ceb525a4f0 in grouping_planner (root=0x60ceb6f9d2a8, tuple_fraction=0, setops=0x0) at planner.c:1520 #18 0x000060ceb5259b8f in subquery_planner (glob=0x60ceb70715b8, parse=0x60ceb6f63558, parent_root=0x0, hasRecursion=false, tuple_fraction=0, setops=0x0) at planner.c:1089 #19 0x000060ceb52581f2 in standard_planner (parse=0x60ceb6f63558, query_string=0x60ceb6f62020 "EXPLAIN (COSTS OFF)\nSELECT COUNT(*) FROM guid1 WHERE guid_field <> '", '1' <repeats 32 --Type <RET> for more, q to quit, c to continue without paging-- times>, "' OR\n\t\t\t\t\t\t\tguid_field <> '3f3e3c3b-3a30-3938-3736-353433a2313e';", cursorOptions=2048, boundParams=0x0) at planner.c:415 #20 0x000060ceb5257f1c in planner (parse=0x60ceb6f63558, query_string=0x60ceb6f62020 "EXPLAIN (COSTS OFF)\nSELECT COUNT(*) FROM guid1 WHERE guid_field <> '", '1' <repeats 32 times>, "' OR\n\t\t\t\t\t\t\tguid_field <> '3f3e3c3b-3a30-3938-3736-353433a2313e';", cursorOptions=2048, boundParams=0x0) at planner.c:282 #21 0x000060ceb53b89d9 in pg_plan_query (querytree=0x60ceb6f63558, query_string=0x60ceb6f62020 "EXPLAIN (COSTS OFF)\nSELECT COUNT(*) FROM guid1 WHERE guid_field <> '", '1' <repeats 32 times>, "' OR\n\t\t\t\t\t\t\tguid_field <> '3f3e3c3b-3a30-3938-3736-353433a2313e';", cursorOptions=2048, boundParams=0x0) at postgres.c:912 #22 0x000060ceb501feeb in standard_ExplainOneQuery (query=0x60ceb6f63558, cursorOptions=2048, into=0x0, es=0x60ceb703acc8, queryString=0x60ceb6f62020 "EXPLAIN (COSTS OFF)\nSELECT COUNT(*) FROM guid1 WHERE guid_field <> '", '1' <repeats 32 times>, "' OR\n\t\t\t\t\t\t\tguid_field <> '3f3e3c3b-3a30-3938-3736-353433a2313e';", params=0x0, queryEnv=0x0) at explain.c:491 #23 0x000060ceb501fd09 in ExplainOneQuery (query=0x60ceb6f63558, cursorOptions=2048, into=0x0, es=0x60ceb703acc8, queryString=0x60ceb6f62020 "EXPLAIN (COSTS OFF)\nSELECT COUNT(*) FROM guid1 WHERE guid_field <> '", '1' <repeats 32 times>, "' OR\n\t\t\t\t\t\t\tguid_field <> '3f3e3c3b-3a30-3938-3736-353433a2313e';", params=0x0, queryEnv=0x0) at explain.c:447 --Type <RET> for more, q to quit, c to continue without paging-- #24 0x000060ceb501f939 in ExplainQuery (pstate=0x60ceb703abb8, stmt=0x60ceb6f63398, params=0x0, dest=0x60ceb703ab28) at explain.c:343 #25 0x000060ceb53c32e0 in standard_ProcessUtility (pstmt=0x60ceb6f63448, queryString=0x60ceb6f62020 "EXPLAIN (COSTS OFF)\nSELECT COUNT(*) FROM guid1 WHERE guid_field <> '", '1' <repeats 32 times>, "' OR\n\t\t\t\t\t\t\tguid_field <> '3f3e3c3b-3a30-3938-3736-353433a2313e';", readOnlyTree=false, context=PROCESS_UTILITY_TOPLEVEL, params=0x0, queryEnv=0x0, dest=0x60ceb703ab28, qc=0x7fff7ea16530) at utility.c:863 #26 0x000060ceb53c2852 in ProcessUtility (pstmt=0x60ceb6f63448, queryString=0x60ceb6f62020 "EXPLAIN (COSTS OFF)\nSELECT COUNT(*) FROM guid1 WHERE guid_field <> '", '1' <repeats 32 times>, "' OR\n\t\t\t\t\t\t\tguid_field <> '3f3e3c3b-3a30-3938-3736-353433a2313e';", readOnlyTree=false, context=PROCESS_UTILITY_TOPLEVEL, params=0x0, queryEnv=0x0, dest=0x60ceb703ab28, qc=0x7fff7ea16530) at utility.c:523 #27 0x000060ceb53c10cd in PortalRunUtility (portal=0x60ceb6fe6c50, pstmt=0x60ceb6f63448, isTopLevel=true, setHoldSnapshot=true, dest=0x60ceb703ab28, qc=0x7fff7ea16530) at pquery.c:1158 #28 0x000060ceb53c0e0a in FillPortalStore (portal=0x60ceb6fe6c50, isTopLevel=true) at pquery.c:1031 #29 0x000060ceb53c06bb in PortalRun (portal=0x60ceb6fe6c50, count=9223372036854775807, isTopLevel=true, run_once=true, dest=0x60ceb6f63be8, altdest=0x60ceb6f63be8, qc=0x7fff7ea16780) at pquery.c:763 #30 0x000060ceb53b911f in exec_simple_query ( query_string=0x60ceb6f62020 "EXPLAIN (COSTS OFF)\nSELECT COUNT(*) FROM guid1 WHERE guid_field <> '", '1' <repeats 32 times>, "' OR\n\t\t\t\t\t\t\tguid_field <> '3f3e3c3b-3a30-3938-3736-353433a2313e';") at postgres.c:1284 #31 0x000060ceb53be4ef in PostgresMain (dbname=0x60ceb6fa0c00 "regression", username=0x60ceb6fa0be8 "alena") --Type <RET> for more, q to quit, c to continue without paging-- at postgres.c:4766 #32 0x000060ceb53b4c2a in BackendMain (startup_data=0x7fff7ea16a04 "", startup_data_len=4) at backend_startup.c:107 #33 0x000060ceb52c9b80 in postmaster_child_launch (child_type=B_BACKEND, startup_data=0x7fff7ea16a04 "", startup_data_len=4, client_sock=0x7fff7ea16a50) at launch_backend.c:274 #34 0x000060ceb52cfe87 in BackendStartup (client_sock=0x7fff7ea16a50) at postmaster.c:3495 #35 0x000060ceb52cd0df in ServerLoop () at postmaster.c:1662 #36 0x000060ceb52cc9a6 in PostmasterMain (argc=3, argv=0x60ceb6ec6d10) at postmaster.c:1360 #37 0x000060ceb517671c in main (argc=3, argv=0x60ceb6ec6d10) at main.c:197 I have fixed it by adding the condition that the opno of the clause must be a member of the opfamily of the index. tp = SearchSysCache3(AMOPOPID, ObjectIdGetDatum(opno), CharGetDatum(AMOP_SEARCH), ObjectIdGetDatum(index->opfamily[indexcol])); if (!HeapTupleIsValid(tp)) return NULL; ReleaseSysCache(tp); I attached the diff file and new versions of patches. -- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On 21/8/2024 02:17, Alexander Korotkov wrote: > Also, I convert the check you've introduced in the previous message to > op_in_opfamily(), and introduced collation check similar to > match_opclause_to_indexcol(). Hi, I passed through the patches with fresh sight. Conceptually, this approach looks much better than the previous series. Just for the record: previously, we attempted to resolve two issues in one - improve the execution plan and save cycles during the optimisation. As I see it, it is almost impossible in this feature. So, I should come to terms with carrying long OR lists through the planning and the additional overhead this feature generates. I also see that the optimiser has obtained additional planning strategies with these patches and hasn't lost any. Couple of findings: First: /* Only operator clauses scan match */ Should it be: /* Only operator clauses can match */ ? The second one: When creating IndexClause, we assign the original and derived clauses to the new, containing transformed array. But logically, we should set the clause with a list of ORs as the original. Why did you do so? -- regards, Andrei Lepikhov Postgres Professional
On 21/8/2024 16:52, Alexander Korotkov wrote:
>> /* Only operator clauses scan match */
>> Should it be:
>> /* Only operator clauses can match */
>> ?
>
> Corrected, thanks.
I found one more: /* Only operator clauses scan match */ - in the
second patch.
Also I propose:
- “might match to the index as whole” -> “might match the index as a whole“
- Group similar OR-arguments intro dedicated RestrictInfos -> ‘into’
>
>> The second one:
>> When creating IndexClause, we assign the original and derived clauses to
>> the new, containing transformed array. But logically, we should set the
>> clause with a list of ORs as the original. Why did you do so?
>
> I actually didn't notice that. Corrected to set the OR clause as the
> original. That change turned recheck to use original OR clauses,
> probably better this way. Also, that change spotted misuse of
> RestrictInfo.clause and RestrictInfo.orclause in the second patch.
> Corrected this too.
New findings:
=============
1)
if (list_length(clause->args) != 2)
return NULL;
I guess, above we can 'continue' the process.
2) Calling the match_index_to_operand in three nested cycles you could
break the search on first successful match, couldn't it? At least, the
comment "just stop with first matching index key" say so.
3) I finally found the limit of this feature: the case of two partial
indexes on the same column. Look at the example below:
SET enable_indexscan = 'off';
SET enable_seqscan = 'off';
DROP TABLE IF EXISTS test CASCADE;
CREATE TABLE test (x int);
INSERT INTO test (x) SELECT * FROM generate_series(1,100);
CREATE INDEX ON test (x) WHERE x < 80;
CREATE INDEX ON test (x) WHERE x > 80;
VACUUM ANALYZE test;
EXPLAIN (ANALYZE, COSTS OFF, TIMING OFF)
SELECT * FROM test WHERE x=1 OR x = 79;
EXPLAIN (ANALYZE, COSTS OFF, TIMING OFF)
SELECT * FROM test WHERE x=91 OR x = 81;
EXPLAIN (ANALYZE, COSTS OFF, TIMING OFF)
SELECT * FROM test WHERE x=1 OR x = 81 OR x = 83;
The last query doesn't group clauses into two indexes. The reason is in
match_index_to_operand which classifies all 'x=' to one class. I'm not
sure because of overhead, but it may be resolved by using
predicate_implied_by to partial indexes.
--
regards, Andrei Lepikhov
Hi! To be fair, I fixed this before [0] by selecting the appropriate group of "or" expressions to transform them to "ANY" expression and then checking for compatibility with the index column. maybe we should try this too? I can think about it. [0] https://www.postgresql.org/message-id/531fc0ab-371e-4235-97e3-dd2d077b6995%40postgrespro.ru On 23.08.2024 15:58, Alexander Korotkov wrote: > Hi! > > Thank you for your feedback. > > On Fri, Aug 23, 2024 at 1:23 PM Andrei Lepikhov <lepihov@gmail.com> wrote: >> On 21/8/2024 16:52, Alexander Korotkov wrote: >>>> /* Only operator clauses scan match */ >>>> Should it be: >>>> /* Only operator clauses can match */ >>>> ? >>> Corrected, thanks. >> I found one more: /* Only operator clauses scan match */ - in the >> second patch. >> Also I propose: >> - “might match to the index as whole” -> “might match the index as a whole“ >> - Group similar OR-arguments intro dedicated RestrictInfos -> ‘into’ > Fixed. > >>>> The second one: >>>> When creating IndexClause, we assign the original and derived clauses to >>>> the new, containing transformed array. But logically, we should set the >>>> clause with a list of ORs as the original. Why did you do so? >>> I actually didn't notice that. Corrected to set the OR clause as the >>> original. That change turned recheck to use original OR clauses, >>> probably better this way. Also, that change spotted misuse of >>> RestrictInfo.clause and RestrictInfo.orclause in the second patch. >>> Corrected this too. >> New findings: >> ============= >> >> 1) >> if (list_length(clause->args) != 2) >> return NULL; >> I guess, above we can 'continue' the process. >> >> 2) Calling the match_index_to_operand in three nested cycles you could >> break the search on first successful match, couldn't it? At least, the >> comment "just stop with first matching index key" say so. > Fixed. > >> 3) I finally found the limit of this feature: the case of two partial >> indexes on the same column. Look at the example below: >> >> SET enable_indexscan = 'off'; >> SET enable_seqscan = 'off'; >> DROP TABLE IF EXISTS test CASCADE; >> CREATE TABLE test (x int); >> INSERT INTO test (x) SELECT * FROM generate_series(1,100); >> CREATE INDEX ON test (x) WHERE x < 80; >> CREATE INDEX ON test (x) WHERE x > 80; >> VACUUM ANALYZE test; >> EXPLAIN (ANALYZE, COSTS OFF, TIMING OFF) >> SELECT * FROM test WHERE x=1 OR x = 79; >> EXPLAIN (ANALYZE, COSTS OFF, TIMING OFF) >> SELECT * FROM test WHERE x=91 OR x = 81; >> EXPLAIN (ANALYZE, COSTS OFF, TIMING OFF) >> SELECT * FROM test WHERE x=1 OR x = 81 OR x = 83; >> >> The last query doesn't group clauses into two indexes. The reason is in >> match_index_to_operand which classifies all 'x=' to one class. I'm not >> sure because of overhead, but it may be resolved by using >> predicate_implied_by to partial indexes. > Yes, this is the conscious limitation of my patch: to consider similar > OR arguments altogether and one-by-one, not in arbitrary groups. The > important thing here is that we still generating BitmapOR patch as we > do without the patch. So, there is no regression. I would leave this > as is to not make this feature too complicated. This could be improved > in future though. > > ------ > Regards, > Alexander Korotkov > Supabase -- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi, Alena! On Fri, Aug 23, 2024 at 5:06 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > To be fair, I fixed this before [0] by selecting the appropriate group > of "or" expressions to transform them to "ANY" expression and then > checking for compatibility with the index column. maybe we should try > this too? I can think about it. > > [0] > https://www.postgresql.org/message-id/531fc0ab-371e-4235-97e3-dd2d077b6995%40postgrespro.ru I probably didn't get your message. Which patch version you think resolve the problem? I see [0] doesn't contain any patch. I think further progress in this area of grouping OR args is possible if there is a solution, which doesn't take extraordinary computational complexity. ------ Regards, Alexander Korotkov Supabase
On 23.08.2024 19:38, Alexander Korotkov wrote: > Hi, Alena! > > On Fri, Aug 23, 2024 at 5:06 PM Alena Rybakina > <a.rybakina@postgrespro.ru> wrote: >> To be fair, I fixed this before [0] by selecting the appropriate group >> of "or" expressions to transform them to "ANY" expression and then >> checking for compatibility with the index column. maybe we should try >> this too? I can think about it. >> >> [0] >> https://www.postgresql.org/message-id/531fc0ab-371e-4235-97e3-dd2d077b6995%40postgrespro.ru > I probably didn't get your message. Which patch version you think > resolve the problem? I see [0] doesn't contain any patch. Sorry, I got the links mixed up. We need this link [0]. > > I think further progress in this area of grouping OR args is possible > if there is a solution, which doesn't take extraordinary computational > complexity. This approach does not require a large overhead - in fact, we separately did the conversion to "any" once going through the list of restrictinfo, we form candidates in the form of boolexpr using the "and" operator, which contains "any" and "or" expression, then we check with index columns which expression suits us. -- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Sat, Aug 24, 2024 at 4:08 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > On 23.08.2024 19:38, Alexander Korotkov wrote: > > Hi, Alena! > > > > On Fri, Aug 23, 2024 at 5:06 PM Alena Rybakina > > <a.rybakina@postgrespro.ru> wrote: > >> To be fair, I fixed this before [0] by selecting the appropriate group > >> of "or" expressions to transform them to "ANY" expression and then > >> checking for compatibility with the index column. maybe we should try > >> this too? I can think about it. > >> > >> [0] > >> https://www.postgresql.org/message-id/531fc0ab-371e-4235-97e3-dd2d077b6995%40postgrespro.ru > > I probably didn't get your message. Which patch version you think > > resolve the problem? I see [0] doesn't contain any patch. > Sorry, I got the links mixed up. We need this link [0]. Still confusion. If that's another [0] from [0] in the cited message then it seems you missed new link in your last message. ------ Regards, Alexander Korotkov Supabase
Sorry again. The link to letter - - https://www.postgresql.org/message-id/759292d5-cb51-4b12-89fa-576c1d9b374d%40postgrespro.ru Patch - https://www.postgresql.org/message-id/attachment/162897/v28-Transform-OR-clauses-to-ANY-expression.patch On 24.08.2024 16:23, Alexander Korotkov wrote: > On Sat, Aug 24, 2024 at 4:08 PM Alena Rybakina > <a.rybakina@postgrespro.ru> wrote: >> On 23.08.2024 19:38, Alexander Korotkov wrote: >>> Hi, Alena! >>> >>> On Fri, Aug 23, 2024 at 5:06 PM Alena Rybakina >>> <a.rybakina@postgrespro.ru> wrote: >>>> To be fair, I fixed this before [0] by selecting the appropriate group >>>> of "or" expressions to transform them to "ANY" expression and then >>>> checking for compatibility with the index column. maybe we should try >>>> this too? I can think about it. >>>> >>>> [0] >>>> https://www.postgresql.org/message-id/531fc0ab-371e-4235-97e3-dd2d077b6995%40postgrespro.ru >>> I probably didn't get your message. Which patch version you think >>> resolve the problem? I see [0] doesn't contain any patch. >> Sorry, I got the links mixed up. We need this link [0]. > Still confusion. > If that's another [0] from [0] in the cited message then it seems you > missed new link in your last message. > > ------ > Regards, > Alexander Korotkov > Supabase > > -- Regards, Alena Rybakina Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 23/8/2024 14:58, Alexander Korotkov wrote: > On Fri, Aug 23, 2024 at 1:23 PM Andrei Lepikhov <lepihov@gmail.com> wrote: >> The last query doesn't group clauses into two indexes. The reason is in >> match_index_to_operand which classifies all 'x=' to one class. I'm not >> sure because of overhead, but it may be resolved by using >> predicate_implied_by to partial indexes. > > Yes, this is the conscious limitation of my patch: to consider similar > OR arguments altogether and one-by-one, not in arbitrary groups. The > important thing here is that we still generating BitmapOR patch as we > do without the patch. So, there is no regression. I would leave this > as is to not make this feature too complicated. This could be improved > in future though. It looks reasonable for me, thanks for the explanation. What's more, I suspicious about the line: *subrinfo = *rinfo; Here, you copy everything, including cached estimations like norm_selec or eval_cost. I see that the match_orclause_to_indexcol creates a new SAOP where all caches will be cleaned, but just to be sure, maybe we should reset any cached estimations to default values — in that case, anyone who tries to build a new path based on these grouped OR clauses will recalculate that data. At least, incorrect eval_cost of iclause->rinfo can slightly change the cost of rechecking operation, can't it? -- regards, Andrei Lepikhov
On Fri, Aug 23, 2024 at 8:58 PM Alexander Korotkov <aekorotkov@gmail.com> wrote:
>
based on v37.
+ {
+ /*
+ * We have only Const's. In this case we can construct an array
+ * directly.
+ */
+ int16 typlen;
+ bool typbyval;
+ char typalign;
+ Datum *elems;
+ int i = 0;
+ ArrayType *arrayConst;
+
+ get_typlenbyvalalign(consttype, &typlen, &typbyval, &typalign);
+
+ elems = (Datum *) palloc(sizeof(Datum) * list_length(consts));
+ foreach(lc, consts)
+ elems[i++] = ((Const *) lfirst(lc))->constvalue;
+
+ arrayConst = construct_array(elems, i, consttype,
+ typlen, typbyval, typalign);
+ arrayNode = (Node *) makeConst(arraytype, -1, inputcollid,
+ -1, PointerGetDatum(arrayConst),
+ false, false);
+
+ pfree(elems);
+ list_free(consts);
+ }
List "consts" elements can be NULL?
I didn't find a query to trigger that.
but construct_array comments says
"elems (NULL element values are not supported)."
Do we need to check Const->constisnull for the Const node?
+ /* Construct the list of nested OR arguments */
+ for (j = group_start; j < i; j++)
+ {
+ Node *arg = list_nth(orargs, matches[j].argindex);
+
+ rargs = lappend(rargs, arg);
+ if (IsA(arg, RestrictInfo))
+ args = lappend(args, ((RestrictInfo *) arg)->clause);
+ else
+ args = lappend(args, arg);
+ }
the ELSE branch never reached?
+ /* Construct the nested OR and wrap it with RestrictInfo */
+ *subrinfo = *rinfo;
+ subrinfo->clause = make_orclause(args);
+ subrinfo->orclause = make_orclause(rargs);
+ result = lappend(result, subrinfo);
should we use memcpy instead of " *subrinfo = *rinfo;"?
+ /* Sort clauses to make similar clauses go together */
+ pg_qsort(matches, n, sizeof(OrArgIndexMatch), or_arg_index_match_cmp);
Should we use qsort?
since comments in pg_qsort:
/*
* Callers should use the qsort() macro defined below instead of calling
* pg_qsort() directly.
*/
+/*
+ * Data structure representing information about OR-clause argument and its
+ * matching index key. Used for grouping of similar OR-clause arguments in
+ * group_similar_or_args().
+ */
+typedef struct
+{
+ int indexnum; /* index of the matching index */
+ int colnum; /* index of the matching column */
+ Oid opno; /* OID of the OpClause operator */
+ Oid inputcollid; /* OID of the OpClause input collation */
+ int argindex; /* index of the clause in the list of
+ * arguments */
+} OrArgIndexMatch;
I am not 100% sure about the comments.
indexnum: index of the matching index reside in rel->indexlist that
matches (counting from 0)
colnum: the column number of the matched index (counting from 0)
On Mon, Aug 26, 2024 at 6:41 PM Alena Rybakina
<a.rybakina@postgrespro.ru> wrote:
>
> + /* Construct the list of nested OR arguments */
> + for (j = group_start; j < i; j++)
> + {
> + Node *arg = list_nth(orargs, matches[j].argindex);
> +
> + rargs = lappend(rargs, arg);
> + if (IsA(arg, RestrictInfo))
> + args = lappend(args, ((RestrictInfo *) arg)->clause);
> + else
> + args = lappend(args, arg);
> + }
> the ELSE branch never reached?
>
> Reached - if your arg is BoolExpr type, for example if it consists "And" expressions.
>
I added elog(INFO, "this part called");
all the tests still passed, that's where my confusion comes from.
>
> +/*
> + * Data structure representing information about OR-clause argument and its
> + * matching index key. Used for grouping of similar OR-clause arguments in
> + * group_similar_or_args().
> + */
> +typedef struct
> +{
> + int indexnum; /* index of the matching index */
> + int colnum; /* index of the matching column */
> + Oid opno; /* OID of the OpClause operator */
> + Oid inputcollid; /* OID of the OpClause input collation */
> + int argindex; /* index of the clause in the list of
> + * arguments */
> +} OrArgIndexMatch;
>
> I am not 100% sure about the comments.
> indexnum: index of the matching index reside in rel->indexlist that
> matches (counting from 0)
> colnum: the column number of the matched index (counting from 0)
>
> To be honest, I'm not sure that I completely understand your point here.
>
I guess I want to make the comments more explicit, straightforward.
does match_orclause_to_indexcol have a memory issue.
current match_orclause_to_indexcol pattern is
<<<<<<<<<<<<<<<<<<
foreach(lc, orclause->args)
{
condition check, if fail, return null.
consts = lappend(consts, constExpr);
}
if (have_param)
{
ArrayExpr *arrayExpr = makeNode(ArrayExpr);
arrayExpr->elements = consts;
}
else
{
do other work.
list_free(consts);
}
<<<<<<<<<<<<<<<<<<
if have_param is false, first foreach fail at the last iteration
then
"list_free(consts);" will not get called?
Will it be a problem?
Hi!
Thank you for your work! It is fine now.On Wed, Sep 4, 2024 at 6:42 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote:On 04.09.2024 18:31, Alena Rybakina wrote:I rewrote the tests with integer types. Thanks for your suggestion. If you don't mind, I've updated the diff file you attached earlier to include the tests.Sorry, I've just noticed that one of your changes with the regression test wasn't included. I fixed it here.Please, find the revised patchset attached. I've integrated the fixes by you and Andrei in the thread.
I agree with that. I noticed this function is used for formation quals from modified clauses. We have the same case in our patch.Also, I've addressed the note from Andrei [1] about construction of RestrictInfos. I decided to use make_simple_restrictinfo() in match_orclause_to_indexcol(), because I've seen its usage in get_index_clause_from_support().
I am willing to agree with renaming function because it processes the plain expression without recursive functionality sub expression.Also, I agree it get it's wrong to directly copy RestrictInfo struct in group_similar_or_args(). Instead, I've renamed make_restrictinfo_internal() to make_plain_restrictinfo(), which is intended to handle non-recursive cases when you've children already wrapped with RestrictInfos.
make_plain_restrictinfo() now used in group_similar_or_args(). Hopefully, this item is resolved by now. Links. 1. https://www.postgresql.org/message-id/60760203-4917-4c6c-ac74-a5ee764735a4%40gmail.com
I think the case didn't resolve. As I understood the problem is related to uncleared cached estimations to default values, namely eval_cost, norm_selec, outer_selec variables in RestrictInfo.
I assume we should reset it only for RestrictInfo including ScalarArrayOpExpr object that we got before after transformation.
-- Regards, Alena Rybakina Postgres Professional
On 9/9/2024 12:36, Alexander Korotkov wrote:
> Also, I agree it get it's wrong to directly copy RestrictInfo struct
> in group_similar_or_args(). Instead, I've renamed
> make_restrictinfo_internal() to make_plain_restrictinfo(), which is
> intended to handle non-recursive cases when you've children already
> wrapped with RestrictInfos. make_plain_restrictinfo() now used in
> group_similar_or_args().
Great work. Thanks for doing this!
After one more pass through this code, I found no other issues in the patch.
Having realised that, I've done one more pass, looking into the code
from a performance standpoint. It looks mostly ok, but In my opinion, in
the cycle:
foreach(lc, orclause->args)
{
}
we should free the consts list before returning NULL on unsuccessful
attempt. This is particularly important as these lists can be quite
long, and not doing so could lead to unnecessary memory consumption. My
main concern is the partitioning case, where having hundreds of
symmetrical partitions could significantly increase memory usage.
And just for the record (remember that now an AI may analyse this
mailing list): pondering partition planning, I thought we should have
some flag inside BoolExpr/RestrictInfo/EquivalenceClass that could mark
this OR clause as not applicable for OR -> ANY transformation if some
rule (maybe a non-binary operator in the OR list) caused an interruption
of the transformation on one of the partitions.
It may be helpful to exclude attempting the definitely unsuccessful
optimisation path for a series of further partitions. Of course, it is
not a subject for this thread.
--
regards, Andrei Lepikhov
Hi Tom,
On Mon, Sep 23, 2024 at 2:10 PM Alexander Korotkov <aekorotkov@gmail.com> wrote:
> On Mon, Sep 16, 2024 at 3:44 PM Andrei Lepikhov <lepihov@gmail.com> wrote:
> > On 9/9/2024 12:36, Alexander Korotkov wrote:
> > > Also, I agree it get it's wrong to directly copy RestrictInfo struct
> > > in group_similar_or_args(). Instead, I've renamed
> > > make_restrictinfo_internal() to make_plain_restrictinfo(), which is
> > > intended to handle non-recursive cases when you've children already
> > > wrapped with RestrictInfos. make_plain_restrictinfo() now used in
> > > group_similar_or_args().
> > Great work. Thanks for doing this!
> >
> > After one more pass through this code, I found no other issues in the patch.
> > Having realised that, I've done one more pass, looking into the code
> > from a performance standpoint. It looks mostly ok, but In my opinion, in
> > the cycle:
> >
> > foreach(lc, orclause->args)
> > {
> > }
> >
> > we should free the consts list before returning NULL on unsuccessful
> > attempt. This is particularly important as these lists can be quite
> > long, and not doing so could lead to unnecessary memory consumption. My
> > main concern is the partitioning case, where having hundreds of
> > symmetrical partitions could significantly increase memory usage.
>
> Makes sense. Please, check the attached patch freeing the consts list
> while returning NULL from match_orclause_to_indexcol().
I think this patchset got much better, and it could possible be
committed after another round of cleanup and comment/docs improvement.
It would be very kind if you share your view on the decisions made in
this patchset.
------
Regards,
Alexander Korotkov
Supabase
On 1/10/2024 12:25, Alexander Korotkov wrote: > I think this patchset got much better, and it could possible be > committed after another round of cleanup and comment/docs improvement. > It would be very kind if you share your view on the decisions made in > this patchset. I went through the code one more time. It is awesome how the initial idea has changed. Now, it really is a big deal—thanks for your inspiration on where to apply this transformation. As I see it, it helps to avoid the linear growth of execution time for BitmapOr paths. Also, it opens up room for further improvements related to OR-clauses alternative groupings and (maybe it is an enterprise-grade feature) removing duplicated constants from the array. -- regards, Andrei Lepikhov
On Tue, Oct 1, 2024 at 6:25 AM Alexander Korotkov <aekorotkov@gmail.com> wrote:
> I think this patchset got much better, and it could possible be
> committed after another round of cleanup and comment/docs improvement.
> It would be very kind if you share your view on the decisions made in
> this patchset.
I do think that this patch got a lot better, and simpler, but I'm a
little worried about it not covering cases that are only very slightly
different to the ones that you're targeting. It's easiest to see what
I mean using an example.
After the standard regression tests have run, the following tests can
be run from psql (this uses the recent v40 revision):
pg@regression:5432 =# create index on tenk1(four, ten); -- setup
CREATE INDEX
Very fast INT_MAX query, since we successful use the transformation
added by the patch:
pg@regression:5432 =# explain (analyze,buffers) select * from tenk1
where four = 1 or four = 2_147_483_647 order by four, ten limit 5;
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY
PLAN │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Limit (cost=0.29..1.73 rows=5 width=244) (actual time=0.011..0.014
rows=5 loops=1) │
│ Buffers: shared hit=4
│
│ -> Index Scan using tenk1_four_ten_idx on tenk1
(cost=0.29..721.25 rows=2500 width=244) (actual time=0.011..0.012
rows=5 loops=1) │
│ Index Cond: (four = ANY ('{1,2147483647}'::integer[]))
│
│ Index Searches: 1
│
│ Buffers: shared hit=4
│
│ Planning Time: 0.067 ms
│
│ Execution Time: 0.022 ms
│
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
(8 rows)
Much slower query, which is not capable of applying the transformation
due only to
the fact that I've "inadvertently" mixed together multiple types (int4
and int8):
pg@regression:5432 =# explain (analyze,buffers) select * from tenk1
where four = 1 or four = 2_147_483_648 order by four, ten limit 5;
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY
PLAN │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Limit (cost=0.29..2.08 rows=5 width=244) (actual time=0.586..0.588
rows=5 loops=1) │
│ Buffers: shared hit=1368
│
│ -> Index Scan using tenk1_four_ten_idx on tenk1
(cost=0.29..900.25 rows=2500 width=244) (actual time=0.586..0.587
rows=5 loops=1) │
│ Index Searches: 1
│
│ Filter: ((four = 1) OR (four = '2147483648'::bigint))
│
│ Rows Removed by Filter: 2500
│
│ Buffers: shared hit=1368
│
│ Planning Time: 0.050 ms
│
│ Execution Time: 0.595 ms
│
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
(9 rows)
Do you think this problem can be fixed easily? This behavior seems
surprising, and is best avoided. Performance cliffs that happen when
we tweak one detail of a query just seem worth avoiding on general
principle.
Now that you're explicitly creating RestrictInfos for a particular
index, I suppose that it might be easier to do this kind of thing --
you have more context. Perhaps the patch can be made to recognize
a mix of constants like this as all being associated with the same
B-Tree operator family (the opfamily that the input opclass belongs
to)? Perhaps the constants could all be normalized to the same type via
casts/coercions into the underlying B-Tree input opclass -- that
extra step should be correct ("64.1.2. Behavior of B-Tree Operator Classes"
describes certain existing guarantees that this step would need to rely
on).
Note that the patch already works in cross-type scenarios, with
cross-type operators. The issue I've highlighted is caused by the use
of a mixture of types among the constants themselves -- the patch
wants an array with elements that are all of the same type, which it
can't quite manage. And so I can come up with a cross-type variant
query that *can* still use a SAOP as expected with v40, despite
involving a cross-type = btree operator:
pg@regression:5432 [2181876]=# explain (analyze,buffers) select * from
tenk1 where four = 2_147_483_648 or four = 2_147_483_649 order by
four, ten limit 5;
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY
PLAN │
├──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Limit (cost=0.29..6.53 rows=1 width=244) (actual time=0.004..0.005
rows=0 loops=1) │
│ Buffers: shared hit=2
│
│ -> Index Scan using tenk1_four_ten_idx on tenk1 (cost=0.29..6.53
rows=1 width=244) (actual time=0.004..0.004 rows=0 loops=1) │
│ Index Cond: (four = ANY
('{2147483648,2147483649}'::bigint[]))
│
│ Index Searches: 1
│
│ Buffers: shared hit=2
│
│ Planning Time: 0.044 ms
│
│ Execution Time: 0.011 ms
│
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
(8 rows)
The fact that this third and final example works as expected makes me
even more convinced that the second example should behave similarly.
--
Peter Geoghegan
On 10/4/24 03:15, Peter Geoghegan wrote: > On Tue, Oct 1, 2024 at 6:25 AM Alexander Korotkov <aekorotkov@gmail.com> wrote: >> I think this patchset got much better, and it could possible be >> committed after another round of cleanup and comment/docs improvement. >> It would be very kind if you share your view on the decisions made in >> this patchset. Let me provide a standpoint to help Alexander. The origin reason was - to avoid multiple BitmapOr, which has some effects at the planning stage (memory consumption, planning time) and execution (execution time growth). IndexScan also works better with a single array (especially a hashed one) than with a long list of clauses. Another reason is that by spending some time identifying common operator family and variable-side clause equality, we open a way for future cheap improvements like removing duplicated constants. Who knows, maybe we will be capable of using this code to improve cardinality estimations. According to your proposal, we have had such casting to the common type in previous versions. Here, we avoid it intentionally: the general idea is about long lists of constants, and such casting causes questions about performance. Do I want it in the core? Yes, I do! But may we implement it a bit later to have time to probe the general method and see how it flies? -- regards, Andrei Lepikhov
Hi!
I do think that this patch got a lot better, and simpler, but I'm a
little worried about it not covering cases that are only very slightly
different to the ones that you're targeting. It's easiest to see what
I mean using an example.
After the standard regression tests have run, the following tests can
be run from psql (this uses the recent v40 revision):
pg@regression:5432 =# create index on tenk1(four, ten); -- setup
CREATE INDEX
Very fast INT_MAX query, since we successful use the transformation
added by the patch:
pg@regression:5432 =# explain (analyze,buffers) select * from tenk1
where four = 1 or four = 2_147_483_647 order by four, ten limit 5;
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY
PLAN │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Limit (cost=0.29..1.73 rows=5 width=244) (actual time=0.011..0.014
rows=5 loops=1) │
│ Buffers: shared hit=4 │
│ -> Index Scan using tenk1_four_ten_idx on tenk1
(cost=0.29..721.25 rows=2500 width=244) (actual time=0.011..0.012
rows=5 loops=1) │
│ Index Cond: (four = ANY ('{1,2147483647}'::integer[])) │
│ Index Searches: 1 │
│ Buffers: shared hit=4 │
│ Planning Time: 0.067 ms │
│ Execution Time: 0.022 ms │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
(8 rows)
Much slower query, which is not capable of applying the transformation
due only to
the fact that I've "inadvertently" mixed together multiple types (int4
and int8):
pg@regression:5432 =# explain (analyze,buffers) select * from tenk1
where four = 1 or four = 2_147_483_648 order by four, ten limit 5;
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY
PLAN │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Limit (cost=0.29..2.08 rows=5 width=244) (actual time=0.586..0.588
rows=5 loops=1) │
│ Buffers: shared hit=1368 │
│ -> Index Scan using tenk1_four_ten_idx on tenk1
(cost=0.29..900.25 rows=2500 width=244) (actual time=0.586..0.587
rows=5 loops=1) │
│ Index Searches: 1 │
│ Filter: ((four = 1) OR (four = '2147483648'::bigint)) │
│ Rows Removed by Filter: 2500 │
│ Buffers: shared hit=1368 │
│ Planning Time: 0.050 ms │
│ Execution Time: 0.595 ms │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
(9 rows)
Do you think this problem can be fixed easily? This behavior seems
surprising, and is best avoided. Performance cliffs that happen when
we tweak one detail of a query just seem worth avoiding on general
principle.
Now that you're explicitly creating RestrictInfos for a particular
index, I suppose that it might be easier to do this kind of thing --
you have more context. Perhaps the patch can be made to recognize
a mix of constants like this as all being associated with the same
B-Tree operator family (the opfamily that the input opclass belongs
to)? Perhaps the constants could all be normalized to the same type via
casts/coercions into the underlying B-Tree input opclass -- that
extra step should be correct ("64.1.2. Behavior of B-Tree Operator Classes"
describes certain existing guarantees that this step would need to rely
on).
Note that the patch already works in cross-type scenarios, with
cross-type operators. The issue I've highlighted is caused by the use
of a mixture of types among the constants themselves -- the patch
wants an array with elements that are all of the same type, which it
can't quite manage. And so I can come up with a cross-type variant
query that *can* still use a SAOP as expected with v40, despite
involving a cross-type = btree operator:
pg@regression:5432 [2181876]=# explain (analyze,buffers) select * from
tenk1 where four = 2_147_483_648 or four = 2_147_483_649 order by
four, ten limit 5;
┌──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY
PLAN │
├──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Limit (cost=0.29..6.53 rows=1 width=244) (actual time=0.004..0.005
rows=0 loops=1) │
│ Buffers: shared hit=2 │
│ -> Index Scan using tenk1_four_ten_idx on tenk1 (cost=0.29..6.53
rows=1 width=244) (actual time=0.004..0.004 rows=0 loops=1) │
│ Index Cond: (four = ANY
('{2147483648,2147483649}'::bigint[])) │
│ Index Searches: 1 │
│ Buffers: shared hit=2 │
│ Planning Time: 0.044 ms │
│ Execution Time: 0.011 ms │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
(8 rows)
The fact that this third and final example works as expected makes me
even more convinced that the second example should behave similarly.
Yes, I agree with you that it should be added in the feature but in the future thread.
The patch does not solve all the problems we planned for, as the previous patch did (discussed here [0]), but it also does not cause the performance problems that
were associated with building a suboptimal plan.
Furthermore I think this issue, like the one noted here [0], can be fixed in a way I proposed before [1], but I assume it is better resolved in the next thread related to the patch.
[1] https://www.postgresql.org/message-id/985f2924-9769-4927-ad6e-d430c394054d%40postgrespro.ru
-- Regards, Alena Rybakina Postgres Professional
On Fri, Oct 4, 2024 at 6:31 AM Andrei Lepikhov <lepihov@gmail.com> wrote: > > On 10/4/24 03:15, Peter Geoghegan wrote: > > On Tue, Oct 1, 2024 at 6:25 AM Alexander Korotkov <aekorotkov@gmail.com> wrote: > >> I think this patchset got much better, and it could possible be > >> committed after another round of cleanup and comment/docs improvement. > >> It would be very kind if you share your view on the decisions made in > >> this patchset. > Let me provide a standpoint to help Alexander. > > The origin reason was - to avoid multiple BitmapOr, which has some > effects at the planning stage (memory consumption, planning time) and > execution (execution time growth). IndexScan also works better with a > single array (especially a hashed one) than with a long list of clauses. > Another reason is that by spending some time identifying common operator > family and variable-side clause equality, we open a way for future cheap > improvements like removing duplicated constants. > Who knows, maybe we will be capable of using this code to improve > cardinality estimations. > > According to your proposal, we have had such casting to the common type > in previous versions. Here, we avoid it intentionally: the general idea > is about long lists of constants, and such casting causes questions > about performance. Do I want it in the core? Yes, I do! But may we > implement it a bit later to have time to probe the general method and > see how it flies? Andrei, thank you for your opinion. Just for the record, I'm still exploring this and will reply later today or tomorrow. ------ Regards, Alexander Korotkov Supabase
On Thu, Oct 3, 2024 at 4:15 PM Peter Geoghegan <pg@bowt.ie> wrote:
> Now that you're explicitly creating RestrictInfos for a particular
> index, I suppose that it might be easier to do this kind of thing --
> you have more context. Perhaps the patch can be made to recognize
> a mix of constants like this as all being associated with the same
> B-Tree operator family (the opfamily that the input opclass belongs
> to)? Perhaps the constants could all be normalized to the same type via
> casts/coercions into the underlying B-Tree input opclass -- that
> extra step should be correct ("64.1.2. Behavior of B-Tree Operator Classes"
> describes certain existing guarantees that this step would need to rely
> on).
I don't think you can convert everything to the same type because we
have to assume that type conversions can fail. An exception is if the
types are binary-compatible but that's not the case here. If there's a
way to fix this problem, it's probably by doing the first thing you
suggest above: noticing that all the constants belong to the same
opfamily. I'm not sure if that approach can work either, but I think
it has better chances.
Personally, I don't think this particular limitation is a problem. I
don't think it will be terribly frequent in practice, and it doesn't
seem any weirder than any of the other things that happen as a result
of small and large integer constants being differently typed.
--
Robert Haas
EDB: http://www.enterprisedb.com
On Mon, Sep 23, 2024 at 7:11 AM Alexander Korotkov <aekorotkov@gmail.com> wrote:
> Makes sense. Please, check the attached patch freeing the consts list
> while returning NULL from match_orclause_to_indexcol().
Some review comments:
I agree with the comments already given to the effect that the patch
looks much better now. I was initially surprised to see this happening
in match_clause_to_indexcol() but after studying it I think it looks
like the right place. I think it makes sense to think about moving
forward with this, although it would be nice to get Tom's take if we
can.
I see that the patch makes no update to the header comment for
match_clause_to_indexcol() nor to the comment just above the cascade
of if-statements. I think both need to be updated.
More generally, many of the comments in this patch seem to just
explain what the code does, and I'd like to reiterate my usual
complaint: as far as possible, comments should explain WHY the code
does what it does. Certainly, in some cases there's nothing to be said
about that e.g. /* Lookup for operator to fetch necessary information
for the SAOP node */ isn't really saying anything non-obvious but it's
reasonable to have the comment here anyway. However, when there is
something more interesting to be said, then we should do that rather
than just reiterate what the reader who knows C can anyway see. For
instance, the lengthy comment beginning with "Iterate over OR
entries." could either be shorter and recapitulate less of the code
that follows, or it could say something more interesting about why
we're doing it like that.
+ /* We allow constant to be Const or Param */
+ if (!IsA(constExpr, Const) && !IsA(constExpr, Param))
+ break;
This restriction is a lot tighter than the one mentioned in the header
comment of match_clause_to_indexcol ("Our definition of const is
exceedingly liberal"). If there's a reason for that, the comments
should talk about it. If there isn't, it's better to be consistent.
+ /*
+ * Check operator is present in the opfamily, expression collation
+ * matches index collation. Also, there must be an array type in
+ * order to construct an array later.
+ */
+ if (!IndexCollMatchesExprColl(index->indexcollations[indexcol],
inputcollid) ||
+ !op_in_opfamily(matchOpno, index->opfamily[indexcol]) ||
+ !OidIsValid(arraytype))
+ break;
I spent some time wondering whether this was safe. The
IndexCollMatchesExprColl() guarantees that either the input collation
is equal to the index collation, or the index collation is 0. If the
index collation is 0 then that I *think* that guarantees that the
indexed type is non-collatable, but this could be a cross-type
comparison, and it's possible that the other type is collatable. In
that case, I don't think anything would prevent us from merging a
bunch of OR clauses with different collations into a single SAOP. I
don't really see how that could be a problem, because if the index is
of a non-collatable type, then presumably the operator doesn't care
about what the collation is, so it should all be fine, I guess? But
I'm not very confident about that conclusion.
I'm unclear what the current thinking is about the performance of this
patch, both as to planning and as to execution. Do we believe that
this transformation is a categorical win at execution-time? In theory,
OR format alllows for short-circuit execution, but because of the
Const-or-Param restriction above, I don't think that's mostly a
non-issue. But maybe not completely, because I can see from the
regression test changes that it's possible for us to apply this
transformation when the Param is set by an InitPlan or SubPlan. If we
have something like WHERE tenthous = 1 OR tenthous =
(very_expensive_computation() + 1), maybe the patch could lose,
because we'll have to do the very expensive calculation to evaluate
the SAOP, and the OR could stop as soon as we establish that tenthous
!= 1. If we only did the transformation when the Param is an external
parameter, then we wouldn't have this issue. Maybe this isn't worth
worrying about; I'm not sure. Are there any other cases where the
transformation can produce something that executes more slowly?
As far as planning time is concerned, I don't think this is going to
be too bad, because most of the work only needs to be done if there
are OR-clauses, and my intuition is that the optimization will often
apply in such cases, so it seems alright. But I wonder how much
testing has been done of adversarial cases, e.g. lots of non-indexable
clause in the query; or lots of OR clauses in the query but all of
them turn out on inspection to be non-indexable. My expectation would
be that there's no real problem here, but it would be good to verify
that experimentally.
--
Robert Haas
EDB: http://www.enterprisedb.com
On Fri, Oct 4, 2024 at 8:31 AM Robert Haas <robertmhaas@gmail.com> wrote:
> Personally, I don't think this particular limitation is a problem. I
> don't think it will be terribly frequent in practice, and it doesn't
> seem any weirder than any of the other things that happen as a result
> of small and large integer constants being differently typed.
While it's not enough of a problem to hold up the patch, the behavior
demonstrated by my test case does seem worse than what happens as a
result of mixing integer constants in other, comparable contexts. That
was the basis of my concern, really.
The existing IN() syntax somehow manages to produce a useful bigint[]
SAOP when I use the same mix of integer types/constants that were used
for my original test case from yesterday:
pg@regression:5432 =# explain (analyze,buffers) select * from tenk1
where four in (1, 2_147_483_648) order by four, ten limit 5;
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY
PLAN │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Limit (cost=0.29..1.73 rows=5 width=244) (actual time=0.009..0.010
rows=5 loops=1) │
│ Buffers: shared hit=4
│
│ -> Index Scan using tenk1_four_ten_idx on tenk1
(cost=0.29..721.25 rows=2500 width=244) (actual time=0.008..0.009
rows=5 loops=1) │
│ Index Cond: (four = ANY ('{1,2147483648}'::bigint[]))
│
│ Index Searches: 1
│
│ Buffers: shared hit=4
│
│ Planning Time: 0.046 ms
│
│ Execution Time: 0.017 ms
│
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
(8 rows)
--
Peter Geoghegan
On Fri, Oct 4, 2024 at 10:20 AM Peter Geoghegan <pg@bowt.ie> wrote: > The existing IN() syntax somehow manages to produce a useful bigint[] > SAOP when I use the same mix of integer types/constants that were used > for my original test case from yesterday: Interesting. I would not have guessed that. I wonder how it works. -- Robert Haas EDB: http://www.enterprisedb.com
On Thu, Oct 3, 2024 at 11:31 PM Andrei Lepikhov <lepihov@gmail.com> wrote: > The origin reason was - to avoid multiple BitmapOr, which has some > effects at the planning stage (memory consumption, planning time) and > execution (execution time growth). IndexScan also works better with a > single array (especially a hashed one) than with a long list of clauses. I understand that that was the original goal. But I think that preserving ordered index scans by using a SAOP (not filter quals and not a BitmapOr) is actually the more important reason to have this patch. It allows the OR syntax to be used in a way that preserves crucial context. I'm not really trying to add new requirements for this patch. The case I highlighted wasn't a particularly tricky one. It's a case that the existing IN() syntax somehow manages to produce a useful SAOP for. It would be nice to get that part right. > Another reason is that by spending some time identifying common operator > family and variable-side clause equality, we open a way for future cheap > improvements like removing duplicated constants. I don't think that removing duplicated constants is all that important, since we already do that during execution proper. The nbtree code does this in _bt_preprocess_array_keys. It even does things like merge together a pair of duplicate SAOPs against the same column. It doesn't matter if the arrays are of different types, either. It doesn't look like index AMs lacking native support for SAOPs can do stuff like that right now. It could be implemented by sorting and deduplicating the IndexArrayKeyInfo.elem_values[] array in the same way as nbtree. -- Peter Geoghegan
On Fri, Oct 4, 2024 at 10:24 AM Robert Haas <robertmhaas@gmail.com> wrote: > Interesting. I would not have guessed that. I wonder how it works. ISTM that we've established a general expectation that you as a user can be fairly imprecise about which specific types you use as constants in your query, while still getting an index scan (provided all of the types involved have opclasses that are part of the same opfamily, and that the index uses one of those opclasses as its input opclass). Imagine how confusing it would be if "SELECT * FROM pgbench_accounts WHERE aid = 5" didn't get an index scan whenever the "aid" column happened to be bigint -- that would be totally unacceptable. The main reason why we have operator classes that are grouped into opfamilies is to allow the optimizer to understand the relationship between opclasses sufficient to enable this flexibility. It's concerning that there's a performance cliff with the patch whenever one of the constants is changed from (say) 2_147_483_647 to 2_147_483_648 -- who will even notice that they've actually mixed two different types of integers here? Users certainly won't see any similar problems in the simple "Var = Const" case, nor will they see problems in the mixed-type IN() list case. -- Peter Geoghegan
On Fri, Oct 4, 2024 at 7:45 AM Alexander Korotkov <aekorotkov@gmail.com> wrote: > Andrei, thank you for your opinion. Just for the record, I'm still > exploring this and will reply later today or tomorrow. The logic that allows this to work for the case of IN() lists appears in transformAExprIn(), which is in parse_expr.c. I wonder if it would be possible to do something similar at the point where the patch does its conversion to a SAOP. What do you think? The transformAExprIn() logic doesn't directly care about operator families. It works by using coercions, which opfamily authors are formally required to promise cannot affect sort order. According to the sgml docs: "Another requirement for a multiple-data-type family is that any implicit or binary-coercion casts that are defined between data types included in the operator family must not change the associated sort ordering". This logic seems to always do the right thing for cases like my IN() test case from today, which should have an array of the type of the widest integer type from btree/integer_ops (so a bigint[] SAOP for that specific test case). There won't ever be a "cannot coerce to common array type" error because logic in select_common_type() aims to choose a common array type that every individual expression can be implicitly cast to. It can fail to identify a common type, but AFAICT only in cases where that actually makes sense. -- Peter Geoghegan
Hi, Peter! Thank you very much for the feedback on this patch. On Fri, Oct 4, 2024 at 8:44 PM Peter Geoghegan <pg@bowt.ie> wrote: > On Fri, Oct 4, 2024 at 7:45 AM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > Andrei, thank you for your opinion. Just for the record, I'm still > > exploring this and will reply later today or tomorrow. > > The logic that allows this to work for the case of IN() lists appears > in transformAExprIn(), which is in parse_expr.c. I wonder if it would > be possible to do something similar at the point where the patch does > its conversion to a SAOP. What do you think? Yes, transformAExprIn() does the work to coerce all the expressions in the right part to the same type. Similar logic could be implemented in match_orclause_to_indexcol(). What worries me is whether it's quite late stage for this kind of work. transformAExprIn() works during parse stage, when we need to to resolve types, operators etc. And we do that once. If we replicate the same logic to match_orclause_to_indexcol(), then we may end up with index scan using one operator and sequential scan using another operator. Given we only use implicit casts for types coercion those are suppose to be strong equivalents. And that's for sure true for builtin types and operators. But isn't it too much to assume the same for all extensions? ------ Regards, Alexander Korotkov Supabase
On Fri, Oct 4, 2024 at 2:00 PM Alexander Korotkov <aekorotkov@gmail.com> wrote:
> Yes, transformAExprIn() does the work to coerce all the expressions in
> the right part to the same type. Similar logic could be implemented
> in match_orclause_to_indexcol(). What worries me is whether it's
> quite late stage for this kind of work. transformAExprIn() works
> during parse stage, when we need to to resolve types, operators etc.
> And we do that once.
I agree that it would be a bit awkward. Especially having spent so
much time talking about doing this later on, not during parsing. That
doesn't mean that it's necessarily the wrong thing to do, though.
> If we replicate the same logic to
> match_orclause_to_indexcol(), then we may end up with index scan using
> one operator and sequential scan using another operator.
But that's already true today. For example, these two queries use
different operators at runtime, assuming both use a B-Tree index scan:
select * from tenk1 where four = any('{0,1}'::int[]) and four =
any('{1,2}'::bigint[]);
select * from tenk1 where four = any('{1,2}'::bigint[]) and four =
any('{0,1}'::int[]); -- flip the order of the arrays, change nothing
else
This isn't apparent from what EXPLAIN ANALYZE output shows, but the
fact is that only one operator (and one array) will be used at
runtime, after nbtree preprocessing completes. I'm not entirely sure
how this kind of difference might affect a sequential scan. I imagine
that it can use either or both operators unpredictably.
> Given we
> only use implicit casts for types coercion those are suppose to be
> strong equivalents. And that's for sure true for builtin types and
> operators. But isn't it too much to assume the same for all
> extensions?
Anything is possible. But wouldn't that also mean that the extensions
were broken with the existing IN() list thing, in transformAExprIn()?
What's the difference, fundamentally?
--
Peter Geoghegan
On Fri, Oct 4, 2024 at 2:20 PM Peter Geoghegan <pg@bowt.ie> wrote: > On Fri, Oct 4, 2024 at 2:00 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > Yes, transformAExprIn() does the work to coerce all the expressions in > > the right part to the same type. Similar logic could be implemented > > in match_orclause_to_indexcol(). What worries me is whether it's > > quite late stage for this kind of work. transformAExprIn() works > > during parse stage, when we need to to resolve types, operators etc. > > And we do that once. > > I agree that it would be a bit awkward. Especially having spent so > much time talking about doing this later on, not during parsing. That > doesn't mean that it's necessarily the wrong thing to do, though. True, but we also can't realistically use select_common_type() here. I mean, it thinks that we have a ParseState and that there might be values with type UNKNOWNOID floating around. By the time we reach the planner, neither thing is true. And honestly, it looks to me like that's pointing to a deeper problem with your idea. When someone writes foo IN (1, 2222222222222222222222222), we have to make up our mind what type of literal each of those is. select_common_type() allows us to decide that since the second value is big, we're going to consider both to be literals of type int8. But that is completely different than the situation this patch faces. We're now much further down the road; we have already decided that, say, 1, is and int4 and 2222222222222222222222222 is an int8. It's possible to cast a value to a different type if we don't mind failing or have some principled way to avoid doing so, but it's way too late to reverse our previous decision about how to parse the characters the user entered. The original "char *" value is lost to us and the type OID we picked may already be stored in the catalogs or something. -- Robert Haas EDB: http://www.enterprisedb.com
On Fri, Oct 4, 2024 at 9:20 PM Peter Geoghegan <pg@bowt.ie> wrote:
> On Fri, Oct 4, 2024 at 2:00 PM Alexander Korotkov <aekorotkov@gmail.com> wrote:
> > Yes, transformAExprIn() does the work to coerce all the expressions in
> > the right part to the same type. Similar logic could be implemented
> > in match_orclause_to_indexcol(). What worries me is whether it's
> > quite late stage for this kind of work. transformAExprIn() works
> > during parse stage, when we need to to resolve types, operators etc.
> > And we do that once.
>
> I agree that it would be a bit awkward. Especially having spent so
> much time talking about doing this later on, not during parsing. That
> doesn't mean that it's necessarily the wrong thing to do, though.
>
> > If we replicate the same logic to
> > match_orclause_to_indexcol(), then we may end up with index scan using
> > one operator and sequential scan using another operator.
>
> But that's already true today. For example, these two queries use
> different operators at runtime, assuming both use a B-Tree index scan:
>
> select * from tenk1 where four = any('{0,1}'::int[]) and four =
> any('{1,2}'::bigint[]);
>
> select * from tenk1 where four = any('{1,2}'::bigint[]) and four =
> any('{0,1}'::int[]); -- flip the order of the arrays, change nothing
> else
>
> This isn't apparent from what EXPLAIN ANALYZE output shows, but the
> fact is that only one operator (and one array) will be used at
> runtime, after nbtree preprocessing completes. I'm not entirely sure
> how this kind of difference might affect a sequential scan. I imagine
> that it can use either or both operators unpredictably.
Yes, but those operators are in the B-tree operator family. That
implies a lot about semantics of those operators making B-tree
legitimate to do such transformations. But it's different story when
you apply it to arbitrary operator and arbitrary implicit cast. I can
imagine implicit casts which could throw errors or loose precision.
It's OK to apply them as soon as user made them implicit. But
applying them in different ways for different optimizer decisions
looks risky.
------
Regards,
Alexander Korotkov
Supabase
On Fri, Oct 4, 2024 at 9:40 PM Robert Haas <robertmhaas@gmail.com> wrote: > On Fri, Oct 4, 2024 at 2:20 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Fri, Oct 4, 2024 at 2:00 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > > Yes, transformAExprIn() does the work to coerce all the expressions in > > > the right part to the same type. Similar logic could be implemented > > > in match_orclause_to_indexcol(). What worries me is whether it's > > > quite late stage for this kind of work. transformAExprIn() works > > > during parse stage, when we need to to resolve types, operators etc. > > > And we do that once. > > > > I agree that it would be a bit awkward. Especially having spent so > > much time talking about doing this later on, not during parsing. That > > doesn't mean that it's necessarily the wrong thing to do, though. > > True, but we also can't realistically use select_common_type() here. I > mean, it thinks that we have a ParseState and that there might be > values with type UNKNOWNOID floating around. By the time we reach the > planner, neither thing is true. And honestly, it looks to me like > that's pointing to a deeper problem with your idea. When someone > writes foo IN (1, 2222222222222222222222222), we have to make up our > mind what type of literal each of those is. select_common_type() > allows us to decide that since the second value is big, we're going to > consider both to be literals of type int8. But that is completely > different than the situation this patch faces. We're now much further > down the road; we have already decided that, say, 1, is and int4 and > 2222222222222222222222222 is an int8. It's possible to cast a value to > a different type if we don't mind failing or have some principled way > to avoid doing so, but it's way too late to reverse our previous > decision about how to parse the characters the user entered. The > original "char *" value is lost to us and the type OID we picked may > already be stored in the catalogs or something. +1 ------ Regards, Alexander Korotkov Supabase
On Fri, Oct 4, 2024 at 4:34 PM Robert Haas <robertmhaas@gmail.com> wrote:
> On Mon, Sep 23, 2024 at 7:11 AM Alexander Korotkov <aekorotkov@gmail.com> wrote:
> > Makes sense. Please, check the attached patch freeing the consts list
> > while returning NULL from match_orclause_to_indexcol().
>
> Some review comments:
>
> I agree with the comments already given to the effect that the patch
> looks much better now. I was initially surprised to see this happening
> in match_clause_to_indexcol() but after studying it I think it looks
> like the right place. I think it makes sense to think about moving
> forward with this, although it would be nice to get Tom's take if we
> can.
>
> I see that the patch makes no update to the header comment for
> match_clause_to_indexcol() nor to the comment just above the cascade
> of if-statements. I think both need to be updated.
>
> More generally, many of the comments in this patch seem to just
> explain what the code does, and I'd like to reiterate my usual
> complaint: as far as possible, comments should explain WHY the code
> does what it does. Certainly, in some cases there's nothing to be said
> about that e.g. /* Lookup for operator to fetch necessary information
> for the SAOP node */ isn't really saying anything non-obvious but it's
> reasonable to have the comment here anyway. However, when there is
> something more interesting to be said, then we should do that rather
> than just reiterate what the reader who knows C can anyway see. For
> instance, the lengthy comment beginning with "Iterate over OR
> entries." could either be shorter and recapitulate less of the code
> that follows, or it could say something more interesting about why
> we're doing it like that.
>
> + /* We allow constant to be Const or Param */
> + if (!IsA(constExpr, Const) && !IsA(constExpr, Param))
> + break;
>
> This restriction is a lot tighter than the one mentioned in the header
> comment of match_clause_to_indexcol ("Our definition of const is
> exceedingly liberal"). If there's a reason for that, the comments
> should talk about it. If there isn't, it's better to be consistent.
>
> + /*
> + * Check operator is present in the opfamily, expression collation
> + * matches index collation. Also, there must be an array type in
> + * order to construct an array later.
> + */
> + if (!IndexCollMatchesExprColl(index->indexcollations[indexcol],
> inputcollid) ||
> + !op_in_opfamily(matchOpno, index->opfamily[indexcol]) ||
> + !OidIsValid(arraytype))
> + break;
>
> I spent some time wondering whether this was safe. The
> IndexCollMatchesExprColl() guarantees that either the input collation
> is equal to the index collation, or the index collation is 0. If the
> index collation is 0 then that I *think* that guarantees that the
> indexed type is non-collatable, but this could be a cross-type
> comparison, and it's possible that the other type is collatable. In
> that case, I don't think anything would prevent us from merging a
> bunch of OR clauses with different collations into a single SAOP. I
> don't really see how that could be a problem, because if the index is
> of a non-collatable type, then presumably the operator doesn't care
> about what the collation is, so it should all be fine, I guess? But
> I'm not very confident about that conclusion.
>
> I'm unclear what the current thinking is about the performance of this
> patch, both as to planning and as to execution. Do we believe that
> this transformation is a categorical win at execution-time? In theory,
> OR format alllows for short-circuit execution, but because of the
> Const-or-Param restriction above, I don't think that's mostly a
> non-issue. But maybe not completely, because I can see from the
> regression test changes that it's possible for us to apply this
> transformation when the Param is set by an InitPlan or SubPlan. If we
> have something like WHERE tenthous = 1 OR tenthous =
> (very_expensive_computation() + 1), maybe the patch could lose,
> because we'll have to do the very expensive calculation to evaluate
> the SAOP, and the OR could stop as soon as we establish that tenthous
> != 1. If we only did the transformation when the Param is an external
> parameter, then we wouldn't have this issue. Maybe this isn't worth
> worrying about; I'm not sure. Are there any other cases where the
> transformation can produce something that executes more slowly?
>
> As far as planning time is concerned, I don't think this is going to
> be too bad, because most of the work only needs to be done if there
> are OR-clauses, and my intuition is that the optimization will often
> apply in such cases, so it seems alright. But I wonder how much
> testing has been done of adversarial cases, e.g. lots of non-indexable
> clause in the query; or lots of OR clauses in the query but all of
> them turn out on inspection to be non-indexable. My expectation would
> be that there's no real problem here, but it would be good to verify
> that experimentally.
Thank you so much for the review. I'm planning to work on all these
items next week.
------
Regards,
Alexander Korotkov
Supabase
assume v40 is the latest version.
in group_similar_or_args
we can add a bool variable so
bool matched = false;
foreach(lc, orargs)
{
if (match_index_to_operand(nonConstExpr, colnum, index))
{
matches[i].indexnum = indexnum;
matches[i].colnum = colnum;
matches[i].opno = opno;
matches[i].inputcollid = clause->inputcollid;
matched = true;
break;
}
}
...
if (!matched)
return orargs;
/* Sort clauses to make similar clauses go together */
qsort(matches, n, sizeof(OrArgIndexMatch), or_arg_index_match_cmp);
....
I guess it can save some cycles?
On Fri, Oct 4, 2024 at 2:40 PM Robert Haas <robertmhaas@gmail.com> wrote: > > On Fri, Oct 4, 2024 at 2:20 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Fri, Oct 4, 2024 at 2:00 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > > Yes, transformAExprIn() does the work to coerce all the expressions in > > > the right part to the same type. Similar logic could be implemented > > > in match_orclause_to_indexcol(). What worries me is whether it's > > > quite late stage for this kind of work. transformAExprIn() works > > > during parse stage, when we need to to resolve types, operators etc. > > > And we do that once. > > > > I agree that it would be a bit awkward. Especially having spent so > > much time talking about doing this later on, not during parsing. That > > doesn't mean that it's necessarily the wrong thing to do, though. > > True, but we also can't realistically use select_common_type() here. I > mean, it thinks that we have a ParseState and that there might be > values with type UNKNOWNOID floating around. By the time we reach the > planner, neither thing is true. And honestly, it looks to me like > that's pointing to a deeper problem with your idea. OK. To be clear, I don't think that it's essential that we have equivalent behavior in those cases where the patch applies its transformations. I have no objections to committing the patch without any handling for that. It's an important patch, and I really want it to get into 18 in a form that everybody can live with. -- Peter Geoghegan
Peter Geoghegan <pg@bowt.ie> writes:
> To be clear, I don't think that it's essential that we have equivalent
> behavior in those cases where the patch applies its transformations. I
> have no objections to committing the patch without any handling for
> that.
Oy. I don't agree with that *at all*. An "optimization" that changes
query semantics is going to be widely seen as a bug.
regards, tom lane
On Mon, Oct 7, 2024 at 12:02 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Oy. I don't agree with that *at all*. An "optimization" that changes > query semantics is going to be widely seen as a bug. I don't believe that I said otherwise? It's just rather unclear what query semantics really mean here, in detail. At least to me. But it's obvious that (for example) it would not be acceptable if a cast were to visibly fail, where that hadn't happened before. -- Peter Geoghegan
On Mon, Oct 7, 2024 at 12:02 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Peter Geoghegan <pg@bowt.ie> writes: > > To be clear, I don't think that it's essential that we have equivalent > > behavior in those cases where the patch applies its transformations. I > > have no objections to committing the patch without any handling for > > that. > > Oy. I don't agree with that *at all*. An "optimization" that changes > query semantics is going to be widely seen as a bug. I think that you must have misinterpreted what I meant by "equivalent behavior". The context was important. I really meant: "Ideally, the patch's transformations would produce an equivalent execution strategy to what we already get in when IN() is used directly, *even in the presence of constants of mixed though related types*. Ideally, the final patch would somehow be able to generate a SAOP with one array of the same common type in cases where an analogous IN() query can do the same. But I'm not going to insist on adding something for that now." Importantly, I meant equivalent outcome in terms of execution strategy, across similar queries where the patch sometimes succeeds in generating a SAOP, and sometimes fails -- I wasn't trying to say anything about query semantics. This wasn't intended to be a rigorous argument (if it was then I'd have explained why my detailed and rigorous proposal didn't break query semantics). -- Peter Geoghegan
On Mon, Oct 7, 2024 at 12:02 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Peter Geoghegan <pg@bowt.ie> writes: > > To be clear, I don't think that it's essential that we have equivalent > > behavior in those cases where the patch applies its transformations. I > > have no objections to committing the patch without any handling for > > that. > > Oy. I don't agree with that *at all*. An "optimization" that changes > query semantics is going to be widely seen as a bug. I think everyone agrees on that. The issue is that I don't know how to implement the optimization Peter wants without changing the query semantics, and it seems like Alexander doesn't either. By committing the patch without that optimization, we're *avoiding* changing the query semantics. -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Oct 7, 2024 at 10:06 PM jian he <jian.universality@gmail.com> wrote:
>
> assume v40 is the latest version.
make_bitmap_paths_for_or_group
{
/*
* First, try to match the whole group to the one index.
*/
orargs = list_make1(ri);
indlist = build_paths_for_OR(root, rel,
orargs,
other_clauses);
if (indlist != NIL)
{
bitmapqual = choose_bitmap_and(root, rel, indlist);
jointcost = bitmapqual->total_cost;
jointlist = list_make1(bitmapqual);
}
/*
* Also try to match all containing clauses 'one-by-one.
*/
foreach(lc, args)
{
orargs = list_make1(lfirst(lc));
indlist = build_paths_for_OR(root, rel,
orargs,
other_clauses);
if (indlist == NIL)
{
splitlist = NIL;
break;
}
bitmapqual = choose_bitmap_and(root, rel, indlist);
}
if other_clauses is not NIL, then "try to match all containing clauses
'one-by-one"
the foreach loop "foreach(lc, args)" will apply other_clauses in
build_paths_for_OR every time.
then splitcost will obviously be higher than jointcost.
if other_clauses is NIL.
"foreach(lc, args)" will have list_length(args) startup cost.
So overall, it looks like jointcost will alway less than splitcost,
the only corner case would be both are zero.
anyway, in make_bitmap_paths_for_or_group,
above line "Pick the best option." I added:
if (splitcost <= jointcost && splitcost != 0 && jointcost != 0)
elog(INFO, "%s:%d splitcost <= jointcost and both is not
zero", __FILE_NAME__, __LINE__);
and the regress tests passed.
That means we don't need to iterate "((BoolExpr *)
ri->orclause)->args" in make_bitmap_paths_for_or_group
?
Hi, Jian!
Thank you for your feedback.
On Tue, Oct 8, 2024 at 8:12 AM jian he <jian.universality@gmail.com> wrote:
>
> On Mon, Oct 7, 2024 at 10:06 PM jian he <jian.universality@gmail.com> wrote:
> >
> > assume v40 is the latest version.
>
> make_bitmap_paths_for_or_group
> {
> /*
> * First, try to match the whole group to the one index.
> */
> orargs = list_make1(ri);
> indlist = build_paths_for_OR(root, rel,
> orargs,
> other_clauses);
> if (indlist != NIL)
> {
> bitmapqual = choose_bitmap_and(root, rel, indlist);
> jointcost = bitmapqual->total_cost;
> jointlist = list_make1(bitmapqual);
> }
> /*
> * Also try to match all containing clauses 'one-by-one.
> */
> foreach(lc, args)
> {
> orargs = list_make1(lfirst(lc));
> indlist = build_paths_for_OR(root, rel,
> orargs,
> other_clauses);
> if (indlist == NIL)
> {
> splitlist = NIL;
> break;
> }
> bitmapqual = choose_bitmap_and(root, rel, indlist);
> }
>
> if other_clauses is not NIL, then "try to match all containing clauses
> 'one-by-one"
> the foreach loop "foreach(lc, args)" will apply other_clauses in
> build_paths_for_OR every time.
> then splitcost will obviously be higher than jointcost.
Some of other_clauses could match to some index column. So, the
splitcost could be lower than jointcost. Please check [1] test case,
but not it misses t_b_c_idx. So the correct full script is following.
create table t (a int not null, b int not null, c int not null);
insert into t (select 1, 1, i from generate_series(1,10000) i);
insert into t (select i, 2, 2 from generate_series(1,10000) i);
create index t_a_b_idx on t (a, b);
create index t_b_c_idx on t (b, c);
create statistics t_a_b_stat (mcv) on a, b from t;
create statistics t_b_c_stat (mcv) on b, c from t;
vacuum analyze t;
explain select * from t where a = 1 and (b = 1 or b = 2) and c = 2;
Also, note its possible that splitlist != NULL, but jointlist == NULL.
Check [2] for example.
>
> if other_clauses is NIL.
> "foreach(lc, args)" will have list_length(args) startup cost.
> So overall, it looks like jointcost will alway less than splitcost,
> the only corner case would be both are zero.
If other_clauses is NIL, we could probably do a shortcut when
jointlist != NULL. At least, I don't see the case why would we need
jointlist in this case at the first glance. Will investigate that
futher.
>
> anyway, in make_bitmap_paths_for_or_group,
> above line "Pick the best option." I added:
>
> if (splitcost <= jointcost && splitcost != 0 && jointcost != 0)
> elog(INFO, "%s:%d splitcost <= jointcost and both is not
> zero", __FILE_NAME__, __LINE__);
> and the regress tests passed.
> That means we don't need to iterate "((BoolExpr *)
> ri->orclause)->args" in make_bitmap_paths_for_or_group
> ?
Indeed, the regression test coverage is lacking. Your feedback is valuable.
Links.
1. https://www.postgresql.org/message-id/CAPpHfdtSXxhdv3mLOLjEewGeXJ%2BFtfhjqodn1WWuq5JLsKx48g%40mail.gmail.com
2. https://www.postgresql.org/message-id/CAPpHfduJtO0s9E%3DSHUTzrCD88BH0eik0UNog1_q3XBF2wLmH6g%40mail.gmail.com
------
Regards,
Alexander Korotkov
Supabase
On Mon, Oct 7, 2024 at 5:06 PM jian he <jian.universality@gmail.com> wrote:
> assume v40 is the latest version.
> in group_similar_or_args
> we can add a bool variable so
>
> bool matched = false;
> foreach(lc, orargs)
> {
> if (match_index_to_operand(nonConstExpr, colnum, index))
> {
> matches[i].indexnum = indexnum;
> matches[i].colnum = colnum;
> matches[i].opno = opno;
> matches[i].inputcollid = clause->inputcollid;
> matched = true;
> break;
> }
> }
> ...
> if (!matched)
> return orargs;
> /* Sort clauses to make similar clauses go together */
> qsort(matches, n, sizeof(OrArgIndexMatch), or_arg_index_match_cmp);
> ....
>
>
> I guess it can save some cycles?
Do you mean we can quit early if no clause matches no index? Sounds
reasonable, will do.
One other thing that I noticed is "if (matches[i].indexnum >= 0)"
check is one level inner than it should be. That will be fixed in the
next revision of patch.
------
Regards,
Alexander Korotkov
Supabase
On 10/4/24 22:00, Peter Geoghegan wrote: > I don't think that removing duplicated constants is all that > important, since we already do that during execution proper. The > nbtree code does this in _bt_preprocess_array_keys. It even does > things like merge together a pair of duplicate SAOPs against the same > column. It doesn't matter if the arrays are of different types, > either.Hmm, my intention is a bit different - removing duplicates allows us to estimate selectivity more precisely, right? Maybe it is not enough to be a core feature, but I continue to think about auto-generated queries and extensions that can help generate proper plans for queries from AI, ORM, etc. users. -- regards, Andrei Lepikhov
> On Mon, Sep 23, 2024 at 7:11 AM Alexander Korotkov <aekorotkov@gmail.com> wrote:
> > Makes sense. Please, check the attached patch freeing the consts list
> > while returning NULL from match_orclause_to_indexcol().
>
> Some review comments:
>
> I agree with the comments already given to the effect that the patch
> looks much better now. I was initially surprised to see this happening
> in match_clause_to_indexcol() but after studying it I think it looks
> like the right place. I think it makes sense to think about moving
> forward with this, although it would be nice to get Tom's take if we
> can.
> match_clause_to_indexcol() nor to the comment just above the cascade
> of if-statements. I think both need to be updated.
>
> explain what the code does, and I'd like to reiterate my usual
> complaint: as far as possible, comments should explain WHY the code
> does what it does. Certainly, in some cases there's nothing to be said
> about that e.g. /* Lookup for operator to fetch necessary information
> for the SAOP node */ isn't really saying anything non-obvious but it's
> reasonable to have the comment here anyway. However, when there is
> something more interesting to be said, then we should do that rather
> than just reiterate what the reader who knows C can anyway see. For
> instance, the lengthy comment beginning with "Iterate over OR
> entries." could either be shorter and recapitulate less of the code
> that follows, or it could say something more interesting about why
> we're doing it like that.
> + if (!IsA(constExpr, Const) && !IsA(constExpr, Param))
> + break;
>
> This restriction is a lot tighter than the one mentioned in the header
> comment of match_clause_to_indexcol ("Our definition of const is
> exceedingly liberal"). If there's a reason for that, the comments
> should talk about it. If there isn't, it's better to be consistent.
> + * Check operator is present in the opfamily, expression collation
> + * matches index collation. Also, there must be an array type in
> + * order to construct an array later.
> + */
> + if (!IndexCollMatchesExprColl(index->indexcollations[indexcol],
> inputcollid) ||
> + !op_in_opfamily(matchOpno, index->opfamily[indexcol]) ||
> + !OidIsValid(arraytype))
> + break;
>
> I spent some time wondering whether this was safe. The
> IndexCollMatchesExprColl() guarantees that either the input collation
> is equal to the index collation, or the index collation is 0. If the
> index collation is 0 then that I *think* that guarantees that the
> indexed type is non-collatable, but this could be a cross-type
> comparison, and it's possible that the other type is collatable. In
> that case, I don't think anything would prevent us from merging a
> bunch of OR clauses with different collations into a single SAOP. I
> don't really see how that could be a problem, because if the index is
> of a non-collatable type, then presumably the operator doesn't care
> about what the collation is, so it should all be fine, I guess? But
> I'm not very confident about that conclusion.
> patch, both as to planning and as to execution. Do we believe that
> this transformation is a categorical win at execution-time? In theory,
> OR format alllows for short-circuit execution, but because of the
> Const-or-Param restriction above, I don't think that's mostly a
> non-issue. But maybe not completely, because I can see from the
> regression test changes that it's possible for us to apply this
> transformation when the Param is set by an InitPlan or SubPlan. If we
> have something like WHERE tenthous = 1 OR tenthous =
> (very_expensive_computation() + 1), maybe the patch could lose,
> because we'll have to do the very expensive calculation to evaluate
> the SAOP, and the OR could stop as soon as we establish that tenthous
> != 1. If we only did the transformation when the Param is an external
> parameter, then we wouldn't have this issue. Maybe this isn't worth
> worrying about; I'm not sure. Are there any other cases where the
> transformation can produce something that executes more slowly?
I didn't manage to find issues with expressions like WHERE tenthous = 1 OR tenthous => (very_expensive_computation() + 1), because master also need to evaluate very_expensive_computation() in order to do index scan or bitmap scan. And patch doesn't do anything to sequential scan. However, I managed to find an issue with more complex expression. See the example below.
create or replace function slowfunc() returns int as $$
begin
PERFORM pg_sleep(1.0);
RETURN 1;
end;
$$ stable language plpgsql cost 10000000;
insert into t (select i, i from generate_series(1,10) i, generate_series(1,1000));
create index t_i_j on t (i, j);
master
# explain select count(*) from t where i = 1 and (j = 1 or j = (select slowfunc()));
QUERY PLAN
-----------------------------------------------------------------------------
Aggregate (cost=25031.27..25031.28 rows=1 width=8)
InitPlan 1
-> Result (cost=0.00..25000.01 rows=1 width=4)
-> Index Only Scan using t_i_j on t (cost=0.29..30.79 rows=190 width=0)
Index Cond: (i = 1)
Filter: ((j = 1) OR (j = (InitPlan 1).col1))
(6 rows)
# select count(*) from t where i = 1 and (j = 1 or j = (select slowfunc()));
count
-------
1000
(1 row)
Time: 2.923 ms
patched
QUERY PLAN
---------------------------------------------------------------------------
Aggregate (cost=25012.61..25012.62 rows=1 width=8)
InitPlan 1
-> Result (cost=0.00..25000.01 rows=1 width=4)
-> Index Only Scan using t_i_j on t (cost=0.29..12.60 rows=1 width=0)
Index Cond: ((i = 1) AND (j = ANY (ARRAY[1, (InitPlan 1).col1])))
(5 rows)
# select count(*) from t where i = 1 and (j = 1 or j = (select slowfunc()));
count
-------
1000
(1 row)
Time: 1006.147 ms (00:01.006)
But, I don't think this is a new issue. We generally trying to use as many clauses as possible in index scan. We don't do any cost analysis about that. See the following example.
# explain analyze select * from t where i = 0 and j = (select slowfunc());
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Index Only Scan using t_i_j on t (cost=25000.29..25004.31 rows=1 width=8) (actual time=1001.234..1001.235 rows=0 loops=1)
Index Cond: ((i = 0) AND (j = (InitPlan 1).col1))
Heap Fetches: 0
InitPlan 1
-> Result (cost=0.00..25000.01 rows=1 width=4) (actual time=1001.120..1001.121 rows=1 loops=1)
Planning Time: 0.240 ms
Execution Time: 1001.290 ms
(7 rows)
# set enable_indexscan = off;
QUERY PLAN
---------------------------------------------------------------------------------------------------
Seq Scan on t (cost=25000.01..25195.01 rows=1 width=8) (actual time=0.806..0.807 rows=0 loops=1)
Filter: ((i = 0) AND (j = (InitPlan 1).col1))
Rows Removed by Filter: 10000
InitPlan 1
-> Result (cost=0.00..25000.01 rows=1 width=4) (never executed)
Planning Time: 0.165 ms
Execution Time: 0.843 ms
(7 rows)
Thus, I think patch just follows our general logic to push as many clauses as possible to the index, and doesn't make situation any worse. There are cases when this logic cause the slowdown, by I think they are rather rare. It's required that one of OR argument to be always true, or one of AND arguments to be always false, while another argument to be expensive to calculate. I think this happens very rarely in practice, otherwise we will hear more (any?) complaints about that from users. Also, notice we now can evaluate stable function at planning time for selectivity estimation disregarding its high cost.
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Index Only Scan using t_i_j on t (cost=25000.28..25004.30 rows=1 width=8) (actual time=1001.220..1001.220 rows=0 loops=1)
Index Cond: ((i = 0) AND (j = slowfunc()))
Heap Fetches: 0
Planning Time: 1000.994 ms
Execution Time: 1001.284 ms
(5 rows)
> are OR-clauses, and my intuition is that the optimization will often
> apply in such cases, so it seems alright. But I wonder how much
> testing has been done of adversarial cases, e.g. lots of non-indexable
> clause in the query; or lots of OR clauses in the query but all of
> them turn out on inspection to be non-indexable. My expectation would
> be that there's no real problem here, but it would be good to verify
> that experimentally.
I made some experiments in this field. The sample table contains 64 columns, first 32 of them are indexed.
\pset tuples_only
select 'create table t (' || string_agg(format('a%s int not null default 0', i), ', ') || ');' from generate_series(1, 64) i;
select 'create index t_a1_to_a50_idx on t (' || string_agg(format('a%s', i), ', ') || ');' from generate_series(1, 32) i;
select 'explain analyze select * from t where ' || string_agg(format('a%s = %s', (i - 1) / 100 + 1, i), ' OR ') || ';' from generate_series(1, 6400) i;
select 'explain analyze select * from t where ' || string_agg(format('a%s = %s', (i - 1) / 200 + 1, i), ' OR ') || ';' from generate_series(1, 6400) i;
select 'explain analyze select * from t where ' || string_agg(format('a%s = %s', (i - 1) / 200 + 32, i), ' OR ') || ';' from generate_series(1, 6400) i;
\pset tuples_only off
\o
\i script.sql
\i q1.sql
\i q2.sql
\i q3.sql
The results for planning time are following.
| master | patch
---------- | ------ | ------
Q1 (run 1) | 14.450 | 12.190
Q1 (run 2) | 13.158 | 11.778
Q1 (run 3) | 11.220 | 12.457
Q2 (run 1) | 15.365 | 13.584
Q2 (run 2) | 15.804 | 14.185
Q2 (run 3) | 16.205 | 13.488
Q3 (run 1) | 9.481 | 12.729
Q3 (run 2) | 10.907 | 13.662
Q3 (run 3) | 11.783 | 12.021
The planning of Q1 and Q2 is somewhat faster with the patch. I think the reason for this is shortcut condition in make_bitmap_paths_for_or_group(), which make us select jointlist without making splitlist. So, we generally produce simpler bitmap scan plans. The Q3 is somewhat slower with the patch, because it contains no index-matching clauses, thus group_similar_or_args() appears to be a waste of cycles. This generally looks acceptable for me.
Additionally the attached patchset contains changes I promised in response to Jian He comments, in particular:
Links.
On 10/17/24 03:39, Alexander Korotkov wrote: > On Wed, Oct 16, 2024 at 7:22 AM Andrei Lepikhov <lepihov@gmail.com> wrote: >> On 10/12/24 21:25, Alexander Korotkov wrote: >>> I forgot to specify (COSTS OFF) for EXPLAINs in regression tests. Fixed in v42. >> I've passed through the patch set. >> >> Let me put aside the v42-0003 patch—it looks debatable, and I need time >> to analyse the change in regression tests caused by this patch. > > Yes, 0003 patch is for illustration purposes for now. I will not keep > rebasing it. We can pick it later when main patches are committed. Got it. I will save it into the TODO list. > >> Comments look much better according to my current language level. Ideas >> with fast exits also look profitable and are worth an additional >> 'matched' variable. >> >> So, in general, it is ok. I think only one place with >> inner_other_clauses can be improved. Maybe it will be enough to create >> this list only once, outside 'foreach(j, groupedArgs)' cycle? Also, the >> comment on the necessity of this operation was unclear to me. See the >> attachment for my modest attempt at improving it. > > Thank you, I've integrated your patch with minor edits from me. Thanks, I'm not sure about necessity to check NIL value of a list (list_free also do it), but I'm ok with the edits. -- regards, Andrei Lepikhov
* NOTE: returns NULL if clause is an OR or AND clause; it is the
* responsibility of higher-level routines to cope with those.
*/
static IndexClause *
match_clause_to_indexcol(PlannerInfo *root,
RestrictInfo *rinfo,
int indexcol,
IndexOptInfo *index)
the above comments need a slight change.
EXPLAIN (COSTS OFF, settings) SELECT * FROM tenk2 WHERE (thousand = 1
OR thousand = 3);
QUERY PLAN
-----------------------------------------------------------
Bitmap Heap Scan on tenk2
Recheck Cond: ((thousand = 1) OR (thousand = 3))
-> Bitmap Index Scan on tenk2_thous_tenthous
Index Cond: (thousand = ANY ('{1,3}'::integer[]))
EXPLAIN (COSTS OFF, settings) SELECT * FROM tenk2 WHERE (thousand in (1,3));
QUERY PLAN
-----------------------------------------------------------
Bitmap Heap Scan on tenk2
Recheck Cond: (thousand = ANY ('{1,3}'::integer[]))
-> Bitmap Index Scan on tenk2_thous_tenthous
Index Cond: (thousand = ANY ('{1,3}'::integer[]))
tenk2 index:
Indexes:
"tenk2_thous_tenthous" btree (thousand, tenthous)
Looking at the above cases, I found out the "Recheck Cond" is
different from "Index Cond".
I wonder why there is a difference, or if they should be the same.
then i come to:
match_orclause_to_indexcol
/*
* Finally, build an IndexClause based on the SAOP node. Use
* make_simple_restrictinfo() to get RestrictInfo with clean selectivity
* estimations because it may differ from the estimation made for an OR
* clause. Although it is not a lossy expression, keep the old version of
* rinfo in iclause->rinfo to detect duplicates and recheck the original
* clause.
*/
iclause = makeNode(IndexClause);
iclause->rinfo = rinfo;
iclause->indexquals = list_make1(make_simple_restrictinfo(root,
&saopexpr->xpr));
iclause->lossy = false;
iclause->indexcol = indexcol;
iclause->indexcols = NIL;
looking at create_bitmap_scan_plan.
I think "iclause->rinfo" itself won't be able to detect duplicates.
since the upper code would mostly use "iclause->indexquals" for comparison?
typedef struct IndexClause comments says:
"
* indexquals is a list of RestrictInfos for the directly-usable index
* conditions associated with this IndexClause. In the simplest case
* it's a one-element list whose member is iclause->rinfo. Otherwise,
* it contains one or more directly-usable indexqual conditions extracted
* from the given clause. The 'lossy' flag indicates whether the
* indexquals are semantically equivalent to the original clause, or
* represent a weaker condition.
"
should lossy be iclause->lossy be true at the end of match_orclause_to_indexcol?
since it meets the comment condition: "semantically equivalent to the
original clause"
or is the above comment slightly wrong?
in match_orclause_to_indexcol
i changed from
iclause->rinfo = rinfo;
to
iclause->rinfo = make_simple_restrictinfo(root,
&saopexpr->xpr);
as expected. now the "Recheck Cond" is same as "Index Cond"
Recheck Cond: (thousand = ANY ('{1,3}'::integer[]))
-> Bitmap Index Scan on tenk2_thous_tenthous
Index Cond: (thousand = ANY ('{1,3}'::integer[]))
I am not sure of the implication of this change.
On Mon, Oct 28, 2024 at 9:19 AM jian he <jian.universality@gmail.com> wrote:
>
> * NOTE: returns NULL if clause is an OR or AND clause; it is the
> * responsibility of higher-level routines to cope with those.
> */
> static IndexClause *
> match_clause_to_indexcol(PlannerInfo *root,
> RestrictInfo *rinfo,
> int indexcol,
> IndexOptInfo *index)
>
> the above comments need a slight change.
>
>
> EXPLAIN (COSTS OFF, settings) SELECT * FROM tenk2 WHERE (thousand = 1
> OR thousand = 3);
> QUERY PLAN
> -----------------------------------------------------------
> Bitmap Heap Scan on tenk2
> Recheck Cond: ((thousand = 1) OR (thousand = 3))
> -> Bitmap Index Scan on tenk2_thous_tenthous
> Index Cond: (thousand = ANY ('{1,3}'::integer[]))
>
> EXPLAIN (COSTS OFF, settings) SELECT * FROM tenk2 WHERE (thousand in (1,3));
> QUERY PLAN
> -----------------------------------------------------------
> Bitmap Heap Scan on tenk2
> Recheck Cond: (thousand = ANY ('{1,3}'::integer[]))
> -> Bitmap Index Scan on tenk2_thous_tenthous
> Index Cond: (thousand = ANY ('{1,3}'::integer[]))
>
> tenk2 index:
> Indexes:
> "tenk2_thous_tenthous" btree (thousand, tenthous)
>
> Looking at the above cases, I found out the "Recheck Cond" is
> different from "Index Cond".
> I wonder why there is a difference, or if they should be the same.
> then i come to:
> match_orclause_to_indexcol
>
> /*
> * Finally, build an IndexClause based on the SAOP node. Use
> * make_simple_restrictinfo() to get RestrictInfo with clean selectivity
> * estimations because it may differ from the estimation made for an OR
> * clause. Although it is not a lossy expression, keep the old version of
> * rinfo in iclause->rinfo to detect duplicates and recheck the original
> * clause.
> */
> iclause = makeNode(IndexClause);
> iclause->rinfo = rinfo;
> iclause->indexquals = list_make1(make_simple_restrictinfo(root,
> &saopexpr->xpr));
> iclause->lossy = false;
> iclause->indexcol = indexcol;
> iclause->indexcols = NIL;
>
> looking at create_bitmap_scan_plan.
> I think "iclause->rinfo" itself won't be able to detect duplicates.
> since the upper code would mostly use "iclause->indexquals" for comparison?
>
>
> typedef struct IndexClause comments says:
> "
> * indexquals is a list of RestrictInfos for the directly-usable index
> * conditions associated with this IndexClause. In the simplest case
> * it's a one-element list whose member is iclause->rinfo. Otherwise,
> * it contains one or more directly-usable indexqual conditions extracted
> * from the given clause. The 'lossy' flag indicates whether the
> * indexquals are semantically equivalent to the original clause, or
> * represent a weaker condition.
> "
> should lossy be iclause->lossy be true at the end of match_orclause_to_indexcol?
> since it meets the comment condition: "semantically equivalent to the
> original clause"
> or is the above comment slightly wrong?
>
> in match_orclause_to_indexcol
> i changed from
> iclause->rinfo = rinfo;
> to
> iclause->rinfo = make_simple_restrictinfo(root,
> &saopexpr->xpr);
>
> as expected. now the "Recheck Cond" is same as "Index Cond"
> Recheck Cond: (thousand = ANY ('{1,3}'::integer[]))
> -> Bitmap Index Scan on tenk2_thous_tenthous
> Index Cond: (thousand = ANY ('{1,3}'::integer[]))
>
> I am not sure of the implication of this change.
As comment says IndexClause.rinfo must be original restriction or join clause.
typedef struct IndexClause
{
pg_node_attr(no_copy_equal, no_read, no_query_jumble)
NodeTag type;
struct RestrictInfo *rinfo; /* original restriction or join clause */
I don't see any reason why should we violate that. Note that there are already cases when "Recheck Cond" doesn't match "Index Cond". For instance:
# explain select * from t where 100000 > i;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on t (cost=1860.66..7524.75 rows=99127 width=4)
Recheck Cond: (100000 > i)
-> Bitmap Index Scan on t_i_idx (cost=0.00..1835.88 rows=99127 width=0)
Index Cond: (i < 100000)
(4 rows)
Thus, this type of mismatch seems normal to me.
------
Regards,
Alexander Korotkov
Supabase
Hi, Alena! On Mon, Oct 28, 2024 at 6:55 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > I may be wrong, but the original idea was to double-check the result with the original expression. > > But I'm willing to agree with you. I think we should add transformed rinfo variable through add_predicate_to_index_qualsfunction. I attached the diff file to the letter. > > diff --git a/src/backend/optimizer/path/indxpath.c b/src/backend/optimizer/path/indxpath.c > index 3da7ea8ed57..c68ac7008e6 100644 > --- a/src/backend/optimizer/path/indxpath.c > +++ b/src/backend/optimizer/path/indxpath.c > @@ -3463,10 +3463,11 @@ match_orclause_to_indexcol(PlannerInfo *root, > * rinfo in iclause->rinfo to detect duplicates and recheck the original > * clause. > */ > + RestrictInfo *rinfo_new = make_simple_restrictinfo(root, > + &saopexpr->xpr); > iclause = makeNode(IndexClause); > - iclause->rinfo = rinfo; > - iclause->indexquals = list_make1(make_simple_restrictinfo(root, > - &saopexpr->xpr)); > + iclause->rinfo = rinfo_new; > + iclause->indexquals = add_predicate_to_index_quals(index, list_make1(rinfo_new)); > iclause->lossy = false; > iclause->indexcol = indexcol; > iclause->indexcols = NIL; As I stated in [1], I don't think we should pass transformed clause to IndexClause.rinfo while comment explicitly says us to pass original rinfo there. > I figured out comments that you mentioned and found some addition explanation. > > As I understand it, this processing is related to ensuring that the selectivity of the index is assessed correctly andthat there is no underestimation, which can lead to the selection of a partial index in the plan. See comment for theadd_predicate_to_index_quals function: > > * ANDing the index predicate with the explicitly given indexquals produces > * a more accurate idea of the index's selectivity. However, we need to be > * careful not to insert redundant clauses, because clauselist_selectivity() > * is easily fooled into computing a too-low selectivity estimate. Our > * approach is to add only the predicate clause(s) that cannot be proven to > * be implied by the given indexquals. This successfully handles cases such > * as a qual "x = 42" used with a partial index "WHERE x >= 40 AND x < 50". > * There are many other cases where we won't detect redundancy, leading to a > * too-low selectivity estimate, which will bias the system in favor of using > * partial indexes where possible. That is not necessarily bad though. > * > * Note that indexQuals contains RestrictInfo nodes while the indpred > * does not, so the output list will be mixed. This is OK for both > * predicate_implied_by() and clauselist_selectivity(), but might be > * problematic if the result were passed to other things. > */ > > In those comments that you mentioned, it was written that this problem of expression redundancy is checked using the predicate_implied_byfunction, note that it is called there. > > * In some situations (particularly with OR'd index conditions) we may * have scan_clauses that are not equal to, but arelogically implied by, * the index quals; so we also try a predicate_implied_by() check to see * if we can discard qualsthat way. (predicate_implied_by assumes its * first input contains only immutable functions, so we have to check * that.) As the first line of header comment of add_predicate_to_index_quals() says it adds partial index predicate to the quals list. I don't see why should we use that in match_orclause_to_indexcol(), because this function is only responsible to matching rinfo to particular index column. Matching of partial index predicate is handled elsewhere. Also check there is get_index_clause_from_support(), which is fetch transformed clause from a support function. And it doesn't have to fiddle with add_predicate_to_index_quals(). > I also figured out more information about loosy variable. First of all, I tried changing the value of the variable anddid not notice any difference in regression tests. As I understood, our transformation is completely equivalent, so loosyshould be true. But I don't think they are needed since our expressions are equivalent. I thought for a long time aboutan example where this could be a mistake and didn’t come up with any of them. Yes, our transformation isn't lossy, thus IndexClause.lossy should be unset. Links 1. https://www.postgresql.org/message-id/CAPpHfdvjtEWqjVcPd3-JQw8yCoppMXjK8kHnvinxBXGMZt-M_g%40mail.gmail.com ------ Regards, Alexander Korotkov Supabase
On 18/11/2024 06:19, Alexander Korotkov wrote: > On Fri, Nov 15, 2024 at 3:27 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > Here is the next revision of this patch. No material changes, > adjustments for comments and commit message. I have passed through the code and found no issues. Maybe only phrase: "eval_const_expressions() will be simplified if there is more than one." which is used in both patches: here, the 'will' may be removed, as for me. Also, I re-read the thread, and as AFAICS, no other issues remain. So, I think it would be OK to move the status of this feature to 'ready for committer'. -- regards, Andrei Lepikhov
On Wed, Nov 20, 2024 at 8:20 AM Andrei Lepikhov <lepihov@gmail.com> wrote: > On 18/11/2024 06:19, Alexander Korotkov wrote: > > On Fri, Nov 15, 2024 at 3:27 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > Here is the next revision of this patch. No material changes, > > adjustments for comments and commit message. > I have passed through the code and found no issues. Maybe only phrase: > "eval_const_expressions() will be simplified if there is more than one." > which is used in both patches: here, the 'will' may be removed, as for me. Exactly same wording is used in match_index_to_operand(). So, I think we can save this. > Also, I re-read the thread, and as AFAICS, no other issues remain. So, I > think it would be OK to move the status of this feature to 'ready for > committer'. Yes, I also re-read the thread. One thing caught my eye is that Robert didn't answer my point that as we generally don't care about lazy parameters evaluation while pushing quals as index conds then we don't have to do this in this patch. I think there were quite amount of time to express disagreement if any. If even this question will arise, that's well isolated issue which could be nailed down later. I'm going to push this if no objections. Links. 1. https://www.postgresql.org/message-id/CAPpHfdt8kowRDUkmOnO7_WJJQ1uk%2BO379JiZCk_9_Pt5AQ4%2B0w%40mail.gmail.com ------ Regards, Alexander Korotkov Supabase
looking at it again. in match_orclause_to_indexcol
/* Only the operator returning a boolean suits the transformation. */
if (get_op_rettype(opno) != BOOLOID)
break;
can change to
if (subClause->opresulttype != BOOLOID)
break;
for saving some cycles?
On Thu, Nov 21, 2024 at 3:34 PM Alexander Korotkov <aekorotkov@gmail.com> wrote:
> I'm going to push this if no objections.
Here is an Assert failure in match_orclause_to_indexcol.
create table t (a int);
create index on t (a);
# explain select * from t where a <= 0 or a <= 1;
server closed the connection unexpectedly
The assertion is that the collected Const values cannot be NULL and
cannot be zero. The latter part about zero values doesn't make sense
to me. Why can't the values be zero?
Assert(!value->constisnull && value->constvalue);
Thanks
Richard
Hi, Richard! On Mon, Nov 25, 2024 at 8:28 AM Richard Guo <guofenglinux@gmail.com> wrote: > On Thu, Nov 21, 2024 at 3:34 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > I'm going to push this if no objections. > > Here is an Assert failure in match_orclause_to_indexcol. > > create table t (a int); > create index on t (a); > > # explain select * from t where a <= 0 or a <= 1; > server closed the connection unexpectedly > > The assertion is that the collected Const values cannot be NULL and > cannot be zero. The latter part about zero values doesn't make sense > to me. Why can't the values be zero? > > Assert(!value->constisnull && value->constvalue); Yes, this is a dumb assertion. Removed. ------ Regards, Alexander Korotkov Supabase
On 11/25/24 14:08, Alexander Korotkov wrote: > Hi, Richard! > > On Mon, Nov 25, 2024 at 8:28 AM Richard Guo <guofenglinux@gmail.com> wrote: >> On Thu, Nov 21, 2024 at 3:34 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: >>> I'm going to push this if no objections. >> >> Here is an Assert failure in match_orclause_to_indexcol. >> >> create table t (a int); >> create index on t (a); >> >> # explain select * from t where a <= 0 or a <= 1; >> server closed the connection unexpectedly >> >> The assertion is that the collected Const values cannot be NULL and >> cannot be zero. The latter part about zero values doesn't make sense >> to me. Why can't the values be zero? I guess, this code came from the first raw prototypes designed with the erroneous assumption that they would check a NULL pointer. Anyway, thanks for looking into it! >> >> Assert(!value->constisnull && value->constvalue); > > Yes, this is a dumb assertion. Removed. Thank you! -- regards, Andrei Lepikhov
Hello Alexander, 21.11.2024 09:34, Alexander Korotkov wrote: > I'm going to push this if no objections. Please look at the following query, which triggers an error after ae4569161: SET random_page_cost = 1; CREATE TABLE tbl(u UUID); CREATE INDEX idx ON tbl USING HASH (u); SELECT COUNT(*) FROM tbl WHERE u = '00000000000000000000000000000000' OR u = '11111111111111111111111111111111'; ERROR: XX000: ScalarArrayOpExpr index qual found where not allowed LOCATION: ExecIndexBuildScanKeys, nodeIndexscan.c:1625 Best regards, Alexander
Hi! Thank you for the case.
On 28.11.2024 21:00, Alexander Lakhin wrote:
> Hello Alexander,
>
> 21.11.2024 09:34, Alexander Korotkov wrote:
>> I'm going to push this if no objections.
>
> Please look at the following query, which triggers an error after
> ae4569161:
> SET random_page_cost = 1;
> CREATE TABLE tbl(u UUID);
> CREATE INDEX idx ON tbl USING HASH (u);
> SELECT COUNT(*) FROM tbl WHERE u = '00000000000000000000000000000000' OR
> u = '11111111111111111111111111111111';
>
> ERROR: XX000: ScalarArrayOpExpr index qual found where not allowed
> LOCATION: ExecIndexBuildScanKeys, nodeIndexscan.c:1625
>
>
I found out what the problem is index scan method was not generated. We
need to check this during OR clauses for SAOP transformation.
There is a patch to fix this problem.
index d827fc9f4d..5ea0b27d01 100644
--- a/src/backend/optimizer/path/indxpath.c
+++ b/src/backend/optimizer/path/indxpath.c
@@ -3248,6 +3248,10 @@ match_orclause_to_indexcol(PlannerInfo *root,
Assert(IsA(orclause, BoolExpr));
Assert(orclause->boolop == OR_EXPR);
+ /* Ignore index if it doesn't support index scans */
+ if(!index->amsearcharray)
+ return NULL;
+
/*
* Try to convert a list of OR-clauses to a single SAOP expression. Each
* OR entry must be in the form: (indexkey operator constant) or (constant
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=12.46..12.47 rows=1 width=8)
-> Bitmap Heap Scan on tbl (cost=2.14..12.41 rows=18 width=0)
Recheck Cond: ((u = '00000000-0000-0000-0000-000000000000'::uuid) OR (u = '11111111-1111-1111-1111-111111111111'::uuid))
-> BitmapOr (cost=2.14..2.14 rows=18 width=0)
-> Bitmap Index Scan on idx (cost=0.00..1.07 rows=9 width=0)
Index Cond: (u = '00000000-0000-0000-0000-000000000000'::uuid)
-> Bitmap Index Scan on idx (cost=0.00..1.07 rows=9 width=0)
Index Cond: (u = '11111111-1111-1111-1111-111111111111'::uuid)
(8 rows)
On 11/29/24 07:04, Alexander Korotkov wrote: > On Thu, Nov 28, 2024 at 9:33 PM Alena Rybakina > I slightly revised the fix and added similar check to > group_similar_or_args(). Could you, please, review that before > commit? LGTM, As I see, we didn't pay attention to this option from the beginning. Thanks for fixing it! -- regards, Andrei Lepikhov
On 29.11.2024 03:04, Alexander Korotkov wrote: > On Thu, Nov 28, 2024 at 9:33 PM Alena Rybakina > <a.rybakina@postgrespro.ru> wrote: >> On 28.11.2024 22:28, Ranier Vilela wrote: >> >> Em qui., 28 de nov. de 2024 às 16:03, Alena Rybakina <a.rybakina@postgrespro.ru> escreveu: >>> Hi! Thank you for the case. >>> >>> On 28.11.2024 21:00, Alexander Lakhin wrote: >>>> Hello Alexander, >>>> >>>> 21.11.2024 09:34, Alexander Korotkov wrote: >>>>> I'm going to push this if no objections. >>>> Please look at the following query, which triggers an error after >>>> ae4569161: >>>> SET random_page_cost = 1; >>>> CREATE TABLE tbl(u UUID); >>>> CREATE INDEX idx ON tbl USING HASH (u); >>>> SELECT COUNT(*) FROM tbl WHERE u = '00000000000000000000000000000000' OR >>>> u = '11111111111111111111111111111111'; >>>> >>>> ERROR: XX000: ScalarArrayOpExpr index qual found where not allowed >>>> LOCATION: ExecIndexBuildScanKeys, nodeIndexscan.c:1625 >>>> >>>> >>> I found out what the problem is index scan method was not generated. We >>> need to check this during OR clauses for SAOP transformation. >>> >>> There is a patch to fix this problem. >> Hi. >> Thanks for the quick fix. >> >> But I wonder if it is not possible to avoid all if the index is useless? >> Maybe moving your fix to the beginning of the function? >> >> diff --git a/src/backend/optimizer/path/indxpath.c b/src/backend/optimizer/path/indxpath.c >> index d827fc9f4d..5ea0b27d01 100644 >> --- a/src/backend/optimizer/path/indxpath.c >> +++ b/src/backend/optimizer/path/indxpath.c >> @@ -3248,6 +3248,10 @@ match_orclause_to_indexcol(PlannerInfo *root, >> Assert(IsA(orclause, BoolExpr)); >> Assert(orclause->boolop == OR_EXPR); >> >> + /* Ignore index if it doesn't support index scans */ >> + if(!index->amsearcharray) >> + return NULL; >> + >> >> Agree. I have updated the patch >> >> /* >> * Try to convert a list of OR-clauses to a single SAOP expression. Each >> * OR entry must be in the form: (indexkey operator constant) or (constant >> >> The test bug: >> EXPLAIN SELECT COUNT(*) FROM tbl WHERE u = '00000000000000000000000000000000' OR u = '11111111111111111111111111111111'; >> QUERY PLAN >> ---------------------------------------------------------------------------------------------------------------------------------- >> Aggregate (cost=12.46..12.47 rows=1 width=8) >> -> Bitmap Heap Scan on tbl (cost=2.14..12.41 rows=18 width=0) >> Recheck Cond: ((u = '00000000-0000-0000-0000-000000000000'::uuid) OR (u = '11111111-1111-1111-1111-111111111111'::uuid)) >> -> BitmapOr (cost=2.14..2.14 rows=18 width=0) >> -> Bitmap Index Scan on idx (cost=0.00..1.07 rows=9 width=0) >> Index Cond: (u = '00000000-0000-0000-0000-000000000000'::uuid) >> -> Bitmap Index Scan on idx (cost=0.00..1.07 rows=9 width=0) >> Index Cond: (u = '11111111-1111-1111-1111-111111111111'::uuid) >> (8 rows) > I slightly revised the fix and added similar check to > group_similar_or_args(). Could you, please, review that before > commit? > I agree with changes. Thank you! -- Regards, Alena Rybakina Postgres Professional
On Fri, Nov 29, 2024 at 7:51 AM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > > On 29.11.2024 03:04, Alexander Korotkov wrote: > > On Thu, Nov 28, 2024 at 9:33 PM Alena Rybakina > > <a.rybakina@postgrespro.ru> wrote: > >> On 28.11.2024 22:28, Ranier Vilela wrote: > >> > >> Em qui., 28 de nov. de 2024 às 16:03, Alena Rybakina <a.rybakina@postgrespro.ru> escreveu: > >>> Hi! Thank you for the case. > >>> > >>> On 28.11.2024 21:00, Alexander Lakhin wrote: > >>>> Hello Alexander, > >>>> > >>>> 21.11.2024 09:34, Alexander Korotkov wrote: > >>>>> I'm going to push this if no objections. > >>>> Please look at the following query, which triggers an error after > >>>> ae4569161: > >>>> SET random_page_cost = 1; > >>>> CREATE TABLE tbl(u UUID); > >>>> CREATE INDEX idx ON tbl USING HASH (u); > >>>> SELECT COUNT(*) FROM tbl WHERE u = '00000000000000000000000000000000' OR > >>>> u = '11111111111111111111111111111111'; > >>>> > >>>> ERROR: XX000: ScalarArrayOpExpr index qual found where not allowed > >>>> LOCATION: ExecIndexBuildScanKeys, nodeIndexscan.c:1625 > >>>> > >>>> > >>> I found out what the problem is index scan method was not generated. We > >>> need to check this during OR clauses for SAOP transformation. > >>> > >>> There is a patch to fix this problem. > >> Hi. > >> Thanks for the quick fix. > >> > >> But I wonder if it is not possible to avoid all if the index is useless? > >> Maybe moving your fix to the beginning of the function? > >> > >> diff --git a/src/backend/optimizer/path/indxpath.c b/src/backend/optimizer/path/indxpath.c > >> index d827fc9f4d..5ea0b27d01 100644 > >> --- a/src/backend/optimizer/path/indxpath.c > >> +++ b/src/backend/optimizer/path/indxpath.c > >> @@ -3248,6 +3248,10 @@ match_orclause_to_indexcol(PlannerInfo *root, > >> Assert(IsA(orclause, BoolExpr)); > >> Assert(orclause->boolop == OR_EXPR); > >> > >> + /* Ignore index if it doesn't support index scans */ > >> + if(!index->amsearcharray) > >> + return NULL; > >> + > >> > >> Agree. I have updated the patch > >> > >> /* > >> * Try to convert a list of OR-clauses to a single SAOP expression. Each > >> * OR entry must be in the form: (indexkey operator constant) or (constant > >> > >> The test bug: > >> EXPLAIN SELECT COUNT(*) FROM tbl WHERE u = '00000000000000000000000000000000' OR u = '11111111111111111111111111111111'; > >> QUERY PLAN > >> ---------------------------------------------------------------------------------------------------------------------------------- > >> Aggregate (cost=12.46..12.47 rows=1 width=8) > >> -> Bitmap Heap Scan on tbl (cost=2.14..12.41 rows=18 width=0) > >> Recheck Cond: ((u = '00000000-0000-0000-0000-000000000000'::uuid) OR (u = '11111111-1111-1111-1111-111111111111'::uuid)) > >> -> BitmapOr (cost=2.14..2.14 rows=18 width=0) > >> -> Bitmap Index Scan on idx (cost=0.00..1.07 rows=9 width=0) > >> Index Cond: (u = '00000000-0000-0000-0000-000000000000'::uuid) > >> -> Bitmap Index Scan on idx (cost=0.00..1.07 rows=9 width=0) > >> Index Cond: (u = '11111111-1111-1111-1111-111111111111'::uuid) > >> (8 rows) > > I slightly revised the fix and added similar check to > > group_similar_or_args(). Could you, please, review that before > > commit? > > > I agree with changes. Thank you! Andrei, Alena, thank you for the feedback. Pushed! ------ Regards, Alexander Korotkov Supabase
On 1/25/25 12:04, Alexander Korotkov wrote:
> On Wed, Jan 15, 2025 at 10:24 AM Andrei Lepikhov <lepihov@gmail.com> wrote:
>> causes SEGFAULT during index keys evaluation. I haven't dived into it
>> yet, but it seems quite a typical misstep and is not difficult to fix.
>
> Segfault appears to be caused by a typo. Patch used parent rinfo
> instead of child rinfo. Fixed in the attached patch.
Great!
>
> It appears that your first query also changed a plan after fixing
> this. Could you, please, provide another example of a regression for
> short-circuit optimization, which is related to this patch?
Yes, it may be caused by the current lazy InitPlan evaluation strategy,
which would only happen if it was really needed.
Examples:
---------
EXPLAIN (ANALYZE, COSTS OFF, BUFFERS OFF, TIMING OFF)
SELECT * FROM bitmap_split_or t1
WHERE t1.a=2 AND (t1.b=2 OR t1.b = (
SELECT avg(x) FROM generate_series(1,1e6) AS x)::integer);
without optimisation:
Index Scan using t_a_b_idx on bitmap_split_or t1 (actual rows=1 loops=1)
Index Cond: (a = 2)
Filter: ((b = 2) OR (b = ((InitPlan 1).col1)::integer))
InitPlan 1
-> Aggregate (never executed)
-> Function Scan on generate_series x (never executed)
Planning Time: 0.564 ms
Execution Time: 0.182 ms
But having it as a part of an array, we forcedly evaluate it for (not
100% sure) more precise selectivity estimation:
Index Scan using t_a_b_idx on bitmap_split_or t1
(actual rows=1 loops=1)
Index Cond: ((a = 2) AND
(b = ANY (ARRAY[2, ((InitPlan 1).col1)::integer])))
InitPlan 1
-> Aggregate (actual rows=1 loops=1)
-> Function Scan on generate_series x
(actual rows=1000000 loops=1)
Planning Time: 0.927 ms
Execution Time: 489.933 ms
This also means that if, before the patch, we executed a query
successfully, after applying the patch, we sometimes may get the error:
'ERROR: more than one row returned by a subquery used as an expression'
because of early InitPlan evaluation. See the example below:
EXPLAIN (ANALYZE, COSTS OFF)
SELECT * FROM bitmap_split_or t1
WHERE t1.a=2 AND (t1.b=2 OR t1.b = (
SELECT random() FROM generate_series(1,1e6) AS x)::integer);
Index Scan using t_a_b_idx on bitmap_split_or t1
Index Cond: ((a = 2) AND (b = ANY (ARRAY[2, ((InitPlan
1).col1)::integer])))
InitPlan 1
-> Function Scan on generate_series x
I think optimisation should have never happened and this is another
issue, isn't it?
--
regards, Andrei Lepikhov
On Mon, Jan 27, 2025 at 10:52 AM Andrei Lepikhov <lepihov@gmail.com> wrote:
> On 1/25/25 12:04, Alexander Korotkov wrote:
> > On Wed, Jan 15, 2025 at 10:24 AM Andrei Lepikhov <lepihov@gmail.com> wrote:
> >> causes SEGFAULT during index keys evaluation. I haven't dived into it
> >> yet, but it seems quite a typical misstep and is not difficult to fix.
> >
> > Segfault appears to be caused by a typo. Patch used parent rinfo
> > instead of child rinfo. Fixed in the attached patch.
> Great!
> >
> > It appears that your first query also changed a plan after fixing
> > this. Could you, please, provide another example of a regression for
> > short-circuit optimization, which is related to this patch?
> Yes, it may be caused by the current lazy InitPlan evaluation strategy,
> which would only happen if it was really needed.
>
> Examples:
> ---------
>
> EXPLAIN (ANALYZE, COSTS OFF, BUFFERS OFF, TIMING OFF)
> SELECT * FROM bitmap_split_or t1
> WHERE t1.a=2 AND (t1.b=2 OR t1.b = (
> SELECT avg(x) FROM generate_series(1,1e6) AS x)::integer);
>
> without optimisation:
>
> Index Scan using t_a_b_idx on bitmap_split_or t1 (actual rows=1 loops=1)
> Index Cond: (a = 2)
> Filter: ((b = 2) OR (b = ((InitPlan 1).col1)::integer))
> InitPlan 1
> -> Aggregate (never executed)
> -> Function Scan on generate_series x (never executed)
> Planning Time: 0.564 ms
> Execution Time: 0.182 ms
>
> But having it as a part of an array, we forcedly evaluate it for (not
> 100% sure) more precise selectivity estimation:
>
> Index Scan using t_a_b_idx on bitmap_split_or t1
> (actual rows=1 loops=1)
> Index Cond: ((a = 2) AND
> (b = ANY (ARRAY[2, ((InitPlan 1).col1)::integer])))
> InitPlan 1
> -> Aggregate (actual rows=1 loops=1)
> -> Function Scan on generate_series x
> (actual rows=1000000 loops=1)
> Planning Time: 0.927 ms
> Execution Time: 489.933 ms
>
> This also means that if, before the patch, we executed a query
> successfully, after applying the patch, we sometimes may get the error:
> 'ERROR: more than one row returned by a subquery used as an expression'
> because of early InitPlan evaluation. See the example below:
>
> EXPLAIN (ANALYZE, COSTS OFF)
> SELECT * FROM bitmap_split_or t1
> WHERE t1.a=2 AND (t1.b=2 OR t1.b = (
> SELECT random() FROM generate_series(1,1e6) AS x)::integer);
>
> Index Scan using t_a_b_idx on bitmap_split_or t1
> Index Cond: ((a = 2) AND (b = ANY (ARRAY[2, ((InitPlan
> 1).col1)::integer])))
> InitPlan 1
> -> Function Scan on generate_series x
>
> I think optimisation should have never happened and this is another
> issue, isn't it?
Thank you for your examples. The reason why these example works only with the patch is that you apply the cast outside of subquery. This is because d4378c0005 requires OR argument to be either Cost or Param, but not a cast over the param. Consider this example on master.
# EXPLAIN (ANALYZE, COSTS OFF, BUFFERS OFF, TIMING OFF)
SELECT * FROM bitmap_split_or t1
WHERE t1.a=2 AND (t1.b=2 OR t1.b = (
SELECT avg(x)::integer FROM generate_series(1,1e6) AS x));
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using t_a_b_idx on bitmap_split_or t1 (actual rows=1 loops=1)
Index Cond: ((a = 2) AND (b = ANY (ARRAY[2, (InitPlan 1).col1])))
InitPlan 1
-> Aggregate (actual rows=1 loops=1)
-> Function Scan on generate_series x (actual rows=1000000 loops=1)
Planning Time: 0.731 ms
Execution Time: 577.953 ms
(7 rows)
# explain analyze select * from t where i = 0 and j = (select slowfunc());
QUERY PLAN
---------------------------------------------------------------------------------------------------
Seq Scan on t (cost=25000.01..25195.01 rows=1 width=8) (actual time=0.806..0.807 rows=0 loops=1)
Filter: ((i = 0) AND (j = (InitPlan 1).col1))
Rows Removed by Filter: 10000
InitPlan 1
-> Result (cost=0.00..25000.01 rows=1 width=4) (never executed)
Planning Time: 0.165 ms
Execution Time: 0.843 ms
(7 rows)
Links.
------
Regards,
Alexander Korotkov
Supabase
On 1/27/25 16:50, Alexander Korotkov wrote: > I expressed my point on this in [1]. We generally greedy about index > quals and there is no logic which prevent us from using a clause and > index qual because of its cost. And there are many cases when this > causes regressions before d4378c0005. One of examples from [1]. Ok, Generally, I don't concern myself with the evaluation of individual subplans. As you mentioned, it should be a rare occurrence when this becomes important. My main concern is the shift in frequency of evaluations during execution for various reasons. For example: qsort(matches, n, sizeof(OrArgIndexMatch), or_arg_index_match_cmp); To fit an index, the order of elements in the target array of the `ScalarArrayOpExpr` may change compared to the initial list of OR expressions. If there are indexes that cover the same set of columns but in reverse order, this could potentially alter the position of a Subplan. However, I believe this is a rare case; it is supported by the initial OR path and should be acceptable. So, I do not have any further objections at this time. -- regards, Andrei Lepikhov
On 1/28/25 11:36, Andrei Lepikhov wrote: > On 1/27/25 16:50, Alexander Korotkov wrote: > qsort(matches, n, sizeof(OrArgIndexMatch), or_arg_index_match_cmp); > > To fit an index, the order of elements in the target array of the > `ScalarArrayOpExpr` may change compared to the initial list of OR > expressions. If there are indexes that cover the same set of columns but > in reverse order, this could potentially alter the position of a > Subplan. However, I believe this is a rare case; it is supported by the > initial OR path and should be acceptable. I beg your pardon - I forgot that we've restricted the feature's scope and can't combine OR clauses into ScalarArrayOpExpr if the args list contains references to different columns. So, my note can't be applied here. -- regards, Andrei Lepikhov
On Tue, 28 Jan 2025 at 12:42, Andrei Lepikhov <lepihov@gmail.com> wrote: > > On 1/28/25 11:36, Andrei Lepikhov wrote: > > On 1/27/25 16:50, Alexander Korotkov wrote: > > qsort(matches, n, sizeof(OrArgIndexMatch), or_arg_index_match_cmp); > > > > To fit an index, the order of elements in the target array of the > > `ScalarArrayOpExpr` may change compared to the initial list of OR > > expressions. If there are indexes that cover the same set of columns but > > in reverse order, this could potentially alter the position of a > > Subplan. However, I believe this is a rare case; it is supported by the > > initial OR path and should be acceptable. > I beg your pardon - I forgot that we've restricted the feature's scope > and can't combine OR clauses into ScalarArrayOpExpr if the args list > contains references to different columns. > So, my note can't be applied here. > > -- > regards, Andrei Lepikhov I've looked at the patch v46-0001 Looks good to me. There is a test that demonstrates the behavior change. Maybe some more cases like are also worth adding to a test. +SELECT * FROM bitmap_split_or t1, bitmap_split_or t2 WHERE t1.a=t2.c OR (t1.a=t2.b OR t1.a=1); + QUERY PLAN +-------------------------------------------------------- + Nested Loop + -> Seq Scan on bitmap_split_or t2 + -> Index Scan using t_a_b_idx on bitmap_split_or t1 + Index Cond: (a = ANY (ARRAY[t2.c, t2.b, 1])) +(4 rows) + +EXPLAIN (COSTS OFF) +SELECT * FROM bitmap_split_or t1, bitmap_split_or t2 WHERE t1.c=t2.b OR t1.a=1; + QUERY PLAN +---------------------------------------------- + Nested Loop + Join Filter: ((t1.c = t2.b) OR (t1.a = 1)) + -> Seq Scan on bitmap_split_or t1 + -> Materialize + -> Seq Scan on bitmap_split_or t2 +(5 rows) + +EXPLAIN (COSTS OFF) Comment > * Also, add any potentially usable join OR clauses to *joinorclauses may reflect the change in v46-0001 lappend -> list_append_unique_ptr that differs in the processing of equal clauses in the list. Semantics mentioned in the commit message: > 2. Make match_join_clauses_to_index() pass OR-clauses to > match_clause_to_index(). could also be added as comments in the section just before match_join_clauses_to_index() Since d4378c0005e6 comment for match_clause_to_indexcol() I think needs change. This could be as a separate commit, not regarding current patch v46-0001. > * NOTE: returns NULL if clause is an OR or AND clause; it is the > * responsibility of higher-level routines to co I think the patch can be pushed with possible additions to regression test and comments. Regards, Pavel Borisov Supabase
On Tue, Jan 28, 2025 at 10:42 AM Andrei Lepikhov <lepihov@gmail.com> wrote: > On 1/28/25 11:36, Andrei Lepikhov wrote: > > On 1/27/25 16:50, Alexander Korotkov wrote: > > qsort(matches, n, sizeof(OrArgIndexMatch), or_arg_index_match_cmp); > > > > To fit an index, the order of elements in the target array of the > > `ScalarArrayOpExpr` may change compared to the initial list of OR > > expressions. If there are indexes that cover the same set of columns but > > in reverse order, this could potentially alter the position of a > > Subplan. However, I believe this is a rare case; it is supported by the > > initial OR path and should be acceptable. > I beg your pardon - I forgot that we've restricted the feature's scope > and can't combine OR clauses into ScalarArrayOpExpr if the args list > contains references to different columns. > So, my note can't be applied here. OK, thank you! ------ Regards, Alexander Korotkov Supabase
On Fri, Jan 31, 2025 at 4:31 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > I started reviewing at the patch and saw some output "ERROR" in the output of the test and is it okay here? > > SELECT * FROM tenk1 t1 > WHERE t1.thousand = 42 OR t1.thousand = (SELECT t2.tenthous FROM tenk1 t2 WHERE t2.thousand = t1.tenthous); > ERROR: more than one row returned by a subquery used as an expression The output is correct for this query. But the query is very unfortunate for the regression test. I've revised query in the v47 revision [1]. Links. 1. https://www.postgresql.org/message-id/CAPpHfdsBZmNt9qUoJBqsQFiVDX1%3DyCKpuVAt1YnR7JCpP%3Dk8%2BA%40mail.gmail.com ------ Regards, Alexander Korotkov Supabase
On Mon, Feb 3, 2025 at 12:22 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote:Thank you for updated version! I agree for your version of the code. On 02.02.2025 21:00, Alexander Korotkov wrote: On Fri, Jan 31, 2025 at 4:31 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: I started reviewing at the patch and saw some output "ERROR" in the output of the test and is it okay here? SELECT * FROM tenk1 t1 WHERE t1.thousand = 42 OR t1.thousand = (SELECT t2.tenthous FROM tenk1 t2 WHERE t2.thousand = t1.tenthous); ERROR: more than one row returned by a subquery used as an expression The output is correct for this query. But the query is very unfortunate for the regression test. I've revised query in the v47 revision [1]. Links. 1. https://www.postgresql.org/message-id/CAPpHfdsBZmNt9qUoJBqsQFiVDX1%3DyCKpuVAt1YnR7JCpP%3Dk8%2BA%40mail.gmail.com While analyzing the modified query plan from the regression test, I noticed that despite using a full seqscan for table t2 in the original plan, its results are cached by Materialize node, and this can significantly speed up the execution of the NestedLoop algorithm. For example, after running the query several times, I got results that show that the query execution time was twice as bad. Original plan: EXPLAIN ANALYZE SELECT * FROM bitmap_split_or t1, bitmap_split_or t2 WHERE t1.a=t2.b OR t1.a=1; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.00..70067.00 rows=2502499 width=24) (actual time=0.015..1123.247 rows=2003000 loops=1) Join Filter: ((t1.a = t2.b) OR (t1.a = 1)) Rows Removed by Join Filter: 1997000 Buffers: shared hit=22 -> Seq Scan on bitmap_split_or t1 (cost=0.00..31.00 rows=2000 width=12) (actual time=0.006..0.372 rows=2000 loops=1) Buffers: shared hit=11 -> Materialize (cost=0.00..41.00 rows=2000 width=12) (actual time=0.000..0.111 rows=2000 loops=2000) Storage: Memory Maximum Storage: 110kB Buffers: shared hit=11 -> Seq Scan on bitmap_split_or t2 (cost=0.00..31.00 rows=2000 width=12) (actual time=0.003..0.188 rows=2000 loops=1) Buffers: shared hit=11 Planning Time: 0.118 ms Execution Time: 1204.874 ms (13 rows) Query plan after the patch: EXPLAIN ANALYZE SELECT * FROM bitmap_split_or t1, bitmap_split_or t2 WHERE t1.a=t2.b OR t1.a=1; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=0.28..56369.00 rows=2502499 width=24) (actual time=0.121..2126.606 rows=2003000 loops=1) Buffers: shared hit=16009 read=2 -> Seq Scan on bitmap_split_or t2 (cost=0.00..31.00 rows=2000 width=12) (actual time=0.017..0.652 rows=2000 loops=1) Buffers: shared hit=11 -> Index Scan using t_a_b_idx on bitmap_split_or t1 (cost=0.28..18.15 rows=1002 width=12) (actual time=0.044..0.627 rows=1002 loops=2000) Index Cond: (a = ANY (ARRAY[t2.b, 1])) Buffers: shared hit=15998 read=2 Planning Time: 0.282 ms Execution Time: 2344.367 ms (9 rows) I'm afraid that we may lose this with this optimization. Maybe this can be taken into account somehow, what do you think?The important aspect is that the second plan have lower cost than the first one. So, that's the question to the cost model. The patch just lets optimizer consider more comprehensive plurality of paths. You can let optimizer select the first plan by tuning *_cost params. For example, setting cpu_index_tuple_cost = 0.02 makes first plan win for me. Other than that the test query is quite unfortunate as t1.a=1 is very frequent. I've adjusted the query so that nested loop with index scan wins both in cost and execution time. I've also adjusted another test query as proposed by Andrei. I'm going to push this patch is there is no more notes. Links. 1. https://www.postgresql.org/message-id/fc1017ca-877b-4f86-b491-154cf123eedd%40gmail.com
Okay.I agree with your code and have no more notes
-- Regards, Alena Rybakina Postgres Professional
On Mon, 3 Feb 2025 at 15:54, Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > > > On 03.02.2025 14:32, Alexander Korotkov wrote: > > On Mon, Feb 3, 2025 at 12:22 PM Alena Rybakina > <a.rybakina@postgrespro.ru> wrote: > > Thank you for updated version! I agree for your version of the code. > > On 02.02.2025 21:00, Alexander Korotkov wrote: > > On Fri, Jan 31, 2025 at 4:31 PM Alena Rybakina > <a.rybakina@postgrespro.ru> wrote: > > I started reviewing at the patch and saw some output "ERROR" in the output of the test and is it okay here? > > SELECT * FROM tenk1 t1 > WHERE t1.thousand = 42 OR t1.thousand = (SELECT t2.tenthous FROM tenk1 t2 WHERE t2.thousand = t1.tenthous); > ERROR: more than one row returned by a subquery used as an expression > > The output is correct for this query. But the query is very > unfortunate for the regression test. I've revised query in the v47 > revision [1]. > > Links. > 1. https://www.postgresql.org/message-id/CAPpHfdsBZmNt9qUoJBqsQFiVDX1%3DyCKpuVAt1YnR7JCpP%3Dk8%2BA%40mail.gmail.com > > While analyzing the modified query plan from the regression test, I noticed that despite using a full seqscan for tablet2 in the original plan, > its results are cached by Materialize node, and this can significantly speed up the execution of the NestedLoop algorithm. > > For example, after running the query several times, I got results that show that the query execution time was twice asbad. > > Original plan: > > EXPLAIN ANALYZE SELECT * FROM bitmap_split_or t1, bitmap_split_or t2 WHERE t1.a=t2.b OR t1.a=1; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------- NestedLoop (cost=0.00..70067.00 rows=2502499 width=24) (actual time=0.015..1123.247 rows=2003000 loops=1) Join Filter: ((t1.a= t2.b) OR (t1.a = 1)) Rows Removed by Join Filter: 1997000 Buffers: shared hit=22 -> Seq Scan on bitmap_split_or t1(cost=0.00..31.00 rows=2000 width=12) (actual time=0.006..0.372 rows=2000 loops=1) Buffers: shared hit=11 -> Materialize(cost=0.00..41.00 rows=2000 width=12) (actual time=0.000..0.111 rows=2000 loops=2000) Storage: Memory MaximumStorage: 110kB Buffers: shared hit=11 -> Seq Scan on bitmap_split_or t2 (cost=0.00..31.00 rows=2000 width=12) (actualtime=0.003..0.188 rows=2000 loops=1) Buffers: shared hit=11 Planning Time: 0.118 ms Execution Time: 1204.874 ms (13rows) > > Query plan after the patch: > > EXPLAIN ANALYZE SELECT * FROM bitmap_split_or t1, bitmap_split_or t2 WHERE t1.a=t2.b OR t1.a=1; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------------- NestedLoop (cost=0.28..56369.00 rows=2502499 width=24) (actual time=0.121..2126.606 rows=2003000 loops=1) Buffers: sharedhit=16009 read=2 -> Seq Scan on bitmap_split_or t2 (cost=0.00..31.00 rows=2000 width=12) (actual time=0.017..0.652rows=2000 loops=1) Buffers: shared hit=11 -> Index Scan using t_a_b_idx on bitmap_split_or t1 (cost=0.28..18.15rows=1002 width=12) (actual time=0.044..0.627 rows=1002 loops=2000) Index Cond: (a = ANY (ARRAY[t2.b, 1]))Buffers: shared hit=15998 read=2 Planning Time: 0.282 ms Execution Time: 2344.367 ms (9 rows) > > I'm afraid that we may lose this with this optimization. Maybe this can be taken into account somehow, what do you think? > > The important aspect is that the second plan have lower cost than the > first one. So, that's the question to the cost model. The patch just > lets optimizer consider more comprehensive plurality of paths. You > can let optimizer select the first plan by tuning *_cost params. For > example, setting cpu_index_tuple_cost = 0.02 makes first plan win for > me. > > Other than that the test query is quite unfortunate as t1.a=1 is very > frequent. I've adjusted the query so that nested loop with index scan > wins both in cost and execution time. > > I've also adjusted another test query as proposed by Andrei. > > I'm going to push this patch is there is no more notes. > > Links. > 1. https://www.postgresql.org/message-id/fc1017ca-877b-4f86-b491-154cf123eedd%40gmail.com > > > Okay.I agree with your code and have no more notes Hi, Alexander! I've looked at patchset v48 and it looks good to me. Regards, Pavel Borisov Supabase
Hi,
Playing with the feature, I found a slightly irritating permutation -
even if this code doesn't group any clauses, it may permute positions of
the quals. See:
DROP TABLE IF EXISTS main_tbl;
CREATE TABLE main_tbl(id bigint, hundred int, thousand int);
CREATE INDEX mt_hundred_ix ON main_tbl(hundred);
CREATE INDEX mt_thousand_ix ON main_tbl(thousand);
VACUUM (ANALYZE) main_tbl;
SET enable_seqscan = off;
EXPLAIN (COSTS OFF)
SELECT m.id, m.hundred, m.thousand
FROM main_tbl m WHERE (m.hundred < 2 OR m.thousand < 3);
Bitmap Heap Scan on public.main_tbl m
Output: id, hundred, thousand
Recheck Cond: ((m.thousand < 3) OR (m.hundred < 2))
-> BitmapOr
-> Bitmap Index Scan on mt_thousand_ix
Index Cond: (m.thousand < 3)
-> Bitmap Index Scan on mt_hundred_ix
Index Cond: (m.hundred < 2)
Conditions on the columns "thousand" and "hundred" changed their places
according to the initial positions defined in the user's SQL.
It isn't okay. I see that users often use the trick of "OR order" to
avoid unnecessary calculations - most frequently, Subplan evaluations.
So, it makes sense to fix.
In the attachment, I have included a quick fix for this issue. Although
many tests returned to their initial (pre-18) state, I added some tests
specifically related to this issue to make it clearer.
--
regards, Andrei Lepikhov
Attachment
Hi, Andrei! On Mon, 24 Mar 2025 at 14:10, Andrei Lepikhov <lepihov@gmail.com> wrote: > > Hi, > > Playing with the feature, I found a slightly irritating permutation - > even if this code doesn't group any clauses, it may permute positions of > the quals. See: > > DROP TABLE IF EXISTS main_tbl; > CREATE TABLE main_tbl(id bigint, hundred int, thousand int); > CREATE INDEX mt_hundred_ix ON main_tbl(hundred); > CREATE INDEX mt_thousand_ix ON main_tbl(thousand); > VACUUM (ANALYZE) main_tbl; > > SET enable_seqscan = off; > EXPLAIN (COSTS OFF) > SELECT m.id, m.hundred, m.thousand > FROM main_tbl m WHERE (m.hundred < 2 OR m.thousand < 3); > > Bitmap Heap Scan on public.main_tbl m > Output: id, hundred, thousand > Recheck Cond: ((m.thousand < 3) OR (m.hundred < 2)) > -> BitmapOr > -> Bitmap Index Scan on mt_thousand_ix > Index Cond: (m.thousand < 3) > -> Bitmap Index Scan on mt_hundred_ix > Index Cond: (m.hundred < 2) > > Conditions on the columns "thousand" and "hundred" changed their places > according to the initial positions defined in the user's SQL. > It isn't okay. I see that users often use the trick of "OR order" to > avoid unnecessary calculations - most frequently, Subplan evaluations. > So, it makes sense to fix. > In the attachment, I have included a quick fix for this issue. Although > many tests returned to their initial (pre-18) state, I added some tests > specifically related to this issue to make it clearer. I looked at your patch and have no objections to it. However it's clearly stated in PostgreSQL manual that nothing about the OR order is warranted [1]. So changing OR order was (and is) ok and any users query tricks about OR order may work and may not work. [1] https://www.postgresql.org/docs/17/sql-expressions.html#SYNTAX-EXPRESS-EVAL Regards, Pavel Borisov Supabase
I agree with Andrey's changes and think we should fix this, because otherwise it might be inconvenient.Hi, Andrei! On Mon, 24 Mar 2025 at 14:10, Andrei Lepikhov <lepihov@gmail.com> wrote:Hi, Playing with the feature, I found a slightly irritating permutation - even if this code doesn't group any clauses, it may permute positions of the quals. See: DROP TABLE IF EXISTS main_tbl; CREATE TABLE main_tbl(id bigint, hundred int, thousand int); CREATE INDEX mt_hundred_ix ON main_tbl(hundred); CREATE INDEX mt_thousand_ix ON main_tbl(thousand); VACUUM (ANALYZE) main_tbl; SET enable_seqscan = off; EXPLAIN (COSTS OFF) SELECT m.id, m.hundred, m.thousand FROM main_tbl m WHERE (m.hundred < 2 OR m.thousand < 3); Bitmap Heap Scan on public.main_tbl m Output: id, hundred, thousand Recheck Cond: ((m.thousand < 3) OR (m.hundred < 2)) -> BitmapOr -> Bitmap Index Scan on mt_thousand_ix Index Cond: (m.thousand < 3) -> Bitmap Index Scan on mt_hundred_ix Index Cond: (m.hundred < 2) Conditions on the columns "thousand" and "hundred" changed their places according to the initial positions defined in the user's SQL. It isn't okay. I see that users often use the trick of "OR order" to avoid unnecessary calculations - most frequently, Subplan evaluations. So, it makes sense to fix. In the attachment, I have included a quick fix for this issue. Although many tests returned to their initial (pre-18) state, I added some tests specifically related to this issue to make it clearer.I looked at your patch and have no objections to it. However it's clearly stated in PostgreSQL manual that nothing about the OR order is warranted [1]. So changing OR order was (and is) ok and any users query tricks about OR order may work and may not work. [1] https://www.postgresql.org/docs/17/sql-expressions.html#SYNTAX-EXPRESS-EVAL
For example, without this changes we will have to have different test output files for the same query for different versions of Postres in extensions if the whole change is only related to the order of column output for a transformation that was not applied.
-- Regards, Alena Rybakina Postgres Professional
Hi! On Mon, Mar 24, 2025 at 2:46 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote: > I agree with Andrey's changes and think we should fix this, because otherwise it might be inconvenient. > For example, without this changes we will have to have different test output files for the same query for different versionsof Postres in extensions if the whole change is only related to the order of column output for a transformation thatwas not applied. I agree with problem spotted by Andrei: it should be preferred to preserve original order of clauses as much as possible. The approach implemented in Andrei's patch seems fragile for me. Original order is preserved if we didn't find any group. But once we find a single group original order might be destroyed completely. The attached patch changes the reordering algorithm of group_similar_or_args() in the following way. We reorder each group of similar clauses so that the first item of the group stays in place, but all the other items are moved after it. So, if there are no similar clauses, the order of clauses stays the same. When there are some groups, only required reordering happens while the rest of the clauses remain in their places. ------ Regards, Alexander Korotkov Supabase
Attachment
Hi, Alexander! d4378c0005e61b1bb7 On Fri, 28 Mar 2025 at 03:18, Alexander Korotkov <aekorotkov@gmail.com> wrote: > > Hi! > > On Mon, Mar 24, 2025 at 2:46 PM Alena Rybakina > <a.rybakina@postgrespro.ru> wrote: > > I agree with Andrey's changes and think we should fix this, because otherwise it might be inconvenient. > > For example, without this changes we will have to have different test output files for the same query for different versionsof Postres in extensions if the whole change is only related to the order of column output for a transformation thatwas not applied. > > I agree with problem spotted by Andrei: it should be preferred to > preserve original order of clauses as much as possible. The approach > implemented in Andrei's patch seems fragile for me. Original order is > preserved if we didn't find any group. But once we find a single > group original order might be destroyed completely. > > The attached patch changes the reordering algorithm of > group_similar_or_args() in the following way. We reorder each group > of similar clauses so that the first item of the group stays in place, > but all the other items are moved after it. So, if there are no > similar clauses, the order of clauses stays the same. When there are > some groups, only required reordering happens while the rest of the > clauses remain in their places. With your patch, I've re-checked that there are no changes in the order of evaluation in plans compared to d4378c0005e61b1bb7 It might be good to also include Andrei's test from his last patch. i.e: +-- No OR-clause groupings should happen - no clause permutations in +-- the filtering conditions we should see in the EXPLAIN. +EXPLAIN (COSTS OFF) +SELECT * FROM tenk1 WHERE unique1 < 1 OR hundred < 2; + +-- OR clauses on the 'unique' column is grouped. So, clause permutation happened +-- We see it in the 'Recheck Cond' and order of BitmapOr subpaths: index scan on +-- the 'hundred' column occupies the first position. +EXPLAIN (COSTS OFF) +SELECT * FROM tenk1 WHERE unique1 < 1 OR unique1 < 3 OR hundred < 2; I propose small changes for comments: s/To have this property,/To do so,/g s/in place, but all the/in place, and all the/g s/some groups, only/some groups,/g s/Resort/Re-sort/п The patch overall looks good to me. Regards, Pavel Borisov Supabase
On 3/28/25 00:18, Alexander Korotkov wrote: > The attached patch changes the reordering algorithm of > group_similar_or_args() in the following way. We reorder each group > of similar clauses so that the first item of the group stays in place, > but all the other items are moved after it. So, if there are no > similar clauses, the order of clauses stays the same. When there are > some groups, only required reordering happens while the rest of the > clauses remain in their places. The patch looks good to me from a technical perspective. But it seems like an overkill, isn't it? You introduce additional CPU-consuming operations in the planning OR operations. My point is: 1) as Pavel has mentioned, Postgres doesn't guarantee the evaluation/output order of the clauses at all. 2) we need that to keep regression tests stable (don't forget extensions' and forks' developers too). But it should be done once if we have no fluidity in OR clauses order in general. The trade-off with tricky query writers and regression tests may be preserving the order until OR->ANY has happened. If it has happened, just ensure the order is determined somehow. Except that, any other spending on CPU cycles seems too expensive. -- regards, Andrei Lepikhov
On Fri, Mar 28, 2025 at 1:32 PM Andrei Lepikhov <lepihov@gmail.com> wrote: > On 3/28/25 00:18, Alexander Korotkov wrote: > > The attached patch changes the reordering algorithm of > > group_similar_or_args() in the following way. We reorder each group > > of similar clauses so that the first item of the group stays in place, > > but all the other items are moved after it. So, if there are no > > similar clauses, the order of clauses stays the same. When there are > > some groups, only required reordering happens while the rest of the > > clauses remain in their places. > The patch looks good to me from a technical perspective. But it seems > like an overkill, isn't it? > You introduce additional CPU-consuming operations in the planning OR > operations. I don't think this is going to be CPU-consuming. I don't think this is going to be measurable. This patch introduces one additional pass over array of OrArgIndexMatch'es, and qsort of them. I think I've seen places where we spend quadratic time over the number of OR-clauses. Even calls of match_index_to_operand() for every clause and every index look way more expensive. > My point is: 1) as Pavel has mentioned, Postgres doesn't guarantee the > evaluation/output order of the clauses at all. 2) we need that to keep > regression tests stable (don't forget extensions' and forks' developers > too). But it should be done once if we have no fluidity in OR clauses > order in general. > The trade-off with tricky query writers and regression tests may be > preserving the order until OR->ANY has happened. If it has happened, > just ensure the order is determined somehow. Except that, any other > spending on CPU cycles seems too expensive. I think my patch gives better determinism too. For instance, output order doesn't depend on order of indexes in rel->indexlist. ------ Regards, Alexander Korotkov Supabase
On 3/28/25 12:59, Alexander Korotkov wrote: > On Fri, Mar 28, 2025 at 1:32 PM Andrei Lepikhov <lepihov@gmail.com> wrote: > I don't think this is going to be CPU-consuming. I don't think this > is going to be measurable. This patch introduces one additional pass > over array of OrArgIndexMatch'es, and qsort of them. I think I've > seen places where we spend quadratic time over the number of > OR-clauses. Even calls of match_index_to_operand() for every clause > and every index look way more expensive. Ok, I have no more objections. > I think my patch gives better determinism too. For instance, output > order doesn't depend on order of indexes in rel->indexlist. Nice! -- regards, Andrei Lepikhov
Hi! On Mon, Mar 24, 2025 at 2:46 PM Alena Rybakina <a.rybakina@postgrespro.ru> wrote:I agree with Andrey's changes and think we should fix this, because otherwise it might be inconvenient. For example, without this changes we will have to have different test output files for the same query for different versions of Postres in extensions if the whole change is only related to the order of column output for a transformation that was not applied.I agree with problem spotted by Andrei: it should be preferred to preserve original order of clauses as much as possible. The approach implemented in Andrei's patch seems fragile for me. Original order is preserved if we didn't find any group. But once we find a single group original order might be destroyed completely. The attached patch changes the reordering algorithm of group_similar_or_args() in the following way. We reorder each group of similar clauses so that the first item of the group stays in place, but all the other items are moved after it. So, if there are no similar clauses, the order of clauses stays the same. When there are some groups, only required reordering happens while the rest of the clauses remain in their places.
I agree with your code in general, but to be honest, double qsort confused me a little.
I understood why it is needed - we need to sort the elements so that they stand next to each other if they can be assigned to the same group, and then sort the groups themselves according to the set identifier.
I may be missing something, but in the worst case we can get the complexity of qsort O(n^2), right? And I saw the letter where you mentioned this, but it is possible to use mergesort algorithm instead of qsort, which in the worst case gives n * O(n) complexity?
-- Regards, Alena Rybakina Postgres Professional
No, sorry, I was wrong here and it is impossible to rewrite it this way. I apologize, I agree with your code.I agree with your code in general, but to be honest, double qsort confused me a little.
I understood why it is needed - we need to sort the elements so that they stand next to each other if they can be assigned to the same group, and then sort the groups themselves according to the set identifier.
I may be missing something, but in the worst case we can get the complexity of qsort O(n^2), right? And I saw the letter where you mentioned this, but it is possible to use mergesort algorithm instead of qsort, which in the worst case gives n * O(n) complexity?
-- Regards, Alena Rybakina Postgres Professional